
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,151,080 | A Series of Tubes | Advent of Code 2017 Day 19 Part 1 This seems familiar... Could I just eyeball... | 16,285 | 2022-07-25T17:05:11 | https://dev.to/rmion/a-series-of-tubes-2a76 | adventofcode, algorithms, computerscience, programming | ## [Advent of Code 2017 Day 19](https://adventofcode.com/2017/day/19)
## Part 1
1. This seems familiar...
2. Could I just eyeball it?
3. How many letters are in my puzzle input?
4. Deciding not to solve it manually
5. Solving it algorithmically
### This seems familiar...
- I'm reminded of [2020 Day 13 - Mine Cart Madness](https://adventofcode.com/2018/day/13)
- Surprisingly - thankfully? - this puzzle has just one moving object: a packet
- Also different: the corner markers - `+` instead of `/` and `\`
### Could I just eyeball it?
- My puzzle input is large, yes
- But it doesn't look like there are many letters
- And with careful study and patience, I could probably follow the tubes with my eyes, recording the letters as I see them
Before I do that, a few exercises.
### How many letters are in my puzzle input?
I could do this one of two ways:
1. Use the `Find...` web browser feature when viewing the raw puzzle input, searching for and recording each capitalized letter of the alphabet, tallying them as I go
2. Write an algorithm
Option two seems far more exciting.
My algorithm works like this:
```
Generate a 2D array representing the tubes:
Split the input at each newline character into an array of strings
Split each string at each character into an array of characters
Identify the letters:
For each row, accumulate an array of characters
For each columns, accumulate an array of characters
If the character is not one of these: `-,|,+, `
Insert the character into the array
```
It works on the example input: `ACFEDB`
It works on my puzzle input: `DRSFXNPJLZ`
Wow! Only 11 letters!
I could probably solve this part manually!
If I do, I would want to make a GIF.
### Deciding not to solve it manually
- I'd have to work on a very small, rotated copy of my puzzle input
- Drawing lines carefully and continually over more and more of the tube tracks
- My mouse is kind of finicky, so that would probably be a frustrating process
- I'm not feeling great about this
I'd much rather solve it algorithmically.
Then, build a simulator that showed the packet moving through the tubes.
### Solving it algorithmically
Ingredients for my algorithm recipe:
- Each tile in the grid: that will be a 2D array of characters
- The number of letters to collect: that will be the length of the list of letters found in the grid
- The current location and direction of the packet: that will be a 3-element array where the first two elements are the row and column and the third element is one of four characters: `v^<>`
- The relative coordinates of each next location based on the direction: that will be a dictionary where the keys are the four characters above and the values are 2-element arrays with `0`, `1` or `-1` for the relative row and column
- An initially empty unique set that will eventually store all the collected letters
The main loop:
```
Do as long as the size of the set of collected letters is not equal to the number of letters in the tubes
Check the character in the next tube
If it's a letter:
Add that letter to the set and continue in the current direction
Else, if it's a +:
Determine which of the four tiles adjacent to the + must be the next tube
If the character at that tile is a letter, add the letter to the set
Update the direction to account for turning a corner
Else (meaning it's a - or |):
Continue in the current direction
```
That all seems straightforward.
But a few details required more code than I was expecting.
#### Determine which of the four tiles adjacent to the + must be the next tube
This animation depicts how my algorithm works:

In more written detail:
```
Start with a list of the four relative adjacent coordinates:
[[-1,0],[0,1],[1,0],[0,-1]]
Filter that list to exclude the pair that corresponds to the current location of the packet
Change each coordinate into a 3-element array with this blueprint:
['character', row #, column #]
Filter that list to exclude the two items where 'character' is a space
Alas, we now have a 1-item array! Flatten it, resulting in:
['character', row #, column #]
```
#### Update the direction to account for turning a corner
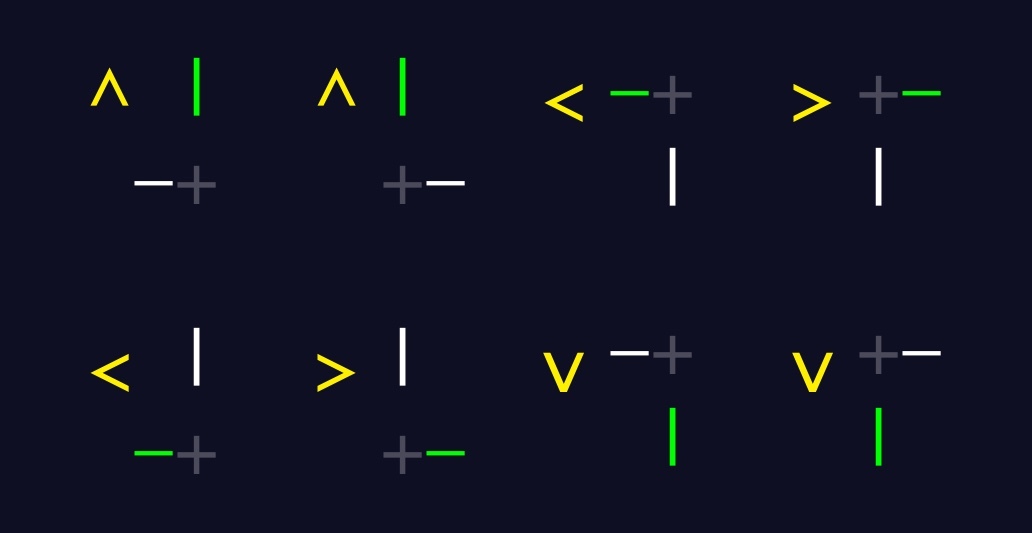
Now that I know the location and character of the next tube that the packet should occupy, I need to:
- Move the packet there
- Update the packet's direction
- Record the letter at that spot if there is one
I used a `switch` statement to update the packet's direction.
Depending on the packet's direction, and either the row or column of the next tube, update the direction according to the following diagram:
#### Testing my algorithm
There was quite a bit of troubleshooting:
- I incorrectly referred to rows instead of columns in one place
- I incorrectly referenced an index in some places
- I collected each number twice
Eventually, my algorithm finished, having collected each letter using the example input and my puzzle input.
I'm debating whether it would be fun to watch in a simulator.
Before I do, I'm anxious to see how much more difficult Part 2 is...
## Part 2
1. Woah! That's it??!!
### Woah! That's it??!!
- Add a variable to track the number of steps
- Increment that variable in three places throughout my loop
- Run it on the example: success!
- Run it on my input: success!
## I did it!!
- I solved both parts!
- I made a GIF to describe one of my smaller algorithms
- I've now bested my star count by this point for any year!
I opted not to make a simulator.
I'm more excited to attempt the next puzzle than I am to spend even an hour making one for this puzzle.
| rmion |
1,151,315 | Top 5 Youtubr channels for learning JavaScript | in this article i will give you the best channels for learning javascript : so let's get started ... | 0 | 2022-07-25T21:11:07 | https://dev.to/lodstare/top-5-youtubr-channels-for-learning-javascript-2lna | javascript, beginners, programming, tutorial | in this article i will give you the best channels for learning javascript :
so let's get started
## 1.Programming with Mosh :
click here =>[Programming with Mosh](https://www.youtube.com/c/programmingwithmosh)
## 2.Dave Gray :
click here => [Dave Gray](https://www.youtube.com/c/DaveGrayTeachesCode)
## 3.freeCodeCamp.org :
[freeCodeCamp.org](https://www.youtube.com/c/Freecodecamp)
## 4.Clever Programmer :
click here => [Clever Programmer](https://www.youtube.com/c/CleverProgrammer)
## 5.Bro Code :
click here => [Bro Code ](https://www.youtube.com/c/BroCodez)
## for know other information about learning javascript
click here => [Article](https://lodstare.blogspot.com/2022/07/javascript.html)
## connect with me on :
- [YouTube](https://www.youtube.com/channel/UCEDF5YBStH5cWnqK2U4BCkw)
- [Twitter](https://twitter.com/ayoub_el_achab)
- [Instagram](https://www.instagram.com/ayoub_el_achab_/)
- [Git Hub](https://github.com/Lodstare)
- [Linkedin](https://www.linkedin.com/in/ayoub-el-achab/)
| lodstare |
1,152,083 | Need Advice: Going to College for Software Developer | Hello everyone. I'm going to college this August for an Associates and then Bachelors in Computer... | 0 | 2022-07-26T17:57:02 | https://dev.to/jackler2/need-advice-going-to-college-for-software-developer-3la7 | beginners, computerscience, discuss | Hello everyone.
I'm going to college this August for an Associates and then Bachelors in Computer Science with a Concentration on Software Development.
Looking through the courses they offer, it's hard to decipher exactly what I'm going to learn and for the sake of career potential, and I'm trying to find out what things I should be learning about in my spare time to compliment my coursework in college.
To start with, its Southern New Hampshire University. They said I could either get a Bachelors in CS or IT, but everything I've read online points to CS. I've read countless job posts on Indeed for Software Engineering/Development, and almost all point to CS, so I changed majors today to CS.
The problem is though, I also compiled a list of no less than 100 common skills/expertise that jobs report looking for; I've come to understand that breaking it down, they are different programming languages, frameworks, APIs, certifications, proficiency in variants of Java or Javascript like Vue.js and scripting languages, etc.
Since this degree is Computer Science and not specifically for Software Engineering, I'm not sure what I need to compliment my learning with during my 4 years of college. I want to make sure I'm fully rounded for the highest chance of success when I finish college, and my career plan is to obtain my Associates so I can begin work, at least as an intern, to have job experience in the field and title, and start a portfolio of projects to show during interviews.
So where should I start? With wanting to jump-start my career with an Associates in CS while continuing to earn my Bachelors, what terms and things should I start researching now? Databases? Algorithms? If you started all over again and your plan was mine, how would you structure your learning path so you would be ready to start at a company when you obtained your Associates?
I look forward to hearing from all of you, and thank you in advance for helping me succeed.
Thank you,
Patrick
| jackler2 |
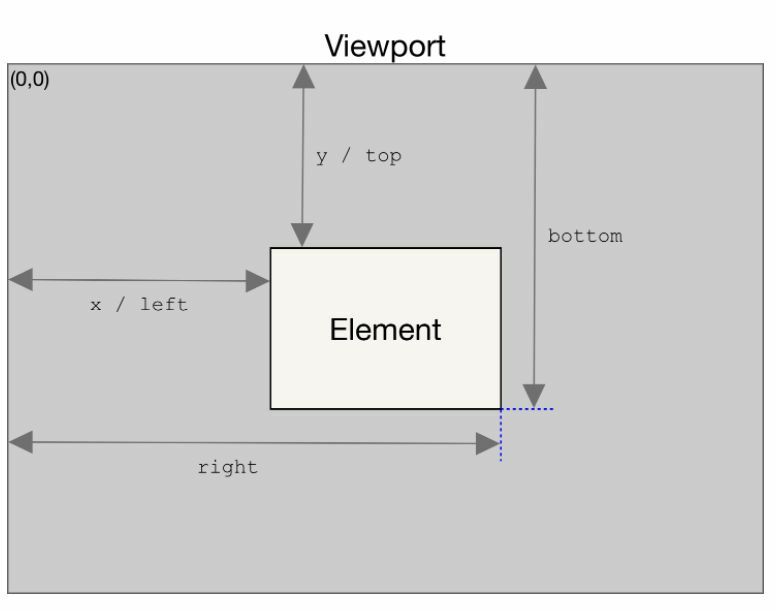
1,152,146 | 𝗘𝗹𝗲𝗺𝗲𝗻𝘁.𝗴𝗲𝘁𝗕𝗼𝘂𝗻𝗱𝗶𝗻𝗴𝗖𝗹𝗶𝗲𝗻𝘁𝗥𝗲𝗰𝘁() 𝘮𝘦𝘵𝘩𝘰𝘥 | 𝗘𝗹𝗲𝗺𝗲𝗻𝘁.𝗴𝗲𝘁𝗕𝗼𝘂𝗻𝗱𝗶𝗻𝗴𝗖𝗹𝗶𝗲𝗻𝘁𝗥𝗲𝗰𝘁() 𝘮𝘦𝘵𝘩𝘰𝘥 𝘳𝘦𝘵𝘶𝘳𝘯𝘴 𝘢 𝘋𝘖𝘔𝘙𝘦𝘤𝘵 𝘰𝘣𝘫𝘦𝘤𝘵 𝘱𝘳𝘰𝘷𝘪𝘥𝘪𝘯𝘨 𝘪𝘯𝘧𝘰𝘳𝘮𝘢𝘵𝘪𝘰𝘯 𝘢𝘣𝘰𝘶𝘵 𝘵𝘩𝘦 𝘴𝘪𝘻𝘦... | 0 | 2022-07-26T18:53:33 | https://dev.to/talenttinaapi/-52ic | react, webdev, frontend, javascript | 𝗘𝗹𝗲𝗺𝗲𝗻𝘁.𝗴𝗲𝘁𝗕𝗼𝘂𝗻𝗱𝗶𝗻𝗴𝗖𝗹𝗶𝗲𝗻𝘁𝗥𝗲𝗰𝘁() 𝘮𝘦𝘵𝘩𝘰𝘥 𝘳𝘦𝘵𝘶𝘳𝘯𝘴 𝘢 𝘋𝘖𝘔𝘙𝘦𝘤𝘵 𝘰𝘣𝘫𝘦𝘤𝘵 𝘱𝘳𝘰𝘷𝘪𝘥𝘪𝘯𝘨 𝘪𝘯𝘧𝘰𝘳𝘮𝘢𝘵𝘪𝘰𝘯 𝘢𝘣𝘰𝘶𝘵 𝘵𝘩𝘦 𝘴𝘪𝘻𝘦 𝘰𝘧 𝘢𝘯 𝘦𝘭𝘦𝘮𝘦𝘯𝘵 𝘢𝘯𝘥 𝘪𝘵𝘴 𝘱𝘰𝘴𝘪𝘵𝘪𝘰𝘯 𝘳𝘦𝘭𝘢𝘵𝘪𝘷𝘦 𝘵𝘰 𝘵𝘩𝘦 𝘷𝘪𝘦𝘸𝘱𝘰𝘳𝘵.
𝘛𝘩𝘦 𝘋𝘖𝘔𝘙𝘦𝘤𝘵 𝘰𝘣𝘫𝘦𝘤𝘵 𝘵𝘩𝘢𝘵 𝘪𝘴 𝘳𝘦𝘵𝘶𝘳𝘯𝘦𝘥 𝘪𝘴 𝘵𝘩𝘦 𝘴𝘮𝘢𝘭𝘭𝘦𝘴𝘵 𝘳𝘦𝘤𝘵𝘢𝘯𝘨𝘭𝘦 𝘵𝘩𝘢𝘵 𝘦𝘯𝘤𝘰𝘮𝘱𝘢𝘴𝘴𝘦𝘴 𝘵𝘩𝘦 𝘸𝘩𝘰𝘭𝘦 𝘦𝘭𝘦𝘮𝘦𝘯𝘵, 𝘪𝘯𝘤𝘭𝘶𝘥𝘪𝘯𝘨 𝘱𝘢𝘥𝘥𝘪𝘯𝘨 𝘢𝘯𝘥 𝘣𝘰𝘳𝘥𝘦𝘳-𝘸𝘪𝘥𝘵𝘩. 𝘛𝘩𝘦 𝘭𝘦𝘧𝘵, 𝘵𝘰𝘱, 𝘳𝘪𝘨𝘩𝘵, 𝘣𝘰𝘵𝘵𝘰𝘮, 𝘹, 𝘺, 𝘸𝘪𝘥𝘵𝘩, 𝘢𝘯𝘥 𝘩𝘦𝘪𝘨𝘩𝘵 𝘢𝘵𝘵𝘳𝘪𝘣𝘶𝘵𝘦𝘴 𝘥𝘦𝘧𝘪𝘯𝘦 𝘵𝘩𝘦 𝘵𝘰𝘵𝘢𝘭 𝘳𝘦𝘤𝘵𝘢𝘯𝘨𝘭𝘦'𝘴 𝘭𝘰𝘤𝘢𝘵𝘪𝘰𝘯 𝘢𝘯𝘥 𝘴𝘪𝘻𝘦 𝘪𝘯 𝘱𝘪𝘹𝘦𝘭𝘴. 𝘖𝘵𝘩𝘦𝘳 𝘵𝘩𝘢𝘯 𝘸𝘪𝘥𝘵𝘩 𝘢𝘯𝘥 𝘩𝘦𝘪𝘨𝘩𝘵, 𝘢𝘭𝘭 𝘱𝘳𝘰𝘱𝘦𝘳𝘵𝘪𝘦𝘴 𝘢𝘳𝘦 𝘳𝘦𝘭𝘢𝘵𝘦𝘥 𝘵𝘰 𝘵𝘩𝘦 𝘷𝘪𝘦𝘸𝘱𝘰𝘳𝘵'𝘴 𝘵𝘰𝘱-𝘭𝘦𝘧𝘵 𝘤𝘰𝘳𝘯𝘦𝘳.
source MDN Web docs
 | talenttinaapi |
1,152,439 | sketchmypic All-in-one photo effect tool to add spark to your selfies and pictures! | The Sketchmypic drawing suite is a full-featured drawing package with immense functionality for... | 0 | 2022-07-27T02:16:32 | https://dev.to/kiyararobins/sketchmypicall-in-one-photo-effect-tool-to-add-spark-to-your-selfies-and-pictures-5c5b | onlinetool, sketchimages, free, colorsketc | The [Sketchmypic](https://sketchmypic.com/) drawing suite is a full-featured drawing package with immense functionality for amateurs and professionals alike. The creative sketch features you get with this app include converting an image to a pencil sketch and an image to a colored pencil sketch effect.
Apart from the sketch filters this app also turns your photos and selfies into amazing artistic paintings. Images can be converted to watercolor paintings, oil paintings, and black-and-white paintings with the Sketchmypic app.
The app has some amazing effects of turning your pictures into pixel images, cartoon images, pop art & ASCII text art.
| kiyararobins |
1,152,513 | Creating a 3D dice in CSS | I'm finally going to touch on a subject I've been putting off for way too long in this article. 3D... | 0 | 2022-07-27T06:09:13 | https://daily-dev-tips.com/posts/creating-a-3d-dice-in-css/ | css | I'm finally going to touch on a subject I've been putting off for way too long in this article.
3D in CSS!
Yes, 3D, and what better example of trying and making a 3D dice in CSS.
The result of this article will be this rotating dice.
(Code and demo at the bottom)

## Setting up the HTML
Let's start with the HTML. We need a dice container and six sides to it.
```html
<div class="dice">
<div class="side one"></div>
<div class="side two"></div>
<div class="side three"></div>
<div class="side four"></div>
<div class="side five"></div>
<div class="side six"></div>
</div>
```
That will be all for our HTML part. Let's quickly move on to the fun part, which will be the CSS.
## Basic styling
Let's start with some basic styling.
First, I ensured the dice element was in the middle of the page since it's easier to work with.
```css
body {
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
}
```
Then I moved on to arranging the dice to be a big square box.
```css
.dice {
position: relative;
width: 200px;
height: 200px;
}
```
Then each side is another wrapper that centers all its children (the dots).
```css
.side {
width: 100%;
height: 100%;
background: #da0060;
border: 2px solid black;
position: absolute;
opacity: 0.7;
display: flex;
align-items: center;
justify-content: center;
}
```
By now, you should see something that looks like this:

It might not look like much, but trust me, there are six sides!
## Creating dice dots in CSS
I will start by explaining how I achieved the dots since this is quite an excellent technique.
I didn't want to use a lot of extra divs, so each option only consists of one pseudo selector.
And it starts with the #1 side.
```css
.side {
&:before {
content: '';
width: 20%;
height: 20%;
background: black;
border-radius: 50%;
}
}
```

I can hear you think, but what about the others?
And there is a very cool trick for that! We can leverage the box-shadow rule for it.
And if we think about it, there are only seven positions a dot can have.
We already have one, so let's look at the other six.
```css
&:before {
content: '';
width: 20%;
height: 20%;
background: black;
border-radius: 50%;
box-shadow: red -50px -50px 0px 0px, blue -50px 0px 0px 0px,
yellow -50px 50px 0px 0px, green 50px -50px 0px 0px, orange 50px 0px 0px 0px,
white 50px 50px 0px 0px;
}
```
I used random colors in the example above so you can see which position is which dot.

> Note: The black dot is our initial dot.
Now let's go ahead and create all possible dot variants.
For the #2 side, we don't need the initial dot so that we can turn off the background.
```css
.two {
&:before {
background: transparent;
box-shadow: #000 -50px -50px 0px 0px, #000 50px 50px 0px 0px;
}
}
```
For number three we can use a similar approach, but not hide the background:
```css
.three {
&:before {
box-shadow: #000 -50px 50px 0px 0px, #000 50px -50px 0px 0px;
}
}
```
Then for the fourth one:
```css
.four {
&:before {
background: transparent;
box-shadow: #000 -50px 50px 0px 0px, #000 -50px -50px 0px 0px,
#000 50px 50px 0px 0px, #000 50px -50px 0px 0px;
}
}
```
And on to number five:
```css
.five {
&:before {
box-shadow: #000 -50px -50px 0px 0px, #000 -50px 50px 0px 0px,
#000 50px -50px 0px 0px, #000 50px 50px 0px 0px;
}
}
```
And last but not least, number six, which we used as our template.
```css
.six {
&:before {
background: transparent;
box-shadow: #000 -50px -50px 0px 0px, #000 -50px 0px 0px 0px,
#000 -50px 50px 0px 0px, #000 50px -50px 0px 0px, #000 50px 0px 0px 0px, #000
50px 50px 0px 0px;
}
}
```
Our result will look weird since our transparent layers sit on each other.

## Arranging a dice in 3D CSS
Now that we have all our elements in place let's start the fun and apply our 3D effect!
We can achieve a 3D perspective in CSS by using transforms. We have three axes to play with: the X, Y, and Z axes.
First, let's put our cube in perspective.
```css
.dice {
transform-style: preserve-3d;
transform: rotateY(185deg) rotateX(150deg) rotateZ(315deg);
}
```
Now, it might look a bit weird if we look at what we got.

This is already 3D, but it doesn't look like a cube yet. We need to modify each side to do its transformation.
Let's start with side one.
```css
.one {
transform: translateZ(100px);
}
```
This will lift the side, so it sticks out at the top.

You might already be able to see where this is going.
Now let's do the opposite end, which is side number six.
We will offset that to a negative 100px. This means the distance between one and six is now 200px (our cube size).
```css
.six {
transform: translateZ(-100px);
}
```

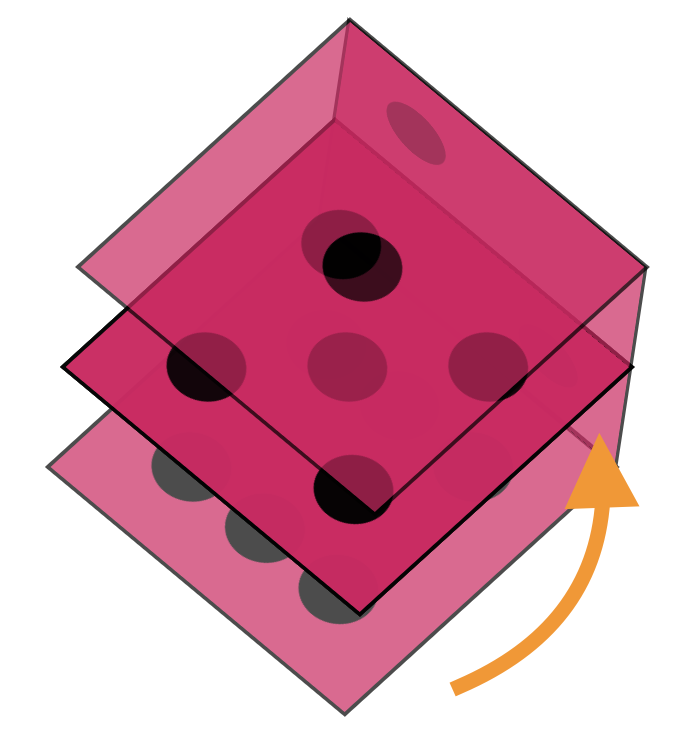
Now let's do the number two side. This one needs to be connected by transforming a different axis.
```css
.two {
transform: translateX(-100px) rotateY(-90deg);
}
```
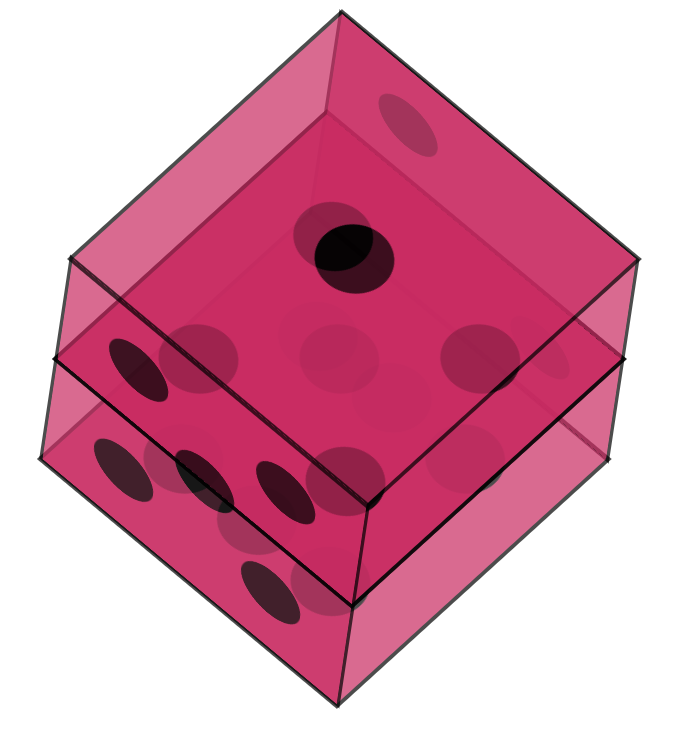
Now the easiest one to connect is the opposite, side number five.
```css
.five {
transform: translateX(100px) rotateY(90deg);
}
```
As you can see, it's the same transformation, but we offset it by 200 pixels.
Two more sides left. Let's do number three.
```css
.three {
transform: translateY(100px) rotateX(90deg);
}
```
As you can see, it's the opposite transformation from two to five.
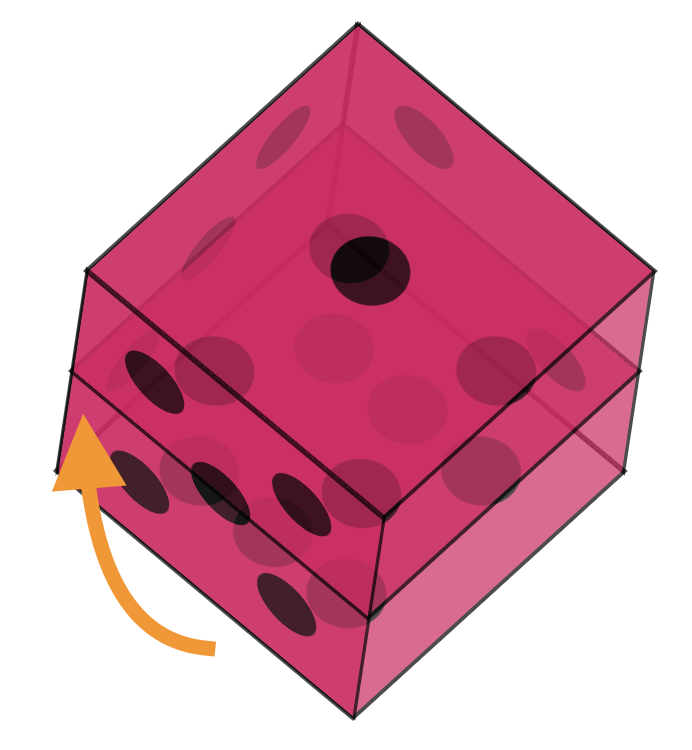
The last one we need is number four, which will be the opposite of number three.
```css
.four {
transform: translateY(-100px) rotateX(90deg);
}
```
With this one in place, our dice are complete!

## Animating the dice
Now that we have our dice let's make it a bit more interactive by animating it!
Each of the sides we described can also be animated, I'll only be turning the dice on one side, but you can have a play around with any of them to achieve a different animation.
```css
@keyframes rotate {
from {
transform: rotateY(0) rotateX(45deg) rotateZ(45deg);
}
to {
transform: rotateY(360deg) rotateX(45deg) rotateZ(45deg);
}
}
.dice {
animation: rotate 5s linear infinite;
}
```
You can find the completed example in this CodePen.
{% codepen https://codepen.io/rebelchris/pen/poLRpbQ %}
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
1,153,185 | Make Inlay Type Hints in Python Appear/Disappear | A Type Hinting Tip for Those Not Completely Onboard TLDR: You can set Inlay Hints:... | 19,069 | 2022-07-27T21:46:57 | https://kjaymiller.com/blog/make-inlay-type-hints-in-python-appear-disappear | python, vscode, beginners, tutorial | ## A Type Hinting Tip for Those Not Completely Onboard
> TLDR: You can set `Inlay Hints: Enabled` to `On/OffUnless pressed` in the settings to show/hide inlay type hints in Python code.
In July the VS Code Python Team released an [update for VS Code](https://devblogs.microsoft.com/python/python-in-visual-studio-code-july-2022-release/) that announced inlay Type Hint Support.
{% embed https://www.youtube.com/watch?v=hHBp0r4w86g %}
Adding type hint inferences next to your code is very nice. The more I started playing with it, I noticed that sometimes the type hints didn't feel helpful and made my code look cluttered.
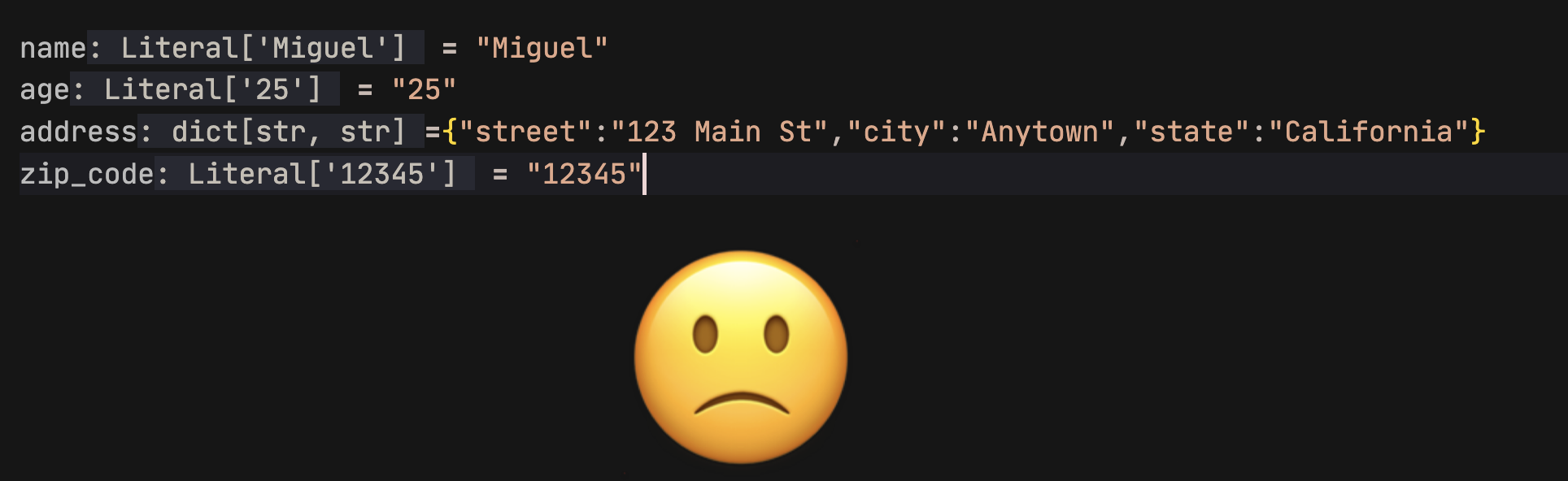
Don't get me wrong, I like type hints. They are a massive help with troubleshooting and documentation. They are even used in [dataclasses](https://docs.python.org/3/library/dataclasses.html), one of my favorite standard library tools. But as I tell my child, there is a time and place for everything. When it comes to type hints, _All the Time!_, is not the answer.
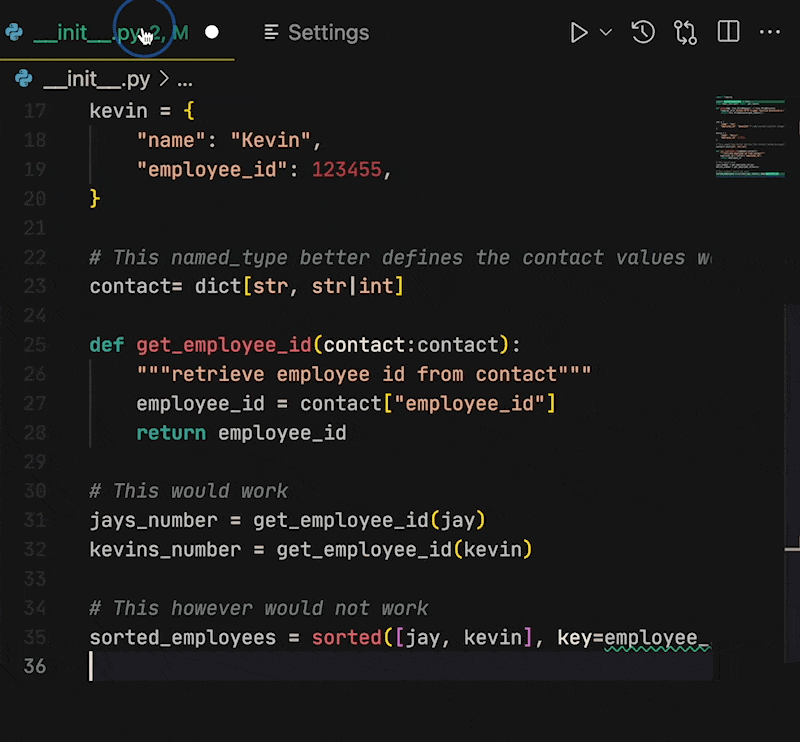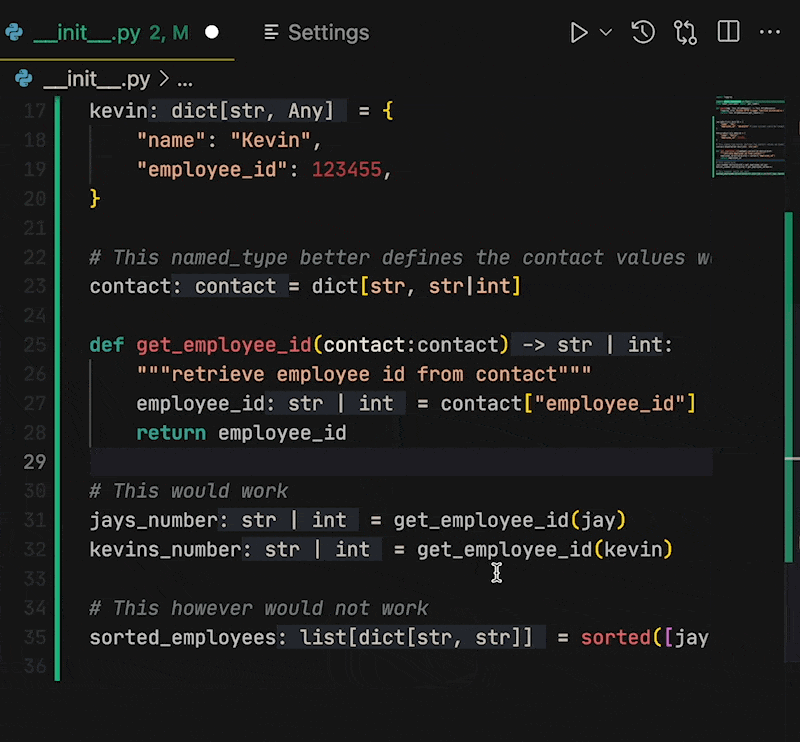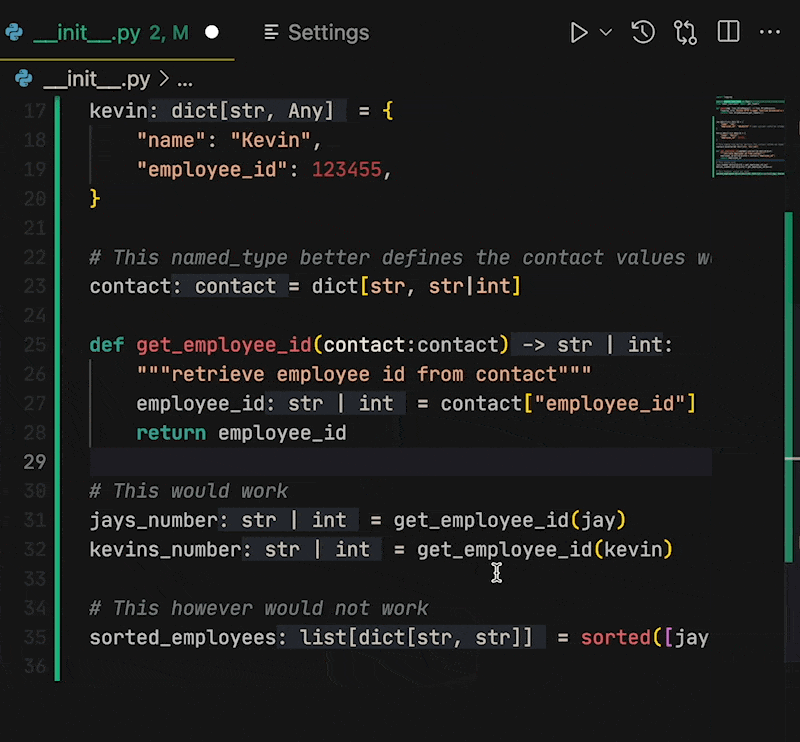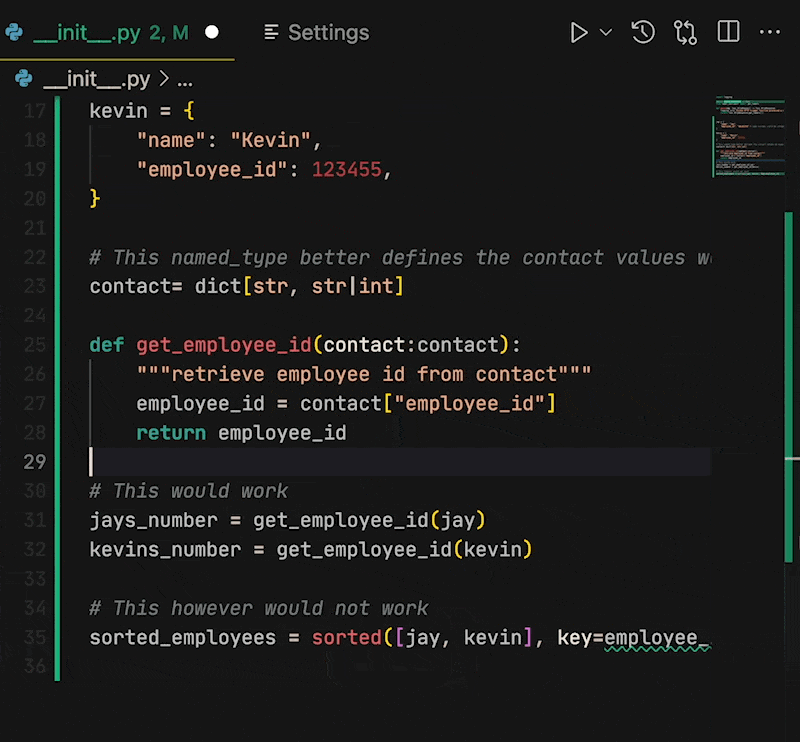
### Let's take the following example.
Let's say we have some dictionary objects that are brought into our code from multiple systems. Sometimes the `employee_id` will be a numerical id and other times it will be a unique string.
```python
jay = {
"name": "Jay",
"employee_id": "abcd1234" # some records could be integers depending on the schema
}
```
If we don't define types, PyLance will assume that the contact `jay` is the type `dict[str, str]` because all the values in the dictionary are `str`. What happens if we have a different record like:
```python
kevin = {
"name": "Kevin",
"employee_id": 12345678
}
```
The variable of `kevin` would be typed `dict[str, Any]` because the type of the `employee_id` differs from the `name`.
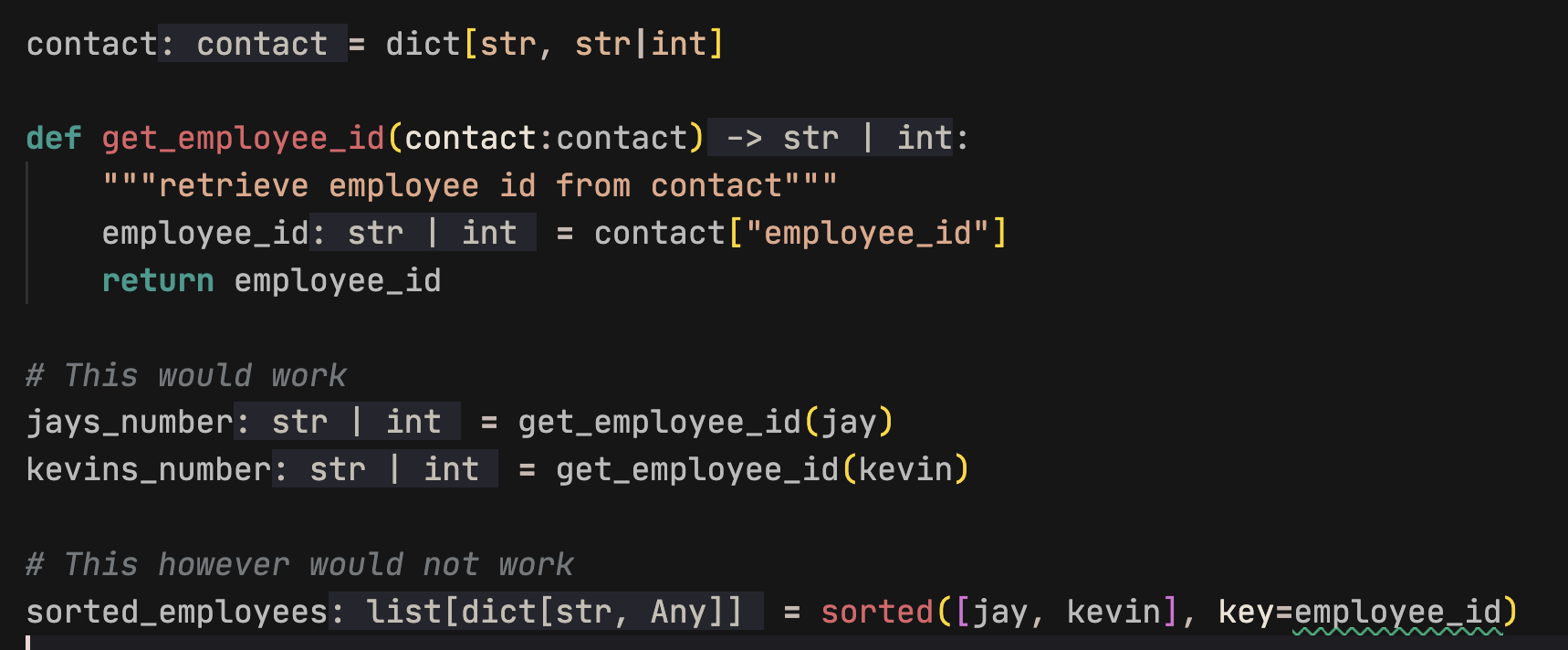
If we build a function that gets the employee id of multiple entries and sorts by `employee_id`, We'll get a `TypeError`.
```python
def get_employee_id(contact):
"""retrieve employee id from contact"""
return contact["employee_id"]
sorted_employees = sorted([jay, kevin], key=get_employee_id)
>>> Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'int' and 'str'
```
The solution is to return the contact variable as a str. Type Hints would have told us that the contact would have been `Any` type (like `kevin`). And this would have been a hint we need to make types consistent.
We could even create a custom named type as Łukasz Langa mentions in his [PyCon US 2022 Keynote](https://youtu.be/wbohVjhqg7c?t=753). This would provide helpful hints as we're writing the code.
## The July 2022 Update
The aforementioned VS Code Python update made it so that types could be inlayed next to your code. This makes adding type hints much simpler because hints (which are not added to your code) are valid Python code and can be added by the author.
In this case the hints would have been helpful but I don't want them always be present. There is an existing feature that may be new to Python developers using VS Code that will make showing your type hints only when you want to see them.
## Turning On Inlay Hints
For this to work you must first turn on Inlay Hints for python. Make sure the [Python Extension](https://marketplace.visualstudio.com/items?itemName=ms-python.python) is installed in VS Code and search "Python Inlay Hints" in settings.
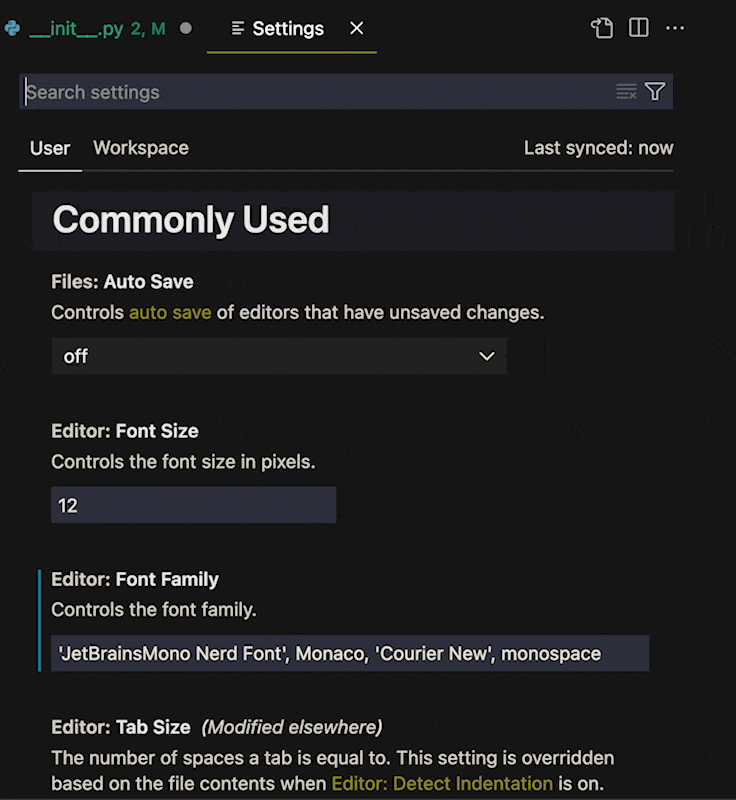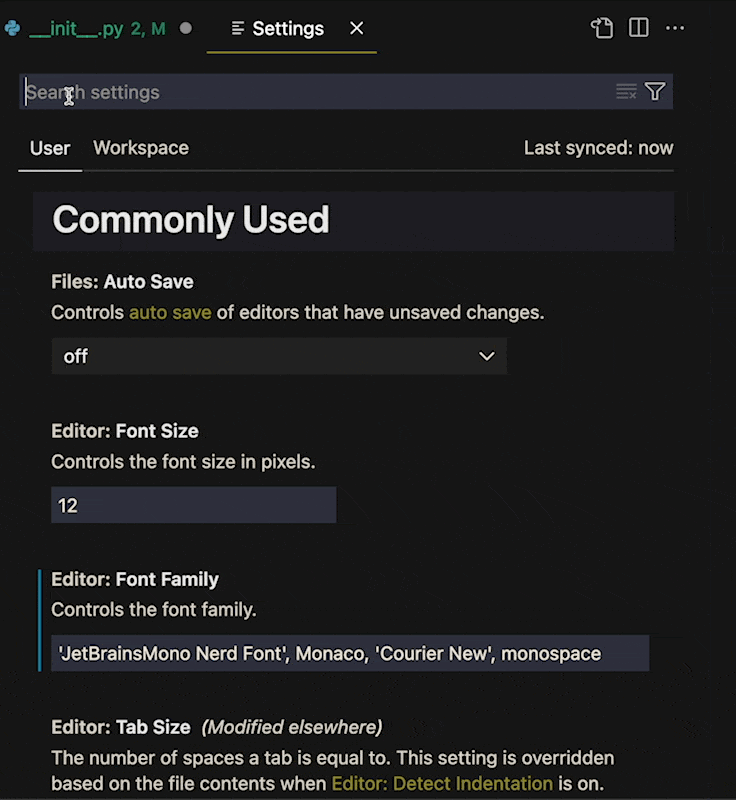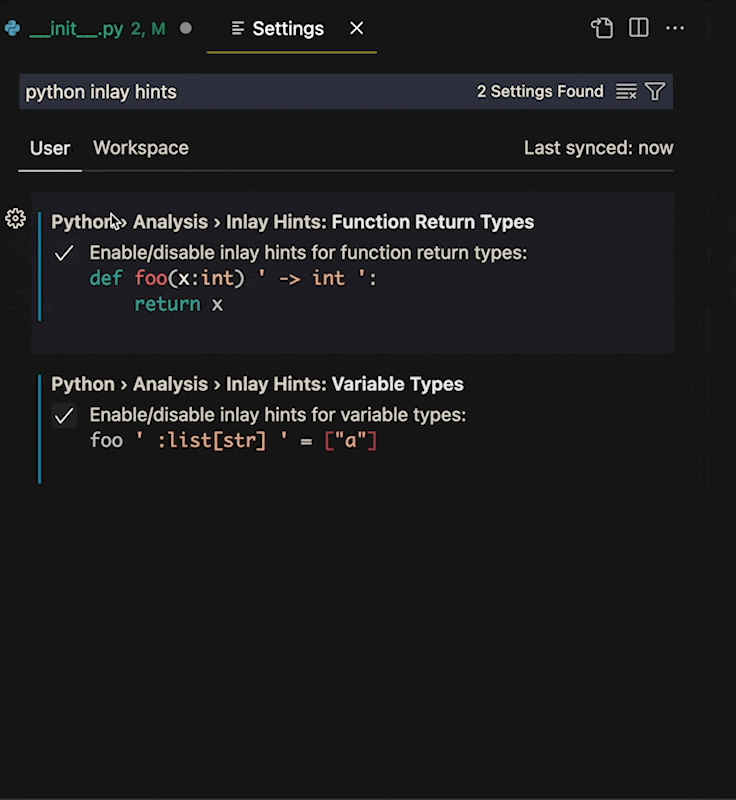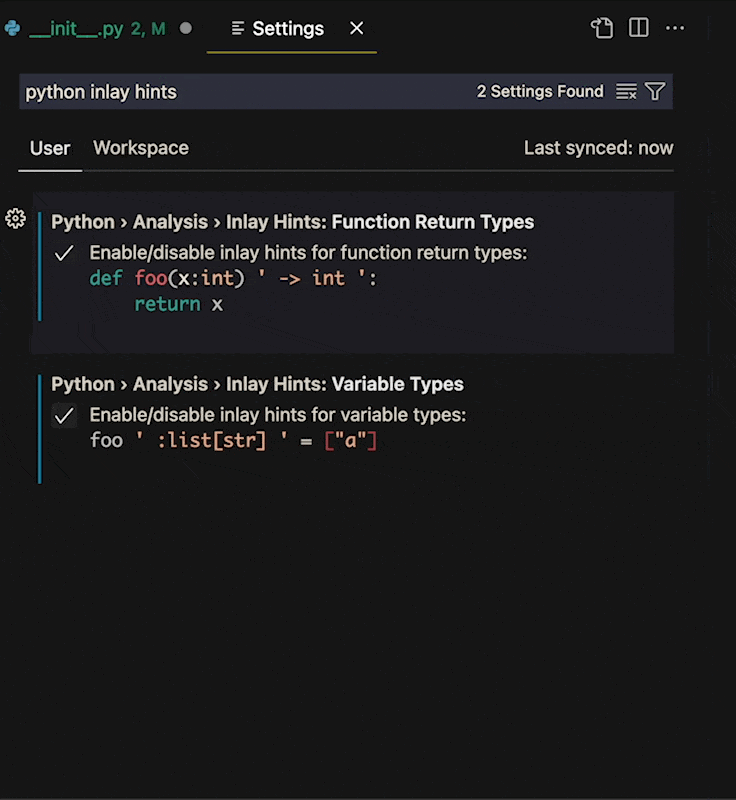
The first value to turn on is `Python › Analysis › Inlay Hints: Function Return Types`. This gives typing for what a function or method is returning.
The second is `Python › Analysis › Inlay Hints: Variable Types`. This inlays hints on variables that are written (like the ones above).
## Customizing How Inlay Hints Present in Your Editor
Next in settings just search for "Inlay". You should find `Editor › Inlay Hints: Enabled`. The value is set to `on` by default, but it has a few options, including `OnUnlessPressed` and `OffUnlessPressed`.
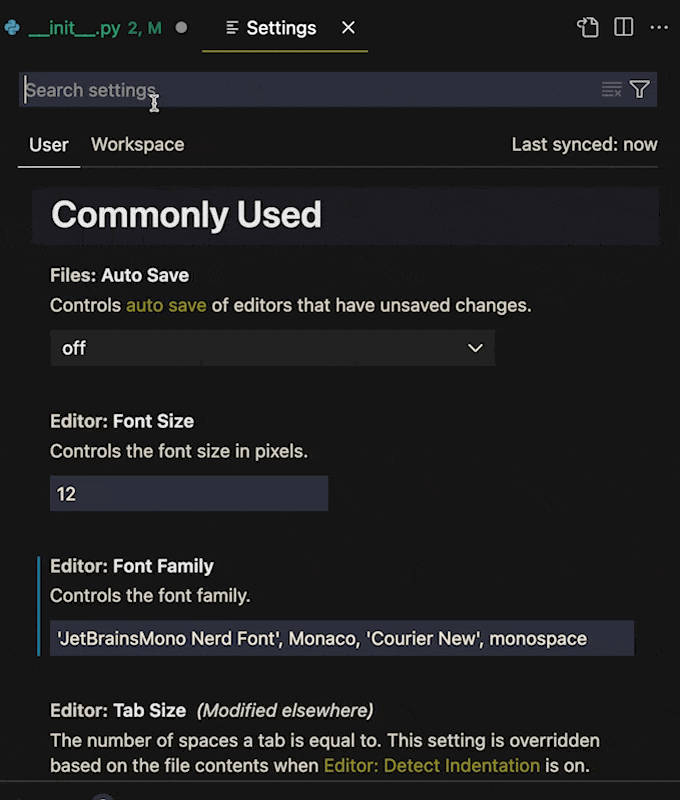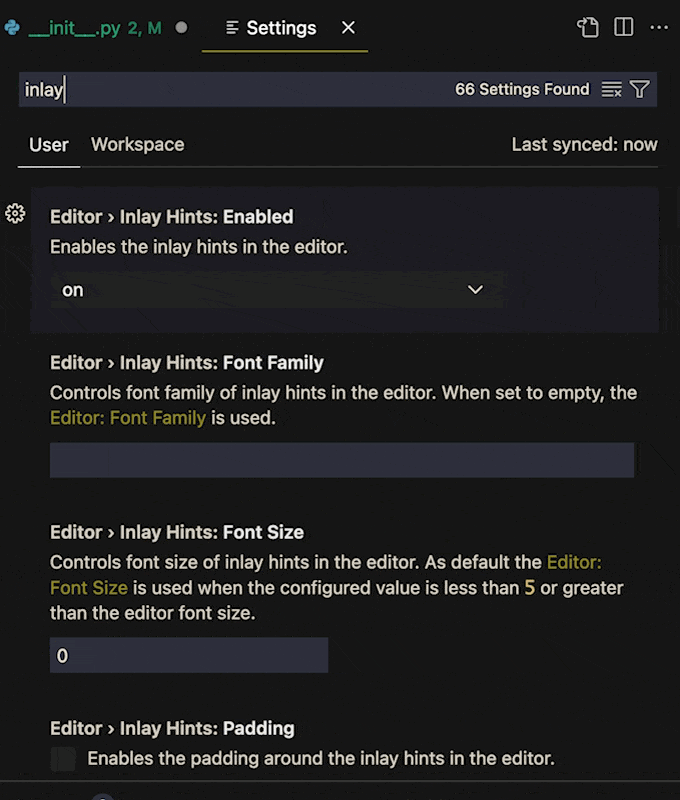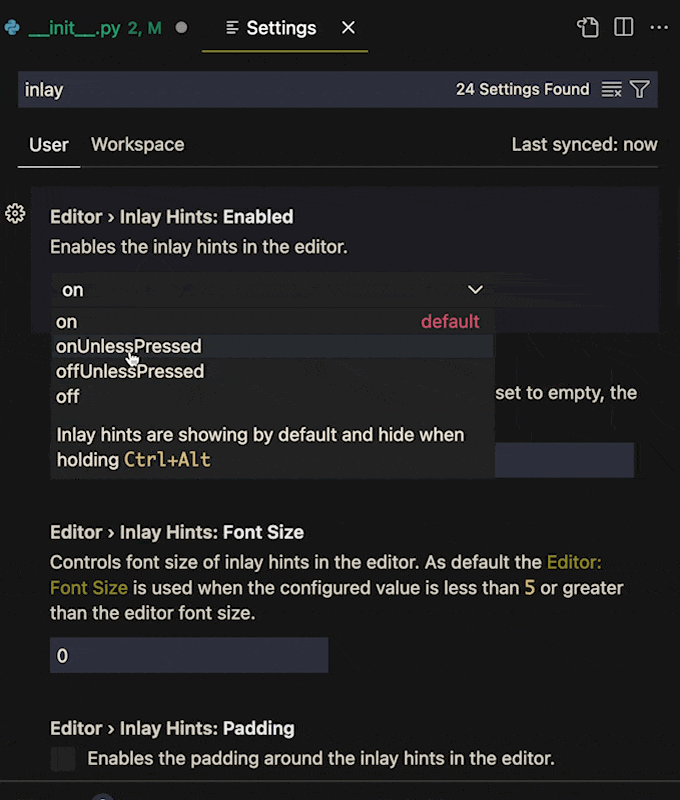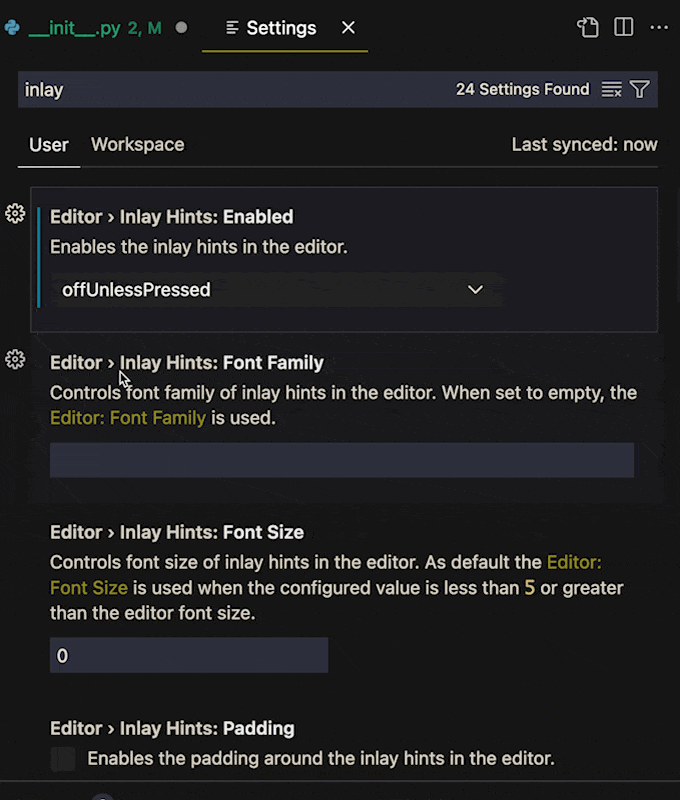
**If you change the value to `OffUnlessPressed`, you will no longer see inlayed hints until you enter _Ctrl + Alt_ (_⌃ + ⌥_ on MacOS)**. When you need a hint, press the keys and the type hints will reappear. Release the keys and they disappear again.
You can also set `OnUnlessPressed`. This does the opposite, only showing the code that exists in the file. This entry in settings is also next to other Inlay hint stylings that may help you differentiate your code from hints. | kjaymiller |
1,153,476 | PrivcacyIN Open Class | PrivacyIN will broadcast an open class on cryptography on 28th Aug. The lecturer is wangxiao,... | 0 | 2022-07-28T07:51:59 | https://dev.to/kingslaugter/privcacyin-open-class-1dm6 | machinelearning, zeroknowledge, platon, privacy |

PrivacyIN will broadcast an open class on cryptography on 28th Aug. The lecturer is
wangxiao, assistant professor at Northwestern University.
scan to sign up.
This session will introduce a ZK system (Mystique)and show the protocol implementation in LatticeX-Rosetta | kingslaugter |
1,153,654 | The useEffect hook in ReactJS | Introduction So, when I was a kid, my mama told me "The new React hooks API is really... | 0 | 2022-07-28T11:56:03 | https://dev.to/kuvambhardwaj/the-useeffect-hook-in-reactjs-2dna | javascript, react | ## Introduction
So, when I was a kid, my mama told me
"The new React hooks API is really cool, the `useEffect` hook replaced `componentDidMount` & `componentDidUpdate` of the Class API"
I wanted to ask her more about it but she got busy optimizing her React component that was re-rendering multiple times.
When I got older, I learned more about React & these hooks API, and today I'll try explaining to YOU what my mom didn't explain to ME & Probably your mom didn't too — **`useEffect`**
## Setup
So, here I created a React app in *codesandbox* on my browser
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1659006078804/PICp8H_WM.png" align="left" />
**Yup! My Web browser!**
Here's the [link](https://codesandbox.io/s/cranky-mcclintock-l5he9q), interact with it yourself!
For those of you lazy folks who don't wanna go anywhere, here's the code 🫠
```javascript
// App.js
import { useEffect, useState } from "react";
export default function App() {
const [counter, setCounter] = useState(0);
useEffect(() => {
console.log(counter);
});
return (
<div style={{ width: "100%", textAlign: "center" }}>
<h3>{counter}</h3>
<button onClick={() => setCounter((prevValue) => prevValue + 1)}>
Increment
</button>
</div>
);
}
```
Simple? huh...
Only 1 state variable defined `counter` which is being incremented at every button tap by `setCounter`, also a `useEffect` with `console.log(counter)` in its function body, nothing kubernetes!
## Code
Let's now focus on the `useEffect` defined here
```javascript
useEffect(() => {
console.log(counter);
});
```
As evident, by the code, the hook takes a function which it'll internally call at "times". Those "times" can be the component re-render, initial component mount or any state update call which causes the component to, of course, re-render.
After running this code, I tap on the increment button 3 times & these are the console logs I get:
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1658992237044/IOOXLZTEg.png" align="left" />
🤔 Hmm... looks like, this particular `useEffect` ran on these occasions:
1. When the component is first mounted ( printed "0" to the console )
2. When I tap the increment button or in short, the state update occurred
Now, lets change the `useEffect` to this:
```javascript
useEffect(() => {
console.log(counter);
}, []);
```
Notice that we're now passing an empty array "[]" (also known as ***Dependency Array***) as the second argument to the `useEffect` hook
Running the code again, I tap on the increment button 3 times & these are the console log I get:
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1658992644563/wc1nrSXHo.png" align="left" />
Okay, so this time the `useEffect` ran only at the time of mount of the component & NOT at the time of state update... INTERESTING! 🧐
<img src="https://media.giphy.com/media/RhPvGbWK78A0/giphy.gif" />
Now, again! let us edit the code once more, bear with me :)
```javascript
//App.js
import { useEffect, useState } from "react";
export default function App() {
const [counter, setCounter] = useState(0);
const [anotherCounter, setAnotherCounter] = useState(0)
useEffect(() => {
console.log("COUNTER VALUE", counter);
}, [counter]);
return (
<div style={{ width: "100%", textAlign: "center" }}>
<h3>{counter}</h3>
<button onClick={() => setCounter((prevValue) => prevValue + 1)}>
Increment
</button>
<br /><br />
<h3>{anotherCounter}</h3>
<button onClick={() => setAnotherCounter((prevValue) => prevValue + 1)}>
Random State Update
</button>
</div>
);
}
```
Alright, so... I've done 3 things here:
1. Add the `counter` state variable to the previously left empty array
2. Add another state variable & called it `anotherCounter`
3. Add the JSX to display & increment the `anotherCounter` variable
I'll now run the app & click on the "Increment" button 3 times & "Random State Update" button 2 times and these are the console logs I got
<img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1658993740296/cfnHngUBa.png" align="left" />
Oohoo! so now the `useEffect` hook is firing our function SELECTIVELY when the `counter` state is changed and not when `anotherCounter` state is changed, although, the `setAnotherCounter` is causing the component to re-render & update the `anotherCounter` to the UI.
Now, you've probably understood to some extent what that "empty array ( [] )" meant...
NICE!
Let us recap what `useEffect` when correctly written can do!
1. With the dependency array left empty, the `useEffect` will run the callback function (defined by us) ONLY ONCE *right after the component renders UI*. (equivalent to `componentDidMount` in class components)
```javascript
useEffect(() => {
/*
Here, state initialization logic can be added
OR, fetch requests to Backend servers can be made for data-fetching
As this is only running once, you're not bombarding your server
*/
}, [])
```
2. With state variable(s) given in the dependency array, the `useEffect` will run when the component first mounts & will also be running whenever the given state variables are changed
```javascript
useEffect(() => {
// ...
}, [...dependencies])
```
3. With no dependency array defined as its second argument, the hook will call our function on EVERY SUBSEQUENT component re-render
```javascript
useEffect(() => {
// I don't prefer this but yeah! it's there if you want to use it!
})
```
---
Aaaand... that's a wrap!
Like this post, if you liked it 🙃<br>
But if you loved it? man you gotta follow me on [Twitter](https://twitter.com/bhardwajkuvam) 😉
Feedback is much appreciated! 🤗
---

Meet you another day with another post ⚡️ | kuvambhardwaj |
1,153,784 | NFTs provide a new funding model for free-to-play games. | NFTs are a new way to fund free-to-play games, but it has to be done right. Here's how to design the game without losing players. | 0 | 2022-07-28T14:24:12 | https://dev.to/garrett/nfts-provide-a-new-funding-model-for-free-to-play-games-2mna | web3, nfts, nft, gamedesign | ---
title: NFTs provide a new funding model for free-to-play games.
published: true
description: NFTs are a new way to fund free-to-play games, but it has to be done right. Here's how to design the game without losing players.
tags: web3, nfts, nft, gamedesign
cover_image: https://garrettmickley.com/wp-content/uploads/2022/03/pexels-photo-5698363-1.jpeg
# Use a ratio of 100:42 for best results.
---
<p>NFTs are a potential funding model for free-to-play games.</p>
<p>You can decide whether or not that funding model is suitable for you.</p>
<p>NFTs are highly debated, maybe even more so in the games community.</p>
<p>I'm not interested in arguing about NFTs.</p>
<p>If you're against NFTs in video games or against NFTs at all in any capacity, stop reading now.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>And definitely don't waste your time commenting just to hate on NFTs.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>That said, I do appreciate the honest discussion.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Discussing ways to fund game development is vital to the industry, especially for Solo Game Devs like me.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>And I would like to have an honest discussion.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Please, poke holes in my ideas here.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Help me make them better.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>We can figure this out together.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>First, let's address some funding models of the past.</p>
<!-- /wp:paragraph -->
<!-- wp:uagb/table-of-contents {"block_id":"12bab932","classMigrate":true,"mappingHeaders":[true,true,true,true,true,true]} /-->
<!-- wp:heading -->
<h2>Self Funded Games</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Self-funding games are how the first games were made and how many indie games are still made today.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This is usually people building small games in their free time.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Or big games in the case of Stardew Valley.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This is still going on today and will probably go on forever.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>But it's not ideal.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>It sucks to work a day job 40 (or more) hours every week, build a game, and still find time to play games and spend time with friends and family.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Investor Funded Games</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Some people can get funding from investors.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This means someone is paying you to build your game for a cut of the profits.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>I don't think this happens very often, but I know it does happen because I have been approached by investors wanting to fund my games.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This isn't ideal for me because I don't like being accountable to someone in that way.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>Crowd Funded Games</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Crowdfunding through platforms like Kickstarter or IndieGoGo is a currently popular way to get the ball rolling, but I have found most of these fail.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>There are games I have put Kickstarter money into almost a decade ago that still haven't come to fruition.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>To be successful in crowdfunding, you first have to have a large following.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>It's infrequent that something on Kickstarter takes off without already having a decent-sized audience.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>People are much warier of crowdfunding now because many don't make it to total funding, and often projects that do make it never end up getting finished.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>I don't think most projects are maliciously trying to make money and run.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>They just mismanage or underestimate the money needed to finish the project.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2>How to Use NFTs to Fund a Game</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Now let's look at the pros and cons of using NFTs to fund your game and how to do it right.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>First things first, the controversy around NFTs.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Anyone who has a problem with NFTs is not your target market.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>So forget about them.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>I frequently have to explain to my marketing clients that you can't be everything to everyone all the time.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>"You can't please everyone" is a well-worn refrain I'm sure you've heard.</p>
<p>It's true, so don't try.</p>
<p>Focus on the people interested in NFTs in games, and don't worry about anyone else.</p>
<p>Next, you need to be fair about the NFTs.</p>
<p>Building a pay-to-win game is not sustainable.</p>
<p>But as we've seen with many games such as Roblox, Guild Wars 2, Fortnite, etc., people are willing to spend real money on aesthetics even if no advanced power comes with it.</p>
<p>On top of that, you should design a game where skills are more important than power.</p>
<p>Diablo III's real-money auction house was not a good idea because it's a game based on power.</p>
<p>Plus, the gameplay loop is Kill => Acquire Loot, and the auction house removed the need to Kill.</p>
<p>The design of your game is essential when adding something in that can be purchased with real money.</p>
<p>Another thing you can do to keep it somewhat fair is not sell any of the NFTs yourself as the game developer.</p>
<p>The players can sell them to each other, but someone has to earn or unlock them first.</p>
<p>That way, people who want to spend real-world money to acquire things can't flood the market by just buying the item off of the developer.</p>
<p>There may be some really awesome-looking armor that is very difficult to obtain.</p>
<p>When you see someone running around with that armor, you know someone there worked really hard to get it.</p>
<p>The person wearing it right now in front of you may have just paid for it.</p>
<p>But someone out there worked very hard to get it.</p>
<p>Which increases the value of the item by a lot.</p>
<p>This is where I think NFTs in games really shine.</p>
<p>The developer makes money off of the trades.</p>
<p>With enough players trading enough in-game, this could easily fund continued development and allow a game to be free to play.</p>
<p>It's essential to maintain a fair percentage of the trade as well.</p>
<p>Too small of a percentage, and your game won't be funded.</p>
<p>And if it's too large, players aren't incentivized to trade.</p>
<p>This also gives players a direct stake in the game that is much bigger than just being a player.</p>
<p>I don't know if Play-to-Earn games will ever reach a point where the average player can earn a living wage.</p>
<p>But if I'm going to play video games anyway, and I enjoy a game, and I can get some real-world money out of playing it, that's the game I will choose.</p>
<p>Even if it only affords me ordering a pizza once a week.</p>
<p>And giving players a reason to help grow the player base will make your game successful.</p>
<p>In fact, I would work in some sort of referral incentive for players to bring their friends in.</p>
<p>Long-term referral incentives would be great.</p>
<p>That way, it's not based on how many people they bring into the game, but how long those people actually stay active.</p>
<p>Comments are open, but as I said, if you're just here to complain about NFTs, don't bother. You'll just get blocked.</p>
<p>Legit discussion is encouraged!</p> | garrett |
1,154,051 | Introduction to Linux | WHAT IS LINUX. Just like Windows, iOS, and Mac OS, Linux is an operating system. One of... | 0 | 2022-07-28T19:44:52 | https://dev.to/muhammadshakirdev/introduction-to-linux-69j | linux, ubuntu, content, opensource |
## WHAT IS LINUX.
Just like Windows, iOS, and Mac OS, Linux is an operating system. One of the most popular platforms on the planet, Android, is powered by the Linux operating system. An operating system is software that manages all of the hardware resources associated with your desktop or laptop. To put it simply, the operating system manages the communication between your software and your hardware. Without the operating system (OS), the software wouldn't function.
The Linux operating system comprises several different pieces:
1. BOOTLOADER
2. KERNAL
3. INIT SYSTEM
4. DAEMONS
5. GRAPHICAL SERVER
6. DESKTOP ENVIRONMENT
7. APPLICATIONS
## BOOT LOADER.
The software that manages the boot process of your computer. For most users, this will simply be a splash screen that pops up and eventually goes away to boot into the operating system.
## **KERNEL.**
This is the one piece of the whole that is called? Linux?. The kernel is the core of the system and manages the CPU, memory, and peripheral devices. The kernel is the lowest level of the OS.
## INIT SYSTEM.
What is init, System Manager? In Linux/Unix-based operating systems, init (short for initialization) is the first process that started during the system boot-up by the kernel. It's holding a process id (PID) of 1. It will be running in the background continuously until the system is shut down. It is the init system that manages the boot process, once the initial booting is handed over from the bootloader (i.e., GRUB or GRand Unified Bootloader).
## DAEMONS.
These are background services (printing, sound, scheduling, etc.) that either start up during boot or after you log into the desktop.
## GRAPHICAL SERVER.
This is the sub-system that displays the graphics on your monitor. It is commonly referred to as the X server or just X.
## DESKTOP ENVIRONMENT.
This is the piece that the users interact with. There are many desktop environments to choose from (GNOME, Cinnamon, Mate, Pantheon, Enlightenment, KDE, Xfce, etc.). Each desktop environment includes built-in applications (such as file managers, configuration tools, web browsers, and games).
## APPLICATIONS.
Desktop environments do not offer the full array of apps. Just like Windows and macOS, Linux offers thousands upon thousands of high-quality software titles that can be easily found and installed. Most modern Linux distributions (more on this below) include App Store-like tools that centralize and simplify application installation. For example, Ubuntu Linux has the Ubuntu Software Center (a rebrand of GNOME Software) which allows you to quickly search among the thousands of apps and install them from one centralized location.
## WHY USE LINUX?
This is the one question that most people ask. Why bother learning a completely different computing environment, when the operating system that ships with most desktops, laptops and servers work just fine?
To answer that question, I would pose another question. Does that operating system you? re currently using work? just fine?? Or, do you find yourself battling obstacles like viruses, malware, slowdowns, crashes, costly repairs, and licensing fees?
If you struggle with the above, Linux might be the perfect platform for you. Linux has evolved into one of the most reliable computer ecosystems on the planet. Combine that reliability with zero cost of entry and you have the perfect solution for a desktop platform.
## OPEN-SOURCE.
Linux is also distributed under an open-source license. Open source follows these keys:
The freedom to run the program, for any purpose.
The freedom to study how the program works, and change it to make it do what you wish.
The freedom to redistribute copies so you can help your neighbor.
The freedom to distribute copies of your modified versions to others.
These points are crucial to understanding the community that works together to create the Linux platform. Without a doubt, Linux is an operating system that is ? by the people, for the people?. These tenants are also the main factor in why many people choose Linux. It's about freedom and freedom of use and freedom of choice.
## WHAT IS DISTRIBUTION.
Linux has some different versions to suit any type of user. From new users to hard-core users, you’ll find a “flavor” of Linux to match your needs. These versions are called distributions (or, in the short form, “distros”). Nearly every distribution of Linux can be downloaded for free, burned onto disk (or USB thumb drive), and installed (on as many machines as you like).
**Popular Linux distributions include:**
1. LINUX MINT
2. MANJARO
3. DEBIAN
4. UBUNTU
5. ANTERGOS
6. SOLUS
7. FEDORA
8. ELEMENTARY OS
9. OpenSUSE
Each distribution has a different take on the desktop. Some opt for very modern user interfaces (such as GNOME and Elementary OS’s Pantheon), whereas others stick with a more traditional desktop environment (openSUSE uses KDE).
| muhammadshakirdev |
1,154,107 | [Algorithms] 9 - Product of Array Except Self | Link for the problem Link for the solution Overview To solve the problem is pretty easy.... | 19,083 | 2022-07-28T21:53:00 | https://dev.to/_ben/algorithms-9-product-of-array-except-self-fk3 | algorithms | [Link for the problem](https://leetcode.com/problems/product-of-array-except-self/)
[Link for the solution](https://github.com/neetcode-gh/leetcode/blob/main/cpp/neetcode_150/01_arrays_%26_hashing/product_of_array_except_self.cpp)
#### Overview
To solve the problem is pretty easy. But the given conditions are what make this problem very tricky. I would like to introduce the problem because the solution is pretty unique.
#### Problem in detail
The constraints for this problem are:
- Time complexity: O(n)
- Space complexity: O(1)
- Cannot use division
> Notice that the problem will not count the returning array as an extra space.
It seems almost impossible to solve the problem with those constraints. Especially achieving O(1) space complexity without using division drove me crazy to think about the solution. So I gave it up and looked at the solution.
#### Solution
The solution was something that I have never seen, but easy to understand. First, we need to think how to get the products without itself. It is actually the product of left side of an element and the right side of an element.
```
[ 1, 2, 3, 4 ]
ex) product without 1
- left side: 1 (does not exist)
- right side: 2*3*4 (without 1)
- left side * right side = 1 * 24 = 24
ex) product without 3
- left side: 1*2 (does not exist)
- right side: 4 (without 3)
- left side * right side = 1 * 2 * 4 = 8
```
Next, we need to find the way to get prefixes and postfixes in a linear time, and using only constant space. Actually this part is very hard to come up with by ourselves.
The way to create prefixes is:
1. Set up a variable prefix, initialized with 1.
2. Push the prefix to the returning array.
3. Keep multiplying prefix as loop goes through.
> Notice that the first prefix is always going to be 1 since there is no element on the left side of the first element.
After the step, we will get an array that filled with prefixes for each element. Now all we need to do is get postfixes for each element and simply update the returning array by multiplying those postfixes.
#### Code implementation
```cpp
vector<int> productExceptSelf(vector<int>& nums) {
vector<int> res;
int prefix = 1;
for (int i = 0; i < nums.size(); i++)
{
res.push_back(prefix);
prefix *= nums[i];
}
int postfix = 1;
for (int i = nums.size()-1; i >= 0; i--)
{
res[i] *= postfix;
postfix *= nums[i];
}
return res;
}
```
| _ben |
1,154,225 | Projeto - Stone | Nesse projeto, fiz um clone da página do banco Stone. Onde usei HTML e CSS para desenvolver a Landing... | 0 | 2022-07-29T02:40:03 | https://dev.to/lucasfelipedonascimento/projeto-stone-46l6 |
Nesse projeto, fiz um clone da página do banco Stone. Onde usei HTML e CSS para desenvolver a Landing Page.
No código procurei fazer padrões, já que vi que em algumas seções sempre tinha **Texto e imagem**, então procurei padronizar para poder economizar na hora de estilizar no CSS. Usei **GRID** para fazer a divisão de textos e imagens nas seções que tinha ambas.
**Link do projeto:** https://lucasfelipedonascimento.github.io/page-stone/
---
Também usei o https://excalidraw.com/ para fazer o protótipo do projeto, onde fiz a divisão da página em seções para facilitar o trabalho na hora de codar. | lucasfelipedonascimento | |
1,170,009 | Introducing a Simple Module for Parsing CSV Files | Today I want to introduce a simple module for parsing CSV files Recently I was exploring my old... | 0 | 2022-08-17T20:48:49 | https://dev.to/atherdon/introducing-a-simple-module-for-parsing-csv-files-310k | 
Today I want to introduce a simple module for parsing CSV files
Recently I was exploring my old repository: https://github.com/Food-Static-Data/food-datasets-csv-parser
Inside I have a cool set of small modules, that helped me a lot. As my code is highly tied to those packages -> I need to pray for developers that build them, so I don't need to spend precious time.
List of modules that I'm using:
- csv-parser
- fs
- lodash
- path
- path-exists
- shelljs
Why did I create this package? It's simple. During our work @ Groceristar, we came around a number of databases and datasets, related to "food-tech". To be able to extract that data and play with it -> you need to parse CSV files.




Link to the repository: https://github.com/Food-Static-Data/food-datasets-csv-parser
Link to npm page: https://www.npmjs.com/package/@groceristar/food-dataset-csv-parser
I will also post updates about building modules for static data on indie hackers. While it didn't help with promotions a lot, founders are pretty positive people and their support really matters. Here is an org that I created few years ago: https://www.indiehackers.com/product/food-static-data
As usually, experienced developers might tell me that I'm stupid and CSV parsing is a mundane procedure. But I don't care. I realized that for a few separate projects we are running similar code. So I decided to isolate it.
I did it a few times before I finally find a way to make it work as I like. And you can see how it looks right now.
I can say, not ideal, but it was working fine for me. Right now I plan to revamp this package a little bit, in order to make it work with the latest versions of rollupjs and babel.






While the idea is simple: connecting a dataset in CSV format, parsing it, and exporting data as you need it, while you need to make it work with 10 different datasets, things arent as easy as they sound in your head.
CSVs not only related to food tech datasets. But for me was important to be able to use different datasets and easy to play with it. It makes other modules that we are building data-agnostic and more independent to a database/frameworks/logic. Basically, around this idea, we created and optimized like 13 repositories. Recently I created a separate organization that will be focused on those repositories only.
Link: https://github.com/Food-Static-Data
Later I plan to remove some repositories when they wouldn't be replaced by other, more popular, and stable tools. This current module can be useful for parsing other datasets too. But making it separate from the food tech topic isn't my task at this point.
And I was able to include and implement cool and important packages, like husky and coveralls. I can't say that I get most from them, but at the same time, it helped me to jump into the "open source ocean" that related to the GitHub rabbit hole that I'm still exploring for so many years.
and it's good to not just type another line of code, but also be able to see that your codebase is solid and nothing breaking it behind your back


CodeClimate(https://codeclimate.com/) helped me to explore and be able to take another look at how to develop things.



Yeah, codeclimate shows that I have code duplicates and ~50h of tech debt. Looks like a lot, right? But this is a small independent package.
Imagine how much tech debt has your huge monolith project. Years of wasted time of developers, probably 🙂
At some point i'll remove duplicates and it will reduce number of hours on this page.
Plus, usually, your product owner or CTO is busy and can't review code and be able to track things inside your code.
CodeClimate can do some stuff for you. Just check those settings. Plus, they support open-source movement. So if your code is open and located on GitHub, you can use it for free.

Stretch goals are simple
- I want to invest some time into CI/CD stuff. At this moment i'll pick Travic CI. At some point i'll extend it, so when a new version of this package is published, i'll run it against our datasets and will see if something breaks or not.
- I also need to remove duplicated code that i was moved into separated packages but still present here, due to back capability.
- and it's also not cool to see JS code with all there csv files at the same repository. I need to came with idea about how to organize folders and make it easy to navigate. While it works for me - other people might find it very confusing.
We even did a great readme file with an explanation of how to run this package




We collected a great number of datasets that can help a wast number of food projects. Some of them even sell the latest updates for money.
Right now this module was tested with:
- FoodComposition dataset
- USDA dataset(i pick 4 major tables with data)
- FAO(Food and Agriculture Organization of the United Nations) dataset
This module is not just for parsing data, we also have a need to write files in JSON format with formatted data inside.
Show some love if you want more articles like this one! any activity will be appreciated.
Similar articles:
- https://hackernoon.com/introducing-a-simple-npm-module-with-email-templates
- https://hackernoon.com/how-i-started-to-build-react-components-for-email-templates
- https://hackernoon.com/organizing-an-advanced-structure-for-html-email-template
- https://hackernoon.com/open-sourcing-regular-expressions-for-markdown-syntax-module
| atherdon | |
1,174,879 | 60 Days of Data Science and Machine Learning | Hello, everyone. Following are third week of this series. You can find them on my github repository.... | 0 | 2022-08-24T07:09:06 | https://dev.to/levintech/60-days-of-data-science-and-machine-learning-1740 | python, datascience, machinelearning, ai | Hello, everyone.
Following are third week of this series. You can find them on my github repository. You can run all the notebook on colab or jupyter as well.
- [Day 15 - Repression Part2](https://github.com/levintech/60-Days-of-Data-Science-and-ML/blob/main/Day_15_Regression_Part2.ipynb)
Topic : Support Vector Regression, Decision Tree Regression and Random Forest Regression
- [Day 17 - Kaggle's Annual Machine Learning and Data Science Survey Part1](https://github.com/levintech/60-Days-of-Data-Science-and-ML/blob/main/Day_17_Kaggle%E2%80%99s_Annual_Machine_Learning_and_Data_Science_Survey_Part1.ipynb)
Topic : Data Cleaning, Preprocessing, EDA and etc
- [Day 18 - DecisionTreeRegressor and RandomForestRegressor](https://github.com/levintech/60-Days-of-Data-Science-and-ML/blob/main/Day_18_DecisionTreeRegressor_and_RandomForestRegressor.ipynb)
Topic : Implement Regressor with Decision Tree and Random Forest
- [Day 19 - Kaggle's Annual Machine Learning and Data Science Survey Part2](https://github.com/levintech/60-Days-of-Data-Science-and-ML/blob/main/Kaggle%27s_Annual_Machine_Learning_and_Data_Science_Survery_Part2.ipynb)
Topic : Data Cleaning, Preprocessing, EDA and etc
- [Day 20 - Detailed Crypto Analysis](https://github.com/levintech/60-Days-of-Data-Science-and-ML/blob/main/Day_20_Detailed_Crypto_Analysis.ipynb)
Topic : Basic intuition to buid model to predict
- [Day 21 - Detailed Analysis of the Netflix Content](https://github.com/levintech/60-Days-of-Data-Science-and-ML/blob/main/Day_21_Detailed_of_the_Netflix_Content.ipynb)
Topic : Detailed analysis of the Netflix Content
Hope my work would be little bit helpful for AI enthusiastic.
If that, please star that repository then follow me on **Github** and **Dev.to**
https://github.com/levintech
https://dev.to/levintech
Best Regards. | levintech |
1,175,027 | Hibernate & JPA Tutorial - Crash Course | Ever looked for a comprehensive tutorial to Hibernate & JPA that is fun and entertaining at the... | 0 | 2022-08-24T10:26:52 | https://dev.to/marcobehler/hibernate-jpa-tutorial-crash-course-57fb | java, tutorial | Ever looked for a comprehensive tutorial to Hibernate & JPA that is fun and entertaining at the same time?
[This video](https://www.youtube.com/watch?v=xHminZ9Dxm4) is a crash course into the [Hibernate](https://hibernate.org/) & JPA universe.
We'll start with getting the correct project dependencies, annotating our classes with JPA annotations and setting up a SessionFactory. This allows us to execute basic CRUD operations, HQL and Criteria queries.
Afterwards we can simply JPAify our code, switching out a couple of classes and you'll understand how Hibernate / JPA & Spring Boot play together.
By the end of it, you'll have a good (initial) understanding of how to use it and what your future Hibernate / JPA learning journey entails.
{% embed https://www.youtube.com/watch?v=xHminZ9Dxm4 %} | marcobehler |
1,175,292 | Lazy Minting NFT - Solidity, Hardhat | What is NFT ? Non-fungible tokens, often referred to as NFTs, are blockchain-based tokens... | 0 | 2022-09-03T04:46:38 | https://dev.to/hussainzz/lazy-minting-nft-solidity-hardhat-30l1 | solidity, web3, nft, hardhat | ## What is NFT ?
Non-fungible tokens, often referred to as NFTs, are blockchain-based tokens that each represent a unique asset like a piece of art, digital content, or media.
## Why Lazy Minting ?
Before understanding what is lazy minting lets understand why we really need it.When minting an NFT the owner needs to pay Gas fee which is a fee that the creator or the one who made the NFTs must pay in exchange for the computational energy needed to process and validate transactions on the blockchain.So with lazy minting we don't have to pay a gas fee when listing an NFT, We only pay gas fee when we actually mint the nft, once the asset is purchased and transfered on chain.
##How it works
Usually when we mint an NFT we call the contract function directly & mint NFT on Chain.But in case of Lazy minting,Creator prepares a cryptographic signature with their wallet private key.
That cryptographic signature is know as "Voucher" which is then used to redeem NFT.It may also include some additional information required while minting the NFT on Chain.
## Tech Stack
Solidity & Hardhat for smart contract development
React Js & Tailwind CSS for dapp
##Let's start
By creating & understanding the signed voucher.In order to accomplish the signing we are going to use
[EIP-712: Typed structured data hashing and signing](https://eips.ethereum.org/EIPS/eip-712)
Which allows us to standardize signing a typed data structure, Which then can be sent to smart contract to claim the NFT.
eg.
```
struct SomeVoucher {
uint256 tokenId;
uint256 someVariable;
uint256 nftPrice;
string uri;
bytes signature;
}
```
Create a new directory called `lazymint`
```
> mkdir lazymint
> cd lazymint
> yarn add -D hardhat
```
Next, Initialize hardhat development environment
```javascript
> yarn hardhat
888 888 888 888 888
888 888 888 888 888
888 888 888 888 888
8888888888 8888b. 888d888 .d88888 88888b. 8888b. 888888
888 888 "88b 888P" d88" 888 888 "88b "88b 888
888 888 .d888888 888 888 888 888 888 .d888888 888
888 888 888 888 888 Y88b 888 888 888 888 888 Y88b.
888 888 "Y888888 888 "Y88888 888 888 "Y888888 "Y888
Welcome to Hardhat v2.10.2
? What do you want to do? …
▸ Create a JavaScript project
Create a TypeScript project
Create an empty hardhat.config.js
Quit
```
Select `Create a JavaScript project` and let it install all the dependencies.
Next, lets install a package called [hardhat-deploy](https://github.com/wighawag/hardhat-deploy) which makes working with hardhat 2x easier & fun 👻
```
> yarn add -D hardhat-deploy
```
And add the following statement to your hardhat.config.js:
```
require('hardhat-deploy');
```
Next,
```
yarn add -D @nomiclabs/hardhat-ethers@npm:hardhat-deploy-ethers ethers
```
All the hardhat.config.js changes can be found in my [REPO](https://github.com/Hussainzz/lazy-mint-contract).
Next, Create a new contract in contracts directory feel free to give any name, i'll call it `LazyMint.sol`
```javascript
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.4;
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721URIStorage.sol";
import "@openzeppelin/contracts/access/Ownable.sol";
import "@openzeppelin/contracts/utils/cryptography/draft-EIP712.sol";
import "@openzeppelin/contracts/access/AccessControl.sol";
contract LazyMint is ERC721, ERC721URIStorage, Ownable, EIP712, AccessControl {
error OnlyMinter(address to);
error NotEnoughValue(address to, uint256);
error NoFundsToWithdraw(uint256 balance);
error FailedToWithdraw(bool sent);
bytes32 public constant MINTER_ROLE = keccak256("MINTER_ROLE");
string private constant SIGNING_DOMAIN = "Lazy-Domain";
string private constant SIGNING_VERSION = "1";
event NewMint(address indexed to, uint256 tokenId);
event FundsWithdrawn(address indexed owner, uint256 amount);
struct LazyMintVoucher{
uint256 tokenId;
uint256 price;
string uri;
bytes signature;
}
constructor(address minter) ERC721("LazyMint", "MTK") EIP712(SIGNING_DOMAIN, SIGNING_VERSION) {
_setupRole(MINTER_ROLE, minter);
}
function mintNFT(address _to, LazyMintVoucher calldata _voucher) public payable {
address signer = _verify(_voucher);
if(hasRole(MINTER_ROLE, signer)){
if(msg.value >= _voucher.price){
_safeMint(_to, _voucher.tokenId);
_setTokenURI(_voucher.tokenId, _voucher.uri);
emit NewMint(_to, _voucher.tokenId);
}else{
revert NotEnoughValue(_to, msg.value);
}
}else{
revert OnlyMinter(_to);
}
}
function _hash(LazyMintVoucher calldata voucher) internal view returns(bytes32){
return _hashTypedDataV4(keccak256(abi.encode(
//function selector
keccak256("LazyMintVoucher(uint256 tokenId,uint256 price,string uri)"),
voucher.tokenId,
voucher.price,
keccak256(bytes(voucher.uri))
)));
}
function _verify(LazyMintVoucher calldata voucher) internal view returns(address){
bytes32 digest = _hash(voucher);
//returns signer
return ECDSA.recover(digest, voucher.signature);
}
// The following functions are overrides required by Solidity.
function _burn(uint256 tokenId) internal override(ERC721, ERC721URIStorage) {
super._burn(tokenId);
}
function tokenURI(uint256 tokenId)
public
view
override(ERC721, ERC721URIStorage)
returns (string memory)
{
return super.tokenURI(tokenId);
}
function supportsInterface(bytes4 interfaceId) public view virtual override(AccessControl, ERC721) returns (bool){
return ERC721.supportsInterface(interfaceId) || AccessControl.supportsInterface(interfaceId);
}
function withdrawFunds() public payable onlyOwner{
uint256 balance = address(this).balance;
if(balance <= 0){revert NoFundsToWithdraw(balance);}
(bool sent,) = msg.sender.call{value: balance}("");
if(!sent){revert FailedToWithdraw(sent);}
emit FundsWithdrawn(msg.sender, balance);
}
}
```
Let's quickly go through the `LazyMint.sol` contract.
i am using `ERC721` & `ERC721URIStorage` from [OpenZeppelin Contracts](https://github.com/OpenZeppelin/openzeppelin-contracts)
**ERC721** - is a standard for representing ownership of non-fungible tokens, that is, where each token id is unique.
**ERC721URIStorage** - is an implementation of ERC721 that includes the metadata standard extensions ( IERC721Metadata ) as well as a mechanism for per-token metadata.
In Simple words, contract implemented without `ERC721Storage` generates tokenURI for tokenId on fly by concatenating baseURI + tokenID.In case of contracts using `ERC721Storage` we provide the tokenURI(metadata) when minting the token which is then stored on-chain.
Next, i am using Ownable & AccessControl.
[**Ownable**](https://docs.openzeppelin.com/contracts/2.x/api/ownership) - which enables contract exclusive access to functions eg. OnlyOwner has access to certain functions.
[**AccessControl**](https://docs.openzeppelin.com/contracts/2.x/access-control) - Which allows us to assign certain roles to address like in our case,Specific address can sign vouchers to mint NFTs, for that we can create a role called `MINTER`. or an admin for the overall contract.
Next, i have defined some custom errors which were introduced in `solidity version 0.8.4`
```javascript
error OnlyMinter(address to);
error NotEnoughValue(address to, uint256);
error NoFundsToWithdraw(uint256 balance);
error FailedToWithdraw(bool sent);
```
Next, we define the minter role, signing domain & version.
so that when minting we can check that the signed voucher explained above was signed by minter address.And includes the same domain and version.
```javascript
bytes32 public constant MINTER_ROLE = keccak256("MINTER_ROLE");
string private constant SIGNING_DOMAIN = "Lazy-Domain";
string private constant SIGNING_VERSION = "1";
```
Next, lets take a look at the Voucher which we defined in solidity using `struct`
```javascript
struct LazyMintVoucher{
uint256 tokenId;
uint256 price;
string uri;
bytes signature;
}
```
Which includes `tokenId` to mint, price, uri[usually a url pointing to metadata] for the nft,and signature.Let's Understand the mintNFT function to understand how this voucher does all the magic 🪄.
```javascript
function mintNFT(address _to, LazyMintVoucher calldata _voucher) public payable {
address signer = _verify(_voucher);
if(hasRole(MINTER_ROLE, signer)){
if(msg.value >= _voucher.price){
_safeMint(_to, _voucher.tokenId);
_setTokenURI(_voucher.tokenId, _voucher.uri);
emit NewMint(_to, _voucher.tokenId);
}else{
revert NotEnoughValue(_to, msg.value);
}
}else{
revert OnlyMinter(_to);
}
}
```
the important part of the voucher is signature which we sign off-chain with the Minters private key which has all the additional data in the same order defined in the above `struct`.Then in `mintNFT` function which expects two arguments `_to` & `_voucher`.
nft will be minted for `_to` address.And voucher basically helps redeem the NFT.First line in `mintNFT` function is to verify the signature from the voucher. to verify the signer we call a cryptographic function from `draft-EIP712.sol` called `_hashTypedDataV4` which takes in our hashed version of our voucher struct and the return value then can be used with a `recover` function from [`Elliptic Curve Digital Signature Algorithm (ECDSA) `](https://docs.openzeppelin.com/contracts/2.x/utilities) to get the signer address.We then compare the recovered signer to check if it matches our `MINTER` address & also check if that signer has the minter_role, If Yes ? we proceed and check the value(eth passed) matches the price value mentioned in the voucher. If yes ? we go ahead and mint the token and emit an event `emit NewMint(_to, _voucher.tokenId)`.
That's it for the Voucher Verification Magic Trick 🪄🪄🪄
Next, we have a `withdrawFunds` which allows only the contract owner to withdraw funds, if any.
## How to sign a voucher ?
Open [createSalesOrder](https://github.com/Hussainzz/lazy-mint-contract/blob/main/scripts/createSalesOrder.js), go to the scripts folder open `createSalesOrder.js` which is a simple script to create vouchers.
First we get the signer account.
```javascript
const [signer] = await ethers.getSigners();
```
Next, We need the signing domain & version these values should same as one defined in the contract.
```javascript
const SIGNING_DOMAIN = "Lazy-Domain";
const SIGNING_VERSION = "1";
const MINTER = signer;
```
As per EIP 712 we need a domain, which is made up of chainId, ContractAddress, domain & the version.
```javascript
const domain = {
name: SIGNING_DOMAIN,
version: SIGNING_VERSION,
verifyingContract: lazyMint.address,
chainId: network.config.chainId
}
let voucher = {
tokenId: i,
price: PRICE,
uri: META_DATA_URI
}
```
`META_DATA_URI` i have already pinned it to [ipfs](https://ipfs.io/ipfs/QmPE9bwcVXiCxtH5q5R3mC2DpDkyDbJUZKmNAbAkhZVfWE)
```javascript
`ghost_metadata.json`
{
"description": "Boooooo",
"image": "https://ipfs.io/ipfs/QmeueVyGRuTH939fPhGcPC8iF6HYhRixGBRmEgiZqFUvEW",
"name": "Baby Ghost",
"attributes": [
{
"trait_type": "cuteness",
"value": 100
}
]
}
```
Next, we need the `createVoucher` function open `voucherHelper.js`. In order to create a signed voucher we need three arguments `domain` `voucher` `types`. Now types is nothing but the `struct` voucher which we have defined in solidity smart contract.Make sure the name of the `struct` & also the order of variables match.
```javascript
const types = {
LazyMintVoucher:[
{name: "tokenId", type:"uint256"},
{name: "price", type:"uint256"},
{name: "uri", type:"string"}
]
}
```
Next, we sign the voucher with the MINTER(signer) wallet & get the signed voucher 🖋️
```javascript
const signature = await signer._signTypedData(domain, types, voucher);
```
In `createSalesOrder.js` at the end once i get the signed vouchers, In my case to keep things simple i am just saving the signed vouchers inside a file called `NFTVouchers.json` which i am creating directly in my dapp `'../lazymintdapp/src/NFTVouchers.json'`.Ideally in real life scenario you store these signed vouchers in your centralized DB 🤪
Done! 🎉🎉
##Contract Tests
I have written some unit tests which can be found in `test/LazyMintUnit.test.js`
```
> yarn hardhat test
```
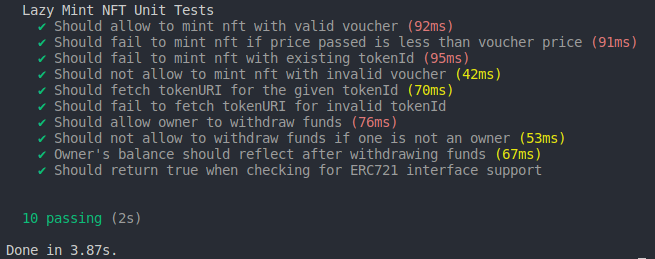
##Deployed Contract & Demo
[https://ghost-mint.vercel.app/](https://ghost-mint.vercel.app/)
[https://mumbai.polygonscan.com/address/0x3077B8941e6337091FbB2E3216B1D5797B065C71](https://mumbai.polygonscan.com/address/0x3077B8941e6337091FbB2E3216B1D5797B065C71)
[**CODE REPO**](https://github.com/Hussainzz/lazy-mint-contract) Don't forget to drop a ⭐⭐⭐⭐⭐
## LazyNFTs Dapp
i won't be going through the dapp completely.But for reactjs dapp development i used `create-react-app`.
**Packages**
- **Wagmi**: https://wagmi.sh/ for contract interaction, Cool and easy react hooks.And their documentation has lots of examples which makes it way easier to implement. 🦍
##Resources
There are multiple ways in which one can approach the lazy minting flow. this was all my learning experience.Here are some resources which help me understand lazy minting.
- https://www.alchemy.com/overviews/lazy-minting
- https://eips.ethereum.org/EIPS/eip-712
- https://medium.com/metamask/eip712-is-coming-what-to-expect-and-how-to-use-it-bb92fd1a7a26
- https://nftschool.dev/tutorial/lazy-minting
That's it on lazy minting. 👻

[](https://www.buymeacoffee.com/shkhussainb) | hussainzz |
1,175,614 | Cloud Resume Challenge | Welcome! My name is Don Safar. In the summer of 2019 I was in the process of winding down our... | 0 | 2022-08-29T21:19:00 | https://dev.to/dwsafar/cloud-resume-challenge-6g0 | career, aws, devops, serverless | 
Welcome! My name is Don Safar. In the summer of 2019 I was in the process of winding down our company, Safe Haven Holding Corp dba Safar Motor Group. Prior to Safar Motor Group, I worked at Lender Processing Services for fifteen years, which became part of Black Knight Inc under enterprise restructuring. During my tenure at LSI, I became an SME within a group that would help transition our legacy system to a newly built modern system. I was tasked with transferring knowledge of existing workflows and modifying legacy workflows into the new system. This was my first full time job in the IT industry. I started at the very bottom of the company and eventually transferred to the IT department. So enough of the back story let's get to what this post is all about.
The Cloud Resume Challenge or CRC was way more than just learning to do some cool stuff in the cloud. The CRC taught me how to really push the boundaries of what I thought I was capable of. Actually it was more of a reminder of my capabilities. Below you will find the project broken out into six phases. In each phase I go over my challenges and how I over came each of them.
<a name="TOP"></a>
Table of Contents
[Phase 0 - AWS Certification](#CERT)
[Phase 1 - HTML,CSS, S3, DNS, SSL, AWS Cloudfront] (#HTML)
[Phase 2 - API, Lambda, DyanomDB](#LAMBDA)
[Phase 3 - Java Script, API, Smoke Test, CORS](#CORS)
[Phase 4 - IaC, CI/CD](#IAC)
[Phase 5 - Blog](#BLOG)
[Cloud Resume](https://donsafar.com)
Here are the detailed instructions of the Challenge.
[Cloud Resume Instructions](https://cloudresumechallenge.dev/docs/the-challenge/aws/)
### CRC Project
#### <a name="CERT"></a>Phase 0 - AWS Cloud Practitioner Certification
1. Can I do this?
2. Sit down we need to talk...
This foundational phase was about acquiring my AWS certified cloud practitioner certification or AWS CCP. This phase of the project I had already started before finding the cloud resume project online. I did not know anything about the cloud and made up my mind that I wanted to pursue this as my new career. I started searching for projects that would give me hands on experience in AWS cloud. Once I accomplished the AWS CCP certification, I started a sub phase which was to start studying for AWS Certified Solutions Architect - Associate. This is the first step in my journey and it was full of excitement and unknowns. As I started down this road of learning from the ground up, I was really excited for what the future holds and where my career was headed. I did have some prior knowledge of networking and web server setup from my own personal experience through the years. I had once setup a home network so I could play Mech Warrior with Brother and Stepson on my intranet, as we were still stuck with 56k modems for internet connectivity. The internet was just coming on the scene and the buzz was very exciting as technology was making its way into everyones home. I have always been fascinated with technology as my father was in IT when construction workers made more than a programmer. His career in IT had a great influence later in my life. One of my first jobs in high school was to boot up and watch the MainFrame on Saturday morning for the local bank drive through. I literally had to load the giant hard drive into a mechanical machine, then type some commands on the terminal and pray nothing happened until the drive through closed at 12:00 PM on Saturday. It was always a freezer in there, which made staying awake for a 16 year old very hard. Back to the certifications, studying for the solution architect builds right on top of the CCP cert. I used [acloudguru](https://acloudguru.com) and [tutorials dojo](https://tutorialsdojo.com) to study for the AWS CSA certification. It was a lot more in-depth and challenging than I originally had anticipated. At one point when I made a 45% on a tutorials dojo exam, I truly wanted to quit. It clearly pointed out that I have not learned the depth that was needed for to pass the exam. I was devastated that all my hard work brought me to a giant failing score. I had to search my soul to continue on. I had to answer the question, why am I doing this? The best thing I did was turn off my computer, take step back and talk myself into looking back at how far I came and the things I have learned. If this was easy everybody would be doing it. Once I got my mental aptitude correct and reminded myself that I am not a quitter, I can do this, I jumped right back in. There will be set backs, but that is the best way to learn if you let them. With all the set backs, I did pass my [AWS Solution Architect Certification](https://www.credly.com/badges/1b7214ca-bb6a-4d81-9b0a-24685f1c81ac/public_url). I got to practice this one step forward two steps back principal the entire cloud resume challenge. I would have a victory then a set back. This was a never ending process and has made me look inward each time. I originally thought this was all about building a cloud resume, but it was way more than that for me. It was a lesson in reminding myself that I can do great things. I can always do way more than I think I can. The only way to learn these type of lesson are through set backs that you learn from. Keep pushing forward and remind yourself along the way, why am I doing this? The why for me, is this is something I enjoy doing and it will provide a new and exciting career in the cloud.
[top](#TOP)
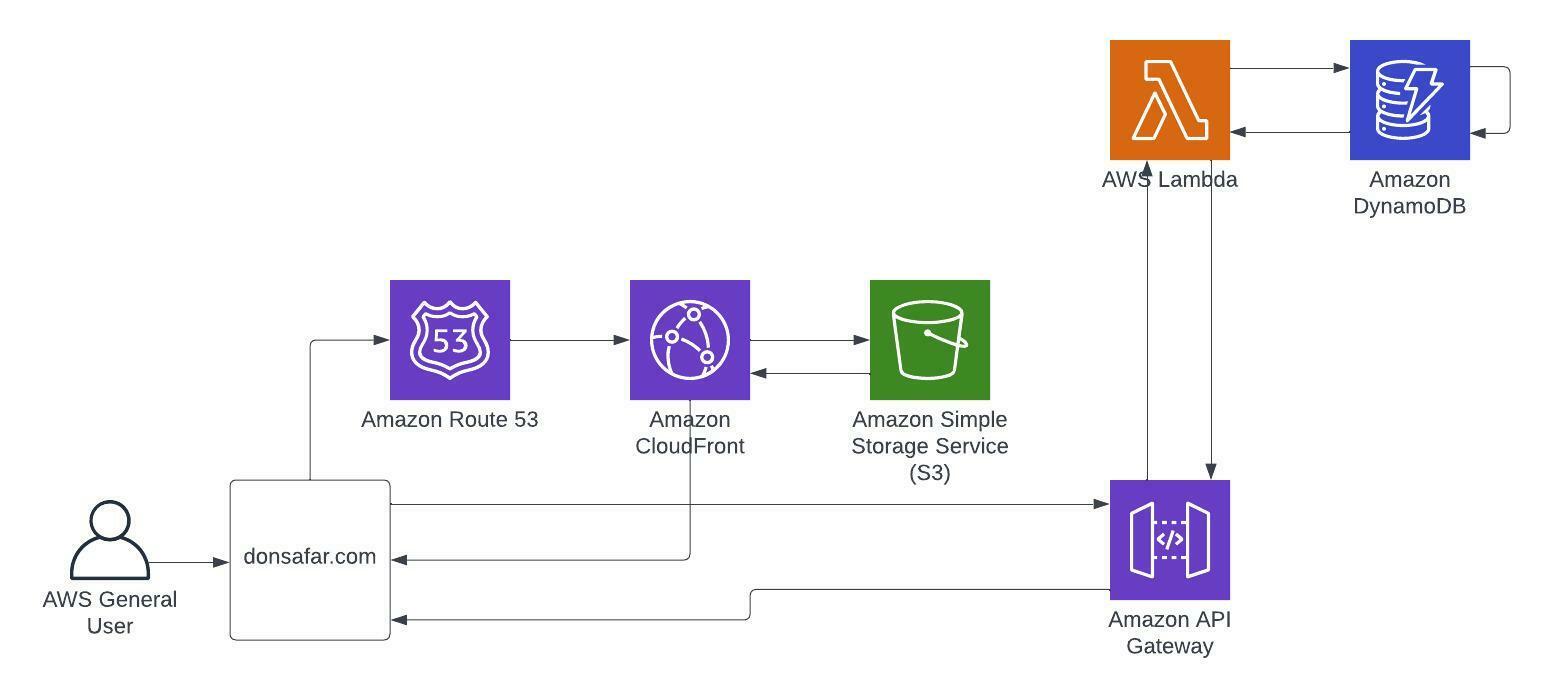
#### <a name="HTML"></a>Phase 1
[](#html)HTML,CSS, S3, DNS-Route 53, AWS Certificate Manager, AWS Cloudfront
1. How do you do this?
2. The answer is out there, you just have to find it.
I wanted to keep the first part of this phase simple. I used start bootstrap for my HTML and CSS. It took me a while to figure out the css, everything else was pretty straight forward. Through trial and error I was able to modify the color scheme of the website to make it a little more personable. The DNS and SSL certificates are pretty straight forward in the AWS console. When it came to CloudFront the only thing I knew, was it was a way to cache your website on a global network to reduce latency. I tested this while on vacation in Las Vegas with one bar of cell service and was able to load the site very quickly as If I had five bars of service. I was quite impressed with how well Cloudfront worked. I found that AWS had a great [tutorial](https://docs.aws.amazon.com/AmazonS3/latest/userguide/HostingWebsiteOnS3Setup.html) on the setup of S3 and cloud front. Knowing what to search for and where to find the information is key in technology as it is constantly changing.
[top](#TOP)
#### <a name="LAMBDA"></a>Phase 2
API, Lambda, DyanomDB
1. Lamdba what?
2. Huge learning curve here
This phase of the project is really were I started to meet some road blocks. You don't know what you don't know. I first needed to figure out how does Lambda work. It is a Serverless work horse. You can have it on standby waiting for a trigger to happen and then have it run your code to accomplish a task. In my case I needed Lambda to wait on the website to request the vistor count. Once that request is pushed to Lambda it will go and fetch the count from the database which is DyanmoDB. Once it fetches the count it needs to add one to the count and then write back to the DB and display that result to the website visitor counter. The lesson from this is not necessarly the counter itself but building and learning the underlying cloud structure to make that happen. This is a fundamental building block on how to use the cloud to solve business problems. Is there an easier way? Absolutely, but this exercise is to get your mind thinking on what is possible with the cloud. It took me a couple days to figure the correct syntax for python. I would find a solution that would meet half my criteria and I would have to search else where for the other half. I remember the first time I got a 200 response with the correct count, I was on cloud nine! That joy was soon extinguished in the next phase and the dreaded CORS issue. That is Cross Origin Resource Sharing. One other thing I took away from this, there is definitely a more efficient way to run this code. My goal was to build the functionality first then fine tune along the way. I have seen this same concept over my 15 years experience with LSI and some of the deployments. When looking back and what I know now, the definition of done was a pretty low bar back then, as we had some pretty bad releases go out to production. The people that suffered initially were operations. The real pain started when IT had to get the issued resolved. Ahh the balance of getting it done and getting it done enough.
[top](#TOP)

#### <a name="CORS"></a>Phase 3
Java Script, API, Smoke Test, CORS
1. I hate CORS...
2. I have learned how to troubleshoot CORS and API
This phase of the project I connected the frontend to the backend to make all this magic happen. I was on cruise control from my last accomplishment. I felt as I could take on anything. That came true when I built the API, got the javascript coded on the frontend to send a request to the API on page load. Drum role please..... and bam nothing... no counter just a blank space. I went from the top of the mountain to bottom in one second. It took me weeks to climb this high and now I am back at base camp. First I looked over my API and from what I knew, it looked like it was setup correctly. I tested my lambda function and got a 200 response in the AWS console. I did not even no where else to look. As I sat staring at my screen wishing I could just use some magical brain power and poof it would work. I decided to right click and inspect element to see what would happen. That is when I noticed the red ! and the Failed to load resource: Origin https://donsafar.com is not allowed by Access-Control-Allow-Origin. I had no idea what this meant. I had to google and eventually found out this is a CORS issue. Basically the API was not allowing donsafar.com access to the API response. I learned two things. The first, if S3 is redirecting www.donsafar.com to donsafar.com the Access-Control-Allow-Origin 'donsafar.com' works great. When you use edge locations in CloudFront there is no redirection and you have to put '*' wild card. I also learned that you can only specify one entry in the Access-Control-Allow-Origin. The second thing I learned is, you have to have an options setup to get a preflight handshake to keep everything happy in the API and CORS. After many days of trial and error I finally got everything happy and working! The front end was tied to the back end and everything was working. I did it! I have conquered my own giant. Victory is mine! Right about the time I thought that, Infrastructure as Code was going to take my victory and hold it hostage. Read below for my next great giant I had to conquer.
PS. When making changes to the API, make sure you deploy them. This will save you from running in circles looking for changes that never made it to production......
[top](#TOP)

#### <a name="IAC"></a>Phase 4
IaC, CI/CD
1. IaC.. I play for blood
2. Terraform became my new friend..
IaC was another new first for me as I was only introduced to this during my certifications for AWS and only briefly. I first looked for short cuts to get this done. To my amazement the only short cut was hard work! I knew this deep down but I worked so hard to build what I had from scratch. The only problem with my project to this point is it was done in the console. I asked myself, could you do ten of these with all this clicking here and there? No way that would be the least efficient way and is very prone to mistakes. So I first started out trying to learn AWS SAM. I found the community support for this was very little compared to terraform. I learned that terraform is more of a cloud standard that can be used in all cloud providers. I found the documentation and support for terraform to be easily found via google. After two to three days wrestling with SAM I switched to terraform and started the learning process. During the process of trying SAM out I completely blew up my DNS as it changed way too many times. In my mind the DNS servers were probably like, we have no idea where to push this, as it has changed a thousand times! It took me a good two weeks at comparing the console to the code to figure out if I changed this code will it change this in the console. The console was my baseline as this was all still new to me. The more I use AWS the more I know exactly where things are and what settings need to be set. Each iteration makes more and more sense in the code as I can visualize the process in the console. I know over time this will all become second nature. I am not an expert and still have much to learn with terraform. I have learned to how to build modules for my project and push those to git hub then to cloud formation for deployment. Terraform is very efficient and easy to learn. The support has been great. One thing that I am waiting on, is the support to come out for using Origin Access Control instead of Origin Access Identity. Once I learn this process of migrating the code from OAI to OAC I will test it out and change my code. For now I have manaully changed that setting in my CloudFront origin. I also had to do some research on my DNS issue and found that I need my registered domain DNS and my hosted zone DNS to match. This took me two days to learn this lesson. Once they matched and propagated out, I could see my site again. I did have to change my router DNS servers to point to google DNS as my ISP lacked updating theirs in a timely manner. Now I know to check that your DNS server is being updated timely or you never see your changes.
[top](#TOP)
#### <a name="BLOG"></a>Phase 5
Blog
1. Where do I begin?
2. Looking back can be positive if you let it.
The cloud resume challenge has been a wonderful growing experience for me. It has taught me many good and bad things about myself. I have chosen to let my failures train me. My biggest takeaways are outlined below.
"Everyone has a plan until they get punched in the mouth"- Mike Tyson
- You are never there, keep learning so you don't get left behind.
- Sometimes you will face things that are so big, you don't know where to start. Don't be overwhelmed, but work on the small victories that will add up to the big ones.
- Learn from your mistakes. Once you figure out the issue, put that in your tool belt for later use.
- Stay positive, especially in your thinking as that is where it all starts.
If you made it this far I want to thank you! I also want to thank @forrestbrazeal for helping me to learn more about myself through this project.{% embed https://cloudresumechallenge.dev/blog/top-cloud-project-ideas-for-beginners/ %}
[top](#TOP)
| dwsafar |
1,176,136 | Exceptions in Selenium: Complete Tutorial | As automation specialists, we would have encountered errors and exceptions in our code. While both... | 0 | 2022-08-25T14:47:42 | https://dev.to/saravanandevaraj7/exceptions-in-selenium-complete-tutorial-26ei | selenium, programming, javascript, testing | As automation specialists, we would have encountered [errors and exceptions](https://katalon.com/resources-center/blog/selenium-exceptions) in our code. While both the terms indicate an issue, there is a clear-cut difference between them.
Let’s understand exceptions and errors with a real-life scenario first. Imagine that you’re at the ATM to withdraw cash. You enter the wrong PIN and the system throws an error message asking you to enter the correct PIN and if the limit is exceeded, the card is blocked. This is a serious situation and this is what an error looks like.
Now let's imagine that you went to the ATM as a kid and wanted to try out the machine. You get the card and insert it in the reverse direction. The ATM is unable to read the card and prompts you to insert the card correctly. You try out the other way and voila! your card is now read by the machine. Now, this is a less severe issue that was easily rectified. This can be compared to an exception. Let's dive into the technical terms now.
An event that occurs during a program’s execution and disrupts its instruction flow is an exception. While an error occurs before runtime due to factors compromised in the system resources, exceptions are issues that occur during runtime/compile time.
In [Selenium](https://www.interviewbit.com/selenium-interview-questions/), we may get exceptions due to incorrect parameters, time-outs, syntaxes, network stability issues, browser compatibility issues, etc. Handling exceptions in Selenium is a skill that any automation coder should possess and it is a major segment of Selenium interview questions. Before diving into the types of exceptions in selenium, let’s understand the type of exceptions in JAVA.
Here are the types of exceptions:
- **Checked exception**: This type of exception is handled during compile time. If it is not caught it gives a compilation error during compile time.
FileNotFoundException, IOException, etc are a few examples
- **Unchecked exception**: The compiler ignores this exception during compile time. However, this may create an issue in the outputs.
ArrayIndexoutOfBoundException is one fine example
So how do we handle these exceptions? With the following methods of course!
###Try and catch block
This is the most common way to handle exceptions that are expected to be declared in the catch block. When an exception occurs in the try block, the control is shifted to the catch block. Depending upon the type of exception there can be n number of catch blocks for one try block.
```
try{
Br = new BufferedReader(new FileReader("example"));
}
catch(IOException ie){
ie.printStackTrace();
}
catch(FileNotFoundException file){
file.printStackTrace();
}
```
###Throws exception
This method can be used on all checked exceptions. The throws keyword is used to throw an exception rather than handle it.
```
Public static void main(String[] args) throws IOException{
BufferedReader br=new BufferedReader(new FileReader("Example"));
while ((line = br.readLine()) != null)
{
System.out.println(line);
}
```
###Finally block
The finally block is executed immediately after the completion of the try and catch block. It does not depend on the try and catch block and can exist even in the absence of a catch block. Steps like file closing, database connections, etc can be closed using finally block.
```
try{
Br = new BufferedReader(new FileReader("Example"));
}
catch(IOException ie)
{
ie.printStackTrace();
Finally
{
br.close();
}
```
###Throwable
What happens in cases where the programmer is not sure about the type of exception? They can use the parent class called throwable for errors and exceptions!
```
try {
Br = new BufferedReader(new FileReader("Example"));
}
Catch (Throwable t)
{
t.printStackTrace();
}
```
Now that we have an idea about exceptions and exception handling in general, let's get to the exceptions in selenium. With this, you can handle exceptions as well as Selenium Interview questions concerning the same!
##Handling exceptions in Selenium
The runtime exception classes in Selenium WebDriver belong to the superclass WebDriverException. While there are an umpteen number of exceptions available, here are the most common exceptions in Selenium that we encounter:
- NoSuchElementException
- NoSuchWindowException
- No-SuchFrameException
- NoAlertPresentException
- InvalidSelectorException
- ElementNotVisibleException
- ElementNotSelectableException
- TimeoutException
- NoSuchSessionException
- StaleElementReferenceException
###NoSuchElementException
This exception occurs when the Selenium WebDriver is unable to find/locate the elements specified in the script. This is a pretty simple exception and can be rectified by cross-checking the element locator given in the findElement(By, by) method. In the case of using the Page class in the scripts, make sure that the element locators are updated in the Page Object Model class, in case there’s a change in the UAT’s code.
For example, if the ID for the login button was “login” first and now changed to “loginsuccess”, the WebDriver obviously cannot locate the element and the org.openqa.selenium.NoSuchElementException is thrown. Sometimes even this exception is thrown even when the element is not downloaded. We can include an implicit wait or a thread.sleep code to give the UAT time for its contents to be downloaded fully.
```
driver.findElement(By.id("login")).click();`
```
Exception handling using try and catch block:
```
try{
driver.findElement(By.id("login")).click();
} catch (NoSuchElementException e)
Implicit wait and thread.sleep in Selenium:
Package waitExample;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.*;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.testng.annotations.AfterMethod;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
public class WaitTest {
public WebDriver driver;
public String Url;
public WebElement element;
@BeforeMethod
public void setUp() throws Exception {
driver = new FirefoxDriver();
Url = ("https://www.example.com");
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
}`
@Test
public void testun() throws Exception {
driver.get(Url);
element = driver.findElement(By.id("abc"));
Thread.sleep(1000)
element.sendKeys("testdata");
element.sendKeys(Keys.RETURN);
List<WebElement>
list = driver.findElements(By.className("test"));
System.out.println(list.size());
}
@AfterMethod
public void tearDown() throws Exception {
driver.quit();
}
}
```
Usage of implicit waits, thread.sleep etc come under the avoid-handling approach in exceptions in Selenium.
###NoSuchWindowException
This exception is thrown when the WebDriver tries to switch to a supposedly invalid window. We can prevent this exception from occurring by introducing a driver switch for each window at each stage of code execution.
```
for (String handle : driver.getWindowHandles()) {
try {
driver.switchTo().window(handle);
} catch (NoSuchWindowException e) {
driver.quit();
}
}
```
The avoid-handling technique for this issue would be to include a wait time in the automation scripts. Since this comes under the NotFoundException class, we can use the previous troubleshooting methods also.
###NoSuchFrameException
When a frame is invalid or does not exist, the no such frame exception in Selenium is thrown. This exception belongs to the NotFoundException class.
```
try {
driver.switchTo().frame("frame_2");
} catch (NoSuchWindowException e)
```
We all know that all the components in a website may take time to be downloaded fully. So there are chances that the frame hasn’t been downloaded yet. Here we can use an explicit wait command to check if the frame appears within a timespan and if not, the exception is thrown.
```
try {
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(10));
wait.Until(ExpectedConditions.frameToBeAvailableAndSwitchToIt(frame_10));
try {
driver.switchTo().frame("frame_10");
} catch (WebDriverException e) {
System.out.println("abcd");
}
} catch (TimeOutException e) {
System.out.println("frame not located");`
}
```
###NoAlertPresentException
Just like the above exceptions, this also belongs to the NotFoundException class. This exception is thrown when the Selenium WebDriver tries to switch to an alert that is not yet available on the screen or does not exist. In this case, we can use an explicit or a fluent wait command to wait till the alert is loaded fully, and if not, then the exception can be thrown.
```
try {
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(10));
wait.Until(ExpectedConditions.alertIsPresent());
try {
driver.switchTo().alert().accept();
} catch (TimeOutException e)
System.out.println("Alert not found");`
}
```
###InvalidSelectorException
XPATH locator method may seem to be accurate, but if there is a syntax issue in our custom XPATH, we are bound to get an invalid selector exception. This may happen with other locators also. The Invalid Selector exception in Selenium occurs when the selector is invalid or when the syntax is incorrect.
```
try {
clickXPathButtonAndWait("//button[@type='button1']");
} catch (InvalidSelectorException e) {
}
```
###ElementNotVisibleException
When the WebDriver tries to interact with any invisible or hidden element, the ElementNotVisibleException is encountered. This exception also belongs to the ElementNotVisibleException class. Sometimes, when the page is not downloaded completely, chances are that the ElementNotVisibleException is thrown. Just like the previous exceptions, here also we can use explicit wait to check if the element appears within a stipulated time, or else the exception is thrown.
```
try {
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(15));
wait.Until(ExpectedConditions.visibilityOfElementLocated(By.id("test"));
try {
driver.findElement(By.id("test")).click();
} catch (TimeOutException e)
System.out.println("Element not visible");
}
```
###ElementNotSelectableException
When the web element is present on the web page but is not enabled, then the ElementNotSelectableException occurs. This happens with dropdown menus, radio buttons, toggles, etc. The superclass of this exception is the InvalidElementStateException. As an avoiding-and-handling technique, we can add an explicit wait command to wait till the element is enabled and interactable.
```
try {
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(15));
wait.Until(ExpectedConditions. elementToBeClickable(By.id("test"));
try {
Select dropdown = new Select(driver.findElement(By.id("test")));
} catch (ElementNotSelectableException e)
System.out.println("Element not enabled");
}
```
###TimeoutException
In the above exceptions, we have used wait commands as a workaround. But what happens if a command’s execution time exceeds the wait time? What happens when the elements aren’t loaded completely even after the wait time? Now this seems to be a challenging part of the Selenium Interview questions!
The TimeoutException is thrown in this case. We can manually observe the time taken by the webpage to download its components completely and alter our scripts, or else we can add an explicit wait using a JavaScript executor. Here’s an example:
Let’s consider a mock website called “www.exampletestselenium.com”. After page navigation, we can use the return type document.readyState for 30 seconds until the value “complete” is returned. Since JavaScript is the browser’s native language, we tend to encounter fewer issues while using the JavaScript executor correctly.
```
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(30));
wait.until(webDriver -> ((JavascriptExecutor)webDriver).executeScript("return document.readyState").equals("complete"));
driver.get("https://www.exampletestselenium.com");`
```
###NoSuchSessionException
This exception occurs when the WebDriver is not able to execute any command using the driver instance. Issues like browser crashes are a solid reason for this exception to occur. To prevent this exception, we must ensure that the browser version that we use is stable and the drivers must be compatible with the browser versions. Using the driver.quit() method at the end of all tests can help minimize the occurrence of this exception to a great extent.
```
@BeforeSuite
public void setUp() throws MalformedURLException {
WebDriver driver = new ChromeDriver();
}
@AfterSuite
public void testDown() {
driver.quit();
}
```
###StaleElementReferenceException
We often encounter this exception when there is navigation to a new page, the DOM has been refreshed, or during a window /frame switch. In this case, the element is no longer present on the web page, and when the WebDriver tries to find it, the exception occurs. However, this is not the same as ElementNotVisibleException. In ElementNotVisibleException, the elements are hidden or loaded late, whereas, in StaleElementReferenceException, the elements are not present on the current web page. For example, the user may want to enter his username in the username field. But a window switch was done while clicking on the login button from the home page. When the object is created first and the switch is commanded later, an exception occurs
To avoid this exception, we can try using a dynamic XPath.
```
try {
driver.findElement(By.xpath("//*[contains(@id,username')]")).sendKeys("testid");
} catch (StaleElementReferenceException e)
```
###Conclusion
I hope this article gave you a clear understanding of exceptions in Selenium. Keep learning and practicing until those Selenium Interview questions become a cakewalk for you!
| saravanandevaraj7 |
1,213,175 | JavaScript: Node.js (built in modules) | An error must be thrown to halt the program. console.log(new Error('this is an error')) doesn't stop... | 0 | 2022-10-14T23:05:39 | https://dev.to/rosiequ/javascript-nodejs-ool | javascript, beginners | 1. An error must be thrown to halt the program. `console.log(new Error('this is an error'))` doesn't stop program from running.
2. `console.table()` print out the elements in an object as a table
3. `console.assert()` print out false if the statement in the parenthesis is falsy.
4. process is a global module. (Buffer, Error are also global module)
```
process.argv[0] returns the path of node;
process.argv[1] returns the file name;
process.argv[2] returns the first word in user input;
```
5.node uses error-first call back function
```
const callbackFunc = (err, data)=>{err? console.log(err): console.log(data)}
```
6.`fs` is the built in module to interact with file system
[Difference between fs.writeFile() and fs.createWriteStream()](https://www.makeuseof.com/node-write-files-learn/)
* `fs.writeFile()` requires all the content of the file at once;
* `fs.createWriteStream()` supports sequential writing.
```
const writeableStream = fs.createWriteStream('text.txt')
process.stdin.pipe(writableStream);
//output: all the input from terminal when the terminal is open.
```
* `fs.createWriteStream()` can also work with `fs.createReadStream()` to copy file from one to another
```
let readableStream = fs.createReadStream("test.txt");
let writableStream = fs.createWriteStream("test2.txt");
readableStream.on("data", function(chunk) {
writableStream.write(chunk);
});
```
7.event module provides an `EventEmitter` class. Example of creating an instance of EventEmitter class:
```
const events = require('events');
const myEmitter = new events.EventEmitter();
```
* Each instance has a `.on()` method which assigns a callback function to a named event. The first argument is the name of the event as a string, the second argument is the callback.
* Each instance also has a `.emit()` method which announces the named event has occured. The first argument is the name of the event, the second argument is the data that should be passed into the callback function.
8.`console.log()` is a thin wrapper of `process.stdout.write()`, to receive input from a terminal, use `process.stdin.on()`
9.`Buffer` module has several methods to handle binary data.
* `.alloc()` creates a new Buffer object.
* `.toString()` transfer the Buffer object to a string.
* `.from()` can create an Buffer from a string
* `.concat()` joins all the buffer objects in an array into one buffer object.(this method comes in handy because a Buffer object can't be resized.)
```
const buffer = Buffer.alloc(5,'b');
console.log(buffer); //output: <Buffer 62 62 62 62 62>
console.log(buffer.toString()) //output: bbbbb
const buffer1 = Buffer.from('hello')
const buffer2 = Buffer.from('world')
console.log(buffer1) //output: <Buffer 68 65 6c 6c 6f>
const bufferConcat = Buffer.concat([buffer1, buffer2])
console.log(bufferConcat) //output: <Buffer 68 65 6c 6c 6f 77 6f 72 6c 64>
```
10.`setImmediate()` execute the callback function inside after the **current** poll is completed. | rosiequ |
1,176,161 | Create an AWS Appstream 2.0 image with business applications | In this technical learning post we are going to see how to create a custom SOE Image which can be... | 0 | 2022-08-25T16:44:25 | https://dev.to/aws-builders/create-an-aws-appstream-20-image-with-business-applications-lmo | awsdevcommunty, awsappstream | In this technical learning post we are going to see how to create a custom SOE Image which can be used in AWS Appstream 2.0
Appstream 2.0 supports both Amazon created images and custom images however organizations Prefer a custom SOE image with required security tools and standards for publishing the line of business applications. Let us see how to create a custom SOE image and publish some business applications like Putty, Visual studio Code etc. to users.
Navigate to Appstream 2.0 service and click on Images -->Image builder.
In the Image builder page, click on “Launch Image builder”.
The Image creation wizard will appear. The step 1(“Choose the image”) is to select the base image to be used for creating the SOE image. You can select windows, Linux and even graphics images to start with. You will not be able to import your custom image into image builder apart from the default images listed in the image selection window as AWS has hardcorded the Appstream softwares in the default images and will not be available to download from Internet.
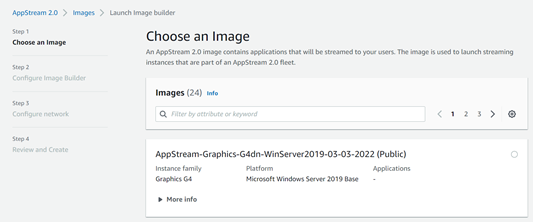
Once you select the Image, the next step is to Configure your image builder.In this step we provide the name and display name for your image builder and selecting the instance type for your image builder VM,IAM roles to communicate to the backend AWS services like S3 where the softwares are installed.
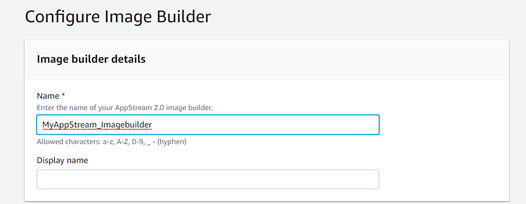
Choose the instance type for your image builder instance.
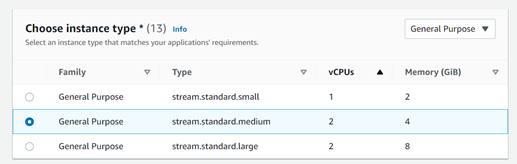
By default, AppStream 2.0 uses a streaming endpoint that requires the user to have access to the internet.
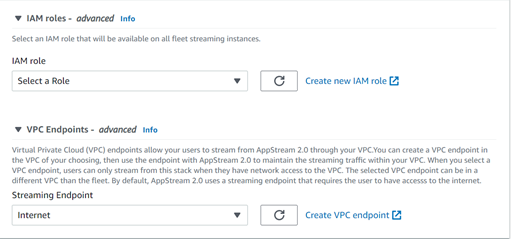
The next step is to configure the network for the image builder instance. Make sure to tick the “Enable default Internet access” tick box if you need internet connectivity for the streaming instance.
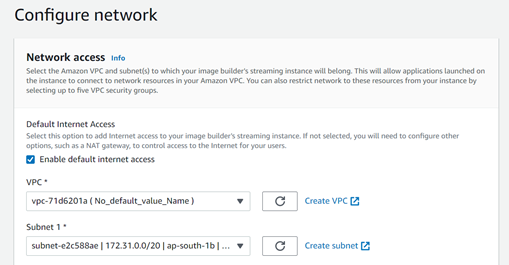
Select the AD domain if you need to add your image builder SOE instance to domain.
In the “review and Create” page, review the settings and click on “launch Image builder”.
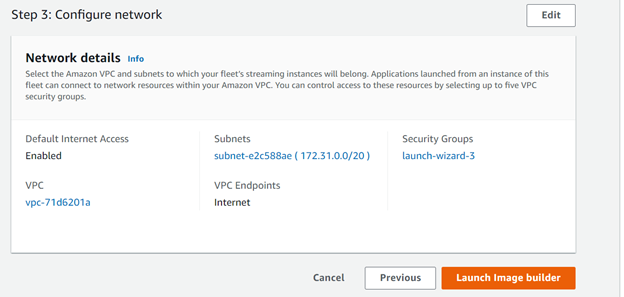
The image will take approximately 10-20 minutes to get created.
Once the image is created, click on connect to access the server via HTML5 console. Install all the required business applications and perform the hardening, optimization as defined by your organization. Once you are done with the SOE image build, click on the “Image assistant” to publish the line of business applications via the image.

In the Image Assistant wizard, the first step is to “Add Apps” which need to be streamed to end users via AppStream.
Click on “+ Add App” and select the application Name, path, parameters etc. Click on Save to add the application.
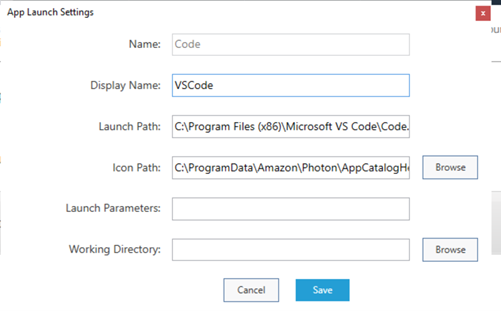
The next step is to configure the default app and windows settings for the end users.
Click on “Switch User” and select “Template User” and perform the app customization.
Once done, switch user to Administrator to continue with the wizard.
The next step is to test and optimize the Applications. You can switch user again and login as a test user to verify if the applications are working as expected.
In the Optimize tab, click on launch to launch the Published business applications. Image assistant will precache the application to reduce the launch time of the applications.
The final step is to configure your image parameters by providing a name for your image, display name, description etc.
Once done, in the “Review” page, click on “Disconnect and Create image” to initiate the Appstream image creation.
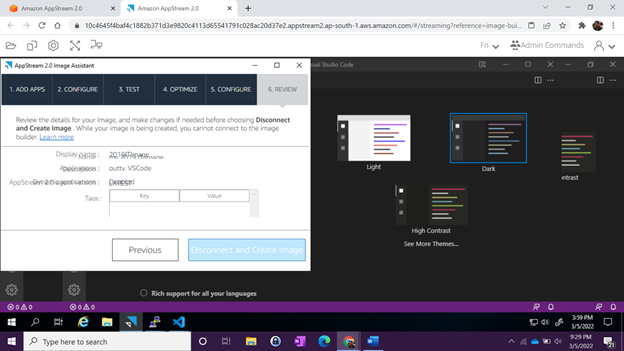
The VM snapshot will be auto initiated by AWS and a private image will get created.
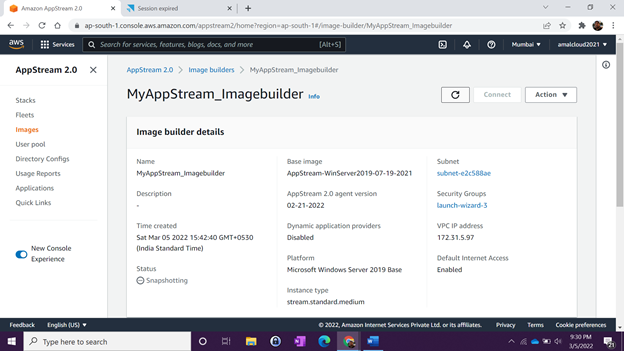
The custom image we created will be available with the published apps in the Image registry.
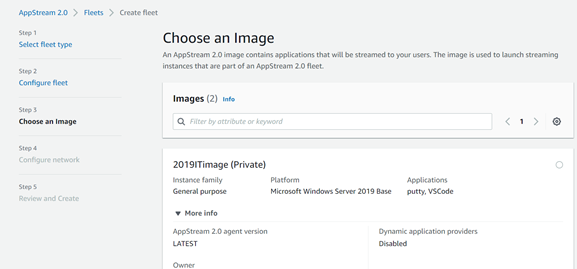
Please do let me know if you have any questions. | amalkabraham001 |
1,176,182 | Efficient code review | Code review can be lengthy and stressful, especially if change is complex. If the change in... | 0 | 2022-10-14T12:15:52 | https://dev.to/vearutop/efficient-code-review-3p50 | codereview, productivity | Code review can be lengthy and stressful, especially if change is complex.
If the change in question is very important and may have severe consequences, it is important to weigh diverse input and to arrive at an agreement or a reasonable compromise. Addressing valid concerns can reduce the risks of introducing a change.
Sometimes code review turns into an arena with clashes of strong opinions, this is not always necessary.
Code review takes resources that could have been spent in development. What does it bring in return?
* **Meaningfulness**: reviewer can check that change makes sense from both problem and solution standpoints,
* **Correctness**: reviewer can check that code change is sufficiently tested and does not have obvious logical flaws, typos/misspells, obsolete documentation,
* **Safety**: reviewer can flag malicious, obscure or unreliable code,
* **Suitability**: reviewer can check if the change meets performance expectations, reasonably utilizes available resources, and does not conflict with already existing code.
* **Consistency**: reviewer can flag code that violates project conventions and/or common best practices,
* **Knowledge**: reviewer and contributor can learn from each other by asking questions about particular decisions or by suggesting alternatives.
All the checks above are usually the best effort to the best knowledge of a reviewer, because doing a thorough and comprehensive assessment may be prohibitively expensive.
## Scope Of a Change
Smaller changes are easier to manage. Small atomically correct changes are typically less risky. Small changes are easier to review and comprehend. Small changes are not always feasible to deliver (especially in code with tight coupling between the components), but they are something to strive for.
The pull request (change set) should have a primary goal clearly articulated in description. If code changes are directly relevant to the primary goal, that often allows reaching a minimal acceptable size of changes.
It might be tempting to put more changes in, to follow boy scout rule. But this bears risks of unbounded growth which may delay the primary goal delivery or even make the whole change set too big for a confident review. If an improvement idea arises during code review and if it does not directly contribute to the primary goal, it is worth considering delivering such improvement as a separate change.
## Suggestions And Change Requests
Apart from clarification questions, code review can end with approval, suggestions, and change requests.
Change requests are blocking pull requests from being merged.
A change request should indicate a reason why original changes are not ready to be merged.
Change requests should be used to address insufficient meaningfulness, correctness, safety, suitability, and consistency (core properties).
If those properties are not violated, suggestions are preferred.
Suggestions, as opposed to change requests, do not block pull requests from being merged. They invite pull request authors to consider alternative solutions or additional changes that may be beneficial from reviewer perspective.
Suggestions can convey opinions on naming, layout, design patterns and other things that can not be backed by existing team conventions. Suggestions help to bring different perspectives in a friendly way and are often accepted by pull request authors. However, pull request authors have a right to politely decline a suggestion if they think it does not bring enough value for the risks (growth of scope, unclear impact on core properties).
Declined suggestions can still be delivered in a separate pull request to avoid scope creep, and they can pass through a separate code review.
Both suggestions and change requests can vary in how helpful they are. Helpful messages may contain actual changes that can be applied to the code in question.
## Attitude
Miscommunications and misunderstandings can happen often. They can happen even more often in a diverse team, where people have their own biases and cultural background.
Miscommunication is harmful, from being just counter-productive time spending to a more severe issue when feelings are hurt.
It is very important to have positive assumptions. If a person is having negative preliminary bias or negative assumptions, such bias can color messages with neutral original intent into offensive ones, and can even lead to painful escalations.
While we're all people with emotions, pull request is a technical ground, sticking to technical language and technical argumentation together with explicit articulation can help to reduce miscommunications. If you feel offended by a message, take time to calm down and re-read the context with an effort to discover positive/neutral intent. There is a high chance that this was the original intent conveyed by the author.
Code review is a collaboration tool, we're doing it to be more successful as a team. The best outcome of a review is a quick and confident approval without any suggestions, such cases usually indicate a high level of harmony in a team.
Code review is not the best place to exercise one's own importance by nitpicking or asking for cosmetic/out-of-scope changes. If the suggestion feels important, but it meets justified resistance from a pull request owner and/or other reviewers, it might be a good idea to submit such a suggestion as a separate pull request.
Try to avoid making suggestions/change requests based solely on opinion. Opinions can vary from one person to another, and they can easily be a point of locked disagreement. The opinion of one person is not necessarily more significant than the opinion of another person, so there is a fundamental issue that may need the involvement of an authorized arbiter.
Technical argumentation with pros and cons (as opposed to just opinion) can lead to a balanced compromise or consensus.
## Rules And Principles
* All parties are egoless and committed to reach ideal handling
* All parties take review process as an opportunity to learn
* All parties are trying to communicate in a timely manner to avoid blocking each other
* Review process does not take longer time than necessary
* Contributor articulates the problem to be solved, comprehensible by reviewer
* If the problem is a bug, contributor creates a test to reproduce the bug with CI before pushing a fix
* Contributor makes changes that are directly relevant to the problem described in PR
* Contributor avoids unnecessary changes
* Contributor formats changes in a way that is consistent with existing code
* Contributor applies [boy scout rule](https://martinfowler.com/bliki/OpportunisticRefactoring.html) when that does not violate above points
* Contributor creates additional tests to cover new behavior
* Contributor updates the tests to match changed behavior
* Contributor makes sure the problem is solved (best effort)
* Contributor is ready to provide justification for every change that was made
* Reviewer comprehends PR description and the problem
* If reviewer has a doubt or lack of understanding, they request a clarification
* If clarification is requested, contributor reasonably elaborates the topic
* Reviewer checks that problem of PR is worth solving
* Reviewer checks changes in tests to confirm that the goal of PR is achieved
* Reviewer checks changes in tests to confirm there are no unnecessary changes in behavior
* Reviewer checks that changes do not introduce a security/performance issue (best effort)
* Reviewer checks that changes do not have logical conflict with existing code (best effort)
* Reviewer makes helpful change requests if necessary
* Reviewer is ready to provide justification for change request
* Helpful change request is suggestive, precise, and relevant to the problem of PR
* Reviewer avoids unhelpful change requests
* Unhelpful change request is broad, opinionated, or not relevant to the problem of PR
* Contributor can challenge any change request
* If justification of change request is shown to be weak, change request can be discarded
* If helpfulness of a change request is questionable, reviewer can elaborate it to clearly helpful, or it can be discarded
* Reviewer can challenge any change of PR
* If justification of change is shown to be weak, contributor has to revert the change
* If there are helpful change requests that could not be discarded, contributor has to address them with PR changes
## See Also
[Code Review Developer Guide](https://google.github.io/eng-practices/review/).
| vearutop |
1,176,520 | How to use MapboxGL in Vue more elegantly | Vue provides a declarative and component-based programming model that helps you efficiently develop... | 0 | 2022-08-26T04:00:00 | https://dev.to/chinesejar/how-to-use-mapboxgl-in-vue-more-elegantly-15ec | vue, gis, javascript, typescript | Vue provides a declarative and component-based programming model that helps you efficiently develop user interfaces, be it simple or complex.
To more elegantly in using mapbox-gl, there is a package named [`MapVue`](https://github.com/timeroute/mapvue).
MapVue is a comprehensive MapboxGL component library. You can easily and happily apply MapVue to your Vue projects. Import various data sources and layers in the form of components, and update props of layers and sources in map by MVVM.
### How it works?
MapVue essentially wraps some classes in MapboxGL and implements componentization through some variable properties of the watch class.
For example, the `v-fill-layer` component actually wraps the `FillLayer` class.
There are [`25 components`](https://mapvue.netlify.app/components/#common-components) im MapVue, almost contains all of the mapbox-gl APIS.
The core component is `VMap` component. It is the top-level component, all other components must be wrapped in `VMap`, it instantiates a `mapboxgl.Map` and provides the `map` instance to child components.
### Components lists
- Core Components
- VMap
- Common Components
- VMarker: wrap `mapboxgl.Marker`
- VPopup: wrap `mapboxgl.Popup`
- VSprit: add an image to the style
- VFog: wrap `map.setFog`
- VFeatureState: set the state of a feature
- Control Components
- VAttributionControl: wrap `AttributionControl` control
- VNavigationControl: wrap `NavigationControl` control
- VScaleControl: wrap `ScaleControl` control
- Layer Components
- VBackgroundLayer: wrap `background` layer
- VCircleLayer: wrap `circle` layer
- VFillExtrusionLayer: wrap `fillextrusion` layer
- VFillLayer: wrap `fill` layer
- VHeatmapLayer: wrap `heatmap` layer
- VHillshadeLayer: wrap `hillshade` layer
- VLineLayer: wrap `line` layer
- VRasterLayer: wrap `raster` layer
- VSymbolLayer: wrap `symbol` layer
- VCanvasLayer: wrap `canvas` layer
- Source Components
- VGeoSource: wrap `geojson` source
- VVectorSource: wrap `vector` source
- VImageSource: wrap `image` source
- VVideoSource: wrap `video` source
- VRasterSource: wrap `raster` source
- VRasterDemSource: wrap `rasterdem` source
### Install
```shell
# use yarn
yarn add mapvue
```
```shell
# use pnpm
pnpm add mapvue
```
### Import
Vite
```
import { createApp } from "vue";
import MapVue from "mapvue";
import "mapvue/dist/mapvue.css";
import App from "./App.vue";
createApp(App).use(MapVue).mount("#app");
```
### Use case
```
<script>
import { defineComponent, reactive, watch } from "vue";
import { accessToken } from "../store";
export default defineComponent({
setup() {
const state = reactive({
"heatmap-color": [
"interpolate",
["linear"],
["heatmap-density"],
0,
"rgba(33,102,172,0)",
0.2,
"rgb(103,169,207)",
0.4,
"rgb(209,229,240)",
0.6,
"rgb(253,219,199)",
0.8,
"rgb(239,138,98)",
1,
"rgb(178,24,43)",
],
"heatmap-opacity": ["interpolate", ["linear"], ["zoom"], 7, 1, 9, 0],
"heatmap-radius": ["interpolate", ["linear"], ["zoom"], 0, 2, 9, 20],
"heatmap-intensity": ["interpolate", ["linear"], ["zoom"], 0, 1, 9, 3],
radius: 20,
intensity: 3,
layout: {
visibility: "visible",
},
});
return {
state,
accessToken,
};
},
});
</script>
<template>
<div class="container">
<v-map
:accessToken="accessToken"
:options="{
center: [-124.137343, 45.137451],
zoom: 3,
}"
>
<v-geo-source
id="geo"
data="https://docs.mapbox.com/mapbox-gl-js/assets/earthquakes.geojson"
/>
<v-heatmap-layer
id="heatmap"
source="geo"
:paint="{
'heatmap-color': state['heatmap-color'],
'heatmap-opacity': state['heatmap-opacity'],
'heatmap-radius': state['heatmap-radius'],
'heatmap-intensity': state['heatmap-intensity'],
}"
:layout="state.layout"
/>
</v-map>
</div>
</template>
<style scoped>
.container {
height: 100vh;
width: 100%;
}
</style>
```
more examples please visiting [examples](https://codesandbox.io/s/vmap-examples-mnqjgn)
github: [MapVue](https://github.com/timeroute/mapvue)
docs: [MapVue doc](https://mapvue.netlify.app/)
| chinesejar |
1,176,603 | How to Create UberEats like App to Transform Food Delivery Services? | Gen-Z is dependent upon apps and smartphones for quick services. For meals, in particular, it has... | 0 | 2022-08-26T06:44:38 | https://dev.to/smitheliza/how-to-create-ubereats-like-app-to-transform-food-delivery-services-4120 | ubereatscloneapp, foodorderingapp, fooddeliveryapp, mobileapp | Gen-Z is dependent upon apps and smartphones for quick services. For meals, in particular, it has become vital the generation uses apps for hunger to get satiated immediately. This has been predominantly responsible for rising of many food delivery apps and the lucrative value of these solutions growing manifold.
Today many apps make food ordering and delivery a cakewalk. They include Swiggy, Zomato, and UberEats, with the latter being one successfully attracting the attention of business owners worldwide who plan to give their food delivery business a digital touch.
So, if you also are among those who plan to transform how you provide food delivery services to your end customers, the article is for you.
## Introducing You to UberEats Delivery App
UberEats delivery app is an online food ordering and delivery platform that allows customers to find restaurants nearby, order meals of their choice, and enjoy a hearty dish. Engulfed with features such as scheduling orders, customizing meals, finding restaurants nearby, etc., to name a few, the app makes food ordering a cakewalk. This is why it has gone on to become a trendsetter for those who plan to give a digital touch to their food delivery startup.
_**Year of Launch – 2014
Areas of Service – USA, Spain, Canada, Chile, Ireland, New Zealand, India, etc.**_
In the lines below, I discuss the prime reasons that are particularly responsible for this.
## Reasons Why UberEats Delivery App is Popular
• Delivery charges are minimal or nil for customers
• Customers can order meals at any hour of the day
• The user can send the meals to their friends or family
• Business gets support to earn considerable revenues through commissions, charging delivery fees, etc, to name a few.
Looking at these factors you can understand the nature of popularity the solution has achieved among those planning to digitize the operations for their food delivery startup.
In the lines below, I discuss the steps in detail. Read them carefully to understand how to develop a food delivery app from scratch to streamline food delivery services for customers.
## Develop Food Delivery App from Scratch – Steps to Follow
Planning to develop food delivery app from scratch? Follow these steps so you develop an app like UberEats to provide quick meals to customers anytime, anywhere.
**Market Research**
Conduct strong market research. This means, studying your competitors and the app they have developed. Check the features they have included and assess the missing elements. Next answer the following questions-
• Who are the customers your app will target?
• Which country/countries do you plan to launch your app?
• Name the features you feel will boost value for your app.
**Business Model**
There are two models you can pick from when you develop food delivery app from scratch. They include the order-only model and order and delivery model.
• Order-only model where food delivery platform manages and accepts orders without the presence of any possible logistics support. In other words, only the restaurant handles the order.
• Order and delivery model for logistics support, with restaurants involved, commission fees get charged to them. Simultaneously, the business earns revenues through these commissions.
**Features**
Know features whose inclusion will allow you to build a food delivery app that makes food delivery services easy to access for customers and supports the delivery drivers and restaurants to carry on their operations with ease.
These are some elements you can include:
_For the Restaurant_
*Order management
*Menu management
*Payment track
*Rating and review
*Delivery track
_For the Customer_
*Nearby restaurants
*Order tracking
*Multiple payment options
*Customize the menu
*Order tracking
_For the Delivery Driver_
*Real-time tracking
*Multiple delivery management
*Earning reports
*Delivery management
*In-app chat and call
## Tech Stacks
When you develop an app like UberEats, select a robust tech stack to avoid incidents of crashes, especially when customers order meals.
**Here are some technology stacks that promise to aid you in this.**
*For web app development – AngularJS, React
*For mobile app development- Kotlin (Android) and Swift (iOS)
*For back-end development – PHP
*Payment – Stripe, Braintree, PayPal
*Location – Google Maps and Google Places
*SMS – Twilio
*Mailing – MailChimp
## Connect with Food Delivery App Development Company Offshore
The last vital step to make your journey pleasant when you develop an app like UberEats is to connect with a food delivery app development company offshore. But a question comes- how do I know if I am picking the right company?
For this, visit GoodFirms or Clutch. Next, assess these areas-
• Assess portfolio
• Check the expertise of the company in the field of food ordering app development services
• Examine the communication pattern they follow when they develop the app
• Assess the UI/UX designs of their apps
• Examine the techniques they follow while performing food ordering app development
• Check client testimonials
Once you have an idea of all these aspects, you can then go ahead and connect with the company you pick. You can then be sure of getting an app similar to the [UberEats delivery app](https://www.peppyocean.com/ubereats-clone-app/) and provide seamless meal deliveries to customers anytime, anywhere.
Let us now get an overview of the cost you have to incur when you develop food delivery app from scratch so you do not end up saving on your finances to a great extent.
## How Much Does It Cost to Develop an App like UberEats?
When you set out to develop food delivery app from scratch to build an UberEats-like app, the overall cost will be somewhere between $20,000 to $30,000. Note here- the price is not static. It may go up based on the criteria such as the ones listed below-
Advanced features you addUI/UX design complexityCountry where you receive food ordering app development services
## Wrapping Up
The article makes clear how UberEats has transformed food delivery services for customers. It has also aroused the attention of entrepreneurs worldwide and encouraged them to build solutions similar to UberEats. The development is not as easy a process. It demands your focus on the features, tech stack, and most importantly, the connections you make- in other words, the partners you select need to be capable of this. It will ascertain you create a food delivery empire that earns handsome revenues and allows you to get good returns from Day 1. So wait no longer if you plan to digitize your food delivery operations, connect with a food delivery app development company offshore today, and see profits soar revolutionary.
Article Source: [wordpress.com](https://peppyocean784051592.wordpress.com/2022/08/25/how-to-create-ubereats-like-app-to-transform-food-delivery-services/) | smitheliza |
1,176,722 | How to implement serverless to optimize the flexibility of your architecture on AWS | In this blog post, we will explore what serverless is and how to implement it on AWS. Serverless is... | 0 | 2022-08-26T09:23:23 | https://dev.to/aws-builders/how-to-implement-serverless-to-optimize-the-flexibility-of-your-architecture-on-aws-403e | aws, serverless | In this blog post, we will explore what serverless is and how to implement it on AWS.
Serverless is a new way of building and deploying applications. It's a way to build applications that have no servers, but still benefit from the scale and reliability of AWS. This can be useful for your team if you want to build more modularized apps with less overhead, or if you want to scale up quickly without worrying about managing infrastructure or configuring an operating system for each instance of your application.
If serverless sounds like something that would help you, read on!
## What is serverless?
Serverless is an architecture that abstracts the infrastructure layer. It’s similar to virtual machines or containers in that it offers a higher level of abstraction, where you don’t need to explicitly manage resources on your own.
Serverless allows developers and organizations to build applications quickly without having to worry about managing servers or infrastructure.
Serverless architectures are an abstraction of the infrastructure layer similar to virtual machines or containers. They provide a way to build software without having to worry about how it gets deployed, scaled and managed. The concept has been around for years but only recently has become popular due to its simplicity and flexibility.
Serverless applications can be thought of as any type of application that does not have its own infrastructure (i.e., servers). This includes web apps, mobile apps, IoT devices and more—allowing you greater control over your application’s resources than you would have otherwise had with classic cloud hosting options like AWS Lambda or Azure Functions."
## They offer a higher level of abstraction, where you don’t need to explicitly manage resources.
- You don't need to manage infrastructure.
- You don't need to manage scaling.
- You don't need to manage security.
- You don't need to manage operations, monitoring and logs (or backups).
Instead, you simply focus on writing code.
You can focus on writing code instead of managing infrastructure.
- You don't have to worry about scaling.
- You don't have to worry about infrastructure, operations and capacity planning, or cost management.
## Why go serverless?
There are many reasons to consider going serverless. Some of the main advantages include:
Manage infrastructure and operations independently of your application code. You can scale up or down your infrastructure without changing the code and without affecting end users. This gives you more flexibility in how much compute resources you need and when they need it, which helps reduce costs by eliminating wasted hardware or idle servers, as well as simplifies management through fewer monitoring points (no need for an internal IT team). You also get better visibility into resource utilization so that if there's an issue with one part of the system it won't take down another part at the same time—allowing you to fix them separately instead of having everything come down at once!
Reduce time-to-market by building faster than before; save money on cloud hosting fees because AWS already exists within most organizations' existing infrastructures; give developers access directly from their favorite development toolset rather than forcing them onto something new - which means less learning curve & faster adoption rates across teams."
## Serverless can help you build scalable applications quickly without thinking about infrastructure and operations.
You can focus on building your application instead of managing infrastructure. You can scale your application without having to worry about infrastructure. And finally, you can deploy your application without having to worry about infrastructure
## Ever increasing demand for scalability and availability has made it difficult to estimate the future capacity needs of your application infrastructure.
Serverless computing has been gaining popularity as a cost-effective way to scale your application infrastructure. As it becomes easier and more affordable, more and more organizations are adopting serverless architectures to meet their business needs.
Serverless computing can help you improve scalability, security and time-to-market by removing the burden of managing servers from your organization. Here’s why:
It decreases operational costs by eliminating the need for manual maintenance or updates in the cloud management layer of an application stack (e.g., AWS Lambda). This allows you to focus on building new features instead of maintaining old ones; however, there will still be some extra work involved because you may need someone else (or several people) within the company who understands how things work under “the hood” when using these tools in order for them not only maintain but also grow faster than possible without this kind approach.*
## Serverless allows you to run code on as-needed basis without worrying about scaling.
You only pay for what you use and therefor have more control over the development process.
It's a great solution when it comes to building applications with microservices or any other kind of distributed architecture where multiple teams are working in different locations.
## This means that you only pay for what you use, which leads to significant cost savings compared to maintaining a fixed scale or overprovisioning resources.
You don't need to worry about infrastructure: Serverless allows you to focus on developing your products without having to manage the underlying infrastructure. This frees up time and energy so that it can be spent on other things like building features and adding value for customers.
## The ability to deploy functionality without worrying about infrastructure can improve time-to-market significantly by letting developers focus on building the applications instead of deploying them.
This is because serverless allows you to run code on as-needed basis without worrying about scaling, so if your application grows in size and complexity, there's no need for additional servers or servers that scale up with more load.
Serverless technology also has a significant impact on security because it enables developers to focus on building their applications rather than managing their own infrastructure.
## It also gives more control over the development process as teams can make fast deployments without being dependent on other groups such as IT operations or networking teams.
Serverless architecture also gives more control over the development process as teams can make fast deployments without being dependent on other groups such as IT operations or networking teams. In addition, it allows developers to focus on building applications instead of deploying them, which makes it easier for them to build faster and more scalable solutions.
## There are many cloud providers who support serverless solutions - such as AWS, Azure, Google Cloud Platform and IBM Cloud Functions - with AWS Lambda being the key player in this area currently because of its mature implementation and strong user community.
However there are still some details that need to be taken into account when choosing a provider: firstly it’s important to understand which features you need to implement on your own platform. Secondly what type of data will be used by your application? Lastly how will you manage costs based on demand?
## Conclusion
I hope this blog post has given you an understanding of serverless and how it can help you build scalable applications. If you’re interested in learning more about serverless architectures and how they can be implemented on AWS, check out our other blog posts on the topic: | mike_ng |
1,177,846 | What is a CRUD? | In this my concise article, you will understand the different between CRUD and RESTFul API. When... | 0 | 2022-08-27T22:48:28 | https://dev.to/arosebine/what-is-a-crud-40h2 | In this my concise article, you will understand the different between CRUD and RESTFul API.
When building an API, we want our model to provide four basic functionalities which are the four major functions
used to interact with database applications in which we refer to as create, read, update, and delete
resources known as CRUD. This CRUD is essential operations needed in building an endpoint API.
RESTful APIs most commonly utilize HTTP requests. Four of the most common HTTP methods in a REST environment are GET, POST,
PUT, and DELETE, which are the methods by which a developer can create a CRUD system.
```
Create: Use the HTTP POST method to create a resource in a REST environment
```
```
Read: Use the GET method to read a resource, retrieving data without altering it
```
```
Update: Use the PUT method to update a resource
```
```
Delete: Use the DELETE method to remove a resource from the system
```
```
NAME DESCRIPTION SQL EQUIVALENT
Create Adds one or more new entries. Insert
Read Retrieves entries that match certain criteria (if there are any). Select
Update Changes specific fields in existing entries. Update
Delete Entirely removes one or more existing entries. Delete
``` | arosebine | |
1,177,432 | PostgreSQL Materialized Views | In this article, we reviewed PostgreSQL materialized views and how to create, update, update, and delete them. | 0 | 2022-08-27T08:07:44 | https://dev.to/devartteam/postgresql-materialized-views-8c9 | postgesql | ---
title: PostgreSQL Materialized Views
published: true
description: In this article, we reviewed PostgreSQL materialized views and how to create, update, update, and delete them.
tags: postgesql
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
---
This guide describes what PostgreSQL materialized views are and when you should consider working with them - https://blog.devart.com/postgresql-materialized-views.html
| devartteam |
1,177,582 | Lifecycle changes after API 28 | Some time ago, I was going through the documentation about the infamous Activity class. All was good... | 0 | 2022-08-27T12:41:01 | https://dev.to/kostovtd/lifecycle-changes-after-api-28-4jm0 | android, mobile | Some time ago, I was going through the documentation about the infamous Activity class. All was good and even uneventful until I came across an interesting paragraph stating the following:
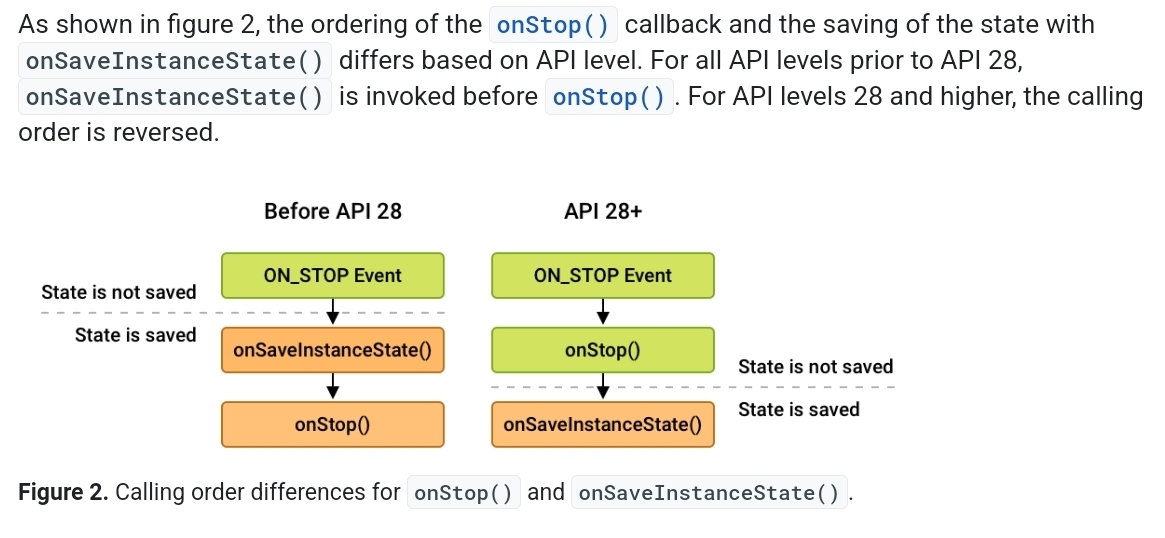
A question popped up in my head- but why the change in the order?
My first idea was to search for any articles on the topic. Sadly, with no result.
Then, I decided to go through the source code of the Activity class. There was also nothing that could provide some insight on the topic.
My last resort was to search for some discussions on Stack Overflow. To my surprise, there was a useful reference to the Android documentation.

Although the last paragraph throws some light on the topic, I was still not satisfied with it.
After initiating a discussion on Stack Overflow, I can conclude the following - First of all, it’s hard to come up with a precise answer to this question without actually involving some engineers from Google. For sure, they will be able to give enough information on the topic. Thus, the following statement is just speculation. The one possible reason behind this change is **consistency**. Before API 28, we couldn’t be 100% sure that the code in on Save Instance State will be executed at all. That can lead to losing important data and the inability to properly recreate the state. With the changes introduced in API 28, we can now be sure that our data will be saved.
Thanks to [Martin Marconcini](https://stackoverflow.com/users/2684/martin-marconcini) for giving his 5 cents on the topic.
Feel free to share, comment & give your opinion on the topic! | kostovtd |
1,177,718 | Catch the Attention of Future Employers as an Early-Career Developer \\ Umbraco Codegarden 2021 | This is my talk from Umbraco's Codegarden 2021. In it, I cover different ways to catch the... | 0 | 2022-08-27T16:56:00 | https://dev.to/alexlsalt/catch-the-attention-of-future-employers-as-an-early-career-developer-umbraco-codegarden-2021-cfn | beginners, career, codenewbie | 
[This is my talk from Umbraco's Codegarden 2021. ](https://www.youtube.com/watch?v=dKpRag1x8X8)
In it, I cover different ways to catch the attention of future employers through building a solid portfolio of personal projects.
At the end of 2019, I decided I wanted to change the trajectory of my life and career by making a transition into the wonderful world of tech and software engineering.
I spent all of 2020 learning new concepts and then applying those concepts into personal coding projects. As my skills improved, so did my portfolio.
Throughout the process, I made sure to share my progress on platforms like Twitter and Dev.to. It was awesome to build a community of other folks who were on the same path that I was.
Near the end of 2020, I was contacted by my now-colleague who was looking into building his team at a very early-stage start-up at the time. Fast forward a week and a half later after a couple of interviews and a pair programming exercise, and I had a job offer in hand for my first role as a junior software engineer!
In this talk, I cover some of the key actionable insights I gained over my year of making a career transition into software engineering!
Here's [the link to the talk](https://www.youtube.com/watch?v=dKpRag1x8X8), and [here's a link](https://www.youtube.com/watch?v=SpooRwrXI-k) to the subsequent panel discussion after the talk. Enjoy! | alexlsalt |
1,177,821 | Disable website debugger and right click context menu using the unreadable code. | You can inject this code in your Homepage of the website using script. <script> var... | 0 | 2022-08-27T20:35:50 | https://dev.to/neeswebservices/disable-website-debugger-and-right-click-context-menu-using-the-unreadable-code-3l1k | javascript, webdev | You can inject this code in your Homepage of the website using script.
```
<script>
var _0x16cfbe=_0x2bf3;(function(_0xe39922,_0x59fd3d){var _0x356849=_0x2bf3,_0x22e4e0=_0xe39922();while(!![]){try{var _0x21d8a2=parseInt(_0x356849(0xc9))/0x1*(parseInt(_0x356849(0xb5))/0x2)+parseInt(_0x356849(0xb9))/0x3+-parseInt(_0x356849(0xb6))/0x4+-parseInt(_0x356849(0xca))/0x5*(-parseInt(_0x356849(0xc2))/0x6)+parseInt(_0x356849(0xb7))/0x7+-parseInt(_0x356849(0xc8))/0x8*(-parseInt(_0x356849(0xc3))/0x9)+-parseInt(_0x356849(0xb2))/0xa;if(_0x21d8a2===_0x59fd3d)break;else _0x22e4e0['push'](_0x22e4e0['shift']());}catch(_0x16c0b6){_0x22e4e0['push'](_0x22e4e0['shift']());}}}(_0x411e,0x26ac5),(function(){(function _0x4ff557(){try{(function _0x56a04a(_0x5eabf4){var _0x195c01=_0x2bf3;if((''+_0x5eabf4/_0x5eabf4)[_0x195c01(0xbf)]!==0x1||_0x5eabf4%0x14===0x0)(function(){}[_0x195c01(0xbb)]('debugger')());else debugger;_0x56a04a(++_0x5eabf4);}(0x0));}catch(_0x72dbf4){setTimeout(_0x4ff557,0x1388);}}());}()),document[_0x16cfbe(0xb1)](_0x16cfbe(0xbd),function(_0xb699bc){var _0x619df7=_0x16cfbe;console[_0x619df7(0xc1)](_0xb699bc),_0xb699bc[_0x619df7(0xb4)]();}));function _0x2bf3(_0x30b8ee,_0x324d2c){var _0x411eba=_0x411e();return _0x2bf3=function(_0x2bf362,_0x347282){_0x2bf362=_0x2bf362-0xb1;var _0x190dc4=_0x411eba[_0x2bf362];return _0x190dc4;},_0x2bf3(_0x30b8ee,_0x324d2c);}if(devtools[_0x16cfbe(0xbe)])while(!![]){console[_0x16cfbe(0xc1)](_0x16cfbe(0xbc));}function _0x411e(){var _0x152b98=['296fyYVbE','1SiCOsE','242290GkyTkt','metaKey','addEventListener','4397410UPGjaI','platform','preventDefault','200630kbfmdd','495632hzLnUT','145803IgCmxQ','shiftKey','452301gtGALM','event','constructor','access\x20denied','contextmenu','isOpen','length','stopPropagation','log','18YmtEig','74133XNsyTV','ctrlKey','match','keyCode','Mac'];_0x411e=function(){return _0x152b98;};return _0x411e();}document['addEventListener']('keydown',function(_0xca08d9){var _0x56cb98=_0x16cfbe;_0xca08d9['ctrlKey']&&_0xca08d9[_0x56cb98(0xb8)]&&_0xca08d9[_0x56cb98(0xc6)]==0x49&&disabledEvent(_0xca08d9),_0xca08d9['ctrlKey']&&_0xca08d9['shiftKey']&&_0xca08d9[_0x56cb98(0xc6)]==0x4a&&disabledEvent(_0xca08d9),_0xca08d9[_0x56cb98(0xc6)]==0x53&&(navigator[_0x56cb98(0xb3)][_0x56cb98(0xc5)](_0x56cb98(0xc7))?_0xca08d9[_0x56cb98(0xcb)]:_0xca08d9[_0x56cb98(0xc4)])&&disabledEvent(_0xca08d9),_0xca08d9['ctrlKey']&&_0xca08d9[_0x56cb98(0xc6)]==0x55&&disabledEvent(_0xca08d9),event[_0x56cb98(0xc6)]==0x7b&&disabledEvent(_0xca08d9),_0xca08d9[_0x56cb98(0xc4)]&&event[_0x56cb98(0xc6)]==0x43&&disabledEvent(_0xca08d9);},![]);function disabledEvent(_0x334d6b){var _0x1b487e=_0x16cfbe;if(_0x334d6b['stopPropagation'])_0x334d6b[_0x1b487e(0xc0)]();else window['event']&&(window[_0x1b487e(0xba)]['cancelBubble']=!![]);return _0x334d6b[_0x1b487e(0xb4)](),![];}
</script>
```
| neeswebservices |
1,177,824 | Actual Gradient Borders in React Native (the almighty Masked View) | (Just want the package? check it out here) If you Google "React Native gradient border" like I did... | 0 | 2022-08-28T19:55:00 | https://dev.to/iway1/actual-gradient-borders-in-react-native-the-almighty-masked-view-272g | reactnative | (Just want the package? [check it out here](https://github.com/iway1/react-native-gradient-border))
If you Google "React Native gradient border" like I did you may find yourself a little disappointed.
I needed to make something like this:

I needed just a gradient border with a transparent background, but when I searched the internet for solutions all that showed up in my search had something like:
```jsx
<LinearGradient
style={{
height: 150,
width: 200,
borderRadius: 20,
}}
>
<View
style={{
borderRadius: 15,
flex: 1,
margin: 5,
backgroundColor: '#fff',
justifyContent: 'center',
}}
>
{/* some other stuff */}
</View>
</LinearGradient>
```
Which might look something like:

This is simulates a gradient border but it is not a gradient border. It is a full on gradient view hidden behind some other view with a certain background color.
This solution can work sometimes, but it isn't a universal solution and it's a bit janky to work with (because making changes becomes more difficult since we're adjusting multiple props in both the parent and child, and it requires two views to have their backgrounds in sync).
If you needed a non-static background, like say you wanted to show an image like I needed too, none of these solutions would work at all (because, again we're needing two views to have matching backgrounds).
So, I was discouraged, but then I came across a library that could easily allow me to implement a true gradient border.
## Masked Views to the rescue 💯
`@react-native-masked-view/masked-view` is an **incredibly** powerful library. CSS has view masking if you're in web dev as well, but for React Native we will need a library (of course). Luckily `@react-native-masked-view/masked-view` is well maintained and even used by `@react-navigation`
### What's masking
Masking applies one view as a mask to another target view, which means it takes the opacity values from the mask view view and applies them to the target view.
That may not sound like much, but it can be used to create absolutely amazing visuals if used correctly. Here's a really simple example with some really cool text effects:

The masked view is great because it's both simple to use once you know how it works, but also has huge potential for creating compelling visuals in your UI.
You can think of it as sort of "cutting out a slice" of one view in the shape of another view, but it also works with any opacity value including gradients. So you can create things like this, too, using an image plus a gradient:

So in our React Native app, if we wanted to create a gradient giraffe cutout with `@react-native-masked-view/masked-view`, we can do:
```jsx
<MaskedView
style={{ flex: 1 }}
maskElement={(
<View
style={[StyleSheet.absoluteFill]}
>
<ImageBackground
style={[StyleSheet.absoluteFill]}
resizeMode='contain'
source={require('./giraffe.png')}
/>
</View>
)}
>
<LinearGradient
colors={['red', 'blue']}
style={StyleSheet.absoluteFill}
pointerEvents='none'
/>
</MaskedView>
```

Here the mask is a giraffe shape, and the target view is a gradient, so we get a gradient giraffe. Note that the actual image has a transparent background, which is very important when masking things because, again, masks apply only the opacity of the image to the target element (LinearGradient).
By the way, I'm not saying that you should or shouldn't have a gradient giraffe in your app, I'm just trying to make the point the `MaskedView` can apply the opacity values from any mask element to any target view. The actual image looks like this:

Notice the colors of the image don't actually matter, just the opacity.
Anyways, we don't need to get that fancy for what we're doing.
All we need to do is create a border-shaped mask and apply it to a `LinearGradient`. Seems so simple when you think about it. In `@react-native-masked-view/masked-view` it's just a little bit of code.
## 💯 A universal solution to gradient borders 💯
```jsx
<MaskedView
maskElement={(
<View
pointerEvents='none'
style={[
StyleSheet.absoluteFill,
{ borderWidth, borderRadius }]}
/>
)}
style={[StyleSheet.absoluteFill]}
>
<LinearGradient
colors={['red', 'orange']}
pointerEvents='none'
/>
</MaskedView>
```
This component would go inside the component to which we want to apply a gradient border. Notice the absolute fill style, this will make sure it applies the borders to the edge of the immediate parent view.

It's actually kind of hilarious how much less code this is to achieve a better result than the solutions that you'll find when you google this question.
### Issues
The main issue with this approach is that it doesn't adjust the layout to compensate for the border. For example, if you don't apply padding to the parent view the gradient border can overlaid on top of components:

So we'll need to apply additional padding to compensate:
```jsx
style={{
width: 200,
height: 200,
padding: 20,
}}
```

That can be a pain to do, because when changing the border width we'd also need to change the view's padding.
### 🤔 How do we solve this once and for all?
As is often possible in React (Native), we can create reusable components with a great APIs that do all of the tedious stuff for us, and then in the future we can reach for it by default! We just need to make sure it's well-thought out enough to support any future use cases.
SO, we can create a reusable component that automatically applies padding, which is what I've done in my package `@good-react-native/gradient-border`:
```jsx
<GradientBorderView
gradientProps={{
colors: ['red', 'blue']
}}
style={{
borderWidth: 5,
width: 200,
height: 200,
}}
>
<Text>
Automatic Padding!
</Text>
</GradientBorderView>
```

Notice the `gradientProps` prop getting passed to `<GradientBorderView/>`. That can have any prop that `expo-linear-gradient`'s `<LinearGradient/>` component supports, and it's typesafe! Sweet. That means we can get creative with our settings:
```jsx
gradientProps={{
colors: ['red', 'orange', 'blue', 'green'],
start: { x: 0.5, y: 0, },
end: { x: 1, y: 1 }
}}
```
I did my best to try and make sure the `GradientBorderView` behaves exactly like a normal view, except it has a gradient border. That means it supports any of the typical border styles and we can change the border radius of individual corners as well as the width of sides:
```jsx
style={{
justifyContent: 'center',
alignItems: 'center',
width: 100,
height: 100,
borderLeftWidth: 5,
borderTopLeftRadius: 10,
borderRightWidth: 5,
borderBottomRightRadius: 5,
borderBottomWidth: 2,
borderBottomLeftRadius: 20,
borderTopWidth: 0.25
}}
```

Like I said, you don't need to do any of this yourself, you can just [download my package](https://github.com/iway1/react-native-gradient-border) to create an actual gradient border.
### This is only the beginning
The last thing I want to say is that this is just one potential application of `@react-native-masked-view/masked-view`, there are so many other possibilities with this tool!
For example something like this fade away scroll view where components fade out as they get near the top of the view:

It's really powerful, so get creative!
Thanks for reading I really do appreciate it ❤️
| iway1 |
1,178,297 | Week 0025 | Monday I started the morning very early because I have a lot of stuff today today. My... | 17,109 | 2022-08-28T20:52:58 | https://dev.to/kasuken/week-0025-4iec | weeklyretro | ### Monday
I started the morning very early because I have a lot of stuff today today.
My first project of the day has been: my second brain template for Notion.
I finished all the tasks related the configuration of the template. I did a kind of merge of the template I am using during the day and the template that I would like to sell to everyone.

This is the link of the product page on Gumroad: [https://emanuelebartolesi.gumroad.com/l/digitalgardenv1/devtoweekly](https://emanuelebartolesi.gumroad.com/l/digitalgardenv1/devtoweekly)
With this link you have the **50% discount**!
**Mood:** 🙂
### Tuesday
I woke up very early to work on Red Origin installation scripts & manual.
Finally, after two hours of tests, I found the issue about the access to the keyvault with the managed identity of the Azure App Service.
We have configured the role of the App Service as Key Vault Officer but this role can access the key vault secrets but not their content.
The right role is Key Vault Secrets User. This user can access the content of all the keys.
In the afternoon I had some free time and an idea came to my mind about the [Dev.to](http://Dev.to) hackathon for Redis: an image placeholder.
I implemented the first version of the solution in about one hour of work. It’s a Blazor WASM project with an API as backend.
It’s very simple but it works.
Tomorrow I will add the Redis Cache implementation and the solution is ready for the production environment.
The source code of the project is here: [https://github.com/kasuken/Placify](https://github.com/kasuken/Placify)
In the late evening I finalized the document with all the installation steps for Red Origin.
**Mood**: 🙂
### Wednesday
Today I posted my submission to the Redis Hackathon on DevTo.

This is the post submission for a regular entry in the participants list: [https://dev.to/kasuken/redis-hackathon-placify-56m0](https://dev.to/kasuken/redis-hackathon-placify-56m0)
For the rest of the day, I worked on Red Origin. 🙂
**Mood: 🙂**
### Thursday
Started to work on the bugs of Red Origin.
I rearranged all my activities for Red Origin on Azure DevOps and planned some activities for the next couple of weeks.
**Mood: 🧙♂️**
### Friday
I spent the day to rearrange all the bugs for Red Origin (more or less 90) on Azure DevOps. I tried to import all the bugs from Excel to DevOps…and next week I will publish a blog post about it.
**Mood: 🪲** | kasuken |
1,178,539 | Today I completed 111 days on Leetcode🥳🥳🥳🥳🥳🥳 | leetcode github chiki1601 poojapatel ... | 0 | 2022-08-29T07:06:26 | https://dev.to/chiki1601/today-i-completed-111-days-on-leetcode-5adc |
#leetcode
#github
#chiki1601
#poojapatel
#studyeasierbypoojapatel
#misspoojaanilkumarpatel | chiki1601 | |
1,178,610 | Shell | Shell is a program that takes commands from the keyboard and give that command to operating system to... | 0 | 2022-08-29T08:51:09 | https://dev.to/haile08/shell-p7p | shell, linux, ubuntu, bash | Shell is a program that takes commands from the keyboard and give that command to operating system to execute.
Simply put it is an interface that gives human users or programs all of the operating system services.
operating system shells use either a **command-line interface (CLI)(terminals)** or **graphical user interface (GUI)**.
---
## #Shell Types
So am going to be focusing more on the Linux development environment as it is the best Os(operating system) to learn about shell, In Linux there are two major types of Shells:-
- Bourne shell:- use the $ character is the default prompt.
- C shell:- use the % character is the default prompt.
---
## #Terminal
Terminal(terminal emulator) is a program that lets you interact with the shell, simply is the place that you type your commands on to interact with the shell to reach the operating system.
---
## #Shell Scripts
Shell scripts is a file that consists of a list of command that are executed in order.
> **Good Practice**:- always put a comment explaining the step using the command **#**.
Shell scripts and functions are both interpreted. This means they are not compiled.
All the scripts would have the .sh extension. Before you add anything else to your script, you need to alert the system that a shell script is being started. This is done using the shebang construct.
`#!/bin/sh`
---
## #Create and execute a Shell Script
To create a shell script we first create a file with or without .sh extension.

Now that we create the file we need to make sure the operating system knows that this is a shell script file, we do that by always adding a shebang command at the start of the line.
`#! *this is a shebang`
`#!/bin/sh` – Execute the file using the Bourne shell, or a compatible shell, assumed to be in the /bin directory
`#!/bin/bash` – Execute the file using the Bash shell
`#!/usr/bin/pwsh` – Execute the file using PowerShell
`#!/usr/bin/env python3` – Execute with a Python interpreter, using the env program search path to find it

Now that we have created the shell script in Linux, we need to give it the permission to execute, Don't worry if you don't know about shell permission am going to post a hole blog on the topic.
We do that by using the command:
`chmod +x`

To execute any shell file we use the command.
`./<SCRIPT_NAME>`

Now the script we created prints the current directory.
> READ: to read more on [shebang](https://en.wikipedia.org/wiki/Shebang_(Unix))
| haile08 |
1,178,900 | How to use VSCode debugger with multiple Docker services | This article explains how to set use VSCode debugger on multiple Docker services | 0 | 2022-08-29T15:17:41 | https://dev.to/loicpoullain/how-to-use-vscode-debugger-with-multiple-docker-services-4g2e | docker, node, express | ---
title: How to use VSCode debugger with multiple Docker services
published: true
description: This article explains how to set use VSCode debugger on multiple Docker services
tags: Docker, NodeJS, ExpressJS
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/4m8hr9wod3as6qkfteyz.png
---
In my company (https://indy.fr), we use Docker and Docker Compose to run our Node.js services locally. Recently, I needed to configure and run the VSCode debugger on some of these services to debug a feature. There are a few things to know to achieve this, which I will share in this article with some basic examples.
Before we start, here are the points that will serve as a guideline in this tutorial:
- We want to keep using Docker and Docker compose to run our services, so that we have the proper environment for each of these services (environment variables, etc).
- We do not want to touch the current `docker-compose.yml` which could, potentially, be used in the future to deploy our services in production.
## The Sample Application
Let's start by creating a first service. It is a simple web server that concatenates two strings, a first name and a last name, and returns the result. This service will live in a `webapp/` directory at the root of the project.
### The Node.JS code
*webapp/package.json*
```json
{
"name": "webapp",
"scripts": {
"start": "node src/server.js"
},
"dependencies": {
"express": "^4.16.1"
}
}
```
*webapp/src/server.js*
```jsx
const express = require('express');
const app = express();
app.get('/fullname', (req, res) => {
const firstName = req.query.firstNme;
const lastName = req.query.lastName;
res.send(`${firstName} ${lastName}`);
});
app.listen(8080, () => console.log('Listening on port 8080...'));
```
*webapp/Dockerfile*
```yaml
FROM node:16
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 8080
CMD [ "node", "src/server.js" ]
```
*webapp/.dockerignore*
```
node_modules
npm-debug.log
```
### The Docker configuration
Now that the application code is written and the `Dockerfile` created, we can add a `docker-compose.yml` file at the root of the project.
*docker-compose.yml*
```yaml
services:
webapp:
build: ./webapp
ports:
- "127.0.0.1:8080:8080"
```
Let's start the service.
```bash
docker-compose build
docker-compose up -d
```
If you go to [http://localhost:8080/fullname?firstName=Foo&lastName=Bar](http://localhost:8080/fullname?firstName=Foo&lastName=Bar), you should see the string `undefined Bar`, which is the unexpected behavior we will debug.
## Debugging the Application in Docker with VSCode
### The debugger command
To allow the future VSCode debugger to attach to the Node service, we need to specify it when we start the process by adding the `--inpect` flag.
> Simply using `--inspect` or `--inspect=127.0.0.1:9229` is not sufficient here because we need the `9229` port to be accessible from outside the service, which is allowed by the `0.0.0.0` address. So this command should only be used when you run the debugger in a Docker service. Otherwise, you would expose the port and the debugger to anyone on the Internet.
>
*webapp/package.json*
```json
{
"name": "webapp",
"scripts": {
"start": "node src/server.js",
"start:docker:debug": "node --inspect=0.0.0.0:9229 src/server.js"
},
"dependencies": {
"express": "^4.16.1"
}
}
```
### The Docker configuration
Following our guideline, we do not modify the initial `docker-compose.yml` but create a second one that extends the first one. We will use the [`-f` flag](https://docs.docker.com/compose/reference/#use--f-to-specify-name-and-path-of-one-or-more-compose-files) of the `docker-compose` CLI to use them both.
*docker-compose.debug.yml*
```yaml
services:
webapp:
command: [ 'npm', 'run', 'start:docker:debug' ]
ports:
- "127.0.0.1:8080:8080"
- "127.0.0.1:9229:9229"
```
Then, to restart the service with debug mode enabled, you can use this command:
```bash
docker-compose build
docker-compose -f docker-compose.yml -f docker-compose.debug.yml up -d
```
The service is now ready to be attached to the VSCode debugger.
### Running the debugger with VSCode
At the root of your project, create a new directory `.vscode` and add the following configuration file.
*.vscode/launch.json*
```json
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "attach",
"name": "Debug webapp",
"remoteRoot": "/app/src",
"localRoot": "${workspaceFolder}/webapp/src"
}
]
}
```
When adding a breakpoint, the `remoteRoot` and `localRoot` properties will match the file's position in the VSCode environment and its location in the Docker service file system.
You can now start the debugger on the `webapp` service. Open the debugging panel and select the `Debug webapp` option. Then click on the play button.
The debugger is started.
Add a breakpoint on line 6 and then go to [http://localhost:8080/fullname?firstName=Foo&lastName=Bar](http://localhost:8080/fullname?firstName=Foo&lastName=Bar).
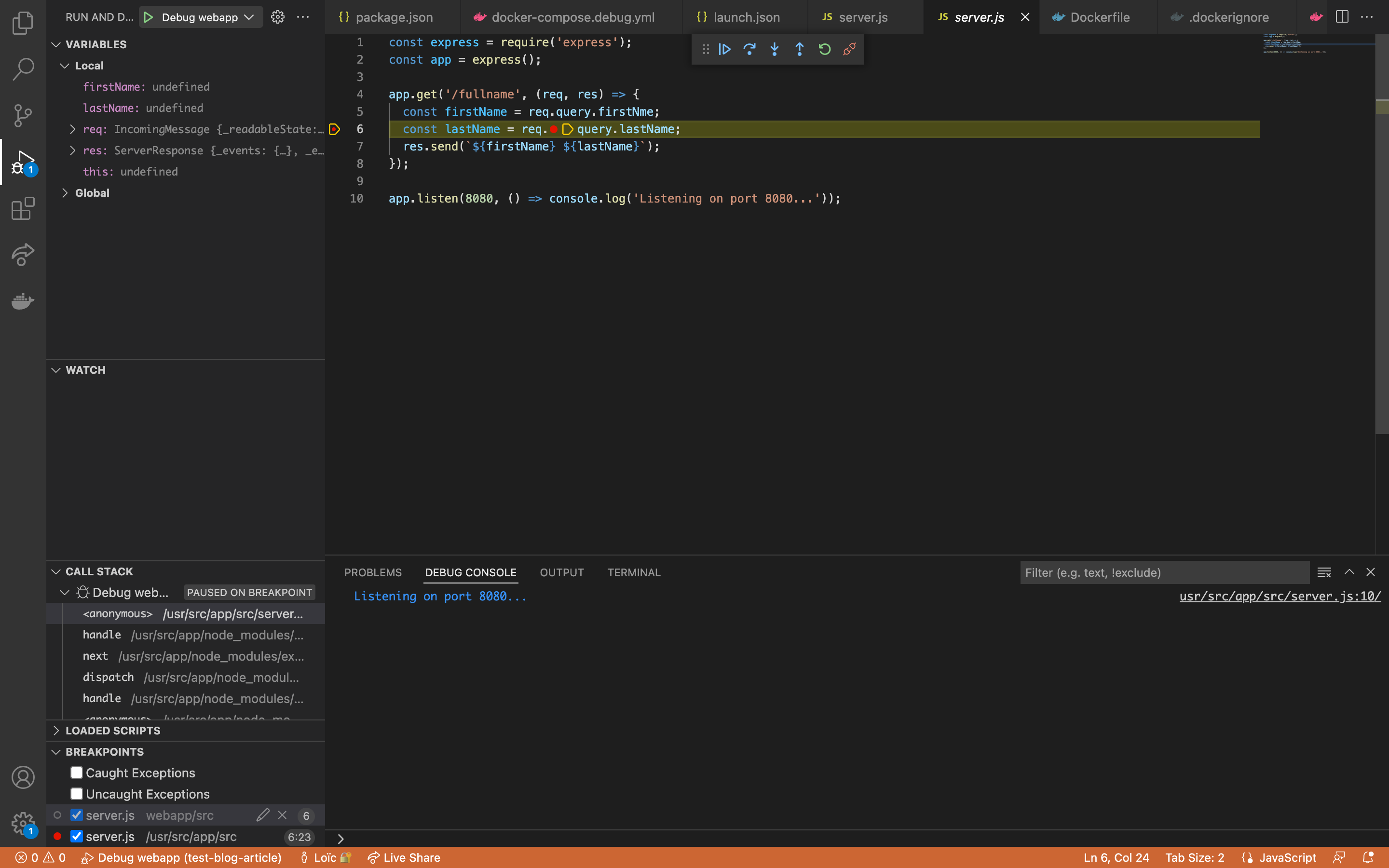
The debugger stops on line 6 and we can see that the variable `firstName` is `undefined`. The problem comes from line 5 where this is a typo on the `firstName` parameter name.
To close the debugger, click on the button with a red square.
## Debugging Multiple Docker Services
### The Node.JS micro-service
To take this a step further, we will add another service, named `micro-service`, which will be called by `webapp`.
First, copy and paste the contents of the `webapp` directory into another directory named `micro-service`.
Then, in the `webapp` directory, install `axios` and update the code as follows.
```bash
npm install axios
```
*webapp/src/server.js*
```jsx
const express = require('express');
const axios = require('axios');
const app = express();
app.get('/fullname', async (req, res, next) => {
try {
const { data: fullName } = await axios.get('http://micro-service:8080/fullname', {
params: req.query
});
res.send(fullName);
} catch (err) {
next(err);
}
});
app.listen(8080, () => console.log('Listening on port 8080...'));
```
> The URL used line 8 is based on the name of the Docker service defined in the next section.
>
### The Docker configuration
Add the new service to your `docker-compose.yml`. Note that it uses a different port so as not to conflict with the `webapp` service.
*docker-compose.yml*
```yaml
services:
webapp:
build: ./webapp
ports:
- "127.0.0.1:8080:8080"
micro-service:
build: ./micro-service
ports:
- "127.0.0.1:3001:8080"
```
Then, in your `docker-compose.debug.yml`, add the new service as well. Note that the debugger port is also different from the first one.
*docker-compose.debug.yml*
```yaml
services:
webapp:
command: [ 'npm', 'run', 'start:docker:debug' ]
ports:
- "127.0.0.1:8080:8080"
- "127.0.0.1:9229:9229"
micro-service:
command: [ 'npm', 'run', 'start:docker:debug' ]
ports:
- "127.0.0.1:3001:8080"
- "127.0.0.1:9230:9229"
```
Now build and start the two services.
```bash
docker-compose build
docker-compose -f docker-compose.yml -f docker-compose.debug.yml up -d
```
### Running multiple debuggers with VSCode
The last thing to do is to add the configuration of the second debugger in `launch.json`.
*.vscode/launch.json*
```json
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "attach",
"name": "Debug webapp",
"remoteRoot": "/app/src",
"localRoot": "${workspaceFolder}/webapp/src"
},
{
"type": "node",
"request": "attach",
"name": "Debug micro-service",
"port": 9230,
"remoteRoot": "/app/src",
"localRoot": "${workspaceFolder}/micro-service/src"
}
]
}
```
Once the configuration is added, you can run the two debuggers for each service.
Once both debuggers are started, add a breakpoint in each service and go to [http://localhost:8080/fullname?firstName=Foo&lastName=Bar](http://localhost:8080/fullname?firstName=Foo&lastName=Bar). The application will stop successively on each breakpoint.
Your VSCode debugger is now fully configured to work with your Docker services. Congratulations!
> _Article originally published here: https://tech.indy.fr/2022/06/10/how-to-use-vscode-debugger-with-multiple-docker-services/_ | loicpoullain |
1,179,178 | Git Flow - Releases [pt-BR] | Vamos aprender para que servem as branches chamadas de releases e como aplicar o uso delas ao lançamento de uma versão no ambiente de produção. | 0 | 2022-08-29T22:18:06 | https://dev.to/danilosilvap/git-flow-releases-pt-br-39ng | gitflow, git, versioncontrol, productivity | ---
title: Git Flow - Releases [pt-BR]
published: true
description: Vamos aprender para que servem as branches chamadas de releases e como aplicar o uso delas ao lançamento de uma versão no ambiente de produção.
tags: ['gitflow', 'git', 'versioncontrol', 'productivity']
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
---
Vamos aprender para que servem as branches chamadas de releases e como aplicar o uso delas ao lançamento de uma versão no ambiente de produção.
---
## Definição
**Releases** são _branches_ de preparação de um <u>novo lançamento em produção</u> e elas permitem pequenas correções de bugs e preparação de metadados para publicação (número da versão, datas de construção, entre outras definições).
Por convenção elas têm o prefixo **release/**.
Por exemplo:
- _release/0.1.0_
Importante ressaltar que as _releases_ (vamos nos acostumar a chamá-lás assim) são criadas *sempre* à partir da _branch_ *develop*.
> 📌 O <u>momento ideal</u> para criar uma nova _branch_ **release** é quando o desenvolvimento (quase) reflete o estado desejado do novo lançamento. Pelo menos todos os recursos que são direcionados para o lançamento a ser construído devem estar presentes na _branch_ **develop**.

> 📝 _Descrição da imagem:_ <br/>
Criação de uma feature a partir da develop _(F - Nova feature)_ e no final do desenvolvimento da funcionalidade _(C - Commit)_ é realizada a mesclagem com a develop _(M - Merge)_. <br/>
Logo após é **criada uma release** _(R - Nova release)_, onde pode haver alteração do número de versão e outras definições e por fim, **a mesclagem com a branch master** _(M - Merge)_ e o código atualizado volta a ser integrado também, à **develop**.
---
## Releases na prática 😎
### Pré-requisitos
- Ter o GIT instalado
- Qualquer repositório com o fluxo do Git Flow inicializado e configurado.
### 1. Criação de releases
Para criar uma release é bem simples:
```console
git flow releases start <número-versão-proposta>
```
Com um comando neste padrão, **será criada uma nova branch através da develop** com o prefixo _release/_, seguido do número de versão que você inserir.
Execute:
```console
git flow release start 0.1.0
```
O retorno do comando é uma nova _branch_ entitulado **release/0.1.0** e já é realizado _checkout_ nessa nova _branch_.
```console
[saída do console]
Switched to a new branch 'release/0.1.0'
Summary of actions:
- A new branch 'release/0.1.0' was created, bases on 'develop'
- You are now on branch 'release/0.1.0'
Follow-up actions:
- Bump the version number now!
- Start commtting last-minute in preparing your release
- When done, run:
git flow release finish '0.1.0'
```
### 2. Finalização de releases
Após terminar o **preparação da aplicação para ser lançada em produção**, a _branch_ estará pronta para ser **finalizada** e **mesclada** à _develop_.
Então você verificou que **está na release, não há nenhum commit a ser feito e nenhum arquivo pendente...**
```console
git checkout release/0.1.0
git status
```
```console
[saída do console]
No ramo release/0.1.0
nothing to commit, working tree clean
```
**Para finalizar uma release**, basta:
```console
git flow release finish <número-versão-proposta>
```
> O número da versão da release é opcional quando você já está presente(checkout) nela.
Execute:
```console
git flow release finish
```
Após esta instruçao, **aparecerá a possibilidade de escrever uma mensagem** que descreverá a versão lançada _(nota de versão)_.
```console
#
# Write a message for tag:
# 0.1.0
# Lines starting with '#' will be ignored.
```
> ⚠️ A finalização de uma release marca a **criação de uma tag** correspondente ao número de versão entitulado na branch release.
Depois de escrever a mensagem, a release **será meclada(merge) à master E à develop**, em seguida deletada _tanto localmente como remotamente_.
```console
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
To <url-repositorito-remoto>
- [deleted] release/0.1.0
Deleted branch release/0.1.0 (was 713d5ac).
Summary of actions:
- Release branch 'release/0.1.0' has been merged into 'master'
- The release was tagged '0.1.0'
- Release branch 'release/0.1.0' has been locally deleted; it has been remotely deleted from 'origin'
- You are now on branch 'master'
```
---
## Considerações finais
✅ _Para garantir que o repositório remoto estará atualizado baseando no status da sua estação de trabalho local, execute os comandos abaixo:_
**EMPURRE (push) as atualizações de todos as branches**
```console
git push --all
```
**SUBA (push) a tag recentemente criada**
```console
git push --tags
```
Pronto, para trabalhar com releases de forma simples e rápida, é isto!!
> ⚡ Nesta **seção sobre Git Flow** você encontrará explicações e usos práticos sobre ***features, hotfixes, tags*** e muito mais.
---
**Obrigado por chegar até aqui!** 😄
| danilosilvap |
1,179,604 | A look into Machine Learning in Sales - What do Dealcode’s models do? | According to a Harvard Business Review study, data-driven decision-making improves business... | 0 | 2022-08-30T12:07:15 | https://dev.to/ochwada/a-look-into-machine-learning-in-sales-what-do-dealcodes-models-do-51hd | According to a Harvard Business Review study, data-driven decision-making improves business performance. Data-driven decision-making refers to the practice of making decisions based on data analysis rather than intuition. These data-driven companies that pioneered the use of AI in sales are overjoyed with the results, which include a more than 50% increase in leads and appointments, 40%-60% cost savings, and 60%-70% call time savings. When the benefit of allowing sales professionals to spend more time completing transactions is considered, AI's allure becomes even more compelling.
## Machine Learning and Artificial Intelligence, a general view
AI and machine learning have the potential to eliminate the most time-consuming, manual activities that prevent sales teams from spending more time with clients — automating marketing processes, using predictive analytics, forecasting, reporting, and advising, all of which help clients upsell. All of these are methods for reducing labor in sales teams. When using data-driven decision-making, businesses in the top third of their industry are 5% more productive and 6% more profitable than their competitors ([McAfee and Brynjolfsson, 2012](https://hbr.org/2012/10/big-data-the-management-revolution)).
[Caruana and Niculescu-Mizil (2006)](https://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml06.pdf) examined the top machine learning models with higher performance as well as those that aren’t as significant and are commonly used in sales. The best machine learning (ML) models, such as random forests, boosting, support vector machines (SVM), and neural networks, are demonstrated in this study. In terms of predictive performance, these models outperform simple, interpretable models such as decision trees, naive Bayes, and decision rules. Companies that do not use the aforementioned open-sourced models use their own patent AI and ML models.
## [Dealcode]( https://www.dealcode.ai?utm_medium=linda) - the AI Selling Software.
[Dealcode]( https://www.dealcode.ai?utm_medium=linda) is an AI Guided Selling Software that extracts data from CRMs and processes it using its own AI and machine learning model. It is a predictive analytics tool that predicts the likelihood of success for sales pipeline prospects and risks. It gives sales teams the most up-to-date information on which deals to prioritize and who to contact right away. This predictive analytics is performed by analyzing sales processes using a patented machine learning model. Dealcode identifies individual factors that contribute to the success or failure of a sales team. Sales are noticeably more effective as a result. It also saves money on expensive resources for complex data analyses.
What services does Dealcode offer? Read more on Dealcode’s capabilities from my blog and company’s website - [link](https://www.dealcode.ai/blog/machine-learning-in-sales-how-does-dealcode-s-model-do?utm_medium=linda). | ochwada | |
1,179,834 | When hiring developers gets tough, focus on developer efficiency | This post highlights an alternative to just hiring developers through all possible channels. By... | 0 | 2022-08-30T17:14:28 | https://wundergraph.com/blog/when-hiring-developers-gets-tough-focus-on-developer-efficiency | webdev, startup, programming, microservices |
This post highlights an alternative to just hiring developers through all possible channels. By leveraging development efficiency potential, you can scale your business even if you can't fill all open engineering positions. A possible approach is to analyze your current tech stack and find efficiency killers.
# When hiring developers gets tough, focus on developer efficiency
Almost every company is looking for software developers.
As the complexity of applications grow, security challenges increase and interfaces multiply, it is obvious that the scarcity of skilled software engineers will not disappear,
but will become even more severe as demand outgrows supply.
As a result, organizations need to look beyond mere recruitment and find other ways to achieve a fast time-to-market for their services - and the key is to make your development teams more efficient. If you can’t grow your team, then enable it to deliver more value in the same time.
## Fishing in an empty pond
When scrolling through the LinkedIn feed, many of the posts I see are about open positions, especially in the area of software development (admittedly, my industry bias will have some effect). Companies are trying really hard to attract talent, but even if there are perks, a more than competitive salary, a high profile role, in many cases this doesn’t lead to more applicants, let alone more hirings.
The reason is that the competition for talent in a scarce environment such as software development is so fierce
that a good or even great offering is not enough –
developers need to find you, you need to attract their attention, and then there should be a cultural match (which, unfortunately in many cases, is omitted to make at least some progress).
In short: the shortage of software engineers will get worse, not better, and just hoping that recruiting will get you where you need to be in order to deliver your products and services will not suffice.
It’s like time: no matter how hard you try, a day will not have more than 24 hours - the only thing you can do is make better use of the time available to you. So what can you do to make your programmers and engineers more efficient and productive (after you’ve tried extra coffee, candy and club mate)?
## Finding the efficiency killers in the software stack
Certainly it’s not cracking the whip (try that with developers, and that’ll be the last you ever saw of them),
and if you have already covered things like working environment, team dynamics, time management, leadership style and other “soft factors” (which warrant their own blog post at a later date), you should move on to taking a look at your tech / software stack to find substantial efficiency killers that are worth tackling.
The trouble with the technological hunt for efficiency is
that any gains are usually harder to achieve because they require more than just a policy change, or a higher pay check.
Nonetheless, not tackling them means that you risk falling behind the competition regarding time-to-market and,
at the end of the day will also end up with a higher churn rate of your development team as developers tend to dislike inefficient systems and tools.
In the current hiring crisis, this is something you should always keep in mind and not underestimate. As a developer-first company, we at WunderGraph are convinced that efficiency starts with the developer experience.
If you are able to make code work not just a positively challenging experience, but also as delightful as possible by removing inefficiencies, you will end up with better software, faster, and a thoroughly motivated and loyal engineering team.
> Better development efficiency will support your time-to-market and competitive advantage, and also result in a modern tech stack which increases the likelihood of your developers staying on board.
## So where should you be looking for the efficiency potential?
Some questions to get you started on leveraging dev efficiency:
### 1. How modern is your tech stack?
Take a look at which programming languages and frameworks are currently in use. There is no general rule what is truly modern and what is old-fashioned or outdated -
the reason behind this question really is the assumption that the older the stack, the less efficient it is.
This also applies to mixtures: the most modern framework in use will hardly be able to compensate for an old database or a legacy component you have to integrate with.
This does not mean that the stack you’re using is inefficient in its operation - in fact, I have seen many well-integrated legacy-type stacks which perform flawlessly and “get the job done” - but what we are looking for is developer efficiency, so the question is: how much effort is it for your development team to actually change or debug something in your stack? And in this respect, it does matter if your stack is modern (usually well-documented) or not.
As an example, in my years in the travel industry I have seen mainframe applications written in COBOL delivering a lot of MIPS (if you have to google this, you probably have been born after 1980 ;) without hiccup.
However, in case of a problem or program change, senior (both in age and experience) programmers
had to come in from their retirement to take care of this, and changes on the host aren’t for the weak of heart.
> A modern, homogenous tech stack is a good facilitator for efficient software development.
### 2. How complex is your tech stack?
So you stack is modern enough, but what about its complexity? The more technologies you have in parallel use doing more or less the same things, the less efficient you’ll be in developing in this environment.
If possible, go for one solution for each problem in your stack - even if you miss out on some efficiency in a particular portion of the stack,
having less is more.
For example, vue.js and React both are great front-end frameworks, but you should opt for one of them.
If you intend to use both, I would recommend to keep their use cases strictly separated. The point is that regardless of a valid use case for multiple solutions in the same area,
it will always increase the complexity your developers will have to manage and thus consume additional time.
Even if you find yourself in the luxurious situation of running dedicated teams, you should ask if this is indeed the most efficient approach, especially if your teams aren’t fully staffed.
> Try to find solutions that don’t overlap in your stack to keep things simple and manageable.
### 3. How much technical debt is incurred over time?
Technical debt is left-over work after something has been shipped; the classic “we will fix this later” religion
which almost always leads to things not getting done and falling on your feet years later when you least expect it
(and in the most inconvenient moment, of course).
Technical debt can, but doesn’t have to be an indicator for a lack of efficiency. If your teams are constantly facing a lot of it, better efficiency can help decrease the amount of technical debt if the management is smart enough not to reduce the time allotted to certain tasks at the same time.
> Be mindful of technical debt as it eats at your efficiency in delivering value and reduce time-to-market.
### 4. How much repetitive work are your developers doing?
Even if Fred Taylor would love to see your developers doing the same things over and over again to become super efficient at it, it’s not the kind of efficiency you want (and developers don’t like Taylorism).
The goal is to only do the necessary steps as seldom as possible. Whenever your team does things repeatedly,
ask yourself if this can be automated with reasonable effort to make for a ROI that works for you.
Most importantly, involve your team in looking for automation potential. Your software engineers are skilled and knowledgeable about finding tools that work for them -
and that’s a critical aspect.
If you impose a tool or process on your team without involving them, you are likely to meet resistance and will have a hard time achieving that ROI you outlined to your CEO before. My advice is to always go developer first with this - if you have a lead architect, ask her to come up with suggestions. If not, ask someone of your dev team to take the lead in finding a solution, or make it a team challenge.
If you already have a solution in mind, be smart about it and ask your team to review it - or simple ask for advice or feedback. This is not a sign of weakness, but of empowerment and good leadership.
> Automate what you reasonably can, and always involve your development team to find solutions that your engineers like and support.
### 5. How many software dependencies does your team have to manage?
As solutions grow, so do dependencies. If you are running a monolithic system, this can quickly become a nightmare to maintain (if it isn’t already), but even in a modern microservice architecture, managing dependencies through APIs can be tricky, especially if you have a zoo of APIs to connect, maintain and secure.
Reducing these dependencies is probably the most important lever on efficiency, but can be a challenge depending on your system complexity and share of legacy services.
However, what you can and should do in any case is get those APIs under control and make sure you have as little effort working with them as possible.
WunderGraph’s approach is to automatically create one unified API for all your data sources as we believe a developer shouldn’t have to worry about individual APIs.
In fact, every API that you don’t have to actively manage will give your team back a lot of time, and if you multiply that across all your APIs, you will end up with a lot of time that your developers can now spend on value creation.
Dependencies are a big lever to save development time.
> Start with your APIs first and consider using a framework like WunderGraph for API automation and management instead of doing it all manually.
**WunderGraph is going Serverless in the coming months. Join our [waitlist](https://8bxwlo3ot55.typeform.com/to/ZMi8Z8pj?typeform-source=admin.typeform.com) to be notified when we go live and to get early access to explore serverless API Integration.**
## Yes, development efficiency makes a difference
Even if you tackle just a few of the efficiency killers discussed above, you should see an impact in your delivery speed and time-to-market.
If the impact is profound enough to replace hiring new developers depends on the size of the team and the level of inefficiency, but shaving even 2h off the workload of a 5 Developer team per week gives you more than a day’s worth of developer impact per week. Imagine what this team alone can do in a month with a week more of development time on their hands.
Of course, this doesn’t scale indefinitely. Once you have optimized your tech stack and all that goes with it (which in itself is a theoretical state, of course), you may still find yourself in the need of hiring software developers.
But by then, your company will be so attractive and the impact of each software engineer so substantial
that every hire will deliver maximum impact.
It’s a nice vision to aim for.
| slickstef11 |
1,179,995 | How To Use List Comprehension in Python | You spend a lot of time coding, which can be exhausting. Python cares about your mental health, which... | 0 | 2022-09-06T14:02:04 | https://dev.to/jacobe/how-to-use-list-comprehension-in-python-3ece | You spend a lot of time coding, which can be exhausting. Python cares about your mental health, which is why it has tools like list comprehension to help you with your work.
List comprehension allows you to create a list with a single line of code. List are collections of data separated by commas and covered by square brackets. A list comprehension is surrounded by square brackets as well, but instead of data, expressions are entered, followed by for-loops and if clauses.
```python
List: [1, 2, 3, 4, "a", "b", True, False, 10.90]
```
```python
List Comprehensions: [expression for value in collection]
```
List comprehension allows us to manipulate items on a list. If you want to change a single list item, simply change the index and the value.
When you want to access a specific item in a list, list comprehension can also help you extract information. it can also be used to filter items in a list.
## For-loops In A List comprehension
The `expression ` below generates the elements in a list, followed by a `for-loop` over collections data this will evaluate the `expression ` for every element in the collection.
```python
[expression for value in comprehension]
```
If you only want to include the `expression ` for certain pieces of data, you can add an if clause after the `for-loop`. The expression will be added to the list only if the if clause is `True`
```python
[expression for value in collection if <test>]
```
You can have more than one if clause as you can see from below and the expression is in the list only if the if clauses are `True`.
```python
[expression for value in collection if <test1> and <test2>]
```
You can also loop over more than one collection in a list
```python
[expression for value1 in collection1 and value2 in collection2]
```
## List A Square Of Numbers
Let’s create an empty list called find square number and loop over 10 positive integers. And append the square of i to the list.
```python
squares = []
for i in range(1, 11):
squares.append(i ** 2)
print(squares)
this will print
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
```
You can use list comprehension to do the same in a single line of code and will arrive at the same result.
```python
squares = [i ** 2 for i in range(1, 10)]
print(squares)
this will print
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
```
## Manipulating List Item With A List Comprehension
List comprehension is always based on the following logic: Assume you already have a list with many products. We'll refer to it as
```python
products_list = [1, 2, 3, 4, 5].
```
You can access this list and do something with it by adding, multiplying, or looking up specific product numbers. After that, save the changes as a new list.
Let's multiply the product list by two. You need access to each list item to multiply them by 2. To accomplish this, You will use a for-loop to loop through the product list. You'll do something similar down below.
```python
create an empty list to store the new changes.
new_product_list = []
products_list = [1, 2, 3, 4, 5]
for an item in products_list: # we will use the .append method to add each item multiplied by 2 in the new list.
new_product_list.append(item * 2)
print(new_product_list)
the print out will be
[2, 4, 6, 8, 10]
```
When you want to create a new list from any iterable, it is a good practice to make use of list comprehension because it aids readability and that's the best practice. Let’s see how you replicate the above using list comprehension.
```python
products_list = [1, 2, 3, 4, 5]
new_product_list = [item * 2 for item in products_list]
print(new_product_list)
the print out will be
[2, 4, 6, 8, 10]
```
List comprehension reads from the left-hand side by multiplying items by 2 then the for-loop loop through the product list.
We have printed the desired result without using the append methods and everything in a single line.
## Repeating Items In A List Comprehension
Let’s say you want to repeat the product list by 2. You will do something like this below.
```python
products_list = [1, 2, 3, 4, 5, ]
product_list = products_list * 2
print(product_list)
This will print [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
```
As you can see the asterisk `(*)` is not for multiplication in this case. It is for repetition.
_**NOTE:**_In python `(**)` represents exponential and if you add two lists, it concatenates them_.
## How To Access A Specific Item In A List
You can also use list comprehension to access a specific item in a list.
To demonstrate this, let’s create a list containing the student registration number, student name, subject, and score.
```python
students = [{'reg_number': 101, 'name': 'Kenny', 'subject': 'python programming Language', 'score': 78},
{'reg_number': 212, 'name': 'Blessing', 'subject': 'java programming Language', 'score': 65},
{'reg_number': 322, 'name': 'Ibrahim', 'subject': 'typeScript programming Language', 'score': 87},
{'reg_number': 434, 'name': 'John', 'subject': 'javaScript programming Language', 'score': 90},
{'reg_number': 545, 'name': 'Enema', 'subject': 'data analyst', 'score': 35}
]
print(students)
[{'reg_number': 101, 'name': 'Kenny', 'subject': 'python programming Language', 'score': 78}, {'reg_number': 212, 'name': 'Blessing', 'subject': 'java programming Language', 'score': 65}, {'reg_number': 322, 'name': 'Ibrahim', 'subject': 'typeScript programming Language', 'score': 87}, {'reg_number': 434, 'name': 'John', 'subject': 'javaScript programming Language', 'score': 90}, {'reg_number': 545, 'name': 'Enema', 'subject': 'data analyst', 'score': 35}]
```
You have been able to create a student dictionary list with the reg number, name, subject, and score as the keys followed by the corresponding value. You can read more on the dictionary list [here](https://dev.to/arvindmehairjan/what-are-the-differences-between-a-list-tuple-dictionary-set-in-python-2lm6).
## You Can Access All Student Names From The List
```python
student_name = [student['name'] for student in students]
print(student_name)
# ['Kenny', 'Blessing', 'Ibrahim', 'John', 'Enema']
this will print
['Kenny', 'Blessing', 'Ibrahim', 'John', 'Enema']
```
What you did is loop through students to enable us to access the name key. You are not limited to the name alone, you can also use the same method to access the subject or score.
## How To Filter List Items
You filter list items to find information about specific items or if they meet a specific condition. Maybe you are looking for the lowest student in a class or the highest student in a class.
What you need to do here is to add conditions that check for students who scored lower marks in a class.
```python
student_name = [student['name'] for student in students if student['score'] <= 35]
print(student_name)
this will print Enema
```
This will print Enema because that is the student with the lowest score.
Suppose you want to find a student whose name starts with the letter **“B”** among your students, you will do something like this below:
```python
names_letters = [name for name in students if name['name'].startswith('B')]
print(names_letters)
[{'reg_number': 212, 'name': 'Blessing', 'subject': 'java programming Language', 'score': 65}]
```
```python
this will print everything regarding the student whose name starts with the letter B.
[{'reg_number': 212, 'name': 'Blessing', 'subject': 'java programming Language', 'score': 65}]
```
You can also check for the names of students and their scores.
You can do something like this below.
```python
name_and_score = [{'name': student['name'], 'score': student['score']} for student in students]
print(name_and_score)
we have this as our output
[{'name': 'Kenny', 'score': 78}, {'name': 'Blessing', 'score': 65}, {'name': 'Ibrahim', 'score': 87}, {'name': 'John', 'score': 90}, {'name': 'Enema', 'score': 35}]
```
## Checking For List Length
You can also check the length of a list using the len() method.
```python
Students_lenght = len(students)
no_of_users = len(students)
print(no_of_users)
this will print 5 because we have 5 students on our list
```
## Wrap up
In this article, I have been able to explain different ways list comprehension can be applied in python code. With list comprehension, you can build a complex list using a single line of code. Python loves you and wants to protect your sanity.
You can follow me on [Twitter ](https://twitter.com/IsahJakub) and on [Linkedin](https://www.linkedin.com/in/isahejacob/)
| jacobe | |
1,180,028 | Code list items with "show more/less" functionality in React | =====================================================================================================... | 0 | 2022-08-30T20:10:49 | https://dev.to/muratcanyuksel/code-list-items-with-show-moreless-functionality-in-react-22k0 | webdev, javascript, react, tutorial | =============================================================================================================================================> I OFFER FULL STACK BLOCKCHAIN DEVELOPMENT SERVICES: ERC20/721 TOKEN CREATION, TOKEN SALE SMART CONTRACT, WHITELISTING, LENDING PROTOCOL, MARKETING REFERRAL, DAO DEVELOPMENT AND MORE.
FRONT END INTEGRATION INCLUDED.
IF YOU NEED SMART CONTRACTS, CONTACT ME.
IF YOU NEED FRONT END INTEGRATION WITH SMART CONTRACTS, CONTACT ME.
SEE MY OFFERS, CLIENT TESTIMONIALS AND PREVIOUS WORK BY VISITING =>https://www.muratcanyuksel.xyz
OR SEND ME AN EMAIL VIA mail@muratcanyuksel.xyz
=============================================================================================================================================>
I want to display a list of elements on my page, and I want each element to have a "show more/less" functionality to expand and shorten the text at will.
For this, I will use React. I will fetch some fake data from the following dummy API => https://jsonplaceholder.typicode.com/
I will use `axios` to do so.
I will have three pages in my structure: App.js, Texts.js, and Text.js.
You can find the repo here => https://github.com/muratcan-yuksel/reactShowHideBlogPost
I will fetch the data in App.js, then send it with props until it reaches the Text.js component.
To start wil, this is my App.js file =>
## App component
```react
//App.js
import { React, useState, useEffect } from "react";
import axios from "axios";
import Texts from "./Texts";
const App = () => {
const url = "https://jsonplaceholder.typicode.com/posts";
const [data, setData] = useState([]);
const getData = async () => {
try {
const req = await axios.get(url);
const res = await req.data;
setData(res.slice(0, 5));
} catch (error) {
console.log(error);
}
};
//useEffect runs once when the component is mounted
useEffect(() => {
getData();
}, []);
return (
<main>
<Texts props={data} />
{/* <div>
{data.map((e) => {
return <div key={e.id}>{e.title}</div>;
})}
</div> */}
</main>
);
};
export default App;
```
I start with importing the hooks I'll use, axios, and the child component `Texts`.
I define the API endpoint I'll make a call to. You can check it following this link => https://jsonplaceholder.typicode.com/posts it returns a user Id, id, title, and body. I'll need the `body` for the text.
The useState hook is used to save the data in the state, and useEffect hook calls the getData function once at component mount.
`getData` is an asynchronous function that calls the API using axios library, with this line of code ` setData(res.slice(0, 5));` I limit the amount of array elements returned from the API to 5 for easy of use and set the state to it. It returns a lot of items, I don't need all of them. I always use the try/catch syntax with async/await when making API calls. That's the best one I know, and I find the syntax more readable.
In my return statement, I send the data I've saved to the state to the Texts component with the props name `props`.
Let's check the Texts component.
## Texts component
```react
//Texts.js
import { React, useState } from "react";
import "./styles/texts.css";
import Text from "./Text";
const Texts = ({ props }) => {
return (
<div className="textComponent">
<div>
{props.map((mappedProps) => {
return <Text key={mappedProps.id} {...mappedProps} />;
})}
</div>
</div>
);
};
export default Texts;
```
After importing the relevant dependencies, I start with destructuring the props by putting the `props` keyword into curly praces. Disregard the style cues, you can check the css file in the github repo.
I map the data I've got from the parent, and create a `Text` component with each mapped element. Skipping this step and trying to map and display the data in this component results with the show/hide logic to apply all the elements at the same time, i.e. when one show/hide button is clicked, all the others will be shown/hidden at the same time. We don't want that. We want each and every element to be shown/hidden separately.
I send the props in the following way `{...mappedProps}` to get individual key titles in the child component so that I can just import what's returned from the API like so =>
```react
//Text.js
const Text = ({ body, id }) => {
...)}
```
## Text component
```react
//Text.js
import { React, useState } from "react";
import "./styles/texts.css";
const Text = ({ body, id }) => {
const [readMore, setReadMore] = useState(false);
return (
<div>
<div className="text" key={id}>
{readMore ? body : `${body.substring(0, 80)}...`}
<button className="btn" onClick={() => setReadMore(!readMore)}>
{readMore ? "show less" : " read more"}
</button>
</div>
</div>
);
};
export default Text;
```
I start by importing the props with their key names given in the API like so => `const Text = ({ body, id }) => {`, this way leaves less room for confusion in my opinion. I know it's `body` I'm looking for. I give id to each individual div, and then with the line
```react
{readMore ? body : `${body.substring(0, 80)}...`}
```
I tell the browser to first check if `readMore` state variable is true, if it is, display the whole test coming from `body`; if it's false, show only the first 80 characters of the text. Since `readMore` state variable is set to false at the beginning, when I open the page, I'll see the shortened text. I have three dots following the shortened text. Then I put a button with the following snippet =>
```react
<button className="btn" onClick={() => setReadMore(!readMore)}>
{readMore ? "show less" : " read more"}
</button>
```
which sets the `readMore` state variable to its opposite. Inside the button there's a text that shows "show less" if the `readMore` state variable is `true`, and "read more" if it's `false`. With this, I'll be able to click on the button to expand and shrink the text.
That's it.
Happy coding!
| muratcanyuksel |
1,180,135 | Update Your AWS Security Group Using Python & boto3 | Why? I'm regularly (once a week) having to update a security group for my EC2 instances... | 0 | 2022-08-31T00:51:38 | https://ducko.uk/update-aws-security-group-using-python-boto3/ | aws, cloud, howto, scripting | ---
title: Update Your AWS Security Group Using Python & boto3
published: true
date: 2022-07-20 19:23:00 UTC
tags: aws,cloud,HowTo,Scripting
canonical_url: https://ducko.uk/update-aws-security-group-using-python-boto3/
---
# Why?

I'm regularly (once a week) having to update a security group for my EC2 instances to allow SSH access due to the nature of consumer home broadband. So your IP changes frequently if you haven't or have the ability to purchase a static IP.
I wanted to create a script that will save time clicking through, logging into AWS, finding your Security group, and amending the rule.
# What was put together?
A small (primitive) python script that will pull your current external IP, and amend the current rule ID located within a security group in AWS, feeds back the response code from AWS (200 = OK) and exits out.
# Outcome?
A quick, easy and painless way to update security groups when you find out you can't SSH to your instances.

_The script runs and provides 200 response codes on completion._
# Where is your script located?
Find it here: [https://github.com/dannyducko/AWS-SG-Update-Python](https://github.com/dannyducko/AWS-SG-Update-Python).
# How can I get it working for myself?
The script is primitive, so apologies if it's messy/ basic.
```
from urllib import response
import requests
import boto3
from botocore.exceptions import ClientError
ec2 = boto3.client('ec2')
my_ip = ""
def myip():
global my_ip
## call the api on my-ip.io
url = "https://api.my-ip.io/ip"
ip_response = requests.request("GET", url)
my_ip = (ip_response.text + "/32")
def des_sg(ip):
## Replace the sgr with the security group rule containing your IP you SSH from.
sg_rules_list = [{'SecurityGroupRuleId': 'sgr-123456789abc',
'SecurityGroupRule': {
'IpProtocol': 'tcp',
'FromPort': 22,
'ToPort': 22,
'CidrIpv4': f'{ip}',
'Description': 'Added SSH port via script'
}
}
]
try:
## replace the below with the security group ID that contains the SG Rule
response = ec2.modify_security_group_rules(GroupId='sg-123456789abc', SecurityGroupRules=sg_rules_list)
print(f"Response code = {response['ResponseMetadata']['HTTPStatusCode']}")
except ClientError as e:
print(e)
def run_sg_replace():
myip()
sg_question = input(f"Would you like to replace your SG Rule to {my_ip}? (y or n)\n... ")
if sg_question == "y" or "Y":
des_sg(my_ip)
#print("Successfully added")
else:
print("Closing...")
exit()
run_sg_replace()
exit()
```
The script will require changes on Line 18 and Li to work with your security group. Please be aware of the difference between Security Group ID and Security Group Rule ID.
- Line 18 – Replace SGR-12345789abc with the Security Group Rule ID you want to amend.
- You can find this rule ID in the AWS console by browsing your security groups, selecting the SG you want to be able to amend and finding the rule containing your TCP 22 SSH Inbound. Next to it, you'll locate your Rule ID.

_Security group rule ID in the AWS console._
- Line 30 – Replace sg-12345789abc with the Security Group ID, found again in your AWS console by browsing your security groups.
You will need pip's relevant packages/ modules to run the script (depending on your version).
```
pip install urllib requests boto3
or
pip3 install urllib requests boto3
```
Also, ensure you have your AWS CLI credentials set up. You can follow the [instructions here](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-quickstart.html) to quickly set this up.
All that's left to do is run the script! (depending on your version)
```
python sg-updates.py
or
python3 sg-updates.py
``` | dannyjones |
1,180,153 | Why is the documentation of tech products so hard to use? (In the user’s point of view) | Nowadays, our documentation of developer tools is hard to use and we tend to find the solution on... | 0 | 2022-08-31T02:00:34 | https://www.summerbud.org/thoughts/why-is-the-documentation-of-tech-products-so-hard-to-use | documentation, webdev, programming, productivity | Nowadays, our documentation of developer tools is hard to use and we tend to find the solution on other sources such as Youtube, GitHub issues, or blog posts. Its content may easily fall behind or the key point has not been mentioned at all. I consider this issue an emergent problem that we should toggle as soon as possible, and I think two major problems needed to be solved first. (In the user’s point of view)
- Documentation is too hard to contribute to
- Documentation easily becomes out of date. People tend to write a blog post rather than contribute to a document because it requires a lot of extra effort without the corresponding incentives.
- The context is clustered
- Documentation itself hardly connects to other resources. The context that makes good documentation is clustered.
In this article, I would like to introduce two concepts around documentation that I think are problematic and then further expand it to 3 thinking points toward solving these two issues.
First of all, please recall some documentation you have visited recently and join me with the explanation below. I would like to take Next.js for example which is currently my most visited documentation. Let's start with the "Getting Started" page.
https://nextjs.org/docs/getting-started
Nextjs's documentation has a structure that is popular through various products, let me call this structure "Isolated listing structure". The reason I call them isolated is that they are mainly maintained by the people behind Next.js(although they are open-sourced).
Furthermore, I would like to conclude the mindset behind this documentation as "Owner's bullet-point".
## Owner's bullet-point
The reason I call it "Owner's bullet point" is the process of generating documentation is usually accomplished by the product owner. At the start of a product, no one has an understanding better than the owner. The owners are the best person to maintain proper documentation for their consumers and maintainers.
But after a while, the product receives a lot of love and begins to build up the community. It becomes harder and harder to follow up on corner cases and bugs. The owners have to catch up with new commits and solve issues daily, on the other hand, they have to explain new designs, and caveats and provide information for newcomers to overcome these problems. The loading is rising high drastically.
Not every product can catch up, the content begins to fall behind, and some solutions may exist in others' blog posts, StackOverflow's answers, GitHub issues, or discussions. A user needs to connect these solutions with search engines, sometimes the solution on documentation is even wrong.
## Isolated listing structure
The isolated listing structure is very common, in e-commerce, in general-purpose websites, on your phone, and in the documentation. It's everywhere.
The structure is mostly arbitrary and opinionated coming from the mindset of "Owner's bullet-point", due to the owner having to first come up with the tree of the structure, in an order that they think is most suitable for their client.
The isolated listing structure is a double-edged sword: To be clear, I am not fully against this structure, it is really helpful in a general context. For example, it's good for initial exploration and if you're familiar with the document, it's quite easy for you to find the information you want.
But on the other hand, it's a fixed structure, it is hard for the structure to evolve and every time the maintainer wants to add something else, it's hard to find an appropriate place if the owner didn't think it well from the beginning. Besides that, users have no other choice but to explore your documentation. They have only one route and it's not enough.
<sup>Martin Grandjean, CC BY-SA 3.0 <https://creativecommons.org/licenses/by-sa/3.0>, via Wikimedia Commons</sup>
Imagine a dynamic structure, like a force-directed graph (Something like Obsidian can accomplish or a tree diagram, you could find many examples right in their publish section[^1]). I am not saying force-directed graphs or tree diagrams are better than isolated listing structures. What I want is to encourage everyone not to think in a "listing way" but in a more "dynamic way", so that people can choose whatever suits their needs best. They can use tree diagrams to explore the structure and use the force-directed graph to acknowledge the connection between topics. Or we could come up with a new structure from the ground up which can solve some of these problems.
In combination, the mindset and the structure lead to the problem I think is problematic, listed below.
## Documentation is too hard to contribute to
In combination with the arbitrary mindset of "Owner bullet's point" and the "Isolated listing structure", what we have is that current documentation can only be properly maintained by the owner, there is no other easy way to contribute to the documentation. The problem is twofold.
First, based on the "Owner's bullet point" mindset, the author doesn't want some inexperienced person to mess up your documentation and it's quite hard to match the tone of documentation if you don't spend much time staying aligned with your maintainers.
Second, your user doesn't have any incentive to contribute to the documentation, people love your product but if they don't get any credit within the construction of the document or some ownership toward some page of documentation, there is no incentive.
You may argue that they can post an issue and explain their suggestion but the problem remains. The feeling of contributing is very simultaneous, it is just like the feeling of buying something. Imagine a parallel world, in here, if you want to buy something, you need to write down 200 words to describe why you want to buy this stuff and what is the benefit the community.
There is no need to gate people from contributing documentation with bureaucracy. We need to come up with another structure that can remain the authority of the documentation and benefit the simultaneous contribution at the same time.
## The context is clustered
The material of good documentation is not just the documentation itself, but the corresponding discussions, issues, related blog posts, and videos. I will call these materials "Contexts".
Until recently we tended to store these contexts distributedly. A regular open-source project stores their discussion in GitHub discussion or a discourse forum, their use cases in product websites, issues right in the GitHub issues, and a self-hosting documentation website elsewhere. Besides that, there is a lot of community-generated content on YouTube and personal blog posts.
In reality, the context of a product becomes clustered. They won't have inter-connection with each other. There may be a discussion about the solution to the specific bug, but there is no reverse link on the documentation section that has mentioned this solution. Sadly we have to deal with the reality that the bi-directional link is not what the current internet is capable of.
### Clustered context is volatile
Imagine a situation where you drop in the product's documentation and quickly find out that the documentation doesn't provide a solution, later the day you find a workable solution on someone else's blog post.
At this moment, with the current documentation, there is no other way to remind other developers that they can solve the same problem with this method described by the blog post, you can't add a reference to the documentation. What you can do is open an issue(if it's open-source) or open a discussion on a forum to remind people about this solution which will soon be flooded by other content.
Every useful solution in any context needs to be resistant to the flood of information we have right now. They have to join this battleground with no anchor point besides search engines.
The awesome list [^2] is a good idea, they provide a way to let good contents stay, but they have the same issue with the "Isolated listing structure" and the "Owner's bullet-point" mindset.
## If the situation remains as is…
The immediate consequence of these issues will be the “Documentation” will deem to decay over time. You could take a look at some tech giant’s documentation including Amazon web services documentation or Google cloud documentation, they are all overwhelming and hard to read.
The worst feeling is you are stucking on a specific problem that you can’t find in the documentation and anywhere else. We will be facing these kinds of situations more if the structure of our documentation can not align with the scope of the product we use.
It may seem overwhelming to come up with a new kind of structure to overcome these issues in the first place. But look closely, we could separate the overall problems into 3 questions to ask ourselves.
- How to encourage users to contribute to the documentation and not interfere with the general purpose of the document? Can we have a more interactive experience for documentation? Can a user directly contribute to the documentation without leaving the page?
- How to gather context together for a better search experience that does not rely on exterior search solutions and brings up inter-connectivity of every context along the way?
- How to experiment with a new structure that may benefit user experience and iterate it over time, or even let users choose it freely?
I want to progressively tackle these issues. If you are interested in or come up with something interesting about this topic, I'd like to hear about it. I would answer any email (summerbud.chiu@gmail.com) about this topic, you could also find me on Twitter (https://twitter.com/EiffelFly).
<sup>Cover Photo by <a href="https://unsplash.com/es/@wesleyphotography?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Wesley Tingey</a> on <a href="https://unsplash.com/s/photos/document?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></sup>
[^1]: [Obsidian publish page](https://obsidian.md/publish)
[^2]: [sindresorhus/awesome](https://github.com/sindresorhus/awesome) | summerbud |
1,180,411 | Building a notebook using Tauri and ReactJS | Hi friends! I'm hudy. A web developer from Hanoi, Vietnam In this post, I'm gonna show you how to... | 0 | 2022-09-08T15:12:13 | https://dev.to/hudy9x/building-a-notebook-using-tauri-and-reactjs-42b | react, tauri, typescript, desktopapp | Hi friends! I'm hudy.
A web developer from Hanoi, Vietnam
In this post, I'm gonna show you how to build a Notebook app - desktop application - using Tauri and ReactJS.
For those who don't know Tauri, it is a toolkit that helps developers make applications for the major desktop platforms - using virtually any frontend framework in existence
A tutorial video:
{% embed https://www.youtube.com/embed/2E5edr4_LXw %}
The source code for this tutorial is available here: [https://github.com/hudy9x/tauri-notebook](https://github.com/hudy9x/tauri-notebook.git)
## Prerequisite
1. [Tauri](https://tauri.app/v1/guides/getting-started/prerequisites) - a toolkit to build desktop app
2. [Nodejs](https://nodejs.org/en/)
3. npm or yarn - package manager
## Table of contents
1. Install Tauri
2. Scaffolding code structure using `create-tauri-app`
3. Using Tiptap library in `<MainEditor/>` and create `<Menubar/>`
4. Time to style
5. Change app's icon
6. Build app
## #1. Install Tauri
The first step is to intall Rust and it's dependencies. Visit Tauri's home page to get it done
- For window users: check this [link](https://tauri.app/v1/guides/getting-
started/prerequisites#setting-up-windows)
- For macOs users: check this [link](https://tauri.app/v1/guides/getting-started/prerequisites#setting-up-macos)
- For Linux users: check this [link](https://tauri.app/v1/guides/getting-started/prerequisites#setting-up-linux)
## #2. Scaffolding code structure using `create-tauri-app`
Make sure that you've installed `npm` already. Then, run the following command to generate code structure
```shell
$ npm create tauri-app
```
Follow the instructions. Just remember to select `react-ts` as main framework

Now, time to install `tiptap` and `remixicon`
```shell
$ npm install @tiptap/react @tiptap/starter-kit remixicon
```
Next, create a `components` folder with 2 files inside it as `Editor.tsx` and `Menubar.tsx`. And add a simple component definition to them

## #3. Using Tiptap library in `<MainEditor/>` and create `<Menubar/>`
Open `src/components/MainEditor.tsx` and add the following code:
```javascript
// src/components/MainEditor.tsx
import { EditorContent, useEditor } from "@tiptap/react";
import StarterKit from "@tiptap/starter-kit";
import Menubar from "./Menubar";
export default function MainEditor() {
const editor = useEditor({
extensions: [StarterKit],
content: `<h2>Hello world</h2>`
})
return <>
{editor ? <Menubar editor={editor} /> : null}
<EditorContent editor={editor} />
</>
}
```
Next, open `src/components/Menubar.tsx`
```javascript
// src/components/Menubar.tsx
import {Editor} from '@tiptap/react'
interface IMenubarProp {
editor: Editor
}
export default function Menubar({editor}: IMenubarProp) {
const getFocus = () => editor.chain().focus()
const isActive = (type: string, options?: any) => {
return editor.isActive(type, options ?? {}) ? 'is-active' : ''
}
const menus = [
[
{icon: 'bold', onClick: () => getFocus().toggleBold().run(), isActive: isActive('bold')},
{icon: 'italic', onClick: () => getFocus().toggleItalic().run(), isActive: isActive('italic')},
{icon: 'strikethrough', onClick: () => getFocus().toggleStrike().run(), isActive: isActive('strike')},
{icon: 'code-line', onClick: () => getFocus().toggleCode().run(), isActive: isActive('code')},
],
// ...
]
return <div className="menu">
{menus.map(group => {
return <div className="group-item">
{group.map(item => {
return <button className="menu-item" onClick={item.onClick}>
<i className={`ri-${item.icon} ${item.isActive}`}></i>
</button>
})}
</div>
})}
</div>
}
```
After that, just import `<MainEditor/>` to `App.tsx`
```javascript
// src/App.tsx
import MainEditor from "./components/MainEditor";
import './App.css'
export default function App() {
return <MainEditor />
}
```
Run app to check the result
```shell
$ npm run tauri dev
```

## #4. Time to style
Alright, everything work well so far. But we still have no style for the app.
Let's add style to `src/App.css` file
```css
.menu {
display: flex;
gap: 0.5rem;
padding: 0 1rem;
position: fixed;
z-index: 10;
}
.group-item {
display: flex;
gap: 0.5rem;
}
.menu-item {
padding: 0.5rem 0.75rem
}
.menu-item .is-active {
color: #55db55;
}
// Editor css
.ProseMirror {
padding: 1rem;
outline: none;
padding-top: 2.5rem;
}
.ProseMirror >
* + * {
margin-top: 0.75em;
}
.ProseMirror ul, .ProseMirror ol {
padding: 0 1rem;
}
.ProseMirror h1, .ProseMirror h2, .ProseMirror h3, .ProseMirror h4, .ProseMirror h5, .ProseMirror h6 {
line-height: 1.1;
}
.ProseMirror code {
background-color: rgba(97, 97, 97, 0.1);
color: #616161;
}
.ProseMirror pre {
background: #0d0d0d;
color: #fff;
font-family: 'JetBrainsMono', monospace;
padding: 0.75rem 1rem;
border-radius: 0.5rem;
}
.ProseMirror pre code {
color: inherit;
padding: 0;
background: none;
font-size: 0.8rem;
}
.ProseMirror img {
max-width: 100%;
height: auto;
}
.ProseMirror blockquote {
padding-left: 1rem;
border-left: 2px solid rgba(13, 13, 13, 0.1);
}
.ProseMirror hr {
border: none;
border-top: 2px solid rgba(13, 13, 13, 0.1);
margin: 2rem 0;
}
// Scrollbar css
::-webkit-scrollbar {
width: 14px;
height: 14px;
}
::-webkit-scrollbar-button {
display: none;
width: 0;
height: 0;
}
::-webkit-scrollbar-corner {
background-color: transparent;
}
::-webkit-scrollbar-thumb {
border: 4px solid rgba(0, 0, 0, 0);
background-clip: padding-box;
border-radius: 8px;
background-color: rgb(182, 182, 182);
}
::-webkit-scrollbar-track {
border: 4px solid transparent;
background-clip: padding-box;
border-radius: 8px;
background-color: transparent;
}
```
Looks good hah ? 😁

## #5. Change app's icon (optional)
By default, Tauri has a default icon. If you want to change it to another using my tool [here](https://github.com/hudy9x/tauri-icon-converter)
Prepare an icon in .PNG format that has size of 1024px x 1024px. And it's name must be 1024x1024. Now clone the tool and install packages
```shell
$ git clone https://github.com/hudy9x/tauri-icon-converter
$ cd tauri-icon-converter && npm install
```
And then, copy the icon to `/tauri-icon-converter` folder and run the below command
```shell
$ node .
```
After genereting process finished, you guys can see a list of icon in `/tauri-icon-converter/outputs`
Just replace all of them, but `.keep` file to `/src-tauri/icons` folder
You could also verify by running `npm run tauri dev`. If the icon showed as below then everything work well

## #6. Build app
Time to package our app to .msi file. Open terminal and run the following
```shell
$ npm run tauri build
```
If you guys got an error like below
That's because your `indentifier` not unique. Just open `src-tauri/tauri.conf.json` and change value to a new one. I changed mine to `com.notebook.dev`

Ok, run the command `npm run tauri dev` again. And see the result
After building process finished you can see the output path like above
## Conclusion
So far, you've learnt how to build a desktop application using Tauri and Reactjs.
You can also improve this app by providing some personal feature like auto update, sign-in, theme, ...etc
Thank you for reading! | hudy9x |
1,212,711 | Hi founders, can you share what is the reason customers pay for your tool? | There is one question that is most important, and most founders ignore it. However, if you want to... | 0 | 2022-10-06T14:10:54 | https://dev.to/shbz/hi-founders-can-you-sharewhat-is-the-reasoncustomers-pay-for-your-tool-1ei8 | startup, business, webdev, beginners | There is one question that is most important, and most founders ignore it. However, if you want to succeed in your startup business, you need to focus on why your customers are paying for your product.
_We have solved a big problem of SaaS products membership and eCommerce store issue of high churn rate._
**What is the churn rate?**
Churn rate is the percentage of subscribers who leave a company within a given time period. (week, month, year)
For example, if you have 5000 customers at any given time and 300 leave over a month, your churn rate for that month is 6%.
With our startup **[Churnfree](https://churnfree.com/)**, businesses can offer their customers that are dynamic offers and discounts as well as feedback, so they don't leave their service and also gets a review of what they like/dislike about their business.
**You can also share yours!** | shbz |
1,212,733 | Beautiful goldish avatar using only one element - A step-by-step tutorial | Tutorial on how to create a beautiful golden avatar using only one element. HTML For... | 0 | 2022-10-06T14:27:52 | https://designyff.com/code/golden_avatar | css, html, webdev, tutorial |
**Tutorial on how to create a beautiful golden avatar using only one element.**

## <u>HTML</u>
For HTML, we need only one div element with class "avatar".
```html
<div class="avatar"></div>
```
CSS
For CSS, first we'll style the "avatar" class.
We'll set width and height of 100x100 pixels with border set to 10px goldish solid.
I'll just set a background image that I found on google and set the size to cover.
To form a circle, simply set border-radius property to 50%.
Lastly, we'll set position to relative.
```css
.avatar {
width: 100px;
height: 100px;
border: 10px solid #d0ab35;
background-image: url('https://dl.memuplay.com/new_market/img/com.vicman.newprofilepic.icon.2022-06-07-21-33-07.png');
background-size: cover;
border-radius: 50%;
position: relative;
}
```
Now we'll style the before pseudo element.
We'll set content and position to absolute with top, bottom, left and right set to -16 pixels.
This means that this element will be by 16 pixels larger on all sides that the div "avatar" element.
We'll set border radius to 50% to form a circle.
Now we'll set background image to linear gradient with some beautiful golden colors.
Using clip-path property, we'll create cut two squares, one on top and one on the right side.
By setting z-index property to -1, this element will go beneath the "avatar" div element, and it will look like a 16 pixels wide border.
```css
.avatar:before {
content: "";
position: absolute;
top: -16px;
bottom: -16px;
left: -16px;
right: -16px;
border-radius: 50%;
background-image: linear-gradient(to right, #BF953F, #FCF6BA, #B38728, #FBF5B7, #AA771C);
clip-path: polygon(54% 0, 53% 5%, 59% 6%, 61% 0, 100% 0, 100% 60%, 94% 58%, 91% 67%, 100% 70%, 100% 100%, 0 100%, 0 0);
z-index: -1;
}
```
Now we'll style the after pseudo element.
We'll set content and position to absolute with top, bottom, left and right set to -11 pixels.
This means that this element will be larger that 11 pixels on all sides that "avatar" div element, and 5 pixels smaller that the before pseudo element.
We'll just set solid white border to 4 pixels with radius of 50% to form a circle.
```css
.avatar:after {
content: "";
position: absolute;
top: -11px;
bottom: -11px;
left: -11px;
right: -11px;
border: 4px solid #fff;
border-radius: 50%;
}
```
And that's it.
You can find video tutorial and full code [here](http://localhost:63981/code/golden_avatar).
Thanks for reading. ❤️ | designyff |
1,213,008 | AWS is Everywhere 🤩 | Fair warning: Long Post TLDR: AWS is everywhere 🤩 This has happened to me on multiple occasions. I... | 0 | 2022-10-06T19:32:05 | https://dev.to/itsmenilik/aws-is-everywhere-411p | aws, cloud | **Fair warning: Long Post**
**TLDR: AWS is everywhere 🤩**
This has happened to me on multiple occasions. I tend to find out that AWS supports every business that has had a huge impact in my life!
To paint you a picture, anytime I would interact with a web service, I’d ask myself “What are the odds that AWS is involved in the infrastructure of this service?”. I ask myself this question everyday ever since I got certified.
I always knew, with a great degree of confidence, that it was likely 99% of the time. Although, every time I guess right I'm always in for a surprise.
It wasn’t until recently that my love for the cloud was reinvigorated! My daily routine consists of going to a dance studio to train in all styles of dance. The studio had their 4th year anniversary. To celebrate, they gave out free demo classes, gift bags, snacks, merch and etc.
They also had a section in the studio where you could take group pictures. I thought it would good for me to interact with other and get my picture taken with them. The experience involved us taking pictures in a Photo Booth like environment, but without being constrained in a small box. Everyone was having the time of their lives. They would wear funky gear to make the picture taking experience that more enjoyable. I also wore the gear. Everyone was happy. From my perspective, It was an alright experience. The funny part was that I was happy, but for different reasons besides the picture. My enjoyment came from understanding the camera!
Once we took our pictures, the photographer provided us with a QR code to scan a digital copy of the pictures. The camera was integrated with the screen. I scanned the QR code from the screen to get a copy. As I saw the weblink load on my screen, I realized that I received deeper insight than I initially realized. I checked to see what DNS the QR code led me to. To my surprise I found out that the picture we took was stored in an AWS S3 bucket! Everyone was accessing the photographers pictures from the companies S3 bucket.
To add icing on the cake, I wanted to know if the S3 bucket still stored my picture. So I requested access to the weblink once more. It wasn’t there! The company set a life cycle configuration. The bucket was required to delete the object based file after a set amount of time! To give context, I accessed the link a day after I requested it for the first time.
This is only one of the many experiences I’ve had in my life where I got to see how others are using AWS to handle their business needs. The kind of experience where I felt like all of the knowledge I've acquired throughout my life wasn't for nothing. That every action I took in my past to get me to this point in my life has allowed my to have a different perspective. The kind of perspective that has been able to challenge my beliefs for the better. It's always exciting to see what the future has in stored for me but for other! How else will AWS get involved?
I’m well aware that others are using amazon web services. Even as I’m writing this, I'm 100% confident that someone other than me is having a similar euphoric experience. I’m just eternally grateful to have the capacity to not only see the bigger picture, but to have the knowledge and wisdom to understand what's happening around me. My eyes truly opened up when I dived deeper into the cloud.
What other cloud related experiences will I find along the way?!?! | itsmenilik |
1,772,418 | Dive into ES6 pt. 2 | In this post, we'll go over, generators, iterators, proxies, and... | 0 | 2024-02-26T12:55:41 | https://dev.to/allyn/dive-into-es6-pt-2-nem | beginners, javascript | In this post, we'll go over, generators, iterators, proxies, and reflections.
Generators.
Generators can be broken down conceptually into 2 parts; the function and the object. But as a whole, they are functions that can return multiple values sequentially. Let's take a look at the syntax first.
```
function* greeting () {
yield 'Hello!';
yield 'Good morning!';
return 'Have a nice day!';
}
```
The reason why generators can be broken down into 2 parts is because when you make your function call, the code does not execute. Instead, it returns an object, known as the generator object, to handle execution. This object consists of 2 values; the `value` property which holds on to the returned value, and `done` which represents the completion status of the function with a boolean.
Let's dive a little deeper.
Since the call to the generator returns the generator object, how will we begin to execute the code? With the `next()` method! When you invoke the `next()` method, it runs the execution until it hits the first yield statement. Once we hit our yield, the function pauses and returns whatever value follows `yield`. In the example above the first call to `greeting().next()` will return "Hello!" and wait for the next call to `greeting().next()` to continue. This also updates our generator object. After the first call to `greeting().next()`, our generator object now looks like this.
```
{ value: 'Hello!', done: false }
```
The `value` property has its value from our yield statement and `done` has a value of false because our function isn't complete. Once our function hits the return statement, the done value will become true. Continuous calls to the next method will progress our function.
A feature of generators is generator composition which allows you to ['transparently "embed" generators in each other'](https://javascript.info/generators#generator-composition). By using the `yield*` syntax, we're able to _compose_ inner generators inside an outer generator. This also does not compromise memory to store the results.
Yield can not only return values, it can also receive them. You can pass arguments into the `next` method which will take the place of the yield statement.
Moving on to iterators.
According to MDN, an iterator can be defined as an object containing a ["`next()` method that returns an object with two properties."](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Iterators_and_Generators#iterators) This would make generators an iterator.
On to Proxies.
In plain English, proxies are something used to represent the value of another thing. In programming, proxies are objects used in place of another object. With proxies, you also can redefine essential object operations including getting and setting.
Proxies are created with 2 parameters: the `target` which is your focal object, and the `handler` which is an object of the operations you are redefining. The proxy object also acts as a prototype chain, meaning you can access properties from your target object and perform lookups.
Handlers are sometimes referred to as traps because they can "trap" certain operations. Let's take a look at this example from MDN.
```
const target = {
message1: "hello",
message2: "everyone",
};
const handler2 = {
get(target, prop, receiver) {
return "world";
},
};
const proxy2 = new Proxy(target, handler2);
```
When we try to access our target properties, what do you think will happen? If you have peered into data structures, specifically hash tables, you remember that JS objects are instances of hash tables, which means they come with getting and setting operations. Instead of calling get or set methods on objects, we use dot or bracket notation. So if we were to try to access our target object's properties, we would get 'world' back instead of the properties because we overwrote our get operation. This is a trap.
Finally, let's peak into Reflections.
Reflections are often used in conjunction with proxies because the Reflect object simplifies creating proxies. The Reflect object consists of static methods and cannot be constructed, like the Math object. These methods are named just like the methods one would redefine in a proxy. Reflections can save you from traps like our `get` method by allowing us to use default operations.
This concludes my dive into ES6. Happy coding!
| allyn |
1,213,279 | Cloudflare Turnstile plugin for Deno Fresh (p1) | TL/DR: If you read the title and know exactly what I mean already, simply go to... | 20,070 | 2022-10-07T16:04:26 | https://dev.to/khuongduybui/cloudflare-turnstile-plugin-for-deno-fresh-3ph0 | fresh, javascript, typescript, webdev | > **TL/DR**: If you read the title and know exactly what I mean already, simply go to https://deno.land/x/fresh_turnstile and follow the README.
**DISCLAIMER**: Hi all, this is my first post after 3 years of reading exclusively on dev.to, so all criticisms are welcome! Coincidentally, I'm also writing about my first open-source project release, so again provide feedback by all means.
## Background
Alright, now that the "noob" disclaimer is out of the way, let me quickly clarify all the nouns I mentioned in the post title:
1. [Cloudflare](https://www.cloudflare.com/about-overview/): CDN, DOS-protection, 1.1.1.1, VPN, etc.
2. [Turnstile](https://blog.cloudflare.com/turnstile-private-captcha-alternative/): Cloudflare's recently released CAPTCHA alternative.
3. [Deno](https://deno.land/): The hopeful successor of NodeJS.
4. [Fresh](https://fresh.deno.dev/): Deno's recently released web framework with a focus on [island architecture](https://jasonformat.com/islands-architecture/).
5. [plugin](https://fresh.deno.dev/docs/concepts/plugins): 3rd-party library to inject CSS and JS into every page in Fresh.
6. CAPTCHA (not in the title, but for completeness' sake): a common instrument to guard against machine-driven web interactions.
_OK, class is dismissed; you will be quizzed on these terms next week._
Kidding 😂
Now that we are absolutely on the same page (we are, right?) about what I made, let's talk about how it's supposed to be used.
In this first release, I'm covering three basic use cases of Turnstile:
1. Protecting a traditional form submission.
2. Protecting a form submitted with AJAX / fetch / etc.
3. Protecting a custom interaction.
## Use Case 1: traditional form submission.
Err not so fast, before you can do anything with the plugin you need to have your Turnstile configured, which leads us to ...
## Prerequisites!
1. You need to give up an email address (to Cloudflare, not me).
2. You need a Cloudflare account (not my call, don't argue).
3. You need a Turnstile site (free for now, again not my call).
Follow the instructions on the official page and you will be good to go in 30 seconds: https://www.cloudflare.com/lp/turnstile/
Oh, and you also need a Fresh app (not any fresh app, _the_ Deno Fresh app, ok?).
Simply run this command to create one if you haven't.
```sh
deno run -A -r https://fresh.deno.dev sample-app
```
Now that you have created your Fresh app, add `fresh-turnstile` to your `import_map.json` for convenience:
```json
{
"imports": {
"$turnstile/": "https://deno.land/x/fresh_turnstile@1.0.0-0/"
}
}
```
Then consume the plugin in your app's `main.ts`.
```ts
import { TurnstilePlugin } from "$turnstile/index.ts";
await start(manifest, {
plugins: [
// ...
TurnstilePlugin(),
// ...
],
});
```
Now you are ready to use the plugin.
## Use case 1 (for real this time)
This is the most common use case for Turnstile.
The basic idea is you have a form, such as a "leave us a note" form, which you only want human beings to be able to submit as that should largely reduce the amount of spam you receive from the form.
To achieve that with Turnstile, on the client side, you put a Turnstile widget inside your form, which will talk to Turnstile API, do the magic, and decide whether the actor is a human. There are several modes of operation for the widget: interactive, non-interactive, and completely hidden, which you chose when you created the Turnstile site in your Cloudflare dashboard. Once the widget has verified (or it thinks it has) that the actor about to submit the form is a human, it will append a hidden input to your form with a token from Turnstile, which gets included as the form is submitted. Then, on the server side, you can validate the token by making a call to the Turnstile API.
This plugin provides a `<CfTurnstile/>` component for you to use on the client side (fill in `sitekey` from your Turnstile site, which can always be retrieved from your Cloudflare dashboard):
```tsx
import CfTurnstile from "$turnstile/components/CfTurnstile.tsx";
// ...
<form action="..." method="POST">
// other form fields such as name, email, message, etc.
<CfTurnstile sitekey="..." />
<input type="submit" />
</form>
```
Once the page is fully rendered, `<CfTurnstile/>` will be replaced with a DOM tree similar to this:
```html
<div class="cf-turnstile">
<iframe><!-- THE WIDGET --><iframe>
<input type="hidden" name="cf-turnstile-response" value="<!-- THE TOKEN -->" />
</div>
```
As the form gets submitted, you can look for `cf-turnstile-response` in your route handler and follow [Turnstile's instructions](https://developers.cloudflare.com/turnstile/get-started/server-side-validation/) for validation.
Or, if your form is submitted to a POST route, you can use the provided handler generator like this (again, fill in `cf_turnstile_secret_key` with your Turnstile site's secret, also retrievable from your Cloudflare dashboard):
```ts
import { CfTurnstileValidationResult, generatePostHandler } from "$turnstile/handlers/CfTurnstileValidation.ts";
import Page from "$flowbite/components/Page.tsx";
export const handler = { POST: generatePostHandler(cf_turnstile_secret_key) };
export default function CfTurnstileValidation({ data }: PageProps<CfTurnstileValidationResult | null>) {
/* 3 scenarios can occur here:
* 1. data is null => the form was not submitted correctly, or the secret key was not provided.
* 2. data.success is false => the form was submitted correctly, but validation failed. data["error-codes"] should be a list of error codes (as strings).
* 3. data.success is true => the form was submitted correctly and validated successfully. data.challenge_ts and data.hostname should be available for inspection.
*/
}
```
**A side note on the interactivity of the widget**:
If you look at the `<CfTurnstile/>` component source code, you will not see an IS_BROWSER guard, which means that it will be interactive even outside an island. That might sound like a violation of the island architecture at first, but with implicit rendering, the actual augmentation of the widget on top of the placeholder `<div/>` is done by Turnstile's own JavaScript, making it very difficult to render a "disabled" widget.
Therefore, I made a decision to leave that alone and rely on the plugin consumers' mental efforts to only use this component inside their islands. If you strongly believe that this decision is a mistake, please file an issue on the plugin repo:
https://github.com/khuongduybui/fresh-turnstile/issues/new
---
That's it for tonight; thank you very much for your time.
In the following posts, I will discuss the remaining use cases. | khuongduybui |
1,213,302 | How to use GIT in shell (basics) | On my full-stack developer journey I've found, that making notes during your learning is a great way... | 0 | 2022-10-07T04:25:19 | https://dev.to/delucasso/how-to-use-git-in-shell-basics-2aij | git, beginners | On my full-stack developer journey I've found, that making notes during your learning is a great way to remember stuff. You can also go back to your notes, if you need some help.
**If you are new to GIT, you can should read a git handbook here:** [https://docs.github.com/en/get-started/using-git/about-git]
####[Here you can learn the branching]:
(https://learngitbranching.js.org/)
##I summarized basics here.
When we are in a local bash and in particular project directory, here is what we can do.
####git phases are:
- WORKING DIRECTORY
- STAGING AREA
- LOCAL REPOSITORY
- REMOTE REPOSITORY
####1. To **INITIALIZE** a git
_git init_
####2. To **INCLUDE ALL FILES** (those listed in .gitignore are omited
_git add ._
####Premade templates for .gitignore files
[https://github.com/github/gitignore]
####3. To **CREATE A LOCAL STAGE**
_git commit -m "Initial Commit"_
####4. To **PUSH** commits to a remote repository
Push the git to the origin main (remote)
Don't forget to commit changes first, then :
_$ git commit -m "Your commit stage description"_
_git remote add origin https://github.com/DeLucasso/NAME_OF_GIT.git_
_git branch -m main_
_git push -u origin main_
####5. To **RESET** to some specifid commit
Use _git log_ command to find a hash of commit that you'd like to reset back to.
_git reset --hard [hash]_
####6. If you want to **PRESERVE** your work, you can use the stash command:
_git stash
git reset --hard [hash]
git stash pop
_
####7. To **IGNORE** (omit) files from the git repository to be uploaded to GitHub: First create a hidden file gitignore
_touch .gitignore_
####8. To **ADD** files to the .gitignore file
_open .gitignore_
####9. To **REMOVE ALL** files from git stage
_git -rm --cashed -r ._
####10. To **REMOVE SINGLE** file from git stage
_git -rm --cashed filename.txt_
####11. To **GET A STATUS** a status of git
_git status_
####12. To **GET A LOG** of the git stage
_git log_
####13. To put a **COMMENT** into .gitignore use #
_#This is a comment line in .gitignore_
####14. To use **WILDCARDS** in .gitignore
_*.txt_
[An article to understand git branching:]
(https://git-scm.com/book/en/v2/Git-Branching-Basic-Branching-and-Merging)
####15. To **MAKE A NEW** a new branch
_git branch -m new_branch_name_
####16. To **CHECK** branch list
_git branch_
####17. To **SWITCH** a branch ( Check Out ), then you can see '*' at
_git checkout branch_name_
####19. To **RENAME** a local branch
_git -m old_name new_name_
####20. To **DELETE** a LOCAL branch
First you have to checkout a branch that you want to delete (if its' marked as *)
Then you can delete a branch
_git -d branch_name_to_delete_
####21. To **DELETE** a REMOTE branch
_git push origin --delete branch_name_
####22.!! Everytime when you want to **COMMIT** changes to the git, you have to do this every time:
_git add ._ // (to include all files to git)
_git commit -m "Your commit comment of the changes you've made"_
####21. To **MERGE** a branch to main, don't forget to add all files and commit changes first!
First if you are happy with the changes in branch, you can merge the branch with main
_git checkout main_
_git merge name_of_branch_that_you_want_to_merge_
The vim editor will open, so you can add comments to merge. Then to save it, just write:
_:q!_
##That's it folks. I wrote everything in an order, that you will probably use it. I hope it help you with a git commands in shell.
[Here is my github repo:](https://github.com/DeLucasso/git/blob/main/how_to_use_git.txt)
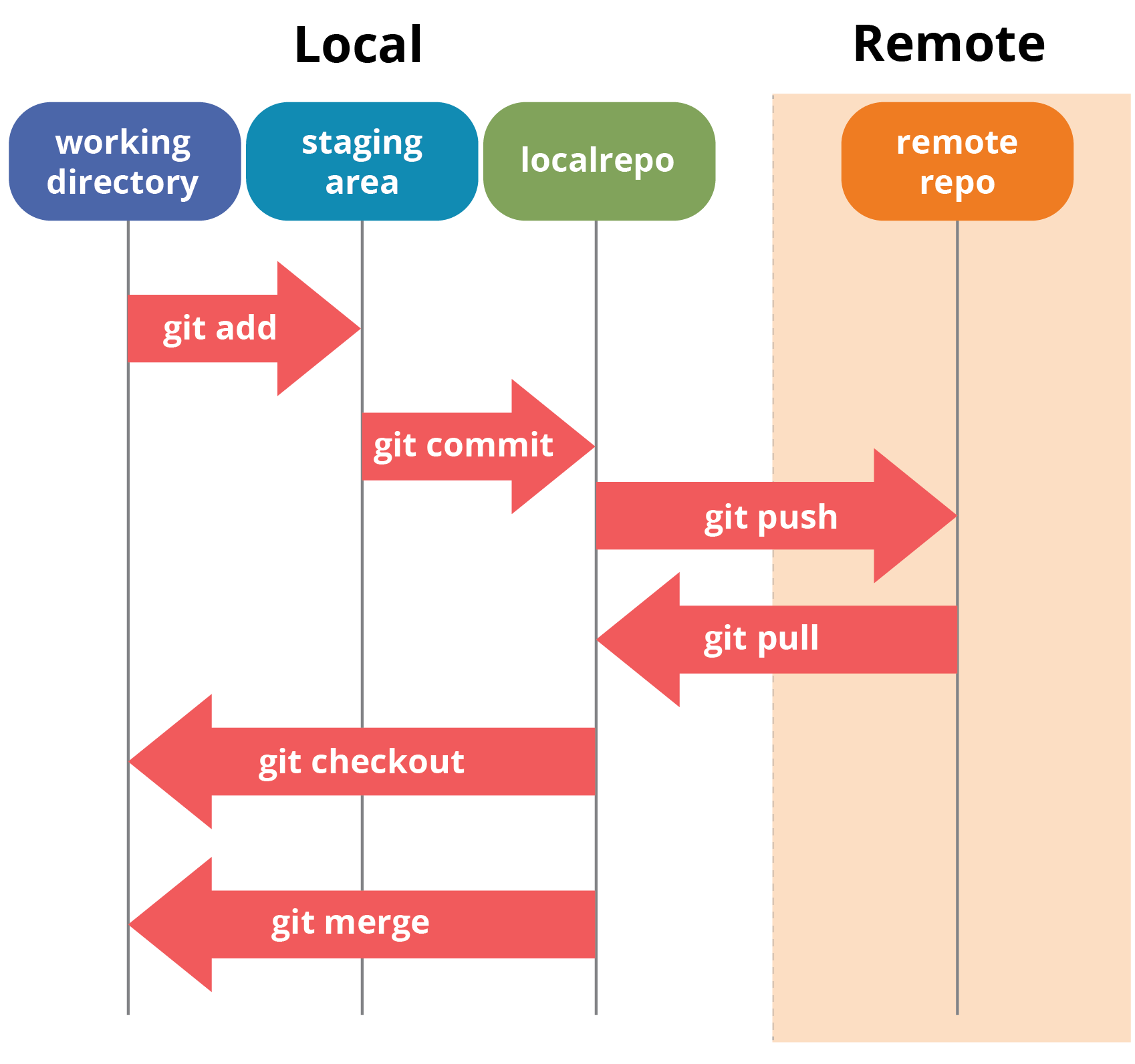 | delucasso |
1,213,412 | Nearshore VS Offshore Development: What to Choose in 2022-2023 | Outsourcing software development allows businesses to improve operational performance and flexible... | 0 | 2022-10-07T07:51:21 | https://dev.to/techmagic/nearshore-vs-offshore-development-what-to-choose-in-2022-2023-2a71 | development, startup | Outsourcing software development allows businesses to improve operational performance and flexible up-scaling, holding your core team's focus on business processes. To be cutting edge, processes must run keeping costs low. Outsourcing software development offers you agility and speed!
The IT outsourcing market is predicted to reach $425 billion by 2026, according to Statista. That's why you need to know nearshoring vs. offshoring remote team models to create digital goods quickly and profitably. Keep reading, and you'll find out about nearshore outsourcing, its benefits, and the value offshore development may provide to your company.
Let's begin!
## **Nearshore**
Nearshore outsourcing is when companies delegate software development to a team in a similar time zone from the same geographical location.
Nearshore outsourcing bridges the gap between offshore and onshore, providing the best of both worlds. As the name implies, the organization with which you will collaborate must be located in a country close to yours and, ideally, share the same time zone (or at least, not have more than 3 hours difference between). Nearshore outsourcing companies provide a larger talent pool with the specific skills and expertise you need for the project.
Working with a nearshore outsourcing partner is accessing the necessary skills, talent pool (i.e find a CTO Co-founder), resources, and capabilities to drive digital transformation. However, this does not have to be the only reason you choose nearshore outsourcing.
Are there any other benefits or drawbacks of nearshore outsourcing? We have the answer.
## **Pros and cons of nearshoring**
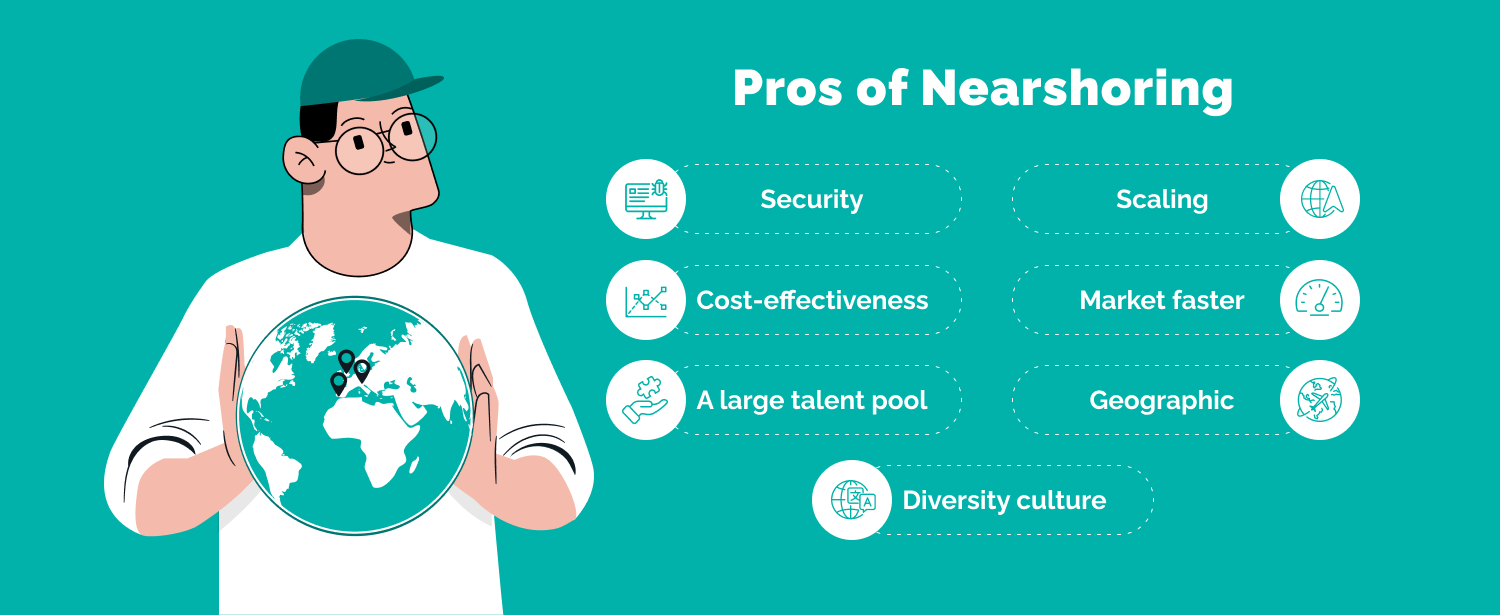
Physical closeness to your staff is the main advantage of nearshoring. Here are a few additional valuable advantages of going nearshore:
**Security**
You gain greater control over your intellectual property by nearshoring your development projects. The same data protection laws make it easier to draft contracts and enforce confidentiality throughout and after the project.
**Cost-effectiveness**
Organizations can significantly reduce their development expenditure by choosing a nearshore software development partner since they avoid the costs associated with in-house recruiting or the higher hourly rate of onshore teams. Furthermore, compared to offshore software development, having an expanded team close by implies that communication may be nearly instantaneous, reducing the time lag between teams, amount of time-sharing information, etc.
**Scaling**
The nearshore approach enables businesses to boost development capacity on-demand to accommodate a single project or a growing development portfolio. The chosen outsourcing partner is in charge of building a team of software engineers with the best-fit talents for the current project, leaving the client's core team to focus on strategies and new technologies.
**Market faster**
The nearshore engagement strategy decreases the time required to educate a team. As a result, the software development lifecycle is reduced, and a customer may deliver up to twice as quickly to market a quality product.
**A large talent pool**
When a firm chooses a nearshore software partner, it gains access to a pool of thousands of highly and diversely qualified professionals without relying on time-consuming internal recruitment. The outsourcing partner creates the dedicated software development team for a client's project and then integrates this additional resource with the organization's in-house team.
**Geographic**
The nearshore approach to software outsourcing brings a broadened IT staff within the "arm's reach" of the client's headquarters. Improved temporal synchrony results in smoother communication, little cultural differences, cooperation, and project delivery. It makes real-time collaboration easier. Moreover, nearshore locations can be reached by plane in two to three hours. Your business trips would be shorter, less expensive, and more productive. The client will have more possibilities to see the outsource team in person frequently.
**Diversity culture**
According to the International Journal of Multidisciplinary, one of the most important factors is cultural affinity, which includes comparable negotiation conduct and viewpoints.
Cultures are broadly similar when work is outsourced to a neighboring country. It is easier for teams to integrate and collaborate with faster communication and more productive interactions, improving deliverables' efficiency and quality.
## **Cons of nearshoring**
**High-cost**
You save money compared to onshore or in-house vendors, but your hourly are higher compared to offshore vendors. You must conduct additional due diligence regarding work quality and vendor capabilities to ensure that the quality of deliverables is worth the additional cost.
**Note:** Nearshore is about outsourcing software development, technical support, and call center jobs in a neighboring country that is a short distance away. Now, let's move on to offshore outsourcing.
## **Offshore**
According to the YouGov report, 48% of companies outsourced offshore and predicted a total market value of $620 billion by 2032.
Offshoring is a business concept in which you outsource a service or project to a firm in another country to get high-quality technology available at a less costly, particularly one that is geographically far from your location. It may even be on the opposite side of the world or with a time difference of five or more hours. As a result, the offshore staff is frequently referred to as "overseas workers."
Many providers in remote areas operate on a low-cost basis, and their pricing might be extremely appealing. If this path is taken, the client organization must spend resources to ensure that communication works effectively on both sides and that the engagement results in a favorable conclusion.
Offshoring might benefit long-term projects that start from MVP development, provided preparation is done to establish frameworks to compensate for the communication risks of different time zones. For instance, a "follow the sun" strategy in which teams overlap shifts to maximize productivity.
So let's take a closer look at benefits of offshore outsourcing and its drawbacks to realize which outsourcing model fits your company.
## **Pros and cons of offshoring**
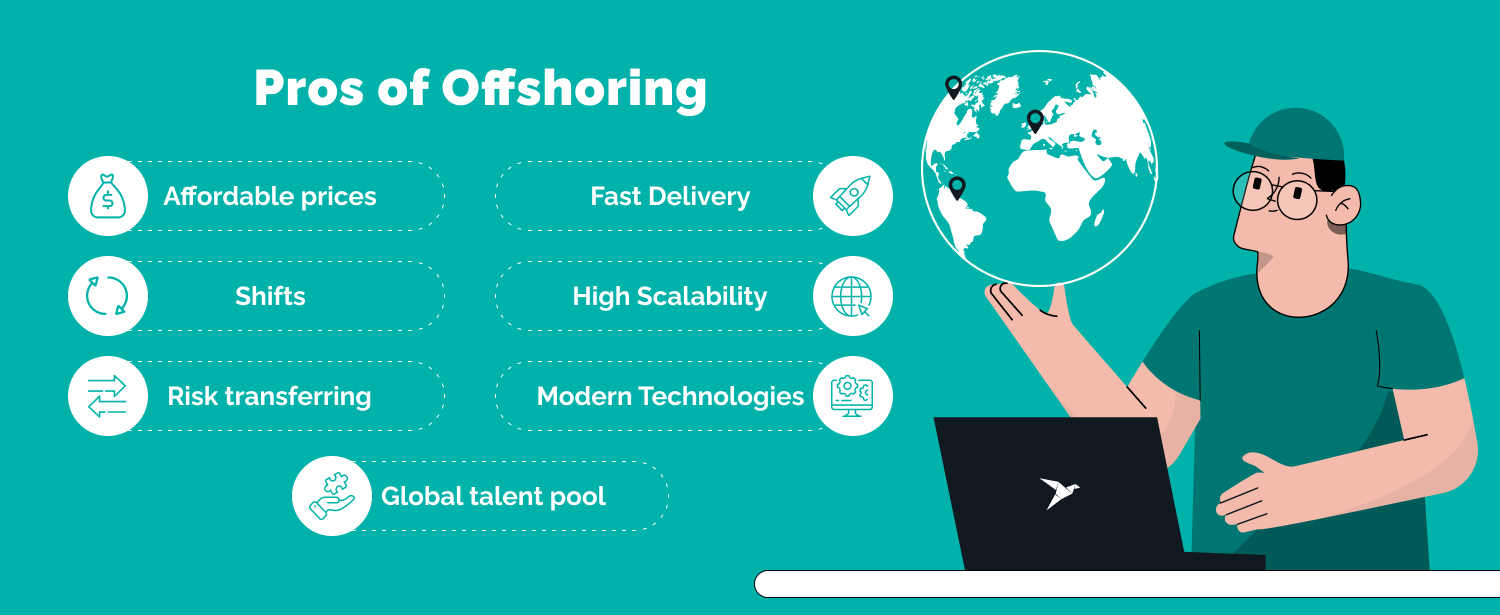
There are main advantages of hiring an offshore software development team.
**Cost savings**
Because of the cost of living and salaries, software development teams may be able to develop at cheaper hourly rates than in other regions of the world.
**Global talent pool**
You can choose your offshoring destination based on your talent requirements. Offshore destinations have seen a spurt in training institutions imparting professional technical courses such as engineering, mathematics, science, and technology. It provides clients access to a large talent pool and more flexible scalability and efficiency than in-house development - with a shorter time-to-market.
**Shifts**
Working in separate time zones might operate 24/7 without needing to work at the company headquarters at night. Offshore professionals are available to work in the shifts their clients want them to. This ensures an overlap of working hours (just like in nearshore countries) and a quick turnaround.

## **Cons of offshoring**
**Time zone differences**
The time zone difference for clients is usually around 10 to 14 hours. This is not easy to overcome, and the working hours overlap somewhat. It affects the frequency and quality of meetings, ultimately affecting project deliverables.
**Communication**
Where it falls short is in the degree of control it provides. With an offshore workforce possibly located on the other side of the world, maintaining smooth communication and organizing face-to-face meetings becomes a significant issue.
**Cultural barriers**
Small percentage of professionals who are trained or have enough experience working with western clients, and cultural barriers can be too much to overcome for remote teams.
**Quality issues**
Verifying vendors' capability and checking their internal processes may be difficult by distance. Many companies outsource software development to vendors that do not have mature processes and cannot meet the quality standards prevailing in the industry.
**Traveling**
Traveling offshore means 15 or more hours of flying. Longer wait times and misunderstandings due to language difficulties and cultural differences might easily raise the prices again. This does not include the stress you experienced during the business process. However, if the lowest hourly cost is your primary concern, offshore outsourcing is most likely your best alternative.
## **What’s the difference between nearshore and offshore?**
It is difficult to determine that outsourcing software development is profitable for many businesses worldwide, from startups to large multinational corporations. Location and money are important considerations, but there is more to it. So, which option should you take?
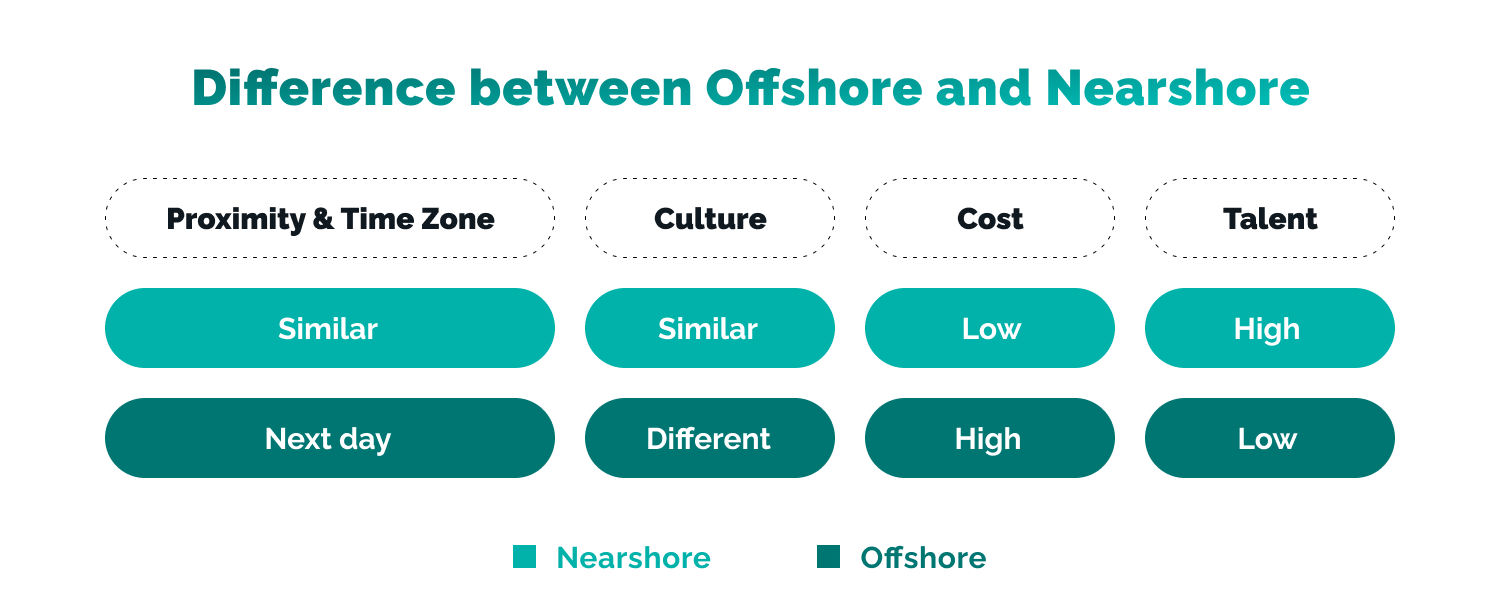
**Proximity & Time Zone**
The first major difference between offshoring and nearshoring is geographic proximity and time zone differences. Today, IT development is more advanced and changing faster than ever. Such tasks often come with liability and risk management issues. This requires careful consideration, clear and effective communication, and the practical need for face-to-face interaction.
**Culture**
Although countries all over the globe speak English, many companies practicing offshoring have encountered serious cultural and communication barriers. Simply put, cultural affinity is a more effective and frustration-free working environment. It also means smoother business cooperation for both.
As the world gets smaller and businesses go global, cultural affinity translates into greater stability and predictability.
**Cost**
Reducing costs is still the primary reason why companies outsource. Being closer to the client country leads to more effective interaction at a lower cost and greater productivity. Time zone proximity erases the need to work extra hours - commonly seen when outsourcing to faraway countries. This means the overall or loaded hourly rate with nearshoring is lower, thus lowering the overall cost.
Consider your personnel expenses and the management of remote teams, infrastructure, and services. For example, your in-house staff may become bored traveling or working late at night or early in the morning.
**Talent**
A thorough comparison between offshoring and nearshoring would not be complete without assessing the talent pool offered by these two forms of IT outsourcing. Historically, companies in the U.S. have offshored low-wage and low-responsibility jobs to cheap labor locations around the globe. However, that trend has changed as more companies rethink their offshoring strategies.
**To recap:** Offshoring is the best choice when money is the main issue and for projects that need little to no visual communication or for the complete team to be online at the same time.
Offshore outsourcing works best when:
- cost is the most important concern,
- real-time cooperation is modest,
- your internal procedures are mature,
- your expected outputs are simple.
When nearshore is the alternative if you want to closely monitor the project and profit from relationships with highly competent and experienced IT workers. It also simplifies communication and time management while hastening the completion of your project.
Now, you might be confused with nearshore and offshore outsourcing comparison. So check out these tips for picking a relevant outsourcing model for you.
## **Tips for choosing the right outsourcing model**

Determine your priorities before hiring a software development business, just like you would looking for the ideal developer. The location of the outsourcing company you pick impacts whether it can match your expectations.
Answer the questions such as:
- What is your budget? (if limited, then it is best to turn to countries with a low rate; if not, then you can focus on the professional level of developers)
- How involved do you intend to be in the project?
- Whether it's important to you to be able to communicate in real-time with developers?
- Are there any specific local laws that you must comply with?
- Is it critical for you to be in the same country or city as the outsourcing provider?
- Do you have full in-house team or need more specialists (if you have the team and need more developers, consider will it be the problem in communication through different shifts)?
So, what do you choose should you go with an offshore or nearshore outsourcing company?
## **The bottom line**
Whether you want to up-scale resources for a single project or need to fill a skills gap to support your in-house team, outsourcing your software development delivers a cost-effective alternative with significant time savings.
Cost savings, cultural affinity, talent, physical closeness, and time zone are all significant benefits of nearshoring, allowing organizations to experience productivity gains, improved morale, and a higher return on investment.
"Nearshore software development is considered best to offshore software development" is neither fair nor factual. All firms have various goals; some may benefit from a mix of nearshore and offshore outsourcing, while others may discover that offshore outsourcing better fulfills their needs.
**The choice is yours!**
TechMagic has delivered over 120+ projects for HR tech, MarTech, healthcare, and FinTech industries. Also, we are a part of the Amazon Web Services, Azure, and partner networks. Contact us if you're looking for technical expertise.
## **FAQs**

**#1. What is the difference between nearshore and offshore outsourcing?**
Nearshore outsourcing means outsourcing to a location close to you or the same country. Offshore outsourcing means outsourcing in another country far away from your location with a different time zone
**#2. What is nearshore in BPO?**
Nearshore is a method of outsourcing Business Process Outsourcing (BPO). That’s a business model offering business processes in countries with low operational costs compared to the United States, Western Europe, or Japan.
**#3. What is a nearshore software development team?**
Nearshore software development teams provide development support to small, midsize, and large companies. Nearshore means a software development team is outside the client's main (home) country, however close to the main. One consideration is the time zone because communication is important. Typically, 60-90% of a nearshore team's work may be performed in a different time zone.
**#4. What is a nearshore project?**
A nearshore project is a project in which a company works completely or partially outside its offices or in another geographic area. Nearshore project teams use communication tools like videoconferencing to interact with the rest of the team.
| techmagic |
1,213,692 | Web scraping Google Play Movies & TV with Nodejs | What will be scraped Full code If you don't need an explanation, have a look at the full code... | 0 | 2022-10-07T15:10:45 | https://dev.to/serpapi/web-scraping-google-play-movies-tv-with-nodejs-3mg3 | webscraping, node, serpapi | <h2 id='what'>What will be scraped</h2>

<h2 id='full_code'>Full code</h2>
If you don't need an explanation, have a look at [the full code example in the online IDE](https://replit.com/@MikhailZub/Scrape-Google-Play-MoviesandTV-with-NodeJS-SerpApi#withPuppeteer.js)
```javascript
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const searchParams = {
hl: "en", // Parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook
category: "MOVIE", // you can see the full list of supported categories on https://serpapi.com/google-play-movies-categories
};
const URL = `https://play.google.com/store/movies/category/${searchParams.category}?hl=${searchParams.hl}&gl=${searchParams.gl}&device=${searchParams.device}`;
async function scrollPage(page, scrollContainer) {
let lastHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (true) {
await page.evaluate(`window.scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.waitForTimeout(4000);
let newHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
if (newHeight === lastHeight) {
break;
}
lastHeight = newHeight;
}
}
async function getMoviesFromPage(page) {
const movies = await page.evaluate(() => {
const mainPageInfo = Array.from(document.querySelectorAll("section .oVnAB")).reduce((result, block) => {
const categoryTitle = block.querySelector(".kcen6d").textContent.trim();
const categorySubTitle = block.querySelector(".kMqehf")?.textContent.trim();
const movies = Array.from(block.parentElement.querySelectorAll(".ULeU3b")).map((movie) => {
const link = `https://play.google.com${movie.querySelector(".Si6A0c")?.getAttribute("href")}`;
const movieId = link.slice(link.indexOf("?id=") + 4);
return {
title: movie.querySelector(".Epkrse")?.textContent.trim(),
link,
rating: parseFloat(movie.querySelector(".LrNMN[aria-label]")?.getAttribute("aria-label").slice(6, 9)) || "No rating",
originalPrice: movie.querySelector(".LrNMN .SUZt4c")?.textContent.trim(),
price: movie.querySelector(".LrNMN .VfPpfd")?.textContent.trim(),
thumbnail: movie.querySelector(".TjRVLb img")?.getAttribute("src"),
video: movie.querySelector(".TjRVLb button")?.getAttribute("data-trailer-url") || "No video preview",
movieId,
};
});
return {
...result,
[categoryTitle]: { subtitle: categorySubTitle, movies },
};
}, {});
return mainPageInfo;
});
return movies;
}
async function getMainPageInfo() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".oVnAB");
await scrollPage(page, ".T4LgNb");
const movies = await getMoviesFromPage(page);
await browser.close();
return movies;
}
getMainPageInfo().then((result) => console.dir(result, { depth: null }));
```
<h2 id='preparation'>Preparation</h2>
First, we need to create a Node.js\* project and add [`npm`](https://www.npmjs.com/) packages [`puppeteer`](https://www.npmjs.com/package/puppeteer), [`puppeteer-extra`](https://www.npmjs.com/package/puppeteer-extra) and [`puppeteer-extra-plugin-stealth`](https://www.npmjs.com/package/puppeteer-extra-plugin-stealth) to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the [DevTools Protocol](https://chromedevtools.github.io/devtools-protocol/) in [headless](https://developers.google.com/web/updates/2017/04/headless-chrome) or non-headless mode.
To do this, in the directory with our project, open the command line and enter `npm init -y`, and then `npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth`.
\*<span style="font-size: 15px;">If you don't have Node.js installed, you can [download it from nodejs.org](https://nodejs.org/en/) and follow the installation [documentation](https://nodejs.dev/learn/introduction-to-nodejs).</span>
📌Note: also, you can use `puppeteer` without any extensions, but I strongly recommended use it with `puppeteer-extra` with `puppeteer-extra-plugin-stealth` to prevent website detection that you are using headless Chromium or that you are using [web driver](https://www.w3.org/TR/webdriver/). You can check it on [Chrome headless tests website](https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html). The screenshot below shows you a difference.

<h2 id='process'>Process</h2>
First of all, we need to scroll through all movies listings until there are no more listings loading which is the difficult part described below.
The next step is to extract data from HTML elements after scrolling is finished. The process of getting the right CSS selectors is fairly easy via [SelectorGadget Chrome extension](https://selectorgadget.com/) which able us to grab CSS selectors by clicking on the desired element in the browser. However, it is not always working perfectly, especially when the website is heavily used by JavaScript.
We have a dedicated [Web Scraping with CSS Selectors](https://serpapi.com/blog/web-scraping-with-css-selectors-using-python/#css_gadget) blog post at SerpApi if you want to know a little bit more about them.
The Gif below illustrates the approach of selecting different parts of the results using SelectorGadget.

<h3 id='code_explanation'>Code explanation</h3>
Declare [`puppeteer`](https://www.npmjs.com/package/puppeteer-extra) to control Chromium browser from `puppeteer-extra` library and [`StealthPlugin`](https://www.npmjs.com/package/puppeteer-extra-plugin-stealth) to prevent website detection that you are using [web driver](https://www.w3.org/TR/webdriver/) from `puppeteer-extra-plugin-stealth` library:
```javascript
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
```
Next, we "say" to `puppeteer` use `StealthPlugin`, write the necessary request parameters and search URL:
```javascript
puppeteer.use(StealthPlugin());
const searchParams = {
hl: "en", // Parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook
};
const URL = `https://play.google.com/store/movies?hl=${searchParams.hl}&gl=${searchParams.gl}&device=${searchParams.device}`;
```
Next, we write a function to scroll the page to load all the articles:
```javascript
async function scrollPage(page, scrollContainer) {
...
}
```
In this function, first, we need to get `scrollContainer` height (using [`evaluate()`](https://pptr.dev/api/puppeteer.page.evaluate) method). Then we use `while` loop in which we scroll down `scrollContainer`, wait 2 seconds (using [`waitForTimeout`](https://pptr.dev/api/puppeteer.page.waitfortimeout) method), and get a new `scrollContainer` height.
Next, we check if `newHeight` is equal to `lastHeight` we stop the loop. Otherwise, we define `newHeight` value to `lastHeight` variable and repeat again until the page was not scrolled down to the end:
```javascript
let lastHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (true) {
await page.evaluate(`window.scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.waitForTimeout(4000);
let newHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
if (newHeight === lastHeight) {
break;
}
lastHeight = newHeight;
}
```
Next, we write a function to get movies data from the page:
```javascript
async function getMoviesFromPage(page) {
...
}
```
In this function, we get information from the page context and save it in the returned object. Next, we need to get all HTML elements with `"section .oVnAB"` selector ([`querySelectorAll()`](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelectorAll) method). Then we use [`reduce()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/reduce) method (it's allow to make the object with results) to iterate an array that built with [`Array.from()`]() method:
```javascript
const movies = await page.evaluate(() => {
const mainPageInfo = Array.from(document.querySelectorAll("section .oVnAB")).reduce((result, block) => {
...
}, {});
return mainPageInfo;
});
return movies;
```
And finally, we need to get `categoryTitle`, `categorySubTitle`, and `title`, `link`, `rating`, `originalPrice`, `price`, `thumbnail`, `video` and `movieId`(we can cut it from`link` using [`slice()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/slice) and [`indexOf()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/indexOf) methods) of each app from the selected category ([`querySelectorAll()`](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelectorAll), [`querySelector()`](https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector), [`getAttribute()`](https://developer.mozilla.org/en-US/docs/Web/API/Element/getAttribute), [`textContent`](https://developer.mozilla.org/en-US/docs/Web/API/Node/textContent) and [`trim()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/trim) methods.
On each itaration step we return previous step result (using [`spread syntax`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Spread_syntax)) and add the new category with name from `categoryTitle` constant:
```javascript
const categoryTitle = block.querySelector(".kcen6d").textContent.trim();
const categorySubTitle = block.querySelector(".kMqehf")?.textContent.trim();
const movies = Array.from(block.parentElement.querySelectorAll(".ULeU3b")).map((movie) => {
const link = `https://play.google.com${movie.querySelector(".Si6A0c")?.getAttribute("href")}`;
const movieId = link.slice(link.indexOf("?id=") + 4);
return {
title: movie.querySelector(".Epkrse")?.textContent.trim(),
link,
rating: parseFloat(movie.querySelector(".LrNMN[aria-label]")?.getAttribute("aria-label").slice(6, 9)) || "No rating",
originalPrice: movie.querySelector(".LrNMN .SUZt4c")?.textContent.trim(),
price: movie.querySelector(".LrNMN .VfPpfd")?.textContent.trim(),
thumbnail: movie.querySelector(".TjRVLb img")?.getAttribute("src"),
video: movie.querySelector(".TjRVLb button")?.getAttribute("data-trailer-url") || "No video preview",
movieId,
};
});
return {
...result,
[categoryTitle]: { subtitle: categorySubTitle, movies },
};
```
Next, write a function to control the browser, and get information:
```javascript
async function getMainPageInfo() {
...
}
```
In this function first we need to define `browser` using `puppeteer.launch({options})` method with current `options`, such as `headless: true` and `args: ["--no-sandbox", "--disable-setuid-sandbox"]`.
These options mean that we use [headless](https://developers.google.com/web/updates/2017/04/headless-chrome) mode and array with [arguments](https://peter.sh/experiments/chromium-command-line-switches/) which we use to allow the launch of the browser process in the online IDE. And then we open a new `page`:
```javascript
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
```
Next, we change default ([30 sec](https://github.com/puppeteer/puppeteer/blob/2a0eefb99f0ae00dacc9e768a253308c0d18a4c3/src/common/TimeoutSettings.ts#L17)) time for waiting for selectors to 60000 ms (1 min) for slow internet connection with [`.setDefaultNavigationTimeout()`](https://pptr.dev/api/puppeteer.page.setdefaultnavigationtimeout) method, go to `URL` with [`.goto()`](https://pptr.dev/api/puppeteer.page.goto) method and use [`.waitForSelector()`](https://pptr.dev/api/puppeteer.page.waitforselector) method to wait until the selector is load:
```javascript
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".oVnAB");
```
And finally, we wait until the page was scrolled, save movies data from the page in the `movies` constant, close the browser, and return the received data:
```javascript
await scrollPage(page, ".T4LgNb");
const movies = await getMoviesFromPage(page);
await browser.close();
return movies;
```
Now we can launch our parser:
```bash
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
```
<h2 id='output'>Output</h2>
```json
{
"Popular family films":{
"subtitle":"Perfect for movie night",
"movies":[
{
"title":"Sing 2",
"link":"https://play.google.com/store/movies/details/Sing_2?id=74GR3HZ5fI0.P",
"rating":4.3,
"originalPrice":"$5.99",
"price":"$3.99",
"thumbnail":"https://play-lh.googleusercontent.com/Z94mZzSVqG975oT1dQ7h1Adiql0wAywGbfatetwyv1Bw08KG_CGAzOFAzZ73roku4WGbGWN4SuplfOjNJXc=s256-rw",
"video":"https://play.google.com/video/lava/web/player/yt:movie:j7MgT6LWNEE.P?autoplay=1&embed=play",
"movieId":"74GR3HZ5fI0.P"
},
... and other results
]
},
"Pre-orders":{
"movies":[
{
"title":"Woman King, The",
"link":"https://play.google.com/store/movies/details/Woman_King_The?id=dYKWSdXf6rw.P",
"rating":3.2,
"price":"$19.99",
"thumbnail":"https://play-lh.googleusercontent.com/JGjCj3XixIQg2zXnAbUbSpBFvdp36YyG1couJnUNB9R_YC3I54Dp_iulAID3J_BDUULDbLHZzb8I954yNg=s256-rw",
"video":"https://play.google.com/video/lava/web/player/yt:movie:OfC5HTg2P4E.P?autoplay=1&embed=play",
"movieId":"dYKWSdXf6rw.P"
},
... and other results
]
},
... and other categories
}
```
<h2 id='serp_api'>Using<a href="https://serpapi.com/google-play-movies"> Google Play Movies Store API </a>from SerpApi</h2>
This section is to show the comparison between the DIY solution and our solution.
The biggest difference is that you don't need to create the parser from scratch and maintain it.
There's also a chance that the request might be blocked at some point from Google, we handle it on our backend so there's no need to figure out how to do it yourself or figure out which CAPTCHA, proxy provider to use.
First, we need to install [`google-search-results-nodejs`](https://www.npmjs.com/package/google-search-results-nodejs):
```bash
npm i google-search-results-nodejs
```
Here's the [full code example](https://replit.com/@MikhailZub/Scrape-Google-Play-MoviesandTV-with-NodeJS-SerpApi#withSerpApi.js), if you don't need an explanation:
```javascript
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const params = {
engine: "google_play", // search engine
gl: "us", // parameter defines the country to use for the Google search
hl: "en", // parameter defines the language to use for the Google search
store: "movies", // parameter defines the type of Google Play store
store_device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook, watch, car
movies_category: "MOVIE", // you can see the full list of supported categories on https://serpapi.com/google-play-movies-categories
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const json = await getJson();
const moviesResults = json.organic_results.reduce((result, category) => {
const { title: categoryTitle, subtitle, items } = category;
const movies = items.map((movie) => {
const { title, link, rating = "No rating", original_price, price, video = "No video preview", thumbnail, product_id } = movie;
const returnedMovie = {
title,
link,
rating,
price,
thumbnail,
video,
movieId: product_id,
};
if (original_price) returnedMovie.originalPrice = original_price;
return returnedMovie;
});
return {
...result,
[categoryTitle]: { subtitle, movies },
};
}, {});
return moviesResults;
};
getResults().then((result) => console.dir(result, { depth: null }));
```
<h3 id='serp_api_code_explanation'>Code explanation</h3>
First, we need to declare `SerpApi` from [`google-search-results-nodejs`](https://www.npmjs.com/package/google-search-results-nodejs) library and define new `search` instance with your API key from [SerpApi](https://serpapi.com/manage-api-key):
```javascript
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
```
Next, we write the necessary parameters for making a request:
```javascript
const params = {
engine: "google_play", // search engine
gl: "us", // parameter defines the country to use for the Google search
hl: "en", // parameter defines the language to use for the Google search
store: "movies", // parameter defines the type of Google Play store
store_device: "phone", // parameter defines the search device. Options: phone, tablet, tv, chromebook, watch, car
movies_category: "MOVIE", // you can see the full list of supported categories on https://serpapi.com/google-play-movies-categories
};
```
Next, we wrap the search method from the SerpApi library in a promise to further work with the search results:
```javascript
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
```
And finally, we declare the function `getResult` that gets data from the page and return it:
```javascript
const getResults = async () => {
...
};
```
In this function first, we get `json` with results, then we need to iterate `organic_results` array in the received `json`. To do this we use [`reduce()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/reduce) method (it's allow to make the object with results). On each itaration step we return previous step result (using [`spread syntax`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Spread_syntax)) and add the new category with name from `categoryTitle` constant:
```javascript
const json = await getJson();
const appsResults = json.organic_results.reduce((result, category) => {
...
return {
...result,
[categoryTitle]: { subtitle, movies },,
};
}, {});
return appsResults;
```
Next, we destructure `category` element, redefine `title` to `categoryTitle` constant, and itarate the `items` array to get all games from this category. To do this we need to destructure the `movie` element, set default value "No video preview" for `video` (because not all games have a video preview) and "No rating" for `rating` and return this constants:
```javascript
const { title: categoryTitle, subtitle, items } = category;
const movies = items.map((movie) => {
const { title, link, rating = "No rating", original_price, price, video = "No video preview", thumbnail, product_id } = movie;
const returnedMovie = {
title,
link,
rating,
price,
thumbnail,
video,
movieId: product_id,
};
if (original_price) returnedMovie.originalPrice = original_price;
return returnedMovie;
});
```
After, we run the `getResults` function and print all the received information in the console with the [`console.dir`](https://nodejs.org/api/console.html#consoledirobj-options) method, which allows you to use an object with the necessary parameters to change default output options:
```javascript
getResults().then((result) => console.dir(result, { depth: null }));
```
<h2 id='serp_api_output'>Output</h2>
```json
{
"New to Rent":{
"subtitle":"Watch within 30 days of rental",
"movies":[
{
"title":"Top Gun: Maverick",
"link":"https://play.google.com/store/movies/details/Top_Gun_Maverick?id=PnS5p3AmpRE.P",
"rating":4.8,
"price":"$4.99",
"thumbnail":"https://play-lh.googleusercontent.com/UJHa0DJftoFAt7rj1M8w7OmVoPxcFoRJAAqV2hbbz8QI-p5xHTxbjidNKM7gE-jxKzDfCuCfIJ7VBxQIcQ=s256-rw",
"video":"https://play.google.com/video/lava/web/player/yt:movie:q8CxTfNkwyA.P?autoplay=1&embed=play",
"movieId":"PnS5p3AmpRE.P"
},
... and other results
]
},
"Deals on movie purchases":{
"subtitle":"undefined",
"movies":[
{
"title":"Alita: Battle Angel",
"link":"https://play.google.com/store/movies/details/Alita_Battle_Angel?id=jwlu7jkYI1A",
"rating":4.6,
"price":"$7.99",
"thumbnail":"https://play-lh.googleusercontent.com/cpvUwWnYh5wcz2MVQE2tTJFW8j3nBTzmPvt8QOiE7E8PIe8JEgRs4OymeJbUMg5yPUU=s256-rw",
"video":"https://play.google.com/video/lava/web/player/yt:movie:Yy-NE9hRt20?autoplay=1&embed=play",
"movieId":"jwlu7jkYI1A",
"originalPrice":"$19.99"
},
... and other results
]
},
... and other categories
}
```
<h2 id='links'>Links</h2>
- [Code in the online IDE](https://replit.com/@MikhailZub/Scrape-Google-Play-MoviesandTV-with-NodeJS-SerpApi#index.js)
- [Google Play Movies Store API](https://serpapi.com/google-play-movies)
If you want other functionality added to this blog post (e.g. extracting additional categories) or if you want to see some projects made with SerpApi, [write me a message](mailto:miha01012019@gmail.com).
---
<p style="text-align: center;">Join us on <a href="https://twitter.com/serp_api">Twitter</a> | <a href="https://www.youtube.com/channel/UCUgIHlYBOD3yA3yDIRhg_mg">YouTube</a></p>
<p style="text-align: center;">Add a <a href="https://github.com/serpapi/public-roadmap/issues">Feature Request</a>💫 or a <a href="https://github.com/serpapi/public-roadmap/issues">Bug</a>🐞</p>
| mikhailzub |
1,213,895 | In One Minute : log4j2 | Apache Log4j 2 is the successor of Log4j 1 which was released as GA version in July 2014. The... | 20,049 | 2022-10-07T18:59:16 | https://dev.to/rakeshkr2/in-one-minute-log4j2-124f | beginners, programming, tutorial, oneminute | Apache Log4j 2 is the successor of Log4j 1 which was released as GA version in July 2014.
{% embed https://youtu.be/cEfSEd98HDw %}
The framework was rewritten from scratch and has been inspired by existing logging solutions, including Log4j 1 and java.util.logging.
One of the most recognized features of Log4j 2 is the performance of the "Asynchronous Loggers".
The library reduces the need for kernel locking and increases the logging performance by a factor of 12.
For example, in the same environment Log4j 2 can write more than 18,000,000 messages per second, whereas other frameworks like Logback and Log4j 1 just write < 2,000,000 messages per second.
Log4j 2 allows users to define their own log levels.
Log4j can be configured through a configuration file or through Java code.
Configuration files can be written in XML, JSON, YAML, or properties file format.
Within a configuration, you can define three main components: Loggers, Appenders, and Layouts.
Configuring logging via a file has the advantage that logging can be turned on or off without modifying the application that uses Log4j.
Official Website :- https://logging.apache.org/log4j/2.x/
| rakeshkr2 |
1,214,045 | Learning project from codesandpen 🖊️🖋️ | .. My learning project I always fork when I am code&decode | 0 | 2022-10-07T23:20:07 | https://dev.to/shashamura/learning-project-from-codesandpen-2feg | codepen | {% codepen https://codepen.io/shashamura/pen/eYrPddQ %}.. My learning project I always fork when I am code&decode | shashamura |
1,214,274 | The Great Merge | Introduction Ethereum is the largest blockchain network next to Bitcoin. It is evolving a... | 0 | 2022-10-08T07:58:39 | https://sainath.tech/the-great-merge | ethereum, merge, blockchain | ---
title: The Great Merge
published: true
date: 2022-09-16 11:42:17 UTC
tags: ethereum, merge, blockchain
canonical_url: https://sainath.tech/the-great-merge
---
### Introduction
Ethereum is the largest blockchain network next to Bitcoin. It is evolving a lot and equally competing with Bitcoin. Ethereum has paved the way for so many blockchains like [Solana](https://solana.com/), [Polygon](https://polygon.technology/), and [Cardano](https://cardano.org/) that try to solve the problems and limitations of Ethereum. The following diagram shows the size of the Bitcoin vs Ethereum blockchain. 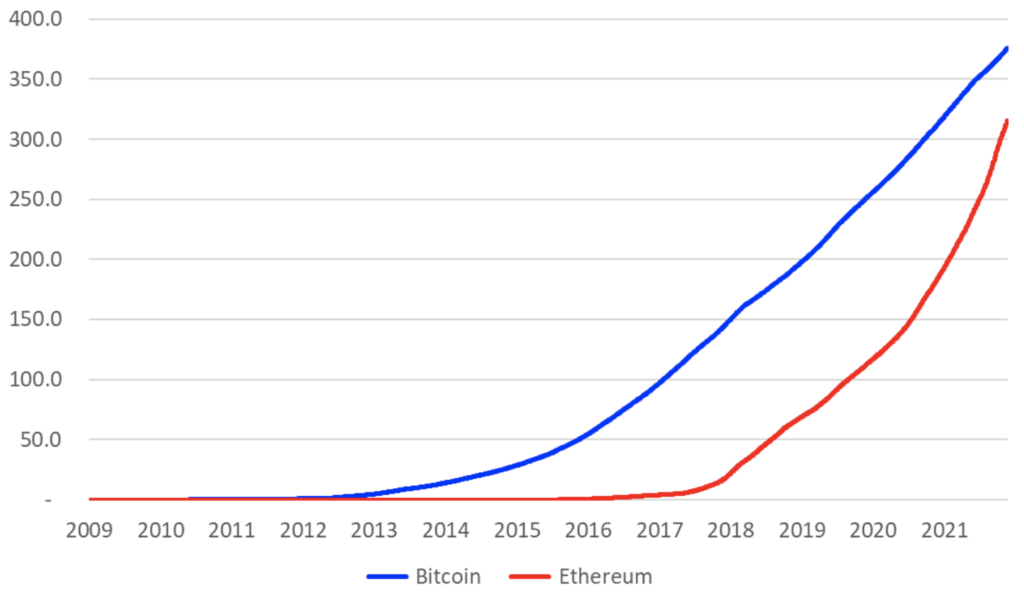
### A Quick History
Ethereum was created with the idea of a permissionless blockchain back in 2015 with Proof-of-Work (PoW) as its consensus mechanism. Until then people have known blockchain only as a cryptocurrency but Ethereum changed it with a plethora of use cases like digital assets, supply chain tracking, etc by leveraging smart contracts and ETH tokens which was famously called a 'gas fee' to validate a transaction which was then paid to the validators in the network for Proof-of-Work done.
### Consensus Mechanism
Ethereum has many networks for development, testing, and production use cases. 'Ethereum Mainnet' was the primary public Ethereum production blockchain based on the consensus mechanism of Proof-of-Work (PoW).
- Proof-of-Work(PoW) is hardware intensive and not eco-friendly as several miners participate using expensive resources in validating the block.
- Proof-of-Stake (PoS) lets a validator participate in the Ethereum network by staking the ETH which is more scalable, energy-efficient, secure, and has a lower barrier to entry than PoW.
### The Evolution of Beacon Chain
In recent years, Web3 gave birth to a lot of products like Decentralized Finance(DeFi), Non-Fungible Tokens (NFT), etc. Networks have to come up with speed and energy efficiency to serve the purpose and maximize the adoption of blockchain. Ethereum launched Beacon Chain based on PoS in late 2020 parallel to the existing Mainnet to slowly replace it with a single consensus i.e the PoS. The Ethereum team knew that PoW won't be good enough for the long run and decided to merge it with the Mainnet.
### The Merger
Ethereum Mainnet merged with Beacon Chain on September 15, 2022. As Mainnet merged with the Beacon Chain, it also merged the entire transactional history of Ethereum. Mining is no longer the means of producing valid blocks in Ethereum. Going forward, the Beacon Chain is the engine of block production. The merger led the Beacon Chain to accept transactions from the original Ethereum chain, bundle them into blocks, and then organize them into a blockchain using a proof-of-stake-based consensus mechanism.
### Terminology change
The term Eth2 has been deprecated. There is nothing called Ethereum 2.0. The new terminologies for Ethereum are as followed,
- Eth1 - Execution Layer
- Eth2 - Consensus Layer
> Execution Layer + Consensus Layer -> ETHEREUM
### Conclusion
ETH remains ETH. You don't need to do anything from your side owing to this change. All you need to know is that Ethereum now has a new engine based on PoS which is eco-friendly, slightly faster, scalable, and more secure.
_Note: This article is more about the technical details of the Ethereum blockchain. Anything related to cryptocurrency is not in the scope of this discussion._
### References
- [Bitcoin vs Ethereum Blockchain Size](https://blog.bitmex.com/bitcoin-vs-ethereum-blockchain-size/)
- [Ethereum Merge](https://ethereum.org/en/upgrades/merge/)
- [Beacon Chain](https://ethereum.org/en/upgrades/beacon-chain/)
- [Eth2 Renaming](https://blog.ethereum.org/2022/01/24/the-great-eth2-renaming)
- [Proof-of-Stake](https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/)
- [Ethereum Networks](https://ethereum.org/en/developers/docs/networks/) | rksainath |
1,214,302 | pet peeve the contact/mailto imbroglio | I'm sick and tired of clicking on a link that says "contact" only to see may email client launching.... | 0 | 2022-10-08T09:26:44 | https://dev.to/baudouinvh/pet-peeve-the-contactmailto-imbroglio-20h7 | webdev, html, ux | I'm sick and tired of clicking on a link that says "contact" only to see may email client launching. I've clicked on yet another mailto:link and I was expecting a contact form.
Could we find a way (an icon ?) that shows when a link is a mailto: link ?
How exactly do you expect a "contact" link to behave : mailto: or contact form ? | baudouinvh |
1,214,439 | Creating Own Types In Typescript | Enum An enumeration is a type that represents named constants and is often refered to as... | 0 | 2022-10-08T21:40:30 | https://dev.to/joaosc17/creating-own-types-in-typescript-h9c | webdev, beginners, typescript, tutorial | ##Enum
An enumeration is a type that represents named constants and is often refered to as an enum. It can be very good if meaning of constant value is'nt apparent, this can make the code easier to understand.
```ts
enum Response{
Ok = 200,
Error = 400
}
if (status === 200) {
// do something
}
if (status === Response.Ok) {
// do something
}
```
The problem with this approach is reflected exactly in numerical enums that are weakly-typed, although string enum are strongly-typed.
```ts
enum Level {
High,
Medium,
Low
}
level = 5; // no error accur
enum Level {
High = "H",
Medium = "M",
Low = "L"
}
level = "VH"; // a type error occur
```
##Object Types
In first typescript has a good inferred types system for objects. When hovering the mouse over object you will see the type inferred to object and if you try to change a property to a value of a different type or try to add a property that there are'nt it will return an error.
```ts
const JackScore = {
name: "Jack",
score: 70
};
JackScore.score = 75; // no error accur
JackScore.score = 'test'; // a type error occur
JackScore.passed = true; // a type error occur
```
There is also an explicit way to type objects and it has the same strength.
```ts
const JackScore: { name: string; score: number; } = {
name: "Jack",
score: 70
};
JackScore.score = 75; // no error accur
JackScore.score = 'test'; // a type error occur
JackScore.passed = true; // a type error occur
```
The both ways are strongly-typed, although if you wish reuse an object type could be tiring redefinning it each time and that's why type aliases and interfaces is so important.
##Type Aliases and Interfaces
Type aliases and interfaces are ways of reuse your types and make typing process faster.
```ts
//without types alias and interfaces
const tomScore: { name: string; score: number } = {
name: "Tom",
score: 70,
};
const bobScore: { name: string; score: number } = {
name: "Bob",
score: 80,
};
const janeScore: { name: string; score: number } = {
name: "Jane",
score: 90,
};
//with types alias and interfaces
type Score = { interface Score {
name:string, or name:string,
score:number score:number
} }
const tomScore: Score = { name: "Tom", score: 70 };
const bobScore: Score = { name: "Bob", score: 80 };
const janeScore: Score = { name: "Jane", score: 90 };
```
##What's difference between interface and type alias
###Representing primitive types
Type aliases can represent primitive types, but interfaces can't.
```ts
type Name = string;
```
###Representing arrays
Both reprensent arrays, although type alias approach is a lot more concise and clearer.
```ts
type Names = string[];
interface Names {
[index: number]: string;
}
```
###Representing tuples
Type aliases can represent tuples types, interfaces can't
```ts
type Point = [number, number];
}
```
###Representing functions
Both can represent functions, but type alias is a lot more concise and clearer.
```ts
type Log = (message: string) => void;
interface Log {
(message: string): void;
}
```
###Creating union types
Only type aliases can represent union types.
```ts
type Status = "pending" | "working" | "complete";
```
###Representing objects
both can represent types of an object and even the type alias being the most concise approach the equals operator (=) can result in the statement being confused for a variable assignment to an object literal.
We can say that there is a tie here.
```ts
type Person = {
name: string;
score: number;
};
interface Person {
name: string;
score: number;
}
```
###Composing objects
Type aliases and interfaces can both compose objects together.
```ts
type Name = {
firstName: string;
lastName: string;
};
type PhoneNumber = {
landline: string;
mobile: string;
};
type Contact = Name & PhoneNumber;
interface Name {
firstName: string;
lastName: string;
}
interface PhoneNumber {
landline: string;
mobile: string;
}
interface Contact extends Name, PhoneNumber {}
```
###Authoring a library
One important feature that interfaces have that type aliases don't is declaration merging:
```ts
interface ButtonProps {
text: string;
onClick: () => void;
}
interface ButtonProps {
id: string;
}
```
This is is useful for adding missing type information on 3rd party libraries. If you are authoring a library and want to allow this capability, then interfaces are the only way to go. | joaosc17 |
1,214,440 | Funding in open source | Recently, @joshuakgoldberg joined me on my stream to discuss TypeScript, TypeScript ESLint, open... | 0 | 2022-10-09T01:57:00 | https://www.iamdeveloper.com/posts/funding-in-open-source-4i6k/ | opensource, career, discuss | Recently, @joshuakgoldberg joined me on [my stream](https://livecoding.ca) to discuss TypeScript, TypeScript ESLint, open source, and Josh’s new book, [Learning TypeScript](https://www.learningtypescript.com).
It was a great conversation. I decided to create a separate video clip for the conversation about open source.
{%embed https://youtu.be/hu1P4FA87mQ %}
Here is the transcript.
Nick Taylor:
<blockquote>
<p>you've been working in open source for a while. I found it really interesting that you went from, what I can only assume was a great job. You were at a ed tech company, right?</p>
<p>It was, Was that it? The name's escaping me.</p>
</blockquote>
Josh Goldberg:
<blockquote>
<p>Yeah. <a href="https://www.codecademy.com/">Codecademy</a>.</p>
<p>It was a great job. Highly recommend Codecademy as a, as a product and a place. Lovely people there.
</p>
</blockquote>
Nick Taylor:
<blockquote>
<p>So you were having fun there. You were enjoying it. You were still contributing in open source, but, I'm curious. What the decision to go full or why did you decide to go kind of all in on working full time on open source?</p>
<p>Because I'm sure there's a ton of people curious about this.</p>
</blockquote>
Josh Goldberg:
<blockquote>
<p>A lot of people who themselves are thinking about it, but it's a scary jump. It took me a while to get there. I'd say working at a company is a good thing for most people. You want to have that support of people around you, a team, a manager, a mentor, mentors, plural.</p>
<p>If you can. But I really like open source software. I like doing things that benefit everyone. Like when I work on TypeScript or TypeScript ESLint, I benefit everyone who uses those tools. Like if I spend 10 hours, let's say, on some bug fixes and a feature in TypeScript. I have just saved the world's un unknowable, but large amounts of time, like I've sped up the rate of human development.</p>
<p>Like, that's cool. I say these things which make myself sound so much cooler than I really am, but it makes me feel good. And when you're at a, when you're a company, even if you have a lot of, thank you, even if you had a lot of time in your day to day to work on open source, it's still for the company.</p>
<p>Why would they hire you to do things that don't benefit them? Yeah. So you don't have as much time or control over your open source stuff. And I just, I just want to do this all the time. So I'm now one of those people very, small but hopefully growing group of people who work on open source full-time.</p>
<p>And instead of a job with health insurance and 401K and all this, I ask for money on the internet. So this is my first shameless plug of the stream. You told me I could. So I will.</p>
</blockquote>
A quick pause in the transcript to mention that the shameless plug was [Josh’s GitHub sponsors page](https://github.com/sponsors/JoshuaKGoldberg) that he put in the Twitch stream chat. If you’re interested in sponsoring Josh, head on over there. Alright, back to the transcript!
Nick Taylor:
<blockquote>
<p>Yeah. Shamelessly plug. Yeah, I dropped your GitHub there, so folks can check that out.</p></blockquote>
Josh Goldberg:
<blockquote>
<p>Thank you. Yeah, the more money people give me, the more I'm able to work on open source that makes your life better. So thanks. But this exposes something real bad, which is that as an industry, we, we don't know how to make people like me work. Like the, the situation I described of, I work in open source tooling that benefits everyone, and somehow I get money.</p>
<p>Like that's not figured out yet. We have ad hoc things like get hub sponsors Open Collective before that Patreon. But like there's no strong incentive for most companies to give to open source other than developers are yelling at finance that someone should do it. And it's like vaguely good for marketing and recruiting.</p>
<p>So I wish we had like, like a, like a B Corp style, like you should do this, or we all feel bad about you and don't join. But that's not really standard.
</p>
</blockquote>
Nick Taylor:
<blockquote>
<p>Yeah, it's definitely interesting cuz like I'm working at Open Source at Netlify right now. I worked, when I was at dev.to, I was working at open Source and that was my job, so getting paid at like that, those are, that's, it's a really compelling reason why I.</p>
<p>Took those jobs too. I'm a big fan of open source and like, you know, just like you said, being able to get paid to work in open source is amazing. So like I happen to find places that did it, but it, there's. You know, then there's, there's kind of like three scenarios. You know, There's like somebody like me who might be working at a place that does open source.</p>
<p>There's people that do it in their free time, and then there's people like yourself who are looking to get sponsored, and it's, you're totally right. It's like, how do you formalize that? Because like, you know, it's weird too because like large companies, you know, like Babel for example, which has had so many hours put into it, I know Henry Zoo gets compensated now through a, I dunno if it's GitHub sponsors or Patreon, and I, I don't know if the other contributors do as well, but you know, that came out of like, I don't know if he went the same route as you or I can't remember the, the story there, but you know.</p>
<p>It's kind of amazing that like most of the planet runs on open source like Linux, and like all these like big companies and maybe Linux people are definitely putting money into it, I guess. But like, you know, I would think, all the places that have been using, you know, like Babel, Webpack, all that stuff, why aren't people or companies, you know, putting money into that, and it's, I don't know how to, I don't have an answer or anything, but it, it is just kind of weird, like, cuz like myself, I do sponsor people, but there's only so much I can do, you know. Like, I mean, I, I need to use money for other stuff too. And it's like, it's not like I'm about to sponsor 200 people.</p>
<p>I, I definitely see the aspect where like, you know, the micro payments could definitely, stack up for sure. Like if a thousand people started paying five bucks a month, you know, that's definitely changes the game. But, why aren't companies like monthly, you know, just donating.</p>
<p>I find it kind of weird is all.</p>
</blockquote>
Josh Goldberg:
<blockquote>
<p>Individuals donating is like yelling at people to use either no straw or paper straws, like, yes, you are doing a good thing, but the real issue is systemically, the capitalist society we in has not adjusted to, to do public goods and services and similar like open source.</p>
<p>That's my rant for the morning.</p>
</blockquote>
**What are your thoughts on funding in OSS?**
Photo by <a href="https://unsplash.com/@hishahadat?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Shahadat Rahman</a> on <a href="https://unsplash.com/s/photos/open-source?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a> | nickytonline |
1,214,489 | Update API Tegro and The Open Network | To start working with our payment system, we recommend that you study the articles. Initial... | 0 | 2022-10-08T17:15:09 | https://dev.to/toncoin/update-api-tegro-and-the-open-network-46d7 | **To start working with our payment system, we recommend that you study the articles.**
[Initial information](https://coinmarketcap.com/community/articles/33395) that you can study before you start. Token Tegro TGR on The Open Network blockchain (learn more about [the payment token](https://coinmarketcap.com/community/articles/32207)).
TON Blockchain Wallet Update — TON Wallet ([Uniton](https://coinmarketcap.com/community/articles/34981)). Bug Bounty: How to earn cryptocurrency for the mistakes of DEX developers ([new program](https://coinmarketcap.com/community/articles/37945)).
Our team is now working daily to create and improve new projects.
**Documentation and API Tegro**
➡️ Payment gateway — [technical documentation](https://tegro.money/docs/en/) and [information for developers](https://tegro.gitbook.io/en/payments/api/general-information).
➡️ TON wallet — [private API](https://api.uniton.app/) for partners.
You can support us by liking our posts and following our other social networks. | toncoin | |
1,214,607 | Amplication - Creating your First Service | What is Amplication? Amplication is an open-source flexible tool for developing a... | 0 | 2022-10-09T12:09:26 | https://dev.to/arnabc27/amplication-creating-your-first-service-d01 | node, beginners, tutorial, opensource | ## What is Amplication?
<a href="https://amplication.com/">Amplication</a> is an open-source flexible tool for developing a full-fledged backend for an application within minutes. Developers only have to create data models and do the configuration using their interactive UI or CLI, and Amplication will generate a NodeJS application with fully functional REST APIs along with an Admin UI, based on the data models, authentication, and role-based authorization done while configuring the application. It also allows the developers to download the generated code and customize it according to them into the application.
## Step 1: Creating a New Service
- Log in to https://app.amplication.com/.
- Click on the **_Amplication logo_** on the top-left corner to land on the **_Projects_** page.
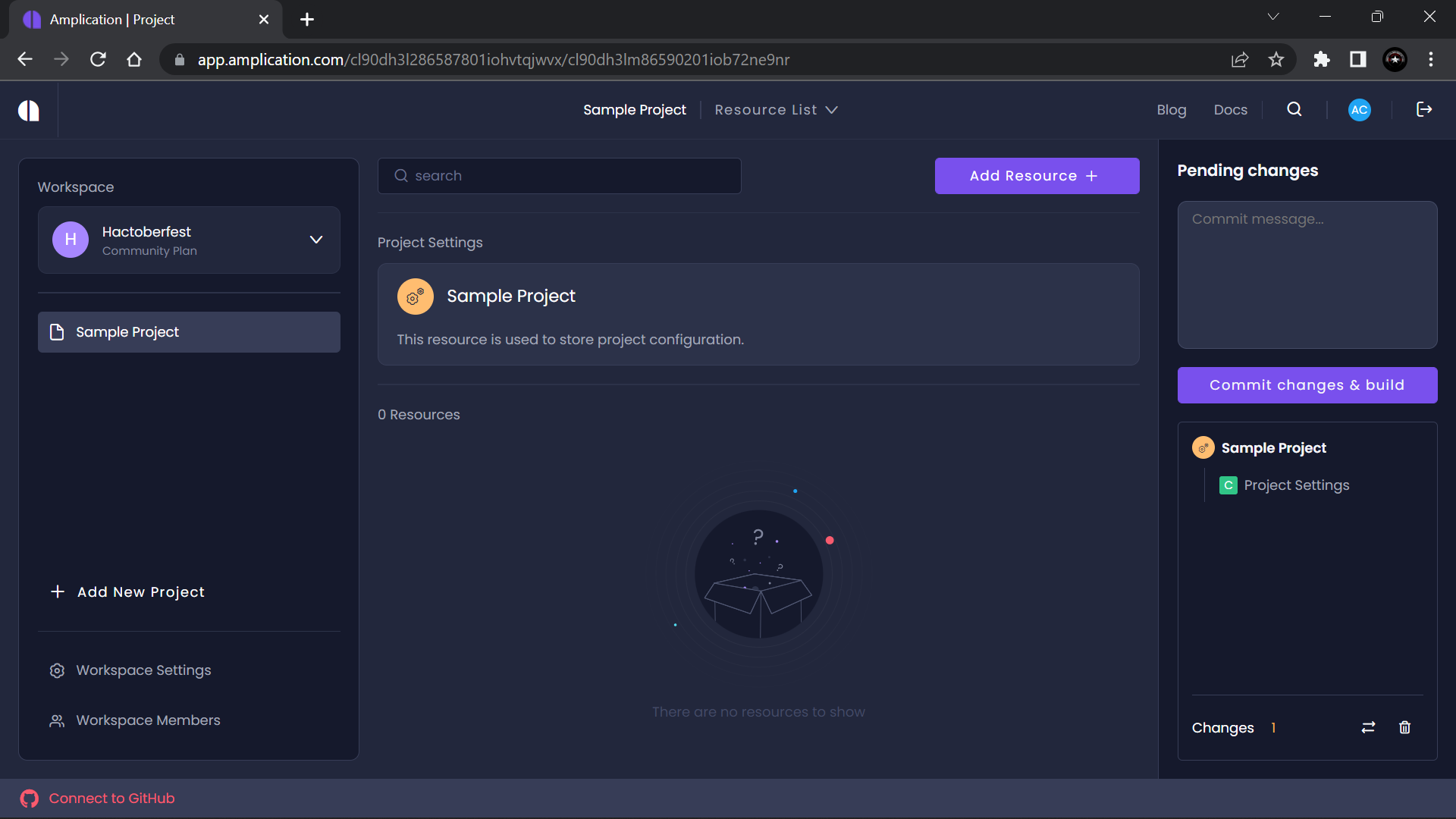
- You can change the **_Workspace_** by selecting or creating a new one in the left pane of the Projects page.
- Now, to create a new service, click on the **_Add Resource_** button on the top-right section and from the drop-down select **_Service_**.
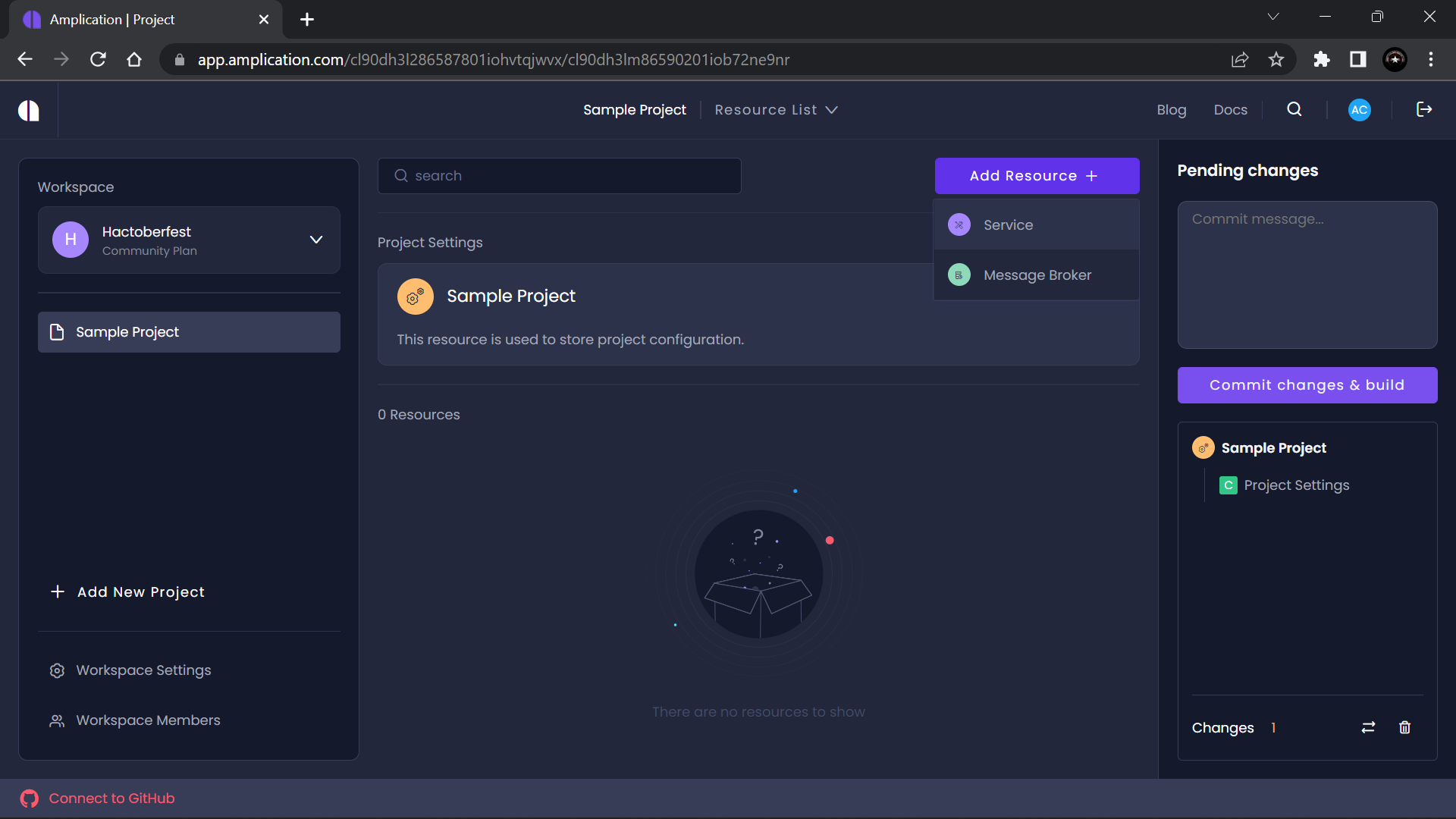
- In the **_New Service page_**, leave everything as default and click **_Create Service_** at the bottom-right corner to create an **_Empty Service_**.
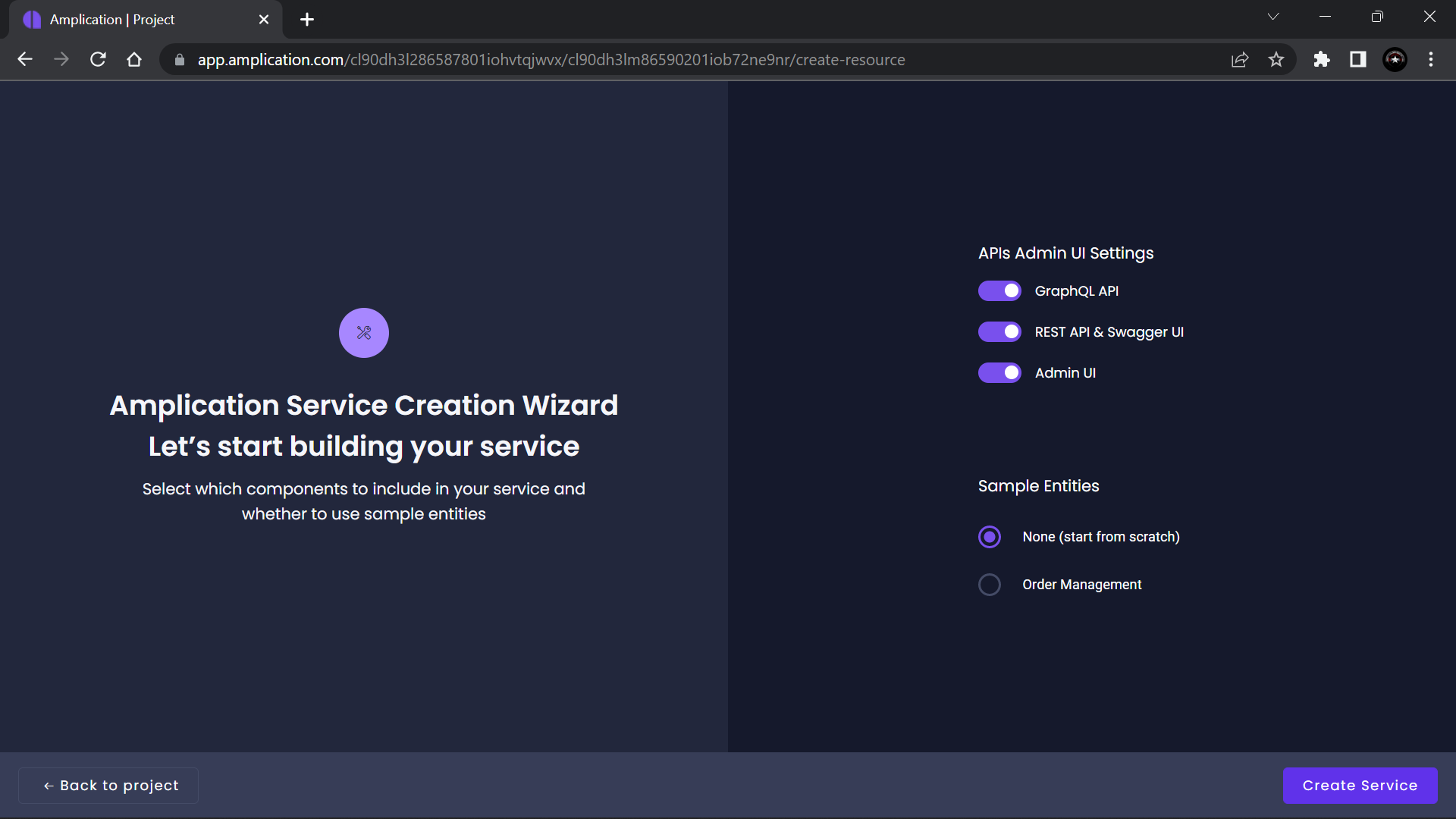
- Upon clicking the Create Service button, the page reloads and brings you to the **_Service Overview page_**.
## Step 2: Create an Enitity
- In the **_Service Overview Page_**, under **_Entities_**, click on **_Go to Entities_** to visit the Entities Page. You can also click on the Entities icon in the left side bar.
- Once on the Entities Page, click on **_Add Entity_** to create a new entity.
- In the New Entity dialog, type "Project" as the name of the entity and then click **_Create Entity_**.
- You will see that 3 fields, namely, **_ID_**, **_Created At_** and **_Updated At_** have been created for you by default. You can add more fields by typing a field name in the **_Add Field_** box and then clicking **_+_**.
- Create fields **_Name_**, **_Description_**, **_Start Date_** and **_Owner_** by typing each field name and clicking +.
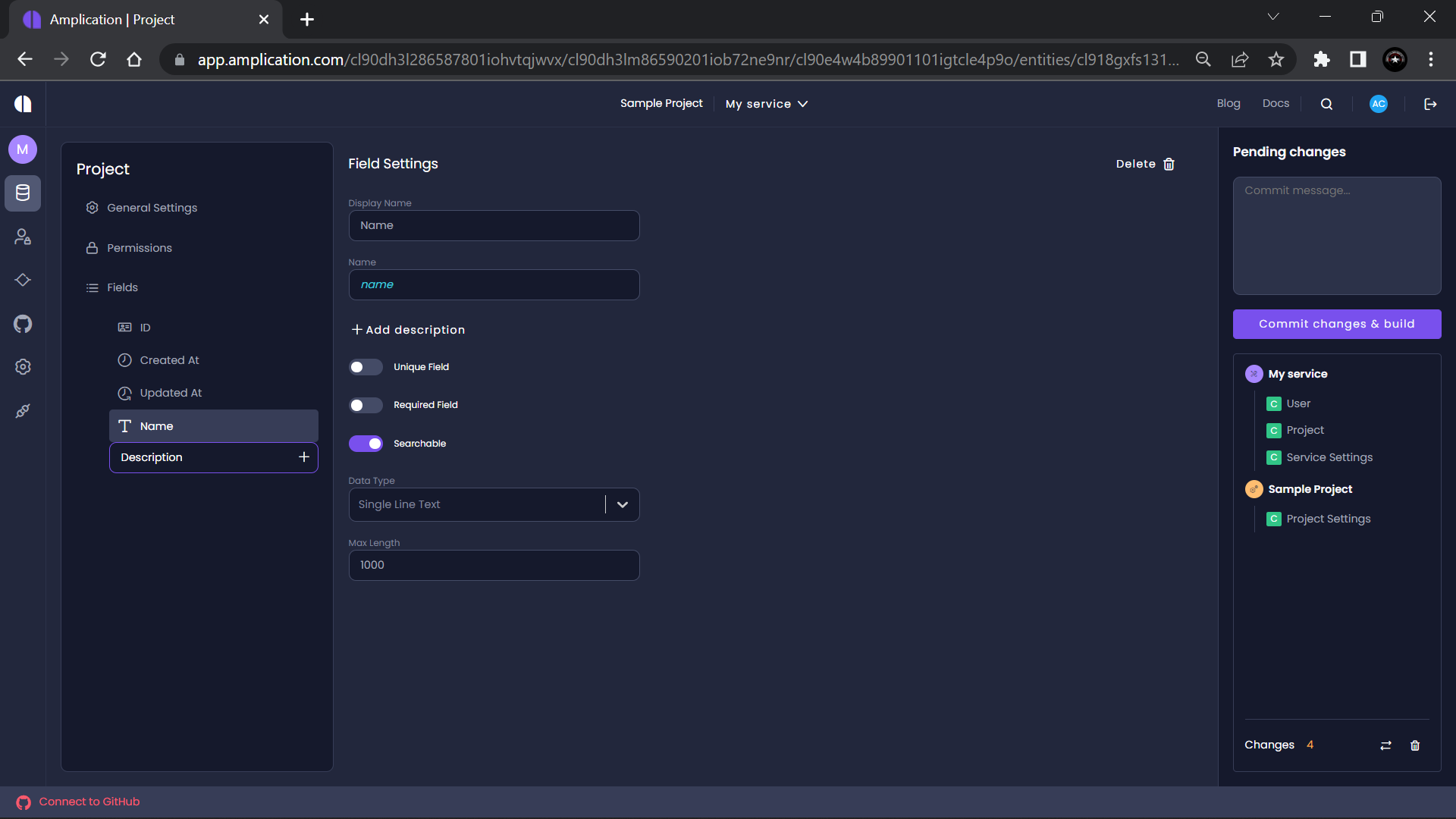
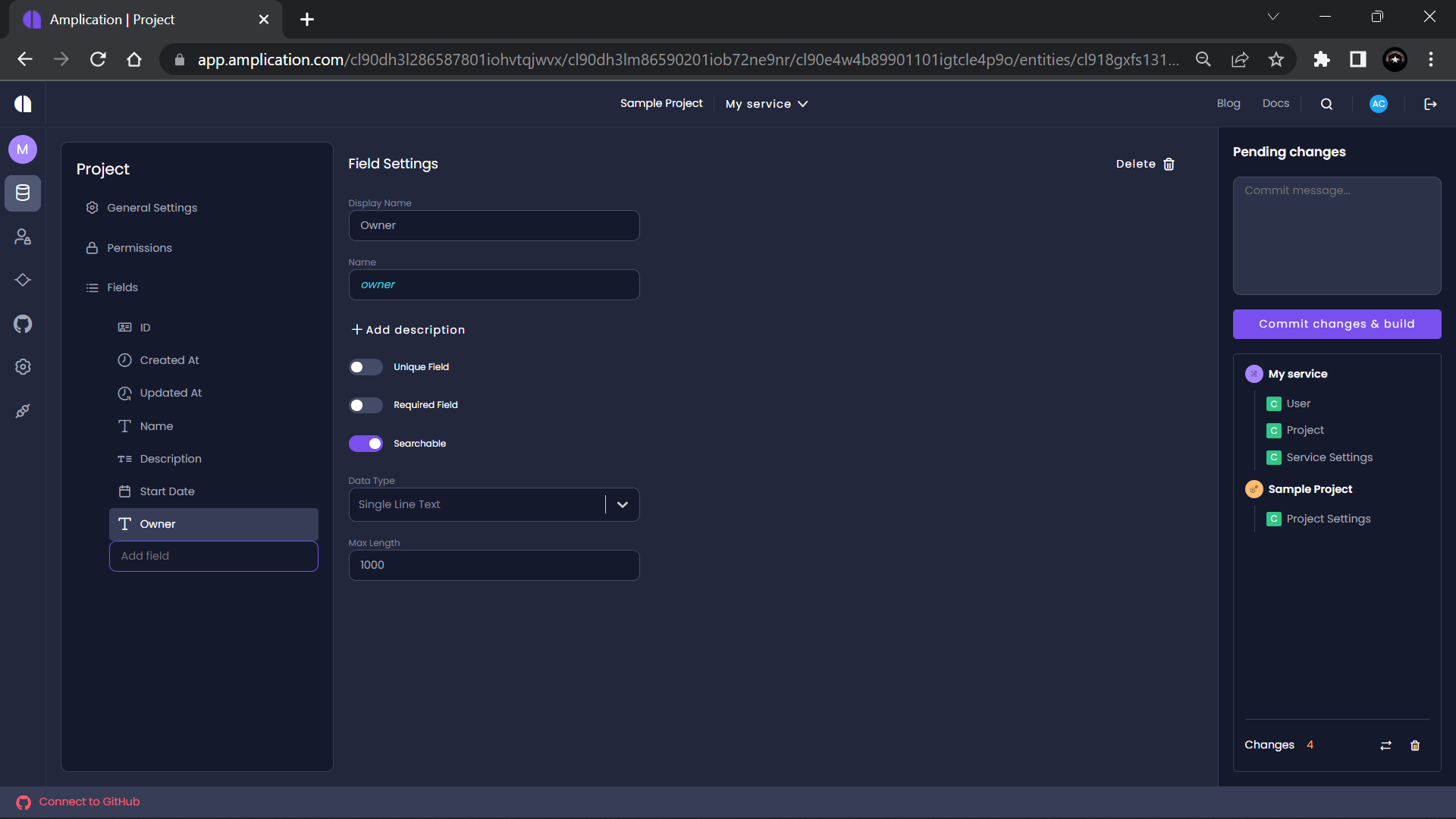
## Step 3: Connect to Github
- Click on Connect to Github at the bottom-left corner of the screen.

- You should appear at the **_Sync with Github_** page. Now click on **_Connect to Github_**.
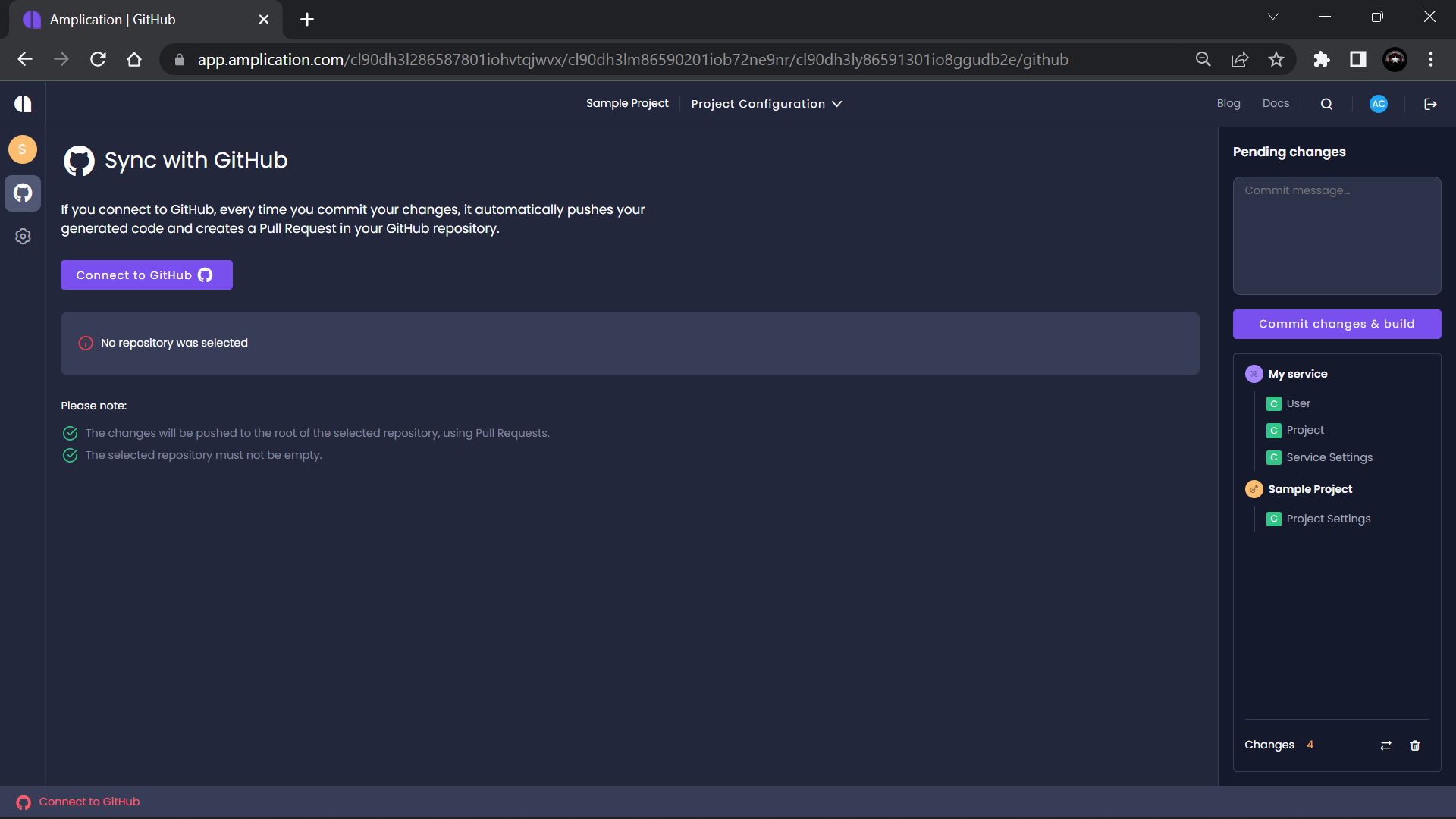
- You'll have to authenticate Github with Amplication. The popup window will allow you to download Amplication in a selected repository of your choice, available on your Github account.
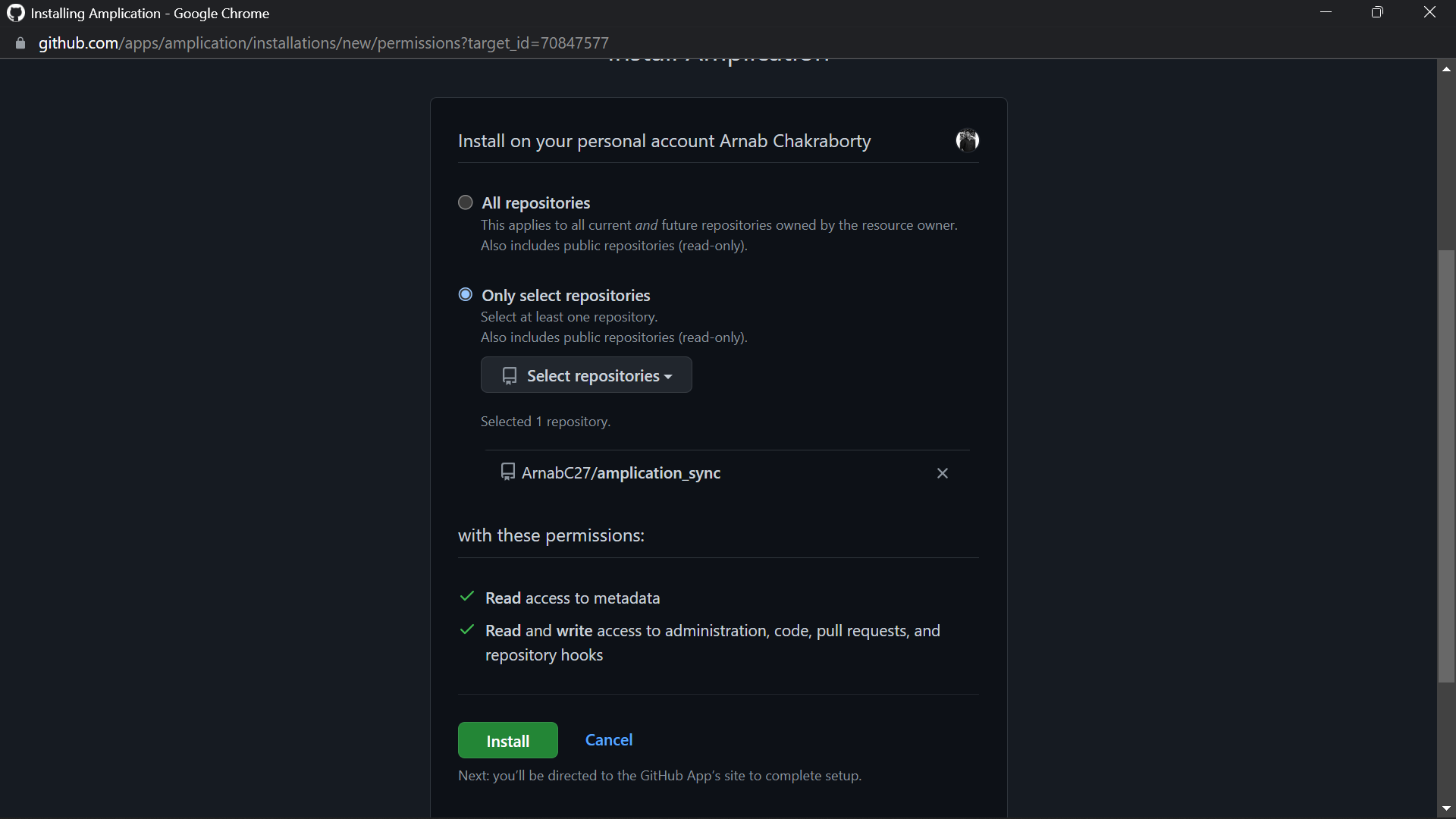
- Upon selecting the repository, click **_Install_**. Your service gets synced with the repository you've selected.
- Back in Sync with Github page, click on **_Select Repository_** and select the one you have selected earlier in the popup dialog box.
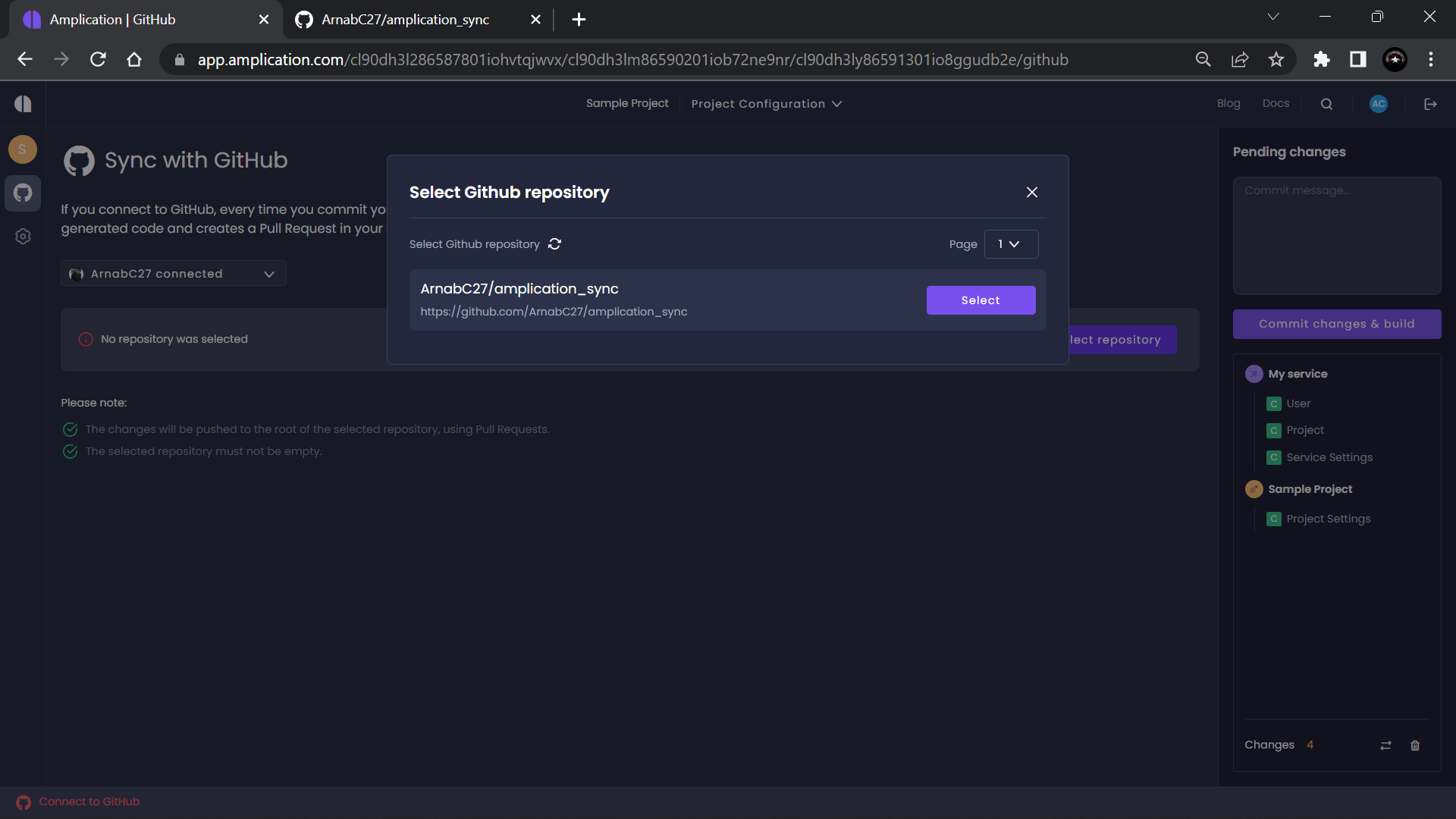
## Step 4: Commit you Changes
- On the right side of the screen, you'll observe a Pending Changes panel. This panel lists all the changes you've made to your service which are not committed to your Github repository.
- Click on **_Commit changes and build_**. All changes will be committed. A build of the first version of your service is automatically created!
- Go to your Github repository and visit the **_Pull Requests_** section. You'll be able to view the Pull Request made by Amplication to your repository. Click on the Pull Request and click **_Merge pull request_**.
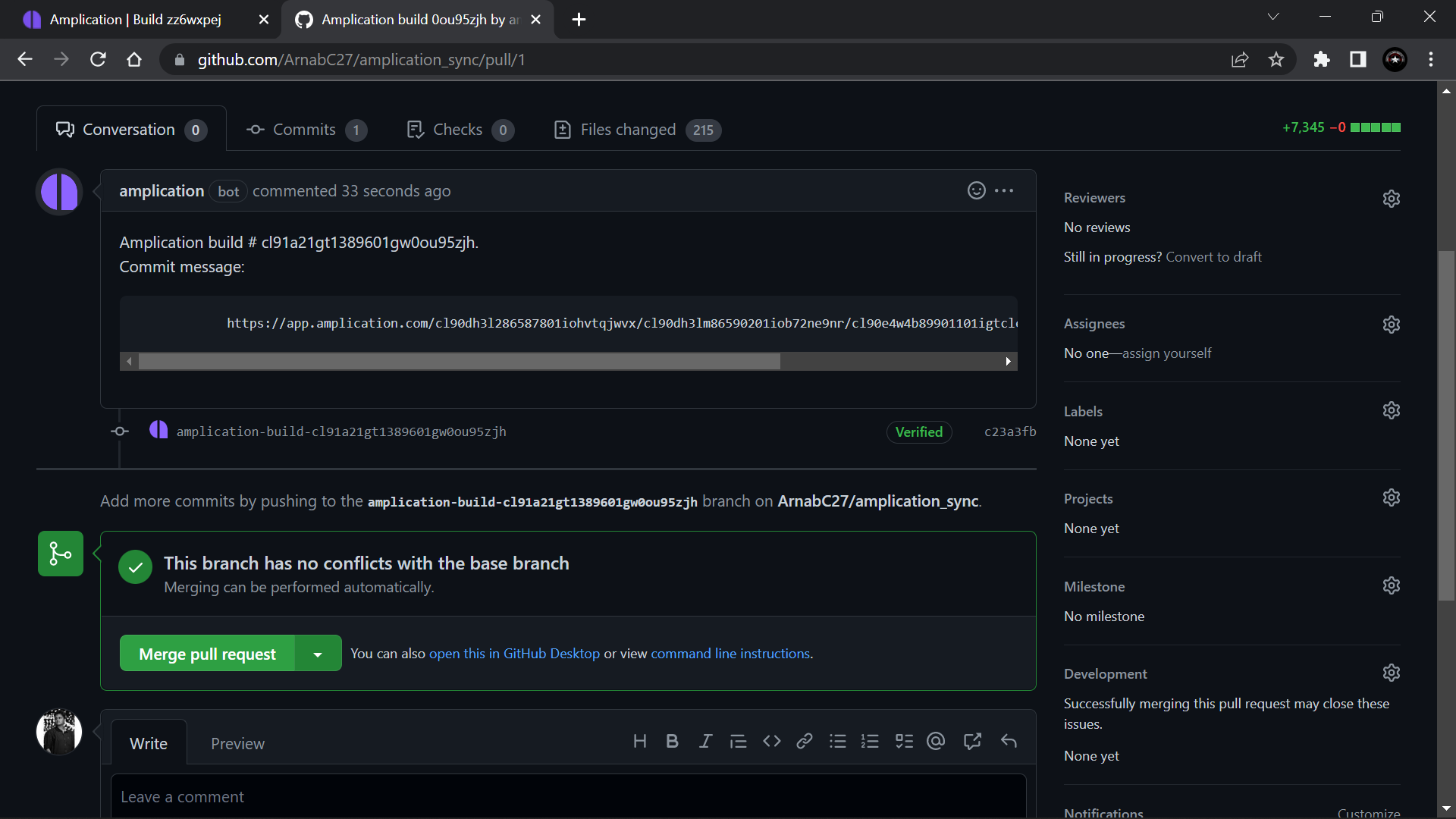
- Back in the Amplication site, you can click on **_Go to view code_** to view the code committed to your Github repo.
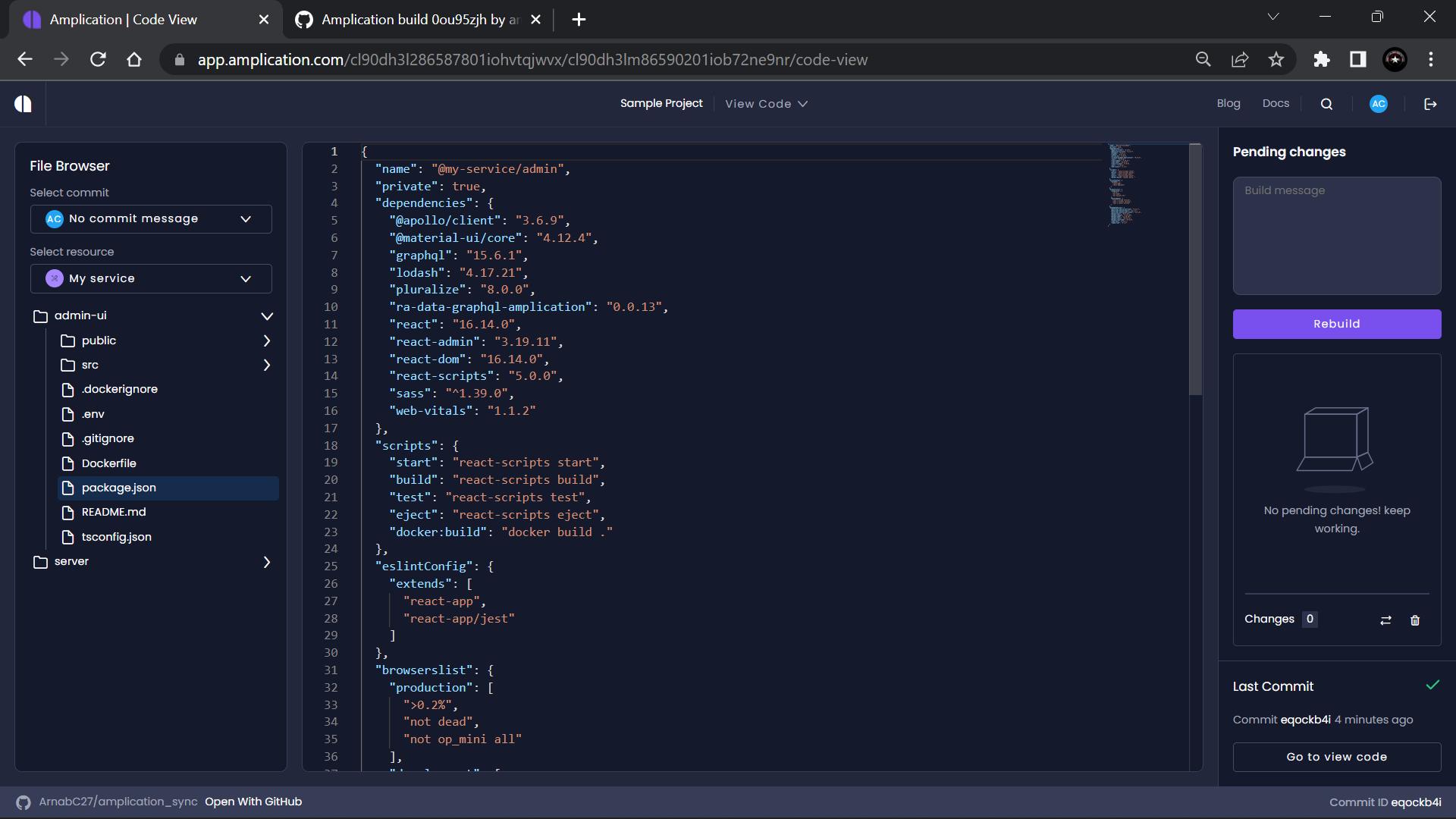
## Conclusion
Amplication is a relatively new platform and there's lot of scope for it to succeed. For more information you can always go through their <a href="https://docs.amplication.com/docs/">Documentaion</a>. To contribute to Amplification, check out their <a href="https://github.com/amplication/amplication">repository on github</a>. To join their community, join their <a href="https://discord.gg/Z2CG3rUFnu">Discord server</a>. | arnabc27 |
1,214,707 | Learn Reactjs, Create Badge | A post by made suande | 0 | 2022-10-09T00:44:15 | https://dev.to/suandedev/learn-reactjs-create-badge-46a7 | react, webdev, beginners |
 | suandedev |
1,214,810 | How I Monorepo | Introduction I am working full-time on a suite of libraries for building games with... | 0 | 2022-10-09T14:24:52 | https://dev.to/hmans/how-i-monorepo-october-2022-edition-1ib4 | monorepo, typescript, npm, github | ### Introduction
I am working full-time on a suite of libraries for building games with Three.js and React; this suite is called the **Composer Suite**, and its growing number of libraries and applications all live [in a single monorepo](https://github.com/hmans/composer-suite). In this post, I will describe the tools I use to manage this repository, and to make both the development as well as the releasing of new packages and package versions as painless as possible.
Please read this list as a snapshot of what I _currently_ use. I rely on good tooling to stay productive (and sane), so sometimes I add one thing and remove another. I will review and update this post over time.
## pnpm
I use [pnpm](https://pnpm.io/) for package management. I am not super-religious about it, having used yarn up until recently, but so far, I've been really enjoying its benefits.
pnpm is primarily known for how, instead of duplicating the same packages into every `node_modules`, it will hard-link them to a central repository, vastly cutting down on both disk space used for dependency installations, but also speeding up the install process significantly.
I'm also enjoying its overall developer experience; it has an exceptionally well-designed CLI, very clear to understand logging output, and I even find its lock file to be easier to make sense of in the rare occasions where I need to find out more about pnpm's current view of my repository.
pnpm can also link packages to dependencies within the same monorepo _that have not yet been published to NPM_, which is great for bootstrapping new packages, which happens surprisingly often in my case. :D
## Preconstruct
For actually building my packages, I use the excellent [Preconstruct](https://preconstruct.tools/). Besides being a very reliable build tool, it enforces an opinionated structure to your packages that just makes sense and helps you avoid a lot of the pitfalls that come with both monorepos and publishing packages to NPM.
But its absolute killer feature is `preconstruct dev`, a command that will link dependent packages within the monorepo in a way that lets packages and apps authored in TypeScript **consume their dependencies' original TypeScript code directly**.
I write all my libraries with TypeScript, and I've always hated firing up build watchers. With `preconstruct dev`, I can fire up an application and just make changes to the code of any of the packages it depends on, and those changes will be reflected immediately, including full support for HMR, without having to spawn any kind of build watchers. It's a huge time-saver that I've come to rely on heavily.
## Changesets
Publishing new versions of packages typically involves multiple steps:
- Bump the version number in the package's `package.json`
- Update the changelog for the package
- Make sure the package is actually built 🤡
- Actually publish to NPM
- Create a Release entry on GitHub
This can be a lot of work — particularly maintaining a useful changelog. Which is why I use [Changesets](https://github.com/changesets/changesets), which — together with its great GitHub Action — **does pretty much all of this work for me**.
Whenever I make a change, fix a bug or add a new feature that warrants a new release, I use the Changesets CLI to create a new _changeset file_, which is just a Markdown file describing the change, and including some meta information about which packages are affected, and should be version-bumped, and what kind of version bump they should get (patch, minor, or major.)
These changeset files are the committed to the repository alongside the change they describe. Then, when I'm ready to publish a new version of my packages, the `changeset version` command will vacuum up all the accumulated changesets, transfer their contents to the relevant `CHANGELOG.md` files, and bump the version numbers in the `package.json` files of the affected packages. I can then run `changeset publish` to have it automatically publish the newly bumped versions to NPM.
And since I'm lazy, and lazy is good, I actually use the excellent [Changesets GitHub Action](https://github.com/changesets/action), which will do all of this for me, by way of a Pull Request it will automatically create (you will often find them in the [Pull Requests tab of the Composer Suite monorepo](https://github.com/hmans/composer-suite/pulls).) I can just merge that Pull Request, and a couple of minutes later, my packages will be published to NPM, and [GitHub Release entries are created for them](https://github.com/hmans/composer-suite/releases), too!
I find this entire approach much better than generating changelogs from commit messages, because changeset files are much more expressive, and can be edited to add more information, or to fix typos, and so on. They also make it much easier to review the changes that are being published, and to make sure that the changelog entries are actually useful.
## GitHub Actions
Speaking of GitHub Actions, **they're just incredible, and you should use them**. In the Composer Suite monorepo, I have one action for [running tests on all branches and Pull Requests](https://github.com/hmans/composer-suite/actions/workflows/tests.yml), and the [Changesets action described above](https://github.com/hmans/composer-suite/actions/workflows/release.yml). If I ever get serious about linting, I'll probably add that, too. The key point here is: automation is good! Go forth and automate!
## Turborepo
The latest addition to the Composer Suite monorepo, [Turborepo](https://turborepo.org/) optimizes monorepo workflows by caching build artifacts. This may sound a little abstract and boring, but what this actually means is that when you build something within your monorepo, Turborepo will make sure only the things that it depends on are rebuilt; everything else will be retrieved from a cache that either lives on your local computer, or a remote cache server. This can make building your entire monorepo very fast, or even no-op:
Adding Turborepo to the Composer Suite monorepo pretty much halved CI build times, but it was also a way to teach [Vercel](https://vercel.com/), which I use for hosting the [various example apps in the repo](https://github.com/hmans/composer-suite/tree/main/apps), to only actually deploy the ones that have changed since their last deployment. And that's really cool!
## VS Code & GitHub PR & Issues Extensions
I do all of my development in Visual Studio Code, and love the official [GitHub Pull Requests and Issues extension](https://marketplace.visualstudio.com/items?itemName=GitHub.vscode-pull-request-github). It essentially integrates the entire Pull Request flow directly into the editor; you can directly check out Pull Requests from its UI, browse around in the code, post and reply to comments, make further changes, open or close the Pull Request for review, and of course also eventually merge and close it. It's such an incredible time saver for interacting with incoming (and also your own) PRs, and I heavily recommend it.
## Conclusion
These are my favorite monorepo things right now. Without them, I would most definitely be a lot less productive. I hope you find these recommendations useful. If you have any questions, or if you have any other tools you'd like to recommend, please let me know in the comments!
| hmans |
1,214,847 | Vanilla Extract | A while ago when I was looking at the results of the State of CSS and State of JS there were quite a... | 0 | 2022-10-09T08:15:26 | https://dev.to/nicm42/vanilla-extract-2fnn | css | A while ago when I was looking at the results of the [State of CSS](https://stateofcss.com/en-us/) and [State of JS](https://www.stateofjs.com/) there were quite a few tools and frameworks that I've never used and am curious about. So I'm taking some small bits and using some of those things to see what they're like.
The first one I tried was [Vanilla Extract](https://vanilla-extract.style/). It's interesting to search for, because you can get a lot of cake recipes if you're not careful. But it's actually a CSS in JS tool.
I've used one before - Styled Components - so I was familiar with the idea. But Vanilla Extract does a lot. You can do your ordinary CSS in it, as well as variables, themes and there's a Tailwind-like utility functions. Because I was only writing something small I only really scratched the surface of what it can do.
In general I found writing it went wrong a lot because you need to put eg `backgroundColor: 'red',`, whereas in CSS you have `background-color: red;`. I kept having to go back and unhyphenate and add quotes. But I think if I used CSS in JS a lot then I would get used to it.
Once I was past the ordinary CSS aspect I was quickly lost. I think that's because I was trying to use a bit of everything to see what it was like. If I had a bigger project or used it on more projects then I think I'd gradually get to understand it.
But I found the documentation on the website was good. Which is just as well as there's not a lot out there and most of it just repeats what's on the website.
I struggled to bit to get it installed and working because I was using it with Vite, which is an unusual combination (Vite is about the only bundler that will work on my old, slow computer).
I don't know that I'll use it again, because it's more than I need for simple side projects. But I can definitely see how it would be useful for larger projects. | nicm42 |
1,214,949 | A Senior Fullstack Engineer Who Couldn't Close An Input Tag - Swizec | Original Tweet From @Swizec Swizec Teller writing a... | 0 | 2022-10-09T15:18:54 | https://infotweets.com/blog/a-senior-fullstack-engineer-who-couldnt-close-an-input-tag-swizec-49o9 | webdev, career, beginners | #### Original Tweet From [@Swizec](https://twitter.com/Swizec)
{% embed https://twitter.com/Swizec/status/1578407730305384448 %}
Yesterday I saw a senior fullstack [web] engineer who couldn't close an <input> tag in React because we asked them not to use Material UI 😐
and that's why we need interviews
I honestly can't stop thinking about it.
An input tag. They couldn't figure it out. I had to rescue them. 5 minutes of fumbling.
And no it wasn't just nerves, the pattern was strong.
No like couldn’t figure out why
<input …>
<child>
<child>
</input>
isn’t working. Even tried
<input …
<child>
<child>
/>
No material ui completely threw them off. Suddenly didn’t know basic syntax
{% embed https://twitter.com/mattconvente/status/1578408836225847296 %}
I'm certain they can code. Just not the kind of code we're looking for.
And I can only evaluate what I see. Otherwise we're back to credentialism, which is objectively worse.
{% embed https://twitter.com/mindplaydk/status/1578482858078785536 %}
Yes I expect a marathoning candidate to be able to walk around the room. And I think that’s reasonable
{% embed https://twitter.com/el_rodrix/status/1578499739166703617 %}
If you approach HTML as “memorizing syntax for every element”, you’re doing it wrong. It’s a language because there’s rules you can follow even in unfamiliar territory.
and a senior web developer should know that.
{% embed https://twitter.com/Programazing/status/1578696662150565888 %}
Click [Here](https://www.knowledge-twitter.com/?utm_source=dev.to) For More Posts Like This [https://www.knowledge-twitter.com](https://www.knowledge-twitter.com/?utm_source=dev.to) | knowledgefromtwitter |
1,215,215 | Predict Purchasing Power per Country using MindsDB | Introduction MindsDB embeds AI and machine learning into databases to assist groups... | 0 | 2022-10-09T21:18:20 | https://dev.to/rutamhere/predict-purchasing-power-per-country-using-mindsdb-1oh7 | tutorial, machinelearning, datascience, database |

## Introduction
MindsDB embeds AI and machine learning into databases to assist groups working with day-to-day data to determine patterns, predict trends, and train models.
Currently, MindsDB offers two types of services to its users.
- [Self-Hosted](https://docs.mindsdb.com/setup/self-hosted/docker/)
- [MindsDB Cloud](https://docs.mindsdb.com/setup/cloud/)
Not only it transforms traditional databases to AI-enabled tables, but also offers a free version (with 10K rows limit) to all its users around the globe.
So, in this tutorial we will be using MindsDB Cloud to train a Predictor Model that can predict the purchasing power of a country based on its `cost_index` and `monthly_income`. You can download the dataset we will use for this tutorial [here](https://www.kaggle.com/datasets/madhurpant/world-economic-data?select=cost_of_living.csv).
Let's get started now with the rest of the steps.
## Adding Data to MindsDB Cloud
We can upload the [dataset](https://www.kaggle.com/datasets/madhurpant/world-economic-data?select=cost_of_living.csv) we downloaded above directly in the MindsDB Cloud GUI and create a table from it easily.
Now let's setup our MindsDB Cloud account first so that we can proceed with the next steps.
**Step 1:** Create a new MindsDB Cloud account [here](https://cloud.mindsdb.com/register) if you don't have one or else simply [login](https://cloud.mindsdb.com/login) to your existing account.
**Step 2:** Once you're in logged in, you can find the MindsDB Cloud Editor opened up for you.
You will find the Query Editor at the top, there's a Result Viewer at the bottom and Learning Hub resources are present at the right side.
**Step 3:** Now click on `Add Data` from the top right corner and switch the tab from `Databases` to `Files`. Then hit the `Import File` button to proceed further.
**Step 4:** Browse and open the `.CSV` file that you just downloaded on the `Import File` dashboard, provide a suitable table name in the `Table Name` field and then hit the `Save and Continue` button to create a table in the given name with the dataset you just uploaded.
**Step 5:** Once the file is successfully uploaded, you will be automatically redirected to the MindsDB Cloud Editor page where you can see two queries that we can execute to check whether the table is created with all the proper data or not.
Execute both the queries to check the results.
``` sql
SHOW TABLES FROM files;
```
``` sql
SELECT * FROM files.country_capita LIMIT 10;
```
We are now ready to move to the next part of the tutorial where we need to train the Predictor model.
## Training a Predictor Model
It is really easy to train a Predictor model using MindsDB. We have to just use a basic SQL kind of statement to do the job.
**Step 1:** We can now simply use the `CREATE PREDICTOR` statement to create and train a new Predictor model. Find the syntax below.
``` sql
CREATE PREDICTOR mindsdb.predictor_name (Your Predictor Name)
FROM database_name (Your Database Name)
(SELECT columns FROM table_name LIMIT 10000) (Your Table Name)
PREDICT target_parameter; (Your Target Parameter)
```
We have to execute this query with the correct parameters required and it should return a successful status in the Result Viewer. The actual query should look something like this.
``` sql
CREATE PREDICTOR mindsdb.country_capita_predictor
FROM files
(SELECT cost_index monthly_income FROM country_capita LIMIT 10000)
PREDICT purchasing_power_index;
```
> Note: You can only train a Predictor Model with 10K data rows maximum in free version. So, we have used `LIMIT 10000` so that the query doesn't error out in case we have more rows in the table.
**Step 2:** Depending on how large the dataset is, the Predictor may take a while to complete its training. Meanwhile, we can check the status of the Predictor with the following statement.
``` sql
SELECT status
FROM mindsdb.predictors
WHERE name='Name_of_the_Predictor';
```
## Describing the Predictor Model
In this section, we will try to find out some basic details about the Predictor model that we just trained above. MindsDB provides a simple `DESCRIBE` statement that we can use to query different details about the model.
Basically, we can use the `DESCRIBE` statement in the following three ways.
- By Features
- By Model
- By Model Ensemble
### By Features
This statement returns the type of encoders used on each column to train the model along with the role that each column serves for the model. The query looks something like this.
``` sql
DESCRIBE mindsdb.predictor_model_name.features;
```
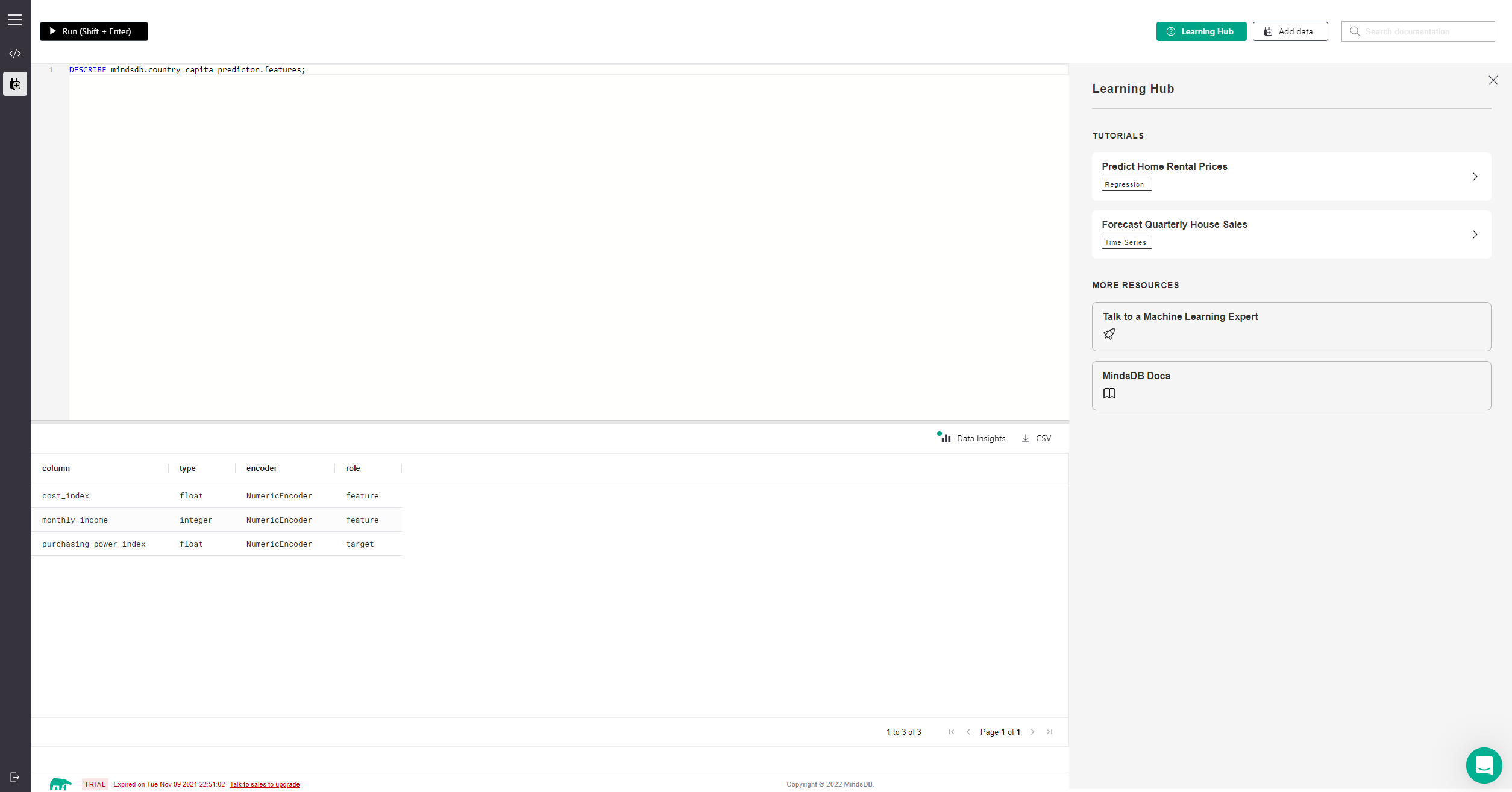
### By Model
This statement returns the candidate model that is selected for the Predictor to do the predictions. The list contains all the candidate models used while training the data and the one with the highest performance gets selected and the `selected` column for this is set to 1 while other are set at 0.
The statament should be as follows.
``` sql
DESCRIBE mindsdb.predictor_model_name.model;
```
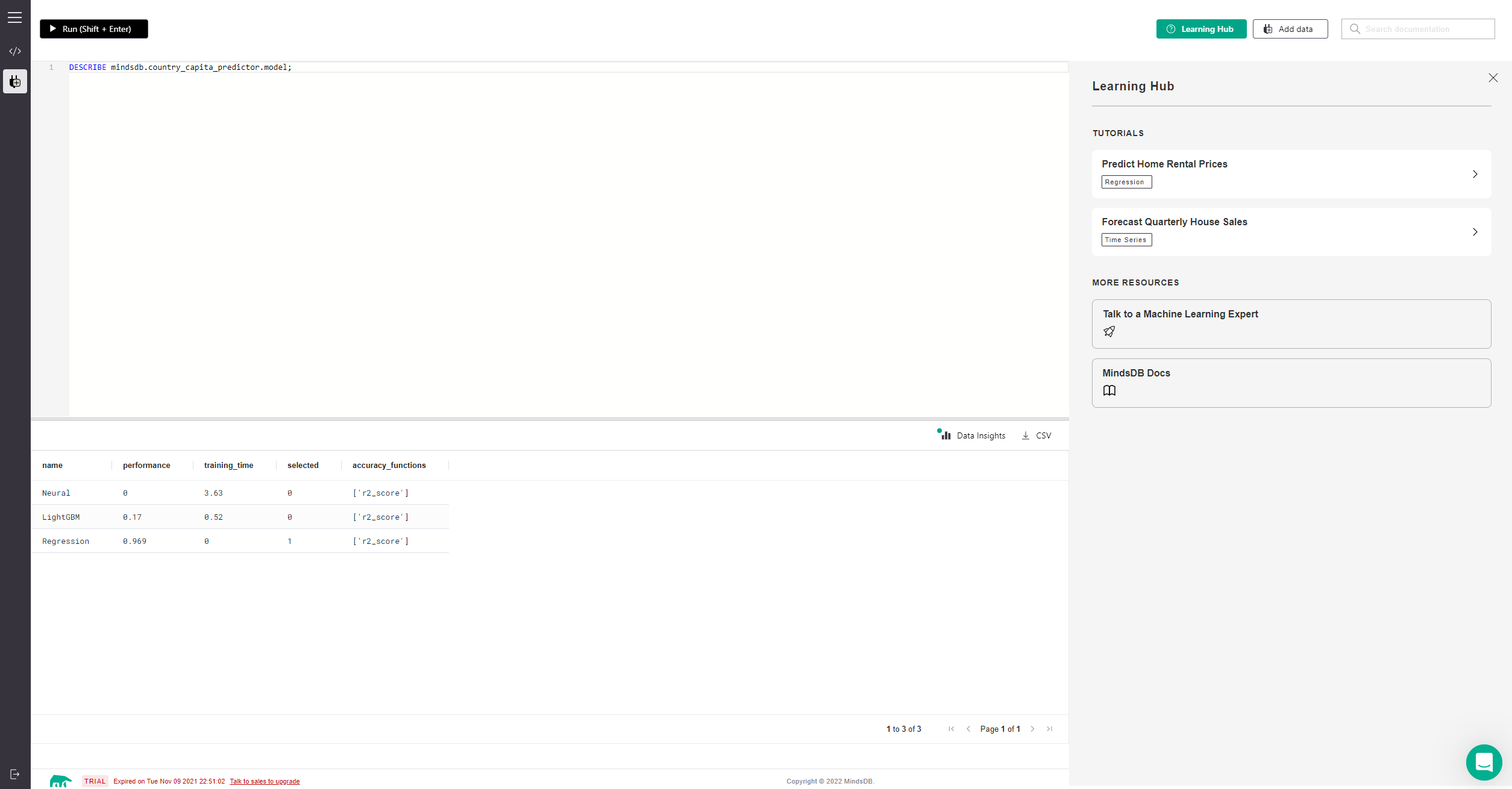
### By Model Ensemble
This statement returns a JSON object with a list of different attributes that are considered to select the best candidate model for the Predictor. We can use the query mentioned below to fetch this output.
``` sql
DESCRIBE mindsdb.predictor_model_name.ensemble;
```
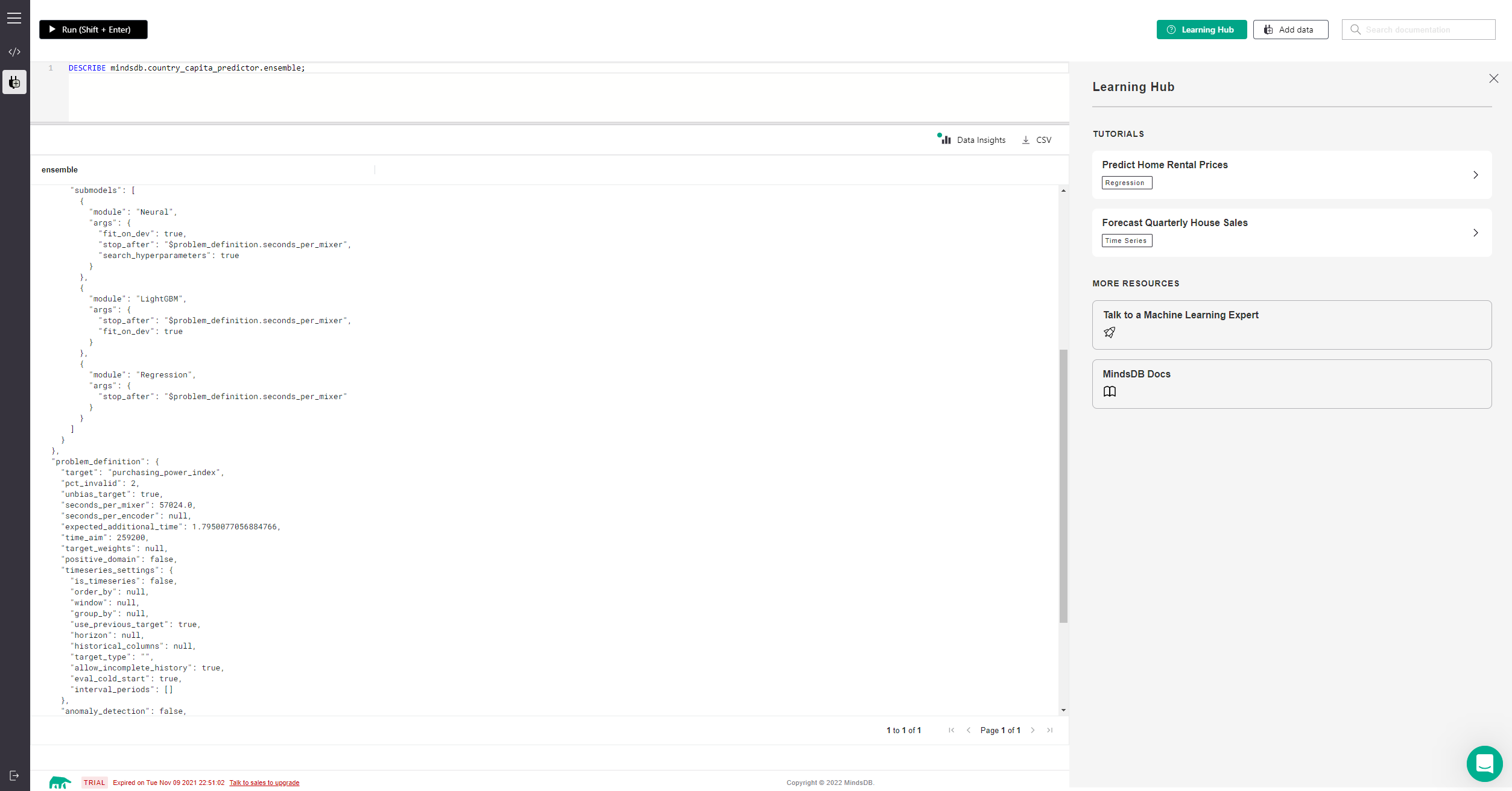
## Querying the Model
The Predictor model is now ready to predict the target values for us. MindsDB eases the user experience as it allows simple SQL-like query statements to do the job.
We will start by predicting the `purchasing_power_index` value based on only single feature parameter. The query for this will be as follows.
``` sql
SELECT purchasing_power_index purchasing_power_index_explain
FROM mindsdb.country_capita_predictor
WHERE cost_index =150;
```
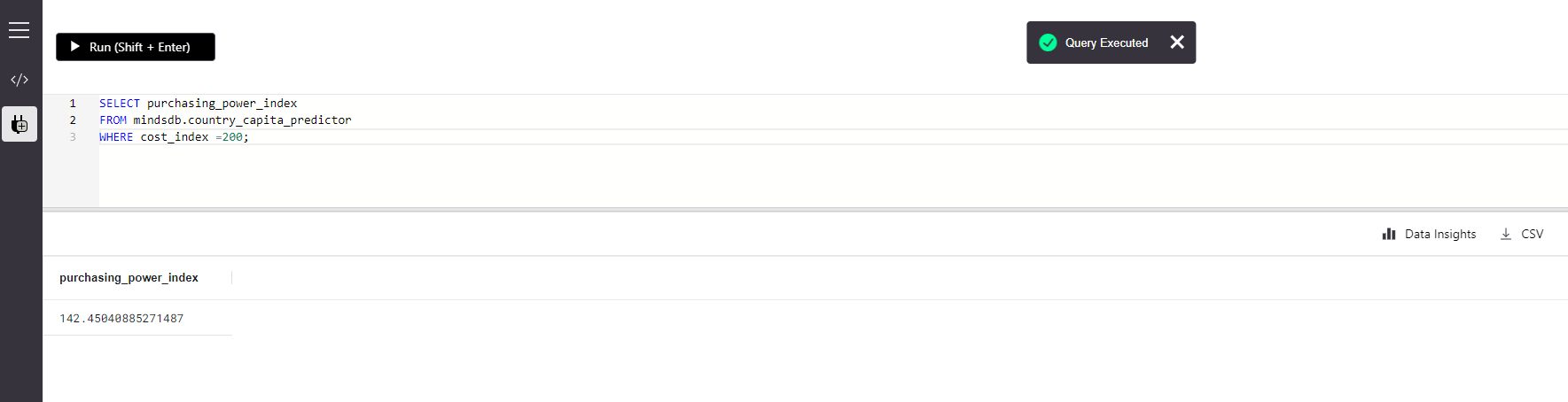
Now, let's try to predict the `purchasing_power_index` value using both the feature parameters i.e., `cost_index` and `monthly_income`. The query will be like the one below.
``` sql
SELECT purchasing_power_index
FROM mindsdb.country_capita_predictor
WHERE cost_index =200 AND monthly_income=100;
```
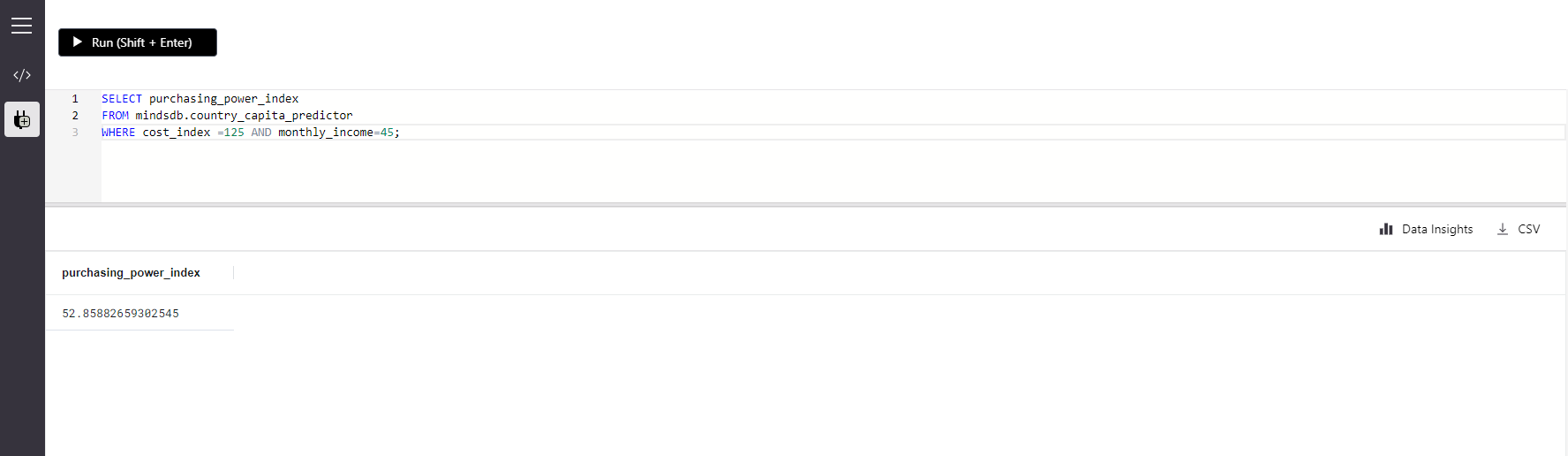
## Conclusion
We have now reached the end of this tutorial. It's time for a quick recap now. So, in this tutorial, we set up our MindsDB Cloud account, uploaded our dataset to the MindsDB GUI directly, created a Predictor Model from the uploaded dataset and finally predicted the purchasing power of a country based on the `cost_index` and `monthly_income`.
Now, I recommend all of you to create your own MindsDB accounts, find some interesting datasets from the internet and then train some amazing Predictor models with MindsDB. Remember, it's all free to use!
Lastly, before you leave this page, show some support by hitting the `LIKE` button and also don't forget to key in your feedback below.
[](https://mindsdb.com/)
[](https://github.com/sponsors/Rutam21)
| rutamhere |
1,215,244 | How to fetch all NFTs owned by a particular Wallet Address using Ankrjs | In this tutorial, we’ll be fetching all the NFTs owned by a particular wallet or owner across... | 0 | 2022-10-09T20:32:14 | https://dev.to/kayprasla/how-to-fetch-all-nfts-owned-by-a-particular-wallet-address-using-ankrjs-1e53 | nfts, wallet, web3, blockchain | In this tutorial, we’ll be fetching all the NFTs owned by a particular wallet or owner across multiple blockchains such as Ethereum, Polygon, and Fantom, to name a few, using [Ankr's Advanced Multichain APIs](https://www.ankr.com/advanced-api/)↗.
### Ankr Advanced APIs
Ankr's Advanced Multichain APIs are the collection of RPC methods created to simplify querying blockchain data. These APIs do all the heavy lifting for us so that we can query on-chain data in a matter of seconds.

Currently, it supports Eight EVM compatible chains: Ethereum, Fantom, Binance Smart Chain, Syscoin, Optimism, Polygon, Avalanche, Arbitrum, with more EVM and non-EVM chains coming soon. To interact with Ankr's Advanced APIs, we are going to use a JavaScript library named [Ankr.js](https://www.npmjs.com/package/@ankr.com/ankr.js)↗.
_____________________________________________
## Getting Started
**Prerequisite:** To successfully finish this guide, you'll need [Node.js](https://nodejs.org/en/)↗ and [Yarn](https://yarnpkg.com/)↗ installed on your machine.
### Step 1: Setting Up Next.js Starter Application
First up, navigate into the directory of your choice where you want to initiate this project and run the following command in your terminal to set up a new Next.js starter page:
```
yarn create next-app --ts ankrjs-fetch-nfts
```
You'll be able to see a couple of files and folders being created for you. Let's dive into the newly created directory and start the development server on localhost:3000.
```
cd ankrjs-fetch-nfts
```
```
yarn dev
```
Visit localhost:3000 to view the starter application and it will resemble the screen attached below:
______________________________________
### Step 2: Installing and Setting Up Ankr.js
In this section, we will install and set up Ankr.js for querying NFT data from the blockchain for a given wallet address.
We will start by installing the ankr.js package from npm:
```
yarn add @ankr.com/ankr.js
```
Now that we have installed the Ankr.js library, let's set up Ankr.js by **creating a new file** named `apis.ts` at the root of your project directory. We will initialize Ankr.js in this file.
**File:** `./apis.ts`
```javascript
import AnkrscanProvider from '@ankr.com/ankr.js';
import type { Blockchain } from '@ankr.com/ankr.js/dist/types';
const provider = new AnkrscanProvider('');
```
To interact with Ankr's Advanced APIs, we have created a provider instance that will serve as an interface to the APIs required to fetch data.
___________________________________
### Step 3: Create getNFTs Function
In this step, you will create a `getNfts` function that accepts a `walletAddress` and returns a list of NFTs owned by that address.
Here, we are going to utilize the `getNFTsByOwner` function provided by Ankr.js for this.
File: `./apis.ts`
```javascript
import AnkrscanProvider from '@ankr.com/ankr.js';
import type { Blockchain } from '@ankr.com/ankr.js/dist/types';
const provider = new AnkrscanProvider('');
export const getNfts = async (address: string) => {
const { assets } = await provider.getNFTsByOwner({
walletAddress: address,
blockchain: 'eth',
});
return {
nfts: assets,
};
};
```
And that's it.
Let's call this function on our page i.e. `./pages/index.tsx` to see the fetched NFTs by the owner's wallet address and log the output. To do so, clear the code from the **index.tsx** file and replace it with the one given below:
**File:** `./pages/index.tsx`
```javascript
import type { NextPage } from 'next';
import { useEffect } from 'react';
import { getNfts } from '../apis';
const Home: NextPage = () => {
useEffect(() => {
(async () => {
const { nfts } = await getNfts(
'0xd8da6bf26964af9d7eed9e03e53415d37aa96045'
);
console.log({ nfts });
})();
}, []);
return (
<div className='p-10 flex flex-col items-center'>
<h1 className='text-3xl font-bold'>NFTs</h1>
</div>
);
};
export default Home;
```
Now, let's see the NFT logs of an inputted wallet address in the developer console of a browser.
- Head over to your localhost and use `Option + ⌘ + J` (on macOS), or `Shift + CTRL + J` (on Windows/Linux).
You should be able to see the list of NFTs owned by a particular address.
You can also extend the toggle to dive into the details of the NFTs held by the owner. Details include: `blockchain`, `collectionName`, `contractAddress`, `contractType`, `imageUrl`, `name`, `symbol`, `tokenId` and `tokenUrl`.
### GitHub Repo
[Find Code Here!](https://github.com/kaymomin/ankrjs-fetch-nfts)
You can also extend what you just learned here into building a [Multichain NFT Viewer.](https://ankr.hashnode.dev/ankrjs-advanced-apis-react-quickstart-guide)↗ | kayprasla |
1,215,458 | How businesses can leverage Cloud-native desktops to accelerate growth | Before focusing on the business value of cloud-native desktops (and applications), let’s take a quick... | 0 | 2022-10-10T04:57:38 | https://blog.neverinstall.com/cloud-native-desktops-for-business-growth/ | cloud, computerscience | Before focusing on the business value of cloud-native desktops (and applications), let’s take a quick review of cloud-native technology.
## What is Cloud-Native?
The term “cloud-native” describes an operational concept for developing, deploying, and running apps on cloud computing systems. In essence, cloud-native software is built to run on the cloud, leveraging its scalability, flexibility, and resilience at all times. The most common examples of cloud-native software are dev tooling essentials such as containers, microservices, APIs, etc.
Running applications and desktops on the public and private cloud offer a few revolutionary advantages:
- cutting down operational costs and human effort,
- faster scaling, and
- flexible pricing based on usage.
Cloud-native applications are built as clusters of independent, loosely attached services. Generally, they tend to be smaller in size and are built for easier development, deployment, and iteration. Since these apps are architected for maximum compatibility with cloud computing models, they can, by their nature, offer faster load speeds, flexibility of access & usage as well as a better end-user experience.
**A cloud-native architecture takes the concept of web apps and applies it to your entire desktop experience.**
Imagine what you see when you switch on your laptop or desktop. You stream all of that - the desktop and applications – the same way you’d stream a movie. However, there’s a major difference – you can interact with, modify, adjust and work with the stream.
Suggested read - [Application streaming: Where it has taken us](https://blog.neverinstall.com/application-streaming-where-it-has-taken-us/)
That entire home screen, along with all the applications installed on your device, can be accessed via your browser as a cloud-native desktop. In other words, instead of downloading and installing applications and files on your device’s local memory, you do so on the cloud.
We’ll be diving into the advantages, especially the business-facing advantages of cloud-native apps and desktops in this article. But a specific key advantage deserves mention here.
**When you’re running a cloud-native desktop, the processing and operational load required is entirely undertaken by a remote server - the one that is streaming your browser-based desktop.**
Your own device only has to take care of running a single browser, and you can access the most updated OS and apps on the market. As an example, you can run resource-heavy design and dev tools (Figma, VSCode, etc.) on a Chromebook without any lag, since the applications are no longer dependent on the Chromebook’s technical abilities to perform at optimal levels.
## The Limitations of Traditional Apps (and Desktops)
By virtue of their design, cloud-native applications generally perform better at delivering business value. Compared to their cloud-native counterparts, traditional applications have a larger and more complex code base. They are also completely dependent on the processing capability of the device running the – hardware, software, OS, and support features.
For example, an app designed for Windows 11 will have a fairly hard time running on older versions of the OS, since the application’s functioning largely depends on the advanced abilities of the OS itself. This imposes limitations on the app’s usability since it can only be fully leveraged by specific device configurations.
This restricts scalability and adaptation to changing technologies. Consider an employer who wants all existing employees to install and utilize a new project management tool with proven benefits; they must first consider employees’ device capabilities. If the tool is designed to work best on a newer OS (Windows 11, macOS 12 Monterey) and 40% of employees are still on older OS versions, they will either be unable to use the tool or use it in a depleted capacity due to incompatibility with the target OS and device.
Traditional apps and desktops need IT teams to constantly update devices across employee pools, which can incur significant expenses for any business. Additionally, onboarding new employees take longer since company-approved devices have to be purchased and sent across locations (for remote/distributed teams), which takes time and more expenditure.
Now that we’re aware of the operational gaps encountered with traditional tech architectures, let’s explore how these gaps are addressed and remediated with cloud-native software ecosystems.
## How cloud-native desktops contribute to business growth
### Device and platform-agnostic performance
As mentioned above, cloud-native desktops make it easy to run resource-consuming apps even if the underlying device does not have RAM and memory juice to do so. All processing required to run and stream the cloud-based desktop is run on a separate machine, while the end-users machine just has to run a regular browser.
Suggested read - [The Curious Case of Chrome's Memory Consumption - Neverinstall it](https://blog.neverinstall.com/the-curious-case-of-chromes-consumption-neverinstall-it/)
Without browsers, apps, and files slowing down a user’s system, IT does not have to deal with frequent support, replacement, and update requests for aging machines - preventing lag, productivity drops, or employee dissatisfaction with work tech.
### Reduced maintenance costs
If users’ devices don’t suffer the wear and tear of running heavy applications, they last longer and encounter fewer issues. This cuts down on the usual costs associated with IT maintenance - support costs, security implementation, lag, slower functioning, etc. Additionally, certain issues may require the user to take the device to a support center or ship it to their employer - further expenditure of unproductive time, money, and effort.
IT teams simply have to manage the cloud-native desktop from a centralized dashboard. They can trigger necessary updates for performance and security, monitor for vulnerabilities, and address any user issues remotely.
### Better security
When working with distributed teams, IT teams have to manage and secure multiple (hundreds or thousands, in some cases) endpoints operating across several locations. Since they no longer have immediate access to all devices in a single office, IT must deal with the constant threat of data theft, unauthorized exposure, device loss, or misplacement.
Suggested read - [For your eyes only: Data Privacy with Neverinstall](https://blog.neverinstall.com/data-privacy-with-neverinstall/)
Cloud-native desktops store all data on remote servers, eliminating these concerns. No data is stored on employee devices, thus minimizing the possibility of device loss leading to data loss. Anytime a device is lost or stolen, IT can remotely lock access to the company’s cloud desktop and reliably secure business data.
### Consistently improved productivity
Cloud-native desktops let you seamlessly work with apps that your actual device may not be equipped to run. As long as the device can support a browser, employees can use industry-best software, regardless of device health.
Companies no longer have to deal with sub-optimal productivity caused by outdated technology. Employees, too, do not have to resort to using unapproved tools to get work done, reducing the likelihood of shadowing IT.
### Ease of access
Employees are not dependent on company-issue devices to accomplish their tasks. They can use any device as long as they have access credentials for the company’s cloud-native workspace. No need to transfer files, align with security protocols or worry about cleaning the device after work is completed. They just log in through a browser and start working.
### Significantly greater ROI
Cloud-native desktops ensure that your employees can effortlessly use resource-intensive applications, such as ones often required by developers and designers. IDEs and design tools tend to make high demands on a device’s processing capabilities, making them unsuitable for hardware on the lower end of the capability spectrum. Trying to run Figma on a regular tablet would probably lead to major lag and a system crash, preventing users from driving their best possible output.
Suggested read - [Cloud desktops vs. On-premises desktops: Understanding ROI with Neverinstall](https://blog.neverinstall.com/cloud-desktops-vs-on-premises-desktops-roi/)
Cloud-native apps run on remote servers equipped to execute and stream all functions with very little contribution from the local device. Businesses no longer have to worry if their employee devices have sufficient RAM or GPUs to process necessary software since all operational overhead is solely undertaken by the cloud.
### Easier employee onboarding
A cloud-native workspace can be initiated, customized, and set up in minutes. New employees no longer have to wait for a company-issued device to reach them before onboarding begins. Even the onboarding process becomes simpler, as the employee does not need to report device status, download organization-approved antivirus, or set up anything at all.
The employee just needs a working computer and a fast enough internet connection. Once your IT team gives them the cloud-desktop login credentials, they can immediately get started.
Bear in mind that easier onboarding also allows businesses to hire people from any internet-enabled location across the world. You can pick from a wider talent pool, and no longer have to turn down talented individuals simply because they live too far away from the office.
### Superior customer experience
On account of its scalability, flexibility, and resilience, application development is far easier on the cloud. As part of modern CI/CD pipelines, cloud-native tools such as containers and testing infra play a central role in building, testing, and deploying high-quality software, fast. Better products result in better customer experiences, boosting brand value and customer trust.
However, cloud-native desktops, such as the ones provided by Neverinstall, also help with boosting customer experience in non-development contexts. For example, collaborative browsing lets customer service folks directly observe a customer on their user journey, see the problem occur in real time, and accelerate resolution - all without screen sharing.
## Leverage business-ready cloud-native desktops on Neverinstall
Leveraging high-functioning, low-latency cloud-native desktops has never been easier than it is with Neverinstall. Here’s a quick glimpse of what you get when you sign up as a Neverinstall user:
- A fully-functional browser-based Linux OS that can be accessed and used via any device with an internet connection.
- Our desktop experience has also been optimized for mobile device users. All Neverinstall workspaces are designed to run effectively on mobile phones. The platform offers responsive design, equipping it to render in different display modes. We also offer single-touch and multi-touch interactions across device classes. A virtual keyboard is also available.
- Fully customizable desktops that come with popular pre-installed and pre-configured applications (Figma, Slack, VSCode, Android Studio, Discord & more). No limitations or reductions in in-app features.
- The ability to select required apps before launching a workspace. For example, if you need Obsidian, VSCode, Chrome, and Spotify, you just select them, launch a workspace, and said apps are installed and prepped for use by the server itself. No effort is required by the user.
- The cloud desktop streams in alignment with the maximum network bandwidth available to a user. Users can launch workspaces through servers in the US and Europe, allowing them to leverage high-speed internet, irrespective of their location.
A low-latency desktop experience, facilitated by the WebRTC streaming protocol.
- Easy, lag-free use of input devices such as keyboards and mice.
- An expanding server network perpetually strives to minimize operational latency. Currently, Neverinstall has server clusters in the US, England, Singapore, and India. Upcoming servers will cover Japan, Australia, Finland, Spain, The Netherlands, and more locations in the US.
## Closing Thoughts
By detaching application and desktop performance from the underlying device and OS, cloud-native desktops have brought about a paradigm shift in how we (individual users and organizations) think of work, technology, and productivity.
The advantages discussed above should make the case for switching from monolith, on-premise architectures to their more reliable, flexible, and manageable cloud-based counterpart. At the heart of this switch lies freedom - the freedom from work from any location, on any device, without worrying about data access, theft, or loss.
In the long-run, cloud-native desktops make life easier for employees, IT teams, management, and investors alike. Better functionality, security, and scalability at a fraction of the price of purchasing and securing employee devices each year - what’s not to like?
Experience browser-based computing with Neverinstall and offload your heavy-duty applications to the cloud. [Sign up](https://neverinstall.com/signup?utm_source=blog&utm_medium=blog&utm_campaign=blog) today! | abhishekatneverinstall |
1,215,464 | Extracting data from a website API and Save as CSV | Background I recently wrote a Python Script that extracted data from US Department of Agriculture... | 0 | 2022-10-12T02:32:32 | https://dev.to/cgitosh/extracting-data-from-a-website-api-and-save-as-csv-o4l | python, datascience, tutorial, analytics | **Background**
I recently wrote a Python Script that extracted data from US Department of Agriculture website, formatted into the desired format and saved it into a CSV file. Since I did some research online while working on the script, I thought it would only be fair that I give back to the community by writing down the steps I followed plus some example code in the hope that someone out there will benefit.
**Problem statement**
The FoodData Central database has amino acid levels for many foods. Extract data from the SR 'Legacy Foods' category and list the food and amino acid level in CSV format with
rows for each food and fields are the various amino acids (18 amino acids)
**Solution**
FoodData Central API provides access to the FoodData Central (FDC), to gain access you have to register for an API Key through this link https://fdc.nal.usda.gov/api-key-signup.html.
For the purpose of this article, I created the Get query on the API web interface, specified all the parameters then copied the URL with parameters and API Key into my script, normally you would specify the parameters in your code. Below is the full 'GET' query URL
```
endpoint = 'https://api.nal.usda.gov/fdc/v1/foods/list?dataType=SR%20Legacy&pageSize=20&pageNumber=3&sortBy=fdcId&sortOrder=asc&api_key=XXXXXXXXX'
```
Next step is I want to query the API endpoint using the python 'requests'HTTP Library
```
response = requests.get(endpoint).json()
```
The response variable above contains the data from the FoodData Central Database, it's time to format the data in the desired format. For each food item, I want to have name of the food item (Description) and the quantity of each amino acid that particular food item contains. Therefore my CSV file will have a total of 19 fields. Next Step is to specify the keys/headers list and an empty dictionary that I will populate with data
```
# keys global variable will be used to generate keys for the response_dict dictionary and for fieldnames for the csv file
keys = ['Description','Alanine', 'Arginine', 'Aspartic','Cysteine','Glutamic','Glycine','Histidine','Isoleucine','Leucine','Lysine','Methionine','Phenylalanine','Proline','Serine', 'Threonine','Tryptophan','Tyrosine','Valine']
```
The next block of code will loop through the response data, match the response data to the respective dictionary key then append that data to the Food_list variable declared above
Below is the complete function
```
def get_data():
# The API endpoint to query data from preformated with the desired parameters
endpoint = 'https://api.nal.usda.gov/fdc/v1/foods/list?dataType=SR%20Legacy&pageSize=20&pageNumber=3&sortBy=fdcId&sortOrder=asc&api_key=3VzJQvEyn9UBBwFgK3pdli3x82rCnpy9sVJFNt3Z'
# The python HTTP requests library queries the endpoint and returns the data in JSON format
response = requests.get(endpoint).json()
food_list = []
for data in response:
#empty dictionary initialized with keys from the 'keys' list variable declared globally
response_dict = {key: 0 for key in keys}
response_dict['Description'] = data['description']
for nutrient in data['foodNutrients']:
if nutrient['name'] in keys:
response_dict[nutrient["name"]] = nutrient['amount']
food_list.append(response_dict)
return food_list
```
Finally let's write our food_list data into a CSV file
```
filename = 'FoodDatacsv.csv'
with open(filename, 'w', newline='') as myfile:
writer = csv.DictWriter(myfile, fieldnames=keys)
writer.writeheader()
writer.writerows(get_data())
```
Below is a sample of the extracted data.
And that is it for today.
P.S.
If you would like some data extraction done, click [Here](https://www.upwork.com/services/product/development-it-data-extracted-from-the-web-and-save-in-csv-file-in-your-desired-format-1580095848756686848?ref=project_share )
| cgitosh |
1,215,614 | Console.time & 4 other webdev tips you may want to know 🚀 | 1. Console.time You can use console.time() to starts a timer to track how long an... | 19,928 | 2022-10-10T15:47:51 | https://dev.to/mustapha/consoletime-4-other-webdev-tips-you-may-want-to-know-2i5d | javascript, css, html, webdev | ## 1. Console.time
You can use `console.time()` to starts a timer to track how long an operation takes. Also, you can also use the timeLog method in between the start and the end of the timer. Here’s a quick example:
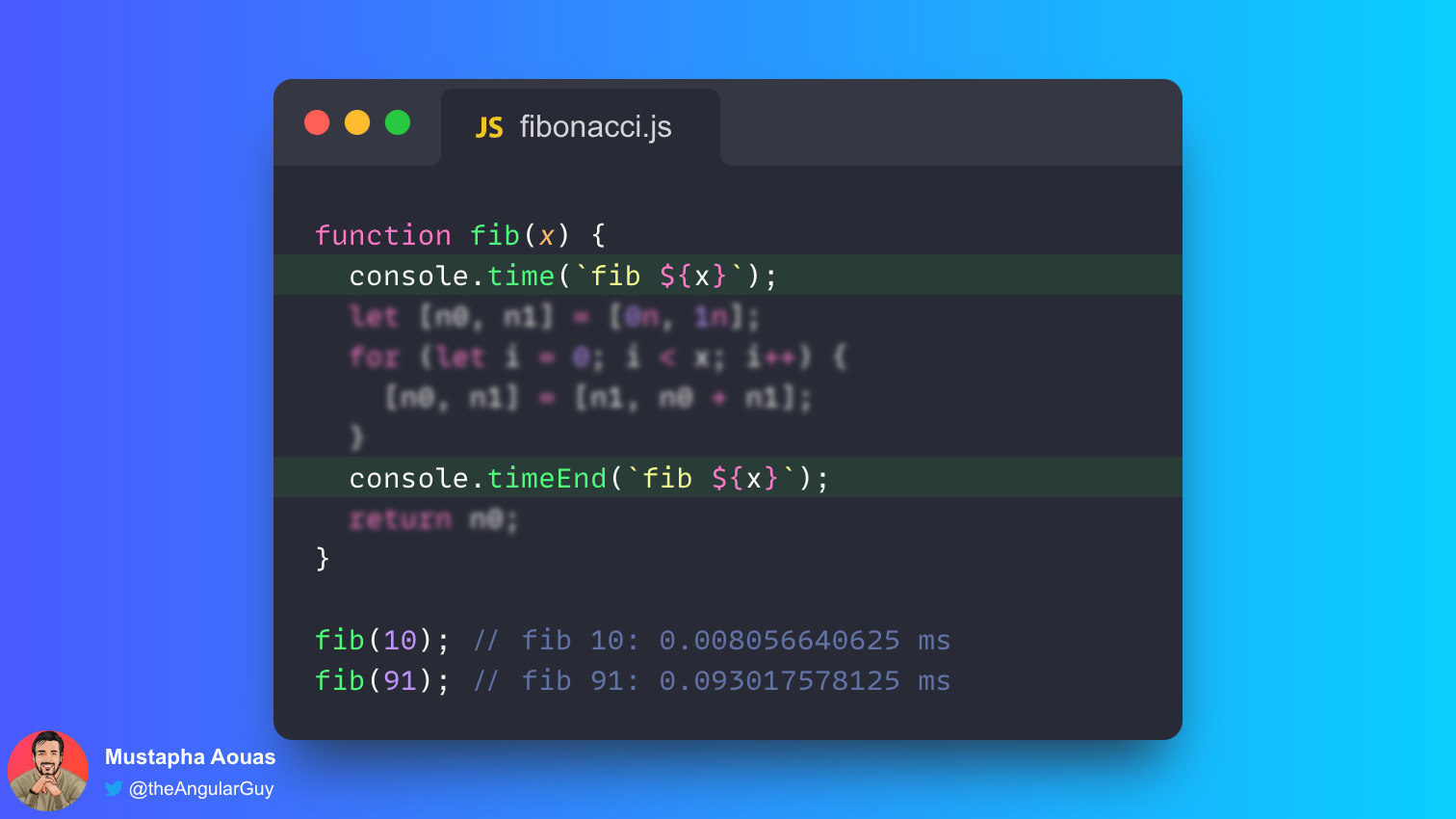
## 2. The importance of input types
You can improve the UX of your app by using the correct input type so the phones/tablets can choose the best keyboard to show to the end user:
## 3. CSS where
The `:where()` Css pseudo-class function takes a selector list as its argument, and selects any element that can be selected by one of the selectors in that list. The code below produce the same output (exept the specificity is different) but the second one is more concise:
There's a lot to say about `:is()` and `:where()`. if you want to read more aboute these pseudo-class selectors, you can click on the link below 👇
{% embed https://dev.to/mustapha/where-is-css-20nk %}
---
Hi there! I'm Mustapha, a technical writer, speaker and a passionate JS / TS developer. Follow me on [Twitter](https://twitter.com/TheAngularGuy) for daily tech tips 🚀
---
## 4. The spellcheck attribute
The spellcheck attribute defines whether an element may be checked for spelling errors.
You can use it in text inputs, textarea and editable content (elements with `contenteditable="true"`).
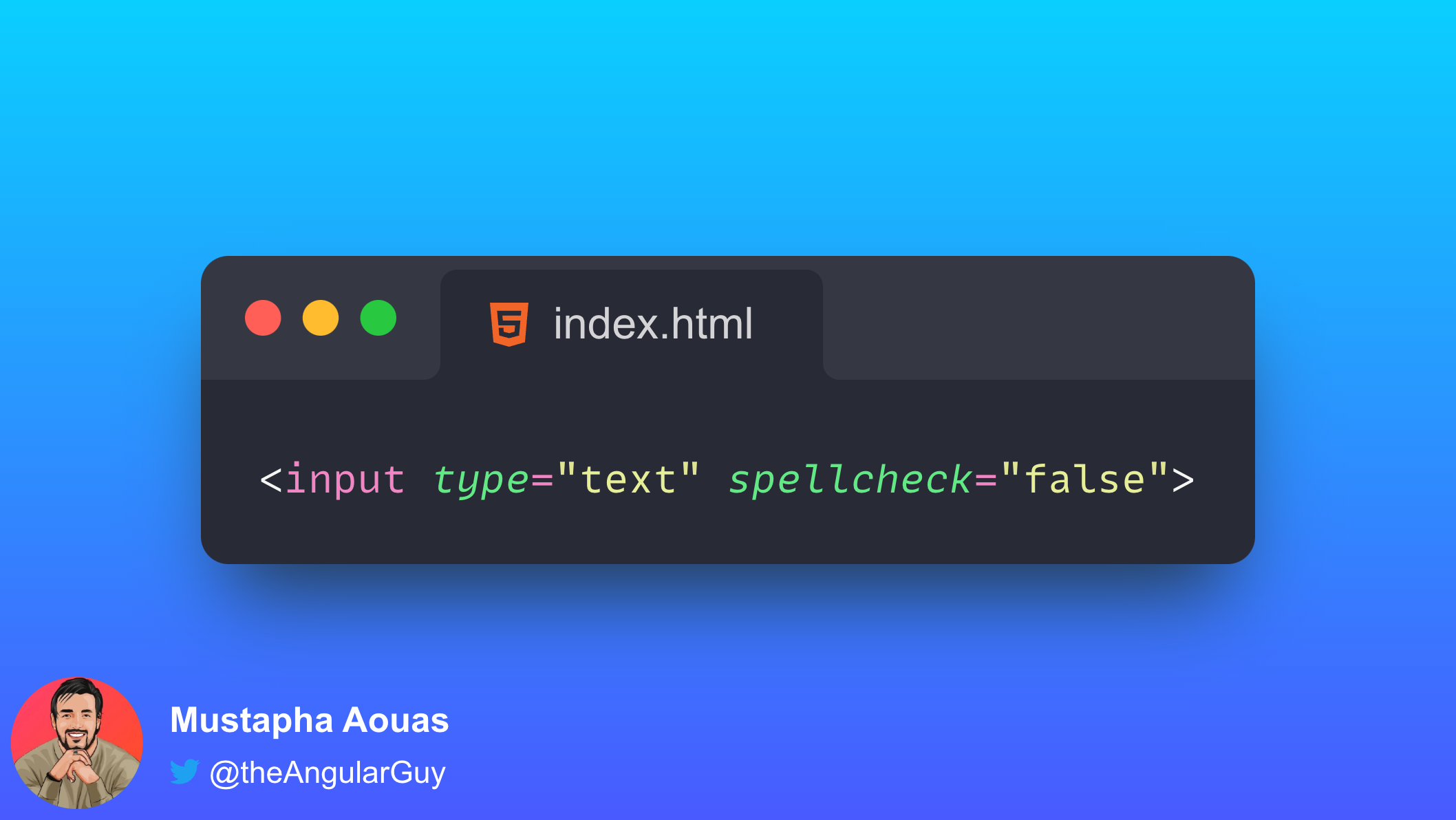
## 5. Attribute selectors
Did you know about the different ways you can use the attribute selectors in CSS?
Have a look:
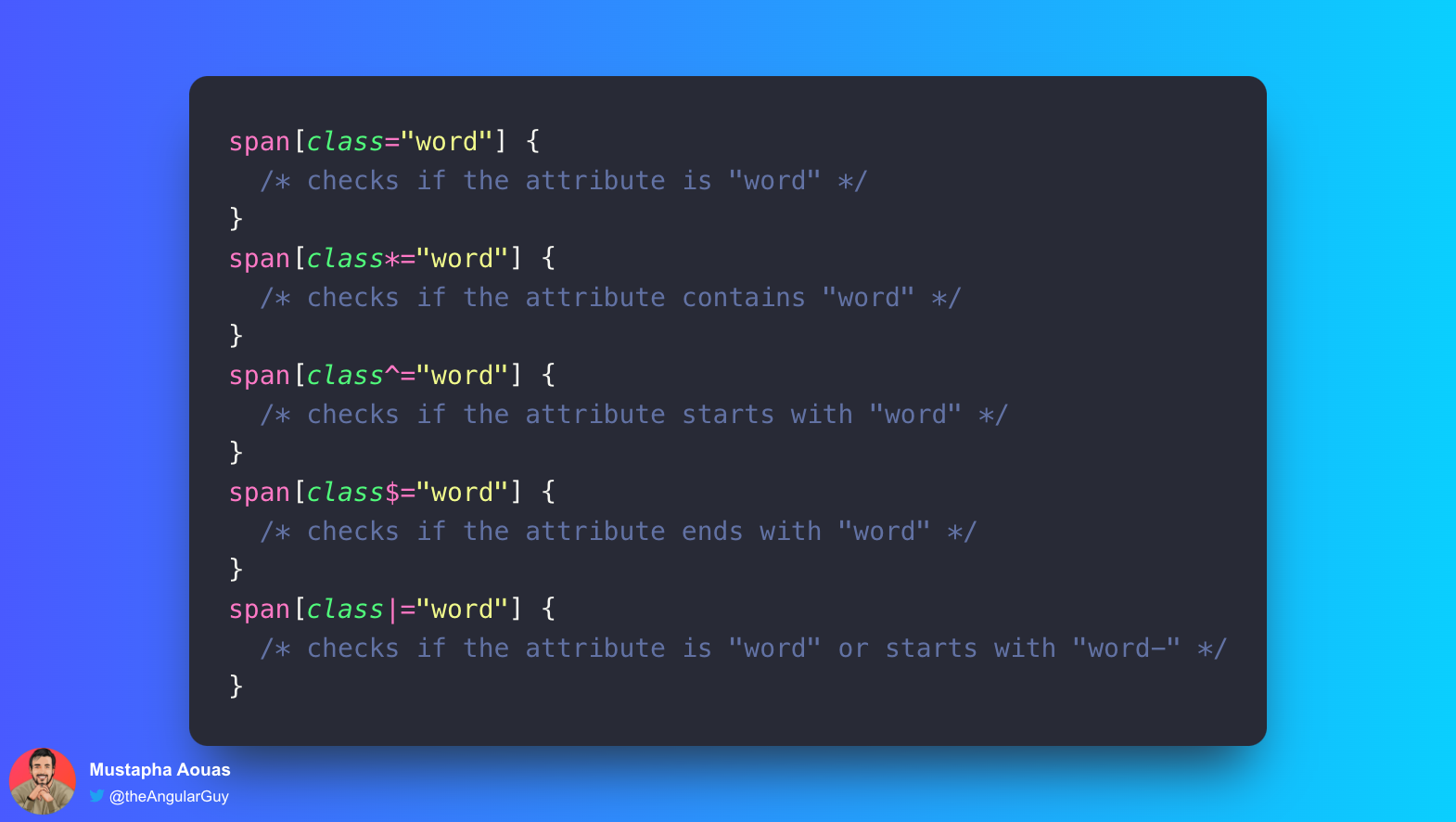
Note that the selector is case sensitive. If you want it to be case insensitive, add an I before the closing bracket:
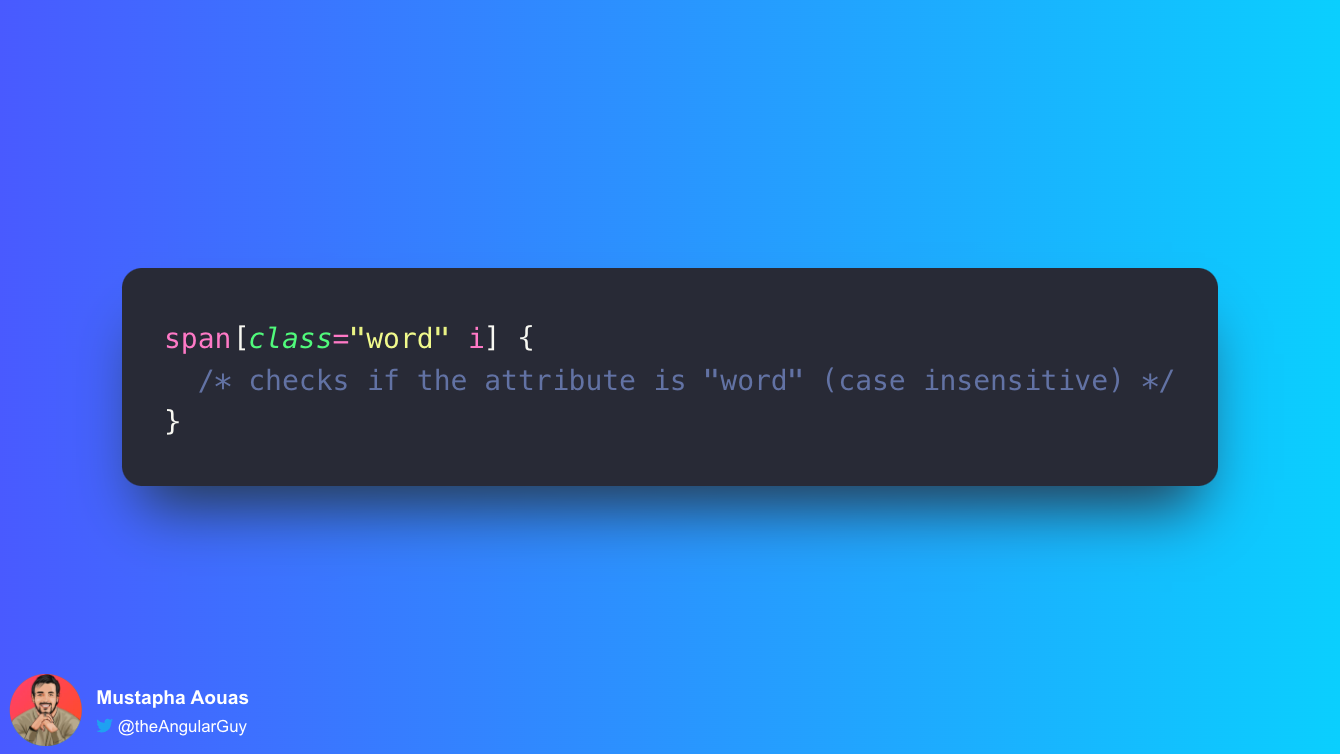
That's all for now. I hope you found this useful!
Leave a comment to let me know which tip (if any) you found useful ⤵
Until next time, have a nice week!
### What to read next?
{% embed https://dev.to/mustapha/i-made-a-working-gameboy-css-art-try-it-out-4m1j %}
| mustapha |
1,215,623 | Pashupati Group lives by the motto of taking care of people and environment. | The group distinctly contributes to circular economy, positively influencing our ecosystem while... | 0 | 2022-10-10T09:59:05 | https://dev.to/pashupatigrp/pashupati-group-lives-by-the-motto-of-taking-care-of-people-and-environment-500p | productivity, beginners, tutorial, career | The group distinctly contributes to circular economy, positively influencing our ecosystem while addressing very critical environment issues that the world faces today.
Visit to know more- [https://pashupatigrp.com/](https://pashupatigrp.com/) | pashupatigrp |
1,215,685 | From Notion to Eleventy | Static Site Generators are a great tool to generate a JAM Stack website from a data feed. That feed... | 0 | 2022-10-11T08:00:33 | https://iamschulz.com/from-notion-to-eleventy/ | javascript, webdev, programming | Static Site Generators are a great tool to generate a JAM Stack website from a data feed. That feed can be markdown files, or like in the case of Eleventy, an API endpoint that returns its data as an object. I thought It would be simple enough to attach Notion, as it makes an awesome CMS. The two seem like they could pair up really well, but getting them actually to play nice with each other takes some work.
## Notion Structure
I'm a beginner in Notion. I use it at work to write some documentation, but that's about the extent of what I know about it.
I first tried to add each article as a separate page, but soon realized I have no way of managing properties of blog posts, or as it's called in static site generators - front matter. The way to go is databases in Notion. They can be set up to have as many properties as you want. Each entry is also automatically a page.
The [Notion API](https://developers.notion.com/) gives me an endpoint to fetch the database and a further endpoint for each post. Eleventy has its `_data` structure, in which it can fetch data from the API and use it to populate a site with content. So my first try was to simply fetch pages from the Notion database and go on with that. If pure text is all you want, it's pretty straightforward. But Notion has a lot more to offer than that. There's formatting, images, embeds, code blocks... And most of them come with a little hurdle.
## Formatting
Notion works with content blocks. Each paragraph and each formatted section is a block on its own. Fetching that from Notion gets me a load of nested objects that are cumbersome to work with. I'm using [NotionToMarkdown](https://github.com/souvikinator/notion-to-md) to take care of that. This will give me a markdown string from a Notion page that's easy to work with. Beware it’s just a markdown string, though. Using it in a template will output the unrendered string. But if we put that into a markdown file, from which eleventy will generate pages, it will also render the markdown string to HTML.
```javascript
// data
require("dotenv").config();
const { Client } = require("@notionhq/client");
const { NotionToMarkdown } = require("notion-to-md");
module.exports = async () => {
const notion = new Client({ auth: process.env.NOTION_KEY });
const n2m = new NotionToMarkdown({ notionClient: notion });
const databaseId = process.env.NOTION_BLOG_ID;
const db = await notion.databases.query({
database_id: databaseId,
filter: {
property: "Draft",
checkbox: { equals: false },
},
sorts: [
{
property: "Date",
direction: "descending",
},
],
});
const getContent = async (id) => {
const mdblocks = await n2m.pageToMarkdown(id);
return n2m.toMarkdownString(mdblocks);
};
const posts = db.results.map((result) => ({
id: result.id,
title: result.properties["Title"].title.pop().plain_text,
content: undefined,
cover: result.cover?.file?.url || result.cover?.external?.url,
coverAlt:
result.properties["Cover Alt"]?.rich_text.pop()?.plain_text || "",
date: result.properties["Date"]?.date.start,
}));
for (i = 0; i < posts.length; i++) {
posts[i].content = await getContent(posts[i].id);
}
return posts;
};
```
```markdown
// foo.md
layout: 'foo.njk'
pagination:
data: foo
size: 1
alias: post
---
{{ post.content }}
```
```javascript
// foo.njk
{% extends "base.njk" %}
{%block content %}
<p>This will not render markdown:</p>
{{ post.content }}
{% endblock %}
{% block content %}
<p>But this will:</p>
{{ content | safe }}
{% endblock %}
```
## Images
Let’s take a look at images. The ones I upload to Notion are stored in Notion’s cloud. But I want to serve them from the same origin as my static site for reasons like performance and security. Eleventy has a really good [Image Plugin](https://www.11ty.dev/docs/plugins/image/), but it won’t replace my Notion images out of the box. I need a custom shortcode for images that invokes the image plugin. The plugin documentation suggests two ways to go about this: an asynchronous and a synchronous function. The asynchronous one works out of the box, but can't be used in Nunjucks macros, because they don't like unresolved Promises when they render HTML. The synchronous one needs some tweaking.
It calls `statsSync` which does not support remote images and asks me to use `statsByDimensionSync`. That one needs manual input for the image width and height, which I don’t know either. But it only uses the image dimensions to write the `width` and `height` attributes on the `<img>` tag. I can manage without that and simply remove them again. The dimensions I give into the `statsByDimensionsSync` call are basically meaningless now.
```javascript
const Image = require("@11ty/eleventy-img");
module.exports = function imageShortcode(src, alt) {
let options = {
widths: [300, 600],
formats: ["avif", "webp", "jpeg"],
outputDir: "./dist/img/",
};
// generate images, while this is async we don’t wait
Image(src, options);
let imageAttributes = {
alt,
sizes: "(min-width: 30em) 50vw, 100vw",
loading: "lazy",
decoding: "async",
};
// get metadata even the images are not fully generated
const metadata = Image.statsByDimensionsSync(src, 600, 600, options);
let html = Image.generateHTML(metadata, imageAttributes);
html = html.replace(/(?:width|height)="[0-9]+"/gm, "");
return html;
};
```
I did have to work around a bug for this to work. Apparently, this method will not process all images correctly, leading to broken image links. Thankfully, this has already been [reported](https://github.com/11ty/eleventy-img/issues/146) and solved. The fix is inside the node package `zeroby0/eleventy-img#issue-146`. I expect this workaround to be obsolete soon.
## Rendering, again
Now I have a custom shortcode in my Nunjucks parser, which can even process remote images, and the matching images in the markdown I get from Notion. But the custom shortcode won't trigger on ``. because it's a custom shortcode, it needs to be invoked with `{% image src="image/location.jpg", alt="alt text" %}`. I’m replacing the markdown image tags for custom shortcuts in the API adapter in `_data`.
```javascript
(markdown) => {
let result = markdown;
const regex = /!\[(?<alt>[^\]]+)?\]\((?<url>[^\)]+)\)/gm;
match = regex.exec(markdown);
while (match != null) {
const mdImage = match[0];
const alt = match[1];
const url = match[2];
if (!url) {
console.error(`url missing for ${mdImage}`);
return;
}
if (!alt) {
console.error(`alt missing for ${mdImage}`);
return;
}
// replace with new url
result = result.replace(mdImage, `{% image "${url}", "${alt}" %}`);
match = regex.exec(markdown);
}
return result;
};
```
But it’s still not doing its thing. [Jed Fox](https://jedfox.com/) on [Eleventy’s Discord](https://www.11ty.dev/blog/discord/) server helped me figure that out. Eleventy’s render pipeline looks a bit like this:

What I’m doing now is this:

The custom shortcode is inserted after my markdown has been converted. I need to re-render it, luckily there’s a solution for that: the [Render Plugin.](https://www.11ty.dev/docs/plugins/render/)

So I installed it, but all I got back was an error inside Eleventy’s Template Renderer. A config key containing the project root had no value, but it all was outside of my scope.
```
[11ty] Unhandled rejection in promise: (more in DEBUG output)
[11ty] EleventyShortcodeError is not defined (via ReferenceError)
[11ty]
[11ty] Original error stack trace: ReferenceError: EleventyShortcodeError is not defined
[11ty] at /home/iamschulz/blorb/node_modules/@11ty/eleventy/src/Plugins/RenderPlugin.js:225:21
[11ty] at processTicksAndRejections (node:internal/process/task_queues:96:5)
```
According to the docs, this shouldn’t happen. Turns out I stumbled onto another [known bug](https://github.com/11ty/eleventy/pull/2577) and the solution is to use the canary build.
```bash
yarn remove @11ty/eleventy
yarn add -D @11ty/eleventy@2.0.0-canary.16
```
Just like the Image Plugin, the Render Plugin needs its own custom shortcode as well. I went with the following:
```javascript
eleventyConfig.addNunjucksAsyncShortcode(
"render",
async (content) =>
await eleventyConfig.javascriptFunctions.renderTemplate(content, "njk")
);
```
Use this at your own discretion. `eleventyConfig.javascriptFunctions` is not documented and might only be working by accident. It might not be there in the next major release. Again, thanks to Jed Fox for guiding me through this.
And finally I got it working. Text, formatting and images from Notion to Eleventy. And even a blueprint on how to integrate other embeds as well, following the image example.
## Deployment
The one thing I really miss in Notion is webhooks, so I can auto-deploy my site on page changes. Or any ability to send POST requests on demand. [Netlify has a build hook](https://docs.netlify.com/configure-builds/build-hooks/), and it only accepts POST requests, so I need some adaptation.
My workaround is a [Zapier](https://zapier.com/) integration. Zapier works natively with Notion, but it only provides a trigger on new database items. It won't fire on database entry changes. That would deploy my blog once I add a new post, even as a draft. But once I set the draft property to `false`, it wouldn't update and the post won't be published.
I work around that with a generic GET endpoint in Zapier. It has a key attached as a query parameter, which Zapier will check. It then sends a POST request to Netlify’s build hook. The GET endpoint works as a normal link in my Notion blog page.

That won’t provide me will full automation, but at least I’ll have a one-click solution to export a blog from Notion to a live website.
| iamschulz |
1,215,708 | sequence of parameters with bind() | I try to put some html element object in a class und write addEventListener which should work for all... | 0 | 2022-10-10T12:49:24 | https://dev.to/erhie/sequence-of-parameters-in-bind-13em | javascript, bind | I try to put some html element object in a class und
write addEventListener which should work for all instances.
I found a solution, but I don´t understand it.
eg.
```
class ValueSlider extends HTMLDivElement {
constructor() {
. . .
this.startDrag = function(el, evt) {
let thisNow = this; // class object
let element = el; // mySvg object
let event = evt; // event object
. . .
}
this.evHandler = this.startDrag.bind(this, this.mySvg);
this.mySvg.addEventListener("mousedown", this.evHandler );
}
}
```
Why the function receives the event object as last parameter ?
Thank you for discussion
Erhie | erhie |
1,216,457 | Remove all tables in a Postgres schema | When working with initial migrations in a project it is often helpful to fast clear all tables and... | 0 | 2022-10-11T08:04:28 | https://dev.to/andreasbergstrom/remove-all-tables-in-a-postgres-schema-58fp | postgres |
When working with initial migrations in a project it is often helpful to fast clear all tables and then re-run all migrations. Instead of removing och re-creating the schema (which will affect everything besides just tables), you can use this script taken from [this SO answer](https://stackoverflow.com/a/36023359/1202214).
```sql
DO $$ DECLARE
r RECORD;
BEGIN
-- if the schema you operate on is not "current", you will want to
-- replace current_schema() in query with 'schematodeletetablesfrom'
-- *and* update the generate 'DROP...' accordingly.
FOR r IN (SELECT tablename FROM pg_tables WHERE schemaname = current_schema()) LOOP
EXECUTE 'DROP TABLE IF EXISTS ' || quote_ident(r.tablename) || ' CASCADE';
END LOOP;
END $$;
``` | andreasbergstrom |
1,215,753 | Kubernetes Tutorial For Beginners | Kubernetes User Authentication and Authorization | A post by jmbharathram | 0 | 2022-10-10T14:15:51 | https://dev.to/jmbharathram/kubernetes-tutorial-for-beginners-kubernetes-user-authentication-and-authorization-2djn | docker, devops, kubernetes | {% youtube 84j25sAUohA %} | jmbharathram |
1,215,930 | Packages that make Emacs Lisp more pleasant | Emacs Lisp can sometimes seem a little archaic compared to more modern languages. In higher level... | 0 | 2022-10-10T16:33:39 | https://themkat.net/2022/10/03/emacs_lisp_better.html | emacs, editor, productivity, lisp | Emacs Lisp can sometimes seem a little archaic compared to more modern languages. In higher level language we are spoiled with a multitude of easy string handling, list handling, pattern matching and so on. What if I told you that some packages can give you the same ease of use for Emacs Lisp? That they provide more clear APIs, give features you are used to from other languages, and/or abstract away the more tedious details.
We will mainly look at 3 packages: [s.el](https://github.com/magnars/s.el), [f.el](https://github.com/rejeep/f.el) and [dash.el](https://github.com/magnars/dash.el). Two of these packages (first and last) are maintained by [Magnar Sveen](https://github.com/magnars), who are also known for [Emacs Rocks](https://emacsrocks.com/) and [What The .emacs.d](http://whattheemacsd.com/) (which are still great resources for learning and finding inspiration for your Emacs configuration!). We will also look at [ht.el](https://github.com/Wilfred/ht.el). These packages are used a lot in many of the Emacs packages you use in a day to day basis, like [lsp-mode](https://github.com/emacs-lsp/lsp-mode) and [rustic](https://github.com/brotzeit/rustic) just to name a few. As most of these already have tons of examples in their READMEs, my main goal of this article is to inspire you to check them out. Hopefully you will know of one new package after reading this article :)
## [s.el](https://github.com/magnars/s.el)
[s.el](https://github.com/magnars/s.el) has a simple mission: to provide more pleasant string handling, and it touts itself as "The long lost Emacs string manipulation library". If you have worked with strings in Emacs Lisp without s.el, it can be a bit tedious. Some functions work like you expect with string inputs, while others expect a list of strings (e.g, `string-join`). Others have completely different prefixes (e.g, concat).
Let's look at some examples of operations from s.el:
```emacs-lisp
;; Test if input is a number
(s-numeric? "123")
;; => t
(s-numeric? "ab34")
;; => nil
;; Get the first or last n characters of a string
(s-left 4 "This is a test")
;; => "This"
(s-right 4 "This is a test")
;; => "test"
;; Transform to (lower) camel case
(s-lower-camel-case "square function")
;; => "squareFunction"
```
There is [a ton more examples in the github repo for s.el](https://github.com/magnars/s.el), so I suggest you check it out if you find it interesting! :) Some of the functions are now provided in newer versions of Emacs (with the `string-`-prefix like string-pad-right and string-pad-left), but there are still some operation that Emacs does not provide (e.g, s-left and s-right to get the first or last n characters in a string respectively).
## [f.el](https://github.com/rejeep/f.el)
Yes, you read that right: [f.el](https://github.com/rejeep/f.el)! f.el provides many functions for handling files and directories, including paths and content. While it is certainly possible to do some of these operations directly in standard Emacs Lisp, it takes quite a lot more instructions than the simple ones provided by f. f makes it way more readable, and makes the intent more clear.
```emacs-lisp
;; Get the filename of the file (or inner directory)
(f-filename "/home/someuser/Programming/Rust/mos/Cargo.toml")
;; => "Cargo.toml"
;; Create a directory
(f-mkdir "Programming" "Emacs")
;; Makes the directories Programming/Emacs
;; Test if input has a file extension
(f-ext-p "/test/test")
;; => nil
(f-ext-p "Cargo.toml")
;; => t
```
Like for the other packages, [f.el provides many examples of usage in its readme](https://github.com/rejeep/f.el).
## [dash.el](https://github.com/magnars/dash.el)
If you have ever read source code for any of the Emacs packages you use, you may have noticed operations like `-let`, `-map`, `-lambda`, `->`, and similar ones all starting with a dash. These are from dash.el, and provides quite a lot of nice syntax! Ranging from improved usage and pattern matching (if let expressions like in Rust is available!), to Lisp constructs often found in other languages (like the threading operator `->`). Clojure is probably the biggest inspiration, and this package makes list operations as pleasant as they are in Clojure! (LISP stands for LISt Processing after all!). If you have coded in Emacs Lisp for a while, you may have used †he various cl-functions (e.g, cl-map), but with dash you get more clear and pleasant APIs to do the same and more.
```emacs-lisp
;; Flatten a list
(-flatten '((1 2 (3 4))))
;; => (1 2 3 4)
;; Pattern matched let
;; (my-hash-table is a hash table with keys "name" and "age")
(-let [(&hash "name" name "age" age) my-hash-table]
(message "Hi %s who is %d years old!" name age))
;; with an example hash table with name=Nils, and age=56, this will print:
;; "Hi Nils who is 56 years old!"
;; There are even pattern matched lambda! -lambda
;; Thread through the chain using the first argument as the last argument in the next function call etc.
(->> '((1 2) 3)
(-flatten)
(message "My list: %S"))
;; prints:
;; "My list: (1 2 3)"
```
I LOOOOVE the pattern matching in dash! The `-let` variant in dash is probably the functionality in this article I use the most. Threading is also something that can be really nice, and I should probably use it more in places where I usually collect results with let and `let*`.
[More examples in the readme](https://github.com/magnars/dash.el) :)
## [ht.el](https://github.com/Wilfred/ht.el)
[ht.el](https://github.com/Wilfred/ht.el) is a library for managing hash tables. While this can be done with the standard library, ht.el makes the intent more clear. They have also [written a bit about the why in their readme](https://github.com/Wilfred/ht.el#why). Like they mention, more consistent naming, common prefixes and more, makes coding in Emacs Lisp more pleasant. It's easy to sometimes forget the name of a function, and a common prefix makes it easier to find when using auto completion.
```emacs-lisp
;; Create a new hash table
(let ((my-hash-table (ht ("key" "val")
("other key" "other val"))))
;; add another key
(ht-set! my-hash-table "EmacsLisp" "More awesome with these libraries!")
;; return the value with the key "MyKey", or "Not found :(" if not found
(ht-get my-hash-table "MyKey" "Not found :("))
```
There are also many more utility functions, like accessing nested hash tables, copying hash tables, getting the size and more! Like usual, there are [more examples in the readme](https://github.com/Wilfred/ht.el) :)
| themkat |
1,215,932 | Day 5-8 of 100DaysOfCode | A summary of the first 3 days | 0 | 2022-10-13T04:52:21 | https://dev.to/domd11/day-5-8-of-100daysofcode-4dmc | nextjs, 100daysofcode | ---
title: Day 5-8 of 100DaysOfCode
published: true
description: A summary of the first 3 days
tags: nextjs, 100DaysofCode
# cover_image:[Image description](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/dvwzx3sdefeppe5qgcwr.png)
# Use a ratio of 100:42 for best results.
---
## A Summary of the first 4 days
I have used ReactJS before so I was easily able to quickly move on to fetching data. I spent the first 3 days practicing how to get data from an API. I spent day 4 making a cocktail project that involved me getting data from a cocktail api, I am currently trying to fix any bugs before I deploy the final product.
## Day 5-8
As I stated in my, about me post, I want to become a full-stack developer. So, I feel like I should start off with front-end since it is a little bit easier than back-end. I am starting with NextJS and I decided to sign up for a [hackathon](https://codebattles.dev/event/dce4b8cd-b48d-4511-b4d6-b0058c179944/). I had created a draft of what I wanted the website to look like in Figma. So, I started off by implementing the API and adding the navigation features and dynamic routes. I plan to work on styling on day 9 and 10. Lastly, I have finally finished the [cocktail project](https://cocktail-recipies.vercel.app/). I plan to come back to this project when I finish the first stage of the five year plan, mastering NextJS, and add more features to it.
# thank you and have a great day! | domd11 |
1,215,970 | how do i use async with array.map | Today I ran into a problem with the sync function. I need to save the asynchronous information that I... | 0 | 2022-10-10T17:28:26 | https://dev.to/abimaelnetz/how-do-i-use-async-with-arraymap-2fk0 | Today I ran into a problem with the sync function. I need to save the asynchronous information that I get from my JSON type database in an array.map which is a synchronous function.
```
/**
* Report Excel ShetReportProduction
*/
async reportExcelRow(reportExcelProductionDetailId: string): Promise<any>{
const sheetProudction = await this.SheetProductionServ.getReportExcelbyId(reportExcelProductionDetailId).pipe().toPromise();
console.log("SheetProduction: ", sheetProudction);
this.exportExcelService.exportAsExcelFile("-", '-');
}
```
I am going to use the information obtained in the arrray.map function to be able to export it to an excel. Currently I have not been able to relate the async function to array.map. Could you help me? | abimaelnetz | |
1,216,005 | Getting started with AWS Multi-account approach | Introduction I write this article first in my own blog... | 0 | 2022-10-10T18:45:16 | https://dev.to/aws-builders/getting-started-with-aws-multi-account-approach-4j5c | aws, security, cloud, beginners |
## Introduction
> I write this article first in my own blog (https://www.playingaws.com/posts/multi-account-approach/).
This is the first article related to the multi-account approach, and the first thing to review is to know when and why I need a multi-account solution.
### When do you need a multi-account solution?
If you are using AWS for your personal projects and you have a simple solution without many resources, it is not worth it. Or maybe your solution is not so simple but you don't want to worry about the additional operational overhead to manage it. I understand it. This was exactly my case but in this article, I want to show you when, why and how to deploy a multi-account solution.
However, in enterprise solutions, you should have a multi-account solution, without a doubt, so you need to know about it.
Then, for me, it is very simple:
- Personal account with simple solution - not necessary multi-account solution
- Personal account with no simple solution or many workloads - depends on you
- Small enterprise solution - depends on you, but even if your company is small is a good idea to take advantage of the multi-account approach
- Medium/Big enterprise solution - mandatory
What AWS says?
> While you may begin your AWS journey with a single account, AWS recommends that you "*set up multiple accounts, as your workloads grow in size and complexity*". Extracted from [here](https://aws.amazon.com/organizations/getting-started/best-practices/?org_console).
>
> Also, "*If you have a single account today and either have production workloads in place or are considering deploying production workloads, we recommend that you transition to the use of multiple accounts so that you can gain the Benefits of using multiple AWS accounts.*" Extracted from [here](https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/single-aws-account.html).
### Why do you need a multi-account solution?
The main reason to do it is **isolation**. An AWS account serves as a resource container and the easiest way to isolate resources is by using different accounts.
There are many reasons to use isolations:
- Environment isolation (testing/production): Apply distinct security controls by environment
- Business units/workloads/applications/products isolation: Group workloads based on business purpose and ownership
- Functional team isolation
- Data isolation: Constrain access to sensitive data. This category includes data stores, which may be necessary because of legal restrictions
Some other advantages of a multi-account solution are:
- **to manage the security** by using policy-based controls
- **to simplify billing** - You can use a tagging strategy and cost allocation tags to track your AWS costs on a detailed level in the same account but is much better to use multiple accounts to do the same.
- Promote innovation and agility
### The disadvantage of a multi-account solution
The main disadvantage if you want a multi-account solution is the **management** of all accounts (do it in the same way, create new accounts, duplicate efforts,... this is, mismanagement).
## Multi-account approach: AWS Organizations
AWS provides a resource to help you centrally manage and govern your environment: [AWS Organizations](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_introduction.html).
### Core concepts
- **Organization**: an entity to administer accounts as a single unit
- **Account**: standard AWS account that contains your AWS resources
- **Organizational Units (OUs)**: a container that helps you to organize your accounts into a hierarchy and make it easier to apply management controls
- **Secure Control Policies (SCPs)**: policies are used to limit what the principals in member accounts can do
### Features / advantages
- Free to use
- Centralized management of your AWS accounts
- Hierarchical grouping of your accounts (in Organizational Units - OUs)
- Access control (IAM Identity Center, successor to AWS Single Sign-On)
- Permission Management (apply Service Control Policies - SCPs)
- Consolidated billing for all member accounts
- Configure supported AWS services to perform actions in your organization.
### AWS Services integration
This is the full list of supported service integration with AWS Organizations service. I have included all the services because is important to know that AWS Organizations can help with many integrations and automatization in the new accounts.
- Amazon **Detective** (makes it easy to analyze, investigate, and quickly identify the root cause of potential security issues or suspicious activities)
- Amazon **DevOps Guru** (analyze operational data and identify behaviors that deviate from normal operating patterns)
- Amazon **GuardDuty** (help to identify unexpected and potentially unauthorized or malicious activity in your AWS environment)
- Amazon **Inspector** (automated vulnerability management service that continually scans Amazon EC2 and container workloads for software vulnerabilities and unintended network exposure)
- Amazon **Macie** (discover, classify, and help you protect your sensitive data in Amazon S3)
- Amazon **VPC IP Address Manager** (makes it easier for you to plan, track, and monitor IP addresses for your AWS workloads)
- Artifact (provides on-demand downloads of AWS security reports)
- AWS **Account Management** (allow to programmatically modify your account information and metadata)
- AWS **Audit Manager** (helps you continuously audit your AWS usage)
- AWS **Backup** (set policies to enforce automatic backups)
- AWS **Control Tower** (straightforward way to set up and govern an AWS multi-account environment, following prescriptive best practices)
- AWS **Health** (visibility into your resource performance and the availability of your AWS services and accounts)
- AWS **Marketplace** - License Management
- AWS **Network Manager** (centrally manage your AWS Cloud WAN core network and your AWS Transit Gateway network)
- AWS **Trusted Advisor** (inspects your AWS environment and makes recommendations)
- **CloudFormation StackSets** (enables you to create, update, or delete stacks across multiple accounts and regions with a single operation)
- **CloudTrail** (enable governance, compliance, and operational and risk auditing of your AWS account)
- **Compute Optimizer** (recommends optimal AWS compute resources based on an analysis of the historical utilization metrics of your resources)
- **Config** (enables you to assess, audit, and evaluate the configurations of your AWS resources)
- **Directory Service** (share your AWS Managed Microsoft AD directories between other trusted AWS accounts in your organization)
- **Firewall Manager** (simplify AWS WAF administration and maintenance)
- **IAM Access Analyzer** (helps you set, verify, and refine permissions to grant the right fine-grained permissions)
- **License Manager** (brings software vendor licenses to the cloud)
- **RAM** (share AWS resources)
- **S3 Storage Lens** (aggregates your usage and activity metrics and displays the information in an interactive dashboard on the Amazon S3 console)
- **Security Hub** (provides you with a comprehensive view of the security state of your AWS resources)
- **Service Catalog** (enables you to create and manage catalogs of IT services that are approved for use on AWS)
- **Service Quotas** (enables you to view and manage your quotas from a central location)
- **Single Sign-On** (centrally provide and manage single sign-on access to all your AWS accounts)
- **Systems Manager** (enables visibility and control of your AWS resources)
- **Tag policies** (an help you standardize tags across resources)
### Recommended organization structure (best practices)
> The following recommendations need to be adapted to each Organization. Each case is different and you have to think about how grouping accounts and how many OUs you need.
AWS recommends that you start with the central services in mind:
- **Security**: Used for centralized security tooling and audit resources. Usually with at least 2 accounts (one for each of mentioned purposes)
- **Infrastructure**: You can use this level to share infrastructure with the other accounts: i.e. networking and IT services
Once you have your foundational Organizational Units, is time to think about the environments, and separate SDLC (non-production) from production because usually have different requirements and you want each of them isolated. Although it can be a new OU categorization, is common to use it as a sub-categorization inside another OU level (for example Security and Infrastructure would have another 2 levels: SDLC and Prod).
> EDIT: SDLC (Software Development Life Cycle) is used here because this article is based in the AWS recommendations and they use it for the name of one OU to include all the non-productive environments, for example here (https://aws.amazon.com/blogs/mt/best-practices-for-organizational-units-with-aws-organizations/) and here (https://aws.amazon.com/organizations/getting-started/best-practices/?nc1=h_ls). Btw, I "introduce" the concept of SDLC when I explain how to add CI/CD to my CDK project in one article of my blog (https://www.playingaws.com/posts/how-to-add-ci-cd-to-my-cdk-project/)
Now, we have to think about all the additional OUs that you need. AWS recommends creating OUs that directly relate to building or running your products or services:
- Sandbox
- Workloads
- Deployments
- Suspended
- Transitional
- Exceptions
- ...
More information in the official AWS links:
- <https://aws.amazon.com/organizations/getting-started/best-practices/?org_console>
- <https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/recommended-ous-and-accounts.html>
- [Best practices for management account and for member accounts](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_best-practices.html)
- [Basic organization](https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/basic-organization.html)
## Get Started with AWS Organizations
**AWS Organizations** is the service to help us with central management for multiple AWS accounts.
To start you only need an AWS account, access to the AWS Organizations and then click "Create an organization":

When you do it, you could view the Organizational Structure of your Organization, and you will have in the left section of the screen the available options: send Invitations, configured supported services, enable policies, the Organization settings and a Get started option.
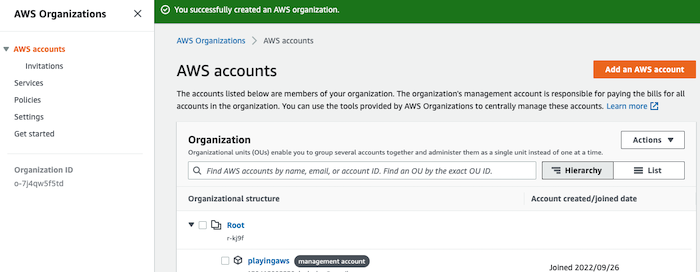
The Get started option is interesting as you can view the 4 steps to "Build your organization":
1. Create accounts or invite existing accounts
2. Organize your organization’s member accounts into OUs
3. Create policies
4. Enable AWS services that support AWS Organizations
And also, a simplified recommended organizational structure
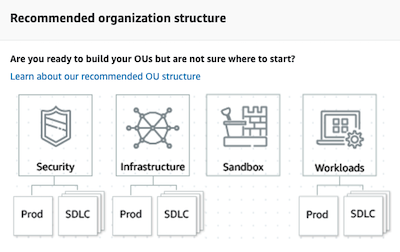
So perfect, now we know how to create an AWS Organization, we can create the different OUs we need, we can create new Accounts and send them an invitation to join our organization, and then configure the enabled services and apply the policies.
Easy? Not really... you can do it all manually if you need heavy customization, but it seems necessary to apply automation for efficient governance and management, and probably we need help to set up our landing zone.
> A landing zone is a well-architected, multi-account AWS environment that is a starting point from which you can deploy workloads and applications.
Fortunately, AWS has another service to help us: **AWS Control Tower**.
## AWS Control Tower
> AWS Control Tower offers the easiest way to set up and govern a new, secure, compliant, multi-account AWS environment. It establishes a **landing zone**, which is a well-architected, multi-account environment based on best-practice blueprints, and enables governance using **guardrails** you can choose. Guardrails are SCPs and AWS Config rules that implement governance for security, compliance, and operations.
>
> **Q: What is the difference between AWS Control Tower and AWS Organizations?**
>
> AWS Control Tower offers an abstracted, automated, and prescriptive experience on top of AWS Organizations. It automatically sets up AWS Organizations as the underlying AWS service to organize accounts and implements preventive guardrails using SCPs. Control Tower and Organizations work well together. You can use Control Tower to set up your environment and set guardrails, then using AWS Organizations, you can further create custom policies (such as tag, backup or SCPs) that centrally control the use of AWS services and resources across multiple AWS accounts.
>
> [Extracted from the FAQS of AWS Organizations](https://aws.amazon.com/organizations/faqs/)
Now, we are going to create our Landing Zone using AWS Control Tower.
First, access the service and click to "Set up landing Zone":

Then, review the first step, set the Home region, if you want to deny access to any Region in which AWS Control Tower is not available and your additional Region for governance:
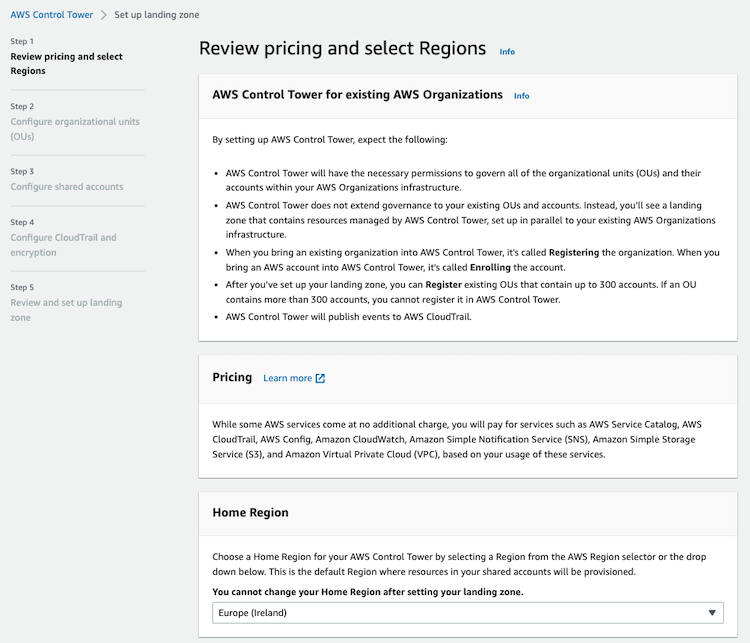
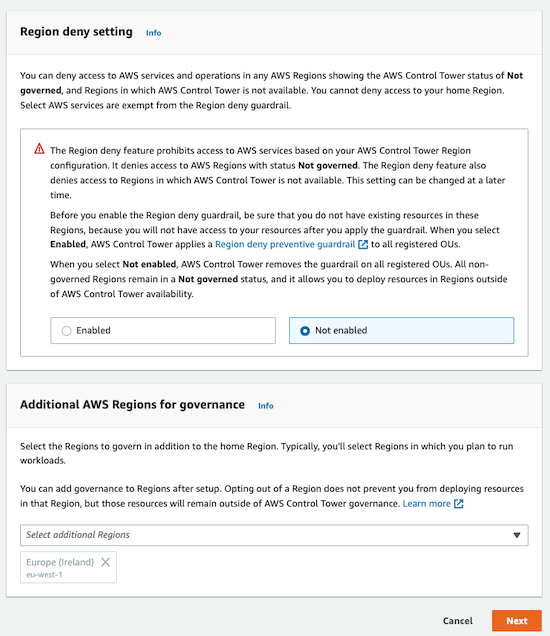
Now set a name for the Foundational Organizational Unit (Security, with 2 accounts: log archive account and security audit account) and the Additional OU (Sandbox):
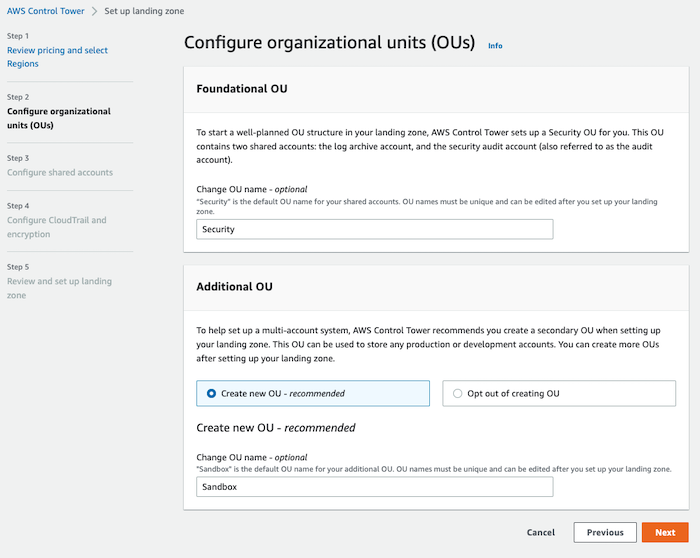
Then configure the shared accounts (Foundational OU - security), set an email associated with the new accounts and a name for these 2 accounts:
- Log archive: *The log archive account is a repository of immutable logs of API activities and resource configurations from all accounts.*
- Security audit: *The audit account is a restricted account. It allows your security and compliance teams to gain access to all accounts in the organization.*
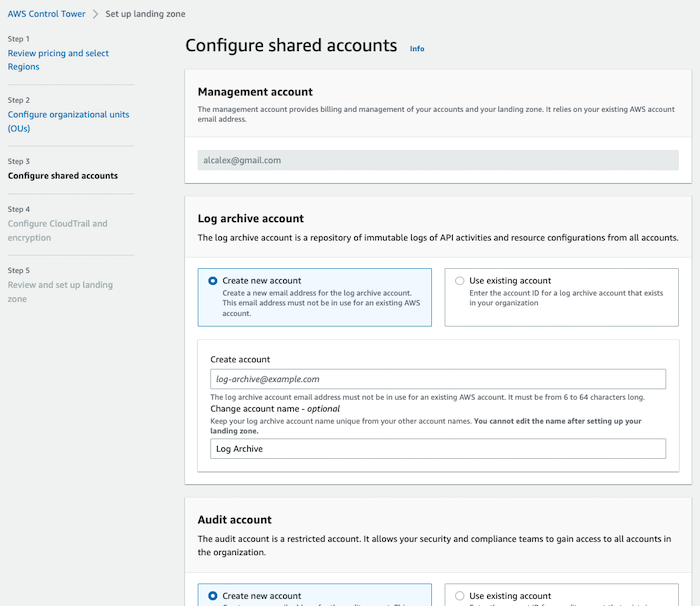
Step 4 is to configure the CloudTrail and the encryption (disabled by default)
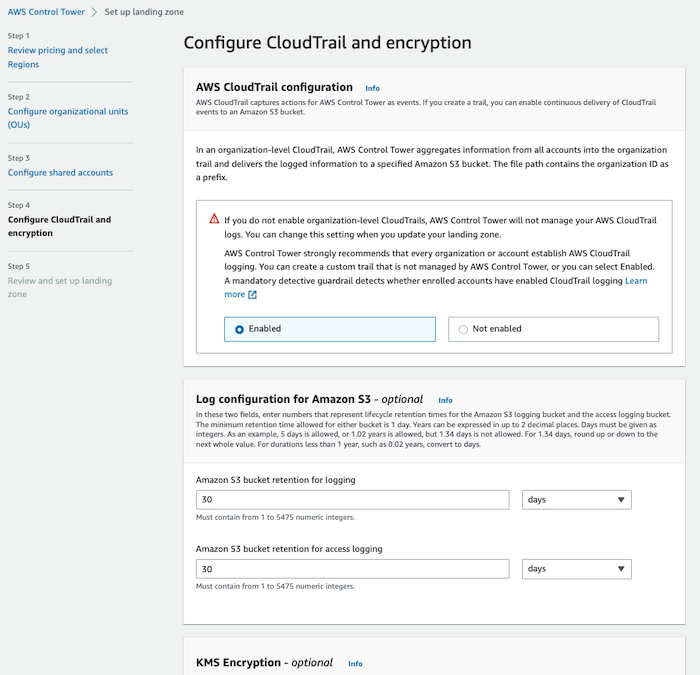
Finally, you need to review all the information and confirm. Next, a new screen will be shown with the progress of the creation of the landing zone. The estimated time is 60 minutes.
> This is the summary of what is being set up:
>
> - **2 organizational units**, one for your shared accounts and one for accounts that will be provisioned by your users
> - **2 new accounts**, for log archive and security audit
> - **A native cloud directory** with preconfigured groups and single sign-on access
> - **20 preventive guardrails** to enforce policies
> **3 detective guardrails** to detect configuration violations
{: .prompt-info }
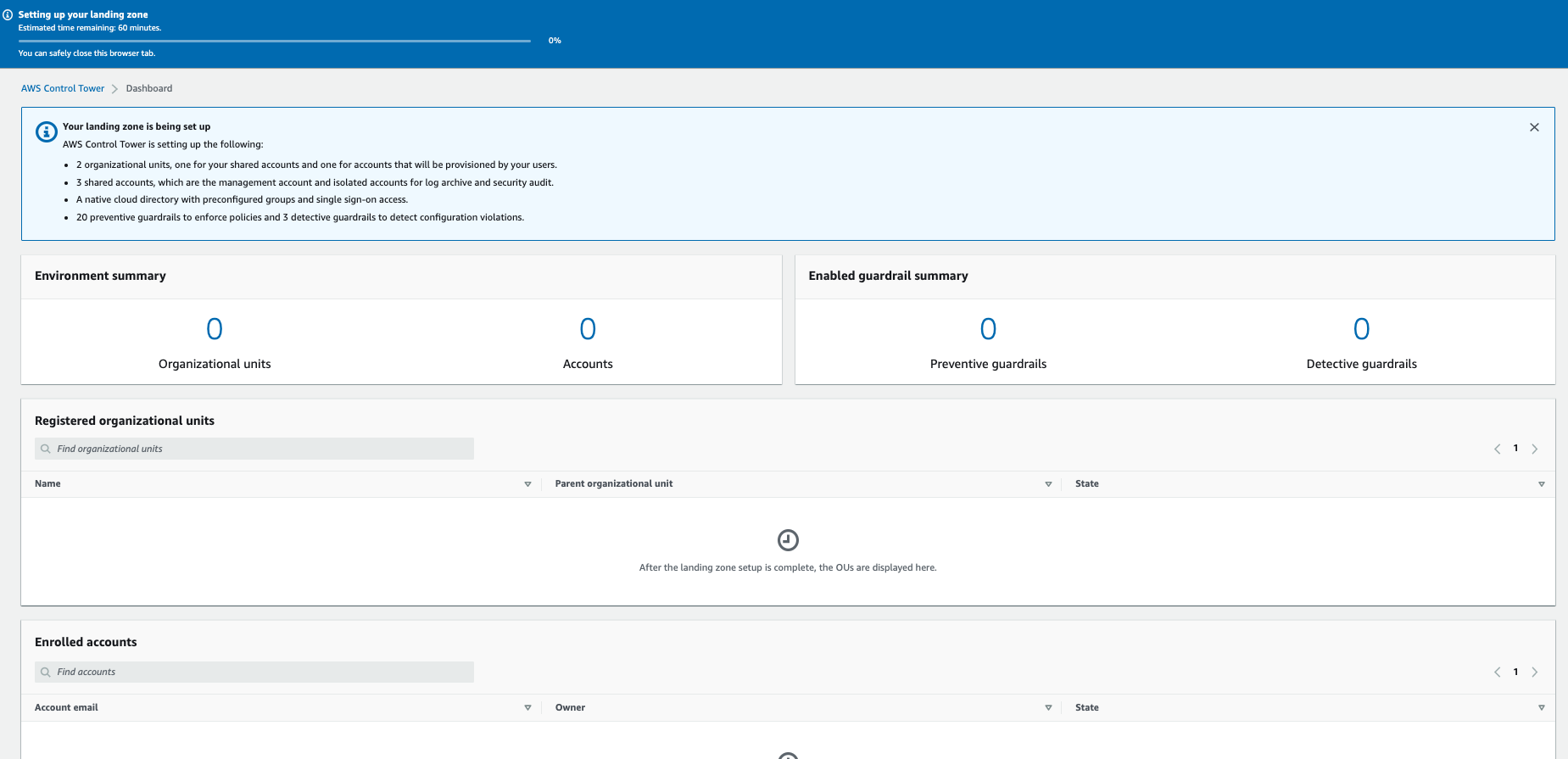
With a little patience, you will receive the confirmation of everything was ok, and the setup of the landing zone will be complete:
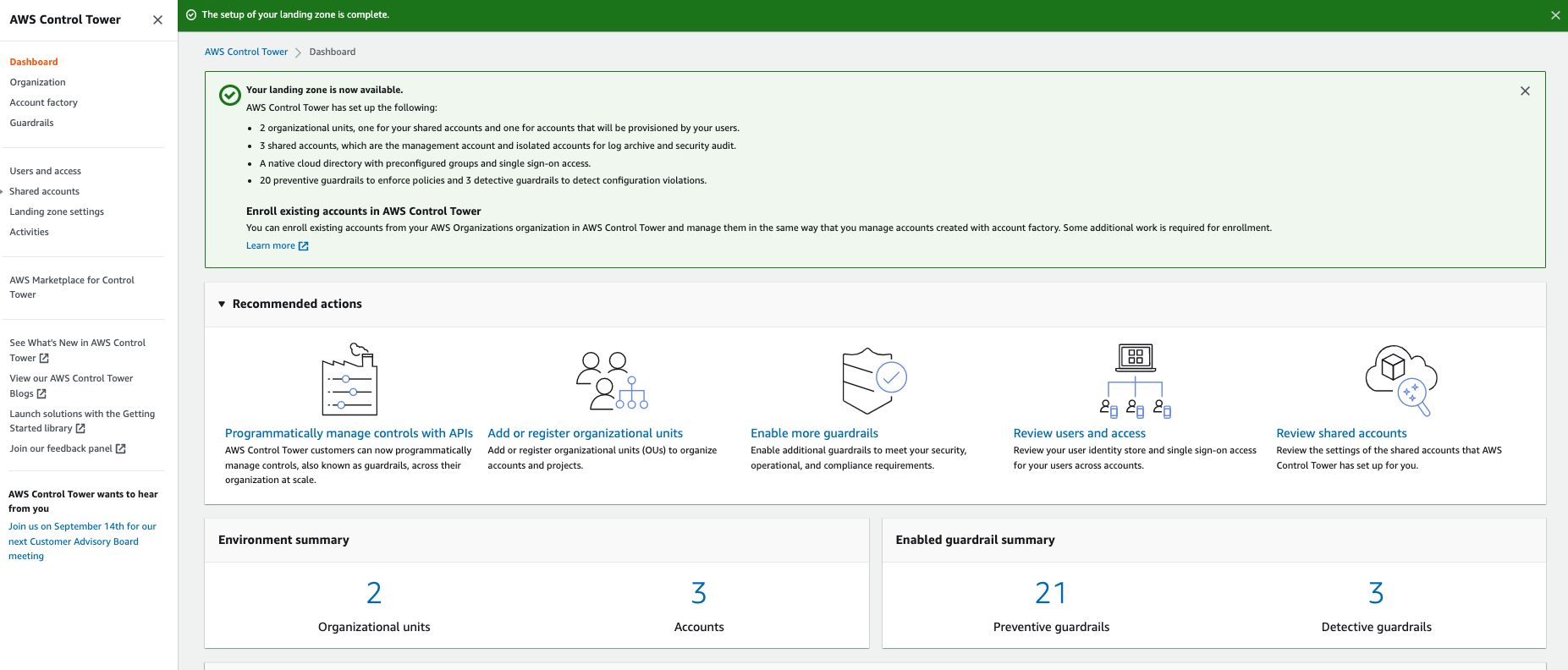
The new structure created is very simple:
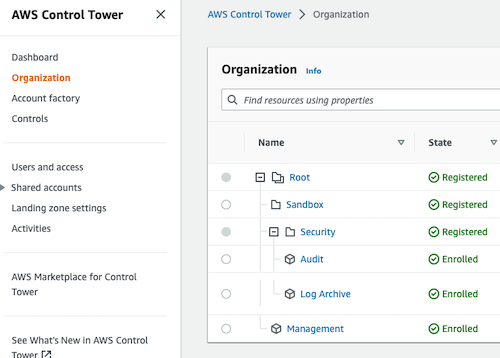
And a new AWS Identity Center configuration (previously AWS SSO) has been configured for you and now you can access this portal to access all your AWS accounts:
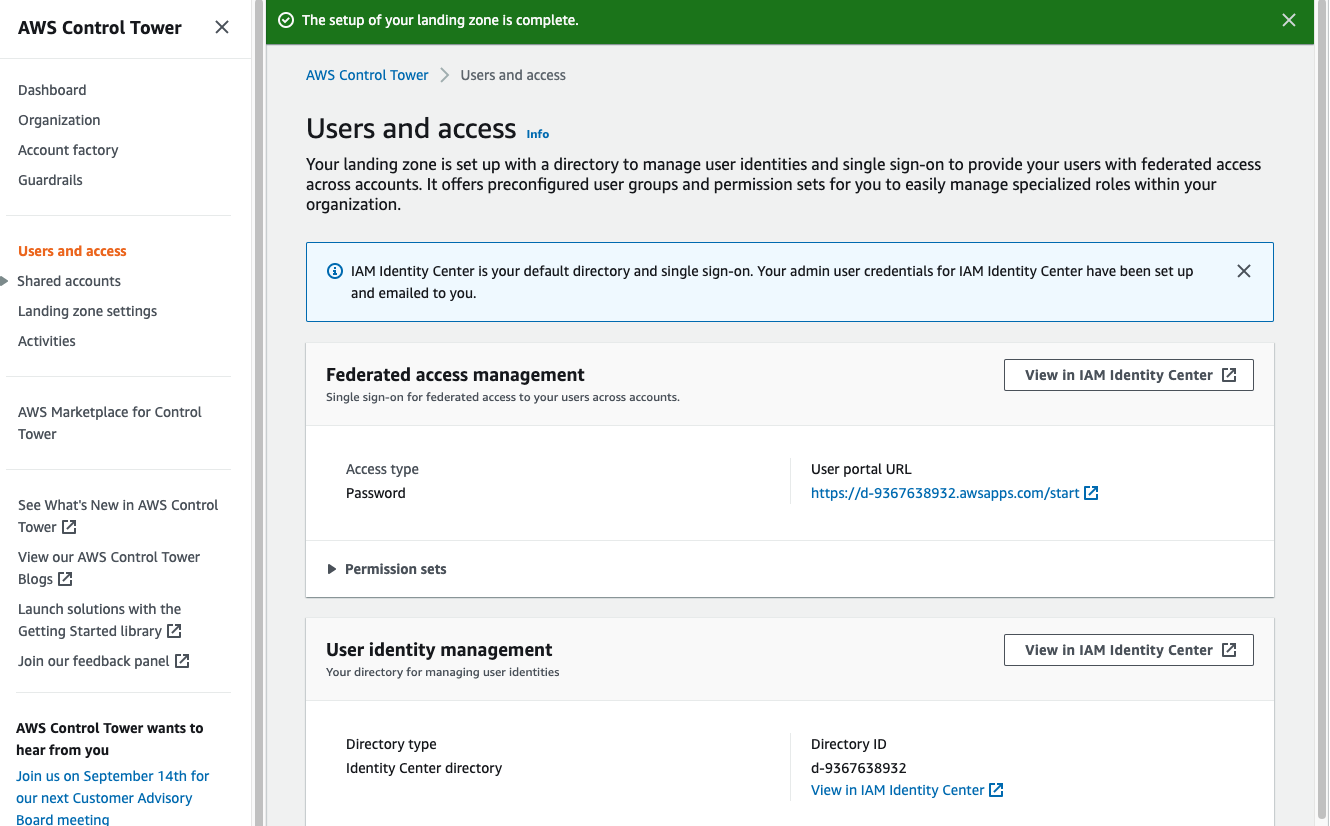
### Clean up
To clean up the AWS Control Tower you need to decommission it and then wait until 2 hours to remove all resources.
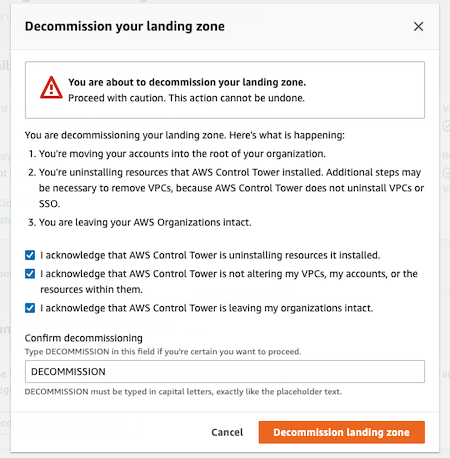
## Next steps
- Next post will be available in my blog soon (AWS Control Tower Deep Dive): www.playingaws.com
- More information (AWS official links)
- [Practice: Workshop of multi-account security governance workshop](https://catalog.us-east-1.prod.workshops.aws/workshops/d3f60827-89f2-46a8-9be7-6e7185bd7665/en-US)
- [Practice: AWS Control Tower Immersion day](https://controltower.aws-management.tools/immersionday/)
- [Example of SCPs](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps_examples.html#examples_general)
- [AWS blog article: migrate AWS Accounts to AWS Control Tower](https://aws.amazon.com/blogs/architecture/lets-architect-architecting-for-governance-and-management/)
- [AWS blog article: Migrate resources between accounts](https://aws.amazon.com/blogs/architecture/migrate-resources-between-aws-accounts/)
- [Landing Zone accelerator on AWS](https://aws.amazon.com/solutions/implementations/landing-zone-accelerator-on-aws/)
- [Dependency checker to migrate between AWS Organizations](https://github.com/aws-samples/check-aws-resources-for-org-conditions) | alazaroc |
1,216,304 | Recursion - 1 | Recursion in computer science is technique where the solution to a problem depends on solutions to... | 0 | 2022-10-11T04:33:26 | https://dev.to/piyush56p/recursion-1-5875 | computerscience, python, codenewbie, algorithms | <u>Recursion in computer science is technique where the solution to a problem depends on solutions to smaller instances of the same problem.</u>
Let problem be f(N) then smaller problem would be like
F(N)= F(N/3) | F(N/3) | F(N/3)
Let us see the most classical example - Factorial
Let N = 5, I want to computer F(N) = 5!
I would break this into smaller subproblem of same type like
Hence F(N) = (N)(N-1)(N-2)....1
It can be written as F(N) = (N)(N-1)!
F(N) = (N)F(N-1)!
F(5) = 5*F(4)
F(4) = 4*F(3)
F(3) = 3*F(2)
F(2) = 2*F(1)
F(1) = 1*F(0) -> **Base Case**
At F(0) We know that it cannot be breakdown further, such a point in algorithm where the condition must stop is called **Base Case**
We generally have the knowledge of base cases. Here in this example we set F(0) which is a base case we intialize it to **1**.
After hitting base case algorithm revert back to original case by replacing functions to values.
For example
F(1) = 1*1 = 1
F(2) = 2*F(1) = 2*1 = 2
F(3) = 3*F(2) = 3*2 = 6
F(4) = 4*F(3) = 4*6 = 24
F(5) = 5*F(4) = 5*24 = 120 **Final Answer**
Dealing with recursion we see two directions:-
1) Simplifying problem towards the base case (Top to down)
2) Combining solutions coming back to the main problem (Down to Top)
<u>Recursion take the help of Call Stack</u>
Another Example!
We can define the operation "Go to Home" as:
**Base Case**
1. If you are at home, stop moving.
**Recursive Case**
2. Take one step toward home.
3. "Go to home".
_**Recursion = Principal of Mathematical Induction**_
1. Figure of the smallest case
2. Always Assume the Subproblem can be solved.
3. Solve the current problem assuming subproblem solution exists.
| piyush56p |
1,216,957 | Composition V.S Inheritance , Which one to choose & Why? | Introduction A lot of articles , books and software engineers advising that it's better to... | 0 | 2022-10-11T16:20:02 | https://dev.to/smuhammed/composition-vs-inheritance-which-one-to-choose-why-3ndm | programming, oop, cleancode | ## Introduction
A lot of articles , books and software engineers advising that it's better to use composition instead of inheritance so why that, let's see.
**What is Inheritance ?**
Inheritance is a one of OOP (Object Oriented Programming) principles that provides to you a facility of reusing , expanding , sharing and building hierarchy of objects , which can make development process for some problems easier , Some programming languages allow multiple inheritance (multiple super class) like C++ and some don't , like Java.
By using inheritance you can remove **duplicate code** and apply **polymorphism** on your logic to provide **extensible** and **maintainable** logic, Till now that's awesome.
**But how can inheritance harms you badly ?**
The problem with inheritance is it's providing you with static base state which preventing you from dealing with different behaviors in same kind of type with flexibility, let's take an example.
We have here a **super class** called **Bird** that gather some properties and behaviors common between birds like **fly()** and **eat()**, also we have 2 **sub classes** OWL and PARROT, They inherit their properties and behaviors from their super class Bird, so good till now.
Problem appears here, let's say we want to add new type of birds like Penguin or Ostrich, and off course these are birds as well, so you make them inherit from Bird class, but you find that there is a fly() logic here and it's not applied to these kind of birds which neither Penguin nor Ostrich can fly, so for first look you can override these methods with empty logic and all good, whenever add new kind of birds override their logic to adapt them.
After a while you figured out that you have to implement **migrate()** logic to most of your subclasses, so you got better idea make this logic in super class, while implanting that you found that you have one type that doesn't migrate so you have to handle this special case also with same above solution.
Now you end with a lot of special cases with multiple handlers, And code now have smells, So you came up with solution that you will divide these relations based on behavioral kind like this.
Yeah it can work with this for a while but with growing of requirements you will find that the hierarchy has became more complex, your logic also became complex, start dealing with multiple If statements in code and your solution is losing his fancy style.
## Composition to the rescue
while inheritance can be described as is-a relation like a Canary is a bird, composition can be described as has-a relation like a Canary has a flying behavior, so instead of building hierarchy of classes, your classes will be like this.
Now with composition you have a better solution with less complex class hierarchy, but best for last it's also provided you with **interchangeable algorithms** that you can assign and change in runtime with 100% of **flexibility**, also with some Factory classes you can change the behavior of logic at runtime easily which impossible to done this with inheritance.
**Is that means Inheritance is bad?**
No, not like that but you have to be careful when using it and also make sure 100% that class hierarchy you build is identical and no special cases, If there any special cases or you are not sure about what you do it's better to use **Composition over Inheritance**.
## Resources
- Object Oriented Thought Process - Chapter 7 Mastering Inheritance and Composition.
- Head First Design Pattern - Chapter 1 Strategy Design Pattern.
IF YOU LIKED THE POST, THEN YOU CAN BUY ME A COFFEE, THANKS IN ADVANCE.
<a href="https://www.buymeacoffee.com/samehmuh95" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
| smuhammed |
1,216,987 | Fetch! Not Just for Dogs Anymore! | In Phase 3 and Phase 4 of the Flatiron School’s Software Engineering bootcamp, the focus is on... | 0 | 2022-10-11T17:24:41 | https://dev.to/johnroy71/fetch-not-just-for-dogs-anymore-lcj | In Phase 3 and Phase 4 of the Flatiron School’s Software Engineering bootcamp, the focus is on creating backend API’s and coherent databases. In Phase 4, integrating the backend and frontend was a main focus of Project Week. While moving data from the frontend to the backend and vice versa is only one step, it is a crucial “make or break” component of your app. Without this data exchange, the front and back of your app are two separate entities, leaving both components purposeless. This “last-mile delivery” of data may be the most important part of your app.
In JavaScript and React, a “fetch” is used to send data back and forth from the frontend and backend. There are different types of fetch that we use depending on what we want to do with the data. A "GET" will retrieve data _from_ the API, a "POST" will _send_ a new piece of data from the frontend, "PATCH" and "PUT" will modify data on the _backend_ using data from the _frontend_, and a "DELETE" will remove data specified on the _frontend_ from the _backend_.
The method by which we will get the data from the API to the frontend is called a “GET” request. You do not need to specify in the fetch request if it is a “GET”. For example:
```
fetch('https://fakesite.com/api')
.then(response => response.json())
.then(resp => console.log(resp);
```
In this fetch request, we are telling the fetch where to look with a URL in the first line. The fact that we are performing a "GET" is implied as we have not specified what fetch we are doing. The second line is telling the fetch that we are expecting the response data in JSON format. This can be JSON, text, specific form data or other formats depending on what you are doing. The third line console.logs the response. You can also assign this to a variable and use the data elsewhere in your application.
Performing a "POST", "PATCH", and "PUT" require more information than a "GET", but are quite similar to each other. In fact, the syntax is the same for all, it's just the data and what's done with it on the backend that are different. Here's an example:
```
fetch("https://fakesite.com/api", {
method: "POST",
headers: {"Content-Type" : "application/json"},
body: JSON.stringify({_this will be the data object you are sending_})
})
.then(resp => resp.json())
.then(data => console.log(data))
```
You can see on the second line that we have had to specify what fetch method we are wanting to use. The third line tells the API that we are sending JSON data. Again, this may vary depending on your requirements. The fourth line converts your data to JSON format. This will send your object to the API and create a new item in the array. "PATCH" and "PUT" function similarly, but you have to specify which object in the array you are addressing. Also, with a "PUT" you have to enter every value for an object. For a "PATCH" you only have to enter data you wish to modify.
To delete and object from an array is much simpler than the other fetch methods. A typical "DELETE" request looks like this:
```
fetch('https://fakesite.com/api', {
method: 'DELETE',
})
```
You will have to have an object specified to make the "DELETE" work. There are multiple ways to do this, but we are not going to touch that in this blog post! You can also return confirmation messages or other things if you wish to after the object is deleted.
This blog post is definitely not earth-shattering. As usual, I took a subject that I didn't feel fully comfortable with and studied it so I could explain it, and this helps my comprehension!a
| johnroy71 | |
1,217,028 | Lerna reborn - What's new in v6? | All the news around the latest Lerna v6 release | 0 | 2022-10-12T18:39:35 | https://blog.nrwl.io/lerna-reborn-whats-new-in-v6-10aec6e9091c?source=friends_link&sk=05bfe6160d197277daab6a14cf94f82f | monorepo, javascript, webdev | ---
title: "Lerna reborn - What's new in v6?"
canonical_url: https://blog.nrwl.io/lerna-reborn-whats-new-in-v6-10aec6e9091c?source=friends_link&sk=05bfe6160d197277daab6a14cf94f82f
published: true
description: 'All the news around the latest Lerna v6 release'
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ojyj32vznhovmwc3fczv.jpg
tags:
- monorepo
- javascript
- webdev
---
Lerna v6 is out!! Here's everything you need to know about the **new Lerna experience!**
## Table of Contents
- [Lerna continues to evolve](#lerna-continues-to-evolve)
- [Fast Lerna with caching by default](#fast-lerna-with-caching-by-default)
- [Remote caching with Lerna](#remote-caching-with-lerna)
- [Defining a task pipeline](#defining-a-task-pipeline)
- [Lerna add-caching command](#lerna-addcaching-command)
- [PNPM support for Lerna](#pnpm-support-for-lerna)
- [Dynamic terminal output](#dynamic-terminal-output)
- [VSCode extension for Lerna workspaces](#vscode-extension-for-lerna-workspaces)
- [Lerna Repair](#lerna-repair)
- [Lerna and Prettier](#lerna-and-prettier)
- [Migrating to Lerna v6](#migrating-to-lerna-v6)
- [Lerna is using Nx now. Can I keep using my Lerna commands?](#lerna-is-using-nx-now-can-i-keep-using-my-lerna-commands)
- [Are you maintaining an OSS repository using Lerna?](#are-you-maintaining-an-oss-repository-using-lerna)
## Lerna continues to evolve
If you already know this, feel free to skip ahead. But surprisingly many still haven't heard that **Lerna is back**, far from obsolete or deprecated and getting brand new features. We from [Nrwl](https://nrwl.io) are the creators of Nx and given our long history in the monorepo space, we offered to [take over stewardship of Lerna](https://blog.nrwl.io/lerna-is-dead-long-live-lerna-61259f97dbd9?source=friends_link&sk=60349b9dc0be3ff730ad052c4cf69df3) when it was declared "dead" in April 2022.
Since we took over, in May 2022, it has been an absolute rollercoaster. We launched [a brand new website](https://lerna.js.org), updated the content of the docs, and [made Lerna 10x faster](https://dev.to/nx/lerna-used-to-walk-now-it-can-fly-3661). And now, **Lerna v6 is out!**
## Fast Lerna with caching by default
Up until Lerna v4, either the `p-map` or `p-queue` npm packages have been used to delegate the task scheduling. With [v5.1](https://dev.to/nx/lerna-used-to-walk-now-it-can-fly-3661) we introduced `nx` as an additional mechanism to schedule tasks. The advantage? Nx has caching built-in, which **also gives Lerna caching support**, making it lightning fast. A recent benchmark test resulted in **Lerna being 2.5x faster than Lage** and around **4x faster than Turbo** (as of Oct 2022; [test it out by yourself](https://github.com/vsavkin/large-monorepo)).
So far you had to enable "Nx support" by setting the `useNx` flag in `lerna.json`:
```json
// lerna.json
{
...
"useNx": true
}
```
We've been testing this opt-in for the last couple of months and got tons of amazing feedback from companies and open source projects. As a result, **with v6 all Lerna workspaces have the useNx set to `true` by default** even if you don't have it in your Lerna config file. If you don't want to use it, you can disable it by setting the flag to false.
To experience fast caching, ensure you have a `nx.json` file at the root of your Lerna workspace where you define the cacheable operations. Check out [the docs for more details](https://lerna.js.org/docs/features/cache-tasks). Here's an example configuration file:
```json
{
"tasksRunnerOptions": {
"default": {
"runner": "nx/tasks-runners/default",
"options": {
"cacheableOperations": ["build", "test"]
}
}
}
}
```
Note that you can also run..
```bash
npx lerna add-caching
```
..to automatically generate a `nx.json` configuration file based on your existing Lerna workspace.
## Remote caching with Lerna
By using Nx as the task scheduler for Lerna it inherits all the capabilities Nx comes with. That not only just includes local caching, but also the possibility of having **remote caching** and **distributed task execution**.
Remote caching allows you to distribute your local cache with your co-workers and your CI system. This is done via [Nx Cloud](https://nx.app). But distributed caching is just one aspect. Nx Cloud also comes with a "run view" that visualizes your CI run with easy grouping and filtering capabilities, but in particular, it comes with the ability to distribute your tasks dynamically across multiple machines. All by optimizing for the best parallelization and machine utilization.
All you need to set this up is to run..
```bash
npx nx connect-to-nx-cloud
```
..in your Lerna workspace, which will guide you through a couple of questions and set you up with an [Nx Cloud](https://nx.app).
Read more [on the docs](https://lerna.js.org/docs/features/cache-tasks#distributed-computation-caching).
## Defining a task pipeline
When running tasks in a monorepo environment, you want to maximize the parallelization, but **still account for potential dependencies among tasks**. For example, assume you have a Remix application that depends on some `shared-ui` library. You want to ensure that `shared-ui` is built before either building or serving the Remix application.
With Lerna v6 you can do so in the `nx.json` file by defining the `targetDefaults`:
```json
// nx.json
{
...
"targetDefaults": {
"build": {
"dependsOn": ["^build"]
},
"dev": {
"dependsOn": ["^build"]
}
}
}
```
In this case, whenever you run either `build` or `dev`, Lerna would first run the `build` task on all the dependent packages.
[Read more on our docs](https://lerna.js.org/docs/concepts/task-pipeline-configuration).
## Lerna add-caching command
If you don’t have caching or your task pipeline set up just yet, no worries. We wanted to make it as easy as possible by providing a dedicated command:
```bash
npx lerna add-caching
```
This will scan your workspace, find all your package.json scripts and then guide you through the **configuration of both, your cacheable operations as well as your task pipeline**.
Here’s a quick walkthrough video:
{% youtube https://youtu.be/jaH2BqWo-Pc %}
You are obviously always free to create the nx.jsonby hand.
## PNPM support for Lerna
In the past, Lerna didn't properly support PNPM. We fixed this in v6. Now whenever you use Lerna in combination with PNPM, we make sure to detect packages based on the `pnpm-workspace.yaml`, to enforce `useWorkspaces: true` , we update the `pnpm-lock.yaml`
accordingly when using `lerna version` and we also added proper support for the `workspace:` protocol that PNPM uses.
You can now finally use one of the fastest package managers in combination with a new fast Lerna experience. Also, make sure to check [out our docs for all the details](https://lerna.js.org/docs/recipes/using-pnpm-with-lerna).
## Dynamic terminal output
When running tasks in parallel across a large number of projects, it can become quite difficult to follow along in the terminal with what got built and where tasks failed. That's why the new Lerna version comes with a dynamic terminal output that only shows only what is most relevant at a given moment.
Note that you would still see all of the output as usual on CI.
## VSCode extension for Lerna workspaces
Lerna now has a [dedicated VSCode extension](https://lerna.js.org/docs/features/editor-integrations) to help you navigate your monorepo. This allows you to run commands directly from the context menu (by right-clicking on a project):
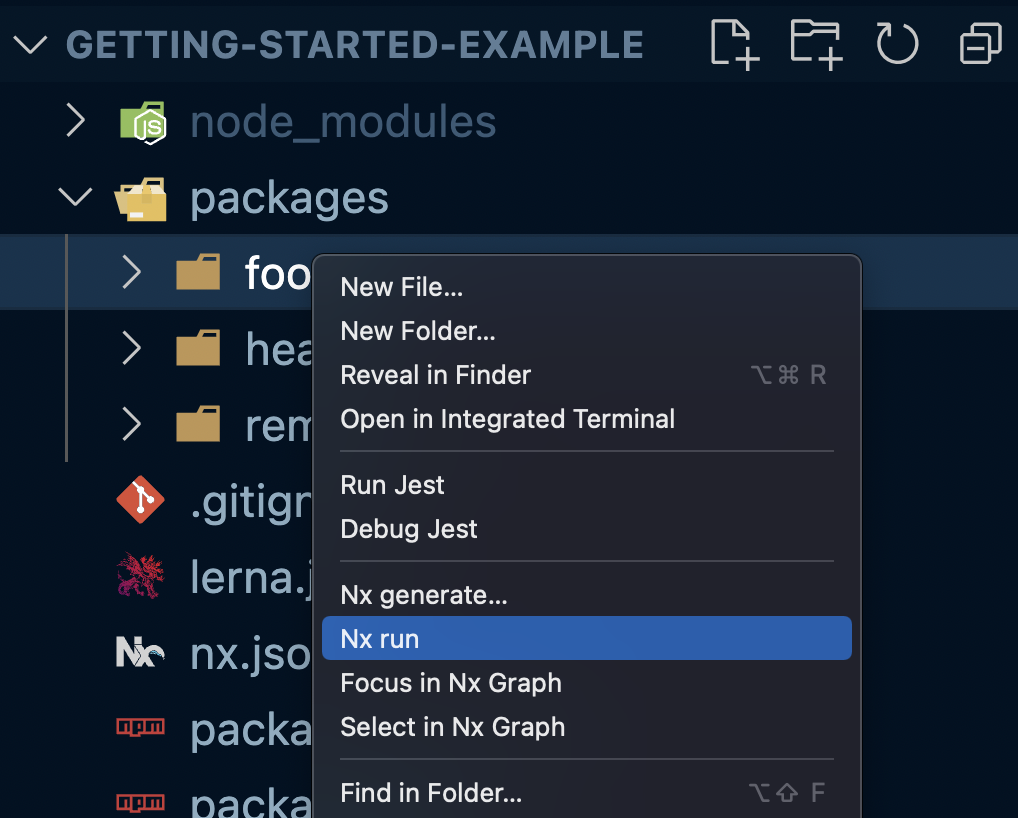
Or visualize a project and its relationships with other projects in the workspace.
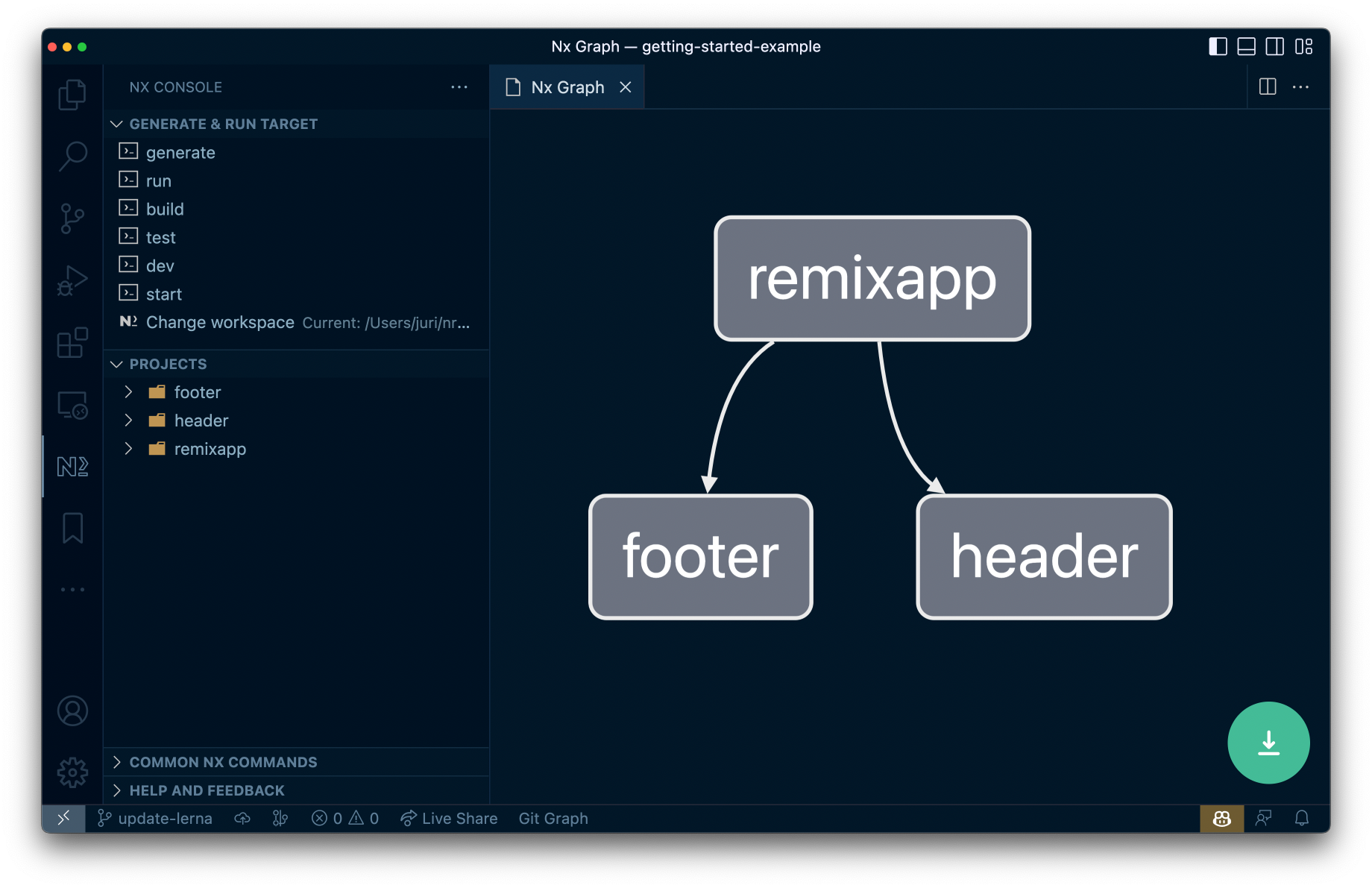
You will also get intelligent autocompletion in configuration files. Here's an example of Nx console providing context-based information when editing the `nx.json` task dependencies.
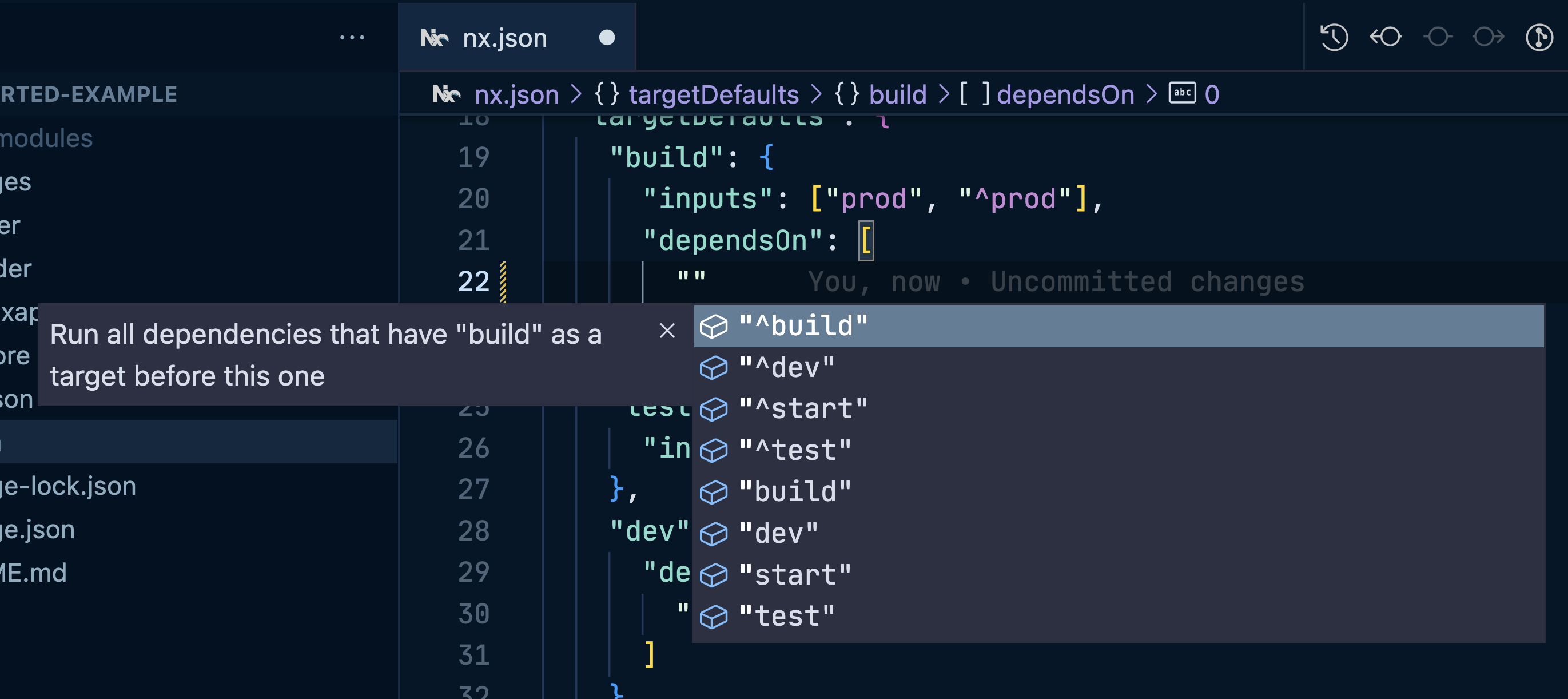
## Lerna Repair
Lerna v6 comes with a built-in `lerna repair` command. Running this command will automatically fix your Lerna configuration. For instance, in Lerna v6, there's no need to have `useNx: true` in your `lerna.json` since that will be the new default going forward. Running `lerna repair` fixes this.
This allows you always to have the most up-to-date Lerna setup and it will become even more powerful as we keep adding migrations in the future.
## Lerna and Prettier
Prettier is part of the standard toolchain of every developer nowadays. In Lerna v6 we added a feature to detect whether Prettier is set up in the workspace. If so, we automatically apply it to all files that get updated by running the lerna version command. No more follow-up commits just to fix the file formatting!
## Migrating to Lerna v6
Migrating from Lerna v5 to v6 is non-breaking. We increased the major because we changed some defaults and wanted to be cautious about that and communicate it properly.
{% twitter https://twitter.com/lernajs/status/1586070293096923139?s=20&t=Xq5i5iJkfE0LDWVZxOXD0A %}
Similarly, if you're still on v4 and want to migrate to v6 it should be pretty straightforward and not be breaking in most cases.
Just update the Lerna package version to the latest and then run..
```bash
npx lerna add-caching
```
..to enable and configure caching for your workspace.
Are you stuck or need help? There is also a community-organized Slack channel where also Nx and Lerna core members hang out. Join https://go.nrwl.io/join-slack and enter the `#lerna` channel.
### Lerna is using Nx now. Can I keep using my Lerna commands?
Absolutely! One of the key advantages of the new integration of Lerna with Nx is that you can keep using your existing Lerna commands without migrating them to a new syntax. They will now just be a lot faster.
You can read more about that [on our docs](https://lerna.js.org/docs/lerna-and-nx).
## Are you maintaining an OSS repository using Lerna?
If you are an OSS maintainer and you use a Lerna workspace, let us know!
Ping the Lerna team [on Twitter](https://twitter.com/lernajs) or ping [me directly](https://twitter.com/juristr). We'd love to have a look and help with the migration, look at the repository and make sure it is configured in the best optimal way in terms of monorepo setup and features like caching.
That said, as an open-source maintainer you also get unlimited free computation caching with Nx Cloud. So we'd love to set you up with that.
---
## Learn more
- 🧠 [Lerna Docs](https://lerna.js.org)
- 👩💻 [Lerna GitHub](https://github.com/lerna/lerna)
- 💬 [Nrwl Community Slack](https://go.nrwl.io/join-slack) (join the `#lerna` channel)
- 📹 [Nrwl Youtube Channel](https://www.youtube.com/nrwl_io)
- 🧐 [Need help with Angular, React, Monorepos, Lerna or Nx? Talk to us 😃](https://nrwl.io/contact-us)
Also, if you liked this, click the :heart: and make sure to follow [Juri](https://twitter.com/juristr) and [Lerna](https://twitter.com/lernajs) on Twitter for more!
{% embed https://dev.to/t/nx %}
| juristr |
1,217,330 | Want to find more references about front end | I'm a Vietnamese who wants to learn more about the fontend array of web programming | 0 | 2022-10-12T03:30:23 | https://dev.to/thanhluan2k3/want-to-find-more-references-about-front-end-7i | javascript, webdev, css, html | I'm a Vietnamese who wants to learn more about the fontend array of web programming | thanhluan2k3 |
1,217,460 | Tips for Perfect Work-Life Balance in Remote Working | Redefining Remote Working into Fun Working with 6 simple steps Talent wins Games, but Teamwork and... | 0 | 2022-10-12T06:53:11 | https://dev.to/lokeshkumarems/tips-for-perfect-work-life-balance-in-remote-working-23c2 | Redefining Remote Working into Fun Working with 6 simple steps
Talent wins Games, but Teamwork and Intelligence win Championships.
This one is said by Helen Keller. Basically, it is more than that powerful team working is a must to enhance the quality of work, employee productivity and increase collaboration which in turn boosts output. However, more than you calling them a team, the team ought to see themselves as one. The current days are more into remote working due to a lot of constraints here and there. Managing an effective culture when employees are not in front of you is surely a challenge. Trust us its not rocket science and just few major points if taken care of well can do wonders for you as a company:
1. Effective Communication
Communicating well at all levels is the first major point which works in a remote working environment. Continuous and constant communication can turn remote working into fun. It can pave the way towards a foundation of efficiency, prosperity and happiness in the team plus being connected with the organizations vision.
2. Constant Learning
A full fledged remote working system can sometimes be hugely complicated thanks to the uncertainties resulting from transitioning from a known system of an office to an unknown one of remote work. In an environment where change is the only constant, a lot of established practices, skills, and knowledge are in dire need of an update. Only those employees who are able to upskill themselves according to the changing requirements will be able to make a meaningful contribution to the organisation. Therefore, it is important that the workplace offers these up skilling opportunities to employees to ensure that they are able to reach maximum productivity both as individuals and as a team. Moreover, expectations placed on employees in a remote work environment have to be different from those placed on office workers. In work-from-home situations, productivity cannot only be measured on the basis of time spent in front of the laptop but rather in terms of tasks completed. For this, organisations should use employee monitoring software or employee tracking software or time tracking tool to keep a check on the individual employee productivity.
3. Not just WORK but some actual FUN too
Remote working can offer a lot of flexibility to employees but can also destroy the balance between work and life. This can lead to some employees feeling overburdened. To ensure such a situation does not occur, the working hours should be clearly defined and there must be time allotted to activities, coffee sessions, fun games and so on. This may be accomplished in a variety of ways, such as organising a lunch, birthdays, or quarterly town halls via a video calling application to allow workers to get to know one another both within and outside of their teams and interact freely. Also, policies like no new tasks allotted after 5 PM or no official communication after 7 PM can be adopted. It would allow employees to have some happy work time and no burning out.
4. Use of Technology
Some of the primary activities that hinder the process of an optimal work culture in remote teams are frequent demotivating messages, inappropriate allocation of work and limited interaction. As a leader in these ongoing times, it is important to incorporate few technology powered mechanisms like a real-time task management board and gamification of performance at the office as a team or as individuals in order to boost employee productivity. A tech powered employee productivity monitoring software like we360.ai could be a great option here
5. Goal Sharing and Corporate Leadership
Leadership shows employees the larger vision of the company and guides them in such a way that they can see the impact of their work on the larger success of the company. Remote work can create a communication gap wherein the vision of the company gets lost as employees fixate on their own tasks and own gain. It is therefore, important to ensure leadership is not lost and employees receive the guidance necessary to do impactful work and feel valuable to the organisation’s growth. This can be done by frequent communication, sharing the wider goal for individual tasks and holding weekly team meetings. | lokeshkumarems | |
1,300,185 | Top 7 sites to find free PNG images in 2022 | You know that feeling when you’re trying to find a PNG file but all you’re getting are JPEGs with... | 0 | 2022-12-16T20:26:34 | https://dev.to/pixmaster/top-7-sites-to-find-free-png-images-in-2022-h2g | png, resource, images | You know that feeling when you’re trying to find a PNG file but all you’re getting are JPEGs with watermark marked as PNG. Today we’ll be having a look at 7 Free PNG Websites that can ease up the process of finding a suitable PNG file for your project.
1. [PNGHERO](https://pnghero.com/)
PNGHERO offers over 55 million PNG images. All content is licensed under Creative Common Zero (CC0) license which means all the images on the platform can be used in commercial projects too.
2. [FAVPNG](https://favpng.com/)
FAVPNG is a community of creative artists offering a wide range of free transparent PNG images. The platform contains more than 16 million PNG images that are free to use for any personal no-commercial and educational projects.
3. [IMGBIN](https://imgbin.com/)
This site provides some amazing high-resolution PNG images and clipart pictures. IMGBIN platform contains free transparent PNG images which can be used in any personal non-commercial project.
4. [Pixel Squid](https://www.pixelsquid.com/)
Pixel Squid is one of the best places for finding beautiful free transparent PNG images and 3D objects. This PNG image site has a variety of 3D graphics and transparent background clipart that are free to use on any personal and non-commercial project.
5. [PNGHUT](https://pnghut.com/)
Find over 10 million free transparent PNG images and icons on PNGHUT. It is a non-commercial website developed by a bunch of graphic designers. This site is exceptionally useful for finding a vast variety of PNG images for non-commercial projects.
6. [Mrcutout](https://www.mrcutout.com/)
Discover gorgeous royalty-free transparent PNG images on the Mrcutout website. All these clear background PNG images are released under the Creative Common Zero (CC0) license, which means you can use these images in your commercial projects as well.
7. [CleanPNG](https://www.cleanpng.com/)
Clean PNG, is a website having more than 3,000,000+ free transparent PNG images. The platform has high-quality free PNG images organized in over 50,000+ categories. The best thing is you can download an unlimited number of images without registering on the platform.
In 2022 this is the list of websites containing beautiful high-resolution PNG images. Bookmark this page for future reference and don’t forget to share this with your designer friends. | pixmaster |
1,217,523 | Vue 3 Mouse and Keyboard event combo | I had trouble figuring out keyboard events in Vue, so I'm writing this for future reference Edit in... | 0 | 2022-10-12T09:05:06 | https://dev.to/barakplasma/vue-3-mouse-and-keyboard-event-combo-3c17 | vue | I had trouble figuring out keyboard events in Vue, so I'm writing this for future reference
[Edit in Vue SFC Playground](https://sfc.vuejs.org/#eNp1U8GOmzAQ/ZURF4iUQKveKInaSpV66K3H0gPgYSELtmUPpBHi3zvGZnfTqr7Y4/f8PPPsWaLPWqfzhFEeFbYxvSawSJO+lBJ49KNWhmABgy2s0Bo1Qsz0uJSe0ChpCTo1o4GzYyVtNVg8vEWf8R6wOH4AcEZJNmA/fzHmUaGaaWQorYT46jjfe0so0SQxawl1k/EREjzA+QKLP+IGY+lcDROyIqYcfXzF/FUeTvVku2Rx/NwTj76C3E+BReoHmV4+JQdYQ9puLjLvEzvEAeGoh4ow+FV0H8IK4NtmSqIMSEUHoA6hnoiUhBoHdYNKCqC7xnAyezlaBNqnUU0Wncq5jHaLyUxYRgEbsJrxDbh5z2gzVNbu+19IltFLViGvHJZlQ9d1v9/fuudAVT3sVfmN7sJOFRnPj7tici556/6BDcynVrkCcIZehnd4yMcTxWVZcHaPsa6sIv5HCEn/ReHQ7Jlne+q8en0dDi3dQ0lehY3Zv0+tjHCmvNe/waqhF1APVfMcPtCtF9Qx+M7guG2xZ/wNNrnoGPkmOY2VTq9WSW6lTbUMAFfLbnulMuLmcTG/DZG2eZbZtnENeLWpMk8Zr1IzSepHTNGOp9qom+UveWWVcPMarX8Ab/IwVw==)
{% embed https://gist.github.com/barakplasma/c66b2bc8c94b9870f2439b3adc074373 %} | barakplasma |
1,217,687 | How we can directly download file from url(using express server with graphql in the code) | A post by DevJyoti0 | 0 | 2022-10-12T12:34:28 | https://dev.to/devjyoti0/how-we-can-directly-download-file-from-urlusing-express-server-with-graphql-in-the-code-12fe | node, graphql | devjyoti0 | |
1,217,786 | Applying Atomic Design to your Next.js project | Written by Nefe James✏️ When starting a new project, CSS is easy to write. However, as the project... | 0 | 2022-10-13T16:31:57 | https://blog.logrocket.com/applying-atomic-design-next-js-project | nextjs, webdev | **Written by [Nefe James](https://blog.logrocket.com/author/nefejames/)✏️**
When starting a new project, CSS is easy to write. However, as the project grows in scale and the number of components, style sheets, and lines of code increases, CSS becomes a nightmare to maintain. Luckily, CSS methodologies create guidelines for writing modular, reusable, and scalable code.
There are a few popular methodologies, including Atomic Design, BEM, SMACSS, and OOCSS. In this article, we will focus on Atomic Design, learn its principles, and apply them to create a basic blog page in a [Next.js](https://blog.logrocket.com/tag/nextjs/) application.
_Jump ahead:_
* [What is Atomic Design in CSS?](#what-atomic-design-css)
* [Creating the Next.js application](#creating-next-js-application)
* [Building a basic blog page in a Next.js application with Atomic Design](#building-basic-blog-page-next-js-application-atomic-design)
* [Creating the title atom](#creating-title-atom)
* [Setting up the navbar molecule](#setting-up-navbar-molecule)
* [Making the table of contents molecule](#making-table-of-contents-molecule)
* [Adding the author’s details molecule](#adding-authors-details-molecule)
* [Designing the blog content molecule](#designing-blog-content-molecule)
* [Building the blog container organism](#building-blog-container-organism)
* [Creating the layout template for the blog page](#creating-layout-template)
* [Bringing it all together on the page](#bringing-all-together-page)
## Prerequisites
To follow along with this tutorial, you’ll need knowledge of Next.js, CSS, SCSS, and the [Atomic Design methodology](https://blog.logrocket.com/atomic-design-react-native/).
## What is Atomic Design in CSS? <a name="what-atomic-design-css">
Atomic Design is a CSS methodology created by [Brad Frost](https://bradfrost.com/blog/post/atomic-web-design/). It provides direction for creating scalable systems, reusable components, and design systems. Atomic Design was inspired by chemistry, which is why the building blocks are called atoms, molecules, organisms, templates, and pages.
Atoms are the smallest building blocks and are composed of HTML tags and HTML elements. Examples of atoms include inputs, buttons, and headings.
Similar to their chemical inspiration, Atomic Design’s molecules are a combination of atoms. For example, a form is a molecule because it combines the label, input, and button elements.
When we combine molecules or atoms, we get organisms. Organisms are groups of molecules and atoms joined to form relatively complex, distinct UI components and sections of an interface.
Continuing with the chemical theme, templates are made up of organisms. They are the structure of the content and are used to create a page's layouts, blueprints, and wireframes.
Finally, pages are the final product. In the architectural world, for example, a template would be the blueprint of a building, and a page would be the completed building.
## Creating a Next.js application <a name="creating-next-js-application">
Now, let’s build the Next.js application.
First, create a new Next.js project by running this command in the terminal:
```shell
npx create-next-app atomic-next-app
```
Next, we navigate into the project directory:
```shell
cd atomic-next-app
```
We will use [Sass](https://sass-lang.com/install) for styling, so install that below:
```shell
npm install --save-dev sass
```
Then, run the command to start the application:
```shell
npm run dev
```
## Using Atomic Design in Next.js <a name="building-basic-blog-page-next-js-application-atomic-design">
We will create a basic blog page with a navigation bar, a table of contents, blog content, and the author's details. Our title will be the only atom we create, while the navbar, table of contents, author's details, and blog content will be our molecules. The blog container will consist of those molecules and will be our organism. The structure of the blog should look like this: 
The folder structure for the project should look like this: 
Now that we’ve defined the atoms, molecules, organisms, templates, and pages, let’s create the components. You can use any component library, CSS processor, or tool. For this article, we will use Sass and [CSS Modules](https://blog.logrocket.com/a-deep-dive-into-css-modules/).
## Creating the title atom <a name="creating-title-atom">
We’ll set our blog page title using the title atom. As an atom, it will only have one `h1` element. To create the title, add a `components/Title.js` file to the application’s root and paste this code:
```javascript
import styles from "../../styles/title.module.scss";
export default function Title() {
return (
<h1 className={styles.blogTitle}>
How to Monitor Your Frontend and Perform Product Analysis with LogRocket
</h1>
);
}
```
Then, for styling, add a `title.module.scss` file to the `styles` folder and enter the styles below:
```css
.blogTitle {
font-size: 2.5rem;
font-weight: 500;
margin-bottom: 1rem;
display: inline-block;
}
```
## Setting up the navbar molecule <a name="setting-up-navbar-molecule">
The navbar molecule comprises the `nav`, an `a` HTML element, and Next.js’ `Link` component.
Create a `components/Navbar.js` file and paste the code:
```javascript
import styles from "../../styles/navbar.module.scss";
import Link from "next/link";
export default function Navbar() {
return (
<nav className={styles.navbarContainer}>
<Link href="#">
<a>The Coolest Blog Ever</a>
</Link>
</nav>
);
}
```
To edit the styling, add a `navbar.module.scss` file to `styles` and paste the styles below:
```css
.navbarContainer {
padding: 1.6rem;
background-color: #8652ff;
box-shadow: 0 4px 16px 0 rgba(41, 0, 135, 0.12);
background-image: linear-gradient(150deg, rgba(99, 31, 255, 0.6), #8652ff);
a {
color: rgb(241, 235, 255);
font-size: 2rem;
}
}
```
## Building the table of contents molecule in Next.js <a name="making-table-of-contents-molecule">
Like the navbar molecule, this molecule consists of the `nav`, `ul`, the `a` HTML elements, and `Link` components.
To set it up, create a `components/TableOfContents.js` file and paste the code below:
```javascript
import styles from "../../styles/tableOfContents.module.scss";
import Link from "next/link";
const TableofContentRoutes = [
{ label: "Introduction", href: "#" },
{ label: "Getting Started", href: "#" },
{ label: "What is LogRocket", href: "#" },
{ label: "How to Monitor Frontend with LogRocket", href: "#" },
{ label: "How to Perform Product Analysis with LogRocket", href: "#" },
{ label: "Why LogRocket is Awesome", href: "#" },
{ label: "Conclusion", href: "#" },
];
export default function TableOfContents() {
return (
<div className={styles.tableOfContentsContainer}>
<h2>Table of Contents</h2>
<nav>
<ul>
{TableofContentRoutes.map((route) => (
<Link href={route.href} key={route.label}>
<a>{route.label}</a>
</Link>
))}
</ul>
</nav>
</div>
);
}
```
We created a `TableofContentRoutes` array in the code above with `label` and `href`. Then, we mapped through the `TableofContentRoutes` routes and rendered a link for each one.
Now, for styling, add a `tableOfContents.module.scss` file to `styles` and insert the styles:
```css
.tableOfContentsContainer {
ul {
display: flex;
flex-direction: column;
list-style: none;
a {
color: inherit;
text-decoration: underline;
}
}
@media (min-width: 768px) {
width: 300px;
}
}
```
## Adding the author’s details molecule <a name="adding-authors-details-molecule">
The author’s molecule will contain the author's image and name. In this tutorial, we will name our author John Doe. We'll use the `Image` component and a `span` tag to set this up.
First, add an `Author.js` file to the components folder and insert the following code:
```javascript
import styles from "../../styles/authorDetail.module.scss";
import Image from "next/image";
export default function AuthorDetail() {
return (
<div className={styles.authorDetailContainer}>
<div className="img-box">
<Image
alt="Author's avatar"
src="/author.jpg"
width="50px"
height="50px"
/>
</div>
<span>John Doe</span>
</div>
);
}
```
To edit the styling, add `authorDetail.module.scss` to `styles` and paste the styles below:
```css
.authorDetailContainer {
display: flex;
gap: 0.5rem;
margin-bottom: 2rem;
.img-box {
position: relative;
border-radius: 50%;
}
}
```
## Designing the blog content molecule <a name="designing-blog-content-molecule">
Next, we’ll set up the blog content molecule to house the blog's texts, which are a collection of `p` tags. For this, add `BlogContent.js` to the components folder:
```javascript
import styles from "../../styles/blogContent.module.scss";
export default function BlogContent() {
return (
<div className={styles.blogContentContainer}>
<p>
Eu amet nostrud aliqua in eiusmod consequat amet duis culpa dolor.
Excepteur commodo proident aliquip aliquip fugiat ex exercitation amet
velit. Mollit id cupidatat duis incididunt. Excepteur irure deserunt
fugiat cillum id. Aliquip nulla pariatur sunt ex. Nulla id ut minim
cupidatat laboris culpa laboris. Anim consectetur veniam ipsum
exercitation ipsum consequat magna quis pariatur adipisicing.
</p>
</div>
);
}
```
Now that we’ve set up the molecule for our text, we need to edit the styling. To do this, add a `blogContent.module.scss` file to `styles` and include the following code:
```css
.blogContentContainer {
p {
margin-bottom: 1rem;
font-size: 1rem;
}
}
```
## Building the blog container <a name="building-blog-container-organism">
We set up all of our blog page’s molecules in the steps above. To create the blog container organism, we will combine the `Title`, `Author`, and `BlogContent` components. For this, add a `BlogContainer.js` file to the components folder:
```javascript
import Title from "../Atoms/Title";
import AuthorDetail from "../Molecules/AuthorDetail";
import BlogContent from "../Molecules/BlogContent";
export default function BlogContainer() {
return (
<div className="blog-container">
<Title />
<AuthorDetail />
<BlogContent />
</div>
);
}
```
Here, we imported `Title`, `AuthorDetail`, and `BlogContent` and plugged them into `BlogContainer`. As you can see, no styling is required for this component. Now, we’ll build the layout template!
## Creating the layout template with Atomic Design <a name="creating-layout-template">
The layout template is where we define the positioning of every other component on the page. To set it up, create a `Layout.js` file in the components folder:
```javascript
import styles from "../styles/layout.module.scss";
import Navbar from "../components/Molecules/Navbar";
import TableOfContents from "../components/Molecules/TableOfContents";
import BlogContainer from "../components/Organisms/BlogContainer";
export default function Layout() {
return (
<div className={styles.layoutContainer}>
<header>
<Navbar />
</header>
<main>
<aside>
<TableOfContents />
</aside>
<article>
<BlogContainer />
</article>
</main>
</div>
);
}
```
Here, we imported the `Navbar`, `TableOfContents`, and `BlogContainer` components and plugged them into the `Layout` component.
Next, for the styling, add a `layout.module.scss` to `styles` and paste the styles below:
```css
.layoutContainer {
main {
display: flex;
flex-direction: column;
gap: 2rem;
padding: 1.6rem;
@media (min-width: 768px) {
flex-direction: row;
justify-content: space-between;
}
}
}
```
## Finalizing the Next.js blog project <a name="Finalizing the Next.js blog project">
To finish up, we will put `Layout` into the `index.js` file to create the page.
```javascript
import Head from "next/head";
import Layout from "../components/Layout";
export default function Home() {
return (
<div>
<Head>
<title>The Coolest Blog Ever</title>
</Head>
<Layout />
</div>
);
}
```
With that, we have successfully applied the principles of Atomic Design to create a blog in Next.js. Our blog will look like this: 
## Conclusion
In this article, we applied the principles of Atomic Design to create the UI of a Next.js blog. By breaking web pages into separate components, Atomic Design prevents repetition and promotes consistency and scalability.
While we applied Atomic Design to a web development project in this article, its principles can also create design systems for UI/UX design.
---
## [LogRocket](https://logrocket.com/signup): Full visibility into production Next.js apps
Debugging Next applications can be difficult, especially when users experience issues that are hard to reproduce. If you’re interested in monitoring and tracking Redux state, automatically surfacing JavaScript errors, and tracking slow network requests and component load time, try [LogRocket](https://logrocket.com/signup).
[](https://logrocket.com/signup)
[LogRocket](https://logrocket.com/signup) is like a DVR for web and mobile apps, recording literally everything that happens on your Next app. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app's performance, reporting with metrics like client CPU load, client memory usage, and more.
The LogRocket Redux middleware package adds an extra layer of visibility into your user sessions. LogRocket logs all actions and state from your Redux stores.
Modernize how you debug your Next.js apps — [start monitoring for free](https://logrocket.com/signup). | mangelosanto |
1,218,056 | 100 DAYS OF CODE CHALLENGE | DAY 5 WHAT I DID TODAY Adding audio to my web page WHAT I LEARNT FROM WHAT I DID... | 0 | 2022-10-12T20:18:55 | https://dev.to/haseenarh/100-days-of-code-challenge-2a2g | ## DAY 5
- WHAT I DID TODAY
Adding audio to my web page
- WHAT I LEARNT FROM WHAT I DID TODAY
The first step I took was to go to YouTube audio library on the YouTube app, then I searched and downloaded a song of my choice, after downloading the song, I dragged and dropped the MP3 file to the folder containing my index.html file, then I headed back to my VS Code.
Within the body element, I created an audio element and listed the source equal to the name of my MP3 file, then I added a Boolean attribute [A Boolean attribute is an attribute that can be true or false]. The Boolean attribute I added was the control attribute within the audio attribute. The end result was looking like this;[<audio controls src="New Moon.MP3>].
With these control attribute, I can play the audio file of my choice, it can be fast forwarded and can also be muted.
| haseenarh | |
1,218,070 | 100 DAYS OF CODE CHANLLENGE | Day 4 What I did today I started my Alt school second semester first assignment, we are told to... | 0 | 2022-10-12T20:43:01 | https://dev.to/lade/100-days-of-code-chanllenge-3fd2 | react | **Day 4**
What I did today
I started my Alt school second semester first assignment, we are told to create a calculator using react on either Replit, Stackblitz or Codestackbox.
I will be using Replit, I started with it already and hopefully, I will finish by tomorrow. | lade |
1,218,218 | Day 634 : The Best | liner notes: Professional : Today, there was an all hands meeting. It was cool to hear what's... | 0 | 2022-10-12T23:29:09 | https://dev.to/dwane/day-634-the-best-nl | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Today, there was an all hands meeting. It was cool to hear what's happening with the company. Then I started back working on the demo application I've been putting together. Basically spent the day searching the internet and docs for any sort of help or code snippets.
- Personal : Got the screen for the side door of my van last night and put it up this morning. I tried it on the passenger side and it fit pretty well. I think it really kept my van cool. It got to 86 degrees, and my van was pretty comfortable. Even got a nice breeze. My plan is to put it on the driver side door since I don't really go through that door. Last night, I worked on my side project. Made some pretty good progress and went to sleep.
Going to do some coding. Watch the first episode of "Chainsaw Man" anime, heard some good things like it's one of the best animes out in a while. Planning on trying to catch up with "The Walking Dead" also.
Have a great night!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube SozX28GZNd0 %} | dwane |
1,218,769 | CryptoJS 用前端加密、解密 | 本篇要解決的問題 一般來說,加密解密這件事兒都是要讓後端來處理,因為前端寫的程式碼全部都會是明碼,加解密的密碼會大辣辣的攤在所有平行宇宙底下。 But!對,就是這個 But!在... | 18,536 | 2022-10-13T13:01:09 | https://www.letswrite.tw/crypto-js/ | crypto, javascript, tutorial | ## 本篇要解決的問題
一般來說,加密解密這件事兒都是要讓後端來處理,因為前端寫的程式碼全部都會是明碼,加解密的密碼會大辣辣的攤在所有平行宇宙底下。
But!對,就是這個 But!在 August 遇過的專案中卻用過二次加解密的功能,主要是一些普通的資料不想一直調用 API 來取得,就暫存在 Cookies 中,儲存的時候寫「12345」跟寫「U2Fs+7ZUKvqr+7C=」之類的就是不一樣。
而且也不是所有工程師看到別人的頁面就會去無聊翻 Cookies 跟 JS 檔去解密吧?加上敢存在前端的資訊不會是什麼重要機密了,所以前端的加、解密就還是有機會用到。
本篇是用 Crypto.js 來進行加解密的動作,選它是因為網路上很多人推薦,GitHub 上星星數也多……對,工程師的選擇就是這麼的樸實無華,再加上實際使用起來真的很簡單,因此就決定是它了。
CryptoJS 官方說明文件:[GitHub](https://github.com/brix/crypto-js)。
---
## 安裝
官方文件提供的安裝方式主要分為二種:前端 Browser、後端 Node.js。
身為一位專業的前端工程師們,我們這邊就傲驕的用前端版的。
前端安裝方式也有二種:直接 CDN 引用、import。
### CDN
基本上搜尋「crypto js cdn」,就會看見一些第三方的 CDN 網站有提供,比方 [cdnjs](https://cdnjs.com/libraries/crypto-js)。
寫這篇時的最新版本是 4.1.1,可以直接引用:
```html
<script src="https://cdnjs.cloudflare.com/ajax/libs/crypto-js/4.1.1/crypto-js.min.js"></script>
```
### import
首先先安裝 package:
```shell
$ npm install crypto-js
# 或
$ yarn add crypto-js
```
接著在 JS 檔中 import,import 時可以選擇直接整包,也可以只引用我們有用到的功能。
本篇不會直接 import 整包,而是只 import 有用到的功能:
```javascript
import AES from 'crypto-js/aes';
import Rabbit from 'crypto-js/rabbit';
import encUtf8 from 'crypto-js/enc-utf8';
```
---
## 使用
官方 API 的文件在這:[GitBook](https://cryptojs.gitbook.io/docs/)。
### AES 加密解密
AES 加解密是官方提供的範例之一,使用方式很簡單:
```javascript
import AES from 'crypto-js/aes';
import encUtf8 from 'crypto-js/enc-utf8';
// 加密
const ciphertext = AES.encrypt('要加密的字串', '加密密碼').toString();
// 解密
const bytes = AES.decrypt(ciphertext, '加密密碼');
const originalText = bytes.toString(encUtf8);
```
`加密密碼` 就是每個人自行設定,把它當通關密語,加密跟解密的雙方都要用這組密碼來認證一樣。
除了加解密字串,文件裡也有提供加解密 Object 的部份,其實就是把 Object 變成字串:
```javascript
import AES from 'crypto-js/aes';
import encUtf8 from 'crypto-js/enc-utf8';
const obj = [{id: 1}, {id: 2}]
// 加密
var ciphertext = CryptoJS.AES.encrypt(JSON.stringify(obj), '加密密碼').toString();
// 解密
var bytes = CryptoJS.AES.decrypt(ciphertext, '加密密碼');
var originalObj = JSON.parse(bytes.toString(CryptoJS.enc.Utf8));
```
### Rabbit 加密解密
除了範例上的 AES,看 API 文件裡提到的 [Rabbit](https://cryptojs.gitbook.io/docs/#ciphers) 好像也是蠻厲害的,寫法跟 AES 差不多。
```javascript
import Rabbit from 'crypto-js/rabbit';
import encUtf8 from 'crypto-js/enc-utf8';
// 加密
const encrypted = Rabbit.encrypt('要加密的字串', '加密密碼');
// 解密
const decrypted = Rabbit.decrypt(encrypted, '加密密碼');
const originalText = decrypted.toString(encUtf8);
``` | letswrite |
1,219,385 | Styling the featured work section - part 7 | Now that we have the recent post section let's look at the last bit of the homepage. This will be the... | 20,074 | 2022-10-14T06:46:09 | https://daily-dev-tips.com/posts/styling-the-featured-work-section-part-7/ | javascript, webdev, beginners, nextjs | Now that we have the [recent post section](https://daily-dev-tips.com/posts/styling-the-recent-posts-part-6/) let's look at the last bit of the homepage. This will be the featured work section.
The design shows us the following element. We can see some outlined items here:
- The section header we created yesterday
- Work sections
## Styling the featured work section
Let's start by creating a new component called `featuredWork.js`, and inside we can bootstrap a very generic component.
```js
import SectionHeader from './sectionHeader';
export default function FeaturedWork() {
return (
<section className='px-6'>
<div className='max-w-4xl mx-auto py-12'>
<SectionHeader title='Featured work' href='#' />
</div>
</section>
);
}
```
You can see we can reuse the header we made yesterday. Now that's convenience.
Let's import this file to our homepage.
```js
import Head from 'next/head';
import IntroHeader from '../components/introHeader';
import RecentPosts from '../components/recentPosts';
import FeaturedWork from '../components/featuredWork';
export default function Home() {
return (
<div>
<Head>
<title>NextJS Portfolio</title>
<meta name='description' content='Generated by create next app' />
<link rel='icon' href='/favicon.ico' />
</Head>
<IntroHeader />
<RecentPosts />
<FeaturedWork />
</div>
);
}
```
From here, let's focus on adding the article components.
We'll create the `work.js` file and place the main markup inside.
```js
export default function Work() {
return (
<article>
<img src='https://via.placeholder.com/240' />
<div>
<h3>Work title</h3>
<span>
<date>2022</date> Tagname
</span>
<p>
Amet minim mollit non deserunt ullamco est sit aliqua dolor do amet
sint. Velit officia consequat duis enim velit mollit. Exercitation
veniam consequat sunt nostrud amet.
</p>
</div>
</article>
);
}
```
Let's start by adding two of these to our `featuredWork` component so we can see what's going on.
```js
import SectionHeader from './sectionHeader';
import Work from './work';
export default function FeaturedWork() {
return (
<section className='px-6'>
<div className='max-w-4xl mx-auto py-12'>
<SectionHeader title='Featured work' href='#' />
<div className='flex flex-col gap-2'>
<Work />
<Work />
</div>
</div>
</section>
);
}
```
I already added a wrapping div with some classes to space them out a bit better.
Resulting in the following:
Let's start by adding some styling to this.
First up is the wrapping element.
```html
<article className="flex items-center border-b-2 py-6"></article>
```
As for the image, we can always set its width to be 1/3rd of the wrapper.
```html
<img src="https://via.placeholder.com/240" className="w-1/3 mr-6 rounded-lg" />
```
Now on to the text elements starting with the title, which is the same as the one we used for the posts.
> Note: You can also convert this into a custom heading component.
```html
<h3 className="text-2xl mb-2 font-medium"></h3>
```
As for the date and text, we use the wrapping div to style the tag and the date tag to create the little pill-like year.
```html
<span className="text-gray-600 mb-4 block">
<date className="bg-blue-800 text-white px-5 py-1.5 mr-4 rounded-xl">
2022
</date>
Dashboard
</span>
```
And that's it!
Let's take a look at the result for today.
You can also find the completed code on [GitHub](https://github.com/rebelchris/next-portfolio/tree/part-7).
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1) | dailydevtips1 |
1,219,413 | The 10 Most Pressing Challenges Confronting IT Today | This blog was originally published on Sphinx Worldbiz CIOs are accustomed to constant change. New... | 0 | 2022-10-14T07:34:28 | https://dev.to/jesmen/the-10-most-pressing-challenges-confronting-it-today-3d75 | react, webdev, it | This blog was originally published on [Sphinx Worldbiz](https://www.sphinxworldbiz.net/the-10-most-pressing-challenges-confronting-it-today/)
CIOs are accustomed to constant change. New technologies enter the market, current ones evolve, corporate demands shift on a dime, and employees come and go. All of this, however, pales in comparison to the turmoil that CIOs are experiencing today.
On top of that, IT executives are now dealing with ongoing pandemic-related interruptions, geopolitical uncertainty, and economic volatility.
These forces are already changing the CIO agenda for 2022, prompting many IT executives to rearrange their top priorities. With that in mind, here’s a look at what’s now capturing the interest of IT executives.
Increasing transformational demands
One of the main challenges noted by CIOs, researchers, and executive advisers is the volume of work arriving at IT, or, as Elizabeth Hackenson, CIO of Schneider Electric, puts it, “the accelerating need for digital capabilities throughout the company concurrently.”
“In the past, we might have had a digital transformation [effort] in HR or sales, but as I talk to a lot of CIOs, we’re all seeing end-to-end digital transformations that are accelerating today,” Hackenson says.
This rising demand, she claims, is a result of all the digitization work corporations have done in reaction to the outbreak over the last two years. That effort provided the groundwork for more sophisticated changes while also creating fresh follow-on possibilities, which businesses are now under pressure to exploit.
“We’re also discovering that it’s all interrelated,” Hackenson says, adding that CIOs and their executive counterparts are understanding that a digital transformation programme in one area, such as sales, must be backed by change in supporting areas such as supply chain.
“There is now a focus on ‘transversal change,'” adds Hackenson.
Customer satisfaction
According to Aamer Baig, a senior consultant at management consulting company McKinsey & Co., market constraints continue to make customer experience a top CIO priority.
“Really knowing the client is critical,” he continues, “therefore CIOs need to be in the front office.”
According to Baig, this continues to be an issue for many CIOs who aren’t yet connected enough to internal and external clients.
“While technology must get closer to the client, middlemen must remain.” “CIOs still have translators, between the real users and the IT organisation,” he argues.
Although customer experience is not only the CIO’s duty, Baig believes that CIOs should do more to include customer experience into IT deliverables and elevate customer experience as a cross-functional goal. They can do so, for example, by implementing real agile principles in which business and engineers collaborate and iterate side by side.
Sarah Angel-Johnson, Save the Children’s CIO and vice president of business and technology solutions, says user experience is one of her main objectives. Angel-Johnson, a human-centered design practitioner, claims to have established a user experience department managed by a recently appointed head of user experience.
“The overarching goal is to begin with the human,” she adds. “Let’s start with a persona or several personas, tie experience to them, and then push all tech and data solutions against them to create superior products.”
Mounting cybersecurity and data privacy risks
Josh Hamit, senior vice president and CIO of Altra Federal Credit Union, says cybersecurity has always been a focus for him, but it has become a greater issue this year.
He attributes this to the Russian invasion of Ukraine, which triggered warnings about Russia-backed hackers ramping up cyberattacks on US targets. As a result, Hamit is focusing more on collaborating with the CISO to enhance security foundations, cyber hygiene best practises, and layered defences.
“Those things aren’t necessarily new, but they’re more significant now than ever before,” says Hamit, a member of ISACA’s Emerging Trends Working Group.
Indeed, Evanta’s 2022 CIO Leadership Perspectives report indicated that cybersecurity initiatives are the topmost choice within the CIO position, up from second place in 2021.
Angel-Johnson says she, too, is concerned about security and, more especially, data protection.
She, like Hamit, cites current events as a reason for raising this to the top of her priority list, explaining that hackers typically maximise their attacks as Save the Children and other such organisations ramp up their operations in response to global crises, seeing increased NGO activity as an opportunity for higher chances of success.
Increasing data possibilities
According to Evanta’s 2022 CIO Leadership Perspectives research, data and analytics are CIOs’ second top priority within the IT department, with CIOs perceiving improving corporate data utilisation as critical to achieving company goals.
Angel-Johnson is of the same mind. “I assumed I was recruited for digital transformation, but what truly needs to happen is data transformation,” she explains. She believes that all businesses, including her own, should advance their use of data to move past monitoring outputs and even outcomes in order to “get to impact, to generating long-term delta change.”
Angel-Johnson has begun on a master data management programme to get there. This programme incorporates technological advancements such as API integration layers for broader, more agile data access, as well as a culture shift promoting more creativity by “testing ideas” using data.
Others agree that data projects are a major priority for CIOs. For example, Hackenson says she’s focused on data and has prioritised its usage in pushing her company’s growing use of machine learning and artificial intelligence.
“Companies like ours, which have an incredible amount of data, are now focusing on finding those use cases that we believe would be most valuable to us,” she adds, adding that Schneider Electric just appointed its first AI officer to spearhead its efforts in this area.
Developing an Enterprise Cloud Strategy
According to the Evanta CIO study, 54% of CIOs are investing in cloud infrastructure, the second most important area of investment for CIOs after cybersecurity.
Other research revealed that CIOs are advancing their usage of the cloud. According to the PwC 2022 Pulse Survey, 43% are revising their IT strategy and operating model to be more flexible, 35% are utilising infrastructure investments to transition from traditional data centres to cloud-based, and 28% are restructuring corporate architectures to be cloud-based.
Developing an Enterprise Cloud Strategy
“There is no IT plan that does not include the cloud at its core,” adds Baig. Furthermore, he claims that it is not about moving current on-premises systems to the cloud, but rather about “using cloud to fundamentally improve the business: lowering costs, increasing time to market, and better supporting consumers.”
6.Geopolitical ramifications on the technology stack
At the same time as CIOs are pushing their cloud plans and advocating a more knowledgeable use of organisational data, an increasing number of tech leaders are dealing with new government regulations affecting both sectors.
According to Gartner’s 2022 CIO and Technology Executive Agenda: Master Business Composability to Succeed in Uncertain Times research, business boards should be concerned about the rise of nationalism/deglobalization, geopolitical and cultural power changes, and instability.
In its February 2022 study titled What Forces Are Driving Digital Geopolitics and Where CIOs Should Focus, Gartner states, “Digital geopolitics is now one of the most chaotic developments that CIOs must manage.”
Others claim it is making way for the Splinternet notion.
According to Baig, evolving norms and regulations are forcing CIOs to create various tech stacks for different areas, with such tech stacks often dispersing along East-West lines. Furthermore, as a result of Russia’s invasion of Ukraine and following Western government sanctions, some CIOs have been forced to relocate IT services out of Russia, he says.
7.Turbulence in the supply chain
Geopolitical concerns have an influence on IT in other ways as well, most recently with supply chain challenges delaying essential technological components. For example, Intel’s CEO stated in April that he expected the chip shortfall to endure until 2024.
“The supply we require is just not available.” It is harming many of the technological systems on which we depend. “You can see it with cell phones and PCs,” says Altra Federal’s Hamit. He claims he ordered 150 micro-PCs in July 2021 but is yet to get them.
“We have to be adaptable, accept whatever equipment we can get our hands on; it may be pricey, it may be from a different brand than we desire,” he says.
8.Cost-cutting measures
The Evanta poll ranks enhancing operational savings and raising productivity as the top priority for CIOs throughout the company.
Others affirm the rising emphasis on leveraging technology to cut expenses – both within IT and across the enterprise.
CIOs and management consultants agree that IT has always been tasked with discovering ways to leverage technology to reduce costs and increase productivity. However, they also claim that the focus on that work varies depending on a variety of circumstances such as the general health of the economy.
Inflation, worries of a recession, and suspicions of stagflation have executives across sectors re-evaluating budgets and, as a result, making cost control a significant aim once again.
“There’s a greater effort to look at IT expenditures and consider rejigging costs in the event that demand declines,” Baig adds.
“Six months ago, the majority of CIOs and CEOs were concerned with growth and how to fulfil demand.” Some businesses are still coping with this, while others are becoming increasingly concerned about demand cycles. As a result, the chequebook has shrunk and may shrink much further; budgets may be reducing.”
9. Fierce Talent Wars
For years, CIOs have faced a difficult market for attracting and keeping IT talent, owing to a shortage of available roles. This is evidenced by the low unemployment rate of 1.3% among technicians. The shift to remote employment in recent years has heightened competitiveness.
“We’re now battling with employers all around,” Hamit explains. During the outbreak, my department had a vacant job, and we went through numerous rounds of advertising and interviews, as well as having individuals accept and then refuse. In comparison to pre-pandemic times, it was a very long procedure. In addition, we ended up broadening our search beyond our local market (where our operations centre is situated) and hiring a remote employee. It only goes to show how tough it is to locate and compete for talent, particularly in IT.”
According to CIOs, such events have emphasised the necessity to nurture in-house talent to guarantee that they stay and are equipped to handle future workloads.
“Talent is the basis upon which all of our successes and prosperity will be built,” says Nicholas Colisto, Avery Dennison’s vice president and CIO.
10. Storming through the instabilities
Executives, particularly CIOs, face several obstacles, including inflation, supply constraints, and significant personnel turnover. And CIOs, like their C-suite counterparts, must work with them to meet objectives and prepare for the future, according to Monika Sinha, a research vice president in Gartner’s CIO Research division.
“One of the fundamental issues that CIOs have is the competence to get things done,” Sinha adds. “There’s a lot of pressure on them to satisfy expectations, and their capacity to succeed is contingent on meeting and surpassing expectations.”
“These aren’t all new, but they’ve become worse, and there’s no real daylight at the end of the tunnel right now,” she says.
She believes that in order to thrive, CIOs must blow past the limitations that have historically kept all tech work and innovation within the IT department and instead shift to distributed development and decentralised IT.
“There are possibilities within the enterprise, markets that CIOs can tap into not just for talents but also for knowledge, to get things done or learn how to execute innovation or solve business challenges,” Sinha adds. “This is presenting tremendous opportunity for CIOs since technology is critical to addressing business concerns.”
Colisto says he’s taking advantage of such possibilities.
“IT is collaborating with its stakeholders to support the company’s objective to use digital technology to better its present business model and generate net new goods, services, and models,” he says. “We are driving the implementation of digital literacy initiatives, internal capabilities, and strategic supplier collaborations in order to strengthen skills across our organisation – to create profitable growth and support goals.”
He claims that the corporation is doing this by utilising its Digital Innovation Center of Excellence (DICE) to “find answers to critical business difficulties by tinkering with emerging technology.”
| jesmen |
1,221,093 | Apa yang menarik di Next.Js 12.3 | Next.js versi 12.3 membawa beberapa peningkatan antara lain: Improved Fast Refresh TypeScript... | 0 | 2022-10-16T07:42:34 | https://dev.to/toufiqnuur/apa-yang-menarik-di-nextjs-123-4j08 | nextjs, javascript, typescript, react | Next.js versi 12.3 membawa beberapa peningkatan antara lain:
- Improved Fast Refresh
- TypeScript Auto-Install
- Image Component
- SWC Minifier
- New Router + Layouts Update
Dari beberapa peningkatan di atas yang membuat saya cukup tertarik adalah adanya TypeScript Auto-Install, simpel tapi sangat membantu. Dengan fitur ini kita bisa tidak perlu ribet setup insatalasi typescript di projek yang sudah ada, cukup menambahkan file typescript next.js akan otomatis menginstall setup yang diperlukan. Fitur ini akan otomatis bekerja saat kita menjalankan perintah `next dev` atau `next build`.
| toufiqnuur |
1,219,574 | This Week In Python | Fri, October 14, 2022 This Week in Python is a concise reading list about what happened in the past... | 0 | 2022-10-14T11:13:44 | https://bas.codes/posts/this-week-python-033 | thisweekinpython, python |
**Fri, October 14, 2022**
This Week in Python is a concise reading list about what happened in the past week in the Python universe.
## Python Articles
- [When Python can’t thread: a deep-dive into the GIL’s impact](https://pythonspeed.com/articles/python-gil/)
- [Decorator shortcuts](https://nedbatchelder.com/blog/202210/decorator_shortcuts.html)
- [Python implementations of time series forecasting and anomaly detection](https://robjhyndman.com/hyndsight/python_time_series.html)
- [Musings on Python Type Hints](https://samgeo.codes/blog/python-types/)
- [The dangers of assert in Python](https://snyk.io/blog/the-dangers-of-assert-in-python/)
## Projects
- [django-consistency-model](https://github.com/occipital/django-consistency-model) – DCM is a set of tools that helps you to keep your data in your Django Models consistent
- [semantic-python-overview](https://github.com/pysemtec/semantic-python-overview) – overview of projects which are related both to python and semantic technologies
- [python-preloaded](https://github.com/albertz/python-preloaded) – Bundle Python executable with preloaded modules
- [inline-sql](https://github.com/ekzhang/inline-sql) – Inline SQL in any Python program
- [pycopy](https://github.com/pfalcon/pycopy) – a minimalist and memory-efficient Python dialect
| bascodes |
1,220,127 | Create Custom Scrollbar Using CSS | I was always interested in learning about how to make a custom scrollbar and finally, I managed to do... | 0 | 2022-10-17T14:33:04 | https://dev.to/highflyer910/create-custom-scrollbar-using-css-4ff3 | css, scrollbar, webdev, tutorial | I was always interested in learning about how to make a custom scrollbar and finally, I managed to do it.
First, let me show the components of a scrollbar. A scrollbar contains the thumb and the track. The thumb is the draggable scrolling handle and the track is the progress bar, the entire scrollbar itself.

**The Scrollbar Width**
First, we define the width of the scrollbar (width for vertical scrollbars and height for horizontal ones) using the following pseudo element: ``::-webkit-scrollbar``
```css
::--webkit-scrollbar {
width: .6em;
}
```
**The Scrollbar Track**
We can style the scrollbar by shadows, border-radius, background-colors and use the pseudo element: ``::-webkit-scrollbar-track``
```css
::--webkit-scrollbar-track {
background-color: transparent;
}
```
**The Scrollbar Thumb**
The scrollbar thumb can be styled by background-colors, gradients, shadows, border-radius. We use the pseudo element ``::-webkit-scrollbar-thumb`` for it.
```css
::--webkit-scrollbar-thumb {
background-color: #e1d3cf;
border-radius: 5px;
border: .2em solid #25649a;
}
```
Other pseudo elements:
``::-webkit-scrollbar-button`` - the arrows pointing upwards and downwards.
``::-webkit-scrollbar-corner`` - the bottom corner of the scrollbar, where both horizontal and vertical scrollbars meet.
Here you can see a codepen demo and play with it:
{% codepen https://codepen.io/HighFlyer/pen/mdLoGMa %}
Unfortunately, this way works on Webkit-based browsers only. For Mozilla Firefox we can use only two parameters: ``scrollbar-color`` and ``scrollbar-width`` and they should be applied to the ``<html>`` element, not the ``<body>``.
The ``scrollbar-width`` has following values: ``auto``, ``inherit``, ``initial``, ``none``, ``revert``, ``thin`` and ``unset``. We can’t define a specific number.
With the ``scrollbar-color`` we define a color for both the scrollbar track and thumb as pair values.
```css
html {
scrollbar-color: #e1d3cf #25649a;
scrollbar-width: thin;
}
```
In this case, we can't use shadows, gradients, or rounded edges to style it.
That's all folks! :tada: Thank you for reading. For further information, please, check out the [MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/::-webkit-scrollbar#browser_compatibility) resource.
| highflyer910 |
1,220,475 | In One Minute : git | Git is free and open source software for distributed version control: tracking changes in any set of... | 20,049 | 2022-10-15T10:48:58 | https://dev.to/rakeshkr2/in-one-minute-git-moe | git, beginners, programming, oneminute | Git is free and open source software for distributed version control: tracking changes in any set of files, usually used for coordinating work among programmers collaboratively developing source code during software development.
Its goals include speed, data integrity, and support for distributed, non-linear workflows.
{% embed https://youtu.be/Sn8pHyf4_J0 %}
Git development began in April 2005, after many developers of the Linux kernel gave up access to BitKeeper, a proprietary source-control management (SCM) system that they had been using to maintain the project since 2002.
Stack Overflow has included version control in their annual developer survey
in 2015 (16,694 responses),
2017 (30,730 responses),
2018 (74,298 responses)
and 2022 (71,379 responses).
Git was the overwhelming favorite of responding developers in these surveys, reporting as high as 93.9% in 2022.
Official Website :- https://git-scm.com/
| rakeshkr2 |
1,220,504 | Application specific preferences on my Mac have gone 😱 | A few weeks ago I head a problem with my applications where whenever I changed a setting they were... | 0 | 2022-10-15T12:47:27 | https://dev.to/richardbray/application-specific-preferences-on-my-mac-have-gone-1iba | application, mac, tutorial, dropbox | A few weeks ago I head a problem with my applications where whenever I changed a setting they were not saving, or the settings had just reverted to their default. My VSCode, ZSH, mechanical keyboard settings had all gone.
After hours I managed to figure out the issue and I've created a video below to show how I did it.
{% embed https://www.youtube.com/watch?v=gavAOJDbbjY %} | richardbray |
1,220,706 | Deploy an App with Express + React on Heroku & Netlify | netlify deploy | 0 | 2022-10-15T18:32:57 | https://dev.to/samschanderl/deploy-an-app-with-express-react-on-heroku-netlify-8i | `netlify deploy` | samschanderl | |
1,221,422 | DORA metric monitoring for your team in just 15 minutes with Apache Dev Lake | DORA (DevOps Research and Assessment) metrics are an excellent way for engineering organisations to... | 0 | 2022-10-16T20:55:48 | https://www.darraghoriordan.com/2022/10/16/report-on-dora-metrics-apache-dev-lake/ | github, development, productivity | ---
title: DORA metric monitoring for your team in just 15 minutes with Apache Dev Lake
published: true
date: 2022-10-16 17:12:33 UTC
tags: #github #development #productivity
canonical_url: https://www.darraghoriordan.com/2022/10/16/report-on-dora-metrics-apache-dev-lake/
---
DORA (DevOps Research and Assessment) metrics are an excellent way for engineering organisations to measure and improve their performance.
Up until now, monitoring the DORA metrics across Github, Jira, Azure Devops etc required custom tooling or a tedious manual process.
With Apache Dev Lake you can get beautiful reporting for DORA metrics on your local machine in as little as 15 minutes (honestly!).
[](/static/8c01179a7caa6efd47c6ba2c3267ca15/4b538/headerJourney.png)
_From Google Sheets to Grafana_
<!-- end excerpt -->
## DORA Metrics
DORA metrics are 4 dimensions for improving your engineering team. The metrics came out of a report by Google in 2020. They’re designed so they balance velocity and stability.
- Deployment Frequency
- Lead time for changes
- Median Time to Restore Service
- Change Failure Rate
These metrics are explained in detail in books ([here](https://www.amazon.com.au/Accelerate-Software-Performing-Technology-Organizations/dp/1942788339)) and blogs ([here](https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance)) so I won’t go in to any detail on what they are here.
I have a note at the end of this article on updates to DORA since 2020 and the newer Microsoft SPACE framework.
## The old way of tracking DORA metrics
Most teams will have various support systems like Github, Azure DevOps, Jira etc.
Extracting the metrics required for DORA across so many developer tools is difficult to automate without custom software. The time cost is too much, especially for small teams.
When I first started tracking DORA I used a spreadsheet and did everything manually.
It wasn’t pretty and it was a lot of work but I was able to see a noticeable increase in deployed work when deployment frequency increased.
[](/static/ce4389ab9ddacdd6fd5afeabc820c0a2/e3f06/manualDora.jpg)
_Custom spreadsheet of DORA metrics_
## Tracking DORA metrics in 2022: Apache Dev Lake
Apache Dev Lake is a project from the Apache Foundation specifically for tracking engineering performance metrics.
The project is new and it is in the incubation stage at the Apache Foundation.
Dev Lake is a set of services in containers - a database, a data pipeline, a grafana instance with pre-built reports and a configuration web application.
The dev lake team provide helm charts and docker compose files for easy setup of the infrastructure.
The benefits of tracking your DORA metrics in Dev Lake are:
- It connects to most major platforms out of the box (Jira, Github, DevOps)
- Comes with pre built Grafana charts for DORA and many other metrics
- Free and you can easily run it locally to get started
- Your data or your client’s data never leaves your organisation
Having the data processed and stored locally is a huge benefit for many organisations. It means you don’t have to add an additional supplier to get started with DORA metrics.
Visit the [dev lake site](https://devlake.apache.org/) for more details.
## Setting up a local instance of Apache Dev Lake
You should have docker desktop installed before continuing.
1. Get the docker compose and .env files from the releases page - [https://github.com/apache/incubator-devlake/releases/latest](https://github.com/apache/incubator-devlake/releases/latest) and place them in a folder
2. Open a terminal in that folder and `mv .env.example .env`
3. `docker compose up`
4. That’s it! Wait for the 4 services to start
5. You should be able to access the configuration site at [https://localhost:4000](https://localhost:4000)
[](/static/d4793f39291bd42e3d916bb044ed2dc1/1d94f/blueprints.png)
_The Dev Lake homepage_
There are some sites already configured on the instance in the image above. Yours will be empty for now.
Now you can add any connections to your engineering tools like Jira or Github.
## Adding connections to common dev tools
Github is very popular so let’s use that to demonstrate setting up a tool connection.
1. Click on Data Connections > Github
2. Give the connection a name you’ll remember
3. The endpoint is `https://api.github.com/` unless you have a special enterprise account - then you’ll need to use your own endpoint
4. Get a personal access token from Github and paste it in the token field ([https://github.com/settings/tokens](https://github.com/settings/tokens))
The PAT permissions you need are:
- `repo:status`
- `repo_deployment`
- `public_repo`
- `repo:invite`
- `read:user`
- `read:org`
I set the github rate limit to 5000 requests per hour but you can leave that as default if you like.
[](/static/4aae45c7e2e23b79d2173cc331fd5674/1d94f/addGithubconnection.png)
_Adding a Github connection_
## Configuring projects in Dev Lake
Now that you have a connection to your dev tools you can configure projects. In Dev Lake a project is called a “Blueprint”.
I’ll add one of my open source projects ([https://github.com/darraghoriordan/eslint-plugin-nestjs-typed](https://github.com/darraghoriordan/eslint-plugin-nestjs-typed)) to show how it works.
1. Click on Blueprints > Add Blueprint in the main left-hand menu
2. Give it a name and select the Github connection you created earlier
[](/static/b06b0a7bd07946f804e0fe1cb143e29f/36405/addingBlueprintScreen1.png)
_Add blueprint screen - summary_
1. Click next and enter the name of the repo(s) associated with your project
[](/static/1c70ca6cd571d66801fe415f484307d2/9e9da/addingBlueprintScreen2.png)
_Add blueprint screen - repository_
1. Click next and on the summary screen click on the “add transformation” link. You have to tell Dev Lake how to identify deploys and incidents for your setup.
[](/static/6d73ee73b695c7a3efc04374bcdf1a93/5c4aa/AddingBlueprintScreen3.png)
_Add blueprint screen - optional transformation_
1. On the add transformation screen you have to configure the tag you use on a Github issue that identifies an incident and the Github actions `Job` that identifies a deploy.
[](/static/e16997929c85b3b07dc8315fec72d236/f349c/addingTransformation.png)
_Add blueprint screen - adding transformation_
For the deployment section make sure that you’re getting the Job name and not the workflow name.
To get the job name on Github, click into an old run of your workflow and you’ll see the job name on the left hand side.
[](/static/ebd095240afa06471df5bb60cd0a0036/f36fd/githubJob.png)
_Github actions settings for transformation_
1. Click on “save and run now” and you should be done configuring Dev Lake. Wait for the blueprint data collection run to complete.
You can open the Blueprints page anytime and click on the graph “squiggle” icon to open the blueprint overview for your project.
[](/static/34ac926bdceb095da93cd4050735a363/99e81/projectBlueprint.png)
_Eslint for NestJs Blueprint overview_
The status overview allows you to see the status of the data pipeline for your project.
## Configuring Sync Settings for Local
Because this is a local instance you can go to settings and change the sync frequency to “Manual”.
This isn’t required but makes sense for local instances.
Then you can use the blueprint status page and the “Run Now” button to manually get the latest data when you need to.
## Viewing the DORA metrics
Ok so now that you have all the data downloaded, filtered and transformed into the DORA metrics you can view them in Grafana.
Click on the “Dashboard” menu button to open Grafana.
Then click on the magnifying glass icon in the left-hand menu to open the search bar.
Search for “DORA” and you should see a dashboard called “DORA”.
[](/static/41afddff21de43306c633e79cbd2234d/669cd/doraDisplay.png)
_DORA dashboard on Grafana_
The image is the metrics for my small open source project. I update it once a month maybe. The users do report issues occasionally so I guess now I’ll have to fix them in a bit quicker!
You can filter to a specific Github Repo if you added more than one.
Along with DORA there are 10-20 other pre-built reports you can access. Here’s one for Github stats.
[](/static/34fdcf68ee788982943d6d3a9e395181/669cd/githubReporting.png)
_Github engineering report on Grafana_
## SaaS Platforms for DORA Metrics
It’s important to mention that there are some excellent platforms for tracking DORA and more metrics if you want more mature, managed applications with support.
### Multitudes
Multitudes tracks DORA but supplements engineering metrics with around well-being and collaboration.
More details on the [multitudes site](https://www.multitudes.co/our-product).
[](/static/8ed22e3ce7403d61fed2b41a7167a0ad/84bf8/multitudes.png)
_Multitudes marketing page_
### Linear B
LinearB tracks DORA metrics and helps you fix workflow issues.
More details on the [LinearB site](https://linearb.io/dora-metrics/).
[](/static/4921441c6aa4e2338591d96b91290115/6acbf/linearb.png)
_LinearB marketing page_
## Developments in Engineering and DevOps Metrics since DORA 2020
There have been developments since these metrics were first published in 2020 and it’s a rapidly changing, exciting space.
The DevOps report of 2022 changed the categorisation to “Low, Medium, High”, removing the “elite” name.
They also added a 5th dimension to DORA for reliability.
Microsoft released their SPACE metrics paper in 2021 and arguably they are much more human focused which is great.
It’s worth reading the microsoft docs for SPACE and the Future of Work Report - [https://www.microsoft.com/en-us/research/publication/the-space-of-developer-productivity-theres-more-to-it-than-you-think/](https://www.microsoft.com/en-us/research/publication/the-space-of-developer-productivity-theres-more-to-it-than-you-think/)
## Conclusion
It’s easier than ever to track your DORA metrics. You can use a local instance of Apache Dev Lake or a SaaS platform like Multitudes or LinearB.
If you’re interested in tracking DORA metrics in your organisation, I’d recommend starting with a local instance of Dev Lake. It’s free and you can get started in minutes.
Like anything, don’t over do it with these metrics. They’re just a tool to help you improve your engineering practices. They shouldn’t be used as a KPI. | darraghor |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.