
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,412,029 | Debugging Multiple .NET Projects in VS Code | It is quite common, especially in medium/large projects, to have to run multiple projects in debug... | 0 | 2023-03-23T09:51:43 | https://dev.to/this-is-learning/debugging-multiple-net-projects-in-vs-code-28kn | vscode, dotnet, webdev | It is quite common, especially in medium/large projects, to have to run multiple projects in debug mode at the same time.
The simplest example is a frontend and its services within the same .NET solution.
But is it so difficult to launch multiple .NET projects simultaneously from Visual Studio Code?
## First Steps
Cr... | kasuken |
1,412,193 | Convert Flutter app to android Native java app | I have a flutter app which I would like to convert to android native java app. PS: just the... | 0 | 2023-03-23T11:04:36 | https://dev.to/anurupjalota/convert-flutter-app-to-android-native-java-app-2n3n | android, flutter, java | I have a flutter app which I would like to convert to android native java app.
PS: just the UI.
Basically I want to add an SDK called 'Tuya IOT SDK' but the problem is it only supports java/swift.
| anurupjalota |
1,412,250 | Mastering Blazor - Part 2: Hot Reloading | Photo by Mike van den Bos on Unsplash In the recent three years I did quite a bit of web development... | 26,920 | 2023-03-23T12:47:28 | https://dev.to/florianrappl/mastering-blazor-part-2-hot-reloading-2b87 | blazor, dotnet, javascript, webdev | *Photo by <a href="https://unsplash.com/@mike_van_den_bos?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Mike van den Bos</a> on <a href="https://unsplash.com/photos/jf1EomjlQi0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>*
In the recent three years I did quite ... | florianrappl |
1,412,389 | SBOM Explained: 📚 An Enterprise Guide to Security Risk Management | In this age of technology, software companies are quickly shifting towards a strict compliance... | 0 | 2023-03-27T16:37:48 | https://boxyhq.com/blog/sbom-explained-an-enterprise-guide-to-security-risk-management | sbom, opensource, riskmanagement, security |
---
title: SBOM Explained: 📚 An Enterprise Guide to Security Risk Management
published: true
date: 2023-03-22 00:00:00 UTC
tags: sbom, opensource,riskmanagement, security
canonical_url: https://boxyhq.com/blog/sbom-explained-an-enterprise-guide-to-security-risk-management
---
In this age of technology, softwa... | nathan_tarbert |
1,412,463 | The Heart Of JavaScript #functions💙 | Functions Function Declaration Function without a parameter and return Function returning... | 0 | 2023-03-23T15:26:42 | https://dev.to/shaikhmd007/the-heart-of-javascript-functions-2lin | - [Functions](#functions)
- [Function Declaration](#function-declaration)
- [Function without a parameter and return](#function-without-a-parameter-and-return)
- [Function returning value](#function-returning-value)
- [Function with a parameter](#function-with-a-parameter)
- [Function with two par... | shaikhmd007 | |
1,412,537 | FastAPI + Celery = ♥ | Interested in Python FastAPI? Wondering how to execute long-running tasks in the background in... | 0 | 2023-03-27T12:15:00 | https://blog.derlin.ch/introduction-to-fastapi-and-celery | python, fastapi, tutorial, showdev |
*Interested in Python FastAPI? Wondering how to execute long-running tasks in the background in Python? You came to the right place!*
---
## The use case
I learned about [FastAPI](https://fastapi.tiangolo.com/) and [Celery](https://docs.celeryq.dev/en/stable/getting-started/introduction.html) when confronted with a... | derlin |
1,412,681 | [JS/TS] Don't declare regex with flags in an object property | While I was writing the package: thiis I found one problem with regex when I tried add a new property... | 0 | 2023-03-23T18:33:12 | https://dev.to/karbashevskyi/jsts-dont-declare-regex-with-flags-in-property-of-object-e67 | javascript, typescript, is, validation | While I was writing the package: [thiis](https://github.com/Karbashevskyi/thiis) I found one problem with regex when I tried add a new property to exist object with regex value.
When I wrote the new package's `is.upperCase()` method, I used a regular expression to find lowercase characters, and if found, it's an error... | karbashevskyi |
1,412,830 | Hosting Your Own Web Application: A Beginner's Guide with Nginx | #Introduction Have you ever desired you could develop a web application locally on your computer... | 0 | 2023-03-23T19:38:53 | https://dev.to/eunice-js/hosting-your-own-web-application-a-beginners-guide-with-nginx-3135 | **#Introduction**
Have you ever desired you could develop a web application locally on your computer without having to pay for web hosting or a virtual private server (VPS)? Or perhaps you just want to explore web development in a safe setting without worrying about public access to your application. Nginx is a perfec... | eunice-js | |
1,414,825 | I tried to fish for compliments from Code GPT | Here's what Code GPT thinks about the quality of my React code: Your code is quite well written... | 0 | 2023-03-25T15:58:59 | https://dev.to/brense/i-tried-to-fish-for-compliments-from-code-gpt-5d3n | gpt3, webdev | Here's what Code GPT thinks about the quality of my React code:
```
Your code is quite well written and structured. However, there are a couple of things that you could consider to improve it:
1. Use meaningful variable names: Try to use descriptive variable names that reflect the purpose of the data that they hold. ... | brense |
1,412,849 | DeGore - Celebrating Two Tremendous Years | Two years already? Whew, time flies! Today marks a very special day for DeGore. Throughout... | 0 | 2023-03-23T19:57:26 | https://dev.to/savvydev06/degore-celebrating-two-tremendous-years-4fa6 | programming, javascript, node, ai | ## Two years already? Whew, time flies!
Today marks a very special day for DeGore. Throughout the past two years, we've celebrated various milestones: Discord bot verification, the major AXON update, one-million users - and many more. Today, we're thrilled to announce that we've reached a new milestone! It's DeGore's t... | savvydev06 |
1,412,921 | Como fazer um Teste Unitário em React Native, utilizando Jest. | Os chamados Testes unitários são uma prática comum na engenharia de software, em que as unidades de... | 0 | 2023-03-23T20:47:08 | https://dev.to/altencirsilvajr/como-fazer-um-teste-unitario-em-react-native-utilizando-jest-l2p | reactnative, react, programming | Os chamados Testes unitários são uma prática comum na engenharia de software, em que as unidades de código são testadas individualmente para garantir que funcionem corretamente. Em React Native, os testes unitários são usados para testar componentes individuais para garantir que eles funcionem corretamente e sem erros.... | altencirsilvajr |
1,412,925 | How to build Alert Messages using TailwindCSS and JavaScript | Alert messaging (or alert notification) is machine-to-person communication that is important or... | 0 | 2023-03-23T21:14:16 | https://mbianoubradon.medium.com/how-to-build-alert-messages-using-tailwindcss-and-javascript-59851a4211db | webdev, tailwindcss, html, javascript |
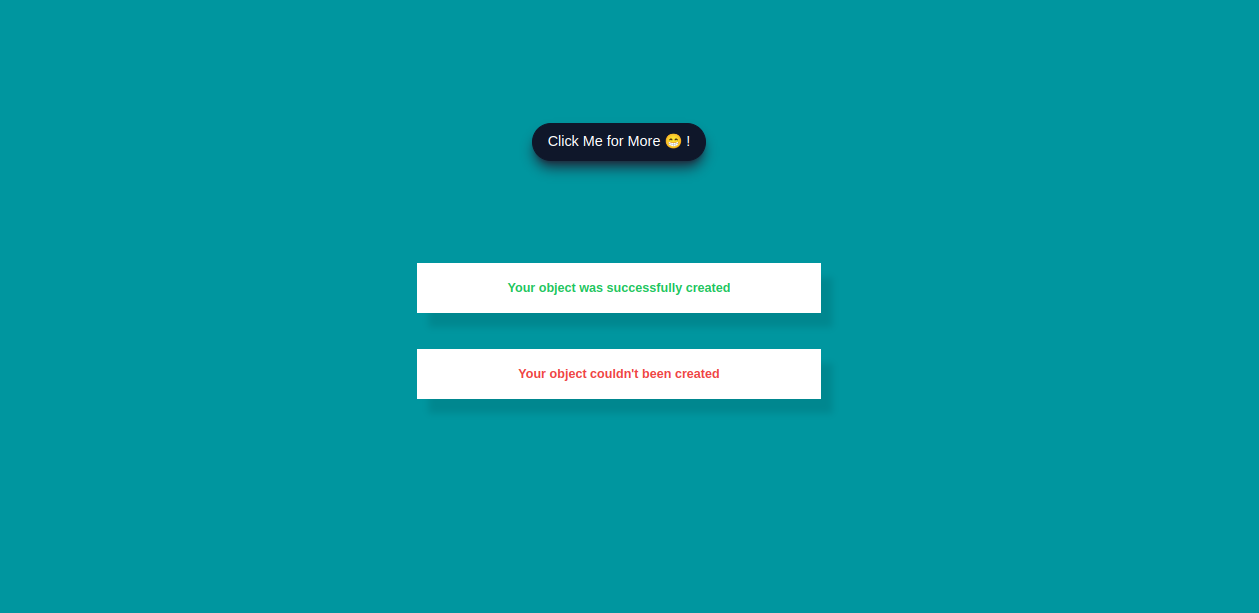
Alert messaging (or alert notification) is **machine-to-person communication that is important or time-sensitive**. An alert may be a calendar reminder or a notification of a new message.
This tutorial will be quite f... | mbianoubradon |
1,413,036 | Token Playground #4: Issue and Mint an Asset in Stellar (classic). | Token Playground Chapter 4: Issue and Mint an Asset in Stellar (classic). Check this... | 22,329 | 2023-03-24T00:01:52 | https://dev.to/esteblock/token-playground-4-issue-and-mint-an-asset-in-stellar-45d4 | # Token Playground Chapter 4: Issue and Mint an Asset in Stellar (classic).
- Check this guide in [https://token-playground.gitbook.io/](https://token-playground.gitbook.io/)
- Edit this guide in it's repo: [https://github.com/esteblock/token-playground/](https://github.com/esteblock/token-playground/)
- Contribute t... | esteblock | |
1,413,177 | In-Depth Guide to High Availability in AWS | Achieving high availability in your AWS infrastructure is crucial for maintaining business continuity... | 0 | 2023-03-24T04:19:47 | https://blog.guilleojeda.com/master-aws-high-availability-in-depth-guide | aws, devops, cloud | Achieving high availability in your AWS infrastructure is crucial for maintaining business continuity and minimizing the impact of service disruptions. In this detailed guide, we delve into various AWS high availability techniques and services, including step-by-step instructions on how to implement them to achieve fau... | guilleojeda |
1,413,277 | The Next Big Thing in Software Development | Software engineering is an ongoing field of study with novel concepts and advancements constantly... | 0 | 2023-03-24T05:43:21 | https://dev.to/amyparker/the-next-big-thing-in-software-development-4o0g | softwaredevelopment, software, webdev | Software engineering is an ongoing field of study with novel concepts and advancements constantly appearing. In this blog entry, we'll precisely consider the likelihood of the following remarkable advancement in software development and how it could change the manner in which we develop and exploit technology. We'll lo... | amyparker |
1,413,338 | Unlocking the Power of Semantics: How It Helps Search Engines Understand Your Content Better | Search engines have come a long way from the days of simply matching keywords. Today, search... | 0 | 2023-03-24T18:30:00 | https://dev.to/parth_brahmaxatri/unlocking-the-power-of-semantics-how-it-helps-search-engines-understand-your-content-better-2l6f | webdev, programming, semantics, seo | Search engines have come a long way from the days of simply matching keywords. Today, search algorithms are more sophisticated, and they use a variety of methods to interpret and understand the content on websites. One of the key technologies that search engines use to understand content is semantics.
Semantics is the... | parth_brahmaxatri |
1,413,375 | Another Unnecessary Post in Favor of Linux? | In a recent discussion about concepts and technologies that you've changed your mind about I... | 22,597 | 2023-03-24T16:52:45 | https://dev.to/ingosteinke/another-unnecessary-post-in-favor-of-linux-1jjp | watercooler, linux, devlive, discuss | In a recent [discussion about concepts and technologies that you've changed your mind about](https://dev.to/isaacdlyman/whats-something-youve-changed-your-mind-about-589) I remembered only a few technical tools that I liked from the start and still do, including Linux, HTML, and the GIMP. But I used to be quite skeptic... | ingosteinke |
1,413,404 | Embedded Rust on BBC Micro Bit: unlocking Vec and HashMap | As an engineer having spent most of 2022 learning the Rust language, I was a little worried about the... | 0 | 2023-03-24T09:41:55 | https://dev.to/cyrilmarpaud/embedded-rust-on-bbc-micro-bit-unlocking-vec-and-hashmap-2nm0 | rust, embedded, microbit, tutorial | As an engineer having spent most of 2022 learning [the Rust language](https://www.rust-lang.org/), I was a little worried about the [`no_std`](https://docs.rust-embedded.org/book/intro/no-std.html) side of embedded systems programming.
Embedded systems, like the [BBC Micro Bit](https://en.wikipedia.org/wiki/Micro_Bit)... | cyrilmarpaud |
1,413,529 | Crux Search Engine in Chrome | In this Post We will be looking at Crux Search Engine In chrome, so without further ado lets get... | 0 | 2023-03-24T10:39:14 | https://sites.google.com/view/tailorinindirapuram/ | In this Post We will be looking at Crux Search Engine In chrome, so without further ado lets get stared :)
## What Is Crux
Crux stands for chrome real user experience report , it is a report that is generated by the field data (real data that chrome gets from our devices :)and then this data is used for checking the C... | arman_94 | |
1,413,552 | The Test Planning Inquiry Technique | Making a test strategy is frequently a challenging task. By using the fundamental concepts of... | 0 | 2023-03-24T11:42:08 | https://dev.to/abhayit2000/the-test-planning-inquiry-technique-k20 | testing, mobile, webdev | Making a test strategy is frequently a challenging task. By using the fundamental concepts of cost-benefit analysis and risk analysis, a [test automation platform](https://www.headspin.io/enterprise) can be created by carefully balancing the following aspects of software development:
**Cost of implementation**: Short-... | abhayit2000 |
1,413,566 | Launching new mobile app in 2 months with Agile transformation | I’m going to tell you a story of how my team launched iOS & Android app for ticketing service in... | 0 | 2023-03-24T12:01:09 | https://dev.to/artem_poluektov/launching-new-mobile-app-in-2-months-with-agile-transformation-4bl | I’m going to tell you a story of how my team launched iOS & Android app for ticketing service in just 2 months, performing the transition from Waterfall to Agile without a lot of pain. I’ll start by describing the initial point of the project, how software development processes worked before and will to highlight key a... | artem_poluektov | |
1,413,580 | Bug name folder Windows 11 | For some reason, while installing an Astro Project , i've inserted invalid name for the folder, and... | 0 | 2023-03-24T12:41:26 | https://dev.to/renanduart3/bug-name-folder-windows-11-5g29 | windows11, bugwindows1, foldernamebug, wsl | For some reason, while installing an [Astro Project ](https://astro.build/) , i've inserted invalid name for the folder, and some way, the framework had done it a folder with a invalid name, ocurring a infinite loop in terminal, when you try to delete a folder with reference to "." , the system cannot find it and you c... | renanduart3 |
1,413,688 | Using TailwindCSS with Nuxt efficiently | How to build Nuxt application with TailwindCSS and the modules for it. | 0 | 2023-03-24T15:31:45 | https://mayashavin.com/articles/working-with-tailwindcss-nuxt | tailwindcss, javascript, nuxt, vue | ---
title: "Using TailwindCSS with Nuxt efficiently"
published: true
description: "How to build Nuxt application with TailwindCSS and the modules for it."
cover_image: https://res.cloudinary.com/mayashavin/image/upload/v1679670844/articles/Nuxt/tailwind_nuxt_icons.jpg
img: "articles/Nuxt/tailwind_nuxt_icons"
tags: ['Ta... | mayashavin |
1,413,838 | Starchart: 1,2,3, Testing! | What is it? After having created a test database for the Starchart project, I went on to... | 0 | 2023-03-24T16:30:32 | https://dev.to/cychu42/starchart-123-testing-58f8 | javascript, prisma, opensource, vite | ## What is it?
After having [created a test database](https://dev.to/cychu42/starchart-mocking-a-database-part-2-2a88) for the [Starchart project](https://github.com/DevelopingSpace/starchart), I went on to working on tests for functions relate to Prisma API calls. (See [PR](https://github.com/DevelopingSpace/starchart... | cychu42 |
1,413,845 | I finally got a DevOps role! Then I got laid off after less than a year. | So much has changed/happened since my last post in summer of '22 after I completed Forrest Brazeal's... | 0 | 2023-03-27T16:30:52 | https://dev.to/ablackladytechblog/i-finally-got-a-devops-role-then-i-got-laid-off-after-less-than-a-year-15lp | devops | So much has changed/happened since my last post in summer of '22 after I completed [Forrest Brazeal's Cloud Resume Challenge](https://cloudresumechallenge.dev/)! Two months after completing the challenge (through some heavy networking, luck, and perseverance), I was able to secure my first DevOps role at a great small ... | ablackladytechblog |
1,413,906 | What's the point in posting here 🧐 | After publishing a six articles with a whopping 8 views...if i'm to promote those blogs externally in... | 0 | 2023-03-24T18:57:09 | https://dev.to/murchie85/whats-the-point-in-posting-here-14ai | After publishing a six articles with a whopping 8 views...if i'm to promote those blogs externally in order to gain views, what makes it different from other better sites like Hackernoon who actually help promote your work? | murchie85 | |
1,413,914 | Creating Cognito User with Auto-Incrementing ID | So there are a couple of interesting topics here. I’ve been leaning into code-less workflows with... | 0 | 2023-03-24T19:11:03 | https://www.binaryheap.com/creating-an-aws-cognito-user-with-an-auto-incrementing-id-using-aws-step-functions/ | aws, serverless, typescript, identity | So there are a couple of interesting topics here.
1. I’ve been leaning into code-less workflows with AWS Step Functions and this State Machine has nothing but native SDK integrations which include
- DynamoDB (Put, Delete, Get)
- Cognito/User Pools (AdminCreateUser)
2. I’ve run into some legacy code that requires ... | benbpyle |
1,414,062 | Governments on GitHub | Local and national governments and their GitHub organizations | 0 | 2023-03-24T20:34:17 | https://dev.to/szabgab/governments-on-github-52ee | opensource, github, government, osdc | ---
title: Governments on GitHub
published: true
description: Local and national governments and their GitHub organizations
tags: opensource, github, government, osdc
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-24 20:31 +0000
---
I am doing some rese... | szabgab |
1,414,075 | Optimize React Context Step-by-step in 4 examples | When using React components in combination with Context, you can optimize rendering by wrapping your... | 0 | 2023-03-24T21:21:46 | https://medium.com/@taala.mahdy/react-memo-and-context-d07448a7bb63 | javascript, webdev, react, nextjs | When using React components in combination with `Context`, you can optimize rendering by wrapping your React component with React.memo right after your context provider. This will prevent unnecessary re-renders.
Here are some examples of how re-rendering works with `Context`:
---
## Example 1:
```javascript
// App ... | mahdita97 |
1,414,320 | A to Z List of Top FREE Online Courses! Just do it!! | TL;DR: https://github.com/asadravian/top-free-courses A to Z list of top FREE courses! Hey there,... | 0 | 2023-03-25T03:51:51 | https://dev.to/asad1/a-to-z-list-of-top-free-online-courses-just-do-it-ae | beginners, tutorial, career, computerscience | TL;DR: https://github.com/asadravian/top-free-courses
A to Z list of top FREE courses!
Hey there, fellow devs and lifelong learners! If you're anything like me, you know there's always room for growth in the ever-evolving world of technology. That's why I've compiled this A to Z list of top FREE online courses that wi... | asad1 |
1,414,329 | The ACLU and EFF have lost the plot on TikTok | With discussions of a potential US government ban of TikTok increasing, civil libertarian... | 0 | 2023-03-25T12:14:39 | https://medium.com/@alexcarooo/aclu-eff-tiktok-ban-cee265df645c | tiktok, china, firstamendment, freespeech | With discussions of a potential US government ban of TikTok increasing, civil libertarian organizations like the [ACLU](https://twitter.com/ACLU/status/1630341121426505729?lang=en) and [EFF](https://www.eff.org/deeplinks/2023/03/government-hasnt-justified-tiktok-ban), [among others](https://pen.org/letter-to-congress-o... | alexcaro |
1,414,487 | Talking Algorithm: Exploration of Intelligent Web Crawlers | Introduction "If I had asked people what they wanted, they would have said faster horses"... | 0 | 2023-03-25T06:57:36 | https://dev.to/tikazyq/talking-algorithm-exploration-of-intelligent-web-crawlers-2kk2 | ai, machinelearning | ## Introduction
> "If I had asked people what they wanted, they would have said faster horses" -- Henry Ford
Today is the era of artificial intelligence. Whether it is ChatGPT or the various intelligent applications that follow, many people see the upcoming sci-fi world that was almost unimaginable a few years ago. H... | tikazyq |
1,414,599 | Introduction To HTML | I wrote this article to help newbies that are about to enter into the world of web design. You may... | 0 | 2023-03-25T10:01:21 | https://dev.to/guonnie/introduction-to-html-11nb | webdev, javascript, beginners, tutorial |
I wrote this article to help newbies that are about to enter into the world of web design.
You may think it's difficult, but it's not. It's very easy.
Just follow through to the end.
[Click to read!](https://link.medium.com/plW67Pu6ryb)
| guonnie |
1,423,116 | Python map(), filter() and reduce() | map(), filter(), and reduce() are built-in Python functions that are used to perform data... | 0 | 2023-04-02T04:17:28 | https://dev.to/max24816/python-map-filter-and-reduce-1ldj | python, programming, tutorial, codenewbie | [map(), filter(), and reduce() are built-in Python functions](https://www.programdoc.com/python/map-filter-reduce) that are used to perform data manipulation on iteratable of data such as lists, tuples, and sets.
## Lambda function
[Python lambda is a anonymous function](https://www.programdoc.com/python/lambda), decl... | max24816 |
1,414,692 | A Step-by-Step Guide to Creating and Valuing Your Own Cryptocurrency on Ethereum using ERC20 Tokens and add USD value to it | In the world of blockchain and cryptocurrencies, creating your own digital asset has become a popular... | 0 | 2023-03-28T15:38:32 | https://cryptoloom.xyz/tokenize-your-dream-a-step-by-step-guide-to-creating-and-valuing-your-own-cryptocurrency-on-ethereum-using-erc20-tokens-and-liquidity-pools-on-uniswap/ | general, cryptocurrency, erc20tokens, ethereum | ---
title: A Step-by-Step Guide to Creating and Valuing Your Own Cryptocurrency on Ethereum using ERC20 Tokens and add USD value to it
published: true
date: 2023-03-25 11:00:23 UTC
tags: General,cryptocurrency,erc20tokens,ethereum
canonical_url: https://cryptoloom.xyz/tokenize-your-dream-a-step-by-step-guide-to-creatin... | cryptoloom |
1,414,702 | Best smm panel service provider | An SMM panel, or Social Media Marketing panel, is a web-based platform that provides various services... | 0 | 2023-03-25T11:51:24 | https://dev.to/smmdepth/best-smm-panel-service-provider-5129 | bestsmmpanel, smmpanel, bangladeshsmmpanel, smmdepth | **[An SMM panel](https://smmdepth.com)**, or Social Media Marketing panel, is a web-based platform that provides various services to help businesses and individuals boost their social media presence. SMM panels offer a range of social media services such as likes, followers, views, shares, and comments on popular socia... | smmdepth |
1,414,759 | Terms used in Reinforcement Leaning | Every AI/ML/Data Science enthusiast knows the definition of Reinforcement Learning - it is a... | 0 | 2023-03-25T13:43:21 | https://dev.to/anurag629/terms-used-in-reinforcement-leaning-56lo | reinforcementlearning, machinelearning, datascience, deeplearning | Every AI/ML/Data Science enthusiast knows the definition of Reinforcement Learning - it is a feedback-based machine learning technique in which an agent learns to behave in an environment by performing actions and observing their outcomes. For each good action, the agent receives positive feedback, and for each bad act... | anurag629 |
1,414,767 | [FEEDBACK] - Quais Problemas vocês encontram na hora de RECEBER ou PAGAR, no EXTERIOR | Pessoal queria que me ajuda-se, me dando um Feed de problemas, causa e experiencias. É pra... | 0 | 2023-03-25T14:02:45 | https://dev.to/abraaoteixeira/feedback-quais-problemas-voces-encontram-na-hora-de-receber-ou-pagar-no-exterior-1hci | Pessoal queria que me ajuda-se, me dando um Feed de problemas, causa e experiencias. É pra ideliazação de uma solução.
| abraaoteixeira | |
1,414,809 | How to implement Dependency Injection in Laravel Livewire | I like to use Dependency Injection (DI) in my code. It helps me to keep my code clean and reduces... | 0 | 2023-03-26T10:32:53 | https://dev.to/iamkirillart/how-to-implement-dependency-injection-in-laravel-livewire-con | php, laravel, livewire, programming | I like to use Dependency Injection (DI) in my code. It helps me to keep my code clean and reduces code coupling.
## What is Dependency Injection
Dependency Injection is a design pattern that allows for the separation of concerns by removing the responsibility of creating objects and their dependencies from the class ... | iamkirillart |
1,422,721 | MatchTheRegex | MatchTheRegex 100 points AUTHOR: SUNDAY JACOB NWANYIM Description How about trying to... | 0 | 2023-04-01T14:32:08 | https://dev.to/brunoblaise/matchtheregex-2pii | regex, cybersecurity, picoctf, beginners | # MatchTheRegex
**100 points**
AUTHOR: SUNDAY JACOB NWANYIM
Description
How about trying to match a regular expression
The website is running here.
*Note:* This challenge launches an instance on demand.
___
Looking inside the script tag we can see:
```html
<script>
function send_request() {
let val = document... | brunoblaise |
1,422,741 | ASDF is a single version manager for all languages | I had to manage multiple versions of NodeJS, so I installed Node Version Manager. Then I had to also... | 0 | 2023-04-01T15:22:41 | https://dev.to/jordanbravo/asdf-is-a-single-version-manager-for-all-languages-a8m | programming | I had to manage multiple versions of NodeJS, so I installed Node Version Manager.
Then I had to also manage multiple versions of Python, so I installed PyEnv.
Then I had to manage multiple versions of Rust, Golang, Lua...
There must be a better way.
Enter `asdf`, a single version manager for all programming languag... | jordanbravo |
1,423,038 | No code ML - Make accurate predictions with Amazon SageMaker Canvas | Empowering you to make decisions with no code ML Organizations are becoming more... | 0 | 2023-04-02T11:36:45 | https://dev.to/aws-heroes/make-predictions-with-no-code-ml-in-amazon-sagemaker-canvas-as-a-business-user-3af2 | aws, machinelearning, analytics, business | ## Empowering you to make decisions with no code ML
Organizations are becoming more data-driven no matter where your company is in the data analytics maturity cycle you may be thinking about your first use case. Whether you work for a startup, consulting, government or banking you may be helping your leaders make deci... | abc_wendsss |
1,423,047 | Creating a Keith Lee Food App w/ React.js & ChatGPT | Creating a Keith Lee Food App w/ React.js & ChatGPT This personal project was... | 0 | 2023-04-02T01:55:29 | https://dev.to/cmcoffeedev/creating-a-keith-lee-food-app-w-reactjs-chatgpt-2no5 | react, javascript, chatgpt, firebase |
## Creating a Keith Lee Food App w/ React.js & ChatGPT
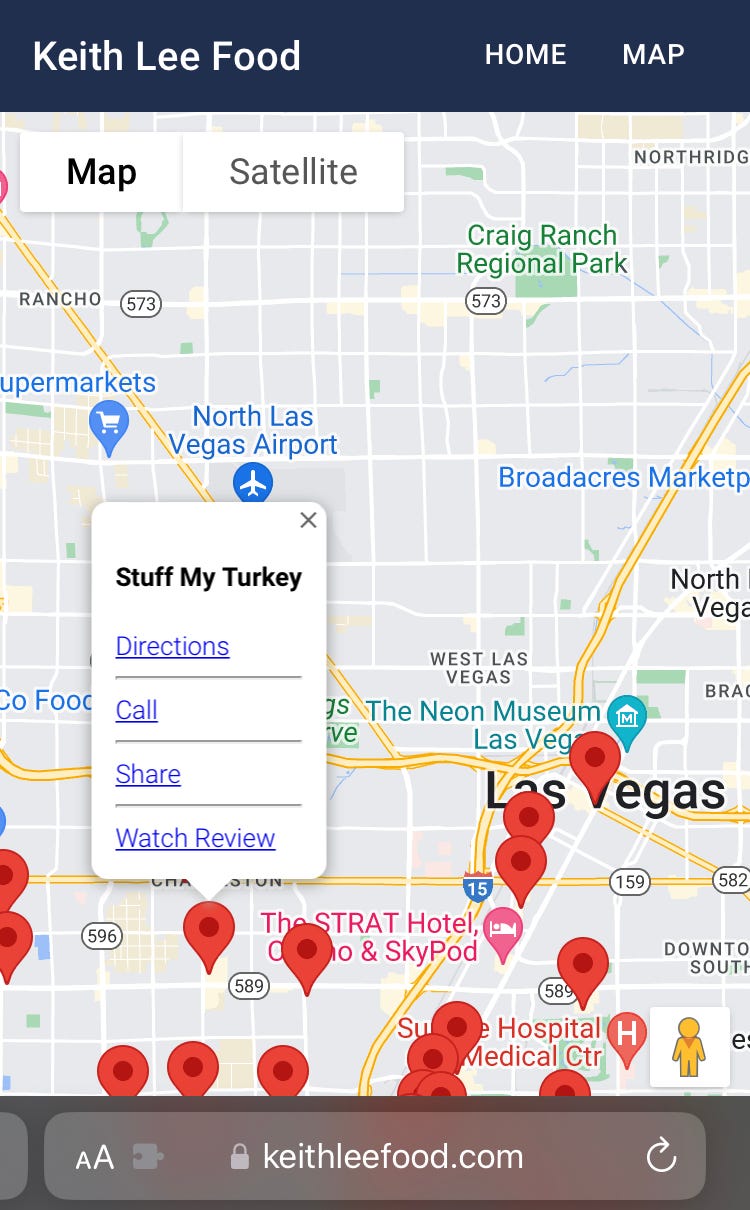
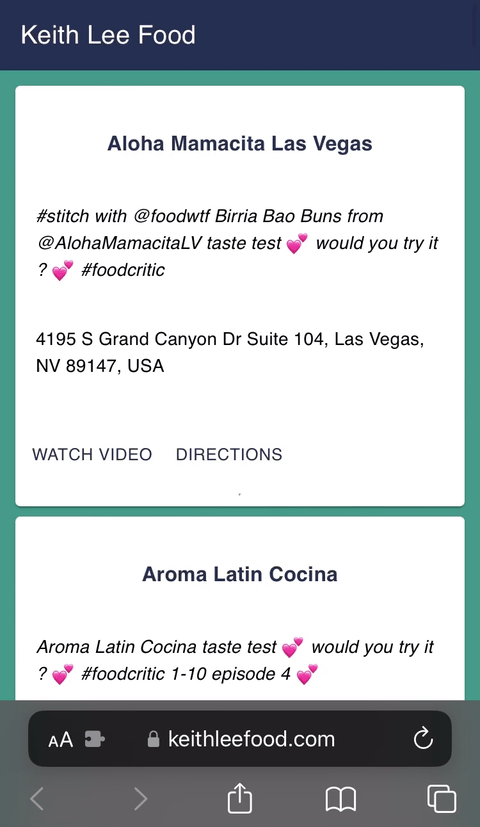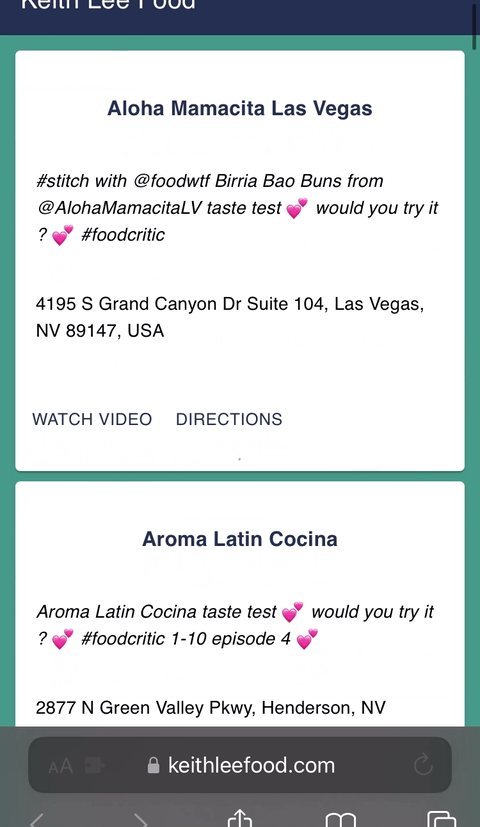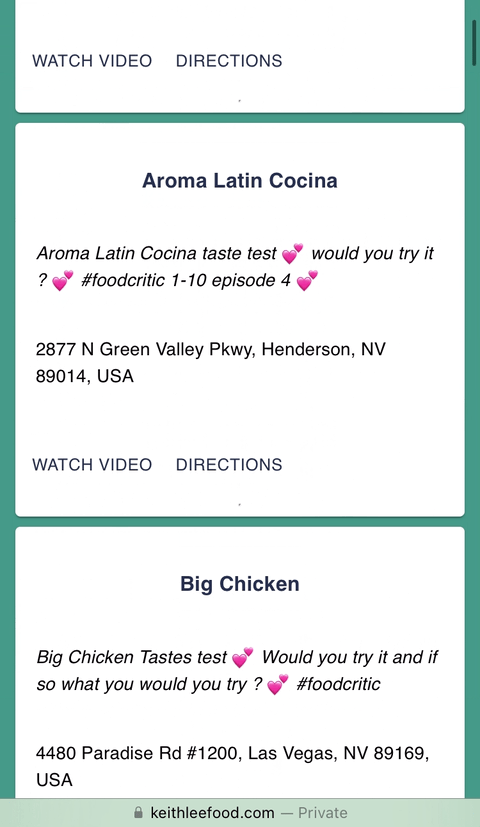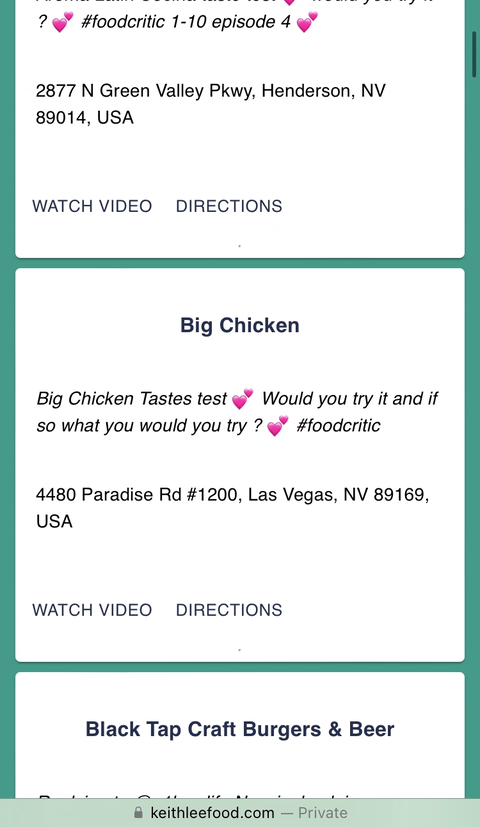
This personal project was inspired by watching Keith Lee and wanting to try the family-owned restaurants he re... | cmcoffeedev |
1,423,597 | Hi this is Irfan, i am reactJs and UI developer | A post by Sayyed Irfan | 0 | 2023-04-02T19:55:06 | https://dev.to/sayyedirfan255/hi-this-is-irfan-i-am-reactjs-and-ui-developer-24d0 | sayyedirfan255 | ||
1,423,158 | The Dangers of Copy-Paste Malware, and how to prevent them | Copy-paste malware has become a growing concern in today's digital age. This type of malware is... | 0 | 2023-04-02T07:04:54 | https://dev.to/oruchepaschal/the-dangers-of-copy-paste-malware-and-how-to-prevent-them-46ie | copypastemalware, phishing, cybersecurity, socialengineering | Copy-paste malware has become a growing concern in today's digital age. This type of malware is designed to infect a computer (running desktop or mobile operating systems) by hiding within copied and pasted text or code. As soon as the copied content is pasted into a new document, the malware infects the system, giving... | oruchepaschal |
1,423,169 | command line game | Dive into a gameplay like never before. summary The game is about akin to dungeons and... | 0 | 2023-04-02T07:59:54 | https://dev.to/symonkipkemei/command-line-game-813 | python, games, programming, beginners | Dive into a gameplay like never before.
### summary
The game is about akin to dungeons and dragons. There are two doors; the left door and the right door. One of the rooms/caves is empty. If you search further/look around you will encounter a sword.
The other room contains a dragon .If you choose to fight the dragon ... | symonkipkemei |
1,423,231 | Network Communication in Python: Sockets, Requests, and Urllib | Python provides several libraries for network communication, including sockets, requests, and urllib.... | 0 | 2023-04-02T08:54:51 | https://dev.to/zubairwazir/network-communication-in-python-sockets-requests-and-urllib-4545 | python, beginners, programming, tutorial | Python provides several libraries for network communication, including sockets, requests, and urllib. These libraries can be used to send and receive data over the internet, make HTTP requests, and more. In this tutorial, we'll explore these libraries and provide examples of how to retrieve the content of a web page us... | zubairwazir |
1,423,238 | Let's build a Node.js project (REST API) | Backend lovers, this is for you! Today I am starting with this development series where I will be... | 0 | 2023-04-02T11:42:19 | https://dev.to/ananyacodes/lets-build-a-nodejs-project-rest-api-pnl | node, development, api, postman | ---
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/85ftcfjy501i4kv6g8rw.png
title: Let's build a Node.js project (REST API)
published: true
date: 2023-03-20 08:05:25 UTC
tags: nodejs, development, API, Postman
canonical_url:
---
Backend lovers, this is for you! Today I am starting with this dev... | ananyacodes |
1,423,252 | How To Deploy Jitsi Meet(video conference) on Ubuntu | Jitsi Meet is an open source video-conferencing application based on WebRTC. A Jitsi Meet... | 0 | 2023-04-02T10:20:06 | https://dev.to/syedasadrazadevops/how-to-deploy-jitsi-meet-on-ubuntu-ph9 | jitsi, meet, jitsimeet, opensource | ####**Jitsi Meet is an open source video-conferencing application based on WebRTC.**
A Jitsi Meet server provides multi-person video conference rooms that you can access using nothing more than your browser and provides comparable functionality to a Zoom or Skype conference call.
### Step 1 — System Hostname
```
sudo... | syedasadrazadevops |
1,423,253 | Connectedminds | https://connectedminds.ai/ A mental health app that helps you discover contentment, purpose &... | 0 | 2023-04-02T09:45:13 | https://dev.to/cmworktemp/connectedminds-5991 | mobile, mentalhealth | https://connectedminds.ai/
**A mental health app that helps you discover contentment, purpose & connection.**
Connect with your mind and start your journey with our mental well-being app that helps you discover health, contentment, purpose, and connection. Connected minds is the number one global mental well-being pl... | cmworktemp |
1,423,296 | Create a Laravel CRUD Restful API and Secure it with Sanctum | Introducton Laravel is a popular PHP framework that allows developers to build web applications... | 0 | 2023-04-02T11:17:47 | https://dev.to/patricklusaya/create-a-laravel-crud-restful-api-and-secure-it-with-sanctum-3p2j | laravel, postgres, api, sanctum | **Introducton**
Laravel is a popular PHP framework that allows developers to build web applications quickly and efficiently. One of the most common use cases for Laravel is to create a RESTful API that can be used to communicate with other applications or services. In this tutorial, we'll show you how to build a Larave... | patricklusaya |
1,423,425 | Laravel 10 jwt auth using tymon/jwt-auth | Firstly install Laravel then install the tymon package: composer require tymon/jwt-auth Add... | 0 | 2023-04-02T15:15:34 | https://dev.to/debo2696/laravel-10-jwt-auth-using-tymonjwt-auth-297g | laravel, jwt, auth, php | Firstly install Laravel then install the tymon package:
`composer require tymon/jwt-auth`
Add following to config/app.php:
```php
'aliases' => Facade::defaultAliases()->merge([
'Jwt' => Tymon\JWTAuth\Providers\LaravelServiceProvider::class,
'JWTFactory' => Tymon\JWTAuth\Facades\JWTFactory::class,
... | debo2696 |
1,423,471 | Tableau: Your Ultimate Guide to Data Visualization | Table of contents I. Introduction II. Getting Started with Tableau III. Creating... | 0 | 2023-04-02T20:15:28 | https://dev.to/bellatrick/tableau-your-ultimate-guide-to-data-visualization-4gki | datascience, visualization, tableau, analytics | ### Table of contents
I. Introduction
II. Getting Started with Tableau
III. Creating Visualizations
IV. Creating a dashboard
V. Sharing and Collaborating
VI. Conclusion
## Introduction
Tableau is one of the most popular data visualization platforms out there and for good reason. Tableau was created by a company... | bellatrick |
1,423,480 | Debugging AWS Lambda Functions in GO | I've spent a fair amount of time on the interwebs reading various resources on the topic of debugging... | 0 | 2023-04-02T17:00:44 | https://dev.to/js10x/debugging-aws-lambda-functions-in-go-1cjk | programming, aws, go, cloudskills | I've spent a fair amount of time on the interwebs reading various resources on the topic of debugging AWS Lambda functions locally for testing. There's really not much helpful information out there. Most resources point you to overengineered solutions that involve way more than you need and the final result still leave... | js10x |
1,425,854 | Dual-boot Ubuntu-Windows 11 | Dual-boot First create a partition for installing there Ubuntu Instal the .iso from... | 0 | 2023-04-04T14:35:46 | https://dev.to/paugarcia32/dual-boot-ubuntu-windows-11-4n69 |
# Dual-boot
First create a partition for installing there Ubuntu
Instal the .iso from [ubuntu webside](https://ubuntu.com/download/desktop)
Install [rufus](https://rufus.ie/es/)
Install the ubuntu iso into a pendrive using rufus software
Restart the pc and setup the usb as the first option to boot
In the ubuntu ins... | paugarcia32 | |
1,427,300 | Help! How do I merge multiple Tailwindcss output from two projects? Let me explain. | I need help as google, AI and my search on Dev.to has resulted in no findings. I'm somewhat new to... | 0 | 2023-04-05T15:22:43 | https://dev.to/dechamp/help-how-do-i-merge-multiple-tailwindcss-output-from-two-projects-let-me-explain-2lfp | help, tailwindcss | I need help as google, AI and my search on Dev.to has resulted in no findings.
I'm somewhat new to Tailwindcss. I rewrote my whole site in it and it's working beautifully. It's performant for what I need.
However, I ran into an issue. First let's understand how I'm using it so you can tell me where I went wrong and... | dechamp |
1,429,448 | Trust issues: The Topic Of ChatGPT & Its Position In The World Of Coding | “That seemed like magic to me,” Pietro Schirano says. “Since it was so brilliant, it scared me a... | 0 | 2023-04-07T17:51:40 | https://pinjarirehan.medium.com/trust-issues-the-topic-of-chatgpt-its-position-in-the-world-of-coding-b68a98f8e429 | gpt3, chatgptreview, chatgpt4, chatgpt | ---
title: Trust issues: The Topic Of ChatGPT & Its Position In The World Of Coding
published: true
date: 2023-04-07 11:00:02 UTC
tags: chatgpt3,chatgptreview,chatgpt4,chatgpt
canonical_url: https://pinjarirehan.medium.com/trust-issues-the-topic-of-chatgpt-its-position-in-the-world-of-coding-b68a98f8e429
---

https://plaza.rakuten.co.jp/fidelityaccount/diary/202304170000/
https://peatix.com/user/168... | fidelity11 | |
1,438,922 | Réduisez l'impact environnemental des vidéos YouTube sur votre site web avec des vignettes. | Il y a quelques semaines, l'un de nos clients (chez Troopers) nous a remis les résultats d'un audit... | 0 | 2023-04-17T17:24:20 | https://dev.to/gautron_marie/reduisez-limpact-environnemental-des-videos-youtube-sur-votre-site-web-avec-des-vignettes-1fb4 | Il y a quelques semaines, l'un de nos clients (chez [Troopers](https://troopers.coop/)) nous a remis les résultats d'un audit d'éco-conception. L’audit a montré que l'une des pages auditées pesait 20 Mo, dont 9,7 Mo étaient attribuables aux lecteurs intégrés de YouTube ! De plus, 51 requêtes de cette page sur 221 conc... | gautron_marie | |
1,438,947 | Avalanche Effect and Proof of Work blockchains | In this article, we will explore the concept of the avalanche effect in cryptography, its... | 0 | 2023-04-17T18:02:35 | https://dev.to/vishakbhaskar/avalanche-effect-and-proof-of-work-blockchains-eg9 | blockchain, ethereum, web3, smartcontract | In this article, we will explore the concept of the avalanche effect in cryptography, its significance in securing data, and its application in blockchain technology, specifically in the case of Bitcoin. By the end of this article, you will have a good understanding of what the avalanche effect is, why it matters, and ... | vishakbhaskar |
1,438,997 | Sematic + Ray: The Best of Orchestration and Distributed Compute at your Fingertips | Finding Dynamic Combos Getting Machine Learning (ML) infrastructure right is really hard.... | 0 | 2023-04-17T19:56:08 | https://dev.to/sematic/sematic-ray-the-best-of-orchestration-and-distributed-compute-at-your-fingertips-328m | machinelearning, mlops, datascience, devops | ## Finding Dynamic Combos
Getting Machine Learning (ML) infrastructure right is really hard. One of the challenges for any ML project getting off the ground is finding the right tools for the job. The number of tools out there that target different parts of the ML lifecycle can easily feel overwhelming.
, our code has essentially been broken up into two parts:
1. Node.js ... | kevthedev |
1,439,404 | Exception Handling | The persistence module handles exceptions by using the Postgres error reporting infrastructure... | 0 | 2023-04-18T06:30:25 | https://dev.to/jerrywang1983/exception-handling-4coh | opengauss | The persistence module handles exceptions by using the Postgres error reporting infrastructure (ereport). An error message is recorded in the system log for each error condition. In addition, the error is reported to the envelope using Postgres’s built-in error reporting infrastructure.
The following exceptions are re... | jerrywang1983 |
1,439,491 | What is Machine Learning (ML)? | What is Machine Learning (ML)? Machine Learning is a specific subset of Artificial... | 0 | 2023-04-18T08:03:44 | https://dev.to/shivamchamoli18/what-is-machine-learning-ml-4b2l | python, infosectrain, machinelearning | ## **What is Machine Learning (ML)?**
Machine Learning is a specific subset of Artificial Intelligence (AI) that uses statistical models and algorithms to enable systems to learn and improve performance from experience without being explicitly programmed automatically. It involves building and training algorithms and m... | shivamchamoli18 |
1,439,628 | Navigating the Legal Landscape of London: Finding the Right Commercial Solicitor for Your Business Needs | Introduction: When it comes to running a successful business in London, having access to... | 0 | 2023-04-18T10:14:12 | https://dev.to/waterfrontlaw/navigating-the-legal-landscape-of-london-finding-the-right-commercial-solicitor-for-your-business-needs-3f3f | law, legal | ## Introduction:
When it comes to running a successful business in London, having access to reliable legal advice is crucial. The city is home to numerous commercial solicitors, [technology solicitors](https://www.waterfront.law/sector/technology/), commercial lawyers, redundancy lawyers, settlement agreement lawyers, ... | waterfrontlaw |
1,439,671 | What is a FinTech API? | According to Tipalti, the global financial sector will be worth 26.5 trillion by the end of 2022. The... | 0 | 2023-04-19T05:34:26 | https://dev.to/ragavi_document360/what-is-a-fintech-api-l4b | fintechapi, api, apidocumentation | According to Tipalti, the global financial sector will be worth 26.5 trillion by the end of 2022. The rapid growth of the worldwide financial sector and the push for digital transformation in businesses are undoubtedly factors contributing to the proliferation of FinTech in recent years. Legacy financial institutions c... | ragavi_document360 |
1,439,685 | Javascript Object #14 | In the Post we are going to some latest ECMA method introduced in Javasciript. ... | 0 | 2023-04-18T12:00:25 | https://dev.to/asir-sam/javascript-object-13-1ai9 | javascript, webdev, beginners, programming | In the Post we are going to some latest ECMA method introduced in Javasciript.
## **Object.values()**
To access the value of an Object we usually use **for...in** loop to iterate over it and access the elements inside the Object.But there is problem with for...in as we have already seen this in past post about for...i... | asir-sam |
1,439,692 | Cracking the Code: Digital Signatures and Bitcoin Transactions | In the modern digital age, security is of the utmost importance. One way to ensure the security of... | 0 | 2023-04-18T12:11:46 | https://blog.learnhub.africa/2023/04/18/cracking-the-code-digital-signatures-and-bitcoin-transactions/ | blockchain, cybersecurity, bitcoin, cryptocurrency | <h3 class="graf graf--h3 graf--empty"></h3>
<p class="graf graf--p">In the modern digital age, security is of the utmost importance. One way to ensure the security of digital documents is through digital signatures, and Bitcoin is creating a more advanced security struture.</p>
<p class="graf graf--p">In this article, ... | scofieldidehen |
1,439,921 | What is the OSI Reference Model? | Open System Interconnection - OSI The OSI Model is a reference model used to... | 0 | 2023-04-18T15:08:00 | https://dev.to/aybikedalbul/what-is-the-osi-reference-model-4o68 | network, security, osimodel | ## Open System Interconnection - OSI
---
The OSI Model is a reference model used to standardize the communication processes of computer networks.
With the emergence of the concept of networking, many protocols were developed, but these protocols were developed by each manufacturer according to their own products, ra... | aybikedalbul |
1,439,923 | Reasons Behind the Open Letter on the Temporary Suspension of AI Training | Elon Musk and more than 5500 people (as of press time), including AI experts, have signed an open... | 0 | 2023-04-18T15:16:34 | https://dev.to/erzawansyah/reasons-behind-the-open-letter-on-the-temporary-suspension-of-ai-training-4fe8 | ai, news, gpt3, openai | Elon Musk and more than 5500 people (as of press time), including AI experts, have signed an open letter calling for a pause in advanced AI development.
The letter, issued by the Future of Life Institute, asks AI labs to stop training on any technology more powerful than OpenAI's GPT-4. The letter warns: this could "r... | erzawansyah |
1,440,030 | Building a prototype with Chunk | Written by Nefe James✏️ Across the tech ecosystem, developers are constantly building new tools and... | 0 | 2023-04-18T17:46:48 | https://blog.logrocket.com/building-prototype-with-chunk | react, webdev | **Written by [Nefe James](https://blog.logrocket.com/author/nefejames/)✏️**
Across the tech ecosystem, developers are constantly building new tools and technologies to make life easier for us. We use many such tools today, significantly improving our productivity and efficiency.
In this article, we will learn about ... | mangelosanto |
1,440,148 | Deploying a Laravel 10.7 and Vue 3 project from GitHub to Hostinger | Shared hosting is kind of overlooked these days in favor of platforms like Vercel and Netlify that do... | 0 | 2023-04-18T18:42:30 | https://dev.to/divewitholeg/deploying-a-laravel-107-and-vue-3-project-from-github-to-hostinger-4lko | laravel, vue, php | Shared hosting is kind of overlooked these days in favor of platforms like Vercel and Netlify that do a courtesy of building and instant deployment of your project. Just push the ok button and watch your website being published online.
I decided to check how fast is a Git deployment with Hostinger and was astonished w... | divewitholeg |
1,440,176 | Merging PDFs in NodeJs | public static async mergeProposalPDFs(frontURL: string, backURL: string): Promise<Buffer> { ... | 0 | 2023-04-18T19:54:04 | https://dev.to/vjnvisakh/merging-pdfs-in-nodejs-53he | ```
public static async mergeProposalPDFs(frontURL: string, backURL: string): Promise<Buffer> {
const pdfDoc = await PDFDocument.create();
const pdf1Data = await fetch(frontURL).then((res) => res.arrayBuffer());
const pdf1 = await PDFDocument.load(pdf1Data);
const copiedPages1 = await pdfDoc.copyPages(... | vjnvisakh | |
1,440,200 | Announcing Public Sharing: Share Your Drafts with the World on Contenda! | Calling all content creators, developer advocates, and storytelling savants! We’re thrilled to... | 0 | 2023-04-18T21:00:33 | https://blog.brainstory.ai/public-sharing/ | sharing, devrel, edgefunctions, astro | ---
title: Announcing Public Sharing: Share Your Drafts with the World on Contenda!
published: true
date: 2023-04-18 00:00:00 UTC
tags: sharing, devrel, edgefunctions, astro
canonical_url: https://blog.brainstory.ai/public-sharing/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/w6fhi2iwb8ar6cqtjq... | cassidoo |
1,440,207 | What is Open Source Software? A Beginner's Guide | Introduction If you have been in the tech industry for a while you may have heard about open source... | 0 | 2023-04-18T21:25:42 | https://www.learn-dev-tools.blog/what-does-open-source-software-mean-a-beginners-guide/ | opensource, beginners, software, codenewbie | <!-- wp:heading -->
<h2>Introduction</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>If you have been in the tech industry for a while you may have heard about open source or open source software. When we talk about open source, you should think of open collaboration, open exchange, participation transparency and c... | learndevts |
1,440,358 | Lógica de programação não é difícil! | Muitas pessoas pensam ser difícil por exigir habilidades matemáticas avançadas ou conhecimentos... | 0 | 2023-04-19T00:06:28 | https://dev.to/ymands/a-logica-de-programacao-nao-e-dificil-3ho6 | braziliandevs, webdev, programming, softwaredeveloper |
Muitas pessoas pensam ser difícil por exigir habilidades matemáticas avançadas ou conhecimentos técnicos complexos. No entanto, essa realidade não é difícil de entender e pode ser aprendida por qualquer pessoa disposta a dedicar tempo e esforço.
A lógica de programação tem a habilidade de desenvolver soluções a prob... | ymands |
1,440,380 | How to overcome the stigma of not having a degree in the software industry. | Overcoming the stigma of not having a degree in the software industry can be challenging, but it's... | 0 | 2023-04-19T00:57:29 | https://dev.to/sukr92329/how-to-overcome-the-stigma-of-not-having-a-degree-in-the-software-industry-1pg6 | Overcoming the stigma of not having a degree in the software industry can be challenging, but it's important to focus on demonstrating your skills and expertise through projects, networking, and job performance. It's also important to be transparent about your education and experience, and to highlight your motivation,... | sukr92329 | |
1,440,406 | Upgrading the XM Cloud Introduction repository to Docker Compose v2 | In case you haven’t heard, Docker has slowly been pushing people to migrate the latest version of... | 0 | 2023-04-19T01:40:10 | https://robearlam.com/blog/docker-compose-v2 | docker, dockercompose, sitecore, xmcloud | ---
title: Upgrading the XM Cloud Introduction repository to Docker Compose v2
published: true
date: 2023-04-19 00:00:00 UTC
tags: docker, dockercompose, sitecore, xmcloud
canonical_url: https://robearlam.com/blog/docker-compose-v2
---
In case you haven’t heard, Docker has slowly been pushing people to migrate the lat... | robearlam |
1,440,607 | AI Generated Images of rich as poor | 1. Elon Musk Elon Reeve Musk FRS is a business magnate and investor. He is the founder,... | 0 | 2023-04-19T16:08:00 | https://dev.to/jon_snow789/ai-generated-images-of-rich-as-poor-1i32 | ai, webdev, javascript, productivity | ### 1. Elon Musk
Elon Reeve Musk FRS is a business magnate and investor. He is the founder, CEO and chief engineer of SpaceX; angel investor, CEO and product architect of Tesla, Inc.; owner and CEO of Twitter; founder of the Boring Company; co-founder of Neuralink and OpenAI; and president of the philanthropic Musk Fo... | jon_snow789 |
1,440,813 | SSO - Build vs Buy: Making the Right Choice for Your Business | Single Sign-On (SSO) - Build vs. Buy is the decision-making process businesses undergo to determine... | 0 | 2023-04-19T10:12:28 | https://ssojet.com/blog/sso-build-vs-buy-making-the-right-choice-for-your-business/ | cybersecurity, authentication, sso, security | **Single Sign-On (SSO) - Build vs. Buy is the decision-making process businesses undergo to determine whether to create a custom solution or purchase a ready-made one. This article explores the benefits and drawbacks of each approach, as well as key factors to consider when making this decision.**
Single Sign-On (SSO... | andrew89 |
1,440,951 | PostmanAPI Workshop SCET | The workshop started with an introduction to API and the importance of API development. Joel then... | 0 | 2023-04-19T12:38:49 | https://dev.to/weebkira/postmanapi-workshop-scet-3jjg | postmanstudent, postmanapi | The workshop started with an introduction to API and the importance of API development. Joel then provided a detailed overview of Postman and its features, including how to create requests, set up environments, and automate tests.
Attendees had the opportunity to get hands-on experience with Postman by creating their ... | weebkira |
1,440,965 | Introducing your new team lead…Kedro | This post explains how Kedro can guide an analytics team to follow best practices and avoid technical... | 0 | 2023-04-19T12:59:06 | https://kedro.org/blog/introducing-your-new-team-lead-kedro | python, datascience, kedro, opensource |
This post explains how Kedro can guide an analytics team to follow best practices and avoid technical debt.
In a recent article, I explained that [following software principles can help you create a well-ordered analytics project](https://towardsdatascience.com/five-software-engineering-principles-for-collaborative-d... | stichbury |
1,441,073 | Introduction to Web Animations with GSAP | GSAP, or GreenSock Animation Platform, is a powerful JavaScript animation library that is used by web... | 0 | 2023-04-19T20:33:56 | https://dev.to/topboyasante/introduction-to-web-animations-with-gsap-645 | gsap, webdev, javascript, react | GSAP, or GreenSock Animation Platform, is a powerful JavaScript animation library that is used by web developers and designers to create interactive and engaging websites. GSAP is known for its versatility, speed, and ease of use, making it a popular choice among developers worldwide.
Today, we're going to learn the b... | topboyasante |
1,441,075 | Five Minute Maintainers: Meet Seth Michael Larson! | Our new five minute maintainer series shares the journeys and opinions of the maintainers behind some... | 0 | 2023-04-19T14:17:54 | https://community.tidelift.com/tidelift/five-minute-maintainers-meet-seth-michael-larson-3oeh | opensource, python, github | Our new five minute maintainer series shares the journeys and opinions of the maintainers behind **some of the most widely used projects in open source.** We ask five big questions in five minutes, with the goal of elevating the voices of open source maintainers who create the open source projects we all rely on.
{% e... | lynmuldrow |
1,441,170 | Cross Account MSK Connectivity using AWS PrivateLink | Sometime back, a couple of months ago actually, I got into a call, and someone presented me with an... | 0 | 2023-04-19T15:00:00 | https://dev.to/kingastra/cross-account-msk-connectivity-using-aws-privatelink-1lb3 | aws, security, kafka, bigdata | Sometime back, a couple of months ago actually, I got into a call, and someone presented me with an interesting problem. In my line of work, I do more of risk and compliance, and that usually means that I get to know about a lot of stuff. I love working with AWS services, and when I got into this call and saw the arch... | kingastra |
1,441,182 | What is Object Reference in JavaScript | If you are yet to get a full grasp of object reference in JavaScript, this article will break it down... | 0 | 2023-04-20T12:03:56 | https://dev.to/odudev/what-is-object-reference-in-javascript-43oc | object, javascript, oop, coding | If you are yet to get a full grasp of object reference in JavaScript, this article will break it down for you. Object are regularly used by developers and thus, its usage needs to be properly understood.
## Primitive data types
Primitive data types (undefined, null, string, number, boolean and symbol) are usually pas... | odudev |
1,441,215 | A Beginners Guide on How to connect a Raspberry Pi Simulator to a Device on IoT Hub | Internet of Things IoT, Internet of Things, is the ability of connected devices to communicate with... | 0 | 2023-04-28T15:09:20 | https://dev.to/yemmyoye/a-beginners-guide-on-how-to-connect-a-raspberry-pi-simulator-to-a-device-on-iot-hub-36bm | iot, iothub, raspberrypisimulator, azureiothub | **Internet of Things**
IoT, Internet of Things, is the ability of connected devices to communicate with each other.
Azure IoT Hub is a bidirectional messaging centre that is hosted in the cloud where messages from an IoT application and its attached IoT devices are collected over the internet. The internet can be used ... | yemmyoye |
1,441,455 | From Idea to Deployment: How I Built Devlinks | I recently finished building devlinks, a developer focused link aggregator similar to Linktree and... | 0 | 2023-04-23T13:19:46 | https://dev.to/killswitchh/from-idea-to-deployment-how-i-built-devlinks-4no | svelte, hackathon, programming, webdev |
I recently finished building [devlinks](https://www.devlink.pro/), a developer focused link aggregator similar to Linktree and Beacons. I would like to share the process of how I converted this idea I had into a fully functional website within a month. I will try to keep this as beginner friendly as possible so everyo... | killswitchh |
1,441,682 | Day 7. Singly Linked List | 876. Middle of the Linked List Given the head of a singly linked list, return the middle... | 0 | 2023-04-20T03:01:00 | https://dev.to/sosunnyproject/day-7-singly-linked-list-2om | leetcode, javascript |
## [876. Middle of the Linked List](https://leetcode.com/problems/middle-of-the-linked-list)
Given the head of a singly linked list, return the middle node of the linked list.
If there are two middle nodes, return the second middle node.
```js
Input: head = [1,2,3,4,5]
Output: [3,4,5]
Explanation: The middle node of... | sosunnyproject |
1,441,903 | How to integrate ChatGPT in the .NET project: A step-by-step guide | ChatGPT is a comprehensive language model trained by brilliant minds at OpenAI. It uses deep learning... | 0 | 2023-04-20T08:37:50 | https://www.ifourtechnolab.com/blog/how-to-integrate-chatgpt-in-the-net-project-a-step-by-step-guide | webdev, chatgpt, dotnet, beginners | ChatGPT is a comprehensive language model trained by brilliant minds at OpenAI. It uses deep learning to generate human-like responses to natural language inputs. One area where ChatGPT has the potential to provide significant benefits is its integration with .NET, a popular software framework used for building applica... | ifourtechnolab |
1,441,937 | Enhanced Security in Node.js v20: The New Permission Model | As Node.js continues to grow in popularity, security has become an increasingly important aspect of... | 0 | 2023-04-22T07:31:46 | https://dev.to/andreasbergstrom/introducing-the-nodejs-permission-model-enhanced-security-and-granular-control-3md0 | node | As Node.js continues to grow in popularity, security has become an increasingly important aspect of application development. With the release of Node version 20, a new experimental security feature has been introduced: the Permission Model. In this blog post, we will dive into the Permission Model, its capabilities, an... | andreasbergstrom |
1,442,011 | DataOps 2023: An Agile Future of Data Science | DataOps is a methodology that focuses on the management and operations of data science projects. As... | 0 | 2023-04-20T09:45:53 | https://dev.to/tanvisinghania/dataops-2023-an-agile-future-of-data-science-2gfc | dataops, datascience, bigdata | DataOps is a methodology that focuses on the management and operations of data science projects. As organizations are collecting more data than ever before, it is becoming increasingly important to manage and analyze it effectively, and that's where DataOps comes in.
DataOps is a relatively new approach to data manage... | tanvisinghania |
1,442,097 | The key things you need to successfully break into tech. | It can be difficult to break into the tech industry, especially for individuals who are just starting... | 0 | 2023-04-20T10:47:29 | https://dev.to/chidiebereomasi/the-key-things-you-need-to-successfully-break-into-tech-5gjp | webdev, javascript, programming, productivity | It can be difficult to break into the tech industry, especially for individuals who are just starting out. However, it is possible to find employment in the tech sector if you have the correct attitude, abilities, and resources. We'll talk about the requirements in this article if you want to succeed in the tech indust... | chidiebereomasi |
1,442,103 | 𝐏𝐲𝐭𝐡𝐨𝐧 𝐑𝐨𝐚𝐝𝐦𝐚𝐩 🛣 | Beginner --->>> Expert Python is a powerful and versatile programming language that has... | 0 | 2023-04-20T11:03:18 | https://dev.to/cybertech/-483i | Beginner --->>> Expert
Python is a powerful and versatile programming language that has become popular for its readability, ease of use, and wide range of applications. Whether a beginner or an experienced programmer, many resources are available to help you learn and improve your Python skills.
![Image description]... | cybertech | |
1,443,447 | CloudTrail in AWS | As more and more businesses are migrating their infrastructure and applications to the cloud, the... | 0 | 2023-04-21T11:44:39 | https://dev.to/shivamchamoli18/cloudtrail-in-aws-5044 | cloudcomputing, cloudsecurity, aws, infosectrain | As more and more businesses are migrating their infrastructure and applications to the cloud, the need for security and compliance has become paramount. To meet these requirements, AWS offers a service called CloudTrail, which provides a detailed record of all API calls made within an AWS account. This article explores... | shivamchamoli18 |
1,442,209 | Errors while Upgrading from springboot 2.5.8 to 2.6.0 | Hi guys, I'm working on a springboot project. it's working perfectly fine when i do a mvn clean... | 0 | 2023-04-20T14:12:45 | https://dev.to/amadou_badiane_0e4ebc2675/errors-while-upgrading-from-springboot-258-to-260-3l6c | java, spring, springboot | Hi guys,
I'm working on a springboot project. it's working perfectly fine when i do a mvn clean verify with the springboot 2.5.8. But as soon as i upgrade to 2.6.0 in my pom.xml, it crashes during the tests (skiptests works fine in 2.6.0). Can you help we with that please ? (My goal is to upgrade to springboot 3. But ... | amadou_badiane_0e4ebc2675 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.