
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
71,282 | Checking if an input is empty with JavaScript | This article shows you how to check if an input is empty with JavaScript | 0 | 2018-12-28T22:52:43 | https://zellwk.com/blog/check-empty-input-js | css, javascript | ---
title: Checking if an input is empty with JavaScript
canonical_url: https://zellwk.com/blog/check-empty-input-js
tags: css, js
description: This article shows you how to check if an input is empty with JavaScript
published: true
cover_image: https://zellwk.com/images/2018/empty-input-validation-js/check.gif
... | zellwk |
71,394 | Announcing SIESGSTarena's Open Source Site | Description below | 0 | 2018-12-30T04:17:03 | https://dev.to/siesgstarena/announcing-siesgstarenas-open-source-site--4324 | opensource, siesgstarena, github, studentdevelopers | ---
title: Announcing SIESGSTarena's Open Source Site
published: true
tags: opensource, siesgstarena, github, student developers
description: Description below
---
<center><img src="https://thepracticaldev.s3.amazonaws.com/i/xolbfpjfj3lyr64qgyp6.png" width="100%"></center>
<a href="https://arena.siesgst.ac.in">... | siesgstarena |
71,455 | Nokogiri installation errors on macos | Quick answer: bundle config build.nokogiri --use-system-libraries && bundle install... | 0 | 2019-01-06T02:56:45 | https://markentier.tech/posts/2018/12/ruby-bundler-nokogiri-macos/ | nokogiri, ruby, bundler, rails | ---
title: Nokogiri installation errors on macos
published: true
tags: nokogiri, ruby, bundler, rails
canonical_url: https://markentier.tech/posts/2018/12/ruby-bundler-nokogiri-macos/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/uxh9hxetameb2z8d94hx.png
---
Quick answer:
```sh
bundle config bu... | asaaki |
72,483 | Tea Break Challenge, Day #2 | Our choices are the sustenance of our behavior. | 0 | 2019-01-02T16:23:53 | https://dev.to/jcutrell/tea-break-challenge-day-2-3of7 | teabreakchallenge, career | ---
title: Tea Break Challenge, Day #2
published: true
description: Our choices are the sustenance of our behavior.
tags: teabreakchallenge, career
---
Our choices are the sustenance of our behavior. It may not be immediately obvious, but choices are not only about what we choose to do, but perhaps even more ab... | jcutrell |
72,901 | 14 useful tools for network engineers | It's important that a network professional know some tools which can increase his productivity and make his work easier. | 0 | 2019-01-03T06:27:13 | https://dev.to/rafaelmonteiro/14-useful-tools-for-network-engineers-2d0l | networking, informationsecurity, tools | ---
title: 14 useful tools for network engineers
published: true
description: It's important that a network professional know some tools which can increase his productivity and make his work easier.
tags: Networking, Information Security, Tools
cover_image: https://thepracticaldev.s3.amazonaws.com/i/b47dre9db4fs2z... | rafaelmonteiro |
73,520 | FlatBuffers (in Rust) | Following up on the last post closing the chapter on Apache Thrift, we’re looking at another... | 0 | 2019-01-07T06:57:46 | https://dev.to/jeikabu/flatbuffers-in-rust-59f9 | rust, flatbuffers, showdev | ---
title: FlatBuffers (in Rust)
published: true
tags: rust,flatbuffers,showdev
canonical_url:
---
Following up on the [last post closing the chapter on Apache Thrift](./thrift-012-1mi9), we’re looking at another serialization library, [FlatBuffers](https://google.github.io/flatbuffers/).
## FlatBuffers
... | jeikabu |
73,702 | Public API's | public api | 0 | 2019-01-08T05:36:32 | https://dev.to/sicksand/public-apis-16dh | api, android | ---
title: Public API's
published: true
description: public api
tags: api, android
---
Yesterday from my Telegram Channel, there is a website that list all public api. I'm a sucker for API. Try to make at least one app (on Android) from the lists. One that caught my attention is Advice Slip (http://api.advicesl... | sicksand |
73,984 | Snippet or not indexed posts |
Sometimes I just want to add quick notes but it's not qualify as proper post. I... | 0 | 2019-01-09T10:54:47 | https://dev.to/k4ml/snippet-or-not-indexed-posts-1dil | meta | Sometimes I just want to add quick notes but it's not qualify as proper post. It's something similar to coderwall.com. Maybe we can add another flag like `indexed: false` and this post will not appear in any feed. But it still public with proper url, or maybe you can view it all at specific url like dev.to/snippets/, a... | k4ml |
74,122 | Fancy Function Parameters of JS | The code is from this post. It makes the params more clear. function renderList(list, { ordere... | 0 | 2019-01-10T01:00:41 | https://dev.to/chenge/fancy-function-parameters-of-js-52b6 | javascript, clean | ---
title: Fancy Function Parameters of JS
published: true
description:
tags: js, clean
---
The code is from [this post](https://www.javascriptjanuary.com/blog/fancy-function-parameters). It makes the params more clear.
```js
function renderList(list, {
ordered = true,
color = '#1e2a2d',
bg... | chenge |
74,142 | Web Page Usability Matters | Users appreciate pages being usable and interactive soon after they're visually ready. UI interactions (scrolls, taps, clicks) can be delayed by script and other browser work so minimizing their impact can really help your users. | 0 | 2019-01-10T17:44:23 | https://addyosmani.com/blog/usability/ | webperf, lighthouse, webdev, timetointeractive | ---
title: "Web Page Usability Matters"
published: true
description: Users appreciate pages being usable and interactive soon after they're visually ready. UI interactions (scrolls, taps, clicks) can be delayed by script and other browser work so minimizing their impact can really help your users.
tags:
- web p... | addyosmani |
74,398 | Two Ways To Get Synergy Out Of An iMac + Macbook Combo | How to use an unloved iMac as both a second screen and a TimeMachine server | 0 | 2019-01-11T16:47:01 | https://dev.to/bhison/two-ways-to-get-synergy-out-of-an-imac--macbook-combo-1f02 | mac, hardware, battlestations | ---
title: Two Ways To Get Synergy Out Of An iMac + Macbook Combo
published: true
description: How to use an unloved iMac as both a second screen and a TimeMachine server
tags: mac, hardware, battlestations
---
 wro... | itamarst |
75,220 | Spring Security with JWT | Simple tutorial to show you how to use Spring Security with JWT | 0 | 2019-01-14T17:43:08 | https://dev.to/kubadlo/spring-security-with-jwt-3j76 | java, spring, security, jwt | ---
title: Spring Security with JWT
published: true
description: Simple tutorial to show you how to use Spring Security with JWT
cover_image: https://jakublesko.com/wp-content/uploads/2019/01/key-in-mans-hand.jpg
tags: java, spring, security, jwt
---
Spring Security’s default behavior is easy to use for a standard web... | kubadlo |
75,242 | ClassicPress development version on your VVV environment |
I love VVV or Varying Vagrant Vagrants. For developers is very useful also to s... | 0 | 2019-01-28T09:54:58 | https://daniele.tech/2019/01/classicpress-development-version-on-your-vvv-environment/ | classicpress, opensource, php | ---
title: ClassicPress development version on your VVV environment
published: true
tags: ClassicPress,Open Source,php
canonical_url: https://daniele.tech/2019/01/classicpress-development-version-on-your-vvv-environment/
---
I love VVV or Varying Vagrant Vagrants. For developers is very useful also to start wor... | mte90 |
75,402 | Using Redis to Store Information in Python Applications |
We're hacking into the new year strong over here at Hackers and Slackers, and... | 0 | 2019-01-18T17:37:01 | https://hackersandslackers.com/using-redis-with-python/ | nosql, python, softwaredevelopment | ---
title: Using Redis to Store Information in Python Applications
published: true
tags: NoSQL,Python,Software Development
canonical_url: https://hackersandslackers.com/using-redis-with-python/
---
 is another place where you can save and share your code online. It's a great place to make quick demos to then show off in your blog posts.
The standard look is like so
```
{% jsfiddle https://jsfiddle.net/link2twenty/7m6ej0m9/ %}
```
{% jsf... | link2twenty |
77,963 | Feature Flag pattern in java | In this article, we will briefly introduce the feature flag pattern in java to al... | 0 | 2019-05-09T08:10:27 | https://apiumhub.com/tech-blog-barcelona/feature-flag-pattern/ | agilewebandappde, programming, softwaredeveloper | ---
title: Feature Flag pattern in java
published: true
tags: Agile web and app de,programming,Software developer
canonical_url: https://apiumhub.com/tech-blog-barcelona/feature-flag-pattern/
---
In this article, we will briefly introduce the feature flag pattern in java to allow uploading features to productio... | apium_hub |
76,477 | Styling Form With Different States And Storybook | There are a lot of different and efficient ways how to improve web app development speed while implementing and testing new features. One of them is to be able to reuse UI components. To develop UI elements in isolation and then apply them to the project, I have tried and learned Storybook. | 0 | 2019-01-19T13:19:54 | https://dev.to/ilonacodes/styling-form-with-different-states-and-storybook-2foj | webdev, showdev, javascript, beginners | ---
title: Styling Form With Different States And Storybook
published: true
cover_image: https://thepracticaldev.s3.amazonaws.com/i/lw91bbnydr1bfoqyaoh7.jpg
description: There are a lot of different and efficient ways how to improve web app development speed while implementing and testing new features. One of them ... | ilonacodes |
76,646 | Friday Blast #54 | Timeouts and cancellations for humans (2018) - a precursor to the Trio article from last week, this o... | 5,293 | 2019-01-20T14:43:28 | https://horia141.com/friday-blast-54.html | fridayblast, links, post | ---
title: Friday Blast #54
published: true
tags: friday_blast,links,post
canonical_url: https://horia141.com/friday-blast-54.html
series: "Friday Blast"
---
[Timeouts and cancellations for humans (2018)](https://vorpus.org/blog/timeouts-and-cancellation-for-humans/) - a precursor to the Trio article from [last week](... | horia141 |
76,966 | Setting Up Vagrant for a Rails Application: Part 2 | Configuring Vagrant for Rails Applications | 0 | 2019-01-24T04:54:17 | https://dev.to/denisepen/setting-up-vagrant-for-a-rails-application-part-2--2gkm | vagrant, devops, rails, codenewbie | ---
title: Setting Up Vagrant for a Rails Application: Part 2
published: true
description: Configuring Vagrant for Rails Applications
tags: #vagrant, #devops, #rails, #codenewbie
---
In a previous [post](https://dev.to/denisepen/setting-up-vagrant-for-a-rails-application-kgc) we configured the Vagrant File in pr... | denisepen |
77,209 | Collecting behavioural data with Segment, Mixpanel and Google Analytics |
The logistics of collecting and analysing behavioural event data can be tricky ... | 0 | 2019-01-22T12:09:02 | http://blog.tdwright.co.uk/2019/01/22/collecting-behavioural-data-with-segment-mixpanel-and-google-analytics/ | behaviouraldata, googleanalytics, mixpanel, segment | ---
title: Collecting behavioural data with Segment, Mixpanel and Google Analytics
published: true
tags: behavioural data,Google Analytics,Mixpanel,Segment
canonical_url: http://blog.tdwright.co.uk/2019/01/22/collecting-behavioural-data-with-segment-mixpanel-and-google-analytics/
---
The logistics of collecting... | tdwright |
77,274 | Top 5 DEV Comments from the Past Week | Highlighting some of the best DEV comments from the past week. | 0 | 2019-01-22T15:44:16 | https://dev.to/devteam/top-5-dev-comments-from-the-past-week-20o2 | bestofdev | ---
title: Top 5 DEV Comments from the Past Week
published: true
description: Highlighting some of the best DEV comments from the past week.
tags: bestofdev
cover_image: https://res.cloudinary.com/practicaldev/image/fetch/s--7VrAA2ln--/c_imagga_scale,f_auto,fl_progressive,h_420,q_auto,w_1000/https://thepracticalde... | peter |
82,839 | Things you could do with Mix | Things you could do with Mix | 0 | 2019-02-13T23:50:08 | https://dev.to/drumusician/things-you-could-do-with-mix-504i | elixir, mix | ---
title: Things you could do with Mix
published: true
description: Things you could do with Mix
tags: elixir, mix
---
Originally posted on [the guild](https://www.theguild.nl/things-you-could-do-with-mix/)
# Things you could do with Mix
## Part 1: Creating Tasks
Recently I gave my very first talk at a c... | drumusician |
77,319 | Google Chrome Licensing API returning 500 error. Need help! | Hi. Any Chrome Extensions developer here? I've developed a chrome extension and I'm trying to provid... | 0 | 2019-01-22T17:35:45 | https://dev.to/sunilc_/google-chrome-licensing-api-returning-500-error-need-help-3efn | help | ---
title: Google Chrome Licensing API returning 500 error. Need help!
published: true
tags: help
---
Hi. Any Chrome Extensions developer here?
I've developed a chrome extension and I'm trying to provide Free Trial to users using Google License API. I'm taking the code here(https://stackoverflow.com/questions... | sunilc_ |
77,356 | OPS - Rethinking Cloud Infrastructure | Unikernels used to be in-accessible to the average developer due to their low level nature. OPS is a free open source tool created to fix that problem and let even non-developers run them locally on their laptop or cloud. | 0 | 2019-01-22T21:46:39 | https://dev.to/eyberg/ops---rethinking-cloud-infrastructure-c40 | unikernels, serverless, containers, virtualization | ---
title: OPS - Rethinking Cloud Infrastructure
published: true
description: Unikernels used to be in-accessible to the average developer due to their low level nature. OPS is a free open source tool created to fix that problem and let even non-developers run them locally on their laptop or cloud.
tags: unikernels... | eyberg |
77,436 | Event Storage in Postgres, Multi-tenant | Buzzword Bingo sold separately. | 0 | 2019-01-23T03:16:59 | https://dev.to/kspeakman/event-storage-in-postgres-multi-tenant-25hc | postgres, sql, eventsourcing, showdev | ---
title: Event Storage in Postgres, Multi-tenant
published: true
description: Buzzword Bingo sold separately.
tags: #postgres #sql #eventsourcing #showdev
---
I previously wrote about [Event Storage in Postgres](https://dev.to/kspeakman/event-storage-in-postgres-4dk2). One thing I did not address at that time... | kspeakman |
77,466 | These are your biggest enemies | Obstacles that will prevent anyone from success | 0 | 2019-01-23T08:37:01 | https://dev.to/hussein_cheayto/these-are-your-biggest-enemies-41ip | education, motivation, inspiration | ---
title: These are your biggest enemies
published: true
description: Obstacles that will prevent anyone from success
tags: education, motivation, inspiration
---
Through my humble experience, these are the biggest enemies if any ambitious person:
<b>1- Luck</b>
Luck can drastically change a person’s life, let’s say... | hussein_cheayto |
77,627 | Architecting the Next Generation of Communication |
With the shift to mobile and the statistics of the “younger” generation (hi t... | 0 | 2019-01-23T23:32:22 | https://blog.joshghent.com/architecting-the-next-generation-of-communication-1fb98545e32a | api, pubnub, softwaredevelopment, aws | ---
title: Architecting the Next Generation of Communication
published: true
tags: api,pubnub,software-development,aws
canonical_url: https://blog.joshghent.com/architecting-the-next-generation-of-communication-1fb98545e32a
---
 <br><br>
<p>Hello to everyone,</p>
In this article, I'm going to talk about the step-by-step imple... | fevziomurtekin |
78,746 | SigSlot | A C++ library for signalling and slotting | 0 | 2019-01-29T09:57:08 | https://dev.to/dwd/sigslot-4iff | cpp | ---
title: SigSlot
published: true
description: A C++ library for signalling and slotting
tags: cpp
---
## SigSlot Introduction
SigSlot is a library I adopted several years ago as a solid implemention of the "[Observer Pattern](https://en.wikipedia.org/wiki/Observer_pattern)" in C++.
It's available on [GitH... | dwd |
79,279 | How To Handle This Type Error | TypeScript Puzzle with explanation. | 0 | 2023-01-14T02:52:40 | https://dev.to/danjfletcher/how-to-handle-this-type-error-2nc1 | typescript, puzzle, programming | ---
title: How To Handle This Type Error
published: true
description: TypeScript Puzzle with explanation.
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/eshuco2erledei22bpqu.png
tags: TypeScript, Puzzle, Programming
---
# Can you spot the Type Error?
```ts
function getProperty<T>(obj: T, proper... | danjfletcher |
79,386 | Skipping tests |
Sometimes you might want to skip a particular test while executing others for s... | 352 | 2019-01-31T06:11:05 | https://wangonya.com/blog/skipping-tests/ | python, testing, beginners | Sometimes you might want to skip a particular test while executing others for some reason. Maybe the database guy isn't done setting up and that particular test requires a database connection. Instead of having to wait, you can just write the test and instruct pytest to skip it, giving the appropriate reason so it does... | wangonya |
79,442 | Why Field Service Management Business Must Have Mobile Apps | 5 Reasons Why your Field Service Management Needs Mobile Apps. This blog highlights major five of those reasons | 0 | 2019-01-31T10:30:12 | https://dev.to/appdevelopmentagency/why-field-service-management-business-must-have-mobile-apps-186e | mobileapps | ---
title: Why Field Service Management Business Must Have Mobile Apps
published: true
description: 5 Reasons Why your Field Service Management Needs Mobile Apps. This blog highlights major five of those reasons
tags: Mobile Apps
---

You must have heard the popular phrase ... | appdevelopmentagency |
79,458 | Do you know there is a version of VSCode available without MS branding, telemetry or licensing? | What do you think of VSCodium? Have you used it? Is the branding,... | 0 | 2019-01-31T11:51:09 | https://dev.to/spences10/do-you-know-there-is-a-version-of-vscode-available-without-ms-branding-telemetry-or-licensing-32a1 | discuss | ---
title: Do you know there is a version of VSCode available without MS branding, telemetry or licensing?
published: true
tags: discuss
cover_image: https://thepracticaldev.s3.amazonaws.com/i/k6zca948lsmhdnf0cdgo.png
---
## What do you think of [VSCodium]?
## Have you used it?
## Is the branding, licenc... | spences10 |
79,473 | Everything is connected - or why I'm focusing on Relational Applications | My point of view in and out of software about the inter-connectivity of things | 0 | 2019-01-31T13:14:24 | https://dev.to/tomavelev/everything-is-connected---or-why-im-focusing-on-relational-applications-2ino | rdbs, connectionsinlife, datastructure | ---
title: Everything is connected - or why I'm focusing on Relational Applications
published: true
description: My point of view in and out of software about the inter-connectivity of things
tags: RDBS, connections-in-life, datastructure
---
<!-- wp:paragraph -->
<p>Everything is connected with everything el... | tomavelev |
79,583 | Build a Fluent Interface in Java in Less Than 5 Minutes |
(Skip to the good part!)
Building a Basic Class
Building classes in... | 0 | 2019-01-31T22:56:14 | https://dev.to/awwsmm/build-a-fluent-interface-in-java-in-less-than-5-minutes-m7e | java, beginners, tutorial, oop | [(Skip to the good part!)](#good-part)
## Building a Basic Class
Building classes in Java is _**EASY!**_ All you need is a class declaration inside a file with the same name as the class (but with a `.java` at the end of it). A minimal example would be something like
```java
// MyClassName.java
// class must be pub... | awwsmm |
79,729 | let, async, await as variable | if i assign let some other value, how interpreter still understand its original use. | 0 | 2019-02-01T13:41:34 | https://dev.to/krshna/let-async-await-as-variable-57fp | javascript | ---
title: let, async, await as variable
published: true
description:
tags: javascript
---
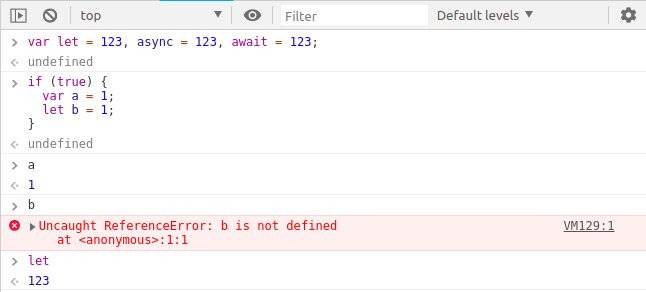
if i assign `let` some other value, how interpreter still understand its original use. | krshna |
134,969 | Create a Simple Dark Mode with CSS Filters | So there's this thing you probably haven't heard of called "dark mode". Yeah, you're right, they're... | 0 | 2019-07-10T06:53:26 | https://dev.to/boyum/create-a-simple-dark-mode-with-css-filters-4ji4 | css, html, frontend | ---
title: Create a Simple Dark Mode with CSS Filters
published: true
description:
tags: CSS, HTML, Frontend
---
So there's this thing you probably haven't heard of called "dark mode". Yeah, you're right, they're everywhere. Let me teach you how to grace the interwebs with even more instances of light on dark! 🌓
**... | boyum |
79,815 | Build an image classification app with NativeScript-Vue and Azure Custom Vision API | Disclaimer: This is my first post, please feel free to leave any comments and suggestions in the co... | 0 | 2019-02-01T23:01:07 | https://dev.to/edlgg/build-an-image-classification-app-with-nativescript-vue-and-azure-custom-vision-api-n2c | javascript, nativescript, azure | ---
title: Build an image classification app with NativeScript-Vue and Azure Custom Vision API
published: true
description:
tags: javascript, nativescript, azure
---

Disclaimer: This is my fir... | edlgg |
80,222 | Why did I write another React Native boilerplate | I was not disappointed with what I found, but they just left me wanting for more... | 0 | 2019-02-03T17:46:28 | https://dev.to/amitm30/why-did-i-write-another-react-native-boilerplate-47cb | reactnative, boilerplates, typescript, templates | ---
title: Why did I write another React Native boilerplate
published: true
description: I was not disappointed with what I found, but they just left me wanting for more...
tags: reactnative, boilerplates, typescript, templates
---
*Most of the boilerplate solutions that I found online were either too simple, just a f... | amitm30 |
80,802 | gRPC and Protocol Buffers as an alternative to JSON REST APIs | gRPC is an open-source remote procedure call framework and Protocol Buffers is a mechanism for serial... | 0 | 2019-02-05T12:23:19 | https://dev.to/franzejr/grpc-and-protocol-buffers-as-an-alternative-to-json-rest-apis-3cg3 | api, distributed | ---
title: gRPC and Protocol Buffers as an alternative to JSON REST APIs
published: true
description:
tags: api, distributed
---
gRPC is an open-source remote procedure call framework and Protocol Buffers is a mechanism for serializing structured data. Both were developed by Google and are used in their intern... | franzejr |
81,128 | A Humility Training Exercise for Technical Interviewers | Humility is an important quality in technical interviewers. | 0 | 2019-02-05T21:40:51 | https://triplebyte.com/blog/a-humility-training-exercise-for-technical-interviewers | career, interview, advice | ---
title: A Humility Training Exercise for Technical Interviewers
published: true
description: Humility is an important quality in technical interviewers.
tags: career, interviews, advice
cover_image: https://cl.ly/a3dced0259e3/download/Image%202019-02-05%20at%204.20.34%20PM.png
canonical_url: https://triplebyte... | ammonb |
81,354 | Job Search So Far and Learning to love Programming Again for The Right Reasons | So it has been a year since I graduated from my 4 year university with a Bachelors in computer scienc... | 0 | 2019-02-06T19:27:17 | https://dev.to/bcampos103/job-search-so-far-and-learning-to-love-programming-again-for-the-right-reasons-10j3 | jobsearch, motivation, computerscience, programming | ---
title: Job Search So Far and Learning to love Programming Again for The Right Reasons
published: true
description:
tags: #jobsearch #motivation #computerscience #programming
---
So it has been a year since I graduated from my 4 year university with a Bachelors in computer science and even though I have to ... | bcampos103 |
81,489 | Creative Computing: Why kids should learn logical programming | In the last years, we have entered into an Artificial Intelligence and Automation Age. This... | 0 | 2019-02-07T13:34:28 | https://dev.to/lechenco/creative-computing-why-kids-should-learn-logical-programming-4a71 | discuss, learn | ---
title: Creative Computing: Why kids should learn logical programming
published: true
description:
tags: #discuss #learn
---
In the last years, we have entered into an Artificial Intelligence and Automation Age. This future/present image has been the target of discussions and fears, since a lot of working ... | lechenco |
81,572 | Github credentials for beginners | A guide using the credential helper of the git command line. | 0 | 2019-02-20T15:25:45 | https://dev.to/paulc_creates/github-credentials-for-beginners-3k2j | git, github, commandline |
---
title: Github credentials for beginners
published: true
description: A guide using the credential helper of the git command line.
tags: git, Github, command line,
---
 has released round... | saiumesh |
81,960 | Around the Web – 20190208 | And now for somethings to read (or watch) over the weekend, if you have some spare time that is.... | 359 | 2019-02-16T15:30:10 | https://wipdeveloper.com/around-the-web-20190208/ | blog | ---
title: Around the Web – 20190208
published: true
tags: Blog
canonical_url: https://wipdeveloper.com/around-the-web-20190208/
cover_image: https://wipdeveloper.com/wp-content/uploads/2017/07/WIPDeveloper.com-logo-black-with-white-background.png
series: Around the Web
---
And now for somethings to read (or ... | brettmn |
82,001 | My Top 3 books to learn Java programming for beginners | The Java programming language is one of the most used programming languages in the world and there... | 0 | 2019-02-10T09:14:58 | https://dev.to/devfanooos/my-top-3-books-to-learn-java-programming-for-beginners-2hkp | java |
---
title: My Top 3 books to learn Java programming for beginners
published: true
description:
tags: java
---

The Java programming language is one of the most used programming languages in the world and there are thousands of books... | devfanooos |
82,093 | Looking for open source contribution - HELP | Link - https://github.com/0xPrateek/Portfolio-Template A portfolio website template for Geeks,Program... | 0 | 2019-02-10T19:52:31 | https://dev.to/0xprateek/looking-for-open-source-contribution---help-21i7 | beginners, javascript, opensource, github | ---
title: Looking for open source contribution - HELP
published: true
description:
tags: beginners,javascript,opensource,github
---
Link - https://github.com/0xPrateek/Portfolio-Template
A portfolio website template for Geeks,Programmers,Developers and hackers. | 0xprateek |
82,118 | The Power of a Testing Framework | My new testing framework has been a success | 0 | 2019-02-10T23:11:36 | https://everythingfunctional.wordpress.com/2019/02/10/the-power-of-a-testing-framework/ | tdd, testing, fortran, framework | ---
title: The Power of a Testing Framework
published: true
description: My new testing framework has been a success
tags: tdd, testing, fortran, framework
cover_image: https://everythingfunctional.files.wordpress.com/2019/02/holdingpower-1200-2-1080x608.jpg
canonical_url: https://everythingfunctional.wordpress.c... | everythingfunct |
82,236 | My EMACS Custom Indent Function Uses 'tab-width' | Sharing a new trick I learned in Elisp. | 0 | 2019-02-11T15:10:25 | https://dev.to/emgodev/my-emacs-custom-indent-function-uses-tab-width-34p8 | elisp, showdev, productivity | ---
title: My EMACS Custom Indent Function Uses 'tab-width'
published: true
description: Sharing a new trick I learned in Elisp.
tags: elisp, showdev, productivity
cover_image: https://camo.githubusercontent.com/38467eb65de742741e216b6df7f986f2d7a621c6/687474703a2f2f7777772e656d61637377696b692e6f72672f706963732f73... | emgodev |
82,886 | Top Tips For Better Cross Browser Testing | Web developers usually are biased towards a browser. They can debate for hours why the latest version of their favorite browser is the best one for all web development projects. Many times, they work in their favorite browser assuming that the code they have developed will run on other browsers too. | 0 | 2019-02-14T08:14:05 | https://www.lambdatest.com/blog/top-tips-for-better-cross-browser-testing/ | testing, tips, beginners, showdev | ---
title: Top Tips For Better Cross Browser Testing
published: true
description: Web developers usually are biased towards a browser. They can debate for hours why the latest version of their favorite browser is the best one for all web development projects. Many times, they work in their favorite browser assuming ... | saifsadiq1995 |
83,014 | How to Export Data to XLSX Files | A while ago I wrote an article about exporting data to different spreadsheet formats. As recently... | 0 | 2019-02-15T01:13:01 | http://djangotricks.blogspot.com/2019/02/how-to-export-data-to-xlsx-files.html | export, python, django, xlsx | ---
title: How to Export Data to XLSX Files
published: true
tags: Export,Python,Django,XLSX
canonical_url: http://djangotricks.blogspot.com/2019/02/how-to-export-data-to-xlsx-files.html
---
 easily upgrades all your network clients by proxying plaintext DNS to encrypted DoH.*
The [Commons Host](https://commons.host) CDN project [recently launched](https://dev.to/commonshost/how-we-built-a-doh-cdn-with-20-global-edge-servers-in-10-days-1man) a public DNS-o... | sebdeckers |
84,416 | Top Resume Tips to Land the Job of Your Dreams | Well-researched tips to help you write a catchy resume and make a great impression when you apply for a new job. | 0 | 2019-02-20T09:14:18 | https://dev.to/drsavvina/top-resume-tips-to-land-the-job-you-want-212k | career, resume, tips, beginners | ---
title: Top Resume Tips to Land the Job of Your Dreams
published: true
description: Well-researched tips to help you write a catchy resume and make a great impression when you apply for a new job.
tags: career, resume, tips, beginners
cover_image: https://1kabswnt2ua3ivl0cuqv2f17-wpengine.netdna-ssl.com/wp-content/u... | drsavvina |
84,665 | An Introduction to Queries in PostgreSQL | An introduction to queries in PostgreSQL | 0 | 2019-02-21T23:47:47 | https://www.digitalocean.com/community/tutorials/introduction-to-queries-postgresql | tutorial, postgres, database | ---
title: An Introduction to Queries in PostgreSQL
published: true
description: An introduction to queries in PostgreSQL
tags: tutorial, postgres, database
canonical_url: https://www.digitalocean.com/community/tutorials/introduction-to-queries-postgresql
cover_image: https://cl.ly/f3bb3f2599bf/Image%202019-02-2... | mdrakedo |
84,735 | Look for advice - need React component library for pet project | Hello! I have a pet project and I plan to rewrite it in React. Couple words about project: It is wo... | 0 | 2019-02-20T23:33:05 | https://dev.to/ntsdk/look-for-advice---need-react-component-library-for-pet-project-1dkk | react, javascript | ---
title: Look for advice - need React component library for pet project
published: true
description:
tags: react, javascript
---
Hello! I have a pet project and I plan to rewrite it in React.
Couple words about project:
- It is working in browser
- It supposes a lot of text editing, visual editing, pl... | ntsdk |
84,768 | Sometimes, in the heat of the moment, it's forgivable to cause a runtime exception. | Perhaps we could benefit from putting more thought into how our code can fail, and who is going to see it when it does. | 0 | 2019-02-21T01:32:39 | https://dev.to/nimmo/sometimes-in-the-heat-of-the-moment-its-forgivable-to-cause-a-runtime-exception-2ko2 | javascript | ---
title: Sometimes, in the heat of the moment, it's forgivable to cause a runtime exception.
published: true
description: Perhaps we could benefit from putting more thought into how our code can fail, and who is going to see it when it does.
tags: javascript
---
Runtime errors _suck_. But when you're working in JS t... | nimmo |
84,826 | Anatomy of functors and category theory | I'll try to give you an intuition about what is a functor and what do they look like in Scala. Then the ones being curious about theory can keep on reading because we'll take a quick glance at category theory and what are functors in category theory terms. Then we'll try to bridge the gap between category theory and pu... | 432 | 2019-02-21T08:51:28 | http://geekocephale.com/blog/2019/02/16/functors-cat-theory | scala, functional | ---
title: "Anatomy of functors and category theory"
published: true
description: "I'll try to give you an intuition about what is a functor and what do they look like in Scala. Then the ones being curious about theory can keep on reading because we'll take a quick glance at category theory and what are functors in ... | mmenestret |
84,930 | Adding Pages to a Gatsby Project | How to add new pages to a Gatsby project and navigate between them with Gatsby's Link component. | 6,774 | 2019-02-21T16:27:43 | https://michaeluloth.com/gatsby-adding-pages/ | gatsby, react, beginners | ---
title: Adding Pages to a Gatsby Project
description: How to add new pages to a Gatsby project and navigate between them with Gatsby's Link component.
canonical_url: https://michaeluloth.com/gatsby-adding-pages/
tags: gatsby, react, beginners
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/7bmn1ovozc4p9gy3t0a... | ooloth |
85,286 | Decorator design pattern [Structural] | The Decorator Design Pattern allows adding new behavior to existing types. We can... | 0 | 2019-02-26T03:25:58 | https://itscoderslife.wordpress.com/2019/02/23/decorator-design-pattern-structural/ | blog, concepts, designpattern, extension | ---
title: Decorator design pattern [Structural]
published: true
tags: blog,concepts,Design Pattern,extension
canonical_url: https://itscoderslife.wordpress.com/2019/02/23/decorator-design-pattern-structural/
---
The Decorator Design Pattern allows adding new behavior to existing types. We can extend the functi... | itscoderslife |
85,294 | Automatización con Shell Scripts | Aprendí a usar Shell Scripting y en este tutorial comparto las cosas que aprendí con un script simple de instalación de un proyecto. | 0 | 2019-02-23T05:00:45 | https://sergiodxa.com/articles/automatizacion-shell-scripts | spanish, shell, automate, todayilearned | ---
title: Automatización con Shell Scripts
published: true
description: Aprendí a usar Shell Scripting y en este tutorial comparto las cosas que aprendí con un script simple de instalación de un proyecto.
tags: spanish, shell, automate, til
canonical_url: https://sergiodxa.com/articles/automatizacion-shell-script... | sergiodxa |
129,183 | Next.js vs. Create React App: Whose apps are more performant? |
Introduction
What are the performance differences between Next.js and ... | 0 | 2019-07-08T20:22:38 | https://blog.logrocket.com/next-js-vs-create-react-app/ | createreactapp, nextjs, react | ---
title: Next.js vs. Create React App: Whose apps are more performant?
published: true
tags: create-react-app,nextjs,react
canonical_url: https://blog.logrocket.com/next-js-vs-create-react-app/
---

## Introduction
What are the performance dif... | bnevilleoneill |
85,504 | Peacock - Choose What to Color | Visually identify different VS Code instances with colors that you select | 0 | 2019-02-24T04:45:13 | https://dev.to/john_papa/peacock---choose-what-to-color-33mg | vscode, javascript, fun | ---
title: Peacock - Choose What to Color
published: true
description: Visually identify different VS Code instances with colors that you select
tags: vscode, javascript, fun
cover_image: https://thepracticaldev.s3.amazonaws.com/i/b6f462wg5xd7ca5mmvat.jpg
---
Last Week I released [Peacock](https://marketplace.... | john_papa |
85,800 | Migrating to TypeScript, Part 2: Trust the compiler! | Header image by Irina Iriser on Unsplash. In part 1, we explored how to initialise a project with... | 443 | 2019-02-25T09:35:46 | https://resir014.xyz/posts/2019/02/25/migrating-to-typescript-part-2/ | typescript, javascript, beginners, programming | ---
title: Migrating to TypeScript, Part 2: Trust the compiler!
published: true
tags: typescript, javascript, beginners, programming
cover_image: https://thepracticaldev.s3.amazonaws.com/i/2zb1km4n88lvvsvmj8bz.jpg
canonical_url: https://resir014.xyz/posts/2019/02/25/migrating-to-typescript-part-2/
series: Migrati... | resir014 |
85,990 | Random gif generator, Pricing cards, Cloudinary uploader & more | Module Monday 29 | Module Monday 29 | 0 | 2019-02-25T17:10:56 | https://guide.anymod.com/module-monday/29.html | showdev, opensource, webdev, javascript | ---
title: Random gif generator, Pricing cards, Cloudinary uploader & more | Module Monday 29
published: true
description: Module Monday 29
tags: showdev, opensource, webdev, javascript
cover_image: https://res.cloudinary.com/component/image/upload/b_rgb:f6f6f6,c_pad,h_370,w_880/v1550949608/gif-generator_j8sqy1.gi... | tyrw |
85,998 | Read YAMLy config with a few lines of code |
Originally posted on detunized.net
I was working on a C# library and in a simp... | 0 | 2019-02-25T17:51:54 | https://detunized.net/posts/2019-02-25-read-yamly-config-with-a-few-lines-of-code/ | csharp, javascript, ruby | ---
title: "Read YAMLy config with a few lines of code"
published: true
canonical_url: https://detunized.net/posts/2019-02-25-read-yamly-config-with-a-few-lines-of-code/
tags:
- c-sharp
- javascript
- ruby
- go
---
*Originally posted on [detunized.net](https://detunized.net/posts/2019-02-25... | detunized |
86,008 | Understanding git for real by exploring the .git directory | “Whoah, I’ve just read this quick tuto about git and oh my god it is cool. I feel now super... | 466 | 2019-02-25T19:09:04 | https://www.daolf.com/posts/git-series-part-1/ | git, junior, showdev, beginners | ---
title: Understanding git for real by exploring the .git directory
published: true
description:
cover_image: https://thepracticaldev.s3.amazonaws.com/i/va29dwhc3dkk6qdq8xi1.png
tags: [git, junior, showdev, beginner]
series: "Mastering Git"
canonical_url: "https://www.daolf.com/posts/git-series-part-1/"
---
> # “Wh... | daolf |
86,039 | How to manage Local vs Dev vs Prod settings.py in latest Django RestAPI? | as we have some common settings in both local and prod; how to manage the settings that are different from local vs dev vs prod; such as database connections, installed apps, etc... | 0 | 2019-02-25T20:31:34 | https://dev.to/thammuio/how-to-manage-local-vs-dev-vs-production-settings-in-latest-django-restapi-28n6 | help, django, python, discuss | ---
title: How to manage Local vs Dev vs Prod settings.py in latest Django RestAPI?
published: true
description: as we have some common settings in both local and prod; how to manage the settings that are different from local vs dev vs prod; such as database connections, installed apps, etc...
tags: help, django, p... | thammuio |
86,592 | How to starting software development | Deneme | 0 | 2019-02-26T13:41:34 | https://dev.to/enesfurkangenc/how-to-starting-software-development-2e3 | ---
title: How to starting software development
published: true
description: Deneme
tags:
---
| enesfurkangenc | |
86,902 | Optional chaining: What is it, and how can you add it to your JavaScript application right now? | Optional chaining gives you a concise way to handle issues that crop up with values in JS that may be `undefined`. | 0 | 2019-02-27T16:40:51 | https://dev.to/nimmo/optional-chaining-what-is-it-and-how-can-you-add-it-to-your-javascript-application-right-now-37ie | javascript, optionalchaining, babel | ---
title: Optional chaining: What is it, and how can you add it to your JavaScript application right now?
published: true
description: Optional chaining gives you a concise way to handle issues that crop up with values in JS that may be `undefined`.
tags: javascript, optionalChaining, babel
---
_This post assumes tha... | nimmo |
107,711 | Time Tracking: Kimai2 0.9 on OpenBSD | Kimai is time-tracking app. It's open source, published under MIT license, and based on the latest PHP Symfony. I'll show how to install Kimai2 in this post. | 880 | 2019-05-12T13:33:44 | https://dev.to/nabbisen/time-tracking-kimai2-1-0-on-openbsd-9k | kimai, timetracking, opensource, installation | ---
title: Time Tracking: Kimai2 0.9 on OpenBSD
published: true
description: Kimai is time-tracking app. It's open source, published under MIT license, and based on the latest PHP Symfony. I'll show how to install Kimai2 in this post.
tags: kimai, time tracking, open source, installation
cover_image: https://thepractic... | nabbisen |
110,257 | Meetups, the right way | Meetups, the right way Under this provocative, clickbait title, I hope these feedback can... | 0 | 2019-05-19T15:04:55 | https://dev.to/paulleclercq/meetups-the-right-way-38bi | meetup | # Meetups, the right way
Under this provocative, clickbait title, I hope these feedback can help meetups organizers to better target their audience and make meetups more valuable for everyone.
These feedback come from meetups of different people, cities and countries: Montpellier, Paris, Marseille, New York, Montréal a... | paulleclercq |
115,022 | Project Euler #4 - Largest Palindrome Product | Solving problem #4 from Project Euler, largest palindrome product | 1,012 | 2019-05-28T13:46:49 | https://dev.to/peter/project-euler-4-largest-palindrome-product-3165 | projecteuler, challenge | ---
title: Project Euler #4 - Largest Palindrome Product
published: true
description: Solving problem #4 from Project Euler, largest palindrome product
tags: projecteuler, challenge
series: Project Euler
---
I'm bumping a "series" that I started last year, where we collectively work on problems from [Project Euler](ht... | peter |
118,253 | Blog post: Release 1.46 of Workflow (Perl) | a release announcement | 0 | 2019-06-05T10:18:56 | https://dev.to/jonasbn/blog-post-release-1-46-of-workflow-perl-5600 | perl, workflow, release | ---
title: Blog post: Release 1.46 of Workflow (Perl)
published: true
description: a release announcement
tags: perl, workflow, release
---
I have just released [Workflow](https://jonasbn.github.io/perl-workflow/) 1.46, a library for building simple state machines in Perl. The release contains a simple patch from an ex... | jonasbn |
128,753 | Right things to do after changing to better domain’s host | .Many things to do after pointing out the domain to another host for whatever rea... | 0 | 2019-06-26T13:11:59 | https://kevinhq.com/things-to-do-after-changing-the-domains-host/ | webhosting, domain | ---
title: Right things to do after changing to better domain’s host
published: true
tags: Web Hosting, domain, web hosting
canonical_url: https://kevinhq.com/things-to-do-after-changing-the-domains-host/
---
.Many things to do after pointing out the domain to another host for whatever reasons. Missing one of them may... | kevinhq |
128,932 | Using Browser Custom Events | A lot of times when writing things you may want want to react to certain events on your page. We do... | 0 | 2019-06-26T18:35:08 | https://dev.to/dropconfig/using-browser-custom-events-1do9 | javascript, webdev, beginners | A lot of times when writing things you may want want to react to certain events on your page.
We do this all the time with builtin ones like `click` or `keydown`
But we can also make our own custom events and have the browser handle all the work for us! Since it's part of the DOM API we get free event code without in... | powerc9000 |
129,146 | while loops that have an index | Perl5 got this syntax that allow to use a while loop without having to explicitly incrementing an... | 0 | 2019-06-27T10:28:45 | https://dev.to/smonff/while-loops-that-have-an-index-56h2 | perl, testing, loop, each | Perl5 got this syntax that allow to use a while loop without having to explicitly incrementing an index by doing an `i++`. It is made possible by the [`each` function](https://perldoc.pl/functions/each).
Let's demonstrate this in a simple test that check that and array and an array ref contains the same things:
```pe... | smonff |
129,182 | Fork Me! FCC: Test Suite Template | A post by Sherry | 0 | 2019-06-27T13:08:42 | https://dev.to/sherrykay/fork-me-fcc-test-suite-template-5mj | codepen | {% codepen https://codepen.io/sherryk/pen/agVWzr %} | sherrykay |
129,227 | Poll: why does clicking a DEV comment link display the comment in isolation? | Do you like DEV's ux for linking to comments? | 0 | 2019-06-27T14:34:36 | https://dev.to/johncarroll/poll-why-does-clicking-a-dev-comment-link-display-the-comment-in-isolation-2k5n | discuss, meta | ---
title: Poll: why does clicking a DEV comment link display the comment in isolation?
published: true
description: Do you like DEV's ux for linking to comments?
tags: discuss, meta
---
For those who aren't familiar, when you click on a comment link in DEV.to, you are taken to a page which displays only that comment ... | johncarroll |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.