
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
343,512 | Beautify your Terminal - WSL2 | I used Ubuntu as a VM for front-end development. But recently I have been testing Windows Subsystem o... | 0 | 2020-05-25T18:15:41 | https://dev.to/rishabk7/beautify-your-terminal-wsl2-5fe2 | linux, terminal, productivity, wsl | I used Ubuntu as a VM for front-end development. But recently I have been testing [Windows Subsystem of Linux (WSL 2)](https://devblogs.microsoft.com/commandline/wsl-2-is-now-available-in-windows-insiders/) and so far it's good.
No need to run VM anymore! (Since I only care about the command line functionality).
Also, ... | rishabk7 |
343,543 | What every developer needs to know about TCP | What is it and why the hell do we use it? | 0 | 2020-05-25T17:27:14 | https://breadth.substack.com/p/the-low-down-on-tcp | webdev, beginners, career, programming | ---
title: What every developer needs to know about TCP
published: true
description: What is it and why the hell do we use it?
tags: webdev, beginners, career, programming
canonical_url: https://breadth.substack.com/p/the-low-down-on-tcp
---
*This article was originally posted on [Breadth](https://breadth.substack.com... | harryblucas |
343,547 | Depois do Café - Episodio 12 - Desenvolvimento de Software no Interior (com André Angelucci e Gabriel Dias) | Neste episódio a gente fala das diferenças, vantagens e desvantagens de ser uma pessoa desenvolvedora no interior. Falamos com o André Angelucci e o Gabriel Dias sobre trabalhar em Fernandópolis - SP. | 0 | 2020-05-25T18:08:44 | https://dev.to/depoisdocafe/depois-do-cafe-episodio-12-desenvolvimento-de-software-no-interior-com-andre-angelucci-e-gabriel-dias-amf | podcast, programação, portugues, interior | ---
title: Depois do Café - Episodio 12 - Desenvolvimento de Software no Interior (com André Angelucci e Gabriel Dias)
published: true
description: Neste episódio a gente fala das diferenças, vantagens e desvantagens de ser uma pessoa desenvolvedora no interior. Falamos com o André Angelucci e o Gabriel Dias sobre tr... | airtonzanon |
343,551 | My Journey Through Tech Volunteering: Anticipation, Passion, Burnout, and Looking Ahead | This is the story about how I found my path volunteering in tech, how it gave that new chapter of my life new meaning, how I burned out, and what's next. | 0 | 2020-05-25T17:39:53 | https://blog.eyas.sh/2020/05/my-journey-through-tech-volunteering/ | volunteering, teaching, career, motivation | ---
title: My Journey Through Tech Volunteering: Anticipation, Passion, Burnout, and Looking Ahead
published: true
description: This is the story about how I found my path volunteering in tech, how it gave that new chapter of my life new meaning, how I burned out, and what's next.
tags: volunteering, teaching, career, ... | eyassh |
343,888 | Different ways of structuring Arrays in Javascript | Arrays are indispensable data-structures in javascript and understanding how to effectively use them... | 0 | 2020-05-26T08:20:08 | https://dev.to/carter/different-ways-of-structuring-arrays-in-javascript-5dac | arrays, datastructures, javascript, destructure | Arrays are indispensable data-structures in javascript and understanding how to effectively use them to solve problems is a crucial skill to master.
We will be taking a look into some of the many ways to create Arrays in Javascript.
----------
**_Table of Contents:_**
- [Basic way](https://www.jeffubayi.site/blog... | carter |
343,924 | What is Blitz.js? | What is Blitz.js? Blitz.js is a new framework that's built on Next.js.It's positioned as a... | 0 | 2020-06-13T11:19:55 | https://blog.sethcorker.com/what-is-blitz-js | react, webdev, javascript, frontend | ---
title: What is Blitz.js?
published: true
date: 2020-05-25 08:36:39 UTC
tags: react,webdev,javascript,frontend
canonical_url: https://blog.sethcorker.com/what-is-blitz-js
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/79soyekjjgx0bjchkzdn.png
---
## What is Blitz.js?
[Blitz.js](https://blitzjs.com/) is a n... | darthknoppix |
343,946 | 40 reasons why I love being a DEV! | My personal reasons to why I love being a developer. | 0 | 2020-05-26T10:13:02 | https://www.codewall.co.uk/40-reasons-why-i-love-being-a-developer/ | webdev, beginners, codenewbie | ---
title: 40 reasons why I love being a DEV!
published: true
description: My personal reasons to why I love being a developer.
canonical_url: https://www.codewall.co.uk/40-reasons-why-i-love-being-a-developer/
tags: webdev, beginners, discuss, codenewbie
---
Here’s my personal list of reasons why I love being a devel... | danenglishby |
343,966 | Build Web App with Go for Beginners Part I | Go was designed at Google in 2007 to improve programming productivity in an era of multicore, netw... | 0 | 2020-05-29T22:04:14 | https://dev.to/iamhabbeboy/build-web-app-with-go-for-beginners-part-i-4cjk | go, webapp | ---
title: Build Web App with Go for Beginners Part I
published: true
description:
tags: #go #golang #webapp
---

> Go was designed at Google in 2007 to improve programming productivity in an era of multicore, networked machines and la... | iamhabbeboy |
343,970 | Blue light optics (glasses) - Myth? | Firstly, I would like to start by saying hello and welcome to anyone who reads this. I have written b... | 0 | 2020-05-30T12:52:27 | https://dev.to/luckynos7evin/blue-light-optics-glasses-myth-197h | health, development, wellbeing | <!-----
NEW: Your output is on the clipboard!
NEW: Check the "Suppress top comment" option to remove this info from the output.
Conversion time: 0.781 seconds.
Using this Markdown file:
1. Paste this output into your source file.
2. See the notes and action items below regarding this conversion run.
3. Check the r... | luckynos7evin |
344,018 | NextJS APIs validator with Middleware | Validate the request.body is a must for every APIs development. NextJS is able to use Connect compati... | 0 | 2020-05-26T11:46:05 | https://dev.to/meddlesome/nextjs-apis-validator-with-middleware-3njl | nextjs, express, middleware, api | Validate the `request.body` is a must for every APIs development. NextJS is able to use [Connect](https://github.com/senchalabs/connect) compatible Middlewares for an extendable feature on top of each request/response like ExpressJS.
Here is a guide to integrating the `express-validator`, a wrapper of `validator.js` i... | meddlesome |
344,024 | Answer: Is it possible to share states between components using the useState() hook in React? | answer re: Is it possible to share st... | 0 | 2020-05-26T12:00:56 | https://dev.to/betula/answer-is-it-possible-to-share-states-between-components-using-the-usestate-hook-in-react-31i9 | {% stackoverflow 62015805 %} | betula | |
344,035 | Finding Meow 😺 — the cutest cat from each town using Elasticsearch | #cutest-cat-per-town Cat fact: Meow is one of the most common names for a cat (for obvious... | 0 | 2020-05-26T12:28:56 | https://medium.com/activeai/finding-meow-the-cutest-cat-from-each-town-using-elastic-search-29a9417bc24d | elasticsearch, sql, codenewbie, challenge | #### #cutest-cat-per-town
Cat fact: **Meow** is one of the most common names for a cat (for obvious reasons 😸).
While researching for this article, I realized there are plenty of people who love cats. There are numerous websites to suggest names for cats, see [www.findcatnames.com](https://www.findcatnames.com) for ... | sharmasha2nk |
344,083 | How to update Google Sheets with JSON API | A short tutorial on how to update Google Sheets with JSON API | 0 | 2020-05-26T13:49:32 | https://maxkatz.org/2020/05/21/how-to-update-google-sheets-with-json-api/ | nocode, tutorial | ---
title: How to update Google Sheets with JSON API
published: true
date: 2020-05-21 23:39:05 UTC
tags: no code, tutorial
canonical_url: https://maxkatz.org/2020/05/21/how-to-update-google-sheets-with-json-api/
description: A short tutorial on how to update Google Sheets with JSON API
---
Google Sheets is a well-know... | maxkatz |
344,199 | Fallacies of Distributed Computing: 5. Topology doesn't change | The fallacies of distributed computing are a set of assertions describing false assumptions made... | 0 | 2020-05-25T00:00:00 | https://dereklawless.ie/fallacies-of-distributed-computing-5-topology-doesnt-change/ | distributedcomputing | ---
title: "Fallacies of Distributed Computing: 5. Topology doesn't change"
date: "2020-05-25T00:00:00.000Z"
tags: ["distributedcomputing"]
---
[The fallacies of distributed computing](https://web.archive.org/web/20171107014323/http://blog.fogcreek.com/eight-fallacies-of-distributed-computing-tech-talk/) are a set of ... | dereklawless |
344,228 | Optional Chaining is amazing, here's why? | Optional Chaining is the new javascript operator, which is included as part of EcmaScript 2020. The o... | 0 | 2020-05-26T17:43:39 | https://learn-n-share.hashnode.dev/optional-chaining-is-amazing-heres-why-ckanokqle023vbbs1xzqfsu1e | optionalchaining, es2020optionalchaining, jsoptionalchaining | **Optional Chaining** is the new javascript operator, which is included as part of EcmaScript 2020. The operator permits reading the value of a property located deep within a chain of connected objects without having to explicitly validate that each reference in the chain is valid. The operator works for validating the... | mishraasoumyaa |
344,232 | Solving "Boo who" / freeCodeCamp Algorithm Challenges | My guide, notes, and solution to freeCodeCamp's basic algorithm challenge, "Boo who" | 6,770 | 2020-05-26T18:51:29 | https://virenb.cc/fcc-010-boo-who | freecodecamp, algorithms, challenge, javascript | ---
title: Solving "Boo who" / freeCodeCamp Algorithm Challenges
published: true
description: My guide, notes, and solution to freeCodeCamp's basic algorithm challenge, "Boo who"
tags: #freeCodeCamp, #algorithms, #challenge, #javascript
canonical_url: https://virenb.cc/fcc-010-boo-who
series: Solving freeCodeCamp's A... | virenb |
344,233 | Make any Static Site Dynamic with Zapier | Without any doubt, there has been a huge adoption for Static Site Generators in these past 2 years, a... | 0 | 2020-05-26T18:12:18 | https://emasuriano.com/blog/make-any-static-site-dynamic-with-zapier | gatsby, static, zapier, release | Without any doubt, there has been a huge adoption for Static Site Generators in these past 2 years, and one of the main reasons was the huge growth of Gatsby and its community.
In my case, Gatsby was my first experience using an SSG (Static Site Generator) and I can confirm that the development experience is wonderful... | emasuriano |
344,248 | Say Hello to Reactjs | Reactjs is trending frontend javascript library in this article we will see how to setup reactjs. In... | 0 | 2020-05-26T18:31:23 | https://saketh-kowtha.github.io/react | react, javascript, babel, webpack | **Reactjs** is trending frontend javascript library in this article we will see how to setup reactjs.
In this blog we are going to setup react app using *create-react-app*
### #1. Install Nodejs and Npm
Before setup we need to install *nodejs* and *npm* you can install from here [click](https://nodejs.org/en/download... | sakethkowtha |
344,257 | Crystal Faith | A post by Crisscrosse | 0 | 2020-05-26T18:49:34 | https://dev.to/crisscrosse/crystal-faith-1fi | crisscrosse | ||
344,332 | Group Conversation on Remote Working | I was happy to sit down with Robert Sösemann, Elizabeth DeGroot, LeeAnne Rimel, Peter Chittum and Kev... | 0 | 2020-05-26T00:00:00 | https://developer.salesforce.com/blogs/2020/04/group-conversation-on-remote-working.html | remote, teams | ---
title: Group Conversation on Remote Working
published: true
date: 2020-05-26 UTC
tags: remote, teams
canonical_url: https://developer.salesforce.com/blogs/2020/04/group-conversation-on-remote-working.html
---
I was happy to sit down with [Robert Sösemann](https://twitter.com/rsoesemann), [Elizabeth DeGroot](http... | joshbirk |
344,515 | Connecting Sucks...it shouldn't be so | Hey there, I'm a 17-year-old but you can bet I've passed through a lot in life. I'm so happy that I... | 0 | 2020-05-26T20:43:37 | https://dev.to/pidoxy/connecting-sucks-it-shouldn-t-be-so-1ola | codenewbie, mentalhealth, beginners, programming | Hey there,
I'm a **17-year-old** but you can bet I've passed through a lot in life. I'm so happy that I even encouraged me to write this post.
From rejections to no replies to ...
There is just so much out there that leads to depression.
I'm learning to javascript presently and I do frontend web design.
From co... | pidoxy |
351,927 | Fully encapsulating vulkan and win32 in mruby | After about a week I finally finished pushing all of my original prototype work into the mruby VM. Pr... | 6,645 | 2020-06-10T01:02:43 | https://dev.to/roryo/fully-encapsulating-vulkan-and-win32-in-mruby-51ag | ruby, cpp | After about a week I finally finished pushing all of my original prototype work into the mruby VM. Previously the program was a C program which called into the mruby VM once per frame. Now it's the opposite, the C program does just enough to set up the VM state and then hand over control into the VM. For example, the `... | roryo |
344,527 | "The Lean Startup" 10 Years On: Have We Failed? | I was going to write a more traditional book review for The Lean Startup (2011) by Eric Ries, which I... | 0 | 2020-05-26T21:18:33 | https://dev.to/awwsmm/the-lean-startup-10-years-on-have-we-failed-1lck | books, healthydebate, startup | I was going to write a more traditional book review for [_The Lean Startup_ (2011) by Eric Ries](https://en.wikipedia.org/wiki/The_Lean_Startup), which I just finished [listening to](https://www.audible.co.uk/pd/The-Lean-Startup-Audiobook/B005LXUMPO) today, until I got to the epilogue. Let me give you a bit of backgrou... | awwsmm |
344,531 | Lógica booleana e operadores lógicos | O assunto de hoje é bem básico, mas é muito importante na programação. Vamos começar falando da lógi... | 0 | 2020-05-26T23:27:18 | https://dev.to/linivecristine/logica-booleana-e-operadores-logicos-269a | beginners, tutorial, go | **O assunto de hoje é bem básico, mas é muito importante na programação**.
Vamos começar falando da lógica booleana.
*Curiosidade: O nome é em homenagem ao George Boole. Um matemático e criador da lógica booleana.*
A lógica booleana trabalha com ``true`` e ``false``, ``0`` e ``1``, ligado e desligado. São apenas do... | linivecristine |
344,552 | All about aria-current attribute | aria-current The aria-current attribute is used when an element within collections is visu... | 0 | 2020-05-26T22:56:27 | https://dev.to/manjula_dube/all-about-aria-current-attribute-3gkf | web, security |
---
title: All about aria-current attribute
published: true
description:
tags: #web #security
---
## `aria-current`
The `aria-current` attribute is used when an element within collections is visually styled to indicate it is the current item in the set. This can be an active tab on the nav bar which visually is sh... | manjula_dube |
344,768 | Amazon UI created with React App | This is my first Project which I have created today...go n check it out below link.... https://rjdon1... | 0 | 2020-05-27T10:30:54 | https://dev.to/rjdon11/amazon-ui-created-with-react-app-5apa | This is my first Project which I have created today...go n check it out below link....
https://rjdon11.github.io/amazon-react/ | rjdon11 | |
349,514 | Remote experienced professional developer teams | Services: Strategy & Consulting We offer process consulting, strategic planning, finance, legal,... | 0 | 2020-06-04T16:59:44 | https://scaleblue.com | Services:
Strategy & Consulting
We offer process consulting, strategic planning, finance, legal, analysis and documentation as a service which can enable and facilitate your business.
Dedicated Team
Your Team, Your Tools and Your Culture. Build a remote development team, remote distributed professionals and get work d... | scaleblueofficial | |
350,021 | "Drawing" with box-shadow | I like to share one "trick" or technique that I really like, it's one of those things that's good to... | 0 | 2020-06-05T22:35:49 | https://dev.to/dan_1s/drawing-with-box-shadow-12kh | css, webdev | I like to share one "trick" or technique that I really like, it's one of those things that's good to have in the tool belt and I've found myself using it pretty often over the years.
## The box-shadow property
When you think of box shadow, it's easy to only think of it as shadows on boxes, but it can do more. You can... | dan_1s |
350,150 | Purging TailwindCSS without ejecting Create-React-App | What's Purging: Purging is a term for eliminating unused css code. It decreases css file size in prod... | 0 | 2020-06-06T08:33:32 | https://dev.to/jmhungdev/purging-tailwindcss-without-ejecting-create-react-app-4mef | tailwindcss, react | What's Purging: Purging is a term for eliminating unused css code. It decreases css file size in production to help browser load files faster. You may hear the term, <b>tree shaking</b> , normally used in the context of eliminating unused libraries to decrease js bundle size. Purge is the same concept.
There's an [off... | jmhungdev |
351,198 | Using Serverless at scale to build a Party Parrot GIFs generator | Have you ever loved something so much that you might never get enough of it? Party Parrots are someth... | 0 | 2020-06-12T18:14:52 | https://dev.to/vipulgupta2048/using-serverless-at-scale-to-build-a-party-parrot-gifs-generator-32be | serverless, azure, beginners, azuredevstories | Have you ever loved something so much that you might never get enough of it? Party Parrots are something like that for me. There hasn't been a single time when these quirky parrots weren't successful in making me smile.

Since t... | vipulgupta2048 |
351,857 | container less cloud computing - wascc | web assembly on the server without a browser, with hot swap capabilities | 0 | 2020-06-09T08:11:47 | https://dev.to/5422m4n/container-less-cloud-computing-wascc-27d3 | cloud, webassembly, rust, polyglot | ---
title: container less cloud computing - wascc
published: true
description: web assembly on the server without a browser, with hot swap capabilities
tags: cloud, webassembly, rust, polyglot
//cover_image: https://direct_url_to_image.jpg
---
If you are curious about a container less secure server side future you ne... | 5422m4n |
351,863 | Protractor Tutorial: Handle Mouse Actions & Keyboard Events | At times, while performing automated browser testing, you often have to deal with elements, which... | 0 | 2020-06-09T08:18:04 | https://www.lambdatest.com/blog/protractor-tutorial-handle-mouse-actions-keyboard-events/ | protractor, javascript, selenium, automation | At times, while performing [automated browser testing](https://www.lambdatest.com/?utm_source=devto&utm_medium=organic&utm_campaign=jun30_rd&utm_term=rd&utm_content=webpage), you often have to deal with elements, which reveals only after you hover on the menu or after you click on them. In such cases, you can opt for u... | paulharshit |
351,956 | Daily Developer Jokes - Tuesday, Jun 9, 2020 | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2020-06-09T12:00:21 | https://dev.to/dailydeveloperjokes/daily-developer-jokes-tuesday-jun-9-2020-4h13 | jokes, dailydeveloperjokes | ---
title: "Daily Developer Jokes - Tuesday, Jun 9, 2020"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
cover_image: "https://private.xtrp.io/projects/DailyDeveloperJokes/thumbnail_generator/?date=Tuesday%2C%20Jun%209%2C%202020"
published: tr... | dailydeveloperjokes |
351,992 | Designing the Life You Want to Live | This post was originally published on June 9, 2020 on my blog. Something's been on my mind for a whi... | 0 | 2020-06-09T12:34:18 | https://dev.to/alexlsalt/designing-the-life-you-want-to-live-2gg4 | womenintech, codenewbie, devjournal | _This post was originally published on June 9, 2020 on [my blog] (https://alexlsalt.github.io/blog)._
Something's been on my mind for a while that I'd love to share here. It's been an idea that's been simmering in my head for the past few weeks (maybe month or two, who really knows where our ideas come from or when th... | alexlsalt |
352,020 | Road to Genius: beginner #2 | Each day I solve several challenges and puzzles from Codr's ranked mode. The goal is to reach genius... | 0 | 2020-06-09T13:30:03 | https://dev.to/codr/2-road-to-genius-4ejg | javascript, beginners, computerscience | Each day I solve several challenges and puzzles from Codr's ranked mode. The goal is to reach genius rank, along the way I explain how I solve them. You do not need any programming background to get started, but you will learn a ton of new and interesting things as you go.
 and finally patte... | 7,108 | 2020-06-09T15:32:33 | https://dev.to/paurakhsharma/beginner-python-tips-day-06-try-except-else-finally-2l5h | python, beginners, codenewbie, tips |
```python
# Python Day 06 - try...except...else...finally
# try, except(also known as catch) and finally pattern is seen in many programming language
# but on top of that Python comes with else block as well,
# else block runs before finally block
# when there is no exception in the try block
# Example 1
try:
p... | paurakhsharma |
352,173 | A Rust Client for PostgREST | At Supabase, we rely heavily on PostgREST, an open source tool that turns your Postgres database into... | 0 | 2020-06-10T12:59:25 | https://dev.to/supabase/a-rust-client-for-postgrest-4ka5 | At [Supabase](https://supabase.io), we rely heavily on [PostgREST](https://postgrest.org/en/stable/index.html), an open source tool that turns your Postgres database into a RESTful API. We even have our own JavaScript client for it in the form of [postgrest-js](https://github.com/supabase/postgrest-js).
But I use Rust... | soedirgo | |
352,265 | Simplifying: Stacks and Queues | Stacks and queues: this is how I remember them: Stacks: I picture something vertical: a pile of pl... | 0 | 2020-06-09T22:36:03 | https://dev.to/moyarich/simplifying-stacks-and-queues-1i3h | stack, queue, computerscience, javascript | 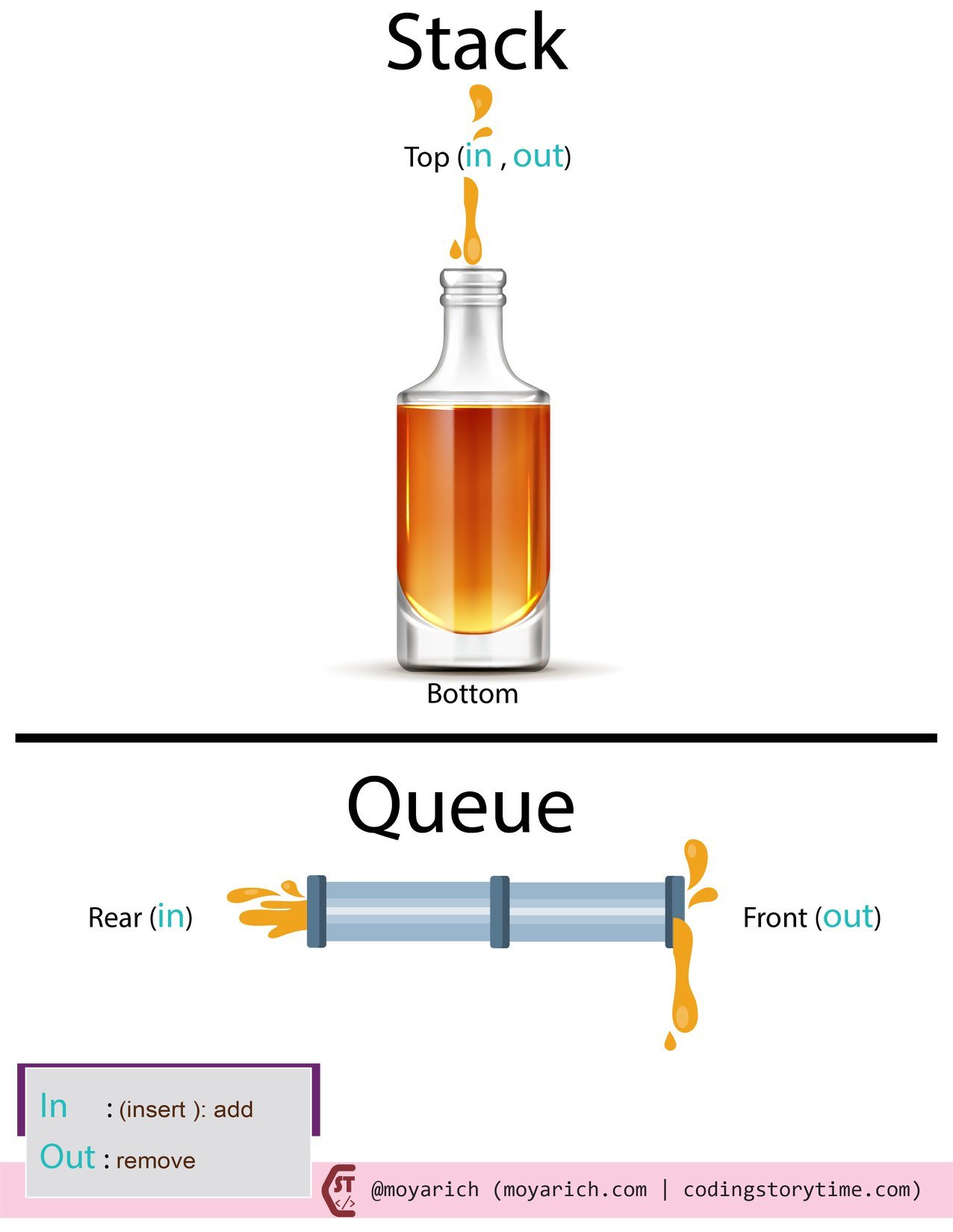
Stacks and queues: this is how I remember them:
**Stacks:** I picture something vertical: a pile of plates,a bottle.
**Queues:** I picture something horizontal: a pipe, a line (I join first, I get served first).
... | moyarich |
352,270 | Touching a quantum computer | Try to remember the first time you saw a computer. Just a regular computer based on a binary set of r... | 0 | 2020-06-09T22:21:46 | https://dev.to/shtabnoy/touching-a-quantum-computer-158k | quantumcomputing, quantumcomputers, quantum, computing | Try to remember the first time you saw a computer. Just a regular computer based on a binary set of rules, that we all use now. What did you feel back then? It was like a whole new world hidden inside it. The whole new universe was captivating you with its infinite tools and options. Some dinosaurs can remember compute... | shtabnoy |
352,293 | Debugging | When will you use breakpoints? A- Breakpoints placed within your code where it will pause so that yo... | 0 | 2020-06-10T00:29:38 | https://dev.to/tony5293/debugging-3m16 | swift, beginners | When will you use breakpoints?
A- Breakpoints placed within your code where it will pause so that you can inspect the program for any bugging issues.
Why would you change the iOS simulator?
A- The reason you'd change the iOS simulator is to make sure the bugs are fixed within all device and aren't localized t... | tony5293 |
352,318 | Things to Avoid to Become a Good Developer | Subscribe to my email list now at http://jauyeung.net/subscribe/ Follow me on Twitter at https://twi... | 0 | 2020-06-10T02:01:43 | https://dev.to/aumayeung/things-to-avoid-to-become-a-good-developer-3358 | career | **Subscribe to my email list now at http://jauyeung.net/subscribe/**
**Follow me on Twitter at https://twitter.com/AuMayeung**
**Many more articles at https://medium.com/@hohanga**
**Even more articles at http://thewebdev.info/**
Being a good developer is hard, but being a bad one is easy. There’re many ways to mak... | aumayeung |
352,328 | Serve Website/Api from your own system | Have you ever seen a condition when you need to change your design or API frequently to meet the dema... | 0 | 2020-06-10T03:05:08 | https://dev.to/anshul_gupta/serve-website-api-from-your-own-system-4ke | api, hosting, agile, opensource | Have you ever seen a condition when you need to change your design or API frequently to meet the demand?
I did, a few days back. Because of lockdown, My colleagues and I were working on a project from home. We are not in the same local network, so to connect backend and frontend I had to push to code to server then my ... | anshul_gupta |
352,345 | Haskell : Parsing a log message | Week 2 of CIS194 has an interesting problem which deals with parsing log messages. A set of types are... | 0 | 2020-06-24T08:05:29 | https://dev.to/anaynayak/haskell-parsing-a-log-message-1290 | haskell | Week 2 of CIS194 has an interesting problem which deals with parsing log messages. A set of types are provided and we need to write a `parseMessage` method which returns a `LogMessage` from a `String` parameter.
##### Provided types:
```haskell
data MessageType = Info
| Warning
| Err... | anaynayak |
352,396 | Getting started with Terraform and Kubernetes on Azure AKS | Using Azure Kubernetes Service (AKS) instead of creating your cluster is convenient if you are a small team and don't want to spend time monitoring and maintaining Kubernetes control planes. But while you can create a cluster with few clicks in the Azure portal, it usually a better idea to keep the configuration for yo... | 0 | 2020-06-11T10:47:56 | https://learnk8s.io/blog/get-start-terraform-aks | kubernetes, azure, aks, terraform | ---
title:Getting started with Terraform and Kubernetes on Azure AKS
published: true
description: Using Azure Kubernetes Service (AKS) instead of creating your cluster is convenient if you are a small team and don't want to spend time monitoring and maintaining Kubernetes control planes. But while you can create a clu... | danielepolencic |
352,397 | Django and Modern JS Libraries - Svelte (3) | Django and Modern JS Libraries - Svelte (Note:This article is originally published on... | 7,199 | 2020-06-22T12:51:00 | https://www.cbsofyalioglu.com/post/django-and-modern-js-libraries-svelte | django, python, svelte, javascript |
# Django and Modern JS Libraries - Svelte
(Note:This article is originally published on [cbsofyalioglu.com](https://www.cbsofyalioglu.com/post/django-and-modern-js-libraries-svelte) while building the websites of [Istanbul private transfer](https://istanbultransferexpert.con), [Istanbul Cruise Port Transfer](https://... | canburaks |
352,491 | What documentation should I ask before I quit from a fully remote job? | A post by padaki-pavan | 0 | 2020-06-10T10:12:53 | https://dev.to/padakipavan/what-documentation-should-i-ask-before-i-quit-from-a-fully-remote-job-39cn | discuss, career | padakipavan | |
352,517 | Globally accessible CSS and SCSS in your Nuxt component files | Introduction When building an App in Nuxt, it's likely you may choose to take advantage of... | 0 | 2020-06-10T11:24:16 | https://medium.com/@wearethreebears/globally-accessible-css-and-scss-sass-in-your-nuxt-component-files-7c1c012d31bd | vue, css, javascript, tutorial | # Introduction
When building an App in Nuxt, it's likely you may choose to take advantage of the style tag with your single file components. The style tag in single file components allows you keep all of your component specific styles together with your component's template markup and scripts.
# Nuxt styling out of th... | wearethreebears |
352,541 | Best Free and Open-Source Icons & Icon Packs of 2023 | Icon sets are a must-have for all web designers. With UI design moving forward and changing... | 0 | 2020-06-10T13:02:29 | https://dev.to/icons/free-icons-jna | icons, html, css, webdev | Icon sets are a must-have for all web designers. With UI design moving forward and changing continually, it can be quite arduous to stay updated with all the new changes in the area of icon design. 2023 has not seen any drastic or radical trend changes. Yet, it is clear that icons have become much more refined, simpler... | icons |
352,547 | 6 Ways to Loop Through an Array in JavaScript | Dealing with arrays is everyday work for every developer. In this article, we are going to see 6 diff... | 0 | 2020-06-10T12:37:29 | https://www.codespot.org/ways-to-loop-through-an-array-in-javascript/ | javascript, beginners, tutorial, webdev | Dealing with arrays is everyday work for every developer. In this article, we are going to see 6 different approaches to how you can iterate through in Javascript.
[**Continue reading...**](https://www.codespot.org/ways-to-loop-through-an-array-in-javascript/) | vasilevskialeks |
352,552 | Random Color Generator Expo App | Table of Content Introduction Getting Setup App Overview Making Navigation Screen State m... | 0 | 2020-06-10T12:51:26 | https://dev.to/utkarshyadav/random-color-generator-expo-app-5g4b | reactnative, react, javascript, expo | # **Table of Content**
- Introduction
- Getting Setup
- App Overview
- Making Navigation Screen
- State management {useState}
- Making App Screen(Simple Color Generating function)
- Ready to Roll 🥳
### **Introduction**
Expo is a framework for React-Applications. Developer can easily built both Ios and Android platf... | utkarshyadav |
353,846 | Good sites satta King and play bazaar | Online Games Chart 2019 Today Gali, Desawar, Gaziabad, Faridabad Delhi Bazar Matka Games http://www.p... | 0 | 2020-06-12T11:47:11 | https://dev.to/sattaking003/good-sites-satta-king-and-play-bazaar-261d | sattaking, playbazaar | Online Games Chart 2019 Today Gali, Desawar, Gaziabad, Faridabad Delhi Bazar Matka Games http://www.playbazzar.xyz/ | sattaking003 |
354,761 | How to Add Subscription Based Throttling to a Django API | Extending the Django Rest Framework to throttle API requests based on user-specific limits | 0 | 2020-06-14T15:55:03 | https://dev.to/mattschwartz/how-to-add-subscription-based-throttling-to-a-django-api-28j0 | python, django, saas, api | ---
title: How to Add Subscription Based Throttling to a Django API
published: true
description: Extending the Django Rest Framework to throttle API requests based on user-specific limits
tags: #python #django #saas #api
//cover_image: https://direct_url_to_image.jpg
---
Python was a natural choice when I started [Soc... | mattschwartz |
354,844 | The only productivity advice you need: The two-day rule
| Productivity craze has taken over the internet with a new passion in the midst of quarantine. And I c... | 0 | 2020-06-13T14:28:13 | https://dev.to/danilapetrova/the-only-productivity-rule-you-need-the-two-day-rule-2aj9 | productivity, motivation, career | Productivity craze has taken over the internet with a new passion in the midst of quarantine. And I can see why. The idea that we can stay safe in our homes and turn the stress and anxiousness over everything that is happening into measurable value for success is tempting.
And I am no exception. I have written an ar... | danilapetrova |
355,995 | Deploy A React app on GitHub pages | GitHub offers more than just a host for your code. In this short tutorial, I will walk you through de... | 0 | 2020-06-15T10:41:34 | https://dev.to/chrisachinga/deploy-a-react-app-on-github-pages-5925 | react, github, deploy | GitHub offers more than just a host for your code. In this short tutorial, I will walk you through deploying a static react app/project on [GitHub Pages](https://pages.github.com/).
I will be deploying a project I did today (Nov, 28 - 2020). To follow along, feel free to clone or fork the repo.
Link to the repo: [... | chrisachinga |
356,270 | Scraping a complicated website for my CLI application | (originally published August 9, 2019) When it came time to make my first application using Ruby, I k... | 0 | 2020-06-15T18:00:41 | https://sharkham.github.io/scraping_and_my_pok_mon_starter_generator_cli_application | ruby, codenewbie | *(originally published August 9, 2019)*
When it came time to make my first application using Ruby, I knew pretty quickly what I wanted to do.
My partner and I run a homebrew Pokémon Tabletop RPG, so a generator app to give our players three randomized choices of Pokémon partner was something I was interested in, fi... | sharkham |
356,283 | TIL: you can use `cd ~number` to navigate back to previously visited directories | If you are a heavy user of the command line (as I am 🤓), there is a high chance that you use the comm... | 0 | 2020-06-15T18:31:19 | https://diamantidis.github.io/tips/2020-06-15-cd-command-hidden-gems | If you are a heavy user of the command line (as I am 🤓), there is a high chance that you use the command `cd` quite often to navigate back and forth to different directories.
Besides the popular `cd <dir>`, `cd` has some more capabilities that are not so widely known and can make the navigation between different dire... | diamantidis | |
356,341 | Validation in ASP .NET Core 3.1 | This is the twenty-second of a new series of posts on ASP .NET Core 3.1 for 2020. In this series, w... | 0 | 2020-06-15T19:49:47 | https://wakeupandcode.com/validation-in-asp-net-core-3-1/ | dotnet, webdev, csharp | ---
title: Validation in ASP .NET Core 3.1
published: true
date: 2020-06-15 14:00:00 UTC
tags: dotnet, webdev, csharp
canonical_url: https://wakeupandcode.com/validation-in-asp-net-core-3-1/
---

This is the twenty-second of a new [ser... | shahedc |
356,347 | Securing a Ruby on Rails API with JWTs | Ruby on Rails is a modern web framework, but also a great way to build an API. The ability to quickly... | 0 | 2020-06-15T19:58:04 | https://fusionauth.io/blog/2020/06/11/building-protected-api-with-rails-and-jwt | rails, ruby, jwts, security | ---
title: Securing a Ruby on Rails API with JWTs
published: true
date: 2020-06-11 06:00:00 UTC
tags: rails,ruby,jwts,security
canonical_url: https://fusionauth.io/blog/2020/06/11/building-protected-api-with-rails-and-jwt
---
Ruby on Rails is a modern web framework, but also a great way to build an API. The ability to... | fusionauth |
356,367 | Flatiron Second Project: Sinatra | The past two weeks have been spent working on my second project for Flatiron’s Software Engineering B... | 0 | 2020-06-15T20:44:27 | https://dev.to/mmcclure11/flatiron-second-project-sinatra-26j9 | ruby, sinatra | The past two weeks have been spent working on my second project for Flatiron’s Software Engineering Bootcamp. It is an MVC app built using Sinatra. For my project I decided to create a recipe catalog that would allow a user to make recipes to save in their catalog, and provide them the option to view all of their recip... | mmcclure11 |
356,465 | imbalanced-learn 0.7.0 is out | imbalanced-learn, probably, is your favorite python package that offers a number of re-sampling techn... | 0 | 2020-06-16T02:24:53 | https://dev.to/chkoar/imbalanced-learn-0-7-0-is-out-1o8 | machinelearning, python, datascience | imbalanced-learn, probably, is your favorite python package that offers a number of re-sampling techniques commonly used in datasets showing strong between-class imbalance.
This is release should be be fully compatible with the latest version of `scikit-learn`.
### Maintenance
- Pipelines can cope with older versi... | chkoar |
356,695 | Roadmap for Modern Frontend Web Development | I am posting this for those who are just getting started with frontend development. If you are new to... | 0 | 2020-06-17T12:44:29 | https://dev.to/ozanbolel/roadmap-for-modern-frontend-web-development-2od6 | webdev, css, javascript, beginners | I am posting this for those who are just getting started with frontend development. If you are new to coding, it could be better for you to learn a low level programming language first to have a deeper understanding of algorithms and computers. In this post however, I'll be giving a roadmap for frontend newbies. Of cou... | ozanbolel |
356,794 | COMPILER EXPLORER ou comment désassembler facilement son code ! | A post by Younup | 0 | 2020-06-16T14:03:29 | https://www.younup.fr/blog/toi-aussi-decompile-ton-code-avec-compiler-explorer | c, compilerexplorer, french, video | {% youtube GzTkqK8vkeA %}
| younup_it |
356,931 | Subscribe to Datasets: New CKAN Feature Explained | Last month, we announced the launch of a new CKAN feature developed by Datopian that allows users to... | 0 | 2020-06-16T15:20:45 | https://dev.to/annabelvandaalen/subscribe-to-datasets-new-ckan-feature-explained-1pf0 | database | Last month, [we announced the launch of a new CKAN feature](https://www.datopian.com/blog/2020/04/28/release-subscribe-to-ckan-datasets/) developed by Datopian that allows users to subscribe to datasets. This is an opt-in feature that sends users an email notification when a dataset to which they are subscribed is chan... | annabelvandaalen |
357,107 | Developing in a docker container | Ah, a new open source project that looks interesting. Let's pull it down from GitHub, open it up in... | 0 | 2020-06-16T20:36:42 | https://SimonReynolds.ie/developing-in-a-docker-container/ | docker, netcore, productivity | ---
title: Developing in a docker container
published: true
date: 2020-06-13 13:26:56 UTC
tags: Docker,NETCore,Productivity
canonical_url: https://SimonReynolds.ie/developing-in-a-docker-container/
---
Ah, a new open source project that looks interesting. Let's pull it down from GitHub, open it up in the IDE of our ch... | simonreynolds |
357,286 | PHP Fatal error: Uncaught ReflectionException: Class mailer does not exist | Sorry. only japanese. | 0 | 2020-06-17T05:08:45 | https://dev.to/a_yasui/php-fatal-error-uncaught-reflectionexception-class-mailer-does-not-exist-2ke6 | laravel | ---
title: PHP Fatal error: Uncaught ReflectionException: Class mailer does not exist
published: true
description: Sorry. only japanese.
tags: laravel
//cover_image: https://direct_url_to_image.jpg
---
よくあるハマりどころ。大体は Facade の書き出しが失敗してたりするのが原因っぽい。
他の考えられるのは、classmap を作成時に全く関係ない箇所でエラーが出ているが `App\Exceptions\Handler` で地... | a_yasui |
357,119 | Top weekly stories in tech and programming - The Grind: Issue #1 | Subscribe to The Grind to get the best tech and programming stories of the week delivered to your in... | 0 | 2020-06-16T20:27:30 | https://dev.to/treyhuffine/top-weekly-stories-in-tech-and-programming-the-grind-issue-1-3pli | javascript, webdev, codenewbie | ---
title: Top weekly stories in tech and programming - The Grind: Issue #1
published: true
description:
tags: javascript,webdev,codenewbie
cover_image: https://miro.medium.com/max/4760/1*IwqaMXLYt1GToBiGnWQlRQ.png
---
[**_Subscribe to The Grind_**](https://thegrind.news) _to get the best tech and programming storie... | treyhuffine |
357,134 | Awesome hackathon prizes? | I’ve been to so many hackathons I can’t count anymore. When it comes to prizes, I thought I have seen... | 0 | 2020-06-17T20:17:55 | https://dev.to/jdorfman/awesome-hackathon-prizes-2ehf | discuss, hackathon | ---
title: Awesome hackathon prizes?
published: true
description:
tags: #discuss #hackathon
cover_image: https://p21.p4.n0.cdn.getcloudapp.com/items/E0uzny0E/Image%202020-06-17%20at%201.25.07%20PM.png?v=308f6c24bfd818eebfaae443a5268394
---
I’ve been to so many hackathons I can’t count anymore. When it comes to prizes... | jdorfman |
357,162 | An Opinionated Review of Asynchronous Team Collaboration Tools for 2020 | The opinionated part is that this review assumes the main purpose of team collaboration software is t... | 0 | 2020-06-16T22:37:06 | https://dev.to/uclusionhq/an-opinionated-review-of-asynchronous-team-collaboration-tools-for-2020-9p9 | productivity, agile | The opinionated part is that this review assumes the main purpose of team collaboration software is to serve the communications needs of the team using it. If you are more in the market for a tool that organizes across projects and teams, focuses on reporting productivity or tracks hours billed then this review will no... | uclusion |
357,175 | Configure Travis CI for Ruby on Rails | Original Article Source Code In this tutorial I am going to show you how to configure Travis CI to... | 0 | 2020-06-17T00:19:13 | https://stevepolito.design/blog/configure-travis-ci-for-ruby-on-rails/ | ruby, rails | - [Original Article](https://stevepolito.design/blog/configure-travis-ci-for-ruby-on-rails/)
- [Source Code](https://github.com/stevepolitodesign/rails-travis-ci-example)
In this tutorial I am going to show you how to configure Travis CI to run your Rails' test suite and system tests everytime you push a new change to... | stevepolitodesign |
357,212 | Day 16 - #100DaysofCode - Understanding MVC | Table Of Contents What is MVC? Model View Controller Advanta... | 7,070 | 2020-06-17T02:14:11 | https://dev.to/sincerelybrittany/day-16-100daysofcode-understanding-mvc-3h75 | ruby, 100daysofcode, womenintech, codenewbie | <center> Table Of Contents
[What is MVC?](#chapter-1)
[Model](#chapter-2)
[View](#chapter-3)
[Controller](#chapter-4)
[Advantages of MVC framework] (#chapter-5)
[Resources](#chapter-6)
</center>
### What is MVC? <a name="chapter-1"></a>
MVC is stands for Model-View-Cont... | sincerelybrittany |
357,304 | HTML Clickable Image Alternative | Yesterday we had a look at the HTML map element, and as mentioned, there might be a better solution n... | 0 | 2020-06-17T06:03:40 | https://daily-dev-tips.com/posts/html-clickable-image-alternative/ | html | Yesterday we had a look at the [`HTML` `map` element](https://daily-dev-tips.com/posts/html-image-map/), and as mentioned, there might be a better solution nowadays.
Today we'll be looking at creating a very similar effect, but with cool hovers.
## HTML Structure
```html
<div class="container">
<img
width="467... | dailydevtips1 |
357,355 | My attempt at recreating AWS | For the last 3 months or so, I have been making a new project that is a service- providing (almost)... | 0 | 2020-06-17T11:16:18 | https://dev.to/17lwinn/my-attempt-at-recreating-aws-5647 | html, javascript | For the last 3 months or so, I have been making a new project that is a service- providing (almost) the same services as Amazon Web Services (AWS).
Not releasing the name in this post yet.
Basically you navigate to https://pws-cluster-list.glitch.me and you'll be on our 'cluster' page, a set of open-source community... | 17lwinn |
357,399 | Hacktoberfest broke its promise | It's almost a year from last Hacktoberfest, same as a many of my friends in Germany, we didn't receiv... | 0 | 2020-06-17T09:34:57 | https://dev.to/tavallaie/hacktoberfest-broke-its-promise-5enh | hacktoberfest, digitalocean | It's almost a year from last Hacktoberfest, same as a many of my friends in Germany, we didn't receive for Hacktoberfest T-shirt of 2019, because their fund was limited! so when I tracked my shirt it comes to Germany but after 3 day return to US. and Now it was destroyed! I'm very frustrated now! | tavallaie |
357,406 | List of Major Android App Development Challenges That Developers Faces | Creating Apps for the Android OS gives a great deal of opportunity to developers and access to an eve... | 0 | 2020-06-17T09:53:18 | https://dev.to/abbasmurtza/list-of-major-android-app-development-challenges-that-developers-faces-347i | development, developmentchallenges, android | Creating Apps for the Android OS gives a great deal of opportunity to developers and access to an ever-developing user base to the app owner. Be that as it may, the developers face numerous Android app development challenges simultaneously.
The Android platform presents extraordinary numerous open doors for Android a... | abbasmurtza |
357,408 | So I Have This New Idea | This post was originally published on June 17, 2020 on my blog. If you know me at all (and by 'know,... | 0 | 2020-06-17T09:57:58 | https://dev.to/alexlsalt/so-i-have-this-new-idea-83e | devjournal, womenintech, codenewbie | _This post was originally published on June 17, 2020 on [my blog] (https://alexlsalt.github.io/blog)._
If you know me at all (and by 'know,' I mean that generously as in 'if you've read some of my blog posts'), you'll know that I love new ideas and sometimes can't contain them and then they end up bursting at the seam... | alexlsalt |
357,417 | Artificial intelligence can be implemented through Javascript. An example is the snake A.I. | A post by Ashwani Kumar | 0 | 2020-06-17T10:13:56 | https://dev.to/consultashwani/artificial-intelligence-can-be-implemented-through-javascript-an-example-is-the-snake-a-i-54m | ai, javascript, gamedev | {% youtube ZxR4yU1c_E8 %} | consultashwani |
357,445 | Neumorphism (aka neomorphism) : new trend in UI design | This area, which arises from a basic human need, such as the urge to communicate, is constantly... | 0 | 2020-06-17T10:43:49 | https://www.ma-no.org/en/web-design/ui-ux-design/neumorphism-aka-neomorphism-new-trend-in-ui-design | neumorphism, ux, webdesign | ---
title: Neumorphism (aka neomorphism) : new trend in UI design
published: true
date: 2020-06-17 10:40:00 UTC
tags: Neumorphism, UX, webdesign
canonical_url: https://www.ma-no.org/en/web-design/ui-ux-design/neumorphism-aka-neomorphism-new-trend-in-ui-design
---
This area, which arises from a basic human need, such a... | salvietta150x40 |
357,592 | Noticeable technology changes related to racism | It is a lot happening around recently. I couldn’t stop writing about it as each voice matters. It's t... | 0 | 2020-06-17T15:07:33 | https://dev.to/rameshvr/noticeable-technology-changes-related-to-racism-4gi7 | It is a lot happening around recently. I couldn’t stop writing about it as each voice matters. It's time to come out of that mindset that existed and existing.
As I work in technology space, highlighting few significant tools who took noticeable steps supporting the cause. Some changes were years old and some are new.... | rameshvr | |
357,598 | Configure Emacs for Clojure | Basic configuration to start using Clojure with Emacs Create the init.el configur... | 7,273 | 2020-06-17T15:15:43 | https://dev.to/ivanguerreschi/configure-emacs-for-clojure-120f | # Basic configuration to start using Clojure with Emacs
## Create the init.el configuration file
Open a terminal and create a directory: *mkdir ~/emacs.d*
Enter the newly created directory: *cd emacs.d*
Create file: *touch init.el*
## Install MELPA repository
Editing file: *emacs init.el*
(require 'package)
... | ivanguerreschi | |
357,609 | Day #7: Number of possible decodable messages | Hello everyone. Today is the Day 7 of the #100DaysOfCodeChallenge. And it's a week!!!! Received a pro... | 7,222 | 2020-06-17T15:31:23 | https://dev.to/nmreddy1911/day-7-number-of-possible-decodable-messages-14nd | python, prolog, beginners |
Hello everyone.
Today is the Day 7 of the #100DaysOfCodeChallenge.
And it's a week!!!!
Received a problem previously asked by Facebook with a hard tag to it.
## The Question On Day #6:
Given the mapping a = 1, b = 2, ... z = 26, and an encoded message, count the number of ways it can be decoded.
For examp... | nmreddy1911 |
358,248 | Real World Learning | Overview Learning new things is the key to success. But if you are waiting for a good time... | 0 | 2020-06-18T17:46:59 | https://dev.to/theamanjs/real-world-learning-2i33 | beginners, developer, learning | #Overview
Learning new things is the key to success. But if you are waiting for a good time to launch yourself and keep learning till then, apparently you are going to lose a lot of great opportunities. Let's see how Learn and Stack in brain is way different from Learning By Doing. I'll try to emphasis on why learning ... | theamanjs |
357,659 | How to: Automate file creation with node's fs module | TL;DR Do you ever find yourself creating the same files over and over again and wish for a... | 0 | 2020-06-17T16:23:57 | https://dev.to/hmintoh/how-to-automate-file-creation-with-node-s-fs-module-3ni1 | tutorial, webdev | ## TL;DR
Do you ever find yourself creating the same files over and over again and wish for a script to do the boring work for you without having to use a third-party library?
## The story
I've been creating a lot of React components lately and wanted to find a way to automate file creation. Specifically, a script th... | hmintoh |
357,669 | Best way to generate and manage SSH keys | Connecting to a remote server using an SSH key is quite simple. However, when you have a lot of keys... | 0 | 2020-06-17T17:18:51 | https://trubavuong.com/articles/ssh-key/ | productivity, devops, tutorial, git | ---
title: Best way to generate and manage SSH keys
published: true
date: 2020-06-17 16:20:02 UTC
tags: productivity, devops, tutorial, git
canonical_url: https://trubavuong.com/articles/ssh-key/
---
Connecting to a remote server using an SSH key is quite simple. However, when you have a lot of keys or multiple GitHub... | trubavuong |
357,692 | How to Verify Your Instagram Account ✅ in Just 4 Minutes (2020) | Instagram Blue Tick Account | Watch Here: https://www.youtube.com/watch?v=pUNVdRTenZc In this video, you learn about how to verify... | 0 | 2020-06-17T17:44:49 | https://dev.to/ankitsaxena06/how-to-verify-your-instagram-account-in-just-4-minutes-2020-instagram-blue-tick-account-3oh4 | instagram, socialaccount, instagramaccount | Watch Here: https://www.youtube.com/watch?v=pUNVdRTenZc
In this video, you learn about how to verify your Instagram account ✅ in Just 4 Minutes | Instagram Blue Badge Account in 2020 | Genuine Process. In this video you are going to learn a practical work.
If You looking for the genuine process that how to apply for ... | ankitsaxena06 |
357,712 | IsAnagram? - Quick Hack | Hello folks, Just sharing a quick hack to find out if two words are anagrams of each other or not.... | 0 | 2020-06-17T18:39:58 | https://dev.to/shyams1993/isanagram-quick-hack-2pm0 | python, useful, quickhack | Hello folks,
Just sharing a quick hack to find out if two words are anagrams of each other or not.
```
def isAnagram(word,word2):
return sorted(word.lower().strip().replace(" ","")) == sorted(word2.lower().replace(" ",""))
print(isAnagram("Dormitory","Dirty room"))
print(isAnagram("School master", "The classroom"... | shyams1993 |
357,826 | yaml quote escape | In double quoted strings if you need to include a literal double quote in your string you can escape... | 0 | 2020-06-18T01:14:55 | https://dev.to/icy1900/yaml-quote-escape-4770 | yaml | > In double quoted strings if you need to include a literal double quote in your string you can escape it by prefixing it with a backslash \ (which you can in turn escape by itself). __In single quoted strings the single quote character can be escaped by prefixing it with another single quote, basically doubling it.__ ... | icy1900 |
357,835 | React Project - Idea to Production - Part Two - Setting up a Component Library | This was originally posted here This is the second post in the series. You can find the first post h... | 0 | 2020-06-18T02:21:01 | https://dev.to/debojitroy/react-project-idea-to-production-part-two-setting-up-a-component-library-41fk | react, typescript, storybook, design | This was originally posted [here](https://debojitroy.com/blogs/react-idea-to-production-part-two/)
This is the second post in the series. You can find the first post [here](https://dev.to/debojitroy/react-project-idea-to-production-part-one-wireframes-and-project-setup-b08)
## Where are we
Ok so till now we have
- ... | debojitroy |
357,868 | TypeScript (patterns?) | Throughout my journey with TypeScript, I've been impressed by its features. The v2 documentation is... | 0 | 2020-06-24T16:01:32 | https://dev.to/hcapucho/typescript-patterns-2d8n | typescript, patterns |
> Throughout my journey with TypeScript, I've been impressed by its features. The v2 [documentation](https://www.typescriptlang.org/docs/home.html) is a really good improvement to the learning resources. However, some patterns are not so easy to find documented in the common ground of TS materials. Therefore, I wrote ... | hcapucho |
357,923 | Automate configuration of Teams Tab SSO with PowerShell. | If you have no interest in reading the blog post and just want the final script, you can find it on... | 0 | 2020-06-18T08:08:06 | https://techwatching.dev/posts/teams-sso-powershell | powershell, azuread, microsoftteams | ---
title: Automate configuration of Teams Tab SSO with PowerShell.
published: true
date: 2020-06-15 00:00:00 UTC
tags: powershell, azuread, microsoftteams
canonical_url: https://techwatching.dev/posts/teams-sso-powershell
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/p85go4um19ucy8zgsp9c.jpg
--... | techwatching |
357,925 | [Easy]: Truncate a table and restart Sequences (Identity and cascade) | Sometimes you may have to delete or truncate your records in the table for your local or dev testing.... | 0 | 2020-06-18T07:55:50 | https://dev.to/jinagamvasubabu/easy-truncate-a-table-and-restart-sequences-identity-and-cascade-1hjp | postgres, sql | Sometimes you may have to delete or truncate your records in the table for your local or dev testing. Easy way is to do with the below command.
```
delete from <table> where <condition> = <value>
```
This Works!!!
But above command doesn't restart the sequences i.e; `IDENTITY` and `CASCADE` associated with table ... | jinagamvasubabu |
357,973 | Git Commands (Continuation) | In this article we are going to talk about pull command and branches. This will be a continuation of... | 0 | 2020-06-18T09:13:03 | http://billyokeyo.codes/articles/git-commands-continuation/ | git, github, beginners, tutorial | ---
title: Git Commands (Continuation)
published: true
date:
tags: git, github, beginners, tutorial
canonical_url: http://billyokeyo.codes/articles/git-commands-continuation/
---
In this article we are going to talk about pull command and branches. This will be a continuation of the second bit of the series. So let'... | billy_de_cartel |
357,982 | Top 13 Challenges Faced In Agile Testing By Every Tester | Even though we strive for success in whatever journey we undertake, sometimes failure is inevitable.... | 0 | 2020-06-18T09:32:33 | https://www.lambdatest.com/blog/top-13-challenges-faced-in-agile-testing-by-every-tester/ | challenge, testing, agile, qa | Even though we strive for success in whatever journey we undertake, sometimes failure is inevitable. But in most cases, if we just avoid a few blunders and get through major challenges hampering progress, the path to success won’t seem so challenging. The same goes for agile testing teams where the pressure of continuo... | vetheedixit |
358,009 | Advantage of going Serverless for app development | As we think about an App Development📱, we mostly think about economic factor 💰 and easiest way to get... | 0 | 2020-06-18T10:40:39 | https://dev.to/bijinazeez/advantage-of-going-serverless-for-app-development-3i7g | aws, serverless | As we think about an App Development📱, we mostly think about economic factor 💰 and easiest way to get into market 👥.So we choose the team 👩💻👨💻 and technology for development based on that. As we go forward, one of our main headache would be server management based on load and activities.No more worries, here i... | bijinazeez |
358,042 | How to build painless multi-language apps with Angular and ngx-translate | I'm sure if you're reading this post is because either you're curious or you understand the pain of... | 2,337 | 2020-06-18T12:11:07 | https://supernovaic.blogspot.com/2020/07/how-to-build-painless-multi-language.html | angular, ngxtranslate, multilanguage, internationalization | I'm sure if you're reading this post is because either you're curious or you understand the pain of supporting multiple languages in Angular.
I love Angular and it's my main JS Modern Framework, but there is something that drives me nuts its poor multi-lingual support. It's extremely over-complicated to my taste.
I h... | fanmixco |
358,165 | Visualizing React state flow and component hierarchy | An extension to display React state flow and component hierarchy React applications are... | 0 | 2020-06-18T15:40:10 | https://dev.to/hmitrea/visualizing-react-state-flow-and-component-hierarchy-39b | webdev, react, opensource | #### An extension to display React state flow and component hierarchy
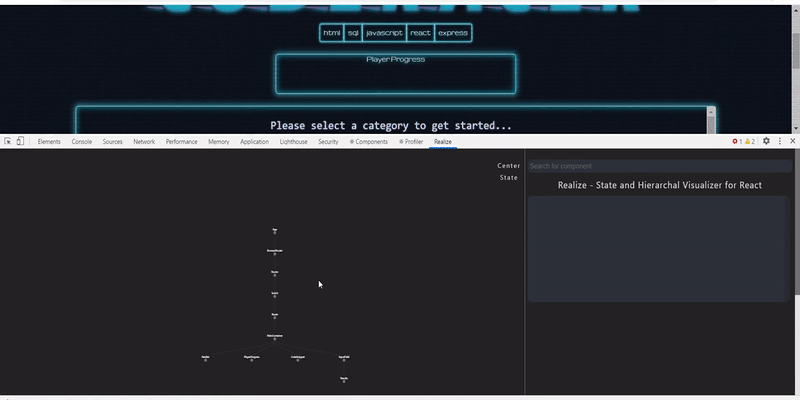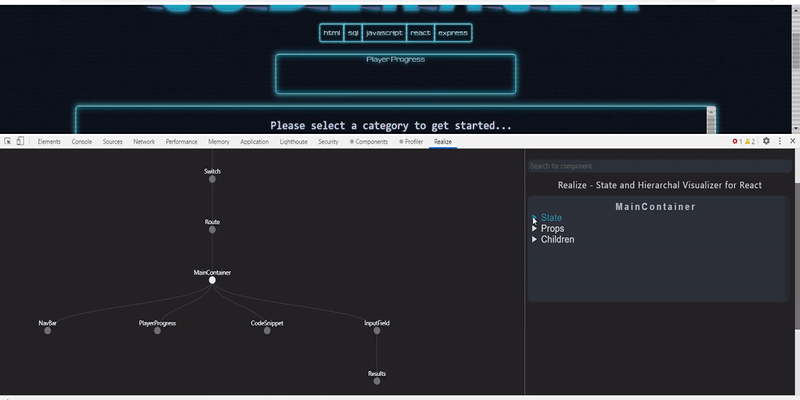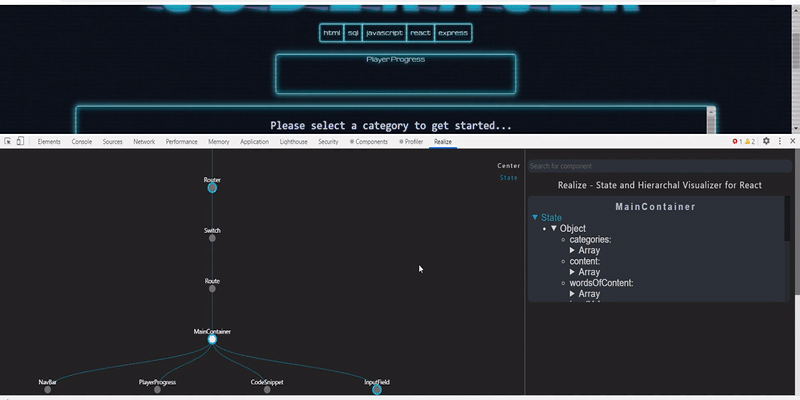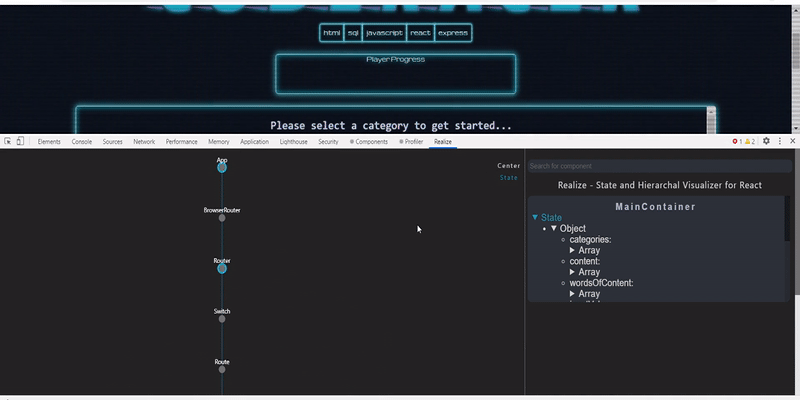
React applications are built of components which are connected with one another and to see the connection with the simple react dev tools when developing an... | hmitrea |
358,175 | A community that converts cars to electric | Do you dream of converting a combustion car into electric? It doesn’t have to be a dream. We talk to... | 0 | 2020-06-18T15:49:41 | http://coders4climatestrike.com/2020/05/a-community-that-converts-cars-to-electric.html | electricvehicles | Do you dream of converting a combustion car into electric? It doesn’t have to be a dream. We talk to Kevin Sharpe of New Electric Ireland
### Tell me a little bit about your company
We are a group of 5 [companies](http://www.newelectric.nl/) headquartered in the Netherlands. We convert boats, buses, cars, and trucks... | coders4climate |
358,275 | How to communicate as an Introvert | I suck at public interactions. Meeting new people, blah. Presentations for the team, dreadful. Quest... | 0 | 2020-06-18T19:04:22 | https://dev.to/musthaveskill/how-to-communicate-as-an-introvert-4hlg | watercooler, inclusion | 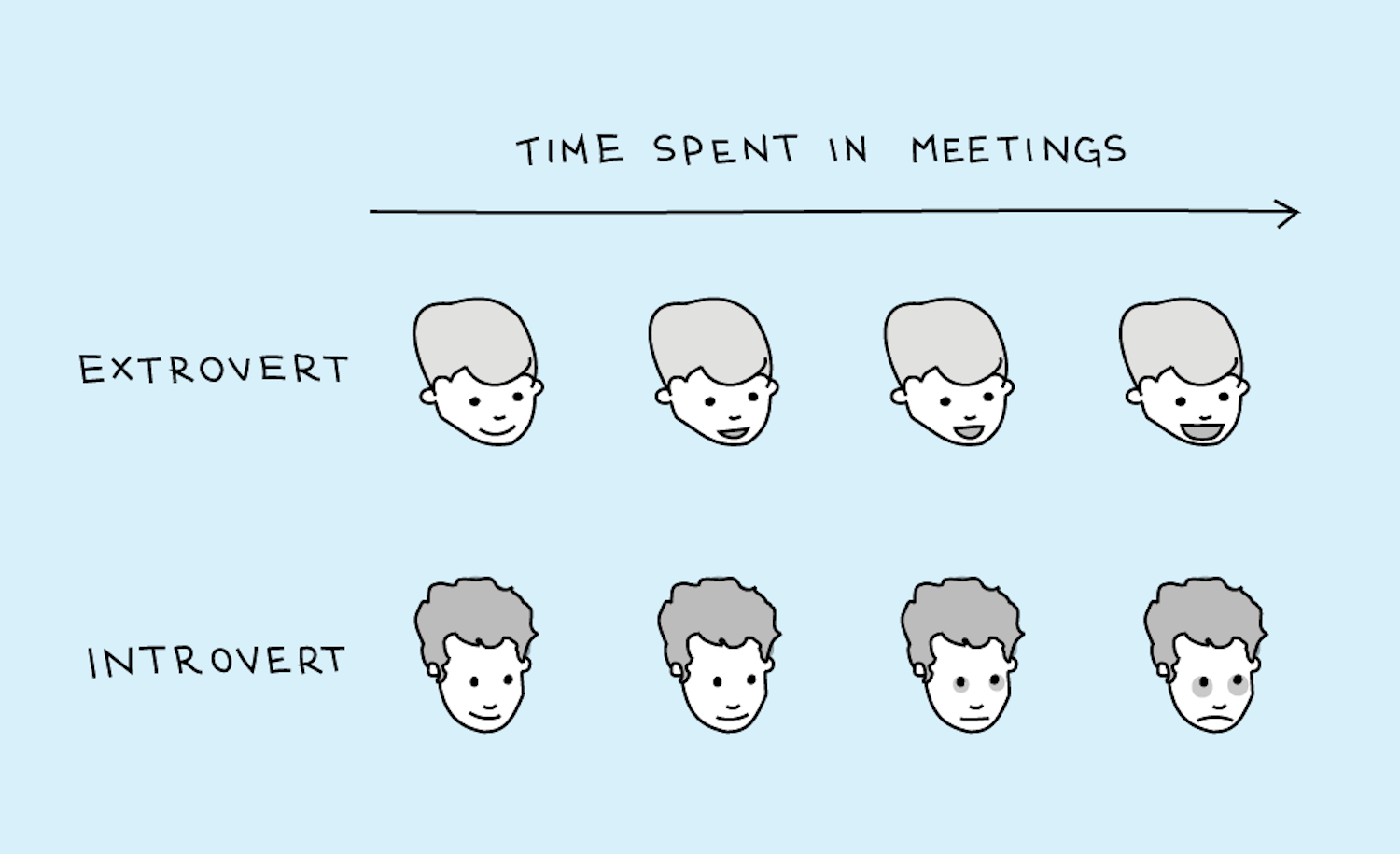
I suck at public interactions. Meeting new people, blah. Presentations for the team, dreadful. Questions? No thank you! Even when I have something I'm proud of and need to show it at work for consideration, I'd rather keep the feelin... | musthaveskill |
358,278 | Angular HTTP Proxy (CORS) in 10 minutes | With Client Side Proxies you can easily redirect cross domain url requests! First create a proxy.co... | 0 | 2020-06-18T19:40:23 | https://dev.to/jwp/angular-http-proxy-fundamentals-2e09 | With Client Side Proxies you can easily redirect cross domain url requests!
- First create a proxy.conf.json file in root directory.
```Typescript
{
"/g": {
"target": "https://www.google.com",
"secure": false,
"pathRewrite": {
"^/g": ""
},
"changeOrigin": true
}
}
```
So if the url is h... | jwp | |
358,293 | Week 9: YelpCamp: Initial Routes and Databases | This week was YelpCamp: Initial Routes and Databases from Colt Steele The Web Developer... | 0 | 2020-06-18T22:08:32 | https://dev.to/code_regina/week-9-yelpcamp-initial-routes-and-databases-54fd | javascript, webdev, codenewbie, beginners | ---
title: Week 9: YelpCamp: Initial Routes and Databases
published: true
description:
tags: javascript, webdev, codenewbie, beginners
cover_image: https://miro.medium.com/max/1400/1*RtLmDhbpg2h1I8cG0l4yyg.png
---
####This week was YelpCamp: Initial Routes and Databases from Colt Steele The Web Developer Bootcamp.
... | code_regina |
358,296 | Applying the Well-Architected Framework, Small Edition | Do you ever tackle a problem and know that you’ve just spent way too much time on it? But you also kn... | 0 | 2020-06-27T15:08:01 | https://dev.to/aws-heroes/applying-the-well-architected-framework-small-edition-18fj | aws, serverless, security | Do you ever tackle a problem and know that you’ve just spent way too much time on it? But you also know that it was worth it? This post (which is also long!) sums up my recent experience with exactly that type of problem.
## tl:dr
- AWS Lambda has a storage limit for `/tmp` of 512MB
- AWS Lambda functions needs to be ... | marknca |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.