
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
882,173 | Query in Apache CouchDB: Views | In this articles, I will talk about how to query documents in Apache CouchDB via Views. ... | 15,248 | 2021-10-30T17:05:18 | https://dev.to/yenyih/query-in-apache-couchdb-views-4hlh | database, node, beginners |
In this articles, I will talk about how to query documents in Apache CouchDB via Views.
##What is Apache CouchDB?
A short introduce about CouchDB first for those who don't know. Apache CouchDB is an open-source document-oriented NoSQL database, implemented in Erlang. It is very easy to use as CouchDB makes use of th... | yenyih |
882,318 | HTML - Let's Talk About Semantics | Salam and hello, folks! Today, let's discuss semantics. So, what's about it? ... | 0 | 2021-10-30T20:08:30 | https://dev.to/alserembani/html-lets-talk-about-semantics-4jo4 | webdev, html, beginners | Salam and hello, folks!
Today, let's discuss semantics. So, what's about it?
---
## Semantics
So, what is the dictionary meaning of semantics?
> Semantics is the study of meaning, reference, or truth.
Then, how about in the computer science field?
> Semantics is the field concerned with the rigorous mathematical... | alserembani |
882,329 | Demystifying Principal Component Analysis: Handling the Curse of Dimensionality | Generally, in machine learning problems, we often encounter too many variables and features in a... | 0 | 2021-11-02T13:33:54 | https://dev.to/charfaouiyounes/demystifying-principal-component-analysis-handling-the-curse-of-dimensionality-2hm6 | datascience, datascienceformi, dimentionalityreduction | Generally, in machine learning problems, we often encounter too many variables and features in a given dataset on which the machine learning algorithm is trained.
The higher the number of features in a dataset, the harder it gets to visualize and to interpret the results of model training and the model’s performance. ... | charfaouiyounes |
882,424 | tsParticles 1.37.1 Released | tsParticles 1.37.1 Changelog Bug Fixes Fixed issue with dynamic imports and... | 13,803 | 2021-10-30T23:41:00 | https://dev.to/tsparticles/tsparticles-1371-released-2gl6 | showdev, javascript, webdev, html | # tsParticles 1.37.1 Changelog
## Bug Fixes
- Fixed issue with dynamic imports and async loading
- Added browserslist to fix some issues with older browsers (should fix #2428)
---
{% github matteobruni/tsparticles %} | matteobruni |
882,435 | Build a Budget App using Flutter and Appwrite | Overview There are multiple components to think about when you are building an App. The... | 0 | 2021-11-02T02:21:12 | https://dev.to/1995yogeshsharma/build-a-budget-app-using-flutter-and-appwrite-1hoi | appwrite, flutter, mobileapp | # Overview
There are multiple components to think about when you are building an App.
The broad component can be categorised as -
1.) The code for app: How data is consumed, displaying the components.
2.) The backend: Where the data is stored, api implementations
For 1, we have multiple solutions like react, ionic, ... | 1995yogeshsharma |
882,551 | Query in Apache CouchDB: Mango Query | In previous articles, we talked about design documents and how to use views to query in CouchDB.... | 15,248 | 2021-10-31T03:38:48 | https://dev.to/yenyih/query-in-apache-couchdb-mango-query-lfd | database, node, beginners | In previous articles, we talked about design documents and how to use views to query in CouchDB. Besides Javascript query server, CouchDB also has a built-in Mango query server for us to query documents. Therefore in this article, I will talk about what is Mango Query, and when to use Mango Query?
---
##What is Mango... | yenyih |
882,571 | Why You Should Write Pure Functions | Originally posted @ CatStache.io - Check it out for more posts and project updates! Pure functions... | 0 | 2021-10-31T05:01:05 | https://dev.to/bamartindev/why-you-should-write-pure-functions-4ea2 | javascript, programming, functional, beginners | ---
title: 'Why You Should Write Pure Functions'
tags: 'javascript, programming, functional, beginner'
---
*Originally posted @ [CatStache.io](https://www.catstache.io/blog/js-pure-functions) - Check it out for more posts and project updates!*
Pure functions are a cornerstone of functional programming, but even if yo... | bamartindev |
882,607 | airth06_01.java | // ~Airthmatic Operators // problem: // airth06_01.java{wirte java program showing the waorking... | 0 | 2021-10-31T07:31:12 | https://dev.to/ukantjadia/airth0601java-1a4o | java, beginners, programming, tutorial | ```java
// ~Airthmatic Operators
// problem:
// airth06_01.java{wirte java program showing the waorking of all Airthmatic Operators.}
class airth06_01
{
public static void main(String args[])
{
int x= 10 , y= 10;
System.out.println("Value of x = "+x+" and value of y = "+y);
System.out.println("SUM of "+x+" and... | ukantjadia |
882,609 | Hacktoberfest 2021 Experience | My first Hacktoberfest experience and it has been an interesting one so far. I got the opportunity to... | 0 | 2021-10-31T07:38:13 | https://dev.to/devcreed/hacktoberfest-2021-experience-8n3 | hacktoberfest, opensource, github | My first Hacktoberfest experience and it has been an interesting one so far. I got the opportunity to be involved with my local tech community during this period, working more with GIT and Github. I will be finishing this edition with 6 PRs .....😊. I'm hoping to participate in the upcoming Hacktoberfest editions.💪
| devcreed |
882,786 | CV's Absurd | One of the responsibilities I have as an Engineering Manager in YouGov is being also a hiring manager... | 0 | 2021-10-31T10:44:42 | https://rogowski.page/posts/cvs-absurd/ | recruitment, cv, career, news | One of the responsibilities I have as an Engineering Manager in YouGov is being also a hiring manager for my team. I'm responsible for the process because I care to find a correct balance between skills & the need for more engineers ([Open Positions](https://jobs.yougov.com)).
{% twitter 1454293034179317764 %}
When I'... | michalrogowski |
882,807 | Spooky Dev Stories | Halloween dev stories | 0 | 2021-10-31T13:38:49 | https://dev.to/crisarji/spooky-dev-stories-5345 | halloween, spooky | ---
published: true
title: Spooky Dev Stories
description: Halloween dev stories
tags: halloween, spooky
cover_image: https://raw.githubusercontent.com/crisarji/blogs-dev.to/master/blog-posts/2021-10-spooky-dev-stories/assets/spooky-dev-stories.png
series:
canonical_url:
---
Hello developer pal!, glad to see you here.... | crisarji |
882,820 | What are the things that scare you as a Developer? 🎃 | Happy Halloween, everyone! I think the question fits the theme, so I'd like to ask everyone: What... | 0 | 2021-10-31T12:47:18 | https://dev.to/rammina/what-are-the-things-that-scare-you-as-a-developer-3gkd | discuss, beginners, programming, career | Happy Halloween, everyone!
I think the question fits the theme, so I'd like to ask everyone:
**What are your fears as a developer?**
Here are the things I'm scared of (reasonable or not aside):
- not being able to find my next freelance client.
- production bugs.
- performance anxiety when showing interviewers and ... | rammina |
883,061 | My First week in BootCamp(TaskForce 4.0) | am very excited to share my first week experience in bootcamp which was prepared by awesomity in... | 0 | 2021-10-31T16:52:03 | https://dev.to/kdany25/my-first-week-in-bootcamptaskforce-40-540e | am very excited to share my first week experience in bootcamp which was prepared by awesomity in parteniship with Code of Africa.
bootcamp started on 25th october and today is the end of first week in 6weeks we have to complete.
i don't know where i can start because i can't put it all in words it might take 100pages... | kdany25 | |
883,084 | My Journey | This is my first post detailing my journey to a career in Software Development! My most proficient... | 0 | 2021-10-31T17:51:07 | https://dev.to/bixxith/my-journey-473d | python, programming, career, beginners | This is my first post detailing my journey to a career in Software Development!
My most proficient language by far is Python. I love doing everything in Python. I don't know if I am interested in a data science career but I would like to do more with it. I learned the Django framework to expand on my Python knowled... | bixxith |
883,308 | Exemplo de Projeto Utilizando Sagemaker MultiModel | Este é um post feito a muitas mãos de um projeto dentro da Conta Azul junto a AWS Leia o artigo aqui | 0 | 2021-11-09T21:52:50 | http://gabubellon.me//blog/exemplo-de-projeto-utilizando-sagemaker-multimodel | aws, python, sagemaker, datascience | ---
title: Exemplo de Projeto Utilizando Sagemaker MultiModel
published: true
date: 2021-04-30 00:00:00 UTC
tags: aws,python,sagemaker,datascience
canonical_url: http://gabubellon.me//blog/exemplo-de-projeto-utilizando-sagemaker-multimodel
---
Este é um post feito a muitas mãos de um projeto dentro da Conta Azul junto... | gabubellon |
883,212 | SPO600 - Update | Where I'm standing currently with my SPO600 course (software portability and optimization) is quite... | 0 | 2021-10-31T19:02:15 | https://dev.to/hyporos/spo600-update-469j | Where I'm standing currently with my SPO600 course (software portability and optimization) is quite behind. I've admittedly been slacking a bit which I know is not good and therefore the lab content is confusing to me.
I will hope to get these labs (3 and 4) done in the next blogging period so that I can keep up with ... | hyporos | |
883,217 | Hacktoberfest: Small changes make a big impact | For my first issue to tackle for realease0.2 I decided to go with something I was more comfortable... | 0 | 2021-10-31T19:09:30 | https://dev.to/amasianalbandian/hacktoberfest-small-changes-make-a-big-impact-29aj | For my first issue to tackle for realease0.2 I decided to go with something I was more comfortable with, but in a different environment.
I picked up an issue from Telescope that was front-end and a bug. This was perfect because it wasn't too much pressure for me, and something I can start without feeling overwhelmed.... | amasianalbandian | |
883,242 | Setting up a MySQL database using Prisma | What is Prisma? Prisma is an open-source Node.js and Typescript ORM (Object Relational... | 0 | 2021-10-31T20:20:25 | https://www.ineza.codes/blog/setting-up-a-mysql-database-with-prisma | prisma, serverless, nextjs | ## What is Prisma?
Prisma is an open-source Node.js and Typescript ORM (Object Relational Mapper) it acts as a sort of middleware between your application and the database helping you to manage and work with your database. It currently supports PostgreSQL, MySQL, SQL Server, SQLite and some of its features also suppor... | inezabonte |
883,261 | My first week in Taskforce 4.0 at CodeofAfrica and Awesomity lab. | Introduction I know this time you are asking yourselves the same question I asked myself... | 0 | 2021-10-31T21:22:55 | https://dev.to/cyimanafaisal/my-first-week-in-taskforce-40-at-codeofafrica-and-awesomity-lab-48o6 | webdev, programming | # Introduction
I know this time you are asking yourselves the same question I asked myself the first time when I heard about taskforce Bootcamp. To know what **Taskforce** is? I suggest you go through the **Awesomity** website. [Awesomity.rw](https://awesomity.rw/our-projects). But really Taskforce "It’s more like a ... | cyimanafaisal |
883,267 | Javascript and code documentation | javaScript is a programming language that conforms to the ECMAScript specification. JavaScript is... | 0 | 2021-10-31T21:43:30 | https://dev.to/mcube25/javascript-and-code-documentation-3hgo | javaScript is a programming language that conforms to the ECMAScript specification. JavaScript is high-level, often just-in-time compiled and multi-paradigm. It has dynamic typing, prototype-based object-orientation and first-class functions.
#### Why code documentation?
If you wrote a couple of functions for making a... | mcube25 | |
883,396 | Oracle SQL - Ways to Work on it | Introduction SQL, yes and it's not MYSQL. SQL is a Structured Query Language, it is a language that... | 0 | 2021-11-01T03:26:01 | https://dev.to/iamanshuldev/oracle-sql-ways-to-work-on-it-5foc | sql, oracle | Introduction
SQL, yes and it's not MYSQL. SQL is a Structured Query Language, it is a language that is used to communicate with the database whereas MYSQL is an open-source database product(RDBMS) that allows users to keep the data organized in a database. I will write another article on this topic specifically. Let's... | iamanshuldev |
883,620 | REST APIs and Designing Best Practices | APIs (Application Programming Interfaces) are necessary for applications or devices to connect and... | 0 | 2021-11-01T07:45:09 | https://dev.to/shoki/rest-apis-and-designing-best-practices-10k | architecture, beginners, database | APIs (Application Programming Interfaces) are necessary for applications or devices to connect and communicate with each other.
In this article, I will explain what REST Api is, which is vary popular one, and the best practice of designing it.
## What is REST?
### History of REST
1. REST was born in 2000, after SOAP... | shoki |
883,814 | Strapi Tutorial: Build a Blog with Next.js | This article was originally posted on my personal blog If you want to start your own blog, or just... | 0 | 2021-11-01T17:28:15 | https://blog.shahednasser.com/strapi-tutorial-build-a-blog-with-next-js/ | javascript, beginners, strapi, node | ---
title: Strapi Tutorial: Build a Blog with Next.js
published: true
date: 2021-11-01 10:13:21 UTC
tags: javascript,beginners,strapi,nodejs
canonical_url: https://blog.shahednasser.com/strapi-tutorial-build-a-blog-with-next-js/
cover_image: https://blog.shahednasser.com/static/7ba78ca821fb59c20235977dcf45de59/bram-nau... | shahednasser |
883,959 | Wetware of writing and doing | Originally presented at Tools for Thought Rocks on October 29, 2021 (with video and timestamps).... | 0 | 2021-11-01T13:18:21 | https://dev.to/rosano/wetware-of-writing-and-doing-4jib | productivity, writing, tutorial, discuss | _Originally presented at [Tools for Thought Rocks](https://lu.ma/tftrocks-oct) on October 29, 2021 (with [video and timestamps](https://cafe.rosano.ca/t/presenting-wetware-of-writing-and-doing-at-tools-for-thought-rocks/148/2)). Below is an expanded text version of my presentation for anyone who prefers reading._
* * ... | rosano |
884,263 | OpenTelemetry Distributed Tracing with ZIO | A tutorial on implementing distributed tracing for Scala applications using OpenTelemetry and various libraries from the ZIO ecosystem. | 0 | 2021-11-01T16:29:00 | https://tuleism.github.io/blog/2021/opentelemetry-distributed-tracing-zio/ | distributedtracing, observability, scala, tutorial | ---
title: OpenTelemetry Distributed Tracing with ZIO
published: true
date: 2021-11-01 00:00:00 UTC
tags: distributedtracing,observability,scala,tutorial
canonical_url: https://tuleism.github.io/blog/2021/opentelemetry-distributed-tracing-zio/
description: A tutorial on implementing distributed tracing for Scala applic... | tuleism |
884,856 | Simple Python Projects for Beginners With Source Code | I believe that the best way to master any programming language is to create real-life projects using... | 0 | 2021-11-02T04:41:42 | https://dev.to/visheshdvivedi/simple-python-projects-for-beginners-with-source-code-4nb8 | python, programming, beginners, tutorial | I believe that the best way to master any programming language is to
create real-life projects using that language. The same is the case with
the python programming language. If you are a beginner python
programmer, and you want to master the python programming language, then it's really important that you start creati... | visheshdvivedi |
885,082 | Why you should never use random module for generating passwords. | Why Random Numbers Are Not Random? The Random Numbers come from a particular seed number... | 15,405 | 2021-11-04T09:43:19 | https://dev.to/vaarun_sinha/why-you-should-never-use-random-module-for-generating-passwords-38nl | python, beginners, programming, security |
## Why Random Numbers Are Not Random?
The Random Numbers come from a particular seed number which is usually the system clock.Run the program below to understand the security risk.
{% replit @MRINDIA1/Random-Numbers-Are-Not-Random %}
The Python Documentation also has a warning about the same: "The **pseudo-random** ... | vaarun_sinha |
885,191 | Top 10 articles about JavaScript of the week💚. | Most popular articles about JavaScript published on the dev.to in this week | 14,901 | 2021-11-02T11:32:01 | https://dev.to/ksengine/top-10-articles-about-javascript-of-the-week-590l | javascript, webdev, beginners, react | ---
title: Top 10 articles about JavaScript of the week💚.
published: true
description: Most popular articles about JavaScript published on the dev.to in this week
cover_image: https://source.unsplash.com/featured/?javascript
tags: javascript,webdev,beginners,react
series: Weekly JS top 10
---
DEV is a community of so... | ksengine |
885,413 | Build an email news digest app with Nix, Python and Celery | In this tutorial, we'll build an application that sends regular emails to its users. Users will be... | 0 | 2021-11-02T13:36:55 | https://docs.replit.com/tutorials/31-build-news-digest-app-with-nix | In this tutorial, we'll build an application that sends regular emails to its users. Users will be able to subscribe to [RSS](https://en.wikipedia.org/wiki/RSS) and [Atom](https://en.wikipedia.org/wiki/Atom_(Web_standard)) feeds, and will receive a daily email with links to the newest stories in each one, at a specifie... | ritzaco | |
885,444 | Being a Softare Engineer: A marathon and not a sprint | So I wrote two technical assessments tests yesterday to apply for a Fullstack role and a Backend role... | 0 | 2021-11-02T14:52:47 | https://dev.to/lekea4/being-a-softare-engineer-a-marathon-and-not-a-sprint-2o1d | programming, react, career, dotnet | So I wrote two technical assessments tests yesterday to apply for a Fullstack role and a Backend role at two different organizations and I honestly feel I did not do well. In fact, I think I was terrible!
The first of the assessments requires building a simple full-stack application (Frontend: React; Backend: ASP.... | lekea4 |
886,244 | dotnet swagger tofile : FileNotFoundException dotnet-swagger.xml | The Problem Trying to generate swagger from the compiled dll using this command with the... | 0 | 2021-11-03T05:30:43 | https://dev.to/wallism/dotnet-swagger-tofile-filenotfoundexception-dotnet-swaggerxml-4425 | dotnet, swagger | ## The Problem
Trying to generate swagger from the compiled dll using this command with the [swagger CLI](https://github.com/domaindrivendev/Swashbuckle.AspNetCore):
```
dotnet swagger tofile --output "swagger-output.json" "C:\projectpath\bin\debug\net5.0\project.dll" v1
```
I encountered this error:
```
FileNotFoundE... | wallism |
886,351 | When Should You Use Type Aliases And Interfaces In Typescript? | A post by pariskrit | 0 | 2021-11-03T07:50:18 | https://dev.to/pariskrit/when-should-you-use-type-aliases-and-interfaces-in-typescript-1k20 | typescript, react | pariskrit | |
886,433 | A very first PicoLisp program | To conclude our "PicoLisp for Beginners" Series, we should talk about naming conventions, and finally... | 14,882 | 2021-11-03T08:19:08 | https://picolisp-blog.hashnode.dev/a-very-first-picolisp-program | picolisp, lisp, functional, tutorial | To conclude our "PicoLisp for Beginners" Series, we should talk about naming conventions, and finally create our first own little program!
-----------------------------
### Naming Conventions
PicoLisp has a few naming conventions that should be followed, in order to introduce name conflicts and keep the code readabl... | miatemma |
886,471 | 7 Useful JS Fiddles | Some useful snippets for you to use. | 0 | 2021-11-03T18:40:01 | https://dev.to/davinaleong/7-useful-js-fiddles-1mg0 | tutorial, programming, javascript, css | ---
title: 7 Useful JS Fiddles
published: true
description: Some useful snippets for you to use.
tags: tutorial, programming, javascript, css
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/cu0hj945fss8tbbufvw9.jpg
---
Sharing some JSFiddles the rest of you may find useful. I often use JSFiddle as... | davinaleong |
886,493 | Mistrymitra a Growing Firm | Mistrymitra as an Indians local search engine, provide services in numerous ways whether it would be... | 0 | 2021-11-03T11:21:57 | https://mistrymitra.com/blog/about-us/mistrymitra-a-growing-firm | Mistrymitra as an Indians local search engine, provide services in numerous ways whether it would be building homes, schools, offices, malls, roads, hospitals, theme parks – everything. It is vital to everyone’s life. Construction is all around us.
As India’s population grows famously, there is a greater demand for ne... | glensmith088 | |
886,518 | 5 Ruang Baca yang Mengingat Anda Pada The Secret Garden | Retret luar ruangan di The Secret Garden oleh Frances Hodgson Burnett adalah tempat lamunan dan... | 0 | 2021-11-03T12:16:43 | https://dev.to/aaridwan16/5-ruang-baca-yang-mengingat-anda-pada-the-secret-garden-3mco | books, tutorial, webdev, beginners | Retret luar ruangan di The Secret Garden oleh Frances Hodgson Burnett adalah tempat lamunan dan penyembuhan, dan sulit untuk tidak membayangkan bahwa itu akan menjadi tempat yang sempurna untuk membaca juga.
Bayangkan: Berada di tempat yang nyaman dengan sebuah buku di tangan, dikelilingi oleh sinar matahari yang han... | aaridwan16 |
886,560 | DevBox Showcase: CRON Explorer | Hi 👋, This is the fourth post in the series showcasing tools from DevBox 🎉, a desktop application or... | 14,629 | 2021-11-03T12:57:14 | https://dev.to/gdotdesign/devbox-showcase-cron-explorer-6df | productivity, tutorial, json, cron | Hi 👋,
This is the fourth post in the series showcasing tools from [DevBox](https://www.dev-box.app) 🎉, a desktop application or browser extension packed with everything that every developer needs.
-------
DevBox has a **CRON Explorer tool**, which is useful for checking [CRON Expressions](https://en.wikipedia.org/... | gdotdesign |
886,647 | Formatting numbers in JavaScript | In the last couple of posts, I showed you how you can format dates and relative dates using the... | 0 | 2021-11-09T09:39:37 | https://dberri.com/formatting-numbers-in-javascript | javascript, formatting | ---
title: Formatting numbers in JavaScript
published: true
date: 2021-11-03 09:00:00 UTC
tags: javascript, formatting
canonical_url: https://dberri.com/formatting-numbers-in-javascript
---
In the last couple of posts, I showed you how you can format dates and relative dates using the native Internationalization API. ... | dberri |
886,770 | Answer: Does LESS have an "extend" feature? | answer re: Does LESS have an "extend"... | 0 | 2021-11-03T13:38:42 | https://dev.to/sudharshan24/answer-does-less-have-an-extend-feature-h26 | {% stackoverflow 69825821 %} | sudharshan24 | |
887,134 | Root to Linux: BIOS | At Forem a few coworkers and I have formed a Linux Club🤓. Joe Doss is leading us on this adventure... | 15,339 | 2021-11-04T20:11:57 | https://dev.to/coffeecraftcode/root-to-linux-bios-16jm | linux, beginners, devops | At Forem a few coworkers and I have formed a Linux Club🤓.
[Joe Doss](https://twitter.com/jdoss) is leading us on this adventure into Linux.
The adventure starts by working through the [Gentoo Handbook](https://wiki.gentoo.org/wiki/Handbook:AMD64) and installing Gentoo(a distribution of Linux) on Lenovo ThinkPads.
... | coffeecraftcode |
891,140 | DOM (Document Object Model) is really easy to understand!!!
| 1. What is DOM? 2. What is “D” “O” “M” for? 3. Is DOM same as... | 0 | 2021-11-07T16:30:03 | https://dev.to/riyadmahmud2021/-what-is-dom-what-is-d-o-m-for-5g44 | javascript, webdev, html, beginners |
1. What is DOM?
-------------------------------------------------------------
2. What is “D” “O” “M” for?
-------------------------------------------------------------
3. Is DOM same as HTML?
-------------------------------------------------------------
4. What is the relation between DOM and HTML?
----------... | riyadmahmud2021 |
892,001 | 30 Projects Ideas! | To-do list app Note-taking app Calendar Application Chat System Weather application Portfolio... | 0 | 2021-11-08T15:15:06 | https://www.buymeacoffee.com/mrdanishsaleem/30-projects-ideas | programming, tutorial, beginners, codenewbie | 1. To-do list app
2. Note-taking app
3. Calendar Application
4. Chat System
5. Weather application
6. Portfolio website
7. Image search
8. Chess game
9. Donation website
10. Budget tracker
11. Tic Tac Toe game
12. Form validator
13. Web Scraper
14. Simple FTP client
15. Port Scanner
16. MP3 Player
17. Tetris game
18. N... | mrdanishsaleem |
894,101 | Getter and Setter - Python | As the title says, I am presenting, Getters and Setters for First, let's review some OOP concepts,... | 0 | 2021-11-10T13:51:04 | https://dev.to/wsadev01/getter-setter-4gj6 | python, oop, programming, tutorial | As the title says, I am presenting, Getters and Setters for
<img align="center" width=75% src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ftgfunsb10xfxwa373p0.png">
First, let's review some OOP concepts, then we will see what are those (If you thought of crocs, consider leaving a unicorn) getters and se... | wsadev01 |
894,788 | How to Optimize Website for Core Web Vitals--A Guide for Designers | You have created a unique website for your business with great visuals and text. But even that is no... | 0 | 2021-11-11T05:06:03 | https://dev.to/hennykel/how-to-optimize-website-for-core-web-vitals-a-guide-for-designers-4dhc | corewebvitals, webdev, websiteoptimization, seo | You have created a unique website for your business with great visuals and text. But even that is no guarantee of the website working well to drive traffic, which is crucial for business growth. What is most important now is that you take into account your users' experience. In other words, you should evaluate your web... | hennykel |
894,891 | Reactjs Overview - (EchLus Community - Part 1) | Halo kawan - kawan kali ini saya akan sharing materi tentang "Reactjs Overview". ini merupakan seri... | 0 | 2021-11-11T07:17:39 | https://dev.to/_satria_herman/reactjs-overview-echlus-community-a06 | react, javascript, webdev, programming | Halo kawan - kawan kali ini saya akan sharing materi tentang "Reactjs Overview". ini merupakan seri sharing session batch tentang Reactjs.
##**Overview Materi**
Di batch ini kita akan belajar tentang
- Install and Setup Reactjs
- Basic Props and State
- React Hooks
- React State Management
- Communicating With Server... | _satria_herman |
894,909 | HacktoberFest Badge | Now i have one more Hacktoberfest Badge | 0 | 2021-11-11T08:02:33 | https://dev.to/rishi098/hacktoberfest-badge-kd | hacktoberfest, devlive, programming, webdev | Now i have one more Hacktoberfest Badge | rishi098 |
894,918 | Working MongoDB with Golang | Every tutorial has a story. In that tutorial you'll find out different contents that is related to... | 0 | 2021-11-11T14:23:47 | https://dev.to/burrock/working-mongodb-with-golang-2g76 | go, mongodb, programming, database | Every tutorial has a story. In that tutorial you'll find out different contents that is related to MongoDB, GoLang and working with mock data and deployment. Here is my content.
## Project structure
PS: Here is th... | burrock |
895,013 | 5 Challenges In Business Intelligence Mobile Application Development | In modern times, data being produced by organizations is in massive numbers. Every small to large... | 0 | 2021-11-11T11:05:59 | https://dev.to/rachael_ray018/5-challenges-in-business-intelligence-mobile-application-development-51ic | mobile, ai, android, programming | In modern times, data being produced by organizations is in massive numbers. Every small to large business is generating data consistently and taking the investigation to the next level. It also involves making an informed decision for the company, allowing you to focus on its core competencies. However, it is not yet ... | rachael_ray018 |
895,190 | The EyeDropper API: Pick colors from anywhere on your screen | With the new EyeDropper API in Chromium, websites can let visitors pick colors from anywhere on their... | 0 | 2021-11-11T13:52:32 | https://polypane.app/blog/the-eye-dropper-api-pick-colors-from-anywhere-on-your-screen/ | javascript, webdev, ux | With the new EyeDropper API in Chromium, websites can let visitors pick colors from anywhere on their screen, adding another
feature to the web that used to require hacky solutions and is now just a few lines of code. The API is
clean and modern and easy to use. In this article we'll discuss how to set it up, handle e... | kilianvalkhof |
895,553 | Advent of Code 2020 - Day 15 | In the spirit of the holidays (and programming), I’ll be posting my solutions to the Advent of Code... | 0 | 2021-11-28T02:23:23 | https://ericburden.work/blog/2020/12/16/advent-of-code-2020-day-15/ | ---
title: Advent of Code 2020 - Day 15
published: true
date: 2020-12-16 00:00:00 UTC
tags:
canonical_url: https://ericburden.work/blog/2020/12/16/advent-of-code-2020-day-15/
---
In the spirit of the holidays (and programming), I’ll be posting my solutions to the [Advent of Code 2020](https://adventofcode.com/) puzzl... | ericwburden | |
895,571 | What is the difference between JOIN and INNER JOIN in SQL? | Introduction If you've ever used SQL, you probably know that JOINs can be very confusing.... | 0 | 2021-11-11T18:52:38 | https://devdojo.com/tutorial/what-is-the-difference-between-join-and-inner-join-in-sql | database, sql, 100daysofcode, webdev | # Introduction
If you've ever used SQL, you probably know that `JOIN`s can be very confusing. In this quick post we are going to learn what the difference between `JOIN` and `INNER JOIN` is!
# Difference between JOIN and INNER JOIN
Actually, `INNER JOIN` AND `JOIN` are functionally equivalent.
You can think of th... | bobbyiliev |
895,591 | Lessons I learned during my first year of programming | I started programming in June of 2020, and have grown so much throughout this process. I wanted to... | 0 | 2021-11-11T21:09:59 | https://dev.to/codergirl1991/lessons-i-learned-during-my-first-year-of-programming-5891 | beginners, webdev, programming, codenewbie | I started programming in June of 2020, and have grown so much throughout this process. I wanted to share the lessons I learned during my first year of programming.
## It's ok not to listen to everyone's opinions
One of things that I realized early on is that everyone has an opinion.
The tech world has a lot of stro... | codergirl1991 |
895,764 | Herding elephants: Wrangling a 3,500-module Gradle project | Note: please do not attempt to herd any actual elephants Every day in Square's Seller organization,... | 0 | 2021-11-12T01:33:53 | https://developer.squareup.com/blog/herding-elephants/ | android, gradle | _Note: please do not attempt to herd any actual elephants_
Every day in Square's Seller organization, dozens of Android engineers run close to 2,000 local builds, with a cumulative cost of nearly 3 days per day on those builds. Our CI system runs more than 11,000 builds per day, for a cumulative total of over 48 days ... | autonomousapps |
895,843 | Catch2 - Testing Framework | Introduction This week, I work on my Static Site Generator (SSG) - Potato Generator. I... | 0 | 2021-11-12T02:51:28 | https://dev.to/kiennguyenchi/catch2-testing-framework-2cdg | opensource | # Introduction
This week, I work on my Static Site Generator (SSG) - [Potato Generator](https://github.com/kiennguyenchi/potato-generator). I implemented the Catch2 - Testing Framework to my project.
There are many testing tools for C++, I could say MSTest, Google Test, built-in test in Visual Studio,... It may take y... | kiennguyenchi |
895,948 | Learning Workflows: Four Ways to Invoke a Workflow | In this video you will learn how to invoke a workflow. There are four ways and they are: scheduled,... | 0 | 2022-02-10T17:52:23 | https://maxkatz.org/2021/11/11/learning-workflows-four-ways-to-invoke-a-workflow/ | nocode, workflows | ---
title: Learning Workflows: Four Ways to Invoke a Workflow
published: true
date: 2021-11-12 05:10:40 UTC
tags: NoCode,Workflows
canonical_url: https://maxkatz.org/2021/11/11/learning-workflows-four-ways-to-invoke-a-workflow/
---
In this video you will learn how to invoke a workflow. There are four ways and they are... | maxkatz |
896,078 | How to get randomly sorted recordsets in Strapi | Lately I had to build page that shows the details of a recordset, and at the bottom a section... | 0 | 2021-11-12T16:31:28 | https://dev.to/drazik/how-to-get-randomly-sorted-recordsets-in-strapi-522d | strapi, headlesscms, javascript | ---
title: How to get randomly sorted recordsets in Strapi
published: true
description:
tags: strapi,headlesscms,javascript
cover_image: https://images.unsplash.com/photo-1605870445919-838d190e8e1b?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=1172&q=80
---
Lately I had to bu... | drazik |
896,119 | Discovering Scrum Artifacts and Their Commitments | Scrum is a technique that helps teams work together. Just as a sports team prepares for a decisive... | 0 | 2021-11-12T11:13:04 | https://dev.to/fireartd/discovering-scrum-artifacts-and-their-commitments-21en | devops, ux, webdev | <p class="wow fadeIn animated" data-wow-delay=".05s">Scrum is a technique that helps teams work together.</p>
<blockquote class="wow fadeIn" data-wow-delay=".05s">
<p><em>Just as a sports team prepares for a decisive game, the team of company employees should learn from the experience gained, master the principles of s... | fireartd |
896,120 | 5 Underrated resources to learn Git and Github | Save you time and use these resources to perfect your Git and GitHub knowledge. This week, I finally... | 0 | 2021-11-19T13:15:09 | https://dev.to/toru/5-underrated-resources-to-learn-git-and-github-4edi | github, git, webdev, beginners |
**Save you time and use these resources to perfect your Git and GitHub knowledge.**
This week, I finally built up the courage to deep dive into learning Git and GitHub without having to relying on GUI and using the command line. We are fortunate enough to have unlimited resources available to us at the click of the... | ifrah |
896,143 | Why You Need an Next-Gen AWS Managed Services Partner | The undoubted leader in all things cloud, AWS has over a million users in their active user base. But... | 0 | 2021-11-12T12:14:13 | https://dev.to/teleglobal/why-you-need-an-next-gen-aws-managed-services-partner-1pdd | aws, awsmanagedservices, awspartner | The undoubted leader in all things cloud, AWS has over a million users in their active user base. But the cloud is a dynamic, ever evolving place and navigating the AWS ecosystem, with its many, many services and features, to identify the best solution to your needs can be a complicated affair. To help their customers ... | teleglobal |
896,477 | Επικοινωνία ανθρώπου-υπολογιστή: Γιατί είναι σημαντική η μελέτη της | Λόγοι μελέτης αλληλεπίδρασης ανθρώπου-υπολογιστή (Α.Α.Υ) και Μοντέλα εργασίας... | 0 | 2021-11-12T17:14:42 | https://blog.eleftheriabatsou.com/logoi-meletis-allilepidrasis-anthropou-upologisti | hci, design, ux | ## Λόγοι μελέτης αλληλεπίδρασης ανθρώπου-υπολογιστή (Α.Α.Υ) και Μοντέλα εργασίας ανθρωποκεντρικής σχεδίασης
Ο τομέας της Α.Α.Υ.() σχετίζεται με πολυάριθμες πτυχές του σύγχρονου τρόπου ζωής και για αυτό η μελέτη της κρίνεται αναγκαία. Πιο συγκεκριμένα μπορεί να έχει μία κοινωνική διάσταση αφού οι υπολογιστές χρησιμοπο... | eleftheriabatsou |
896,845 | Code testing with Jest | This week I looked at code testing for my Static Site Generator static-dodo. I picked Jest for this... | 0 | 2021-11-13T03:10:33 | https://dev.to/menghif/code-testing-with-jest-3b4h | This week I looked at code testing for my Static Site Generator [static-dodo](https://github.com/menghif/static-dodo). I picked [Jest](https://jestjs.io) for this since it is a very popular unit testing tool used by many open source projects.
### How to setup Jest
I started by installing Jest using npm
```console
npm ... | menghif | |
896,856 | JavaScript Tips: Using Array.filter(Boolean) | What does .filter(Boolean) do on Arrays? This is a pattern I've been coming across quite a... | 15,530 | 2021-11-13T12:26:14 | https://mikebifulco.com/posts/javascript-filter-boolean | javascript, react, programming | ---
title: JavaScript Tips: Using Array.filter(Boolean)
published: true
date: 2021-11-12 00:00:00 UTC
tags: [javascript, react, programming]
cover_image: https://res.cloudinary.com/mikebifulco-com/image/upload/f_auto,q_auto/v1/posts/javascript-filter-boolean/cover.webp
canonical_url: https://mikebifulco.com/posts/javas... | irreverentmike |
897,108 | Aplikasi VPN Terbaik | Dibanding kebingungan harus check dan ricek untuk dapetin program VPN terbaik, lebih bagus sahabat... | 0 | 2021-11-13T12:36:14 | https://dev.to/genemil/aplikasi-vpn-terbaik-289m | Dibanding kebingungan harus check dan ricek untuk dapetin program VPN terbaik, lebih bagus sahabat tekno baca saja pembahasan berikut ini mengenai program VPN terbaik versus website tehnologi indonesia. Baca sampai akhir ya sob!
1. VPN Master
VPN gratis yang ini mempunyai size yang yang paling kecil sama ukuran 6,7 M... | genemil | |
897,124 | Create a simple editable table with search and pagination in React JS in 2 min | React JS… | Create a simple editable table with search and pagination in React JS in 2 min | React JS... | 0 | 2021-11-13T15:39:53 | https://gyanendraknojiya.medium.com/create-a-simple-editable-table-with-search-and-pagination-in-react-js-in-2-min-react-js-56328e067733 | editabletable, frontend, reactjsdevelopment, reactjstutorials | ---
title: Create a simple editable table with search and pagination in React JS in 2 min | React JS…
published: true
date: 2021-11-01 18:22:03 UTC
tags: editabletable,frontenddevelopment,reactjsdevelopment,reactjstutorials
canonical_url: https://gyanendraknojiya.medium.com/create-a-simple-editable-table-with-search-an... | gyanendraknojiya |
897,251 | How do i connect with www.mywifiext.net login setup page for Netgear Extender setup | To get to mywifiext Setup, plug in your Netgear extender and turn it on. Using your web browser, go... | 0 | 2021-11-13T14:51:22 | https://dev.to/mywifiext_login_setup/how-do-i-connect-with-wwwmywifiextnet-login-setup-page-for-netgear-extender-setup-22b4 | mywifiextsetup, mywifiextlocal, mywifiextnet, mywifiextnetsetup | To get to mywifiext Setup, plug in your Netgear extender and turn it on. Using your web browser, go to the mywifiext configuration page right now. Mywifiext.net is a local url that cannot be found online. On the configuration tab, you should see a New extender setup button. Click on the finish Setup button.
Connect y... | mywifiext_login_setup |
897,257 | Top 33 JavaScript Projects on GitHub (November 2021) | 2021 is coming to its end, and we may do another snapshot of 33 most starred open-sourced JavaScript... | 0 | 2021-11-13T15:23:08 | https://dev.to/trekhleb/top-33-javascript-projects-on-github-november-2021-41d4 | javascript, webdev, opensource, github | 2021 is coming to its end, and we may do another snapshot of **33 most starred open-sourced JavaScript repositories** on GitHub **as of November 13th, 2021**.
> Previous snapshots: [2018](https://trekhleb.dev/blog/2018/top-33-javascript-projects-on-github-august-2018/), [2020](https://trekhleb.dev/blog/2020/top-33-jav... | trekhleb |
897,432 | Fast and easy way to setup web developer certificates | Modern days having that cookies auth etc depends on https we need to have https local web... | 0 | 2021-11-13T21:00:22 | https://dev.to/istarkov/fast-and-easy-way-to-setup-web-developer-certificates-450e | devops, webdev | Modern days having that cookies auth etc depends on https we need to have https local web environment.
Before to generate local certificates I used [minica](https://github.com/jsha/minica).
The main issue that you need a big readme for osx, linux and windows users, how to regenerate keys,
how to add minica certific... | istarkov |
897,463 | React Tic Tac Toe | GitHub Repo // index.js import React from 'react'; import ReactDOM from 'react-dom'; import... | 0 | 2021-11-13T22:10:16 | https://dev.to/sagordondev/react-tic-tac-toe-2gab | react, programming, computerscience, gamedev | [GitHub Repo](https://github.com/sagordon-dev/my-app)
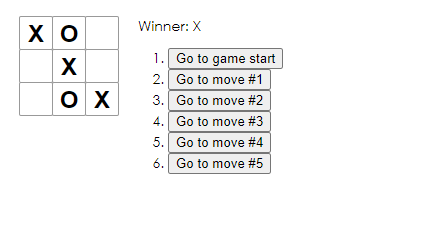
```react
// index.js
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
function Square(props) {
return (
<button className=... | sagordondev |
897,575 | Implementing Dark Mode (Part 1) | I'd like to share the story behind one of my favorite contributions to Open Sauced so far, which is... | 15,537 | 2021-11-16T15:34:47 | https://dev.to/opensauced/implementing-dark-mode-part-1-3ono | I'd like to share the story behind one of my favorite contributions to Open Sauced so far, which is the addition of "Dark Mode", [PR #1020](https://github.com/open-sauced/open-sauced/pull/1020). This PR touched 25 files and was pretty substantial in scope, so I'm going to break this up into 3 parts. Part 1 is here is j... | mtfoley | |
897,580 | Integrating Live Chat to Your WordPress, Shopify or Webflow Site Has Never Been this Easy! | Full post originally published at Aviyel, do check it out. As a business owner who has to interact... | 0 | 2021-11-15T18:35:00 | https://aviyel.com/post/1340/integrating-live-chat-to-your-wordpress-shopify-or-webflow-site-has-never-been-this-easy | chatwoot, livechat, wordpress, shopify | <a href="https://aviyel.com/post/1340/integrating-live-chat-to-your-wordpress-shopify-or-webflow-site-has-never-been-this-easy">Full post originally published at Aviyel, do check it out.</a>
As a business owner who has to interact with customers quite often, live chat support is the best plausible option. However, the... | victoreke |
897,610 | Store Alphabet in a list with Python | Step1: import string to your code. > import string Step2: create alphabet list with... | 0 | 2021-11-14T05:46:04 | https://dev.to/hishakil/store-alphabet-in-a-list-with-python-34df | python, programming | Step1: import string to your code.
> import string
Step2: create alphabet list with uppercase and lowercase.
> small_letter = string.ascii_lowercase
Step3: store it...
> lowerletter_list = list(small_letter)
Finish, You can run to see the result. | hishakil |
897,655 | Webhooks in Kraken CI for GitHub, GitLab and Gitea | Kraken CI is a new Continuous Integration tool. It is a modern, open-source, on-premise CI/CD system... | 12,501 | 2021-11-15T11:49:39 | https://kraken.ci/docs/guide-webhooks | ci, cd, devops, github | [Kraken CI](https://kraken.ci/) is a new Continuous Integration tool. It is a modern, open-source, on-premise CI/CD system that is highly scalable and focused on testing. It is licensed under Apache 2.0 license. Its source code is available on [Kraken CI GitHub page](https://github.com/Kraken-CI/kraken).
This tutorial... | godfryd |
897,693 | Keyoxide | This is an OpenPGP proof that connects my OpenPGP key to this dev.to account. For details check out... | 0 | 2021-11-14T08:12:52 | https://dev.to/rintan/keyoxide-18c0 | This is an OpenPGP proof that connects [my OpenPGP key](https://keyoxide.org/4792BF13985872DC12546B6FD679E0532311765C) to [this dev.to account](https://dev.to/rintan). For details check out https://keyoxide.org/guides/openpgp-proofs
[Verifying my OpenPGP key: openpgp4fpr:4792BF13985872DC12546B6FD679E0532311765C] | rintan | |
897,883 | Weekly Digest 45/2021 | Welcome to my Weekly Digest #45. This weekly digest contains a lot of interesting and inspiring... | 10,701 | 2021-11-14T15:19:11 | https://dev.to/marcobiedermann/weekly-digest-452021-2mok | css, javascript, react, webdev | Welcome to my Weekly Digest #45.
This weekly digest contains a lot of interesting and inspiring articles, videos, tweets, podcasts, and designs I consumed during this week.
---
## Interesting articles to read
### Rust Is The Future of JavaScript Infrastructure
Why is Rust being used to replace parts of the JavaScr... | marcobiedermann |
898,015 | Track App Interactions with TraceContext | This is a placeholder testing 123 | 0 | 2021-11-14T17:16:43 | https://dev.to/capndave/track-app-interactions-with-tracecontext-5da9 | programming, node, tutorial, webdev | ## This is a placeholder
testing 123 | capndave |
898,032 | Welcome to the free open-source OLAP server project | Welcome to the site of the eMondrian project. eMondrian is a free open-source OLAP server. It is... | 0 | 2021-11-15T13:59:06 | https://dev.to/sergeisemenkov/welcome-to-the-free-open-source-olap-server-project-132f | Welcome to the site of the [**eMondrian**](https://sergeisemenkov.github.io/eMondrian) project.
eMondrian is a free open-source [OLAP](https://en.wikipedia.org/wiki/Online_analytical_processing) server. It is based on the [Mondrian](https://github.com/pentaho/mondrian) project. OLAP server allows you to represent your... | sergeisemenkov | |
898,046 | Pie Time | Canvas pie chart clock with second, minute, && hour progression. | 0 | 2021-11-14T18:09:13 | https://dev.to/libanzakariya9409081201/pie-time-170l | codepen | <p>Canvas pie chart clock with second, minute, && hour progression.</p>
{% codepen https://codepen.io/tmrDevelops/pen/VYKyge %} | libanzakariya9409081201 |
898,261 | The First Git Commit | GitHub link: https://github.com/git/git/commit/e83c5163316f89bfbde7d9ab23ca2e25604af290 | 0 | 2021-11-14T23:30:53 | https://dev-to-dev.hashnode.dev/the-first-git-commit | git | 
GitHub link: [https://github.com/git/git/commit/e83c5163316f89bfbde7d9ab23ca2e25604af290](https://github.com/git/git/commit/e83c5163316f89bfbde7d9ab23ca2e25604af290) | rosberglinhares |
898,295 | How to calculate accuracy ratio in Excel using only a formula | Risk practitioners often use accuracy ratio (AR) to measure the discriminatory power of binary... | 0 | 2021-11-15T13:48:36 | https://addin.qrstoolbox.com/pages/demos/how-to-calculate-accuracy-ratio-excel/ | excel, risk, statistics, datascience | ---
title: How to calculate accuracy ratio in Excel using only a formula
published: true
description:
tags: excel, risk, statistics, datascience
canonical_url: https://addin.qrstoolbox.com/pages/demos/how-to-calculate-accuracy-ratio-excel/
cover_image: https://addin.qrstoolbox.com/pages/demos/how-to-calculate-accuracy... | wynntee |
911,011 | Accessible card component with pure (S)CSS (no JavaScript, the pseudo-content trick) | When creating the card component, sometimes it’s advisable (or required by design) to make the whole... | 0 | 2021-11-27T23:51:55 | https://www.damianwajer.com/blog/accessible-card-component/ | css, a11y, tutorial, webdev | When creating the card component, sometimes it’s advisable (or required by design) to make the whole card clickable. But how to do so without compromising the usability? Below I share a useful pseudo-content trick to make the whole card clickable and maintain its accessibility.
## Problem statement
* the whole card ne... | damianwajer |
911,369 | UI Dev Newsletter #85 | Links Backgrounds Chrome Developers share a module where you will learn how to style text... | 0 | 2021-12-02T14:16:56 | https://mentor.silvestar.codes/reads/2021-11-29/ | html, css, javascript, webdev | ## Links
[Backgrounds](https://bit.ly/3Ed1VZO)
Chrome Developers share a module where you will learn how to style text on the web.
[My Custom CSS Reset](https://bit.ly/3xtz2pK)
Josh Comeau shares his custom CSS reset and explains every rule in detail with examples.
[How I made Google’s data grid scroll 10x faster... | starbist |
913,737 | Building a scraping tool with Python and storing it in Airtable (with real code) | A startup often needs extremely custom tools to achieve its goals. At Arbington.com we've had to... | 15,325 | 2021-12-30T00:27:30 | https://dev.to/kalobtaulien/building-a-scraping-tool-with-python-and-storing-it-in-airtable-with-real-code-4pbl | python | A startup often needs extremely custom tools to achieve its goals.
At [Arbington.com](https://arbington.com) we've had to build scraping tools, data analytics tools, and custom email functions.
> None of this required a database. We used files as our "database" but mostly we used Airtable.
## Scrapers
Nobody wan... | kalobtaulien |
913,759 | What type of developer would a startup hire? | "The world has a shortage of developers." You might have heard this before. It's fairly common for... | 15,325 | 2022-01-04T16:39:53 | https://dev.to/kalobtaulien/what-type-of-developer-would-a-startup-hire-3bbp | "The world has a shortage of developers."
You might have heard this before. It's fairly common for people to say this.
It's kind of true, but not really...
Here's the truth.
"The world has a shortage of **[senior]** developers."
Because companies don't like hiring junior or intermediate developers because they... | kalobtaulien | |
913,900 | Weekly web development resources #98 | Twind A small, fast, most feature complete tailwind-in-js solution. Using... | 0 | 2021-12-01T06:52:12 | https://dev.to/vincenius/weekly-web-development-resources-98-3o6i | weekly, webdev |
______
##[Twind](https://twind.dev/)
[](https://twind.dev/)
A small, fast, most feature complete tailwind-in-js solution.
______
##[Using Emojis in HTML, CSS, and JavaScript](https://www.kirupa.com/html5/emoji.htm)
[
### Submission Category:
Wacky Wildcards
### Yaml File or Link to Code
Workflow:
```YAML
name: Add membe... | abhigoyani |
913,941 | โม้ว่าทำอะไรเกี่ยวกับ Rust บ้าง 2021 | ทีแรกผมจะเขียนเตรียมไว้พูดในงาน Rustacean Bangkok 2.0.0 แต่ว่าวันงานไม่ว่าง ก็เลยเอามารวมเป็น blog... | 0 | 2021-12-01T09:27:38 | https://dev.to/veer66/omwaathamaairekiiywkab-rust-baang-33ib | ---
title: โม้ว่าทำอะไรเกี่ยวกับ Rust บ้าง 2021
published: true
description:
tags:
//cover_image: https://direct_url_to_image.jpg
---
ทีแรกผมจะเขียนเตรียมไว้พูดในงาน Rustacean Bangkok 2.0.0 แต่ว่าวันงานไม่ว่าง ก็เลยเอามารวมเป็น blog ไว้ก่อนแล้วกัน
ผมจะเล่าว่าผมทำอะไรกับภาษา Rust บ้างซึ่งก็คงไม่ครบถ้วน จะเขียนไปตาม... | veer66 | |
913,997 | November 21' Month Updates for Developers 🚀 | NEW! This is the November 2021 release announcement. Here is a list of all new enhancements and... | 0 | 2021-12-01T15:03:03 | https://www.videosdk.live/blog/november-month-updates | ---
title: November 21' Month Updates for Developers 🚀
published: true
teg: webrtc, showdev, webdev, beginners
canonical_url: https://www.videosdk.live/blog/november-month-updates
---

**NEW! This i... | sagarkava | |
914,029 | N, manage easily your node versions | Before share a node JS tool you should consider these things: Your tool has no bugs Your tool has... | 0 | 2021-12-01T13:33:30 | https://dev.to/gatomo_oficial/n-manage-easily-your-node-versions-f8k | javascript, node, tutorial, productivity | Before share a node JS tool you should consider these things:
- Your tool has no bugs
- Your tool has documentation
- **Your tool has compatibility between versions**
Compatibility is something important to keep in mind. Developers needs different versions according to their needs, so your tool must have support for ... | gatomo_oficial |
914,049 | Setup-Cpp | setup-cpp Install all the tools required for building and testing C++/C... | 0 | 2021-12-06T16:51:47 | https://dev.to/aminya/setup-cpp-3ia4 | actionshackathon21, cpp, github, devops | # setup-cpp
Install all the tools required for building and testing C++/C projects.

Setting up a **cross-platform** environment for building and testing C++/C projects is a bit tricky. Each platform has its own compilers, an... | aminya |
914,087 | Schema Validation with Zod and Express.js | Overview In the past I've done articles on how we can use libraries like Joi and Yup to... | 0 | 2021-12-01T10:31:47 | https://dev.to/franciscomendes10866/schema-validation-with-zod-and-expressjs-111p | node, javascript, tutorial, webdev | ## Overview
In the past I've done articles on how we can use libraries like [Joi](https://dev.to/franciscomendes10866/schema-validation-with-joi-and-node-js-1lma) and [Yup](https://dev.to/franciscomendes10866/schema-validation-with-yup-and-express-js-3l19) to create middleware that does input validation coming from th... | franciscomendes10866 |
914,144 | How to recover the firmware of a NAS | QNAP Firmware Recovery Check Hardware Turn Off NAS. Unplug Harddrives. Use... | 0 | 2021-12-01T11:46:53 | https://dev.to/jeromesch/how-to-recover-the-firmware-of-a-nas-4nb | nas, recovery, backup, homeserver | # QNAP Firmware Recovery
##Check Hardware
1. Turn Off NAS.
2. Unplug Harddrives.
3. Use HDMI / USB plugs to control the nas manualy.
(Keyboard / Mouse / Monitor)
4. Turn On NAS.
If the Bios won't boot without Harddrives the internal storage most likely has a Problem.
A.) This might be the case if you just updated... | jeromesch |
914,174 | first project starting | A post by Bijay | 0 | 2021-12-01T12:24:59 | https://dev.to/bijay05487063/first-project-starting-4nig | codepen | {% codepen https://codepen.io/bijay124r3/pen/ZEXYKYr %} | bijay05487063 |
914,177 | What to start with as a begginer in Web Dev?? | Well all the YouTube videos, some are true some are false.. But the statement I always say... | 0 | 2021-12-01T12:27:04 | https://dev.to/sumanta_thefrontdev/what-to-start-with-as-a-begginer-in-web-dev-4eg | discuss, webdev, beginners | Well all the YouTube videos, some are true some are false.. But the statement I always say ....
Don't spend money. As it can happen that after spending money, sometimes the money goes waste and you don't learn anything..
So the first thing to do is. Start with HTML5. And see YouTube to start learning...
## CONCLUSI... | sumanta_thefrontdev |
914,384 | Learn Solidity helping Santa Claus | Advent of Code is a yearly series of 25 puzzles that are released between the first and 25th of... | 0 | 2021-12-01T15:52:08 | https://dev.to/ethsgo_/learn-solidity-helping-santa-claus-129b | blockchain, adventofcode, solidity, javascript | Advent of Code is a yearly series of 25 puzzles that are released between the first and 25th of December. You might have heard of them, lot's of people do them – to have fun, to show off their speed, or to learn a new language.
We'll be going through these puzzles, doing them in Solidity (and JS) - https://github.com/... | ethsgo_ |
914,391 | 10 Best Free B2B Lead Generation Tools - A Comprehensive List 2022 | How do you grow your B2B business without spending money on advertising? The answer lies in... | 0 | 2021-12-01T16:12:36 | https://dev.to/fahadconall/10-best-free-b2b-lead-generation-tools-a-comprehensive-list-2022-1pki | leadgeneration, bigdata, productivity, database | How do you grow your B2B business without spending money on advertising? The answer lies in generating your own leads through lead generation tools. While some of these tools may look similar, they all serve different purposes and can be used in combination with each other to maximize the number of leads generated whil... | fahadconall |
914,648 | How to Rename Local and Remote Git Branch | Have you ever wondered or come across a situation where you want to rename a Git branch? If yes then... | 0 | 2021-12-01T18:26:59 | https://kodewithchirag.com/how-to-rename-local-and-remote-git-branch | git, webdev, productivity, tutorial | Have you ever wondered or come across a situation where you want to rename a Git branch? If yes then this article will help you with that. Earlier, I faced the same situation where I wanted to rename the git branch locally and on remote, and luckily I found that git allows us to rename the branch very easily, lets see ... | kodewithchirag |
914,680 | Factory Method Pattern | Factory Method(virtual constructor) provides an interface for creating objects in a super-class, but... | 15,752 | 2021-12-01T20:44:12 | https://dev.to/eyuelberga/factory-method-pattern-3od | algorithms, java, beginners, codenewbie |
> Factory Method(virtual constructor) provides an interface for creating objects in a super-class, but defers instantiation to sub-classes.
## Motivation
Consider an application which has to access a class, but does not know which class to choose form among a set of sub-classes of the parent class. The application c... | eyuelberga |
915,354 | C vs. C++: Who is the winner? | Hello Techies, It's Nomadev back with another blog. So today's blog is on one of the most debatable... | 0 | 2021-12-02T12:20:01 | https://dev.to/thenomadevel/c-vs-c-who-is-the-winner-4h12 | Hello Techies, It's [Nomadev](https://twitter.com/thenomadevel) back with another blog. So today's blog is on one of the most debatable topics, **Who's the winner: C Vs C++**. A lot of beginners have had the same questions when they started their programming journey. There was a long time where I didn't know the answe... | thenomadevel | |
914,683 | Introduction | Creational patterns hide how instance of classes are constructed. Thereby enabling more independence... | 15,752 | 2021-12-01T19:54:05 | https://dev.to/eyuelberga/introduction-4bal | Creational patterns hide how instance of classes are constructed. Thereby enabling more independence and increasing flexibility in a system. In this series, we try to look at the most common creational patterns and their unique features.
To demonstrate the implementation of the creational patterns, we will use, as an ... | eyuelberga | |
915,063 | What are Pet Tags and Details to include on them? | Pet Tags are used to identify the pet's owner or the pet that is wearing it. The tags are usually... | 0 | 2021-12-02T05:53:28 | https://dev.to/leashkings/what-are-pet-tags-and-details-to-include-on-them-59cp | Pet Tags are used to identify the pet's owner or the pet that is wearing it. The tags are usually made of plastic, cloth, metal, or paper. They are usually found on the pets' necks. They, like humans, are used to identify the owner and animal. Along with this, these can be used in cases of lost animals.
The pet tag is ... | leashkings |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.