
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
129,601 | Crypto Exchange clone Scripts to start your exchange like Binance | Get a cryptocurrency clone script to start your exchange as like binance,coinbase,etc | 0 | 2019-06-28T12:05:33 | https://dev.to/harryzaara/crypto-exchange-clone-scripts-to-start-your-exchange-like-binance-4j9h | bitdealclonescript | ---
title: Crypto Exchange clone Scripts to start your exchange like Binance
published: true
description: Get a cryptocurrency clone script to start your exchange as like binance,coinbase,etc
tags: bitdeal clonescript
---
Bitdeal - Leading Clone Script Provider, furnishes the best clone scripts of top crypto exchanges... | harryzaara |
129,667 | Explore cosmos with Serverless | Serverless, JavaScript and CosmosDB | 0 | 2019-06-29T11:38:47 | https://dev.to/azure/explore-cosmos-with-serverless-422o | serverless, javascript, tutorial, showdev | ---
title: Explore cosmos with Serverless
published: true
description: Serverless, JavaScript and CosmosDB
tags: serverless, javascript, tutorial, showdev
cover_image: https://thepracticaldev.s3.amazonaws.com/i/3lz77fmx35f6qoaysxti.gif
---
Follow me on [Twitter](https://twitter.com/chris_noring), happy to take your su... | softchris |
129,851 | Around the Web – 20190628 | And now for somethings to read (or watch) over the weekend, if you have some spare time that is.... | 359 | 2019-07-22T13:55:41 | https://wipdeveloper.com/around-the-web-20190628/ | blog | ---
title: Around the Web – 20190628
published: true
tags: Blog
canonical_url: https://wipdeveloper.com/around-the-web-20190628/
cover_image: https://wipdeveloper.com/wp-content/uploads/2017/07/WIPDeveloper.com-logo-black-with-white-background.png
series: Around the Web
---
And now for somethings to read (or watch) ov... | brettmn |
129,894 | How to Start Your Day Calmly | As a software developer, it is imperative to have a calm start to the day and remain focused all day. So here is how I found that calm when I followed the 9 steps.. | 0 | 2019-06-29T08:32:25 | https://dev.to/lucpattyn/how-to-start-your-day-calmly-1mdf | calm, focus, software, development | ---
title: How to Start Your Day Calmly
published: true
description: As a software developer, it is imperative to have a calm start to the day and remain focused all day. So here is how I found that calm when I followed the 9 steps..
tags: #calm #focus #software #development
---
1) Wake up early
2) Don't touch the ... | lucpattyn |
129,954 | graphql reddit | Postman now supports GraphQL! - https://blog.graphqleditor.com/graphql-postman/ Generate code from yo... | 0 | 2019-06-29T14:01:28 | https://dev.to/kkrzeminski/graphql-reddit-5ae9 | graphql, materia | Postman now supports GraphQL! - https://blog.graphqleditor.com/graphql-postman/
Generate code from your GraphQL schema with a single function call - https://graphql-code-generator.com/
Introduction to Materia — An API Builder made for Frontend developers https://medium.com/materia-in-depth/introduction-to-materia-an-a... | kkrzeminski |
129,999 | As Spoken by a Dead Enterprise Developer by the Tree | Programmer said, 1. Like a good shepherd gently corrects the route of a wayward lamb, the shepherd... | 0 | 2019-06-29T17:27:24 | https://dev.to/vivainio/as-spoken-by-a-dead-enterprise-developer-by-the-tree-1nh2 | programming | ---
title: As Spoken by a Dead Enterprise Developer by the Tree
published: true
tags: programming
canonical_url:
---

Programmer said,
**1.** Like a good shepherd gently corrects the route of a wayward lamb, the shepherd of an application st... | vivainio |
130,060 | Pure CSS hover effect | Pure css button and link hover effect using text-shadow animation, no data-attribute or pseudo... | 0 | 2020-03-07T08:40:16 | https://dev.to/4rm/pure-css-hover-effect-479l | codepen | ---
title: Pure CSS hover effect
published: true
tags: codepen
---
<p>Pure css button and link hover effect using text-shadow animation, no data-attribute or pseudo classes needed.</p>
{% codepen https://codepen.io/fromwireframes/pen/agqNGx %}
| 4rm |
130,082 | Card Hover Effect | CSS | Cubic Bezier Updated | Hey there! Here's my new pen, check it out also on my youtube video to see the whole process http... | 0 | 2019-06-30T00:21:01 | https://dev.to/kaioalmeidacost/card-hover-effect-css-cubic-bezier-updated-542f | codepen, sass, html, code | {% codepen https://codepen.io/KaioRocha/pen/orpKxq %}
Hey there! Here's my new pen, check it out also on my youtube video to see the whole process https://youtu.be/Izm8SutcQv4 | kaioalmeidacost |
130,221 | File Creation Time in Linux | The stat utility can be used to retrieve the Unix file timestamps namely atime, ctime and mtime. Of t... | 0 | 2019-06-30T14:28:43 | https://www.anmolsarma.in/post/linux-file-creation-time/ | linux, filesystem, todayilearned | ---
title: File Creation Time in Linux
published: true
tags: linux, filesystem, todayilearned
canonical_url: https://www.anmolsarma.in/post/linux-file-creation-time/
---
The [`stat`](http://man7.org/linux/man-pages/man1/stat.1.html) utility can be used to retrieve the Unix file timestamps namely `atime`, `ctime` and ... | anmolsarma |
130,245 | Fixing the World With Software | There are so many big problems the world faces today. We hear about them in the news every day. You want to do something good in the world. You want to make a change. But you like building software. What can a software developer do to make the world a better place? | 0 | 2019-06-30T15:29:35 | https://jorin.me/fixing-the-world-with-software/ | career, motivation, technology, life | ---
title: Fixing the World With Software
published: true
description: There are so many big problems the world faces today. We hear about them in the news every day. You want to do something good in the world. You want to make a change. But you like building software. What can a software developer do to make the world... | jorinvo |
130,353 | Você já pode atualizar suas AWS Lambdas para o Node.js 10 LTS | Não faz muito tempo que a AWS anunciou que um dos seus serviços que mais uso (AWS Lambda) daria então... | 0 | 2019-06-30T21:36:18 | https://malaquias.dev/posts/voce-pode-atualizar-aws-lambdas-nodejs-10-LTS/ | node, aws, serverless | Não faz muito tempo que a [AWS anunciou que um dos seus serviços que mais uso (AWS Lambda) daria então suporte ao runtime do Node.js 10 LTS](https://aws.amazon.com/about-aws/whats-new/2019/05/aws_lambda_adds_support_for_node_js_v10/), isso provavelmente faz parte dos planos da empresa de cada vez mais suportar platafor... | malaquiasdev |
130,356 | Decoupling code and secrets | A personal insight on better practices for dealing with secrets management in codebases | 0 | 2019-07-05T18:16:35 | https://dev.to/a0viedo/decoupling-code-and-secrets-1562 | codebases, secretsmanagement, decoupling, software | ---
title: Decoupling code and secrets
published: true
description: A personal insight on better practices for dealing with secrets management in codebases
tags: codebases, secrets management, decoupling, software
cover_image: https://www.howtogeek.com/wp-content/uploads/2015/11/encryption.png.pagespeed.ce.r1UYcb9ZXB.p... | a0viedo |
130,771 | Considerations in Migrating From Ember to React | Are you considering migrating your Ember app to React? With explosive popularity and extensive... | 0 | 2019-07-01T23:48:20 | https://www.thisdot.co/blog/considerations-in-migrating-from-ember-to-react | ember, react | Are you considering migrating your Ember app to React?
With explosive popularity and extensive adoption of React within the JavaScript community, many developers have been exploring the opportunity to migrate to one of the most popular technologies in today’s market.
As our Ember friends have begun to explore React a... | thisdotmedia_staff |
130,792 | Is the Suspense Getting to You? | 0 | 2019-07-31T17:19:25 | https://dev.to/westbrook/is-the-suspense-getting-to-you-2k5m | lithtml, litelement, webcomponents, slots | ---
title: Is the Suspense Getting to You?
published: true
description:
tags: lit-html, litelement, web components, slots
cover_image: https://thepracticaldev.s3.amazonaws.com/i/vh0zvdx2huosert8ajlg.jpeg
---
> _DISCLAIMER: While the code discussed in this article is fairly short in lines of code, it has a pretty robu... | westbrook | |
131,261 | Jumpstart your API onboarding using Postman | Jumpstart your API onboarding using Postman | 0 | 2019-07-02T20:27:07 | https://www.dwolla.com/updates/jumpstart-your-api-onboarding-using-postman/ | api, testing, webdev, postman | ---
title: Jumpstart your API onboarding using Postman
published: true
description: Jumpstart your API onboarding using Postman
tags: api, testing, webdev, postman
canonical_url: https://www.dwolla.com/updates/jumpstart-your-api-onboarding-using-postman/
cover_image: https://cdn.dwolla.com/com/prod/20190625100458/post... | spencerhunter |
131,267 | What is Artificial Intelligence? | Revolution of Artificial Intelligence will more impactful than the invention of Personal Computers,... | 0 | 2019-07-02T19:55:49 | https://dev.to/jay_tillu/what-is-artificial-intelligence-4038 | machinelearning, computerscience, ai | Revolution of Artificial Intelligence will more impactful than the invention of Personal Computers, Internet, Smartphone or any other invention that is ever created by humans.
As we all know there is only one reason behind all the that was ever made by human hands were to automate the tedious and repeated task and to ... | jay_tillu |
131,980 | Two Programmers Walk Into a Bar... | Uncaught TypeError: bar is not a function | 0 | 2019-07-03T14:50:41 | https://dev.to/bennypowers/two-programmers-walk-into-a-bar-4bp4 | jokes | ---
title: Two Programmers Walk Into a Bar...
published: true
tags: jokes
---
Uncaught TypeError: bar is not a function
| bennypowers |
132,013 | Continuous Integration Explained | What is Continuous Integration (CI)? A software development practice of merging code changes to a main branch many times per day. Learn how to get started. | 0 | 2019-07-03T16:03:55 | https://semaphoreci.com/continuous-integration | cicd, productivity, beginners, devops | ---
title: Continuous Integration Explained
published: true
description: "What is Continuous Integration (CI)? A software development practice of merging code changes to a main branch many times per day. Learn how to get started."
tags: cicd, productivity, beginners, devops
canonical_url: https://semaphoreci.com/contin... | markoa |
132,054 | Stages of learning | I realized there are five stages of learning: Awareness, Panic, Avoidance, Acceptance, and finally Learning | 0 | 2019-07-03T17:47:40 | https://zellwk.com/blog/stages-of-learning | learning, thoughts | ---
title: Stages of learning
description: "I realized there are five stages of learning: Awareness, Panic, Avoidance, Acceptance, and finally Learning"
canonical_url: https://zellwk.com/blog/stages-of-learning
tags: learning, thoughts
published: true
---
Over time, I realized there are five stages of learning.
1. Aw... | zellwk |
133,014 | Freeing up space on a Ubuntu server | This is my first DEV.to post. If I'm using wrong tags or doing some weird formatting, please tell me.... | 0 | 2019-07-05T17:35:53 | https://dev.to/redcreator37/freeing-up-space-an-a-ubuntu-server-526c | ubuntu, server | <sup>This is my first DEV.to post. If I'm using wrong tags or doing some weird formatting, please tell me. It'd be much appreciated.</sup>
I have a small Ubuntu Server-powered server. A nettop<sup>[1]</sup> with a 40 GB disk drive which I use for experimenting with Linux stuff (because I don't care that much if it bre... | redcreator37 |
132,062 | Was not able to comment out jsx in react, so I made my own snippets | While I was on a react project, I was not able to comment out jsx which was really frustrating. The... | 0 | 2019-07-04T14:47:12 | https://dev.to/raisaugat/was-not-able-to-comment-out-jsx-in-react-so-i-made-my-own-snippets-2853 | vscode, productivity, react, tutorial | While I was on a react project, I was not able to comment out jsx which was really frustrating.
The way we comment out jsx is
` {/* comment */}`
But the default comment function on vscode doesnot comment out jsx. So, I made my own snippets to comment out jsx.
First, open command palette
 another state management tool | Redux vs. MobX? Most current state management solutions don't let you manage state using h... | 0 | 2019-07-05T15:13:56 | https://dev.to/adamklein/why-we-wrote-yet-another-state-management-tool-el3 | javascript, react, frontend, redux | ## Redux vs. MobX?
Most current state management solutions don't let you manage state using hooks, which causes you to manage local and global state differently and have a costly transition between the two.
Which brought us to look for solutions that use React hooks. The problem is that hooks only run inside React c... | adamklein |
132,940 | Javascript String Methods You Must Know to Become an Algorithms Wizard | In this article I want to talk about few basic string methods which are most commonly used in Javascr... | 1,610 | 2019-07-06T12:07:20 | https://dev.to/uptheirons78/javascript-string-methods-you-must-know-to-become-an-algorithms-wizard-c84 | javascript, codenewbie, beginners, webdev | In this article I want to talk about few basic string methods which are most commonly used in Javascript and very useful when it comes to solve problems and algorithms.
I've been working on solving algorithms both on FreeCodeCamp and CodeWars for the last 4 weeks and find out I used a lot of times this methods.
If y... | uptheirons78 |
133,021 | Scripting Docker Commands With Spinup.sh | In Day 3, I included a blurb from my DevOps-y friends about the natural progression of abstractions o... | 1,373 | 2019-07-05T17:51:08 | https://blog.henryneeds.coffee/scripting-docker-commands-with-spinup-sh/ | devops, docker, productivity, bash | In Day 3, I included a blurb from my DevOps-y friends about the natural progression of abstractions on top of containers:
> You usually start with docker run CLI commands and graduate to tools with more layers of abstraction as you need them. Docker-compose comes next, followed by automating several commands with Bash... | quinncuatro |
133,177 | POP's cloud-based security services | As part of our general security automation toolkit we use a number of third-party cloud-based... | 0 | 2019-07-11T06:32:23 | https://dev.to/wegotpop/pop-s-cloud-based-security-services-43ej | security, devops, automation | ---
title: POP's cloud-based security services
published: true
description:
tags: security, devops, automation
---
As part of our general security automation toolkit we use a number of third-party cloud-based services that allow us to take advantage of expertise and specialisation in those partners.
The services we ... | rrees |
133,264 | my friend site contact form is not working | Hello everyone i am new to this website. i have try almost each and everything which available at go... | 0 | 2019-07-06T06:39:29 | https://dev.to/samsuna/my-friend-site-contact-form-is-not-working-1eo8 | wordpress | Hello everyone
i am new to this website. i have try almost each and everything which available at google.
but my contact form is not sending data to my email.
here is my frnd site
http://www.fridaypic.com/contact/ | samsuna |
133,462 | Video: Disagreements are learning opportunities 📹 | When people passionately debate something, I'm immediately curious and interested. Some of my best learning moments have come out of observing an intense debate. | 0 | 2019-07-06T15:09:22 | https://dev.to/conw_y/video-disagreements-are-learning-opportunities-2g3l | learning, debate, arguments, disagreements | ---
title: Video: Disagreements are learning opportunities 📹
published: true
description: When people passionately debate something, I'm immediately curious and interested. Some of my best learning moments have come out of observing an intense debate.
tags: learning, debate, arguments, disagreements
cover_image: https... | conw_y |
133,542 | Container with the Most Water - Code Challenge | Leetcode Problem 11 This problem is pretty straight forward. Given an array of heights, find the tw... | 1,220 | 2019-07-06T21:33:30 | https://dev.to/rygelxvi/container-with-the-most-water-code-challenge-34ff | ruby, javascript, beginners, challenge |
[Leetcode Problem 11](https://leetcode.com/problems/container-with-most-water/)
This problem is pretty straight forward.
Given an array of heights, find the two indices that could contain the most water between them.
Generally there are two ways of solving this, the brute force method, and the two pointer metho... | rygelxvi |
133,582 | Try Reinforcement Learning with Donkey Car | 1 create virtual env I'm using pyenv $ python -m virtualenv py37 --python=python3.7... | 0 | 2019-07-10T01:21:57 | https://dev.to/0xkoji/try-reinforcement-learning-with-donkey-car-5e4a | machinelearning, python | ### 1 create virtual env
I'm using pyenv
```
$ python -m virtualenv py37 --python=python3.7
``` zsh
Activate py37 and install packages
```
$ pip install python-socketio flask eventlet pygame numpy pillow h5py scikit-image opencv-python gym
```
I created `dCar folder` for the following repos
### 2 Clone donkeycar
```... | 0xkoji |
133,684 | React Navigation - A Light Overview | Introduction One of the most important tasks while building a react native app that need... | 0 | 2019-07-08T12:52:08 | https://dev.to/kpose/react-navigation-a-light-overview-fc3 | react, reactnative, reactnavigation | ---
title: React Navigation - A Light Overview
published: true
description:
tags: react, react native, react navigation
---
### **Introduction**

One of the most important tasks while building a react native app that needs some n... | kpose |
133,706 | Publish a modern JavaScript (or TypeScript) library | Did you ever write some library code together and then wanted to publish it as an NPM package but rea... | 1,422 | 2019-07-07T11:47:10 | https://tobias-barth.net/blog/Publish-a-modern-JavaScript-or-TypeScript-library/ | javascript, typescript, library, howto | ---
title: Publish a modern JavaScript (or TypeScript) library
series: Publish a modern JavaScript (or TypeScript) library
canonical_url: https://tobias-barth.net/blog/Publish-a-modern-JavaScript-or-TypeScript-library/
published: true
description:
cover_image: https://thepracticaldev.s3.amazonaws.com/i/k9yi2eiqfetm2io... | 4nduril |
133,930 | 6 Months at Microsoft | I started off 2019 with my 2018 summary where I announced that I had left Readify and joined... | 0 | 2019-07-08T06:03:27 | https://www.aaron-powell.com/posts/2019-07-08-6-months-at-microsoft/ | career, microsoft, devrel | ---
title: 6 Months at Microsoft
published: true
tags: career,microsoft,meta,devrel
canonical_url: https://www.aaron-powell.com/posts/2019-07-08-6-months-at-microsoft/
---
I started off 2019 with my [2018 summary](https://dev.to/aaronpowell/2018---a-year-in-review-mi0-temp-slug-5290213) where I announced that I had le... | aaronpowell |
134,213 | Pros of Using Django for Web Development | 0 | 2019-07-08T16:44:36 | https://djangostars.com/blog/top-14-pros-using-django-web-development/ | django, python, webdev, programminglanguages | ---
title: Pros of Using Django for Web Development
cover_image: https://djangostars.com/blog/uploads/2019/01/Cover-1-11-.png
published: true
description:
tags: django, python, web development, programming languages
canonical_url: https://djangostars.com/blog/top-14-pros-using-django-web-development/
---
**Django is ... | djangostars | |
134,281 | My desktop setup - Part 3: The VS Code | I already discussed at length about my OS look and my terminal configuration. Now it is time to talk... | 1,336 | 2019-07-08T18:18:39 | https://manoel.tech/03-my-desktop-setup-3/ | I already discussed at length about my [OS look](/01-my-desktop-setup) and my [terminal configuration](/02-my-desktop-setup-2). Now it is time to talk about my main daily companion, the VS Code editor.
---
When I first started to learn how to do web pages, I used the Notepad from Windows to edit HTML code (good old t... | manoeltlobo | |
134,298 | Never use array_merge in a loop in PHP | array_merge in loop is a performance killer. | 0 | 2019-07-08T19:13:09 | https://dev.to/klnjmm/never-use-arraymerge-in-a-for-loop-in-php-5go1 | performance, php, loop | ---
title: Never use array_merge in a loop in PHP
published: true
description: array_merge in loop is a performance killer.
tags: performance, php, loop
---
I often see people using `array_merge` function in a `for`/`foreach`/`while` loop 😱 like this :
```php
$arraysToMerge = [ [1, 2], [2, 3], [5, 8] ];
$arraysMe... | klnjmm |
134,753 | Run Puppeteer/Chrome Headless on EC2 Amazon Linux AMI | — augmented on June 2019 This article is based closely on MockingBot’s article of the same title. Th... | 0 | 2019-07-09T16:08:22 | https://dev.to/kerion7/run-puppeteer-chrome-headless-on-ec2-amazon-linux-ami-2ae8 | headless, puppeteer, aws, tutorial | — augmented on June 2019
This article is based closely on MockingBot’s [article of the same title](https://medium.com/mockingbot/run-puppeteer-chrome-headless-on-ec2-amazon-linux-ami-6c9c6a17bee6). The original article helped a great deal, but some parts were outdated due to new libraries’ and packages’ versions. Henc... | kerion7 |
134,901 | New "How to build an App" series by Tom Scott | Everything you didn't know you needed to know | 0 | 2019-07-10T01:01:52 | https://dev.to/turnerj/new-how-to-build-an-app-series-by-tom-scott-39c3 | beginners, app, business | ---
title: New "How to build an App" series by Tom Scott
published: true
description: Everything you didn't know you needed to know
tags: beginner, app, business
---
Tom Scott is a [popular YouTuber](https://www.youtube.com/user/enyay) who (amongst many other things) made [Emojli](https://en.wikipedia.org/wiki/Emojli)... | turnerj |
134,927 | Next-level visualizations with ExploreTrees.SG | Last year, I wrote about one of my most ambitious side project ever, ExploreTrees.SG. It was simply b... | 0 | 2019-07-12T00:42:28 | https://cheeaun.com/blog/2019/07/next-level-visualizations-exploretrees-sg/ | visualizations, trees, singapore | ---
title: Next-level visualizations with ExploreTrees.SG
published: true
tags: visualizations, trees, singapore
canonical_url: https://cheeaun.com/blog/2019/07/next-level-visualizations-exploretrees-sg/
---
Last year, I [wrote about one of my most ambitious side project ever](https://cheeaun.com/blog/2018/04/building... | cheeaun |
135,024 | Blockchain No-Brainer: Ownership in the Digital Era | We discuss how the meaning and perception of ownership is changing, while the second will discuss how Smart Contract automation can help deliver safe, fair, fast, low-cost, transparent and auditable transactional interoperability. | 0 | 2019-07-10T09:44:20 | https://dev.to/erlangsolutions/blockchain-no-brainer-ownership-in-the-digital-era-1dch | blockchain, smartcontracts, dlt | ---
title: Blockchain No-Brainer: Ownership in the Digital Era
published: true
description: We discuss how the meaning and perception of ownership is changing, while the second will discuss how Smart Contract automation can help deliver safe, fair, fast, low-cost, transparent and auditable transactional interoperabilit... | erlangsolutions |
139,483 | Shawn Wang on His Involvement in Open Source: I Look for Projects That Will Die if I Don't Get Involved | We talked to Shawn Wang, a full-stack developer who works on Developer Experience at... | 0 | 2019-07-17T06:45:15 | https://dev.to/gitnation/shawn-wang-on-his-involvement-in-open-source-i-look-for-projects-that-will-die-if-i-don-t-get-involved-5fn3 | react, reactnative, typescript | ### We talked to Shawn Wang, a full-stack developer who works on Developer Experience at Netlify, helps moderate [/r/reactjs](https://reddit.com/r/reactjs), and teaches React and TypeScript at Egghead.io
*Shawn Wang, a proud full-stack developer and, as he calls himself, an infinite builder from Netlify, has talked to... | gitnation |
139,598 | DISCUSS: What are you loving about "on-call" in your role? | Hey there! Jay here, host of On-Call Nightmares Podcast and Azure Cloud Advocate. Are you current... | 0 | 2019-07-12T13:45:27 | https://dev.to/azure/discuss-what-are-you-loving-about-on-call-in-your-role-1pcp | mentoring, beginners, infra, discuss | Hey there!

Jay here, host of [On-Call Nightmares Podcast](https://oncallnightmares.podomatic.com/) and [Azure Cloud Advocate](https://developer.microsoft.com/en-us/advocates/index.html?WT.mc_id=devto-blog-jagord).
Are you currently on-call at y... | jaydestro |
139,889 | Hacking 101 | What does it actually mean to be a hacker? Well here's a clip of a dark web hacke... | 0 | 2019-07-24T01:02:33 | https://dev.to/spencerlindemuth/hacking-101-122c | hacking, security |
#What does it actually mean to be a hacker?
####Well here's a clip of a dark web hacker in action:
Hacking is clearly the precise combination of finding the right ski-mask, and clever use of your banana hand. The people behind the Equifax data breach... | spencerlindemuth |
140,261 | The CLI part 2: Interacting with Heroku in the command line | How to use the CLI to deploy to heroku | 0 | 2019-07-16T15:20:47 | https://dev.to/heroku/the-cli-part-2-interacting-with-heroku-in-the-command-line-4p6l | cli, bash, tips, webdev | ---
title: The CLI part 2: Interacting with Heroku in the command line
published: true
description: How to use the CLI to deploy to heroku
tags: cli, bash, tips, web-dev
---
A large part of what makes Heroku special is the user’s ability to execute a variety of tasks within the command line. Any user can create & scal... | nocnica |
140,460 | Optimized Script loading for Browser | for more info- https://jasonformat.com/modern-script-loading/ | 1,485 | 2019-07-14T13:54:05 | https://dev.to/64bitdev/optimized-script-loading-for-browser-1o9j | javascript, scriptloading, browser, perf | for more info- https://jasonformat.com/modern-script-loading/ | 64bitdev |
140,484 | Create Page in React | Page in React | 0 | 2019-07-16T08:32:22 | https://dev.to/aziziyazit/create-page-in-react-1mj6 | react, reactpage, reactarchitecture | ---
title: Create Page in React
published: true
description: Page in React
tags: #react, #reactpage #react-architecture
---
## Page
Page can be defined as a Container of the modules. Page is the closest common ancestor for its modules (container children).
One of the important technique when creating a page is [Lift... | aziziyazit |
140,490 | Typescript HOCs with Apollo in React - Explained. | Typescript HOCs with Apollo is pretty tricky. I don't know maybe it is just me but this… This is i... | 0 | 2019-07-14T16:22:57 | https://medium.com/@mickeyboston/apollo-typescript-hocs-in-react-explained-93032db3e89a?sk=ec5b1010055762efcfe69e4c95c9c1ea | react, typescript, graphql, apollo | Typescript HOCs with Apollo is pretty tricky. I don't know maybe it is just me but this…
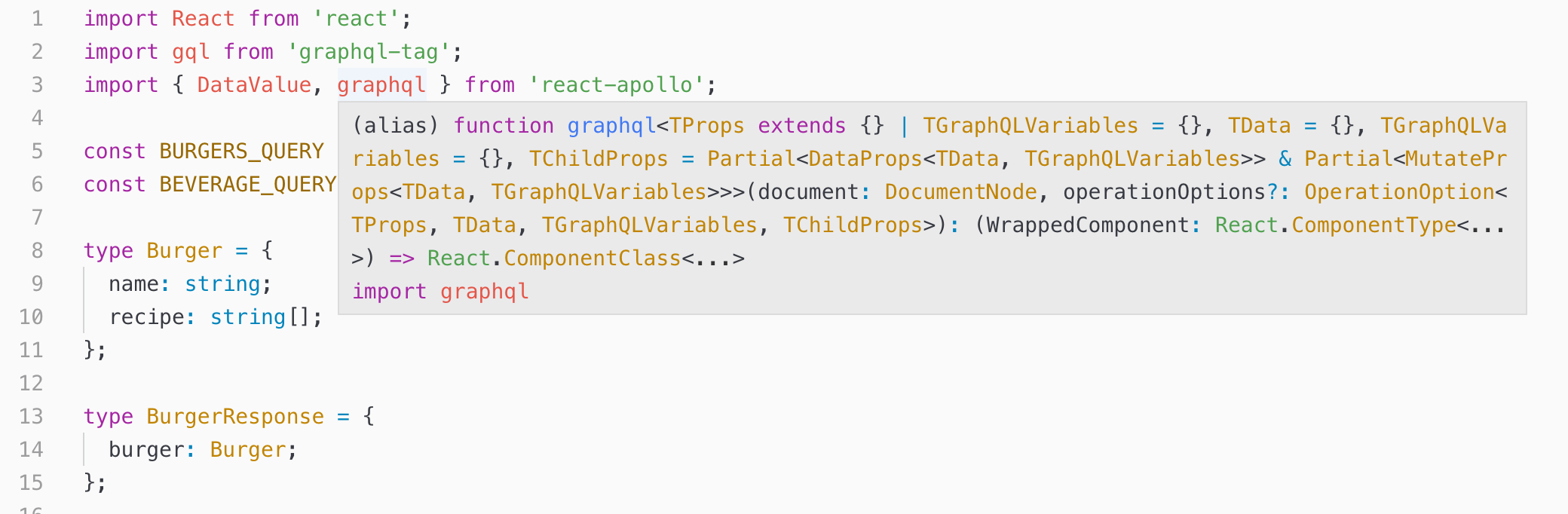
This is intimidating, but it is undoubtedly necessary. How else do you want compiler to check your props in and... | georgeshevtsov |
140,509 | Learning a New Language? | Is anyone currently learning a new language? What language and why? How are you going about... | 0 | 2019-07-14T17:47:14 | https://dev.to/dinocodes/learning-a-new-language-1ag6 | watercooler | ---
title: Learning a New Language?
published: true
description:
tags: watercooler
---
Is anyone currently learning a new language?
What language and why?
How are you going about learning it?
I am currently learning Italian with my wife. My great-grandfather on my dads side came from Italy and my grandfather wo... | dinocodes |
140,863 | Incremental improvements can lead to significant gains | While reading the book Atomic Habits by James Clear, I was reflecting that my choice of embracing Ema... | 0 | 2019-07-15T14:59:50 | https://dev.to/shrysr/incremental-improvements-can-lead-to-significant-gains-48k | emacs, habits, productivity | ---
title: Incremental improvements can lead to significant gains
published: true
tags: emacs,habits, productivity
canonical_url:
---
While reading the book [Atomic Habits by James Clear](https://jamesclear.com/atomic-habits), I was reflecting that my choice of embracing [Emacs](https://www.gnu.org/software/emacs/) a... | shrysr |
141,199 | Displaying Geofences and Polygons on Google Maps | Well, the last few weeks I had been working in the redesign of LOCALLY Engage which will be launched... | 0 | 2019-07-16T08:02:21 | https://dev.to/danvoyce/displaying-geofences-and-polygons-on-google-maps-3lio | geofences, googlemaps, location | Well, the last few weeks I had been working in the redesign of <a href="https://locally.io/products/engage">LOCALLY Engage</a> which will be launched in the next few days! This feature was quite challenging and required me to use things I haven’t used for a long time! One of the things I had to do was plotting a map to... | danvoyce |
141,349 | Angular 2+ vs ReactJS vs Vue.js | Intro Sometimes to make a choice regarding the Javascript framework might be not that easy... | 0 | 2019-07-16T15:35:01 | https://2muchcoffee.com/blog/angular-react-vue/ | angular, react, javascript | ##Intro
<p align="justify">Sometimes to make a choice regarding the Javascript framework might be not that easy. The popular frameworks as Angular and React got a serious competitor like VueJS. Of course, there are other frameworks, however, this article will focus on these 3 frameworks as the most well-known. A lot of... | 2muchcoffeecom |
141,548 | Markdown Image Alignment | I'm having a problem with markdown images. It seems markdown only center align images. How do I left... | 0 | 2019-07-16T23:33:05 | https://dev.to/johntelford/markdown-image-alighment-3dek | gatsby | I'm having a problem with markdown images. It seems markdown ![]() only center align images. How do I left align markdown images?
| johntelford |
141,580 | Removing Short Imports in NativeScript, the Easy Way (with VS Code) | As NativeScript continues to evolve, some of the features that made sense in 2015 are creating more t... | 0 | 2019-07-17T03:42:58 | https://dev.to/toddanglin/removing-short-imports-in-nativescript-the-easy-way-with-vs-code-660 | nativescript, vscode, regex, javascript | As NativeScript continues to evolve, some of the features that made sense in 2015 are creating more trouble than they're worth in 2019. One such feature is the so called "short import."
Short imports were intended to improve the developer experience by saving a few key strokes. Instead of this:
```typescript
import {... | toddanglin |
141,589 | A Simple Introduction to git | Version Control Systems(VCS) are one of the most important things a developer needs to know about. Si... | 0 | 2019-07-23T22:00:01 | https://dev.to/dagasatvik10/a-simple-introduction-to-git-55df | beginners, productivity, git | *Version Control Systems(VCS) are one of the most important things a developer needs to know about. Since its release in 2005, git has continued to be one of the most widely used VCS. So without further delay, lets get started with basics of git.*
First thing to do is install git on whatever OS you are using. Let's se... | dagasatvik10 |
141,630 | Design Systems (Part I: Foundations) | The web was built as a set of interconnected pages, and blossomed from how content was historically c... | 1,622 | 2019-07-17T08:02:17 | https://dev.to/emmabostian/design-systems-part-i-foundations-45hd | design | The web was built as a set of interconnected pages, and blossomed from how content was historically consumed: through books. Since books format content in a series of pages, it was only natural for web pages to leverage the familiar paradigm. Thus, web pages were born.
Other technology terminology stems from printed b... | emmabostian |
141,904 | End to End testing with Selenium — Retrospective | Original article here: End to End testing with Selenium — Retrospective I was working on the QA auto... | 0 | 2019-07-17T20:22:28 | https://dev.to/neetjn/end-to-end-testing-with-selenium-retrospective-3o07 | selenium, testing, qa, automation | Original article here: [End to End testing with Selenium — Retrospective](https://medium.com/p/f7673ce5035b)
I was working on the QA automation team at Transparent Language for roughly a year. I helped establish the team, as well as develop and mature their infrastructure, tools, and training processes. The following ... | neetjn |
141,912 | The Name's CORS. Rack::CORS. | My latest project required using Rails to create an API backend. Ruby has a nifty --api flag that cre... | 0 | 2019-07-17T22:41:42 | https://dev.to/aidiri/the-name-s-cors-rack-cors-27og | beginners, ruby, rails, todayilearned | My latest project required using Rails to create an API backend. Ruby has a nifty `--api` flag that creates a repo with only the folders you would need. It cuts down a lot of the extra folders you would get when normally creating a new Rails app. It also automatically adds a line into your gemfile to include Rack-CORS.... | aidiri |
141,963 | Iris version 11.2 released | It is my pleasure and honor to spread the news about the new Iris release. As open-source proje... | 1,532 | 2019-07-19T19:27:10 | https://dev.to/kataras/iris-version-11-2-released-22bc | go, webdev, opensource, github | It is my pleasure and honor to spread the news about the new [Iris](https://github.com/kataras/iris) release.
<a href="https://iris-go.com"> <img align="right" width="169px" src="https://iris-go.com/images/icon.svg?v=a" title="logo created by @merry.dii" /> </a>
As open-source project authors and/or managers, we owe... | kataras |
142,002 | Clip Path Transitions | published: false | 0 | 2019-07-18T05:39:00 | https://dev.to/ahmadbassamemran/clip-path-transitions-3kai | codepen, clippath, css3, animation | published: false | ahmadbassamemran |
142,013 | Weekly Coding Challenge - Week #18 - Social Media Buttons | Week #18 of the Weekly Coding Challenge program - Social Media Buttons | 512 | 2019-07-18T06:22:06 | https://www.florin-pop.com/blog/2019/07/social-media-buttons/ | challenge, html, css | ---
title: Weekly Coding Challenge - Week #18 - Social Media Buttons
published: true
description: Week #18 of the Weekly Coding Challenge program - Social Media Buttons
tags: challenge, html, css
canonical_url: https://www.florin-pop.com/blog/2019/07/social-media-buttons/
cover_image: https://www.florin-pop.com/static/... | florinpop17 |
142,017 | Creating a Domain Model rapidly with Java and Spring Boot | In this short article, we are creating a domain model for a simple application. All the examples are in Java language. We use Spring Boot to accelerate the application startup. | 0 | 2019-07-18T07:02:52 | https://dev.to/colaru/creating-a-domain-model-rapidly-with-java-and-spring-boot-i85 | java, spring | ---
title: Creating a Domain Model rapidly with Java and Spring Boot
published: true
description: In this short article, we are creating a domain model for a simple application. All the examples are in Java language. We use Spring Boot to accelerate the application startup.
tags: Java, Spring
cover_image: https://thep... | colaru |
142,091 | Una interfaz para controlarlos a todos: Patrón adapter | Este bicho lleva implementando el patrón millones de años
Siguiendo con la serie... | 0 | 2019-07-18T10:29:43 | https://medium.com/all-you-need-is-clean-code/una-interfaz-para-controlarlos-a-todos-patr%C3%B3n-adapter-a9073f3460b | designpatterns, ddd, diseñodepatrones, portsandadapters | ---
title: Una interfaz para controlarlos a todos: Patrón adapter
published: true
tags: design-patterns,ddd,diseño-de-patrones,ports-and-adapters
canonical_url: https://medium.com/all-you-need-is-clean-code/una-interfaz-para-controlarlos-a-todos-patr%C3%B3n-adapter-a9073f3460b
---
 is being a number. Also, `NaN`... | shafikshaon |
142,612 | Laravel Dockerization out of the box! | Docker is an open-source platform that makes it possible for software developers to Build, Ship, and... | 0 | 2019-07-21T20:34:19 | https://dev.to/nedsoft/laravel-dockerization-out-of-the-box-4aej | laravel, docker, devops | ---
title: "Laravel Dockerization out of the box!"
tags: ['laravel', 'docker', 'DevOps']
published: true
cover_image: https://thepracticaldev.s3.amazonaws.com/i/er5dfy5gr5scx952x242.png
---
[Docker](https://www.docker.com/what-docker) is an open-source platform that makes it possible for software developers to Build, ... | nedsoft |
142,635 | Time Distort in Super Intergalactic Gang (and in video games in general?) | When I started to develop SIG I had only a couple of things clear: It was going to be a Shoot em'... | 0 | 2019-07-19T14:08:56 | https://dev.to/martin_cerdeira/time-distort-in-super-intergalactic-gang-and-in-video-games-in-general-1hgb | gamedevelop, showdev, beginners | When I started to develop SIG I had only a couple of things clear:
- It was going to be a Shoot em' up.
- It was going to have a slow motion mechanics, as if it were Neo and the famous "bullet time".
<em>Video demo</em>
[](https://www.youtube.com/w... | martin_cerdeira |
142,653 | How to easily implement new In-App update feature to your Android App | Working all night to fix a bug or add a groundbreaking feature to your Android app and seeing only a... | 0 | 2019-07-19T14:30:57 | https://dev.to/sanojpunchihewa/how-to-easily-implement-new-in-app-update-feature-to-your-android-app-9e9 | android | Working all night to fix a bug or add a groundbreaking feature to your Android app and seeing only a few users have updated their apps? No worries now, Android have now released a new feature called [in-app updates](https://developer.android.com/guide/app-bundle/in-app-updates) where you can prompt the user to update t... | sanojpunchihewa |
142,680 | Understanding RxJS Observables and why you need them | What is RxJS? RxJS is a framework for reactive programming that makes use of... | 0 | 2019-07-19T17:07:51 | https://blog.logrocket.com/understanding-rxjs-observables/ | rxjs | ---
title: Understanding RxJS Observables and why you need them
published: true
tags: rxjs
canonical_url: https://blog.logrocket.com/understanding-rxjs-observables/
---

## What is RxJS?
[RxJS](https://rxjs-dev.firebaseapp.com/) is a framework f... | bnevilleoneill |
142,767 | List of Variable Fonts | OpenType variable fonts were introduced in 2016 as an extension to the OpenType specification. Techni... | 0 | 2019-07-21T06:31:32 | https://vuild.com/variable-fonts | tutorials | ---
title: List of Variable Fonts
published: true
tags: Tutorials
canonical_url: https://vuild.com/variable-fonts
---
OpenType variable fonts were introduced in 2016 as an extension to the OpenType specification. Technically they allow a single font file to store a continuous range of design variants. In simple terms ... | vuild |
142,785 | [Suggestion Needed] : Generate complex PDF using puppeteer | I am working on to generate pdf having complex header, footer & page border | 0 | 2019-07-19T20:50:03 | https://dev.to/irfaan008/suggestion-needed-generate-complex-pdf-using-puppeteer-28h5 | headless, pdf, puppeteer, node | ---
title: [Suggestion Needed] : Generate complex PDF using puppeteer
published: true
description: I am working on to generate pdf having complex header, footer & page border
tags: headless, pdf, puppeteer, node
---
While chrome headless is best option out in the market with open source tag for generating PDF, screens... | irfaan008 |
145,532 | How to get started with Selenium and Python | Step one, you need to get chromedriver. What is chromedriver? It is a separate binary that you must... | 0 | 2019-07-22T12:54:48 | https://dev.to/tonetheman/how-to-get-started-with-selenium-and-python-7p | selenium, python, automation | ---
title: How to get started with Selenium and Python
published: true
description:
tags: selenium,python,automation
---
Step one, you need to get chromedriver.
What is chromedriver? It is a separate binary that you must run to get Selenium and Chrome working. See for tiny explantion of what chromedriver does : http... | tonetheman |
145,778 | A Quick Intro to Apollo Client | A few months ago, we posted an article about how to fetch data from a GraphQL API. In it, we looked a... | 0 | 2019-07-20T18:05:41 | https://dev.to/eveporcello/a-quick-intro-to-apollo-client-1247 | graphql, javascript, tutorial | A few months ago, we posted an article about how to [fetch data from a GraphQL API](https://moonhighway.com/fetching-data-from-a-graphql-api). In it, we looked at the [Snowtooth API](https://snowtooth.moonhighway.com), a fake ski resort with a real GraphQL API, and we were able to send queries to get data and send muta... | eveporcello |
145,863 | The Greatest Learning Technique For Learning to Code | I started programming when I was 18 years old, but I did it just because it was required in school, I... | 0 | 2019-07-21T04:28:02 | https://dev.to/stevenanthony/the-greatest-learning-technique-for-learning-to-code-1ha5 | javascript, career, beginners, codenewbie | I started programming when I was 18 years old, but I did it just because it was required in school, I just did what was required, that's it. I didn't retain any information, nothing at all.
When I started university, I began to take things a bit more seriously. A lot of my curriculum was focused on Object Oriented p... | stevenanthony |
145,965 | Docker Containers vs VMs | Virtual Machines (VMs) and Docker containers are two technologies used to improve resource utilization. This post will help you understand the background of both as well as how they differ. | 0 | 2019-07-21T15:26:11 | https://dev.to/npentrel/docker-containers-vs-vms-257i | docker, containerization, containers, vms | ---
title: Docker Containers vs VMs
published: true
description: Virtual Machines (VMs) and Docker containers are two technologies used to improve resource utilization. This post will help you understand the background of both as well as how they differ.
tags: docker, containerization, containers, VMs
cover_image: ht... | npentrel |
145,986 | WebGL month. Day 21. Rendering a minecraft terrain | In this tutorial we'll render a minecraft terain | 0 | 2019-07-21T16:40:55 | https://dev.to/lesnitsky/webgl-month-day-21-rendering-a-minecraft-terrain-24b5 | beginners, javascript, webgl | ---
title: WebGL month. Day 21. Rendering a minecraft terrain
published: true
description: In this tutorial we'll render a minecraft terain
tags: beginners, javascript, webgl
cover_image: https://thepracticaldev.s3.amazonaws.com/i/zf3sev83jaggq3n990rj.jpg
---
This is a series of blog posts related to WebGL. New post w... | lesnitsky |
146,251 | Preparing For My First Tech Conference | Today I will be attending Codeland Conference in NYC. This my first ever tech conference, and I'm ner... | 0 | 2019-07-22T10:40:58 | https://dev.to/sarahscode/preparing-for-my-first-tech-conference-59m6 | codenewbie, conference | ---
title: Preparing For My First Tech Conference
published: true
tags: codenewbie, conference
canonical_url:
---
Today I will be attending Codeland Conference in NYC. This my first ever tech conference, and I'm nervous but excited.
Codeland is organized by [CodeNewbie](https://www.codenewbie.org/), a podcast and su... | sarahscode |
146,264 | A Comprehensive Guide to CSM | Know Why CSM Certification is taking the World by Storm Are you stuck at the bottom of the corporate... | 0 | 2019-07-22T11:25:42 | https://dev.to/samsuna/a-comprehensive-guide-to-csm-5hdg | Know Why CSM Certification is taking the World by Storm
Are you stuck at the bottom of the corporate ladder? Are you finding it difficult to get noticed? And is it not your style to brag about your skills to get ahead? Then you might want to consider opting for recognised certification programs.
There are several of ... | samsuna | |
146,281 | Beginner’s Guide to Learning JavaScript as a WordPress Developer | If you have been following the happenings in the WordPress community for the past couple of months, y... | 0 | 2019-07-22T12:19:20 | https://www.codeinwp.com/blog/learning-javascript-for-wordpress/ | wordpress, webdev, javascript, beginners | ---
title: Beginner’s Guide to Learning JavaScript as a WordPress Developer
published: true
description:
tags: wordpress, webdev, javascript, beginners
canonical_url: https://www.codeinwp.com/blog/learning-javascript-for-wordpress/
cover_image:
---
If you have been following the happenings in the WordPress community... | fitzchris |
146,367 | what is a locator in Selenium (and Python) | In order to interact with a web page in Selenium you have to locate the element. As a human you do... | 0 | 2019-07-25T12:24:48 | https://dev.to/tonetheman/what-is-a-locator-in-selenium-and-python-45o8 | selenium, python, automation | ---
title: what is a locator in Selenium (and Python)
published: true
description:
tags: selenium,python,automation
---
In order to interact with a web page in Selenium you have to locate the element. As a human you do this without much thought. In Selenium it requires more thought (sadly).
There are lots of ways t... | tonetheman |
146,400 | Wordpress HTML to Markdown for Gatsby | I am currently in the process of creating my blog using WordPress as the backend and Gatsby for the f... | 0 | 2019-07-22T16:34:37 | https://www.shubho.dev/coding/wordpress-html-to-markdown-for-gatsby/ | gatsby, wordpress, javascript | I am currently in the process of creating my blog using WordPress as the backend and Gatsby for the frontend. One of the most enticing features of Gatsby is plugins. Almost every feature you might want on your blog is available as a plugin, or you can create one for yourself. As a developer who has dabbled with WordPre... | shubho |
146,412 | TPP Topic 10: Orthogonality |
This post originally appeared on steadbytes.com
See the first post in The Pr... | 0 | 2019-07-22T16:24:01 | https://dev.to/steadbytes/tpp-topic-9-orthogonality-kcd | thepragmaticprogrammer, book, programming, education | ---
categories:
- The Pragmatic Programmer
published: true
tags:
- The Pragmatic Programmer
- book
- programming
- education
title: 'TPP Topic 10: Orthogonality'
---
> This post originally appeared on [steadbytes.com](https://steadbytes.com/blog/the-pragmatic-programmer-20th/topic-10-challenges/)
<div></div>
> See th... | steadbytes |
146,422 | Building Svelte 3 Budget Poll App [2] | Where we ended In my last post I covered basics of Svelte3 installation and usage. We crea... | 1,559 | 2019-07-22T16:47:42 | https://dev.to/corvusetiam/building-svelte-3-budget-poll-app-2-1cid | javascript, webdev, svelte, tutorial | # Where we ended
In my last [post](https://dev.to/corvusetiam/how-to-build-budget-poll-app-in-svelte3-13c8) I covered basics of Svelte3 installation and usage. We created git repository and made multipage form component and panel component.
Now, we will try to design our content panels.
# Starting up
Open up our r... | corvusetiam |
146,633 | Continuous Testing | Definition, Benefits & How to Perform | Due date: 23:59 p.m Oct 25th, 2021 The State of Quality Report 2021 Wouldn’t it be great to know how... | 0 | 2019-07-23T04:41:50 | https://dev.to/katalon/continuous-testing-definition-benefits-how-to-perform-1kio | cicd, continuous, automationtesting, softwaretesting | ---
title: Continuous Testing | Definition, Benefits & How to Perform
published: True
tags: cicd, continuous,automationtesting,softwaretesting
---
>**Due date: 23:59 p.m Oct 25th, 2021**
>**The State of Quality Report 2021**
>_Wouldn’t it be great to know how peers and experts are staying ahead of their quality assuran... | testingnews1 |
146,634 | Angular CDK Virtual Scroll | What is Virtual Scrolling? Modern web application are complex. They have a lot of moving p... | 0 | 2019-07-27T09:26:39 | https://dev.to/hassam7/angular-cdk-virtual-scroll-4ldj | angular, cdk, virtualscroll, material |
# What is Virtual Scrolling?
Modern web application are complex. They have a lot of moving parts, complexity and often times they have to deal with huge amount of data.
Consider that you have application in which you have to display a list of users, a very common use case.
As the number of items in the list increas... | hassam7 |
146,638 | Creating Trimmed Self Contained Executables in .NET Core | A great new way to create simple self contained executables in .NET Core | 2,159 | 2019-07-23T05:29:35 | https://dev.to/pluralsight/creating-trimmed-self-contained-executables-in-net-core-4m08 | csharp, programming, dotnet, tutorial | ---
title: Creating Trimmed Self Contained Executables in .NET Core
published: true
description: A great new way to create simple self contained executables in .NET Core
tags: csharp,programming,dotnet,tutorial
series: Getting to know .NET Core
---
I'm going to show you a cool new feature in [.NET Core 3.0](https://do... | jeremycmorgan |
166,700 | How we get awesome testimonials from our customers | Customer testimonials are important to us for both marketing and social validation. We feature them a... | 0 | 2019-09-30T10:54:55 | https://blog.leavemealone.app/how-we-get-testimonials/ | testimonials, airtable | ---
title: How we get awesome testimonials from our customers
published: true
tags: Testimonials, Airtable
canonical_url: https://blog.leavemealone.app/how-we-get-testimonials/
cover_image: https://images.unsplash.com/photo-1510034696085-597d716bd162?ixlib=rb-1.2.1&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ix... | dinkydani21 |
166,788 | Browser API's localization: why can't you do this, Chrome? | Hey, devs! I'd like to share an interesting thing I've found, and ask your thoughts about it. I was... | 0 | 2019-09-06T13:24:59 | https://dev.to/room_js/browser-api-s-localization-why-can-t-you-do-this-chrome-1epk | chrome, google, javascript, browser | Hey, devs! I'd like to share an interesting thing I've found, and ask your thoughts about it.
I was playing with `Date`'s `toLocaleString()` method in order to get a month name translated with the browser's API only. The code looks like this:
```javascript
const date = new Date();
date.toLocaleString('en-GB', { month... | room_js |
166,848 | Dojo Widget Middleware | The newest features of Dojo 6 include the new function based widgets and widget middleware. Class ba... | 0 | 2019-09-06T15:43:58 | https://learn-dojo.com/dojo-widget-middleware/ | dojo, webdev, typescript | The newest features of [Dojo 6](https://dojo.io/blog/version-6-dojo) include the new function based widgets and widget middleware.
Class based widgets come with decorators to [watch for property changes](https://learn-dojo.com/watch-for-property-changes-in-widgets) and work with [metas](https://learn-dojo.com/dojo-fro... | odoenet |
169,594 | Embracing a mentality of prediction – evaluation – exploration | A while ago I started to play a little game when doing test-driven development: Every time I run my... | 0 | 2019-09-12T22:43:22 | https://cleandatabase.wordpress.com/2019/09/12/embracing-a-mentality-of-prediction-evaluation-exploration/ | reflection, learning, life | ---
title: Embracing a mentality of prediction – evaluation – exploration
published: true
tags: Reflection,Learning,Life
canonical_url: https://cleandatabase.wordpress.com/2019/09/12/embracing-a-mentality-of-prediction-evaluation-exploration/
---
A while ago I started to play a little game when doing test-driven devel... | pesse |
171,344 | In the Guts of a Shiv App - Building SaaS #24 | In this episode, we got our hands dirty with the Django Shiv app that we build to work out issues... | 2,058 | 2020-01-21T18:02:51 | https://www.mattlayman.com/building-saas/guts-shiv-app/ | python, django, saas | {% youtube 0kS-uPMOLlg %}
In this episode, we got our hands dirty with the Django Shiv app that we build to work out issues with finding templates and other settings problems.
Show notes for this stream are at [Episode 24 Show Notes](https://www.mattlayman.com/building-saas/guts-shiv-app/).
To learn more about the s... | mblayman |
173,900 | Cloud e OpenStack: Uma breve introdução | Cloud Computing Computação em Nuvem, ou Cloud Computing, é uma tecnologia desenvolvida par... | 0 | 2019-09-22T00:53:27 | https://dev.to/opendevufcg/cloud-e-openstack-uma-breve-introducao-49cb | cloud, openstack, distributedsystems, ptbr |
# Cloud Computing
Computação em Nuvem, ou **Cloud Computing**, é uma tecnologia desenvolvida para flexibilizar os recursos que uma aplicação/sistema tem disponível. Nesse caso, quando falamos de recursos, estamos nos referindo a memória RAM, armazenamento, CPU e afins. Através da Cloud, é possível criar uma **infraes... | martalais |
175,053 | Git hooks and HuskyJS | When using Git, like most of projects today do, code goes through 4 stages. Those stages are: Untra... | 0 | 2019-09-22T18:59:55 | https://dev.to/hi_iam_chris/git-hooks-and-huskyjs-13gb | husky, git, githooks, javas | When using Git, like most of projects today do, code goes through 4 stages. Those stages are:
- Untracked
- Files/changes are visible, but those will not be committed.
- Staged
- Changes get into this state by executing git add command. Once changes are staged, with next commit those will be committed.
- Commi... | hi_iam_chris |
175,087 | That was quite an episode... | Rails + React + Redux - Pt 5 This post is going to focus on creating an Appearance for each queen... | 3,838 | 2019-09-22T22:08:21 | https://dev.to/jaredharbison/dragnet-2nmf | ruby, rails | <h1><center>Rails + React + Redux - Pt 5</center></h1>
*********************************************************
This post is going to focus on creating an Appearance for each queen. I'll iterate through each Episode's contestants' ids to find_or_create_by the contestants' drag_names then create the Appearance using t... | jaredharbison |
175,111 | Half Done... | As a mother to a very active child I have a habit of leaving things half finished. Shelves of half re... | 0 | 2019-09-22T23:57:20 | https://dev.to/nerdmom630/half-done-1of9 | blogging, mom | As a mother to a very active child I have a habit of leaving things half finished. Shelves of half read books and folders on my computer full of half completed projects. There just never seems to be time to finish especially if I would like to sleep like a normal functioning human.
So how do you get over this problem?... | nerdmom630 |
175,180 | Securing Microservices with Auth0 Pt. 2 (Resource Service) | This is the second part to a series of posts called Securing Microservices with Auth0. If you missed... | 2,373 | 2019-09-25T21:59:36 | https://dev.to/bbenefield89/securing-microservices-with-auth0-pt-2-2c23 | react, spring, microservices, tutorial | This is the second part to a series of posts called **Securing Microservices with Auth0**. If you missed the [previous post](https://dev.to/bbenefield89/securing-your-microservices-with-auth0-20e3), I would suggest you go back and read that post first.
# Overview
In this part of the **Securing Microservices with Aut... | bbenefield89 |
175,195 | React Ionic Framework and Hooks | building a sample application using react hooks api, useState & useReducer | 3,623 | 2019-09-24T04:04:04 | https://dev.to/ionic/react-ionic-framework-and-hooks-5135 | javascript, react, reacthooks, ionic | ---
title: React Ionic Framework and Hooks
published: true
description: building a sample application using react hooks api, useState & useReducer
tags: #javascript #react #reacthooks #ionic
cover_image: https://thepracticaldev.s3.amazonaws.com/i/nty8zwujft3ydudvu58m.png
series: Ionic Framework & Firebase React Hooks
-... | aaronksaunders |
175,237 | Angular: Build more dynamic components with ngTemplateOutlet 🎭 | Introduction To build reusable and developer-friendly components, we need to make them... | 0 | 2019-10-15T11:48:35 | https://dev.to/mustapha/angular-build-more-dynamic-components-with-ngtemplateoutlet-3nee | angular, webdev, beginners, tutorial |
# Introduction
To build reusable and developer-friendly components, we need to make them more dynamic (read more adaptable). Great news, Angular comes with some great tools for that. For instance, we could inject content to our components using `<ng-content>`:
```typescript
@Component({
selector: 'child-componen... | mustapha |
175,342 | Why You Should Use Windows VPS Hosting for a Growing Website | A VPS or virtual private server hosting plan is responsible for providing the user site with own set... | 0 | 2019-09-23T13:10:23 | https://dev.to/rishabhsinha/why-you-should-use-windows-vps-hosting-for-a-growing-website-21j2 | vpshosting | A VPS or virtual private server hosting plan is responsible for providing the user site with own set of resources like- operating system, disk space, and bandwidth. This is a huge contrast when compared to other hosting plans, where most of the resources are shared with other users present on the server. VPS hosting gi... | rishabhsinha |
175,366 | Migrating to the cloud but without screwing it up, or how to move house | For an application that's ready to scale, not using managed cloud architecture these days is like ins... | 0 | 2019-09-23T14:51:07 | https://victoria.dev/verbose/migrating-to-the-cloud-but-without-screwing-it-up-or-how-to-move-house/ | serverless, webdev, devops, beginners | ---
title: Migrating to the cloud but without screwing it up, or how to move house
published: true
tags: ["serverless",”webdev”,”devops”,"beginners"]
canonical_url: https://victoria.dev/verbose/migrating-to-the-cloud-but-without-screwing-it-up-or-how-to-move-house/
cover_image: https://victoria.dev/verbose/migrating-to... | victoria |
175,440 | Testing Jasmine Speed | I was told that a single IT within a DESCRIBE was an order of magnitude faster than multiple ITS within the same DESCRIBE. To say I was dubious would be an understatement. | 2,154 | 2019-12-09T13:32:19 | https://dev.to/rfornal/testing-jasmine-speed-38e9 | jasmine, javascript, unittesting, performance | ---
title: Testing Jasmine Speed
published: true
description: I was told that a single IT within a DESCRIBE was an order of magnitude faster than multiple ITS within the same DESCRIBE. To say I was dubious would be an understatement.
series: Front-End Testing
tags: Jasmine, JavaScript, Unit Testing, Performance
cover_i... | rfornal |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.