
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,221,427 | CSSBattle | #31 Equals | Welcome to CSSBattle Challenges! In this short article, I go through my solution for CSSBattle - #31... | 17,102 | 2022-10-16T16:24:10 | https://dev.to/npranto/cssbattle-31-equals-70h | css, challenge, cssbattle, equals | Welcome to CSSBattle Challenges!
In this short article, I go through my solution for [CSSBattle - #31 Equals](https://cssbattle.dev/play/31) challenge. Please refer to the code snippet below to get a better insight into my thought processes and the implementation detail.
---
> #### Challenge:
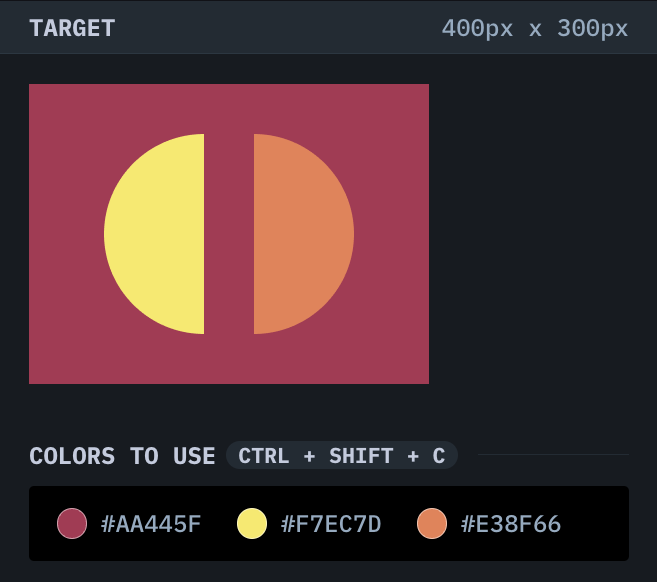
---
> #### Solution:
```html
<div class="container">
<div class="semi-circle left"></div>
<div class="semi-circle right"></div>
</div>
<style>
* {
padding: 0;
margin: 0;
box-sizing: border-box;
}
.container {
width: 100vw;
height: 100vh;
background: #aa445f;
}
.semi-circle {
width: 200px;
height: 100px;
border-top-right-radius: 100px;
border-top-left-radius: 100px;
position: absolute;
top: 50%;
left: 50%;
}
.right {
background: #e38f66;
transform: translate(calc(-50% + 75px), -50%) rotate(90deg);
}
.left {
background: #f7ec7d;
transform: translate(calc(-50% - 75px), -50%) rotate(-90deg);
}
</style>
```
---
> #### Key Takeaway(s):
- create semi-circles with height half the size of the width along with border radius properties
- use multiple transform properties to shift or rotate an element in multiple ways
As always, I welcome any feedback or questions regarding the implementation detail of the challenge. Otherwise, I hope this was useful! | npranto |
1,221,465 | Some links to pimp your gitHub profile | https://dev.to/dailydevtips1/pimp-your-github-profile-hoc https://docs.github.com/en/account-and-pro... | 0 | 2022-10-16T18:12:18 | https://dev.to/dgloriaweb/some-links-to-pimp-your-github-profile-4koa | https://dev.to/dailydevtips1/pimp-your-github-profile-hoc
https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-github-profile/customizing-your-profile/about-your-profile
https://medium.com/nerd-for-tech/stand-out-by-personalizing-your-github-profile-f0a5d73f2b4d
| dgloriaweb | |
1,221,640 | Is It Possible To Run A Digital Startup on a Chromebook? | The other day, my 2012 Mac Book Pro hard drive cable decided to give in...So, the last option I had... | 0 | 2022-10-17T01:27:00 | https://dev.to/vonthecreat0r/is-it-possible-to-run-a-mobile-startup-on-a-chromebook-8a0 | tutorial, productivity, opensource |

The other day, my 2012 Mac Book Pro hard drive cable decided to give in...So, the last option I had was to go out and find a quick replacement without breaking the bank.
I picked the Duet 3 Chromebook off Kijiji from a local place.

And, being into software and hardware, this Chromebook is, not bad at all...
If you think about it, most our phones today have enough power to run a mini web server backed with a SQLite database; given today's world of digital everything,
You can see where this could end up...
Chromebooks have a unique power if you have a technical know-how of making them produce extra-ordinary results using basic tools.
Like a friend once said:
> 'Pro tools don't make you a pro, with tools...'
To say the least, what I'm getting at is, you can do far more on a Chromebook today, with very few distractions in the way; compared to the other major operating systems.
### The future is mobile;
I strongly sense, Chromebooks have a greater chance at taking over the digital space overnight...
These are simply my observations based on a few technical trends and software patterns I am noticing:
Such as, [rust programming language being introduced into the Linux kernel](https://www.zdnet.com/article/linus-torvalds-rust-may-make-it-into-the-next-linux-kernel-after-all/), JavaScript (ES6) being at the forefront of front-end and back-end development of web services...
Of course some of these trends have been a norm for a while; but ask yourself, why more and more hardware manufactures pushing towards ARM architecture?
From my perspective, I say few reasons:
- Due to the past 2 and a half years that took a hit on the chip supply,
- Crunching down for true optimisation (ARM is great at this)
- To counter the chip shortage with smaller, faster and more efficient alternatives.
Therefore if a chip can be smaller & still maintain the same output on the software side, while also being able to save on size, power input & simultaneously adding new processing clusters that do special computations...
> It is no wonder why even the forbidden fruit has taken the same root of action...
Which means the focus is on whatever works well with arm architecture.
Most of our digital lives today evolve around:
- Art
- Commerce
- Entertainment
That means:
- Speed
- Access
- Ease of use
So to conclude everything, you now see how the Chromebook could have a edge here?
Please note: I am in no way sponsored by chrome or google, I am simply stating that if you compare all major platforms that can hit those three categories without trouble: it would be the Chromebook.
They're:
- Cheap
- Accessible
- Easy to use
<br>
<br>
You can say well, but then what?
That's it?
If you look at technical history timeline; you realise that at every turn, there's always a urge to reinvent the wheels based on a few catalysts,
The first wave was that we wanted to take our library into our pockets. And indeed it is so, Arts, Entertainment, Commerce; now live at your finger tips, today.
As for the following wave, I'm sure you notice a few patterns too: **privacy**, **censorship**, **security (cryptography)**, mobility & ease-of-access...
Of all these: the major key pulling all these strings together are: **mobility & access**.
Therefore; **privacy** and **security** ought to be paramount.
Sure Chromebooks have a chance, but I'd agree more, to say that: we all prefer variety over singular especially in these times...
So my final thought is...
**Who can make the most secure, fastest, accessible platform and hardware haven for the next generation of computing that people can trust?** | vonthecreat0r |
1,221,718 | How can I read this type of font? | A post by RicardoViteriR | 0 | 2022-10-17T03:11:39 | https://dev.to/rviteri/how-can-i-read-this-type-of-font-2d76 | tesseract |

| rviteri |
1,221,862 | Running Minecraft servers from Docker | This article is also available on my blog. Since picking up docker last year it's completely changed... | 20,159 | 2022-10-17T07:50:33 | https://jamesnewman.dev/blog/docker-minecraft-servers/ | docker, devops, minecraft, guide | _This article is also available [on my blog](https://jamesnewman.dev/blog/docker-minecraft-servers/)._
Since picking up docker last year it's completely changed how I set up projects, home network applications, and now how I deploy Minecraft servers for friends. Gone are the days of figuring out which version of JDK I need on an ubuntu box and remembering the commands to reconnect to a [screen](https://help.ubuntu.com/community/Screen) session.
In this post I'll walk you through setting up a few different Minecraft servers, running vanilla, Paper and Forge, all on the same host. In a [follow up post](/blog/routing-minecraft-servers) I go through routing to these server on the same port.
Before we get started, I'd recommend having some basic command line and linux knowledge. In addition, pre-existing docker and docker-compose experience is a bonus but **not** required.
### The Environment
Docker being docker, you can run this on Windows, Linux, macOS - A spare computer, the cheapest DigitalOcean droplet, heck even a Raspberry Pi! Just make sure your systems up to date, has docker and docker-compose installed. Here's what we'll be using:
- A docker host, the steps below are for Ubuntu but you can use any.
- [itzg/minecraft-server](https://hub.docker.com/r/itzg/minecraft-server) docker image to run the server.
#### Install Docker & Docker Compose
Go ahead and follow the [Docker install steps](https://docs.docker.com/engine/install/) for the platform you wish to run the server on. Here's the [Ubuntu guide](https://docs.docker.com/engine/install/ubuntu/).
_Handy tip: if you're on linux, make sure you add your user to the docker group:_
``` bash
sudo usermod -aG docker $USER
```
_You'll need to log out and back in again after._
Now you should be all set! To double check, run the following:
``` bash
# Check the Docker version
docker -v
# Check Docker Compose version
docker compose -v
```
### Creating our first server with Docker Compose
It's vary rarely I'll run a docker image with the docker command line, remembering the command and all the arguments I need is a faff. So lets define our first Minecraft server, a simple vanilla server, in a docker compose YAML file.
First up, we'll create a directory to contain all our files including the Minecraft servers:
``` bash
# Create directory
mkdir minecraft-servers
# cd into the directory
cd minecraft-servers
# Create a docker-compose.yaml file
touch docker-compose.yaml
# Create a directory to store our vanilla server files in
mkdir -p vanilla/server
```
Go ahead and open the `docker-compose.yaml`. You can use nano, vim or even connect [VS Code with SSH](https://code.visualstudio.com/docs/remote/ssh).
In here we want to define our vanilla service:
``` yaml
version: "3.8"
services:
vanilla:
container_name: vanilla
image: itzg/minecraft-server
ports:
- 25565:25565
environment:
EULA: "TRUE"
MEMORY: 2G
volumes:
- ./vanilla/server:/data
restart: unless-stopped
tty: true
stdin_open: true
```
This is the bare minimum configuration, but there's a whole bunch of options you can define such as ops, whitelist, difficulty etc, all documented [here](https://github.com/itzg/docker-minecraft-server/blob/master/README.md#server-configuration). Now we're ready to test our first server works, so lets spin it up!
``` bash
# Start the service
docker compose up
```
You'll should now see the server begin to start up. It'll take a little while on the first launch as it downloads the image and generates server files. You'll know it's ready when you see:
``` log
vanilla | [17:22:18] [Server thread/INFO]: Done (13.045s)! For help, type "help"
```
Congratulations, you can now connect to your new server using the server IP or `localhost` if you're running it on the same machine! To exit, you can use `ctrl + c` in the terminal.
If you take a look in the `vanilla/server` directory we created earlier, you'll see it's generated all the server files needed. You *can* edit the `server.properties` to make changes to the servers configuration, however I'd recommend adding these to the `environment` block in our `docker-compose.yaml` and simply deleting the `server.properties` file. This file will be recreated when you next start the server with your newly added environment options.
### Adding different server types
So we have our vanilla server set up, but if we want to use some plugins to manage permissions or add prefixes to usernames in chat, we'll need to use a different server type. For a vanilla server that you can connect an unmodded client to, you have a few options: Bukkit, Spigot and Paper. We'll use Paper for the sake of this post.
First, lets create a directory to keep our plugins in:
``` bash
mkdir vanilla/plugins
```
You can go ahead and add any plugins to this directory and we'll configure the container to mount these. You can also leave it blank for now and once we start the server you'll see `bStats` automatically added by Paper.
Now in our `docker-compose.yaml` file, we'll add a new entry to the `environment` block of our `vanilla` service, defining the server type. We'll also mount the plugins directory we just created.
``` yaml
version: "3.8"
services:
vanilla:
container_name: vanilla
image: itzg/minecraft-server
ports:
- 25565:25565
environment:
# Add our server type
TYPE: PAPER
EULA: "TRUE"
MEMORY: 2G
volumes:
- ./vanilla:/data
# Mount our plugins directory
- ./vanilla/plugins:/plugins
restart: unless-stopped
tty: true
stdin_open: true
```
Lets spin up the updated server, you'll see it download the new jar and create some new files.
``` bash
# Start the service
docker-compose up
```
Now you should be able to edit the configuration files for the plugins you added, log in and see them working!
### Proxying and Routing domains to Minecraft Servers
In a follow up post, I go through adding adding [itzg/mc-router](https://hub.docker.com/r/itzg/mc-router) to route domains to multiple servers, all using the default `25565` port. No more ugly server addresses with different ports! You can read about that [here](https://jamesnewman.dev/blog/routing-minecraft-servers)
### Closing thoughts
So in this post we've created a Vanilla server, maintained and managed through docker. I highly recommend reading through the [docs](https://github.com/itzg/docker-minecraft-server) for this image as there's tons of configuration available, including support for modded servers. You can add more servers to this config and use something like [BungieCord](https://github.com/SpigotMC/BungeeCord) or [PaperMC Waterfall](https://github.com/PaperMC/Waterfall) switch servers ingame.
_This article is also available [on my blog](https://jamesnewman.dev/blog/docker-minecraft-servers/)._ | jam3sn |
1,221,927 | 5 Preferences Tweaks For A New Mac | 1. Screenshot Shortcut The default when taking a screenshot is to save it, but most often... | 0 | 2022-10-22T11:02:33 | https://dev.to/danielbellmas/5-preferences-tweaks-for-a-new-mac-2f4f | productivity, customize, tooling, ios | ## 1. Screenshot Shortcut
The default when taking a screenshot is to save it, but most often we want to just send it to someone right away so to make things easier, change the shortcut to:
<kbd>⌘ Cmd</kbd> + <kbd>⇧ Shift</kbd> + <kbd>4</kbd>
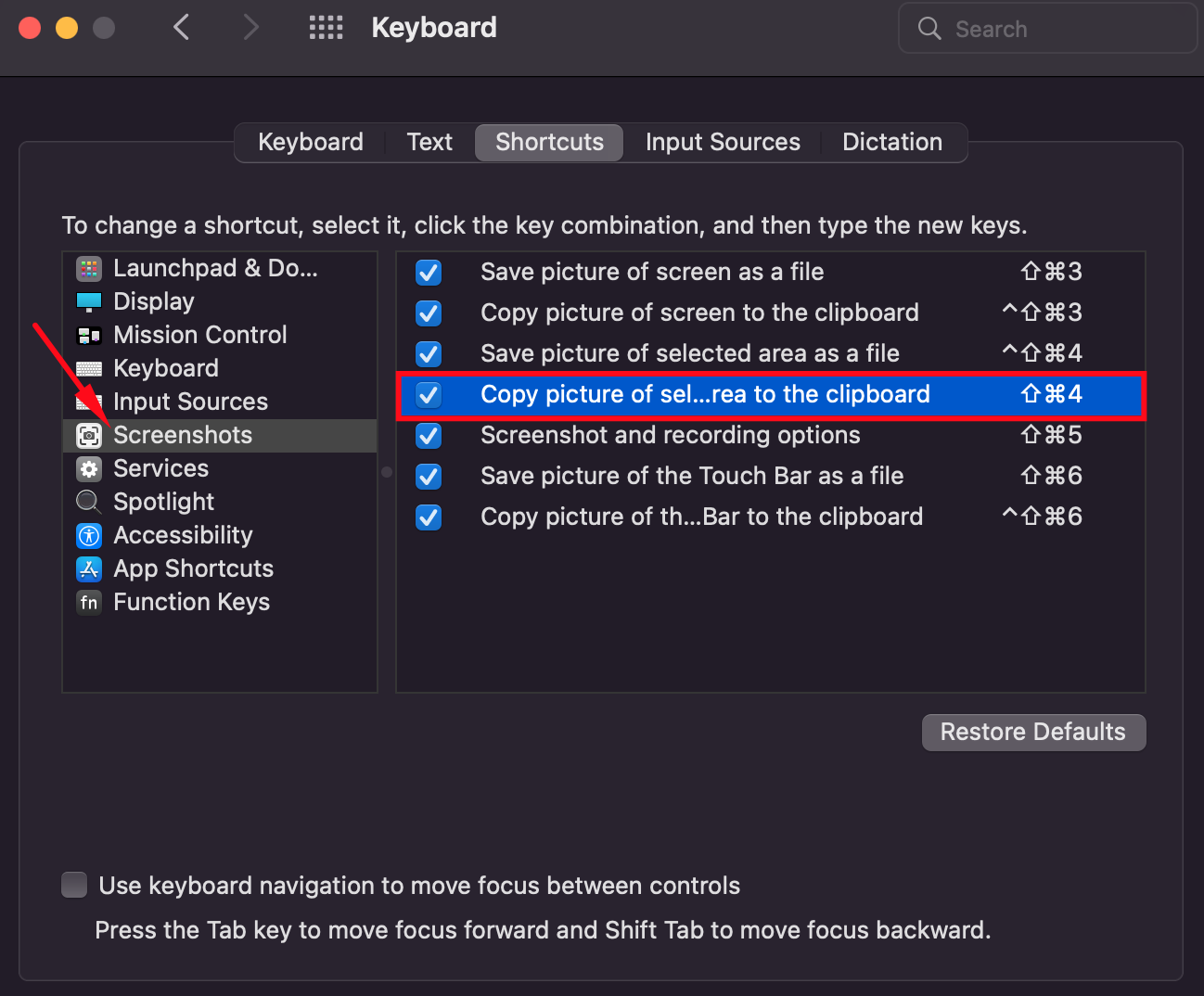
> Go to `System Preferences` -> `Keyboard` -> `Shortcuts` tab
---
## 2. Speed of Mouse Cursor
The default speed is too slow in my opinion, change it to your liking, he is mine 🙂
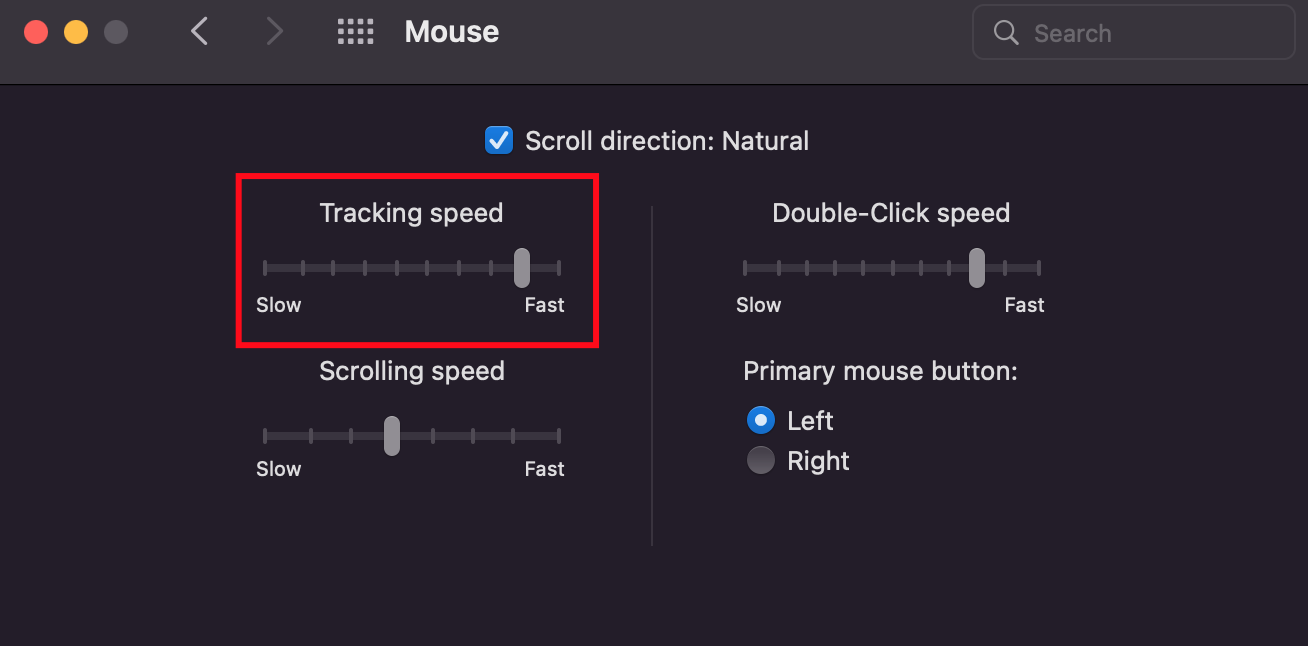
> Go to `System Preferences` -> `Mouse`
---
## 3. Speed of keyboard Cursor
The default here is also slower than what I prefer.
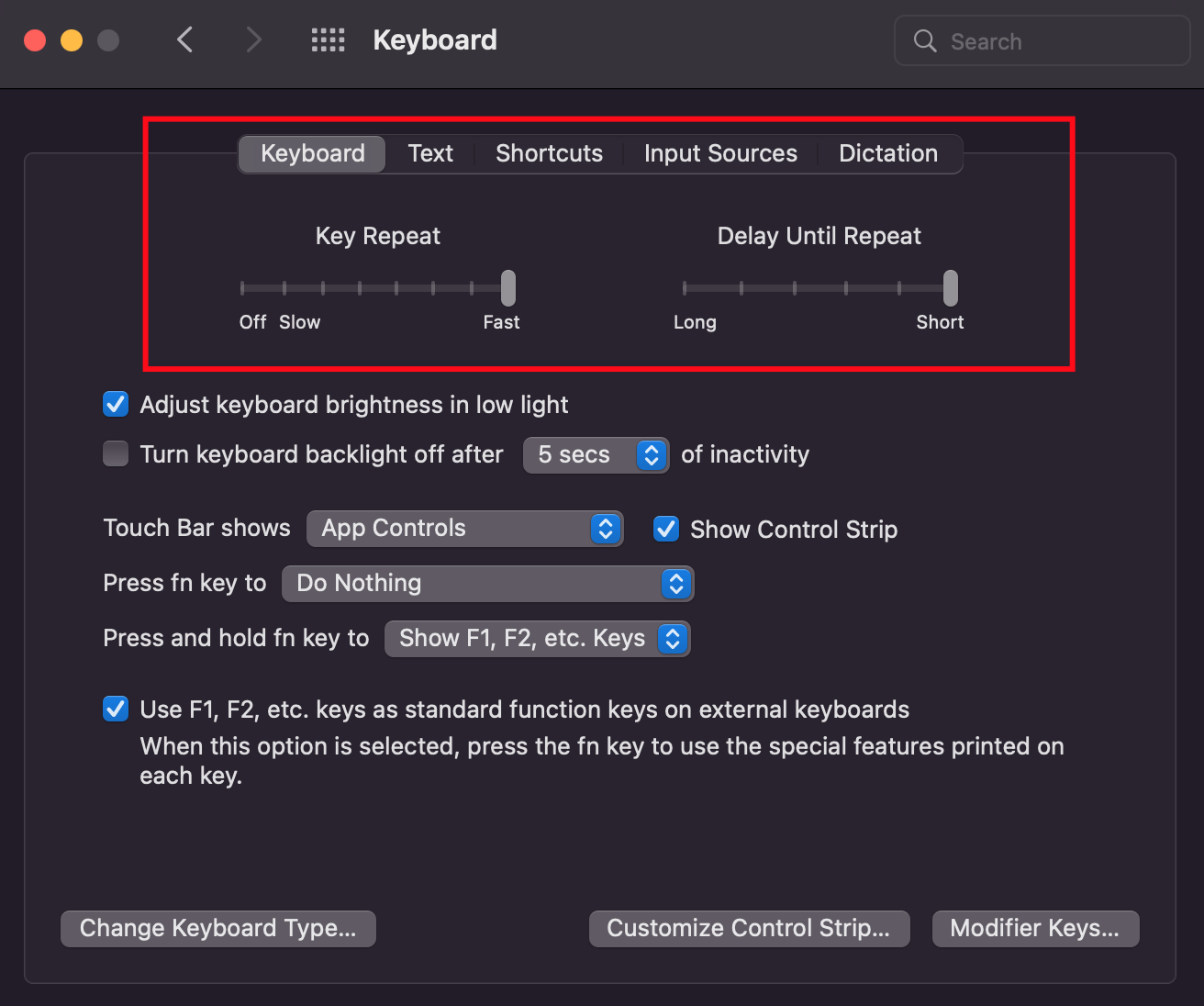
> Go to `System Preferences` -> `Keyboard`
---
## 4. Untick the `fn` Option
This option will remove the need for pressing the `fn` key with one of the `F1, F2, F3....` keys.
Most often I use the <kbd>F2</kbd> key to [change variable names in `VsCode`](https://dev.to/danielbellmas/productivity-boost-with-cmd-ctrl-1nh8#bonus-productivity-tip-%EF%B8%8F).
> Unfortunately, this only works for an apple keyboard, not external ones.
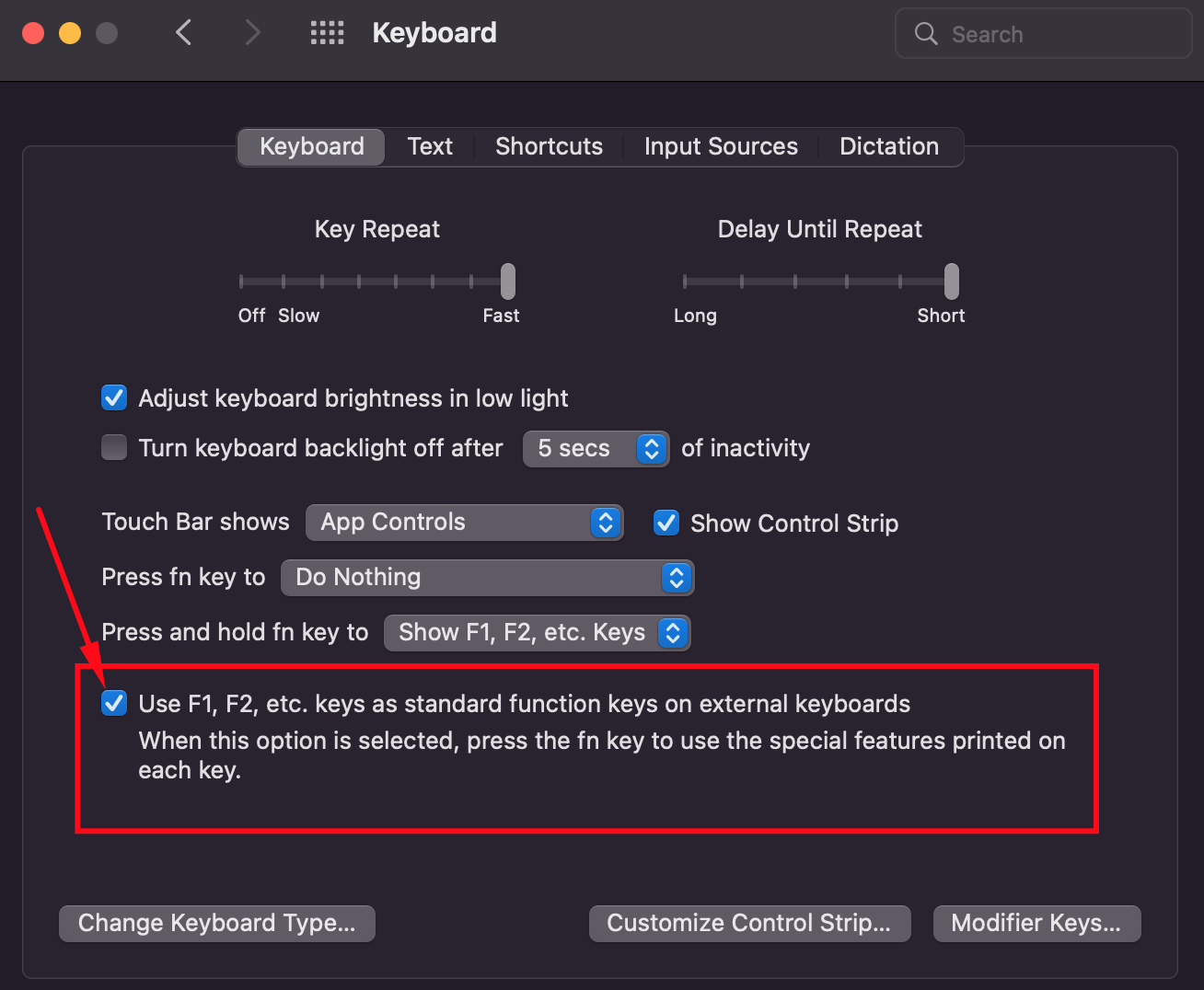
> Go to `System Preferences` -> `Keyboard`
---
## 5. Text Replacements
Save time by putting your most frequently used phrases here.
My favorite is the email one :)
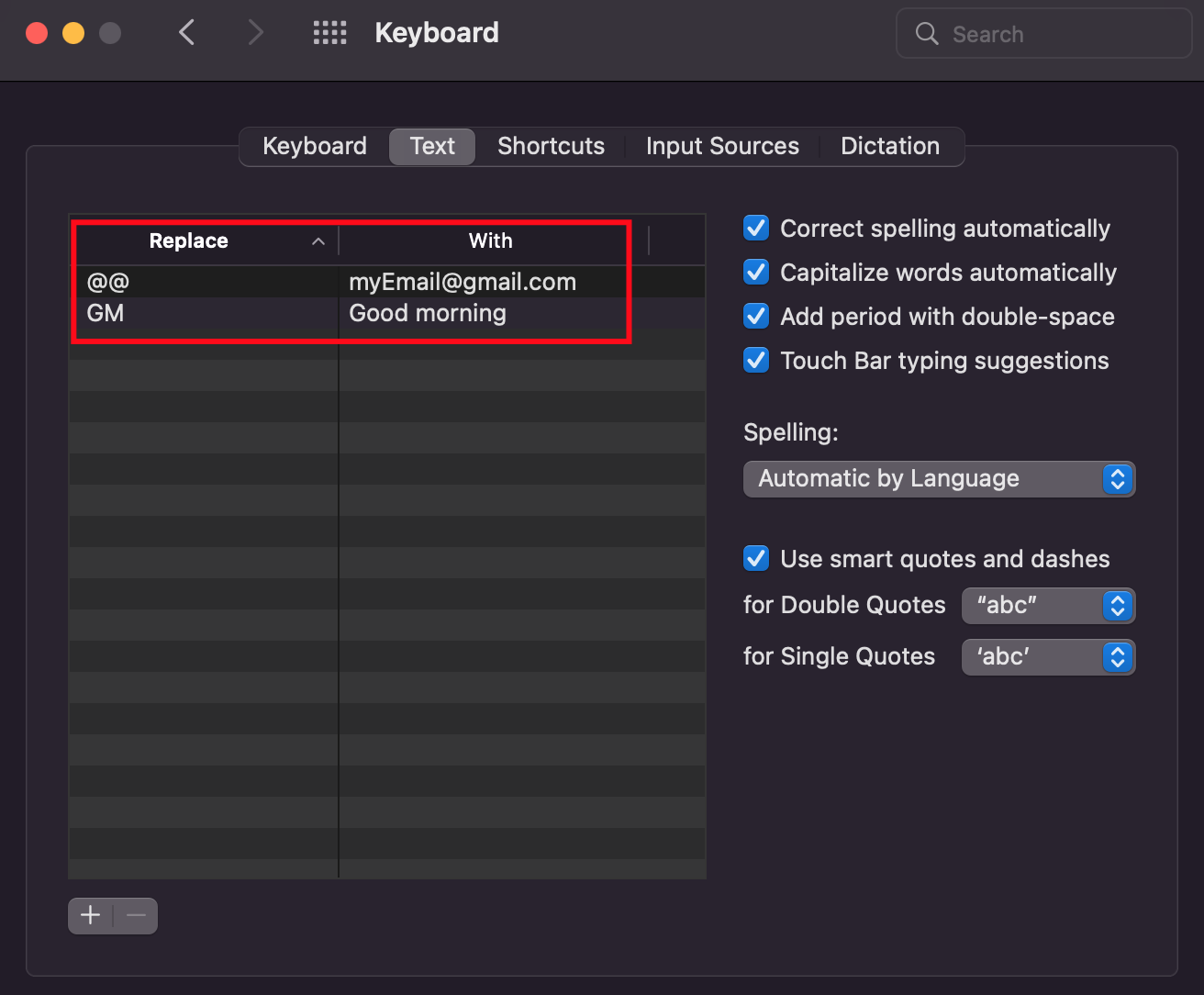
> Go to `System Preferences` -> `Keyboard` -> `Text`
| danielbellmas |
1,222,076 | Implementing Cursor-based Pagination For Every GraphQL API | Implementing Cursor-based Pagination For Every GraphQL API Backends often return a massive... | 0 | 2022-10-17T12:02:26 | https://stepzen.com/blog/implementing-cursor-based-pagination-graphql | Implementing Cursor-based Pagination For Every GraphQL API
==========================================================
Backends often return a massive amount of data, and intaking all data simultaneously causes more overhead and increases the response time. Pagination preserves the application's performance by receiving small pieces of data in subsequent requests until the entire dataset is received.
When Facebook publicly released GraphQL as a client-driven API-based query language, it quickly gained hype because it allowed front-end developers to modify their backends easily. Applications using GraphQL are more efficient and work promptly on slow networks, and therefore, it is quickly replacing the traditional API architectures like REST. Pagination is an essential concept in GraphQL, but there aren't many resources on pagination in GraphQL.
In this post, we'll compare the different ways to handle pagination in GraphQL and learn how to configure a REST directive to perform cursor-based pagination for every REST API using StepZen.
> **TL;DR**: You can find the complete documentation on paginating GraphQL using StepZen [here](https://stepzen.com/docs/connecting-backends/rest-services-graphql-pagination).
Comparing Different Methods of Pagination in GraphQL
----------------------------------------------------
Pagination in GraphQL is not different from pagination in REST APIs, although some types of pagination better fit GraphQL. Before discussing the preferred pagination method in GraphQL, let's look at different pagination types. Typically, APIs offer three methods for pagination. These are:
* [Offset Pagination](https://stepzen.com/blog#1-offset-pagination)
* [Page Number Pagination](https://stepzen.com/blog#2-page-number-pagination)
* [Cursor Pagination](https://stepzen.com/blog#3-cursor-pagination)
### 1\. Offset Pagination
Offset pagination consists of two primary parameters: limit and offset. The limit indicates the maximum number of results to show. And the offset denotes the position in the list from where the pagination starts.
Suppose you have a list of 100 students. If you set the limit parameter to 10 and offset to 20, the database engine will count from the 20th student and display the following ten students in each iteration. For instance, the first iteration will show the students from 20 to 30, then from 30 to 40, etc.
Although offset pagination is the most straightforward, it has a significant drawback. When some items are added or deleted, offset pagination results in repeated or missing data values.
**Pros:**
* Most common way to do pagination in general.
* Relatively simple implementation.
* Most SQL-based databases support the limit and the offset variables, so it's easier to map values.
**Cons:**
* Prone to data inconsistencies (repeated or missing data).
* It doesn't provide information about more pages, total pages, or retrieval of previous pages.
### 2\. Page Number Pagination
As the name specifies, page number pagination returns a single page per request. You all have seen a "next page" option when working with tables; each sheet shows the same number of results or entries. Similarly, page number pagination returns the same number of results per request.
Let's take an example to understand how it works. Page number pagination uses the after parameter to indicate the starting point for pagination. For instance, if you have a list of 30 students and set the after and the limit parameters to 23 and 5, respectively, then the output list will show a list of 5 students from the 23rd to 28th entry.
Page number pagination is more reliable as the upcoming results start from the last fetched values.
**Pros:**
* Easier to implement.
* It doesn't require complex logical analysis.
**Cons:**
* Data inconsistencies.
### 3\. Cursor Pagination
The third kind of pagination is cursor-based pagination. However, it is most complicated but is adaptable to dynamic data. Therefore, it is the preferred way to do pagination in GraphQL.
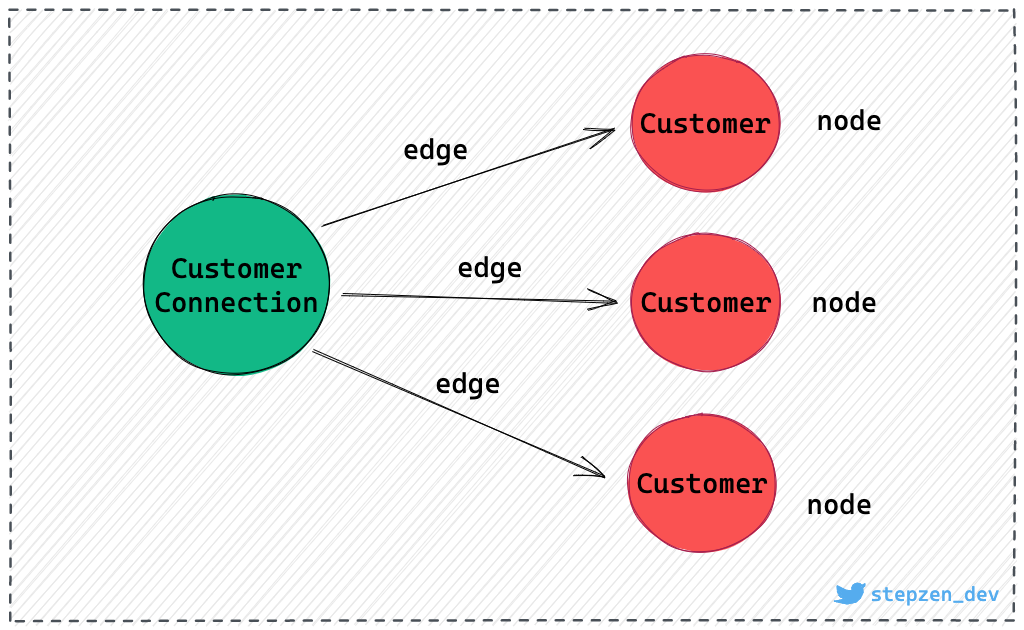
This method includes a specific parameter for the cursor. A cursor is nothing but a reference point that shows the position of an item in the database. The data are represented as nodes and a cursor as an edge in the graphical representation.
A cursor is a base64 encoded number. The query written for cursor-based pagination returns an object representation instead of a list.
**Pros:**
* The preferred way to do pagination in GraphQL.
* Provides valuable data for UX uses.
* Allows reverse pagination.
* No issues in the case of dynamic data as pagination are done to a specific row.
**Cons:**
* It doesn't allow random access.
* Needs complicated queries.
How to Implement Pagination in GraphQL using StepZen
----------------------------------------------------
Now you know about all the possible pagination methods and the preferred way of doing pagination in GraphQL, which is cursor-based pagination. If your REST API supports offset or page number pagination, you can easily implement cursor-based pagination in GraphQL using StepZen.
The two essential parameters you need to specify for every type of pagination are `type` and `setters`. The `type` parameters define the pagination style you want to implement. It has three possible values: `PAGE_NUMBER`, `OFFSET`, and `NEXT_CURSOR`. Next comes the `setters` parameters, which need to be pointed towards a field that indicates how many results or pages the response will output. You can find the list of all parameters with different pagination styles in the [documentation](https://stepzen.com/docs/connecting-backends/rest-services-graphql-pagination/).
Let's look at some examples:
### 1\. Implementing Cursor Pagination for Offset
The below snippet illustrates how to implement GraphQL cursor-based pagination using StepZen for REST APIs supporting offset pagination. Note that the parameter `first` is set to the number of required results. The second parameter, `after`, is set to the starting point of the pagination.
```graphql
customers(
first: Int! = 20
after: String! = ""
): CustomerConnection
@rest(
endpoint:"https://api.example.com/customers?limit=$first&offset=$after"
pagination: {
type: OFFSET
setters: [{field:"total" path: "meta.total_count"}]
}
)
```
Since it's the first request, the `after` parameter is equal to an empty string. The `first` parameter is set to `20`, which means that the first 20 results will be returned. On the second request, you can change the value for `after` to be equal to the value of `first` from the previous request. Every new request will be a multiple of the `first` parameter.
### 2\. Implementing Page Number Pagination
Take a look at the following code to get a better understanding of implementing cursor-based pagination in GraphQL using StepZen, when your REST API is relying on page number pagination:
```graphql
customers(
first: Int! = 20
after: String! = ""
): CustomerConnection
@rest(
endpoint:"https://api.example.com/customers?page=$after&per_page=$first"
pagination: {
type: NEXT_CURSOR
setters: [{field:"nextCursor" path: "meta.next"}]
}
)
```
The above example illustrates some important aspects. The `after` parameter is set to an empty string, which indicates that it is the first request. In contrast, the first parameter is set to `20`, meaning that 20 results will be returned per page. Remember, the value of the first parameter remains the same for subsequent requests as well. The `after` parameter in the upcoming request will be according to the page number you want to be returned. For instance, it is `3` for the third and `4` for the fourth page.
### 3\. Implementing Cursor Pagination
Implementing cursor-based pagination is very similar to the other two pagination methods. The only difference is that you need to specify the `type` parameter as `NEXT_CURSOR`, and change the setters parameter to point towards the field that indicates the next cursor.
```graphql
customers(
first: Int! = 20
after: String! = ""
): CustomerConnection
@rest(
endpoint:"https://api.example.com/customers?first=$first&after=$after"
pagination: {
type: NEXT_CURSOR
setters: [{field:"nextCursor" path: "meta.next"}]
}
)
```
This, of course, only applies if your REST API already supports cursor-based pagination.
How to Query Cursor Pagination in GraphQL
-----------------------------------------
In the previous section, you've learned how to implement cursor-based pagination for any REST API using StepZen. Cursor-based pagination is for example, used by [Relay](https://relay.dev/graphql/connections.htm), and is also supported by the StepZen GraphQL API. Cursor-based pagination is the preferred way to do pagination in GraphQL, as it provides valuable data for UX uses. But it comes with the downside of being more complex to query, as we saw in the first section.
Let's look at the `Connection` type that is used by cursor-based pagination:
```graphql
type Customer {
activities: [Activity]
addresses: [Address]
contacts: Contacts
description: String
designation: String
}
type CustomerEdge {
node: Customer
cursor: String
}
type CustomerConnection {
pageInfo: PageInfo!
edges: [CustomerEdge]
}
```
The `CustomerConnection` type is the one that is returned by the `customers` query. It contains a `pageInfo` field, which is of type `PageInfo`. The `PageInfo` type contains the following fields:
```graphql
query MyQuery {
customers {
pageInfo {
endCursor
hasNextPage
hasPreviousPage
startCursor
}
}
}
```
These fields inform you about the current page, and whether there are more pages to be fetched. The `endCursor` and `startCursor` fields are the cursors that you need to use in the next request. The `hasNextPage` and `hasPreviousPage` fields indicate whether there are more pages to be fetched.
The `edges` field contains a list of `CustomerEdge` objects. The `CustomerEdge` type contains a `node` field of type `Customer`. To get the information about the customer, you would need to use the `node` field:
```graphql
query MyQuery {
customers(first: 3, after: "eyJjIjoiTzpRdWVyeTpwYXJrcyIsIm8iOjl9") {
edges {
node {
id
description
}
}
}
}
```
The concept of "edges and nodes" is a bit confusing but very straightforward. It comes from the concept that everything in GraphQL is a graph. The `edges` field contains a list of `CustomerEdge` objects, information that is specific for this connection but not shared by all nodes. The `CustomerEdge` type contains a `node` field of type `Customer`. This is the actual customer information.
For Relay, you can find more information on GraphQL connections in the [documentation](https://relay.dev/graphql/connections.htm).
Conclusion
----------
GraphQL allows different kinds of pagination. But how does one decide which one will work best? GraphQL recommends using cursor-based pagination. However, it depends on the requirements of your application. If you are using a REST API already supporting cursor-based pagination, then it's a no-brainer. But if you are using a REST API that is not supporting cursor-based pagination, then you can use StepZen to implement it.
The common and the most straightforward kinds of pagination are **offset** and **page number**. Although they are relatively simple to implement, they are more suitable for static data. In contrast, **cursor-based pagination** is complex but best for changing data as it prevents data inconsistencies. With StepZen, it's straightforward to implement cursor-based pagination for any API.
Learn more by visiting [StepZen Docs](https://stepzen.com/docs/quick-start). Try it out with a [free account](https://stepzen.com/signup), and we'd love to get your feedback and answer any questions on our [Discord](https://discord.com/invite/9k2VdPn2FR). | gethackteam | |
1,222,094 | The testing pyramid is outdated! E2E tests are now easy to write | No doubt having a well-tested code base allows us to cover regression errors during releases. ... | 0 | 2022-10-19T15:39:13 | https://dev.to/gioboa/the-testing-pyramid-is-outdated-e2e-tests-are-now-easy-to-write-414a | testing, webdev, programming, frontend | No doubt having a well-tested code base allows us to cover regression errors during releases.
### Unit test
Often we just test the business logic with unit tests, because they have a smaller scope and a very high execution speed.
These tests are a fair compromise between the effort spent and the benefits we get with a well-tested code base.
### End-to-end
There are also other types of tests such as End-to-End ones, they are more demanding and time-consuming to write and require more execution time.
Until recently, I was also on the same line of thinking until I tried to use ... Cypress.
It is an automatic tool and allows us to write and execute E2E tests quickly and easily.
Wow, this is awesome, but there is more...
Now with Cypress Studio, you can record tests quickly and easily instead of writing them.
### But how can I register for my test
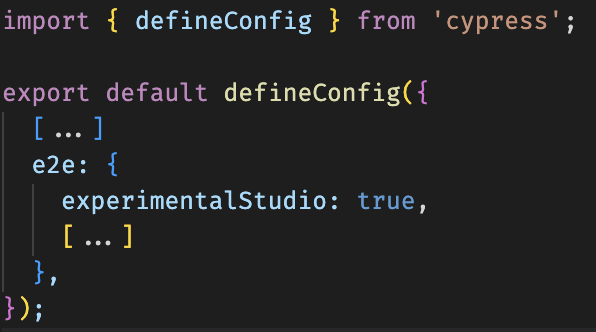
Once [Cypress has been installed](https://docs.cypress.io/guides/end-to-end-testing/writing-your-first-end-to-end-test) a "trigger" test and the _experimentalStudio_ property in the cypress configuration will be sufficient to start recording your first test.
#### Cypress configuration
#### Trigger test
Now you can start Cypress Studio and record new tests like this example:
<img width="100%" style="width:100%" src="https://s4.gifyu.com/images/ezgif-4-fc4ecc7cfd.gif">
✅ In the [docs](https://docs.cypress.io/guides/references/cypress-studio) you can the official example and all the steps to use it.
### Final thought
Recently I introduced this functionality in a project that we wanted to cover with the E2E test.
Together with the users of the platform we recorded the core flows of the application.
The results are excellent, with a little effort we were able to strengthen our tests and now we can sleep more peacefully.
You can [follow me on Twitter](https://twitter.com/giorgio_boa), where I'm posting or retweeting interesting articles.
I hope you enjoyed this article, don't forget to give ❤️.
Bye 👋
{% embed https://dev.to/gioboa %}
| gioboa |
1,222,365 | AWS Cognito ( Facebook log ). Why token doesn't have an email? | I tried google and Facebook login using AWS Cognito & Amplify. Google login works fine. But... | 0 | 2022-10-17T17:02:49 | https://dev.to/jacksonkasi/aws-cognito-facebook-log-why-token-doesnt-have-an-email-48ln | aws, javascript, webdev, react | I tried google and Facebook login using `AWS Cognito & Amplify`.
Google login works fine.
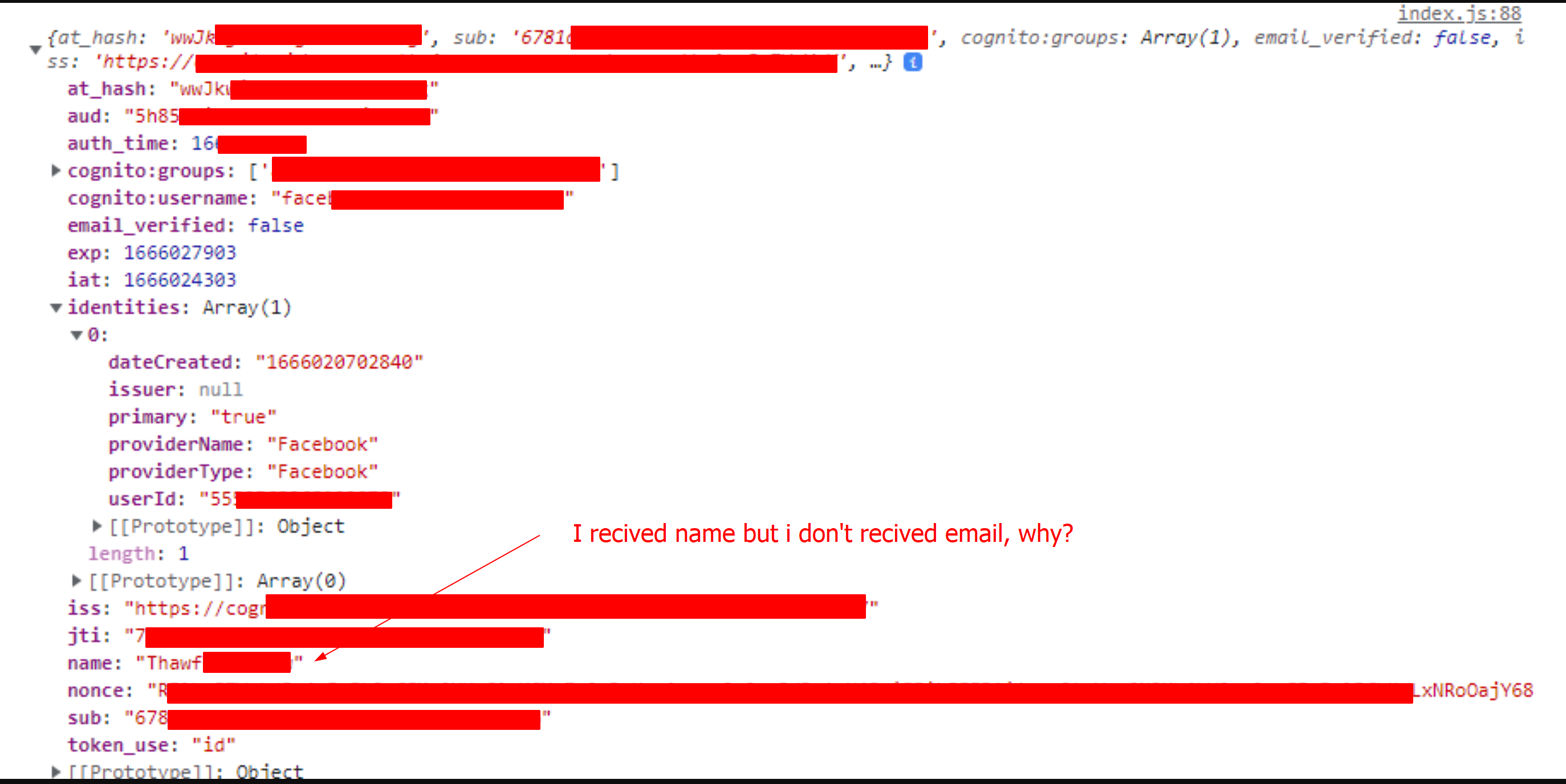
But when I log in to Facebook, if I decode the token that comes, I don't get the email only.
But I think I did everything right.
Please help me if you have an answer to my question!
Thanks
## Code:
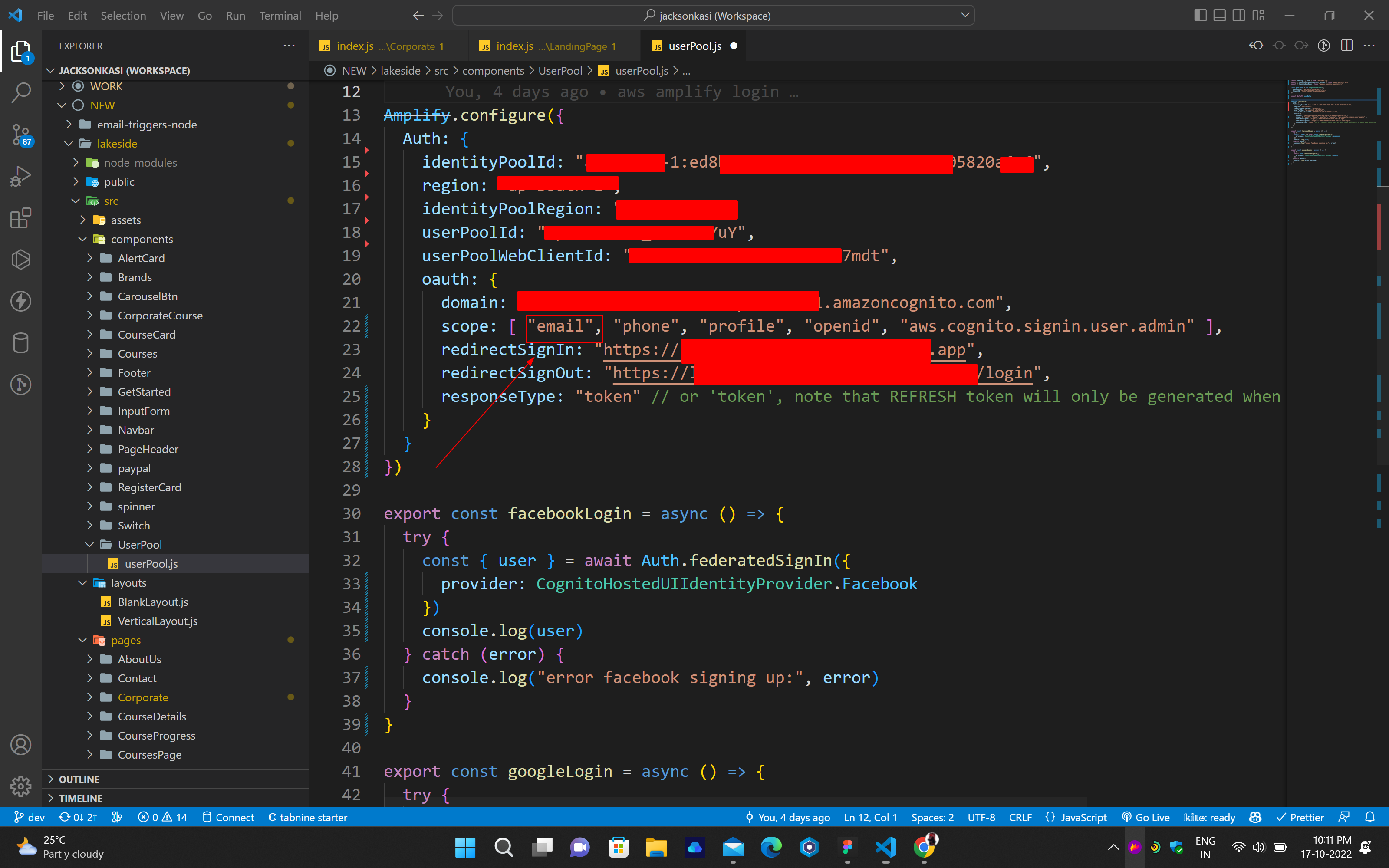
## Cognito:
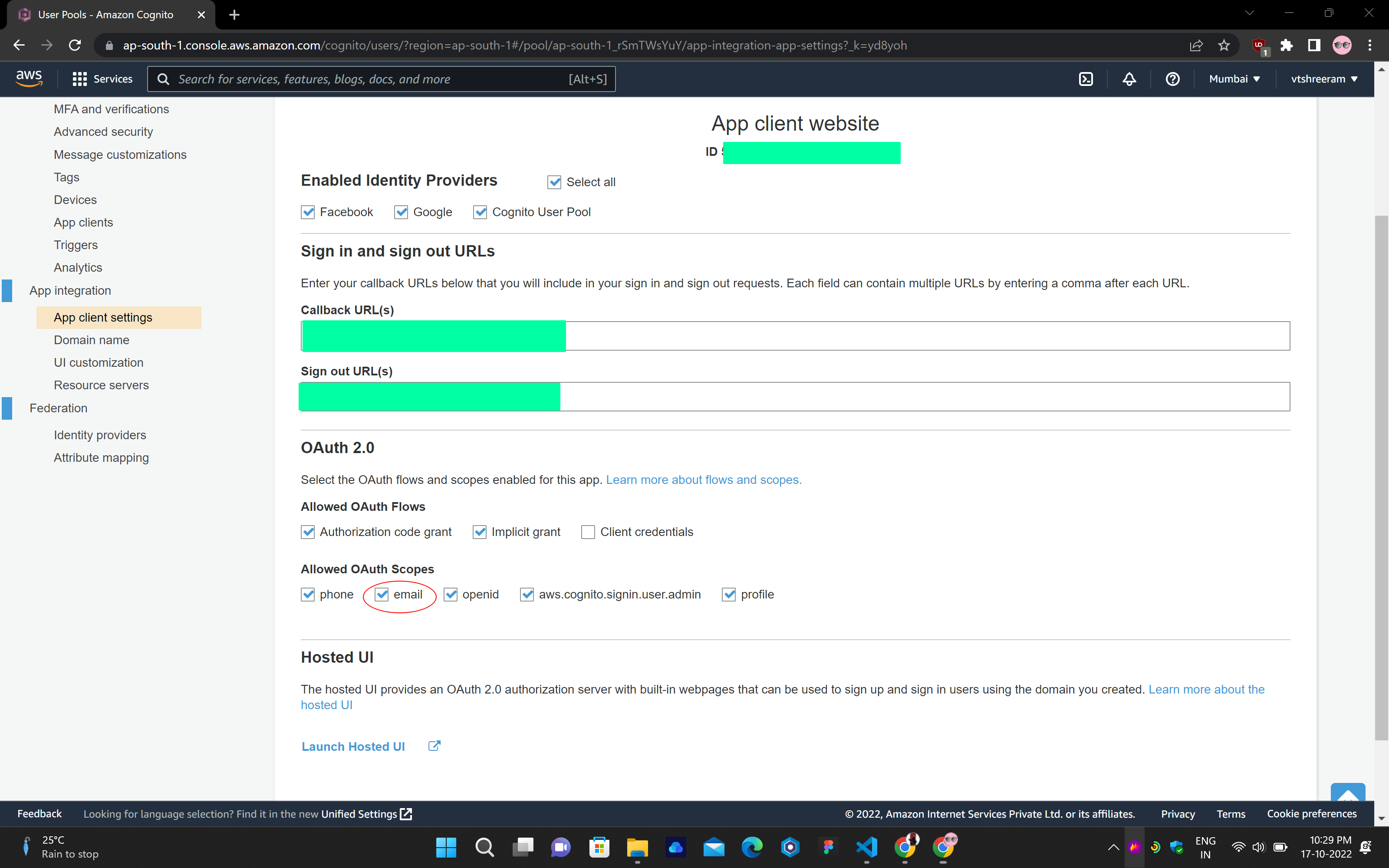
## response:
| jacksonkasi |
1,222,373 | Demonstration Sample Project "Practice1" (Movie) | Shirates (shirates-core) Shirates is an integration testing framework that makes it easy... | 0 | 2022-10-17T17:32:45 | https://dev.to/wave1008/demonstration-sample-project-practice1-movie-5412 | ## Shirates (shirates-core)
Shirates is an integration testing framework that makes it easy and fun to write test code for mobile apps.
[shirates-core](https://github.com/ldi-github/shirates-core) is core library.
---
## Demonstraion
This is a demonstration movie for the article [Introducing Shirates, a Mobile Testing Automation Tool](https://dev.to/wave1008/introducing-shirates-a-mobile-testing-automation-tool-3nmc).
{% embed https://youtu.be/kwCL11BU2SQ %}
| wave1008 | |
1,222,483 | Edit Someone Else’s Website: contenteditable & designMode | The first time I opened up my devtools and changed the contents of a website, I actually thought... | 0 | 2022-10-18T16:46:50 | https://austingil.com/contenteditable-and-designmode/ | development, frontend, html, coding | ---
title: Edit Someone Else’s Website: contenteditable & designMode
published: true
tags: Development,FrontEnd,HTML,coding
canonical_url: https://austingil.com/contenteditable-and-designmode/
cover_image: https://austingil.com/wp-content/uploads/HTML-Blog-Cover.png
---
{% embed https://www.youtube.com/watch?v=vnhwbuyXEmk %}
The first time I opened up my devtools and changed the contents of a website, I actually thought that I had hacked it. I thought, “Oh my gosh, what sort of crazy powers have I unlocked?”
Little did I know that it was just a local change that would go away when I reload the browser. Still, it is kind of cool to think we can do that.
I bring it up today because there’s actually a couple APIs that are sort of related, that I wanted to highlight.
## `contenteditable`
`contenteditable` is an HTML attribute that when assigned the value of `"true"`, allows for the content of the element to be modified from the front end.
`contenteditable` is cool because you can add it to any HTML element you want, and allow users to modify the content on of that element from their end.
Now, if your first thought is a low cost visual editor for websites, unfortunately, [`contenteditable` is not really a great solution](https://medium.engineering/why-contenteditable-is-terrible-122d8a40e480). It has a lot of ‘s a lot of pitfalls that the industry has agreed that it’s not the right approach.
(see “[Why ContentEditable is Terrible](https://medium.engineering/why-contenteditable-is-terrible-122d8a40e480)” by [Nick Santos](https://twitter.com/nicksantos))
Nevertheless, it’s a pretty fun and interesting attribute that I wanted to share. And I bring that up because contenteditable is a good introduction to this next thing that I wanted to share.
## `designMode`
There’s an API on the `document` object called `designMode` and you can set it to either `"on"` or `"off"`. The cool thing about this `designMode` is that it allows you to enable that `contenteditable` state on the entire document.
So we can go to my website, open up devtools, set the `document.designMode` to `"on"`, and then close devtools, now every single thing on the website can be editable.
```js
document.designMode = "on"
```
Which means with just a couple of clicks and keystrokes we can turn this:
Into this:

How about that? I’ve defaced my own website.
If you haven’t heard of these two browser features, I’m not surprised because they’re pretty uncommon. The reason being that there’s not many very good use-cases for them.
Maybe you could create a browser extension that could toggle `designMode` on and off. Then allow for users to easily modify a webpage in order to provide feedback to team members or maybe capture it in a screenshot or send it to Slack or GitHub. I don’t know, I’m sure there’s something there, but it probably isn’t going to be useful for most folks very frequently.
…Unless you’re someone like me that likes to make satirical article titles from the New York Times.

And let me just explicitly state for legal reasons: I do not encourage or promote using these features to modify websites, to spread misinformation. That is a terrible thing to do.
Nevertheless, these are cool, interesting APIs that I thought I’d share.

Thank you so much for reading. If you liked this article, please [share it](https://twitter.com/share?via=heyAustinGil). It's one of the best ways to support me. You can also [sign up for my newsletter](https://austingil.com/newsletter/) or [follow me on Twitter](https://twitter.com/heyAustinGil) if you want to know when new articles are published.
* * *
_Originally published on [austingil.com](https://austingil.com/contenteditable-and-designmode/)._ | austingil |
1,222,600 | Setup local k8s cluster using kind | In k8s world, there is a need for testing before going production. One among them is using kind to... | 0 | 2022-10-18T00:36:09 | https://dev.to/hyohung/setup-simple-kind-cluster-19jp | kubernetes | In k8s world, there is a need for testing before going production. One among them is using `kind` to build local cluster.
There are many ways in [official document](https://kind.sigs.k8s.io/docs/user/quick-start/), here is my prefer way using yaml to define my expectation.
Creating a yaml file named `kind.yaml` as below to configure 1 master and 2 workers:
```
apiVersion: kind.x-k8s.io/v1alpha4
kind: Cluster
nodes:
- role: control-plane
image: kindest/node:v1.22.0@sha256:b8bda84bb3a190e6e028b1760d277454a72267a5454b57db34437c34a588d047
extraPortMappings:
- containerPort: 30778
hostPort: 30778
listenAddress: "0.0.0.0"
protocol: tcp
- role: worker
image: kindest/node:v1.22.0@sha256:b8bda84bb3a190e6e028b1760d277454a72267a5454b57db34437c34a588d047
- role: worker
image: kindest/node:v1.22.0@sha256:b8bda84bb3a190e6e028b1760d277454a72267a5454b57db34437c34a588d047
```
Install kind if not have. If you're using MacOS, run: `brew install kind` for package manager using brewk
Run command to setup cluster: `kind create cluster --name local --config kind.yaml`
Here is my result, tested in Mac M1 chip:
```
kind create cluster --name local --config kind.yaml
Creating cluster "local" ...
✓ Ensuring node image (kindest/node:v1.22.0) 🖼
✓ Preparing nodes 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-local"
You can now use your cluster with:
kubectl cluster-info --context kind-local
Have a nice day! 👋
```
With k8s contents as below:
```
kubectl config set-context local-kind Context "local-kind" created.
kubectl get node
NAME STATUS ROLES AGE VERSION
local-control-plane Ready control-plane,master 7m58s v1.22.0
local-worker Ready <none> 7m26s v1.22.0
local-worker2 Ready <none> 7m26s v1.22.0
``` | hyohung |
1,222,607 | Table stakes for Detection Engineering | What is a rule, really? Dracula refuses a call with a security vendor For as long as I... | 0 | 2022-10-18T00:56:41 | https://dev.to/teachmetechy/table-stakes-for-detection-engineering-1h68 | security, detectionengineering, threatdetection | ## What is a rule, really?

*Dracula refuses a call with a security vendor*
For as long as I have been in the security industry, there has been a concerted effort to sort through massive troves of data with powerful and mysterious tools called “rules”. It allows us mere mortals to take a million line logfile and separate each line into two buckets: interesting or not interesting, malicious or not malicious, vulnerable or not vulnerable. If you know what “bad” or “vulnerable” is, then you can codify it and let the computer do the sorting for you.
I cut my teeth in security research writing WAF rules for modsecurity and looking for interesting HTTP-based attacks on behalf of a customer base. I also launched the security detection and research team at startups that are now public. At my current gig, I help my organization write detection content against 100s of data sources with terabytes of cloud-based control-plane and data-plane events flowing through our systems. Seeing how detection and research have evolved in my 10+ year career has been rewarding and tiring.
The security elders at my previous companies would scoff at my WAF rules. They would talk to me about a time when vulnerability scanner rules were the only thing that mattered. A team of researchers would feverishly comb through binaries and RE tools like the Matrix. When they would find a vulnerability, they would rush out a rule so their company would be the first to disclose it and have a detection before their competitors.

*A security researcher from McAfee deploys a new rule to their vulnerability scanner (2003, colorized)*
At the end of the day, this fell into the realm of "security research". Companies would scoop up new grads and old heads alike, put them on a security research team, and put them to work. They would then measure how many rules and detections they could push into production in a month. Hopefully, it was enough to claim that their products protected customers from more attacks and vulnerabilities than their competitors.
This go-to-market strategy can be effective but suffers diminishing returns. It begs the question: why is "more" better, and why is "lots more", lots better? In the age of vulnerability scanners, more rules meant more vulnerabilities being detected. This translates to better coverage, which is a great sales statistic. The same pervasiveness of coverage crept into threat detection products, but threats are not equal to vulnerabilities. Sure, you want to have coverage against an overwhelming number of threats, but is that going to help protect you and your firm? Can you do “all” threats, forever? More than a competitor, more than a threat actor? Probably not.
This culture of more is better has caused burnout and pain for researchers at these companies. It doesn't matter if you wrote an exceptional rule that was relevant, contextual, and precise: it carried the same weight as another bad rule with bad results within the game of quotas. When detection counts are up, the sales engine gets revved up, and they rush to their pipelines to close more deals.

*Detorction rules are like stonks, they can only go up*
## Threat detection is dead. Long live threat detection!
The security research team in these times (maybe not as much now, but I have recency bias) was treated like wizards. They were the identity of the company. They had cringe-inducing named research teams, such as the IBM Hacker Ninjas or the McAfee Alpha Bro Exploiter Extraordinaires. The wizards would come down from their spire and preach to the world their latest findings, present at Blackhat and DEFCON. Afterwards, they would head back up the spire and close the door behind them. Their rules, research, and detections would then be left for other people to deal with. They had bigger things to worry about, like writing more rules to hit that damn quota.
In my opinion, this concept of "more is better" for detection rules is a sign that a company's go-to market is either a) stuck in the past of vulnerability research coverage or b) doesn't know what they are doing so they just do as much as possible to hide that fact. Believe me, I was part of this a few times in my career.
Now, I am not saying that you shouldn’t crank them out for the sake of coverage. There are legitimate reasons to write, deploy and maintain a vast ruleset. What I am saying is that I think we got into this mess because we think more coverage is more secure. This fallacy can lead internal teams, or in my case a product detection team, down rabbit holes that aren't fruitful in the longrun. And the more I get into my career, the more I realize that I can’t solely blame sales or marketing people for this strategy. It's up to us, the researchers, to let them know which path is the more fruitful and why.
When a company relies heavily on a research team to pump out content, they need to make sure that the team has the right people supporting them. This will enable the team to focus on the nuances of security detection. Companies should provide access to project management resources, software engineering capabilities to scale rule writing efforts and infrastructure, and consider the impact of rules using tried and tested methods in everyone’s favorite high school class: statistics.
I think the industry is starting to see that security detection and research, for the sole purpose of writing threat detection rules, is evolving into a more advanced and exciting type of security engineer: the Detection Engineer!
## Detection Engineering is the new hotness but requires solid foundations in more than just security subject matter expertise
Detection Engineering, in my opinion, is the next level of security research. It's an evolution because companies have realized that it's more scalable to require security researchers to have skills in software engineering, project management, and statistics. If you want to scale your detection program, you need to hire a Detection Engineering team that can complement each other in the following areas:
1. Subject matter expertise in security
2. Software engineering
3. Statistics
That's it. That's all you need. Of course, this list can be picked apart, stretched, and folded under other areas like DevOps or Infrastructure. However, at the end of the day, these 3 pillars can get you far without having to hire a ton of bodies.
You can't write detections for your network security product if you don't have network security experts. This is the same for endpoint, cloud, application and host-based detections. It’s like having a bunch of data scientists build a machine learning model to detect asthma in patients. However, they forgot to bring in a doctor to show them how pneumonia patients would give the model false positives. You need the subject matter experts. This has not changed in the industry, nor should it.
What has changed is that these experts need a solid basis in software engineering principles. You can't scale all of those detections and deploy them in a modern environment, manage sprints (yes this is software engineering :)), or write unit, integration, and regression tests without lots of bodies or lots of automation. I can reliably say my boss would rather hear that I can scale the problem away with software than with hiring more people.
Lastly, and I think this is the next step in the evolution of security research to detection engineering: we all must improve the explainability, and thus impact, of our rules, and statistics is how you do it. You can't reliably create, improve, deprecate or justify your detections to your sales teams, internal leadership, or customers without a background in statistics. This does not mean you need a graduate degree, but I think if security engineers and researchers spent some time looking at concepts like sampling bias and error, confusion matrices, precision and recall, they could better understand how rules perform under certain conditions and spot errors much earlier on before a rule hits production.

The more you learn, the more you realize you don't know anything
## Conclusion
I am excited to see these 3 pillars being talked about more in the detection engineering and security realm. It shows how much we've matured as an industry. I wrote this post as a rant but also as a warning: do not do what I did. Do not fall victim to the "more is better" farce. I have a few more post ideas going into detail on what separates a good detection from a great detection (my team asks this question all the time), or what a go-to-market strategy for security detection rules should be (it's covering the right things, not more things). But for now, my parting advice for aspiring researchers and engineers is this Einstein quote:
"If I had only one hour to save the world, I would spend fifty-five minutes defining the problem, and only five minutes finding the solution."
Also, turns out, Einstein may not have said this, but the premise is still great. We write solutions (detections) trying to find problems (threats) without focusing on the problem (threat) beforehand. Don't do what I did. Don't commit to a quota!
| teachmetechy |
1,228,494 | What is react ?And How to learn react in one week | So before moving to react you should know how the web works from giving a request to getting a... | 0 | 2022-10-24T16:47:30 | https://dev.to/vivek7038/how-react-works--bkf | javascript, react, webdev, beginners | **So before moving to react you should know how the web works from giving a request to getting a response from the server.__**

_First of all React is not a framework like angular and vue ,it is a javascript librabry.React APP is basically a collection of components .What is component ' Component are a simple function that you can call with some input and they render some output.
As they are reusable and interactable, so you can merge many components in order to make a entire React app.
..
Best resources and yt channels for learning react :
1. freecodecamp
2. code evolution
3. 6 pack programmer
4. perdotech
HOW TO LEARN REACT IN ONE WEEK?
FIRST I WILL SHARE HOW I LEARNED REACT IN ONE WEEK .
**DAY 1**
I LEARNT ABOUT WHY DO WE ACTUALLY USE REACT RATHER THAN PURE VANILLA JS.THEN I REFRESHED ES6 JS CONCEPTS AND GET FAMILIER ABOUT THE FILE STRUCTURE OF REACT.
**DAY 2**
I LEARNT ABOUT JSX ,PROPS AND STYLING IN REACT .
**DAY 3**
ON THIRD DAY I LEARNT ABOUT FORMS IN REACT AND ALSO USESTATE AND USEEFFECT HOOKS .
**DAY 4**
CREATED A SIMPLE TO DO LIST APP TO KNOW HOW WE PERFORM CRUD OPERATIONS AND MAMNAGE THE COMPONENTS RENDERING
**DAY5**
I LEARNT ABOUT THE ROUTING IN REACT USING REACT-ROUTER-DOM.YOU SHOULD MUST LEARN IT WELL .THE OFFICIAL DOCS ARE PRETTY WELL FOR THAT .
**DAY 6**
THEN I LEARNT ABOUT THE REACT LIFECYCLE AND CLASS BASED COMPONENTS .ON THE SAME DAY I SOLVDED ALL THE REACT CHALLENGES ON FREECODECAMP.COM.IT WAS GREAT TO PRACTISE ALL THAT I HAVE LEARNT .
**DAY 7**
THEN I FINALLY MADE A CLONE OF MI STORE SITE .ALSO USED REACT BOOSTRAP .IT IS PRETTY GOOD FOR FAST DEVELOPEMENT OF INTERFACES.
**ADVICE FOR THE BEGINNERS :**
`_
1.DON'T TRY TO LEARN EVERYTHING ON ONE DAY AND RUSH TOWARDS THE ADVANCED TOPICS .TAKE YOUR OWN TIME.
2.AFTER WATCHING A TUTORIAL FIRST PRACTISE IT THEN SWITCH TO ANOTHER TOPIC.REMEMBER YOU GET GOOD AT ANYTHING BY CREATING NOT JUST ONLY BY CONSUMING .
3.DO PEER PROGRAMMING .MEANS FIND SOMEONE WHO ALSO WANTS TO LEARN REACT AND PASSIONATE ABOUT THE FRONT END .BELEIVE ME IT'S GREAT WAY TO LEARN .
4.CREATE AS MANY PROJECTS AS YOU CAN .YOU DON'T NEED TO LEARN THE SYNTAX DOCS AND GOOGLE IS ALWAYS THERE JUST BUILD THE LOGIC ABOUT WHERE YOU NEED TO USE WHICH CONCEPT
5.GO THROUGH THE CODE OF OTHERS ON GITHUB .OBSERVE HOW THEY MAINATAIN COMPONENTS FOLDER ,EXTENSIONS OF VS CODE FOR REACT,AND MANY STUFFS FIGURE OUT ALONG THE JOURNEY .
6.THERE IS NO SHORTCUT YOU JUST HAVE TO START .
_`
| vivek7038 |
1,245,284 | Introduction to WEB and HTML | What is Web Server? Web servers are an important part of a website and it is important to... | 0 | 2022-11-06T07:08:55 | https://dev.to/sm8uti/introduction-to-web-and-html-159j | iwritecode, webdev, html, webserver | ### What is Web Server?
**Web servers** are an important part of a website and it is important to understand how a web server works on the internet or the World wide web. A website doesn't just depend on the coding or content part it depends on how the website performs on the internet and how much it is efficient so we need a good web server.
> A website is a collection of web pages while a web server is software that responds to the request for web resources.
<br>

<br>
A **web server** is a computer where web content is stored and also the content is served on the internet. that's why a user visits your website and sees your all content over the world because of a web server.
Nowadays worldwide most famous & widely used web server is [Apache 2](https://httpd.apache.org/) and other web servers are `Nginx, Lighttpd`, etc.

The biggest advantage of using this server is supports all operating systems ( `Windows, Mac, and Linux, etc.` ) and most websites ( around 70% ) are using `Apache` for hosting their content. `Apache is open-source` which means it is available for free, and can easily be accessed through online communities. a lot of online support is available in case you are stuck in a problem or error.
### How does it be Works?
The **web server** responds to the client's request in two ways one is sending the file to the client associated with the requested URL ( `Uniform Resource Locator` ) and the second ways generating a response by invoking a script and communicating with the server.
> URL is an acronym for Uniform Resource Locator and is a reference (an address) to a resource on the Internet
<br>
```
Example of URL : http://example.com
where the http is protocol identifier and the example.com is resource address.
```
When you type a URL into a browser that means the client sends a request for a web page, the web server searches for the requested page if it exists or is found then it will send it to the client with an HTTP ( `Hypertext Transfer Protocol` ) response. and if the requested web page is not found or does not exist web server sends an HTTP response ( `404 not found` )
### What is HTML ?
Basically, **HTML** is the main part of a web page. its full form is `Hypertext Markup Language`. and you can also imagine `HTML is a bone of a web page` because you use it to structure your web page.

The origin of the `HTML language` dates back to the `physicist Tim Berners-Lee`, its creator, a worker at CERN (European Organization for Nuclear Research) who at the end of 1989 proposed the HTML language together with the HTTP protocol, whose objective was to create a means to be able to share information between physicists of the time who worked all over the world.
The first version of HTML was released in 1991 ( HTML 1 ) .
- HTML 2 - Released in 1995
- HTML 3 - Released in 1997
- HTML 4 - Released in 1999
- HTML 5 - Released in 2014
HTML 5 is the latest version and this version includes many outstanding features.
#### Basic structure of HTML:
```html
<!DOCTYPE html>
<html>
<head>
<title>SM8UTI</title>
</head>
<body>
<h1>Smruti Ranjan Nayak</h1>
<p>SM8UTI</p>
</body>
</html>
```
in the above html code the `<!DOCTYPE html>` declaration defines that this document is an HTML document or file. the `html, head, title, body these are called elements or tags`. `<html>` is the root element. `<head>`, this element contains meta information, title, and links etc. and `<body>`, this element contains the body part of web page or content part.
The two most used extensions of HTML documents are `.html` and `.htm`.
Thank you very much for reading.
Sm8uti
| sm8uti |
1,244,346 | 用 HTML 的 capture 屬性,開啟手機鏡頭進行拍照、錄影 | 本篇要解決的問題 以前研究過一下怎麼用 JavaScript 打開手機的鏡頭,進行拍照或錄影,當時做出了 Demo 後,然後就……突然一陣子忙,就忘記寫文章了... | 18,536 | 2022-11-05T10:03:18 | https://www.letswrite.tw/html-capture/ | webdev, beginners, tutorial, html | ## 本篇要解決的問題
以前研究過一下怎麼用 JavaScript 打開手機的鏡頭,進行拍照或錄影,當時做出了 Demo 後,然後就……突然一陣子忙,就忘記寫文章了 XD。
直到昨天看到一篇文章,才知道原來 HTML 本身就有 attribute 讓使用者開啟鏡頭,進行拍照或錄影,而且寫起來 Hen~ 簡單,就決定製作一個小 Demo,並寫出這篇筆記文。
參考的文章及 MDN 的說明連結在這:
- [You Can Access A User’s Camera with Just HTML](https://austingil.com/html-capture-attribute/)
- [HTML attribute: capture](https://developer.mozilla.org/en-US/docs/Web/HTML/Attributes/capture)
製作出來的 Demo 在這,只能用手機操作,用桌機的話無法使用。
<https://letswritetw.github.io/letswrite-html-capture/>
---
## HTML 屬性開啟鏡頭
這邊直接提供開啟手機鏡頭的 HTML 屬性是什麼:
- capture:`user` 前鏡頭、`environment` 後鏡頭
- accept:`audio` 聲音檔、`video` 影片檔、`image` 圖檔
這二個屬性是寫在 `input type="file"` 裡的,範例如下:
```html
<!-- 開啟 前鏡頭 錄影、拍照 -->
<input type="file" capture="user" accept="video/*"/>
<input type="file" capture="user" accept="image/*"/>
<!-- 開啟 後鏡頭 錄影、拍照 -->
<input type="file" capture="environment" accept="video/*"/>
<input type="file" capture="environment" accept="image/*"/>
```
想看效果的朋友可以進到 Demo 裡去玩一玩,Demo 頁不會把大家的照片或影片給存下來,一切都是在頁面上操作而已 ~~(因為沒有酷錢錢買空間存)~~。
另外,August 用 iPhone 實測時,前鏡頭預設會打開閃光燈,拍照前記得關掉,不然會被閃到看見人生的跑馬燈。
---
## 把使用者照片、影片放到頁面上預覽
在 Demo 頁上如果大家有試玩拍照跟錄影,會看見 August 有把拍照的照片跟錄影的影片給放在結果顯示區,這個不用擔心,並不是先存到某台主機上後,再把路徑丟回給頁面,而是直接用 [FileReader](https://developer.mozilla.org/zh-TW/docs/Web/API/FileReader) 把各位當下的檔案給塞到頁面上 `img`、`video` 的 `src` 裡。
這段是要寫怎麼把照片、影片給轉成網頁可讀的 `src`~~(買不起空間啊廣告還不點起來讓本站賺個微簿的酷錢錢)~~。
### 轉圖片
最簡單的方式,先在 HTML 上放個不寫 `src` 的 `img`,之後抓到 Base64 後再寫進 `src` 裡。
```html
<img id="Im_image">
```
```javascript
const input = document.getElementById('xxx');
input1.addEventListener('change', handleFilesImage, false);
function handleFilesImage() {
const fileData = this.files;
const reader = new FileReader();
reader.addEventListener('load', file => {
const img = document.getElementById('Im_image');
img.src = file.target.result;
});
reader.readAsDataURL(fileData[0]);
}
```
### 轉影片
一樣用最簡單的方式,先在 HTML 上放個不寫 `src` 的 `video`,之後抓到 Blob 後再寫進 `src` 裡。
轉影片的 JavaScript 主要參考這篇:[How to read large video files in JavaScript using FileReader?](https://stackoverflow.com/questions/61012790/how-to-read-large-video-files-in-javascript-using-filereader)
```html
<video id="Im_video" controls="controls"></video>
```
```javascript
const input = document.getElementById('xxx');
input1.addEventListener('change', handleFilesVideo, false);
function handleFilesVideo() {
const fileData = this.files;
const reader = new FileReader();
reader.readAsArrayBuffer(fileData[0]);
reader.addEventListener('load', file => {
const buffer = file.target.result;
const videoBlob = new Blob([new Uint8Array(buffer)], { type: 'video/mp4' });
const url = window.URL.createObjectURL(videoBlob);
const video = document.getElementById('Im_video');
video.src = url;
});
}
```
---
## 關於客製 input file
如果直接用 `input type="file"`,預設會長的像這樣:

但因為這邊我們讓使用者做的動作是「打開鏡頭」,如果顯示的像預設那樣是寫「選擇檔案」,使用者會感到疑惑,所以 Demo 上有客製了 input file 的樣子成一個按鈕,上面可以寫上我們想要的文字:

客製 input file 的方式本站以前有寫過,這邊就不再重複寫,有興趣的朋友可以點連結觀看:
[File API 客製上傳檔案按鈕 / input file](https://www.letswrite.tw/file-api-custom-input/)
---
## 支援度、安全性
HTML `capture` 這個 attribute 的支援度,在 [Can I use](https://caniuse.com/html-media-capture) 上是這樣:

可以看到支援的部份全在手機,這也正常,現在大家都手機不離身了,要拍照或錄影也不會用電腦來使用。
關於安全性,這邊要寫的並不是說用這個 HTML 的屬性安不安全,而是像參考連結裡第一篇文章提到的,用 `capture` 這個方式,並不會像用 App 那樣,會先詢問使用者能不能授權開啟相機功能,而是直接就打開了,這對使用者來說會有安全的疑慮。
但就像參考文章中說的,這最後的產出是一個 input 裡的檔案,當我們逛網頁時,如果自己點擊了 input,打開相機,又自己按下了拍照或錄影,然後又按下了確定使用照片或影片,這都是我們自己決定的,而且至少要 3 次的點擊才會把照片傳到網頁上,這中間的過程,目前只能說,在瀏覽器並未限制使用者點擊了帶有 `capture` 屬性的 `input` 的當下,大家逛網站真的是不要亂點不信任的網站任何按鈕或連結,看到點了某個按鈕時突然打開了鏡頭時,更要當心。 | letswrite |
1,244,534 | Journey of a web page - A mind map ! | Ever wondered what happens when you hit enter after typing a url in the browser’s address bar?... | 0 | 2022-11-06T07:33:38 | https://dev.to/abhighyaa/the-journey-of-a-web-request-a-mind-map-4g5g | webdev, webperf, architecture, html |
Ever wondered what happens when you hit enter after typing a url in the browser’s address bar? 🤔

Oh, I wish!😨
The browser BTS does so many things for this to appear so seamless. And understanding those are very important to make our applications highly performant.

Let's understand these one by one -
1. You enter some input 
2. Browser parses the input to check if its a url or a search query.
For search query => it redirects to the search engine.
3. For URL, it -
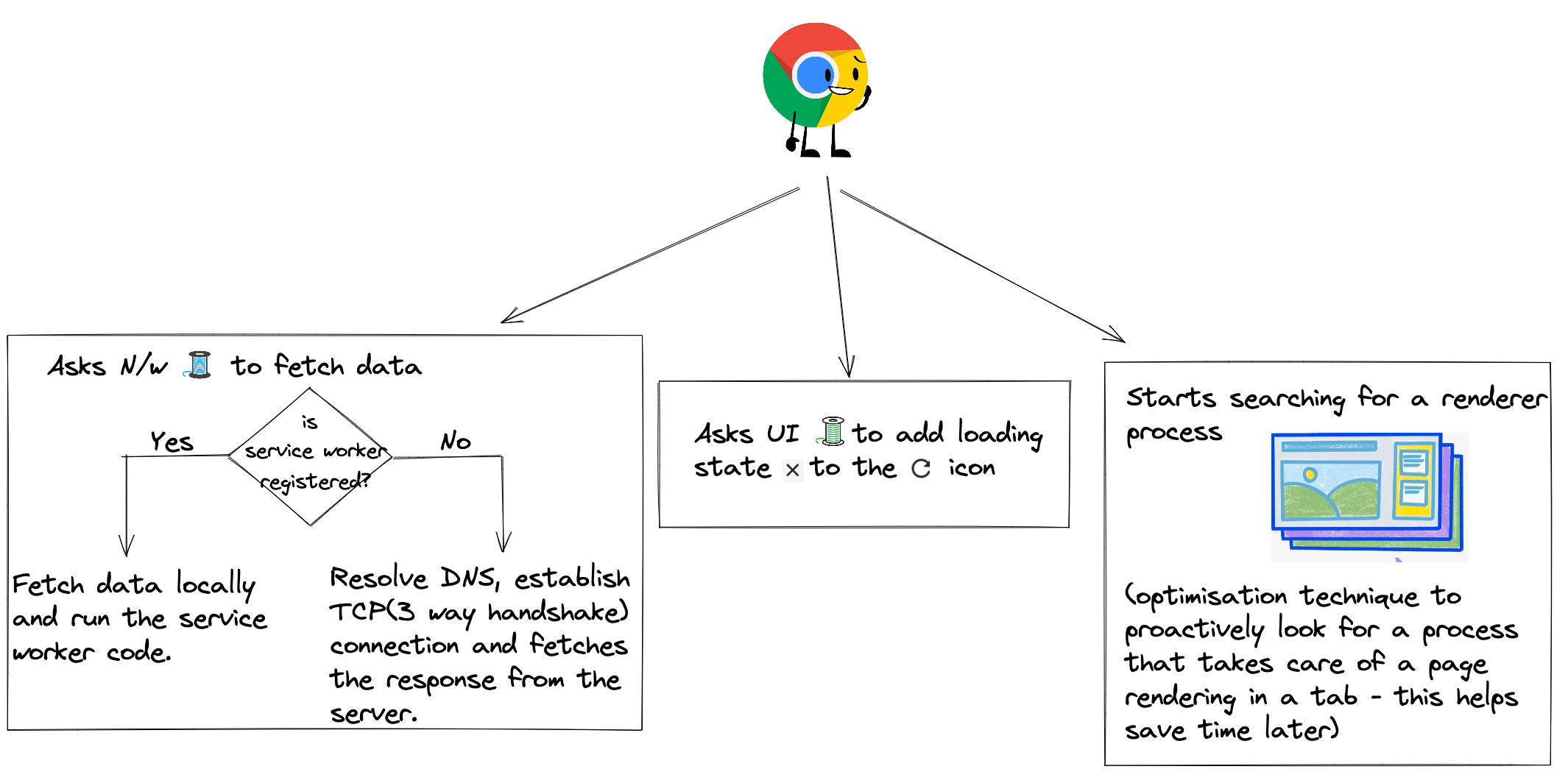
💡 In the n/w response, we can see vast differences between 14kb and 15kbs response size, but not between 15 and 16 kbs. Knowing which all Kbs are more critical than others can give you a big time [TTFB](https://web.dev/ttfb/) benefit. More details [here](https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work#tcp_slow_start_14kb_rule).
4. Once the response is fetched, it -
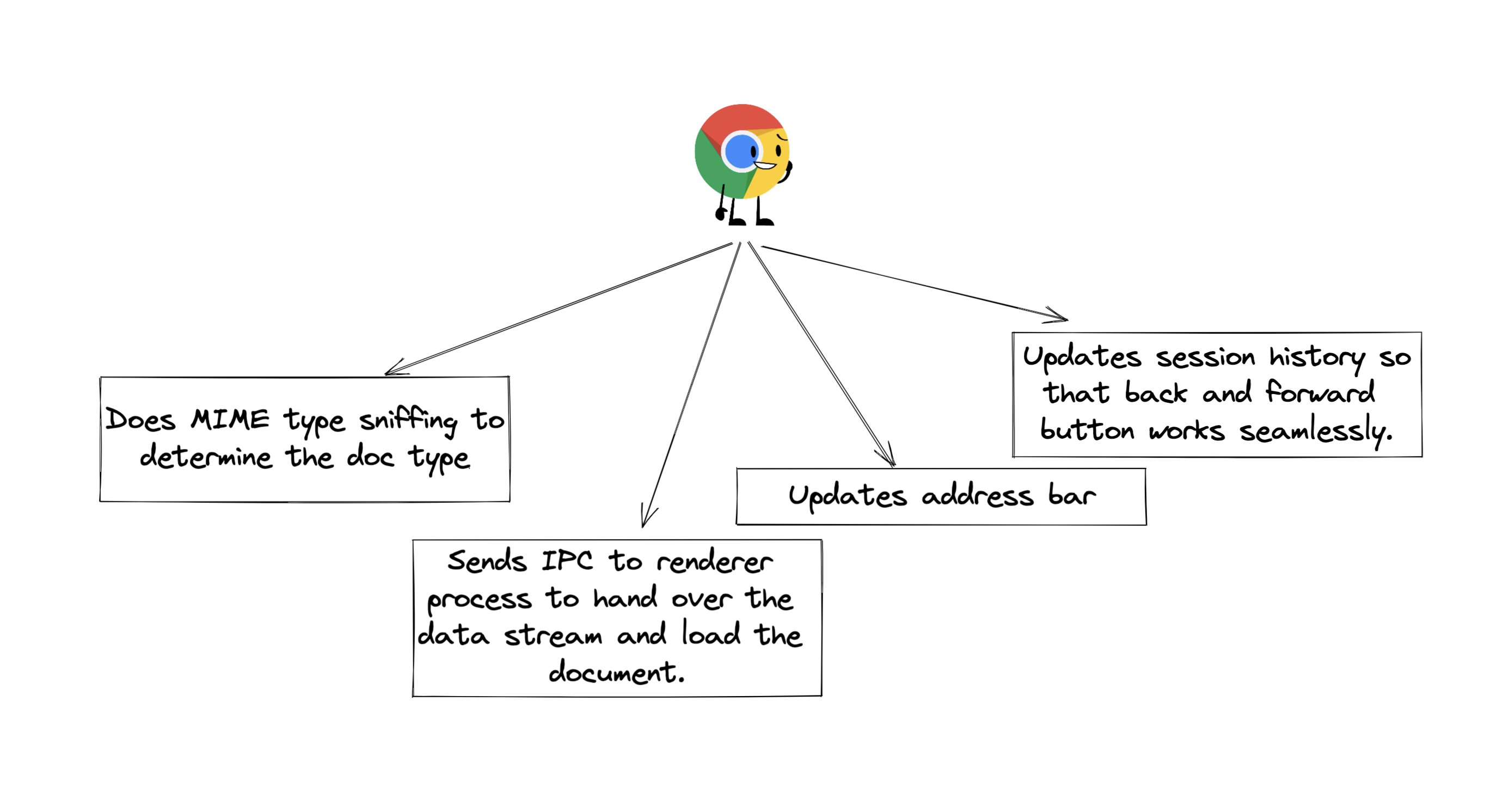
5. Once renderer process receives the IPC and data stream, it -
* Starts parsing the HTML received. HTML received is in bytes format.

* [DOM](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction) (the data structure browsers use to process html into web pages) - it contains all the nodes of HTML and their relationships.
* When parser comes across downloading resources(like css, js, assets like fonts, image, video), it sends requests to the network thread in the browser process.
* Preload scanner is a browser optimisation technique to speeden up this process. It peaks at the tokens generated by parsers and sends requests to the network thread in the browser process.
* CSS, JS are render blocking resources. They stop html parsing and block page rendering, thus creating more delays and worsening the page load times.
* 💡 This is why we use techniques like [preloads](https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preload), [preconnects](https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preconnect), [async](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script#attr-async), [defer](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script#attr-defer), splitting CSS into critical and non critical and defer the non critical one etc wherever suitable.
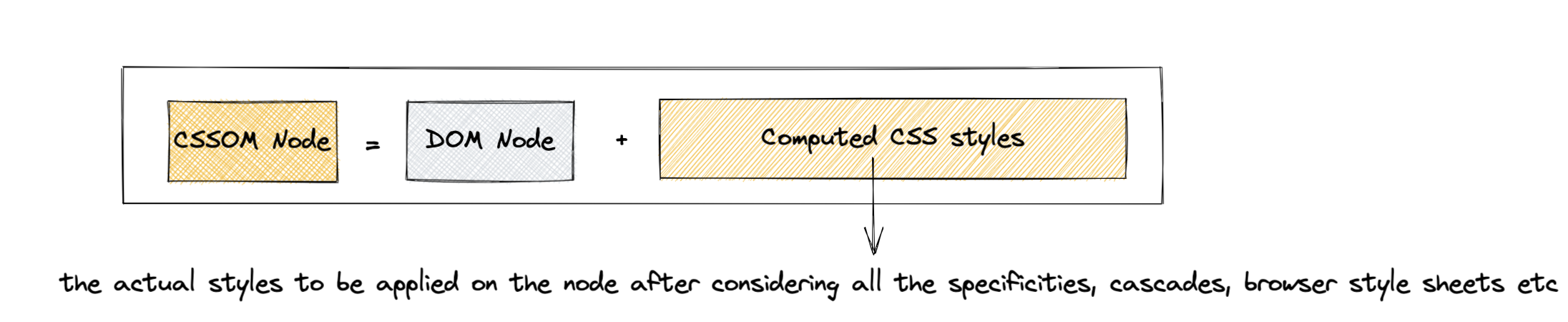
6. Once the DOM is constructed, the main thread parses the CSS to create [CSSOM](https://developer.mozilla.org/en-US/docs/Web/API/CSS_Object_Model) - the data structure similar to DOM, but containing the computed styles for each node in the DOM.
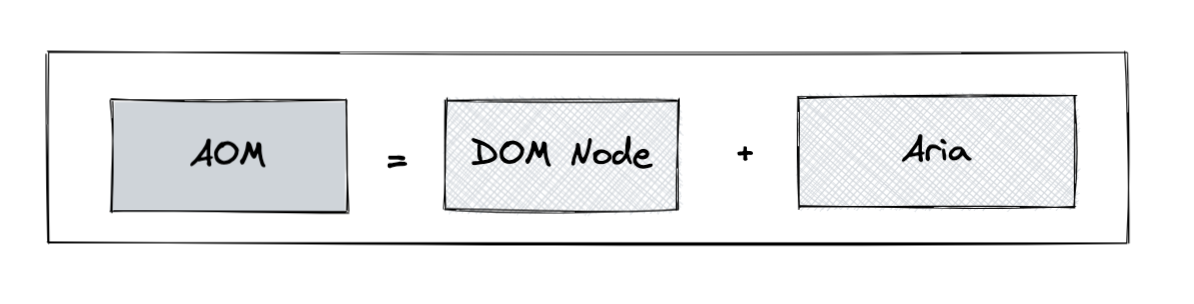
7. Now the browser creates an [accessibility tree](https://developer.mozilla.org/en-US/docs/Glossary/Accessibility_tree) - AOM - semantic version of DOM - to be used by screen readers and other accessibility devices.
8. Now to render the page, the browser needs to know the exact positions of the nodes. So, it creates the render/layout tree, containing the coordinates information for the nodes which are to be shown on the page, considering all line breaks, height and width of elements.
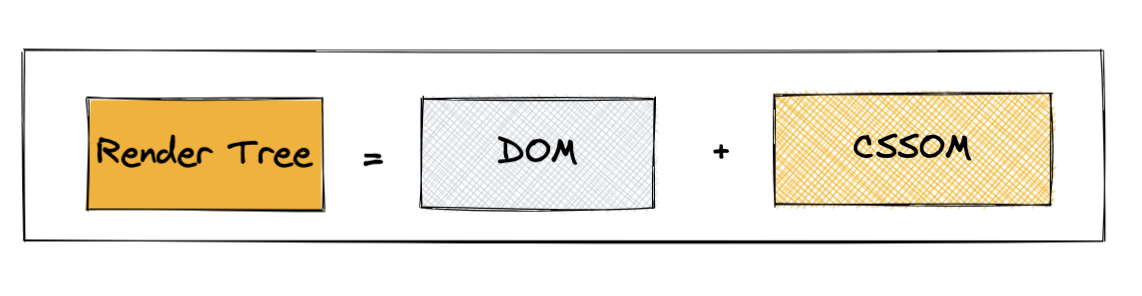
🤔 Why do we need it, if we have dom and cssom?
Because CSS is mighty 💪🏻 It can hide elements from the web page even if they are present in DOM. Vice versa, it can add info(using the pseudo classes), even if they are not present in DOM. It can make the elements float to one side, mask overflow items, and change writing directions.
- Subsequent calculation of these positions is called reflow.
- 💡 If for elements like image, we can provide dimensions before loading, reflow can be saved improving the [CLS](https://web.dev/cls/).
9. Next it creates paint records - to add z-index and determine orders in which to paint.
10. Now comes the step where we actually see something on the screen - rasterization - transforming the images created into actual pixels using GPUs.
To optimise this, the browser creates layers of the page (based on video, canvas, 3d transform, [will-change css property](https://developer.mozilla.org/en-US/docs/Web/CSS/will-change)). These layers are individually rasterized and then composited to form the actual page.
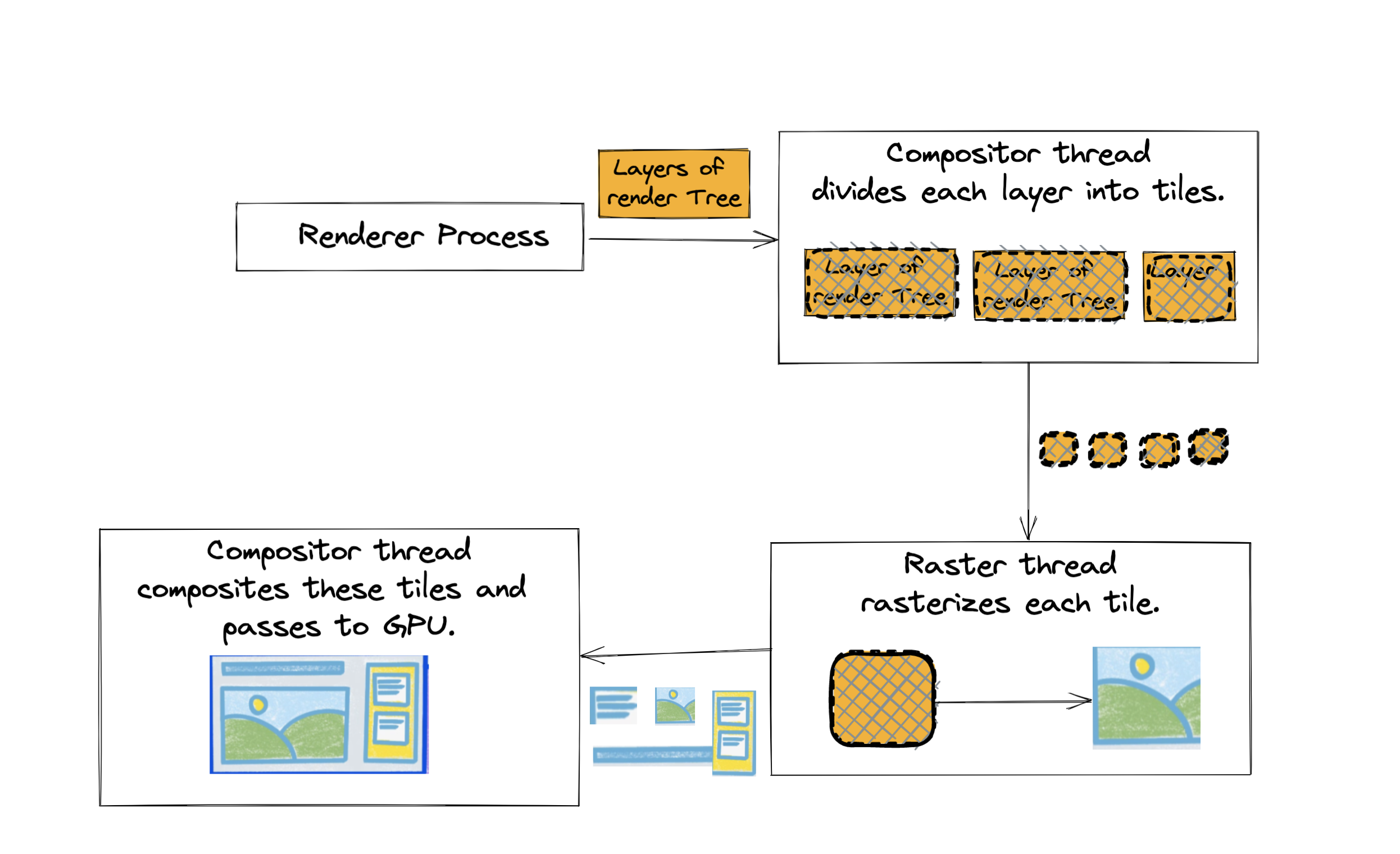
- The first occurrence of this marks the [FCP](https://developer.mozilla.org/en-US/docs/Glossary/First_contentful_paint#:~:text=First%20Contentful%20Paint%20(FCP)%20is,the%20page%20is%20actually%20loading).
- Also, the entire time duration from when the DNS lookup started to here, marks our [TTI](https://developer.mozilla.org/en-US/docs/Glossary/Time_to_interactive).
- 💡 When we encounter janky scrolls and animations, we should check reflows and repaints, it must be skipping some frames.
11. It is now that the renderer process sends a message back to the browser process to replace the spinner with reload icon. And all onload events are fired.

This is how eventful and expensive a web page’s journey is. So, be mindful of the renders next time you code an application.
| abhighyaa |
1,244,537 | REMOTE Data Science Job that pays up to $165K - Santhoscheeku77 | Original Tweet From @Santhoscheeku77 Santhosh Kumar ... | 0 | 2022-11-05T13:45:34 | https://infotweets.com/blog/remote-data-science-job-that-pays-up-to-165k-santhoscheeku77-19np | career, job, productivity | #### Original Tweet From [@Santhoscheeku77](https://twitter.com/Santhoscheeku77)
{% embed https://twitter.com/Santhoscheeku77/status/1588546664918405122 %}
### 1 Decentral, US
▪ Role - Machine Learning Engineer
▪ Salary - $70k – $120k • 0.3% – 1.5% ( equity )
[https://angel.co/company/decentralinc/jobs/576333-machine-learning-engineer](https://angel.co/company/decentralinc/jobs/576333-machine-learning-engineer)
### 2 Weights & Biases, US
▪ Role - Machine Learning Engineer
▪ Salary - $100k – $160k
[https://angel.co/company/wandb/jobs/1193123-machine-learning-engineer-customer-success-remote](https://angel.co/company/wandb/jobs/1193123-machine-learning-engineer-customer-success-remote)
AdSpace Here!!
### 3 Neo Cybernetica
▪ Role - AI Research Engineer
▪ Salary - $60k – $140k
[https://angel.co/company/neo-cybernetica-1/jobs/2432007-ai-research-engineer-reasoning](https://angel.co/company/neo-cybernetica-1/jobs/2432007-ai-research-engineer-reasoning)
### 4 Generally Intelligent
▪ Role - Machine Learning Engineer
▪ Salary - $140k
[https://angel.co/company/generally-intelligent/jobs/1490456-machine-learning-engineer-remote](https://angel.co/company/generally-intelligent/jobs/1490456-machine-learning-engineer-remote)
AdSpace Here!!
### 5 Light, Europe
▪ Role - AI developer
▪ Salary - €65k – €100k • 0.1% – 0.5% ( equity )
[https://angel.co/company/light-15/jobs/2458863-ai-developer](https://angel.co/company/light-15/jobs/2458863-ai-developer)
### 6 Paleo
▪ Role - Data Scientist
▪ Salary - $85k – $165k • 1.0% – 15.0% ( equity )
[https://angel.co/company/paleo-3/jobs/2466427-data-scientist](https://angel.co/company/paleo-3/jobs/2466427-data-scientist)
AdSpace Here!!
###7 Growthday, US
▪ Role - Data Analyst
▪ Salary - $70k – $90k
[https://angel.co/company/growthday/jobs/2462744-data-analyst](https://angel.co/company/growthday/jobs/2462744-data-analyst)
That's a wrap! & Thank you for Reading ❤
AdSpace Here!!
If you enjoyed this thread:
1. I plan to share such resources in Future
2. Follow me [@Santhoscheeku77](https://twitter.com/Santhoscheeku77) for more of this Data Science content
3. Like & RT the tweet below to share this thread with your audience [https://twitter.com/Santhoscheeku77/status/1588546664918405122](https://twitter.com/Santhoscheeku77/status/1588546664918405122)
Click [Here](https://www.knowledge-twitter.com/?utm_source=dev.to) For More Posts Like This [https://www.knowledge-twitter.com](https://www.knowledge-twitter.com/?utm_source=dev.to) | knowledgefromtwitter |
1,244,544 | Variables in JavaScript | In JavasScript, variables are containers in which we can accumulate some information. There are 3... | 0 | 2022-11-05T16:51:42 | https://dev.to/kima_badalyan/variables-in-javascript-14po | variable, javascript, scope, visibility | In JavasScript, variables are containers in which we can accumulate some information.
There are 3 ways of **declaring** the variables:
1. var(used 1995-2015);
2. let(created in 2015);
3. const(created in 2015).
The differences between these three types will be discussed later.
The declaration of the variable starts from the variable type, and then we write the name of the variable we want to create;
let name;
For creating the names of variables in JS, there are several rules:
- We can use letters, numbers, underscore(_), and the dollar symbol($);
- The name must begin with a letter; _ or $;
- The variable names are sensitive, which means small letters(y) and capital letters(Y) are different;
- We cannot use reserved names, such as JS keywords or variable names.
After declaring the variables, we can give some values o these variables. In JS, it is called **assigning**. We assign a value to the variable using the = symbol:
let name;
name = value;
Alternatively, we assign the value immediately after creating the variable:
let name = value;
The value can be:
- **number**:
let name = 42;
- a text, which is called **string** in JS, and is written in double or single quotation marks ('' or ""):
let name = "This is a string";
- a **boolean value**, which means that variable is eather _true_ or _false_:
let name = true;
There are some differences between var, let, and const.
One difference is whether it may or may not be **redeclared**. Const and let can be declared only once in the same {} or globally, while var can be redeclared as many times as we want.
So
var x = 10;
var x = 25;
is going to work, but
let x = 10;
let x = 25;
and
const x = 10;
const x = 25;
are going to result in an Error.
Nevertheless, const and let can be redeclared in different {}.
Another difference is whether the variables can be **used before declaring**. For var, it will work out, while for let and const, they should be declared before we can use them:
So
x = x + 7;
var x;
will work while
x = x + 7;
let x;
and
x = x + 7;
const x;
will result in an error.
One more difference between the variable declaration types is their **scope**. Scope determines the **visibility **or **accessibility **of variables.
Let, and const are **block** scope, while var is not. This means when a variable is created with let or const inside {}, it is local, and it does not work outside of the {}, but if the variable is created by var, it is created **globally**. Outside of the {}, when the variables are created, they are the same because they all have global scope.
So far, we have not seen any difference between the let and const. The let can constantly be reassigned with a new value, while const is constant and does not change its value.
So
const PI = 3.141592653589793;
PI = 3.14;
will give an Error, but
let number = 93;
number = 444;
will reassign 444 to the variable number.
However, the word constant is a little misleading. For a constant variable, we cannot reassign a constant value, array, or object, but we can change the array's elements and the object's value properties.
| kima_badalyan |
1,244,607 | FTDI Bitbanging GCC | This is a short note on how to setup a C programming environment for the FTDI chip in bit banging... | 0 | 2014-05-18T10:00:00 | https://ladvien.com/ftdi-bitbanging | robots, ftdi, gcc | ---
title: FTDI Bitbanging GCC
tags: robots, ftdi, gcc
published_at: 20140518T10:00Z
canonical_url: https://ladvien.com/ftdi-bitbanging
main_image: https://ladvien.com/images/FTDI.jpg
published: true
---
This is a short note on how to setup a C programming environment for the FTDI chip in bit banging mode, since that's what I had difficulty doing.
There may be easier ways to go about this, but I wanted to use GCC to compile a small C program to control the 8 IOs. The purpose was to write a small command-line program that would reset my LPC1114 before and after programming.
To setup the environment:
1. I downloaded and setup [MinGW32](http://www.mingw.org/wiki/HOWTO_Install_the_MinGW_GCC_Compiler_Suite).
2. I then downloaded [FTD2XX libraries](http://www.ftdichip.com/Drivers/D2XX.htm). **This included the ftd2xx.h file and ftd2xx.lib**.
3. I then stole the test code from Hack-a-Day's article on [bitbanging with the FTDI](http://hackaday.com/2009/09/22/introduction-to-ftdi-bitbang-mode/).
4. I modified the code as they suggested by including, in this order, the Windows compatibility files:
```cpp
#include <stdio.h>
#include <stdarg.h>
#include <windows.h>
#include <windef.h>
#include <winnt.h>
#include <winbase.h>
#include <string.h>
#include <math.h>
#include "ftd2xx.h"
```
5. I then used the rest of their code as a base: [Hack-a-Day's FTDI PWM Code](https://github.com/Ladvien/FTDI_Bitbangin_GCC/blob/master/ftdi_Test.c)
I used this line to build it:
```bash
gcc -o ftdi_PWM ftdi_Test.c -L./ -lftd2xx
```
You must have both the ftd2xx.h and ftd2xx.lib in the same directory as you attempt to build.
6. I then wrote two programs, one to send DTR and CTS high and low in order to reset the LPC1114 into **programming mode. ** Second, to send DTR and CTS high and low in order to send the LPC1114 into **run program mode.** The idea being, I could use the typical [Sparkfun FTDI programmer](https://www.sparkfun.com/search/results?term=ftdi) to program my [LPC1114](http://letsmakerobots.com/content/lpc1114-setup-bare-metal-arm).
1. [LPC1114_reset_to_program](https://github.com/Ladvien/FTDI_Bitbangin_GCC/blob/master/LPC1114_reset_to_program.c)
2. [LPC1114_reset_to_bootloader](https://github.com/Ladvien/FTDI_Bitbangin_GCC/blob/master/LPC1114_reset_to_bootloader.c)
That's it. Just wanted to make sure this was out in the universe for the next guy's sake. | ladvien |
1,245,535 | 【TypeScript 30】Day 1:型別推論及註記 | 【TypeScript 30】Day 1:型別推論及註記 距離上次寫文章已經相隔了四個月,在這四個月期間大量練習了 React、node.js、Boostrap... | 0 | 2022-11-06T12:41:32 | https://dev.to/angushyx/typescript-30-day-1xing-bie-tui-lun-ji-zhu-ji-o2n | webdev, typescript |
## 【TypeScript 30】Day 1:型別推論及註記

距離上次寫文章已經相隔了四個月,在這四個月期間大量練習了 React、node.js、Boostrap 等等技術,也大致上掌握以上技術的核心,也因此都沒有好好沉澱寫文章,最近在學習 Next.js、typeScript 以及 tailwindcss,因為對於 React、Boostrap 都蠻熟習的,因此在學習 Next.js 和 tailwind 上 gap 比較小,相對的 typeScript 就比較需要花時間研究,接下來就聊聊 typeScript 吧!!!
最一開始來建置 ts 專案,因為平常習慣使用 React 開發,就使用方便的 create react app 吧。
### Insatll
npx create-react-app ts-30 --template typescript
或
yarn create react-app ts-30 --template typescript
安裝完後,緊接著安裝使用 typeScript 時所需要的套件,一樣可以選擇使用 npm 或是 yarn
### Install
npm install — save typescript @types/node @types/react @types/react-dom @types/jest
或
yarn add typescript @types/node @types/react @types/react-dom @types/jest
接著在專案中安裝 eslint 以及 prettier 模組
yarn add prettier eslint-config-prettier eslint-plugin-prettier eslint-plugin-react-hooks
再加入設定檔於 /src 底下,專案建立完成後,先來釐清最基本的觀念【型別推論及註記】

> # **【型別推論**(Inference)**及註記**(Annotation)**】**
下面就要來介紹個別的原理以及使用時機
**型別大致上分為幾種**
**原始型別 Primitive Types :**number, string, boolean, undefined, null ES6 的 symbol與時常會在**函式型別**裡看到的 void皆屬於**原始型別。**
**物件型別 Object Types:**這些型別的共同特徵是 — — ***從原始型別或物件型別組合出來的複合型態***(比如物件裡面的 Key-Value 個別是 string 和 number 型別組合成)
* 基礎物件型別:JSON 物件,陣列,類別以及類別產出的物件(也就是 Class 以及藉由 Class *new* 出來的 Instance)
* TypeScript 擴充型別:Enum、Tuple(皆內建於 TS )
* 函式型別 Function Type:型別樣貌像是 ( input ) => ( output )
**明文型別 Literal Type:**值的本身也可以成為一個型別。如下圖,常數 string 被賦值 ' hello ts ' ,直接被宣告為 string 類型。

**特殊型別**:參考的部落格作者所細分出的型別,即 any、never即以及 unknow ,這三種看起來都是沒有被定義型別所衍生出的型別,後面會介紹他們的差異。
**複合型別**:同上,即 union 與 intersection 的型別組合,但是跟其他的型別的差別在於:這類型的型別都是由邏輯運算子組成,分別為 | 與 &。
> 大致上將 typeScript 的型別多分類後,我們先回到最一開始要介紹的主題:型別推論及註記的原理以及使用時機
**型別推論:**還記得上面的這張圖嗎 ? 完美的展示了型別推論,typeScript 會**自動幫你推論型別。**

不過讀者也許會思考那這樣 ts 和 js 的寫法哪裡不一樣了呢 ? 在這個案例中 typeScript 的確是幫我們把型別定義好,不過在更多情況下 ts 會把型別定義為 any那既然都已經使用 typeScript 開發了,當然還是不要讓型別是 any 的情況發生。
如下圖,如果把 nothing 這個變數設置為undefiend數就會被定義為 any ,正常情況下這邊並不會爆出錯誤,不過因為已經使用了 eslint ,所以這個錯誤直接被 eslint 判斷出來。
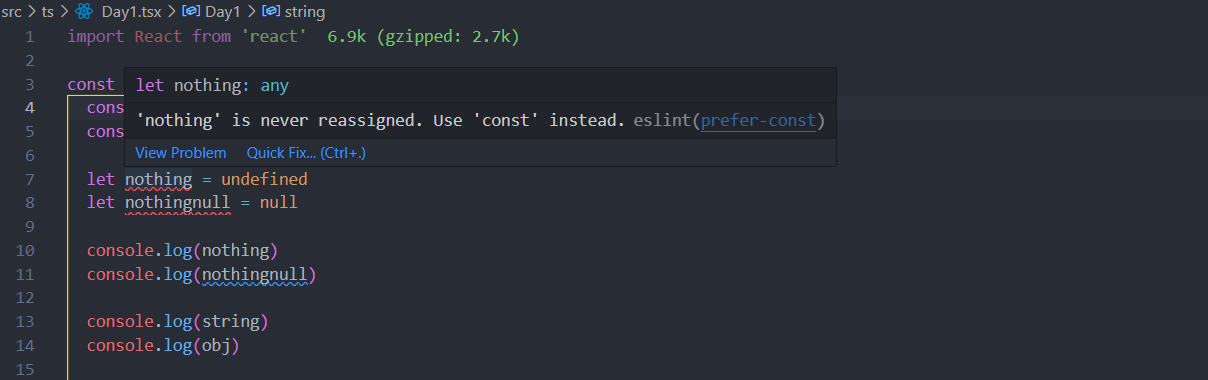
* *此類 null 跟 undefined 稱為 **Nullable Types **這類 **Nullable Types **會被推論為 any。*
不過,型別推論的本意並不是在這裡,而是當變數已經被推論過後,ts 就會跳出警告 — 不能再更改其型別。
拿上面 string這個變數例子,如果重新賦值該變數為數字型別的 22 ts 的型別小蚯蚓就跑出來了。

TypeScript 就會提出這個變數應該是 string 類型這個質疑。

那在這邊我們回到剛剛所提到的 ***Nullable Types ***測試看看,並不會跳出紅色蚯蚓。

檢查完型別後會發現是 any,結論就是當型別被定義為 any 時某種程度上就已經失去使用 TypeScript 幫我們監督程式碼的本意了,因此在大多情況之下,盡量避免讓型別是 any 。

### 遲滯性初始 Delayed Initialization
除了沒有定義好型別之外,還有一種狀況會出現 any,就和原生的 JS 類似,當今天先定義了變數後,不直接指派值,**而是程式碼執行到後面才賦值**
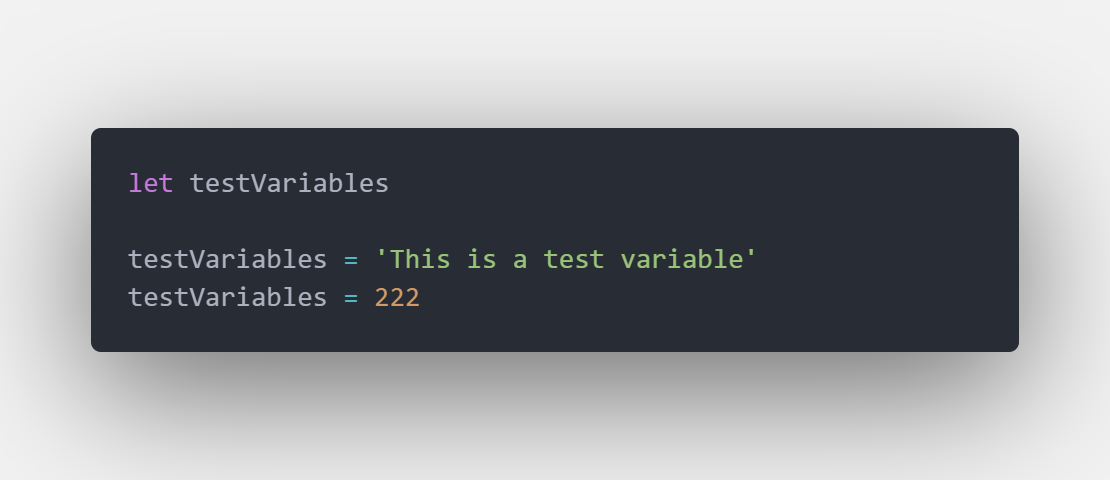
在這邊 TS 已經把 testVariables 這個變數的型別認定為 any ,因此後面無論賦值是字串或是數字,TypeScript 都並不會檢查出錯誤。

概念其實就與我們剛剛提到的 ***Nullable Types ***有關,當只有宣告變數而沒有給他值時,該值自然就是 ***Nullable Types ***的 undefined,也因此型別就等於是 any 。

> 如何避免 any 的型態出現 — — 型別註記 ( Type Annotation )
我們將 absoluteNothingVariables 和 absoluteNullVariables註記型別後再重新賦值
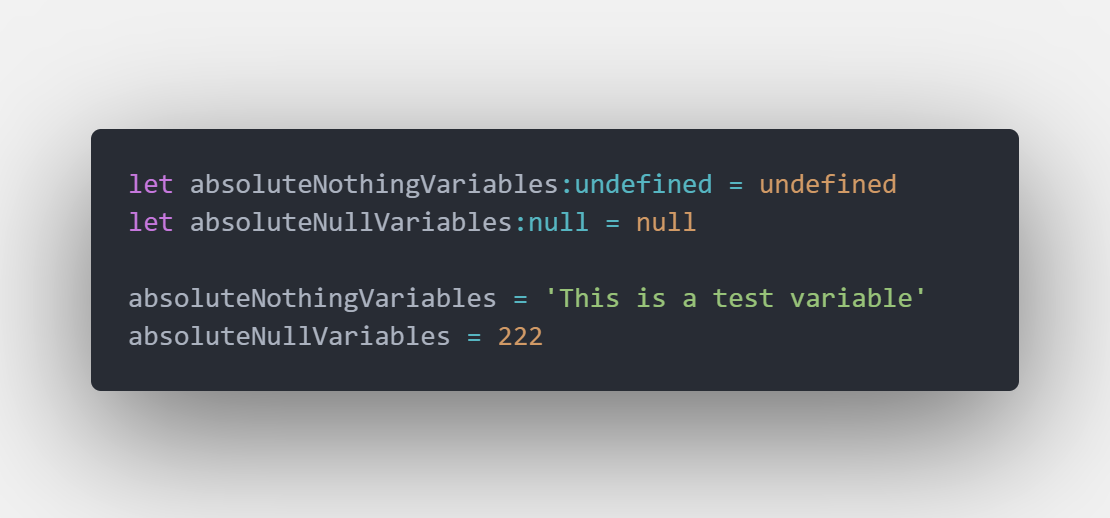
TypeScript 就會把錯誤拋出來了

再測試看看
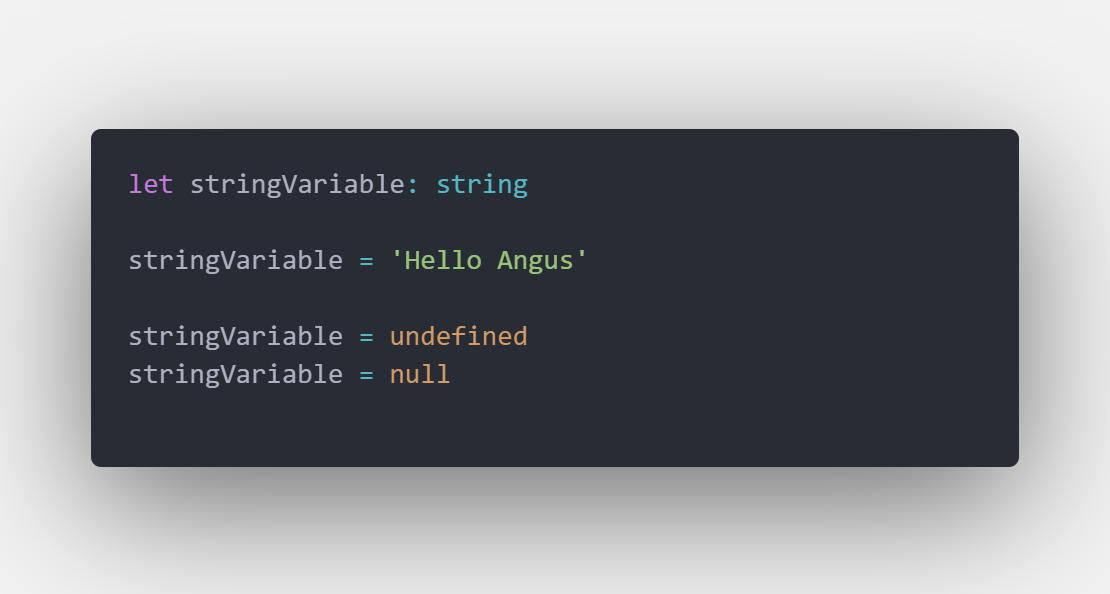
可以發現,經過型別註記後重新賦與註記的型別 ( 這裡是 string ) 後,接下來重新賦予 string 類型的值並不會出錯,不過一但清除為 undefined 或 null 就跳出錯誤,原因是: TS 已經將 stringVariable認定為 string 類型。

不過如果還沒指派值之前就使用該變數,那這個 stringVariable雖然已經進行型別註記了,不過該值也還是 undefiend 不是嗎 ?
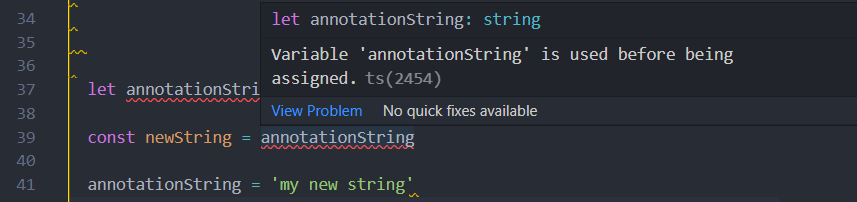
來嘗試看看,就像這樣,在annotationString 還沒賦值的情況之下,先使用了該變數

跳出的錯誤非常明顯指出不能在還沒賦值時就使用該變數,有寫過 JS 的讀者應該對於這個問題比較熟悉,概念有點像 TDZ (Temporal Dead Zone,暫時性死區)這個討論範圍就延伸到了 JavaScript 的作用域,因此就不在這裡多做討論了。
小結:起初想說 TypeScript 不就只是加入型別而已沒甚麼,聽到大家說TypeScript 學習門檻很高,不太相信,不過經過這兩到三天的整理發現好像其實並不只是單純的加入型別這樣而已,剛開始就冷汗直流,希望能夠讓整理文章的速度再快一點。
參考資料:
[**Day 02. 前線維護・型別推論 X 註記 - Type Inference & Annotation - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天**](https://ithelp.ithome.com.tw/articles/10214719)
[**Adding TypeScript | Create React App**](https://create-react-app.dev/docs/adding-typescript/)
[**HiSKIO 專業技能線上學習平台 | 來自全球高品質的職場專業課程**](https://hiskio.com/account/courses?tab=completed&type=course)
| angushyx |
1,245,793 | Rust-04: More operators and loops | In the last post we improved the simple program to be extendable with other operators. In this post... | 20,451 | 2022-11-09T11:00:00 | https://dev.to/nidomiro/rust-04-more-operators-and-loops-3g21 | rust, programming | In the last post we improved the simple program to be extendable with other operators.
In this post we will implement more operators and a loop.
Let's start with the simple task: adding more operators.
To support more operators we have to change two parts of the calculator, the parsing and the evaluation.
First let's look into changing the parser.
For this we simply add the new operators (`-*/`) to the regex inside `Operation::from_string`.
The resulting regex will look like this: `^\s*(\d+)\s*([+\-*/])\s*(\d+)\s*$`.
Now the parser accepts the new operators; first part done.
The second part to change is the evaluation of the parsed operation.
Adding the new operators is as simple as adding more arms to `match`:
```rust
let result = match operation {
Operation { left, operator: '+', right } => Ok(left + right),
Operation { left, operator: '-', right } => Ok(left - right),
Operation { left, operator: '*', right } => Ok(left * right),
Operation { left, operator: '/', right } => Ok(left / right),
x => Err(format!("{} is not a valid operator", x.operator)),
};
```
With the current state, the app can now accept `+`, `-`, `*`, `/` as operators and calculate the result.
Since we expanded the capabilities, we can also look for some possible refactorings.
You might see, that the execution of the `Operation` still happens inside the main function.
It would be cleaner to move the evaluation closer to `Operation` itself.
So let's add another function to `impl Operation` called `execute` and move the mentioned code to that function.
```rust
impl Operation {
// <snip>
fn execute(&self) -> Result<i32, String> {
match self {
Operation { left, operator: '+', right } => Ok(left + right),
Operation { left, operator: '-', right } => Ok(left - right),
Operation { left, operator: '*', right } => Ok(left * right),
Operation { left, operator: '/', right } => Ok(left / right),
x => Err(format!("{} is not a valid operator", x.operator)),
}
}
}
```
Right now `execute` only returns a `String` in case of an error.
To be more specific, what error occurred we add another struct to represent this error.
```rust
struct InvalidOperatorError { operator: char }
// <snip>
impl Operation {
// <snip>
fn execute(&self) -> Result<i32, InvalidOperatorError> {
match self {
Operation { left, operator: '+', right } => Ok(left + right),
Operation { left, operator: '-', right } => Ok(left - right),
Operation { left, operator: '*', right } => Ok(left * right),
Operation { left, operator: '/', right } => Ok(left / right),
x => Err(InvalidOperatorError {operator: x.operator}),
}
}
}
```
After these changes, we are at state: [2d6c605a](https://github.com/nidomiro/learning-rust-calculator/tree/2d6c605ac172308c7f06ec19a965c61cb12f3459).
Until now, we have completed task one: implementing more possible operators.
The second task is to change the calculator to accept multiple calculations one after the other.
A loop is a prime example to achieve this behaviour.
Just wrapping everything in a loop does enable multiple calculations, but the user of our calculator has no way of exiting the program.
We want to be able to type 'quit' to exit the program.
The code below will achieve just that.
```rust
fn main() {
loop {
println!("Please enter a calculation (or quit to exit)");
let mut input = String::new();
std::io::stdin()
.read_line(&mut input)
.expect("Could not read line");
if input.trim().eq("quit") {
println!("exiting...");
break
}
let operation = Operation::from_string(&input).expect("Your input is invalid");
let result = operation.execute();
println!("The result is: {}", result.unwrap());
}
}
```
But we have another problem to fix.
Since we allow multiple calculations we don't want the calculator to crash on an invalid input anymore.
Using `expect` and `unwrap` as error-handlers, will result in a crash of the app if they encounter an error-state;
so we need to exchange them.
Obviously we use `match` instead:
```rust
fn main() {
loop {
println!("Please enter a calculation (or quit to exit)");
let mut input = String::new();
std::io::stdin()
.read_line(&mut input)
.expect("Could not read line");
if input.trim().eq("quit") {
println!("exiting...");
break
}
let operation = match Operation::from_string(&input) {
None => {
println!("Your input was invalid");
continue
},
Some(x) => x
};
let result = match operation.execute() {
Err(InvalidOperatorError { operator: op}) => {
println!("The operator {} is invalid", op);
continue
},
Ok(x) => x
};
println!("The result is: {}", result);
}
}
```
Now we get an info, if the input is invalid and can try again on the next iteration.
After all changes of this post, we are at state: [8322be09](https://github.com/nidomiro/learning-rust-calculator/tree/8322be09454ab3e77a77e9984a1d3c5638d26b2d).
In the next post we will change the structure radically to be able to support multiple operators in one input - at least on the execution side. | nidomiro |
1,245,925 | A Marketer's Take on Client-Side Routing with React Router | Currently, I am learning the ins and outs of ReactJS. I have built a minimal viable product using... | 0 | 2022-11-07T03:39:14 | https://dev.to/timtran007/a-marketers-take-on-client-side-routing-with-react-router-4n1b | clientsiderouting, react, reactrouter | Currently, I am learning the ins and outs of ReactJS. I have built a minimal viable product using React called [TripSave](https://github.com/timtran007/phase-02-project-tripsave). It is a mock application where you can add a destination, budget, current savings and an inspiring destination image to work towards that goal of saving for that trip.
Anyways, throughout learning React, I have been building Single-Page Applications (SPAs) as practice to get really familiar with syntax and learn how to solve common problems for features such as controlled forms, when to create states, use props, perform CRUD actions, etc. However, one thing that I have noticed while writing React code is that these SPAs do not mimic a "traditional" website in regards to changing the browser's URL when routing to a different portion of the application.
## First of All... What is Routing?
Routing is where users are navigated to different pages on a website.
Normally, with web pages built with HTML, CSS and vanilla JavaScript, each page created for the website lives on a server. The website uses server-side routing in order to send a GET fetch request to the server each time users navigate to different pages and this changes the URL path in the browser's URL.
However, with client-side routing, there is only one request sent to the server at the beginning, which pulls in all the data and code necessary to conditionally render the Single-Page-Application based on features within the web application itself. Like mentioned before, this does not change the URL.
## React & Routing
By default, there is a lot of code and work around that would go into making client-side routing mimic server-side routing within a React application.
We won't get into those details today...
However, we will be talking about an awesome library that was made specifically to handle routing in React that mimics a server-side approach of changing the URL's path in the browser that users have grown accustomed to in a traditional website, while providing a better user experience.
## Pros & Cons of Client-Side Routing
So let's dive right into it...
Pros:
- Better user experience with "lightning fast" speed while navigating through different components ("pages")
- Developers can create animations in between the load of components allowing users to see that data is loading in a fun way.
- As users navigate through the React application, there are no refreshes or reloads of the "pages". Components are rendered quickly and does not need to talk to the server to serve new user interfaces.
Cons:
- The initial load time could be a bit longer, since the app is making one request server request to get all data into its components.
- Harder to implement web analytics tracking with Single-Page-Applications.
As a marketer since 2016 exploring programming, at the end of the day, we should take into consideration the end users. Therefore in my opinion, when the circumstance is right, having the appearance of lightning fast speed across navigating the website outweighs doing more work to implement web analytics (been there and done that with Google Analytics & Tag Manager).
With that, let's dive into how to create client-side routing for a React application with React Router!
## Introducing React Router
React Router is a library created to deliver a better user experience for React applications by allowing users to create Route components that allows users to navigate to "different" portions of the application.
### Getting Started
First let's make sure you have the latest version of npm
In terminal you could do the following you can check the version of npm by writing:
`npm -v`
If you need the latest version you can write this into terminal:
`npm install -g npm`
Assuming that you have a React project already, go ahead and type the following into terminal in order download React Router version 5 package:
`npm install react-router-dom@5`
### Adding React Router to your React Application.
There are a few components that are important in making client-side routing with React Router with your React application: BrowserRouter, Switch, Route and NavLink(Link).
#### BrowserRouter Component
The BrowserRouter component allows you to wrap the components you would like to use add routing. Usually this would be the top-level component.
So, let's go ahead and start by importing the BrowserRouter component to your top-level component and wrapping the component around the App component.
```
import React from 'react'
import {BrowserRouter} from 'react-router-dom'
import Nav from "./Nav"
function App(){
return(
<BrowserRouter>
<h1>Welcome to the App</h1>
<Nav />
</BrowserRouter>
)
}
export default App;
```
#### Switch & Route Components
The Switch component makes sure that we only render one Route at a time, while the Route component tells us which component will be rendered on the path that matches the URL.
Route is one of the most important components within React Router and it requires the need for a prop called exact to exactly match the path..
`<Route exact path="/">{Home}</Route>`
If you do not have the exact prop attached you will not be able to route to other pages because Switch is rendering only one and the Route that matches first, so if you have a path of '/', which is home (normally), without the prop you will not be able to access '/about'.
Let's go ahead and add the components to our code above:
```
import React from 'react'
import {BrowserRouter, Switch, Route} from 'react-router-dom'
import Nav from './Nav'
import Home from './
import Location from './Location'
import About from './About'
function App(){
return(
<BrowserRouter>
<Nav />
<Switch>
<Route exact path="/">{Home}</Route>
<Route path="/location">{Location}</Route>
<Route path="/about">{About}</Route>
</Switch>
</BrowserRouter>
)
}
export default App;
```
#### Should I Use the Link or NavLink Component?
The Link and NavLink components act like the anchor tags and href attribute. The difference between Link and NavLink is the whether you want the selected link to be highlighted our not.
If you do, you can use NavLink with the prop of activeClassName to see what is currently showing. Otherwise, they have the same functionality.
So let's go ahead and add the NavLinks to our Nav.
```
import React from 'react'
import {NavLink} from 'react-router-dom'
function Nav(){
return(
<nav>
<ul>
<li>
<NavLink to="/" activeClassName="active">
Home
</NavLink>
</li>
<li>
<NavLink to="/location" activeClassName="active">
Location
</NavLink>
</li>
<li>
<NavLink to="/about" activeClassName="active">
About
</NavLink>
</li>
</ul>
</nav>
)
}
```
## Conclusion
Again, client-side routing can provide an amazing experience for users navigating through a Single-Page Application with "lightning fast" speeds rendering various components based on routes.
##TLDR;
### Using BrowserRouter, Switch & Route Components
Use BrowserRouter component to wrap the top-level component where you want to use Routes.
Use Switch and Route components to create paths for components that match what you want to see in browser's URL, while making sure it loads one Route at a time.
```
import React from 'react'
import {BrowserRouter, Switch, Route} from 'react-router-dom'
import Nav from './Nav'
import Home from './
import Location from './Location'
import About from './About'
function App(){
return(
<BrowserRouter>
<Nav />
<Switch>
<Route exact path="/">{Home}</Route>
<Route path="/location">{Location}</Route>
<Route path="/about">{About}</Route>
</Switch>
</BrowserRouter>
)
}
export default App;
```
### Using NavLink or Link Components
Use NavLink or Link to create "anchor tags" with the "to" prop to point where the link takes a user.
```
import React from 'react'
import {NavLink} from 'react-router-dom'
function Nav(){
return(
<nav>
<ul>
<li>
<NavLink to="/" activeClassName="active">
Home
</NavLink>
</li>
<li>
<NavLink to="/location" activeClassName="active">
Location
</NavLink>
</li>
<li>
<NavLink to="/about" activeClassName="active">
About
</NavLink>
</li>
</ul>
</nav>
)
}
```
| timtran007 |
1,247,033 | .NET MAUI for production code? | I've been working on a new mobile app for some time now. I wanted to implement it in .NET MAUI. This... | 0 | 2022-11-07T21:22:57 | https://dev.to/fp/net-maui-for-production-code-238b | programming, maui, discuss | I've been working on a new mobile app for some time now. I wanted to implement it in .NET MAUI. This has been in General Availability status since the end of May and has been positioned as the successor to Xamarin.
During the development of the app, disillusionment quickly set in because I was affected by one of the more than 1200 issues that are open in Github which are flagged as bugs. I haven't checked Github beforehand, so I was really astonished how many bugs are reported and still not solved. Some of them are already flagged with .NET8.
Besides these bugs there are several hundred other issues.
These numbers are of course across all supported platforms.
On some controls like the CollectionView properties or methods are still marked as "To be added".
Using third party tools does not make one’s life easier, because many .NET MAUI controls are still in preview mode.
To use unit tests on Windows you have make manual modifications in the project files of the app to be tested. Also something which is not really well done.
All in all, .NET MAUI doesn't look like a system I want to use productively. Love to read your opinion about .NET MAUI in the comments.
| fp |
1,247,199 | Here are the top 20 code contributors to the ethereum ecosystem | Vitalik is the face of ethereum but here are 19 others that have contributed significantly to the... | 0 | 2022-11-07T22:37:46 | https://dev.to/shivkodam/here-are-the-top-20-code-contributors-to-the-ethereum-ecosystem-3448 | ethereum, opensource, github, webdev | Vitalik is the face of ethereum but here are 19 others that have contributed significantly to the ethereum ecosystem code base. #notallheroeswearcapes
Disclaimer: All data from open source github repos
Let me know in the comments if you'd like to see more interesting ethereum facts.
| shivkodam |
1,300,222 | C++ Software Design by Klaus Iglberger | The first time I - virtually - met Klaus was at C++ On Sea, I think in 2020. He held a workshop about... | 0 | 2022-12-17T14:55:50 | https://www.sandordargo.com/blog/2022/12/17/cpp-software-design-by-klaus-iglberger | cpp, architecture, designpatterns, books |
The first time I - virtually - met Klaus was at C++ On Sea, I think in 2020. He held a workshop about modern software design which I managed to partially attend. He spoke in a slow and friendly manner which both helped participants to follow along and it also encouraged us to ask questions.
Then I saw some of his talks, one in live - again at a later C++ On Sea - and I always came away with the same feelings. Klaus is a very good teacher who doesn't make you feel bad if you don't know something, even if it's a basic piece of knowledge.
Given all that, I was very happy to see his post some time ago saying that his first book was going to be published soon. Its title is [C++ Software Design](https://www.amazon.com/Software-Design-Principles-Patterns-High-Quality/dp/1098113160?&_encoding=UTF8&tag=sandordargo-20&linkCode=ur2&linkId=e9b6f64671aac55ff52ecfd91e137d6e&camp=1789&creative=9325) and now that I read it, I think it's a great book.
It won't teach you the implementation details of how to write modern C++ code, it has no such promise, but it does teach you how to design a modern C++ system. The book is structured into 10+1 chapters and in each chapter, you'll find a couple of guidelines. The first few chapters are about design patterns in general: what is software design, what are abstractions and what's the purpose of design patterns?
After having these things covered, a few design patterns are covered in detail. Not all of the [Gang of Four Design Patterns](https://en.wikipedia.org/wiki/Design_Patterns) are covered, but what is covered, are covered in such a depth that was not possible in the GoF book. But not only GoF patterns are covered in this book. After all, that's an old book and while it's still completely relevant, a lot of time passed, and there are other ones identified. In any case, this book focuses on C++ which has some other relevant modern patterns.
Each design pattern is explained first, the author shared what problems each solves and what's the classical object-oriented implementation. But when we talk about object-oriented implementations, we often talk about inheritance, runtime polymorphism and the usage of reference/pointer semantics. In modern C++, we try to use value semantics whenever possible so that we can understand the flow of our program better, and can reason about it more easily. Often the performance is even better thanks to the removal of virtual dispatching. So the author examines each presented design pattern, and whether it's possible to implement it in a modern, value-semantic way. If so, what advantages and disadvantages does it have compared to the classical implementation, when you should use one or the other?
The book starts with one of the more complex design patterns: the visitor. It's the one that you should use to extend the operations on existing types. Besides the old implementation, we can also learn about `std::variant` and how to use it with `std::visit`. Before closing the chapter there is one guideline dedicated also to the acyclic visitor.
In the coming chapter, two design patterns are covered that are somewhat similar but they serve different purposes. The strategy pattern's goal is to isolate how things are done, while the command's intent is to isolate what things are done. They are both covered in detail, both classical inheritance-based approaches are presented just as modern value semantics-based solutions. In this chapter, in guideline 22, Klaus also explains why we should prefer value semantics over reference semantics.
In chapter 6, three design patterns are covered, one of the is a sort of curiosity, though it's more and more widespread in modern C++. Besides the adapter and observer patterns, the CRTP is explained. Something I also wrote about some time ago. Probably it would have been worth mentioning how [deducing this](https://www.sandordargo.com/blog/2022/02/16/deducing-this-cpp23) will change the suage of CRTP. Nevertheless, it's very useful to read about how to use the static inheritance provided by the CRTP pattern in order to create compile-time mixin classes
Chapter 7 introduces the bridge, prototype and external polymorphism patterns. If you know the recent works of Klaus, at this point you can suspect even without looking at the table of contents where this all lead. I mean using the strategy pattern, emphasizing the importance of value semantics and then introducing the prototype and external polymorphism patterns all culminating towards the next chapter, which finally combines many of the presented techniques under the name of *type erasure*.
So chapter 8 is all about type erasure, which is implemented first as a combination of the strategy, the prototype and the external polymorphism design templates. If you're looking for a deep introduction and you don't have the book yet, I recommend this recording of the author's talk at [CppCon 2021](https://www.youtube.com/watch?v=4eeESJQk-mw). The analysis goes quite deep, it shows many alternatives that are in the standard library, or other design patterns to achieve similar results and it also details the performance issues and benefits you might run into. Speaking about the performance, the readers also learn about some possible performance optimizations of the type erasure design pattern, such as small buffer optimization or manual virtual dispatch. While I think that Klaus is a big fan of this design pattern, he didn't forget to mention its costs and limits.
Before concluding the book, there are two more patterns explained, the decorator one and the singleton. What? The Singleton? - you might ask. Yes, and it's worth noting that the author classified singleton not as a design pattern, but as an implementation pattern. Also, he focused on presenting how to design singletons for change and testability. As such, singletons can be useful. I almost wrote useful abstractions, but as Klaus explained, a singleton is not an abstraction and as soon we recognize that and we handle it simply as an implementation pattern, we'll have fewer bad feelings about this pattern.
## Conclusion
[C++ Software Design by Klaus Iglberger](https://www.amazon.com/Software-Design-Principles-Patterns-High-Quality/dp/1098113160?&_encoding=UTF8&tag=sandordargo-20&linkCode=ur2&linkId=e9b6f64671aac55ff52ecfd91e137d6e&camp=1789&creative=9325) is a great book that, in my opinion, every non-beginner C++ developer should read. My personal opinion is the chapters coming after the one on type erasure do not perfectly fit into the chain of thoughts, the story he wants to tell, but as he shares essential knowledge there too, I couldn't say those should be skipped. I'm glad I learned more about those. And I encourage you to do the same and learn deeper about these design patterns and probably it would be a good exercise to think about more patterns and try to implement them in a modern way just as an exercise inspired by this book. A highly recommended read, I hope not the last one by Klaus! | sandordargo |
1,247,469 | Device-Based Ads And App Binary | Device-Based Ads And App Binary Suggest Native App Binary based on their IP and also Tailor/Target... | 0 | 2022-11-08T03:52:40 | https://dev.to/legaciespanda/device-based-ads-and-app-binary-j23 | webdev, javascript, news, tutorial | Device-Based Ads And App Binary
Suggest Native App Binary based on their IP and also Tailor/Target Ads for user OS or Browser.
Let's look at a more clearer example of this, for instance you want to download Visual Studio Tools from Microsoft website https://visualstudio.microsoft.com/downloads/, the website will automatically detect your operating system and will suggest the type of build to download. If you are using a windows machine, you will be asked to download the windows build for Visual Studio Tools.
Sometimes they are some website you may want to download a software from. they will automatically detect your operating system and trigger a download build for your operating system.
With IpForensics, you can detect users operating system or device and implement your logic.
See code documentation here
https://ipforensics.gitbook.io/ipforensics/code-implantation/device-based-ads-and-app-binnary[](https://ipforensics.gitbook.io/ipforensics/code-implantation/device-based-ads-and-app-binnary)
Follow us on LinkedIn
https://www.linkedin.com/company/ipforensics/
Visit our website for more
https://ipforensics.net | legaciespanda |
1,247,484 | 7 Websites That Will Help You Spend Your Time Wisely! | The internet is a great treasure for someone who knows how to use it. Instead of killing off time on... | 0 | 2022-11-08T04:49:42 | https://dev.to/madhukaranand/7-websites-that-will-help-you-spend-your-time-wisely-ein | The internet is a great treasure for someone who knows how to use it. Instead of killing off time on platforms like Twitter and Instagram, you can use the hundreds of websites out there. Almost every day, an interactive website is created by people for the needs of other people.
#1 - Earth Nullschool
Earth Nullschool is a website that provides an interactive map with detailed information about all the winds worldwide. The information and details on the website are updated every three hours based on NASA's supercomputer.
#2 - The Collected Papers of Albert Einstein
After Einstein died, tens of thousands of documents were left behind. The Princeton University Press has made all of Einstein's legacy available. The Collected Papers of Einstein project has collected around 30,000 documents from Einstein.
#3 - Brilliant
Brilliant.org is a tool developed by two Silicon Valley engineers who've gone bonkers over fundamental fields such as math and science. Instead of explanatory videos, they have a method where self-motivated individuals can learn by reading up on the topics.
#4 - River Runner
A raindrop that fell on Arizona's Tonto National Forest travels 724 km and arrives in Golfo, located in California. Sam Learner created the River Runner website that interactively shows us where a raindrop goes after it falls on the earth.
#5 - The Fry Universe
Chris Williams created a website that discusses the 3D models of various french fries and the designs and physics behind them. Obtaining interesting information about one's likes also increases the taste behind it.
#6 - Why Time Flies?
As a person nearing age 40, I have no idea how time has passed in my past. Why Time Flies is a fantastic website showing how time flies as we age.
#7 - Neal.Fun
Fun may be the best website in the world. It's a website type that makes you laugh and think simultaneously. There are a lot of things worth discovering with your child. | madhukaranand | |
1,247,835 | Multi-node local kubernetes cluster with loadbalancer and private registry | Multi-node local kubernetes cluster with loadbalancer | 0 | 2022-11-08T11:50:22 | https://dev.to/freakynit/multi-node-local-kubernetes-cluster-with-loadbalancer-and-private-registry-44mm | kubernetes, k8s, docker | ---
title: Multi-node local kubernetes cluster with loadbalancer and private registry
published: true
description: Multi-node local kubernetes cluster with loadbalancer
tags: kubernetes, k8s, docker
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2022-11-08 11:40 +0000
---
I’ll keep this one short and to the point. Mostly copy-paste commands.
1. We’ll use sample go-lang helloworld application from this link: https://github.com/freakynit/go-k8s. Don’t worry if you don’t know go-lang. This tutorial has nothing to do with the programming language.
2. For k8s cluster, we’ll use [k3d](https://k3d.io/), an excellent tool to setup local kubernetes cluster.
3. Loadbalancer component will allow us to expose our k8s services externally.
4. Private registry(docker registry) will allow us to speed-up our code-build-push-pull iterations as we’ll not need to push new image every time we make changes to docker hub or any other public registry
#### Let’s begin
1. Clone the repo: https://github.com/freakynit/go-k8s
2. cd into it: `cd go-k8s`
3. Install k3d by following their official guide
4. Edit your docker config file (`~/.docker/daemon.json`) and add following (enables insecure registries, our private one basically):```json
"insecure-registries": [
"registry.localhost:5000"
],
"registry-mirrors": [
"https://registry-1.docker.io"
]
```
5. Start local registry server in docker container:```shell
k3d registry create registry.localhost --port 5000
```
6. Create multi-node kubernetes cluster with name: `mycluster` and `2 worker nodes`. Notice that we are also specifying `loadbalancer` and our local registry config file path(k3d-registries.yaml):```
k3d cluster create --api-port 0.0.0.0:6550 -p "8081:80@loadbalancer" --registry-use k3d-registry.localhost:5000 --registry-config k3d-registries.yaml --agents 2 mycluster
```
7. Build docker image for application:```shell
docker build -t freakynit/go-k8s:1.0.0 .
```
8. Tag this image with local registry host:```shell
docker tag freakynit/go-k8s:1.0.0 k3d-registry.localhost:5000/go-k8s:1.0.0
```
9. Add following entries to `/etc/hosts` so that you can access your k8s services on `loadbalancer` host and local registry:```shell
127.0.0.1 loadbalancer
127.0.0.1 k3d-registry.localhost
::1 k3d-registry.localhost
```
10. Push your app image to local registry:```shell
docker push k3d-registry.localhost:5000/go-k8s:1.0.0
```
11. Apply kubernetes config file:```shell
kubectl apply -f k8s-deployment.yaml
```
12. Check if pods are running.. keep trying every few seconds until all pods show status as running:```shell
kubectl get pod
```
13. Access your application:```shell
curl localhost:8081/
# OR
curl loadbalancer:8081/
```
> Once done, you can delete the cluster using:```shell
k3d cluster delete mycluster
```
---
k3d has a lot more options that allow much configuration and customization. Do explore these.
That’s all folks. Let me know if you face any issues in this.
| freakynit |
1,247,895 | Doubt in Debugging | Doubt isn’t fun. We want to have confidence in our direction and doubt is most powerful just when we... | 0 | 2022-11-08T15:23:43 | https://debugagent.com/doubt-in-debugging | programming, beginners, mentalhealth, career | Doubt isn’t fun. We want to have confidence in our direction and doubt is most powerful just when we need the courage to move. When we don’t have the right amount of experience. But in a different light doubt is caution. An important guardrail against our inherent risk taking.

[See on twitter](https://twitter.com/debugagent/status/1582732171198205955)
Doubt is probably the worst when we’re debugging. At 2am when we’re staring at the screen, completely out of ideas… Should I even do this? Am I qualified? Do other programmers spend this much time looking at problems like this? I should have solved it by now!
Well. Yes. If you don’t go through those feelings, then you probably didn’t build anything interesting and aren’t dedicated enough to chase an issue to its conclusion. Yes, going to sleep is the best way to deal with some issues, but sometimes it isn’t enough. Sometimes it isn’t an option and sometimes I won’t fall asleep until the issue is resolved. Doubt doesn’t die when we kill the bug, you live to fight another day.
## Why Debugging?
I don’t want to talk about impostor syndrome, I’m not a psychologist and have nothing interesting to say on the subject. I think it’s interesting that the point in which we feel it the most is a long and ugly debugging session. After all, there are many areas where it should creep during the day but when speaking to developers it’s universal when we debug.
There are many reasons for that but I think one of the core reasons is that we are impostors to debugging. We pretend to know how to debug but there’s no taught technique. We didn’t learn debugging in bootcamp or university. Maybe the “step-over” button and inspecting a variable. That’s about it. Look at the logs and bang your head against the wall.
Even as we try to fix the problems, we look at that process as taking out the trash. We hold our nose and run to the door. Trying not to breathe in the stench. There’s no technique. No learning. No joy. Just a terrible path we need to take. No wonder we feel doubt, we don’t want to be here. We don’t have the tooling to figure this out and we’re probably not really qualified for this.
Learning debugging techniques and embracing that process won’t make doubt go away. That’s a fixture. But it will make it manageable and will reduce the time when it rears its ugly head. Solving issues quickly and effectively provides a level of confidence that only public speaking can rival.
I wrote about debugging a lot in the previous blog, e.g. with [this series](https://talktotheduck.dev/series/140). I’m redoing a lot of that work with the hope of reducing this particular pain and making debugging more accessible for all. Also, there’s a [book coming out](https://www.amazon.com/dp/1484290410/), which you can preorder now…
I’m also working on a new course on the same subject to further clarify some things that are harder to explain in writing. It will follow a similar path to the book. I hope that in a small way it will help one of the big pain points I had as a young programmer.
I have a [talk covering debugging techniques](https://www.meetup.com/londonjavacommunity/events/289073610/) in a couple of weeks. The last time I gave it the [reviews were pretty amazing](https://twitter.com/debugagent/status/1573250587151458305).
## A Solution to Twitter
On a different subject, with everyone going to mastodon (including [me](https://mastodon.social/@debugagent)) I’ve been thinking about improving the situation a bit. The first problem with moving to something like that is the lack of content. Many content creators don’t post directly to twitter. When inspiration strikes we write to a buffering tool. This gets tweeted/posted at times that make more sense in the social network. Some tools are even smart enough to retweet recent posts so people don’t miss them.
Right now the top tools are commercial and have lots of issues. None support mastodon. I’d like to create a free/open source tool like that. Ideally something that’s more “hacker friendly” and works with git. For this purpose I tried to work with the twitter API which is nothing short of a disaster. It’s got several levels and versions. If you don’t have the higher access level, then you can’t use version 1.1 APIs. For version 1.1 we have twitter4j which is simple and excellent. But we can’t use it without the elevated status of the developer account. It seems everyone responsible for elevating developer accounts was fired. I’m also concerned they’ll cut some permissions like that in the fight against bots.
The problem is that APIs don’t work well with version 2. Even twitter itself hasn’t ported media upload to version 2 so they expect you to use version one for images and version two for everything else. The documentation is plentiful and unhelpful for anything beyond the most basic use cases. Pretty frustrating. If you have experience with server side social networks and know what to do with [this issue](https://github.com/redouane59/twittered/issues/421), then drop me a line.
## Leaving Lightrun
On a more personal note. I left Lightrun. I joined the company as the first non-founder and wrote the initial implementations of the server, plugin and CLI. It’s been a lot of fun but hasn’t been as much fun in the past few months. Right now I’m muling my options. I signed up to write another book which I just started on. I’m also creating new online courses and working on a few OSS projects.
I also have an idea for something cool in the Java space. I’m exploring that and might build it out.
I will speak at the [ADDO conference](https://www.alldaydevops.com/addo-speakers/shai-almog-0), but if you listen to only one of my talks, please join me for my [LJC talk](https://www.meetup.com/londonjavacommunity/events/289073610/). It’s one of my better talks as I [mentioned above](https://twitter.com/debugagent/status/1573250587151458305).
| codenameone |
1,249,130 | SeverLess programming with React + Supabase - 1 | This example provides the steps to build a basic user management app. It includes: Supabase... | 0 | 2022-11-09T08:10:01 | https://dev.to/mhcrocky/severless-programming-with-react-supabase-1-5m8 | supabase, react, serverless | This example provides the steps to build a basic user management app. It includes:
- Supabase Database: a Postgres database for storing your user data.
- Supabase Auth: users can sign in with magic links (no passwords, only email).
- Supabase Storage: users can upload a photo.
- Row Level Security: data is protected so that individuals can only access their own data.
- Instant APIs: APIs will be automatically generated when you create your database tables.
By the end of this guide you'll have an app which allows users to login and update some basic profile details:
## Project set up
Before we start building we're going to set up our Database and API. This is as simple as starting a new Project in Supabase and then creating a "schema" inside the database.
### Create a project
1. Go to app.supabase.com.
2. Click on "New Project".
3. Enter your project details.
4. Wait for the new database to launch.
### Set up the database schema#
Now we are going to set up the database schema. We can use the "User Management Starter" quickstart in the SQL Editor, or you can just copy/paste the SQL from below and run it yourself.
1. Go to the SQL Editor page in the Dashboard.
2. Click User Management Starter.
3. Click Run.
`SQL`
```
-- Create a table for public profiles
create table profiles (
id uuid references auth.users not null primary key,
updated_at timestamp with time zone,
username text unique,
full_name text,
avatar_url text,
website text,
constraint username_length check (char_length(username) >= 3)
);
-- Set up Row Level Security (RLS)
-- See https://supabase.com/docs/guides/auth/row-level-security for more details.
alter table profiles
enable row level security;
create policy "Public profiles are viewable by everyone." on profiles
for select using (true);
create policy "Users can insert their own profile." on profiles
for insert with check (auth.uid() = id);
create policy "Users can update own profile." on profiles
for update using (auth.uid() = id);
-- This trigger automatically creates a profile entry when a new user signs up via Supabase Auth.
-- See https://supabase.com/docs/guides/auth/managing-user-data#using-triggers for more details.
create function public.handle_new_user()
returns trigger as $$
begin
insert into public.profiles (id, full_name, avatar_url)
values (new.id, new.raw_user_meta_data->>'full_name', new.raw_user_meta_data->>'avatar_url');
return new;
end;
$$ language plpgsql security definer;
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
-- Set up Storage!
insert into storage.buckets (id, name)
values ('avatars', 'avatars');
-- Set up access controls for storage.
-- See https://supabase.com/docs/guides/storage#policy-examples for more details.
create policy "Avatar images are publicly accessible." on storage.objects
for select using (bucket_id = 'avatars');
create policy "Anyone can upload an avatar." on storage.objects
for insert with check (bucket_id = 'avatars');
create policy "Anyone can update their own avatar." on storage.objects
for update using (auth.uid() = owner) with check (bucket_id = 'avatars');
```
### Get the API Keys
Now that you've created some database tables, you are ready to insert data using the auto-generated API. We just need to get the URL and anon key from the API settings.
1. Go to the Settings page in the Dashboard.
2. Click API in the sidebar.
3. Find your API URL, anon, and service_role keys on this page.
## Building the App#
Let's start building the React app from scratch.
### Initialize a React app#
We can use Create React App to initialize an app called supabase-react:
```
npx create-react-app supabase-react
cd supabase-react
```
Then let's install the only additional dependency: supabase-js.
```
npm install @supabase/supabase-js
```
And finally we want to save the environment variables in a .env. All we need are the API URL and the anon key that you copied earlier.
`.env
`
```
REACT_APP_SUPABASE_URL=YOUR_SUPABASE_URL
REACT_APP_SUPABASE_ANON_KEY=YOUR_SUPABASE_ANON_KEY
```
Now that we have the API credentials in place, let's create a helper file to initialize the Supabase client. These variables will be exposed on the browser, and that's completely fine since we have Row Level Security enabled on our Database.
`src/supabaseClient.js
`
```
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = process.env.REACT_APP_SUPABASE_URL
const supabaseAnonKey = process.env.REACT_APP_SUPABASE_ANON_KEY
export const supabase = createClient(supabaseUrl, supabaseAnonKey)
```
And one optional step is to update the CSS file src/index.css to make the app look nice. You can find the full contents of this file here.
### Set up a Login component#
Let's set up a React component to manage logins and sign ups. We'll use Magic Links, so users can sign in with their email without using passwords.
`src/Auth.js
`
```
import { useState } from 'react'
import { supabase } from './supabaseClient'
export default function Auth() {
const [loading, setLoading] = useState(false)
const [email, setEmail] = useState('')
const handleLogin = async (e) => {
e.preventDefault()
try {
setLoading(true)
const { error } = await supabase.auth.signInWithOtp({ email })
if (error) throw error
alert('Check your email for the login link!')
} catch (error) {
alert(error.error_description || error.message)
} finally {
setLoading(false)
}
}
return (
<div className="row flex-center flex">
<div className="col-6 form-widget" aria-live="polite">
<h1 className="header">Supabase + React</h1>
<p className="description">Sign in via magic link with your email below</p>
{loading ? (
'Sending magic link...'
) : (
<form onSubmit={handleLogin}>
<label htmlFor="email">Email</label>
<input
id="email"
className="inputField"
type="email"
placeholder="Your email"
value={email}
onChange={(e) => setEmail(e.target.value)}
/>
<button className="button block" aria-live="polite">
Send magic link
</button>
</form>
)}
</div>
</div>
)
}
```
### Account page#
After a user is signed in we can allow them to edit their profile details and manage their account.
Let's create a new component for that called Account.js.
`src/Account.js
`
```
import { useState, useEffect } from 'react'
import { supabase } from './supabaseClient'
const Account = ({ session }) => {
const [loading, setLoading] = useState(true)
const [username, setUsername] = useState(null)
const [website, setWebsite] = useState(null)
const [avatar_url, setAvatarUrl] = useState(null)
useEffect(() => {
getProfile()
}, [session])
const getProfile = async () => {
try {
setLoading(true)
const { user } = session
let { data, error, status } = await supabase
.from('profiles')
.select(`username, website, avatar_url`)
.eq('id', user.id)
.single()
if (error && status !== 406) {
throw error
}
if (data) {
setUsername(data.username)
setWebsite(data.website)
setAvatarUrl(data.avatar_url)
}
} catch (error) {
alert(error.message)
} finally {
setLoading(false)
}
}
const updateProfile = async (e) => {
e.preventDefault()
try {
setLoading(true)
const { user } = session
const updates = {
id: user.id,
username,
website,
avatar_url,
updated_at: new Date(),
}
let { error } = await supabase.from('profiles').upsert(updates)
if (error) {
throw error
}
} catch (error) {
alert(error.message)
} finally {
setLoading(false)
}
}
return (
<div aria-live="polite">
{loading ? (
'Saving ...'
) : (
<form onSubmit={updateProfile} className="form-widget">
<div>Email: {session.user.email}</div>
<div>
<label htmlFor="username">Name</label>
<input
id="username"
type="text"
value={username || ''}
onChange={(e) => setUsername(e.target.value)}
/>
</div>
<div>
<label htmlFor="website">Website</label>
<input
id="website"
type="url"
value={website || ''}
onChange={(e) => setWebsite(e.target.value)}
/>
</div>
<div>
<button className="button primary block" disabled={loading}>
Update profile
</button>
</div>
</form>
)}
<button type="button" className="button block" onClick={() => supabase.auth.signOut()}>
Sign Out
</button>
</div>
)
}
export default Account
```
### Launch!#
Now that we have all the components in place, let's update App.js:
`src/App.js
`
```
import './index.css'
import { useState, useEffect } from 'react'
import { supabase } from './supabaseClient'
import Auth from './Auth'
import Account from './Account'
export default function App() {
const [session, setSession] = useState(null)
useEffect(() => {
supabase.auth.getSession().then(({ data: { session } }) => {
setSession(session)
})
supabase.auth.onAuthStateChange((_event, session) => {
setSession(session)
})
}, [])
return (
<div className="container" style={{ padding: '50px 0 100px 0' }}>
{!session ? <Auth /> : <Account key={session.user.id} session={session} />}
</div>
)
}
```
Once that's done, run this in a terminal window:
```
npm start
```
And then open the browser to localhost:3000 and you should see the completed app.
## Bonus: Profile photos#
Every Supabase project is configured with Storage for managing large files like photos and videos.
### Create an upload widget#
Let's create an avatar for the user so that they can upload a profile photo. We can start by creating a new component:
`src/Avatar.js
`
```
import { useEffect, useState } from 'react'
import { supabase } from './supabaseClient'
export default function Avatar({ url, size, onUpload }) {
const [avatarUrl, setAvatarUrl] = useState(null)
const [uploading, setUploading] = useState(false)
useEffect(() => {
if (url) downloadImage(url)
}, [url])
const downloadImage = async (path) => {
try {
const { data, error } = await supabase.storage.from('avatars').download(path)
if (error) {
throw error
}
const url = URL.createObjectURL(data)
setAvatarUrl(url)
} catch (error) {
console.log('Error downloading image: ', error.message)
}
}
const uploadAvatar = async (event) => {
try {
setUploading(true)
if (!event.target.files || event.target.files.length === 0) {
throw new Error('You must select an image to upload.')
}
const file = event.target.files[0]
const fileExt = file.name.split('.').pop()
const fileName = `${Math.random()}.${fileExt}`
const filePath = `${fileName}`
let { error: uploadError } = await supabase.storage.from('avatars').upload(filePath, file)
if (uploadError) {
throw uploadError
}
onUpload(filePath)
} catch (error) {
alert(error.message)
} finally {
setUploading(false)
}
}
return (
<div style={{ width: size }} aria-live="polite">
<img
src={avatarUrl ? avatarUrl : `https://place-hold.it/${size}x${size}`}
alt={avatarUrl ? 'Avatar' : 'No image'}
className="avatar image"
style={{ height: size, width: size }}
/>
{uploading ? (
'Uploading...'
) : (
<>
<label className="button primary block" htmlFor="single">
Upload an avatar
</label>
<div className="visually-hidden">
<input
type="file"
id="single"
accept="image/*"
onChange={uploadAvatar}
disabled={uploading}
/>
</div>
</>
)}
</div>
)
}
```
### Add the new widget#
And then we can add the widget to the Account page:
`src/Account.js
`
```
// Import the new component
import Avatar from './Avatar'
// ...
return (
<div className="form-widget">
{/* Add to the body */}
<Avatar
url={avatar_url}
size={150}
onUpload={(url) => {
setAvatarUrl(url)
updateProfile({ username, website, avatar_url: url })
}}
/>
{/* ... */}
</div>
)
```
| mhcrocky |
1,300,645 | Terraform: Create VPC, Subnets, and EC2 instances in multiple availability zones | In this article, I will demonstrate how to create VPC, Subnets, EC2 instances, Internet gateway, NAT... | 0 | 2022-12-17T11:03:05 | https://palak-bhawsar.hashnode.dev/terraform-create-vpc-subnets-and-ec2-instances-in-multiple-availability-zones | ---
title: Terraform: Create VPC, Subnets, and EC2 instances in multiple availability zones
published: true
date: 2022-12-17 10:37:03 UTC
tags:
canonical_url: https://palak-bhawsar.hashnode.dev/terraform-create-vpc-subnets-and-ec2-instances-in-multiple-availability-zones
---
In this article, I will demonstrate how to create VPC, Subnets, EC2 instances, Internet gateway, NAT gateway, and Security groups using Terraform in two availability zones.
**Architecture**
**Prerequisite**
- AWS account and AWS Access key and Secret key created
- Terraform installed on your IDE
- AWS CLI installed and configured on your IDE
- Basic understanding of AWS services and Terraform
**Objective**
1. Choose a region in which you want your VPC to reside and availability zones where you want to create public and private subnets for high availability.
2. Decide the CIDR blocks range for your VPC and Subnets.
3. Create public and private subnets in each availability zone.
4. Create an internet gateway to allow communication between your VPC and the internet.
5. Create an EC2 instance in each public subnet in both the availability zones and create AWS key pair to SSH into your instances.
6. Create a route table for the public and private subnets and associate the route table with subnets to control where network traffic is directed.
7. Create a NAT gateway to enable private subnets to connect to services outside your VPC. A NAT gateway must be in a public subnet.
8. Finally, create a VPC security group and open port 80 to allow HTTP traffic from anywhere and open port 22 to SSH into the instances.
**Code Repository**
Use [GitHub](https://github.com/palakbhawsar98/Terraform/tree/main/terraform-vpc-hands-on) to find providers.tf, variables.tf, and outputs.tf files.
Let's get started with the configuration of the project
# Create VPC
We are creating VPC in the us-east-1 region and attaching it to the internet gateway.
```
resource "aws_vpc" "vpc" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "my-vpc"
}
}
resource "aws_internet_gateway" "internet_gateway" {
vpc_id = aws_vpc.vpc.id
tags = {
Name = "inernetGW"
}
}
```
# Create public and private subnets
Creating one public and one private subnet in both us-east-1a and us-east-1b zones.
```
resource "aws_subnet" "vpc_public_subnet" {
vpc_id = aws_vpc.vpc.id
count = length(var.subnets_count)
availability_zone = element(var.availability_zone, count.index)
cidr_block = "10.0.${count.index}.0/24"
map_public_ip_on_launch = true
tags = {
Name = "pub-sub-${element(var.availability_zone, count.index)}"
}
}
resource "aws_subnet" "vpc_private_subnet" {
count = length(var.subnets_count)
availability_zone = element(var.availability_zone, count.index)
cidr_block = "10.0.${count.index + 2}.0/24"
vpc_id = aws_vpc.vpc.id
tags = {
Name = "pri-sub-${element(var.availability_zone, count.index)}"
}
}
```
# Create a route table and associate it with the public subnet
A route table contains a set of rules that are used to determine where network traffic is directed. Associate a public subnet with the default route (0.0.0.0/0) pointing to an internet gateway.
```
resource "aws_route_table" "public_route_table" {
vpc_id = aws_vpc.vpc.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.internet_gateway.id
}
tags = {
Name = "public-route-tbl"
}
}
resource "aws_route_table_association" "public_route_table_association" {
count = length(var.subnets_count)
subnet_id = element(aws_subnet.vpc_public_subnet.*.id, count.index)
route_table_id = aws_route_table.public_route_table.id
}
```
# Create a NAT gateway and associate it with Elastic IP
Create a public NAT gateway in a public subnet and associate it with an elastic IP address to route traffic from the NAT gateway to the Internet gateway for the VPC.
```
resource "aws_eip" "elasticIP" {
count = length(var.subnets_count)
vpc = true
}
resource "aws_nat_gateway" "nat_gateway" {
count = length(var.subnets_count)
allocation_id = element(aws_eip.elasticIP.*.id, count.index)
subnet_id = element(aws_subnet.vpc_public_subnet.*.id, count.index)
tags = {
Name = "nat-GTW-${count.index}"
}
}
```
# Create a route table and associate it with the private subnet
```
resource "aws_route_table" "private_route_table" {
count = length(var.subnets_count)
vpc_id = aws_vpc.vpc.id
route {
cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.nat_gateway[count.index].id
}
tags = {
Name = "private-route-tbl"
}
}
resource "aws_route_table_association" "private_route_table_association" {
count = length(var.subnets_count)
subnet_id = element(aws_subnet.vpc_private_subnet.*.id, count.index)
route_table_id = element(aws_route_table.private_route_table.*.id,
count.index)
}
```
# Create security group
For the inbound connections open port 80 to allow HTTP traffic from anywhere and open port 22 to SSH into the instance and open all the ports for the outbound connections.
```
resource "aws_security_group" "vpc_sg" {
name = "vpc_sg"
description = "Security group for vpc"
vpc_id = aws_vpc.vpc.id
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = -1
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "vpc-sg"
}
}
```
# Create EC2 instances in public subnets
Create EC2 instance with user-data scripts to install Apache server and access static webpage. Also, create AWS key pair to SSH into instances
```
resource "tls_private_key" "key" {
algorithm = "RSA"
rsa_bits = 4096
}
resource "local_file" "private_rsa_key" {
content = tls_private_key.key.private_key_pem
filename = "private_rsa_key"
}
resource "aws_key_pair" "public_rsa_key" {
key_name = "public_rsa_key"
public_key = tls_private_key.key.public_key_openssh
}
resource "aws_instance" "my_app_server" {
ami = var.instance_ami
instance_type = var.instance_size
key_name = aws_key_pair.public_rsa_key.key_name
count = length(var.subnets_count)
subnet_id = element(aws_subnet.vpc_public_subnet.*.id, count.index)
security_groups = [aws_security_group.vpc_sg.id]
associate_public_ip_address = true
user_data = <<-EOF
#!/bin/bash
sudo apt update -y
sudo apt install apache2 -y
sudo systemctl start apache2
sudo systemctl enable apache2
sudo apt install git -y
git clone https://github.com/palakbhawsar98/FirstWebsite.git
cd /FirstWebsite
sudo cp index.html /var/www/html/
EOF
tags = {
Name = "my_app_server-${count.index}"
}
}
```
We are ready to deploy all our changes to AWS. Perform the below commands:
- **terraform init** to initialize the working directory and download all the plugins for providers.
- **terraform fmt** to rewrite Terraform configuration files to a canonical format and style.
- **terraform validate** to check that our code is error-free.
- **terraform plan** to create the execution plan for the resources we are going to create in AWS.
- **terraform apply** to execute the actions proposed in a terraform plan and to deploy your infrastructure.
You can see the resources created in AWS Console. Take the public IPV4 and search it in the browser on port 80 that we opened for HTTP connections.


You can access the HTML static webpage using public IPV4

If you want you can destroy the infrastructure we just create using **terraform destroy** command. | palakbhawsar98 | |
1,249,413 | Building Applications Faster with ILLA and TiDB | ILLA, the low code open source platform for developers, is proud to announce a collaboration with... | 0 | 2022-11-09T11:17:40 | https://www.illacloud.com/blog/building-applications-faster | programming, webdev, lowcode, startup | [ILLA](https://www.illacloud.com/), the low code open source platform for developers, is proud to announce a collaboration with PingCAP’s [TiDB](https://www.pingcap.com/tidb/), an open-source distributed NewSQL database that features horizontal scalability, high availability, real-time Hybrid Transactional and Analytical Processing (HTAP), and MySQL compatibility. This partnership aims to simplify application development by providing a database that meets data consistency, reliability, availability, scalability, and disaster tolerance requirements.
Today, organizations have to store, process, and manage more and more data; single-machine databases are hitting their physical limits. Traditional sharding mechanisms are unwieldy and hard to maintain as the business grows. TiDB solves these problems transparently through its distributed architecture while maintaining MySQL compatibility. TiDB Cloud, the fully managed TiDB service, can also simplify deployment, management, and maintenance through a web-based management interface in the cloud.
This tutorial will show you how to set up a TiDB cluster and build an administration panel that allows you to create, read, update, and delete entries. We’ll display the data in a table and use a panel to tab between creating and editing forms. We’ll do all this in less than 10 minutes.
## Create a free cluster on TiDB Cloud
To create a cluster on TiDB Cloud:
1. [Sign in](https://tidbcloud.com/) with your TiDB Cloud account. If you are a new user, [sign up](https://tidbcloud.com/free-trial/) for an account.
2. Create a free cluster and connect to it. Click [Quick Start TiDB](https://docs.pingcap.com/tidb/dev/dev-guide-build-cluster-in-cloud) to learn how to use it. After running the sample application, you will get the TiDB connection information, including the server name, port number, database name, user name, and password. Be sure to note these; you’ll be using them in later steps.
## Connect to TiDB with ILLA Builder
Now that you have a free TiDB Cluster, it’s time to connect it to the [ILLA Builder](GitHub - illa-family/illa-builder: An open-source low-code Platform for Developers.).
1. Create a free account and sign in on the ILLA Builder welcome page.
2. Create a new application.
3. Connect to TiDB as an ILLA resource. Do one of the following:
<ul>
<li>If you already have a PingCAP resource in ILLA Builder, you can click + <strong>New</strong> to select it.</li>
<li>If you don’t have a TiDB resource in the ILLA builder, you need to click + <strong>New Resource</strong> to set up a new connection.</li>
</ul>
Test the new connection. If the connection is successful, save the connection as a new resource.
4. Use actions to execute basic create, read, update, and delete (CRUD) operations in the TiDB database. Actions bridge data and ILLA components and are essential to building an application.
a. Choose a TiDB resource and create actions.
b. In the input box, enter the SQL statement, save it as a new action
c. Click **Run** to execute the statement.
d. Run a query action to see if the insert action runs successfully.
You can create multiple actions and use different components to control their execution
## Connect the component to the action
Components in ILLA Builder are built-in front-end UI libraries such as buttons and input boxes. To connect a component to an action:
1. Under the component inspect panel on the right, select and drag the “text” and “input” components to the canvas in the middle.
<center style={{whiteSpace: 'break-spaces'}}>
<figcaption>Select & Drag</figcaption>
</center>
2. Create and save the required actions. You can refer to the component or action data by typing `“{{”`
Here we will create two actions, tidb_query_data and tidb_insert_data, for later use.
<center style={{whiteSpace: 'break-spaces'}}><figcaption>Query data from the person table</figcaption>
</center>
<center style={{whiteSpace: 'break-spaces'}}><figcaption>Insert data into the person table</figcaption>
</center>
You have successfully connected the component to the action.
## Implement a simple web application with TiDB Cloud
Now that we have everything ready let’s build a simple web application with the basic components to add, delete, modify, or query the data from a TiDB table.
## Create and configure an Insert button
1. Click on the **Insert** button component you just added to enter the **Inspect** panel on the right.
2. Under the **Inspect** panel, add an event handler, and configure the event handler as:
- Event: **Click**
- Action: **Trigger query**
- Query: **tidb_insert_data**
<center style={{whiteSpace: 'break-spaces'}}><figcaption>Insert Button Setup</figcaption>
</center>
## Query data from a table
1. Click on the **Query new data** button you just created. This displays the **Inspect** panel on the right side of the screen.
2. In the **Inspect** panel, add an event handler, and configure it as follows:
- Event: **Click**
- Action: **Trigger query**
- Query: **tidb_query_data**
<center style={{whiteSpace: 'break-spaces'}}><figcaption>Query Date Setup</figcaption>
</center>
Now you can execute the query action against the specified table in TiDB.
## Visualize the query as a chart
1. In the Inspect panel on the right side, specify the dataset of the chart component to `{{tidb_query_data.data}}`.
2. Adjust the chart component settings, such as the chart type, location, and size.
3. Adjust the dataset settings, such as dataset values and aggregation method. The chart will update as you go.
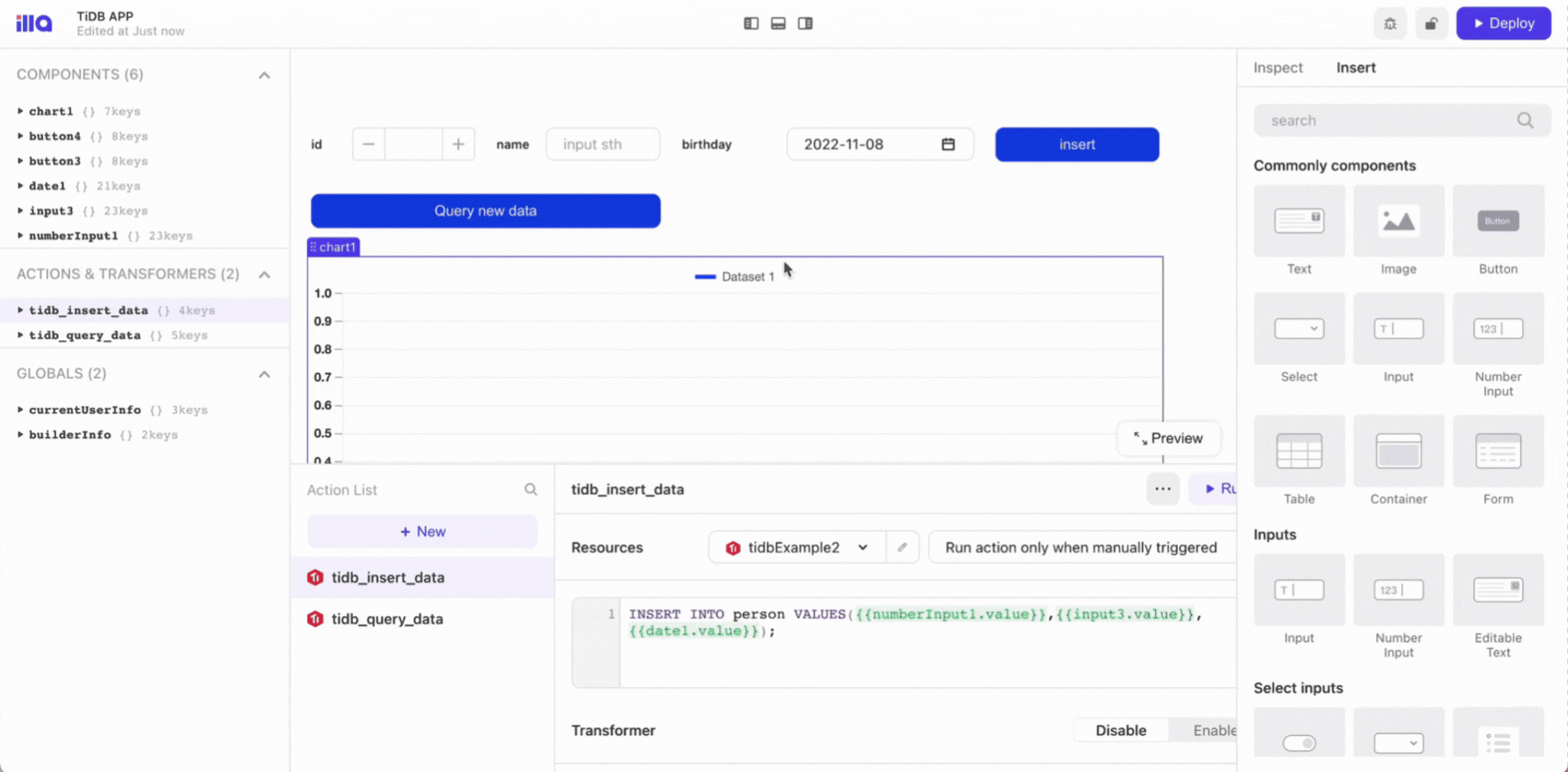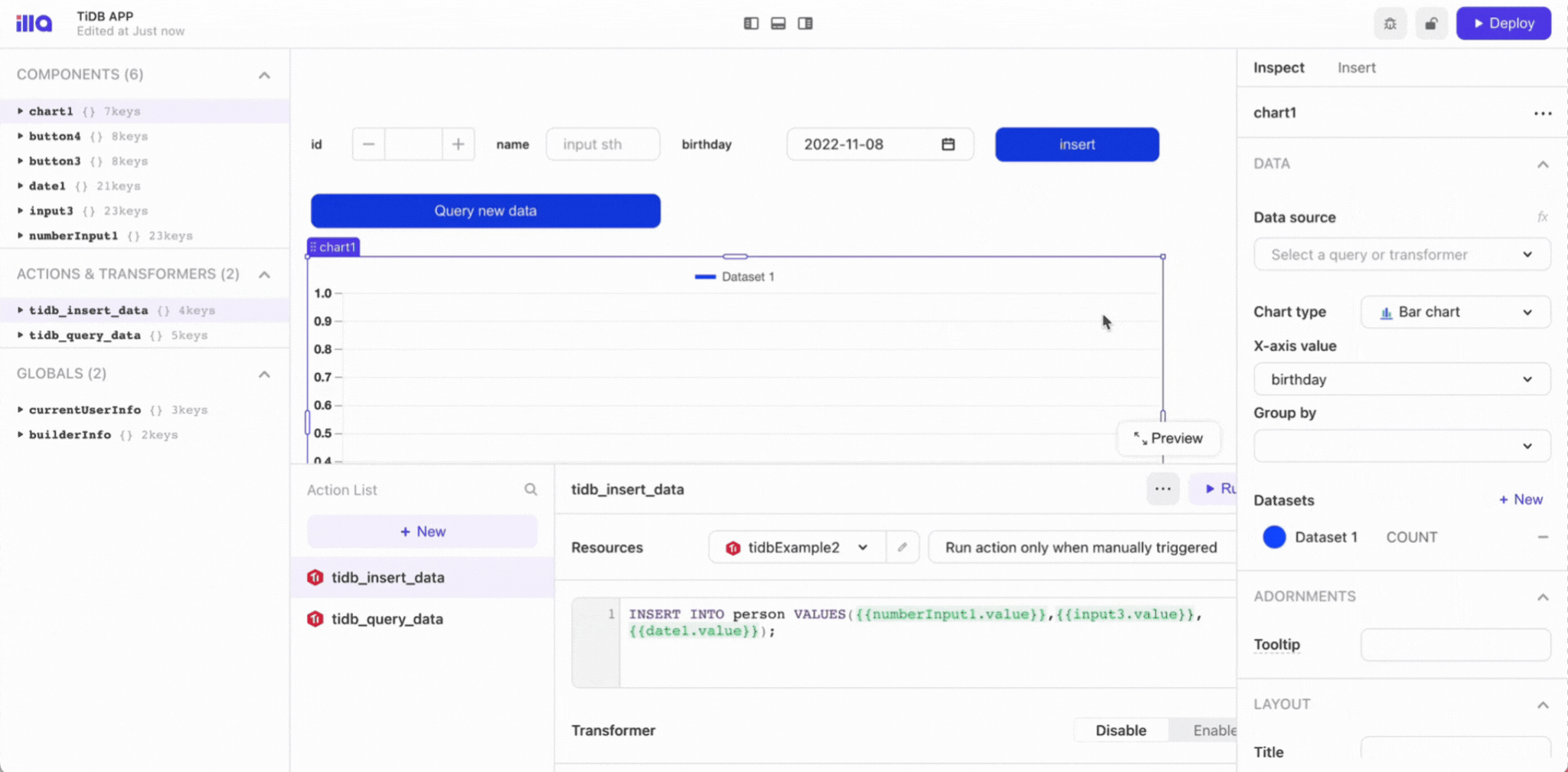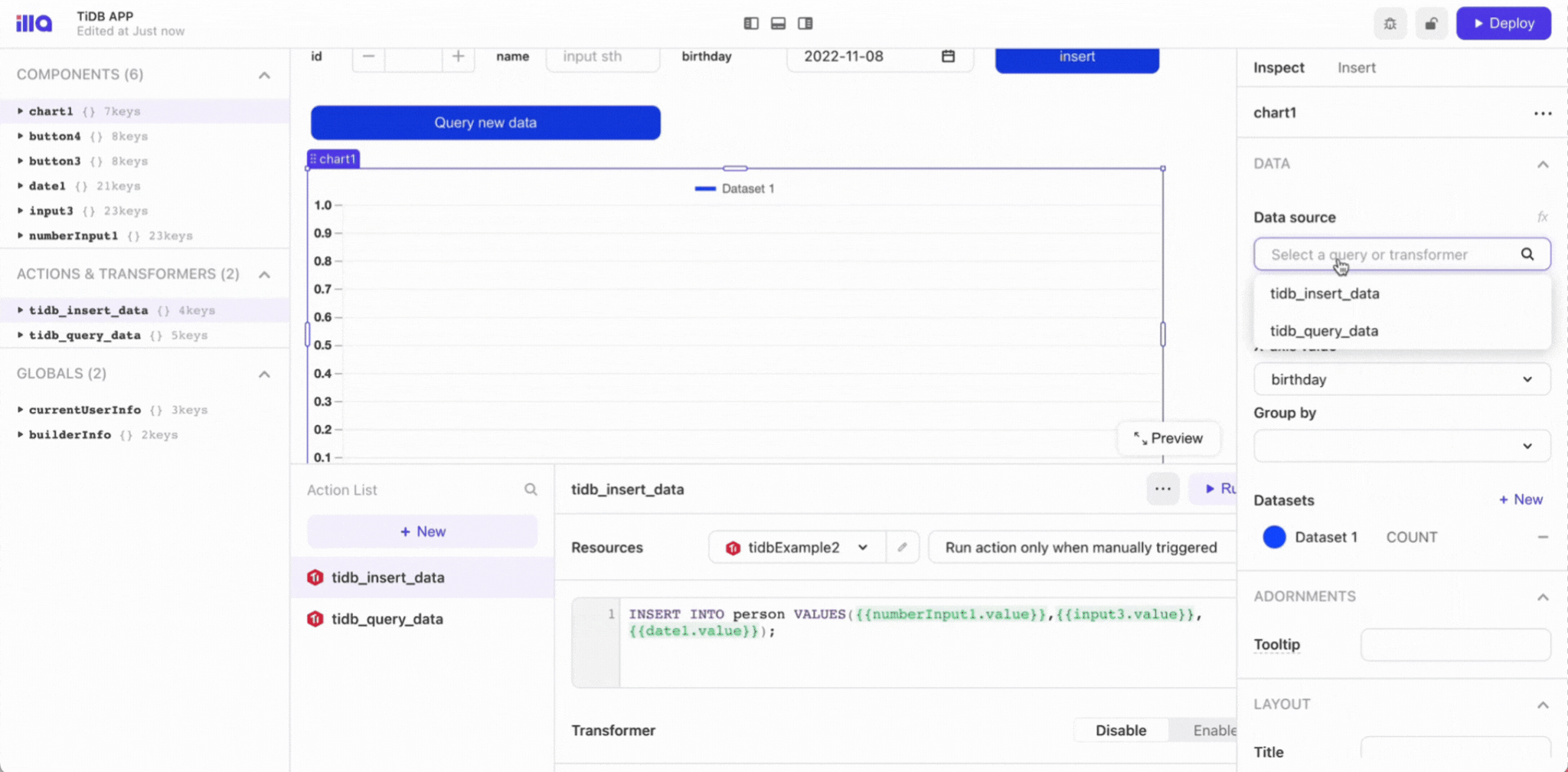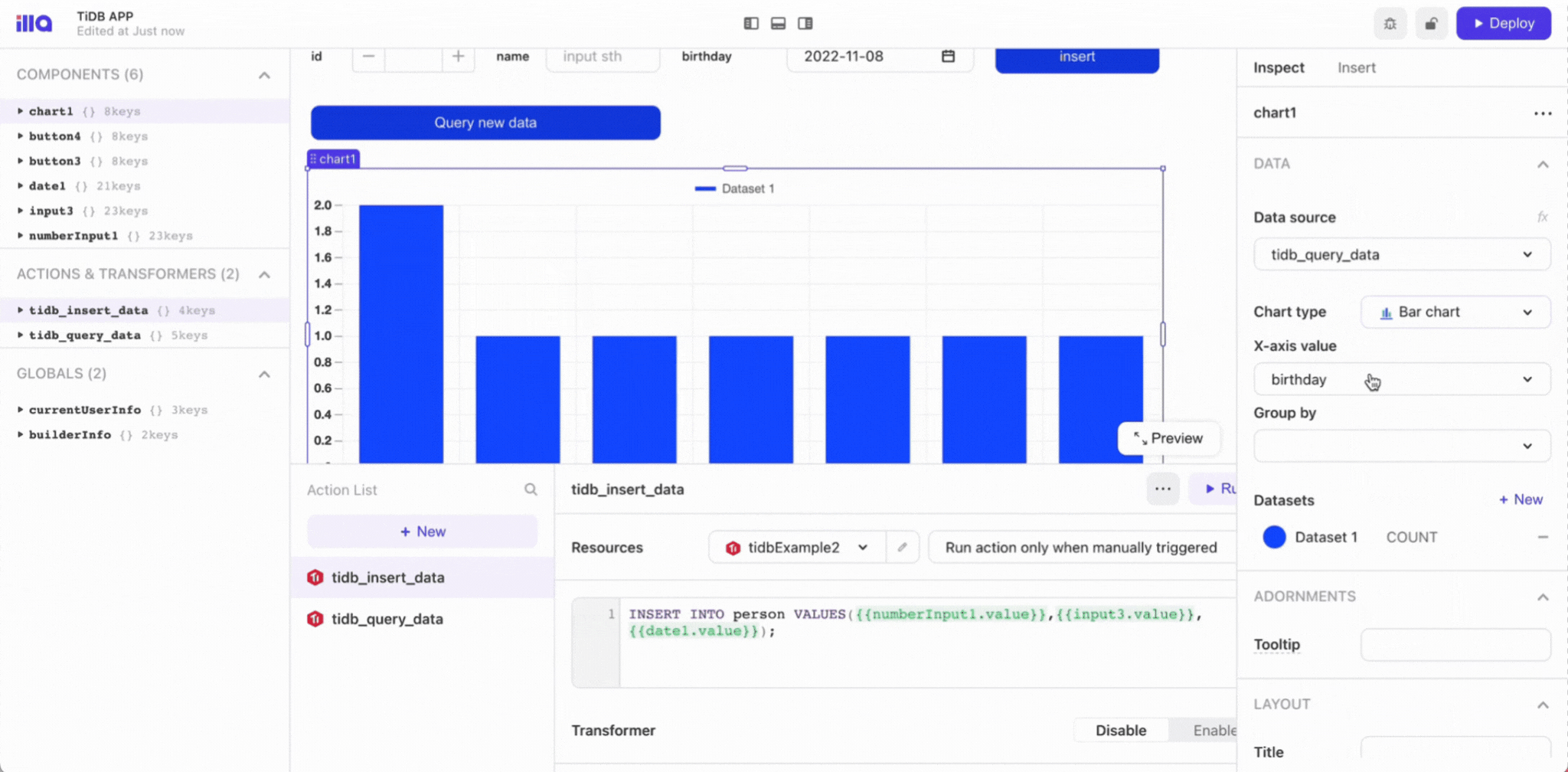<center style={{whiteSpace: 'break-spaces'}}><figcaption>Data Visualization</figcaption>
</center>
## Summary
In this article, we implemented a simple TiDB application that inserts new data, executes queries, and displays the query results as a chart. Integrating TiDB Cloud and ILLA builder can make developing your applications much faster and more efficient.
We believe the key to a successful open-source project is not only to code but also to collaborate through code. You are welcome to join our project. Check [ILLA’s website](https://www.illacloud.com) or join the [Discord community](https://discord.com/invite/illafamily) for more information.
> #### You can check ILLA’s website here at https://illacloud.com
> #### GitHub page: https://github.com/illa-family
> #### Join Discord community: https://discord.com/invite/illafamily
| jerrymaomao |
1,249,450 | Functions in JavaScript | Function is a piece of code created to preform a certain task. The function structure is built once,... | 0 | 2022-11-09T13:01:45 | https://dev.to/kima_badalyan/functions-in-javascript-2gnd | javascript, function, decleration, argument | Function is a piece of code created to preform a certain task. The function structure is built once, then it works every time we "call" it, and produces different results different with arguments.
There are some functions already created in local libraries of JavaScript, such as Math.sqrt(), console.log(), alert(), toString(), etc.
Yet we can **create functions** for the particular project.
Functions have certain design which we need to use to **declare** them. It has the following stracture:
function name(argument) {
statements
}
We write function, give it a unique **name**, **argumennt(s)** (if necessary) in the brackets, then, inside the curly brackets, we write the **code that defines the function**, which should work every time we call the function.
In the code there may be used the given **arguments**, which are new variables created within the function. Inside the function, the arguments behave as **local variables** and the change is not reflected globally. The function may also not require arguments and work without them. In this case the brackets are left empty.
After the necessary code that should be working when we call the function is written inside the function and we want to give back some value out of the function, we should **return** that value. For that, at the end of the function, we write return and add the **value** that should be returned.
function sayHi(name) {
return "Hello " + name;
}
A function can return only one value. If additional returns are added, JavaScript will just ignore them.
When the function is ready, we can **call** it every time we need it by writing the function name and adding the brackets, necesserally with the arguments:
function sayHi(name) {
return "Hello " + name;
}
let firstHi = myFunction(Kima);
console.log(firstHi);
As a result in a console we'll have printed _Hello Kima_.
Functions can be used in all types of formulas, assignments, and calculations.
let x = German(library);
let text = "This word is " + x + " in German";
or we can use the function directly in the variable:
let text = "This word is " + German(library) + " in German";
| kima_badalyan |
1,249,776 | The Fundamentals of Android Development. | Learning objectives Provide an overview of the difference between mobile apps and mobile... | 0 | 2022-11-10T20:39:41 | https://dev.to/dbriane208/the-fundamentals-of-android-development-1ffi | beginners, android, mobile, kotlin | **<u>Learning objectives</u>**
1. Provide an overview of the difference between mobile apps and mobile websites.
2. Explain how the mobile Operating system works.
3. The Android Operating system.
4. Introduction to Android development.
**<u>Mobile Platforms</u>**
A mobile app is an installable software that runs on a smartphone device. Mobile apps use the device's hardware, and software features and usually provide an efficient, more intuitive, and seamless user experience.
_What is the difference between a mobile app and a mobile website?_
A mobile app is software that runs on a hardware device whereas a mobile website works on a mobile app and does not involve any hardware to be functional.
_What are the advantages of mobile apps and a mobile website?_
<u>Mobile app</u>
1. Faster than mobile websites
2. Can access resources eg location, Bluetooth, etc.
3. Can work without internet access
<u>Mobile website</u>
1. Cheap to build and maintain
2. Need not to be built from scratch to be compatible with other platforms
3. No approval is required from Appstore
**Note:**_To determine whether to develop a mobile website or mobile app always ask yourself what specific actions you expect your product to perform._
## How does a Mobile OS work
The most fundamental software for any mobile device is its OS. An OS is designed to coordinate communications that occur between the hardware and apps of mobile devices. It manages the overall experiences of an app.
**Mobile operating system**
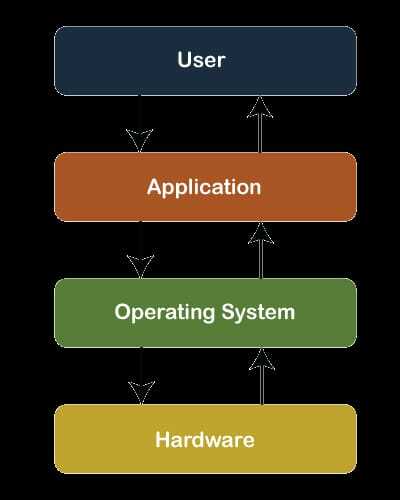
A mobile OS typically starts up when a device powers on, displaying different application icons and user interface (UI) elements to users.
<u>_Uses of Operating system_</u>
1. Allows smartphones, tablets, and personal digital assistants (PDAs) to run applications.
2. OS provides a channel with which applications can access device resources such as the processor, memory, Wi-Fi, Bluetooth, and more.
The most common operating systems are _Android_ and _iOS_.
**<u>Android</u>**

- Android is a mobile OS that was released in 2008.
- Android OS is based on a modified version of the Linux kernel and is an open-source software which means anyone can modify it.
- Android OS was built primarily for smartphones, Chromebook, Android TV, and Android Auto, as well as wearables such as smartwatches.
- Android has built-in sensors such as gyroscopes and accelerometers, which gives users a multi-touch experience.
**<u>iOS</u>**

- iOS is Apple’s proprietary OS that runs on the iPhone, iPad, and other mobile devices
- Same as Android, iOS has built-in sensors such as gyroscopes and accelerometers, which gives users a multi-touch experience through several actions such as swiping, pulling, and tapping, and users can seamlessly interact with the screen.
- With the rise in popularity of iOS, developers now have more controls and access to its features.
Other mobile operating systems include _**kaiOS**_ which runs on Mozilla Firefox, _**SailfishOS**_ from Jolla, and _**Huawei's HarmonyOS**_ which was released in 2019 and runs on a microkernel that Huawei developed. Mostly used in IoT devices.
## Android Platforms
- Being the most used operating system in the world, Android is not limited to only mobile devices. Android is also used to power other devices due to its openness to others.
- Android platforms include, Chromebook, Android TV, Android Auto, and WearOS.
**Chromebook**

- Chromebooks are portable laptops that have support for running Android apps, which gives them more features.
- Chromebooks operate on Google's ChromeOS.
- Ability to use convertible form factors to not necessarily build apps from scratch for phones and tablets from ChromeOS.
**Android TV**

- Android TV is designed to bring the mobile experience to your TV.
- The voice control feature of the TV allows you to have complete control over your devices.
**Android Auto**

- It allows you to connect your phone to your car display.
- It automatically shows your apps on your car display and makes it possible for you to get driving directions and navigate seamlessly.
- Android Auto is made to help you stay focused on the road.
**WearOS**
- WearOS is Google's Android OS that is specifically designed to power smartwatches and other wearables.
- The early release of WearOS allowed watching owners to install WearOS apps through their mobile phones from the google play store.
## Introduction to Android Development
**Android Languages**
- In the world of Android development, **Java** and **Kotlin** are both extremely popular programming languages.
- Java, which was released by Sun Microsystems in 1995 while Kotlin was introduced by JetBrains in 2011.

-Kotlin has officially become the preferred language for Android app development due to the following reasons;
1. It is concise and standardized hence low code errors.
2. Easier to maintain complex projects due to low code.
3. It is compatible with java hence easy to convert java
code to Kotlin.
4. Kotlin handles errors that crash Android apps better
than java.
**The Android OS**
- Android is a Linux-based OS primarily designed for touchscreen mobile devices such as smartphones and tablets.
- Some of the unique features and characteristics of the Android OS include:
1. _**Near-field communication**_: This feature makes it easy for electronic devices to communicate over short distances.
2. _**Wi-Fi**_: With this feature, users can connect to various wireless access points around them due to these in-built technologies that support Wi-Fi protocols.
3. _**Custom home screen**_: Android OS allows you to further personalize your home screen the way you like it.
4. _**Widgets**_: Used for home-screen customization to give you a glance view of users' most important data.
5. _**App downloads**_: users can unlock the full potential of the Android operating system through app downloads.
6. _**Custom ROMS**_: Android can use customized and modified versions of Android OS to access features of a recent on an older device.
**The Android OS Architecture**
- Consists of components that Android needs to be functional.
- Android is built on top of an open-source Linux kernel and other C and C++ libraries exposed via application framework services.
- The Android OS is a stack of software components roughly divided into five sections:
1. Applications
2. Application frameworks
3. Android runtime
4. Platform Libraries
5. Linux Kernel
- These are separated into 4 layers, as shown in the architecture diagram below.
## Android App Cheatsheet
- To get started with developing an app, you need a clear understanding of relevant concepts.
- These concepts include:
**Top-level component**
- Enables apps to connect to the internet, make calls, and take pictures through BroadcastReceiver, ContentProvider, and Service and activity accessible in Android SDK.
**Activity Components**
- These are activities present for content users to interact with on the screen.
- Single activity architecture pattern allows one activity or a relatively small number of activities to be used for an entire app.
**Android views**
- This is the design interface that occupies a rectangular area on the screen and is responsible for drawing and event handling. It displays text, images, and more.
**Android layout files**
- In Android, each layout is represented by an XML file. These plain text files serve as blueprints for the interface that your application presents to the user.
**Project files**
- Android Project Files belong to one of three main categories: **configuration**,**code**, and **resource**. _Configuration files_ define the project structure, _code files_ provide the logic, and _resource files_ provide essentially everything else.
## Anatomy of An Android App
- This basically looks into the components that go in when creating an App.
- An Android app is made up of four major components that serve as the building blocks of any Android app in the market.
- The four major components include:
1. **Activities**: This is the entry point of users that represent a single user. It allows you to place UI components, widgets, or user interfaces on a single screen. eg _a music player app may have an activity that shows you a list of your favorite songs, another activity that allows you to play a specific song, and another which shows you a list of trending songs._
2. **Services**: They run in the background and constantly update the data sources and activities with the latest changes. It also performs tasks when users are not active on applications. eg _A good example of a service is chatting with someone whilst listening to music._
3. **Broadcast Receiver**: Its purpose is to respond to messages from other applications or systems in real time. eg,_imagine you're enjoying your favorite song on your music app when you get a notification that you're running low on battery power._
4. **Content providers**: It's responsible for sharing data between applications. eg _A typical example is a social media app that allows users to share their images online._
These Android components are coupled by a configuration file called **AndroidManifest.xml**. It is used to specify each component and how they interact with each other.

## Extensible Markup Language(XML)
- XML (Extensible Markup Language) is used in the presentation of different kinds of data. Its main function is to create data formats that are used to encode information for documentation, records, transactions, and several other data formats.

- For an XML document to be valid, the following conditions must be fulfilled:
1. The document must be well-formed.
2. The document must comply with all the rules of the XML syntax.
**THE END.**
**Thank you for taking the time to go through the article!!**

| dbriane208 |
1,249,836 | Full text search in postgres | https://twitter.com/ghousek1ofcl/status/1581141049933643777?s=20&t=eWq5-IcRzfMzFOM3JSXJVw | 0 | 2022-11-09T17:36:52 | https://dev.to/ghousek1/full-text-search-in-postgres-56f3 | https://twitter.com/ghousek1ofcl/status/1581141049933643777?s=20&t=eWq5-IcRzfMzFOM3JSXJVw
 | ghousek1 | |
1,250,190 | What is React ? | Today, front-end frameworks and libraries are becoming an essential part of the modern web... | 0 | 2022-11-09T19:49:49 | https://dev.to/sualehfarooq/what-is-react--kl | react, reactnative, javascript, webdev |
Today, front-end frameworks and libraries are becoming an essential part of the modern web development stack. React.js is a front-end library that has gradually become the go-to framework for modern web development within the JavaScript community.
The React.js framework is an open-source JavaScript framework and library developed by Facebook. It’s used for building interactive user interfaces and web applications quickly and efficiently with significantly less code than you would with vanilla JavaScript.
React allows developers to use individual parts of their application on both the client and server sides, and any changes they make will not affect the application’s logic. This makes the development process extremely fast. The use of HTML tags and JS codes makes it easy to work with a huge dataset containing DOM.
React acts as an intermediary that represents the DOM and helps you decide which component requires changes to get accurate results.React is incredibly user-friendly and makes any UI interactive. It also allows you to quickly and efficiently build applications, which is time-saving for clients and developers alike. One-way data-binding in react implies that absolutely anyone can trace all the changes that have been made to a segment of the data. This is also one of the reasons that makes React so easy. | sualehfarooq |
1,250,613 | Join us to build the future of E-Commerce through automation | Join us this November to build a future where e-commerce meets Media Automation. Over the past... | 0 | 2022-11-10T02:10:10 | https://dev.to/shotstack/join-us-to-build-the-future-of-e-commerce-through-automation-3d93 | webdev, hacktoberfest, programming, beginners | Join us this November to build a future where e-commerce meets Media Automation. Over the past decade, we’ve witnessed a rapid digital transformation in online commerce. Content like user generated content, testimonials, product images, data-driven creatives, etc in the form of digital media has been a crucial part of marketing for sellers. The demand for product content is only going to grow as more users adopt online shopping.
But what are we doing to solve this demand? Do the brands have the right tools? How can we use the latest technologies like AI and [automation](https://shotstack.io/learn/what-is-video-automation/) to efficiently solve this problem? That is exactly what this hackathon aims to solve - **to develop creative applications that can efficiently generate marketing content for e-commerce sellers through automation**.
With Shotstack's cloud based [video editing API] (https://shotstack.io/product/video-editing-api/), developers can build media applications faster than ever.
## Hackathon details
- **When?**🤔: 11-17th November 2022
- **Where?**🌐: Virtual (You can be literally anywhere)
- **Prize**🏆: Gift worth USD $200 for the winning project
## What's in it for you?
🤝 Networking with other innovative developers interested to build apps for e-commerce
😍 Opportunity to receive free Shotstack API rendering credits valued up to $2,000
✅ An opportunity to reshape the future of e-commerce through automation
## What can you build for this hackathon?
You can build anything that uses the Shotstack API to generate media and helps the e-commerce sellers. Some project ideas could be:
- An automated product video generator plugin for an e-commerce platform like Shopify, Amazon, Wix, WooCommerce, Ebay, BigCommerce, Magento, Etsy, etc.
- Web apps that automatically generate product content tailored for e-commerce.
- E-commerce tailored video and graphic design marketplace.
- A personalized video bot for e-commerce platforms that automatically generates personalized videos when customers buy.
- Data-driven automated media generator for re-marketing based on customer behavior.
- Testimonial banner generator that automatically generates content from product reviews for social media marketing
and much more. To see it in action, try our [automated product promo video generator](https://shotstack.io/use-cases/scenarios/api/generate-promo-videos/) from code.
## How to participate?
- Submit this [hackathon entry form](https://forms.gle/Fik7gpk2Qi81mrqe7)
- Sign up for a free [Shotstack developer account](https://dashboard.shotstack.io/register?utm_source=devto&utm_campaign=hackathon) to get your API key
- Use Shotstack API to build your submission
- [Submit your project](https://forms.gle/dwAozLyXFT2B7dz96) before 17 November 2022, 11:59 p.m.(PT)
Learn more details about the hackathon on our [website](https://shotstack.io/learn/shotstack-hackathon/?utm_campaign=hackathon).
Join the Shotstack hackathon [community forum](https://community.shotstack.io/t/media-automation-for-e-commerce-hackathon/376?utm_campaign=hackathon) to join the discussion or ask any other questions.
We can't wait to see what you build!🚀
| kushal_70 |
1,250,931 | Is the Developer Economy around the corner? | The #CreatorEconomy with ~50 million creators after only 10 years is estimated at over $100 billion... | 0 | 2022-11-10T08:58:45 | https://dev.to/paydevs/is-the-developer-economy-around-the-corner-2j8a | developereconomy, creatoreconomy, devtech, devtools | The #CreatorEconomy with ~50 million creators after only 10 years is estimated at over [$100 billion in 2022](https://www.forbes.com/sites/theyec/2022/07/18/make-the-most-of-the-creator-economy/?sh=1cf199e316e9).
Today, we have approx. 27 million Software Developers worldwide growing with 1 million YoY. Not including Low-Code / No-Code developers, Data Scientists, and DevOps Engineers. Github even claims there are [91 million Open-Source developers](https://twitter.com/github/status/1590403278793101312).
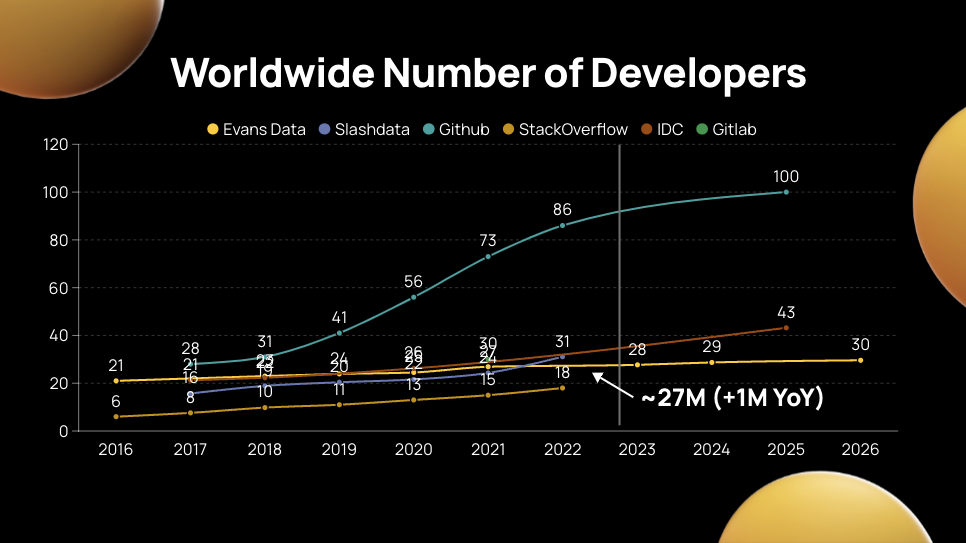
When will a #DeveloperEconomy emerge for #DevTech, #DevTools, and #OpenSource with software creators as well as dev influencers - similar to the #CreatorEconomy?
What do you think?
| joergrech |
1,251,208 | Android app development with React Native | This post covers the main notes needed, from bootstrapping the app to publishing to the Play... | 0 | 2022-11-10T12:52:27 | https://sevic.dev/react-native-android-app/ | reactnative, android | ---
title: Android app development with React Native
published: true
tags: ['reactnative', 'android']
canonical_url: https://sevic.dev/react-native-android-app/
---
This post covers the main notes needed, from bootstrapping the app to publishing to the Play store.
### Prerequisites
- experience with React
- installed Android studio
### Bootstrapping the app
Run the following commands
```bash
npx react-native init <app_name>
cd <app_name>
```
### Running the app on the device via USB
Enable developer options, USB debugging, and USB file transfer on the device. Run the following commands
```bash
npx react-native start
npx react-native run-android
```
Install the app via the following command
```bash
npx react-native run-android --variant=release
```
### App name
It can be changed in `android/app/src/main/res/values/strings.xml` file
### Logo
[Icon Kitchen](https://icon.kitchen) can be used for generating images. Downloaded images should be stored in mipmap (`android/app/src/main/res/mipmap-*hdpi/ic_launcher.png`) folders.
### Splash screen
A splash screen is the first thing user sees after opening the app, and it usually shows an app logo with optional animations. More details are covered in [Splash screen with React Native post](https://sevic.dev/notes/splash-screen-react-native)
### Bottom navigation bar
`react-native-paper` provides a bottom navigation bar component, and route keys are mapped with the components. `react-native-vector-icons` is needed for the proper vector rendering, and a list of available icons can be found [here](https://callstack.github.io/react-native-paper/icons.html)
```bash
npm i react-native-paper react-native-vector-icons
```
```js
// App.js
import React, { useState } from 'react';
import { StyleSheet } from 'react-native';
import { BottomNavigation, Text } from 'react-native-paper';
const HomeRoute = () => <Text style={style.text}>Home</Text>;
const SettingsRoute = () => <Text style={style.text}>Settings</Text>;
const style = StyleSheet.create({
text: {
textAlign: 'center'
}
});
const App = () => {
const [index, setIndex] = useState(0);
const [routes] = useState([
{
key: 'home',
title: 'Home',
icon: 'home'
},
{
key: 'settings',
title: 'Settings',
icon: 'settings-helper'
}
]);
const renderScene = BottomNavigation.SceneMap({
home: HomeRoute,
settings: SettingsRoute
});
return (
<BottomNavigation
navigationState={{ index, routes }}
onIndexChange={setIndex}
renderScene={renderScene}
/>
);
};
export default App;
```
file: `android/app/build.gradle`
```gradle
apply plugin: "com.android.application"
import com.android.build.OutputFile
import org.apache.tools.ant.taskdefs.condition.Os
apply from: "../../node_modules/react-native-vector-icons/fonts.gradle" // <-- ADD THIS
// ...
```
### Forms
[formik](https://github.com/jaredpalmer/formik) and [yup](https://github.com/jquense/yup) libraries can handle custom forms and complex form validations (including the case when one field validation depends on other fields' value). Values inside nested components can be set with `setFieldValue` function.
```js
const FormSchema = Yup.object().shape({
rentOrSale: Yup.string().required(customErrorMessage),
furnished: Yup.array()
.of(Yup.string())
.when('rentOrSale', (rentOrSale, schema) => {
if (rentOrSale === 'rent') {
return schema.min(1, customErrorMessage);
}
return schema;
})
});
export const CustomForm = () => {
const handleCustomSubmit = async (values) => {
// ...
};
return (
<Formik
initialValues={
{
// ...
}
}
validationSchema={FormSchema}
onSubmit={handleCustomSubmit}
>
{({ errors, touched, handleSubmit, setFieldValue }) => (
<View>
{/* */}
{touched.furnished && errors.furnished && (
<Text style={style.errorMessage}>{errors.furnished}</Text>
)}
<Button style={style.submitButton} onPress={handleSubmit}>
Submit
</Button>
</View>
)}
</Formik>
);
};
```
### Lists
`FlatList` component can handle list data. It shouldn't be nested inside the `ScrollView` component. Its header and footer should be defined in ListHeaderComponent and ListFooterComponent props.
```js
// ...
return (
<FlatList
// ...
renderItem={({ item }) => <ApartmentCard apartment={item} />}
ListHeaderComponent={/* */}
ListFooterComponent={/* */}
/>
);
// ...
```
Its child component should be wrapped as a higher-order component with `memo` to optimize rendering.
```js
import React, { memo } from 'react';
const ApartmentCard = ({ apartment }) => {
/* */
};
export default memo(ApartmentCard);
```
#### Loading data
`FlatList` can show a refresh indicator (loader) when data is loading. `progressViewOffset` prop sets the vertical position of the loader.
```js
import { Dimensions, FlatList, RefreshControl } from 'react-native';
// ...
<FlatList
// ...
refreshControl={
<RefreshControl
colors={['#3366CC']}
progressViewOffset={Dimensions.get('window').height / 2}
onRefresh={() => {
console.log('loading data...');
}}
refreshing={isLoading}
/>
}
/>;
```
#### Scrolling
`FlatList` also provides a scrolling (to its items) feature when its size changes. Specify its reference and fallback function for scrolling (`onScrollToIndexFailed`).
```js
import React, { useRef } from 'react';
// ...
const listRef = useRef();
// ...
return (
<FlatList
// ...
ref={listRef}
onContentSizeChange={() => {
// some custom logic
listRef?.current?.scrollToIndex({ index, animated: false });
}}
onScrollToIndexFailed={(info) => {
console.error('scrolling failed', info);
}}
/>
);
// ...
```
One of the additional scrolling functions is based on the offset.
```js
import { Dimensions } from 'react-native';
// ...
listRef?.current?.scrollToOffset({
offset: Dimensions.get('window').height + 250
});
```
Scrolling to the top can be done with offset 0.
```js
// ...
listRef?.current?.scrollToOffset({
offset: 0,
animated: false
});
```
### Links
`Linking.openURL(url)` method opens a specific link in an external browser. A webview can open a link inside the app, and it can also override the back button handler.
```js
// ...
import { BackHandler /* */ } from 'react-native';
import { WebView } from 'react-native-webview';
const handleClosingWebview = () => {
// some custom logic
};
useEffect(() => {
const backHandler = BackHandler.addEventListener(
'hardwareBackPress',
function() {
handleClosingWebview();
return true;
}
);
return () => backHandler.remove();
}, []);
// ...
if (isWebviewOpen) {
return (
<SafeAreaView style={style.webview}>
<TouchableOpacity onPress={handleClosingWebview}>
<Icon
style={style.webviewCloseButton}
size={25}
color={theme.colors.primary}
name="close-circle-outline"
/>
</TouchableOpacity>
<WebView
source={{ uri: webviewUrl }}
style={style.webview}
startInLoadingState
renderLoading={() => (
<View style={style.webviewLoader}>
<ActivityIndicator color={theme.colors.primary} />
</View>
)}
/>
</SafeAreaView>
);
}
// ...
```
### SVG files
`react-native-svg` library can be used for handling SVG files.
```js
import React from 'react';
import { SvgXml } from 'react-native-svg';
export function Logo() {
const xml = `<svg>...</svg>`;
return <SvgXml xml={xml} />;
}
```
### State management
React provides Context to deal with state management without external libraries.
#### Context setup with app wrapper
```js
// src/context/index.js
import { createContext, useContext, useMemo, useReducer } from 'react';
import { appReducer, initialState } from './reducer';
const appContext = createContext(initialState);
export function AppWrapper({ children }) {
const [state, dispatch] = useReducer(appReducer, initialState);
const contextValue = useMemo(() => {
return { state, dispatch };
}, [state, dispatch]);
return (
<appContext.Provider value={contextValue}>{children}</appContext.Provider>
);
}
export function useAppContext() {
return useContext(appContext);
}
```
#### Reducer setup
```js
// src/context/reducer.js
import { INCREMENT_COUNTER } from './constants';
export const initialState = {
counter: 0
};
export const appReducer = (state, action) => {
switch (action.type) {
case INCREMENT_COUNTER: {
return {
...state,
counter: state.counter + 1
};
}
default:
return state;
}
};
```
```js
// src/context/constants.js
export const INCREMENT_COUNTER = 'INCREMENT_COUNTER';
```
#### Wrapped app with Context and its usage
```js
// App.js
import React, { useEffect, useState } from 'react';
import { StyleSheet } from 'react-native';
import SplashScreen from 'react-native-splash-screen';
import { BottomNavigation, Button, Text } from 'react-native-paper';
import { AppWrapper, useAppContext } from './src/context';
import { INCREMENT_COUNTER } from './src/context/constants';
const HomeRoute = () => {
const { state } = useAppContext();
return <Text style={style.text}>counter: {state.counter}</Text>;
};
const SettingsRoute = () => {
const { dispatch } = useAppContext();
const onPress = () => {
dispatch({ type: INCREMENT_COUNTER });
};
return <Button onPress={onPress}>Increment counter</Button>;
};
const style = StyleSheet.create({
text: {
textAlign: 'center'
}
});
const App = () => {
const [index, setIndex] = useState(0);
const [routes] = useState([
{
key: 'home',
title: 'Home',
icon: 'home'
},
{
key: 'settings',
title: 'Settings',
icon: 'settings-helper'
}
]);
const renderScene = BottomNavigation.SceneMap({
home: HomeRoute,
settings: SettingsRoute
});
useEffect(() => SplashScreen.hide(), []);
return (
<AppWrapper>
<BottomNavigation
navigationState={{ index, routes }}
onIndexChange={setIndex}
renderScene={renderScene}
/>
</AppWrapper>
);
};
export default App;
```
### Custom events
React Native provides `NativeEventEmitter` for handling custom events so components can communicate with each other in that way.
```js
import { NativeEventEmitter } from 'react-native';
const eventEmitter = new NativeEventEmitter();
eventEmitter.emit('custom-event', { data: 'test' });
eventEmitter.addListener('custom-event', (event) => {
console.log(event); // { data: 'test' }
});
```
### Local storage
[@react-native-async-storage/async-storage](https://github.com/react-native-async-storage/async-storage) can handle storage system in asynchronous way
```js
import AsyncStorage from '@react-native-async-storage/async-storage';
export async function getItem(key) {
try {
const value = await AsyncStorage.getItem(key);
if (value) {
return JSON.parse(value);
}
return value;
} catch (error) {
console.error(`Failed getting the item ${key}`, error);
return null;
}
}
export async function setItem(key, value) {
try {
await AsyncStorage.setItem(key, JSON.stringify(value));
} catch (error) {
console.error(`Failed setting the item ${key}`, error);
}
}
```
### Error tracing
[Sentry](https://sentry.io/) can be used for it
#### Prerequisites
- React Native project created
#### Setup
Run the following commands
```bash
npm i @sentry/react-native
npx @sentry/wizard -i reactNative -p android
```
### Analytics
It is helpful to have more insights about app usage, like custom events, screen views, numbers of installations/uninstallations, etc. React Native Firebase provides analytics as one of the services.
#### Prerequisites
- created Firebase project
#### Setup
Create an Android app within created Firebase project. The package name should be the same as the one specified in the Android manifest (`android/app/src/main/AndroidManifest.xml`). Download `google-service.json` file and place it inside `android/app` folder.
Extend the following files
file: `android/app/build.gradle`
```gradle
apply plugin: "com.android.application"
apply plugin: "com.google.gms.google-services" <-- ADD THIS
```
file: `android/build.gradle`
```gradle
buildscript {
// ...
dependencies {
// ...
classpath("com.google.gms:google-services:4.3.14") <-- ADD THIS
}
}
// ...
```
Run the following commands
```bash
npm i @react-native-firebase/app @react-native-firebase/analytics
```
#### Usage
The following change can log screen views.
```js
// App.js
import analytics from '@react-native-firebase/analytics';
// ...
const App = () => {
// ...
const onIndexChange = (i) => {
if (index === i) {
return;
}
setIndex(i);
analytics()
.logScreenView({
screen_class: routes[i].key,
screen_name: routes[i].key
})
.catch(() => {});
};
// ...
return (
<AppWrapper>
<BottomNavigation
navigationState={{ index, routes }}
onIndexChange={onIndexChange}
renderScene={renderScene}
/>
</AppWrapper>
);
};
// ...
```
The following code can log custom events.
```js
// src/utils/analytics.js
import analytics from '@react-native-firebase/analytics';
export const trackCustomEvent = async (eventName, params) => {
analytics()
.logEvent(eventName, params)
.catch(() => {});
};
```
### Publishing to the Play store
#### Prerequisites
- Verified developer account on Google Play Console
- Paid one-time fee (25$)
#### Internal testing
Internal testing on Google Play Console is used for testing app versions before releasing them to the end users. Read more about it on [Internal testing React Native apps post](https://sevic.dev/notes/internal-testing-react-native-android)
#### Screenshots
[Screenshots.pro](https://screenshots.pro/) can be used for creation of screenshots
### Boilerplate
Here is the [link](https://sevic.dev/react-native-starter?ref=devto) to the boilerplate I use for the development.
| zsevic |
1,292,192 | How to run Azure CLI with Docker | To run the Azure CLI in a Docker container, you can use the following command: Azure... | 0 | 2022-12-11T02:39:33 | https://dev.to/nelsonmendezz_/how-to-run-azure-cli-with-docker-582k | azure, cli, docker, nelsoncode | To run the Azure CLI in a Docker container, you can use the following command:
### Azure CLI
```bash
docker run -it --rm -v ${PWD}:/work -w /work --entrypoint /bin/sh mcr.microsoft.com/azure-cli:latest
```
### Login to Azure
```bash
az login
az account list
```
### Output
```json
[
{
"cloudName": "AzureCloud",
"id": "00000000-0000-0000-0000-000000000000",
"isDefault": true,
"name": "PAYG Subscription",
"state": "Enabled",
"tenantId": "00000000-0000-0000-0000-000000000000",
"user": {
"name": "user@example.com",
"type": "user"
}
}
]
```
### Set suscription
```bash
az account set --subscription="00000000-0000-0000-0000-000000000000"
``` | nelsonmendezz_ |
1,293,432 | B2B Commerce w. Medusa: Set up a Next.js storefront (2/2) | In part 1 of the B2B series, you learned how to set up your Medusa server for a B2B ecommerce use... | 20,902 | 2022-12-12T13:27:41 | https://medusajs.com/blog/medusa-b2b-part-2 | webdev, javascript, opensource, programming | In part 1 of the B2B series, you learned how to set up your [Medusa](https://github.com/medusajs/medusa) server for a B2B ecommerce use case. You set up a B2B Sales Channel, Customer Groups, and Price List. You also added an endpoint that checks whether a customer is a B2B customer or not.
In this part of the series, you’ll customize Medusa’s [Next.js storefront](https://docs.medusajs.com/starters/nextjs-medusa-starter) to add a Wholesaler login screen and a different way of displaying products for B2B customers. You’ll also explore how the checkout flow works for B2B customers.
You can find the full code for this tutorial series in [this GitHub repository](https://github.com/shahednasser/medusa-b2b).
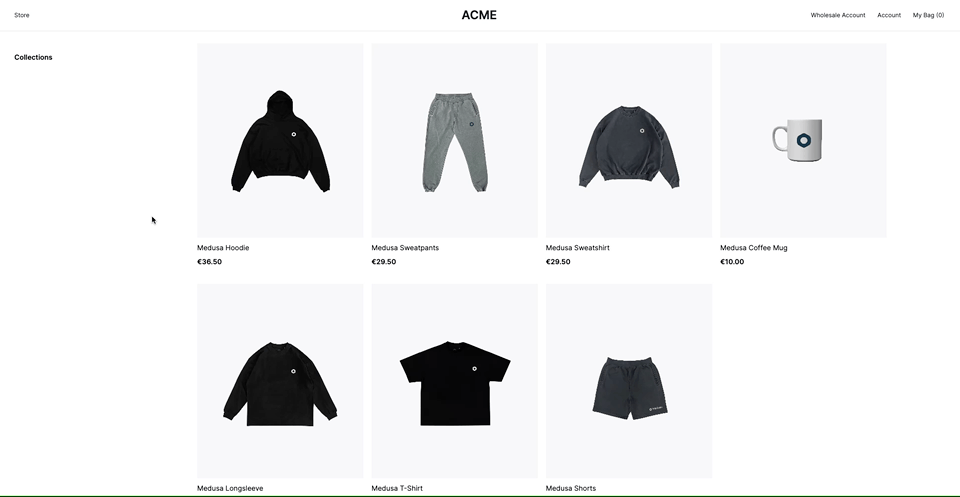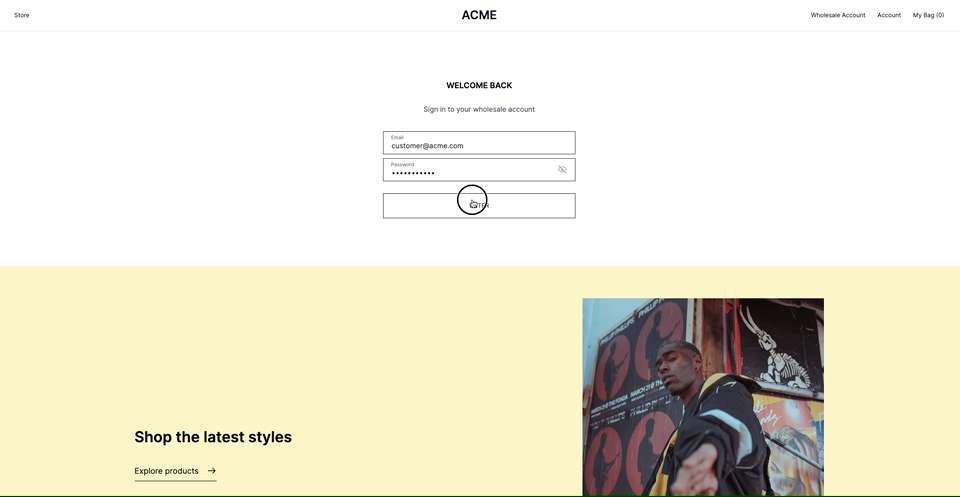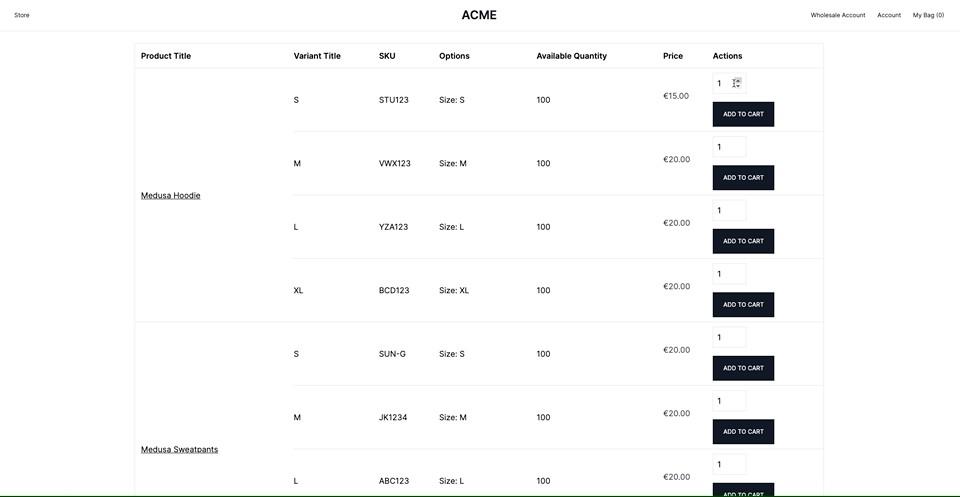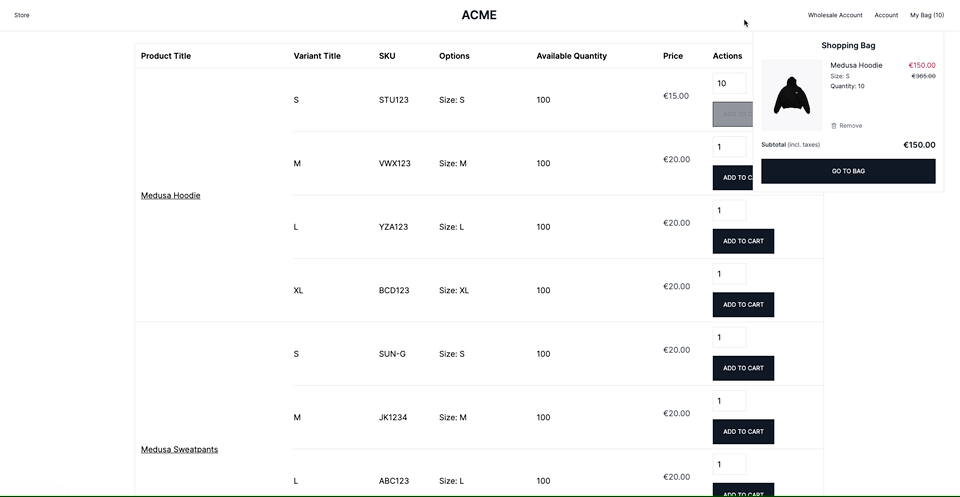
## Install Next.js Storefront
In your terminal, run the following command to install the Next.js Storefront:
```bash
npx create-next-app -e https://github.com/medusajs/nextjs-starter-medusa b2b-storefront
```
This installs the Next.js storefront in a newly created directory `b2b-storefront`.
Then, change to the `b2b-storefront` directory and rename the `.env.template` file:
```bash
cd b2b-storefront
mv .env.template .env.local
```
### Install Dependencies
To ensure you’re using the latest version of Medusa dependencies, run the following command to update Medusa dependencies:
```bash
npm install @medusajs/medusa@latest @medusajs/medusa-js@latest medusa-react@latest
```
In addition, install `axios` to send requests to the custom endpoint you created in the previous tutorial:
```bash
npm install axios
```
### Add Sales Channel Environment Variable
You’ll be using the Sales Channel you created in the first part to retrieve B2B products for B2B customers and to set the correct Sales Channel for B2B customers’ carts.
So, you need to set the ID of the sales channel in an environment variable.
If you’re unsure what the ID of the sales channel is, you can send a request to the [List Sales Channel](https://docs.medusajs.com/api/admin/#tag/Sales-Channel/operation/GetSalesChannels) admin endpoint. You should find a Sales Channel with the name “B2B”. Copy the ID of that Sales Channel.
Then, add the following environment variable in `.env.local`:
```bash
NEXT_PUBLIC_SALES_CHANNEL_ID=<YOUR_SALES_CHANNEL_ID>
```
Where `<YOUR_SALES_CHANNEL_ID>` is the ID of the B2B Sales Channel.
## Create a Wholesale Login Page
In this section, you’ll add a login page specific to B2B customers. This requires adding some new pages and files, but also customizing existing logic.
### Change AccountContext
The Next.js storefront defines an `AccountContext` that allows you to get access to customer-related data and functionalities across your storefront. You need to make changes to it to add a new variable to the context: `is_b2b`. This variable will allow you to check whether the customer is a B2B customer or not throughout the storefront.
In `src/lib/context/account-context.tsx`, add the `is_b2b` attribute to the `AccountContext` interface:
```tsx
interface AccountContext {
//...
is_b2b: boolean
}
```
Then, at the beginning of the `AccountProvider` function, add a new state variable `is_b2b`:
```tsx
export const AccountProvider = ({ children }: AccountProviderProps) => {
const [is_b2b, setIsB2b] = useState(false)
//...
}
```
Next, add a new callback function `checkB2b` inside the `AccountProvider` function:
```tsx
import axios from "axios"
import { useRouter } from "next/router"
import { MEDUSA_BACKEND_URL, medusaClient } from "@lib/config"
//...
export const AccountProvider = ({ children }: AccountProviderProps) => {
//...
const checkB2b = useCallback(async () => {
if (customer) {
//check if the customer is a b2b customer
const { data } = await axios.get(`${MEDUSA_BACKEND_URL}/store/customers/is-b2b`, {
withCredentials: true
})
setIsB2b(data.is_b2b)
} else {
setIsB2b(false)
}
}, [customer])
useEffect(() => {
checkB2b()
}, [checkB2b])
//...
}
```
This function sends a request to the `/store/customers/is-b2b` endpoint that you created in part 1. It then changes the value of the `is_b2b` state variable based on the response received.
You also run this callback function in `useEffect` which triggers the function whenever there’s a change in the callback. In other words, whenever the `customer` is changed.
You also need to set the value of `is_b2b` back to `false` when the customer logs out. You can add that in the `handleLogout` function in `AccountProvider`:
```tsx
const handleLogout = () => {
useDeleteSession.mutate(undefined, {
onSuccess: () => {
//...
setIsB2b(false)
},
})
}
```
Lastly, pass `is_b2b` in the `value` prop of `AccountContext.Provider`:
```tsx
return (
<AccountContext.Provider
value={{
//...
is_b2b
}}
>
{children}
</AccountContext.Provider>
)
```
These are all the changes necessary to enable checking whether the customer is a B2B customer or not throughout the storefront.
There’s also one last change to make that enhances the customer experience. Change the `checkSession` function in `AccountProvider` to the following:
```tsx
const checkSession = useCallback(() => {
if (!customer && !retrievingCustomer) {
router.push(router.pathname.includes("wholesale") ? "/wholesale/account/login" : "/account/login")
}
}, [customer, retrievingCustomer, router])
```
Previously, the function redirects the customer to `/account/login` if they were trying to access account pages. To ensure that a guest customer gets redirected to the wholesaler login page when they try to access a wholesale page, you add a condition that determines where the guest customer should be redirected.
### Change StoreContext
The Next.js storefront also defines a `StoreContext` that manages the store’s regions, cart, and more.
In this section, you’ll make changes to the `StoreContext` to ensure the correct sales channel is assigned to B2B customers’ carts.
In `src/lib/context/store-context.tsx`, change the `createNewCart` function in the `StoreProvider` function to the following:
```tsx
import { MEDUSA_BACKEND_URL, medusaClient } from "@lib/config"
import axios from "axios"
import React, { createContext, useCallback, useContext, useEffect, useState } from "react"
//...
export const StoreProvider = ({ children }: StoreProps) => {
//...
const createNewCart = async (regionId?: string) => {
const cartData: {
region_id?: string,
sales_channel_id?: string
} = { region_id: regionId }
if (process.env.NEXT_PUBLIC_SALES_CHANNEL_ID) {
//check if customer is b2b
const { data } = await axios.get(`${MEDUSA_BACKEND_URL}/store/customers/is-b2b`, {
withCredentials: true
})
if (data.is_b2b) {
cartData.sales_channel_id = process.env.NEXT_PUBLIC_SALES_CHANNEL_ID
}
}
await createCart.mutateAsync(
cartData,
{
onSuccess: ({ cart }) => {
setCart(cart)
storeCart(cart.id)
ensureRegion(cart.region)
},
onError: (error) => {
if (process.env.NODE_ENV === "development") {
console.error(error)
}
},
}
)
}
//...
}
```
Previously, this function only passed the region ID to the `createCart` mutation. By making the above change you check first if the customer is a B2B customer and add the `sales_channel_id` field to the data to be passed to the `createCart` mutation.
Next, change the `resetCart` function in the `StoreProvider` function to the following:
```tsx
export const StoreProvider = ({ children }: StoreProps) => {
//...
const resetCart = async () => {
deleteCart()
const savedRegion = getRegion()
const cartData: {
region_id?: string,
sales_channel_id?: string
} = { region_id: savedRegion?.regionId }
if (process.env.NEXT_PUBLIC_SALES_CHANNEL_ID) {
//check if customer is b2b
const { data } = await axios.get(`${MEDUSA_BACKEND_URL}/store/customers/is-b2b`, {
withCredentials: true
})
if (data.is_b2b) {
cartData.sales_channel_id = process.env.NEXT_PUBLIC_SALES_CHANNEL_ID
}
}
createCart.mutate(
cartData,
{
onSuccess: ({ cart }) => {
setCart(cart)
storeCart(cart.id)
ensureRegion(cart.region)
},
onError: (error) => {
if (process.env.NODE_ENV === "development") {
console.error(error)
}
},
}
)
}
//...
}
```
This change is similar to the previous change. It ensures that the correct sales channel ID is assigned to the cart when it’s reset.
Finally, change the `ensureCart` function inside `useEffect` to the following:
```tsx
useEffect(() => {
const ensureCart = async () => {
const cartId = getCart()
const region = getRegion()
if (cartId) {
const cartRes = await medusaClient.carts
.retrieve(cartId)
.then(async ({ cart }) => {
if (process.env.NEXT_PUBLIC_SALES_CHANNEL_ID && cart.sales_channel_id !== process.env.NEXT_PUBLIC_SALES_CHANNEL_ID) {
//check if b2b customer
const { data } = await axios.get(`${MEDUSA_BACKEND_URL}/store/customers/is-b2b`, {
withCredentials: true
})
if (data.is_b2b) {
//update cart's sales channel
const response = await medusaClient.carts.update(cart.id, {
sales_channel_id: process.env.NEXT_PUBLIC_SALES_CHANNEL_ID
})
return response.cart
}
}
return cart
})
.catch(async (_) => {
return null
})
if (!cartRes || cartRes.completed_at) {
deleteCart()
await createNewCart(region?.regionId)
return
}
setCart(cartRes)
ensureRegion(cartRes.region)
} else {
await createNewCart(region?.regionId)
}
}
if (!IS_SERVER && !cart?.id) {
ensureCart()
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, [])
```
Similar to the previous changes, this ensures that when the storefront is opened and the cart is retrieved, the correct sales channel is assigned to the cart.
### Change the Nav Component
To ensure customers can access the wholesale login page, you’ll add a new link to the navigation bar.
In `src/modules/layout/templates/nav/index.tsx` add the following in the returned JSX above the Account link:
```tsx
<Link href="/wholesale/account">
<a>Wholesale Account</a>
</Link>
<Link href="/account">
<a>Account</a>
</Link>
```
### Add Login Form Component
The login page should display a login form for the customer.
To create the login form, create the file `src/modules/wholesale/components/login/index.tsx` with the following content:
```tsx
import { FieldValues, useForm } from "react-hook-form"
import { MEDUSA_BACKEND_URL, medusaClient } from "@lib/config"
import Button from "@modules/common/components/button"
import Input from "@modules/common/components/input"
import axios from "axios"
import { useAccount } from "@lib/context/account-context"
import { useCart } from "medusa-react"
import { useRouter } from "next/router"
import { useState } from "react"
interface SignInCredentials extends FieldValues {
email: string
password: string
}
const Login = () => {
const { refetchCustomer, is_b2b } = useAccount()
const [authError, setAuthError] = useState<string | undefined>(undefined)
const router = useRouter()
const { cart, updateCart } = useCart()
const handleError = (_e: Error) => {
setAuthError("Invalid email or password")
}
const {
register,
handleSubmit,
formState: { errors },
} = useForm<SignInCredentials>()
const onSubmit = handleSubmit(async (credentials) => {
medusaClient.auth
.authenticate(credentials)
.then(async () => {
refetchCustomer()
if (process.env.NEXT_PUBLIC_SALES_CHANNEL_ID && cart?.sales_channel_id !== process.env.NEXT_PUBLIC_SALES_CHANNEL_ID) {
const { data } = await axios.get(`${MEDUSA_BACKEND_URL}/store/customers/is-b2b`, {
withCredentials: true
})
if (data.is_b2b) {
updateCart.mutate({
sales_channel_id: process.env.NEXT_PUBLIC_SALES_CHANNEL_ID
})
}
}
router.push(is_b2b ? "/wholesale/account" : "/account")
})
.catch(handleError)
})
return (
<div className="max-w-sm w-full flex flex-col items-center">
<h1 className="text-large-semi uppercase mb-6">Welcome back</h1>
<p className="text-center text-base-regular text-gray-700 mb-8">
Sign in to your wholesale account
</p>
<form className="w-full" onSubmit={onSubmit}>
<div className="flex flex-col w-full gap-y-2">
<Input
label="Email"
{...register("email", { required: "Email is required" })}
autoComplete="email"
errors={errors}
/>
<Input
label="Password"
{...register("password", { required: "Password is required" })}
type="password"
autoComplete="current-password"
errors={errors}
/>
</div>
{authError && (
<div>
<span className="text-rose-500 w-full text-small-regular">
These credentials do not match our records
</span>
</div>
)}
<Button className="mt-6">Enter</Button>
</form>
</div>
)
}
export default Login
```
This login form shows the customer the fields `email` and `password`. When the customer submits the form and they’re authenticated successfully, you check if the customer is a B2B customer and accordingly update the cart’s sales channel ID.
This is important as products can only be added to a cart that belongs to the same sales channel.
### Add Login Template Component
The login template component will be displayed on the Login page.
Create the file `src/modules/wholesale/templates/login-template.tsx` with the following content:
```tsx
import Login from "../components/login"
import { useAccount } from "@lib/context/account-context"
import { useEffect } from "react"
import { useRouter } from "next/router"
const WholesaleLoginTemplate = () => {
const { customer, retrievingCustomer, is_b2b } = useAccount()
const router = useRouter()
useEffect(() => {
if (!retrievingCustomer && customer ) {
router.push(is_b2b ? "/wholesale/account" : "/account")
}
}, [customer, retrievingCustomer, router, is_b2b])
return (
<div className="w-full flex justify-center py-24">
<Login />
</div>
)
}
export default WholesaleLoginTemplate
```
In this template, you first check if the customer is already logged in and redirect them to their account page based on whether they’re a B2B customer or not.
If the customer is not logged in, you show the `Login` form component.
### Add Login Page
Create the file `src/pages/wholesale/account/login.tsx` with the following content:
```tsx
import Head from "@modules/common/components/head"
import Layout from "@modules/layout/templates"
import LoginTemplate from "@modules/wholesale/templates/login-template"
import { NextPageWithLayout } from "types/global"
const Login: NextPageWithLayout = () => {
return (
<>
<Head title="Sign in" description="Sign in to your Wholesale account." />
<LoginTemplate />
</>
)
}
Login.getLayout = (page) => {
return <Layout>{page}</Layout>
}
export default Login
```
This is the login page that the customer sees when they access the `/wholesale/account/login` path. It shows the `LoginTemplate` component.
### Add Wholesale Account Page
The last part you’ll add to finish the Wholesale login functionality is the account page for wholesalers. This page is shown when the B2B customer is logged in.
Create the file `src/pages/wholesale/account/index.tsx` with the following content:
```tsx
import AccountLayout from "@modules/account/templates/account-layout"
import Head from "@modules/common/components/head"
import Layout from "@modules/layout/templates"
import { NextPageWithLayout } from "types/global"
import OverviewTemplate from "@modules/account/templates/overview-template"
import { ReactElement } from "react"
import { useAccount } from "@lib/context/account-context"
import { useRouter } from "next/router"
const Account: NextPageWithLayout = () => {
const { customer, is_b2b } = useAccount()
const router = useRouter()
if (customer && !is_b2b) {
router.push("/account")
}
return (
<>
<Head title="Wholesale Account" description="Overview of your account activity." />
<OverviewTemplate />
</>
)
}
Account.getLayout = (page: ReactElement) => {
return (
<Layout>
<AccountLayout>{page}</AccountLayout>
</Layout>
)
}
export default Account
```
In this page, you first check whether the customer is logged in but they’re not a B2B customer. In that case, you redirect them to the `/account` page which is used by other types of customers.
On this page, you show the same `OverviewTemplate` that is shown by default for customers. This is for the simplicity of the tutorial. If you want to display other information to B2B customers, you can make the changes on this page.
### Test Wholesale Login
Make sure the Medusa server you created in part 1 is running. Then, run the following command to run the Next.js storefront:
```bash
npm run dev
```
Open the storefront at `localhost:8000` and click on the Wholesale Account link in the navigation bar. This will open the login page you created.
In part 1 you created a customer in a B2B customer group. Use the email and password of that customer to log in.
Once you’re logged in, you’ll be redirected to the `/wholesale/account` page.
## Create B2B Products Page
In this section, you’ll customize the current product page (available on the page `/store`) to show products as a list of variants in a table. This makes it easier for B2B customers to view available products and their variants and add big quantities of them to the cart.
### Change ProductContext
Another context that the Next.js storefront defines is the `ProductContext` which manages a product’s options, price, variants, and more.
You’ll be customizing this context to expose in the context the `setQuantity` function that allows setting the quantity to be added to the cart.
In `src/lib/context/product-context.tsx`, add in the `ProductContext` interface the `setQuantity` function:
```tsx
interface ProductContext {
//...
setQuantity: (quantity: number) => void
}
```
Then, add the function to the object passed to the `ProductActionContext.Provider`'s `value` prop:
```tsx
return (
<ProductActionContext.Provider
value={{
//...
setQuantity
}}
>
{children}
</ProductActionContext.Provider>
)
```
Please note that the function is already defined in the context with the `quantity` state variable.
### Create ProductActions Component
The `ProductActions` component is a component that displays a button and a quantity input and handles the add-to-cart functionality. It’ll be displayed for each variant in the products table.
Create the file `src/modules/wholesale/components/product-actions/index.tsx` with the following content:
```tsx
import { Product, Variant } from "types/medusa"
import React, { useEffect, useMemo, useState } from "react"
import Button from "@modules/common/components/button"
import { isEqual } from "lodash"
import { useProductActions } from "@lib/context/product-context"
type ProductActionsProps = {
product: Product
selectedVariant: Variant
}
const ProductActions: React.FC<ProductActionsProps> = ({ product, selectedVariant }) => {
const { updateOptions, addToCart, inStock, options, quantity, setQuantity } =
useProductActions()
useEffect(() => {
const tempOptions: Record<string, string> = {}
for (const option of selectedVariant.options) {
tempOptions[option.option_id] = option.value
}
if (!isEqual(tempOptions, options)) {
updateOptions(tempOptions)
}
}, [selectedVariant.options, options])
return (
<div className="flex flex-col gap-y-2">
<input type="number" min="1" max={selectedVariant.inventory_quantity} value={quantity} disabled={!inStock}
onChange={(e) => setQuantity(parseInt(e.target.value))} className="border p-2 w-max mt-2" />
<Button onClick={addToCart} className="w-max my-2">
{!inStock ? "Out of stock" : "Add to cart"}
</Button>
</div>
)
}
export default ProductActions
```
This component uses the `useProductActions` hook which exposes the values in the `ProductContext`. In `useEffect`, it preselects the options in the current variant.
It displays a quantity input and an add-to-cart button. Both the value of the quantity input and the add-to-cart handler are managed by `ProductContext`.
### Create ProductPrice Component
The `ProductPrice` component handles showing the correct variant price to the customer. It’ll be used to show the price of variants in the products table.
Create the file `src/modules/wholesale/components/product-price/index.tsx` with the following content:
```tsx
import { Product } from "@medusajs/medusa"
import { Variant } from "types/medusa"
import clsx from "clsx"
import { useMemo } from "react"
import useProductPrice from "@lib/hooks/use-product-price"
type ProductPriceProps = {
product: Product
variant: Variant
}
const ProductPrice: React.FC<ProductPriceProps> = ({ product, variant }) => {
const price = useProductPrice({ id: product.id, variantId: variant?.id })
const selectedPrice = useMemo(() => {
const { variantPrice, cheapestPrice } = price
return variantPrice || cheapestPrice || null
}, [price])
return (
<div className="mb-4">
{selectedPrice ? (
<div className="flex flex-col text-gray-700">
<span>
{selectedPrice.calculated_price}
</span>
</div>
) : (
<div></div>
)}
</div>
)
}
export default ProductPrice
```
This component uses the `useProductPrice` hook which makes it easier to manage the price of a variant, then display the price to the customer.
### Create Products Component
The `Products` component is the products table that will be shown to the B2B customer.
Create the file `src/modules/wholesale/components/products/index.tsx` with the following content:
```tsx
import { ProductProvider, useProductActions } from "@lib/context/product-context"
import { useCart, useProducts } from "medusa-react"
import { useMemo, useState } from "react"
import Button from "@modules/common/components/button"
import Link from "next/link"
import ProductActions from "../product-actions"
import ProductPrice from "../product-price"
import { StoreGetProductsParams } from "@medusajs/medusa"
type GetProductParams = StoreGetProductsParams & {
sales_channel_id?: string[]
}
type ProductsType = {
params: GetProductParams
}
const Products = ({ params }: ProductsType) => {
const { cart } = useCart()
const [offset, setOffset] = useState(0)
const [currentPage, setCurrentPage] = useState(1)
const queryParams = useMemo(() => {
const p: GetProductParams = {}
if (cart?.id) {
p.cart_id = cart.id
}
p.is_giftcard = false
p.offset = offset
return {
...p,
...params,
}
}, [cart?.id, params, offset])
const { products, isLoading, count, limit } = useProducts(queryParams, {
enabled: !!cart
})
function previousPage () {
if (!limit || !count) {
return
}
const newOffset = Math.max(0, offset - limit)
setOffset(newOffset)
setCurrentPage(currentPage - 1)
}
function nextPage () {
if (!limit || !count) {
return
}
const newOffset = Math.min(count, offset + limit)
setOffset(newOffset)
setCurrentPage(currentPage + 1)
}
return (
<div className="flex-1 content-container">
{!isLoading && products && (
<>
<table className="table-auto w-full border-collapse border">
<thead>
<tr className="text-left border-collapse border">
<th className="p-3">Product Title</th>
<th>Variant Title</th>
<th>SKU</th>
<th>Options</th>
<th>Available Quantity</th>
<th>Price</th>
<th>Actions</th>
</tr>
</thead>
<tbody>
{products.map((product) => (
<>
<tr>
<td className="p-3" rowSpan={product.variants.length + 1}>
<Link href={`/products/${product.handle}`} passHref={true}>
<a className="underline">{product.title}</a>
</Link>
</td>
</tr>
{product.variants.map((variant) => (
<ProductProvider product={product} key={variant.id}>
<tr className="border-collapse border">
<td>{variant.title}</td>
<td>{variant.sku}</td>
<td>
<ul>
{variant.options.map((option) => (
<li key={option.id}>
{product.options.find((op) => op.id === option.option_id)?.title}: {option.value}
</li>
))}
</ul>
</td>
<td>{variant.inventory_quantity}</td>
<td><ProductPrice product={product} variant={variant} /></td>
<td>
<ProductActions product={product} selectedVariant={variant} />
</td>
</tr>
</ProductProvider>
))}
</>
))}
</tbody>
</table>
<div className="my-2 flex justify-center items-center">
<Button onClick={previousPage} disabled={currentPage <= 1} className="w-max inline-flex">
Prev
</Button>
<span className="mx-4">{currentPage}</span>
<Button onClick={nextPage} disabled={count !== undefined && limit !== undefined && (count / (offset + limit)) <= 1} className="w-max inline-flex">
Next
</Button>
</div>
</>
)}
</div>
)
}
export default Products
```
This component retrieves the products in the B2B Sales Channel and displays them in a table. It also shows pagination controls to move between different pages.
For each product, you loop over its variants and display them one by one in different rows. For each variant, you use the `ProductActions` and the `ProductPrice` components you created to show the quantity input, the add to cart button, and the variant’s price.
### Change Store Page
Currently, the store page displays products in an infinite-scroll mode for all customers. You’ll change it to display the Products table for B2B customers, and the infinite-scroll mode for other customers.
Change the content of `src/pages/store.tsx` to the following:
```tsx
import Head from "@modules/common/components/head"
import InfiniteProducts from "@modules/products/components/infinite-products"
import Layout from "@modules/layout/templates"
import { NextPageWithLayout } from "types/global"
import Products from "@modules/wholesale/components/products"
import RefinementList from "@modules/store/components/refinement-list"
import { StoreGetProductsParams } from "@medusajs/medusa"
import { useAccount } from "@lib/context/account-context"
import { useState } from "react"
const Store: NextPageWithLayout = () => {
const [params, setParams] = useState<StoreGetProductsParams>({})
const { is_b2b } = useAccount()
return (
<>
{!is_b2b && (
<>
<Head title="Store" description="Explore all of our products." />
<div className="flex flex-col small:flex-row small:items-start py-6">
<RefinementList refinementList={params} setRefinementList={setParams} />
<InfiniteProducts params={params} />
</div>
</>
)}
{is_b2b && (
<>
<Head title="Wholesale Products" description="Explore all of our products." />
<div className="flex flex-col small:flex-row small:items-start py-6">
<Products params={{
...params,
sales_channel_id: [process.env.NEXT_PUBLIC_SALES_CHANNEL_ID || ""]
}} />
</div>
</>
)}
</>
)
}
Store.getLayout = (page) => <Layout>{page}</Layout>
export default Store
```
You first retrieve `is_b2b` from `useAccount`. Then, if `is_b2b` is false, you display the `InfiniteProducts` component. Otherwise, for B2B customers, you display the `Products` component that you created.
### Change Store Dropdown
When you hover over the Store link in the navigation bar, it currently shows a dropdown with some products and collections. As this is distracting for B2B customers, you’ll remove it for them.
In `src/modules/layout/components/dropdown-menu/index.tsx`, retrieve the `is_b2b` variable from the `AccountContext`:
```tsx
import { useAccount } from "@lib/context/account-context"
//...
const DropdownMenu = () => {
const { is_b2b } = useAccount()
//...
}
```
And change the returned JSX to the following:
```tsx
const DropdownMenu = () => {
//...
return (
<>
{is_b2b && (
<div className="h-full flex">
<Link href="/store" passHref>
<a className="relative flex h-full">
<span className="relative h-full flex items-center transition-all ease-out duration-200">
Store
</span>
</a>
</Link>
</div>
)}
{!is_b2b && (
<div
onMouseEnter={() => setOpen(true)}
onMouseLeave={() => setOpen(false)}
className="h-full"
>
<div className="flex items-center h-full">
<Popover className="h-full flex">
<>
<Link href="/shop" passHref>
<a className="relative flex h-full">
<Popover.Button
className={clsx(
"relative h-full flex items-center transition-all ease-out duration-200"
)}
onClick={() => push("/store")}
>
Store
</Popover.Button>
</a>
</Link>
<Transition
show={open}
as={React.Fragment}
enter="transition ease-out duration-200"
enterFrom="opacity-0"
enterTo="opacity-100"
leave="transition ease-in duration-150"
leaveFrom="opacity-100"
leaveTo="opacity-0"
>
<Popover.Panel
static
className="absolute top-full inset-x-0 text-sm text-gray-700 z-30 border-y border-gray-200"
>
<div className="relative bg-white py-8">
<div className="flex items-start content-container">
<div className="flex flex-col flex-1 max-w-[30%]">
<h3 className="text-base-semi text-gray-900 mb-4">
Collections
</h3>
<div className="flex items-start">
{collections &&
chunk(collections, 6).map((chunk, index) => {
return (
<ul
key={index}
className="min-w-[152px] max-w-[200px] pr-4"
>
{chunk.map((collection) => {
return (
<div key={collection.id} className="pb-3">
<Link
href={`/collections/${collection.id}`}
>
<a onClick={() => setOpen(false)}>
{collection.title}
</a>
</Link>
</div>
)
})}
</ul>
)
})}
{loadingCollections &&
repeat(6).map((index) => (
<div
key={index}
className="w-12 h-4 bg-gray-100 animate-pulse"
/>
))}
</div>
</div>
<div className="flex-1">
<div className="grid grid-cols-3 gap-4">
{products?.slice(0, 3).map((product) => (
<ProductPreview {...product} key={product.id} />
))}
{loadingProducts &&
repeat(3).map((index) => (
<SkeletonProductPreview key={index} />
))}
</div>
</div>
</div>
</div>
</Popover.Panel>
</Transition>
</>
</Popover>
</div>
</div>
)}
</>
)
}
```
If `is_b2b` is true, the dropdown is hidden. Otherwise, `is_b2b` is shown.
### Test Products Page
Make sure your Medusa server is still running and restart your Next.js storefront.
Then, open the Next.js storefront and, after logging in as a B2B customer, click on the Store link in the navigation bar at the top left. You’ll see your list of product variants in a table.
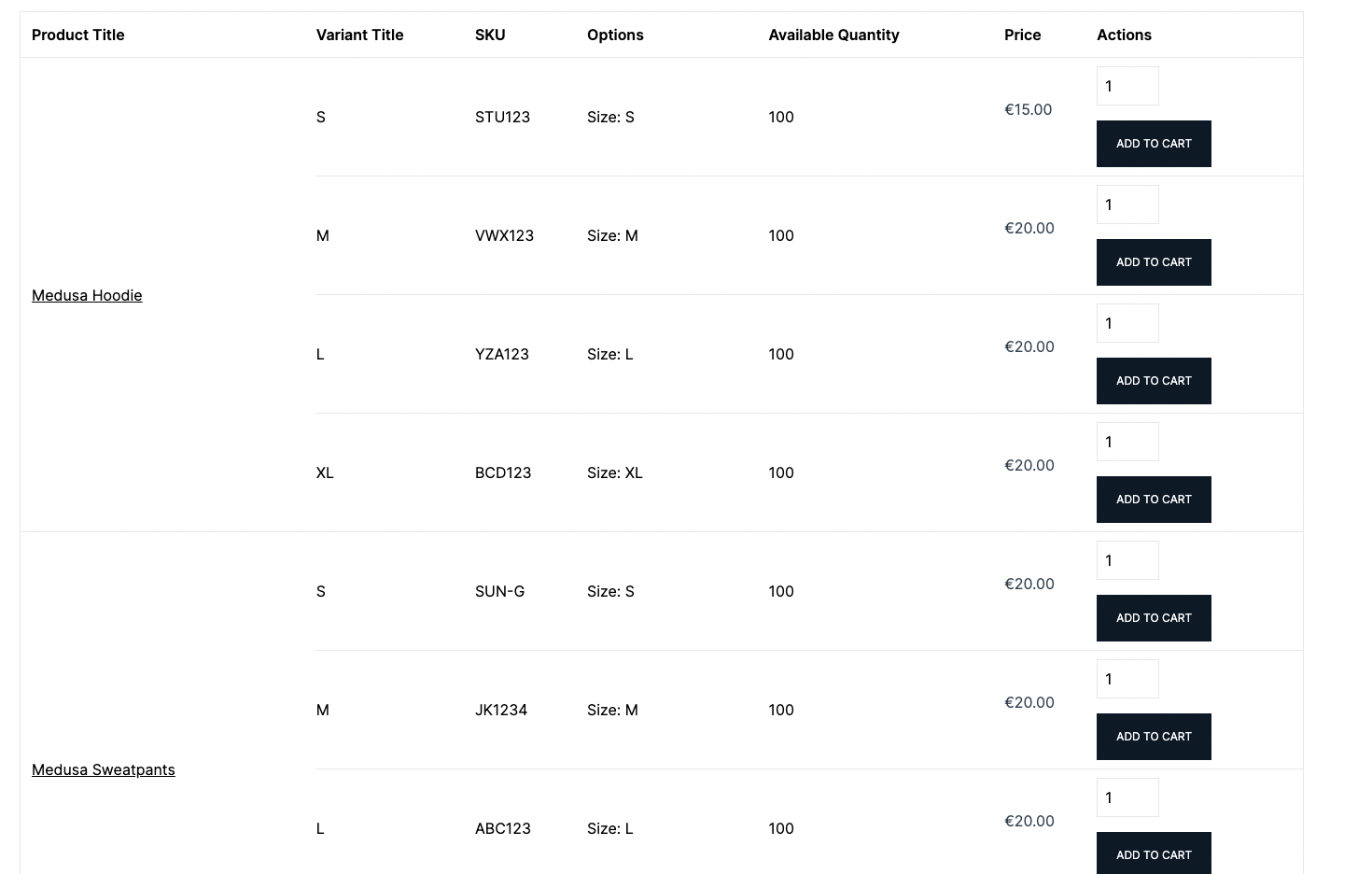
Notice how the prices of the variants are different than those shown to other customers. These prices are the prices you defined in the B2B Price List.
You can also test the prices with quantity-based conditions you added to the Price List. For example, if the condition was that product Medusa Hoodie’s variant S should have a different price if its quantity in the cart is more than 10, try changing the quantity to 10 or more and clicking Add to Cart. You’ll see a different price for that variant in the cart.
## Test Checkout Flow
The checkout flow is pretty similar to those of regular customers:
- Add a couple of items to the cart from the table.
- Click on the My Bag link at the top right of the navigation bar.
- Click on Go to Checkout.
- Fill out the Shipping Address information and choose a Fulfillment method.
- Choose a payment method. Since in this tutorial you didn’t add any payment methods, you’ll use the manual payment method. However, you can integrate many other payment methods with Medusa such as [Stripe](https://docs.medusajs.com/add-plugins/stripe) or [PayPal](https://docs.medusajs.com/add-plugins/paypal), or [create your own](https://docs.medusajs.com/advanced/backend/payment/how-to-create-payment-provider).
- Click on the Checkout button.
This places the order on the Medusa server. Please note that Medusa does not capture the payment when an order is placed; it only authorizes it. You’ll need to capture it from the Medusa admin.
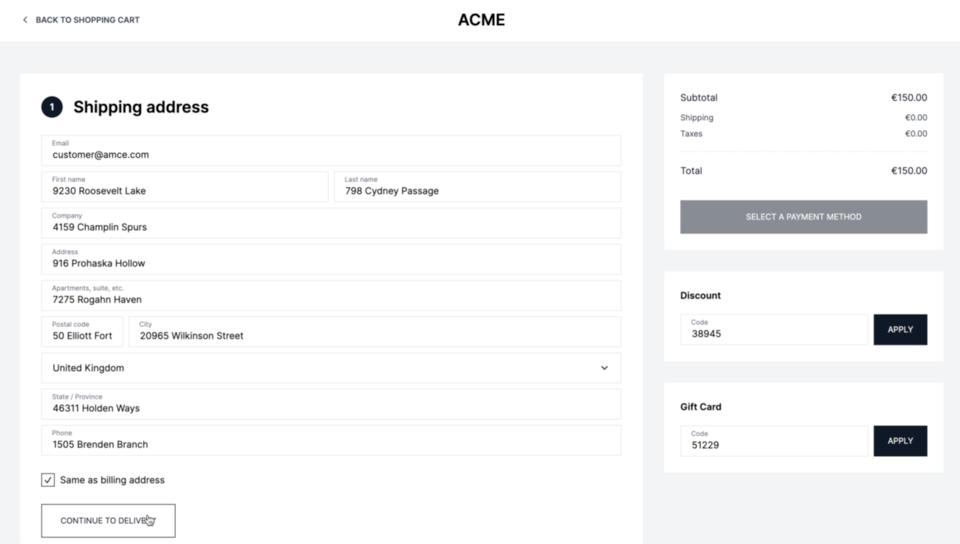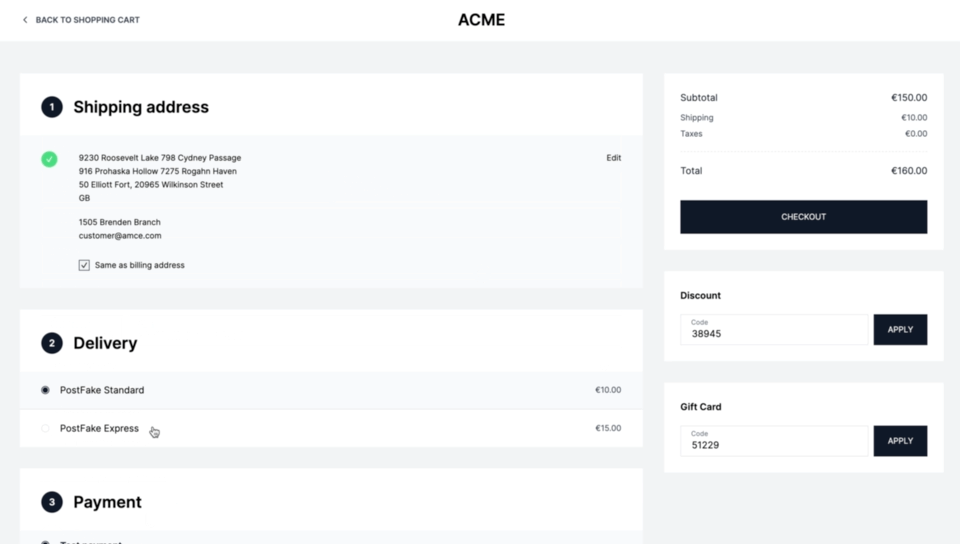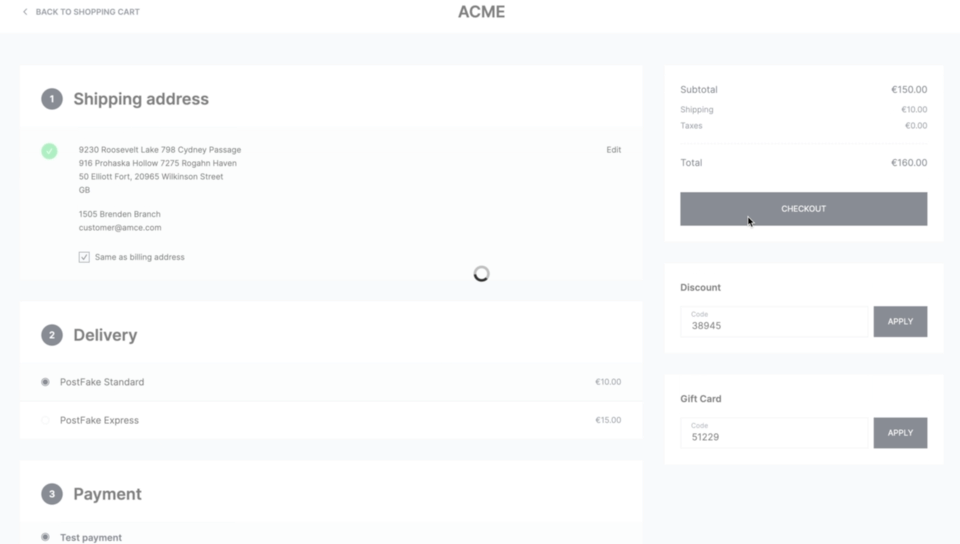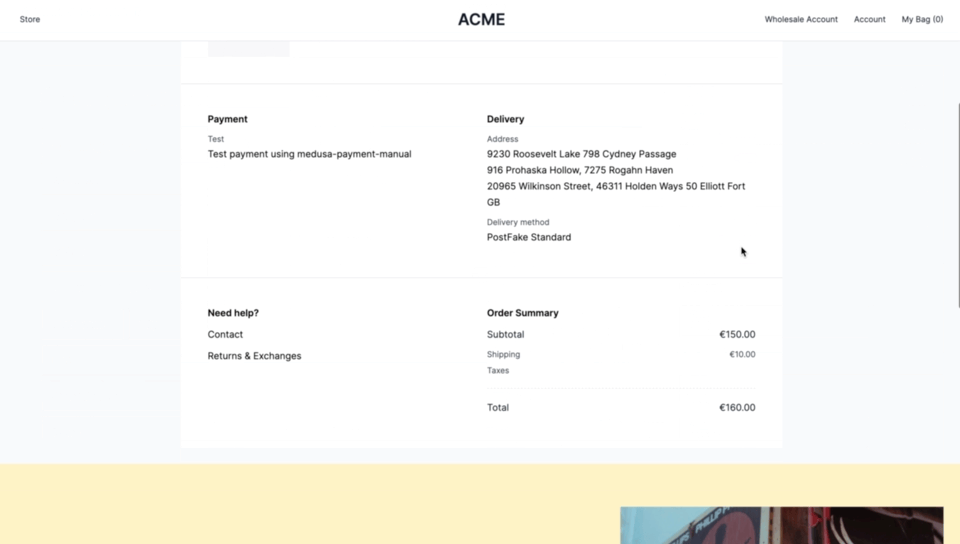
## View Order Details on Medusa Admin
Run both the Medusa server and Medusa admin you created in part 1. Then, access the Medusa admin on `localhost:7000`.
After logging in, you should see the list of orders in your store. In the list, you can see the payment status of the order, the sales channel, and more.
You should find the order you just created in the list. Click on the order to view its details.
On the order details page, you can see all the details of the order such as the items ordered, the payment and fulfillment details, the customer’s details, and more.
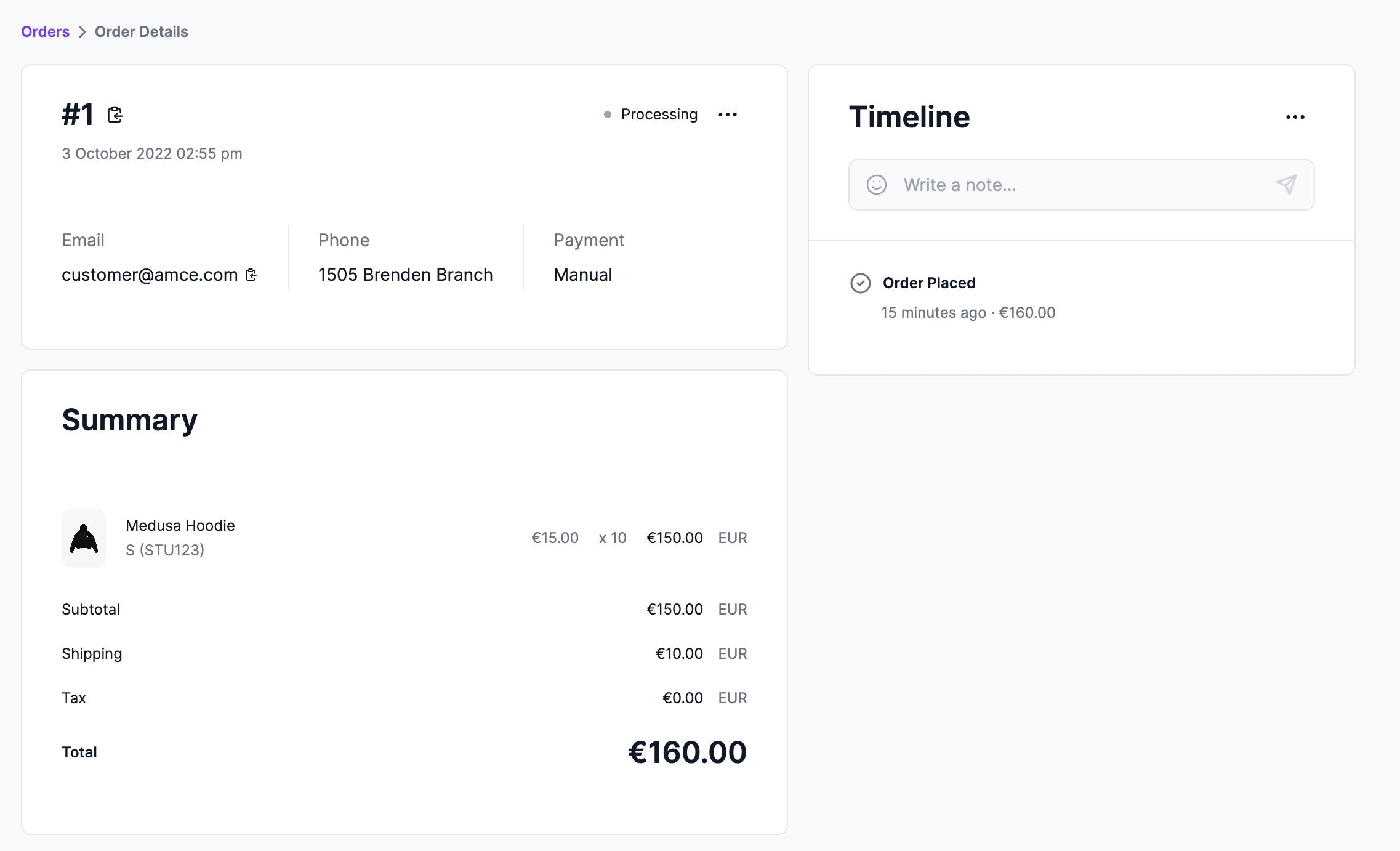
### Capture Payment
To capture the payment of the order:
1. Scroll to the Payment section.
2. Click on the Capture Payment.
If you chose the Test payment provider during checkout, this will not actually do anything other than change the payment status of the order. If you’re using other payment providers such as Stripe, this is when the payment will actually be captured.
## Conclusion
By following this two-part tutorial series, you should have the basis of a B2B ecommerce store built with Medusa.
You can read more about how Medusa supports B2B and compares to other OS B2B platforms [on our webpage](https://medusajs.com/b2b-commerce-platform).
Likewise, you can perform much more customizations and add additional features to your store including:
1. Add a payment provider. As mentioned, you can add payment providers like [Stripe](https://docs.medusajs.com/add-plugins/stripe) and [PayPal](https://docs.medusajs.com/add-plugins/paypal), or [create your own](https://docs.medusajs.com/advanced/backend/payment/how-to-create-payment-provider).
2. [Create a Fulfillment Provider](https://docs.medusajs.com/advanced/backend/shipping/add-fulfillment-provider).
3. Integrate search engines such as [Algolia](https://docs.medusajs.com/add-plugins/algolia) or [MeiliSearch](https://docs.medusajs.com/add-plugins/meilisearch).
> Should you have any issues or questions related to Medusa, then feel free to reach out to the Medusa team via [Discord](https://discord.gg/F87eGuwkTp). | shahednasser |
1,292,300 | Advent of Code 2022 - Day 11 | I'm trying to solve all the Advent of Code puzzles in this video series. | 0 | 2022-12-11T08:00:28 | https://dev.to/kalaspuffar/advent-of-code-2022-day-11-294p | ---
title: Advent of Code 2022 - Day 11
published: true
description: I'm trying to solve all the Advent of Code puzzles in this video series.
tags:
cover_image: https://i.ytimg.com/vi/Aot_ORkkvP4/maxresdefault.jpg
---
{% youtube Aot_ORkkvP4 %}
I'm trying to solve all the Advent of Code puzzles in this video series. | kalaspuffar | |
1,292,435 | Cannot connect to sftp server | Cannot connect to sftp server — “Too many authentication failures for user” I faced this issue when... | 0 | 2022-12-11T13:43:16 | https://dev.to/hemanlinux/cannot-connect-to-sftp-server-5c85 | linux, ssh, beginners, cloud | Cannot connect to sftp server — “Too many authentication failures for user”
I faced this issue when trying to use Filezilla client to access a remote ftp location.
The initial stack trace ( with debug level set to 3) is as follows.
```
Trace: Trying Pageant key #0
Trace: Server refused public key
Trace: Trying Pageant key #1
Trace: Server refused public key
Trace: Trying Pageant key #2
Trace: Received disconnect message (protocol error)
Trace: Disconnection message text: Too many authentication failures for facade
Trace: Server sent disconnect message
Trace: type 2 (protocol error):
Trace: "Too many authentication failures for facade"
Error: Server sent disconnect message
Error: type 2 (protocol error):
Error: "Too many authentication failures for facade"
Trace: CSftpControlSocket::ResetOperation(66)
Trace: CControlSocket::ResetOperation(66)
Error: Could not connect to server
Status: Waiting to retry...
```
Thanks to this post:
https://www.howtouselinux.com/post/2-ways-to-fix-ssh-too-many-authentication-failures
I identified that the reasons for this issue are follows.
- At the time of the issue, I had used “ssh-add” to add several keys for accessing multiple other instances.
- FileZilla does’t know which keys it needs to try and tries every available keys
- The server had set a maximum retry count (3) and as I had more than 3 keys, FileZilla failed after trying only 3 keys.
| hemanlinux |
1,292,484 | How to Make Responsive Accordion in HTML | In this article, we will make Responsive Accordion in HTML CSS & JavaScript. So what we do here... | 0 | 2022-12-11T14:57:28 | https://dev.to/patelrohan750/how-to-make-responsive-accordion-in-html-48e9 | html, css, javascript, beginners | In this article, we will make Responsive Accordion in HTML CSS & JavaScript. So what we do here is, we will add some divs for accordion titles, in which we will write some information and details. This information and details will be hidden by default, so to show that we will add a plus icon to extend the accordion. Once the information gets extended then we will replace the plus icon with cross icon to hide again the details.
[Read More](https://rocoderes.com/how-to-make-responsive-accordion-in-html-css-js/) | patelrohan750 |
1,292,624 | Seeding the Query Cache | A new RFC about first class support for Promises has been released last week, and it got some talk... | 11,644 | 2022-12-11T18:50:38 | https://tkdodo.eu/blog/seeding-the-query-cache | react, webdev, javascript, typescript | A new RFC about [first class support for Promises](https://github.com/reactjs/rfcs/pull/229) has been released last week, and it got some talk going about how this would introduce fetch waterfalls if used incorrectly. So what are fetch waterfalls exactly?
## Fetch waterfalls
A waterfall describes a situation where one request is made, and we wait for it to complete before firing another request.
Sometimes, this is unavoidable, because the first request contains information that is needed to make the second request. We also refer to these as [dependent queries](https://tanstack.com/query/v4/docs/guides/dependent-queries):
In many cases though, we can actually fetch all the data we need in parallel, because it is independent data:
In React Query, we can do that in two different ways:
```tsx
// 1. Use useQuery twice
const issues = useQuery({ queryKey: ['issues'], queryFn: fetchIssues })
const labels = useQuery({ queryKey: ['labels'], queryFn: fetchLabels })
// 2. Use the useQueries hook
const [issues, labels] = useQueries([
{ queryKey: ['issues'], queryFn: fetchIssues },
{ queryKey: ['labels'], queryFn: fetchLabels },
])
```
In both variants, React Query will kick off data fetching in parallel. So where do waterfalls come in?
### Suspense
_**Note**: Please keep in mind that at the time of this writing, suspense for data fetching is still experimental! In the following examples, I will not be using the proposal from the RFC, but rather the suspense implementation that is already available in React Query (which is also experimental)._
As described in the above linked RFC, suspense a way to unwrap promises with React. A defining trait of promises is that they can be in three different states: pending, fulfilled or rejected.
When rendering components, we are mostly interested in the success scenario. Handling loading and error states in each and every component can be tedious, and suspense is aimed at solving this problem.
When a promise is _pending_, React will unmount the component tree and render a fallback defined by a _Suspense_ boundary component. In case of errors, the error is bubbled up to the nearest _ErrorBoundary_.
This will decouple our components from handling those states, and we can focus on the happy path. It almost acts like synchronous code that just _reads_ a value from a cache:
```jsx
function Issues() {
// 👓 read data from cache
const { data } = useQuery({
queryKey: ['issues'],
queryFn: fetchIssues,
// ⬇️ this enables experimental suspense mode
suspense: true,
})
// 🎉 no need to handle loading or error states
return (
<div>
{data.map((issue) => (
<div>{issue.title}</div>
))}
</div>
)
}
function App() {
// 🚀 Boundaries handle loading and error states
return (
<Suspense fallback={<div>Loading...</div>}>
<ErrorBoundary fallback={<div>On no!</div>}>
<Issues />
</ErrorBoundary>
</Suspense>
)
}
```
#### A note on TypeScript
Sadly, when using TypeScript, data will still be potentially _undefined_ in the above example, as _suspense_ is just a flag on _useQuery_ that can be turned on and off at will. It can also be combined with the _enabled_ option, which will make the query not fire and thus make the component _not_ suspend at all.
We might change this in the future with a dedicated _useSuspenseQuery_ hook.
### Suspense waterfalls
So this is nice and all, but it can backfire when you use multiple queries in the same component that have suspense turned on. Here is what happens:
- Component renders, tries to read the first query
- Sees that there is no data in the cache yet, so it suspends
- This unmounts the component tree, and renders the fallback
- When the fetch is finished, the component tree is remounted
- First query is now read successfully from the cache
- Component sees the second query, and tries to read it
- Second query has no data in the cache, so it suspends (again)
- Second query is fetched
- Component finally renders successfully
This will have pretty impactful implications on your application's performance, because you'll see that fallback for waaay longer than necessary.
The best way to circumvent this problem is to make sure that there is already data in the cache when the component tries to read it.
## Prefetching
The earlier you initiate a fetch, the better, because the sooner it starts, the sooner it can finish. 🤓
- If your architecture supports server side rendering - consider [fetching on the server](https://tanstack.com/query/v4/docs/guides/ssr).
- If you have a router that supports loaders, consider [prefetching there](https://tanstack.com/query/v4/docs/guides/ssr).
But even if that's not the case, you can still use _prefetchQuery_ to initiate a fetch before the component is rendered:
```tsx
const issuesQuery = { queryKey: ['issues'], queryFn: fetchIssues }
// ⬇️ initiate a fetch before the component renders
queryClient.prefetchQuery(issuesQuery)
function Issues() {
const issues = useQuery(issuesQuery)
}
```
The call to _prefetchQueries_ is executed as soon as your JavaScript bundle is evaluated. This works very well if you do [route base code splitting](https://reactjs.org/docs/code-splitting.html#route-based-code-splitting), because it means the code for a certain page will be lazily loaded and evaluated as soon as the user navigates to that page.
This means it will still be kicked off before the component renders. If you do this for both queries in our example, you will get those parallel queries back even when using suspense.
As we can see, the query will still suspend until both are done fetching, but because we've triggered them in parallel, the waiting time is now drastically reduced.
**Note**: _useQueries_ doesn't support _suspense_ right now, but it might do in the future. If we add support, the goal is to trigger all fetches in parallel to avoid those waterfalls.
**Update**: _useQueries_ supports _suspense_ as of [v4.15.0](https://github.com/TanStack/query/releases/tag/v4.15.0). 🎉
### The use RFC
I don't know enough about the RFC yet to properly comment on it. A big part is still missing, namely how the cache API will work. I do think it is a bit problematic that the default behaviour will lead to waterfalls unless developers explicitly seed the cache early on. I'm still pretty excited about it because it will likely make internals of React Query easier to understand and maintain. It remains to be seen if it is something that will be used in userland a lot.
## Seeding details from lists
Another nice way to make sure that your cache is filled by the time it is read is to seed it from other parts of the cache. Oftentimes, if you render a detail view of an item, you will have data for that item readily available if you've previously been on a list view that shows a list of items.
There are two common approaches to fill a detail cache with data from a list cache:
### Pull approach
This is the one also described [in the docs](https://tanstack.com/query/v4/docs/guides/initial-query-data#initial-data-from-cache): When you try to render the detail view, you look up the list cache for the item you want to render. If it is there, you use it as initial data for the detail query.
```tsx
const useTodo = (id: number) => {
const queryClient = useQueryClient()
return useQuery({
queryKey: ['todos', 'detail', id],
queryFn: () => fetchTodo(id),
initialData: () => {
// ⬇️ look up the list cache for the item
return queryClient
.getQueryData(['todos', 'list'])
?.find((todo) => todo.id === id)
},
})
}
```
If the _initialData_ function returns _undefined_, the query will proceed as normal and fetch the data from the server. And if something is found, it will be put into the cache directly.
Be advised that if you have _staleTime_ set, no further background refetch will occur, as initialData is seen as _fresh_. This might not be what you want if your list was last fetched twenty minutes ago.
As shown [in the docs](https://tanstack.com/query/v4/docs/guides/initial-query-data#initial-data-from-the-cache-with-initialdataupdatedat), we can additionally specify _initialDataUpdatedAt_ on our detail query. It will tell React Query when the data we are passing in as _initialData_ was originally fetched, so it can determine staleness correctly. Conveniently, React Query also knows when the list was last fetched, so we can just pass that in:
```tsx
const useTodo = (id: number) => {
const queryClient = useQueryClient()
return useQuery({
queryKey: ['todos', 'detail', id],
queryFn: () => fetchTodo(id),
initialData: () => {
return queryClient
.getQueryData(['todos', 'list'])
?.find((todo) => todo.id === id)
},
initialDataUpdatedAt: () =>
// ⬇️ get the last fetch time of the list
queryClient.getQueryState(['todos', 'list'])?.dataUpdatedAt,
})
}
```
🟢 seeds the cache "just in time"
🔴 needs more work to account for staleness
### Push approach
Alternatively, you can create detail caches whenever you fetch the list query. This has the advantage that staleness is automatically measured from when the list was fetched, because, well, that's when we create the detail entry.
However, there is no good callback to hook into when a query is fetched. _onSuccess_ on _useQuery_ would technically work, but it would be executed for every instance of _useQuery_. If we have multiple observers, this would lead to the same data being written to the cache multiple times. The global _onSuccess_ callback on the cache itself might also work, but it would be executed for every query, so we'd have to narrow it down to the right query key.
The best way I've found to execute the push approach is to do it directly in the _queryFn_, after data has been fetched:
```tsx
const useTodos = () => {
const queryClient = useQueryClient()
return useQuery({
queryKey: ['todos', 'list'],
queryFn: async () => {
const todos = await fetchTodos()
todos.forEach((todo) => {
// ⬇️ create a detail cache for each item
queryClient.setQueryData(['todos', 'detail', todo.id], todo)
})
return todos
},
})
}
```
This would create a detail entry for each item in the list immediately. Since there is no one interested in those queries at the moment, those would be seen as _inactive_, which means they might be garbage collected after _cacheTime_ has elapsed (default: 15 minutes).
So if you use the push approach, the detail entries you've created here might no longer be available once the user actually navigates to the detail view. Also, if your list is long, you might be creating way too many entries that will never be needed.
🟢 staleTime is automatically respected
🟡 there is no good callback
🟡 might create unnecessary cache entries
🔴 pushed data might be garbage collected too early
---
Keep in mind that both approaches only work well if the structure of your detail query is exactly the same (or at least assignable to) the structure of the list query. If the detail view has a mandatory field that doesn't exist in the list, seeding via _initialData_ is not a good idea. This is where _placeholderData_ comes in, and I've written a comparison about the two in [#9: Placeholder and Initial Data in React Query](https://tkdodo.eu/blog/placeholder-and-initial-data-in-react-query).
---
That's it for today. Feel free to reach out to me on [twitter](https://twitter.com/tkdodo)
if you have any questions, or just leave a comment below. ⬇️ | tkdodo |
1,293,448 | Comparar dos Objetos en JavaScript | En ocasiones es necesario comparar dos objetos en JavaScript, por ejemplo, para saber si son iguales... | 0 | 2022-12-14T15:00:00 | https://asjordi.dev/blog/comparar-dos-objetos-en-javascript/ | javascript, tutorial, beginners, spanish | En ocasiones es necesario comparar dos objetos en JavaScript, por ejemplo, para saber si son iguales o no. En este artículo veremos cómo hacerlo.
A simple vista, parece que comparar dos objetos en JavaScript es una tarea sencilla, pero no lo es. Esto se debe a que los objetos en JavaScript son referencias a una ubicación de memoria, por lo que si dos variables apuntan al mismo objeto, entonces son iguales.
Por ejemplo, si utilizamos el operador de igualdad `===` no funcionará dado que las variables apuntan a una ubicación de memoria diferente, y no se comparan valores como en los datos primitivos.
Otra forma de realizar esta comparación es convirtiendo los objetos a cadenas de texto con `JSON.stringify` y luego compararlas con el operador de igualdad `===`, pero si los atributos del objeto no están en el mismo orden, entonces no serán iguales.
## Comparar dos Objetos en JavaScript
Para realizar la comparación de dos objetos podemos crear una función que realice esta tarea implementando diferentes validaciones, dado que los objetos pueden tener diferentes tipos de datos, y objetos anidados.
```js
function compareObjects(obj1, obj2) {
const firstObjectKeys = Object.keys(obj1);
const secondObjectKeys = Object.keys(obj2);
if (firstObjectKeys.length !== secondObjectKeys.length)
return false;
return firstObjectKeys.every((key) => {
if(obj1[key] === null && obj2[key] === null)
return true;
if(obj1[key] === null || obj2[key] === null)
return false;
if(typeof obj1[key] === 'object' && typeof obj2[key] === 'object')
return compareObjects(obj1[key], obj2[key])
return obj1[key] === obj2[key]
});
}
```
Esta función realiza la validación de diferentes escenarios:
* Objetos con atributos en diferente ordene.
* Objetos con diferentes cantidades de atributos.
* Objetos con atributos de diferentes tipos de datos.
* Objetos con atributos anidados.
* Objetos con atributos nulos.
* Objetos con objetos anidados.
Por ejemplo, se tienen los siguientes dos objetos:
```js
const personOne = {
name: 'John',
age: 30,
address: {
street: 'Main Street',
number: 123,
city: 'New York',
country: 'USA',
},
};
const personTwo = {
age: 30,
name: 'John',
address: {
street: 'Main Street',
number: 123,
city: 'New York',
country: 'USA',
},
};
```
Si ejecutamos la función `compareObjects` con los objetos `personOne` y `personTwo` como parámetros, nos devolverá `true`:
```js
compareObjects(personOne, personTwo); // true
```
En conclusión, podemos comparar dos objetos en JavaScript de diferentes formas, la mostrada en este artículo es una de ellas, pero existen otras formas de realizar esta tarea. | asjordi |
1,293,015 | Java By Example: Values | Java has various value types including String , Integer, Double, Boolean, etc. Here are a few basic... | 20,899 | 2022-12-12T06:09:27 | https://dev.to/alantsui5/java-by-example-values-1mng | java, beginners, programming | Java has various value types including `String` , `Integer`, `Double`, `Boolean`, etc. Here are a few basic examples.
The usage of these data types are shown in the below code block
```java
class Values {
public static void main(String[] args) {
// Strings, that can be added together with +.
System.out.println("Java" + " " + "Lang");
// Integer and Double
Integer sum = 1+1;
Double division = 7.0/3.0;
System.out.println("1+1 = " + sum);
System.out.println("7.0/3.0 =" + division);
//Booleans, with boolean operators as you’d expect.
System.out.println(true && false);
System.out.println(true || false);
System.out.println(!true);
}
}
```
Below are the commands and output.
```shell
javac Values.java
java Values
# Java Lang
# 1+1 = 2
# 7.0/3.0 = 2.3333333333333335
# false
# true
# false
``` | alantsui5 |
1,293,209 | How to make a python algorithm that will predict the results of a soccer game | It is not possible to create an algorithm that can accurately predict the results of a soccer game,... | 0 | 2022-12-12T10:33:22 | https://dev.to/daniel000/how-to-make-a-python-algorithm-that-will-predict-the-results-of-a-soccer-game-26c4 | It is not possible to create an algorithm that can accurately predict the results of a soccer game, let alone a World Cup semi-final. Soccer is a complex sport with many variables at play, including the skills and strengths of the individual players, the tactics of the coaches, and the specific conditions of the game (e.g. the field, the weather, etc.). There are too many unknowns and factors that can affect the outcome of the game to create a reliable predictive algorithm.
Even if you could somehow gather all the necessary data about the teams and players, the best you could hope for is to create a model that would give you the probability of each team winning, drawing, or losing. But even then, the model's predictions would not be guaranteed to be accurate, as there are always unexpected events and circumstances that can influence the outcome of a soccer game.
Here is an example of how you could approach creating a simple model to predict the outcome of a soccer game using Python:
Gather data on the teams and players, such as their past performance, individual player stats, and team tactics.
Use this data to create features that represent the relevant characteristics of each team and player. For example, you could create features for each team's average number of goals per game, the number of shots on target, the percentage of passes completed, etc.
Use a machine learning algorithm, such as a decision tree or a random forest, to train a model on this data. The model will learn to predict the outcome of a game based on the input features.
Test the model on a separate dataset to evaluate its accuracy.
However, as mentioned earlier, even the most advanced models and algorithms will not be able to accurately predict the outcome of a soccer game with complete certainty. The best you can do is to create a model that will give you an indication of the likely outcome based on the available data. | daniel000 | |
1,293,366 | How to implement OIDC authentication with Django and Okta | This article details how to implement OIDC authentication using Django and mozilla-django-oidc with... | 0 | 2022-12-13T10:38:26 | https://dev.to/hesbon/oidc-oauth2-authentication-using-django-and-mozilla-django-oidc-with-okta-4jll | python, django, okta, tutorial | This article details how to implement [OIDC](https://curity.io/resources/openid-connect) authentication using [Django](https://www.djangoproject.com/) and [mozilla-django-oidc](https://mozilla-django-oidc.readthedocs.io/en/stable/) with [Okta](https://developer.okta.com/) as our identity provider
## Introduction
- **OpenID Connect (OIDC)** is a protocol that allows a user to authenticate with a third-party service and then use that authentication to sign in to other services. OIDC is built on top of the OAuth2 protocol and adds an additional layer of authentication on top of it. This allows a user to not only grant permission for a service to access their data, but also to verify their identity.
- **Django** is a popular web framework for building web applications in Python. It includes a robust authentication system that can be easily configured to support OIDC.
- **Mozilla-django-oidc** is an open-source library that adds OIDC support to Django, making it easy to authenticate users with an OIDC provider.
- **Okta** is an identity and access management platform that enables organizations to securely connect users to technology. It supports the OIDC protocol, which allows users to be authenticated and receive information about their identity and access rights across different applications.
**Note**: _Here's a link to the final project on Github. {% embed https://github.com/Hesbon5600/oidc-connect %}_
---
## Part 1 : Setting up an Okta Account
To set up an Okta account for our OIDC account, follow these steps:
1. Go to the [Okta developer website](https://developer.okta.com/signup/) and create an account. Use your `gmail` account in order to get a free developer account.
2. After you have created your Okta account, log in to the Okta dashboard.
3. Click on the `Applications` tab in the left menu and then click on the `Create App Integration` button.
4. Choose `OIDC - OpenID Connect` `Sign-in method` and Select an `Application type` of `Web Application`, then click Next
5. Enter an App integration name (e.g oidc-connect).
Enter the Sign-in redirect URIs for local development, such as http://localhost:8080/authorization-code/callback.
6. Optionally Enter the Sign-out redirect URIs for both local development, such as http://localhost:8080/signout/callback.
7. In the `Assignments section`, define the type of `Controlled access` for your app. Select the `Everyone` group for now. For more information, see the [Assign app integrations](https://help.okta.com/okta_help.htm?type=oie&id=ext-lcm-user-app-assign) topic in the Okta product documentation.
8. `Click Save` to create the app integration. The configuration pane for the integration opens after it's saved.
**Note:** _Keep this pane open as you copy some values when configuring your app._
---
## Part 2.0 : Setting up the Django application
To set up a Django application, follow these steps:
1. Install Django by running the following command: ```bash
pip install django
```
2. Create a new Django project by running the following command:```bash
django-admin startproject oidc_app
```
3. This will create a new directory called "oidc_app" with the basic structure for a Django project. Change into the new directory by running the following command:```bash
cd oidc_app
```
4. Apply the default database migrations using the command.```bash
python manage.py migrate
```
5. Run the app on port `8080` using the following command.```bash
python manage.py runserver 8080
```
5. That's it! Your Django application is now set up and you are ready to move on to the next step: configuring Django to use OIDC.
---
## Part 2.2 : Creating a dummy login page and home screen
1. Create a superuser with the following command: ```bash
python manage.py createsuperuser```
2. Create a new app in your project directory by running the command: ```python manage.py startapp authentication```
3. Add `authentication` to the `INSTALLED_APPS` in `settings.py` as follows:```python
#oidc_app/settings.py
INSTALLED_APPS = [
...
"authentication",
]
```
3. Let's make our login page! By default, Django will look for auth templates within a templates folder. To create a login page, create a directory called `templates`, and within it a directory called `registration`.
4. Inside the `registration` directory, create a file called `login.html`. Add the following piece of code. ```html
<!-- oidc_app/templates/registration/login.html -->
<h2>Log In</h2>
<form method="post">
{% csrf_token %}
{{ form.as_p }}
<button type="submit">Log In</button>
</form>
```
5. Update the `settings.py` file to tell Django to look for a templates folder inside the oidc_app directory. Update the `DIRS` setting within `TEMPLATES` as follows.```json
# django_project/settings.py
TEMPLATES = [
{
...
'DIRS': [BASE_DIR.joinpath("oidc_app/templates")],
...
},
]
```
6. If you start the app and navigate to: `http://127.0.0.1:8080/accounts/login/`, You should see/test the login page. 
7. For the home page, we need to make a file called `home.html` located in the `templates` folder. The home page will display a different message to `logged out` and `logged in` users.```html
<!-- oidc_app/templates/base.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>{% block title %}Django OIDC{% endblock %}</title>
</head>
<body>
<main>
{% if user.is_authenticated %}
Hi {{ user.username }} - {{ user.email }}!
<p><a href="{% url 'logout' %}">Log Out</a></p>
{% else %}
<p>You are not logged in</p>
<a href="{% url 'login' %}">Log In</a>
{% endif %}
</main>
</body>
</html>
```
8. We now update the `urls.py` file in order to display the home page.```python
from django.contrib import admin
from django.urls import path, include
from django.views.generic.base import TemplateView
urlpatterns = [
path("admin/", admin.site.urls),
path("accounts/", include("django.contrib.auth.urls")),
path('', TemplateView.as_view(template_name='home.html'), name='index')
]
```
9. Now that we have a homepage view we should use that instead of the default setup. We update the settings file as follows: ```python
#oidc_app/settings.py
LOGIN_REDIRECT_URL = "index"
LOGOUT_REDIRECT_URL = "index"
```
9. Let's create a `superuser` that we can use to test the authentication. Type in the command: ```bash
python manage.py createsuperuser
```
10. Enter your desired username, email address and password. You should now have a superuser created for your Django project.
<table>
<tr>
<th>Logged Out</th>
<th>Logged In</th>
</tr>
<tr>
<td> <img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pnwr2x4ickiy82gq6c3w.png" alt="Logged Out" style="width: 250px;"/> </td>
<td> <img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/59n84rui5g66rh99efcq.png" alt="Logged in" style="width: 250px;"/> </td>
</tr>
</table>
**Note:** The above steps are a very basic example of how to set up a Django application. In a real-world scenario, you would likely want to do more advanced configuration and set up additional features such as a database and static file serving. For more information on how to do this, please see the [Django documentation](https://www.djangoproject.com/).
---
## Part 3.0 : Configuring Django to use OIDC.
**Note:** _We will be using the OpenID Connect Authorization Code Flow. Refer to the [Curity documentation](https://curity.io/resources/learn/openid-code-flow/) for more details._
> The Authorization Code Flow is the most advanced flow in OpenID Connect. It is also the most flexible, that allows both mobile and web clients to obtain tokens securely. It is split into two parts, the authorization flow that runs in the browser where the client redirects to the OpenID Provider (OP) and the OP redirects back when done, and the token flow which is a back-channel call from the client to the token endpoint of the OP.
`mozilla-django-oidc` package has abstracted all of the code flow steps required to enable OIDC authentication.
1. Once you’ve created and configured your Django application, you can start configuring `mozilla-django-oidc`. First, install mozilla-django-oidc using pip:```bash
pip install mozilla-django-oidc
```
2. Make the following changes to your `settings.py` file:```python
# oidc_app/settings.py
# Add 'mozilla_django_oidc' to INSTALLED_APPS
INSTALLED_APPS = (
# ...
'django.contrib.auth',
'mozilla_django_oidc', # Load after auth
# ...
)
# Add 'mozilla_django_oidc' authentication backend
AUTHENTICATION_BACKENDS = (
'mozilla_django_oidc.auth.OIDCAuthenticationBackend',
# ...
)
OKTA_DOMAIN = "[Your Okta domain]"
OIDC_RP_CLIENT_ID = "[Your Okta application’s client ID]"
OIDC_RP_CLIENT_SECRET = "[Your Okta application’s client secret]"
OIDC_RP_SIGN_ALGO = "RS256"
OIDC_OP_AUTHORIZATION_ENDPOINT = f"https://{OKTA_DOMAIN}/oauth2/default/v1/authorize" # The OIDC authorization endpoint
OIDC_RP_TOKEN_ENDPOINT = f"https://{OKTA_DOMAIN}/oauth2/default/v1/token" # The OIDC token endpoint
OIDC_OP_USER_ENDPOINT = f"https://{OKTA_DOMAIN}/oauth2/default/v1/userinfo" # The OIDC userinfo endpoint
OIDC_OP_TOKEN_ENDPOINT = f"https://{OKTA_DOMAIN}/oauth2/default/v1/token" # The OIDC token endpoint
OIDC_OP_JWKS_ENDPOINT = f"https://{OKTA_DOMAIN}/oauth2/default/v1/keys" # The OIDC JWKS endpoint
```
3. Next, edit your `urls.py` and add the following:```python
#oidc_app/settings.py
from mozilla_django_oidc import views as oidc_views
urlpatterns = [
# ...
path("authorization-code/authenticate/", oidc_views.OIDCAuthenticationRequestView.as_view(), name="oidc_authentication_init"),
path("authorization-code/callback/", oidc_views.OIDCAuthenticationCallbackView.as_view(), name="oidc_authentication_callback"),
# ...
]
```
4. We need to add `Login with Okta` option to our `login` page. Edit the `login.html` file as follows:```html
<!-- oidc_app/templates/registration/login.html -->
<h2>Log In</h2>
<form method="post">
{% csrf_token %}
{{ form.as_p }}
<button type="submit">Log In</button>
<br />
or
<br />
<a href="{% url 'oidc_authentication_init' %}">
<button type="button">Log In with Ota</button>
</a>
</form>
```
**Note:**
- You can get your `Okta Domain` by clicking on your profile section on the top right side of the page. 
- The Okta `client ID` and `client secret` are fund in the application settings (`oidc-connect` app we created)
## Part 3.1 Testing the Okta integration
1. Your login page should now have a 'Login with Okta' option
2. When you click the 'Login with Okta' button, you should be redirected to the okta domain for authentication.
3. Enter your username and password or sign in with Google.
4. After successful authentication, you should be redirected to the `home` page.

**Note:** The Username is a base64 encoded sha224 of the email address. More information can be found [here](https://github.com/mozilla/mozilla-django-oidc/blob/63f56222e3/mozilla_django_oidc/auth.py#L24)
**That's it!** You now have a Django app that authenticated with Okta.
The `mozilla-django-oidc` package can be further customized to better suit your application needs.
**Next Up:** {% embed https://dev.to/hesbon/customizing-mozilla-django-oidc-544p %}
Feel free to leave a comment or suggestion. Thank you!
| hesbon |
1,293,431 | Debugging the Laughter: Programming Memes for Nerdy Humor | Share your meme in the comments. | 0 | 2022-12-12T13:24:02 | https://dev.to/fahad_islam/programming-memes-mgp | programming, meme | Share your meme in the comments.

| fahad_islam |
1,293,457 | What is Super App [In-depth 📕 Explanation] | What is a Super App? A super app is a mobile application that offers a wide range of... | 0 | 2022-12-12T14:10:23 | https://dev.to/sandeep_modi123/what-is-super-app-in-depth-explanation-km7 | flutter, mobile, appdev, android | ## What is a Super App?
A super app is a mobile application that offers a wide range of services and features, including communication, social networking, e-commerce, entertainment, and more. Awesome apps are designed to be an all-in-one solution for users, providing access to a wide variety of services and content within a single app. This can provide convenience for users, as they do not have to download and manage multiple separate apps for different services.
## What Types of Categories Can You Add In Your Super App?
The types of categories that can be included in a super app will depend on the specific services and features offered by the app, as well as the target audience and market. However, some common categories that may be included in a super app are communication, social networking, e-commerce, entertainment, finance, health and fitness, travel, news and media, and more. Additionally, a super app may offer specialized categories for specific services or industries, such as food delivery, ride-sharing, or real estate. Ultimately, the types included in a super app should be tailored to the needs and interests of the app's users.
### Social networking
A super app may include a social networking function, allowing users to connect with friends, family, and other contacts, share updates and photos, and participate in group conversations or activities. This can provide a convenient way for users to stay in touch and engage with their social network within a single app rather than having to use separate apps for different social networking services. The specific features and functions of the social networking aspect of a super app will depend on the app's design and target audience. Still, it may include features such as creating and managing a user profile, adding and connecting with other users, posting and sharing updates and photos, participating in group conversations or activities, and more.
### E-commerce
A super app may include an e-commerce function, allowing users to browse and shop for products and services directly within the app. This can provide convenience and a seamless shopping experience for users who do not have to leave the app to visit a separate e-commerce website or platform. The specific features and capabilities of the e-commerce aspect of a super app will depend on the app's design and target audience. Still, it may include features like the ability to browse and search for products, view detailed product information and reviews, add items to a virtual shopping cart, complete the checkout process, and track orders and deliveries. Some super apps may offer additional e-commerce features such as personalized product recommendations, special offers and promotions, and integrated payment and shipping options.
### Entertainment
A super app may include an entertainment function, providing users access to various entertainment content and experiences. This can include music and video streaming, gaming, news and media, and more. The specific entertainment offerings of a super app will depend on the app's design and target audience. Some common examples include the ability to stream music and videos, play games, read news and articles, watch live sports or events, and more. The entertainment aspect of a super app can provide a convenient and engaging way for users to access and enjoy various content and experiences within a single app.
### Finance
A super app may include a finance function, allowing users to manage their money and make financial transactions directly within the app. This can provide a convenient and secure way for users to access and manage their financial accounts, pay bills, transfer funds, and more. The specific features and capabilities of the finance aspect of a super app will depend on the app's design and target audience. Still, it may include features such as linking and managing multiple banks and credit card accounts, viewing account balances and transaction history, making payments and transfers, setting up and managing budgets and financial goals, and more. Some super apps may offer additional finance-related features such as investment and savings tools, credit and loan services, and personalized financial advice and recommendations.
### Health and Fitness
A super app may include a health and fitness function, providing users with tools and resources to track and improve their physical and mental well-being. This can include fitness tracking, health, and nutrition information, mental health and mindfulness resources, and more. The specific health and fitness offerings of a super app will depend on the app's design and target audience. Some common examples include the ability to track physical activity and nutrition, set and track fitness goals, access health and nutrition information and resources, participate in virtual fitness classes or challenges, and more. The health and fitness aspect of a super app can provide a convenient and comprehensive way for users to improve and maintain their overall health and well-being.
### Travel, News, and Media
A super app may include a travel function, allowing users to plan and book their travel arrangements directly within the app. This can have flights, hotels, rental cars, and more. The specific travel offerings of a super app will depend on the app's design and target audience. Still, some common examples include the ability to search and compare flights, hotels, and rental cars, view and compare itineraries and prices, book and manage travel arrangements, access travel information and resources, and more. The travel aspect of a super app can provide a convenient and streamlined way for users to plan and book their travel without having to visit multiple websites or apps.
A super app may also include a news and media function, providing users access to a wide range of news and media content. This includes local, national, and international news, sports, entertainment, and more. The specific information and media offerings of a super app will depend on the app's design and target audience. Some common examples include the ability to access and read news articles and stories, watch videos and live events, listen to podcasts, and more. The news and media aspect of a super app can provide a convenient and engaging way for users to stay informed and entertained.
Developing a super app is a great way to get your business' name in front of many customers. You can also add value to your brand by integrating a financial service within your mobile app. That way, you can have a cohesive customer experience. It also allows you to leverage artificial intelligence predictive analytics.
## Design Considerations for a Super app
Creating a super app is a challenging task. It requires a great deal of thought and planning. The process involves:
Identifying and understanding your target audience.
Determining their demographics.
Devising a long-term strategy to maximize revenue and increase wallet share.
A super app provides a unified user experience across multiple services. This helps customers reduce the need to install individual apps and reduces re-acquisition costs. It also reduces the need for users to maintain various login credentials. It is also space-efficient and time-efficient. Combining many services into one app eliminates the need to sift through a library of apps.
Whether you're building a healthcare, retail, or payment app, a well-defined design strategy is essential for a satisfying user experience. This includes UI/UX design, wireframes, and testing tools. It would help if you also considered the programming language and typography used and where and how services will be placed.
Another challenge in developing a super app is managing the API integration. It's essential to ensure that the app has a smooth and responsive user experience while maintaining privacy. It would help if you also considered implementing robust user login authentication to create a top-notch security experience.
Embedding financial services within a brand's app gives a coherent customer experience.
Embedded finance is a hot topic in the financial services industry. These services can be delivered through various means, including mobile, online, and in-person. Embedded finance can catalyze a company's growth by introducing new revenue streams and repurposing existing assets. It may be too early to tell where this industry is headed, but we've already seen some notable winners.
The best way to judge the state of play is to look at the big picture, which consists of a few pillars. Among them is a large pool of consumers willing to partake in financial services through digital channels and new and emerging technologies. As the market expands, providers must become more adept at sharing customers and data to survive. A few major players are starting to offer a wider variety of digital services, from mobile apps to real-time payments.
## Embracing Artificial Intelligence Predictive Analytics
Embracing artificial intelligence predictive analytics when developing a super app is a great way to enhance customer experience, reduce costs, and increase revenue. The technology can help businesses optimize supply chain management and marketing, better project demand, and improve employee productivity. It can also help companies provide a rich, personal, and convenient user experience.
The use of AI to create competitive advantages is already underway. For instance, Ocado, the UK online supermarket, has deployed an AI application that uses machine learning to guide the driver of its warehouse robotics, whisking bags of groceries from the store to the van. This allows the robot to pick the best route based on traffic, weather, and other data.
A survey of 3,000 business leaders found that most need help integrating AI into their organizations. However, the study's results demonstrate that successful programs require adapting capabilities, culture, and management practices.
The report's findings indicate that the most critical enablers of successful AI programs are data access and management and seamless data exchange. A successful program will likely require investment to develop capabilities in workers and managers. Ultimately, success will depend on demonstrating the economic applications of AI.
## Cost to Develop a Super App
Developing a super app requires a significant amount of resources and capital. However, the benefits of building a super application for your business are substantial.
The benefits include:
Increased business connections.
A more extensive user base.
More opportunities to generate revenue.
Businesses can also use data to improve the customer experience. For example, super apps can provide customers with a more convenient and hassle-free way to pay for services. It can also reduce the chances of IT product-based failure.
Various industries can benefit from super apps. For example, healthcare apps can offer diet plans, medication monitoring, and online doctor consultations. The convenience of using super apps can help consumers conduct all their Internet activities in one place. Many startups are opting for Flutter for Super app development.
Super applications can help businesses attract a more extensive consumer base. Aside from creating a new revenue stream, these apps can improve user retention rates. When the user is satisfied with the services they receive, they may even become mouth marketers.
## Examples of Super Apps
A super app is a mobile application that offers a wide range of services and functions within a single app. Some examples of super apps include WeChat, Gojek, and Alipay. These apps often include features such as messaging, payment processing, ride-hailing, food delivery, and more.
### WeChat
WeChat is a popular Chinese multi-purpose messaging, social media, and mobile payment app developed by Tencent. It is often referred to as a "super app" because it offers a wide range of services and functions within a single app, including messaging, payment processing, ride-hailing, food delivery, and more. WeChat has over 1 billion monthly active users and is widely used in China and other Asia.
### Gojek
Gojek is a famous Indonesian multi-purpose app that offers a wide range of services and functions within a single app. It is often referred to as a "super app" because it includes features such as on-demand food and grocery delivery, ride-hailing, and payment processing. Gojek was founded in 2010 and has since expanded to serve users in several countries in Southeast Asia. It has a large user base and is known for its convenient and user-friendly platform.
It was founded in 2010 by Nadiem Makarim and has since grown to serve users in several countries in Southeast Asia.
It is often referred to as a "super app" because it includes features such as on-demand food and grocery delivery, ride-hailing, and payment processing.
Gojek has a large user base and is known for its convenient and user-friendly platform.
In 2018, Gojek merged with another Indonesian ride-hailing company, Grab, to create a joint venture called Gojek-Grab.
Gojek has raised over $3 billion in funding from investors, including Alphabet's venture capital arm, Google Ventures.
The company has also expanded into other areas, such as digital financial and health services.
## Flutter for Supper Apps Development?
One of the main reasons to use Flutter for building super apps is that it allows developers to create a single codebase that can be used to build both Android and iOS apps. This means that developers only need to write the code once, and they can then use it to build native-looking apps for both platforms. This can save a lot of time and effort, and it also makes it easier to maintain and update the app in the future.
Another reason to use Flutter is that it has a number of built-in design elements and widgets that can be used to create beautiful and intuitive user interfaces. This means that [Flutter developers](Flutter developers) can focus on building the app's functionality and features, rather than spending a lot of time and effort on creating a visually appealing user interface.
Flutter is also known for its fast performance, which is important for building super apps that need to be able to handle a large amount of data and provide a smooth and responsive user experience. It uses the Dart programming language, which is compiled ahead-of-time into native code, which allows it to run smoothly and efficiently on both Android and iOS devices.
Overall, Flutter is a powerful and flexible framework that is well-suited for building super apps. It has a number of features that make it an attractive choice for developers, including its ability to create a single codebase for both Android and iOS, its built-in design elements and widgets, and its fast performance.
## What Are the Challenges of Developing a Super App?
There are several challenges that businesses may face when developing a super app, including the following:
Integration of multiple services: A key feature of a super app is integrating multiple services, such as messaging, social media, e-commerce, and gaming. This can be a complex process, requiring careful planning and coordination to ensure that the different services work seamlessly together.
User experience: Another challenge in super app development is ensuring that the user experience is consistent and intuitive across all of the different services offered by the app. This requires a deep understanding of user behavior and the ability to design an app that is easy to use and navigate.
Scalability: Super apps often have a large user base and a high volume of transactions, making scalability a vital consideration. The app must be able to handle a large number of users and transactions without experiencing performance issues or downtime.
Security: Since super apps often handle sensitive user information and financial transactions, security is crucial. The app must be designed and developed with robust security measures to protect user data and prevent fraud and other security threats.
Regulatory compliance: Depending on the services offered by the app and the countries where it is used, a super app may be subject to various regulatory requirements. Meeting these requirements can be challenging, especially if the app is being developed in multiple countries with different regulatory frameworks.
## What Technologies Are Typically Used in the Development of a Super App?
The specific technologies used in the development of a super app will depend on the app's specific features and services and the development team's preferences. However, some standard technologies used in the development of mobile apps, in general, include the following:
Programming languages: Many mobile apps are developed using Java, Kotlin, and Swift. These languages are designed to be easy to use and scalable, making them well-suited to developing complex apps like super apps.
Developers often use frameworks and libraries to make app development more efficient and reduce the amount of code that needs to be written. Some examples of popular frameworks and libraries used in mobile app development include React Native, Flutter, and Ionic.
Databases and data storage: Mobile apps often need to store and manage large amounts of data, such as user information and transaction records. This can be done using databases and other data storage technologies, such as SQLite, Realm, and Firebase.
APIs: Many mobile apps use APIs (Application Programming Interfaces) to communicate with other systems and services. For example, a super app may use APIs to integrate with social media platforms, payment gateways, and other services.
Security technologies: To protect user data and prevent security threats, mobile apps often use various security technologies, such as encryption, authentication, and access control. Examples of standard security technologies used in mobile app development include SSL/TLS, OAuth, and JSON Web Tokens (JWTs.
## How Can Businesses Ensure the Success of Their Super App?
There is no surefire way to guarantee a super app's success, as any app's success depends on various factors. However, there are some steps that businesses can take to increase the chances of success for their super app, including the following:
### Conduct market research
Before beginning development, it's essential to conduct thorough market research to understand the needs and preferences of the target audience. This can help businesses identify the services and features that users want and tailor the app to their needs.
### Collaborate with partners
A super app often integrates with other services and platforms, such as social media, payment gateways, and e-commerce platforms. To ensure the app's success, it's essential to build strong partnerships with these platforms and collaborate closely on integration and other aspects of the app.
### Focus on user experience
A critical factor in the success of any app is the user experience. Businesses should prioritize the user experience in the design and development of their super app, ensuring that it is easy to use and offers a consistent experience across all services.
### Invest in marketing and promotion
To attract users and drive the app's adoption, businesses need to invest in marketing and promotion. This can include advertising, public relations, and partnerships with influencers and other organizations.
### Monitor and optimize performance
After launching the app, monitoring its performance and gathering user feedback is essential. This can help businesses identify areas for improvement and optimize the app to provide the best possible experience for users.
## Conclusion
There are several reasons businesses may choose to work with an expert [mobile app development services](https://ultroneous.com/mobile-application-development) company rather than developing an app in-house or working with a freelance developer. Some of these reasons include the following: Expertise and experience, Efficiency and speed, Support and maintenance, Access to a broader talent pool, Better project management. | sandeep_modi123 |
1,293,727 | How VuePress can save your time? | VuePress is a static site generator based on the Vue.js JavaScript framework. It is designed to be... | 0 | 2022-12-12T17:40:35 | https://dev.to/pulkitsingh/how-vuepress-can-save-your-time-1i6f | vue, jamstack, javascript, tutorial | VuePress is a static site generator based on the Vue.js JavaScript framework. It is designed to be simple and easy to use, and it allows developers to quickly create and publish static sites with minimal configuration.
Today we are going to take a look at VuePress's features to make a simple content, Git-Based Blog.
1. Install VuePress: To use VuePress, you first need to install it. You can do this by running the following command:
```
npm install -g vuepress
```
2. Create a new project directory: Next, create a new directory for your project and navigate to it in your terminal.
3. Initialize the project: Once you are in your project directory, run the following command to initialize the project:
```
vuepress init
```
4. Create a new markdown file: **VuePress** uses _markdown_ files to generate static pages, so you will need to create a new markdown file for your blog post. To do this, create a new file called **blog-post.md** in your project directory.
5. Add the content for your blog post: Open the blog-post.md file in a text editor and add the content for your blog post. You can use regular markdown syntax to format your text and add images, links, and other elements.
6. Start the VuePress development server: VuePress includes a built-in development server that allows you to preview your blog post as you work on it. To start the development server, run the following command:
```
vuepress dev
```
7. Preview your blog post: Once the development server is running, you can preview your blog post by opening a web browser and navigating to the following URL:
```
http://localhost:8080/blog-post.html
```
8. Build the static site: Once you are satisfied with your blog post, you can build the static site by running the following command:
```
vuepress build
```
For more about `VuePress` visit the Vuepress docs [here](https://vuepress.vuejs.org/guide/)
> I hope this helps! Let me know if you have any other questions.
| pulkitsingh |
1,293,810 | Creating a simple CRUD app on Spring Boot using H2, Hibernate | Introduction Creating a CRUD (Create, Read, Update, Delete) application on Spring Boot using H2,... | 0 | 2022-12-12T20:48:30 | https://dev.to/ashutoshdubey133/creating-a-simple-crud-app-on-spring-boot-using-h2-hibernate-o3p | java, beginners, programming | **Introduction**
Creating a CRUD (Create, Read, Update, Delete) application on Spring Boot using H2, Hibernate is a great way to quickly develop a powerful and efficient web application. In this tutorial, we will walk through the steps of creating a simple CRUD application on Spring Boot using H2, Hibernate.
**Prerequisites**
Before starting this tutorial, you should have the following installed:
- Java 8 or higher
- Apache Maven 3.x
- Eclipse IDE
You should also have a basic understanding of the Spring Boot framework and the H2 and Hibernate databases.
**Step 1: Create a Spring Boot Project**
The first step to creating a CRUD application on Spring Boot using H2, Hibernate is to create a Spring Boot project. To do this, open the Eclipse IDE and select “File > New > Spring Starter Project” from the menu bar.
In the next window, enter a project name, choose the language as Java, and select the Spring Boot version. Then, click “Next”.
On the next screen, select the dependencies for your project. For this tutorial, we will choose “Web”, “H2 Database”, and “JPA (Hibernate)”. Click “Finish” to create the project.
**Step 2: Create the Database Tables**
Now that we have our project created, we need to create the database tables. To do this, open the “application.properties” file located in the “src/main/resources” folder.
In this file, we will set the database URL, username, and password. For this tutorial, we will use “jdbc:h2:mem:testdb” as the database URL. Set the username and password as “sa”.
Next, we will create the database tables. To do this, create a new file called “schema.sql” in the “src/main/resources” folder. In this file, we will write the SQL code to create the database tables. For example:
```
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255)
);
CREATE TABLE posts (
id INTEGER PRIMARY KEY,
title VARCHAR(255),
content VARCHAR(255)
);
```
**Step 3: Create the Entity Classes**
The next step is to create the entity classes. These classes will be used to map the database tables to Java objects.
Create a new package called “entities” in the “src/main/java” folder. In this package, create two classes called “User” and “Post”.
For the User class, add the following code:
```
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Getters and setters
}
```
For the Post class, add the following code:
```
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
// Getters and setters
}
```
**Step 4: Create the Repository Classes**
The next step is to create the repository classes. These classes will be used to access the database and perform CRUD operations.
Create a new package called “repositories” in the “src/main/java” folder. In this package, create two classes called “UserRepository” and “PostRepository”.
For the UserRepository class, add the following code:
```
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}
```
For the PostRepository class, add the following code:
```
@Repository
public interface PostRepository extends JpaRepository<Post, Long> {
}
```
**Step 5: Create the Service Classes**
The next step is to create the service classes. These classes will be used to manage the data and perform operations.
Create a new package called “services” in the “src/main/java” folder. In this package, create two classes called “UserService” and “PostService”.
For the UserService class, add the following code:
```
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> getAllUsers() {
return userRepository.findAll();
}
public User getUserById(Long id) {
return userRepository.findById(id).get();
}
public User createUser(String name, String email) {
User user = new User();
user.setName(name);
user.setEmail(email);
return userRepository.save(user);
}
public User updateUser(Long id, String name, String email) {
User user = userRepository.findById(id).get();
user.setName(name);
user.setEmail(email);
return userRepository.save(user);
}
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
}
```
For the PostService class, add the following code:
```
@Service
public class PostService {
@Autowired
private PostRepository postRepository;
public List<Post> getAllPosts() {
return postRepository.findAll();
}
public Post getPostById(Long id) {
return postRepository.findById(id).get();
}
public Post createPost(String title, String content) {
Post post = new Post();
post.setTitle(title);
post.setContent(content);
return postRepository.save(post);
}
public Post updatePost(Long id, String title, String content) {
Post post = postRepository.findById(id).get();
post.setTitle(title);
post.setContent(content);
return postRepository.save(post);
}
public void deletePost(Long id) {
postRepository.deleteById(id);
}
}
```
**Step 6: Create the Controller Classes**
The final step is to create the controller classes. These classes will be used to map the requests to the service classes.
Create a new package called “controllers” in the “src/main/java” folder. In this package, create two classes called “UserController” and “PostController”.
For the UserController class, add the following code:
```
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserService userService;
@GetMapping
public List<User> getAllUsers() {
return userService.getAllUsers();
}
@GetMapping("/{id}")
public User getUserById(@PathVariable Long id) {
return userService.getUserById(id);
}
@PostMapping
public User createUser(@RequestBody User user) {
return userService.createUser(user.getName(), user.getEmail());
}
@PutMapping("/{id}")
public User updateUser(@PathVariable Long id, @RequestBody User user) {
return userService.updateUser(id, user.getName(), user.getEmail());
}
@DeleteMapping("/{id}")
public void deleteUser(@PathVariable Long id) {
userService.deleteUser(id);
}
}
```
For the PostController class, add the following code:
```
`@RestController
@RequestMapping("/posts")
public class PostController {
@Autowired
private PostService postService;
@GetMapping
public List<Post> getAllPosts() {
return postService.getAllPosts();
}
@GetMapping("/{id}")
public Post getPostById(@PathVariable Long id) {
return postService.getPostById(id);
}
@PostMapping
public Post createPost(@RequestBody Post post) {
return postService.createPost(post.getTitle(), post.getContent());
}
@PutMapping("/{id}")
public Post updatePost(@PathVariable Long id, @RequestBody Post post) {
return postService.updatePost(id, post.getTitle(), post.getContent());
}
@DeleteMapping("/{id}")
public void deletePost(@PathVariable Long id) {
postService.deletePost(id);
}
}`
```
**<u>Conclusion</u>**
In this tutorial, we have walked through the steps of creating a simple CRUD application on Spring Boot using H2, Hibernate. We have created our project, created the database tables, created the entity classes, created the repository classes, created the service classes, and created the controller classes.
With this application, we can now easily create, read, update, and delete data using the H2 and Hibernate databases. | ashutoshdubey133 |
1,294,198 | Serving Notion Presigned Images with Cloudflare Workers | I recently made a pretty big change on my website. For the first time ever, my posts don’t live in... | 0 | 2022-12-13T04:56:01 | https://macarthur.me/posts/serving-notion-presigned-images-with-cloudflare | cloudflare, edge, notion, jamstack | ---
title: Serving Notion Presigned Images with Cloudflare Workers
published: true
date: 2022-12-12 05:00:00 UTC
tags: cloudflare, edge, notion, jamstack
canonical_url: https://macarthur.me/posts/serving-notion-presigned-images-with-cloudflare
---
I recently made a pretty big change on my website. For the first time ever, my posts don’t live in Markdown files. Instead, they’re all in Notion, the tool I’ve been using to draft posts for quite some time now. It’s nice being able to have a top-notch writing experience without the need to perform a clunky Markdown export when it’s finally time to publish.
Most of the migration was pretty boring & straightforward, but there was a particular piece of it that was interesting to navigate: **serving images**.
If you look at the underlying URL of any image in Notion, you’ll notice it’s [presigned](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-presigned-url.html), and after a fixed number of hours has passed, that URL will expire. This posed a challenge. My site is statically generated with Next.js, and if I directly embedded those raw Notion links, my images would all cease to work after a while.
I needed a cheap solution that wouldn’t require a painfully complicated process to set up. Thankfully, CloudFlare has some handy tools in its suite for pulling this off.
## The P **anacea that is Cloudflare**
There are two distinct problems to solve here, each of which paired nicely with one of Cloudflare’s offerings.
First, whenever one of my pages containing images is viewed, I needed to intercept each image request in order to serve it from a location that’s _not_ Notion. A Cloudflare Worker is perfect for this job. Workers operate at the edge, so you can run server-side code with a similar level of performance as serving a static file from a CDN. Plus, the free tier is generous and the developer experience is buttery smooth.
Second, I needed a place to put those images before they’re served on my site. Not long ago, Cloudflare introduced a tempting alternative to Amazon’s S3 product — [R2 Object Storage](https://www.cloudflare.com/products/r2/). It touts zero egress fees (meaning it’s dirt cheap if you’re largely just reading static assets), and an API that’s fully compatible with S3 (bonkers). I knew this would mesh nicely with what I was aiming to do.
## The Build
With these tools at my disposal, here’s how I set it up:
### Step #1: Upload images on site build.
It’s nice that R2 is compatible with AWS, because all this meant was installing the `aws-sdk`, configuring it with my Cloudflare access key, and setting up the code to upload images when my Next.js site is built. This process involved two main parts.
**Determining Image Keys**
First, I determined the key by which I’m save each image by hacking apart the URL embedded within my Notion posts. In raw form, they look something like this:
```
https://s3.us-west-2.amazonaws.com/secure.notion-static.com/d527ddf8-acdc-4284-914d-8d4fefeda507/Untitled.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAT73L2G45EIPT3X45%2F20221016%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20221016T223440Z&X-Amz-Expires=86400&X-Amz-Signature=841d76d1a556204dc3d9c5a3d838913e3409224fe6d070a92fc9a9738918479e&X-Amz-SignedHeaders=host&response-content-disposition=filename%20%3D%22Untitled.png%22&x-id=GetObject
```
I chose to use the random-looking string of characters immediately following the hostname. This would be the unique identifier by which I upload each image to R2:
```
function extractKey(imageUrl: string): string {
const url = new URL(imageUrl);
const parts = url.pathname.split("/");
return parts[parts.length - 2];
}
const key = extractKey(
"https://s3.us-west-2.amazonaws.com/secure.notion-static.com/d527ddf8-acdc-4284-914d-8d4fefeda507/Untitled.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAT73L2G45EIPT3X45%2F20221016%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20221016T223440Z&X-Amz-Expires=86400&X-Amz-Signature=841d76d1a556204dc3d9c5a3d838913e3409224fe6d070a92fc9a9738918479e&X-Amz-SignedHeaders=host&response-content-disposition=filename%20%3D%22Untitled.png%22&x-id=GetObject"
);
// key: 802f4ae5-100d-4ce1-9912-82fe84b11733
```
**Conditionally Upload Based on Key**
Once the key was determined, it was time for the upload itself, which I bypass if the upload has already occurred. I wrote a `StaticAssetService` class to perform this work, which uses R2 as a `provider` responsible for hosting those assets. The interesting part of that code looks like this. Feel free to [dive in more here](https://github.com/alexmacarthur/macarthur-me-next/blob/main/lib/StaticAssetService.ts#L14).
```
async put(imageUrl: string, key: string): Promise<any> {
try {
// I've already uploaded an image with this key! Don't do it again.
if (await this.get(key)) {
return Promise.resolve();
}
} catch (e) {
console.error(`Retrieval failed! Key: ${key}, url: ${imageUrl}`);
}
try {
// Upload the image!
return this.provider.uploadImage({
imageUrl,
key,
});
} catch (e) {
console.error(`Upload failed! Key: ${key}, url: ${imageUrl}`);
return Promise.resolve();
}
}
```
**Important: Setting the Correct Content-Type**
There’s one gotcha worth calling out regarding this process. By default, `binary/octet-stream` is set as the content type upon upload (rather than something like `image/png`), which would prevent the image from rendering when it’s finally served. The solution is to set that type on each upload, based on file you’re attempting to process. Here’s a closer look at that `uploadImage` method:
```
async uploadImage({ imageUrl, key }: { imageUrl: string; key: string }) {
const res = await fetch(imageUrl);
const blob = await res.arrayBuffer();
return s3
.upload({
Bucket: BUCKET_NAME,
Key: key,
Body: Buffer.from(blob),
// Set the correct `ContentType` here!
ContentType: res.headers.get("Content-Type") as string,
})
.promise();
}
```
A special shout-out is due to the participants of [this GitHub issue](https://github.com/SoftwareBrothers/adminjs-upload/issues/37) for helping resolve this. With that piece in place, I can see every new upload appear in Cloudflare after I build my site:

The entire process can be represented like so:

### Step #2: Rewrite image URLs before generating HTML.
You can only use a worker to intercept requests on _your own domain_ set up with Cloudflare. So, if I wanted to handle my images in a certain way when they’re requested (like swap them out with an image from R2), I’d need to make it _look_ like they belong to my domain before I build my HTML. I landed on transforming each presigned URL into a relative path with the following pattern: `/proxy/IMAGE_ID`. My worker would then be configured to listen for requests to this path and do as I see fit.
### Writing the Pattern
In order to perform this URL transformation, I used a regular expression that would swap out the presigned URL with my `/proxy/IMAGE_KEY` path, using the image key I extracted earlier.
The image “block” I’d get from Notion each time is composed of normal Markdown, containing an optional “alt” description and the long, presigned URL.
```

```
In order to preserve that description while I update the path, I used the following pattern:
```
!\[(.*?)\]\((.*)\)
```
Here’s a brief breakdown of that pattern:
| **Pattern Part** | **Description** |
| --- | --- |
| `!\[(.*?)\]` | Captures the “alt description” between square brackets, so I could preserve it in my updated markup. |
| `\(.*\)` | Matches against the remaining URL between parentheses, in order to replace it with an updated path. |
Finally, I used `.replace()` to perform the operation:
```
let key = keyExtractedEarlierInTheBuild();
let updatedMarkdownImage = originalMarkdownImage.replace(
/!\[(.*?)\]\(.*\)/,
``
);
```
Now that my images would all attempt to be requested from my own domain, I could finally set up a worker to intercept and pull them from R2.
### #3. Intercept Image Requests with a Worker
One of the reasons this solution works so well is due to Cloudflare Workers’ first-class integration with R2. As such, the flow for my worker isn’t complex and can be visualized by the following sequence diagram:

In words, any given request is handled like so:
- For **image requests** (those made to `/proxy/IMAGE_ID`), intercept and return the the image by the embedded path ID from R2.
- For **all other requests,** allow the request to pass through to my site on Vercel.
### Setting Up My Worker
While you can write it directly in the browser, I chose to [use Wangler](https://developers.cloudflare.com/workers/get-started/quickstarts/) to build & experiment with my worker locally. There’s a learning curve, but it’s minimal, and eased by the fact that Cloudflare Workers are built on the [fetch API](https://developers.cloudflare.com/workers/runtime-apis/fetch/). If you’ve spent a decent amount of time with it in the browser, it won’t take long to feel at home with it here too.
My worker is simple — consisting of only one “route,” set up with [itty-router](https://github.com/kwhitley/itty-router). Starting from scratch, it first looked something like this:
```
import { Router } from "itty-router";
const router = Router();
router.get(
"/proxy/:imageId",
async (request: Request, env: AppEnv, ctx: ExecutionContext) => {
return new Response("hello");
}
);
export default {
async fetch(
request: Request,
env: AppEnv,
context: ExecutionContext
): Promise<Response> {
// If an exception is thrown, hit the origin server.
context.passThroughOnException();
return router.handle(request, env, context).then(response => response);
}
};
```
When any request hits my worker, it’ll try to match against that `/proxy/:imageId` endpoint. If it doesn’t, the request will be forwarded to the origin server like normal (in this case, Vercel, where my site is hosted). But if it does match, the request will be intercepted and returned with a `new Response()`:

### Retrieving an Image from R2
After that, I took it to the next level by integrating with R2. Each request comes in with an `imageId` that corresponds to an image that was previous uploaded to R2. Cloudflare makes it easy to connect a bucket of your choosing to your worker. That meant creating a binding in my `wrangler.toml` file, which specifies the buckets I use in production & development:
```
# ... the rest of my wrangler.toml
[[r2_buckets]]
binding = 'MACARTHUR_ME'
bucket_name = 'macarthur-me'
preview_bucket_name = 'macarthur-me-dev'
```
Then I could use that binding to fetch objects in my worker:
```
import { Router } from "itty-router";
interface AppEnv {
MACARTHUR_ME: R2Bucket;
}
interface IRequest extends Request {
method: "GET";
url: string;
params: { imageId: string }
}
const router = Router();
router.get(
"/proxy/:imageId",
async (request: IRequest, env: AppEnv, ctx: ExecutionContext) => {
const { imageId } = request.params;
// Fetch the image by ID:
const obj = await env.MACARTHUR_ME.get(imageId);
if (!obj) {
return new Response(`Image not found: ${imageId}`, { status: 404 });
}
return new Response(obj.body);
}
);
```
After that, the result of my request yielded a different result:

### Setting up Client Headers
After that, I just needed to adjust a couple headers on response sent to the browser. The first was “Content-Type,” which ensures that browsers can correctly serve images, and the second is “Cache-Control,” which tells clients they’re permitted to locally cache the image for up to a year.
```
router.get(
"/proxy/:imageId",
async (request: IRequest, env: AppEnv, ctx: ExecutionContext) => {
// ...
+ const response = new Response(obj.body);
+ const headers = {
+ "Content-Type": obj.httpMetadata!.contentType as string,
+ "Cache-Control": "public, max-age=31560000",
+ };
+ const response = new Response(obj?.body, { headers });
ctx.waitUntil(caches.default.put(cacheKey, response.clone()));
return response;
}
);
```
This met minimal needs, but it could be improved with one more small caching optimization…
### Setting up Object Caching
In addition to being able to tell the client how to cache an asset, workers can leverage a proprietary cache provided by Cloudflare. It provides a simple key/value interface, which uses a (cloned) request as the cache key. When a request comes in, if we already have a response matching that request, we can return that. And if not, the image is fetched from R2 and stuck into the same cache for later.
```
router.get(
"/proxy/:imageId",
async (request: IRequest, env: AppEnv, ctx: ExecutionContext) => {
const { imageId } = request.params;
// Create a cache key from existing request.
const cacheKey = new Request(request.url.toString(), request);
const cachedImage = await caches.default.match(cacheKey);
if (cachedImage) {
console.log(`Cache HIT for ${imageId}`);
return cachedImage;
}
// ... other code for retrieving the image ...
const response = new Response(obj.body, { headers });
// Save the response to cache.
ctx.waitUntil(caches.default.put(cacheKey, response.clone()));
return response;
}
);
```
It’s nothing world-changing, but should reduce the number of requests to my R2 bucket. And I’m all for some free micro-optimization.
## Just the Beginning
This was my first experience dabbling with a Cloudflare Worker. Up until now, the use cases all felt pretty hypothetical. But now that I’ve personally found value in using one to solve a problem, I imagine it won’t be long before I reach for one again — especially with the [wide range of capabilities](https://developers.cloudflare.com/workers/examples/) they empower.
If you’d like to dig into what’s here a little more, check out these links:
- [My Next Site](https://github.com/alexmacarthur/macarthur-me-next)
- [Image Proxying Worker](https://github.com/alexmacarthur/cloudflare-image-proxying)
Hoping this encourages you to try one out for yourself! | alexmacarthur |
1,294,234 | HackNITR 4.0 | Register here As the legacy continues, we bring our flagship event back. HackNITR 4.0 is a... | 0 | 2022-12-13T06:59:25 | https://dev.to/eswar3008/hacknitr-40-4pp9 | hackathon, programming, community, beginners | [Register here](https://www.hacknitr.com/)

As the legacy continues, we bring our flagship event back. HackNITR 4.0 is a collaboration between DSC NIT Rourkela and OpenCode, is all set to get the ball rolling with a larger definition than the previous editions. With more than 2200 registrations, 50+ sponsors and INR 5,00,000+ worth prizes, HackNITR 3.0 is in itself a testimony to the grandeur we await this time.
Buckle up! HackNITR 4.0 is going to be a bumpy ride full of perks, goodies, experience and fun.
With the love and feedback that we received from the last edition, here are a few added perks why you should definitely join us in this hacking extravaganza
**About HackNITR 4.0**
HackNITR 4.0 is a hackathon to encourage you to use your imagination and invention to develop cutting-edge technology-based solutions to challenges in the real world. It was put together by a large group of tech enthusiasts from Google Developer Student Club (GDSC) NIT Rourkela and OpenCode. The main goal is to grow our local community and give hackers an unforgettable experience. The plethora of fun and excitement is waiting for you from 6th Jan 2023.
**HackNITR accomplishments so far!**
HackNITR is glad to announce its 1000+ registration. But this is just the beginning. We provide you with this wonderful opportunity to network with others who share your interests, collaborate with them, and share expertise to quickly create exceptional projects and find answers to urgent real-world problems.

Register now to experience one of the largest student-run hackathon of India.
**How can I participate?**
As the countdown starts for D-day Our HackNITR team is all set to begin with the registrations. Still here? Head over to the website link given below and register right away for the largest student-run hackathon in East India, HackNITR 4.0 and complete the first step to discovering all that we have in store for you.
PS - There is absolutely no prerequisite. If you look forward to your first hackathon or craving an offline tint to your hacking journey, we have it all covered.
[Registration Link](https://www.hacknitr.com/)

Follow our Social Handles to stay tuned
[HackNITR Website](https://www.hacknitr.com/)
[HackNITR Instagram](https://www.instagram.com/hacknitr/)
[HackNITR LinkedIn](https://www.linkedin.com/company/hacknitr/)
[HackNITR Twitter](https://twitter.com/hacknitr)
Let's make this event grand and succesfull
Thank you❤️
| eswar3008 |
1,294,530 | BindableObject + Behaviors to enhance MVVM in .NET MAUI Maps | This publication is part of the C# Advent Calendar 2022, an initiative led by Matthew D. Groves and... | 0 | 2022-12-13T12:34:00 | https://dev.to/icebeam7/bindableobject-behaviors-to-enhance-mvvm-in-net-maui-maps-3je9 | maui, dotnetmaui, dotnet | This publication is part of the [C# Advent Calendar 2022](https://www.csadvent.christmas/), an initiative led by [Matthew D. Groves](https://twitter.com/mgroves) and [Calvin A. Allen](https://twitter.com/_calvinallen). Check it out for more interesting C# articles posted by community members.
With the release of .NET 7 and the corresponding [update](https://devblogs.microsoft.com/dotnet/dotnet-maui-dotnet-7/) in .NET MAUI, one of the newest additions is the [Map Control](https://learn.microsoft.com/en-us/dotnet/maui/user-interface/controls/map?view=net-maui-7.0) that you can use in order to include a control that supports annotation and display of native map controls across Android and iOS mobile applications.
While this control includes several powerful features, not all of them can be used directly with Data Binding. The following actions can't be the target of data bindings in a .NET MAUI Map
- **Displaying a specific location on a Map and/or Moving the map** (for example, setting the initial position of the map to an specific location, otherwise the map is centered on Maui, Hawaii by default). For both operations, a **MapSpan** object is involved.
- **Pin interaction (click)**. You can't even add a TapGestureRecognizer, sadly.
- **Drawing polygons, polylines, and circles**. Perhaps you want to highlight specific areas on a map with these shapes.
[MVVM](https://learn.microsoft.com/en-us/dotnet/architecture/maui/mvvm) is a great pattern that is highly used in .NET development. We want to decouple every layer so our code is reusable, maintainable, etc. [Behaviors](https://learn.microsoft.com/en-us/dotnet/maui/fundamentals/behaviors?view=net-maui-7.0) is a class that help us to add functionality to UI controls in a separate class that is not a subclass of them, but attached to the control as if it was part of the control itself. The idea is to directly interact with the API of the control in such a way that it can be concisely attached to the control and packaged for reuse across more than one application.
And then we have [BindableObjects](https://learn.microsoft.com/en-us/dotnet/api/microsoft.maui.controls.bindableobject?view=net-maui-7.0), which allows us to propagate changes that are made to data in one object to another, by enabling validation, type coercion, and an event system. We can combine the potential advantages of BindableObjects and Behaviors into one class, a BindableBehavior, that can be reused in MVVM to extend capabilities of controls such as a .NET MAUI Map. **Enough theory, show me the code!**
**Step 1. Set up** Clone [this GitHub repo](https://github.com/icebeam7/MapDemoNetMaui) (`master` branch)
This is a .NET MAUI app that:
- Targets .NET 7
- Has already been configured to display a map in a `ContentPage`. Check [the official documentation](https://learn.microsoft.com/en-us/dotnet/maui/user-interface/controls/map?view=net-maui-7.0) for specifics on how to do it, such as: adding the `Microsoft.Maui.Controls.Maps` Nuget package, adding `.UseMauiMaps()` method in MauiProgram.cs and adding the `Map` control with the `Microsoft.Maui.Controls.Maps` namespace on a `ContentPage`.
- It also includes a basic MVVM setup with a Model (`Place `class), ViewModel (`BaseViewModel` and `MapViewModel`, which gets the current location, which is added to the `Places` collection), and a View (`MapView`, which displays the map with the features mentioned in the VM, the `ItemsSource `that displays a pin uses Data Binding)
If you are testing the app on Android, there is an additional thing to do: Add a **Google Maps API key** in the `AndroidManifest.xml`.
This is how the app looks in Android when is executed for the first time.
It asks for permission, then it shows the current location after pressing the button:
BUT you must manually navigate through the map to find the pin:
**Step 2. BindableBehavior class** Create a folder (`Behaviors`) and a class `BindableBehavior` that extends from `Behavior<T>`. The class includes a generic `AssociatedObject` (a UI control) and overrides the two basic methods from the Behavior class: `OnAttachedTo `and `OnDetachingFrom`, which are typically used to add and remove the behavior from a control. Moreover (and this is the key point of everything in this implementation), the BindingContext of the associated control is also referenced, so we can notify (and get notified) about changes in properties from the class and control. This is the code:
```
namespace MapDemo.Behaviors
{
public class BindableBehavior<T> : Behavior<T> where T : BindableObject
{
public T AssociatedObject { get; private set; }
protected override void OnAttachedTo(T bindable)
{
base.OnAttachedTo(bindable);
AssociatedObject = bindable;
if (bindable.BindingContext != null)
BindingContext = bindable.BindingContext;
bindable.BindingContextChanged += Bindable_BindingContextChanged;
}
private void Bindable_BindingContextChanged(object sender, EventArgs e)
{
OnBindingContextChanged();
}
protected override void OnDetachingFrom(T bindable)
{
base.OnDetachingFrom(bindable);
bindable.BindingContextChanged -= Bindable_BindingContextChanged;
}
protected override void OnBindingContextChanged()
{
base.OnBindingContextChanged();
BindingContext = AssociatedObject.BindingContext;
}
}
}
```
**Step 3. MapBehavior class** Now it is time to consume the above class. Create a new class (`MapBehavior`). Here:
- Add namespaces: `Microsoft.Maui.Controls.Maps`, `Microsoft.Maui.Maps`, and `MapDemo.Models`. Moreover, use an alias for a `Map` object to avoid ambiguity (there's another [Map](https://learn.microsoft.com/en-us/dotnet/maui/platform-integration/appmodel/maps) class already included in the global usings). We call it `MauiMap`.
- This class extends from the BindableBehavior class that we just created. The generic T member is a MauiMap.
- Create a MauiMap local object.
And here we also have the most important part which includes 3 elements: A BindableProperty, a public property, and a method:
- `IsReadyProperty` is a public static BindableProperty member that gets notified when there is a change in the value of `IsReady` public property. When it happens, the `OnIsReadyChanged` method is invoked.
- `IsReady` is a public boolean property that is bound to `IsReadyProperty` for notifications when its value changes.
- `OnIsReadyChanged` method handles the value change. We have access to the previous and new value, and the `ChangePosition` method is invoked.
The IsReady property will be the target for data binding in the View after the Behavior is attached, and its value will be affected/read from the ViewModel. More on that later :-).
Then we also have another `BindableProperty` element: `PlacesProperty`, which is bound to `Places`, an `IEnumerable` of `Place`. When there is a change in this collection value, the OnPlacesChanged method is invoked, which in turn executes `ChangePosition` (and DrawLocation, if it contains only one element).
You might wonder **_why_** `Places` is an `IEnumerable` rather than just one `Place` object. The answer is that in an upcoming post I'll use the `Places` collection to draw a route between the first point and another one (selected by the user).
The `ChangePosition` method uses `MoveToRegion` from the map reference to display the map in an specific location, while `DrawLocation` highlights the location by drawing a `Circle` on the map (it is drawn at the moment it is added to the Elements collection of the map).
Both `OnAttachedTo` and `OnDetachingFrom` overriden methods set and remove the map reference, respectively. The implementations from the base class are also invoked (if you remember, we set the BindingContext there).
The code goes as follows:
```
using Microsoft.Maui.Controls.Maps;
using Microsoft.Maui.Maps;
using MauiMap = Microsoft.Maui.Controls.Maps.Map;
using MapDemo.Models;
namespace MapDemo.Behaviors
{
public class MapBehavior : BindableBehavior<MauiMap>
{
private MauiMap map;
public static readonly BindableProperty IsReadyProperty =
BindableProperty.CreateAttached(nameof(IsReady),
typeof(bool),
typeof(MapBehavior),
default(bool),
BindingMode.Default,
null,
OnIsReadyChanged);
public bool IsReady
{
get => (bool)GetValue(IsReadyProperty);
set => SetValue(IsReadyProperty, value);
}
private static void OnIsReadyChanged(BindableObject view, object oldValue, object newValue)
{
var mapBehavior = view as MapBehavior;
if (mapBehavior != null)
{
if (newValue is bool)
mapBehavior.ChangePosition();
}
}
public static readonly BindableProperty PlacesProperty =
BindableProperty.CreateAttached(nameof(Places),
typeof(IEnumerable<Place>),
typeof(MapBehavior),
default(IEnumerable<Place>),
BindingMode.Default,
null,
OnPlacesChanged);
public IEnumerable<Place> Places
{
get => (IEnumerable<Place>)GetValue(PlacesProperty);
set => SetValue(PlacesProperty, value);
}
private static void OnPlacesChanged(BindableObject view, object oldValue, object newValue)
{
var mapBehavior = view as MapBehavior;
if (mapBehavior != null)
{
mapBehavior.ChangePosition();
if (mapBehavior.Places.Count() == 1)
mapBehavior.DrawLocation();
}
}
private void DrawLocation()
{
map.MapElements.Clear();
if (Places == null || !Places.Any())
return;
var place = Places.First();
var distance = Distance.FromMeters(50);
Circle circle = new Circle()
{
Center = place.Location,
Radius = distance,
StrokeColor = Color.FromArgb("#88FF0000"),
StrokeWidth = 8,
FillColor = Color.FromArgb("#88FFC0CB")
};
map.MapElements.Add(circle);
}
private void ChangePosition()
{
if (!IsReady || Places == null || !Places.Any())
return;
var place = Places.First();
var distance = Distance.FromKilometers(1);
map.MoveToRegion(MapSpan.FromCenterAndRadius(place.Location, distance));
}
protected override void OnAttachedTo(MauiMap bindable)
{
base.OnAttachedTo(bindable);
map = bindable;
}
protected override void OnDetachingFrom(MauiMap bindable)
{
base.OnDetachingFrom(bindable);
map = null;
}
}
}
```
** Step 4. ViewModel** Now let's proceed to modify MapViewModel:
- Two new observable properties are added: `isReady` (a boolean) and `bindablePlaces` (an observable collection of Place). They are a bridge between the View and the BindableBehavior.
- In the `GetCurrentLocationAsync` method, set the location obtained from the sensor into a new object (`place`) that is added to the already existing `Places` observable collection object. Then, insert it into an IEnumerable object that is used to create a new instance of the `BindablePlaces` object. Moreover, `IsReady` is set to true.
This is the code:
```
...
using CommunityToolkit.Mvvm.ComponentModel;
namespace MapDemo.ViewModels
{
public partial class MapViewModel : BaseViewModel
{
...
[ObservableProperty]
bool isReady;
[ObservableProperty]
ObservableCollection<Place> bindablePlaces;
...
[RelayCommand]
private async Task GetCurrentLocationAsync()
{
try
{
...
var place = new Place()
{
Location = location,
Address = address,
Description = "Current Location"
};
Places.Add(place);
var placeList = new List<Place>() { place };
BindablePlaces = new ObservableCollection<Place>(placeList);
IsReady = true;
}
catch (Exception ex)
{
// Unable to get location
}
}
}
}
```
**Step 5. View** Finally, let's attach the behavior to the map. Go to `MapView` and add a reference to the `Behaviors` namespace; then, inside the Map definition access the Behaviors section where you'll include:
- a MapBehavior instance
- The IsReady property from the behavior is bound to the `IsReady` from the viewmodel.
- The `Places` property from the behavior is bound to the `BindablePlaces` from the viewmodel.
Here we are connecting everything we prepared earlier! Check the code:
```
<?xml version="1.0" encoding="utf-8" ?>
<ContentPage ...
xmlns:behaviors="clr-namespace:MapDemo.Behaviors"
...>
<Grid ...>
<maps:Map ...>
<maps:Map.Behaviors>
<behaviors:MapBehavior
IsReady="{Binding IsReady}"
Places="{Binding BindablePlaces}"/>
</maps:Map.Behaviors>
</maps:Map>
</Grid>
</ContentPage>
```
**Let's run the application!** Once we click on the button, the map will immediately be centered around the current location where we will see the pin and red circle (before, we manually had to scroll through the map to the pin location).
In case you want the app to directly access the current location, simply get rid of the button and invoke the `GetCurrentLocationCommand` command in the `OnAppearing` method from the `MapView` `ContentPage` class.
The final code is [here](https://github.com/icebeam7/MapDemoNetMaui/tree/bindable-behavior), which is the `bindable-behavior` branch from the MapDemoNetMaui project.
| icebeam7 |
1,294,716 | need help | can someone fix this problem? or help me to make new fake facebook comments in html file landign... | 0 | 2022-12-13T12:22:07 | https://dev.to/oyokuu/need-help-58p7 | webdev, html, programming, css |
can someone fix this problem?
or help me to make new fake facebook comments in html file landign page
| oyokuu |
1,294,731 | Amazon CloudWatch Tutorial | AWS Certification | Cloud Monitoring Tools | AWS Tutorial | This Tutorial on "Amazon CloudWatch Tutorial” will help you understand how to monitor your AWS... | 0 | 2022-12-13T12:46:55 | https://dev.to/damon_lamare/amazon-cloudwatch-tutorial-aws-certification-cloud-monitoring-tools-aws-tutorial-3ghh | aws, cloudwatch, cloud, tutorial | This Tutorial on "Amazon CloudWatch Tutorial” will help you understand how to monitor your AWS resources and applications using Amazon CloudWatch a versatile monitoring service offered by Amazon.
Following are the list of topics covered in this session:
1. What is Amazon CloudWatch?
2. Why do we need Amazon CloudWatch Events?
3. What do Amazon CloudWatch Logs do?
4. Hands-on
{% embed https://www.youtube.com/watch?v=__knpcBRLHg %} | damon_lamare |
1,294,746 | Building a Docker-Jenkins CI/CD Pipeline for a Python App (Part 2) | This is a continuation of the tutorial for building a Docker Jenkins pipeline to deploy a simple... | 0 | 2022-12-13T13:15:35 | https://nyukeit.dev/posts/docker-jenkins-pipeline-part2/ | tutorial, docker, devops, jenkins | This is a continuation of the tutorial for building a Docker Jenkins pipeline to deploy a simple Python app using Git and GitHub. The first part of the tutorial can be found [here](https://dev.to/codenamenuke/building-a-docker-jenkins-cicd-pipeline-for-a-python-app-part-1-f07).
## Installing Jenkins
We now have the basics ready for deploying our app. Let's install the remaining software to complete our pipeline.
We begin by importing the GPG key which will verify the integrity of the package.
```bash
curl -fsSL https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo tee \
/usr/share/keyrings/jenkins-keyring.asc > /dev/null
```
Next, we add the Jenkins softwarey repository to the sources list and provide the authentication key.
```bash
echo deb [signed-by=/usr/share/keyrings/jenkins-keyring.asc] \
https://pkg.jenkins.io/debian-stable binary/ | sudo tee \
/etc/apt/sources.list.d/jenkins.list > /dev/null
```
```bash
sudo apt update
```

Now, we install Jenkins
```bash
sudo apt-get install -y jenkins
```
Wait till the entire installation process is over and you get back control of the terminal.

To verify if Jenkins was installed correctly, we will check if the Jenkins service is running.
```bash
sudo systemctl status jenkins.service
```

Press **Q** to regain control.
## Jenkins Configuration
We have verified that the Jenkins service is now running. This means we can go ahead and configure it using our browser.
Open your browser and type this in the address bar:
```bash
localhost:8080
```
You should see the Unlock Jenkins page.

Jenkins generated a default password when we installed it. To locate this password we will use the command:
```bash
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
```

Copy this password and paste it into the box on the welcome page.
On the next page, select 'Install Suggested plugins'

You should see Jenkins installing the plugins.

Once the installation has completed, click on Continue.
On the Create Admin User page, click 'Skip and Continue as Admin'. You can alternatively create a separate Admin user, but be sure to add it to Docker group.
Click on 'Save and Continue'
On the **Instance Configuration** page, Jenkins will show the URL where it can be accessed. Leave it and click 'Save and Finish'
Click on 'Start Using Jenkins'. You will land on a welcome page like this:

We have now successfully setup Jenkins. Let's go back to the terminal to install Docker.
## Installing Docker
First we need to uninstall any previous Docker stuff, if any.
```bash
sudo apt-get remove docker docker-engine docker.io containerd runc
```
Most likely, nothing will be removed since we are working with a fresh install of Ubuntu.
We will use the command line to install Docker.
```bash
sudo apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release
```

Next, we will add Docker's GPG key, just like we did with Jenkins.
```bash
sudo mkdir -p /etc/apt/keyrings
```
```bash
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
```
Now, we will setup the repository
```bash
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
```
Next we will install the Docker Engine.
```bash
sudo apt-get update
```
```bash
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
```

Now verify the installation by typing
```bash
docker version
```

Notice that you will get an error for permission denied while connecting to Docker daemon socket. This is because it requires a root user. This means you would need to prefix sudo every time you want to run Docker commands. This is not ideal. We can fix this by making a docker group.
```bash
sudo groupadd docker
```
The docker group may already exist. Now let's add the user to this group.
```bash
sudo usermod -aG docker $USER
```
Apply changes to Unix groups by typing the following:
```bash
newgrp docker
```
> Note: If you are following this tutorial on a VM, you may need to restart your instance for changes to take effect.
Let's verify that we can now connect to the Docker Engine.
```bash
docker version
```

As we can see, Docker is now fully functional with a connection to the Docker Engine.
We will now create the Dockerfile that will build the Docker image.
## Creating the Dockerfile
Inside your terminal, within your folder, create the Dockerfile using the nano editor.
```bash
sudo nano Dockerfile
```
Type this text inside the editor:
```bash
FROM python:3.8
WORKDIR /src
COPY . /src
RUN pip install flask
RUN pip install flask_restful
EXPOSE 3333
ENTRYPOINT ["python"]
CMD ["./src/helloworld.py"]
```
## Building the Docker Image
From the Dockerfile, we will now build a Docker image.
```bash
docker build -t helloworldpython .
```

Now let's create a test container and run it a browser to check if our app is displaying correctly.
```bash
docker run -p 3333:3333 helloworldpython
```
Open your browser and go to ```localhost:3333``` to see our python app in action.

Now let's see how we can automate this printing every time we make a change to our python code.
## Creating the Jenkinsfile
We will create a Jenkinsfile which will elaborate a step-by-step process of building the image from the Dockerfile, pushing it to the registry, pulling it back from the registry and running it as a container.
Every change pushed to the GitHub repository will trigger this chain of events.
```bash
sudo nano Jenkinsfile
```
In the nano editor, we will use the following code as our Jenkinsfile.
```bash
node {
def application = "pythonapp"
def dockerhubaccountid = "nyukeit"
stage('Clone repository') {
checkout scm
}
stage('Build image') {
app = docker.build("${dockerhubaccountid}/${application}:${BUILD_NUMBER}")
}
stage('Push image') {
withDockerRegistry([ credentialsId: "dockerHub", url: "" ]) {
app.push()
app.push("latest")
}
}
stage('Deploy') {
sh ("docker run -d -p 3333:3333 ${dockerhubaccountid}/${application}:${BUILD_NUMBER}")
}
stage('Remove old images') {
// remove old docker images
sh("docker rmi ${dockerhubaccountid}/${application}:latest -f")
}
}
```
## Explaining the Jenkinsfile
Our Jenkins pipeline is divided in 5 stages as you can see from the code.
- Stage 1 - Clones our Github repo
- Stage 2 - Builds our Docker image from the Docker File
- Stage 3 - Pushes the image to Docker Hub
- Stage 4 - Deploys the image as a container by pulling it from Docker Hub
- Stage 5 - Removes the old image to stop image pile up.
Now that our Jenkinsfile is ready, let's push all of our source code to GitHub.
## Pushing files to GitHub
First, let's check the status of our local repo.
```bash
git status
```

As we can see, there are no commits yet and there are untracked files and folders. Let's tell Git to track them so we can push them to our remote repo.
```bash
git add *
```
This will add all the files present in the git scope.
Git is now tracking our files and they are ready to be commit. The commit function pushes the files to the staging area where they will be ready to be pushed.
```bash
git commit -m "First push of the python app"
```

Now, it's time to push our files.
```bash
git push -u origin main
```
Let's go to our repo on GitHub to verify that our push was successful.

## Creating Jenkins Credentials
In the Jenkins dashboard, go to **Manage Jenkins**.

In the Security section, go to **Manage Credentials**.

In the credentials section, click on **System**. On the page that opens, click on **Global Credentials Unrestricted**


Now click on **Add Credentials**.
Keep 'Kind' as 'Username and Password'
In 'username' type your Docker Hub username.
In 'password' type your Docker Hub password.
> Note: If you have enabled 2FA in your Docker Hub account, you need to create an access token and use it as a password here.
In 'ID', type 'dockerHub'
Finally, click on **Create**

## Creating a Jenkins Job
To close our pipeline, we will create a Jenkins job which will be triggered when there are changes to our GitHub repo.
> Note: In Jenkins, if not already installed, install the plugins Docker and Docker Pipeline. Restart your Jenkins instance after installation.
Click on **New Item** in your Jenkins dashboard. Enter any name you like. Select **Pipeline** and click okay.

In the configuration page, type in any description that you want.

In 'Build Triggers' select **Poll SCM**.

In 'Schedule', type ```* * * * *``` (with spaces in between. This will poll our GitHub repo every minute to check if there any changes. This is mostly too quick for any project, but we are just testing our code.
In the 'Pipeline' section, in 'definition' select **Pipeline Script from SCM**. This will look for the Jenkinsfile that we uploaded to our repo in GitHub and apply it.
Next, in SCM in the Repositories section, copy and paste your GitHub repo **HTTPS URL**.

In 'Branches to Build', by default, it will have master. Change it to main, since our branch is called main.
Make sure the 'Script Path' has 'Jenkinsfile' already populated. If not, you can type it out.

Click on **Save**.
Now our Jenkins job is created. It is time to see the whole pipeline in action.
Click on 'Build Now'. This will trigger all the steps and if we have all the configurations correct, it should have our container running with the python app and our custom image uploaded on Docker Hub. Let's verify this.


As we can see, our custom built image is now available in our Docker Hub account.
Now let's verify if the container is running.
```bash
docker ps
```
## Committing changes to Python App
To see the full automated flow in action, let's change the python app a bit and go back to our browser to see the changes being reflected automatically.
We have changed the output text from *Hello World!* to *Hello World! I am learning DevOps!*
Save the file and push the file to GitHub.
As we can see, this action triggered an automatic job creation on Jenkins, which resulted in Build No. 2 of our app.

We can now see that our app has 2 builds. In the first build, we can see 'no changes' because we manually triggered the first build after creating our repository. All subsequent commits will result in a new build.
We can see that Build No 2 mentions there was 1 commit.

As for our webapp, the message displayed has now changed.

This is how we can create a Docker-Jenkins automation.
## Resources
[Installing Jenkins](https://www.jenkins.io/doc/book/installing/linux/#debianubuntu)
[Installing Docker on Ubuntu](https://docs.docker.com/engine/install/ubuntu/)
[Fix Docker Socket Permission Denied](https://www.digitalocean.com/community/questions/how-to-fix-docker-got-permission-denied-while-trying-to-connect-to-the-docker-daemon-socket)
[Dockerize your Python Application](https://runnable.com/docker/python/dockerize-your-python-application)
[Containerize A Python Application](https://www.section.io/engineering-education/how-to-containerize-a-python-application/) | nyukeit |
1,294,766 | Amazon EC2 Storage - Basics | Let's have a look at EC2 Storage. There are different storage options for EC2 instances. 💾... | 0 | 2022-12-13T13:42:13 | https://dev.to/anja/amazon-ec2-instance-storage-basics-4f88 | aws | Let's have a look at EC2 Storage. There are different storage options for EC2 instances.
### 💾 EBS Volumes
An EBS volume is a network drive that can be attached to an instance. It stores data even after the termination of the instance, when you configure it to. EBS volumes are bound to a specific availabilty zone. If you want to move an EBS volume to a different Availability zone(AZ) you need to create a snapshot first and then copy it to the new AZ. You can also detach an EBS volume to attach it to a different instance.
### 💾 EC2 Instance Store
The EC2 instance store is a temporary storage for your instance. It is located on disks that are physically attached to the host computer. If you need a high-performance disk, this option is a good choice. The instance store gets deleted when your instance is stopped.
### 📁 EFS - Elastic File Storage
EFS is a scalable shared file system that can be mounted to a lot of EC2 instances. It works across multiple Availability Zones. EFS Infrequent Access (EFS-IA) is a storage class that is less expensive than EFS Standard. Its fitting when your instance doesn't access your files every day. When you enable Amazon EFS Lifecycle Management for your file system, Amazon EFS will automatically move your files to the lower cost storage class based on the last time they were accessed.
### 📁 Amazon FSx
Amazon FSx is a service to launch high-performance file systems on AWS. There are three different options: FSx for Lustre, FSx for Windows File Server and FSx for NetApp ONTAP. FSx for Lustre can be used for High-Perfomance Computing (HPC) and needs to run on Linux based instances.
### 💻 AMI - Amazon Machine image
An Amazon Machine Image (AMI) is an image from AWS that provides the information required to launch an instance. You can also create your own customized image. On the AWS Marketplace you can find and buy AMIs which have been created by a third party. AMIs can be build from your instances.
| anja |
1,294,796 | hi | hi | 0 | 2022-12-13T14:23:46 | https://dev.to/devtodev/hi-eib | hi | devtodev | |
1,294,920 | K8s forcefully delete resources | Sometimes, when we are working with custom resources, they are stucked in a Terminating... | 11,280 | 2023-01-16T14:34:00 | https://dev.to/mxglt/k8s-forcefully-delete-resources-4jlp | kubernetes, devops, sre | Sometimes, when we are working with custom resources, they are stucked in a `Terminating` phase.
Today, we will see how to resolve this use easily.
---
# Warning
First I need to warn you. Force deleting a custom resource can be risky and generate other issues. So be sure about what you are doing before forcing the deletion.
---
To force delete a custom resource, follow these steps :
- Edit the Object : `kubectl edit customresource/name`
- Remove finalizer parameter
- Delete the object : `kubectl delete customresource/name`
And that's it!
I hope it will help you! 🍺
| mxglt |
1,295,178 | Efficiently Computing Permissions at Scale—Our Engineering Approach | A few weeks ago, we introduced a new Role-based Access Management (RBAC) feature in the GitGuardian... | 0 | 2022-12-13T19:41:18 | https://blog.gitguardian.com/efficiently-computing-permissions-at-scale-our-engineering-approach/ | A few weeks ago, we [introduced](https://blog.gitguardian.com/it-takes-a-team-to-solve-hardcoded-secrets/) a new Role-based Access Management (RBAC) feature in the GitGuardian Internal Monitoring platform. This release resulted from several months of hard work where we had to thoroughly review our data model and implement a very resource-efficient permissions calculation mechanism. I thought this was the perfect opportunity to offer a deep dive into the research, problems, and dead-end roads we encountered on this journey.
_Disclaimer: I’ll be using Django in my code examples, but the ideas can be generalized; however, a relational database is a stronger requirement._
## I. Defining the problem
In a nutshell, the RBAC feature creates the notion of “Teams”, a perimeter where each member can see and act upon a restricted number of incidents. In our domain, an incident is a logical unit corresponding to a unique leaked secret. Since a secret can leak in multiple repos, we call **occurrences** the various locations of this secret in one or more repositories. A set of repos defines a team, so a user belonging to a team can act on any secret detected once or more on one of these repos.
Since an incident can have two occurrences owned by two different teams, our first conceptual problem was: how to distribute incidents across teams?
💡_Note: Directly attaching repositories to a team is by no mean the only possibility. We could decide, for example, to assign an entire GitHub organization to a team so that repositories created later in this organization are automatically added to the team's perimeter. But this implementation is out of the scope of this article, so we’ll assume we have a direct link between teams and repositories._
But that’s not all. We also needed to allow the possibility of giving access to one particular incident to a user or a team. A user has its own perimeter, which is the union of the perimeter of its teams, and the incidents they have been granted access to individually.
Here is a visualization to help you grasp the relationships between these concepts:
Class diagram for our models
Finally, knowing which incidents are part of the user’s perimeter was just half the story; what we wanted, in the end, was to know what the user could do with them. Here are the three permission levels:
- `READ`: user can see the incident
- `WRITE`: user can act on the incident—ignore, assign, resolve, etc.
- `ADMIN`: user can share the incident with other users and teams, adding it to their perimeter.
These permissions can, again, be inherited from the team the user is a member of, or be directly attributed. For a given incident, the user’s permission is therefore the **maximum** permission level accorded by these two means. And this maximum permission needs to be computed dynamically (on the fly).
### Why we didn’t go for the straightforward solution
One straightforward solution would be to have a table persisting _per-user_ permissions. But this would be very difficult to maintain. Why? Let’s imagine a user is removed from a team. The incidents for which he had inherited some permissions by belonging to the team are no longer in the user’s perimeter. Therefore, all the permissions for the team’s incidents should be recomputed, to check if the user lost access or had their permission reduced on the incidents.
Going with a per-user permissions table would necessarily imply a higher order of magnitude in the number of operations necessary to update all the user permissions.
As we wanted to keep table operations as synchronous as possible, we added the permission fields on three relations to dispatch the workload:
- the User-Incident relation
- the Team-Incident relation
- the User-Team relation
After doing some research, we decided to compute these permissions in SQL. Not relying on per-user permissions also meant we could not rely on the common Django permissions libraries (including `django.contrib.auth`), which are all object-based.
In the table below, we map the number of rows impacted by a new event (new incident, new repo added to a team’s perimeter, etc..). We can see that the per-object solution scales linearly with the number of users in a team. But we don’t want our team sizes to be limited:
| condition | affected # user-incident | affected # of team-incident |
| --- | --- | --- |
| new incident | \# of teams × # of team’s users | \# of teams |
| new repository in the team | \# of repository incident × # of team’s users | \# of repository incidents |
| new user in the team | \# of team incidents | 0 |
| new team incident (direct access) | \# of team users | 1 |
Although we discarded early on the User-Incident relation as the ultimate source of truth, we had to use per-object permissions for the Team-Incident relation. That choice was motivated by performance reasons: the read operation through the _Repository_ and _Occurrence_ tables was too slow, and we made the assumption that the number of teams would be smaller than the number of users.
## II. How our model works
### A simple trick: using binary masks
Once we defined the permissions specs, we needed to determine how to store them in our database. I mentioned three levels of permission, but it was evident that in the future we would need to add many more to allow more granularity in the business domain roles. To avoid having many boolean fields and to simplify the logic of checking authorizations, we preferred to store authorizations in their binary representation. Thanks to the use of binary masks, we can store all the permissions in a single Integer field.
💡 **How to check permissions stored as a binary mask**
Let’s say we have 2 resources A and B, and the permissions READ and WRITE
We’ll store that in two bytes. Let’s assume for simplicity that WRITE implies READ,
Cases for A:
- `0b0011` is the `WRITE: A` permission
- `0b0001` is the `READ: A` permission
Cases for B:
- `0b1100` is the `WRITE: B` permission
- `0b0100` is the `READ: B` permission
and obviously:
- `0b0000` is no permission.
With a bitwise `AND`, we encode for example `0b0111` as being the `WRITE: A` and `READ: B` permission. Conversely, to check a permission, all we have to do is a bitwise `AND` on the permission mask and the binary value of the field.
So to check if a user has permission `WRITE: A`, we’ll do `0b0011` & the permission of the user. The result will be equal to the mask only if the user has the permissions:
- `0b1111` & `0b0011` = `0b0011` → OK
- `0b0111` & `0b0011` = `0b0011` → OK
- `0b1101` & `0b0011` = `0b0001` → not OK
- `0b0000` & `0b0011` = `0b0000` → not OK
To implement this in Django we used the `IntegerChoices` classes, as well as a simple helper to help check permissions in our Python code.
### Django models
Now that we know the relationships between our objects, and where to store the permissions we need, we can implement it with Django models.
Let’s say we use the default Django User model, here are our models:
Quite straightforward, let’s move on to the use cases.
## III. Our implementation in practice
### Filtering the incidents for a user
First, getting all the incidents of a user, or all users having access to an incident is simple, because the existence of the models themselves implies the READ permission, so we don’t have to check permissions. We can do the following:
💡 Distinct is needed because a user can be allowed access to an incident through multiple lines.
The query could be done through subqueries instead. In practice, we leverage the fact that we already have access to the user’s teams to simplify it.
After checking what incidents to display to a user, we want to know which permissions they have on these incidents to know which actions they are allowed to do.
Let’s stay with three permission levels:
- `0b001` is `READ` which allows seeing the incident
- `0b011` is `WRITE` (implying `READ`) which allows acting on the incident
- `0b111` is `ADMIN` (implying `READ` + `WRITE`) which allows granting access to the incident to other users and teams.
And, of course, `0b000` is no permissions at all.
Let’s write the Django query for this, by constructing the `user_permission` annotation that will contain the aggregated permission of the user on each incident.
A user’s permission within a team is the lowest (computed with the AND binary operation) permission between the permission of the team in the incident and the permission of the user in the team:
And a user’s permission within multiple teams is the highest permission (computed with the OR binary operation) across all teams:
But the user can also get access to incidents individually, so we’ll use `Coalesce(..., 0)` that will replace nullish values with 0, our null permission, when the user does not have access through teams, or individually. Otherwise, we couldn’t apply our binary operation (`NULL` is not a binary value).
Finally, we filter the queryset for our user:
### Filtering a queryset by permission
We have everything we need, but it’s not yet practical to fetch all the user’s objects for which they have a certain permission level with our binary logic.
We could craft a custom queryset filter, but let’s make something more reusable: let’s define a custom Lookup to implement the `Permission.is_authorized` method directly in SQL:
It’s important to note that although our incident permissions computation works in all cases, we should not forget about shortcuts.
For example, the `Manager` role enables access to all the incidents, so it doesn’t make sense to compute the permissions for it. Similarly, the “all-incidents team” provides access to all the organization’s incidents, allowing us to eliminate the perimeter computation.
Also, in paginated endpoints, we just have to compute the permissions on the page we want to return!
## We’re done!
Implementing the Teams feature was far from straightforward, and I know that we are not the first engineering team to be confronted with this kind of challenge. It required a thoughtful reflection on the data models we use, and on how to implement the feature with the least possible impact both on performance and on the rest of the application. In the end, I think this was a really good exercise and we learned many things that we will be able to apply to other parts of our code.
Time for our next challenge! | eugenenelou | |
1,295,506 | Javascript map() function | 1. theory The map method in JavaScript is a method that is used to create a new array from... | 0 | 2022-12-15T03:22:29 | https://dev.to/atharvashankar/javascript-map-function-2kfd | javascript, webdev, tutorial, beginners | ## 1. theory
The map method in JavaScript is a method that is used to create a new array from an existing array by applying a callback function to each element in the original array. This allows us to transform the elements in the original array into new elements that are added to the new array.
The general syntax for using the map method is as follows:
```
const newArray = originalArray.map(callbackFunction);
```
Here, the callbackFunction is a function that is applied to each element in the original array. This function takes in the current element being processed and returns the new element that should be added to the new array.
For example, if we have an array of numbers and we want to double each number in the array, we can use the map method like this:
```
const numbers = [1, 2, 3, 4, 5];
// Double each number in the array
const doubledNumbers = numbers.map(number => number * 2);
console.log(doubledNumbers); // [2, 4, 6, 8, 10]
```
In this example, we pass a callback function to the map method that takes in a number and returns the number doubled. This results in a new array with each number doubled.
The map method is very useful for transforming arrays of data into new arrays that can be used for other purposes, such as creating HTML markup or performing calculations.
## 2. example
this is gonna be a straightforward names section in react. and to display names, we are gonna use the map() function.
{% codesandbox jtpvh2 %}
| atharvashankar |
1,295,992 | Keep Calm! Kubernetes Cluster!! with helm file | Hi there. Thanks for the interest in this post, where we are going to be calmly deploying kubernetes... | 0 | 2022-12-25T16:13:41 | https://dev.to/deoluoyinlola/keep-calm-kubernetes-cluster-with-helm-file-1172 | kubernetes, helm, helmfile, devops | Hi there.
Thanks for the interest in this post, where we are going to be calmly deploying kubernetes cluster together with helmfile. Chance are that you are either a Cloud engineer, DevOps engineer, software developer or average techie who want to add to his/her body of knowledge. So I have decided to make it both beginner's friendly and a sort of refresher for the expert.
While I know that this sort of effort has been done already by others, but I think that it's okay for people to have options. Like other of my posts (or are in the process of writing) they will remain a work in progress. Open to feedback, comment, expansion and improvement. Please feel free to provide your thoughts on ways that I can improve things. Your input would be much appreciated.
### **Contents** <a name="Contents"></a>
* [Project Objectives](#Project Objectives)
* [Pre-requisites](#Pre-requisites)
* [Demonstration](#Demonstration)
* [Part 1 - Provision cluster with eskctl](#Provision cluster with eskctl)
* [Part 2 - Deploy Microservices with helmfile](#Deploy Microservices with helmfile)
* [Github repo](https://github.com/deoluoyinlola/aws-eksctl-helm).
### Project Objectives <a name="Project Objectives"></a>
By the end of each part of this project, we will know how to;
* provision scalable managed kubernetes(eks) cluster resources in AWS with the help of eksctl.
* deploy highly performant microservices applications with helmfile.
### Pre-requisites <a name="Pre-requisites"></a>
So that we all be on the same page, it will be nice to have following in our tool belt;
#### Knowledge requirement
Basic knowledge of how AWS, kubernetes, helm and yaml works.
#### Tools
<table style="width:100%">
<tr>
<th>Tools</th>
<th>Official Links</th>
</tr>
<tr>
<td>AWS CLI</td>
<td>https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html</td>
</tr>
<tr>
<td>eksctl</td>
<td>https://eksctl.io/</td>
</tr>
<tr>
<td>helm</td>
<td>https://helm.sh/</td>
</tr>
</table>
[Back to Contents](#Contents)
### Demonstration <a name="Demonstration"></a>
#### Part 1 - Provision cluster with eskctl <a name="Provision cluster with eskctl"></a>
* Step 1: Install and configure kubectl, AWS CLI and eksctl. You can quickly look up the documentation for each to set up before proceeding with this demo. [Link to How](https://docs.aws.amazon.com/eks/latest/userguide/getting-started.html).
Also, careful to set and utilise profile name when working with multiple accounts in your machine.
* Step 2: Create programmatic access for the new user from AWS console management. We need to create new IAM User credential for this project, with policies to manage eks cluster. Avoid the use of root account for security reason and best practice consideration.
* Step 3: Creating cluster with (1.) a name (2.) version 1.22 (3.) nodegroup name, type and number in a specify region. Run the command;
```
eksctl create cluster --name ecommerce --version 1.22 --nodegroup-name clusternode --node-type t3.micro --nodes 2 --managed
```
* Step 4: After some minutes, check the Cloudformation and eks from AWS management console.
With this single command, we have successfully create an eks cluster with 2 nodegroup.
##### Configure kubectl to communicate with cluster
* Step 1; Configure your computer to communicate with your cluster. Run this command;
```
aws eks update-kubeconfig --region us-east-1 --name ecommerce
```
* Step 2; Confirm your context and test your configuration. Run these commands first to list your contexts and check your configuration
```
kubectl config get-contexts
```
```
kubectl get svc
```
[Back to Contents](#Contents)
#### Part 2 - Deploy Microservices with helmfile<a name="Deploy Microservices with helmfile"></a>
Let’s quickly remind ourselves that;
* The microservices source code repository for this project is from this link; [google-microservices-demo](https://github.com/GoogleCloudPlatform/microservices-demo), containing 11 services we will deploy with this demo. Also, from the same repo, it was illustrated and visualized how these services are connected to each other including a 3rd party service for database - redis. Among the services, Frontend serves as an entrypoint for all the services receiving external requests from the browser. Meanwhile, the load generator deployment is optional, so in this demo we wouldn't bother deploying it.
* Image names for each Microservices, expected environment variables including which port each starts and decision on namespace depending on developer's access must be a collaborative effort between Dev and Ops team.
* Also, deployment options among few others includes imperative, declarative approach and templating engine with helm. In this demo, we are going to be exploring declarative approach with helmfile, but if you so desire to use kubernetes declarative approach you can check these following steps.
##### Deploy Microservices Declaratively - Alternative
This is not best practice for more complex and dynamic projects. So be sure of the project requirements before trying out this option.
* Step 1; Create a project folder and config yaml file from scratch containing;
```
touch config.yaml
```
1) deployment configuration for each microservices and
2) service configuration for each microservices.
Where we appropriately adjust each service image name, pod label, image url, container port, target port, service port, environment variable and external IP(NodePort) for frontend service. You can clone the exact config code from my repo for this projects(link at the end of this project). If you want to explore this approach, be sure to have kubeconfig connect to the cluster.
* Step 2; Deploy the microservices with the;
```
kubectl apply -f config.yaml
```
##### Deploy Microservices Declaratively with helmfile
Yeah, the main deployment approach for this demonstration. I admit that the initial configuration for helmfile can be challenging for a beginner but is actually a great alternative for complex microservices especially in a more dynamic environment. So let's get our hand dirty.
##### Create helm charts
Before starting to carry out the steps accordingly, first install helm. Second, create a project folder that will contain another folder named charts. Inside the charts folder, we are going to create a shared helm chart for the 10 similar applications and another helm chart for redis service. In the case of redis, to persist the data, we are going to use the volume type of emptyDir and mount it into the container volume.
Project folder > charts folder > common & redis
* Step 1: cd into charts folder and create shared helm chart for the 10 microservices by running this command;
```
helm create common
```
Which will auto generate a folder named after what we call our chart, containing; charts folder, template folder, Chart.yaml, values.yaml, .helmignore file.
* Step 2: Inside the template folder, you can clean up the default files and create another ``deployment.yaml`` and ``service.yaml``, where we will define all our yaml blueprint for all the deployment and services respectively. For all the attributes we want to make configurable, we will use placeholders to enable dynamic input for the actual values, where the variable name will be defined inside the values.yaml.
* deployment.yaml code;
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.appName }}
spec:
replicas: {{ .Values.appReplicas }}
selector:
matchLabels:
app: {{ .Values.appName }}
template:
metadata:
labels:
app: {{ .Values.appName }}
spec:
containers:
- name: {{ .Values.appName }}
image: "{{ .Values.appImage }}:{{ .Values.appVersion }}"
ports:
- containerPort: {{ .Values.containerPort }}
env:
{{- range .Values.containerEnvVars}}
- name: {{ .name }}
value: {{ .value | quote }}
{{- end}}
```
* service.yaml code;
```
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.appName }}
spec:
type: {{ .Values.serviceType }}
selector:
app: {{ .Values.appName }}
ports:
- protocol: TCP
port: {{ .Values.servicePort }}
targetPort: {{ .Values.containerPort }}
```
* Step 3: Set the -range built-in function for working with lists of environment variables; mostly use in the env attribute and also observe quote built-in function for working with string value.
* Step 4: Also in the ``values.yaml`` file where we define the variable name in flat structure, set the default values for the template files. Meanwhile, in each template file, the .Values built-in object defined inside the template placeholder is passed into the template from the values.yaml file in the chart and not neither from user-defined nor parameter passed.
* Step 5; Create helm chart for redis. We are going to replicate same processes as above for redis, we intentionally didn't include it to the common chart because this third party service; (1.) is stateful and (2.) does not share same lifecycle with our Microservices. cd into the charts folder, then run;
```
helm create redis
```
* Step 6; For better structure, we will create another folder named values at the root of project directory, that will contain config files for all the microservice which will override the default value in the ``values.yaml``
With all these steps, we should have successfully parametize everything inside the config files. Do well to clone my repo for the exact config or expand on it as desire.
Next, we are going to deploy the microservices into the cluster.
##### Deploy microservices to the cluster
* Step 1; To preview if the config files for each service defined are correct before actual deployment, run this command for each service file;
```
helm template -f <path/to/the/file> <path/to/the/chart>
```
this validate our manifest locally
or
```
helm install --dry-run -f <path/to/the/file> <release-name> <path/to/the/chart>
```
this send files to Kubernetes cluster to validate
or
```
helm lint -f <path/to/the/file> <path/to/the/chart>
```
* Step 2; Individually check if microservices successfully deploy to the cluster. Here we are going to install a chart, overrides values from a file, give a release name and chart name with this command;
```
helm install -f <path/to/the/file> <releases-name> <path/to/the/chart>
```
* Step 3; To list the deploy microservices with this command;
```
helm ls
```
or
```
kubectl get pod
```
At this point, we have about three option to deploy all microservices to the cluster; (1.) deploy each file with ``helm install`` command, (2.) write and execute a script, the script basically contains lines of helm install for each services. (3.) deploy with helmfile. We are going to use the later;
* Step 4; Install helmfile tool, with this command for macOS user;
```
brew install helmfile
```
We can now use the helmfile command from the next step henceforth.
* Step 5; Create and configure a helmfile at the root of project folder - ``helmfile.yaml``.
Containing the following code, which is basically release name, chart and value for each services;
```
releases:
- name: rediscart
chart: charts/redis
values:
- values/redis-values.yaml
- appReplicas: "1"
- volumeName: "redis-cart-data"
- name: emailservice
chart: charts/common
values:
- values/email-service-values.yaml
- name: cartservice
chart: charts/common
values:
- values/cart-service-values.yaml
- name: currencyservice
chart: charts/common
values:
- values/currency-service-values.yaml
- name: paymentservice
chart: charts/common
values:
- values/payment-service-values.yaml
- name: recommendationservice
chart: charts/common
values:
- values/recommendation-service-values.yaml
- name: productcatalogservice
chart: charts/common
values:
- values/productcatalog-service-values.yaml
- name: shippingservice
chart: charts/common
values:
- values/shipping-service-values.yaml
- name: adservice
chart: charts/common
values:
- values/ad-service-values.yaml
- name: checkoutservice
chart: charts/common
values:
- values/checkout-service-values.yaml
- name: frontendservice
chart: charts/common
values:
- values/frontend-values.yaml
```
* Step 6; Declare the manifests into the cluster;
```
helmfile sync
```
If all went well, all the microservices should deploy after this command.
We can as well check on browser through our IP address, if we are sure to configure the frontend service to NodePort. Which is our entry point to the microservices.
* Step 7; Clean up the resources, so you don't get charge pls!
```
helm destroy
```
Voila! we have come to the end.
I'd like to hear from you.
[LinkedIn](https://www.linkedin.com/in/deoluoyinlola/)
Wait! a minutes, there's a good chance that if you ask me a technical question I may not know the answer immediately or might take few minutes to consult docs and stackoverflow. So please be gentle with your comments and request.
[Back to Contents](#Contents) | deoluoyinlola |
1,296,252 | Kafka mTLS Setup | Learn how to route osquery logs. OSQuery is an open source tool that lets you query operating system... | 0 | 2022-12-14T14:20:02 | https://dev.to/hkdulay/kafka-mtls-setup-4ki8 | osquery, flink, cybersecurity, pulsar | Learn how to route osquery logs.
OSQuery is an open source tool that lets you query operating system events using SQL.The events can be fed into a #streaming platform, in this case Pulsar, for subsequent transformation and routing on the stream using Decodable.
[](https://www.decodable.co/blog/routing-osquery-events-via-apache-pulsar)
| hkdulay |
1,296,396 | AWS SQS | AWS Simple Queue Service | How SQS Works | AWS Tutorial | This video on "AWS SQS" will first explain what is Amazon Simple Queue Service, followed by its... | 0 | 2022-12-14T18:06:28 | https://dev.to/damon_lamare/aws-sqs-aws-simple-queue-service-how-sqs-works-aws-tutorial-42cm | aws, cloud | This video on "AWS SQS" will first explain what is Amazon Simple Queue Service, followed by its architecture and benefits. It also concludes the session by working on Amazon SQS Queue.
{% embed https://www.youtube.com/watch?v=vLNDaZuA3Dc %} | damon_lamare |
1,296,607 | Designing Your Blog Structure | If you are Laravel geek and thinking about to build a new blog application then you are on the right... | 0 | 2022-12-15T19:57:29 | https://larachamp.com/designing-your-blog-structure/ | laravel | ---
title: Designing Your Blog Structure
published: true
date: 2022-12-14 18:17:12 UTC
tags: Laravel,laravel
canonical_url: https://larachamp.com/designing-your-blog-structure/
---
If you are Laravel geek and thinking about to build a new blog application then you are on the right place. And let’s learn how we can start building a blog in Laravel. Well, In this article / blog I am going to talk about the structure of blog in Laravel. Not the frontend design. If you are majoring it by reading the design keyword at in front of title.
As you have read the point. Now I want say that there are few technologies or you can say frameworks that we are going to use in this Laravel blog read List.
I love using Livewire if needed and along with some Javascript if needed. And there is alpine.js that I have not used before will consider to use that as well.
[](https://larachamp.com/designing-your-blog-structure/)
**Building the structure/Design of Laravel blog**.
## Create A Flowchart To Design the Blog Structure
Basically a flowchart says what you are going to build. What will be the process and steps in your amazing project. Having a clear vision that what you want to achieve or build is important in everywhere. Whether it is your own project or it’s any client’s project. Having a flowchart is most important things. Well, I just want to say that we have to build the flowchart first of all while we are going to build any kind of application not just in Laravel, it can be any other tech stack as well.
You can draw it on a white paper as well.
What you have to build in flowchart. Listen, you don’t have specific roles so you have to do everything on your own.
### Why to create flowchart first
Building a flowchart makes things clear in mind. These are just the basic things that you have to consider while building.
1. Define all the steps from login to commenting and registering everything in a flow. See the image below.
2. Be real and define everything in squence
3. Think what you can add to flowchart so that will make some more impact.

_flowchart image_
## Build Database Structure
Now, you have clear process that what you have to build in your blog and now you can define that which modules you have to build first and this is how you can create a good working process in your project (blog) and for them which module needs more focus. That means, for example you should think it as a expandable project. Maybe you want to add some more functionality or stuff in this blog after few months. So, it should be expand able.
For scalable projects having a good database structure is much important. If you are not a database guy take advice from who is already there. Don’t just rush. If this is something that is representing your business then it’s not just a blog it’s a big thing which is getting leads for you. Well, building a good database structure is important as well as other things.
## Schedule Tasks And Time Limit
This is the important thing as I have implemented and saw that when we are into any kind of process then we work with more productive manner when we do have time limits. I don’t know why whether it is the fear of time limit or something else. But it works. If you have decided to build this application in under one month. Then you should schedule your tasks and should create tasks for every module so that you will be writing module one by one and building them faster. This is all about scheduling tasks, but it works.
## Write Scalable Code
By scalable I mean use **[DRY](https://www.digitalocean.com/community/tutorials/what-is-dry-development#:~:text=DRY%2C%20which%20stands%20for%20'don,of%20abstractions%20and%20avoiding%20redundancy.)**method. Well, I am a PHP developer love writing code using **DRY** method. If you don’t know what dry is then DRY means ” Don’t Repeat Yourself”. And this is most important thing when it comes to coding. You can write scalable code easily. It just needs your **Clear Thinking**. Well, you can have this also when you know that you have clearly defined what you are going to build in your flowchart. Then you can easily think what you need again and again.
Now, OOPs are my favorite subject in PHP. Because this the way we can easily write scalable code.
I hope this blog will help you. If I have wrote something that is not convenient or not useful then don’t forget to ping me. Thanks.
The post [Designing Your Blog Structure](https://larachamp.com/designing-your-blog-structure/) appeared first on [Larachamp](https://larachamp.com). | robinkashyap_01 |
1,296,614 | Understanding Syntax While Writing a Function in JS | I took the time to detail what each component of was in the line to try and explain what exactly... | 0 | 2022-12-14T20:06:31 | https://dev.to/kellilil/understanding-syntax-while-writing-a-function-in-js-2133 | javascript, webdev, beginners |

I took the time to detail what each component of was in the line to try and explain what exactly the code it doing.
Then followed with an example to further demonstrate what is happening when you call the function you write. | kellilil |
1,296,680 | My year in review | Photo by Mantas Hesthaven on Unsplash This is going to be challenging to write. This year felt like... | 0 | 2022-12-14T23:02:02 | https://dev.to/this-is-learning/my-year-in-review-341d | review, journey |
Photo by <a href="https://unsplash.com/@mantashesthaven?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Mantas Hesthaven</a> on <a href="https://unsplash.com/s/photos/journey?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
This is going to be challenging to write. This year felt like my last 10 years combined. If you follow me on Twitter, you already know this was not the best year I had. I was expecting things to go right. We (my partner and me) gave it a lot of thought, and we decided to move to a new country. I could get a DevRel job in the future, and we will have a better life for our daughter. End of 2021 was doing all the documentation to move to Germany, which was very stressful.
Thanks to my friend Serkan for helping me get this Job.
## Start of 2022
Finally, after all the processes, it was time to move, and I took my flight on 14th January 2022 to reach Germany. Due to a delay in my family’s Visa, I decided to move alone first to find a house for us, and they will join me in March.
## The setback with the move
My family was able to get a visa appointment in March. I was growing restless as this was the first time in 13 years we were not together for so long.
Even after getting the appointment, our documentation was incomplete, and we got a month to submit all documents. The relocation agency assigned by my new employer did a lousy job.
I got COVID in March 2022, which made me feel more homesick, it was a tough time, as I had to manage alone, and my friend Serkan helped me with groceries.
Also, I started struggling financially because of multiple reasons:
* I had savings of around 14k USD for the next few months, but I forgot I needed to pay taxes. I paid 9k USD in taxes after I moved.
* I took a pay cut to move to Germany, expecting once my family joins me, I will have to manage my expenses in Germany.
* Due to a delay in my family visa, I had to pay for rent in 2 countries and groceries and utilities.
* I tried to reach out to some of my friends for financial help but decided not to take that path. I took some help from Vijay. He was generous to help whenever needed.
Glad I had some shares, which I sold to support my family for the next few months and sent some money from Germany.
## Setback with Job
After coming to Germany, I struggled to get my family to Germany and find a house to stay in, because of which I couldn’t give my 100% to the Job.
Also, there were no Angular projects to work on for a long time, my friend Serkan tried to keep me busy with some Angular work, but things didn’t work out.
I also went into defensive mode whenever there was any issue in the project and I was asked questions. The reason was I already had burnout, and it was at its peak.
I asked my employer if I could travel to India to see my family, but it was never approved. They had the fear that I would not come back.
## Fear of losing everything
I worked hard over the years to reach a point where my family and I could have a stable life.
I wrote about my life journey
{% embed https://twitter.com/SantoshYadavDev/status/1479562904835747841 %}
My family’s Visa was delayed every month, and the relocation agency had no idea about it. Even things not going well at work made me scared.
Many things went wrong:
* With my job not working out, I wanted to quit but was scared of what in case I needed to go back to India.
* My wife and daughter also had difficulty managing everything alone in India.
* I was scared to write code, and I started hating code.
There were 2 options I could see:
* Leave the job and go back to India and start from ZERO again.
* Work at the Job for the next 2 years, which I was not enjoying.
But I learned some valuable lessons:
* I was trying to force myself to enjoy the work, which I was not.
* I realized it’s good to quit sometime rather than suffer.
* I realized that staying at this job won’t do any good for my employer and myself.
* I thought quitting this job would make me a loser, and I should fight to make it work. I was wrong. Quit if you are not enjoying it.
## Help from friends
I was in depression for many months, and it felt like Twitter was the only place where I could be more open and talk to my friends.
After seeing my tweets, many friends reached out and spoke to me.
Special shout-out to [Lars](https://twitter.com/LayZeeDK) and [Tanay](https://twitter.com/tanay1337); they both used to follow up on my situation, ask if I am doing okay, and have regular chats/calls.
Tanay is from India, so he guided me with the rules and regulations related to the Job in Germany. Finally, I got enough confidence to apply for a new job. He even recommended to the people in the DevRel community, one of them leading to a Job offer.
I met Lars at his house in Denmark in May and was so happy to see him and his family, especially his daughters. While leaving his home, his daughter hugged me, and I cried a lot after Lars dropped me at the station. It was close to 5 months by that time, not seen my daughter and partner.


## Moving to the new house
In June, I finally got a house in a village in Germany. The home is far away from Hamburg City, but gorgeous and peaceful.
## Meeting new friends
In Hamburg, I tried to meet new people from the Indian community, but people were not so welcoming. After moving to the new place, I learned about some Indian people around my house, and I met 2 friends who are more of a family now.
Anuj and Sajith helped me with any documentation work related to my family’s Visa and my resident permit.
They invited me to their house to have dinner, and I could finally spend time with people who understood what I was going through and were ready to help.
Anuj even helped me financially, as I had to pay some money back to my employer when I left the job and was very short on cash to pay my rent the next month.
## Things changing for Good
Sometimes it’s God’s plan to send you to the right place. Moving to this new city made a few things simpler for me:
* As this a village unlike other cities where you have to wait for months to get City registration done, I got it done in a day. I dont even need an appointment.
* Got my resident permit appointment in less than 10 days.
* My family’s Visa process moved ahead and looked positive after 7 months.
* For my daughter’s school, I quickly got admission to a German Public school as there are fewer kids here in the village.
## New Job
After completing my probation, I decided to leave my job and start with [Celonis ](https://www.celonis.com/careers/jobs/)(We are hiring ), my new employer. During my interview process with Celonis, they really made me feel this is the place where I will be trusted and appreciated. The interview process felt more like a discussion and was one of my best experiences.
## Gaining confidence
After joining, I was scared and very low on confidence. I decided to talk openly with my colleague Yazan. I told him he has to keep some patience, as I am scared to write even a single line of code.
The kind of support I got from him is commendable. He was always ready to help, jump on calls to discuss, showing trust in my work.
I am a changed man after joining Celonis. My confidence is back. I can contribute more to the community and at work with more confidence.
## Family Visa
After moving to this new job, the first thing I wanted to do was travel to India. But before I could plan my travel, we got the good news, we were asked to submit the travel date and resident permit.
I received my resident permit a week after this mail. My partner and I decided I dont need to travel to India now, as we are already short on money, and they can come as soon as they get the Visa.
## The conferences months
After not so good start to 2022, till August, I had no plan to speak at conferences/meetups. I just wanted to stay away from code and community. But I realized things were changing now, my family was about to receive the Visa, and I had a job where I was making more money now, and it was a great place to work.
After joining Celonis, things started getting better.
* I got my resident permit, so I could travel outside Germany.
* My manager at Celonis was okay with me returning to India for a few weeks to see my family.
* We got a more solid response from the Embassy on the approval of Visas for my family.
## Nx Conf
After joining Celonis, I was offered an opportunity to speak at [Nx Conf](https://youtu.be/-g3NABhePJg). As it was only my first month at Celonis, I reached out to my manager Bardh to check If I could do it. Bardh was so helpful; he asked me to do it and suggested the topic.
Also, he asked me if I wanted to represent Celonis at conferences. Which I was more than happy to do.
Now I am doing some DevRel stuff for Celonis. Even though we dont really have a DevRel role, I manage my work, travel to conferences, and talk about my favorite tools, Nx and Angular.
After Joining Celonis, I traveled to the below conferences between Oct and Dec:
* Ng-DE as an attendee
* Nx Conf — Presented my talk on “Nx at Celonis”
* Firebase Summit as an attendee
* JSPolandConf — Presented my talk “Be Smart choose Nx”
* Madrid Celonis Office — Presented my talk “Be Smart choose Nx”
* NgRome — Presented my talk “Angular Router MasterClass”
* DevFest Hamburg — Presented my talk “Be Smart choose Nx”
* Angular London — Presented my talk “Be Smart choose Nx”
I took many photos with friends and met many of them for the first time. The first talk I gave at Nx Conf in Phoenix was my 14 years into Tech, my first visit to the USA, and my first in-person talk after Feb 2020.
I was honored to share the stage with many amazing folks from the community.









and many more....
## Angular Course Launch
I planned to release my Angular Course but kept delaying it due to burnout. Finally, after many months and after things became stable with job and family visa, I reached out to FreeCodeCamp, for my future courses, which I wanted to post on their YouTube channel. They liked my Angular Getting Started course, and we decided to collaborate.
In September, my course was published on FreeCodeCamp, and I got great feedback from the community. This was my gift to the community for helping me during my burnout.
{% embed https://youtu.be/3qBXWUpoPHo %}
## Reunion
I booked my family flight ticket for 22nd October. I came from the US on 20th October after attending Nx Conf and Firebase summit.
I was very excited to see my family after 10 months. We were happy that we were together now.
I decided to take them for a short vacation to Berlin and Poland. I had a talk in Poland next week after they arrived.

## What’s Next
Things are going good at my new job. I can follow my passion for the community, contribute to the work where I am respected, and make decisions to improve our software processes.
I am looking forward to 2023. I want to contribute more to the community. I will try to speak at many conferences next year and work on my Angular Courses, which will be free.
My main focus would be ensuring my family settles down well in Germany. We are still buying and setting up our new house, which was almost empty before they arrived.
And as I said before, **To quit is not an option.**
| santoshyadavdev |
1,296,899 | Wonder Shine Font | Download Wonder Shine Font Free for Windows, macOS and Linux in OTF and TTF formats with basic... | 0 | 2022-12-15T03:06:12 | https://dev.to/fontaza/wonder-shine-font-4573 | fon, webdev | Download Wonder Shine Font Free for Windows, macOS and Linux in OTF and TTF formats with basic features completely. Use it for commercial purposes: here.
Wondershine Font is an elegant, beautiful and smooth serif font.
It is suitable for invitation cards, decorations, clothing products, greeting cards and others.
This font is PUA encoded which means you can access the available glyphs and swashes with ease!
Download here: https://fontaza.com/serif-fonts/wonder-shine-font/ | fontaza |
1,297,143 | 2022 in Review | Today I sat for my last final exam, which also means I am now done with all my courses at Seneca... | 0 | 2022-12-15T07:14:52 | https://dev.to/batunpc/2022-in-review-4mgm | programming, productivity, opensource | Today I sat for my last final exam, which also means I am now done with all my courses at Seneca College. It feels strange to suddenly come to a stop from the crazy busy schedule I was pursuing for the last many semesters. Suddenly, I have all the time in the world to do whatever I like, but first, I must pay back my sleep debt.
2022 has been great in terms of personal growth. I learned to navigate the strange world of remote learning which at times got difficult. I also learned to work under pressure from my many programming courses and work in the open through my open-source development class. Working collaboratively on open-source projects with people I don't know made me more confident in my programming skills. Just a year ago, my GitHub profile had barely any projects uploaded, but now I have developed the muscle memory to intuitively upload all my projects in GitHub, make frequent commits, and have gotten good at navigating my way around it.
## Some 2022 Accomplishments 🎉

### December open-source contributions 🚀
This month I challenged myself to work on many small issues within just 10 days. I enjoyed working for Seneca College's internal project repos, therefore, picked two of them to work on.
My two most recent open-source contributions were made for a Seneca College Internal Project. I decided to go ahead and make 2 different pull requests to this repo to challenge myself to learn new skills.
#### 1) [My Photohub](https://github.com/humphd/my-photohub) 📸
{% embed https://github.com/humphd/my-photohub/issues/33 %}
#### _The solution_
This issue required me to understand how two of my other peers before me were writing the code. Through this, I was able to practice my skill in reading and understanding other people's codes and then integrating them.
{% embed https://github.com/humphd/my-photohub/pull/35 %}
#### 2) [vscode Extension for Seneca](https://github.com/Seneca-CDOT/vscode-seneca-college) 🧩
I had no prior experience working with VS Code extensions, so I had to study some VS Code documentation before making this pull request. Making a VS code extension can get difficult if the features needed are big.
{% embed https://github.com/Seneca-CDOT/vscode-seneca-college/issues/11 %}
#### _The solution_
{% embed https://github.com/Seneca-CDOT/vscode-seneca-college/pull/16 %}
#### 3) [Climate Action Secretariat - CleanBC Industry Fund](https://github.com/bcgov/cas-cif) 🏢
As I was browsing for some issues to contribute to, I came across this repo by the government of British Columbia. I liked the project and decided to make a small contribution here.
{% embed https://github.com/bcgov/cas-cif/issues/1221 %}
#### _The solution_
{% embed https://github.com/bcgov/cas-cif/pull/1251 %}
### Reflection
I am really happy with the contributions I have done over the last 3 months. I have big goals planned for 2023 to develop both personally and professionally. | batunpc |
1,297,168 | TIL; favicon| tables| difference between internal and external CSS styles| Lists | Favicon; the small image displayed next to the page title in the browser tab. Example : <link... | 0 | 2022-12-15T07:55:12 | https://dev.to/keizzey/til-favicon-tables-difference-between-internal-and-external-css-styles-lists-874 | webdev, html, css |
- Favicon; the small image displayed next to the page title in the browser tab.
Example : `<link rel="icon" type="image/jpeg" href="./Mavensey.jpeg"/>`
- Tables (`<table>`);
The table tag helps to insert tables in a document(data in rows and columns). Table values include:
- `<th>` which define table headers
- `<tr>` which define table rows, and
- `<td>` which define the table data in a cell.
- `<thead>`
- `<tbody>`
- `<tfoot>`
- Table size
Styling the size of a single cell, affects the styling of all the cells in the column of that cell. The width of a cell `<td>` is specified in percentages.
The height of a row `<tr>` is specified in pixels.
Column span `colspan`
Row span `rowspan`
Table caption `<caption>`
Tables usually need styling(borders) to clearly separate the various cells.
- Border-collapse: separate
- Border-collapse
- Border-spacing
- Border-radius
- Border-color
- Border-style
- Border-width
- Internal CSS style is defined using a style tag in an html file.
- External CSS style is defined in a separate css file and linked to the html file using the `link` tag.
Padding and spacing
Padding properties include; padding-left , right, top, bottom
Cell Spacing(border-spacing) is the space between the cells
Zebra stripes is a stylistic effect in a table that can easily be achieved using the ‘nth child’ selector.
The ‘nth child(even or odd)’; is a css selector that enables you to select an html element based on its position within its parent.
- Colgroup (`<colgroup>`): this allows a user to efficiently style a number of cells in a column in a particular way. This tag is not always reliable.
NB: Rowgroups do not exist.
Lists
Unordered HTML lists (`<ul>`); Allows a user to add lists to an html document when there is no required order for the list items.
Ordered HTML lists(`<ol>`); Allows a user to add lists to an html document in an ordered manner.
List item(`<li>`;Allows the user to state the list data/particular list item
- Description list `<dl>`; this is used to specify a list of items and their definitions.
- Description term `<dt>`; specifies the specific term to be defined
- Description definition `<dd>`; the definition of the term.
`List-style-type`; Helps the user to specify the list style in a list.
The list style types options include `disc`, `circle`, `square` and `none`, with `disc` being the default style type.
- Nested lists; these are lists within a list.
- The type attribute; allows the user to specify the type of numbering in an ordered list. Type attribute styles include `<type="1">`; which specifies numbers
`<type="i">`; which specifies lowercase roman numerals
`<type="I">`; which specifies uppercase roman numerals
`<type="a">`; which specifies lowercase letters
`<type="B">`; which specifies uppercase letters | keizzey |
1,297,177 | Turbo Stream responses that spark joy | Turbo Streams, either fired via a controller action or over websockets are an incredibly easy but... | 0 | 2022-12-15T10:27:45 | https://dev.to/spinal/turbo-stream-responses-that-spark-joy-25mj | rails, hotwire, turbo, ux | [Turbo Streams](https://turbo.hotwired.dev/handbook/streams), either fired via a controller action or over websockets are an incredibly easy but powerful way to make your apps more responsive and interactive.
At [Spinal](https://spinalcms.com/), the micro-SaaS I've founded I'm all-in on this “boring Rails stack”. It helps me ship features quickly without a lot of overhead.
There is one technique that I haven't seen talked about before in the Rails/Hotwire sphere, but I use it often to spark joy when using my SaaS app: **add an animation when inserting elements into the DOM via Turbo Streams**.
It's simple, really. Have an optional `animated: false` attribute on the ViewComponent or the partial that you insert. Let's see some of these in action and then go over each step needed to replicate this.
## Fade in a new icon
Customers can change the icon for their content type. Upon save, the icon is shown on the page with a subtle fade- and zoom-in animation.
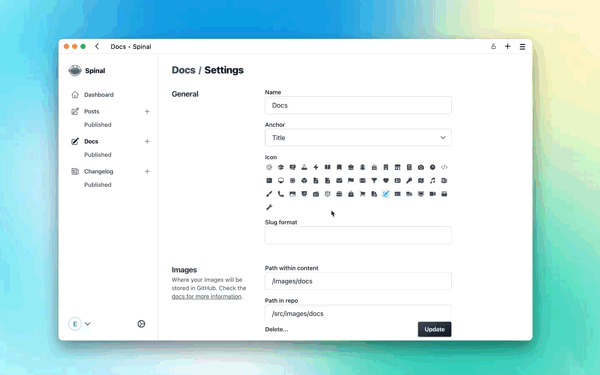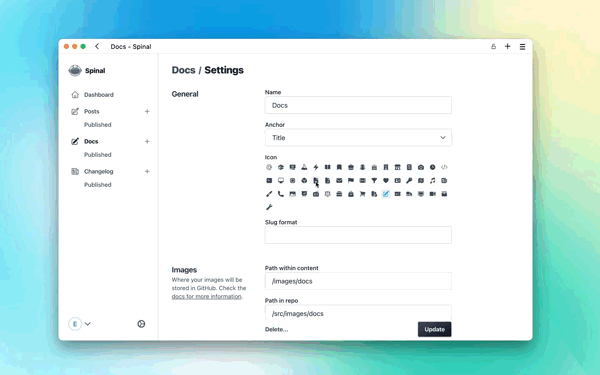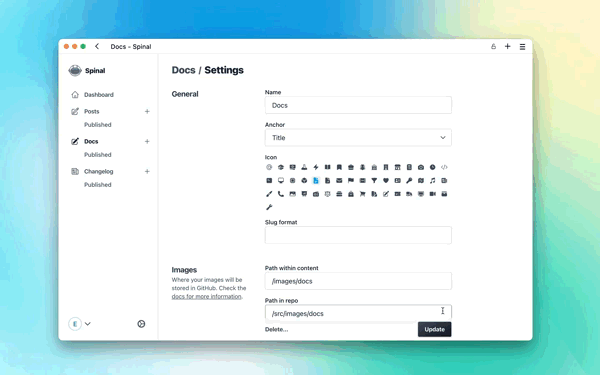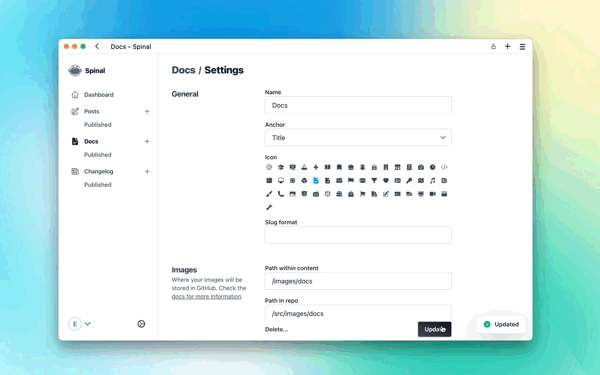
## Animate content rows
When changing the order of the content, each row is fading in one row at a time.
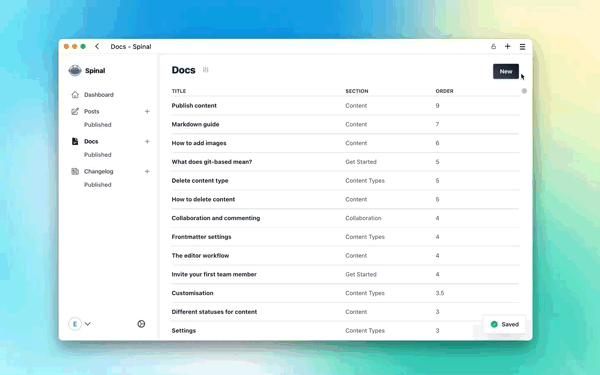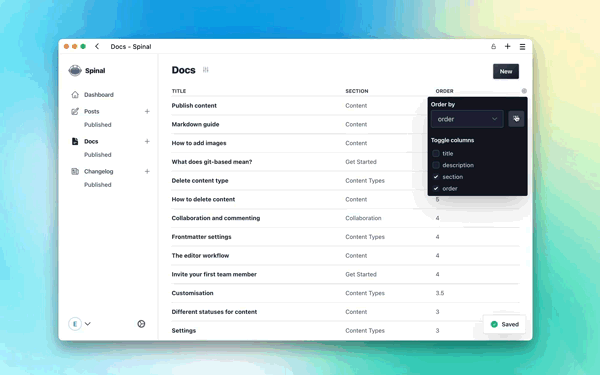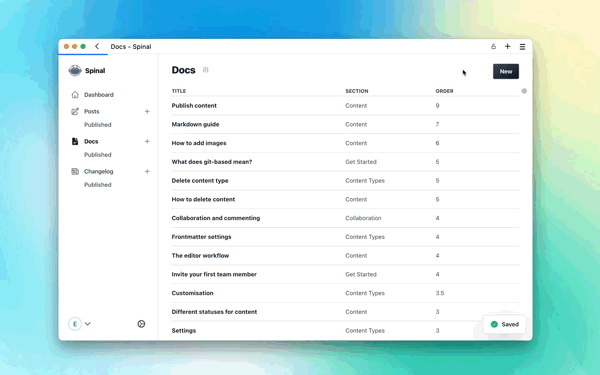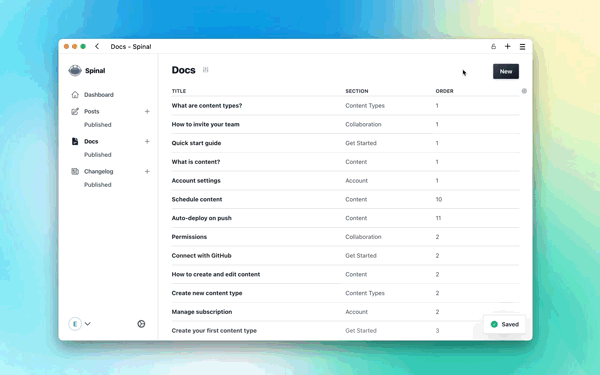
## Animate content cells individually
When customising which columns are visible in the content overview, they are shown top to bottom and from left to right with a fade-in animation. Notice how they are not fading in all at once, but one at the time. Sparking all the more joy.
It's important to note that these animations do not get triggered on regular page visits—which would get annoying pretty quickly, but only when triggered via Turbo Streams. So how do you this?
_Feel free to [sign up for Spinal](https://spinalcms.com/) to see these little animations in 4K instead of a crappy gif._
## How to spark joy yourself
Let's walk through all the critical parts on how to do this. I'm using [ViewComponent](https://github.com/viewcomponent/view_component), but the same principles apply if you use Rails' partials.
### ViewComponent class
```ruby
class ContentRowComponent < ApplicationComponent
def initialize(content_row:, content_row_counter:, animate: false)
@content_row = content_row
@animate = animate
@content_row_counter = content_row_counter
end
# … other methods omitted for brevity
def row_css
class_names(
"content-row",
{"animate-fadeIn": @animate}
)
end
end
```
First initialise the `@content_row_counter` and the `@animate` instance variable (set it to `false` by default). The `content_row_counter` is a variable coming from [ViewComponent](https://viewcomponent.org/guide/collections.html#collection-counter).
Then a `row_css` method where all the css for the `<li />`-element is defined. Here the most interesting is the `class_names()` helper from [ActionView](https://api.rubyonrails.org/classes/ActionView/Helpers/TagHelper.html#method-i-token_list). It only appends the `animate-fadeIn` class if `@animate` is `true`.
### ViewComponent erb
```ruby
<%= tag.li @content_row, class: row_css, style: "animation-delay: #{@content_row_counter * 70}ms;" %>
```
`row_css` is referenced here. Also a delay for the animation is set which simply is `@content_row_counter` multiplied by 70(ms). This then makes each row fade in one after another.
### Turbo Stream response
```ruby
<%= turbo_stream.update "content-rows" do %>
<%= render ContentRowComponent.with_collection(@content, animate: true) %>
<% end %>
```
And finally, where the magic happens. Upon saving, this turbo_stream method is called. It updates the element with the id of `content-rows`. And only here is `animate` set to `true`.
You are, of course, not limited to a boolean `animate` variable. You could as well pass the animation name as a string and like that add more advanced animation option based on your needs. For example: `animate: fadeInSlow`.
And that's the bare essentials of sparking joy to your Turbo Streams. If you do apply this technique, do share the results with. Love to see it. | eelco_spinal |
1,297,386 | What is something library docs do that make it difficult to follow for newbie developers? | In your opinion, when newbie developers read docs, what is the most frustrating part? I've asked... | 0 | 2022-12-15T10:31:50 | https://dev.to/savvasstephnds/what-is-something-library-docs-do-that-make-it-difficult-to-follow-for-newbie-developers-3i7k | discuss, webdev, programming, codenewbie | In your opinion, when newbie developers read docs, what is the most frustrating part?
[I've asked this question on Twitter](https://twitter.com/SavvasStephnds/status/1603074085180825602) yesterday and got a few responses:
> lack of examples! I skim thru when i view any docs.. if it doesn't have examples, i struggle a bit at first 😅
-- [@CuriouZmystee](https://twitter.com/CuriouZmystee)
> Not having working example code or obsolete code that doesn't work and or compile.
-- [@tswain555](https://twitter.com/tswain555)
> Jargon and term standardization is always a killer.
> Hot take: add a synonym guide in the back of all documentation.
-- [@Quasicodo](https://twitter.com/Quasicodo)
What would you add? What has been your experience?
| savvasstephnds |
1,297,434 | Debug Angular Apps Easily Using Angular DevTools | It’s not a secret that the Angular community has needed better tools to inspect the structure of... | 0 | 2022-12-15T12:37:32 | https://www.syncfusion.com/blogs/post/debug-angular-apps-easily-using-angular-devtools.aspx | angular, webdev, debugging, productivity | ---
title: Debug Angular Apps Easily Using Angular DevTools
published: true
date: 2022-12-15 11:42:40 UTC
tags: angular, webdev, debugging, productivity
canonical_url: https://www.syncfusion.com/blogs/post/debug-angular-apps-easily-using-angular-devtools.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/00o3tjzn2u9y2d2hsn9o.png
---
It’s not a secret that the Angular community has needed better tools to inspect the structure of Angular applications and profile their performance. [Angular DevTools](https://angular.io/guide/devtools "Angular DevTools") has been introduced for just that!
This article will go through Angular DevTools in detail and provide step-by-step guidance on making the best of it.
## Angular DevTools
Angular DevTools is a browser extension introduced with Angular 12. It visualizes the structure of your app and previews the directive and component instances’ state. It gives you insight into the change detection cycles and helps you understand the app’s execution.
Angular DevTools is available for both [Google Chrome](https://chrome.google.com/webstore/detail/angular-developer-tools/ienfalfjdbdpebioblfackkekamfmbnh "Angular DevTools extension on Google Chrome") and [Mozilla Firefox](https://addons.mozilla.org/en-GB/firefox/addon/angular-devtools/ "Angular DevTools extension on Mozilla Firefox"). It supports Angular apps built with version 9 or above with Ivy enabled.
## Getting Started with Angular DevTools
You can download the Chrome extension for Angular DevTools from [here](https://chrome.google.com/webstore/detail/angular-devtools/ienfalfjdbdpebioblfackkekamfmbnh "Angular DevTools extension on Google Chrome"), and if you are a Firefox user, you can find the add-on at [this link](https://addons.mozilla.org/en-GB/firefox/addon/angular-devtools/ "Angular DevTools extension on Mozilla Firefox").
After installing the DevTools extension, open an Angular application that runs in development mode. There, you can see that the extension’s icon color changes from black to red, indicating that you can debug the application. Now, open the developer tools and select the **Angular** tab.
The running Angular version and the latest commit hash for the extension will be visible in the top-right corner of the DevTools. Additionally, as shown in the following image, when you open the DevTools, you’ll see two subtabs: Components and Profiler.

## Debugging the Application
The Components subtab visualizes the application’s structure, lets you inspect the directive and component instances, and lets you preview or edit their states. In addition, you can examine the application’s component tree from here, which exhibits the hierarchical relationship between directives and the components within.
Let’s go through some of the tasks that can be carried out under this tab.
### View and Modify Property Values
As illustrated in the screenshot, when a specific component or directive instance is selected, additional information, such as properties, metadata, inputs, and outputs, is displayed on the right panel. This panel also allows you to modify a property value and see the feedback immediately in the UI, as shown in the following image.
**Note:** Text input won’t be visible if the edit functionality is unavailable for a specific property value.
### Look Up a Component or Directive
Imagine you need to jump directly to a specific directive or component using its name. You can do this simply by using the search box above the component tree. **Enter** and **Shift + Enter** keyboard shortcuts come in handy to navigate into the next and previous search matches, respectively.
### Navigate to the Source Code
Angular DevTools also allow you to navigate to a particular component’s source code. After selecting a specific component, you just click on the **<>** icon at the top-right corner of the right panel. Then, it will navigate to the source code of the selected component.
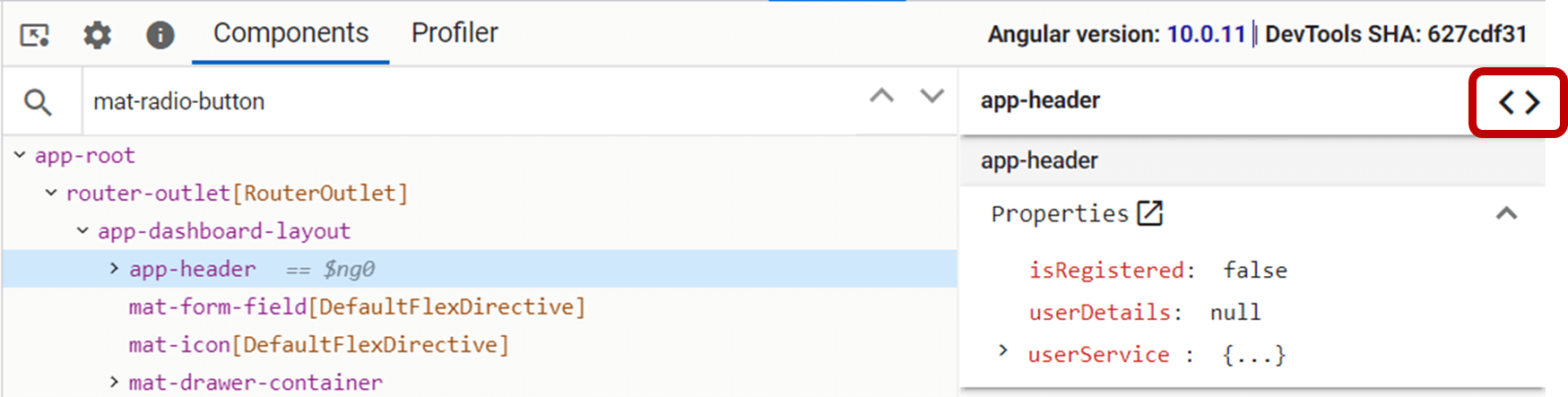
### Access the Recently Selected Component or Directive
Angular DevTools gives you access to the instances of the recently selected directives and components via the console. While **$ng0** provides a reference to the currently selected instance, **$ng1** works as a reference for instances chosen previously. Using this reference, you can easily read any value or method related to the referenced directive or component.
## Profiling the Application
Not only can you debug an app with Angular DevTools, you can also profile your app to identify the factors that degrade its performance.
You can profile your application using the **Profiler** tab next to the Components tab.
To start profiling your app, click on the **Start recording** icon at the top-left corner of the **Profiler** tab (or upload an existing recording). Then, during profiling, when you interact with the elements in the app, each event execution, such as change detection or implementation of a lifecycle hook, will be captured by the profiler. Finally, by clicking on the icon again, you can finish recording.
I will go through some of the tasks that can be carried out under this tab in detail.
### Understand the Application’s Execution
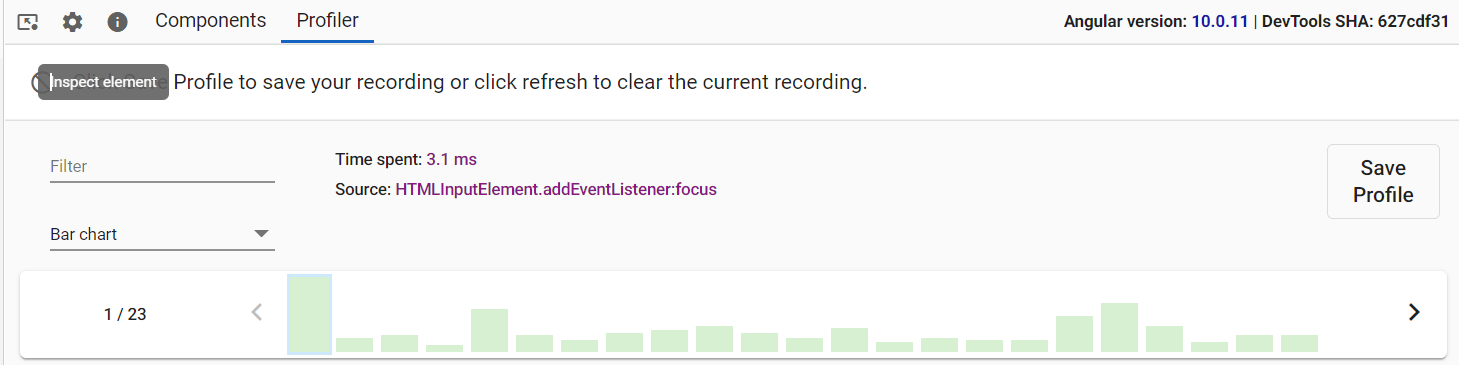As shown in the previous screenshot, after you complete the recording, you can see a sequence of bars, each depicting a separate change detection cycle. The height of a bar represents the time you spent on each cycle.
As shown in the following screenshot, when you click on a particular bar, it will display further information, such as total time spent, the source of the change detection, and the directives and components affected by the cycle.
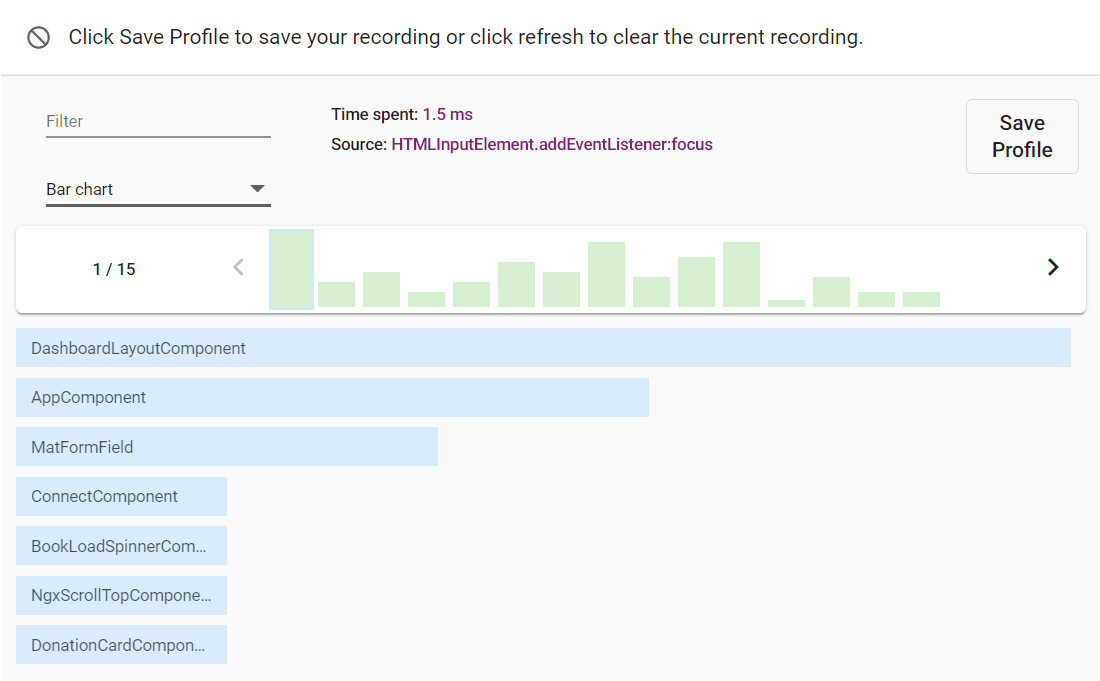As visible in the previous screenshot, each directive or component used during the cycle is sorted based on the time it took. This can be used to find the heaviest components in your application.
### Inspect the Execution of Components or Directives
Each of these component bars displays additional information. For example, you’ll see the total time taken by each component, the exact methods triggered, and the parent hierarchy of the selected element.
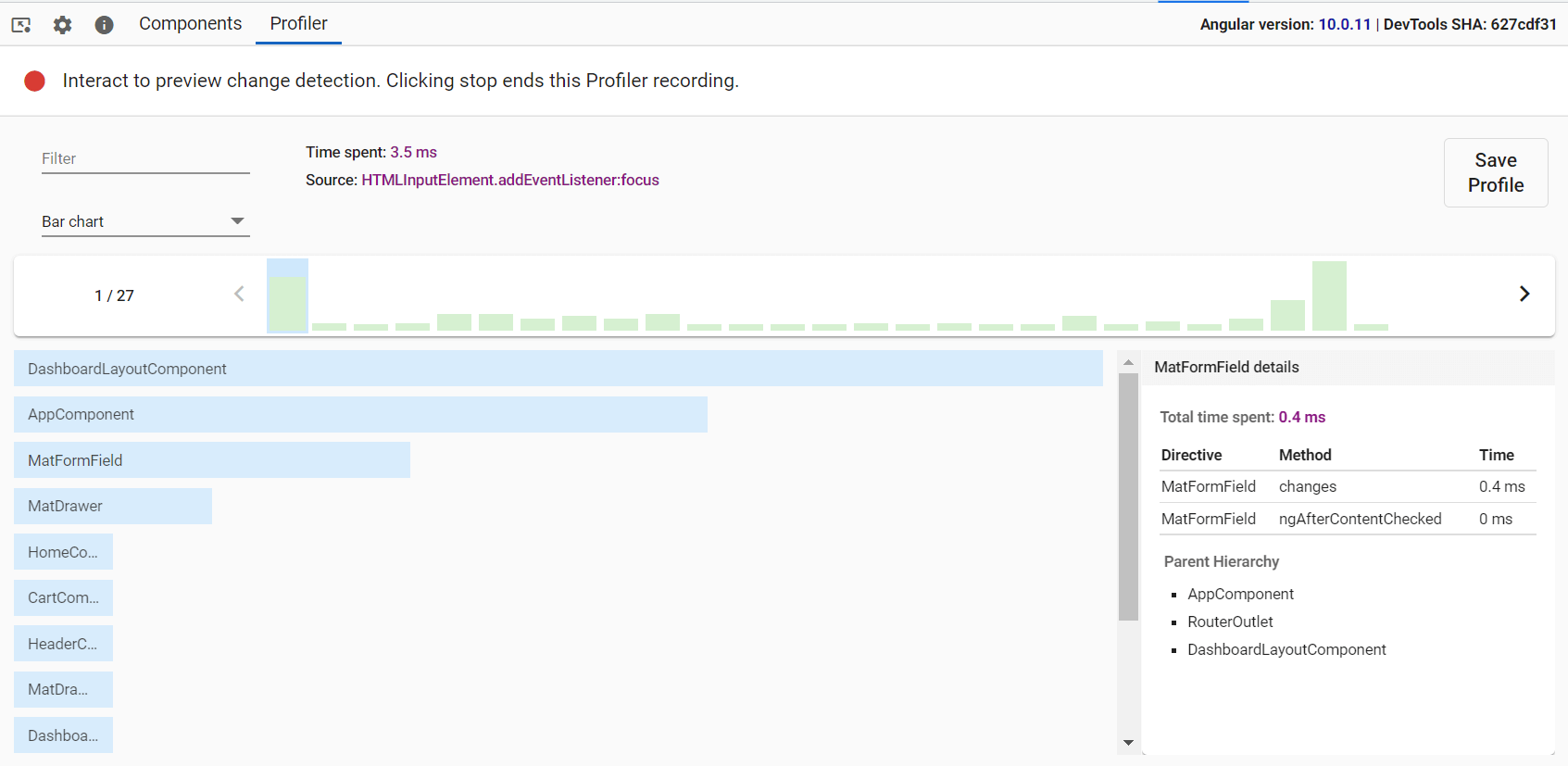
### Different Visualizations to Better Understand the Execution
From the bar chart view, you can switch to tree map or flame graph views to visualize the change detection to better understand your application’s execution.
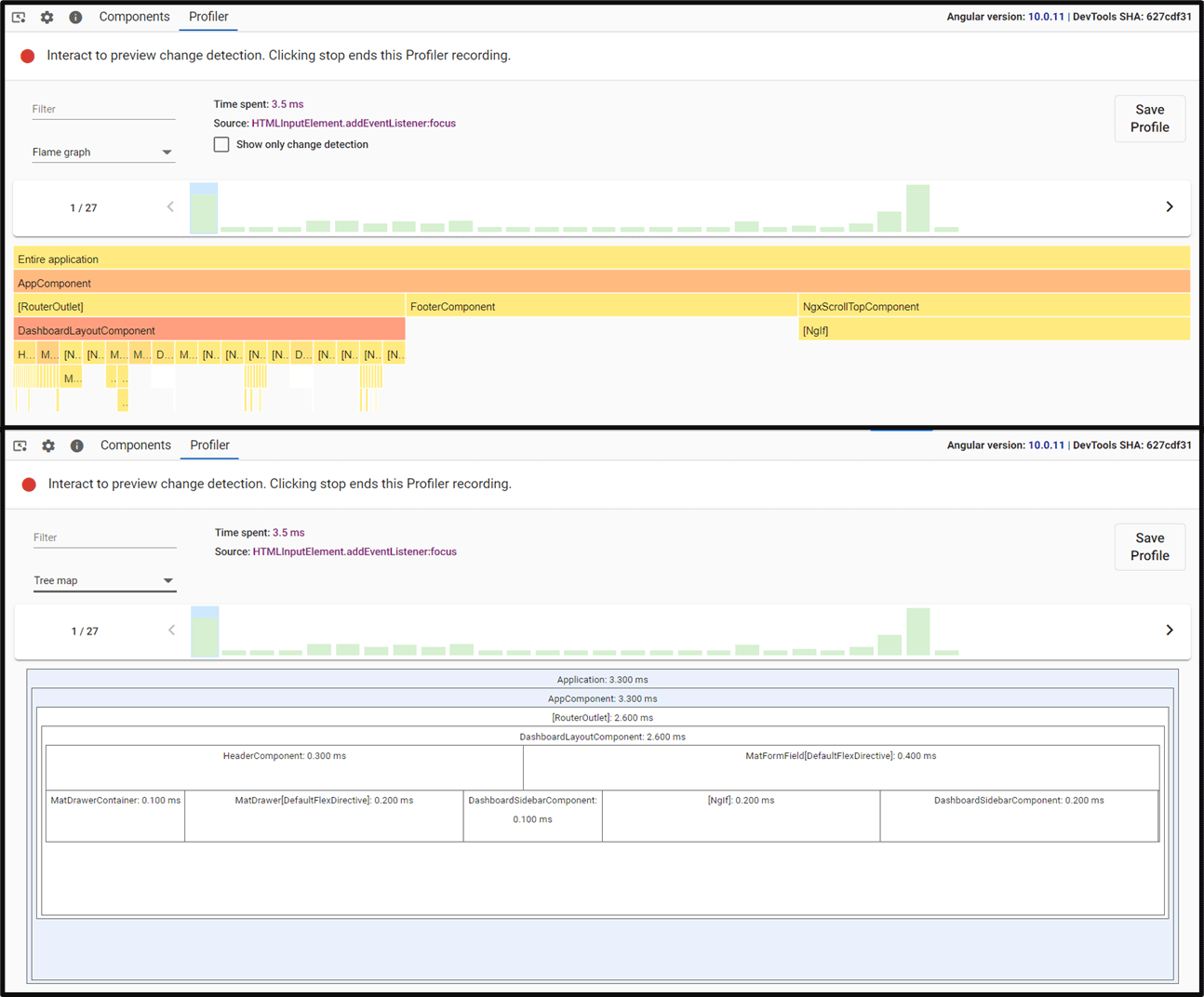
In the flame graph view, the color of each block represents the time the app spent on that component. DevTools changes the intensity of the color based on the time consumed by each component relative to the component where the app spent the most time in change detection. That means the more time an app spent on a specific component, the higher the intensity of the block color will be.
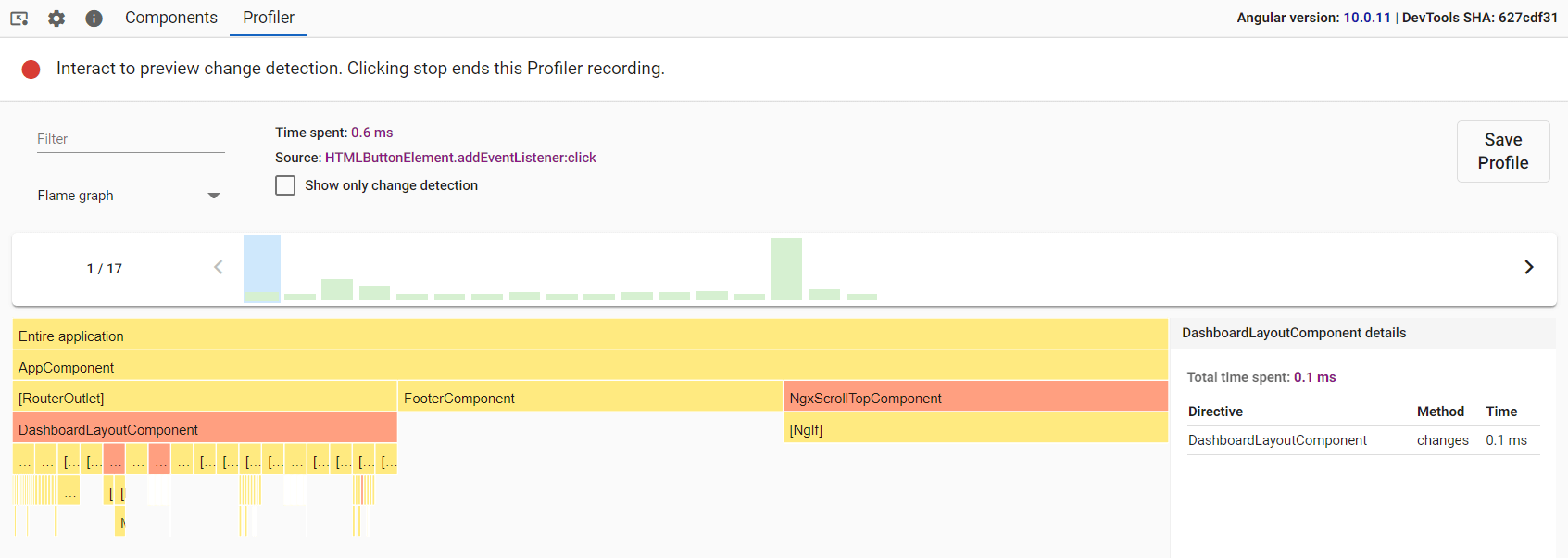Similar to in the bar chart view, additional details will appear on a panel next to a specific block when you click on it.
As you can see in the previous screenshot, the component and directives executed under the **DashboardLayoutComponent** are not clearly visible. However, you can double-click on the **DashboardLayoutComponent** block and zoom into it to get a clear view of its nested children.
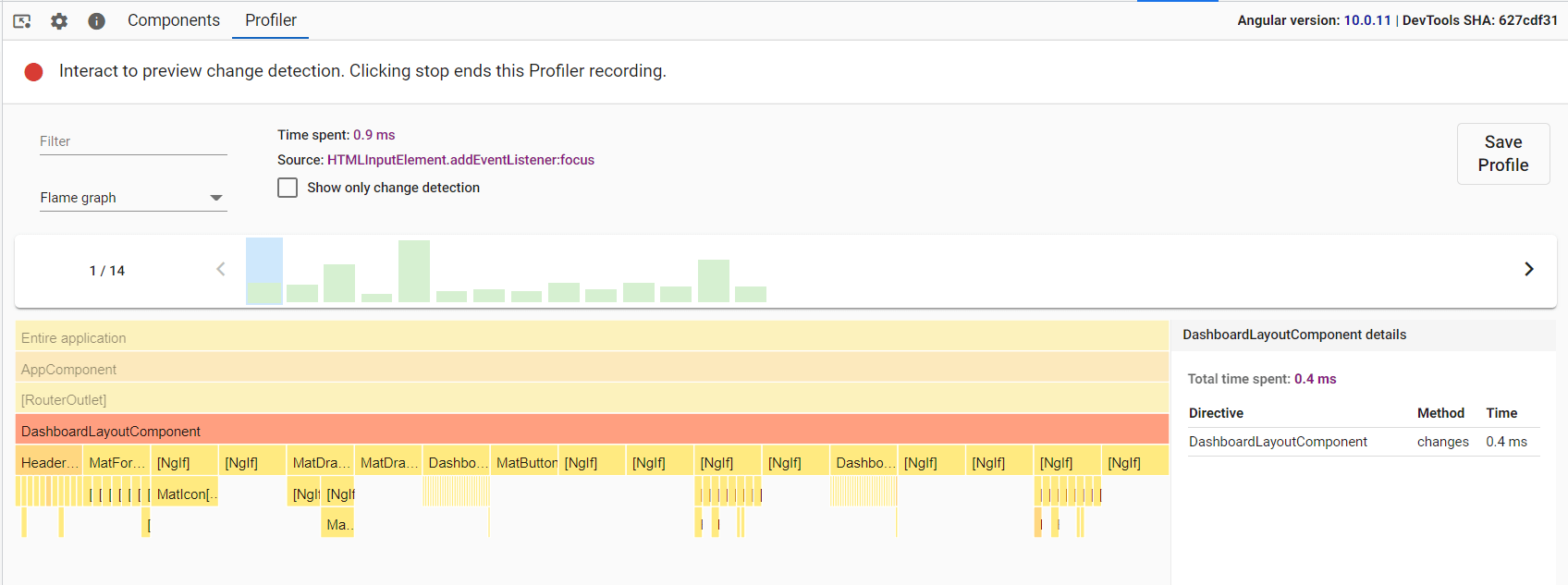To view only the components that were affected by the change detection, check the check box on top of the sequence of bars. It will change the color of the blocks in which changes are detected blue, while the rest will be turned gray.
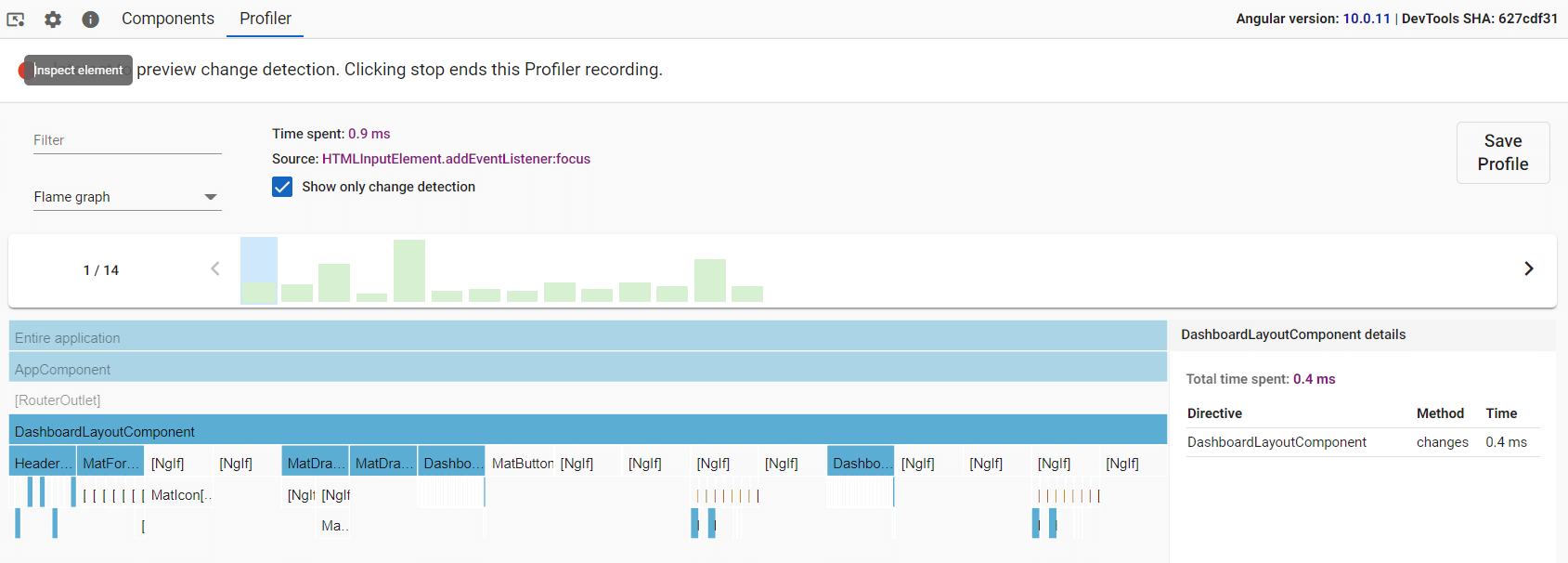Finally, you can export the recorded profiler as a JSON file by clicking the **Save Profile** button at the top-right corner.
**Make sure your profiler recording doesn’t contain confidential information if you share it with someone else.**
## Conclusion
In this article, I’ve discussed the features of Angular DevTools and how to use them. Even though it’s relatively new to the Angular community, DevTools eases your development process and brings transparency. If you still haven’t tried it out, I encourage you to do so.
Thank you for reading!
Syncfusion’s [Angular UI component](https://www.syncfusion.com/angular-ui-components "Angular Components Library") library is the only suite you will ever need to build an app. It contains over 75 high-performance, lightweight, modular, and responsive UI components in a single package.
For existing customers, the newest Essential Studio version is available for download from the [License and Downloads](https://www.syncfusion.com/account/downloads "License and download page of Essential Studio") page. If you are not yet a Syncfusion customer, you can try our 30-day [free trial](https://www.syncfusion.com/downloads "Free evaluation of the Syncfusion Essential Studio") to check out the available features. Also, check out our demos on [GitHub](https://github.com/syncfusion "Syncfusion examples on GitHub").
If you have questions, you can contact us through our [support forums](https://www.syncfusion.com/forums "Syncfusion Support Forum"), [support portal](https://support.syncfusion.com/ "Syncfusion Support Portal"), or [feedback portal](https://www.syncfusion.com/feedback/angular "Syncfusion Feedback Portal"). We are always happy to assist you!
## Related blogs
- [Easy Steps to Create a Read-Only Angular PDF Viewer ](https://www.syncfusion.com/blogs/post/easy-steps-to-create-a-read-only-angular-pdf-viewer.aspx "Blog: Easy Steps to Create a Read-Only Angular PDF Viewer")
- [Easily Generate Bulk Reports Using Mail Merge in Angular ](https://www.syncfusion.com/blogs/post/easily-generate-bulk-reports-using-mail-merge-in-angular.aspx "Blog: Easily Generate Bulk Reports Using Mail Merge in Angular ")
- [Top 7 Features of Angular 14 ](https://www.syncfusion.com/blogs/post/top-7-features-of-angular-14.aspx "Blog: Top 7 Features of Angular 14")
- [Building Custom Structural and Attribute Directives in Angular](https://www.syncfusion.com/blogs/post/building-custom-structural-and-attribute-directives-in-angular.aspx "Blog: Building Custom Structural and Attribute Directives in Angular") | jollenmoyani |
1,297,539 | Unlock the power of sorting algorithms with this easy-to-remember trick | Are you tired of struggling to remember sorting algorithms? Do you want to unlock the full potential... | 0 | 2022-12-15T18:04:31 | https://dev.to/shreyashchavan/unlock-the-power-of-sorting-algorithms-with-this-easy-to-remember-trick-3po6 | cpp, algorithms, productivity, codenewbie | Are you tired of struggling to remember sorting algorithms? Do you want to unlock the full potential of these powerful techniques and boost your coding skills?
Look no further! My simple, easy-to-remember trick will help you master sorting algorithms in no time.
By incorporating this trick into your workflow, you'll be able to quickly and easily implement sorting algorithms in your projects, making you more efficient and effective as a coder.
Sorting algorithms are productivity boosters, Don't miss out on this opportunity to take your coding skills to the next level - try this sorting algorithm trick today!
There are a few different ways to remember the different sorting algorithms, but here's one method you might find helpful because I used the same.
Start by thinking about the different characteristics of each sorting algorithm. For example, some algorithms are more efficient for certain types of data, while others are better at handling large datasets.

Next, try to come up with a mnemonic to help you remember the different algorithms.
For example, you might use the acronym
"**BUBBLE**" to represent the bubble sort algorithm:
B - Bubble Sort
U - Unstable (because it is an unstable sorting algorithm)
B - Basic (because it is a simple algorithm to implement)
B - Brute Force (because it is not very efficient for large datasets)
L - Low Memory (because it does not require a lot of memory to implement)
E - Exchanges (because it works by exchanging adjacent elements in the dataset)
Similarly,
Here are a few more mnemonics you can use to help you remember the different sorting algorithms:
**Quicksort**:
"_QUICK_" (Quick to implement, Unstable, In-place, Clever, Keys)
**Merge sort**:
"_SPLIT_" (Stable, Parallelizable, Logarithmic memory, In-place, Two-way merge)
**Insertion sort**:
"_SLIDE_" (Stable, Linear time for small inputs, In-place, Delta-based, Efficient for partially sorted data)
**Selection sort:**
"_PICK_" (Poor performance, In-place, Constant memory, Keys)
**Heap sort**:
"_HEAP_" (Heap data structure, Efficient for large data sets, In-place, Automatically balanced)
Remember, these mnemonics are just one way to help you remember the different sorting algorithms. You may find that a different method works better for you.
The important thing is to find a method that helps you remember the key characteristics of each algorithm so that you can choose the right one for a given situation.
In conclusion, sorting algorithms can be daunting and complex for beginners. However, by implementing the "divide and conquer" approach and using the "_mnemonic_" trick, sorting algorithms can be simplified and made more manageable.
This trick not only helps improve understanding and efficiency, but also makes sorting algorithms more memorable.
Give it a try and see the difference it can make in your coding skills.
Share this post with your friends and let us know in the comments how this trick has helped you. | shreyashchavan |
1,297,787 | TIL; typescript - classes | public fields in constructor | the use of public on arguments on the constructor is a shorthand that allows us to automatically... | 0 | 2022-12-15T14:57:12 | https://dev.to/seyofori/til-typescript-classes-public-fields-in-constructor-14gd | typescript, webdev | - the use of `public` on arguments on the constructor is a shorthand that allows us to automatically create properties with that name
```jsx
class Student {
fullName: String;
constructor(
public firstName: string,
public lastName: string
){
this.fullName = firstName + " " + lastName;
}
}
```
> in this case, the class has been given 3 public properties; fullName, firstName and lastName. firstName and lastName were created as public properties on the class by using the public keyword in the constructor params
- classes in TS are just a shorthand for the same prototype-based OO that is frequently used in JS | seyofori |
1,297,837 | Streamline your git workflow with HighFlux: the automated git client | Do you ever forget to commit a crucial file and end up with a broken build? Or your latest work is on... | 0 | 2022-12-15T16:23:13 | https://dev.to/mathijs81/streamline-your-git-workflow-with-highflux-the-automated-git-client-2mbk | git, devops | Do you ever forget to commit a crucial file and end up with a broken build? Or your latest work is on your desktop, and you can't continue working on your laptop because you forgot to push? These are common challenges for developers, and we want to fix those with HighFlux.
[Read the full article about HighFlux here!](https://www.highflux.io/blog/streamline-git-workflow-automated-client) | mathijs81 |
1,297,849 | O básico de Stimulus em Rails | Talvez você tenha se perguntado a existência da gem stimulus que Rails instala por padrão, mas não se... | 0 | 2022-12-15T21:53:02 | https://dev.to/xandekk/o-basico-de-stimulus-em-rails-395j | rails, stimulus | Talvez você tenha se perguntado a existência da gem `stimulus` que Rails instala por padrão, mas não se preocupe, que aqui você vai aprender sobre ele.
**Observação: Esse post é necessário que tenha um conhecimento DOM. Se não, pode ser complicado em entender.**
## O que é Stimulus?
Eu vou traduzir a documentação, pois, sinceramente, não consigo explicar isso em outras palavras.
Stimulus é um framework Javascript com ambições modesta.
Ao contrário de outros frameworks front-end, Stimulus é projetado para aprimorar HTML estático ou renderizado pelo servidor - o "HTML que você possui" - conectando objetos Javascript a elementos da página usando anotações simples.
Esses objetos JavaScript são chamados de controllers, e o Stimulus monitora continuamente a página esperando que os atributos `data-controller` apareçam no HTML. Para cada atributo, o Stimulus examina o valor do atributo para encontrar uma classe controller correspondente, cria uma nova instância dessa classe e a conecta ao elemento.
Você pode pensar desta maneira: Assim como o atributo `class` é uma ponte que conecta HTML a CSS, o atributo `data-controller` do Stimulus é uma ponte que conecta HTML a Javascript
Além dos controllers, os outros três principais conceitos de Stimulus são:
- `actions`, que conectam métodos do controller a eventos DOM usando atributos `data-action`;
- `targets`, que localizam elementos de significado dentro de um controller;
- `values`, que leem, escrevem e observam atributos de dados no elemento do controller.
O uso de atributos de dados pelo Stimulus ajuda a separar o conteúdo do comportamento da mesma forma que o CSS separa o conteúdo da apresentação. Além disso, as convenções do Stimulus naturalmente encorajam você a agrupar códigos relacionados por nome.
Por sua vez, o Stimulus ajuda você a criar controllers pequenos e reutilizáveis, fornecendo estrutura suficiente para evitar que seu código se transforme em uma “sopa de JavaScript”.
Talvez, com essa explicação, você não tenha entendido muito, então vamos para a prática para fixar isso.
## Prática
Eu estava pensando que tipo de aplicação eu criaria para isso, porém, não consegui em pensar em nada. Então vai ser uma aplicação aleatória que possa aproveitar o máximo do Stimulus.
Então, execute os comandos abaixo para preparar o terreno.
```bash
rails new exemplo_stimulus
cd exemplo_stimulus
rails g controller Pagina index
```
Abra o arquivo `config/routes.rb`.
```ruby
# config/routes.rb
Rails.application.routes.draw do
root 'pagina#index'
end
```
Agora, o nosso terreno está pronto.
## Controllers
Vá no arquivo `app/views/pagina/index.html.erb` e adicione o código abaixo.
```erb
<!-- app/views/pagina/index.html.erb -->
<div data-controller="hello"></div>
```
Rode o servidor e vá para URL `localhost:3000` e veja a mágica acontecer.
Viu, apareceu o "Hello world!", mas como?
Antes de explicar, o que aconteceu, vamos, primeiro, entender sobre o atributo `data-controller`.
Como foi explicado lá em cima, que o Stimulus procura no html pelo o atributo `data-controller` para criar uma instância de classe e conectar com o elemento.
Só que a dúvida é, onde está essa classe?
Bem, na sua aplicação, procure o arquivo no diretório `app/javascript/controllers` e verá ele lá.
Achou? E qual é o nome do arquivo?
`hello_controller.js` é o nome do arquivo, ou seja, o Stimulus vai usar o valor do atributo para procurar um arquivo do diretório `app/javascript/controllers`.
Vamos fazer um teste, mude o valor do `data-controller`.
```erb
<!-- app/views/pagina/index.html.erb -->
<div data-controller="ola"></div>
```
Agora, reinicie a página e verá ...
Nada, obviamente, esperava o que?
Bem, por que não apereceu nada?
É que Stimulus está procurando um arquivo com nome `ola_controller.js` e esse arquivo não existe.
Então, vamos mudar o nome do arquivo `hello_controller.js` para `ola_controller.js` e reinicie a página.
Agora, funcionou.
Uma observação, é necessário que tenha o nome `_controller.js` no final do arquivo.
Bem, eu acho que você sacou como que funciona o `data-controller`.
Agora, vamos abrir o `app/javascript/controllers/ola_controller` e observar ele.
```javascript
// app/javascript/controllers/ola_controller
import { Controller } from "@hotwired/stimulus"
export default class extends Controller {
connect() {
this.element.textContent = "Hello World!"
}
}
```
Não tem muito segredo nesse arquivo, então eu vou só explicar o método `connect`, pois o resto dá para entender de boa.
O método `connect` é executado, quando usar o atributo `data-controller`.
Beleza, agora vamos nos aprofundar um pouco.
## Actions
Vá para o arquivo `app/views/pagina/index.html.erb` e coloque o código abaixo.
```erb
<!-- app/views/pagina/index.html.erb -->
<div data-controller="ola">
<input type="text" data-action="keyup->ola#mudarTexto">
<p></p>
</div>
```
Ok, nós temos um novo atributo.
O `data-action` serve para lida com evento DOM do seu controller.
Vamos observar o valor do nosso atributo `data-action`.
Observando ele, você pode notar um padrão, que é, começa com evento DOM `keyup` e vai para o controller `ola` e execute o método `mudarTexto`.
Ou seja, é desse jeito o padrão `evento->controller#método`.
Não tem muito mistério sobre isso, basta lembrar desse padrão.
Então vamos para o arquivo `app/javascript/controllers/ola_controller.js` e colocar o novo método e remover o `connect`.
```javascript
// app/javascript/controllers/ola_controller.js
import { Controller } from "@hotwired/stimulus"
export default class extends Controller {
mudarTexto(event) {
console.log(event.target.value);
}
}
```
Pronto, reinicie a página e abra o dev tools para ver o console.
Viu, ele está imprimindo o valor do input.
Você pode pensar, nossa, que simples.
Sim, de fato, é muito simples.
Agora vamos mergulhar mais, que já estamos quase no fim.
## Targets
Novamente, edite o arquivo, `app/views/pagina/index.html.erb`.
```erb
<!-- app/views/pagina/index.html.erb -->
<div data-controller="ola">
<input type="text" data-action="keyup->ola#mudarTexto">
<p data-ola-target="texto"></p>
</div>
```
Hum, um outro atributo.
Esse atributo é bem diferente, se prestar atenção, você pode ver o nome do controller no meio, ou seja, para usar ele, tem que seguir esse padrão, `data-nome_do_controller-target`.
Mas a questão é, o que ele faz?
Como o nome diz, ele é um alvo do controller.
O uso dele seria equivalente a `GetElementById`, só que mais simples.
Vamos para o arquivo `app/javascript/controllers/ola_controller.js`.
```javascript
// app/javascript/controllers/ola_controller.js
import { Controller } from "@hotwired/stimulus"
export default class extends Controller {
static targets = [ "texto" ]
mudarTexto(event) {
this.textoTarget.textContent = `olá, ${event.target.value}`
}
}
```
Pode notar que existe uma variável `targets`, em que, está atribuindo um array com um valor `"texto"`, ou seja, tem ter o valor igual, onde foi posto no HTML.
Agora, se você observar o `this.textoTarget`, ele é o elemento, a qual você colocou o atributo `data-ola-target`.
Então reinicie a página, e veja a mágica acontecer.
## Values
O último conceito do Stimulus, então, abra o arquivo index novamente.
```erb
<!-- app/views/pagina/index.html.erb -->
<div data-controller="ola" data-ola-nome-value="Zulano" >
<input type="text" data-action="keyup->ola#mudarTexto">
<p data-ola-target="texto"></p>
</div>
```
Beleza, antes de explicar esse atributo, vamos primeiro para o arquivo javascript.
```javascript
// app/javascript/controllers/ola_controller.js.
import { Controller } from "@hotwired/stimulus"
export default class extends Controller {
static targets = [ "texto" ]
static values = {
nome: String
}
mudarTexto(event) {
console.log(this.nomeValue)
this.textoTarget.textContent = `olá, ${event.target.value}`
}
}
```
Pode notar que ele meio que equivalente ao target, o que muda é que o targets aceita um array, enquanto o values é um JSON.
O padrão do atributo é `data-nome_do_controller-chave-value`.
Novamente, reinicie a página e veja o console do dev tools.
Bem, eu vou acabar por aqui, isso é o básico do Stimulus.
Eu sinto que esse post foi um desastre, mas se houver qualquer dúvida, pode comentar que vou responder.
Bem, então é isso, tchau!
| xandekk |
1,298,166 | Bito AI: Change how you do dev with AI, in your IDE | Hi Dev Community, 👋 I am excited to bring you Bito AI, a product that we think can transform your... | 0 | 2022-12-15T19:46:02 | https://dev.to/amargoel/bito-ai-change-how-you-do-dev-with-ai-in-your-ide-26dm | ai, programming, productivity, testing | Hi Dev Community, 👋
I am excited to bring you [Bito AI](https://bito.co), a product that we think can transform your development experience. We want to help you be a 10x developer, or at least save a couple of hours a day!
As a developer there are so many things to do, from actually writing code, to testing it, to remembering syntax, understanding new code, making your code secure and performant, etc – the list goes on and on. Many of them are boring, and don’t let you focus on high impact work. 😤
We thought wouldn’t it be great if we could use AI to help you do this, and thus Bito’s AI was born. 🤞 Bito’s AI Assistant is like a Swiss Army knife that can do so many things – and make you that elusive 10x developer!
It works right in your favorite IDE (we support Visual Studio Code and all Jetbrains IDEs like IntelliJ, PyCharm, GoLand, etc) and is also available as a Chrome Extension. Check out our [2-minute demo](https://bit.ly/BitoDemo).
[Bito AI](https://bito.co) is a **FREE** app! 👍
What does Bito’s AI Assistant help with? Basically, ask any technical question:
☝️ Command Syntax: “how to set git config variables”, “create an encrypted s3 bucket using the AWS cli”
🥇 Test Cases: “Generate test cases for this code ”
🔑 Explain code: “explain this code ”
🔥Generate Code: Examples: “code in java to convert a number from one base to another”, “code to implement a simple rest API in go”
✍️ Comment Method: “Explain this code and explain the parameters ”
⚡ Improve Performance: “how can I improve performance of this code ”
🔒 Check Security: “Is this code secure?”
📽️ Explain concepts: "explain B+ trees, give an example with code", “explain banker’s algorithm”
Trained on billions of lines of code and millions of docs, it’s pretty incredible what [Bito AI](https://bito.co) can help you do without having to search the web or waste time on tedious stuff.
We'd love to have you try it out, let us know what you think! It’s totally free. We know we have a long way to go, but your feedback will make it incredible!
One more thing: Security is something we take very seriously, and we never store or view your code in any way.
Thanks so much for your feedback. Please email us at founders@bito.co with any questions, we are really eager to get your thoughts.
-Amar, Anand, and Mukesh
[Bito AI](https://bito.co)
| amargoel |
1,298,199 | How to manage browser driver with Web Driver Manager | In this article i will explain how to use Web Driver Manager to manage browser driver easily ... | 0 | 2022-12-15T21:09:28 | https://dev.to/zettasoft/how-to-manage-browser-driver-with-web-driver-manager-3k53 | programming, beginners, tutorial, python | In this article i will explain how to use Web Driver Manager to manage browser driver easily
##Background
when we make a project using selenium library every time there is a newer version of the driver we need to download it and we have to set the corresponding executable path explicitly. After that, we make object from the driver and continue with the code we want to run. these steps become complicated as we need to repeat these steps out every time the versions change.So therefore, we use WebDriverManager to easily manage it.
##Task
Create a simple session to open google.com and search with keyword "web scrapping"
##Getting Started
assuming python is intalled on your machine or virtual environment, then you must install WebDriverManager and selenium
```
pip install webdriver-manager
pip install selenium
```
after that on code editor lets import all library we need
```
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
```
next we start the session by instatiating driver object
```
driver = webdriver.Chrome(options=Options, service=ChromeService(ChromeDriverManager().install()))
```
the script above will install driver browser automatically,
then, lets call the driver object to take action on google.com
```
driver.get("https:www.google.com")
```
and lets find element search and send key "web scraping" on it
```
search_el = driver.find_element(By.CSS_SELECTOR,"input[title='Search']")
search_el.send_keys("web scrapping")
```
if you have arrived at this step, then your screen will be the same as this image
##Conclusion
now we know that WebDriverManager automates the browser setup in the Selenium code and this make the difficult steps to store newer version of driver become automatic so we can focus on our execution script rather than browser settings
Github :https://github.com/muchamadfaiz
Email : muchamadfaiz@gmail.com
| muchamadfaiz |
1,298,212 | How to settle HFSQL connection with ODBC via PDO for Php | I've been struggling for weeks before being able to connect and request an HyperFileSQL (HFSQL)... | 0 | 2023-01-02T09:29:44 | https://dev.to/gaeldigard/how-to-settle-hfsql-odbc-via-pdo-for-php-3jd6 | hfsql, pdo, php, odbc | I've been struggling for weeks before being able to connect and request an HyperFileSQL (HFSQL) database in PHP, using ODBC via PDO.
Here's a complete guide tested with `PHP 8.0.15`, `Apache 2.4.23` and `ODBC Drivers 26.0101d`, on `Windows 10 Entreprise 64 bits (10.0, build 19044)`.
# HyperFileSQL
As a reminder, HFSQL is a database engine from the late 80's, developped by a french company named PC SOFT. This company is also responsible for WinDev, WebDev, and many others monstruosities. All that mess is natively Windows compatible, not working really well on Linux.
> Source : https://fr.wikipedia.org/wiki/PC_SOFT
You'll notice there's no Wiki article about HFSQL, demonstrating its popularity. You barely can find useful information on stackOverflow either, or just some crumbs, that you have to gather, tries after tries.
# Probable stack reminder
I think it works like that.
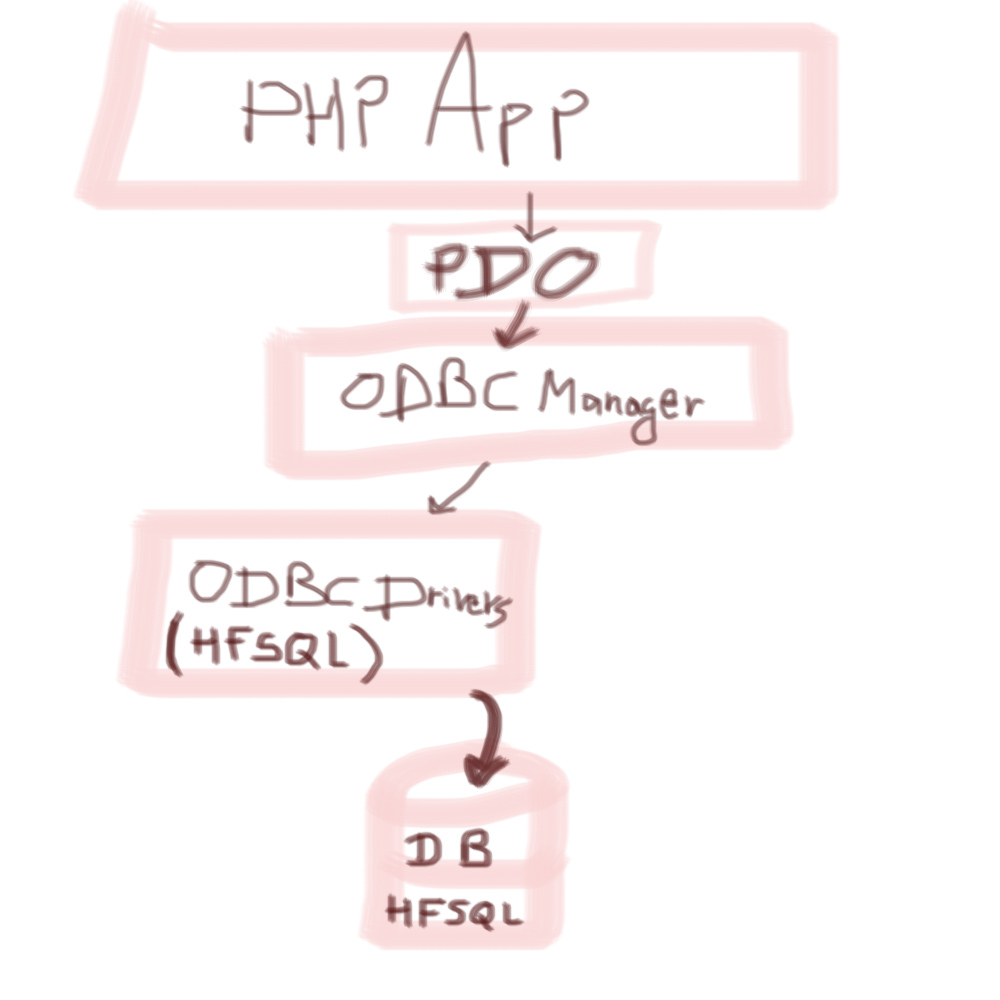
# ODBC driver on the HFSQL server
You'll need to install ODBC drivers on the machine where your DB server is. I actually didn't work on this part, it was made by the owner of the DB. But I'm pretty sure he did what's explained in this part : [HFSQl Drivers](#hfsql-drivers) on the server side.
I've also found a vague note on the official website, [here](https://doc.pcsoft.fr/?2028086&name=parametres_des_bases_donnees#NOTE9_1).
It doesn't matter if drivers aren't installed on your server, because we will explore a local solution for development. You can continue this tutorial anyway.
---
Now we will only focus on the app side, where your php is runing, on **Windows**.
# Php on the app side
You need Php installed, and this extension turned on :
> `pdo_odbc`
Locate you php.ini file :
> `;extension=pdo_odbc`
Remove the semicolon before, save file and restart Apache.
Because we are on windows, you might be using WAMP stack, so, your file might be there :
> `C:\wamp64\bin\php\php8.0.15\php.ini`
This extension will allow you to communicate with your DB via ODB, and request Db via PDO. But that's not all...
# HFSQL drivers
You also need some drivers, to tell ODBC how to communicate with this nudnik which is HFSQL. They are available on PC SOFT website.
> Source : https://pcsoft.fr/st/telec/modules-communs-26/wx26_101d.htm
Scroll down and select **ODBC26PACK101d.exe** to download HFSQL drivers for ODBC for **Windows**.
They're as well available for Linux, but, after 2 days of try hard, with 2 different persons, on 2 different linux systems (both Debian based and up-to-date), we were only facing "`Segmentation fault`" when trying to connect to any HFSQL DB from shell (not even from php). That's why this article will deal only with Windows platform.
Once downloaded, just double click to launch the installer, and "next" each step, reading or not what is written.
# Local HFSQL database
## HFSQL server
To test your installation, you can create a local DB by installing an HFSQL Server. This will help us to skip all the potential problems of remote authenticating / network / firewall.
If you're sure about your connectivity and your credential, skip this part and just go to [PDO via ODBC](#pdo-via-odbc)
You can download HFSQL server application on the same webpage than the drivers :
> Source : https://pcsoft.fr/st/telec/modules-communs-26/wx26_101d.htm
Scroll down and select **HFSQL26INSTALL101.exe** to download it.
While you'll install it, you'll be asked to create a new DB on the fly. You'll have to chose a directory where your data will be saved, anywhere will fit.
Check the server name and remove any blank space.
Check the port : 4900 by default.
If it's your first HFSQL DB server on this computer, default name and port will be ok, if it's not, you'll have to change your port and server name to something else (eg. ComputerName_2 & 4901)
Default username is "Admin" and there's no default password. You can set one if needed. Very well. Next.
Skip the SMTP part.
Skip the Active Directory part.
Accept or not to participate to survey.
Then the magic will happen.
## HFSQL client
While you installed the server, PC SOFT installed a client as well. It's called "Centre de contrôle", or "Control Center" in very good english. It's your PhpMyAdmin or MySQL Workbench-like software.
> It's located in : `C:\Program Files\PC SOFT\CC HFSQL`
Double-click `CC260HF64.exe` file
Check-in "New connection" and fill it up with `127.0.0.1` or `localhost `for the server address or name, the port, user and password, as set in the previous step, when you were installing the server.
You should connect locally to your server. If not, don't go further and check everything back.
It should look like this :
You can make a new DB by clicking "Nouvelle base de données" near the button to shutdown the server (Arrêter le serveur). Enter the name of your DB and validate.
It should look like that if you logged in your DB.
I haven't been further into HFSQL by creating tables and inserting data here. I've just copy-past some files I got from the production server here :
> `C:\PC SOFT\Serveur HFSQL OrdinateurDeGael_2\BDD\devto-demo`
Yep. That's all. `.FIC` and `.NDX` files dumped here and you got your DB. You can as well have directories into this directory, we will talk about this agony later.
Now you have proven your ability to connect to your local HFSQL server with a dedicated software, you can try to do the same it with Php, via ODBC/PDO.
# PDO via ODBC
To connect to a HFSQL server you need a `DSN`, also known as _Data Source Name_. According to your version of the ODBC drivers, this long string can change. Reminder : we use version 26 of driver. And you should too.
Into your php test file, type down :
``` php
$hf_dsn = sprintf("odbc:DRIVER={HFSQL};Server Name=%s;Server Port=%s;Database=%s;UID=%s;PWD=%s;", '127.0.0.1', '4900', 'database_name', 'Admin', '');
```
Please note that **`{HFSQL}`** is necessary and might not be replaced by any other value.
You can find on old forums, some of these values :
> `{Hyper File 7}, {HyperFileSQL} # WRONG `
They're are **not working** since version 26 (that we are using).
For the rest : host, port, database name (that you might have created before), username (Admin is default on your local) and password (here I wrote no password).
---
Now we got a complete DSN, we can try to connect via PDO :
```php
$hf_hostname = "127.0.0.1";
$hf_port = "4900";
$hf_database = "devto-demo";
$hf_user = "Admin";
$hf_password = "";
$hf_dsn = sprintf("odbc:DRIVER={HFSQL};Server Name=%s;Server Port=%s;Database=%s;UID=%s;PWD=%s;", $hf_hostname, $hf_port, $hf_database, $hf_user, $hf_password);
try{
$hf_dbh = new PDO($hf_dsn, $hf_user,$hf_password, [ PDO::ATTR_PERSISTENT => true]);
}
catch(PDOException $ex){
echo($ex->getMessage());
}
```
You will notice I've stored credential into variables, because they are passed twice : once in the DSN, and once in PDO. Dunno why. But it has to.
If everything if fine, nothing will appear. If an error occurs, you messed up somewhere. The most common mistake I got was the wrong driver name `{HFSQL}`, or the driver not installed (but we addressed these steps above). If it still not works, check login, password, server, port, a bit like with MySQL.
# Queries, syntax and subtilities
## Queries
Now it's time to query your DB.
``` php
try{
$query = "SELECT * FROM [articles] WHERE (Author='JeanMatteo')";
$stmt = $hf_dbh->query($query);
$result = $stmt->fetchAll(PDO::FETCH_ASSOC);
var_dump($result);
}
catch(PDOException $ex){
echo($ex->getMessage());
}
```
Here's a simple request which get all the articles wrote by author named _JeanMatteo_ : table name is between **square brackets** and the WHERE condition is between **parentheses**.
The rest of the code is common PDO code.
## Diacritics
Guess what ? You can put accents, or diacritics (like é, à, ù) in your tables NAME, and, ALSO in your cols name. What a pleasure to request a french 🥖 database.
### Column name
Imagine that our table `articles` has a column named `Libellé`, which means "Label" in english. Character encoding will make some mess, and will return some �. So, how to access our column ?
**With array index.** First of all, fetch all data in `FETCH_BOTH` mode :
``` php
// ...
$result = $stmt->fetchAll(PDO::FETCH_BOTH);
// ...
```
this will returns an array both with numerical and associative indexes :

Now you can access to your `Libell�` attribute like this :
```php
$article->{'2'}; // $article->Libellé won't work because of the DB encoding ;
```
As you see, DB encoding isn't matching the one of our app. I couldn't set the DB connection encoding to utf-8, and I didn't want to change all my php app encoding to something else.
### Table name + column name containing diacritics
Imagine a table named `Détails`. With a column named `IDDétail`?
How to query it ?
```php
$query = 'SELECT * FROM ['utf8_decode('Détail).'] WHERE ('.utf8_decode('IDDétail').' = 69') ';
```
`utf8_decode` will be your friend.
## Subdirectory (nesting)
As told previously, you can have directories into your DB directory. They can be used to differenciate deptartments, or companies. In HFSQL language, it's easy to access a subdirectory via backslash :
``` SQL
SELECT * FROM [CompanyA\articles] WHERE (Author='JeanMatteo');
```
in PHP you will replace the backslash with an underscore :
``` PHP
$query = "SELECT * FROM [CompanyA_articles] WHERE (Author='JeanMatteo')";
```
# Slowness
If you access a big database, with a lot of tables and a lot of columns in each, with subdirectories and all, you will probably face delay issues.
This is because HFSQL engine sends the totality of the tables name, structure, plus, (IMO) indexes. Because of this stunning behavior, I could see transiting between my Apache and the HFSQL remote server, around 10mb/s of data for 2 or 3 minutes, before the website shows up. It's totaly useless for a web usage.
If your DB isn't that huge but connection is still slow, you can specify a parameter to your PDO connection method :
```php
$hf_dbh = new PDO($hf_dsn, $hf_user,$hf_password, [
PDO::ATTR_PERSISTENT => true
]);
```
The `PDO::ATTR_PERSISTENT => true` **in the constructor** won't close the HFSQL connection at the end of the script, as it usualy do.
Then the visitor won't have to reconnect at every page he loads in its browser. It means the first page loading will still be slow, but not the next ones. It will be almost instant.
The connection will be closed after a certain amount of time, but I couldn't find out how much, and how to set it (no documentation, no parameter).
But if your DB is way to huge, you wont have any other solution to make another 'lite' database, containing only the few tables you are using, and syncing them with the original DB sometimes. That's how we proceed in our project.
Good luck ! | gaeldigard |
1,298,749 | Best Tech Movies to Watch | All work and no play makes Jack a dull boy. Just like any other career, programmers are entitled... | 0 | 2022-12-16T06:45:22 | https://dev.to/larymak/inspirational-films-for-techies-1poc | productivity, programming, beginners, career | > All work and no play makes Jack a dull boy.
Just like any other career, programmers are entitled to rest, or what do you think? As a person relaxing is good for not only your mind but also your health, and it makes you feel calm and at peace. Our body also needs rest, and it is important to identify the signs that the body shows when it is overworked.
We have a tone of ways on which you can relax your mind and body, different people will opt for different methods. It is during this time our bodies will relaxed and free from work.
As we speak in our society today, it's through movies that we get to visualize and see the importance of technology and possible outcomes that can be achieved with it's help in our day to day lives. Now to help you find the right film to watch here are some of my all time favorite shows.
But before we get started, allow me to share somethings to point out while you entertain yourself. Even though this is considered a relaxing time it's also good practice to take this opportunity to learn a few things and tricks.
As the famous tweet say *Close your laptop brethren, you've done enough for this year*
## Movies List
### Films for Designers

1. **Abstract - The Art of Design** - a documentary television series that profiles various designers and their creative process in fields such as architecture, graphic design, and product design.
2. **The Creative Brain** - a documentary film about the science of creativity, featuring interviews with various researchers and creative professionals.
3. **Minimalism** - a documentary film about the philosophy and movement of minimalism, which advocates for simplicity and the reduction of unnecessary possessions and distractions.
4. **The People's Designer** - a documentary film about the life and career of designer Bruce Mau, who is known for his work in sustainability, innovation, and social responsibility.
5. **Floyd Norman - An Animated Life** - a documentary film about the career of Floyd Norman, an animator who has worked on numerous iconic films and television shows.
6. **The Toys that Made Us** - a documentary television series that explores the history and impact of iconic toy franchises such as Star Wars, Barbie, and Lego.
7. **The 00 Years Show** - a documentary film about Carmen Herrera, a Cuban-American artist who gained recognition for her work late in life after being overlooked for decades.
8. **Design Canada** - a documentary film about the history and evolution of graphic design in Canada, featuring interviews with various designers and examples of their work.
9. **Print the Legend** - a documentary film about the rise of 3D printing and its potential impact on various industries, including manufacturing, healthcare, and architecture.
### Movies about Cyber-Security

1. **Sneakers** - a film about a group of hackers and security experts who are hired to steal a black box that can crack any encryption.
2. **Who Am I** - a film about a computer hacker who becomes a hero after uncovering a conspiracy involving a corrupt businessman and the German government.
3. **Blackhat** - a film about a convicted hacker who is released from prison to help track down a cyber criminal who is attacking global infrastructure.
4. **Hackers** - a film about a group of young hackers who are targeted by a corrupt businessman and the FBI.
5. **War Games** - a science fiction film about a young computer hacker who accidentally starts a global nuclear war simulation.
6. **Takedown** - a film based on the true story of Kevin Mitnick, a notorious computer hacker who was pursued by the FBI for years.
7. **Mr. Robot** - a television series about a hacker who becomes involved in a conspiracy to bring down a major corporation.
8. **Snowden** - a biographical film about Edward Snowden, a former NSA contractor who leaked classified information about government surveillance programs.
9. **Citizenfour** - a documentary film about Edward Snowden and the revelations he made about government surveillance programs.
10. **Anonymous** - a film about the group of hackers known as Anonymous and their involvement in various high-profile cyber attacks.
11. **The Great Hack** - a documentary film about the Cambridge Analytica scandal and the role of data privacy in modern society.
12. **Algorithm** - a film about a young computer programmer who is recruited by a mysterious organization to crack a complex code.
13. **The Hacker Wars** - a documentary film about the conflict between hackers, the government, and corporations.
### Movies about AI

1. **Person of Interest** - a television series about a former CIA agent and a billionaire who team up to prevent violent crimes using a highly advanced artificial intelligence system.
2. **Ex Machina** - a science fiction film about an artificial intelligence experiment that goes awry.
3. **Simi** - a science fiction film about a woman who is given a device that allows her to communicate with her future self.
4. **Iron Man** - a superhero film about a billionaire inventor who creates a high-tech suit of armor to fight crime.
5. **A.I. Artificial Intelligence** - a science fiction film about a highly advanced android who is programmed to love and seeks to become a real boy.
6. **Her** - a science fiction film about a man who falls in love with a highly advanced artificial intelligence operating system.
7. **Transcendence** - a science fiction film about a researcher who uploads his consciousness into a computer, leading to unintended consequences.
8. **Morgan** - a science fiction film about a genetically engineered being who begins to exhibit dangerous behavior.
9. **Robot Chitti** - a science fiction film about a scientist who creates a highly advanced android, but becomes concerned when it starts to exhibit human-like emotions.
10. **I Am Mother** - a science fiction film about a young girl who is raised by a robot after a global disaster, and begins to question the robot's motivations when a human survivor arrives.
11. **Ready Player One** (2018) - a science fiction film about a virtual reality world that becomes the target of a corporate takeover
### Other Movies include:

1. **The Social Network** - a drama film about the creation of Facebook and the legal battles that followed.
2. **Pirates of Silicon Valley** - a biographical drama film about the rivalry between Steve Jobs and Bill Gates in the early days of the personal computer revolution.
3. **Silicon Valley** - a television series about a group of tech entrepreneurs trying to build a startup company in Silicon Valley.
4. **Jobs** - a biographical film about Steve Jobs, co-founder of Apple Inc.
5. **Source Code** - a science fiction film about a soldier who is sent into a simulated reality to prevent a terrorist attack, and begins to question the nature of his mission.
6. **The Social Dilemma** - a documentary film about the impact of social media on society and the ways in which it is used to manipulate and control users.
7. **The Imitation Game** - a biographical film about Alan Turing, a mathematician and computer scientist who played a key role in cracking Nazi codes during World War II.
8. **THE INTERNSHIP** - a comedy film about two salesmen who land internships at Google and must compete with a group of young, tech-savvy employees.
9. **The Circle** (2017) - a science fiction thriller about a powerful technology company that begins to violate the privacy of its users.
10. **Codebreakers** (1995) - a documentary film about the history of codes and codebreaking, including the work of Alan Turing and others
### Conclusion
There are numerous films that inspire techies with their innovative storylines, thought-provoking themes, and captivating characters. This films range from documentaries about the pioneers of the tech industry to science fiction thrillers that explore the possibilities of artificial intelligence and virtual reality, through this we are able to get a wide perspectives on the world of technology. Whether you are a budding entrepreneur looking for inspiration or a seasoned professional seeking to stay current on the latest trends, these films are sure to provide plenty of food for thought. | larymak |
1,298,815 | 19 Graph Algorithms You Can Use Right Now | The fastest to run any graph algorithm on your data is by using Memgraph and MAGE. It’s super easy.... | 0 | 2022-12-16T09:15:48 | https://memgraph.com/blog/graph-algorithms-list | memgraph, graphdatabase, database, graphalgorithms | The fastest to run any graph algorithm on your data is by using Memgraph and MAGE. It’s super easy. [Download Memgraph](https://memgraph.com/download?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost), import your data, pick one of the most popular graph algorithms, and start crunching the numbers.
**Memgraph** is an in-memory graph database. You can use it to traverse networks and run sophisticated graph algorithms out-of-the-box.
**MAGE** is an open-source repository tool supported by Memgraph. MAGE carries different modules and graph algorithms in the form of query modules.
You can choose from 19 graph algorithms along with their GitHub repositories for your query modules. You can use these algorithms with Memgraph and Mage immediately.
## Algorithms List
Here is the list of 19 algorithms that we support. You can use these algorithms immediately with Memgraph (graph DB) and Mage (graph library).
### 1. Betweenness Centrality
Centrality analysis provides information about the node’s importance for an information flow or connectivity of the network. [Betweenness centrality](https://en.wikipedia.org/wiki/Betweenness_centrality) is one of the most used centrality metrics. Betweenness centrality measures the extent to which a node lies on paths between other nodes in the graph. Thus, nodes with high betweenness may have considerable influence within a network under their control over information passing between others. The calculation of betweenness centrality is not standardized, and there are many ways to solve it.
It is defined as the number of shortest paths in the graph that passes through the node divided by the total number of shortest paths. The implemented algorithm is described in the paper "[A Faster Algorithm for Betweenness Centrality](http://snap.stanford.edu/class/cs224w-readings/brandes01centrality.pdf)" by Ulrik Brandes of the [University of Konstanz](https://www.uni-konstanz.de/en/).
A larger circle means larger betweenness centrality. The middle one has the largest amount of shortest paths flowing through it.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/betweenness-centrality-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 2. Biconnected Components
[Biconnected components](https://en.wikipedia.org/wiki/Biconnected_component) are parts of the graph important in the initial analysis. Finding biconnected components means finding a maximal biconnected subgraph. Subgraph is biconnected if:
* It is possible to go from each node to another within a biconnected subgraph
* The first scenario remains true even after removing any vertex in the subgraph
The problem was solved by [John Hopcroft](https://en.wikipedia.org/wiki/John_Hopcroft) and [Robert Tarjan](https://en.wikipedia.org/wiki/Robert_Tarjan) with linear time complexity. Depending on the use case, biconnected components may help to discover hidden structures within the graph.
Different colors are different components. Multi-colored vertices are articulation points.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/biconnected-components-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 3. Bipartite Matching
A bipartite graph is a graph in which we can divide vertices into two independent sets, such that every edge connects vertices between these sets. No connection can be established within the set.
Matching in bipartite graphs (bipartite matching) is described as a set of edges that are picked in a way to not share an endpoint. Furthermore, maximum matching is such matching of maximum cardinality of the chosen edge set. The algorithm runs in O(|V|*|E|) time, where V represents a set of nodes and E represents a set of edges.
This little tool can become extremely handful when calculating assignments between entities. Assigning stuff between two sets of entities is done in a large number of industries, and therefore having a method to find it can make the developing process easier.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/bipartite-matching-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 4. Bridge Detection
As in the real world, the definition of a bridge in graph theory denotes something that divides an entity into multiple components. Thus, more precisely, the [bridge](https://en.wikipedia.org/wiki/Bridge_(graph_theory)) in graph theory denotes an edge that, when removed, divides the graph into two separate components.
Example of bridges on the graph. Bold edges represent bridges.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/bridges-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 5. Community Detection
The notion of community in a graph represents similarly to what it represents in the real world. Different social circles are examples of such communities. Analogously, in graphs, community represents a partition of a graph, ie a set of nodes. [M. Girvan](https://scholar.google.com/citations?user=npKBI-oAAAAJ&hl=en) and [M. E. J. Newman](http://www-personal.umich.edu/~mejn/) argue that nodes are more strongly connected within a community, i.e. there are more edges, while on the other hand, nodes are sparsely connected between communities themselves.
There are more potential candidates to address community detection. Among the more popular algorithms are:
1. [Louvain community detection](https://en.wikipedia.org/wiki/Louvain_method) - based on modularity optimization - measures network connectivity within a community
2. [Leiden community detection](https://www.nature.com/articles/s41598-019-41695-z) - adjustment of Louvain's algorithm that introduces one level of refinement and brings together strongly connected communities
3. [Label propagation](https://en.wikipedia.org/wiki/Label_propagation_algorithm) - a machine learning technique that assigns labels to unmarked nodes and modifies them with respect to neighbors
Community detection labels each node with a community label. Here, labels are colored in different colors.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/community-detection-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 6. Cycle Detection
In graph theory, a cycle represents a path within the graph where only starting and ending nodes are similar. Furthermore, cycles can be double-connected links between neighboring nodes or self-loops.
The simplest concept of a solution for finding a cycle was defined by [Robert W. Floyd](https://en.wikipedia.org/wiki/Robert_W._Floyd) in his [tortoise and hare algorithm](https://en.wikipedia.org/wiki/Cycle_detection#Floyd's_tortoise_and_hare), where a hare moves at twice the speed of a tortoise and thus encounters it if there is a cycle. There are many implementations of cycle detection, and among them, the fastest is Professor [Donald B. Johnson](https://en.wikipedia.org/wiki/Donald_B._Johnson) from the Pennsylvania State University - [Finding all the elementary circuits of a directed graph](https://www.cs.tufts.edu/comp/150GA/homeworks/hw1/Johnson%2075.PDF).
Cycles are not only popular in graph structures but also play an important role in number theory and cryptography. Nevertheless, graph theory concepts are used in other disciplines, and cycle detection is placed as an extremely important tool in initial graph analysis.
There are two cycles in the graph from the examples, each colored differently.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/cycle-detection-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 7. Graph Coloring
Certain applications require the special labeling of a graph called [graph coloring](https://en.wikipedia.org/wiki/Graph_coloring). This “special” labeling refers to the assignment of labels (which we call colors) in such a way that connected neighbors must not be given the same color. Since this problem is [NP-hard](https://en.wikipedia.org/wiki/NP-hardness), there doesn't exist an algorithm that can solve the problem in a polynomial time. Therefore, various computer science techniques called [heuristics](https://en.wikipedia.org/wiki/Heuristic_(computer_science)) are used to solve graph coloring.
Of course, the main part of the problem is in assigning a minimum number of labels. There are greedy algorithms that solve the problem, however not optimal. Using dynamic programming, the fastest algorithm guarantees O(2.44 ^ n) complexity. While on the other hand, there are heuristic applications like the one with [genetic algorithms](https://en.wikipedia.org/wiki/Genetic_algorithm).

Example of graph coloring on a simple graph. Labels are denoted with different colors.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/graph-coloring-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 8. Node Similarity
The notion of [similarity](https://en.wikipedia.org/wiki/Similarity_(network_science)) can be described in several different ways, but within graph theory, it encompasses several generally accepted definitions. The similarity of graph nodes is based on a comparison of adjacent nodes or the neighborhood structure. These are traditional definitions that take into account only the layout of the graph. If we extend the definition of a node with additional properties, then it is possible to define comparisons based on these properties as well, but this is not the topic of the methods mentioned here.
The result of this type of algorithm is always a pair of nodes and an assigned value indicating the match measure between them. We will mention only the most popular measures based on neighborhood nodes with their brief explanations.
* [Cosine similarity](https://en.wikipedia.org/wiki/Cosine_similarity) - the cosine of the angle by which the product is defined as the cardinality of the common neighbors of the two nodes, and the denominator is the root of the product of the node degrees
* [Jaccard similarity](https://en.wikipedia.org/wiki/Jaccard_index) - a frequently used measure in different models of computer science includes the ratio of the number of common neighbors through the total
* [Overlap similarity](https://developer.nvidia.com/blog/similarity-in-graphs-jaccard-versus-the-overlap-coefficient-2/) - defined as the ratio of the cross-section of a neighborhood to the less than the number of neighbors of two nodes. Overlap similarity works best in the case of a small number of adjacent nodes
Example of a graph where nodes share a neighborhood. This information is used to calculate similarity.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/node-similarity-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 9. PageRank
In the domain of centrality measurements, [PageRank](https://en.wikipedia.org/wiki/PageRank) is arguably the most popular tool. Today, the most popular search engine in the world, [Google](https://en.wikipedia.org/wiki/Google#Early_years), owes its popularity solely to this algorithm, developed in the early days by its founders.
If we present nodes as pages and directed edges between them as links, the PageRank algorithm outputs a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page.
PageRank can be used as a measure of influence that can be used on a variety of applications, not just on website rankings. A popular type of PageRank is [Personalized PageRank](https://dl.acm.org/doi/10.1145/2488388.2488433), which is extremely useful in recommendation systems.
PageRank on a simple network. The biggest vertex points to an adjacent vertex and therefore making it more important.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/pagerank-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 10. Union Find
This is yet another important graph analytics algorithm. By using a [disjoint-set](https://en.wikipedia.org/wiki/Disjoint-set_data_structure) - a data structure that keeps track of non-overlapping sets, the algorithm enables the user to quickly check whether a pair of given nodes are in the same or different connected components. The benefit of having this structure is that a check on a pair of nodes is effectively executed in O(1) time.
The implementation of the disjoint-set data structure and its operations uses the union by rank and path splitting optimizations described in "Worst-case Analysis of Set Union Algorithms", developed by [Robert Tarjan](https://en.wikipedia.org/wiki/Robert_Tarjan) and [Jan van Leeuwen](https://en.wikipedia.org/wiki/Jan_van_Leeuwen).

Structure of the disjoint set on the right side, and graph example on the left. When checking the components, the algorithm only checks the shallow tree on the left.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/traditional-graph-analytics/union-find-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 11. Dynamic node2vec
Dynamic Node2Vec is a random walk-based method that creates embeddings for every new node added to the graph. For every new edge, there is a recalculation of probabilities (weights) that are used in walk sampling. A goal of the method is to enforce that the embedding of node v is similar to the embedding of nodes with the ability to reach node v across edges that appeared one before the other.
**Why Dynamic node2vec**
Many methods, like node2vec, DeepWalk, focus on computing the embedding for static graphs which has its qualities but also some big drawbacks.
Networks in practical applications are dynamic and evolve constantly over time. For example, new links are formed (when people make new friends on social networks) and old links can disappear. Moreover, new nodes can be introduced into the graph (e.g., users can join the social network) and create new links to existing nodes.
Naively applying one of the static embedding algorithms leads to unsatisfactory performance due to the following challenges:
* Stability: the embedding of graphs at consecutive time steps can differ substantially even though the graphs do not change much.
* Growing Graphs: All existing approaches assume a fixed number of nodes in learning graph embeddings and thus cannot handle growing graphs.
* Scalability: Learning embeddings independently for each snapshot leads to running time linear in the number of snapshots. As learning a single embedding is computationally expensive, the naive approach does not scale to dynamic networks with many snapshots
Dynamic Node2Vec is created by F.Beres et al in the "Node embeddings in dynamic graphs".
[Implementation Link](https://memgraph.com/docs/mage/algorithms/dynamic-graph-analytics/node2vec-online-algorithm#implementation)
### 12. Dynamic PageRank
In the domain of estimating the importance of graph nodes, [PageRank](https://en.wikipedia.org/wiki/PageRank) is arguably the most popular tool. Today, the most popular search engine in the world, [Google](https://en.wikipedia.org/wiki/Google#Early_years), owes its popularity solely to this algorithm, developed in the early days by its founders.
If we present nodes as pages and directed edges between them as links the PageRank algorithm outputs a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page.
The need for its dynamic implementation arose at the moment when nodes and edges arrive in a short period of time. A large number of changes would result in either inconsistent information upon arrival or restarting the algorithm over the entire graph each time the graph changes. Since such changes occur frequently, the dynamic implementation allows the previously processed state to be preserved, and new changes are updated in such a way that only the neighborhood of the arriving entity is processed at a constant time. This saves time and allows us to have updated and accurate information about the new values of the PageRank.
There are also some disadvantages of this approach, and that is that such an approach does not guarantee an explicitly correct solution but its approximation. Such a trade-off is common in computer science but allows fast execution and guarantees that at a large scale such an approximation approaches the correct result.
Valuable work explaining how to quickly calculate these values was developed by [Bahmani et. al.](https://scholar.google.com/citations?user=v-hyE4MAAAAJ&hl=en), engineers from [Stanford](http://snap.stanford.edu/) and [Twitter](https://twitter.com/home?lang=en). The paper is worth reading at [Fast Incremental and Personalized PageRank](http://snap.stanford.edu/class/cs224w-readings/bahmani10pagerank.pdf 📖).

[Implementation Link](https://memgraph.com/docs/mage/algorithms/dynamic-graph-analytics/pagerank-online-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 13. Dynamic Community Detection
To address the hidden relations among the nodes in the graph, especially those not connected directly, [community detection](https://en.wikipedia.org/wiki/Community_structure) can provide help. This familiar graph analytics method is being solved in various different ways. However, demand for scale and speed has increased over the years and therefore led to the construction of dynamic community detection algorithms. To leverage the needs for scalability and speed, community detection lends itself well to dynamic operations for two reasons:
* Complexity: algorithms often have high time complexity that scales with the number of nodes in the network
* Locality: community changes tend to be local in scope after partial updates.
Academic research of temporal graphs yielded [LabelRankT: Incremental Community Detection in Dynamic Networks via Label Propagation](https://arxiv.org/abs/1305.2006) (Xie et al.).
Illustration of how a dynamic community detection algorithm adapts to local changes
[Implementation Link](https://memgraph.com/docs/mage/algorithms/dynamic-graph-analytics/community-detection-online-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 14. Graph Neural Networks (GNN)
[Machine learning](https://en.wikipedia.org/wiki/Machine_learning) methods are based on data. Because of everyday encounters with data that are audio, visual, or textual such as images, video, text, and speech - the machine learning methods that study such structures are making tremendous progress today.
Connection-based data can be displayed as graphs. Such structures are much [more complex than images](https://towardsdatascience.com/machine-learning-on-graphs-part-1-9ec3b0bd6abc) and text due to multiple levels of connectivity in the structure itself which is completely irregular and unpredictable. With the development of neural networks organized in the structure of graphs, the field of [graph machine learning](https://arxiv.org/abs/2005.03675) is improving.
Applying the same principle used, for example, in images (convolutions) to graphs would be a mistake. Such principles are based on grid structures, while on graphs of arbitrary sizes, complex topologies, and random connections applying the same strategy would result in a disaster.
All convolutional network graph methods are based on [message propagation](https://en.wikipedia.org/wiki/Belief_propagation). Such messages carry information through a network composed of nodes and edges of the graph, while each node entity carries its computational unit. The task of each node is to process the information and pass it on to the neighbors.
Various possibilities have been developed that enable machine learning with graph neural networks. Starting with the graph of convolutional networks published in “[Spectral Networks and Deep Locally Connected Networks on Graphs](https://arxiv.org/abs/1312.6203)” (Bruna et al, 2014).
Today's most popular models are [GraphSAGE](https://arxiv.org/abs/1706.02216), [Graph Convolutional Networks (GCN)](https://arxiv.org/abs/1609.02907), [Graph Attention Networks (GAT)](https://arxiv.org/abs/1710.10903), and [Temporal Graph Networks (TGN)](https://arxiv.org/abs/2006.10637) - important for dynamic networks.
The above network shows the computation graph of message propagation in GNNs.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/gnn-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 15. Graph Classification
Let’s look at one useful tool that allows you to analyze a graph as a whole. [Graph classification](https://paperswithcode.com/task/graph-classification) enables this. The structure and arrangement of nodes can reveal some hidden features in a graph.
So, for example, fraudsters who have a common pattern of behavior can be detected by searching that pattern in the graph of their connections.
To make this possible, the main technique is to design features over the structure of the graph itself and then apply a classification algorithm. This can be achieved in several ways:
* [Graphlet features](https://en.wikipedia.org/wiki/Graphlets) - the number of a particular graphlet indicates a single element of the feature vector
* [Weisfeiler-Lehman kernel](https://www.jmlr.org/papers/volume12/shervashidze11a/shervashidze11a.pdf) - color refinement, teaching colors to the neighborhood until convergence is achieved
* Graph Deep Learning - designing a network that can extract a deeper feature depending on the structure of the graph
Probability of different labels on graph classification for molecular structures
[Implementation Link](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/graph-classification-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 16. Link Prediction
[Link prediction](https://www.sciencedirect.com/topics/computer-science/link-prediction) is the process of predicting the probability of connecting the two nodes that were not previously connected in a graph. A wide range of different solutions can be applied to such a problem.
The problem is of great importance in recommendation systems, co-authorship prediction, drug discovery, and many, many more.
Solving methods range from traditional to machine learning-based. Traditional methods are mostly based either on neighborhood similarity. A link between two nodes is more likely to exist if there are many common neighbors. These are:
1. [Jaccard similarity](https://en.wikipedia.org/wiki/Jaccard_index)
2. [Overlap similarity](https://en.wikipedia.org/wiki/Overlap_coefficient)
3. [Adamic-Adar index](https://en.wikipedia.org/wiki/Adamic/Adar_index)
On the other hand, such a prediction can be learned from the node endpoints by looking at similarity metrics. The more similar the nodes are, the greater the likelihood of connectivity between them. [Cosine similarity and Euclidean distance](https://www.baeldung.com/cs/euclidean-distance-vs-cosine-similarity) are one example of such.
Then, there are the most advanced models so far and they are based on [graph embeddings](https://towardsdatascience.com/graph-embeddings-the-summary-cc6075aba007), which serve as features for further classification tasks. Likewise, it is possible to drive graph neural network (GNN) methods for the same task.
Predicted relationships within the certain community
[Implementation Link](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/link-prediction-algorithm#implementation)
### 17. Node Classification
Prediction can be done at the node level. The basis of such prediction systems are features extracted from graph entities.
Extracting a feature can be a complicated problem, and it can be based on different graph attributes — node properties, node adjacency, or the structure of the neighborhood.
Traditional methods of extracting knowledge from nodes include measures of [centrality](https://en.wikipedia.org/wiki/Centrality), importance, or feature structure such as [graphlets](https://en.wikipedia.org/wiki/Graphlets).
Somewhat more advanced methods are extracting the [embedding](https://towardsdatascience.com/graph-embeddings-the-summary-cc6075aba007) of individual nodes, and then a prediction algorithm that takes knowledge from the embeddings themselves. The most popular such tool is [Node2Vec](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/node2vec-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost).
However, these methods are only a few. Today's graph machine learning is being developed and among them, we distinguish many different models such as:
1. [GraphSAGE](http://snap.stanford.edu/graphsage/)
2. [DeepWalk](https://towardsdatascience.com/deepwalk-its-behavior-and-how-to-implement-it-b5aac0290a15)
3. [Graph convolutional networks (GCN)](https://towardsdatascience.com/understanding-graph-convolutional-networks-for-node-classification-a2bfdb7aba7b)
4. [Graph Attention Network (GAT)](https://arxiv.org/abs/1710.10903)
and many, many more. This task has become quite popular and is used in many industries where knowledge is stored in the form of a graph structure.
Previously labeled nodes can be used to determine the class of unclassified ones
[Implementation Link](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/node-classification-algorithm#implementation)
### 18. Node2Vec
[Embedding](https://towardsdatascience.com/node-embeddings-for-beginners-554ab1625d98) methods serve to map graph entities into n-dimensional vectors. The goal of such an approach is to map closely related entities to vectors with a high degree of similarity according to the chosen method of similarity estimation.
[Node2Vec](https://snap.stanford.edu/node2vec/) stands out as the most popular method. It is based on random walks. The point of this method is mapping nodes that are most likely to be within a common random walk to the same place in n-dimensional space. The method was developed by [Aditya Grover](https://aditya-grover.github.io/) and [Jure Leskovec](https://cs.stanford.edu/people/jure/), professors at Stanford University in their paper "[node2vec: Scalable Feature Learning for Networks](https://arxiv.org/abs/1607.00653)"
The optimization of the mapped vectors themselves is done by a well-known machine learning method such as gradient descent. In the end, the result obtained can be used for node classification or link prediction, both truly popular.
Illustration of how graph embeddings can be mapped to 2D space. Boundaries between classes are more visible than in a graph.
[Implementation Link](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/node2vec-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
### 19. Graph Clustering
In [graph theory](https://en.wikipedia.org/wiki/Graph_theory), graph clustering is used to find subsets of similar nodes and group them together. It is part of graph analysis which has been attracting increasing attention in recent years due to the ubiquity of networks in the real world.
Graph clustering also known as network partitioning can be of two types:
* structure-based
* attribute-based clustering
The structure-based can be further divided into two categories, namely community-based, and structurally equivalent clustering.
Community-based methods aim to find dense subgraphs with a high number of intra-cluster edges and a low number of inter-cluster edges. Examples are the following algorithms:
* [A min-max cut algorithm for graph partitioning and data clustering](https://ieeexplore.ieee.org/document/989507)
* [Finding and evaluating community structure in networks](https://arxiv.org/abs/cond-mat/0308217)
Structural equivalence clustering, on the contrary, is designed to identify nodes with similar roles (like bridges and hubs). An example is [SCAN: A Structural Clustering Algorithm for Networks](http://web.cs.ucla.edu/~yzsun/classes/2014Spring_CS7280/Papers/Clustering/SCAN.pdf)
One example that can vary between community-based and structurally equivalent clustering is [Node2Vec](https://arxiv.org/abs/1607.00653).
Attribute-based methods utilize node labels, in addition to observed links, to cluster nodes like the following algorithm: [Graph clustering based on structural/attribute similarities](https://dl.acm.org/doi/10.14778/1687627.1687709)
Structure-based community clustering
[Implementation Link](https://memgraph.com/docs/mage/algorithms/machine-learning-graph-analytics/graph-clustering-algorithm?utm_source=devto&utm_medium=referral&utm_campaign=blog_repost#implementation)
## Conclusion
These are the top 19 graph algorithms to check out - there’s everything in here from Pagerank to Centrality. Give them a go and let us know if you have any challenges in using them with Memgraph by posting on [Discourse](https://discourse.memgraph.com) or [Discord](https://discord.gg/memgraph)
[](https://memgraph.com/blog?topics=Graph+Algorithms&utm_source=devto&utm_medium=referral&utm_campaign=blog_repost&utm_content=banner#list) | memgraphdb |
1,298,822 | What is Hydration & why does it concern us? | A plain English explainer on why we should care about Hydration. | 20,946 | 2022-12-16T13:24:16 | https://punits.dev/jargon-free-intros/hydration/ | react, javascript, webdev, webperf | ---
title: What is Hydration & why does it concern us?
published: true
description: A plain English explainer on why we should care about Hydration.
tags: react, javascript, webdev, webperf
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/zx0e7fpisytedm8ylz6h.png
canonical_url: https://punits.dev/jargon-free-intros/hydration/
series: Jargon Free Explainers
# Use a ratio of 100:42 for best results.
# published_at: 2022-12-16 09:26 +0000
---
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-2"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/iyxb2brrkmkkfn77uq9u.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-3"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/njzw04mhb3pcallhxjlm.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-4"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/vznono96fh4pd5t1lk27.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-5"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/cu5m3up794yorkl3p1la.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-6"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/o56ikvq60qd2kzwo2wri.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-7"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/4h0b3eso4ugaw1j9x3g3.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-8"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/1usnfk7kodf5f5trsll5.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-9"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/feiomlkrgq3vg600667r.png" /></a>
<a href="https://punits.dev/jargon-free-intros/hydration/#slide-10"><img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/vi26x8s1godcvw9ciajm.png" /></a>
<hr />
I create jargon-free infographics explaining the fundamentals of things I've been working on for last few years. If you have questions or feedback, please let know.
Carousel version of this explainer (for better readability) <a href="https://punits.dev/jargon-free-intros/hydration/">here</a>.
Other similar explainers <a href="https://punits.dev/jargon-free-intros/">here</a>. | geekybiz |
1,299,044 | Top 10 trending github repos of the week🍻. | Most popular trending Github repos in this week(Fri Dec 16 2022). | 14,942 | 2022-12-16T11:37:14 | https://dev.to/ksengine/top-10-trending-github-repos-of-the-week-102c | chatgpt, openai, cli, library | ---
title: Top 10 trending github repos of the week🍻.
published: true
description: Most popular trending Github repos in this week(Fri Dec 16 2022).
cover_image: https://images.unsplash.com/photo-1654095923893-6a255e5ed4d3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=MnwyODI4ODF8MHwxfHJhbmRvbXx8fHx8fHx8fDE2NzExOTA2MzM&ixlib=rb-4.0.3&q=80&w=1080
tags: chatgpt,openai,cli,library
series: Weekly Github top 10
---
GitHub is where over 65 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and features, power your CI/CD and DevOps workflows, and secure code before you commit it.
Here is the most popular repos published on this platform.
## [1. fuergaosi233/wechat-chatgpt](https://github.com/fuergaosi233/wechat-chatgpt)
Use ChatGPT On Wechat via wechaty
<a href="https://github.com/fuergaosi233/wechat-chatgpt">

</a>
---
## [2. acheong08/ChatGPT](https://github.com/acheong08/ChatGPT)
Lightweight package for interacting with ChatGPT's API by OpenAI. Uses reverse engineered official API.
<a href="https://github.com/acheong08/ChatGPT">

</a>
---
## [3. transitive-bullshit/chatgpt-api](https://github.com/transitive-bullshit/chatgpt-api)
Node.js client for the unofficial ChatGPT API. 🔥
<a href="https://github.com/transitive-bullshit/chatgpt-api">

</a>
---
## [4. AutumnWhj/ChatGPT-wechat-bot](https://github.com/AutumnWhj/ChatGPT-wechat-bot)
ChatGPT for wechat
<a href="https://github.com/AutumnWhj/ChatGPT-wechat-bot">

</a>
---
## [5. rawandahmad698/PyChatGPT](https://github.com/rawandahmad698/PyChatGPT)
⚡️ Python client for the unofficial ChatGPT API with auto token regeneration, conversation tracking, proxy support and more.
<a href="https://github.com/rawandahmad698/PyChatGPT">

</a>
---
## [6. louislam/uptime-kuma](https://github.com/louislam/uptime-kuma)
A fancy self-hosted monitoring tool
<a href="https://github.com/louislam/uptime-kuma">

</a>
---
## [7. ange-yaghi/engine-sim](https://github.com/ange-yaghi/engine-sim)
Combustion engine simulator that generates realistic audio.
<a href="https://github.com/ange-yaghi/engine-sim">

</a>
---
## [8. alibaba/havenask](https://github.com/alibaba/havenask)
null
<a href="https://github.com/alibaba/havenask">

</a>
---
## [9. jart/blink](https://github.com/jart/blink)
tiniest x86-64-linux emulator
<a href="https://github.com/jart/blink">

</a>
---
## [10. openai/openai-cookbook](https://github.com/openai/openai-cookbook)
Examples and guides for using the OpenAI API
<a href="https://github.com/openai/openai-cookbook">

</a>
---
Enjoy these repos.
Follow me for more articles.
Thanks 💖💖💖
| ksengine |
1,299,676 | c++ da A=> a ga ozgartish | int main (){ char a; cin >> a; cout << char(a+32); Enter fullscreen mode ... | 0 | 2022-12-16T14:19:49 | https://dev.to/rakhimjonova13/c-da-a-aga-93h | beginners, webdev, programming, tutorial |
```cpp
int main (){
char a;
cin >> a;
cout << char(a+32);
```
bu kata Adan kichkina aga ozgartiradigan kod
```cpp
using namespace std;
int main (){
char a;
cin >> a;
cout << char(a-32);
return 0;
}
```
Bu esa adan Aga ozgartiradi
@dawroun | rakhimjonova13 |
1,299,913 | Top 5 Featured DEV Tag(#opensource) Posts from the Past Week | Documentation 101: creating a good README for your software project Having a good... | 0 | 2022-12-16T15:30:31 | https://dev.to/c4r4x35/top-5-featured-dev-tagopensource-posts-from-the-past-week-30kg | opensource, c4r4x35 | ##Documentation 101: creating a good README for your software project
Having a good documentation for your open source project is an important (and often overlooked) feature to drive adoption and show the full potential of what users can accomplish with your application...
{% link https://dev.to/erikaheidi/documentation-101-creating-a-good-readme-for-your-software-project-cf8 %}
##Free Python Converter Tool - DataFrames, OpenAPI, CSV to Models, DataTables
Hello Coders!
The video mentioned in this article explains how to use a free conversion tool written in Python to manipulate and convert information into different formats. The tool is a simple UI...
{% link https://dev.to/sm0ke/free-python-converter-tool-dataframes-openapi-csv-to-models-datatables-26jn %}
##5 best open source platforms for B2B ecommerce
B2B ecommerce can be a complicated matter and imposes new requirements for an ecommerce platform compared to what is required to handle regular B2C commerce.
Getting an overview of the B2B features...
{% link https://dev.to/medusajs/5-best-open-source-platforms-for-b2b-ecommerce-1kg4 %}
##Fun but not useful extensions for devs
As developers, we spend a lot of time in our code editors and IDEs, constantly working to improve our skills and deliver great products. But sometimes, it can all feel a little bit too serious and...
{% link https://dev.to/chainguns/fun-but-not-useful-extensions-for-devs-p0h %}
##B2B Commerce w. Medusa: Set up a headless Node.js backend (1/2)
This tutorial series covers how you can use Medusa and its different components and features to implement a B2B commerce store. The series is split in two parts:
Part one: Covers how to prepare your...
{% link https://dev.to/medusajs/b2b-commerce-w-medusa-set-up-a-headless-nodejs-backend-12-2n7m %}
| c4r4x35 |
1,299,930 | Python global name 'self' is not defined | self is the self-reference in a Class. Your code is not in a class, you only have functions defined.... | 0 | 2022-12-16T16:07:11 | https://dev.to/fixsyntax/python-global-name-self-is-not-defined-42oo |
self is the self-reference in a Class. Your code is not in a class, you only have functions defined. You have to wrap your methods in a class, like below. To use the method main(), you first have to instantiate an object of your class and call the function on the object.
Further, your function setavalue should be in __init___, the method called when instantiating an object. The next step you probably should look at is supplying the name as an argument to init, so you can create arbitrarily named objects of the Name class ;)
class Name:
def __init__(self):
self.myname = "harry"
def printaname(self):
print "Name", self.myname
def main(self):
self.printaname()
if __name__ == "__main__":
objName = Name()
objName.main()
Have a look at the Classes chapter of the Python tutorial an at Dive into Python for further references.
| fixsyntax | |
1,300,024 | Who's not Afraid of Z-index? | Z-index is a CSS property that we use to alter the standard order of the HTML layers. The standard... | 0 | 2022-12-16T19:34:30 | https://dev.to/cleveslabcodes/whos-not-afraid-of-z-index-2c5k | webdev, css, html, programming | Z-index is a CSS property that we use to alter the standard order of the HTML layers. The standard behavior of the browser is to render the next element in front of the last one.
Here at Labcodes we’ve had some interesting experiences with this, that’s why in this post we’ll show you good and bad practices with Z-Index and help you understand the logic behind it --- > https://lab.codes/who-isnot-afraid-zindexdt | cleveslabcodes |
1,300,751 | How can we effectively explain large codebases? | Hello DEV! After starting to wrap up on NextSketch 2, we decided to write on the issue NextSketch 2... | 0 | 2022-12-17T11:55:30 | https://dev.to/nextsketch/how-can-we-effectively-explain-large-codebases-3gip | Hello DEV!
After starting to wrap up on NextSketch 2, we decided to write on the issue NextSketch 2 is planning to solve; How do we efficiently explain huge projects?
## The Problem
Often times when trying to understand the way a huge codebase works, we turn to documentation, which is sometimes not the best way to get started. People experienced with the Project aren't always available to query (especially if they're in a different time zone), and not everyone is the best at explaining. Language can also be a huge barrier to getting up to speed.
Often, the context of the explanation can get lost in our language semantics. We think that Diagrams are a much more universally understood way of explaining how the project works from a 10,000ft high perspective. Using diagrams in this case (compared to text-based docs), are much easier to parse, and preserve more context.
## How can NextSketch 2 help?
This is why we started working on NextSketch 2.
For those who don't know, NextSketch 2 is an IntelliJ-Platform Plugin for designing diagrams explaining how your project architecture to others. It provides a fast editor experience, the ability to create multiple levels of diagrams, attach source files, and store diagrams right inside the project, making it self-documenting. Being a Plugin, it also makes the overhead of using an additional tool as slim as possible.
To be clear, NextSketch 2 is not a tool to generate diagrams automatically from code. Diagrams such as these often have questionable utility as there is not much insight to be gained from looking at the code-graph instead of just reading the code itself.
We're hoping to release in January of 2023 if everything goes well! Also, let us know below how you get started on large codebases in the comments!
Thanks for Reading! | skyloft7 | |
1,301,176 | Mastering MongoDB and Mongoose in Node.js | MongoDB is a popular NoSQL database that is commonly used in Node.js applications. Mongoose is an... | 0 | 2022-12-18T08:19:13 | https://dev.to/abbhiishek/mastering-mongodb-and-mongoose-in-nodejs-1be5 | javascript, node, webdev, beginners | MongoDB is a popular NoSQL database that is commonly used in Node.js applications. Mongoose is an Object Data Modeling (ODM) library that provides a straight-forward, schema-based solution to model your application data in MongoDB. In this blog, we will learn how to work with MongoDB and Mongoose in a Node.js application.
## Setting up MongoDB
To start working with MongoDB, you need to have MongoDB installed on your system. You can download and install MongoDB from the official website (https://www.mongodb.com/download-center/community).
Once you have MongoDB installed, you need to start the MongoDB server. To start the server, open a terminal and navigate to the directory where MongoDB is installed. Then, run the following command:
```bash
mongod
```
This will start the MongoDB server and it will listen for connections on the default port 27017.
## Connecting to MongoDB with Mongoose
To connect to MongoDB from a Node.js application, we will use the Mongoose library. Mongoose provides a simple and straight-forward way to model your application data and interacts with MongoDB.
To install Mongoose, run the following command:
```bash
npm install mongoose
```
Once you have Mongoose installed, you can connect to MongoDB by creating a connection. Here's an example of how to create a connection to MongoDB using Mongoose:
```js
const mongoose = require('mongoose');
mongoose.connect('mongodb://localhost/myapp', { useNewUrlParser: true });
const db = mongoose.connection;
db.on('error', console.error.bind(console, 'connection error:'));
db.once('open', function() {
console.log('Connected to MongoDB');
});
```
In the above code, we are connecting to a database named "myapp" on the local machine. The mongoose.connect function establishes the connection to the database. The useNewUrlParser option is used to specify that we want to use the new URL parser introduced in MongoDB 4.0.
The db object represents the connection to the database. We are binding an event listener to the error event, which will be triggered if there is an error while connecting to the database. We are also binding an event listener to the open event, which will be triggered when the connection is successfully established.
## Defining a Mongoose schema
A Mongoose schema defines the structure of the document, default values, validators, and other options for the documents stored in a collection. To define a Mongoose schema, we need to create a new file and define a schema using the mongoose.Schema constructor.
Here's an example of how to define a schema for a user document:
```js
const mongoose = require('mongoose');
const userSchema = new mongoose.Schema({
name: {
type: String,
required: true
},
email: {
type: String,
required: true,
unique: true
},
password: {
type: String,
required: true
},
createdAt: {
type: Date,
default: Date.now
}
});
``
```
## Creating a Mongoose model
A Mongoose model is a wrapper on the Mongoose schema that provides methods for CRUD operations on the documents of a collection. To create a model, we need to pass the schema to the mongoose.model function.
Here's an example of how to create a model from the user schema defined above:
```js
const User = mongoose.model('User', userSchema);
```
The first argument of the mongoose.model function is the name of the model, which will be used to create the collection in the database. The second argument is the schema that the model will use.
## Creating and saving documents
To create and save a new document in the database, we can use the save method of the model. Here's an example of how to create and save a new user document:
```js
const user = new User({
name: 'John Doe',
email: 'john@doe.com',
password: 'password'
});
user.save((error) => {
if (error) {
console.log(error);
} else {
console.log('User saved successfully');
}
});
```
In the above code, we are creating a new instance of the User model and setting the values for the name, email, and password fields. Then, we are calling the save method on the instance to save it to the database. The save method accepts a callback function that will be called when the save operation is complete.
## Finding documents
To find documents in the database, we can use the find method of the model. The find method returns an array of documents that match the query.
Here's an example of how to find all users in the database:
```js
User.find((error, users) => {
if (error) {
console.log(error);
} else {
console.log(users);
}
});
```
The find method accepts a callback function that will be called when the find operation is complete. The callback function will be passed two arguments: an error object (if an error occurred) and an array of documents.
We can also specify a query to filter the documents that we want to find. For example, to find all users with a specific email address, we can use the following query:
```js
User.find({ email: 'john@doe.com' }, (error, users) => {
if (error) {
console.log(error);
} else {
console.log(users);
}
});
```
## Updating documents
To update a document in the database, we can use the findOneAndUpdate method of the model. This method finds a single document and updates it based on the provided data.
Here's an example of how to update a user document:
```js
User.findOneAndUpdate(
{ email: 'john@doe.com' },
{ name: 'John Smith' },
(error, user) => {
if (error) {
console.log(error);
} else {
console.log('User updated successfully');
}
}
);
```
In the above code, we are finding the user with the email "john@doe.com" and updating their name to "John Smith". The findOneAndUpdate method accepts three arguments: a query to find the document, the data to update, and a callback function. The callback function will be called when the update operation is complete and will be passed two arguments: an error object (if an error occurred) and the updated document.
## Deleting documents
To delete a document from the database, we can use the findOneAndDelete method of the model. This method finds a single document and deletes it.
Here's an example of how to delete a user document:
```js
User.findOneAndDelete({ email: 'john@doe.com' }, (error) => {
if (error) {
console.log(error);
} else {
console.log('User deleted successfully');
}
});
```
The findOneAndDelete method accepts two arguments: a query to find the document and a callback function. The callback function will be called when the delete operation is complete and will be passed an error object (if an error occurred).
## Conclusion
In this blog, we learned how to work with MongoDB and Mongoose in a Node.js application. We learned how to connect to the database, define a schema, create a model, create and save documents, find documents, update documents, and delete documents. With these basic operations, you can start building your own MongoDB-powered Node.js applications. | abbhiishek |
1,301,191 | Top 5 Optimization Tips to Improve Django Performance | As a popular Python web framework, Django is known for its simplicity and ease of use. However, as... | 0 | 2022-12-18T04:31:34 | https://dev.to/giasuddin90/top-5-optimization-tips-to-improve-django-performance-1cma | django, python, webdev | As a popular Python web framework, Django is known for its simplicity and ease of use. However, as with any web framework, performance can be an issue. In this article, we will explore some tips and techniques that can help you optimize your Django application for better performance.
**1.Use caching:** One of the most effective ways to improve the performance of a Django application is to use caching. By caching the results of expensive database queries and template rendering, you can significantly reduce the load on your server and improve the response time of your application. Django provides several built-in caching mechanisms, including the cache template tag and the cache middleware.
Here is an example of how to use the cache template tag to cache the results of a database query:
```
{% load cache %}
{% cache 500 object_list "object_list_view" %}
{% for object in object_list %}
{{ object }}
{% endfor %}
{% endcache %}
```
**2.Use a reverse proxy server: **Another way to improve the performance of a Django application is to use a reverse proxy server, such as nginx or Apache. A reverse proxy server acts as an intermediary between the client and the server, caching static content and forwarding dynamic requests to the Django application. This can significantly reduce the load on the Django server and improve the overall performance of the application.
Here is an example of how to configure nginx as a reverse proxy server for a Django application:
```
server {
listen 80;
server_name example.com;
location /static/ {
root /path/to/static/files;
}
location / {
proxy_pass http://localhost:8000;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
}
}
```
**3.Optimize your database queries:** A common cause of poor performance in Django applications is inefficient database queries. To improve the performance of your application, it is important to optimize your queries and use the appropriate indexes. Django provides several tools for optimizing queries, including the django-debug-toolbar and the EXPLAIN command in PostgreSQL.
Here is an example of how to use the EXPLAIN command in PostgreSQL to optimize a query:
```
EXPLAIN SELECT * FROM my_table WHERE my_field = 'value';
```
**4.Use efficient template rendering:** Template rendering can be a performance bottleneck in Django applications. To improve the performance of your application, it is important to use efficient template rendering techniques.
Here is an example of how to use the tag to render a template:
```
{% include "template.html" %}
```
**5.Use a Python profiler:** To identify specific performance bottlenecks in your Django application, it can be helpful to use a Python profiler, such as cProfile or the built-in timeit module. These tools allow you to measure the execution time of specific functions and identify areas of the code that could be optimized.
Here is an example of how to use cProfile to profile a function in your Django application:
```
import cProfile
def my_function():
```
By following these tips and techniques, you can significantly improve the performance of your Django application and provide a better user experience for your users
Thank you for reading my article! If you enjoyed it and would like to support my work, please consider buying me a coffee at **[Buy Me a Coffee](https://www.buymeacoffee.com/giasuddin)**. You can also learn more about me and my work by visiting my **[Giasuddin Bio ](https://bio.link/giasuddi)**and following me on LinkedIn and Twitter. Thank you for your support! | giasuddin90 |
1,301,273 | What to do after learning basics of React? | I finished learning React from scrimba. I took their free course and it was amazing and I did build... | 0 | 2022-12-18T07:46:44 | https://dev.to/aayush99910/what-to-do-after-learning-basics-of-react-5h1h | I finished learning React from scrimba. I took their free course and it was amazing and I did build apps using react. But I dont know where to go from here. Do I keep building react apps? I need a bit of help on where to head next. | aayush99910 | |
1,301,530 | Last week top 5 posts tagged(#github) | Code brushes for GitHub Copilot GitHub Copilot is incredible, and if you check what's... | 0 | 2022-12-18T16:30:41 | https://dev.to/c4r4x35/last-week-top-5-posts-taggedgithub-1n75 | github, c4r4x35 | ##Code brushes for GitHub Copilot
GitHub Copilot is incredible, and if you check what's happening in the preview released as the Copilot Labs extension it will only get more amazing.
Check this out:
Let's start with a basic...
{% link https://dev.to/codepo8/code-brushes-for-github-copilot-4hij %}
##Automated Frontend Workflow
In a world where robots have not yet taken our place, we still have to deal with repetitive tasks. We are constantly trying to find the easiest and laziest way to accomplish something, some people...
{% link https://dev.to/helmuthdu/automated-frontend-workflow-4665 %}
##Preparing to move away from Twitter
I opened my Twitter account more than 13 years ago, in August 2009. For 12 years, I kept focusing on professional-related content: Java, the JVM, programming, etc. I built my audience, trying to...
{% link https://dev.to/nfrankel/preparing-to-move-away-from-twitter-3fm2 %}
##20 Git Commands you (probably) didn't know about 🧙♂️
If you've ever browsed the git manual (or run man git), then you'll have noticed there's a whole lot more to git than what most of us use on a daily basis. A lot of these commands are incredibly...
{% link https://dev.to/lissy93/20-git-commands-you-probably-didnt-know-about-4j4o %}
##The Power of GitHub Actions for Streamlining DevOps Workflows
Introduction
GitHub Actions is a powerful tool for automating development workflows, and it has quickly become a staple in the DevOps world. With its ability to integrate with various tools and...
{% link https://dev.to/pramit_marattha/the-power-of-github-actions-for-streamlining-devops-workflows-1h91 %}
| c4r4x35 |
205,517 | CSS Variables | A beginners guide to CSS variables | 2,671 | 2019-11-14T21:50:04 | https://dev.to/ziizium/css-variables-1n72 | beginners, css | ---
title: CSS Variables
published: true
description: A beginners guide to CSS variables
tags: beginners, css
series: FrontEnd Development Zero to Hero
---
_In computer science and programming, variables are memory locations_ that store data, and the data can be accessed later via the variable name. Some programming language allow the reassignment of the same variable name to another data or value in the program and the compiler or interpreter will just do the same during the course of the program execution and some programming language strictly forbid this.
Forgive me if the last paragraph seems intimidating to you if you've not programmed before and if you follow this series till the end, you will definitely write a few programs (in the JavaScript section) to perform basic tasks albeit in the web browser.
I know this post is about CSS variables and some will argue that CSS developers are not really programmers, but we just need to know the uses of variables and where they originated from which is why this post started the way it did.
Variables have been a requested feature in CSS since the year 1998. Dave Hyatt and Daniel Glazman shaped the [first concrete proposal]( http://disruptive-innovations.com/zoo/cssvariables/) in 2008.
Some were concerned that [CSS needed no variables]( https://meiert.com/en/blog/why-css-needs-no-variables/) and Bert Bos [considered CSS variables harmful]( https://www.w3.org/People/Bos/CSS-variables).
Fast forward to 2012, the specification was provided by the World Wide Web Consortium (W3C) and CSS variables were implemented in Chrome and Firefox. Two years later, the specification was improved, Firefox modified their implementation and Chrome postponed their implementations effort to allow things to settle down.
In the late 2015, browser support was minimal for CSS variables, however in 2016 the browser support went up.
The question now is: Why variables in CSS? When you work on a project (big or small) you'll use CSS for the layouts, backgrounds, colors e.t.c and some property declarations will be duplicated across multiple CSS rules. For example:
```css
p {
color: #1560bd; /* duplicate */
font-size: 1.2em;
}
span {
color: #1560bd; /* duplicate */
display: block;
}
```
Now, let's see how we can use variables in our CSS code.
I'll be making use of the [specification]( https://www.w3.org/TR/css-variables-1/) in subsequent explanations, so I'll encourage you to open the link in a new tab or a new window in your web browser.
_Save the following HTML with the `.html` extension and create a blank CSS file and make sure its linked with the HTML file. All HTML snippet will be in the `body` tag._
```html
<div>
<p>Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do
eiusmod tempor incididunt ut labore et dolore magna aliqua.
Ut enim ad minim veniam, quis nostrud exercitation ullamco
laboris nisi ut aliquip ex ea commodo
consequat.
Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur.
<span>Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt</span>
mollit anim id est laborum.</p>
</div>
```
_And kindly note that all screenshots are from <b>Firefox 70</b> web browser and its Developer Tools._
With that out of the way. Let's start.
<hr>
Officially speaking, CSS variables are called _custom properties_ in the [specification]( https://www.w3.org/TR/css-variables-1/#defining-variables). The [specification defines a custom property]( https://www.w3.org/TR/css-variables-1/#custom-property) as:
> any property whose name starts with two dashes (U+002D HYPHEN-MINUS), like `--foo`
I believe this explanation is straight forward but lets clarify it with code.
Using our previous example, we can declare the `color` at a single place and we will be able to reuse it in the `p` and `span` elements.
```css
:root {
/*
* the --color is the variable here and
* #1560bd is the value.
*/
--color: #1560bd;
}
```
In the code snippet above, the variable is declared in the `:root` pseudo-class which represents the root element (`html`) and hence it will be available to all page element since all page elements are descendants of the root element.
Now that we have declared our variable, You might ask: _How can we access the variable?_ We can access our declared variable using the `var()` function.
The job of the `var()` function is to substitute the value of the variable into another property.
The function accepts two arguments (values):
* The first argument to the function is the name of the custom property (the variable) to be substituted.
* The second argument to the function, if provided, is a fallback value, which is used as the substitution value when the referenced custom property is invalid.
Its syntax is as follows:
`var( variable name, fallback value(s) )`
Using our previous CSS example, the
* variable name will be `--color`
* The _fallback value(s)_ is used when the variable value is invalid
We'll demonstrate the _fallback value_ later, but for now let's update our code to use variables. Let your CSS match the following:
```css
:root {
/*
* the --color is the variable here and
* #1560bd is the value.
*/
--color: #1560bd;
}
p {
color: var(--color); /* variables!! */
font-size: 1.2em;
}
span {
color: var(--color); /* variables!! */
display: block;
font-weight: bold;
}
```
Save and refresh your file. The `p` and `span` text element will be a variant blue.

###__VARIABLES AND INHERITANCE__
Custom variables are [inherited](https://dev.to/ziizium/css-inheritance-3pi1), which means a child element can use the value of a variable in its parent's element.
Using the previous CSS code. Perform the following actions:
* Load the HTML in your browser
* Use "Inspect Element" on the text
* Check under the __Rules__ tab
You will notice that the color of the `p` element is actually _inherited_ from the `:root` element.
This tells us that: CSS variables (custom properties) can be inherited and like most properties that can be inherited from the parent element we can reassign the value in the child element.
Update your `p` element CSS rule to match the following:
```css
p {
--color: blue; /* Note this */
color: var(--color);
font-size: 1.2em;
}
```
Save your file, refresh your browser and note the change in the _Developer Tools_. You will realize the `p` element is now using the value of the variable we declared in its CSS rule and not the inherited value from the `:root` element. The `span` is also blue because it's a child element of `p`.
###__INVALID VARIABLES__
From the [specification] (https://www.w3.org/TR/css-variables-1/#invalid-at-computed-value-time) (emphasis mine):
> A variable can be invalid if it uses a valid custom property, but the property value, after substituting its var() functions, is invalid.
> When this happens, the <b>computed value of the property is either the property’s inherited value</b> or its <b>initial value</b depending on <b>whether the property is inherited or not</b>, respectively, as if the property’s value had been specified as the `unset` keyword.
This means: when we declare a property in our CSS rule and then we decide to assign it a value using a variable, if the variable contains a value that is invalid to this said property, the browser will use the property initial value* unless we explicitly specify a fallback value. Say what?
<center><small>_*The initial value is the elements default value._</small></center>
Given the code snippet below.
```css
body {
--color: 23; /* Note this */
}
div {
background-color: var(--color); /* This wont work */
}
```
Save and refresh your browser. You'll notice the background color is _white_. Why? What happened?
We declared a variable with the following:
`body { --color: 23; }`
This is fine and the variable is valid, then we used it for the `background-color` in our `div` element.
`div { background-color: var(--color); }`
This is the same as writing:
`div {background-color: 23; }`
The last time i checked `23` is __not a valid background color__, so the browser used the `background-color` _initial value_ which is white (`#ffffff` in Hex and `rgba(0,0,0,0,0)` in rgb format). You can see this in the __Computed__ tab of the _Developer Tools_.
This means we should note our variable values and make sure they will work when we need them.
A variable can also be __invalid if its value is invalid__. The [spec]( https://www.w3.org/TR/css-variables-1/#syntax) states:
> While `<declaration-value>` __must represent at least one token__, that one token may be whitespace.
This means: if the value of your __variable is empty it will be invalid__ and this is when the _fallback value_ comes into the picture.
Update your CSS to match the following:
```css
body {
--color:; /* The value is empty */
}
div {
background-color: var(--color, green); /* The fallback value will be used */
padding: 1.2em;
color: #ffffff;
}
```
It's evident from the code above that our `--color` variable has an empty value. Save your file and refresh your browser. The browser will apply the `green` fallback color.
Somethings to note about CSS variables or custom properties:
* Their names are case-sensitive. Which means `--color` is not the same as `--Color`
* You cannot reset a CSS variable with the `all` property
* [The CSS-wide keywords](https://www.w3.org/TR/css3-values/#common-keywords) can be used in CSS variables
###__BROWSER SUPPORT__
Based on data available at [caniuse](https://caniuse.com/#feat=css-variables), the global usage of CSS variables as of November 2019 is `93.16%`with decent browser support.
###__THINGS I LEFT OUT__
I consider this topics "advanced" for this beginners post.
* Dependency Cycles
* Global and Local Scope
You might be feeling adventurous, so here are some links for you:
* [Scope in CSS](https://www.quirksmode.org/blog/archives/2019/03/scope_in_css.html)
* [Resolving Dependency Cycles](https://www.w3.org/TR/css-variables-1/#cycles)
We are getting closer to CSS properties that will aid us in web page layouts.
We'll start with _CSS Floats_. Next.
_Updated July 1, 2021: Changed a statement in paragraph 4 under "VARIABLES AND INHERITANCE" to reflect that you can only reassign a variable in child elements and not change them_.
| ziizium |
1,301,536 | SQL 基礎 Part 03 -- docker-compose で立てたコンテナで立ち上げ時に DB と全権力ユーザーを作成して、外部からログインする | why Spring で実際につなぐために、接続情報があり、テーブルが自動生成される PostgreSQL サーバーを Docker で立てたくなった。 ... | 20,922 | 2022-12-18T16:41:30 | https://dev.to/kaede_io/sql-ji-chu-part-03-docker-compose-deli-tetakontenadeli-tishang-geshi-ni-db-toquan-quan-li-yuzawozuo-cheng-site-wai-bu-kararoguinsuru-4cen | sql, docker |
## why
Spring で実際につなぐために、接続情報があり、テーブルが自動生成される PostgreSQL サーバーを Docker で立てたくなった。
---
## Docker Compose で ログイン情報を書いて SQL ファイルでテーブル作成を試す
https://zenn.dev/msksgm/articles/20220603-kotlin-jdbc-postgresql#db
この記事を参考に、docker-compose.yml に
* DB の名前
* ユーザー名
* パスワード
これらを書いて
読み込まれる SQL でテーブルの作成を擦るように書いてみた。
しかし、これだと DB と USER が作られていないので
DB にログインしてテーブルができているか確認することができなかった。
---
## SQL でユーザーと DB の作成を行い、DB の権限をユーザーに渡す
https://amateur-engineer.com/docker-compose-postgresql/
この記事を参考に
```yml
version: '3.2'
services:
#
# PostgreSQL
#
person-db:
image: postgres:14-bullseye
container_name: person-db
ports:
- 5444:5432
volumes:
- ./postgresql/init:/docker-entrypoint-initdb.d
environment:
POSTGRES_USER: kaede
POSTGRES_PASSWORD: pass
POSTGRES_DB: person-db
POSTGRES_INIT_DB_ARGS: --encoding=UTF-8
```
init を初期位置の *.sql として
00-init.sql を作り(名前はなんでもOK)
```kotlin
CREATE USER kaede;
CREATE DATABASE person-db;
GRANT ALL PRIVILEGES ON DATABASE person-db TO kaede;
```
user と db と権限作ったら
```kotlin
dc up
WARNING: Found orphan containers (psql_pgadmin_1, postgres_dc, psql_postgres_1, sample-pg) for this project. If you removed or renamed this service in your compose file, you can run this command with the --remove-orphans flag to clean it up.
Starting person-db ... done
Attaching to person-db
person-db |
person-db | PostgreSQL Database directory appears to contain a database; Skipping initialization
person-db |
person-db | 2022-12-18 16:36:57.296 UTC [1] LOG: starting PostgreSQL 14.6 (Debian 14.6-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
person-db | 2022-12-18 16:36:57.296 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
person-db | 2022-12-18 16:36:57.296 UTC [1] LOG: listening on IPv6 address "::", port 5432
person-db | 2022-12-18 16:36:57.298 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
person-db | 2022-12-18 16:36:57.303 UTC [26] LOG: database system was shut down at 2022-12-18 16:36:14 UTC
person-db | 2022-12-18 16:36:57.309 UTC [1] LOG: database system is ready to accept connections
```
ちゃんと起動して DB が作られて
```php
psql -h localhost -p 5444 -U kaede -d person-db
Password for user kaede:
psql (12.12 (Ubuntu 12.12-0ubuntu0.20.04.1), server 14.6 (Debian 14.6-1.pgdg110+1))
WARNING: psql major version 12, server major version 14.
Some psql features might not work.
Type "help" for help.
person-db=#
```
user kaede
db person-db
これで接続することができた。
| kaede_io |
1,301,775 | Top 10 Best Text Editors For Window | Are you a Windows user looking for a text editor? If so, you’ve come to the right place. Text editors are essential tools for writing, coding, and editing. Whether you're a student, a professional, or a hobbyist, you'll want to find the right text editor for your purposes. | 0 | 2022-12-18T22:52:36 | https://axxellanceblog.com/posts/top-10-best-text-editors-for-window | windows | ## Introduction
Are you a Windows user looking for a text editor? If so, you’ve come to the right place. Text editors are essential tools for writing, coding, and editing. Whether you're a student, a professional, or a hobbyist, you'll want to find the right text editor for your purposes.
We’ve rounded up the 10 best text editors for Windows. Each of these editors offers something unique, so read on to discover the best one for you.
The original source of this article can be found [here](https://axxellanceblog.com/posts/top-10-best-text-editors-for-window).
> Note: that this numbering is arrang randomly and not according to which is best and which is not
### 1: Notepad++ [🔗](https://notepad-plus-plus.org/)

Notepad++ is a free source code editor and Notepad replacement that supports several languages. Running in the MS Windows environment, its use is governed by the GPL license.
It supports tabbed editing, which allows working with multiple open files in a single window. The editor has syntax highlighting for many languages and supports macros and plugins, which users can download and install to extend its features.
### 2: Visual Studio Code [🔗](https://code.visualstudio.com/)

Visual Studio Code (VS Code) is an open-source, cross-platform code editor created by Microsoft. It is a lightweight editor with powerful features such as IntelliSense, debugging, and Git integration.
VS Code is customizable and can be used for web development, mobile development, and even game development. It also has a wide range of extensions and plugins, which allow users to customize VS Code to their needs.
VS Code is free to download and use, making it one of the most popular code editors available.
### 3: Sublime Text [🔗](https://www.sublimetext.com/)

Sublime Text is a sophisticated text editor for code, markup, and prose. It features a slick user interface, extraordinary features, and amazing performance.
Sublime Text is cross-platform and available for Mac, Windows, and Linux. It has powerful features like syntax highlighting, auto-completion, and split editing, making it an ideal choice for editing code.
It is also customizable, allowing users to customize the look, feel, and behavior of the editor to fit their specific needs.
### 4: Atom [🔗](https://atom.io/)

Atom is a free, open-source text editor developed by GitHub. It is designed to be highly customizable and extensible, allowing users to tailor it to their needs.
It is built using HTML, CSS, and JavaScript and has a modern user interface with a number of features, including syntax highlighting, multiple tabs, autocomplete, and git integration.
Atom also supports a wide range of programming languages and file formats, making it a great choice for web development, software development, and writing.
### 5: Vim [🔗](https://www.vim.org/)

Vim is a highly configurable text editor for creating and changing any kind of text. It is especially useful for editing program code, markup, and configuration files.
It's an advanced text editor that is highly configurable and extensible, making it an ideal choice for users who need a powerful text editor for their day-to-day tasks. Vim is often called a "programmer's editor" and has been around since 1991.
Vim provides syntax highlighting, a powerful search and replace feature, and a plethora of customizable settings. It also has a built-in macro language, allowing users to create powerful editing commands. Vim is available for all major operating systems, and is free and open source.
### 6: Brackets [🔗](https://brackets.io/)

Brackets is a free and open-source text editor developed by Adobe Systems for web development. It is written in HTML, CSS, and JavaScript with the help of Node.js integration.
Brackets was created to combine the power of a modern web development tool with the speed and simplicity of a text editor.
It features syntax highlighting, autocompletion, and bracket matching. It also integrates with popular version control systems like Git and SVN. Brackets has become a popular choice for web development due to its easy-to-use interface and powerful features.
### 7: Emacs [🔗](https://www.gnu.org/software/emacs/)

Emacs is a popular, open-source text editor. It was created in the 1970s and has been developed and maintained by many people over the years. It is highly extensible, meaning that users can customize it in many ways to suit their individual needs.
Emacs supports a wide range of programming languages and file formats and is a popular choice for web development, software engineering, and scientific research. It also includes features like syntax highlighting, auto-completion, and spellchecking for a variety of programming and markup languages.
### 8: UltraEdit [🔗](https://www.ultraedit.com/)

UltraEdit is a feature-rich text editor with support for over 100 programming languages. It includes an integrated FTP client, hex editor, and script builder.
It is used by millions of users around the world to edit text and code. It has features such as syntax highlighting, code folding, customizable syntax files, custom keyboard shortcuts, column mode editing, and more. It is available for both Windows and Mac operating systems, as well as a Linux version.
### 9: Notepad2 [🔗](https://notepad2.com/)

Notepad2 is a free, open-source text editor developed by Flo's Freeware. It is a lightweight text editor with a lot of features for editing plain text files.
It is highly customizable and has syntax highlighting for various programming languages. It also includes search and replace functions, tabbed document support, auto-indentation, line numbering, and a variety of text formatting options.
Notepad2 is an excellent choice for any user looking for a lightweight text editor with powerful features.
### 10: TextPad [🔗](https://www.textpad.com/home)

TextPad is a text editor for Windows and OS/2\. It is a powerful, feature-rich text editor that can be used to create and edit plain text files.
It includes features such as syntax highlighting, customizable keyboard shortcuts, auto-completion, spell-checking, and drag-and-drop support. TextPad also has support for macros and plugins.
It is a great tool for web developers, programmers, and anyone who needs to work with text files.
### Conclusion
The top 10 best text editors for Windows are invaluable tools for any programmer or web developer. From the lightweight Notepad++ to the powerful Atom, there is a text editor for everyone. With the variety of options available, you will be sure to find the perfect one for your needs. Whether you are coding for a living or just for fun, these text editors will ensure that your work is precise and your code is clean. | mc-stephen |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.