
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
329,379 | Converting Excel to PDF in Java Application | PDF is a portable document format that cannot be easily edited or modified. So sometimes when we send... | 0 | 2020-05-07T06:09:03 | https://dev.to/codesharing/converting-excel-to-pdf-in-java-application-474i | excel, java, pdf | PDF is a portable document format that cannot be easily edited or modified. So sometimes when we send Excel files to others and don’t want the important formulas to be viewed or modified, we will convert the Excel to PDF. This article will demonstrate two methods to convert Excel to PDF by using Free Spire.XLS for Java... | codesharing |
329,392 | Reimplementing JavaScript Array methods | Mastering JavaScript Array methods by reimplementing them | 0 | 2020-05-07T06:54:05 | https://dev.to/webit/reimplementing-javascript-array-methods-46bl | javascript, arrays, programming, webdev | ---
title: Reimplementing JavaScript Array methods
published: true
description: Mastering JavaScript Array methods by reimplementing them
tags: javascript, arrays, programming, webdev
---
*This is cross-post from medium, where I published it first.*
, I added branches and commits. Though I have good idea what's happening behind t... | kenakamu |
329,510 | Event-driven integration #4 - Outbox publisher (feat. IHostedService & Channels) [ASPF02O|E043] | In this episode, we’ll implement the outbox publisher, or better yet, two versions of it, one better suited for lower latency and another for reliability. As we continue our event-driven path, this will be a good opportunity to introduce a couple of interesting .NET Core features: IHostedService (and BackgroundService)... | 71 | 2020-05-07T10:26:44 | https://blog.codingmilitia.com/2020/05/07/aspnet-043-from-zero-to-overkill-event-driven-integration-04-outbox-publisher-feat-ihostedservice-channels/ | dotnet, aspnetcore, efcore | ---
title: Event-driven integration #4 - Outbox publisher (feat. IHostedService & Channels) [ASPF02O|E043]
published: true
date: 2020-05-07 09:30:00 UTC
tags: dotnet,aspnetcore,efcore
canonical_url: https://blog.codingmilitia.com/2020/05/07/aspnet-043-from-zero-to-overkill-event-driven-integration-04-outbox-publisher-f... | joaofbantunes |
329,548 | Quick Demo! Two months of building. | Now in Supabase: Set up Postgres in less than 2 minutes Auto-generated APIs! (they are a bit flaky,... | 0 | 2020-05-07T11:57:31 | https://dev.to/supabase/quick-demo-one-month-of-building-21no | showdev, postgres, supabase | Now in [Supabase](https://app.supabase.io):
- Set up Postgres in less than 2 minutes
- Auto-generated APIs! (they are a bit flaky, go easy)
- Query your database directly from the dashboard
- Analyze your queries and make them faster :rocket:
## Important Notes
1/ Supabase is NOT production ready. Have a play around... | supabase_io |
329,557 | How I learned a lot from deploying an app that does nothing | I did it! Frontend, backend, database, deployment. It was all me! ...aaaand it's empty. Today I w... | 0 | 2020-05-08T07:33:43 | https://dev.to/reiallenramos/how-i-learned-a-lot-from-deploying-an-app-that-does-nothing-3ipc | webdev, showdev, codenewbie | I did it! Frontend, backend, database, deployment. It was all me!

...aaaand it's empty.
Today I want to share my journey on a personal project with a huge disclaimer that it's not exciting nor groundbreaking. My intention was not t... | reiallenramos |
329,749 | Tutorial how does Git Rebase work and compare with Git Merge and Git Interactive Rebase | This article was originally published at: https://www.blog.duomly.com/git-rebase-tutorial-and-compari... | 0 | 2020-05-11T07:54:41 | https://www.blog.duomly.com/git-rebase-tutorial-and-comparison-with-git-merge/ | github, beginners, programming, git | This article was originally published at: https://www.blog.duomly.com/git-rebase-tutorial-and-comparison-with-git-merge/
---
###Intro###
There are many ways of working with git, if they're clean, and don't do damages, probably most of them are good.
But same as space vs. tab, in the IT world is a war between fans of... | duomly |
329,768 | the #1 Ruby benchmarking tool you didn't know you need | Attention web developers working with lots of data - below are first class problems to consider: sl... | 0 | 2020-05-09T16:50:41 | https://dev.to/andy4thehuynh/the-1-ruby-benchmarking-tool-you-didn-t-know-you-need-153l | postgres, rails, ruby, heroku | Attention web developers working with lots of data - below are first class problems to consider:
- slow database queries
- page time outs
When customer support barks at you to resolve a 500 error, what do you do? Initial instincts suggest the two problems are related. Especially in applications with lots of user data... | andy4thehuynh |
329,811 | Looking at Pipedream's Event Sources | Before I begin, know that everything I'm discussing here is currently in beta form. It may, and will,... | 0 | 2020-05-11T22:02:06 | https://www.raymondcamden.com/2020/05/07/looking-at-pipedreams-event-sources | webdev, serverless, javascript | ---
title: Looking at Pipedream's Event Sources
published: true
date: 2020-05-07 00:00:00 UTC
tags: webdev,serverless,javascript
canonical_url: https://www.raymondcamden.com/2020/05/07/looking-at-pipedreams-event-sources
cover_image: https://static.raymondcamden.com/images/banners/water_source.jpg
---
Before I begin, ... | raymondcamden |
329,817 | Current development trends in software engineering | Starting from some basic insights, it is important to know in which age group our respondents belong: 35% of developers worldwide are between 25 and 34 years old. The second largest demographic – almost 28%- is the young developers, aged 18 to 24 years old. | 0 | 2020-05-07T17:06:44 | https://dev.to/stateofdevnation/current-development-trends-in-software-engineering-3j24 | developertrends, programminglanguages, frontendframeworks, developerpopulation | ---
title: Current development trends in software engineering
published: True
description: Starting from some basic insights, it is important to know in which age group our respondents belong: 35% of developers worldwide are between 25 and 34 years old. The second largest demographic – almost 28%- is the young develope... | developernationsurvey |
329,920 | My first post as a Storyblok ambassador | Storyblok @storyblok... | 0 | 2020-05-07T20:33:52 | https://www.storyblok.com/tp/tailwindcss-express-js-amp-sites | amp, tailwindcss, node, storyblok | {% tweet 1258410263021342720 %}
🎉 I'm officially an ambassador at Storyblok 🎉
I wanted to share it with you, I'm very excited, it's the technology that has allowed me to create [my blog](https://www.dawntraoz.com/blog/) and being part of it is a dream come true 😍
In this article, I show you how to build a valid A... | dawntraoz |
329,991 | How to handle Database in Spring Boot | Core data for Spring Boot with Database. Please you may use more source in there link. This provide... | 0 | 2020-05-08T01:23:29 | https://dev.to/urunov/how-to-handle-database-in-spring-boot-560 | security, database, serverless, spring |
Core data for Spring Boot with Database. Please you may use more source in there [link] (https://github.com/Urunov/SpringBoot-Database).
This provides Database implementation in the Spring Boot. Especially, we'll briefly inform here concept of Spring, Spring Boot, JDBC, JPA, H2 and result of our experience project(... | urunov |
330,011 | Add Serverless Functions to Any Static Site | Quickly add a serverless backend to any static site, including React, Vue, or other SPA static sites. | 0 | 2020-05-08T02:34:03 | https://swank.dev/blog/add-serverless-functions/ | netlify, serverless, node | ---
title: Add Serverless Functions to Any Static Site
published: true
description: Quickly add a serverless backend to any static site, including React, Vue, or other SPA static sites.
tags: netlify, serverless, node
---
Adding just a bit of backend functionality to your Netlify-hosted static site is a perfect use-ca... | briansw |
330,030 | HTTP 🤩🤩 !!!! Flutter | Flutter is meant to create UI/Client oriented stack, but without a backend we cannot deliver a full f... | 0 | 2020-05-08T03:50:47 | https://dev.to/prakashselvaraj/http-flutter-1dp2 | flutter, flutterdev | Flutter is meant to create UI/Client oriented stack, but without a backend we cannot deliver a full fledged business functionality to the user.
In this post we are going to see how we can consume the http services.
Let see in action 😇
Our first step would be add the package [HTTP](https://pub.dev/packages/http) to *... | prakashselvaraj |
330,051 | Want to develop real time app | Hey guys, this is kind of a newbie question. So right now, I'm not too much experienced with MERN (Mo... | 0 | 2020-05-08T04:35:00 | https://dev.to/andrykwiatow/want-to-develop-real-time-app-5078 | help, react, node, mongodb | Hey guys, this is kind of a newbie question.
So right now, I'm not too much experienced with MERN (Mongo, Express, React NodeJS) development... I mean I've made some projects but that's it. I want to develop a real-time app and I suggested MERN as the solution for this app, even though I don't know too much about, I th... | andrykwiatow |
330,184 | JavaScript .flatMap() | In my previous post, I wrote about Celebrating JavaScript .flat() and how to flatten arrays, giving a... | 0 | 2020-05-16T04:58:35 | https://dev.to/katkelly/javascript-flatmap-2gi7 | beginners, codenewbie | In my previous post, I wrote about [Celebrating JavaScript .flat()](***LINK HERE***) and how to flatten arrays, giving a lot of love to `flat()`. I naturally wanted to follow it up with a post about `flatMap()` and look at how it works and what it does.
###flatMap()
The `flatMap()` method is a super merger of `flat()`... | katkelly |
330,843 | Code Tryouts - Natural Selection | Hey, In the last week I wrote simulation in Unity3d, In this simulation we have animals that can walk... | 0 | 2020-05-09T14:28:16 | https://dev.to/eranelbaz/code-tryouts-natural-selection-1ap1 | simulation, life, gene, animals | Hey,
In the last week I wrote simulation in Unity3d,
In this simulation we have animals that can walk around the map and they search for food, water and another animal to mate with.
Each animal currently have 2 genes - Speed and Search Radius.
When a new animal is born it can inherent each gene from one of the parent... | eranelbaz |
330,233 | Vue.js + GitHub + Tailwind Css | I implemented this small application that generates a card with Tailwind CSS based on data from the G... | 0 | 2020-05-08T10:41:58 | https://dev.to/daviducolo/vue-js-github-tailwind-css-1iho | showdev, vue, github, todayilearned | I implemented this small application that generates a card with Tailwind CSS based on data from the GitHub REST API V3 using the Vue.js framework.
{% github davidesantangelo/github-vue-card %}
deployed on netlify at https://github-vue-card.netlify.app
| daviducolo |
330,293 | When do you write CSS and when CSS/CSS3 or CSS3? | A post by pandaquests | 0 | 2020-05-08T12:03:22 | https://dev.to/pandaquests/when-do-you-write-css-and-when-css-css3-or-css3-3lj9 | css, career, webdev, web | pandaquests | |
330,308 | Let's code: graphs in java | I have been obsessed with graphs for a few years now. This obsession has resulted in three projects:... | 0 | 2020-06-18T01:47:45 | https://dev.to/moaxcp/lets-code-graphs-in-java-1kem | java, tdd, tutorial, graphs | I have been obsessed with graphs for a few years now. This obsession has resulted in three projects: [graph-dsl](https://github.com/moaxcp/graph-dsl), [graphs](https://github.com/moaxcp/graphs), and [graph-wm](https://github.com/moaxcp/graph-wm). Graphs are excellent data structures that have helped me in a few situati... | moaxcp |
330,316 | JS Fundamentals: Object Assignment vs. Primitive Assignment | A quick look at object assignment in JavaScript aimed at newcomers to the language. | 0 | 2020-05-08T12:32:45 | https://dev.to/nas5w/js-fundamentals-object-assignment-vs-primitive-assignment-5h64 | javascript, beginners, webdev, tutorial | ---
title: JS Fundamentals: Object Assignment vs. Primitive Assignment
published: true
description: A quick look at object assignment in JavaScript aimed at newcomers to the language.
tags: javascript, beginner, webdev, tutorial
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/t2oz7swuutjdt58jpspx.png
---
# Intr... | nas5w |
330,357 | how developers can cope with stress | We are in a period where working from you living room, kitchen or garage is the norm. Remote work is... | 0 | 2020-05-08T13:20:59 | https://dev.to/brunner1000/how-developers-can-cope-with-stress-41pj | devops, productivity, codenewbie | We are in a period where working from you living room, kitchen or garage is the norm. Remote work is new to some industries. But it isn't the case for developers.
All a developer needs to get to work is his laptop, a connection to the internet and a good electricity supply. There are many software systems available.
... | brunner1000 |
342,065 | BULMA - A CSS Only alternative for Bootstrap | Monotonous Bootstrap After the usage of bootstrap in multiple projects i got monotonous wi... | 0 | 2020-05-23T08:55:10 | https://medium.com/@pradeepn/bulma-a-css-only-alternative-for-bootstrap-9a977e065dcc | bulma, bootstrap, css, uiframework | ## Monotonous Bootstrap ##
After the usage of bootstrap in multiple projects i got monotonous with bootstrap. Particular with [Bootstrap4](https://getbootstrap.com/). I lost my fun towards bootstrap and started looking for alternatives. The next famous UI framework that shine before me was Googles Material design. It l... | pradeepn |
330,360 | The Superlative Guide to Big O | Is there a computer science topic more terrifying than Big O? Don’t let the name scare you, Big O is not a big deal. Learn the fundamentals in this superlative guide. | 0 | 2021-01-13T11:49:51 | https://jarednielsen.com/big-o/ | career, algorithms, computerscience, beginners | ---
title: The Superlative Guide to Big O
published: true
description: Is there a computer science topic more terrifying than Big O? Don’t let the name scare you, Big O is not a big deal. Learn the fundamentals in this superlative guide.
tags: career, algorithms, computerscience, beginners
canonical_url: https://jaredn... | nielsenjared |
330,446 | Discover 7 amazing tips and tricks about the CSS background image | This article was originally published at https://www.blog.duomly.com/css-background-image-tutorial-wi... | 0 | 2020-05-08T15:38:33 | https://www.blog.duomly.com/css-background-image-tutorial-with-examples/ | css, programming, beginners, webdev | This article was originally published at <a href-"css-background-image-tutorial-with-examples">https://www.blog.duomly.com/css-background-image-tutorial-with-examples</a>
---
The background image is probably one of the CSS properties which all of us, front-end developers, used at least a few times in our careers. Mos... | duomly |
330,546 | Story of a self-taught web developer: humble beginnings #1 | 🔥 Burnout 2 years ago I found myself in a bad place. I had worked in a fintech startup as... | 6,520 | 2020-05-08T19:10:47 | https://dev.to/anzelika/story-of-a-self-taught-web-developer-humble-beginnings-1-c72 | beginners, womenintech | ##🔥 Burnout
2 years ago I found myself in a bad place. I had worked in a fintech startup as a customer support for 4 years, and while I adored the people, any meaningful career change within the company never happened. I had side projects, sure, but at the end of the day my worth was still calculated very plainly by t... | anzelika |
330,559 | Rails 6 carrierwave production settings for digitalocean spaces with a custom subdomain | Hello, I recently worked on both Active Storage and CarrierWave to store user uploaded files and d... | 0 | 2020-05-08T17:41:35 | https://pikseladam.com/rails-6-carrierwave-production-settings-for-digitalocean-spaces | digitalocean, rails, carrierwave, storage | ---
title: Rails 6 carrierwave production settings for digitalocean spaces with a custom subdomain
published: true
date: 2020-05-08 02:00:00 UTC
tags: digitalocean, rails, carrierwave, storage
canonical_url: https://pikseladam.com/rails-6-carrierwave-production-settings-for-digitalocean-spaces
---
[? | This is a tutorial to get Microsoft Office 365 Word, Powerpoint and Excel. I have looked at other ver... | 0 | 2020-05-08T22:16:38 | https://dev.to/alex_dev123/how-to-install-microsoft-office-365-on-linux-not-online-version-426f | linux, ubuntu | This is a tutorial to get Microsoft Office 365 Word, Powerpoint and Excel. I have looked at other versions of this tutorial and they have simply found roundabout ways of using Word Online. Others just straight up recommend other tools, so if you are one of those people - people want Microsoft Office, NOT alternatives.
... | alex_dev123 |
330,642 | Bring fortune to your Linux terminal with cowsay figlet lolcat | We will cover a few interesting commands today, they are figlet toilet lolcat fortune cowsay shuf. To... | 0 | 2020-05-08T21:07:41 | https://www.chuanjin.me/2020/05/08/fortune-cowsay-lolcat/ | linux | We will cover a few interesting commands today, they are `figlet` `toilet` `lolcat` `fortune` `cowsay` `shuf`. To learn a new command, I believe the best way is always to check `tldr` for the basic usage and then play with it.
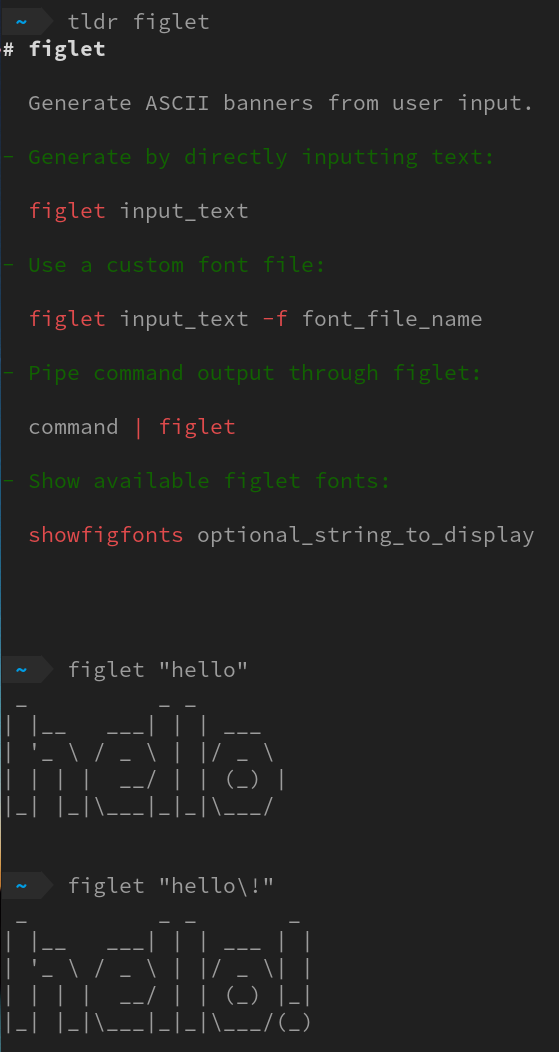
 {
let num: u32 = rand::random();
println!("generated rand integer: {}", num);
... | bitecode |
330,805 | A Story of Becoming a Web Developer | Let me tell you a story about Silvestar, a fellow who learned how to code, took some chances during h... | 6,515 | 2020-05-09T05:43:05 | https://www.silvestar.codes/articles/a-story-of-becoming-a-web-developer/ | career, beginners | Let me tell you a story about Silvestar, a fellow who learned how to code, took some chances during his career and become a solid, confident web developer.
Silvestar never coded in his life. He thought he would work as an IT engineer. But the situation at the market made him apply to a web developer job ad. Future bos... | starbist |
337,304 | 🦕🦀Writing WebAssembly in Rust and running it in Deno! | Requirements You need to have to follow tools installed on your machine: rustc rustup ca... | 0 | 2020-05-17T13:17:02 | https://dev.to/lampewebdev/writing-webassembly-in-rust-and-runing-it-in-deno-144j | deno, rust, webassembly, beginners | ### Requirements
You need to have to follow tools installed on your machine:
- rustc
- rustup
- cargo
- deno
These are standard things you usually use while developing Rust and working with Deno.
We now need to install wasm specific tools for rust.
First we need to add a compiler target like that:
```bash
rustup targe... | lampewebdev |
338,736 | Junior Developers Checklist for Landing a Remote Job | As more and more companies go remote, these positions were once the holy grail among developers. The competition is fierce, but it's not impossible to succeed. This post is to help you land a job. This is how I did it a year ago. | 0 | 2020-05-19T09:34:13 | https://dev.to/ugglr/junior-developers-checklist-for-landing-a-remote-job-2ldb | remote, webdev, beginners, career | ---
cover_image: https://images.unsplash.com/photo-1499951360447-b19be8fe80f5?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=3450&q=80
title: Junior Developers Checklist for Landing a Remote Job
published: true
description: As more and more companies go remote, these positions were once the holy grail ... | ugglr |
338,742 | Serverless Cobol | I'm currently in the process of writing a post covering how to run Laravel Serverless on Google Cloud... | 0 | 2020-05-19T08:32:25 | https://dev.to/atymic/serverless-cobol-22dh | serverless, docker, showdev, php | I'm currently in the process of writing a post covering how to run Laravel Serverless on Google Cloud. There I was, sitting there hashing out the post and I wrote this:
> This pretty much means you can run anything that responds to HTTP request, hell you could even run Cobol if you wanted!
Well, I can't really claim ... | atymic |
338,804 | Migrate Azure DevOps Repos to GitHub in 8 PROBLEMS | Migrating your Git repository from Azure DevOps Repos to GitHub should be easy. But it is not always... | 0 | 2020-05-19T10:03:54 | https://dev.to/n3wt0n/migrate-azure-devops-repos-to-github-in-8-problems-2d87 | github, devops, git, migration | Migrating your Git repository from Azure DevOps Repos to GitHub should be easy. But it is not always like that.
We need to take care of Authentication, Clone, Branches, Tags, History... and much more...
In this video we will tackle all this problems and we will successfully migrate our repo to GitHub (__including fu... | n3wt0n |
338,814 | Constructor Overloading in C++ | Constructor Overloading in C++ A constructor can overload to overloading functions in a similar way.... | 0 | 2020-05-19T10:29:01 | https://dev.to/nikhilk29693498/constructor-overloading-in-c-3858 | <a href="https://www.chlopadhe.com/constructor-overloading-in-c/">Constructor Overloading in C++</a>
A constructor can overload to overloading functions in a similar way.
Constructors overloaded have the same name (class name) but a varying number of arguments.
A specific constructor is named according to the number an... | nikhilk29693498 | |
338,822 | The Knowledge Base: A Podcast on Personal Productivity Tools | The Why Today, the landscape of productivity tools is vast and vibrant. Each one of us is... | 6,777 | 2020-05-19T11:16:04 | https://dev.to/bozho/the-knowledge-base-a-podcast-on-personal-productivity-tools-2j53 | discuss, productivity, tools, digitalgarden | # The Why
Today, the landscape of productivity tools is vast and vibrant. Each one of us is using a different set of tools to manage their own personal knowledge base. We also vary in what parts of our knowledge base we manage: some annotate books, others stick to their to do lists, bookmarks and/or personal finances.... | bozho |
338,904 | Google Maps & Google Places in React Tutorial | A post by Leigh Halliday | 0 | 2020-05-19T11:41:29 | https://dev.to/leighhalliday/google-maps-google-places-in-react-tutorial-npk | tutorial, video, react, googlemaps | {% youtube WZcxJGmLbSo %} | leighhalliday |
338,923 | Closure in Javascript | The closure in javascript is one of the main concepts which each javascript developer needs to grasp.... | 0 | 2020-05-18T00:00:00 | https://dev.to/marekdano/closure-in-javascript-1gn6 | javascriptfundamentals, interviewing | ---
slug: 'closure-in-javascript'
title: 'Closure in Javascript'
draft: false
published: true
path: '/posts/closure-in-javascript'
layout: post
description:
tags:
- 'Javascript fundamentals'
- 'Interviewing'
category: Coding
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/4f40d80big6b5d0ik5e5.jpg
date: '2020... | marekdano |
338,935 | Building my new site with gridsome(vue.js) | Originally published here. I'm really excited to finally launch my new website 🥳. It's been a labor... | 0 | 2020-05-19T13:07:34 | https://lewiskori.com/blog/building-my-new-site-with-gridsome-vue-js/ | vue, showdev, growth, webdev | Originally published [here](https://lewiskori.com/blog/building-my-new-site-with-gridsome-vue-js/).
I'm really excited to finally launch [my new website](https://lewiskori.com/) 🥳. It's been a labor of love and in terms of growth, I must say I really enjoyed working on it. For the tech stack, I went out of my comfort... | lewiskori |
338,956 | Web Development Firms: The Role Of Website In Business | The role of a website in your business is great. That is why you need one of the web development firm... | 0 | 2020-05-19T12:44:39 | https://dev.to/mssvs/web-development-firms-the-role-of-website-in-business-19jf | <em><strong>The role of a website in your business is great. That is why you need one of the web development firms.</strong></em>
Did you know that <a href="https://www.pymnts.com/news/retail/2018/omichannel-ecommerce-consumer-habits/" rel="nofollow">88% among customers</a> spend time to evaluate online products befor... | mssvs | |
339,081 | Home Surveillance System With Node and a Raspberry Pi | Have you ever wondered how to build a home surveillance system? Perhaps to monitor your children,... | 0 | 2020-05-19T14:07:46 | https://www.nexmo.com/blog/2020/05/19/home-surveillance-system-with-node-and-a-raspberry-pi | sms, video, node, raspberrypi | ---
title: Home Surveillance System With Node and a Raspberry Pi
published: true
date: 2020-05-19 13:31:31 UTC
tags: sms,video,node,raspberrypi
canonical_url: https://www.nexmo.com/blog/2020/05/19/home-surveillance-system-with-node-and-a-raspberry-pi
---
Have you ever wondered how to build a home surveillance system? ... | gregholmes |
339,107 | Embracing the Chaos | So I’ve done quite a few posts recently about resiliency. And it’s a topic that more and more is very... | 0 | 2020-05-21T20:28:48 | https://dev.to/documentednerd/embracing-the-chaos-12mn | technology, engineering, practices | ---
title: Embracing the Chaos
published: true
date: 2020-05-15 02:52:27 UTC
tags: Technology,engineering,practices
canonical_url:
---
So I’ve done quite a few posts recently about resiliency. And it’s a topic that more and more is very important to everyone as you build out solutions in the cloud.
The new buzz word... | documentednerd |
339,122 | Learn Angular 9 with Tailwind CSS by building a banking app - Lesson 1: Start the project | This article was originally published at https://www.blog.duomly.com/angular-course-building-a-bankin... | 6,834 | 2020-05-21T10:37:53 | https://www.blog.duomly.com/angular-course-building-a-banking-application-with-tailwind-css-lesson-1-start-the-project/ | angular, webdev, tutorial, beginners | This article was originally published at https://www.blog.duomly.com/angular-course-building-a-banking-application-with-tailwind-css-lesson-1-start-the-project/
---
A few days ago we posted an <a href="https://www.blog.duomly.com/sql-injection-attack-tutorial-for-beginners/">SQL injection tutorial</a> where you were ... | duomly |
339,164 | Democratizar el lenguaje de signos | Primera clase en todos los videos Mientras pensaba en mi post previo sobre capacidades de... | 0 | 2020-05-19T17:03:50 | https://dev.to/carloshm/democratizar-el-lenguaje-de-signos-1lk8 | text2sign, asl, lse, video | ## Primera clase en todos los videos
Mientras pensaba en mi [post previo](https://dev.to/carloshm/como-publicar-traducciones-de-microsoft-translate-en-microsoft-stream-4naf) sobre capacidades de traducción en videos, mientras veía la sesión de [Microsoft Build](https://build.microsoft.com), me he dado cuenta de un nuev... | carloshm |
339,180 | useReducer for the win | Hey, how are you there? Well, here is a story. It's quite small, but it can save your time and health... | 0 | 2020-05-25T18:42:58 | https://dev.to/viscoze/usereducer-for-the-win-413f | react | Hey, how are you there? Well, here is a story. It's quite small, but it can save your time and health. So keep reading.
We wanted to have a sequence of steps in our application which it’s changed depending on user’s answers. Take a look:
```
step with yes/no question -> if yes: Step 1 -> if yes: Step 2 -> Step 3 -> St... | viscoze |
342,096 | Reducing our Carbon Docker image size further! | This article is a direct follow-up to my last article : Reducing Docker's image size while creating... | 0 | 2020-05-23T09:43:33 | https://lengrand.fr/reducing-our-docker-image-size-further/ | docker, containers, node, development | ---
title: Reducing our Carbon Docker image size further!
published: true
date: 2020-05-22 23:43:15 UTC
tags: docker,containers,node,development
canonical_url: https://lengrand.fr/reducing-our-docker-image-size-further/
---
 ไม่ได้เป็นของใหม่อะไรเลย โดย FAH เป็นโปรเจคการประมวลผลแบบกระจาย (d... | 0 | 2020-05-19T17:35:27 | https://dev.to/ph9/folding-home-covid-19-1j07 | # Folding@home (FAH, F@h)
ไม่ได้เป็นของใหม่อะไรเลย โดย FAH เป็นโปรเจคการประมวลผลแบบกระจาย (distributed computing) สำหรับการจำลองพลวัตของโปรตีน (protein dynamics) รวมไปถึงการประมวลผลเพื่อจำลองการขดตัว หรือการเคลื่อนไหวของโปรตีน โดยใครที่มีเครื่องคอมพิวเตอร์ว่าง ๆ ก็เอามาให้มันประมวลผลเพื่อช่วยในโปรเจคนี้ได้ ซึ่งผลของกา... | ph9 | |
339,264 | Introducing Vue Formulate — truly delightful form authoring. | Vue Formulate has been in the wild for 2 months now, and with the latest release (v2.3) the project h... | 6,796 | 2020-05-19T19:38:53 | https://dev.to/justinschroeder/introducing-vue-formulate-truly-delightful-form-authoring-56f5 | vue, forms, webdev, javascript | [Vue Formulate](https://vueformulate.com/) has been in the wild for 2 months now, and with the latest release (v2.3) the project has enough momentum to warrant a post from its creator (me, [Justin Schroeder](https://twitter.com/jpschroeder)) on why it exists, what it does, and where it is going.
![Quick example of Vue... | justinschroeder |
339,271 | customizing Chakra UI theme in a Gatsby project | So this is going to be my first post on DEV.to 🎉 In this article, I'm going to explain how to add yo... | 0 | 2020-05-19T18:49:38 | https://dev.to/jesuissuyaa/customizing-chakra-ui-theme-in-a-gatsby-project-3jmc | gatsby, react, webdev, beginners | So this is going to be my first post on DEV.to :tada:
In this article, I'm going to explain how to add your own custom themes to your Gatsby project.
## TL;DR
1. create a new file in `src/gatsby-plugin-chakra-ui/theme.js`
2. import original theme from `@chakra-ui/core` & add your own properties
3. restart server
##... | jesuissuyaa |
339,279 | Announcing Torah && Tech; The Book. | About a year and a half ago, my friend Ben Greenberg and I were trying to come up with a project that... | 6,785 | 2020-05-19T19:38:25 | https://blog.yechiel.me/announcing-torah-tech-the-book-2cf2e9c91d82 | showdev, books, learning, coding | ---
title: Announcing Torah && Tech; The Book.
published: true
date: 2020-05-19 19:01:30 UTC
tags: showdev,books,learning,coding
canonical_url: https://blog.yechiel.me/announcing-torah-tech-the-book-2cf2e9c91d82
series: Torah && Tech
cover_image: https://res.cloudinary.com/practicaldev/image/fetch/s--wMEq9tYJ--/c_limit... | yechielk |
339,332 | What skill you never thought to be useful which you can't live without now? | A post by Zigmas Slusnys | 0 | 2020-05-19T21:01:39 | https://dev.to/slushnys/what-skill-you-never-thought-to-be-useful-which-you-can-t-live-without-now-30k9 | skill, useful, development, programming | slushnys | |
339,351 | Post Graduation, week 2 | My trials and triumps in searching for my first software engineering role. | 6,612 | 2020-05-19T21:43:32 | https://dev.to/jbshipman/post-graduation-week-2-5735 | jobsearch, career, productivity, codenewbie | ---
title: Post Graduation, week 2
published: true
description: My trials and triumps in searching for my first software engineering role.
tags: jobsearch, career, productivity, codenewbie
series: Software Engineer Job Searching in a Pandemic
cover_image: https://thumbs.dreamstime.com/z/job-search-concept-chart-keyword... | jbshipman |
339,391 | a Weather App with Monetization Feature | [Instructions]: While I am still waiting for the free-trial account Coil, I am trying to build someth... | 0 | 2020-05-20T00:17:57 | https://dev.to/peterhychan/a-weather-app-with-monetization-feature-517g | gftwhackathon | [Instructions]: While I am still waiting for the free-trial account Coil, I am trying to build something basic but meaningful for experimenting with the Monetization API.
## What I built
- a Simple Weather App with Monetization Feature
- Currently, if the Monetization API along Coil plugin at the client side is prop... | peterhychan |
340,708 | Enhanced Analytic System for Smart University Assistance | An integration specific system development based on Agile Methodology to provide an easy solution for... | 0 | 2020-05-21T08:49:25 | https://dev.to/rahulbordoloi/enhanced-analytic-system-for-smart-university-assistance-1hlk | datascience, webdev, machinelearning, computerscience | An integration specific system development based on Agile Methodology to provide an easy solution for “newcomers” in college. It helps to allocate hostel rooms, suggest suitable stream, and provide daily class schedules and pending tasks. Moreover it makes an easy solution to students to do few tasks without the help o... | rahulbordoloi |
342,038 | Need help deploy Docker that needs storage on GCP | For example, https://github.com/umputun/remark42 Internal BoltDB Uses docker-compose.yml h... | 0 | 2020-05-23T06:51:07 | https://dev.to/patarapolw/need-help-deploy-docker-that-needs-storage-on-google-2l7n | docker, devops, googlecloudplatform, help | For example,
- https://github.com/umputun/remark42
- Internal BoltDB
- Uses `docker-compose.yml`
- https://posativ.org/isso/
- Internal SQLite
- I also like Discourse, but [it seems expensive](https://www.discourse.org/pricing).
I need a persistent storage, but I cannot use external MongoDB, MySQL or PostGRES.
... | patarapolw |
342,057 | Flood Fill Algorithm | Description Flood fill also known as Seed Fill algorithm helps us to find connected area t... | 0 | 2020-05-23T08:26:27 | https://dev.to/ashishpanchal/flood-fill-algorithm-2blj | algorithms, python, programming, recursion | ---
title: Flood Fill Algorithm
published: true
description:
tags: #algorithms, #python, #programming, #recursion
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/g3e4p5u1qhr0jy66443m.jpg
---
Description
------------
Flood fill also known as Seed Fill algorithm helps us to find connected area to a node in multi... | ashishpanchal |
342,113 | Why No Modern Programming Language Should Have a 'Character' Data Type | Photo by Henry & Co. from Pexels Standards are useful. They quite literally allow us to commu... | 0 | 2020-05-27T21:52:42 | https://dev.to/awwsmm/why-no-modern-programming-language-should-have-a-character-data-type-51n | history, javascript, healthydebate | Photo by [Henry & Co.](https://www.pexels.com/@hngstrm?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels) from [Pexels](https://www.pexels.com/photo/gray-concrete-wall-2599543/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels)
---
Standards are useful. They quite literally all... | awwsmm |
342,118 | Convince Your Boss to Pay for Coding Courses | While learning to code is important to get a job, keeping up with your learning after you get that po... | 0 | 2020-05-23T10:55:05 | https://dev.to/adriantwarog/convince-your-boss-to-pay-for-coding-courses-363 | career, motivation, productivity | While learning to code is important to get a job, keeping up with your learning after you get that position can lead to things like pay rises, higher positions, and even the chance to grow outside of your skillset/department.
If we are lucky enough to be in a position of employment, we should seek to ask our current e... | adriantwarog |
342,146 | A Contacts App on Kubernetes | How I found out about Kubernetes? During my last internship, I was assigned a pilot projec... | 0 | 2020-05-23T11:54:47 | https://dev.to/namitdoshi/a-contacts-app-on-kubernetes-1h1l | octograd2020, docker, kubernetes | ---
title: A Contacts App on Kubernetes
published: true
description:
tags: octograd2020, docker, kubernetes
---
# How I found out about Kubernetes?
During my last internship, I was assigned a pilot project, that was a contacts app. I completed building my contacts app, then they wanted me to Dockerize the application... | namitdoshi |
342,179 | YEW Tutorial: 04 ...and services for all! | Never break a promise (Photo by LexScope on Unsplash) In this fourth part we are going first to do s... | 5,838 | 2020-05-23T13:25:11 | https://dev.to/davidedelpapa/yew-tutorial-04-and-services-for-all-1non | rust, yew, webassembly | Never break a promise (Photo by LexScope on Unsplash)
In this fourth part we are going first to do some "minor" improvements,
and hopefully show a little more the potential of the [Yew framework](https://yew.rs)
In this article we will be tinkering around,as usual; after which we'll start to see the light and usefuln... | davidedelpapa |
342,202 | #My Final Year Project | My Final Project Every student in his final year of graduation is tasked with submitting a... | 0 | 2020-05-23T17:25:16 | https://dev.to/blank1611/my-final-year-project-1c25 | octograd2020 | [Comment]: # (All of this is placeholder text. Use this format or any other format of your choosing to best describe your project and experience.)
[Note]: # (If you used the GitHub Student Developer Pack on your project, add the "#githubsdp" tag above. We’d also love to know which services you used and how you used it... | blank1611 |
342,207 | Handshaking lemma / Degree sum formula | Exploring the degree sum formula and what it tells us about simple graphs. | 0 | 2020-05-23T20:39:37 | https://dev.to/adnauseum/handshaking-lemma-degree-sum-formula-419a | math, graphtheory | ---
title: Handshaking lemma / Degree sum formula
published: true
description: Exploring the degree sum formula and what it tells us about simple graphs.
tags: math, graph theory
---
Behold, the degree sum formula:
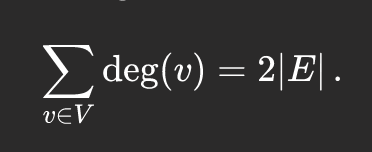
The degr... | adnauseum |
342,437 | Aiding your Research Internship's exploration | During my four years of engineering, I have seen friends who were interested in doing research intern... | 0 | 2020-05-23T17:54:23 | https://dev.to/littlestar642/aiding-your-research-internship-s-exploration-1i6g | angular, research, career, college | During my four years of engineering, I have seen friends who were interested in doing research internships under a qualified professor. This made them to frenziedly search for the professor over an entire plethora of institutions and their faculty list. I saw this as a pain point that I could solve and hence built this... | littlestar642 |
342,468 | The Purpose of Programming | The purpose of programming is to create value. | 0 | 2020-05-23T19:26:07 | https://dev.to/aceafrica/the-purpose-of-programming-17lc | <p>The purpose of programming is to create value.<p> | aceafrica | |
342,494 | All about console logging in JavaScript | In this article I want to collect all the information about logging in the console. Do you want to pu... | 0 | 2020-05-23T20:17:35 | https://dev.to/s0xzwasd/all-about-console-logging-in-javascript-588 | javascript, webdev, beginners, tutorial | In this article I want to collect all the information about logging in the console. Do you want to pump your skill in this and surprise familiar developers? Then let's get started! ✨
## console.log()
This is probably one of the most frequent commands that we use when debugging the application. However, even this comm... | s0xzwasd |
342,522 | Dart and C : how to ffi and wasm (4) buffer pointer | This document is a continuation of the previous one. In This document, I introduce to how to use pon... | 10,918 | 2020-05-23T21:48:00 | https://dev.to/kyorohiro/dart-and-c-how-to-ffi-and-wasm-4-buffer-pointer-1n8e | dart, c, ffi, webassembly | This document is a continuation of [the previous one](https://dev.to/kyorohiro/dart-and-c-how-to-ffi-and-wasm-3-int-doube-buffer-pointer-832).
In This document, I introduce to how to use ponter and buffer at ffi and wasm.
# How to use Pointer and Buffer
### Create clang function
```ky.c
#include <stdio.h>
#includ... | kyorohiro |
342,697 | Important CSS Concepts To Learn. | CSS(Cascading Style Sheets) is a rule-based language. It's used to style and lay out pages by definin... | 0 | 2020-05-24T12:53:01 | https://dev.to/frontenddude/important-css-concepts-to-learn-57j3 | css, codenewbie, 100daysofcode, beginners | CSS(Cascading Style Sheets) is a rule-based language. It's used to style and lay out pages by defining specific groups of styles that get applied to elements or groups of elements.
Many people find themselves learning CSS in conjunction with HTML. Both languages work in unison (CSS rules style HTML elements) but due t... | frontenddude |
343,738 | I'm watching you 👀 | A post by Webtechno-G | 0 | 2020-05-26T01:10:06 | https://dev.to/webtechnog/i-m-watching-you-1p2p | codepen | {% codepen https://codepen.io/webtechno-g/pen/RwWOyOm %} | webtechnog |
342,711 | My first React App: Nüte | Nüte is an appplication that makes me smile, because I didn't know nothing about React, but I had to... | 0 | 2020-05-24T10:14:49 | https://dev.to/hectormtz22/my-first-react-app-nute-29ie | devgrad2020, octograd2020, showdev, githubsdp | Nüte is an appplication that makes me smile, because I didn't know nothing about React, but I had to do an entrepreneurial project.
As a developer I decided to make a notes web application in React, because I was interested in learn how to do a Progressive Web App.
To make matters worse, I was just learning NodeJS, a... | hectormtz22 |
342,749 | Using Retrospective to Improve Yourself | Every Sunday I take half an hour to review my week. I learned this thing in college as CS people use... | 0 | 2020-05-24T11:49:44 | https://dev.to/lankinen/using-retrospective-to-improve-yourself-44ek | productivity | Every Sunday I take half an hour to review my week. I learned this thing in college as CS people use Scrum often as a project management tool and it contains these retrospectives. One day I realized that if this works in teams, why I couldn’t use it alone.
There are three questions that I answer: How well you achieved... | lankinen |
342,771 | CSS – An Introduction to Flexbox | The Flexible Box Layout Module (Flexbox) is a useful and easy-to-use CSS module that helps us to make... | 0 | 2020-05-24T12:42:12 | https://rajeshdhiman.in/an-introduction-to-flexbox/ | css, webdev, codenewbie, beginners | The [Flexible Box Layout](https://www.w3.org/TR/css-flexbox-1/) Module (Flexbox) is a useful and easy-to-use CSS module that helps us to make our content responsive. Flexbox takes care of any spacing calculations for us, and it provides a bunch of ready-to-use CSS properties for structuring content.
You can play with s... | paharihacker |
342,812 | Swift Debugging: better printing with a simple trick | Add timestamps, source, and emoji to Swift logs. | 0 | 2020-05-24T13:42:53 | https://dev.to/ccheptea/swift-debugging-better-printing-with-a-simple-trick-4khi | swift, xcode, debugging, logging | ---
title: Swift Debugging: better printing with a simple trick
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/00b8w7z76pvvv80ezloo.png
published: true
description: Add timestamps, source, and emoji to Swift logs.
tags:
- swift
- Xcode
- debugging
- logging
---
Coming from Android Development to iOS/Swift... | ccheptea |
342,869 | Dive into Ruby | Features ? and ! in method names. 1_000_000. local, Readonly, $global, @instance and @... | 0 | 2020-05-24T15:14:47 | https://mmap.page/dive-into/ruby/ | ---
title: Dive into Ruby
published: true
date:
tags:
canonical_url: https://mmap.page/dive-into/ruby/
---
## Features
- `?` and `!` in method names.
- `1_000_000`.
- `local`, `Readonly`, `$global`, `@instance` and `@@class`.
- Structs as light weight classes.
- `class SameName` merges, including core classes.
- `m... | weakish | |
342,878 | Notes on A little Java, a Few Patterns | Advantages of Java a small core language with a simple semantic model gc Desig... | 0 | 2020-05-24T15:26:29 | https://mmap.page/java/a-little/ | ---
title: Notes on A little Java, a Few Patterns
published: true
date:
tags:
canonical_url: https://mmap.page/java/a-little/
---
## Advantages of Java
- a small core language with a simple semantic model
- gc
## Design Patterns
Design patterns are used:
- to organize your code
- to communicate with others
## I... | weakish | |
342,950 | Automating a conference submission workflow: deploying to production | In the first post of this series, we detailed the setup of a software to automate submissions to conf... | 0 | 2020-05-24T16:23:18 | https://blog.frankel.ch/automating-conference-submission-workflow/3/ | automation, workflow, deployment, production | In the [first post](https://blog.frankel.ch/automating-conference-submission-workflow/1/) of this series, we detailed the setup of a software to automate submissions to conferences. In the second one, we configured the [integration endpoints](https://blog.frankel.ch/automating-conference-submission-workflow/2/). This t... | nfrankel |
342,958 | Behind the scenes: From the moment you enter a URL | Recently in a job interview, I was asked- "What happens from the moment you enter a URL in the browse... | 0 | 2020-05-27T17:43:35 | https://dev.to/salyadav/behind-the-scenes-from-the-moment-you-enter-a-url-1img | webdev, beginners, computerscience, architecture | Recently in a job interview, I was asked- "What happens from the moment you enter a URL in the browser?". Although, I had an overall idea, I was quite unable to construct the entire flow loquaciously. This article is meant to give you (and me) a seamless flow chart of what happens from top to bottom until you see the v... | salyadav |
342,998 | Loop for range em go | Hoje vamos falar um pouco mais sobre loops. Vocês já ouviram valar sobre o for range? Calma que... | 0 | 2020-05-24T21:23:26 | https://dev.to/linivecristine/loop-for-range-em-go-39n7 | go, beginners, tutorial | Hoje vamos falar um pouco mais sobre loops.
Vocês já ouviram valar sobre o ``for range``?

*Calma que não é esse tipo de ranger...*
Ele é outra versão do loop for, muito utilizado com slices, arrays, maps e strings. *O que esses tipos ... | linivecristine |
343,013 | Why Contribute to Open Source | Contributing to open source projects can be a rewarding way to learn, teach, and build experience in... | 0 | 2020-05-24T19:13:32 | https://dev.to/caelinsutch/why-contribute-to-open-source-225j | opensource, contributing, software, community | Contributing to open source projects can be a rewarding way to learn, teach, and build experience in any skill. Even better, there's a special type of satisfaction that comes from helping out the broader programming way with your skills.
Why do people contribute to open source projects?
# Improve software you rely on... | caelinsutch |
343,031 | How to sell your idea to the team | The key is to be prepared. Everything can be changed or improved. Sooner or later, you will have id... | 0 | 2020-06-04T18:19:34 | https://dev.to/andsmile/how-to-sell-your-idea-to-the-team-pal | career, personalgrowth, softskills, advice | The key is to be prepared.
Everything can be changed or improved. Sooner or later, you will have ideas for improving something in the project you work on. Maybe you read something, watched something, or just had time to think about the current situation, and an idea came to you.
It can be anything:
- how to improv... | andsmile |
343,195 | TRICK: Easy requirements build | A few days ago I was doing a project in Python and wanted to let it practice for anyone who wanted to... | 0 | 2020-05-25T03:52:00 | https://dev.to/lucs1590/trick-easy-requirements-build-k1h | python, pip, help, productivity | A few days ago I was doing a project in Python and wanted to let it practice for anyone who wanted to access it, and one of the steps for that was to build the requirements.txt, that commonly loads the necessary packages to run the projects in Python and the easiest alternative is:
- view the packages in the project;
... | lucs1590 |
343,057 | Placeholder title | What I built Submission Category: Demo Link to Code... | 0 | 2020-05-24T20:51:41 | https://dev.to/elsaxo/placeholder-title-45nk | gftwhackathon | [Instructions]: # (To submit to the Grant For The Web x DEV Hackathon, please fill out all sections.)
## What I built
### Submission Category:
[Note]: # (Foundational Technology, Creative Catalyst, or Exciting Experiments)
## Demo
## Link to Code
[Note]: # (Our markdown editor supports prett... | elsaxo |
343,068 | How I make my npm package conformable to TypeScript? | Last time we made an NPM package with JavaScript. How I publi... | 6,900 | 2020-05-24T23:00:21 | https://en.taishikato.com/posts/how-i-make-my-npm-package-conformable-to-typescript | npm, typescript, node, productivity | Last time we made an NPM package with JavaScript.
{% link taishi/how-i-published-my-first-npm-package-28hi %}
Yes. It’s great! We made it😎.
BUT, there is one problem. We can not use it with TypeScript projects out of the box because there is no type definition file and TS project can’t know any types of this NPM pa... | taishi |
343,119 | Let's Build an Ubuntu Remix - The Easiest Yet Most Difficult Job [Short Tutorial/Semi-Rant] | All remixes and official flavors have different workflows, teams, and purpose. We are not building an... | 0 | 2020-05-24T23:59:37 | https://dev.to/kailyons/let-s-build-an-ubuntu-remix-the-easiest-yet-most-difficult-job-short-tutorial-semi-rant-1m28 | ubuntu, linux, bash, desktop | All remixes and official flavors have different workflows, teams, and purpose. We are not building an Ubuntu Studio but more of an Ubuntu MATE. Changing the desktop, and maybe adding a couple of custom additions. I will describe this through my methods of work on Ubuntu Lumina so far. We will be using Lumina as an exam... | kailyons |
343,156 | Programming for Beginners: The Real 101 | # Introduction Hi there, how are you doing? If you reading this, you have voided your warr... | 0 | 2020-05-25T02:15:22 | https://dev.to/jaovitorm/the-real-101-41io | beginners, codenewbie | # # Introduction
Hi there, how are you doing?
If you reading this, you have voided your warranty, please contact customer support.
Wait. Wrong article. Sorry, let me start again.
Hi there, how are you doing?
If you're reading this, you probably never wrote a computer program, or have wrote one computer program.
Or,... | jaovitorm |
343,179 | Developer Fears: Legacy Code | About the series This is part of a series of posts dedicated to talk about the biggest fea... | 6,895 | 2020-05-26T01:50:52 | https://dev.to/viguza/developer-fears-legacy-code-2dol | fears, legacycode, career, coding |
## About the series
This is part of a series of posts dedicated to talk about the biggest fears that we face as developers.
## What is legacy code?
I’m sure that most of us have heard of legacy code, usually associated to something bad.
You probably have your own definition for it, just like everyone else. But let... | viguza |
343,242 | I made a free theme 👨💻🍣 | Lasagna free restaurant website | 0 | 2020-05-25T06:31:48 | https://dev.to/atulcodex/i-made-a-free-theme-1j0f | html, css, javascript, frontend | ---
title: I made a free theme 👨💻🍣
published: true
description: Lasagna free restaurant website
tags: html, css, javascript, frontend
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/emopniqykxue1gcdufr5.jpg
---
As you might know guys I am a junior frontend developer work in an agency. When I was started to ... | atulcodex |
343,281 | แชร์ SSH Session ข้ามเครือข่าย | ประเดิม dev.to ด้วยเรื่องนี้ก่อนเลย ที่มา - ข้ามไปได้ มี Pain Point หนึ่งเมื่อต้อง Suppor... | 0 | 2020-05-25T08:53:06 | https://dev.to/kapong/ssh-session-1md0 | linux, ssh, tmate | ประเดิม dev.to ด้วยเรื่องนี้ก่อนเลย
## ที่มา - ข้ามไปได้
มี Pain Point หนึ่งเมื่อต้อง Support ลูกค้าจำนวนมากๆ โดยต้อง SSH เข้าไปยัง Server ปลายทาง ที่ลูกค้าไม่อยากให้เราเข้าถึง IP ตรงๆ และรู้ Username/Password (ผมก็ไม่อยากรู้ให้เดือดร้อนในภายหลัง)
วิธีที่คิดออกไวๆ คือ Anydesk (หรือ Team Viewer) เข้าไปยังเครื่องของลู... | kapong |
343,321 | Animation libraries ReactJs | Hi! Does anyone have experience with animation libraries for ReactJs? For a school project I'm looki... | 0 | 2020-05-25T09:40:55 | https://dev.to/janessalabeur/animation-libraries-reactjs-gpo | animation, react, discuss, javascript | Hi!
Does anyone have experience with animation libraries for ReactJs? For a school project I'm looking into react-spring or anime.js. What are you're experiences with this?
Thanks in advance! | janessalabeur |
343,403 | [Bahasa] Implementasi Draggable View di Android | Alkisah ketika sedang mendevelop prototipe UI mesin vending powerbank ReCharge yang dapat menampilkan... | 0 | 2020-05-25T12:24:56 | https://dev.to/hyuwah/implementasi-draggable-view-di-android-576d | android, bahasa | Alkisah ketika sedang mendevelop prototipe UI mesin vending powerbank [ReCharge](https://recharge.id/) yang dapat menampilkan iklan layar penuh, ada kebutuhan untuk suatu elemen / widget yang bisa dipindah-pindah di layar. Waktu itu yang terbayang adalah *chat head* nya Facebook dan *lucky egg* nya Tokopedia.

And then, exported it to: [https://enes.in/sorte... | scriptype |
343,415 | Machine Learning - Over-fitting & Under-fitting | In my last post on "BIAS and VARIANCE" we heard about two words - Under-Fit and Over-Fit. In this pos... | 0 | 2020-05-25T12:40:31 | https://dev.to/seluccaajay/machine-learning-over-fitting-under-fitting-o91 | machinelearning, datascience | In my last post on "BIAS and VARIANCE" we heard about two words - Under-Fit and Over-Fit. In this post, I am going to tell you precise;y what is Over-fitted and Under-Fitted model.
UNDER-FITTING:
It occurs when the model is too simple, say when there is Low Variance and High Bias. When the accuracy of the model is to... | seluccaajay |
343,456 | Answer: create list from pandas dataframe column values | answer re: get list from pandas dataf... | 0 | 2020-05-25T14:26:42 | https://dev.to/nilotpalc/answer-create-list-from-pandas-dataframe-column-values-4n76 | pandas, list | {% stackoverflow 22341390 %} | nilotpalc |
343,484 | React vs Vue: Compare and Contrast | Neither ReactJS or VueJS are overly novel anymore. With lots of time to establish identities, can we... | 6,947 | 2020-05-25T15:19:42 | https://dev.to/ben/react-vs-vue-compare-and-contrast-13jp | healthydebate, javascript, vue, react | Neither ReactJS or VueJS are overly novel anymore. With lots of time to establish identities, can we have a discussion about what fundamentally differentiates these popular JavaScript approaches?
Feel free to debate, but keep it respectful. 😇 | ben |
343,792 | <header> vs. <head> vs. <h1> through <h6> Elements | Hi i know u may find it boring but i added something interesting some things beginners like me get co... | 6,932 | 2020-05-26T03:41:20 | https://dev.to/saifyusuph/header-vs-head-vs-h1-through-h6-elements-j02 | html, css, javascript, beginners | Hi i know u may find it boring but i added something interesting some things beginners like me get confused of.
It is easy to confuse the <header> element with the <head> element or the heading elements, <h1> through <h6>. They all have different semantic meanings and should be used according to their meanings. For re... | saifyusuph |
343,499 | How to graceful multiple select dom with mouse move area? | Select elements in the drag area using the mouse or touch. | 0 | 2020-05-25T15:59:39 | https://dev.to/ihavecoke/how-to-graceful-multiple-select-dom-with-mouse-move-area-2i5f | javascript, vue, react | ---
title: How to graceful multiple select dom with mouse move area?
published: true
description: Select elements in the drag area using the mouse or touch.
tags: Javascript, Vue.js, React
---
I have found a awesome repo which can select elements in the drag area using the mouse or touch.
In my case i just use it to ... | ihavecoke |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.