
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,354,320 | The most efficient way to debug problems with PHPUnit mocks | PHPUnit can be overwhelming to those who are just learning the basics of programming and/or unit... | 0 | 2023-02-05T10:52:40 | https://dev.to/nikolastojilj12/the-most-efficient-way-to-debug-problems-with-phpunit-mocks-2fhj | php, tutorial, testing, phpunit | PHPUnit can be overwhelming to those who are just learning the basics of programming and/or unit testing in PHP. It is a powerful and robust tool which has been a cornerstone of unit testing in PHP world for many years now, which means it has a huge set of features covering almost any case you could encounter.
One of ... | nikolastojilj12 |
1,354,329 | 100 Days of Code: The Complete Python Pro Bootcamp for 2022 - Day 28 - Pomodoro GUI Application | Liquid syntax error: 'raw' tag was never closed | 0 | 2023-02-05T11:30:06 | https://dev.to/mikekameta/100-days-of-code-the-complete-python-pro-bootcamp-for-2022-day-28-pomodoro-gui-application-19og | Main.py
````python
from tkinter import *
import math
# ---------------------------- CONSTANTS ------------------------------- #
PINK = "#e2979c"
RED = "#e7305b"
GREEN = "#9bdeac"
YELLOW = "#f7f5dd"
FONT_NAME = "Courier"
WORK_MIN = 25
SHORT_BREAK_MIN = 5
LONG_BREAK_MIN = 20
reps = 0
timer = NONE
# --------------------... | mikekameta | |
1,354,380 | Practical Vim command workflow | There are many commands in Vim, which means that you can achieve a same goal with many approaches.... | 0 | 2023-02-05T11:44:53 | https://m4xshen.dev/posts/vim-command-workflow | vim, linux, programming, productivity | There are many commands in Vim, which means that you can achieve a same goal with many approaches. Therefore it is difficult for beginner to learn how to accomplish an editing task with less keystrokes. In this tutorial, I'll share my Vim command workflow and give you some guidelines about how to move/edit text in Vim ... | m4xshen |
1,354,440 | JavaScript double exclamation mark explained (with examples) | ✋ Update: This post was originally published on my blog decodingweb.dev, where you can read the... | 0 | 2023-02-05T14:01:01 | https://www.decodingweb.dev/javascript-double-exclamation-mark | javascript, webdev, beginners | > ✋ **Update:** This post was originally published on my blog [decodingweb.dev](https://www.decodingweb.dev), where you can read the [latest version](https://www.decodingweb.dev/javascript-double-exclamation-mark) for a 💯 user experience. _~reza_
## What are those double not operators in JavaScript?
You might have n... | lavary |
1,354,672 | MongoDB Aggregation Pipeline - $function Stage | An Overview A popular NoSQL database called MongoDB offers a scalable and adaptable option... | 0 | 2023-02-05T18:45:48 | https://dev.to/shubhamdutta2000/the-function-stage-in-mongodb-aggregation-pipeline-590d | webdev, javascript, mongodb, productivity | ### An Overview
A popular NoSQL database called MongoDB offers a scalable and adaptable option for storing and handling enormous amounts of data. The aggregation pipeline, which enables users to carry out complex data analysis and manipulation, is one of MongoDB's core features. The `$function` stage of the MongoDB ag... | shubhamdutta2000 |
1,354,738 | Introducing Escape the Wave. My Exciting New Game! | Last week, I officially released my first game, Falling Square, which marked a great milestone for... | 21,725 | 2023-02-09T14:00:00 | https://blog.emilienleroy.fr/introducing-escape-the-wave-my-exciting-new-game | programming, gamedev, opensource, showdev | Last week, I officially released my first game, [Falling Square](https://github.com/EmilienLeroy/FallingSquare/), which marked a great milestone for me. However, the serious work now begins. This week, I'm starting development on my second game, [Escape the Wave](https://github.com/EmilienLeroy/EscapeTheWave). It will ... | emilienleroy |
1,355,120 | Top 5 Featured DEV Tag(#algorithms) Posts from the Past Week | The 4 Essential Skills of the Software Developers There are 4 main skill groups where all... | 0 | 2023-02-06T06:23:42 | https://dev.to/c4r4x35/top-5-featured-dev-tagalgorithms-posts-from-the-past-week-4d6g | algorithms, c4r4x35 | ##The 4 Essential Skills of the Software Developers
There are 4 main skill groups where all programmers must have. Most of these skills are resistant in time and are not influenced by the development in specific technologies (that are changing...
{% link https://dev.to/noriookawa/the-4-essential-skills-of-the-software-... | c4r4x35 |
1,355,154 | Super useful a state management library "Recoil" | Have you ever used a state management library called Recoil? This is super useful and easy... | 0 | 2023-02-06T07:34:04 | https://dev.to/yuya0114/super-useful-a-state-management-library-recoil-3a9j | react, javascript, webdev, programming | ## Have you ever used a state management library called Recoil?
This is super useful and easy to understand.
This article explains the basics of Recoil.
Please click the Like button and Save button if you like this article.
## What you will learn in this article
- RecoilRoot
- Atom
- Selectors
## What is Recoi... | yuya0114 |
1,355,256 | Good React Practices To Adopt while building UI | React is one of the best frameworks we can use for the development of the front-end size of our app.... | 0 | 2023-02-06T09:39:56 | https://dev.to/jaykaranja/good-react-practices-to-adopt-while-building-ui-2536 | react, javascript, webdev | React is one of the best frameworks we can use for the development of the front-end size of our app. It is great at handling states, dealing with data and visualizing it, and responding to user input and actions seamlessly. This is good for the user experience, as they will interact with the app in a very efficient ma... | jaykaranja |
1,355,274 | Build an Instagram Web App with Supabase and Next.js 🚀 | TL;DR In this tutorial, you'll learn how to create an Instagram web app utilizing... | 0 | 2023-02-07T14:43:31 | https://livecycle.io/blogs/nextjs-supabase-instagram/ | javascript, webdev, nextjs, tutorial | ## TL;DR
In this tutorial, you'll learn how to create an Instagram web app utilizing Supabase.js and Next.js.
## Intro
You may be familiar with an app called Instagram 🤪.
Instagram has exploded in popularity in recent years and currently boasts about 2 billion monthly active users worldwide.
** 4d 3d 2d terjitu hari ini di Riano.org. Semoga prediksi dan forum kode syair bisa membantu anda untuk JP | syairsingapura | |
1,363,453 | Users and Groups in Linux — How to use chown and chgrp commands? | When it comes to large organization, the Users and Groups plays important role in every side of... | 20,967 | 2023-02-13T04:43:52 | https://www.gogosoon.com/blog/users-and-groups-in-linux-how-to-use-chown-and-chgrp-commands | linux, beginners, chown, users |
When it comes to large organization, the Users and Groups plays important role in every side of people. There will be different levels of users in an organization. In order to scale this, We need a strong understanding of users and groups.
To protect files and directories in Linux from various types of users we can u... | 5minslearn |
1,363,944 | THE GOLDEN RULES OF UI/UX DESIGN TO INCREASE USER ENGAGEMENTS | You must be familiar with Attention-deficit hyperactivity (ADH). Your short attention span causes it... | 0 | 2023-02-13T13:56:27 | https://dev.to/quokkalabs/the-golden-rules-of-uiux-design-to-increase-user-engagements-15f4 | ux, uiweekly, design | You must be familiar with Attention-deficit hyperactivity (ADH). Your short attention span causes it if you often feel restless, agitated, or fidgety when trying to focus on a task. The shrinking attention span phenomenon comes into action after this. Every individual is now overwhelmed & overloaded with information. V... | mayankranjan |
1,365,274 | Python OOP: Harnessing the Power of Classes and Objects | Python OOP, or Object-Oriented Programming, is a programming paradigm that emphasizes the use of... | 0 | 2023-02-14T14:14:51 | https://dev.to/ml_82/python-oop-harnessing-the-power-of-classes-and-objects-lce | programming, webdev, javascript, tutorial |

Python OOP, or Object-Oriented Programming, is a programming paradigm that emphasizes the use of objects to represent and interact with data and functionality. In Python, objects are created by defining classes, whi... | ml_82 |
1,365,277 | Porque usar o componente Image do NextJs e o conceito CLS e LCP | A tag IMG do HTML é uma velha conhecida, uma senhora da terceira idade, mas que negócio é esse de... | 0 | 2023-02-14T19:46:36 | https://dev.to/andpeicunha/pra-que-serve-a-tag-no-nextjs-e-o-conceito-cls-c3e | nextjs, react, html, tag | A tag IMG do HTML é uma velha conhecida, uma senhora da terceira idade, mas que negócio é esse de `<Image>` do NextJs?
Acredite meu camarada, se você trabalha com Front deve se preocupar com isso agora, seu SEO tem relação com essa tag.
---
#Pra que serve e porque usar?
> _Vamos entender porque a Vercel criou essa... | andpeicunha |
1,365,301 | Software buatan anak bangsa | Latar Belakang Kini teknologi sudah semakin maju dan juga penggunaan software semakin banyak, akan... | 0 | 2023-02-14T14:21:27 | https://dev.to/verlinof/software-buatan-anak-bangsa-3l93 | programming, magangsrdkomatik2023 |

**Latar Belakang**
Kini teknologi sudah semakin maju dan juga penggunaan software semakin banyak, akan tetapi kita sering menggunakan software-software buatan negara lain dan juga pendiri software buatan indonesia p... | verlinof |
1,365,393 | Whatsapp Bot Reminder : whatsapp bot yang terintegrasi dengan google calendar. | Fitur baru whatsapp yang memungkinkan kita untuk memberi pesan untuk diri sendiri banyak dimanfaatkan... | 0 | 2023-02-15T05:29:38 | https://dev.to/heavenaulianisa/whatsapp-bot-reminder-whatsapp-bot-yang-terintegrasi-dengan-google-calendar-ckd | magangsrdkomatik2023, mobile, idea, programming | Fitur baru whatsapp yang memungkinkan kita untuk memberi pesan untuk diri sendiri banyak dimanfaatkan untuk menuliskan to do list atau daftar kegiatan yang ingin dilakukan, menuliskan tenggat dari suatu tugas, hingga menuliskan tanggal ulang tahun teman. Pemilihan whatsapp disini karena aplikasi ini senantiasa dibuka s... | heavenaulianisa |
1,365,678 | Interop 2023, Chrome 110, Lighthouse 10, Edge 110, Polypane 13, Safari TP 163, and more | Front End News #090 | NOTE: This is issue #090 of my newsletter, which went live on Monday, February 13. If you find this... | 9,151 | 2023-02-14T18:38:31 | https://frontendnexus.com/news/090/ | newsletter, frontendnews, news | > **NOTE:** This is issue #090 of my newsletter, which went live on Monday, February 13. If you find this information useful and interesting and you want to receive future issues as they are published, ahead of everyone else, I invite you to join the subscriber list at [frontendnexus.com](https://frontendnexus.com/).
... | adriansandu |
1,365,736 | Networking on AWS - Part 3 | In the previous parts, we discussed the basics of networking on AWS and how to set up and configure a... | 0 | 2023-02-14T19:50:50 | https://dev.to/vanhoangkha_2k/networking-on-aws-part-3-1a4b | In the previous parts, we discussed the basics of networking on AWS and how to set up and configure a VPC on AWS. In this part, we will take a closer look at advanced networking concepts on AWS.
VPC Peering
VPC peering allows you to connect two VPCs, allowing instances in one VPC to communicate with instances in the ... | vanhoangkha_2k | |
1,365,743 | SceneDelegate | In iOS, the SceneDelegate is a class that is responsible for managing the scenes in your app. A scene... | 0 | 2023-02-14T20:03:19 | https://dev.to/arkilis/scenedelegate-6h4 | ios, swift, swiftui | In iOS, the SceneDelegate is a class that is responsible for managing the scenes in your app. A scene is a discrete unit of your app's user interface, such as a window or tab. The SceneDelegate class provides methods that are called at various points in the lifecycle of a scene, such as when a scene is about to be disp... | arkilis |
1,365,748 | ChatGPT $18 trial credit | ChatGPT offers $18 free trial credit, which is about to be exhausted soon. !ask Write me a HTML page... | 0 | 2023-02-14T20:13:04 | https://dev.to/doctorlai/chatgpt-18-trial-credit-23dk | chatgpt, blog | [ChatGPT](https://helloacm.com/how-chatgpt-impacts-ugc-user-generate-content/) offers $18 free trial credit, which is about to be exhausted soon.
!ask Write me a HTML page that shows a heart in animation using Javascript to my wife as a Valentine's gift. Could you make sure it can be viewed nicely on the mobile?
```h... | doctorlai |
1,365,807 | Hola mundo! | Soy nuevo por acá y solo quiero hacer comunidad y amigos. | 0 | 2023-02-14T21:06:50 | https://dev.to/jussef/hola-mundo-5482 | Soy nuevo por acá y solo quiero hacer comunidad y amigos. | jussef | |
1,365,882 | Day 1.1, Here I Come! | Here's what I learned today: Block off time each week that I can dedicate myself to connecting with... | 0 | 2023-02-14T23:10:12 | https://dev.to/yjj/day-11-here-i-come-4a7d | Here's what I learned today:
- Block off time each week that I can dedicate myself to connecting with the developer community. Do 1-2 activities during the time.
- Google/search in SNS a topic from the course. Learn more about it.
- Read a blog post.
- Document my learning
| yjj | |
1,366,153 | My First Blog | I'm absolutely excited to be joining in this community.Looking forward to learning a lot of things.. | 0 | 2023-02-15T05:14:34 | https://dev.to/samaresh96/my-first-blog-29pi | I'm absolutely excited to be joining in this community.Looking forward to learning a lot of things.. | samaresh96 | |
1,366,250 | How To Install Ubuntu Server on Virtual Machine | cout << "Calzy Akmal - 2101569"; First, open up the link down below and select the button to... | 0 | 2023-02-15T07:14:28 | https://dev.to/calzkmal/how-to-install-ubuntu-server-on-virtual-machine-347o | `cout << "Calzy Akmal - 2101569";`
First, open up the link down below and select the button to download the Ubuntu Server.iso on your computer.
If you have finished downloading, I assume you have... | calzkmal | |
1,366,251 | HTML accessibility: designing web pages that are accessible to people with disabilities. | In the current digital era, it's critical to make sure that everyone, including those with... | 0 | 2023-02-15T06:57:13 | https://dev.to/radnicks44/html-accessibility-designing-web-pages-that-are-accessible-to-people-with-disabilities-2nj8 | webdev, beginners, devops, typescript |
In the current digital era, it's critical to make sure that everyone, including those with disabilities, has access to internet content. We know the process of creating web pages that are accessible to those with impairments using HTML as HTML accessibility. This article will discuss the significance of HTML accessib... | radnicks44 |
1,366,268 | Merge multiple kubeconfig files | We use kubeconfig files to organize information about clusters, users, namespaces, and authentication... | 0 | 2023-02-15T07:24:04 | https://dev.to/akyriako/merge-multiple-kubeconfig-files-20gb | kubernetes, kubectx, kubectl, kubeconfig | We use `kubeconfig` files to organize information about clusters, users, namespaces, and authentication mechanisms. `kubectl` command-line tool itself, uses `kubeconfig` files to source the information it needs in order to connect and communicate with the API server of a cluster.
By default, `kubectl` requires a file ... | akyriako |
1,391,021 | 30-Day Plan to build a Side Project -For Beginners | Devs, It's the first Monday of the month 🗓️ If you start today, in the next 4 weeks, you can have a... | 0 | 2023-03-06T21:19:47 | https://dev.to/zubairanwarkhan/30-day-plan-to-build-a-side-project-for-beginners-48o4 | ---
title: 30-Day Plan to build a Side Project -For Beginners
published: True
description:
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-06 21:13 +0000
---
Devs, It's the first Monday of the month 🗓️
If you start today, in the next 4 weeks, yo... | zubairanwarkhan | |
1,366,324 | Instalasi Ubuntu Server di Virtual Box Manager | Untuk tugas mata kuliah sistem operasi Unduh file ISO Ubuntu Server dari situs web resmi... | 0 | 2023-02-15T09:12:48 | https://dev.to/talim/instalasi-ubuntu-server-di-virtual-box-manager-1fbi | linux, ubuntu, devops, server | ## Untuk tugas mata kuliah sistem operasi
1. Unduh file ISO Ubuntu Server dari situs web resmi [Ubuntu](https://ubuntu.com/download/server)
2. Unduh aplikasi [Virtual Box Manager](https://www.virtualbox.org/wiki/Dow... | talim |
1,366,339 | Introducing LT Debug: A faster, efficient, and simple debugging Chrome extension | We leverage Debugging tools, otherwise known as debuggers, to identify if there is any coding error... | 0 | 2023-02-15T08:53:03 | https://www.lambdatest.com/blog/introducing-lt-debug/ | debugging, testing, chrome, extensions |
We leverage Debugging tools, otherwise known as debuggers, to identify if there is any coding error present at different development stages and [Software Testing Life Cycle (STLC)](https://www.lambdatest.com/blog/software-testing-life-cycle/?utm_source=devto&utm_medium=organic&utm_campaign=jfeb_15kj&utm_term=kj&utm_co... | aamritaangappa |
1,366,427 | Creating a Custom Solana Connect Wallet UI with React and Chakra UI | If you have worked with the Solana Wallet Adapter before, you will know that it is very easy to set... | 0 | 2023-02-15T09:44:00 | https://blog.anishde.dev/creating-a-custom-solana-connect-wallet-ui-with-react-and-chakra-ui | web3, react | If you have worked with the [Solana Wallet Adapter](https://github.com/solana-labs/wallet-adapter) before, you will know that it is very easy to set up a Connect Wallet button with a decent modal.
However, customization is pretty limited. We can only add some custom CSS hence changing the styles but that is about it. ... | anishde12020 |
1,386,069 | Coupa Testing: All You Need to Know | Real-time operation monitoring is a challenge for supply chain organizations, and the resulting... | 0 | 2023-03-03T05:27:37 | https://www.reverbtimemag.com/blogs_on/coupa-testing-all-you-need-to-know | coupa, testing | 
Real-time operation monitoring is a challenge for supply chain organizations, and the resulting unsustainable expenses are a common result. To boost the effectiveness of the supply chain, many have put in place a sol... | rohitbhandari102 |
1,386,074 | LLaMA - Meta's new AI can run on a PC | Meta releases LLaMA, a state-of-the-art foundational large single-gpu language model | 0 | 2023-03-03T05:51:49 | https://dev.to/codingmoney/llama-metas-new-ai-can-run-on-a-pc-18ob | ai, machinelearning, nlp, chatgpt | {% embed https://www.youtube.com/watch?v=atMU1qo2Pok %}
Meta releases LLaMA, a state-of-the-art foundational large single-gpu language model | codingmoney |
1,386,199 | Get the host address for WSL2 | If you need to do something like accessing the services on the WSL2 host, you need to get the address by yourself. | 0 | 2023-03-03T08:54:27 | https://dev.to/socrateslee/get-the-host-address-for-wsl2-2b2 | ---
title: Get the host address for WSL2
published: true
description: If you need to do something like accessing the services on the WSL2 host, you need to get the address by yourself.
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-01 09:43 +0000
... | socrateslee | |
1,386,345 | Improvements to Planet Perl and Perlanet | This is a story of one of those nice incidents where something starts off simple, then spirals out of... | 0 | 2023-03-03T10:24:30 | https://perlhacks.com/2023/03/improvements-to-planet-perl-and-perlanet/ | programming, docker, perlanet, planetperl | ---
title: Improvements to Planet Perl and Perlanet
published: true
date: 2023-03-03 10:16:30 UTC
tags: Programming,docker,perlanet,planetperl
canonical_url: https://perlhacks.com/2023/03/improvements-to-planet-perl-and-perlanet/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/euw4rpgg4ws6jfcm4iyo... | davorg |
1,386,360 | How to Build a Fully Responsive Sign Up Form Using TailwindCSS | A community is a social unit with commonality such as place, norms, religion, values, customs, or... | 0 | 2023-03-04T07:30:00 | https://medium.com/@mbianoubradon/how-to-build-a-fully-responsive-sign-up-form-using-tailwindcss-8500e1306c8c | webdev, html, tailwindcss |
](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/kf49i1d0zugqcifirbg5.png)
A community is a social unit with commonality such as place, norms, religion, values, customs, or identity. There are many different type of communities, ranging from rel... | mbianoubradon |
1,386,368 | How To Hash Password with PostgreSQL Function in Nodejs | Introduction Storing user passwords in plain text is a major security vulnerability. In... | 0 | 2023-03-03T11:12:09 | https://dev.to/ndohjapan/how-to-hash-password-with-postgresql-function-in-nodejs-3571 | postgres, node, express, database | ## Introduction
Storing user passwords in plain text is a major security vulnerability. In order to protect user data, it is important to hash passwords before storing them in a database. In this tutorial, we will be discussing how to hash passwords with PostgreSQL in a Node.js application by creating a PostgreSQL fun... | ndohjapan |
1,386,463 | 10 Best Continuous Integration Tools In 2023 | Technology is growing exponentially and to be in the game, organisations have no choice but to be... | 0 | 2023-03-03T12:30:39 | https://dev.to/pcloudy_ssts/10-best-continuous-integration-tools-in-2023-2j9f | Technology is growing exponentially and to be in the game, organisations have no choice but to be technologically enabled. Talking about ‘technology’ basically means creating solutions that are ‘faster, ‘convenient’ and ‘qualitative’. To keep up with the highly demanding technological dynamics, not only human resources... | pcloudy_ssts | |
1,386,488 | Ansible : Deploying a Node.js App on EC2 Using Ansible | Deploying a Node.js App on EC2 Using Ansible Ansible is a popular open-source tool used... | 0 | 2023-03-03T13:14:40 | https://dev.to/arunbingari/ansible-deploying-a-nodejs-app-on-ec2-using-ansible-2o97 | devops, ansible, node, aws | ## Deploying a Node.js App on EC2 Using Ansible
Ansible is a popular open-source tool used for automation, configuration management, and orchestration of IT infrastructure. It is widely used by system administrators, DevOps engineers, and developers to simplify the deployment process of various applications on differe... | arunbingari |
1,386,685 | Mastering CSS Border Style: A Comprehensive Guide | CSS Borders refers to the line outside the padding and inside the margin of the CSS Box Model. This... | 0 | 2023-03-03T15:24:45 | https://www.lambdatest.com/blog/css-borders/ | css, webdev, beginners |
CSS Borders refers to the line outside the **padding** and inside the **margin** of the CSS Box Model. This line wraps around the padding and content in every HTML Element. That is both semantic and non-semantic elements.
Borderlines don’t have to be a solid straight line. We can apply different styles to it to cha... | alexanie |
1,387,533 | AWS Cloud Quest: Decoupling Applications Study Note | This is the DIY challenge of the Decoupling Applications in AWS Cloud Quest. DIY... | 21,167 | 2023-03-03T23:38:38 | https://dev.to/arc/aws-cloud-quest-decoupling-applications-23mo | aws | This is the DIY challenge of the Decoupling Applications in AWS Cloud Quest.
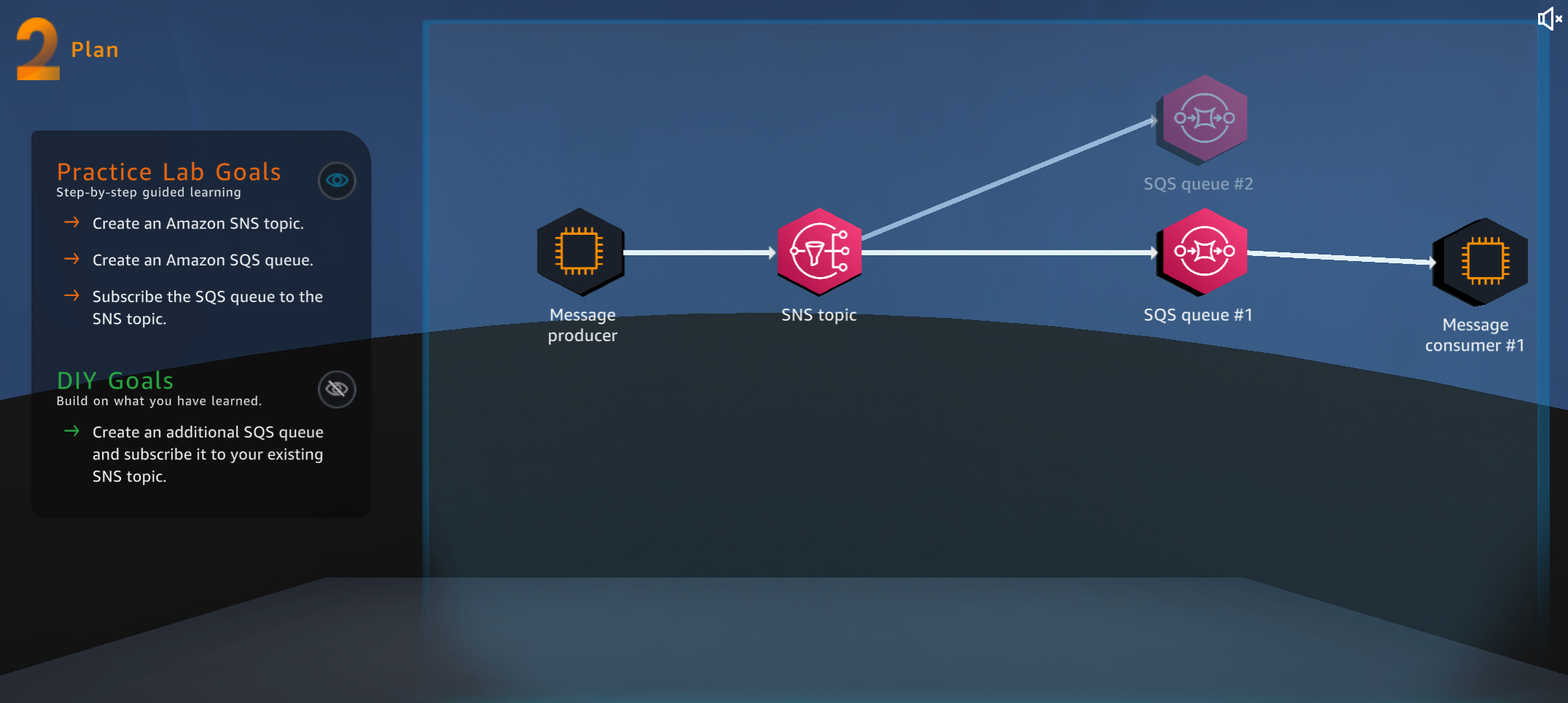
### DIY Steps:
1. Repeat step 6-15 to create another SQS queue and subscribe
| arc |
1,387,684 | 9 Reasons you need Continuous Monitoring in your company | Continuous monitoring is a step towards the end of the DevOps process. It informs all relevant teams... | 0 | 2023-03-06T02:31:00 | https://dev.to/pragyanatvade/9-reasons-you-need-continuous-monitoring-in-your-company-2170 | devops, continuousmonitoring, devjournal, programming | Continuous monitoring is a step towards the end of the DevOps process. It informs all relevant teams about the errors encountered during the production deployment.
## 9 Reasons you need continuous monitoring in your company
1. It detects any network or server problems.
2. It determines the root cause of any issues.... | pragyanatvade |
1,387,695 | Python Programming: Essential Tips for Beginners, Intermediates, and Experts - Part 1 | This is going to be my first post in Dev.to In this post we are basically going to cover 15 Python... | 0 | 2023-03-04T06:20:54 | https://dev.to/debakarroy/python-programming-essential-tips-for-beginners-intermediates-and-experts-part-1-1kc7 | python, beginners, tips | This is going to be my first post in Dev.to
In this post we are basically going to cover 15 Python tips. 5 beginner, 5 intermediate and 5 advanced. You can try out the code present in this post [**here**](https://replit.com/@DebakarRoy/Python-Tips-Part-1#main.py).
---
### 👶 5 Beginner Python Tips for Efficient Codi... | debakarroy |
1,387,858 | [Flutter] Solved Android clashing when native back button pressed. | You can solve by 👇 Future<bool> _onWillPop() async { final isFirstRouteInCurre ntTab =
!await _navigatorKeys[_currentTab].currentState.maybePop();
if (isFirstRouteInCurrentTab) {... | kaedeee |
1,387,998 | Database Replication | The term database replication means sharing the data to make sure it stays consistent between... | 20,359 | 2023-03-04T11:48:15 | https://pragyasapkota.medium.com/database-replication-e13299b3346d | distributedsystems, architecture, systems, beginners | The term database replication means sharing the data to make sure it stays consistent between redundant sources like multiple databases. This helps improve reliability, fault tolerance, and accessibility.
There are two kinds of replication for the database. Let’s look at them individually.
## Master-Slave Replication... | pragyasapkota |
1,388,023 | Check file size in Ubuntu | Introduction Linux is one of the most popular operating systems in the world. It is... | 0 | 2023-03-04T13:02:19 | https://dev.to/hemanlinux/check-file-size-in-ubuntu-51pj | ubuntu |
# Introduction
Linux is one of the most popular operating systems in the world. It is Unix-like, and it is also open-source. Quite a big percentage of developers use Linux because it can be customized in so many ways.
What's cool about Linux is its command line. Every 'hackers' paradise. There are a ton of commands.... | hemanlinux |
1,388,170 | A Beginner's Guide to Curl: Part 2 - Options | If you want to teach yourself how to use curl, the best resource is the manual. Type the following... | 22,101 | 2023-03-04T16:00:31 | https://dev.to/jvon1904/a-beginners-guide-to-curl-part-2-2dko | zsh, bash, http | If you want to teach yourself how to use curl, the best resource is the manual.
Type the following command in your terminal.
```bash
$ man curl
```
The `man` command is used to read the manual for other command line utilities (like curl). To exit the manual, just type `q`.
You should see a brief synopsis of what c... | jvon1904 |
1,388,222 | Beginner's Guide to rtx (mise) | Learn how to install and use node and python for local development | 0 | 2023-03-04T19:37:48 | https://dev.to/jdxcode/beginners-guide-to-rtx-ac4 | python, node, asdf, rtx | ---
title: Beginner's Guide to rtx (mise)
published: true
description: Learn how to install and use node and python for local development
tags: python,node,asdf,rtx
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-04 17:07 +0000
---
_NOTE: rtx has been re... | jdxcode |
1,388,480 | What Does Passwordless Actually Mean? | Passwords have been around for a long time, and while they are easy to understand, they do come with... | 22,058 | 2023-03-07T15:40:00 | https://dev.to/propelauth/what-does-passwordless-actually-mean-cd4 | webdev, beginners, security, cybersecurity | Passwords have been around for a long time, and while they are easy to understand, they do come with some drawbacks. They are essential for keeping our online accounts secure, but they can also be a hassle to remember and manage. Luckily, there’s a way to log in that eliminates the need for passwords altogether: passwo... | propelauthblog |
1,388,525 | Planejamento[0] <04:05>/23 | Vamos Começar Definindo que tecnologias vou estudar Preciso estudar Python, mais... | 0 | 2023-03-05T01:21:23 | https://dev.to/devmedeiros/planejamento0-23-29m7 | study, programming, organization, planning | ## Vamos Começar Definindo que tecnologias vou estudar
- Preciso estudar Python, mais especificamente o SKLearn, numpy e outras bibliotecas para utilizar e implementar no trabalho, assim como AWS Cloud e estudar um pouco sobre a área DevOps. {A+}
- Também preciso ver C# e .NET, há tutoriais excelentes da Microsoft sob... | devmedeiros |
1,388,526 | Http Client API in Java: The basics | Overview The new HttpClient API was introduced in Java 11. It is a replacement for the old... | 22,450 | 2023-03-05T12:18:13 | https://dev.to/noelopez/http-client-api-in-java-26e | java, http, beginners | ## Overview
The new HttpClient API was introduced in Java 11. It is a replacement for the old HttpURLConnection API which was not suitable for HTTP protocol. This new API uses builder pattern and fluent API to create the required objects to communicate over the Network. It also provides the below features:
1. Support... | noelopez |
1,388,597 | Process Scheduling in Linux | cron is a process scheduler for Linux. The crontab is a list of commands that you want to run on a... | 0 | 2023-03-05T04:12:03 | https://dev.to/waji97/process-scheduling-in-linux-262k | linux, bash, beginners | > **cron** is a process scheduler for Linux. The **`crontab`** is a list of commands that you want to run on a regular schedule, and also the name of the command used to manage that list.
>
<aside>
👉 `cron` is a time-based job scheduler in Unix-like operating systems. Users can schedule jobs (commands or scripts) to... | waji97 |
1,388,645 | Dependency Injection and Different ways to inject it using .NET Core API | In this blog, we are going to discuss dependency injection and its usage and benefits. Also, discuss... | 0 | 2023-03-05T05:15:45 | https://dev.to/jaydeep007/dependency-injection-and-different-ways-to-inject-it-using-net-core-api-5570 | csharp, dotnet, dotnetcore, asp | In this blog, we are going to discuss dependency injection and its usage and benefits. Also, discuss different ways to implement dependency injection.
## Prerequisites:
Basic understanding of C# Programming Language.
Understanding of Object-Oriented Programming.
Basic Understanding of .NET Core.
## The purpose behin... | jaydeep007 |
1,388,769 | React - Preventing Event Propagation from Parent Elements, Event Bubbling, Capturing, and Propagation | This topic is not directly related to React, but understanding Event Bubbling and Capturing in HTML... | 0 | 2023-03-05T08:37:15 | https://dev.to/nakzyu/react-preventing-event-propagation-from-parent-elements-event-bubbling-capturing-and-propagation-4npp | react, javascript, beginners, webdev | This topic is not directly related to React, but understanding Event Bubbling and Capturing in HTML and JS can be applied to React as well.
Suppose there is a component with a div tag as the parent and a button tag as the child rendered in the DOM, as shown below:
```jsx
const Example = () => (
<div
onClick={(e... | nakzyu |
1,388,836 | Vanilla JS for selecting a local text file and reading its content | Recently I am working a small side project that aims to build a mechanical 4-keys macropad with the... | 0 | 2023-03-05T09:28:20 | https://dev.to/tobychui/vanilla-js-for-selecting-a-local-text-file-and-reading-its-content-31oh | javascript, webdev |
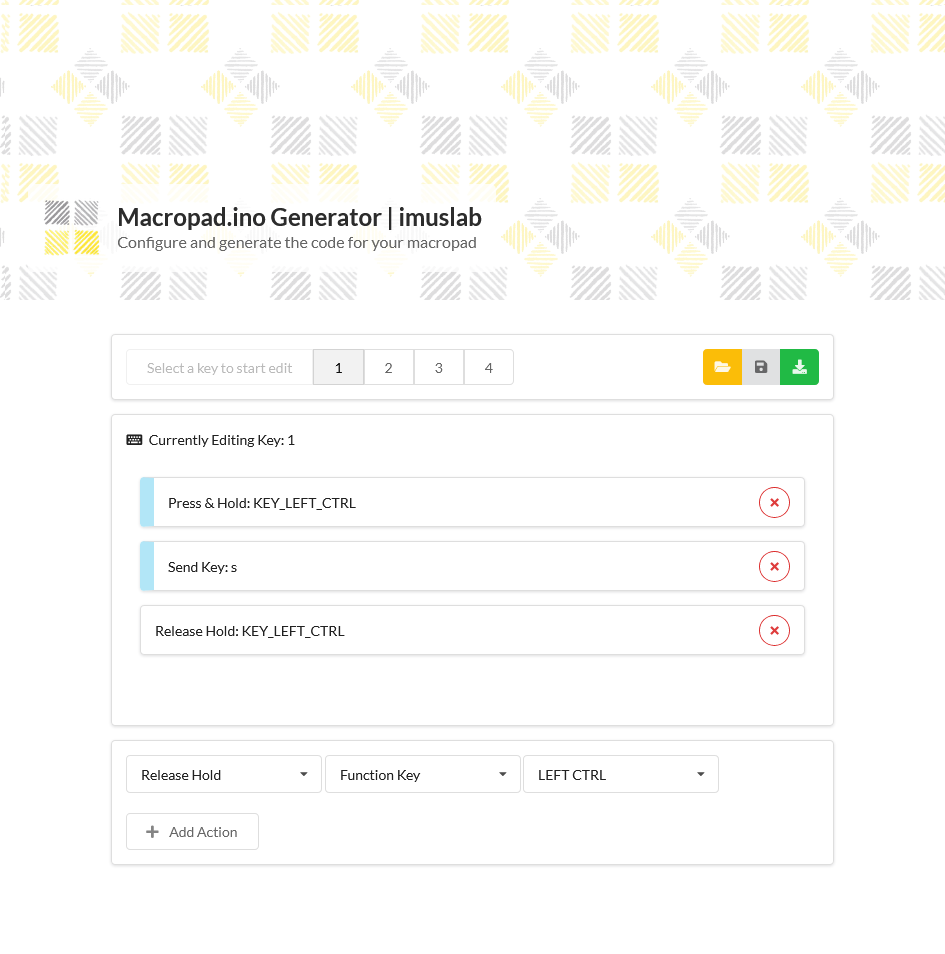
Recently I am working a small side project that aims to build a mechanical 4-keys macropad with the lowest cost possible. To make it more user friendly, I need to develop a website that let user load their previou... | tobychui |
1,388,902 | Some thoughts on Rust and Elm | Last week, my friend Joe asked me what's the best way to learn a programming language. I replied:... | 0 | 2023-03-05T12:00:23 | https://tonghe.xyz/2023/q1/rust-elm/ | Last week, my friend Joe asked me what's the best way to learn a programming language.
I replied: Go through the basics as quickly as possible. Then begin building things with it. This is how I learn Golang.
I had been curious about Rust for a while. And a coworker talked about how Rust was his favorite language wi... | t0nghe | |
1,388,916 | 5 best practices for AWS Lambda function design standards | Here are a few best practices to incorporate into your Lambda function design standards. 1.... | 0 | 2023-05-21T08:00:44 | https://dev.to/harithzainudin/5-best-practices-for-aws-lambda-function-design-standards-1564 | javascript, aws, lambda | Here are a few best practices to incorporate into your Lambda function design standards.
## 1. Store and reference dependencies locally
If your code retrieves any externalized configuration or dependencies, make sure they are stored and referenced locally after initial execution. For example, if your function retrieve... | harithzainudin |
1,388,937 | Stack Creation through Step Function Workflow Execution | “ I have to create a stack automatically so I got the way to do it using step function workflow... | 0 | 2023-03-05T12:37:26 | https://dev.to/aws-builders/stack-creation-through-step-function-workflow-execution-3p7h | awsstepfunction, s3, cloudformation, iam | “ I have to create a stack automatically so I got the way to do it using step function workflow execution. It's very easy to set up using api parameters and cost will be based on the services as s3 and step function.”
AWS Step Functions is a serverless orchestration service that lets you combine AWS Lambda functions a... | bhatnagargargee |
1,389,015 | CLI Genie: Revolutionizing Command Line Workflow with Native Language Input and OpenAI's GPT-3 API | project - https://github.com/JM-Lab/cli-genie CLI Genie CLI Genie is a tool that assists... | 0 | 2023-03-05T14:46:21 | https://dev.to/jmlab/how-cli-genie-uses-openais-gpt-3-api-to-help-users-write-cli-commands-in-their-native-language-4fib | gpt3, cli, chatgpt, openai | project - https://github.com/JM-Lab/cli-genie
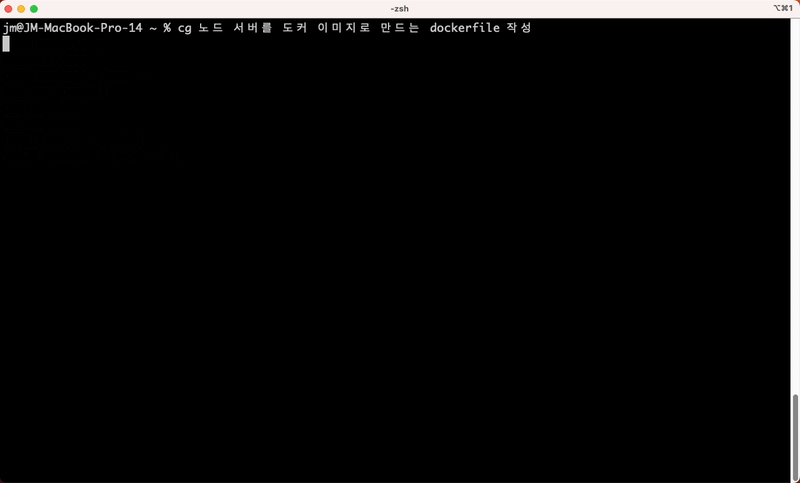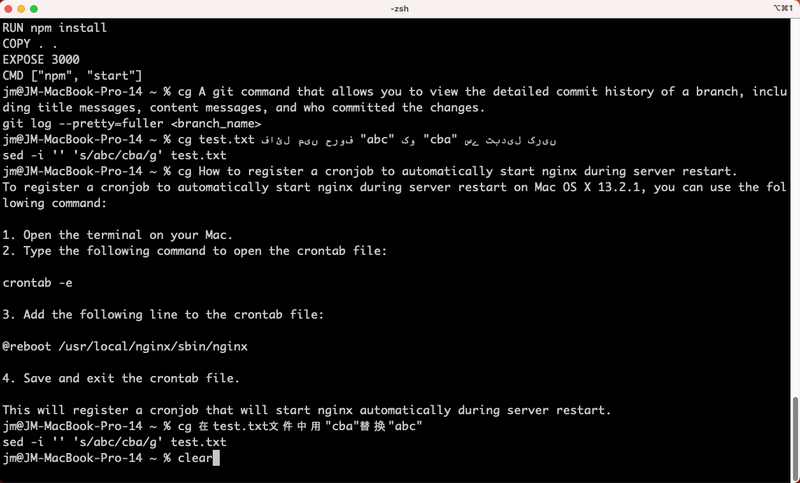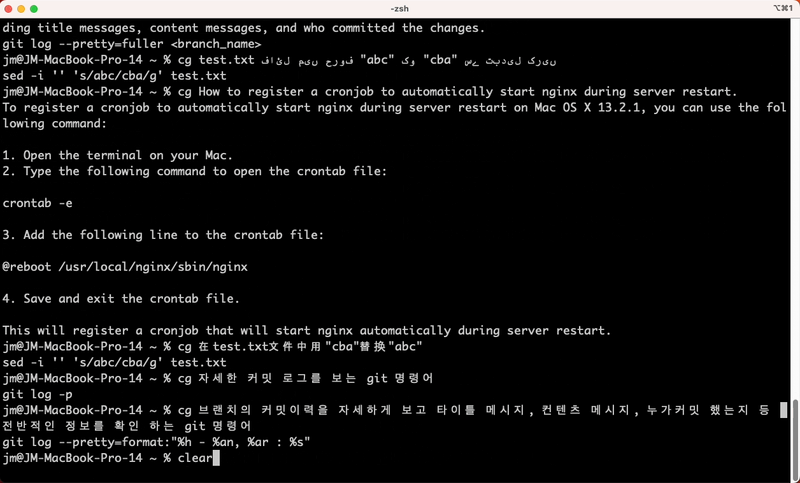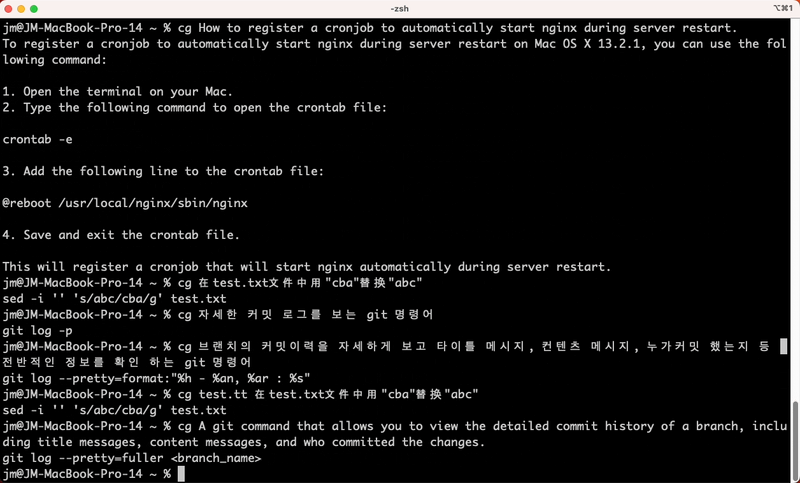
# CLI Genie
CLI Genie is a tool that assists users in writing CLI commands using their native language through OpenAI's GPT-3 API.
To put it simply, CLI Genie helps users who are not comf... | jmlab |
1,389,022 | python: unit test with mock functions from different modules | I recently started learning python 3 and unit test with pytest and unittest. As I struggle to figure... | 0 | 2023-03-05T15:14:14 | https://dev.to/kenakamu/python-unit-test-with-mock-functions-from-different-modules-cla | python, testing, mock | I recently started learning python 3 and unit test with ``pytest`` and ``unittest``.
As I struggle to figure out how to mock in several situations, I am taking note here so that anyone has same issue maybe find this useful someday.
## Structures and code
Before writing tests, this is my folder and files structures.
... | kenakamu |
1,389,143 | Mettre en place l'authentification sur Nginx | Quand on utilise Nginx, il se peut que l'on veut restreindre l'accès à certaines URL ou chemins. Pour... | 0 | 2023-03-13T14:50:00 | https://dev.to/mxglt/mettre-en-place-lauthentification-sur-nginx-1cjj | sre, devops, webdev | Quand on utilise Nginx, il se peut que l'on veut restreindre l'accès à certaines URL ou chemins. Pour cela, on peut mettre en place une authentification, et c'est ce que l'on va voir aujourd'hui.
---
## Fichier htpasswd
Afin de permettre aux utilisateurs de se connecter, Nginx doit avoir le fichier `htpasswd` qui va ... | mxglt |
1,389,157 | Symfony Station Communiqué — 03 March 2023. A look at Symfony, Drupal, PHP, Cybersecurity, and Fediverse news! | This communiqué originally appeared on Symfony Station, your source for cutting-edge Symfony, PHP,... | 0 | 2023-03-05T18:17:20 | https://www.symfonystation.com/Symfony-Station-Communique-03-March-2023 | symfony, drupal, php, cybersecurity | This communiqué [originally appeared on Symfony Station](https://www.symfonystation.com/Symfony-Station-Communique-03-March-2023), your source for cutting-edge Symfony, PHP, and Cybersecurity news.
Welcome to this week's Symfony Station Communiqué. It's your review of the essential news in the Symfony and PHP developm... | reubenwalker64 |
1,389,248 | CheatGPT - The Ultimate Cheat Engine Powered by OpenAI | Are you tired of studying for hours and still not being able to ace your tests? Look no further,... | 0 | 2023-03-05T19:59:51 | https://dev.to/epavanello/cheatgpt-the-ultimate-cheat-engine-powered-by-openai-1l85 | chatgpt, ai, svelte, saas | Are you tired of studying for hours and still not being able to ace your tests? Look no further, because **CheatGPT** is here to save the day!
**CheatGPT** is a SaaS project that uses the power of AI to help you cheat your way to success. Simply submit your question, whether it's in text or image form, and CheatGPT wi... | epavanello |
1,389,577 | NodeList vs Array | Cuando usamos una misma clase para múltiples elementos de HTML, podemos acceder a todos estos nodos... | 0 | 2023-03-06T04:35:47 | https://dev.to/cesar_ramez/nodelist-vs-array-87 | javascript, webdev, programming, frontend | Cuando usamos una misma clase para múltiples elementos de HTML, podemos acceder a todos estos nodos mediante la propiedad `document.querySelectorAll('.class-name')`. Esto nos mostrará un tipo de dato llamado ***NodeList*** el cual, a su vez, pese a mostrar todos los elementos que coinciden con la clase enviado a `query... | cesar_ramez |
1,389,632 | Difference between git rebase and git pull | git pull and git rebase are both Git commands that are used to integrate changes from one branch into... | 0 | 2023-03-06T05:43:06 | https://dev.to/atultrp/difference-between-git-rebase-and-git-pull-f40 | git, pull, programming, beginners | `git pull` and `git rebase` are both Git commands that are used to integrate changes from one branch into another. However, they work differently and have different effects on your Git repository's history.
`git pull` is used to update your local branch with changes from a remote branch. It combines the git fetch comm... | atultrp |
1,389,771 | An alternative to docker for php development? | Hi everyone! I start a opensource project, created for PHP and Web engineers using MacOS systems for... | 0 | 2023-03-06T08:49:00 | https://dev.to/xpf0000/an-alternative-to-docker-for-php-development-3g48 | webdev, opensource, docker, php | Hi everyone!
I start a opensource project, created for PHP and Web engineers using MacOS systems for development, to provide a more simple and useful tool to manage the local server environment.
For myself, I now use this tool for php development, as a replacement for mamp pro
I'm not sure if this tool is useful for ot... | xpf0000 |
1,389,782 | Minesweeper | I created my first full game in python and it's minesweeper! This project was assigned by... | 0 | 2023-03-06T09:13:28 | https://dev.to/jehrl/minesweeper-397b | beginners, python | I created my first full game in python and it's minesweeper!
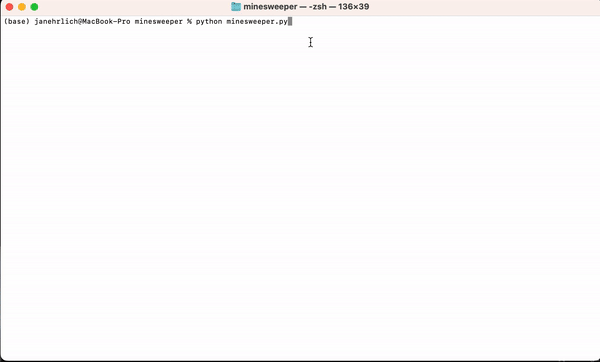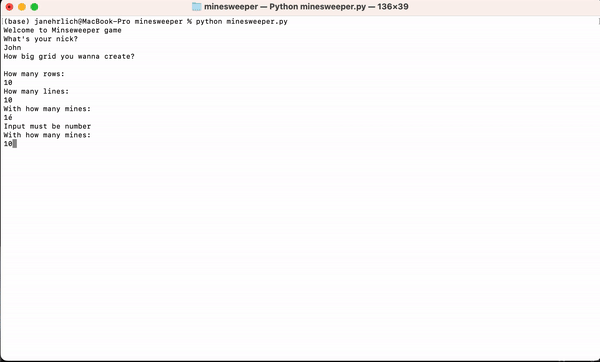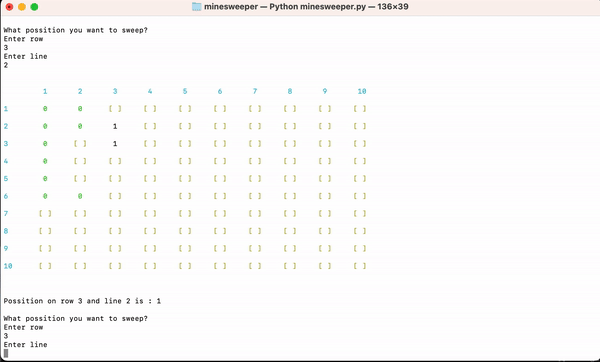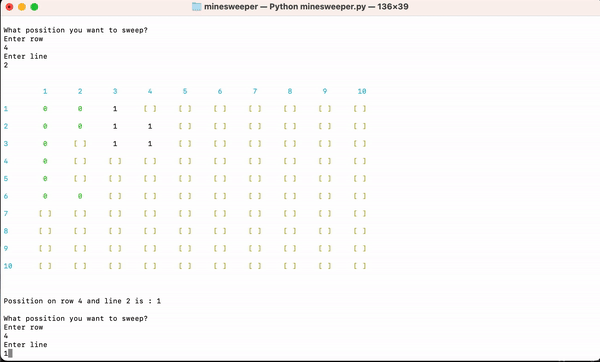
This project was assigned by Codecadamy in my Learn to Python course as final project.
I was creating it only with skills learn in course.
It takes pla... | jehrl |
1,389,829 | Constraints | Constraint clauses specify constraints that new or updated rows must satisfy for an INSERT or UPDATE... | 0 | 2023-03-06T09:57:58 | https://dev.to/llxq2023/constraints-1ik | opengauss | Constraint clauses specify constraints that new or updated rows must satisfy for an INSERT or UPDATE operation to succeed. If there is any data behavior that violates the constraints, the behavior is terminated by the constraints.
Constraints can be specified when a table is created (by executing the CREATE TABLE stat... | llxq2023 |
1,394,354 | Best online Dsa Course | Having trouble finding the best Course for dsa? Data structure courses will teach you the material,... | 0 | 2023-03-09T12:15:04 | https://dev.to/hrishii07/best-online-dsa-course-38cc | webdev, javascript, beginners | Having trouble finding the best Course for dsa? Data structure courses will teach you the material, push you to apply what you've learned, and encourage you to overcome challenges.
In addition to the best DSA Course Online, Skillslash also offers job placement assistance. Skillslash has made a name for itself as a le... | hrishii07 |
1,390,613 | Catch up on JavaScript 2: Easepick, magic-regexp, Token CSS, and more | Easepick Adding a date picker to an application is always a pain. Recently I found this... | 21,994 | 2023-03-06T14:26:59 | https://marcin.codes/posts/catch-up-on-javascript-2:-easepick-magic-regexp-token-css-and-more/ | webdev, javascript, beginners, react | 
## [Easepick](https://github.com/easepick/easepick/)
Adding a date picker to an application is always a pain. Recently I found this library and its react wrapper — it’s amazing. Easy to use and customize also have an excelle... | marcin_codes |
1,390,622 | How to handle custom error handling in express js | what is error handler an error handler is a function that is called when an error occurs... | 0 | 2023-03-06T14:50:24 | https://dev.to/krishnacyber/how-to-handle-custom-error-handling-in-express-js-1gpo | javascript, express, programming, tutorial | ## what is error handler
an error handler is a function that is called when an error occurs in an application. In the context of web development with Node.js and Express, an error handler is a middleware function that is used to handle errors that occur during the request-response cycle.
## purpose of error handler
... | krishnacyber |
1,390,683 | Meme Monday 😝 | Meme Monday! Today's cover image comes from last week's thread. DEV is an inclusive space! Humor in... | 0 | 2023-03-06T15:35:23 | https://dev.to/ben/meme-monday-193h | watercooler, discuss, jokes | **Meme Monday!**
Today's cover image comes from [last week's thread](https://dev.to/ben/meme-monday-59gk).
DEV is an inclusive space! Humor in poor taste will be downvoted by mods. | ben |
1,390,840 | My dev experience at The Collab Lab | As a self-taught developer, there are 2 things that I always missed during my learning journey:... | 0 | 2023-03-06T17:31:30 | https://www.cristina-padilla.com/collablab.html | webdev, beginners, programming, productivity | As a self-taught developer, there are 2 things that I always missed during my learning journey: building projects in a team and getting feedback. I thought that both things could help me improve my coding skills much faster so I started to look for any kind of experience or community that could provide me that. And one... | crispitipina |
1,390,908 | O uso de Chakra em aplicações feita com React. | Quando criamos uma aplicação seja mobile ou web, pensamos no que será necessário inserir,que... | 0 | 2023-03-06T18:22:20 | https://dev.to/altencirsilvajr/o-uso-de-chakra-em-aplicacoes-feita-com-react-1d3b | react, beginners, programming | Quando criamos uma aplicação seja mobile ou web, pensamos no que será necessário inserir,que linguagem usar, consumo de APIs, estilização entre outras coisas. Infelizmente, muitas alternativas visuais que gostaríamos de utilizar podem acabar deixando nossso sistema com requisições em excesso e o tornando lento. Seria m... | altencirsilvajr |
1,391,205 | Conectadas: Mercado Livre e Reprograma oferecem curso online e 100% gratuito de tecnologia para jovens mulheres | O Conectadas é um programa criado em parceria entre o Mercado Livre e o Reprograma com o objetivo... | 0 | 2023-03-07T01:09:43 | https://guiadeti.com.br/conectadas-mercado-livre-reprograma-curso-gratuito/ | bolsas, cursogratuito, inclusão, treinamento | ---
title: Conectadas: Mercado Livre e Reprograma oferecem curso online e 100% gratuito de tecnologia para jovens mulheres
published: true
date: 2023-03-06 23:55:30 UTC
tags: Bolsas,CursoGratuito,Inclusão,Treinamento
canonical_url: https://guiadeti.com.br/conectadas-mercado-livre-reprograma-curso-gratuito/
---
. This time, I mock multiple functions in the test to see how I can handle them.
## Structures and code
This is almost same as before, just adding one more function in util.py.
```she... | kenakamu |
1,391,467 | Carbonmade vs Squarespace vs Authory | Carbonmade insists that "templates are boring.” Squarespace is known for its gorgeous,... | 0 | 2023-03-07T09:07:06 | https://authory.com/blog/carbonmade-vs-squarespace-vs-authory/ | portfolio | ---
title: Carbonmade vs Squarespace vs Authory
published: true
date: 2023-02-08 20:12:36 UTC
tags: Portfolio
canonical_url: https://authory.com/blog/carbonmade-vs-squarespace-vs-authory/
---

Carbonmade insi... | protimauthory |
1,391,486 | Service Discovery | Service discovery is a process of detecting services within network clusters. It works on Service... | 20,359 | 2023-03-07T06:42:49 | https://pragyasapkota.medium.com/service-discovery-8184d05bdc0e | systems, microservices, architecture, beginners | Service discovery is a process of detecting services within network [clusters](https://dev.to/pragyasapkota/clustering-how-much-does-it-differ-from-load-balancing-3i1e). It works on Service Discovery Protocol (SDP) — a networking standard for detecting network service by identifying resources. Usually, we see services ... | pragyasapkota |
1,391,498 | Top 15 Tech Websites to Bookmark Now to Stay Updated | In the fast-paced world of technology, staying updated is crucial for everyone, whether you are a... | 0 | 2023-03-07T07:03:32 | https://dev.to/tigereye_zr/top-15-tech-websites-to-bookmark-now-to-stay-updated-40k7 | technews, technologytrends, websiterecommendations, stayupdated | In the fast-paced world of technology, staying updated is crucial for everyone, whether you are a tech enthusiast, a student, or a professional. To keep yourself up-to-date with the latest technological advancements and news, you need to bookmark some reliable websites that provide relevant information.
In this arti... | tigereye_zr |
1,391,514 | Write a program to implement triangle questions in java. | Requirements and Specifications Write a program that inputs 3 numbers, and determines if these... | 0 | 2023-03-07T07:26:59 | https://dev.to/mick_jenifer006/write-a-program-to-implement-triangle-questions-in-java-2fe1 | java, javahomeworkhelp, programmingassignmenthelp, javaassignmenthelp |
Requirements and Specifications
Write a program that inputs 3 numbers, and determines if these numbers are sides of a triangle. if a value <=0 is entered ignore that data, and exit the program.
To be a triangle. the sum of any 2 sides of a triangle must be greater than the 3rd side. all the numbers input will be int... | mick_jenifer006 |
1,391,612 | openGauss Adding or Deleting a Standby Node | Availability This feature is available since openGauss 2.0.0. ... | 0 | 2023-03-07T09:04:30 | https://dev.to/liyang0608/opengauss-adding-or-deleting-a-standby-node-2p12 | ## Availability
This feature is available since openGauss 2.0.0.
## Introduction
Standby nodes can be added and deleted.
## Benefits
If the read pressure of the primary node is high or you want to improve the disaster recovery capability of the database, you need to add a standby node. If some standby nodes in a clus... | liyang0608 | |
1,391,709 | Scribe Chrome Extension: The Ultimate Tool for Documenting Your Processes | In today’s fast-paced business world, effective process documentation is essential for streamlining... | 0 | 2023-03-07T10:25:42 | https://dev.to/esedev/scribe-chrome-extension-the-ultimate-tool-for-documenting-your-processes-4kif | scribe, documentprocess, chromeextension, productivity | In today’s fast-paced business world, effective process documentation is essential for streamlining workflows and increasing productivity. The Scribe Chrome Extension is the ultimate tool for documenting your processes, making it easier than ever to capture and organize key information and collaborate with team members... | esedev |
1,391,841 | File Privacy | 3DES is one of the most prominent forms of encryption and has a symmetric-key block cipher algorithm.... | 0 | 2023-03-07T13:10:18 | https://dev.to/vengito/file-privacy-k9d | security, privacy, encryption | 3DES is one of the most prominent forms of encryption and has a symmetric-key block cipher algorithm. File Privacy uses Triple DES (3DES or TDES).
You encrypt your files using the key file. The key file is created within the program. First you select the file you want to encrypt and then the folder where the output fil... | vengito |
1,391,908 | Conor McGregor's Net Worth: How He Built His Fortune | Articlesworlds.com is a platform where everyone can read or search for any kind of article and also... | 0 | 2023-03-07T13:36:07 | https://dev.to/articlesworlds/conor-mcgregors-net-worth-how-he-built-his-fortune-3o3m | [Articlesworlds.com](https://www.articlesworlds.com/) is a platform where everyone can read or search for any kind of article and also can share their ideas with us in the comment section. Today our topic is [Conor McGregor's Net Worth](https://www.articlesworlds.com/2023/03/conor-mcgregors-net-worth-how-he-built.html)... | articlesworlds | |
1,392,265 | React Custom Hooks: Reusable and Efficient Stateful Logic | Hooks in react are built-in functions introduced in React version 16.8. React hooks allow the use of... | 0 | 2023-03-07T20:07:39 | https://dev.to/judeebekes67/react-custom-hooks-reusable-and-efficient-stateful-logic-4nja | webdev, react, beginners, javascript | Hooks in react are built-in functions introduced in React version 16.8. React hooks allow the use of React library features such as lifecycle methods, state, and context in functional components without having to worry about rewriting it to a class.
**What are custom hooks?**
Custom hooks in React are a powerful and f... | judeebekes67 |
1,392,562 | Obtain data in openGauss via ODBC (example) | // This example demonstrates how to obtain data in openGauss through ODBC. // DBtest.c (compile... | 0 | 2023-03-08T03:33:59 | https://dev.to/490583523leo/obtain-data-in-opengauss-via-odbc-example-1hkp | ```
// This example demonstrates how to obtain data in openGauss through ODBC.
// DBtest.c (compile with: libodbc.so)
#include <stdlib.h>
#include <stdio.h>
#include <sqlext.h>
#ifdef WIN32
#include <windows.h>
#endif
SQLHENV V_OD_Env; / / Handle ODBC environment
SQLHSTMT V_OD_hstmt; // Handle statement
SQLHDBC V_OD_hd... | 490583523leo | |
1,392,775 | Today's Fun Joke For Developers - Daily Developer Jokes | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2023-03-08T08:00:03 | https://dev.to/dailydeveloperjokes/todays-fun-joke-for-developers-daily-developer-jokes-2kkd | jokes, dailydeveloperjokes | ---
title: "Today's Fun Joke For Developers - Daily Developer Jokes"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
published: true
tags: #jokes, #dailydeveloperjokes
---
Hi there! Here's today's Daily Developer Joke. We hope you enjoy it; it... | dailydeveloperjokes |
1,392,787 | Tiny Container Images With Distroless Containers | When deploying applications using containers, it's usually a goal to minimize the size of the... | 0 | 2023-03-08T08:18:10 | https://blog.jonstodle.com/tiny-container-images-with-distroless-containers/ | docker, rust, go, node | ---
title: Tiny Container Images With Distroless Containers
published: true
date: 2021-10-16 00:00:00 UTC
tags: Docker,Rust,Go,nodejs
canonical_url: https://blog.jonstodle.com/tiny-container-images-with-distroless-containers/
---
When deploying applications using containers, it's usually a goal to minimize the size of... | jonstodle |
1,392,872 | Ecommerce, where should I start? | Hello, I am a Junior Developer with 1 yr of experience, mostly FrontEnd and a bit of BackEnd. And I... | 0 | 2023-03-08T09:50:59 | https://dev.to/green8888elephant/ecommerce-where-should-i-start-4pb0 | webdev, ecommerc, nextjs, aws | Hello, I am a Junior Developer with 1 yr of experience, mostly FrontEnd and a bit of BackEnd. And I was always wondering, how to make my own ecommerce website, to sell some products there.
My knowledge:
ReactJS/NextJS 4/5
TailwindCSS 4/5
ExpressJS/tRPC 2.5/5
PostgeSQL 3/5
Docker Deployment with CI/CD from GitHub 3.5/5... | green8888elephant |
1,425,771 | A Beginner's Guide to Amazon S3 Permissions and Access Control | Sign in to the AWS Management Console at [https://console.aws.amazon.com] using your AWS account... | 0 | 2023-04-04T13:57:11 | https://dev.to/beauty/a-beginners-guide-to-amazon-s3-permissions-and-access-control-4kn3 | + Sign in to the AWS Management Console at [https://console.aws.amazon.com] using your AWS account credentials.
+ Navigate to the S3 Dashboard by selecting S3 from the list of services.
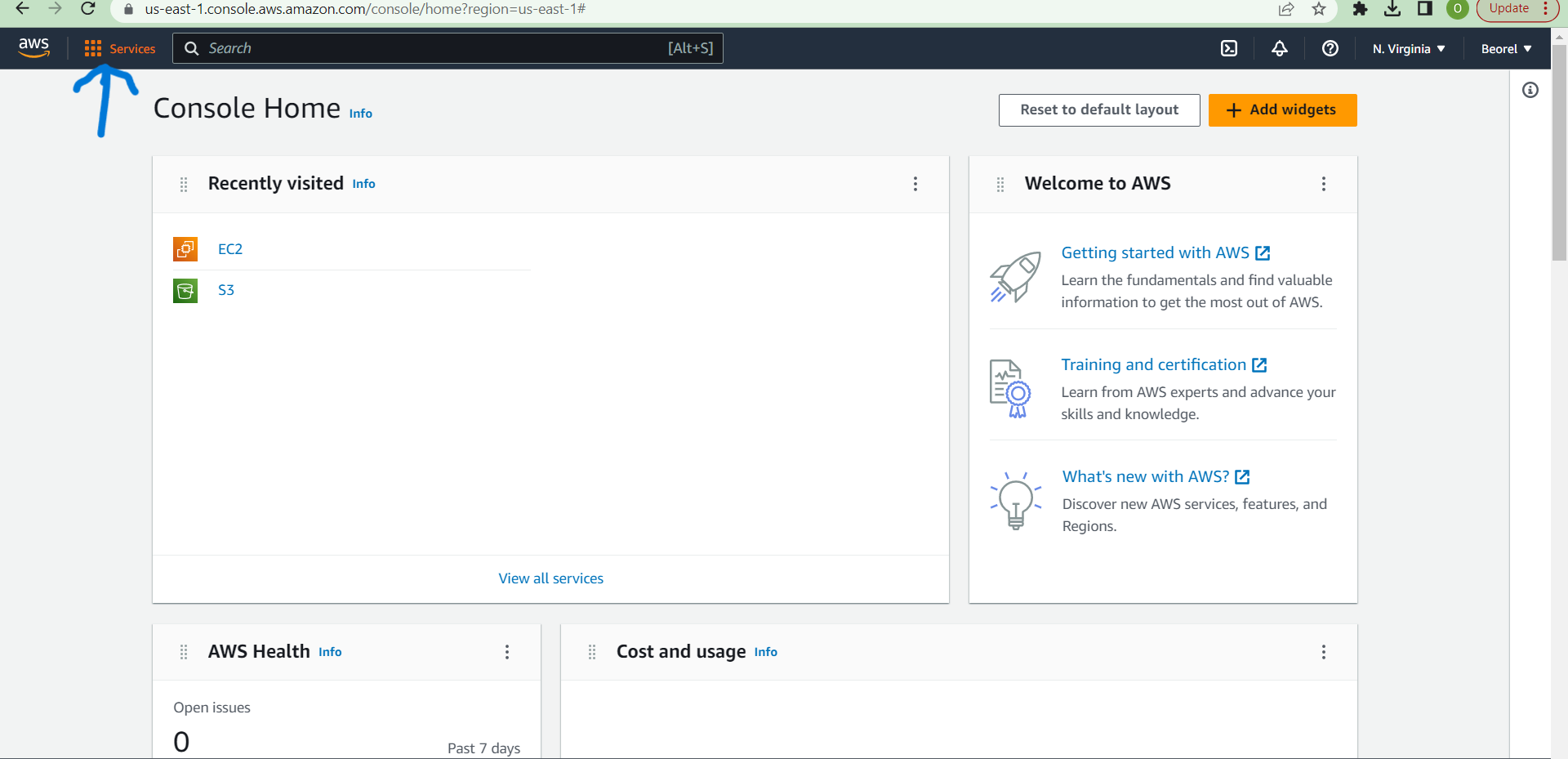
+ Click the "Create Bucket"... | beauty | |
1,393,041 | How to Use a Sass/SCSS with Expo SDK v48 and TypeScript | If you're a mobile app developer using Expo, you're probably already familiar with how easy it is to... | 0 | 2023-03-08T14:12:54 | https://dev.to/gihanrangana/how-to-use-a-sassscss-with-expo-sdk-v48-and-typescript-3nef | expo, saas, scss, reactnative | If you're a mobile app developer using Expo, you're probably already familiar with how easy it is to build a high-quality app with minimal setup. However, if you're used to using Sass/SCSS in your web development workflow, you might be wondering how to incorporate it into your Expo project. In this tutorial, we'll walk... | gihanrangana |
1,393,213 | Auto-updating hosts file using cronjob | In this post I will show you how you can easily set your hosts file in "/etc/hosts" to automatically... | 0 | 2023-03-08T15:46:31 | https://dev.to/spignelon/auto-updating-hosts-file-using-cronjob-2fdc | cron, cronjob, linux, hosts | In this post I will show you how you can easily set your hosts file in "/etc/hosts" to automatically update with the help of cron.
<!--more-->
## What is cron?
*cron is the time-based job scheduler in Unix-like computer operating systems. cron enables users to schedule jobs (commands or shell scripts) to run periodica... | spignelon |
1,393,240 | ¿Qué son los Server-Sent Events (SSE) y cómo funcionan? | En una aplicación web tradicional, la actualización de información en tiempo real puede ser un... | 0 | 2023-03-08T16:33:51 | https://dev.to/andersonsinaluisa/que-son-los-server-sent-events-sse-y-como-funcionan-fk4 |
En una aplicación web tradicional, la actualización de información en tiempo real puede ser un problema, ya que requiere una comunicación constante entre el cliente y el servidor. En estos casos, se suelen utilizar... | andersonsinaluisa | |
1,393,306 | CSS advanced | I will start my portfolio. I'm thinking on creating a personal page for my cats as a project. ,-. ... | 0 | 2023-03-08T17:21:52 | https://dev.to/neto1895/css-advanced-37b9 | I will start my portfolio. I'm thinking on creating a personal page for my cats as a project.
,-. _,---._ __ / \
/ ) .-' `./ / \
( ( ,' `/ /|
\ `-" \'\ / |
`. , \ \ / |
/`. ,'-`----Y |
( ; | '
| ,-. ,-' ... | neto1895 | |
1,393,347 | Indifikators | C++ indificator: indifikatorlar bu noyob isimlar yani "ism son yosh kun hafta" ya'ni "name num ege... | 0 | 2023-03-08T18:31:05 | https://dev.to/nuriddin152/indifikators-3enj | cpp, programming, beginners | C++ indificator:
indifikatorlar bu noyob isimlar yani "ism son yosh kun hafta"
ya'ni "name num ege day month"
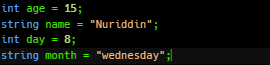
| nuriddin152 |
1,393,492 | Neptune Intro | Hello Everyone, This is my first post 😊 I'm excited to become a part of this community. I am in IT... | 0 | 2023-03-08T19:55:41 | https://dev.to/neptune/introduction-4n07 | neptune | Hello Everyone,
This is my first post 😊 I'm excited to become a part of this community.
I am in IT industry since 3+ years as a QA Engineer mostly works on automation testing with Selenium and Rest assured.
-Neptune | neptune |
1,393,584 | Beyond Basics: Building Scalable TypeScript Applications with Chain of Responsibility Design Pattern | Chain of Responsibility (CoR) is a behavioral design pattern that passes a request between a chain of... | 0 | 2023-03-08T21:49:24 | https://samuelkollat.hashnode.dev/beyond-basics-building-scalable-typescript-applications-with-chain-of-responsibility-design-pattern | typescript, designpatterns, architecture, programming | Chain of Responsibility (CoR) is a behavioral design pattern that passes a request between a chain of objects. In this pattern, each object in the chain can either handle the request or pass it on to the next object in the chain.
Today we will explore how to implement this design pattern in TypeScript.
Using CoR in T... | samuelkollat |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.