
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
714,819 | Apache Kafka: Apprentice Cookbook | Apache Kafka is a distributed event streaming platform built over strong concepts. Let’s dive into... | 0 | 2021-07-01T07:03:57 | https://aveuiller.github.io/kafka_apprentice_cookbook.html | tutorial, eventdriven, kafka |
Apache Kafka is a distributed event streaming platform built over strong concepts. Let’s dive into the possibilities it offers.
[Apache Kafka](https://kafka.apache.org/) is a distributed event streaming platform built with an emphasis on reliability, performance, and customization. Kafka can send and receive messages in a [publish-subscribe](https://aws.amazon.com/pub-sub-messaging/) fashion. To achieve this, the ecosystem relies on few but strong basic concepts, which enable the community to build many features solving [numerous use cases](https://kafka.apache.org/uses), for instance:
* Processing messages as an [Enterprise Service Bus](https://www.confluent.io/blog/apache-kafka-vs-enterprise-service-bus-esb-friends-enemies-or-frenemies/).
* Tracking Activity, metrics, and telemetries.
* Processing Streams.
* Supporting [Event sourcing](https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/).
* Storing logs.
This article will see the concepts backing up Kafka and the different tools available to handle data streams.
## Architecture
The behaviour of Kafka is pretty simple: **Producers** push _Messages_ into a particular _Topic_, and **Consumers** subscribe to this _Topic_ to fetch and process the _Messages_. Let’s see how it is achieved by this technology.
### Infrastructure side
Independently of the use, the following components will be deployed:
* One or more **Producers** sending messages to the brokers.
* One or more Kafka **Brokers**, the actual messaging server handling communication between producers and consumers.
* One or more **Consumers** fetching and processing messages, in clusters named **Consumer Groups**.
* One or more [**Zookeeper**](https://zookeeper.apache.org/) instances managing the brokers.
* (Optionally) One or more **Registry** instances uniformizing message schema.
As a scalable distributed system, Kafka is heavily relying on the concept of _clusters_. As a result, on typical production deployment, there will likely be multiple instances of each component.
A **Consumer Group** is a cluster of the same consumer application. This concept is heavily used by Kafka to balance the load on the applicative side of things.
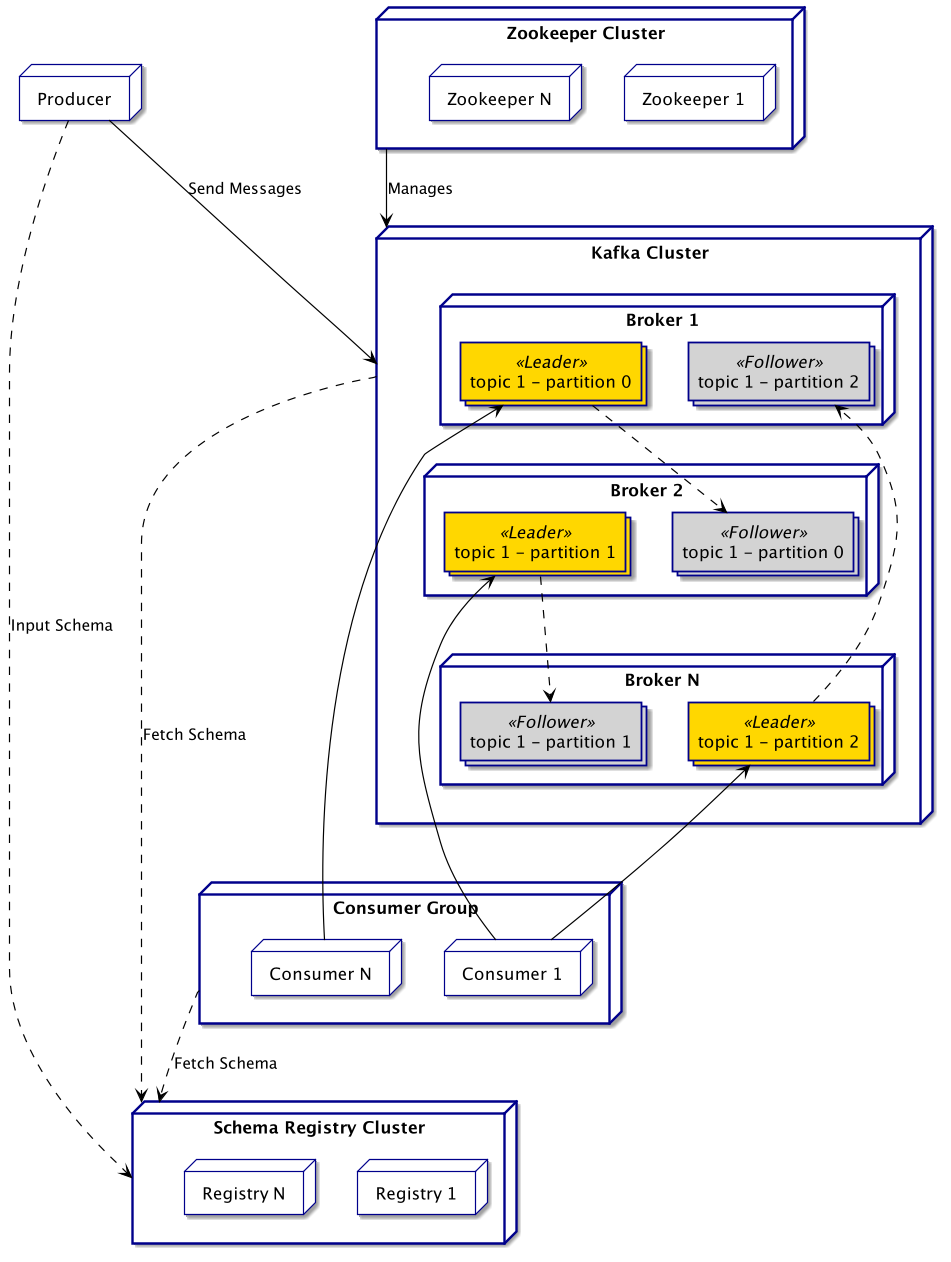
_Note: The dependency on Zookeeper will be removed soon, Cf._ [_KIP-500_](https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum)
> Further Reading:
> [Design & Implementation Documentation](https://kafka.apache.org/documentation/#majordesignelements)
> [Kafka Basics and Core Concepts: Explained — Aritra Das](https://hackernoon.com/kafka-basics-and-core-concepts-explained-dd1434dv)
### Applicative side
A **Message** in Kafka is a `key-value` pair. Those elements can be anything from an integer to a [Protobuf message](https://developers.google.com/protocol-buffers), provided the right serializer and deserializer.
The message is sent to a **Topic**, which will store it as a **Log**. The topic should be a collection of logs semantically related, but without a particular structure imposed. A topic can either keep every message as a new log entry or only keep the last value for each key (a.k.a. [Compacted log](https://docs.confluent.io/platform/current/kafka/design.html#log-compaction)).
To take advantage of the multiple brokers, topics are [sharded](https://en.wikipedia.org/wiki/Shard_%28database_architecture%29) into **Partitions** by default. Kafka will assign any received message to one partition depending on its key,
or using [a partitioner algorithm](https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner) otherwise, which results in a random assignment from the developer's point of view. Each partition has a **Leader** responsible for all I/O operations, and **Followers** replicating the data. A follower will take over the leader role in case of an issue with the current one.
The partition holds the received data in order, increasing an **offset** integer for each message. However, there is no order guarantee between two partitions. So for order-dependent data, one must ensure that they end up in the same partition by using the same key.
Each partition is assigned to a specific consumer from the consumer group. This consumer is the only one fetching messages from this partition. In case of shutdown of one customer, the brokers will [reassign partitions](https://medium.com/streamthoughts/understanding-kafka-partition-assignment-strategies-and-how-to-write-your-own-custom-assignor-ebeda1fc06f3) among the customers.
Being an asynchronous system, it can be hard and impactful on the performances to have every message delivered exactly one time to the consumer. To mitigate this, Kafka provides [different levels of guarantee](https://kafka.apache.org/documentation/#semantics) on the number of times a message will be processed (_i.e._ at most once, at least once, exactly once).
> Further Reading:
> [Log Compacted Topics in Apache Kafka — Seyed Morteza Mousavi](https://towardsdatascience.com/log-compacted-topics-in-apache-kafka-b1aa1e4665a7)
> [(Youtube) Apache Kafka 101: Replication — Confluent](https://www.youtube.com/watch?v=Vo6Mv5YPOJU&list=PLa7VYi0yPIH0KbnJQcMv5N9iW8HkZHztH&index=5)
> [Replication Design Doc](https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication)
> [Processing Guarantees in Details — Andy Briant](https://medium.com/@andy.bryant/processing-guarantees-in-kafka-12dd2e30be0e)
### Schema and Registry
Messages are serialized when quitting a producer and deserialized when handled by the consumer. To ensure compatibility, both must be using the same data definition. Ensuring this can be hard considering the application evolution. As a result, when dealing with a production system, it is recommended to use a schema to explicit a contract on the data structure.
To do this, Kafka provides a **Registry** server, storing and binding schema to topics. Historically only [Avro](https://avro.apache.org/docs/current/) was available, but the registry is now modular and can also handle [JSON](https://json-schema.org/) and [Protobuf](https://developers.google.com/protocol-buffers) out of the box.
Once a producer sent a schema describing the data handled by its topic to the registry, other parties (_i.e._ brokers and consumers) will fetch this schema on the registry to validate and deserialize the data.
> Further Reading:
> [Schema Registry Documentation](https://docs.confluent.io/platform/current/schema-registry/index.html)
> [Kafka tutorial #4-Avro and the Schema Registry— Alexis Seigneurin](https://aseigneurin.github.io/2018/08/02/kafka-tutorial-4-avro-and-schema-registry.html)
> [Serializer-Deserializer for Schema](https://docs.confluent.io/platform/current/schema-registry/serdes-develop/index.html#serializer-and-formatter)
## Integrations
Kafka provides multiple ways of connecting to the brokers,
and each can be more useful than the others depending on the needs. As a result, even if a library is an abstraction layer above another, it is not necessarily better for every use case.
### Kafka library
There are client libraries available in [numerous languages](https://docs.confluent.io/platform/current/clients/index.html) which help develop a producer and consumer easily. We will use Java for the example below, but the concept remains identical for other languages.
The producer concept is to publish messages at any moment, so the code is pretty simple.
```java
public class Main {
public static void main(String[] args) throws Exception {
// Configure your producer
Properties producerProperties = new Properties();
producerProperties.put("bootstrap.servers", "localhost:29092");
producerProperties.put("acks", "all");
producerProperties.put("retries", 0);
producerProperties.put("linger.ms", 1);
producerProperties.put("key.serializer", "org.apache.kafka.common.serialization.LongSerializer");
producerProperties.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
producerProperties.put("schema.registry.url", "http://localhost:8081");
// Initialize a producer
Producer<Long, AvroHelloMessage> producer = new KafkaProducer<>(producerProperties);
// Use it whenever you need
producer.send(new AvroHelloMessage(1L, "this is a message", 2.4f, 1));
}
}
```
The code is a bit more complex on the consumer part since the consumption loop needs to be created manually. On the other hand, this gives more control over its behaviour. The consumer state is automatically handled by the Kafka library. As a result, restarting the worker will start at the most recent offset he encountered.
```java
public class Main {
public static Properties configureConsumer() {
Properties consumerProperties = new Properties();
consumerProperties.put("bootstrap.servers", "localhost:29092");
consumerProperties.put("group.id", "HelloConsumer");
consumerProperties.put("key.deserializer", "org.apache.kafka.common.serialization.LongDeserializer");
consumerProperties.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer");
consumerProperties.put("schema.registry.url", "http://localhost:8081");
// Configure Avro deserializer to convert the received data to a SpecificRecord (i.e. AvroHelloMessage)
// instead of a GenericRecord (i.e. schema + array of deserialized data).
consumerProperties.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
return consumerProperties;
}
public static void main(String[] args) throws Exception {
// Initialize a consumer
final Consumer<Long, AvroHelloMessage> consumer = new KafkaConsumer<>(configureConsumer());
// Chose the topics you will be polling from.
// You can subscribe to all topics matching a Regex.
consumer.subscribe(Pattern.compile("hello_topic_avro"));
// Poll will return all messages from the current consumer offset
final AtomicBoolean shouldStop = new AtomicBoolean(false);
Thread consumerThread = new Thread(() -> {
final Duration timeout = Duration.ofSeconds(5);
while (!shouldStop) {
for (ConsumerRecord<Long, AvroHelloMessage> record : consumer.poll(timeout)) {
// Use your record
AvroHelloMessage value = record.value();
}
// Be kind to the broker while polling
Thread.sleep(5);
}
consumer.close(timeout);
});
// Start consuming && do other things
consumerThread.start();
// [...]
// End consumption from customer
shouldStop.set(true);
consumerThread.join();
}
}
```
> Further Reading:
> [Available Libraries](https://docs.confluent.io/platform/current/clients/index.html)
> [Producer Configuration](https://docs.confluent.io/platform/current/installation/configuration/producer-configs.html)
> [Consumer Configuration](https://docs.confluent.io/platform/current/installation/configuration/consumer-configs.html)
### Kafka Streams
Kafka Streams is built on top of the consumer library. It continuously reads from a topic and processes the messages with code declared with a functional DSL.
During the processing, transitional data can be kept in structures called [KStream](https://kafka.apache.org/23/javadoc/org/apache/kafka/streams/kstream/KStream.html) and [KTable](https://kafka.apache.org/23/javadoc/org/apache/kafka/streams/kstream/KTable.html), which are stored into topics. The former is equivalent to a standard topic, and the latter to a compacted topic. Using these data stores will enable automatic tracking of the worker state by Kafka, helping to get back on track in case of restart.
The following code sample is extracted from the [tutorial provided by Apache](https://kafka.apache.org/28/documentation/streams/tutorial). The code connects to a topic named `streams-plaintext-input` containing strings values, without necessarily providing keys. The few lines configuring the `StreamsBuilder` will:
1. Transform each message to lowercase.
1. Split the result using whitespaces as a delimiter.
1. Group previous tokens by value.
1. Count the number of tokens for each group and save the changes to a KTable named `counts-store`.
1. Stream the changes in this Ktable to send the values in a KStream named `streams-wordcount-output`.
```java
public class Main {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
builder.<String, String>stream("streams-plaintext-input")
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
// The consumer loop is handled by the library
streams.start();
latch.await();
}
}
```
> Further Reading:
> [Kafka Streams Concepts](https://docs.confluent.io/platform/current/streams/concepts.html)
> [Developer Guide](https://docs.confluent.io/platform/current/streams/developer-guide/write-streams.html)
> [Kafka Stream Work Allocation — Andy Briant](https://medium.com/@andy.bryant/kafka-streams-work-allocation-4f31c24753cc)
### Kafka Connect
Kafka Connect provides a way of transforming and synchronizing data between almost any technology with the use of **Connectors**. Confluent is hosting a [Hub](https://www.confluent.io/hub/), on which users can share connectors for various technologies. This means that integrating a Kafka Connect pipeline is most of the time only a matter of configuration, without code required. A single connector can even handle both connection sides:
* Populate a topic with data from any system: _i.e._ a **Source**.
* Send data from a topic to any system: _i.e._ a **Sink**.
The source will read data from CSV files in the following schema then publish them into a topic. Concurrently, the sink will poll from the topic and insert the messages into a MongoDB database. Each connector can run in the same or a distinct worker, and workers can be grouped into a cluster for scalability.

The connector instance is created through a configuration specific to the library. The file below is a configuration of the [MongoDB connector](https://www.confluent.io/hub/mongodb/kafka-connect-mongodb). It asks to fetch all messages from the topic `mongo-source` to insert them into the collection `sink` of the database named `kafka-connect`. The credentials are provided from an external file, which is a feature of Kafka Connect to [protect secrets](https://docs.confluent.io/platform/current/connect/security.html#externalizing-secrets).
```json
{
"name": "mongo-sink",
"config": {
"topics": "mongo-source",
"tasks.max": "1",
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"connection.uri": "mongodb://${file:/auth.properties:username}:${file:/auth.properties:password}@mongo:27017",
"database": "kafka_connect",
"collection": "sink",
"max.num.retries": "1",
"retries.defer.timeout": "5000",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.BsonOidStrategy",
"post.processor.chain": "com.mongodb.kafka.connect.sink.processor.DocumentIdAdder",
"delete.on.null.values": "false",
"writemodel.strategy": "com.mongodb.kafka.connect.sink.writemodel.strategy.ReplaceOneDefaultStrategy"
}
}
```
Once the configuration complete, registering the connector is as easy as an HTTP call on the running [Kafka Connect instance](https://docs.confluent.io/home/connect/userguide.html#configuring-and-running-workers). Afterwards, the service will automatically watch the data without further work required.
```shell
$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
http://localhost:8083/connectors -d @sink-conf.json
```
> Further Reading:
> [Getting Started Documentation](https://docs.confluent.io/platform/current/connect/userguide.html#connect-userguide)
> [Connector Instance API Reference](https://docs.confluent.io/platform/current/connect/references/restapi.html)
> [(Youtube) Tutorials Playlist — Confluent](https://www.youtube.com/playlist?list=PLa7VYi0yPIH1MB2n2w8pMZguffCDu2L4Y)
### KSQL Database
Ksql is somehow equivalent to Kafka Streams, except that every transformation is declared in an SQL-like language. The server is connected to the brokers and can create **Streams** or **Tables** from topics. Those two concepts behave in the same way as a KStream or KTable from Kafka Streams (_i.e._ respectively a topic and a compacted topic).
There are three types of query in the language definition:
1. **Persistent Query** (_e.g._ `CREATE TABLE <name> WITH (...)`): Creates a new stream or table that will be automatically updated.
2. **Pull Query** (_e.g._ `SELECT * FROM <table|stream> WHERE ID = 1`): Behaves similarly to a standard DBMS. Fetches data as an instant snapshot and closes the connection.
3. **Push Query** (_e.g._ `_SELECT * FROM <table|stream> EMIT CHANGES_`): Requests a persistent connection to the server, asynchronously pushing updated values.
The database can be used to browse the brokers' content. Topics can be discovered through the command `list topics`, and their content displayed using `print <name>`.
```sql
ksql> list topics;
Kafka Topic | Partitions | Partition Replicas
----------------------------------------------------
hello_topic_json | 1 | 1
----------------------------------------------------
ksql> print 'hello_topic_json' from beginning;
Key format: KAFKA_BIGINT or KAFKA_DOUBLE or KAFKA_STRING
Value format: JSON or KAFKA_STRING
rowtime: 2021/05/25 08:44:20.922 Z, key: 1, value: {"user_id":1,"message":"this is a message","value":2.4,"version":1}
rowtime: 2021/05/25 08:44:20.967 Z, key: 1, value: {"user_id":1,"message":"this is another message","value":2.4,"version":2}
rowtime: 2021/05/25 08:44:20.970 Z, key: 2, value: {"user_id":2,"message":"this is another message","value":2.6,"version":1}
```
The syntax to create and query a stream, or a table is very close to SQL.
```sql
-- Let's create a table from the previous topic
ksql> CREATE TABLE messages (user_id BIGINT PRIMARY KEY, message VARCHAR)
> WITH (KAFKA_TOPIC = 'hello_topic_json', VALUE_FORMAT='JSON');
-- We can see the list and details of each table
ksql> list tables;
Table Name | Kafka Topic | Key Format | Value Format | Windowed
----------------------------------------------------------------------
MESSAGES | hello_topic_json | KAFKA | JSON | false
----------------------------------------------------------------------
ksql> describe messages;
Name : MESSAGES
Field | Type
------------------------------------------
USER_ID | BIGINT (primary key)
MESSAGE | VARCHAR(STRING)
------------------------------------------
For runtime statistics and query details run: DESCRIBE EXTENDED <Stream,Table>;
-- Appart from some additions to the language, the queries are almost declared in standard SQL.
ksql> select * from messages EMIT CHANGES;
+--------+------------------------+
|USER_ID |MESSAGE |
+--------+------------------------+
|1 |this is another message |
|2 |this is another message |
```
Kafka recommends using a [headless ksqlDB server](https://www.confluent.io/blog/deep-dive-ksql-deployment-options/) for production, with a file declaring all streams and tables to create. This avoids any modification to the definitions.
_Note: ksqlDB servers can be grouped in a cluster like any other consumer._
> Further Reading:
>
> [Official Documentation](https://docs.confluent.io/platform/current/streams-ksql.html)
>
> [KSQL Query Types In Details](https://docs.ksqldb.io/en/latest/concepts/queries/)
>
> [(Youtube) Tutorials Playlist — Confluent](https://www.youtube.com/playlist?list=PLa7VYi0yPIH2eX8q3mPpZAn3qCS1eDX8W)
## Conclusion
This article gives a broad view of the Kafka ecosystem and possibilities, which are numerous. This article only scratches the surface of each subject. But worry not, as they are all well documented by Apache, Confluent, and fellow developers.
Here are a few supplementary resources to dig further into Kafka:
* [(Youtube) Kafka Tutorials - _Confluent_](https://www.youtube.com/playlist?list=PLa7VYi0yPIH0KbnJQcMv5N9iW8HkZHztH)
* [Kafka Tutorials in Practice](https://kafka-tutorials.confluent.io/)
* [Top 5 Things Every Apache Kafka Developer Should Know — Bill Bejeck](https://www.confluent.io/blog/5-things-every-kafka-developer-should-know/)
* [Kafkacat user Guide](https://docs.confluent.io/platform/current/app-development/kafkacat-usage.html)
* [Troubleshooting KSQL Part 2: What’s Happening Under the Covers? — Robin Moffatt](https://www.confluent.io/blog/troubleshooting-ksql-part-2)
* [Apache Kafka Internals — sudan](https://ssudan16.medium.com/kafka-internals-47e594e3f006)
_The complete experimental code is available on my [GitHub repository](https://github.com/aveuiller/frameworks-bootstrap/tree/master/Kafka)._
*Thanks to Sarra Habchi, and Dimitri Delabroye for the reviews*
| aveuiller |
714,973 | iOS App Security Cheatsheet | In a previous article we saw an example on how an attacker could analyse an app in the search of vuln... | 0 | 2021-06-02T08:44:17 | https://apiumhub.com/tech-blog-barcelona/ios-app-security-cheatsheet/ | agilewebandappdevelo, ioscheatsheet, iossecurity | ---
title: iOS App Security Cheatsheet
published: true
date: 2021-06-01 08:57:15 UTC
tags: Agilewebandappdevelo,iOSCheatsheet,iOSSecurity
canonical_url: https://apiumhub.com/tech-blog-barcelona/ios-app-security-cheatsheet/
---
In a [previous article](https://dev.to/apium_hub/security-awareness-in-an-ios-environment-1683) we saw an example on how an attacker could analyse an app in the search of vulnerabilities, and perform an XSS attack through the misuse of a web view. Hopefully after reading that, if you weren’t aware of how easy it is to at least get into some source code of an app published on the AppStore, now you are and you might be wondering if there are other ways to hack an iOS application and how to prevent it.
In this article I will try to make a compilation of stuff to check if you want to ensure your app handles most common security flaws. We will cover the following topics: system API’s, Data Handling, Data transportation and App Hardening.
## System API’s Usage
- **Cryptography:** Use CryptoKit whenever possible and check correct usage of it. Avoid implementing custom crypto algorithms, apart from mistakes it could be an issue during AppStore reviews.
- **App backgrounding:** If the app handles any sensitive user data visible on the screen, you may want to implement a way to hide the content when the app is entering background mode (a snapshot of the app is taken at this moment and stored on the device). Check `applicationDidEnterBackground.`
- **Handle the pasteboard securely:** if pasteboard persistence is enabled, check that it’s being cleared when application backgrounds. Check `UIPasteboardNameFind` and `UIPasteboardNameGeneral`.
- **Disable auto-correction** for sensitive input fields or mark them as secure (passwords, credit cards, etc).
- Check for unwanted screen recordings and capturing of **sensitive data**. Subscribe to `userDidTakeScreenshotNotification` and use `UIScreen.isCaptured()` in order to blur or hide the content.
- Keep in mind possible **SQL injection** or formatted strings injection vulnerabilities (the latter should not be an issue in Swift). Always use parameterized strings for NSPredicates and for formatted strings. E.g.: instead of using `NSPredicate(format: “(email LIKE ‘\(user.email)’) AND (password LIKE ‘\(user.password)’)”, nil)` you should better use `NSPredicate(format: “(email = @) AND (password = @)”, user.email, user.password)`. If necessary input text validation measures can be taken in place before saving to the database or interacting with the server.
- Ensure a **proper use of Web Views** , check and validate possible javascript code injection.
## Data Handling
- Setting a **Protection Level** for writing data: Check for desired usage of Data Protection API, refer to `NSData.WritingOptions` and `URLFileProtection`.
- CoreData and Realm store the databases as .db files that can be copied from your bundle, and easily read. **Make sure to encrypt sensitive data before storing it to your database**.
- Do not use `UserDefaults` to store any sensitive data, such as Access Tokens, subscription flags, or relevant account information. It can be easily accessed from outside the app. Use KeychainService API instead.
- Hash data using **CryptoKit** instead of Swift Standard Library hashing functions, as the latter have a high collision rate.
- Check [Apple documentation](https://developer.apple.com/library/archive/documentation/FileManagement/Conceptual/FileSystemProgrammingGuide/FileSystemOverview/FileSystemOverview.html#//apple_ref/doc/uid/TP40010672-CH2-SW12) in order to be sure on where to store your data in the file system.
## Data Transportation
- Configure **App Transport Security** (ATS) correctly, try to avoid adding exceptions for it.
- **Use TLS/SSL securely**. Check for any HTTP and replace by HTTPS, also check for any token being sent in the URL, they should always be sent in the headers.
- Keep in mind that HTTP Requests/Responses are cached by NSURLSession by default in a Cache.db file. If handling sensitive data, you may want to use `ephemeralSessionConfiguration` which does not store cookies nor caches. Global cache can also be disabled, check URLCache, you can assign 0 capacity to it and assign it to `URLCache.shared`.
## App Hardening
- Check if you want to support third party keyboards, and disable them if you believe it can be a threat for your data.
- Run **XCode** static analysis report. It can help to reveal memory leaks and other common bugs.
- **Debug logs** : keep in mind that logs are public by default, so never log sensitive information, and use the appropriate tools for it. Avoid the usage of prints.
- **Code obfuscation** : code can be easily reverse engineered, so in order to prevent that we can obfuscate the code. There are many third party libraries for that matter.
- Do not abuse URL schemes usage, and validate each URL you will handle to prevent XSS attacks.
- Ensure you have a strong **Jailbreak detection system** , jailbreak is still possible for most devices and iOS’s. Attackers from jailbroken devices can reverse engineer your app and access sensitive data.
## Conclusion
As you can see, there are a considerable amount of things to keep in mind when addressing the security of your application. And of course these are not all of them, but at least with this list you have a point to start checking your application and think which items are relevant for your application security profile. I hope this short read was useful for you and that you keep it handy for the next time you have to audit an application’s security. | apium_hub |
715,112 | TUTORIAL: How to create a modal in UI Builder | A modal is a common UI element used to grab the user’s attention by overlaying the page. In this step... | 0 | 2021-06-01T14:26:31 | https://dev.to/backendless/tutorial-how-to-create-a-modal-in-ui-builder-5b97 | ux, webdev | A modal is a common UI element used to grab the user’s attention by overlaying the page. In this step-by-step tutorial, we will show you how to implement, style, and interact with modals in UI Builder.
Also known as overlays or dialog windows, modals are an easy way to ensure your user receives information or takes an action you want them to take. In order to guarantee the user interacts with the modal, most modals prevent the user from interacting with the underlying page.
While this can be effective in small doses, the modal UI element should be used in moderation as it tends to disrupt the user experience.
Check out an example of the component [in this demo](https://eu.backendlessappcontent.com/8AAA8E74-06F7-48FD-9154-1AA3227BFA24/D8E91033-BD89-40C0-9FD9-126973003E38/files/web/app/index.html?page=Modal).
In this tutorial, we will take you through the process of implementing a modal in Backendless’ built-in UI Builder. To follow along, simply login or create a free Backendless account.
_Note from the author: The names for the classes and elements in this component are used for example. You can them to whatever you prefer._
##Modal Structure In UI Builder
Let’s start assembling the modal window by creating the component structure on the User interface tab.
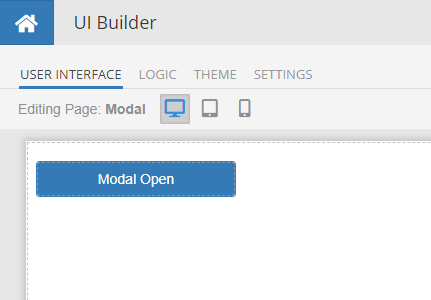
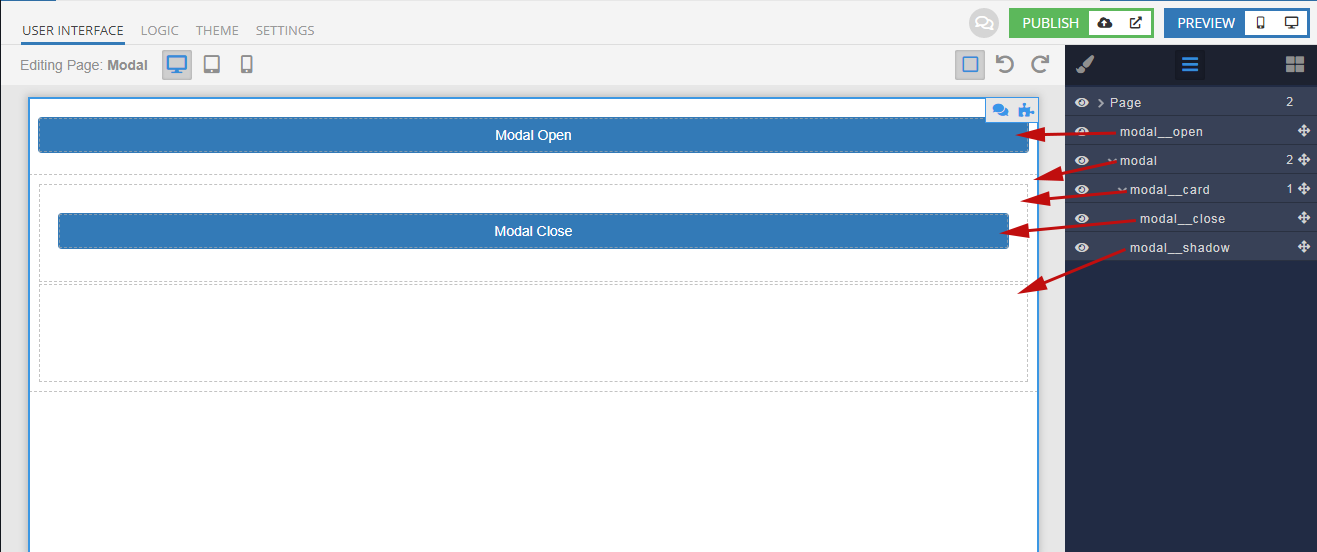
The general structure of the component is shown below. For clarity, element IDs are named the same as classes.
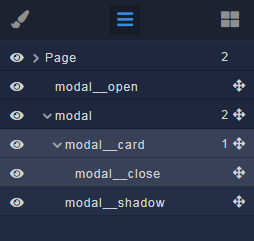
###Descriptions
*`modal__open` – button for opening a modal window (can be any of your custom solutions)
*`modal` – root element of the modal (required)
*`modal__card` – root block for your content; inside this element put what you need (required)
*`modal__close` – button to close the modal window (you can do as you need)
*`modal__shadow` – shading curtain behind the modal window, restricts access to other elements of the page (required)
All elements of the component, except buttons, use the Block component.
For the buttons, we will use the Button element but you can use whatever you want.
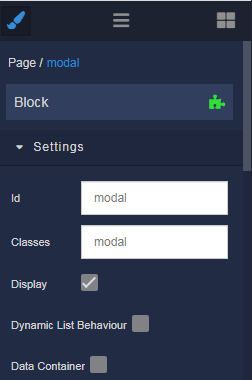
When creating elements, immediately assign ID and Classes according to this structure:
As a result, you should get something similar to this:
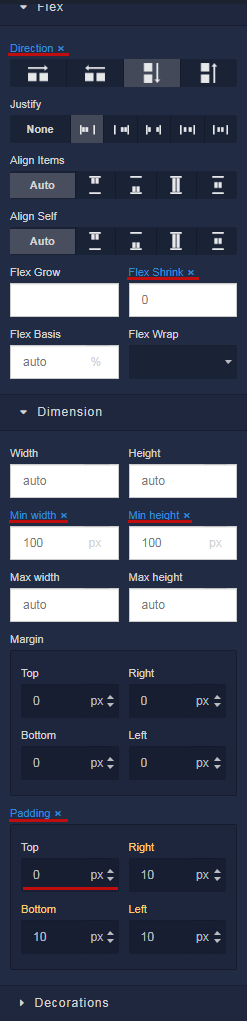
After you create the entire structure of the component, you need to reset all settings for the Block elements. To do this, you need to delete all the selected properties. Later, we will indicate the necessary ones through the styles. The Padding property is set to 0 and then reset in the same way.
##Styles
To create styles, switch to the Theme tab. Inside the page, select the Editor tab and then Extensions.
Now we’ll create Extensions. You can change the names as you like.
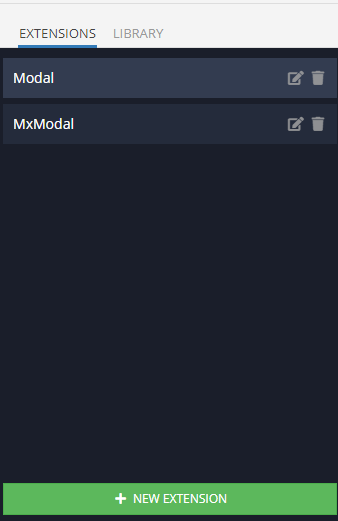
Extension `MxModal` is a LESS-mixin in which the basic styles of the component are taken out for ease of multiple use. Edit only if you know what you are doing!
[Learn more about CSS LESS in UI Themes.](https://backendless.com/how-to-add-customized-styles-to-your-app/)
```
.mx-modal {
display: none !important;
position: fixed !important;
top: 0 !important;
bottom: 0 !important;
left: 0 !important;
right: 0 !important;
z-index: 1000 !important;
flex-direction: column !important;
justify-content: center !important;
align-items: center !important;
width: 100% !important;
height: 100% !important;
padding: 0 15px !important;
&.open {
display: flex !important;
}
@media (min-width: 768px) {
padding: 0 !important;
}
}
.mx-modal__curtain {
position: fixed !important;
top: 0 !important;
bottom: 0 !important;
left: 0 !important;
right: 0 !important;
z-index: -1 !important;
background-color: rgba(0, 0, 0, 0.7);
width: 100% !important;
height: 100% !important;
}
.mx-modal__card {
width: 100% !important;
@media (min-width: 768px) {
width: 600px !important;
}
}
```
The Extension `Modal` contains the general styling of the component on the page according to your project. The most important thing is to import mixins; any other properties can be adjusted as you like.
```
.modal__open {
width: 200px !important;
}
.modal {
.mx-modal();
}
.modal__card {
.mx-modal__card();
flex-direction: column !important;
justify-content: flex-end !important;
align-items: flex-end !important;
background-color: #fff;
height: 300px !important;
border-radius: 5px;
box-shadow: 0px 3px 1px -2px rgba(0, 0, 0, 0.20),
0px 2px 2px 0px rgba(0, 0, 0, 0.14),
0px 1px 5px 0px rgba(0, 0, 0, 0.12);
}
.modal__close {
width: 200px !important;
}
.modal__shadow {
.mx-modal__curtain();
}
```
##Logic
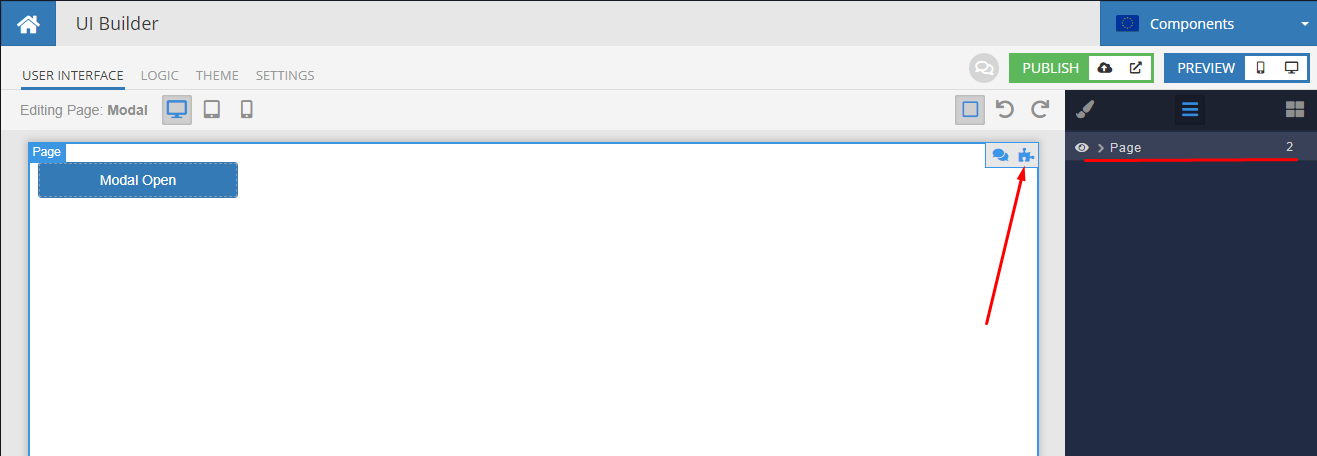
Let’s start adding [Codeless logic](https://backendless.com/features/backendless-core/codeless) from the root Page element. To do this, we return to the User interface tab, select the Page element and click on the puzzle icon as in the screenshot.
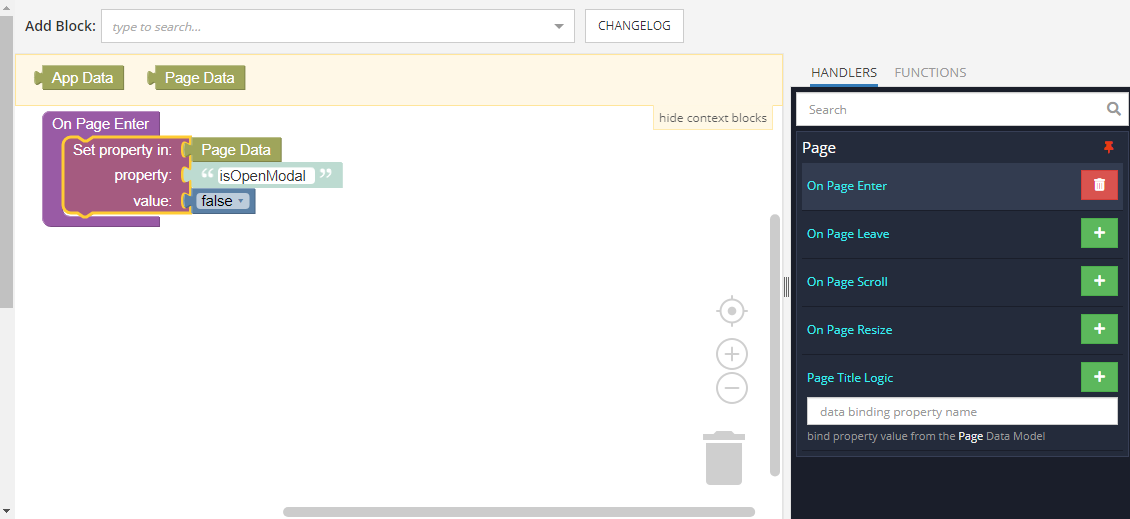
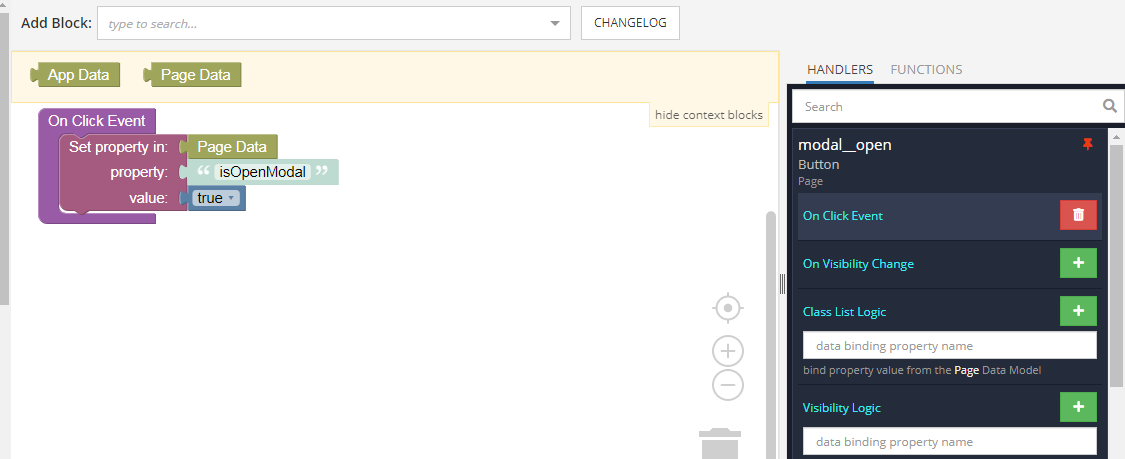
In the Logic tab that opens for the Page element, we hang the logic on the On Page Enter event as in the screenshot. This will create a global modal state variable `isOpenModal` for the entire page. We set the value to `false`, which in our logic will define a closed modal window.
If you want to use several different modals, add a unique variable for each window.
In order not to switch between tabs to select the following items, we will use the navigator. To do this, unpin the Page element by clicking on the button icon.
Now we add logic for the rest of the elements.
On the window open button, use the On Click Event. Set the `isOpenModal` variable to `true`.
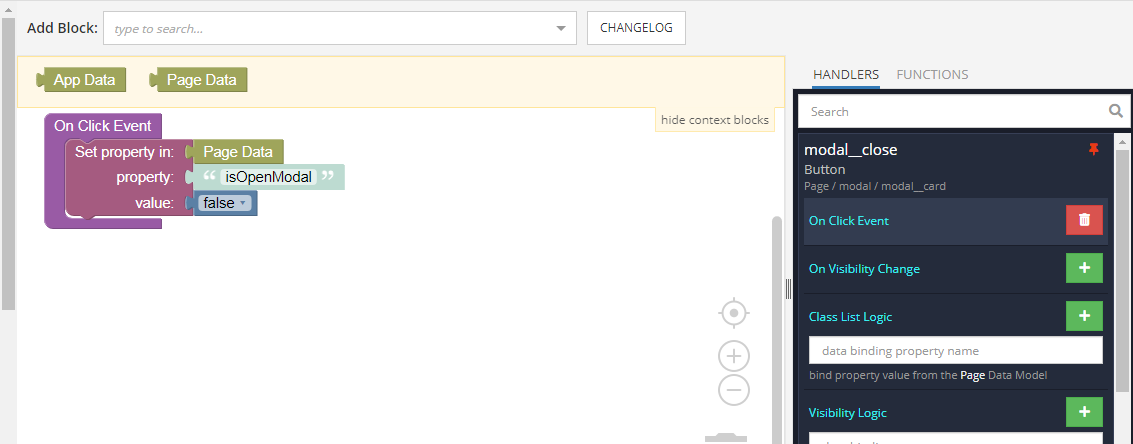
Similarly, add a handler for the On Click Event for the close button and shade curtain.
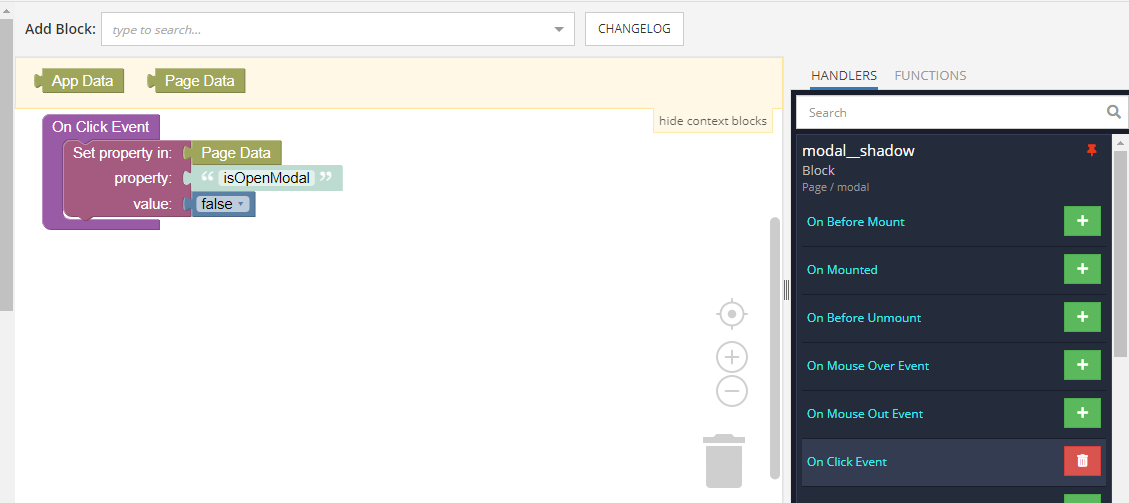
Now, all that remains is to add logic to the element with the `modal` class. For this, we use the Class List Logic event. Here, depending on the value of the `isOpenModal` variable, the open class is added or removed.
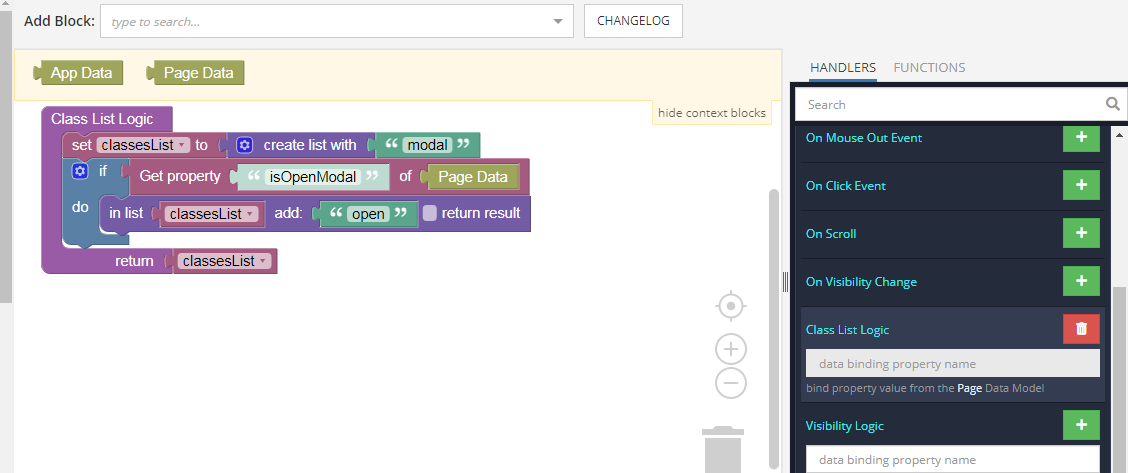
That’s all there is to it! We hope that you found this useful and, as always, happy codeless coding! | backendless |
715,267 | Twitch EventSub - The Direct Approach to Getting Started With It | Start Here You want to write something to react to Twitch Events. You look at the docs, an... | 0 | 2021-06-02T05:51:08 | https://dev.to/wyhaines/twitch-eventsub-the-direct-approach-to-getting-started-with-it-3dcj | tutorial, crystal | # Start Here
You want to write something to react to Twitch Events. You look at the docs, and maybe it is a little confusing. You see a table of contents that looks like this:

Authentication
Twitch API
EventSub
PubSub
If you click around a little, you might get more confused. There are a lot of details, and there seems to be more than one way to do things, at least in some cases, and it is easy to lose track of the thread of things amidst all of the information.
You might look at PubSub, and you might think, "Wow! This seems very simple and straightforward!"
You would be right. It is. Then you might discover that it only provides access to a small percentage of the Twitch events, and things that you really want, like *channel.follow* notifications, are not available.
Eventually, you look more at EventSub. This is the future. This is what everyone should be using:

"Awesome!" you think. "Let's dive in and....wait, how do I use this?"
To use it, you have to subscribe to events. And to subscribe to events, you have to have authorization. And to be authorized...there are no links there, but in the left menu there is an *Authentication* link, so you click there, and...
OK, more steps. Registering the app. Then getting a token. Only there are 5 different kinds. Which one is needed? OK, and how do I get that? And how do I use it once I have it?
You get the picture. The details are all there, in the documentation, but it is a maze of twisty little passages, and you may spend a lot of time flipping from one page to another to piece it all together.
Fear not. I've done the flipping. I've got your back.
## Step 1 -- You need to register your app
First things first -- app registration. In order for your app to interact with eventsub, Twitch wants to know about it as a unique entity. So, you need to register it.
Go to [https://dev.twitch.tv/console](https://dev.twitch.tv/console). On the right of the page, there should be a section labeled *Applications*. Click on the  button.
In the form that is on the next page, you have to provide a few elements of information.

Give your app a name.

Unless you know with certainty what this is or will be, just put `https://localhost` in, and press the *Add* button.

Finally, select an appropriate category for your app, and then press the *Create* button.
You will be taken to the Apps Console, where you will see something like this:

The next step is to click the *Manage* button on your newly created app. You will be taken back to a page that looks just like the one where you created the app, except that it has a few extra bits of information at the bottom:

The Client ID is public information. There is no need to hide that. The application secret, however, is, well, secret. It will be generated when you press the  button. Take note of the string of characters that are revealed when you press that button, and save it somewhere else for later use. You can not see it again once you leave the page, so if you lose the secret, you will have to regenerate a new one, which expires the old one.
See? This is easy so far.
The next thing that you need to do is to generate an access token for your application, using the *Client-ID* and *Client-Secret* that you have just generated.
## Step 2 -- Generate your access token
The next step is to generate your access token. There are five different types of access token, but the one that is needed for EventSub is the [OAuth Client Credentials Flow](https://dev.twitch.tv/docs/authentication/getting-tokens-oauth/#oauth-client-credentials-flow) token type.
This type of token is an Application Access Token, intended only for server-to-server API requests, which is exactly what is needed for EventSub activities.
To get your very own shiny, new Application Access Token, you need to make a POST request to the Twitch API. The documentation detailing what is needed is in the link above, but it has the potential to be a little bit confusing.
HTTP *GET* requests pass extra parameters within the query string of the URL.
`GET /foo?param1=abc¶m2=123`
HTTP *POST* requests typically pass parameters within the body of the HTTP request. The examples show a *POST* being done with the data in the URL as a Query String.

While this is not illegal per the HTTP spec, it is not typical, nor is it required when working with the Twitch API.
If you want to generate an access key manually, you can do this using `curl`:
```bash
curl -d client_id=$TWITCH_CLIENT_ID \
-d client_secret=$TWITCH_CLIENT_SECRET \
-d grant_type=client_credentials \
https://id.twitch.tv/oauth2/token
```
If your *Client-ID* and your *Client-Secret* are stored in a couple of environment variables, *TWITCH_CLIENT_ID* and *TWITCH_CLIENT_SECRET*, the above should work from most unix-like command lines.
What is returned is one of two things. If either your *Client-ID* is invalid, there will be an error like this:
```json
{"status":400,"message":"invalid client"}
```
If the *Client-ID* is valid, but the *Client-Secret* is invalid, the error will look like this:
```json
{"status":403,"message":"invalid client secret"}
```
If both are valid, the result will be returned in JSON something like this:
```json
{"access_token":"q3b5n90ua7du0mgpwl149ge2yf90r0","expires_in":4776914,"token_type":"bearer"}
```
The value for the `access_token` key is your golden ticket. It is what permits you to access the rest of the EventSub API.
If you want or need your software to be able to generate an access key at will, though, you will need to issue the request and receive the response programmatically. The details of this may vary considerably depending on your programming language, but maybe I can help with a few examples:
### Ruby
```ruby
require "uri"
require "net/http"
require "json"
uri = URI("https://id.twitch.tv/oauth2/token")
response = Net::HTTP.post(
uri,
{"client_id" => CLIENT_ID,
"client_secret" => CLIENT_SECRET,
"grant_type" => "client_credentials"}.to_json,
{"Content-Type" => "application/json"})
access_code = JSON.parse(response.body)["access_token"]
```
### Javascript
The Javascript example assumes the use of *Fetch*.
```javascript
const Url = "https://id.twitch.tv/oauth2/token"
const Data = {
client_id: CLIENT_ID,
client_secret: CLIENT_SECRET,
grant_type: "client_credentials"
}
const Params = {
headers: { "Content-Type": "application/json" },
body: Data,
method: "POST"
}
let access_token = ""
fetch(Url, Params)
.then(response => {access_token = response.json()["access_token"]}
```
### Crystal
```crystal
require "http/client"
require "json"
response = HTTP::Client.post(
url: "https://id.twitch.tv/oauth2/token",
headers: HTTP::Headers{ "Content-Type" => "application/json" },
body: {
"client_id" => CLIENT_ID,
"client_secret" => CLIENT_SECRET,
"grant_type" => "client_credentials"}.to_json)
access_token = JSON.parse(response.body)["access_token"].as_s
```
### Bash
The Bash example assumes that the [jq](https://stedolan.github.io/jq/) utility is installed.
```bash
DATA=`curl -d client_id=CLIENT_ID \
-d client_secret=CLIENT_SECRET \
-d grant_type=client_credentials \
-s https://id.twitch.tv/oauth2/token`
ACCESS_TOKEN=echo $DATA | jq .access_token
```
Once you have a valid *access token*, the world is your oyster. The rest of the Twitch EventSub API is accessible.
## A Quick Note About the EventSub API URL
The sections that follow provide examples for how to perform each of the EventSub management actions, and an astute reader will note that the URL for each of the sections is the same. All EventSub API actions operate through the same API URL:
`https://api.twitch.tv/helix/eventsub/subscriptions`'
What differentiates the different types of actions that can be performed with EventSub requests are the HTTP verbs that are used to perform the request and the payload that accompanies it.
## Listing Subscriptions
The EventSub API provides a mechanism to see what subscriptions a client currently has and their status. This is important, because there is a limited number of subscriptions allowed per client (10000), and even failed subscription requests count against that limit. This makes it important to monitor all current subscriptions so that failed or unneeded subscriptions can be deleted.
To access a list of subscriptions, a *GET* request must be issues to *https://api.twitch.tv/helix/eventsub/subscriptions*. This request should provide *Client-ID* and *Authorization* parameters, where the value of the *Authorization* parameter is the access token generated earlier, with `Bearer ` prepended to it:
```
Authorization: Bearer deadbeefdeadbeef
```
With a valid access token, the response will be a JSON payload with a `data` field containing a list of subscriptions, along with some fields showing the limit on the number of subscriptions, as well as how many total subscriptions the client has.
A full specification for this API request can be found at [https://dev.twitch.tv/docs/api/reference#get-eventsub-subscriptions](https://dev.twitch.tv/docs/api/reference#get-eventsub-subscriptions).
## Creating a Subscription
This is the most complex operations when dealing with EventSub, as subscription creation also involves a verification step that allows Twitch to validate that the callback that was given in the subscription request is owned by the client that requested it, as well as a signature validation to allow the client to verify that the Twitch verification request is itself valid.
#### Step 1 -- Request a subscription
A subscription request is initiated by sending a *POST* request to *https://api.twitch.tv/helix/eventsub/subscriptions* with the following HTTP Headers:
```HTTP
Client-ID: CLIENT_ID
Authorization: Bearer ACCESS_TOKEN
Content-Type: application/json
```
Within the body of the request, a JSON payload with four keys, `version`, `type`, `condition`, and `transport` is expected. Each should have a value as follows:
* **version** : Currently, this is always `1`.
* **type** : This is the [name of the event](https://dev.twitch.tv/docs/eventsub/eventsub-subscription-types) to subscribe to.
* **condition** : This is an object which itself will have a single key, `broadcaster_user_id`, which contains the numeric user id of the account that is requesting the subscription.
* **transport** : This is an object with three keys, `method`, `callback`, and `secret`, which are used to specify the transport mechanism for Twitch to send event information. Currently only `webhook` is supported for the `method` key, though the documentation alludes to plans to support others in the future. The `callback` will be the URL that Twitch will contact when the subscribed-to-event occurs, and the `secret` should be a 10 to 100 character secret value unique to this subscription.
The secret will be used to validate the subsequent subscription request verification, so your code must remember what it sent as the secret for this subscription.
The whole package to issue a request for a *channel.follow* subscription will look something like this:
```json
{
version: "1",
type: "channel.follow",
"condition": {
"broadcaster_user_id": "12826"
},
"transport": {
"method": "webhook",
"callback": "https://example.com/webhooks/callback",
"secret": "abcdefghij0123456789"
}
}
```
#### Step 2 -- Receive a response indicating request status
In response to the subscription request, Twitch will send a JSON payload as a response. If the request was successfully received, the response from Twitch will be similar to that described above when listing subscriptions, except that the subscription contained in the *data* array will have a status of *webhook_callback_verification_pending*:
```json
"status": "webhook_callback_verification_pending"
```
This indicates that Twitch has received and will be verifying the subscription request.
#### Step 3 -- Receive verification
Twitch must verify that the callback provided in the subscription request belongs to the caller. To that end, it will contact the callback URL in order to initiate a verification exchange.
It will make a *POST* request to the callback URL. The handler for the callback URL must be able to recognize a Twitch verification request and respond appropriately. Twitch sets a number of custom HTTP headers on the request, several of which are particularly important:
* **Twitch-Eventsub-Message-Id** : This is a UUID representing the unique ID of this specific message. This will be used in *step 4*.
* **Twitch-Eventsub-Message-Timestamp** : The timestamp is also used in *step 4*
* **Twitch-Eventsub-Message-Type** : This is the message type. For a verification attempt, this will be set to `webhook_callback_verification`.
* **Twitch-Eventsub-Message-Signature** : This is a *HMAC-SHA256* message signature in the format of `sha256=4471d611ed1f44cf2fe1d7a462fc62`. This is used in *step 4*
* **Twitch-Eventsub-Subscription-Type** : This is the subscription type that is being verified. From the example above, this would be `channel.follow`.
In the body of the request will be a JSON payload that contains another copy of the subscription, in the same format that has already been discussed, along with a *challenge* key, and a value in the form of a random string of letters and digits separated into clusters by dashes. The *challenge* will be used after the request is validated, in *step 5*.
#### Step 4 -- Validate the request's *Message-Signature*
The *Twitch-Eventsub-Message-Signature* is calculated with *HMAC-SHA256* using the secret that was provided to Twitch in the original subscription request. It is a concantenation of the value of the *Twitch-Eventsub-Message-Id* and the *Twitch-Eventsub-Message-Timestamp* headers with the message body, signed using *HMAC-SHA256* with the aforementioned secret.
If the calculated signature does not match the signature that was provided in the *Twitch-Eventsub-Message-Signature* header, return a 403 status. If it does match, continue to *step 5*.
Your code will probably look something like this:
```crystal
calculated_signature = OpenSSL::HMAC.hexdigest(
OpenSSL::Algorithm::SHA256,
secret,
request.headers["Twitch-Eventsub-Message-Id"] +
request.headers["Twitch-Eventsub-Message-Timestamp"] +
request.body.gets_to_end
)
signature = request.headers["Twitch-Eventsub-Message-Signature"]
if signature != calculated_signature
response.respond_with_status(403)
else
# Yay! The Signature was verified. Continue with processing.
end
```
#### Step 5 -- Respond to the verification request with the *challenge*
At this point, your code will have validated Twitch's request for verification. The only thing that is left to do is to respond to the validation request.
As mentioned previously, the JSON payload in the body of the request will have contained a key *challenge*. The value for this key must be returned in a status code 200 response to the Twitch request, with nothing added or changed.
A sample of how this might look is as follows:
```crystal
body = request_body.gets_to_end
params = JSON.parse(body)
challenge = params["challenge"]?
if challenge
response.status_code = 200
response.write challenge.as_s.to_slice
response.close
end
```
#### Step 6 -- There is no step 6
At this point the subscription is active.
## Deleting a Subscription
At some point, you will want to delete a subscription, either because you no longer need the information, or because a subscription request failed, and you need to clear it out.
Deleting subscriptions is a straight forward process, fortunately.
Every subscription has a UUID that identifies it. This ID can be retrieved from the JSON response that is returned when subscriptions are listed. To delete a subscription, a *DELETE* request is sent to the *https://api.twitch.tv/helix/eventsub/subscriptions* URL, with *Client-ID* and *Authorization* headers, just as for listing subscriptions.
## Handling Notifications
When an event occurs for one of the active subscriptions, Twitch will send a *POST* request to the callback URL with the details. The headers will be the same as was discussed above for subscription verification, except that the *Twitch-Eventsub-Message-Type* header will have a value of `notification.
The JSON payload for the request will contain an object with two top-level keys, `subscription`, and `event`.
The value for the `subscription` key will contain a copy of the subscription that generated the event.
The value for the `event` key will contain an object that describes the event details. The precise values that will be available in this object depend on the event type. Please [refer to the Twitch documentation](https://dev.twitch.tv/docs/eventsub/eventsub-reference) in order to figure out what to expect.
It is expected that the notification will be verified in exactly the same manner that the subscription request was verified, by checking the *HMAC2SHA256* signature of the request before trusting it. If it is validated, it is expected that a 200 response will be sent back to Twitch to confirm that the event was received. If validation fails, it is expected that a 403 response (or other appropriate 4xx response) is sent to Twitch to indicate the validation failure.
If Twitch isn't sure that the event was received (such as a case where neither a 2xx nor a 4xx response are received in response to an event), Twitch may resend the event, so one's event handler must be able to cope if an event that was already received is received a second time.
## All Of The Details Are In The API Docs
The Twitch API documentation contains all of the above details, and while they are not presented in a linear fashion that is easy to implement-your-own-code from, they are all present in full details if one hunts enough.
Please use this as a guide to get yourself going, and then refer back to the Twitch documentation for full details, as in many places some of the details have been elided in order to keep this guide as direct and simple as possible.
---
I stream on Twitch for The Relicans. [Stop by and follow me at https://www.twitch.tv/wyhaines](https://www.twitch.tv/wyhaines), and feel free to drop in any time. In addition to whatever I happen to be working on that day, I'm always happy to field questions or to talk about anything that I may have written. | wyhaines |
715,451 | Kotlin monthly wrap up - May 2021 | Let me share with you 3 interesting articles from #kotlin from May 2021. I follow here the example... | 13,419 | 2021-06-01T20:22:01 | https://dev.to/jmfayard/the-3-most-interesting-kotlin-posts-of-may-2021-4i4g | kotlin, bestofdev, android | Let me share with you 3 interesting articles from [#kotlin](https://dev.to/t/kotlin/top/month) from May 2021.
I follow here the example from @sandordargo [for #c++](https://dev.to/sandordargo/the-3-most-interesting-c-posts-of-may-2021-1974), and like him, it's not a popularity contest, I add subjectivity to the list yet try not to include multiple articles from the same author.
This month, it's all about Jetpack Compose!
----
@zachklipp does a deep dive inside Compose reactive state model. He takes an historical look at how we used to write code with callbacks, what RxJava brought to the table and what questions were left open. He then shows how Jetpack Compose allows us to write fully reactive apps with less boilerplate and hopefully less cognitive overhead than we’ve been able to do in the past. Simple, clear code that is easy to read and understand will (usually) just work as intended. In particular, Compose makes mutable state not be scary anymore.
{% link https://dev.to/zachklipp/a-historical-introduction-to-the-compose-reactive-state-model-19j8 %}
---
@tkuenneth has started a cartography of Jetpack Compose. It's not a tutorial on how to use it, but an exploratory approach of what Jetpack Compose is made of. What belongs to the runtime? What is in the compiler? What is inside the foundation?
{% link https://dev.to/tkuenneth/cartographing-jetpack-compose-compiler-and-runtime-1605 %}
---
So much for the theory, here goes some coding. Sebastian Aigner from @kotlin tells us how he built a small clone of the classic arcade game Asteroids with Jetpack Compose for Desktop, a port from JetBrains to MacOS/Windows/Linux. Impressively the code is only 300 lines of code and was written in one night!
{% link https://dev.to/kotlin/how-i-built-an-asteroids-game-using-jetpack-compose-for-desktop-309l %}
---
Happy coding, feel free to share your favorite one in the comments.
| jmfayard |
715,722 | How To Deploy Django App To Heroku- The Simple Way | Have you ever tried uploading your django app to heroku but felt it was too complicated? If so, in... | 0 | 2021-06-02T14:06:14 | https://dev.to/rabbilyasar/how-to-deploy-django-app-to-heroku-the-simple-way-21mh | django, heroku, github, git | Have you ever tried uploading your django app to heroku but felt it was too complicated? If so, in this segment we will look at how you can upload your app to heroku. Don't worry, it is going to be short and to the point.
For this tutorial, I will be assuming you have an app built, so the next step you will be delving into, is on how to deploy your app to heroku.
Keeping that in mind, let's dive in and see how we can setup the app.
## Prepare your app
### Requirements.txt
If you are already working in a `virtualenv` you can easily run to create your `requirements.txt` file.
```
pip freeze > requirements.txt
```
If you want to manually write the version of the package just go to pypi website and find the latest version.
It should look something like this:
```
asgiref==3.3.4
Django==3.2.3
gunicorn==20.1.0
Pillow==8.2.0
pytz==2021.1
sqlparse==0.4.1
django-heroku==0.3.1
whitenoise==5.2.0
```
### Procfile
- Create a file with name `Procfile` (Make sure to not have any extension). The `Procfile` should be in the same directory as your `manage.py` file.
- Install gunicorn.
```
pip install gunicorn
```
- Make sure to add gunicorn to your `requirements.txt` file.
- Add the following line to your `Procfile`. The app name is basically the folder name where you have your `wsgi.py` file.
```
web: gunicorn <app_name>.wsgi
```
### settings.py
- Next we will be installing a package called `django-heroku`, after installing make sure to add it on the `requirements.txt` file.
```
pip install django-heroku
```
- Now go to your `settings.py` and import it on top.
```
import django_heroku
```
and paste this at the bottom of the file or else you are going to get a `KeyError`.
```
django_heroku.settings(locals())
```
### Django Static
- Now to setup the static assets.
```python
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/1.9/howto/static-files/
STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
STATIC_URL = '/static/'
```
This will basically tell django where to look for the static files and which folder to look for when `collectstatic` is run.
- Install WhiteNoise and update your `requirements.txt` file.
```
pip install whitenoise
```
- Next, install WhiteNoise into your Django application. This is done in settings.py‘s middleware section (at the top):
```python
MIDDLEWARE_CLASSES = (
# Simplified static file serving.
# https://warehouse.python.org/project/whitenoise/
'whitenoise.middleware.WhiteNoiseMiddleware',
...
```
- Finally, if you would like gzip functionality enabled, also add the following setting to settings.py.
```python
# Simplified static file serving.
# https://warehouse.python.org/project/whitenoise/
STATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'
```
We will need to create one more file called `runtime.txt`. This will tell heroku which version of python needs to be installed. This step is optional because heroku will use a python version automatically when building but if you want a specific python version you can add it like this.
```
python-3.8.5
```
That is it for configuring our app for deployment. Now we go to the heroku cli and see how to upload the app.
## Deployment
If you don't have heroku installed on your machine follow this [link](https://devcenter.heroku.com/articles/heroku-cli)
- login to heroku.
```
heroku login
```
After successful login we will be able to create our app directly from the terminal.
- Create a heroku app
```
heroku create
```
This will create a heroku app with a random available name. However, if you want to give a name of your choice, just add the name after `heroku create`. Make sure the name is unique and available.
If you already have a heroku app and want to add the app as a Git remote, you need to execute
```
heroku git:remote -a <yourapp>
```
- Now add all the files to git and commit.
```
git add .
git commit -m "deploy heroku"
```
- Push all the files and build.
```
git push heroku master
```
Once done this will deploy your app. Once deployed, we will need to migrate our database.
```
heroku run bash
```
This will give us a quick terminal to control our app. Here you can run all your django commands.
```
python manage.py migrate
```
- This will migrate all our files to the database.
## Conclusion
That is all for now. If you have followed all the steps above you should have an app which is now running on heroku. If you have come across any issues please leave a comment or knock-me. I will try to help fix them.
Best of luck. Happy coding :D | rabbilyasar |
715,838 | Font Snag in my code | Hey Guys! Quick question.. I have run into a lil snag with my code and not sure what i'm doing wrong.... | 0 | 2021-06-02T09:45:05 | https://dev.to/mikacodez/font-snag-in-my-code-a7g | beginners, help | Hey Guys! Quick question.. I have run into a lil snag with my code and not sure what i'm doing wrong...
Is there any reason my h1 title is coming out as Comic sans instead of any other Google Fonts I try?? | mikacodez |
715,962 | flutter-doctor: Android Studio (not installed) | After installing Android studio and run "flutter-doctor" on windows terminal, it gives me an error sa... | 0 | 2021-06-02T10:47:55 | https://dev.to/thiagoanjos/fixed-android-studio-not-installed-1cao | After installing Android studio and run "flutter-doctor" on windows terminal, it gives me an error saying that: Android Studio ( not installed ). After some research, I found this solution that worked pretty well.
On terminal type: flutter config --android-studio-dir=<android studio path>
**Example on Windows:**
flutter config --android-studio-dir="C:\Program Files\Android\Android Studio"
**Example on Linux:**
flutter config --android-studio-dir="/snap/android-studio/current/android-studio"
| thiagoanjos | |
715,982 | Cryptography- Shift Cipher | Shift cipher is the most basic and simple substitution cipher ever existed. It was used by numerous k... | 0 | 2021-06-06T09:45:15 | https://dev.to/sirri69/cryptography-shift-cipher-2oki | python, security, cybersecurity, javascript |
Shift cipher is the most basic and simple substitution cipher ever existed. It was used by numerous kings and common people in ancient times, because of its simplicity. It is also known as the Caesar cipher as he used a generalized form of it known as ROT-13.
##How Shift Cipher Works:-
Shift cipher is nothing but substitution of letters to their left or right by some specific number of letters, and that number of letters will be known as the key of the cipher. Once the key is decided and the plaintext is encrypted to ciphertext, we can send the cipher text to whomever we want. If he/she will have the key, then he/she will easily decrypt the message and read it and can reply to that encrypting the message with the same key.
##Encrypting the text using Shift Cipher
1. Select a key, if you want to shift your letters to right, choose a number which is positive, a negative number will result in shifting of letters to left side.
2. Once the key is selected, convert the letters to their respective numeric positions, where A->1, B->2 and so on.
Now apply the given formula to every number:-
```
C=(P+K)%26
```
Where P is your plaintext converted to numeric positions, K is the key and C is the numeric positions of the letters in ciphertext.
Now convert the numeric positions of ciphertext (C) to alphabets according to 0->Z, 1->A so on, and you have your plaintext encrypted!!!
Example:-
Let our plaintext to be:-
“ ”
Then numeric positions of our plaintext will be:-
| k | i | l | l | t | h | e | k | i | n | g | t | o | n | i | g | h | t |
|----|---|----|:--:|:--:|---|---|----|---|----|---|----|----|----|---|---|---|----|
| 11 | 9 | 12 | 12 | 20 | 8 | 5 | 11 | 9 | 14 | 7 | 20 | 15 | 14 | 9 | 7 | 8 | 20 |
Let our key be 7, after using the formula for encryption, the number will look like:-
| 11 | 9 | 12 | 12 | 20 | 8 | 5 | 11 | 9 | 14 | 7 | 20 | 15 | 14 | 9 | 7 | 8 | 20 |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| 18 | 16 | 19 | 19 | 1 | 15 | 12 | 18 | 16 | 21 | 14 | 1 | 22 | 21 | 16 | 14 | 15 | 1 |
And finally, converting the numbers back to letters will give us our ciphertext,
| 18 | 16 | 19 | 19 | 1 | 15 | 12 | 18 | 16 | 21 | 14 | 1 | 22 | 21 | 16 | 14 | 15 | 1 |
|:--:|:--:|:--:|:--:|:-:|:--:|:--:|:--:|:--:|:--:|:--:|:-:|:--:|:--:|:--:|:--:|:--:|:-:|
| R | P | S | S | A | O | L | R | P | U | N | A | V | U | P | N | O | A |
Letters after conversion are :-
> 'RPSSAOLRPUNAVUPNOA'
The gibberish above is ciphertext, it is often written without any spaces to add complexity to the ciphertext.
##Writing Python code for Shift Cipher
Writing code for this cipher is really easy, a one liner, some might say. Here's the code:--
```py
def shift_encrypt(plain_text: str, key: int):
cipher_text = [] # stores encrtypted text
plain_text = plain_text.lower().replace(' ','') # reduce complexity
for i in list(plain_text):
cipher_text.append(chr((ord(i)-97 + key)%26 + 97)) # real encryption happens here
return "".join(cipher_text)
```
The code up here is pretty self explanatory, except a few lines. Let's go through all the lines on by one.
```py
cipher_text = [] # stores encrtypted text
plain_text = plain_text.lower().replace(' ','') # reduce complexity
```
These two lines define a list names `cipher_text` to store the text after encryption and reduces the complexity of the plain text by converting the text to lower case and removing all the whitespaces.
Then comes the most important line in the code:-
```py
cipher_text.append(chr((ord(i)-97 + key)%26 + 97))
```
First of all, this line of code converts the letters to their ASCII representation using the `ord` function, which means a will become 97, b will become 98, and so on.
Then it will subtract 97 from the ASCII code, which will convert 97 to 0, hence placing 'a' at 0th position and placing 'z' at 25th position. This is done to simplify the operation of shifting.
After that is done, we proceed and add the `KEY` to shift and actually encrypt the data.
Then we do `mod 26` because after subtracting 97 our alphabets lies from 0 to 25, and doing `mod 26` makes sure that nothing goes out of range of our alphabets. 97 is added in end to convert the the shifted numbers back to their ASCII representations.
After this much is done, we convert the shifted ASCII codes back to characters using the `chr` function. And the encryption is done.
You can see that this line is inside a for loop, that is to ensure that the transformation in this line of code is applied to every single letter of the `plain_text`.
In the end,
```py
return "".join(cipher_text)
```
We convert the encrypted characters to a string and return it.
Decryption part of the cipher is also pretty much the same, except a small thing.
```py
def shift_decrypt(cipher_text: str, key: int):
plain_text = []
cipher_text = cipher_text.lower().replace(' ','')
for i in cipher_text:
plain_text.append(chr((ord(i)-97 - key)%26 + 97))
return "".join(plain_text)
```
Instead of adding `KEY`, we subtract it this time to perform a inverse of the shift operation we did in the encryption process.
You can try the code here:--
(JUST CLICK ON THE RUN(>) BUTTON)
{% replit @PranavPatel4/CryptoCode %} | sirri69 |
716,131 | Python on the ev3dev framework | Introduction: Recently, I have been working on a project to use Python on the ev3dev platf... | 0 | 2021-06-02T15:27:23 | https://dev.to/colewilson/python-on-the-ev3dev-framework-4ali | python, ev3, robotics, linux | ---
title: Python on the ev3dev framework
published: true
date: 2020-07-20 21:37:53 UTC
tags: python,ev3,robotics,linux
canonical_url:
---
## Introduction:
Recently, I have been working on a project to use Python on the ev3dev platform. This is useful, because you can write complex programs for your robots. For example, you could [connect the ev3 to a PS4 controller.](https://by-the-w3i.github.io/2018/01/03/EV3-PS4-controller/) For me, I was working on a SumoBot, a robot that battles with another, and tries to push it out of a ring. However, this approach will work with an sort of robot.
## Overview:
In this tuorial, I will show you how to:
- Download the ev3dev operating system for your brick.
- Connect your brick to your Windows or Mac computer.
- Setup PyCharm on your computer.
- Connect to a GitHub repo.
- Sync the code to your brick.
## Materials:
You will need the following:
- A Windows or Mac with a working Internet and Bluetooth connection.
- An ev3 brick with various sensor and motors.
- A 2-16gb SD card.
- A way to put the SD card into your computer.
## 1: Getting started:
1. First, you will have to download the ev3dev boot image for the ev3 brick. This enables it to work with the Python programming language. You can find the image here.
2. Unzip the file, and move the contents to somewhere where you can easily access them.
3. Next, flash the image onto your SD card.
> **Note:** to do this, use a program like Etcher, or Rufus, or use the command line. Make sure that you select the correct disk image.
4. Insert the SD card into the slot in the brick. Make sure that your brick is off.
5. Next, turn on your brick. It will flash wierdly and show lots of text. If it doesn’t show a menu screen in 15 minutes, repeat steps 4-5.
6. Next, we need to connect the brick to your computer.
7. [View this website for instructions on how to connect your brick to the computer.](https://www.ev3dev.org/docs/tutorials/connecting-to-the-internet-via-bluetooth/)
8. Connect to your computer with ssh:
- If you have a Windows computer download PuTTy, and launch it. Next type in `ev3dev.local`

- Then, type `robot` as the username.
- If you have a Mac, then open Terminal, then type `ssh robot@ev3dev.local`
- Next type in `maker` as the password.
> Having an error message? Make sure your robot is on, and that you have connected the brick. Also, make sure you have the correct username and password.
- You have access to your brick’s inner workings! Try typing `fortune` to get a witty response from the computer.
- Your home folder is `/home/robot` this is where you are put when you connect to the brick.
> **Some basic commands:**
>
> - **cd {path}** : changes the current working directory to
> - **ls** : This shows all the files and folders in the current working directory.
> - **cat {file}** : This returns the contents of the specified file.
> - **nano {file}** : This opens an editor for the specified file. Press `ctrl+x` (`^x`)to save and exit.
> - **clear** : Clears the terminal.
> - **logout** : Logs out of remote connection.
> - **rm -rf {path}** : Deletes file or folder. - **python3 {file}** : Runs the specified python program.
- Right now, you can `nano` files into existence and run them from the terminal, but this is less than ideal, in the next section, you will set up PyCharm and Git.
## 2: Setting up a Development Environment:
1. [Download PyCharm community edition](https://www.jetbrains.com/pycharm/download/) (or the Pro version if you have it, it’s not needed.)
2. Open the file and install it to your computer.
3. If you have Windows, you have to configure Git, if you have Mac, you already have it installed, so skip to step 4.
- Download [git-scm for Windows](https://git-scm.com/download/win).
- Open and follow the install instructions with default options.
- Open PyCharm, and push `ctrl + alt + s` to open preferences.
- Goto `Version Control > git` and in the top file path put `C:\Users\<your username>\AppData\Local\Programs\Git\git.exe`
4. Now, [get a GitHub account](https://github.com/signup) if you don’t have one yet. They are free, and tremendously useful.
5. Goto [https://github.com/new](https://github.com/new) and create a new repository with the name `ev3`, and select the option to include a `README.md`.

6. Open PyCharm.
7. Goto `Checkout from Version Control` and go to the GitHub tab. Sign in, and select your `ev3` repository. 
8. Now, you should have your code in PyCharm. As you can see, all that you have now is a file called `README.md`.
## 3: Adding Code to the Program.
1. First, in the upper lefthand corner, it will say your project name. Right click on it, and push Create New Python file.
2. Pycham should ask you if you wan to add the file to Git. You should do this, and select the option to automatically do this.
3. In the new file, type:
```
import time
print('The program is starting...')
time.sleep(2)
print('The program is ending.')
```
4. In the VCs tab in PyCharm, press commit changes.
5. Click the blue arrow next to the COMMIT button, and push `Commit and Push`.
6. Then push `Push`.
7. Your code is now on GitHub, but how to get it on the brick?
> You can view your code by going to https://github.com/{your-username}/ev3.
## 4: Adding code to the brick:
1. If you are on Windows, open Git-Bash from the start menu, if you have a Mac, open Terminal.
2. Type `git clone https://github.com/{ github username }/ev3.git`. This copies your code into a local file.
3. Next, type `sftp robot@ev3dev.local`, _notice it is not `ssh`_
4. Put in your password.
5. Now type `cd ~`, then `put ev3`
6. Now open up your SSH session. Type `ls` to view your files.
7. You should see a blue or green folder called `ev3`
8. Go into the folder by typing `cd ~/ev3`
9. Then, type `python3 main.py`
10. Your program takes a while to load, but then it runs!
## 5. Simplifying the process:
1. Every time you would like to add code to your robot, you will have to remove the old code from the robot, and then do all of sections 3 and 4 again.
2. We will simplify this process.
3. Close your terminal. (Either Git-Bash, or Terminal)
4. Open a new terminal.
5. Type nano `e.sh`
6. Add this code to the file:
```
echo "Starting..."
rm -rf ev3
git clone htttps://github.com/< username >/ev3
sftp robot@ev3.local:~ <<< $'put {ev3}'
echo "Done."
```
7. Push `^X` to save, and type `chmod + x e.sh`
8. Now, all you have to do is type `rm -rf ~/ev3` on the robot, and `sh e.sh` on the local computer to update the brick.
9. We can go even further and make custom commands on the brick!
10. On the brick, type `sudo nano /etc/bash/bash.rc` and enter your password.
11. Add this to the end of the file:
```
alias prep='rm -rf ~/ev3'
alias run='python3 ~/ev3/main.py'
```
12. Restart the brick.
## 6. So far…
Now, you write the program in Pycharm, and commit+push to GitHub. Then, on an SSH session, you type `prep` to clear the brick. Then, on your local terminal, type `sh e.sh`. On your SSH session, type `run`. | colewilson |
716,278 | CSS object-fit 속성 사용하기 | CSS object-fit 속성 사용하기 오늘은 CSS의 object-fit 속성을 사용해볼 것입니다. 최근 프로필 컴포넌트 개발 중 정사각형 컨테이너... | 0 | 2021-06-02T15:46:41 | https://dev.to/smilejin92/css-object-fit-mdg | html, css | # CSS object-fit 속성 사용하기
오늘은 CSS의 `object-fit` 속성을 사용해볼 것입니다.
최근 프로필 컴포넌트 개발 중 정사각형 컨테이너에 프로필 이미지를 표시해야하는 일이 있었습니다. 요구사항을 구체적으로 작성해보면 아래와 같습니다.
* 만약 이미지 크기가 컨테이너 크기보다 작거나 같다면, 컨테이너에 가득 채워서 표시
* 만약 이미지 크기가 컨테이너 크기보다 크다면, 해당 이미지의 정중앙 영역을 컨테이너 크기만큼 표시
바쁘신 분들은 [샌드박스 링크](https://codesandbox.io/s/css-object-fit-property-ubwgu)에 방문하여 소스코드를 먼저 살펴봐주세요.
## 1. width 100%; height 100%;
가장 먼저 시도해본 것은 이미지 전체를 컨테이너에 맞춰 표시해보는 것이었습니다. 아래 코드를 확인해주세요.
```html
<section>
<h2>1. 너비가 높이보다 더 큰 이미지</h2>
<div class="block">
<div class="img-wrapper">
<!-- 컨테이너 너비에 맞춤 -->
<img class="fit-width" src="./greater-width.jpg" alt="프로필 이미지" />
</div>
<div class="img-wrapper">
<!-- 컨테이너 높이에 맞춤 -->
<img class="fit-height" src="./greater-width.jpg" alt="프로필 이미지" />
</div>
<div class="img-wrapper">
<!-- 컨테이너 너비, 높이에 맞춤 -->
<img class="fit-width-height" src="./greater-width.jpg" alt="프로필 이미지"/>
</div>
</div>
</section>
<section>
<h2>2. 높이가 너비보다 더 큰 이미지</h2>
<div class="block">
<div class="img-wrapper">
<!-- 컨테이너 너비에 맞춤 -->
<img class="fit-width" src="./greater-height.jpg" alt="프로필 이미지" />
</div>
<div class="img-wrapper">
<!-- 컨테이너 높이에 맞춤 -->
<img class="fit-height" src="./greater-height.jpg" alt="프로필 이미지" />
</div>
<div class="img-wrapper">
<!-- 컨테이너 너비, 높이에 맞춤 -->
<img class="fit-width-height" src="./greater-height.jpg" alt="프로필 이미지" />
</div>
</div>
</section>
```
```css
/* width에 맞추기 */
.fit-width {
width: 100%;
}
/* height에 맞추기 */
.fit-height {
height: 100%;
}
/* width, height 둘 다 맞추기 */
.fit-width-height {
width: 100%;
height: 100%;
}
```

너비가 더 큰 이미지를 컨테이너 너비에 맞춰 표시하면 하단 여백이 남습니다. 반대로, 컨테이너 높이에 맞춰 표시하면 이미지가 컨테이너 밖으로 넘치게되죠. 최후의 수단인 `width: 100%; height: 100%`를 사용했지만 역시 이미지 비율이 유지되지 않습니다. 이러한 문제는 높이가 더 큰 이미지에서도 똑같이 발생합니다. 이 방법은 아닌 것 같아요.
## 2. background-image 사용
두 번째로 시도한 방법은 `<img>` 태그가 아닌 다른 태그를 사용하여, 해당 요소의 배경 이미지로 프로필 이미지를 표시하는 것이었습니다. 아래 코드를 확인해주세요.
```html
<section>
<h2>3. background-image 사용</h2>
<div class="block">
<div class="img-wrapper">
<div class="background greater-width-img"></div>
</div>
<div class="img-wrapper">
<div class="background greater-height-img"></div>
</div>
</div>
</section>
```
```css
/* background-image 사용 */
.background {
width: 100%;
height: 100%;
background-position: center;
background-size: cover;
}
.greater-width-img {
background-image: url("./greater-width.jpg");
}
.greater-height-img {
background-image: url("./greater-height.jpg");
}
```

`background-image`를 사용하여 프로필 이미지를 표시했을 때, 앞서 작성한 요구사항을 모두 충족합니다. 하지만 마크업이 마음에 들지 않아요. 무언가 semantic하지 않은 느낌입니다. 접근성 관점에서도 만족스럽지 않아요. `role`, `aria-label` 속성을 사용하여 마크업을 수정해보았습니다.
```html
<section>
<h2>3. background-image 사용</h2>
<div class="block">
<div class="img-wrapper" role="img" aria-label="프로필 이미지">
<div class="background greater-width-img"></div>
</div>
<div class="img-wrapper" role="img" aria-label="프로필 이미지">
<div class="background greater-height-img"></div>
</div>
</div>
</section>
```
ARIA 속성을 사용하여 마크업을 수정했지만, 그래도 의미에 맞는 `<img>` 태그를 사용하고 싶어요. 이때 사용한 속성이 `object-fit` 속성입니다.
## 3. object-fit
CSS `object-fit` 속성은 **대체 요소(replaced element)**의 컨텐츠를 컨테이너 크기에 맞게 설정한다고 합니다. 그렇다면 대체 요소는 무엇일까요?
> **replaced element**
>
> **elements whose contents are not affected by the current document's styles.** The position of the replaced element can be affected using CSS, but not the contents of the replaced element itself.
>
> ex) `<iframe>`, `<video>`, `<embed>`, `<img>`
>
> 출처: https://developer.mozilla.org/en-US/docs/Web/CSS/Replaced_element
대체 요소는 자신의 컨텐츠가 문서 스타일(document's styles)에 영향을 받지 않는 요소를 뜻합니다. 즉, CSS 스코프에서 벗어난 친구들이죠. 하지만 딱 두 가지 경우 CSS의 영향을 받는다고 적혀있습니다.
1. 대체 요소의 위치 설정(대체 요소의 컨텐츠 위치 X)
2. **컨테이너 영역 안에서** 대체 요소의 컨텐츠를 positioning
여기서부터 뇌피셜이지만, 첫 번째 경우 `<img>` 요소는 CSS로 위치를 변경 할 수 있지만, `<img>` 요소의 컨텐츠인 이미지 그 자체는 위치를 변경 할 수 없다는 뜻으로 이해했습니다.
두 번째 경우는 `<img>` 요소의 컨텐츠인 이미지를 컨테이너 영역 안에서 제어하는 [CSS 속성](https://developer.mozilla.org/en-US/docs/Web/CSS/Replaced_element#controlling_object_position_within_the_content_box)이 있다는 것입니다. 그 중 하나가 오늘 사용해볼 `object-fit` 속성입니다.
```html
<section>
<h2>4. object-fit 속성 사용</h2>
<div class="block">
<div class="img-wrapper">
<img class="object-fit" src="./greater-width.jpg" alt="프로필 이미지" />
</div>
<div class="img-wrapper">
<img class="object-fit" src="./greater-height.jpg" alt="프로필 이미지" />
</div>
</div>
</div>
</section>
```
```css
/* object-fit 사용 */
.object-fit {
display: block;
width: 100%;
height: 100%;
object-fit: cover;
}
```

`object-fit` 속성을 사용하여 앞서 요구사항에 맞게 코드를 작성 할 수 있었습니다. 주의해야 할 것은 `object-fit` 속성은 IE에서 전혀 지원되지 않는다는 것입니다. 아래는 브라우저별 지원 현황입니다. (2021/6/3 기준)

이번 포스트는 여기서 마치도록 하겠습니다.
| smilejin92 |
716,289 | Node.Js Api Cheat Sheet | Spawn - passthru the in/out var spawn = require('child_process').spawn; var proc = spawn... | 0 | 2021-06-02T16:09:23 | https://dev.to/kimanh333/node-js-api-cheat-sheet-53j5 | node, cheatsheet, javascript, java |
### Spawn - passthru the in/out
var spawn = require('child_process').spawn;
var proc = spawn(bin, argv, { stdio: 'inherit' });
proc.on('error', function(err) {
if (err.code == "ENOENT") { "does not exist" }
if (err.code == "EACCES") { "not executable" }
});
proc.on('exit', function(code) { ... });
// also { stdio: ['pipe', 'pipe', process.stdout] }
// also { stdio: [process.stdin, process.stderr, process.stdout] }
proc.stdout.on('data', function (data) {
});
proc.stderr.on('data', function (data) {
});
[all]: http://nodejs.org/api/all.html
### Snippets
info = require('../package.json')
info.version
process.stdout.write(util.inspect(objekt, false, Infinity, true) + '\n');
### [Globals] exec
var exec = require('child_process').exec,
var child = exec('cat *.js bad_file | wc -l',
function (error, stdout, stderr) {
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
if (error !== null) {
console.log('exec error: ' + error);
}
});
### Globals
__filename
__dirname
### Reference
* [Node.Js Api Cheat Sheet](https://cheatsheetmaker.com/nodejs-api) - [Cheat Sheet Maker](https://cheatsheetmaker.com) | kimanh333 |
716,335 | Using Custom Events to communicate between legacy jQuery code and new Framework code | This is an updated version of one my older blogs: Old Post While writing a new feature using React o... | 0 | 2021-06-02T17:52:13 | https://dev.to/findniya/using-custom-events-to-communicate-between-legacy-jquery-code-and-new-framework-code-1kof | react, javascript, legacycode, codequality | *This is an updated version of one my older blogs: [Old Post](https://medium.com/@findniya/using-custom-events-to-communicate-between-legacy-jquery-code-and-new-framework-code-e34bb725c734)*
While writing a new feature using React one of my hurdles was figuring out a way to make the new React code and the old jQuery code communicate with each other. My new component, had to get date and time from the date picker written in jQuery code as users interacted with it. At this time I didn’t have the option to rewrite the date picker in React.
My solution to this problem was to use Custom Events.
The custom event was setup in the jQuery function to dispatch every time it returned a result. Then I setup the React component to listen for this custom event and update state.
###Let’s Look At Some Code Samples
**The React Component:**
```
const MyComponent ()=> {
const [dateRange, setDateRange] = useState({from:'', to:''})
return <div id='containerId' />
}
```
This component renders a div with an id that I will need for the jQuery to use. My state object has the keys from and to that needs the date and time information from the jQuery date picker.
###Part of jQuery Code handling the DatePicker:
```
setDateTime: function() {
var from = moment(picker.from).utcOffset(this.utcOffset());
var to = moment(picker.to).utcOffset(this.utcOffset());
this.setView(from, to);
}
```
The above snippet is the small part of a larger file using global variables to trigger the `setDateTime` function. This then passes the `from` and `to` values to other functions in the jQuery file. Functionally the jQuery date picker works well, code wise though its super fragile and impossibly hard to figure how it all connects.
Thankfully the above snippet is all I needed. Every time the `setDateTime` function was triggered I need it to send the `from` and `to` values to my React component.
###Adding my custom event:
```
setDateTime: function() {
var from = moment(picker.from).utcOffset(this.utcOffset());
var to = moment(picker.to).utcOffset(this.utcOffset());
var myEvent = new CustomEvent('dateTimeEvent',
{ bubbles: true, detail: { dateTime: {from, to} });
document.querySelector('#containerId').dispatchEvent(myEvent);
this.setView(from, to);
}
```
As the `from` and `to` are set in the setDateTime function, I have my custom event named myEvent that then bubbles the dateTime object with these values. The event is dispatched to the `div` with the `id='containerId'` in my React component. This function does not in any way interfere with the rest of the jQuery code. It just passes the information I need without changing any other existing functionality.
###Update the React Component
```
useEffect(()=>{
window.addEventListener('dateTimeEvent',
onDateTimeChange(e))
},[])
```
I added the event listener to the `useEffect`. Any time the `setDateTime` function in the jQuery is triggered the listener will capture `dateTime` object and pass it into my function `onDateTimeChange`.
```
const onDateTimeChange = (e) => {
setDateRange({
from: e.detail.dateTime.from,
to: e.detail.dateTime.to
})
}
```
Every time the `onDateTimeChange` is triggered it updates state in my React component with the date time value from the jQuery code.
In this way my new React component could coexist with the jQuery date picker without having to worry about the legacy code interfering. Plus the changes to the jQuery code were minimal and didn’t affect any of its existing functions.
###What The React Component Looks Like Now
```
const MyComponent ()=> {
const [dateRange, setDateRange] = useState({from:'', to:''})
const onDateTimeChange = (e) => {
setDateRange({
from: e.detail.dateTime.from,
to: e.detail.dateTime.to
})
}
useEffect(()=>{
window.addEventListener('dateTimeEvent',
onDateTimeChange(e))
},[])
return <div id='containerId' />
}
```
This was an interim solution that allowed me to continue working on the new feature, without having to do a costly rewrite at the same time. | findniya |
716,560 | The Right Way and the Wrong Way to use Switch Statements | Once I learned how to write switch statement, I never wanted to go back to if/else statements... | 0 | 2021-06-14T20:43:56 | https://dev.to/mathlete/the-right-way-and-the-wrong-way-to-use-switch-statements-9m2 | <img width="100%" style="width:100%" src="https://media.giphy.com/media/MbXKzbvQOgRZ6/giphy.gif">
Once I learned how to write `switch` statement, I never wanted to go back to `if`/`else` statements because switch statements are so much cleaner looking and easier to read. But I have learned that even if a switch statement works correctly, that doesn't mean you've used it correctly. My mistake was using `true` as the expression to be evaluated. Even though it works, this is considered bad practice.
The [Mozilla Developer Network Web Docs states the following:](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/switch)
> A switch statement first evaluates its expression. It then looks for the first case clause whose expression evaluates to the same value as the result of the input expression...
####The Wrong Way to use a `switch` statement
```javascript
let myVar = "Saturday";
myFunction = () => {
switch (true) {
case myVar === "Tuesday":
console.log("weekday");
case myVar === "Saturday":
console.log("weekend");
default:
return null;
}
};
myFunction();
// "weekend"
```
---
####The Right Way to use a `switch` statement
```javascript
let myVar = "Saturday";
myFunction = () => {
switch (myVar) {
case "Tuesday":
console.log("weekday");
case "Saturday":
console.log("weekend");
default:
return null;
}
};
myFunction();
// "weekend"
```
####Controversy
That said, [some people](https://seanbarry.dev/posts/switch-true-pattern) like using the `switch (true)` pattern because it can make code blocks easier to read compared to long, complex `if`/`else` statements. This whole issue is [quite controversial](https://news.ycombinator.com/item?id=26777090). My advice is to only use the `switch (true)` pattern under the following circumstances:
1. The readability of the code is significantly improved when using `switch (true)`
2. Your team is ok with using this pattern
####Another Wrong Usage of a Switch statement: Comparing Values
While we're on the subject, you can't use the `switch` statement if you are comparing values. As said above, `switch` is for evaluating the input expression and then testing to find the first case expression whose evaluation matches the input expression. For example, this won't work:
####The Wrong Way to compare values
```javascript
let myVar = 5;
myFunction = () => {
switch (myVar) {
case myVar > 10:
console.log(`greater than ten`);
case myVar < 10:
console.log(`less than ten`);
default:
return null;
}
};
myFunction();
```
####The Right Way to compare values
```javascript
let myVar = 5;
myFunction = () => {
if (myVar > 10) {
console.log(`greater than ten`);
} else if (myVar < 10) {
console.log(`less than ten`);
}
};
myFunction();
// less than ten
```
The moral of the story is:
- Use a `switch` statement if you want to *test* the value of a variable
- Use an `if`/`else` statement if you want to *compare* the value of a variable | mathlete | |
716,728 | New Demo POsts | Writing a Great Post Title Think of your post title as a super short (but compelling!) description... | 0 | 2021-06-03T04:55:58 | https://dev.to/thefuckergithub/new-demo-posts-575h | ddddd, eeeee, fffff, ggggg | Writing a Great Post Title
Think of your post title as a super short (but compelling!) description — like an overview of the actual post in one short sentence.
Use keywords where appropriate to help ensure people can find your post by search.
 | thefuckergithub |
716,840 | Solution: Maximum Area of a Piece of Cake After Horizontal and Vertical Cuts | This is part of a series of Leetcode solution explanations (index). If you liked this solution or fou... | 11,116 | 2021-06-03T08:16:36 | https://dev.to/seanpgallivan/solution-maximum-area-of-a-piece-of-cake-after-horizontal-and-vertical-cuts-45p8 | algorithms, javascript, java, python | *This is part of a series of Leetcode solution explanations ([index](https://dev.to/seanpgallivan/leetcode-solutions-index-57fl)). If you liked this solution or found it useful,* ***please like*** *this post and/or* ***upvote*** *[my solution post on Leetcode's forums](https://leetcode.com/problems/maximum-area-of-a-piece-of-cake-after-horizontal-and-vertical-cuts/discuss/1248591).*
---
#### [Leetcode Problem #1465 (*Medium*): Maximum Area of a Piece of Cake After Horizontal and Vertical Cuts](https://leetcode.com/problems/maximum-area-of-a-piece-of-cake-after-horizontal-and-vertical-cuts/)
---
#### ***Description:***
<br />(*Jump to*: [*Solution Idea*](#idea) || *Code*: [*JavaScript*](#javascript-code) | [*Python*](#python-code) | [*Java*](#java-code) | [*C++*](#c-code))
>
Given a rectangular cake with height `h` and width `w`, and two arrays of integers `horizontalCuts` and `verticalCuts` where `horizontalCuts[i]` is the distance from the top of the rectangular cake to the `i`th horizontal cut and similarly, `verticalCuts[j]` is the distance from the left of the rectangular cake to the `j`th vertical cut.
>
Return _the maximum area of a piece of cake after you cut at each horizontal and vertical position provided in the arrays `horizontalCuts` and `verticalCuts`_. Since the answer can be a huge number, return this modulo `10^9 + 7`.
---
#### ***Examples:***
>
Example 1:||
|---:|---|
Input:| h = 5, w = 4, horizontalCuts = [1,2,4], verticalCuts = [1,3]
Output:| 4
Explanation:| The figure above represents the given rectangular cake. Red lines are the horizontal and vertical cuts. After you cut the cake, the green piece of cake has the maximum area.
Visual:|
>
Example 2:||
|---:|---|
Input:| h = 5, w = 4, horizontalCuts = [3,1], verticalCuts = [1]
Output:| 6
Explanation:| The figure above represents the given rectangular cake. Red lines are the horizontal and vertical cuts. After you cut the cake, the green and yellow pieces of cake have the maximum area.
Visual:|
>
Example 3:||
|---:|---|
Input:| h = 5, w = 4, horizontalCuts = [3], verticalCuts = [3]
Output:| 9
---
#### ***Constraints:***
>
- `2 <= h, w <= 10^9`
- `1 <= horizontalCuts.length < min(h, 10^5)`
- `1 <= verticalCuts.length < min(w, 10^5)`
- `1 <= horizontalCuts[i] < h`
- `1 <= verticalCuts[i] < w`
- It is guaranteed that all elements in `horizontalCuts` are distinct.
- It is guaranteed that all elements in `verticalCuts` are distinct.
---
#### ***Idea:***
<br />(*Jump to*: [*Problem Description*](#description) || *Code*: [*JavaScript*](#javascript-code) | [*Python*](#python-code) | [*Java*](#java-code) | [*C++*](#c-code))
The trick to this problem is realizing that if the horizontal slices and vertical slices are perpendicular, then all vertical slices cross all horizontal slices. This means that we just need to find the largest of each, and the cross-section should be the largest slice.
To find the largest slice of each, we need to first **sort** the horizontal cuts (**hc**) and vertical cuts (**vc**), then iterate through both sets and keep track of the maximum difference found between two consecutive cuts (**maxh**, **maxv**). We need to not forget to include the two end cuts, which are found using **0** and **h**/**w**, as well.
Once we have the largest difference for both, we can just **return** the product of these two numbers, **modulo 1e9+7**.
- _**Time Complexity: O(N * log(N) + M * log(M))** where **N** is the length of **hc** and **M** is the length of **vc**_
- _**Space Complexity: O(1)**_
---
#### ***Javascript Code:***
<br />(*Jump to*: [*Problem Description*](#description) || [*Solution Idea*](#idea))
```javascript
var maxArea = function(h, w, hc, vc) {
hc.sort((a,b) => a - b)
vc.sort((a,b) => a - b)
let maxh = Math.max(hc[0], h - hc[hc.length-1]),
maxv = Math.max(vc[0], w - vc[vc.length-1])
for (let i = 1; i < hc.length; i++)
maxh = Math.max(maxh, hc[i] - hc[i-1])
for (let i = 1; i < vc.length; i++)
maxv = Math.max(maxv, vc[i] - vc[i-1])
return BigInt(maxh) * BigInt(maxv) % 1000000007n
};
```
---
#### ***Python Code:***
<br />(*Jump to*: [*Problem Description*](#description) || [*Solution Idea*](#idea))
```python
class Solution:
def maxArea(self, h: int, w: int, hc: List[int], vc: List[int]) -> int:
hc.sort()
vc.sort()
maxh, maxv = max(hc[0], h - hc[-1]), max(vc[0], w - vc[-1])
for i in range(1, len(hc)):
maxh = max(maxh, hc[i] - hc[i-1])
for i in range(1, len(vc)):
maxv = max(maxv, vc[i] - vc[i-1])
return (maxh * maxv) % 1000000007
```
---
#### ***Java Code:***
<br />(*Jump to*: [*Problem Description*](#description) || [*Solution Idea*](#idea))
```java
class Solution {
public int maxArea(int h, int w, int[] hc, int[] vc) {
Arrays.sort(hc);
Arrays.sort(vc);
int maxh = Math.max(hc[0], h - hc[hc.length-1]),
maxv = Math.max(vc[0], w - vc[vc.length-1]);
for (int i = 1; i < hc.length; i++)
maxh = Math.max(maxh, hc[i] - hc[i-1]);
for (int i = 1; i < vc.length; i++)
maxv = Math.max(maxv, vc[i] - vc[i-1]);
return (int)((long)maxh * maxv % 1000000007);
}
}
```
---
#### ***C++ Code:***
<br />(*Jump to*: [*Problem Description*](#description) || [*Solution Idea*](#idea))
```c++
class Solution {
public:
int maxArea(int h, int w, vector<int>& hc, vector<int>& vc) {
sort(hc.begin(), hc.end());
sort(vc.begin(), vc.end());
int maxh = max(hc[0], h - hc.back()),
maxv = max(vc[0], w - vc.back());
for (int i = 1; i < hc.size(); i++)
maxh = max(maxh, hc[i] - hc[i-1]);
for (int i = 1; i < vc.size(); i++)
maxv = max(maxv, vc[i] - vc[i-1]);
return (int)((long)maxh * maxv % 1000000007);
}
};
``` | seanpgallivan |
716,903 | Why not to "Abandon React!!1" | The past two years there has been a growing dissatisfaction towards React. You can find people trying... | 0 | 2021-06-03T10:09:37 | https://dev.to/merri/why-not-to-abandon-react-1-3nai | react, javascript, webdev | The past two years there has been a growing dissatisfaction towards React. You can find people trying to find arguments against choosing React. I've done that too, because there are some severe issues in how we use (or don't use) React. Mostly the issues have to do with stuff like performance, search engine optimization, accessibility. It is easy to point your finger to what appears to be the "root of all evil", React.
So what are the problems with React and are there any ways we could deal with them?
## "React becomes messy in large applications"
The above is one of the statements which I could agree on, but not without conditions. Because the real problem here is not really React in itself!
The biggest thing one can argue against React is how it puts HTML and DOM away from sight. When looking at JSX you don't really see that much of clean HTML structure by looking at all the combinations of components. This means that to have good HTML you really have to have good component level abstraction which would allow pretty much any developer to produce mostly good semantic HTML with minimal effort. Or you'd have to setup tooling that validates HTML, and aggresively encourage using browser devtools with focus on the HTML.
And these things are a problem. First one requires there to be at least one developer who builds good component abstractions so other could just focus on building a good app. Second one means you need somebody to be aware of the need in the first place, and the time to do that and actively advocate.
To me it seems neither of the above really happens. Instead you have a lot of projects where people have chosen React because that is what everybody is using, yet the teams consist more of generalist programmers rather than many who have high HTML, CSS, web standards knowledge.
And once we have this kind of a team: how likely you think it is that they choose the best additional libraries to use? I'll throw one example that probably shouldn't have caught as much popularity as it has: CSS-in-JS.
Why I say this? Well, it limits even further the visibility and knowledge of web standards, in this case CSS. You're unlikely to learn much of CSS selector usage with CSS-in-JS, mostly you deal with just pretty basic styling. CSS-in-JS also encourages "duct tape" type of components, so when discipline is missing instead of having a good set of base components you end up with lots of style utility components.
This kind of embracing React and JavaScript, and sort of an "elimination of web standards" from direct visibility is likely a reason why many new front-end developers working at companies have quite a challenge creating good usable, accessible components with semantic HTML, and robust CSS. The written code doesn't embrace them and the only way you gain the knowledge is by knowing to research, likely requiring one to spend their free time to learn, or by having a mentor who knows the web well.
## "React is bad for thing X"
You have HTML mostly out of sight because JSX, and focus being on components. You have CSS mostly out of sight because CSS-in-JS. You have everything controlled via JavaScript.
A truly wonderful thing about HTML is how fast browsers can process it. And the same goes for CSS. The traditional wisdom has been to have as little JavaScript as possible. We used to only enrich HTML progressively with JS.
With React this has turned upside down. One of the reasons for this is how we use React. We probably render the entire page with React on server side. Then we also take control of the whole client DOM tree with React. This means the whole page is being taken over by JavaScript.
To workaround performance issues we have thought to do intelligent code splitting, so bundles per page could be smaller. The typical end result to this is pages with something like 20+ JS bundles being loaded on first page load. Because we also thought prefetching improves performance for the next page load.
We now have tools like Lighthouse and Web Vitals to measure how this kind of setup performs, and well, it ain't pretty. It is very hard to optimize when React takes over the entire DOM.
There are also other issues with React taking over the entire DOM. A typical example is growth hacking. While I don't really like the whole concept and the current way it is being done with A/B testing that needs months of time to see any results, it is still a thing that exists and companies seem to like to do it. And the challenge here is that you need to provide places for external scripts to hook into your page. This easily gets into conflict with React having made to have the entire DOM for itself!
Growth hacking is not the only case. People may use Google Translate, or other localization tools. React controlled sites tend to break pretty bad and become unusable. For a business this can mean lost sales.
## Fixing the process
For companies with a continuous project there are a couple of things they can do to help avoid these issues from piling up. One possibility is to hire more of your own developers, and aim for having people working on your projects for longer. Give them time to learn alongside work, maybe arrange mentorship, ensure you have some devs with longer experience, and especially people who are passionate specifically about the web. Prioritize your business needs so that there aren't too many big features needing to be done at the same time.
I think all of these are very hard and not many companies can confidently cross all the boxes. Of course consultants can work fine as well, but it is harder to guarantee their longevity in a project. Many consultancy companies seem to favor rotation to ensure satisfaction with new challenges every now and then.
As for developer level one of the things is to reconsider the way React apps are written: maybe you don't need to wrap the entire HTML everywhere. Maybe you can have "widgets" instead: load React miniapp for specific feature as needed. So even if you render the whole page with React on server side, you could abandon most of universality, as that will guarantee you don't need to hydrate the entire DOM tree with React in one go. This is a very possible scenario for sites that have content focus.
Of course this kind of change is hard to accomplish. Some of you may use React frameworks like Gatsby or Next.js. So far I haven't had a look whether these frameworks can be customized this much; probably not. Luckily there is a new player on town that lets you have only as much JS as you need: [Remix](https://remix.run/). It is still in beta, but it encourages existing web standards a lot more than other solutions. In the other hand it does cost money, so that can be a blocker for new devs.
## Use the web standards
As conclusion React is a valuable tool and we get stuff done with it. The problems we may have with it is in the way we use it, often due to ignoring cost of hydrating and controlling the entire DOM tree on client browser, and in the other hand by encouraging coding where JavaScript is made to control everything.
To cure this: embrace HTML and CSS over JS (when it makes sense). Front-end facing code should reflect more that you're working with HTML and CSS. Accomplishing this is not an easy task, and I don't yet know how to actually successfully shift code so that even though you'd be using React, you would also bring HTML and CSS in as first-class citizens. So that even the new devs working with the code would get the idea of what is important on the browser side, that it wouldn't get lost in all the code even on a larger project.
A possible issue here is that we're breaking the "universality" of having the exact same code executing on client and server.
I guess splitting to two parts may feel like we might be doing "double the work", but I think that might be an illusion. Often the features we do for browser side are very front-end only. Some things like checkouts might not even make much sense to have with server side rendering.
But I don't know. How do you feel about React codebases that you face every day? Does it seem like HTML and CSS is obvious to you, or is it out of your face? If someone with less experience had a look at the code would web standards be obvious to them? Do your tests reflect that, indeed, you are really outputting HTML? Do the tests include accessibility checks? HTML validation? Is the code rich on a variety of HTML elements, or do you only have a bunch of divs and spans? Does the JavaScript code rely on native browser features, or are existing browser features rather mimicked by JS?
At least I miss many of these on my everyday project at work. | merri |
717,037 | Day 81 of 100 Days of SwiftUI | I just completed day 81 of 100 days of swiftui. Today, I learnt about how to schedule local notificat... | 0 | 2021-06-03T13:38:22 | https://dev.to/sanmiade/day-81-of-100-days-of-swiftui-17jp | swift, 100daysofcode | I just completed day 81 of 100 days of swiftui. Today, I learnt about how to schedule local notifications and also how to add packages in Xcode. | sanmiade |
717,081 | Perry Morse on the Amazon Appstore: | https://www.amazon.com/s?i=mobile-apps&rh=p_4%3APerry+Morse&search-type=ss | 0 | 2021-06-03T14:41:53 | https://dev.to/morse_game_dev/perry-morse-on-the-amazon-appstore-5c1j | https://www.amazon.com/s?i=mobile-apps&rh=p_4%3APerry+Morse&search-type=ss | morse_game_dev | |
717,118 | How to handle different keyboard layouts in X11 Ubuntu in c language | I have app which runs x11 server to receive keyboard and mouse events. Please let me know how I can d... | 0 | 2021-06-03T15:37:37 | https://dev.to/osakishore/how-to-handle-different-keyboard-layouts-in-x11-51cc | I have app which runs x11 server to receive keyboard and mouse events. Please let me know how I can detect different types of keyboard layouts & how to get keycode & charcode. I want to support different keyboard layouts. | osakishore | |
717,386 | Stand-up | For June, the monthly Virtual Coffee, a developer community, challenge is to build in public. As part... | 0 | 2021-06-04T19:05:42 | https://dev.to/jarvisscript/stand-up-37al | For June, the monthly Virtual Coffee, a developer community, challenge is to build in public. As part of this we are using Stand-up to keep each other informed on our progress. I wrote a brief introduction to stand-up for the group. I thought I could expand it in to a post here. SEO branding tip, reuse the content you create.
<figcaption>Not that kind of stand-up</figcaption>
## What is Stand-up?
A series of daily meeting with set questions to give a quick update on your current progress. Usually held a start of the day so all team members can get a quick update on where everyone is. sThere is a set time limit, around 15 minutes, and only one person talks at a time. This is often controlled by having a focus object like a book. Only the person holding the object is allowed to speak when they are done they pass the object around. Our Bootcamp TAs recommended the item be heavy or unwieldy so no one will want to hold it too long. We used a broken chair arm.
The questions are.
- What did you do yesterday?
- What are you doing today?
- Do you have any blockers?
**What did you do yesterday?**

- What did you accomplish yesterday or since the last update? Did you meet your goal? What did you learn?
**What are you doing today?**
- What do you plan to do today. Any particular goals you want to met before the end of day.
**Do you have any blockers?**
- A blocker is something keeping you from your goal. A problem you need some help to resolve. Anything team mates can help with. Team members can give you some quick tips. For more involved answers you can set up a one on one discussion outside of the stand-up. By using a phrase like "Let's talk about this more after the meeting."
Everyone should get a chance to announce where they stand and if they need help. Over all these should be quick focused meetings to keep the group informed of any progress. In larger companies departments may do their own stand-up and then send a representative to a larger company or division stand-up.

Stand-ups are a good tool to reduce meetings and get people back to creating. Too many meetings can kill productivity and concentration.
##Let's talk about this more after the meeting.
Does your company have stand-up traditions? Do you have a certain object you pass around?
```
-$JarvisScript git push
``` | jarvisscript | |
717,652 | My journey to Software Engineering | I graduated high school from a very small town in Northern California. There were three stop lights a... | 0 | 2021-06-04T03:38:16 | https://dev.to/swing8202/my-journey-to-software-engineering-d8p | I graduated high school from a very small town in Northern California. There were three stop lights and the closest mall was more than 30 minutes away in Oregon. The only thing to fight my boredom was looking forward to college. Math was my favorite subject in high school so naturally it became my declared major in college. One of the lower division requirements for a math major was C+ programming, which was my first experience with coding.
Several years later and after several major changes, I eventually graduated with a degree in accounting and finance. After my undergrad studies I contemplated the different paths I could pursue. I could take the CPA exam or apply to grad school or even law school, but I didn't have the motivation.
It wasn't until the unprecedented year of 2020 that started my journey into software engineering. I began to contemplate life again. The one thing I did know for sure was I love working Microsoft Excel (and still love today) so I decided to pursue a certificate in computer programming at my local community college. One of the requirements for the certificate was an intro to computer science class so I enrolled last summer and this was when I fell in love with coding!
I found my motivation! I respectfully made arrangements to leave my job last fall, started my journey and haven't looked back. After months and months of research I finally chose to pursue my software engineering certificate with Flatiron school. I will complete my program in October 2021 and I'm looking forward to it! | swing8202 | |
719,763 | 6 HTML tags you might not know | Introduction (Skippable) A few days ago I was working on my desk and next to me was my lov... | 0 | 2021-06-07T07:41:16 | https://dev.to/kubeden/6-html-tags-you-might-not-know-50id | html, codenewbie | ## Introduction (Skippable)
A few days ago I was working on my desk and next to me was my lovely girlfriend who was interested in what I really do for a living. She already knows I am doing IT and she also knows I write some code sometimes. She asked me how she can understand if she likes writing code. I did what I had to do. I explained to her how I believe a website code is working, showed her a couple of videos, and opened [w3schools](https://w3schools.com) for her. I navigated to the HTML section and opened [Visual Studio Code](https://code.visualstudio.com/) with a [Live Server](https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer) turned on. And she started.
Little did I know, she would know more HTML tags than me in a couple of hours. It was then, when I realized HTML is actually a lot more flexible than I imagined.
## Post Structure
The structure of this post is the following:
* HTML tag name
* Explanation of the tag
* Usage example
* Link to W3Schools page
Ready? Let's begin!
We will start with the most (in my opinion) interesting & useful ones.
## MAP
The *< map >* tag is used to map an image. That means you can define areas on the image and when interacted with, you can set a different outcome. For example, you could map an image and have 2 areas, when you click on area 1 - you get to Google, when you click on area 2 - you get to Twitter.
### Syntax
```
<img src="https://asciiden.com/assets/img/profile-img.jpg" usemap="#map-name">
<map name="map-name">
<area target="_blank" alt="ALT_TEXT" title="TITLE_TEXT" href="https://example.com" coords="93,57,305,169" shape="rect">
<area target="" alt="ALT_TEXT" title="TITLE_TEXT" href="https://example.com" coords="144,248,253,278" shape="rect">
</map>
```
{% codepen https://codepen.io/denislav__/pen/XWMqQyr %}
[W3Schools Link](https://www.w3schools.com/html/html_images_imagemap.asp)
**TIP**
You can use [this website](https://www.image-map.net/) to generate image maps automatically!
## PICTURE
The **< picture >** tag is used similar to the **<image>** tag but it gives developers more flexibility. You can define different viewports on different sources, therefore showing different images on different screens without any CSS.
### Syntax
```
<picture>
<source media="(max-width: <WIDTH>px)" srcset="someimage.jpg">
<source media="(min-width: <WIDTH>px)" srcset="someimage.jpg">
<img src="DEFAULT_IMAGE" style="width:auto;">
</picture>
```
{% codepen https://codepen.io/denislav__/pen/zYZjXQG %}
[W3Schools Link](https://www.w3schools.com/html/html_images_picture.asp)
## SUP
The *< sup >* tag lifts the text a little higher. It stands for superscripted text.
### Syntax
```
<sup> supscripted text </sup>
```
{% codepen https://codepen.io/denislav__/pen/poeVBoL %}
[W3Schools Link](https://www.w3schools.com/html/html_formatting.asp)
## SUB
The *< sub >* tag lowers the text. It stands for subscripted text.
### Syntax
```
<sub> subscripted text </sub>
```
{% codepen https://codepen.io/denislav__/pen/RwpyOGG %}
[W3Schools Link](https://www.w3schools.com/html/html_formatting.asp)
## BDO
The *< bdo >* tag is used to choose a text direction. It can override the current direction.
### Syntax
```
<bdo dir="ltr"> text from left to right </bdo>
<bdo dir="rtl"> text from right to left </bdo>
```
{% codepen https://codepen.io/denislav__/pen/rNyvbjR %}
[W3Schools Link](https://www.w3schools.com/html/html_quotation_elements.asp)
## DL
The **< dl >** tag defines 'description list' which is one more list you can use in HTML. It pushes the list items a little to the right which in a way creates the feeling of a description.
### Syntax:
```
<dl>
<dt>Item title</dt>
<dd>Item description</dd>
</dl>
```
{% codepen https://codepen.io/denislav__/pen/jOBxoER %}
[W3Schools Link](https://www.w3schools.com/html/html_lists_other.asp)
## About the author
I am Dennis, going by ASCIIden online and I am a DevOps engineer. However, I don't like the title of 'DevOps' to identify myself with. I rather consider myself a futurist & tech enthusiast.
I am doing IT for about 2 years now. I am striving to become a helping hand to all juniors in the industry and I am doing my best to provide good, understanding (even fun!) content for you all to enjoy.
If you want to hit me up for a project or just want to say hi, feel free to do it on my [Twitter profile](https://twitter.com/asciiden) | kubeden |
720,666 | How To Borrow Using MakerDAO | The Maker protocol allows the users to generate DAI by depositing collateral in the Maker Vault. In t... | 0 | 2021-06-08T06:39:43 | https://medium.com/coinmonks/how-to-borrow-using-makerdao-22a7329dbc1a | ethereum, defi, makerdao, dai | ---
title: How To Borrow Using MakerDAO
published: true
date: 2021-06-07 14:52:21 UTC
tags: ethereum,defi,makerdao,dai
canonical_url: https://medium.com/coinmonks/how-to-borrow-using-makerdao-22a7329dbc1a
---
_The Maker protocol allows the users to generate DAI by depositing collateral in the Maker Vault. In this article, we will explain how you can create Maker Vaults and generate DAI by depositing collateral._

MakerDAO is a decentralized organization based upon Ethereum that allows users to lend and borrow cryptocurrencies without any involvement of a third party.
The MakerDAO platform supports two native currencies:
- **DAI ** — Stablecoin, soft-pegged to the U.S. dollar.
- **MKR ** — Governance token.
The [MakerDAO](https://makerdao.com/en/) community manages the Maker protocol. The protocol consists of a set of smart contracts that allow the users to generate DAI by using collateral assets. This protocol is managed by the users who hold the MKR platform governance token. The community also monitors the different risk parameters of DAI to ensure its stability and transparency.
Users can generate DAI by depositing collateral in Maker Vaults. The generated DAI can be used in other crypto transactions.
**OASIS App**
The MakerDao borrow and lend features are supported by the Oasis interface. The Oasis application allows the users to interact with the Maker protocol. The application offers three major features:
- **Trade — ** Supports trading of DAI generated or purchased through the exchange.
- **Borrow — ** Allows the users to generate DAI by depositing collateral in a Maker Vault.
- **Save — ** Helps the users to earn savings on locked Dai into the DSR

**Borrow**
In this article, we will mainly focus on the MakerDAO borrow feature supported by the Oasis application.
Go to the Oasis [page](https://oasis.app/).
Click on Borrow, and it will redirect you to the MakerDAO borrow [page](https://oasis.app/borrow) in the Oasis interface.

Oasis supports multiple wallets, including hardware wallets like Ledger and Trezor. Choose as per your requirement.
Connect your MetaMask Wallet.
Your Oasis landing page looks like this.
**Open Vault**
To start with, users will open a vault. It involves a few steps.
**Select Collateral**
Once you click on **Get Started** , it will display a list of collateral types along with various parameters like stability fee, liquidity ratio, liquidity fee, your available balance, and DAI balance available to that particular collateral type.
We have selected ETH-A.
**Vault Management**
Click on **Setup** and confirm the transaction of vault creation in MetaMask.

**Generate DAI**
Once vault creation approval is done, you can now select how much collateral (ETH in our case) you want to give to generate DAI.
**Important** : MakerDao allows us to generate a minimum of 100 DAI.
The application shows you the max amount of DAI you can generate with the given ETH. You can also check your collateralization ratio. (Always try to maintain your collateralization ratio above the threshold, i.e., in the case of MakerDAO above 150%.) It is suggested not to generate the max amount of DAI which is showing by the application, otherwise, your vault will be at the risk of liquidation.
**Important:** The Liquidation Ratio is the collateralization ratio of DAI to ETH for each vault that a user needs to maintain in order to prevent liquidation. Maker protocol’s Oracle keeps track of the collateral price and notifies the system once the ratio crosses the threshold value and makes the vault available for liquidation.
**Confirmation**
After providing all the necessary details for vault creation, click on the **Open Vault** button.
You will now receive a confirmation message like this.
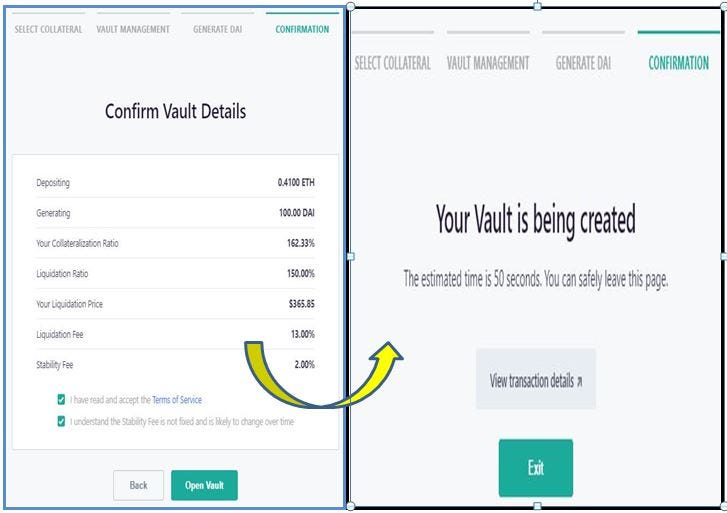
**User Vault**
Your vault is created. You can see the vault details like vault ID, your collateralization ratio, DAI balance, deposited ETH, etc.) from the **Overview** tab.

A more detailed view of the vault properties can be seen from the **ETH-A ** tab **.**
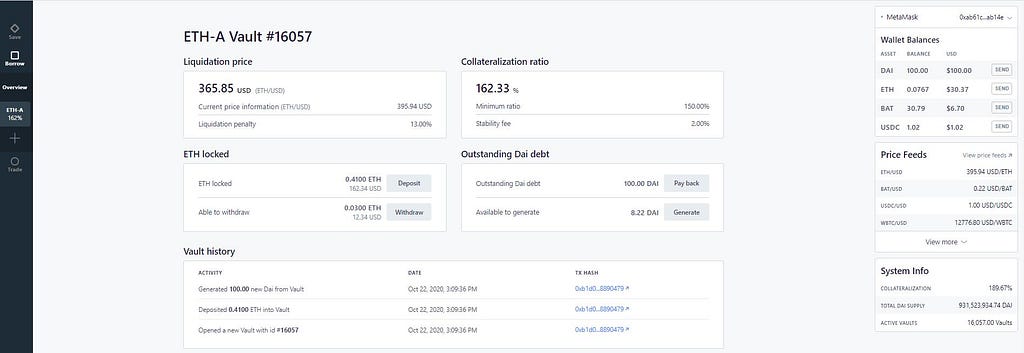
**Check DAI in MetaMask Wallet**
You will receive the generated DAI in your MetaMask wallet.
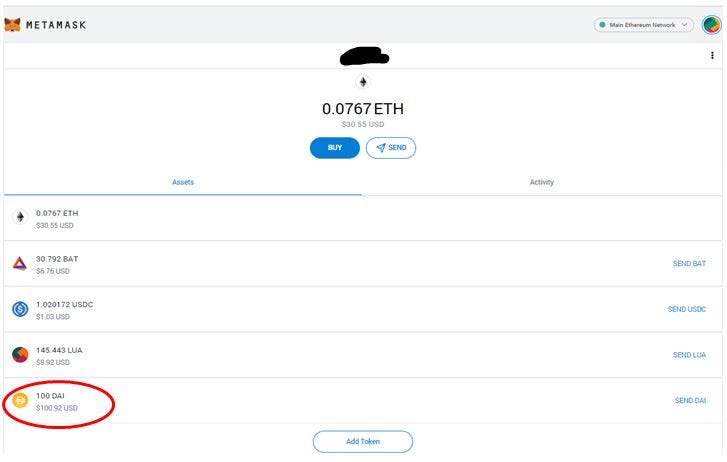
**Trade**
The Oasis trade option provides flexibility to the users to trade tokens ranging from simple swap to market trade. Users need to unlock these tokens before starting any transaction activity.
**Market**
The Oasis Market tab contains various trading-related details like order book, price chart, trade history, etc. You can create a buy/sell limit order here.
Users need to select the type of trading, i.e., buy or sell, and a token which they want to trade. Submit the order request. See the order history from the bottom of the page.
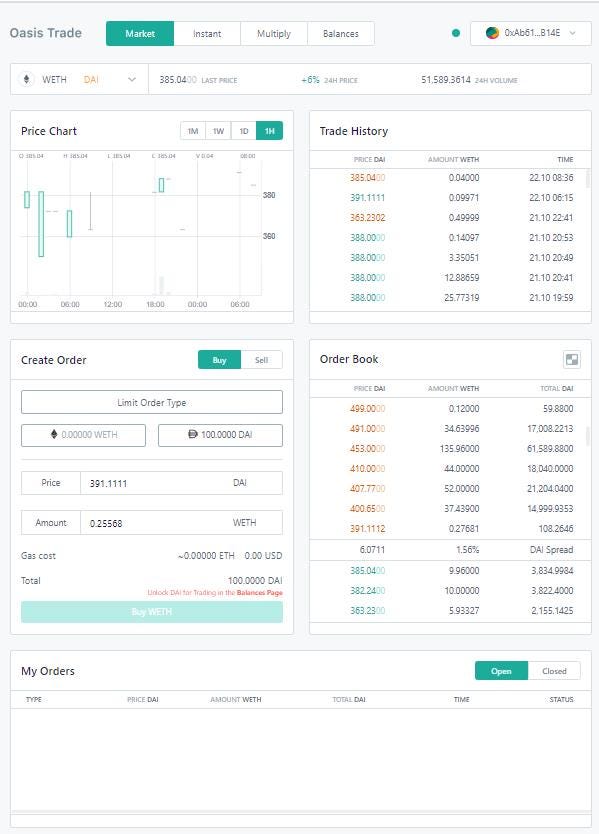
**Instant**
Through this option, you can easily buy/sell tokens without providing much detail. You just need to fill in the input token type, input token value, and the output token, and the application then automatically calculates the values of the output token.

Click on **Start transaction** and confirm the transaction in MetaMask. Once the transaction is successful, you will see the token in your wallet.
**Multiply**
With Multiply, use ETH as collateral to borrow DAI. Use the generated DAI to buy more ETH, and so on, creating multiples of up to 2x. This way, it allows the users to create long multiplied positions without the need to borrow funds from a counter-party.

**Balances**
Users can unlock tokens through the Balance tab. Before using any tokens, each token needs to be unlocked. The unlocking process will trigger a transaction in MetaMask and after confirmation, you will be able to use the token.
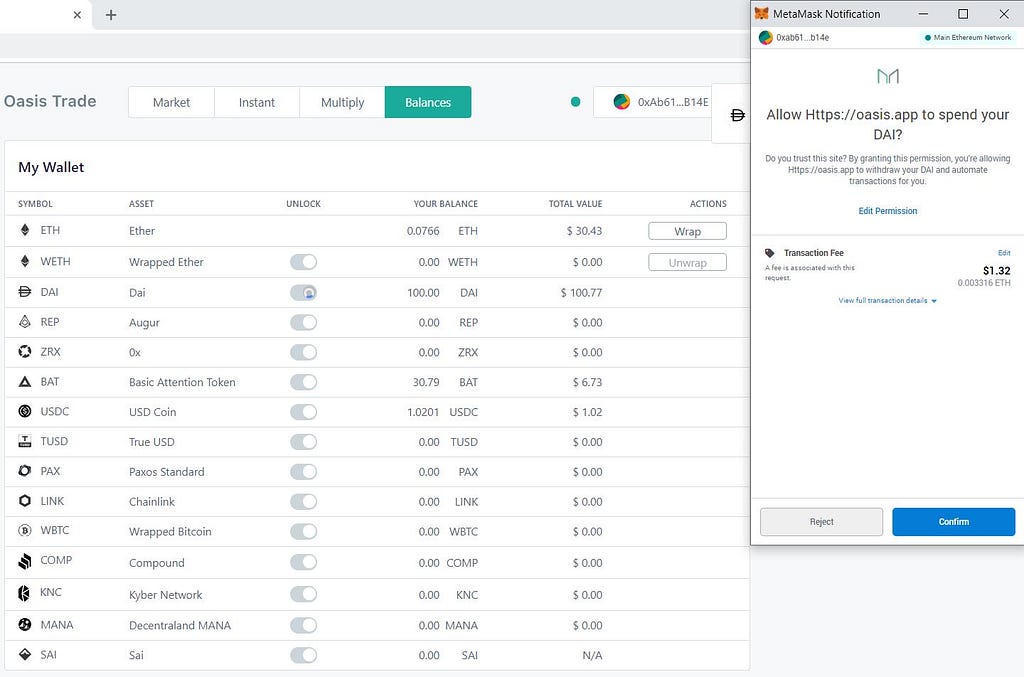
**Pay Debt**
Users can check their outstanding debt and pay it back easily.
Note that your DAI debt will always be greater than the outstanding debt.

Approve transactions in MetaMask. Now you can check **zero outstanding debt** in your vault.
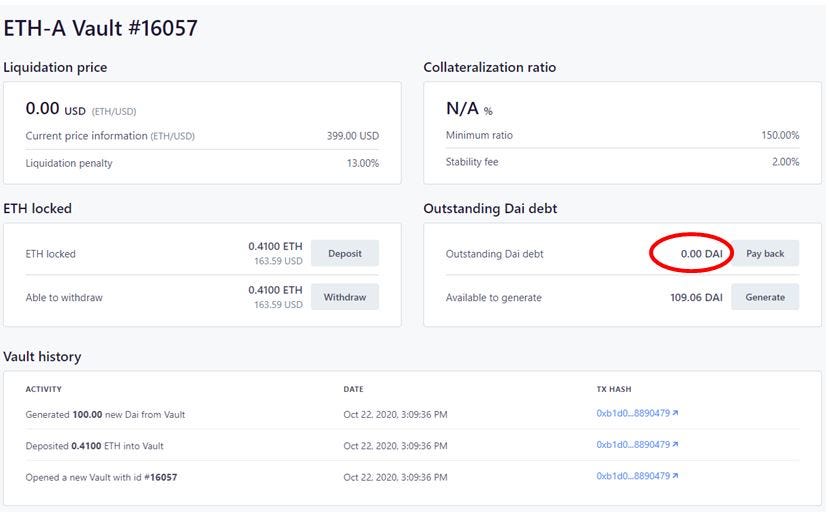
**Withdraw ETH**
Withdraw the locked ETH after paying the debt.
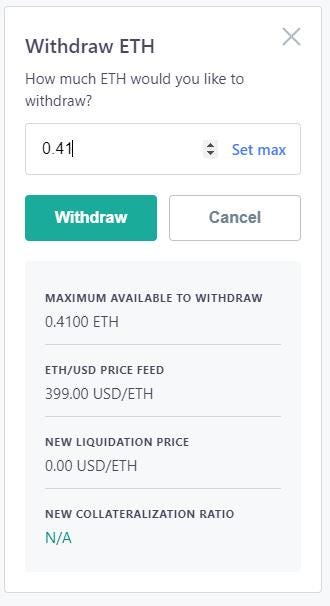
Just click on the **Withdraw** button and fill in the amount you would like to withdraw and confirm your transaction.
Your MetaMask wallet will now have the ETH amount.
**Conclusion**
Maker is one of the first decentralized finance (Defi) applications that have earned significant adoption. DAI is the most popular decentralized stable coin. The project has gained trust over the years and has significant TVL. However, with the introduction of competitors like Synthetix and Linear Finance, MakerDAO has a task in hand to keep up with the lot in the coming days.
**Resouces:** MakerDAO Official [Website](https://makerdao.com/)
**_Note:_** _This post was first published_ [_here_](https://www.altcoinbuzz.io/bitcoin-and-crypto-guide/exploring-the-borrow-feature-of-makerdao/) _on_ [**_Altcoinbuzz.io_**](http://www.altcoinbuzz.io/)_._
**Join using my referral**
[Binance](https://binance.com/en/register?ref=E8PCD3AF) — [Crypto.com](https://platinum.crypto.com/r/sut3pd9bzn)
**Follow Me**
**👉** [Twitter](https://twitter.com/rumadas123)
**👉** [Linkedin](https://www.linkedin.com/in/ruma-das-a1439320/)
* * * | coinmonks |
721,748 | IAM Service Account For aws-node DaemonSet | In another words, this post is about Configuring the Amazon VPC CNI plugin to use IAM roles... | 13,481 | 2021-06-08T16:50:47 | https://dev.to/vumdao/iam-service-account-for-aws-node-daemonset-1p5j | aws, eks, cloudopz, devops | ## **In another words, this post is about Configuring the Amazon VPC CNI plugin to use IAM roles for service accounts**
- The Amazon VPC CNI plugin for Kubernetes is the networking plugin for pod networking in Amazon EKS clusters. The plugin is responsible for allocating VPC IP addresses to Kubernetes nodes and configuring the necessary networking for pods on each node. The plugin:
- Requires IAM permissions, provided by the AWS managed policy `AmazonEKS_CNI_Policy`, to make calls to AWS APIs on your behalf.
- Creates and is configured to use a service account named `aws-node` when it's deployed. The service account is bound to a Kubernetes `clusterrole` named `aws-node`, which is assigned the required Kubernetes permissions.
<br>
## **Why do we need service account seperated for aws-node daemonset?**
- The aws-node daemonset is configured to use a role assigned to the EC2 instances to assign IPs to pods. This role includes several AWS managed policies, e.g. AmazonEKS_CNI_Policy and EC2ContainerRegistryReadOnly that effectly allow all pods running on a node to attach/detach ENIs, assign/unassign IP addresses, or pull images from ECR. Since this presents a risk to your cluster, it is recommended that you update the aws-node daemonset to use IRSA.
---
## What’s In This Document
- [Create IRSA and attach proper policy](#-Create-IRSA-and-attach-proper-policy)
- [Annotate the IRSA to aws-node service account](#-Annotate-the-IRSA-to-aws-node-service-account)
- [Restart the aws-node daemonset to take effect](#-Restart-the-aws-node-daemonset-to-take-effect)
- [Conclusion](#-Conclusion)
---
### 🚀 **[Create IRSA and attach proper policy](#-Create-IRSA-and-attach-proper-policy)**
- Pre-requisite: EKS cluster with OpenID connect, IAM identity provider (Ref to [Using IAM Service Account Instead Of Instance Profile For EKS Pods
](https://dev.to/vumdao/using-iam-service-account-instead-of-instance-profile-for-eks-pods-262p) for how to)
- First create the IAM role which is federated by IAM identiy provider and assumed by `sts:AssumeRoleWithWebIdentity`, then attach policy to provide proper permission for the role. Brief of CDK code in python3:
- `iam_oic` is the stack of creating IAM identity provider which is used OIDC as provider, `open_id_connect_provider_arn` is its ARN attribute from the stack.
```
eks_cni_statement = iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=[
"ec2:AssignPrivateIpAddresses",
"ec2:AttachNetworkInterface",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DescribeInstances",
"ec2:DescribeTags",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeInstanceTypes",
"ec2:DetachNetworkInterface",
"ec2:ModifyNetworkInterfaceAttribute",
"ec2:UnassignPrivateIpAddresses",
"ec2:CreateTags"
],
resources=['*'],
conditions={'StringEquals': {"aws:RequestedRegion": "ap-northeast-2"}}
)
daemonset_role = iam.Role(
self, 'DaemonsetIamRole',
role_name='sel-eks-oic-daemonset-sa',
assumed_by=iam.FederatedPrincipal(
federated=f'arn:aws:iam::{env.account}:oidc-provider/{oidc_provider}',
conditions={'StringEquals': string_like('kube-system', 'aws-node')},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
daemonset_role.add_to_policy(eks_cni_statement)
```
### 🚀 **[Annotate the IRSA to aws-node service account](#-Annotate-the-IRSA-to-aws-node-service-account)**
- Note: If you're using the Amazon EKS add-on with a 1.18 or later Amazon EKS cluster, we just need to add the Amazon VPC CNI Amazon EKS add-on with the role we select or default `aws-node`
- Important note; VPC CNI is also provided as a managed add-on, however I am not a big fan of this particular component to be managed by AWS. I would suggest you simply deploy your own configuration of VPC CNI (YAML format) using Flux. That way you will stay in control of what is actually being deployed. There were many issues with it and I won’t recommend moving this to be a managed add-on. So Manually Configuring the Amazon VPC CNI plugin to use IAM roles for service accounts
- If CNI version is later than 1.6 you can skip next step of applying CNI v1.7
```
kubectl describe daemonset aws-node --namespace kube-system | grep Image | cut -d "/" -f 2
```
- Download `aws-k8s-cni.yaml` to custom IAM role (optional) and then apply it
```
kubectl apply -f https://raw.githubusercontent.com/aws/amazon-vpc-cni-k8s/release-1.7/config/v1.7/aws-k8s-cni.yaml
```
- Annotate the IRSA to aws-node service account
```
$ kubectl annotate serviceaccount -n kube-system aws-node eks.amazonaws.com/role-arn=arn:aws:iam::123456789012:role/sel-eks-oic-daemonset-sa
```
### 🚀 **[Restart the aws-node daemonset to take effect](#-Restart-the-aws-node-daemonset-to-take-effect)**
- Rollout restart `aws-node` daemonset
```
$ kubectl rollout restart daemonset aws-node -n kube-system
$ kubectl get pod -n kube-system | grep aws-node
aws-node-bnb8v 0/1 Running 0 16s
```
- Check `aws-node` ENV to confirm EKS Pod Identity Webhook mutates `aws-node` pods with a ServiceAccount
```
$ kubectl exec aws-node-qct7x -n kube-system -- env |grep "AWS_ROLE\|AWS_REG"
AWS_REGION=ap-northeast-2
AWS_ROLE_ARN=arn:aws:iam::123456789012:role/sel-eks-oic-daemonset-sa
```
### 🚀 **[Conclusion](#-Conclusion)**
- This is just a small steps in the field of EKS K8S securities but we get our foot in
- Read [Using IAM Service Account Instead Of Instance Profile For EKS Pods](https://dev.to/vumdao/using-iam-service-account-instead-of-instance-profile-for-eks-pods-262p) to have better understand about IRSA
---
<h3 align="center">
<a href="https://dev.to/vumdao">:stars: Blog</a>
<span> · </span>
<a href="https://github.com/vumdao/aws-eks-the-hard-way">Github</a>
<span> · </span>
<a href="https://stackoverflow.com/users/11430272/vumdao">stackoverflow</a>
<span> · </span>
<a href="https://www.linkedin.com/in/vu-dao-9280ab43/">Linkedin</a>
<span> · </span>
<a href="https://www.linkedin.com/groups/12488649/">Group</a>
<span> · </span>
<a href="https://www.facebook.com/CloudOpz-104917804863956">Page</a>
<span> · </span>
<a href="https://twitter.com/VuDao81124667">Twitter :stars:</a>
</h3>
| vumdao |
722,185 | Tuning Neural Networks | When modeling a neural network, you most likely won’t run into satisfactory results immediately. Whet... | 0 | 2021-06-08T23:47:27 | https://dev.to/hoganbyun/tuning-neural-networks-33l | When modeling a neural network, you most likely won’t run into satisfactory results immediately. Whether it’s underfitting or overfitting, there are always small, tuning changes that can be made to improve upon the initial model. For the most part, for overfit models, these are the main techniques you can use: normalization, regularization, optimization
### Dealing with Overfitting
Here is an example of what an overfit model would look like:
Here we can see that as the training accuracy increases, at a certain point, the validation accuracy stagnates. This means that the model is getting too good at recognizing purely the training data that it fails to recognize general patterns.
**Regularization**
Regularization is often used when the initial model is overfit. In general, you have three types to choose from: l1, l2, and dropout.
L1 and l2 regularization basically penalizes weight matrices that are too large and in the back propagation phase. An example of it being used:
```python
model.add(Dense(128, activation='relu',
kernel_regularizer=regularizers.l2(0.005)))
```
Dropout, on the other hand, sets random nodes in the network to 0 on a given rate. This is also an effective counter measure to overfitting. The number within the dropout function represents the rate at which dropout will occur. An example:
```python
model.add(Dropout(.2))
```
**Normalization**
Another countermeasure to overfitting a model is to normalize the input data. The easiest thing to do is to normalize to scale the data to be between 0 and 1. What this does is potentially cut down training time and stablize convergence. You could also normalize within layers such as the random normal:
```python
model.add(Dense(64, activation='relu',
kernel_initializer=initializers.RandomNormal())
```
**Optimization**
Lastly, you could try different optimization functions. The three most used are probably Adam, SGD, and RMSprop.
Adam (“Adaptive Moment Estimation”) is one of the most popular and works very well.
### Dealing with Underfitting
Underfit models would look like the opposite of the above graph, where training accuracy/loss fails to improve. There are a few ways to deal with this.
**Add Complexity**
A likely reason that a model is underfit is that it is not complex enough. That is, it isn't able to identify abstract patterns. A way to fix this is to add complexity to the model by: 1) adding more layers or 2) increasing the number of neurons
**Training Time**
Another reason that a model may be underfit is the training time. By giving a model more time and iterations to train, you give it more chances to converge to a more ideal solution.
### Summary
To summarize, overfit models require regularization, normalization, and optimization while underfit models require more complexity and training time. Neural networks are all about making small, incremental changes until you reach a good balance. These tips will ensure that you are moving in the correct direction when you inevitably find the need to tune a model. | hoganbyun | |
725,395 | Orphaned CloudFormation Stacks — HouseKeeping | Scenario There could be some stacks missed out during teardown process due to some issues and this... | 0 | 2021-06-11T15:57:21 | https://dev.to/aws-builders/orphaned-cloudformation-stacks-housekeeping-370l | aws, cloudformation, housekeeping, cost | **Scenario**
* There could be some stacks missed out during teardown process due to some issues and this might leave those stacks orphaned.
* Also when App teams create a new stack without deleting their previous stack, this will leave the previous stack orphaned.
**Solution**
* List out all the stacks based on the state in the corresponding account using below python script. Filter the suspecting orphaned stacks from the list.
```
# Function: EvaluateOrphanedStacks
# Purpose: List out stacks based on the state and accounts
import boto3
import json
from datetime import datetime
from datetime import date
cfn_client=boto3.client('cloudformation')
def list_stacks():
paginator = cfn_client.get_paginator('list_stacks')
response_iterator = paginator.paginate(
StackStatusFilter=[
'CREATE_IN_PROGRESS',
'CREATE_FAILED',
'CREATE_COMPLETE',
'ROLLBACK_IN_PROGRESS',
'ROLLBACK_FAILED',
'ROLLBACK_COMPLETE',
'DELETE_IN_PROGRESS',
'DELETE_FAILED',
'UPDATE_IN_PROGRESS',
'UPDATE_COMPLETE_CLEANUP_IN_PROGRESS',
'UPDATE_COMPLETE',
'UPDATE_ROLLBACK_IN_PROGRESS',
'UPDATE_ROLLBACK_FAILED',
'UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS',
'UPDATE_ROLLBACK_COMPLETE',
'REVIEW_IN_PROGRESS',
'IMPORT_IN_PROGRESS',
'IMPORT_COMPLETE',
'IMPORT_ROLLBACK_IN_PROGRESS',
'IMPORT_ROLLBACK_FAILED',
'IMPORT_ROLLBACK_COMPLETE'
]
)
for page in response_iterator:
for stack in page['StackSummaries']:
print(stack['StackName'])
if __name__ == '__main__':
list_stacks()
```
Note:
Its ALWAYS recommended and good practice to reduce the orphaned stacks and unwanted resources ! | aklm10barca |
727,980 | How to show different email notifications for different types of users in a TalkJS chat | Roles allow you to change the default behavior of TalkJS for different users. You can assign roles to... | 0 | 2021-06-14T14:21:23 | https://dev.to/talkjs/how-to-show-different-email-notifications-for-different-types-of-users-in-a-talkjs-chat-2eic | webdev, javascript, api, chat | Roles allow you to change the default behavior of [TalkJS](https://talkjs.com/) for different users. You can assign roles to a certain group of your users and have full control over which user gets which role. Email notifications can then be customized for different roles. In this post, we will look at how we can set this up.
## TalkJS Roles
TalkJS allows different groups of users to have different settings by assigning them a specific role. You have full control over which user gets which role.
For example, you may want one group of users to receive email notifications if they have a new message, or give another group of users the ability to share files. You can do all of this using roles.
A role allows you to define the following settings for a group of users:
* Allow/disallow file or location sharing
* Create custom email notification templates
* Configure SMS settings
* Configure text/contact information suppression
* Configure how links in chat messages will be opened
* Customize the standard TalkJS user interface using [themes](https://talkjs.com/docs/Features/Themes/index.html)
You can create roles from the TalkJS [dashboard](https://talkjs.com/dashboard). Let’s create two roles, with each receiving a different type of email notification.
## Creating a role in TalkJS
Creating a role in TalkJS is simple, and can be accomplished using the dashboard.
### 1. Add a role in the dashboard
To add a role, click on **Roles** at the top left corner of your [dashboard](https://talkjs.com/dashboard).
Next, click on the **Create new role** button and put “buyer” as the name of the role. You can decide if the role will copy data from previous roles or use the default role setting.
After this, you can manage the settings for the role by using the checkboxes next to each setting.
### 2. Assign a role to a user
You assign a role to a user when you create the user. For example, if the name of the role you created on the dashboard is buyer, you can assign this role to the user "Alice" in your code like this:
```
const me = new Talk.User({
id: "123456",
name: "Alice",
email: "alice@example.com",
photoUrl: "https://demo.talkjs.com/img/alice.jpg",
welcomeMessage: "Hey there! How are you? :-)"
role: "buyer" // <-- that's the one!
});
```
Make sure the role matches the role name you chose in the dashboard, in this case, “buyer”.
For the purpose of this example, you may want to set the email to an email address you have access to. This will allow you to access the email that gets sent.
Repeat this process, except this time create a new role called “seller”. Create another user and set the role to be “seller”. At this stage, you should have two roles, “buyer” and “seller”, and a single user set up with each role.
## How Email notifications are Sent
If a user has a [role](https://talkjs.com/docs/Reference/Concepts/Roles.html) set and has at least one email address, they will automatically start receiving email notifications when they are offline. Users can have more than one email address and TalkJS will notify all email addresses on record.
Email notifications are not sent with each message but rather grouped and sent after a period of inactivity to avoid spamming the user's inbox.
The TalkJS notification system has been carefully designed to send notifications as quickly as possible while ensuring your users do not feel like they’re being spammed. We use a number of heuristics to get this balance right.
There are a few conditions that must be met in order to send notifications:
* The user is offline.
* The user is online but has a different conversation selected in the UI.
* The user is online, has the current conversation selected in the UI, but the browser tab/window does not have focus.
In other words, a notification is not sent out when the user has the current conversation selected in the UI and the tab containing TalkJS is focused.
To keep the email count low, subsequent messages are grouped together. After a user sends a message, TalkJS tracks whether they continue typing. A notification is sent when the user has stopped typing for several seconds. This notification will contain all of the messages they sent since they first started typing.
This also holds for group conversations. if two users have a quick real-time interaction, then the notification sent to the other participants will include all messages sent since the first user started typing until the last user stopped typing.
TalkJS is designed to be a slow chat solution, which supports reply-via-email functionality. When a user replies to a notification email, their reply will show up in the conversation.
## Managing your email notification settings through the dashboard
To modify the email notification that TalkJS sends, first head to the TalkJS Dashboard and then click on **Roles** in the top left corner, inside of the role editor you'll see a section for **Email settings**.
The first option you’ll see is the **Enable Email notifications** checkbox. When enabled, you have the option to change the subject, theme, and template for your email
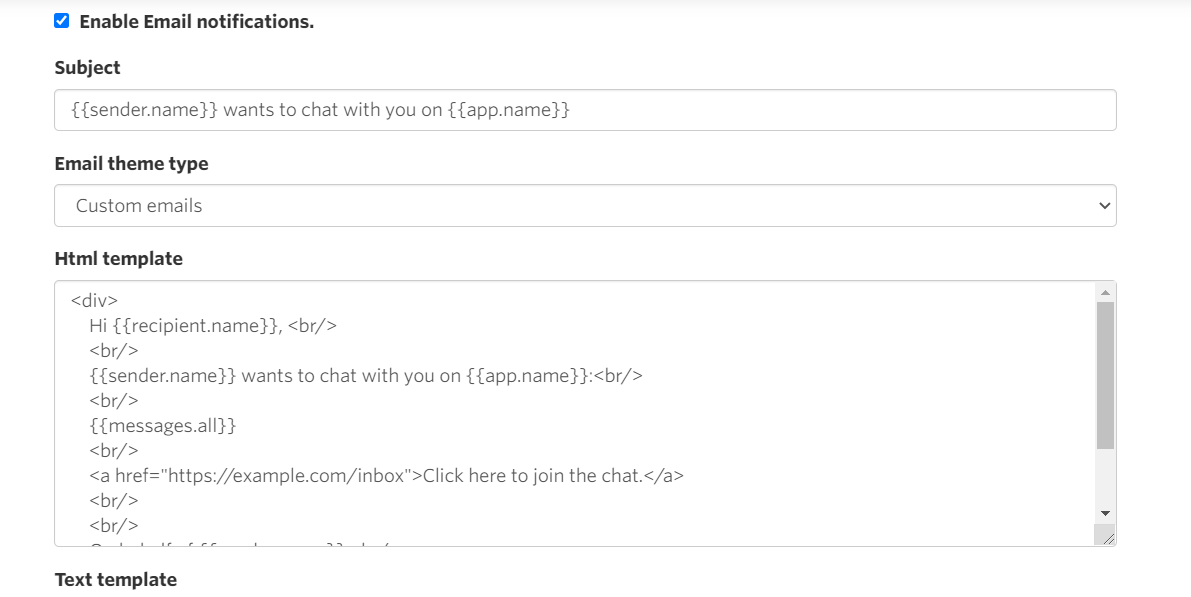
The next option you’ll see is the **Enable replying to email notifications via email** checkbox. This allows recipients of email notifications to reply directly to the email that they receive, and have the response sent back to the chat.
You can also decide whether users can send attachments with their replies. However, no images are allowed to be sent no matter what. This is due to being unable to determine the difference between purposefully attached images, and those automatically include in the footer such as company logos.
Use these role settings to send different emails to users depending on whether they are buyers or sellers.
## Complete control over the emails your users receive
The concept of roles allows you to easily set up different email templates for different types of users. We have covered how to create roles, how to add a role to a user, and finally how to configure the notifications that are sent for a role. This provides you with a highly configurable system that can be tailored to your specific needs. It also ensures your users are getting relevant notifications that are genuinely helpful and address their unique situations.
| andybone |
728,878 | Top 8 Skills Required to Become a Front End Developer 2021? | A front end engineer is somebody who carries out website architectures through programming dialects... | 0 | 2021-06-15T10:58:56 | https://dev.to/aartiyadav/top-8-skills-required-to-become-a-front-end-developer-2021-5dp4 | beginners, webdev, programming | A front end engineer is somebody who carries out website architectures through programming dialects like HTML, CSS, and JavaScript. The front end engineers work with the plan and standpoint of the site. While, the back end engineers program what goes on in the background like information bases.Also check the main difference betweem them on <a href="https://en.wikipedia.org/wiki/Front_end_and_back_end">wikipedia</a>. In the event that you head to any site, you can see crafted by a front end designer in the route, formats, and furthermore the manner in which a site appears to be unique from your mobile device.
If you’re looking for a career as a front end developer, you will face many burning questions. How long will it take to learn all the essential skills? What is the average front end developer salary ? What does a typical day of a front end developer look like?
Top 8 Technical skills that a front end developer must possess:
1. HTML/CSS
2. JavaScript/jQuery
3. Responsive Design
4. Frameworks
5. Testing/Debugging
6. Version Control/Git
7. Browser Developer Tools
8. CSS Preprocessing
I hope this post on “8 skills you need to be a good front end developer” was helpful and relevant to you. | aartiyadav |
730,310 | Logo Instagram | A post by Frank GP Support | 0 | 2021-06-16T18:01:13 | https://dev.to/fgp555/logo-instagram-3bld | codepen | {% codepen https://codepen.io/fgp555/pen/XWMyRZo %} | fgp555 |
730,592 | Sinatra Project: Yarn Stasher | Originally posted on March 20, 202` as a project requirement for Flatiron School I have been a... | 0 | 2021-06-17T02:59:15 | https://dev.to/jrrohrer/sinatra-project-yarn-stasher-2ddd | ruby, sinatra | *Originally posted on March 20, 202` as a project requirement for Flatiron School*
I have been a crafter for a couple of decades now. If you've met me over zoom, you will see a whole wall of yarn and related implements behind me in my home office. I can spin my own yarn from wool or alpaca fibers, I can knit, and I can crochet. The downside to having this particular hobby is the lack of digital support. There are little apps you can download to keep track of what pattern row you're on, but there aren't many for quick references when you're standing in the yarn aisle wondering if you already have a particular yarn in your stash at home.

Photo by <a href="https://unsplash.com/@mkvandergriff?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Maranda Vandergriff</a> on <a href="/s/photos/yarn-stash?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
I made yarn stasher because it's something I would use, and it's something my friends could use. The basic idea is that a user can sign up, log in, and create yarn objects that will be stored in a table view for them to reference. I wanted it to be quick and easy to use. Users cannot view other users' stashes, but they can view individual yarns if another user sends them a link to that yarn's show page.
I started my project by using the Corneal gem to build out my boilerplate code and filesystem. I added a couple of folders for views so that they could be separated by model. I added controller files (users_controller and yarns_controller) which inherit from the application_controller file. Next, I removed some gems from the gemfile that I don't need (like database cleaner) and ran bundle install. Now I'm ready to get coding.
The next step was to create the models. This app currently has two models: User and Yarn. A User has_many yarns and a Yarn belongs_to a user. I added some ActiveRecord validations to my User controller to ensure that each user has a unique username. Then I made use of the bcrypt gem to protect the user's password by adding the has_secure_password macro to the User model. Both models inherit from ActiveRecord::Base.
Next, I set up the UsersController and YarnsController files and mounted them in the config.ru file. While I was there, I added access to Rack middleware with the line "user Rack::MethodOverride" so that my app will have access to HTTP verbs other than GET and POST. This is the line that makes PATCH and DELETE requests possible.
Back in the ApplicationController, I enabled sessions and set a session secret. Now that everything is connected, I can save and get to work on my migrations.
I created two migrations with rake db:create_migration: one for the users table and one for the yarns table. My users table has four colums: username, email, password_digest (so that bcrypt will salt and hash the user's password), and timestamps (not necessary at this point, but could be useful later). The primary key is assigned automatically and I do not have to add a column for it. Thanks, ActiveRecord!
The yarns table has 6 columns. Name, color, weight, fiber, user_id (where the yarns table joins the users table) and timestamps (again, not needed now, but could be useful in the long run).
I then created a seed file to fill the table with data. This will be useful for anyone who is testing out the app: it gives the database some dummy data to play with and test the app's functionality.
I then ran rake db:migrate, which went smoothly, and then rake db:seed. I now had a database with a couple of users who each have 1 or 2 yarns. Time to start working on controllers and views.
The first thing I did was to set the index get route. Corneal initially sets this route to render a welcome.erb view. I deleted that view and replaced it with my own index.erb file, then populated it with a header so that I could test that my route worked correctly. I updated the get route for the index page to render my index.erb file, then moved on to the users controller.
In order to create a RESTful MVC app, I hashed out the routes I wanted to create and filled them with comments saying what I want each route to do. The UsersController should have the routes related to the user actions: logging in, signing up, creating a new user, redirecting to a landing page, and logging out. So I hashed out a get '/login' , post '/login', get '/signup', post '/signup', and get '/logout' routes. I initially also had a get '/users/:id' route that rendered a user show page, but decided later that it was redundant and created a security problem where other people could see a user's show page, so I removed it and used the /yarns/stash.erb view as the read route for both users and yarns.
With the UsersController created and hashed out, I began filling the routes with their required variables and logic. As I worked, I realized that I would need some helper methods because I was repeating some of the same lines of code over and over. So I went back to the ApplicationController and added some helper methods to set the current_user and determine if the user was logged in.
I continued on, creating views with the necessary forms as I went. The views/users folder in my app has two files: signup.erb and login.erb. The index and layout erb files are contained in the parent views folder. Both the signup and login files now contained the appropriate HTML form for both functions. I later added a "back" button to both forms so that the user could easily return to the welcome page if they chose the wrong option.
I have made the login page so that a user will only be logged in if they enter credentials that exist in the database. I also used the authenticate method from bcrypt If they enter unknown credentials or submit an empty form, they will be sent back to the login page again. I later added flash messages to tell the user why their login attempt failed.
The signup page will only create a new account for a user that does not already exist in the database. I did this by checking the entered username against the usernames in the database. If a user with that name already exists, the user is redirected back to the signup page and shown a flash message that asks them to log in if they already have an account or choose a different username if they do not have an account. If a blank form is submitted, the signup page will reload and show the user a flash message telling them they need to fill in the form completely.
Once a user is created and logged in, they will land on the yarns/stash.erb view. So this is the next view I set up. I made a simple header that greets the user, then went to the YarnsController and began hashing out the routes and logic needed. The YarnsController has a get '/yarns' route that renders the landing page which will display all of the yarns created by that user. It has a get '/yarns/new' route that renders a form for creating a new yarn, and a post 'yarns/new' that creates and persists the new Yarn object to the database, then loads the show page for that yarn, which is rendered by a get '/yarns/:id' route. This route sets the yarn so that the view has access to its attributes, then renders the yarn's individual show page. It also has a get '/yarns/:id/edit' route that renders a form to edit a given yarn, and a patch '/yarns/:id' route that updates the given yarn based on the user's input in the edit form. Finally, there is a delete '/yarns/:id' route that checks if a user owns the yarn they are trying to delete, then deletes the yarn and redirects the user back to their stash page.
When I was writing these routes, I realized I was setting yarn variables repeatedly with the line: @yarn = Yarn.find(params[:id]), so I contained this in a private helper method.
I also realized I was checking if a user owned a yarn repeatedly, so I added a helper method to the ApplicationController to help me check if a user is authorized to change or delete something.
Now that my application is behaving the way it should, I can get to some UX stuff. Mainly adding buttons, making navigation easier, and doing a little styling.
I started by adding a nav bar, which allows the user to get around the app and contains a link for logging out. This nav bar is viewable only when a user is logged in. I added some CSS styling to my anchor tags to make them appear horizontally across the top of the viewscreen, give them a background color and a hover action.
Next, I added flash messaging at the top of the wrapper div where all the content is displayed. This will make the flash message appear (if it exists) at the top of the content area where the user will see it.
I then added some styling on my navigation links, gave the app a new background color, and added a favicon that will show up on the browser tab.
Finally, I used CSS to style my forms and the table that displays all of the user's yarns.
I feel pretty confident at this point that my project meets the criteria, but I have a couple of stretch goals:
1. More attributes for the Yarn objects: yardage, number of skeins owned, perhaps a field where users can record where they bought the yarn.
2. Some sort of sorting option would be good. Allowing the user to sort their list of yarn objects seems like a handy UX feature, especially if the user has a long list of yarns.
3. I need to comb over my code to make sure I've taken care of redundancies or see if there is a better way to refactor some of the logic in my controllers.
I'm going to take a few days to see what else I can make this app do, and then I will be satisfied to add it to my portfolio. | jrrohrer |
730,617 | Does Sanity CMS Work in China? | What is Sanity CMS? Sanity is one of many headless CMS (content management systems) for... | 13,263 | 2021-06-17T03:32:39 | https://www.21cloudbox.com/solutions/does-sanity-cms-work-in-china.html | sanity, netlify, javascript, node | ---
canonical_url: https://www.21cloudbox.com/solutions/does-sanity-cms-work-in-china.html
---
## What is Sanity CMS?
Sanity is one of many headless CMS (content management systems) for structured content. Headless CMS helps content editors, marketers, and developers work together to deliver a better content experience to their users.
<p> </p>
## Does Sanity CMS work in China?
The short answer is No.
Why? Sanity is built and hosted on top of the Google Cloud Platform which is blocked completely in China.
<p> </p>
Here is the long answer:
We reached out to the Sanity team to see if their service works in China, and here is what we got:
<p> </p>
<p> </p>
So simply put, if the Sanity team doesn't have experience with China, you are unlikely to get good support from them. If you are just testing Sanity out, and don't need your site to be highly available in China. It doesn't hurt to try.
Since the Sanity CMS is based on GCP (Google Cloud Platform), if GCP has good support in China, we probably can still use it in production, but what we found was this:
> " **Google does not offer and has not offered cloud platform services inside China** and Google Cloud is not weighing options to offer the Google Cloud Platform (GCP) in China."
> – [Google's Media Statement](https://techcrunch.com/2020/07/08/google-reportedly-cancelled-a-cloud-project-meant-for-countries-including-china/)
So this looks like Sanity CMS doesn't work in China by "words" and it is also not in the coverage area of the Sanity and GCP. The next thing we want to know is: if a website is published with Sanity CMS, whether the site can be loaded in China or not. More specifically, how fast the site loads in China. Here are the speed test results:
...
To read the full content of this post, go to: [https://launch-in-china.21cloudbox.com/solutions/does-sanity-cms-work-in-china.html](https://launch-in-china.21cloudbox.com/solutions/does-sanity-cms-work-in-china.html)
<p> </p>
<p> </p> | 21yunbox |
730,754 | Active Learning Tutorial with the Nvidia Transfer Learning Toolkit | How to go from a quick prototype to a production ready object detection system using active... | 0 | 2021-06-17T08:07:37 | https://www.lightly.ai/post/active-learning-with-nvidia-tlt | tutorial, machinelearning, python, datascience | ## How to go from a quick prototype to a production ready object detection system using active learning and Nvidia TLT
Active Learning Tutorial with the Nvidia Transfer Learning Toolkit
How to go from a quick prototype to a production ready object detection system using active learning and Nvidia TLT
One of the biggest challenges in every machine learning project is to curate and annotate the collected data before training the machine learning model. Oftentimes, neural networks require so much data that simply annotating all samples becomes an insurmountable obstacle for small to medium sized companies. This tutorial shows how to make a prototype based on only a fraction of the available data and then iteratively improve it through active learning until the model is production ready.
Active learning describes a process where only a small part of the available data is annotated. Then, a machine learning model is trained on this subset and the predictions from the model are used to select the next batch of data to be annotated. Since training a neural network can take a lot of time, it makes sense to use a pre-trained model instead and finetune it on the available data points. This is where the Nvidia Transfer Learning Toolkit comes into play. The toolkit offers a wide array of pre-trained computer vision models and functionalities for training and evaluating deep neural networks.
The next sections will be about using Nvidia TLT to prototype a fruit detection model on the MinneApple dataset and iteratively improving the model with the active learning feature from [Lightly](https://app.lightly.ai/), a computer vision data curation platform.
### Why fruit detection?
Accurately detecting and counting fruits is a critical step towards automating harvesting processes. Fruit counting can be used to project expected yield and hence to detect low yield years early on. Furthermore, images in fruit detection datasets often contain plenty of targets and therefore take longer to annotate which in turn drives up the cost per image. This makes the benefits of active learning even more apparent.
### Why MinneApple?
MinneApple consists of 670 high-resolution images of apples in orchards and each apple is marked with a bounding box. The small number of images makes it a very good fit for a quick-to-play-through tutorial.
## Let's get started
This tutorial follows its [Github counter-part](https://github.com/lightly-ai/NvidiaTLTActiveLearning). If you want to play through the tutorial yourself, feel free to clone the repository and try it out.
### Upload your Dataset
To do active learning with [Lightly](https://app.lightly.ai/), you first need to upload your dataset to the platform. The command lightly-magic trains a self-supervised model to get good image representations and then uploads the images along with the image representations to the platform. Thanks to self-supervision, no labels are needed for this step so you can get started with your raw data right away. If you want to skip training, you can set trainer.max_epochs=0. In the following command, replace MY_TOKEN with your token from the platform.
```
lightly-magic \
input_dir=./data/raw/images \
trainer.max_epochs=0 \
loader.num_workers=8 \
collate.input_size=512 \
new_dataset_name="MinneApple" \
token=MY_TOKEN
```
For privacy reasons, it's also possible to upload thumbnails or even just metadata instead of the full images.
Once the upload has finished, you can visually explore your dataset in the [Lightly Platform](https://app.lightly.ai/). You will likely detect different clusters of images. Play around with it and see what kind of insights you can get.

### Initial Sampling
Now, let's select an initial batch of images for annotation and training.
Lightly offers different sampling strategies, the most prominent ones being CORESET and RANDOM sampling. RANDOM sampling will preserve the underlying distribution of your dataset well while CORESET maximizes the heterogeneity of your dataset. While exploring our dataset in the Lightly Platform, we noticed many different clusters. Therefore, we choose CORESET sampling to make sure that every cluster is represented in the training data.
To do an initial sampling, you can use the script provided in the Github repository or you can write your own Python script. The script should include the following steps.
Create an API client to communicate with the Lightly API.
```python
# create an api client
client = ApiWorkflowClient(
token=YOUR_TOKEN,
dataset_id=YOUR_DATASET_ID,
)
```
Create an active learning agent which serves as an interface to do active learning.
```python
# create an active learning agent
al_agent = ActiveLearningAgent(client)
```
Finally, create a sampling configuration, make an active learning query, and use a helper function to move the annotated images into the data/train directory.
```python
# make an active learning query
cofnig = SamplerConfig(
n_samples=100,
method=SamplingMethod.CORESET,
name='initial-selection',
)
al_agent.query(config)
# simulate annotation step by copying the data to the data/train directory
helpers.annotate_images(al_agent.added_set)
```
The query will automatically create a new tag with the name initial-selection in the Lightly Platform.
### Training and Inference
Now that we have our annotated training data, let's train an object detection model on it and see how well it works! Use the Nvidia Transfer Learning Toolkit to train a YOLOv4 object detector from the command line. The cool thing about transfer learning is that you don't have to train a model from scratch and therefore require fewer annotated images to get good results.
Start by downloading a pre-trained object detection model from the Nvidia registry.
```
mkdir -p ./yolo_v4/pretrained_resnet18
ngc registry model download-version nvidia/tlt_pretrained_object_detection:resnet18 \
--dest ./yolo_v4/pretrained_resnet18
```
Finetuning the object detector on the sampled training data is as simple as the following command. Make sure to replace YOUR_KEY with the API token you get from your Nvidia account.
```
mkdir -p $PWD/yolo_v4/experiment_dir_unpruned
tlt yolo_v4 train \
-e /workspace/tlt-experiments/yolo_v4/specs/yolo_v4_minneapple.txt \
-r /workspace/tlt-experiments/yolo_v4/experiment_dir_unpruned \
--gpus 1 \
-k YOUR_KEY
```
Now that you have finetuned the object detector on your dataset, you can do inference to see how well it works.
Doing inference on the whole dataset has the advantage that you can easily figure out for which images the model performs poorly or has a lot of uncertainties.
```
tlt yolo_v4 inference \
-i /workspace/tlt-experiments/data/raw/images/ \
-e /workspace/tlt-experiments/yolo_v4/specs/yolo_v4_minneapple.txt \
-m /workspace/tlt-experiments/yolo_v4/experiment_dir_unpruned/weights/yolov4_resnet18_epoch_050.tlt \
-o /workspace/tlt-experiments/infer_images \
-l /workspace/tlt-experiments/infer_labels \
-k MY_KEY
```
Below you can see two example images after training. It's evident that the model does not perform well on the unlabeled image. Therefore, it makes sense to add more samples to the training dataset.

The model is missing multiple apples in the image from the unlabeled data. This means that the model is not accurate enough for production yet.
### Active Learning Step
You can use the inferences from the previous step to determine which images cause the model problems. With Lightly, you can easily select these images while at the same time making sure that your training dataset is not flooded with duplicates.
This section is about how to select the images which complete your training dataset. You can use the active_learning_query.py script again but this time you have to indicate that there already exists a set of preselected images and point the script to where the inferences are stored.
Note that the `n_samples` argument indicates the total number of samples after the active learning query. The initial selection holds 100 samples and we want to add another 100 to the labeled set. Therefore, we set `n_samples=200`.
Use CORAL instead of CORESET as a sampling method. CORAL simultaneously maximizes the diversity and the sum of the active learning scores in the sampled data.
The script works very similarly to before but with one significant difference: This time, all the inferred labels are loaded and used to calculate an active learning score for each sample.
```python
# create a scorer to calculate active learning scores based on model outputs
scorer = ScorerObjectDetection(model_outputs)
```
The rest of the script is almost the same as for the initial selection:
```python
# create an api client
client = ApiWorkflowClient(
token=YOUR_TOKEN,
dataset_id=YOUR_DATASET_ID,
)
# create an active learning agent and set the preselected tag
al_agent = ActiveLearningAgent(
client,
preselected_tag_name='initial-selection',
)
# create a sampler configuration
config = SamplerConfig(
n_samples=200,
method=SamplingMethod.CORAL,
name='al-iteration-1',
)
# make an active learning query
al_agent.query(config, scorer)
# simulate the annotation step
helpers.annotate_images(al_agent.added_set)
```
### Re-training
You can re-train our object detector on the new dataset to get an even better model. For this, you can use the same command as before. If you want to continue training from the last checkpoint, make sure to replace the pretrain_model_path in the specs file by a `resume_model_path`.
If you're still unhappy with the performance after re-training, you can repeat the training, prediction, and active learning steps again - this is then called the active learning loop. Since all three steps are implemented as scripts, iterations take little effort and are a great way to continuously improve the model.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Philipp Wirth
Machine Learning Engineer
lightly.ai | philippmwirth |
730,893 | When should you pick up the phone? | I’m a big advocate of distributed teams, and work-from-home policies for those who want it. But this... | 0 | 2021-06-18T10:19:28 | https://jhall.io/archive/2021/06/17/when-should-you-pick-up-the-phone/ | team, remotework, practices, communication | ---
title: When should you pick up the phone?
published: true
date: 2021-06-17 00:00:00 UTC
tags: team,remotework,practices,communication
canonical_url: https://jhall.io/archive/2021/06/17/when-should-you-pick-up-the-phone/
---
I’m a big advocate of distributed teams, and work-from-home policies for those who want it. But this always raises the question: How do we handle meetings and other forms of communication?
I’ve talked about my take on this [in a video](https://www.youtube.com/watch?v=OcUZxA4IICs&t=994s). But I was recently involved in a conversation on a specific aspect of this:
**How do you decide when to take a conversation off of Google Docs or Jira and move it to a more real-time channel?**
My basic rule for something like this is to use something like Google Docs/Jira/GitHub/whatever as a system of record. Make sure all important decisions are stored there.
If the discussion ever becomes emotional, repetitive, or otherwise unproductive, that’s a great time to take it to a more (virtually) face-to-face medium. Just make sure that any conclusions from that meeting are then recorded back into the system of record. And if possible, even record the face-to-face call for future reference.
A simple heursistic you might use is what I’ve heard called the **upshift reply threshold**. The idea is to make an agreement with your team about how many replies are needed before a more real-time communication medium is triggered. For example, with an upshift reply threshold of three, a third reply on GitHub might trigger a Slack conversation. A third reply on Slack might trigger a Zoom call. Choose a threshold that works for your team and situation.
* * *
_If you enjoyed this message, [subscribe](https://jhall.io/daily) to <u>The Daily Commit</u> to get future messages to your inbox._ | jhall |
731,055 | Will `.at()` be something useful? | I recently read a post here on dev about the consideration of .at() implementation in JS. If you... | 0 | 2021-06-17T13:28:03 | https://dev.to/edo78/will-at-be-something-useful-3fcf | javascript, discuss | I recently read a post [here](https://dev.to/laurieontech/at-coming-soon-to-ecmascript-1k91) on dev about the consideration of `.at()` implementation in JS.
If you don't want to read the original post (you should) here's a little recap.
## .at()
As far as I get this new function can be used as a replacemente for the classic `[]` if used with a positive index but can also access elements in reverse order if used with negative index.
Eg.
```JavaScript
const arr = [ 'a', 'b', 'c', 'd'];
arr.at(0); // 'a'
arr.at(3); // 'd'
arr.at(4); // undefined
arr.at(-1); // 'd'
arr.at(-4); // 'a'
arr.at(-5); // undefined
```
Just looking at this (pun intended) show to me that `.at(-1)` is a sugar syntax to get the last element of an array without using `.length` nor `.slice()`.
## Doubts
I still have to dig deeper but I already have a couple of doubts.
### How oftend do we need it?
`.at(-1)` can be useful (and a lot of languages has something to get the last item) but how often do you need to get the second or third last item? I image as often as you need the second or the third so not so much.
### Loop in reverse order
You (or at least someone) could think that it can be handy for looping in a reverse order. An out of bound index return `undefined` so it should be easy, right? Well, no because array can have undefined element even in the middle
```JavaScript
const arr = ['a', undefined, 'c'];
```
so we still have to rely on the old way with
```Javascript
for (let i = 1; i <= arr.length; i++) {
const item = arr.at(-i);
}
```
very much like
```JavaScript
for (let i = arr.length - 1 ; i >= 0; i--) {
const item = arr[i];
}
```
or in a simpler way
```Javascript
for (const item of arr.slice().reverse()) {
```
The examples are from the comments written by [Henry Ing-Simmons](https://dev.to/hisuwh) on the original post.
### Negative index
I know, I know. Javascript allow only non negative index in arrays but we all knows that sometimes it allows some crazy shit like
```JavaScript
const arr=[];
arr[-1]="a";
arr[0] ="b";
arr[1] ="c";
console.log(arr); // ["b", "c"]
console.log(arr[-1]); // "a"
```
Obviosuly it's not black magic but it's just creating a property `-1` for the object `arr`
```JavaScript
// do you remember that
const arr=[];
console.log(typeof(arr)); // object
```
Ok, this one was just to screwing around and keep you from falling asleep while reading my post.
## Recap
IMHO `.at()` will be used just to get the last item of an array.
If you think I'm missing something I urge you to point me in the right direction because I'm struggling on my own in finding a real purpouse for `.at()` | edo78 |
731,101 | How to Build a CRUD App with React and a Headless CMS | For many years, web projects have used Content Management Systems (CMS) to create and manage content,... | 0 | 2021-06-17T14:33:58 | https://strapi.io/blog/how-to-build-a-crud-app-with-react-and-a-headless-cms |
For many years, web projects have used Content Management Systems (CMS) to create and manage content, store it in a database, and display it using server-side rendered programming languages. WordPress, Drupal, Joomla are well-known applications used for this purpose.
One of the issues the traditional CMSes have is that the backend is coupled to the presentation layer. So, developers are forced to use a certain programming language and framework to display the information. This makes it difficult to reuse the same content on other platforms, like mobile applications, and here is where headless CMSes can provide many benefits.
A Headless CMS is a Content Management System not tied to a presentation layer. It's built as a content repository that exposes information through an API, which can be accessed from different devices and platforms. A headless CMS is designed to store and expose organized, structured content without concern over where and how it's going to be presented to users.
This decoupling of presentation and storage offers several advantages:
- **Flexibility:** Developers can present content on different devices and platforms using the same single source of truth.
- **Scalability:** Headless CMSes allow your content library to grow without affecting the frontend of your app and vice-versa.
- **Security:** You can expose only the data you want on the frontend and have a completely separate login for web administrators who edit the content.
- **Speed:** As data is consumed through an API, you can dynamically display data on pages without re-rendering the content.
In this article, I will show you how to create a Pet Adoption CRUD application. You will use a headless CMS called [Strapi](<https://strapi.io/>) for the backend, and [React](https://reactjs.org/) with [Redux](https://redux.js.org/) for the frontend. The application will display a list of pets, with details related to each, and you will be able to add, edit or delete pets from the list.
## Planning the Application
**CRUD** stands for Create, Read, Update and Delete. CRUD applications are typically composed of pages or endpoints that allow users to interact with entities stored in a database. Most applications deployed to the internet are at least partially CRUD applications, and many are exclusively CRUD apps.
This example application will have `Pet` entities, with details about each pet, and you will be able to execute CRUD operations on them. The application will have a screen with a list of pets and a link to another screen to add a pet to the list. It will also include a button to update pet details and another one to remove a pet from the database.
## Building the Backend Data Structure
To create, manage and store the data related to the pets, we will use [Strapi](<https://strapi.io/>), an open-source headless CMS built on Node.js.
Strapi allows you to create *content types* for the entities in your app and a dashboard that can be configured depending on your needs. It exposes entities via [its Content API](<https://strapi.io/documentation/developer-docs/latest/developer-resources/content-api/content-api.html>), which you'll use to populate the frontend.
If you want to see the generated code for the Strapi backend, you can download it from [this GitHub repository](https://github.com/fgiuliani/pet-adoption-backend).
To start creating the backend of your application, install Strapi and create a new project:
```
npx create-strapi-app pet-adoption-backend --quickstart
```
This will install Strapi, download all the dependencies and create an initial project called `pet-adoption-backend`.
The `--quickstart` flag is appended to instruct Strapi to use SQLite for the database. If you don't use this flag, you should install a local database to link to your Strapi project. You can take a look at [Strapi's installation documentation](<https://strapi.io/documentation/developer-docs/latest/setup-deployment-guides/installation.html>) for more details and different installation options.
After all the files are downloaded and installed and the project is created, a registration page will be opened at the URL [http://localhost:1337/admin/auth/register-admin](http://localhost:1337/admin/auth/register-admin).

Complete the fields on the page to create an Administrator user.
After this, you will be redirected to your dashboard. From this page, you can manage all the data and configuration of your application.

You will see that there is already a `Users` collection type. To create a new collection type, go to the **Content-Types Builder** link on the left menu and click **+ Create new collection type**. Name it *pet*.

After that, add the fields to the content type, and define the name and the type for each one. For this pet adoption application, include the following fields:
- `name` (Text - Short Text)
- `animal` (Enumeration: Cat - Dog - Bird)
- `breed` (Text - Short Text)
- `location` (Text - Short Text)
- `age` (Number - Integer)
- `sex` (Enumeration: Male - Female)

For each field, you can define different parameters by clicking **Advanced Settings**. Remember to click **Save** after defining each entity.
Even though we will create a frontend for our app, you can also add new entries here in your Strapi Dashboard. On the left menu, go to the `Pets` collection type, and click **Add New Pet**.

New entries are saved as "drafts" by default, so to see the pet you just added, you need to publish it.
### Using the Strapi REST API
Strapi gives you a complete REST API out of the box. If you want to make the pet list public for viewing (not recommended for creating, editing, or updating), go to **Settings**, click **Roles**, and edit **Public**. Enable **find** and **findone** for the **Public** role.

Now you can call the [http://localhost:1337/pets](http://localhost:1337/pets) REST endpoint from your application to list all pets, or you can call `http://localhost:1337/pets/[petID]` to get a specific pet's details.

### Using the Strapi GraphQL Plugin
If instead of using the REST API, you want to use a [GraphQL](https://graphql.org/) endpoint, you can add one. On the left menu, go to **Marketplace**. A list of plugins will be displayed. Click **Download** for the GraphQL plugin.

Once the plugin is installed, you can go to [http://localhost:1337/graphql](http://localhost:1337/graphql) to view and test the endpoint.

## Building the Frontend
For the Pet List, Add Pet, Update Pet, and Delete Pet features from the application, you will use React with [Redux](<https://redux.js.org/>). Redux is a state management library. It needs an intermediary tool, `react-redux`, to enable communication between the Redux store and the React application.
As my primary focus is to demonstrate creating a CRUD application using a headless CMS, I won't show you all the styling in this tutorial, but to get the code, you can fork [this GitHub repository](<https://github.com/fgiuliani/pet-adoption>).
First, create a new React application:
```
npx create-react-app pet-adoption
```
Once you've created your React app, install the required npm packages:
```
npm install react-router-dom @reduxjs/toolkit react-redux axios
```
- `react-router-dom` handles the different pages.
- `@reduxjs/toolkit` and `react-redux` add the redux store to the application.
- `axios` connects to the Strapi REST API.
Inside the `src` folder, create a helper `http.js` file, with code that will be used to connect to Strapi API:
```
import axios from "axios";
export default axios.create({
baseURL: "http://localhost:1337",
headers: {
"Content-type": "application/json",
},
});
```
Create a `petsService.js` file with helper methods for all the CRUD operations inside a new folder called `pets`:
```
import http from "../http";
class PetsService {
getAll() {
return http.get("/pets");
}
get(id) {
return http.get(`/pets/${id}`);
}
create(data) {
return http.post("/pets", data);
}
update(id, data) {
return http.put(`/pets/${id}`, data);
}
delete(id) {
return http.delete(`/pets/${id}`);
}
}
export default new PetsService();
```
Redux uses *actions* and *reducers*. According to the [Redux documentation](https://redux.js.org/tutorials/fundamentals/part-3-state-actions-reducers#designing-actions), actions are "an event that describes something that happened in the application." Reducers are functions that take the current state and an action as arguments and return a new state result.
To create actions, you first need to define action types. Create a file inside the `pets` folder called `actionTypes.js`:
```
export const CREATE_PET = "CREATE_PET";
export const RETRIEVE_PETS = "RETRIEVE_PETS";
export const UPDATE_PET = "UPDATE_PET";
export const DELETE_PET = "DELETE_PET";
```
Create an `actions.js` file in the same folder:
```
import {
CREATE_PET,
RETRIEVE_PETS,
UPDATE_PET,
DELETE_PET,
} from "./actionTypes";
import PetsService from "./petsService";
export const createPet =
(name, animal, breed, location, age, sex) => async (dispatch) => {
try {
const res = await PetsService.create({
name,
animal,
breed,
location,
age,
sex,
});
dispatch({
type: CREATE_PET,
payload: res.data,
});
return Promise.resolve(res.data);
} catch (err) {
return Promise.reject(err);
}
};
export const retrievePets = () => async (dispatch) => {
try {
const res = await PetsService.getAll();
dispatch({
type: RETRIEVE_PETS,
payload: res.data,
});
} catch (err) {
console.log(err);
}
};
export const updatePet = (id, data) => async (dispatch) => {
try {
const res = await PetsService.update(id, data);
dispatch({
type: UPDATE_PET,
payload: data,
});
return Promise.resolve(res.data);
} catch (err) {
return Promise.reject(err);
}
};
export const deletePet = (id) => async (dispatch) => {
try {
await PetsService.delete(id);
dispatch({
type: DELETE_PET,
payload: { id },
});
} catch (err) {
console.log(err);
}
};
```
To create your reducers, add a new `reducers.js` file in the same folder:
```
import {
CREATE_PET,
RETRIEVE_PETS,
UPDATE_PET,
DELETE_PET,
} from "./actionTypes";
const initialState = [];
function petReducer(pets = initialState, action) {
const { type, payload } = action;
switch (type) {
case CREATE_PET:
return [...pets, payload];
case RETRIEVE_PETS:
return payload;
case UPDATE_PET:
return pets.map((pet) => {
if (pet.id === payload.id) {
return {
...pet,
...payload,
};
} else {
return pet;
}
});
case DELETE_PET:
return pets.filter(({ id }) => id !== payload.id);
default:
return pets;
}
}
export default petReducer;
```
Now that you have the actions and the reducers, create a `store.js` file in the `src` folder:
```
import { configureStore } from "@reduxjs/toolkit";
import petReducer from "./pets/reducers";
export default configureStore({
reducer: {
pets: petReducer,
},
});
```
Here you are configuring the Redux store and adding a `petReducer` function to mutate the state. You're setting the store to be accessible from anywhere in your application. After this, wrap the whole app inside the store using the Redux wrapper.
Your `index.js` file should now look like this:
```
import App from "./App";
import { Provider } from "react-redux";
import React from "react";
import ReactDOM from "react-dom";
import store from "./store";
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById("root")
);
```
Create a new component called `PetList.jsx`:
```
import React, { Component } from "react";
import { connect } from "react-redux";
import { Link } from "react-router-dom";
import { retrievePets, deletePet } from "../pets/actions";
class PetList extends Component {
componentDidMount() {
this.props.retrievePets();
}
removePet = (id) => {
this.props.deletePet(id).then(() => {
this.props.retrievePets();
});
};
render() {
const { pets } = this.props;
return (
<div className="list row">
<div className="col-md-6">
<h4>Pet List</h4>
<div>
<Link to="/add-pet">
<button className="button-primary">Add pet</button>
</Link>
</div>
<table className="u-full-width">
<thead>
<tr>
<th>Name</th>
<th>Animal</th>
<th>Breed</th>
<th>Location</th>
<th>Age</th>
<th>Sex</th>
<th>Actions</th>
</tr>
</thead>
<tbody>
{pets &&
pets.map(
({ id, name, animal, breed, location, age, sex }, i) => (
<tr key={i}>
<td>{name}</td>
<td>{animal}</td>
<td>{breed}</td>
<td>{location}</td>
<td>{age}</td>
<td>{sex}</td>
<td>
<button onClick={() => this.removePet(id)}>
Delete
</button>
<Link to={`/edit-pet/${id}`}>
<button>Edit</button>
</Link>
</td>
</tr>
)
)}
</tbody>
</table>
</div>
</div>
);
}
}
const mapStateToProps = (state) => {
return {
pets: state.pets,
};
};
export default connect(mapStateToProps, { retrievePets, deletePet })(PetList);
```
You will use this component in your `App.js` file, displaying it on the homepage of the app.
Now create another file, `AddPet.jsx`, with a component to add a pet to the list:
```
import React, { Component } from "react";
import { connect } from "react-redux";
import { createPet } from "../pets/actions";
import { Redirect } from "react-router-dom";
class AddPet extends Component {
constructor(props) {
super(props);
this.onChangeName = this.onChangeName.bind(this);
this.onChangeAnimal = this.onChangeAnimal.bind(this);
this.onChangeBreed = this.onChangeBreed.bind(this);
this.onChangeLocation = this.onChangeLocation.bind(this);
this.onChangeAge = this.onChangeAge.bind(this);
this.onChangeSex = this.onChangeSex.bind(this);
this.savePet = this.savePet.bind(this);
this.state = {
name: "",
animal: "",
breed: "",
location: "",
age: "",
sex: "",
redirect: false,
};
}
onChangeName(e) {
this.setState({
name: e.target.value,
});
}
onChangeAnimal(e) {
this.setState({
animal: e.target.value,
});
}
onChangeBreed(e) {
this.setState({
breed: e.target.value,
});
}
onChangeLocation(e) {
this.setState({
location: e.target.value,
});
}
onChangeAge(e) {
this.setState({
age: e.target.value,
});
}
onChangeSex(e) {
this.setState({
sex: e.target.value,
});
}
savePet() {
const { name, animal, breed, location, age, sex } = this.state;
this.props.createPet(name, animal, breed, location, age, sex).then(() => {
this.setState({
redirect: true,
});
});
}
render() {
const { redirect } = this.state;
if (redirect) {
return <Redirect to="/" />;
}
return (
<div className="submit-form">
<div>
<div className="form-group">
<label htmlFor="name">Name</label>
<input
type="text"
className="form-control"
id="name"
required
value={this.state.name}
onChange={this.onChangeName}
name="name"
/>
</div>
<div className="form-group">
<label htmlFor="animal">Animal</label>
<input
type="text"
className="form-control"
id="animal"
required
value={this.state.animal}
onChange={this.onChangeAnimal}
name="animal"
/>
</div>
<div className="form-group">
<label htmlFor="breed">Breed</label>
<input
type="text"
className="form-control"
id="breed"
required
value={this.state.breed}
onChange={this.onChangeBreed}
name="breed"
/>
</div>
<div className="form-group">
<label htmlFor="location">Location</label>
<input
type="text"
className="form-control"
id="location"
required
value={this.state.location}
onChange={this.onChangeLocation}
name="location"
/>
</div>
<div className="form-group">
<label htmlFor="age">Age</label>
<input
type="text"
className="form-control"
id="age"
required
value={this.state.age}
onChange={this.onChangeAge}
name="age"
/>
</div>
<div className="form-group">
<label htmlFor="sex">Sex</label>
<input
type="text"
className="form-control"
id="sex"
required
value={this.state.sex}
onChange={this.onChangeSex}
name="sex"
/>
</div>
<button onClick={this.savePet} className="btn btn-success">
Submit
</button>
</div>
</div>
);
}
}
export default connect(null, { createPet })(AddPet);
```
This component will add a pet to the state.
Now, create an `EditPet.jsx` file:
```
import React, { Component } from "react";
import { connect } from "react-redux";
import { updatePet } from "../pets/actions";
import { Redirect } from "react-router-dom";
import PetService from "../pets/petsService";
class EditPet extends Component {
constructor(props) {
super(props);
this.onChangeName = this.onChangeName.bind(this);
this.onChangeAnimal = this.onChangeAnimal.bind(this);
this.onChangeBreed = this.onChangeBreed.bind(this);
this.onChangeLocation = this.onChangeLocation.bind(this);
this.onChangeAge = this.onChangeAge.bind(this);
this.onChangeSex = this.onChangeSex.bind(this);
this.savePet = this.savePet.bind(this);
this.state = {
currentPet: {
name: "",
animal: "",
breed: "",
location: "",
age: "",
sex: "",
},
redirect: false,
};
}
componentDidMount() {
this.getPet(window.location.pathname.replace("/edit-pet/", ""));
}
onChangeName(e) {
const name = e.target.value;
this.setState(function (prevState) {
return {
currentPet: {
...prevState.currentPet,
name: name,
},
};
});
}
onChangeAnimal(e) {
const animal = e.target.value;
this.setState(function (prevState) {
return {
currentPet: {
...prevState.currentPet,
animal: animal,
},
};
});
}
onChangeBreed(e) {
const breed = e.target.value;
this.setState(function (prevState) {
return {
currentPet: {
...prevState.currentPet,
breed: breed,
},
};
});
}
onChangeLocation(e) {
const location = e.target.value;
this.setState(function (prevState) {
return {
currentPet: {
...prevState.currentPet,
location: location,
},
};
});
}
onChangeAge(e) {
const age = e.target.value;
this.setState(function (prevState) {
return {
currentPet: {
...prevState.currentPet,
age: age,
},
};
});
}
onChangeSex(e) {
const sex = e.target.value;
this.setState(function (prevState) {
return {
currentPet: {
...prevState.currentPet,
sex: sex,
},
};
});
}
getPet(id) {
PetService.get(id).then((response) => {
this.setState({
currentPet: response.data,
});
});
}
savePet() {
this.props
.updatePet(this.state.currentPet.id, this.state.currentPet)
.then(() => {
this.setState({
redirect: true,
});
});
}
render() {
const { redirect, currentPet } = this.state;
if (redirect) {
return <Redirect to="/" />;
}
return (
<div className="submit-form">
<div>
<div className="form-group">
<label htmlFor="name">Name</label>
<input
type="text"
className="form-control"
id="name"
required
value={currentPet.name}
onChange={this.onChangeName}
name="name"
/>
</div>
<div className="form-group">
<label htmlFor="animal">Animal</label>
<input
type="text"
className="form-control"
id="animal"
required
value={currentPet.animal}
onChange={this.onChangeAnimal}
name="animal"
/>
</div>
<div className="form-group">
<label htmlFor="breed">Breed</label>
<input
type="text"
className="form-control"
id="breed"
required
value={currentPet.breed}
onChange={this.onChangeBreed}
name="breed"
/>
</div>
<div className="form-group">
<label htmlFor="location">Location</label>
<input
type="text"
className="form-control"
id="location"
required
value={currentPet.location}
onChange={this.onChangeLocation}
name="location"
/>
</div>
<div className="form-group">
<label htmlFor="age">Age</label>
<input
type="text"
className="form-control"
id="age"
required
value={currentPet.age}
onChange={this.onChangeAge}
name="age"
/>
</div>
<div className="form-group">
<label htmlFor="sex">Sex</label>
<input
type="text"
className="form-control"
id="sex"
required
value={currentPet.sex}
onChange={this.onChangeSex}
name="sex"
/>
</div>
<button onClick={this.savePet} className="btn btn-success">
Submit
</button>
</div>
</div>
);
}
}
export default connect(null, { updatePet })(EditPet);
```
You can now run the application by pointing the API calls to your local instance of Strapi. To run both the Strapi development server and your new React app, run the following:
```
# Start Strapi
npm run develop
# Start React
npm run start
```
Now Strapi will be running on port `1337`, and the React app will be running on port `3000`.
If you visit [http://localhost:3000/](http://localhost:3000/), you should see the app running:

## Conclusion
In this article, you saw how to use [Strapi, a headless CMS](https://strapi.io/), to serve as the backend for a typical CRUD application. Then, you used React and Redux to build a frontend with managed state so that changes can be propagated throughout the application.
Headless CMSes are versatile tools that can be used as part of almost any application's architecture. You can store and administer information to be consumed from different devices, platforms, and services. You can use this pattern to store content for your blog, manage products in an e-commerce platform, or build a pet adoption platform like you've seen today. | shadaw11 | |
731,264 | Automatic image slider in Html Css | Awesome CSS Slideshow | Hello guys, today I am going to show you how to create an automatic image slide in Html css, in this... | 0 | 2021-06-17T16:01:28 | https://dev.to/stackfindover/automatic-image-slider-in-html-css-awesome-css-slideshow-kd8 | html, css, beginners, webdev | ***Hello guys, today I am going to show you how to create an automatic image slide in Html css, in this video you will learn how do you create an awesome CSS slideshow with fade animation.***
{% youtube BAnuWHgwZU8 %} | stackfindover |
731,406 | The Arguments Object in Javascript | In javaScript we are free to pass as many argument as we want and javaScript won't show us error. For... | 0 | 2021-06-19T10:32:24 | https://dev.to/shahab570/the-arguments-object-in-javascript-1a37 | javascript, array, arguments, webdev | In javaScript we are free to pass as many argument as we want and javaScript won't show us error. For example:
```
function multiply(x) {
var result = x * 10;
console.log(result);
}
multiply(5,7,8,9); //50
```
This code won't show error becuase javaScript avoids these extra arguments. But if we want,we can access them via an Object which is called arguments object.
Those parameters which are present in funciton definition can only be accessed by the parameter name.Other additional parameter will have to access throguh arguments object.
Let'see and example:
```
function wage(salary, month) {
const total = salary * month;
const invoice = total + arguments[0];
console.log(invoice);
}
wage(1000, 5, 1000);
```
The output of the above funciton is 6000. IF you add more arguments , we also can access them throgh argument object.
Remember that It's not an Array , It's an arry like object which doesn't have any array like properties except length. You can calculate legth of the argument with **arguments.length**. For example:
```
function wage(salary, month) {
console.log(arguments.length)
}
wage(1,2,3,4,5,6,7,8,9,10); //10
```
Althoguh arguments object don't have array properties and methods but we can convert them to array and use all the Array properties
#4 ways to convert Argument Object to Array
**First Method:**
```
function wage(x,y) {
return Array.prototype.slice.call(arguments);
}
wage(1, 2, 3); //[1,2,3]
```
**Second Method:**
function wage(salary) {
return [].slice.call(arguments);
}
wage(1, 2, 3); //[1,2,3]
**Third Method:**
```
function wage(salary) {
return Array.from(arguments);
}
wage(1, 2, 3); //[1.2.3]
```
**Fourth Method:**
function wage(salary) {
return [...arguments];
}
wage(1, 2, 3); //[1.2.3]
I hope you now have a clear idea of converting this array like object to an actual array. You can also check type of arguments passed in the funciton. FOr example
```
function wage() {
console.log(typeof arguments[0]); //Number
console.log(typeof arguments[1]); //String
console.log(typeof arguments[2]); //Object
console.log(typeof arguments[3]); //Object
}
wage(1, "John", ["A","B"],{age: 25,gender: "Male"});;
```
Thanks for reading my article.
| shahab570 |
731,510 | Understanding the use of useRef hook & forwardRef in React | The useRef hook in react is used to create a reference to an HTML element. Most widely used scenario... | 0 | 2021-06-17T20:43:45 | https://dev.to/sajithpradeep/understanding-the-use-of-useeffect-hook-forwardref-in-react-57jf | javascript, webdev, react, tutorial | The *useRef* hook in react is used to create a reference to an HTML element. Most widely used scenario is when we have form elements and we need to reference these form elements to either print their value or focus these elements etc.
So the *{useRef}* hook is imported from *"react"* like other react hooks and we use them inside functional components to create references and this can be assigned to an html element in the *jsx* by using the *"ref"* attribute.
An example for using the useRef hook is shown below-
```javascript
import React, { useEffect, useRef } from "react";
const UseRefHookExplained = (props) => {
// Creating refs for username and password
const userNameRef = useRef(null);
const passwordRef = useRef(null);
// We are also creating a reference to the Login button
const submitBtnRef = useRef(null);
// useEffect to set the initial focus to the user name input
useEffect(() => {
userNameRef.current.focus();
}, []);
// This function is used to handle the key press.
// Whenever user hits enter it moves to the next element
const handleKeyPress = (e, inputType) => {
if (e.key === "Enter") {
switch (inputType) {
// Checks if Enter pressed from the username field?
case "username":
// Moves the focus to the password input field
passwordRef.current.focus();
break;
// Checks if Enter pressed from the password field?
case "password":
// Moves the focus to the submit button
submitBtnRef.current.focus();
e.preventDefault();
break;
default:
break;
}
}
};
// Function to handle the submit click from the button
const handleSubmit = () => {
alert("submitted");
};
// getting the style as prop from the parent.
// Basic style to center the element and apply a bg color
const { style } = props;
return (
<div style={style}>
<h2>Example for using useRef Hook</h2>
<h3>Login</h3>
<input
type="text"
name="username"
ref={userNameRef}
onKeyDown={(e) => handleKeyPress(e, "username")}
/>
<input
type="password"
name="password"
ref={passwordRef}
onKeyDown={(e) => handleKeyPress(e, "password")}
/>
<button ref={submitBtnRef} onClick={handleSubmit}>
Login
</button>
</div>
);
};
export default UseRefHookExplained;
```
So the concept of *useRef* hook is straight forward as you can see in the above code. Follow the following steps -
1. We import useRef hook from react
2. We initialize this hook (eg: *const inputRef = useRef(null)*)
3. The reference created is attached to an html element using the "ref" attribute.
Now we will have a reference to this element readily available to be used to make changes like getting the value, focusing etc
Output
Initial state when the page loads -
Focus State after entering user name and pressing enter -
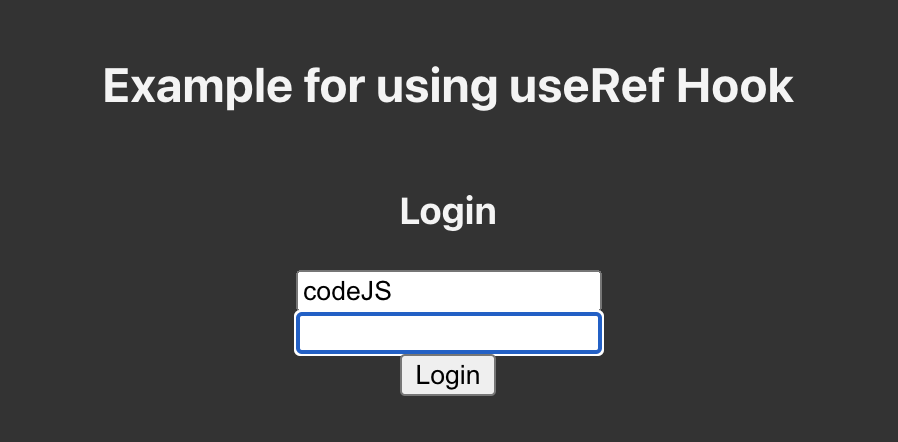
Focus state moving to the button after entering the password and clicking on Enter
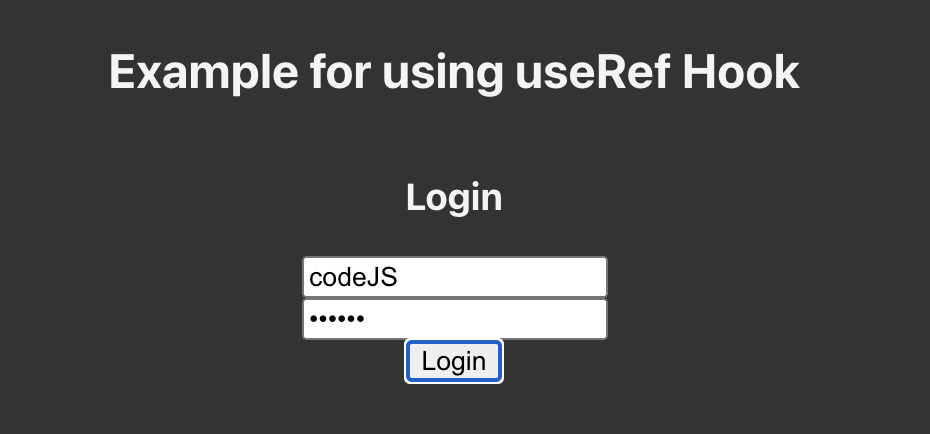
So, this much should be pretty clear by now. Now let us look at a scenario when we will be using another React component for input.
In this case it becomes a little difficult to pass on the reference that we have defined in the parent component as a property to the child (Input component).
React provides us a way to handle this scenario and forward the refs to the child component using **React.forwardRef**
Let us check the example code to see the changes -
( I have added a comment **"//new"** to identify the newly added lines)
```javascript
import React, { useEffect, useRef } from "react";
import Input from "./Input"; // new
const UseRefHookExplained = (props) => {
// Creating refs for username and password
const userNameRef = useRef(null);
const passwordRef = useRef(null);
// We are also creating a reference to the Login button
const submitBtnRef = useRef(null);
// useEffect to set the initial focus to the user name input
useEffect(() => {
userNameRef.current.focus();
}, []);
// This function is used to handle the key press.
// Whenever user hits enter it moves to the next element
const handleKeyPress = (e, inputType) => {
if (e.key === "Enter") {
switch (inputType) {
// Checks if Enter pressed from the username field?
case "username":
// Moves the focus to the password input field
passwordRef.current.focus();
break;
// Checks if Enter pressed from the password field?
case "password":
// Moves the focus to the submit button
submitBtnRef.current.focus();
e.preventDefault();
break;
default:
break;
}
}
};
// Function to handle the submit click from the button
const handleSubmit = () => {
alert("submitted");
};
// getting the style as prop from the parent.
// Basic style to center the element and apply a bg color
const { style } = props;
return (
<div style={style}>
<h2>Example for using useRef Hook</h2>
<h3>Login</h3>
{/* New. Using the Component instead of input element */}
<Input
type="text"
name="username"
ref={userNameRef}
onKeyDown={(e) => handleKeyPress(e, "username")}
/>
{/* New. Using the Component instead of input element */}
<Input
type="password"
name="password"
ref={passwordRef}
onKeyDown={(e) => handleKeyPress(e, "password")}
/>
<button ref={submitBtnRef} onClick={handleSubmit}>
Login
</button>
</div>
);
};
export default UseRefHookExplained;
```
Now let us look at the Input.js component
```javascript
import React from "react";
/* In the functional component, a second argument
is passed called ref, which will have access to
the refs being forwarded from the parent */
const Input = (props, ref) => {
/* assigning the ref attribute in input and spreading
the other props which will contain type, name, onkeydown etc */
return <input {...props} ref={ref} />;
};
// wrapping the Input component with forwardRef
const forwardedRef = React.forwardRef(Input);
// Exporting the wrapped component
export default forwardedRef;
```
So, React.forwardRed provides us a way with which we can still pass on or forward the refs defined in the parent component to the child component.
Hope you learned something new today!
| sajithpradeep |
731,746 | Kentico Xperience Design Patterns: Good Layout Hygiene | Learn how to maintain a clean and focused _Layout.cshtml file using Razor Partials and View Components. | 10,963 | 2021-07-12T15:57:50 | https://dev.to/seangwright/kentico-xperience-design-patterns-good-layout-hygiene-3ob6 | xperience, kentico, aspnetcore, csharp | ---
title: Kentico Xperience Design Patterns: Good Layout Hygiene
published: true
description: Learn how to maintain a clean and focused _Layout.cshtml file using Razor Partials and View Components.
tags: xperience, kentico, aspnetcore, csharp
series: Kentico Xperience Design Patterns
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/hcusgcjdsp4aozej50g9.jpg
---
It can be easy for Kentico Xperience developers to focus applying well known software design patterns, like DRY, composition, abstraction, and separation of concerns to their C# code, but these patterns are just as important in Razor code 🧐.
We can use Page Builder Widget Sections and Widgets to decompose the Page layout and design into reusable pieces, but what about the parts of a site common to every Page, like navigation, headers, footers, meta elements, and references to CSS and JavaScript 🤷🏽♂️?
By applying the above design patterns we can make sure we practice good Layout hygiene 🚿, keeping our Razor `_Layout.cshtml` organized and maintainable.
> If you are looking for other tips on keeping a clean Kentico Xperience application, checkout my post [Kentico Xperience Design Patterns: Good Startup.cs Hygiene ](https://dev.to/seangwright/kentico-xperience-design-patterns-good-startup-cs-hygiene-3klm).
## 📚 What Will We Learn?
- [What is a Razor Layout](#what-is-a-layout)
- [The problems with unmaintained Razor Layouts](#an-unmaintained-layout)
- [When to use Partial Views and View Components](#janitorial-tools)
- [How to clean up and organize a messy Layout](#cleaning-up-a-messy-layout)
## 🚀 [What is a Layout?](#what-is-a-layout)
According to the [documentation for ASP.NET Core](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/layout?view=aspnetcore-5.0), a Layout "defines a top level template for views in the app."
By convention, the `_Layout.cshtml` file in our `~/Views/Shared` folder is the Layout used by all Views in our application. This can be changed by modifying the `Layout` value specified in `_ViewStart.cshtml` at the root of the project or by overriding the `Layout` value on a per-View basis 🤓.
The Layout is where we define all the markup that should appear on all (or most) Pages in our site. This includes headers and footers (navigation), `<script>` and `<link>` elements, marketing tags, meta tags, and any markup that wraps the main body of our Razor Views.
If we take a [semantic HTML](https://dev.to/kenbellows/stop-using-so-many-divs-an-intro-to-semantic-html-3i9i) approach to our markup, we might have something that looks like this:
```html
<head>
<!-- links, meta tags -->
</head>
<body>
<header>
<!-- nav, banners -->
<header>
<main>
<!-- page content -->
@RenderBody()
</main>
<footer>
<!-- nav, social icons -->
</footer>
</body>
```
`@RenderBody()` is where the markup from our Page specific Views will end up, and everything else is rendered _from_ our Layout (but not necessarily _by_ our Layout 😉).
Some of this markup might be the same between Pages (navigation) and other parts will be more dynamic, including Page specific content, like [Open Graph meta tags](https://ogp.me/).
## 🚽 [An Unmaintained Layout](#an-unmaintained-layout)
If we look at the [Dancing Goat sample site](https://docs.xperience.io/installation/quick-installation#Quickinstallation-StartingtheDancingGoatsamplesite)'s `_Layout.cshtml` we can see what happens when our Layout grows in complexity to serve the needs of our site's functionality.
It's about 160 lines long and renders the following:
- Static meta
- Kentico Xperience dynamic (page specific) meta
- Kentico Xperience marketing features scripts
- Kentico Xperience Page Builder script and styles
- The site's styles
- A tracking consent form
- The site's header
- Navigation
- Authenticated user avatar
- Shopping cart icon
- A language/culture switcher
- Search box
- The site's main content container
- The site's footer
- Company address
- Social links
- Newsletter subscription form
- The site's JavaScript
> Here's [a link](https://gist.github.com/seangwright/7265642e82736dcade11e57e9a0d84da) to the `_Layout.cshtml` in case you don't have access to it.
This seems like way too much for 1 file, but it is entirely plausible that an unmaintained Layout could evolve into this.
The main problem is that it's hard to reason about 😵! There's simply too much going on in 1 file. We can see some Razor code blocks that define C# variables - these are effectively creating global variables for the Razor file and global variables always make code more confusing 👍🏿.
If we remember that Razor files [generate C# classes](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/razor?view=aspnetcore-5.0#directives) at compile time, it's easier to realize the benefits we might gain from simplifying this file - a C# class with this kind of complexity is definitely a [code smell](https://www.martinfowler.com/bliki/CodeSmell.html).
This Layout is also more likely to result in merge conflicts because of its size and mixed purposes. If a developer is working on an entirely different feature than another teammate, a well structured application will make it unlikely for them both to have to modify the same file for their changes. Merge conflicts, in this scenario, can also sometimes be a code smell 👃🏼 - especially if they are painful to resolve.
Maybe we could clean 🧼 it up?
> The Dancing Goat site [is meant to demo Kentico Xperience's capabilities](https://devnet.kentico.com/articles/kentico-xperience-sample-sites-and-their-differences), not be the pinnacle of software architecture 😋.
## 🧹 [Janitorial Tools](#janitorial-tools)
So what tools ⚒ can we use to clean up this smelly 💩 mess?
### 🧩 Partial Views
[Partial Views](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/partial?view=aspnetcore-5.0) are perfect for encapsulating a section of markup and giving it a name. They make it easier to understand and modify the markup in the Partial and do the same wherever the Partial is referenced - in our case, that's going to be the Layout.
If we are trying to reduce merge conflicts and make a bit of markup more readable, Partial Views are a great solution.
Partials can be passed parameters that become the View Model of the Partial, however these are not strongly typed and if the wrong type is passed as the View Model, we'll experience a runtime exception.
In ASP.NET Core, if we need to pass some data to a Partial, we might instead reach for another powerful tool - the View Component.
### 🖼 View Components
[View Components](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/view-components?view=aspnetcore-5.0) give us an opportunity to separate data and logic from the declarative presentation of HTML. They mirror the MVC pattern by having 3 parts - the View Component class (Controller), View Model class, and Razor View.
Using the Tag Helper syntax for View Components (ex: `<vc:our-view-component>`), we get strongly typed parameters passed to the View Component, which can improve the developer experience and make our code more refactor-proof 😎.
Since View Component classes participate in dependency injection and have access to all the same helper 'context' properties that Controllers do, we can use them in much the same way. If we need access to state, services, or execute some logic to restructure a model, View Components are perfect 👏🏻.
We might see examples of injecting services directly into Views using [View Service Injection](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/dependency-injection?view=aspnetcore-5.0). While this technique is _very_ convenient, I advise against using it too much 😮. Views are declarative presentation concerns and any complex logic or data access should definitely be performed in C# classes.
As a concrete example, using an injected `IHtmlLocalizer` for localizing content is a great use-case for View Service Injection 💪🏾, however accessing a repository or any of Kentico Xperience's 'Retriever' services (`IPageRetriever`, `IPageAttachmentUrlRetriever`) in a View should be considered an anti-pattern - use a Controller or View Component instead.
> If you want to learn more about using View Components in Kentico Xperience, checkout my post [Kentico Xperience 13 Beta 3 - Page Builder View Components in ASP.NET Core ](https://dev.to/seangwright/kentico-xperience-13-beta-3-page-builder-view-components-in-asp-net-core-onm) or [Kentico Xperience Design Patterns: MVC is Dead, Long Live PTVC ](https://dev.to/seangwright/kentico-xperience-design-patterns-mvc-is-dead-long-live-ptvc-4635).
Now that we've covered our motivations for cleaning up our Layout and the tools we can use, let's jump into the task at hand.
## 🚿 [Cleaning Up a Messy Layout](#cleaning-up-a-messy-layout)
There's two observations we are going to make about the code in the Layout:
- What bits of markup share a common purpose?
- What needs application state or context to render?
Let's analyze these below...
### 🎨 Abstract Based on Purpose
First, we should identify which parts of the Layout belong together 👩🏾🤝🧑🏼 based on their purpose. Things that change together should stay together and we can relate this recommendation to the [Single-Responsibility Principle](https://en.wikipedia.org/wiki/SOLID).
> The lack of a single responsibility for this giant Layout is what makes it so complex.
We already have an outline of the different parts of our Layout, organized by purpose, with our original list at the beginning of this post, but let's look from an even higher 🌍 level.
#### HTML Head Element
The `<head>` element is an obvious starting point for refactoring:
```html
<head id="head">
<meta name="viewport" content="width=device-width, initial-scale=1" />
<meta charset="UTF-8" />
@Html.Kentico().PageDescription()
@Html.Kentico().PageKeywords()
@Html.Kentico().PageTitle(ViewBag.Title as string)
<link rel="icon" href="~/content/images/favicon.svg" type="image/svg+xml" />
<link href="~/Content/Styles/Site.css" rel="stylesheet" type="text/css" />
<link rel="canonical" href="@Url.Kentico().PageCanonicalUrl()" />
@RenderSection("styles", required: false)
@Html.Kentico().ABTestLoggerScript()
@Html.Kentico().ActivityLoggingScript()
@Html.Kentico().WebAnalyticsLoggingScript()
<page-builder-styles />
</head>
```
We can take this whole block of code and move it into a Partial view. I typically like to leave the top level elements (like `<head>` and `<body>`) in the Layout, so let's just take the contents of the `<head>` and move them to a new Partial `~/Views/Shared/_Head.cshtml`.
We'll also need to move over the 2 namespaces being used by the HtmlHelpers in this Partial:
```html
@using Kentico.OnlineMarketing.Web.Mvc
@using Kentico.Activities.Web.Mvc
```
This will change the Layout to the following:
```html
<!DOCTYPE html>
<html>
<head id="head">
<partial name="_Head" />
@RenderSection("styles", required: false)
</head>
```
We have to move the `@RenderSection()` out of the Razor we copied to the `_Head.cshtml` Partial because Mvc doesn't support rendering sections from Partials.
#### HTML Header Element
Next, we'll move the `<header>` element and all of its contents to a new `~/Views/Shared/_Header` Partial (along with the `@using Kentico.Membership.Web.Mvc` `using` that gives us access to the `AvatarUrl()` `HtmlHelper` extension).
This will reduce our Layout to the following, with a total of 59 lines for the file 🥳:
```html
<!DOCTYPE html>
<html>
<head id="head">
<partial name="_Head" />
</head>
<body class="@ViewData["PageClass"]">
<div class="page-wrap">
<vc:tracking-consent />
<partial name="_Header" />
<!-- ... -->
```
The `_Header` Partial can be simplified further but let's finish working with the Layout first.
#### Footer HTML Element
We only have a few sections of markup left in our Layout and the next one that we'll abstract into a Partial is the 'footer'.
The Dancing Goat footer includes a `<div class="footer-wrapper">` container element. Even though the actual `<footer>` element is nested inside it, the wrapper is part of the footer from a design perspective, so let's take the wrapper and all of its contents and move them to a new Partial `~/Views/Shared/_Footer.cshtml`. We'll also need to move the `@using DancingGoat.Widgets` `using` to our Partial to get access to the Newsletter subscription widget types.
Our updated Layout is shaping up 😊 and looks as follows:
```html
<body class="@ViewData["PageClass"]">
<div class="page-wrap">
<vc:tracking-consent />
<partial name="_Header" />
<div class="container">
<div class="page-container-inner">
@RenderBody()
<div class="clear"></div>
</div>
</div>
</div>
<partial name="_Footer" />
<!-- ... -->
```
#### Page Scripts
The last bit of markup to abstract out of our Layout includes all the `<script>` tags, which we will move to another new Partial `~/Views/Shared/_Scripts.cshtml`. We will leave the `@RenderSection("scripts", required: false)` call in the Layout, just like the `RenderSection` call for styles.
We've completely cleaned up the Layout and trimmed it down to a lovely 27 lines 😅:
```html
<!DOCTYPE html>
<html>
<head id="head">
<partial name="_Head" />
</head>
<body class="@ViewData["PageClass"]">
<div class="page-wrap">
<vc:tracking-consent />
<partial name="_Header" />
<div class="container">
<div class="page-container-inner">
@RenderBody()
<div class="clear"></div>
</div>
</div>
</div>
<partial name="_Footer" />
<partial name="_Scripts" />
@RenderSection("scripts", required: false)
</body>
</html>
```
We were able to do this without creating any new abstractions - just organizing code by common concerns. In our Layout, these common concerns can often be identified by high level HTML elements, like `<head>`, `<header>`, and `<footer>`.
> This clean up also lets us see additional places we could insert `@RenderSection()` calls if we wanted to give our Views more places to hook into the Layout 🤔.
### 🔬 Identify What Needs State
The `_Footer` and `_Head` Partials are simple and only a few lines of code. However, the `_Header` Partial we created is 88 lines long. It includes a Razor code block, has multiple conditional statements, and 2 navigation blocks 😨 (header navigation and the 'additional' navigation).
The Razor code block in the view is often a code smell - it indicates we are executing some logic in our View. This specific code block not only executes some logic, but it also access application state - the `@ViewContext`.
The `_Header` Partial also accesses state through the `ClaimsPrincipal User` and the `HttpContext Context` properties of the Razor page. While these properties are accessible from the Razor view, I like to think of them as a convenience and not necessarily something that should be used when considering best practices for larger applications.
Any time we have logic in our Layout (or Partials), and especially when we are accessing application state, I see it as an opportunity to leverage a View Component instead of a Partial 🤓.
View Components have access to the same context specific state (like `ViewContext`, `User`, and `Context`) but they are more testable and appropriate for C# code and logic 👍🏼.
#### Header View Component
The only portion of the `_Header` Partial using this context state is the contents of the `<ul class="additional-menu">` element, so let's use that as the starting point for our View Component.
Let's create a new View Component `~/Components/ViewComponents/HeaderMenu/HeaderMenuViewComponent.cs`:
```csharp
public class HeaderMenuViewComponent : ViewComponent
{
public IViewComponentResult Invoke()
{
string cultureCode = ViewContext
.RouteData
.Values["culture"];
var currentCultureCode = Convert.ToString(cultureCode);
var currentLanguage = currentCultureCode.Equals(
"es-es", StringComparison.OrdinalIgnoreCase)
? "ES" : "EN";
bool isCultureSelectorVisible = HttpContext.Response.StatusCode == (int)System.Net.HttpStatusCode.OK;
var vm = new HeaderMenuViewModel(
User.Identity.IsAuthenticated,
currentLanguage,
isCultureSelectorVisible);
return View(
"~/Components/ViewComponents/HeaderMenu/_HeaderMenu.cshtml", vm);
}
}
public record HeaderMenuViewModel(
bool IsUserAuthenticated,
string CurrentLanguage,
bool IsCultureSelectorVisible);
```
We've moved all of the logic of our View into the View Component class and created a View Model `record` that represents the state we need to expose to the View, with property names that have a clear purpose.
We can now move the `<ul class="additional-menu">` element and its contents into `~/Components/ViewComponents/HeaderMenu/_HeaderMenu.cshtml` add a `@model DancingGoat.Components.ViewComponents.HeaderMenu.HeaderMenuViewModel` directive at the top of the file, and use the View Model properties instead of the context helper properties.
We can see the effect this has on the culture selector in the View Component View 🤩:
```html
@if (Model.IsCultureSelectorVisible)
{
<li class="dropdown">
<a class="dropbtn">@Model.CurrentLanguage</a>
<div class="dropdown-content">
<culture-link link-text="English" culture-name="en-US" />
<culture-link link-text="Español" culture-name="es-ES" />
</div>
</li>
}
```
We can now update the `~/Views/Shared/_Header.cshtml` Partial, replacing the former location of `<ul class="additional-menu">` with a reference to our View Component `<vc:header-menu />`:
```html
<header data-ktc-search-exclude>
<nav class="navigation">
<div class="nav-logo">
<div class="logo-wrapper">
<a href="@Url.Kentico().PageUrl(ContentItemIdentifiers.HOME)" class="logo-link">
<img class="logo-image" alt="Dancing Goat" src="~/Content/Images/logo.svg" />
</a>
</div>
</div>
<vc:navigation footer-navigation="false" />
<vc:header-menu /> <!-- 😃 -->
</nav>
<div class="search-mobile">
<form asp-action="Index" asp-controller="Search" method="get" class="searchBox">
<input name="searchtext" type="text" placeholder="@HtmlLocalizer["Search"]" autocomplete="off" />
<input type="submit" value="" class="search-box-btn" />
</form>
</div>
</header>
```
#### If Tag Helper
Coming from ASP.NET MVC 5 in Kentico 12, we are probably used to seeing Html Helper calls and Razor statements all over our Views.
I've found that adopting [Tag Helpers](https://docs.microsoft.com/en-US/aspnet/core/mvc/views/tag-helpers/intro?view=aspnetcore-5.0), which look much more like HTML, leads to more readable Views. As a bonus, if you've had experience with any client-side JavaScript frameworks, like React, Vue, or Angular, ASP.NET Core Tag Helpers are going to look like the server-side equivalents of what those frameworks already support.
To this end, it could be nice 😏 to replace the Razor `@if()` syntax with a Tag Helper. First, let's see what we're working with:
```html
<div class="dropdown-content">
@if (Model.IsUserAuthenticated)
{
<a asp-controller="Account" asp-action="YourAccount">
@HtmlLocalizer["Your account"]
</a>
<form method="post" asp-controller="Account"
asp-action="Logout">
<input type="submit"
value="@HtmlLocalizer["Sign out"]"
class="sign-out-button" />
</form>
}
else
{
<a asp-controller="Account" asp-action="Register">
@HtmlLocalizer["Register"]
</a>
<a asp-controller="Account" asp-action="Login">
@HtmlLocalizer["Login"]
</a>
}
</div>
```
Using the `<if>` Tag Helper detailed by Andrew Lock in [this blog post](https://andrewlock.net/creating-an-if-tag-helper-to-conditionally-render-content/), we can update our View to look more HTML-ish:
```html
<div class="dropdown-content">
<if include-if="Model.IsUserAuthenticated">
<a asp-controller="Account" asp-action="YourAccount">
@HtmlLocalizer["Your account"]
</a>
<form method="post" asp-controller="Account"
asp-action="Logout">
<input type="submit"
value="@HtmlLocalizer["Sign out"]"
class="sign-out-button" />
</form>
</if>
<if exclude-if="Model.IsUserAuthenticated">
<a asp-controller="Account" asp-action="Register">
@HtmlLocalizer["Register"]
</a>
<a asp-controller="Account" asp-action="Login">
@HtmlLocalizer["Login"]
</a>
</if>
</div>
```
This is a matter of taste 🥪, but I've found many of the ASP.NET Core Tag Helpers to be much more readable than their Html Helper and Razor syntax equivalents (including the [Partial Tag Helper](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/tag-helpers/built-in/partial-tag-helper?view=aspnetcore-5.0) and [View Component Tag Helper](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/view-components?view=aspnetcore-5.0#invoking-a-view-component-as-a-tag-helper) we've already used).
## 🧠 Conclusion
We've reduced the size of the Dancing Goat `_Layout.cshtml` file from 160 lines to 27 and the largest Partial or View Component View that we now have from our refactoring is the `_HeaderMenu.cshtml` at 64 lines.
We could continue the refactoring with additional View Components or Partial Views to reduce that size even further - likely separating the Avatar markup and Login/Register links next. I'll leave that task for the now-very-capable reader 😁.
By identifying a problematic area of the application, the tools that ASP.NET Core puts at our disposal, and applying some common refactoring patterns, we've created a clean an maintainable Layout.
Let me know ✍ your patterns and practices for Layouts in Kentico Xperience applications in the comments below...
As always, thanks for reading 🙏!
---
<figcaption>Photo by <a href="https://unsplash.com/@markusspiske">Markus Spiske
</a> on <a href="https://unsplash.com">Unsplash</a></figcaption>
---
## References
- [Kentico Xperience Design Patterns: Good Startup.cs Hygiene ](https://dev.to/seangwright/kentico-xperience-design-patterns-good-startup-cs-hygiene-3klm)
- [ASP.NET Core Docs - Layouts](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/layout?view=aspnetcore-5.0)
- [Stop using so many divs! An intro to semantic HTML ](https://dev.to/kenbellows/stop-using-so-many-divs-an-intro-to-semantic-html-3i9i)
- [Kentico Xperience Docs - Dancing Goat Sample Site Installation Process](https://docs.xperience.io/installation/quick-installation#Quickinstallation-StartingtheDancingGoatsamplesite)
- [Kentico Xperience sample sites and their differences](https://devnet.kentico.com/articles/kentico-xperience-sample-sites-and-their-differences)
- [ASP.NET Core Docs - Razor Directives](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/razor?view=aspnetcore-5.0#directives)
- [Martin Fowler - Code Smells](https://www.martinfowler.com/bliki/CodeSmell.html)
- [ASP.NET Core Docs - Partial Views](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/partial?view=aspnetcore-5.0)
- [ASP.NET Core Docs - View Components](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/view-components?view=aspnetcore-5.0)
- [ASP.NET Core Docs - View Service Injection](https://docs.microsoft.com/en-us/aspnet/core/mvc/views/dependency-injection?view=aspnetcore-5.0)
- [Kentico Xperience 13 Beta 3 - Page Builder View Components in ASP.NET Core ](https://dev.to/seangwright/kentico-xperience-13-beta-3-page-builder-view-components-in-asp-net-core-onm)
- [Kentico Xperience Design Patterns: MVC is Dead, Long Live PTVC ](https://dev.to/seangwright/kentico-xperience-design-patterns-mvc-is-dead-long-live-ptvc-4635)
- [Single-Responsibility Principle](https://en.wikipedia.org/wiki/SOLID)
- [ASP.NET Core Docs - Tag Helpers](https://docs.microsoft.com/en-US/aspnet/core/mvc/views/tag-helpers/intro?view=aspnetcore-5.0)
- [Andrew Lock - If Tag Helper](https://andrewlock.net/creating-an-if-tag-helper-to-conditionally-render-content/)
---
We've put together a list over on [Kentico's GitHub account](https://github.com/Kentico/Home/blob/master/RESOURCES.md) of developer resources. Go check it out!
If you are looking for additional Kentico content, checkout the Kentico or Xperience tags here on DEV.
{% tag kentico %}
{% tag xperience %}
Or my [Kentico Xperience blog series](https://dev.to/seangwright/series), like:
- [Kentico Xperience Xplorations](https://dev.to/seangwright/series/8185)
- [Kentico Xperience MVC Widget Experiments](https://dev.to/seangwright/series/9483)
- [Bits of Xperience](https://dev.to/seangwright/series/8740)
| seangwright |
732,242 | Async/Await in JavaScript | Async functions are brought to JavaScript by ES8 (ES2017) and are used to facilitate the management... | 13,296 | 2021-06-18T14:45:13 | https://dev.to/rezab/async-await-in-javascript-noe | async, await, promise, javascript | Async functions are brought to JavaScript by ES8 (ES2017) and are used to facilitate the management of asynchronous operations. Async functions use Promises under their own skin.
To use this feature to manage an asynchronous operation, we first use the `async` keyword when defining a function. We always write the word `async` at the beginning of the function definition:
```
const users = async () =>{ }
```
When we use `async`, we have another keyword called `await`. When the `await` keyword is at the beginning of a expression, our code waits for the output of that expression to be specified and then goes to the next lines. We use await as follows:
```
const users = async () => {
let users = await getUsers();
console.log(users);
}
```
One thing to keep in mind is that the `await` keyword should only be used within a function that uses the `async` keyword at the beginning. Otherwise we get an error.
The next point to keep in mind is that if the expression in front of the `await` is not a Promise, it will automatically become a resolved Promise when it is done.
The output of an async function is always a Promise and we can treat it like a Promise.
```
const users = async () =>{
let users = await getUsers();
return users;
}
users.then(console.log); //list of users
```
P.S.: Async code is simpler and more readable than the Promises we had to use with chain methods. | rezab |
732,283 | Learning Python - Week 2 | So this week I learned about creating functions, control flow (if else/elif statements) and for... | 0 | 2021-06-18T15:29:22 | https://dev.to/evanrpavone/learning-python-week-2-3on | python, learning | So this week I learned about creating functions, control flow (if else/elif statements) and for loops. It was a slow week for me so I will only be talking about functions and their scope. I only got through a few lessons but next week I will be talking a lot more about these areas.
For me, creating functions and understanding them seemed a lot easier than learning about functions in the other languages I know even though it is very similar. You would set it up like a function you would see in JavaScript, but for me this looks like a method in Ruby. You would pass a parameter when defining a function and you would pass an argument when you are outputting like so:
```
def greet_person(value = “your name”): # passing a parameter of value with a default value
“””
DOCSTRING: This returns a greeting / This section is also comments
INPUT: value
OUTPUT: Hello… name
“””
print(“Hello “ + str(value) + “, this is the greet_person function”)
greet_person()
greet_person(“Evan”)
greet_person(23)
```
The three greet_persons are different examples. The first will just print the default value and place it in the string, the second will put Evan, and the third will change the integer to a string and put 23. The second and the third are passing in arguments which will change the parameter value and place it in the string. Anything outside of this function would be considered the global scope and anything inside the function is considered the local scope. So if I have a variable of age that is set to 23 and a function increase_age that also has a variable of age that is set to 30, I will not get the increase_age function age if I just print(age) outside of the function. I would end up getting the original age outside of the function, 30.
```
age = 23
def increase_age():
age = 30
print(age)
print(age) # returns 23 because it calling the age variable outside of the function - global scope
increase_age() # returns 30 because it is inside the function - local scope
```
Sorry if this got confusing to read but this is what I learned this week. This wasn’t all I learned but this is what really stood out to me. Python is a lot of fun and I am enjoying it. Come back next week!
| evanrpavone |
732,619 | Explain Private and Public keys (SSH) Like I'm Five | On paper I think I understand the concept: you have a matching key file to one on a remote machine... | 0 | 2021-06-19T01:31:26 | https://dev.to/ads-bne/explain-private-and-public-keys-ssh-like-i-m-five-1107 | On paper I think I understand the concept: you have a matching key file to one on a remote machine that grants you access. Yet, I've never been able to get these working. It's a mysterious box to me.
ELI5? | ads-bne | |
732,707 | Aura Components | *8 components in Aura Bundle. *3js, 1css, 1svg, 1 cmp, 1doc, *TO run Bundle need App Attributes... | 0 | 2021-06-20T06:37:18 | https://dev.to/bhanukarkra/aura-components-7m | *8 components in Aura Bundle.
*3js, 1css, 1svg, 1 cmp, 1doc,
*TO run Bundle need App
Attributes name="xyz" value =1 replaces variables to show in front end
To show <attribute values -->{!v.xyz}
v signify Component (ie; visual value)
c signify controller (ie; Controller value)
For back end use .js controller
<aura:attribute> can be defined directly in application also because both are front end.
Now we have 2 different ways to to to define aura:attribute
1. Creating a lightning component and then calling it in the lightning application,
2. lightning component attribute inside application
Button
<ui:button label="Click Me" press="{!c.myname}"/>
Js Controller = all functionality inside this.
**implements**
<aura:component implements="flexipage:availableForAllPageTypes" access="global"> : to make your component available for record pages and any other type of page,
**Calculator App**
Component=AddComponent.cmp
```
<aura:component >
<aura:attribute name="num1" type="Integer" default="30"/>
<aura:attribute name="num2" type="Integer" default="20"/>
<aura:attribute name="sum" type="Integer" />
{!v.num1} + {!v.num2} = {!v.sum}
<br></br>
<ui:button label= "Press Me" press="{!c.add}"/>
</aura:component>
```
Js.Controller =AddComponent.js
```
({
add : function(component) {
var xyz = component.get("v.num1") + component.get("v.num2");
component.set("v.sum",xyz);
}
})
```
Output:
You can only use {!} Syntax in markup languages like HTML, hence in .app and .cmp we are using {!} for expression.
<h4>ifElse</h4>
```
<aura:component>
<aura:attribute name="edit"
type="Boolean"
default="True"/>
<aura:if isTrue="{!v.edit}">
<ui:button label="submit"/>
<aura:set attribute="else">
Hello, Welcome to SalesfrceKid Platform
</aura:set>
</aura:if>
</aura:component>
```
Output

<h4>Value Providers</h4>
Value providers encapsulate related value together, similar to how an object encapsulates properties and methods.
The value providers for a component are v(view) and c(controller).
A component's view refers to its attribute set.
A component's controller enables you to wire up event handlers and action for the components. It's where you control your component's logic.
<h5>Global Value Providers /h5>
Here are some global value providers you need to know :
globalId: It returns the global ID for a component has a unique globalId, which is generated runtime-unique ID of the component instance.
$Browser: It returns information about the hardware and operating system of the browser accessing the application.
$Label: It enables you to access labels stored outside your code.
.
.
.
.
etc
```
<aura:component>
Browser running on Tablet: {!$Browser.isTablet}
<br></br>
Is it running on IPhone: {!$Browser.isIPhone}
<br></br>
Is it running on Android: {!$Browser.isAndroid}
<br></br>
I am Running on : {!$Browser.FormFactor}
</aura:component>
```
output
Browser running on Tablet: false
Is it running on IPhone: false
Is it running on Android: false
I am Running on DESKTOP
<h4>Server Side Controller or Apex Class</h4>
**With Sharing**: To respect salesforce security to connect with client side controller
**Static and stateless methods**: Method don't care who is calling them
**@AuraEnabled**:to enable the client and server-side access to the method.
Example: Apex class (server side component).apxc
```
public with sharing class simpleController//with sharing to share
{
@AuraEnabled //to enable access
public static String serverEcho (String firstName) //static
{
return('Hello from the server'+ firstName);
}
}
```
<h6> component</h6>
```
<aura:component controller="simpleController"> //linking apex
<aura:attribute name="firstName"
type="string"
default="salesforceKid"/>
<ui:button label ="callServer" press="{!c.echo}"/> //calling js
</aura:component>
```
<h6>JS controller (client side controller)</h6>
```
//This is not class. It is JSON object with map of name value pair. Having only action handlers.
In function (component, event, and helper—though you can name them differently)
({
echo : function(cmp, event, helper) { //Action handler as func.
//can have only 3 paramtr
var action = cmp.get("c.serverEcho");//linking serverside (ssc)
controller function serverEcho
action.setParams({ //Sending parameter to SSC
firstName : cmp.get("v.firstName")
})
action.setCallback(this, function(response){ //callback
var state = response.getState(); //add to variable
if(state === "SUCCESS") //comparing
{
alert("This is from server ::"+ response.getReturnValue()); //gets the value returned from
the server.
}
else if(state === "INCOMPLETE")
{
//do something
}
else if(state === "ERROR")
{
var error = response.getError();
if(error)
{
console.log("error"+errors);
}
}
});
$A.enqueueAction(action);// $A.enqueueAction adds the
server-side action to the queue.
All actions that are enqueued
will run at the end of the event loop
}
})
```
**Important:**
c. IN component represent client side Component
c. in JS controller represent server side component (apex)
c: is the default namespace. It represents Aura component code you’ve added to your org.
**Lightning Application**
```
<aura:application extends="force:slds"> //for SLDS
<c:serverSide/>
</aura:application>
```
**wrapper Class**: Reduce server call and get data at one call
```
public class wrapperClassController {
@AuraEnabled
public static wrapper method(){
//Get Required Account And Contact List by SOQL STEP 2
List<Account> getAccount = [Select Id, Name FROM Account];
List<Contact> getContact = [Select Id, Name FROM Contact];
//Instance before adding a list STEP 3
wrapper wrp = new wrapper();
wrp.accList = new List<Account>(getAccount);
wrp.conList = new List<Contact> (getContact);
return wrp;
}
//Main Wrapper Class STEP 1
public class wrapper{
@AuraEnabled //Annotation when using for lightning component
public List<Account> accList;
@AuraEnabled
public List<Contact> conList;
}
}
```
**Init**
//doInIt Handler To call the c.doInIt action when screen load
<aura:handler name="init" value="{!this}" action="{!c.abc}"/>
//abc is funtion name on CSC.(client side controller)
<h4>Events in Aura</h4>
<h6>component composition </h6>
communicate from parent component to child component, we include child component inside the parent component.
<h6> Parent To Child</h6>
example: parentComponent.cmp
```
<aura:component>
<aura:attribute name="valueToChild"
value="String">
<h6>This is parent component</h6>
//Including child component in parent
<c:childComponent value="{v.valueToChild}"/>
</aura:component>
```
Parent To Child Component Communication :
In parent to child component communication, we can communicate by passing value from parent to child as explained above example.
But when we want to communicate from Child To Parent we cannot directly pass value inside an attribute. In that case, we use lightning Events ⚡️
<h6> Event for Child to parent</h6>
1)Component Event
2) Application Event

**1)Component Event**
Component Event On child-->Register it on Childcmp-->fire Event from Child Js-->use parent JS to handle Event--> pass value to parent cmp to use.
**lightning Tag vs UI tag**
UI tag was initially introduced
lightning tag has inbuilt SLDS we do not need to put extra effort to improve the look and feel, also it has may awesome tags to handle the Error or bad inputs.
[Link](https://www.sfdckid.com//2020/02/component-events-in-salesforce-lightning.html)
[Link](https://developer.salesforce.com/blogs/developer-relations/2017/04/lightning-inter-component-communication-patterns.html)
| bhanukarkra | |
732,784 | [GIT] Please enter a commit to explain why this merge is necessary | This often appear when you are working on merging branches to the main one. So, how can we solve... | 13,303 | 2021-06-19T07:21:26 | https://dev.to/chelsey0527/git-please-enter-a-commit-to-explain-why-this-merge-is-necessary-470m |
This often appear when you are working on merging branches to the main one. So, how can we solve this problem ?
1. finish the commit message
2. press `esc`
3. press `:wq` to write and quite | chelsey0527 | |
732,962 | Migrating Azure ARM templates to Bicep | You may have heard of Bicep, and you may be wondering how much effort it is going to take to move all... | 0 | 2021-06-27T07:48:25 | https://www.rickroche.com/2021/06/migrating-azure-arm-templates-to-bicep/ | bicep, arm, azure, devops | ---
title: Migrating Azure ARM templates to Bicep
published: true
date: 2021-06-18 07:00:00 UTC
tags: bicep, arm, azure, devops
canonical_url: https://www.rickroche.com/2021/06/migrating-azure-arm-templates-to-bicep/
cover_image: https://www.rickroche.com/2021/06/migrating-azure-arm-templates-to-bicep/migrating-to-bicep-cover.png
---
You may have heard of [Bicep](https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/overview "What is Bicep?"), and you may be wondering how much effort it is going to take to move all your ARM templates to this new way of deploying Azure resources.
I gave migrating from ARM to Bicep a go. This post will cover going from JSON ARM templates to shiny new Bicep templates that have no errors and don't contain any warnings or linting issues!
## Why should you migrate?
If you have ever deployed infra to Azure you have most likely used ARM templates before. They do the job, the docs aren't bad and there are built in tasks for ADO which make deploying them super straightforward. However, working with JSON is always going to be verbose, ARM templates have a lot of boilerplate required, making reusable templates is clunky and deployments can get tricky.
Aiming to address these (and other) issues, Azure is working on a project called Bicep. From the [projects overview](https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/overview "What is Bicep?"):
> Bicep is a domain-specific language (DSL) that uses declarative syntax to deploy Azure resources. It provides concise syntax, reliable type safety, and support for code reuse. We believe Bicep offers the best authoring experience for your Azure infrastructure as code solutions.
Essentially it is a DSL built on-top of ARM that makes the development of templates simpler and promotes reuse through modules. Judging by the release rate [on their GitHub](https://github.com/Azure/bicep/releases "Bicep Releases") the team is working hard to make it awesome very quickly and according to them, as of v0.3, Bicep is now supported by Microsoft Support Plans and Bicep has 100% parity with what can be accomplished with ARM Templates. So Bicep is definitely prod ready (at time of writing v0.4.63 was the latest release)!
## Getting started
Ensure you have the [latest version](https://github.com/Azure/bicep/releases "Bicep Releases") of Bicep installed (excellent installation guide [here](https://github.com/Azure/bicep/blob/main/docs/installing.md "Setup your Bicep development environment")). I went with the `az cli` install option and all my examples will be using that variant. I also use Visual Studio Code and installed the [Bicep VS Code Extension](https://github.com/Azure/bicep/blob/main/docs/installing.md#install-the-bicep-vs-code-extension "Install the Bicep VS Code extension") for enhanced editing.
## Decompiling ARM to Bicep
First things first, it is possible to [decompile](https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/decompile?tabs=azure-cli "Decompiling ARM template JSON to Bicep") an ARM template into Bicep by running the below command (all our ARM templates are in separate folders with an `azuredeploy.json` file for the template)
```bash
az bicep decompile --file azuredeploy.json
```
This creates a `azuredeploy.bicep` file in the same directory. Depending on your template, you will most likely get a stream of yellow warnings in the console, or potentially some red errors: don't panic! Even a single error will result in all the console output being red (at least on macOS) and at the very least you will get this warning message:
> WARNING: Decompilation is a best-effort process, as there is no guaranteed mapping from ARM JSON to Bicep.
> You may need to fix warnings and errors in the generated bicep file(s), or decompilation may fail entirely if an accurate conversion is not possible.
> If you would like to report any issues or inaccurate conversions, please see https://github.com/Azure/bicep/issues.
**It is important to note that the migration from ARM to Bicep will highlight issues in your ARM templates. ARM was more forgiving in certain aspects, after the migration, your templates will be in a better state.**
Errors come in the form of `Error BCPXXX: Description` and the descriptions generally let you get to the root of the problem quickly. E.g. *Error BCP037: The property "location" is not allowed on objects of type "Microsoft.EventHub/namespaces/eventhubs". Permissible properties include "dependsOn".*
If the decompilation gives you any errors, my preferred approach is to fix the ARM template and then run the decompilation again until you get a "clean" decompilation (warnings are fine, just ensure you decompile with no errors).
Warnings come in two flavours, ones that have a code (*Warning BCPXXX*) and ones that don't have a code but have a link at the end. As of `v0.4` there is a [linter](https://github.com/Azure/bicep/blob/main/docs/linter.md "Bicep Linter") which helps you get your templates into great shape -- these are the warnings with the links at the end. Both kinds of warnings are generally quick to fix and are sensible updates to start getting the benefits from Bicep.
## Common errors and how to fix them
### User defined functions are not supported (BCP007, BCP057)
If you have created user defined functions in ARM, these will not be decompiled (follow the [issue](https://github.com/Azure/bicep/issues/2)) and you will get two cryptic errors
> Error BCP007: This declaration type is not recognized. Specify a parameter, variable, resource, or output declaration.
> Error BCP057: The name "`functionName`" does not exist in the current context.
**To fix, move the function logic into your template (this may require duplication, but can be neatened up in the Bicep template later)**
### Nested dependsOn (BCP034)
Sometimes the use of nested `dependsOn` properties in your ARM templates gets weird with Bicep (`dependsOn` can often be [removed entirely](https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/compare-template-syntax#resource-dependencies "Bicep Resource dependencies") in Bicep). The ARM version would have validated and deployed perfectly fine however you will get the following error when decompiling to Bicep.
> Error BCP034: The enclosing array expected an item of type "module[] | (resource | module) | resource[]", but the provided item was of type "string".
Fortunately [Bicep handles dependencies](https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/compare-template-syntax#resource-dependencies "Bicep Resource dependencies") in a much smarter way than ARM meaning you can safely remove your nested dependencies and run again.
> For Bicep, you can set an explicit dependency but this approach isn't recommended. Instead, rely on implicit dependencies. An implicit dependency is created when one resource declaration references the identifier of another resource.
**To fix, delete your nested dependencies and validate (consider removing your `dependsOn` references entirely)**
### Strict schema validation (BCP037, BCP073)
Bicep validates the schema of each resource much more diligently than ARM. As a result you will probably find a bunch of places where you have added properties like `location` or `tags` to a resource that doesn't support them and ARM didn't mind this. These will be expressed as `Error BCP037`.
E.g. I had `location` on [Microsoft.EventHub/namespaces/eventhubs](https://docs.microsoft.com/en-us/azure/templates/microsoft.eventhub/namespaces/eventhubs?tabs=json "Microsoft.EventHub/namespaces/eventhubs schema")
> Error BCP037: The property "location" is not allowed on objects of type "Microsoft.EventHub/namespaces/eventhubs". Permissible properties include "dependsOn".
The one error I did run into was for [Azure Logic Apps](https://azure.microsoft.com/en-us/services/logic-apps/ "Azure Logic Apps") where the schema for [Microsoft.Logic/workflows](https://docs.microsoft.com/en-us/azure/templates/microsoft.logic/workflows?tabs=json "Microsoft.Logic/workflows schema") is missing the `identity` property needed for using Managed Identity with your Logic App:
> Error BCP037: The property "identity" is not allowed on objects of type "Microsoft.Logic/workflows". Permissible properties include "dependsOn".
Another common error I encountered was having read-only parameters in my templates (these tend to come along if you have exported templates from the Azure Portal). E.g.
> Error BCP073: The property "kind" is read-only. Expressions cannot be assigned to read-only properties.
**To fix both types of errors, remove the properties that the error messages highlight and run the decompilation again.**
### Reserved words as parameters (BCP079)
In ARM templates you can have the same name for a parameter, variable, function etc as these are all addressed directly using `parameters('name')` or `variables('name')` etc. In Bicep the syntax is simplified and as such you will get errors if you have used a reserved word as a parameter. We had a couple of templates taking in a parameter called `description` resulting in a cryptic error message:
> Error BCP079: This expression is referencing its own declaration, which is not allowed.
**To fix, rename the parameter in your ARM template, update its usages and run the decompilation again.**
## Common warnings and how to fix them
Hopefully by now you are out of the error zone, for warnings you can now start editing the Bicep file itself. The [Bicep VS Code Extension](https://github.com/Azure/bicep/blob/main/docs/installing.md#install-the-bicep-vs-code-extension "Install the Bicep VS Code extension") gives you great intellisense and highlights issues in the Bicep file.
To test an update on your Bicep file, run
```bash
az bicep build --file azuredeploy.bicep
```
### Schema warnings, enums and types (BCP035, BCP036, BCP037, BCP073, BCP081, BCP174)
[Data types](https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/data-types "Bicep Data Types") in Bicep are stricter than in ARM. If you have used `True` or `False` for booleans these need to be updated to be `true` and `false`. When using enums, they need to match the enums in the schema exactly (case-sensitive). E.g. if you used `ascending` and the template schema defines `Ascending` this adjustment needs to be made. Examples of these warnings are shown below.
> Warning BCP036: The property "kafkaEnabled" expected a value of type "bool | null" but the provided value is of type "'False' | 'True'".
> Warning BCP036: The property "order" expected a value of type "'Ascending' | 'Descending' | null" but the provided value is of type "'ascending'".
Similar to the errors thrown by BCP037 and BCP073 you will get warnings on schema mismatches using codes BCP035, BCP037 and BCP073. These highlight schema mismatches, missing properties and read-only properties used. Examples below.
> Warning BCP035: The specified "object" declaration is missing the following required properties: "options".
> Warning BCP037: The property "apiVersion" is not allowed on objects of type "Output". No other properties are allowed.
> Warning BCP073: The property "status" is read-only. Expressions cannot be assigned to read-only properties.
I did find an instance where the Bicep template matches the schema perfectly however warnings are still thrown. I think this is due to [this issue](https://github.com/Azure/bicep/issues/3215 "Property values originating from resource properties are not validated correctly") and fortunately doesn't break anything.
**To fix, update the offending property to match the schema or data type**
### String interpolation
`concat` gets to disappear in Bicep thanks to the lovely string interpolation option. I experienced two variants:
> Warning prefer-interpolation: Use string interpolation instead of the concat function. [https://aka.ms/bicep/linter/prefer-interpolation]
**To fix, search for all usages of `concat` and replace with the new syntax: `'string-${var}'`.**
> Warning simplify-interpolation: Remove unnecessary string interpolation. [https://aka.ms/bicep/linter/simplify-interpolation]
**To fix, remove the `${}` and reference the variable directly. E.g. `'${variable}'` becomes `variable`.**
### Environment URLs
We had a lot of hardcoded URL's in our templates for storage suffixes, front door etc. There is a much better way to do this by using the `environment()` function. Caveat here, if you had `environment` as a parameter to your ARM template, update this to be something else like `env` for example otherwise you won't be able to use the function.
> Warning no-hardcoded-env-urls: Environment URLs should not be hardcoded. Use the environment() function to ensure compatibility across clouds. Found this disallowed host: "core.windows.net" [https://aka.ms/bicep/linter/no-hardcoded-env-urls]
**To fix, have a look at all the [URLs that the environment function provides](https://docs.microsoft.com/en-za/azure/azure-resource-manager/templates/template-functions-deployment?tabs=json#environment "Environment Template Function") and replace your hard-coded version with `environment().<property>`. **
E.g. for Azure Storage where `core.windows.net` had been hard coded, replacing with `environment().suffixes.storage` gives the desired result.
### Scopes (BCP174)
Bicep introduces the concept of target scopes which dictates the scope that resources within that deployment are created in. This gives you a new way to define resources where you previously would have used the `/providers/` syntax (role assignments, diagnostic settings etc). The warning you get looks as follows.
> Warning BCP174: Type validation is not available for resource types declared containing a "/providers/" segment. Please instead use the "scope" property. [https://aka.ms/BicepScopes]
These are the most time-consuming to fix, essentially you need to
- use the schema reference of the actual resource (so for diagnostic settings us `microsoft.insights/diagnosticSettings@2017-05-01-preview`) instead of the parent resource `/providers`/
- add a `scope` referencing the parent resource
- rename so as not to reference the parent resource
- remove unnecessary properties and `dependsOn`
**Before**
```bicep
resource functionAppLogAnalytics 'Microsoft.Web/sites/providers/diagnosticSettings@2017-05-01-preview' = {
name: '${functionAppName}/Microsoft.Insights/LogAnalytics'
tags: tagsVar
properties: {
name: 'LogAnalytics'
workspaceId: resourceId(logAnalyticsResourceGroup, 'Microsoft.OperationalInsights/workspaces', logAnalyticsWsName)
logs: [
{
category: 'FunctionAppLogs'
enabled: true
}
]
}
dependsOn: [
functionApp
]
}
```
**After**
```bicep
resource functionAppLogAnalytics 'microsoft.insights/diagnosticSettings@2017-05-01-preview' = {
name: LogAnalytics
scope: functionApp
properties: {
workspaceId: logAnalyticsResourceId
logs: [
{
category: 'FunctionAppLogs'
enabled: true
}
]
}
}
```
## Should you migrate?
A resounding yes from me! The process above goes quite quickly, and I was on shiny new Bicep templates in less than an hour. Bicep is a much friendlier syntax to work with and the IDE support is great. What I also enjoyed is cleaning up all the errors that were present in my ARM templates that would have remained if not for the migration.
There is a neat comparison of ARM syntax vs Bicep syntax here which highlights a lot of the constructs that become simpler as well: https://docs.microsoft.com/en-us/azure/azure-resource-manager/bicep/compare-template-syntax
Enjoy the migration! I will be playing around with modules and reuse next and will share what I find.
Featured image background by [Nick Fewings](https://unsplash.com/@jannerboy62?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/s/photos/bird-migrating?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
| rickroche |
732,964 | Laravel Inversion of Control Implementation using Contextual Binding | Introduction In this post, we will tackle about "Inversion of Control" principle. We will... | 0 | 2021-06-19T12:13:09 | https://dev.to/carlomigueldy/laravel-inversion-of-control-implementation-using-contextual-binding-31cj | laravel, php, ioc, oop | ## Introduction
In this post, we will tackle about "Inversion of Control" principle. We will learn when to use it and how we can use it with Laravel using [Contextual Binding](https://laravel.com/docs/8.x/container#contextual-binding) in the [Service Container](https://laravel.com/docs/8.x/container). Although this topic assumes that you have the basic knowledge with Laravel and a general OOP concepts.
At the time of writing this, the current version for Laravel is on version 8.
## What is Inversion of Control?
If you know what is [Dependency Injection](https://en.wikipedia.org/wiki/Dependency_injection) then it's basically just a reverse of it. For Dependency Injection the code typically depends directly on the [class](https://www.w3schools.com/php/php_oop_classes_objects.asp). With [Inversion of Control (IoC)](https://en.wikipedia.org/wiki/Inversion_of_control) we invert it, the code does not depend on the class directly but only to the interface and we bind it in the [service container](https://laravel.com/docs/8.x/container). So when we Inject dependency to a certain class or [Controller](https://laravel.com/docs/8.x/controllers) we call the [Interface](https://www.w3schools.com/php/php_oop_interfaces.asp) and not the class.
## When to use Inversion of Control?
One must be aware and has to fully understand the scenario or what problem or certain feature to be implemented. There are a lot of problems and are a lot of ways to address it. But to choose the proper method of addressing the problem is a good way to approach it. Things does not have to be complex and should just be simple as possible.
Other than that, say for a given scenario, your client wants to support multiple payment providers for the project that you are building. At your first glance you might think that you'll have to create a lot of classes for it and have different implementation details on each one of them, but the problem arises that you might have to inject a lot these in your Controllers or that you might have to put up some conditional logics just to use the correct payment provider.
That can work but it may not the ideal implementation. Then that's the time we will make use of abstraction using Inversion of Control, we can then only inject a single dependency to a Controller or whatever class it requires and that leaves us lesser code to write. It keeps it simple, and that also means it'll be easier to maintain it in the long term.
## Creating a PaymentInterface
Just for a quick, simple, and straight-forward example let's have a `PaymentInterface` that requires 1 method to implement whichever a class implements this interface or abstract.
So let's just create a directory under `app` directory of a fresh Laravel project, and call this directory as `Interfaces` and have a file created named as `PaymentInterface.php` and for its content, we have this
```php
<?php
namespace App\Interfaces;
interface PaymentInterface
{
/**
* @param float $amount
* @return mixed
*/
public function pay(float $amount): string;
}
```
We only require classes to implement `pay` method that takes an argument `$amount` type hinted with `float` and it returns a `string`
## Creating payment services that implements PaymentInterface
Let's say the client wants to have at least 3 payment providers, let's just call it whatever we want in this case.
- Paypal
- SquarePay
- Stripe
We have at least 3 payment providers but with different implementation details because we might have to setup a few configuration for each of these third party APIs. Typically we want these configuration setup private and should not be exposed publicly, we only expose what is defined in the `PaymentInterface`
So let's define these services, we'll start off with `Paypal`
```php
<?php
namespace App\Services;
use App\Interfaces\PaymentInterface;
class PaypalService implements PaymentInterface
{
public function pay(float $amount): string
{
return "From PaypalService $amount";
}
}
```
The `PaypalService` implements the `PaymentInterface` and the `pay` method as well, and as defined from the abstract class or interface that `pay` should return a `string` then we'll return it with a type of `string` so we basically just know right away what we should be returning.
For the `SquarePayService`
```php
<?php
namespace App\Services;
use App\Interfaces\PaymentInterface;
class SquarePayService implements PaymentInterface
{
public function pay(float $amount): string
{
return "From SquarePayService $amount";
}
}
```
For the `StripeService`
```php
<?php
namespace App\Services;
use App\Interfaces\PaymentInterface;
class StripeService implements PaymentInterface
{
public function pay(float $amount): string
{
return "From StripeService $amount";
}
}
```
Now we have those defined and implemented the `PaymentInterface` we can move on to having to dynamically bind the interface with the corresponding class or payment provider.
## Exposing the payment service providers to REST API
Now let's go over and create the controllers for each of these payment service providers that we defined. If you are coding along then open up your terminal and let's create these controllers using the artisan commands.
```bash
# Will create a directory called "PaymentProvider" and have
# the controller named as defined "PaypalController" for example
# Paypal
php artisan make:controller PaymentProvider/PaypalController
# Stripe
php artisan make:controller PaymentProvider/StripeController
# SquarePay
php artisan make:controller PaymentProvider/SquarePayController
```
Then we'll go over each of these controllers and we will inject `PaymentInterface` into the constructor and pass it down into a private field.
`PaypalController`
```php
<?php
namespace App\Http\Controllers\PaymentProvider;
use App\Http\Controllers\Controller;
use App\Contracts\PaymentInterface;
use Illuminate\Http\Request;
class PaypalController extends Controller
{
private $paymentService;
public function __construct(PaymentInterface $paymentService)
{
$this->paymentService = $paymentService;
}
public function index()
{
return response()->json([
'data' => $this->paymentService->pay(250.0),
]);
}
}
```
`StripeController`
```php
<?php
namespace App\Http\Controllers\PaymentProvider;
use App\Http\Controllers\Controller;
use App\Contracts\PaymentInterface;
use Illuminate\Http\Request;
class StripeController extends Controller
{
private $paymentService;
public function __construct(PaymentInterface $paymentService)
{
$this->paymentService = $paymentService;
}
public function index()
{
return response()->json([
'data' => $this->paymentService->pay(10.0),
]);
}
}
```
`SquarePayController`
```php
<?php
namespace App\Http\Controllers\PaymentProvider;
use App\Http\Controllers\Controller;
use App\Contracts\PaymentInterface;
use Illuminate\Http\Request;
class SquarePayController extends Controller
{
private $paymentService;
public function __construct(PaymentInterface $paymentService)
{
$this->paymentService = $paymentService;
}
public function index()
{
return response()->json([
'data' => $this->paymentService->pay(5.0),
]);
}
}
```
Once that's done, we can then expose these controllers as an endpoint to the REST API.
We define it in `api.php`
```php
<?php
use App\Http\Controllers\PaymentProvider\PaypalController;
use App\Http\Controllers\PaymentProvider\SquarePayController;
use App\Http\Controllers\PaymentProvider\StripeController;
use Illuminate\Support\Facades\Route;
Route::get('pay-with-paypal', [PaypalController::class, 'index']);
Route::get('pay-with-stripe', [StripeController::class, 'index']);
Route::get('pay-with-squarepay', [SquarePayController::class, 'index']);
```
I just defined it with `GET` request HTTP method just for simplicity of the tutorial. But for actual payment implementations, prefer to use `POST` instead that it contains a payload data of payment information containing the amount, the account ID and any other sensitive information.
So there we defined it, you might be tempted to test it out with your HTTP client to see if it works. But actually it won't work yet as we didn't define it to act that way. So let's proceed to using Contextual Binding implementation.
## Contextual Binding
We will be defining these bindings in the `AppServiceProvider` or you can create a different service provider that is relevant to its implementation, it can be `PaymentServiceProvider` (or any other name as you prefer) and have it registered in `AppServiceProvider`. But just for the sake of simplicity for the tutorial I will just bind the interface and their corresponding services directly into the `AppServiceProvider`.
```php
<?php
namespace App\Providers;
use App\Http\Controllers\PaymentProvider\PaypalController;
use App\Http\Controllers\PaymentProvider\SquarePayController;
use App\Http\Controllers\PaymentProvider\StripeController;
use App\Interfaces\PaymentInterface;
use App\Services\PaypalService;
use App\Services\SquarePayService;
use App\Services\StripeService;
use Illuminate\Http\Request;
use Illuminate\Support\ServiceProvider;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
$this->app->when(PaypalController::class)
->needs(PaymentInterface::class)
->give(PaypalService::class);
$this->app->when(StripeController::class)
->needs(PaymentInterface::class)
->give(StripeService::class);
$this->app->when(SquarePayController::class)
->needs(PaymentInterface::class)
->give(SquarePayService::class);
}
/**
* Bootstrap any application services.
*
* @return void
*/
public function boot()
{
//
}
}
```
On the `register` method of the `AppServiceProvider` is where we define the Contextual Binding, as you can see it checks on the `Controller` using the `when` method then the `needs` is referring to the dependency of that particular controller, and the last method chaining is `give` which is what we want to bind it to, these are the service classes that we defined `PaypalService`, `StripeService`, and `SquarePayService`.
In other words, if the `PaypalController` injects the `PaymentInterface` the service container would know that its corresponding binding will result to `PaypalService` and the same goes for `StripeController` and `SquarePayController`.
Now that we defined that in the service container, we can proceed to testing it out manually using our HTTP or just the browser to see if it worked.
## Manually Testing in browser
It's just a simple test. So make sure you have an active server running via `php artisan serve` and then just put up the endpoints that we defined in `api.php`; We have the following:
- `/api/pay-with-paypal`
- `/api/pay-with-stripe`
- `/api/pay-with-squarepay`
Now let's see each of these if it returns the actual implementation from each services that we defined above when creating them.
`/api/pay-with-paypal`
That is exactly what we wrote in `PaypalService` to return a string from the `pay` method and we even specified it with "PaypalService" just for us to indicate where the implementation is coming from. So using Contextual Binding works and it solves our problem!
`/api/pay-with-stripe`
And this is for Stripe.
`/api/pay-with-squarepay`
And our last payment provider that our client wants. We got it.
## Conclusion
Now that we learned how to tackle multiple payment providers using the **Inversion of Control (IoC)** principle, we learned how to implement it with Laravel's service container using Contextual Binding, and we understand that we'll always go with the best approach to address a problem. Don't use Inversion of Control when it's not really relevant solution at all, no need to add complexity. Only use it when it seems the best solution.
I hope this was useful and that you have learned something new. Thanks for taking the time to read and have a good day!
[Full Source Code](https://github.com/carlomigueldy/laravel-inversion-of-control-tutorial) | carlomigueldy |
733,022 | The Game of Life | The Game of Life or cellular automaton was developed by John Horton Conway in 1970 with just some... | 0 | 2021-06-19T13:16:47 | https://dev.to/lukegarrigan/the-game-of-life-28fm | javascript | The Game of Life or [cellular automaton](https://www.wikiwand.com/en/Cellular_automaton) was developed by [John Horton Conway](https://en.wikipedia.org/wiki/John_Horton_Conway) in 1970 with just some paper and a Go board. It takes place on a two-dimensional grid where each cell is in one of two states on (alive) or off (dead). The state of a cell is determined by its neighbours, and 4 simple rules determine whether the given state will live or die.
## Rules
There are four rules that determine a cell’s fate.
1. **Underpopulation:** Any live cell that has less than two neighbours dies.
2. **Overpopulation:** Any live cell that has more than three neighbours dies.
3. Any cell with two or three neighbours survives.
4. **Reproduction:** Any dead cell with exactly three neighbours becomes a live cell.
These rules can be further simplified for implementation:
1. Any live cell with two or three neighbours survives
2. Any dead cell with three live neighbours becomes a live cell
3. Everything else is now a dead cell
## Implementing
I’m going to [be using p5.js to implement](https://codeheir.com/2019/02/01/what-is-p5-js-0/) this, [all the code can be found here](https://editor.p5js.org/codeheir/sketches/gu41ikOre).
The first step is to create a grid and randomly choose whether the cell is dead or alive:
```javascript
let grid;
let columns;
let rows;
let size = 20;
function setup() {
createCanvas(800, 600);
columns = width / size;
rows = height / size;
grid = createGrid();
for (let i = 0; i < columns; i++) {
for (let j = 0; j < rows; j++) {
grid[i][j] = floor(random(2));
}
}
}
function draw() {
background(0);
for (let i = 0; i < columns; i++) {
for (let j = 0; j < rows; j++) {
let x = i * size;
let y = j * size;
if (grid[i][j] == 1) {
fill(0, 255, 255);
stroke(0, 255, 255);
rect(x, y, size, size);
}
}
}
}
```
Which should give us something like the following, where the blue colour represents a live cell:

The next step is to create the next generation.
```javascript
function createNewGeneration() {
let nextGeneration = createGrid();
for (let i = 0; i < columns; i++) {
for (let j = 0; j < rows; j++) {
let currentState = grid[i][j];
let count = countNeighbours(i, j);
if (currentState == 1 && count == 2 || count == 3) {
nextGeneration[i][j] = 1;
} else if (currentState == 0 && count == 3) {
nextGeneration[i][j] = 1;
} else {
nextGeneration[i][j] = 0;
}
}
}
return nextGeneration;
}
function countNeighbours(x, y) {
let sum = 0;
for (let i = -1; i <= 1; i++) {
for (let j = -1; j <= 1; j++) {
let col = (x + i + columns) % columns;
let row = (y + j + rows) % rows;
sum += grid[col][row];
}
}
sum -= grid[x][y];
return sum;
}
```
Now all that's needed is to assign the new generation to the current grid: `grid = createNewGeneration()` in the draw function and we're good to go!

Let's make each cell a little smaller, thus increasing the population size: `let size = 5`

## Conclusion
The Game of Life is a marvellous simulation. It demonstrates how just a few simple rules and structures can form very complex systems. There's far more to learn about the Game of Life, [there's a whole lexicon of patterns](https://playgameoflife.com/lexicon/295P5H1V1) that perform particular behaviours.
What is even more remarkable about the Game of Life is that it is [Turing Complete](https://www.wikiwand.com/en/Turing_completeness). It is able to make any arbitrarily complex computation, meaning a computer can be built in the Game of Life that can run a simulation of the Game of Life, which of course, [has been done](https://www.youtube.com/watch?v=hsXCKPt8u3I). | lukegarrigan |
733,205 | Acumos the New Power for AI | The last few years have marked a significant shift in our lives by the advancement of Artificial... | 0 | 2021-06-19T18:02:48 | https://dev.to/anveshk3/acumos-the-new-power-for-ai-15if | machinelearning, deeplearning | The last few years have marked a significant shift in our lives by the advancement of [Artificial Intelligence](https://analyticsbloq.com/importance-of-ai/). It has forged its way from a science fiction fantasy to the reality of our lives. Today, we utilize AI technologies for interacting with our cell phones, using devices like Alexa, Siri, etc.
The AI is consistently growing to impact the lives of future generations. For instance, cars today are operated by deploying automation in driving and detecting the surroundings.
The AI is fostering today only under the technical giants like Google, IBM, Microsoft, Apple, and Facebook as it is a very sophisticated project to develop AI-driven technologies. For example, there are very few or no big players in the field of networking and communication
The development of AI technology continues to remain difficult today. The significant growth is seen in the image and processing area, where the research began many years ago. The only open-source solution for this problem is ACUMOS. It helps in building precise AI applications.
**What is ACUMOS?**
The Linux Deep learning foundation hosts the ACUMOS. It is an open-source AI platform that is co-developed with the help of AT&T and Tech Mahindra, hosted by Linux Deep Learning. ACUMOS is a breakthrough invention for making AI applications. It aids in developing AI technologies efficiently.
**How will ACUMOS change the AI space?**
There are already so many frameworks in the market for Artificial Intelligence. The problem with these frameworks is they are very typical and challenging; a beginner struggles to deal with them. As it includes the cloud-based environment, just advanced engineers can handle them.
ACUMOS AI comprises Design Studio established on Linux, which assists in integrating these frameworks, and it furnishes a simple form of deployment for beginners.
**ACUMOS Architecture**
ACUMOS drives the data scientists by delivering custom integrated solutions complemented with creative AI models. The models under it are built using other collaborative and supportive languages like Java, Python, and R can also be formulated, deployed, and documented.
The framework is fully interoperable with other models of ACUMOS AI built apart from other AI frameworks. ACUMOS includes five significant modules that have a crucial role in building its environment. These modules support facilitating the AI development process in the ACUMOS ecosystem.
**TEAM UP** - This module, ACUMOS, empowers an open-source ecosystem for people to work together, experiment, and share their thoughts and solutions to generate better outcomes.
**Design Studio** - This tool is used for graphical means; it's mainly formulated for chaining, filters, multiple models, and many more features together into a single solution, like a run-time environment. You can use Design studio in various settings for solving different data sources and issues.
**Marketplace** - Marketplace is in the mainstream of AI using ACUMOS. Plus, it also functions as go to go site for generating data-powered decisions. In addition, ACUMOS makes it easy to utilize initiative in design studios and marketplaces.
**Onboarding** - ACUMOS focuses on interoperability, which helps it in providing enhanced support in diverse AI toolkits. Many onboarding tools are accessible in the market like H2O, TensorFlow, generic Java, RCloud, and many more; these tools help in better functioning.
**SDN and ONAP** - This is deployed as a community for many market place solutions. It can also be directly used in SDC.
**Steps to build AI models in ACUMOS based on Linux**
The four main steps that are involved during AI development on ACUMOS are as follows -
**1. Onboarding and building Artificial Intelligence applications** - This step involves building AI applications with an API. Applications are trained and instructed by several kinds of Machine Learning/Deep learning libraries such as TensorFlow, SciKit-Learn, RCloud, and H20.
**2. Register and Dockerize the application to ACUMOS AI** -
Dockerization deploys environment variables and configuration files to build an environment-friendly application.
Dockerizing an application is interpreted as altering an application to run, debug, and test within a Docker Container. The same process is also implicated in the ACUMOS platform to Register AI apps into the ACUMOS environment.
**3. Sharing and integrating knowledge** - There are many prominent frameworks available in the market, such as TensorFlow, SciKit-Learn, RCloud, and H20. These frameworks build the AI applications very effectively. The problem is the integration of these frameworks with each other individually is not possible.
ACUMOS solved this problem by providing a platform for integration and sharing knowledge among several AI applications. Thus, several AI applications can transfer knowledge to produce better outputs.
**4. Share AI applications into the marketplace** - Install created AI apps in the Marketplace, comprising public and private modules. It furthermore has infrastructure engineers to retain the deployed AI applications.
**ACUMOS AI Features**
1. ACUMOS classifies the differences between [machine learning](https://tutorialmastery.com/machine-learning-interview-questions/) or deep learning libraries. A familiar Application programming interface then encloses these.
2. Dockerization provides an easy way of developing and deploying AI applications.
3. Design studio that is ACUMOS GUI tool. It is utilized to develop visual programming code for AI applications.
4. ACUMOS provides a better ecosystem for Artificial Intelligence.
5. ACUMOS delivers a marketplace for sharing, rating, and collaborative intelligence with Artificial Intelligence prototypes in public and private areas.
6. It also provides API connect, toolkits as microservices, and chain models.
7. ACUMOS offers a unique option to export AI applications in Docker images to run in private and cloud settings.
8. You can easily add models with the help of awesome tool kits on the ACUMOS platform.
9. It generates an onboarding ramp for AI toolkits and ML models.
**Conclusion**
Artificial Intelligence is going to change the workflow of the systems around us through its breakthrough solutions. Also, there is a bundle of limitations that are preventing the AI revolution. But ACUMOS established on Linux doesn’t let this happen because it facilitates stimulation of the AI innovation room by integrating with various popular AI frameworks (TensorFlow, SciKit Learn, iCloud, and H20) with each other.
image credits: [Unsplash](https://unsplash.com/@hiteshchoudhary)
| anveshk3 |
733,379 | Getting started with #100daysofcode -day0 | Today i will be accepting a 100 day challenge because i was not able to give my 100% on my skills... | 0 | 2021-06-20T03:11:14 | https://dev.to/gauravpawar3102/getting-started-with-100daysofcode-day0-119h | challenge, 100daysofcode, beginners | Today i will be accepting a 100 day challenge because i was not able to give my 100% on my skills
*Hopefully i will be sharing my journey with you amazing people
i will be learning HTML css and javascript and then react.js and node.js
| gauravpawar3102 |
733,460 | How to Build a Strong Professional Network Online | Whether you’re a company leader, an expert, an online course creator, a student or a Fortune 500... | 0 | 2021-06-20T05:18:32 | https://dev.to/nehasoni__/how-to-build-a-strong-professional-network-online-b7k | devjournal, career, opensource | Whether you’re a company leader, an expert, an online course creator, a student or a Fortune 500 company, the benefits of building an online community are undeniable. Networking is the key to a successful career but making new connections can be difficult because a global pandemic has made meeting new people nearly impossible.
Does this mean we should give up on networking altogether?<br>
So the answer to this question is NO, just because we can’t meet people face-to-face doesn't mean we should give up networking entirely. You can still connect with people in your industry by learning how to build a network online.
Today I am going to share some tips that will help you to build your professional network online, even if you're not a natural schmoozer.
# 1.) Choose the right platforms
You are familiar with social media platforms, right? You add friends on Snapchat and gain followers on Instagram.

In the professional sense, networking is like establishing connections with people typically in your field. As you know, **LINKEDIN** is the most popular professional networking platform. Yet, other options like **FACEBOOK**, **TWITTER**, **QUORA**, **ALIGNABLE**, etc. have specific strengths that approach networking in different and meaningful ways. <br>
If you are searching for job seekers, looking to build your personal brand, **Linkedin** is best for that. Here you can find people who work in various companies you are interested in. **Twitter’s** use of hashtags makes it easy to find trending topics and experts and join the conversations too. The more you use social media with professional networking in mind, the more you’ll be able to connect with others.
# 2.) Maintain your profile: Be Fresh, Be Relevant
To make a strong impact, make sure you put together a solid, detailed, and accurate profile. Continuously update your profile because as your career grows and changes so should your profile. Choose a clear, close-up image of yourself wearing something that you would wear to work for your profile picture. A well-written profile will give you credibility and will establish you as a trustworthy potential employee. If you update your profile timely there are great chances to get better job opportunities and it also attracts unexpected opportunities. So, *Update your profile and upload your resume if not done already.*
# 3.) Be open to new connections

Having the right people in your network can give you tons of opportunities, but you have to take the first step. Don't limit yourself to connecting with people you think can help you. If you have your eye on a specific company, try connecting with the people who work there. Establishing an online network of your peers can help you stay engaged and once you start connecting with people you can discover more people through mutual connections. Share your accomplishments, thoughts, show off your work, and also start interacting with people.
# 4.) Be clear with your intentions

It is important to make your intentions clear when you are reaching out to someone new. Do not just drop 'Hi', 'Hey', 'Hello'. Don't expect a response for:-
1.) Please be my girlfriend/boyfriend.
2.) Let's chat on WhatsApp.
3.) send me money.
4.) get Subscribers for my YouTube.
...etc. For your time pass just don't kill other’s time. Be professional, clear, and concise. Planning your questions in advance can also help the meeting run smoothly.
You should follow basic ethics and motivate people like you to help the society who is eager to learn and grow.<br>
*" Be clear on what you want. You will get a better response if you do this. "*
# 5.) Help people out

Volunteering your time, money, or energy to help others doesn't just make the world better—it also makes you better. When you help someone you earn respect from them, your networking partner will be grateful and want to return the favor. If you provide others value, they’ll eventually help you without even thinking twice. So be helpful and supportive. Support their valuable content, share their work so that it can help others too.
# 6.) Be naturally curious to learn new things

Being curious is the key to excel at any task and do it better, as you ask questions, learn from others, and look for ways to do your job better. When curious people fail, they analyze their failure, because they are keen on knowing the reasons, so they can do better the next time. This increases their chances for success.
# Conclusion
Building your online network is a lot like building it in person-it requires perseverance, persistence, and a desire to connect. It can also make you a better, more interesting person.<br>
So are you ready to expand your network? Go for it. And remember: be kind, be professional, and be yourself.<br>
If you liked this article, share it with others and **"Let's learn and grow together"**
### Thanks for reading 🤝🤝
I would ❤ to connect with you at [Twitter](https://twitter.com/nehasoni__) | [LinkedIn](https://www.linkedin.com/in/neha-soni-70a6231b1/) | [GitHub](https://github.com/nehasoni05)
Let me know in the comment section if you have any doubts or feedback.
**You should definitely check out my other Blogs:**
- [Plasma Donation Website](https://dev.to/nehasoni__/plasma-donation-website-using-mern-stack-26f5)
- [Random Quote Generator Using HTML, CSS, and JavaScript](https://dev.to/nehasoni__/random-quote-generator-using-html-css-and-javascript-3gbp)
- [Digital Clock using JavaScript](https://dev.to/nehasoni__/digital-clock-using-javascript-2648)
- [Introduction to JavaScript: Basics](https://dev.to/nehasoni__/introduction-to-javascript-basics-g6n)
- [Playing with JavaScript Objects](https://dev.to/nehasoni__/playing-with-javascript-objects-k4h)
- [7 JavaScript Data Structures you must know](https://dev.to/nehasoni__/7-javascript-data-structures-you-must-know-57ah)
- [Digital Clock using JavaScript](https://dev.to/nehasoni__/digital-clock-using-javascript-2648)
- [Introduction to ReactJS
](https://dev.to/nehasoni__/introduction-to-reactjs-3553)
See you in my next Blog article, Take care!!<br>
**Happy Learning😃😃**
| nehasoni__ |
733,526 | Introduction to Node.js | Node.js is a runtime environment for executing JavaScript code outside of a browser. Before... | 0 | 2021-06-20T17:17:54 | https://dev.to/kasuncodes/introduction-to-node-js-2d5a | node, javascript, programming, tutorial | **Node.js is a runtime environment** for executing **JavaScript** code outside of a browser.
Before Node.js, JavaScript has long been used in web pages and run only by browsers. But now we can execute JavaScript code without a browser with the help of **Node.js** which is built on **Chrome’s V8 JavaScript engine.**
Here’s a formal definition as given on the [nodejs.org](https://nodejs.org/)
>Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine.
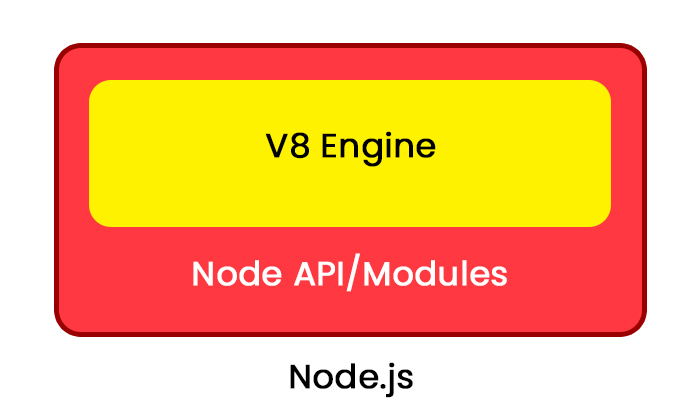
Node is ideal for building highly scalable, data-intensive, and real-time back-end services.
##What's so special about Node.js?
+ Node.js is easy to get started and can be used for prototyping and agile development.
+ JavaScript everywhere. If you're a front-end developer who knows JavaScript, you can easily get started Node.js without learning a new programming language.
+ It also can be used for building superfast & highly scalable services. Node is used in production by large companies like Netflix, Uber, PayPal &, etc.
+ Node.js has the largest ecosystem of open-source libraries. There're a lot of free open source libraries out there that we can use to build our services.
##Simple Node.js program.
*First install node on your machine. There are many tutorials online to guide the installation based on your operating system.*
Once you have installed Node.js, Create a file named **server.js** containing the following contents:
```javascript
const http = require('http');
const hostname = '127.0.0.1';
const port = 3002;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
```
Now open your terminal, change the directory to the folder where the file is saved and run **node server.js** to start your **web server.**
Now, visit http://localhost:3002 and you will see a message saying "Hello World".
Cool! you’ve just written **Hello World** in Node.js.
Refer [official documentation](https://nodejs.dev/learn) for a more comprehensive guide to getting started with Node.js.
###Here's the Node.js timeline so far:
*(source: [nodejs.dev] (https://nodejs.dev/learn/a-brief-history-of-nodejs))*
####2009
+ Node.js is born
+ The first form of [npm](https://www.npmjs.com/) is created
####2010
+ [Express](https://expressjs.com/) is born
+ [Socket.io](https://socket.io/) is born
####2011
+ npm hits version 1.0
+ Larger companies start adopting Node.js: LinkedIn, Uber, etc.
+ [hapi](https://hapijs.com/) is born
####2012
+ Adoption continues very rapidly
####2013
+ First big blogging platform using Node.js: [Ghost](https://ghost.org/)
+ [Koa](https://koajs.com/) is born
####2014
+ The Big Fork: [io.js](https://iojs.org/) is a major fork of Node.js, with the goal of introducing ES6 support and moving faster
####2015
+ The [Node.js Foundation](https://foundation.nodejs.org/) is born
+ IO.js is merged back into Node.js
+ npm introduces private modules
+ Node.js 4 (versions 1, 2 and 3 never previously released)
####2016
+ The [leftpad incident](https://blog.npmjs.org/post/141577284765/kik-left-pad-and-npm)
+ [Yarn](https://yarnpkg.com/en/) is born
+ Node.js 6
####2017
+ npm focuses more on security
+ Node.js 8
+ HTTP/2
+ V8 introduces Node.js in its testing suite, officially making Node.js a target for the JS engine, in addition to Chrome
+ 3 billion npm downloads every week
####2018
+ Node.js 10
+ [ES modules](https://nodejs.org/api/esm.html).mjs experimental support
+ Node.js 11
####2019
+ Node.js 12
+ Node.js 13
####2020
+ Node.js 14
+ Node.js 15
####2021
+ Node.js 16 | kasuncodes |
733,585 | 50+ Tech abbreviations I wish I knew earlier | It's always hard being a Developer. When learning to code and being in the community, there are many... | 0 | 2021-07-01T00:19:15 | https://dev.to/programmerlist/50-tech-abbreviations-i-wish-i-knew-earlier-1gle | programming, webdev, general | It's always hard being a Developer. When learning to code and being in the community, there are many short forms we hear but it's hard to guess sometimes. Some months back I had the same experience. But now I know some abbreviation you can see the below, hope it will help you.
---
- `SMM` : **Social Media Marketing** (It is the utilization of online media stages to associate with your crowd to fabricate your image, increment deals, and drive site traffic.)
- `ISP` : **Internet Service Provider** (organization that gives Internet associations and administrations to people and associations.)
- `CMS` : **Content Management System** (It is an application that is utilized to oversee web content, permitting numerous supporters of make, alter and distribute.)
- `TCP` : **Transmission Control Protocol** (It is a transport convention that is utilized on top of IP to guarantee solid transmission of bundles.)
- `NDA` : **Nondisclosure Agreement**(It is an official agreement that sets up a classified relationship )
- `LMS` : **Learning management system**(It is a computerized learning climate that deals with all parts of an organization's different preparing endeavors.)
- `SaaS` : **Software As A Service**(It permits clients to interface with and use cloud-based applications over the Internet. )
- `RSS` : **Really Simple Syndication**(it permits clients and applications to get to updates to sites in a normalized, PC lucid configuration.)
- `AWS` : **Amazon Web Services**(It offers solid, versatile, and reasonable distributed computing administrations. Allowed to join, pay just for what you use.)
- `IoT` : **Internet of things**(It alludes to an arrangement of interrelated, web associated objects that can gather and move information over a remote organization without human intercession. )
- `PaaS` : **Platform As a Service**(as the name recommends, gives you figuring stages which normally incorporates working framework, programming language execution climate, information base, web worker and so forth)
- `AMI` : **Amazon Machine Engine**
- `CSRF` : **Cross Site Request Forgery**
- `SEO` : **Search engine Optimization**
- `SMO` : **Social Media Optimization**
- `TLS` : **Transport Layer Security**
- `SQL` : **Structured Query Language**
- `CSS` : **Cascading Style Sheet**
- `HTML` : **Hyper Text Markup Language**
- `JS` : **JavaScript**
- `ToS` : **Terms Of Service**
- `SERP` : **Search Engine Result Page**
- `SSO` : **Single Sign-on**
- `SSL` : **Security Socket Layer**
- `WYSIWYG` : **What You See Is What You Get**
- `DDoS` : **Distributed Denial Of Services**
- `MFA` : **Multi-factor authentication**
- `S3` : **Simple Storage System**
- `JDK` : **Java Development Kit**
- `AI` : **Artifical Intelligence**
- `ML` : **Machine learning**
- `CV` : **Curriculum Vitae**
- `JSON` : **JavaScript Object Notation**
- `XML` : **Extensible Markup Language**
- `SDK` : **Software Development Kit**
- `XSS` : **Cross-site Scripting**
- `CI/CD` : **Continous Integration/Continous Deployment**
- `SSH` : **Secure Shell**
- `CTA` : **Call to action**
- `DNS` : **Domain Name System**
- `HTTPS` : **HyperText Transport Protocol Secure**
- `OSS` : **Open Source Software**
- `FaaS` : **Function as-a-Service**
- `PPC` : **Pay Per Click**
- `IP` : **Internet Protocol**
- `B2B/C` : **Business to business/consumer**
- `CNAME` : **Canonical Name**
- `GA` : **Google Analytics**
- `WP` : **WordPress**
- `CTR` : **Click through rate**
- `AMA` : **Ask Me Anything**
- `CPM` : **Conversion per 1000 impressions**
- `VCS` : **Version Control System**
- `SVG` : **Scalable Vector Graphics**
- `CDN` : **Content Delivery Network**
- `CPC` : **Cost per click**
- `API` : **Application Programming Interface**
---
Thank you for Reading, above I have explained what are necessary ones nad left the common ones, if you still need to know just comment it down, I'll add them ASAP. If you gotta add something here, please comment it down below and share your knowledge. | programmerlist |
733,595 | Flutter 101: A simple Snackbar in Flutter | Flutter 101: A simple Snackbar in Flutter | 0 | 2021-06-20T09:17:15 | https://dev.to/danytulumidis/flutter-101-a-simple-snackbar-in-flutter-5d4 | flutter, dart, developer | ---
title: Flutter 101: A simple Snackbar in Flutter
published: true
description: Flutter 101: A simple Snackbar in Flutter
tags: flutter, dart, developer
cover_image: https://images.unsplash.com/photo-1597415581463-4b7a5a87be62?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=1650&q=80
---
# Introduction
Hello there!
Welcome to my very first **Flutter 101** post where I introduce you to Flutter basics!
Inside an App, the App should give the user feedback when something happens. For example, when you click a Button to save something inside an App the user should be notified that something happened. Feedback improves the user experience a lot.
Today i want you to show how to do that in Flutter. Let's go!
# What's a Snackbar?
In Flutter everything is a Widget. So there is no surprise that we also have a Widget for something that provides the user with feedback. In Flutter a Widget that does exactly this job is the [SnackBar](https://api.flutter.dev/flutter/material/SnackBar-class.html).
The SnackBar widget is an easy way to quickly display a lightweight message at the bottom of the screen and its implemented in a few minutes. In addition, its highly customizable (like everything in this beautiful framework) and you can change things like for example the duration of how long the message should be visible.
Enough theory let's jump into some code!
# Snackbar in Flutter
First, we start with the entry of the application inside the main.dart:
```
import 'package:fliflaflutter/topics/snackbar/app.dart';
import 'package:flutter/material.dart';
void main() {
runApp(MyApp());
}
```
Nothing special just a simple starting point.
Next up is the heart of our application:
```
import 'package:fliflaflutter/topics/snackbar/snackbar.dart';
import 'package:flutter/material.dart';
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Snackbar',
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: Scaffold(
appBar: AppBar(
title: Text('Snackbar in action'),
),
body: Snackbar(),
),
);
}
}
```
Here we have our MaterialApp Widget that holds the central point of our app. Inside the home property, we have a Scaffold, and inside it as a property the body that holds our Snackbar. The
```
body: Snackbar(),
```
is not the SnackBar widget itself. It's a custom widget from me and within it i hold the code for the real snackbar.
One important thing to mention here is that a SnackBar needs to be wrapped within a Scaffold. Why? Because the SnackBar uses the ScaffoldMessengerState to show the SnackBar Widget for the right Scaffold instance.
Now let's jump into the code that is the reason you currently reading this. The actual SnackBar implementation!
```
import 'package:flutter/material.dart';
// INFOS & TIPS:
// Snackbar needs an Scaffold around it
class Snackbar extends StatelessWidget {
@override
Widget build(BuildContext context) {
return Center(
child: ElevatedButton(
onPressed: () {
final snackBar = SnackBar(
content: Text('Have a nice weekend!'),
action: SnackBarAction(
label: 'Close',
onPressed: () {},
),
);
ScaffoldMessenger.of(context).showSnackBar(snackBar);
},
child: Text('Open Snackbar'),
),
);
}
}
```
Let me explain me the code. First, we want the button to show the SnackBar in the middle of our screen. Center Widget helps us here. Then we use an ElevatedButton Widget to have an actual button. So far so good. Then we come to the onPressed property where we define what happens when we click on the button. And here the magic happens!
We define a new variable with the type SnackBar and initialize it with the following properties:
- content: Defines the text inside the message
- action: Calls the SnackBarAction class where we can define the label for the button inside the SnackBar message and where we could also define what should happen when closing the message. It will close the SnackBar anyway but we could also let other things happen if we want to.
Like i mentioned above we could customize it further and define properties like duration and width:
```
duration: const Duration(milliseconds: 1200), // Defines when the SnackBar should dissapear automatically
width: 120.0, // Width of the SnackBar.
```
Have a look [here](https://api.flutter.dev/flutter/material/SnackBar-class.html) if you want to know more about the SnackBar properties and what you can customize.
And that's it! And this is how i looks like:
# Conclusion
I hope you learned something and now know how to implement a SnackBar in your next Flutter application!
Stay connected to me and my content on [Twitter](https://twitter.com/danytulumidis).
I love to improve myself every single day even if it's just a tiny bit!
Stay safe and healthy guys!
And as always: develop yourself! | danytulumidis |
733,622 | Excel Formulas to Calculate the Compound Interest ~ Simple Tricks!! | We have already learned the formulas to calculate the annual compound interest schedule. Likewise,... | 0 | 2021-06-28T09:24:32 | https://geekexcel.com/excel-formulas-to-calculate-the-compound-interest/ | excelformula, excelformulas | ---
title: Excel Formulas to Calculate the Compound Interest ~ Simple Tricks!!
published: true
date: 2021-06-20 08:14:28 UTC
tags: ExcelFormula,Excelformulas
canonical_url: https://geekexcel.com/excel-formulas-to-calculate-the-compound-interest/
---
We have already learned the formulas to **[calculate the annual compound interest schedule](https://geekexcel.com/excel-formulas-calculate-annual-compound-interest-schedule/)**. Likewise, here we will show the formulas to **calculate the compound interest (Future Value) in Excel**. Let’s see them below!! Get an official version of ** MS Excel** from the following link: [https://www.microsoft.com/en-in/microsoft-365/excel](https://www.microsoft.com/en-in/microsoft-365/excel)
[](https://geekexcel.com/excel-formulas-to-calculate-the-compound-interest/calculate-cmpound-interest/#main)<figcaption id="caption-attachment-47694">Calculate Compound Interest</figcaption>
## General Formula:
- You can use the below formulas to calculate the compound interest in Excel.
**=FV(rate,nper,pmt,pv)**
## Syntax Explanations:
- **FV** – In Excel, the **FV function** is represented as a financial function that returns the **future value** of an investment.
- **Nper** – It is the total number of payment periods (months, quarters, years, etc.) in an annuity.
- **Pmt ** – It is the payment made every period.
- **Pv** – The present value of all future payments.
- **Rate** – It represents the interest rate.
- **Comma symbol (,)** – It is a separator that helps to separate a list of values.
- **Parenthesis ()** – The main purpose of this symbol is to group the elements.
## Practical Example:
Refer to the below example image.
- Here we will enter the input values in **Column B** and **Column C**.
- Now we are going to calculate the Future value.
<figcaption id="caption-attachment-47696">Input Ranges</figcaption>
- Select any cell and apply the above-given formula.
<figcaption id="caption-attachment-47695">Enter the formula</figcaption>
- Finally, press the ** ENTER** key, you can get the result as shown below.
<figcaption id="caption-attachment-47693">Result</figcaption>
## Conclusion:
So yeah guys this is how you can easily **calculate the interest which means the future value of a certain amount in Excel**. I hope that this article is useful to you. Let me know if you have any **doubts** regarding this article or any other article on this site.
Thank you so much for visiting **[Geek Excel](https://geekexcel.com/)!! **If you want to learn more helpful formulas, check out [**Excel Formulas**](https://geekexcel.com/excel-formula/) **!! **
### Read Also:
- **[Excel Formulas to Calculate the Bond Valuation ~ Easy Tutorial!!](https://geekexcel.com/excel-formulas-calculate-the-bond-valuation/)**
- **[Formulas for Finding Largest Value Smaller than a Specified Number!!](https://geekexcel.com/formulas-for-finding-largest-value-smaller-than-a-specified-number/)**
- **[Excel Formulas to Calculate the Annual Compound Interest Schedule!!](https://geekexcel.com/excel-formulas-calculate-annual-compound-interest-schedule/)**
- **[Excel Formulas to Calculate Annuity Solve for Interest Rate ~ Quickly!!](https://geekexcel.com/excel-formulas-calculate-annuity-solve-for-interest-rate/)** | excelgeek |
733,706 | Developed an app to transcribe and translate from images | Hey guys, I developed an application that you can easily get a transcription and translation from... | 13,823 | 2021-06-21T00:11:14 | https://dev.to/toffy/developed-an-app-to-transcribe-and-translate-from-images-32gp | develop, application | Hey guys,
I developed an application that you can easily get a transcription and translation from images.
[](https://gyazo.com/eec97dbffb7364afd24f2e9a2e0372b8)
URL→https://pictranslator.info/
* This article is the fifth week of trying to write at least one article every week.
Past articles are listed below.
- [React + TypeScript: Face detection with Tensorflow](https://dev.to/yuikoito/face-detection-by-using-tensorflow-react-typescript-3dn5)
- [UI Components website Released!](https://dev.to/yuikoito/ui-components-website-released-2g8e)
- [I made 18 UI components for all developers](https://dev.to/yuikoito/i-made-18-ui-components-for-all-developers-17l6)
- [Image Transformation: Convert pictures to add styles from famous paintings](https://dev.to/yuikoito/image-transformation-convert-pictures-to-add-styles-from-famous-paintings-24ml)
## Functions
- Automatically gets the language of the user's browser and sets it as the default language. (EN, DE, FR, ZH, JA)
- Transcribe with the click of a button
- Translates to the default language (the language of the user's browser) with the click of a button.
- If need to change the language, it is possible to change the language.
- Transcribed or translated text can be easily copied with the click of a button.
## Points to consider
I tried to make it as simple as possible! So, you can understand it without any description.
As a result, it looks like this.
When you drag an image, you can select the Transcribe or Translate button like this.
Initially my application needed selected which language you want to translate.
However, I was wondering if I wanted to translate an image, it might be bother to select language before translating. If your browser language is English, of course you want to translate to English, not to Japanese, Chinese or others. So I decided to make it possible to translate into the user's browser language with just one button.
Of course, if the language displayed is different from your native language (or the language you want to translate is different), you can use the button on the upper right to convert it to a different language.
If you need to translate or transcribe from images, please use this!
Also I posted this to Product Hunt!↓
https://www.producthunt.com/posts/pic-translator
🌖🌖🌖🌖🌖🌖🌖🌖
Thank you for reading!
I would be really grad if you use this website and give me any feedback!
🍎🍎🍎🍎🍎🍎
Please send me a message if you need.
yuiko.dev@gmail.com
https://twitter.com/yui_active
🍎🍎🍎🍎🍎🍎
| toffy |
733,955 | How to resolve the "Could not create MokListXRT: Out of Resources" Debian boot error on Dell computers | Uh oh, you just rebooted your Debian Dell machine to effect a system update, only to get the... | 0 | 2021-06-20T18:56:55 | https://dev.to/jdrch/how-to-resolve-the-could-not-create-moklistxrt-out-of-resources-debian-boot-error-on-dell-computers-504o | debian, dell, uefi, boot | Uh oh, you just rebooted your Debian Dell machine to effect a system update, only to get the following error message:

```
Could not create MokListXRT: Out of Resources
Something has gone seriously wrong: import_mok_state() failed: Out of Resources
```
You can resolve the above by doing [this](https://askubuntu.com/questions/1333492/21-04-uefi-boot-fails-could-not-create-moklistxrt-out-of-resources#comment2302242_1333772). | jdrch |
733,985 | Boost your productivity with this app | I'm one of those people who loves to be constantly looking for apps to help me with my productivity.... | 0 | 2021-06-20T21:30:43 | https://dev.to/franciscomendes10866/boost-your-productivity-with-this-app-14o6 | tooling, productivity | I'm one of those people who loves to be constantly looking for apps to help me with my productivity. The overwhelming majority of people who know me personally know that I love being as productive as possible and to be honest, if I can do more than one thing in a single application, I'm more than satisfied.
However, I am fully aware that it depends on the needs of everyday life, sometimes we need an application that is good with whiteboards, other times we need an application that helps us take notes on something.
I personally like an application that is solid enough to get away with in everyday life and I don't care if it's totally perfect in some respects.
And with all these aspects in mind, this week I'm going to talk a little bit about [Whimsical](https://whimsical.com).

Without any doubts, Whimsical has been a game changer for me. With a single application it is possible to do everything related to productivity, to the point that I have not used another application.
I usually like taking notes, brainstorming and to create low fidelity wireframes for my personal projects. In the first two I mentioned, Whimsical is great, just how I like it, simple and fast.
However, if we talk about wireframe creation, the difference with its competitors is notorious, however I don't see Whimsical as a design application. But for what it takes, it's super convenient, with great quality mockups and I like the idea of having ready-made elements to put in our UI.

I'm fully aware that many will prefer certain applications for certain cases, but I think this is a good alternative for those who want to handle several things in a single application and it's amazing to know that I only need to use one app to save my day.
But the use of Whimsical is quite vast, it's not just tied to brainsorms, docs and wireframes. We can do more things like sticky notes and flow charts. Not to mention some templates that you have at your disposal to start the project ideation process as quickly as possible.

One of the favorable aspects of this application is the learning curve, which in my opinion is almost nil if you've used similar applications in the past and if you haven't in less than five minutes you start to understand how everything works because it's very intuitive.
## What about yout?
What is the application that helps you the most in your daily life? | franciscomendes10866 |
734,011 | What is a relational database? | When you develop functional websites and web applications. A major requirement to hold customer data... | 0 | 2021-06-20T22:32:14 | https://dev.to/terrythreatt/what-is-a-relational-database-54ep | database, webdev, beginners, codenewbie | When you develop functional websites and web applications. A major requirement to hold customer data is a persistent data storage.
This will be key to allowing useful interaction and so it is foundational to learn about databases to be a web developer.
#### What is a database?
A database is storehouse for types of data and is usually a server or computer. A database is developed to model all your data in tables and columns to be easy to read and retrieve way.
#### What is a relational database?
A relational database is a type of database that consists of data that is relational. The database is structured in a way to create a relationship from one unit of data to another.
#### What is a relational database management system?
A relational database management systems(RDMS) is software that is used to manage a relational database. This includes creating database administrators and all the functions of managing the data.
#### What is SQL?
SQL is a structured query language for managing your data in a database management system. This language gives your the power to read and write to a database and create advanced queries to analyze your data in useful ways.
#### Learn More
Deep dive into [Non-relational databases](https://docs.microsoft.com/en-us/azure/architecture/data-guide/big-data/non-relational-data)
Popular relational database management systems:
* [SQLite](https://www.sqlite.org/index.html)
* [MySQL](https://www.mysql.com/)
* [PostgreSQL](https://www.postgresql.org/)
#### Let's chat about databases
We briefly described a relational database, relational database management systems, and the database query language (SQL). If you enjoyed this post feel free to leave a comment about your experience working with databases.
Happy Coding,
Terry Threatt | terrythreatt |
734,102 | How to Create a TypeScript Project with ExpressJS the Simplest Way!! By SilvenLEAF | If you are wondering how to create a TypeScript BackEND project, fear not my brave knight. It's way... | 0 | 2021-06-21T02:47:34 | https://dev.to/silvenleaf/how-to-create-a-typescript-project-with-expressjs-the-simplest-way-578a | javascript, typescript, node, silvenleaf | If you are wondering how to create a TypeScript BackEND project, fear not my brave knight. It's way easier than you can ever imagine!! Let go!
### Step 1
First init our project by running **npm init -y** on our terminal, it'll create a package.json file. Then let's install these packages by running the following command on our terminal
```bash
npm i typescript ts-node express @types/node @types/express
```
typescript is the core package for typescript, ts-node is the typescript version of node for runnig .ts files just as we do with node app.js, in this case we do, ts-node app.ts. @types/node and @types/express has all the types for node and express respectively. You say why? Well typescript is all about type na :)
## Bonus Step
Now let's install some helping dev stuff
```
npm i --D nodemon ts-node-dev
```
ts-node-dev package binds nodemon with typescript. The typescript version for **nodemon app.js** is **ts-node-dev app.ts**
Now let's update our package.json file
```json
....keep others unchanged
"main": "app.ts",
"scripts": {
"start": "ts-node app.ts",
"dev": "ts-node-dev app.ts"
},
...keep others unchanged
```
## Step 2
Run the following command, it'll will create a tsconfig.json file.
```
tsc --init
```
## Step 3
Let's create an express App
Write these on the app.ts file that we created
```typescript
import express, { Request, Response } from 'express';
import path from 'path';
// -------------------firing express app
const app = express();
app.use(express.json());
app.use(express.urlencoded({extended:false}));
app.use(express.static(path.join(__dirname, 'client/build')));
// -------------------routes
app.get('/home', (request: Request, response: Response)=>{
console.log(request.url)
response.json({ message: `Welcome to the home page!` })
});
// --------------------Listen
const PORT = process.env.PORT || 5000;
app.listen(PORT, ()=>{
console.log(`Server running on PORT ${ PORT }`);
})
```
Yippie, our very first typescript express app is ready. Let's run and test it
Type either **npm start** or **npm run dev** and then go to the **localhost:5000/home** and test it out yourself. Enjoy! | silvenleaf |
734,290 | The Web Monetization meta tag and API | Part 1 of this series made clear why web monetization is a good thing. Part 2 described the Coil... | 0 | 2021-07-06T10:00:33 | https://dev.to/coil/the-web-monetization-meta-tag-and-api-3eh9 | webmonetization, coil, webdev | [Part 1](https://dev.to/coil/let-s-talk-about-money-47i5) of this series made clear why web monetization is a good thing. [Part 2](/coil/how-it-works-1b1) described the Coil system at high level. In this third article we're going to take a closer look at details: the `<meta>` tag and the JavaScript API.
The [Coil developer site](https://developers.coil.com/) contains more information about technical topics, including a few example scripts.
## The meta tag
During the sign-up process for Coil and Interledger you set up a wallet, which enables you to receive payments. You are given a payment pointer for that wallet in the form `$url.of.server/someID`. In order to monetize a page you should add a `<meta>` tag on that page that contains this pointer:
```
<meta name="monetization" content="$url.of.server/someID">
```
Right now you need tthe Coil extension to read out the `<meta>` tag — but in the future, when browsers support web monetization natively, they will do so themselves. If a page contains multiple monetization `<meta>`tags the extension uses the first one and ignores the others.
All this works without JavaScript. Neither the current extension nor the future standard are reliant on scripting for the initiation of a payment stream. If you want to get any information, though, or if you want to change the payment stream’s direction, you need JavaScript.
You can change the payment pointer by changing the `<meta>`tag. It's ugly, but it works:
```
<meta name="monetization" content="$url.of.server/someID" id="paymentPointer">
function changePointer() {
let meta = document.querySelector('#paymentPointer');
meta.setProperty('content','$url.of.server/myOtherID');
}
```
The plugin will pick up on this change even in the middle of a session and divert all future payments to the new payment pointer.
One reason to do so is a collaborative article. If an article has, say, three authors, JavaScript could pick one of them at random and send the payment stream their way. Technically, you do this by switching the `<meta>`tag's content, as shown above. See [this article](https://webmonetization.org/docs/probabilistic-rev-sharing/) for more information.
You could also use the Intersection Observer to figure out which page element is in view right now, and change the payment pointer based on that information. This could be useful if one page shows art by several creators, for instance. [This article](https://coil.com/p/sabinebertram/Web-Monetized-Image-Gallery-Intersection-Observer-Demo-/HY5nl9NT) gives an overview and a code example.
### Future: link
In the future specification the `<meta>` tag will likely change to a link tag, like this one:
```
<link rel="monetization" content="https://url.of.server/someID">
```
The reasons are complex and can be [read here](https://github.com/WICG/webmonetization/issues/19#issuecomment-705407129). The [upcoming Firefox implementation](https://community.webmonetization.org/wmfirefox/exploring-integration-of-web-monetization-into-the-web-platform-grant-report-1-5ama) uses this link, and not a `<meta>`.
That means that in the future any script that changes the payment pointer has to be rewritten, possibly changing the pointer in both the `<meta>` and the link tag. For that reason it would be nicer if the JavaScript API offered a direct, imperative way of setting the pointer, like:
```
document.monetization.pointer = '$url.of.server/someOtherID';
```
Right now the API doesn’t support this, although it is one of the many ideas [under discussion](https://github.com/wicg/webmonetization/issues/).
## JavaScript API
Since we’re on the topic anyway, let’s discuss the [JavaScript API](https://webmonetization.org/docs/api/). It’s a light-weight, useful thing to have in your back pocket while messing about with payment streams. It consists of the `document.monetization` container, three events, and one property.
This API is part of the proposed standard, and if browsers start supporting web monetization natively they’ll take over this API as well. In that sense, current extension serves as a polyfill and scripts you write now will continue to work in the future.
### document.monetization
`document.monetization` is the container for all API functionality, and its presence indicates that your current visitor supports monetization:
```
if (document.monetization) {
// user may monetize you;
// find out and do something
} else {
// user is certain not to monetize you
}
```
`document.monetization` is a `<div>` DOM node that is not inserted into the document. Thus you can read `document.monetization.nodeName` and most other DOM properties, even though there is no practical reason to do so.
Making it a DOM node allows the firing of the custom monetization events we’ll treat in a moment. Without this trick it appears to be quite difficult to fire custom events from extensions, though specific information is surprisingly hard to find.
### state
`document.monetization.state` contains information about the current monetization state. It can take three values:
* `started`: a monetization stream has started and you will receive money. At least one valid Interledger package has been received.
* `pending`: a monetization stream has not yet started, but the extension is trying to connect.
* `stopped`: no monetization stream possible: the page has no `<meta>` tag, or the pointer is invalid.
If no `<meta>` tag is found the initial state is `stopped`. If a `<meta>` tag is present the initial state is `pending`.
If the `<meta>` tag contains no valid payment pointer the state becomes `stopped`. If a valid payment pointer is present the extension connects to the Interledger server and waits for the first package. Once that package arrives the state becomes `started`.
The state remains `started` even if the connection drops — the extension keeps track of the time spent on the site, after all.
If you change the payment pointer the extension first goes to `pending` and then to either `started` or `stopped`, depending on the validity of the new pointer.
So this snippet tells you if the user is currently paying you:
```
if (document.monetization && document.monetization.state === 'started') {
// user is currently paying you
}
```
### Events
`document.monetization` allows you to capture four events, three of which mirror the `state` property pretty closely:
* `monetizationpending`: a monetization stream is being started up, but is not sending payments yet. Fires when the `state` is set to `pending`.
* `monetizationstart`: a monetization stream has started. Fires when the `state` is set to `started`.
* `monetizationprogress`: a new single payment has arrived. See below.
* `monetizationstop`: a monetization stream has stopped. Fires when the `state` is set to `stopped`.
Typically, when a payer enters a payee’s page and a `<meta>` tag is present. the `monetizationpending` event will fire, followed by a `monetizationstart` event and an indeterminate amount of `monetizationprogress` events. If the payment pointer is invalid `monetizationstop` fires.
This is exactly the same sequence as with the `state` property, except that no event will fire if no `<meta>` tag is present. The sequence restarts at `pending` whenever you change the payment pointer.
The information the events deliver allows you to build a basic script to show/hide extra content:
```
if (document.monetization) {
let extraContent = document.querySelector('#extraContent');
document.monetization.addEventListener('monetizationstart',function() {
extraContent.style.display = 'block';
// or any other way of showing content
});
document.monetization.addEventListener('monetizationstop',function() {
extraContent.style.display = 'none';
});
}
```
Again, this script is fairly easy to hack, and won't work without JavaScript being enabled. It’s not suited for serious use, especially not in web development sites. Still, it serves as an example of using the monetization events.
### monetizationprogress
The monetizartionprogress event fires whenever an Interledge package with a non-zero sum arrives from the Coil servers, which is generally every second or so. It contains information about the amount that's been paid so far, and you could use it to build a [micropayment counter](https://webmonetization.org/docs/counter/).
If the connection drops the payment stream also drops and the monetizationprogress event stops firing. If the connection is restored the event resumes after a new connection to the Interledger server has been made. As we saw before, the extension keeps track of the time the user has spent on your site, and the first payment after the restoration of the connection will pay for that entire time. Thus, you cannot assume that the payer stopped paying just because monetizationprogress stops firing.
### Event properties
If you want to find out wha the current payment status is you can use the special properties of these events. All these are properties of `event.detail`.
* `amount` is the amount contained in the current Interledger package, as an integer.
* `assetCode` is a code for the currency, either a cryptocurrency or a real one.
* `assetScale` is the number of places past the decimal for the amount. This serves to keep `amount` an integer.
* `paymentPointer` is the payment pointer the extension read from the `<meta>` tag.
* `receipt` is a proof of payment sent back to the payer.
* `requestID` is a transient ID temporarily assigned to your payment stream.
For instance, this gives you the amount the last package delivered:
```
document.monetization.addEventListener('monetizationprogress',function(e){
let amt = e.detail.amount;
let scale = e.detail.assetScale;
let code = e.detail.assetCode;
let amount = amt * Math.pow(10,-scale);
let printableAmount = code + ' ' + amount;
// do something with amount or printableAmount
})
```
`paymentPointer` contains the same information as the `<meta>` tag. `receipt` and `requestID` contain values that are internal to the Interledger packages. You can use it to write a [receipt verifyer](https://webmonetization.org/docs/receipt-verifier/) if you like.
Reading out the amount of money an Interledger package contains requires the amount-related properties. For instance, if `amount` is 17 and `assetScale` is 3 you received 17*10^-3, or 0.017, of the currency indicated in `assetCode`.
That concludes our study of the `<meta>` tag and API. In the [final part](/coil/the-future-of-web-monetization-2n3) we’ll take a look at web monetization’s future, which includes a formal W3C standard. | ppk |
734,446 | Arquitetura limpa | Arquitetura e Arquitetura limpa O que é Arquitetura? Resumindo arquitetura de... | 0 | 2020-08-19T12:57:37 | https://programadev.com.br/arquitetura-limpa/ | java, patterns, architecture | ---
title: Arquitetura limpa
published: true
date: 2021-06-21 06:57:37 UTC
tags: java, patterns, architecture
canonical_url: https://programadev.com.br/arquitetura-limpa/
---
# Arquitetura e Arquitetura limpa
## O que é Arquitetura?
Resumindo arquitetura de software pode ser descrito da seguinte forma: _"... a arquitetura envolve: decisões sobre as estruturas que formarão o sistema, controle, protocolos de comunicação, sincronização e acesso a dados, atribuição de funcionalidade a elementos do sistema, distribuição física dos elementos escalabilidade e desempenho e outros atributos de qualidade."_
Quebrando um pouco mais essa explicação e tentando deixá-la mais suscinta eu diria que a arquitetura de software é a ideia que trata da relação entre o mapeamento de componentes de um software e os detalhes que são levados em conta na hora de implementar esses elementos na forma de código.
Resumindo ainda mais a arquitetura consiste em um modelo de alto nível que possibilita um entendimento e uma análise mais fácil do software a ser desenvolvido.
Como o nome diz e levando pro mundo real é como ver um arquiteto de uma casa onde ele desenha a planta e todas as partes da construção se encaixam e como elas devem interagir uma com a outra.
### Por que existe?
A ideia de arquitetura de software surgiu nos anos 60 e se tornou popular nos anos 90.
A ideia era enfatizar a importância de estruturar um sistema antes de seu desenvolvimento.
### O que resolve?
A ideia é que uma boa arquitetura resolva parafrasenado Robert Martin (Uncle Bob):
_"O objetivo da arquitetura de software é minimizar os recursos humanos necessários para construir e manter um determinado sistema."_
A ideia é que com uma boa arquitetura o custo para mudanças não seja alto, que uma simples mudança não entrave a aplicação.
## Arquitetura limpa
Com esses conceitos em mente por volta de 2012 Robert C. Martin (Uncle Bob) criou a Arquitetura Limpa, um estilo com similaridades com a Arquitetura Cebola e a Arquitetura Hexagonal.
### O que resolve?
A arquitetura limpa tem como ideia principal, a modulação das informações que serão codificadas, facilitando a manutenção; os módulos precisam ser independentes o suficiente para que possam ser trabalhados pelos desenvolvedores em equipes diferentes
- Independência entre componentes, quer dizer cada módulo não conhece o outro, então mudanças em cada módulo não quebram ou necessitam de ajustes nos demais.
- Independência de framework, os frameworks que tanto gostamos aqui são tratados como meros detalhes, as aplicações não são mais amarradas ao framework, podendo assim haver substituição rápida de um framework por outro sem nenhum impacto na aplicação.
- Independência de banco de dados, assim como os frameworks o banco de dados é tratado como um detalhe.
- Testabilidade aqui vale um ponto importante, quanto mais fácil for pro seu sistema ser testado menos acoplamento ele terá isso significa que mudanças serão faceis de ocorrer e de serem testadas.
- Independência de interface de usuário, seja um GUI, API ou que quer que seja deve haver independência e não deve interferir no funcionamento do sistema.
- Independência de agentes externos, a nossa regra de negócio não deve depender de nada externo.
### Como funciona?
Neste modelo proposto por Robert C. Martin, Uncle Bob, a arquitetura é representada por camadas circulares concêntricas passando a proposta de baixo acoplamento e alta coesão:
### Acoplamento
Dizemos sobre acoplamento em um software quando as partes que o compõe são altamente dependentes umas das outras o que dificulta a manutenção os testes e ainda mais mudanças.
### Coesão
Dizemos sobre baixa coesão em um software quando uma parte dele realiza diversas tarefas ou possui multiplas responsabilidades.
Buscamos sempre um sistema que tenha baixo acoplamento e alta coesão. Na imagem abaixo vemos como a Arquitetura Limpa demonstra como resolver essas questões:

Começando do centro pra fora:
### Entidades
A Entidade é a camada mais ao centro e mais alta na Arquitetura Limpa, é aqui onde devem ficar os objetos de domínio da aplicação, as regras de negócio cruciais e que não irão mudar com facilidade.
### Casos de Uso
Casos de uso contém regras de negócio mais específicas referente à aplicação, ele especifíca a entrada a ser fornecida, a saída a ser retornada e os passos de processamento envolvidos.
### Adaptadores de Interface
Camada que tem como finalidade converter dados da maneira mais acessível e conveniente possível para as camadas Entidades e Casos de Uso. Um exemplo seria o uso de _Mapper's_, onde eu poderia controlar as estruturas transmitidas entre Casos de Uso e Entidades com o interface do usuário, por exemplo.
## Frameworks e Drivers
Contém qualquer frameworks ou ferramentas para poder rodar na aplicação.
## Exemplo prático
Ápos toda a teoria vamos mostrar na prática com um projeto simples onde teremos três pontos de entrada da aplicação.
Com o desenrolar do projeto vamos perceber que nesse modelo arquitetural o mais importante são as camadas mais internas e as mais externas serão tratados como detalhe e é aí que mora a quebra de tabu da Arquitetura Limpa, pois o foco é no negócio e não nas tecnologias; mas ainda estamos trabalhando com um sistema automatizado e precisamos seguir alguns paradigmas, mas só o que é realmente indispensável.
Vamos fazer um projeto de cadastro de **Power Rangers**, nele um usuário vai enviar os seus dados e a aplicação irá criar um Ranger de uma cor dependendo de algumas características.
Vamos usar a linguagem **Java** como um projeto modular **Maven** e a partir dele conseguimos modularizar as nossas camadas.
## Criando projeto
Dentro do nosso diretória vmos criar um arquivos _pom.xml_, esse arquivos vai ser o raiz da nossa aplicação, é nele que teremos as dependências declaradas com suas versões que usuaremos e também teremos aqui a declaração dos nossos módulos, segue o exemplo:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>clean-architecture-example</artifactId>
<packaging>pom</packaging>
<version>1.0</version>
<modules>
<module>entity</module>
</modules>
<properties>
<revision>1.0</revision>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>11</java.version>
<lombok-version>1.18.10</lombok-version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<junit-jupiter.version>5.5.1</junit-jupiter.version>
<junit-platform>1.5.1</junit-platform>
</properties>
<dependencyManagement>
<dependencies>
<!-- Jupiter -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>${junit-jupiter.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>${junit-jupiter.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
<version>${junit-platform}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
<version>${junit-platform}</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
```
Aqui temos o mínimo para começar, temos a declaração da versão do java, o **JUnit** que será o nosso framework de testes unitários e temos a declaração do nosso primeiro módulo chamado _entity_.
## Entidade
Agora vamos para a nossa entidade, esse é o ponto mais ao centro e mais acima do nosso projeto, dentro dele devemos ter os nossos objetos de domínio e regras de negócio que podem viver sem um sistema automatizado. Esse é o módulo que será visto por todos os outros mas não conhece os demais, ele é totalmente isolado de dependências externas.
Então pensando no nosso projeto aqui modelamos o nosso domínio de ususários, onde vamos ter o nome, email, idade, personalidade e o nome do ranger que será criado.
Vamos criar um diretório onde está o nosso _pom_ raiz com o nome de _entity_ e dentro dele vamos criar o _pom.xml_ da nossa _entity_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>entity</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- Jupiter -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
</dependency>
</dependencies>
</project>
```
Podemos ver que nesse pom temos somente a versão do Java e o JUnit que nos ajudará a fazer os testes unitários.
Vamos criar a nosso primeira classe de domínio que chamaremos de **User** e vamos ter os atributos que definimos do nosso usuários:
```java
package com.gogo.powerrangers.entity;
public class User {
private final String name;
private final String email;
private final int age;
private final Personality personality;
private final String ranger;
User(String name, String email, int age, Personality personality, String ranger) {
this.name = name;
this.email = email;
this.age = age;
this.personality = personality;
this.ranger = ranger;
}
public String getRanger() {
return ranger;
}
public String getName() {
return name;
}
public String getEmail() {
return email;
}
public int getAge() {
return age;
}
public Personality getPersonality() {
return personality;
}
}
```
Temos aqui a nossa entidade e colocamos um **Enum** pra Personalidade e um construtor com acessibilidade _package default_ que é um construtor que só pode ser acessado dentro do pacote onde ele foi declarado e criamos apenas os _getters_.
Agora temos a nossa entidade que é um **POJO** e vamos adicionar nesse projeto a regra de negócio que pode viver sem existir uma aplicação.
No universo dos **Power Rangers** cada ranger é escolhido de acordo com a sua personalidade, pra cada tipo de personalidade uma cor diferente e essa regra é independente de existir um software ou não, é uma regra dos **Power Rangers** então essa regra pertence a **Entidade**.
Pra isso eu vou separar essa definição para acontecer no momento em que um usuário for criado, então vamos usar um padrão de **Builder** para criar o nosso usuário e definir qual a cor do ranger de acordo com a sua pernsonalidade:
```java
package com.gogo.powerrangers.entity;
public final class UserBuilder {
private String name;
private String email;
private int age;
private Personality personality;
private String ranger;
UserBuilder() {
}
public UserBuilder name(String name) {
this.name = name;
return this;
}
public UserBuilder email(String email) {
this.email = email;
return this;
}
public UserBuilder age(int age) {
this.age = age;
return this;
}
public UserBuilder personality(String personality) {
this.personality = Personality.of(personality);
this.ranger = this.discoverRanger(this.personality);
return this;
}
public User build() {
return new User(this.name, this.email, this.age, this.personality, this.ranger);
}
private String discoverRanger(Personality personality) {
switch (personality) {
case LIDERANCA:
return "Vermelho";
case ENTUSIASMO:
return "Preto";
case TRANQUILIDADE:
return "Amarelo";
case INTELIGENCIA:
return "Azul";
case RIQUEZA:
return "Rosa";
case PERSISTENCIA:
return "Verde";
case FORCA:
return "Branco";
default:
return "";
}
}
}
```
Aqui temos a criação de um **User** e já temos a definição da cor do ranger de acordo com a personalidade, vamos também adicionar o nosso builder dentro da nossa classe **User**:
```java
public static UserBuilder builder() {
return new UserBuilder();
}
```
## Casos de uso
Agora que criamos a nossa entidade vamos criar a próxima camada que são os Casos de Uso. Nem toda regra de negócio é pura como a regra de negócio que está na Entidade, algumas regras de negócio fazem sentido existirem em um sistema automatizado, software, e é aqui que eles são usados, nos Casos de Uso, aqui faremos validações, controle de fluxo e temos as portas de comunicação com os adapatadores, como no caso de persistência de dados.
Então vamos criar um novo diretório chamado _usecase_ e nele teremos um arquivo _pom.xml_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>usecase</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<!-- Unit Test -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
</dependency>
</dependencies>
</project>
```
Aqui temos a dependência da _entity_ e vamos criar o nosso primeiro caso de uso, a criação de um usuário. Criamos uma classe com nome **CreateUser** com um método create que irá receber um **User** e irá aplicar as validações necessárias para criar um usuário e iremos persistir essa informação em algum lugar. Não especificamos onde iremos persistir pois aqui isso é um mero detalhe que não é da preocupação dos Casos de Uso, podemos usar **JDBC** puro, **Spring Data**, cache em memória ou arquivo de texto essa responsabilidade não nos interessa aqui.
```java
package com.gogo.powerrangers.usecase;
import com.gogo.powerrangers.entity.User;
public class CreateUser {
public CreateUser() {
}
public User create(final User user) {
return user;
}
}
```
Vamos adicionar primeiramente a nossa validação, aqui vamos imaginar que o usuário não pode ser menor de 18 anos e não pode ser repetido e iremos verificar pelo email essa informação.
Vamos criar uma classe chamada **UserValidator**:
```java
package com.gogo.powerrangers.usecase.validator;
import com.gogo.powerrangers.entity.User;
import com.gogo.powerrangers.usecase.exception.PowerRangerNotFoundException;
import com.gogo.powerrangers.usecase.exception.UserValidationException;
import static java.util.Objects.isNull;
public class UserValidator {
public static void validateCreateUser(final User user) {
if(isNull(user)) {
throw new UserValidationException("Usuario nao pode ser null");
}
if(user.getAge() < 18) {
throw new UserValidationException("Usuario deve ser maior de 18 anos");
}
if(user.getPersonality().getPersonality().isEmpty()){
throw new PowerRangerNotFoundException("Power Ranger não localizado com personalidade informada");
}
}
}
```
Aqui temos a nossa validação e customizamos as nossas **Exceptions** com a **UserValidationException** e a **PowerRangerNotFoundException**, em seguida acionamos o nosso método estático a nossa classe de criação de usuário:
```java
package com.gogo.powerrangers.usecase;
import com.gogo.powerrangers.entity.User;
import com.gogo.powerrangers.usecase.exception.UserAlreadyExistsException;
import com.gogo.powerrangers.usecase.validator.UserValidator;
public class CreateUser {
private final UserRepository repository;
public CreateUser(UserRepository repository) {
this.repository = repository;
}
public User create(final User user) {
UserValidator.validateCreateUser(user);
if (repository.findByEmail(user.getEmail()).isPresent()) {
throw new UserAlreadyExistsException(user.getEmail());
}
return user;
}
}
```
Pronto temos a nossa validação e agora precisamos de alguma forma informar que queremos persistir essa informação, porém como fazer isso se os drivers e frameworks estão na camada mais externa e a ideia aqui é deixar o Caso de Uso desacoplado de deles?
Usaremos _interfaces_ e inversão de controle, trocando em miúdos vamos dizer na nossa classe **CreateUser** que queremos salvar um usuário mas como ele será salvo já não nos importa.
Então vamos criar a interface **UserRepository** com os métodos que queremos:
```java
package com.gogo.powerrangers.usecase.port;
import com.gogo.powerrangers.entity.User;
import java.util.List;
import java.util.Optional;
public interface UserRepository {
User create(User user);
Optional<User> findByEmail(String email);
Optional<List<User>> findAllUsers();
}
```
O resultado final da **CreateUser** fica:
```java
package com.gogo.powerrangers.usecase;
import com.gogo.powerrangers.entity.User;
import com.gogo.powerrangers.usecase.exception.UserAlreadyExistsException;
import com.gogo.powerrangers.usecase.port.UserRepository;
import com.gogo.powerrangers.usecase.validator.UserValidator;
public class CreateUser {
private final UserRepository repository;
public CreateUser(UserRepository repository) {
this.repository = repository;
}
public User create(final User user) {
UserValidator.validateCreateUser(user);
if (repository.findByEmail(user.getEmail()).isPresent()) {
throw new UserAlreadyExistsException(user.getEmail());
}
var createdUser = repository.create(user);
return createdUser;
}
}
```
## Adaptadores de interface
Nessa camada podemos ver que exitem os nossos **Controllers**, **Gateways** e **Presenters**, aqui temos a comunicação pra dentro das nossa **Entidades** mas também a comunicação externa e representação do objeto de retorno que será exposto.
Vamos criar um diretório chamado _adapter_ e dentro dele outro diretório chamado _controller_ e um arquivos _pom.xml_ que terá como dependência a _entity_ e aa _usecase_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>controller</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
</project>
```
Vamos começar aqui criando o nosso objeto de resposta da nossa aplicação, não queremos que a nossa entidade seja retornada aqui pois caso a apresentação seja alterada temos um ponto único de alteração e podemos ainda aqui realizar qualquer transformação que seja importante para exibição. Então criamos a classe **UserModel**:
```java
package com.gogo.powerrangers.model;
import com.gogo.powerrangers.entity.User;
public class UserModel {
private String name;
private String email;
private int age;
private String personality;
private String ranger;
public static UserModel mapToUserModel(User user) {
var userModel = new UserModel();
userModel.name = user.getName();
userModel.email = user.getEmail();
userModel.age = user.getAge();
userModel.personality = user.getPersonality().getPersonality();
userModel.ranger = user.getRanger();
return userModel;
}
public static User mapToUser(UserModel userModel) {
//@formatter:off
return User.builder().name(userModel.getName())
.age(userModel.getAge())
.email(userModel.getEmail())
.personality(userModel.getPersonality())
.build();
//@formatter:on
}
@Override
public String toString() {
return "UserModel{" +
"name='" + name + '\'' +
", email='" + email + '\'' +
", age=" + age +
", personality='" + personality + '\'' +
", ranger='" + ranger + '\'' +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPersonality() {
return personality;
}
public void setPersonality(String personality) {
this.personality = personality;
}
public String getRanger() {
return ranger;
}
public void setRanger(String ranger) {
this.ranger = ranger;
}
}
```
Aqui temos os métodos que fazem a mudança de _Model-to-User_ e _User-to-Model_ e agora vamos criar o nosso controlador:
```java
package com.gogo.powerrangers;
import com.gogo.powerrangers.model.UserModel;
import com.gogo.powerrangers.usecase.CreateUser;
public class UserController {
private final CreateUser createUser;
public UserController(CreateUser createUser){
this.createUser = createUser;
}
public UserModel createUser(UserModel userModel){
var user = createUser.create(UserModel.mapToUser(userModel));
return UserModel.mapToUserModel(user);
}
}
```
## Frameworks e Drivers
Aqui é a nossa última camada, aqui temos os **Drivers**, **Frameworks**, **UI** e qualquer **Dispositivo** ou chamada externa em nossa aplicação é a camada mais "suja" pois é aqui que temos a entrada da nossa aplicação, ela conhece todas as outras camadas porém não é conhecida por nenhuma.
### Qual o benefício disso?
O benefício é que com isso temos uma aplicação altamente desacoplada, as camadas mais internas não tem conhecimento de como a aplicação é executada, se estamos usando uma aplicação Web, linha de comando, desktop e etc, isso torna a aplicação plugável a qualquer framework ou driver, contanto que ele siga a contrato, _interface_, que definimos na camada de **Caso de Uso**.
Aqui vamos criar três pontos de entrada, um com **Java** puro executando por terminal e com um banco em memória, outro com **Spring Boot** e persistência com **JDBC Template** e outro com **VertX** e **Hibernate**.
## Aplicação Java executada pelo terminal
Começando pela aplicação **Java** puro executado pelo terminal. Dentro do diretório _adapter_ vamos criar um outro diretório chamado _repository_ e dentro dele outro diretório chamado _in-memory-db_ e dentro dele um arquivo _pom.xm_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>in-memory-db</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
<!-- Unit Test -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
</dependency>
</dependencies>
</project>
```
E vamos criar a classe **InMemoryUserRepository** que implementa **UserRepository**:
```java
package com.gogo.powerrangers.db;
import com.gogo.powerrangers.entity.User;
import com.gogo.powerrangers.usecase.port.UserRepository;
import java.util.*;
public class InMemoryUserRepository implements UserRepository {
private final Map<String, User> inMemoryDb = new HashMap<>();
@Override
public User create(User user) {
inMemoryDb.put(user.getEmail(), user);
return user;
}
@Override
public Optional<User> findByEmail(String email) {
return inMemoryDb.values().stream().filter(user -> user.getEmail().equals(email)).findAny();
}
@Override
public Optional<List<User>> findAllUsers() {
return Optional.of(new ArrayList<>(inMemoryDb.values()));
}
}
```
E aqui temos um **Map** e simulamos em cache as operações de persistência.
Agora vamos criar um diretório a partir do nosso diretório raiz chamada _application_ e dentro desse repositório um diretórioa chamadp _manual-app_ e dentro dele um _pom.xml_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>manual-app</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
<plugin>
<!-- Build an executable JAR -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.gogo.powerrangers.Main</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>controller</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>in-memory-db</artifactId>
<version>${revision}</version>
</dependency>
<!-- Unit Test -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
</dependency>
</dependencies>
</project>
```
Aqui podemos verificar que nas dependências temos acesso as outras camadas, agora precisamos criar a classe **Main** que irá executar essa aplicação, mas antes vamos precisar fazer o controle e injeção das dependências, pra vamos criar uma classe de configuração chamada **ManualConfig**:
```java
package com.gogo.powerrangers.config;
import com.gogo.powerrangers.db.InMemoryUserRepository;
import com.gogo.powerrangers.usecase.CreateUser;
import com.gogo.powerrangers.usecase.SearchUser;
public class ManualConfig {
private final InMemoryUserRepository dataBase = new InMemoryUserRepository();
public CreateUser createUser(){
return new CreateUser(dataBase);
}
}
```
Aqui temos a criação da instância do **InMemoryUserRepository** e a injeção dessa dependência na classe **CreateUser** que irá usar essa instância para realizar a persistência.
Vamos criar agora a classe **Main**:
```java
package com.gogo.powerrangers;
import com.gogo.powerrangers.config.ManualConfig;
import com.gogo.powerrangers.model.UserModel;
public class Main {
public static void main(String[] args) {
var config = new ManualConfig();
var createUser = config.createUser();
var controller = new UserController(createUser);
var userModel = new UserModel();
userModel.setName(args[0]);
userModel.setEmail(args[1]);
userModel.setAge(Integer.parseInt(args[2]));
userModel.setPersonality(args[3]);
final var userCreated = controller.createUser(userModel);
System.out.println(userCreated);
}
}
```
Se executarmos essa aplicação pelo terminal:
```
java -jar target/manual-app-1.0.jar Guilherme fake@mail.com 34 Persistência
```
Temos o retorno:
```
UserModel{name='Guilherme', email='guiherme@gmail.com', age=34, personality='Persistência', ranger='Verde'}
```
## Spring Boot e JDBC Template
Agora vamos fazer a aplicação com um frameworks web e outro pra banco de dados.
Antes de mais nada vamos adicionar ao nosso _pom_ raiz as dependências dos frameworks:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.3.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.3.0.RELEASE</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-jdbc -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
</dependency>
```
Agora vamos usar o **JDBC Template**, vamos então criar um diretório em _repository_ chamado _spring-jdbc_ e vamos criar o nosso _pom.xml_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>spring-jdbc</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</project>
```
O nosso _pom_ agora tem as dependências das camadas da nossa aplicação e a dos drivers e framework jdbc, vamos criar o objeto que será persistido no nosso banco de dados chamado **UserEntity**:
```java
package com.gogo.powerrangers.entity;
public class UserEntity {
private String id;
private String name;
private String email;
private int age;
private String personality;
private String ranger;
public static User toUser(UserEntity entity){
var user = User.builder().name(entity.getName()).age(entity.getAge())
.email(entity.getEmail()).personality(entity.getPersonality()).build();
return user;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPersonality() {
return personality;
}
public void setPersonality(String personality) {
this.personality = personality;
}
public String getRanger() {
return ranger;
}
public void setRanger(String ranger) {
this.ranger = ranger;
}
}
```
O **JDBC Template** pede para implementarmos uma interface **RowMapper** que nos auxilia no mapeamento do objeto que retorna do banco para o objeto **UserEntity**:
```java
package com.gogo.powerrangers.mapper;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
import com.gogo.powerrangers.entity.UserEntity;
public class UserRowMapper implements RowMapper<UserEntity> {
@Override
public UserEntity mapRow(ResultSet resultSet, int i) throws SQLException {
UserEntity entity = new UserEntity();
entity.setId(resultSet.getString("ID"));
entity.setAge(resultSet.getInt("AGE"));
entity.setEmail(resultSet.getString("EMAIL"));
entity.setRanger(resultSet.getString("RANGER"));
entity.setName(resultSet.getString("NAME"));
entity.setPersonality(resultSet.getString("PERSONALITY"));
return entity;
}
}
```
Agora vamos implementar a nossa **UserRepository** numa classe chamada **SpringJdbcUserRepository**:
```java
package com.gogo.powerrangers;
import java.util.List;
import java.util.Optional;
import java.util.UUID;
import java.util.stream.Collectors;
import javax.sql.DataSource;
import org.springframework.dao.EmptyResultDataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;
import com.gogo.powerrangers.entity.User;
import com.gogo.powerrangers.entity.UserEntity;
import com.gogo.powerrangers.mapper.UserRowMapper;
import com.gogo.powerrangers.usecase.port.UserRepository;
public class SpringJdbcUserRepository implements UserRepository {
private JdbcTemplate jdbcTemplate;
public DataSource dataSource(){
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2)
.addScript("classpath:schema.sql").build();
}
public JdbcTemplate jdbcTemplate(){
return new JdbcTemplate(this.dataSource());
}
public SpringJdbcUserRepository() {
this.jdbcTemplate = this.jdbcTemplate();
}
@Override
public User create(User user) {
//@formatter:off
String sql = new StringBuilder().append("INSERT INTO ")
.append(" USER(id, name, age, email, personality, ranger) ")
.append(" VALUES(?, ?, ?, ?, ?, ?)").toString();
//@formatter:on
jdbcTemplate.update(sql, UUID.randomUUID().toString(), user.getName(), user.getAge(), user.getEmail(), user.getPersonality().getPersonality(), user.getRanger());
return user;
}
@Override
public Optional<User> findByEmail(String email) {
String sql = "SELECT id, name, age, email, personality, ranger FROM USER WHERE email = ?";
try {
UserEntity userEntity = jdbcTemplate.queryForObject(sql, new UserRowMapper(), email);
User user = UserEntity.toUser(userEntity);
return Optional.of(user);
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
@Override
public Optional<List<User>> findAllUsers() {
String sql = "SELECT id, name, age, email, personality, ranger FROM USER";
List<UserEntity> userEntityList = jdbcTemplate.query(sql, new UserRowMapper());
List<User> userList = userEntityList.stream().map(entity -> {
return UserEntity.toUser(entity);
}).collect(Collectors.toList());
return Optional.of(userList);
}
}
```
Temos a nossa implementação da parte de persistência de dados e agora precisamos criar a aplicação web com **Spring Boot**.
No diretório _application_ criamos outro diretório chamado _spring-boot_ e dentro dele um arquivo _pom.xml_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>spring-boot</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>controller</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Unit Test -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-runner</artifactId>
</dependency>
</dependencies>
</project>
```
Aqui temos as dependências das camadas da nossa aplicação e as dependências do framework.
Quando usamos **Spring Boot** precisamos de uma classe principal que chamaremos de **Application**:
```java
package com.gogo.powerrangers;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args){
SpringApplication.run(Application.class, args);
}
}
```
Essa classe possui a _annotation_ **@SpringBootApplication** e tudo o que é necessário para uma aplicação **Spring Boot** ser iniciada.
Mas agora precisamos fazer a nossa configuração de injeção de dependências e nisso o **SPring Boot** nos ajuda através dos **Beans**, então vamos criar uma classe de configuração chamada **SpringBootConfig**:
```java
package com.gogo.powerrangers.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.gogo.powerrangers.SpringJdbcUserRepository;
import com.gogo.powerrangers.UserController;
import com.gogo.powerrangers.usecase.CreateUser;
import com.gogo.powerrangers.usecase.port.UserRepository;
@Configuration
public class SpringBootConfig {
@Bean
public UserRepository dataBase(){
return new SpringJdbcUserRepository();
}
@Bean
public CreateUser createUser(){
return new CreateUser(this.dataBase());
}
@Bean
public UserController userController(){
return new UserController(this.createUser();
}
}
```
Aqui temos a _annotation_ **@Configuration** que nos auxilia e indica ao Spring que aqui temos os nossos **Beans** que serão processados pelo container do Spring e deixarão esses **Beans** disponíveis para serem injetados na aplicação. Também temos os nosso **Beans** própriamente ditos e prontos para serem usados, então vamos a criação do nosso endpoint com a classe **AddUserController**:
```java
package com.gogo.powerrangers.endpoint;
import com.gogo.powerrangers.UserController;
import com.gogo.powerrangers.model.UserModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/api/powerrangers")
public class AddUserController {
@Autowired
private UserController userController;
@PostMapping("add")
public ResponseEntity<UserModel> addUser(@RequestBody UserModel userModel){
return ResponseEntity.ok(userController.createUser(userModel));
}
}
```
Aqui temos a nossa injeção através da _annotation_ **@Autowired** da **UserController** e as declarações necessárias para a criação de um endpoint que recebe um **UserModel** através de um **POST** e faz a criação e persistência desse usuário.
## VertX e Hibernate
Agora vamos criar uma aplicação com o framework **VertX** e com persistência de dados com o **Hibernate**. Para isso vamos começar com o **Hibernate**, criaremos um diretório dentro de _repository_ com nome _hibernate_ e nele criamos um arquivo _pom.xml_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>hibernate</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
</dependency>
<!--Compile time JPA API -->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>javax.persistence-api</artifactId>
</dependency>
<!--Runtime JPA implementation -->
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
</dependency>
</project>
```
No nosso _pom_ temos nossas dependências e também adicionamos as dependências que são necessárias para o **Hibernate** funcionar. O **Hibernate** precisa de um arquivo de configuração dentro da pasta **META-INF** em _resources_ chamado _persistence.xml_ e dentro dele ficam as configurações das propriedades que o **Hibernate** usa:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
<persistence-unit name="jpa-h2">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>com.gogo.powerrangers.entity.UserEntity</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<properties>
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="javax.persistence.jdbc.driver"
value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:h2:mem:test" />
<property name="javax.persistence.jdbc.user" value="sa" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="hibernate.dialect"
value="org.hibernate.dialect.H2Dialect" />
<property name="hibernate.hbm2ddl.auto" value="update" />
<property name="show_sql" value="true" />
<property name="hibernate.temp.use_jdbc_metadata_defaults"
value="false" />
</properties>
</persistence-unit>
</persistence>
```
Agora precisamos mapear o nosso objeto que vai representar a tabela no banco de dados:
```java
package com.gogo.powerrangers.entity;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "USER")
public class UserEntity {
@Id
private String id;
private String name;
private String email;
private int age;
private String personality;
private String ranger;
public static User toUser(UserEntity entity) {
var user = User.builder().name(entity.getName()).age(entity.getAge())
.email(entity.getEmail()).personality(entity.getPersonality()).build();
return user;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPersonality() {
return personality;
}
public void setPersonality(String personality) {
this.personality = personality;
}
public String getRanger() {
return ranger;
}
public void setRanger(String ranger) {
this.ranger = ranger;
}
}
```
Aqui na **UserEntity** temos todas as anotações necessárias para o **Hibernate**. E agora vamos criar a nossa classe que irá implementar a **UserRepository** que chamaremos de **HibernateUserRepository** onde vamos criar a nossa instância do **EntityManager** para gerenciar as nossas transações com o banco de dados:
```java
package com.gogo.powerrangers;
import java.util.List;
import java.util.Optional;
import java.util.UUID;
import java.util.stream.Collectors;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.NoResultException;
import javax.persistence.Persistence;
import javax.persistence.TypedQuery;
import com.gogo.powerrangers.entity.User;
import com.gogo.powerrangers.entity.UserEntity;
import com.gogo.powerrangers.usecase.port.UserRepository;
public class HibernateUserRepository implements UserRepository{
private EntityManagerFactory emf = null;
public HibernateUserRepository() {
emf = Persistence.createEntityManagerFactory("jpa-h2");
}
@Override
public User create(User user) {
EntityManager entityManager = emf.createEntityManager();
entityManager.getTransaction().begin();
UserEntity entity = new UserEntity();
entity.setId(UUID.randomUUID().toString());
entity.setName(user.getName());
entity.setEmail(user.getEmail());
entity.setAge(user.getAge());
entity.setPersonality(user.getPersonality().getPersonality());
entity.setRanger(user.getRanger());
entityManager.persist(entity);
entityManager.getTransaction().commit();
entityManager.close();
return user;
}
@Override
public Optional<User> findByEmail(String email) {
EntityManager entityManager = emf.createEntityManager();
//@formatter:off
TypedQuery<UserEntity> query = entityManager.createQuery(new StringBuilder()
.append("SELECT user ")
.append(" FROM UserEntity user ")
.append(" WHERE user.email = :email").toString(), UserEntity.class);
// @formatter:on
try {
UserEntity userEntity = query.setParameter("email", email).getSingleResult();
return Optional.of(UserEntity.toUser(userEntity));
} catch (NoResultException e) {
return Optional.empty();
}
}
@Override
public Optional<List<User>> findAllUsers() {
EntityManager entityManager = emf.createEntityManager();
List<UserEntity> userEntityList = entityManager.createQuery("SELECT user FROM UserEntity user", UserEntity.class).getResultList();
List<User> userList = userEntityList.stream().map(UserEntity::toUser).collect(Collectors.toList());
return Optional.of(userList);
}
}
```
Agora vamos criar a nossa aplicação com o framework **VertX**, vamos no diretório _application_ e criar uma pasta chamada _vertx_ e adicionar o _pom.xml_:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>clean-architecture-example</artifactId>
<groupId>com.gogo.powerrangers</groupId>
<version>1.0</version>
<relativePath>../../../clean-architecture-example/pom.xml</relativePath>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>vertx</artifactId>
<version>${revision}</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>entity</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>usecase</artifactId>
<version>${revision}</version>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>controller</artifactId>
<version>${revision}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.vertx/vertx-web -->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</dependency>
<dependency>
<groupId>com.gogo.powerrangers</groupId>
<artifactId>hibernate</artifactId>
<version>${revision}</version>
</dependency>
</project>
```
Temos as nossas dependências das camadas internas, as dependências do **VertX** e a dependência do _jackson-core_ que nos ajuda com o nosso endpoint. E agora vamos criar a nossa classe de configuração onde teremos a injeção das nossas dependências:
```java
package com.gogo.powerrangers.config;
import com.gogo.powerrangers.HibernateUserRepository;
import com.gogo.powerrangers.usecase.CreateUser;
import com.gogo.powerrangers.usecase.port.UserRepository;
public class VertxConfig {
public final UserRepository repository() {
return new HibernateUserRepository();
}
public final CreateUser createUser() {
return new CreateUser(this.repository());
}
}
```
E criaremos agora o nosso _controller_ que utiliza a instâncai que foi injetada do nosso **UserController**
```java
package com.gogo.powerrangers.endpoint;
import io.vertx.core.buffer.Buffer;
import io.vertx.core.http.HttpServerResponse;
import io.vertx.core.json.JsonObject;
public abstract class Controller {
public boolean isNull(final Buffer buffer) {
return buffer == null || "".equals(buffer.toString());
}
public void sendError(int statusCode, HttpServerResponse response) {
response
.putHeader("content-type", "application/json")
.setStatusCode(statusCode)
.end();
}
public void sendSuccess(JsonObject body, HttpServerResponse response) {
response
.putHeader("content-type", "application/json")
.end(body.encodePrettily());
}
}
```
```java
package com.gogo.powerrangers.endpoint;
import com.gogo.powerrangers.UserController;
import com.gogo.powerrangers.model.UserModel;
import io.vertx.core.json.JsonObject;
import io.vertx.ext.web.RoutingContext;
public class AddUserController extends Controller{
private final UserController controller;
public AddUserController(UserController controller) {
this.controller = controller;
}
public void createUser(final RoutingContext routingContext) {
var response = routingContext.response();
var body = routingContext.getBody();
if (isNull(body)) {
sendError(400, response);
} else {
var userModel = body.toJsonObject().mapTo(UserModel.class);
var user = controller.createUser(userModel);
var result = JsonObject.mapFrom(user);
sendSuccess(result, response);
}
}
}
```
Temos aqui uma classe abstrata **Controller** que serve apenas como utilitário que outros controllers podem usar.
Agora precisamos o nosso ponto de entrada da aplicação e fazer as configurações do **VertX**:
```java
package com.gogo.powerrangers;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.gogo.powerrangers.config.VertxConfig;
import com.gogo.powerrangers.endpoint.AddUserController;s
import io.vertx.core.AbstractVerticle;
import io.vertx.core.Launcher;
import io.vertx.core.json.Json;
import io.vertx.ext.web.Router;
import io.vertx.ext.web.handler.BodyHandler;
public class VertxApplication extends AbstractVerticle{
private final VertxConfig config = new VertxConfig();
private final UserController userController = new UserController(config.createUser(), config.searchUser());
private final AddUserController addUserController = new AddUserController(userController);
@Override
public void start() {
Json.mapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
var router = Router.router(vertx);
router.route().handler(BodyHandler.create());
router.post("/add").handler(addUserController::createUser);
vertx.createHttpServer().requestHandler(router::accept).listen(8080);
}
public static void main(String[] args) {
Launcher.executeCommand("run", VertxApplication.class.getName());
}
}
```
Aqui temos as configurações do **VertX** e rotas no método _start_ e o _main_ que é o ponto de entrada.
## Conclusão
Podemos ver que com esse modelo de arquitetura temos uma aplicação plugável, quer dizer essa aplicação pode usar outras camadas sem que isso tenha impacto direto nas camadas mais internas. Vimos também que o foco está na regra de negócio e a facilidade em fazer testes é maior.
#### Prós
- Independente de Framework
- Altamente testável
- Independente de UI
- Independente de Banco de Dados
- Independente de qualquer agente externo
#### Contras
- Maior curva de aprendizado
- Mais classes, pacotes e mais sub-projetos
[link do projeto](https://github.com/guilhermegarcia86/clean-architecture-example) | guilhermegarcia86 |
734,498 | Scientific.net Number of reads WebHook | In the meantime i've coded a small webhook to retrieve the number of reads from a paper published on... | 0 | 2021-06-21T12:53:24 | https://dev.to/aeonlabs/scientific-net-number-of-reads-webhook-1k87 | scientificnet, researchpaper, publications | In the meantime i've coded a small webhook to retrieve the number of reads from a paper published on scientific.net and insert it to any author/ researcher webpage:
HTML frontend code:
```html
<script src="js/jquery-3.4.1.min.js"></script>
<small id="include-aef-stats">
<script>
$(function(){ $("#include-aef-stats").load("kernel/loadstats.php"); });
</script>
</small>
```
loadstats.php backend code:
```php
<?php
$url = "https://www.scientific.net/Paper/GetDownloadsAndVisitorsCount?paperId=523460";
$scientificNetCounter = file_get_contents($url);
echo $scientificNetCounter." reads on A.E.F. website"
?>
```
 | aeonlabs |
734,748 | Data Mesh on AWS | This article is one of series of articles on Data Lake: Architecture options for building a basic... | 0 | 2021-06-22T15:24:02 | https://dev.to/aws-builders/data-mesh-on-aws-57ah | aws, datamesh, data, analytics | This article is one of series of articles on Data Lake:
1. [Architecture options for building a basic Data Lake on AWS - Part 1](https://dev.to/aws-builders/architecture-options-for-building-a-basic-data-lake-on-aws-part-1-18hc)
1. [Power of AWS Lake House](https://dev.to/aws-builders/power-of-aws-lake-house-1la0)
1. Data Mesh on AWS
In this article we provide a set of propositions to help you to apply Data Mesh principles on AWS. Alongside, we show not only theory but also a set of technical and organizational examples to help to build understanding of the concepts.
# Data Mesh promises
You may have heard of a Data Mesh before but do you know what stands behind this concept? In simplest words, it's a mix of DDD and microservices approaches in a context of data. Let's decouple those concepts here briefly, so that it would be easier for us to understand the principles and apply them easily.
## Domain Driven Design
Domain Driven design is "an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain" [ref](https://martinfowler.com/bliki/DomainDrivenDesign.html). The idea is simple and reaffirms [Conway's law](https://en.wikipedia.org/wiki/Conway%27s_law), so that it allows for modelling, building and changing systems. It ensures the solution is optimal for the business function.
When creating a system in accordance with DDD, it's necessary to be aware of the so-called [Bounded Context](https://martinfowler.com/bliki/BoundedContext.html). When moving to a project setting, you generally try to keep as few domains that are necessary to realize your goal and have systems that converge the domains. Having a small number of domains is to optimize business costs, whereas the second will help to achieve goals of DDD.
## Microservices
What are microservices? In simplest words it "is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API" [ref](https://martinfowler.com/articles/microservices.html). It is a design that avoids creating a single unmaintainable monolith, so that the system is able to deliver valuable features in the long run and keeps costs at bay.
How to split the functionalities in microservices approach? DDD can be helpful here. Teams can be created around domains and services can be created around the domains as well. To support the development teams, separate infrastructure teams can be established to help the teams with frameworks, libraries and infrastructure setup, so that a development team is able to quickly deliver functionalities. Having a supportive team also helps developers to take full ownership of functionalities.
# Data Mesh principles
Let's see now how the Data Mesh applies those practices in a realm of data with the [5 principles](https://martinfowler.com/articles/data-mesh-principles.html).
## Domain Ownership
As with DDD, the data needs to be decentralized to achieve distribution of responsibility to people who are closest to it. It should be avoided to have a separate team that manages the data on S3, that has no idea what the contents of the data are. It's the team that creates the data should be managing it. If a team does not have proper capabilities to put the data, a data infrastructure team should provide them tools to do so, without having the infra team being involved in the domain.
Here we need to mention the topic of moving the data away from the services and storage. Why? There is a logical [dichotomy](https://www.confluent.io/blog/data-dichotomy-rethinking-the-way-we-treat-data-and-services/): Data systems are about exposing data. Services are about hiding it. What does this mean? In order to build a good system, it's necessary to draw a boundary between your data and your services. You may want to decouple [data and compute](https://martinfowler.com/articles/data-mesh-principles.html#LogicalArchitectureDomain-orientedDataAndCompute) although it must be ensured the methods of delivery within a domain will not create any friction, that is deployments between working teams (data and apps teams) can be as independent as possible.
From a cloud perspective, domain ownership **does not** imply making each team have a separate account. Teams can work on a shared infrastructure as long as they bear responsibility for the data.
## Data as a product
Have you heard the phrase [Products over Projects](https://martinfowler.com/articles/products-over-projects.html), that software should always be treated as a product and not as a project? Software projects are popular ways of funding development although with many projects, after a while you end up with a set of incohesive systems. The same happens to your data. After a series of projects that make changes to your data that is shared with other teams, the data can often become unreadable. Imagine a Word document that had 100 pages at the beginning but after multiple years has 500 pages and you need to pass this documentation to a new development team. The amount of effort to decipher the information and amount of meetings to discuss documentation can render any future project too expensive. That's why you should treat your data as a product as well.
That's why it's important to have a metadata system in place, easily accessible to others, kept up to date and without "project specific" deviations.
A question can arise if we should use well defined data exchange models, like ones from [Object Management Group](https://www.omg.org/spec/), [Energistics](https://www.energistics.org/) etc? Although those data models are good when setting up integrations between a high number of organizations, if used internally, that will generate friction. It is better to use data models designed specifically for business needs, even [consumer packaged goods (CPG) industry](https://aws.amazon.com/blogs/industries/how-to-create-a-modern-cpg-data-architecture-with-data-mesh/) can benefit from the Data Mesh.
## Self-serve data platform
How to make teams be able to push data to S3/Kinesis/Kafka, populate metadata in Glue Data Catalog/Atlas/Confluent Schema Registry and have time to work on their own domain? It's mandatory to have a set of managed tools, so that even teams that are not proficient in a given tech are able to provision their infra and deliver data products.
In the cloud, tools like Terraform, CDK or a self crafted set of scripts and services helps to achieve this goal.
## Federated computational governance
How to ensure high interoperability of the data shared by potentially various teams of people even if they use common tools? It's necessary to enforce decisions to achieve that, otherwise you may end up in a data swamp. Definitions of what constitutes a good data quality, how security is defined or how to comply with regulations are parts of the federated governance.
Governance is always the hardest part of any system, especially if you don't want to put a lot of constraints on the teams. There are tools in place to govern the decentralized data, that can help with at least the initial setup. Example on AWS is Lake Formation.
# Data Lake gone wild
Enterprises or large institutions would love to transform into data-driven organizations. It's a new dream that has been pursued. So the Big Data and Data Lake bring hope for enterprises and also developers for achieving those goals. However, given the structure of organization, which is usually vast and often hard to comprehend, the same Data Lake called as a saviour, becomes the bottleneck. When you think of a data lake, you might automatically think of centralization of data repository to a single source of truth. That's when our story begins.
# Scenario based examples
But before that, let's assess some examples of potentially real world situations when data mesh principle might or might not be applied.
## Example 1
The ***Power United*** company has difficulty producing reports to their stakeholders in a timely manner. They want to be able to access the data easily and consistently. Currently, the spreadsheet is all over the place. No data repository. So they bought a big data platform and hired data engineers to bring all the data into a single repository, so that everyone can request reports and dashboards from the data engineering team. The data team will ask each data owner to provide the data and once the data is in place, they will ingest the data, create a pipeline etc. They will have proper meetings for the status update and integration between each team if there are changes. What do you think of this, is it good or bad?
## Example 2
In each department at ***Dough First***, there is a data team that maintains all the data inside the unit. They have their own data analyst, scientist and engineer that work closely with the apps team inside the department. They have the proper governance inside the team. Every department has its own processes and tools. If they need data from another unit, they will set up a procedure and workflow that will be sent into another department. The data then will be exported based on the request, and then they will have their own copy for that data for their analytical purposes. If something happens, the teams organize another set of meetings to align. No shared database or whatsoever is in place as they don't want to share their production database.
## Example 3
Kyle the new CFO needs to learn about his company ***Light Corp*** as they will soon go public. CFO asks IT about where the data, reporting etc. Jon the CDO gives access to Kyle for the company dashboard in their data platform that gives the overview of overall performance, key performance and company metrics.
He then tries to make some analysis and needs some more data. Jon teaches him how to search the data sets in a data platform so that he can find the data easily. The data also have a quality score, freshness and data is well documented on the platform.
Kyle finds some interesting anomaly and needs to get more data on the found case. He then requests additional data from the owner on the data platform and has the request responded instantaneously, without a meeting to ask for the proper access level and clearance. Every request is done and approved from the platform.
Kyle finally can visualize the data in the platform easily. In the first weekly management meeting, everyone just opens the dashboard without using PowerPoint and they are able to understand what's happening and what's next based on looking at the dashboard. They are also able to drill down and conduct interesting discussions based on their findings.
After the first executive meeting, Kyle found some interesting anomalies in their pricing model. Seems that it can be improved for targeting the specific customer for the experience and brand loyalty. He asks Jon for a brainstorming session, they invite their peers and data owner into a call.
They discuss what data product that can be used for this internally. They find the right data in the dashboard and create a simple visualization and analytics based on tools provided by the data infra team. They found out that some customer pricing can be improved. They also find new clusters that can be reached with a different product. They didn't expect to find out new findings while doing something that was totally unrelated.
## To be continued ...
So which company do you prefer to work with? ***Power, Dough or Light***? You might prefer Light Corp among those.
# Is the *power* of data lake good at *Dough* or is it *Light*?
With the promise of data lake, businesses now want to get benefits from Big Data and get the return of investment. Everyone wants a new dashboard, use case and heaven forbids realtime analytics. Nevertheless, the data team is still small, young and the skills are not there yet, people still learn, the talent is not available in the market. As a result the Data Engineering team can't keep up with new data sources, new data consumers and new demand from business that has been promised from the big investment on infrastructure. They want results. And they needed it yesterday. It's not the technology that becomes the bottleneck. It's human. It's become costly because the pipeline is slow.
Data Lake has been pretty in theory but practice proved otherwise. It's difficult to process without proper governance. It's difficult to access data that is not well structured as used before. The data gets duplicated, the coordination between the team is lacking and another silos is created. It's like a town without rules.
We forget the basic principles of software design like encapsulation, modularity, loose coupling, high cohesion and divide and conquer. We couple the well defined contextes between departments. We bring the data into a single data store, then try to understand all of that from the perspective of a tiny data department that doesn't know the behaviour of the data. Of course, they will try to learn from the source system expert but everyone has their own job and becomes their last priority for that day. Who loves endless meetings to explain their system to other departments over and over again? It might be OK for just 1 source system, but mid size organizations have hundreds of systems. Each system contains multiple databases. And you know the rest with tables and fields, right? Where do we start then? It's a huge web of interconnected systems that has a long history.
The system might be bought or built by a different vendor or outsourcing company or created in house. The behaviour of users, vendor delivery methods, architecture can differ as well. On top of that, each product has different data lifecycle. Even people inside the department might not be able to understand all the data within their apps and where it's stored. The knowledge of business and technical knowledge also have a huge variance. How come a single data department that consists of only 10 people would be able to cope with that. Not to forget anything can happen in production in the middle of the night.
Every tool gets bored and dies every once a whole but in the end, only the concepts and fundamentals matter. We still need a proper design, even in the data space. People forget that it's still applied regardless of the domain. We create a great microservice architecture but at the end we are trying to join everything again into one big giant data monolith that is hard to use and understand.
As engineers, we get paid to solve business or society problems with technology. Let's not create a problem by inappropriate use of technology. Great weapons in the hands of wrong people can bring chaos. We need to get back into the basics and fundamentals once again. It's a business that we as engineers need to understand better, how they operate and how to remove friction and increase collaboration to bring down walls that create silos structure. That brings us once again into the Domain Driven Design concept by collaborating with business to increase agility in the whole organization.
So what we know is that currently we struggle with data explosion with unmanageable structure and lack of proper governance and lack of team capacity, knowledge and man power. How can we do this differently? Why not go back to basics and remove the pains? We need to honour the bounded context and create a proper collaboration with the business. We might have one data platform but we can always create proper boundaries, so that each team will have their own data product inside the service boundary. Clean separation between services is still happening not only in application/service level but also data level. Encapsulation everyone?
# Setting up good data mesh
Having said what constitutes a good data mesh, let's try to give some starting point cases and how a good architecture can be built.
## From the zero, when nothing is in place
Since this is a green field project, it's the easiest one you can imagine. You may not have much constraints in place on how the platform should be built, so you can try to build it in a way, so that will he highly efficient even if it grows big.
There is a high number of services and tools available on AWS are versatile and allow for advanced functionalities like [data anonymization](https://aws.amazon.com/blogs/big-data/anonymize-and-manage-data-in-your-data-lake-with-amazon-athena-and-aws-lake-formation/) or [ACID transactions](https://aws.amazon.com/blogs/big-data/part-3-effective-data-lakes-using-aws-lake-formation-part-3-using-acid-transactions-on-governed-tables/).
### Example with AWS services and tools
Let's see how we can implement a good Data Mesh on AWS. Diagram below shows an example of this approach.
We can distinguish two main groups there:
1. Data infrastructure that is managed by a separate team that owns a Domain
1. Domain infrastructure that relies on IaC provided by the infra team to deliver values required by a given Domain
### Principles vs AWS offerings and alternatives
What AWS service should be used to help satisfy each Data Mesh principle? What OSS alternatives can be used on AWS cloud since as we know, OSS presence here is [dominant](https://medium.com/sapphire-ventures-perspectives/what-is-the-open-data-ecosystem-and-why-its-here-to-stay-60c06f19011b)? Below is a short, not exhaustive list of options:
| Data Mesh Principle | AWS service/tool | OSS alternative |
| ------------- |:-------------:| -----:|
| Domain Ownership | S3 | [lakeFS](https://lakefs.io/data-mesh-applied-how-to-move-beyond-the-data-lake-with-lakefs/), [Delta Lake](https://delta.io/) |
| Data as a product | Glue | [Project Nessie](https://projectnessie.org/), [Apache Atlas](https://atlas.apache.org/), [Hive Metastore](https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-hive-metastore.html), [Apache Iceberg](https://iceberg.apache.org/) |
| Self-serve data platform | CloudFormation, CDK, Amazon Managed Workflows for Apache Airflow, EKS, EMR, QuickSight | [Terraform](https://www.terraform.io/), [K8S](https://kubernetes.io/), [Rancher](https://rancher.com/), [jupyter](https://jupyter.org/), [Kibana](https://www.elastic.co/kibana) |
| Federated computational governance | Lake Formation, Organizations | [Apache Atlas](https://atlas.apache.org/) |
### Getting Started
At a bare minimum, you should have at the start one person that has knowledge of Cloud system engineer and one data engineer. In enterprise settings, you should consider having [Cloud Center of Excellence (CCOE)](https://aws.amazon.com/blogs/enterprise-strategy/using-a-cloud-center-of-excellence-ccoe-to-transform-the-entire-enterprise/).
Remember the company partners ***Power United*** in our story before? Let's continue using that one.
They have 2 hard-working people in the company **Jackie** (*Cloud Administrator*) and **Alex** (*Data Engineer Lead*) from centralized *Analytics and Data-warehouse department*. They've been assigned to create a new initiative for a new data analytics platform in AWS.
Currently, in the company, there are multiple squads that handle domain microservices like billing, finance, inventory, shipping etc. Luckily, they already have their own domain and microservices.
Let's see how it works.
1. Jackie starts creating a new AWS environment (S3 bucket, IAM, Roles and Policy, etc. ) for Alex to ingest data into S3 with CKD, for a reuse by domains.
2. Alex is just getting started, he wants to make sure everything in the pipeline is working. He just uses AWS Lake Formation to ingest the data and create catalog from their existing database. Do some queries with Athena and creates visualizations in QuickSight.
3. It just works! Given this confidence, Alex invites the lead developers from each squad (billing, finance, inventory, etc) for a workshop. He also invites his data engineering team from analytics. Currently, data engineering is centralized in one place under Jackie.
4. Alex assigns each member of his team to the existing service/domain team. They also gather knowledge from the existing BE developers, and BE also aware of what's needed for the data product from their side.
The data engineer collaborates with the backend engineer to provide the data to s3 with proper schema and data dictionary in AWS Glue Catalog. DE uses AWS Glue (pyspark) to ingest and transform the data.
5. They manage to publish each data product into S3 with proper schema put to the company catalog.
6. The complex reporting that combines the whole organization data can easily be provided by searching from a data catalog and then everyone from the organization can directly self serve their own needs.
7. They are also able to connect existing Tableau into their data platform on AWS.
8. Once in a while they need to create separate teams for maintaining data products like dynamic pricing, customer recommendation, fraud detection etc. but it can easily be done by using the existing knowledge, IaC code and other shared tools and the way they work.
## From an existing data lake, that's not performing as expected
This is a more complex case. There already is an analytical system in place and you discover that there are noticeable bottlenecks that slow the company down. You could have already invested heavily in products like Cloudera or other data monoliths, so you need to apply a sliced approach.
How to solve the bottlenecks? Apply data mesh principles in order to remove unnecessary bottlenecks. You can split your data lake like a monolith server/service. Find the domains, define the boundaries and build the data around the domain thoughtfully. Diagram below visualizes this approach:
Once done, you can keep slicing the monolith until the monolith can be decommissioned.
## Lack of ownership and responsibilities
Even though the case above is common, that is not always a problem. There are situations when there is a separate team that manages the data and a separate one that is providing the data. How to resolve this issue? You need to bring up the data ownership topic. Ideally, the team that manages the data needs to transition to a data infra team and support ones that are actually working on data.
Diagram below shows how a problem with a lack of ownership can be resolved. The data team needs to focus on providing a domain infrastructure IaC, so that the team responsible for Domain can be also responsible for the data.
## Scaling the mesh
What if you have an existing platform and want to scale it, that is to add a new team? The team will take time to get up to speed to deliver the value. Shared self service tools (data discovery/catalog/schema) and shared infra can speed them up. If you grow the number of teams that work on the data, you should invest into the self-serve data platform, to ensure high performance of the new teams.
Scaling of a data mesh within an AWS account is a relatively easy task although it is not a case at an enterprise. An enterprise can make use of hundreds of AWS accounts and in order to handle this usual case, a proper approach must be defined.
From an approach of data governance, [two design types](https://aws.amazon.com/blogs/big-data/design-patterns-for-an-enterprise-data-lake-using-aws-lake-formation-cross-account-access/) can be distinguished:
1. Centralized - with centralized Lake Formation and storage
1. De-centralized - with decentralized Lake Formation and storage
Because the decentralized design type allows for more organizational configurations to be implemented, let's consider below a case with this design.
Domain A and Domain B resides in an AWS account [OU](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_ous.html) A, with its own Lake Formation and Glue Catalog. What we want to have, is to enable Domain C to access the data in other domains. Domain C resides in OU B account, also with its own Lake Formation and Glue Catalog. To deliver this task, we need to make use of AWS [RAM](https://docs.aws.amazon.com/ram/latest/userguide/what-is.html) and share [Glue resources](https://docs.aws.amazon.com/ram/latest/userguide/shareable.html#shareable-glue) between accounts.
Diagram below shows how this can be realized.
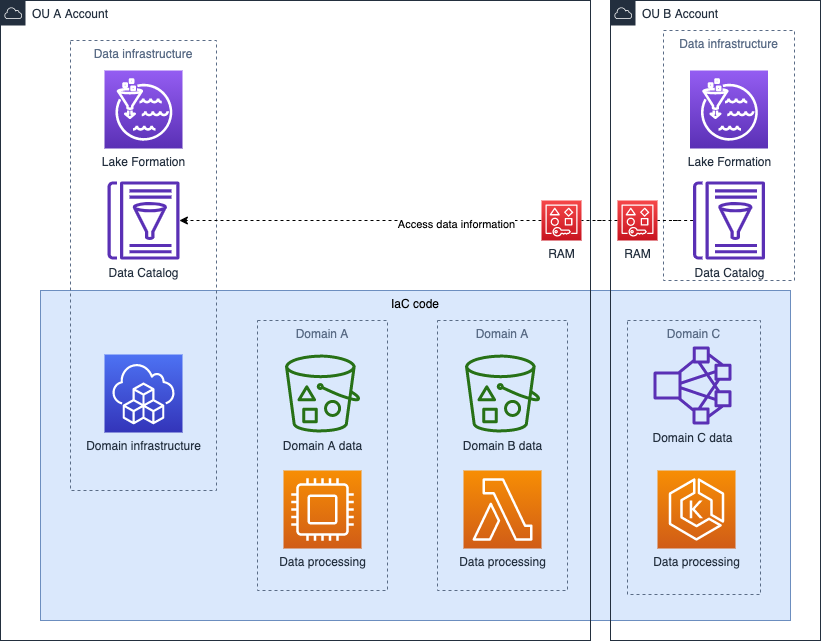
## Hybrid cloud and multi cloud
All the above cases consider a simple case, where there is only one provider and there is no data on-premise. That's not always the case, there are organizations applying hybrid cloud approach, multi cloud approach or both, hybrid and multi cloud. Designing an interoperable system that would accommodate such a setup can be challenging, most because of vendor lock-in.
As usual, it's best to either look at OSS offerings or write your own solutions that would help. An example of a self written platform is Airbnb and their [Minerva platform](https://medium.com/airbnb-engineering/how-airbnb-achieved-metric-consistency-at-scale-f23cc53dea70), that is vendor independent.
The whole topic is very extensive although the general rules of a data mesh still apply, with prevailing domain ownership. The premise of a self-serve data platform can be challenging as it is hard to provide tools that would work across a versatile portfolio of platforms at a reasonable cost. Definitely suggestions provided in [Cloud Strategy](https://architectelevator.com/book/cloudstrategy/) are helpful to craft the best possible data mesh for the organization.
## Data Mesh for Fintech
At this step, it's worth distinguishing fintech companies from other sectors because of their special characteristics. The nature of fintech companies is that they are able to process information effectively. Moreover, most of the capital market professionals believe that data analysis will be the most important skill at trading desks in the near future [ref](https://www.greenwich.com/press-release/new-report-analyzes-impact-data-analysis-trading-desks). To remain competitive, a further adjustment towards better tools for data analysis at companies providing Financial Services is necessary.
Each organization may generate 20 to 400 GB of data from stock exchanges per day, if we exclude high-frequency trading (HFT). To create proper data models, an analyst may need about 20 years of data, which means there is a need for PBs storage and high processing capacity. Assuming that, an extensive platform for this purpose is necessary.
One approach might be to leverage basic managed services and build a platform that conforms to requirements but it is also possible to make use of a managed service specifically designed for fintech, [Amazon FinSpace](https://docs.aws.amazon.com/finspace/latest/userguide/finspace-what-is.html). It allows for configuration of [environments](https://docs.aws.amazon.com/finspace/latest/userguide/create-an-amazon-finspace-environment.html) where a set of data and users who can operate on the data can be configured. Once the environment is added and data feeds are configured for the purposes of an analyst, it's possible to begin processing even [PBs of data](https://aws.amazon.com/blogs/big-data/analyzing-petabytes-of-trade-and-quote-data-with-amazon-finspace/).
How can Amazon FinSpace be leveraged to support Data Mesh paradigms? Finspace can be treated as a tool for a single Domain. That can be a proper tool for end users to rely on data provided by other Domains.
# Data Mesh and Joy of Data-driven Organization Journey
Organizations [strive to be data driven](https://www.cio.com/article/3449117/what-exactly-is-a-data-driven-organization.html) but how can this be done well and to ensure the data flows can be setup well at various units effectively? We hope that after reading this article, you will have a better overview on the general rules and concrete realizations on AWS you should follow to achieve that.
The Data Mesh can be applied to vast sizes of organizations, from smaller ones like [DPG Media](https://levelup.gitconnected.com/data-mesh-a-self-service-infrastructure-at-dpg-media-with-snowflake-566f108a98db?gi=85e6b6394e22) to bigger ones like [JP Morgan](https://aws.amazon.com/blogs/big-data/how-jpmorgan-chase-built-a-data-mesh-architecture-to-drive-significant-value-to-enhance-their-enterprise-data-platform/). Hope you can do it too!
# About Authors
## Patryk Orwat
Software and cloud architect with about 10 years of experience, Developer Consultant at ThoughtWorks, helping clients achieving their goals. After work, OSS contributor and a self-taught aroid plant grower.
## Welly Tambunan
Co-founder and CTO at Scifin Technologies (Crypto Derivatives HFT firm). Doing distributed system and real-time streaming analytics for about 15 years in O&G, Banking, Finance and Startups. | patrykorwat |
734,828 | How to conditionally select array or array of objects in Javascript ? | If you have ever come across a use case where you have multiple arrays like below, const array1 =... | 0 | 2021-06-21T18:18:18 | https://dev.to/jav7zaid/how-to-conditionally-select-array-or-array-of-objects-in-javascript-4i7k | javascript, tutorial, programming, webdev | If you have ever come across a use case where you have multiple arrays like below,
```
const array1 = [1,2,3];
const array2 = [4,5,6];
const array3 = [{ a: 1 }, { b: 2 }];
```
What if you want the resultant array to conditionally include one or more arrays, one way to do it
```
const arrayWeWant = [];
if(condition1) {
arrayWeWant.push(array1);
}
if(condition2) {
arrayWeWant.push(array2);
}
if(condition3) {
arrayWeWant.push(array3);
}
```
well that's not a bad approach, but we can do better
```
const arrayWeWant = [
...(condtion1 ? array1 : []),
...(conditon2 ? array2 : []),
...(conditon3 ? array3 : [])
];
```
It's a much cleaner way isn't it.
Happy to share!😊 | jav7zaid |
734,849 | Implement reverse scrolling effect on webpage | Hey guys, when you create a website, the browser loads it at the top of your design, and viewers... | 0 | 2021-06-21T18:52:59 | https://dev.to/tbaveja/implement-reverse-scrolling-effect-on-webpage-58g0 | webdev, html, css, scrolling | Hey guys, when you create a website, the browser loads it at the top of your design, and viewers scroll down. But what if your design is more interesting the other way around? What if you'd like a page to start at the bottom and scroll up? In this blog you'll learn how to implement reverse scrolling on your website in just 3 steps...
**1. Start with just 7 lines of HTML:**
>*Create panels/ sections inside one main container. I created 5 but you can create as per requirement.*
```
<div class="panelCon">
<div id="pane-5" class="panel">Section 5</div>
<div id="pane-4" class="panel">Section 4</div>
<div id="pane-3" class="panel">Section 3</div>
<div id="pane-2" class="panel">Section 2</div>
<div id="pane-1" class="panel">Section 1</div>
</div>
```
**2. Few lines of CSS:**
>* _Set the height of each panel to viewport height._
* _Set the position as fixed of main container and bottom as 0. Set the body height as (100*Number of panels)vh._
* _Below you can see height of body is set as 500vh as I have created 5 panels._
```
body {
margin: 0;
padding: 0;
height: 500vh;
}
.panelCon {
position: fixed;
bottom: 0;
left: 0;
width: 100%;
z-index: 99990;
}
.panel {
width: 100%;
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
font-size: 30px;
line-height: 35px;
text-transform: uppercase;
}
#pane-1 {
background-color: pink;
}
#pane-2 {
background-color: #e8e8e8;
}
#pane-3 {
background-color: red;
}
#pane-4 {
background-color: pink;
}
#pane-5 {
background-color: yellow;
}
```
**3. Finally, just 3 lines of JS:**
>*Inside onScroll function of window, increase the bottom value but in negative* 😉
```
$(window).on("scroll", function () {
$(".panelCon").css("bottom", $(window).scrollTop() * -1);
});
```
and you're done.
.
**Don't want to follow the steps? Below is Github link for you :)**
Demo: https://tbaveja.github.io/reverse-scrolling/
Code: https://github.com/tbaveja/reverse-scrolling
.
Thanks for reading !
> Connect with me on LinkedIn:
https://www.linkedin.com/in/tarun-baveja-000a9955/
| tbaveja |
734,882 | EP1: Rust Ownership for Toddlers | "Rust is too hard to learn," You whined. "Maybe because you're a toddler?" 🧸... | 13,333 | 2021-06-22T16:00:07 | https://dev.to/pancy/ep1-rust-ownership-for-toddlers-3pe1 | rust, tutorial, codepen, beginners | "Rust is too hard to learn," You whined.
"Maybe because you're a toddler?"

## 🧸 Ownership
> 💡 Ownership IS the only big concept in Rust. It is not unique, and C++ has it too. Understand this well.
Repeat after me, __"Thou shall be the only one owning a toy."__
That's it. Alice has a toy, then Bob snatches it from Alice. Alice no longer has the toy. Bob runs away and gets bullied by Tim, looting the toy. Then Bob has no toy. Tim has the toy.
If you later asked Alice for the toy, she would just cry and slap you on and on, yelling, "Bob took my toy!"
If you asked Bob to get back the toy, he would lash out with a black eye. "Tim has it!"

```rust
fn main() {
let alice = String::from("Teddy");
{
/// Bob suddenly shows up and snatches it from Alice.
let bob = alice;
/// "Bob took it!" Alice cried.
println!("Alice, where is the {}", alice);
let tim = bob;
/// "Tim stole it!" Bob lashed out.
println!("Bob, did you take the {} from Alice?", alice);
/// Tim, an alien under a kid skin, eats the bear.
/// Then, Tim and Bob vanishes into ether.
}
/// "Who's Bob?" Alice said, Teddy no longer in her arm.
/// Cue the X-file music...
println!("Alice, did Bob return the {}", alice);
}
```
### 🔮 Reflect
Although this may sound confusing, it is pretty simple in the real, physical world. You were just too spoiled by your X language. Here is the hard fact -- You just can't have more of a thing. A piece of data is not made of pixie dust. It is a bunch of electrons making tricks on a couple of latches to spell out enough 0 and 1 digits to make up a piece of data. As real as a teddy bear.
### 🐍 What other languages do
What most languages do is basically telling Alice and Bob to share, which they can on a good day. On a bad one, they are yanking the toy on each end. On the worst, either one might misplace it and the other explodes. This one hip language named after a fat snake takes it too far by buying a duplicate for every toy for Alice, Bob, Tim, and any other kids who want to play with it.
> 🍼 Try-sies
Instead of a `String::from("Teddy")`, try a string literal "Teddy" or an integer and keep the code. What happens? Use this [playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=54aebc47a49e72cd4c554268cf407109).
Sensibly, in order for Alice to have the toy, Bob (or whoever was owning it) should return the toy to her.
```rust
/// mut means I can change what I have later.
let mut alice = Toy("Teddy");
let bob = alice;
let mut tim = bob;
tim = daghan_does_something(tim);
/// "No!" Alice yelled.
println("Did you get the {:?} back, Alice?", alice);
alice = tim;
/// Print just fine!
println("Now, did you get the {:?} back?", alice);
```
Since Tim eventually returned the toy back to Alice, Alice is happy.
> ### Stay tuned for EP2: Rust Borrows for Toddlers: All You Gotta Do is Ask.
👀 **Follow** me so you don't miss the next episodes!
🦄 **Upvote** this so Netflax renews the episodes!
>
> I'm also on [Medium](https://pancy.medium.com/) and [Twitter](https://twitter.com/pancychain). Come say 👋 | pancy |
735,962 | IntelliJ IDEA as a LaTeX editor | TL;DR: IntelliJ Idea is great for working with LaTeX. The basic functionality is provided by... | 0 | 2021-06-22T18:14:44 | https://asvid.github.io/intellij-latex-editor | latex, intellij, productivity, todayilearned |
> TL;DR: IntelliJ Idea is great for working with LaTeX. The basic functionality is provided by plugins, and a lot of additional automation can be set using File Watchers. I only miss displaying chapters and sections like in TexStudio.
## LaTeX in IntelliJ IDEA
I don't work with LaTeX very often, but this format has many advantages, especially when working on longer written forms, containing a lot of graphics, diagrams, mathematical formulas, etc. I used to use TexStudio, but decided to check if and how IntelliJ IDEA will do I use every day.
And it's doing great. I won't be coming back to TexStudio :) Because I would use IntelliJ to write, for example, code fragments, which I would then paste into a dedicated LaTeX editor. And I like to have everything in a single IDE.
## My requirements
I decided that I want a framework for writing longer texts, ultimately for publication as an e-book or print. Preferably having everything in the code (diagrams, charts), using version control, which is how I usually work. That is why I immediately rejected Google Docs or MS Office. LaTeX seems like a pretty good solution:
- everything is in the code, text, formatting styles, code fragments in dedicated files, diagrams
- organization of the project in many folders and files, e.g. separate files for chapters and one main file collecting the entire document
- great support for bibliography, footnotes, and table of contents
- easy PDF generation
- ... and probably a lot of other advantages that I haven't got to know yet.
However, there are some problems:
- document preview - not available immediately, only after compilation. This can even be an advantage because I don't focus on appearance, but content. And the appearance itself should be subject to predetermined rules for the entire document. You can set up automatic compilation and preview inside the IDE.
- code syntax coloring - so far, no official support for `Kotlin`, but I found a template on [GitHub](https://github.com/cansik/kotlin-latex-listing)
- diagram support - I think there are some packages for LaTeX, but I don't want to learn them. I like `PlantUML` and would prefer to use it directly.
## Plugins
The IDE doesn't have LaTeX support by default, but there are some useful plugins that I used:
### Texify
The most important plugin is [Texify](https://plugins.jetbrains.com/plugin/9473-texify-idea) which provides tons of LaTeX-related functionality. From highlighting and syntax prompting to compiling files into PDF.
Additionally, you can set the plugin in such a way that it generates a preview of the file automatically after each change.
The document can be compiled manually by clicking on the icon next to the `\begin` block, or by creating a custom action if you need a more complex process.
### PDF Viewer
Basically a maintenance-free plugin that allows you to display PDFs directly in the IDE. Texify works well with it, automatically displaying the resulting PDF file after compilation. [Plugin page](ttps://plugins.jetbrains.com/plugin/14494-pdf-viewer)
### PlantUML Integration
I am using `PlantUML` on the blog to create diagrams, mainly class diagrams. The tool itself is quite powerful but friendly at the same time. This plugin provides IDE support for generating preview and exporting diagrams to `.svg` or `.png` files. [Plugin page](https://plugins.jetbrains.com/plugin/7017-plantuml-integration)
### File Watchers
I think this is a pre-installed one. The plugin for creating some sort of automation inside the IDE. It allows you to set the type and location of watched files, and what should happen if they are changed/updated/created.
Usually this will be a command line command with specific parameters, for example:
[Plugin page](https://plugins.jetbrains.com/plugin/7177-file-watchers)
**In addition, of course, LaTeX must be installed in the system, e.g. `MiKTeX`, which the IDE will use to compile files to PDF.**
## My workflow
Ultimately, I would like my workflow to look like this:
1. I write text in a LaTeX document, mapping the document's structure into the folder structure.
2. I get to the point where I want to insert the code snippet.
1. I create a new file in the appropriate folder with the extension for the given programming language.
2. The IDE provides syntax support for the selected technology, code formatting, etc.
3. After writing the code, I link the file in the LaTeX document.
4. LaTeX correctly generates the code in PDF, keeping the rules of syntax highlighting.
3. I want to add a diagram, e.g. class diagram
1. I add a new `.puml` file, create a diagram in it using `PlantUML`.
2. The IDE displays a preview of the diagram.
3. I link the diagram in the LaTeX document.
4. LaTeX generates a PDF with a correctly displayed diagram, drawn in vector (no blurry image, ability to select texts from the diagram, etc.).
4. PDF preview is generated after each change in the document.
### Issues
IntelliJ with the `Texify` plugin offers similar possibilities as the dedicated LaTeX editors, but I don't want to manually copy code fragments, or generate `.svg` from the diagram and put them in the document. Added to this is the lack of support for `Kotlin` in the` listings` package for displaying code blocks in LaTeX and no direct support for `.svg`.
#### Kotlin
The `listings` package is fairly easy to use, and it supports multiple languages. Unfortunately not `Kotlin`, but fortunately it allows you to add your syntax highlighting rules. Syntax highlighting in the generated PDF is not obligatory, but every time I open a physical book with code examples that are all the same color, I feel like rewriting it in the IDE. I just don't read it well, and it takes me much longer to understand what is going on.
Ready to use `Kotlin` syntax scheme I found at [GitHub](https://github.com/cansik/kotlin-latex-listing). You just need to add the file to your LaTeX project and link it like this:
```latex
% LaTeX package used for code blocks
\usepackage{listings}
% linking the file with Kotlin syntax highliting scheme
\input{kotlin_def.tex}
% adding code block from file `Simple.kt`
\lstinputlisting[caption={Simple code listing.}, label={lst:example1}, language=Kotlin]{Simple.kt}
```
I especially like keeping the code OUT of a LaTeX document. This way I work with the code like I usually do and then just link the file in the document. Coloring and syntax prompting make me a bit lazy, but it also allows me to work more efficiently.
#### PlantUML Diagrams
This is where things get complicated. There is no ready-made support for diagrams from `PlantUML` to LaTeX (or at least not found). You can manually generate a graphic file from the diagram in a separate file and then link it to the document. But LaTeX doesn't support `.svg` either, and I don't want to have `.png` stretched in my lovely PDF. So I would have to generate the `.svg` from the diagram and then convert the file to the`.pdf` that I link in the LaTeX document.
This is where `File Watcher` is coming handy. With a little help of a LaTeX `svg` package.
First, I had to install tools called by `File Watchers`:
- `PlantUML` with Homebrew `brew install plantuml`. After installation command `plantuml` should be available in command line.
- `Inscape` is a standard GUI app, that you can get from [here](https://inkscape.org/release/inkscape-1.1/). Its good to create a symlink, for easier use from command line: `sudo ln -s /Applications/Inkscape.app/Contents/MacOS/inkscape /usr/local/bin`
I've set 2 `File Watchers`:
1. After each `.puml` file change (that I have support for in `PlantUML Integration` plugin) it runs command `plantuml $FileName$ -tsvg` - generating a `.svg` file from diagram code.
2. After each change of `.svg` file (like generating it in previous step) run command `inkscape --file=$FileName$ --export-pdf=$FileName$.pdf` - generating a `.pdf` file with a diagram using `Inkscape` app, without actually opening it.
And this automagically generated file I can use in LaTeX document:
```latex
\begin{figure}[htbp]
\centering
\includesvg{test.svg}
\caption{svg image}
\label{fig:figure}
\end{figure}
```
Note that I am giving the name of the `.svg` file and not `.pdf` - the `svg` package for LaTeX will look for a PDF matching the given file name.
The `LaTeX` project I used for testing is [here](https://github.com/asvid/LatexTest).
## Gaps
What I miss the most is the nice chapter and section division that I had in TexStudio. IntelliJ can't display it yet, or I don't know how to get it. By organizing the folder structure in a project, you can probably achieve similar readability, but I haven't checked it in practice yet. I'd love to have it displayed like fields and methods in code files.
## Summary
IntelliJ IDEA with a set of plugins and `File Watchers` successfully replaced the dedicated LaTeX editors. It seems to me that it provides even more possibilities thanks to easy automation and the use of external tools. What is missing is a nice division of `.tex` files into sections and chapters. The undoubted advantage of using one IDE is good support for multiple technologies and languages. Editing code snippets in LaTeX editors or pasting it from another IDE is not very convenient, it can cause errors or unreadable formatting.
If it wasn't for working with code and diagrams (which I also like to have in code), GoogleDocs would probably be enough for me. But working in LaTeX and keeping everything in code and separate files allows for a nice versioning of Git changes. So I have a very familiar workflow, even though the result is PDF, not software :)
## Used Tools
- [MiKTeX](https://miktex.org/)
- [PlantUML](https://plantuml.com/)
- [Inkscape](https://inkscape.org/release/inkscape-1.1/)
- [Kotlin color scheme for Latex listing](https://github.com/cansik/kotlin-latex-listing)
- [IntelliJ IDEA Community](https://www.jetbrains.com/idea/)
- [Texify](https://plugins.jetbrains.com/plugin/9473-texify-idea)
- [PlantUML integration](https://plugins.jetbrains.com/plugin/7017-plantuml-integration)
- [File Watchers](https://plugins.jetbrains.com/plugin/7177-file-watchers)
- [PDF Viewer](ttps://plugins.jetbrains.com/plugin/14494-pdf-viewer)
- MacOS, but should work similar on any Unix
- [My GIT repo for playing with LaTeX](https://github.com/asvid/LatexTest) | asvid |
736,058 | Selection sort algorithm | Definition of selection sort Selection sort is one of the simplest sorting algorithms, it... | 13,547 | 2021-06-22T23:21:37 | https://dev.to/ayabouchiha/selection-sort-algorithm-5ke | algorithms, computerscience, beginners, python |
## Definition of selection sort
Selection sort is one of the simplest sorting algorithms, it works by continually finding the minimum number in the array and inserting it at the beginning.
## Space and Time complexity
The time complexity of selection sort is **O(n<sup>2</sup>)** and it's space complexity is **O(1)**
## Selection sort algorithm
1. itertate from 0 to len(arr) - 1
2. seting to minimunIdx variable the first element index in the unsorted part
3. loop trough the unsorted part
4. if arr[j] < arr[minimumIdx] => minimumIdx = j
5. swaping arr[minimumIdx] with the first in the unsorted part (unsortedPart[0])
## Implementation of selection sort using python
```python
def selectionSortAlgorithm(arr: list) -> list:
"""
[ name ] => Selecion sort
[ type ] => Sorting algorithms
[ time complexity ] => O(n^2)
[ space complexity ] => O(1)
[ params ] => ( arr {list} array to sort )
[ return ] => sorted list
[ logic ] => (
1. itertate from 0 to len(arr) - 1
2. seting to minimunIdx variable the first element index in the unsorted part
3. loop trough the unsorted part
4. if arr[j] < arr[minimumIdx] => minimumIdx = j
5. swaping arr[minimumIdx] with the first in the unsorted part (unsortedPart[0])
)
"""
# itertate from 0 to len(arr) - 1
for i in range(len(arr)):
# setting to minimunIdx variable the first element index in the unsorted part
minIdx = i
# loop trough the unsorted part
for j in range(i + 1, len(arr)):
# if arr[j] < currentMinimum (arr[minIdx])
if arr[j] < arr[minIdx]:
# minIdx will be the index of the new minimum
minIdx = j
# swaping the minimum with the first element in the unsorted part
arr[minIdx], arr[i] = arr[i], arr[minIdx]
return arr
```
## Implementation of selection sort using javascript
````javascript
/**
* sort an array using selection sort algorithm
* time complexity : O(n^2)
* space complexity : O(1)
* @param {Array} arr array to sort
* @returns {Array} sorted array
*/
const SelectionSortAlgorithm = (arr) => {
// iterate from 0 to arr.length - 1
for (let i = 0; i < arr.length; i++){
// setting to minimunIdx variable the first element index in the unsorted part
var minIdx = i;
// loop trough the unsorted part
for (let j = i + 1; j < arr.length; j++) {
// if arr[j] < currentMinimum (arr[minIdx])
if (arr[j] < arr[minIdx]) {
// minIdx will be the index of the new minimum
minIdx = j;
}
}
// swaping the minimum with the first element in the unsorted part
[arr[minIdx], arr[i]] = [arr[i], arr[minIdx]];
}
return arr
}
```
## Exercise
sort an array in descending order using the selection sort algorithm
## References and useful resources
+ [https://www.geeksforgeeks.org/python-program-for-selection-sort/](https://www.geeksforgeeks.org/python-program-for-selection-sort/)
+ [https://www.programiz.com/dsa/selection-sort](https://www.programiz.com/dsa/selection-sort)
+ [https://stackoverflow.com/questions/22898928/selection-sort-in-javascript](https://stackoverflow.com/questions/22898928/selection-sort-in-javascript)
+ [https://www.youtube.com/watch?v=EnodMqJuQEo](https://www.youtube.com/watch?v=EnodMqJuQEo)
+ [https://www.geeksforgeeks.org/selection-sort/](https://www.geeksforgeeks.org/selection-sort/)
+ [https://www.youtube.com/watch?v=xWBP4lzkoyM](https://www.youtube.com/watch?v=xWBP4lzkoyM)
Have a good day :)
\#day_10 | ayabouchiha |
736,127 | JavaScript fácil: Coerção de tipos | Tipos de dados em Javascript Em JavaScript a tipagem de dados é dinâmica, isso quer dizer... | 0 | 2021-06-22T22:02:38 | https://dev.to/tashima42/javascript-facil-coercao-de-tipos-3j5j | javascript, programming | ## Tipos de dados em Javascript
Em JavaScript a tipagem de dados é dinâmica, isso quer dizer que ao reservar um espaço na memória, não é necessário declarar para que tipo de dado aquele espaço será usado.
Ex: var minhaIdade = 18; Nesse caso, a variável contém um dado de tipo numérico, porém, diferente de Java ou C, é possível simplesmente atribuir outro tipo de dado sem nenhum problema. minhaIdade = "Não te interessa"; agora a variável minhaIdade contém um texto. Para uma explicação mais detalhada, recomendo a leitura deste texto.
***
## A coerção
Responda a seguinte pergunta: Quanto é 345 + vermelho?
Ela não faz sentido, não? Lógico que não. vermelho não é um número. Para seu computador isso também não faz.
Quando uma operação não faz sentido, os valores são convertidos automaticamente para que passe a fazer. Isso é a coerção de tipos.
Ex:
- Código:
``` js
var numeroExemplo = 345; //atribuindo um número
var palavraExemplo = 'vermelho'; //atribuindo um texto
var resultado = numeroExemplo + palavraExemplo; //somando o numero e o texto
console.log(resultado); //Mostrando no console o resultado
```
- Console:
```
>"345vermelho"
```
Nesse exemplo, o número 345 foi convertido para o "texto" 345. Por mais estranho que isso possa parecer, é possível entender melhor com os próximos exemplos.
- Código:
``` js
var numeroUm = 1; //declarando 1 como valor numérico
var palavraUm = '1'; //declarando 1 como um texto
var resultado = numeroUm + palavraUm; //somando as duas variáveis
console.log(resultado); //Mostrando no console o resultado
```
- Console:
```
>"11"
```
Obviamente 1+1 é igual a 2, mas o console nos mostra 11. O que aconteceu? A variável palavraUm continha um texto e da mesma maneira que no exemplo anterior, então o computador transformou numeroUm também em um texto e concatenou os dois.
>**_con·ca·te·nar_**
>(latim concateno, -are)
>verbo transitivo e pronominal
>_Estabelecer(-se) relação ou .sequência lógica entre ideias ou argumentos. = **ENCADEAR, JUNTAR, LIGAR**_
Ou seja, ele juntou os textos, da mesma maneira que acontece se fizermos o seguinte:
- Código:
``` js
var meuNome= 'Pedro'; //declarando um texto
var meuSobrenome= 'Tashima'; //declarando um texto
var resultado = numeroUm + palavraUm; //concatenando os textos
console.log(resultado); //Mostrando no console o resultado
```
- Console:
```
>"PedroTashima"
```
***
Agora sim tudo voltou a fazer sentido, 1 + 1 ainda é 2 e você entende o conceito de coerção de tipos, mas para não passar vergonha falando que 1 + 0 é 10, você deveria ver os seguintes links para entender mais do assunto (e ver minhas referências também):
- [Explicação mais detalhada do que é coerção de tipos](https://medium.com/trainingcenter/explicando-a-coer%C3%A7%C3%A3o-de-tipos-em-javascript-d6c9203c4e5)
- [Documentação da Mozilla e a diferença entre coerção e conversão](https://medium.com/r/?url=https%3A%2F%2Fdeveloper.mozilla.org%2Fen-US%2Fdocs%2FGlossary%2FType_coercion)
- [Representação visual do que acontece na prática](https://medium.com/r/?url=https%3A%2F%2Fdorey.github.io%2FJavaScript-Equality-Table%2F)
- [Livro: Javascript: Básico ao Avançado: Guia completo para iniciantes](https://medium.com/r/?url=https%3A%2F%2Fwww.amazon.com%2FJavascript-B%25C3%25A1sico-ao-Avan%25C3%25A7ado-Portuguese-ebook%2Fdp%2FB07F36KXNW)
- [Outra explicação, caso você não entenda as outras](https://medium.com/r/?url=https%3A%2F%2Fcrisgon.github.io%2Fposts%2FCoercao-de-tipos-javascript%2F)
| tashima42 |
757,859 | Creating Python's Input Function In Ruby | A tutorial showing how to implement python's input function in Ruby. The input function is used to get user's input | 0 | 2021-07-13T07:23:30 | https://www.kudadam.com/blog/python-input-ruby | python, ruby, function | ---
title: Creating Python's Input Function In Ruby
tags: python, ruby, function
description: A tutorial showing how to implement python's input function in Ruby. The input function is used to get user's input
published: true
canonical_url: https://www.kudadam.com/blog/python-input-ruby
cover_image: https://kudadam.sirv.com/blog/ruby_input.png
---
[Repost from my blog](http://kudadam.com/blog/python-input-in-ruby)
[Ruby](https://www.ruby-lang.com/en) is a general-purpose programming language and it's syntax is close to Python's own.
When I started learning Ruby, I was marveled at it's simplicity.
Since I was coming from a Python background. I found it very easy to learn. Because of it's similarity in syntax, I wanted some of Python's function in Ruby.
One of the functions I wanted to implement was the `input()` function. The reason was that, Ruby unlike Python, you will need to use both `puts` and `gets` if you want to get a user's input whiles displaying text in Ruby.
## Creating our function
Well, to create this function in Ruby is very simple. Just open your Ruby file and type the following code inside
```ruby
def input(prompt ='')
puts prompt
return gets
end
```
## Explaining the function
Well, so as we can see, the function is just four lines of code. Pretty simple huh!
The function was made to just replicate Python's own so they work in the same way.
The `input` function takes an optional parameter called prompt. On the next line, the `puts` method displays the `prompt` to stdout and then the `gets` method retrieves any user input and returns it.
## Trying out the function
In order to use the method we just created, make sure the code is in the same file as the one you are working with.
```ruby
name = input("What is your name?")
print "Hello " + name
```
In our example, we called our function with the string _"What is your name?"_ and the value was stored in the variable `name`. On the next line, we printed 'Hello' + name.
See, that wasn't hard! :smile: | lubiah |
757,889 | How to view source code of a website on mobile device | A tutorial showing how the view the source code of any website on your mobile device | 0 | 2021-07-13T07:29:24 | https://www.kudadam.com/blog/website-source-code-mobile | website, html, browser | ---
title: How to view source code of a website on mobile device
tags: website, html, browser
published: true
description: A tutorial showing how the view the source code of any website on your mobile device
canonical_url: https://www.kudadam.com/blog/website-source-code-mobile
cover_image: https://kudadam.sirv.com/blog/code_image.jpg
---
Most of the times, when we visit a nice looking website, we always want to look at it's HTML source code. On desktop browsers, we simple just right-click and click on "view page source" from the context menu but there's no option like this on mobile devices. So then, how do we view the source code on a mobile device?
If we are to observe carefully, whenever we click on "view page source" on a desktop browser, it opens a new url in this format `view-source:https://path/to/url`.
If we apply this same trick on a mobile device, it works as expected.
## Steps to view source code
1. Visit the website which you want to view it's source code.

2. Click inside the address bar and append `view-source:` before the url of the website.

3. Click the send button and the page will load with the source code of the file.

__NB:__ Even though I used Chrome's mobile browser, the method is the same in all the major browsers. | lubiah |
757,937 | Implementing Google OAuth to use Google API in Cloudflare Workers | Recently I had the opportunity to build a small application that needed to authenticate and authorize... | 0 | 2021-11-30T08:42:42 | https://apiumhub.com/tech-blog-barcelona/implementing-google-oauth-google-api-cloudflare-workers/ | agilewebandappdevelo | ---
title: Implementing Google OAuth to use Google API in Cloudflare Workers
published: true
date: 2021-07-12 22:41:23 UTC
tags: Agilewebandappdevelo
canonical_url: https://apiumhub.com/tech-blog-barcelona/implementing-google-oauth-google-api-cloudflare-workers/
---
Recently I had the opportunity to build a small application that needed to authenticate and authorize a user using Google’s sign-in mechanism, and requests on their behalf data from a Google API.
I choose to implement this as a Cloudflare Worker as a [serverless compute service](https://www.cloudflare.com/learning/serverless/what-is-serverless/) leveraging [Cloudflare key-value storage (KV)](https://developers.cloudflare.com/workers/learning/how-kv-works) for session storage. The tooling from Cloudflare ([`wrangler`](https://developers.cloudflare.com/workers/cli-wrangler)) has evolved nicely since my first attempt at Cloudflare Workers, so I thought it was a high time that I gave it another try.
As any good software engineer would, I started searching for any repository I could use a template to wire up Google OAuth easily. But I failed to find anything that would play nicely with Cloudflare Web worker, or had some proper documentation/tests, or had a decent quality to it. So in this blog post (and in the companion GitHub repository [jazcarate/cloudflare-worker-google-oauth](https://github.com/jazcarate/cloudflare-worker-google-oauth)), I want to document, explain and go over some interesting decisions so someone just like me would have this to springboard their development.
That being said, feel free to _yoink_ any or all of the code from the [repo](https://github.com/jazcarate/cloudflare-worker-google-oauth).
## Result
First of all, this is what we’ll develop: An app that can display and filter a user’s Drive files; and provide a link to them.

I choose Google’s Drive listing API as an excuse. Everything we’ll see from now on can be easily changed to use any of the [myriad of Google APIs](https://developers.google.com/workspace/products), as they all require roughly the same authentication and setup.
##
### Structure and Systems
To decouple the logic from external sources \*such as Google), the project is best understood as a slim entry point `index.ts`, the core business logic in the handling method (`handler.ts`), and every external dependency in the `lib/` folder.
The main interface from `handler.ts` is a function that [injects](https://en.wikipedia.org/wiki/Dependency_injection) all the systems
```
export default function (
kv: KVSystem,
google: GoogleSystem,
env: EnvSystem,
crypto: CryptoSystem,
): (event: FetchEvent) => Promise<Response> {
const { remove, get, save } = kv
const { tokenExchange, removeToken, listDriveFiles } = google
const { isLocal, now } = env
const { generateAuth } = crypto
//...
```
This not only helps separate concerns but allows us to mock external dependencies in the tests.
### Initial request
Once we have all systems initialized, we do match if the request is an `/auth` callback. We’ll come back to this section later. If the request is not a callback, then I check if the user is authenticated. There are several ways in which a user might not be.
Like if they don’t present any cookies.
```
const cookies = request.headers.get('Cookie')
if (!cookies) return login(env, google, url)
```
Or if they have cookies, but not the one we care (`auth`)
```
const auth = findCookie(AUTH_COOKIE, cookies)
if (!auth) return login(env, google, url)
```
Or the KV does not have an entry for that auth cookie (either because it has expired, or that the client is malicious and trying to guess)
```
const token = await get(auth)
if (!token) return login(env, google, url)
```
### Authenticated
After this point, I know that the user is authenticated. This means I have access to their `token` to query Google API.
So now I need to choose one of three paths:
1. f it is to the root (`/`)
2. If the request is to `/logout`
3. or any other path.
Of note, this is just the `pathname`, it does not include search params like `?q=foo`; so the URL `/?q=foo` `.pathname` is just `'/'`
```
switch (url.pathname) {
case '/': // ...
case '/logout': // ...
default: // ...
}
```
#### List files
If the request is to the root, then I query Google API with the `Authorization` token like the [API](https://developers.google.com/drive/api/v2/search-files) expects
```
async function listDriveFiles(
accessToken: string,
query: string | null,
): Promise<DriveFiles> {
const url = new URL('https://www.googleapis.com/drive/v2/files')
if (query) url.searchParams.append('q', `title contains '${query}'`)
const response = await fetch(url.toString(), {
headers: { Authorization: `Bearer ${accessToken}` },
})
/// ...
}
```
If the `fetch` returns something, I check the body for errors and panic if needed
```
const resp = await response.json()
if (resp.error) throw new Error(JSON.stringify(resp.error))
```
Once Google answers a list of files, then it is just a matter of rendering them. I decided to keep the rendering simple, and inline the whole HTML; but this can be easily adapted to return a JSON, or use a proper template engine. I’ll leave this as an exercise for the reader.
#### Logout
In the logout case, we revoke the token with google, we remove the auth from the KV and we reply to the client with a deleted cookie.
```
event.waitUntil(Promise.allSettled([removeToken(token), remove(auth)]))
return new Response('Loged out', {
headers: setCookie('deleted', EXPIRED),
})
```
I leverage the [`waitUntil`](https://developers.cloudflare.com/workers/learning/fetch-event-lifecycle#waituntil) lifecycle to respond to the client immediately, and call google and remove the KV in the background. And I use `allSettled` as I don’t particularly care if the KV couldn’t be deleted, or if Google had trouble removing the token as there is not much more I would be able to do.
#### Not found
Otherwise, I simply return a status `404 Not Found`.
```
return new Response('Not found', { status: 404 })
```
### Callback
Going back to the `/auth` request; this needs no authentication (as we are in the process of creating it). So I just check for the contract that [Google sign-in documents](https://developers.google.com/identity/protocols/oauth2/web-server#sample-oauth-2.0-server-response). The query params has no errors
```
const error = url.searchParams.get('error')
if (error !== null)
return new Response(`Google OAuth error: [${error}]`, { status: 400 })
```
And it has a `code`
```
const code = url.searchParams.get('code')
if (code === null)
return new Response(`Bad auth callback (no 'code')`, { status: 400 })
```
If so, we can exchange the code for a proper `token` via another Google API
```
const response = await fetch('https://oauth2.googleapis.com/token', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
body,
})
```
and again check for errors
```
const resp = await response.json()
if (resp.error) throw new Error(resp.error)
```
With a valid Google `access_token` in hand, we generate a random string for the application’s authentication
```
const newAuth = generateAuth()
```
And store in the KV the way to translate from `newAuth` to `access_token`
```
await save(
newAuth,
tokenResponse.access_token,
//...
)
```
Finally, we send the client back to wherever they came from, with their new authentication cookie. _We stored the original URL in the `state` param that Google OAuth allows us to send._
```
return redirect(
'/' + decodeURIComponent(url.searchParams.get('state') || ''),
setCookie(newAuth, new Date(expiration)),
)
```
## Other systems
The systems in the `lib/` folder are quite straightforward, and can be divided into two subgroups conceptually:
### Cloudflare enhanced dependencies
As this application is running in Cloudflare Workers (both the real environment in the cloud and the dev environment generated by `npm run dev`), some variables are injected into the global scope. These variables are typed in the `bindings.d.ts` file; and are generated by steps 2 and 3 from [README.md#Setup wrangler](https://github.com/jazcarate/cloudflare-worker-google-oauth#setup-wrangler).
- **KV** module uses the global `authTokens` variable that Cloudflare Worker injects into the worker. More information about how KV work can be found [here](https://developers.cloudflare.com/workers/learning/how-kv-works).
- **Env** module keeps the environment injectable. Even though we could use the global variables _(`CLIENT_ID` and `CLIENT_SECRET`)_ injected to the web worker, this approach allows me to test the `handler` without having to re-wire global variables; that is a pain.
### Utils
And some other systems that are not Cloudflare Worker dependant, but more like utility functions, grouped by their specific domain.
- **http** module has some utils to parse the Cookies header format and build a `302 Redirect` response.
- **Google** module has a types API using just `fetch`.
- **Crypto** module is a small utility to use the `crypto` API to generate a secure-random string.
If all this is too complicated; you can try out our Identity Management Solution – [VYou](https://www.vyou-app.com/) which was developed by [Apiumhub software developers](https://apiumhub.com/). | apium_hub |
757,962 | Using API Management Policies to enforce access restriction policies | This post was originally published on Tue, Jun 22, 2021 at cloudwithchris.com. We recently... | 13,616 | 2021-07-13T10:05:04 | https://www.cloudwithchris.com/blog/api-management-and-policies | api, azure, cloud, integration | **This post was originally published on Tue, Jun 22, 2021 at [cloudwithchris.com](https://www.cloudwithchris.com/blog/api-management-and-policies/).**
We [recently introduced you to API Management, how it maps to architectural principals and why you may consider using it as a producer or consumer of APIs](www.cloudwithchris.com/blog/introduction-to-api-management). In this post, we'll be continuing on the story - focusing mostly on the API Management policies functionality.
## An introduction to API Management Policies
Azure API Management Policies are a way to implement configuration which changes the behaviour of an API Operation or set of APIs. These policies are executed sequentially in either the request to or response from an API. Consider the API Management as a broker between the client and the API, acting a little like a gatekeeper. This means that policies have the potential to be used in a variety of scenarios, e.g. rate limiting, conversion from XML to JSON or validate a JSON Web Token (JWT), which is a common activity for Authentication/Authorization in modern web applications. In this blog post, I'm going to assume that you have a working understanding of these concepts (otherwise the blog post would become too large!)
Let's first navigate to the Azure Resource that we created in the previous blog post. You may notice from the below screenshot that it's in a different subscription. This is the same resource, though I have been doing a bit of tidying up of my Azure Subscriptions.
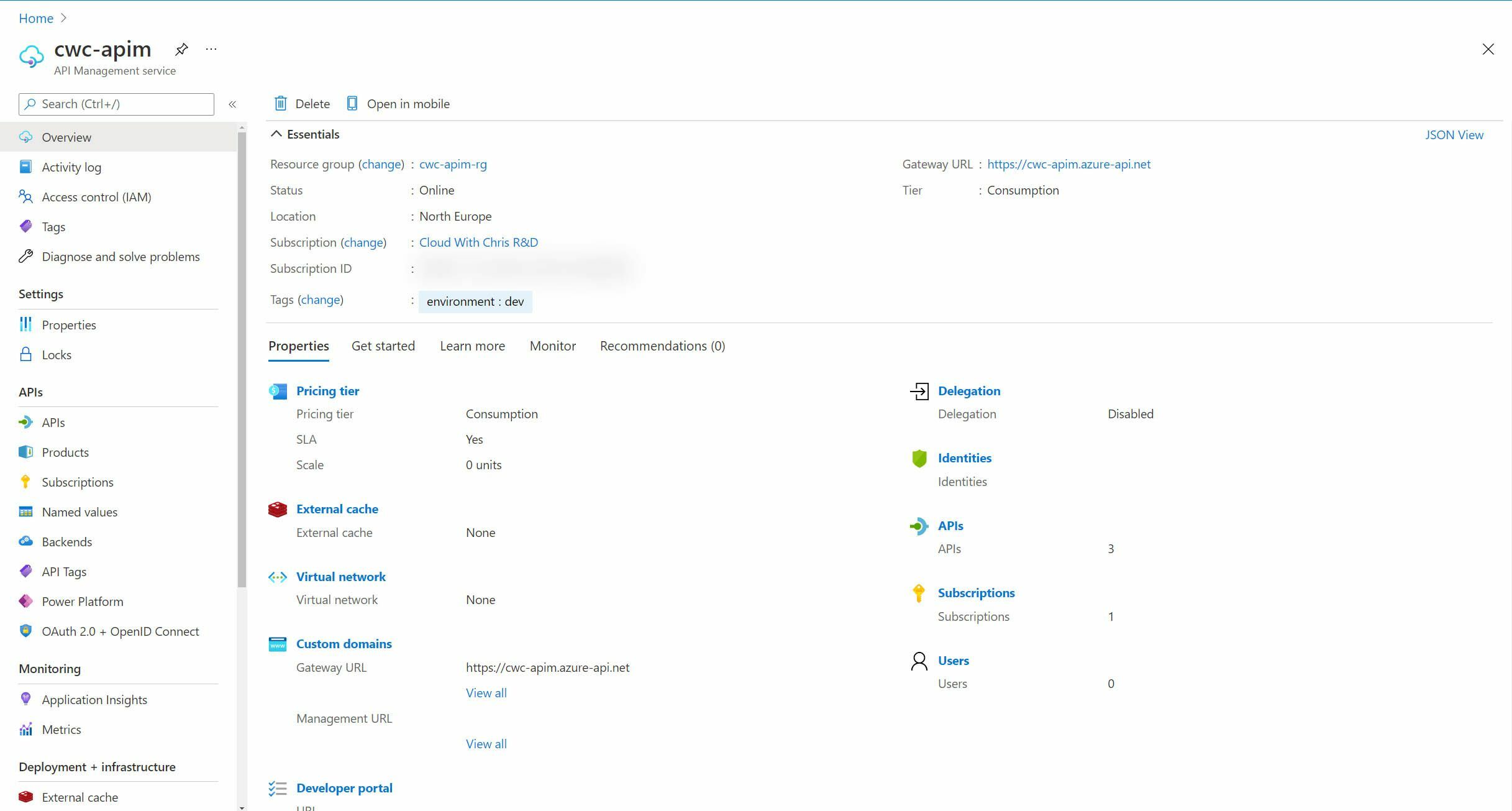
Click on the **APIs** menu item on the left hand menu in the Azure Portal. You'll be directed to a familiar looking page, that we reviewed in the first blog post.
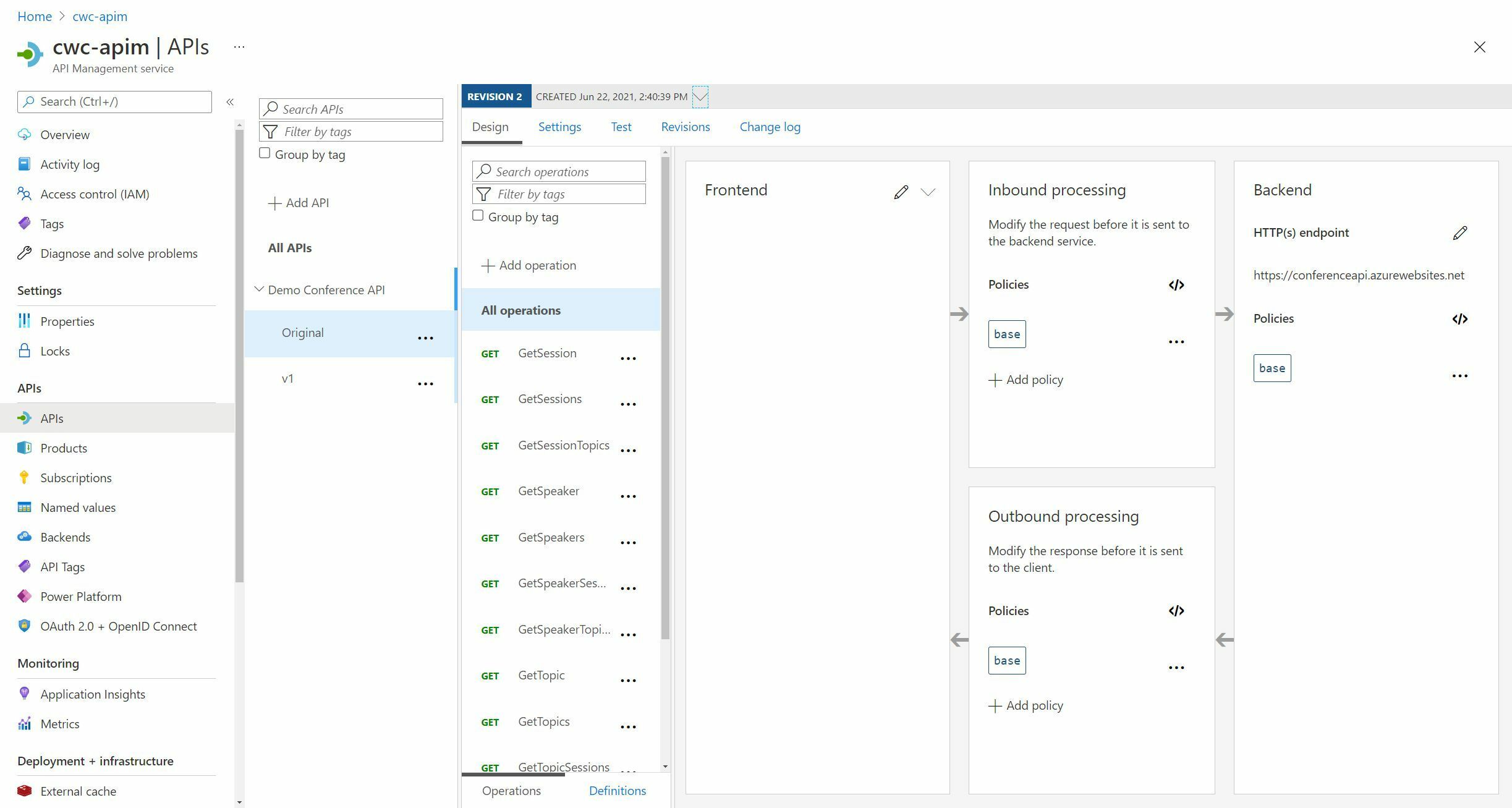
Let's draw our attention to the **Inbound Processing** and **Outbound Processing** areas of the page. This is where you define your API Management Policies. You can do that by either clicking the **Add policy** button (which will show you the user interface directly below the next tip), or you can edit the code directly using the **</>** button.
> **Tip:** This view is available at the **All operations** level, as well as each **individual operation**. You may also notice that there's an **All APIs** option in the left hand column as well, which presents you with the same view.
>
> Why is this important? You may want to set your API Management policies at different levels of scope -
>
> * **All APIs** - A global policy across your API Management Service instance
> * **All operations** - A policy which applies to **all** operations associated with a specific API.
> * **Individual operation** - A policy which applies to a specific API operation only.
>
> You can even apply policies to **Backends**, so that you can enforce certain requirements when communicating with your backend APIs (e.g. conversion from XML to JSON). You can also apply policies to the **Products** that you have configured within the API Management service. We won't be exploring this in the blog post, but do feel free to explore if you may have a valid use case (e.g. enforcing certain requirements based upon a product that a user has access to).
Each of these API Management policies are clearly documented, with a [reference available in the Azure Docs](https://docs.microsoft.com/en-us/azure/api-management/api-management-policies). The UI gives you a way to set policies without having to use the XML Code representation of the policies if preferred. However, the docs provide example snippets for a variety of scenarios to get you going very quickly.
As an example, you'll see that the above screenshot is the user interface to configure a JWT Validation Policy. The Azure Docs have a wealth of information on the [JWT Validation Policy](https://docs.microsoft.com/en-gb/azure/api-management/api-management-access-restriction-policies#ValidateJWT), including Simple token validation, Token validation with RSA certificate, Azure Active Directory (AAD) token validation, AAD B2C token validation and Authorize access to operations based on token claims.
I'm sure you'll agree - plenty to get you started with your scenario! So much so, that I used a slight variation of the Azure Active Directory (AAD) token validation snippet. My final snippet looked like this -
```xml
<validate-jwt header-name="Authorization" failed-validation-httpcode="401" failed-validation-error-message="Unauthorized. Access token is missing or invalid.">
<openid-config url="https://login.microsoftonline.com/cloudwithchris.com/.well-known/openid-configuration" />
<audiences>
<audience>d3414b61-53f8-4ad5-aa1d-1e2a15579f60</audience>
</audiences>
</validate-jwt>
```
What is the above policy doing? Effectively, we're looking for a JSON Web Token that has been provided by the cloudwithchris.com tenant in Azure Active Directory. That token must have an audience with the id ``d3414b61-53f8-4ad5-aa1d-1e2a15579f60``. This means that I have an App Registration in Azure Active Directory with the Client ID ``d3414b61-53f8-4ad5-aa1d-1e2a15579f60``. Of course, if you're working through this blog post from beginning to end - you may not have an App Registration.
Let's go ahead and do that now.
> **Tip:** If you're following this post in your own subscription with your own Azure Active Directory Tenant, you'll likely have the appropriate access to create an app registration within your subscription.
>
> However, if you're working on this within a corporate environment - It's possible and even likely that the creation/management of app registrations in Azure Active Directory is restricted to a subset of users. This is because App Registrations can be used... as the name implies... to register your applications to Azure Active Directory. What does that mean? It means you can pass in an identifier/representation to your application, so that you can call APIs that are available (e.g. Microsoft Graph, other Application APIs, etc.)
>
> This blog post is by no means a recommended or best practice way of setting up your App Registrations, but merely a demonstration of API Management Policies being used for JWT validation within your API Management service as a Façade, before reaching your backend APIs. If you're looking for something more rigorous, I would encourage you to review the Azure Docs relating to Azure Active Directory / Azure Active Directory B2C.
## Creating an App Registration in Azure Active Directory
Navigate to ``App Registrations`` in the Azure Portal. You can find this by either going to ``Azure Active Directory > App Registrations`` or by searching for ``App Registrations`` in the search bar at the top. Assuming that you have the appropriate access, create a new App Registration.
From the screenshot below, you can see that I gave my application a name of **cwc-apim-demo-api**. That relates to my own naming convention and works well for me, but name it something that makes sense for yourself.
You'll notice that there are four supported account types options -
* **Accounts in this organizational directory only** - Only allow users that are part of your tenant (e.g. cloudwithchris.com) to use the application
* **Accounts in any organizational directory** - Allow users that are part of any tenant Azure Active Directory (AAD) tenant
* **Accounts in any organizational directory and personal Microsoft Accounts** - Allow users that are part of any tenant Azure Active Directory (AAD) tenant or Microsoft Accounts (e.g. Skype, Xbox, non-corporate accounts)
* **Personal Microsoft Accounts Only** - Only allow accounts not associated with Azure Active Directory (AAD), but personal accounts (e.g. Skype, Xbox, non-corporate accounts)
For my purposes, I'll be using the first option. What if you need to allow users to access your applications through social identities (e.g. Facebook, Twitter, GitHub, etc.)? Then you may need to look through the differences of Azure Active Directory B2B and Azure Active Directory B2C. There's a [great Azure Doc available here](https://docs.microsoft.com/en-us/azure/active-directory/external-identities/compare-with-b2c#compare-external-identities-solutions) for you to review.
For the time being, we're assuming in this scenario that only users from the same Azure Active Directory (AAD) tenant are able to access the application.
> **Tip:** I'll only be creating a single app registration. However, if you had a user interface (e.g. Single Page Application), that interacted with multiple backend APIs, then it's likely you would have multiple app registrations. You would have a registration for the Single Page App (SPA) frontend, and separate app registrations for the custom-built APIs that you will be accessing. (I say custom-built, as there are built-in APIs available for access to Microsoft Services, such as the Microsoft Graph API).
>
> Then it's a case of exposing an API from the app registration that is associated to your backend API, and granting API permissions to the app registration that is aligned to your Single Page App. When you expose the API, you provide it a name (e.g. myapi.read). That is then the scope that you would pass in when you acquire the access token for the call. [This example](https://docs.microsoft.com/en-us/azure/active-directory/develop/scenario-spa-overview) shows how to do this for a Single Page Application calling the Microsoft Graph (so, not a custom API - which is the slight difference in what we described here).
>
> Why all of this complexity? Because, we don't necessarily want to grant one application access to all other applications. Likewise, as an organization - we may not want to grant admin consent to this, and in fact give this freedom of choice back to the end-user. Remember those dialogues when you use a social identity provider to login to a site? You're commonly told they'll access your User Name, E-Mail, etc.? This is the similar concept to consider with API permissions.
>
> If there is interest, I can write a blog post up on this topic. However, the purpose of this blog post is really to introduce the concept and power of API Management policies. This scenario could be a blog post in its own right.
Depending on the application, you may need to specify the redirect URI, so that the application knows where to redirect the user (and that this is matched up correctly in the application code, and not hijacked/spoofed along the way).
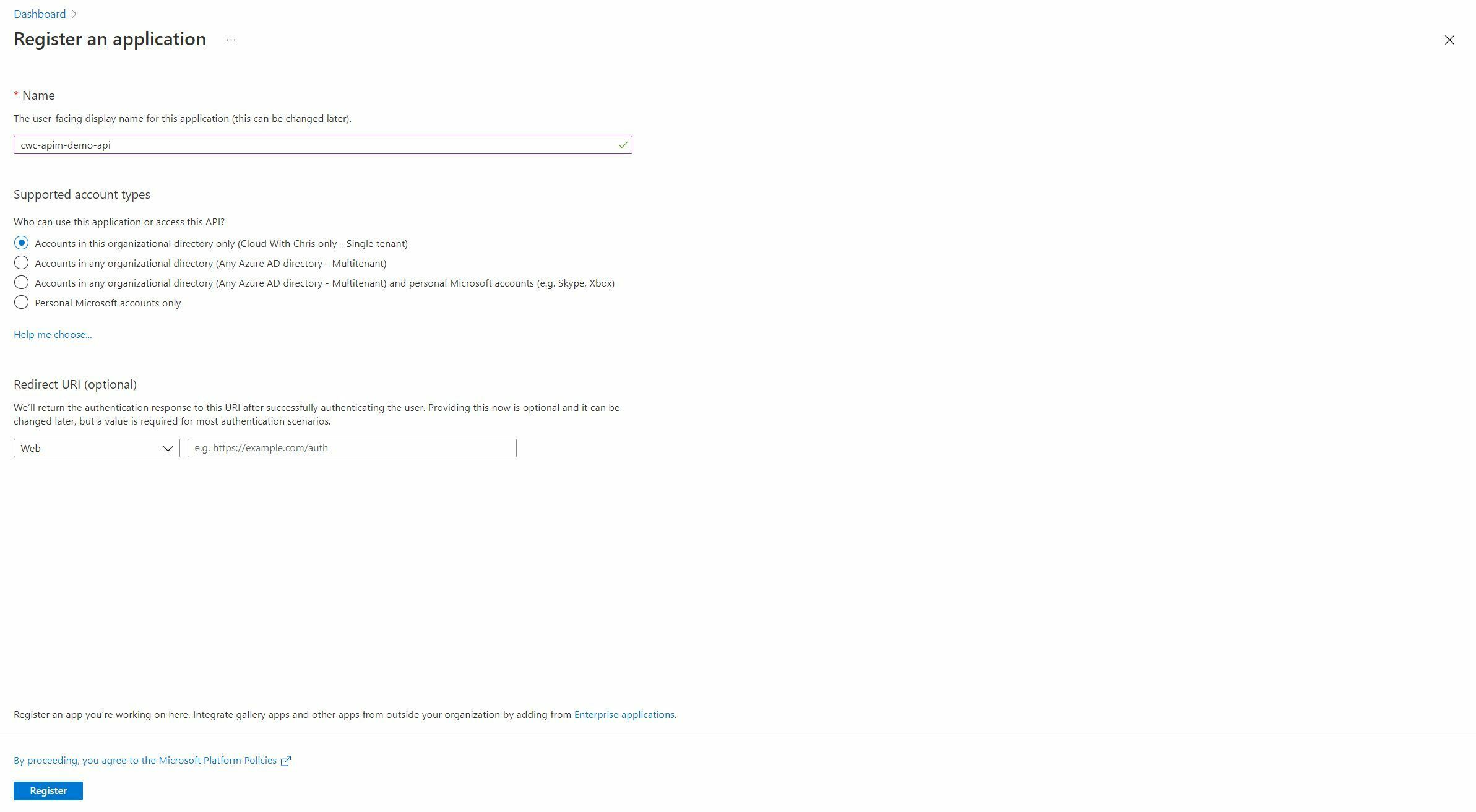
After creating your app registration, you should have a resource that looks similar to the below.
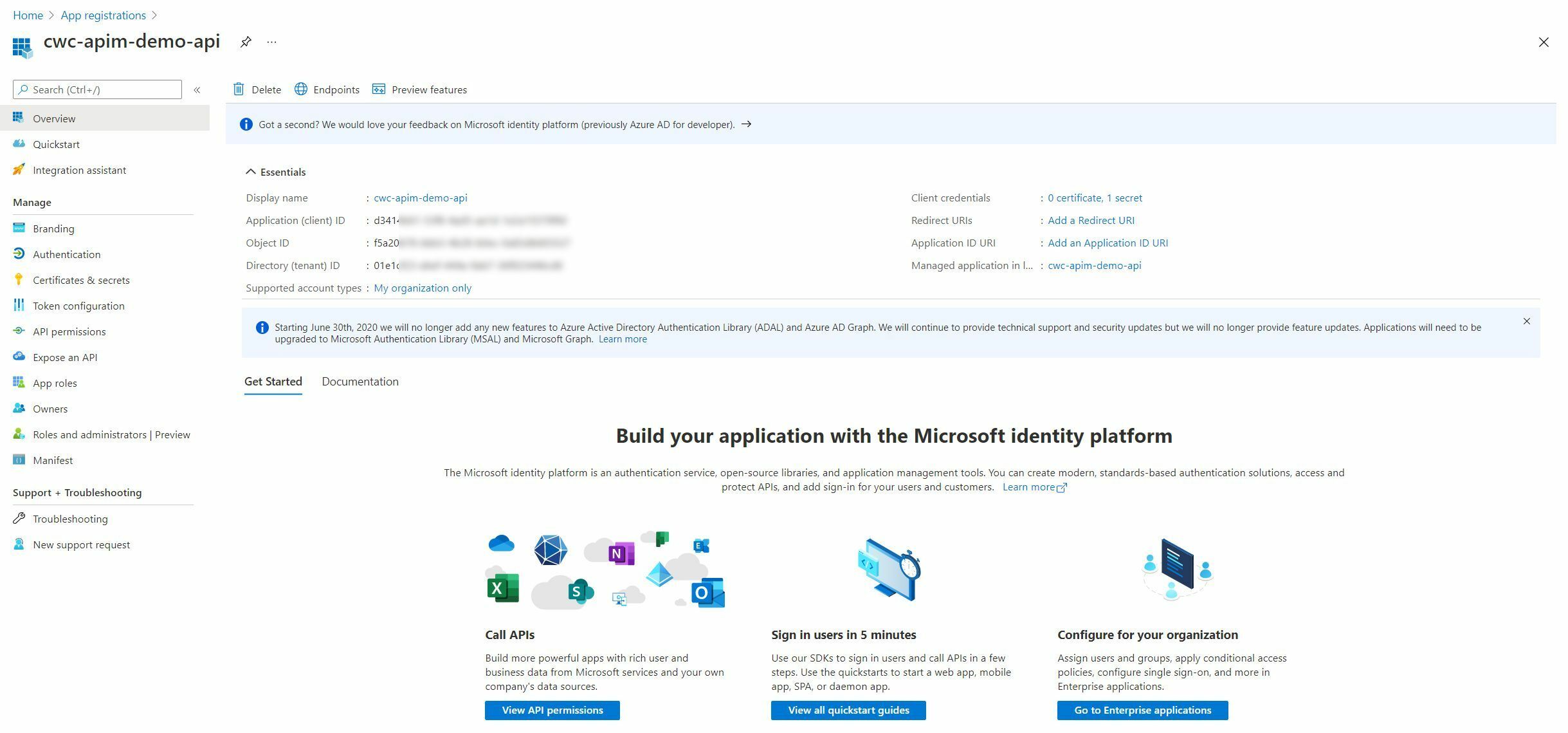
Purely to prove the purpose of API Management policies, I'm going to generate a Client Secret that we can use in postman to generate a *** to authenticate against API Management. In a real-world scenario, you may not need to create a client secret against this resource. At least, not for the calls from a client app (e.g. Single Page Application), as that access would be granted through API Permissions in the Client's App Registration. You may need to go ahead and use Client Secrets for authorization on the backend APIs though (more on that in the next blog post though!)
Navigate to the **Certificates & Secrets** menu item in your App Registration. Give the secret a meaningful name, and an appropriate duration according to your security policy.
> **Tip:** Speaking of security policy, you may notice that there's an option to upload certificates against this App Registration. Client Secrets are useful in proof of concept scenarios. Though ask yourself, how well do we typically store those passwords? How often do we rotate them? Could a certificate be more secure in this instance? For ease, I'll be obtaining my access token in postman by using a Client Secret, though you may want to consider this point in a production implementation. There's a great [stack exchange discussion](https://security.stackexchange.com/questions/3605/certificate-based-authentication-vs-username-and-password-authentication/3627#3627) on the same pros/cons of each.
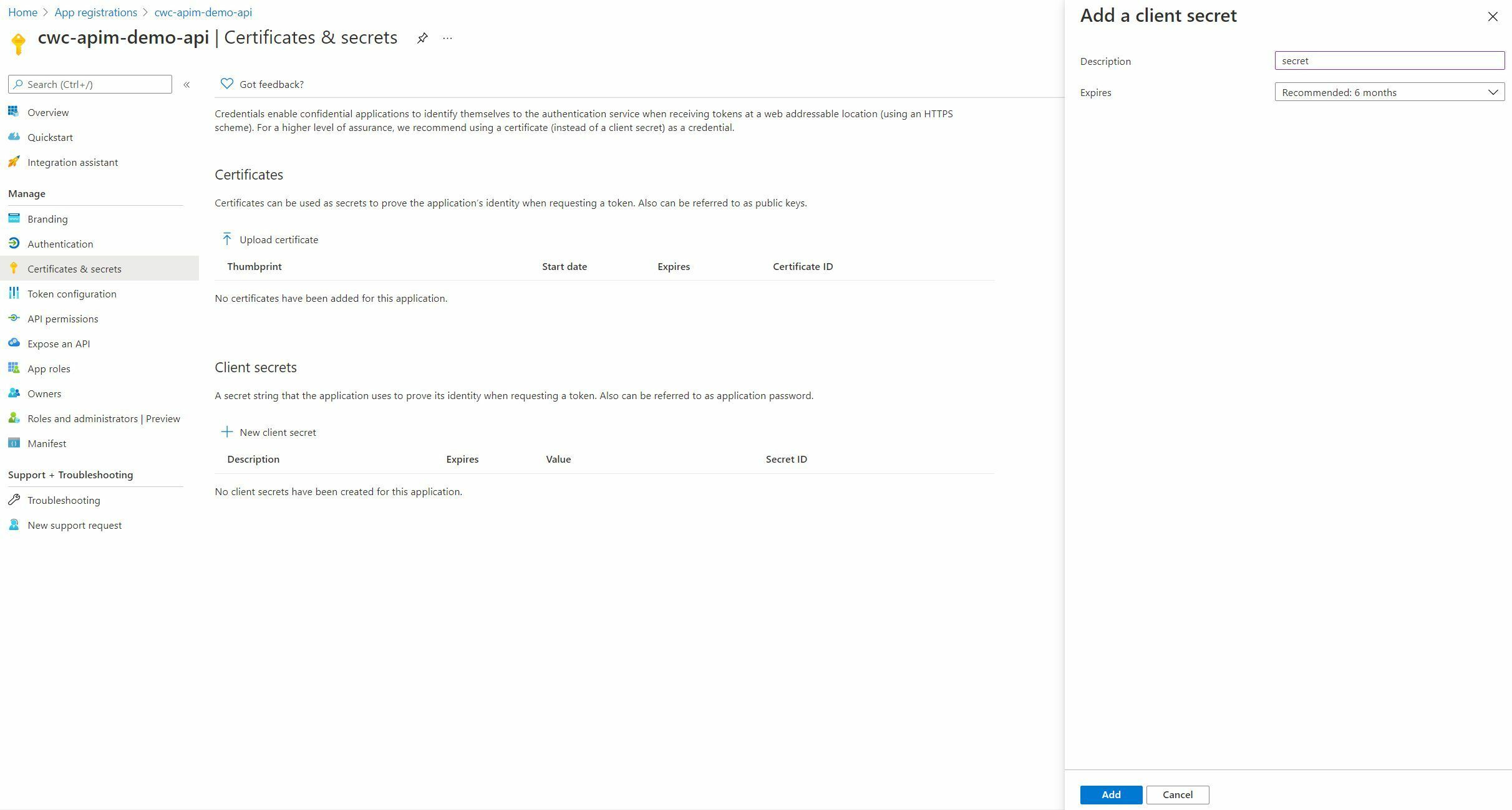
Once created, the Client Secret is now available that can be used in postman for the call to Azure Active Directory to obtain the access token.
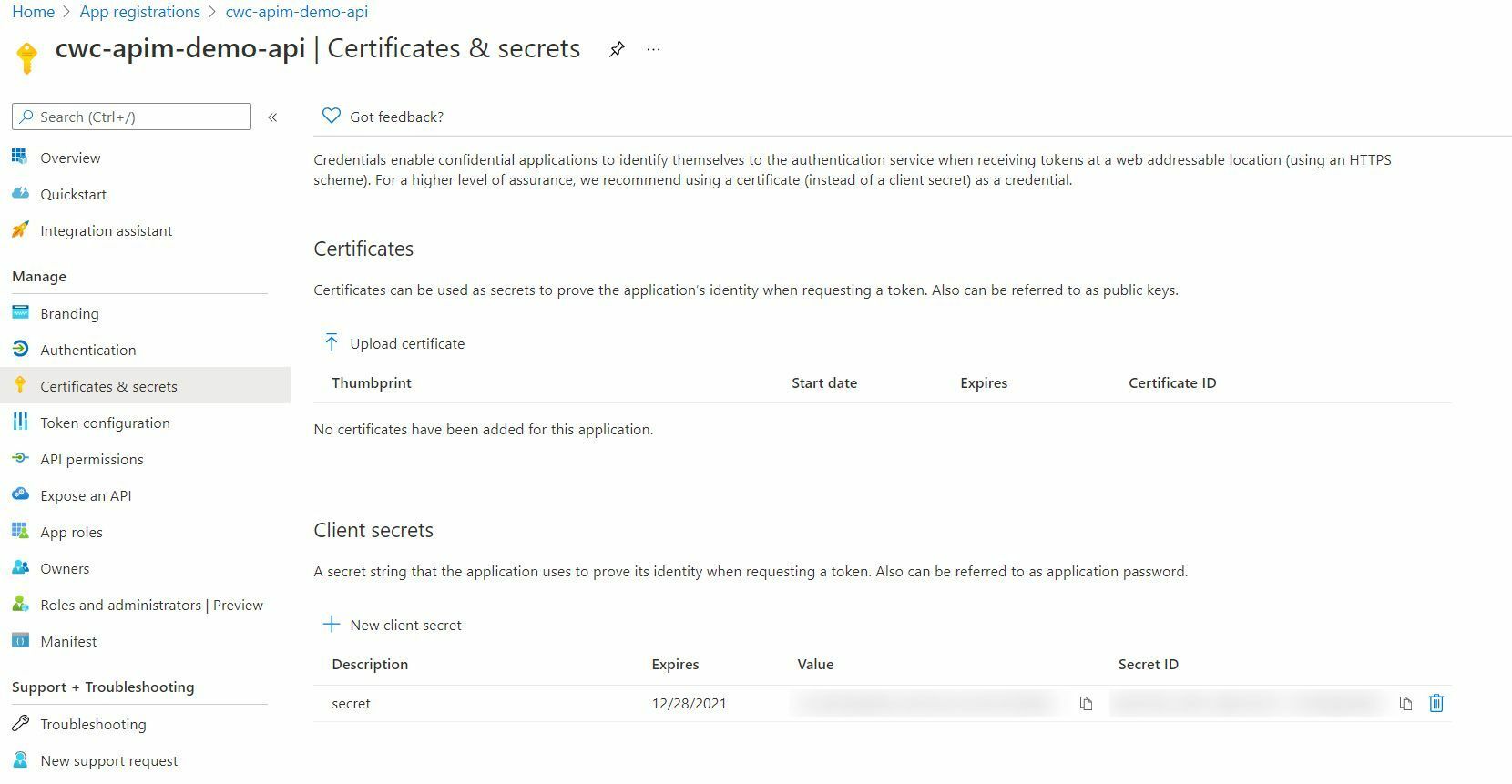
## Obtaining an Access Token
At this point, we have the details needed to obtain an Access Token from Azure Active Directory. This is not a flow that an end-user would typically use, as explained over in the [Azure Docs](https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-oauth2-client-creds-grant-flow). This is about enabling a web service (or confidential client) to use its own credentials when calling another web service. For the purposes of demonstration in this blog post, it allows us to easily generate a bearer token that can be used as part of our API Management demonstration.
> **Tip:** If you are new to identity, it's certainly worth reviewing the [OAuth 2.0 and OpenID Connect protocols](https://docs.microsoft.com/en-us/azure/active-directory/develop/active-directory-v2-protocols). It's important to understand the different type of flows, and which one makes the most sense in your scenario.
>
> For example, it was common for interactive user logins to use the [implicit grant flow](https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-oauth2-implicit-grant-flow). However, the strong recommendation is to use [authorization code flow](https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-oauth2-auth-code-flow), especially for Single Page Applications.
At this point, I have opened [Postman](https://www.postman.com/) so that I can call the token endpoint and receive the needed bearer token (In this case, I'm simulating a service. As a reminder, this is **not** what you would typically do in an end-user scenario).
I've set my postman request up with the following details:
* A **GET** request to ``https://login.microsoftonline.com/cloudwithchris.com/oauth2/v2.0/token``
* Added a **Content-Type** header with the value ``application/x-www-form-urlencoded``
* Added the following items as **form-data** to the **request body**:
* Set grant_type as client_credentials
* Set client_id as the Client ID from the app registration
* Set client_secret as the Client Secret from the app registration
* Set scope as the Client ID with ``/.default`` appended to the end, e.g. ``d3414b61-53f8-4ad5-aa1d-1e2a15579f60/.default``.
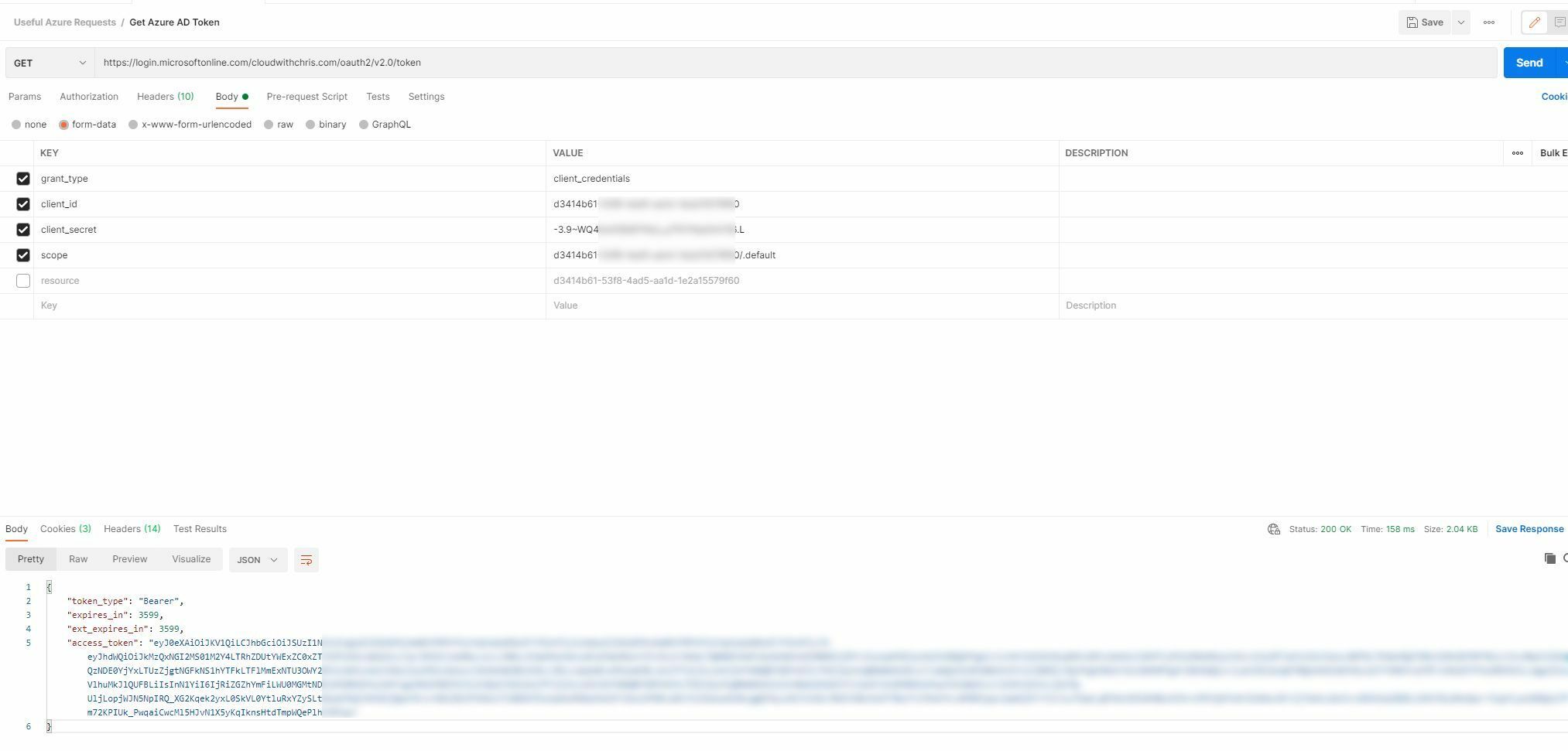
Once you execute the request, you'll hopefully receive an ``HTTP Status 200 OK`` response! This response contains a JSON object, with an access_token property - similar to the below.
```json
{
"token_type": "Bearer",
"expires_in": "3599",
"ext_expires_in": "3599",
"expires_on": "1624882328",
"not_before": "1624878428",
"resource": "d3414b61-53f8-4ad5-aa1d-1e2a15579f60",
"access_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiIsIng1dCI6Im5PbzNaRHJPRFhFSzFqS1doWHNsSFJfS1hFZyIsImtpZCI6Im5PbzNaRHJPRFhFSzFqS1doWHNsSFJfS1hFZyJ...A Load of extra characters here"
}
```
Copy the value associated with the ``access_token`` property key. You'll need this as we call our API Management resource.
> **Tip:** What is that long token value anyway? It's a JSON Web Token, and is a common transfer format to show a claims of a given entity, commonly used in OAuth workflows. You can actually look inside the contents of those files using tools like [jwt.ms/](https://jwt.ms/).
>
> Hopefully this comes as an obvious health warning. **Be careful** on where you share your *** The idea of ***** is **give access to the bearer of this token**. It comes from the same concept as a bearer cheque if you have heard of that previously. In which case, like any secrets - please don't share your *** openly!
Notice the GUID that is in the aud (audience) claim type? It's the same as what we configured in our API Management resource. So, if you're still following on - you've probably guessed - this token will allow us to make a request through Azure API Management.
## Calling the Secured API Operation in API Management
Now for the moment of truth. Let's navigate back to our Azure API Management service instance. Select one of the APIs which is in the scope of your API Management Policies.
> **Tip:** Remember that you can apply your API Management Policies at several levels -
>
> * **All APIs** - A global policy across your API Management Service instance
> * **All operations** - A policy which applies to **all** operations associated with a specific API.
> * **Individual operation** - A policy which applies to a specific API operation only.
I applied my policy at the **All operations** level of my **original** version API. Therefore, any operation that I request within that API version now has to have an appropriate JSON Web Token (JWT) to be called appropriately.
Let's prove this out. You can see in the below screenshot that I am calling my GetSessions API through the Test tab of API Management. This just returns a collection of sessions that are available within the conference. However, notice that we are not passing in any additional headers to the API. You'll see that the API returns with an ``HTTP 401 Unauthorized`` error, and a message of Unauthorized. Access token is missing or invalid.
Why did we get that error, and error message? I'll give you a hint... Take a look further up in the blog post. This is exactly what we're expecting to see, as this is what we configured in our API Management policy. Awesome!
Now, let's use that access token that we received in our request when we used Postman. Make the same API call, but this time specify the ``Authorization`` as a key in the headers. The value should be ``Bearer {AccessToken}``, where you'll replace ``{AccessToken}`` (including the curly braces, with your access token from earlier).
You should now see a result with ``HTTP Status Code 200 OK`` (or whatever is appropriate for your API, if you have used a different API!). Either way, you should no longer be receiving an ``HTTP 401 Unauthorized``. If you are, you may need to check if the access token that you have provided matches against the expected details in API Management.
> **Tip:** This is where things get interesting. You can use API Management to even inspect the claims inside of a JWT. Consider the scenario where certain APIs should only be accessible by certain groups of the business (e.g. IT or Finance). Or, consider the scenario where it should only be allowed by a certain role (e.g. Admin or Moderator). These are pieces of information (claims) that you could pass back within a JWT within your login/token request process (out of scope for this blog post), and used as part of your JWT validation step in the API Management Policy.
## But, what about the backend?
You may be thinking, at this point - this is all awesome. We've secured our API - we can call it a day! But consider one aspect. What is protecting our backend API? Right now, the backend API is publicly accessible by anybody, without any JWT validation required. It's **only** if the user goes through the API in API Management that a JWT token will be validated.
What does that mean? Well, you'll need to consider how you protect the backend API as well. I've seen a couple of ways -
* Use networking restrictions so that only the API Management resource can communicate to the backend API
* Check for a valid token on the backend API.
Which scenarios should you consider? Well, it depends! If you're restricting access to the backend to only the API Management, then you are inherently trusting everything that comes through the API Management resource.
* What happens if there is a misconfiguration of the API Management resource, which allows insecure traffic to the backend?
* Likewise, what happens if the networking rules are misconfigured, and in fact you're allowing **any** internal traffic to access the backend?
* Depending on your requirements, you may be okay with any internal traffic accessing the backend API. But what about a zero-trust model?
This is where you may also want to consider validating a token on the backend API. Typically it would be **the same** token as what we passed into API Management, as we don't want to lose the original user context. However, we could use API Management to pass a new token to the Backend API for verification. From chatting with a friend on this (Thanks Jelle!), this *could* be useful for a legacy API which is expecting app tokens, rather than end-user tokens. But, passing the end-user token to the backend as well is common.
Why use the same token in both APIM and the backend? How do you implement this? This is exactly what we'll be doing in the next blog post (considering zero trust / defence in depth), replacing our backend API with a different Azure Function and controlling the authorization.
## Wrap-up
There we go! That's been a fair amount to take in, hasn't it? We've walked through an example of Azure API Management Policies and how they may be able to help you secure your APIs. There are many other policies out there, both for inbound processing (requests) and outbound processing (responses). I highly encourage you to take a look through them all! Likewise, we haven't covered the OAuth Flows in significant depth, and assumed some initial understanding around OAuth and Identity more broadly. I'd encourage you to [look into the Microsoft Learn Modules available for Identity](https://docs.microsoft.com/en-us/learn/browse/?products=azure&terms=Identity&roles=developer).
But - we know there's still more that we can do to protect our backend APIs (as we eluded to in the above section). That's exactly what we'll be looking into in the next post in this series. So that's it for this blog post! I hope it's been useful, and that you've enjoyed reading. As always, feedback is appreciated. I'd love to hear how you plan on using Azure API Management policies (or even, already are!) as part of your own Azure Application Deployments. Let me know over on [Twitter, @reddobowen](https://twitter.com/reddobowen).
Otherwise, until the next post - Thank you for watching, and bye for now! | reddobowen |
757,980 | Building an App Like TikTok: The Ultimate Tech Stack | Did you know that TikTok is not the only video editing app that attracts millions of users? Such... | 0 | 2021-07-13T10:35:18 | https://dev.to/mariiayuskevych/building-an-app-like-tiktok-the-ultimate-tech-stack-3egc | mobile, design, android, ios | Did you know that TikTok is not the only video editing app that attracts millions of users? Such applications as Likee or Byte are now becoming powerful TikTok’s competitors. Additionally, more and more similar solutions are getting popular each month.
So, yes, now is a great time to roll out your own video editing and sharing app. How can you do that? We talked about all steps in great detail in [this article](https://perpet.io/blog/how-to-make-an-app-like-tiktok-essential-steps-and-top-features/). As for now, let’s focus on the essential aspect of the app development process: choosing all the right tools.
## Developing for the platforms
The first step of developing any kind of app is to decide which market to target: iOS, Android, or maybe both. Depending on this decision, your tech stack will vary.
If you go for an iOS app, a Swift or Objective-C developer has to be on the team. At the same time, you can choose between Kotlin, Java, or C# for an Android app. Of course, there are more languages for each platform, but those are the most widely used ones.
If you go for both iOS and Android apps, there is one more option: cross-platfrom development. Frameworks like Flutter or React Native allow building one application for both platforms, which, of course, saves you time and budget.
## Database management
Now, let’s move on to the backend part of our app. TikTok-like apps usually contain quite a lot of information, especially when it comes to user data. All of this has to be organized and managed correctly, so you can retrieve any info when needed.
There are many database management solutions; the most commonly used options are MySQL and MongoDB.
## Cloud integration
It is hard to imagine any mobile app without cloud integration, especially when it comes to solutions that rely heavily on content sharing. Cloud is a must for an application similar to TikTok — it helps users edit videos and see the changes right away as well as upload their content. All the videos also need to be stored somewhere to make them easily accessible on the app.
As for the cloud providers, you might consider AWS, Azure, and Google Cloud Platform as good options.
## AR filters
All those video effects and filters are probably the main reason why so many people start using TikTok and similar apps in the first place. It is important to have a good selection of the augmented reality filters as well as allow your users to create some on their own.
To make all of this possible, you need to add AR integration to your to-do list. The tool choice depends on your platform; for instance, ARCore is Google’s SDK (software development kit) for Android devices, while ARKit is the one created for iOS.
## Real-time analytics
One more aspect to take care of is the in-app analytics. Clearly, you need to understand what kind of interactions your users are engaged in and which features they like the most.
To do that, your development team has to integrate some real-time analytics tools, for example, Azure Stream Analytics or Google Analytics.
## Adding the chat feature
Finally, let’s not forget about messaging — it is an essential part of your video editing and sharing app. Users should have the possibility to send each other messages and exchange content. There are many live chat tools available on the market, such as Twilio or Agora.
## Is there anything else?
Of course, there are some more tools you would want to use to create an excellent TikTok-like app. For instance, you would also need to work on notification management or geolocation integration. It all depends on how complex you want your app to be.
Remember that getting an app similar to TikTok is not as complicated as it might seem, especially if you find a reliable team to trust with the task.
Have some more questions? In our [recent blog post](https://perpet.io/blog/how-to-make-an-app-like-tiktok-essential-steps-and-top-features/), we discussed each aspect of building a video editing and sharing app just like TikTok — give it a read! | mariiayuskevych |
758,080 | Top 10 DevOps Online Courses and Certifications [2021 July] | DevOps aims to create agile and scalable systems that foster a culture of collaborative software... | 13,618 | 2021-07-13T11:48:26 | https://techstudyonline.com/10-best-devops-courses-and-certifications-you-can-do-online-free/ | DevOps aims to create agile and scalable systems that foster a culture of collaborative software development. These purpose-built systems assist development teams – from the initial brainstorming phase through to actual deployment on the network. With recent security concerns, continuous security is now part of the DevOps evolution.
DevOps professionals are in huge demand, and that is why our team has compiled a list of top 10 courses and certifications, most of which can be done online for free!
<strong>Disclaimer</strong>: We may receive affiliate compensation for some of the links below at no cost to you.
<!-- wp:heading {"level":3} -->
<h3 id="1-1--professional-certificate-in-introduction-to-devops-practices-and-tools-by-edx-">1. <a href="https://www.edx.org/professional-certificate/linuxfoundationx-introduction-to-devops-practices-and-tools" target="_blank" rel="noreferrer noopener">Professional Certificate in Introduction to DevOps: Practices and Tools by edX</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">First on our list is the DevOps Practices and Tools Professional Certificate program is addressed to developers and IT operators exploring new approaches for building software, professionals focused on site reliability and quality assurance, and anyone involved in the software delivery process.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">You will start by learning how DevOps is influencing software delivery, how cloud computing has enabled organizations to rapidly build and deploy products, new features and expand capacity, how the open container ecosystem, with Docker and Kubernetes in the lead, what and how of writing Infrastructure as Code (IaC).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">You will also learn about Continuous Integration and Continuous Delivery (CI/CD), what a deployment pipeline looks like, the role played by observability systems, role that Jenkins plays in the software development lifecycle (SDLC), how to install a Jenkins server, how to build software for it, how to manage third party integrations/plugins and how to scale and secure Jenkins, and how to build serverless functions that can run on any cloud, without being restricted by limits on the execution duration, languages available, or the size of your code.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">The instructors for the course are Gourav Shah, Devops Trainer, Author and Consultant at School of Devops with 15 years of training experience with organizations like Adobe, Visa, Walmart Labs, Cisco, Mercedes, Dreamworks, Intuit, RBS, Accenture, Oracle, and so on. Along with Alex Ellis, a CNCF Ambassador and the Founder of OpenFaaS and inlets; and Deepika Gautam, an author, speaker, trainer, and DevOps evangelist with almost two decades of experience in the software industry.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>Experts from LinuxFoundationX</li><li>3 skill building courses</li><li>Flexible schedules</li><li>Almost 90 hours of online learning</li><li>Industry recognized certificate</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="2-2--professional-certificate-in-devops-foundations-software-development-optimization-by-edx-">2. <a href="https://www.edx.org/professional-certificate/anahuacx-devops-foundations" target="_blank" rel="noreferrer noopener">Professional Certificate in DevOps Foundations: Software Development Optimization by edX</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">Next on our list is this course to Improve software development processes with state-of-the-art continuous integration and delivery technologies to stand out in the industry.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This program will teach you about security to minimize risks in development and deployment with state-of-the-art tools (Linux, Jenkins, Puppet, Ansible, Terraform and more) to, reduce the time to launch and deliver products, assuring greater quality and reliability in software businesses, which in turn, promotes productivity, costs reduction and a higher launch rate thanks to the processes automation these tools provide.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This program has been authored by Anahuac and Holberton, bringing together two Education leaders in Latin America and the USA. Instructed by Miguel A. Guirao Aguilera, Mtro. Universidad Anáhuac Mayab; Eduardo Rodríguez del Angel, Doctorate in Computer Science at Universidades Anáhuac; and Sylvain Kalache, Co-founder at Holberton and previously Senior Site Reliability Engineer at LinkedIn Holberton School.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>Experts from Universidades Anáhuac</li><li>2 skill building courses</li><li>Flexible schedules</li><li>60+ hours of online learning</li><li>Industry recognized certificate</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="3-3--continuous-delivery-amp-devops-by-coursera-">3. <a href="https://www.coursera.org/learn/uva-darden-continous-delivery-devops" target="_blank" rel="noreferrer noopener">Continuous Delivery & DevOps by Coursera</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This course, developed at the Darden School of Business at the University of Virginia and taught by top-ranked faculty, will provide you with the interdisciplinary skill set to cultivate a continuous deployment capability in your organization.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">You will learn about how to diagnose a team’s delivery pipeline and bring forward prioritized recommendations to improve it, the skill sets and roles involved in DevOps and how they contribute toward a continuous delivery capability, how to review and deliver automation tests across the development stack, and how to facilitate prioritized, iterative team progress on improving a delivery pipeline.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">Alex Cowan will be the instructor for this course. Alex was an entrepreneur, starting and selling two companies. He’s currently on the faculty at UVA Darden where he focuses on digital innovation. He’s also advises corporations and invests in digital ventures. His Venture Design framework is widely used by practitioners and instructors for creating new products in agile, hypothesis-driven environments.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">With a rating of 4.64 out of 5, Alex has taught over 327,000 students and can help you kickstart your career in DevOps too!</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>36% learners started a new career after completing these courses</li><li>22% got a tangible career benefit from this course</li><li>Shareable Certificate</li><li>Flexible schedules</li><li>Subtitles available in Arabic, French, Portuguese (European), Italian, Vietnamese, German, Russian, English, Spanish</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="4-4--cloud-devops-engineer-professional-certificate-by-coursera-">4. <a href="https://www.coursera.org/professional-certificates/sre-devops-engineer-google-cloud" target="_blank" rel="noreferrer noopener">Cloud DevOps Engineer Professional Certificate by Coursera</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">With a super high rating of 4.8 out of 5, advance your career as a SRE and DevOps Engineer with this certification from Google Cloud Training who have trained more than 1.6 million learners on Coursera.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">Learn the skills needed to be successful in a cloud DevOps engineering role, Prepare for the Google Cloud Professional Cloud DevOps Engineer certification exam, Techniques for monitoring, troubleshooting, and improving infrastructure and application performance in Google Cloud guided by principles of SRE, Understand the purpose and intent of the Professional Cloud DevOps Engineer certification and its relationship to other Google Cloud certifications in this course that has been taken by over 16000 learners.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This professional certificate incorporates hands-on labs using our Qwiklabs platform. Projects will incorporate topics such as Google Cloud Platform products, which are used and configured within Qwiklabs. You can expect to gain practical hands-on experience with the concepts explained throughout the modules.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>30% learners started a new career after completing these courses</li><li>23% got a tangible career benefit from this course</li><li>Shareable Certificate</li><li>Flexible schedules for 65 hours of online learning</li><li>Subtitles available in English, French, German, Russian, Spanish, Japanese, Portuguese (European)</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="5-5--terraform-on-aws-with-sre-amp-iac-devops-by-udemy-">5. <a href="https://www.udemy.com/course/terraform-on-aws-with-sre-iac-devops-real-world-demos/" target="_blank" rel="noreferrer noopener">Terraform on AWS with SRE & IaC DevOps by Udemy</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">Next on our list is this bestseller course on Udemy from Kalyan Reddy Daida, an Architect with 15 Years of experience in designing complex Infrastructure solutions, Java programming and design with major payroll clients across the world.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This DevOps course has 4.8 out of 5 rating and covers 22 modules with real world demos. You will also have 20 lessons on <a href="https://techstudyonline.com/10-best-aws-courses-and-certifications-you-can-do-online-free/" target="_blank" rel="noreferrer noopener">AWS</a> Services and 37 lessons on Terraform concepts. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">You will learn about Terraform in a Real-world perspective with 22 demos, build AWS VPC 3-Tier Architecture, Load balancers CLB, ALB and NLB, DNS to DB Architecture on AWS, Autoscaling with Launch Configuration, Autoscaling with Launch Templates, AWS CloudWatch Alarms, implement IaC DevOps usecase using AWS CodePipeline for your Terraform Configurations, learn about Terrafrom State, Local and Remote Backends, learn and implement all Terraform Provisioners, and Terraform Modules with 2 types (Public Modules and Local Modules).</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">If this is the career choice for you, check out our pick on Udemy that will give you amazing Hands-on Step by Step Learning Experiences.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>22 hours on-demand video and 5 articles</li><li>Full lifetime access</li><li>Real Implementation Experience</li><li>Certificate of completion</li><li>30 Day "No Questions Asked" Money Back Guarantee!</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="6-6--devops-masterclass-git-docker-jenkins-kubernetes-terraform-by-udemy-">6. <a href="https://www.udemy.com/course/devops-training/" target="_blank" rel="noreferrer noopener">DevOps MasterClass: GIT Docker Jenkins Kubernetes Terraform by Udemy</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This is One of the Finest & Multi-Technology DevOps Certification Course On Udemy with 20000 DevOps Certified Engineers with DevOps Specialization.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">The instructor LevelUp360 DevOps team in this DevOps training course focuses heavily on the use of Docker containers, GIT & GitHub, Jenkins Kubernetes & Docker Swarm a technology that is revolutionizing the way apps are deployed in the cloud today and is a critical skillset to master in the cloud age.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">What you will get is an understanding of DevOps and the modern DevOps Tools Docker, Kubernetes, Jenkins, Docker Swarm, Kubernetes Helm, ability as DevOps Engineer to Automate Code Delivery and Deployment Pipeline Using Jenkins, Docker Containers & Docker Swarm Orchestration & Kubernetes, learn Building the Apps Dockerize using Docker Containers and Docker File & HELM as DevOps Engineer, Kubernetes Development and Complete Deployment on Kubernetes & Docker Containers, and Jenkins Multiple Integration with Modern Technology Tools like Docker, Code Delivery Pipeline, Git & GitHub .</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This DevOps Certification Training Course with 62 sections and 359 lectures will prepare you for a career in DevOps, the fast-growing field that bridges the gap between software developers and operations.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>53+ hours on-demand video</li><li>48 articles and 356 downloadable resources</li><li>Real Implementation Experience</li><li>Certificate of completion</li><li>30 Day Money Back Guarantee!</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="7-7--aws-certified-devops-engineer-professional-2021---hands-on-by-udemy-">7. <a href="https://www.udemy.com/course/aws-certified-devops-engineer-professional-hands-on/" target="_blank" rel="noreferrer noopener">AWS Certified DevOps Engineer Professional 2021 - Hands on by Udemy</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">With this bestseller course on Udemy, pass the AWS Certified DevOps Engineer Professional Certification (DOP-C01) with 20 hours of advanced hands-on videos.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This course is entirely hands-on to provide you with the experience needed to understand, analyze and solve the questions asked at the AWS Certified DevOps Engineer Professional exam. The only thing you should hold is an associate-level certification in AWS (AWS Certified Developer Associate is preferred) and experience using AWS at your work.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">Stephane Maarek, your instructor in this course is an AWS Certified DevOps Engineer Professional, AWS Certified Solutions Architect, AWS Certified Developer, AWS Certified SysOps, AWS Certified Big Data, and the author of highly-rated & best-selling courses on AWS Lambda, AWS CloudFormation & AWS EC2. He has already taught 879,000+ students and received 280,000+ reviews that give him a 4.7star rating.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">The course has 8 sections and 225 lectures.. all downloadable as an PDF!</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>20+ hours on-demand video</li><li>14 articles and 1 downloadable resource (all slides as one PDF)</li><li>Real Implementation Experience with 1 practice test</li><li>Certificate of completion</li><li>30 Day Money Back Guarantee!</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="8-8--devops-leaning-path-by-pluralsight-">8. <a href="https://www.pluralsight.com/paths/understanding-devops" target="_blank" rel="noreferrer noopener">DevOps Learning path by Pluralsight</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This learning path on Pluralsight gets it’s place in our Top 10 list because it covers the whole spectrum from Beginners to Intermediate and Advance level.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">There are no prerequisites for this path and you will learn about the philosophy behind DevOps, implementing DevOps, AgilePM Project Management,Test-driven Development, Continuous Integration and Continuous Delivery, Automation and Orchestration, Infrastructure from Code, and Testing Automation.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">The instructions for the DevOps Learning path come from 7 industry and subject matter experts - Richard Seroter, Paul Bradley, Jason Olson, Barry Luijbregts, Josh Duffney , Jason Helmick, Jason Roberts, David Clinton; who will take you through the basics of DevOps to learn about AgilePM®, test-driven development, and continuous integration and continuous delivery in intermediate section, and finally, orchestration and automation, infrastructure from code, and testing automation in the advanced level.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>Courses authored by industry experts</li><li>Trusted by 70% of the Fortune 500 companies</li><li>Certificate of completion</li><li>Flexible schedule</li><li>10-days free trial</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="9-9--post-graduate-program-in-devops-by-simplilearn-">9. <a href="https://www.simplilearn.com/pgp-devops-certification-training-course">Post Graduate Program in DevOps by Simplilearn</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">This professional DevOps course, designed in collaboration with Caltech CTME, prepares you for a career in DevOps, bridging the gap between software developers and operations teams.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">You can fast track your career in the DevOps field with this DevOps certification training course via a comprehensive curriculum covering the concepts of DevOps, Git, and GitHub, CI/CD with Jenkins, configuration management, Docker, Kubernetes, and much more. Kickstart your DevOps journey with our preparatory courses: Linux Training, Programming Refresher, Agile Scrum Foundation, Agile Scrum Master.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">The Program Director Dr. Rick Hefner has over 40 years of experience in systems development and has served in academic, industrial, and research positions. He will be supported by Matthew Dartez, who teaches at Caltech CTME, specializing in software and systems engineering, DevOps adoption, process automation, and cloud-based implementations; and Eugene Lai is an innovator in Information Technology and process engineering with over 20 years of experience in leading DevOps teams.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">You will also have a capstone Project and choice of electives to pursue!</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>Caltech CTME Post Graduate Certificate and Circle membership</li><li>Receive upto 25 CEUs from Caltech CTME upon course completion</li><li>250+ hours of Applied Learning</li><li>20+ real-life projects on integrated labs and Capstone project in 3 domains</li><li>Enrolment in Simplilearn’s JobAssist</li></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 id="10-10--free-devops-course-by-linkedin-learning-">10. <a href="https://www.linkedin.com/learning/devops-foundations/development-and-operations-2">Free DevOps Course by LinkedIn Learning</a></h3>
<!-- /wp:heading -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">Last on our list is this beginner’s course by LinkedIn Learning that you can do in one go as it will just take less than 3 hours to complete!</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">In this course, well-known DevOps practitioners Ernest Mueller and James Wickett provide an overview of the DevOps movement, focusing on the core value of CAMS (culture, automation, measurement, and sharing). They cover the various methodologies and tools an organization can adopt to transition into DevOps, looking at both agile and lean project management principles and how old-school principles like ITIL, ITSM, and SDLC fit within DevOps.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size">With more than 256,000 enrolments in this DevOps Course, this is last but not the least on our top 10 choices for DevOps courses and certifications.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"fontSize":"medium"} -->
<p class="has-medium-font-size"><strong>Top 5 reasons we love this course</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"fontSize":"medium"} -->
<ul class="has-medium-font-size"><li>Industry recognized certification</li><li>Crash course in less than 3 hours</li><li>Covers beginners foundational learning</li><li>Interactive quizzes to test skills</li><li>Free 1-month trial</li></ul>
<!-- /wp:list --> | techstudyonline | |
758,126 | Coding Standards and Best Practices for Python Code Quality | In this testing tutorial, you’ll read about the best Python unit test frameworks to test and correct... | 0 | 2021-07-13T12:33:44 | https://www.zenesys.com/blog/unit-testing-frameworks-in-python | python, codequality, codingstandards | In this testing tutorial, you’ll read about the best [Python] (https://www.zenesys.com/blog/coding-standards-and-best-practices-for-python-code-quality) unit test frameworks to test and correct individual units of code thus helping in overall test automation.
As the name indicates, Unit testing is a software testing method meant for testing small units of code. These are typically small, automated pieces of code written by software developers to check and ensure that the particular piece of code only behaves the way it was intended to. In python, there are several frameworks available for this purpose and here we will discuss the major “python test automation frameworks”.
##Best Python Unit Test Frameworks:
###1. Unittest:
It was inspired by the Junit, a Unit Testing framework of Java programming language and if you are coming from the java background, you get hold of it easily. It is a default testing framework of [Python](https://www.zenesys.com/web-development-services/python-web-development), and that’s why most developers use it for python test automation.
An example of code with this framework is as follows:
import unittest2 standard_library_import_a
text = ‘unit testing in python
class TestString(unittest2.TestCase):
def test_string_uppercase(self):
self.assertEqual(text.upper(),‘UNIT TESTING IN PYTHON’)
import third_party_import_c
def test_string_isupper(self):
self.assertTrue(‘UNIT TESTING IN PYTHON’.isupper())
self.assertFalse(‘unit testing in python’.isupper())
def test_string_split(self):
self.assertEqual(text.split(),[‘unit’, ‘testing’, ‘in’, ‘python’])
How to Discover Tests:
>> cd project_folder
>> python -m unittest discover
####Skipping test cases:
Unittest allows test cases to be skipped if certain conditions are not met by using the skip() decorator.
For Example:-
@unittest2.skip(“An example of Skipping”)
def test_nothing(self):
pass
@unittest2.skipUnless(sys.platform.startswith(“win”), “Windows Platform needed”)
def test_windows_support(self):
A specific windows only code
pass
Unittest offers simple test execution and faster report generation. One more important plus point for this module is that it is a part of the Python standard library and hence no extra efforts needed to install it. There are also certain drawbacks like it uses camelCase convention instead of snake case convention of Python
###2. PyTest:
Pytest is an open-source library and pip is needed to install this. In comparison to unittest, PyTest makes the testing simple and easy with less coding. It is a general-purpose python unit test framework but used especially for functional and API testing.
Instead of several assert statements, a simple assert method is used in Pytest to reduce confusion and keep the text easy.
Here is an example:
def test_uppercase():
assert “pytest example”.upper() == “PYTEST EXAMPLE”
def test_reversed_list():
assert list(reversed([‘a’, ‘b’, ‘c’, ‘d’]))== [‘d’, ‘c’, ‘b’, ‘a’]
def test_odd_number():
assert 13 in{
num
for num in range(1, 100)
if num % 2 == 1
}
Upon running the above code, the output looks like:
$ pytest
================= test session starts ==================
platform linux — Python 3.8.5, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: /home/abhinav/PycharmProjects/python_testing_framework/test_code
collected 3 items
test_code.py … [100%]
================== 3 passed in 0.02s =====================
Fixtures in Pytest:
Fixtures are used when to provide a consistent reliable input context for the tests. In Pytests, fixtures are made by a function syntax by a decorator usually, as shown in the example below.
For Example:-
@pytest.fixture
def number():
a = 10
b = 20
c = 30
return [a, b, c]
def test_method1(number):
x = 10
assert number[0] == x
def test_method2(number):
y = 15
assert number[1] == y
def test_method3(number):
z = 30
assert number[2] == z
Pytest has several plugins and is able to run tests in parallel. If you work with the Django framework for building APIs, there is a special plugin named pytest-Django for this purpose.
###3. Doctest:
The Doctest module searches for docstrings to verify that all the examples work as documented in the code. It checks if all the interactive python shell examples still work as documented.
For Example:-
from doctest import testmod
#
define a function to test
def square_of_number(n):
‘’’
This function calculates the square of number a provides output:
>>> square_of_number(3)
9
>>> square_of_number(-5)
25
‘’’
return n * n
#
call the testmod function
if __name__ == ‘__main__’:
testmod(name=’square_of_number’, verbose=True)
When you try the above piece of code running it as a file, you will get the following output.
Trying:
square_of_number(3)
Expecting:
9
ok
Trying:
square_of_number(-5)
Expecting:
25
ok
1 item had no tests:
square_of_number
1 item passed all tests:
2 tests in square_of_number.square_of_number
2 tests in 2 items.
2 passed and 0 failed.
Test passed.
The doctest has two functions, testfile() and testmod(), we’ve used testmode() in this example which is used for a module. The test file function uses a file as documentation. The problem with doctest is that it only compares the printed output. Any variation from that will result in a test failure.
###4.Testify:
It is modelled after unittest in such a way that the tests are written for unittest will run with some minor adjustments. It is a replacement to both unittest and nose2. It has a class level setup and contains class level teardown and fixture methods. Its fixtures take a decorator-based approach thus eliminating the need for the superclass.
For Example:-
from testify import *
class SquareTestCase(TestCase):
@class_setup
def initialise_the_variable(self):
self.variable = 2
@setup
def square_the_variable(self):
self.variable = self.variable * self.variable
print(self.variable)
def test_the_variable(self):
assert_equal(self.variable, 4)
@teardown
def square_root_the_variable(self):
self.variable = self.variable /self.variable
@class_teardown
def get_rid_of_the_variable(self):
self.variable = None
if __name__ == “__main__”:
run()
The output of the above test is shown below. As you run the tests you will notice that the code seems more Pythonic than unittest.
It has a better pythonic naming convention than unittest, extensible plugin system for additional functionality, and an enhanced
test discovery which can drill down into packages to find the test cases.
(venv) zenesys@python_testing_framework$ python3 testify_example.py
4
.
PASSED. 1 test / 1 case: 1 passed, 0 failed. (Total test time 0.00s)
###5. Nose2:
Nose2 can run both doctest and unittests, it is a successor to the Nose regiment. It is also called “extended unit test” pr “unittest with a plugin” because it is based upon most unit modules.
Nose2 only supports the python versions which are currently supported by python teams officially. While nose loads test lazily, nose2 loads all tests first and then begins test execution. It only supports the same level of fixtures as that of the unittest, which means only class level and module level fixtures are supported and not package level ones.
An example of unit test and output is as follows:
For Example:-
import unit test from nose2.tools import params
@params(1, 2, 3)
def test_nums(num):
assert num < 4
class Test(unittest.TestCase):
@params((1, 2), (2, 3), (4, 5))
def test_less_than(self, a, b):
assert a < b
nose2
………
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Ran 9 tests in 0.001s
OK
The mp plugin of nose2 enables it to run across multiple processors. This multiprocessing may speed up if the tests are heavily IO bound but it also complicates the text fixtures and can conflict with the plugins which are not designed to work with it.
###Conclusion:
As python is growing in its popularity, more and more updates are coming to existing libraries making it more simplistic and user-friendly. In my opinion, if you want to continue with python, you should focus on more pythonic libraries, as python has more about easy and well-structured syntax. Slowness in many cases is reduced by C extensions of Python libraries and that works well.
The Unit Tests provide the code more validity and ensure that the code works the way it was supposed to work. I have cleared all the basics for these 5 major testing frameworks. There is much more to learn in unit testing but I hope that this blog has provided you much the needed introduction and foundation to move forward and choose the framework as per your compatibility and requirement. | h32239897jay |
758,166 | How to hide Passwords in HTML ? | Hiding the password is commonly known as Password Masking. It is hiding the password characters when... | 0 | 2021-07-13T13:44:50 | https://dev.to/hariketsheth/how-to-hide-passwords-in-html-3oen | html, css, password | Hiding the password is commonly known as **Password Masking**. It is hiding the password characters when entered by the users by the use of bullets (•), an asterisk (*), or some other characters.
It is always a good practice to use password masking to ensure security and avoid its misuse. Generally, password masking is helpful to hide the characters from any user when the screen is exposed to being projected so that the password is not publicized.
In this article, we will learn to hide the password using HTML.
### Approach:
### Method 1: Using the input type = “password"
```html
<input type="password" placeholder="Enter your Password">
```
**Example:**
```html
<!DOCTYPE html>
<html>
<head>
<style>
@import url(https://fonts.googleapis.com/css?family=Salsa);
* {
font-family: Salsa;
font-weight: bolder;
margin: 2px;
padding: 10px;
text-align: center;
position: flex;
}
h2 {
margin-left: 350px;
background: #000;
color: #fff;
padding: 10px;
width: 100px;
position: inline;
text-align: center;
border-radius: 10px;
}
body {
margin-top: 10%;
}
input{
font-weight: normal;
}
button{
background: #0275d8;
color: #fff;
padding: 15px;
border: none;
border-radius: 30px;
width: 100px;
}
</style>
</head>
<body>
<h2>DEV</h2>
<b>Hiding password</b>
<form action="#" method="POST">
<label> <b>Username:</b> </label>
<input type="text" placeholder="Enter Username" required />
<br /><br />
<label> <b>Password:</b> </label>
<input type="password" placeholder="Enter Password" required />
<br /><br />
<button type="submit">Submit</button>
</form>
</body>
</html>
```
**Code Output:**

<br> <br>
### Method 2: Using the input type = “text”
- This method is not very much preferred, in this method we would just be camouflaging the text into some characters of our own choice.
- This method is deprived of security and is recommended only for password masking with other characters such as squares, circles, etc.
<ol>
<li> For Squares: -webkit-text-security: square </li>
<li> For Circles: -webkit-text-security: circle </li>
</ol>
**Example:**
-
```html
<!DOCTYPE html>
<html>
<head>
<style>
* {
font-family: Arial;
margin: 2px;
padding: 10px;
text-align: center;
position: flex;
}
button{
background: #000;
color: #fff;
font-weight: bolder;
padding: 15px;
border: none;
border-radius: 30px;
width: 100px;
}
body {
margin-top: 10%;
}
</style>
</head>
<body>
<form action="#" method="POST">
<label> <b>Username</b> </label>
<input type="text"
placeholder="Enter Username" required />
<br /><br />
<label> <b>Password</b> </label>
<input type="text"
style="-webkit-text-security: circle"
placeholder="Enter Password" required />
<br />
<label> <b>Password</b> </label>
<input type="text"
style="-webkit-text-security: square"
placeholder="Enter Password" required />
<br /><br />
<button type="submit">Submit</button>
</form>
</body>
</html>
```
**Code Output:**

| hariketsheth |
758,242 | This is an OpenPGP proof | This is an OpenPGP proof that connects my OpenPGP key to this dev.to account. For details check out... | 0 | 2021-07-13T15:37:30 | https://dev.to/edo78/this-is-an-openpgp-proof-11ii | This is an OpenPGP proof that connects [my OpenPGP key](https://keyoxide.org/4C0F1D12323E3F0BF7F19123AAC34E954E9ADFDE) to [this dev.to account](https://dev.to/edo78). For details check out https://keyoxide.org/guides/openpgp-proofs
[Verifying my OpenPGP key: 4C0F1D12323E3F0BF7F19123AAC34E954E9ADFDE] | edo78 | |
758,474 | API Security 101: Excessive Data Exposure | Hey, I found your access tokens on your profile page. Photo by Rachel LaBuda on... | 0 | 2021-07-13T20:40:16 | https://blog.shiftleft.io/api-security-101-excessive-data-exposure-a730d351fbae | softwareengineering, programming, cybersecurity, softwaredevelopment | ---
title: API Security 101: Excessive Data Exposure
published: true
date: 2021-07-13 15:56:30 UTC
tags: softwareengineering,programming,cybersecurity,softwaredevelopment
canonical_url: https://blog.shiftleft.io/api-security-101-excessive-data-exposure-a730d351fbae
---
#### Hey, I found your access tokens on your profile page.
<figcaption>Photo by <a href="https://unsplash.com/@rlabuda96?utm_source=medium&utm_medium=referral">Rachel LaBuda</a> on <a href="https://unsplash.com?utm_source=medium&utm_medium=referral">Unsplash</a></figcaption>
You’ve probably heard of the OWASP top ten or the top ten vulnerabilities that threaten web applications. OWASP also periodically selects a list of top ten vulnerabilities that threaten APIs, called the OWASP API top ten. The current API top ten are _Broken Object Level Authorization_, _Broken User Authentication_, _Excessive Data Exposure_, _Lack of Resources & Rate Limiting_, _Broken Function Level Authorization_, _Mass Assignment_, _Security Misconfiguration_, _Injection_, _Improper Assets Management_, and _Insufficient Logging & Monitoring_.
Many of these vulnerabilities affect application components besides APIs as well, but they tend to manifest themselves in APIs. Last time, we talked about broken user authentication and how they affect API systems. This time, let’s dive into my favorite vulnerability to find in APIs: OWASP API #3, Excessive Data Exposure.
Why is excessive data exposure my favorite API vulnerability to find? Because I realized that I’ve been looking for it throughout my bug hunting and pentesting career, without even realizing that it’s one of the top vulnerabilities that affect APIs! Today, let’s talk about what these vulnerabilities are, how I usually look for them, and how you can prevent them.
#### OWASP API #3
What is OWASP API #3, Excessive Data Exposure, exactly? It’s when applications reveal more information than necessary to the user via an API response.
Let’s consider a simple use case of APIs. A web application retrieves information using an API service, then uses that information to populate a web page to display to the user’s browser.
```
displays data requests data
user <----------------- application -------------------> API service
(browser) (API client)
```
For many API services, the API client applications do not have the ability to pick and choose which data fields are returned in an API call. Let’s say that an application retrieves user information from the API to populate user profiles. The API call to retrieve user information looks like this:
```
https://api.example.com/v1.1/users/show?user_id=12
```
The API server will respond with the entire corresponding user object:
```
{
"id": 6253282,
"username": "vickieli7",
"screen_name": "Vickie",
"location": "San Francisco, CA",
"bio": "Infosec nerd. Hacks and secures. Creates god awful infographics.",
"api_token": "8a48c14b04d94d81ca484e8f32daf6dc",
"phone_number": "123-456-7890",
"address": "1 Main St, San Francisco, CA, USA"
}
```
You notice that besides basic information about the user, this API call also returns the API token, phone number, and address of that user. Since this call is used to retrieve data to populate the user’s profile page, the application only needs to send the username, screen name, location, and bio to the browser.
Some application developers assume that if they do not display the sensitive information on the webpage, users cannot see it. So they in turn send this entire API response to the user’s browser without filtering out the sensitive info first and rely on client-side code to filter out the private information. When this happens, anyone who visits a profile page will be able to intercept this API response and read sensitive info about that user!
Attackers might also be able to read sensitive data by visiting certain endpoints that leak information or perform a MITM attack to steal API responses sent to the victim.
#### Preventing excessive data exposure
Excessive data exposures happen when the API client application does not filter the results it gets before returning the data to the user of the application.
When APIs send data that is sensitive, the client application should filter the data before forwarding it to the user. Carefully determine what the application’s user should know and make sure to filter out anything the user should not be allowed to access. Ideally, return the minimum amount of data needed to render the webpage.
If the API allows it, you could also request the minimum amount of data needed from the API server. For instance, GraphQL APIs allow you to specify the exact object fields you need in an API request.
Finally, avoid transporting sensitive information with unencrypted traffic.
#### Hunting for excessive data exposure
I mentioned that I’ve always looked out for these vulnerabilities when I hunt for bugs. As a bug hunter and penetration tester, I got into the habit of grepping every server response for keywords like “key”, “token”, and “secret”. And more often than not, I’d find sensitive info leaks this way.
A lot of the time, these sensitive info leaks are caused by precisely the problem I described here: the server being too permissive and returning the entire API response from the API server instead of filtering it before forwarding it to the user.
Excessive Data Exposure is, unfortunately, extremely common. And when combined with OWASP API #4, Lack of Resources & Rate Limiting, they could become an even bigger issue. Next time, let’s look at the OWASP API top ten #4, Lack of Resources & Rate Limiting, and why and when they become issues. Next time, why you should not overlook those bug reports about the lack of rate-limiting.
What other security concepts do you want to learn about? I’d love to know. Feel free to connect on Twitter [@vickieli7](https://twitter.com/vickieli7).
Want to learn more about application security? Take our free OWASP top ten courses here: [https://www.shiftleft.io/learn/](https://www.shiftleft.io/learn/).
* * * | vickieli7 |
758,559 | Custom JDK Versions Per Project With SDKMAN! | SDKMAN! allows us to easily install and use different JDKs. It can become frustrating to have to... | 13,628 | 2021-07-13T20:57:24 | https://www.davidsalter.com/view/custom-jdk-versions-per-project-with-sdkman | java, jdk, sdkman | [SDKMAN!](https://sdkman.io) allows us to easily install and use different JDKs. It can become frustrating to have to change JDK versions manually for different projects. Fortunately, SDKMAN! has a solution to this in the form of the `sdk env` command. This command allows us to define a different JDK per project which can be easily switched to, without having to remember the JDK version. Additionally, it can be configured to automatically change to the required JDK when changing directories.
For more information about installing and using SDKMAN!, check out my article - [Managing JDK Versions With SDKMAN!](https://dave-s.medium.com/managing-jdk-versions-with-sdkman-bb20618c854e)
## Updating SDKMAN!
Before we can start using the `sdk env` command, we must first ensure we are using the latest version of SDKMAN! The software can be updated by using the `sdk selfupdate` command
``` sh
% sdk selfupdate
No update available at this time.
```
## Specifying a JDK Version For A Project
SDKMAN! uses a hidden file called `.sdkmanrc` which contains a parameter specifying which JDK version to use for a project. To configure and use this file is a simple 3 step process.
1 **Create the `.sdkmanrc` file**. This can easily be created by navigating to the required directory and executing `sdk env init`
``` bash
% sdk env init
.sdkmanrc created.
```
2 **Configure the version**. Once we've created the file, edit it and add a line `java=x.x.x.x` specifying the version of Java to use. For example to use Adopt Open JDK version 11, the file would look like:
``` bash
% cat .sdkman
java=11.0.2.hs-adpt
```
3 **Initialize the environment**. After editing the `.sdkmanrc` fille, we can configure the environment by executing the `sdk env` command.
``` bash
% sdk env
Using java version 11.0.2-open in this shell.
%
% java -version
openjdk version "11.0.2" 2019-01-15
OpenJDK Runtime Environment 18.9 (build 11.0.2+9)
OpenJDK 64-Bit Server VM 18.9 (build 11.0.2+9, mixed mode
```
## Specifying a JDK Automatically
Finally, we can get SDKMAN! to automatically change JDK to the version defined within `.sdkmanrc` by changing configuration. To do this, edit the `~/.sdkman/etc/config` file and add/edit the property `sdkman_auto_env=true`. This will probably already exist and be set to `false`, so make sure you edit this setting if it is there rather than duplicating it.
Now, whenever you change into a directory containing a `.sdkmanrc` file in it, the JDK will automatically be changed to your desired version. Fantastic !
``` bash
% cd project1
Using java version 11.0.2-open in this shell.
%
% cd project2
Using java version 14.0.1-open in this shell.
```
## Credits
Photo by [Octavian Dan](https://unsplash.com/@octadan?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com/?utm_source=medium&utm_medium=referral) | davey |
758,567 | What s useState? | well is a hook. Which in other words, is a function, which is imported from react import {... | 0 | 2021-07-13T21:12:10 | https://dev.to/whil/what-s-usestate-69 | react | well is a hook. Which in other words, is a function, which is imported from react
```
import { useState } from 'react'
```
but which is your function?
Help us to controller a state, recive a first param which is the initial state
```
useState(initialState)
```
But what a the initial state?
It is the value which initiates our state
For example:
```
A object useState({}) or Array useState([])
A string useState('whil')
A number useState(5)
A Boolean useState(true)
```
every time our functional component Renders. Begins with the initial state
But what a return?
Returns us two values. Which is a current state and a function for update
```
const [state, setState] = useState(false)
```
But which is our current state?
Well is our initial state which is your current state. Why?
Remember that Provide a initial state. That initial state is our current state during the first rendering
How update our current state?
Remember that useState return a function which we can update the current state
```
setState
```
the shape for update our current value is like that.
```
const handleState = () =>{
setState(true)
}
Or
JSX.
Return(
<button onClick={() =>setState(true)} > Click Me </button>
)
```
because is not called createState?
Because it wouldn't be right. Because the state Only Be create one-time when our functional component Be render for first time
setState is not function async. Just calling to enqueueState or enqueueCallback when update and your execution feels how If it were async
| whil |
759,035 | I'm Changing How I Review Code | I'm a big advocate for code reviews. I've written about my experiences reviewing code, including... | 0 | 2021-07-14T10:43:07 | https://dev.to/dangoslen/i-m-changing-how-i-review-code-328g | codereview, career, teamwork | I'm a big advocate for code reviews. I've written about my experiences reviewing code, including lists of dos and don'ts, [how to survive your first code review](https://dangoslen.me/blog/surviving-your-first-code-review/), and [why we should review code at all](https://dangoslen.me/blog/whats-the-point-to-code-reviews-anyway/).
My views have been mainly shaped by my experience with a particular kind of code review - the pull request. Like many devs, I've grown accustomed to the pull request model to help facilitate reviews. While it isn't perfect, I've always found it to be a great tool and overall an improvement to formal code review processes or reviews over email.
Recently, though, I've been seeing thoughts expressing a different sentiment. Many devs are starting to become frustrated with the [pull request model](https://jessitron.com/2021/03/27/those-pesky-pull-request-reviews/). There is a sense that pull requests actually might make it _too_ easy to comment on a line of code. This ease might be leading to the conflicts and hyper-zealous commenting that frustrates many in our industry.
Another common critique is that the pull requests encourage reviewers to only look at the code. They never even pull down the changes they are reviewing! To be completely transparent, I'm guilty of that myself.
After reading the article and seeing some related ideas via Twitter, I wondered: are there better ways that I could review code? What could I do differently?
After asking, I've decided to start making some changes in how I review code. They've been helping me recently, so I think they could help you and your team as well.
## Commenting on Code vs. Collaborating on Code
One of the top thoughts that made me start questioning how I review code comes from the [article above](https://jessitron.com/2021/03/27/those-pesky-pull-request-reviews/):
> Pull requests are an improvement on working alone. But not on working together.
That struck a chord. Indeed, pull requests _aren't_ the primary way to collaborate with people after all.
Collaborating on code is vital to a team's ability to maintain a codebase. If a single member of a team is left to write an entire codebase without working with other team members, there is a high probability that the rest of the team won't be able to contribute to it after a while. Worse, if left alone, a single team member might even get things wrong or be unable to solve a problem. Therefore, collaborating early and often is a good idea.
The next question that arises is this: how _does_ a team collaborate on code? Further, can a team collaborate too early? Too often?
Many teams seem to have concluded that a pull request is a great place to have collaboration. I don't think they are wrong. First, a team member feels ready to share a version of their code with the rest of the team for direct feedback. Then, like an author writing a book, they submit it for a first review to get feedback. The rest act as editors, ready to help get the draft ready to print.
There isn't anything wrong with teams seeing pull requests as a place for collaborating. The problem is when teams think collaboration is _restricted_ only to the code review process.
Teams should be working together on problems, ideas, and code well before code is submitted for review. Mentors should be advising mentees, peers should be offering help to each other, and pair programming or debugging sessions should be routine. If an author were to send the first draft to their editor without disclosing what the book is about, it would make it harder for the editor. The editor now has more they need to understand to give useful feedback. As a result, the publication date is likely to get pushed later than anticipated.
Genuine collaboration is more than just leaving a comment or a suggestion. It's discussing alternative solutions, prodding at requirements, and having real-time feedback loops with your team.
I will be working towards making this form of collaboration more common within my team. I'm hoping to move us beyond collaboration via comments and get back to real-time collaboration.
## Run. The. Code.
Commenting on and rejecting a pull request without ever running or stepping through the changes made sounds silly when said directly. But many developers - including me! - do this all the time.
As engineers, we shouldn't evaluate code only by how "clean" it is or how wonderfully abstracted it is. Instead, we still need to measure code by how well it does what it is supposed to do - deliver some value when it runs.
To drive this point home, when was the last time you looked at Google's source code for Google Search? If you did see it, would it change how well you think it works as a product? Probably not.
I'm not trying to be hyper-reductionistic here. The quality of code does matter! It should be clean, crisp, mutable, etc.
But part of what makes that code good is how well it solves a problem. Does it do what it needs to do to meet requirements? Will the end product be better? At the least, all code needs to make the end product better.
What is the best way to see if the code makes the product better? You have to run it. Treat a pull request as a chance to do a mini-demo of the added or fixed functionality. Use it. Poke at it. Heck, even _test_ it yourself!
I've been incredibly guilty about this. I tend to trust our automation that the code changes produced the desired behavior changes without observing the behavior myself! I want to start changing this and running code more frequently.
## More Navigating and Less Backseat Driving
When a problem (or even a difference of opinion) is spotted in code, it can be easy for a reviewer to recommend a concrete change right then and there. For example, they might include a block of code in their comment or add a GitHub suggestion of their improved implementation. They might even include citations and links.
And they do this for every issue they see.
While there are times adding such comments can be appropriate, it often can feel like the reviewer is attempting to take control. They are dictating what the code _should_ be rather than providing feedback on the written code. The reviewer is giving directions as if they were a backseat driver. And no one likes backseat drivers.
Great code reviewers know the difference between being a backseat driver and being a navigator. Both give directions, but one has the destination in mind while the other is trying to control the driver. A navigator knows multiple ways to reach a destination, but a backseat driver complains when the driver takes Martin Street instead of Hampton street - it could have saved one whole minute!
What does a navigator look like in a code review? Instead of focusing on how to change the code, they are focused on why the code needs changing. They care more about the final outcome rather than the concrete classes that are written. The navigator is primarily focused on understanding where they need to go and to help them get there.
I want to be more of a navigator. Not every single detail needs commenting, and not every difference of opinion needs to be shared. I want to review code in such a way that I'm helping rather than controlling.
---
The goal of all of this is really more than becoming a better code reviewer. It's about becoming a better teammate. Knowledge work isn't just an individual grinding away on an intense thought or task anymore. Knowledge work - or at least meaningful knowledge work - tends to be accomplished by teams.
And I want to be a great teammate.
---
_Originally published at [https://dangoslen.me](https://dangoslen.me/blog/changing-how-i-review-code/)._
_Photo by <a href="https://unsplash.com/@gallarotti?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Francesco Gallarotti</a> on <a href="https://unsplash.com/s/photos/prune?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>_ | dangoslen |
759,046 | All PHP Releases | Some time ago, i'm writed an article about... | 0 | 2021-07-14T11:17:50 | https://dev.to/alexandrefreire/all-php-releases-4g95 | Some time ago, i'm writed an article about laragon.
https://dev.to/alexandrefreire/laragon-the-dev-environment-for-web-artisans-40em
With laragon you can have many php versions, other softwares relateds too have this. What i want to show is this page with all releases of php, for you choose easily, sometimes we work with older php projects, and if you not work with docker its is a solution.
https://windows.php.net/downloads/releases/archives/ | alexandrefreire | |
759,145 | Infrastructure as Code: The Good, the Bad and the Future | Infrastructure as Code, or IaC for short, is a fundamental shift in software engineering and in the... | 0 | 2021-07-14T12:25:59 | https://dev.to/humanitec_com/infrastructure-as-code-the-good-the-bad-and-the-future-6hd | Infrastructure as Code, or IaC for short, is a fundamental shift in software engineering and in the way Ops think about the provisioning and maintenance of infrastructure. Despite the fact that IaC has established itself as a de facto industry standard for the past few years, many still seem to disagree on its definition, best practices, and limitations.
This article will walk through the evolution of this approach to infrastructure workflows and the related technologies that were born out of it. We will explain where IaC came from and where it is likely going, looking at both its benefits and key limitations.
From Iron to Clouds
Remember the Iron age of IT, when you actually bought your own servers and machines? Me neither. Seems quite crazy right now that infrastructure growth was limited by the hardware purchasing cycle. And since it would take weeks for a new server to arrive, there was little pressure to rapidly install and configure an operating system on it. People would simply slot a disc into the server and follow a checklist. A few days later it was available for developers to use. Again, crazy.
With the simultaneous launch and widespread adoption of both AWS EC2 and Ruby on Rails 1.0 in 2006, many enterprise teams have found themselves dealing with scaling problems previously only experienced at massive multinational organizations. Cloud computing and the ability to effortlessly spin up new VM instances brought about a great deal of benefits for engineers and businesses, but it also meant they now had to babysit an ever-growing portfolio of servers.
The infrastructure footprint of the average engineering organization became much bigger, as a handful of large machines were replaced by many smaller instances. Suddenly, there were a lot more things Ops needed to provision and maintain and this infrastructure tended to be cyclic. We might scale up to handle a load during a peak day, and then scale down at night to save on cost, because it's not a fixed item. Unlike owning depreciating hardware, we're now paying resources by the hour. So it made sense to only use the infrastructure you needed to fully benefit from a cloud setup.
To leverage this flexibility, a new paradigm is required. Filing a thousand tickets every morning to spin up to our peak capacity and another thousand at night to spin back down, while manually managing all of this, clearly starts to become quite challenging. The question is then, how do we begin to operationalize this setup in a way that's reliable and robust, and not prone to human error?
Webinar: Developer self-service on Kubernetes
Infrastructure as Code
Infrastructure as Code was born to answer these challenges in a codified way. IaC is the process of managing and provisioning data centers and servers through machine-readable definition files, rather than physical hardware configuration or human-configured tools. Now, instead of having to run a hundred different configuration files, IaC allows us to simply hit a script that every morning brings up a thousand machines and later in the evening automatically brings the infrastructure back down to whatever the appropriate evening size should be.
Ever since the launch of AWS Cloudformation in 2009, IaC has quickly become an essential DevOps practice, indispensable to a competitively paced software delivery lifecycle. It enables engineering teams to rapidly create and version infrastructure in the same way they version source code and to track these versions to avoid inconsistency among IT environments. Typically, teams implement it as follows:
Developers define and write the infrastructure specs in a language that is domain-specific
The files that are created are sent to a management API, master server, or code repository
An IaC tool such as Pulumi then takes all the necessary actions to create and configure the necessary computing resources
And voilá, your infrastructure is suddenly working for you again instead of the other way around.
There are traditionally two approaches to IaC, declarative or imperative, and two possible methods, push and pull. The declarative approach is about describing the eventual target and it defines the desired state of your resources. This approach answers the question of what needs to be created, e.g. “I need two virtual machines”. The imperative approach answers the question of how the infrastructure needs to be changed to achieve a specific goal, usually by a sequence of different commands. Ansible playbooks are an excellent example of an imperative approach. The difference between the push and pull method is simply around how the servers are told how to be configured. In the pull method, the server will pull its configuration from the controlling server, while in the push method the controlling server pushes the configuration to the destination system.
The IaC tooling landscape has been in constant evolution over the past ten years and it would probably take up a whole other article to give a comprehensive overview of all the different options one has to implement this approach to her specific infrastructure. We have however compiled a quick timeline of the main tools, sorted by GA release date:
AWS CloudFormation (Feb 2011)
Ansible (Feb 2012)
Azure Resource Manager (Apr 2014)
Terraform (Jun 2014)
GCP Cloud Deployment Manager (Jul 2015)
Serverless Framework (Oct 2015)
AWS Amplify (Nov 2018)
Pulumi (Sep 2019)
AWS Copilot (Jul 2020)
This is an extremely dynamic vertical of the DevOps industry, with new tools and competitors popping up every year and old incumbents constantly innovating; CloudFormation for instance got a nice new feature just last year, Cloudformation modules.
The good, the bad
Thanks to such a strong competitive push to improve, IaC tools have time and again innovated to generate more value for the end-user. The largest benefits for teams using IaC can be clustered in a few key areas:
Speed and cost reduction: IaC allows faster execution when configuring infrastructure and aims at providing visibility to help other teams across the enterprise work quickly and more efficiently. It frees up expensive resources to work on other value-adding activities.
Scalability and standardization: IaC delivers stable environments, rapidly and at scale. Teams avoid manual configuration of environments and enforce consistency by representing the desired state of their environments via code. Infrastructure deployments with IaC are repeatable and prevent runtime issues caused by configuration drift or missing dependencies. IaC completely standardizes the setup of infrastructure so there is a reduced possibility of any errors or deviations.
Security and documentation: If all compute, storage and networking services are provisioned with code, they also get deployed the same way every time. This means security standards can be easily and consistently enforced across companies. IaC also serves as a form of documentation of the proper way to instantiate infrastructure and insurance in the case employees leave your company with important knowledge. Because code can be version-controlled, IaC allows every change to your server configuration to be documented, logged and tracked.
Disaster recovery: As the term suggests, this one is pretty important. IaC is an extremely efficient way to track your infrastructure and redeploy the last healthy state after a disruption or disaster of any kind happens. Like everyone who woke up at 4am because their site was down will tell you, the importance of quickly recovering after your infrastructure got messed up cannot be understated.
There are more specific advantages to particular setups, but these are in general where we see IaC having the biggest impact on engineering teams’ workflows. And it’s far from trivial, introducing IaC as an approach to manage your infrastructure can be a crucial competitive edge. What many miss when discussing IaC however, are some of the important limitations that IaC still brings with it. If you have already implemented IaC at your organization or are in the process of doing so, you’ll know it’s not all roses like most blog posts about it will have you believe. For an illustrative (and hilarious) example of the hardships of implementing an IaC solution like Terraform, I highly recommend checking out The terrors and joys of terraform by Regis Wilson.
In general, introducing IaC also implies four key limitations one should be aware of:
Logic and conventions: Your developers still need to understand IaC scripts, and whether those are written in HashiCorp Configuration Language (HCL) or plain Python or Ruby, the problem is not so much the language as the specific logic and conventions they need to be confident applying. If even a relatively small part of your engineering team is not familiar with the declarative approach (we see this often in large enterprises with legacy systems e.g. .NET) or any other core IaC concepts, you will likely end up in a situation where Ops plus whoever does understand them becomes a bottleneck. If your setup requires everyone to understand these scripts in order to deploy their code, onboarding, and rapid scaling will create problems.
Maintainability and traceability: While IaC provides a great way for tracking changes to infrastructure and monitoring things such as infra drift, maintaining your IaC setup tends to itself become an issue after a certain scale (approx. over 100 developers in our experience). When IaC is used extensively throughout an organization with multiple teams, traceability and versioning of the configurations are not as straightforward as they initially seem.
RBAC: Building on that, Access Management quickly becomes challenging too. Setting roles and permissions across the different parts of your organization that suddenly have access to scripts to easily spin up clusters and environments can prove quite demanding.
Feature lag: Vendor agnostic IaC tooling (e.g. Terraform) often lags behind vendor feature release. This is due to the fact that tool vendors need to update providers to fully cover the new cloud features being released at an ever growing rate. The impact of this is sometimes you cannot leverage a new cloud feature unless you 1. extend functionality yourself 2. wait for the vendor to provide coverage or 3. introduce new dependencies.
Once again, these are not the only drawbacks of rolling out IaC across your company but are some of the more acute pain points we witness when talking to engineering teams.
The future
As mentioned, the IaC market is in a state of constant evolution and new solutions to these challenges are being experimented with already. As an example, Open Policy Agents (OPAs) at present provide a good answer to the lack of a defined RBAC model in Terraform and are default in Pulumi.
The biggest question though remains the need for everyone in the engineering organization to understand IaC (language, concepts, etc.) to fully operationalize the approach. In the words of our CTO Chris Stephenson “If you don’t understand how it works, IaC is the biggest black box of them all”. This creates a mostly unsolved divide between Ops, who are trying to optimize their setup as much as possible, and developers, who are often afraid of touching IaC scripts for fear of messing something up. This leads to all sorts of frustrations and waiting times.
There are two main routes that engineering team currently take to address this gap:
Everyone executes IaC on a case by case basis. A developer needs a new DB and executes the correct Terraform. This approach works if everybody is familiar with IaC in detail. Otherwise you execute and pray that nothing goes wrong. Which works, sometimes.
Alternatively, the execution of the IaC setup is baked into a pipeline. As part of the CD flow. the infrastructure will be fired up by the respective pipeline. This approach has the upside that it conveniently happens in the background, without the need to manually intervene from deploy to deploy. The downside however is that these pipeline-based approaches are hard to maintain and govern. You can see the most ugly Jenkins beasts evolving over time. It’s also not particularly dynamic, as the resources are bound to the specifics of the pipeline. If you just need a plain DB, you’ll need a dedicated pipeline.
Neither of these approaches really solves for the gap between Ops and devs. Both are still shaky or inflexible. Looking ahead, Internal Developer Platforms (IDPs) can bridge this divide and provide an additional layer between developers and IaC scripts. By allowing Ops to set clear rules and golden paths for the rest of the engineering team, IDPs enable developers to conveniently self-serve infrastructure through a UI or CLI, which is provisioned under the hood by IaC scripts. Developers only need to worry about what resources (DB, DNS, storage) they need to deploy and run their applications, while the IDP takes care of calling IaC scripts through dedicated drivers to serve the desired infrastructure back to the engineers.
We believe IDPs are the next logical step in the evolution of Infrastructure as Code. Humanitec is a framework to build your own Internal Developer Platform. We are soon publishing a library of open-source drivers that every team can use to automate their IaC setup, stay tuned to find out more at https://github.com/Humanitec. | humanitec_com | |
759,274 | Catching tricky bugs with runtime code analysis | If you’re using the Forem mobile app, you may have gotten a sequence of unexpected mobile... | 0 | 2021-07-15T12:19:07 | https://dev.to/appmap/catching-tricky-bugs-with-runtime-code-analysis-1f1c | rails, architecture, webdev, database | If you’re using the Forem mobile app, you may have gotten a sequence of unexpected mobile notifications.
Now, I love dev.to, but I didn’t understand why I got these notifications because I wasn’t involved in any of these threads! Well, an email from the Forem team (the open source code behind dev.to) a couple of days later cleared it up - a coding mistake had accidentally notified a small portion of users about comments they hadn’t subscribed to. The disclosure was prompt and even included a link to the commit that fixed the problem. This is *awesome*, because usually when things like this happen, companies go into “cover your ass” mode and their disclosures don't include any technical details. That makes it hard to study how these types of problems can be prevented. So, first of all, kudos to the Forem dev team!
I have a deep interest in improving developer tools and processes to prevent more errors like this from happening. Some types of errors, like buffer overflows and SQL injection, are somewhat amenable to automatic detection by static analysis. But coding logic errors like this one are definitely not.
So, if these problems can’t be found by static analyzers, how can they be found? Well, there are really only two ways - code review and testing. Getting extra eyes on the code sure is a lot better than not doing it - especially for tricky bugs like this one. And testing is important - especially automated tests - but problems like this one are difficult to catch because, for starters, you have to test the code with multiple different user profiles created and active at the same time. Forem has extensive test coverage - over 5,000 tests at my last count. But the fact that this bug happened is evidence that we, as a profession, need more effective ways to catch and fix problems like this one before they slip into production.
At this point, I’ll get a little bit more opinionated about what can be done. I’ve said that static analysis can’t help us here. I’ve also said that aside from automated tests, code review is our best tool for ensuring code quality. Code review isn’t perfect - I’ll be the first to agree. It’s hard to do an in-depth code review, because code is complex, and there’s a lot of pressure to approve the PR and keep the features flowing.
But I don’t think that hasty code review or pressure was the primary contributing factor in this case - or in many other cases. The Forem PR was reviewed and approved by senior developers, and co-authored by the head of engineering. Nope - I think the biggest flaw with code review in cases like this is that the traditional line-by-line diff of the code doesn’t make problems obvious enough.
I’ve [written previously about code observability](https://dev.to/appland/observability-of-software-design-what-it-is-and-why-it-matters-1ke4), and I think this particular situation is a perfect illustration of what code observability is all about - making the behavior of the code obvious, so that we don’t have to do mental gymnastics while reviewing code.
To make code behavior obvious, we need tools that observe and report on the code as it truly behaves, as it runs: runtime code analysis. If you combine runtime code analysis, code observability, and code review, what do you get? Presentations, visualizations, or views of code that make the behavior of code more obvious.
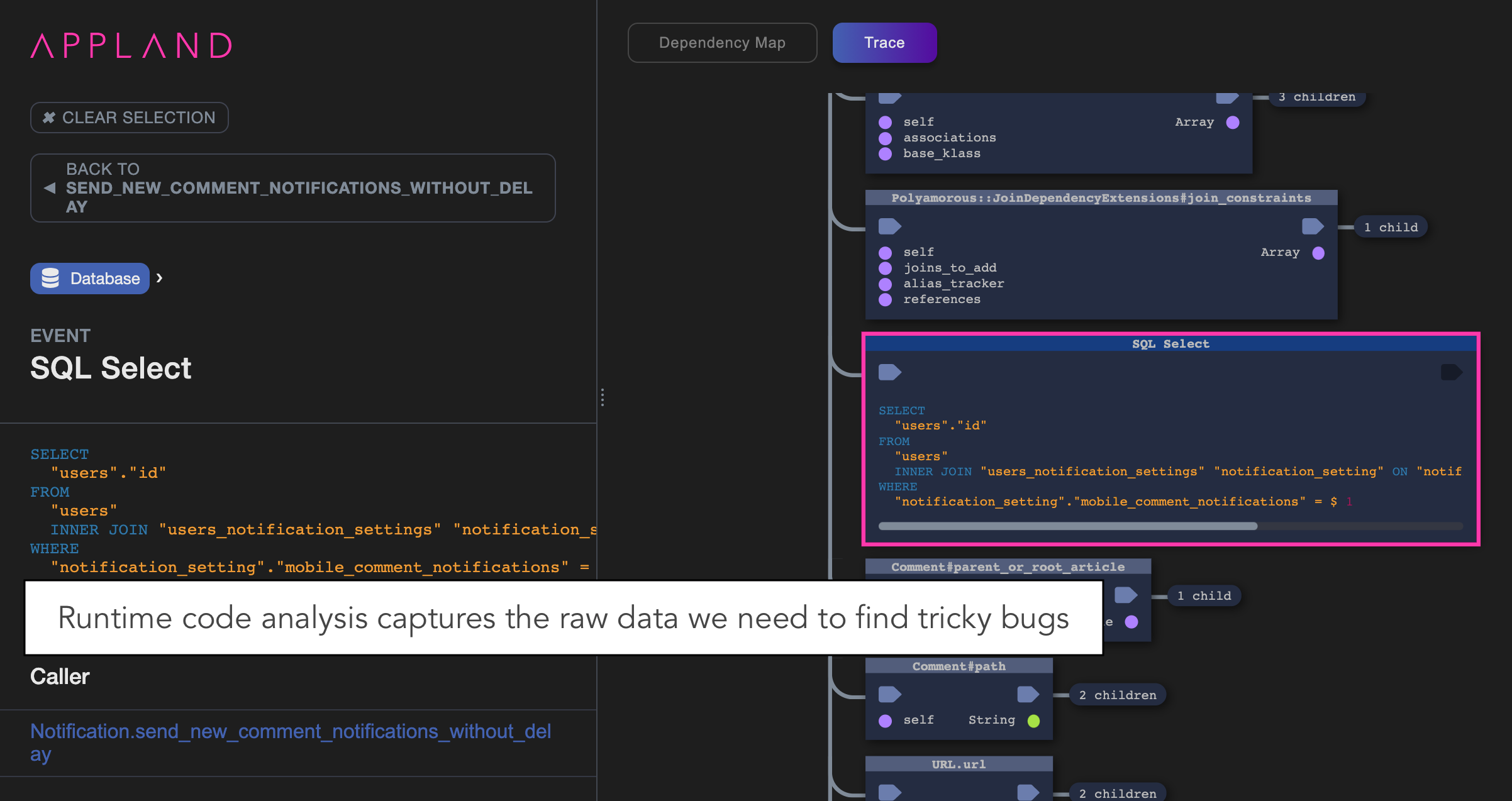
So here’s the nut: The reason why coding mistakes that lead to problems like the Forem notification bug are so hard to spot is that the behavior of the code is obfuscated, rather than revealed, by the way we choose to view the code. Want to catch more flaws in code review? Capture information about code behavior using runtime code analysis, and then process this data into views of code behavior, design, and architecture that make problems easier to spot.
To review:
- Code review is our last line of defense for catching tricky bugs before they ship.
- By their nature, tricky bugs are hard to spot from a basic line by line code diff.
- A heavy burden is placed on the reviewer to both imagine how the code works AND identify flaws in its construction.
- Specialized views of code changes can make flaws much more obvious.
- Runtime code analysis can collect information about code that makes these views feasible.
What kind of views, you ask? Well, the ideal view depends on the need. Here, there is a ton of thought, research and experimentation that needs to be done. But let’s take a simple example.
This particular Forem bug was caused by a query which did not have a filter condition. The query should have read: *Find all enabled mobile notifications for a particular user*. But instead it read: *Find all enabled mobile notifications*. The clause to limit the query results to a particular user was missing. That’s why I (and perhaps you) received errant notifications. The query found other people’s notifications and sent them to you.
So what information could we present to a code reviewer that would have caught their attention? This bug was introduced in a [big PR](https://github.com/forem/forem/pull/14121) - 132 commits touching 103 files. So to catch this flaw, we would need a view that really makes this mistake pop out.
The first thing I tried was just to list all the queries across the different code versions and compare them. But there were a lot of query changes, and the signal was lost in the noise. So I made a few optimizations:
* Remove all the columns from `SELECT` clauses (`SELECT` is not relevant to filtering).
* Compress any sequence of `IN` clause placeholders like `( $?, $?, $? )` to a single placeholder `( $? )` (there’s no loss of query intent).
* Switch from “line” diff (Git style) to “word” diff.
Now the resulting diff is actually pretty small, considering the magnitude of the code changes and the size of the PR. Do you think you could spot this problematic query change in this type of a SQL diff view?

To take it further, and catch other types of issues, how about tracking and reviewing:
* Queries that have no LIMIT clause.
* Queries that join more than four tables.
* Queries that have more than four expressions in the WHERE clause.
* Queries that have no filter condition on a user, group, role or organization.
You get where I’m going. These are likely trouble spots... and this is just SQL. Runtime code analysis can also correlate SQL with context like web services routes, key functions, calls to other web services, cloud services, etc. There are many possibilities to explore.
So hearing all this, maybe you'd like to implement this kind of analysis for your own repos! Stay tuned for a follow-up post in which I will go step by step through the tools, data, and code that I used to generate this post. I'll show you how I used [AppMap](https://appland.com/docs/appmap-overview.html), an open source tool I created, which stores runtime code analysis data as JSON.
**PS** For an even more in-depth description of the issue from the Dev.to team, check out yesterday's post [Incident Retro: Failing Comment Creation + Erroneous Push Notifications](https://dev.to/devteam/incident-retro-failing-comment-creation-erroneous-push-notifications-55dj).
| kgilpin |
761,614 | NEW APP | Hypermc is an open source minecraft mod manager! You click ONE button and the mod is installed! Check... | 0 | 2021-07-17T01:56:44 | https://dev.to/techpenguineer/new-app-k4c | Hypermc is an open source minecraft mod manager! You click ONE button and the mod is installed! Check it out! Maybe even leave a star!
https://github.com/TechPenguineer/Hypermc | techpenguineer | |
759,621 | How to reuse form field widget to add and update cloud firestore documents - #100DaysOfCode - Day 17 | Introduction This post is part of my 100DaysOfCode series. In this series, I write about... | 13,535 | 2021-07-15T00:11:50 | https://dev.to/curtlycritchlow/how-to-use-the-same-form-field-to-add-and-update-cloud-firestore-documents-100daysofcode-day-17-3job | 100daysofcode, flutter, firebase, dart | ##Introduction
This post is part of my 100DaysOfCode series. In this series, I write about what I am learning on this challenge. For this challenge, I will be learning flutter and firebase by building an Agriculture Management Information System.
## Recap
On Day 16 we discussed how to reuse a screen widget to personalize our app for the currently signed-in user.
## Overview
In this post, we'll discuss how to use our farmer form screen to add and update cloud firestore documents. We have already implemented the Add functionality so we will focus on the update functionality.
### Location Filter Enum
The first step is to create a Farm Type enum. `enum FarmType { add, update }`. This enum value will be passed to the `FarmerFormScreen()` widget to modify the screen into an add farmer form and an update farmer form.
```Dart
class FarmerFormScreen extends StatefulWidget {
static String routeName = 'AddFarmerScreen';
final FarmerServiceModel? farmerModel;
final FormType formType;
FarmerFormScreen({
this.farmerModel,
required this.formType,
Key? key,
}) : super(key: key);
@override
_FarmerFormScreenController createState() => _FarmerFormScreenController();
}
```
This widget accepts an optional `final FarmerServiceModel? farmerModel;` that will be used to update the farmer document.
### Text Form Field widget with Controller
```Dart
class _FarmerFormScreenController extends State<FarmerFormScreen> {
@override
Widget build(BuildContext context) => _FarmerFormScreenView(this);
late TextEditingController dateOfBirthController;
@override
void initState() {
super.initState();
dateOfBirthController = TextEditingController();
if (widget.formType == FormType.update) {
dateOfBirthController = TextEditingController(
text: DateFormat.yMMMd().format(widget.farmerModel!.dateOfBirth!));
} else {
dateOfBirthController = TextEditingController();
}
}
```
The date of birth text form field initial value will be null when adding a farmer and the farmer date of birth when updating a farmer document.
### Text Form Field widget without controller
```Dart
class LastNameTextFormField extends StatelessWidget {
const LastNameTextFormField({
Key? key,
required this.state,
}) : super(key: key);
final _FarmerFormScreenController state;
@override
Widget build(BuildContext context) {
return TextFormField(
decoration: FormStyles.textFieldDecoration(labelText: 'Last Name'),
focusNode: state.lastNameFocusNode,
textInputAction: TextInputAction.next,
autovalidateMode: AutovalidateMode.onUserInteraction,
validator: state.farmer.validateRequiredField,
onSaved: state.farmer.saveLastName,
initialValue: state.widget.formType == FormType.update
? state.widget.farmerModel!.lastName
: null,
);
}
}
```
The initialValue is assigned the farmer document lastname value if `state.widget.formType == FormType.update` and null otherwise. This same methodology was repeated for all other form field widgets.
### Wrap Up
In this post, we discussed how to reuse our farmer form screen widget to add and update a farmer document.
## Connect with me
Thank you for reading my post. Feel free to subscribe below to join me on the #100DaysOfCodeChallenge or connect with me on [LinkedIn](https://www.linkedin.com/in/curtlycritchlow/) and [Twitter](https://twitter.com/CritchlowCurtly). You can also [buy me a book](https://www.buymeacoffee.com/curtlycritchlow) to show your support. | curtlycritchlow |
759,805 | Scrape Google Local Place from Organic Search with Python | Contents: intro, why bother reading, what will be scraped, imports, process, code, links, outro. ... | 12,790 | 2021-07-15T05:22:17 | https://serpapi.com/blog/scrape-google-local-place-from-organic-search-with-python | python, tutorial, webscraping, datascience | Contents: intro, why bother reading, what will be scraped, imports, process, code, links, outro.
### Intro
This blog post is a continuation of Google's web scraping series. Here you'll see how to scrape Local Place Results from organic search results using Python with `beautifulsoup`, `requests`, `lxml` libraries. An alternative API solution will be shown.
*Note: This blog post assumes that you know the basics understanding of web scraping using `bs4`, `requests`/`regex`/`css` selectors.*
### Why bother reading?
You can do:
- place analysis in the local area(s).
- compare analysis of the same place in different areas.
- analysis of user feedback (rating, reviews).
- compare one place to a competitor place in Google results, who appears on the page and try to understand why.
- create a dataset for analysis.
### What will be scraped

### Imports
```python
import requests, lxml
from bs4 import BeautifulSoup
from serpapi import GoogleSearch
```
### Process
Selecting `CSS` selectors to extract **container** with all data, **title, address, phone** (if there), **open hours, place options, website, directions link** to Google Maps.
[SelectorGadget](https://selectorgadget.com/) extension were used in the illustrated GIF.
<img width="100%" style="width:100%" src="https://media.giphy.com/media/8Lm4dx8zsd7VPMFgOL/giphy.gif">
**Extract phone numbers correctly**
To extract phone numbers no matter what language and country is used, e.g. German, Japanese, French, Italian, Arabic, etc. I used `regex` which you can see in action on [regex101](https://regex101.com/r/cwLdY8/1).
It also could be done with `xpath` but `beautifulsoup` doesn't support `xpath` directly and using [lxml.etree](https://lxml.de/tutorial.html) that supports `xpath` I didn't want either (*Examples from [Ian Hopkinson on GitHub](https://gist.github.com/IanHopkinson/ad45831a2fb73f537a79)).* I found really difficult or impossible to make it work with `CSS` selectors, so `regex` was used instead.
Firstly, a GIF illustration for a bit of familiarization.
<img width="100%" style="width:100%" src="https://media.giphy.com/media/j69D9KolEHs7EOzJw0/giphy.gif">
Secondly, it's because of this (*French language/country was used*):


Thirdly, now you see that sometimes `<span>` with a class `lqhpac` have <mark>**2** or **3**</mark> `<div>` elements inside it and **only the <mark>phone numbers</mark>** need to be extracted. That's why regular expression comes into play.
*A quick note: this issue doesn't occur at all if you're using `hl=en&gl=us` and this step could be skipped if you don't need data other than English.*
**Solution**
The solution is incredibly simple yet does what is supposed to:
1. locates ` · ` symbol that always appears.
2. creates a [capture group](https://docs.python.org/3/library/re.html#regular-expression-syntax) for the phone numbers and use `.*` which selects everything afterward.
3. the final regular expression will look like this: ` · ?(.*)`
*The screenshot below shows what is being captured with regular expression. Notice how the phone numbers differ and are still being captured.*

*You can learn about regular expressions on [regexone](https://regexone.com/), can't recommend it enough, such a great place to learn `regex`.*
### Code
```python
import requests, lxml, re, json
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
# phone extracting works with different countries, languages
params = {
"q": "mcdonalds",
"gl": "jp",
"hl": "ja", # japanese
}
response = requests.get("https://www.google.com/search", headers=headers, params=params)
soup = BeautifulSoup(response.text, 'lxml')
local_results = []
for result in soup.select('.VkpGBb'):
title = result.select_one('.dbg0pd span').text
try:
website = result.select_one('.yYlJEf.L48Cpd')['href']
except:
website = None
try:
directions = f"https://www.google.com{result.select_one('.yYlJEf.VByer')['data-url']}"
except:
directions = None
address_not_fixed = result.select_one('.lqhpac div').text
# removes phone number from "address_not_fixed" variable
# https://regex101.com/r/cwLdY8/1
address = re.sub(r' · ?.*', '', address_not_fixed)
phone = ''.join(re.findall(r' · ?(.*)', address_not_fixed))
try:
hours = result.select_one('.dXnVAb').previous_element
except:
hours = None
try:
options = result.select_one('.dXnVAb').text.split('·')
except:
options = None
local_results.append({
'title': title,
'phone': phone,
'address': address,
'hours': hours,
'options': options,
'website': website,
'directions': directions,
})
print(json.dumps(local_results, indent=2, ensure_ascii=False))
------------------------------------------
'''
# Japanese results:
{
"title": "マクドナルド 上田バイパス店",
"phone": "0268-28-4551",
"address": "長野県上田市",
"hours": " ⋅ 営業開始: 6:00",
"options": [
"イートイン",
"店先受取可",
"宅配"
],
"website": "https://map.mcdonalds.co.jp/map/20515",
"directions": "https://www.google.com/maps/dir//%E3%80%92386-0001+%E9%95%B7%E9%87%8E%E7%9C%8C%E4%B8%8A%E7%94%B0%E5%B8%82%E4%B8%8A%E7%94%B0+%E5%AD%97%E9%A6%AC%E9%A3%BC%E5%85%8D%EF%BC%91%EF%BC%98%EF%BC%94%EF%BC%90%EF%BC%8D%EF%BC%91+%E3%83%9E%E3%82%AF%E3%83%89%E3%83%8A%E3%83%AB%E3%83%89+%E4%B8%8A%E7%94%B0%E3%83%90%E3%82%A4%E3%83%91%E3%82%B9%E5%BA%97/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x601dbd18e95fda63:0x6e7cae08b9fb4c6c?sa=X&hl=ja&gl=jp"
}
------------------------------------------
# Arabic results:
{
"title": "McDonald's",
"phone": "",
"address": "Bahía Blanca, Buenos Aires Province",
"hours": " ⋅ سوف يفتح في 7:00 ص",
"options": [
"الأكل داخل المكان",
"خدمة الطلب أثناء القيادة",
"التسليم بدون تلامس"
],
"website": "https://www.mcdonalds.com.ar/",
"directions": "https://www.google.com/maps/dir//McDonald's,+Brown+266,+B8000+Bah%C3%ADa+Blanca,+Provincia+de+Buenos+Aires/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x95edbcb37fd850d3:0x5223e03c35a5110d?sa=X&hl=ar&gl=ar"
}
------------------------------------------
# Arabic results №2 (hl=ar (Arabic), gl=dz (Algeria))
{
"title": "McDonald's",
"phone": "+212 669-599239",
"address": "تطوان، المغرب",
"hours": "مفتوح ⋅ سيتم إغلاقه في 10:00 م",
"options": [
"الأكل داخل المكان",
"خدمة الطلب أثناء القيادة",
"التسليم بدون تلامس"
],
"website": "http://www.mcdonalds.ma/",
"directions": "https://www.google.com/maps/dir//McDonald's%D8%8C+Avenue+9+Avril,+%D8%AA%D8%B7%D9%88%D8%A7%D9%86+93000%D8%8C+%D8%A7%D9%84%D9%85%D8%BA%D8%B1%D8%A8%E2%80%AD/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0xd0b430da777d3cd:0x31a4be8cb9167e69?sa=X&hl=ar&gl=dz"
}
------------------------------------------
# French results:
{
"title": "McDonald's",
"phone": "04 70 28 00 16",
"address": "Saint-Victor",
"hours": "Ouvert ⋅ Ferme à 22:30",
"options": [
"Repas sur place",
"Service de drive",
"Livraison"
],
"website": "http://www.restaurants.mcdonalds.fr/mcdonalds-saint-victor",
"directions": "https://www.google.com/maps/dir//McDonald's,+Zone+Industrielle+de+la+Loue,+03410+Saint-Victor/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x47f0a77a2fb7e253:0x7c68ab4798e1655a?sa=X&hl=fr&gl=fr"
}
------------------------------------------
# Russian results:
{
"title": "Макдоналдс",
"phone": "8 (495) 103-38-85",
"address": "Москва",
"hours": "Открыто ⋅ Закроется в 00:30",
"options": [
"Еда в заведении",
"Еда навынос",
"Бесконтактная доставка"
],
"website": "https://www.mcdonalds.ru/",
"directions": "https://www.google.com/maps/dir//%D0%9C%D0%B0%D0%BA%D0%B4%D0%BE%D0%BD%D0%B0%D0%BB%D0%B4%D1%81,+%D1%83%D0%BB.+%D0%9A%D0%B8%D0%B5%D0%B2%D1%81%D0%BA%D0%B0%D1%8F,+2,+%D0%9C%D0%BE%D1%81%D0%BA%D0%B2%D0%B0,+121059/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x46b54b0efab9de2f:0x2e3336864cc08e8f?sa=X&hl=ru&gl=ru"
}
------------------------------------------
# German results:
{
"title": "McDonald's",
"phone": "03622 900140",
"address": "Laucha",
"hours": "Geöffnet ⋅ Schließt um 00:00",
"options": [
"Speisen vor Ort",
"Drive-in",
"Kein Lieferdienst"
],
"website": "https://www.mcdonalds.com/de/de-de/restaurant-suche.html/l/laucha/gewerbestrasse-1/549&cid=listing_0549",
"directions": "https://www.google.com/maps/dir//McDonald's,+Gewerbestra%C3%9Fe+1,+99880+Laucha/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x47a480ee11b6e809:0x403e2aa4d3d85996?sa=X&hl=de&gl=de"
}
------------------------------------------
# English results:
{
"title": "McDonald's",
"phone": "(620) 251-3330",
"address": "Coffeyville, KS",
"hours": " ⋅ Opens 5AM",
"options": [
"Curbside pickup",
"Delivery"
],
"website": "https://www.mcdonalds.com/us/en-us/location/KS/COFFEYVILLE/302-W-11TH/4581.html?cid=RF:YXT:GMB::Clicks",
"directions": "https://www.google.com/maps/dir//McDonald's,+302+W+11th+St,+Coffeyville,+KS+67337/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x87b784f6803e4c81:0xf5af9c9c89f19918?sa=X&hl=en&gl=us"
}
'''
```
### Using [Google Local Pack API](https://serpapi.com/local-pack)
SerpApi is a paid API with a free plan.
I would say that the difference is that iterating over rich, structured `JSON` is better than coding everything from scratch, and you don't need to use `regex` to find specific data, it's already there ʕ•́ᴥ•̀ʔ
```python
import json
from serpapi import GoogleSearch
params = {
"api_key": "YOUR_API_KEY",
"engine": "google",
"q": "mcdonalds",
"gl": "us",
"hl": "en"
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['local_results']['places']:
print(json.dumps(result, indent=2, ensure_ascii=False))
-------------------------
'''
# English result:
{
"position": 1,
"title": "McDonald's",
"place_id": "18096022638459706144",
"lsig": "AB86z5UHvsX5Pdo5ua4vplcxlXYG",
"place_id_search": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=en&lsig=AB86z5UHvsX5Pdo5ua4vplcxlXYG&ludocid=18096022638459706144&q=mcdonalds&tbm=lcl",
"rating": "A",
"links": {
"website": "https://www.mcdonalds.com/us/en-us/location/VA/RICHMOND/7527-STAPLES-MILL-RD/3735.html?cid=RF:YXT:GMB::Clicks",
"directions": "https://www.google.com/maps/dir//McDonald's,+7527+Staples+Mill+Rd,+Richmond,+VA+23228/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x89b115b9ff1b78cd:0xfb21fcb67cd15b20?sa=X&hl=en&gl=us"
},
"phone": "(804) 266-8600",
"address": "Richmond, VA",
"hours": "Closed ⋅ Opens 5:30AM",
"gps_coordinates": {
"latitude": 37.618504,
"longitude": -77.49884
}
}
-------------------------
# Arabic results:
{
"position": 1,
"title": "McDonald's",
"place_id": "2793317375272005807",
"lsig": "AB86z5XgEbNCVDhyL9L0Vp7aqSA4",
"place_id_search": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=ar&lsig=AB86z5XgEbNCVDhyL9L0Vp7aqSA4&ludocid=2793317375272005807&q=mcdonalds&tbm=lcl",
"rating": "A",
"links": {
"website": "https://www.mcdonalds.com/us/en-us/location/WA/SPOKANE/1617-NORTH-HAMILTON-STREET/36304.html?cid=RF:YXT:GMB::Clicks",
"directions": "https://www.google.com/maps/dir//McDonald's,+1617+N+Hamilton+St,+Spokane,+WA+99202/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x549e18c208497f9b:0x26c3db5a6a03b0af?sa=X&hl=ar&gl=us"
},
"phone": "(509) 484-8641",
"address": "1617 N Hamilton St",
"hours": "مغلق ⋅ سوف يفتح في 6:00 ص",
"gps_coordinates": {
"latitude": 47.672504,
"longitude": -117.39688
}
}
'''
```
### Links
[Code in the online IDE](https://replit.com/@DimitryZub1/Scrape-Google-Organic-Local-Place-Results-python#main.py) • [Google Local Pack API](https://serpapi.com/local-pack)
### Outro
If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at [@serp_api](https://twitter.com/serp_api).
Yours,
Dimitry, and the rest of SerpApi Team. | dmitryzub |
760,139 | Targeted Ads: A rare, good experience | On this week's episode of tech is just an enabler. I want to share something I have come across this... | 0 | 2021-07-24T13:57:08 | https://dev.to/igbominadeveloper/targeted-ads-a-rare-good-experience-1m55 | 
On this week's episode of tech is just an enabler.
I want to share something I have come across this week that I find interesting.
So you know how banks, - I live in Nigeria - So I can say something about how banks around here send you targeted emails for salary advance almost everytime - Access Bank does this to me a lot.
Anyways, there is this platform I use [https://app.letsdeel.com](Deel) to receive payments. They handle everything for managing contracts. From drawing up contracts, signing it, generating invoices, remittances to any destination account in the entire universe, they even support payments in crypto. You should check them out if you are looking for something really nice to manage your contractors or you need somewhere to get your funds moved across to your local bank accounts.
Let me get right on before I head down the path where I keep sounding like this is a promo article for Deel.
I was supposed to receive payment for last month's invoice some few days ago but I got word from the company I work with that the payment was going to come in a bit later than expected. Ideally, the payment should have been made to Deel already by the company that way, it enables Deel to make remittance to my account the exact day and date I have on the contract.
But since this month's didn't arrive already and they couldn't credit me, I got an email subtly letting me know that while I was waiting for the payment, I could apply for an advance if I needed it.
I wasn't surprised when the email came in, but I was really impressed and was all smiles, laying on my bed reading it when it came in. The timing was perfect because when I was expecting to get an email that I received a payment, I got one instead telling me about an advance payment option they had.
For me, it just reminds me of the following:
1. Building a product is the happy and simple part. Marketing it is another ball game entirely.
2. Just like people we meet everyday, we remember products for the tastes they leave in our mouths.
3. Data is powerful and could be used to great effects.
Another side to this is having to deal with data privacy and it just makes me wonder the good and amazing things companies could do with the user data they have access to. I have seen videos on the internet and responses to polls that suggest that people really don't mind targeted Ads/emails suggesting to them, stuffs to buy based on their needs or spending/shopping patterns. But for companies to be able to serve useful stuffs, they need to keep collecting data about their users and basically trusting them to do the right thing with the data. | igbominadeveloper | |
760,150 | Out of this World: Virgin Galactic Makes a Giant Leap for Mankind | From vinyl records to tech and travel, Richard Branson has pretty much got us covered in every aspect... | 0 | 2021-07-15T13:24:40 | https://dev.to/cleversoftwaregroup/out-of-this-world-virgin-galactic-makes-a-giant-leap-for-mankind-4bod | From vinyl records to tech and travel, Richard Branson has pretty much got us covered in every aspect of daily life.
This may not be a custom software development based blog this week, but at [Clever Software Group](https://cleversoftwaregroup.com/services), we like to keep our finger on the pulse when it comes to revolutionary moments in history. What took place last Sunday afternoon was most certainly one of those moments (and no, we are not talking about THAT Euro’s final).
Richard Branson and a crew of talented individuals embarked on Virgin Galactic’s first out of this world adventure. Having already conquered the music, telecommunications and health industries, it only seems natural that the next steps for the founder of one of the world’s most iconic brands, was to explore space travel.
At 3.30pm on Sunday 11th July 2021, Branson and the crew of Unity 22, were launched into the great unknown. The flight was a great success and in the dawn of a new age space race, Branson and the Virgin Galactic team entered the stratosphere 9 days ahead of Amazon founder, Jeff Bezos. Coined the ‘Billionaire Space Race’, Bezos founded Blue Origin in 2000, with Virgin Galactic following suit 4 years later. 2 decades have passed since two of the world’s wealthiest men began their space odyssey mission, with Branson just pipping the post with his flight last week.
The launch not only marked the spaceline’s fourth space flight, but its first fully crewed test flight. Having reach an altitude of 53.3 miles, the flight took place from Spaceport America, located in New Mexico, Texas. Spaceport America is the first purpose-built commercial space port. It seems that Branson is still continuing to add to the already gigantic number of ‘firsts’ he already has under his belt.
With a rich legacy now behind him, Branson originally founded Virgin Records in the 1970s, as a company that sold records via mail order. Having crossed literal oceans and broken many records throughout his outstanding career, the groundbreaking entrepreneur was hungry for his next big challenge. Branson has even described Virgin Galactic as being “the greatest adventure of them all”.
Virgin Galactic is intended to be the world’s first commercial spaceline. Although it may seem like a sci-fi idea to many, the dream is that space travel will become an everyday occurrence for everyday people. Just like popping on a flight from Bristol to Edinburgh, space travel will be accessible for all. Humankind has been venturing into space for just shy of 65 years. What was unimaginable over half a century ago, has become run of the mill in today’s digital society. The general public being able to experience space travel first hand, will be a very poignant aspect of the not-so-distant future. Now, it is more about when it will become a daily occurrence, instead of how and by what means.
Virgin Galactic’s first fully crewed test flight one small step towards a bigger advancement in space travel, but one giant leap towards an exciting new adventure of humankind. | cleversoftwaregroup | |
760,290 | Splitting huge NetlifyCMS config.yml file to multiple JS files | For a long time, I have been procrastinating in finding a solution to my ever-growing NetlifyCMS... | 0 | 2021-07-16T19:08:01 | https://iliascreates.com/blog/post/splitting-netlifycms-config-to-multiple-js-files/ | ---
title: Splitting huge NetlifyCMS config.yml file to multiple JS files
published: true
date: 2021-07-15 00:00:00 UTC
tags:
canonical_url: https://iliascreates.com/blog/post/splitting-netlifycms-config-to-multiple-js-files/
---
For a long time, I have been procrastinating in finding a solution to my ever-growing NetlifyCMS config.yml file.
## Context
The website I have been working on consists of 18 unique pages (home page, about page, contact page, etc) as well as of a blog feature. The content of each page is stored in frontmatter inside markdown files, except for the content of the blog posts which is stored in actual markdown.
To demonstrate the differences between the content of each page, have a look at the following snippets of 3 of those pages:
**Home page**
```yaml
---
title: Home
seo:
title: Lorem ipsum dolor sit amet
description: >-
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do
eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim
veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea
commodo consequat.
header:
title:
text_part_1: Sed ut perspiciatis
text_part_2: unde omnis iste natus
button:
text: Lorem ipsum
url: /lorem
subtitle: Lorem ipsum dolor sit amet, consectetur adipiscing elit.
key_facts_section:
title: At vero eos et accusamus
key_facts:
- title: Et harum quidem
icon: static/images/icons/clock.svg
- title: Nam libero tempore
icon: static/images/icons/earth.svg
testimonials: ...
---
```
**About page**
```yaml
---
title: About
menu:
footer:
weight: 40
main:
weight: 20
seo:
title: Quis autem vel eum
description: Et harum quidem rerum facilis est et expedita distinctio.
header:
title: About
video_section:
text: >-
Et harum quidem rerum facilis est et expedita distinctio. Nam libero
tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus
id quod maxime placeat facere possimus.
title: Rerum necessitatibus saepe
video: https://player.vimeo.com/video/845028457
team_section: ...
---
```
**Blog post**
```yaml
---
title: Et harum quidem rerum facilis est et expedita
date: 2017-02-28
description: >-
Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit
quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda
est, omnis dolor repellendus. Temporibus autem quibusdam et aut.
image: /images/uploads/featured-image.jpg
---
This is the body of the **blog post** , written in markdown.
```
As you can see the content of each page is vastly different from the others, yet there are some patterns that repeat themselves. To create a NetlifyCMS configuration file for all of the 18 pages and other data files I needed a **2’000 lines of code** config.yml file. This approach works, but the code is not very DRY and it is really hard to change something or add something new. It’s time to improve.
## Make the NetlifyCMS configuration code DRY
One valid approach to not repeatting parts of the YAML configuration would be to use [YAML anchors (`&`), aliases (`*`), and overrides (`<<`)](https://support.atlassian.com/bitbucket-cloud/docs/yaml-anchors/). But I discovered a better approach. ✨
### Using JavaScript instead of YAML
Through the [related GitHub issue](https://github.com/netlify/netlify-cms/issues/3624#issuecomment-616076374) and the new [beta NetlifyCMS feature of manual initialization](https://www.netlifycms.org/docs/beta-features/#manual-initialization) I discovered that I am not restricted to using YAML to configure the CMS. Using JS does not only allow me to split the configuration into multiple files but to create objects and functions to keep my code DRY as well.
#### File structure
The file structure that fits my needs is the following (the tree view is simplified to only show the related pages from the example snippets I mentioned above). Below I explain what the purpose and contents of each file are.
```
└── cms
├── index.js
├── editor-components.js
└── config/
├── index.js
├── fields.js
├── patterns.js
└── collections/
├── blog-posts
│ └── index.js
└── pages
├── about.js
├── blog.js
├── home.js
└── index.js
```
##### `cms/index.js`
Here is where I import the NetlifyCMS library. This file will eventually be parsed by Webpack in my setup and included in the `admin.html` file that is used to load the CMS.
```js
// Import NetlifyCMS library
import CMS from "netlify-cms";
import "netlify-cms/dist/cms.css";
// Import custom editor component from cms/editor-components.js
import myCustomEditorComponent from "./editor-components";
// Import NetlifyCMS JS configuration object from cms/config/index.js
import config from "./config";
// Disable loading of the configuration from the default config.yml file
window.CMS_MANUAL_INIT = true;
// Initialize NetlifyCMS with the JS configuration objext
window.CMS_CONFIGURATION = config;
CMS.init({ config });
// Register the custom editor component
CMS.registerEditorComponent(myCustomEditorComponent);
```
##### `cms/editor-components.js`
This file is not necessary to explain the setup, I’ve written another blog post on [creating custom NetlifyCMS editor components](/blog/post/embeding-youtube-videos-markdown-gatsby-netlifycms/), check it out!
##### `cms/config/index.js`
This is where we build our NetlifyCMS JS configuration object.
```js
// Import the configuration of each collection from cms/config/collections
import blogPostsCollection from "./collections/blog-posts";
import pagesCollection from "./collections/pages";
import pressReleasesCollection from "./collections/press-releases";
import servicesCollection from "./collections/services";
import siteConfigurationCollection from "./collections/site-configuration";
import testimonialsCollection from "./collections/testimonials";
// Build the Netlify JS configuration object
const config = {
backend: {
name: "gitlab",
repo: "website",
branch: "staging",
auth_type: "implicit",
app_id: "MY_APP_ID",
api_root: "https://my-self-hosted-gitlab.com/api/v4",
base_url: "https://my-self-hosted-gitlab.com",
auth_endpoint: "oauth/authorize",
},
// It is not required to set `load_config_file` if the `config.yml` file is
// missing, but will improve performance and avoid a load error.
load_config_file: false,
publish_mode: "editorial_workflow",
media_folder: "site/static/images/uploads",
public_folder: "/images/uploads",
collections: [
// Include the collections imported from cms/config/collections
pagesCollection,
servicesCollection,
blogPostsCollection,
commonPageSectionsCollection,
testimonialsCollection,
pressReleasesCollection,
siteConfigurationCollection,
],
};
export default config;
```
##### `cms/config/collections/pagesCollection/index.js`
This file groups together all the configuration objects from each individual page.
```js
import { collectionDefaults } from "../../patterns";
import homePageConfig from "./home";
import aboutPageConfig from "./about";
const pagesCollection = {
...collectionDefaults("Pages", "pages"),
files: [homePageConfig, aboutPageConfig],
};
export default pagesCollection;
```
##### `cms/config/collections/pagesCollection/home.js`
The configuration of a page. It utilizes fields and groups of fields (patterns) to keep the configuration code of the page DRY.
```js
import { stringField, textField, objectField, listField } from "../../fields";
import {
pageDefaults,
buttonDefaults,
titleWithSubtitleDefaults,
} from "../../patterns";
export default {
label: "Home page",
name: "home",
file: "site/content/_index.md",
fields: [
...pageDefaults,
objectField("Header", "header", [
...titleWithSubtitleDefaults(),
buttonDefaults(),
]),
objectField("Keyfacts section", "keyfacts_section", [
...titleWithSubtitleDefaults(),
listField("Keyfacts", "keyfacts", [
stringField("Title", "title", true),
textField("Text", "text"),
stringField("Icon", "icon", true),
]),
]),
],
};
```
##### `cms/config/fields.js`
The basic building blocks of the configuration file. Creating functions that return JS objects allows us to keep the code DRY by passing the necessary parameters when needed.
```js
export const textField = (label = "Text", name = "text", required = false) => ({
label,
name,
widget: "text",
required,
})
export const stringField = (
label = "String",
name = "string",
required = false
) => ({
label,
name,
widget: "string",
required,
})
export const objectField = (
label = "Object",
name = "object",
fields = [],
required = true
) => ({
label,
name,
widget: "object",
fields,
required,
})`
```
##### `cms/config/patterns.js`
Sometimes, patterns in the configuration of pages and collections emerge. This file groups fields together and exports these patterns.
```js
import { stringField, textField, objectField, hiddenField } from "./fields";
export const collectionDefaults = (label, name) => ({
label,
name,
editor: {
preview: false,
},
});
export const pageDefaults = [
stringField("Menu title", "title", true),
hiddenField("Menu", "menu"),
objectField("SEO", "seo", [
stringField("SEO title", "title"),
textField("SEO description", "description"),
]),
];
export const multiColorTitleDefaults = objectField("Title", "title", [
stringField("Text part 1", "text_part_1"),
stringField("Text part 2", "text_part_2"),
]);
export const buttonDefaults = (label = "Button", name = "button") =>
objectField(label, name, [
stringField("Text", "text", true),
stringField("URL", "url", true),
]);
export const titleWithSubtitleDefaults = (subtitleIsMarkdown = false) => [
multiColorTitleDefaults,
subtitleIsMarkdown
? markdownField("Subtitle", "subtitle")
: textField("Subtitle", "subtitle"),
];
```
## Conclusion
The above setup helped me reduce the total lines of code from around 2000 to just 900. It has also been proven that making updates to the configuration of each page has become a piece of cake 🍰 (navigating to the dedicated file is very easy by typing for example _“cms about”_ into the search bar of my editor to reach the configuration of the about page).
## Other resources
- [Configuring NetlicyCMS manual initialization in Gatsby](https://mrkaluzny.com/blog/dry-netlify-cms-config-with-manual-initialization/) | nop33 | |
760,426 | How to build a YouTube downloader in Python | Ever wanted to learn how to build your own YouTube downloader? I wrote a tutorial on how to do it in... | 0 | 2021-07-15T19:13:55 | https://dev.to/assemblyai_2/how-to-build-a-youtube-downloader-in-python-5748 | python, youtube, downloader, cli | Ever wanted to learn how to build your own YouTube downloader? I wrote a tutorial on how to do it in Python [here](https://www.assemblyai.com/blog/how-to-build-a-youtube-downloader-in-python) | assemblyai_2 |
760,490 | Early termination in functional folds a.k.a. reduce | Preface: This post is based on a dynamically typed version of Javascript called scriptum, i.e.... | 0 | 2021-07-15T20:15:31 | https://dev.to/iquardt/early-termination-in-functional-folds-a-k-a-reduce-3o94 | javascript, functional, tutorial, types | ---
title: Early termination in functional folds a.k.a. reduce
published: true
description:
tags: #javascript #functional #tutorial #types
//cover_image: https://direct_url_to_image.jpg
---
Preface: This post is based on a dynamically typed version of Javascript called scriptum, i.e. vanilla Javascript with explicit type annotations.
----
In imperative programming special constructs like `break` are used to programmatically terminate a loop before the underlying data structure is exhausted.
The functional counterpart of loops is recursion, but since recursion is a functional primitive we try to avoid it using folds as a more appropriate abstraction.
In lazy evaluated languages the special fold `scanl`, which stores all intermediate results of a computation, suffices. But in eagerly evaluated Javascript we must use another approach that includes local continuations:
```javascript
const foldk = fun(
f => init => xs => {
let acc = init;
for (let i = 0; i < xs.length; i++)
acc = f(acc) (xs[i]).run(id);
return acc;
},
"(b => a => Cont<b, b>) => b => [a] => b");
```
`foldk` looks pretty convoluted, but the type annotation alleviates the cognitive load:
```
"(b => a => Cont<b, b>) => b => [a] => b"
// ^^^^^^^^^^^^^^^^^^^^^^ ^ ^^^ ^
// | | | |
// 2-argument-function b-value array-of-a-values b-value
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ => ^^^^^^^^^^
// | |
// arguments result
```
It takes three arguments, a binary function, a value, an array of values and returns a value. `a` and `b` are placeholders for values of optionally different types.
We haven't discussed the most complicated part of the type though. The binary function `b => a => Cont<b, b>` returns a continuation. Luckily this is the only place where continuations appear, that is to say we only need to wrap the result of our binary function into `Cont`. This doesn't sound too hard.
So what is a continuation? Nothing more than a (partially applied) function with a function argument as its last formal parameter. So `inck` is not a continuaion, but `inck(2)` is:
```javascript
const inck = n => k => k(n + 1);
// ^^^^^^^^^^^^^
// |
// continuation
const continuation = inck(2);
continuation(x => x); // 3
```
With scriptum we don't use the bare continuation but put it into a type wrapper `Cont(k => k(n + 1))`. In order to access the continuation inside the wrapper, scriptum supplies the `.run` method.
Now that we clarified this let's come back to the original task to terminate from a fold programatically in order to see how `foldk` is applied in practice:
```javascript
foldk(fun(
x => s => Cont(fun(
k => x >= 5
? x // A
: k(x + s.length), // B
"(Number => Number) => Number")),
"Number => String => Cont<Number, Number>"))
(0) (["f","fo","foo","fooo","foooo"]); // 6
```
In line `B` we call the continuation `k`, i.e. the folding proceeds as usual. In line `A`, however, we just return the intermediate result without calling `k`. The folding is short circuited. The above computation calculates `"f".length + "fo".length + "foo".length` and then terminates the program due to the programatic reason that `x >= 5` yields `true`.
So far we haven't leveraged scriptum's runtime type system. We will use the `ANNO` symbol to access the intermediate types of each function application:
```javascript
foldk[ANNO]; // (b => a => Cont<b, b>) => b => [a] => b
result = foldk(fun(
x => s => Cont(fun(
k => x >= 5
? x // A
: k(x + s.length), // B
"(Number => Number) => Number")),
"Number => String => Cont<Number, Number>"));
result[ANNO]; // Number => [String] => Number
result = result(0)
result[ANNO]; // [String] => Number
result(["f","fo","foo","fooo","foooo"]); // 6
```
Hopefully, this little sketch gives a first insight how thinking in FP looks like and how type annotation can assist us in finding reliable solutions.
scriptum is published on [Github](https://github.com/kongware/scriptum). | iquardt |
760,533 | Easy access public APIs for projects! | Based from the title, you're probably wondering why if there is Google to help you look?... | 0 | 2021-07-18T19:16:02 | https://dev.to/tolentinoel/easy-access-public-apis-for-projects-94o | api, codenewbie, programming | Based from the title, you're probably wondering why if there is Google to help you look? Right?
Well, when I was was in the bootcamp, we had to build projects every phase and in need of these types of resources and build our own web app from it. I know there is alot more ways to search for these online, but this blog is to help save one's time in doing so.
First, what is a public API?
A public API is also known as open API. Open for public use and is usually free!
So, here's a few public APIs that either just caught my eye for a future build, or have used on my old projects!
#### 1.[Pexels](https://www.pexels.com/api/documentation/?language=javascript#introduction)
- Photo/Video API
- _[Authorization](https://www.pexels.com/api/documentation/?language=javascript#authorization): You would just need to request an API key by making a Pexels account and on the Doc is the format how to utilize that key on your code. It'll get you 20,000 request limit per month._
**Easy to follow Docs:**
**Sample photo from the API:**
<img src="https://images.pexels.com/photos/3573351/pexels-photo-3573351.png" alt="trees on drone footage"/>
#### 2.[NHTSA - National Highway Traffic Safety Administration](https://vpic.nhtsa.dot.gov/api/)
- Vehicle Info/Specs API(_Seems always updated, currently on Version: 3.7 - Last Code Change 6/12/2021_)
- Authorization: No API key needed!
**Sample response from the API:Variable List**

#### 3.[Random Joke](https://official-joke-api.appspot.com/random_joke)
- There's also endpoints like `/random_ten, /jokes/random,` or `/jokes/ten`.
- Authorization: No API key needed!
**Sample response from the API:/random_ten endpoint**

#### 4.[Pokemon API](https://pokeapi.co/api/v2/pokemon/)
- Free and open to use source of Pokemon data! From names, to sprites, to evolution chain! There are so much ways you can utilize this API with so much information it holds.
- Authorization: No API key needed!
**Sample images from the API:** _https://pokeapi.co/api/v2/pokemon/{:id}_ endpoint

#### 5.[MakeUp API](https://makeup-api.herokuapp.com/)
- Free source of cosmetic products, very usefule if you need to build a mock cosmetic webapp (Con: some of the image links aren't updated and you might need a default photo for those)
- Authorization: No API key needed!
**Easy to follow Docs:**
**Sample response from the API: Base URL**
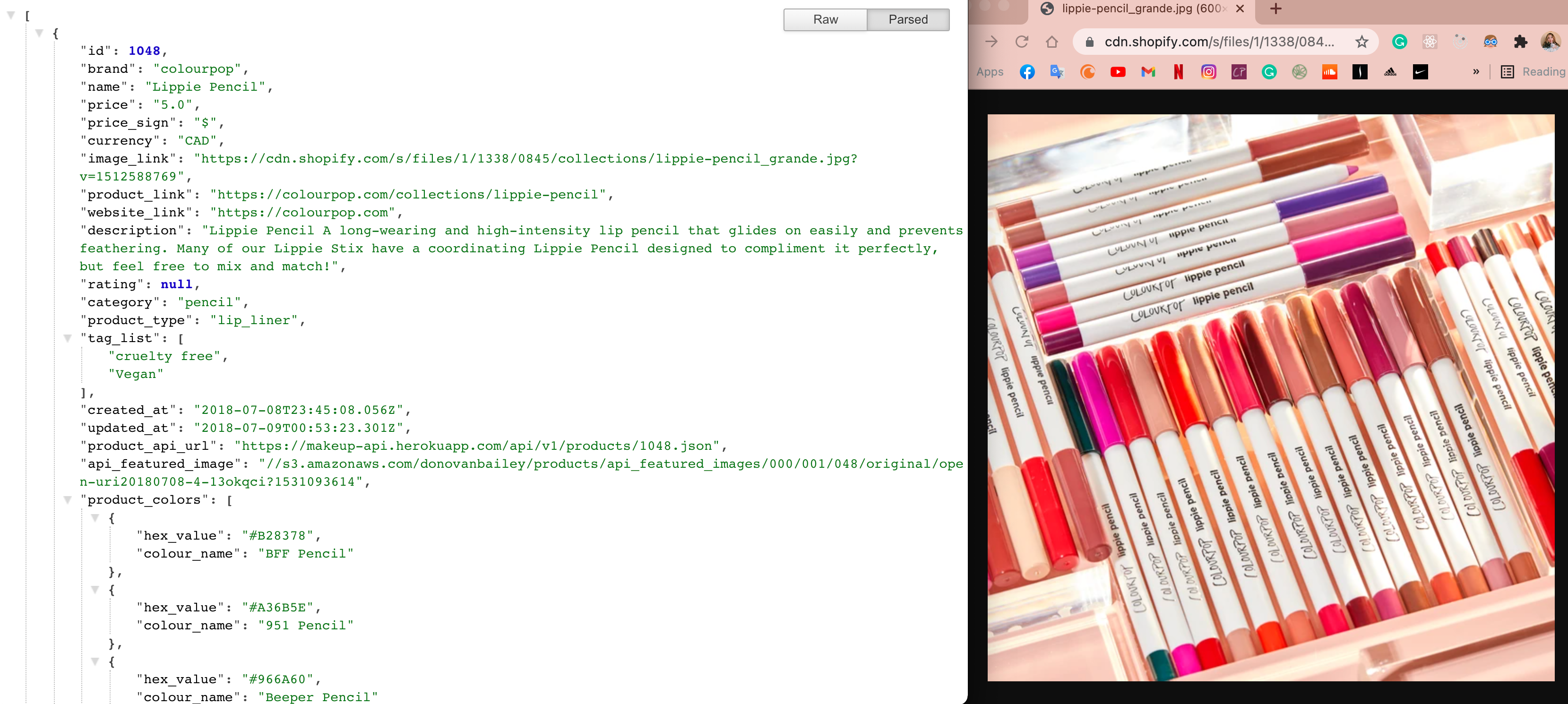
#### 6.[Skincare API](https://skincare-api.herokuapp.com/products)
- 1,700+ skincare products with their ingredient list and brand.
- Authorization: No need for API key or signup

#### 7. [Random Colors](https://www.colr.org/api.html)
- Returns a random hex-code in a string. Responses can be JSON and you can search by tags.
- Authorization: No need for API key or signup

#### 8. [Dictionary API](https://dictionaryapi.dev/)
- Base URL syntax: `https://api.dictionaryapi.dev/api/v2/entries/<language_code>/<word>`
- Free and supports 13 languages!
- Authorization: No API key needed!
**Easy to follow Docs:**
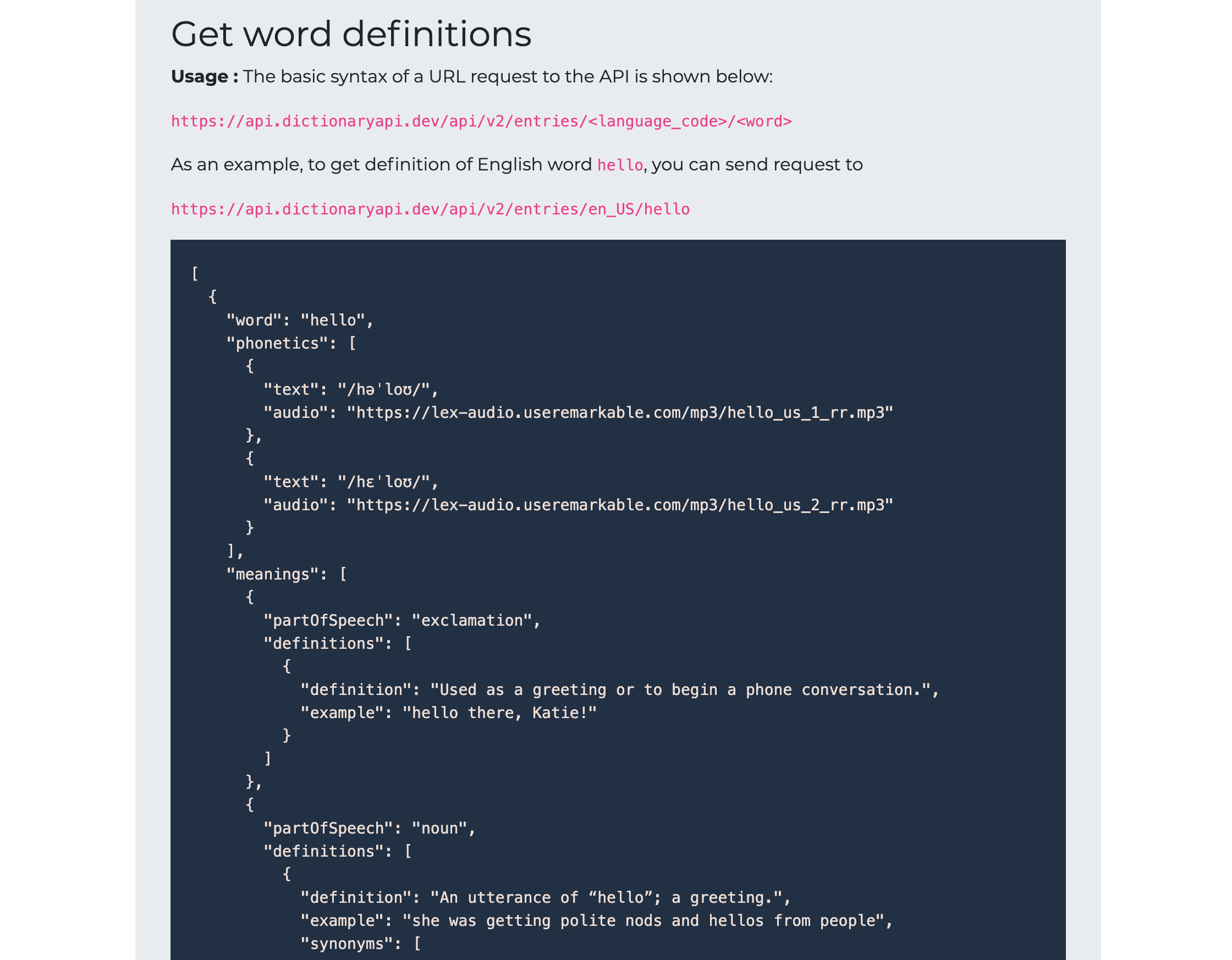
#### 9. [Songsterr](https://www.songsterr.com/a/wa/api/)
- Returns an array of songs per artist or word search. It supports xml, json, and plist.
- Authorization: No need for API key or signup
**Easy to follow Docs:**
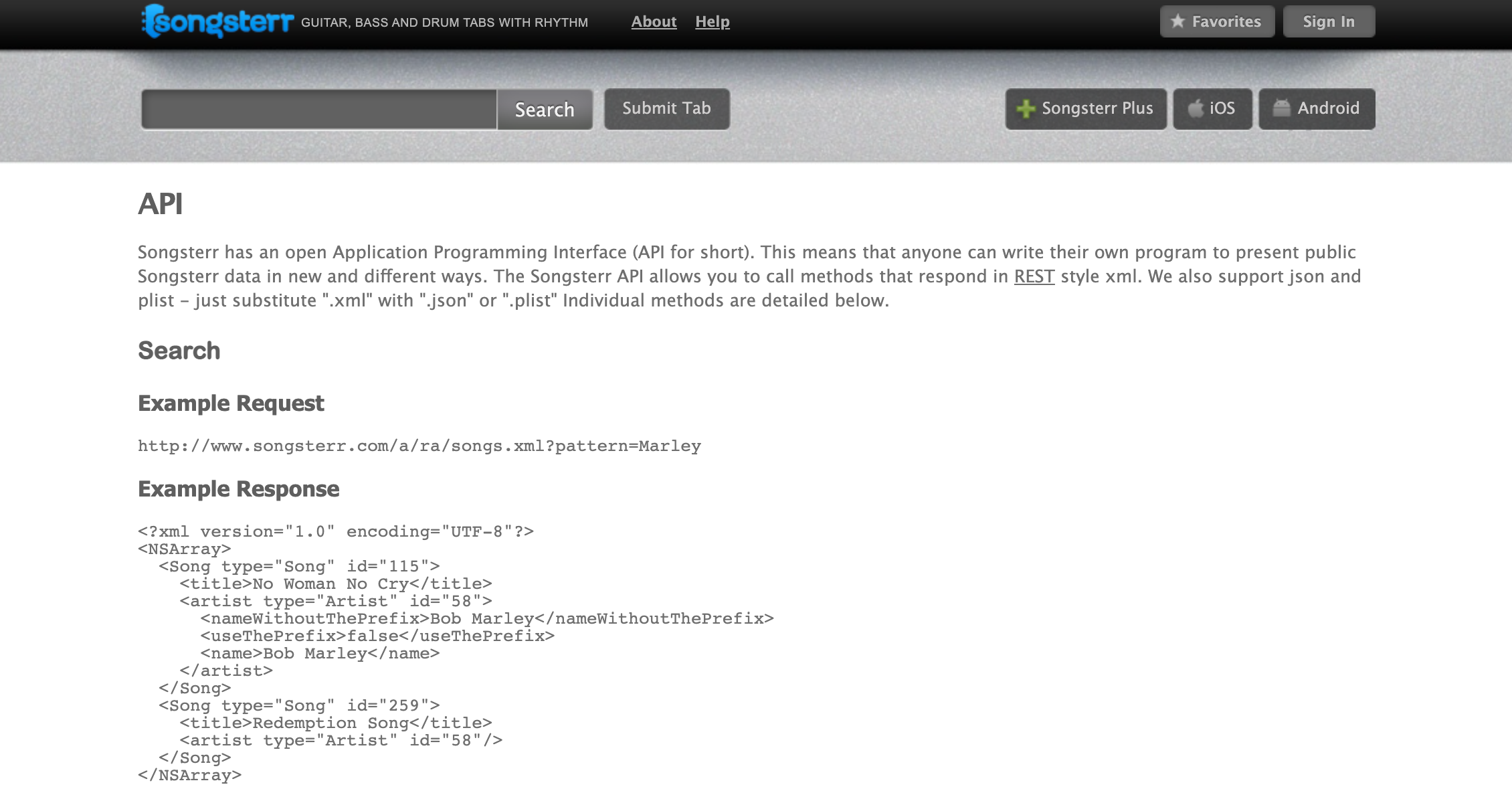
**Other sources for free API that I have used are from:**
- [RapidAPI](https://rapidapi.com/collection/list-of-free-apis)
- [Public API - Github repo](https://github.com/public-apis/public-apis) - Easy to go through since its sorted if you need any authorization.
- [Postman Public API](https://www.postman.com/explore/apis) - might need a little more time to browse around to see details of each API.
Hope this was helpful to anyone looking into utilizing some free & easy-access APIs into their projects! If you have any other suggestions of resources, feel free to share it in the comments below!
Until the next one!
| tolentinoel |
760,565 | Day 409 : In The Middle | liner notes: Professional : Today was the day! Had my workshop that I've been preparing. Before... | 0 | 2021-07-15T22:34:37 | https://dev.to/dwane/day-409-in-the-middle-3hpi | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Today was the day! Had my workshop that I've been preparing. Before that, I had a couple of meetings. A little after lunch it was time. I had everything set up. I was using 3 screens, everything was working. Awesome! About half way, everything is going fine, people seem to be interested, then my computer starts to get slower until it finally shuts off in the middle of my presentation. I thought the dongle was charging the laptop while powering the devices I had plugged into it. Apparently not. Had to wait a couple of minutes for it to charge up enough to turn on. Longest couple of minutes of my life. Luckily a co-worker was also there and was able to talk about something else. Got back on and continued where I left off. Still managed to get everything done within the time limit. Needless to say, I was tired and needed to take a nap after. haha.
- Personal : Watched the 'Loki' season finale. It was really good. I kind of knew already how it was ending but didn't know I would like it that much. Looking forward the the new season. Also watched an episode of "Fire Force". That's a good anime series and can't wait to catch up. Haven't heard back from that company that I was using their API to analyze my recorded videos from https://untilit.works to get a summary automatically created.
Just got up from a nap. Going to eat dinner and watch an episode of "Fire Force" and then probably finish putting together the radio show for this week and put together stuff for Sunday. Not sure if I'll do any coding.
Have a great night!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube cegTk1FZa1c %} | dwane |
760,610 | compose or pipes | Introduction Functional programming often use pipe and compose functions. They are higher... | 0 | 2021-08-18T02:50:20 | https://dev.to/mcube25/compose-or-pipes-3gi0 | ### Introduction
Functional programming often use pipe and compose functions. They are higher order functions. A higher order function is any function that takes a function as an argument, returns a function or both. We are going to have a look at the compose and pipe functions, the way they are built and a simple explanation of how they work.
##### Compose
when compose is called on a function, it gives a new function. for example
```
const dreamBig = (db) => { return console.log('hello' + db / 8) }
const dreamSmall = (ds) => { return console.log('hello' + ds + 6) };
const dreamLittle = (dl) => { return console.log('hello' + dl * 6); }
const result = dreamBig(dreamSmall(dreamLittle(4)));
console.log(result);
```
the variable result, is a function composition. The dreamBig executes first, and then the dreamSmall and lastly dreamLittle. They are nested functions and they execute from right to left.
A compose function is a nested function that runs from right to left.
To get the compose order from right to left as we see with nested functions calls in our example above, we need a reduceRight() method.
```
const compose = (...ftn) => val => ftn.reduceRight((prev, fn) => fn(prev), val);
```
The reduce function takes a list of values and applies a function to each of those values, accumulating a single result.
The method uses the currying method. The function is called or invoked immediately. It starts at the right and terminates at the left.
```
const composeResult = compose(dreamBig, dreamSmall, dreamLittle)(8)
console.log(composeResult);
```
#### pipes
For those that do not like reading from right to left as done in compose, pipes essentially changes the order of compose from left to right. It works like compose but uses the reduceLeft()
method instead.
```
const pipe = (...ftn) => val => ftn.reduce((prev, fn) => fn(prev), val);
const pipeResult = pipe(dreamLittle, dreamSmall, dreamBig)(8)
console.log(pipeResult);
```
We often see the functions on a separate line whether you are using a pipe or compose.
```
const composeResult2 = compose(
dreamBig,
dreamSmall,
dreamLittle
)(8);
```
The examples we have looked at use a pointer free style and with unary functions, we don't see the parameter passed between each function, only the parameters passed at the end of the compose or
pipe function when immediately invoking the function.
#### Deep dive into compose and pipe
Let us take a look at an example where we have possibly more than one parameter or when not working with a unary function
```
const divideBy = (divisor, num) => num / divisor;
//this function requires two parameters, the divisor and the num and it implicitly returns the result
const pipeResult3 = pipe(
dreamBig,
dreamSmall,
dreamLittle,
x => divideBy(7, x)
)(8);
console.log(pipeResult3);
```
Look at how we provide divideBy using the pipe method, all the results gotten from each of the functions is being passed to x.
then we use an anonymous function and we call divideBy, we provide a number and x goes into the function. This is how to reduce a function with multiple parameters in a pipe or compose function.
Could we curry the divideby function to get a unary function if we have already hard coded the number in the compose or method pipe.
```
const multiplyBy = (multiplier) => (num) => num * multiplier;
const multiplyBy2 = multiplyBy(2); //partially applied unary function
```
Here is what we can do
```
const pipeResult4 = pipe(
dreamBig,
dreamSmall,
dreamLittle,
multiplyBy2
)(8);
console.log(pipeResult3);
console.log(pipeResult4);
```
it will still work like the other unary function. Let us take a look at some other examples
```
const bahrain = "bahrain is a ccountry situated in the eastern part of arabia precisely the middle east"
```
here we are just going to count the words in the paragraph. lets define a couple of functions
```
const spaceSPlit = (str: string) => str.split(' ');
const number = (arr: string | any[]) => arr.length;
```
The spaceSplit method is going to look for each space in the paragraph while the function number is going to count how many words we have after splitting the string.
```
const howMany = pipe(
spaceSPlit,
number
);
```
if we create a pipe function and apply it on the string it will invoke first the spaceSplit function and then the number function. We don't have to call the function immediately but we can go ahead and log the function
```
console.log(howMany(bahrain));
```
So the major differences between compose and pipe is the order of their execution. | mcube25 | |
760,656 | Cuidados básicos para proteger as suas informações | Os celulares smartphone e os tablets são ferramentas poderosas para uma comunicação ágil e prática,... | 0 | 2021-07-16T01:36:15 | https://dev.to/nataliagranato/cuidados-basicos-para-proteger-as-suas-informacoes-545f | security | Os celulares smartphone e os tablets são ferramentas poderosas para uma comunicação ágil e prática, pois são portáteis e integram os recursos de telecomunicação instantânea por voz, vídeos, textos e dados. Muito utilizados no ambiente corporativo, esses equipamentos requerem dos usuários a adoção de comportamentos seguros, para preservar as informações armazenadas e acessadas neles.
São muitas as ameaças virtuais que podem atacar e invadir aparelhos que não estejam protegidos. Geralmente, essas ameaças têm o objetivo de espionar e roubar informações pessoais ou de alto valor para os negócios.
Os ataques de espionagem, comumente induzem a vítima a liberar permissões excessivas a aplicativos, clicar em links e imagens em mensagens recebidas ou digitar alguma de suas informações pessoais ou senhas em sites não confiáveis.
Assim como tomamos cuidados com os computadores, utilizando meios e ferramentas apropriadas para evitar que pessoas mal-intencionadas tenham acesso às informações, é imprescindível ter a mesma preocupação para manter os smartphones e tablets seguros.
Estar sempre alerta e adotar alguns cuidados simples, minimizam os riscos de informações importantes caírem em mãos alheias:
• Utilizar senhas e biometria para acesso ao celular e também aos aplicativos;
• Sempre atualizar o firmware e software do smartphone ou tablet, quando disponibilizado pelo fabricante;
• Instalar um bom antivírus e antimalware e sempre mantê-los atualizados;
• Configurar a conexão via bluetooth para não ser localizado por outros aparelhos;
• Não usar redes públicas e desprotegidas, principalmente wi-fi aberta ao público geral;
• Não armazenar senhas, dados importantes e informações de negócios e de clientes;
• Não acessar sites duvidosos;
• Não baixar aleatoriamente aplicativos ou arquivos, mesmo aqueles disponibilizados nas AppStore oficiais. Alguns aplicativos permitem rastreamento do celular e nem sempre são confiáveis;
• Utilizar formas de bloqueio aos aplicativos e mante-los atualizados;
• Avaliar as permissões e concessões requeridas na instalação dos aplicativos, como acesso à lista de chamadas, galeria de fotos, localização do aparelho e outros acessos remotos;
• Criptografar as informações sensíveis ou inclui-las em pastas protegidas;
• Não divulgar informações relacionadas à empresa em grupos de chat ou redes sociais;
• Nunca compartilhar celulares corporativos com outros colaboradores ou pessoas que não têm credencial para utilização;
• Obter e armazenar a identificação do IMEI do aparelho. Essa informação é essencial para lavrar o boletim de ocorrência em casos de perda, furto ou roubo;
• Ao trocar de aparelho ou se desfazer do seu celular, apague todas as informações contidas e restaure para configuração de fábrica;
• Comunicar à área de Telecom em caso de perda ou furto do celular corporativo.
Em caso de celular pessoal:
a) Informar sua operadora e solicitar o bloqueio do seu número;
b) Registrar Boletim de Ocorrência na delegacia mais próxima e informar os números IMEI do aparelho;
c) Alterar as senhas armazenadas e de contas registradas;
d) Bloquear cartões de crédito cujos números estejam armazenados em seu dispositivo ou aplicativos;
e) Ativar uma opção de acesso remoto do perfil do usuário, assim poderá rastrear onde o aparelho está ou apagar todos os dados nele armazenados.
Manter o celular ou tablet seguro é uma medida crucial para proteção dos dados pessoais
| nataliagranato |
760,819 | Learn Coding With Pomodoro Technique | Pomodoro. Have you heard it? The Pomodoro Technique is a time management method developed by... | 0 | 2021-07-16T06:15:29 | https://dev.to/manushifva/learn-coding-with-pomodoro-technique-4hdl | beginners, watercooler, learn | Pomodoro. Have you heard it? The Pomodoro Technique is a time management method developed by Francesco Cirillo in the late 1980s. The technique uses a timer to break down work into intervals, traditionally 25 minutes in length, separated by short breaks. Each interval is known as a pomodoro, from the Italian word for 'tomato', after the tomato-shaped kitchen timer that Cirillo used as a university student.
And, here it's a practice example:

So, based on this technique, i modify a bit to help you learn coding. So let's start.
## What all you need
- one project concept.
- code editor.
- any timer, you can use analog or digital.
## The rule
So, here it's the rule. I have classify this technique with 3 steps. First, read. Second, write. Last, read+write.
Read
At first, we read all documentation that we need. In this step, you are prohibited from doing any coding stuff, you also prohibited to note anything from the documentation that you read. This step duration is 5 minutes.
Write
After read the documentations, you need to write the code now. In this step, you are prohibited to read any type of documentation. This step duration is 10 minutes.
Read + Write
Lastly, in this step, you can read documentations and write the code at the same time. You can correct your wrong code, or write the forgotten syntax. This step duration is 10 minutes. After this step, you can take a short break (5-10 minutes).
You can do that 3 steps for some cycles. So here it's the technique conclusion:
- read 5 minutes
- write 10 minutes
- read+write 10 minutes
- break 5-10 minutes
This technique help me 2x faster to learn a new language. That's all, Thanks for reading! | manushifva |
760,834 | Best Makefile for Docker project (M1 Compatible) | Hi ! Here is the best Makefile ever, It's now easy to use Registry Gitlab to push your docker... | 0 | 2021-07-16T07:13:07 | https://dev.to/simerca/best-makefile-for-docker-project-m1-compatible-516p | docker, devops | Hi !
Here is the best Makefile ever,
It's now easy to use Registry Gitlab to push your docker images and use repo name as image name.
```makefile
REGISTRY_ID=$(shell grep gitlab.com .git/config|sed 's/url = https:\/\//registry./g'|sed -e "s/\.git$$//g"|xargs)
TAG=$(shell git symbolic-ref --short -q HEAD|sed -e 's/master$$/latest/g'|sed 's/\([a-zA-Z]*\)\//\1-/g')
build:
docker build -t $(REGISTRY_ID):$(TAG) .
run: build
docker run --rm $(REGISTRY_ID):$(TAG)
dev:
docker run --rm $(REGISTRY_ID):$(TAG)
push:
docker push $(REGISTRY_ID):$(TAG)
pushm1:
docker buildx build --platform linux/amd64 --push -t $(REGISTRY_ID):$(TAG) .
buildm1:
docker buildx build --platform linux/amd64 -t $(REGISTRY_ID):$(TAG) .
```
Realy easy to use:
Build images
`make build`
Push images
`make push`
Run images
`make run`
Test images
`make dev``
For Mac M1 Chip, to use for build AMD64 images
Build for amd64 when your use macbook m1
`make buildm1`
Push for amd64
`make pushm1`
| simerca |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.