
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
846,352 | Protected routes in react with react router and redux | Protected routes can only be accessed by authenticated users in an application. React-router and... | 0 | 2021-10-02T06:11:16 | https://dev.to/akanstein/protected-routes-with-react-router-and-redux-3e62 | react, redux, routes, reactrouter | Protected routes can only be accessed by authenticated users in an application. React-router and redux have been winning a combination for a lot of SPA(single page applications), but for a newbie, figuring how to combine these two packages to implement a protected route can seem a bit complex. We'll be looking at how t... | akanstein |
846,406 | Ultimate Guide to setup React Context API with a custom hook [Typescript] | This is a guide to help you set up React Context API with typescript. 🤨 What is React... | 0 | 2021-09-30T10:09:35 | https://damiisdandy.com/articles/ultimate-guide-to-setup-react-context-api-with-custom-hook-and-typescript/ | typescript, javascript, react, tutorial | This is a guide to help you set up React Context API with typescript.
## 🤨 What is React Context API?
Context is designed to share data that can be considered “global” for a tree of React components, This prevents [Prop drilling](https://kentcdodds.com/blog/prop-drilling) and allows you to pass data around your react... | damiisdandy |
846,412 | Modernizing Amazon database infrastructure - migrating from Oracle to AWS | AWS White Paper Summary | 1. Challenges with using Oracle databases Amazon started facing a number of challenges... | 0 | 2021-09-30T08:40:20 | https://dev.to/awsmenacommunity/modernizing-amazon-database-infrastructure-migrating-from-oracle-to-aws-aws-white-paper-summary-ej7 | aws, database | #1. Challenges with using Oracle databases
Amazon started facing a number of challenges with using Oracle databases to scale its services.
##1.1 Complex database engineering required to scale
• Hundreds of hours spent each year trying to scale the Oracle databases horizontally.
• Database shards was used to handle t... | haythammostafa |
846,445 | Getting Started with HTML | Get Started What do you need Any code editor and a browser on your 💻 Here are some... | 0 | 2021-09-30T09:51:59 | https://dev.to/nikiljos/getting-started-with-html-2n1d | html, webdev, beginners | ### Get Started
**What do you need**
> Any code editor and a browser on your 💻
>>Here are some good options
>> - [VSCode](https://code.visualstudio.com/)
>> - [Atom](https://atom.io/)
>
>> And these are some really useful VSCode extensions
>> - [Prettier](https://marketplace.visualstudio.com/items?it... | nikiljos |
846,518 | The Red Team Chronicles — No such thing as a miracle solution | Red Team Chronicles — No such thing as a miracle solution Now you’ve met Philippe, let’s... | 0 | 2021-10-11T13:51:04 | https://medium.com/gitguardian/the-red-team-chronicles-no-such-thing-as-a-miracle-solution-6fdb2170463a | pentesting, cybersecurity, redteam, applicationsecurity | ---
title: The Red Team Chronicles — No such thing as a miracle solution
published: true
date: 2021-06-24 14:52:51 UTC
tags: pentesting,cybersecurity,redteam,applicationsecurity
canonical_url: https://medium.com/gitguardian/the-red-team-chronicles-no-such-thing-as-a-miracle-solution-6fdb2170463a
---
### Red Team Chron... | cwinqwist |
846,523 | Have you ever needed to import CSV files from your users? 3 super tools that that make this a breeze! | If you've ever tried to implement a CSV importer, you know how annoying it can be to devote expensive... | 0 | 2021-09-30T11:50:43 | https://dev.to/sangoitejas/have-you-ever-needed-to-import-csv-files-from-your-users-3-super-tools-that-that-make-this-a-breeze-16ap | webdev, csv, dataimporter, datauploader | If you've ever tried to implement a CSV importer, you know how annoying it can be to devote expensive development time to a feature only to see your users struggle with it.
In certain cases, developers aim to improve the user experience by providing FAQs and tutorials that explain consumers how to use their importer a... | sangoitejas |
846,557 | GitHub integration for Orbit for anyone with multiple communities | Orbit is "mission control for your community", a single, shared view of members and activity. For... | 0 | 2021-11-24T13:44:13 | https://dev.to/floord/github-integration-for-orbit-for-anyone-with-multiple-communities-28he | github, orbit, community, actionshackathon21 | [Orbit](https://orbit.love) is "mission control for your community", a single, shared view of members and activity.
For my work for k6 I've been adding integrations to our Orbit "workspace" so that I can make correlations between data points, and to act accordingly.
For instance: this person asking a question on Tw... | floord |
846,743 | 3 Sites for FREE UI KITS! | Save for later. uistore.design ui8.net uispace.net P.S.... | 0 | 2021-09-30T13:37:14 | https://dev.to/deyrupak/3-sites-for-free-ui-kits-1ghg | webdev, productivity, design, uiweekly | _Save for later._
<br/>
### [uistore.design](https://www.uistore.design/)
<br/>
### [ui8.net](https://ui8.net/)
<br/>
### [uispace.ne... | deyrupak |
846,870 | Começando com Spark | O Spark é uma ferramenta para processamento de dados em grande escala, escrita na linguagem de... | 0 | 2021-09-30T17:38:33 | https://dev.to/dgoposts/comecando-com-spark-g30 | datascience, javascript | O Spark é uma ferramenta para processamento de dados em grande escala, escrita na linguagem de programação funcional **Scala**, possui foco em velocidade, facilidade de uso e análises sofisticadas. Netflix, Yahoo e eBay são algumas empresas que implementaram soluções através do Spark.
## Spark Ecosystem
O ecossistem... | dgoposts |
846,885 | Introducing the First Set of Syncfusion .NET MAUI Controls | The wait is over! Syncfusion has rolled out its first set of .NET MAUI controls in its Essential... | 0 | 2021-10-04T06:59:17 | https://www.syncfusion.com/blogs/post/introducing-the-first-set-of-syncfusion-net-maui-controls.aspx | maui, dotnet, csharp | ---
title: Introducing the First Set of Syncfusion .NET MAUI Controls
published: true
date: 2021-09-30 13:52:33 UTC
tags: maui, dotnet, csharp
canonical_url: https://www.syncfusion.com/blogs/post/introducing-the-first-set-of-syncfusion-net-maui-controls.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/... | sureshmohan |
847,097 | Which companies are doing DevRel? | Have you ever been asked or wondered - "How many companies have a DevRel program?" So have we, and... | 0 | 2021-09-30T19:01:44 | https://dev.to/carolinelewko/which-companies-are-doing-devrel-16h4 | devrel | Have you ever been asked or wondered - "How many companies have a DevRel program?"
So have we, and we never had a good answer, or a reference to point to so we created a Developer Relations Program Directory.
Developer Products include APIs, SDKs, HDKs, tools, and reference designs. There are also Developer Services... | carolinelewko |
847,114 | Streaming Analytics Using FlinkSQL Webinar | I wanted to share some resources from today's talk. Documentation on Using Flink SQL on... | 0 | 2021-09-30T20:13:30 | https://dev.to/tspannhw/streaming-analytics-using-flinksql-webinar-3fa9 |


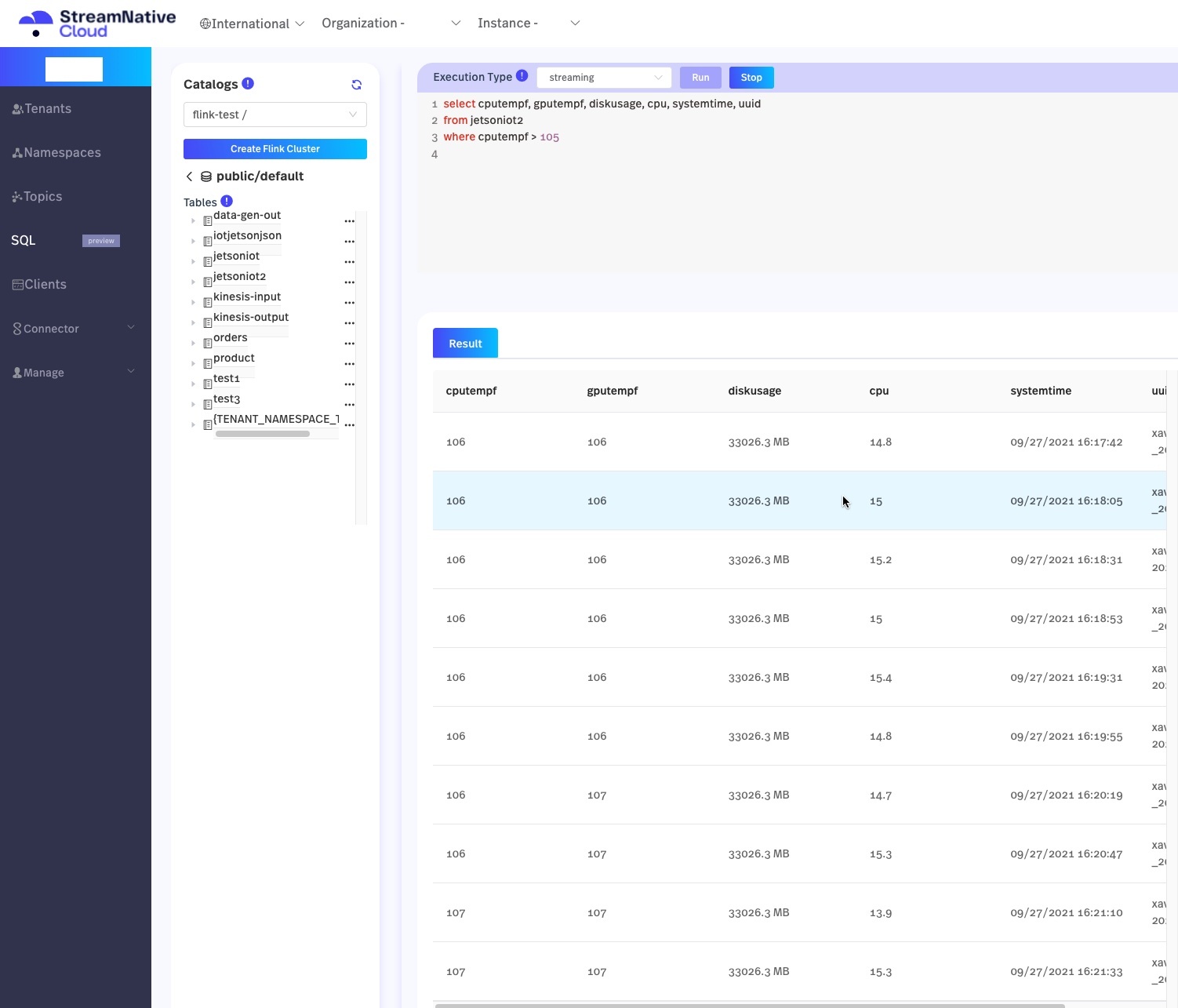
I wanted to share some resources from today's talk.
... | tspannhw | |
847,116 | Utiliser WebSockets avec React | Pour mon dernier projet, j'ai dû utiliser Websockets pour créer un site Web qui affiche des données... | 0 | 2021-09-30T20:13:56 | https://dev.to/muratcanyuksel/utiliser-websockets-avec-react-4061 | react, websockets, javascript | Pour mon dernier projet, j'ai dû utiliser Websockets pour créer un site Web qui affiche des données de trading en temps réel. Je ne connaissais rien aux WebSockets, et il m'a fallu quelques heures redoutables pour commencer. C'est le seul problème, en fait, pour commencer; le reste est assez clair. Ce court article esp... | muratcanyuksel |
847,275 | Mi nueva startup - Mensajería y paquetería express en Mérida, Yucatán | Ahora me voy a rifar un servicio de paquetería y mensajería express y una app para delivery... | 14,836 | 2021-10-01T01:54:57 | https://dev.to/g7b/mi-nueva-startup-mensajeria-y-paqueteria-express-en-merida-yucatan-3on2 | startup, react, aws, nextjs | ## Ahora me voy a rifar un servicio de paquetería y mensajería express y una app para delivery en Mérida, Yucatán.
---
### ¿Por qué?
Pues la ciudad esta creciendo bastante y servicios como iVoy o 99minutos no dan servicio en esta ciudad y aunque estuvieran me vale madres.
### ¿Qué creo que se necesita?
* **Clientes,... | g7b |
847,711 | Pricing Table In Tailwind CSS | In this pricing table, we used Tailwind CSS components and utility classes. For making responsive we... | 0 | 2021-10-01T10:00:35 | https://dev.to/w3hubs/pricing-table-in-tailwind-css-4jp5 | css, html, webdev, codenewbie | In this pricing table, we used Tailwind CSS components and utility classes. For making responsive we used responsive classes which are already in utility classes.
Here we used responsive grid classes and text-color with font-size classes. Also, we used ul and li to show features in the list view.
Make it yours now by... | w3hubs |
847,732 | Time is on my side: active time | I hope you hear the Rolling Stones song with the name of this blogpost in your head, and if you... | 14,843 | 2021-10-01T14:02:38 | https://dev.to/fritshooglandyugabyte/time-is-on-my-side-active-time-1k35 | postgres, performance, internals, yugabyte | I hope you hear the Rolling Stones song with the name of this blogpost in your head, and if you don't: visit [youtube](https://youtu.be/sEj8lUx0gwY) or even if you hear it in your head you also might go there and play the song.
Tuning a database is all about time, and understanding where time has gone. Sadly, there is... | fritshooglandyugabyte |
847,777 | Flash messages with Hotwire | I’ll show you how to add flash messages to Rails, using a simple stimulus controller to auto dismiss... | 14,845 | 2021-10-02T15:35:30 | https://dev.to/phawk/flash-messages-with-hotwire-2o15 | rails, hotwire, tutorial, stimulus | I’ll show you how to add flash messages to Rails, using a simple stimulus controller to auto dismiss them and some basic styling with tailwind css.
{% youtube gk_qDsKMIrM %}
---
## Summary of what was done
### `app/views/layouts/application.html.erb`
```erb
<!DOCTYPE html>
<html>
<head>
<!-- ... -->
</head... | phawk |
847,817 | A cap of tea | A story about distributed systems, hype-driven design and the Socratic hardships of friendship ... | 0 | 2021-10-05T19:56:13 | https://dev.to/pzavolinsky/a-cap-of-tea-2io5 | distributedsystems, tea | _A story about distributed systems, hype-driven design and the [Socratic hardships](https://en.wikipedia.org/wiki/Socratic_method) of friendship_
## Fancy some tea?
- Me: Hey, fancy some tea?
- You: Sure, I'm always up for some tea!
- Me: Cool, let's share a cap of tea
- You: You mean a _cup_ of tea right?
- Me: No n... | pzavolinsky |
848,034 | Mac 設定 Part 2 -- VS Code 個人用設定 | why 私はこれらを必ずカスタムして使う。 なので初期設定用に記事しておく。 VSCode Extensions 5 つ 設定ファイルの編集での設定 5 つ ... | 19,271 | 2021-11-01T06:34:55 | https://dev.to/kaede_io/my-vs-code-setting-2a55 | vscode |
# why
私はこれらを必ずカスタムして使う。
なので初期設定用に記事しておく。
1. VSCode Extensions 5 つ
2. 設定ファイルの編集での設定 5 つ
---
---
# Extensions 5 つ
---
## 1. Vim
私には必須。
hjkl での移動や yy dd pp でのコピー削除貼り付けができるようになる
jj で escape する方法は後述
---
## 2. Rainbow Brackets
 (check out [https://salaries.infosec-jobs.com/](https://salaries.infosec-jobs.com/) if you haven’t y... | infosec_jobscom |
848,090 | Blog Post of My Learning | The week of September 20, 2021 saw me get frustrated and confused as I continued with my learning of... | 0 | 2021-10-01T16:40:45 | https://dev.to/edouble79/kdfjdklsjf-2nh2 | The week of September 20, 2021 saw me get frustrated and confused as I continued with my learning of Ruby in Codecademy. I learned "Printing the Output" which uses string methods to capitalize. "Control Flow in Ruby" was interesting because I learned about Environment, If and True expressions, white space, and Els... | edouble79 | |
848,329 | Hacktoberfest: Contribute to our temporal database system | We are a (very) small team working on a database system in our spare time (https://sirix.io |... | 0 | 2021-10-01T21:34:10 | https://dev.to/johanneslichtenberger/hacktoberfest-contribute-to-our-temporal-database-system-5hf2 | hacktoberfest, database, java, kotlin | We are a (very) small team working on a database system in our spare time (https://sirix.io | https://github.com/sirixdb/sirix).
{% github sirixdb/sirix %}
It began as a research system at the University of Konstanz and was the main focus of two PhD thesis and several bachelor and master thesis.
Johannes, the curren... | johanneslichtenberger |
848,357 | React Native Mobile Apps, Integrating Expo Image Picker, Supabase Buckets and Image Upload | This is a short video following up on the previous react-native Expo Camera and upload to Supabase... | 14,606 | 2021-10-01T22:24:48 | https://dev.to/aaronksaunders/react-native-mobile-apps-integrating-expo-image-picker-supabase-buckets-and-image-upload-51pi | reactnative, supabase, imagepicker, video | This is a short video following up on the previous react-native [Expo Camera](https://docs.expo.dev/versions/latest/sdk/camera/) and upload to Supabase video that I made last week. In this video, I am working with [Expo Image Picker](https://docs.expo.dev/versions/latest/sdk/imagepicker/) in react native to pick image ... | aaronksaunders |
848,669 | Is there an alternative for document.execCommand('SaveAs', null, 'myFile.html'); in chromium browsers (Microsoft-Edge) | Is there an alternative for... | 0 | 2021-10-02T06:45:23 | https://dev.to/ambareeshc92/is-there-an-alternative-for-document-execcommand-saveas-null-myfile-html-in-chromium-browsers-microsoft-edge-fgj | javascript | {% stackoverflow 69414397 %} | ambareeshc92 |
848,691 | Railway FBP v1.0.8 is released 🎉 | Railway FBP v1.0.8 introduce Monads. A rework was done on this release when deepen into monads... | 0 | 2021-10-02T08:04:57 | https://dev.to/darkwood-fr/railway-fbp-v1-0-8-is-released-1kn2 | Railway FBP v1.0.8 introduce Monads.
A rework was done on this release when deepen into monads theory and their implementation in PHP. This could give the project deeper approach when considering the implementation to get much cleaner way to use it.
https://github.com/darkwood-fr/railway-fbp/releases/tag/v1.0.8 | matyo91 | |
848,723 | Open Sourcing URL Shortener | Taking our first steps in Open Source. In this article, we want to share our journey in making URL Shortener service open source. And we welcome your contributions. | 0 | 2021-10-02T09:26:42 | https://www.smallcase.com/blog/open-sourcing-url-shortener/ | fastify, urlshortener, opensource | ---
title: Open Sourcing URL Shortener
published: true
description: Taking our first steps in Open Source. In this article, we want to share our journey in making URL Shortener service open source. And we welcome your contributions.
tags: fastify, urlshortener, openSource
cover_image: https://www.smallcase.com/blog/wp-... | rishabh570 |
848,830 | Ways to Make Money? | hello guys! I won't explain you with long and complicate words for that coz everybody can make money... | 0 | 2021-10-02T09:49:07 | https://dev.to/thuhtetdev/ways-to-make-money-19gc | productivity, webdev, career, programming | hello guys!
I won't explain you with long and complicate words for that coz everybody can make money on their own way,
so here's the key points to modify your mind.
1. Don't ever think about making money is hard
2. You can make money right now but amount will be based on yours.
3. You can't make money right now .. it... | thuhtetdev |
848,845 | AZ CLI - Deleting Terraform Test Resource Groups | This is a series of quick posts, tips and tricks when working with the Azure CLI. Deleting... | 0 | 2021-10-02T10:41:29 | https://dev.to/dylanmorley/az-cli-deleting-terraform-test-resource-groups-4kkg | azure, terraform, cloud | This is a series of quick posts, tips and tricks when working with the Azure CLI.
## Deleting Multiple Resource Groups
When working with the Terraform Provider for Azure, you may be adding a new feature that requires you to run the test automation packs.
In cases where there are errors in the Provider as you're develo... | dylanmorley |
848,864 | CAP Theorem : Scenarios explained | CAP theorem applies to behavior exhibited by the distributed system with respect to three attributes... | 0 | 2021-10-02T15:50:05 | https://dev.to/sridharanprasanna/cap-theorem-scenarios-explained-31a6 | cap | CAP theorem applies to behavior exhibited by the distributed system with respect to three attributes Consistency, Availability and Partition tolerance, for definition refer to the [wiki](https://en.wikipedia.org/wiki/CAP_theorem).
The theorem defines the choice of behavior that the system can exhibit from the end user... | sridharanprasanna |
848,930 | How to change base repo in Github CLI? | When you use Github cli for fist time on locally clone forked repo, then you get some message that... | 0 | 2021-10-02T14:35:27 | https://dev.to/utsavladani/how-to-change-base-repo-in-github-cli-5fhp | github, githubcli, issue | When you use Github cli for fist time on locally clone forked repo, then you get some message that asked to setup base repo to execute all queries.
```
$ gh issue list
? Which should be the base repository (used for e.g. querying issues) for this directory? [Use arrows to move, type to filter]
<name of owner> / <na... | utsavladani |
849,127 | Automate CI/CD build pipeline for your Springboot app using Jenkins and Github Webhooks | In this article, you will be learning how to set up a CI/CD pipeline for your springboot application... | 0 | 2021-10-02T16:49:56 | https://dev.to/saucekode/automate-ci-cd-build-pipeline-for-a-springboot-app-using-jenkins-and-github-webhooks-3h30 | devops, beginners, jenkins | ---
title: Automate CI/CD build pipeline for your Springboot app using Jenkins and Github Webhooks
published: true
description:
tags: #devops #beginners #jenkins
//cover_image: https://direct_url_to_image.jpg
---
In this article, you will be learning how to set up a CI/CD pipeline for your springboot application usin... | saucekode |
849,162 | Create Mirrored Cursor Movement with CSS and JavaScript | This week's Codepen Challenge was "Reflections" so I created a pen where a light follows your cursor... | 0 | 2021-10-03T17:54:43 | https://dev.to/dianale/create-mirrored-cursor-movement-with-css-and-javascript-249i | css, codepen, javascript, webdev | This week's Codepen Challenge was **"Reflections"** so I created a pen where a light follows your cursor and generates and mirrors the reflection on the opposite side:
{% codepen https://codepen.io/pursuitofleisure/pen/LYLveKE %}
## Set up the light and its reflection in the HTML
```html
<div id="container">
<div ... | dianale |
849,353 | The Math of TypeScript's Types | I've been studying functional programming for a few years and in doing so I've learned a lot about... | 0 | 2021-10-02T23:24:47 | https://dev.to/jethrolarson/the-algebras-of-typescript-s-types-1akd | typescript, functional, math | I've been studying functional programming for a few years and in doing so I've learned a lot about types that I would not have otherwise. In particular, studying Haskell and related technology begets some interesting concepts. The one I want to talk about this time is "algebraic types".
From [wikipedia](https://en.wik... | jethrolarson |
849,497 | Vue the world and React accordingly | :) | 0 | 2021-10-03T05:06:43 | https://dev.to/kit/vue-the-world-and-react-accordingly-fh5 | :) | kit | |
882,479 | 3 Books that will boost your Leadership Skills | This blog post is different than the usual content from here. This time I would like to share with... | 0 | 2021-12-30T13:20:52 | https://magdamiu.medium.com/3-books-that-will-boost-your-leadership-skills-350c999add4c | management, leadership, motivation, books | ---
title: 3 Books that will boost your Leadership Skills
published: true
date: 2021-10-25 08:30:00 UTC
tags: management,leadership,motivation,books
canonical_url: https://magdamiu.medium.com/3-books-that-will-boost-your-leadership-skills-350c999add4c
---
This blog post is different than the usual content from here. T... | magdamiu |
849,656 | API Integration and Agile Business simulation game in Task force | Today, we are closing week 5 in the task force, this week was very different to all other 4 weeks... | 0 | 2021-10-03T09:49:22 | https://dev.to/ntwariegide/api-integration-and-agile-business-simulation-game-in-task-force-567g | codeofafrica, awesomitylab, agile, devjournal | Today, we are closing week 5 in the task force, this week was very different to all other 4 weeks we've covered.
This week started with improving the ShowApp project. We wanted to add functionality of cropping image upload which was tough but educational. In the afternoon APIs for the LOT dashboard were ready, so we ... | ntwariegide |
849,799 | Weekly Digest 39/2021 | Welcome to my Weekly Digest #39. This weekly digest contains a lot of interesting and inspiring... | 10,701 | 2021-10-03T17:11:44 | https://dev.to/marcobiedermann/weekly-digest-39-2021-3dh8 | css, javascript, react, webdev | Welcome to my Weekly Digest #39.
This weekly digest contains a lot of interesting and inspiring articles, videos, tweets, podcasts, and designs I consumed during this week.
It's the time of the year again. [Hacktoberfest](https://hacktoberfest.digitalocean.com/) just started, so let's give something back to our wonde... | marcobiedermann |
849,800 | Deploy React Apps using Apache2, how and why? | In this article we will together go through the process of deploying front end applications to... | 0 | 2021-10-03T11:23:12 | https://gist.github.com/AmrHalim/6fff4aa9130f893482f0b72774ab0059 | react, javascript, devops, webdev | In this article we will together go through the process of deploying front end applications to production environments ( specifically [React](https://reactjs.org/) applications ).
### How does the web work?
Before we dig into the actual steps needed to deploy React applications, let’s first think about how the web wor... | amrhalim |
849,895 | Master CSS Selectors | Finding the correct selector was one of the hardest parts when I did my first web automated test and... | 0 | 2021-10-03T14:28:43 | https://dev.to/isolderea/master-css-selectors-4me7 | Finding the correct selector was one of the hardest parts when I did my first web automated test and it took me some time to find the right resources for every problematic selector I had.
If you want to know how you can learn CSS Selectors with not more than 5 minutes a day come join me explore them and resolve fun ... | isolderea | |
858,620 | Considerations for Building a Web Component | There are a lot of things to consider when creating a new web component. What attributes and... | 15,883 | 2021-10-10T17:36:11 | https://dev.to/opencoder/considerations-for-building-a-web-component-5c19 | There are a lot of things to consider when creating a new web component. What attributes and properties do we need? How are we going to style it? Are there accessibility concerns? What about security? The list goes on. Today, I'll go through the thought process of a making a new component with an example.
## The Desig... | opencoder | |
850,664 | SvelteKit GraphQL Queries using fetch Only | SvelteKit GraphQL queries using fetch only: how you can drop Apollo client and urql dependencies altogether to make your Svelte app leaner. | 0 | 2021-10-04T09:21:17 | https://rodneylab.com/sveltekit-graphql-queries-fetch/ | svelte, graphql, webdev, javascript | ---
title: "SvelteKit GraphQL Queries using fetch Only"
published: "true"
description: "SvelteKit GraphQL queries using fetch only: how you can drop Apollo client and urql dependencies altogether to make your Svelte app leaner."
tags: "svelte, graphql, webdev, javascript"
canonical_url: "https://rodneylab.com/sveltekit... | askrodney |
857,981 | Split Cards Effect | so in this post i wont write much but will link a video where i have shown and explained every step... | 0 | 2021-10-10T02:56:15 | https://dev.to/official_fire/split-cards-effect-2mhp | so in this post i wont write much but will link a video where i have shown and explained every step :) and made it easier so you can understand 😊

so here is the link - https://www.youtube.com/watch?v=8MdlGXaK0YQ&t=14s
*So... | official_fire | |
858,470 | Nest.js integration tests | Nest.js integration tests TDD is really hype shortcut, but it's hard to follow this... | 0 | 2021-10-10T15:46:31 | https://dev.to/devsilk/nest-js-integration-tests-o8n | # Nest.js integration tests
TDD is really hype shortcut, but it's hard to follow this approach with only unit tests. The answer for this problem are integration tests .
Here I'll present you how to setup those tests with Nest.js framework and PostgresSQL database. Those tests will cover whole API request lifecycle, fr... | olgierd | |
858,587 | 7 javaScript Array methods you should know | Arrays are one of the most common things a programmer uses or is likely to come across in a project.... | 0 | 2021-10-11T13:11:17 | https://dev.to/mcube25/7-javascript-array-methods-you-should-know-7mf | javascript, webdev, beginners, programming | Arrays are one of the most common things a programmer uses or is likely to come across in a project. In this regard the array method we are going to look into should come in handy.
We are going to use a single array for our examples
```javascript
const clubs = [
{ name: "All-stars", fans: 20000 },
{ name: "Bay",... | mcube25 |
858,601 | Weekly Digest 40/2021 | Welcome to my Weekly Digest #40 of this year. This weekly digest contains a lot of interesting and... | 10,701 | 2021-10-10T17:00:55 | https://dev.to/marcobiedermann/weekly-digest-40-2021-2dld | css, javascript, react, webdev | Welcome to my Weekly Digest #40 of this year.
This weekly digest contains a lot of interesting and inspiring articles, videos, tweets, podcasts, and designs I consumed during this week.
---
## Interesting articles to read
### How I built a modern website in 2021
Kent rewrote [kentcdodds.com](http://kentcdodds.com/... | marcobiedermann |
858,700 | hey. | I'm new here. What’s up guys? | 0 | 2021-10-10T21:03:36 | https://dev.to/wtfcxt/hey-27lp | I'm new here. What’s up guys? | wtfcxt | |
858,904 | A list of 75 app ideas, that don't exist yet and that people would actually use | https://github.com/Divide-By-0/app-ideas-people-would-use It's difficult to stay motivated coding or... | 0 | 2021-10-11T02:26:04 | https://dev.to/yushian/i-made-a-list-of-75-app-ideas-that-don-t-exist-yet-and-that-people-would-actually-use-5733 | githunt, ideas, projects, webdev | https://github.com/Divide-By-0/app-ideas-people-would-use
It's difficult to stay motivated coding or on a side project when you don't know if people will use it, or if your end goal is solving a solved problem. This list aims to fix that. Would love to hear the community's thoughts :) | yushian |
859,044 | How to Easily Format Markdown Files in VS Code | Every respectable software project needs a README. This file provides crucial information about what... | 0 | 2021-10-11T11:10:38 | https://betterprogramming.pub/how-to-easily-format-markdown-files-in-vs-code-9c6bcecbe6f2 | tutorial, vscode, markdown, productivity | Every respectable software project needs a `README`. This file provides crucial information about what the project is, how to work with it, and other relevant information for developers. `README` files are written in *markdown*, a special markup syntax. The syntax for markdown is simple enough, but it can be a pain to ... | thawkin3 |
859,059 | Integration Testing in Flutter | In case it helped :) We will cover briefly: Setup for integration test flutter Using Robot... | 0 | 2021-10-13T15:02:03 | https://dev.to/aseemwangoo/integration-testing-in-flutter-18pf | computerscience, productivity, flutter, programming | *In case it helped :)*
<a href="https://www.buymeacoffee.com/aseemwangoo" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Pass Me A Coffee!!" style="height: 41px !important;width: 174px !important;box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;-webki... | aseemwangoo |
859,123 | Set vs Array | There are several ways you can solve coding problems as a JavaScript developer, thanks to the... | 0 | 2021-10-11T07:13:52 | https://dev.to/david4473/set-vs-array-14c0 |
There are several ways you can solve coding problems as a JavaScript developer, thanks to the plethora of pre-established data structures designed to solve simple to real-world problems.
Data structures are techniques for storing and organizing data, which enables efficient modification. The data structure also dete... | david4473 | |
859,138 | Learn functional, learn systems and learn object oriented | If you are a junior or intermediate, you should consider picking up projects or languages that help... | 0 | 2021-10-11T19:00:43 | https://dev.to/ebuckley/learn-functional-learn-systems-and-learn-object-oriented-10ie | systems, javascript, clojure, go | If you are a junior or intermediate, you should consider picking up projects or languages that help you round out the functional, object oriented and systems trio of languages. After 10 years of putting text files into compilers and interpreters, here is my take.
## why we should do it
We should do it as a form of pr... | ebuckley |
859,358 | [Part 2] A proactive approach to handling application errors | NOTE: You will need to create a sentry account for this tutorial. This is the second part in a 3... | 14,906 | 2021-10-11T08:30:43 | https://dev.to/wednesdaysol/part-2-a-proactive-approach-to-handling-application-errors-34bo | devops, javascript, webdev, react | <b>NOTE: You will need to create a sentry account for this tutorial.</b>
This is the second part in a 3 part series on how to proactively handle errors in your applications across the stack.
Issues on the front-end are more easily noticeable. In a lot of applications this is beautifully handled by having an error bou... | wednesdaysol |
859,410 | Social Media Icons Hover Animation | A post by valeshgopal | 0 | 2021-10-11T09:43:20 | https://dev.to/valeshdev/social-media-icons-hover-animation-4e70 | codepen | {% codepen https://codepen.io/valeshgopal/pen/dyzyLgZ %} | valeshdev |
859,471 | Let's Showwcase - A platform to connect, build, show, and grow | What does Growth mean to you as a developer, programmer, or creator? To me, growth is an... | 0 | 2021-10-11T13:15:39 | https://blog.greenroots.info/lets-showwcase-a-platform-to-connect-build-show-and-grow | programming, showdev, codenewbie, beginners | What does `Growth` mean to you as a developer, programmer, or creator? To me, growth is an ever-increasing metric to identify that you are doing great in,
- Acquiring knowledge.
- Connecting to like-minded, discussing ideas.
- Building communities.
- Getting opportunities.
- Creating products.
- Providing services.
- ... | atapas |
859,475 | makeStyles is dead, long live makeStyles! | Material-ui decided to deprecate the hook API in v5 in favour of the styled API. I worked with them... | 0 | 2021-10-11T10:54:20 | https://dev.to/garronej/makestyles-is-dead-long-live-makestyles-i67 | typescript, react, css | 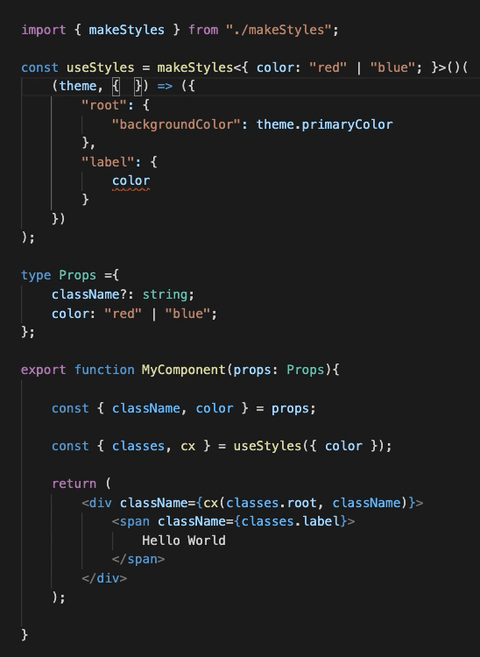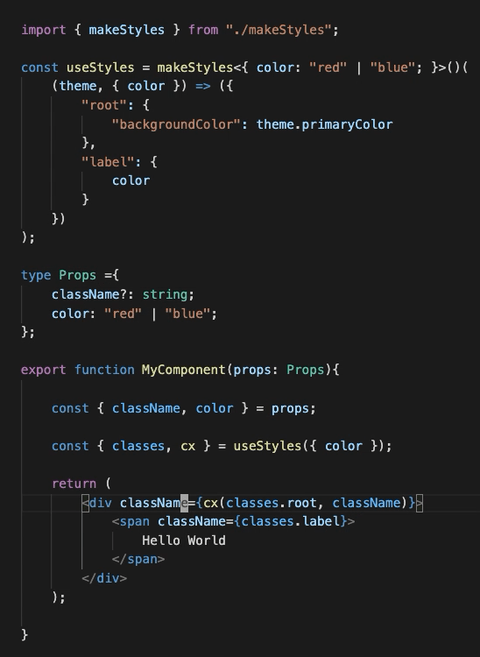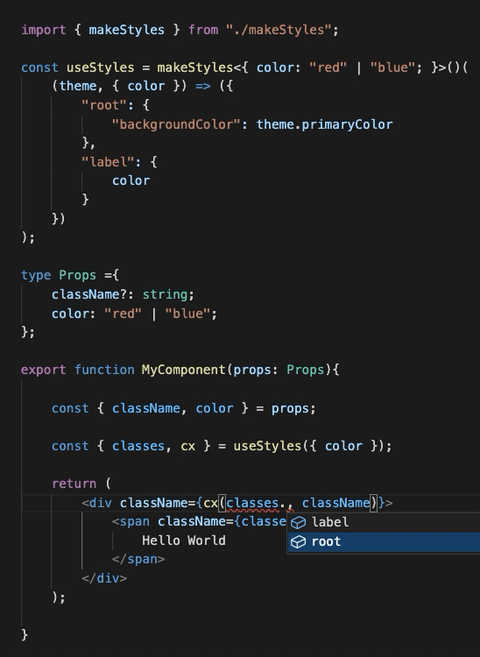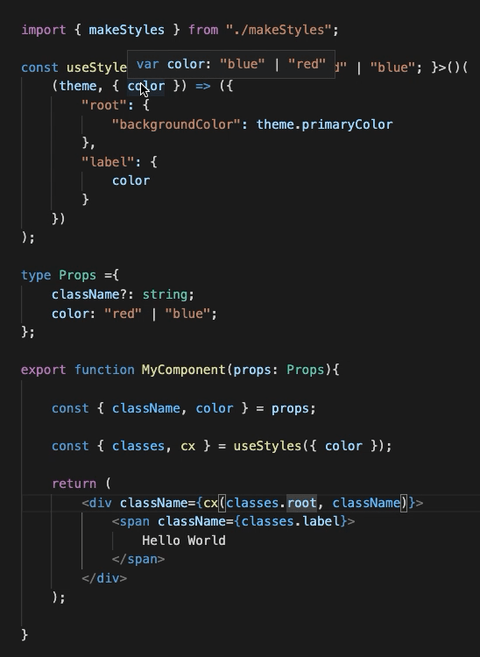
Material-ui decided to [deprecate the hook API](https://github.com/mui-org/material-ui/issues/26571#issuecomment-878641387) in v5 in favour of the styled API.
I worked with them to provide an alternati... | garronej |
859,489 | Top 10 dev.to articles of the week😱. | Most popular articles published on the dev.to | 14,897 | 2021-10-11T11:36:40 | https://dev.to/ksengine/top-10-dev-to-articles-of-the-week-2opj | webdev, javascript, beginners, css | ---
title: Top 10 dev.to articles of the week😱.
published: true
description: Most popular articles published on the dev.to
cover_image: https://source.unsplash.com/featured/?coding
tags: webdev,javascript,beginners,css
series: Weekly dev.to top 10
---
DEV is a community of software developers getting together to help... | ksengine |
860,200 | What HTML tag do you use for Sarcasm? | Ah yes, sarcasm, the pinnacle of human language. Life would be so incredibly dull without it. And... | 0 | 2021-10-12T16:00:32 | https://auroratide.com/posts/making-sarcastic-text | html, webdev | Ah yes, sarcasm, the _pinnacle_ of human language. Life would be so _incredibly_ dull without it.
And yet, despite sarcasm's profound influence on both oral and written conversation, we don't have a way to denote it in text! I mean, at least in person you can roll your eyes or change your tone to indicate some witty d... | auroratide |
860,207 | Chokoku CAD - A breakthrough CAD software on your browser | Chokoku CAD can create complex shapes with few and simple... | 0 | 2021-10-11T21:46:56 | https://dev.to/itta611/chokoku-cad-a-breakthrough-cad-software-on-your-browser-hic | javascript | Chokoku CAD can create complex shapes with few and simple controls.
https://github.com/itta611/ChokokuCAD
 | itta611 |
860,324 | 7 Ways to Escape CSS Hell | Ever have this happen? lol Yeah, me too. Here are the 7 ways to completely center whatever you... | 0 | 2021-10-12T00:23:51 | https://dev.to/stackbit/7-ways-to-escape-css-hell-2ck6 | css, webdev, beginners, tutorial | Ever have this happen? lol
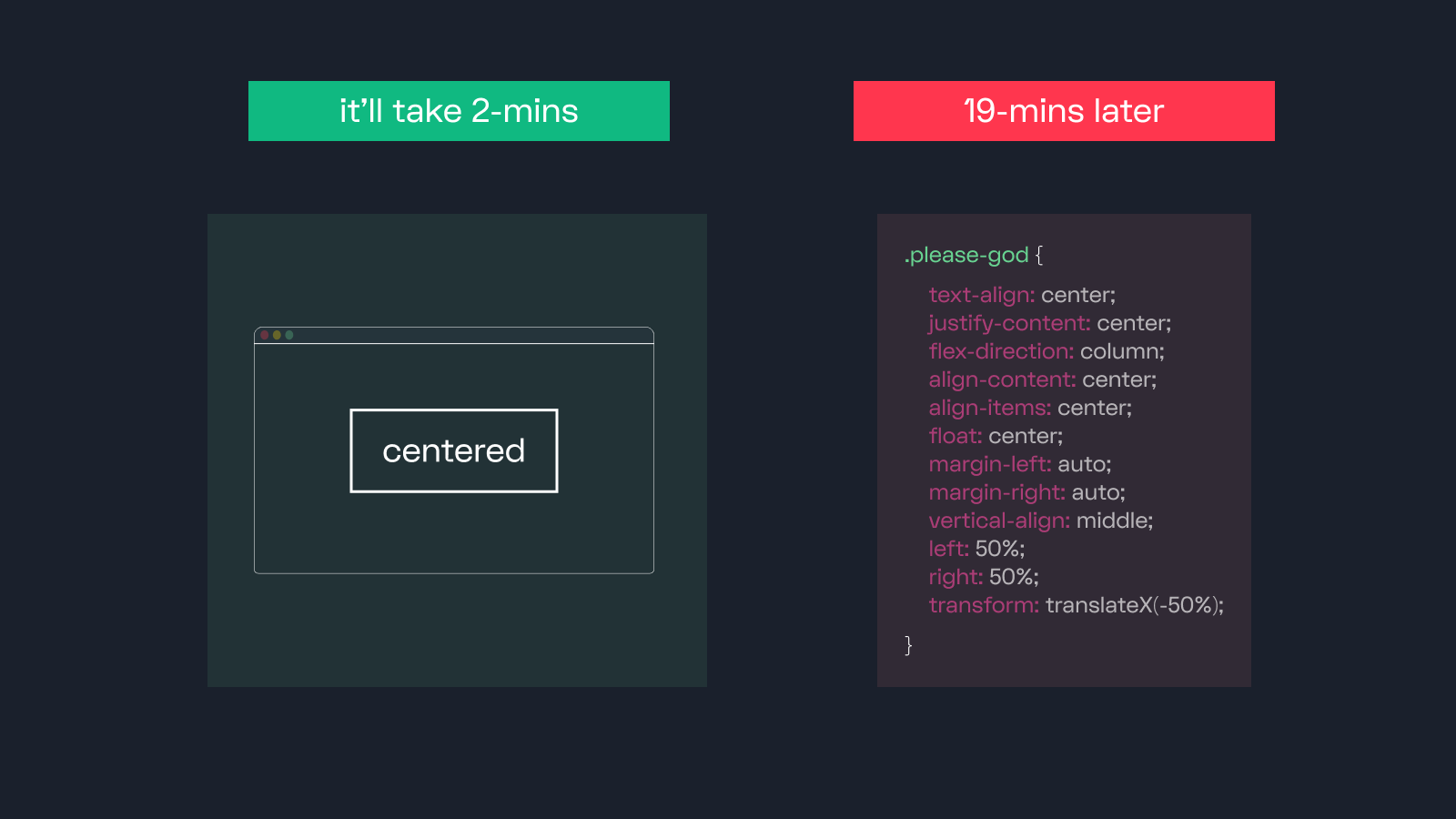
Yeah, me too.
Here are the 7 ways to completely center whatever you want with CSS.
## `1. text-align: center;`
This works only on `display: inline` & `display: inline... | rylandking |
860,348 | Avaliação comparativa entre gRPC e REST com .NET Core | Resultados preliminares do meu projeto para o mestrado da UFABC Título do... | 0 | 2021-11-01T20:07:57 | https://dev.to/bernardo/avaliacao-comparativa-entre-grpc-e-rest-com-net-core-4imh | dotnet, grpc, rest, benchmark | **Resultados preliminares do meu projeto para o mestrado da UFABC**
## **Título do Projeto**
*Avaliação comparativa entre gRPC e REST com .NET Core*
## **Objetivo**
*Comparar duas formas de execução de API para definir qual seria a mais performática quanto a tempo de execução em milissegundos dentro de um contexto ... | bernardo |
860,531 | Power Plant Equipment Suppliers | Skv Energy Services Private Limited power plant equipment or spare suppliers provide Boiler Spare... | 0 | 2021-10-12T06:41:05 | https://dev.to/energyskv/power-plant-equipment-suppliers-28n9 | beginners, startup, webdev | Skv Energy Services Private Limited power plant equipment or spare suppliers provide Boiler Spare parts , ash handling spares , fuel handling spares and hardware general items with the best quality you can check the Boiler Spare parts list and all other items on our website <p><a href="https://www.skvenergyservices.c... | energyskv |
860,753 | Advanced Javascript Functions | What is a Javascript functions A function is a block of organized,reusable code that is... | 0 | 2021-10-12T09:49:26 | https://dev.to/luxacademy/advanced-working-with-functions-d0b | javascript, beginners, webdev, tutorial | ## What is a Javascript functions
A function is a block of organized,reusable code that is used to perform a single,related action.
## Advanced Working with Functions
Function basics include function declarations,passing parameters and function scope.
check out this article that cover into to Javascript functions.
[Ja... | wanjema |
860,773 | Ten Powerful AI Chatbot Development Frameworks
| Nowadays, the use of Chatbots has evolved, and now you can see them in use on any social media... | 0 | 2021-10-12T10:34:38 | https://dev.to/webocculttechnologies/ten-powerful-ai-chatbot-development-frameworks-50ip | ai, aidevelopment | Nowadays, the use of Chatbots has evolved, and now you can see them in use on any social media platform like Telegram, Hangouts, Facebook, Slack, or your website.
Creating effective and powerful Customer Loyalty Management (CRM) takes a lot of effort and time. Chatbot helps you scale and balance your business cycle an... | webocculttechnologies |
860,865 | Statement of work vs scope of work | When your business reaches a new level, it may need to expand or even form a new team to complete... | 0 | 2021-10-12T12:40:19 | https://dev.to/maddevs/statement-of-work-vs-scope-of-work-6kg | management, webdev | When your business reaches a new level, it may need to expand or even form a new team to complete tasks on a large scale. If you give an assignment to the team without a detailed description, for example, "Make a delivery application". Briefly and concisely. Most likely, it will lead you to an unexpected result. But if... | maddevsio |
860,878 | Clean React-Redux, Redux-Saga client-side solution. | Hello there! On my previous post MERN client-side I have talked about a MERN client application with... | 0 | 2021-10-13T07:31:33 | https://dev.to/alanst32/clean-react-redux-redux-saga-client-side-solution-np | react, redux, typescript, saga | Hello there!
On my previous post [MERN client-side](https://dev.to/alanst32/a-mern-stack-update-for-2021-part-b-client-side-24o6) I have talked about a MERN client application with React, Typescript and the use of RxJs as an observables solution to collect and subscribe api response data.
Then I got on my mind, "How a... | alanst32 |
861,200 | Improving Backend Performance Part 1/3: Lazy Loading in Vaadin Apps | If you have a table or data grid with, say, more than a few hundred rows in it, you should be using... | 14,995 | 2021-10-12T17:06:59 | https://dzone.com/articles/improving-backend-performance-part-1-lazy-loading-in-vaadin-apps | java, vaadin | If you have a table or data grid with, say, more than a few hundred rows in it, you should be using lazy loading. This is especially true in the case of Vaadin's `Grid` component which makes it very easy to show data from an array or collection of POJOs. In this article, I'll show you how easy it is to take advantage o... | alejandro_du |
882,800 | Memory Management in Java | Heap vs Stack | In Java, a variable can either hold a primitive type or a reference of an object. This holds true for... | 0 | 2021-10-31T11:41:08 | https://dev.to/wasinaseer/memory-management-in-java-heap-vs-stack-3i63 | heap, stack, memory, java | In Java, a variable can either hold a primitive type or a reference of an object. This holds true for all cases. Primitive types are stored in stack and objects are stored in heap. To store objects, it needs to maintain their structure.

**Input and Output**
In this section, we will learn about how to take input and give output in Python. Till now we were writing static programs, it means that we were not taking any input f... | introschool |
861,862 | How to setup HPC cluster on AWS using AWS Parallel Cluster 2.0 | With Monitoring tool Grafana | In this tutorial, you will learn about High-performance computing using AWS. You will design 3 nodes... | 0 | 2021-10-14T06:38:54 | https://dev.to/aws-builders/how-to-setup-hpc-cluster-on-aws-using-aws-parallel-cluster-20-with-monitoring-tool-grafana-28ep | aws, hpc, tutorial, awshpc | In this tutorial, you will learn about High-performance computing using AWS. You will design 3 nodes cluster ( 1 master node, 2 compute nodes). Once you will set up a cluster then you will integrate the Grafana tool to monitor the cluster resources. Grafana is multi-platform open-source analytics and interactive visua... | sam4aws |
861,938 | Why and when you should use Vuex | As developers, we sometimes fall into the trap of using technologies just because they are popular... | 0 | 2021-10-13T08:32:27 | https://fiddit.io/blog/why-and-when-you-should-use-vuex/ | javascript, webdev, vue | As developers, we sometimes fall into the trap of using technologies just because they are popular and or commonly used together. That's why it can be beneficial to take a step back and truly understand the **why** of each technology we use.
In this blog post, I will try to do this in regards to [Vuex](https://vuex.vu... | carstenbehrens |
862,143 | AWS Access Keys - A Reference | AWS Access Keys are the credentials used to provide programmatic or CLI-based access to the AWS APIs.... | 0 | 2021-10-13T10:46:33 | https://www.nojones.net/posts/aws-access-keys-a-reference | aws, security, cloud, devops | ---
canonical_url: https://www.nojones.net/posts/aws-access-keys-a-reference
published: true
---
AWS Access Keys are the credentials used to provide programmatic or CLI-based access to the AWS APIs. This post outlines what they are, how to identify the different types of keys, where you're likely to find them across th... | njonesuk |
862,294 | Fontes de Dados - Data Science | As fontes de dados (datasets) são o principal insumo para a Ciência de Dados. Datasets completos e... | 0 | 2021-10-13T14:29:49 | https://dev.to/dgoposts/fontes-de-dados-data-science-2acm | datascience, analytics, data | As fontes de dados (datasets) são o principal insumo para a Ciência de Dados. Datasets completos e confiáveis fornecem subsídios fundamentais, formam a base de qualquer análise de dados de alto nível.
Quase em sua totalidade, são representados por dados tabulares em formato de planilha onde as linhas são os registros ... | dgoposts |
862,536 | How to Handle Required Inputs in Angular | Handling Required Inputs in Angular Directive and Component. Hey, this article presents... | 0 | 2021-10-13T16:08:17 | https://medium.com/@redin.gaetan/angular-for-everyone-required-inputs-ee916b2feaae | typescript, angular, javascript, decorators | ---
title: How to Handle Required Inputs in Angular
published: true
date: 2021-09-02 09:40:40 UTC
tags: typescript,angular,javascript,decorators
canonical_url: https://medium.com/@redin.gaetan/angular-for-everyone-required-inputs-ee916b2feaae
---
#### Handling Required Inputs in Angular Directive and Component.

===============================================================
**The term “API” gets thrown around a lot these days, but what does it mean? What can you use an API for? Do you have to have a developer on your team to build or use an API? In this guide, w... | karllhughes | |
862,573 | Advanced MessagePack capabilities | Photo by Peretz Partensky / CC BY-SA 2.0 MessagePack is a binary format for data serialization. It... | 0 | 2021-10-13T16:36:52 | https://dev.to/tarantool/advanced-messagepack-capabilities-4735 | php, programming, datacompression, tutorial | <figcaption>Photo by Peretz Partensky / CC BY-SA 2.0</figcaption>
MessagePack is a binary format for data serialization. It is positioned by the authors as a more efficient alternative to JSON. Due to ... | tarantool |
862,613 | PrabhuPay WooCommerce Plugin for WordPress | PrabhuPAY is a mobile wallet with mobile based payment solution under Prabhu Technology Pvt. Ltd.... | 0 | 2021-10-13T18:10:37 | https://dev.to/madhavdhungana/prabhupay-woocommerce-plugin-for-wordpress-37n2 | wordpress, programming | PrabhuPAY is a mobile wallet with mobile based payment solution under Prabhu Technology Pvt. Ltd.
Now PrabhyPay plugin is available for WooCommerce. Get the plugin from the following github link
https://github.com/madhav-dhungana/prabhu-pay-woocommerce | madhavdhungana |
938,065 | Timeout using context package in Go | Key takeaways context.WithTimeout can be used in a timeout implementation. WithDeadline... | 0 | 2021-12-28T04:27:05 | https://dev.to/hgsgtk/timeout-using-context-package-in-go-1b3c | go | ## Key takeaways
- [context.WithTimeout](https://pkg.go.dev/context#WithTimeout) can be used in a timeout implementation.
- [WithDeadline](https://cs.opensource.google/go/go/+/refs/tags/go1.17.5:src/context/context.go;l=434;drc=refs%2Ftags%2Fgo1.17.5) returns [CancelFunc](https://pkg.go.dev/context#CancelFunc) that te... | hgsgtk |
862,871 | Creating through a crisis | You’re a maker, right? Why don’t you make something? | 0 | 2021-10-13T23:09:52 | https://dev.to/jasonleowsg/creating-through-a-crisis-228o | beginners, codenewbie, covid19, decodingcoding | ---
title: Creating through a crisis
published: true
description: You’re a maker, right? Why don’t you make something?
tags: beginners, codenewbies, covid19, decodingcoding
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/zieq1kqg161y1a5924ak.jpg
---
### *You’re a maker, right? Why don’t you make ... | jasonleowsg |
863,004 | Swift Result for API wrangling | https://www.youtube.com/watch?v=AIb3CQH8_jg | 0 | 2021-10-14T02:18:34 | https://dev.to/ybapps/swift-result-for-api-wrangling-3pjp | https://www.youtube.com/watch?v=AIb3CQH8_jg | ybapps | |
863,014 | Divtober Day 14: Fancy | Cartoon of a fancy-looking gentleman done with CSS and a single HTML element. | 14,881 | 2021-10-14T11:59:44 | https://dev.to/alvaromontoro/divtober-day-14-fancy-al1 | codepen, divtober, css, showdev | ---
title: Divtober Day 14: Fancy
description: Cartoon of a fancy-looking gentleman done with CSS and a single HTML element.
published: true
tags: codepen,divtober,css,showdev
series: divtober
---
The word of the day is "fancy"... so here's a cartoon of a fancy-looking British gentleman with a hat, a monocle, and an u... | alvaromontoro |
863,016 | Smart contract for Voting | jaymakwanacodes.me To view source code all at once head over to my Github Let's understand with the... | 0 | 2021-10-14T05:19:48 | https://dev.to/jmakwana01/smart-contract-for-voting-4ca4 | blockchain, solidity, web3, smartcontract | [jaymakwanacodes.me](https://www.jaymakwanacodes.me/)
To view source code all at once head over to my [Github](https://github.com/jmakwana01/Simple-Bank-Smart-Contract)
Let's understand with the basic, why blockchain and how this smart contract adds value to the existing system
In the Traditional sense there are some... | jmakwana01 |
863,018 | Refactoring with Git | This is the 6th Week that I've been being in OSD 600. And this week we have a new work to do -- Lab... | 0 | 2021-10-15T03:07:55 | https://dev.to/derekjxy/refactoring-with-git-4cn4 | opensource, github, javascript, html | This is the __6th Week__ that I've been being in __OSD 600__. And this week we have a new work to do -- __Lab 5__. _Different from_ the previous labs we had, this week we are going to __modify__ our code of SSG program and make it __looks better__. It's about __refactoring__ our code.
_Due to we added new features to ... | derekjxy |
863,222 | using c++ like plain c | its a bubble sort (sorting algorithm), i was trying to make it look more readable for beginners.... | 0 | 2021-10-14T07:38:31 | https://dev.to/prathamesh_holay/using-c-as-c-5ed6 | cpp | its a bubble sort (sorting algorithm), i was trying to make it look more readable for beginners. Without any function and any class just simple as c. | prathamesh_holay |
863,237 | LeetCode - Unique Paths | LeetCode - unique paths in m X n grid using C++, Golang and Javascript. | 0 | 2021-10-14T08:41:48 | https://alkeshghorpade.me/post/leetcode-unique-paths | leetcode, cpp, go, javascript | ---
title: LeetCode - Unique Paths
published: true
description: LeetCode - unique paths in m X n grid using C++, Golang and Javascript.
tags: #leetcode, #cpp, #golang, #javascript
canonical_url: https://alkeshghorpade.me/post/leetcode-unique-paths
---
### Problem statement
A robot is located at the top-left corner of... | _alkesh26 |
863,457 | Startup Landing page in sveltekit, svelte, TailwindCSS | I made a Startup landing page in sveltekit and tailwind CSS for a competition. DEMO... | 0 | 2021-10-14T11:02:09 | https://dev.to/vanshcodes/startup-landing-page-in-sveltekit-svelte-tailwindcss-48d9 | 
I made a Startup landing page in sveltekit and tailwind CSS for a competition.
###DEMO VIDEO: https://youtu.b... | vanshcodes | |
864,144 | Laravel 🔥 tip: Generating migrations easier | Generating database migrations in Laravel is already really easy to do with the php artisan... | 0 | 2021-10-15T01:31:15 | https://dev.to/grantholle/laravel-tip-generating-migrations-easier-2jd8 | laravel | Generating database migrations in Laravel is already really easy to do with the `php artisan make:migration`. There are some nice ergonomics that aren't documented that will make it even easier.
I find myself struggling to write the name in snake case (replacing spaces with the `_` character). I was thinking, wouldn't... | grantholle |
864,756 | User-informed load tests | June this year I joined k6. A week later I heard that we were being acquired by Grafana Labs. I was... | 0 | 2021-10-15T12:57:25 | https://dev.to/floord/user-informed-load-tests-2foj | testing, performance, usability, script | June this year I joined k6. A week later I heard that we were being acquired by Grafana Labs. I was positively thrilled, I know Grafana as a great open source citizen. Anyway, k6 is in the performance space, and although I have some experience with testing (usability and accessibility testing), I've never really touche... | floord |
342,240 | Build a Forum App, from Code to Deploy | Hi there! I recently graduated from the coding bootcamp Flatiron School. Flatiron’s excellent curricu... | 6,878 | 2020-05-23T19:11:20 | https://dev.to/speratus/build-a-forum-app-from-code-to-deploy-3lcc | webdev |
Hi there! I recently graduated from the coding bootcamp Flatiron School. Flatiron’s excellent curriculum taught the skills required to build full stack applications from start to finish. We learned everything from SQL to React.
One thing that we did not learn, though, is how to deploy the apps we build. So, if you’re... | speratus |
866,729 | . | Hello!! I'm Anshoool & looking forward to explore more on this virtual world and learn as much as... | 0 | 2021-10-17T15:13:19 | https://dev.to/anshulxd/welcome-thread-155j | beginners, cybersecurity, programming, welcome | Hello!!
I'm Anshoool & looking forward to explore more on this virtual world and learn as much as possible. Hoping to work with everyone so as to make this place better, secure and more reliable to be used.😀😀🤗 | anshulxd |
880,119 | How To Build APIs That Are Resilent From 3rd Party Failures | There are many possible reasons for failures, from an outage of a third-party service (API, DB, etc.)... | 0 | 2021-10-28T20:27:52 | https://dev.to/mashaa/handling-system-failures-during-3rd-party-api-communications-499j | devops, programming |
There are many possible reasons for failures, from an outage of a third-party service (API, DB, etc.) to a hardware failure, to the “classic” software bug (after all, software developers are humans too, aren’t we? 🤔).
*Fault tolerance is a requirement, not a feature.*
This post is an a attempt to address handling s... | mashaa |
880,460 | Stack overflow is down forever. Discuss what you would do. | (Not real obviously). Discuss what you would do if Stack overflow was down forever! | 0 | 2021-10-29T04:46:23 | https://dev.to/__manucodes/stack-overflow-is-down-forever-discuss-what-you-would-do-mfa | (Not real obviously). Discuss what you would do if Stack overflow was down forever! | __manucodes | |
880,872 | iPhone 13 Previews | Found iPhone 13 previews on the accounts of https://www.pinterest.com/anddasjdsa/ on Pinterest and... | 0 | 2021-10-29T10:37:04 | https://dev.to/andrewmalrowe/iphone-13-previews-3hfj | Found iPhone 13 previews on the accounts of https://www.pinterest.com/anddasjdsa/ on Pinterest and https://dribbble.com/andddrew85 on Dribbble.
iPhone 13-series device previews are located on a board called Devices https://www.pinterest.com/anddasjdsa/devices/:
* [iPhone 13 Mini](https://www.pinterest.com/pin/3419921... | andrewmalrowe | |
881,419 | Adding Shopify to Your Next.js Stack is 🚀 + 💰 + 🙌 | You have probably heard about all of the technologies I am going to mention in this post, so I won't... | 0 | 2021-10-29T19:03:38 | https://dev.to/iskurbanov/adding-shopify-to-your-nextjs-stack-is--3ahg | shopify, nextjs, react, javascript | You have probably heard about all of the technologies I am going to mention in this post, so I won't bore you with defining each one.
In this post I want tell you why adding Shopify to your Next.js/React/JavaScript tech stack is probably one of the best decisions you can make for your freelancing or even as a career ... | iskurbanov |
938,167 | Exactly How to Check Wifi Password Windows 10? | It has been said that Sometimes some of the people who generally forget the passwords of the wifi or... | 0 | 2021-12-28T06:57:16 | https://dev.to/designdare16/exactly-how-to-check-wifi-password-windows-10-4g9m | It has been said that Sometimes some of the people who generally forget the passwords of the wifi or face a great level of the difficulty in remembering the same try to keep those passwords safe by writing those down on the notebook or online in the notes app in the smartphone, but if you are not one of them who write ... | designdare16 | |
881,427 | The Things to Keep in Mind about Auth | Five things to keep in mind about auth for the busy developer. | 0 | 2021-10-29T18:52:42 | https://developer.okta.com/blog/2021/10/29/things-to-keep-in-mind-about-auth | beginners, security, learning, cybersecurity | ---
title: The Things to Keep in Mind about Auth
published: true
description: Five things to keep in mind about auth for the busy developer.
tags: beginners, security, learning, cybersecurity
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/r6hiulxjdo8shqwa746y.png
canonical_url: https://developer.... | alisaduncan |
881,721 | Imposter Syndrome | Healthy Imagination Not sure why developers struggle feeling like fakes. All people... | 0 | 2021-10-30T03:55:46 | https://dev.to/gregrossdev/imposter-symptom-46ml | beginners, webdev, programming, codenewbie | ## Healthy Imagination
Not sure why developers struggle feeling like fakes. All people pretend till they become what they imagine. If no creative action is taking then it’s just fantasy.
### Willingness
The dedication developers put into understanding abstract computer science concepts is so admirable. From recognizin... | gregrossdev |
881,774 | Escape If-else hell in Javascript | Backstory / Problem Few months ago, there is a certain case where I need to calculate the... | 0 | 2021-10-31T06:52:01 | https://dev.to/melvnl/escape-if-else-hell-in-javascript-odn | javascript, tutorial, productivity, beginners | ###Backstory / Problem
Few months ago, there is a certain case where I need to calculate the percentage of input file in each form that user has filled (It was for a react native app that take user feedback by filling several form that represent different category such as personal information form, the user property i... | melvnl |
882,091 | 7 Nice API for your projects ! | API is the acronym for Application Programming Interface, which is a software intermediary that... | 0 | 2021-10-30T14:41:31 | https://dev.to/codeoz/7-nice-api-for-your-projects--3ap | javascript, webdev, beginners, codenewbie | **API** is the acronym for Application Programming Interface, which is a software intermediary that allows two applications to talk to each other!
Today I will share with you some nice API to use for your projects!!
### 🍿 Movie database (IMDB)
_https://developers.themoviedb.org/3/getting-started/introduction_
If y... | codeoz |
882,120 | 1 line of code: How to get the index of the lowest numeric item of an Array | const indexOfLowestNumber = arr => arr.indexOf(Math.min.apply(null,arr)); Enter fullscreen... | 15,146 | 2021-10-30T14:56:46 | https://dev.to/martinkr/1-line-of-code-how-to-get-the-index-of-the-lowest-numeric-item-of-an-array-5d8o | javascript, webdev, performance, codequality | ```javascript
const indexOfLowestNumber = arr => arr.indexOf(Math.min.apply(null,arr));
```
Returns the index of the first occurrence of the lowest numerical item of the array.
---
## The repository & npm package
You can find the all the utility functions from this series at [github.com/martinkr/onelinecode](https:... | martinkr |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.