
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,442,295 | Chapter 1-Database Cluster, Databases And Tables | 1.1 Logical Structure Of Database Cluster. In PostgreSQL, the term database cluster refers... | 0 | 2023-04-20T15:14:17 | https://dev.to/muhammadzeeshan03/chapter-1-database-cluster-tables-1hei | postgres, bitnine, database | ##1.1 Logical Structure Of Database Cluster.
In PostgreSQL, the term database cluster refers to a collection of databases, not a group of servers. A PostgreSQL server runs on a single host and manages a single database cluster. A database in a cluster is a group of database objects. According to relational database t... | muhammadzeeshan03 |
1,442,442 | Scrum Master Start? | Being a developer on a team presents the opportunity to work with different roles within the team.... | 0 | 2023-04-20T16:10:20 | https://dev.to/devarzia/scrum-master-start-1b5b | scrum, webdev, agile, beginners | Being a developer on a team presents the opportunity to work with different roles within the team. Arguably, one of the most important roles on an Agile development team is the Scrum Master.
The Scrum Master is the enforcer when it comes to Agile methodologies and practices being implemented within a team.
As a dev... | devarzia |
1,442,454 | "Mastering Data Flow in React with the Context API: A Complete Guide" | The Context API is a powerful feature in React, a widely-used JavaScript library for building user... | 0 | 2023-04-20T16:27:10 | https://dev.to/sdgsnehal/mastering-data-flow-in-react-with-the-context-api-a-complete-guide-4gpo | The Context API is a powerful feature in React, a widely-used JavaScript library for building user interfaces. It offers a way to pass data through the component tree without having to manually pass props at every level. This is particularly useful when you have data that needs to be accessible to many components at di... | sdgsnehal | |
1,442,464 | Career Development in Web Development | I've been a web developer for over a decade (feel old yet?). Over my career I've gradually moved from... | 0 | 2023-04-20T16:54:59 | https://dev.to/jquinten/career-development-in-web-development-k1n | career, growth, leadership, learning | I've been a web developer for over a decade (feel old yet?). Over my career I've gradually moved from an entry level junior at a web agency where I learned not to drop tables, jQuery (yes) and the woes of supporting ie6 even!
Over the years I've grown in experience and have been focused more on becoming a well rounded... | jquinten |
1,442,480 | 48 berufliches Vorwärtskommen: Helfet den Neidern. Ja, helfen. | Moin Moin, helfet den Neidern. Helfet ihnen aus der mangelnden Selbstwertschätzung→ und aus der... | 22,304 | 2023-04-23T04:31:00 | https://dev.to/amustafa16421/48-berufliches-vorwartskommen-helfet-den-neidern-ja-helfen-4b82 | deutsch, career, motivation, discuss | Moin Moin,
helfet den Neidern. Helfet ihnen aus der mangelnden [Selbstwertschätzung→](https://dev.to/amustafa16421/comment/266jd) und aus der ungeschulten Selbsteinschätzung. Auch wenn es in einem Unternehmen keine Rückmeldegespräche gibt, so können wir als Arbeitskollegen uns gegenseitig regelmäßig Rückmeldung geben ... | amustafa16421 |
1,442,522 | Services provided by AWS | AWS, a portion of Amazon.com, Inc., gives on-demand cloud computing stages and APIs to shoppers,... | 0 | 2023-04-20T18:23:32 | https://dev.to/shriom_03/services-provided-by-aws-45l4 | blog, aws, amazon, cloudskills | AWS, a portion of Amazon.com, Inc., gives on-demand cloud computing stages and APIs to shoppers, associations, and governments. AWS offers a wide extend of merchandise and administrations to assist businesses of all sizes create and scale. This blog will talk about a few of Amazon Web Services' most well-known and valu... | shriom_03 |
1,442,713 | React Router: A Beginners guide to useParams hook. | In this guide, we will be unravelling the complexity in one of React Router's hook called: useParams.... | 0 | 2023-04-20T20:53:32 | https://dev.to/stanlisberg/react-router-a-beginners-guide-to-useparams-hook-38pj | webdev, react, javascript | In this guide, we will be unravelling the complexity in one of React Router's hook called: `useParams`. We will learn about its implementation and functionality. Ride along with me.
**Prerequisite**
You should have the following to follow along with this guide:
- A very basic knowledge of react.
- A code editor.
- A ... | stanlisberg |
1,442,748 | DlteC do Brasil oferece 9 cursos gratuitos com certificado em Cibersegurança, Linux e mais! | Com a crescente demanda por profissionais especializados em tecnologia da informação, é essencial... | 0 | 2023-04-20T22:25:10 | https://guiadeti.com.br/dltec-do-brasil-cursos-ciberseguranca-mais/ | cursogratuito, cisco, cursosgratuitos, cybersecurity | ---
title: DlteC do Brasil oferece 9 cursos gratuitos com certificado em Cibersegurança, Linux e mais!
published: true
date: 2023-04-20 21:54:50 UTC
tags: CursoGratuito,cisco,cursosgratuitos,cybersecurity
canonical_url: https://guiadeti.com.br/dltec-do-brasil-cursos-ciberseguranca-mais/
---
 | dsschnau | |
1,442,920 | .NET 8 Preview 3: Simplified Output Path format for Builds | If you're like me, you're used to finding your .NET build artifacts in /bin and /obj directories... | 0 | 2023-04-21T00:44:53 | https://dev.to/dsschnau/net-8-preview-3-simplified-output-path-format-for-builds-jl6 | ---
title: .NET 8 Preview 3: Simplified Output Path format for Builds
published: true
date: 2023-04-20 19:31:26 UTC
tags:
canonical_url:
---
If you're like me, you're used to finding your .NET build artifacts in `/bin` and `/obj` directories inside your source projects. It's been this way my whole career.
In .NET 8... | dsschnau | |
1,443,005 | Good practices in js that I use every day | Hey guys, my name is Vinicius and I started working as a dev in 2018. This is my first post ever, I... | 0 | 2023-04-21T04:01:18 | https://dev.to/viniielopes/good-practices-in-js-that-i-use-every-day-27pj | javascript, programming, beginners, webdev | Hey guys, my name is Vinicius and I started working as a dev in 2018.
This is my first post ever, I don't really like to expose myself, I'm trying to change that over time, but as it's a really nice environment here, I decided to bring some good practices that I use in my day to day.
## 1 - Function with three or mor... | viniielopes |
1,443,167 | Apache AGE & Python(Pt. 2) | In Part-1 of this blog post, we explored how the Python driver in Apache AGE enables Python... | 0 | 2023-04-21T06:33:31 | https://dev.to/huzaiifaaaa/apache-age-pythonpt-2-17jc | apacheage, postgres, database, apache | In [Part-1](https://dev.to/huzaiifaaaa/apache-age-python-1pg7) of this blog post, we explored how the Python driver in Apache AGE enables Python developers to interact with the database. In this part, we'll dive deeper into some of the advanced features of the driver and how they can be used to build complex graph appl... | huzaiifaaaa |
1,443,198 | Hello | A post by Dynato TIV | 0 | 2023-04-21T07:22:47 | https://dev.to/dynato_tiv_8266084c460654/hello-1e96 | dynato_tiv_8266084c460654 | ||
1,443,228 | Chart library design | Data visualization is a common task in modern software. Users can better understand large data sets... | 0 | 2023-04-24T05:41:34 | https://dev.to/titovmx/chart-library-design-5dal | frontend, programming, designsystem, tutorial | Data visualization is a common task in modern software. Users can better understand large data sets visually represented and get meaningful insights. There are a bunch of libraries that help to solve it. They render different types of charts based on data that is passed into them. Usually, chart libraries use D3.js und... | titovmx |
1,443,353 | The Future of High Skilled Education and Training in Australia: Trends and Predictions | overview of The Future of High Skilled Education and Training in Australia: Trends and... | 0 | 2023-04-21T10:45:42 | https://dev.to/universitybure1/the-future-of-high-skilled-education-andtraining-in-australia-trends-and-predictions-4ho8 | overview of [The Future of High Skilled Education and Training in Australia: Trends and Predictions
](https://universitybureau.com/blogs/high-skilled-education-and-training-australia)
Increasing Demand for High Skilled Workers:
Growth in Vocational Education and Training (VET):
Emergence of Online Learning:
Collabor... | universitybure1 | |
1,443,433 | Why Mobile App Development Services are Essential for Businesses in Today's Digital Landscape | As technology continues to advance, it's becoming increasingly important for businesses to have a... | 0 | 2023-04-21T11:27:18 | https://dev.to/ronasit/why-mobile-app-development-services-are-essential-for-businesses-in-todays-digital-landscape-10f8 | webdev, mobile, startup | As technology continues to advance, it's becoming increasingly important for businesses to have a mobile app presence. In today's fast-paced world, customers don't want to wait or have to navigate a clunky website on their mobile device. Mobile apps provide a more streamlined and user-friendly experience, making it eas... | ronasit |
1,443,797 | What’s on your Whiteboard? | I like to use my whiteboard as a space to keep lasting tools, and to quickly diagram. What’s on... | 0 | 2023-04-21T18:46:14 | https://dev.to/wra-sol/whats-on-your-whiteboard-147o | discuss, workstations, productivity |
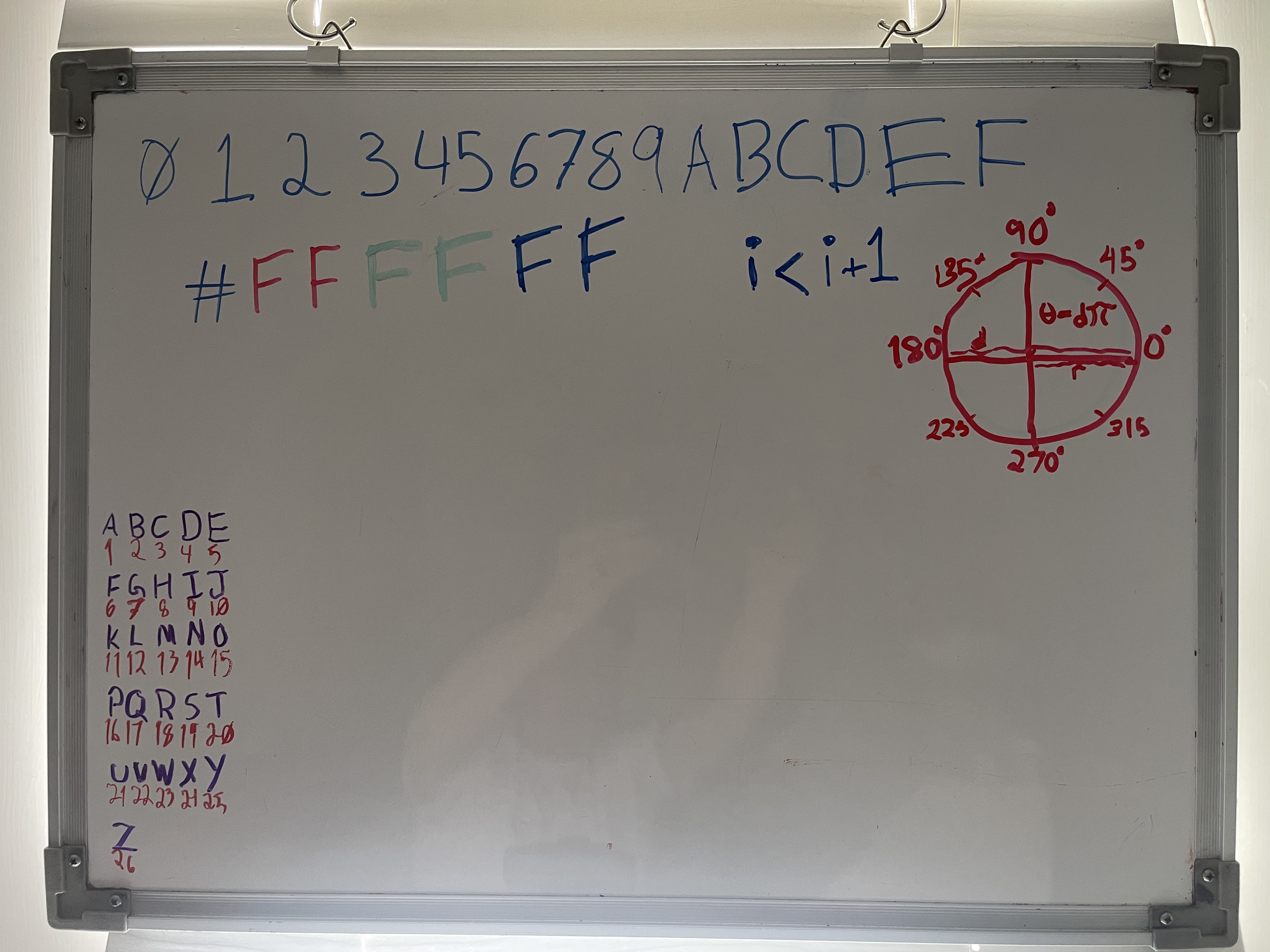
I like to use my whiteboard as a space to keep lasting tools, and to quickly diagram.
What’s on your whiteboard? | wra-sol |
1,443,892 | DAY 25-PANDAS | import pandas as pd df =... | 0 | 2023-04-21T20:50:05 | https://dev.to/sandeepsamanth/day-25-pandas-14gj | ```
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
```
**DROP and SET INDEX**
```
df.drop('PassengerId',axis=1,inplace=True)//permanently drops passengerID
df.drop(3,inplace=True)//drops 3rd row
df.set_index("Name",inplace=True)
df.reset_index()... | sandeepsamanth | |
1,443,971 | 6 cursos gratuitos em Forense Digital oferecidos pela Academia de Forense Digital | Bem-vindo à Academia de Forense Digital, onde você encontrará uma ampla variedade de cursos em... | 0 | 2023-04-23T23:09:16 | https://guiadeti.com.br/cursos-gratuitos-em-forense-digital/ | cursogratuito, cursosgratuitos, cybersecurity, forense | ---
title: 6 cursos gratuitos em Forense Digital oferecidos pela Academia de Forense Digital
published: true
date: 2023-04-21 20:02:29 UTC
tags: CursoGratuito,cursosgratuitos,cybersecurity,forense
canonical_url: https://guiadeti.com.br/cursos-gratuitos-em-forense-digital/
---

When it comes to... | anurag_vishwakarma |
1,444,313 | Subtle rainbow gradient buttons | Some subtle rainbow colored buttons that reveals a nice gradient border & overlay ✨ See the... | 0 | 2023-04-22T09:09:03 | https://dev.to/lukyvj/subtle-rainbow-gradient-buttons-4lp1 | codepen, lukyvj, css, houdin | <p>Some subtle rainbow colored buttons that reveals a nice gradient border & overlay ✨</p>
<p>See the thread about it: <a href="https://twitter.com/LukyVJ/status/1646927645425164313" target="_blank">https://twitter.com/LukyVJ/status/1646927645425164313</a></p>
{% codepen https://codepen.io/LukyVj/pen/bGmELYR %} | lukyvj |
1,444,391 | This week's API round-up: movie recommendations, Movie Reviews and Movie Cast And Crew | As usual, we will introduce three new APIs to you this week. We hope that the APIs we have picked for... | 0 | 2024-01-01T10:38:00 | https://dev.to/worldindata/this-weeks-api-round-up-movie-recommendations-movie-reviews-and-movie-cast-and-crew-51df | api, moviedata, entertainment, movieapi | As usual, we will introduce three new APIs to you this week. We hope that the APIs we have picked for the weekly roundup will be helpful to you. We will explore the purpose, industry, and client types of these APIs. The complete details of the APIs can be found on [Worldindata's API marketplace](https://www.worldindata... | worldindata |
1,444,664 | Kuda bank transfer code | https://www.bankfanz.com/kuda-bank-transfer-code/ https://plaza.rakuten.co.jp/kudabank2023/diary/2023... | 0 | 2023-04-22T17:29:42 | https://dev.to/kudabank22/kuda-bank-transfer-code-39o4 | [https://www.bankfanz.com/kuda-bank-transfer-code/](https://www.bankfanz.com/kuda-bank-transfer-code/#utm_source=backlinks&utm_medium=search&utm_campaign=darry+ring+us&utm_content=Michelle)
https://plaza.rakuten.co.jp/kudabank2023/diary/202304220000/
https://peatix.com/user/16980478/
https://www.provenexpert.com/kuda-b... | kudabank22 | |
1,444,714 | Dash: A Revolutionary Hashing Technique for Efficient Data Storage on Persistent Memory | Dash is a novel hash table design that was introduced in a paper published at the 2017 ACM Symposium... | 0 | 2023-04-22T19:51:32 | https://dev.to/rainleander/dash-a-revolutionary-hashing-technique-for-efficient-data-storage-on-persistent-memory-575p | database, memory | Dash is a novel hash table design that was introduced in a [paper](https://www.vldb.org/pvldb/vol13/p1147-lu.pdf) published at the 2017 [ACM Symposium on Operating Systems Principles](https://en.wikipedia.org/wiki/Symposium_on_Operating_Systems_Principles) (SOSP). The paper was authored by Da Zheng, Xiang Li, Chang Lou... | rainleander |
1,444,729 | Encryption | I'm sure you've heard this term before. Most likely in a spy movie, as the characters try to hack a... | 0 | 2023-04-24T15:04:56 | https://dev.to/benjaminklein99/encryption-5h62 | I'm sure you've heard this term before. Most likely in a spy movie, as the characters try to hack a security system, or maybe in a history lesson about the famous German Enigma code. Many people know what encryption is, but few understand how encryptions function and their use in our day-to-day life. In this post, I wi... | benjaminklein99 | |
1,444,762 | How to install Stable Difussion WebUI and ControlNet 1.1 on Ubuntu | In this tutorial, I will explain how to configure Ubuntu 22.04 to take advantage of an Nvidia GPU and... | 0 | 2023-04-22T22:42:26 | https://dev.to/felipelujan/set-up-stable-difussion-webui-and-controlnet-on-ubuntu-2204-hbm | stabledifussion, controlnet, setup, txt2img |
In this tutorial, I will explain how to configure Ubuntu 22.04 to take advantage of an Nvidia GPU and run stable Diffusion via Stable-diffusion-webui.
This is a permanent alternative as Google might restrict the use of Colab for Stable Difussion in the future.
**Stable-diffusion-webui Prerequisites:**
- Python 3.10.... | felipelujan |
1,445,027 | Passwords, passwords, passwords!! | This article was originally posted on Patreon and has been brought over here to get all of the... | 0 | 2023-04-25T14:00:00 | https://dev.to/grim/passwords-passwords-passwords-4ke0 | passwords, pidgin, pidgin3, repost | > This article was originally posted on [Patreon](https://www.patreon.com/posts/passwords-76065457) and has been brought over here to get all of the Pidgin Development/History posts into one single place.
We have quite the history when it comes to password storage... For many years we suggested either not storing pass... | grim |
1,445,036 | ageing in mice | creation d'un modèle de vieillissement de la souris souffrant d'adipsie sévère avec l'âge... | 0 | 2023-04-23T06:00:11 | https://dev.to/erwansimon15/ageing-in-mice-4fpl | codepen | <p>creation d'un modèle de vieillissement de la souris souffrant d'adipsie sévère avec l'âge (défaillances de la pression osmotique cellulaire et de la régulation des ions Na+ et Cl-)</p>
https://codepen.io/collection/VYxOvy | erwansimon15 |
1,445,165 | Testing on Kotlin Multiplatform and a Strategy to Speed Up Development Time (2023 Update) | This article was originally posted on my blog, for better viewing experience try it out there. The... | 0 | 2023-04-23T09:09:39 | https://akjaw.com/testing-on-kotlin-multiplatform-and-strategy-to-speed-up-development/ | testing, multiplatform, kotlin | ---
title: Testing on Kotlin Multiplatform and a Strategy to Speed Up Development Time (2023 Update)
published: true
date: 2023-04-15 06:00:00 UTC
tags: Testing,Multiplatform,Kotlin
canonical_url: https://akjaw.com/testing-on-kotlin-multiplatform-and-strategy-to-speed-up-development/
---
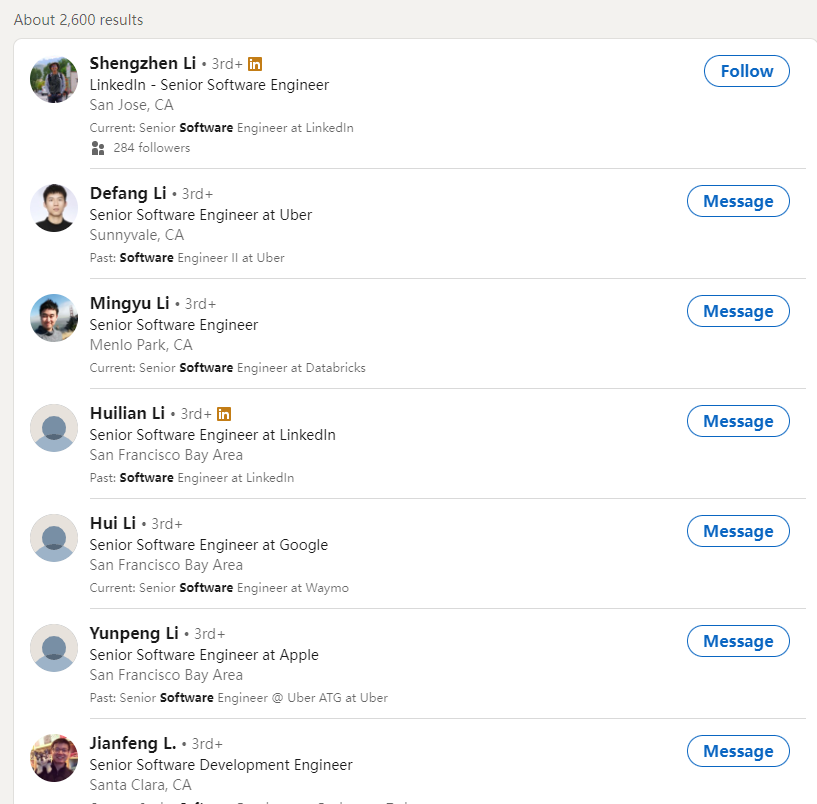
As you can see, how do I get LinkedIn's 1001st and more search results.
Who can help me? | __10d2242450977720b1c3 | |
1,445,476 | Distributing Task Queuing using Django & Celery | Have you ever had a backend system that needed to perform time-consuming tasks, such as sending... | 0 | 2023-04-24T21:08:44 | https://dev.to/mazenr/distributing-task-queuing-using-django-celery-ol7 | Have you ever had a backend system that needed to perform time-consuming tasks, such as sending emails, processing data, or generating reports?
These tasks can take a long time to complete and tie up server resources, which can lead to slow response times and a poor user experience.
This is where task queuing comes in... | mazenr | |
1,445,499 | ASQai - WE WANT YOU | AI Developer: An AI developer should have expertise in machine learning, deep learning,... | 0 | 2023-04-23T17:58:37 | https://dev.to/namenotavilable/asqai-we-want-you-4539 | ## AI Developer:
An AI developer should have expertise in machine learning, deep learning, and natural language processing (NLP). They will be responsible for developing initial AI model used in the solution.
## Data Scientist:
A data scientist should have expertise in data analysis, statistics, and data visualizati... | namenotavilable | |
1,445,560 | Master the Search Engines with 70+ ChatGPT SEO Prompts | With its human-like text generation capabilities, ChatGPT is an AI-powered language model created by... | 0 | 2023-04-23T18:23:10 | https://dev.to/killianellie1/master-the-search-engines-with-70-chatgpt-seo-prompts-3i9o | With its human-like text generation capabilities, ChatGPT is an AI-powered language model created by OpenAI that proves to be a valuable resource for optimizing website content and enhancing search engine rankings.
In this article, we’ll take a closer look at ChatGPT prompts for SEO and their advantages for websites s... | killianellie1 | |
1,445,613 | Creating an Interactive Scroll Page Progress Bar with CSS to Enhance User Engagement | Scroll page progress bars are a useful feature to help users track their progress as they scroll... | 0 | 2023-04-23T20:02:47 | https://dev.to/techiebundle/creating-an-interactive-scroll-page-progress-bar-with-css-to-enhance-user-engagement-272a | webdev, frontend, css | Scroll page progress bars are a useful feature to help users track their progress as they scroll through long pages. By adding an interactive scroll page progress bar to your website or application, you can enhance user engagement and improve the overall user experience.
In this article, we will explore how to create ... | techiebundle |
1,459,332 | Will OpenAI be blocked in the EU? | Italy has blocked the use of ChatGPT, an artificial intelligence tool, for not respecting data... | 0 | 2023-05-06T09:36:30 | https://dev.to/makiai/will-openai-be-blocked-in-the-eu-1l4d | openai, ai, productivity, chatgpt |

Italy has blocked the use of ChatGPT, an artificial intelligence tool, for not respecting data protection legislation and minors' access to content.
Although this measure only affects Italian companies, there are ... | makiai |
1,459,893 | Readability | Is creating readable code an important feature of writing quality software? Is it something that you... | 0 | 2023-05-07T00:43:08 | https://qualitysoftwarematters.com/readability | ---
title: Readability
published: true
date: 2015-06-25 05:00:00 UTC
tags:
canonical_url: https://qualitysoftwarematters.com/readability
---
Is creating readable code an important feature of writing quality software?
Is it something that you would mention when reviewing code for one of your team members?
Typically,... | toddmeinershagen | |
1,459,918 | O Método de Documentação C4Model e sua aplicação com PUML | TL;DR: O C4Model é uma técnica de documentação de arquitetura de software que permite representar... | 22,996 | 2023-05-10T23:59:59 | https://dev.to/pedropietro/o-metodo-de-documentacao-c4model-e-sua-aplicacao-com-puml-3jdd | documentation, uml, braziliandevs | **TL;DR**: O C4Model é uma técnica de documentação de arquitetura de software que permite representar sistemas complexos de maneira hierárquica e fácil de entender. Neste artigo, exploraremos como usar o PlantUML para criar diagramas do C4Model e apresentaremos exemplos práticos.
## Introdução
O C4Model é uma abordag... | pedropietro |
1,460,122 | Add Multiple Filter using one function in jQuery, Ajax | Most beginners when they need a filter in a website create multiple functions for each filter, for... | 0 | 2023-05-07T07:44:47 | https://dev.to/shubhamraturi37/add-multiple-filter-using-one-function-in-jquery-ajax-1d56 | jquery, aja, javascript | Most beginners when they need a filter in a website create multiple functions for each filter, for example, price filter, date-range filter, tag filter, and category filter.
**We can create a multiple filters using a single function**
_below we have a code example._
Creating a predefined variable for all filters
```
... | shubhamraturi37 |
1,460,506 | Realistic Switch button in CSS | Realistic Switch button in CSS HTML Code <input name="switch" id="switch"... | 22,810 | 2023-05-08T07:15:00 | https://dev.to/jon_snow789/realistic-switch-button-in-css-2a2h | css, design, animation, webdev | Realistic Switch button in CSS
---

---
### HTML Code
```html
<input name="switch" id="switch" type="checkbox">
<label class="switch" for="switch"></label>
```
### CSS Code
```css
#switch {... | jon_snow789 |
1,460,695 | Local Storage vs Session Storage in JavaScript | Let's dive into two fundamental web storage mechanisms in JavaScript: Local Storage and Session... | 0 | 2023-05-07T22:43:48 | https://dev.to/valentinaperic/local-storage-vs-session-storage-in-javascript-1p8h | webdev, javascript, frontend, localstorage | Let's dive into two fundamental web storage mechanisms in JavaScript: Local Storage and Session Storage. These two mechanisms are important for creating personalized user experiences by using data persistence. They both store data in the users browser in a way that cannot be read by a server. We are going to dive into ... | valentinaperic |
1,460,883 | whoer.net IP Checker | whoer.net IP Checker Overview of Whoer.net Whoer.net is an online platform that... | 0 | 2023-05-08T05:37:49 | https://dev.to/lalicatbrowser/whoernet-ip-checker-2b8n | whoerip, whoernet, lalicat, antidetectbrowser | # [whoer.net IP](https://www.lalicat.com/whoer-net-proxy-ip-checker) Checker
## Overview of Whoer.net
[Whoer.net](https://www.lalicat.com/whoer-net-detection) is an online platform that provides users with various tools and resources with the aim to safeguard their online privacy and security. The website offers ... | lalicatbrowser |
1,461,139 | Analysis And Generation Model ML | Analysis_And_Generation_Model_ML BEFORE READING THIS REPOSITORY IT IS RECOMMENDED TO START... | 0 | 2023-05-08T10:37:44 | https://dev.to/insidbyte/analysisandgenerationmodelml-15l | python, machinelearning, programming, opensource | # Analysis_And_Generation_Model_ML
__BEFORE READING THIS REPOSITORY IT IS RECOMMENDED TO START FROM:__
https://github.com/insidbyte/Analysis_and_processing
***I have in fact decided to generate a custom vocabulary to train the model and it would be appropriate to look at the repository code.***
---
# SEE THIS REPO... | insidbyte |
1,461,200 | Designing a User-Friendly Course Catalog With Pink Design and Nuxt | Creating a course catalogue that is both visually appealing and easy to use can be a challenge.... | 0 | 2023-05-08T11:42:17 | https://dev.to/hackmamba/designing-a-user-friendly-course-catalog-with-pink-design-and-nuxt-5bdg | javascript, nuxt, beginners, webdev | Creating a course catalogue that is both visually appealing and easy to use can be a challenge. However, with the combination of [Pink Design](https://pink.appwrite.io/?utm_source=hackmamba&utm_medium=hackmamba-blog) and Nuxt.js, we can design an excellent and intuitive catalogue for users.
In this article, we'll lea... | olanetsoft |
1,461,375 | Comparing Compression Methods on Linux: gzip, bzip2, xz, and zstd | Introduction A recent test was conducted to compare the performance of four popular Linux... | 0 | 2023-05-08T15:36:01 | https://dev.to/cookiebinary/comparing-compression-methods-on-linux-gzip-bzip2-xz-and-zstd-3idd | ## Introduction
A recent test was conducted to compare the performance of four popular Linux compression methods: gzip, bzip2, xz, and zstd. The test involved compressing a 4 GB SQL dump file using the standard compression strength, and then with their strongest compression levels. This article presents the results of ... | cookiebinary | |
1,461,515 | How to Create a Custom WPF Material Theme | Learn how to create a custom WPF material theme in your desktop application. See more from ComponentOne today. | 0 | 2023-05-08T18:21:35 | https://www.grapecity.com/blogs/how-to-create-a-custom-wpf-material-theme | webdev, devops, dotnet, tutorial | ---
canonical_url: https://www.grapecity.com/blogs/how-to-create-a-custom-wpf-material-theme
description: Learn how to create a custom WPF material theme in your desktop application. See more from ComponentOne today.
---
In the latest ComponentOne 2023 v1 release, we’ve made theme customization easier for our WPF contr... | chelseadevereaux |
1,461,614 | Let's Get Started with Flask, Shall We? | No, not a Vacuum or Thermos flask, okay? I mean Flask, a very popular Python micro-web framework. It... | 0 | 2023-05-08T19:16:08 | https://kambale.dev/lets-get-started-with-flask | ---
title: Let's Get Started with Flask, Shall We?
published: true
date: 2021-08-12 21:05:06 UTC
tags:
canonical_url: https://kambale.dev/lets-get-started-with-flask
---
_No, not a Vacuum or Thermos flask, okay?_
I mean Flask, a very popular Python micro-web framework. It is so because it requires no particular tool... | kambale | |
1,486,339 | Hyrum's law in modern frontend | The best professional books for you are the books that are revealing situational problems that you... | 0 | 2023-05-30T21:38:02 | https://dev.to/mihneasim/hyrums-law-in-modern-frontend-1ma5 | frontend, softwareengineering, javascript, programming | The best professional books for you are the books that are revealing situational problems that you will encounter in your engineering journeys. I had the fortune to read about Hyrum's law in [Software Engineering at Google: Lessons Learned From Programming Over Time](https://www.google.ro/books/edition/Software_Enginee... | mihneasim |
1,486,522 | #Anewera #we move #Whenyoustoplearning #youstopliving | One can actually learn any skill insofar he or she is whatever that is conceived can be achieved. | 0 | 2023-05-31T03:21:11 | https://dev.to/vinlight16/anewera-we-movewhenyoustoplearning-youstopliving-25pn | One can actually learn any skill insofar he or she is whatever that is conceived can be achieved. | vinlight16 | |
1,487,086 | How BEM (Block-Element-Modifier) CSS actually Work! | BEM, or Block-Element-Modifier, is a popular naming convention for writing CSS code. It was developed... | 0 | 2023-05-31T12:51:52 | https://dev.to/aramoh3ni/how-bem-block-element-modifier-css-actually-work-ogl | css, bem, frontend | BEM, or Block-Element-Modifier, is a popular naming convention for writing CSS code. It was developed by the team at Yandex, a Russian search engine, as a way to create scalable and maintainable CSS code for their large and complex web projects. BEM has since become widely adopted by developers around the world and is ... | aramoh3ni |
1,487,159 | Integration Digest: May 2023 | 🔥 The new Integration Digest for May 2023 is now published! 📚 In this edition, you'll find a wealth... | 23,208 | 2023-05-31T14:38:40 | https://wearecommunity.io/communities/integration/articles/3284 | api, kafka, opensource, cloud | 🔥 The new Integration Digest for May 2023 is now published!
📚 In this edition, you'll find a wealth of articles, ranging from best practices for developer portals to a review of Kubernetes-native API management tools. Don't miss out on both parts of "A Playbook for Enterprise API Adoption".
📢 We're featuring news ... | stn1slv |
1,487,491 | I'm Switching to Medium: Here's Why | Greetings to my now over 400 followers! Thanks for your support over the last couple of months - I... | 0 | 2023-05-31T19:18:50 | https://dev.to/verisimilitudex/follow-me-on-medium-3473 | medium, verisimilitudex, piyush, writing | Greetings to my now over 400 followers! Thanks for your support over the last couple of months - I really appreciate it! I'm actually planning on mirroring my posts to Medium for only one reason: a public follower count. If you like my content and would like to continue reading them, then please give me a follow there:... | verisimilitudex |
1,487,760 | Text-based tools - the ultimate format for everything | Having lived in the world of technology for two to three decades now, I’ve come to a fundamental... | 0 | 2023-07-06T12:29:36 | https://timwise.co.uk/2023/06/01/text-based-tools-the-ultimate-format-for-everything/ | ---
title: Text-based tools - the ultimate format for everything
published: true
date: 2023-06-01 00:00:00 UTC
tags:
canonical_url: https://timwise.co.uk/2023/06/01/text-based-tools-the-ultimate-format-for-everything/
---
Having lived in the world of technology for two to three decades now, I’ve come to a fundamental... | timabell | |
1,488,097 | JS Asynchronous-Technical Paper | Callbacks a callback function is a function that is passed as an argument to another... | 0 | 2023-06-01T09:17:51 | https://dev.to/codebyank/js-asynchronous-technical-paper-25lo | webdev, javascript, programming, tutorial |
### Callbacks
a callback function is a function that is passed as an argument to another function and is intended to be called later, often after an asynchronous operation or a certain event occurs. Callbacks are a fundamental concept in JavaScript for handling asynchronous code execution.
Example:-
function fetc... | codebyank |
1,488,823 | Data Structures in C# Part 2: Lists <T> | Hey There 👋🏻 In part 1 of this series, I talked about arrays, which are cool and provide... | 23,236 | 2023-06-02T13:20:47 | https://dev.to/rasheedmozaffar/data-structures-in-c-part-2-lists-e76 | csharp, programming, webdev, dotnet | ## Hey There 👋🏻
In part 1 of this series, I talked about **arrays**, which are cool and provide amazing functionality, and to extend on the data structures that you the developer could use, we'll be learning the **generic lists** in C#, which is an essential data structure that any C# developer should have at their d... | rasheedmozaffar |
1,489,049 | All you need to know about Sorting | Sorting means rearranging a sequence, such as a list of numbers, so that the elements are put in a... | 0 | 2023-06-02T01:18:43 | https://dev.to/x64x2/all-you-need-to-know-about-sorting-dcc | beginners, programming, codenewbie, learning | Sorting means rearranging a sequence, such as a list of numbers, so that the elements are put in a specific order (e.g. ascending or descending). In computer science sorting is quite a wide topic, there are dozens of sorting algorithms, each with pros and cons and different attributes are being studied, e.g. the algori... | x64x2 |
1,489,131 | Convert Base64 string into PDF using Angular | Convert Base64 string into PDF | 0 | 2023-06-02T03:49:10 | https://dev.to/ktrajasekar/convert-base64-string-into-pdf-using-angular-6b4 | ---
title: Convert Base64 string into PDF using Angular
published: true
description: Convert Base64 string into PDF
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-06-02 03:46 +0000
---
- When you get base64 string from API encoded browser will not u... | ktrajasekar | |
1,489,344 | The DynamoDB-Toolbox v1 beta is here 🙌 All you need to know! | The DynamoDB-Toolbox v1 beta is here 🙌 All you need to know! | 0 | 2023-06-09T17:29:54 | https://dev.to/slsbytheodo/the-dynamodb-toolbox-v1-beta-is-here-all-you-need-to-know-22op | typescript, dynamodb, aws, serverless | ---
published: true
title: The DynamoDB-Toolbox v1 beta is here 🙌 All you need to know!
cover_image: https://raw.githubusercontent.com/ThomasAribart/dev-to-articles/master/blog-posts/dynamodb-toolbox-v1-beta/dynamodb-toolbox-v1-beta.png
description: The DynamoDB-Toolbox v1 beta is here 🙌 All you need to know!
tags: T... | thomasaribart |
1,493,148 | 10 inspirational trends of web data harvesting with Python in 2023 | Modern trusted proxy websites perform different functions related to gathering web data including... | 0 | 2023-06-06T06:47:33 | https://dexodata.com/en/blog/10-inspirational-trends-of-web-data-harvesting-with-python-in-2023 | ai, python, dataharvesting, dexodata |

Modern trusted proxy websites perform different functions related to gathering web data including buying residential and mobile proxies for cybersecurity reasons. During its processing on the enterprise level information take... | dexodatamarketing |
1,489,398 | Let's create a Color Picker from scratch with HTML5 Canvas, Javascript and CSS3 | How to create a Color Picker from scratch with HTML5 Canvas, Javascript and CSS3 | 0 | 2023-06-02T11:25:00 | https://www.ma-no.org/en/web-design/let-s-create-a-color-picker-from-scratch-with-html5-canvas-javascript-and-css3 | html, css, javascript, development | ---
title: Let's create a Color Picker from scratch with HTML5 Canvas, Javascript and CSS3
published: true
description: How to create a Color Picker from scratch with HTML5 Canvas, Javascript and CSS3
date: 2023-06-02 00:25:00 UTC
tags: html, css, javascript, development
canonical_url: https://www.ma-no.org/en/web-desi... | salvietta150x40 |
1,489,503 | What is a vector database? | Vector databases are all the rage these days. The reason is simple: theyve rapidly become a popular... | 0 | 2023-06-02T11:52:27 | https://blog.apify.com/what-is-a-vector-database/ | ai, chatgpt, machinelearning, webscraping | ---
title: What is a vector database?
published: true
date: 2023-04-25 11:21:45 UTC
tags: ai, chatgpt, machinelearning, webscraping
canonical_url: https://blog.apify.com/what-is-a-vector-database/
---
Vector databases are all the rage these days. The reason is simple: theyve rapidly become a popular way to add long-te... | theovasilis1 |
1,491,735 | How to built a simple template engine with Python and regex | Prologue
As I mentioned previously I want to create a static content creation system. The first step is A Template Engine. Rather than building a fully featured template engine, I am planning on what is just needed, in this major iteration.
I have al... | 0 | 2023-06-04T23:08:11 | https://dev.to/birnadine/how-to-built-a-simple-template-engine-with-python-and-regex-122b | ## Prologue
As I mentioned [previously](https://fyi.birnadine.guru/so-i-joined-the-time-complexity-cult) I want to create a static content creation system. The first step is A Template Engine. Rather than building a fully featured template engine, I am planning on what is just needed, in this major iteration.
**I hav... | birnadine | |
1,491,745 | End to end testing concept | End-to-end test là loại test toàn diện nhất, nó kiểm tra hệ thống từ đầu đến cuối, bao gồm tất cả các... | 0 | 2023-06-04T23:23:16 | https://dev.to/mossi4476/end-to-end-testing-concept-9oa | testing | End-to-end test là loại test toàn diện nhất, nó kiểm tra hệ thống từ đầu đến cuối, bao gồm tất cả các thành phần liên quan.
Nó có các đặc điểm chính sau:
Kiểm tra toàn bộ quy trình hoạt động của hệ thống từ đầu đến cuối. Từ giao diện người dùng đến cơ sở dữ liệu.
Sử dụng các trình duyệt hoặc ứng dụng thực sự để thực... | mossi4476 |
1,492,894 | Different Types of JavaSript Functions | 1. Function Declarations: function add(a, b) { return a + b; } Enter fullscreen... | 0 | 2023-06-05T21:38:08 | https://dev.to/gaurbprajapati/different-types-of-javasript-functions-4pn7 | javascript, webdev, programming, tutorial |
**1. Function Declarations:**
```javascript
function add(a, b) {
return a + b;
}
```
Function declarations define a named function with the `function` keyword, followed by the function name and a set of parentheses for parameters. They are hoisted to the top of their scope, meaning they can be cal... | gaurbprajapati |
1,493,269 | Hard Reset iPhone SE | Quickly press the volume up button Quickly press the volume down button Press and hold the side... | 0 | 2023-06-06T07:46:08 | https://dev.to/x2i/hard-reset-iphone-se-182p | iphone, force, reboot, hardreset | - Quickly press the volume up button
- Quickly press the volume down button
- Press and hold the side (power) button until you see activity and then release.
This should force the phone to reboot | x2i |
1,493,367 | MBaaS: Mobile Backend as a Service | MBaaS stands for Mobile Backend as a Service. It is a cloud computing service model that provides... | 23,271 | 2023-06-06T10:48:26 | https://dev.to/sardarmudassaralikhan/mbaas-mobile-backendas-a-service-36lm | cloud, cloudcomputing, azure, aws | MBaaS stands for Mobile Backend as a Service. It is a cloud computing service model that provides developers with a backend infrastructure to support mobile application development.
Traditionally, developing the backend infrastructure for mobile applications required setting up servers, managing databases, and implem... | sardarmudassaralikhan |
1,493,408 | A Smoother User Experience with Image Caching in .NET MAUI | Image caching is a technique that stores images in cache memory to improve an app’s performance. If... | 0 | 2023-06-06T13:17:42 | https://www.syncfusion.com/blogs/post/image-caching-in-dotnet-maui.aspx | dotnetmaui, development, mobile | ---
title: A Smoother User Experience with Image Caching in .NET MAUI
published: true
date: 2023-06-06 11:15:00 UTC
tags: dotnetmaui, development, mobile
canonical_url: https://www.syncfusion.com/blogs/post/image-caching-in-dotnet-maui.aspx
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/b33l7w153... | jollenmoyani |
1,493,647 | Navigating the Data Universe: Unleashing the Power of Cypher Query Language | In the vast landscape of data exploration, Cypher stands tall as a specialized query language that... | 0 | 2023-06-06T15:30:24 | https://dev.to/abmanan/navigating-the-data-universe-unleashing-the-power-of-cypher-query-language-ine | In the vast landscape of data exploration, Cypher stands tall as a specialized query language that opens doors to the realm of graph databases. With its expressive syntax and powerful traversal capabilities, Cypher empowers developers and data analysts to navigate the intricacies of interconnected data. In this blog po... | abmanan | |
1,493,656 | Building a Real-time API with Next.js, Nest.js, and Docker: A Comprehensive Guide | In this blog post, I will guide you through the process of creating a real-time API using the... | 0 | 2023-06-07T14:09:58 | https://dev.to/deepak22448/building-a-real-time-api-with-nextjs-nestjs-and-docker-a-comprehensive-guide-3l6l | webdev, api, typescript, docker | In this blog post, I will guide you through the process of creating a real-time API using the powerful combination of Next.js, Nest.js, and Docker. We will start by building a simple UI and demonstrate how to listen for server changes in real-time from the frontend. Additionally, I will show you how to leverage Docker ... | deepak22448 |
1,493,992 | How to act in a job interview | I recently made the decision to check out a more technology related job position at the company I... | 0 | 2023-06-06T19:15:27 | https://dev.to/pcabreram1234/how-to-act-in-a-job-interview-3f4c | webdev, interview, beginners, programming | <p align="justify">I recently made the decision to check out a more technology related job position at the company I work for.</p>
<p align="justify">When I attended said test, the first thing I noticed was that one of the members of said department was programming in JavaScript 😁 which I already started to like.</p>... | pcabreram1234 |
1,494,403 | 10 AI Website Builders You Didn't Know About | Are you tired of the same old website builders? Want to try something new? Well, I've got some news... | 0 | 2023-06-07T09:14:23 | https://dev.to/hr21don/10-ai-website-builders-you-didnt-know-about-1582 | ai, productivity, programming, webdev | Are you tired of the same old website builders? Want to try something new? Well, I've got some news for you! I've compiled a list of 10 AI website builders that you probably haven't heard of. Yes, you heard me right, AI website builders! These builders use artificial intelligence to help you create a website that is bo... | hr21don |
1,496,879 | A Comprehensive Guide to Distributed Tracing in Microservices | Introduction Distributed tracing is a technique used to monitor and profile applications... | 0 | 2023-06-07T20:05:02 | https://dev.to/subhafx/a-comprehensive-guide-to-distributed-tracing-in-microservices-3h8j | webdev, javascript, microservices, systemdesign | ## Introduction
Distributed tracing is a technique used to monitor and profile applications in complex, distributed systems. It involves tracking and recording the flow of requests as they traverse across multiple microservices or components. By capturing timing and context information at each step, distributed tracing... | subhafx |
1,497,224 | Setting up continuous integration with CircleCI and GitLab | Learn how to set up continuous integration pipelines with GitLab and CircleCI. | 0 | 2023-06-07T23:12:45 | https://circleci.com/blog/setting-up-continuous-integration-with-gitlab/ | circleci, gitlab, cicd, tutorial | ---
title: Setting up continuous integration with CircleCI and GitLab
published: true
description: Learn how to set up continuous integration pipelines with GitLab and CircleCI.
tags: circleci,gitlab,cicd,tutorial
cover_image: https://ctf-cci-com.imgix.net/3FPR2tmaqQeWPvKBQWQjTb/17ead46fd065f2f4c0fdf9447f2e3325/Tutoria... | zmarkan |
1,497,225 | New Language vs. Complex Requirements - What's Your Pick? | If given a choice, would you rather work on a coding project that demands you to learn a completely... | 22,092 | 2023-06-16T07:00:00 | https://dev.to/codenewbieteam/new-language-vs-complex-requirements-whats-your-pick-4d7g | discuss, beginners, codenewbie | If given a choice, would you rather work on a coding project that demands you to learn a completely new programming language or one that allows you to stick with your favorite language but comes with complex requirements?
Join the conversation and let's unravel the trade-offs of these intriguing coding paths!
Follow... | ben |
1,497,943 | Appwrite OSS Fund Sponsors Strawberry | Hi readers 👋, welcoming you back to the "Appwrite OSS Fund" series, where we celebrate open-source... | 18,938 | 2023-06-09T16:29:18 | https://dev.to/appwrite/appwrite-oss-fund-sponsors-strawberry-558i | Hi readers 👋, welcoming you back to the "Appwrite OSS Fund" series, where we celebrate open-source maintainers. 🎉
## 🤔 What Is OSS Fund?
On the 4th of May, the Appwrite team launched the [OSS Fund](https://appwrite.io/oss-fund), an initiative to support open-source project maintainers. Being an open-source company... | haimantika | |
1,498,496 | Day 758 : You Gotta Start Somewhere | liner notes: Professional : Good day today. Got up early to sit in on a meeting that was scheduled... | 0 | 2023-06-08T23:00:02 | https://dev.to/dwane/day-758-you-gotta-start-somewhere-594a | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Good day today. Got up early to sit in on a meeting that was scheduled to get more folks in other areas that can't attend at other times. After that, I went back to sleep for a couple of more hours. Responded to some community questions. Followed up with folks about questions I had. Upda... | dwane |
1,499,405 | Need text area with number of lines limit, characters per line and total character count in React js functional | Need text area with number of lines limit, characters per line and total character count | 0 | 2023-06-09T17:17:50 | https://dev.to/bharathibillakanti/text-area-in-react-project-1lm6 | ---
title: Need text area with number of lines limit, characters per line and total character count in React js functional
published: true
description: Need text area with number of lines limit, characters per line and total character count
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 ... | bharathibillakanti | |
1,499,641 | The Essential Role of JavaScript in Modern Frontend Development | JavaScript is an essential technology that has a pivotal role in contemporary frontend development.... | 0 | 2023-06-10T01:56:56 | https://dev.to/uzafar90/the-essential-role-of-javascript-in-modern-frontend-development-3m0 | frontend, javascript, modernjs, tutorial |
JavaScript is an essential technology that has a pivotal role in contemporary frontend development. It grants developers the ability to craft engaging and interactive user experiences, validate and manipulate user input, introduce asynchronous functionality, construct intricate web applications utilizing frameworks an... | uzafar90 |
1,500,201 | 6 Must-Try Coding Problem Websites 💻 | Do you know your language? No, really. A lot of us (myself included) can learn the basics of a... | 0 | 2023-06-10T15:53:13 | https://dev.to/jd2r/6-must-try-coding-problem-websites-53c0 | algorithms, programming, coding | Do you know your language?
No, really.
A lot of us (myself included) can learn the basics of a programming language and think that we've mastered every possible dimension.
And while all you really need are the basics to get started, it's helpful to test your newfound knowledge as you begin to dive deeper into the sp... | jd2r |
1,500,363 | Generate Breadcrumb and Navigation in SvelteKit | Building Dynamic Navigation As we know that in SvelteKit, +page.svelte files point to the... | 0 | 2023-06-10T19:43:19 | https://blog.aakashgoplani.in/generate-breadcrumb-and-navigation-in-sveltekit | sveltekit, breadcrumb, navigationbar | ### Building Dynamic Navigation
As we know that in SvelteKit, `+page.svelte` files point to the actual web page. So, to generate navigation, we need to figure out a way to get the list of all `+page.svelte` files. Currently, SvelteKit (v1.20.2) does not have any built-in mechanism to give us a list of all pages. The s... | aakashgoplani |
1,500,776 | Azure Container Apps, Easy Auth and .NET authentication | Liquid syntax error: Unknown tag 'endraw' | 0 | 2023-06-11T08:17:20 | https://johnnyreilly.com/azure-container-apps-easy-auth-and-dotnet-authentication | azurecontainerapps, easyauth, aspnet, authentication | ---
title: Azure Container Apps, Easy Auth and .NET authentication
published: true
tags: azurecontainerapps,easyauth,aspnet,authentication
canonical_url: https://johnnyreilly.com/azure-container-apps-easy-auth-and-dotnet-authentication
---
Easy Auth is a great way to authenticate your users. However, when used in the c... | johnnyreilly |
1,500,823 | Enhancing Your CSS Skills: Dive into :not, :is, and :where Pseudo-Classes. | Introduction: In the world of CSS, readability and maintainability are crucial factors... | 0 | 2023-06-11T15:52:06 | https://dev.to/deepak22448/enhancing-your-css-skills-dive-into-not-is-and-where-pseudo-classes-2pm | css, beginners, webdev, frontend |
#Introduction:
In the world of CSS, readability and maintainability are crucial factors when it comes to writing clean and efficient code. Fortunately, CSS provides powerful pseudo-classes such as `:is`, `:where`, and `:not`, which can significantly improve the readability of your stylesheets. These pseudo-classes all... | deepak22448 |
1,501,350 | 100 Days Coding Challenge - Day 23: FreeCodeCamp JavaScript Algorithms and Data Structures | Today I finish the first code of the certification, a palindrome checker, I did it with a queue... | 0 | 2023-06-12T00:01:41 | https://dev.to/alexmgp7/100-days-coding-challenge-day-23-freecodecamp-javascript-algorithms-and-data-structures-1mb8 | webdev, javascript, programming, 100daysofcode | Today I finish the first code of the certification, a palindrome checker, I did it with a queue function that I found on internet, it was easy
| alexmgp7 |
1,503,418 | The Prospects of the Healthcare Industry in the Metaverse | A potentially game-changing technology for a number of industries is the metaverse. The healthcare... | 0 | 2023-06-13T16:30:34 | https://dev.to/donnajohnson88/the-prospects-of-the-healthcare-industry-in-the-metaverse-29j6 | blockchainhealthcare, blockchain, webdev, metaverse | A potentially game-changing technology for a number of industries is the metaverse. The healthcare sector is one such industry.
From virtual checkups to data security, the metaverse, when developed with [Blockchain Healthcare Application Development](https://blockchain.oodles.io/blockchain-healthcare-services/), can o... | donnajohnson88 |
1,504,291 | Multifunktionales PostgreSQL GUI Tool | Steigern Sie Ihre Produktivität mit einem plattformübergreifenden GUI-Client für PostgreSQL: dbForge... | 0 | 2023-06-14T12:11:48 | https://dev.to/devartteam/multifunktionales-postgresql-gui-tool-59jg | postgres, postgressql, dbforge, dbforgestudio | Steigern Sie Ihre Produktivität mit einem plattformübergreifenden GUI-Client für PostgreSQL: dbForge Studio for PostgreSQL - https://www.devart.com/de/dbforge/postgresql/studio/
 | devartteam |
1,504,398 | This Week In React #148: Remix Routing, Hydration, React.FC, Vite + RSC, Astro, Valhalla, Reanimated, Expo-Apple-Targets... | Hi everyone! Well, Dan Abramov is on holiday, which is probably why there hasn't been much happening... | 18,494 | 2023-06-14T14:32:19 | https://thisweekinreact.com/newsletter/148 | react, reactnative | ---
series: This Week In React
canonical_url: https://thisweekinreact.com/newsletter/148
---
Hi everyone!
Well, Dan Abramov is [on holiday](https://twitter.com/dan_abramov/status/1666459095979753477), which is probably why there hasn't been much happening this week in our beloved ecosystem 😅.
We do, however, have a... | sebastienlorber |
1,504,648 | How @Autowired works in Spring - A detailed guide | In last post we have seen how @Autowired can be used at multiple places to inject the dependent... | 0 | 2023-06-19T14:53:09 | https://dev.to/themayurkumbhar/how-autowired-works-in-details-14a5 | springboot, spring, java | In [last post](https://dev.to/themayurkumbhar/wiring-in-spring-51lc) we have seen how `@Autowired` can be used at multiple places to inject the dependent beans. Spring framework handles the dependency between the components and based on field, setter or constructor injection injects appropriate objects.
## Issue?
Wha... | themayurkumbhar |
1,504,768 | Situações que NullPointerException podem acontecer no Kotlin | Uma das motivações de usar o Kotlin é por ser uma linguagem segura, muito por conta da segurança a... | 0 | 2023-06-16T11:23:00 | https://dev.to/alexfelipe/situacoes-que-nullpointerexception-podem-acontecer-no-kotlin-2g3h | kotlin, programming | Uma das motivações de usar o Kotlin é por ser uma linguagem segura, muito por conta da segurança a referências nulas ou [Null Safety](https://kotlinlang.org/docs/null-safety.html).
De uma forma resumida, é a habilidade para evitar que apps escritos em Kotlin lancem a famosa [`NullPointerException`](https://kotlinlang... | alexfelipe |
1,505,166 | Offshore Java Developers vs. Onshore: Making the Right Choice | In today's competitive digital landscape, businesses are constantly seeking the best talent and... | 0 | 2023-06-15T05:53:31 | https://dev.to/hiredevelopersdev/offshore-java-developers-vs-onshore-making-the-right-choice-50ln | offshorejavadevelopers, offshorejavadevelopment | In today's competitive digital landscape, businesses are constantly seeking the best talent and cost-effective solutions to meet their software development needs. When it comes to Java development, companies often face the decision of whether to hire offshore Java developers or opt for onshore resources. This article a... | hiredevelopersdev |
1,505,348 | Web Application Testing Tutorial: A Comprehensive Guide With Examples And Best Practices | Web application testing is an approach to ensure the correct functioning and performance of the web... | 0 | 2023-06-15T08:30:37 | https://dev.to/nazneenahmd/web-application-testing-tutorial-a-comprehensive-guide-with-examples-and-best-practices-h1 | webapplicationtest, webdev, tutorial, softwaretesting | Web application testing is an approach to ensure the correct functioning and performance of the web application by following a structured process.
With web application testing, detection of bugs or errors is done, and ensure that all such are removed before the web application goes live.
The primary purpose of web ap... | nazneenahmd |
1,505,402 | Streamlining Busy Schedules: The Role of Student Athlete Shuttles in NYC | Introduction Balancing academics and athletics can be an arduous task for student... | 0 | 2023-06-15T09:52:33 | https://dev.to/limousinecarservices_5/streamlining-busy-schedules-the-role-of-student-athlete-shuttles-in-nyc-4c77 | ## **Introduction**
Balancing academics and athletics can be an arduous task for student athletes. With demanding practice schedules, training sessions, and competitions, managing time efficiently becomes crucial. This is where student athlete shuttles come to the rescue, providing a reliable and convenient transportat... | limousinecarservices_5 | |
1,505,703 | Accessible anchor links with Markdown-it and Eleventy | I like to be able to link directly to a section in a long content. I wish every site provided anchor... | 0 | 2023-06-15T14:23:32 | https://nicolas-hoizey.com/articles/2021/02/25/accessible-anchor-links-with-markdown-it-and-eleventy/ | ---
title: Accessible anchor links with Markdown-it and Eleventy
published: true
date: 2021-02-25 21:08:34 UTC
tags:
canonical_url: https://nicolas-hoizey.com/articles/2021/02/25/accessible-anchor-links-with-markdown-it-and-eleventy/
---
I like to be able to link directly to a section in a long content. I wish every ... | nhoizey | |
1,506,014 | Exploring Nodejs: Chapter 2 — URLS AND THE INTERNET | Chapter 2 is here! In this chapter, we will talk about how the internet works, what happens when we... | 23,403 | 2023-06-15T18:19:03 | https://dev.to/itsmohamedyahia/exploring-nodejs-chapter-2-urls-and-the-internet-1e14 | webdev, beginners, tutorial, node | Chapter 2 is here! In this chapter, we will talk about how the internet works, what happens when we go to a url, different parts of the url and how does DNS Servers help us traverse the web. Hope you enjoy it.
---
### WHAT HAPPENS UNDER THE HOOD WHEN I ENTER A URL IN THE BROWSER ADDRESS BAR??
Well, you need to know ... | itsmohamedyahia |
1,506,204 | Healthcare’s Digital Accessibility Problem | The push for digital accessibility aims to ensure equal access and inclusion for all individuals. So... | 0 | 2023-06-15T21:58:03 | https://devinterrupted.com/podcast/healthcares-digital-accessibility-problem-w-ros-plum-ertz/ | devops, programming, podcast, interview | The push for digital accessibility aims to ensure equal access and inclusion for all individuals. So why are healthcare companies failing to keep up?
In this week’s episode of Dev Interrupted, we sit down with Plum Ertz, Director of Engineering at [Ro](https://ro.co/), to dissect healthcare’s digital accessibility pro... | conorbronsdon |
1,506,687 | Configuring connection for Oracle NetSuite REST connector | Configuring connection for Oracle NetSuite REST connector Step 1: Enabling an... | 0 | 2023-06-16T10:40:02 | https://tech.forums.softwareag.com/t/configuring-connection-for-oracle-netsuite-rest-connector/278219/1 | webmethods, oracle, rest, integration | ---
title: Configuring connection for Oracle NetSuite REST connector
published: true
date: 2023-05-04 05:05:27 UTC
tags: webMethods, oracle, rest, integration
canonical_url: https://tech.forums.softwareag.com/t/configuring-connection-for-oracle-netsuite-rest-connector/278219/1
---
## Configuring connection for Orac... | techcomm_sag |
1,508,181 | Tủ nấu cơm công nghiệp chất lượng, giá tốt | https://tunaucom.com.vn/ Chuyên cung cấp các dòng tủ nấu cơm, tủ hấp cơm công nghiệp ✔️Chất... | 0 | 2023-06-18T02:02:11 | https://dev.to/tunaucomnewsun/tu-nau-com-cong-nghiep-chat-luong-gia-tot-1p2h | https://tunaucom.com.vn/ Chuyên cung cấp các dòng tủ nấu cơm, tủ hấp cơm công nghiệp ✔️Chất lượng✔️Chính hãng ✔️Bảo hành lâu dài✔️Giá tốt nhất thị trường✔️✔️✔️
0963.997. 355
Số 28 ngõ 168 Nguyễn Xiển, Thanh Xuân, Hà Nội
#tucomcongnghiep #tunaucomcongnghiep #tuhapcomcongnghiep #noinaucomcongnghiep #noihapcomcongnghiep
... | tunaucomnewsun |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.