
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
201,732 | js typewriter | A post by weptim | 0 | 2019-11-07T10:00:55 | https://dev.to/weptim/js-typewriter-3a4f | 100daysofcode | {% codepen https://codepen.io/weptim/pen/dyyeVQx %} | weptim |
201,823 | Convert PDF to Editable DOCX with Python | While working with document conversion feature, you came across a requirement to convert PDF to DOCX.... | 0 | 2019-11-07T12:56:18 | https://blog.groupdocs.cloud/2019/11/06/convert-pdf-to-editable-word-document-with-python-sdk/ | python, pdftodocx, documentconversion, restapi | While working with document conversion feature, you came across a requirement to convert PDF to DOCX. I would like to introduce GroupDocs.Conversion Cloud SDK for Python for the purpose. It can also convert all popular industry standard documents from one format to another without depending on any third-party tool or s... | tilalahmad |
201,881 | Day 5 of⚡️ #30DaysOfWebPerf ⚡️: Your laptop is a filthy liar | Sia Karamalegos @thegree... | 3,017 | 2019-11-07T14:32:24 | https://sia.codes/posts/30-days-web-perf-5/ | webperf, devtools, webpagetest, webdev | {% twitter 1192448463717437440 %}
{% twitter 1192448470419943429 %}
{% twitter 1192448472202518531 %}
{% twitter 1192448473196613633 %}
{% twitter 1192448474379423744 %}
| thegreengreek |
201,922 | Don't throw away your old MBP, upgrade it!. | I have a Mid-2010 MBP that my kids use for homework, youtube and "stuff". Back then Apple allowed yo... | 0 | 2019-11-07T16:00:39 | https://dev.to/hminaya/don-t-throw-away-your-old-mbp-upgrade-it-1ld0 | hardware, mac, beginners, upgrade | I have a Mid-2010 MBP that my kids use for homework, youtube and "stuff".
Back then Apple allowed you to swap out some of the internal components (HDD, RAM, Battery) and perform upgrades. If you still have one of these MBPs it's still worth it to do some small upgrades and get some more life out if.
So far I've done ... | hminaya |
884,640 | How I Manage My Knowledge | This post is originally from my blog. This is an overview of the tools and software I use to... | 0 | 2021-11-01T21:16:18 | https://dev.to/uzayg/how-i-manage-my-knowledge-1cgp | automation, python, productivity, git | This post is originally from my [blog](https://www.uzpg.me/general/2021/07/20/my-knowledge-process.html).
This is an overview of the tools and software I use to maintain and index of my knowledge and life in an efficient and shareable way.
# Tech
The main knowledge base program I use to save and gather information ... | uzayg |
202,140 | What is cloud computing, benefits and services? | Cloud computing provides a simple way to access servers, storage, databases and a broad set of applic... | 0 | 2019-11-08T03:28:36 | https://dev.to/siddharthr0318/what-is-cloud-computing-benefits-and-services-22ao | aws, linux, cloudcomputing | Cloud computing provides a simple way to access servers, storage, databases and a broad set of application services over the Internet.
Benefits of Cloud Computing:
Flexibility
Pay per service
Security
Environmental Friendly
Disaster Recovery
Read More: https://realprogrammer.in/what-is-cloud-computing-benefits-and-s... | siddharthr0318 |
202,166 | What is Big-O Notation? Understand Time and Space Complexity in JavaScript. | As we know, there may be more than one solution to any problem. But it is hard to define, what is the... | 0 | 2020-01-10T08:43:05 | https://dev.to/chandra/what-is-big-o-notation-understand-time-and-space-complexity-in-javascript-4684 | javascript, productivity, bigonotation, algorithms | As we know, there may be more than one solution to any problem. But it is hard to define, what is the best approach and method of solving that programming problem.
Writing an algorithm that solves a definite problem gets more difficult when we need to handle a large amount of data. How we write each and every syntax i... | chandra |
202,205 | Symfony on a lambda: first deployment | Deploy easely Symfony application on a AWS Lambda | 3,140 | 2019-11-08T07:27:54 | https://julesmatsounga.com/en/article/symfony-lambda-chapter-1 | php, symfony, lambda, serverless | ---
title: Symfony on a lambda: first deployment
published: true
description: Deploy easely Symfony application on a AWS Lambda
tags: PHP, Symfony, Lambda, Serverless
series: Symfony on a lambda
canonical_url: https://julesmatsounga.com/en/article/symfony-lambda-chapter-1
---
# Symfony on a lambda: first deployment
**... | hyoa |
202,291 | What's the most inefficient thing you do? | We all have weird things we do, long ways around short problems. We should probably get around to... | 0 | 2019-11-08T11:03:54 | https://dev.to/moopet/what-s-the-most-inefficient-thing-you-do-4bmh | discuss, workflow, watercooler | ---
title: What's the most inefficient thing you do?
published: true
tags: discuss, workflow, watercooler
cover_image: https://thepracticaldev.s3.amazonaws.com/i/j1egpfb1l5pamnsfseec.jpg
---
We all have weird things we do, long ways around short problems. We should probably get around to sorting them out, but we've go... | moopet |
202,342 | Setting Up a Python Remote Interpreter Using Docker | Why a Remote Interpreter instead of a Virtual Environment? A well-known pattern in Python... | 0 | 2019-11-08T13:28:19 | https://dev.to/alvarocavalcanti/setting-up-a-python-remote-interpreter-using-docker-1i24 | python, pycharm, vscode, tdd | # Why a Remote Interpreter instead of a Virtual Environment?
A well-known pattern in Python (and many other languages) is to rely on virtual environment tools (`virtualenv`, `pyenv`, etc) to avoid the [SnowflakeServer](https://martinfowler.com/bliki/SnowflakeServer.html) anti-pattern. These tools create an isolated en... | alvarocavalcanti |
202,369 | How to build applications with Vue’s composition API | Written by Raphael Ugwu✏️ Vue’s flexible and lightweight nature makes it really awesome for... | 0 | 2019-11-10T16:53:29 | https://blog.logrocket.com/how-to-build-applications-with-vues-composition-api/ | vue, javascript, tutorial, webdev | ---
title: How to build applications with Vue’s composition API
published: true
date: 2019-11-08 14:00:31 UTC
tags: vue,javascript,tutorial,webdev
canonical_url: https://blog.logrocket.com/how-to-build-applications-with-vues-composition-api/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/qjup3j93vxj4foj548zh.p... | bnevilleoneill |
202,381 | 9 Ways to Increase Your Financial Flow | The simplest way of calculating your cash flow is to deduct your expenses from your income. The formu... | 0 | 2019-11-08T14:38:09 | https://dev.to/anna_j_stinson/9-ways-to-increase-your-financial-flow-3age | The simplest way of calculating your cash flow is to deduct your expenses from your income. The formula itself is rather simple and tells you that you can increase your disposable cash by either increasing your income or reducing your expenses. Both are valid ways, but often the best results are achieved by combining b... | anna_j_stinson | |
202,408 | Dual-booting Linux Mint | Why Linux I’ve always heard that Linux is the way to go but I never tried it. I had... | 0 | 2019-11-21T17:53:10 | https://dev.to/stephencavender/dual-booting-linux-mint-3cgk | linux | ---
title: Dual-booting Linux Mint
published: true
date: 2019-11-08 05:00:00 UTC
tags: Linux
canonical_url:
---
## Why Linux
I’ve always heard that Linux is the way to go but I never tried it. I had Windows and it worked fine for me. I took some training at work that required Linux so I started using it inside a vir... | stephencavender |
202,441 | Spartan Breakpoints! | Just wanted to get some opinions from other UI Enthusiasts about the breakpoints they are using for their UIs | 0 | 2019-11-08T22:57:39 | https://dev.to/srsheldon/spartan-breakpoints-59a1 | responsive, css, breakpoints, ux | ---
title: Spartan Breakpoints!
published: true
description: Just wanted to get some opinions from other UI Enthusiasts about the breakpoints they are using for their UIs
tags: responsive, css, breakpoints, ux
---

So I know this topic has pr... | srsheldon |
202,494 | problem rendering images in react app | Hello I am fairly new to react & node. I have an app which displays image buttons amongst other t... | 0 | 2019-11-08T18:39:36 | https://dev.to/rrn518/problem-rendering-images-in-react-app-5d64 | Hello
I am fairly new to react & node. I have an app which displays image buttons amongst other things. When starting from visual studio code they render perfectly unless my associated node listener is started first on the same port, in which case they don't render at all. 404 is returned for all. Why is that and what... | rrn518 | |
886,077 | A new life transition | Its true that with any transition in life there’s upheaval, fear, and frustration, that’s the point... | 0 | 2021-11-03T02:46:01 | https://dev.to/mikeketterling/a-new-life-transition-5kd | beginners, career | Its true that with any transition in life there’s upheaval, fear, and frustration, that’s the point of a transition. I think that sharing any life transition ultimately helps inspire at least someone out there, and therefore, doing something good for someone. That’s all I hope for with this and any other posts I’ll b... | mikeketterling |
202,507 | Machine Learning Applications in Tabletop Gaming | Digital Dungeon Diving Those who know me are well aware of my passion for gaming (To those who don... | 0 | 2019-11-08T19:11:35 | https://dev.to/geoffreyianward/machine-learning-applications-in-tabletop-gaming-dng | <h3>Digital Dungeon Diving</h3>

<p>Those who know me are well aware of my passion for gaming (To those who don't know me - hello! I love gaming). While I love all forms of gaming, I have a special place in my heart for tabletop games. I lo... | geoffreyianward | |
202,539 | Default a View in NavigationView with SwiftUI | A guide to default a View in NavigationView with SwiftUI | 3,158 | 2019-11-08T21:14:42 | https://medium.com/@maeganwilson_/default-a-view-in-navigationview-with-swiftui-b6e64a17fb20 | swift, swiftui | ---
title: Default a View in NavigationView with SwiftUI
published: true
description: A guide to default a View in NavigationView with SwiftUI
tags: swift, swiftui
canonical_url: https://medium.com/@maeganwilson_/default-a-view-in-navigationview-with-swiftui-b6e64a17fb20
series: SwiftUI Examples
---
# Default a View i... | maeganwilson_ |
202,591 | Python: Compile standalone executable with nuitka | So nuitka compile python code into an executable. I have always impress with Go ability to generate s... | 0 | 2019-11-09T02:07:47 | https://dev.to/k4ml/python-compile-standalone-executable-with-nuitka-1ml1 | python | So nuitka compile python code into an executable. I have always impress with Go ability to generate single binary and even cross compile for different OS. I wish we can have the same thing with python.
As always, let's start with just a simple script first:-
```
import requests
resp = requests.get("https://httpbin... | k4ml |
202,732 | Noob Exercises | Just started with a place, where I am trying to give some of people, I have been teaching some assign... | 0 | 2019-11-09T14:48:38 | https://dev.to/th3n00bc0d3r/noob-excercises-19kj | html, tutorial, css, javascript | Just started with a place, where I am trying to give some of people, I have been teaching some assignment, thought if there are more people interested in it, would be a good share.
We are starting with Vanilla JS, CSS and HTML
I will be personally looking at all submission and will do my best to comment on the submis... | th3n00bc0d3r |
202,769 | Reading through the Python standard library | A couple of years ago I decided to read the entire Python standard library. A few months back, I fin... | 0 | 2019-11-27T18:05:43 | https://www.mattlayman.com/blog/2016/readthrough-python-standard-library/ | python | A couple of years ago I decided to read the entire Python standard library. A few months back, I finished.
What I learned is this: **while there is some interesting "hidden" stuff in there, you don't need to do this to become proficient.**
Did you know that nearly all the HTTP status codes are in the standard librar... | mblayman |
202,779 | HELLO Docker Desktop Windows Subsytem for Linux 2 Tech Preview | A couple of days ago, during my Thursday Twitch stream. I made the amazing discovery that Docker has... | 0 | 2019-11-09T18:50:54 | https://dev.to/talk2megooseman/hello-docker-desktop-windows-subsytem-for-linux-2-tech-preview-4kp2 | ubuntu, docker, tutorial | A couple of days ago, during my Thursday Twitch stream. I made the amazing discovery that [Docker has a `Docker Desktop WSL 2 Tech Preview`.](https://docs.docker.com/docker-for-windows/wsl-tech-preview/)
### [Why is this amazing?](#why)
Now applications that are running inside of `Linux Subsystem` can directly run do... | talk2megooseman |
202,799 | Branch Previews with Google App Engine and GitHub Actions | Leveraging GitHub Actions for easy-to-use, automated branch preview deployments | 0 | 2019-11-09T19:20:00 | https://dev.to/bobheadxi/branch-previews-with-google-app-engine-and-github-actions-3pco | automation, tutorial, devops, deployment | ---
title: Branch Previews with Google App Engine and GitHub Actions
published: true
description: Leveraging GitHub Actions for easy-to-use, automated branch preview deployments
tags: automation, tutorial, devops, deployment
cover_image: https://bobheadxi.dev/assets/images/posts/appengine/branch-staged.png
---
> **⚠️ ... | bobheadxi |
202,877 | Comparing Services for Cheap Cloud Hosting and Storage (Cloud / AWS / S3 / Amazon Cloudfront / ... ???) | Hi Dev.to! 👋👋👋 Some questions for all you performance aficionados and AWS / Cloud experts out there... | 0 | 2019-11-09T22:54:03 | https://dev.to/kp/comparing-services-for-cheap-cloud-hosting-and-storage-cloud-aws-s3-amazon-cloudfront-3i1g | explainlikeimfive, help, aws | Hi Dev.to! 👋👋👋
Some questions for all you performance aficionados and AWS / Cloud experts out there.
I'm looking for a cheap (as close to free as possible) service for:
#### 1. Hosting AND serving images. These images will be used on a website, in emails, etc. I want to plan for:
* 100GB of added storage / mont... | kp |
202,911 | Recursion | Recursion | 0 | 2019-11-10T02:54:53 | https://dev.to/nickytonline/recursion-5fbf | jokes | [Recursion](https://dev.to/nickytonline/recursion-5fbf)
{%instagram B4qzQvlpN1g %} | nickytonline |
202,954 | React app global state management with hooks | React app global state management made easy with hooks and Context API: https://link.medium.com/bZ... | 0 | 2019-11-10T08:41:01 | https://dev.to/spinalorenzo/react-app-global-state-management-with-hooks-5b20 | react, javascript |

React app global state management made easy with hooks and Context API:
https://link.medium.com/bZs5cKG6r1
How to achieve this:
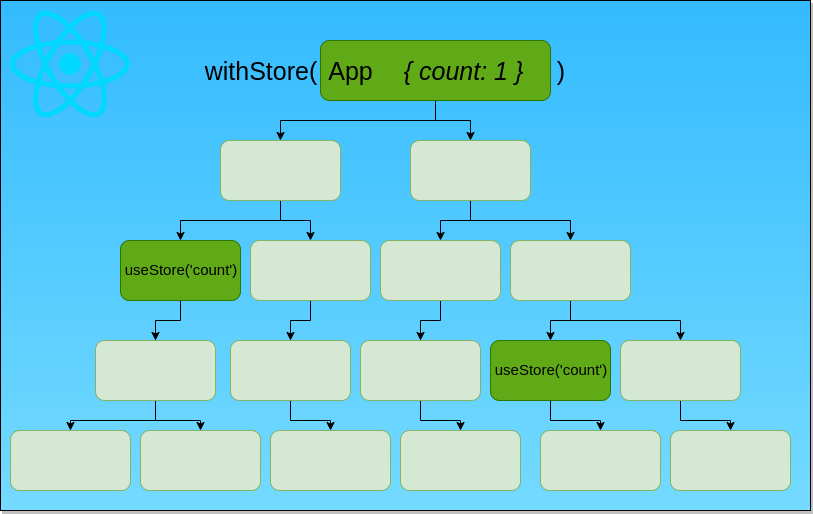
You can read how it works... | spinalorenzo |
202,981 | Building URL Shortener with MongoDB, Express Framework And TypeScript | This post was first published on my blog. Hi, in the last post I published, I talked about Express... | 0 | 2019-11-10T09:32:50 | https://dev.to/itachiuchiha/building-url-shortener-with-mongodb-express-framework-and-typescript-4a71 | typescript, mongodb, javascript, express | *This post was first [published on my blog](https://aligoren.com/building-url-shortener-with-mongodb-express-framework-and-typescript/).*
Hi, in the last post I published, I [talked](https://dev.to/aligoren/developing-an-express-application-using-typescript-3b1 "talked") about Express Framework and TypeScript. In thi... | itachiuchiha |
203,086 | Monadic parser combinators in C# | The concept of parsing has always seemed very complicated to me. I thought that to work in this area... | 0 | 2019-11-10T15:55:35 | https://tyrrrz.me/blog/monadic-parser-combinators | csharp, parser, monads, functional | The concept of parsing has always seemed very complicated to me. I thought that to work in this area you had to have access to some secret knowledge brought by an alien race or something.
Some time ago, I had to implement proper markdown parsing in [DiscordChatExporter](https://github.com/Tyrrrz/DiscordChatExporter) s... | tyrrrz |
203,126 | Code is for co-workers, not compilers | An argument for making code more readable for humans | 6,831 | 2019-11-10T18:38:57 | https://dev.to/fluffynuts/code-is-for-co-workers-not-compilers-580g | programming, style, refactoring | ---
title: Code is for co-workers, not compilers
published: true
description: An argument for making code more readable for humans
tags: programming,style,refactoring
cover_image: https://thepracticaldev.s3.amazonaws.com/i/qu102h74vs6ssfq8sv1i.jpg
series: pragmatic-programmer
---
Whilst the primary intent of code is t... | fluffynuts |
203,132 | Running laravel queue worker on two different applications that share the same database | Prerequisites PHP LARAVEL NOTE: If you already understand laravel queues, and you're... | 0 | 2019-11-10T21:06:19 | https://dev.to/ajimoti/running-laravel-queue-worker-on-two-different-applications-that-share-the-same-database-ff3 | laravel, queue, php | ---
title: Running laravel queue worker on two different applications that share the same database
published: true
description:
tags: laravel, queue, PHP
cover_image: https://cdn-images-1.medium.com/max/1600/0*JuDOoqYySHEoMX-x.jpg
---
#Prerequisites
1. PHP
2. LARAVEL
**NOTE:** If you already understand laravel queue... | ajimoti |
203,206 | Stockpile of Resources | There is an endless supply of articles, tutorials, frameworks, etc out there on the internet. If noth... | 3,656 | 2019-11-10T23:06:48 | https://dev.to/jaredharbison/the-little-things-3egk |
There is an endless supply of articles, tutorials, frameworks, etc out there on the internet. If nothing else, this is a catch-all for me to keep track of the resources I've come across that I imagine will help me out in the future. I'm currently thinking I'll refresh this single post often with my favorites, rather t... | jaredharbison | |
203,277 | What's New in Angular 9? | Angular 9 is the smaller, faster, and easier to use and it will be making Angular developers life eas... | 0 | 2019-11-11T05:23:52 | https://dev.to/anilsingh/what-s-new-in-angular-9-56j9 | angular, typescript, angular9 | Angular 9 is the smaller, faster, and easier to use and it will be making Angular developers life easier. The fully version of Angular 9 will be released in the month of October/November 2019.
Added Angular 9 Features -
1. Added undecorated classes migration schematic in the core.
2. The formControlName also accepts a... | anilsingh |
203,305 | Qt Installer Framework: TypeError cannot read property name | Qt Installer Framework: TypeError can... | 0 | 2019-11-11T07:30:48 | https://dev.to/matthijs990/qt-installer-framework-typeerror-cannot-read-property-name-3p8b | {% stackoverflow 58791830 %} | matthijs990 | |
203,352 | WEB COMPONENTS VS. FRAMEWORKS: A Podcast | Happy Friday, Hackers! Today we've got some food-for-thought content for you! Davy and Danny discuss... | 0 | 2019-11-11T11:01:59 | https://dev.to/hackflix_dev/web-component-vs-frameworks-a-podcast-732 | javascript, webdev, typescript, todayilearned | Happy Friday, Hackers! Today we've got some food-for-thought content for you! Davy and Danny discuss when to use PWAs vs. Native App or if you need an app at all and just a really responsive website. Continue to watch the FULL VIDEO on a discussion about web components vs. frameworks and much more!
WATCH THE FULL VID... | hackflix_dev |
203,387 | Mongodb replace external id after $lookup | Hi, im going crazy... I want to replace the userId inside the comments with the real user after the... | 0 | 2019-11-11T10:43:52 | https://dev.to/d0xzen/mongodb-replace-external-id-after-lookup-je7 | help | Hi, im going crazy...
I want to replace the userId inside the comments with the real user after the $lookup, i tried in many ways, i tried to group but i cant really reach what i want
This is my field inside the page collection:
<pre>
"comments" : [
{
"user_Id" : ObjectId("aaa"),
"content" : "aaaa",
"rep... | d0xzen |
203,394 | The Git Supremacy | After addressing the elephant in the room (Git vs GitHub). Let's look at how to start working with bo... | 0 | 2019-11-11T12:55:46 | https://medium.com/@mayank.uiet7/the-git-supremacy-fd469fb06777 | github, git, beginners, tutorial | After addressing the elephant in the room (Git vs GitHub).
Let's look at how to start working with both.
###Scenario 1:
**You are going to work on a repository that already exists.**
+ **FORK**
1. Forking is copying the contents of the main repository and pasting it in a new repository on your _GitHub_ account.
... | mayankarya |
203,434 | Data Privacy Impact Assessment Module | Helical is a unified cybersecurity management solution. This solution provides Automated assessment t... | 0 | 2019-11-11T12:15:45 | https://dev.to/helicalinc/data-privacy-impact-assessment-module-4005 | Helical is a unified cybersecurity management solution. This solution provides Automated assessment to evaluate the readiness and maturity of privacy controls per relevant regulatory requirements like as GDPR and CCPA.
Read more: https://helical-inc.com/hlcproducts/data-privacy-regulatory-assessment/ | helicalinc | |
203,507 | Some useful TypeScript snippets | Pick If you need to construct a new type based on some properties of an interface you alwa... | 0 | 2019-11-11T15:53:25 | https://dev.to/mbrtn/some-useful-typescript-snippets-2278 | typescript, productivity, codenewbie, tutorial | ## Pick
If you need to construct a new type based on some properties of an interface you always can get the `Pick` utility type.
```typescript
interface MyInterface {
id: number;
name: string;
properties: string[];
}
type MyShortType = Pick<MyInterface, 'name' | 'id'>;
```
Now `MyShortType` only have `name` a... | mbrtn |
203,541 | How many people dream about code? | At least once a week I have intense stress dreams about fixing bugs in my teams code base. Then I wa... | 0 | 2019-11-11T16:24:53 | https://dev.to/cloakedstudios/how-many-people-dream-about-code-1ika | At least once a week I have intense stress dreams about fixing bugs in my teams code base. Then I wake up in a panic and realize everything is fine. Anyone else experience this? I don't see myself as being under a lot of stress. | cloakedstudios | |
203,545 | who into NLP? 📚 | my ObservableHQ NLP collection | 0 | 2019-11-11T16:34:15 | https://dev.to/tarasnovak/who-into-nlp-1hco | discuss, nlp, jsnotebooks, collections | ---
title: who into NLP? 📚
published: true
description: my ObservableHQ NLP collection
tags: #discuss #nlp #jsNotebooks #collections
---
For the NLP & Observable HQ [#jsNotebooks 📚](https://twitter.com/search?q=%23jsNotebooks&src=typed_query) fans out there:
https://observablehq.com/collection/@randomfractals/nlp
... | tarasnovak |
203,581 | Why successful blockchains should be built on the BEAM. | Learn how Arc Block (founding sponsors of the Erlang Ecosystem Foundation) use the Erlang VM to build a blockchain framework and why the BEAM is perfect for building dApps. | 0 | 2019-11-11T17:22:53 | https://dev.to/erlang_solutions/why-successful-blockchains-should-be-built-on-the-beam-4na7 | dapps, blockchain, erlang, beamvm | ---
title: Why successful blockchains should be built on the BEAM.
published: true
description: Learn how Arc Block (founding sponsors of the Erlang Ecosystem Foundation) use the Erlang VM to build a blockchain framework and why the BEAM is perfect for building dApps.
tags: dApps, blockchain, Erlang, BEAM VM,
cover_im... | erlangsolutions |
203,593 | Jobless is better than in the wrong job. Insecurity is better than secure-but-with-caveats | Friday I took a decision, I did something I have never done before in my life: I put values ahead of... | 0 | 2019-11-11T17:41:29 | https://dev.to/samuelemattiuzzo/jobless-is-better-than-in-the-wrong-job-insecurity-is-better-than-secure-but-with-caveats-175f | life, choices, values | Friday I took a decision, I did something I have never done before in my life: I put values ahead of money, fear and security. I decided that being jobless was better than being in the wrong job, furthering a really bad cause.
I had accepted a new job in the gambling sector. For a month, that did my head in. It's not ... | samuelemattiuzzo |
203,727 | Three layers of productivity and my recommends | I think there are three layers in the productivity. The first one is personal productivity, the seco... | 0 | 2019-11-11T21:15:58 | https://dev.to/yuno_miyako/three-layers-of-productivity-and-my-recommends-19d7 | I think there are three layers in the productivity.
The first one is personal productivity, the second one is team productivity, and the last layer is the architecture(or organization) productivity.
# Personal Productivity
My recommends for boosting **personal productivity** in coding are TDD, knowing data structure ... | yuno_miyako | |
203,759 | Create and Host a Svelte App in 5 minutes or less | Before you start Yes! You can have a Svelte based app up and running in as fast as 90 seco... | 0 | 2019-11-12T17:13:12 | https://triptych.writeas.com/create-and-host-a-svelte-app-in-5-minutes-or-less?pk_campaign=rss-feed | svelte, github, hosting, javascript | ---
title: Create and Host a Svelte App in 5 minutes or less
published: true
date: 2019-11-11 22:44:10 UTC
tags: svelte, github, hosting, javascript
canonical_url: https://triptych.writeas.com/create-and-host-a-svelte-app-in-5-minutes-or-less?pk_campaign=rss-feed
---
## Before you start
Yes! You can have a [Svelte](h... | triptych |
203,858 | Day 13 - Digging Deeper into CSS - Grid Layout | Well, I got busy the past 3 days and got sick but I am back. For some reason, this was a much easier... | 3,222 | 2019-11-12T04:05:12 | https://dev.to/jojonwanderlust/day-13-digging-deeper-into-css-grid-layout-3im7 | html, css, codenewbie | Well, I got busy the past 3 days and got sick but I am back.
For some reason, this was a much easier concept to learn.
What is the Grid layout? On [MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Grid_Layout/Basic_Concepts_of_Grid_Layout), it is defined as "a two-dimensional grid system to CSS". What that m... | jojonwanderlust |
203,880 | Docker Containers Explained by Renting Office Space | If you have ever visited a coworking space, then you can understand Docker via this visual tutorial. | 0 | 2019-11-12T04:53:17 | https://dev.to/kbk0125/docker-containers-explained-by-renting-office-space-p0o | webdev, beginners | ---
title: Docker Containers Explained by Renting Office Space
published: true
description: If you have ever visited a coworking space, then you can understand Docker via this visual tutorial.
tags: #webdev, #explainlikeimfive, #beginners
cover_image: https://i1.wp.com/blog.codeanalogies.com/wp-content/uploads/2019/11/... | kbk0125 |
203,939 | disable view on laravel nova attach | to disable view on attach item add this to the resource that want to be disable to view public func... | 0 | 2019-11-12T07:44:31 | https://dev.to/anditsung/disable-view-on-laravel-nova-attach-oll | laravel, nova | to disable view on attach item add this to the resource that want to be disable to view
```
public function authorizedToView(Request $request)
{
if($request->query->get("viaResource")) {
return false;
}
return true;
}
```
"$request->query->get("viaResource")" to find if the resource is accessed f... | anditsung |
203,979 | 5 Mistakes to Avoid When Building Your First Product | Mistake #1 - Solving a problem that no one has (or that no one is willing to pay for) Paul... | 0 | 2019-11-12T08:30:32 | https://www.zakmiller.com/posts/mistakes-to-avoid-when-building-your-first-product/ | startup, beginners |
## Mistake #1 - Solving a problem that no one has (or that no one is willing to pay for)
[Paul Graham wrote](http://www.paulgraham.com/startupideas.html) about how trying to come up with a startup idea is a pretty bad way to come up with a good idea. You generate a bunch of plausible-sounding ideas (that superficiall... | zakmiller |
204,002 | Challenge yourself with a JS Coding Challenge | As a mentor via CodingCoach.io I'm currently working my way through the 21 Days of Code coding challe... | 0 | 2019-11-12T09:11:24 | https://dev.to/jquinten/challenge-yourself-with-a-js-coding-challenge-20ma | javascript, codenewbie, learning, codingchallenge | As a mentor via [CodingCoach.io](https://codingcoach.io/) I'm currently working my way through the *[21 Days of Code](https://coding-challenge.lighthouselabs.ca/) coding challenge by Lighthouse Labs* with my mentees. I thought to share our findings and resolutions here, as well as offer some perspective on these events... | jquinten |
204,024 | Implementing Simple PCA using NumPy | I am open to job offers, feel free to contact me for any vacancies abroad. In this article, I will i... | 0 | 2019-11-12T20:57:58 | https://dev.to/akaame/implementing-simple-pca-using-numpy-3k0a | python, numpy, datascience, machinelearning | _I am open to job offers, feel free to contact me for any vacancies abroad._
In this article, I will implement PCA algorithm from scratch using Python's NumPy. To test my results, I used PCA implementation of scikit-learn.
```python
from sklearn.decomposition import PCA
import numpy as np
k = 1 # target dimension(s)... | akaame |
204,196 | Explain Open Source like I'm five | Explaining the concept of open source in an easy-to-understand way. | 0 | 2019-11-12T15:44:50 | https://dev.to/peter/explain-open-source-like-i-m-five-264e | explainlikeimfive | ---
title: Explain Open Source like I'm five
published: true
description: Explaining the concept of open source in an easy-to-understand way.
tags: explainlikeimfive
---
How would you explain the concept of open-source to a five year old? | peter |
205,203 | The Accessibility Tree | You can also read this post on my blog. Disabled users can and do use your page with a variety of as... | 0 | 2019-11-14T04:04:14 | https://blog.benmyers.dev/accessibility-tree/ | webdev, a11y | *You can also read this post [on my blog](https://blog.benmyers.dev/accessibility-tree).*
Disabled users can and do use your page with a variety of assistive technologies. They use screenreaders, magnifiers, eye tracking, voice commands, and more. All of these assistive technologies share a common need: they all need ... | bendmyers |
204,248 | Business Logic of an Application - My Experience as Newbie Programmer | This post appears as an entry on my personal blog also: https://mydev-journey.blogspot.com/2019/11/bu... | 0 | 2019-11-12T17:11:22 | https://dev.to/zoltanhalasz/business-logic-of-an-application-my-experience-as-newbie-programmer-1oh0 | csharp, dotnet, sql, beginners | This post appears as an entry on my personal blog also: https://mydev-journey.blogspot.com/2019/11/business-logic-of-application-my.html
If you read my other blog posts, especially the first ones, I explain there that my background is 15 years of corporate controlling (management accounting). And 2019 was for me a tra... | zoltanhalasz |
204,610 | Designing For Data Protection - Episode 106 | The practice of data management is one that requires technical acumen, but there ... | 0 | 2019-11-13T02:59:29 | https://www.dataengineeringpodcast.com/data-protection-regulations-episode-106/ | <p>The practice of data management is one that requires technical acumen, but there are also many policy and regulatory issues that inform and influence the design of our systems. With the introduction of legal frameworks such as the EU GDPR and California's CCPA it is necessary to consider how to implement data protec... | blarghmatey | |
204,676 | Lwing : Send Stylish Messages on Whatsapp, Messenger and More | ShowDEV Lwing! | 0 | 2019-11-13T07:03:48 | https://dev.to/bauripalash/lwing-send-stylish-messages-on-whatsapp-messenger-ans-more-550g | showdev, javascript, unicode | ---
title: Lwing : Send Stylish Messages on Whatsapp, Messenger and More
published: true
description: ShowDEV Lwing!
cover_image: https://thepracticaldev.s3.amazonaws.com/i/varz9iv8zaoufw8w9jix.png
---
Let's Make It Quick! 🚀
## 🔥 What is Lwing?
lwing (Pronounced as "el-wing") is basically a unicode text styler. It ... | bauripalash |
204,682 | TIL: docker commit | When I need to create a new custom Docker image, I usually start with a base imag... | 0 | 2019-11-13T10:40:08 | https://flaviabastos.ca/2019/11/13/til-docker-commit/ | commandline, todayilearned, docker | ---
title: TIL: docker commit
published: true
date: 2019-11-13 05:00:00 UTC
tags: command line,til,docker
canonical_url: https://flaviabastos.ca/2019/11/13/til-docker-commit/
---
When I need to create a new custom Docker image, I usually start with a base image (alpine, debian, python, etc, depending on the project), ... | flaviabastos |
204,815 | CORS .NET Core API, NGINX | Hello, After 2 weeks, still having a CORS issue when my vuejs frontend (running on gnix) try to reac... | 0 | 2019-11-13T12:19:01 | https://dev.to/yveralonen/cors-net-core-api-nginx-lm7 | vue, csharp, nginx, cors | Hello,
After 2 weeks, still having a CORS issue when my vuejs frontend (running on gnix) try to reach my .net core api (running on kestrek with a nginx reverse proxy).
However, I've followed all the examples and advices I've got.
Where am I wrong ? :( | yveralonen |
204,854 | What is Fragmentation? | Now that you've seen the extent of fragmentation in devices, platforms, browsers, and screen resolu... | 2,993 | 2019-11-13T13:28:50 | https://www.browserstack.com/blog/what-is-fragmentation/ | devicefragmentation, fragmentationinos, testing, softwaretesting | <a href="https://bit.ly/2X9HKHL" target="_blank"><img src="https://www.browserstack.com/blog/content/images/2019/11/Infographic_Fragmentation-01--2-.png" class="kg-image"></a>
Now that you've seen the extent of fragmentation in devices, platforms, browsers, and screen resolutions, learn how to take them into account w... | arnav1712 |
204,952 | Visualizing Hacktoberfest 2018 | I know this post is about the last year, I would like if you want a 'Visualizing Hacktoberfest 2019'... | 0 | 2019-11-13T16:33:38 | https://app.scope.ink/ | hacktoberfest, productivity, github, opensource | I know this post is about the last year, I would like if you want a 'Visualizing Hacktoberfest 2019' :)
The objective of this event is to increase contributions in Open Source projects. If you make four pull requests to an Open Repository in GitHub, you win a free t-shirt and stickers.
GitHub hosted more than 96M proj... | maluzzz |
205,017 | Model View Controller: The 3 dimensions of programming | It has been about a year since I decided that I want to switch over to computer science, and since th... | 0 | 2019-11-13T18:38:43 | https://dev.to/jihoshin28/model-view-controller-nmp | beginners | It has been about a year since I decided that I want to switch over to computer science, and since then it has been an exciting journey learning about how computers worked. All my life I have been a fairly casual computer user, and for me computers have always been something like magic to me. I would click on the butto... | jihoshin28 |
205,070 | Criando layouts responsivos e adaptativos com React e Styled-Components | Fala Techs! Sabemos que nos dias atuais, para criar sites e web apps precisamos sempre est... | 0 | 2019-11-26T03:30:31 | https://dev.to/carloscne/criando-paginas-responsivas-e-adaptativas-com-react-e-styled-components-1gje | react, javascript, css, design | ###Fala Techs!
Sabemos que nos dias atuais, para criar sites e web apps precisamos sempre estar preocupados com os diversos dispositivos e tamanhos de telas.
Muitas vezes temos um profissional de UI que faz aquele layout maravilhoso para uma tela de 1440px de largura e aí quando vamos construindo o layout usando as m... | carloscne |
205,112 | Code snippets to recreate those cool effects seen on famous(ish) sites | Today we will be looking at some snippets you can use to recreate those awesome effects you see on ot... | 0 | 2019-11-13T22:55:27 | https://dev.to/saijogeorge/code-snippets-to-recreate-those-cool-effects-seen-on-famous-ish-sites-4o16 | html, css, design | Today we will be looking at some snippets you can use to [recreate those awesome effects](https://codemyui.com/tag/deconstruction/) you see on other sites.
#Reebok Promo Image Transition - [Codepen](http://codepen.io/flacu/pen/BoLRPw/)
[ which includes the registry, the enterprise accounts and basically everything of value owned by Docker Inc. The company is now left with a shell of its former business. Even though the sale amount is... | mohanarpit |
205,278 | What Is Trackby in Angular? | The “track by” expression to specify unique keys. The trackBy function takes the index and the curre... | 0 | 2019-11-14T09:08:05 | https://dev.to/anilsingh/what-is-trackby-in-angular-27j6 | angular | The “track by” expression to specify unique keys.
The trackBy function takes the index and the current item as arguments and needs to return the unique identifier for this item.
As an Example,
https://www.code-sample.com/2019/11/trackby-in-angular-ngfor-ng-repeat.html | anilsingh |
205,292 | Google Cloud Firestore Client Library | FireO A modern and simplest convenient ORM package in Python. FireO is specifical... | 0 | 2019-11-14T09:57:02 | https://dev.to/axeemhaider/google-cloud-firestore-client-library-4mg | firestore, python, orm, fireo | # FireO
### A modern and simplest convenient ORM package in Python. FireO is specifically designed for the Google's Firestore, it's more than just ORM. It implements validation, type checking, relational model logic and much more facilities.
## Installation
```
pip install fireo
```
## Usage Example
```python
fro... | axeemhaider |
205,435 | Cómo Correr Migraciones Durante Despliegue de Aplicación Rails en Heroku | Se sabe bien que subir aplicaciones web a Heroku es sencillo. En muchos casos es solo cuestión de cor... | 0 | 2019-11-14T15:53:02 | https://otroespacioblog.wordpress.com/2019/11/10/como-correr-migraciones-durante-despliegue-de-aplicacion-rails-en-heroku/ | rails, heroku, spanish | Se sabe bien que **subir aplicaciones web a Heroku es sencillo**. En muchos casos es solo cuestión de correr comandos en la terminal y con una que otra configuración solo con subir los cambios al repositorio basta.
Y si bien tenemos esa facilidad, hay cosas que Heroku deja de hacer por conveniencia, ahorro o que sé yo... | cescquintero |
205,447 | How to know if oauth2.0 authentication setup might be an overkill? | So, I'm assigned with a task to create APIs for an Instagram-like application. An... | 0 | 2019-11-14T16:20:23 | https://dev.to/chandlerbing016/how-to-know-if-oauth2-0-authentication-setup-might-be-an-overkill-2dd8 | laravel, oauth20, oauth | ---
title: How to know if oauth2.0 authentication setup might be an overkill?
published: true
tags: help, laravel, oauth2.0, oauth
---
So, I'm assigned with a task to create APIs for an Instagram-like application. And, Laravel is the framework that we decided to go with. I'm setting up authentication and the last time... | swadhwa16 |
205,510 | Serverless Security with Unikernels | How do you secure your serverless infrastructure? How do you secure the rest of your infrastructure? | 0 | 2019-11-14T20:29:31 | https://dev.to/eyberg/serverless-security-with-unikernels-eb0 | unikernels, serverless, security, javascript | ---
title: Serverless Security with Unikernels
published: true
description: How do you secure your serverless infrastructure? How do you secure the rest of your infrastructure?
tags: unikernels, serverless, security, javascript
cover_image: https://thepracticaldev.s3.amazonaws.com/i/a1eni5e86v8spllnqqwt.jpg
---
Securi... | eyberg |
205,540 | 2nd Interview Experience(Python-Dev) | Interview experience for a python developer position | 0 | 2019-11-14T20:05:18 | https://dev.to/mujeebishaque/2nd-interview-experience-python-dev-35p0 | python, career, beginners | ---
title: 2nd Interview Experience(Python-Dev)
published: true
description: Interview experience for a python developer position
tags: #python #career #beginners
cover_image: https://thepracticaldev.s3.amazonaws.com/i/q99kjqostk9h0jtlfvsa.gif
---
### Introduction
I found the post on a local facebook page that shares ... | mujeebishaque |
205,548 | Bdbdbd | Dbbshs | 0 | 2019-11-14T19:49:26 | https://dev.to/barkanyid/bdbdbd-51b6 | Dbbshs | barkanyid | |
205,616 | Vanilla JavaScript Infinite Scroll using WordPress REST API | This pen is a real example of how to build an Infinite Scroll in Vanilla JavaScript. I've used Fetch API, Intersection Observer API, and WordPress REST API to fetch posts. Feel free to fork, use, and modify this code. | 0 | 2019-11-14T22:42:22 | https://dev.to/castroalves/vanilla-javascript-infinite-scroll-using-wordpress-rest-api-2pjl | javascript, wordpress, showdev, tutorial | ---
title: Vanilla JavaScript Infinite Scroll using WordPress REST API
description: This pen is a real example of how to build an Infinite Scroll in Vanilla JavaScript. I've used Fetch API, Intersection Observer API, and WordPress REST API to fetch posts. Feel free to fork, use, and modify this code.
published: true
ta... | castroalves |
205,756 | Heroku vs DigitalOcean: An Experiment in the Making | The Experiment's Table of Contents Part 1: An Experiment in the Making Part 2: Getting Started with D... | 3,266 | 2019-11-15T03:36:24 | https://medium.com/@standingdreams/heroku-vs-digital-ocean-an-experiment-in-the-making-ce375e7976d | devops, heroku, digitalocean, mediatemple | The Experiment's Table of Contents
Part 1: An Experiment in the Making
Part 2: [Getting Started with DigitalOcean](https://dev.to/standingdreams/heroku-vs-digitalocean-getting-started-with-digitalocean-29j0)
---
I have been a loyal customer of [MediaTemple](http://bit.ly/2hnP7tF) for years. They made my hosting needs... | standingdreams |
205,859 | The golden age of SaaS | Most people overestimate what they can do in one year and underestimate what they can do in ten... | 0 | 2019-11-15T10:54:24 | https://dev.to/happydragos/the-golden-age-of-saas-591i | saas, developer, startup, growth | ---
title: The golden age of SaaS
published: true
description:
tags: #saas #developer #startup #growth
---
Most people overestimate what they can do in one year and underestimate what they can do in ten years.
Most likely, this Bill Gates quote refers to building businesses. It can take a lot of effort and persisten... | happydragos |
236,604 | A step towards a faster Web: Early flushing in c#.net | A simple demonstration to Early flushing in dotnet. Flushing, Early flushing, head flushin... | 0 | 2020-01-12T08:40:26 | https://dev.to/uzumakinarut0/early-flushing-in-c-net-c2 | dotnet, csharp, webdev, webperf | ## A simple demonstration to Early flushing in dotnet.
Flushing, Early flushing, head flushing or Progressive HTML is when the server sends the initial part of the HTML document to the client before the entire response is ready. All major browsers start parsing the partial response.If done correctly, the browser won't ... | uzumakinarut0 |
205,905 | Tips to Safeguard Your Magento E-Commerce Store | This post showcases the essential security tips that will help protect the Magento eCommerce store. | 0 | 2019-11-15T13:17:35 | https://dev.to/apptechblogger/tips-to-safeguard-your-magento-e-commerce-store-173 | ecommerce, ecommercedevelopment, magentodevelopment | ---
title: Tips to Safeguard Your Magento E-Commerce Store
published: true
description: This post showcases the essential security tips that will help protect the Magento eCommerce store.
tags: ecommerce, ecommerce development, magento development
---
A recent study by a leading research group found that in the Alexa T... | apptechblogger |
205,963 | Use CSS Subgrid to layout full-width content stripes in an article template | CSS Grid was missing one important piece when it's Level 1 specification was released into the world:... | 0 | 2019-11-15T19:44:54 | https://bryanlrobinson.com/blog/use-css-subgrid-laying-out-full-width-article-stripes/ | css, cssgrid, webdev, tutorial | ---
title: Use CSS Subgrid to layout full-width content stripes in an article template
published: true
date: 2019-11-15 00:00:00 UTC
tags: css, cssgrid, webdev, tutorial
canonical_url: https://bryanlrobinson.com/blog/use-css-subgrid-laying-out-full-width-article-stripes/
cover_image: https://bryanlrobinson.com/images/s... | brob |
206,006 | Less confusing defaults | A few thoughts about less confusing default configuration. | 0 | 2019-11-15T17:08:02 | https://dev.to/rumkin/less-confusing-defaults-1h2m | programming, javascript, node, web | ---
title: Less confusing defaults
published: true
description: A few thoughts about less confusing default configuration.
tags: programming, javascript, nodejs, web
---
The less confusing (and harmful) defaults for code and configuration are different and opposite. Here it is:
# By Default
1. Run production code.
2... | rumkin |
206,032 | ⚡ Announcing Byteconf GraphQL: a free GraphQL conference, streamed online | I'm super excited to announce the return of Byteconf, Bytesized Code's free live-streamed conference... | 0 | 2019-11-15T18:17:34 | https://dev.to/bytesizedcode/announcing-byteconf-graphql-a-free-graphql-conference-streamed-online-2a0b | graphql, showdev, webdev | I'm super excited to announce the return of Byteconf, Bytesized Code's free live-streamed conference series.
**On January 31st, join us for Byteconf GraphQL, whether you're on your couch, at your office, or wherever you may find yourself at the beginning of the new decade.**
I'm thrilled to be announcing the conferen... | signalnerve |
206,044 | Networking with Benefits | I was not born to talk to people. I was super introverted all the way through college. I was okay... | 0 | 2019-11-15T20:25:41 | https://dev.to/williamjfermo/networking-with-benefits-gn8 | networking, datascience, linkedin | 
I was not born to talk to people. I was super introverted all the way through college. I was okay with studying then go home and play videogames all day. It didn't take till I went to graduate school that I started to open up more and ... | williamjfermo |
206,131 | Drag and Drop Tables with React-Beautiful-DND (Part I) | This week, I wanted to experiment learning a new React component and implementing it into my Effectiv... | 0 | 2019-11-16T02:40:51 | https://dev.to/milandhar/drag-and-drop-table-with-react-beautiful-dnd-54ad | react, npm, ux, webdev | This week, I wanted to experiment learning a new React component and implementing it into my [EffectiveDonate](http://effectivedonate.herokuapp.com) website. I began to think of what aspects of the site could use a cool new feature to improve its UX, and focused in on the Profile page. Previously, the Profile page allo... | milandhar |
206,377 | Um pouco de clean code com Clojure 🔮 | Nomes significativos 😏 O nome de um símbolo ou função deve "responder a todas as grandes q... | 0 | 2019-11-16T16:27:45 | https://dev.to/wakeupmh/um-pouco-de-clean-code-com-clojure-4ok0 | clojure, todayilearned | ## Nomes significativos 😏
O nome de um símbolo ou função deve "responder a todas as grandes questões".
Deve dizer por que existe, o que faz e como é usado.
Se um nome exigir um comentário, ele não revela sua intenção.
❌ **Forma incorreta**

✅ **Forma correta**
 across the globe. These folks are i... | 3,571 | 2019-12-02T17:55:48 | https://fluin.io/blog/how-to-become-an-angular-gde | angular, gde, webdev, community | Today, there are over 100 Angular Google Developer Experts (GDEs) [across the globe](https://developers.google.com/community/experts/directory). These folks are impactful for the community, well versed in the world of building great web experiences, and experts in the technologies that make up [Angular](https://angular... | stephenfluin |
219,432 | 9 web development tips and tricks out of the blue | In this article, I gathered 9 tips and tricks for web developers that I used recently. | 0 | 2019-12-16T14:39:00 | https://dev.to/armelpingault/9-web-development-tips-and-tricks-out-of-the-blue-119i | javascript, webdev, tutorial, beginners | ---
title: 9 web development tips and tricks out of the blue
published: true
description: In this article, I gathered 9 tips and tricks for web developers that I used recently.
tags: javascript, webdev, tutorial, beginners
---
In this article, I gathered 9 tips and tricks for web developers that I used recently. Even ... | armelpingault |
214,283 | Introducing our December 2019 sponsors | Our wonderful sponsors are vital to the health of dev.to and it is great to work with companies contributing so much to the ecosystem. | 0 | 2019-12-06T15:00:58 | https://dev.to/devteam/introducing-our-december-2019-sponsors-4po3 | meta | ---
title: Introducing our December 2019 sponsors
published: true
description: Our wonderful sponsors are vital to the health of dev.to and it is great to work with companies contributing so much to the ecosystem.
tags: meta
cover_image: https://p78.f0.n0.cdn.getcloudapp.com/items/9ZuNe404/Image+2019-12-02+at+7.14.16+P... | ben |
214,314 | Coroutine Delay | Handler().postDelayed({ doSomething() }, 3000)
DispatchQueue.main.asyncAfter(dea... | 0 | 2019-12-03T01:50:39 | https://patrickjackson.dev/coroutine-delay/?utm_source=rss&utm_medium=rss&utm_campaign=coroutine-delay | android, ios, kotlinmultiplatform | ---
title: Coroutine Delay
published: true
date: 2019-12-03 00:09:28 UTC
tags: android,ios,kotlin-multiplatform
canonical_url: https://patrickjackson.dev/coroutine-delay/?utm_source=rss&utm_medium=rss&utm_campaign=coroutine-delay
cover_image: https://thepracticaldev.s3.amazonaws.com/i/1tbr43z1s5aca1wl5h8h.jpg
---
```
... | patjackson52 |
214,400 | Agile Git Integration with GitWorkflows | In this article we’ll explore the use of feature branches based off of GitWorkflow to integrate... | 3,313 | 2019-12-03T07:00:43 | https://killalldefects.com/2019/12/03/agile-git-integration-with-gitworkflows/ | devops, git, productivity, agile | ---
title: Agile Git Integration with GitWorkflows
published: true
date: 2019-12-03 06:48:20 UTC
tags: devops, git, productivity, agile
series: Software Quality Defense In Depth
cover_image: https://i1.wp.com/killalldefects.com/wp-content/uploads/2019/12/GitWorkflows.png?fit=768%2C313&ssl=1
canonical_url: https://killa... | integerman |
214,410 | How to take a screenshot on Mac | A quick tutorial | Sometimes, while working on the internet we need to save some pictures while browsing to check them o... | 0 | 2019-12-03T07:28:34 | https://dev.to/gangapackers/how-to-take-a-screenshot-on-mac-a-quick-tutorial-18c9 | takeascreenshotonmacbook, takeascreenshotonmac, howtoscreenshotonmac | Sometimes, while working on the internet we need to save some pictures while browsing to check them offline. Taking a screenshot is the easiest way to save pictures from the internet. There are some shortcuts for taking a screenshot on all operating systems. The shortcuts may be different on different operating systems... | gangapackers |
214,424 | Warped Re-rendering | React performance optimization | Introducing a new approach to optimize your react app for isolating the re renders to the particular required subtree. | 0 | 2019-12-03T10:16:13 | https://dev.to/aftabnack/warped-re-rendering-react-performance-optimization-512i | react, hooks, optimization | ---
title: Warped Re-rendering | React performance optimization
published: true
description: Introducing a new approach to optimize your react app for isolating the re renders to the particular required subtree.
tags: reactjs, hooks, optimization
---
In this post, I will be introducing a new optimization that will sig... | aftabnack |
217,033 | How Game Dev and Physics Constants Made Me Think About Religion | I am an atheist and developer, I’ve found it surprising how often these two identities collide. I’m... | 0 | 2019-12-08T16:16:25 | https://qvault.io/2019/12/08/how-game-dev-and-physics-constants-made-me-think-about-religion/?utm_source=rss&utm_medium=rss&utm_campaign=how-game-dev-and-physics-constants-made-me-think-about-religion | atheism, gamedev, programming, constants | ---
title: How Game Dev and Physics Constants Made Me Think About Religion
published: true
date: 2019-12-08 16:10:03 UTC
tags: atheism,gamedev,Programming,constants
canonical_url: https://qvault.io/2019/12/08/how-game-dev-and-physics-constants-made-me-think-about-religion/?utm_source=rss&utm_medium=rss&utm_campaign=how... | wagslane |
219,269 | How to Write the Best Meta Description | When you are creating a blog, the only thing that matters is the content. You know the saying, conten... | 0 | 2019-12-12T05:53:34 | https://dev.to/rahuuzz/how-to-write-the-best-meta-description-2efi | meta, description, seo, blogging | When you are [creating a blog](https://storylens.io), the only thing that matters is the content. You know the saying, content is king. But when you’re dealing with search engines, there are a few complimentary things that matter too like metadata, title length, keywords, etc. Although those who have spent a lot of yea... | rahuuzz |
219,287 | How to make HTML form using googlesheet as a Database | I have a google spreadsheet, where some rows append on daily basis and using the google spreadsheet,... | 0 | 2019-12-12T06:37:10 | https://dev.to/mike7755/how-to-make-html-form-using-googlesheet-as-a-database-4fci | googleappsscript | I have a google spreadsheet, where some rows append on daily basis and using the google spreadsheet, the customer feedback team follows up.
Google Spreadsheet Data.
https://docs.google.com/spreadsheets/d/1V-XZdCUZAQVkfCat9vXVxITjjNMxNMPDin6B5j9uMWY/edit?usp=sharing
The above mentioned Google Spreadsheet always hav... | mike7755 |
219,293 | Máy phát điện xoay chiều Vinafarm | Theo một số ý kiến thì bất kỳ loại máy phát điện nào tạo ra một dòng điện xoay chiều đều gọi là máy p... | 0 | 2019-12-12T06:59:49 | https://dev.to/thnvinafarm/may-phat-di-n-xoay-chi-u-vinafarm-21bi | Theo một số ý kiến thì bất kỳ loại máy phát điện nào tạo ra một dòng điện xoay chiều đều gọi là máy phát điện xoay chiều. Nhưng theo như lý thuyết máy phát điện xoay chiều được ghi trong giấy tờ sách vở thì lại khác. Bởi vì máy phát điện xoay chiều phải sản sinh ra điện năng nhờ vào hiện tượng cảm ứng điện từ.
Máy phát... | thnvinafarm | |
219,342 | Hidden Tutorial Gems (Easy but Great Ones) | Besides the previous posts' main, impactful tutorials, I came across some nice material in slightly m... | 0 | 2019-12-14T09:13:36 | https://dev.to/zoltanhalasz/hidden-tutorial-gems-easy-but-great-ones-1afm | dotnet, angular, javascript, tutorial | Besides the previous posts' main, impactful tutorials, I came across some nice material in slightly more hidden/unknown places. There are authors that deserve more attention, because their content is high quality, and even more importantly, teach the foundations of fresh developments.
**A. The .NET stack**
For me, *... | zoltanhalasz |
219,458 | Forms, Web Components and Redux | I think this was because I was thinking along the lines of But it's just a form, we build forms on the web every other day. By the end of this task, I went to my team with a big smile on my face and said I Reduxed the hell out of that form. | 0 | 2019-12-17T07:14:20 | https://medium.com/@gerybbg/forms-web-components-and-redux-59e2ffd2fc79 | redux, lithtml, javascript, forms | ---
title: Forms, Web Components and Redux
description: I think this was because I was thinking along the lines of But it's just a form, we build forms on the web every other day. By the end of this task, I went to my team with a big smile on my face and said I Reduxed the hell out of that form.
published: true
tags: R... | gerybbg |
219,476 | Lightsaber prototyping with the Nordic Thingy:52 | We're building a lightsaber!!! I don't want to give too much away, but a few weeks ago we started with the 3D print… I decided that while I wait for all of the components to arrive, I would get started on a prototype. | 0 | 2019-12-18T13:42:34 | https://medium.com/@gerybbg/lightsaber-prototyping-with-the-nordic-thingy-52-890d54493b86 | javascript, prototyping, iot, bluetooth | ---
title: Lightsaber prototyping with the Nordic Thingy:52
description: We're building a lightsaber!!! I don't want to give too much away, but a few weeks ago we started with the 3D print… I decided that while I wait for all of the components to arrive, I would get started on a prototype.
published: true
tags: JavaScr... | gerybbg |
219,535 | The Magic of the Fibonacci Numbers & why we love computing them - part 1 | Interview questions regarding the Fibonacci series are very popular, so there are very few developers... | 3,724 | 2020-01-12T09:10:37 | https://dev.to/kruzzy/the-magic-of-the-fibonacci-numbers-why-we-love-computing-them-part-1-18gp | computerscience, algorithms, mathematics | Interview questions regarding the Fibonacci series are very popular, so there are very few developers that haven't heard of or computed the sequence in one way or another. They are defined by the following relation:

But why is that? Why does everyone love the Fibonacci N... | kruzzy |
220,173 | I'm Leaving a Job I Love, and I'm Ready | I'm a week out from leaving a perfect, full-time, dreamy remote work position. I've been with the com... | 0 | 2019-12-12T22:17:36 | https://dev.to/alexlsalt/i-m-leaving-a-job-i-love-and-i-m-ready-2l7p | career, codenewbie, 100daysofcode | I'm a week out from leaving a perfect, full-time, dreamy remote work position. I've been with the company for a little under two years as a customer support specialist and it's entirely possible that I would've stayed in that position for the next ten years if they let me.
But the thing is - it's time to move on. Sur... | alexlsalt |
220,204 | Hello World | Hello and welcome to my new blog! My name is Spencer Pollock and I'm an aspiring software developer.... | 0 | 2019-12-13T01:12:26 | https://spollock.ca/blog/posts/ | helloworld, blog | Hello and welcome to my new blog! My name is Spencer Pollock and I'm an aspiring software developer. I find myself often reading up on new technology and working to use their best practices to make some new things. I jump from project to project, trying to expand my knowledge where possible. Follow me along on my journ... | srepollock |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.