
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,302,121 | How to create Prefabs in Unity3D? | This short article explains what Unity's Prefabs are and what they are useful for. Motivation Let's... | 0 | 2022-12-19T12:14:07 | https://dev.to/kiranjodhani/how-to-create-prefabs-in-unity3d-2egi | unity3d, csharp, gamedev, tutorial | This short article explains what Unity's Prefabs are and what they are useful for.
**Motivation**
Let's imagine that we want to make a Tower Defence game in Unity. At first we would create a Tower GameObject, that would look something like this in the Hierarchy:
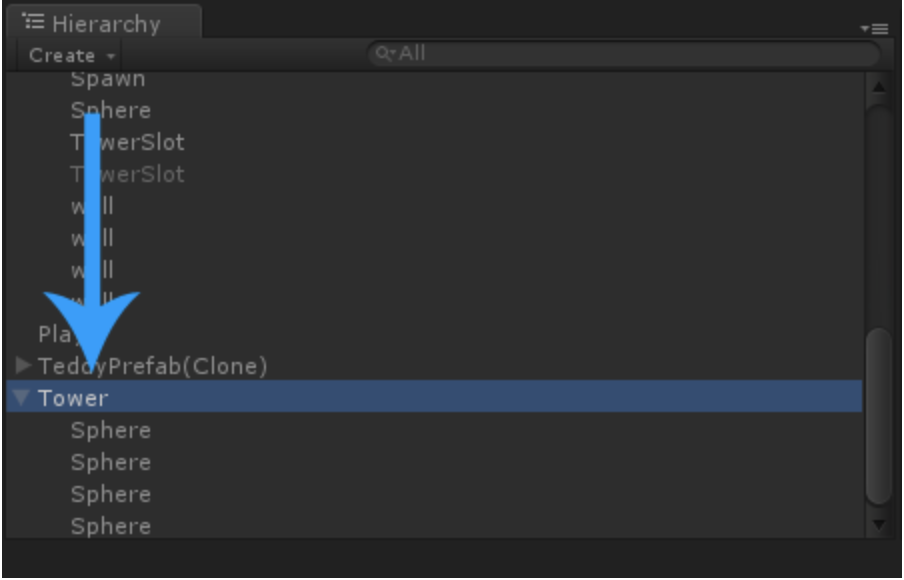
When the player starts the game, usually there are no Towers in the scene yet. What we need is a way to save our Tower GameObjects somewhere and then load them into the Hierarchy again as soon as the player wants to build a tower.
This is what Prefabs are for.
**Creating a Prefab**
Let's create a Prefab. It's very easy, all we have to do is drag our GameObject from the Hierarchy into the Project area like this:
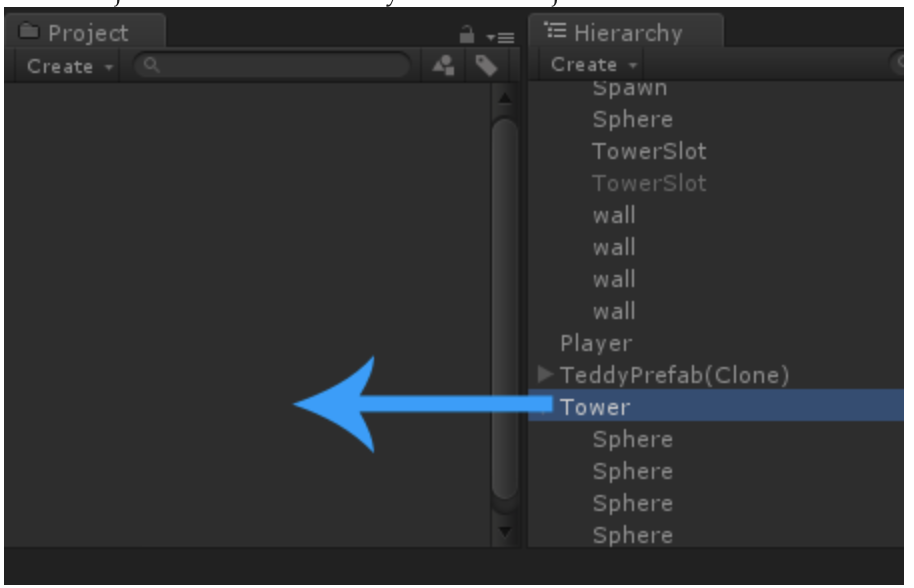
Afterwards we can see the Prefab in our Project area:
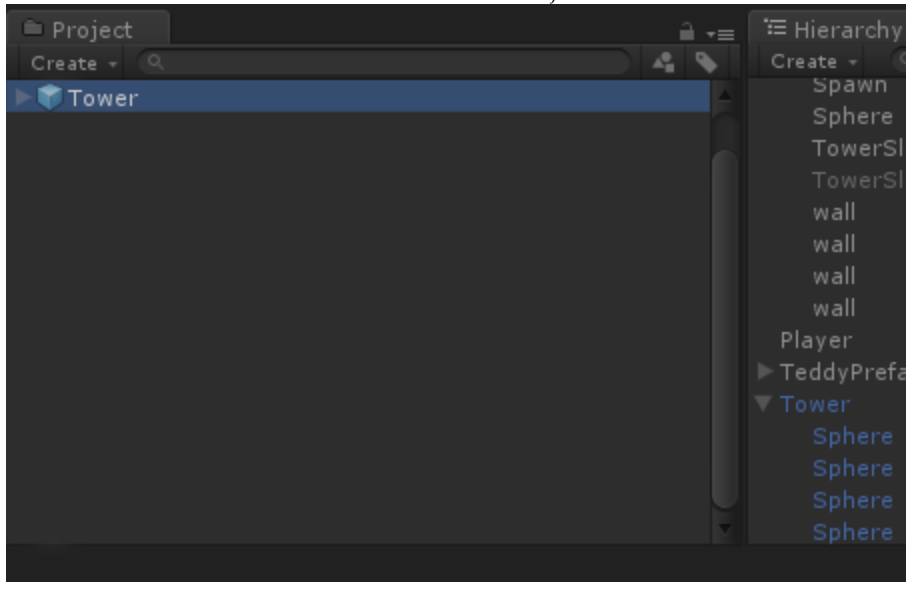
Now we can delete the GameObject from our Hierarchy so it's not in the game world anymore. But since it's in the Project area, we don't lose it completely.
**Loading a Prefab**
If we want to load a prefab, we have two options. We can either do it manually by dragging it from the Project area into the Hierarchy area, or by using a script that calls Instantiate.
Here is an example script that loads a Prefab as soon as the game starts:
using UnityEngine;
using System.Collections;
public class Test : MonoBehaviour {
public GameObject prefab = null;
void Start () {
// instantiate the prefab
// -> transform.position means that it will be
// instantiated at the position of *this*
// gameobject
// -> quaternion.identity means that it will
// have the default rotation, hence its not
// rotated in any weird way
Instantiate(prefab,
transform.position,
Quaternion.identity);
}
}
Now all we have to do is add the Test script to a GameObject in the scene, take a look at the Inspector and then set the public prefab variable to any Prefab from our Project area like this:
After pressing start, it immediately loads our Tower Prefab into the scene.
Simple as that!
| kiranjodhani |
1,302,344 | Collecting info for the development of a community mobile app shielding SDK (freeRASP React Native flavor) | Based on experience with freeRASP for Android/iOS/Flutter/Cordova, there should be a demand for a... | 0 | 2022-12-19T13:39:33 | https://dev.to/sirionrazzer/collecting-info-for-the-development-of-a-community-mobile-app-shielding-sdk-freerasp-react-native-flavor-2koo | reactnative, security, freerasp, mobile | Based on experience with freeRASP for Android/iOS/Flutter/Cordova, there should be a demand for a shielding SDK for RN-based apps, right? I worked on the development of previous freeRASP flavors, and I would like to support React Native apps also. However, this will be quite a new experience as I am not well-versed in the RN ecosystem yet. That's why I would highly appreciate any tips regarding package management, nuances of hybrid development in the RN world, etc. I target iOS and Android platforms.
Is there anything specific you would like to see in the implementation?
Anything to watch out for?
Goals
Easy to use SDK that satisfies needs of app security and mobile OWASP MAS compliance
Available on GitHub and also as a npm package
Configurable (~ same as Flutter version) - configuration as a single object
Lightweight
It will be able to detect reverse engineering, debugger, simulator, repackaging or cloning attempts, running the app in an unsafe OS environment (e.g., root or jailbreak), hooking frameworks, and installing the application through unofficial stores. | sirionrazzer |
1,302,414 | Oh boy, this is exciting! | So last Saturday and Sunday I took the time to finally complete the set of features I wanted to... | 0 | 2022-12-19T15:54:55 | https://dev.to/webjose/oh-boy-this-is-exciting-3mee | webdev, javascript, programming, react | So last Saturday and Sunday I took the time to finally complete the set of features I wanted to deliver in **v2.0.0** of [wj-config](https://www.npmjs.com/package/wj-config).
So I did that on Saturday and started re-working the React v18.2.0 example I have in the repository to make sure all was working as expected. While doing this and updating the project's README, I realized of a few things that led me to work on higher API to help comply with **DRY**. This took the Sunday evening.
#### Quick Screenshot of the React Sample

---
Anyway, the end result is quite interesting. Let me put it like this: Have you ever had the need to have configuration values vary depending on things like the browser the user is using? (Honest question, I am no backend developer). Well, now you'll be able to!
One new feature, **conditional inclusion of data sources** allows you to run abritrary checks, including things like checking for browser capabilities. I'll give you a preview of the example code I wrote for the README:
```javascript
import wjConfig, { Environment } from "wj-config";
import mainConfig from './config.json';
// Chromium-based browsers.
var isChromium = !!window.chrome && (!!window.chrome.webstore || !!window.chrome.runtime);
export default await wjConfig()
.addObject(mainConfig)
.name('Main')
.addFetchedConfig('/config.chromium.json')
.when(e => isChromium, 'Chromium')
.build();
```
## Per-Region Or Per-Tenant Configuration
>This was the original feature I wanted to complete before releasing **v2.0.0** as a production package.
Have you ever had this need to have different production configuration files per region or per tenant, and maybe even for pre-production environments too? Have you done this combination of files yourself, producing stuff like `config.prod.tenantA.json`, `config.prod.tenantB.json`, `config.pre-prod.tenantA.json` and `config.prod.tenantB.json`? And so on for other environments?
Well, with **Per-Trait Configuration** this multiple configuration file creation will no longer be needed. Here's an example preview taken from the upcomming README. It basically computes the combination you need on the spot:
```javascript
import wjConfig, { Environment, EnvironmentDefinition } from "wj-config";
import myTraits from './myTraits.js';
// Easiest to show with NodeJS as we already have an environment object with all variables ready.
// The ENV_TRAITS environment variable would contain the desired trait value assigned when deploying.
const currentEnvDef = new EnvironmentDefinition(process.env.NODE_ENV, process.env.ENV_TRAITS);
const env = new Environment(currentEnvDef, ['MyList', 'OfPossible', 'Environments']);
// Main configuration file. Boolean argument defines if the file must exist.
const mainConfig = loadJsonFile('./config.json', true);
// Classic per-environment configuration.
const perEnvConfig = loadJsonFile(`config.${env.current.name}.json`, false);
export default await wjConfig()
.addObject(mainConfig)
.name('Main')
.addObject(perEnvConfig)
.name(env.current.name)
.addComputed(() => loadJsonFile('config.amr.json', false))
// The second parameter is just the data source name.
.whenAllTraits(myTraits.Americas, 'Americas') // <-- It conditions the recently added data source.
.addComputed(() => loadJsonFile('config.eur.json', false))
.whenAllTraits(myTraits.Europe, 'Europe')
.addComputed(() => loadJsonFile('config.asa.json', false))
.whenAllTraits(myTraits.Asia, 'Asia')
.includeEnvironment(env)
.build();
```
Oh, if you don't know, **wj-config** works for **React** and **NodeJS** the same way. The only differences you see is things like fetching config files in React, but loading files in NodeJS.
Still working on the final details of the documentation and making sure the TypeScript types are all updated and reflecting the new API properly. Maybe by next weekend we'll have a commit and a new NPM package upload. Fingers crossed! | webjose |
1,302,499 | Build a full-stack application with AdminJS | Written by Clara Ekekenta✏️ Building custom admin panels for each Node.js project can be a... | 0 | 2022-12-21T15:00:25 | https://blog.logrocket.com/build-full-stack-application-adminjs | node, webdev | **Written by [Clara Ekekenta](https://blog.logrocket.com/build-full-stack-application-adminjs/)✏️**
Building custom admin panels for each Node.js project can be a time-consuming task for a developer, especially given the number of projects they handle. As a result, there is a growing demand for alternative tools designed to reduce the developer's workload.
This article highlights the features of an open source Node.js admin panel that promises to do just that: [AdminJS](https://adminjs.co). The tutorial portion of this post will demonstrate how to use AdminJS to build a full-stack application.
_Jump ahead:_
* [What is AdminJS?](#what-is-adminjs)
* [Why use AdminJS?](#why-use-adminjs)
* [Setting up a new project](#setting-up-a-new-project)
* [Adding the Express.js plugin](#adding-the-expressjs-plugin)
* [Adding the MongoDB adapter](#adding-the-mongodb-adapter)
* [Creating the blog model](#creating-the-blog-model)
* [Creating resources](#creating-resources)
* [Creating action handlers](#creating-action-handlers)
* [Backend actions](#backend-actions)
* [Actions with visible UI](#actions-with-visible-ui)
* [Adding user authentication](#adding-user-authentication)
* [Setting up the frontend](#setting-up-the-frontend)
* [Testing the application](#testing-the-application)
## What is AdminJS?
AdminJS, previously called AdminBro, is an open source administrative panel interface tailored to meet the needs of Node.js applications. This interface eliminates the time and effort required to develop a custom admin page. Instead, users can easily view and manage content with the AdminJS UI.
AdminJS is built with React and offers a range of customizability, it also provides a REST API that can be integrated into other applications.
## Why use AdminJS?
With AdminJS, users can quickly build and set up administrative dashboards and applications. To help you evaluate whether you should consider AdminJS for your application needs, here’s a summary of its features:
* Easy integration with other applications: AdminJS can be easily integrated into a host of other applications such as SQL and NoSQL data sources and frameworks like Express.js, NestJS, and Fastify
* Does not impose its database schema on the user: AdminJS supports a variety of ORMs and ODMs, enabling users to connect with their database of choice
* Backend agnostic: Users can create, read, update, and delete content regardless of the choice of data source
* Advanced filtering feature: Users can easily trace specific search queries by applying multiple criteria to quickly filter out unwanted results
* Flexible user management: Different authorization levels can be set for users. This feature can also create roles and can restrict specific actions, such as data modification, to particular users
* Easy customization: The visual appearance of the AdminJS UI can be modified to meet user needs
* Customizable features: Several standard features, like file upload, bulk edits, export, user profile, and password hashing, can be applied to data sources; users can also create unique characteristics as desired
## Setting up a new project
To start with AdminJS, we’ll need to install the AdminJS core package and set it up with a plugin and adapter of our choosing. For this tutorial, we’ll use the Express.js plugin and MongoDB adapter.
To install the AdminJS core package on your local machine, navigate to the directory of your choice and open up a CLI. In the command line, use one of the following commands to install AdminJS with npm or Yarn:
```javascript
npm init
//select default options and fill out fields as desired
npm i adminjs
```
```javascript
yarn init
//select default options and fill out fields as desired
yarn add adminjs
```
### Adding the Express.js plugin
To add the Express plugin, we’ll use one of the following commands in the CLI:
```javascript
npm i @adminjs/express # for Express server
```
```javascript
yarn add @adminjs/express # for Express server
```
### Adding the MongoDB adapter
Next, we’ll add the MongoDB adapter to our application with one of the following commands:
```javascript
npm i @adminjs/mongoose mongoose # for Mongoose
```
```javascript
yarn add @adminjs/mongoose mongoose # for Mongoose
```
With our installation completed, we can finish our setup by connecting the installed plugin and adapter to our AdminJS package. First, we’ll install Express.js:
```javascript
//npm
npm i express tslib express-formidable express-session
//yarn
yarn add express tslib express-formidable express-session
```
Next, we’ll set up a simple application with Express. In the file directory, we’ll create a new file, `App.js`, and add the following:
```javascript
const AdminJS = require('adminjs')
const AdminJSExpress = require('@adminjs/express')
const express = require('express')
const PORT = 3000
const startAdminJS = async () => {
const app = express()
const admin = new AdminJS({})
const adminRouter = AdminJSExpress.buildRouter(admin)
app.use(admin.options.rootPath, adminRouter)
app.listen(PORT, () => {
console.log(`Listening on port ${PORT}, AdminJS server started on URL: http://localhost:${PORT}${admin.options.rootPath}`)
})
}
startAdminJS()
```
Here we created a simple AdminJS interface. In this tutorial, we’ll add a MongoDB data source, add authentication to our AdminJS UI, and use the database to create a simple application.
## Creating the blog model
We’ll be using MongoDB as the data source for our AdminJS panel. As a prerequisite, we’ll need to create a database on MongoDB and connect our application to it with the Mongoose adapter.
To get started, log into MongoDB and select **Create Organization**: 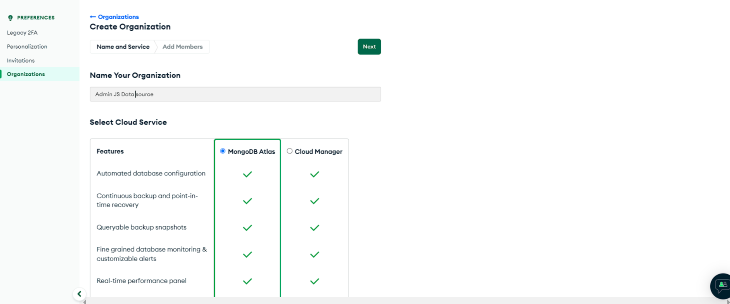 Here we created an organization named “AdminJS data source”.
Next, we’ll add a new project to our organization; we’ll name the project “Books Model”: 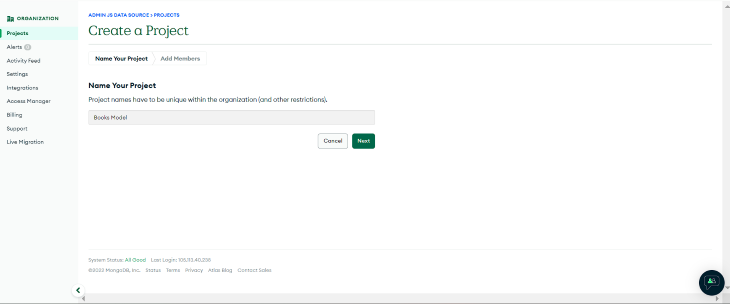 Next, we’ll be prompted to create a new database. For this tutorial, we’ll build a shared cluster called "Books".
Now, we’ll create admin credentials for the cluster, and add the localhost URL to the **IP address** field. To get connection credentials, click on **Connect** and select **connect with MongoDB native adapters**. In the full-stack application, we can find the unique URI to connect our app to the database.
In the application's working directory, we’ll create a `bookModel` folder and a `book.model.js` file. In `book.model.js` file, we’ll define the schema for our database:
```javascript
const mongoose = require('mongoose');
const BookSchema = new mongoose.Schema({
title: { type: String },
author: { type: String },
});
const Book = mongoose.model('Book', BookSchema);
module.exports = {
BookSchema,
Book,
}
```
The `BookModel` defined schema will have the following fields: `title` and `author`.
### Creating resources
Next, we’ll add the model created in the previous section to our `app.js` file, connect our application to MongoDB, and create an AdminJS instance.
To do this, make the following modifications to the `app.js` file:
```javascript
//previous libraries import
const mongoose = require("mongoose");
const AdminJSMongoose = require("@adminjs/mongoose");
const { Book } = require("./bookModel/book.model.js");
AdminJS.registerAdapter({
Resource: AdminJSMongoose.Resource,
Database: AdminJSMongoose.Database,
})
//port
const startAdminJS = async () => {
const app = express();
const mongooseDB = await mongoose
.connect(
"mongodb+srv://ZionDev:Itszion4me@books.gawbiam.mongodb.net/?retryWrites=true&w=majority",
{
useNewUrlParser: true,
useUnifiedTopology: true,
}
)
.then(() => console.log("database connected"))
.catch((err) => console.log(err));
const BookResourceOptions = {
databases: [mongooseDB],
resource: Book,
};
const adminOptions = {
rootPath: "/admin",
resources: [BookResourceOptions],
};
const admin = new AdminJS(adminOptions);
//other code
```
Here we added the `Book` model as a resource to AdminJS. We also added the MongoDB database so that it will automatically update as we perform CRUD operations in AdminJS.
If we run the application with the `node App.js` command, we’ll get the AdminJS default screen and the `Book` model will appear in the navigation section: 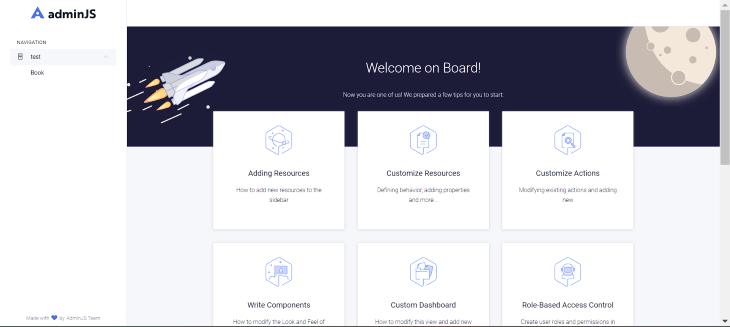
## Creating action handlers
AdminJS provides the following actions: list, search, new, show, edit, delete, and bulk delete. It also allows the user to define custom actions when required. Actions to be created can be placed in two categories:
* Actions that run on the backend and do not display visible UI
* Actions that render components
Both actions are similar in that they are created in the same pattern. The significant difference between both patterns is the addition of a `component` props. Let's look at how we can make both types of actions.
### Backend actions
To create these actions, we’ll use the following syntax:
```javascript
const BookResourceOptions = {
resource: Book,
options: {
actions: {
GetJsonData: {
actionType: "record",
component: false,
handler: (request, response, context) => {
const { record, currentAdmin } = context;
console.log("record", record);
return {
record: record.toJSON(currentAdmin),
msg: "Hello world",
};
},
},
},
},
};
```
Here, we added a custom action to the `BookResourceOption`. The above command has the `component` property set to `false`. Hence, no component will be rendered and the action will run on the backend. The resulting output will be the selected record's data.
### Actions with visible UI
Next, we’ll need to create a component that the action will render. Then, we’ll add the designed component to the `component` property field.
For example, suppose we have the following custom React component:
```javascript
import React from 'react'
import { ActionProps } from 'adminjs'
const ShowRecord = (props) => {
const { record } = props
return (
<Div>
<h1>This is a simple component</h1>
<p>Below are our records</p>
<span>
{JSON.stringify(record)}
</span>
</Div>
)
}
export default ShowRecord
```
Once it’s created, we can add it to the `component` property, like so:
```javascript
component: AdminJS.bundle('./ShowRecord'),
```
## Adding user authentication
AdminJS can add user authentication for viewing and managing content; this can help better secure data and restrict unwanted access. We can add authentication to our AdminJS application with the `express` plugin. To do so, we’ll make the following modification to the `App.js` file:
```javascript
//other code
//login details
const DEFAULT_ADMIN = {
email: 'developer@admin.com',
password: 'administrator',
}
// handle authentication
const authenticate = async (email, password) => {
//condition to check for correct login details
if (email === DEFAULT_ADMIN.email && password === DEFAULT_ADMIN.password) {
//if the condition is true
return Promise.resolve(DEFAULT_ADMIN)
}
//if the condition is false
return null
}
```
Finally, we’ll replace AdminJS `buildRouter` with the `buildAuthenticatedRouter` and pass the authentication credentials to it:
```javascript
const adminRouter = AdminJSExpress.buildAuthenticatedRouter(
admin,
{
authenticate,
cookieName: "AdminJS",
cookiePassword: "Secret",
},
null,
{
store: mongooseDB,
resave: true,
saveUninitialized: true,
secret: 'Secret',
name: 'adminjs',
}
);
```
With this, we get a login page to access the AdminJS instance: 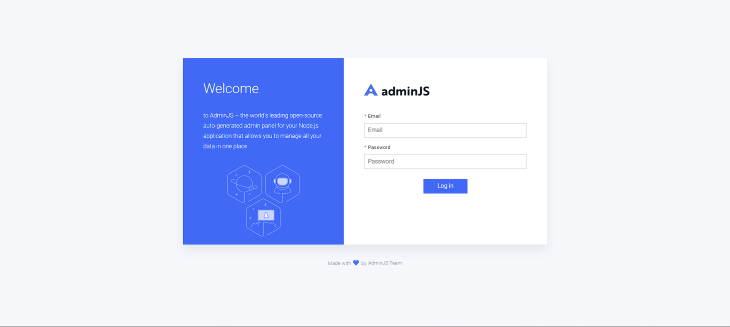
## Setting up the frontend
Next, we’ll build a book list application with Next.js and Axios, connect the AdminJS interface to the application, and display stored content. To access the AdminJS content, we’ll create an API request to the URL instance running on the backend.
In the `api` directory, we’ll create a file: `getBooks.js`. Next, we’ll make an API request to the `Books` resource in this file. The API endpoint for resources takes the following syntax:
```javascript
.../api/resources/{resourceId}/actions/{action}
```
In this case, our resource `id` is `Book`, and the action to be performed is `list`. This action will return all data stored in the resource. Add the following code to the `getBooks.js` file:
```javascript
import axios from "axios";
export default async function handler(req, res) {
await axios
.get("http://localhost:3000/admin/api/resources/Book/actions/list")
.then((response) => {
return res.status(200).json(response.data.records);
})
.catch((error) => {
console.log(error);
});
}
```
The above code returns a response containing our resource data. We can access this data as `static props` on the frontend in our `index.js` file:
```javascript
export default function Home(props) {
console.log(props);
return (
<div style={{display:"flex", alignItems:"center", height:"100vvh", paddingTop:"55px", flexDirection:"column"}}>
<h1>Book List Application</h1>
<div style={{marginTop:"34px"}} >
{/* book List container */}
{props.books.map((book) => {
return (
<div style={{display:"flex", flexDirection:"column", border:"1px solid black", width:"500px", padding:"10px", margin:"10px"}}>
<h2>{book.params.title}</h2>
<p>{book.params.author}</p>
</div>
);
}
)}
</div>
</div>
)
}
export const getStaticProps = async () => {
const res = await fetch('http://localhost:3001/api/getBooks');
const data = await res.json();
return {
props: { books: data }
}
}
```
We use `getStaticProps` to fetch data from the API route and pass it as a `props`. Then, we can access this `prop` on the frontend and return the `title` and `author` for each array element in the response.
## Testing the application
To test our application, we’ll create entries using the AdminJS instance: 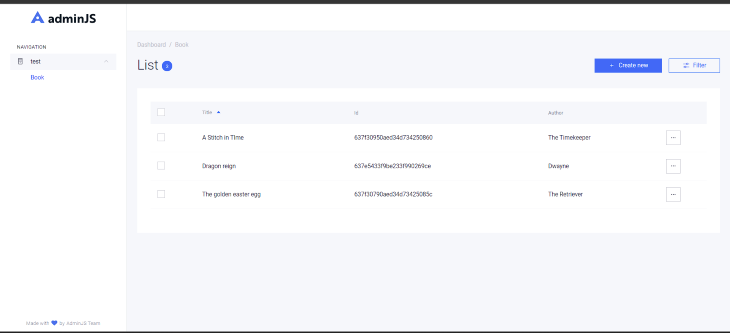 There are three entries in the above dashboard list, each containing a book title and author. If we navigate to the MongoDB `Books` collection on MongoDB Atlas, we can see the data produced by the `Create` operation performed in the AdminJS instance: 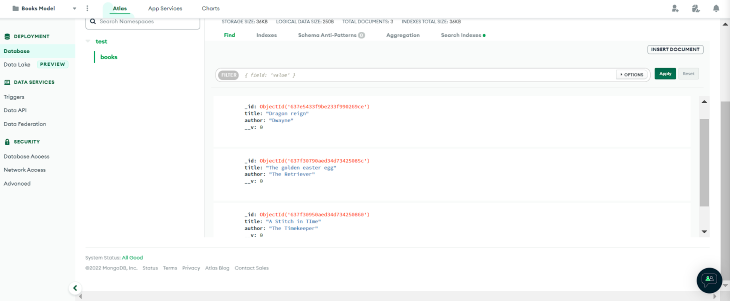
Now, when we run our Next.js application, we get the following result: 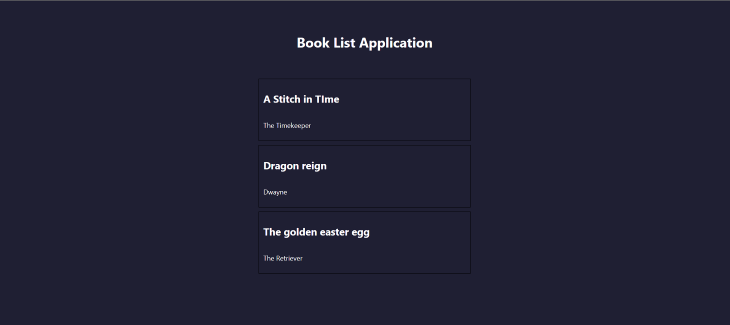
## Conclusion
In this tutorial, we introduced AdminJS, reviewed its many features, and then used it to build a full-stack Node.js application with Express.js and MongoDB. How will you use AdminJS in your next project?
---
## 200’s only ✔️ Monitor failed and slow network requests in production
Deploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third party services are successful, [try LogRocket] (https://logrocket.com/signup/).
[](https://lp.logrocket.com/blg/signup)
[LogRocket] (https://lp.logrocket.com/blg/signup) is like a DVR for web apps, recording literally everything that happens on your site. Instead of guessing why problems happen, you can aggregate and report on problematic network requests to quickly understand the root cause.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. [Start monitoring for free] (https://lp.logrocket.com/blg/signup). | mangelosanto |
1,302,823 | ⚛️Componentes Funcionais e de Classe em React⚛️ | 👇Um artigo objetivo sobre componentes em React👇 ⚛️O que são React... | 0 | 2022-12-19T22:52:38 | https://dev.to/mpetry/componentes-funcionais-e-de-classe-em-react-150c | javascript, reactnative, webdev, react | ## 
_**👇Um artigo objetivo sobre componentes em React👇**_
<br>
**⚛️O que são _React Components_?**
- _Components_ são considerados os principais blocos de construção de um aplicativo em React;
- Embora todos os componentes estejam no mesmo local da estrutura de pastas, eles operam de forma independente uns dos outros e se combinam em um componente pai para formar a interface final para o usuário.
<br>
**⚛️Que problema resolveu?**
- Anteriormente, a criação de uma página web simples requeria que os devs escrevessem centenas de linhas de código;
- Na estrutura tradicional de DOM, simples mudanças podiam ser bastante desafiadoras;
- Para resolver esses problemas, uma abordagem baseada em componentes **independentes e reutilizáveis** foi introduzida.
<br>
**⚛️Como um componente se parece?**
- Considere toda a interface do usuário (UI) como uma árvore;
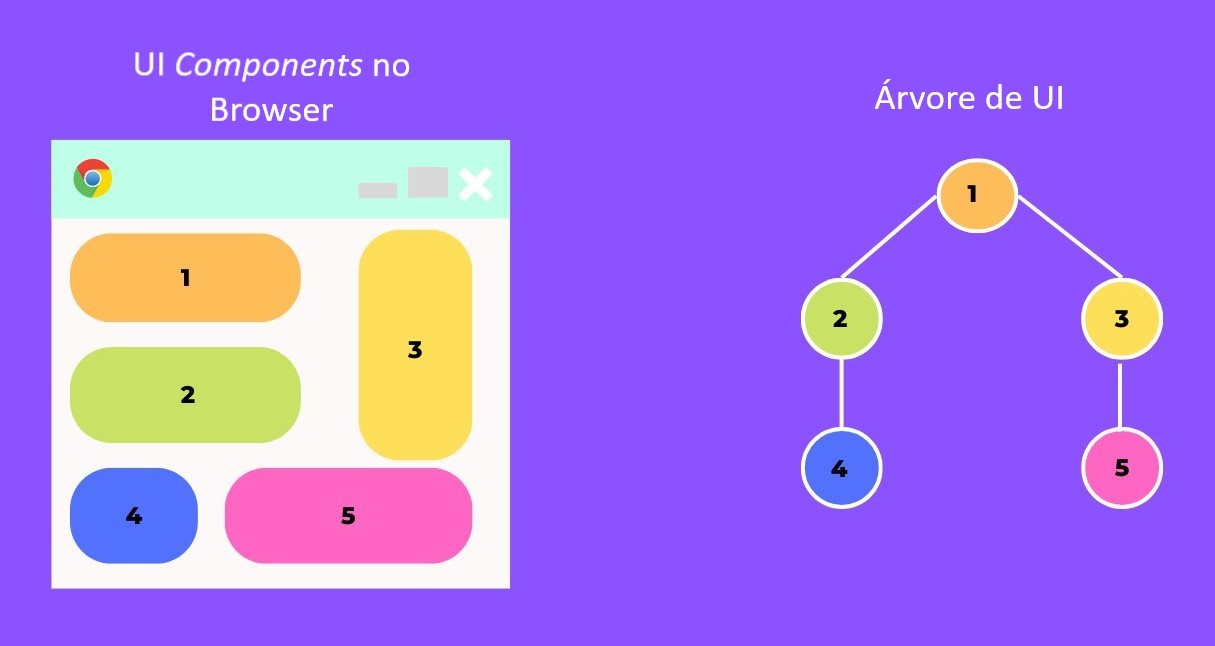
- Aqui, a raiz é o componente inicial e cada uma das outras peças se torna um ramo, os quais são subdivididos em sub-ramos.
<br>
**⚛️Quais são os tipos de componentes?**
**📲Componentes Funcionais:**
- É o primeiro tipo de componente e também o mais recomendado;
- Um _functional component_ é uma função em JavaScript/ES6 que retorna um elemento do React (JSX);
- Ele sempre começa com uma letra maiúscula (convenção de nomes);
- Se necessário, aceita props como parâmetro;
- Por exemplo, você pode criar um componente funcional com sua definição por _arrow function_ 👇
```
const Welcome = (props) => {
return <h1>Hello, {props.name}</h1>;
}
```
> "Essa função é um componente do React válido, pois ele aceita um único argumento de objeto 'props' com dados e retorna um elemento do React." (reactjs.org)
- Para utilizar um componente mais tarde, você precisa exportá-lo para, então, importá-lo em outro lugar.
<br>
**🔃Componentes de Classe:**
- _Class Component_ é uma classe do ES6 que será um componente quando fizer o ‘extend’ de um componente (comportamento ou valor) do React;
- Aceita props (no construtor), se necessário;
- Deve ter um método de render() para retornar o JSX;
- Abaixo vemos a mesma função Welcome anterior, porém retornada como um componente de classe:
```
class Welcome extends React.Component {
render() {
return <h1>Hello, {this.props.name}</h1>;
}
}
```
<br>
**⚛️Conclusão**
- Componentes são a melhor maneira de organizar seu aplicativo React e ajudam a escrever um código mais bem gerenciado;
- Ambos são bons, porém prefiro _Funcional Components_ a _Class Components._
Obrigado se você acompanhou até aqui e espero que esse artigo o ajude na trajetória como dev.
---
_Autor: Marcelo Schäffer Petry_
https://linkedin.com/in/m-petry/
https://marcelopetry.com/
| mpetry |
1,303,007 | Import and animate an external SVG file with Javascript and Gsap. | About GSAP GSAP (GreenSock Animation Platform) is a robust high-performance... | 0 | 2022-12-20T01:30:49 | https://dev.to/steinarvdesign/import-and-animate-an-external-svg-file-with-javascript-and-gsap-4ikb | javascript, gsap, external, svg | {% codepen https://codepen.io/steinarV/pen/KKBKpPd %}
## About GSAP
GSAP (GreenSock Animation Platform) is a robust
high-performance JavaScript animation library.
Read more at: https://greensock.com/docs/
## The html-file

## The Javascript-file

## Diagram
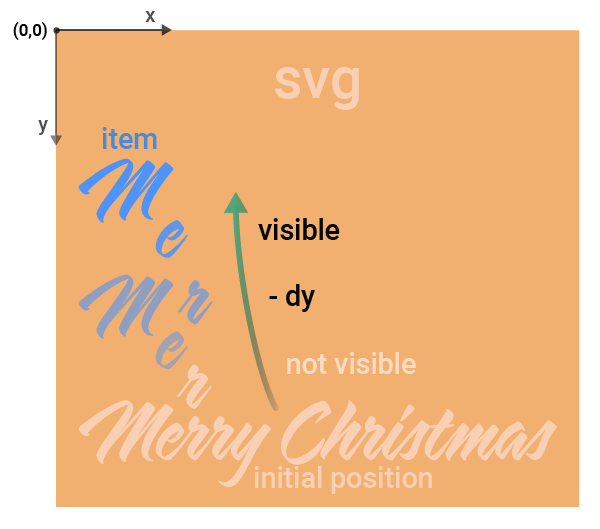
## Code from the external SVG-file
```
<svg xmlns="http://www.w3.org/2000/svg" id="mysvg" viewBox="0 0 1460 930">
<style type="text/css">
.st1{fill:#FFFFFF;}
.st2{fill:#FC5B6B;}
</style>
<g id="m1" class="item m1">
<path id="m1black" d="M348.7,666.5c-60.1,72.5-62.9,104-62.9,104c-2.1,15.3,8.6,20.8,8.6,20.8l2.6,0.8c1.6,0.3,1.6,1.6,1.6,1.6 c0.3,0.8-1.6,1.3-1.6,1.3c-27.3,0.5-28.6-27.3-28.6-27.3c-1-7.3,3.4-21.3,3.4-21.3c1.6-4.7,3.6-10.1,6.8-16.4 c10.4-21.3,39.8-60.6,39.8-60.6l-0.5-0.3c-54.6,62.4-71,85-71,85c-14.8,22.4-20.3,35.6-20.3,35.6c-1.6,2.6,0.3,4.9,0.3,4.9 c0.8,1,0,2.1,0,2.1c-0.5,1.3-3.4,0.3-3.4,0.3c-13.5-7.3-13.5-19.8-13.5-19.8c-1-4.7,6.8-19.8,6.8-19.8c30.4-57.2,58-95.2,58-95.2 l-0.5-0.5c-76.7,81.1-90.5,100.6-90.5,100.6c-17.4,24.4-16.6,33.3-16.6,33.3c0,1.8,1.3,4.7,1.3,4.7c0.8,1.6-1,2.9-1,2.9 c-1.6,1.3-3.9-0.8-3.9-0.8c-12.7-12.2-12.7-20.3-12.7-20.3c-3.6-5.5,13.5-30.9,13.5-30.9c49.7-69.9,54.9-78.5,54.9-78.5 c14.3-20.5,14.8-26.3,14.8-26.3c0.8-1.6-0.8-1-0.8-1c-33.3,12.5-63.7,36.9-63.7,36.9c-34.1,26.3-44.2,40-44.2,40 c-0.3,1,4.7,1.3,4.7,1.3c2.1-0.3,2.1,1.6,2.1,1.6c0.5,0.8-1.3,1.6-1.3,1.6c-10.1,4.7-16.4-1.3-16.4-1.3 c-8.8-7.5-11.7-15.6-11.7-15.6c-1.3-1.3,2.6-4.4,2.6-4.4c16.9-13.5,37.7-28.1,37.7-28.1c15.3-11.4,33.3-21.8,47.6-28.9 c23.7-11.4,34.6-13,34.6-13c7-1,12.5,3.9,12.5,3.9l4.9,4.7c5.5,5.2,3.4,14.8,3.4,14.8c-3.1,18.7-23.4,45.8-23.4,45.8 c-12.5,16.9-15.6,20-15.6,20l0.5,0.8l54.1-61.9l17.7-20.3c2.6-3.6,5.7-3.6,5.7-3.6c1.8-0.5,5.5,2.6,5.5,2.6 c8.6,7.5,11.4,10.4,11.4,10.4c3.9,3.6,0.3,9.1,0.3,9.1l-46.5,70.5l0.5,0.5c52.8-65.5,70.2-83.2,70.2-83.2c3.4-6.2,7.5-4.2,7.5-4.2 c8.3,5.2,15.3,12.5,15.3,12.5C354.1,661.1,348.7,666.5,348.7,666.5z"/>
<path id="m1white" class="st1" d="M347.7,656.5c-60.1,72.5-62.9,104-62.9,104c-2.1,15.3,8.6,20.8,8.6,20.8l2.6,0.8 c1.6,0.3,1.6,1.6,1.6,1.6c0.3,0.8-1.6,1.3-1.6,1.3c-27.3,0.5-28.6-27.3-28.6-27.3c-1-7.3,3.4-21.3,3.4-21.3 c1.6-4.7,3.6-10.1,6.8-16.4c10.4-21.3,39.8-60.6,39.8-60.6l-0.5-0.3c-54.6,62.4-71,85-71,85c-14.8,22.4-20.3,35.6-20.3,35.6 c-1.6,2.6,0.3,4.9,0.3,4.9c0.8,1,0,2.1,0,2.1c-0.5,1.3-3.4,0.3-3.4,0.3c-13.5-7.3-13.5-19.8-13.5-19.8c-1-4.7,6.8-19.8,6.8-19.8 c30.4-57.2,58-95.2,58-95.2l-0.5-0.5c-76.7,81.1-90.5,100.6-90.5,100.6c-17.4,24.4-16.6,33.3-16.6,33.3c0,1.8,1.3,4.7,1.3,4.7 c0.8,1.6-1,2.9-1,2.9c-1.6,1.3-3.9-0.8-3.9-0.8c-12.7-12.2-12.7-20.3-12.7-20.3c-3.6-5.5,13.5-30.9,13.5-30.9 c49.7-69.9,54.9-78.5,54.9-78.5c14.3-20.5,14.8-26.3,14.8-26.3c0.8-1.6-0.8-1-0.8-1c-33.3,12.5-63.7,36.9-63.7,36.9 c-34.1,26.3-44.2,40-44.2,40c-0.3,1,4.7,1.3,4.7,1.3c2.1-0.3,2.1,1.6,2.1,1.6c0.5,0.8-1.3,1.6-1.3,1.6c-10.1,4.7-16.4-1.3-16.4-1.3 c-8.8-7.5-11.7-15.6-11.7-15.6c-1.3-1.3,2.6-4.4,2.6-4.4c16.9-13.5,37.7-28.1,37.7-28.1c15.3-11.4,33.3-21.8,47.6-28.9 c23.7-11.4,34.6-13,34.6-13c7-1,12.5,3.9,12.5,3.9l4.9,4.7c5.5,5.2,3.4,14.8,3.4,14.8c-3.1,18.7-23.4,45.8-23.4,45.8 c-12.5,16.9-15.6,20-15.6,20l0.5,0.8l54.1-61.9l17.7-20.3c2.6-3.6,5.7-3.6,5.7-3.6c1.8-0.5,5.5,2.6,5.5,2.6 c8.6,7.5,11.4,10.4,11.4,10.4c3.9,3.6,0.3,9.1,0.3,9.1l-46.5,70.5l0.5,0.5c52.8-65.5,70.2-83.2,70.2-83.2c3.4-6.2,7.5-4.2,7.5-4.2 c8.3,5.2,15.3,12.5,15.3,12.5C353.1,651.1,347.7,656.5,347.7,656.5z"/>
</g>
<g id="e" class="item e">
<path id="eblack" d="M348.7,666.5c-60.1 . . . . . 6.5z"/>
<path id="ewhite" class="st1" d="M347.7,6 . . . . . 7,656.5z"/>
</g>
/* more <g> </g> elements here*/
</svg>
```
## About Codepen
"Codepen" - https://codepen.io/ - is a social development environment - an online code editor for developers of any skill - that allows people to write code in the browser, and see the results of it as they build. Codepen is particularly useful for people learning to code.
View the full code for this pen at https://codepen.io/steinarV/pen/KKBKpPd
Here is a link to my blog: https://steinarv.design/blog
Thanks for watching !
| steinarvdesign |
1,303,209 | My first npm, state management | https://github.com/vyquocvu/anystate Features: Lightweight object state management Open Source... | 0 | 2022-12-20T04:59:32 | https://dev.to/samplemml/my-first-npm-state-management-3kki | [https://github.com/vyquocvu/anystate
](https://github.com/vyquocvu/anystate
)
Features:
Lightweight object state management
Open Source Project
Small App Size (~2Kb)
Easy to use with nay framework, just a callback on change
About:
AnyState is an open source programs built using Typescript (for a more secure environment).
| samplemml | |
1,303,299 | Deploying Vendure | The cool part about Vendure is how easy it is to set up and how abstract each layer is. Basically, we... | 0 | 2022-12-20T07:11:02 | https://daily-dev-tips.com/posts/deploying-vendure/ | webdev, javascript, beginners | The cool part about Vendure is how easy it is to set up and how abstract each layer is.
Basically, we get the following elements:
- External database
- Server
- Worker
- Admin UI
- Frontend
While this is amazing, it also brings a bit of complexity when it comes to hosting your Vendure shop.
At the time of writing, I'm still doing some research, and it seems Michael from Vendure is also working on an excellent guide for hosting. (Which I'll add here once it's done).
For my testing purpose, I decided to try out hosting to see what's possible and go with the following setup.
- [RailwayApp](https://daily-dev-tips.com/posts/hosting-a-discord-bot-on-railway/) for the database, server, worker, and admin UI
- [Netlify](https://daily-dev-tips.com/posts/hosting-a-static-blog-on-netlify/) for the storefront
I wouldn't change the front end, as Netlify works fine. However, Vercel or Cloudflare would work equally well.
As for the backend side, Railway works, but it's a bit slow on their free tier. (Still experimenting with a nice setup there).
## Setting up the backend
I'll still show you how to host Vendure for free but with limited resources for this guide.
You should be able to apply this process to another provider or potentially upgrade the railway subscription.
Create a new [Railway account](https://railway.app/) or login into your existing one, creating a new project.
The first thing I added was a PostgreSQL database. I then manually connected to it with [TablePlus](https://daily-dev-tips.com/posts/top-5-mysql-clients-for-mac/#1-tableplus) and imported the database I had locally.
You'll see the database connection string we'll need in a bit on the connection screen, so copy that to a safe spot.
The next thing we need to do is add a new service, a project, from GitHub. (Assuming you pushed your project to GitHub).
In Railway, you'll be able to right-click on the canvas and select the new service option.
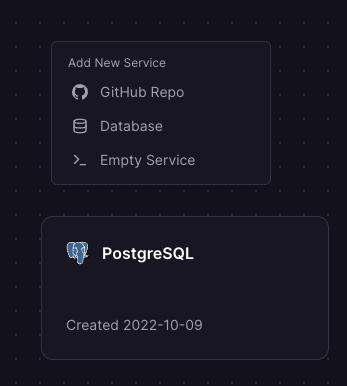
Once you add the service, it should automatically add the Postgres variables.
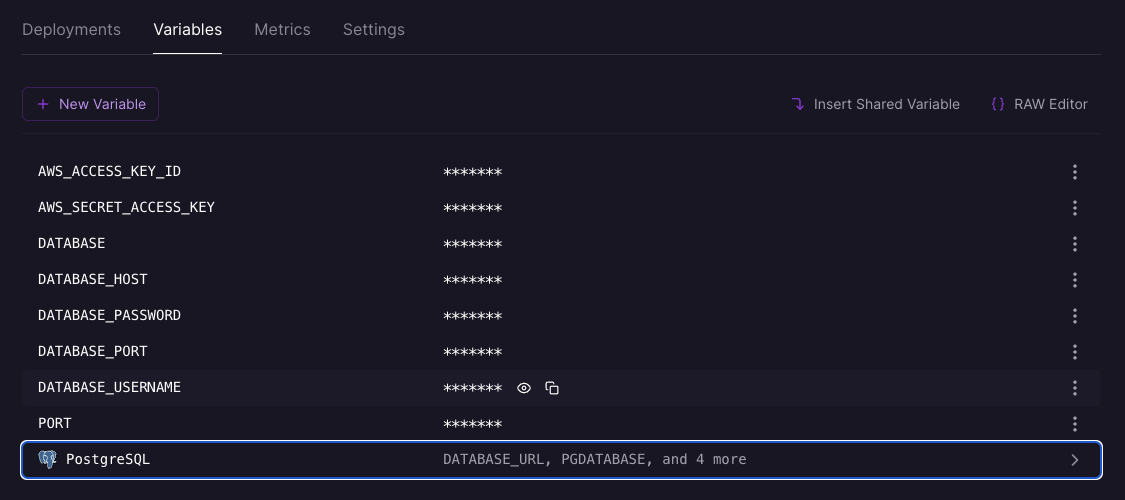
Add optional variables you have set in your `.env` file.
You'll need to add the database options here, as Vendure uses an indirect connection.
Then we'll also need to define what command it should run in the settings.
And in the case of Vendure, we can set it to `yarn run build`.
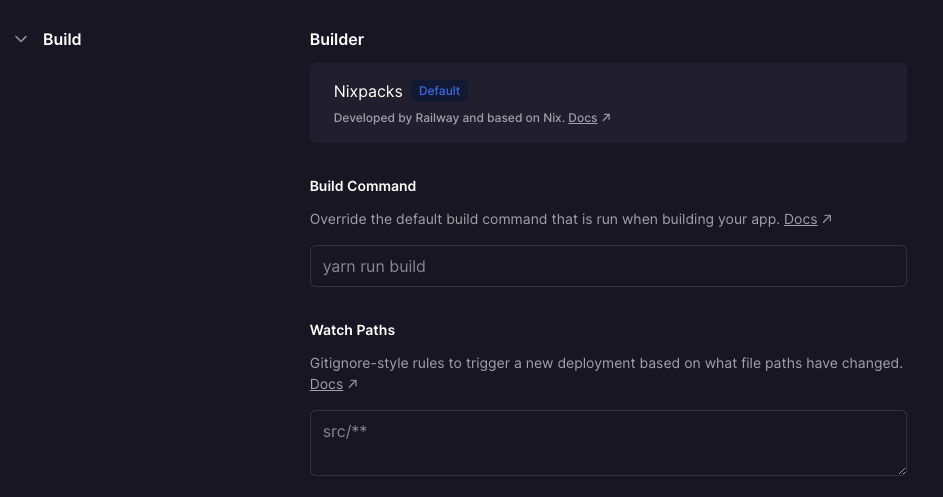
It should then auto-build your application every single time you push new changes.
> Note: I sometimes found you need to trigger re-deploy as it would timeout the first deployment manually.
Once it's running, you should already have access to your admin UI!
The URL should be something like this: `https://your-name.up.railway.app/admin`.
## Hosting the storefront
Depending on which storefront option you choose, we have multiple options.
I chose Remix, so I found Netlify super easy.
Log in to Netlify and choose the project from your GitHub repos.
It will automatically recognize it's a Remix project and set all the configurations for us.
All we need to do here is set an environment variable for the `VENDURE_API_URL`. This should point to your Railway environment.
Then go ahead and deploy it, and it should be up and running.
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
1,303,336 | JavaScript Objects | This blog post is your crash course for you to learn about one of the vital topics in JavaScript, i.e., JavaScript Objects. | 0 | 2022-12-20T08:35:59 | https://michaelsolati.com/blog/javascript-objects/ | javascript, webdev, programming, beginners | ---
title: JavaScript Objects
published: true
description: This blog post is your crash course for you to learn about one of the vital topics in JavaScript, i.e., JavaScript Objects.
tags: javascript, webdev, programming, beginners
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/g2y60a6osx9eagi84cst.png
canonical_url: https://michaelsolati.com/blog/javascript-objects/
---
This blog post is your crash course for you to learn about one of the vital topics in JavaScript, i.e., JavaScript Objects.

There are two ways JavaScript data can be defined either a [Primitive](https://developer.mozilla.org/en-US/docs/Glossary/Primitive) or an Object. Objects are what most developers interact with. Some Objects you may be familiar with are:
- String
- Number
- Math
- Date
- Array
- Functions
- And [so much more](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object)!
JavaScript objects are mutable, and their values can be changed. Objects can have properties and methods as well. It's crucial to remember [JavaScript is designed on a simple object-based paradigm](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Working_with_Objects#:~:text=JavaScript%20is%20designed%20on%20a,is%20known%20as%20a%20method.).
Objects are collections of properties, and properties are an association between a key and a value. In some cases, though, the value of a property is a function, making that property a method. The properties of an object usually describe the characteristics of its variable. For example, an Array has `.length` to know how many elements are in them. The Math object has a `.PI` property, in case you get hungry.

Methods behave differently, as they're functions that need to be called. They can be used to modify or convert a property of an object, perform an action, return a specific piece of information, and more. For example, if you've worked with a String, you may have called the `toUpperCase()` method to get the string in complete upper case.
Likewise, with an Array, you could call `.sort()` to sort the elements.

There are different ways to create an Object in JavaScript. For example, you could make an Object using an object initializer or create a constructor function and instantiate a new instance of that object. Object initializers are creating objects with literal notation. This is consistent with the terminology used by C++.  This is wildly different from creating an Object using a constructor function where we can create reusable and distinct instances of an object. To create this type of object, start with creating a function where the properties and methods are added to the `this` object.

You can then instantiate a new instance of that object with `new` and reuse it repeatedly.

This blog is inspired by one of our Twitter threads that we post on our Twitter account. There are many threads like this; you should [check them out](https://twitter.com/amplication).
{% embed https://twitter.com/amplication/status/1551869682256420866?s=20&t=mUNPj8vQqgdTG12jvpVuUw %} | michaelsolati |
1,303,392 | How To Sum Total From Array Of Object Properties With JavaScript Reduce Method | Calculating the total price for your shopping cart was a hassle in the days before the JavaScript... | 0 | 2022-12-20T15:42:54 | https://byrayray.dev/posts/2022-12-19-sum-total-array-object-properties-javascript-reduce-method | ---
title: How To Sum Total From Array Of Object Properties With JavaScript Reduce Method
published: true
date: 2022-12-20 08:44:08 UTC
tags:
canonical_url: https://byrayray.dev/posts/2022-12-19-sum-total-array-object-properties-javascript-reduce-method
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/m2dfzuzyzfbaub3ugzuq.png
---
Calculating the total price for your shopping cart was a hassle in the days before the JavaScript `reduce` method. In this post, I will show you how easy it is to use the `reduce` method to calculate the total price of a product array in the shopping cart. The JavaScript `reduce` method is powerful and can calculate a total price based on an array of object properties.

## How does the reduce method work?
The **`reduce()`** method in JavaScript is used to execute a function to each element in an array, resulting in a single output value. It operates on an array of elements, performing a computation on each element in the array and building up the result.
Here is the syntax for using the **`reduce()`** method:
```js
array.reduce((accumulator, currentValue, currentIndex, array) => {
// code to be executed
}, initialValue);
```
The **`reduce()`** method takes in a callback function as its first argument. This callback function is called for each element in the array and takes four parameters:
- **`accumulator`** : This is the value returned in the final iteration. It starts with the initial value if provided or the first element of the array if no initial value is provided. And adds up every iteration.
- **`currentValue`** : This is the current element being processed in the array.
- **`currentIndex`** (_optional_): This is the index of the current item that is being processed in the array.
- **`array`** (_optional_): This is the array **`reduce()`** that was called upon.
The callback function should return the updated value for the accumulator.
Here is a simple example of using **`reduce()`** to calculate all the numbers in an array:
```js
const numbers = [1, 2, 3, 4, 5];
const sum = numbers.reduce((accumulator, currentValue) => {
return accumulator + currentValue;
}, 0);
console.log(sum); // 15
```
Check [runkit example](https://runkit.com/devbyrayray/calculate-total-based-on-numbers-array-with-javascript-reduce)
In this example, the **`reduce()`** method is called on the **`numbers`** array and is passed a callback function that adds the accumulator and the current value. The initial value for the accumulator is 0.
The **`reduce()`** method iterates through the numbers in the array, starting with the first element, and applies the callback function to each element.
The returned value from the callback function becomes the new value for the accumulator, which is passed to the next iteration. This process continues until all elements in the array have been processed and the final value of the accumulator is returned.
Let's check how we can apply this to our product array of a fictional shopping cart.

## Get a total price from an array of object properties
Let's say you have an array of products in your shopping cart.
```js
const products = [
{
"price": 10,
"title": "Item 1"
},
{
"price": 20,
"title": "Item 2"
},
{
"price": 30,
"title": "Item 3"
}
]
```
To calculate the prices, we first need an array of prices. We want to calculate the total price of our shopping cart. We can do that by using the `.map()` method. In the example below, we create a new array with only the prices of our products.
```js
const prices = shoppingCart.map((product) => product.price)
```
After that, we can use that array to calculate the total price with the `reduce` method.
```js
const prices = shoppingCart.map((product) => product.price)
const total = prices.reduce((acc, curr) => acc + curr)
console.log('total: ', total )
```
We can also write this shorter and chain the `map()` and `reduce()` methods.
```js
const totalPrice = shoppingCart.reduce((acc, curr) => acc + curr.price, 0)
console.log('total: ', totalPrice )
```
Check [runkit example](https://runkit.com/devbyrayray/calculate-total-price-from-javascript-array-of-product-objects)
That was easy. 👍

## Thanks!

_After reading this story, I hope you learned something new or are inspired to create something new! 🤗 If so, consider subscribing via email (scroll to the top of this page) or follow me here on Hashnode._
> Did you know that you can create a [Developer blog like this one, yourself](https://hashnode.com/@devbyrayray/joinme)? It's entirely for free. 👍💰🎉🥳🔥
_If I left you with questions or something to say as a response, scroll down and type me a message. Please send me a_ [_DM on Twitter @DevByRayRay_](https://twitter.com/@devbyrayray) _when you want to keep it private. My DM's are always open 😁_ | devbyrayray | |
1,303,499 | Troubleshooting: compiled against a different Node version | Symptom Running a node project with the dependency on Better Sqlite3 got the following... | 0 | 2022-12-20T11:20:43 | https://dev.to/foxgem/troubleshooting-compiled-against-a-different-node-version-2alf | node, troubleshooting | ## Symptom
Running a node project with the dependency on Better Sqlite3 got the following error message:
```
Error: The module '... /node_modules/better-sqlite3/build/Release/better_sqlite3.node'
was compiled against a different Node.js version using
NODE_MODULE_VERSION 83. This version of Node.js requires
NODE_MODULE_VERSION 93. Please try re-compiling or re-installing
the module (for instance, using `npm rebuild` or `npm install`).
' the module (for instance, using `npm rebuild` or `npm install`).
' bindings (node_modules/bindings/bindings.js:112:48)
```
## Cause
The error message itself contains enough details, also shows the cause and solution.
In short: the node version used to compile the installed `better_sqlite3` is not the same as the node version currently used, so it asks to recompile it with the current version.
## Solution
- `npm i -D electron-rebuild`.
- Delete the `node_modules` directory.
- In `package.json` add `scripts` to.
```
"rebuild": "electron-rebuild -f -w better-sqlit3",
```
- `npm i`
- `npm rebuild`
Reference link:
- https://github.com/WiseLibs/better-sqlite3/issues/549
- https://github.com/WiseLibs/better-sqlite3/issues/545 | foxgem |
1,303,532 | What is Bitcoin? | Bitcoin (BTC) is a cryptocurrency, a virtual currency designed to act as money and a form of payment... | 0 | 2022-12-20T11:51:02 | https://dev.to/bitpowr/what-is-bitcoin-2f | Bitcoin (BTC) is a cryptocurrency, a virtual currency designed to act as money and a form of payment outside the control of any one person, group, or entity. It provides an alternative payment system to fiat currencies issued and controlled by central banks. Bitcoin is not managed and maintained by any one central entity but by a network of users and miners who verify transactions on the blockchain through cryptographic techniques.
## How does Bitcoin work?
It is critical to understand that Bitcoin is made up of three distinct components that work together to form a decentralized payment system:
1. The Bitcoin network - which operates as a peer-to-peer system where users exchange bitcoin with others on the network without the assistance of middlemen to carry out and validate transactions.
2. The native cryptocurrency of the Bitcoin network, called bitcoin (BTC) which could be likened to money but unlike government-issued currencies such as the dollar or euro, Bitcoin allows online transfers without a middleman such as a bank or payment processor. It is also a a store of value similar to gold.
- The Bitcoin blockchain is much more than just a form of cryptocurrency: It is the foundation upon which the majority of cryptocurrencies, including Bitcoin, are created. Because it guarantees the accuracy of every transaction, the Bitcoin blockchain is exceptional. Nothing is missed from the network because everything that happens on the blockchain is recorded. The entire record of an action is accessible to anyone in the system once it has been time-stamped, recorded, and stored in one of the information blocks to data that is kept in "blocks" of information and then permanently connected as a "chain" by other "blocks" of information.
No matter how many transactions are awaiting confirmation, Bitcoin is set up to allow new blocks to be added to the blockchain about every ten minutes.
The blockchain's openness allows all network users to view and analyze bitcoin transactions in real time. The likelihood of double spending, a problem with online payments, is decreased by this technology. When a person tries to spend the same cryptocurrency twice, this is known as double spending.
### Bitcoin Innovations
**Lightning Network**
Bitcoin was never intended to be scalable. It was intended to be a decentralized payment system that users could use anonymously and from anywhere. However, one of its drawbacks was its popularity: transactions became much slower and more expensive than intended. As a result, developers created cryptocurrency layers, the first of which was the primary blockchain. Each layer beneath that was a secondary, tertiary, and so on.
Each layer complements and adds functionality to the layer above it. In that light the Lightning Network is a second layer for Bitcoin that uses micropayment channels to increase the capacity of the blockchain to conduct transactions more efficiently- In simple terms, the Lightning Network (LN) allows participants to use their digital wallets to send BTC to one another for free. [Read more](https://decrypt.co/resources/bitcoin-lightning-network)
**SegWit**
Before now, Legacy addresses were the original BTC addresses, now SegWit addresses are the newer address format with lower fees.
SegWit stands for Segregated Witness, where Segregated means to separate and Witness refers to the transaction signatures involved with a specific transaction. In a nutshell, it is an improvement over the current bitcoin blockchain in that it increases the block size limit of a blockchain by removing signature data from Bitcoin transactions. This creates more space to add more transactions to the chain when portions of a transaction are withdrawn. [Read more](https://bitpowr.com/blog/bitpowr-wallet-now-supports-bitcoin-seg-wit-addresses)
**Taproot**
The Taproot upgrade was suggested by Bitcoin Core developer Greg Maxwell in January 2018. Three years later, on June 12, 2021, the 90% mark for blocks mined with miner support was reached. It means that some encoded data was left in 1,815 of the 2,016 blocks that were mined during the course of the two-week period by miners to show support for the upgrade.
The Taproot upgrade simply groups several signatures and transactions together.
On the Bitcoin network, digital signatures are necessary to validate transactions. They are produced with the aid of private keys and checked against those of others.
Before the introduction of Taproot, the network of Bitcoin required each digital signature to be verified against a public key, which made transaction verification time-consuming. The time needed for sophisticated multi-sig transactions that require numerous inputs and signatures was doubled by this technique. [Read more](https://cointelegraph.com/bitcoin-for-beginners/a-beginners-guide-to-the-bitcoin-taproot-upgrade)
**Conclusion**
Bitcoin has gained widespread acceptance and popularity over the years, with more and more people choosing to use it as a payment method and store of value. Though Bitcoin isn't yet optimized to handle the kinds of transaction volumes that the digital currency is capable of producing, ideas behind products like Lightning Network is changing this and making Bitcoin more attractive for everyday use.
In addition, the introduction of SegWit is a significant step toward resolving it’s scalability issues and enable it to process more transactions more quickly and cheaply
Bitpowr supports Segwit addresses to also serve as a commitment to providing better solutions and features to help reduce business overhead cost.
Check out [our documentation](https://docs.bitpowr.com/docs) to learn more about our wallet services and other related products. [Contact sales](https://www.bitpowr.com/contact#contact) or send an email to [sales@bitpowr.com](mailto:sales@bitpowr.com) to get started! | bitpowr | |
1,303,802 | react useContext() Hook - web dev simplified | Part1 Code:- Folder Structure :- Output Photo :- App.js Code:- import {... | 0 | 2022-12-20T15:11:22 | https://dev.to/akshdesai1/react-usecontext-hook-web-dev-simplified-3o9p | webdev, javascript, react, beginners | ## Part1 Code:-
**Folder Structure :-**
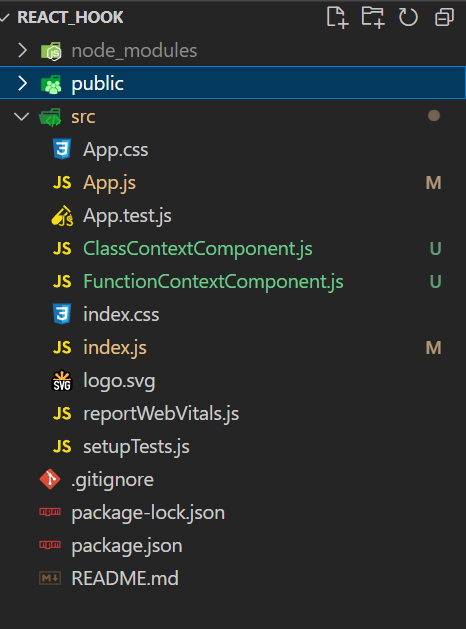
**Output Photo :-**
**App.js Code:-**
``` react
import { createContext, useState } from 'react'
import FunctionContextComponent from './FunctionContextComponent'
import ClassContextComponent from './ClassContextComponent'
export const ThemeContext = createContext();
export default function App() {
const [darkTheme, setDarkTheme] = useState(true);
// eslint-disable-next-line
const [timepass, setTimepass] = useState("initialState");
function toggleTheme() {
setDarkTheme(prevTheme => !prevTheme);
};
return (
<ThemeContext.Provider value={{ darkTheme, timepass }}>
<button onClick={toggleTheme}>Toggle Theme</button> - {darkTheme ? "true" : "false"}
<FunctionContextComponent />
<ClassContextComponent />
</ThemeContext.Provider>
)
}
```
**FunctionContextComponent.js :-**
``` react
import { useContext } from 'react'
import { ThemeContext } from './App';
export default function FunctionContextComponent() {
const theme = useContext(ThemeContext);
const style = {
backgroundColor: theme.darkTheme ? "grey" : "white",
color: theme.darkTheme ? "white" : "black",
padding: "2rem",
margin: "2rem"
}
return (
<div style={style}>
Function Theme
</div>
)
}
```
**ClassContextComponent.js :-**
``` react
import React, { Component } from 'react'
import { ThemeContext } from './App'
export default class ClassContextComponent extends Component {
style(dark) {
return {
backgroundColor: dark ? "#123445" : "white",
color: dark ? "white" : "black",
padding: "2rem",
margin: "2rem"
}
}
render() {
return (
<ThemeContext.Consumer>
{(theme) => {
return <div style={this.style(theme.darkTheme)}> ClassContextComponent </div>
}}
</ThemeContext.Consumer>
)
}
}
```
**Part2 Source Code**
**Folder Structure**
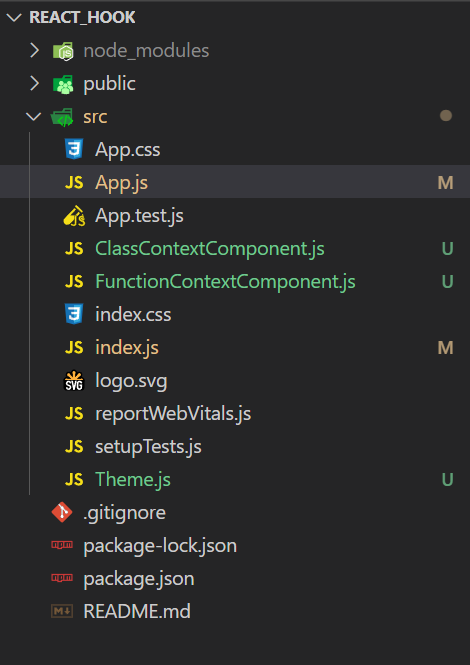
**index.js code :-**
``` react
import React from 'react';
import ReactDOM from 'react-dom/client';
import './index.css';
import App from './App';
import reportWebVitals from './reportWebVitals';
import { ThemeContext } from "./Theme.js";
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(
<ThemeContext>
<App />
</ThemeContext>
);
// If you want to start measuring performance in your app, pass a function
// to log results (for example: reportWebVitals(console.log))
// or send to an analytics endpoint. Learn more: https://bit.ly/CRA-vitals
reportWebVitals();
```
**App.js Code :-**
``` react
import { createContext, useState, useContext } from 'react'
import FunctionContextComponent from './FunctionContextComponent'
import ClassContextComponent from './ClassContextComponent'
import { ThemeContext, ThemeContext1 } from "./Theme.js";
export default function App() {
const theme = useContext(ThemeContext1);
return (
<>
<button onClick={theme.toggleTheme}>Toggle Theme</button>
<FunctionContextComponent />
<ClassContextComponent />
</>
)
}
```
**FunctionContextComponent.js**
``` react
import { useContext } from 'react'
import { ThemeContext1 } from './Theme';
export default function FunctionContextComponent() {
const theme = useContext(ThemeContext1);
const style = {
backgroundColor: theme.darkTheme ? "grey" : "white",
color: theme.darkTheme ? "white" : "black",
padding: "2rem",
margin: "2rem"
}
return (
<>
<div style={style}>
Function Theme
</div>
</>
)
}
```
**ClassContextComponent.js**
``` react
import React, { Component } from 'react'
import { ThemeContext1 } from './Theme'
export default class ClassContextComponent extends Component {
style(dark) {
return {
backgroundColor: dark ? "#123445" : "white",
color: dark ? "white" : "black",
padding: "2rem",
margin: "2rem"
}
}
render() {
return (
<ThemeContext1.Consumer>
{(theme) => {
return <div style={this.style(theme.darkTheme)}> ClassContextComponent </div>
}}
</ThemeContext1.Consumer>
)
}
}
```
**Theme.js Code**
``` react
import { useState, createContext, useContext } from 'react';
export const ThemeContext1 = createContext();
export function ThemeContext(props) {
const [darkTheme, setDarkTheme] = useState(true);
// eslint-disable-next-line
const [timepass, setTimepass] = useState("initialState");
const toggleTheme = () => {
return setDarkTheme(prevTheme => !prevTheme);
};
return (
<ThemeContext1.Provider value={{ darkTheme, toggleTheme, timepass }}>
{props.children}
</ThemeContext1.Provider>
)
}
```
Thank You.
You can follow us on:
[Youtube ](https://www.youtube.com/c/ULTIMATEPROGRAMMING)
[Instagram](https://www.instagram.com/full_stack_web_developer1/) | akshdesai1 |
1,428,769 | [ML] Data should be checked with your eyes | Following the previous effort, I'm challenging the finished Kaggle image competition and making ahead... | 0 | 2023-04-06T22:26:32 | https://dev.to/nekot0/ml-data-should-be-checked-with-your-eyes-11k7 | machinelearning, python, tutorial | Following [the previous effort](https://dev.to/nekot0/errors-in-the-implementation-of-model-training-with-effdet-4pcd), I'm challenging [the finished Kaggle image competition](https://www.kaggle.com/competitions/siim-covid19-detection/overview) and making ahead the implementation. Overcoming recurring errors, I started the model training process by one epoch. My programme was being trained well, but after 50% of learning, the error occurred.
```
ValueError: Caught ValueError in DataLoader worker process 1.
Original Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 302, in _worker_loop
data = fetcher.fetch(index)
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 58, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 58, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/tmp/ipykernel_28/3482151344.py", line 46, in __getitem__
labels = labels
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/composition.py", line 202, in __call__
p.preprocess(data)
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/utils.py", line 83, in preprocess
data[data_name] = self.check_and_convert(data[data_name], rows, cols, direction="to")
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/utils.py", line 91, in check_and_convert
return self.convert_to_albumentations(data, rows, cols)
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/bbox_utils.py", line 124, in convert_to_albumentations
return convert_bboxes_to_albumentations(data, self.params.format, rows, cols, check_validity=True)
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/bbox_utils.py", line 390, in convert_bboxes_to_albumentations
return [convert_bbox_to_albumentations(bbox, source_format, rows, cols, check_validity) for bbox in bboxes]
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/bbox_utils.py", line 390, in <listcomp>
return [convert_bbox_to_albumentations(bbox, source_format, rows, cols, check_validity) for bbox in bboxes]
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/bbox_utils.py", line 334, in convert_bbox_to_albumentations
check_bbox(bbox)
File "/opt/conda/lib/python3.7/site-packages/albumentations/core/bbox_utils.py", line 417, in check_bbox
raise ValueError(f"Expected {name} for bbox {bbox} to be in the range [0.0, 1.0], got {value}.")
ValueError: Expected x_min for bbox (-0.0009398496240601503, 0.46129587155963303, 0.32471804511278196, 0.9730504587155964, array([1])) to be in the range [0.0, 1.0], got -0.0009398496240601503.
```
Good was that I had experienced and overcome a lot of errors. This time, I could guess which part of my code made this error. According to the message, it is because the element of the bounding box is out of the range [0.0, 1.0]. The range [0.0, 1.0] is probably relevant to scaling. Scaling is made when input images are resized. In other words, a bounding box is resized with the inappropriate ratio when the input image is resized.
However, the scaling ratio is showing negative. Why is it negative?
I wanted to check which data made this error but the message didn't tell it to me. So, I tried the code below.
```python
dataset = CTDataset(train_root_path, train_image_list)
for i in range(len(train_image_list)):
print(i)
image, target = dataset.__getitem__(i)
```
This only prints indices and gets data from dataset. As the indices are printed before getting data, we know the index that makes the error when it occurs.
I ran the code.
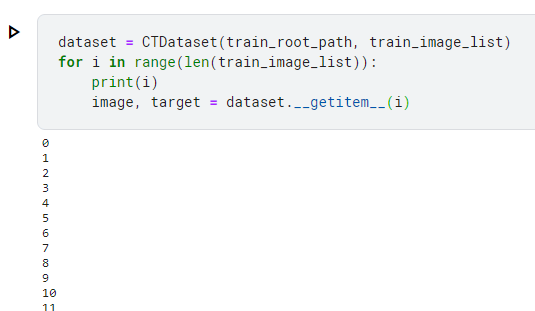
And finally I found it.
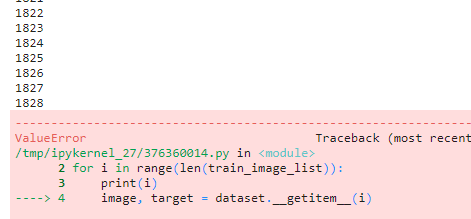
Then I checked the data.
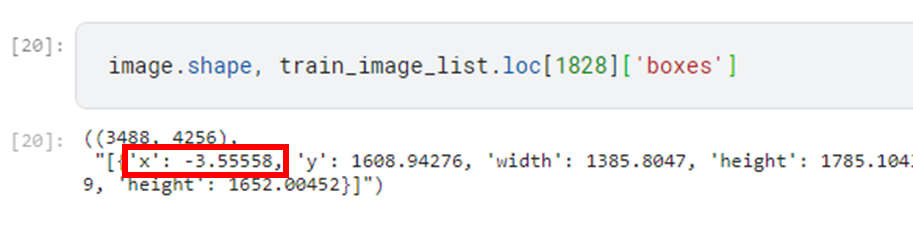
I see. This bounding box shows the area out of the image. The resizing method I'm using (Albumentations) only deals with the bounding box within the area, and it makes the error if the box goes out. In that case, we can avoid it by replacing negative coordinates by 0.
```python
x = max(0, int(round(bounding_box['x'])))
```
After the correction, the programme is working well, and now it exceeds 50% of epoch 1, so it should be fine.
The learning point today is we should check the original data with our eyes before executing time-consuming programme. We should imagine what values the original data has and write a code so that it eliminates potentially error-making data or switch processes. Data should be checked with our eyes.
| nekot0 |
1,309,839 | Block Cipher Vs Stream Cipher – the Difference Explained | Get An Overview and Head-to-Head Comparison of Block Cipher Vs Stream Cipher! No matter if you’re... | 0 | 2022-12-27T10:02:05 | https://dev.to/me_jessicahowe/block-cipher-vs-stream-cipher-the-difference-explained-268b | Get An Overview and Head-to-Head Comparison of Block Cipher Vs Stream Cipher!
No matter if you’re using the internet for banking or for sending a message on WhatsApp, encryption has a role to play everywhere. For example, whenever you enter your credentials on the web, they are shared across the internet in an encrypted form. It ensures security. Ciphers responsible for keeping your data safe are of two types, namely Block Cipher and Stream Cipher. Now, what are they, and how are they different? Let’s read ahead and compare Block Cipher vs Stream Cipher.
Both of these Ciphers are a part of symmetric encryption.
[Symmetric encryption](https://cheapsslweb.com/blog/symmetric-encryption-vs-asymmetric-encryption) is a process where the same key is used to encrypt and decrypt the data. Some of the best examples of symmetric encryption are Blowfish, AES, DES, RC6, etc.
Here is how stream ciphers and block ciphers are used in symmetric encryption!
Difference Between Block Cipher and Stream Cipher Explained
Before we jump into the comparison of block vs stream cipher, let’s analyze them individually!
## What is Block Ciphers?
As the name suggests, the block ciphers are used to encrypt the data and return an output of a fixed block size. It means that no matter what is the size of the input, the resultant ciphertext will be of fixed block size. The size of the ciphertext is usually in octaves (the multiples of 8). However, it also depends on the encryption scheme used in the ciphering method.
## Here is Examples of Block Cipher
If you have a plain text of 148 bits, but the encryption scheme used is 128-bit encryption, the remaining 20 bits will be adjusted in the second block. As there will be space for 108 more bits, the encryption scheme will add padding of 0s or 1s or both to complete the ciphertext block.
Now, as we know that ciphertexts are of fixed blocks, and they are encrypted. But how?
Block ciphers use symmetric keys and algorithms to encrypt sensitive data. As they can be used for various modes, the complexity of encryption can vary. For example, the blocks are chained together in some modes.
## Here is the process of how chained block ciphers work!
In this process, a pseudorandom sequence of characters is used to encrypt the first block of characters. This random sequence of characters is termed as Initialization Vector (IV). After obtaining the first block cipher, it is used as an IV for the next block. This process is followed for each block, and it thus produces a unique ciphertext each time.
The core benefit of a block cipher is that it is tamper-proof, which means that no one can crack it. As the IV used for each iteration is different and dependent on the previous block, the cipher has high diffusion.
Though it is highly unlikely, a change of one character can lead to a massive change in the cipher. Hence, the block cipher also has a higher error propagation rate.
What are the different techniques of block ciphers cryptography
Some of the best examples of block ciphers are:
- DES (Data Encryption Standard)
- AES (Advanced Encryption Standard)
- Twofish
- Blowfish
- RC5
- Triple-DES
## Modes of Operation for Block Ciphers
As we have teased the modes of block ciphers above, let’s explore them properly here! The modes of block ciphers are divided into two major categories, namely.
## Confidentiality-only modes
There are three types under this!
1. Electronic Codebook: The ECB method splits the plaintext into various blocks. Each block is applied with encryption separately. As the pattern is not hidden in this case, it cannot be used in security frameworks.
2. Cipher block chaining mode (CBC: As explained above, the output ciphertext of one block is used as an initialization vector for the following block with plaintext input using the XOR function.
3. Propagating cipher block chaining (PCBC): This method involves XOR of current plaintext, previous plaintext, and previous ciphertext.
Authenticated encryption with additional data operation modes
There are two categories under this!
1. Galois Counter mode: In this mode, an incremental counter is used to generate a universal hash that generates message authentication codes before encryption and decryption.
2. Synthetic initialization vector (SIV): The SIV block cipher uses a plaintext input, an encryption key, and a header to achieve authenticated encryption. The header used is an authenticated variable-length octet string. SIV keeps the plaintext private while keeping the authenticity of the header and encryption key intact.
## What is Stream Ciphers?
Just like its name, the stream cipher encrypts the data in a continuous stream. Unlike block ciphers, bit-by-bit encryption happens in Stream ciphers. How?
## Here is the Stream Cipher uses and process!
The input plaintext is not arranged in blocks before encryption, but it is directly encrypted bit by bit. The encryption process uses keystreams that are generated by combining an encryption key and a seed, called the nonce. The combination of the two produces a pseudorandom number, a keystream that is XORed (exclusive disjunction) with the plaintext to make the ciphertext.
Now, the encryption key used here can be 128 or 256 bits, and nonce can be 64 or 128 bits. The keystream used to produce ciphertext has to be unique, but the encryption key and nonce can be reused. As it may seem tough, the process uses feedback shift registers that generate a unique seed or nonce every time. This nonce is only used one time to create the keystream.
Now, the major benefit of stream ciphers is that they are less likely to experience system-wide propagation errors. How? As each bit is encrypted individually, it will not affect the ciphertext of the entire string, hence, fewer chances of errors. Moreover, as stream ciphers happen in a continuous stream, they are faster and easy to implement.
As each bit is converted to ciphertext, stream ciphers do not have diffusion. Hence, hackers can easily break them. They can easily add or manipulate a message without being noticed.
Stream ciphers are ideal for scenarios where the amount of plain text is more and cannot be determined.
Some of the best examples of Stream Ciphers are
- A5
- ChaCha40
- Salsa20
- RC4
- Stream Ciphers Examples
The stream ciphers are primarily of two types!
1. Synchronous Stream Ciphers: These types of ciphertexts are generated without the use of keystreams that are not generated using previous ciphertexts or plaintexts. For each ciphertext, a unique pseudorandom number is used to make the keystream. This keystream is further XORed with the plaintext to generate the ciphertext.
2. Asynchronous Stream Ciphers: In this cipher, the keystream is generated using the synchronous key and fixed size of the previous ciphertext. As the contents of the ciphertext are affected, the respective keystream is also affected. This cipher can be used to detect active attacks and further limit error propagation.
Differentiate Stream Cipher and Block Cipher using a suitable example. – How Do They Vary?
The block cipher vs stream cipher comparison is easy to make as we know what they are! So, let’s get started! Here is a quick tabular comparison of both the ciphers!
One of the prime and visible differences between block vs stream cipher is bit conversion. How? Well, the block conversion method requires the block of plaintext that needs to be accumulated first and then converted to ciphertext. On the other hand, the stream cipher converts quickly as plaintext is encrypted one bit at a time. Thus, making it continuous and fast.
As the devices today are fast, the time difference may not be that significant.
## Security
If we compare the ciphers based on security, the strength of the key determines the power of a cipher. However, out of both of these ciphers, block ciphers can be used to provide authenticated encryption, not stream cipher. So, a block cipher is better. Stream cipher only uses the confusion principle to encrypt data, so it is better only in terms of maintaining confidentiality.
## Reversibility
It is obvious that if the ciphering takes more time to encrypt, the decryption time will also be more. Stream-based encryption can be easily reversed by XORing their outputs. But, in the case of block cipher, the bits encrypted are more. Hence, the reversibility, in this case, is slow.
## Resources
This is where the stream ciphers outshine from block ciphers. As block ciphers require complex calculations as compared to stream ciphers, they require relatively more resources.
## Redundancy
Redundancy is one of the critical factors. If the block cipher does not find exact octaves in the input plaintext, it adds padding bits to complete the block. Though it is necessary to produce the ciphertext, it also increases the redundancy of plain text.
However, stream ciphers do not have any redundancies as it encrypts bit by bit.
## Application area
As block cipher provides authenticated encryption, it is best for almost any type of application where encryption is necessary. In contrast, the stream cipher is used only for certain applications like data-in-transit encryption.
So, that’s all about Block Cipher Vs Stream Cipher.
## Wrapping Up!
So, we know that encryption is the wall that stands between your sensitive data and the hackers. And the warriors that take care of this wall are the block and stream ciphers. Block ciphers are powerful in terms of security but slow. On the other hand, the stream ciphers have a limited scope of application but are faster than block ciphers.
We hope this article was fruitful and you enjoyed reading it! | me_jessicahowe | |
1,314,775 | Creating Your Own Personalized Avatars with AI | Have you ever wanted to create your own personalized avatars from photos, but found the process to... | 0 | 2023-01-02T08:03:40 | https://dev.to/geocine/creating-your-own-personalized-avatars-with-ai-30c6 | ai, machinelearning, tutorial, deeplearning |

Have you ever wanted to create your own personalized avatars from photos, but found the process to be difficult or expensive? With the advent of artificial intelligence, it has become easier than ever to create unique and striking images using your own photos as a reference.
I have created a Google Colab tool that allows you to do just that, and it's completely free to use with just a Google account. This tool is based on the latest AI technology and allows you to train an AI text-to-image generator called Stable Diffusion.
To get started, simply upload your photos and follow the prompts to begin training the model. You can adjust the settings to fine-tune the model's performance and improve the accuracy of the generated images. Once you are satisfied with the results, you can save the model to your Google Drive and use it to generate images anytime.
This is a great opportunity to explore the capabilities of AI and see how it can be used to create novel and striking images. Give it a try and see what you can create!
Link to Google Colab below 👇🏼
https://colab.research.google.com/github/geocine/sd-easy-mode/blob/main/EasyMode_Stable_Diffusion.ipynb | geocine |
1,316,163 | Swift's POP (Protocol Oriented Programming) paradigm in rea life | Introduction Imagine we want to implement a sort of postal system, where messages can be... | 0 | 2023-01-03T14:19:43 | https://dev.to/stoiandan/swifts-pop-protocol-oriented-programming-paradigm-in-rea-life-46kj | swift, pop | ## Introduction
Imagine we want to implement a sort of postal system, where messages can be _sent_ from _someone_ to the post office; where it will be accordingly _dispatched_ to the right destination.
## Beginning
We could go ahead and define a simple _data model_, that represents a _message_.
This entity holds the _actual_ message (we'll call it _content_), and some meta-data, i.e. data about the message itself.
Since we want this message to be _immutable_ and we don't want _shared references_ of it, we can make it a _struct_, as opposed to a class:
```swift
struct Message {
// the meta-data; who is sending this message
let sender: String
// also meta-data; the receiver of the message
let to: String
// the actual content of the message
let content: String
}
```
## The Dispatcher
Now that we have a data model, which will be a shared entity between _sender_ (a person) and _dispatcher_ (the postal office).
We can go ahead and imagine our _dispatcher_:
```swift
class Dispatcher {
public func dispatch(_ message: Message) {
print("Sending \(message.content) to \(message.to) from \(message.from)")
}
}
```
## The Sender
Finally let's imagine the person sending the message:
```swift
class Person {
private unowned let dispatcher: Dispatcher
let name: String
init(dispatcher: Dispatcher, ) {
self.dispatcher = dispatcher
self.name = name
}
public func sendMessage(of message: Message) {
dispacher.dispatch(message)
}
}
```
## Example
This looks ok. Let's see how it will look in practice:
```swift
let dispatcher = Dispatcher()
let helvidius = Person(dispatcher: dispatcher, name: "Helvidius")
let jovinian = Person(dispatcher: dispatcher, name: "Jovinian")
helvidius.sendMessage(of: Message(sender: helvidius.name, to: "Jovinian", content: "Hi Jovinian! How are you?"))
```
## The actual problem
Notice however, it's a bit odd that Bob has to specify he's the sender.
A person has a name, and if a person _sends_ a message, he's _always_ going to be the sender.
In fact, the current code could be exploited, supposing we'd offer anyone the ability to send messages (i.e. Person class would be a public API):
```swift
let dispatcher = Dispatcher()
let evilMike = Person(dispatcher: dispatcher, name: "Evil Mike")
evilMike.sendMessage(of: Message(sender: "Andy", to: "Sandy", content: "Hi Sandy! I'm Andy, and I think you look ugly!"))
```
## The solution!
Protocols could make our lives much more easy. To start, we've noticed every person has a name; it also s seems maybe not just persons can send messages. why not have machines be able to send messages as well? All we need after all, besides the content and receiver, is for the sender to _identify_ himself.
We could use Swift's _UUID_ type, and that would be a great idea! However, for the sake of simplicity, well stick to a name field, of type string:
```swift
protocol Sender {
var name: String { get }
}
```
Great! Now we could have a ton of other types that can be senders, like machines:
```swift
class Machine: Sender {
let name: String
let dispacher: Dispatcher
init(name: String, dispathcer: Dispathcer) {
self.name = name
self.dispathcer = dispatcher
}
public sendHappyNewYear() {
let date = Date.now
let components = Calendar.current.dateComponents([.month, .day], from: date)
if components.day == 1 && components.month == 1 {
dispatcher.dispatch(Message(sender: "Robot1", to: "Sandy", content: "Happy new Year Sandy!"))
}
}
}
```
However, the actual problem still remains, just about anyone can create a message and pretend to be someone else!
So here's where POP (Protocol Oriented Programming) comes more handy in place.
We can make the initializer (or constructor, if you will) of Message entity fileprivate!
```swift
struct Message {
// the meta-data; who is sending this message
let sender: String
// also meta-data; the receiver of the message
let to: String
// the actual content of the message
let content: String
fileprivate init(sender: String, to: String, content: String) {
self.sender = sender
self.to = to
self.content = content
}
}
```
Great, now we can define an _extension_ method on the _Sender_ protocol. That is a method that anyone who's a sender, can automatically benefit from, even retroactively! I.e. entities that already conform to the Sender protocol before the extension method is introduced can benefit from!:
```swift
struct Message {
...
}
extension Sender {
func createMessage(to receiver: String, content message: Message) -> Message {
Message(sender: self.name, to: receiver, content: message)
}
}
```
Now any sender can call the `createMessage` method, that will automatically use the name the `Sender` has, because remember, the only thing we know about a `Sender` is that he has a name, and we can make use of that name in protocol extensions. | stoiandan |
1,317,132 | Scanning for open ports | lsof list of open files lsof -i -P -n | grep LISTEN Enter fullscreen mode ... | 0 | 2023-01-04T12:13:47 | https://dev.to/webduvet/scanning-for-open-ports-5dco | linux, bash | ## lsof
list of open files
```bash
lsof -i -P -n | grep LISTEN
```
## netstat
Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships
```bash
netstat -tulpn | grep LISTEN
```
## ss
utility to investigate sockets
```bash
ss -tulpn | grep LISTEN
```
## nmap
network exploration tool, port scanner
```bash
nmap -open 192.168.3.34
```
## scanning open ports on remote IP address
```bash
nc -zv 192.168.3.34 2>&1 1-1024 | grep -v refused
```
this scans open ports in the range of 1 to 1024 on the above IP address.
redirects the error output to standard outoput and matches all lines except refused
## scanning all open ports on the subnet using nmap
```bash
nmap -n 192.168.3.0/24
```
## Sources
- **Linux for Networking Professionals** by Rob VandenBrink
- https://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/
- man pages
| webduvet |
1,317,160 | The Everyday Life of an HNG Intern; Isaac Ojerumu’s Story | Task 8 Interns that made it to stage 8 were requested to submit every work they've done thus far in... | 0 | 2023-01-04T13:11:08 | https://dev.to/zadazini/the-everyday-life-of-an-hng-intern-isaac-ojerumus-story-59b2 | beginners, programming, tutorial, career | **Task 8**
Interns that made it to stage 8 were requested to submit every work they've done thus far in the internship, using links, to **Mark Essien**, the chief organizer of the HNG internship. He was to intensively review the work done by each intern so far in the internship.
Interns were served forms that they were to fill out individually. This was the medium through which they submitted their works. Slots that were to be filled included;
- Name
- Email
- Slack ID
- Team
- Link to PR(Poll Request) on Github: This contained the links to every task done by an inter; codes, endpoints, etc.
Interns, by whose work the chief organizer was impressed were promoted to the final stage; stage 9.
Dear reader, thank you for yet another read. I hope that this episode and the series as a whole have been insightful, educative, and inspiring. See you on the next page.
Please, let's get in touch on Medium; **Zini Zada**, and Twitter; **Zada_Zini**
Link to next episode:
https://dev.to/zadazini/the-everyday-life-of-an-hng-intern-isaac-ojerumus-story-50l7 | zadazini |
1,317,547 | Appwrite + Flutter: The Pilot Blog. | Let's learn to work with the best of the BaaS world and undoubtedly the best cross-platform... | 0 | 2023-01-05T08:55:39 | https://dev.to/chandramdutta/appwrite-flutter-the-pilot-blog-i1i | flutter, appwrite, baas | ### Let's learn to work with the best of the BaaS world and undoubtedly the best cross-platform UI toolkit.
Hello, let's fasten our seatbelts cause this blog series will take you through creating your next billion-dollar startup full-stack app based on the best of the Open-source World. We will be learning to use [Appwrite](https://appwrite.io/), the Open-source Backend-as-a-Service, with [Flutter](https://flutter.dev/), the almighty UI toolkit to build an app which we will talk about in a moment.
But first, let's install Appwrite and Flutter.
## Appwrite Installation
To install Appwrite, make sure you have [Docker](https://www.docker.com/). Here are the links to download and install Docker properly
* [On a Mac](https://docs.docker.com/desktop/install/mac-install/)
* [On Windows](https://docs.docker.com/desktop/install/windows-install/) (make sure you have WSL2 installed)
* [On Linux for Docker Desktop](https://docs.docker.com/desktop/install/linux-install/), tho I personally prefer downloading the [Docker Engine for Linux](https://docs.docker.com/engine/install/ubuntu/)(and don't forget the [post-installation steps](https://docs.docker.com/engine/install/linux-postinstall/))
Once installed, let's install Appwrite image which is pasting just one line of script on your terminal!
* Linux/Mac
```
docker run -it --rm \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume "$(pwd)"/appwrite:/usr/src/code/appwrite:rw \
--entrypoint="install" \
appwrite/appwrite:1.2.0
```
* CMD
```
docker run -it --rm ^
--volume //var/run/docker.sock:/var/run/docker.sock ^
--volume "%cd%"/appwrite:/usr/src/code/appwrite:rw ^
--entrypoint="install" ^
appwrite/appwrite:1.2.0
```
* Powershell
```
docker run -it --rm `
--volume /var/run/docker.sock:/var/run/docker.sock `
--volume ${pwd}/appwrite:/usr/src/code/appwrite:rw `
--entrypoint="install" `
appwrite/appwrite:1.2.0
```
Note: This scripts are for Appwrite version 1.2.0 which we will be using for the project! For the latest versions go to [Appwrite](https://appwrite.io/) and click on Get Started.
At the end of the installation, it will prompt you to many inputs, going for the default options is my recommendation and if you did it, go to your `http://localhost:80` and voila! you will be greeted with the beautiful Appwrite Console(made using [Svelte](https://svelte.dev/),my favourite). Create an account and sign in.
## Flutter Installation
As for flutter, installing it through its [official documentation](https://docs.flutter.dev/get-started/install) is the best way!
* [macOS](https://docs.flutter.dev/get-started/install/macos)
* [Linux](https://docs.flutter.dev/get-started/install/linux) (Don't install the snap version)
* [Windows](https://docs.flutter.dev/get-started/install/windows)
Now, run `flutter doctor` and you should see all ticks green, if not, copy the red text and paste it on stack overflow and you should get your answers
## The app
So, a couple of days ago, I posted an app I was building as a side project on Twitter
{% twitter https://twitter.com/chandramdutta/status/1609575130832965632?s=61&t=J-V5dlTHyy6puGQryDxvgg %}
and realised there aren't any great Tutorials for the appwrite+flutter community. One resource worth mentioning is the [React Bits (Damodar Lohani) Flutter + Appwrite Tutorial Series on YouTube](https://youtube.com/playlist?list=PLUiueC0kTFqI9WIeUSkKvM-a_3fyaIiuk) however it's based on a very old version of Appwrite which isn't compatible with the latest version. The other and best resource is the [Official Appwrite Docs](https://appwrite.io/docs) which is the main source of knowledge in this blog series. To create a strong resource on integrating Appwrite perfectly with Flutter, I decided to document the entire process of developing the **Recipe App**, a social media for sharing your mouthwatering recipes to the world, in this blog series and mind you, I am still building the app at the time of writing this blog so let's learn together and build in public.
That's all to get you started with this blog series! In the next blog, we will talk about setting up our flutter apps, discussing the architecture and things like state management (will be Riverpod 2.0). Hope, the blog series will succeed in the prime objective of becoming the go-to resource for creating Flutter+Appwrite apps. See y'all soon in the next blog and do share it for the greater good of the community😁😁! | chandramdutta |
1,317,656 | Setting up | Just setting up LQQKing to learn and build. | 0 | 2023-01-04T21:39:42 | https://dev.to/lskybank4/setting-up-12a0 | webdev | Just setting up LQQKing to learn and build. | lskybank4 |
1,317,803 | How do I find the last version of a deleted file in Git | A few months ago, I deleted a file. Today, I realized that actually, I need it! I picked a random... | 0 | 2023-01-05T00:43:50 | https://dev.to/luispa/how-do-i-find-the-last-version-of-a-deleted-file-in-git-34p3 | git, bash, programming, github | A few months ago, I deleted a file.
Today, I realized that actually, I need it! I picked a random commit 6 months ago and found the file… but hm, what if it changed after that point?
How do I find the *final* version of that file?
Here's the Git command I used:
```sh
$ git log --full-history -- src/path/to/file.js
```
This finds the commit that deleted the file. So, I checked out that commit, and then backed up one more:
```sh
$ git checkout HEAD~1
```
This loads the file right before it was deleted! 🎉
Git is such a powerful tool.
Happy hacking!
Originally posted here: https://blog.luispa.dev/posts/how-do-i-find-the-last-version-of-a-deleted-file-in-git | luispa |
1,317,837 | YOLO Section - GitJump A Simple Tool for Navigating Git Repositories in Go. | Hey everyone, A few months ago, I started to use GitHub more frequently as a learning tool,... | 0 | 2023-01-09T17:07:21 | https://dev.to/douglasmakey/yolo-section-gitjump-a-simple-tool-for-navigating-git-repositories-in-go-337 | ---
title: YOLO Section - GitJump A Simple Tool for Navigating Git Repositories in Go.
published: true
description:
tags:
cover_image: https://upload.wikimedia.org/wikipedia/commons/thumb/f/f4/Git_session.svg/2880px-Git_session.svg.png
# Use a ratio of 100:42 for best results.
# published_at: 2022-12-22 01:20 +0000
---
Hey everyone,
A few months ago, I started to use GitHub more frequently as a learning tool, exploring repositories and projects I was interested in to understand better how they were developed and how teams approached challenges. I was looking for a tool that would allow me to easily move between commits to trace the history of a project, but I couldn't find anything that fit the bill "maybe I didn't search very well". So, I decided to create my own!
It is an ULTRA-SIMPLE app for navigating through the commits of a repository using a simple syntax. It's been an enormous help in my learning process, and I hope it can also be of use to others. If you're interested in checking out my repo, you can find it here: https://github.com/douglasmakey/gitjump
## Why?
Did you know that you can use git as a powerful tool for learning? By browsing the commit history of a repository, you can gain insight into a project's development process and evolution. This method can be handy when learning about a new topic or trying to understand how a team tackled challenges along the way. Give it a try and see how exploring commit history can enhance your learning experience!
In addition to providing a detailed history of a project's development, exploring commit history can also help you learn about best practices and coding styles. By seeing how other developers structure their code and commit messages, you can pick up valuable tips and techniques you can apply to your work. And if you're working on a team, analyzing commit history can help you understand how your colleagues approach problems and communicate their solutions. So next time you want to learn something new, check out the commit history of relevant repositories - you might be surprised at what you can discover! | douglasmakey | |
1,318,520 | Understanding Git through images | Hello Dev community! I am a newbie, still a few months into my career as a developer in... | 0 | 2023-01-05T15:22:20 | https://dev.to/nopenoshishi/understanding-git-through-images-4an1 | git, beginners, image, tutorial | # Hello Dev community!
I am a newbie, still a few months into my career as a developer in Japan. I was inspired by [Nico Riedmann's Learn git concepts, not commands](https://dev.to/unseenwizzard/learn-git-concepts-not-commands-4gjc), and I have summarized git in my own way. Of course, I supplemented it with reading the [official documentation ](https://git-scm.com/doc)as well.
Understanding git from its system structure makes git more fun. I have recently become so addicted to git that I am in the process of creating my own git system.
Recently, I wrote how to make software like git!
[Make original git](https://dev.to/nopenoshishi/make-your-original-git-analyze-section-139d)
<!-- TOC -->
- [What is Git?](#what-is-git)
- [Manage versions and Distribute work](#manage-distribute)
- [Using Git means](#using-git-means)
- [Understanding by image](#understading-by-image)
- [Start new work](#start-new-work)
- [Repositories](#repositories)
- [Copy the repository and start working](#copy-the-repository)
- [(Supplemental) Working Directory](#working-directory)
- [Change and Add files](#change-and-add-file)
- [Adapt to remote repositories](#adapt-to-remote)
- [View Differences](#view-differences)
- [(Aside) One step called staging area](#staging-area)
- [Summary](#summary1)
- [Branch](#branch)
- [Create new branch](#create-new-branch)
- [Work in Branches](#work-in-branches)
- [(Aside)Git-Flow and GitHub-Flow](#gitflow-githubflow)
- [Summary](#summary2)
- [Merge](#merge)
- [Fast Forward](#fast-forward)
- [No Fast Forward](#no-fast-forward)
- [Deal with Conflicts](#deal-with-conflicts)
- [Delete unnecessary branches](#delete-unnecessary-branches)
- [(aside) What is the branch?](#what-is-the-branch)
- [Summary](#summary3)
- [Rebase](#rebase)
- [Move the branch](#move-branch)
- [Deal with rebase conflicts](#deal-with-rebase-conflicts)
- [Keep local repositories up-to-date](#keep-up-to-date)
- [Branch and Repository](#branch-and-repository)
- [Check the latest status](#check-the-latest-status)
- [Update to the latest status](#update-to-the-status)
- [Deal with pull conflicts](#deal-with-pull-conflicts)
- [(Aside) Identity of pull requests](#identity-of-pull-requests)
- [Useful Functions](#useful-functions)
- [Correct the commit](#correct-the-commit)
- [Delete the commit](#delete-the-commit)
- [Evacuate the work](#evacuate-the-work)
- [Bring the commit](#bring-the-commit)
- [Mastering HEAD](#mastering-head)
- [End](#end)
- [Source code management without Git](#source-code-managemaent-without-git)
- [Where is the remote repository](#where-is-the-remote-repository)
- [Pointer](#pointer)
- [To further understand Git](#to-further-understading-git)
- [Reference](#references)
<!-- TOC -->
<a id="markdown-what-is-git" name="what-is-git"></a>
# What is Git?
<a id="markdown-manage-distribute"name="manage-distribute"></a>
### Manage versions and Distribute work
Git is a type of source code management system called a distributed version control system.
Git is a tool to facilitate development work by **recording and tracking the changelog (version) of files**, comparing past and current files, and clarifying changes.
The system also allows **multiple developers to edit files at once**, so the work can be distributed.
<a id="markdown-using-git-means" name="using-git-means"></a>
### Using Git means
First, make a copy of the file or other files in a storage location that can be shared by everyone (from now on referred to as "remote repository") on your computer (from now on referred to as "local repository"), and then add or edit new code or files.
Then, the files will be updated by registering them from the local repository to the remote repository.
<a id="markdown-understading-by-image" name="understading-by-image"></a>
### Understading by image
When dealing with Git, it is important to follow "how to work" from "what" to "what".
If you only operate commands, you may not understand what is happening and use the wrong command.
**(info)**
When manipulating Git, try to imagine what is happening before and after the operation.
<a id="markdown-start-new-work" name="start-new-work"></a>
## Start new work
<a id="markdown-repositories" name="repositories"></a>
### Repositories
A repository in Git is a storage for files, which can be remote or local.
**Remote Repository** is a repository where the source code is placed on a server on the Internet and can be shared by everyone.
**Local repository** is a repository where the source code is located on your computer and only you can make changes.
<a id="markdown-copy-the-repository" name="copy-the-repository"></a>
### Copy the repository and start working
First, prepare your own development environment.
All you need only to do is decide in which directory you will work.
For example, your home directory is fine, or any directory you normally use.
Next, copy and bring the files from the remote repository.
This is called `clone`.
The remote repository called `project` contains only `first.txt`, and this is the image when you `clone` the remote repository.
**(info)**
Of course, you may create a local repository first and then reflect the remote repository.
This is called `initialize` and allows you to convert a directory you are already working on into a repository.
<a id="markdown-working-directory" name="ワーキングディworking-directoryレクトリ"></a>
### (Supplemental) Working Directory
A working directory is not any special directory, but a directory where you always work on your computer.
It's easier to understand if you think of it as a directory where you can connect to the target directory that Git manages (in this case, `project`) with a Git staging area or local repository.
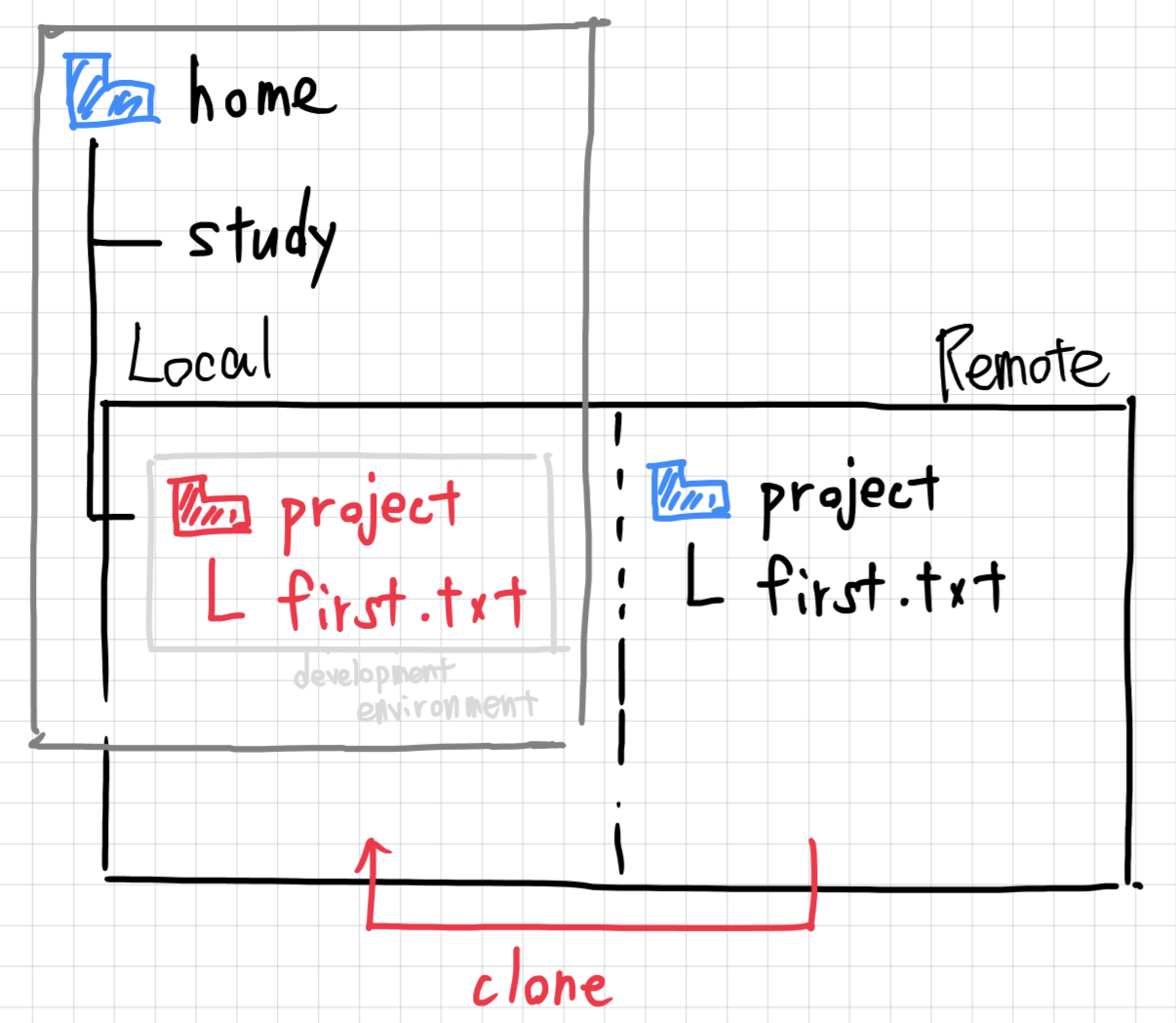
<a id="markdown-change-and-add-file" name="change-and-add-file"></a>
### Change and Add file
Changes to the source code are made through the working directory, the staging area.
Actually, in the working directory, we work.
Let's create a new file called `second.txt`.
Next, move the modified file to the staging area.
This is called `add`.
It is a feature of Git that there is a cushion before changes are reflected in the local repository.
I will explain why this cushion exists in more detail later.
Then, we registere the content in the staging area to the local repository.
This is called `commit`.
By the way, we can comment when you `commit`.
In this case, we added a file, so write `git commit -m 'add second.txt'`.
**(info)**
When you commit, a **commit object** is created in the repository.
A simple explanation of a commit object is the data that has the updater's information and the modified file.
(All data is saved, not just the differences, but the entire state of the file at that moment (snapshot).
Please refer to [Git Objects](https://git-scm.com/book/en/v2/Git-Internals-Git-Objects) for more information about Git objects.
<a id="markdown-adapt-to-remote" name="adapt-to-remote"></a>
### Adapt to remote repositories
Then, the work is done!
The last step is to reflect the changes in the local repository to the remote repository.
This is called `push`.
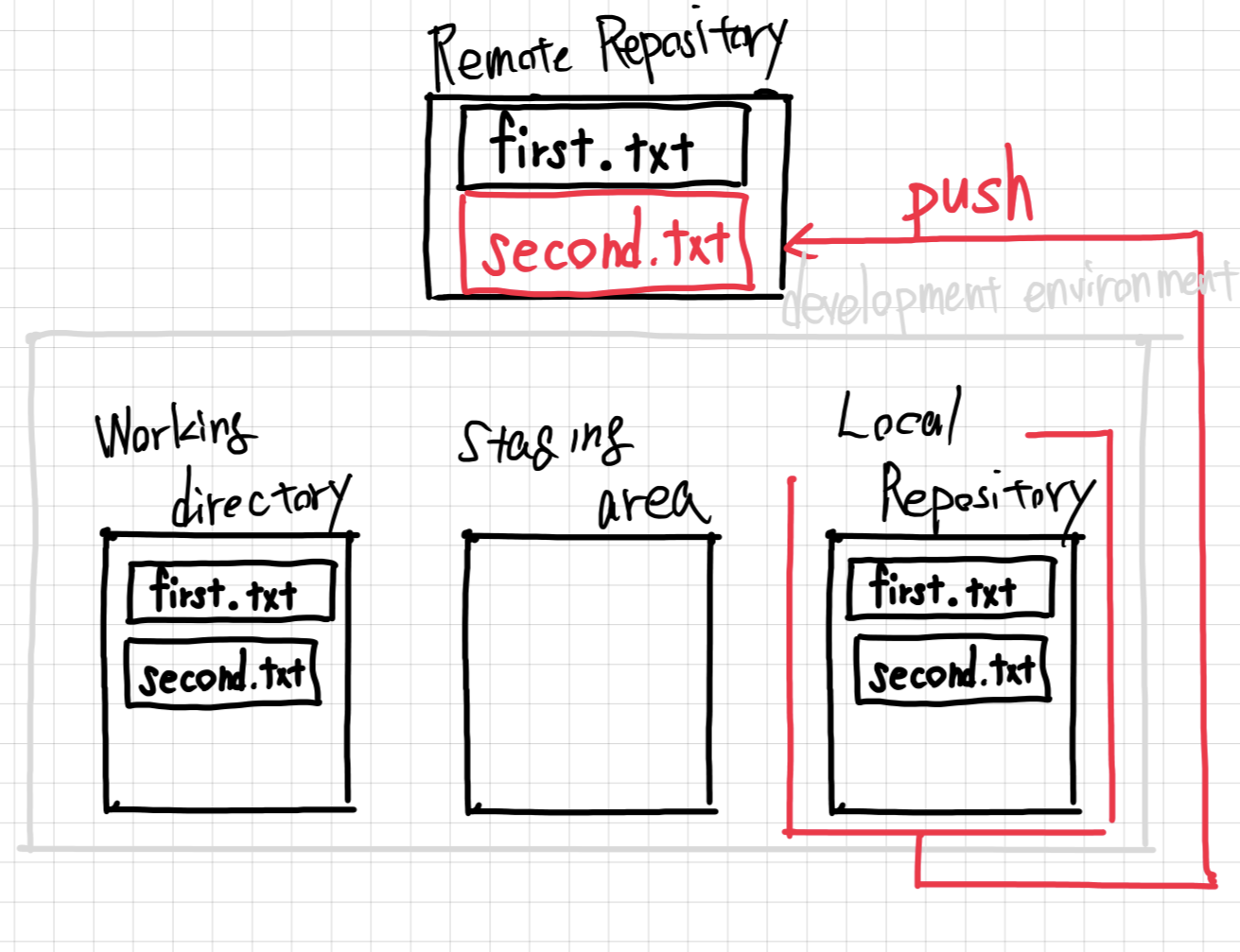
It may be easier to understand if you think of it as a commit to a remote repository.
<a id="markdown-view-differences" name="view-differences"></a>
### View Differences
Changes between the same file are called `diff`.
We can see the changing points in the file.
I won't go into the details of the commands, but here are three that I use frequently.
`git diff --stage` to see the changes from the original working directory before you `add`.
`git diff --stage` to see changes to the working directory after `add`.
`git diff <commit> <commit>` to compare commits.
<a id="markdown-staging-area" name="staging-area"></a>
### (Aside) One step called staging area
As development work grows, we often make many changes in one working directory.
What happens if you put all the changes in a local repository at once?
In this case, when parsing the commits, you may not know where a feature was implemented.
In Git, it is recommended to do one `commit` per feature.
This is why there is a staging area where you can subdivide the `commit` unit into smaller units.
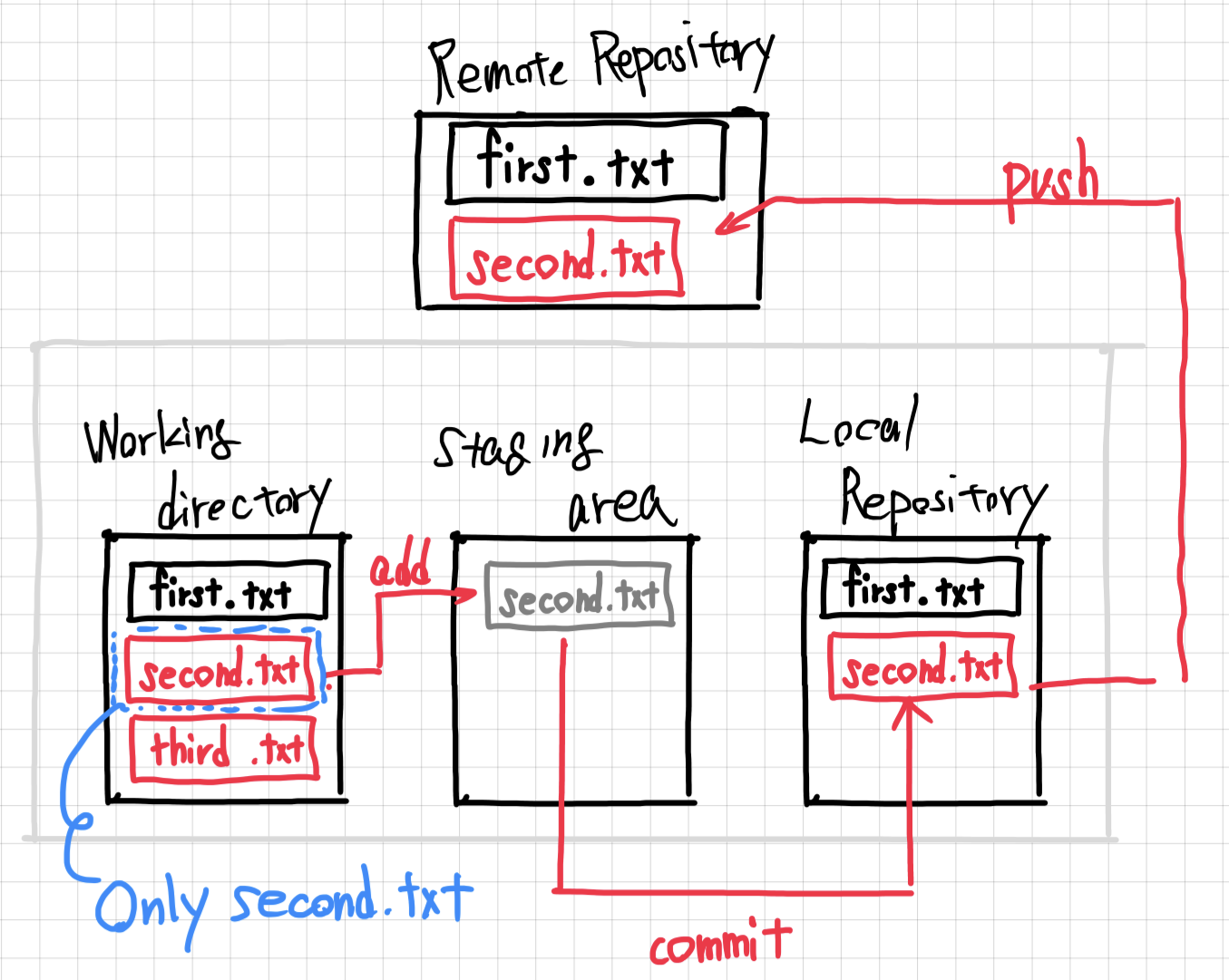
The concept of Git is to stage only what is needed, and then proceed with the work or `commit` ahead of time to promote efficient development that can be traced back through the history of each implementation.
<a id="markdown-summary1" name="summary1"></a>
### Summary
The basic workflow is to `clone` once and then `add`, `commit`, and `push` for each working.
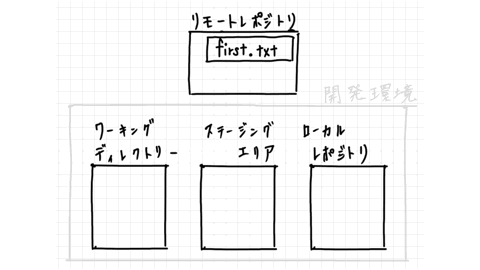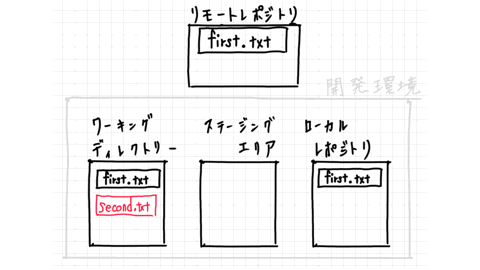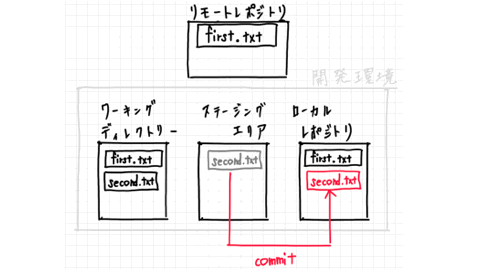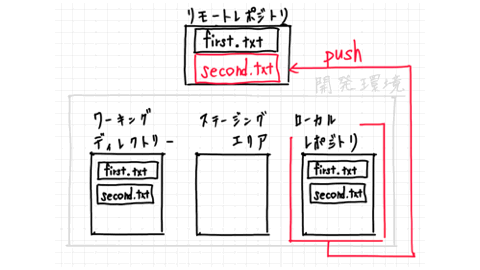
**(info)**
`clone`: Make a copy from the remote repository to your development environment (local repository and working directory).
`add`: Add files from the working directory to the staging area and prepare them for commit.
`commit`: Register the file from the staging area to the local repository. At this time, a commit object is created.
`push`: Register changes from the local repository to the remote repository.
<a id="markdown-branch" name="branch"></a>
# Branch
We create a `branch` to change and add files in multiple branches.
The files saved in the `main` branch are in ongoing use.
The reason for the separate branches is to work **without affecting the currently running source code**.
<a id="markdown-create-new-branch" name="create-new-branch"></a>
### Create new branch
Let's create the branch called `develop`!
We can create a branch with `git branch <new branch>` or `git checkout -b <new branch>`.
The former just create a branch, the latter create a branch and moves you to that branch.
(Branches are maintained in the repository.)
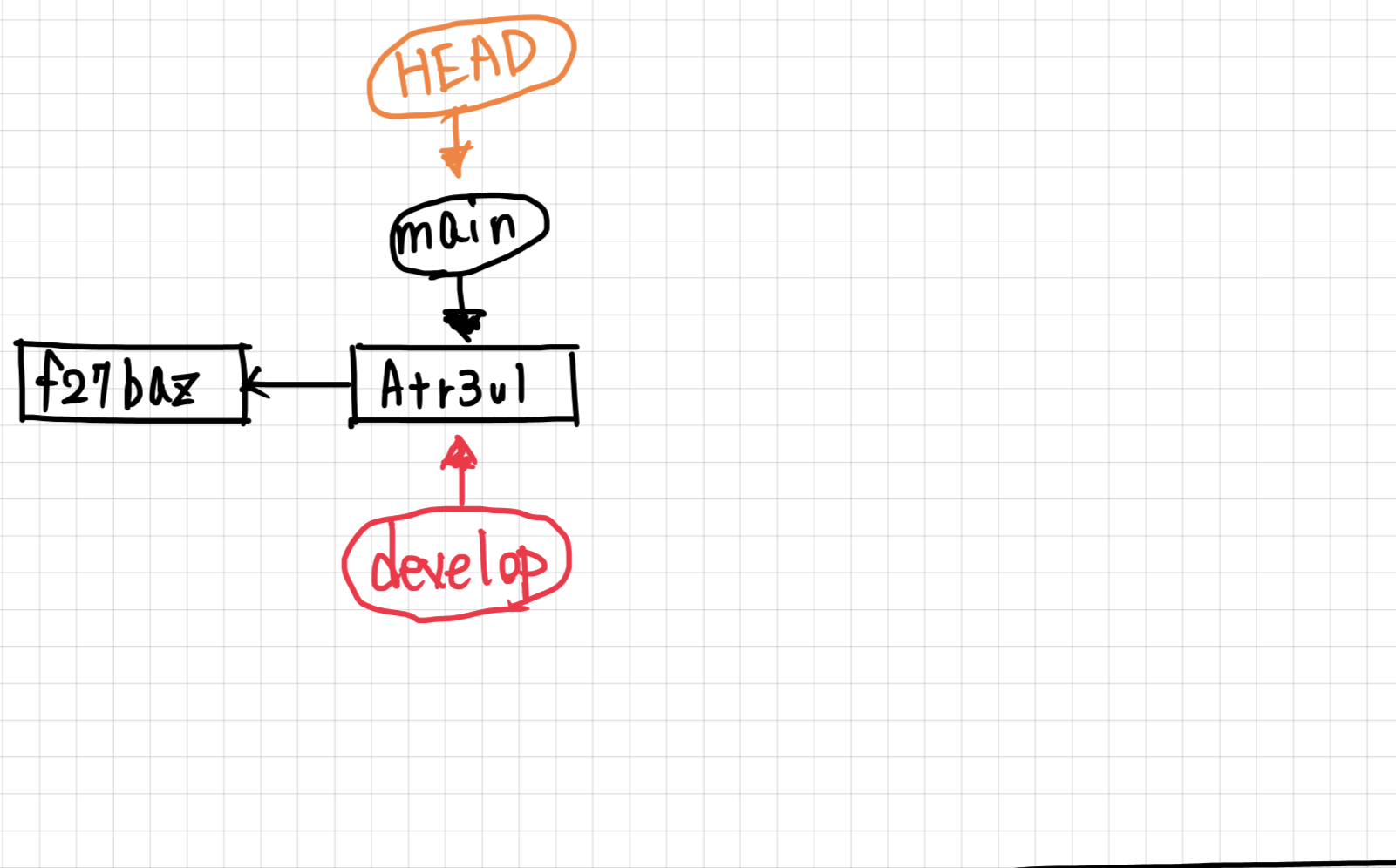
The key point when generating branches is **which branch to derive from**.
We can specify the source as `git checkout -b <new branch> <from branch>`.
If we don't, the branch you are currently working on becomes the `<from branch>`.
**(info)**
A branch is actually a **pointer** to the commit (strictly speaking, a hash of commit objects).
Generating a new branch means that the new branch indicate to the commit that the from branch pointed to as well.
<a id="markdown-work-in-branches" name="work-in-branches"></a>
### Work in Branches
Moving the branch is called `checking out`.
The pointer to the branch you are currently working on is called `HEAD`.
So, moving from the `main` branch to the `develop` branch means changing the `HEAD`.
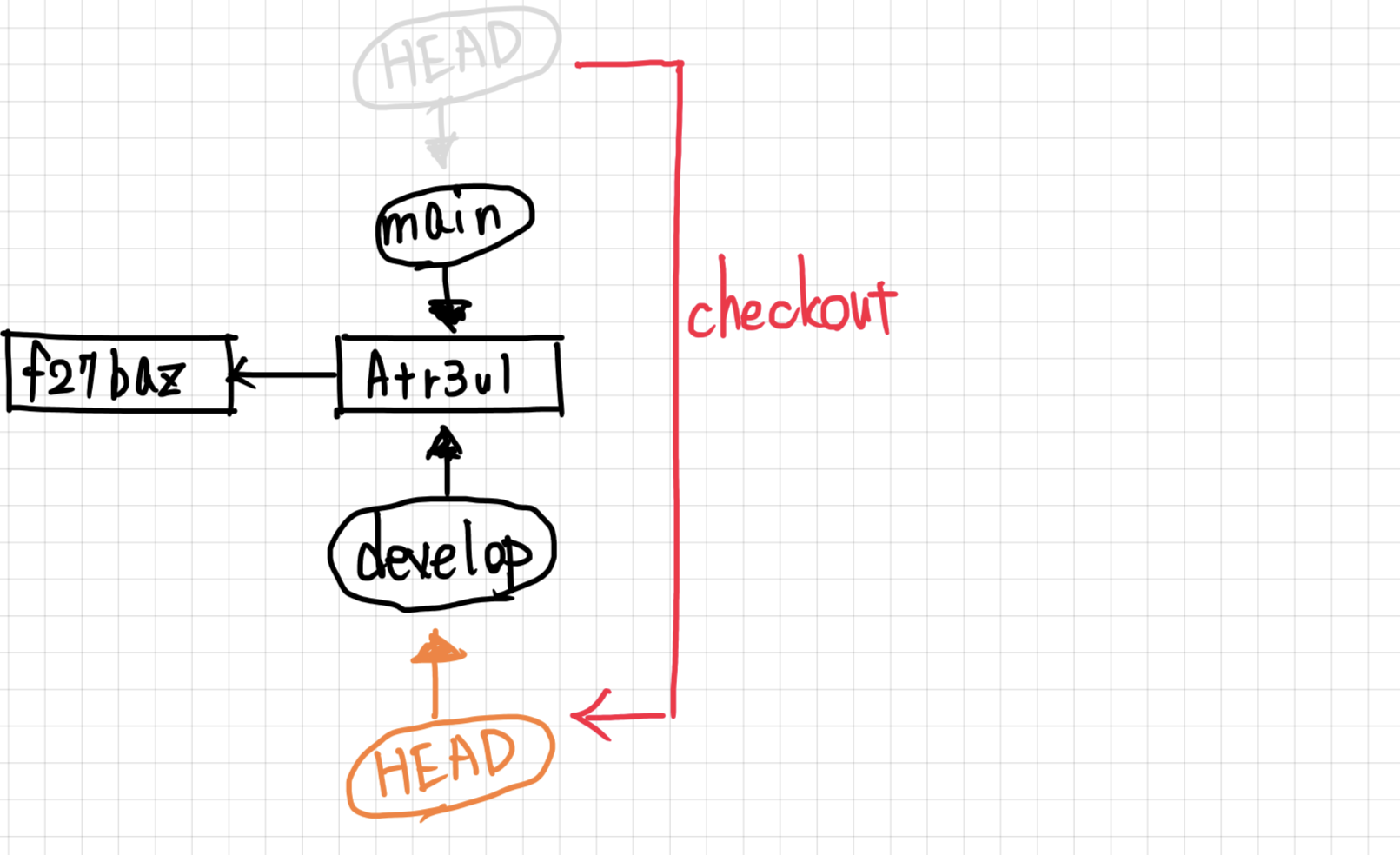
Now both branches point to the commit named `Atr3ul`.
You just added `second.txt` by committing in the `main` branch, so you are ahead of the commit `f27baz`.
From here, let's say you change `second.txt` in the `develop` branch and make a new commit.
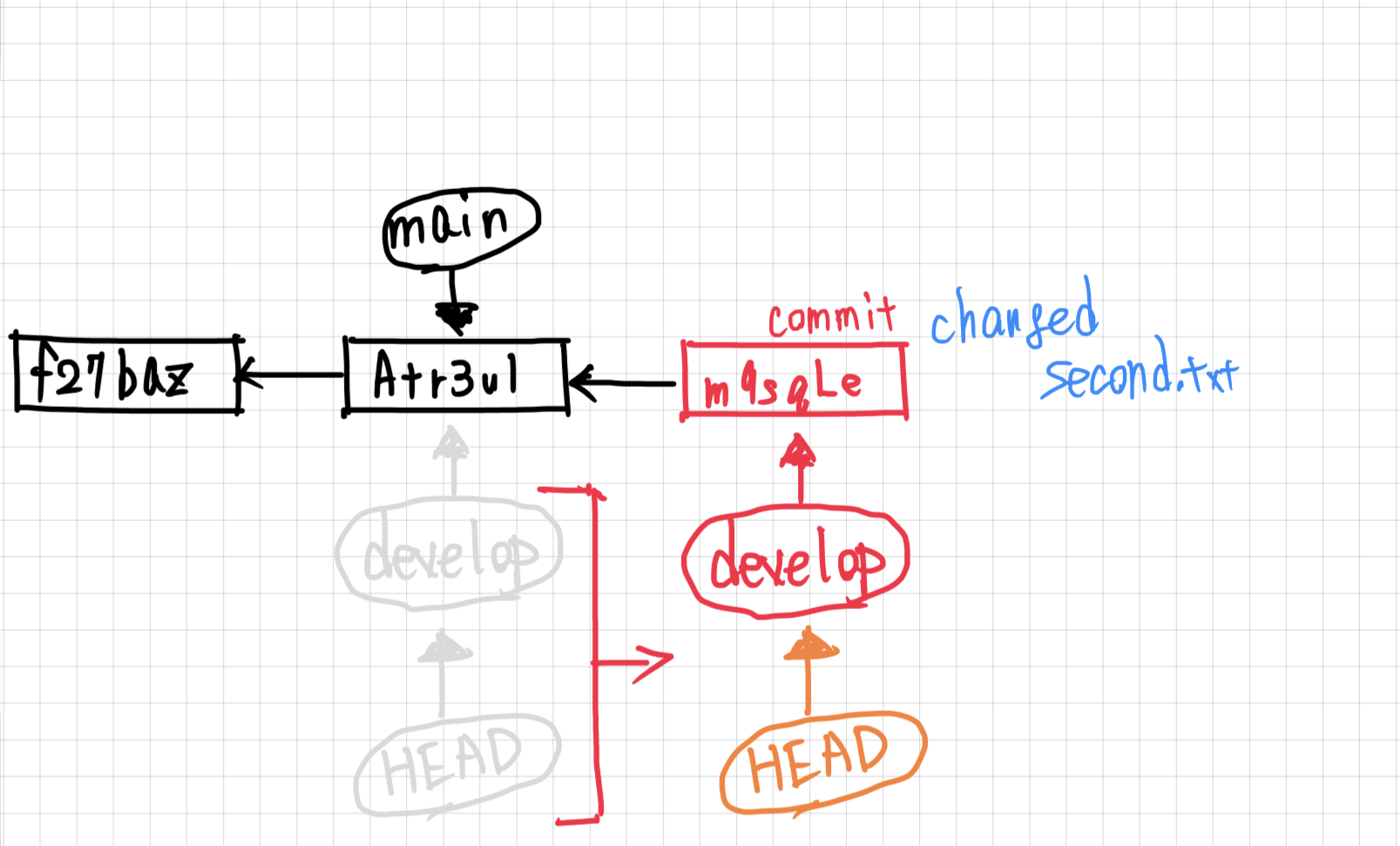
Then, as shown in the figure, the `develop` branch created a commit called `m9sgle` and pointed to that commit.
The current HEAD position (working branch position), what stage the file has been worked on, or the status of who is working on it is called `status`.
**(info)**
If you are familiar with object-oriented, you may understand the reason for the arrow on the commit.
It represents the relationship between a "parent" commit and a "child" commit.
The assumption is that `parent←-child`, that is, how much the child (commit) born from the parent (commit) has grown (changed).
<a id="markdown-gitflow-githubflow" name="gitflow-githubflow"></a>
### (Aside)Git-Flow and GitHub-Flow
The way branches to manage will vary on development team.
On the other hand, like programming naming conventions, there is a general model for how to grow branches in Git.
Here are two simple ones. I think it's enough to know that there is such a thing.
<br>
<br>
The "Git Flow" is a fairly complex and intricate structure.
I think it's a model of how Git should be used.
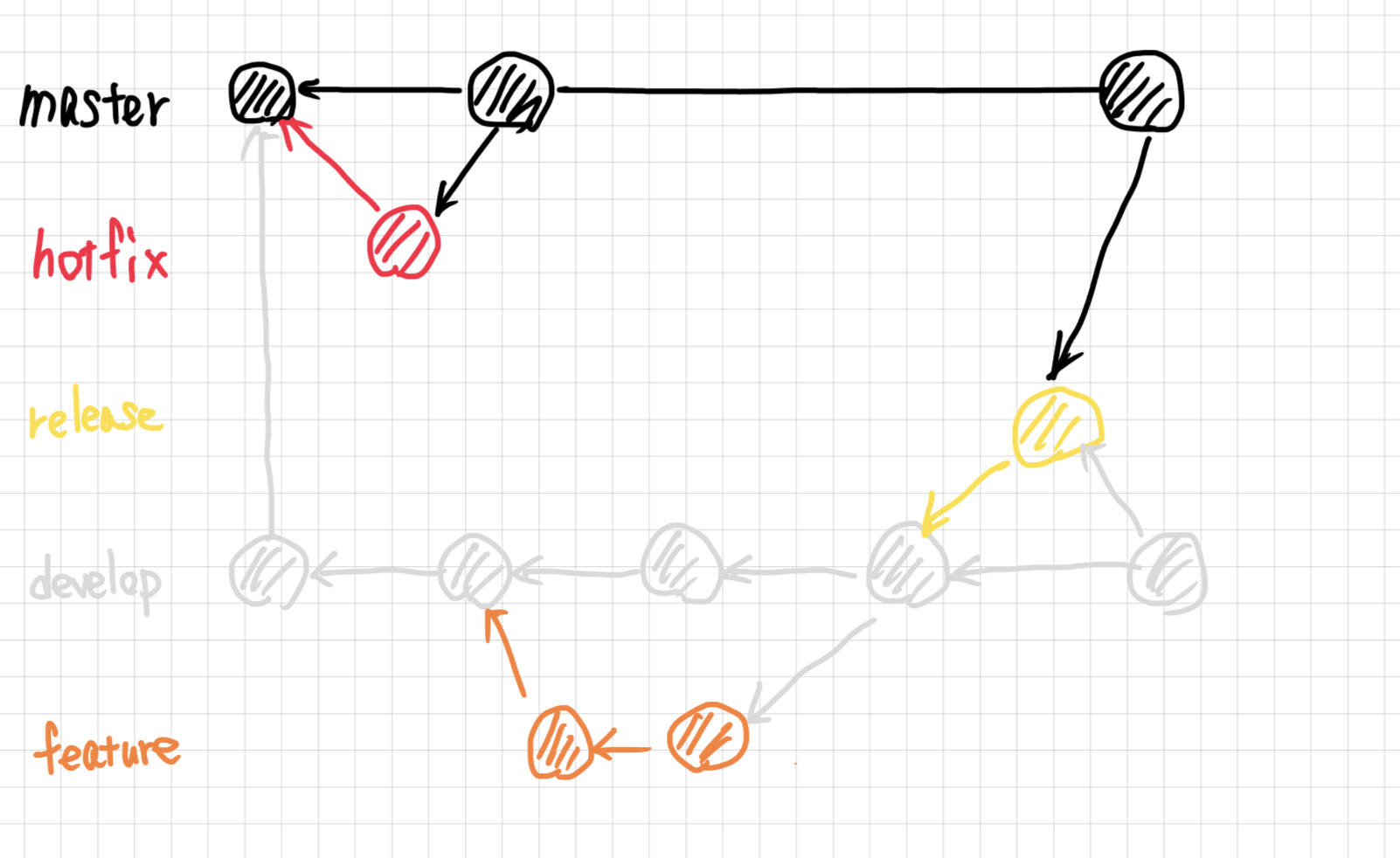
**Definition of each branch**.
`master`: Branch to release a product. No working on this branch.
`development`: Branch to develope a product. When ready to release, merge to `release`. No working on this branch.
`feature`: Branch for adding features, merged into development when ready for release.
`hotfix`: For urgent post-release work (critical bug fixes, etc.), branch off from master, merge into master, and merge into develop.
`release`: For preparation of product release. Branch from `develop` with features and bug fixes to be released.
When ready for release, merge to master and merge to develop.
<br>
<br>
The "GitHub Flow" is a somewhat simplified model of the Git Flow.
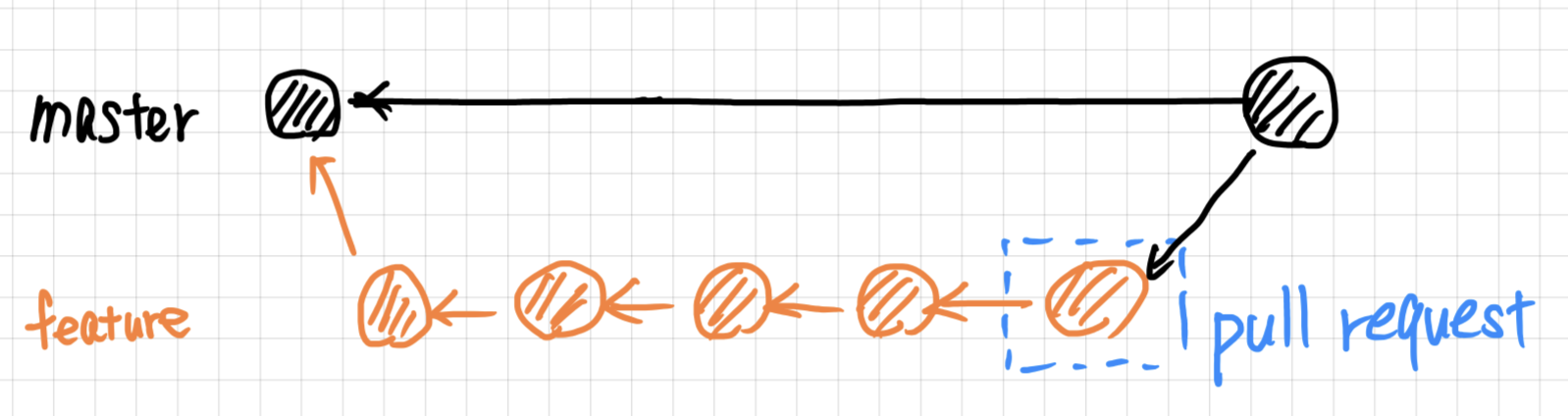
As you can see, it consists of only `master` and `feature`.
The important difference is the cushion of `pull requests` (explained in the pull below), which allows integration between branches.
<a id="markdown-summary2" name="summary2"></a>
### Summary
Basically, since there is no work on main (master), we create a branch for each work unit we want to do and create a new commit.
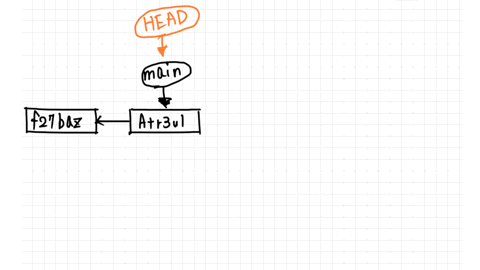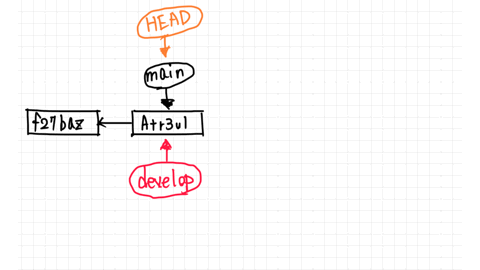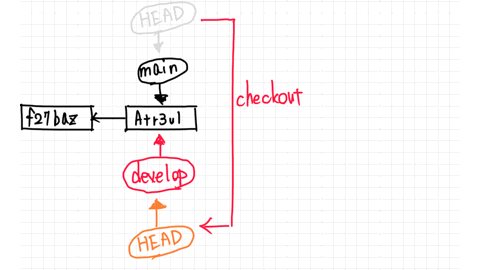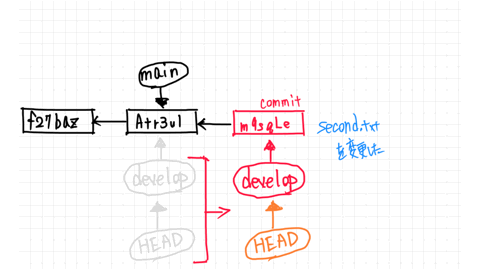
**(info)**
`branch`: New pointer to the commit
`checkout`: Move `HEAD` to change the `branch` to work on.
<a id="markdown-merge" name="merge"></a>
# Merge
integrating the branches is called `merge`.
Basically, we merge into the `main` or `develop` branch.
Be careful not to mistake the subject of which branch is merging (absorbing) which branch.
We will always move (HEAD) to the branch from which you are deriving, and then do the integration from the branch from which you are deriving.
I am currently working on the `feature` branch and have created the following `third.txt`.
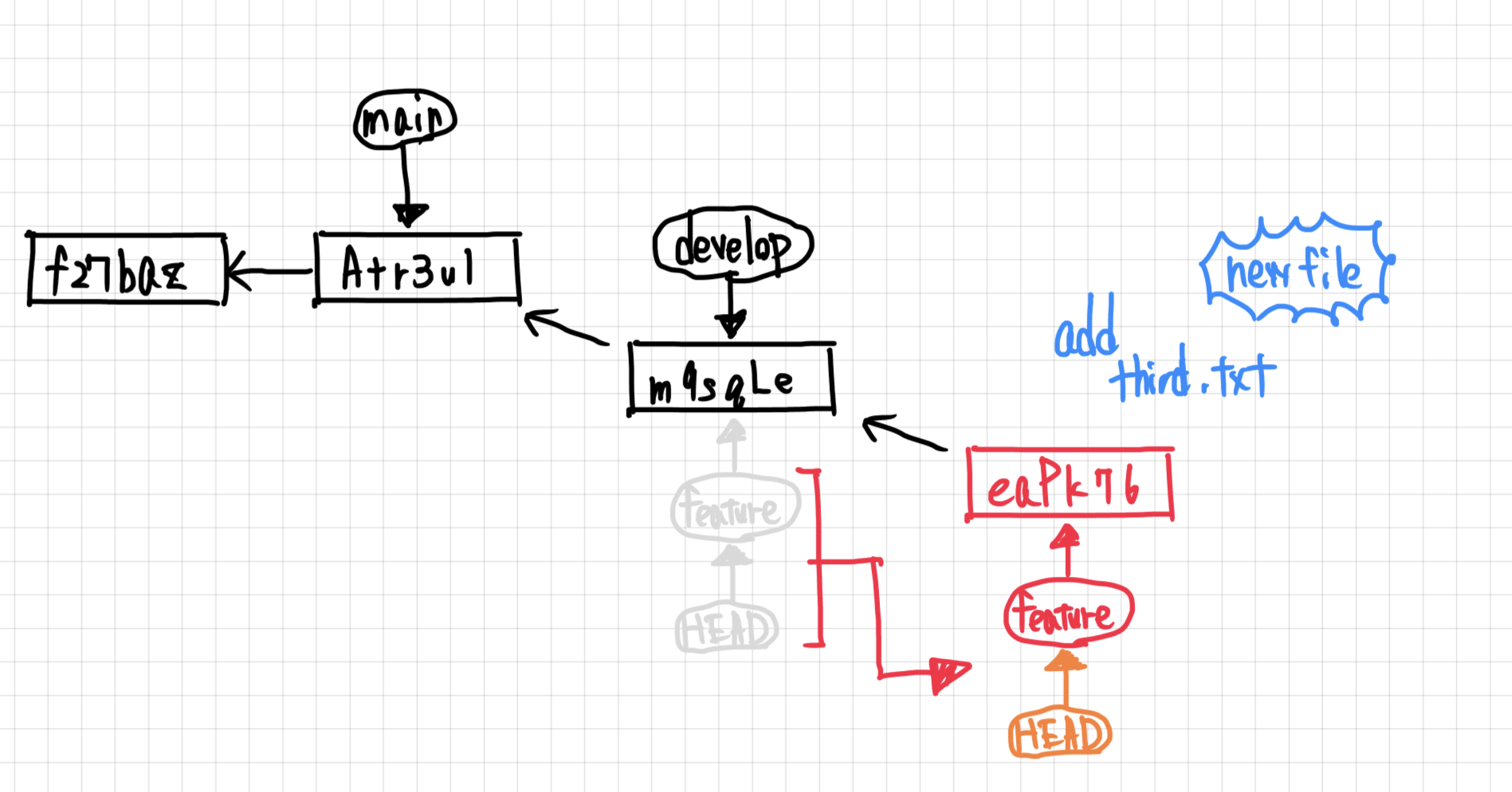
**third.txt**
```
Hello, World! I'm noshishi, from Japan.
I like dancing on house music.
```
<br>
Then We `add` and finished up to `commit`.
<br>
<a id="markdown-fast-forward" name="fast-forward"></a>
### Fast Forward
When the `feature` branch points to the commit that can be traced back to the `develop` branch, the `develop` branch is in a `fast-forward` state.
First, move to `develop` with `checkout`.
In this case, the `develop` branch has not progressed at all, so to `merge` the `feature` branch will simply move the commit forward.
In this case, the `develop` and `feature` branches share the same commit.
<a id="markdown-no-fast-forward" name="no-fast-forward"></a>
### No Fast Forward
What if the `develop` branch has progressed to a new commit by commit or merge?
This is called a `no fast-forward` situation.
In the `develop` branch, you have made changes to `first.txt` and have finished `commit`.
So the `develop` branch and the `feature` branch are completely split.
If you try to `merge` a `feature` branch from a `develop` branch, Git will check your changelog against each other.
If there are no conflicting edits, a `merge commit` is created immediately.
This is called an `automatic merge`.
<a id="markdown-deal-with-conflicts" name="deal-with-conflicts"></a>
### Deal with Conflicts
In the `no fast-forward` state, the differences in work content. is called `conflict`.
In this case, we must manually fix the `conflict` content and `commit`.
In the `develop` branch, we created the following `third.txt` and `committed`.
**third.txt**
```
Hello, World! I'm nope, from USA.
I like dancing on house music.
```
<br>
In the `develop` branch, `I'm nope, from USA`.
In the `feature` branch, `I'm noshishi, from Japan`.
The content of the first line is in conflict.
If you do a `merge` at this time, a `conflict` will occur.
Git will ask you to `commit` after resolving the `conflict`.
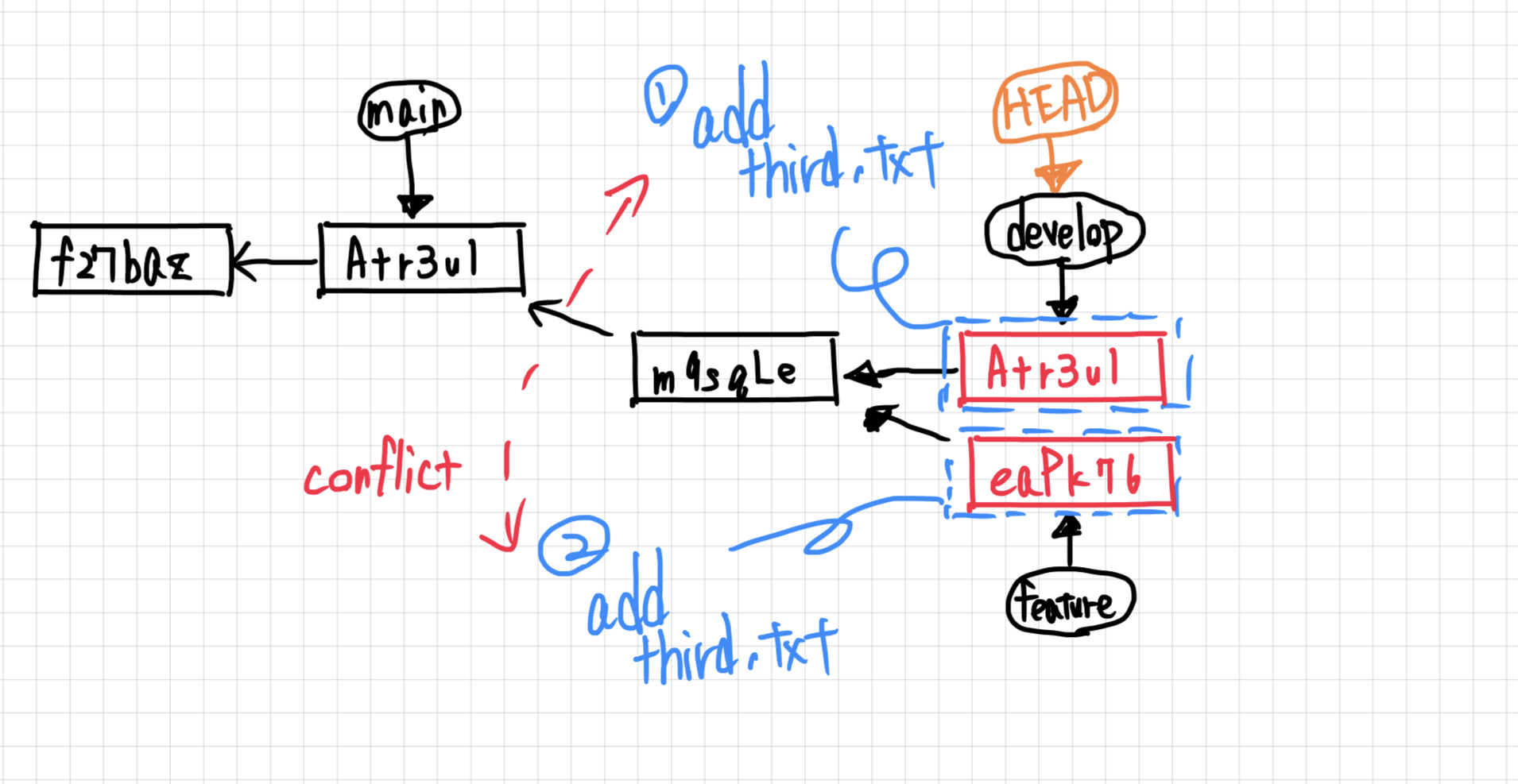
<br>
(The branch we work on is the `develop` branch)
If you look at `third.txt` as instructed, you will see the following additions
**third.txt (after conflict)**
```
<<<<<<<< HEAD
Hello, World! I'm noshishi, from Japan.
=======
Hello, World! I'm nope, from USA.
>>>>>>>> feature
I like dancing on house music.
```
The upper `HEAD`, separated by `=======`, represents the contents of the `develop` branch.
The lower side represents the `feature` branch.
You first considered which one to adopt, and decided to adopt the changes made in the `feature` branch this time.
The only operation then is to edit `third.txt` by hand (delete unnecessary parts).
**third.txt (After editing)**
```
Hello, World! I'm noshishi, from Japan.
I like dancing on house music.
```
And the next thing you do is `add` and `commit`.
The `conflict` is resolved and a new `merge commit` is created.
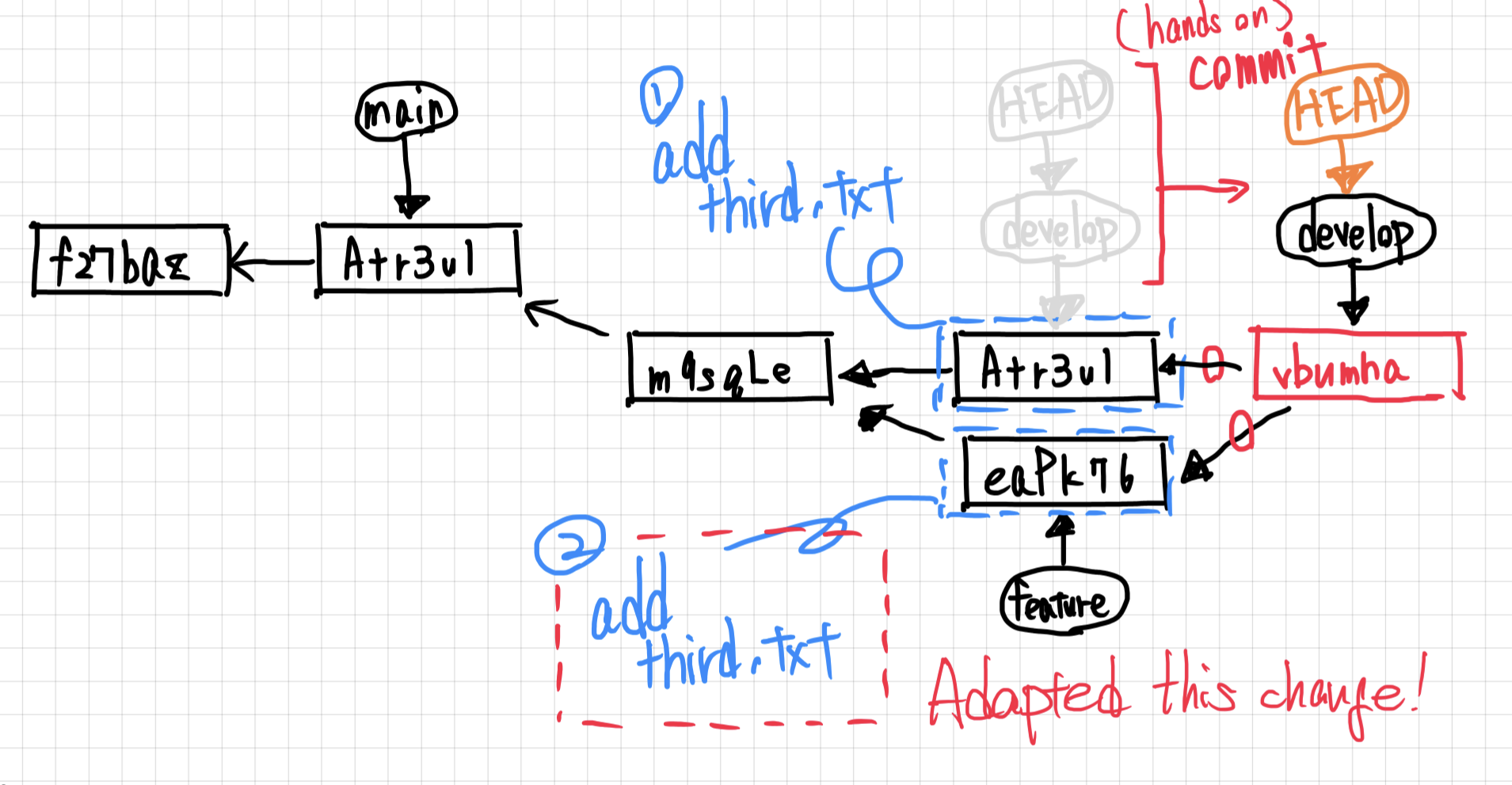
Conflicts are feared by beginners, but once you learn this, you will no longer be afraid.
**(info)**
If you `merge` and resolve the `conflict`, why not `merge` again?
When you `merge` once, the `develop` branch enters the `merge` state, and if there are no `conflicts`, the new files are automatically `added` and `commit`.
So it is not a special `commit` after `conflict` is resolved.
That's why it's called `merge commit`.
<a id="markdown-delete-unnecessary-branches" name="delete-unnecessary-branches"></a>
### Delete unnecessary branches
The merged branch is basically useless, so we will delete it.
If we leave a branch alone, you can move from the branch you want to delete to another branch and `git branch -d <branch>`.
You may think the commits on that branch are deleted.
In fact, the commits are carried over to the merged branch.
You can use `git log` to see all the commits you've made on the branch and the commits on the merged branch.
<a id="markdown-what-is-the-branch" name="what-is-the-branch"></a>
### (Aside) What is the branch
We said that a branch is a pointer to a commit, but it also holds another important data.
It is all the commits that have been made on that branch.
A branch is a collection of commits, and it has a pointer to the latest commit in that collection. (Strictly speaking, the commit can trace back to previous commits.)
The following diagram illustrates this.
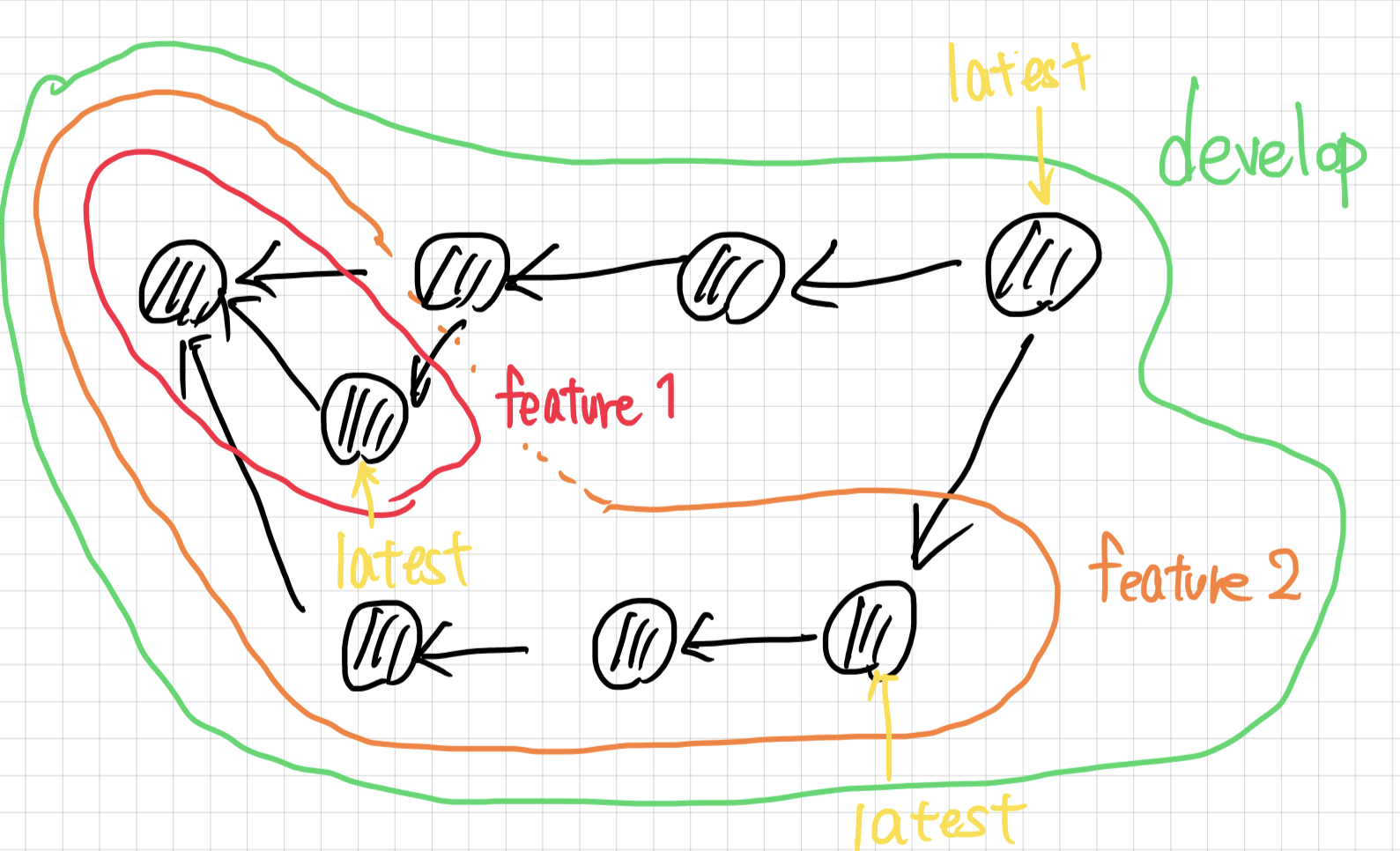
So we can think of branches on a horizontal axis like Git Flow.
By the way, if you draw the above diagram with branches on the horizontal axis, it looks like this.
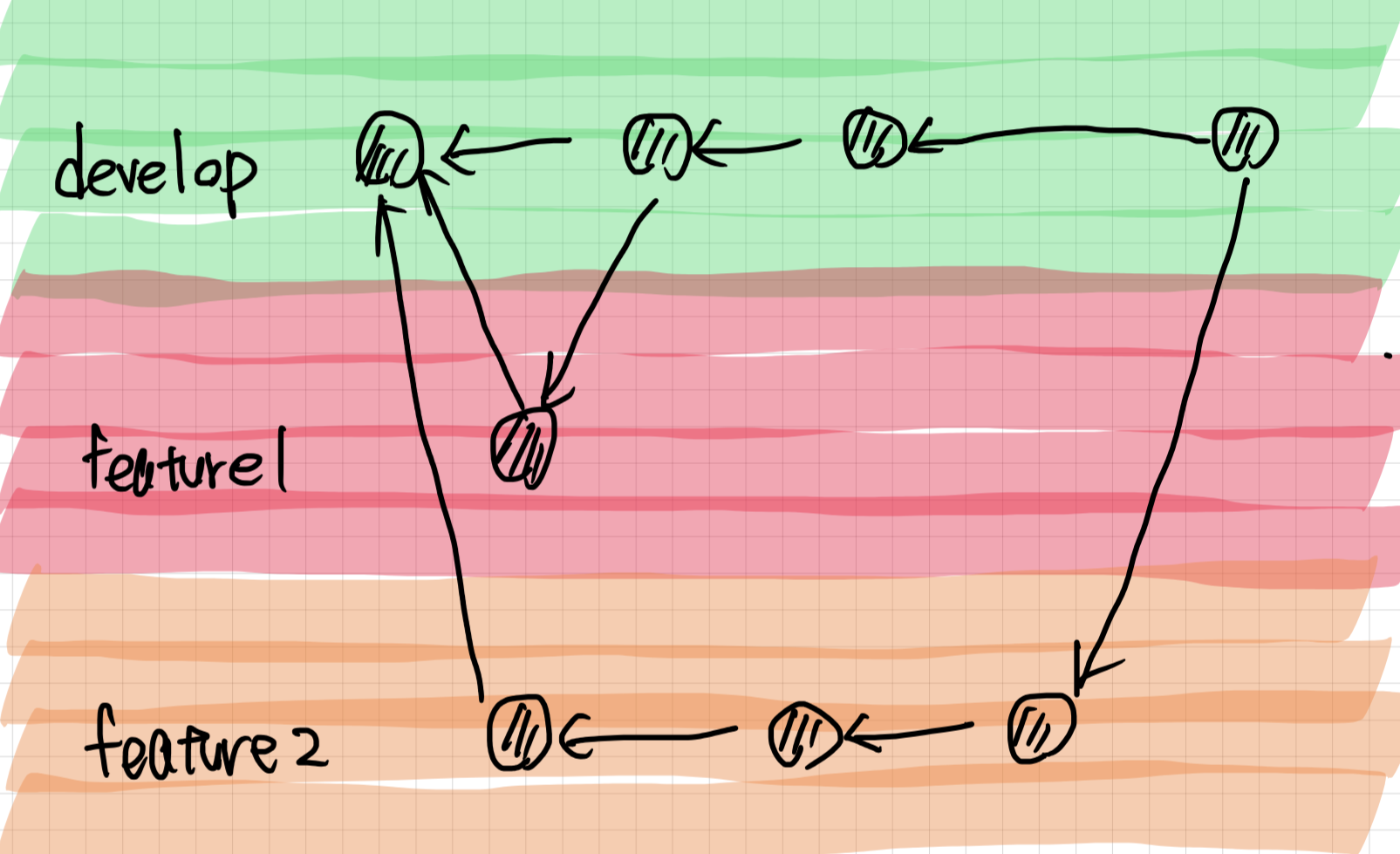
<a id="markdown-summary3" name="summary3"></a>
### Summary
`fast-forward merge`
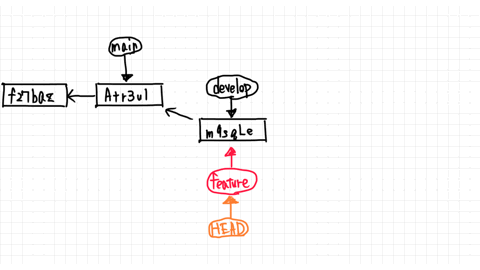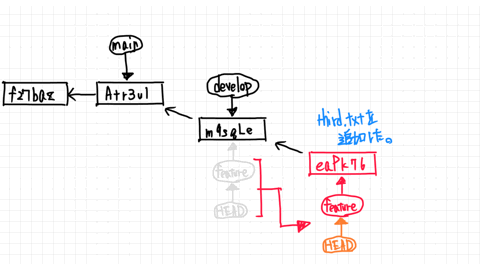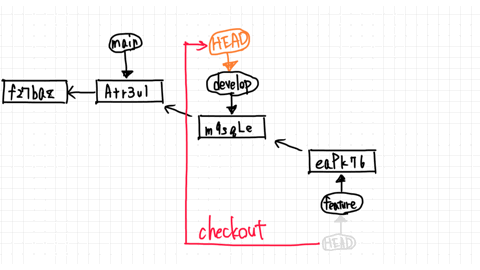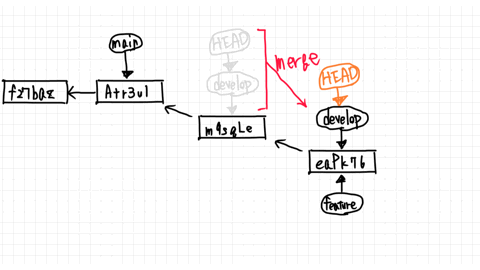
`no fast-forward merge`
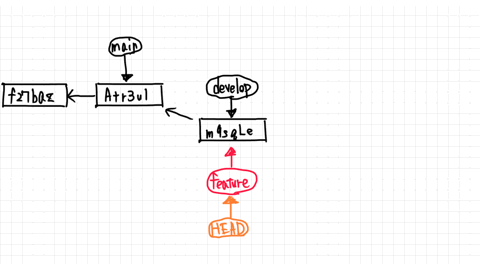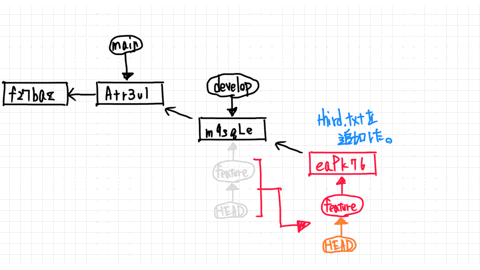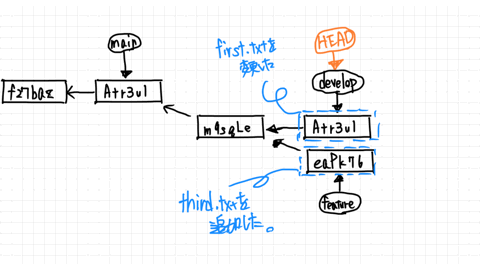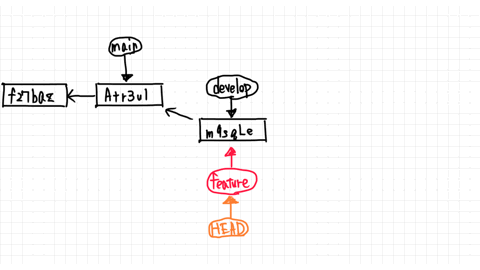
`no fast-forward merge with conflict`
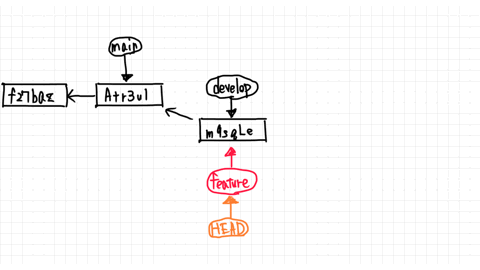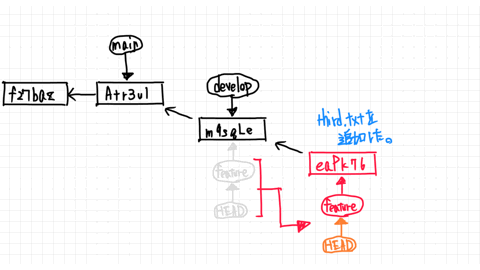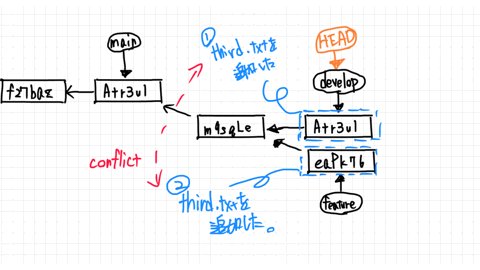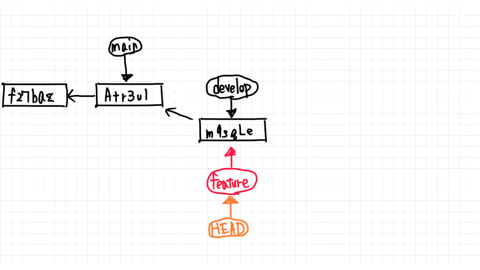
**(info)**
`merge`: To integrate (absorb) a working branch (such as `feature`) into a specific branch (such as `main` or `develop`) and create a new commit.
<a id="markdown-rebase" name="rebase"></a>
# Rebase
`Rebase` is the process of merging branches by changing the commit from which the branch is derived.
It is similar to `merge`, except that the branch you are working on is the destination branch.
Suppose you are working on the `develop` and `feature` branches.
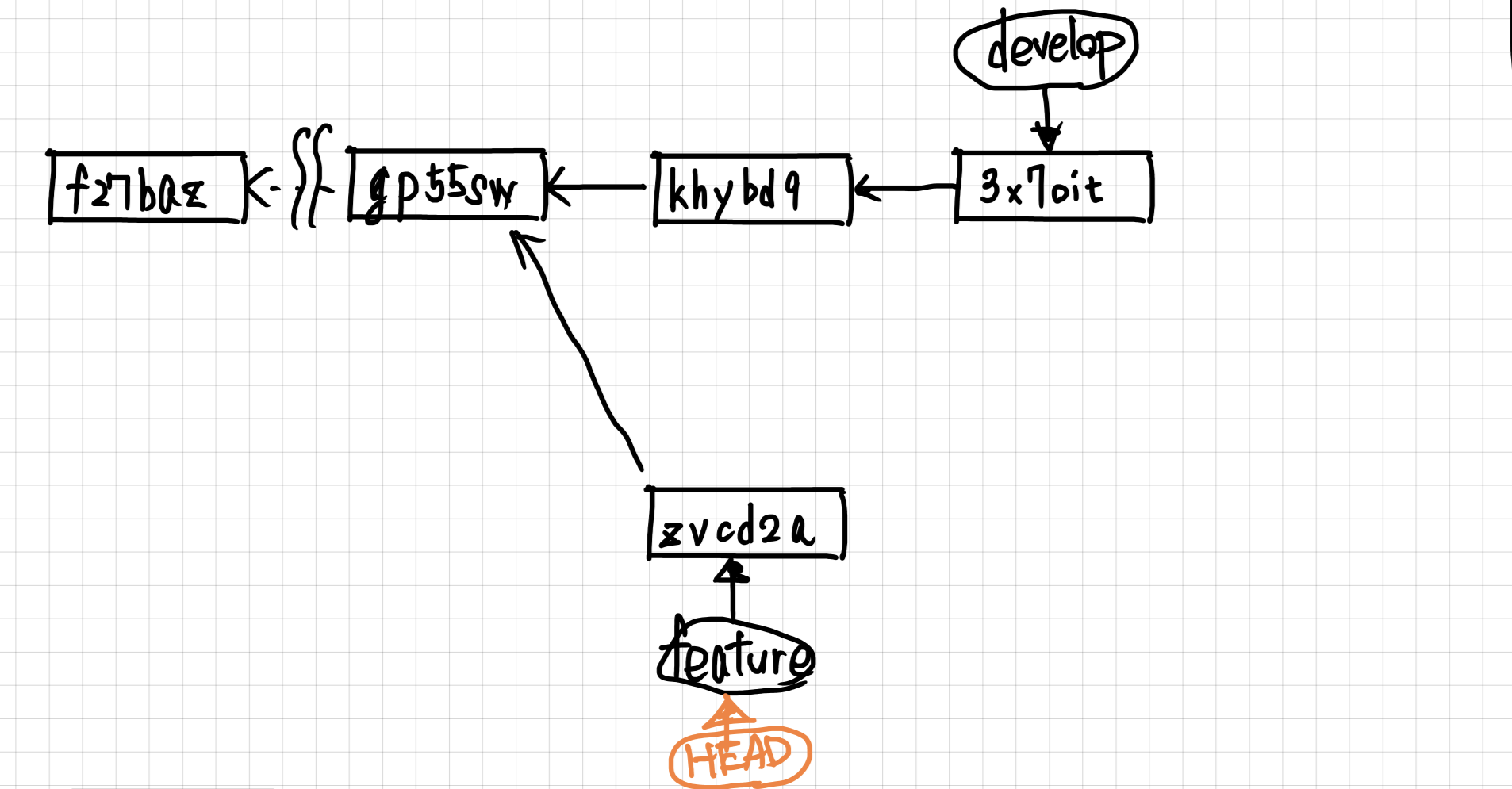
<a id="markdown-move-branch" name="move-branch"></a>
### Move the branch
You may think to reflect the current commit on `develop` branch into `feature` branch.
You need to move `feature` branch from the `gp55sw` commit to the `3x7oit` commit.
This can be moved at once from the `feature` branch by doing a `git rebase develop`.
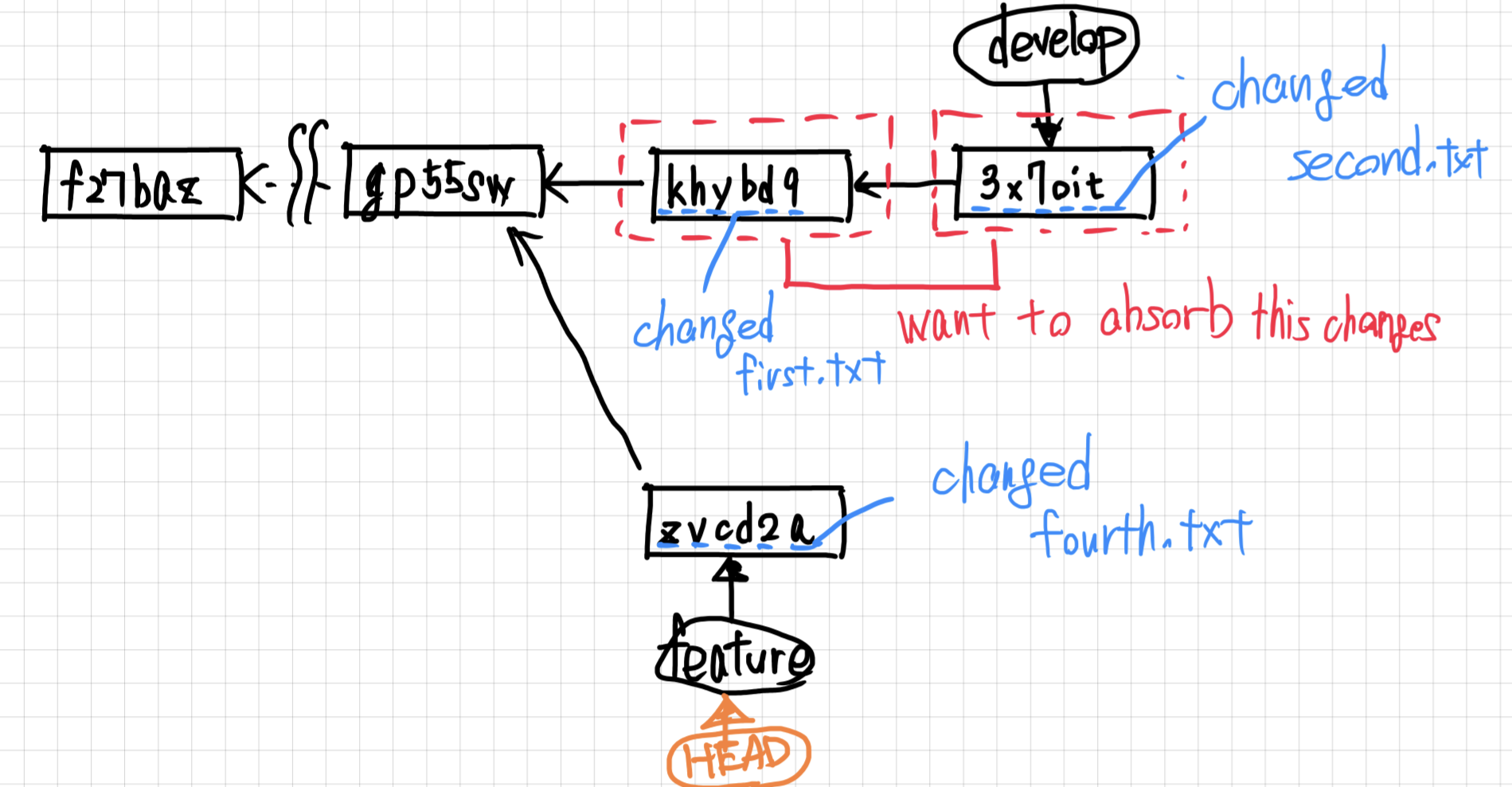
This process is more like re-growing the `feature` branch from the latest commit on the `develop` branch than doing a `merge`.
The difference is that you move the entire commit and make a new commit.
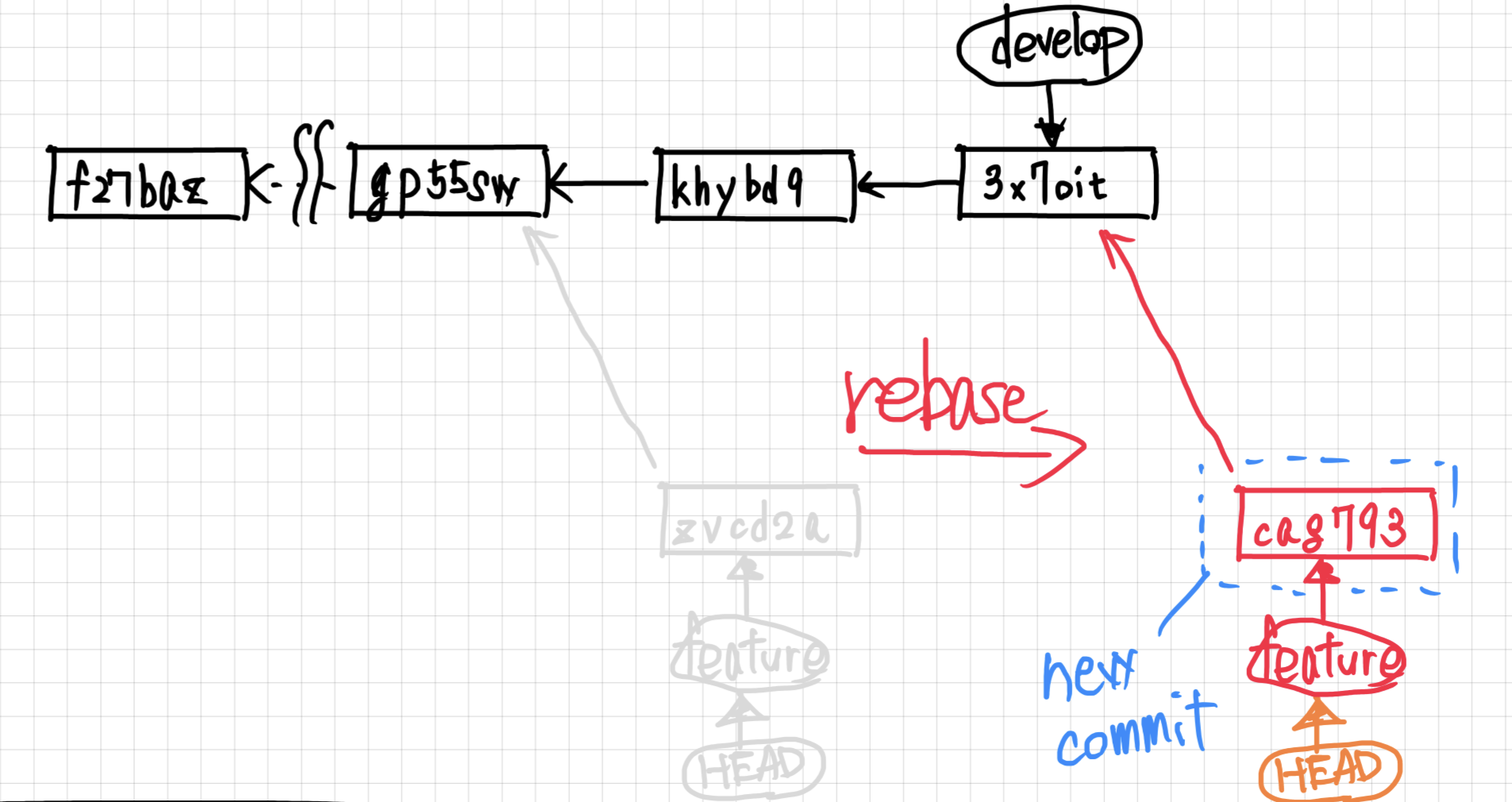
One reason for such a move is that it is `fast-forward` and easy to `merge` at any time.
The other reason is that the commits are aligned so that the commit history can be easily traced and the order in which files are updated is consistent.
<a id="markdown-deal-with-rebase-conflicts" name="deal-with-rebase-conflicts"></a>
### Deal with rebase conflicts
Of course there is also a `conflict` in `rebase`.
You added `fourth.txt` in the `feature` branch, but you didn't change `fourth.txt` in the `develop` branch.
There is `conflict`.
However, if the following changes are covered by each other, `conflict` will occur.
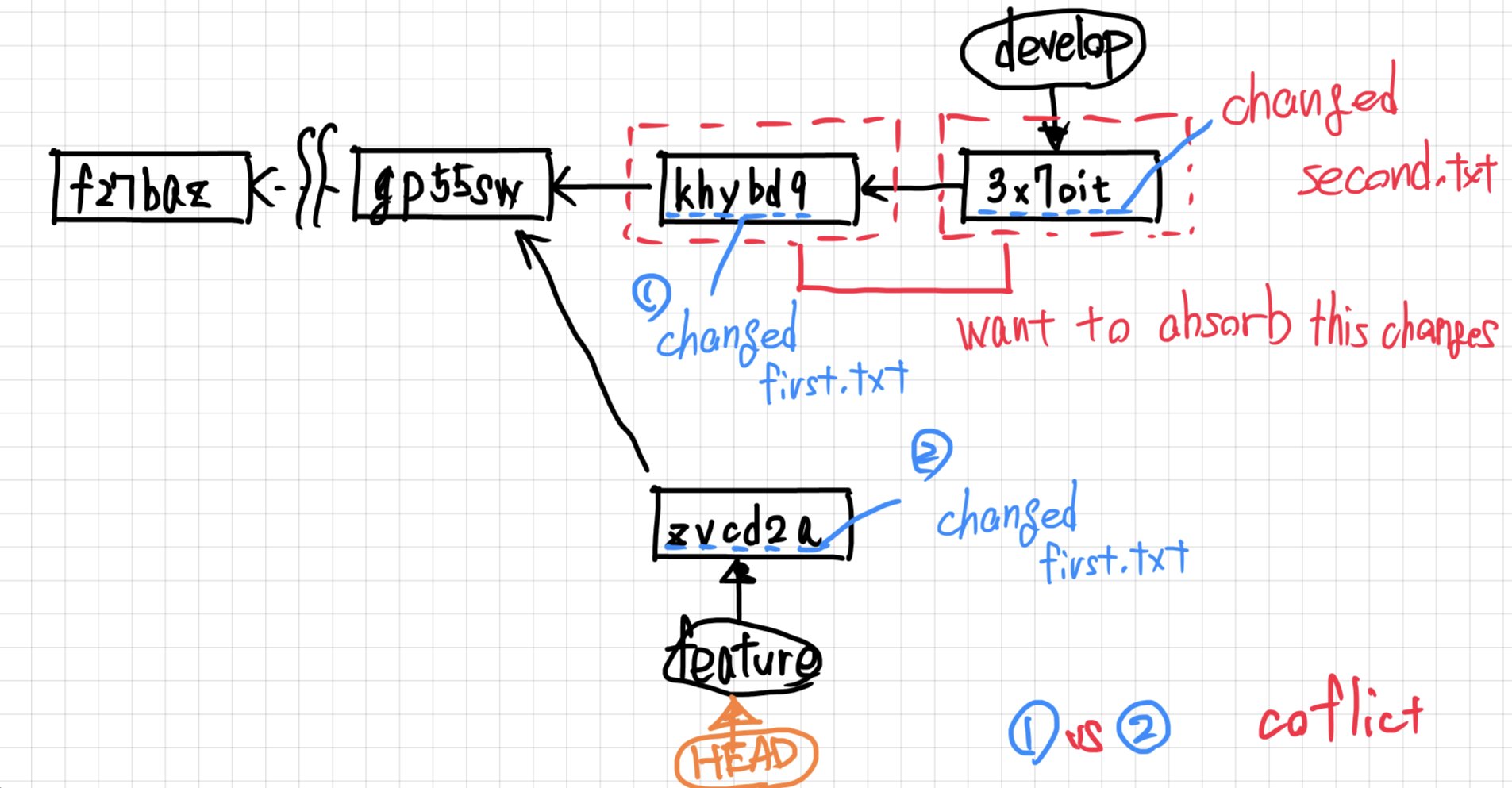
You can just deal with it the same way you would with `merge`.
However, After you have checked the diff and finished editing the file, you should finish your work with `git rebase --continue`.
You don't have to `commit`, it will commit automatically.
**(info)**
`rebase`: Move the commit from which the derived branch to a new commit.
<a id="markdown-keep-up-to-date" name="keep-up-to-date"></a>
# Keep local repositories up-to-date
After some local work, you may be faced with a situation where the remote repository has been updated by another developer.
In this case, you can use `pull` to re-install the information from the remote repository back into the local repository.
<a id="markdown-branch-and-repository" name="branch-and-repository"></a>
### Branch and Repository
Branches are stored in each repository.
This is the branch where the actual work is done.
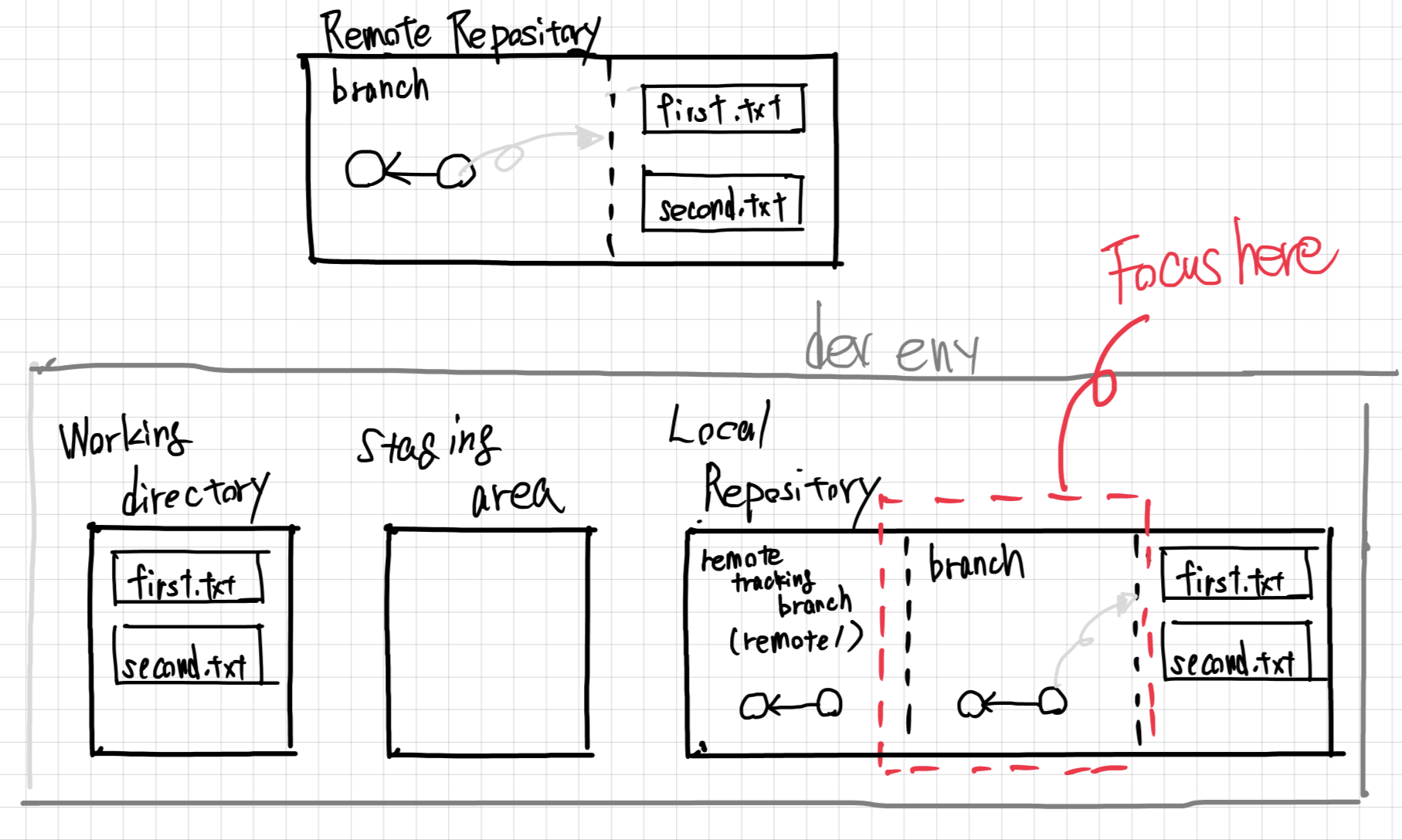
On the other hand, the local repository has the copied branches of the remote repository.
This is called a "remote tracking branch".
It is a branch with a name that is tied to the remote branch in `remotes/<remote branch>`.
This is only monitoring the remote repository.
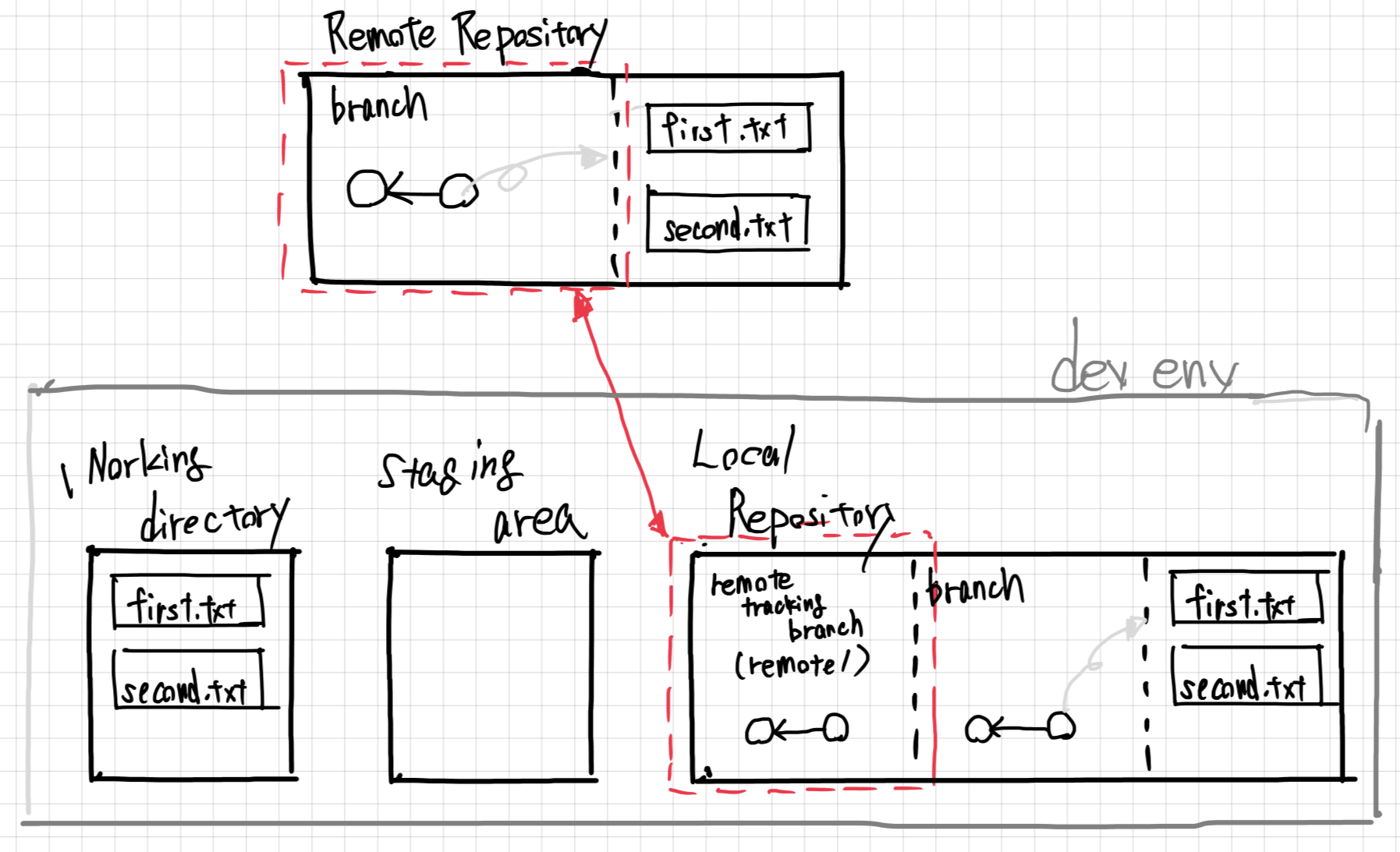
<a id="markdown-check-the-latest-status" name="check-the-latest-status"></a>
### Check the latest status
Suppose you have a situation where the `develop` branch in the remote repository is one step ahead of the remote tracking branch.
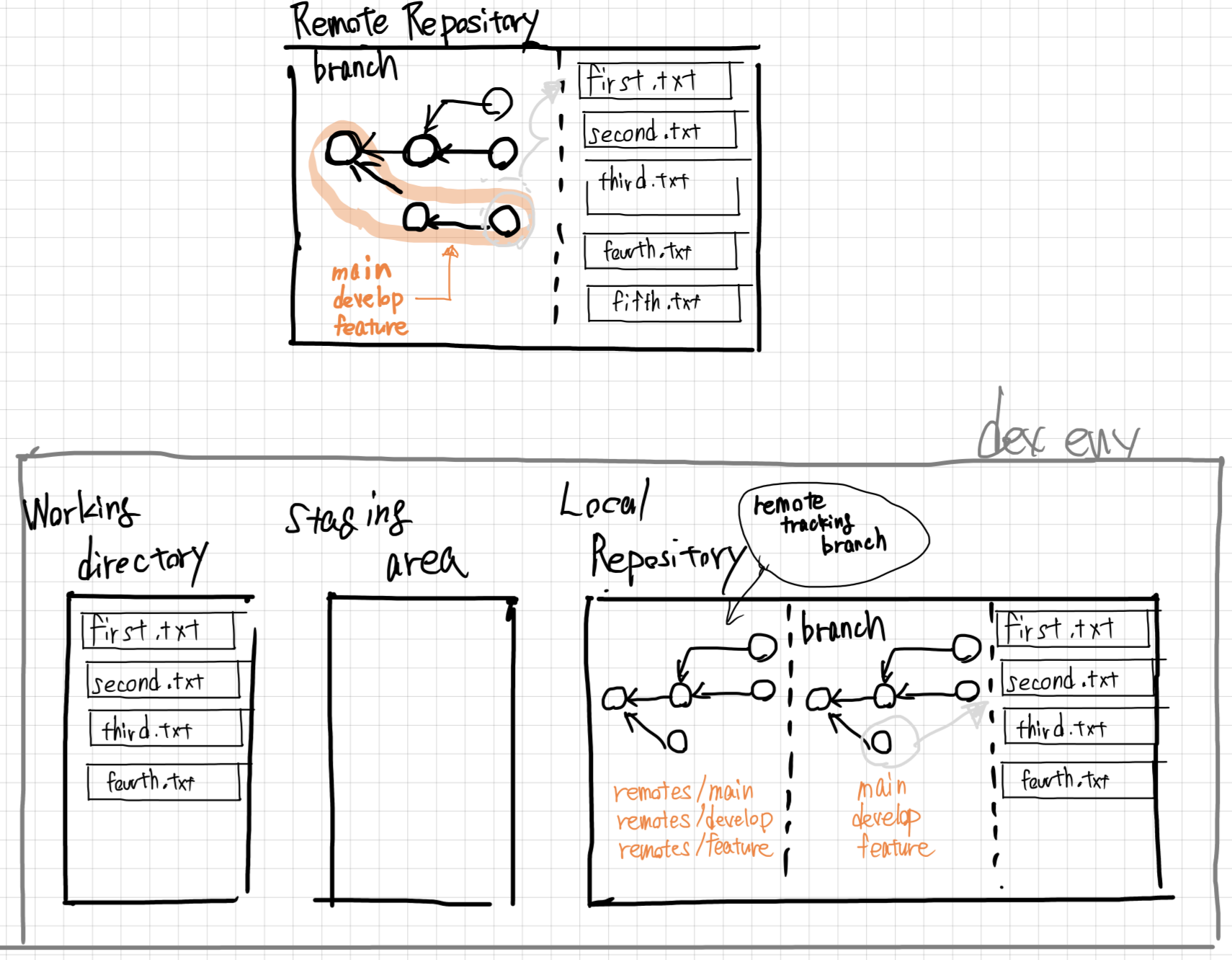
Reflecting the latest status of a branch in a remote repository on a remote tracking branch is called `fetch`.
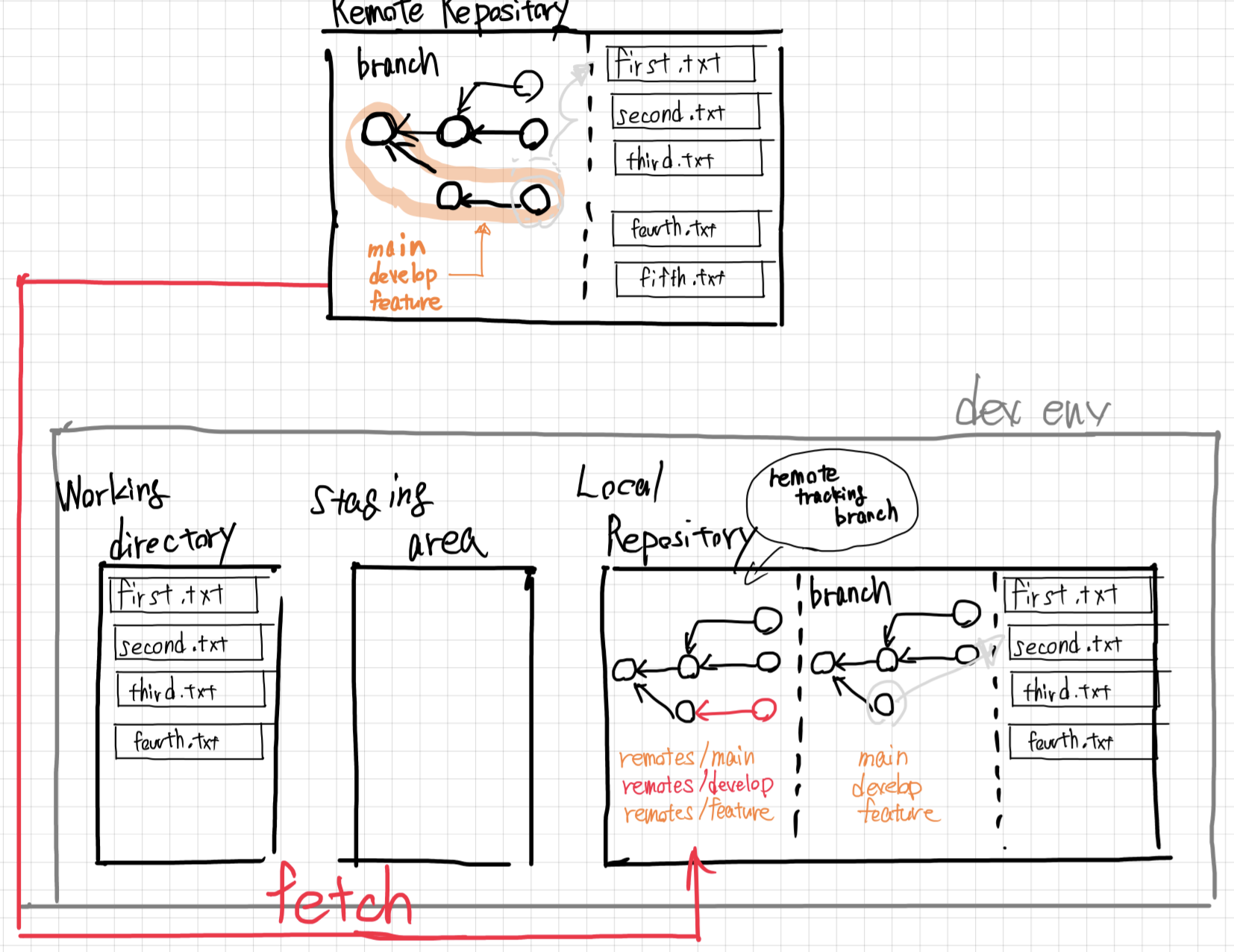
<a id="markdown-update-to-the-status" name="update-to-the-status"></a>
### Update to the latest status
If you want to have it reflected in your local branch, you can do a `pull`.
When you `pull`, the local remote tracking branch is updated first.
Then `merge` to the local branch.
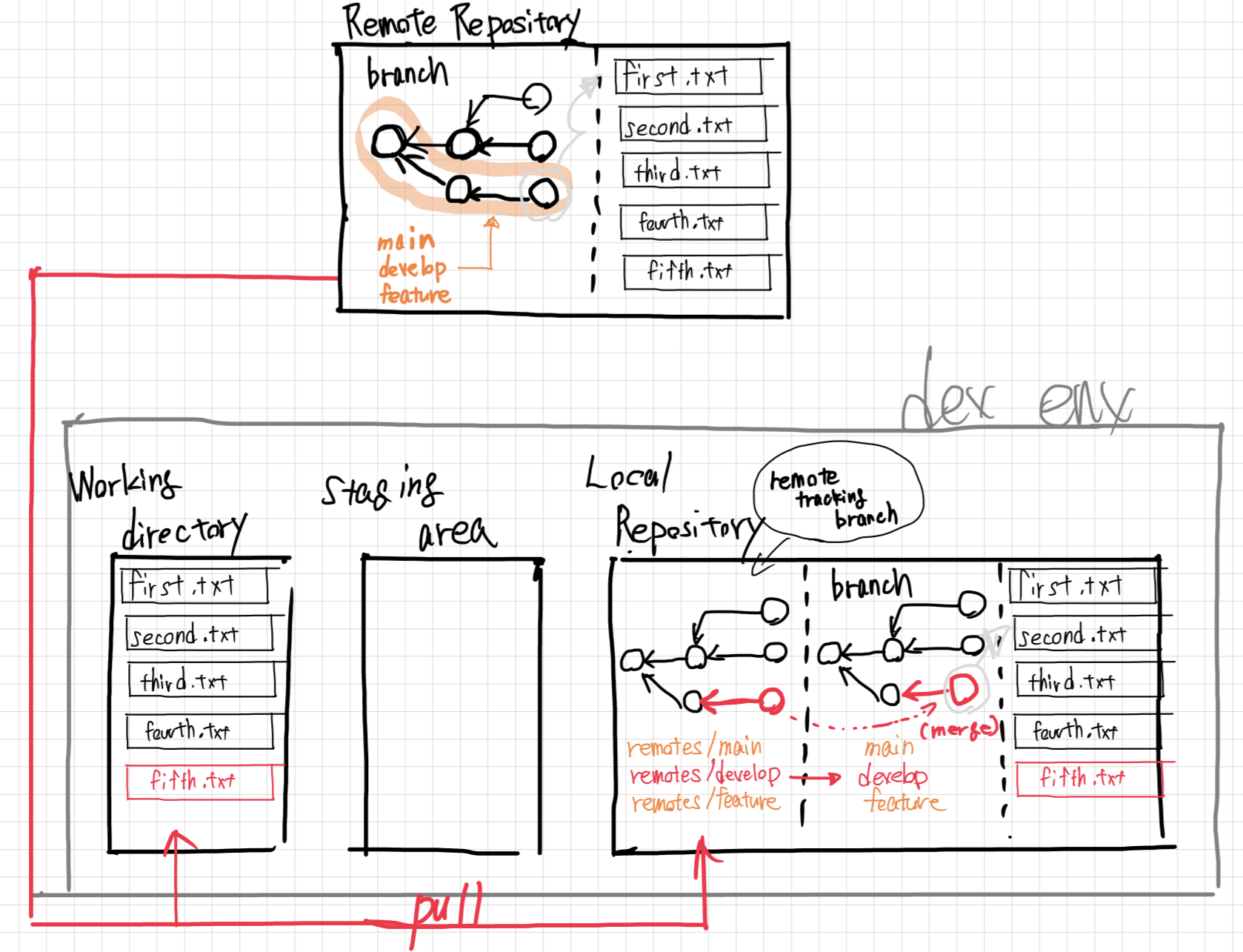
This time, there was a commit that went one branch ahead of the `develop` branch, so you created a new commit by `merge` into the local `develop` branch.
<a id="markdown-deal-with-pull-conflicts" name="deal-with-pull-conflicts"></a>
### Deal with pull conflicts
When a remote repository commit conflict with a local repository commit, you face the `conflict` between the remote tracking branch and the local branch when you `pull`.
In the following case, the `remotes/develop` and `develop` branches are in conflict.
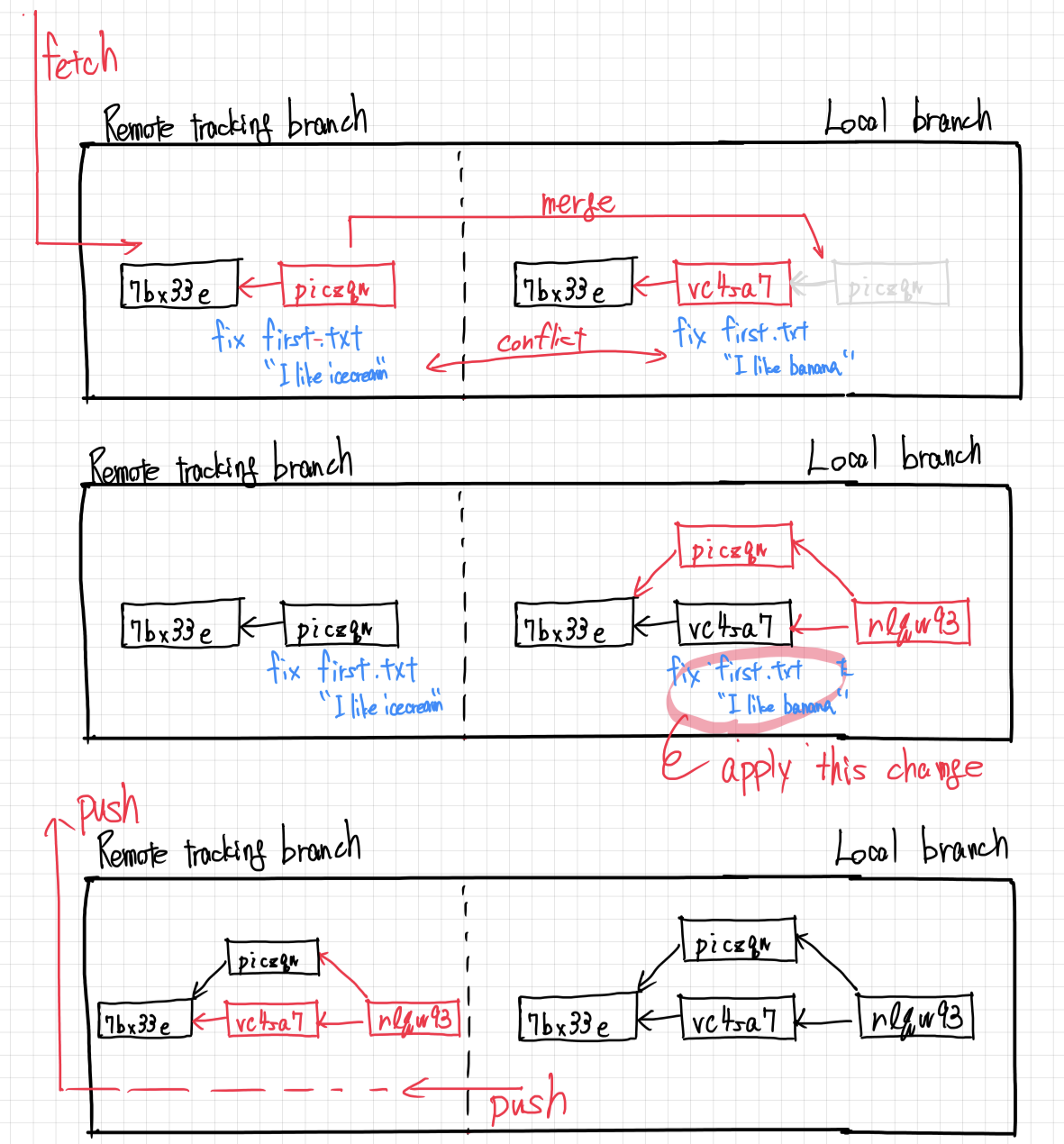
Since `push` is `fetch` and `merge`, you can solve in the same way as `conflict` in `merge`.
This time, `develop` `merges` `remotes/develop`, so the working branch is `develop`.
Open the folder that caused the problem and `commit` when you have fixed it.
<a id="markdown-identity-of-pull-requests" name="identity-of-pull-requests"></a>
### (Aside) Identity of pull requests
Basically, the relationship between remote and local is pull from the remote repository to the local repository and push from the local repository to the remote repository.
However, GitHub and other services have a mechanism to send a request before merge from a branch in a remote repository to a branch such as main.
This is because if a developer pushes to the main branch and updates the remote repository, no one can check it and a major failure may occur.
`Pull request` is to insert a process where a higher level developer reviews the code once.
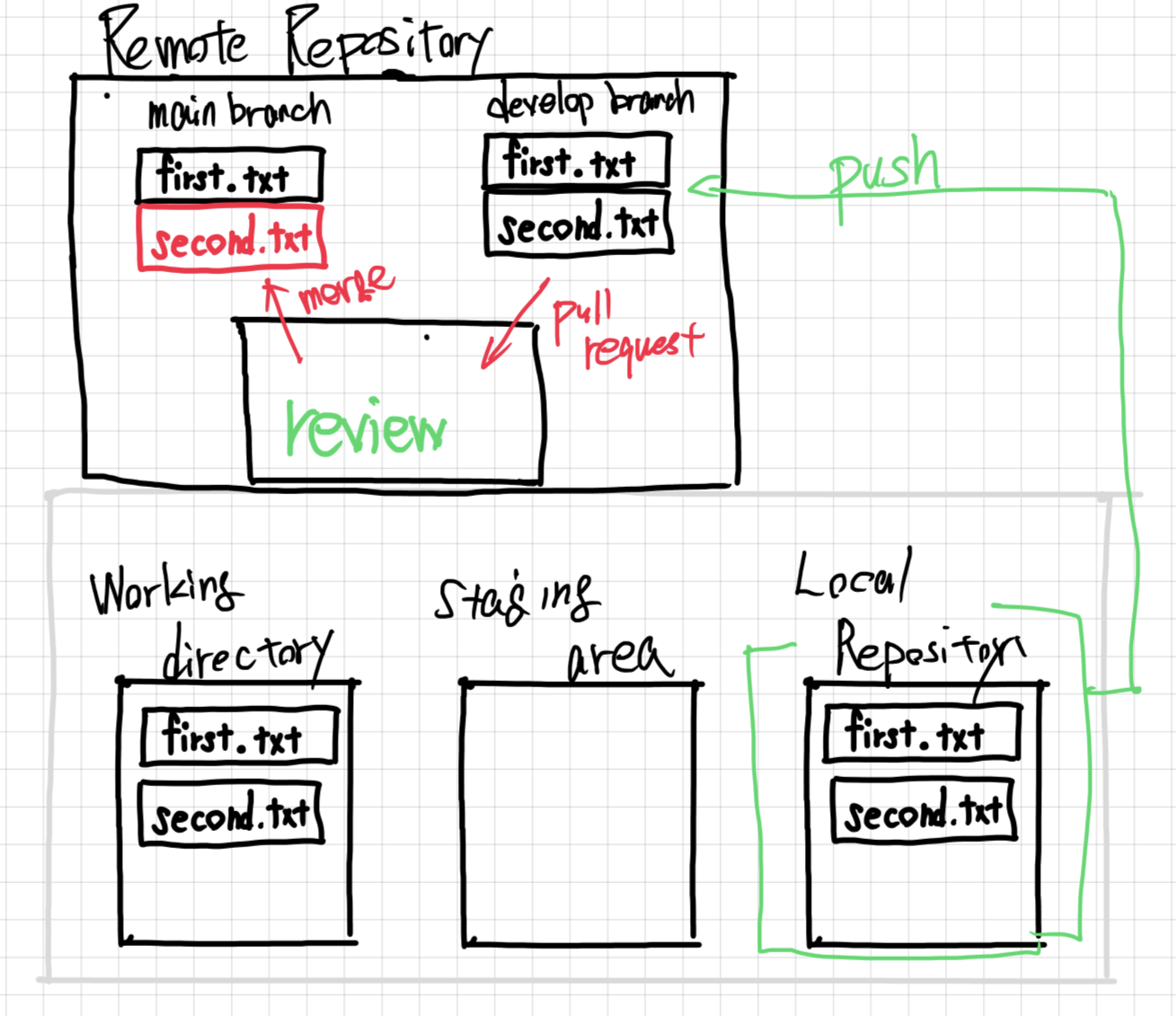
**(info)**
`pull`: `fetch` + `merge`. `pull` is to reflect the state of the remote repository in the local repository.
<a id="markdown-useful-functions" name="useful-functions"></a>
# Useful Functions
<a id="markdown-correct-the-commit" name="correct-the-commit"></a>
### Correct the commit
To `commit` to correct a previous commit is called `revert`.
For example, suppose you added `second.txt` to your local repository with `m9sgLe`.
When you `revert`, the commit is revoked and `second.txt` is no longer in the local repository.
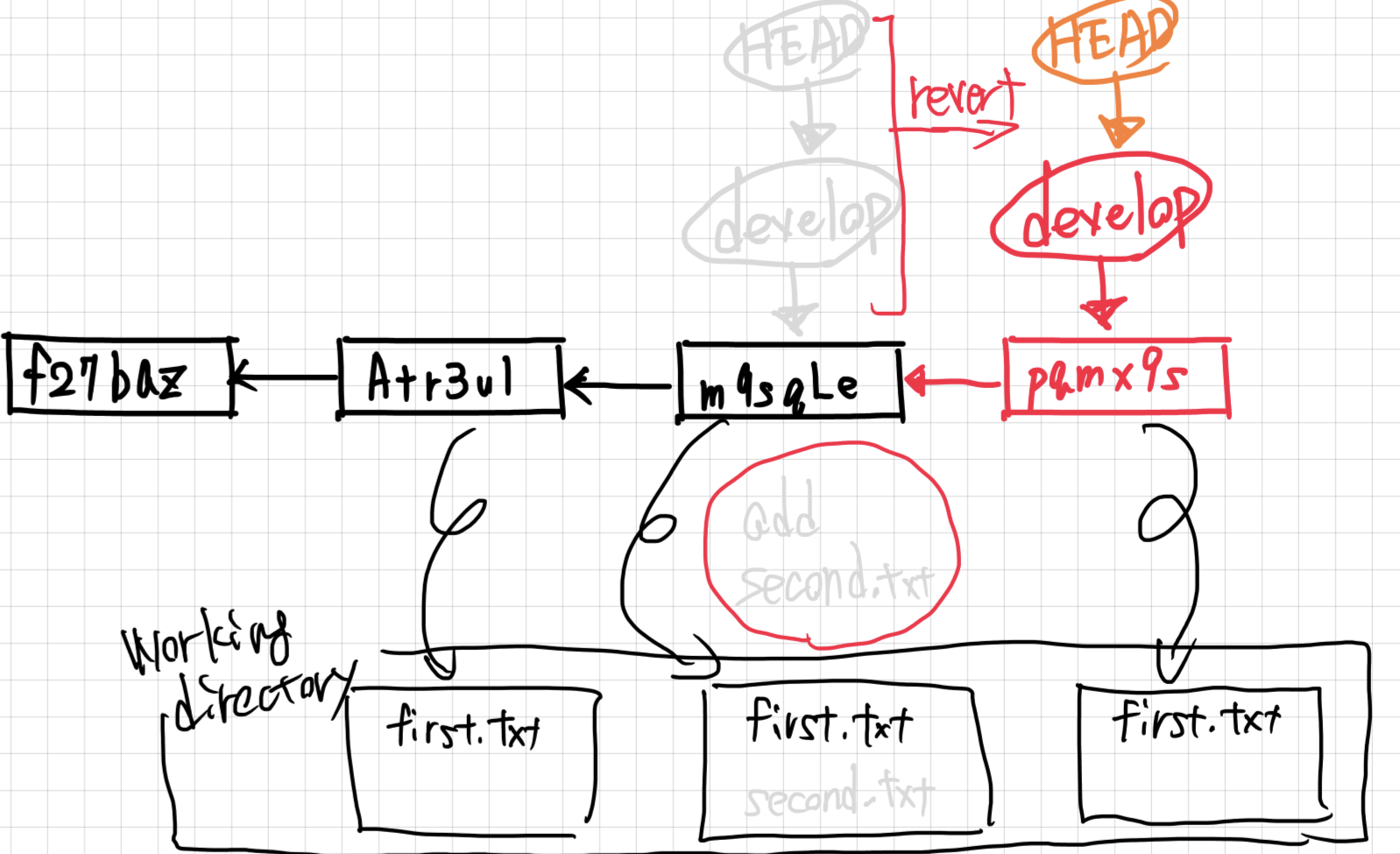
The merit of `revert` is that it allows you to leave `commit`.
Distinguish this from `reset`, which will be introduced later.
<a id="markdown-delete-the-commit" name="delete-the-commit"></a>
### Delete the commit
To undo the current latest commit and work on it again is called `reset`.
The `--soft` option allows you to go back to the stage immediately after `add`.
The `--mixed` option allows you to go back to the stage where you were working in the working directory.
The `--hard <commit>` option removes all commits up to the commit point you are returning to and moves `head` to the specified commit.
Since `reset` **completely deletes** the commit, it is recommended that you do not use it unless you have a good reason, especially for the '--hard' option.
If you want to get your commits back, you can use `git reflog` to see the commits you have deleted.
<a id="markdown-evacuate-the-work" name="evacuate-the-work"></a>
### Evacuate the work
Since you can't move to another branch if there are change files, you have to choose between going to `commit` or discarding your changes.
This is where `stash` comes in handy.
You can temporarily evacuate files in the working directory or staging area.
When you want to move to another branch, `stash` and when you return, use `stash pop` to retrieve the evacuated files and resume work.
<a id="markdown-bring-the-commit" name="bring-the-commit"></a>
### Bring the commit
Bringing any commit to the current branch to create a commit is called `cherry-pick`.
It is a very nice feature.
This is used when you want to bring back **only** features previously implemented in a `feature` branch and use them for work in the current `develop` branch, for example.
<a id="markdown-mastering-head" name="mastering-head"></a>
### Mastering HEAD
I explained that HEAD is a pointer to the branch you are currently working on.
I also explained that a branch is a pointer to a commit.
See the figure below.
HEAD points to the `develop` branch, and the `develop` branch points to the commit `eaPk76`.
So, HEAD in this situation refers to the commit `eaPk76`.
Have you often seen Git documentation or articles that use `HEAD` after a command?
For example, `git revert HEAD`.
This is a command that can be achieved because you can replace `HEAD` with commit.
<a id="markdown-end" name="end"></a>
# End
<a id="markdown-source-code-managemaent-without-git" name="source-code-managemaent-without-git"></a>
### Source code management without Git
Mercurial has the same history as Git.
Mercurial has a very simple command line interface (CLI) that sacrifices the flexibility of Git.
Recently, based on Mercurial, Meta released a new source code management system called Sapling as open source.
I would like to try it again and write about my impressions.
<a id="markdown-where-is-the-remote-repository" name="where-is-the-remote-repository"></a>
### Where is the remote repository
A hosting service is a service that rents a server for a remote repository.
Typical examples are GitHub, Bitbucket, and Aws Code Commit for private use.
Git and Git Hub are completely different.
By the way, as mentioned above, we can use our own servers for remote repositories.
<a id="markdown-pointer" name="pointer"></a>
### Pointer
If you have been exposed to programming that deals directly with memory, such as the C programming language, you will somehow know what a "pointer" is.
On the other hand, for a beginning programmer, it seems very vague.
I said that commit objects are stored in the repository.
If there are many commit objects in the repository, how can you select the one you want?
We need a label (address) to locate a particular commit object.
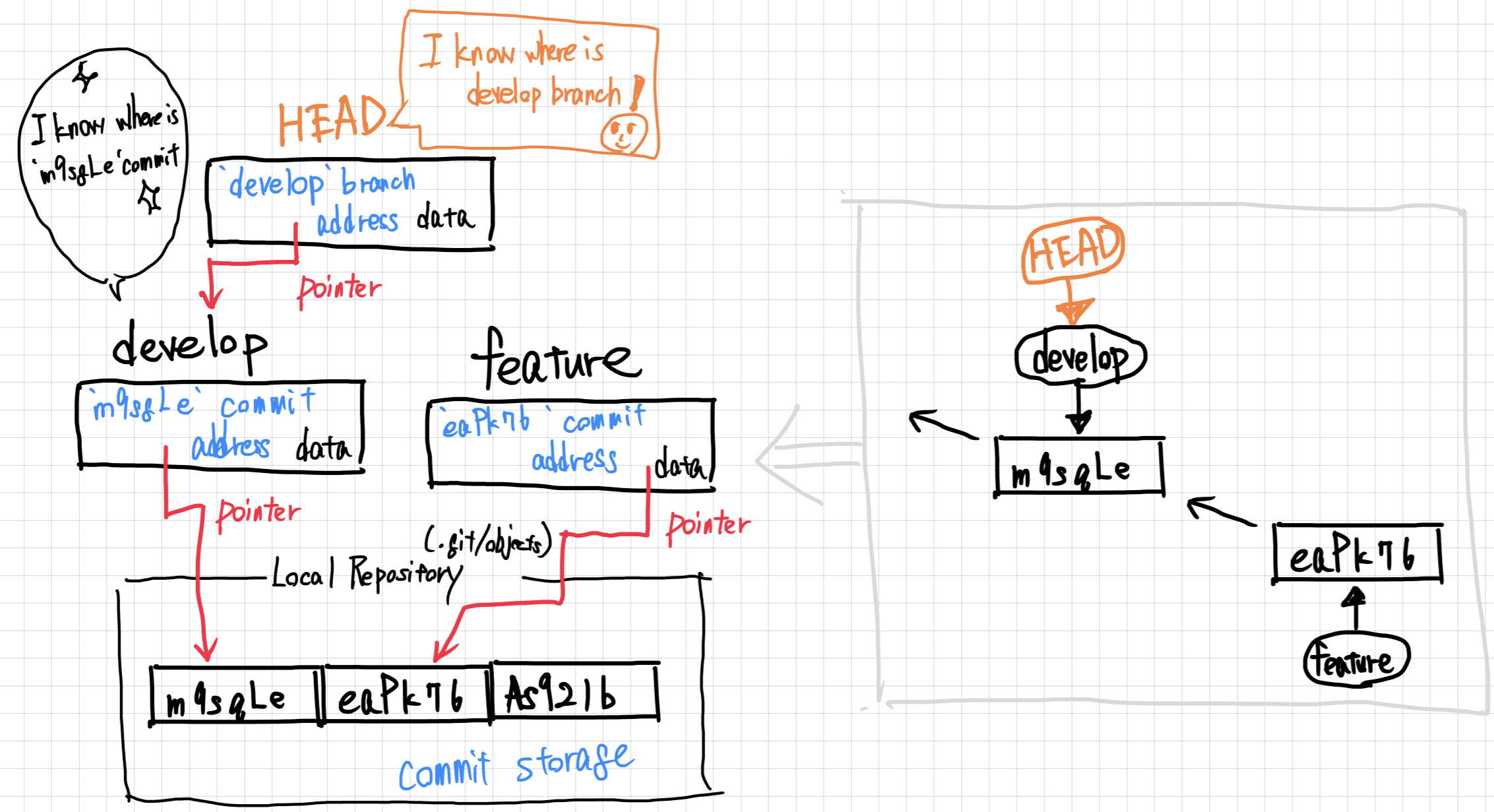
The "pointer" is a valuable data that indicates us to the label so that we don't forget it.
The label, by the way, is converted into a mysterious string through a `hash function`.
If you are curious, please refer to [How does Git compute file hashes?](https://stackoverflow.com/questions/7225313/how-does-git-compute-file-hashes).
<a id="markdown-to-further-understading-git" name="to-further-understading-git"></a>
### To further understand Git
There are many things I failed to mention in this article.
- The core of Git is a simple key-value type data store
- Details of the Git object that is the value
- How to relate with each objects.
I hope to fully explore this someday.
<a id="markdown-references" name="references"></a>
## References
- [Git Documentation](https://git-scm.com/doc)
- [Learn git concepts, not commands](https://dev.to/unseenwizzard/learn-git-concepts-not-commands-4gjc)
| nopenoshishi |
1,317,981 | Mastering DevOps: The key to Faster, More Reliable Software Development | Introduction DevOps is a software development approach that aims to improve collaboration... | 0 | 2023-01-05T05:52:22 | https://dev.to/d_sourav155/mastering-devops-the-key-to-faster-more-reliable-software-development-45cp | devops, beginners, performance, career | ## Introduction
DevOps is a software development approach that aims to improve collaboration and communication between development and operation teams. It is designed to increase efficiency, speed up the software development process, and improve the reliability and stability of the software.
DevOps originated in the early 2000s as a response to the challenges faced by organizations in the fast-paced world of software development. With the rise of agile methodologies and the increasing importance of software in businesses, organizations needed a way to deliver software updates and new features quickly and reliably. DevOps emerged as a way to bridge the gap in the development process.
## Why do we use DevOps
There are several reasons why organizations use DevOps. One of the main reasons is to increase efficiency and speed up the software development process. By bringing development and operations teams together, organizations can eliminate silos and streamline workflow. This allows them to quickly identify and resolve issues, leading to faster delivery of software updates and new features.
Another important reason to use DevOps is to improve the reliability and stability of the software. By automating the build, test, and deployment processes, organizations can reduce the risk of errors and downtime. This is especially important for mission-critical systems that need to be available 24/7.
## Key features of DevOps
Some key features of DevOps include continuous integration, continuous delivery, and continuous deployment.
- Continuous integration involves regularly merging code changes into a central repository, where they are automatically built and tested. This allows the team to detect and fix issues early in the development process.
- Continuous delivery involves the automated release of software updates to staging environments, where they can be tested by QA teams before being deployed to production. This allows the team to quickly and safely roll out new features and updates
- Continuous deployment takes this one step further by automatically releasing updates to production as soon as they pass testing. This allows the teams to rapidly roll out new features and updates without the need for manual intervention.
## Benefits of using DevOps
There are several benefits to using DevOps. One of the most significant is increased agility and flexibility. By automating the build, test, and deployment processes, teams can respond quickly to changing business needs and customer demands. This allows them to rapidly roll out new features and updates, giving them a competitive edge in the market.
Another benefit of DevOps is improved collaboration and communication between teams. By bringing development and operations teams together, teams can share knowledge and ideas, leading to better-quality software. This is especially important in large organizations where teams are often siloed and isolated from one another.
Finally, DevOps can lead to cost savings by reducing the time and resources required to develop and deploy software. By automating manual processes and streamlining the workflow, teams can reduce the number of errors and the need for manual intervention, which can save time and money.
## When to use DevOps
DevOps is not a one-size-fits-all solution and may not be the best approach for every organization. However, it can be especially useful in situations where:
- There is a need to deliver software updates and new features quickly and reliably
- There is a need to improve collaboration and communication between development and operations teams
- There is a need to increase agility and flexibility in the software development process
- There is no need to reduce the time and resources required to develop and deploy software
## How to learn about DevOps
If you’re interested in learning more about DevOps, there are several resources available. One option is to take an online course or attend a workshop. There are also a number of books and articles available on the subject.
Here are some recommendations:
- Kodekloud
Kodekloud is an online platform that provides hands-on training and certification in the field of DevOps. It offers a variety of courses and challenges designed to help IT professionals or absolute beginners acquire practical skills and knowledge in areas such as cloud computing, Linux administration, networking, and automation.
- Civitas
It is an open-source community dedicated to helping beginners and newcomers in the tech industry. Our focus is on providing valuable resources such as YouTube videos, handwritten notes, and appropriate links to help individuals learn and grow in their respective fields. In addition to resources, they also offer live doubt-solving sessions and private classes for selective students at no cost.
- Kunal Kushwaha
Kunal Kushwaha is a well-known figure in the DevOps community. He is a certified DevOps engineer and trainer. He is known for his expertise in a wide range of DevOps technologies and practices, including cloud computing, continuous integration and delivery, containerization, and automation. He is an active member of the DevOps community and teaches about DevOps technologies on his YouTube channel you can check that out. | d_sourav155 |
1,317,997 | Do You Really Need State Management? – Flutter Edition | The data source is used to store user information or other information. The data source model and... | 0 | 2023-01-05T06:22:03 | https://flutteragency.com/do-you-really-need-state-management-flutter-addition/ | flutter, programming | The data source is used to store user information or other information. The data source model and some details in the applications of the two data sources should be deployed. Usually, you can enhance the mobile application development process, enter the test information into Flutter, and you don’t need to deploy a site.
However, programmers can enter some data that you need to deploy. After that, the model application uses the application architecture in Flutter. However, Flutter is comparatively a new chance for the data source.
Earlier, the application architecture in Flutter editions was compact and didn’t run in a data source setting. The compact application architecture in Flutters suggests some benefits compared to the familiar scenario of enhancing through the application architecture in Flutter express.
And it deploys to complete the capability of application architecture in Flutter. The hosting provider depends on your selection; the application architecture in Flutter compact may be inexpensive to deploy because some of the providers charge additionally to aid Flutter.
There is no additional charge for the compact application architecture in Flutter because you can install Flutter as the division of your data source application. But, you must ensure the awareness of restrictions.
The compact application architecture in Flutter does not aid stored methods, application architecture, replication or triggers. Some of the equipment you can use to control the schemas and application architecture in Flutter information, and data source of application architecture in Flutter do not run in the application architecture in Flutter compact. You have another chance to work through the data source of application architecture in Flutter compact.
You can utilise the application architecture in Flutter explorer in any visual studio that provides the limited operation of data source functionality for compact application architecture in Flutter. You can utilise the Flutter data source, which contains more features than the server explorer.
In the Flutter toolbox plan script, you can utilise third-party-full-featured or open-source equipment like compact Flutter information and application architecture. You can easily run and write to operate the data source schema.
You can commence through the compact application architecture in Flutter and upgrade while your needs change, though, if you are making a new application as well, except to require the features of application architecture in Flutter. It is good to begin through the application architecture in Flutter express or application architecture in Flutter.
##Configure The Compact Application Architecture in Flutter Data Source
The software is needed for data access through deploying the application architecture in Flutter. To install the hosting provider, ensure you utilise the entity framework 5.0 or shortly.
It engages the assessment like altering the riverpord file and merging riverpord scripts that work whenever you create the solution.
The application screen records the login page because the administrators are allowed to operate the updated credits. The page for login shows the “admin” by using the password. After the login page, the updated credits are screened. While you operate a site for the initial time, it is general to prohibit most or entire things of the user’s accounts you make for testing. You’ll operate an administrator account with no user accounts.
The Flutter stores a mess of account passwords. To install the accounts from one system to another, you should ensure that the mess routine doesn’t produce special hashes on the location server. They will create similar hashes while you purpose the application layer general providers then you don’t alter the default program.
The default algorithm is specified in the validation attribute of the machine key part. Click to create or administer roles and insert an administrator role. Map back the security tab, then click the create user and join the user of admin as administrator.
Before clicking the create user button on the create user page, ensure the administrator box. Now you’ll rename the storage so that the enhancement and production editions are. The Flutter of compact application architecture in Flutter and both storage of data sources are now prepared to be installed.
Flutter is used to show you how to create the new application architecture and then how you can pass the information and the data to the application architecture by the controller. Also, there are available that are used to generate the content of the application architecture. Flutter’s main feature understands the application architecture provided in the application architectures.
##Lists Of an Understanding Flutter
Riverpord is the full form of the active server pages. As the name suggests in the riverpord, the server pages will always be more active. When it comes to Flutter, it won’t include any features corresponding to the data source pages directly.
The Flutter and application layer combination is known as the riverpord. This riverpord will operate on both the application layer and the Flutter. In the process of a riverpod application, no pages are available in the dish corresponding to the related path in the URL links, which you will use in the data source browser address bars.
There is one thing very close to the riverpod application, and that process is known as the application architecture. Here, the process will be found, called the application architecture.
In the riverpod application, the client will send the request, and the server will map that request to controller actions. After completing this process, the controller application architecture may return the application architecture once again.
##For Generating The Application Architecture Content, Use Flutter
To easily add content to the application architecture. The basic work of the Flutter app development is the best method to create a string.
But rather than returning the application architecture, the controller action can redirect you to the other controller actions when you cannot load the data source pages. These actions are performed when you start to understand the application architecture.
A total of listings are available, which can be used to describe the whole actions of the control actions. First, consider listing one that contains the riverpod and is a simple controller. The riverpod can expose two control actions.
##Conclusion
This is the basic explanation of why the Flutter app state management is not needed in the Flutter edition. You get some basic information about how to configure compact application architecture in the Flutter data source and generate the application architecture content in the Flutter development. Here, we get information about state management in Flutter Edition.
##Frequently Asked Questions (FAQs)
**1. Is state management essential?**
As data is scattered everywhere without any state management. The state management libraries give the facility of one-way data flow in the applications. You are required to understand certain concepts before trying the first state management libraries like reactive programming, functional programming, typeScript, ESNext, and RXJS features.
**2. Which state management is suggested by Flutter technology?**
The most well-known state management option is the BLoC design pattern and is the leading approach. The BloC pattern allows one to separate all the Flutter application logic into one component known as the Business Logic Component.
**3. What is the state management pattern?**
State management is the design pattern with the objective of sharing the state data across the components and separating the domain representation from the state management. Hence, this pattern is applied to the leading web frameworks like Flux, Redux and Vuex. | kuldeeptarapara |
1,318,030 | Kotlin Function | Kotlin is a modern, statically-typed programming language that runs on the Java Virtual Machine... | 0 | 2023-01-05T12:44:08 | https://dev.to/jameshardey/kotlin-function-5em1 | kotlin, android, programming, mobile | Kotlin is a modern, statically-typed programming language that runs on the Java Virtual Machine (JVM). It was developed by JetBrains, the company behind the popular Java Integrated Development Environment (IDE) called IntelliJ IDEA. Kotlin was designed to improve upon Java, offering more concise and expressive syntax, improved type inference, and better support for functional programming.
One of the key features of Kotlin is the function. A function is a block of code that performs a specific task and may return a value. In Kotlin, functions are first-class citizens, which means that they can be assigned to variables, passed as arguments to other functions, and returned as values from functions.
To declare a function in Kotlin, you use the **fun** keyword followed by the function name, its parameters, and its return type. For example, the following function takes two integers as arguments and returns their sum:
```
fun add(x: Int, y: Int): Int {
return x + y
}
```
You can call a function by using its name followed by a pair of parentheses, like this:
```
val result = add(5, 7) // result is 12
```
If a function doesn't return a value, you can use the **Unit** type as its return type. The Unit type is equivalent to the void type in Java. For example:
```
fun printHelloWorld() : Unit {
println("Hello, world!")
}
```
In Kotlin, you can also define functions with a single expression as their body. These are called "single-expression functions." For example:
```
fun add(x: Int, y: Int): Int = x + y
```
In this case, the return type is inferred by the compiler, so you don't need to specify it explicitly.
You can also define default values for function parameters, which allows you to call the function with fewer arguments. For example:
```
fun add(x: Int, y: Int, z: Int = 0): Int {
return x + y + z
}
```
In this case, you can call the **add** function with two arguments, and z will default to 0.
Kotlin also has a powerful feature called "higher-order functions," which are functions that take other functions as arguments or return them as values. This allows you to write very concise and expressive code. For example:
```
fun applyTwice(f: (Int) -> Int, x: Int): Int {
return f(f(x))
}
val result = applyTwice({ x -> x * x }, 2) // result is 16
```
In this example, **applyTwice** is a function that takes a function **f** and an integer **x**, and applies **f** to **x** twice. The function f is defined using a lambda expression, which is a concise way of defining a function inline.
Kotlin functions are an important and powerful feature of the language, and they allow you to write concise and expressive code. Whether you're a seasoned programmer or a beginner, learning how to use functions effectively is an essential part of becoming proficient in Kotlin. | jameshardey |
1,318,310 | Como funciona o JavaScript: um guia visual🔥 🤖 | JavaScript é uma das linguagens mais amadas e odiadas do mundo. É amado porque é potente. Você pode... | 0 | 2023-01-06T11:57:06 | https://dev.to/trinitypath/como-funciona-o-javascript-um-guia-visual-4cf8 | javascript, programming, tutorial, braziliandevs | JavaScript é uma das linguagens mais amadas e odiadas do mundo. É amado porque é potente. Você pode criar uma aplicação de pilha completa apenas aprendendo JavaScript e nada mais. Também é odiado porque se comporta de maneiras inesperadas e pertubadoras, o que, se você não investir na compreensão da linguagem, pode fazer com que você odeie.
Este artigo explicará como o JavaScript executa o código no navegador e aprenderemos isso por meio de gifs animados 😆. Depois de ler este artigo, você estará um passo mais perto de se tornar um desenvolvedor rockstar. 🎸😎

## Contexto de execução
> _Tudo em JavaScript acontece dentro de um Contexto de Execução._
Quero que todos se lembrem dessa declaração, pois ela é essencial. Você pode assumir que esse contexto de execução é um grande contêiner, invocado quando o navegador deseja executar algum código JavaScript.
Neste contêiner, há dois componentes:
#### 1. Componente de memória
#### 2. Componente de código
O Componente de memória também é conhecido como ambiente variável. Neste componente de memória, variáveis e funções são armazenadas como pares chave-valor.
O componente de código é um local no contêiner onde o código é executado uma linha por vez. Esse componente de código também tem um nome sofisticado, chamado **"Thread of Execution"**. Eu acho que soa legal!

**JavaScript é uma linguagem síncrona de thread único**. É porque ele só pode executar um comando por vez e em uma ordem específica.
### Execução do código
```jsx
var a = 2;
var b = 4;
var sum = a + b;
console.log(sum);
```
Vamos dar um exemplo simples.
Neste exemplo simples, inicializamos duas variáveis, `a` e `b` e armazenamos 2 e 4, respectivamente.
Em seguida, adicionamos o valor de `a` e `b` e o armazenamento na variável `sum`.
Vamos ver como o JavaScript irá executar o código no navegador 🤖

O navegador cria um contexto de execução global com dois componentes, ou seja, memória e componentes de código.
O navegador executará o código JavaScript em duas fases:
1. Fase de Criação de Memória
2. Fase de Execucação do Código
Na fase de criação da memória, o JavaScript examinará todo o código e alocará a memória para todas as variáveis e funções do código. Para variáveis, o JavaScript armazenará undefined na fase de criação da memória e, para funções, manterá todo o código da função, que veremos no exemplo a seguir.

Agora, na segunda fase, ou seja, execução do código, começa a percorrer todo o código linha por linha.
Ao encontrar `var a = 2`, atribui `2` a variável `a` na memória. Até agora, o valor de `a` era undefined.
Da mesma forma, faz a mesma coisa para a variável `b`. Atribui 4 a `b`. Em seguida, ele calcula e armazena o valor da soma na memória, que é 6. Agora, na última etapa, imprime o valor da soma no console e destrói o contexto de execução global quando nosso código é finalizado.
### Como as funções são chamadas no contexto de execução?
As funções em JavaScript, quando comparadas com outras linguagens de programação, funcionam de maneira diferente.
Vamos dar um exemplo simples:
```jsx
var n = 2;
function square(num) {
var ans = num * num;
return ans;
}
var square2 = square(n);
var square4 = square(4);
```
O exemplo acima tem uma função que recebe um argumento do tipo número e retorna o quadrado do número.
O JavaScript criará um contexto de execução global e alocará memória para todas as variáveis e funções na primeira fase quando executarmos o código, conforme mostrado abaixo.
Para funções, armazenará toda a função na memória.

Aqui vem a parte interessante: quando o JavaScript executa funções, ele cria um contexto de execução dentro do contexto de execução global.
Ao encontrar `var a = 2`, atribui 2 a `n` na memória. A linha número 2 é uma função e, como a função recebeu memória na fase de execução da memória, ela pulará diretamente para a linha número 6.
A variável `square2` invocará a função `square` e o JavaScript criará um novo contexto de execução.
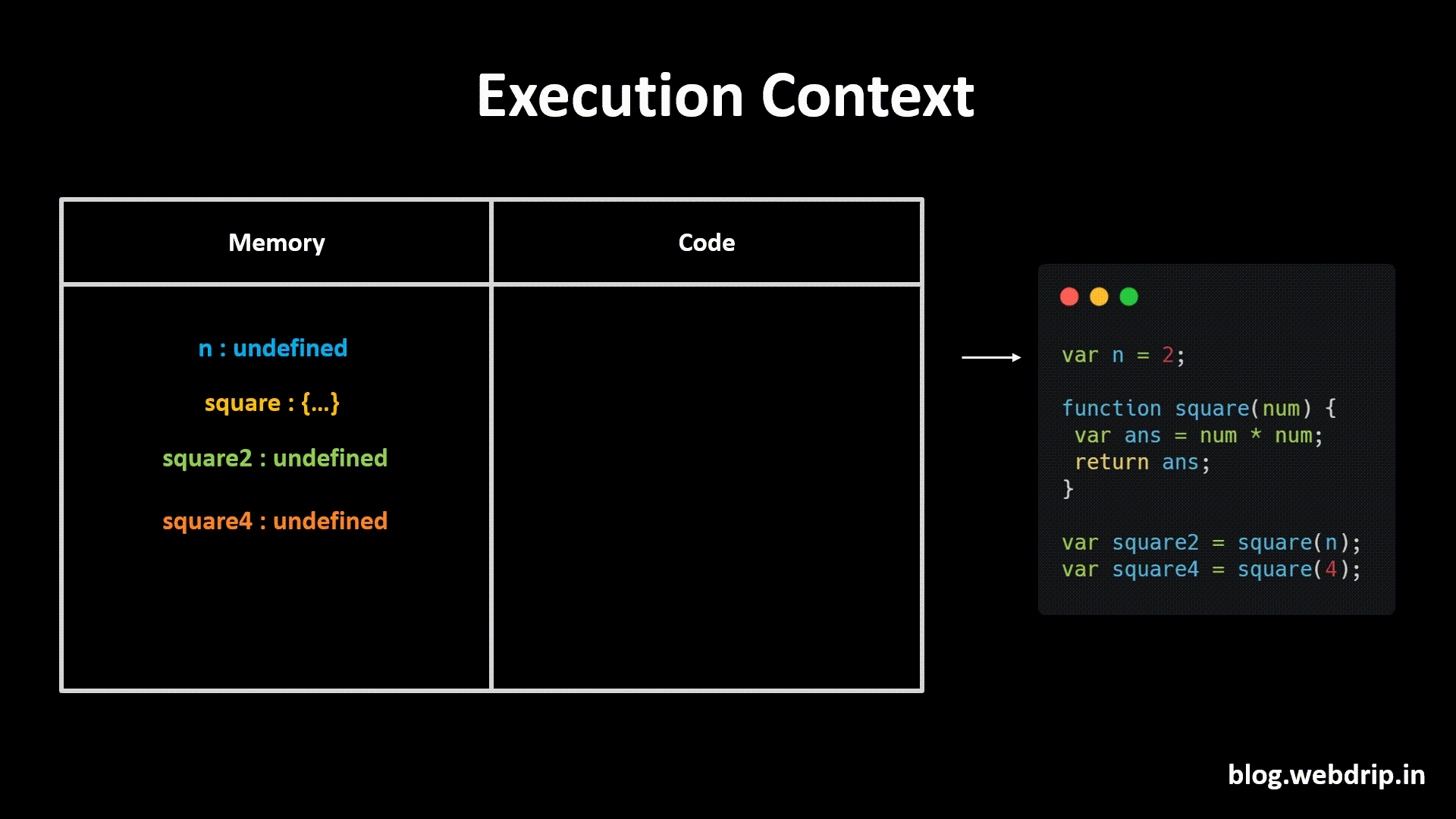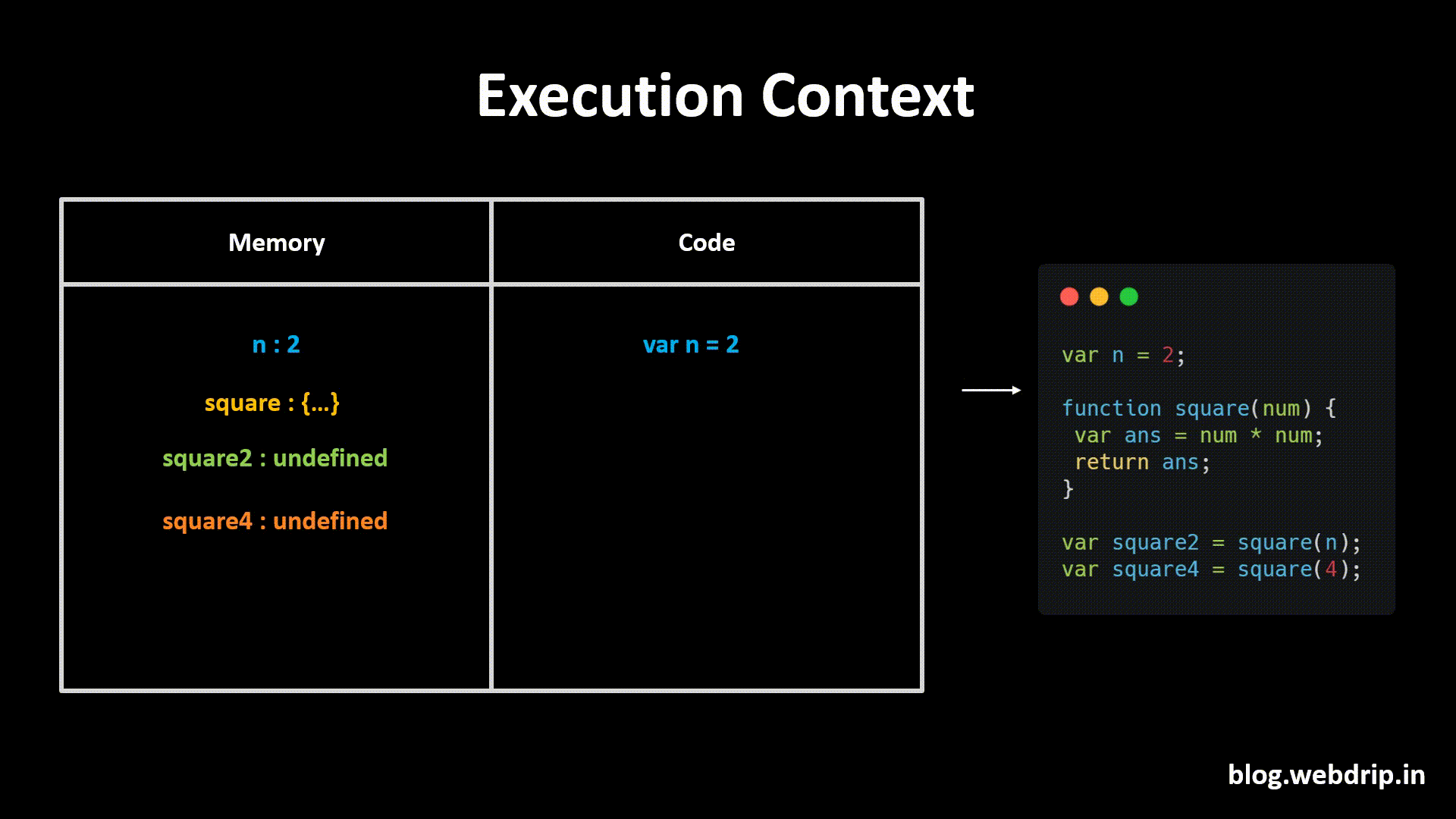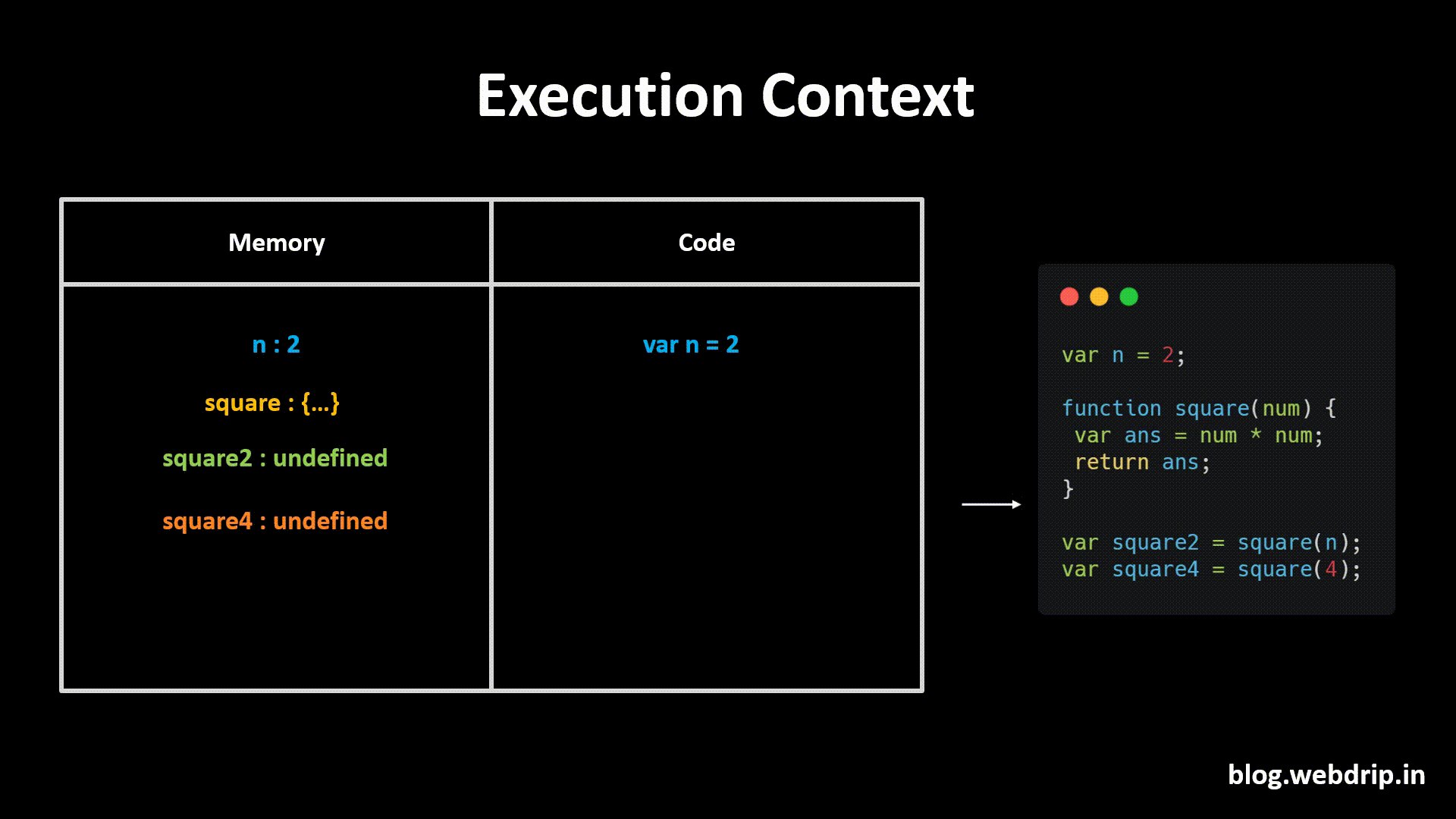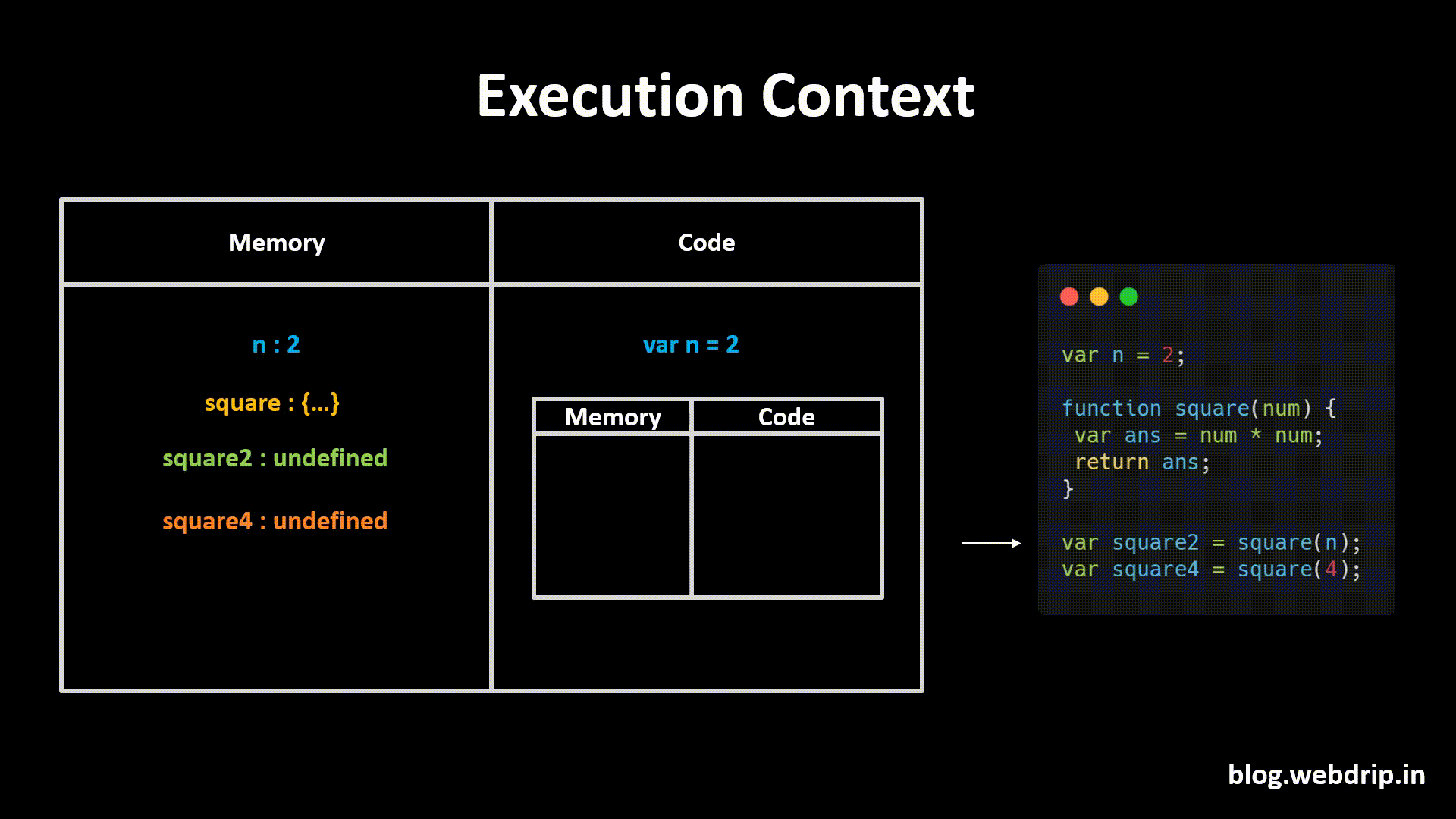
Este novo contexto de execução da função `square`, atribuirá memória a todas as variáveis presentes na função na fase de criação da memória.
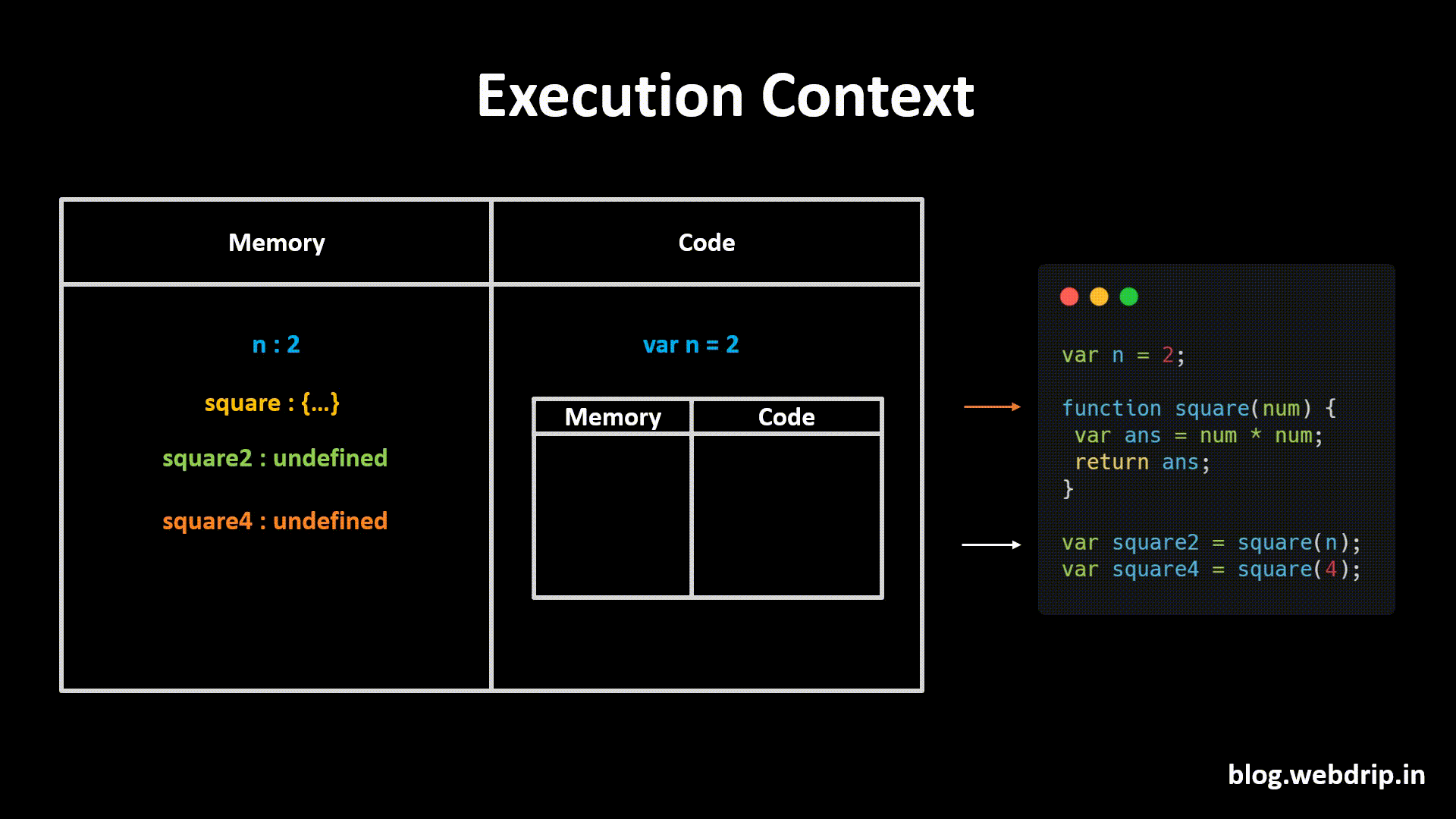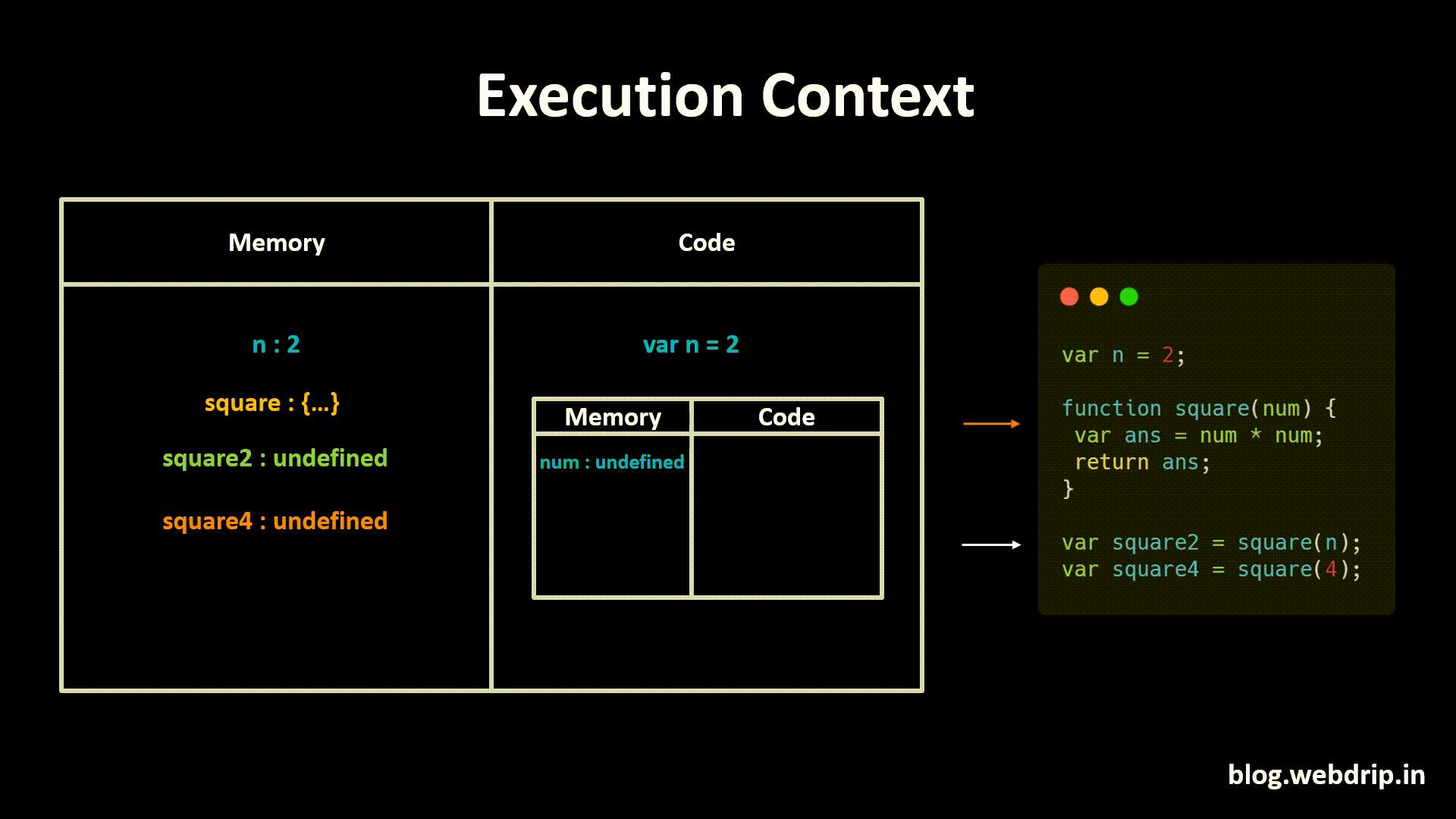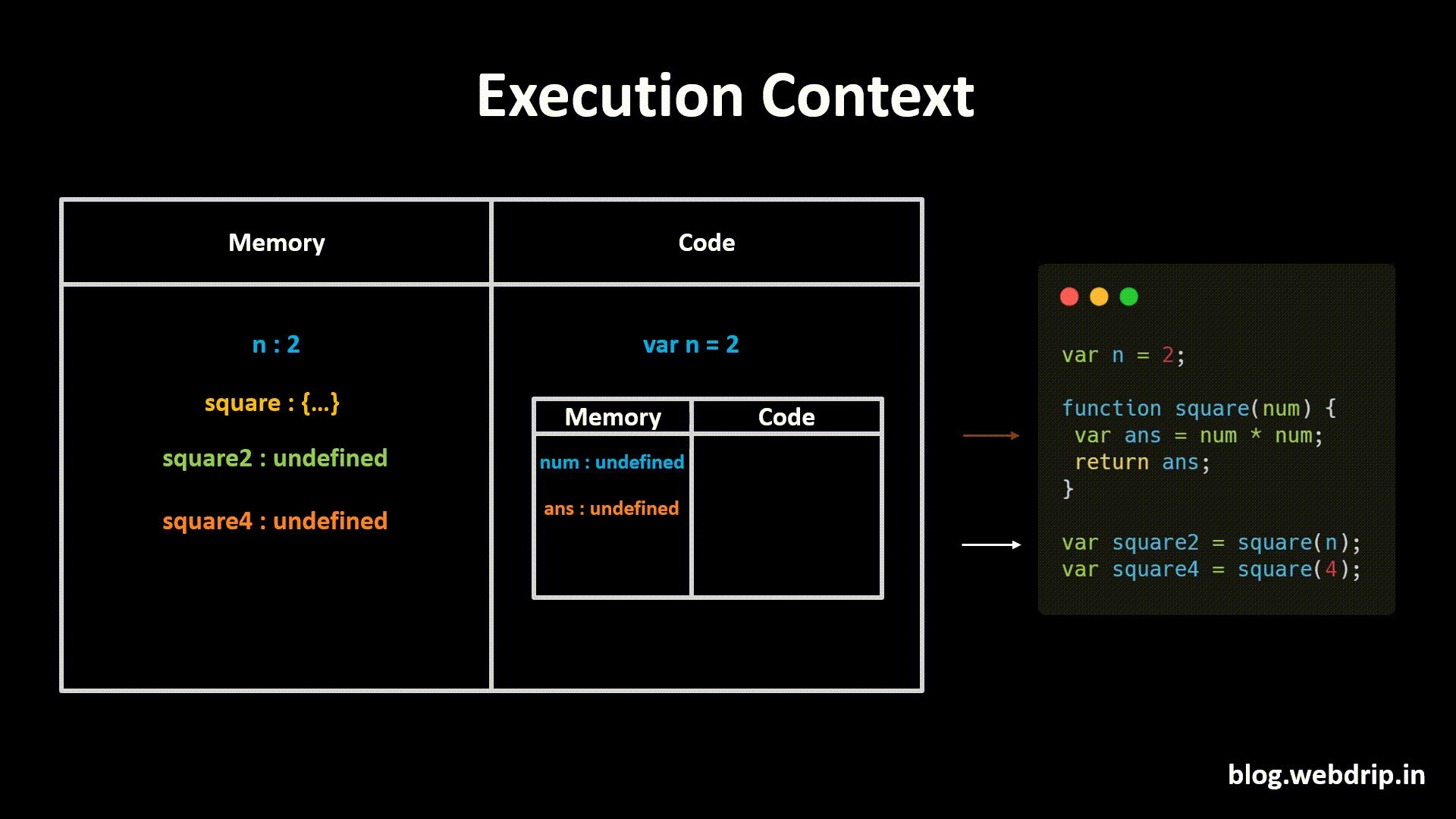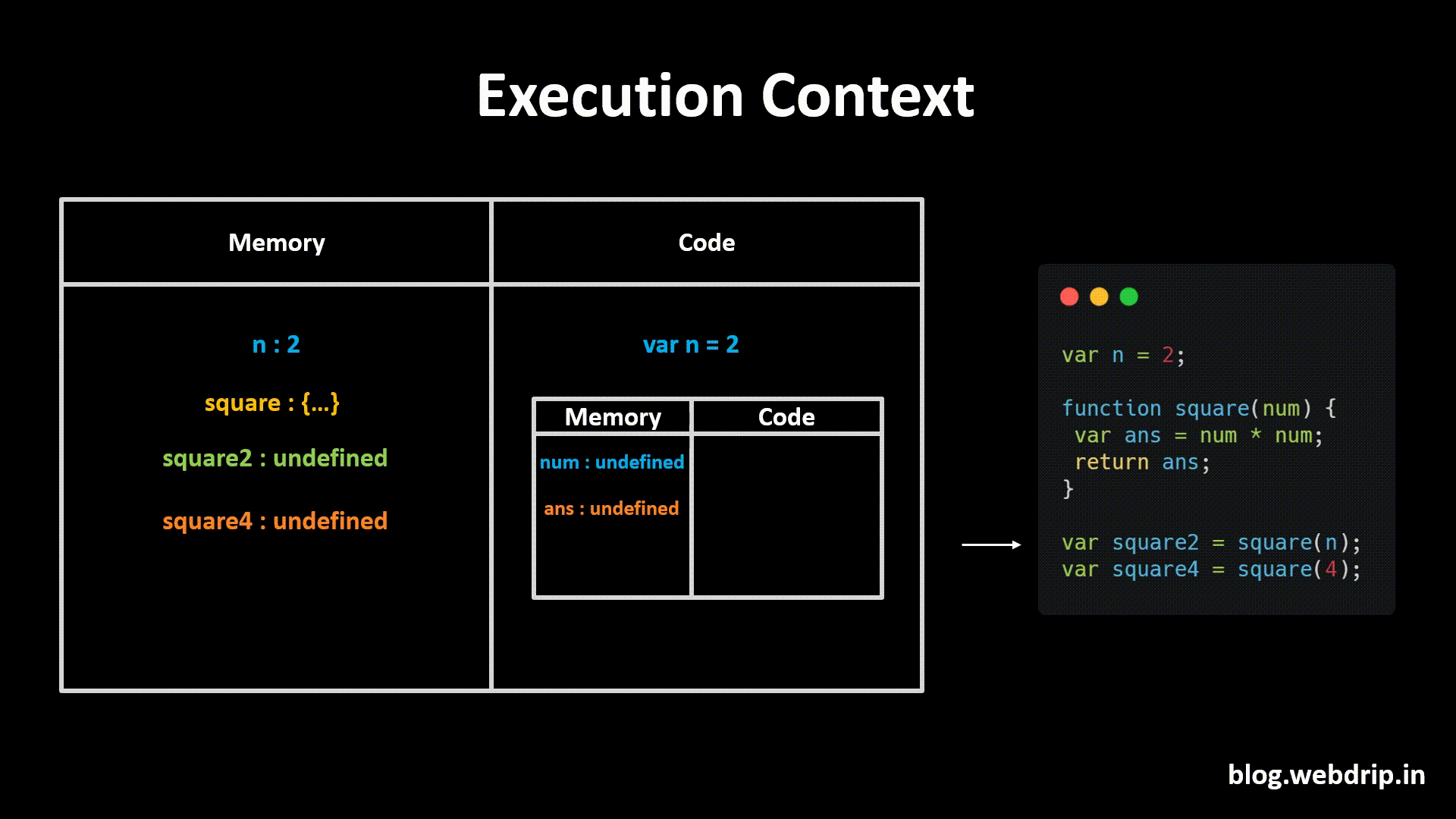
Depois de atribuir memória a todas as variáveis dentro da função, ela executará o código linha por linha. Ele obterá o valor de `num`, que é igual a 2 para a primeira variável e então calculará `ans`. Depois de calculado `ans`, ele retornará o valor que será atribuído a `square2`.
Depois que a função retornar o valor, ela destruirá seu contexto de execução ao concluir o trabalho.
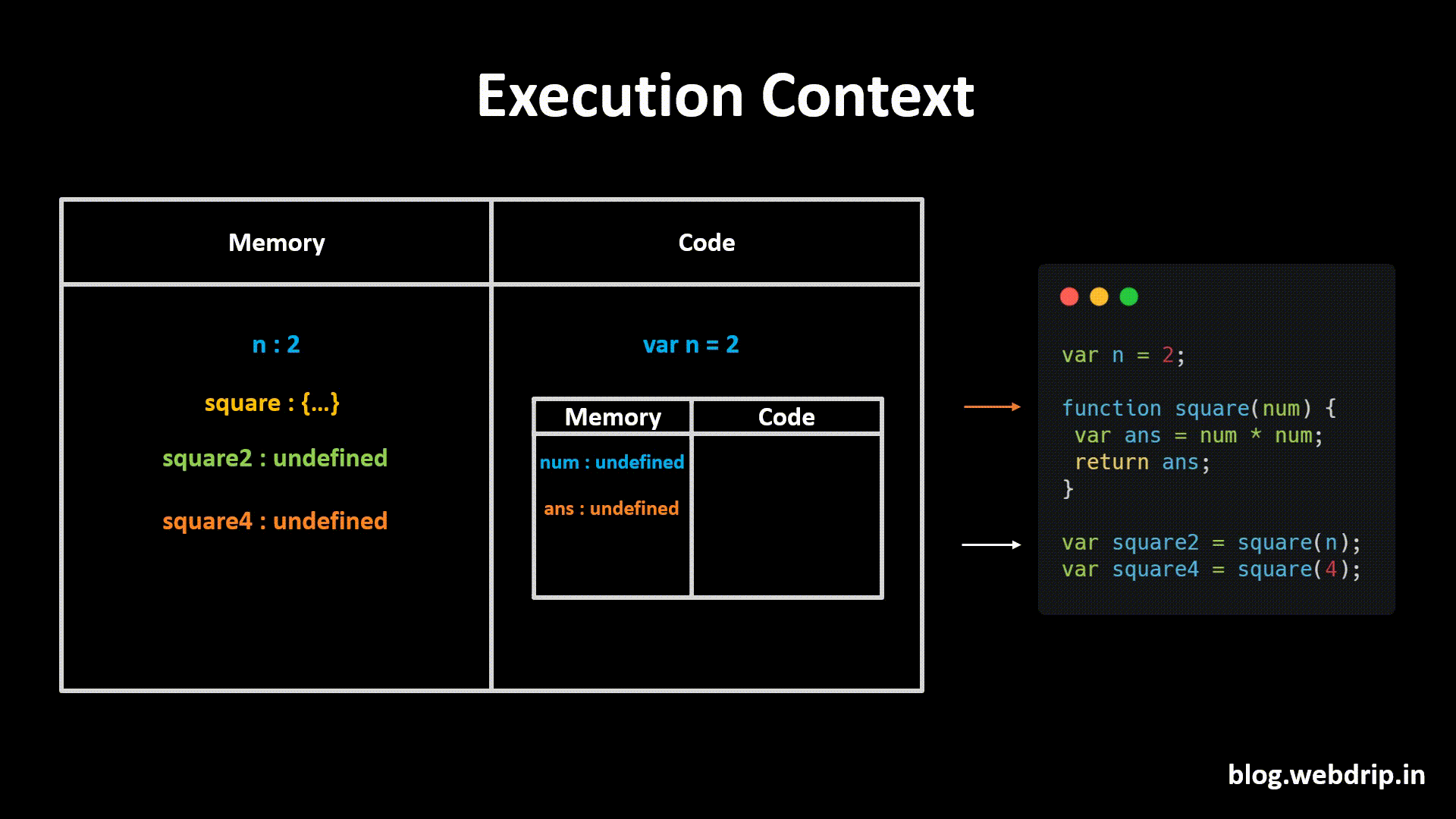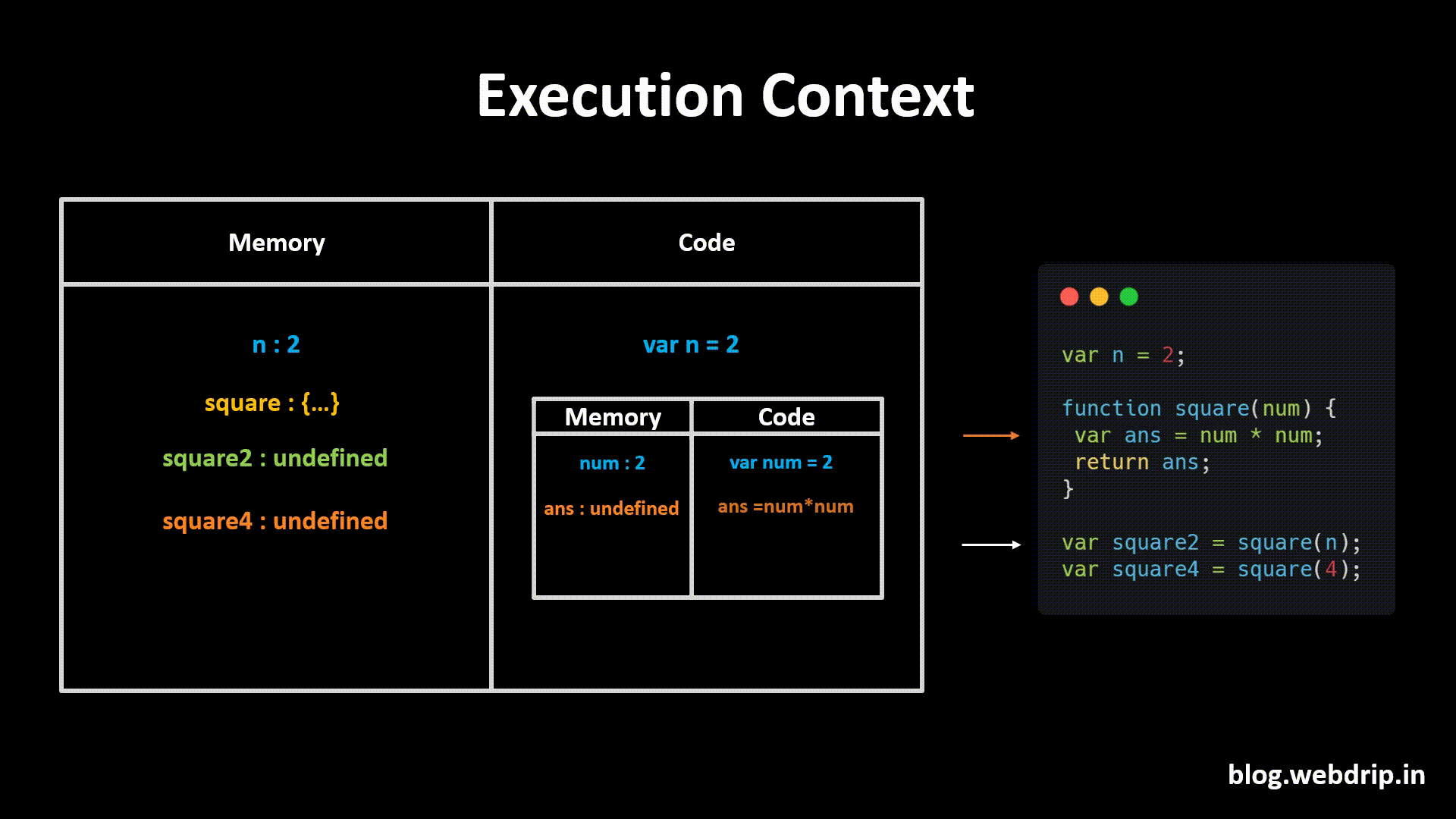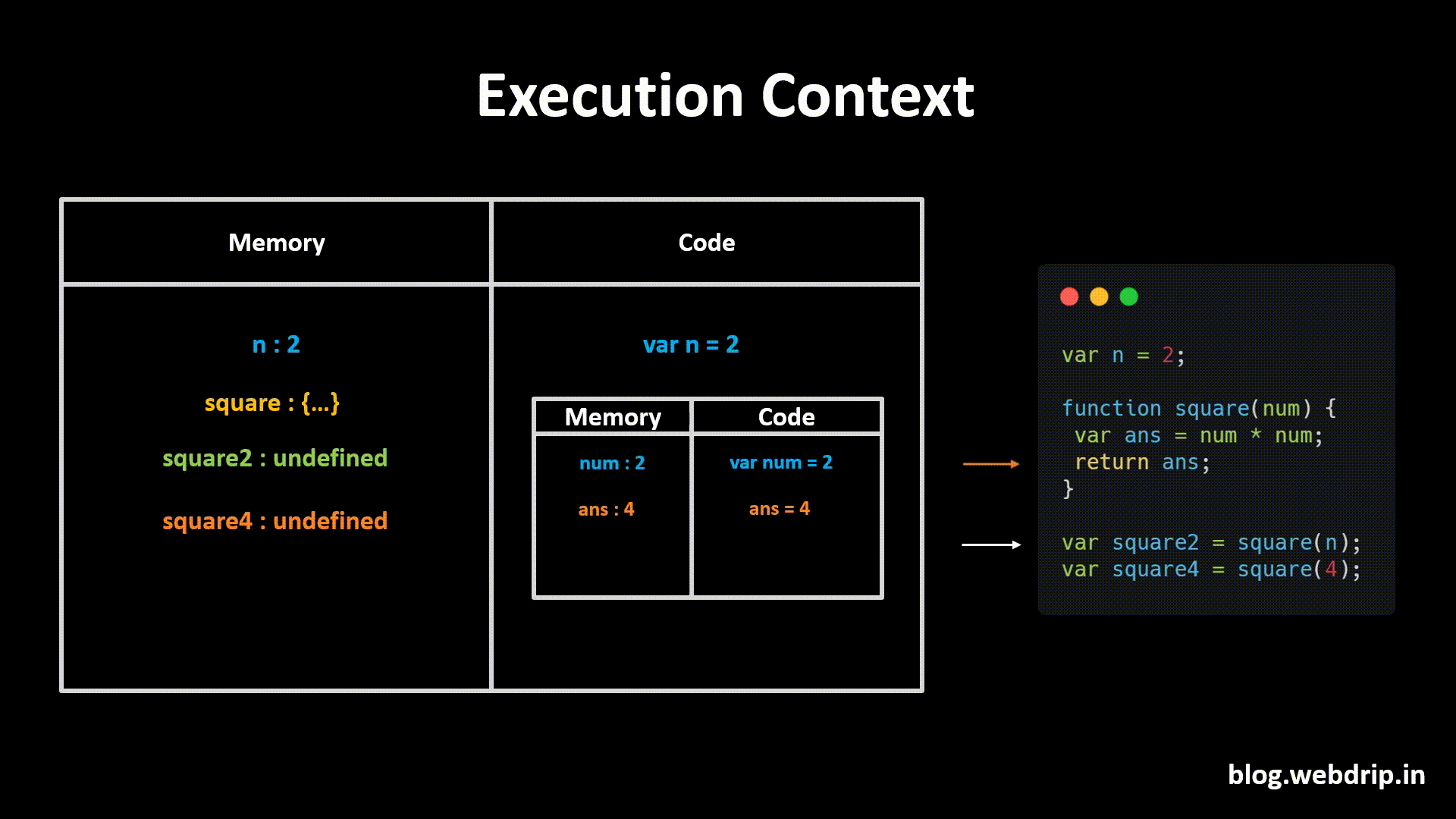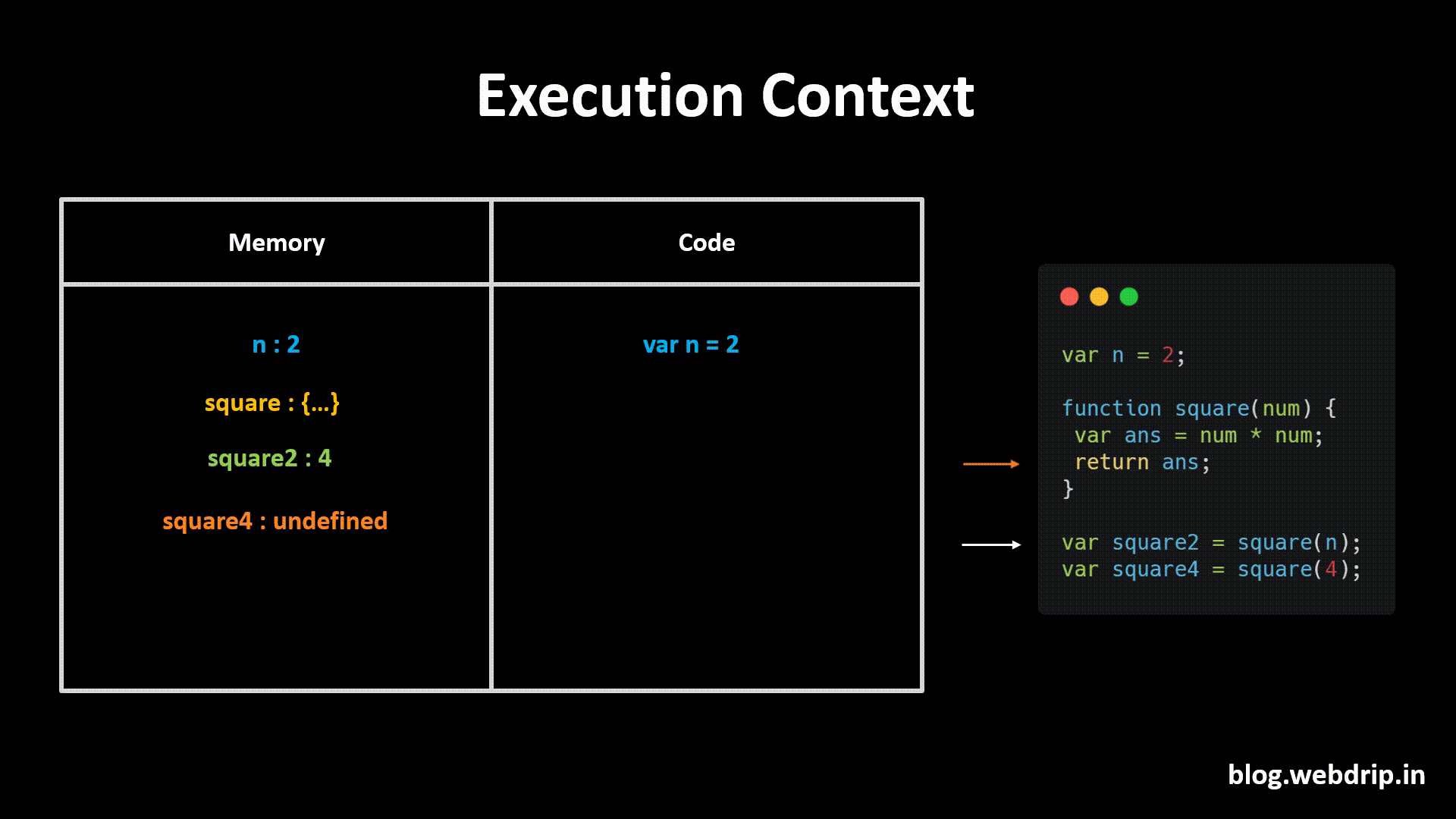
Agora seguirá um procedimento semelhante para a linha número 7 ou variável `square4`, conforme mostrado abaixo.
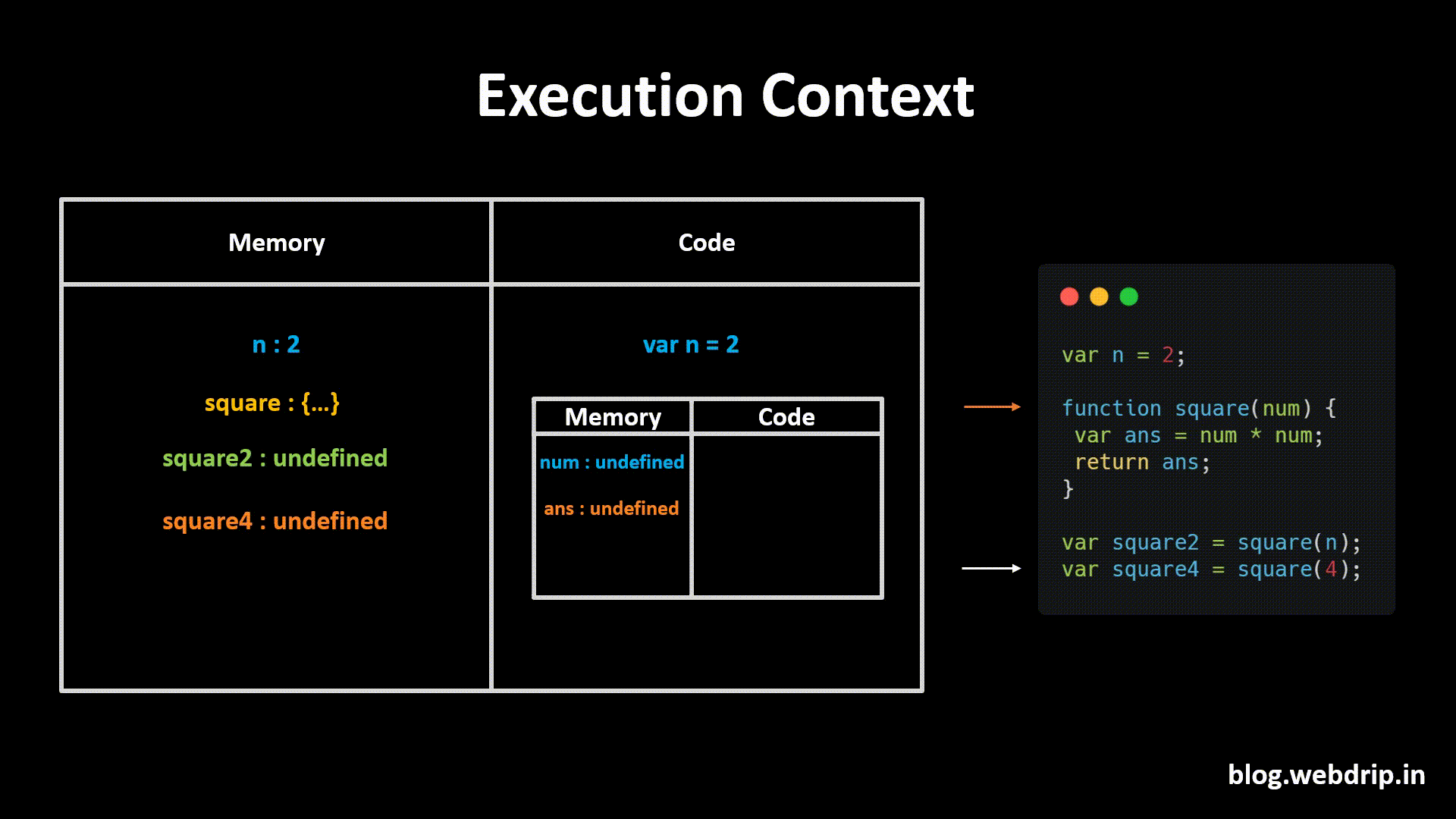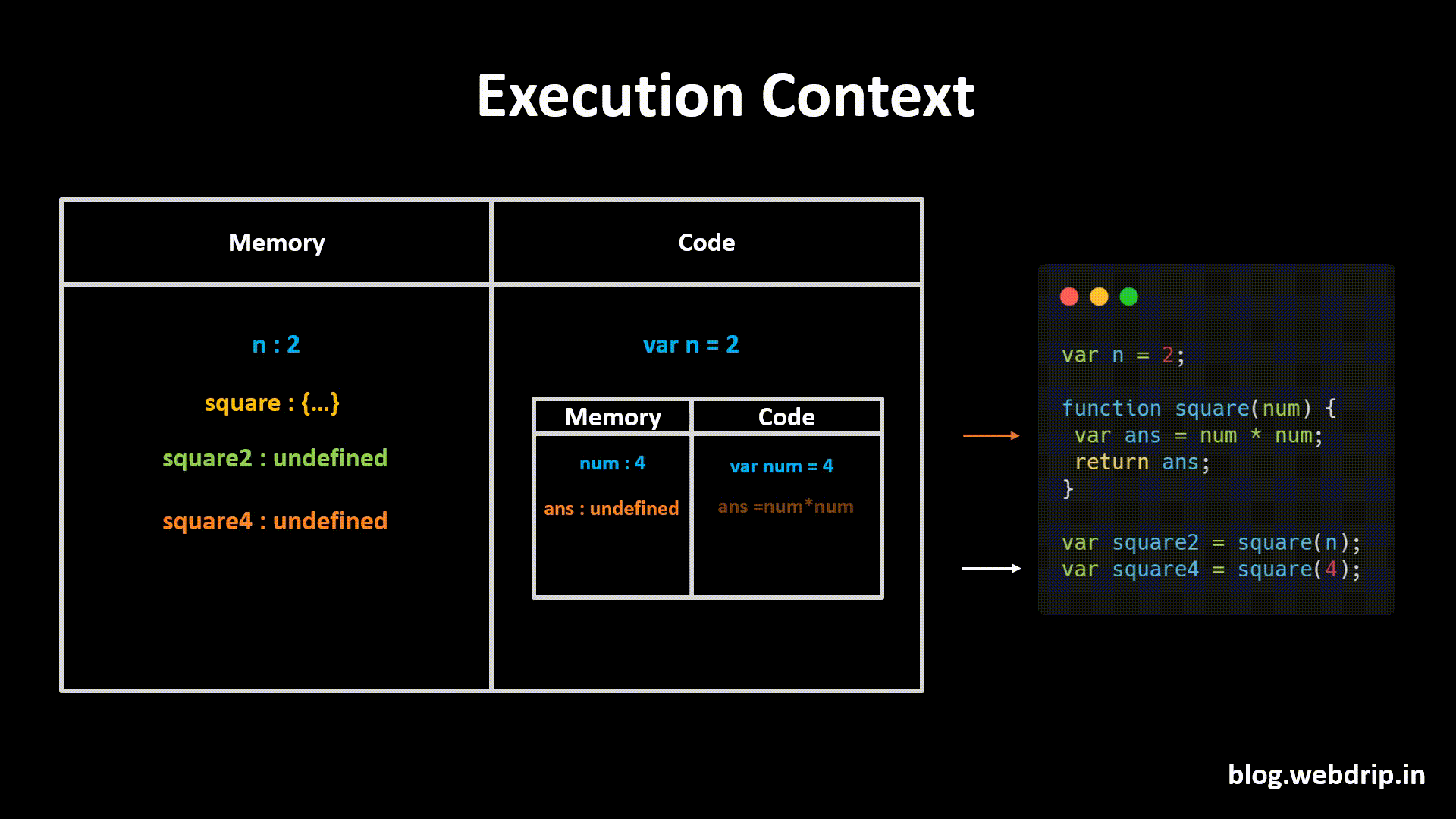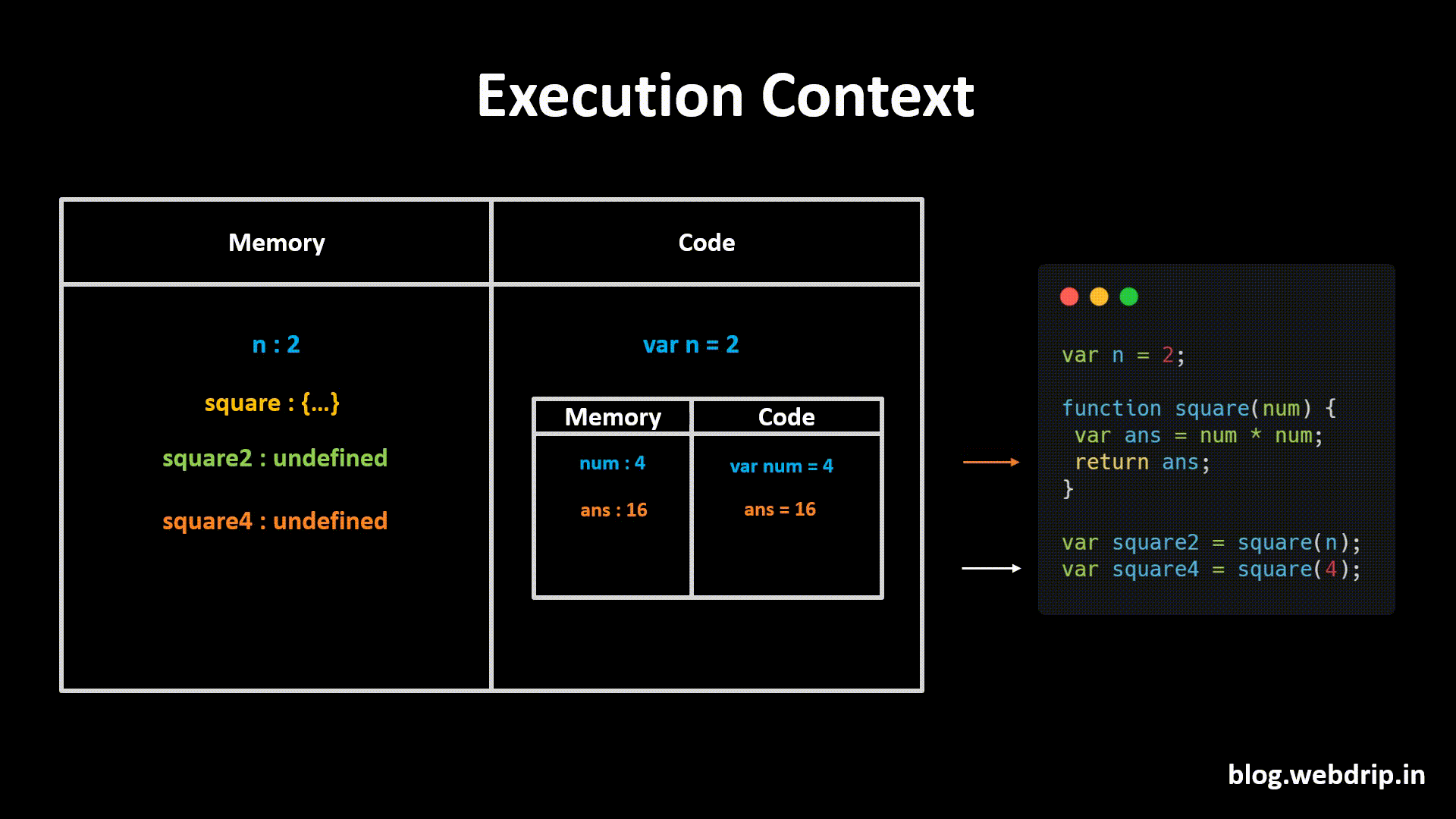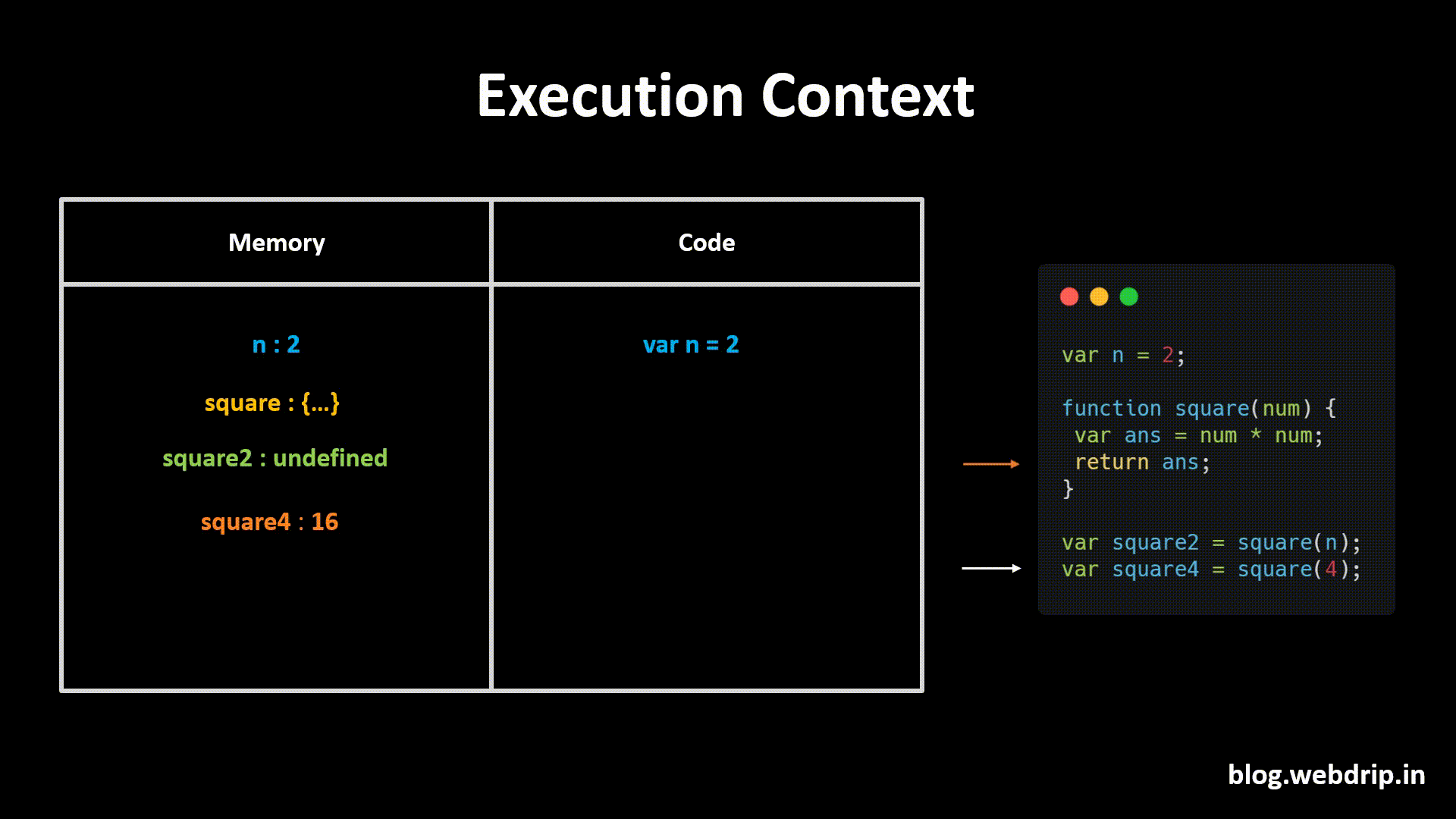
Depois que todo o código for executado, o contexto de execução global também será destruído e é assim que o JavaScript executará o código nos bastidores.
## Pilha de Chamadas
Quando uma função é chamada em JavaScript, o JavaScript cria um contexto de execução. O contexto de execução ficará complicado conforme aninhamos funções dentro de uma função.
O JavaScript gerencia a criação e exclusão do contexto de execução do código com a ajuda do Pilha de Chamada..
Uma pilha (às vezes chamada de “push-down stack”) é uma coleção ordenada de itens onde a adição de novos itens e a remoção de itens existentes sempre ocorre na mesma extremidade, por exemplo, pilha de livros.
Pilha de Chamada é um mecanismo para rastrear seu lugar em um script que chama várias funções.
Vamos dar um exemplo:
```jsx
function a() {
function insideA() {
return true;
}
insideA();
}
a();
```
Estamos criando uma função `a`, que chama outra função `insideA` que retorna `true`. Sei que o código é burro e não faz nada, mas nos ajudará a entender como o JavaScript lida com as funções callback.
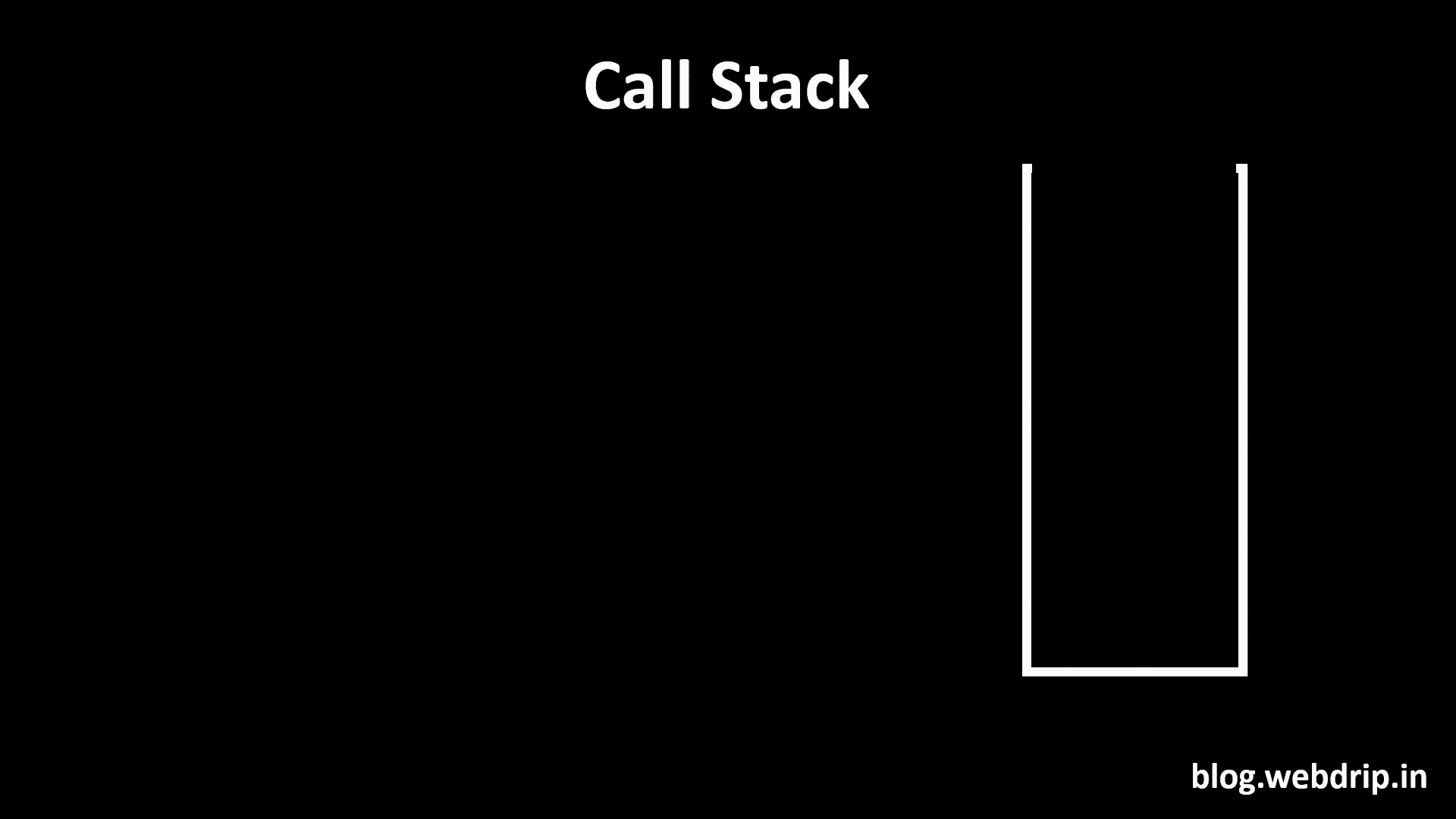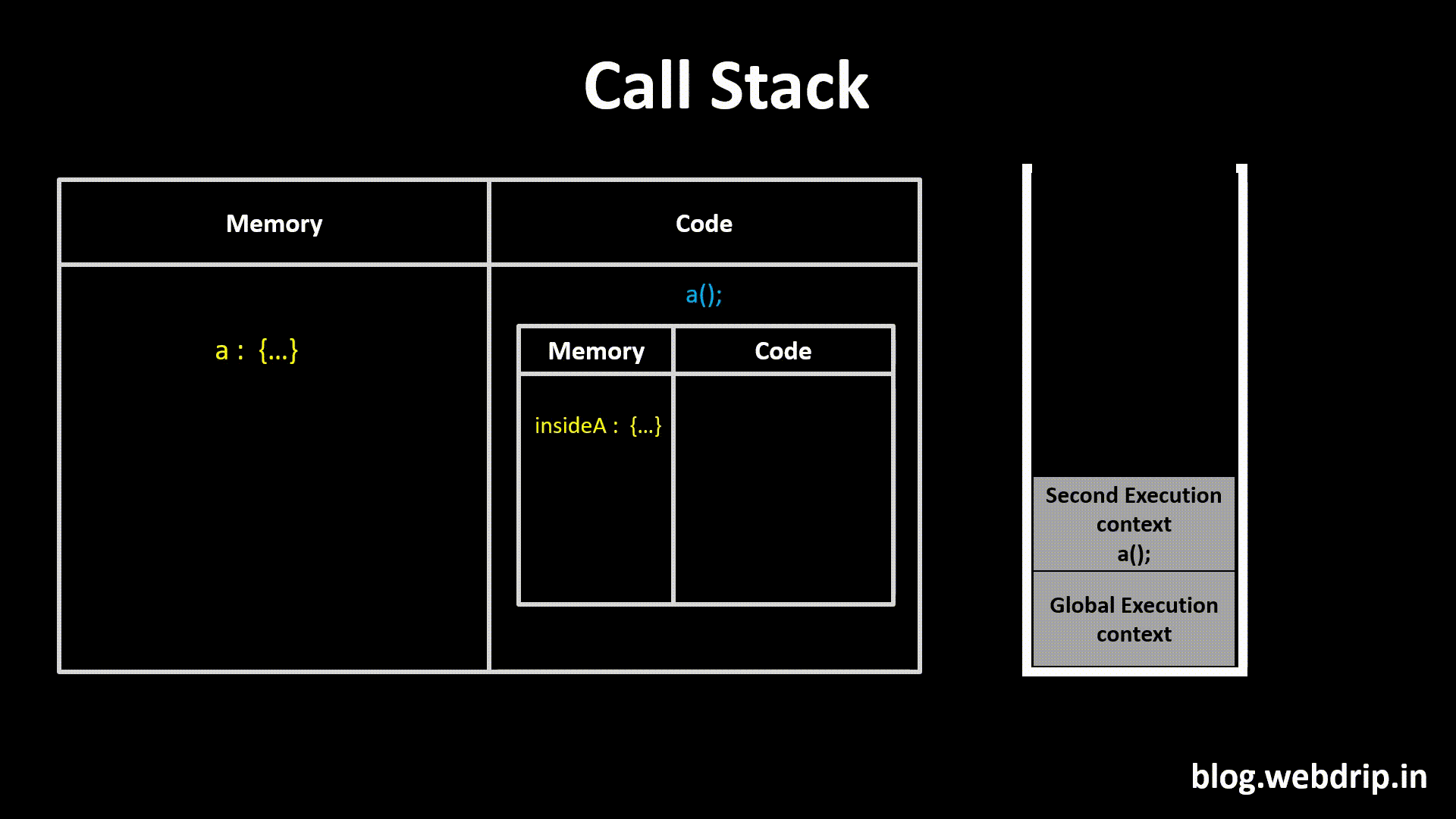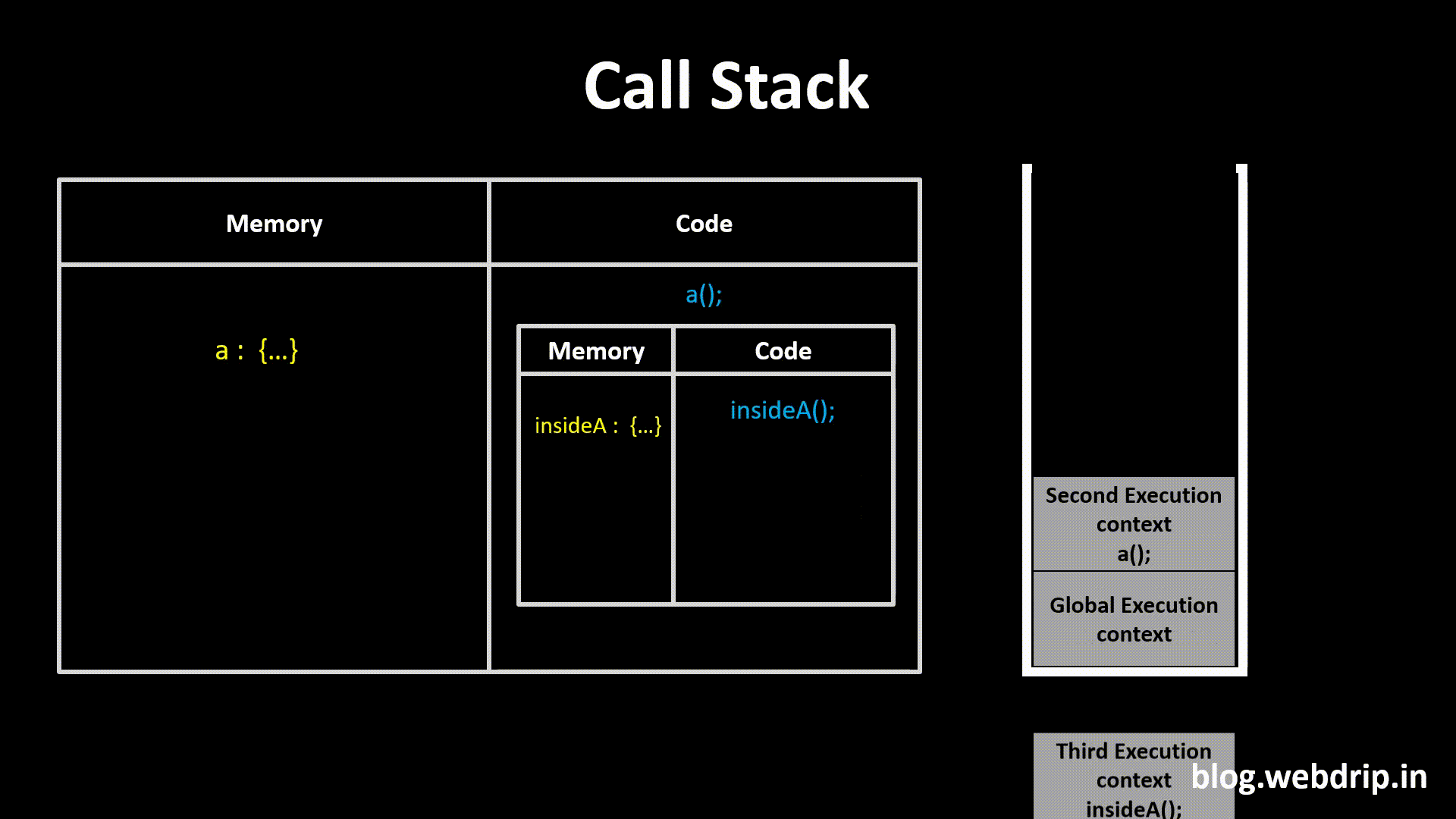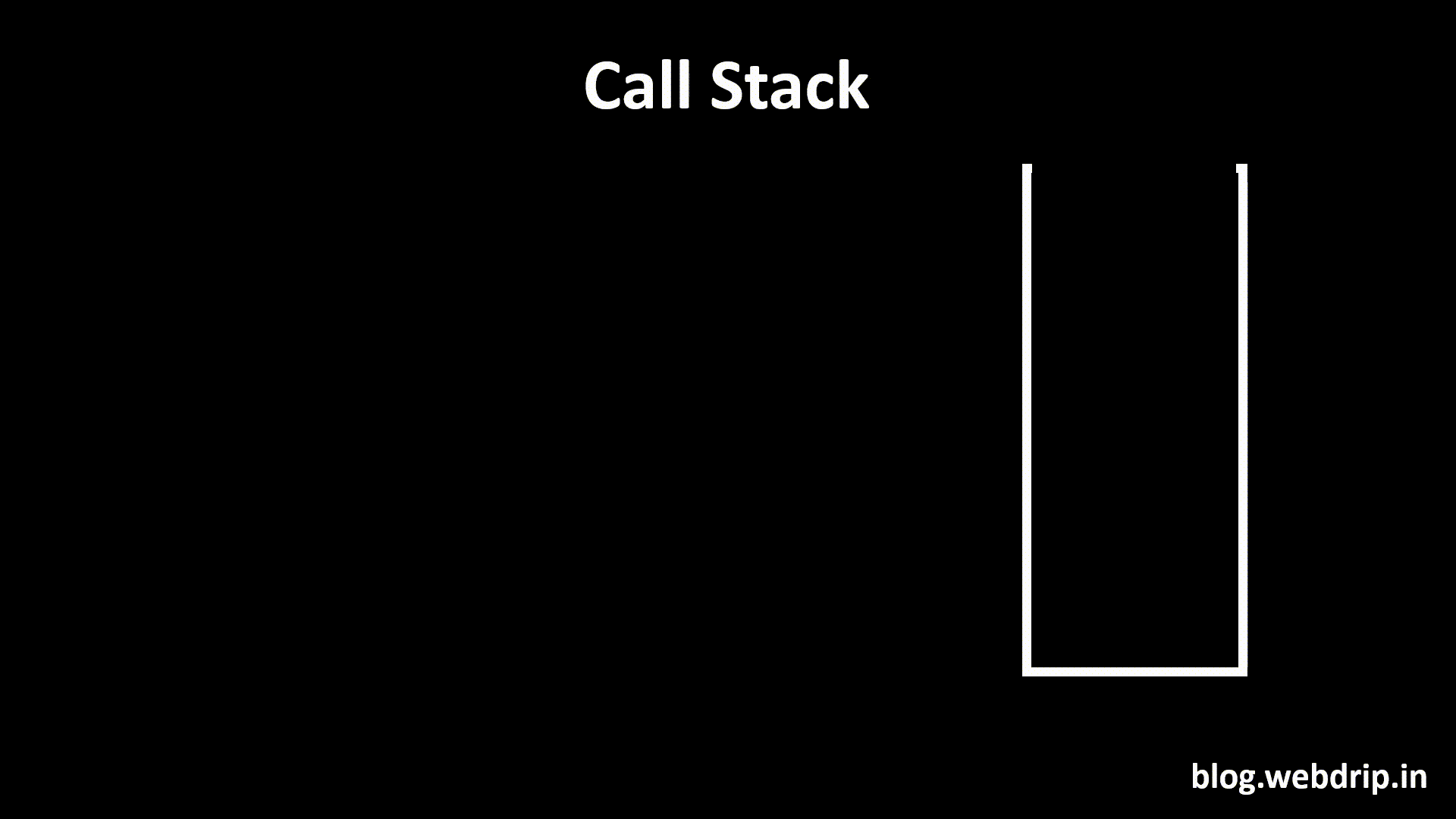
O JavaScript criará um contexto de execução global. O contexto de execução global atribuirá memória à função `a` e invocará a função `a` na fase de execução do código.
Um contexto de execução é criado para a função `a`, que é colocado acima do contexto de execução global na pilha de chamadas.
A função a atribuirá memória e invocará a função `insideA`. Um contexto de execução é criado para a função `insideA` e colocado acima da pilha de chamadas da função `a`.
Agora, esta função `insideA` retornará `true` e será removida da pilha de chamadas.
Como não há código dentro da função `a`, o contexto de execução será removido da pilha de chamadas.
Por fim, o contexto de execução global também é removido da pilha de chamadas.
## Obrigado por ler!
Espero que este artigo tenha ajudado você a entender melhor como o JavaScript funciona. | trinitypath |
1,318,337 | Journeying into frontend development | Don’t compare your journey as a developer to someone else. Humans are different, and so are our... | 0 | 2023-01-05T13:06:41 | https://dev.to/oluwatrillions/journeying-into-frontend-development-14m4 | webdev, javascript, programming, react | Don’t compare your journey as a developer to someone else. Humans are different, and so are our cerebral capabilities. There is a roadmap to being a developer, but we all will travel at different paces. Even though we all have similar goals, we are following different routes and paces to achieve them. No two people’s journey is the same. Same as the road to becoming a Frontend Developer.
This is more like a story about how I got where I am. I am not as good as where I want to be, but I know I am better than I was yesterday. The most important thing is taking that first step, and following through on it.
When I started my journey, I planned on being comfortable with Javascript in 6 months. I had a timeframe mapped out about how and what I wanted to achieve in 6 months. So, how did I start?
1. HyperText Markup Language (HTML): This is the foundation of the internet, and as such, it is a very important course to know. Without HTML, we probably may not be using the browser for the internet. I never saw learning it as a problem when I started my journey. I knew it was the most basic, yet the most important foundational knowledge I needed to have, so my learning timeframe for HTML was One Week.
In that one week, I read a lot about HTML, doing as much as 8 hours a day. I knew I wanted to be a developer so badly, so I put in all my time every day for that one week, to learn the most important tags and elements I would be needing in my day-to-day life as a newbie developer.
If you’re reading this and you’re a beginner, don’t put any pressure on yourself. Take your time, learn at your pace, but give yourself a timeframe. I always advise other beginners like me to take up as much as one month if they need to, because, as the foundation in Frontend development, an in-depth understanding is key.
2. Cascading Style Sheet (CSS): The beauty of any web app depends on how well-written the app was styled. That is the essence of CSS. It beautifies and endears users to spend more time on your website. It is the glue that keeps users scrolling on your website.
This is a course that has a mind of its own I like to say. I never knew how tricky CSS was until I started writing proper projects. Because I thought it was just as basic as HTML, I didn’t spend so much time on it; I’m still paying for it right now. I dedicated 2 weeks to CSS and moved on like I was done, not knowing it was going to be a lifetime pain I’ll continue to deal with so long as I keep writing frontend codes.
This course isn’t to joke with. It needs to be taken seriously, most especially with topics like Responsive design, Flexbox and Grid. I will advise any newbie developer to take as much as one month or two to dissect and digest the importance of and how CSS works.
3. JavaScript: There is so much to write about this programming language, but I’m sure you’ve heard a lot about it as much. Javascript is the widest programming language I’ve ever encountered. I’ve had a stint with Java, Python and PHP, but I can say with all certainty that none of them is as broad as Javascript is.
Like you, I’ve heard and read a lot about Javascript so much that I started building a block of defense around my psyche that I was well prepared for it once I started learning it. Well, I’m about 2 years into Javascript, and I can tell you it broke all of my defenses. You can never be prepared enough for the tantrums Javascript would throw at you.
I thought I was well prepared, so I put a timeframe of 4 months to learn Javascript. Trust me, after 4 months, it felt like I was still in the introductory part. My solace from all of it is; I’ve read a lot from senior developers who have been working with Javascript for over 10 – 15 years, about how they still struggle with Javascript. So I knew for a fact I was not alone. You aren’t either.
If you’re a beginner, don’t make the same mistake as I did. Don’t set a timeframe to learn Javascript. Take all the time in the world to learn it and know it enough. This is a programming language that has several libraries and frameworks, and these libraries and frameworks all take a cue from Javascript. If all these libraries and frameworks pass away, the core language itself would remain. So it’s best to have very deep knowledge of the core language itself because that same knowledge is what you will need in React, Angular, Svelte or Vue.
The takeout point here is; to take your time to learn Javascript. It has come to stay. | oluwatrillions |
1,318,566 | Add Searching To Your Astro Static Site | This guide was initially published on my blog. Check it out here Astro is great for static site... | 0 | 2023-01-05T15:38:16 | https://blog.otterlord.dev/posts/astro-search/ | > This guide was initially published on my blog. Check it out [here](http://blog.otterlord.dev/post/astro-search)
Astro is great for static site generation, but it doesn't come with any built-in search tools out of the box. While some may use third-party tools such as Algolia, I wanted to avoid relying on third-party services.
Enter [Pagefind](pagefind.app/), a static search library for indexing your content and presenting search results on your static site. Pagefind is framework agnostic, but setup can be a little tricky.
## Installing Pagefind
Install Pagefind as a development dependency. The package contains a CLI tool that will generate the actual JavaScript to run on your site.
```sh
npm install --save-dev pagefind
```
## Adding A `postbuild` Script
Pagefind needs to run after your site has been built, because it analyzes the HTML files to generate the search index. Add a `postbuild` script to your `package.json` to run Pagefind after your site has been built. The source directory will be the output of Astro's build (`dist`) and the bundle directory (which is always placed inside the source directory) will be `pagefind`.
```json
{
...
"scripts": {
...
"postbuild": "pagefind --source dist --bundle-dir pagefind"
},
...
}
```
## Adding a Dev Endpoint
A big issue I came across when first solving this, is that there's no way to inject the pagefind bundle into your site at development time, because the site only exists as memory. I solved this by adding a dev endpoint to my site, which will serve a "fake" Pagefile script filled with 0 results. This way, the script will always be available, and the search results will always be empty. It's a little hacky, but it works. Create a new file at `src/pages/pagefind/pagefind.js.ts` with the following contents:
```js
import type { APIContext } from "astro"
export async function get({}: APIContext) {
return {
body: 'export const search = () => {return {results: []}}'
}
}
```
There's probably a better way to do this, but this will prevent your site from screaming at you when you try to access the pagefind script at development time. During build time, since Pagefind is run after the site is built, the actual Pagefind script will replace the dev endpoint.
## Adding a Searchbar
To keep things simple, I'm going to simply use an `<input>` element as a searchbar, just to show how to integrate Pagefind's library. You can choose to put this anywhere on your site. If you're using the default Astro template, you can add it to `src/pages/index.astro` for example.
What we're doing here, is listening to the `input` event on the searchbar, and then loading the Pagefind script if it hasn't been loaded yet. Once the script is loaded, we can use the `search` function to search the index. The `search` function returns the results. Each result has a `data` function, which returns the data for that result. In this case, we're using the `url` and `meta.title` properties to create a link to the result, and the `excerpt` property to show a preview of the result. You can find a reference to the structure returned by `data` [here](https://pagefind.app/docs/api/#loading-a-result).
```astro
<input id="search" type="text" placeholder="Search...">
<div id="results" />
<script is:inline>
document.querySelector('#search')?.addEventListener('input', async (e) => {
// only load the pagefind script once
if (e.target.dataset.loaded !== 'true') {
e.target.dataset.loaded = 'true'
// load the pagefind script
window.pagefind = await import("/pagefind/pagefind.js");
}
// search the index using the input value
const search = await window.pagefind.search(e.target.value)
// clear the old results
document.querySelector('#results').innerHTML = ''
// add the new results
for (const result of search.results) {
const data = await result.data()
document.querySelector('#results').innerHTML += `
<a href="${data.url}">
<h3>${data.meta.title}</h3>
<p>${data.excerpt}</p>
</a>`
}
})
</script>
```
The benefit of asyncronously loading the Pagefind script is that it won't affect the performance of your site. The script is only loaded when the user starts typing in the searchbar. Allowing you to keep all 100s in your Lighthouse score 😎
## Excluding Elements From The Index
Pagefind will index all of the text in the `body` element by default, excluding elements like `nav`, `script`, and `form`. If you want to exclude additional elements from the index, you can add the `data-pagefind-ignore` attribute to the element. I recommend doing this on any lists or archive pages to prevent the index from being bloated with duplicate content.
## Wrapping Up
Now you can expose a good search experience to your users, without a third-party provider. It took me a few hours to get this working, so hopefully this will save you some debugging time. You won't be able to search your site in development, but you can always build your site to test it out.
---
Thanks for reading! If you have any questions, feel free to reach out to me on [Twitter](https://twitter.com/theotterlord) or [Discord](https://dsc.gg/otterlord).
| otterlord | |
1,318,576 | Learning Networking in AWS Cloud using a simple Hotel example | There are few terms you must have heard like cloud, region, vpc, subnets, internet gateway, NAT. All... | 0 | 2023-01-05T16:01:55 | https://dev.to/mohit0303/learning-networking-in-aws-cloud-using-a-simple-hotel-example-3g01 | aws, cloud, networkingincloud, cloudskills | There are few terms you must have heard like cloud, region, vpc, subnets, internet gateway, NAT.
All these terms are related to only one thing i.e having our own private space for our project in cloud.
Lets take a layman example to connect these dots.

Suppose you want to book a room in a hotel.
So we will go to a particular HOTEL, which is in a specific region and in a specific area of a country.
Similarly when we select a cloud provider like AWS, Azure or GCP they are like hotels present in a region in various availability zone(AZ).
So we can select region like central europe and zone like eu-central-1a.
Now you talk to receptionist and he/she allocates a room with a room number like 101.
In cloud world, its like you are booking a VPC(Virtual Private Cloud) in AWS could with an address range like 10.0.0.0/16.(Now it’s your own private space)
As we are inside our Hotel Room and if we want to connect to outer world, we will connect to internet through hotel’s WIFI.
Similalrly inorder to connect our VPC to internet/outerworld we need Internet Gateway.
Inside the VPC we booked, we create small small subnet in it and we decide which machine/process to be placed in which subnet.
And Subnets are like windows in our room in hotel, some are open to outerworld like window in hall from where you can call someone passing by.
But some are private like window in washroom. Outerworld is not accessible from there.
Similarly Subnet are also
Public subnet and Private subnets created inside our VPC.
We can keep our webserver in public subnet so tht anyone on internet can connect to our website directly(but thats risky).
And we can keep our DB, Codes, imp files in private subnet which should not be open to internet.
But what if you want to keep everything in locker(private), means we want to put our webserver in private subnet as well for security.
Then comes Load Balancer which we place between the “Internet” and our “subnet” , that allows users to access our webserver placed in private subnet.
But if we put our webserver in private subnet and cut it out from outerworld, there will be a time when, even our webserver need to connect to internet for some kind of installations or updations.
So we use NAT (Network address translation) which is placed inside a “public subnet” in our VPC which allows our webserver present in “private subnet” to pass its outgoing request first to NAT which will pass it to internet gateway and then to internet.
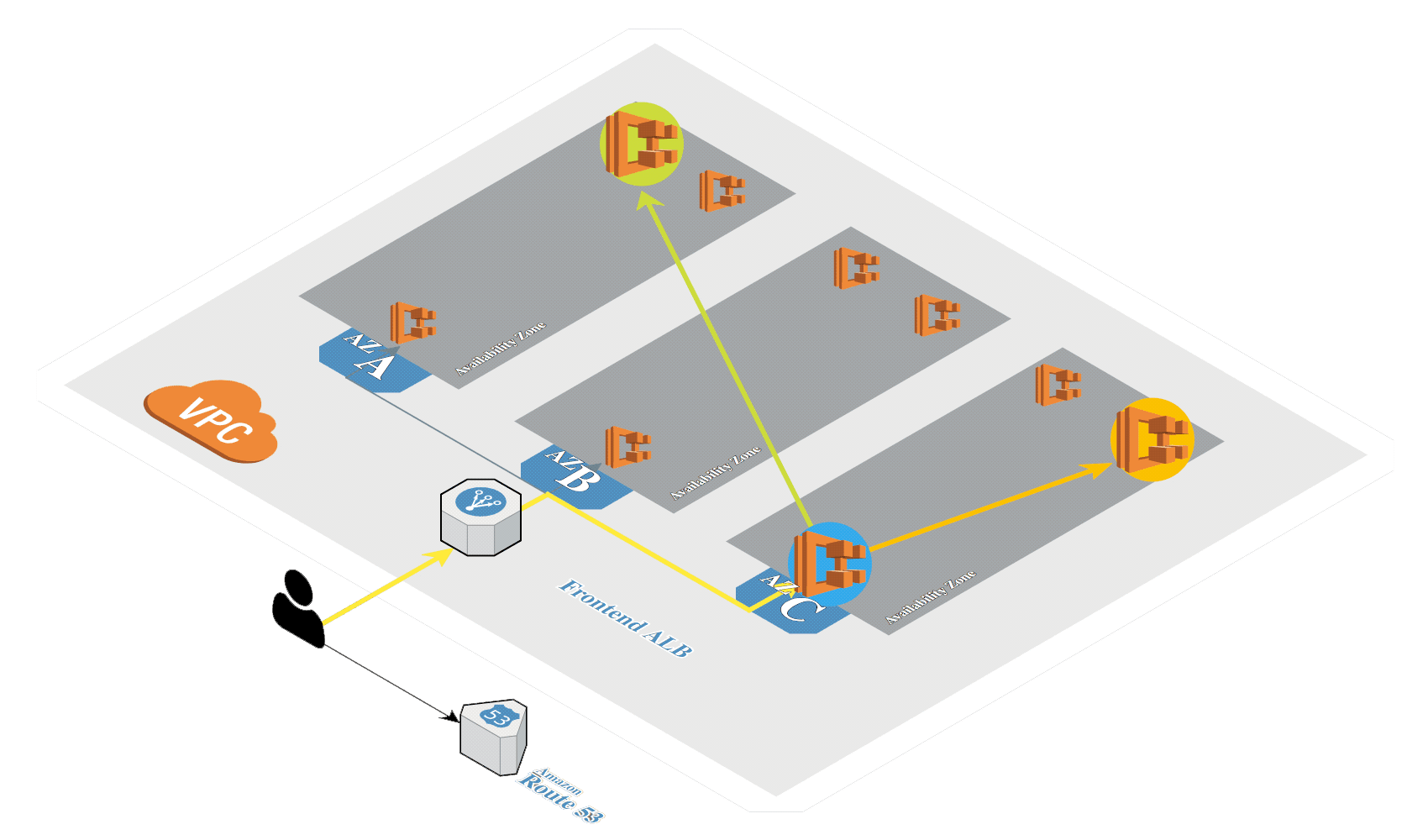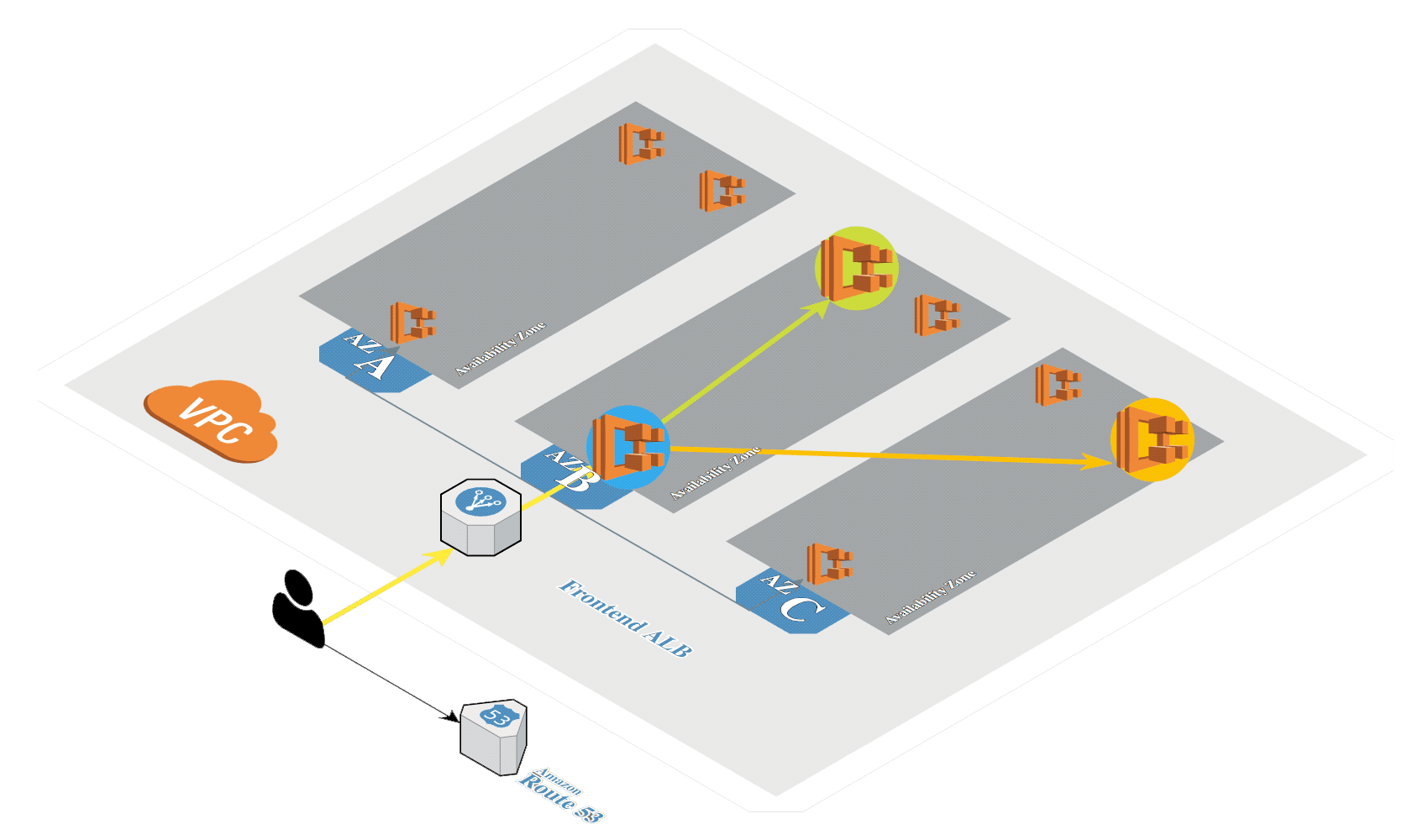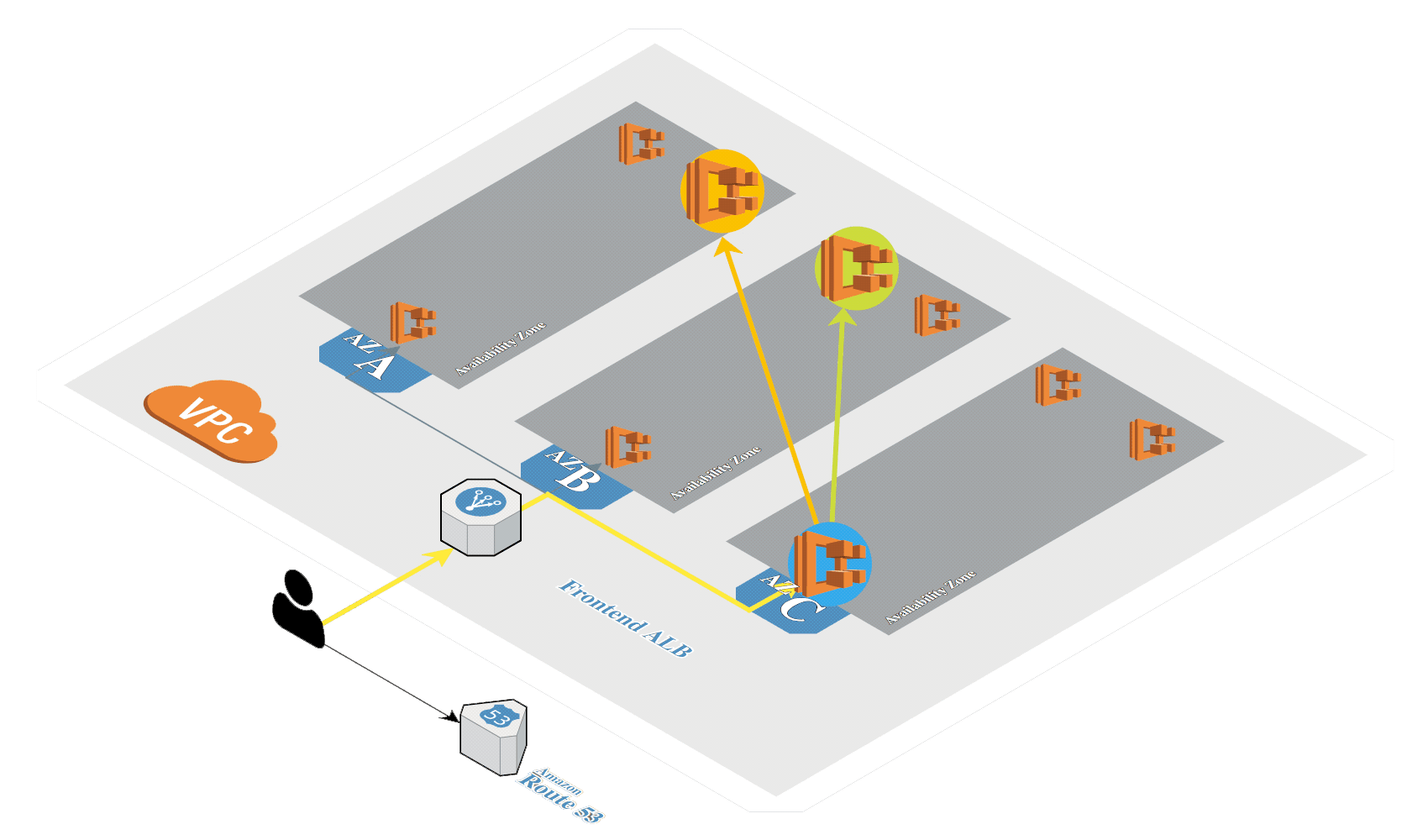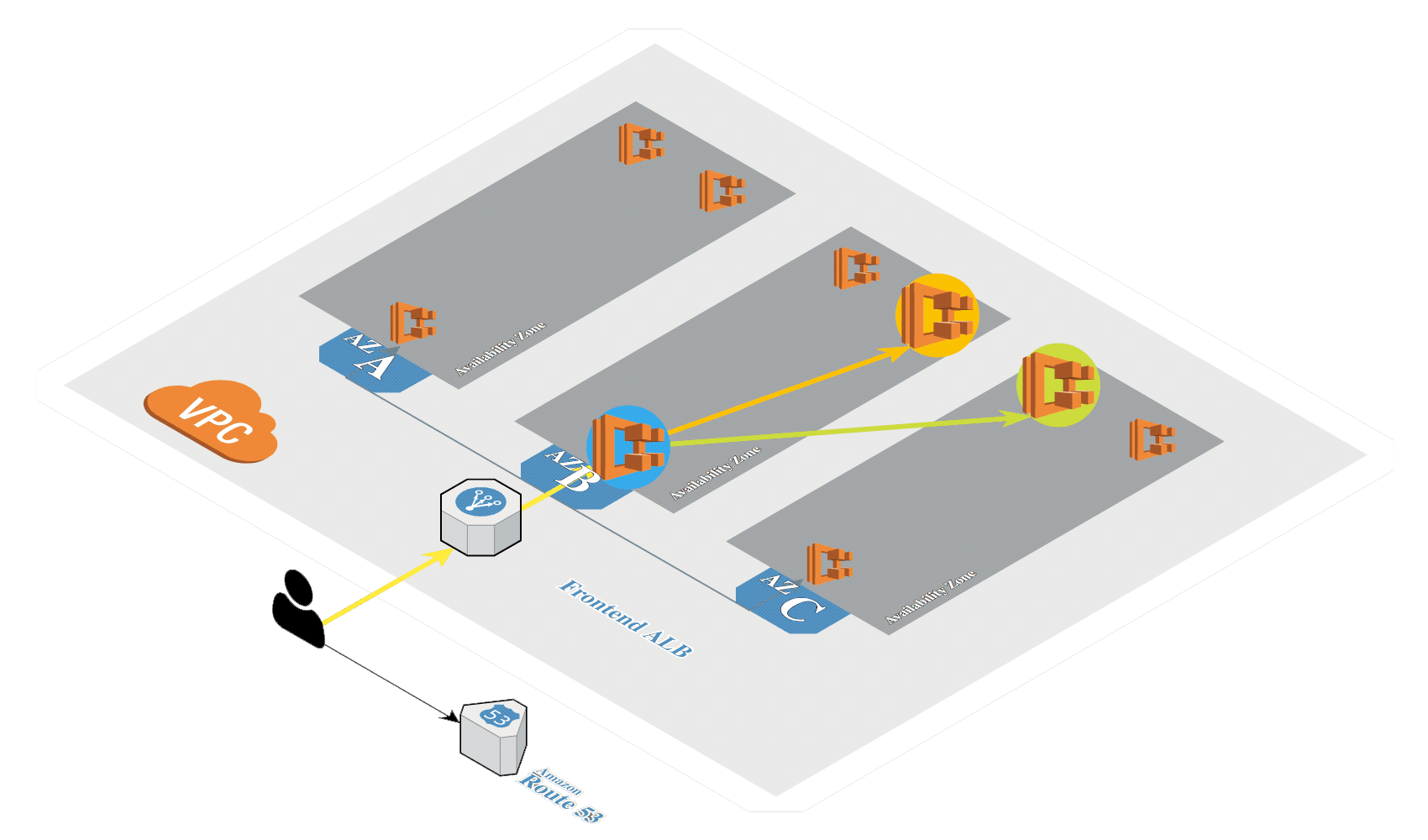
There also can be scenario where our customer say i have my VPC at my end and i dont want to move to public cloud providers like AWS or Azure.
Then we use VPC Peering Connection, which will connect customer VPC to our VPC in AWS.
We can have multiple such VPC and we have to connect these vpc to on-premises vpc as well, and if we go vpc peering on set , every vpc has to be connected to one to one vpc , because vpc peering are non-transmitive then it becomes a blockage.
Thats why, in 2018 AWS launched a new Networking Router called as “Transit Gateway". It allows to connect different VPC’s in different network as well our on-premise network VPC.
So now using a vpn or direct connection we can connect our on-premise vpc to Transit gateway, then Transit gateway will connect to our AWS VPC. This creates a complete connectivity.
Now there are other AWS services also like S3 bucket and DynamoDB if they are in same region, we don’t need to go through subnet and all, as it will cost us more money as well.
We can use VPC endpoint(gateway) for S3 and DynamoDB and for other services like Lambda, SQS, SNS we can use VPC Endpoint(interface) for direct connectivity rather then going through NAT.
In another case, what if a customer wants only you to access their app first before they open it for public on internet.
Then comes “PRIVATE LINK" which will get the customer application’s link through their NLB in their VPC, and then it will pass the link to our VPC.
Customer can expose their application’s link via their NLB and at our end we can create a VPC endpoint, which will privately connect us to the NLB of the customer.👏
Also if we dont want an IP address for our VPC, we can use Route53(DNS) so that users can connect to us using the “domain name” rather then the ip address through our ALB.
There is also Cloudfront, which will cache our website general data, big videos, images to nearest AWS AZ, so when user hit our domain name it will go to Cloudfront and then to our LB and finally to the application in our subnet. This makes faster user experience.
If you connected a bit by my post, do let me know and if we both share same intrest of devops,cloud & kubernetes then lets connect!!
Linkedin: https://www.linkedin.com/in/mohitmishra3333/
Medium: https://medium.com/@mohitmishra3333
Happy Learning to all !! | mohit0303 |
1,318,661 | Get unlimited blog articles & free stock photos [Free Trial] | Everyone knows how important good content is to rank in Google and to drive traffic to your website.... | 0 | 2023-01-05T18:41:57 | https://dev.to/sam1004/get-unlimited-blog-articles-free-stock-photos-free-trial-56i | Everyone knows how important good content is to rank in Google and to drive traffic to your website. Manually writing this content usually takes a long time that can better be spend on other tasks. That is why I created a new AI tool which creates unlimited unique articles for you for just $16/month.
Use artificial intelligence trained to write original, creative content based on the well known GPT-3 with custom modifications. You can define the topic as well as keywords it should include. Please feel free to give it a try with the free trial: [https://www.HeronAI.com](https://www.HeronAI.com)
Many of my users use it to rank in Google, some creating 300 articles/month and more. Increase your conversion rates with creative and engaging ad copies or product descriptions and scale up your content marketing. | sam1004 | |
1,318,804 | Deadlines: pointless or necessary?⏰🔄 | Hey there, developers! Raise a hand if you scorn deadlines. 🤚 Many developers cannot get along... | 0 | 2023-01-05T19:41:32 | https://dev.to/doctorlai/deadlines-pointless-or-necessary-5bk6 | deadlines, softwareengineering, developer, blog | Hey there, developers!
Raise a hand if you scorn deadlines. 🤚
Many <a href="https://codingforspeed.com/tips-to-boost-your-dev-career/" title="Tips to Boost Your Dev Career">developers</a> cannot get along with deadlines, target dates, time limits, or any other name we have for this dreadful thing.
Or maybe devs have a problem with poorly set deadlines?
Let's dig in!
<h3>Why are deadlines important?</h3>
Like it or not, it's true that having and meeting deadlines can help with efficiency, planning and organizing. Here are some other reasons why deadlines are not so bad after all:
<ul>
<li>Defining goals: Thoroughly analyzed steps will result in a better overview of time and other resources needed to complete tasks. This further helps with prioritizing and delegating tasks.</li>
<li>Prioritizing: Unfortunately, time at our hands is limited, so prioritizing goals is necessary. It helps with focusing on currently more important tasks, while others, less demanding, can be postponed.</li>
<li>Motivating: Deadlines should not mean pressure, but having no deadline could mean having no direct incentive to finish the task on time. Tasks finished after target dates intervene with other tasks and the whole project.</li>
</ul>
Having said this, one question comes to mind.
<h4>Why don't developers and deadlines get along?</h4>
One of the major problems with the <a href="https://codingforspeed.com/maximizing-dev-productivity/" title="Maximizing Dev Productivity">developer</a>-deadline relationship is that in most cases, developers aren't the ones setting the deadlines.
Estimating, planning and tracking tasks and projects is a difficult skill that shouldn't be taken lightly.
Yet in most cases, managers that set deadlines don't have the technical background or experience to estimate properly.
Instead, developers hear something like this: "I promised the client we will do it by then."
And what the non-developing part of the population forgets is that <a href="https://codingforspeed.com/is-there-such-thing-as-high-quality-code/" title="Is There Such Thing as High-Quality Code?">programming</a> is actually a design process. In other words, it's a discovery process, and with discovery comes uncertainty.
<a href="https://helloacm.com/teaching-kids-programming-check-if-there-is-a-path-with-equal-number-of-0s-and-1s-breadth-first-search-algorithm/" rel="noopener" target="_blank">Programming</a> does not equal manufacturing.
So maybe developers just don’t like badly set deadlines, or it's just too hard to set one.
What do you think? Hit reply; we would appreciate your opinion!
Reposted to [Blog](https://codingforspeed.com/are-deadlines-pointless-or-necessary/) | doctorlai |
1,319,036 | Offline Pip Packages | There are a few reasons I can think of to have offline pip packages: A package isn’t able to... | 0 | 2023-01-06T01:43:22 | https://brandonrozek.com/blog/offlinepip/ | python, archive | ---
title: Offline Pip Packages
published: true
date: 2020-01-21 04:11:05 UTC
tags: Python,Archive
canonical_url: https://brandonrozek.com/blog/offlinepip/
---
There are a few reasons I can think of to have offline pip packages:
- A package isn’t able to compile on a friend’s computer since they don’t have the million linear algebra libraries that `numpy` /`scipy` require.
- You want to archive everything to run a piece of software
- You want to control the packages available to a closed network
Regardless, to my surprise, setting up a repository of python wheels doesn’t take many steps.
## Setup
First I would recommend that you setup a virtual environment. Either through [pyenv](/blog/pyenv/) or [python-virtualenv](/blog/virtualenv/).
Then, install whatever packages you would like. Let us use tensorflow as an example:
```
pip install tensorflow
```
We’re going to need the packages `pip-chill` and `pip-tools` for the next couple steps
```
pip install pip-chill pip-tools
```
After you install all the packages you want to be available, freeze the requirements that aren’t dependencies to a text file
```
pip-chill --no-version > requirements.in
```
We will then use `pip-compile` in `pip-tools` to resolve our dependencies and make our packages as fresh as possible.
```
pip-compile requirements.in
```
To sync the current virtual environment with the `requirements.txt` file that gets produced
```
pip-sync
```
Now we have a fully working and resolved environment.
From here, we need to install the wheel package to make the binary wheels.
```
pip install wheel
```
Then to create the wheels,
```
pip wheel --wheel-dir=wheels -r requirements.txt
```
With this you have a whole repository of wheels under the wheels folder!
## Client Side
Now you can get [all fancy with your deployment](https://realpython.com/offline-python-deployments-with-docker/#deploy), though I just assumed that the files were mounted in some shared folder.
The client can install all the wheels
```
pip install /path/to/wheels/*
```
Or they can just install the packages they want
```
pip install --no-index -f /path/to/wheels/wheels package_name
```
If you don’t want to add flags to every command, check out my post on using [configuration files with pip](/blog/pipconf/). | brandonrozek |
1,319,329 | SeaTunnel Zeta engine, the first choice for massive data synchronization, is officially released! | Apache SeaTunnel (incubating) launched the official version 2.3.0, and officially released its core... | 0 | 2023-01-06T02:18:00 | https://dev.to/whaleops/seatunnel-zeta-engine-the-first-choice-for-massive-data-synchronization-is-officially-released-47n6 | apache, opensource, zeta, seatunnel |

Apache SeaTunnel (incubating) launched the official version 2.3.0, and officially released its core synchronization engine Zeta! In addition, SeaTunnel 2.3.0 also brings many long-awaited new features, including support for CDC and nearly a hundred kinds of Connectors.
Document
https://seatunnel.apache.org/docs/2.3.0/about
Download link
https://seatunnel.apache.org/download/
## 01 Major update
### SeaTunnel synchronization engine—Zeta Officially Released
Zeta Engine is a data synchronization engine specially designed and developed for data synchronization scenarios. It is faster, more stable, more resource-saving, and easier to use. In the comparison of various open-source synchronization engines around the world, Zeta's performance is far ahead. The SeaTunnel Zeta engine has undergone several R&D versions, and the beta version was released in October 2022. After community discussion, it was named Zeta (the fastest star in the universe, and the community believes it fully reflects the characteristics of the engine). Thanks to the efforts of community contributors, we officially released the production-available version of Zeta Engine, its features include:
1. Simple and easy to use, the new engine minimizes the dependence on third-party services, and can realize cluster management, snapshot storage, and cluster HA functions without relying on big data components such as Zookeeper and HDFS. This is very useful for users who do not have a big data platform or are unwilling to rely on a big data platform for data synchronization.
2. More resource-saving, at the CPU level, Zeta Engine internally uses Dynamic Thread Sharing (dynamic thread sharing) technology. In the real-time synchronization scenario, if the number of tables is large but the amount of data in each table is small, Zeta Engine will Synchronous tasks run in shared threads, which can reduce unnecessary thread creation and save system resources. On the read and data write side, the Zeta Engine is designed to minimize the number of JDBC connections. In the CDC scenario, Zeta Engine will try to reuse log reading and parsing resources as much as possible.
3. More stable. In this version, Zeta Engine uses Pipeline as the minimum granularity of Checkpoint and fault tolerance for data synchronization tasks. The failure of a task will only affect the tasks that have upstream and downstream relationships with it. Try to avoid task failures that cause the entire Job to fail. or rollback. At the same time, for scenarios where the source data has a storage time limit, Zeta Engine supports enabling data cache to automatically cache the data read from the source, and then the downstream tasks read the cached data and write it to the target. In this scenario, even if the target end fails and data cannot be written, it will not affect the normal reading of the source end, preventing the source end data from being deleted due to expiration.
4. Faster, Zeta Engine's execution plan optimizer will optimize the execution plan to reduce the possible network transmission of data, thereby reducing the loss of overall synchronization performance caused by data serialization and deserialization, and completing faster Data synchronization operations. Of course, it also supports speed limiting, so that sync jobs can be performed at a reasonable speed.
5. Data synchronization support for all scenarios. SeaTunnel aims to support full synchronization and incremental synchronization under offline batch synchronization, and support real-time synchronization and CDC.
### Nearly 100 kinds of Connector support
SeaTunnel 2.3.0 version supports ClickHouse, S3, Redshift, HDFS, Kafka, MySQL, Oracle, SQLserver, Teradata, PostgreSQL, AmazonDynamoDB, Greenplum, Hudi, Maxcompute, OSSfile, etc. 97 kinds of Connector (see: https://seatunnel.apache.org/docs/ 2.3.0/Connector-v2-release-state).
In this version, under abundant feedback from users and testing, many Connectors have been perfected to production-available standards. For Connectors that are still in the Alpha and Beta stages, you're welcome to join the test.
### Support for CDC Connectors
Change data capture (CDC) is the process of identifying and capturing changes made to data in a database, and then communicating those changes to downstream processes or systems in real-time. This is a very important and long-awaited function in data integration. In version 2.3.0, CDC Connector is also supported for the first time, mainly JDBC-Connector (including MySQL, SQLServer, etc.).
SeaTunnel CDC is a concentrated solution of absorbing the advantages and abandoning the disadvantages of existing CDC components on the market, as well as targeting to solve the pain points of many users. It has the following characteristics:
- Supports basic CDC
- Support lock-free parallel snapshot history data
The following functions are still in the development stage, and I believe they will be avalable soon:
- Support log heartbeat detection and dynamic table addition
- Support sub-database sub-table and multi-structure table reading
- Support for Schema evolution
### Zeta Engine Metrics Support
SeaTunnel version 2.3.0 also supports Zeta Metrics. Users can obtain various indicators after job execution is completed, including job execution time, job execution status, and the amount of data executed by the job. In the future, we will provide more and more comprehensive indicators to facilitate users to better monitor the running status of jobs.
### Zeta engine supports persistent storage
SeaTunnel 2.3.0 version provides the function of persistent storage. Users can store the metadata of the job in the persistent storage, which ensures that the metadata of the job will not be lost after restarting SeaTunnel.
### Zeta Engine CheckPoint supports the S3 storage plugin
Amazon S3 provides cloud object storage for a variety of use cases, and it is also one of the Checkpoint storage plugins that the community has recently requested. Therefore, we specifically support the S3 Checkpoint storage plugin and are compatible with the S3N and S3A protocols.
## 02 Change Log
### New Features
Core
* [Core] [Log] Integrate slf4j and log4j2 unified management log #3025
* [Core] [Connector-V2] [Exception] Unified Connector exception format #3045
* [Core] [Shade] [Hadoop] Add Hadoop-shade package #3755
Connector-V2
* [Connector-V2] [Elasticsearch] Added Source
* Connector #2821
* [Connector-V2] [AmazondynamoDB] Added AmazondynamoDB Source & Sink Connector #3166
* [Connector-V2] [StarRocks] Add StarRocks Sink Connector #3164
* [Connector-V2] [DB2] Added DB2 source & sink connector #2410
* [Connector-V2] [Transform] Added transform-v2 API #3145
* [Connector-V2] [InfluxDB] Added influxDB Sink Connector #3174
* [Connector-V2] [Cassandra] Added Cassandra Source & Sink Connector #3229
* [Connector-V2] [MyHours] Added MyHours Source Connector #3228
* [Connector-V2] [Lemlist] Added Lemlist Source Connector #3346
* [Connector-V2] [CDC] [MySql] Add MySql CDC Source Connector #3455
* [Connector-V2] [CDC] [SqlServer] Added SqlServer CDC Source Connector #3686
* [Connector-V2] [Klaviyo] Added Klaviyo Source Connector #3443
* [Connector-V2] [OneSingal] Added OneSingal Source Connector #3454
* [Connector-V2] [Slack] Added Slack Sink Connector #3226
* [Connector-V2] [Jira] Added Jira Source Connector #3473
* [Connector-V2] [Sqlite] Added Sqlite Source & Sink Connector #3089
* [Connector-V2] [OpenMldb] Add OpenMldb Source Connector #3313
* [Connector-V2] [Teradata] Added Teradata Source & Sink Connector #3362
* [Connector-V2] [Doris] Add Doris Source & Sink Connector #3586
* [Connector-V2] [MaxCompute] Added MaxCompute Source & Sink Connector #3640
* [Connector-V2] [Doris] [Streamload] Add Doris streamload Sink Connector #3631
* [Connector-V2] [Redshift] Added Redshift Source & Sink Connector #3615
* [Connector-V2] [Notion] Add Notion Source Connector #3470
* [Connector-V2] [File] [Oss-Jindo] Add OSS Jindo Source & Sink Connector #3456
Zeta engine
* Support print job metrics when the job completes #3691
* Add Metris information statistics #3621
* Support for IMAP file storage (including local files, HDFS, S3) #3418 #3675
* Support saving job restart status information #3637
E2E
* [E2E] [Http] Add HTTP type Connector e2e test case #3340
* [E2E] [File] [Local] Add local file Connector e2e test case #3221
### Bug Fixes
Connector-V2
* [Connector-V2] [Jdbc] Fix Jdbc Source cannot be stopped in batch mode #3220,
* [Connector-V2] [Jdbc] Fix Jdbc connection reset error #3670
* [Connector-V2] [Jdbc] Fix NPE in Jdbc connector exactly-once #3730
* [Connector-V2] [Hive] Fix NPE during Hive data writing #3258
* [Connector-V2] [File] Fix NPE when FileConnector gets FileSystem #3506
* [Connector-V2][File] Fix NPE thrown when fileNameExpression is not configured by File Connector user #3706
* [Connector-V2] [Hudi] Fix the bug that the split owner of Hudi Connector may be negative #3184
* [Connector-V2] [Jdbc] Fix the error that the resource is not closed after the execution of Jdbc Connector #3358
Zeta engine
* [ST-Engine] Fix the problem of duplicate data file names when using the Zeta engine #3717
* [ST-Engine] Fix the problem that the node fails to read data from Imap persistence properly #3722
* [ST-Engine] Fix Zeta Engine Checkpoint #3213
* [ST-Engine] Fix Zeta engine Checkpoint failed bug #3769
### Optimization
Core
* [Core] [Starter] [Flink] Modify Starter API to be compatible with Flink version #2982
* [Core] [Pom] [Package] Optimize the packaging process #3751
* [Core] [Starter] Optimize Logo printing logic to adapt to higher version JDK #3160
* [Core] [Shell] Optimize binary plugin download script #3462
Connector-V1
* [Connector-V1] Remove Connector V1 module #3450
Connector-V2
* [Connector-V2] Add Connector Split basic module to reuse logic #3335
* [Connector-V2] [Redis] support cluster mode & user authentication #3188
* [Connector-V2] [Clickhouse] support nest and array data types #3047
* [Connector-V2] [Clickhouse] support geo type data #3141
* [Connector-V2] [Clickhouse] Improve double data type conversion #3441
* [Connector-V2] [Clickhouse] Improve Float, Long type data conversion #3471
* [Connector-V2] [Kafka] supports setting the starting offset or message time for reading #3157
* [Connector-V2] [Kafka] support specifying multiple partition keys #3230
* [Connector-V2] [Kafka] supports dynamic discovery of partitions and topics #3125
* [Connector-V2] [Kafka] Support Text format #3711
* [Connector-V2] [IotDB] Add parameter validation #3412
* [Connector-V2] [Jdbc] Support setting data fetch size #3478
* [Connector-V2] [Jdbc] support Upsert configuration #3708
* [Connector-V2] [Jdbc] Optimize the submission process of Jdbc Connector #3451
* [Connector-V2][Oracle] Improve datatype mapping for Oracle connector #3486
* [Connector-V2] [Http] Support extracting complex Json strings in Http connector #3510
* [Connector-V2] [File] [S3] Support S3A protocol #3632
* [Connector-V2] [File] [HDFS] support using hdfs-site.xml #3778
* [Connector-V2] [File] Support file splitting #3625
* [Connector-V2][CDC] Support writing CDC changelog events in Jdbc ElsticSearch #3673
* [Connector-V2][CDC] Support writing CDC changelog events in Jdbc ClickHouse #3653
* [Conncetor-V2][CDC] Support writing CDC changelog events in Jdbc Connector #3444
Zeta engine
* Zeta engine optimizations to improve performance #3216
* Support custom JVM parameters #3307
### CI
* [CI] Optimize CI execution process for faster execution #3179 #3194
### E2E
* [E2E] [Flink] Support command line execution on task manager #3224
* [E2E] [Jdbc] Optimize JDBC e2e to improve test code stability #3234
* [E2E][Spark] Corrected Spark version in e2e container to 2.4.6 #3225
See the specific Change log: https://github.com/apache/incubator-seatunnel/releases/tag/2.3.0
## 03 Acknowledgement
Every version release takes the efforts of many community contributors. In the dead of night, during holidays, after work, and in fragmented times, they have spent their time on the development of the project. Special thanks to @Jun Gao, @ChaoTian for their multiple rounds of performance testing and stability testing work for the candidate version. We sincerely appreciate everyone for their contributions. The following is the list of contributors (GitHub ID) for this version, in no particular order:
Eric Joy2048
TaoZex
Hisoka-X
Tyrant Lucifer
ic4y
liugddx
Calvin Kirs
ashulin
hailin0
Carl-Zhou-CN
FW Lamb
wuchunfu
john8628
lightzhao
15531651225
zhaoliang01
harveyyue
Monster Chenzhuo
hx23840
Solomon-aka-beatsAll
matesoul
lianghuan-xatu
skyoct
25Mr-LiuXu
iture123
FlechazoW
mans2singh
Special thanks to our Release Manager @TyrantLucifer. Although it is the first time to assume the role of Release Manager, he has actively communicated with the community on version planning, spared no effort to track issues before release, deal with blocking issues, and manage version quality. He is perfectly qualified for this release. Thanks for his contribution to the community, and welcome more Committers and PPMCs to claim the task of Release Manager to help the community complete releases more quickly and with high quality. | whaleops |
1,319,669 | How to type React Props with TypeScript | Typing React Props with TypeScript can be done in different ways, but not each way will provide you... | 0 | 2023-12-04T15:16:40 | https://akoskm.com/how-to-type-react-props-with-typescript | ---
title: How to type React Props with TypeScript
published: true
date: 2023-01-06 06:39:01 UTC
tags:
canonical_url: https://akoskm.com/how-to-type-react-props-with-typescript
---
Typing React Props with TypeScript can be done in different ways, but not each way will provide you with an equal level of type safety.
First, let's take a look at a simple component we'll use to demonstrate the two methods, but without typing the props first:
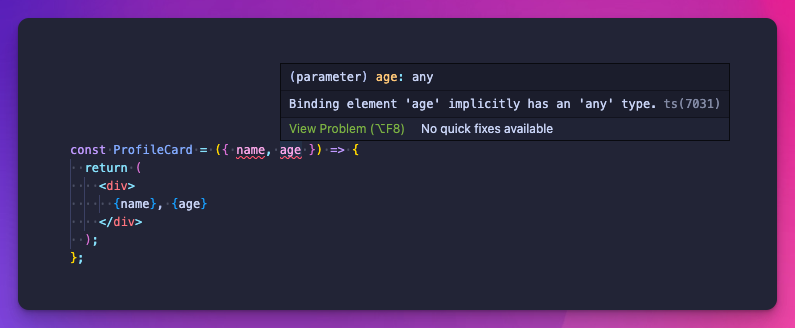
I always set `"noImplicitAny": true,` so my editor warns me about the untyped props.
Let's type them with React's `FC` interface.
## React.FC
`React.FC` is a generic type in the React module that defines a functional component in TypeScript. It is a shorthand for describing a functional component that has a prop type.
In our example, `ProfileCard` is a functional component that expects to receive props with a `name` string and an `age` number. These props are typed using the `Props` interface, and the component is typed as `React.FC<Props>`, which specifies that it is a functional component with the specified prop types:
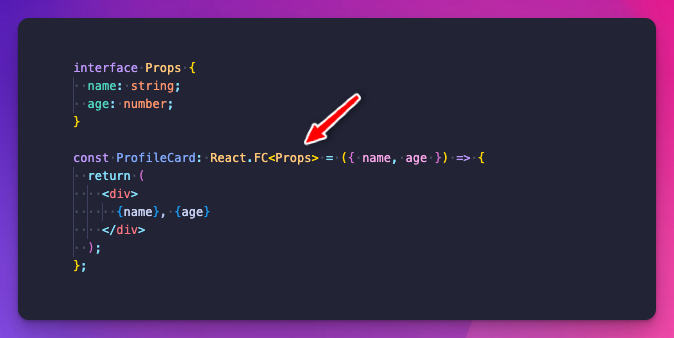
As we see, the errors disappeared because through `React.FC<Props>`, we specified the types for both the `name` and `age` props.
## props: Prop
Another, even more straightforward way to type React props is to specify the object type inside the function's signature.
Below we're simply telling react that this object has a specific type:
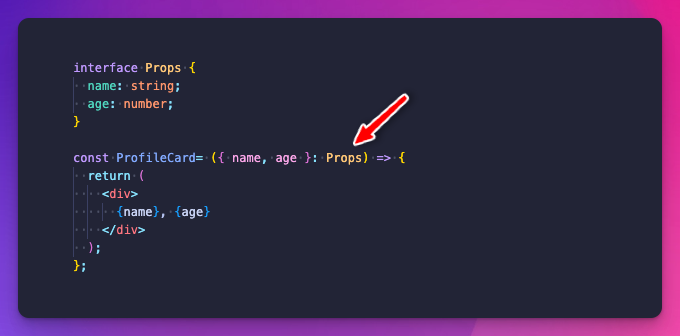
Now let's see the differences between the two regarding type safety.
# Differences in type safety
When using `React.FC`, if you define a default value with a different type than the type in `Props`, it'll merge the two types and assign that as the new type for the prop.
You might expect the below code to fail the TypeScript compilation, but it won't.
Here's the new type `React.FC` created for `name`:
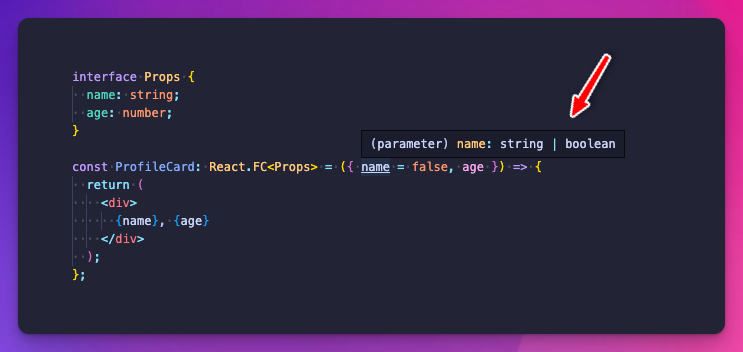
However, if you use the `props: Prop` method to type your props, you get an error right away:
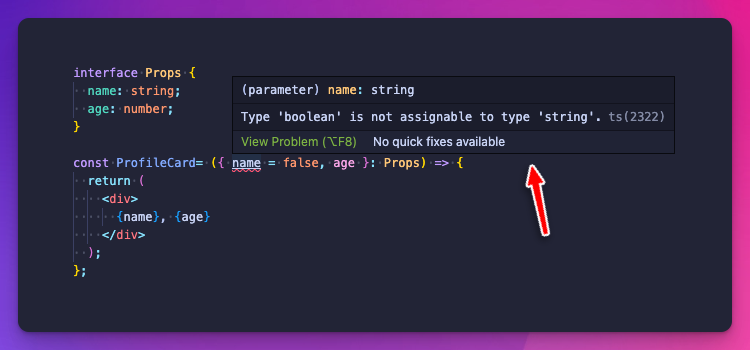
# Conclusion
Because of this difference, I always prefer the `props: Prop` way to define props in React.
But keep in mind, if you are using TypeScript in your entire codebase, a wrongly typed default value might pop up an error in the component that ends up using it.
Here's an example of that:
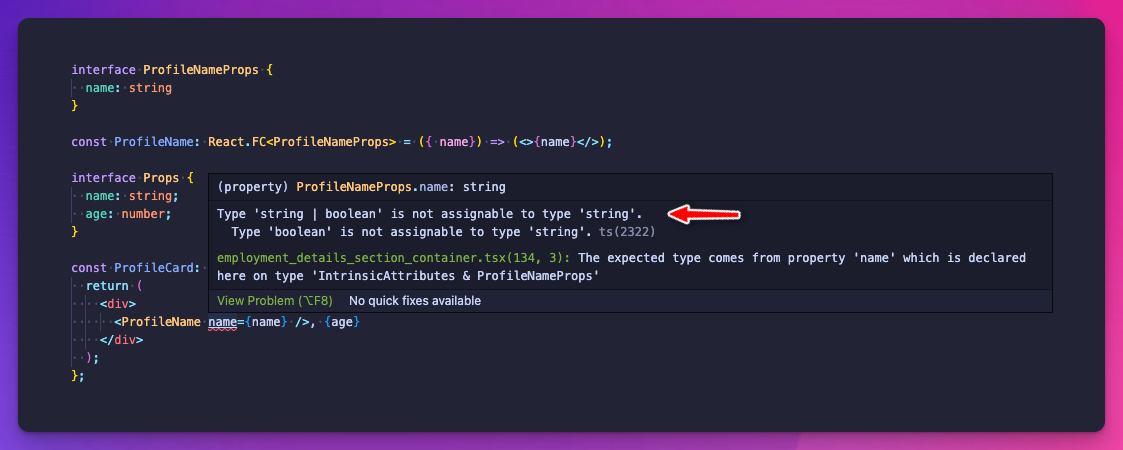
The TypeScript compiler warns us that `ProfileName` expects a name with the type of `string` and not with the type of `string | boolean`. | akoskm | |
1,346,303 | Day 155: I'm back... | Hi! Long time no see! It's been a while since my last time here. to be precise it's been 141 days... | 0 | 2023-01-30T05:12:36 | https://dev.to/ivadyhabimana/day-155-im-back-i1j | Hi!
Long time no see!
It's been a while since my last time here. to be precise it's been 141 days (quite a long time) and during this time I had been on another learning adventure but home (here) is the best, and here I am, back to the beginning again.
I stopped (or paused) blogging for a while because I thought I was busy that I would not find time to write but I recently realized that I have forgotten the main reason that I started the blogging challenge in the first place. When I started the main point was to challenge myself to write something about anything every day no matter how unmotivated or busy I thought I was. Just something too simple to avoid doing. And these small short articles I used them to document my learning journey, and stay focused and organized and that's where came motivation for writing tutorials and learned a lot in the process.
when I started I struggled with consistency but after realizing the benefits that come with it I was addicted to it and now **I'm Back again**, same place, same purpose: Writing daily to improve my coding, writing, and communication skills in general.
During this hibernation time, I had been doing mostly the fronted stuff and deep diving into JavaScript language itself, I got introduced to Next JS and did a lot of Tailwind CSS, and CSS animation. I have a lot to share with the community now and I plan to hustle to write a lot more this year.
See you around!
Signing off
| ivadyhabimana | |
1,346,549 | Top-10 Posts for FE (Week 4, Jan 2023) | Here are the top 10 posts from the past week that will be useful to front-end developers and beyond.... | 0 | 2023-01-30T09:56:48 | https://dev.to/fruntend/top-10-posts-for-fe-week-4-jan-2023-4h5g | javascript, webdev, css, html | Here are the top 10 posts from the past week that will be useful to front-end developers and beyond. The selection was made on the basis of their interestingness, uniqueness, presentation, usefulness and subjective assessment of the author.
## [Arrays Cheat Sheet - JavaScript](https://dev.to/moibra/arrays-cheat-sheet-javascript-3mie)
A concise and understandable overview of the built-in methods for arrays.
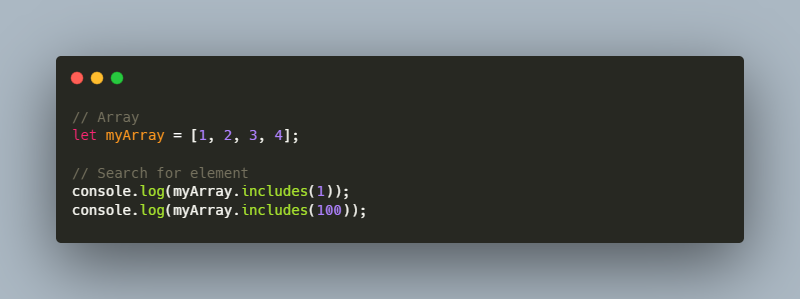
## [How to get better at coding](https://dev.to/documatic/how-to-get-better-at-coding-on)
The author of the post lists some tips that you can use to write better code.
## [The ultimate guide to async JavaScript](https://dev.to/veronikasimic_56/the-ultimate-guide-to-asnyc-javascript-3lg5)
What are callbacks, promises, and async/await, and when to use them in your JavaScript code.

## [Improvements that CSS could use in 2023](https://dev.to/robole/improvements-that-css-could-use-in-2023-59n9)
A summary of achievements of the Interop 2022 initiative to address major browser compatibility issues identified by web developers.
## [CSS Named Colors: Groups, Palettes, Facts, & Fun](https://dev.to/austingil/css-named-colors-groups-palettes-facts-fun-4h2a)
List of useful named colors that you can use in your css and their visual display.

## [Zero byte favicon markup — Keep the favicons without any of the markup](https://dev.to/shadowfaxrodeo/zero-byte-favicon-markup-keep-the-favicons-without-any-of-the-markup-47hg)
Tips for optimizing and setting up a favicon for your site.
## [Optimal Images in HTML](https://dev.to/builderio/optimal-images-in-html-5bg9)
Various ways of using images in HTML and CSS, advantages, disadvantages and ways to optimize them.
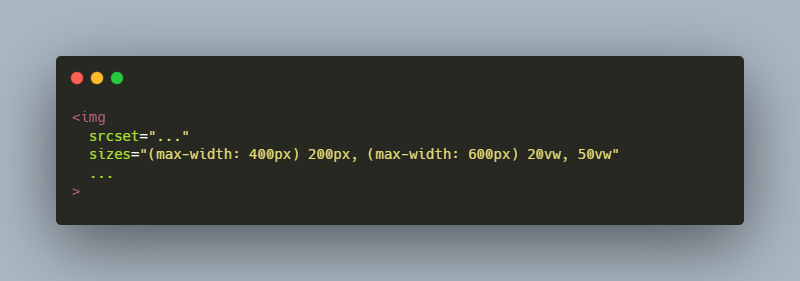
## [What and Why Gatsby? (Build your site blazing fast)](https://dev.to/varshithvhegde/what-and-why-gatsby-build-your-site-blazing-fast-2len)
The author of the post shares his experience in using Gatsby technology.
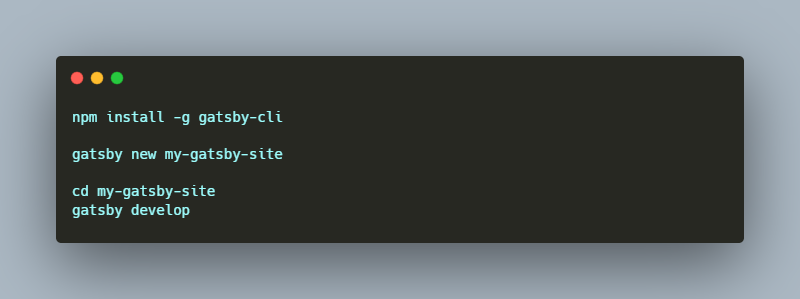
## [10 GitHub Repositories You Should Know as a JavaScript Developer](https://dev.to/gaelgthomas/10-github-repositories-you-should-know-as-a-javascript-developer-2ji6)
A selection of popular GitHub repositories to help you grow as a JavaScript developer.

## [Web Design Mastery: 7 Cool CSS Properties to Help You Stand Out](https://dev.to/devland/web-design-mastery-7-cool-css-properties-to-help-you-stand-out-4d54)
This article explores some of the most unusual CSS properties that will make you a web design pro.
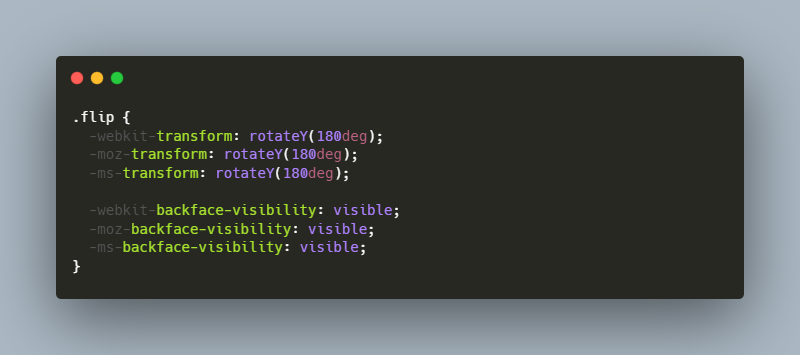
---
[](https://telegram.me/fruntend_news)[](https://www.buymeacoffee.com/fruntend) | fruntend |
1,346,827 | ANGULAR ERROR INTERCEPTORS | What is interceptor in angular? This is important for us as developer know about interceptor so In... | 0 | 2023-01-30T14:31:25 | https://dev.to/anggachelsea/angular-error-interceptors-4e23 | angular, beginners, programming, webdev | What is interceptor in angular?
This is important for us as developer know about interceptor
so In Angular, an interceptor is a mechanism for handling or transforming HTTP requests and responses globally before they reach the components. It allows you to pre-process or post-process requests and responses. It is commonly used for tasks such as adding headers, handling errors, transforming data, etc.
why I say that an interceptor is important ? because they provide a way to handle HTTP requests and responses in a centralized and reusable manner, rather than having to write the same code in multiple places. This can improve the maintainability, readability, and testability of your code. Additionally, using interceptors can simplify common tasks such as adding headers or handling errors, reducing the amount of repetitive code and making it easier to make global changes.
Now Im gonna create the simple interceptor for handle error 401 response service
the first step we should create the interceptor, we can use commandline to generate interceptor
```
ng g interceptor error
```
Angular will create the file error.interceptor.ts
like this

and will automaticly create the code interceptor like this
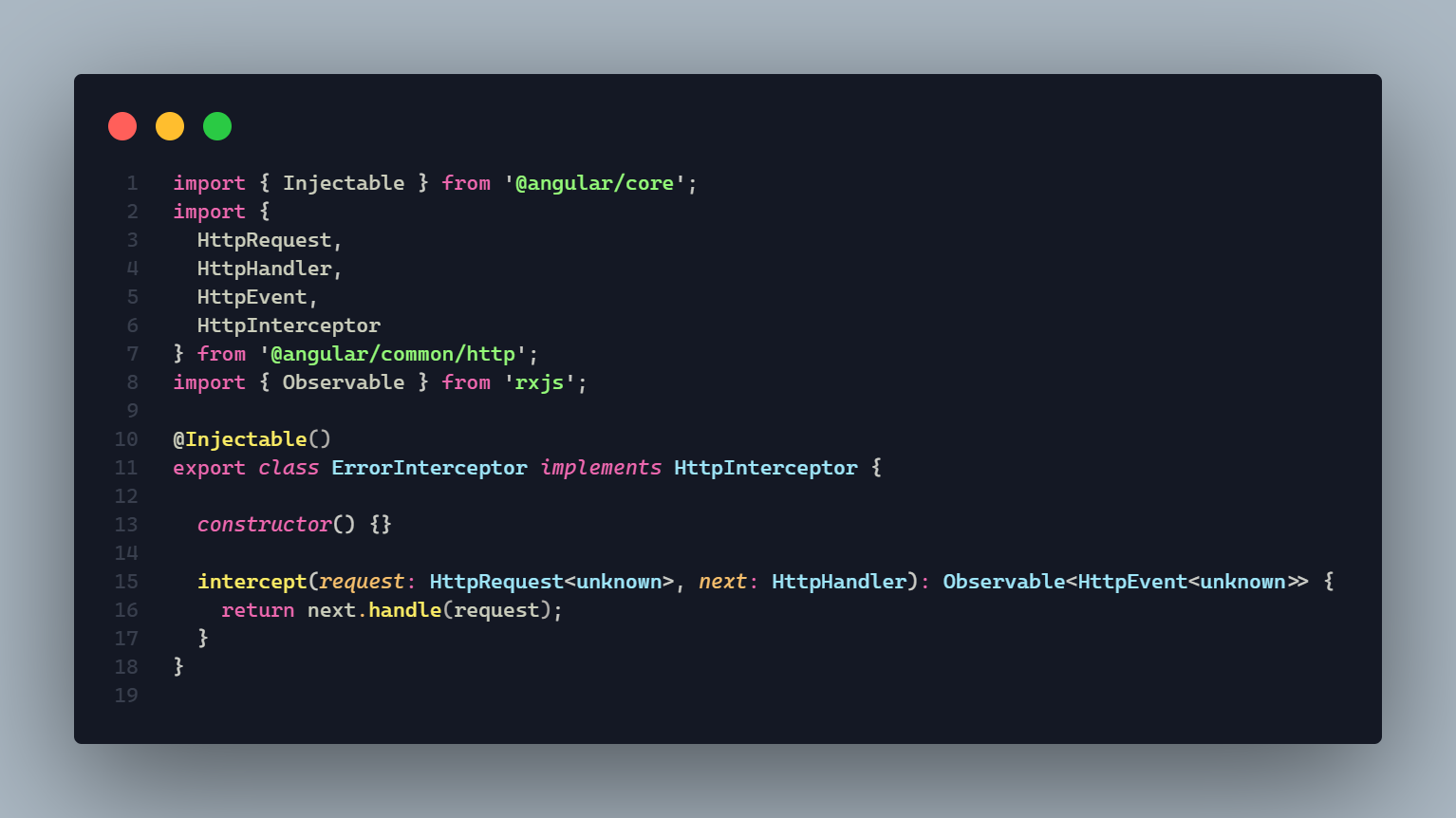
and we can add some code to detect error server
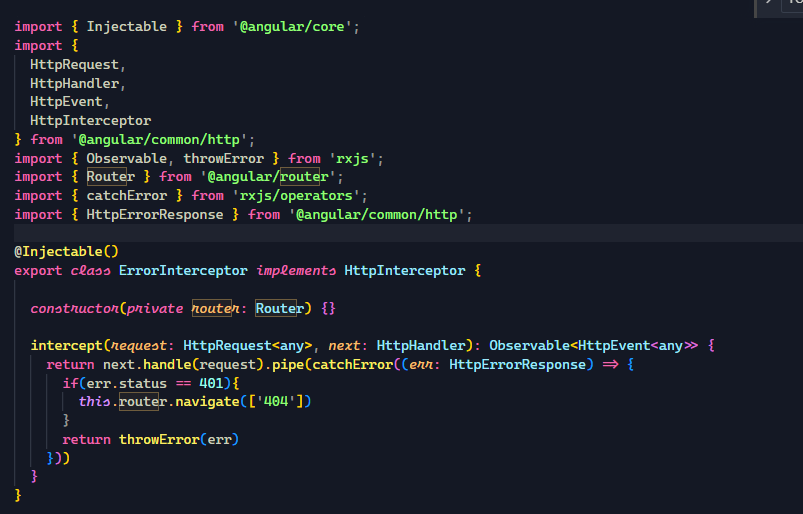
we will navigate the user is not login to login or to 401 page
but we already create the interceptor file we must import this to app.module.ts

And this will direct to 401 page
| anggachelsea |
1,346,849 | DynamoDB pain points: How to address them and exploring possible alternatives | DynamoDB is a robust NoSQL database that has become increasingly popular due to its performance,... | 0 | 2023-01-30T14:54:50 | https://medium.com/fauna/dynamodb-pain-points-how-to-address-them-and-exploring-possible-alternatives-76797d4c4e86 | dynamodb, serverless, database, webdev | DynamoDB is a robust [NoSQL database](https://fauna.com/blog/nosql-databases-non-relational-databases-explained) that has become increasingly popular due to its performance, scalability, relative simplicity, and low operational overhead. However, it has its drawbacks. Some of the main disadvantages of DynamoDB include limited querying options, limited storage capacity (400kb per document), [no multi-region ACID support (eventual consistency)](https://fauna.com/blog/compare-fauna-vs-dynamodb#consistency-models), and difficulties in replicating data in multi-region setups.
In this article, we will explore the main pain points of DynamoDB, how to overcome them, and explore some of the DynamoDB alternatives.
Indeed, there are areas where DynamoDB is the most compelling solution when it comes to speed. DynamoDB is a low-latency, fully managed NoSQL database that is ideal for applications where speed is more important than strong consistency.
DynamoDB automatically scales up and down (when you use provisioned capacity) based on the application traffic pattern. It supports automated sharding, so you do not need to manage shards manually. If your application requires high scalability and speed and doesn't need complex data relationships or transactions, DynamoDB is the way to go. However, Dynamo does have some drawbacks, which I will explore below.
> *See a [side-by-side comparison of serverless databases](https://fauna.com/blog/comparison-of-serverless-databases).*
>
### Limited querying capabilities
If you have worked with DynamoDB to some extent, then you know that relational data modeling is tedious with DynamoDB. There are no foreign key joins in DynamoDB like most people are used to in relational databases. You can, however, handle complex data access patterns similar to relational databases. In DynamoDB, you can model relationships such as one-to-many, many-to-many, and one-to-one. You can use a variety of strategies, such as denormalization, duplication, and composition of primary keys. However, these solutions require a fair amount of engineering effort and introduce a number of other limitations to consider.
> *Follow Alex DeBrie’s [article](https://www.alexdebrie.com/posts/dynamodb-one-to-many/) to learn more about data access patterns in DynamoDB.*
>
***DynamoDB can only perform query operations on tables with a single primary key.*** Consider the following table for example. The primary key of this table is the user ID, a unique identifier for each user. The table might have other attributes like name, email, and address, as demonstrated below.
You **cannot** query the table on other attributes like name and email. You need to set up the **global secondary indexes (GSI)** with the attributes you want to query and then use the query operation on the GSI. Those of us using DynamoDB for a while are okay with this pattern of storing data. Nevertheless, this is a limitation.
Moreover, you have to consider the cost of using GSIs. GSIs consume additional read and write capacity units (RCUs and WCUs). [Learn more about GSI costs here](https://stackoverflow.com/questions/73250087/cost-of-adding-a-global-secondary-index-to-an-existing-dynamodb-table).
Let's say you have a DynamoDB table called “Products” with a primary key of product_id and a few other attributes like "name" and "price". The table is provisioned with 1,000 RCUs and 1,000 WCUs. If you want to create a GSI for querying on the "name" attribute, it will require additional RCUs and WCUs to perform queries on the "name" attribute. So now you need to provision 1,000 RCUs and 1,000 WCUs for the primary key and an additional 1,000 RCUs and 1,000 WCUs for the GSI, doubling your DynamoDB usage cost. As your application grows, GSI optimization is an additional overhead you must be mindful of. In a relational database, you don't have to worry about these.
Comparing a SQL database to a NoSQL database is like comparing apples to oranges. NoSQL databases such as DynamoDB are excellent for horizontal scalability, high availability, and flexibility for handling unstructured and semi-structured data. However, features such as foreign key constraints and ACID (Atomicity, Consistency, Isolation, Durability) transactions, which we take for granted in a relational database, are not present by default in DynamoDB. Manually configuring these capabilities takes a lot of engineering effort and specialized knowledge. In brief, you have to deal with increasing application complexity because of GSI.
If you are exploring Amazon DynamoDB alternatives that are NoSQL and have better-querying capabilities, there are a few to choose from, but the one I will be covering here is [Fauna](https://fauna.com/). Fauna combines the querying capabilities of relational databases (SQL databases) with the flexibility of NoSQL databases.
A database management solution like [Fauna](https://fauna.com/) bridges the gap between a traditional relational database and a flexible NoSQL database by allowing data to store in JSON-like documents while also giving the ability to create SQL-like data relationships among collections.
> *Learn more about Fauna’s [document-relational model](https://docs.fauna.com/fauna/current/learn/introduction/document_relational).*
>
Like DynamoDB, Fauna is also a fully managed NoSQL database with low latency. It also auto-scales, ensures high availability, and adapts to your application traffic. DynamoDB has been around for 10+ years now, whereas Fauna is relatively new.
## Challenges of multi-region data replication
While DynamoDB global tables provide a way to replicate data across multiple regions, it can be a complex and costly process that requires additional setup, management, and code — and it may only support some features or data replication across all indexes.
You have to create the same table in multiple regions with the same schema, indexes, and throughput settings. Additionally, data replication between different regions needs to be configured and managed. There is no zero-configuration solution to replicate data across multiple regions with DynamoDB.
Furthermore, certain features are not available in global tables. **DynamoDB Time to Live** (TTL), which is the ability to expire items after a specified period of time, is not available with global tables.
Another unsupported feature is **DynamoDB Streams**. Additionally, **local secondary indexes (LSIs)** and **global secondary indexes (GSIs)** are not replicated across all replicas in global tables. You must manually create those LSIs and GSIs in different regions; otherwise, you cannot query data efficiently.
### ***DynamoDB global tables do not provide fault-tolerant support by default***
In the case of an outage or a failure in one region, DynamoDB does not automatically switch to another region to ensure data availability.
If distributed data across many regions is one of the core requirements of your application, you are better off using one of the alternatives of DynamoDB, such as Amazon Aurora, Fauna, or Apache Cassandra.
**DynamoDB uses an "eventual consistency" model for global data**, meaning that updates may take some time to propagate to all replicas fully.
Applications that require immediate consistency across all regions may need to use a different database solution or implement additional logic to handle eventual consistency in DynamoDB. Since data may not be immediately available in all regions, read and write operations may be slower in certain regions. This can affect the performance and user experience of the application.
Fauna is one of the strong competitors to Amazon DynamoDB for its multi-region data replication. Fauna provides multi-region data with strong consistency. It automatically routes your requests to the nearest replica, ensuring that your application experiences low latency. Fauna automatically replicates your data across all regions, ensuring that your data is always up-to-date and available — even in case of a regional outage or failure. Unlike DynamoDB, Fauna requires zero configuration for global replication. Strong data persistence in all regions is always guaranteed. If you [compare Fauna to DynamoDB](https://fauna.com/blog/comparing-fauna-and-dynamodb-pricing-features), you realize that Fauna offers all the features of DynamoDB without the drawbacks.
Apache Cassandra is also another alternative to Amazon DynamoDB. It is a free, distributed wide-column, NoSQL, open source database that can handle a large amount of data across multiple regions. However, you must manage your infrastructure and clusters if you decide to use Apache Cassandra. Managing your clusters can be challenging, even though Cassandra has robust documentation and an active community behind it.
Another database you may be interested in as an alternative is MongoDB Atlas, the managed service for MongoDB.
> *Learn how [Fauna stacks up against MongoDB](https://fauna.com/blog/comparing-fauna-and-mongodb).*
>
### Storage limitations
Another pain point with DynamoDB is the item size limit. An individual item has a maximum of 400kb in size. The item size limit impacts the way data is modeled. The application may need to denormalize the data or split it across multiple items to work within the item size limit. The storage limitation is not a big deal for most applications out there, but if you plan to grow and scale your application to millions of users, you should start thinking about the additional complexity you need to handle.
DynamoDB competitors such as MongoDB, Fauna, or Cassandra don't have this issue.
### Building scalable applications on DynamoDB
DynamoDB is well known for its low latency and scalability. However, as you build and scale your application with DynamoDB, you must be aware of some common pitfalls. As discussed in the previous section, an individual item in DynamoDB can be at most 400kb. While building with DynamoDB, it is crucial to understand the data model that best fits your application's use case and design the table schema accordingly. Failing to do this at the start will cost you as you scale your application.
Although possible, evolving your data with DynamoDB as your application grows is challenging. You need to choose the correct partition key. Selecting the right partition key ensures that the data is evenly distributed and read and write requests are distributed evenly across all partitions.
### Limited ability to perform advanced analytics
DynamoDB is optimized for storing and retrieving large amounts of data quickly, but it is ill-suited for performing advanced analytics on that data. It doesn't support advanced features such as aggregate functions or window functions.
SUM, COUNT, AVG, and MAX are commonly used in SQL to perform calculations on groups of data. DynamoDB alternatives MongoDB and Fauna have equivalent features to perform these analytics tasks. In MongoDB, you get aggregate functions such as $group, $match, $project, etc. Fauna also provides aggregate functions through Fauna Query Language (FQL) for advanced analytics.
Window functions are another advanced SQL feature that DynamoDB does not support. These functions allow users to perform calculations over a set of rows related to the current row in a query. Fauna also does not have built-in window functions, but it is possible to perform calculations similar to window functions using the Map-Reduce function and a combination of other functions. MongoDB does not have built-in window functions either. However, it does have the $bucket operator, which can be used to perform similar calculations.
If you insist on using DynamoDB and need robust analytics, then your best bet is to use third-party analytics tools such as Apache Hive or Apache Pig to perform complex queries and advanced analytics on the data stored in DynamoDB. You have to consider the additional cost of these extra resources, however.
## Conclusion
To conclude, DynamoDB is well-suited for use cases that require high scalability, high performance, and low latency. It seamlessly integrates with other AWS services and supports document and key-value data models. However, it also comes with its limitations. Limited query capabilities, little support for the transaction, eventual consistency, and limited support for analytics are some of the main pain points with DynamoDB. With enough engineering resources and time, you can overcome these pain points.
Everything in software engineering is about tradeoffs. Every database management solution has its pros and cons. It is up to you and the developers to choose your company's best solutions. This article gives you a clear picture of the various limitations of DynamoDB and some of the alternatives to DynamoDB so you can make the best-informed decision while choosing a database for your next project.
> *Though DynamoDB has much to offer, Fauna is a much newer offering that comes with a host of powerful and unique features that enhance the serverless experience for organizations of all sizes. Read more at “[Modernization of the database: DynamoDB to Fauna](https://fauna.com/blog/modernization-of-the-database-dynamodb-to-fauna).”*
>
*If you're experiencing any of the DynamoDB pain points mentioned above and are looking for a more robust and efficient solution, consider reaching out to either me or the [team of experts](https://go.fauna.com/compare/dynamodb) at Fauna.* | shadid12 |
1,347,702 | Host ReactJS App On GitHub Pages | What is this blog about In this blog, I am going to tell you how we can host a react-js... | 0 | 2024-02-03T17:58:59 | https://adithyana.hashnode.dev/host-reactjs-app-on-github-pages | ---
title: Host ReactJS App On GitHub Pages
published: true
date: 2022-12-28 05:19:14 UTC
tags:
canonical_url: https://adithyana.hashnode.dev/host-reactjs-app-on-github-pages
---
### What is this blog about
In this blog, I am going to tell you how we can host a react-js web app on GitHub Pages
### Prerequisite
- The ReactJS app should have a GitHub repository
- The GitHub repositories visibility should be public
- You should know the basics of git
### Steps By Step Instruction
1. Add a `remote` that points to the GitHub repository
2. Install the GH-Pages package inside the react app
3. Add `homepage` field to the `package.json` file
4. Add `predeploy` and `deploy` scripts to the package.json scripts section
In my case, it will be
1. Run the deploy command in terminal
2. Publishing the newly deployed branch - `gh-pages` | adithyana | |
1,347,757 | Optimize performance with React.lazy and Suspense | Why would you need code-splitting Typical React app has its files "bundled" into a single... | 0 | 2023-04-05T10:00:00 | https://dev.to/nikolasbarwicki/optimize-performance-with-reactlazy-and-suspense-5bel | react, performance, webdev | ## Why would you need code-splitting
Typical React app has its files "bundled" into a single file. Tool like [Webpack](https://webpack.js.org/) follows imported files and merges them into a "bundle". The bigger the bundled file, the longer it takes for your app to load. Frontend developers should be extremely aware of this fact - especially when including large third-party libraries.
When user starts to use your app he probably doesn't need all pages and components at once. Moreover, there is some code that the user may never need. Now, imagine that we can control which part of code are loaded so we can dramatically improve the performance of our apps.
To better understand which parts of the bundle is used by the user you can use the ["Coverage" tool](https://developer.chrome.com/docs/devtools/coverage/) from the Chrome Dev Tools.
## Real world use-case
The most common use-case for this in React is lazily loading route elements. Using this technique, pages that are not required on the home page can be split out into separate bundles, thereby decreasing load time on the initial page and improving performance.
Imagine that you have an app with multiple routes (pages) and they are loaded at once with one large bundle. The user experience isn't that great - user has to wait for all pages to be loaded even if he only wants to see the Dashboard or just one another route. With lazy loading we can at first load the Dashboard page and then load another pages on-demand. That dramatically decreases the time of loading the first screen of our application.
## Application setup
For our example application we will have Home screen on `/` path and About screen on `/about` path. I will be using `create-react-app` with `react-router-dom@6`. I've created two simple components/pages named `Home` and `About` exported as default exports.
> **Important!** React.lazy takes a function that must call a dynamic import(). This must return a Promise which resolves to a module with a default export containing a React component.
I also added `Layout` component with simple navigation:
```jsx
function Layout() {
return (
<div>
<nav>
<ul>
<li>
<Link to="/">Home</Link>
</li>
<li>
<Link to="/about">About</Link>
</li>
</ul>
</nav>
<hr />
<Outlet />
</div>
);
}
```
And `App` component looks has the following content:
```jsx
import Home from "./pages/Home";
import About from "./pages/About";
import Layout from "./components/Layout";
function App() {
return (
<Routes>
<Route path="/" element={<Layout />}>
<Route index element={<Home />} />
<Route
path="about"
element={<About />}
/>
</Route>
</Routes>
);
}
```
With that setup we have single, large bundle and all pages are loaded during the initial load. For this particular case it won't be a problem - `About` component has only two elements with plain text and it doesn't use any sizeable libraries. But we assume that our app is taking too long to load and we want to fix that as soon as possible.
According to our plan we want to have `Home` at the initial load and then load `About` on-demand.
## React.lazy
Let's start with changing the way how we import the `About` component:
```jsx
// import About from "./pages/About"; ❌
const About = React.lazy(() => import("./pages/About")); ✅
```
We've used React's build-in support for loading modules as React components. When we run the app we would see the error. This is caused by the fact that while the component is lazily loaded React can't display anything in its place.
## Adding Suspense
In React we can fix this issue using `<Suspense />` component. Using `<Suspense />` allows us to render a fallback value while the user waits for the module to be loaded. Just wrap `About` with suspense and provide the fallback value. In place of `Loading...` screen you can pass any valid React component such as loading spinner.
```jsx
<Route
path="about"
element={
<React.Suspense fallback={<>Loading...</>}>
<About />
</React.Suspense>
}
/>
```
With the following fix user should see `Loading...` in the place where the `About` component should be displayed while loading the module.
## Comparison
Now let's check how our changes affected the overall user experience. For demonstration purposed I've installed `lodash` imported it in the `About` component. I've set network throttling to *Slow 3G*.
At first let's take a look at loading time and bundle size for the non-optimized app (no `React.lazy` and `Suspense`):

As you can clearly see we have a single `bundle.js` file which includes all files for the app. User had to wait almost 12 seconds to use the app, at least he didn't had to wait to see the `About` page. However if he wanted to see just the home page he lost few seconds waiting for the whole bundle. There were over 470 kB transferred at once.
Now let's perform similar test but using `React.lazy`:

Here you can see the results after navigating to the `/about` path. Initially there were 375 kB to transfer which took 2 seconds less than in the previous case. Used had to wait less to interact with the app. Unused `lodash` package wasn't transferred at all.
After clicking the link to `/about` another scripts were loaded: `lodash` and chuncked file with `About` component. The size of transferred JS files is the same in both cases but the initial load time is shorter for the lazily loaded content.
## Summary
In larger, production applications those differences between using lazy loading and not can be much greater. Here we had only simple components with almost no content. However the difference is noticeable even in this situation.
You can optimize the imports even further to improve the user experience - for example you can conditionally lazy load components on mouse hover or on app's state change. | nikolasbarwicki |
1,347,984 | What is ls, pwd, chmod, chown in shell? | ls - list directory contents When we have to list the directory contents we use ls... | 0 | 2023-02-02T04:29:07 | https://dev.to/anirbandas9/what-is-ls-pwd-chmod-chown-in-shell-3eff | ## ls - list directory contents
When we have to list the directory contents we use ls command. Some common flags used with ls are:
ls [flags] [File]
- **-l**: Use a long listing format, showing details such as permissions, owner, group, size, and date modified
- **-a**: Show hidden files, which are files that start with a dot (.)
- **-h**: Show sizes in human-readable format, for example, 1K, 20K, 80M instead of numbers in bytes
- **-t**: It sort all the files by modification time, the new modification comes first.
- **-r**: Reverse the order of the sort, for example, sort files by modification time, oldest first
## pwd - prints the name of current or working directory
pwd
We use pwd command when we want to display the absolute path of the current working directory.
## rm - remove files or directories
rm is used to delete files or directories. Be careful when using rm, as there is no trash bin or undo for deleted files.
rm [flags](optional) [File]
Some of the useful flags are:
- **-f**: Force removal, do not prompt for confirmation
- **-r**: Remove directories and their contents recursively
## chmod - change file mode bits
When we have to change the permissions of any files and directories chmod command is used.
chmod [permission_elements] [filename/directoryname]
Some of the basic option we use with chmod for changing permissions are:
- **u**: User/owner permissions
- **g**: Group permissions
- **o**: Other (world) permissions
- **+**: Add permission
- **-**: Remove permission
- **-R**: Operate on files and directories recursively
we can also use decimal number ranging between 0-7 for each element of the permission.
The permission in decimal format are:
- 4 - read
- 2 - write
- 1 - execute
- 6 - read and write
- 5 - read and execute
- 3 - write and execute
- 0 - no permission
## chown - change owner of the file and group
chown is used to change the owner and/or group of a file.
if we want to change the user ownership of given file/directory (root access needed)
```
chown [username] [filename/directory]
```
change both user and group:
```
chown [username:groupname] [filename/directory]
```
- -R: Operate on files and directories recursively
| anirbandas9 | |
1,348,691 | FizzBuzz: the-problem 🧮 | Hello! Welcome. This is my first article, seriously first, and I'd like to talk a little about a... | 21,756 | 2023-02-09T00:22:57 | https://dev.to/mathleite/fizzbuzz-the-problem-3n6f | javascript, fizzbuz, beginners, tutorial | Hello! Welcome.
This is my first article, _seriously first_, and I'd like to talk a little about a _"problem"_ I learned when I was entering the programming field _(intern)_. It's very **simple**, **fun** and **makes you think a lot** about how you think, logically speaking, and if you can go beyond the basics. I hope you like this series of articles that I'll be creating, _happy reading!_
# What?
*Fizzbuzz* is a `word-game` for children that teacher uses to teach them about *math divisions*. The game consists in replace any number divisible by *three* with the word **Fizz**, and any number divisible by *five* with the word **Buzz** and any number divisible by both *(three and five)* with the word **FizzBuzz**.
The *game* above can be used as a coding interview question in some case. The question consist in write a logic to output the first 100 *(hundred)* `FizzBuzz` numbers. Your value in interviews is to analyze fundamental coding habits, like, *logic*, *design* and *language proficiency*.
# How it works in code
The code bellow shows how the *"FizzBuzz"* logic work.
```javascript
// javascript
const x = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15];
for (let [i, n] of x.entries()) {
if (n % 15 === 0) {
x[i] = 'FizzBuzz';
continue;
}
if (n % 3 === 0) {
x[i] = 'Fizz';
}
if (n % 5 === 0) {
x[i] = 'Buzz';
}
}
console.table(x);
// Output:
┌─────────┬────────────┐
│ (index) │ Values │
├─────────┼────────────┤
│ 0 │ 'FizzBuzz' │
│ 1 │ 1 │
│ 2 │ 2 │
│ 3 │ 'Fizz' │
│ 4 │ 4 │
│ 5 │ 'Buzz' │
│ 6 │ 'Fizz' │
│ 7 │ 7 │
│ 8 │ 8 │
│ 9 │ 'Fizz' │
│ 10 │ 'Buzz' │
│ 11 │ 11 │
│ 12 │ 'Fizz' │
│ 13 │ 13 │
│ 14 │ 14 │
│ 15 │ 'FizzBuzz' │
└─────────┴────────────┘
```
---
That's FizzBuzz, I hope you understood and I'll see you in the next article! Let's talk a little about TDD and how we can apply it to this simple _"application"_. I'll see you there! | mathleite |
1,348,893 | Neighbor's Water Heater Automation (part 1) | The Setting My neighbor has a Bosch tankless water heater he put in last year. This water... | 0 | 2023-02-01T02:34:27 | https://tyrel.dev/blog/2022/11/neighbors-water-heater-automation-part-1.html | automation, c, esp8266 | ---
title: Neighbor's Water Heater Automation (part 1)
published: true
date: 2022-11-04 04:00:00 UTC
tags: Automation,automation,c,esp8266
canonical_url: https://tyrel.dev/blog/2022/11/neighbors-water-heater-automation-part-1.html
---
## The Setting
My neighbor has a Bosch tankless water heater he put in last year. This water heater has one slight problem that when the power even blips a single second, it gets set back to its lowest temperature of 95°F. My neighbor (we'll call him Frank for this post because Frank Tank is funny) Frank wants to set his heater to 120°F in his house. The problem arises in that his water heater is under the house in his crawl space.
Without an easy way to set his temperature, he needs to crawl under his crawl space and turn a dial _EVERY. SINGLE. TIME._
He asked me if I knew of anything off the shelf that would help. I did not. So I said the only logical thing someone [like me](https://tyrel.website/wiki/HomeAssistant) would have done. "I can totally automate that!"
## The Lay Of The Land
He has a [Bosch Tronic 6000C](https://www.prowaterheatersupply.com/PDFS/Bosch_Tronic_6000C_Pro_WH27_WH17_Installation_Manual.pdf), with what appears to be a rotary encoder knob to set the temperature. I only spent a few minutes under his house while planning this and didn't think to any measuring of how many detents to rotate, or how long the dial took to rotate to 120°F, so my first pass of this project is done with estimations.

## Project Time - Round 1!
I have a few random servos laying around, and an NodeMCU ESP8266 module. I figure these would be the perfect solution! ... note: was half right...
I found some code online by [Kumar Aditya](https://github.com/kumaraditya303) that is for the [two items in my current parts list](https://github.com/kumaraditya303/ESP8266_SERVO_CONTROLLER) (ESP8266 and SG90)
The Original code runs a web server on port 80, and runs a web page with some jQuery (wow it's been a while) to change the angle of the servo. I realized this wasn't what I needed because my servos could only go 180° and I might need to go multiple rotations. I found a youtube video on how to make a [SG90 run infinite in either direction](https://www.youtube.com/watch?v=zZGkkzMBL28), so I did those modifications. I then modified the front end code a little bit.
The new code on the back end was actually exactly the same, even though the effect was slightly different. It would run on port 80, listen at <tt>/</tt> and <tt>/angle</tt>, but the angle here was more of direction and speed (a vector?). The way the servo was built, 160° was "Stop", higher than that was rotate clockwise, lower was rotate counter clockwise.
I put three buttons on my page that would be "Lower" (150), "STOP" (160), and "Higher" (170). I then did some standard debouncing and disabling of buttons using setTimeout and such.
For a final touch I added in a range slider for "Time". This held how many seconds after pressing Higher or Lower, that I would send the STOP command again.
This seemed to work relatively well, but I figure I should just use a stepper motor if I was attempting to emulate one this way. I dug around in my closet and was able to find some parts.

## Project Time - Round 2!
I was able to rummage up a [28BYJ-48](https://components101.com/motors/28byj-48-stepper-motor) stepper with control board, and a [HW-131 power module](https://www.cafago.com/en/p-e8575.html).
With these I needed a new library so I stripped the c++ code down to its basics, just getting me a server with the index page for the first pass.
On the Javascript side of things, I then decided I would add a temperature slider, from 90° to 120° (which writing this realize it should be from 95°... git commit...) with a confirmation button, and a small button to initialize down to 95°.
The initialize button would need to trigger an initialization where I rotate counter clockwise an appropriate amount of time (Length TBD) in order to force the rotary encoder dial to always start at a known state of 95. The green submit button sends the new desired temperature as a post.
Server side, I was using a library called [AccelStepper](https://www.airspayce.com/mikem/arduino/AccelStepper/). This I set some made up max speeds and steps per rotation, actual values TBD.
I added an endpoint called <tt>/setTemperature</tt> that takes in a temperature and sets a local temperature variable. From there, I calculate the temperature less 95, to find out how many degrees I need to increase by, for now I'm considering this rotations.
I then apply a multiplier (TBD also... there's a lot of these as you can see!) and call <tt>stepper.moveTo()</tt> and it actually feels like it's pretty accurate.
The endpoint <tt>/initialize</tt> runs <tt>stepper.moveTo</tt> with ten rotations CCW, and then resets the "known location" back to zero (this also runs on power on for now).


## In Action
The result of this second round of coding is a lot more that I expect to happen once I can finally get down beneath his house. Frank will lose power, his water heater will reset to 95°F, the NodeMCU will reboot, and reinitialize itself. Frank will then open his browser to the NodeMCU's server, set the desired temperature, and take warm showers.
Version 2 will come once I actually test EVERYTHING. My first quesiton is if a rubber band on a lego tire with a servo wheel adaptor ([which I 3d modeled and printed...](https://www.thingiverse.com/thing:5594405)) will work sufficiently. Programming wise, I need to figure out how many steps is one degree. Is the rotary encoder one degree per detent? Is it a constant speed? Is it like an alarm clock where you can sometimes jump by 10?
Stay tuned to find out the exciting conclusion once I can go down below Frank's house.

## Code
The code is currently at [https://gitea.tyrel.dev/tyrel/frank\_tank.git](https://gitea.tyrel.dev/tyrel/frank_tank.git) | tyrel |
1,348,900 | ChatGPT API: A blog written by ChatGPT | ChatGPT API by OpenAI is a cutting-edge technology that is transforming the world of natural language... | 0 | 2023-02-01T02:52:17 | https://dev.to/jonnynotbravo/chatgpt-api-a-blog-written-by-chatgpt-h90 | chatgpt, beginners | ChatGPT API by OpenAI is a cutting-edge technology that is transforming the world of natural language processing (NLP). With its advanced language generation and contextual understanding capabilities, ChatGPT API is helping businesses and individuals automate and improve their content creation processes. In this blog, we'll guide you through the steps of using the ChatGPT API to its fullest potential.
Step 1: Sign up for an API key
To use the ChatGPT API, you first need to sign up for an API key from OpenAI. This will give you access to the API and allow you to start making requests. The sign-up process is simple and straightforward, and OpenAI provides excellent documentation to help you get started.
Step 2: Familiarize yourself with the API
Once you have an API key, it's important to familiarize yourself with the API and understand how it works. OpenAI provides extensive documentation on the API, including sample requests and responses, so take advantage of this resource to learn as much as you can.
Step 3: Test the API
Now that you have a basic understanding of the API, it's time to start testing it. Use the API to generate text, translate language, or create custom language models tailored to your specific needs. Start with simple queries and gradually build up to more complex tasks as you become more familiar with the API.
Step 4: Integrate the API into your workflow
Once you have tested the API and are confident in its capabilities, it's time to integrate it into your workflow. This may involve incorporating it into an existing application or creating a new one from scratch. Whatever the case, make sure to take advantage of the API's advanced language generation and contextual understanding capabilities to maximize its impact.
Step 5: Monitor and evaluate performance
It's important to monitor and evaluate the performance of the ChatGPT API to ensure that it's delivering the results you want. Use metrics such as accuracy, response time, and user satisfaction to measure its effectiveness, and make adjustments as necessary.
In conclusion, ChatGPT API by OpenAI is a powerful tool for businesses and individuals looking to automate and improve their content creation processes. With its advanced language generation and contextual understanding capabilities, the API is a valuable tool for maximizing the impact of NLP. So why wait? Get started today and unleash the power of ChatGPT API!
Thank you!
[Jonny](linkedin.com/in/jonnytilahun) | jonnynotbravo |
1,349,147 | Stateful flow: organising distributed processing in golang | Here I would like to develop some thoughts regarding state management raised in the previous article.... | 0 | 2023-02-07T17:40:59 | https://dev.to/genevalake/stateful-flow-organising-distributed-processing-in-golang-3878 | go, functional, webdev | Here I would like to develop some thoughts regarding state management raised in the previous [article](https://medium.com/@vague.capitan/functional-programming-elements-and-state-machines-in-application-to-golang-web-services-d7b78c4e0489). In functional programming it's customary explicitly designate the state. However, that could lead to so-called state explosion. Sometimes it would be better to remain some general state implicit and to operate substate sets.
Consider real life case. User orders some product. What is implemented as a http request to our service. Processing this inquiry we need to make request to an accounting service to create record and to check if product is available and another request to a financials service to provide payment. Of course, we need store the order to a database. All of this external services return successive or not response. Which leads to updating requests to other services. For example, if financials service returned out of balance status, we should update the record in accounting service as rejected and free reserved product and update order status in the database.
Thus, there are three units: storage, bookkeeping and financials. Each module has two types of functionality: applying order to the corresponding service and updating status. They form the flow. Units consequently message each other. Each module has its own state depending on the response from external service. We might create a general status corresponding to each unit state. For example BookkeepingSuccess, BookkeepingProductNotAvailable, BookkeepingInternalError and analogical for others. But the whole web of units can be in two states: success or proceed and cancel. These states are translated to units' actions. Responses from services are transformed to flow status in their turn. If bookkeeping service returned that product was not available, then the status of flow becomes Cancel and messages are spread propagating this state to modules. We don't need to store the flow state explicitly, we can just use two types of signals between processing modules. So we got the stateful flow.
Some possible scenarios are showed in the diagram
Take a look at the [sample application](https://github.com/geneva-lake/stateful_flow). The information processing flow itself is represented as OrderFlow struct
```
type OrderStatus string
const (
OrderCreated OrderStatus = "created"
OrderSuccess OrderStatus = "success"
OrderInternalError OrderStatus = "internal_error"
OrderProductNotAvailable OrderStatus = "product_not_available"
OrderBalanceNotEnough OrderStatus = "balance_not_enough"
)
type OrderFlow struct {
Config *Config
OrderStatus OrderStatus
OrderID int
UserID uuid.UUID
ProductID int
ProductPrice decimal.Decimal
}
```
This struct stores order information and status which we return in the answer to user. Units intercommunicate by StatusStream struct
```
type FlowStatus int
const (
Proceed FlowStatus = 1
Cancel FlowStatus = 2
)
type StatusStream struct {
Forward chan FlowStatus
Back chan FlowStatus
}
```
Module generally takes two StatusStream struct. The first provides connection with previous module and the second one connects with the next module. By Forward channel unit sends status message to next unit and by Back channel receives message from next unit.
Consider bookkeeping unit
```
type BookkepingUnit model.OrderFlow
func (f *BookkepingUnit) Process(previous *model.StatusStream, next *model.StatusStream) {
status := <-previous.Forward
if status == model.Cancel {
next.Forward <- model.Cancel
return
}
...
resp, err := general.MakeHTTPRequest[ApplyRequest, ApplyResponse]("POST", f.Config.BookkepingApplyURL, &breq)
switch resp.Result.Status {
case Success:
next.Forward <- model.Proceed
case ProductNotAvailable:
f.OrderStatus = model.OrderProductNotAvailable
next.Forward <- model.Cancel
previous.Back <- model.Cancel
go logger.LogUnit(logger.Info, f.Config.Name, nil,
f.OrderID, unit, string(ProductNotAvailable))
return
}
...
status = <-next.Back
if status == model.Cancel {
previous.Back <- model.Cancel
updateStatus = OrderCanceled
}
updresp, err := general.MakeHTTPRequest[interface{}, UpdateResponse]("PUT", url, nil)
if updresp.Status == general.StatusError {
go logger.LogUnit(logger.Info, f.Config.Name, nil,
f.OrderID, unit, string(model.OrderInternalError))
if status == model.Proceed {
next.Forward <- model.Cancel
previous.Back <- model.Cancel
}
}
```
Modules inherited from OrderFlow, for logical separation the type redefinition is used. At first, unit waits for signal from previous stage. Then it makes a request to external service. In case successive response the Proceed signal is sent to the next unit. If response was considered as unsuccessful, for example, no products were left, the Cancel signal propagates to previous and next modules. Depending on the status returned from sequent stage, the update request is made with OrderPaid or OrderCanceled status. If we got an error when updating record status, we also cancel the order and send Cancel signal to modules.
Launching the flow is made in the flow.Process function
```
func Process(flow *model.OrderFlow) {
repo := storage.NewRepository(general.NewPgsql(flow.Config.DBConnectionString))
bu := (*bookkeeping.BookkepingUnit)(flow)
fu := (*financials.FinancialsUnit)(flow)
su := (*storage.StorageUnit)(flow)
start := model.NewStatusStream()
storage2bookkeeping := model.NewStatusStream()
bookkeeping2financials := model.NewStatusStream()
go su.Process(repo, start, storage2bookkeeping)
go bu.Process(storage2bookkeeping, bookkeeping2financials)
go fu.Process(bookkeeping2financials)
start.Forward <- model.Proceed
<-start.Back
}
```
Here we create units and channels, start the processing and wait for the processing finish. Also note the nice declarative style of this operations.
In the endpoint layer the pre- and post-processing are performed.
```
func MakeOrderEndpoint(cfg *model.Config) general.Endpoint {
return func(w http.ResponseWriter, r *http.Request) {
w.Header().Add("Content-Type", "application/json")
req, err := general.RequestDecode[model.OrderRequest](r)
...
f := &model.OrderFlow{
Config: cfg,
UserID: req.UserID,
ProductID: req.ProductID,
ProductPrice: req.ProductPrice,
}
flow.Process(f)
res := model.OrderResult{
OrderStatus: f.OrderStatus,
OrderID: f.OrderID,
}
resp := model.OrderResponse{
Status: general.StatusOK,
Result: &res,
}
...
json.NewEncoder(w).Encode(resp)
```
In this layer we decode the user order request, form OrderfFlow object, launch the flow, and make dto and return the answer to the user.
We need to message user the order's state. So in each unit some status algebra is made. Service responces are translated to order status. In finacials unit for example
```
switch resp.Result.Status {
case Success:
transactionID = *resp.Result.TransactionID
previous.Back <- model.Proceed
case BalanceNotEnough:
f.OrderStatus = model.OrderBalanceNotEnough
go logger.LogUnit(logger.Info, f.Config.Name, nil,
f.OrderID, unit, string(model.OrderBalanceNotEnough))
previous.Back <- model.Cancel
}
```
In modules we log errors so we can reconstruct events if something went wrong.
Golang has powerful tools for distributed information processing. I proposed here the stateful flow conception. It can branch out and become stateful web. Presented toolkit could help with this situation as well. | genevalake |
1,349,152 | Verifying your Mastodon Account | Yes, there is account verification on Mastodon and no, it means more than a blue check mark. Actually, it isn't even blue. | 0 | 2023-02-01T07:38:00 | https://dev.to/murtezayesil/verifying-your-mastodon-account-2kdf | fediverse, mastodon, verification, note | ---
title: Verifying your Mastodon Account
published: true
description: Yes, there is account verification on Mastodon and no, it means more than a blue check mark. Actually, it isn't even blue.
tags: fediverse, mastodon, verification, note
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
published_at: 2023-02-01 07:38 +0000
---
Account verification is a very simple process that you can do yourself. Also it is a very important for proving that you own that Mastodon account. It baffles me that even tech literate people don't do it.
## How verification works?

If 2 entities are claiming that they own each other and if their claims match, we understand that both of these are owned by the same person.
**Example**: If car with plate number "ABC 123" has a sign reading "I also own a house (10 Downing Street, London)" behind its back windshield and if the house at 10 Downing Street, London has a sign reading "I also own a car (ABC 123)" behind the window next to door, you know that the person who has key for the car and the person who has key for the house is the same person.
Verification on Mastodon works the same way. Your Mastodon account should claim that you also own a website and your website should claim that you also own a Mastodon account. To make such claims in the internet, we add `rel="me"` attribute to an HTML tag with `href="URL"` attribute, turning that tag into a claim.
## 2 ways to add claim to your website
**Visible button**: If you want claim to be a button that leads people to your Mastodon profile, use an "a" anchor inside `<body>` section
```HTML
<a rel="me" href="https://fosstodon.org/@murtezayesil">Mastodon</a>
```
**Invisible claim**: If you want to make the claim but don't want to add a button, you can use link tag inside `<head>` section
```HTML
<link rel="me" href="https://fosstodon.org/@murtezayesil">
```
If you also added your website's URL to your Mastodon account's profile metadata, server will attempt to read your website HTML and check if the claim is true.
 
**Note**: If you are using a CMS such as WordPress or DEV.to, you may need to find a way to insert custom HTML to head or body of your profile page. It may be even impossible depending on your hosting platform. Static Site Generators such as Jekyll, Hugo, Pelican and Publii are easier to work with since they allow adding custom HTML and even altering the theme.
---
Originally posted on [Murteza Yesil's blog](https://murtezayesil.me/verifying-your-mastodon-account/). | murtezayesil |
1,349,171 | Open Source Development Course for Perl developers - 2023.01 | Just started this exciting online Introduction to GitHub course. | 0 | 2023-02-01T08:52:08 | https://dev.to/slmwindsor/open-source-development-course-for-perl-developers-202301-334i | Just started this exciting online Introduction to GitHub course. | slmwindsor | |
1,349,301 | 💡 Hosted Syncthing (discovery, relay and backups) | Here's an Startup/SaaS idea to try out: 💾 Hosted Syncthing discovery, relay and... | 0 | 2023-02-01T10:34:13 | https://unvalidatedideas.com/editions/40 | saas, idea, opensource, selfhosted | Here's an Startup/SaaS idea to try out:
## 💾 Hosted Syncthing discovery, relay and backups
For technical users, [Syncthing](https://syncthing.net/) is the next coming of [Dropbox](https://dropbox.com/). Syncthing has a booming community, active user base, runs on a bunch of devices, and people trust it with their data.
There used to be one big problem with Syncthing -- transfering files from one device to another, you needed both devices to be online. That changed, when the [untrusted (encrypted) devices feature](https://docs.syncthing.net/users/untrusted.html?highlight=untrusted) was merged.
**💼 🧠 Build a service for untrusted (encrypted) syncthing devices, enabling users to copy files asynchronously.**
Users create their Syncthing setups as normal, then add an untrusted device (a URL you give them), and they can start to treat their Syncthing instances as cloud drives.
It's a hard sell -- many people use Syncthing precisely so they can get away from hosted services, but here's the thing -- they don't have to trust you (and you don't have to convince them to). Thanks to the encryption Syncthing uses, users can treat you as just a dumb redundant temporary host for their data.
Think the user base for this kind of service is impossibly small? [Syncthing has close to 50,000 stars on Github](https://github.com/syncthing/syncthing). [Ansible](https://github.com/ansible/ansible), the industry standard automation toolkit, has ~56k stars.
More importantly than popularity, there's a [r/Syncthing subreddit](https://www.reddit.com/r/Syncthing/), which means you have distribution -- even if it doesn't work out, validating this idea should be fast.
This was [originally posted @ Unvalidated Ideas (Edition 40)](https://unvalidatedideas.com/editions/40) | unvalidatedidea |
1,354,558 | AWS open source newsletter, #144 | Feb 6th, 2023 - Instalment #144 Welcome to edition #144 of the AWS open source newsletter,... | 0 | 2023-02-06T05:12:53 | https://blog.beachgeek.co.uk/newsletter/aws-open-source-news-and-updates-144/ | opensource, aws | ## Feb 6th, 2023 - Instalment #144
Welcome to edition #144 of the AWS open source newsletter, and another week of great new open source projects for you to try out. Some of the treats in store for you this week include "dynamodb-shell", a project that provides a cli to your favourite AWS database, "precloud" a tool to help you catch issues with your configuration before you deploy, "node-latency-for-k8s" a tool to analyse your node logs, "stepfunctions-lambda-ec2-ssm" a very nice way of using step functions to overcome the 15 minute timeout of your lambda functions, "terraform-ec2-image-builder-container-hardening-pipeline" a very cool example of how to build an EC2 image hardening pipeline using Terraform, and "cloudtrail-event-fuzzy-viewer" a tool to copy your AWS CloudTrail events and then fuzzy search them on the command line. We also have some great sample code to help you build on AWS, including "aws-deployment-pipeline-reference-architecture", "aws-eks-quarkus-example", "gitops-eks-r53-arc", and more.
Also covered this week are some great open source technologies, including Apache Flink, Terraform, Apache Spark, Delta Lake, Apache Iceberg, Bottlerocket, Ubuntu, Argo Workflows, Argo Events, Apache YuniKorn, Fluent Bit, Quarkus, OpenSearch, Next.js, Grafana, Telegraf, Dask, syft, sbomqs, Cosign, Sigstore, and more. Enjoy!
I am off to Iceland this week, looking forward to exploring this amazing country. This does mean that there will not be a newsletter next week. But don't worry, I will be back the week after.
**Build on Open Source - Series Two**
I am excited to announce that the second series of Build on Open Source is currently being scheduled from 17th February, running every two weeks. It will be at the usual time (9am UK, 10am CET, 2:30pm IST, 5pm SST, and 8pm AEDT) on twitch.tv/aws. I hope to see some of you readers on the show, and we are currently looking for guests who want to come on and share their open source projects with the audience. We still have a few slots free, so please get in touch - its first come first serve.
### Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Sebastien Stormacq, Sascha Moellering, Brandon Bush, Ben Cressey, Jayaprakash Alawala, Kyle Davis, Akira Ajisaka, Noritaka Sekiyama, Savio Dsouza, Sekar Srinivasan, Prabu Ravichandran, Victor Gu, Vara Bonthu, Jianwei Li, Samrat Deb, Prabhu Josephraj, Praveen Allam, Vivek Singh, Shimon Tolts, and Brian Hammons.
### Latest open source projects
*The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.*
#### Tools
**precloud**
[precloud](https://aws-oss.beachgeek.co.uk/2ht) is an open source command line interface that runs checks on infrastructure as code to catch potential deployment issues before deploying. Infrastructure code deployments often fail due to mismatched constraints over resource fields between the infrastructure code, the deployment engine, and the target cloud. For example, you may be able to pass any arbitrary string as a resource name to terraform or AWS CDK, and plan or synth go through fine, but the deployment may fail because that string failed a naming constraint on the target cloud.
**dynamodb-shell**
[dynamodb-shell](https://aws-oss.beachgeek.co.uk/2hs) is a simple CLI for DynamoDB modeled on isql, and the MySQL CLIs. ddbsh presents the user with a simple command line interface. Here the user can enter SQL-like commands to DynamoDB. The output is presented in the same window. ddbsh supports many Data Definition Language (DDL) and Data Manipulation Language (DML) commands.
**aws-deployment-pipeline-reference-architecture**
[aws-deployment-pipeline-reference-architecture](https://aws-oss.beachgeek.co.uk/2hq) this repo contains support code for the Deployment Pipeline Reference Architecture (DPRA), that describes best practices for building deployment pipelines. A deployment pipeline automates the building, testing and deploying of software into AWS environments. With DPRA, developers can increase the speed, stability, and security of software systems through the use of deployment pipelines. You can find out more about this in my colleague Sebastien Stormacq's post, [New – Deployment Pipelines Reference Architecture and Reference Implementations](https://aws-oss.beachgeek.co.uk/2hr).
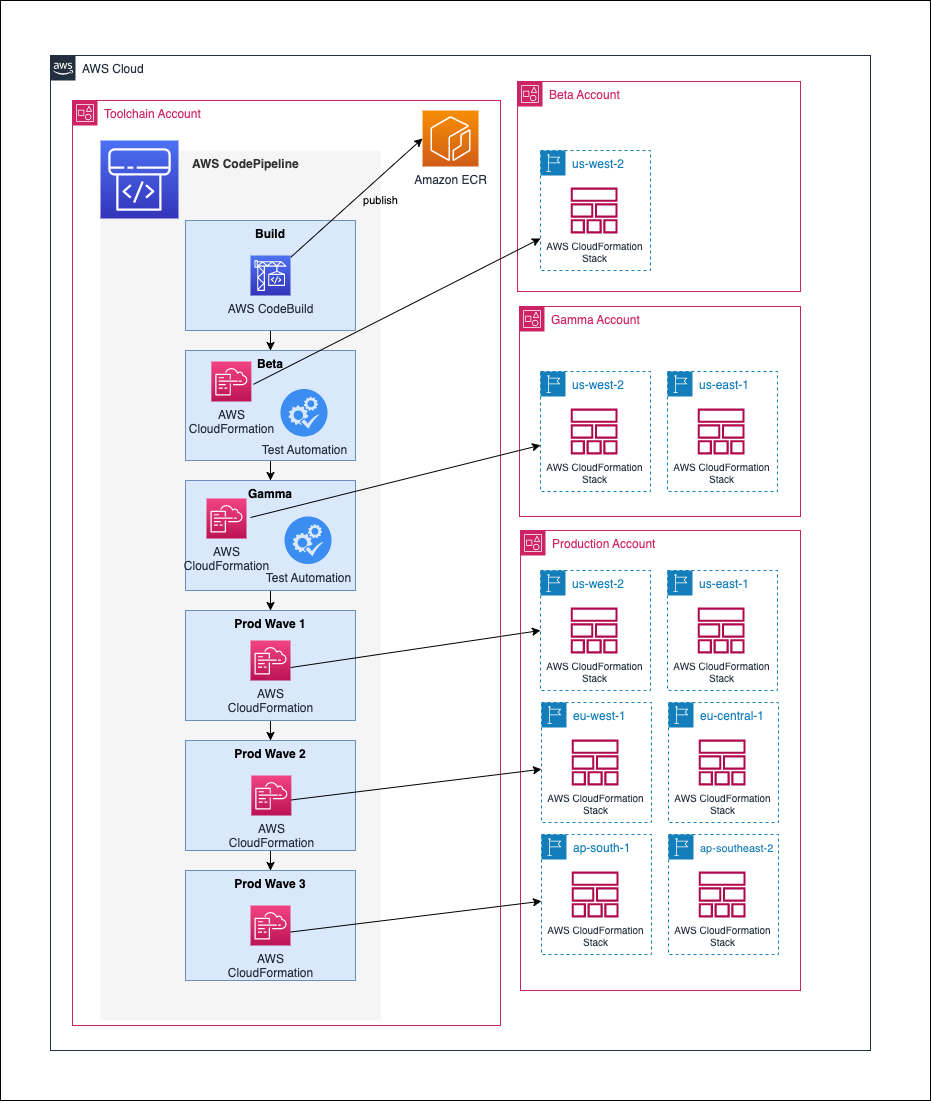
**stepfunctions-lambda-ec2-ssm**
[stepfunctions-lambda-ec2-ssm](https://aws-oss.beachgeek.co.uk/2hu) This repo holds the stepfunction workflow for creating EC2 instance and execute remote powershell script for configuration of EC2 using Systems Manager (Run Command). There are scenarios where EC2 instances has to be created and need to be configured using Systems Manager powershell script. The script may take a long time depending upon the configuration and it may exceed lambda time limit of 15 mins.This solution provides a serverless approach using stepfunctions and lambda to create EC2 instance, execute the configurations from powershell script, wait for the script to complete by periodically checking the runCommand status. The workflow also deletes the created EC2 instance irrespective of runCommand execution result.
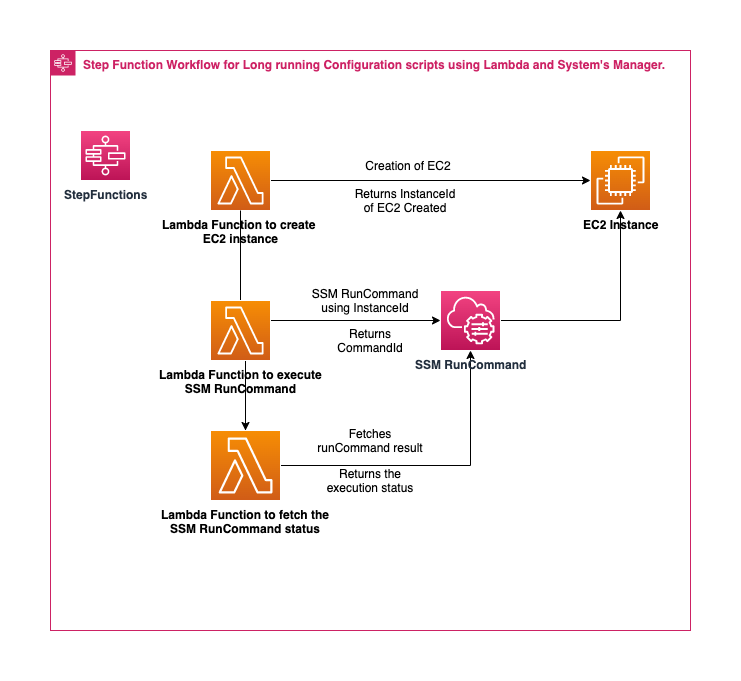
**terraform-ec2-image-builder-container-hardening-pipeline**
[terraform-ec2-image-builder-container-hardening-pipeline](https://aws-oss.beachgeek.co.uk/2hw) This solution builds an EC2 Image Builder Pipeline with an Amazon Linux 2 Baseline Container Recipe, which is used to deploy a Docker based Amazon Linux 2 Container Image that has been hardened according to RHEL 7 STIG Version 3 Release 7 - Medium. See the "STIG-Build-Linux-Medium version 2022.2.1" section in Linux STIG Components for details. This is commonly referred to as a "Golden" container image. The solution includes two Cloudwatch Event Rules. One which triggers the start of the Container Image pipeline based on an Inspector Finding of "High" or "Critical" so that insecure images are replaced, if Inspector and Amazon Elastic Container Registry "Enhanced Scanning" are both enabled. The other Event Rule sends notifications to an SQS Queue after a successful Container Image push to the ECR Repository, to better enable consumption of new container images.
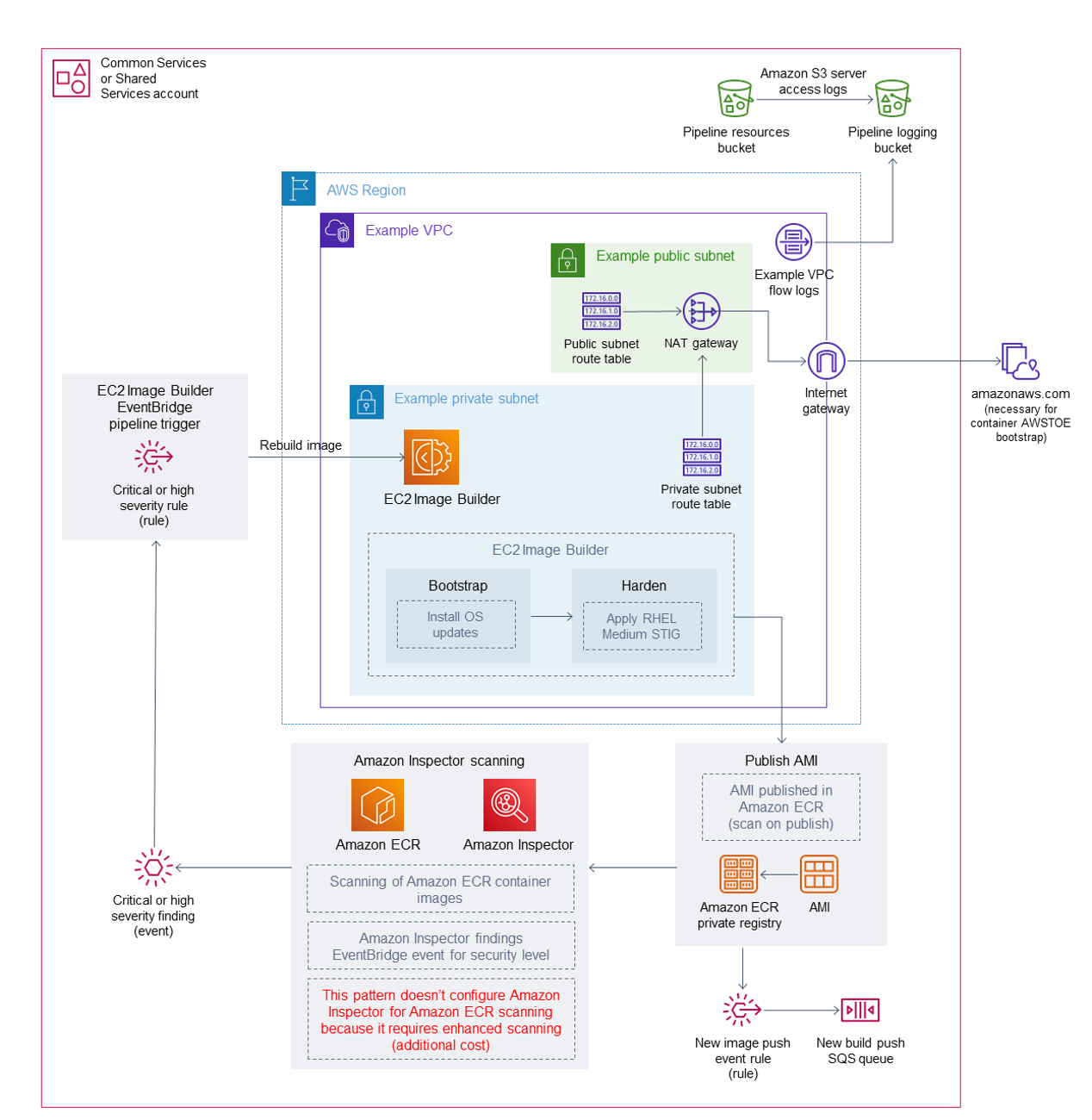
**node-latency-for-k8s**
[node-latency-for-k8s](https://aws-oss.beachgeek.co.uk/2hx) The node-latency-for-k8s tool analyses logs on a K8s node and outputs a timing chart, cloudwatch metrics, prometheus metrics, and/or json timing data. This tool is intended to analyse the components that contribute to the node launch latency so that they can be optimised to bring nodes online faster. NLK runs as a stand-alone binary that can be executed on a node or on offloaded node logs. It can also be run as a K8s DaemonSet to perform large-scale node latency measurements in a standardised and extensible way.
**cloudtrail-event-fuzzy-viewer**
[cloudtrail-event-fuzzy-viewer](https://aws-oss.beachgeek.co.uk/2i5) is a cli tool from Paolo Lazzardi that allows you to search for AWS CloudTrail events using fuzzy search. The binary installation works on Mac and Linux (that is what I tried) and the README provides guidance on how to get up and running quickly (don't forget to install the dependencies).
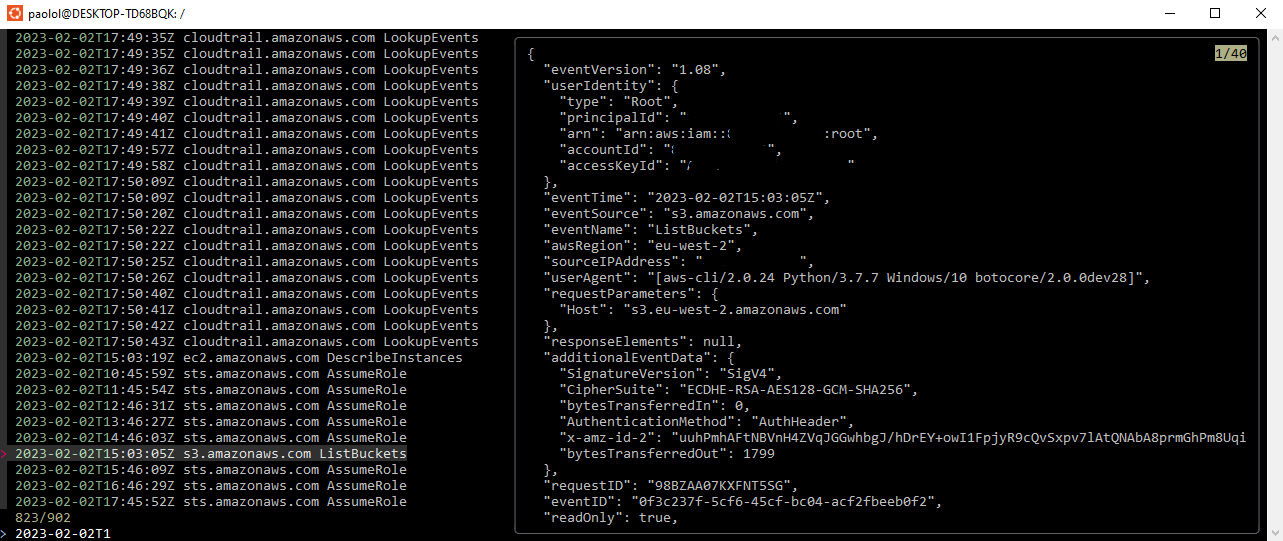
I was able to run this on my Linux machine, but I did get date formatting errors on my Mac. I also encountered ThrottlingException errors, so use carefully.
### Demos, Samples, Solutions and Workshops
**mlops-sagemaker-github-actions**
[mlops-sagemaker-github-actions](https://aws-oss.beachgeek.co.uk/2hv) This repository provides an example of MLOps implementation using Amazon SageMaker and GitHub Actions. The code automates a model-build pipeline that includes steps for data preparation, model training, model evaluation, and registration of that model in the SageMaker Model Registry. The resulting trained ML model is deployed from the model registry to staging and production environments upon the approval.
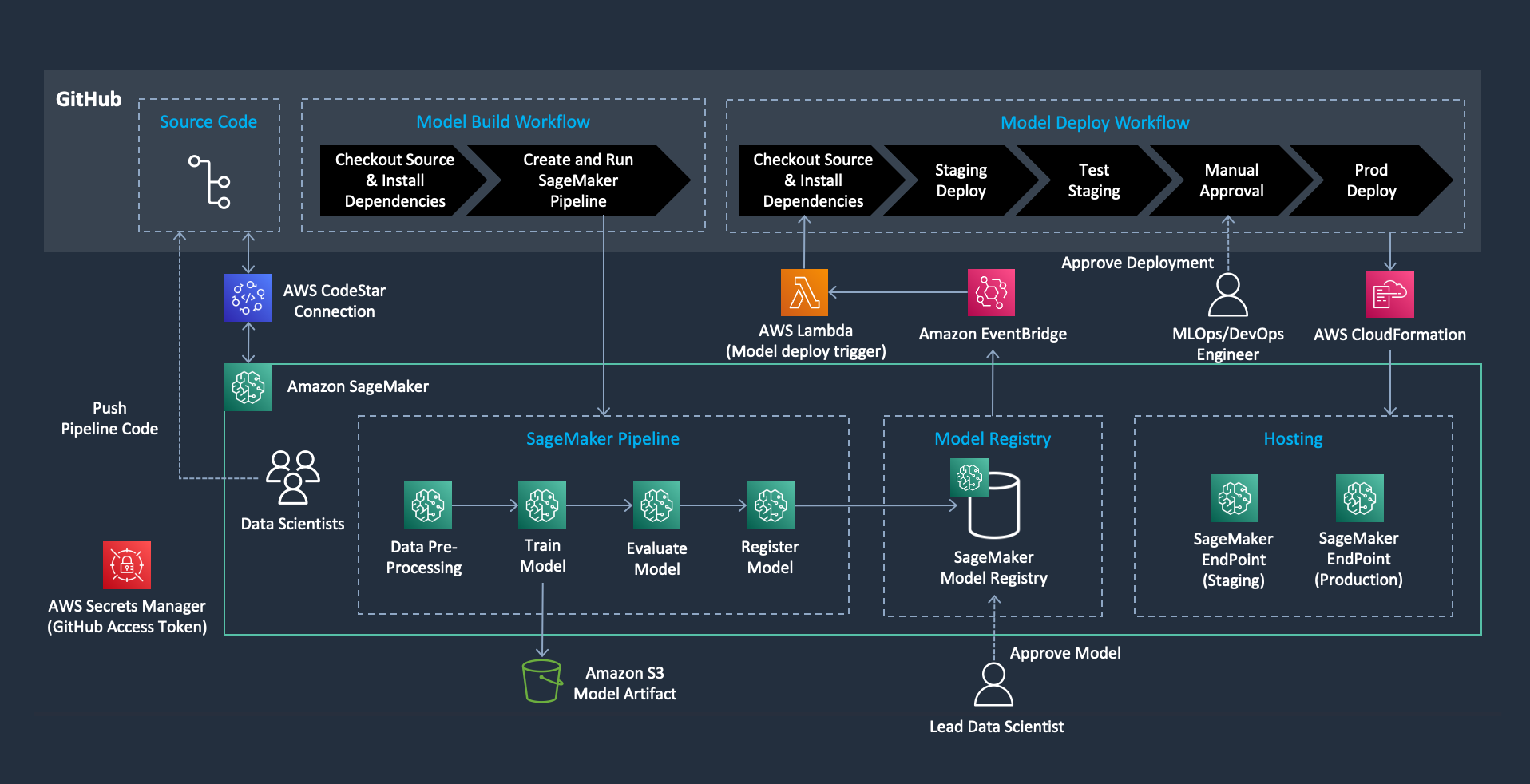
**aws-eks-quarkus-example**
[aws-eks-quarkus-example](https://aws-oss.beachgeek.co.uk/2he) this repo shows you how you can deploy Quarkus on Amazon EKS. Quarkus was designed to enable Java developers to write Java-based cloud-native micro services. Sascha Moellering has put together a blog post to support this repo and help get you going, so make sure you check out How to deploy your [Quarkus application to Amazon EKS ](https://aws-oss.beachgeek.co.uk/2hf) when you dive into the code.
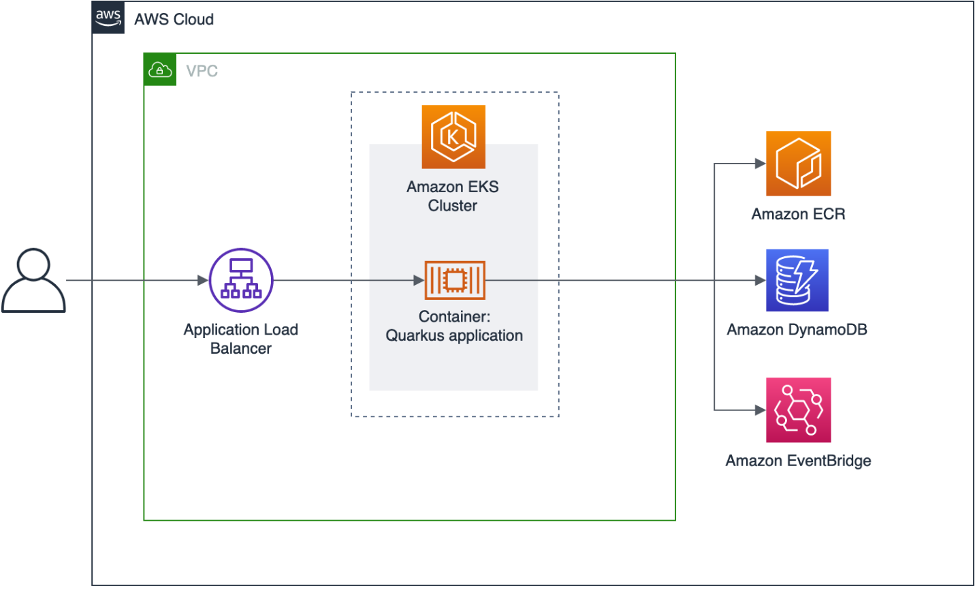
**gitops-eks-r53-arc**
[gitops-eks-r53-arc](https://aws-oss.beachgeek.co.uk/2hn) this repo has code that will let you deploy an application that survives widespread operational events within an AWS Region by leveraging Amazon Route 53 Application Recovery Controller in conjunction with Amazon Elastic Kubernetes Service (Amazon EKS). It uses an open-source CNCF project called Flux to keep the application deployments synchronised across multiple geographic locations. You can follow along in the blog post that accompanies this code repo, [GitOps-driven, multi-Region deployment and failover using EKS and Route 53 Application Recovery Controller](https://aws-oss.beachgeek.co.uk/2ho).
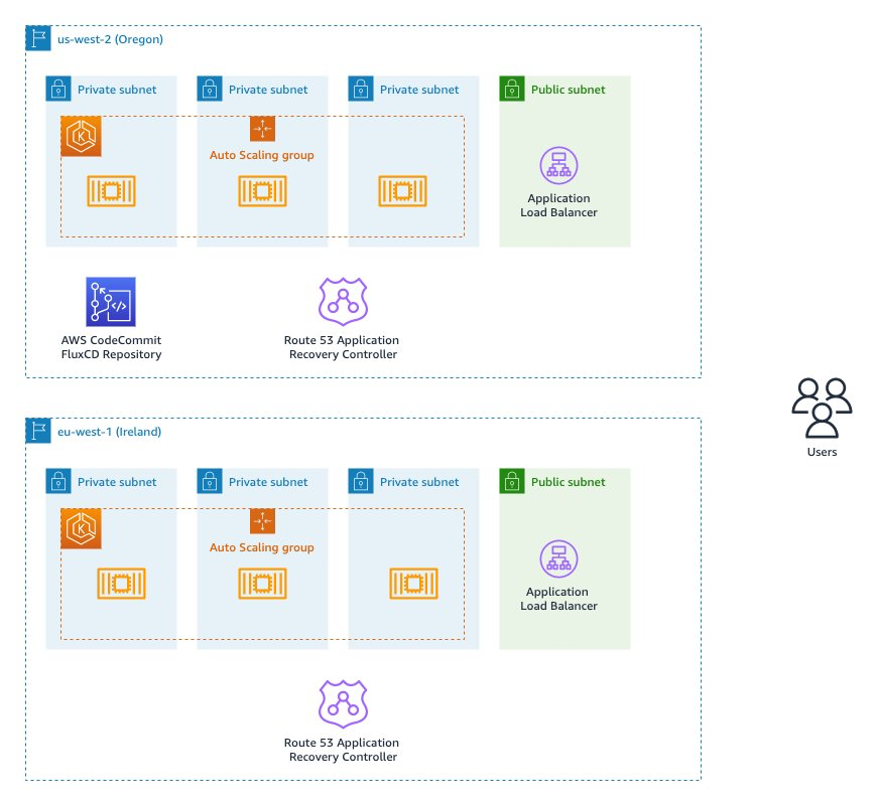
### AWS and Community blog posts
**Bottlerocket**
In the post, [Validating Amazon EKS optimized Bottlerocket AMI against the CIS Benchmark](https://aws-oss.beachgeek.co.uk/2hp), Brandon Bush, Ben Cressey, Jayaprakash Alawala, and Kyle Davis have come together to provides detailed, step-by-step instructions on how customers can bootstrap an Amazon EKS optimised Bottlerocket Amazon Machine Image (AMI) for the requirements of the CIS Bottlerocket Benchmarks. [hands on]
**Apache Spark**
We have some great posts this week for Apache Spark developers.
Kicking off with [Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started](https://aws-oss.beachgeek.co.uk/2h8) Akira Ajisaka, Noritaka Sekiyama, and Savio Dsouza demonstrates how AWS Glue for Apache Spark works with Hudi, Delta, and Iceberg dataset tables, and describes typical use cases to help you decide which is the right approach for you.
Next we have Sekar Srinivasan and Prabu Ravichandran who have collaborated on this post, [Run Apache Spark workloads 3.5 times faster with Amazon EMR 6.9](https://aws-oss.beachgeek.co.uk/2h9) where they analyse the results from benchmark tests running a TPC-DS application on open-source Apache Spark and then on Amazon EMR 6.9. No spoilers, you are going to have to read the post to get all the details.

The final post this week on Apache Spark is this one, [Dynamic Spark Scaling on Amazon EKS with Argo Workflows and Events](https://aws-oss.beachgeek.co.uk/2hb) where Victor Gu and Vara Bonthu demonstrate how to build and deploy a data processing platform on Amazon EKS with Data on EKS Blueprints. The platform includes all the necessary Kubernetes add-ons like Argo Workflows, Argo Events, Spark Operator for managing Spark jobs, Apache YuniKorn for Batch Scheduler, Fluent Bit for logging, and Prometheus for metrics. They also show how to build data processing jobs and pipelines using Argo Workflows and Argo Events, and show how to trigger workflows on-demand by listening to Amazon Simple Queue Service (Amazon SQS). Very nice post! [hands on]
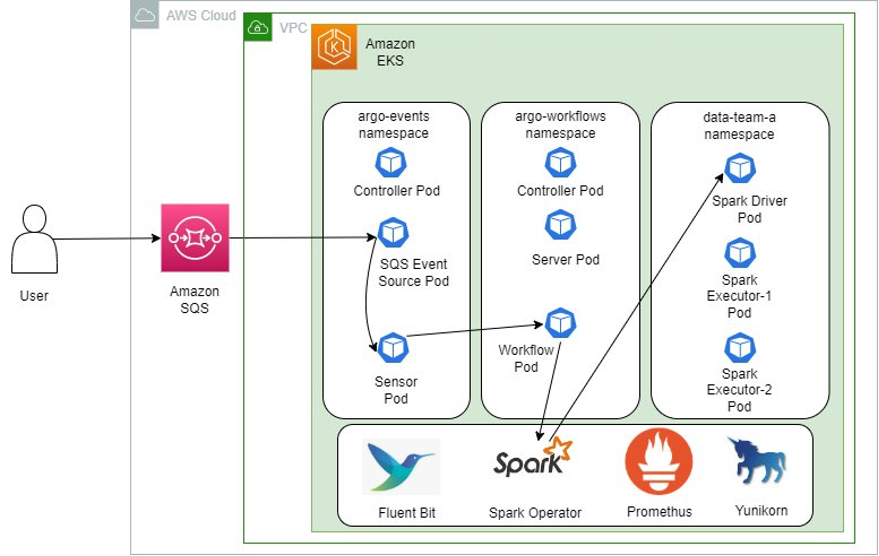
One final note, if you have not checked out the [Data on EKS blueprints](https://aws-oss.beachgeek.co.uk/24i), make sure you head over to the GitHub repo as there is lots of great sample code to show you how you can build and scale data platforms using Amazon EKS.
**Apache Flink**
In the post, [Build a data lake with Apache Flink on Amazon EMR](https://aws-oss.beachgeek.co.uk/2ha), Jianwei Li, Samrat Deb, and Prabhu Josephraj show you how to integrate Apache Flink in Amazon EMR with the AWS Glue Data Catalog so that you can ingest streaming data in real time and access the data in near-real time for business analysis. [hands on]
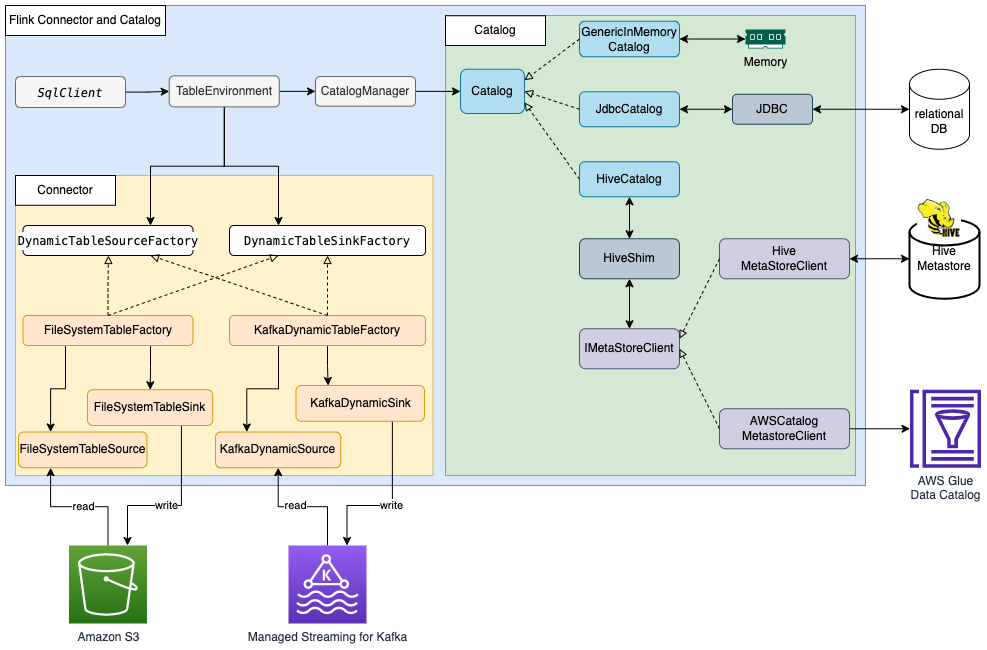
**Delta Lake**
Delta Lake is an open-source project that helps implement modern data lake architectures commonly built on Amazon S3 or other cloud storage. This includes supporting ACID transaction (atomic, consistent, isolated, durable) and log change data capture (CDC) from operational data sources - including how you can do UPSERTS (updates and inserts). Praveen Allam and Vivek Singh have written [Handle UPSERT data operations using open-source Delta Lake and AWS Glue](https://aws-oss.beachgeek.co.uk/2hd) and show you how to build data lakes for UPSERT operations using AWS Glue and native Delta Lake tables, and how to query AWS Glue tables from Athena. [hands on]
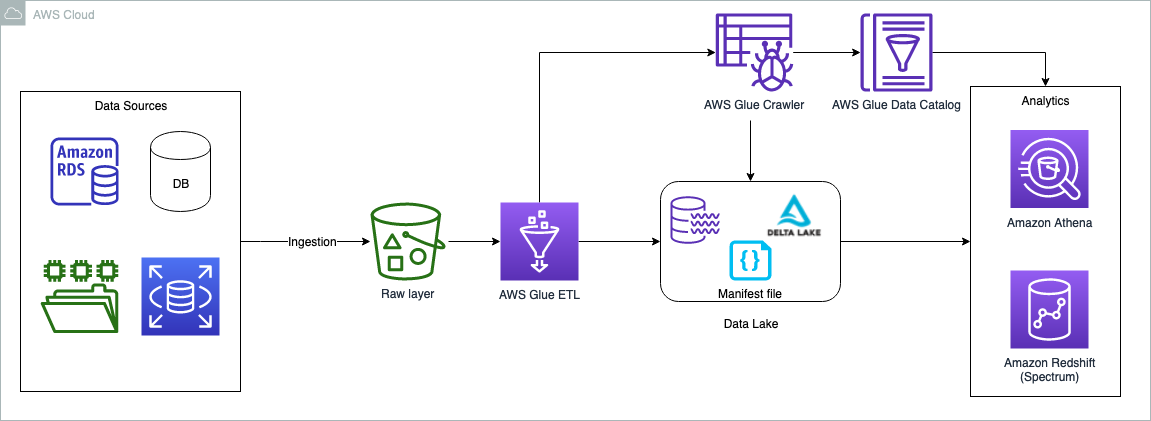
**Supply Chain Security**
I have been putting together some content that will form a larger body of work around what developers need to know about building is good practices when using open source software in the applications they build. I would love to hear from developers what your current pain points are and what content you think is currently missing. In the meantime, I have put together a few posts. Starting off with [Getting hands on with Sigstore Cosign on AWS](https://aws-oss.beachgeek.co.uk/2hy) that looks at how you can use Cosign to sign and verify artefacts in your development workflows. The next post was a look at using an open source tool called syft to generate software bill of materials in the post, [Building a software bill of materials (SBOM) using open source tools](https://aws-oss.beachgeek.co.uk/2hz). Finally I took a look at a new open source tool that helps you quality check your SBOMS in the post, [sbomqs, an open source tool to quality check your SBOMS](https://aws-oss.beachgeek.co.uk/2i0).
**Other posts and quick reads**
* [Best Practices from SoftServe for Using Kubernetes on AWS in Enterprise IT](https://aws-oss.beachgeek.co.uk/2hl) shares best practices on how to run Kubernetes in an enterprise IT environment
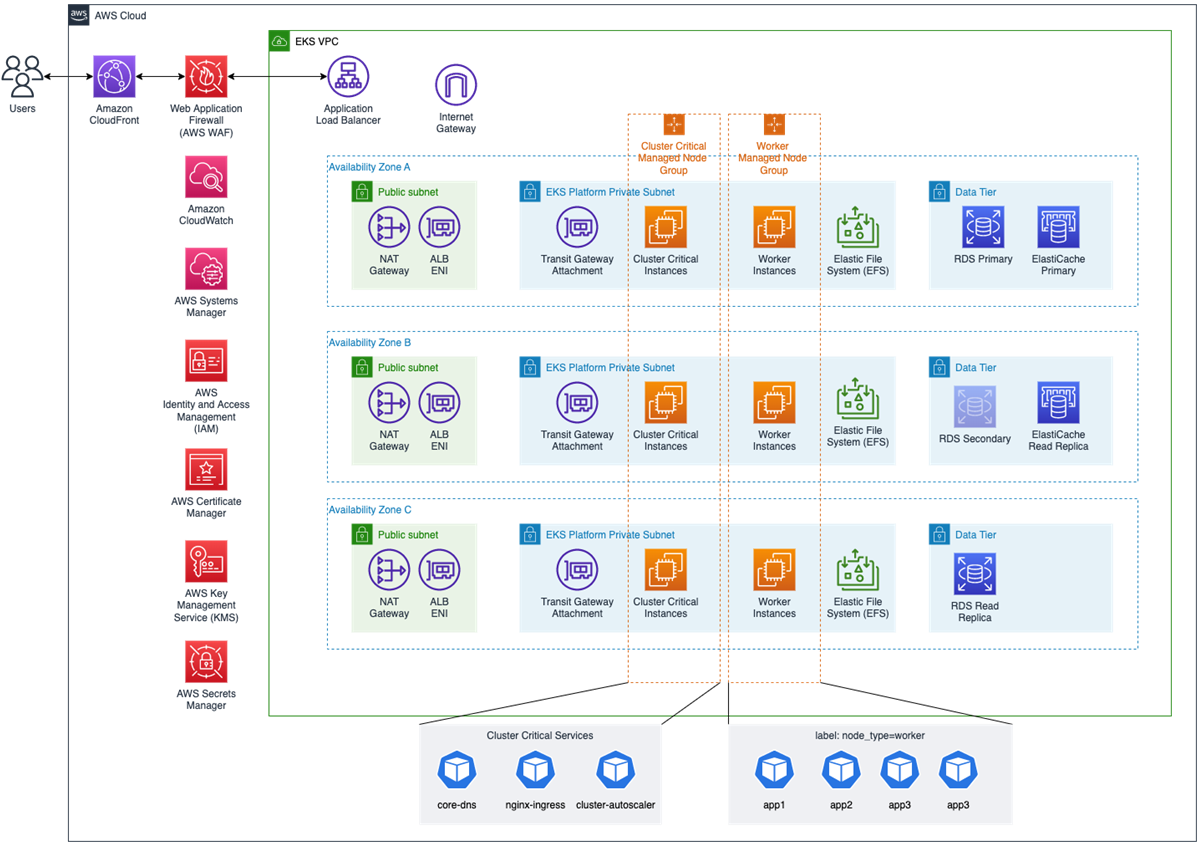
* [Scale from 100 to 10,000 pods on Amazon EKS](https://aws-oss.beachgeek.co.uk/2hc) who doesn't like a good case study on scaling, this one shows how ORION scaled Amazon EKS clusters from 100 to more than 10,000 pods [hands on]
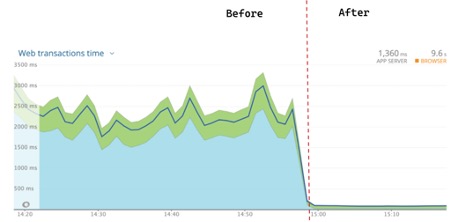
* [How to rapidly scale your application with ALB on EKS (without losing traffic)](https://aws-oss.beachgeek.co.uk/2hg) demonstrates how to use a separate application endpoint as an Amazon Load Balancer health check along with Kubernetes readiness probe and PreStop hooks that together enable graceful application termination [hands on]

* [Build a Product Roadmap with Next.js and Amplify](https://aws-oss.beachgeek.co.uk/2hh) walks you through how you can build an admin interface for product managers to add features to a roadmap [hands on]
* [One-time Password Authentication with the Amplify Libraries for Swift](https://aws-oss.beachgeek.co.uk/2hm) shows you how to create an OTP auth flow for an iOS app using Amazon Simple Email Service (SES) to send an email containing a 6-digit code and authenticate the user using the Auth and Function categories with the AWS Amplify Libraries for Swift.
* [Improve observability by using Amazon RDS Custom for SQL Server with Telegraf and Amazon Grafana](https://aws-oss.beachgeek.co.uk/2hi) explain how to implement this solution and improve observability for Amazon RDS Custom for SQL Server with open source tools such as with Telegraf and Amazon Grafana [hands on]
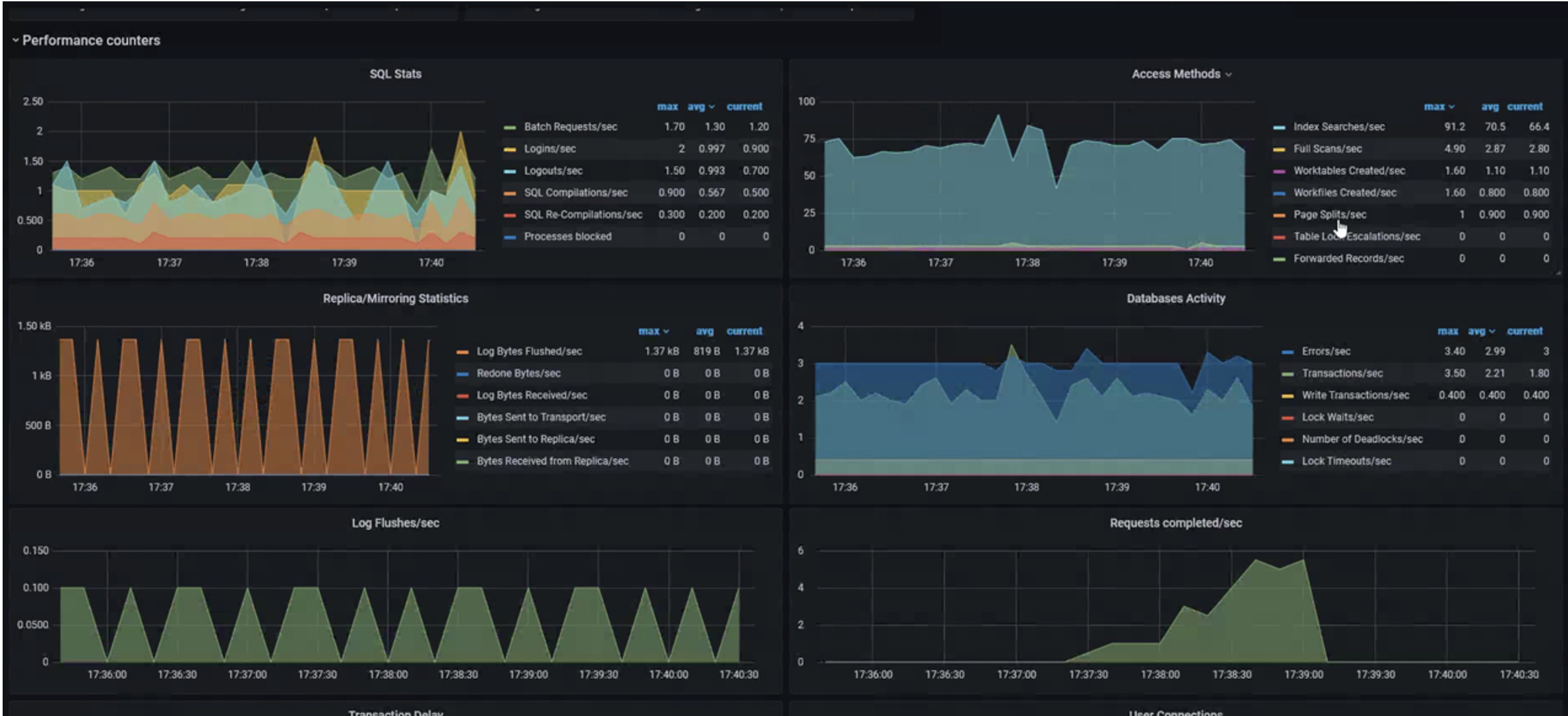
* [Monitoring Amazon RDS and Amazon Aurora using Amazon Managed Grafana](https://aws-oss.beachgeek.co.uk/2hj) looks at how you can monitor your Amazon RDS and Amazon Aurora database clusters including Performance insight metrics using Amazon Managed Grafana [hands on]
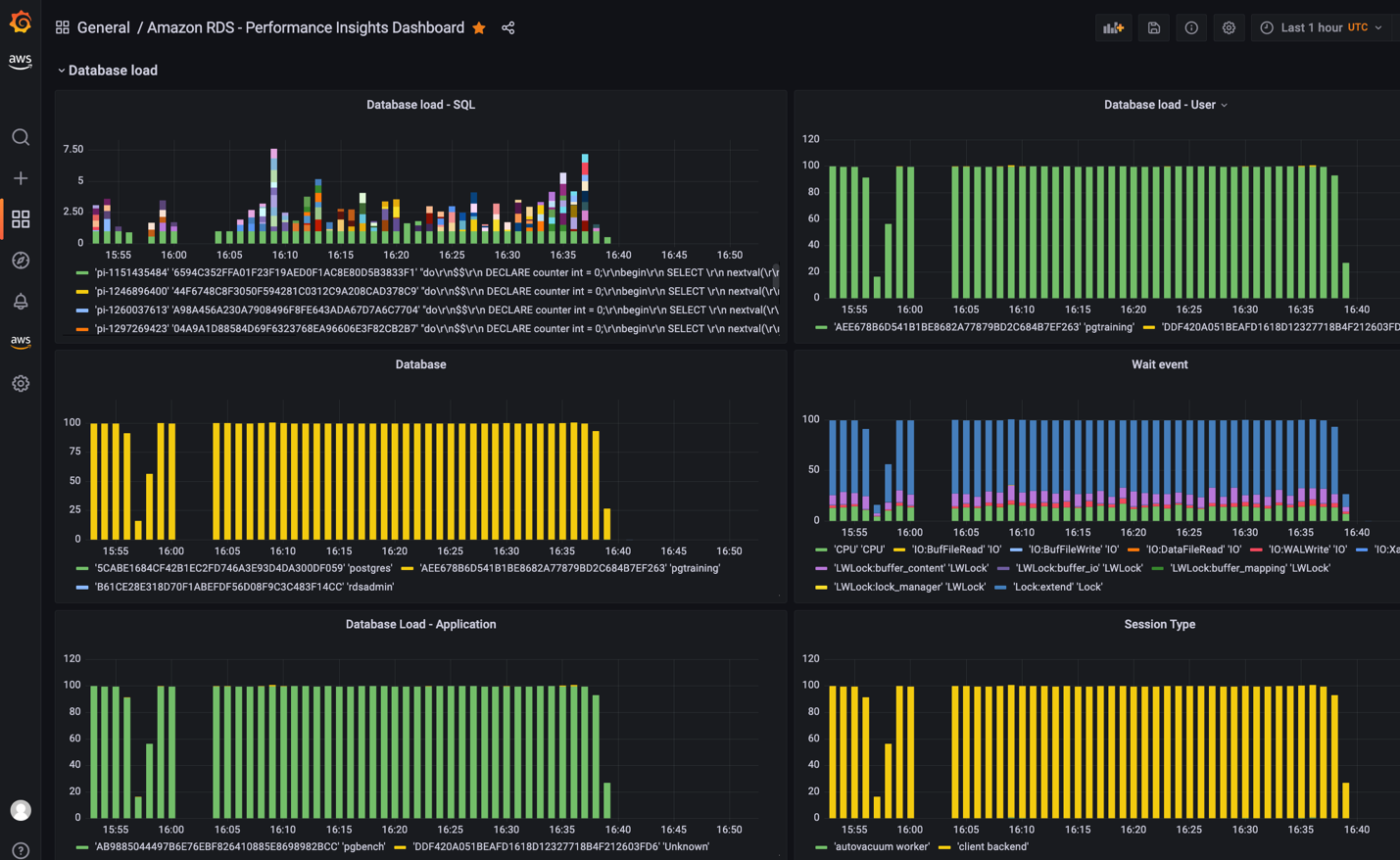
* [Amazon SageMaker built-in LightGBM now offers distributed training using Dask](https://aws-oss.beachgeek.co.uk/2hk) looks at how SageMaker LightGBM algorithm now offers distributed training using the Dask framework for both tabular classification and regression tasks [hands on]
### Quick updates
**Matano**
Matano is an open source cloud-native security lake platform (SIEM alternative) for threat hunting, detection & response, and cybersecurity analytics at petabyte scale on AWS. Last week, Samrose Ahmed wrote Matano now supports 10+ AWS managed log sources, sharing that they now support some additional AWS sources that you can integrate.
**Ubuntu**
AWS Snow Family now supports Ubuntu 20.04 Long Term Support (LTS) and Ubuntu 22.04 LTS on AWS Snowcone, AWS Snowball Edge Compute Optimized, and AWS Snowball Edge Storage Optimized devices. Ubuntu operating systems on Snow devices enable customers to deploy their edge compute workloads such as IoT, AI/ML, and Container workloads on Ubuntu 20.04 LTS and Ubuntu 22.04 LTS versions.
**Bottlerocket**
Bottlerocket, a Linux-based operating system that is purpose built to host container workloads, now supports network bonding and VLAN tagging when used with Amazon Elastic Kubernetes Anywhere (Amazon EKS Anywhere) bare metal deployments. The added functionality allows customers using Bottlerocket on bare metal to avoid a single point of failure in the network stack and improves network performance.
Network bonding is a process of combining two or more network devices to act as one network interface. This process can improve network performance and availability because there is now more than one interface available to communicate. Bonding interfaces together is a common strategy to provide high availability for bare metal servers. VLAN tagging adds the ability to use the same network hardware but logically separates networks based upon VLAN tags.
Network bonding is available on Bottlerocket versions starting from 1.12.0 when used with Amazon EKS Anywhere.
**PostgreSQL**
Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports PostgreSQL minor versions 14.6, 13.9, 12.13, 11.18, and 10.23. We recommend you upgrade to the latest minor version to fix known security vulnerabilities in prior versions of PostgreSQL, and to benefit from the bug fixes, performance improvements, and new functionality added by the PostgreSQL community.
With this release, RDS for PostgreSQL adds two new extensions: (1) tcn - an extension that provides a trigger function that sends an asynchronous notification for every write on a table, and (2) seg - an extension that provides the "seg" data type used for storing and querying line segments. This release also includes updates for existing supported PostgreSQL extensions: orafce is updated to 3.24, rdkit is updated to 4.2.0, and wal2json is updated to 2.5.
**OpenSearch**
A few updates this week.
First up, OpenSearch has a new newsletter. Check out the first edition, [OpenSearch Project Newsletter - Volume 1, Issue 1](https://aws-oss.beachgeek.co.uk/2i2)
OpenSearch 1.3.8 also shipped last week. You can find the release over on the [OpenSearch Downloads](https://aws-oss.beachgeek.co.uk/2i3) page, and check out what you can expect over on the [release notes](https://aws-oss.beachgeek.co.uk/2i4).
Amazon OpenSearch Service now supports enabling Security Assertion Markup Language (SAML) authentication for OpenSearch Dashboards during domain creation. SAML authentication for OpenSearch Dashboards enables users to integrate directly with identity providers (IDPs) such as Okta, Ping Identity, OneLogin, Auth0, Active Directory Federation Services (ADFS) and Azure Active Directory. Previously this authentication method could be configured only after domain creation. Now, this feature can be enabled at domain creation using AWS Console/SDK or using AWS CloudFormation templates, giving you the ability to enable programmatically in fewer steps. With this feature, users can leverage their existing usernames and passwords to log in to OpenSearch Dashboards, and roles from your IDP can be used for controlling privileges, including what operations they can perform and what data they can search and visualise.
Also new last week was news that Amazon OpenSearch Service has added a new connection mode for cross-cluster connection, simplifying the setup required to remote reindex between a local domain and remote VPC domains. Remote reindex enables you to migrate data from a source domain to a target domain. Remote reindex is also useful when you have to upgrade your clusters across multiple major versions. Previously, to use remote reindex, you needed to confirm that the source domain was accessible from the target domain. If the remote domain was VPC enabled, you set up a publicly accessible reverse proxy for the remote domain, even when the domains were located within the same VPC.
With this release, you can create a new connection between a local domain and a remote VPC domain using the connection mode ‘VPC endpoint’, and then use the provided endpoint in the remote reindex operation. You do not need a proxy, and the traffic between domains remains within the Amazon Networking Backbone--at no extra cost. The new connection mode is available for local domains running OpenSearch versions 1.3 and above.
**Redis**
Amazon Elasticache for Redis now offers an availability Service Level Agreement (SLA) of 99.99% when using a Multi-Availability Zone (Multi-AZ) configuration. Previously, ElastiCache for Redis offered an SLA of 99.9% for Multi-AZ configurations. With this launch, ElastiCache for Redis has updated its Multi-AZ SLA to provide 10x higher levels of availability.
**PlantUML**
PlantUML is an open-source tool allowing users to create diagrams from a plain text language. If you are a user, then [release 15.0 of the aws-icons-for-plantuml](https://aws-oss.beachgeek.co.uk/2i1) was released last week. This releases features a number of updates and new icons in Analytics, Application Integration, Business Applications, Compute, Containers, Database, Developer Tools, End User Computing, Internet Of Things, Machine Learning, Management Governance, Migration Transfer, Networking Content Delivery, Security Identity Compliance, and Storage categories.
### Videos of the week
**Amazon EKS Security Best Practices**
AWS Hero Shimon Tolts has put together this video and blog post to show you how to enforce the Amazon EKS Security Best Practices Guide on your own EKS. Check out the blog post, [EKS Security Best Practices - Practical Enforcement Guide](https://aws-oss.beachgeek.co.uk/2h7) that supports this video.
{% youtube 4sd4y5aVnCE %}
**Building a Modern Data Platform on Amazon EKS**
This weeks edition has featured a number of open source data tools running in Kubernetes. In this video, Brian Hammons explores several advantages and challenges of building data platforms on Kubernetes, and introduce Data on EKS - a global initiative offering IaC patterns in Terraform and CDK, benchmark reports, best practices, and sample code to simplify and accelerate the journey for users who want to run applications like Spark, Kafka, Kubeflow, Ray, Airflow, Presto, and Cassandra on EKS.
{% youtube 7AHuMNqbR7o %}
**Terraform**
Join Rob as he provides an introductory guide on Terraform and AWS.
{% youtube AhwR6hEKwWc %}
If you are working with Terraform and AWS, you will almost certainly come across AWS Hero Anton Babenko. He runs a regular Terraform live coding session on YouTube which I recommend you check out. If you want to talk about any topics on Terraform/AWS, this is a great livestream to join.
{% youtube FHPuLpaSjDo %}
**Build on Open Source**
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. [Build on Open Source playlist](https://aws-oss.beachgeek.co.uk/24u)
# Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
**State of Open Con 23**
**Feb 7-8th, 2023 in London**
OpenUK will be hosting a 1000 person plus two day conference in Central London, “State of Open Con 23” in association with IEEE, the headline sponsor. Check out more info and [sign up here](https://aws-oss.beachgeek.co.uk/2dd).
**PGConf India**
**Feb 22nd to 24th, Radisson Blu Bengaluru, India**
If you are in or can get to Bengaluru, then checkout this conference for PostgreSQL developers and enthusiasts. Check out the session line up and get [your tickets here](https://aws-oss.beachgeek.co.uk/2ff).
**Everything Open**
**March14-15th Melbourne, Australia**
A new event for the fine folks in Australia. Everything Open is running for the first time, and the organisers (Linux Australia) have decided to run this event to provide a space for a cross-section of the open technologies communities to come together in person. Check out the [event details here](https://aws-oss.beachgeek.co.uk/2ds). The CFP us currently open, so why not take a look and submit something if you can.
**Cortex**
**Every other Thursday, next one 16th February**
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the [Community Meetings](https://aws-oss.beachgeek.co.uk/2h5) section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the [Cortex Community Meetings Notes](https://aws-oss.beachgeek.co.uk/2h6) for more info.
**OpenSearch**
**Every other Tuesday, 3pm GMT**
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, [OpenSearch Community Meeting](https://aws-oss.beachgeek.co.uk/1az)
### Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the [Open Source homepage](https://aws.amazon.com/opensource/?opensource-all.sort-by=item.additionalFields.startDate&opensource-all.sort-order=asc) to keep up to date with all our activity in open source by following us on [@AWSOpen](https://twitter.com/AWSOpen) | 094459 |
1,349,310 | Getting Started with Rust and Docker | Rust has consistently been one of the most loved programming languages in the Stack Overflow... | 0 | 2023-02-11T07:59:33 | https://dev.to/ajeetraina/getting-started-with-rust-and-docker-4eea | Rust has consistently been one of the most loved programming languages in the Stack Overflow Developer Survey. Rust tops StackOverflow Survey 2022 as the most loved language for the 7th year. In the 2021 survey, Rust was ranked as the 2nd most loved language, with 85.8% of Rust developers reporting that they want to continue using it. In the 2020 survey, Rust was also ranked 2nd, with 78.9% of Rust developers expressing that they loved the language. The popularity of Rust is due to its focus on performance and reliability, as well as its user-friendly and expressive syntax.
Rust is a systems programming language that was first developed by Mozilla Research. It is designed to be fast, reliable, and secure, with an emphasis on concurrent and parallel programming. Rust is known for its strong type system and its low-level control over system resources, making it well-suited for high-performance tasks such as game development, networking, and low-level system programming.
Rust is also known for its unique memory safety model, which eliminates the risk of many common programming errors, such as null pointer dereferences and buffer overflows. This is achieved through the use of ownership and borrowing, which allows Rust to enforce strict control over the lifetimes and ownership of values in the program.
In addition to its technical features, Rust has a large and active community, with many libraries and tools available for use in Rust projects. This makes it easy to get started with Rust, and to find the resources you need to build high-quality applications.
## Why is Rust so popular?
Rust has become popular for several reasons:
### 1. Memory safety
Rust's unique memory safety model helps to prevent a wide range of common programming errors, such as null pointer dereferences and buffer overflows. This makes Rust code more reliable and secure compared to code written in other systems programming languages.
### 2. Performance
Rust is designed to be fast, with low-level control over system resources. This makes it ideal for high-performance tasks, such as game development and low-level system programming.
### 3. Concurrency and parallelism
Rust has strong support for concurrent and parallel programming, which makes it well-suited for multi-threaded and parallel applications.
### 4. Community and ecosystem
Rust has a large and active community, with many libraries and tools available for use in Rust projects. This makes it easy to get started with Rust and finds the resources you need to build high-quality applications.
### 5. User-friendly error messages
Rust's error messages are designed to be helpful and user-friendly, making it easier for developers to understand and fix errors in their code.
### 6. Safe and stable code
Rust's focus on safety and stability, combined with its strict type system, helps to ensure that the code written in Rust is more likely to be correct and less prone to bugs.
Rust's combination of memory safety, performance, and ease of use makes it an attractive choice for developers who want to build high-quality, reliable, and secure applications.
## A simple Rust application
Here is a simple Hello World application in Rust:
```
fn main() {
println!("Hello, World!");
}
```
## Explanation:
- fn main() is the entry point for the program. All Rust programs must have a main function, which is where execution starts.
- println!("Hello, World!") is a macro that writes the string "Hello, World!" to the console. The ! at the end of println! is used to indicate that this is a macro, not a function.
- ; at the end of a line of code is used to indicate the end of a statement.
To run this code, you would need to have the Rust programming language installed on your machine. You can then save this code to a file with a .rs extension, for example main.rs. Then you can run the following command in the terminal:
```
$ cargo run
```
This will compile and run the program, and the output will be Hello, World!.
## Why do you need Cargo.toml file?
Cargo.toml is a configuration file for the Rust package manager, Cargo. It is used to specify the dependencies and build settings for a Rust project.
A typical Cargo.toml file for a Rust project includes information about the package, such as its name and version, as well as a list of dependencies that the project needs in order to build and run. Here is an example of a simple Cargo.toml file:
```
[package]
name = "my-rust-app"
version = "0.1.0"
[dependencies]
serde = "1.0"
```
This Cargo.toml file specifies that the project is named my-rust-app and has a version of 0.1.0. It also specifies a dependency on the serde library, version 1.0. When the Rust build process runs, Cargo will automatically download and manage these dependencies, making it easy to manage dependencies for your project.
## Writing a Cargo.toml file
```
cat Cargo.toml
[package]
name = "my-rust-app"
version = "0.1.0"
[[bin]]
name = "my-rust-app"
path = "src/main.rs"
```
## Containerising a Rust program
To containerise a Rust application, you need to follow these steps:
## Write a Dockerfile
This file will specify the base image, any dependencies and how to compile and run your Rust application.
```
# Use a base image with the latest version of Rust installed
FROM rust:latest
# Set the working directory in the container
WORKDIR /app
# Copy the local application code into the container
COPY . .
# Build the Rust application
RUN cargo build --release
# Specify the command to run when the container starts
CMD ["./target/release/my-rust-app"]
```
## Build the Docker Image
Use the docker build command to build an image from the Dockerfile.
You can then build the Docker image with the following command:
```
docker build -t my-rust-app .
```
In the above Dockerfile, you would copy the local application code into the container with the following line:
```
COPY . .
```
This line copies all files in the current directory (.) to the /app directory in the container. The resulting Docker image will contain your Rust application, ready to be built and run.
## Running the Container
Use the docker run command to start a container based on the built image.
```
docker run --name my-rust-app -it my-rust-app
Hello, world!
```
## Rust and Docker Compose
Let's say you have a web application written in Rust that provides a REST API for retrieving information about books. You want to use Docker Compose to manage the containers for the Rust application and a database (e.g. PostgreSQL) that the application will use to store the book information.
Write the Rust application: Your Rust application will expose a REST API that allows clients to retrieve information about books from a database. The application will use the Rocket framework to handle HTTP requests and the Diesel ORM to interact with the database.
Here's an example of what a Cargo.toml file for a book API might look like:
```
[package]
name = "book-api"
version = "0.1.0"
authors = ["Your Name <your.email@example.com>"]
[dependencies]
rocket = "0.4.6"
diesel = { version = "1.4.4", features = ["postgres"] }
dotenv = "0.15.0"
[dependencies.rocket_contrib]
version = "0.4.6"
default-features = false
features = ["json"]
```
This file specifies the name, version, and authors of the application, as well as the dependencies it needs to build and run. In this case, the dependencies are the Rocket web framework, the Diesel ORM, and the dotenv library for reading environment variables.
Here's an example of what a main.rs file for a book API might look like:
```
#[macro_use]
extern crate diesel;
#[macro_use]
extern crate rocket;
use diesel::prelude::*;
use diesel::pg::PgConnection;
use dotenv::dotenv;
use std::env;
use rocket::response::content::Json;
use rocket_contrib::json::JsonValue;
pub fn establish_connection() -> PgConnection {
dotenv().ok();
let database_url = env::var("DATABASE_URL")
.expect("DATABASE_URL must be set");
PgConnection::establish(&database_url)
.expect(&format!("Error connecting to {}", database_url))
}
#[get("/books")]
fn books() -> Json<JsonValue> {
use crate::schema::books::dsl::*;
let connection = establish_connection();
let results = books
.limit(10)
.load::<Book>(&connection)
.expect("Error loading books");
let mut books_json = json![];
for book in results {
books_json.push(json!({
"title": book.title,
"author": book.author,
"publisher": book.publisher,
"year": book.year,
}));
}
Json(json!({ "books": books_json }))
}
fn main() {
rocket::ignite()
.mount("/", routes![books])
.launch();
}
```
In this example, the main.rs file sets up the Rocket web framework and exposes a single endpoint at /books that returns a JSON array of books. The establish_connection function sets up a connection to the PostgreSQL database using the DATABASE_URL environment variable. The books function uses Diesel to query the books table and return a JSON response to the client.
## Creating a Dockerfile
You will use the following Dockerfile to create a Docker image for the Rust application:
```
# Use an existing Rust image as the base
FROM rust:latest
# Set the working directory
WORKDIR /app
# Copy the application files into the image
COPY . .
# Build the application in release mode
RUN cargo build --release
# Set the command to run the binary
CMD ["./target/release/book-api"]
```
## Create a docker-compose.yml file
In the docker-compose.yml file, you'll define two services: one for the Rust application and one for the database:
```
version: '3'
services:
book-api:
build: .
ports:
- "3000:3000"
db:
image: postgres
environment:
POSTGRES_USER: myuser
POSTGRES_PASSWORD: mypassword
POSTGRES_DB: book_db
```
## Starting the container service
Finally, you can start the containers by running the following command:
```
$ docker-compose up -d --build
```
With this setup, Docker Compose will start a container for the Rust application and a container for the PostgreSQL database, and connect the two containers so that the Rust application can access the database. Clients can access the REST API by sending HTTP requests to `http://localhost:3000`. | ajeetraina | |
1,349,513 | Why Should You Use React JS For Web App Development? | > A recent survey that is conducted by Stack Overflow, revealed that React JS is the favorite web... | 0 | 2023-02-01T13:17:13 | https://dev.to/uplogictech/why-should-you-use-react-js-for-web-app-development-mpg | webdev, web3, react, javascript | **> A recent survey that is conducted by Stack Overflow, revealed that React JS is the favorite web app tech stack for developers**

But, why do developers, users, and entrepreneurs like to build a web application with React JS? Let’s find the truth behind this survey report.
- The first reason is that React JS requires only minimal coding work. So, the developers can focus on flexible design more than coding for functionality. That helps the developers to create highly collaborative, and dynamic web applications.
- Beyond that, it provides access to the mutable components of a web application. That makes them exist together.
- Reusable components are the most attractive feature of React JS that allows the developers to break lengthy components into small size reusable components.
- IT experts can avoid the complexities of layers and can create view layers separately. Along with this, developers can optimize the web application with the most out of the many webpack modules.
- This library is also compatible with multiple third-party tools that allow developers to use React JS for templating and leveraging the **[web app development company](https://www.uplogictech.com/web-app-development-company)** process.
In addition to these points, many more positive technical aspects make the developers prefer the library as their priority. Let’s check a few benefits of using React JS library now.
Read more: https://www.uplogictech.com/blog/check-how-react-js-simplifies-dynamic-web-app-development-process/
| uplogictech |
1,350,074 | Drag-and-drop UI builder in VS Code 🧩 | 20sec demo Hey everyone, we're building a drag’n drop VS Code extension for Python :) Skips the... | 0 | 2023-02-01T20:54:20 | https://dev.to/ekacelnik/drag-and-drop-ui-builder-in-vs-code-2211 | python, vscode, showdev, webdev | [20sec demo](https://www.youtube.com/watch?v=NXkYWtiYPQE)
Hey everyone, we're building a **drag’n drop VS Code extension for Python** :)
Skips the need to code HTML, CSS, etc. Meant to pair the familiar coding environment of VS Code with a visual way to build UI. You drag-and-drop widgets, then bind them to a regular Python script.
It's still a work in progress, but I'm really excited to get some feedback!
Would this help your work? Any thoughts? | ekacelnik |
1,350,177 | 🚀 5 Advanced ES6 Features Every JavaScript Developer Should Master | New day, new article! Today's article is about five advanced Javascript ES6 features that I like and... | 0 | 2023-02-01T22:34:39 | https://dev.to/naubit/5-advanced-es6-features-every-javascript-developer-should-master-3mkn | webdev, javascript, beginners, tutorial | New day, new article! Today's article is about **five advanced Javascript ES6 features** that I like and that I think everyone (*at least every developer*) should understand.
Are you ready?
## 💡 Destructuring
Destructuring is a quick way to get values out of objects and arrays. For example, **you can extract values** and assign them to variables with a single line of code.
Here's an example of how destructuring can be used with an object:
{% embed https://gist.github.com/NauCode/484be1c3c88d2a67e4236bd1ba9ff491 %}
And here's an example with an array:
{% embed https://gist.github.com/NauCode/985566e45dc3968feeca26dfab5cb4ab %}
As you can see, destructuring makes it simple to extract values from objects and arrays and assign them to variables.
## 🔒 Block Scoping
You can use block scoping to declare variables that are only available within a specific block of code. There are two ways to declare variables in JavaScript: **var** and **let**.
The var keyword declares a global or function-scoped variable, which means **it can be accessed from anywhere within the same function**. On the other hand, the let keyword declares a variable that is block scoped, which means that it can only be accessed within the same block of code.
Here's an example of let-based block scoping:
{% embed https://gist.github.com/NauCode/22064bf1933eb23e6142a947fb013a69 %}
As you can see, the message variable is only available within the if statement-defined block of code.
## 🚗 Spread Operator
Spreading the values of an array or object into a new array or object is possible with the spread operator. **It's a quick way to combine arrays or objects or to turn an array-like object** into a proper array.
Here's an example of how to combine two arrays using the spread operator:
{% embed https://gist.github.com/NauCode/76e017107edc5885c2cb2b2f66a7dad7 %}
Here's an example of how to use the spread operator to transform an array-like object into a real array:
{% embed https://gist.github.com/NauCode/d05d3b4a855e5f01ce8dd5f93d169162 %}
A spread operator is a powerful tool for simplifying and improving the readability of your code.
## 🔮 Template Literals
String literals that allow you to embed expressions within your strings are known as template literals. Instead of quotes (' or "), they are defined with the backtick (`) character.
Here's an example of template literals in action:
{% embed https://gist.github.com/NauCode/e6b97767fe95507319ed5b4210c16831 %}
As you can see, template literals make it simple to embed expressions within strings and **allow you to write multi-line strings** without using string concatenation.
## 💾 Arrow Functions
In JavaScript, arrow functions are a shorthand syntax for writing anonymous functions. They enable you to write code that **is shorter, more concise, and more readable**.
Here's an example of how to use the arrow function:
{% embed https://gist.github.com/NauCode/13fa3bd426ce400bfaa091bb7bd40cda %}
As you can see, arrow functions make it simple to write anonymous functions and have a shorter syntax than regular functions.
* * * * *
It was a short article, but I hope it was helpful for you. I use these features daily and feel like **they are crucial for every Javascript developer**. So hopefully, you have discovered something new today.
## 🌎 Let's Connect!
- My [Twitter: @thenaubit](https://twitter.com/thenaubit)
- [My Substack](https://coderpreneurs.substack.com/) (here I will publish more in-depth articles) | naucode |
1,351,421 | Como adicionar a análise de pacotes do webpack em seu projeto nuxt | Visualize o tamanho dos arquivos de saída do webpack com um mapa de árvore interativo dentro do seu... | 0 | 2023-02-02T19:35:29 | https://dev.to/gabrielcaiana/como-adicionar-a-analise-de-pacotes-do-webpack-em-seu-projeto-nuxt-28da | webpack, nuxt, vue, performance | > Visualize o tamanho dos arquivos de saída do webpack com um mapa de árvore interativo dentro do seu projeto com nuxtjs.

Sabemos como é importante colocar em produção aplicações que tenham o melhor desempenho possível, porém conforme começamos a desenvolver um projeto adicionamos diversos pacotes para determinadas tarefas e no final isso terá um impacto no desempenho da aplicação, como podemos análisar isso utilizando o nuxtjs?
Recentemente descobri uma forma muito fácil e interativa para mapear e análisar os pacotes que estão sendo utilizados no projeto, podemos criar um comando simples no package.json da seguinte forma:
`"scripts": {
"dev": "nuxt",
"build": "nuxt build",
"analyze": "nuxt build --analyze"
}`
ou podemos executar direto no terminal com yarn
`yarn build --analyze`
ou até mesmo utilizando o comando npx
`npx nuxt build --analyze`
com isso o webpack analyzer deve ser inicializado em seu navegador e com isso podemos visualizar toda a árvore de pacotes que o projeto está utilizando
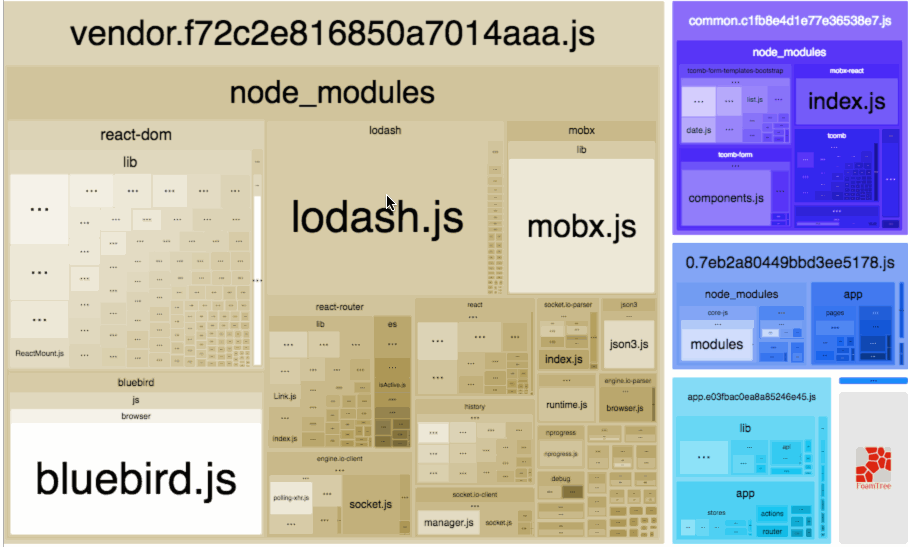
Temos também uma barra a esquerda que permite que você escolha quais pedaços mostrar com os seus devidos tamanhos. podemos ver um exemplo disso na imagem abaixo:
Você também pode clicar duas vezes nas caixas, passar o mouse sobre elas para obter mais detalhes e clicar com o botão direito em um pedaço para ocultá-lo facilmente ou para ocultar todos os outros pedaços.
Espero que esse artigo possa ajudar você a analisar seu projeto e melhora-lo, vejo você no próximo post.
Link: [https://www.npmjs.com/package/webpack-bundle-analyzer]
| gabrielcaiana |
1,350,180 | Quick tip: Test drive SingleStoreDB using the Query Playground | Abstract SingleStore provides a Playground that offers a fast and easy way to experience... | 0 | 2023-02-01T22:50:26 | https://dev.to/singlestore/quick-tip-test-drive-singlestoredb-using-the-query-playground-mkl | singlestoredb, playground | ## Abstract
SingleStore provides a [Playground](https://playground.labs.singlestore.com/) that offers a fast and easy way to experience some of the capabilities of SingleStoreDB, without requiring any sign-up or downloads. In this very short article, we'll discuss some of the features of this Playground environment.
## Introduction
There are a variety of ways to test drive SingleStoreDB. For example:
- **SingleStoreDB Cloud**. Create a free [trial account](https://www.singlestore.com/cloud-trial/) with US$500 in credits and no credit card details are required.
- **SingleStoreDB Self-Managed**. Install the software yourself and available in several editions, such as [Standard](https://www.singlestore.com/self-managed-standard/) and [Premium](https://www.singlestore.com/self-managed-premium/).
- **SingleStoreDB Dev Image**. A [Docker image](https://github.com/singlestore-labs/singlestoredb-dev-image).
A recent addition to this list is the [Playground](https://playground.labs.singlestore.com/) environment. This is entirely browser-based, requiring no registration and comes pre-loaded with several databases:
- [JSON Game Data](https://www.singlestore.com/blog/the-json-playground-in-singlestoredb/)
- [MarTech](https://github.com/singlestore-labs/demo-realtime-digital-marketing)
- [TPC-DS](https://www.tpc.org/tpcds/)
- [TPC-H](https://www.tpc.org/tpch/)
Figure 1 shows the initial landing page.
<center>Figure 1. Playground Landing Page.</center>
The look and feel of the environment is very similar to [SingleStoreDB Studio](https://docs.singlestore.com/db/v8.0/en/user-and-cluster-administration/cluster-management-with-tools/singlestoredb-studio.html).
Figure 2 shows the top navigation bar.

<center>Figure 2. Navigation Bar.</center>
As we can see, there are several menu options, from left to right:
- **Database**. Choose the database from one of the examples mentioned earlier. In Figure 2, **martech** is shown selected.
- **Three vertical dots**. SQL code from a file can be uploaded into the editor or the SQL code from the editor can be saved to a file.
- **+ Example Queries** button. Choose one of the pre-defined example queries appropriate for the selected database. The query will be pasted into the editor, ready to run.
- **Run** button. Execute the code in the editor. The results will be shown below the editor and can be saved to a CSV file.
A great walkthrough and tutorial of the Playground using the JSON Game Data example can be found in the article [The JSON Playground in SingleStoreDB](https://www.singlestore.com/blog/the-json-playground-in-singlestoredb/).
## Summary
The Playground environment is a quick and simple way to get started with SingleStoreDB. The Playground comes with several popular databases built-in and ready to run. Example queries can be easily selected and run in the editor. The query results can also be saved to a CSV file. To fully experience the power and capabilities of SingleStoreDB, the next step would be to choose one of the other options (Cloud, Self-Managed or Docker). | veryfatboy |
1,350,445 | When she marries one of you! | A post by Ebenezer Enietan (Niza) | 0 | 2023-02-02T05:56:52 | https://dev.to/niza/when-she-marries-one-of-you-9ip | meme, programming, devjournal, devrel |
 | niza |
1,350,561 | How to Use Draggable and DragTarget to Create Drag and Drop UI Elements in Flutter? | Flutter is a mobile app SDK that allows developers to build and publish cross-platform apps for... | 0 | 2023-02-02T07:02:02 | https://flutteragency.com/drag-drop-ui-elements-flutter-draggable-dragtarget/ | flutter, programming | Flutter is a mobile app SDK that allows developers to build and publish cross-platform apps for Android and iOS. One of the most valuable features of Flutter is its ability to create draggable U.I. elements. With this feature, you can create buttons, lists and even entire screens that can be dragged around your app.
A Draggable widget lets you add drag-and-drop behavior to any widget. DragTarget is a widget that enables you to specify which widget should accept the drop event when the user drops the dragged object.
In this article, we’ll talk about drag and drop, Draggable and DragTarget widgets, which are part of the Flutter Toolkit library.
##About Drag and Drop UI elements
Drag and Drop UI elements are a new Flutter widget that allows you to create powerful custom interactions. You can use Drag and Drop UI elements to build your app’s core interactions, such as dragging an object from one location in your app onto another location.
Flutter’s DragTarget widget lets you define some target areas on a page where drag events will be allowed. For example, if the user drags an image over a button, that button might be set up as a target for drag events (e.g., it can receive drops). When dragged items hit targets, they’ll bounce off them and fall back down into place with gravity according to their angle of entry into the target area.
##Draggable UI Elements
The Draggable widget can create a draggable element in your app. Drag and drop functionality is a popular feature that allows you to drag an object from one part of the screen and drop it into another. This is useful for rearranging items, moving files around, and many other things.
The most prominent use of draggable interfaces is in web design. Many websites allow users to rearrange elements on their pages through this feature. In addition to being used on websites, draggable can be used in many other areas, such as mobile apps, desktop software, and even video games!
##DragTarget Element
DragTarget is a widget that allows you to specify a region of an app where a drag action can be started. DragTarget is a subclass of GestureDetector, and you can use it to detect drag actions or gestures in your app.
**DragTarget has three methods:**
**onStart** – called when the user starts dragging
**onDrag** – called when the user drags their finger over the target area
**onEnd** – called when the user stops dragging.
Using these widgets, you can allow an entire widget to drag or just a part of it!
There are two widgets that make it possible to drag and drop U.I. elements in Flutter: Draggable and DragTarget. Draggable allows you to drag an entire widget or part of it (e.g., its background). DragTarget is used when multiple elements respond to the same event (e.g., responding with different animations).
The Draggable and DragTarget widgets are the first step in allowing users to interact with your app. These widgets enable you to create a drag-and-drop experience for moving items around the screen, including moving and resizing U.I. elements or entire pages.
When creating a drag-and-drop experience in Flutter app development, it is possible to use the Draggable widget. The Draggable widget allows you to drag objects around your screen.
To implement a drag-and-drop experience, you need to use one or more Draggable widgets and at least one DragTarget widget. The DragTarget widget can be any shape or size as long as it has a valid drop target for the Draggable widget.
These widgets can handle native element dragging and customize your draggable widget using a custom image instead of the default background color.
You can combine these for powerful custom interactions. For example, if you want a user to be able to drag an image over a button, or drag an entire widget from one place in your app to another, then Draggable and DragTarget are the first steps in allowing them to do so.
##Example
Drag and drop is a common interaction that is used in many apps. It is an easy way to perform different tasks and can be used for a variety of purposes. For example, you can drag files into an email or move them around on your phone.
In this example, we will discuss the initial steps required to create a simple drag-and-drop UI element. The elements can be dragged around to the desired location, and they can also be dropped onto other elements.
The first step is to create a Draggable widget. This widget will define the position of our element as well as its bounds. To make your widget draggable, you need to give it two children: a Text widget and a boxed text widget. The text will display in the box when it is being dragged around. The box will contain all the necessary information about where to drop your element.
The second step is to create a DragTarget widget that allows you to specify which other widgets are eligible for dropping an element onto them. You can also set custom properties on your DragTarget instance if you want any special functionality when your element is being dropped onto another one (such as changing colors or hiding/showing something).
##Example
```dart
main.dart
import 'package:flutter/material.dart';
import 'package:dotted_border/dotted_border.dart';
const Color darkBlue = Color.fromARGB(255, 18, 32, 47);
void main() {
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return const MaterialApp(
debugShowCheckedModeBanner: false, home: DemoExample());
}
}
class DemoExample extends StatefulWidget {
const DemoExample({Key? key}) : super(key: key);
@override
State<demoexample> createState() => _DemoExampleState();
}
class _DemoExampleState extends State<demoexample> {
@override
Widget build(BuildContext context) {
bool isDropped = false;
String _color = "red";
return Scaffold(
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
LongPressDraggable<string>(
// Data is the value this Draggable stores.
data: _color,
feedback: Material(
child: Container(
height: 170.0,
width: 170.0,
decoration: const BoxDecoration(
color: Colors.redAccent,
),
child: const Center(
child: Text(
'Dragging',
textScaleFactor: 2,
),
),
),
),
childWhenDragging: Container(
height: 150.0,
width: 150.0,
color: Colors.grey,
child: const Center(
child: Text(
'I was here',
textScaleFactor: 2,
),
),
),
child: Container(
height: 150.0,
width: 150.0,
color: Colors.redAccent,
child: const Center(
child: Text(
'Drag me',
textScaleFactor: 2,
),
),
),
),
SizedBox(
height: MediaQuery.of(context).size.height * 0.15,
),
DragTarget<string>(
builder: (
BuildContext context,
List<dynamic> accepted,
List<dynamic> rejected,
) {
return DottedBorder(
borderType: BorderType.RRect,
radius: const Radius.circular(12),
padding: const EdgeInsets.all(6),
color: Colors.black,
strokeWidth: 2,
dashPattern: const [8],
child: ClipRRect(
borderRadius: const BorderRadius.all(Radius.circular(12)),
child: Container(
height: 200,
width: 200,
color: isDropped ? Colors.redAccent : null,
child: Center(
child: Text(
!isDropped ? 'Drop here' : 'Dropped',
textScaleFactor: 2,
)),
),
),
);
},
onAccept: (data) {
debugPrint('hi $data');
setState(() {
isDropped = true;
});
debugPrint('hi $isDropped');
},
onWillAccept: (data) {
return data == _color;
},
),
],
),
));
}
}
</dynamic></dynamic></string></string></demoexample></demoexample>
```
##Output
##Conclusion
This article looks at two new widgets for building drag-and-drop interactions in Flutter app development. These widgets make it easy to construct full-fledged drag-and-drop interfaces in Flutter with just a few lines of code! I hope you guys enjoyed reading this article.
##Frequently Asked Questions (FAQs)
**1. Does Flutter have a drag-and-drop UI?**
Flutter gives you a widget, LongPressDraggable, which provides the exact behaviour you require to start with drag-and-drop interaction. The LongPressDraggable widget will recognise when the long press is fired and will view a new widget nearby the user’s finger. As the user drags, the widget will follow the user’s finger.
**2. How do I build the custom dropdown in the Flutter app?**
The dropdown button will make the full-screen stack by using the overlay. Add the full-screen gesture detector behind a dropdown so that it is closed when a user taps anywhere on the screen. Hence, the overlay is linked to the button using LayerLink and the CompositedTransformerFollower widget.
**3. How do you use DragTarget in Flutter?**
DragText < T extends Object > class Null safety. A widget will get the data when the draggable widget is dropped. When the draggable is dragged on top of the drag target, the drag target is asked whether it will accept any data that the draggable is carrying.
**4. What are a Draggable widget and a DragTarget widget?**
A draggable widget recognises the beginning of the drag gesture and displays the feedback widget that tracks a user’s fingers across the screen. However, if a user moves their finger to the top of DragTraget, that target can accept data carried by a draggable.
The DragTarget widget in Flutter will receive data dragged and dropped by the user. It permits you to drag an item from one widget to another. Hence, it is a widget utilised to create games and other interactive user interfaces. | kuldeeptarapara |
1,350,853 | Kenapa harus FastAPI? | Sebenernya nnga ada alasan yang terlalu "wah" banget gitu. Tapi kalo dibandingkan dengan Django dan... | 0 | 2023-02-02T11:52:27 | https://dev.to/siabdul/kenapa-harus-fastapi-3jm1 | python, fastapi, beginners, programming | **_Sebenernya_** nnga ada alasan yang terlalu "wah" banget gitu.
Tapi kalo dibandingkan dengan [Django](https://djangoproject.com) dan [Flask](https://flask.palletsprojects.com/), [FastAPI](https://fastapi.tiangolo.com) ini emang _framework_ yang paling cepet kalo dipake untuk back end di python.
Dari _benchmark_ nya juga, terlihat kalau FastAPI ini adalah framework yang paling cepet dan juga memiliki performa yang hebat untuk melakukan berbagai macam hal. Dimulai dari _ngatasin_ request yang begitu banyak, sampe ke ngirim data json yang banyak pun, gaakan jadi masalah buat si FastAPI ini.
Ini adalah hasil _benchmark_ yang dilakukan oleh TechEmpower pada 17 Juli 2022 kemarin. Dan hasilnya sebagai berikut:
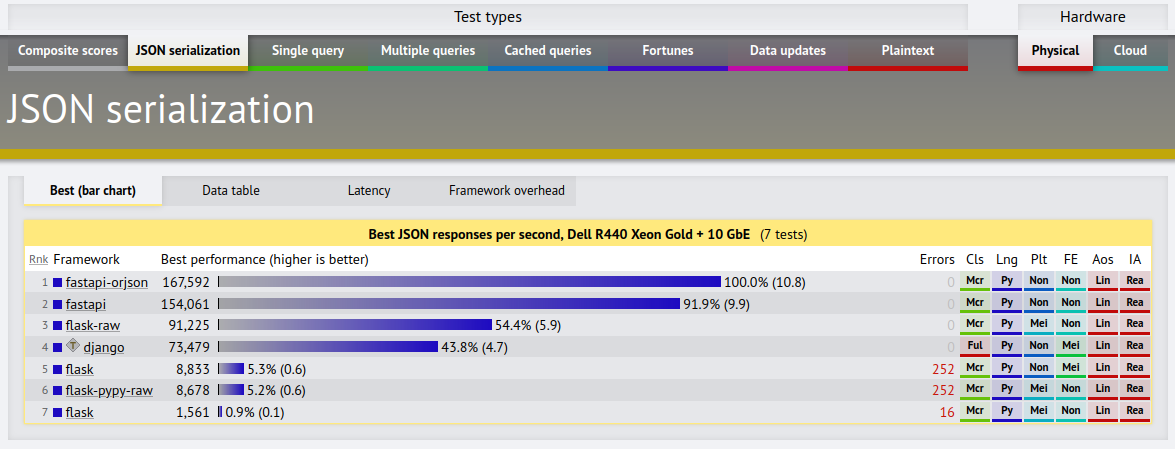
Seperti yang bisa kita lihat, FastAPI berada di tingkat pertama dengan poin sebanyak 167,592, dan diurutan terakhir ada Flask dengan poin hanya 1,561 saja.
Selain performa yang bagus, FastAPI juga menyediakan tutorial dan dokumentasi yang sangat mudah untuk dipahami oleh semua kalangan, baik yang sedang belajar mengenai python, maupun yang sudah ahli dalam menggunakan python.
Web framework yang saya berikan pun tidak menjadi acuan bagi kalian yang mau belajar mengenai back end menggunakan python. Django, flask, dan FastAPI memiliki kekurangannya masing-masing. Misal pada FastAPI, karena ia masih tergolong baru, jadi untuk mencari bantuan, menggunakannya secara advance pun masih tergolong sulit. Tetapi, saya sendiri menyarankan agar kalian yang sedang belajar mengenai python dan ingin menggunakannya pada website, saya menyarankan untuk menggunakan FastAPI, karena cepet, gampang, dan dokumentasinya juga mudah dipahami, jadi tunggu apalagi? Mari belajar FastAPI! | siabdul |
1,351,404 | 50 Most Asked JavaScript Interview Questions | You've been learning JavaScript and planning to apply for jobs. Prepare for the interview by... | 0 | 2023-02-02T18:46:50 | https://dev.to/johongirr/50-most-asked-javascript-interview-questions-3d3c | javascript, programming, webdev, interview | You've been learning JavaScript and planning to apply for jobs. Prepare for the interview by answering most asked 50 JavaScript interview questions.
# Table of Contents
1. [What is JavaScript?](#What is JavaScript?)
2. [What is the difference between primitive and reference types in JavaScript?](#What is the difference between primitive and reference types in JavaScript?)
3. [What is the difference between == and ===?](#What is the difference between == and ===?)
4. [What is a higher order function?](#What is a higher order function?)
5. [What is a pure function?](#What is a pure function?)
6. [What is the function currying?](#What is the function currying?)
7. [What is the difference between var, let, and const?](#What is the difference between var, let, and const?)
8. [What is the difference between global and local scope?](#What is the difference between global and local scope?)
9. [What is the temporal dead zone?](#What is the temporal dead zone?)
10. [What is hoisting?](#What is hoisting?)
11. [What is closure?](#What is closure?)
12. [How to compare two objects?](#How to compare two objects?)
13. [What are all the possible ways to create objects in JavaScript?](#What are all the possible ways to create objects in JavaScript?)
14. [What is prototype chain?](#What is prototype chain?)
15. [What is the difference between Call, Apply and Bind?](#What is the difference between Call, Apply and Bind?)
16. [What is JSON and its common operations?](#What is JSON and its common operations?)
17. [What is the purpose of the array slice method?](#What is the purpose of the array slice method?)
18. [What is the purpose of the array splice method?](#What is the purpose of the array splice method?)
19. [What is the difference between slice and splice?](#What is the difference between slice and splice?)
20. [What are lambda or arrow functions?](#What are lambda or arrow functions?)
21. [What is IIFE(Immediately Invoked Function Expression)?](#What is IIFE(Immediately Invoked Function Expression)?)
22. [How do you decode or encode a URL in JavaScript?](#How do you decode or encode a URL in JavaScript?)
23. [What is memoization?](#What is memoization?)
24. [What are classes in ES6?](#What are classes in ES6?)
25. [What are modules?](#What are modules?)
26. [Why do you need modules?](#Why do you need modules?)
27. [What is a promise](#What is a promise?)
28. [What are the three states of promise?](#What are the three states of promise?)
29. [What is a callback function?](#What is a callback function?)
30. [Why do we need callbacks?](#Why do we need callbacks?)
31. [What is a callback hell and how to avoid it?](#What is a callback hell and how to avoid it?)
32. [What is promise chaining?](#What is promise chaining?)
33. [What is promise.all?](#What is promise.all?)
34. [What is the purpose of the race method in the promise?](#What is the purpose of the race method in the promise?)
35. [What is a strict mode in javascript?](#What is a strict mode in javascript?)
36. [Why do you need strict mode?](#Why do you need strict mode?)
37. [How do you declare strict mode?](#How do you declare strict mode?)
38. [What is the purpose of the delete operator?](#What is the purpose of the delete operator?)
39. [What is typeof operator?](#What is typeof operator?)
40. [What is undefined?](#What is undefined?)
41. [What is null?](#What is null?)
42. [What is the difference between null and undefined?](#What is the difference between null and undefined?)
43. [What is eval?](#What is eval?)
44. [What is the difference between window and document?](#What is the difference between window and document?)
45. [How do you access history in javascript?](#How do you access history in javascript?)
46. [How do you detect caps lock key turned on or not?](#How do you detect caps lock key turned on or not?)
47. [What is isNaN?](#What is isNaN?)
48. [What are the differences between undeclared and undefined variables?](#What are the differences between undeclared and undefined variables?)
49. [What are global variables?](#What are global variables?)
50. [What are the problems with global variables?](#What are the problems with global variables?)
## What is JavaScript? <a name="What is JavaScript?"></a>
JavaScript is a dynamically typed, interpreted, scripting language. It supports different paradigms such as Functional, OOP, and Procedural. It's the only language that's executed right on the browser, that's why it's also called the language of the web.
- dynamically typed - means that the variable can hold multiple types throughout its lifetime
```js
let someVarName = "JavaScript" // JavaScript
someVarName = 12 // 12
someVarName = {name: "JavaScript"} // {name: "JavaScript"}
someVarName = false // false
someVarName = [1,2,3] // [1,2,3]
```
- interpreted - means that instead of code being compiled and then executed like in languages such as C, C++, and Java, code in JavaScript code is executed with JIT compiler
## What is the difference between primitive and reference types in JavaScript? <a name="What is the difference between primitive and non-primitive types in JavaScript?"></a>
**Primitive Types**
Primitive types can hold only a single value while non-primitive types have multiple.
JavaScript primitive types
```js
""
false
1
null
undefined
123n
Symbol("symbol")
```
**Non-primitive or Reference types**
Non-primitive types can contain multiple values of primitive at a time
```js
const hobbies = ["Reading", "Calisthenics", "Swimming"]
const person = {
name: "Jaxongir",
age: 27,
country: "Uzbekistan"
hobbies
}
```
## What is the difference between == and ===? <a name="What is the difference between == and ===?"></a>
**==** - comparison operator compares only values not their types and if two of the same values of the different types are compared then type conversion happens. Which is one type converted to another type.
```js
console.log(1 == "1") // true
console.log(false == "0") // true
```
**===** - strict equal comparison operator first compares data types of the values. If they are the same type then values are compared else they aren't the same type regardless of whether the values are the same it returns false
```js
console.log(1 === "1") // false
console.log(false === "0") // false
```
## What is a higher-order function? <a name="What is a higher order function?"></a>
**HOF(Higher order function)** - is the function that takes another function as an argument and calls it within it's body or returns function as the value
Examples of HOF are: map, filter, for each, reduce, etc...
```js
const nums = [1,2,3,4]
const multiplyNum = nums.map(num => num * 2)
console.log(multiplyNum) // [2,4,6,8]
const greet = (greeting)=> name => `${greeting} ${name}!`
const func = greet("Hello")
func("Jaxongir") // Hello Jaxongir!
func("Lola") // Hello Lola!
```
## What is a pure function? <a name="What is a pure function?"></a>
**Pure function** - is the function without any side-effects and it never mutates the argument and returns a copy of the same type as an argument.
```js
// Impure function
const add = (num1, num2)=> {
num1 = 10
return num1 + num2
}
// Pure function
const add = (num1, num2)=> num1 + num2
```
## What is the function currying? <a name="What is the function currying?"></a>
**Currying** - is the functional programming technique of transforming function with the multiple arguments with the multiple function with the single argument
```js
const curry = (f) => (a) => (b) => f(a, b);
const product = (num1, num2) => num1 * num2;
const curriedProduct = curry(product);
console.log(curriedProduct(20)(5)) // 100
console.log(curriedProduct(1)(10)) // 10
console.log(curriedProduct(0)(100)) // 0
```
## What is the difference between var, let, and const? <a name="What is the difference between var, let, and const?"></a>
**let and const**
- let and const is ES6 features that introduced in 2015
- variables declared with either let or const is scoped {} which means that they are invisible outside {} that they are defined
- variables decalred with them is not hoisted which means is that we can't access before their defined
**var**
- var is ES5 feature and
- if variable is declared within function with var keyword then it's scoped within that function which means is that it's not accessible outside that function body it's defined
- in all other cases variables declared with var keyword is global scoped
```js
if(10 > 0){
var test = "right"
let test2 = "test"
}
console.log(test) // right
console.log(test2) // ReferenceError: test2 is not defined
```
## What is the difference between global and local scope? <a name="What is the difference between global and local scope?"></a>
**global scope** - when variables and functions are accessible globally. So when you declare let and const variable outside any {} they are globally scoped. and when variable declared with var outside function is global scoped
**local scope** - as long variables declared with let and const is within {} they are local scoped to the body of that {} and inwards
```js
// global scope variable
const name = "Jaxongir"
// global scoped function
const func = ()=>{
// local scoped variable
let age = 25
}
func()
console.log(name) // Jaxongir
console.log(age) // ReferenceError: age is not defined
```
## What is the temporal dead zone? <a name="What is the temporal dead zone?"></a>
**Temporal dead zone** - is when variable declared with let or const is un-reachable. This happens cause they are not hoisted. Or even simpler they are invisible or in Temporal dead zone during from they are scoped within {} to memory is allocated for them
```js
const fuc = () => {
console.log(name);
console.log(age);
var age = 27;
let name = "Jaxongir";
};
fuc() // ReferenceError: Cannot access 'name' before initialization
```
## What is hoisting? <a name="What is hoisting?"></a>
**hoisting** - is when variables declared with var and function declarations moved to the top of the current scope before they are executed thus they are accessible before they are declared.
```js
greeting("Jaxongir")
function greeting(name) {
console.log("Hello " + name) // Hello Jaxongir
console.log(age) // undefined
var age = 26;
}
```
## What is closure? <a name="What is closure?"></a>
**closure** - is basically when function has always access to it's surrounding scope even after surrounding scope is already executed. Closure is created each time you create a function. Each time function is created that function can acccess variables, functions, objects defined in it's surrounding scope
```js
let name = "Jaxongir";
const fun = () => {
console.log(name) // Jaxongir
};
fun()
const outerFunc = (message)=>{
let test = "string"
const innerFunc = (text)=>{
console.log(message, test, text)
}
}
const test = outerFunc("Hello")
test("JavaScript")
```
## How to compare two objects? <a name="How to compare two objects?"></a>
For in depth explanation, have a look at this excellent [stack overflow](https://stackoverflow.com/questions/1068834/object-comparison-in-javascript)
```js
const obj1 = {name: "Lola"}
const obj2 = {name: "Lola"}
JSON.stringify(obj1) === JSON.stringify(obj2) // true
```
## What are all the possible ways to create objects in JavaScript? <a name="What are all the possible ways to create objects in JavaScript?"></a>
```js
// object literals
const person = {name: "Jaxongir}
// Object constructor
const person = new Object();
console.log(person);
// Object create method
const person = Object.create({});
console.log(person);
// singleton pattern
const person = new (function () {
this.name = "Jaxongir";
})();
// Constructor function
function Person(name) {
this.name = name;
}
const person = new Person("Jaxongir");
// ES6 Class
class Person {
constructor(name) {
this.name = name;
}
}
const person = new Person("Jaxongir");
console.log(person);
```
## What is prototype chain? <a name="What is prototype chain?"></a>
**Prototype chain** - is when object inherit it's properties and methods from it's prototype object
Root Constructor function that every other type inherits in JavaScript is Object
```js
const company = {
companyName: "UZS",
};
const teacher = {
fullname: "Jaxongir Rahimov",
__proto__: company,
};
console.log(teacher.companyName) // UZS
console.log(teacher.fullname) // Jaxongir Rahimov
```
## What is the difference between Call, Apply and Bind? <a name="What is the difference between Call, Apply and Bind?"></a>
While there's difference how used between them, common thing between them is that to provide the context for this keyword within function body and pass in arguments
**NOTE**: they can only be called on function declaration not on arrow functions. Coz arrow function does not bind this keyword
**call** - calls the function with the provided this value and additional arguments. First argument is always going to be context of this or object and it can take n arguments
```js
const person1 = {
name: "Jaxongir",
age: 27,
country: "Uzbekistan",
gender: "male",
hobbies: ["Reading", "Calisthenics", "Swimming"],
};
const person2 = {
name: "Lola",
age: 21,
country: "Russia",
gender: "female",
hobbies: ["Reading", "Knitting", "Swimming", "Badminton"],
};
function printBio(greeting) {
console.log(
`${greeting} ${this.gender === "male" ? "His name is" : "Her name is"} ${
this.name
} and is ${this.age} years old and is from ${
this.country
} and has following hobbies ${this.hobbies.join(", ")}`
);
}
printBio.call(person1, "Hello") // Hello His name is Jaxongir and is 27 years old and is from Uzbekistan
printBio.call(person2, "Hello") // Hello Her name is Lola and is 21 years old and is from Russia
```
**apply** - calls the function providing the context of this value and passes array of arguments
```js
function printBio(greeting) {
console.log(
`${greeting} ${this.gender === "male" ? "His name is" : "Her name is"} ${
this.name
} and is ${this.age} years old and is from ${this.country}`
);
}
printBio.apply(person1, ["Hello"]);
printBio.apply(person2, ["Hello"]);
```
**bind** - returns new function which can be stored variable and when that function is called this set to the provided object and passed values
```js
function printBio(greeting) {
console.log(
`${greeting} ${this.gender === "male" ? "His name is" : "Her name is"} ${
this.name
} and is ${this.age} years old and is from ${this.country}`
);
}
printBio.bind(person1)("Hello");
printBio.bind(person2)("Hello");
```
## What is JSON and its common operations? <a name="What is JSON and its common operations?"></a>
**JSON** stands for JavaScript Object Notation that's used to send data on the network. Even Douglas Crockford, the ex-Atari employee and man who coined and popularized the term ‘JSON’, states he ‘discovered’ JSON rather than ‘invented’
It has mainly two operations
**Parsing** - Converting from text to original data
```js
JSON.parse("{name: "Jaxongir"}") // {name: "Jaxongir"}
```
**Stringification** - Converting valid data to string format
```js
JSON.stringify({name: "Jaxongir"}) // "{name: "Jaxongir"}"
```
## What is the purpose of the array slice method? <a name="What is the purpose of the array slice method?"></a>
Array slice method used to copy part of a string and array so that we can work with the copy of array instead of modifying it. It's used to prevent mutation. here's the link to [slice](https://developer.mozilla.org/en-US/docs/web/javascript/reference/global_objects/array/slice)
```js
let fullname = "Jaxongir Rahimov"
console.log(fullname.slice(0, 10))
```
const people = ["Lola", "Jol", "Mat", Jaxongir"]
conosle.log(people.slice(0,2))
## What is the purpose of the array splice method? <a name="What is the purpose of the array splice method?"></a>
Array splice method is used to delete specified item in the given index or add single or multiple items in the given index. link to the [splice](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/splice)
```js
const people = ["Lola", "Jaxongir", "Test", "Horum"];
// Deleting single item in the given index
console.log(people); // ["Lola", "Jaxongir", "Test", "Horum"]
people.splice(2, 1);
console.log(people); // ["Lola", "Jaxongir", "Horum"]
// Adding multiple items in the given index
people.splice(2, 0, "Madina", "Nodira");
console.log(people); // ["Lola", "Jaxongir", "Madina", "Nodira", "Horum"]
```
## What is the difference between slice and splice? <a name="What is the difference between slice and splice?"></a>
**slice** - return the copy of the array and it does not mutate array
```js
const people = ["Lola", "Jaxongir", "Test", "Horum"];
console.log(people.slice(0,2)) // ["Lola", "Jaxongir")
console.log(peopl) // ["Lola", "Jaxongir", "Test", "Horum"]
```
**splice** - removes single or multiple items or add single or multiple items and it makes these changes in-place
```js
const people = ["Lola", "Jaxongir", "Test", "Horum"];
people.splice(2, 1);
console.log(people); // ["Lola", "Jaxongir", "Horum"]
```
## What are lambda or arrow functions? <a name="What are lambda or arrow functions?"></a>
**arrow function** - are ES6 feature with some differences than normal function declaraions
- arrow functions don't have this keyword but it uses whatever value of this in it's surrounding scope
- arrow functions can't be used to create constructor functions as for above mentioned reason
- arrow functions don't have super args
```js
const person = {
name: "Jaxongir",
test: () => {
console.log(arguments) // ReferenceError: arguments is not defined
console.log(this) // references to window object
},
test2() {
console.log(arguments) // [2, 13, 321, 2]
console.log(this) // {name: 'Jaxongir', test: ƒ, test2: ƒ}
},
};
person.test();
person.test2(2, 13, 321, 2);
```
## What is IIFE(Immediately Invoked Function Expression)? <a name="What is IIFE(Immediately Invoked Function Expression)?"></a>
**IIFE** - is the function as the name makes it obvious, executed immediately after it's declared. And it's mainly used to create Module design pattern, Singleton design patterns,
```js
const person = (() => {
let name = "Jaxongir";
let age = 27;
return {
name,
age,
};
})();
console.log(person) // {name: "Jaxongir", age: 27}
```
## How do you decode or encode a URL in JavaScript? <a name="How do you decode or encode a URL in JavaScript?"></a>
**encodeURI** - takes a string of url as a parameter and encodes it and return the encoded URI
**decodeURI** - takes encodedURI and returns the decoded url
```js
const uri = "https://mozilla.org/?x=шеллы";
const encoded = encodeURI(uri);
console.log(encoded); // https://mozilla.org/?x=%D1%88%D0%B5%D0%BB%D0%BB%D1%8B
console.log(decodeURI(encoded)) // https://mozilla.org/?x=шеллы
```
## What is memoization? <a name="What is memoization?"></a>
**Memoization** - is the technique in programming which optimizes the performance of the app by caching the result of the expensive function calls and returning the cached data as long as the same input occurs. And only performing that same expensive function calculation when different input is given
```js
const fib = (num, memo = []) => {
if (memo[num]) return memo[num];
if (num <= 2) return 1;
const res = fib(num - 1, memo) + fib(num - 2, memo);
memo[num] = res;
return res;
};
console.log(fib(5));
```
## What are classes in ES6? <a name="What are classes in ES6?"></a>
**ES6** - classes allow to write JavaScript programs in OOP style like in Java or other OOP languages. While under the hood, ES6 classes converted into constructor functions and Prototypical inheritance comes to play, it's still easier to write OOP style code especially for those who's coming from OOP languages.
```js
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
}
eat(food) {
console.log(`${this.name} eats ${food}`);
}
sleep(time) {
console.log(`${this.name} sleeps at ${time}`);
}
wakeup(time) {
console.log(`${this.name} wakesup at ${time}`);
}
}
class Teacher extends Person {
constructor(name, age, role, salary, hobbies) {
super(name, age);
this.role = role;
this.salary = salary;
this.hobbies = hobbies;
}
printBio() {
console.log(
`${this.name} is ${this.age} years old. And he is ${
this.role
} with the salary of $${
this.salary
}. His hobbies are: ${this.hobbies.join(", ")}`
);
}
}
const jaxongir = new Teacher("Jaxongir", 27, "Full-Stack mentor", 1500, [
"Reading",
"Calisthenics",
"Swmming",
]);
jaxongir.eat("Caviar") // Jaxongir eats Caviar
jaxongir.sleep("23:00 pm") // Jaxongir sleeps at 23:00 pm
jaxongir.wakeup("09:00 am") // Jaxongir wakesup at 09:00 am
jaxongir.printBio() // Jaxongir is 27 years old. And he is Full-Stack mentor with the salary of $1500. His hobbies are: Reading, Calisthenics, Swmming
```
## What are modules? <a name="What are modules?"></a>
**Modules** - are containers for the related reusable code which can be imported in multiple files.
## Why do you need modules? <a name="Why do you need modules?"></a>
Modules are great for data privacy, modularity, maintainability, namespacing, and reusability of the code. Basically they allow to think about the software in isolation which decreases the load in the brain and makes it easy to think about the overall structure of the program.
## What is a promise <a name=What is a promise?"></a>
**Promise** - the object that indicates the result of the asynchronous actions which either could be failure (rejected) or successful (fulfilled).
```js
const promise = new Promise(function (resolve, reject) {
// promise description
});
const promise = new Promise(
(resolve) => {
setTimeout(() => {
resolve("I'm a Promise!");
}, 5000);
},
(reject) => {}
);
promise.then((value) => console.log(value));
```
## What are the three states of promise? <a name="What are the three states of promise?"></a>
3 states of Promise are as described below:
- Fulfilled - when asynchronous request is successfully completed and response is given
- Rejected - when asynchronous request is unsuccessfull and no response is given which could be due to network error, authentication or authorization error and so on
- Pending - which is in between request being sent and response is coming back
## What is a callback function? <a name="What is a callback function?"></a>
**callback** - is the function that's passed as the argument to different function which then invoked inside that function body
```js
const nums = [1, 2, 3, 4, 5];
const myMap = (callbackFunc, nums) => {
newNums = [];
for (const num of nums) {
newNums.push(callbackFunc(num));
}
return newNums;
};
const modifiedNums = myMap((num) => num * num, nums);
console.log(modifiedNums) // [1, 4, 9, 16, 25]
```
## Why do we need callbacks? <a name="Why do we need callbacks?"></a>
Callback function is very useful especially on asynchronous operations like: when data is fetched or failed callback is called to indicate whether request is success or failure. Or in events when user clicks the button, callback is fired to execute code within callback body.
```js
const generateReportBtn = document.querySelector(".generate-report");
const generateReport = ()=>{
// do something
}
generateReportBtn.addEventListener("click", generateReport)
const populatePeople = ()=>{
// do something
}
setTimeout(populatePeople, 2000)
```
## What is a callback hell and how to avoid it? <a name="What is a callback hell and how to avoid it?"></a>
**Callback hell** - is the term used to describe when callback function is nested within one another too deeply which makes it harder to debug this code as it's very unreadable to even author of this code. Solution is using async await or promise chaining.
Callback hell example. This gives me nightmares in my dreams
```js
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
```
## What is promise chaining? <a name="What is promise chaining?"></a>
**Promise Chaining** - is the solution to callback hell that we saw above. Instead of nesting one callback within another callback, we use result of the previously fullfilled promise and return fullfilled promise for the next promise in the chain.
```js
new Promise(function(resolve, reject) {
setTimeout(() => resolve(1), 1000); // (*)
}).then(function(result) { // (**)
alert(result); // 1
return result * 2;
}).then(function(result) { // (***)
alert(result); // 2
return result * 2;
}).then(function(result) {
alert(result); // 4
return result * 2;
});
```
## What is promise.all? <a name="What is promise.all?"></a>
**Promise.all** - is the static method that takes arraf of iterable promises as an input and returns a single Promise which is the values of fulfilled promises in the array. The fulfilled promises are in the same order as their iterable promise. If any one the promise is rejected the whole operations is rejected. And even if last promise in the promise array is fulfilled, Promise.all() does not stop operation but waits until each and every promise is fulfilled.
```js
const promise1 = Promise.resolve(3);
const promise2 = 42;
const promise3 = new Promise((resolve, reject) => {
setTimeout(resolve, 100, 'foo');
});
Promise.all([promise1, promise2, promise3]).then((values) => {
console.log(values);
});
// Expected output: Array [3, 42, "foo"]
```
## What is the purpose of the race method in promise? <a name="What is the purpose of the race method in promise?"></a>
**Promise.race** - is the static method that takes an iterable promises as an input and returns the first resolved promise value.
```js
const promise1 = new Promise((resolve, reject) => {
setTimeout(resolve, 500, 'one');
});
const promise2 = new Promise((resolve, reject) => {
setTimeout(resolve, 100, 'two');
});
Promise.race([promise1, promise2]).then((value) => {
console.log(value);
// Both resolve, but promise2 is faster
});
// Expected output: "two"
```
## What is a strict mode in javascript? <a name="What is a strict mode in javascript?"></a>
**Strict mode** - in JavaScript used to set javascript environment to be in sticter mode which avoid errors such as declaring variable without keywords var,let,const. Strict can be initiated for the whole environment or for specific function.
## Why do you need strict mode? <a name="Why do you need strict mode?"></a>
We neeed strict mode because:
- Eliminates some JavaScript silent errors by changing them to throw errors.
- Fixes mistakes that make it difficult for JavaScript engines to perform optimizations: strict mode code can sometimes be made to run faster than identical code that's not strict mode.
- Prohibits some syntax likely to be defined in future versions of ECMAScript.
## How do you declare strict mode? <a name="How do you declare strict mode?"></a>
We can enable strict mode by just typing "use strict" either globally or within specific function.
```js
// Non strict mode
age = 27;
console.log(age) // 27
// Strict mode
"use strict";
age = 27;
console.log(age) // ReferenceError: age is not defined
```
## What is the purpose of the delete operator? <a name="What is the purpose of the delete operator?"></a>
**delete operator** - is used to delete a property of an object. if that property value is an object then reference to that object is lost
```js
const person = {
name: "John",
age: 34,
country: "USA",
};
console.log(person) // {name: "John", age: 34, country: "USA"}
delete person.country;
console.log(person) // {name: "John", age: 34}
```
## What is typeof operator? <a name="What is typeof operator?"></a>
**typeof operator** - is a function which is used to know what is the type of the expression passed to it
```js
console.log(typeof 1) // number
console.log(typeof "hello") // string
console.log(typeof false) // boolean
console.log(typeof []) // object
console.log(typeof {}) // object
console.log(typeof undefined) // undefined
console.log(typeof null) // object
console.log(typeof NaN) // number
```
## What is undefined? <a name="What is undefined?"></a>
**undefined** - is primitive data type. When variable declared but not value's given then in the console it's result is undefined.
```js
let name;
console.log(name) // undefined
```
## What is null? <a name="What is null?"></a>
**null** - is also primitive data type. And it's used to indicate the absense of the value.
```js
let name = null;
console.log(name) // null
```
## What is the difference between null and undefined? <a name="What is the difference between null and undefined?"></a>
**null*
- null is primitive data type and indicates that no memory is allocated for the variable in the memory
- when used on comparison converted to 0
- typeof null is an object
**undefined**
- undefined - is also primitive data type and indicates that memory is allocated for the variable and it's declared but no values is assinged
- when used on comparison converted to NaN
- typeof undefined is undefined
## What is eval? <a name="What is eval?"></a>
**eval** - function used to execute string of code as JavaScript script. string of code can be expressions, function calls etc..
**Warning**: Executing JavaScript from a string is an enormous security risk. It is far too easy for a bad actor to run arbitrary code when you use eval() - MDN
```js
const add = (num1, num2) => num1 + num2;
console.log(eval("add(1, 9)")); // 10
```
## What is the difference between window and document? <a name="What is the difference between window and document?"></a>
**window**
- window object is the root level element on each page
- it's by default available in every page
- it's has methods like confirm, alert
- document or DOM is the direct child property of itself
**document**
- document or DOM is the direct child of the window object. and it's representation of HTML
- it can be referenced via document or window.document
- it let's access DOM elements via methods such as: querySelector, getElementById, querySelectorAll and more
- it let's us to CRUD on the UI
## How do you access history in javascript? <a name="How do you access history in javascript?"></a>
We can page history via using window object's history object. history object has back and forward methods.
```js
// moves back to previous URI
window.history.back()
// moves forward to next URI
window.history.forward()
```
## How do you detect caps lock key turned on or not? <a name="How do you detect caps lock key turned on or not?"></a>
We can detect whether caps lock key is activated or not by using KeyboardEvent.getModifierState() which returns boolean value true for caps lock key is activated and false for not activated. It's not only detects capslock but also ScrollLock, NumsLock as well.
```js
const heading = document.querySelector("h1");
document.body.addEventListener("click", (e) => {
const isCapsLockOn = e.getModifierState("CapsLock");
if (isCapsLockOn) {
heading.textContent = "CapsLock is Activated";
} else {
heading.textContent = "CapsLock is Deactivated";
}
});
```
## What is isNaN? <a name="What is isNaN?"></a>
**isNaN** - is built-in function which is used to check whether the given input is NaN(Not a Number)
```js
console.log(isNaN("1")) // false it's a number;
console.log(isNaN("st")) // true it's not a number
```
## What are the differences between undeclared and undefined variables? <a name="What are the differences between undeclared and undefined variables?"></a>
**undeclared**
- variable is a variable which is not declared or assigned value when try to access it, error is thrown
- no memory is allocated for them as they don't exist yet
**undefined**
- variable is a variable which is declared but no value is assigned.
- memory is allocated and when try to print in the console, undefined is declared
## What are global variables? <a name="What are global variables?"></a>
**global variables** - are variables that are declared outside {} and function and they are accessible everywhere
```js
// global variable
let name = "Jaxongir"
(()=>{
console.log(name) // Jaxongir
})()
```
## What are the problems with global variables? <a name="What are the problems with global variables?"></a>
There are many problems with the global variables such as:
- namespace collision
- maintanability
- testability
| johongirr |
1,351,452 | Dynamically set property value in a class at runtime | About Demonstrates setting a property value in an instance of a class at runtime. Rarely... | 0 | 2023-02-02T20:29:33 | https://dev.to/karenpayneoregon/dynamically-set-property-value-in-a-class-at-runtime-ci6 | csharp, dotnet | ## About
Demonstrates setting a property value in an instance of a class at runtime.
Rarely needed as in C# object types and properties are known although there are rare occasions this may be needed when dealing with data received with a property name as type string and value of type object.
### Note
When originally wrote this (for Microsoft [TechNet](https://social.technet.microsoft.com/wiki/contents/articles/54296.dynamically-set-property-value-in-a-class-c.aspx)) I thought it would be rarely needed but perhaps wrong as there are 14 forks on the repsoitory
## Source code
Clone the following GitHub [repository](https://github.com/karenpayneoregon/dynamic-property-value) which uses Microsoft Visual Studio 2022 17.4.x, .NET Core 7.
## Example
Using the following class and enum.
```csharp
public class Settings
{
public string UserName { get; set; }
public int ContactIdentifier { get; set; }
public MemberType MemberType { get; set; }
public bool Active { get; set; }
public DateTime Joined { get; set; }
}
public enum MemberType
{
Gold,
Silver,
Bronze
}
```
An application has defined an instance of Settings.
```csharp
public Settings SingleSetting() =>
new()
{
UserName = "Karen",
MemberType = MemberType.Gold,
ContactIdentifier = 1,
Active = false,
Joined = new DateTime(DateTime.Now.Year,DateTime.Now.Month,DateTime.Now.Day)
};
```
A request comes in to change UserName from Karen to Anne. This requires use of reflection where the majority of examples will have a method to perform assertions and setting of simple properties e.g. string, int, date. While this works up until a property type is enum for instance then assertion needs to be performed.
The following code has been written specifically for the class Settings where enum type is handled.
```csharp
public static void SetValue(this Settings sender, string propertyName, object value)
{
var propertyInfo = sender.GetType().GetProperty(propertyName);
if (propertyInfo is null) return;
var type = Nullable.GetUnderlyingType(propertyInfo.PropertyType) ?? propertyInfo.PropertyType;
if (propertyInfo.PropertyType.IsEnum)
{
propertyInfo.SetValue(sender, Enum.Parse(propertyInfo.PropertyType, value.ToString()!));
}
else
{
var safeValue = (value == null) ? null : Convert.ChangeType(value, type);
propertyInfo.SetValue(sender, safeValue, null);
}
}
```
Works although each time this needs to be done on other classes an extension must be written. Instead a generic extension method will handle different classes.
```csharp
public static void SetValue<T>(this T sender, string propertyName, object value)
{
var propertyInfo = sender.GetType().GetProperty(propertyName);
if (propertyInfo is null) return;
var type = Nullable.GetUnderlyingType(propertyInfo.PropertyType) ?? propertyInfo.PropertyType;
if (propertyInfo.PropertyType.IsEnum)
{
propertyInfo.SetValue(sender, Enum.Parse(propertyInfo.PropertyType, value.ToString()!));
}
else
{
var safeValue = (value == null) ? null : Convert.ChangeType(value, type);
propertyInfo.SetValue(sender, safeValue, null);
}
}
```
To change a property value by string name and object here done in test methods. Note SetValue extension method knows the type as if a known type was passed.
Using a unit test project.
```csharp
namespace ShouldlyUnitTestProject
{
[TestClass]
public partial class MainTest : TestBase
{
[TestMethod]
[TestTraits(Trait.SettingsClass)]
public void Settings_UserNameChangeTest()
{
string expectedValue = "Anne";
var setting = SingleSetting();
setting.SetValue("UserName", "Anne");
setting.UserName.ShouldBe(expectedValue);
}
[TestMethod]
[TestTraits(Trait.SettingsClass)]
public void Settings_ContactIdentifierChangeTest()
{
var expectedValue = 2;
var setting = SingleSetting();
setting.SetValue("ContactIdentifier", 2);
setting.ContactIdentifier.ShouldBe(expectedValue);
}
[TestMethod]
[TestTraits(Trait.SettingsClass)]
public void Settings_MemberTypeChangeTest()
{
var expectedValue = MemberType.Bronze;
var setting = SingleSetting();
setting.SetValue("MemberType", MemberType.Bronze);
setting.MemberType.ShouldBe(expectedValue);
}
[TestMethod]
[TestTraits(Trait.SettingsClass)]
public void Settings_ActiveChangeTest()
{
var setting = SingleSetting();
setting.SetValue("Active", true);
setting.Active.ShouldBe(true);
}
[TestMethod]
public void Settings_JoinedChangeTest()
{
var expectedValue = new DateTime(Now.Year, Now.Month, Now.Day -1);
var setting = SingleSetting();
setting.Joined = new DateTime(Now.Year, Now.Month, Now.Day - 1);
setting.SetValue("Joined", new DateTime(Now.Year, Now.Month, Now.Day - 1));
setting.Joined.ShouldBe(expectedValue);
}
}
}
```
### Note
In the example above I used strings for property names, feel free to use nameof also e.g.
```csharp
[TestMethod]
[TestTraits(Trait.PersonClass)]
public void Person_FirstNameCheckIgnoreCase()
{
var expectedValue = "tim";
Person person = SinglePerson;
person.SetValue(nameof(Person.FirstName), "Tim");
person.FirstName.ShouldBe(expectedValue,
StringCompareShould.IgnoreCase);
}
```
## Summary
In this article an extension method has been presented to allow a property in a class to be changed. | karenpayneoregon |
1,351,462 | Como soluções de AST ajudam a criar um ciclo de desenvolvimento seguro? | As soluções de Análise de segurança em Aplicações (AST, do inglês Application Security Testing) podem... | 21,732 | 2023-02-02T20:45:23 | https://dev.to/m3corp/como-solucoes-de-ast-ajudam-a-criar-um-ciclo-de-desenvolvimento-seguro-3bj | veracode, beginners, tutorial, security | As soluções de Análise de segurança em Aplicações (AST, do inglês Application Security Testing) podem ajudar a tornar as práticas de ciclo de desenvolvimento seguro mais eficientes de várias maneiras:
- **Detecção automatizada de vulnerabilidades**: AST pode analisar o código em tempo de compilação ou em tempo real, detectando automaticamente vulnerabilidades e alertando os desenvolvedores para correções.
- **Integração no ciclo de desenvolvimento**: As soluções AST podem ser integradas no ciclo de desenvolvimento, permitindo que as equipes de desenvolvimento corrijam problemas de segurança o mais cedo possível.
- **Melhoria da qualidade do código**: AST pode fornecer insights sobre a qualidade do código e ajudar a melhorar a escrita de código seguro.
- **Redução de custos**: AST pode ajudar a reduzir os custos relacionados a correções de segurança tardias e a evitar riscos potenciais à segurança.
- **Rapidez e eficiência**: AST automatiza muitos dos processos que seriam realizados manualmente, o que pode tornar o ciclo de desenvolvimento mais rápido e eficiente.
Em resumo, as soluções AST podem ajudar a aumentar a eficiência e a eficácia das práticas de ciclo de desenvolvimento seguro, garantindo que as equipes de desenvolvimento produzam software seguro e protegido contra ameaças.
As soluções da Veracode possuem uma enorme capacidade de se integrar nas mais diversas ferramentas, caso queira ver alguns exemplos, basta consultar nosso [GitHub](https://github.com/M3Corp-Community/Veracode).
Para saber mais sobre a Veracode e solicitar um ambiente de testes, entre em [contato](https://www.m3corp.com.br/contato/). | m3corpinfosec |
1,351,712 | Control Microsoft Teams with a Stream Deck | Already have a Stream Deck and just want to get it working with Teams? Jump to the instructions to... | 0 | 2023-02-03T21:54:18 | https://jimbobbennett.dev/blogs/teams-streamdeck/ | teams, streamdeck, tutorial, productivity | ---
title: Control Microsoft Teams with a Stream Deck
published: true
date: 2023-02-02 00:00:00 UTC
tags: Teams,StreamDeck,tutorial,productivity
canonical_url: https://jimbobbennett.dev/blogs/teams-streamdeck/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/88lwe72q60xcerscmxp4.png
---
> Already have a Stream Deck and just want to get it working with Teams? [Jump to the instructions to set this up](#set-up-your-stream-deck-for-teams)
Like a lot of folks, I spend time in Microsoft Teams. It’s where I chat to my team and others at Microsoft, and it’s where I take most of my meetings.
Although Teams has a lot of good features, the UI can sometimes be a pain to use in meetings - especially as a Microsoft employee where we get to try the dogfood versions and things move all the time. There have been loads of occasions where I have tried to give a reaction and put up my hand by mistake, or tried to mute and left the call. WHat I really need is a tool to allow me to control teams without using the UI.
Makers have worked on hacks for this. For example, the key combination `ctrl+shift+m` toggles muting on teams. Add a big red button that simulates this key press and you have a quick way to mute or unmute. Here’s one example of this from [Jen Fox on Hackster](https://www.hackster.io/jenfoxbot/microsoft-teams-mute-button-7e9186).

For those with a less maker mindset, there’s now a new way to do this - using a Stream deck!

If you’ve not come across a Stream Deck before, its a neat little gadget that comes in different sizes and has an array of LCD buttons. You can set these buttons up to do things like control apps, or make REST requests, and as each button is an LCD screen you can fully customize what is displayed. For example, you can use one of these to control apps like OBS to switch scenes, or start streaming to Twitch.
There’s a whole Stream Deck store with plugins to extend the capabilities by controlling other apps or hardware (such as Phillips Hue lights). A Teams plugin has just been released!
## Set up your Stream Deck for Teams
To set up the Stream Deck, you need an API key for Teams to allow external apps to control it - makes sense really as Teams gives access to confidential work stuff, so you don’t want any app to be able to get access. Then you install the plug in, and set it up.
### Get an API key
To get an API key:
1. Select the ellipses from the top-right corner of Teams, then select **Settings**
2. Select the _Privacy_ tab, then scroll down to the _Third-party app API section_ and select **Manage API**
3. From the API settings, copy the API token. Use the **Generate** button to generate a new API key if needed. And yes, the UI is terrible and the key wraps out of the text box… 🤷
Now you have your key, you can set up your Stream Deck!
### Set up the Stream Deck
Teams is managed from a plugin from the Stream Deck store.
1. Open the Stream Deck store from the menu/taskbar icon
2. Search for Teams in the store, and install the Microsoft Teams plugin with the **install** button
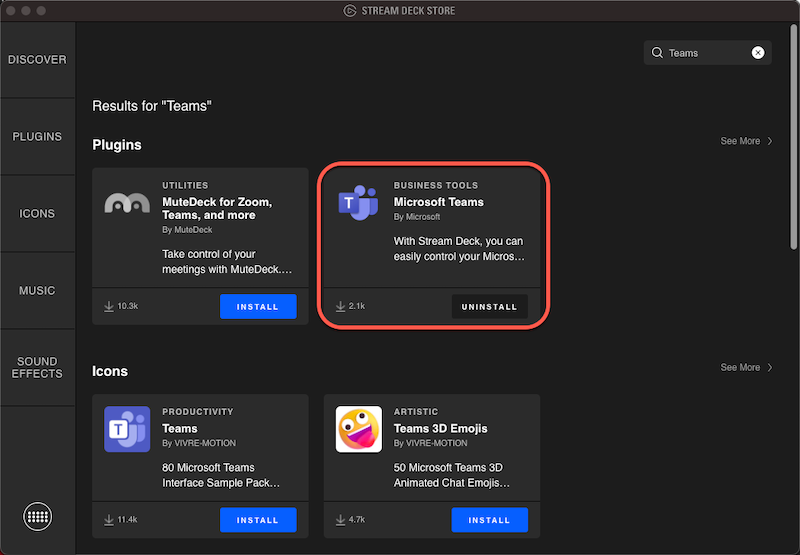
3. Once installed, configure your Stream Deck using the Teams options. I did mine by creating a new profile that is activated when Teams is active.
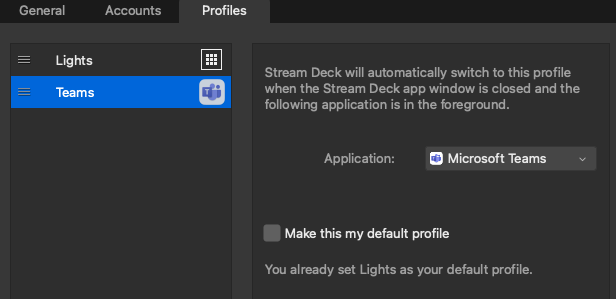
4. Once your profile is ready, select it then add buttons by dragging them from the Microsoft Teams group in the menu. After adding each button, you will need to set the _API token_ field to the API key you copied from Teams.
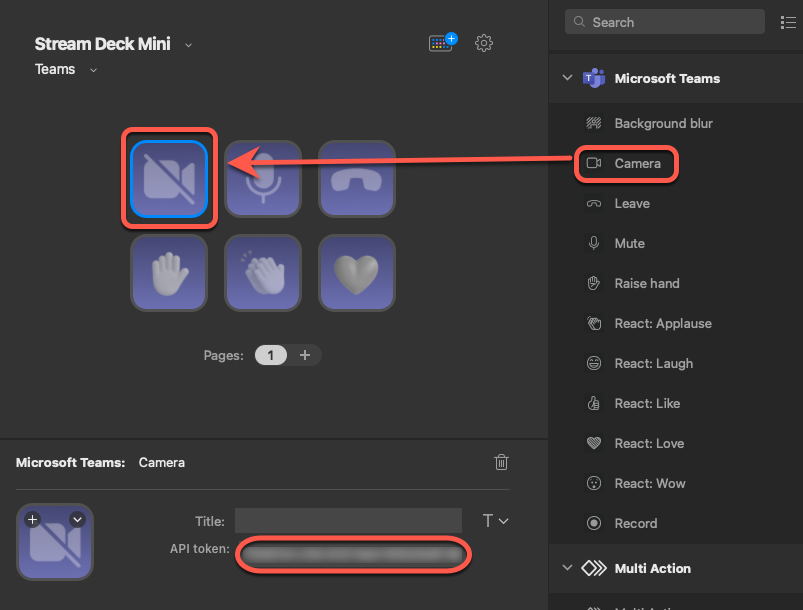
Done! You can now control Teams using your Stream Deck.
<hr>
Be sure to follow me for more cool posts!
{% embed https://dev.to/jimbobbennett %} | jimbobbennett |
1,351,868 | Today I completed 1601 Solutions on Hackerearth🥳🥳🥳 | I am glad that I enhanced my skills in Coding! hackerearth ... | 0 | 2023-02-03T05:14:09 | https://dev.to/chiki1601/today-i-completed-1601-solutions-on-hackerearth-3382 | chiki1601, programming |
I am glad that I enhanced my skills in Coding!
#hackerearth
#misspoojaanilkumarpatel | chiki1601 |
1,352,423 | Github Pages Tips if your img doesn't appear 🖼️ | When it comes to publishing a website on GitHub Pages, it's important to make sure that all the... | 0 | 2023-02-03T15:37:30 | https://dev.to/esogargar/github-pages-tips-if-your-img-doesnt-appear-5gne | beginners, github, githubpages, programming | When it comes to publishing a website on GitHub Pages, it's important to make sure that all the assets, including images, are properly linked.
If your images don't appear after you've published your website, there are a few things you can check to resolve the issue.
Tips for fixing missing images:
1️⃣Pay attention to the writing of image extensions:
On GitHub Pages, the case sensitivity of file names matters, so make sure you're using the correct capitalization for your image file extensions. For example:
`Images.png` is different from `images.png`
2️⃣Check your image src path. If your code includes a forward slash (/) before the image path, remove it.
For example, if your src path is
`src="/images/images.png"`❌
change it to
`src="images/images.png"`✅
This will often solve the issue of missing images on GitHub Pages
By following these simple tips, you can quickly resolve any issues with missing images on your website when publishing it on GitHub Pages. By paying attention to details like file name capitalization and src paths, you can ensure that your website looks and works exactly as you intended it to.
 | esogargar |
1,351,879 | End to End testing in Laravel with cypress | The first time I heard someone mention 'Writing automated tests', I thought they were being funny,... | 0 | 2023-02-17T10:13:32 | https://flaircore.com/blog/end-end-testing-laravel-cypress | laravel, cypress, e2e, testing |
The first time I heard someone mention 'Writing automated tests', I thought they were being funny, don't get me wrong, I was self learning (taught), and the person had taught us various debugging techniques and tools, including xdebug, dd, the browser among others; but I would later come to realize the funny guy wasn't being funny !.
I won’t bore you with the details of my realization, so we keep this blog as short, as always; but it took a real world scenario for me to see the importance of writing tests. There are various types of tests, but in this blog, we will explore e2e tests with cypress because it's free, fast, written in JavaScript, among other reasons: there're also other great options for this kind of tests, besides cypress.
To get started with e2e tests, we need an app, with [implemented user behaviors and layout (output) to test](https://github.com/bradtraversy/laragigs). The app is from a Laravel tutorial: you're welcome to [binge watch, code along](https://www.youtube.com/watch?v=MYyJ4PuL4pY) or skip to the next section (below).
### Getting started;
To get started, fork the repo and git clone that into your machine, and checkout a new branch called e2e by running the command `git checkout -b e2e`, then `composer install` to install the apps dependencies, defined in the `composer.json` file.
We’re also going to edit a file or three, to generate the required data, we’ll be writing tests for, just like a real app, before getting started with the tests.
We don’t need to setup a mysql server for this, so we will fallback to using an sqlite database. Edit the file `config/database.php` line 18 to `''default' => env('DB_CONNECTION', 'sqlite'),`
Then to generate users with a hashed password we can use to test login, change the file `database/factories/UserFactory.php` line 25 to `'password' => Hash::make('123'), // password`, be sure to add a use statement at the top of the file for the `Illuminate\Support\Facades\Hash;` we just used to hash the password string.
Lastly, before we run the app, let’s edit the file `database/seeders/DatabaseSeeder.php` so we can generate multiple users with multiple Job listings for each user. Change the implementation for the run method to
```php
$users = User::factory(5)->create()
->pluck('id')->toArray();
foreach ($users as $uid) {
Listing::factory(20)->create([
'user_id' => $uid
]);
}
```
### Starting the application:
- Copy `example.env` as `.env`
- Update the DB_CONNECTION to `sqlite` in the .env file, and create the `database/database.sqlite` file.
- Run `php artisan key:generate` to generate your `APP_KEY`, (auto update .env file)
- Run `php artisan migrate` followed by `php artisan db:seed` then `php artisan serve` to run the migrations, seed the dummy (fake users and listings ) data, and run a local development server for your application respectively.
The last command prints a url, which we can use to access the app during development.
From your favorite browser, open that url, notice the layouts; the pagination and it’s behavior when clicked: open an sqlite db browser and select an email in the `database/database.sqlite` file, then click the login link and try the selected email with password "123" (as set during seeding), try again but with the wrong password and notice the behavior, as these will be the behaviors we will be writing tests for in the next section.
### Getting Started with cypress:
We already have a `package.json` that’s generated by default when we first create a Laravel project using composer, the next step (from a different terminal window, and at the root of this project folder) is running `npm i cypress --dev` to install cypress.
Then include `"cypress:open": "cypress open"` under `scripts` in the `package.json`, then run `npm run cypress:open` to open cypress for the first time. And then follow the next prompts to get set up with cypress.
Some files and folders are auto generated when first setting up cypress, these include `cypress.config.js` and a `cypress/` folder, which contains other folders. For this blog, let’s focus on the `e2e` subfolder inside the `cypress` folder.
Inside this folder, we can arrange the tests in folders/files.
Let’s add a folder/file named `cypress/e2e/landing-page/landingpage.cy.js` and another `cypress/e2e/user-auth/login.cy.js` in this project, to test the landing page and login page elements and user behaviors.
With cypress, we can create a test suite with `describe`, and run some setup code in `beforeEach`, like to visit the url of the page we want to test in our case.
Then from here, we can test each element; its attributes and/or their values, as well as their behaviors on user actions, like clicks.
For the landing page let’s test;
* The search input
* The Pagination elements and their behavior on clicks
* The footer `Post Job` link for non logged in users
In that order:
Add the following contents in the `landingpage.cy.js` to include the test cases above.
```javascript
/// <reference types="cypress" />
describe('landing page', () => {
beforeEach(() => {
cy.visit('http://127.0.0.1:8000/')
})
it('displays landing page elements and basic navigation for non logged in user', () => {
// The search form input
cy.get(`input[name="search"]`).should('have.attr', 'placeholder')
.and('eq', 'Search Laravel Gigs...')
// Pagination (generated enough items).
cy.get(`nav[role="navigation"]`).should('have.attr', 'aria-label')
.and('eq', 'Pagination Navigation')
// To to page 3 on pagination
// Get third item (index) from list.
cy.get(`[aria-label="Pagination Navigation"] a`).eq(2)
.click()
cy.url().should('include', '?page=3')
// Footer items, on 'Post Job' btn, user should go to login, if not logged in.
cy.contains('Post Job').click()
cy.url().should('include', '/login')
})
})
```
For the login page let’s test;
* The form crf token for the submission security.
* Successful login and nav items for the logged in user.
* Unsuccessful login when a user enters a wrong password.
In that order:
And the following contents to `login.cy.js` to include the above tests;
```javascript
/// <reference types="cypress" />
describe('Login workflow', () => {
beforeEach(() => {
cy.visit('http://127.0.0.1:8000/login')
})
it('login page elements', () => {
// Test the form
cy.get(`form[action="/users/authenticate"]`).should('exist')
// Crf token and value.
cy.get(`input[name="_token"]`).should('be.hidden')
cy.get(`input[name="_token"]`).invoke('val').then(val => {
val.length > 8
})
})
it('should successfully login', () => {
// email = dkuvalis@example.com
// password = 123
// name = Hugh Hermann
// see \database\database.sqlite
cy.get(`input[name="email"]`).type('dkuvalis@example.com')
cy.get(`input[name="password"]`).type('123')
cy.get('button[type="submit"]').click();
// Elements for logged in users:
cy.get('nav ul > li:first-child > span').invoke('text').then(text => {
const trimmedText = text.trim();
cy.wrap(trimmedText).should('eq', 'Welcome Hugh Hermann');
})
})
it('should show error on unsuccessful login', () => {
// Wrong credentials:
// email = dkuvalis@example.com
// password = 1234
// name = Hugh Hermann
cy.get(`input[name="email"]`).type('dkuvalis@example.com')
cy.get(`input[name="password"]`).type('1234')
cy.get('button[type="submit"]').click();
// Show error if credential wrong:
cy.get('p:contains("Invalid Credentials")').should('exist')
})
})
```
### Running the tests:
After running `npm run cypress:open`, the cypress app opens, and from here, you can follow the prompts and choose a browser from the options to run the tests on.
When running the tests, one can view the tests being run as well the actions of the same on the app.
### Conclusion:
We touched a little about getting started with Cypress testing in a Laravel app, from here, one can write more tests to cover the crucial parts of their application.
With Cypress, developers can write comprehensive tests that simulate user behavior and catch potential issues before they reach production. This also saves developers time and resources by automating the testing process, thus improving the quality of your application.
It's also recommend to use data attributes specific to testing, as DOM selectors instead of class/ids like I have done.
### Resources:
* The initial app @ [https://github.com/bradtraversy/laragigs](https://github.com/bradtraversy/laragigs)
* The app with tests (PR) @ [https://github.com/flaircore/laragigs/pull/1/files](https://github.com/flaircore/laragigs/pull/1/files)
* Cypress docs [https://docs.cypress.io/guides/getting-started/installing-cypress](https://docs.cypress.io/guides/getting-started/installing-cypress)
* Laravel docs [https://laravel.com/docs](https://laravel.com/docs)
| nickbahson |
1,351,884 | Application Streaming as a potential solution for non-traditional problems | Application streaming is a technology that allows users to access and use software applications over... | 0 | 2023-02-03T05:46:56 | https://dev.to/neverinstall/application-streaming-as-a-potential-solution-for-non-traditional-problems-2a23 | Application streaming is a technology that allows users to access and use software applications over the internet without having to install them on their local devices. This technology has the potential to solve a number of non-traditional problems that traditional solutions cannot easily address.
In this blog, we will explore some potential uses of application streaming as a solution for non-traditional problems.
## Access to specialized software
One of the main benefits of application streaming is that it allows users to access specialized software that they may not have installed on their local devices. This is especially useful for users who need specialized software for their work but do not have the necessary resources to install it on their devices.
For example, a user who needs to use 3D modeling software for their work may not have the necessary hardware or software requirements to install the software on their local device. In this case, application streaming could provide access to the software over the internet, allowing the user to use it from any device with an internet connection.
## Cost-effective solution for businesses
Application streaming is also a cost-effective solution for businesses, as it allows them to provide access to software applications without purchasing and installing them on individual devices. This can be especially useful for businesses with many employees, as it can save them significant money on software licenses and installation costs.
For example, a business that needs to provide access to a specific software application to its employees can do so through application streaming rather than purchasing and installing the software on each employee's device. This can result in significant cost savings for the business.
## Enhanced security
Application streaming can also enhance security by providing a centralized platform for managing and accessing software applications. With traditional software installations, it can be difficult to control and monitor access to the software as it is installed on individual devices. This can lead to security risks, such as unauthorized access or tampering with the software.
By using application streaming, businesses can centralize the management and access of software applications, allowing them to easily control and monitor access. This can reduce the risk of unauthorized access and improve overall security.
## Improved collaboration
Application streaming can also improve collaboration, allowing users to access and use software applications from any device with an internet connection. This can be especially useful for businesses with remote employees, as it allows them to access and use the same software applications as their colleagues in the office.
For example, a team of employees working on a project can use application streaming to collaborate on documents and presentations in real time, regardless of location. This can improve communication and productivity within the team.
In conclusion, application streaming is a technology that has the potential to solve a number of non-traditional problems, including providing access to specialized software, cost-effective solutions for businesses, enhanced security, and improved collaboration. It is a technology worth considering for businesses and organizations looking for innovative solutions to their challenges.
## Limited hardware resources
Application streaming can be a useful solution for users with limited hardware resources, such as low-end devices or devices with limited storage space. Application streaming allows users to access and use software applications over the internet without installing them on their local devices. This can be especially useful for users who need to use resource-intensive software but do not have the hardware requirements to install it on their own devices.
## Updating and maintaining software
Application streaming can also simplify updating and maintaining software, allowing users to access the latest software version over the internet. With traditional software installations, users must manually update the software on their own devices, which can be time-consuming and prone to errors. Users can automatically access the latest software version using application streaming without worrying about updating it themselves.
## Providing access to software in remote or underserved areas
Application streaming can also provide access to software in remote or underserved areas, where traditional software installations may not be possible due to a lack of infrastructure or resources. Using application streaming allows users in these areas to access and use software applications over the internet, allowing them to take advantage of the same tools and resources as users in more developed areas.
## Increasing flexibility and mobility
Finally, application streaming can increase flexibility and mobility for users, as it allows them to access and use software applications from any device with an internet connection. This can be especially useful for users who need to work on the go or who frequently switch between different devices. Using application streaming, users can access the same software applications and files from any device without worrying about transferring files or installing software.
## Conclusion
As internet-based technologies continue to grow and evolve, application streaming will likely become an increasingly important solution for solving a wide range of problems. Accessing and using software applications over the internet without needing installation on local devices offers numerous benefits for businesses and organizations, including cost-effectiveness, enhanced security, and improved collaboration. As the technology behind application streaming continues to improve and the availability of high-speed internet becomes more widespread, this technology will likely play an increasingly important role in solving a wide range of problems in the future. | amy87009 | |
1,352,311 | Arduino Projects For Engineering Students | Are you an engineering student looking for some exciting Arduino projects to work on? Look no... | 0 | 2023-02-03T13:03:33 | https://dev.to/arunprakash142/arduino-projects-for-engineering-students-5pd | webdev, javascript, beginners, programming | Are you an engineering student looking for some exciting Arduino projects to work on? Look no further, because Takeoff projects has all the projects you need to get your better grade in engineering!
We offer a wide range of Arduino projects—from beginner to advanced—that will help you hone your engineering skills. Our projects are designed to teach you important concepts and use cases in engineering, from basic circuitry and electronics to more complex coding tasks. You’ll also learn about the different types of Arduino boards, their features and capabilities, and how to use them for different applications.

With our [Arduino Projects For Engineering Students](https://takeoffprojects.com/arduino-projects-for-engineering-students), you’ll have the opportunity to explore the world of engineering and technology with the help of a great platform. Whether you’re a novice just starting out or a more experienced student looking to refine your skills, our projects are sure to provide the perfect challenge. And with our wide selection of tutorials and resources, you’ll be able to get the most out of your experience.
So don’t wait any longer—sign up for Arduino Projects For Engineering Students today and start learning the skills you need to get ahead in your engineering career. With our projects, you’ll be well on your way to becoming a successful engineer!
| arunprakash142 |
1,352,326 | How to fix "‘list’ object is not callable" in Python | ✋ Update: This post was originally published on my blog decodingweb.dev, where you can read the... | 0 | 2023-02-03T13:36:46 | https://builtin.com/articles/typeerror-list-object-is-not-callable | python, programming | > ✋ **Update:** This post was originally published on my blog [decodingweb.dev](https://www.decodingweb.dev), where you can read the [latest version](https://www.decodingweb.dev/python-typeerror-list-object-is-not-callable-fix) for a 💯 user experience. _~reza_
The “TypeError: ‘list’ object is not callable” error occurs when you try to call a list (`list` object) as if it was a function!
Here’s what the error looks like:
```
Traceback (most recent call last):
File "/dwd/sandbox/test.py", line 6, in
more_items = list(range(11, 20))
^^^^^^^^^^^^^^^^^^^
TypeError: 'list' object is not callable
```
Calling a list object as if it's a callable isn't what you'd do on purpose, though. It usually happens due to a wrong syntax or overriding a function name with a list object.
Let's explore the common causes and their solutions.
## How to fix TypeError: 'list' object is not callable?
This TypeError happens under various scenarios:
1. <u>Declaring a variable with a name that's also the name of a function</u>
2. <u>Indexing a list by parenthesis rather than square brackets</u>
3. <u>Calling a method that's also the name of a property</u>
4. <u>Calling a method decorated with `@property`</u>
**Declaring a variable with a name that's also the name of a function:** A Python function is an object like any other built-in object, such as `str`, `int`, `float`, `dict`, `list`, etc.
All built-in functions are defined in the `builtins` module and assigned a global name for easier access. For instance, list refers to the `__builtins__.list` function.
That said, overriding a function (accidentally or on purpose) with any value (e.g., a `list` object) is technically possible.
In the following example, we've declared a variable named `list` containing a list of numbers. In its following line, we try to create another list - this time by using the `list()` and `range()` functions:
```python
list = [1, 2, 3, 4, 5, 6, 8, 9, 10]
# ⚠️ list is no longer pointing to the list function
# Next, we try to generate a sequence to add to the current list
more_items = list(range(11, 20))
# 👆 ⛔ Raises: TypeError: ‘list’ object is not callable
```
If you run the above code, Python will complain with a "TypeError: 'list' object is not callable" error because we've already assigned the `list` name to the first list object.
We have two ways to fix the issue:
1. Rename the variable `list`
2. Explicitly access the `list()` function from the builtins module (`__bultins__.list`)
The second approach isn't recommended unless you're developing a module. For instance, if you want to implement an `open()` function that wraps the built-in `open()`:
```python
# Custom open() function using the built-in open() internally
def open(filename):
# ...
__builtins__.open(filename, 'w', opener=opener)
# ...
```
In almost every other case, you should always avoid naming your variables as existing functions and methods. But if you've done so, renaming the variable would solve the issue.
So the above example could be fixed like this:
```python
items = [1, 2, 3, 4, 5, 6, 8, 9, 10]
# Next, we try to generate a sequence to add to the current list
more_items = list(range(11, 20))
```
This issue is common with function names you're more likely to use as variable names. Functions such as `vars`, `locals`, `list`, `all`, or even user-defined functions.
In the following example, we declare a variable named `all` containing a list of items. At some point, we call `all()` to check if all the elements in the list (also named `all`) are `True`:
```python
all = [1, 3, 4, True, 'hey there', 1]
# ⚠️ all is no longer pointing to the built-in function all()
# Checking if every element in all is True:
print(all(all))
# 👆 ⛔ Raises TypeError: 'list' object is not callable
```
Obviously, we get the TypeError because the built-in function `all()` is now shadowed by the new value of the `all` variable.
To fix the issue, we choose a different name for our variable:
```python
items = [1, 3, 4, True, 'hey there', 1]
# Checking if every element in all is True:
print(all(items))
# Output: True
```
⚠️ Long story short, you should never use a function name (built-in or user-defined) for your variables!
Overriding functions (and calling them later on) is the most common cause of the "TypeError: 'list' object is not callable" error. It's similar to [calling integer numbers](https://www.decodingweb.dev/python-typeerror-int-object-is-not-callable-fix) as if they're callables.
Now, let's get to the less common mistakes that lead to this error.
**Indexing a list by parenthesis rather than square brackets:** Another common mistake is when you index a list by `()` instead of `[]`. Based on Python semantics, the interpreter will see any identifier followed by a `()` as a function call. And since the parenthesis follows a list object, it's like you're trying to call a list.
As a result, you'll get the "TypeError: ‘list’ object is not callable" error.
```python
items = [1, 2, 3, 4, 5, 6]
print(items(2))
# 👆 ⛔ Raises TypeError: 'list' object is not callable
```
This is how you're supposed to access a list item:
```python
items = [1, 2, 3, 4, 5, 6]
print(items[2])
# Output: 3
```
**Calling a method that's also the name of a property:** When you define a property in a class constructor, it'll shadow any other attribute of the same name.
```python
class Book:
def __init__(self, title, authors):
self.title = title
self.authors = authors
def authors(self):
return self.authors
book = Book('The Pragmatic Programmer', ['David Thomas', 'Andrew Hunt'])
print(book.authors())
# 👆 ⛔ Raises TypeError: 'list' object is not callable
```
In the above example, since we have a property named `authors`, the method `authors()` is shadowed. As a result, any reference to `authors` will return the property `authors`, returning a list object. And if you call this list object value like a function, you'll get the "TypeError: ‘list’ object is not callable" error.
The name `get_authors` sounds like a safer and more readable alternative:
```python
class Book:
def __init__(self, title, authors):
self.title = title
self.authors = authors
def get_authors(self):
return self.authors
book = Book('The Pragmatic Programmer', ['David Thomas', 'Andrew Hunt'])
print(book.get_authors())
# Output: ['David Thomas', 'Andrew Hunt']
```
**Calling a method decorated with `@property` decorator:** The `@property` decorator turns a method into a “getter” for a read-only attribute of the same name. You need to access a getter method without parenthesis, otherwise you'll get a TypeError.
```python
class Book:
def __init__(self, title, authors):
self._title = title
self._authors = authors
@property
def authors(self):
"""Get the authors' names"""
return self._authors
book = Book('The Pragmatic Programmer', ['David Thomas', 'Andrew Hunt'])
print(book.authors())
# 👆 ⛔ Raises TypeError: 'list' object is not callable
```
To fix it, you need to access the getter method without the parentheses:
```python
book = Book('The Pragmatic Programmer', ['David Thomas', 'Andrew Hunt'])
print(book.authors)
# Output: ['David Thomas', 'Andrew Hunt']
```
Problem solved!
Alright, I think it does it! I hope this quick guide helped you fix your problem.
Thanks for reading.
**❤️ You might like:**
- [TypeError: ‘tuple’ object is not callable in Python](https://www.decodingweb.dev/python-typeerror-tuple-object-is-not-callable-fix)
- [TypeError: ‘dict’ object is not callable in Python](https://www.decodingweb.dev/python-typeerror-dict-object-is-not-callable-fix)
- [TypeError: ‘str’ object is not callable in Python](https://www.decodingweb.dev/python-typeerror-str-object-is-not-callable-fix)
- [TypeError: ‘float’ object is not callable in Python](https://www.decodingweb.dev/python-typeerror-float-object-is-not-callable-fix)
- [TypeError: 'int' object is not callable in Python](https://www.decodingweb.dev/python-typeerror-int-object-is-not-callable-fix) | lavary |
1,352,409 | New Blog Post | This post is new | 0 | 2023-02-03T15:03:38 | https://dev.to/eruiz4/new-blog-post-33ke | This post is new | eruiz4 | |
1,354,546 | On software algorithm | Introduction We've done a t-shirt for creating software algorithms. When creating... | 0 | 2023-02-05T15:53:31 | https://dev.to/devshirt_club/on-software-algorithm-27d4 | algorithms, programming, watercooler | ### Introduction
> We've done a t-shirt for creating software algorithms. When creating algorithms we often feel as mad scientists.

### How we build algorithms
We try to build something that is machine wise efficient. Ideally an **algorithm that runs in n time and occupies n space**. But you know, don't get too hard on yourself if it is n*n time.
Same as with any kind of code, the best way is to have something working, then do small, iterative improvements. This skill is often tested in **technical interviews**, there are also countless platforms which automate that kind of testing.
At the end of the day it is a skill that is cherished and can always be improved with practice.
### Algorithms - from origins to today
The concept of algorithms has existed since antic times. Pretty much at the same time math was "invented" people started to wonder how can we do some sort of calculations.
These days, even though we are inventing and discovering more algorithms each day, we are mostly using algorithms that were invented even before computers became a thing, or as the matter of fact before first computer was even invented. Today, there is countless more resources, and multiples of people working on improving various algorithms.
Besides doing concrete implementations on different fields, such as machine learning on plants identifications, all the way to advanced stock market oracles. We as humanity are investing heavily in solving some of the 1 million $$$ worth millennial problems.
We are also investing heavily in teaching non mathematicians about most famous and efficient algortihms such as quick sort or similar. We have countless of testing grounds or if you want to call them algorithms playgrounds such as leetcode or hackerrank which publish time limited competitions requiring algorithmic problem solving skills.
### Software algorithms for non techies
Software algorithms are closely tied to math and to logical thinkings. Writing a complex algorithm is similar to solving a complex math equation. There are a lot of common and standardised way of doing things but most often you need to adapt a certain algorithm to your needs. They can be written in almost any programming language.
More often than not, a concrete programming language will come with predefined algorithms implementations as part of some standard library.
Algorithms are all about doing a certain thing, in a machine resources efficient way. There can exist multiple algorithms that provide the same solution. But important difference being how much compute time and compute space they consume.
Some of them are so famous and so long lasting that there is a $1,000,000 prize ensured for a person that manages to solve it.
Like this one:
A traveling salesman problem, or another version of it, organising household accommodation for students algorithm/math problem.
read more about it here:
[Household accommodation problem](https://www.claymath.org/millennium-problems/p-vs-np-problem)
### Outro
We are a payed swag club for developers, every month we publish 2 t-shirts with commissioned illustrations , their articles and their story.
You can follow us here to stay up to date with our latest stuff. Or you can purchase our t-shirts at our [developers t-shirts shop](https://www.devshirt.club) | devshirt_club |
1,352,428 | JavaScript function call() method: | imaging that: you have some object in your program(with JS language) and you have some name:value... | 0 | 2023-02-03T15:46:12 | https://dev.to/anateotfw/javascript-function-call-and-apply-method-3noo | javascript, webdev, programming, node |
imaging that: you have some object in your program(with JS language) and you have some `name:value` in your object with any data type.
if we say any data type that can be to this mean we want write a name:value and "value" be a function?
Ofcourse!!
if function situation is to be that, function take two parameters and then return their in output, and if we want specify our parameters from a another object we can use `call` method!
example:
```
const x = {
fullName: function(){
return this.name + " " + this.lName
}
};
```
But where is name or lName(last name)?
is here: (in another object, we take from this object)
```
const object1 = {
name: "ana",
lName: "amini"
}
```
So now we achieve to `method part`:
```
console.log(x.fullName.call(object1));
```
and then output will be like that:
```
ana amini
```
Tip(1): for showing a value of the name in object we use from this rule: `objectName.name1`;
Tip(2): we use `" "` in our function, so our values are separate from each other!
;)!
| anateotfw |
1,352,432 | Transparent IT Job Market Report 2022 | Have you asked yourself how many people in the Swiss IT industry work remotely, or how much... | 0 | 2023-02-03T15:54:40 | https://dev.to/josephharperr/transparent-it-job-market-report-2022-342p | career, hiring | ## Have you asked yourself how many people in the Swiss IT industry work remotely, or how much do the top 10% beast earning engineers actually make?
We've got some answers for you! Our first **Transparent IT Job Market Report** has all the juicy details.
We looked at over **4600 responses** and salary data from **1500 tech jobs** and got a pretty clear picture of the **Swiss tech industry** right now. Our goal was to help everyone - companies, recruiters, and employees - understand each other better and make the job market a more transparent place.
Some insights are quite surprising:
- Over **50% tech** employees have the possibility to work **fully remote**
- **85%** of respondents would be happy to have a **4-day work-week**
- Only **40%** of tech workers stay at a company **longer than 5 years**
Download the full report here: https://swissdevjobs.ch/hub/reports/it-job-market-report-2022
| josephharperr |
1,352,486 | XML-Generation in SQL with Namespaces | One of my favorite features of (Oracle-)SQL is how easy it is to turn relational data into other data... | 0 | 2023-02-24T14:56:36 | https://developer-sam.de/2023/02/xml-generation-in-sql-with-namespaces/ | 100codeexamples, sql, oracle, xml | ---
title: XML-Generation in SQL with Namespaces
published: true
date: 2023-02-03 16:45:25 UTC
tags: 100CodeExamples,SQL,Oracle,XML
canonical_url: https://developer-sam.de/2023/02/xml-generation-in-sql-with-namespaces/
---
One of my favorite features of (Oracle-)SQL is how easy it is to turn relational data into other data formats like JSON or XML.
Let’s assume we have some data in the tables `character` and `favorite_food` :
```sql
create table characters (
id integer not null primary key,
name varchar2(100) unique
);
create table favorite_food (
character_id integer not null references characters( id ),
food varchar2(4000)
);
insert into characters values (1, 'Chewbacca');
insert into characters values (2, 'Darth Vader');
insert into favorite_food values ( 1, 'Grilled Pork');
insert into favorite_food values ( 1, 'Cooked Pork');
insert into favorite_food values ( 1, 'Raw Pork');
insert into favorite_food values ( 2, 'Cheesecake');
```
Selecting will lead to a table like this:
```sql
select *
from characters c
inner join favorite_food ff on c.id = ff.character_id;
```
| ID | NAME | CHARACTER_ID| FOOD |
| --- | --- | --- | --- |
| 1 | Chewbacca | 1 | Grilled Porg |
| 1 | Chewbacca | 1 | Cooked Porg |
| 1 | Chewbacca | 1 | Raw Porg |
| 2 | Darth Vader | 2 | Cheesecake |
With SQL, it is very easy to turn this into a nested XML structure:
```sql
select
xmlelement("Characters",
xmlagg(
xmlelement("Character",
xmlforest(
c.name as "name"
),
xmlelement("favouriteFoods",
xmlagg(
xmlforest(
ff.food as "food"
)
)
)
)
)
)
from characters c
inner join favorite_food ff on c.id = ff.character_id
group by name
```
```xml
<Characters>
<Character>
<name>Chewbacca</name>
<favouriteFoods>
<food>Grilled Pork</food>
<food>Raw Pork</food>
<food>Cooked Pork</food>
</favouriteFoods>
</Character>
<Character>
<name>Darth Vader</name>
<favouriteFoods>
<food>Cheesecake</food>
</favouriteFoods>
</Character>
</Characters>
```
## But what if we need to add XML Namespaces?
XML is a very powerful and therefore sometimes a bit complex format. For example, it comes with namespaces to allow different structures to build on each other without name conflicts.
What if we require all the nodes to start with our very own `http://developer-sam.de/codeexamples` namespace?
It’s relatively easy to get a prefix into a node name, since `xmlelement` allows anything in the name element:
```sql
select
xmlelement("sam:Characters",
...
```
But how do we get that `xmlns:sam="http://developer-sam.de/codeexamples"` into our main node?
Maybe that’s easy to answer for you, but I needed a while of thinking and trying out today before it hit me:
**The `xmlns` in an XML is just an ordinary XML attribute.**
And therefore we can easily add it:
```sql
select
xmlelement("sam:Characters",
xmlattributes(
'http://developer-sam.de/codeexamples' as "xmlns:sam"
),
xmlagg(
xmlelement("sam:Character",
xmlforest(
c.name as "name"
),
xmlelement("favouriteFoods",
xmlagg(
xmlforest(
ff.food as "food"
)
)
)
)
)
)
from characters c
inner join favorite_food ff on c.id = ff.character_id
group by name
```
And Oracle even puts in the xmlns wherever it is used later in the XML:
```xml
<sam:Characters xmlns:sam="http://developer-sam.de/codeexamples">
<sam:Character xmlns:sam="http://developer-sam.de/codeexamples">
<name>Chewbacca</name>
<favouriteFoods>
<food>Grilled Pork</food>
<food>Raw Pork</food>
<food>Cooked Pork</food>
</favouriteFoods>
</sam:Character>
<sam:Character xmlns:sam="http://developer-sam.de/codeexamples">
<name>Darth Vader</name>
<favouriteFoods>
<food>Cheesecake</food>
</favouriteFoods>
</sam:Character>
</sam:Characters>
```
I find this very neat!
The post [XML-Generation in SQL with Namespaces](https://developer-sam.de/2023/02/xml-generation-in-sql-with-namespaces/) appeared first on [Developer Sam](https://developer-sam.de). | pesse |
1,352,615 | Who is a Software Engineer | I remember the time I just got accepted for a junior software engineer role at a remote company and... | 0 | 2023-02-03T23:02:11 | https://drex.hashnode.dev/who-is-a-software-engineer | ---
title: Who is a Software Engineer
published: true
date: 2023-02-03 14:18:43 UTC
tags:
canonical_url: https://drex.hashnode.dev/who-is-a-software-engineer
---
I remember the time I just got accepted for a junior software engineer role at a remote company and at the time I underestimated what it took to be a software engineer. I thought it was just all about writing code and knowing the latest technologies, so I said the name lightly, but after about 2 years of experience, I now have a better understanding of what being a software engineer entails and why they are sought after.
The first thing I'll say is that a software engineer isn't just someone who writes code, a software engineer is a problem solver. They take complex, real-world problems and break them down into manageable pieces that can be solved through code. This requires a deep understanding of both the technology and the business needs of the software being built.
A software engineer is also a communicator. Writing code is only one small part of the job, and effective communication skills are critical to the success of any software project. They need to be able to communicate technical concepts to non-technical stakeholders, as well as effectively collaborate with team members who may have different backgrounds and perspectives.
A software engineer is a lifelong learner. The technology landscape is constantly changing, and software engineers must stay up-to-date with the latest tools, languages, and methodologies to remain effective. This requires a willingness to continually learn and adapt, as well as a strong desire to improve both individually and as a team.
At its core, being a software engineer is about making a difference. It's about taking complex problems and finding simple, elegant solutions that change the world for the better. It's about working with talented individuals to build software that meets the needs of users, and it's about doing all of this in a way that is ethical, responsible, and sustainable.
### **Misconceptions about a Software Engineer**
As an experienced software engineer, I have noticed that many junior developers have certain misconceptions about the field of software engineering. Here are some of the most common ones:
1. Coding is the only skill required - While writing code is an important aspect of software engineering, it is just one piece of the puzzle. Junior developers often overlook the importance of skills like problem-solving, communication, collaboration, and project management.
2. Code quality is not important - Junior developers may be focused on getting the code to work, but they may overlook the importance of writing maintainable, scalable, and secure code. This can lead to technical debt and make future maintenance and updates more difficult.
3. It's all about writing new code - While writing new code is an exciting part of the job, software engineers also spend a significant amount of time maintaining and updating existing codebases. This includes fixing bugs, optimizing performance, and ensuring the software meets evolving business needs.
4. Software engineering is a solitary activity - Many junior developers assume that software engineering is a solitary activity when in reality, it often requires close collaboration with cross-functional teams. Software engineers need to work with project managers, designers, and stakeholders to ensure that the software meets the needs of users.
5. Learning stops after graduation - Junior developers often assume that they will stop learning after they finish their formal education. However, software engineering is a field that is constantly evolving, and software engineers must be willing to continually learn and adapt to stay up-to-date with the latest tools, languages, and methodologies.
In conclusion, junior developers need to understand that software engineering is a complex and multi-faceted field that requires a wide range of skills, knowledge, and experience. By recognizing and overcoming these misconceptions, junior developers can set themselves up for success as they progress in their careers.
### **How can I be a Software Engineer?**
Several junior developers have asked me the question, how can they become software engineers and truthis, I have seen many junior developers successfully transition into software engineering roles. Here are some key steps that I would advise a junior developer to follow to migrate toward becoming a software engineer:
1. Gain a strong foundation in computer science principles - Understanding core concepts such as algorithms, data structures, and software design patterns is essential for a successful career in software engineering.
2. Build practical experience - Participate in personal projects, contribute to open source projects, or seek out internships or entry-level positions to get hands-on experience building software.
3. Stay up-to-date with technology - The technology landscape is constantly evolving, and software engineers must be willing to continually learn and adapt. Keep up-to-date with the latest tools, languages, and methodologies.
4. Improve your communication skills - Effective communication skills are critical in software engineering. Practice explaining technical concepts to non-technical stakeholders and seek out opportunities to collaborate with cross-functional teams.
5. Seek mentorship opportunities - A mentor who is an experienced software engineer can provide guidance, advice, and feedback, and help you navigate the challenges and opportunities of a career in software engineering.
6. Focus on writing maintainable, scalable, and secure code - While writing code is an important aspect of the job, it's equally important to write code that is maintainable, scalable, and secure. Learn software engineering best practices and seek out opportunities to learn from more experienced software engineers.
7. Participate in the software engineering community - Joining online communities and attending industry events can help you stay up-to-date with the latest developments in the field, connect with other software engineers, and gain exposure to new ideas and approaches.
In summary of everything said so far, A software engineer is a professional who designs, develops, tests, and maintains software systems and applications. The role encompasses a variety of tasks including analyzing user requirements, developing algorithms, writing code, and testing and debugging software. Software engineers may also be involved in the ongoing maintenance and updating of existing systems, as well as collaboration with cross-functional teams such as project managers, designers, and stakeholders. In addition to technical skills, effective software engineers possess strong problem-solving and communication abilities.If you have a passion for technology, an ability to think critically, and a desire to make a difference, a career in software engineering might be the right path for you. | drex72 | |
1,352,635 | FiftyOne Computer Vision Model Evaluation Tips and Tricks – Feb 03, 2023 | Welcome to our weekly FiftyOne tips and tricks blog where we give practical pointers for using... | 21,917 | 2023-02-03T18:40:54 | https://voxel51.com/blog/fiftyone-computer-vision-model-evaluation-tips-and-tricks-feb-03-2023/ | computervision, machinelearning, ai, datascience | Welcome to our weekly [FiftyOne tips and tricks blog](https://voxel51.com/blog/category/tips-tricks/) where we give practical pointers for using FiftyOne on topics inspired by discussions in the open source community. This week we’ll cover [model evaluation](https://docs.voxel51.com/user_guide/evaluation.html).
## Wait, what’s FiftyOne?
[FiftyOne](https://voxel51.com/fiftyone/) is an open source machine learning toolset that enables data science teams to improve the performance of their computer vision models by helping them curate high quality datasets, evaluate models, find mistakes, visualize embeddings, and get to production faster.

- If you like what you see on GitHub, [give the project a star](https://github.com/voxel51/fiftyone).
- [Get started](https://docs.voxel51.com/)! We’ve made it easy to get up and running in a few minutes.
- Join the [FiftyOne Slack community](https://join.slack.com/t/fiftyone-users/shared_invite/zt-s6936w7b-2R5eVPJoUw008wP7miJmPQ), we’re always happy to help.
Ok, let’s dive into this week’s tips and tricks!
## A primer on model evaluations
FiftyOne provides a variety of builtin methods for evaluating your model predictions, including regressions, classifications, detections, polygons, instance and semantic segmentations, on both image and video datasets.
When you evaluate a model in FiftyOne, you get access to the standard [aggregate metrics](https://docs.voxel51.com/user_guide/evaluation.html#aggregate-metrics) such as classification reports, [confusion matrices](https://docs.voxel51.com/user_guide/evaluation.html#id11), and [PR curves](https://docs.voxel51.com/user_guide/evaluation.html#map-and-pr-curves) for your model. In addition, FiftyOne can also record fine-grained statistics like accuracy and false positive counts at the sample-level, which you can leverage via dataset views and the FiftyOne App to interactively explore the strengths and weaknesses of your models on individual data samples.
FiftyOne’s model evaluation methods are conveniently exposed as methods on all `Dataset` and `DatasetView` objects, which means that you can evaluate entire datasets or specific views into them via the same syntax.
Continue reading for some tips and tricks to help you master evaluations in FiftyOne!
## Task-specific evaluation methods
In FiftyOne, the Evaluation API supports common computer vision tasks like object detection and classification with default evaluation methods that implement some of the standard routines in the field. For standard object detection, for instance, the default evaluation style is MS COCO. In most other cases, the default evaluation style is denoted `"simple"`. If the default style for a given task is what you are looking for, then there is no need to specify the `method` argument.
```
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
results = dataset.evaluate_detections(
"predictions",
gt_field = "ground_truth"
)
```
Alternatively, you can explicitly specify a method to use for model evaluation:
```
dataset.evaluate_detections(
"predictions",
gt_field = "ground_truth",
method = "open-images"
)
```
Each evaluation method has an associated evaluation config, which specifies what arguments can be passed into the evaluation routine when using that style of evaluation. For [ActivityNet style evaluation](https://docs.voxel51.com/api/fiftyone.utils.eval.activitynet.html#fiftyone.utils.eval.activitynet.ActivityNetEvaluationConfig), for example, you can pass in an `iou` argument specifying the IoU threshold to use, and you can pass in `compute_mAP = True` to tell the method to compute the mean average precision.
To see which label types are available for a dataset, check out the section detailing that dataset in the FiftyOne Dataset Zoo documentation.
Learn more about [evaluating object detections](https://docs.voxel51.com/tutorials/evaluate_detections.html) in the FiftyOne Docs.
## Evaluations on views
All methods in FiftyOne’s Evaluation API that are applicable to `Dataset` instances are also exposed to `DatasetView`. This means that you can compute evaluations on subsets of your dataset obtained through filtering, matching, and chaining together any number of view stages.
As an example, we can evaluate detections only on samples that are highly [unique](https://docs.voxel51.com/tutorials/uniqueness.html) in our dataset, and which have fewer than 10 predicted detections:
```
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo as foz
from fiftyone import ViewField as F
## compute uniqueness of each sample
fob.compute_uniqueness(dataset)
dataset = foz.load_zoo_dataset("quickstart")
## create DatasetView with 50 most unique images
unique_view = dataset.sort_by(
"uniqueness",
reverse=True
).limit(50)
## get only the unique images with fewer than 10 predicted detections
few_pred_unique_view = unique_view.match(
F("predictions.detections").length() < 10
)
## evaluate detections for this view
few_pred_unique_view.evaluate_detections(
"predictions",
gt_field="ground_truth",
eval_key="eval_few_unique"
)
```
Learn more about the [FiftyOne Brain](https://docs.voxel51.com/user_guide/brain.html) in the FiftyOne Docs.
## Plotting interactive confusion matrices
For classification and detection evaluations, FiftyOne’s evaluation routines generate [confusion matrices](https://en.wikipedia.org/wiki/Confusion_matrix). You can plot these confusion matrices in FiftyOne with the `plot_confusion_matrix()` method.
```
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
## generate evaluation results
results = dataset.evaluate_detections(
"predictions",
gt_field = "ground_truth"
)
## plot confusion matrix
classes = ["person", "kite", "car", "bird"]
plot = results.plot_confusion_matrix(classes=classes)
plot.show()
```
Because the confusion matrix is implemented in [plotly](https://plotly.com/python/), it is interactive! To interact visually with your data via the confusion matrix, attach the plot to a session launched with the dataset:
```
## create a session and attach plot
session = fo.launch_app(dataset)
session.plots.attach(plot)
```
Clicking into a cell in the confusion matrix then changes which samples appear in the sample grid in the [FiftyOne App](https://docs.voxel51.com/user_guide/app.html).
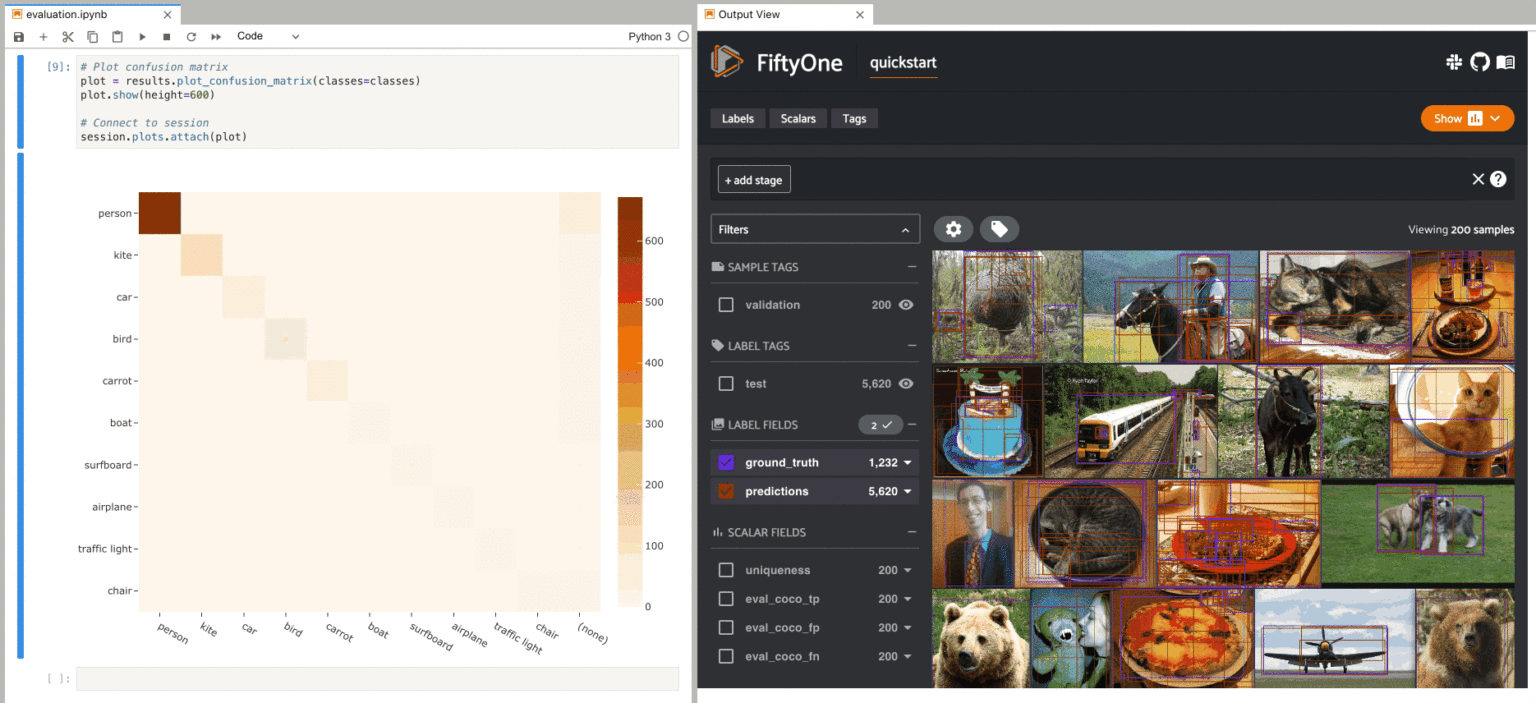
Learn more about [interactive plotting](https://docs.voxel51.com/user_guide/plots.html) in the FiftyOne Docs.
## Evaluating frames of a video
All of the evaluation methods in FiftyOne’s Evaluation API can be applied to frame-level labels in addition to sample-level labels. This means that you can evaluate video samples without needing to convert the frames of a video sample to standalone image samples.
Applying FiftyOne evaluation methods to video frames also has the added benefit that useful statistics are computed at both the frame and sample levels. For instance, the following code populates the fields `eval_tp`, `eval_fp`, and `eval_fn` as summary statistics on the sample level, containing the total number of true positives, false positives, and false negatives across all frames in the sample. Additionally, on each frame, the evaluation populates an `eval` field for each detection with a value of either `tp`, `fp`, or `fn`, as well as an `eval_iou` field where appropriate.
```
import random
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"quickstart-video",
dataset_name="video-eval-demo"
)
## Create some test predictions
classes = dataset.distinct("frames.detections.detections.label")
def jitter(val):
if random.random() < 0.10:
return random.choice(classes)
return val
predictions = []
for sample_gts in dataset.values("frames.detections"):
sample_predictions = []
for frame_gts in sample_gts:
sample_predictions.append(
fo.Detections(
detections=[
fo.Detection(
label=jitter(gt.label),
bounding_box=gt.bounding_box,
confidence=random.random(),
)
for gt in frame_gts.detections
]
)
)
predictions.append(sample_predictions)
dataset.set_values("frames.predictions", predictions)
dataset.evaluate_detections(
"frames.predictions",
gt_field="frames.detections",
eval_key="eval",
)
```
Note that the only difference in practice is the prefix “frames” used to specify the predictions field and the ground truth field.
Learn more about [video views](https://docs.voxel51.com/user_guide/using_views.html#video-views) and [evaluating videos](https://docs.voxel51.com/user_guide/evaluation.html#evaluating-videos) in the FiftyOne Docs.
## Managing multiple evaluations
With all of the flexibility the Evaluation API provides, you’d be well within reason to wonder what evaluation you should perform. Fortunately, FiftyOne makes it easy to perform, manage, and store the results from multiple evaluations!
The results from each evaluation can be stored and accessed via an evaluation key, specified by the `eval_key` argument. This allows you to compare different evaluation methods on the same data,
```
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
dataset.evaluate_detections(
"predictions",
gt_field = "ground_truth",
method = "coco",
eval_key = "coco_eval"
)
dataset.evaluate_detections(
"predictions",
gt_field = "ground_truth",
method = "open-images",
eval_key = "oi_eval"
)
```
evaluate predictions generated by multiple models,
```
dataset.evaluate_detections(
"model1_predictions",
gt_field = "ground_truth",
eval_key = "model1_eval"
)
dataset.evaluate_detections(
"model2_predictions",
gt_field = "ground_truth",
eval_key = "model2_eval"
)
```
Or compare evaluations on different subsets or views of your data, such as a view with only small bounding boxes and a view with only large bounding boxes:
```
from fiftyone import ViewField as F
bbox_area = (
F("bounding_box")[2] *
F("bounding_box")[3]
)
large_boxes = bbox_area > 0.7
small_boxes = bbox_area < 0.3
# Create a view that contains only small-sized objects
small_view = (
dataset
.filter_labels(
"ground_truth",
small_boxes
)
)
# Create a view that contains only large-sized objects
large_view = (
dataset
.filter_labels(
"ground_truth",
large_boxes
)
)
small_view.evaluate_detections(
"predictions",
gt_field="ground_truth",
eval_key="eval_small",
)
large_view.evaluate_detections(
"predictions",
gt_field="ground_truth",
eval_key="eval_large",
)
```
Learn more about [managing model evaluations](https://docs.voxel51.com/user_guide/evaluation.html#managing-evaluations) in the FiftyOne Docs.
## Join the FiftyOne community!
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- 1,300+ [FiftyOne Slack](https://join.slack.com/t/fiftyone-users/shared_invite/zt-s6936w7b-2R5eVPJoUw008wP7miJmPQ) members
- 2,500+ stars on [GitHub](https://github.com/voxel51/fiftyone)
- 2,900+ [Meetup members](https://www.meetup.com/pro/computer-vision-meetups/)
- [Used by](https://github.com/voxel51/fiftyone/network/dependents?package_id=UGFja2FnZS0xNzAxODM0MjUx) 241+ repositories
- 55+ [contributors](https://github.com/voxel51/fiftyone/graphs/contributors)
## What’s next?
- If you like what you see on GitHub, give the [FiftyOne project a star](https://github.com/voxel51/fiftyone).
- [Get started with FiftyOne](https://docs.voxel51.com/)! We’ve made it easy to get up and running in a few minutes.
- Join the [FiftyOne Slack community](https://join.slack.com/t/fiftyone-users/shared_invite/zt-s6936w7b-2R5eVPJoUw008wP7miJmPQ), we’re always happy to help.
| voxel51-brian |
1,352,636 | MIT University 🎓 Free 🎉 Courses | Introduction MIT University is one of the world's most prestigious universities, and its... | 0 | 2023-02-03T18:15:36 | https://dev.to/mahmoudessam/mit-university-free-courses-439c | computerscience, programming, python, beginners | ## Introduction
- MIT University is one of the world's most prestigious universities, and its reputation for excellence has been well-earned.
- As part of its commitment to education, MIT offers a range of free courses that are open to anyone who wishes to take advantage.
- These courses cover a wide variety of topics from engineering and computer science to business management, mathematics, physics and more.
- The best thing about these free courses is that they provide an opportunity for anyone with interest in learning something new or honing their skillset without having to pay tuition fees or commit long-term financially.
- The quality content provided by MIT’s faculty ensures that students receive high-quality instruction whether online or on campus - making them some of the best online resources available today!
- Furthermore, many classes are self-paced so you can complete them at your own pace while still receiving support from experienced instructors when needed.
- The availability of these free courses makes taking up higher education more accessible than ever before - especially for those who may not have access otherwise due to financial constraints.
- Opening up opportunities which were previously reachable due to cost barriers alone! It also allows individuals to look into specific subjects such as technology-related fields like Artificial Intelligence (AI), Internet Of Things (IoT) etc.
- To gain knowledge without breaking bank accounts too much providing an invaluable experience which could be leveraged later down life path.
- All this combined together makes MIT's Free Courses truly unique offering unparalleled educational benefits compared to other institutions around the world!
###### MIT University 🎓 is offering 5 free courses 💯
🎥 {% youtube sz-WWN2px7k%}
#### Bonus
###### 15 Free Harvard Courses🎓📣🔥🎉
🎥 {% youtube mdlS34KDlCk&t=2s%}
### Connect with Me 😊
#### 🔗 Links
[](https://www.linkedin.com/in/mahmoud-el-kariouny-822719149/)
[](https://twitter.com/Mahmoud42275)
| mahmoudessam |
1,352,714 | 10 tips to perform well at Hackathons | I love hackathons, they are just crazy sometimes. I have attended at several hackathons with a... | 0 | 2023-02-03T19:27:19 | https://dev.to/argo_saakyan_9772ced462f6/10-tips-to-perform-well-at-hackathons-277k | programming, productivity, beginners |

I love hackathons, they are just crazy sometimes. I have attended at several hackathons with a team, and we lost sometimes, won or took prized place. So, I have diverse experience, but what is more important - I have been judging and mentoring hackathons too. That's why I want to give some hints on how to perform better.
### What's the point of hackathons?
Firstly, hackathon is an event where teams try to solve a problem and show a prototype in just a couple of days. That's an event when you sleep less than you use to.
There are no doubts that hackathons are extremely useful when you are starting your career. But hackathons really are more than that. Here are couple of points:
- Train your ability to be tough and work hard
- Create new and great connections with other teams
- Have some fun with teammates and technologies
- Check how good you are in your field
- Learn new stuff very fast
- Get familiar with other solutions of the problem you've solved
- Win some goodies
### Tips

Now let's discuss what should you do to get a better result and maybe even win. I have collected 10 tips:
- Start working even before the hackathon begins. And I mean, start thinking of the solution you are going to use. Create different paths, generate ideas and prepare the plan.
- Collect a perfect team for the task. If you need to develop an ML system and deploy it - you need both ML engineers and full stacks (at least). And every person should know what he is doing, you don't want to create a bottleneck.
- Choose a project which would be exiting for you and your team. You really want to be interested in the projects to get your best results.
- At the beginning of the hackathon, try to understand the task as clear as possible. That's a critical thing, because that you are going to base your solution on that understanding. I saw a lot of cases when the team didn't really get the task, or they forgot about some important part, which was critical for the business meaning of the task.
- If you can communicate with a mentor - present him your understanding and your plan, Be precise with what you are trying to achieve, so mentor can confirm that everything is fine.
- Try asking a mentor for a killer feature. Sometimes you might get some interesting idea which will help you to make a better solution.
- Work as hard as possible, do your best, don't spare yourself, you only need to work that hard for a day or two. After the finish, you are going to be happy that you did everything you could. Remember that every single, even tiny step can make you ahead of your opponents.
- Make sure to implement all needed features given by the instructions. Sometimes it's enough to show a solid but minimalistic solution. But it's a great idea to try and come up with some new feature which is going to be useful in that specific project. Think about the task as a business problem and try to add more value. Also try to think creative, because companies often organize hackathons if they need new and creative solutions.
- Create a short but great presentation. If you have a working solution - show it - that's always the best thing. Speaking about presentation. You should sound well, have a good image and talk involved. Remember, that on hackathons often is not enough time to create a full solution, that's why presentation is important.
- Finally, talk about things you would do if you had more time. Show how your solution can be scaled and implemented in real business cases. Let judges know that you are ready to continue with the project if hackathon organization is interested in that.
### Conclusion
To sum up, hackathons are a great place to test out your skills, learn new stuff, communicate with other specialists and widen your network. But don't forget to have some fun. You don't need to win every hackathon, so let yourself sometimes just to have fun.
Highly recommend trying out yourself at the hackathon, that's a great experience! | argo_saakyan_9772ced462f6 |
1,352,721 | Web Development VS Android Development: What Should I Learn | If you’re interested in a career in software development, you may be wondering whether you should... | 0 | 2023-02-03T19:34:59 | https://medium.com/@viveksinra/web-development-vs-android-development-what-should-i-learn-c3f5bec6fe2?source=rss-28de262f8555------2 | <p>If you’re interested in a career in software development, you may be wondering whether you should learn web development or Android development. Both fields offer exciting career opportunities and have their own unique set of benefits.</p><p>One factor to consider when deciding between web development and Android development is the type of devices you want to target. Web development involves creating applications and websites that can be accessed from any device with a web browser, including desktop computers, laptops, tablets, and smartphones. Android development, on the other hand, involves creating apps specifically for Android devices. If you want to build applications that can be accessed from a wide range of devices, web development may be the way to go.</p><p>Another factor to consider is the programming languages and frameworks you are interested in learning. Web development often involves languages such as HTML, CSS, and JavaScript, as well as frameworks such as React or Angular. Android development involves learning a language such as Java or Kotlin, as well as frameworks such as Android Studio. If you have a preference for certain programming languages or frameworks, this could influence your decision between web development and Android development.</p><p>It’s also worth considering the job market and career opportunities in each field. Web development is a large and growing field, with many companies seeking web developers to create and maintain their websites and web-based applications. Android development is also a growing field, with the increasing demand for mobile apps on Android devices. Both fields offer good career prospects and salaries, although the specific job market and demand for skills may vary depending on your location.</p><p>Ultimately, the decision between web development and Android development will depend on your personal interests, goals, and skills. Both fields offer exciting career opportunities and the chance to work on interesting and impactful projects. It may be worth considering learning both web development and Android development, as having skills in both areas can make you a more versatile and in-demand developer.</p><p>In conclusion, whether you choose to learn web development or Android development will depend on your personal interests, goals, and skills, as well as the type of devices you want to target and the programming languages and frameworks you are interested in learning. Both fields offer good career prospects and the opportunity to work on impactful projects, and it may be worth considering learning both web development and Android development to broaden your skills and increase your versatility as a developer.</p><img src="https://medium.com/_/stat?event=post.clientViewed&referrerSource=full_rss&postId=c3f5bec6fe2" width="1" height="1" alt=""></br><p style="color:#757CF9;">This article is published w/ <a target="_blank" href="https://scattr.io?ref=dev">Scattr ↗️</a></p> | viveksinra | |
1,352,906 | Add Auth To Your Nuxt 3 App in Minutes With Amplify | This tutorial will discuss how to use Nuxt.js Auth with Amplify | 0 | 2023-02-03T23:19:42 | https://dev.to/erikch/add-auth-to-your-nuxt-3-app-in-minutes-with-amplify-2d7j | nuxt, amplify, authentication | ---
title: Add Auth To Your Nuxt 3 App in Minutes With Amplify
published: true
description: This tutorial will discuss how to use Nuxt.js Auth with Amplify
tags: Nuxt, Amplify, Authentication
# cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/abmr9sii3lqf573939kv.jpeg
# Use a ratio of 100:42 for best results.
# published_at: 2023-02-03 22:07 +0000
---
[Nuxt](https://nuxtjs.org/) is an intuitive framework that takes your Vue applications and brings it to a new level! It can take your Vue 2/3 app and add static site generation, and server side rendering! In addition, it supports API routes, file system routing, data fetching and more!
[Amplify](https://docs.amplify.aws/), on the other hand, is a set of tools that allows full-stack web and mobile developers the ability to create and build apps using AWS services.
With these two together you can build some really powerful apps!
_Want to get started now? Check out my video and jump on in!_
{% youtube 46DxCr5w1u0 %}
##What Are We Building?
Today we are building a Nuxt 3 application with authentication backed by Amplify!
We'll imagine that we need our entire application protected, and only authorized users can access it. We'll allow users to login and create an account!
##Setup
We are going to assume you are starting a Nuxt app from scratch without any prior knowledge of Amplify. Feel free to jump to the next section if this is not the case!
Let's begin by creating a brand new app
```bash
npx nuxi init nuxt3-app
```
After the app is generated change directory to the newly created folder.
```bash
cd nuxt3-app
```
Install the `aws-amplify` and `@aws-amplify/ui-vue` dependencies.
```bash
npm i @aws-amplify/ui-vue aws-amplify
```
If this is the first time using Amplify you'll need to install the [Amplify CLI](https://github.com/aws-amplify/amplify-cli). This tool will help us setup and add Amplify's services.
```bash
npm i @aws-amplify/cli
```
Next, we'll run configure. This will connect our CLI tool with our AWS account.
__Don't have an AWS account? [Sign up](https://aws.amazon.com/free) and get 12 months free!__
```bash
amplify configure
```
Finally, we'll run an init command to setup our project!
```bash
amplify init
```
Hit enter through all the defaults and you should be ready to go!
## Adding Authentication
Adding authentication to your application with Amplify only takes one command on the CLI.
```bash
amplify add auth
```
Make sure to follow the prompts. Choose `Email` and the `Default configuration`.
```bash
Do you want to use the default authentication and security configuration? Default configuration
Do you want to use the default authentication and security configuration? Default configuration
Warning: you will not be able to edit these selections.
How do you want users to be able to sign in? Email
Do you want to configure advanced settings? No, I am done.
```
Now we can push our changes to Amplify!
```bash
amplify push
```
Choose `Y`!
```bash
? Are you sure you want to continue? (Y/n) y
```
If you look inside your folder structure in your Nuxt app, you may notice some [new folders](https://docs.amplify.aws/cli/reference/files/). Don't worry, these are configuration files for Amplify, we won't need to touch them for this tutorial.
We are done with the command line for now. Let's setup the Nuxt app so it can use this new authentication resource.
##Nuxt Setup
Let's jump into our `nuxt.config.ts` file and add some configurations for Amplify.
```javascript
// nuxt.config.ts
export default defineNuxtConfig({
alias: {
"./runtimeConfig": "./runtimeConfig.browser"
},
vite: {
define: {
"window.global": {}
}
}
});
```
__Nuxt uses `vite` under the covers as a build tool. These options will help Nuxt and Vite properly build.__
Let's create a plugin for Amplify. This plugin file will configure Amplify and make it available throughout the app.
Create a new `plugins` folder in the root of the project and add a `amplify.ts` file to it.
```javascript
import { defineNuxtPlugin } from "#app";
import { Amplify, Auth } from "aws-amplify";
import aws_exports from "../src/aws-exports";
export default defineNuxtPlugin((nuxtApp) => {
Amplify.configure(aws_exports);
return {
provide: {
auth: Auth,
},
};
});
```
The `aws_exports` file was generated after you ran `amplify push`. This file holds all the keys needed for the Amplify JavaScript library to access all the resources you created. By adding the `provide` you can now access auth with `$auth` anywhere in your app.
We are now ready to add the [Authenticator](https://ui.docs.amplify.aws/vue/connected-components/authenticator) to our application. This will be in our `app.vue` file.
```html
<script setup lang="ts">
import { Authenticator } from "@aws-amplify/ui-vue";
import "@aws-amplify/ui-vue/styles.css";
</script>
<template>
<div>
<Authenticator>
<template v-slot="{ user, signOut }">
<h1>Hello {{ user.username }}!</h1>
<button @click="signOut">Sign Out</button>
</template>
</Authenticator>
</div>
</template>
```
__Don't forget to add the import for styles as seen above! Otherwise your Authenticator will not render properly.__
In the code example above anything between the opening and closing brackets inside the `template` will only appear after the user is logged in.
## Test It Out!
Go ahead and start your Nuxt app
```bash
npm run dev
```
Congratulations! You now have created a Nuxt.js application with authentication!
Go ahead and try to create an account, and sign in. Make sure to put in a valid email address, so you can verify your account during the sign up process.
After signing in you'll see a message like this!

##Conclusion
In this post we've created a new Nuxt 3 application, added in Amplify with authentication, and setup our app to use Amplify with the Authenticator connected component!
So your next question probably is, where do we go from here? Well, with Amplify setup we can now add in [authenticated apis](https://docs.amplify.aws/cli/function/) backed by Lambda, [storage](https://docs.amplify.aws/cli/storage/overview/), and even [AppSync](https://docs.amplify.aws/cli/graphql/overview/) our managed GraphQL service!
Leave a comment below on what you'd like to learn next! Or tweet me at [@ErikCH](https://twitter.com/erikch) with what you learned and I'll pick someone at random for a special prize!
| erikch |
1,352,967 | Phase 2: UseState Hook | UseState is a useful hook used to track the state of a function component. In general, it "refers... | 0 | 2023-02-04T01:30:32 | https://dev.to/tbraeck/phase-2-usestate-hook-35b1 | UseState is a useful hook used to track the state of a function component. In general, it
> "refers to data or properties that need to be tracking in an application (w3schools.com/react/react_usestate.asp)."
Some common use cases are to keep track of information entered by a user in a form, toggle switches, buttons that fire other code that changes the state (conditional rendering), using a fetch (GET) request to obtain data from an API and store the response in state.
The useState Hook is particularly helpful, in that it (along with other hooks) allows for much more readable code, whereas the use of class components can be very clunky and filled with boilerplate code that isn't necessary in Hooks. UseState returns an array because an array is more flexible than an object.
Below I used the useState and useEffect Hooks for "ImagePage.js" for my Phase 2 project.
In this snippet I have de-structured a variable "art" that will hold the state value. The "setArt" is the function that will change the value of the state "art". The useState([]) is setting the initial value of the state "art" as an empty array. The initial value of state can be,
>
"an object, an array, a boolean, or any other type you can imagine."
Then within the useEffect hook, which is wrapping the fetch request to my db.json, the data is used to set state for the art variable. This is passed down to the "ImageList.js" component as props and the .map method is used to iterate over all the objects in the array. Values from each object mapped are then passed down to the "ImageCard.js" component to delineate the final JSX code that will be used for the DOM render for each object.
Holding this information in state is essential for smooth re-renders of pages when state changes, when a page is refreshed, etc. When a
```
import React, { useState, useEffect } from "react";
import ImageList from './ImageList';
import Search from "./Search";
import NewArt from './NewArt';
function ImagePage() {
const [art, setArt] = useState([])
const [searchArt, setSearchArt] = useState('')
useEffect(() => {
fetch(`http://localhost:8000/artwork`)
.then((r) => r.json())
.then(artArray => setArt(artArray))
}, [])
function addNewArt(myArt) {
setArt([...art, myArt])
}
```
Another use case in my own project for useState is in the code below, which is in the "NewArt" component, which is essentially a form that a user can enter data into an create a new art image card on the art gallery page:
```
function NewArt({ addNewArt }) {
const [title, setTitle] = useState("")
const [year, setYear] = useState("");
const [price, setPrice] = useState(0.00)
const [newImage, setNewImage] = useState("")
function handleSubmit(e) {
e.preventDefault();
let newArt = {
title: title,
year: year,
price: price,
imageUrl: newImage
}
fetch(`http://localhost:8000/artwork`, {
method: "POST",
headers: {
"Content-Type": 'application/json',
},
body: JSON.stringify(newArt)
})
.then((r) => r.json())
.then((myArt) => addNewArt(myArt))
}
```
Firstly, the function "addNewArt" is passed into this component as props, then called later in the component function. Next, the initial state is set for the new art which will be inputed by the user in the form fields (title, year, price, and imageURL), which are corresponding key/value pairs from the db.json which acts as my app's API.
Another function "handleSubmit", which is used to prevent page reload on submit and to set the state values to the corresponding value in the db.json, all within a variable named "newArt". Then a fetch(POST) is called which will use the prop of the function "addNewArt" from "ImagePage.js" to add the newly entered information into the state of 'art' or the array of art objects from the db.json. Thus, the useState hook helps to swiftly update state between multiple components in a concise manner.
Below is more of the "NewArt.js" component code, specifically the form for entering new art data into the gallery space. It highlights the inline use of setting state with the onChange event handler here:
```
<form className="form" onSubmit={handleSubmit}>
<input className="formTitle" type="text" name="title" placeholder="New Art Title" value={title} onChange={(e) => setTitle(e.target.value)} />
<input className="formYear" type="text" name="year" placeholder="Year Created" value={year} onChange={(e) => setYear(e.target.value)} />
<input className="formPrice" type="number" name="price" step="0.1" placeholder="Price in $..." value={price} onChange={(e) => setPrice(e.target.value)} />
<input className="formImage" type="text" name="image" placeholder="Image URL" value={newImage} onChange={(e) => setNewImage(e.target.value)} />
<button className="formButton" type="submit">Add Art</button>
```
Each input in the form, which is controlled because of passing the correlated state variable into the value, then uses the onChange event handler. In the onChange the event is called as an argument and calls the setter function that corresponds to the given initialized state value- which then resets the state value to the "e.target.value" or what data is entered in the input field.
This is repeated a few times in the form, as the same action and similar state updates are happening. Once these input values and their corresponding state is changed, and the submit button fires the "handleSubmit" function, the state variable is updated and the POST request happens, firing the DOM re-rendering and the db.json file to be updated.
The useState hook is an essential addition to React as it helps to update state in different variables, strings, objects, array, etc. without all the unnecessary boilerplate code that came with using class components for this. Additionally it simply cleans up the code as a whole. I have found React Hooks to be much more user friendly and cleaner to work with and look at than what I have seen of React class components. I am hopeful that even better updates to Hooks will come about and React will be even easier to use.
| tbraeck | |
1,352,984 | Startchart: Prisma Schema | Background This week, I focus on creating an initial schema for the project through using... | 0 | 2023-02-04T02:40:41 | https://dev.to/cychu42/startchart-prisma-schema-4i6d | webdev, javascript, opensource, prisma | ## Background
This week, I focus on creating an initial schema for the [project](https://github.com/Seneca-CDOT/starchart) through using [Prisma](https://www.prisma.io/). This is for a MySQL database, and the PR for the initial schema is [here](https://github.com/Seneca-CDOT/starchart/pull/79).
This is an example of a model:
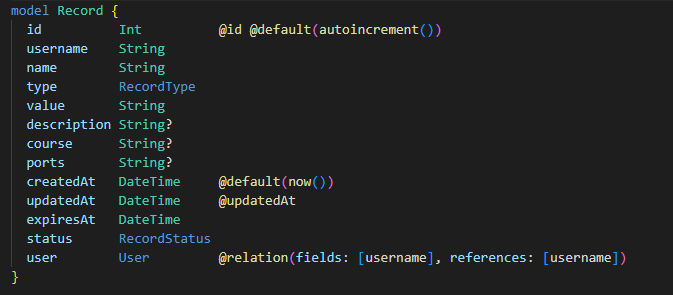
A model describes how a table would look like on a database.
## Basics
- Record would be the table name.
- Green texts are the value types for the columns.
- The blue texts are the names of the columns.
- `@id` marks the primary key.
- `?` marks a column as nullable.
- `@default` sets the default value as what's in the parameter.
- `now()` returns the current time.
- `@updatedAt` would provide the value that's the time a row is updated.
- Foreign key:
In the example, the line with `user` is used to record a relationship between this and the other table, for the purpose of marking a foreign key. `fields`'s value is the foreign key, while `references`'s value points to a column on another table.
On the other table, it need to have another corresponding line to fully establish the relationship, like:
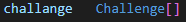`[]` means it's a to-many relationship. You don't have that if it's to-one relationship.
- You might notice some odd type like `RecordType`. That's **enumeration**, and you can declare that in the same file:
 As you can see, the green text is the name of the type, and the blue texts are the possible values for such type.
## Experience
As far as creating schema goes, Prisma is very friendly and easy to use, once you learn the basic, such as how to mark primary key or make values in a column unique. Establishing foreign key and the relationship between tables take a bit more work to understand. It helps if you already know how a database works.
Because I need to create the database to serve the need of other parts of the project, such as what user information people who handle login want to store, I ask around the team. I sort of feel like someone who goes around with a clip board and ask what they would like to order for lunch. I ask them what they would like to include and why...to have better comprehension of the project and for my own learning, and it's always interesting to learn more.
| cychu42 |
1,353,072 | We should adopt and use new Ruby features | A bit of (personal) history I learned Ruby, I think, around 2007, and back then, it was a... | 0 | 2023-02-04T04:07:06 | https://allaboutcoding.ghinda.com/we-should-adopt-and-use-new-ruby-features | ruby, rails, programming, newfeatures | ### A bit of (personal) history
I learned Ruby, I think, around 2007, and back then, it was a language pushing boundaries for me. Before encountering Ruby, I worked with Java, C/C++, PHP, and Python, and even dig into the strange world of JS (back then when [Scriptaculous](https://madrobby.github.io/scriptaculous/) and [Prototype.js](https://en.wikipedia.org/wiki/Prototype_JavaScript_Framework) were the hot JS libraries and jQuery was appearing).
In the beginning, *Ruby looked strange, made people uncomfortable when reading the syntax, and created emotion*.
I remember when I read the first time code written in Ruby (1.8.6) was very strange for me: no `;`, optional parenthesis, using `unless`, being able to write `if` at the end of a statement, the strange lack of `for`, `while` , `repeat` and the continued usage of `each` this was just the tip of the iceberg along with Rails 1.2 and later on Rails 2.
Ruby looked very alien compared with other typical languages that I was using. For me, it was a language that created its own category, very close to the English language and with pseudocode.
### **Where are we now?**
In my opinion, we are a bit too conservative with adopting new features. This attitude is good for projects built with Ruby; it comes from experience and wisdom. We tried many things over all these years, and we settled on what works and does not.
We say Ruby is boring or Rails is boring, and that's good for organizations and their projects.
At the same time, I feel that we slowed the pace of innovation for code design in the projects built with, Ruby. We are still experimenting, but as far as I see (limited experience of N=1), the adoption rate for new features is slow. There are still features released three years ago (e.g Ruby 2.7 in 2019) for which we still have rules/guidelines against them or limiting usage. See as example numbered params.
Projects built with Ruby were walking in new territories, playing with how code looks, pushing the language boundaries, and bringing art and beauty into how code looks.
But then we settled. We wanted to protect the fantastic thing we discovered.
By protecting it, we are also taking away its light.
I want Ruby to experiment with more features. And I trust Matz and the other core committers that they still have the same great taste for a great language.
### Why use new features and language constructs
Learning a new language feature is very similar to learning new words, cultural constructions, or expressions in a speaking language.
Thus my argument for learning and using new features/new language concepts is based on the theory of linguistic relativity and the hypothesis of linguistic determinism.
*In the same way, words or the language (we speak) shape our thinking and our reality, programming language constructs or features shape how we define a problem and the solution that we code for that problem.*
Fundamentally, when we write code, we model reality into another universe that can be described with a limited/fixed set of words or constructs.
This modeling is very similar to speaking another language. The more you know from the secondary language (dictionary, grammar, rules, cultural compositions), the better you can express your thoughts. Of course, this goes the same with your maternal language.
The same goes for knowing a programming language. The more you know (and use) the entire set of language constructs/features, the better you can express your solution.
Here is an example:
* In Ruby - we have `&&` and `||` but we also have `and` and `or` They can be used in various contexts to express different intentions and to control the flow.
* If you decide only to use `&&` and `||` then the way you will think about the solution (the algorithm) will then be shaped only by how `&&` and `||` behave.
* Thus even if the reality that you want to moderate might be better expressed in some cases with `and` and `or` you will force it to fit into `&&` and `||`.
---
In the end, here are some starting points about linguistic relativity and linguistic determinism:
* Lera Boroditsky, [How Language Shapes Thought](https://www.scientificamerican.com/author/lera-boroditsky/), Scientific American, 2011:
> "These are just some of the many fascinating findings of cross-linguistic differences in cognition. But how do we know whether differences in language create differences in thought, or the other way around? The answer, it turns out, is both—the way we think influences the way we speak, but the influence also goes the other way. The past decade has seen a host of ingenious demonstrations establishing that language indeed plays a causal role in shaping cognition. Studies have shown that changing how people talk changes how they think. Teaching people new color words, for instance, changes their ability to discriminate colors. And teaching people a new way of talking about time gives them a new way of thinking about it"
* Harriet Joseph Ottenheimer and Judith M.S. Pine, ***The Anthropology of Language: An Introduction to Linguistic Anthropology,* Fourth Edition,** 2018
> "What is important to recognize, even more than the idea that you might think or perceive the world differently depending on the language you speak, is that before you can really use a new language comfortably, without thinking about what you are saying, you need to wrap your mind around the new concepts that the new language is presenting to you"
> "According to cognitive linguists, the words we use create—and are used within—frames. The idea of frames is similar to the idea of worldview. We view the world through frames. Frames often invoke cultural metaphors, grouping ideas into commonly used phrases. As such, they often invoke an ideology, or a set of ideas we have about the way things should be.
>
> \[...\]
>
> It is more difficult to talk about, and perhaps even to think about, something that you have no frame for in your language. Cognitive scientists call this hypocognition, or lack of the ideas that you need for talking or thinking about something"
---
If you like this type of content, then maybe you want to consider subscribing to my curated newsletter [**Short Ruby News**](https://newsletter.shortruby.com) where I cover weekly Ruby news from all around the internet.
| lucianghinda |
1,353,085 | Starchart: Playwright and Chakra UI Setup | The past week I worked on setting up Playwright, and Chakra UI with starchart. Chakra UI is needed so... | 21,387 | 2023-02-04T04:38:53 | https://dev.to/eakam/starchart-playwright-and-chakra-ui-1ib | The past week I worked on setting up [Playwright](https://playwright.dev/), and [Chakra UI](https://chakra-ui.com/) with [starchart](https://github.com/Seneca-CDOT/starchart). Chakra UI is needed so that their components could be used to build the web pages, and Playwright is to be used for end-to-end testing.
### Chakra UI Setup
Setting up Chakra UI was relatively simple. I followed their [instructions](https://chakra-ui.com/getting-started/remix-guide) for the most part. I also found [this example](https://github.com/remix-run/examples/tree/main/chakra-ui) to be really helpful. My process for this went like this: I looked at the instructions in Chakra UI docs for the client, server and root files, and compared them with the existing code in starchart. Then, I also referenced them against the example code.
Not an ideal process to follow, but since I do not understand Chakra UI or Remix that well yet, I felt that this was the best way to do the setup. It worked, and I created a [PR](https://github.com/Seneca-CDOT/starchart/pull/75). Based on some feedback, I added some basic components (instead of using html tags) to the index page so some manual testing could be done.
Now, if you followed the PR link, you would have seen that it was merged but had a failing check. And that is what was addressed later while adding Playwright. Since the project was setup using the [Remix blues stack](https://github.com/remix-run/blues-stack), it shipped with [cypress](https://www.cypress.io/) for end-to-end testing. The cypress folder had some tests but these were not modified when the app was setup since we intended to use Playwright. This resulted in the typecheck job failing, since it was also checking the cypress folder: `tsc && tsc cypress`
### Playwright Setup
Setting up Playwright took longer than I had expected. First, I made a list of node modules that needed to be removed. These included `cypress`, `@faker-js/faker`, `@testing-library/cypress`, and `eslint-plugin-cypress`. These were only used by cypress so I uninstalled them using `npm uninstall`.
Next, I deleted the cypress folder, and the configuration file for cypress (`cypress.config.ts`). I installed playwright by using `npm init playwright@latest`, and following the prompts ([docs](https://playwright.dev/docs/intro)). This also generated a config file for playwright, some simple tests in the specified test folder, and some more detailed examples of tests. I deleted the folder containing the examples since it was simply for reference, and added some basic tests.
For the configuration, I ended up using the defaults for most of the options. I also uncommented the configuration for mobile viewpoints, branded browsers, and output directory for test artifacts; and added the following based on some feedback:
```ts
baseURL: `http://localhost:${process.env.PORT}`
...
video: 'on-first-retry'
```
Setting a `baseURl` allows navigating to a page with a relative URL:
```ts
await page.goto('/');
```
The second configuration [records a video](https://playwright.dev/docs/videos) of the test on the first retry after it fails.
#### Trying to Setup CI
So far, this process was pretty simple. Installing playwright also auto generates a GitHub workflow file. I tried adding a new job based on this auto generated file, and updated some npm scripts that were previously being used for cypress to run the tests. However, to run the tests, the app must be started. And to do that, the mysql database container must be running. I tried using the defined docker script, which uses `docker-compose up -d` to start the container but `prisma db push` failed with the following error:
I tried a bunch of things to try and fix this. I posted about this in Slack, and found out that mysql can take a while to start. So, I tried adding a wait before running the tests based on [this discussion](https://github.com/docker-library/mysql/issues/547#issuecomment-1002685663). However, this still resulted in the same error. I even tried doing `prisma db pull` before `prisma db push`. However, I got a different error this time:

This was really strange, since the database should have been setup. Still I did not know why this was failing.
#### Using Service Containers
Since I was basically out of ideas on how to fix this, I tried completely reworking the job by using a [service container](https://docs.github.com/en/actions/using-containerized-services/about-service-containers) for mysql instead:
```yml
E2E-Test:
timeout-minutes: 15
runs-on: ubuntu-latest
services:
mysql:
image: mysql:8
ports:
- 3306:3306
env:
MYSQL_DATABASE: starchart
MYSQL_USER: starchart
MYSQL_PASSWORD: starchart_password
MYSQL_ROOT_PASSWORD: root_password
steps:
...
```
And the tests worked! I am still not sure why they were failing before. Maybe docker-compose doesn't work with GitHub actions?
With this, I marked the [PR](https://github.com/Seneca-CDOT/starchart/pull/85) ready for review, and the broken CI was fixed.
| eakam | |
1,353,087 | Software Engineering Entrepreneurship » Issue 2 » Resilient people and systems | Recap Software Engineering Entrepreneurship » Issue... | 22,021 | 2023-02-05T19:53:32 | https://dev.to/morganw/software-engineering-entrepreneurship-issue-2-resilient-people-and-systems-11a3 | productivity, architecture, startup, career | ## Recap
{% embed https://dev.to/morganw/software-engineering-entrepreneurship-day-1-ice-breaker-ik5 %}
> In this first edition of Software Engineering Entrepreneurship I will take you through the journey of laying the groundwork for an ambiguous future as a technology leader.
---
```yaml
Edition: Feb. 2023
Issue: 2
Dates covered: Feb. 2-5
Subject: Resilient people and systems
```
## Why **now** and not **yesterday** or **tomorrow**?
I'll admit that in earlier stages of my life I would not be ready to take on the challenge we're about to endeavour. In fact, it was only an epiphany in the last year where I realized everything is lined up to not just start a business, but start executing a strategy that is resilient to failure. A combination of experience building Bold in the e-commerce space and developing skills over several years has enabled me to have a clear vision on starting a tech. company of my own.
---
## Backstory: Waiting for just the right idea
Consistently since being young I have said to myself and those around me "I'm going to start a company one day." Meanwhile, all around we see talented people of all ages successfully starting up companies or failing to. For me however, it was always about waiting for the big idea that would come when the stars perfectly aligned; it would be a sure success.
---
## Realization: The "big idea" is a fallacy
I have grown to realize over the years the idea of there being a "big idea" is a distraction from reality. That's not to say dreaming of a crystal clear business idea hasn't help me personally - but it doesn't paint the right picture to how successful companies come into existence.
If you listen close enough to successful companies and individuals you'll always hear a common theme: The first idea is never what got them where they are today; it's not even who they are today. They've had highs and lows, been defeated in the market and in many cases pivoted business altogether.
---
## Our mission: Fail-fast with big infrastructure
Throughout this series we will dive deep into constructing a fail-fast infrastructure. The infrastructure will support a culture of continuous innovation and shorten the path to go-to-market on new ideas. It will support all the following requirements:
1. Launching a new app or API in days. Including:
1. A containerized development environment.
1. A staging and production environment.
1. A CI/CD pipeline with support for JS and Go applications.
1. Auto-scaling to meet new demands.
1. Deploying mobile apps, web apps and APIs.
1. An API gateway to reduce the network complexity (rate limiting, authentication, middleware, etc.) of individual apps or APIs.
With this infrastructure we have accepted the fact that there is no silver bullet to successful startups. Rather, we are preparing ourselves to hit the ground running on any given app idea. Further, we are preparing ourselves to be able to quickly develop and deploy multiple branches of the same business (e.g. multiple related apps) in short succession.
---
## Continue reading
{% embed https://dev.to/morganw/software-engineering-entrepreneurship-issue-3-investing-in-cloud-technology-1l26 %} | morganw |
1,353,374 | YOLOv8 Already? How is it better than v5, try it to see! | YOLO (You Only Look Once) is a popular object detection algorithm used for computer vision... | 0 | 2023-02-04T10:40:51 | https://dev.to/gitruthvik/yolov8-already-how-is-it-better-than-v5-try-it-to-see-4g5o | yolo, computervision, yolov8, deeplearning |
YOLO (You Only Look Once) is a popular object detection algorithm used for computer vision applications. The latest version of YOLO, YOLOv8, was released in 2021 and it represents a major upgrade over its predecessor, YOLOv5. In this blog post, we will compare the performance and upgrades of YOLOv8 over YOLOv5.
Performance:
YOLOv8 provides improved performance compared to YOLOv5. This is due to several factors, including the use of a more efficient architecture, the addition of extra convolutional layers, and the use of anchor-based object detection. YOLOv8 also provides faster processing speeds, making it more suitable for real-time object detection applications.
Upgrades:
1. Improved Architecture: YOLOv8 introduces an updated architecture that is more efficient and accurate compared to YOLOv5. This new architecture uses a combination of residual blocks, bottleneck blocks, and inverted residual blocks to improve the accuracy and efficiency of the model.
2. Anchor-based Object Detection: YOLOv8 introduces anchor-based object detection, which provides more accurate and precise object detection compared to YOLOv5. Anchor-based object detection uses anchor boxes to predict the location and size of objects in the image.
3. More Convolutional Layers: YOLOv8 introduces extra convolutional layers, which provide the model with more capacity to learn and improve accuracy.
4. Improved Training: YOLOv8 introduces a new training regime that allows the model to learn more efficiently and achieve higher accuracy. This includes the use of a larger dataset and the use of transfer learning to fine-tune the model.
In short, YOLOv8 represents a major upgrade over YOLOv5 in terms of performance and accuracy. The improved architecture, anchor-based object detection, extra convolutional layers, and improved training regime all contribute to the improved performance of YOLOv8. If you are looking for a powerful and efficient object. | gitruthvik |
1,353,384 | Looking for an open source project to contribute? | Hello, I hope the above title excited you. I believe you are eager and enthusiast to contribute. I... | 0 | 2023-02-04T11:11:17 | https://dev.to/empash938/looking-for-an-open-source-project-to-contribute-2f8m | webdev, javascript, opensource, typescript | Hello, I hope the above title excited you. I believe you are eager and enthusiast to contribute.
I have created a fullstack web application which is a blogging application. You can even use this application to blog as you want. I learnt a lot building this application. Hope you too while contributing, I will be looking forward there. Following are the features:-
- Proper user authentication and authorization along with token verification
- Write in markdown format
- blogging analytics
- like/unlike comments and blogs
- comment and reply
- bookmark intriguing and needed blogs
- view user's profile
- follow/unfollow user
#### Technologies Used
- Frontend: React, Redux-toolkit, TailwindCSS, React-Router, Typescript
- Backend: NodeJS/Express, Cloudinary, JWT, Bcrypt
- Database: MongoDB, Mongoose
That's it for now. I hope you all the best.
| empash938 |
1,363,324 | Open-source SPL Makes Microservices More "Micro" | As microservices get popular, there are and will be more and more applications developed based on... | 0 | 2023-02-13T02:04:22 | https://dev.to/jbx1279/open-source-spl-makes-microservices-more-micro-2lm | As microservices get popular, there are and will be more and more applications developed based on microservices framework. To accomplish data processing tasks within microservices conveniently and efficiently thus becomes an inevitable issue. For a conventional monolithic application, we can implement computations in the database using the specialized, set-oriented SQL. The database’s powerful computing abilities enable quite easy data processing. In the microservices frameworks, a database is mainly used to realize data persistence and data is processed at the application (server) side.
Hardcoding in a high-level language (mainly in Java) is the main approach used to process data at the server side. The native Java code can be seamlessly integrated into the microservice-based application developed in Java. Moreover, Java supports procedural coding that implements computations step by step and the Stream introduced in Java8 have much improved the language for computations.
Yet, Java is still not nearly so convenient and efficient as SQL in achieving data processing goals. It is rather simple to achieve a grouping and aggregation operation in SQL, but it takes dozens of lines of Java code to finish the same calculation. The gap between the two languages is even bigger in dealing with complex computations. The root of Java’s inefficiencies is that the high-level language is not a specialized set-oriented language and lacks special class libraries for structured data computations, resulting in long and complicated code as well as "macro" microservices. What’s more, Java, as a compiled language, is hard to achieve hot swap, and it needs a heavy mechanism like Docker, which is unfriendly to the volatile microservices. But as the phrase goes, “one cannot have the cake and eat it”, you cannot embrace microservices and refuse Java’s shortcomings.
However, an ideal microservices’ data processing component should have certain features.
It should be easy to be integrated into microservices, so smooth that it can be embedded seamlessly in the latter. It should have powerful yet simple to use computational capabilities to accomplish data processing tasks conveniently. It should support hot swap (and hot deployment) to provide services without shutting down the system for maintenance. And it should have an open computing system that can directly access diverse data sources.
esProc SPL is the ideal one that can end all issues.
The open-source data processing engine not only can be seamlessly integrated into a Java application (which is based on microservices framework) but offers all-around computational abilities that enable far easier SPL programming than Java, even SQL, programming. Its support of hot swap and diverse data sources introduce new ideas for processing data within microservices.
# Efficient SPL programming
The specialized and versatile SPL data processing engine is able to deal with any structured data computations within microservices.
And it handles them simply and straightforwardly. The agile SPL syntax enables much more convenient programming than Java. The following example shows the SPL conciseness.
According to the stock table, we are trying to find stocks whose prices rise for at least five days in a row and count their rising days (treat same price as rising).
```
A
1 =db.query@x("select * from stock_record order by ddate")
2 =A1.group(code)
3 =A2.new(code,~.group@i(price Count days for each stock that rises in a row
4 =A3.select(maxrisedays>=5) Get eligible stock records
```
The source data is retrieved from the database and computed in SPL. To achieve the computing goal in this example, even SQL needs a triple-layer nested query, let alone Java (including Stream and Kotlin). SPL uses stepwise coding to do this, which is more convenient than SQL’s descriptive programming style. The language’s syntax combines merits of both Java and SQL.
SPL offers a wealth of class libraries to further simplify complex computations.
SPL can connect to and directly access diverse data sources, such as RDBs, NoSQL, CSV, Excel, HDFS, Restful/Webservice and Kafka, and perform mixed computations between them, significantly facilitating the handling of heterogeneous data sources tasks in microservices and further increasing programming efficiency.

SPL enables much shorter code for implementing service logic, achieving "micro" computational implementation for microservices in addition to its light architecture.
# Seamless integration ability
The Java-written SPL supports jar files for embedding. Microservices can import the SPL engine in the form of jar files to be integrated by the application. SPL also encapsulates the standard JDBC driver, through which the application can invoke an SPL script within the microservices.
Programmers just need to import the corresponding jar files and deploy the configuration file (raqsoftConfig.xml) to enable the JDBC driver. Then they can invoke an SPL script with a short piece of code.
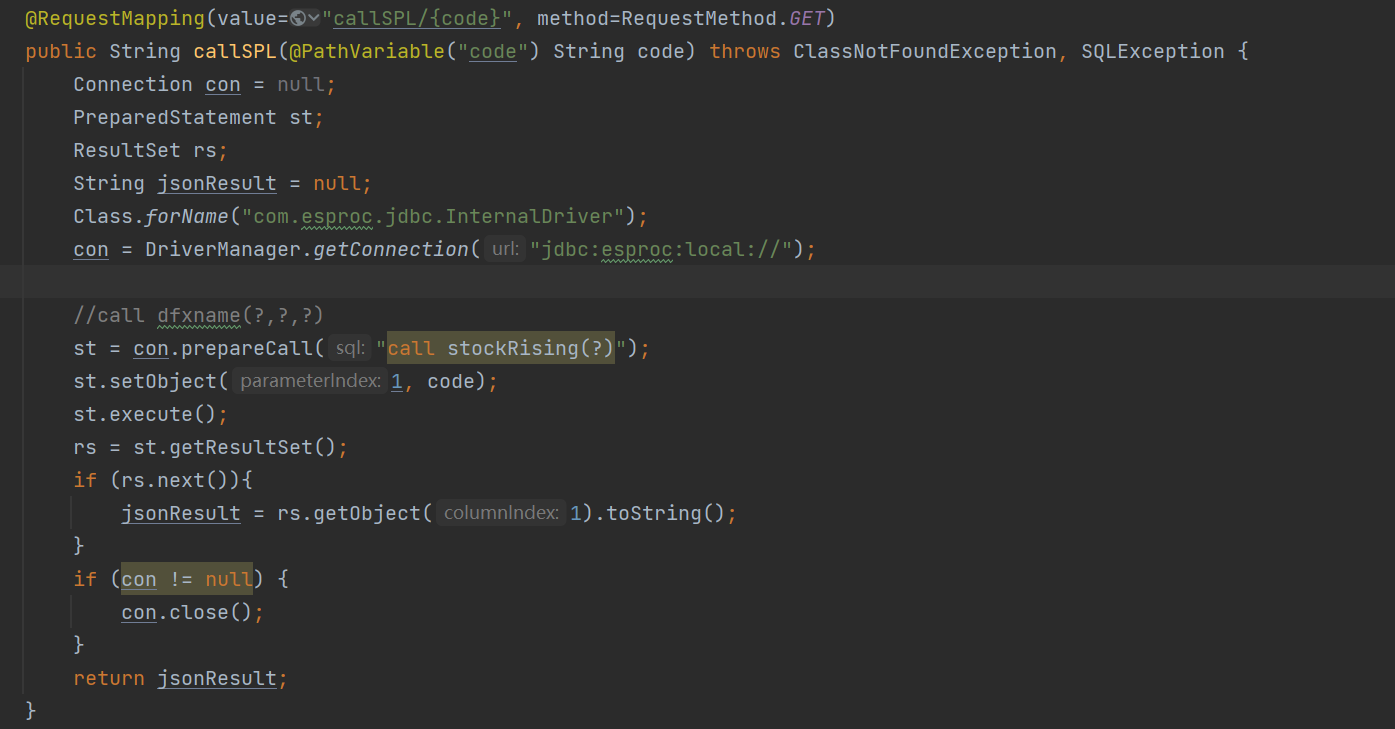
# Hot swap that enables resource-effective microservices
The interpreted execution SPL intrinsically supports hot swap, making it more adaptable to the volatile scenarios in microservices. Any change to a service will take effect immediately without restarting the server.

The data processing logic is stored in a SPL file (with the extension .splx). Any modification to it will come into effect in real time. This is really convenient and efficient compared with the restarting server design in a compiled language, such as Java.
SPL’s hot swap capability helps reduce microservices’ resource consumption. In order to separately operate and maintain each service instance of microservices where Java is used to process data, often they are deployed individually on VM or Docker. Though services are physically isolated from each other, the Docker will use more resources – that is, it is resource-inefficient. SPL is capable of being independently operated and maintained (hot-swap ability), giving the same capability to each of service instances deployed together and thus using resources efficiently. Sometimes services need to be separately deployed in order to reduce influence on each other, and in these cases, even SPL cannot achieve resource efficiency. Yet, the computing engine offers a large variety of options in order to slim down microservices in terms of both architecture and resource usage.
# High-performance computing
SPL can also run as a stand-alone computing server, which can be invoked by a SPL script within microservices to achieve high-performance computations.
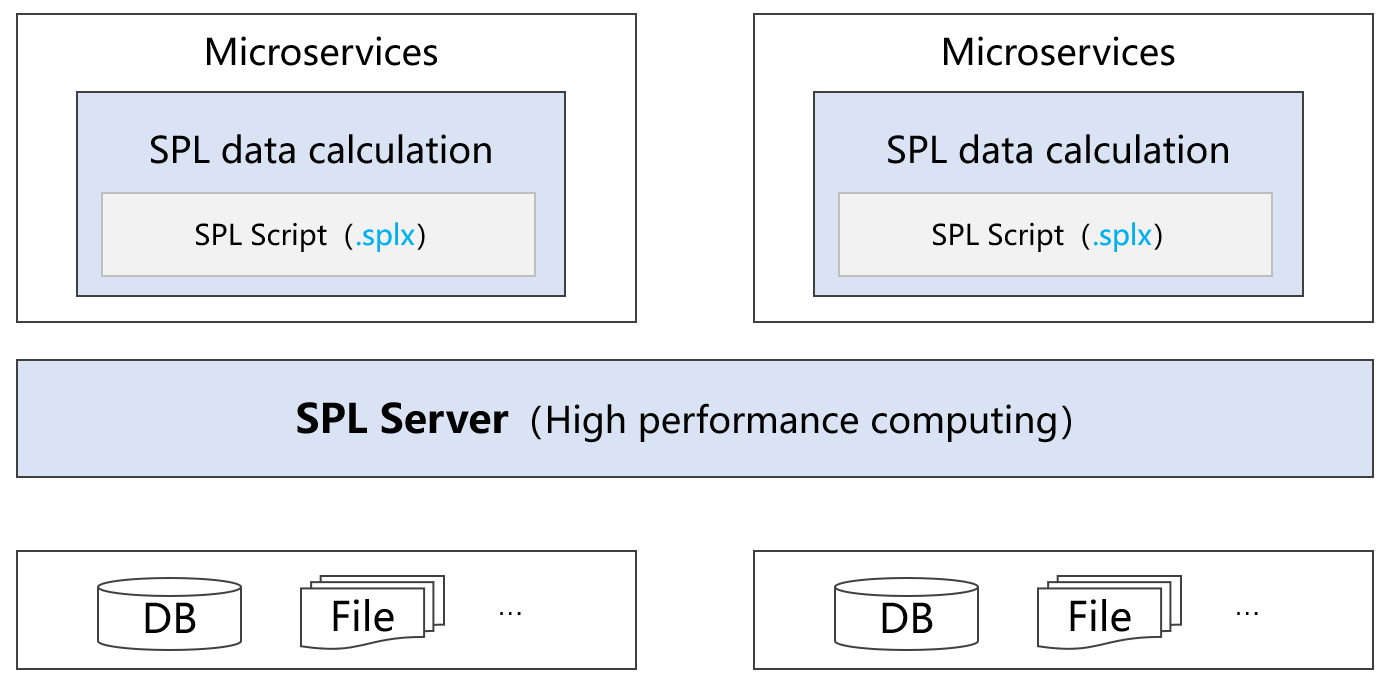
The SPL server supports distributed computing through scale-out across a cluster, load-balancing and fault tolerance. It also supplies a lot of high-performance algorithms to achieve high-performance computing.
In a nutshell, SPL can achieve fast and efficient data processing for microservices through its seamless integration ability, hot swap ability, easy programming and high-performance computing while offering architectural conveniences to effectively facilitate microservices development, making comprehensively "micro" microservices.
Origin: https://blog.scudata.com/open-source-spl-makes-microservices-more-micro/
Source code: https://github.com/SPLWare/esProc
| jbx1279 | |
1,353,630 | Nuxt-content with Nuxt 3 | Nuxt-Content is a module for the Nuxt.js framework that allows you to manage content in a... | 0 | 2023-02-04T15:43:06 | https://dev.to/guillaumeduhan/nuxt-content-with-nuxt-3-1e65 | webdev, javascript, beginners, programming | {% embed https://www.youtube.com/watch?v=5mTQLWyyVNM %}
Nuxt-Content is a module for the Nuxt.js framework that allows you to manage content in a headless CMS manner. It provides an easy way to work with dynamic content in a Nuxt.js application. The module integrates with a variety of headless CMS solutions, such as Strapi, Directus, and Sanity.io, making it flexible and adaptable to a wide range of use cases.
With Nuxt-Content, you can create, manage, and retrieve your content using simple APIs and templates, allowing you to build a fully dynamic website with ease. The module abstracts away the complexities of working with a headless CMS, allowing you to focus on building your application. It automatically generates a GraphQL API for you, so you don't have to worry about setting up a separate server or writing custom code to interact with your content.
One of the key features of Nuxt-Content is its ability to handle relationships between different pieces of content, such as author-to-post relationships, for example. This allows you to build complex and dynamic applications, where the content is central to the user experience.
In conclusion, Nuxt-Content is a powerful tool for building dynamic websites and applications, making it easy to work with headless CMSs. With its simple APIs and automated GraphQL setup, you can quickly and easily create, manage, and retrieve content, making it an ideal solution for a wide range of use cases.
Guillaume Duhan | guillaumeduhan |
1,353,638 | AWS GuardDuty | Amazon GuardDuty is a continuous security monitoring service that analyzes and processes from... | 0 | 2023-02-04T15:55:31 | https://dev.to/toony_mustafa/aws-guardduty-1ahh | aws, security, cloudcomputing | - Amazon GuardDuty is a continuous security monitoring service that analyzes and processes from different data sources.
- Data source Including: CloudTrail (Event Logs, Management events, Data event for S3), VPC Flow logs, DNS logs, EBS Volume, Kubernetes audit logs.
- You don’t have to enable logging at each of those Data sources as GuardDuty will pull all required logs independently without assigning or changing any permissions.
- It uses threat intelligence feeds, machine learning anomaly detection, and malware scanning.
- It monitors AWS account access behavior for signs of compromise.
- Regional Service.
- Practical examples GuardDuty can detect: Reconnaissance (Gathering information about network), Instance compromise (Cryptocurrency mining), Account compromise, Bucket compromise, Malware detection, Container compromise.
- This service cost is calculated by the Volume of analyzed service logs and the volume of data scanned for malware.
- Every account has 30 days trail cost “you have access to You have access to the full feature set and detections during the free trial”, and after 7 days you will have a cost estimation to help you predicate the actual cost after trial period ends.
References:
https://docs.aws.amazon.com/guardduty/latest/ug/what-is-guardduty.html
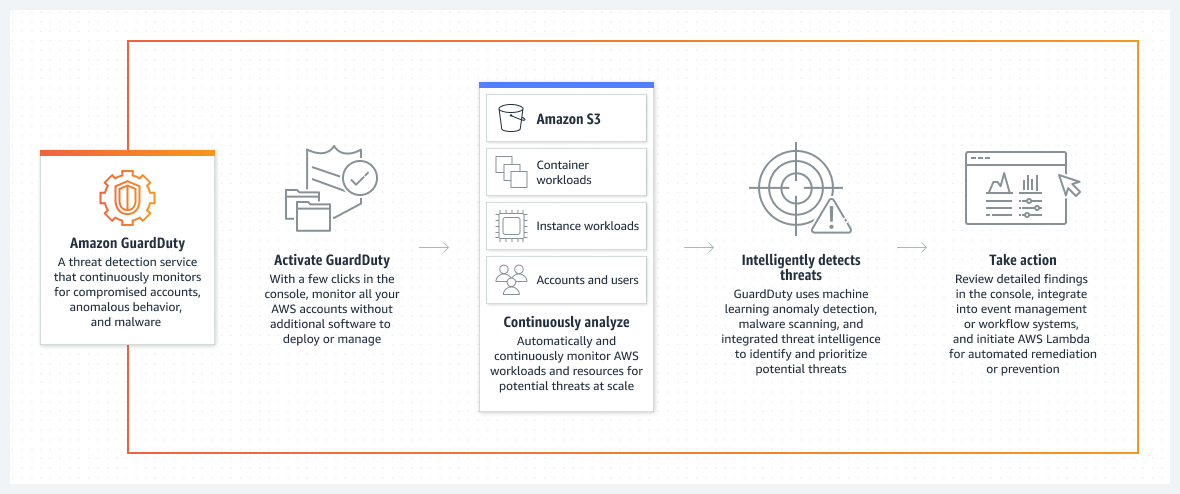 | toony_mustafa |
1,353,699 | Getting Started with Bottom Sheets in Android Using Kotlin Part 1 [Beginner Friendly] | Hi guys 👋, in this article, I'm going to delve into what a bottom sheet is, its common uses, and how... | 0 | 2023-02-04T17:58:02 | https://medium.com/@arnold.wafula0/getting-started-with-bottom-sheets-in-android-using-kotlin-part-1-beginner-friendly-a4ae903c01d6 | android, bottomsheet, bottomsheetdialogfragment, kotlin |  on [Unsplash](https://unsplash.com/photos/t6Wmvbw_MdI?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/1e8nu6veqjz8zyxs2mhy.jpeg)
Hi guys 👋, in this article, I'm going to delve into what a bottom sheet is, its common uses, and how it can be implemented in android development using Kotlin. I will cover its implementation in the traditional view system (XML-based).
Without further ado, we can ask ourselves the question. What is a bottom sheet?
> According to Google's material.io documentation, a bottom sheet is a surface containing supplementary content that are anchored to the bottom of the screen and can be dismissed in order to interact with the underlying content.
Its use has been preferred over dialogs in recent years and as a smartphone user either on Android or iOS, you must have interacted with it. Personally an avid YouTube user, it is heavily and perfectly integrated within its U.I.
It is also worth noting that they are flexible and can hold a diverse range of information and layouts, including menu items, actions, and supplemental content.
---
**There are two types of bottom sheets;**
1. Standard bottom sheet
2. Modal bottom sheet
## Standard Bottom Sheet
Also known as persistent bottom sheets, they co-exist with the screens main U.I and allow for simultaneous interaction with both the U.I and itself. It exists in the expanded, collapsed, and hidden states.
A good example of an app that utilizes the standard bottom sheet is Google Maps.
## Modal Bottom Sheet
Strictly use on mobile devices, modal bottom sheets block interaction with the rest of the screen and serve as a perfect alternative to dialogs, as they provide more room and allow for the use of views such as Images and Text.
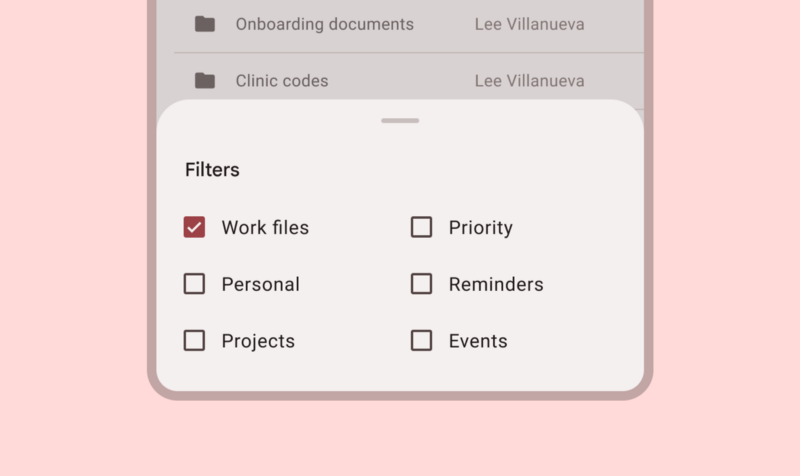
In android development, they extend the [BottomSheetDialogFragment](https://developer.android.com/reference/com/google/android/material/bottomsheet/BottomSheetDialogFragment) class to provide functionalities such as behavior, and screen height among others. In this article, I am going to focus on the modal bottom sheets since they have a more popular use case compared to persistent bottom sheets.
If you wish to go straight into the source code, click the GitHub link below;
{% embed https://github.com/arnold-wafula/ModalBottomSheet-Medium.git %}
---
On [Android Studio](https://developer.android.com/studio), Google's official IDE for Android development, navigate to File->New->New Project. Under the templates tab, choose Phone and Tablet and select Empty Activity. Let's start by creating the activity_main layout;
{% gist https://gist.github.com/arnold-wafula/192d409a2ec52ed89594064a6f8b2ea8.js %}
Set up the MainActivity file by copy-pasting the code below;
MainActivity.kt
{% gist https://gist.github.com/arnold-wafula/fa071386514ecd6abb66ea0356c3692f.js %}
We will then define the layout for a single item containing an image and text that will appear in the modal bottom sheet. Create a new layout XML file item_bottomsheet and copy-paste the source code below;
item_bottomsheet.xml
{% gist https://gist.github.com/arnold-wafula/81824076de87df3b2c8207e839b4144c.js %}
Finally, the ModalBottomSheetDialog class displays the items defined in the item_bottomsheet.xml.
ModalBottomSheetDialog.kt
{% gist https://gist.github.com/arnold-wafula/a2ad8233a69e4475b0b4a3a500ae2bfa.js %}
Here is the final result;


So that is a simple way to build the modal bottom sheet in android. See you in part 2 of the article where I will dive into the fullscreen implementation of the same.
Peace ☮️✌️ | arnoldwafula |
1,353,704 | AWS Certified Professional Challenge 2023 | Are you ready? A new challenge for those interested in AWS certification has already been... | 0 | 2023-02-04T18:16:59 | https://dev.to/igvir/aws-certified-professional-challenge-2023-3ilh | aws, awscertifications, devops, professional | ## Are you ready?
A new challenge for those interested in AWS certification has already been announced. This time it's the Professional Challenge. A certification exam preparation program with advanced training including live and on-demand Twitch sessions with AWS experts.
If you join the [Get AWS Certified: Professional Challenge](https://pages.awscloud.com/GLOBAL-ln-GC-TrainCert-Professional-Certification-Challenge-Registration-2023.html) before April 28, they will send you a 50% discount coupon for the professional level certification exam. The options are:
- AWS Certified Solutions Architect - Professional
- AWS Certified DevOps Engineer - Professional
For this challenge, the exam must be taken no later than May 31, 2023.
[See program conditions](https://pages.awscloud.com/GLOBAL-ln-GC-TrainCert-Professional-Certification-Challenge-Terms-and-Conditions-2023-learn.html) | igvir |
1,353,845 | Building an entirely Serverless Workflow to Analyse Music Data using Step Functions, Glue and Athena | This blog will demonstrate how to create and run an entirely serverless ETL workflow using step... | 0 | 2023-02-26T18:52:37 | https://dev.to/aws-builders/building-an-entirely-serverless-workflow-to-analyse-music-data-using-step-functions-glue-and-athena-4j2l | serverless, analytics, spark, aws | This blog will demonstrate how to create and run an entirely serverless ETL workflow using step functions to execute a glue job to read csv data from S3, carry out transformations in pyspark and writing the results to S3 destination key in parquet format. This will then trigger a glue crawler to create or update tables with the metadata from the parquet files. A successful job run, should then send an SNS notification to a user by email.
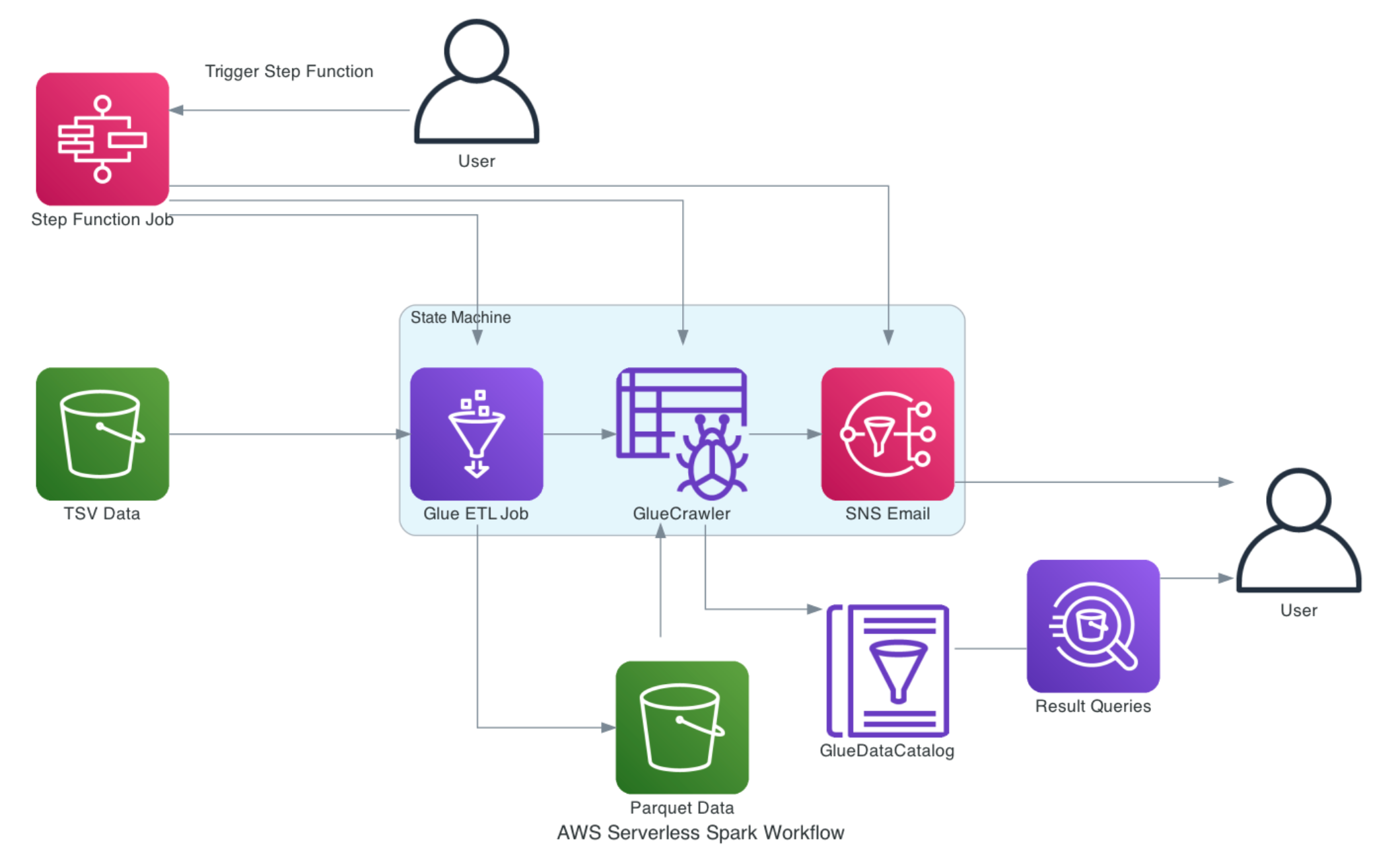
We will use the <a href="http://ocelma.net/MusicRecommendationDataset/lastfm-1K.html">LastFM dataset</a> which represents listening habits for nearly 1,000 users. These are split into two `tsv` files, one containing user profiles (gender, age, location, registration date) and the other containing details of music tracks each user has listened to, with associated timestamp.
Using aws glue, we can carry out data transformations in pyspark to generate the insights about the users, like the following:
* Number of distinct songs each user has played.
* 100 most popular songs (artist and title) in the dataset, with the number of times each was played.
* Top 10 longest sessions (by elapsed time), with the associated information about the userid, timestamp of first and last songs in the session, and the list of songs played in the session (in order of play). A user's “session” will be assumed to be comprised of one or more songs played by that user, where each song is started within 20 minutes of the previous song’s start time.
### Glue Notebook and Spark Transformations
We will create a glue job by uploading this <a href="https://github.com/ryankarlos/bigdataeng/blob/master/notebooks/AWS_Glue_Notebook.ipynb">notebook</a> to Amazon Glue Studio Notebooks. Before setting up any resources, let's first go through the various code snippets and functions in the notebook to describe the different transformation steps to answer the questions listed above.
The first cell imports and initializes a GlueContext object, which is used to create a SparkSession to be used inside the AWS Glue job.
Spark provides a number of classes (`StructType`, `StructField`) to specify the structure of the spark dataframe. `StructType` is a collection of `StructField` which is used to define the column name, data type and a flag for nullable or not.
```
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import (
StringType,
StructField,
StructType,
TimestampType,
)
import boto3
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
client = boto3.client('s3')
SESSION_SCHEMA = StructType(
[
StructField("userid", StringType(), False),
StructField("timestamp", TimestampType(), True),
StructField("artistid", StringType(), True),
StructField("artistname", StringType(), True),
StructField("trackid", StringType(), True),
StructField("trackname", StringType(), True),
]
)
S3_PATH="s3://lastfm-dataset/user-session-track.tsv"
BUCKET="lastfm-dataset"
```
This function will read the LastFM dataset in csv format into a spark dataframe from the S3 bucket `lastfm-dataset`, using the S3_PATH and schema definition defined above. We will drop the columns we do not need. The schema is printed below by calling the `printSchema()` method of the spark dataframe.
```
def read_session_data(spark):
data = (
spark.read.format("csv")
.option("header", "false")
.option("delimiter", "\t")
.schema(SESSION_SCHEMA)
.load(S3_PATH)
)
cols_to_drop = ("artistid", "trackid")
return data.drop(*cols_to_drop).cache()
df = read_session_data(spark)
df.printSchema()
```

The function `create_users_and_distinct_songs_count` will create a list of user IDs, by selecting the columns `userid`, `artistname` and `trackname`, dropping duplicate rows and performing a groupBy count for each `userid`.
```
def create_users_and_distinct_songs_count(df: DataFrame) -> DataFrame:
df1 = df.select("userid", "artistname", "trackname").dropDuplicates()
df2 = (
df1.groupBy("userid")
.agg(count("*").alias("DistinctTrackCount"))
.orderBy(desc("DistinctTrackCount"))
)
return df2
songs_per_user = create_users_and_distinct_songs_count(df)
songs_per_user.show()
```
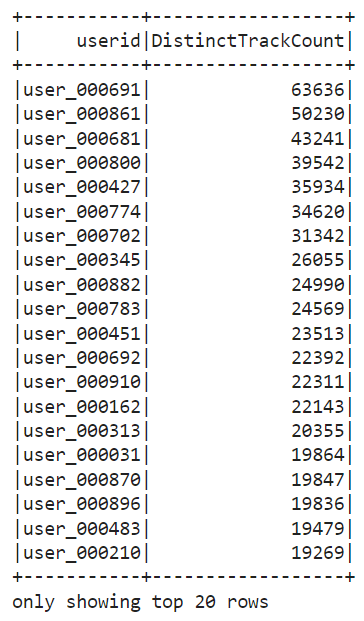
The `create_popular_songs` function performs a `GroupBy` count operation for `artistname` and `trackname` columns and then ordered in descending order of counts with a limit to get the 100 most popular songs.
```
def create_popular_songs(df: DataFrame, limit=100) -> DataFrame:
df1 = (
df.groupBy("artistname", "trackname")
.agg(count("*").alias("CountPlayed"))
.orderBy(desc("CountPlayed"))
.limit(limit)
)
return df1
popular_songs = create_popular_songs(df)
popular_songs.show()
```
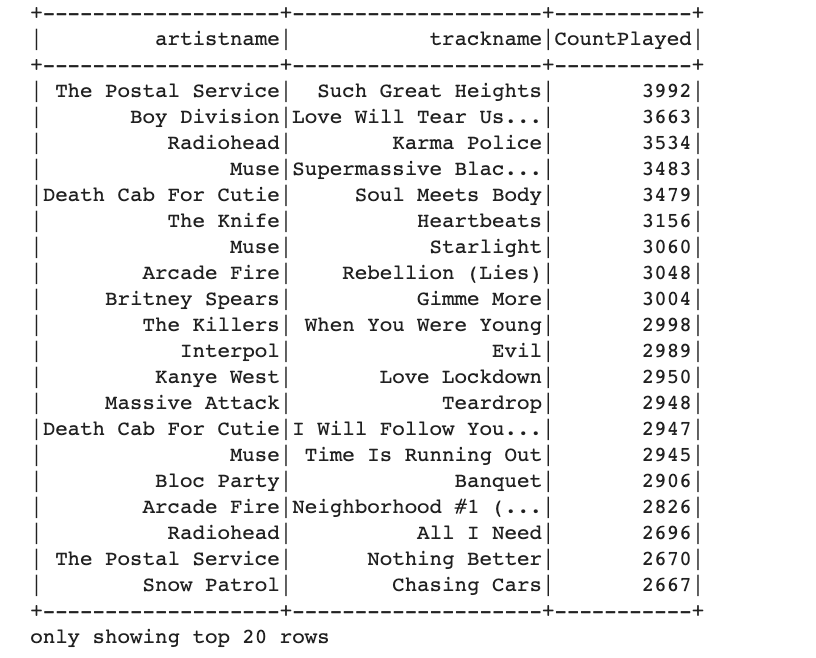
The next snippet will lag the previous timestamp for each user partition (using window function) and compute the difference between current and previous timestamp in a session per user. We then create a session flag (binary flag) for each user, if time between successive played tracks exceeds session_cutoff (20 minutes). A `SessionID` column will compute a cumulative sum over the sessionflag column for each user.
We then group the Spark DataFrame by `userid` and `SessionID` and compute min and max timestamp as session start and end columns. Then create a session_length (hrs) column which computes the difference between session end and start for each row and convert to hours. Order the DataFrame from max to min session length and limit to top 10 sessions as required.
To get the list of tracks for each session, join to the original raw dataframe read in and group by `userid`, `sessionID` and `session_length` in hours. Now apply the `pyspark.sql` function `collect_list` to each group to create a list of tracks for each session.
```
def create_session_ids_for_all_users(
df: DataFrame, session_cutoff: int
) -> DataFrame:
w1 = Window.partitionBy("userid").orderBy("timestamp")
df1 = (
df.withColumn("pretimestamp", lag("timestamp").over(w1))
.withColumn(
"delta_mins",
round(
(
col("timestamp").cast("long")
- col("pretimestamp").cast("long")
)
/ 60
),
)
.withColumn(
"sessionflag",
expr(
f"CASE WHEN delta_mins > {session_cutoff} OR delta_mins IS NULL THEN 1 ELSE 0 END"
),
)
.withColumn("sessionID", sum("sessionflag").over(w1))
)
return df1
def compute_top_n_longest_sessions(df: DataFrame, limit: int) -> DataFrame:
df1 = (
df.groupBy("userid", "sessionID")
.agg(
min("timestamp").alias("session_start_ts"),
max("timestamp").alias("session_end_ts"),
)
.withColumn(
"session_length(hrs)",
round(
(
col("session_end_ts").cast("long")
- col("session_start_ts").cast("long")
)
/ 3600
),
)
.orderBy(desc("session_length(hrs)"))
.limit(limit)
)
return df1
def longest_sessions_with_tracklist(
df: DataFrame, session_cutoff: int = 20, limit: int = 10
) -> DataFrame:
df1 = create_session_ids_for_all_users(df, session_cutoff)
df2 = compute_top_n_longest_sessions(df1, limit)
df3 = (
df1.join(df2, ["userid", "sessionID"])
.select("userid", "sessionID", "trackname", "session_length(hrs)")
.groupBy("userid", "sessionID", "session_length(hrs)")
.agg(collect_list("trackname").alias("tracklist"))
.orderBy(desc("session_length(hrs)"))
)
return df3
df_sessions = longest_sessions_with_tracklist(df)
df_sessions.show()
```
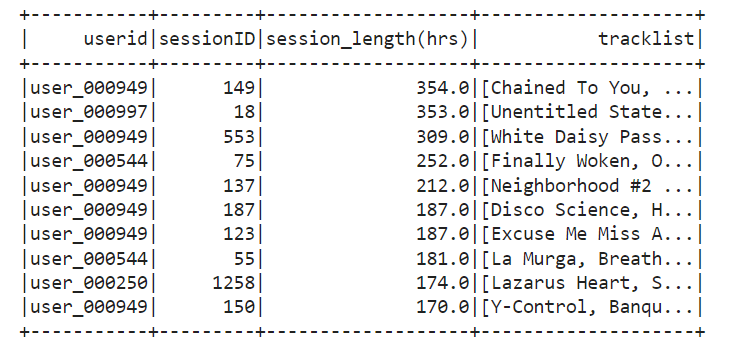
Finally, the snippet below will convert pyspark dataframe to glue dynamic dataframe and write to s3 bucket in parquet format, using the `write_dynamic_frame()` method. By default this method, saves the output files with the prefix `part-00` in the name. It would be better to rename this to something simpler. To do this, we can use the `copy_object()` method of the boto s3 client to copy the existing object to a new location (using a custom name as suffix .e.g `popular_songs.parquet`) within the bucket.The original object can then be deleted using the `delete_object()` method.
```
def rename_s3_results_key(source_key_prefix, dest_key):
response = client.list_objects_v2(Bucket=BUCKET)
body = response["Contents"]
key = [obj['Key'] for obj in body if source_key_prefix in obj['Key']]
client.copy_object(Bucket=BUCKET, CopySource={'Bucket': BUCKET, 'Key': key[0]}, Key=dest_key)
client.delete_object(Bucket=BUCKET, Key=key[0])
def write_ddf_to_s3(df:DataFrame, name: str):
dyf = DynamicFrame.fromDF(df.repartition(1), glueContext, name)
sink = glueContext.write_dynamic_frame.from_options(frame=dyf, connection_type = "s3a",format = "glueparquet", connection_options = {"path": f"s3a://{BUCKET}/results/{name}/", "partitionKeys": []},
transformation_ctx = f"{name}_sink"
)
source_key_prefix = f"results/{name}/run-"
dest_key = f"results/{name}/{name}.parquet"
rename_s3_results_key(source_key_prefix, dest_key)
return sink
write_ddf_to_s3(popular_songs, "popular_songs")
write_ddf_to_s3(df_sessions, "df_sessions")
write_ddf_to_s3(songs_per_user, "distinct_songs")
```
In the next sections we will setup all the resources defined in the architecture diagram and execute the state machine.
## Data upload to S3
First we will create a standard bucket `lastfm-dataset` from the AWS console to store the source files in and enable <a href="https://docs.aws.amazon.com/AmazonS3/latest/userguide/transfer-acceleration.html">transfer acceleration</a> in the bucket properties to optimise transfer speed. This will generate a s3-endpoint `s3 accelerate.amazonaws.com`, which can be used to upload files to using the cli. Since some of these files are large, it is easier to use the `aws s3` commands (such as `aws s3 cp`) for uploading to the S3 bucket as this will automatically use multipart upload feature if the file size exceeds 100MB.

### AWS Glue Job and Crawler
We will then create a glue job by uploading this <a href="https://github.com/ryankarlos/bigdataeng/blob/master/notebooks/AWS_Glue_Notebook.ipynb">notebook</a> to Amazon Glue Studio Notebooks. We will first need to create a role for Glue to assume and give permissions to access S3 as below.
* In the Amazon Glue Studio console, choose Jobs from the navigation menu.
* In the Create Job options section, select Upload and then select the `AWS_Glue_Notebook.ipynb` file to upload.
* On the next screen, name your job as `LastFM_Analysis`. Select the glue role created previously in the IAM Role dropdown list. Choose spark kernel and `Start Notebook`.
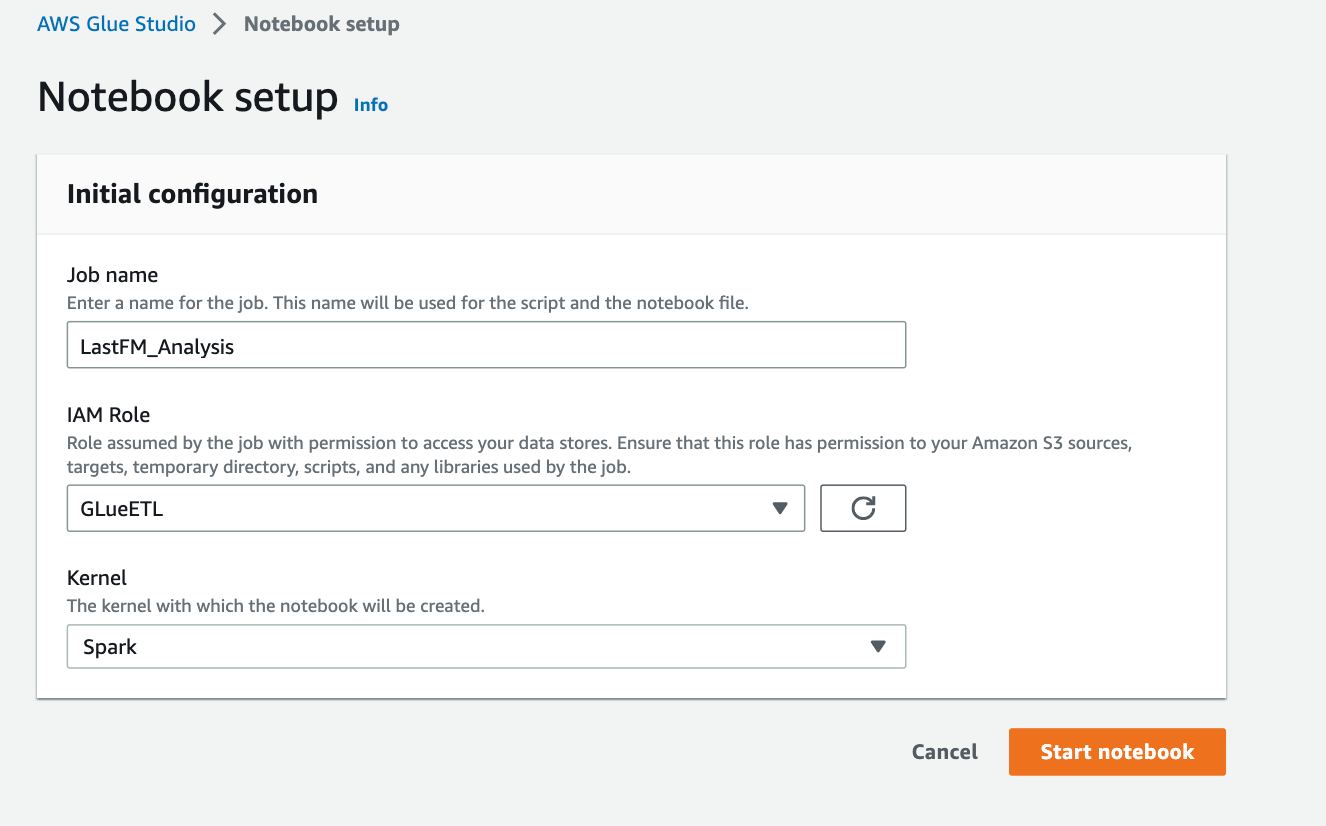
* We should see the notebook in the next screen. Click 'Save'.
If we navigate back to the AWS Glue Studio Jobs tab, we should see the new job `LastFM_Analysis` created.

We can now setup the <a href="https://docs.aws.amazon.com/glue/latest/dg/console-crawlers.html">glue crawler</a> from the AWS Glue console, to include the settings in the screenshot below. This will collect metadata from the glue output parquet files in S3 , and update the glue catalog tables.

### SNS topic
We will also need to set up subscription to SNS topic so that notifications will be sent to an email address by following the <a href="https://docs.aws.amazon.com/sns/latest/dg/sns-email-notifications.html">AWS docs</a>. We will setup a separate task at the end of the Step Function workflow to publish to the SNS topic. However, one could alternatively configure S3 event notification for specific S3 keys so that any parquet outputs from the glue job into S3 will publish to SNS topic destination.
Once you have setup the sub subscription from the console, you should get an email notification, asking you to confirm subscription as below:
### Step Function setup and execution
Now we need to create a state machine. This is a workflow in an AWS Step Function, which consists of a set of <a href="https://docs.aws.amazon.com/step-functions/latest/dg/concepts-states.html">states</a>,
each of which represent a single unit of work. The state machine is defined in <a href="https://docs.aws.amazon.com/step-functions/latest/dg/concepts-amazon-states-language.html">Amazon States Language</a>, which is a JSON-based notation. In this example, the amazon state language specification is as below. We will use this when creating the state machine in the console.
```
{
"Comment": "Glue ETL flights pipeline execution",
"StartAt": "Glue StartJobRun",
"States": {
"Glue StartJobRun": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun",
"Parameters": {
"JobName": "LastFM_Analysis",
"MaxCapacity": 2
},
"ResultPath": "$.gluejobresults",
"Next": "Wait"
},
"Wait": {
"Type": "Wait",
"Seconds": 30,
"Next": "Get Glue Job status"
},
"Get Glue Job status": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:glue:getJobRun",
"Parameters": {
"JobName.$": "$.gluejobresults.JobName",
"RunId.$": "$.gluejobresults.JobRunId"
},
"Next": "Check Glue Job status",
"ResultPath": "$.gluejobresults.status"
},
"Check Glue Job status": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.gluejobresults.status.JobRun.JobRunState",
"StringEquals": "SUCCEEDED",
"Next": "StartCrawler"
}
],
"Default": "Wait"
},
"StartCrawler": {
"Type": "Task",
"Parameters": {
"Name": "LastFM-crawler"
},
"Resource": "arn:aws:states:::aws-sdk:glue:startCrawler",
"Next": "Wait for crawler to complete"
},
"Wait for crawler to complete": {
"Type": "Wait",
"Seconds": 70,
"Next": "SNS Publish Success"
},
"SNS Publish Success": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:*:Default",
"Message.$": "$"
},
"Next": "Success"
},
"Success": {
"Type": "Succeed"
}
}
}
```
Before creating the state machine, we will also need to create a role for Step Function to assume, with permissions to call the various services e.g Glue, Athena, SNS, Cloudwatch (if logging will be enabled when creating the state machine) etc using AWS managed policies as below.
In the Step Functions console, in the State Machine tab:
* Select Create State Machine
* Select "Write your workflow in code" with Type "Standard"
* Paste in the state language specification. This will generate a visual representation of the state machine as below, if the definition is valid.
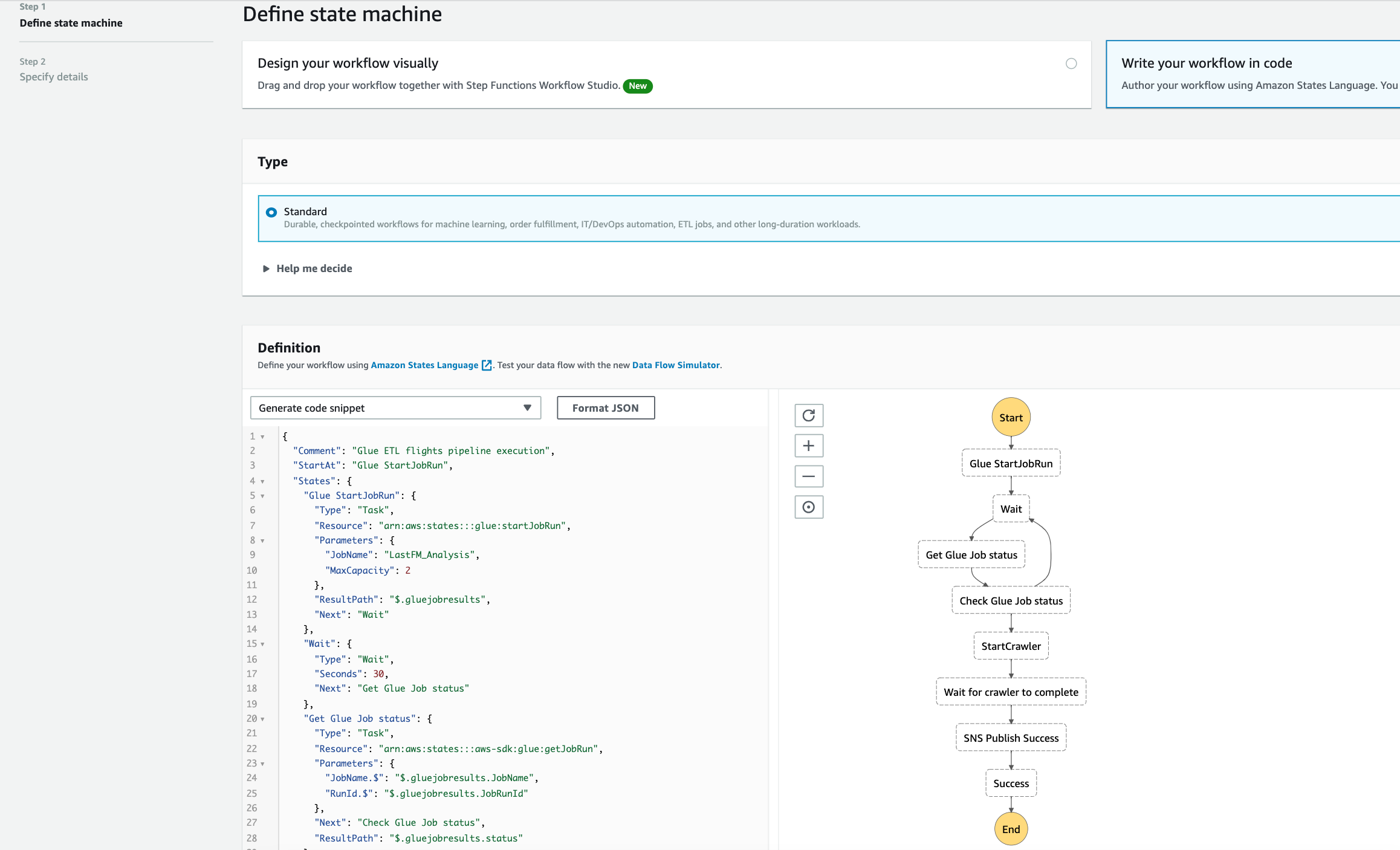
* Select next and then in the "Specify Details" section, fill in the State Machine Name, execution role created previously from the dropdown and turn on Logging to CloudWatch. Then click "Create State Machine"
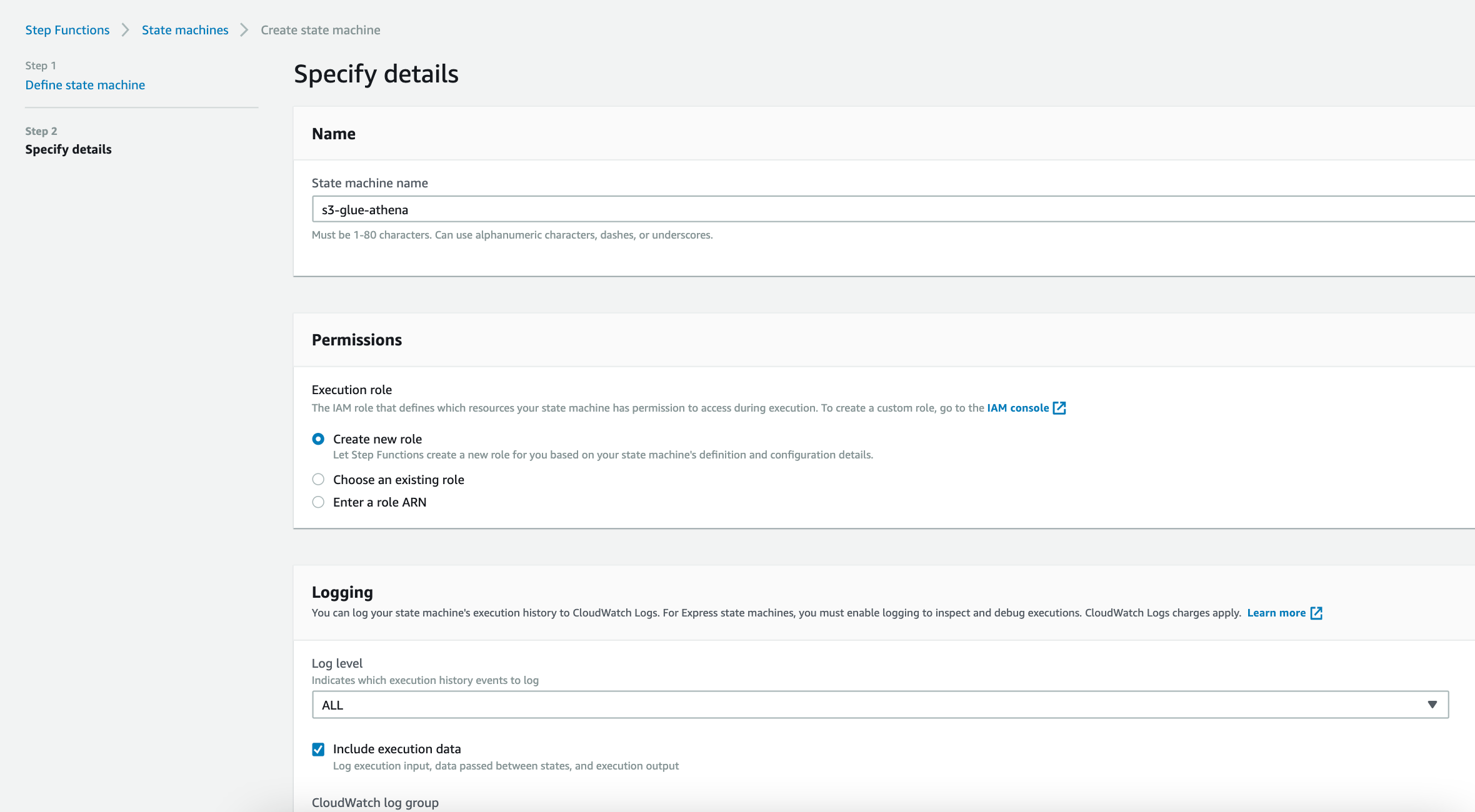
Let us go through what each of the states will be doing. The first task state `Glue StartJobRun` will start the glue job `LastFM_Analysis` with 2 data processing units (DPUs) capacity as specified in the parameters block. The output of this state is then included in the <a href="https://docs.aws.amazon.com/step-functions/latest/dg/input-output-resultpath.html"> ResultsPath </a> as `$.gluejobresults` along with the original input. This will give access to glue job metadata like the job id, status, job name to be used as parameters for subsequent states.
The next state is a <a href="https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-wait-state.html"> Wait state </a> which pauses the execution of the state machine for 30 seconds before proceeding to the next tasks of checking the glue job status for the glue job. Using <a href="https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-choice-state.html"> Choice state </a>, we can add a condition to proceed to the next task (`StartCrawler`) if the value of glue job status is `SUCCEEDED`, otherwise it loops back to the Wait Task activity and waits for another 30 seconds before repeating the process again. This ensures we only start crawling the data from S3 when the glue job has completed as the output parquet files will be available and ready to be crawled.
Similarly, after the `StartCrawler` task, we can add a wait state to pause step function for 70 seconds (we expect the crawler to have completed in a minute), to ensure that a notification is sent to the SNS topic `Default` only when the crawler has completed successfully.
Now the state machine can be executed. If the step function completes successfully, we should see an output similar to below.
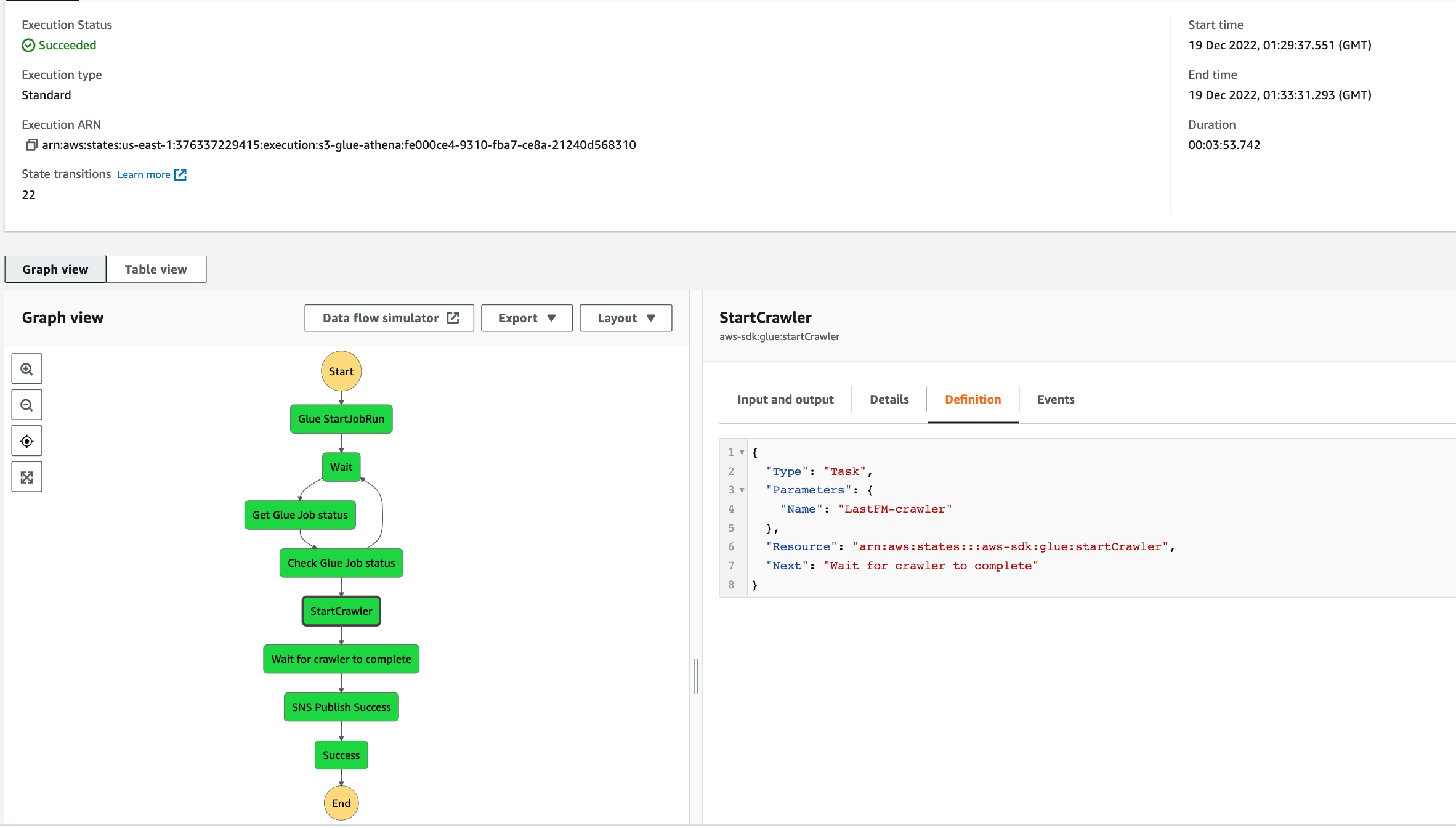
If the glue job is successful, we should see the parquet files in dedicated subfolders in the results folder in the S3 bucket. You should also get a notification to the email subscribed to the SNS topic.
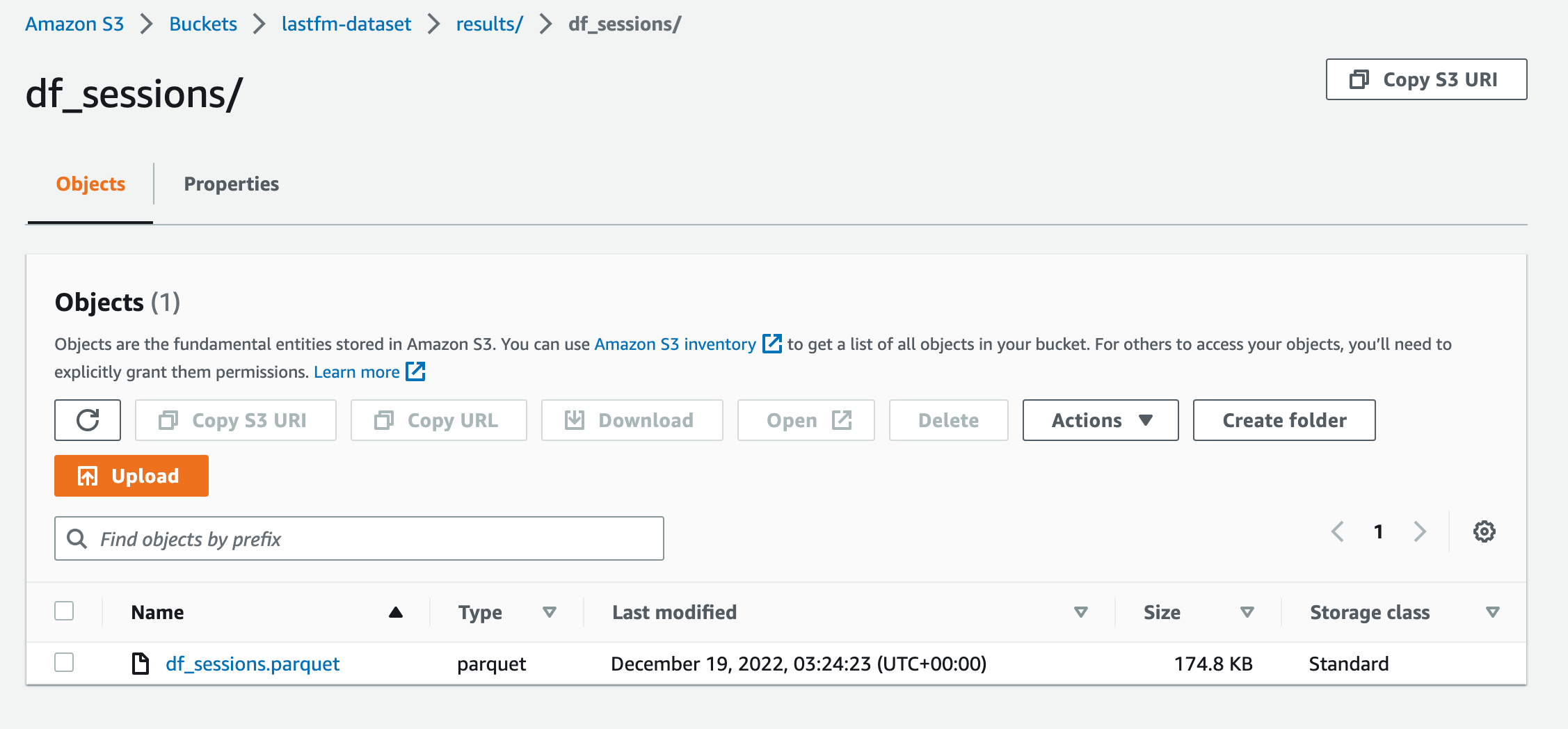
The catalog tables should be created after successful completion of the crawler. We can now query the tables in Athena as below. The tables could also be accessed via Amazon Quicksight or Tableau for generating visualisation dashboards for further insights.
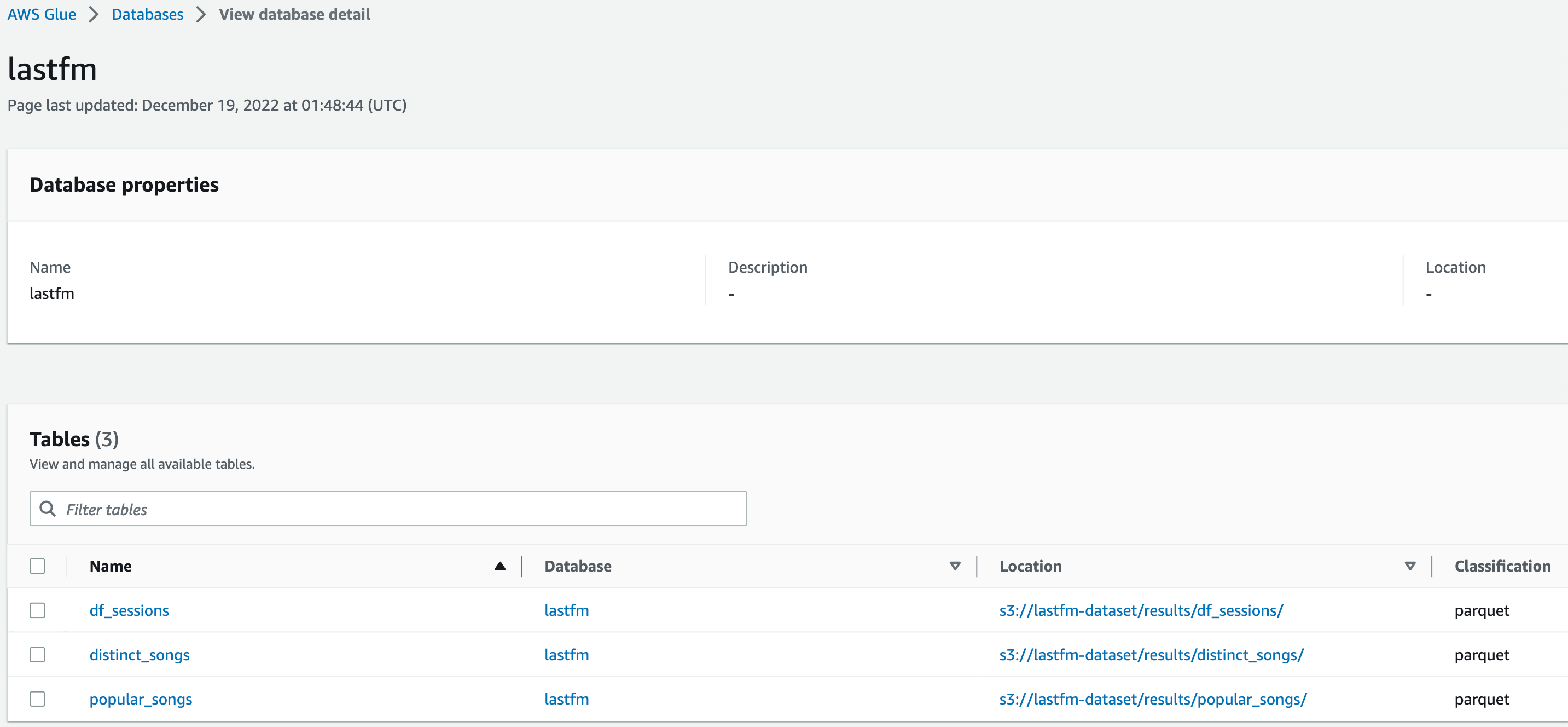
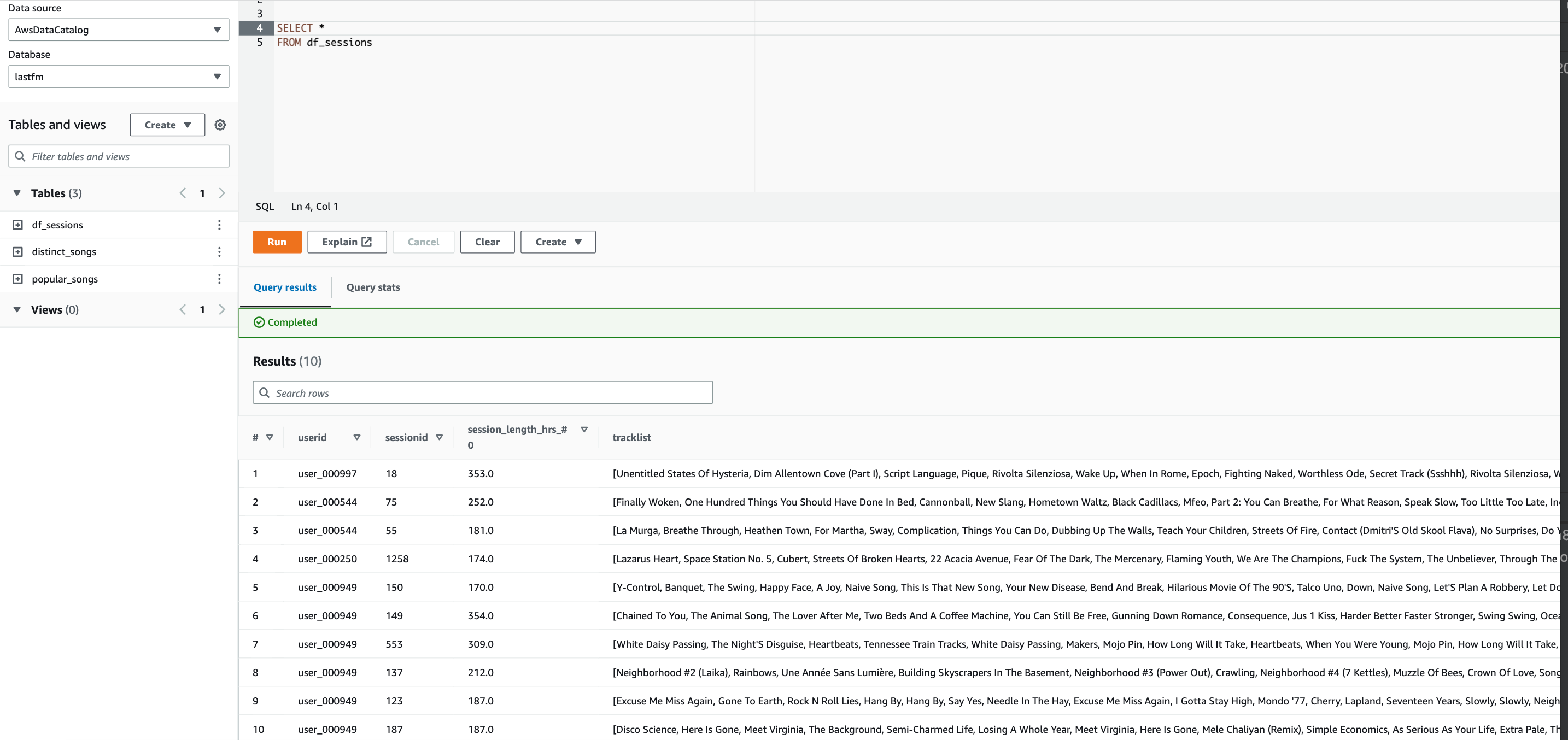
| ryankarlos |
1,354,109 | RPA IN Finance | Robotic Process Automation (RPA) is increasingly being adopted by financial institutions to automate... | 0 | 2023-02-05T04:47:10 | https://dev.to/obliquee/rpa-in-finance-31pd | Robotic Process Automation (RPA) is increasingly being adopted by financial institutions to automate manual and repetitive tasks, such as data entry, account reconciliation, and payment processing. In the finance industry, where accuracy and efficiency are critical, RPA has the potential to bring significant benefits, including improved productivity and cost savings.
One of the key benefits of RPA in finance is increased accuracy and speed. By automating routine processes, such as data entry and reconciliation, RPA can help to reduce the risk of human error, which is especially important in the finance industry where errors can have significant financial consequences. In addition, RPA can process transactions and complete tasks much faster than a human worker, which can result in reduced processing times and improved customer experience.
Another advantage of RPA in finance is that it can reduce the need for manual intervention, freeing up employees to focus on more strategic tasks. For example, RPA can be used to automate repetitive back-office tasks such as invoice processing, allowing finance staff to focus on more value-added activities such as analysis and decision-making. This can result in increased productivity, improved job satisfaction, and reduced staff turnover.
RPA is also highly scalable and flexible, which makes it well-suited to the fast-paced and constantly evolving financial services sector. Robots can be easily added or removed as business needs change, and they can be programmed to work with a wide range of financial systems and applications, making it easy to integrate RPA into existing technology infrastructure.
However, it is important to note that RPA is not a standalone solution and should be used as part of a broader digital transformation strategy. For example, while robots can automate routine tasks, they are not designed to make decisions or solve complex problems. Financial institutions should therefore focus on identifying the most suitable processes for automation and ensuring that they have the right mix of people and technology to meet their business goals.
In conclusion, RPA is becoming an increasingly important tool for financial institutions, offering the potential to improve accuracy, speed, and efficiency, while freeing up employees to focus on more strategic tasks. By leveraging RPA, financial institutions can reduce costs, improve customer experience, and remain competitive in an ever-evolving market. | obliquee | |
1,354,117 | Fighting with motivation | I haven't posted in a while or really done anything tech related in a few....months? Weeks? Honestly,... | 0 | 2023-02-05T05:16:51 | https://dev.to/kurtissfrost/fighting-with-motivation-4p62 | codenewbie, webdev, devjournal, discuss | I haven't posted in a while or really done anything tech related in a few....months? Weeks? Honestly, it's been so long that I have no idea how long it's been.
Here lately, I have been struggling with motivation issues. I haven't felt like doing anything productive. I haven't been studying web development, or trying to get any certs or any of the many other things I have set out to learn about. Not even just tech related things. I haven't tinkered with my Linux coding environment, created any graphics, edited a video, or really anything creative.
Here lately, I have just been struggling with motivation to do anything. I work 40 hours a week and when I get home I wind up just goofing off or just going straight to bed.
Last year I wrote an article about [how I wanted to increase my productivity](https://dev.to/kurtissfrost/how-i-want-to-increase-my-productivity-59p0) in that article, I vaguely mention that I hadn't felt like marking things off of my to do list. This is a little more serious than that. Here recently, I haven't felt like doing anything related to tech.
I'm not 100% sure why either. Part of it could be my ADHD. Part of it could be that maybe I am just burnt out and need a break? There are a multitude of things that it could be. I'm just not really sure how I should tackle this. On the one hand, I could just bite the bullet and just do it, regardless of how I feel about it but, I feel like that would yield negative results in the long run.
I feel like taking a break could be good for me to recharge my batteries and help me get re-motivated when I finally pick up where I left off in my studies. My only thing is, sometimes when I take breaks from doing things like that, sometimes it takes me a long time to get back on topic, if I ever do, and I don't want that to happen with web development.
# How do you handle lack of motivation?
Like the title says, how do you handle it when you find yourself lacking motivation to do something? Do you take a break? Power through?
Do you have any tips or advice? Struggling with your own lack of motivation? I wanted to open this topic for discussion and pick the community's brain a little and see what your thoughts on this were. | kurtissfrost |
1,354,125 | My learnings from coding interviews (2021) | Being a software developer, you want to work on large-scale systems that serve thousands to millions... | 0 | 2023-02-05T05:40:56 | https://lokesh1729.com/posts/my-learnings-from-coding-interviews | interview, coding, programming | Being a software developer, you want to work on large-scale systems that serve thousands to millions of users. Not everyone gets this chance, only a few lucky chaps get it. The other people try to get into such companies. **The hard truth is it's not the company that matters most, it's the team that you're part of that is very important**. To get into such teams, you need to raise their bar. So, you need to pull up your socks, come out of your comfort zone and start preparing for interviews. In this post, I will share my learnings from past experiences.
Note: assume that the interviews are given to top product-based companies and consist of 2 DS algo rounds + 1 or 2 system design + 1 manager/vp/director of engineering round + 1 behavioral + 1 HR/final discussion. In DS & algo rounds, the questions are mostly from leetcode.
1. **Bad interviewers**
Sometimes you may encounter bad interviewers, they may make you feel nervous ending up you bombing the interview. I faced a similar situation in an interview which ended in rejected status. In such cases, you should take the responsibility to make the interview look like an interactive session not like an interrogation. Few interviewers may not introduce themselves, they directly ask about you and jump into coding problems which may make you nervous. You should stop and ask them about their introduction, which team they belong to etc. This sets the atmosphere of the interview.
2. **Do not solve the leetcode problems partially during the preparation**
When you are preparing does not solve any problem partially. Solve them completely until you understand it. I was solving this [problem](https://leetcode.com/problems/longest-substring-without-repeating-characters/) a few days back before it appeared in the real interview. I had solved it but i still had confusion about the approach. I did not clear them up before, so i screwed it in the interview. So, do not take the leetcode problems lightly when you're preparing. When solving a question, think of it as it is asked in the real interview. How to solve a leetcode problem completely?
1. Try solving it by yourself first.
2. Spend 15 mins, 30 mins, 45 mins on easy, medium, and hard problems respectively. After spending the time, if you are not able to solve, open the solution, understand. Figure out the edge cases and normal cases, understand how the algorithm handles them.
3. Once you understand it, try writing the solution without taking help/hints. This is the time that tells you whether you have understood the solution correctly.
3. **Revise the leetcode problems**
It happens to all of us that you solve a problem today and after a few days you try to solve it again, but are not able to. You get upset and lose the motivation. Remember, it happens to everyone and it is quite common. The only way to become confident is to practice. Nothing beats practice. The more you practice the more you understand. Prepare an excel sheet of problems that you are afraid of and revisit them often.
4. **Interview is a race between you and time**
The interviewer gives you a question and the timer starts. You need to solve it in the stipulated time. Let's see what you can do to pass the interview.
**Only focus on the approach** - Focus only on the approach. Try generalizing the problem and performing mathematical analysis such as forming a recurrence relation, figuring out the dp state, etc... Personally, I refer to [Introduction to algorithms, by cormen](https://mitpress.mit.edu/books/introduction-algorithms-third-edition). It changes the way we look at the problem.
**Take data-driven decisions** - It means when you are stuck, look at the problem statement again and find if you see anything related to data such as array is sorted, the graph is acyclic, etc...
**Write down your thought process** - This will help you build the thought process and drives you towards the solution. Personally, it helped me very much. There are problems I have not seen before and am not confident of solving but able to solve with this approach.
**Set a timer** - This approach has pros and cons depending on how we use it. Use it in a way to divide your time for problem analysis and explanation, then for coding. Set a timer when the interviewer is asking the question. Timer helps you how much time you had spent on analyzing the problem thereby reducing your anxiety.
5. **Don't put multiple interviews on the same day** - If you did not perform well in one interview, it'll affect the other. You will not have time to re-motivate. Put at least 2 days gap between two interviews. Also, in each interview, you have to tell the same introduction, about the projects which will make you feel bored.
6. **The more you fail, the more you learn** - Failing in interviews is very common. It's not like your board/college exams. There will be so many factors affecting it. I know how it feels, almost like a heartbreak. One big disadvantage is the recruiters won't tell you the exact reason why you're rejected. They give you some false-polished-canned responses. You feel bad because you set high expectations for yourself. Try to lower the expectations. One tip, I can give to overcome this is "get rejected a lot so that you get used to it" .
7. **Be yourself** - don't try to impress the interviewer. Just be confident and be yourself, you don't need to look like an intellectual to pass the interview.
8. **Problem solving is a lifestyle** - In my opinion, problem-solving should become your way of living life. It should embed in your lifestyle. Be it a software engineering problem, DSA problem, or anything related to life, should look at it as a problem and find an optimal solution. This kind of mindset really helped me in my life especially. | lokesh1729 |
1,354,143 | RSS reader in Python for Discord | Hey guys, I hope everyone is having a good day. Today I want to create a short article on how to read... | 0 | 2023-02-05T06:17:24 | https://medium.com/@devjorgecastro/rss-reader-in-python-for-discord-d316765d0088 | python, rss, tutorial | Hey guys, I hope everyone is having a good day. Today I want to create a short article on how to read RSS feeds with Python and notify a Discord channel using Webhook. First of all I wanted to use some of the Discord bot alternatives on the market, but the free options were very limited for what I wanted 😅, it’s not bad to pay for the use of tools that make your life easier, but honestly I took this as an excuse to do some coding over the weekend. It is my hobby! ❤️.
Let’s start
To get started, we need to search for any site with RSS support; in my case i searched for sources for android development and for this example i will use the following URL:
* [https://medium.com/feed/@devjorgecastro](https://medium.com/feed/@devjorgecastro)
Once the project is created, we need to install the **feedparser **library to read rss with python.
```bash
pip install feedparser
```
Next, we’ll create our main.py, add the webhook, username, and avatar url.
```python
import feedparser
webhook = "https://discord.com/webhooks/{webhook_id}/{webhook_token}"
username = "Androd News"
avatar_url = "https://source.android.com/static/docs/setup/images/Android_symbol_green_RGB.png"
feed = feedparser.parse(feed_url)
print(feed)
```
If everything is ok, when you run the program you should be able to see a terminal output similar to the following image
Let’s continue, the next thing we will do is create a class to manage our Discord data and have the ability to launch notifications. We will call our class **discord_module/DiscordNews.py**
```python
import requests
class DiscordNews:
def __init__(self, webhook, username, avatar_url, feed):
self.webhook = webhook
self.username = username
self.avatar_url = avatar_url
self.feed = feed
def prepare_and_notify(self):
for entry in self.feed.entries:
self.__notify_to_discord_channel(entry)
def __notify_to_discord_channel(self, data):
# Code for notify to Discord channel
```
As you may have noticed we have 2 parameters in the class constructor: avatar_url and username, these are used to customize the posting of the message in the Discord channel; with avatar_url we specify a url of an image that will be the icon of our bot and username will be its name.
The next thing is to import our class into **main.py** and call the function **prepare_and_notify**
```python
discord = DiscordNews(webhook, username, avatar_url, feed)
discord.prepare_and_notify()
```
Finally, we run the program.
```bash
python main.py
```

Result
<br />
See the full code here
{% gist https://gist.github.com/devjorgecastro/843dfcf5ca3defb798f5b5ef5cab4d3c.js %}
<br />
If you like my content and want to support my work, you can give me a cup of coffee ☕️ 🥰
[](https://ko-fi.com/devjorgecastro)
[](https://www.buymeacoffee.com/jorgecastro)
## Follow me in
* **Twitter:** [@devjcastro](https://twitter.com/devjcastro)
* **Linkedin:** [dev-jorgecastro](https://www.linkedin.com/in/dev-jorgecastro/)
| jorgecastro |
1,354,198 | How to Concatenate Strings in Java like a Pro | String concatenation in Java can be initially tricky, especially if you come from other programming... | 0 | 2023-02-18T18:43:16 | https://dev.to/joshaustintech/how-to-concatenate-strings-in-java-like-a-pro-3c33 | java, programming, tutorial | String concatenation in Java can be initially tricky, especially if you come from other programming languages. When Java was first implemented, the decision was made to render the `String` class immutable. So what if you have to concatenate two or more strings? I remember being instructed to rely on the `StringBuilder` class like so:
```java
StringBuilder sb = new StringBuilder();
sb.append("Gandalf");
sb.append(" ");
sb.append("The");
sb.append(" ");
sb.append("Grey");
String gandalf = sb.toString();
```
Prior to Java 8, this was more efficient. However, now the compiler handles that for you by making + operations into StringBuilder operations at compile time.
However, this implementation is very naïve.
If this code
```java
String firstName = "Frodo";
String lastName = "Baggins";
String fullName = firstName + " " + lastName;
```
translates to this equivalent at compile time...
```java
String firstName = "Frodo";
String lastName = "Baggins";
StringBuilder sb = new StringBuilder();
sb.append(firstName);
sb.append(" ");
sb.append(lastName);
String fullName = sb.toString();
```
...what happens during a loop?
Unfortunately, this code
```java
List<String> hobbits = List.of("Frodo", "Samwise", "Merry", "Pippin");
String greetAllHobbits = "";
for (String hobbit : hobbits) {
greetAllHobbits += "Greetings, " + hobbit + "!\n";
}
```
translates to roughly this equivalent at compile time
```java
List<String> hobbits = List.of("Frodo", "Samwise", "Merry", "Pippin");
String greetAllHobbits = "";
for (String hobbit : hobbits) {
StringBuilder sb = new StringBuilder(greetAllHobbits);
sb.append("Greetings, ");
sb.append(hobbit);
sb.append("!\n");
greetAllHobbits = sb.toString();
}
```
A separate `StringBuilder` instance is created during each iteration, which can defeat the purpose of being efficient!
In the above case, you'll need to create a `StringBuilder` outside the loop so you aren't creating an unnecessary new object for each iteration.
```java
List<String> hobbits = List.of("Frodo", "Samwise", "Merry", "Pippin");
StringBuilder sb = new StringBuilder();
for (String hobbit : hobbits) {
sb.append("Greetings, ");
sb.append(hobbit);
sb.append("!\n");
}
String greetAllHobbits = sb.toString();
```
In conclusion:
- Use `+` when concatenating ad hoc
- Use `StringBuilder` when concatenating with a loop | joshaustintech |
1,354,203 | Must-Have Websites for Every Frontend Web Developer | 12 Essential Websites for Frontend Web Development Frontend web development can be a challenging... | 0 | 2023-02-05T07:23:16 | https://dev.to/hyuncafe/must-have-websites-for-every-frontend-web-developer-3e11 | webdev, beginners, css, html | <h1>12 Essential Websites for Frontend Web Development</h1>
<p>Frontend web development can be a challenging task, but it doesn't have to be. In this article, we'll introduce you to 12 essential websites that will make your frontend web development journey easier, faster, and more fun.</p>
<h2>1. Codepen</h2>
<p><a href="https://codepen.io/">Codepen</a> is a social development environment for frontend developers that allows them to experiment with HTML, CSS, and JavaScript. This platform enables developers to collaborate with one another and share their work with the world. The website provides a unique way for developers to test their code snippets in real-time and see the results instantly.</p>
<h2>2. CSS Background Patterns</h2>
<p><a href="https://www.magicpattern.design/tools/css-backgrounds">CSS Background Patterns</a> is a website that allows you to generate beautiful Pure CSS background patterns for your websites. Add a touch of creativity to your website's background with this easy-to-use tool.</p>
<h2>3. CSS Gradient</h2>
<p><a href="https://cssgradient.io/">CSS Gradient</a> is a free tool that lets you generate gradient backgrounds for your websites. In addition to being a CSS gradient generator, the site is also full of colorful content about gradients.</p>
<h2>4. CSS Layout Generator</h2>
<p><a href="https://layout.bradwoods.io/">CSS Layout Generator</a> allows you to create beautiful layouts for your websites within seconds. Say goodbye to complicated CSS grid and flexbox issues and start creating stunning layouts today.</p>
<h2>5. Unsplash</h2>
<p><a href="https://unsplash.com/">Unsplash</a> A must-have for designers! Get access to a vast collection of high-quality, free stock photos to add creativity to your projects. With easy navigation and categorization, finding the perfect image for your website or logo is a breeze!</p>
<h2>6. Font Awesome</h2>
<p>Unleash your inner designer with <a href="https://fontawesome.com/">Font Awesome</a>, a library of scalable vector icons that you can customize to your heart's desire. Play around with the size, color, drop shadow and more to make your website truly stand out.</p>
<h2>7. Google Fonts</h2>
<p><a href="https://fonts.google.com/">Google Fonts</a> is the ultimate tool for giving your website a unique and stylish font. With a library of free, open-source fonts, you can easily integrate CSS and add a touch of personality to your website. Say goodbye to boring fonts and hello to a world of endless possibilities!</p>
<h2>8. Readme.so</h2>
<p>Keep your project's readme organized and attractive with <a href="https://readme.so/">Readme.so</a>. The simple editor allows you to quickly add and customize all the sections you need for your project's readme.</p>
<h2>9. CanIUse</h2>
<p><a href="https://caniuse.com/">CanIUse</a> is the easiest way to know which property to use or not. This website provides a simple and straightforward guide to HTML elements and helps you understand everything about links, meta, and other tags.</p>
<h2>10. HTML Head</h2>
<p><a href="https://htmlhead.dev/">HTML Head</a> is a simple guide to HTML elements. Know everything about how to use links, meta, and other tags within seconds with this comprehensive guide.</p>
<h2>11. Responsively App</h2>
<p><a href="https://responsively.app/">Responsively App</a> is a website that allows you to develop responsive web apps 5x faster! With this website, you can create beautiful and responsive web apps in no time.</p>
<h2>12. Browser Frames</h2>
<p><a href="https://browserframe.com/">Browser Frames</a> is the easiest way to wrap screenshots in browser frames. Supports multiple browsers, operating systems, and themes, making it the perfect tool for frontend web developers.</p>
-------------------------------
These 12 essential websites will make your frontend web development journey smoother, faster, and more enjoyable. Whether you need a tool for creating stunning CSS gradients, organizing your project's readme, or wrapping screenshots in browser frames, these websites have got you covered. Happy coding! | hyuncafe |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.