
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
778,865 | Convert string to list in Python | In this short tutorial, find how to convert string to list in Python. We look at all the ways you can... | 0 | 2021-08-02T06:36:06 | https://flexiple.com/convert-string-to-list-in-python/ | python, programming, tutorial, beginners | In this short tutorial, find how to convert string to list in Python. We look at all the ways you can achieve this along with their pros and cons.
This tutorial is a part of our initiative at [Flexiple](https://flexiple.com/), to write short curated tutorials around often used or interesting concepts.
### Table of Co... | hrishikesh1990 |
779,008 | Refresh SwiftUI views | Refresh a SwiftUI view with the new refreshable modifier introduced at WWDC21 | 0 | 2021-08-02T08:37:53 | https://dev.to/gualtierofr/refresh-swiftui-views-33n | swift, swiftui | ---
title: Refresh SwiftUI views
published: true
description: Refresh a SwiftUI view with the new refreshable modifier introduced at WWDC21
tags: swift, swiftui
//cover_image: https://direct_url_to_image.jpg
---
A nice addition to SwiftUI at WWDC21 is the new refreshable modifier to refresh view contents. This new fe... | gualtierofr |
779,091 | Cache me if you can 🏃 | A Guide to keep your cache fresh as a daisy with stale-while-revalidate | 0 | 2021-08-02T09:47:00 | https://dev.to/iamshouvikmitra/cache-me-if-you-can-2g94 | http, browser, cache, swr | ---
title: Cache me if you can 🏃
published: true
description: A Guide to keep your cache fresh as a daisy with stale-while-revalidate
tags: http, browser, cache, swr
cover_image: https://askleo.askleomedia.com/wp-content/uploads/2013/11/cache.jpg
---
## A Guide to keep your cache fresh as a daisy with stale-while-r... | iamshouvikmitra |
779,193 | 7 Different Ways To Create Objects In Javascript 2022 | Watch this video if you don't know https://youtu.be/HRP-5MS9DkQ | 0 | 2021-08-02T12:30:11 | https://dev.to/ravics09/7-different-ways-to-create-objects-in-javascript-160j | javascript, javascriptobject | Watch this video if you don't know
https://youtu.be/HRP-5MS9DkQ | ravics09 |
779,201 | How to Create an AR Measuring Tape App in 15 Minutes or Less [Tutorial] | Here’s an easy demo for creating a simple measurement application (i.e., AR ruler app or tape... | 0 | 2021-08-02T12:41:57 | https://dev.to/echo3d/how-to-create-an-ar-measuring-tape-app-in-15-minutes-or-less-tutorial-420k | tutorial, augmentedreality, programming, unity3d | Here’s an easy demo for creating a simple measurement application (i.e., AR ruler app or tape measurement app) using AR Foundation, Unity, and echoAR. Tested on Android devices. The full demo can also be found on echoAR’s [GitHub](https://github.com/echoARxyz/Unity-ARFoundation-echoAR-demo-Measurement-with-AR).

### About
𝐈𝐦𝐚𝐠𝐞 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧𝐬: with different file formats, Responsive Images Markup, mannual and automatic optimzations, lazy loading
𝐉𝐒 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐢𝐭𝐢𝐨𝐧: modularization, async-defer, lazy loading, minifiers
𝐂𝐒𝐒 𝐎𝐩𝐭�... | bipul |
779,503 | This branch is out-of-date | When you are working by yourself or with a small school project team the source control requirements... | 0 | 2021-08-02T18:17:57 | https://dev.to/ankitxg/this-branch-is-out-of-date-1hb6 | github, productivity, devops, codereview | When you are working by yourself or with a small school project team the source control requirements are pretty low. You do not have to worry about keeping builds healthy all the time or the impact broken builds may have on others. But the story is very different when one is working in large engineering teams. Therefor... | ankitxg |
779,632 | Enhance your skills in Html Css and Js ? | Top 10 website where you can enhance your Html,Css and JS skills. 1. Css Battle 2. 100days of... | 16,565 | 2021-08-19T19:57:31 | https://dev.to/buddhadebchhetri/enhance-your-skills-in-html-css-and-js-4pne | challenge, javascript, html, css | Top 10 website where you can enhance your Html,Css and JS skills.
**1. [Css Battle](https://cssbattle.dev/)**
**2. [100days of css](https://100dayscss.com/)**

##Introduction to Firebase for Mobile App##
As mobile apps evolved from being simple entertainment platforms for people to more sophisticated and challenging tools for even enterprises, there was a huge need to improve its... | joseprest |
779,831 | Combining Jest and Cypress code coverage reports in your Angular app | Photo by Isaac Smith on Unsplash When writing front-end tests, code coverage is an important metric... | 0 | 2021-08-03T02:55:54 | https://fasterinnerlooper.medium.com/combining-jest-and-cypress-code-coverage-reports-in-your-angular-app-595b2bd4a125 | jest, cypress, angular, testing | ---
title: Combining Jest and Cypress code coverage reports in your Angular app
published: true
date: 2021-07-31 18:38:58 UTC
tags: jest,cypress,angular,testing
canonical_url: https://fasterinnerlooper.medium.com/combining-jest-and-cypress-code-coverage-reports-in-your-angular-app-595b2bd4a125
---
 vs Base.__init__ Method | When defining a subclass, there are different ways to call the __init__ method of a parent class.... | 0 | 2024-01-08T08:58:15 | https://bhavaniravi.medium.com/python-super-vs-base-init-method-d923ca595ad3 | django, flask, python | ---
title: Python super() vs Base.__init__ Method
published: true
date: 2024-01-08 08:58:00 UTC
tags: django,flask,python,pythonprogramming
canonical_url: https://bhavaniravi.medium.com/python-super-vs-base-init-method-d923ca595ad3
---
When defining a subclass, there are different ways to call the \_\_init\_\_ method ... | bhavaniravi |
780,342 | Maneira simples de construir objetos utilizando Object.assign | Quando trabalhamos com formulário as vezes precisamos ter uma maneira mais prática de fazer "a coisa"... | 0 | 2021-08-03T19:38:39 | https://dev.to/michael08928874/maneira-simples-de-construir-objetos-utilizando-object-assign-55ml | Quando trabalhamos com formulário as vezes precisamos ter uma maneira mais prática de fazer "a coisa" acontecer.
Passei por uma situação quer precisava realizar a união de dois objetos, literalmente fazer um merge.
E encontrei essa solução que achei incrível e sem dúvida vai me facilitar muito a vida a partir de hoj... | michael08928874 | |
780,568 | bug report | when ever i comment the site automatically makes me like my own comment not sure if it is intentional... | 0 | 2021-08-03T17:06:30 | https://dev.to/aheisleycook/bug-report-4ck0 | when ever i comment the site automatically makes me like my own comment not sure if it is intentional or nont anyone else experience this? | aheisleycook | |
780,572 | So you ever wonder what the heck is kubernetes | Well kubernetes is like a control panel of a space ship that manages and gives a form of control of... | 0 | 2021-08-03T17:11:30 | https://dev.to/greatness1504/so-you-ever-wonder-what-the-heck-is-kubernetes-36aj | kubernetes, devops, docker, aws | Well kubernetes is like a control panel of a space ship that manages and gives a form of control of the different engines, network, and components of the space ship to the space pilot; Kubernetes simply controls and manage a huge list of mini like computers that are kind of isolated from each other.
It's management p... | greatness1504 |
780,659 | TIL: Wildcard SSL certificate does not support nested subdomains | A wildcard SSL certificate for *.example.net will match sub.example.net but not sub.sub.example.net.... | 0 | 2021-08-03T18:48:52 | https://dev.to/jadia/til-wildcard-ssl-certificate-does-not-support-nested-subdomains-47bf | todayilearned, web | ---
title: TIL: Wildcard SSL certificate does not support nested subdomains
published: true
description:
tags: til, web
//cover_image: https://direct_url_to_image.jpg
---
A wildcard SSL certificate for `*.example.net` will match sub.example.net but not `sub.sub.example.net`. You need to generate a separate certificat... | jadia |
780,817 | Astro + Foresty CMS Revisited | Static sites powered by Forestry's git-based CMS, made even easier. | 0 | 2021-08-07T17:13:35 | https://navillus.dev/blog/astro-plus-forestry-revisited/ | astro, cms | ---
title: Astro + Foresty CMS Revisited
description: Static sites powered by Forestry's git-based CMS, made even easier.
published: true
date: 2021-08-03 00:00:00 UTC
cover_image: https://navillus.dev/posts/2021-08-03-astro-plus-forestry-revisited.jpg
tags: astro, cms
canonical_url: https://navillus.dev/blog/astro-plu... | navillus_dev |
781,026 | JWT: JsonWebToken demystified | Warning: This is not a how-to, but a what-is. Somebody already wrote a really nice how-to here:... | 0 | 2021-08-04T03:00:32 | https://dev.to/khoinguyenkc/jwt-jsonwebtoken-demystified-3dc6 | Warning: This is not a how-to, but a what-is. Somebody already wrote a really nice how-to here: https://medium.com/@nick.hartunian/knock-jwt-auth-for-rails-api-create-react-app-6765192e295a
But I think it can be broken down to even simpler terms. We'll learn how you can use JWT in your backend and frontend. You'll lear... | khoinguyenkc | |
781,047 | Hello World! | Hello world! I've been a long time lurker and have posted may once or twice under a different name,... | 0 | 2021-08-04T04:21:42 | https://dev.to/victorlamssc/hello-world-cna | devjournal, beginners | Hello world! I've been a long time lurker and have posted may once or twice under a different name, but switching over here since this is my serious name. All jokes aside, I'm making it a point now to focus on development, blogging, and sharpening my skills in order to both share and monetize a couple of blogs as a sid... | victorlamssc |
781,174 | borb, the open source, pure Python PDF library | Hyphenation ensures your document just flows, without the hideous gaps borb allows you to use... | 0 | 2021-08-04T06:24:11 | https://dev.to/jorisschellekens/borb-the-open-source-pure-python-pdf-library-4b94 | python, pdf, borb | 1. Hyphenation ensures your document just flows, without the hideous gaps
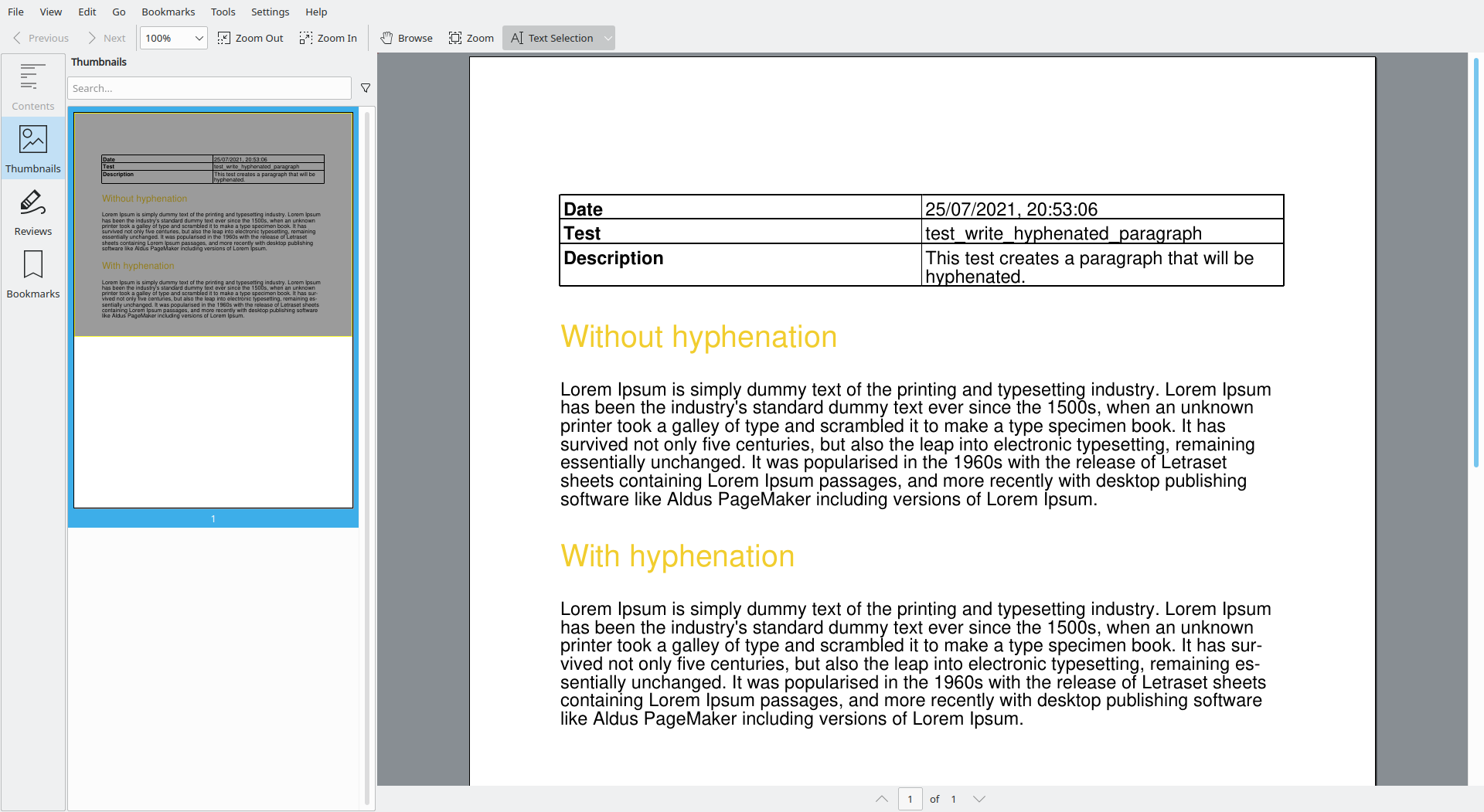
2. borb allows you to use emoji, even if your font doesn't contain these characters.
. Asynchronous functions allow asynchronous code to be written as if it were synchronous. For demonstration purposes, we used Xcode 13 beta with the Swift 5.5 version.
<br/>
##A new... | igorcekelis |
781,217 | Why I fell out of love with inheritance | A tale of growing up, and realizing your heroes have flaws The Beginning Almost... | 0 | 2021-08-18T08:32:12 | https://dev.to/yonatankorem/why-i-fell-out-of-love-with-inheritance-1fh | design, oop | ## A tale of growing up, and realizing your heroes have flaws
#### The Beginning
Almost nine years ago, when I was near the end of my BSc, I was sure that inheritance is the greatest thing an OO programmer has in their arsenal of tools. During most of my studies, we were taught the principles of OOP, why interfaces ar... | yonatankorem |
781,220 | How to make Infinity! | New Method to make Infinity! So... I found a new way to make Infinity in Javascript! ... | 0 | 2021-08-04T08:46:17 | https://dev.to/mafee6/how-to-make-infinity-1pa7 | javascript | ### New Method to make `Infinity`!
> So... I found a new way to make `Infinity` in Javascript!
#### This is how:
> Using `parseInt()` with `.repeat()`! 🤣
#### Meaning of `parseInt()`
> `parseInt()` basically converts a string into Integer. If some invalid string is passed (like: "hi"), it returns `NaN`
#### Meaning... | mafee6 |
781,226 | AWS IAM Policy Simulator | Not the hero we want, but the hero we need TL;DR; You can use the Policy Simulator of AWS... | 0 | 2021-08-07T20:05:21 | https://dev.to/hristiyan/aws-iam-policy-simulator-3i2j | cloudskills, aws, iam | ## Not the hero we want, but the hero we need
TL;DR; You can use the Policy Simulator of AWS to test your IAM policies. This allows you to quickly find the correct access rights and to debug problems with your policies.
Recently I started experimenting with AWS. Following the least privilege principle, I created a se... | hristiyan |
781,296 | JINA AI | Cloud native neural search | Jina AI is a neural search company. Jina is the core product, released on April 28th, 2020. The... | 0 | 2021-08-04T11:38:55 | https://dev.to/adityamangal1/jina-ai-1e66 | jina | Jina AI is a neural search company. Jina is the core product, released on April 28th, 2020. The official tagline Jina put on it's Github repository is: Jina is a cloud-native neural search solution powered by state-of-the-art AI and deep learning. To put it simply, you can use Jina to search for anything: image-to-imag... | adityamangal1 |
781,326 | Are you above average? | “It seems like everyone with more than 5 years coding experience thinks they’re above average.” — A... | 0 | 2021-08-05T07:50:21 | https://jhall.io/archive/2021/08/04/are-you-above-average/ | seniordev, juniordev | ---
title: Are you above average?
published: true
date: 2021-08-04 00:00:00 UTC
tags: seniordev,juniordev
canonical_url: https://jhall.io/archive/2021/08/04/are-you-above-average/
---
> “It seems like everyone with more than 5 years coding experience thinks they’re above average.”
> — A developer friend of mine, in ... | jhall |
781,478 | So you want to create a design system, pt. 2: Colors | Color is probably the most distinctive element of any design, and also the most important expression... | 0 | 2021-08-05T09:12:14 | https://dev.to/mobileit7/so-you-want-to-create-a-design-system-pt-2-colors-5a9f | design, uiweekly, ux, devops | Color is probably the most distinctive element of any design, and also the most important expression of brand identity (at least until Material You completely reverses this relationship, but it remains to be seen how it will be adopted). So how do we approach color when designing and implementing a design system so tha... | mobileit7 |
781,490 | Android App Development: You Should Avoid Common Things to | Let us find out some of the many common mistakes that every developer should avoid when developing an... | 0 | 2021-08-04T14:03:28 | https://dev.to/technobyt/android-app-development-you-should-avoid-common-things-to-1p02 | <div class="s-blog-body s-blog-padding">
<div class="s-repeatable s-block s-component s-mh ">
<div class="s-block-item s-repeatable-item s-block-sortable-item s-blog-post-section blog-section">
<div class="container">
<div class="sixteen columns">
<div class="s-blog-section-inner">
<div class="s-component s-text">
<div... | technobyt | |
781,499 | tmux new-session | This one starts a new chapter in our series that is going to open up a whole new set of workflow... | 13,642 | 2021-08-04T14:35:39 | https://waylonwalker.com/tmux-new-session/ | cli, linux, tmux | ---
tags: ['cli', 'linux', 'tmux',]
series: tmux
title: tmux new-session
canonical_url: https://waylonwalker.com/tmux-new-session/
published: true
---
This one starts a new chapter in our series that is going to open up a whole new set of workflow productivity options, understanding how the `new-session` command is a ... | waylonwalker |
781,785 | My first VSCode Theme... | Hi Folks 👋🏻, Hope you are safe out there! VSCode is a place where developers spent most of their... | 0 | 2021-08-04T17:19:30 | https://dev.to/rajezz/my-first-vscode-theme-o2a | vscode, extension, theme | Hi Folks 👋🏻,
Hope you are safe out there!
VSCode is a place where developers spent most of their time, right. So, it should look appealing to us. I know there are innumerable themes in VSCode. But, I just thought why can't be a part of that. Also, I personally love playing around with themes. So, I tried to create ... | rajezz |
781,828 | Field Guide to Technical Editing | You’ve been tasked with editing material with deep knowledge—it’s complex and highly... | 0 | 2021-08-04T19:36:38 | https://draft.dev/learn/posts/field-guide-to-technical-editing | 
You’ve been tasked with editing material with deep knowledge—it’s complex and highly industry-specific. You’re an expert in the art of writing, but perhaps not exactly an expert on this particular topic. Perhaps even far from it. Now what?
Don’t panic. I’ve been a... | karllhughes | |
781,835 | Beginner Kafka tutorial: Get started with distributed systems | Distributed systems are collections of computers that work together to form a single computer for... | 0 | 2021-08-04T19:59:15 | https://www.educative.io/blog/beginner-kafka-tutorial | beginners, tutorial, opensource, webdev | Distributed systems are collections of computers that work together to form a single computer for end-users. They allow us to scale at exponential rates, and they can handle billions of requests and upgrades without downtime. Apache Kafka has become one of the most widely used distributed systems on the market today.
... | erineducative |
781,955 | OpenShift for Dummies - Part 2 | Thank you for reading part two of OpenShift for Dummies! In this article, I will briefly outline... | 13,945 | 2021-08-04T23:47:31 | https://dev.to/stevenmcgown/openshift-for-dummies-part-2-2eg4 | devops, docker, kubernetes, python | 
Thank you for reading part two of OpenShift for Dummies! In this article, I will briefly outline advantages and use cases of OpenShift. Additionally, I will go into technical detail of how you can get started using OpenS... | stevenmcgown |
781,964 | Making beautiful websites: Top 5 FREE color palettes resources | Choosing a beautiful and pleasing color scheme is one of the most difficult tasks for every... | 13,909 | 2021-08-05T17:07:10 | https://dev.to/martinkr/making-beautiful-websites-top-5-free-color-palettes-resources-4jpd | webdev, design | Choosing a beautiful and pleasing color scheme is one of the most difficult tasks for every designer.
Even with the general rule of using a base, accent and a neutral color for your palette, choosing the colors is mostly a matter of intuition and experience.
Don't worry, I have you covered - check out the top five reso... | martinkr |
782,166 | VS Code plugins to increase coding speed | Hey world, here is the list of plugins that I found helpful for react native developers to increase... | 0 | 2021-08-17T05:08:21 | https://dev.to/harikrshnan/vs-code-plugins-to-increase-coding-speed-4469 | reactnative, vscode, react | Hey world, here is the list of plugins that I found helpful for react native developers to increase coding speed.
1. **[AutoRename Tag](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-rename-tag)**
Since VS code will not rename the paired tag automatically, this plugin will help you solv... | harikrshnan |
782,249 | A photographer’s view on alt text | Images are visual communication. Consider what you're trying to communicate before you do. | 0 | 2021-08-05T07:51:18 | https://www.erikkroes.nl/blog/a-photographer-s-view-on-alt-text/ | a11y, html, webdev | ---
title: A photographer’s view on alt text
published: true
canonical_url: https://www.erikkroes.nl/blog/a-photographer-s-view-on-alt-text/
description: Images are visual communication. Consider what you're trying to communicate before you do.
tags: a11y, html, webdev
cover_image: https://www.erikkroes.nl/assets/media... | erikkroes |
782,381 | A Fun Programming Joke To Start Your Day | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2021-08-05T12:00:20 | https://dev.to/dailydeveloperjokes/a-fun-programming-joke-to-start-your-day-44gp | jokes, dailydeveloperjokes | ---
title: "A Fun Programming Joke To Start Your Day"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
published: true
tags: #jokes, #dailydeveloperjokes
---
Hi there! Here's today's Daily Developer Joke. We hope you enjoy it; it's a good one.
... | dailydeveloperjokes |
782,389 | Hello, World! in 10 different languages 🔥🔥 | 1. Python print("Hello World!") Enter fullscreen mode Exit fullscreen... | 0 | 2021-08-05T12:15:41 | https://dev.to/rohidisdev/hello-world-in-10-different-languages-6ko | programming, helloworld, coding, languages | #1. Python
```python
print("Hello World!")
```
#2. Java
```java
public class Main {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
#3. JavaScript
```javascript
console.log("Hello, World!")
```
#4. C Sharp
```c#
using System;
class Hello {
static voi... | rohidisdev |
782,465 | “Greenfield” doesn't exist in agile projects | Many engineers love the idea of working on greenfield projects. That is, new projects, where design... | 0 | 2021-08-09T10:16:06 | https://jhall.io/archive/2021/08/05/greenfield-doesnt-exist-in-agile-projects/ | refactoring, greenfield, brownfield, rewrite | ---
title: “Greenfield” doesn't exist in agile projects
published: true
date: 2021-08-05 00:00:00 UTC
tags: refactoring,greenfield,brownfield,rewrite
canonical_url: https://jhall.io/archive/2021/08/05/greenfield-doesnt-exist-in-agile-projects/
---
Many engineers love the idea of working on [greenfield projects](https:... | jhall |
782,473 | whatsapp message sending bot using selenium | in this post i will say how to send whatsapp message using selenium libaries required are""'iam also... | 0 | 2021-08-05T12:49:37 | https://dev.to/vaibhav688/whatsapp-message-sending-bot-using-selenium-2i51 | in this post i will say how to send whatsapp message using selenium
libaries required are""'iam also begnniner in python """
selenium
and code goes here
# import selenium libary in that import webdriver
from selenium import webdriver
'''now create variable which calls ur default browser anything i have used chrome,for... | vaibhav688 | |
783,783 | Making Your First Game in Blue | Hello everyone! Today, I'm writing a post about how to get started with Blue. Blue is a creative,... | 0 | 2021-08-11T23:18:40 | https://dev.to/i8sumpi/making-your-first-game-in-blue-f8k | gamedev, javascript, beginners | Hello everyone! Today, I'm writing a post about how to get started with Blue. Blue is a creative, graphical, and browser-based programming language which makes it easy and enjoyable to get started with programming. First off, you can check it out at https://blue-js.herokuapp.com. Blue is also open source, and its GitHu... | i8sumpi |
784,429 | Programming Term: "glob" | glob patterns specify sets of filenames with wildcard characters. For example, the Unix Bash shell... | 0 | 2021-08-07T10:23:52 | https://dev.to/a510/programming-term-glob-5234 | **glob patterns** specify sets of filenames with wildcard characters. For example, the Unix Bash shell command `mv *.txt textfiles/` moves (`mv`) all files with names ending in `.txt` from the current directory to the directory `textfiles`. Here, `*` is a wildcard standing for "any string of characters" and `*.txt` is ... | a510 | |
788,907 | How to execute shell commands in Javascript | Working in Javascript apps, you might have to use shell commands to retrieve some informations or... | 11,206 | 2021-09-21T11:28:13 | https://dev.to/mxglt/how-to-execute-shell-commands-in-javascript-123b | Working in Javascript apps, you might have to use shell commands to retrieve some informations or execute some treatments.
So here is the snippet to do it!
---
## Code
```javascript
const childProcess = require('child_process');
async function sh(cmd_to_execute) {
return new Promise(function (resolve, reject) ... | mxglt | |
789,875 | A TelegramBot for true paranoids. | https://t.me/MasquerBot I watched Snowden in 2016. It was the year, I became paranoid.... | 0 | 2021-08-12T18:15:30 | https://dev.to/ra101/a-telegrambot-for-true-paranoids-16po | telegram, python, showdev, cryptography | {% youtube yH3SVmCZD7Q %}
### https://t.me/MasquerBot
I watched Snowden in 2016. It was the year, I became paranoid. 👻
Introducing 𝗠𝗮𝘀𝗾𝘂𝗲𝗿𝗕𝗼𝘁! It is a telegram_bot that can hide any given text message inside any given image, by manipulating the very pixels of that image (steganography)
• URL changes eve... | ra101 |
790,759 | Web Log a Minimal Design Blogging Site | Web Log is a clean SEO friendly blog theme with minimal design architecture. It is a cool and perfect... | 0 | 2021-08-14T06:11:05 | https://wprefers.com/web-log-a-minimal-design-blogging-site/?utm_source=rss&utm_medium=rss&utm_campaign=web-log-a-minimal-design-blogging-site | themes, thememiles, weblog, wordpress | ---
title: Web Log a Minimal Design Blogging Site
published: true
date: 2021-07-21 06:02:49 UTC
tags: Themes,ThemeMiles,WebLog,WordPress
canonical_url: https://wprefers.com/web-log-a-minimal-design-blogging-site/?utm_source=rss&utm_medium=rss&utm_campaign=web-log-a-minimal-design-blogging-site
---
**[Web Log](https://... | wprefers |
791,004 | What was your win this week? | Got to all your meetings on time? Started a new project? Fixed a tricky bug? | 0 | 2021-08-13T17:36:53 | https://dev.to/devteam/what-was-your-win-this-week-46ik | discuss, weeklyretro | ---
title: What was your win this week?
published: true
description: Got to all your meetings on time? Started a new project? Fixed a tricky bug?
tags: discuss, weeklyretro
cover_image: https://cl.ly/188e843c2985/download/Image%202019-02-15%20at%202.36.37%20PM.png
---
Hey there!
**Looking back on your week, what was... | graciegregory |
791,157 | Led Circuit Using Arduino | Loop Iteration Circuit Using Arduino Hi Fellows! During this project, we'll discuss the method to... | 0 | 2021-08-13T18:31:16 | https://dev.to/projectiot123/led-circuit-using-arduino-47cd | programming, arduion, beginners, arduino | Loop Iteration Circuit Using Arduino
Hi Fellows! During this project, we'll discuss the method to blink LEDs victimization for loop. The LEDs can light one when the opposite. The LEDS square measure turned on and off, in sequence, by victimization Arduino Module. Let's begin the method.
## Introduction:
There squar... | projectiot123 |
791,209 | React Cookies management with simple hooks | The post has been moved to https://pavankjadda.dev/react-cookies-management-with-simple-hooks/ | 0 | 2021-08-13T21:58:28 | https://dev.to/pavankjadda/react-cookies-management-with-simple-hooks-3h5i | react, javascript, typescript | The post has been moved to https://pavankjadda.dev/react-cookies-management-with-simple-hooks/ | pavankjadda |
791,326 | SDS Internship Experience! | Camilo Cortes Blog SDS Introduction TransitHealth is a website that allows the general population to... | 0 | 2021-08-14T02:56:25 | https://dev.to/camilocortes/sds-internship-experience-7o | internship, computerscience, python, sql | Camilo Cortes
Blog SDS
Introduction
TransitHealth is a website that allows the general population to access comparative data and other metrics concerning the cross of the CTA and health within the Chicago community. Data from the CTA is compiled and processed in an offline pipeline using custom metrics.
I utilized CT... | camilocortes |
791,653 | Build a simple Pie Chart with HTML and CSS | You can create a Pie Chart in HTML using a simple CSS function called conic-gradient. First, we add... | 0 | 2021-08-14T18:32:45 | https://dev.to/cscarpitta/build-a-simple-pie-chart-with-html-and-css-32dn | css, webdev, html, beginners | You can create a **Pie Chart** in HTML using a simple CSS function called `conic-gradient`.
First, we add a `<div>` element to our HTML page, which acts as a placeholder for our pie chart.
```html
<div id="my-pie-chart"></div>
```
We need to provide a `width` and a `height` to the `<div>` element, which determine th... | cscarpitta |
791,838 | How to replace an existing document in MongoDB | For a full overview of MongoDB and all my posts on it, check out my overview. MongoDB provides... | 13,964 | 2021-08-14T15:53:24 | https://donaldfeury.xyz/how-to-replace-an-existing-document-in-mongodb/ | mongodb | ---
title: How to replace an existing document in MongoDB
published: true
date: 2021-08-14 15:41:40 UTC
tags: MongoDB
canonical_url: https://donaldfeury.xyz/how-to-replace-an-existing-document-in-mongodb/
cover_image: https://donaldfeury.xyz/content/images/2021/08/MongoDB_Logo2-1.png
series: "Small Bytes of MongoDB"
--... | dak425 |
792,021 | Use of string concatenation within loops in JAVA | In Java, do you know about the pitfall of using string concatenation within loops?? Since strings are... | 0 | 2021-08-14T21:18:12 | https://dev.to/faizm4765/use-of-string-concatenation-within-loops-in-java-2j6l | java, strings, loops | In Java, do you know about the pitfall of using string concatenation within loops??
Since strings are immutable in JAVA, when we try to append another char to a string, it creates a new copy of the string and updates the copy instead of the original string.😯
Example :
```java
String s = "value";
s.concat("d");
```
On... | faizm4765 |
792,036 | 10 Of The Most Amazing JS Libraries That Almost You Will Enjoy Using Them In Your Project! | Hello everybody, I'm Aya Bouchiha, in this post, I'll share with you 10 amazing javascript libraries.... | 14,581 | 2021-08-14T23:27:38 | https://dev.to/ayabouchiha/10-of-the-most-amazing-js-libraries-that-almost-you-will-enjoy-using-them-in-your-project-3amo | javascript, typescript, webdev, tutorial | Hello everybody, I'm [Aya Bouchiha](developer.aya.b@gmail.com), in this post, I'll share with you 10 amazing javascript libraries.
## Chart.js
**Chart.js** is an open-source library that lets you visualize data.
+ [github](https://github.com/chartjs/Chart.js)
+ [docs](https://www.chartjs.org/docs/)
+ [demo](https:/... | ayabouchiha |
792,084 | Flutter & Dart Tips - Week In Review #10 | Hello Reader, Welcome back to the 10th post of the Flutter & Dart Tips series. Ten weeks ago,... | 13,200 | 2021-08-15T00:28:36 | https://dev.to/offlineprogrammer/flutter-dart-tips-week-in-review-10-55o8 | flutter, dart, beginners, codenewbie |
Hello Reader,
Welcome back to the 10th post of the Flutter & Dart Tips series.

Ten weeks ago, I started this series to share the tips I tweet during the week. My goal is to have at least 100 tips in this series.
1- LayoutBuilder helps to create a widge... | offlineprogrammer |
792,096 | Microtasks and (Macro)tasks in Event Loop | JavaScript has a concurrency model based on an event loop, which is responsible for executing the... | 0 | 2021-08-15T02:01:40 | https://dev.to/saravanakumarke/microtasks-and-macro-tasks-in-event-loop-4h2h | javascript, webdev | JavaScript has a concurrency model based on an **event loop**, which is responsible for executing the code, collecting and processing events, and executing queued sub-tasks.
Here, we will see about microtask and macrotask in event loop and how event loop will handle tasks.
let’s dive in! 🏃♂️
Within the Event Loop,... | saravanakumarke |
792,116 | Quasar's QTable: The ULTIMATE Component (4/6) - ALL The Slots! | What's black, blue, and PACKED full of QTable slots? ... The video version of this blog... | 0 | 2021-08-19T13:19:03 | https://dev.to/quasar/quasar-s-qtable-the-ultimate-component-4-6-all-the-slots-40g2 | quasar, vue, javascript, webdev | What's black, blue, and PACKED full of QTable slots?
...
The video version of this blog post!
{% youtube cxNvoSkeLcM %}
The ideal progression for customizing **rows** with Quasar's `QTable` is this:
1. **No slots**, only props
2. The **generic** "cell" slot (`#body-cell`)
3. **Specific** "cell" slots (`#body-cell-[... | ldiebold |
792,200 | Rust Trait Objects Demystified | Dealing with Trait Objects in Rust is a trap for young players, especially when you want to obtain a... | 0 | 2021-08-15T05:44:29 | https://dev.to/bsodmike/rust-trait-objects-demystified-54dk | rust | Dealing with Trait Objects in Rust is a trap for young players, especially when you want to obtain a composition of traits.
Here's a deep-dive with code-examples and a Github repo for you to play with - Enjoy!
https://desilva.io/posts/rust-trait-objects-demystified | bsodmike |
792,208 | Create PDF documents with AWS Lambda + S3 with NodeJS and Puppeteer | This post was originally posted on my blog Intro Recently I had to create two serverless... | 0 | 2021-08-15T06:31:25 | https://dev.to/javiertoscano/create-pdf-documents-with-aws-lambda-s3-with-nodejs-and-puppeteer-3phi | aws, serverless, node, javascript | This post was originally posted on my [blog](https://javtoscano.com/create-pdf-documents-with-aws-lambda-s3-with-nodejs-and-puppeteer)
# Intro
Recently I had to create two serverless functions for a client that needed to create a PDF document from an existing HTML format and merge it with another PDF documents provid... | javiertoscano |
792,239 | Big Shout to Zuri | Thank you Zuri team for giving me a chance to be part of this cohort(Frontend Track).The... | 0 | 2021-08-15T08:05:02 | https://dev.to/techmadi/big-shout-to-zuri-i75 | react, figma | <main>
Thank you Zuri team for giving me a chance to be part of this cohort(Frontend Track).The internship has several tracks : -
<ul>
<li>
Frontend Track
</li><li>
Backend Track
</li>
<li>
Devops Track
</li>
<li>
Entrepreneurship Track
... | techmadi |
792,241 | Why ditched Windows for Linux | What Is Linux When it comes to this topic there are two kinds of people. People who react... | 0 | 2021-08-15T08:17:51 | https://dev.to/ishanpro/why-ditched-windows-for-linux-1og3 | linux | ## What Is Linux
When it comes to this topic there are two kinds of people. People who react What is Linux even? and the People who say like Yeah I know Linux and I have it on my pc.
Well, Linux is not a single operating system but a whole family of them. A man named Linus Torvalds created the Linux Kernel (A program ... | ishanpro |
792,279 | HNG Internship Goals | If you're a developer with an eye out for internships, you must've heard of the HNG internship and... | 0 | 2021-08-15T09:32:55 | https://dev.to/web_walkerx/hng-internship-goals-221a | programming, goals, internship, zuri | If you're a developer with an eye out for internships, you must've heard of the HNG internship and the drills they put developers through to make them world class software engineers.
The internship is open to anyone and aims at creating a virtual work environment that fishes out the best candidates from a pool of part... | web_walkerx |
792,363 | ✅ Tell Me About A Time You Worked With A Difficult Person | Facebook Behavioral Interview (Jedi) Series 🔥 | Before we discuss this question, let us recap what the Behavioral Interview Round at Facebook... | 12,638 | 2021-09-26T18:05:28 | https://dev.to/theinterviewsage/tell-me-about-a-time-you-worked-with-a-difficult-person-facebook-behavioral-interview-jedi-series-1j79 | beginners, tutorial, programming, career | {% youtube T_kM3daDx2k %}
Before we discuss this question, let us recap what the Behavioral Interview Round at Facebook is.
1. Behavioral Interview Round is also known as the Jedi Interview round at Facebook.
2. It is about you and your history, your résumé, and your motivation.
3. The purpose of this interview is ... | theinterviewsage |
792,369 | How to make JARVIS in Python? | Hello and welcome in this post I am going to talk about how to make jarvis in python. I am going to... | 0 | 2021-08-15T10:24:04 | https://crunchythings.xyz/how-to-make-jarvis-in-python/ | Hello and welcome in this post I am going to talk about how to make jarvis in python. I am going to provide you complete source code of this project. Also I am going to explain line by line chords and then the complete code will be given to you. There are no limitation of this voice assistant. All the voice commands ar... | sushantdhiman2004 | |
792,421 | My Expectations at Zuri Internship Program | ZURI INTERNSHIP Background I am Atwine Nickson, a software developer with 3 years of playing with... | 0 | 2021-08-15T12:23:44 | https://dev.to/atwinenickson/my-expectations-at-zuri-internship-program-2763 | ZURI INTERNSHIP
Background
I am Atwine Nickson, a software developer with 3 years of playing with code experience. Apart from UI development (Frontend), I am a full-stack developer pro efficiently with Python(Django and Flask).
I am always looking for new challenges to help me improve my skills and that is when I fo... | atwinenickson | |
792,468 | HNGi8 x I4G Internship Goals | My name is Pius Osuji. I am a 400L Computer Science student at Imo State University, Owerri Imo State... | 0 | 2021-08-15T14:08:24 | https://dev.to/pius_osuji/hngi8-x-i4g-internship-goals-5agc | webdev | My name is Pius Osuji. I am a 400L Computer Science student at Imo State University, Owerri Imo State and aspiring Frontend Developer.
I am super excited to be part of this internship program for this year organized by 14G. I have heard a lot about this program and how they help build and push those who make it to the... | pius_osuji |
792,543 | Understanding WebAssembly better by learning WebAssembly-Text | This article tries to teach yoy the low level of WebAssembly using WebAssembly-Text | 0 | 2021-08-15T14:52:27 | https://dev.to/fabriciopashaj/understanding-webassembly-better-by-learning-webassembly-text-50bj | webassembly, wat, lowlevel | # Understanding WebAssembly better by learning WebAssembly Text
WebAssembly is a true revolution in tech, not just in the web, but thanks to WASI and friends, it is becoming available everywhere.
One of the best things WebAssembly offers is being a compilation target
instead of just another programming language. This... | fabriciopashaj |
792,603 | [TECH] Unity で iOS/Android アプリの設定値をセキュアに扱う方法 🔑 | はじめに iOS/Android でユーザーの情報をセキュアに扱う必要があったので、調査したところ Android には EncryptedSharedPreferences... | 0 | 2021-08-15T15:46:39 | https://zenn.dev/nikaera/articles/unity-ios-android-secret-manager | unity3d, ios, android |
# はじめに
iOS/Android でユーザーの情報をセキュアに扱う必要があったので、調査したところ Android には [EncryptedSharedPreferences](https://developer.android.com/reference/androidx/security/crypto/EncryptedSharedPreferences) が存在することを知りました。iOS には [Keychain Services](https://developer.apple.com/documentation/security/keychain_services) が存在します。
今回は Unity の i... | nikaera |
792,656 | Can anyone take me with him/her any C++/python/JS project ... ? Want to learn the things actually ... please ... | just a mail ... sarkar99ratul@gmail.com | 0 | 2021-08-15T17:01:29 | https://dev.to/noobdev/can-anyone-take-me-with-him-her-any-c-python-js-project-want-to-learn-the-things-actually-please-4pci | python, javascript, cpp | just a mail ... sarkar99ratul@gmail.com | noobdev |
792,696 | Frontend Mentor - Order Summary Component | Order Summary Component design from the website Frontend... | 0 | 2021-08-15T18:41:49 | https://dev.to/aituos/frontend-mentor-order-summary-component-3ffi | frontendmentor, webdev, css | 
Order Summary Component design from the website Frontend Mentor.
https://www.frontendmentor.io/challenges/order-summary-component-QlPmajDUj
You can see my finished version here:
[Github repo](https://github.com... | aituos |
792,700 | Backend shorts - Use database transactions | Database transactions have many use cases, but in this post we will be only looking at the simplest... | 14,128 | 2021-08-15T19:38:41 | https://dev.to/hbgl/backend-shorts-use-database-transactions-36fj | webdev, backend, laravel, shorts | Database transactions have many use cases, but in this post we will be only looking at the simplest and most common one: all or nothing semantics aka atomicity.
If you issue **multiple related** database queries that modify data (INSERT, UPDATE, DELETE), then you should most likely use a transaction. Here is a quick e... | hbgl |
792,786 | The HNG internship: My goals and aspirations | "You learn so much from taking chances, whether they work out or not. Either way, you can grow from... | 0 | 2021-08-15T19:51:07 | https://dev.to/dcwhitesnake/the-hng-internship-my-goals-and-aspirations-4pl7 | internship, programming, hng, zuri | "*You learn so much from taking chances, whether they work out or not. Either way, you can grow from the experience and become stronger and smarter.*" ~ John Legend
For the past 4-months, I have been asking myself, "what next?" Well, as luck would have it, that question got answered by a post I saw... | dcwhitesnake |
792,954 | What is Cloud native? | A post by jmbharathram | 0 | 2021-08-15T21:44:28 | https://dev.to/jmbharathram/what-is-cloud-native-1gmn | kubernetes, cloudnative, cloud | {% youtube PTnVHDXJ-sk %} | jmbharathram |
792,965 | My tech journey so far (HNG8) | My journey into tech started on twitter, when I saw a post from Zuri internship, offering to train... | 0 | 2021-08-15T22:05:05 | https://dev.to/toogood208/my-tech-journey-so-far-hng8-479m | flutter, kotlin, android | My journey into tech started on twitter, when I saw a post from Zuri internship, offering to train people transitioning into tech for the first time.
I registered for the training with a lot of expectations. I chose mobile development because I have always been curious about how mobile apps work.
After 3 months of ri... | toogood208 |
792,971 | MY GOALS FOR HNG INTERNSHIP | The HNG internship is a 3-month remote internship designed to find and develop the most talented... | 0 | 2021-08-15T22:26:52 | https://dev.to/pertrick/my-goals-for-hng-internship-1oh | The HNG internship is a 3-month remote internship designed to find and develop the most talented software developers in which everyone is welcome to participate (there is no entrance exam). Interested Interns can access the internship using their laptop. Tasks are given to interns weekly. Interns who complete the tasks... | pertrick | |
792,975 | Tracking The Flow of Information in React.js | A major advantage of React is that it facilitates the overall process of writing components which can... | 0 | 2021-08-15T22:55:31 | https://dev.to/davidnnussbaum/tracking-the-flow-of-information-in-react-js-2589 | A major advantage of React is that it facilitates the overall process of writing components which can then in turn be reused. It can become challenging to track the flow of information from one component to another, especially when one wants to keep track of the props. Having a flow chart to be used as an available re... | davidnnussbaum | |
792,982 | HNG Internship | I am currently in the HNG i8 internship which will last for a period of eight(8) weeks. The goal is... | 0 | 2021-08-15T23:01:19 | https://dev.to/jesmanto/hng-internship-5fa2 | I am currently in the HNG i8 internship which will last for a period of eight(8) weeks. The goal is to test yourself and compete with great minds as well. It's gonna be a smooth and as well rough experience, even though the goal is to get a T-Shirt and brag about the completion of the internship... Lolz
For me, I hope... | jesmanto | |
807,068 | Finding Types at Runtime in .NET Core
| One of the best features of .NET has always been the type system. In terms of rigor I place it... | 0 | 2021-08-29T14:34:46 | https://dev.to/bobrundle/finding-types-at-runtime-in-net-core-1lpg | dotnet | One of the best features of .NET has always been the type system. In terms of rigor I place it midway between the rigidness of C++ and the anything-goes of JavaScript which in my view makes it just right. However one of my frustrations over the years has been finding types at runtime.
At compile time you find the in... | bobrundle |
793,073 | Measuring Developer Relations | DevRel is hot but nobody knows how to measure it. That's because we don't agree on what effective DevRel *is*, and we don't agree on the tradeoffs of lagging vs leading metrics for a creative, unattributable, intimately human endeavor. | 0 | 2021-08-16T01:06:41 | https://www.swyx.io/measuring-devrel | dx, devrel, content | ---
title: Measuring Developer Relations
published: true
description: DevRel is hot but nobody knows how to measure it. That's because we don't agree on what effective DevRel *is*, and we don't agree on the tradeoffs of lagging vs leading metrics for a creative, unattributable, intimately human endeavor.
tags: DX, devr... | swyx |
793,079 | Python + Flask Pt 2 ... adding React | The last post was about creating a Python + Flask application and deploying on Heroku. This post we... | 0 | 2021-08-16T02:02:43 | https://dev.to/roadpilot/python-flask-pt-2-adding-react-4j8d | The last post was about creating a Python + Flask application and deploying on Heroku. This post we are going to take that same Python + Flask application and add a React frontend to it. First some unfinished touches on the Python + Flask backend. To make it run locally, we'll need to make some changes:
In our app.... | roadpilot | |
793,136 | Basics of Object Detection (Part 1) | This article is originally from the book "Modern Computer Vision with PyTorch" ... | 0 | 2021-08-16T06:20:38 | https://dev.to/sally20921/basics-of-object-detection-part-1-1i52 | deeplearning | *This article is originally from the book "Modern Computer Vision with PyTorch"*
## Introduction
Imagine a scenario where we are leveraging computer vision for a self-driving car. It is not only necessary to detect whether the image of a road contains the images of vehicles, a sidewalk, and pedestrians, but it is als... | sally20921 |
793,146 | HNG Internship - HNGi8: My coding goals for the next 8 weeks. | Zuri training is a free beginner training for complete tech novices handled by veteran tech experts... | 0 | 2021-08-16T06:02:01 | https://dev.to/austinug8/hng-internship-hngi8-311f | Zuri training is a free beginner training for complete tech novices handled by veteran tech experts with track records in the tech industry. HNG internship is an internship outfit of zuri training that its interest is aimed at providing training, support, mentorship and a collaborative environment to its participants t... | austinug8 | |
793,290 | Astro recipe collection website - Part 5 Hosting on Netlify | We finished our Astro recipe website, and now it's time to publish our fantastic website on the World... | 0 | 2021-08-16T07:03:16 | https://daily-dev-tips.com/posts/astro-recipe-collection-website-part-5-hosting-on-netlify/ | astro, netlify | We finished our Astro recipe website, and now it's time to publish our fantastic website on the World Wide Web.
We'll be using [Netlify](https://www.netlify.com/) as our hosting provider, as it's a super simple system and setup.
## Fixing our Astro source code
Before we do anything, let's make sure we add two steps ... | dailydevtips1 |
793,300 | BGP (Border Gateway Protocol) | BGP, genellikle Internet Service Provider (İnternet Servis Sağlayıcıları) tarafından kullanılan... | 0 | 2021-08-16T07:19:37 | https://dev.to/etkirac/bgp-border-gateway-protocol-6np | bgp | BGP, genellikle Internet Service Provider (İnternet Servis Sağlayıcıları) tarafından kullanılan gelişmiş bir yönlendirme protokolüdür. BGP’de routerlara otonom sistem (AS) numarası tanımlanır. BGP, yönlendirme tablosunu oluşturmak için metrik hesaplar, bu hesaplama hedefe giderken üzerinden geçilen otonom sistem sayısı... | etkirac |
793,340 | How to prepare for front-end interview for 2022? | As a front-end developer, 80% of the interview is based on JavaScript, then 15% of HTML and CSS. 5%... | 0 | 2021-08-16T08:28:38 | https://dev.to/codewithnithin/how-to-prepare-for-front-end-interview-for-2022-4mnm | javascript, webdev, codenewbie, discuss | As a front-end developer, 80% of the interview is based on JavaScript, then 15% of HTML and CSS. 5% on JS frameworks, am i right? | codewithnithin |
793,350 | Call To Action button with pure HTML CSS | Buttons are very important for any type of websites like static website, dynamic website, eCommerce... | 0 | 2021-08-16T08:45:10 | https://atulcodex.com/call-to-action-button-with-pure-html-css/ | html, css, codenewbie, todayilearned | Buttons are very important for any type of websites like static website, dynamic website, eCommerce website or any kind of website. Buttons are designed to make someone take action.
If you have filled any online registration or signup form you have absolutely seen some button at the end of the form like submit or sign... | atulcodex |
807,062 | CSS Silly button generator for creative developers | Buttons! Buttons! Buttons! You know them, right? When you are visiting a webpage there are lots (At... | 0 | 2021-08-29T13:53:55 | https://www.tronic247.com/css-silly-button-generator-for-creative-developers/ | css, showdev, codenewbie | Buttons! Buttons! Buttons! You know them, right?
When you are visiting a webpage there are lots (At least one) of buttons. But most of them look boring and the same. Here’s a Silly little button generator that might increase your creativity.
{%codepen https://codepen.io/Tronic247/pen/MWoaGZv %}
Each page load gener... | posandu |
807,063 | mysql database connection in php | Hi guys, Today, we will see about mysql database connection in php. In the world of web... | 0 | 2021-08-29T13:57:47 | https://dev.to/pavankumarsadhu/mysql-database-connection-in-php-lj | mysql, php, webdev, wordpress | Hi guys,
Today, we will see about mysql database connection in php.
In the world of web development, data plays a key role. To give best experience to the users, we need to keep track of user steps to make comfortable. Definitely we need to store data related to users.
```php
<?php
$servername = "localhost"; //your ... | pavankumarsadhu |
807,066 | Animated no-element typewriter | After sharing a typewriter effect with CSS, ChallengesCss beat the drums of "CSS War" and created a different effect, and InHuOfficial hopped in and is preparing a "type-righter"... Here's another entry: an animated no-element cartoon of a typewriter | 14,440 | 2021-08-29T14:22:33 | https://dev.to/alvaromontoro/animated-no-element-typewriter-2835 | css, html, webdev, art | ---
title: Animated no-element typewriter
published: true
description: After sharing a typewriter effect with CSS, ChallengesCss beat the drums of "CSS War" and created a different effect, and InHuOfficial hopped in and is preparing a "type-righter"... Here's another entry: an animated no-element cartoon of a typewrite... | alvaromontoro |
807,242 | Konversiyon Bozukluğunun Nedenleri ve Belirtileri | Konversiyon Bozukluğu nedir? Anksiyete, panik atak, fobiler ve obsesif kompulsif bozukluklar dahil... | 0 | 2021-08-29T19:11:24 | https://dev.to/insanpsikolojisi/konversiyon-bozuklugunun-nedenleri-ve-belirtileri-2hea | Konversiyon Bozukluğu nedir? Anksiyete, panik atak, fobiler ve obsesif kompulsif bozukluklar dahil olmak üzere çeşitli zihinsel sağlık koşullarının bir kombinasyonu olarak sınıflandırıldığından, dönüşüm bozukluğunun ne olduğu sorusu karmaşıktır. Bu bozukluğun gerçek nedeni bilinmemektedir ve yalnızca geniş bir şekilde ... | insanpsikolojisi | |
807,263 | #100daysofcode [Day - 07] | Alhumdulillah today is the seventh day of my 100 days of coding challenge, and today i tried to make... | 0 | 2021-08-29T20:05:13 | https://dev.to/thekawsarhossain/100daysofcode-day-07-38a6 | javascript, programming | Alhumdulillah today is the seventh day of my 100 days of coding challenge, and today i tried to make a site using sportsdb api. Where you can search clubs by name of club and you can get the details of the club by clicking a button.
Here is the site Link : https://football-club-api.netlify.app/
And here is the code... | thekawsarhossain |
807,507 | Best Low Interest Personal Loans | Pretty much every advance – vehicle advance, home advance, business credit just as close to home... | 0 | 2021-08-30T03:28:00 | https://dev.to/jackasimpson1/best-low-interest-personal-loans-59kj | lowinterestpersonalloans, pinjamanperibadi, malaysiapersonalloans | <a href="https://dev.to/">Pretty much every advance</a> – vehicle advance, home advance, business credit just as close to home advance – utilizes a financing cost (or ‘benefit rate’ in case it is an Islamic advance). The financing cost is determined in a sectional request and is likewise charged to your primary advance... | jackasimpson1 |
807,553 | example | A post by surajpatil510 | 0 | 2021-08-30T06:02:00 | https://dev.to/surajpatil510/javascript-behind-the-scene-3p64 | surajpatil510 | ||
807,562 | Answer: How to see docker image contents | answer re: How to see docker image... | 0 | 2021-08-30T06:26:25 | https://dev.to/icy1900/answer-how-to-see-docker-image-contents-27d5 | docker | {% stackoverflow 46526598 %} | icy1900 |
807,777 | Thoughts On Types | This article was initially published on my website. Introduction I've used multiple... | 0 | 2021-08-30T11:10:50 | https://sayedhajaj.com/posts/thoughts-on-types | programming | This article was initially published on [my website](https://sayedhajaj.com/posts/thoughts-on-types).
## Introduction
I've used multiple programming languages, each with their own ideas of how types should be handled.
Each of these approaches created some issues and solved other issues, and my goal in this article i... | sayedhajaj |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.