
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,915,624 | Liman Dağıtım Eklentisi Kurulumu | Eklenti Kurulum Dokümantasyonu İçindekiler Sanal Makine Kurulumu Veritabanı... | 0 | 2024-07-08T13:20:12 | https://dev.to/aciklab/liman-dagitim-eklentisi-kurulumu-8f8 | #Eklenti Kurulum Dokümantasyonu
## İçindekiler
- [Sanal Makine Kurulumu] (#sanal-makine-kurulumu)
- [Veritabanı Sunucusu Kurulumu](#veritabanı-sunucusu-kurulumu)
- [PostgreSQL Kurulumu (Varsa Atlayın)](#postgresql-kurulumu-varsa-atlayın)
- [Veritabanı ve Kullanıcı Oluşturma](#veritabanı-ve-kullanıcı-oluşturma)
- [... | erenalpteksen | |
1,915,625 | 30+ Breaking Changes in TYPO3 v13.2 | Welcome to my TYPO3 v13 Feature Release series! In this blog, we'll discuss the recently released... | 0 | 2024-07-08T11:11:22 | https://dev.to/sanjaychauhan/30-breaking-changes-in-typo3-v132-12c5 | typo3, development, tutorial, programming | Welcome to my TYPO3 v13 Feature Release series!
In this blog, we'll discuss the recently released TYPO3 v13.2. This blog introduces [TYPO3 v13.2](https://t3planet.com/blog/typo3-v13-2/), highlighting its key features, breaking changes, and deprecations. Editors can expect significant improvements, and exciting enhance... | sanjaychauhan |
1,915,627 | Các Cách Bảo Mật Website WordPress Từ A – Z Hiệu Quả Nhất | Bảo mật website WordPress là một quá trình liên tục nhằm bảo vệ website khỏi các mối đe dọa như tấn... | 0 | 2024-07-08T11:13:15 | https://dev.to/terus_technique/cac-cach-bao-mat-website-wordpress-tu-a-z-hieu-qua-nhat-55n3 | website, digitalmarketing, seo, terus |

Bảo mật website WordPress là một quá trình liên tục nhằm bảo vệ website khỏi các mối đe dọa như tấn công, hack, phá hoại. Điều này không chỉ giúp bảo vệ thông tin nhạy cảm, mà còn [duy trì hoạt động ổn định của webs... | terus_technique |
1,915,629 | So Sánh Wix Và WordPress – Nên Lựa Chọn Nền Tảng Nào? | Wix và WordPress là hai nền tảng phổ biến để xây dựng website, mỗi nền tảng đều có những ưu và nhược... | 0 | 2024-07-08T11:15:10 | https://dev.to/terus_technique/so-sanh-wix-va-wordpress-nen-lua-chon-nen-tang-nao-2lm8 | website, digitalmarketing, seo, terus |

Wix và WordPress là hai nền tảng phổ biến để xây dựng website, mỗi nền tảng đều có những ưu và nhược điểm riêng. Wix là một công cụ [xây dựng website trực quan, dễ sử dụng](https://terusvn.com/thiet-ke-website-tai-h... | terus_technique |
1,915,630 | 🔐Password manager with react, nodejs & mysql part II🚀 | In the past week, we created a password manager where users can add and encrypt passwords, save them... | 0 | 2024-07-08T11:15:36 | https://dev.to/brokarim/password-manager-with-react-nodejs-mysql-part-ii-a2a | react, mysql, node, googlecloud | In the past week, we created a password manager where users can add and encrypt passwords, save them to the database, and decrypt them when needed.
Now, we will implement an authentication system to ensure that only authorized users can access their passwords, preventing other users from viewing them. We will also ens... | brokarim |
1,915,635 | Jetpack Là Gì? Những Thông Tin Về Plugin Jetpack WordPress | Jetpack là một plugin miễn phí và mạnh mẽ cho WordPress, được phát triển bởi Automattic - công ty mẹ... | 0 | 2024-07-08T11:19:54 | https://dev.to/terus_technique/jetpack-la-gi-nhung-thong-tin-ve-plugin-jetpack-wordpress-22k4 | website, digitalmarketing, seo, terus |

Jetpack là một plugin miễn phí và mạnh mẽ cho WordPress, được phát triển bởi Automattic - công ty mẹ của WordPress.com. Jetpack cung cấp một bộ các tính năng và công cụ mạnh mẽ để giúp người dùng WordPress [quản lý,... | terus_technique |
1,915,631 | ドキュメント・リリースノート - 2024年5月 | 2024年5月のドキュメントのハイライトをご覧ください。 | 0 | 2024-07-08T11:17:12 | https://dev.to/pubnub-jp/dokiyumentoririsunoto-2024nian-5yue-2dp9 | pubnub, documentation, releases, releasenotes | この記事は[https://www.pubnub.com/docs/release-notes/2024/may](https://www.pubnub.com/docs/release-notes/2024/may?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)に掲載されたものです。
今月のリリースノートへようこそ!PubNubはあなたの作業を効率化し、利便性を高めるためのアップデートをお届けします。
パッケージの中身は?
App Contextのデータフィルタリングのドキュメントを統一し、PythonとAsync... | pubnubdevrel |
1,915,632 | 문서 릴리즈 노트 - 2024년 5월 | 2024년 5월의 모든 문서 하이라이트를 확인하세요. | 0 | 2024-07-08T11:17:13 | https://dev.to/pubnub-ko/munseo-rilrijeu-noteu-2024nyeon-5weol-77m | pubnub, documentation, releases, releasenotes | 이 문서는 원래 [https://www.pubnub.com/docs/release-notes/2024/may](https://www.pubnub.com/docs/release-notes/2024/may?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 에 게시되었습니다.
이번 달의 릴리즈 노트에 오신 것을 환영합니다! PubNub에서 작업을 간소화하고 편의성을 높이기 위한 업데이트 패키지를 제공합니다.
패키지에는 무엇이 포함되어 있나요?
앱 컨텍스트 데이터 필터링 문서를... | pubnubdevrel |
1,915,633 | Topic Modeling with Top2Vec: Dreyfus, AI, and Wordclouds | Extracting Insights from PDFs with Python: A Comprehensive Guide This script demonstrates... | 0 | 2024-07-08T11:18:31 | https://dev.to/roomals/topic-modeling-with-top2vec-dreyfus-ai-and-wordclouds-1ggl | python, machinelearning, nlp, ai | ## Extracting Insights from PDFs with Python: A Comprehensive Guide
This script demonstrates a powerful workflow for processing PDFs, extracting text, tokenizing sentences, and performing topic modeling with visualization, tailored for efficient and insightful analysis.
### Libraries Overview
- **os**: Provides funct... | roomals |
1,915,634 | Nguyên Lý Thị Giác Là Gì? Ứng Dụng Trong Thiết Kế Website | Nguyên tắc trực quan (Visual principles) là những quy tắc, nguyên lý cơ bản liên quan đến cách con... | 0 | 2024-07-08T11:19:34 | https://dev.to/terus_digitalmarketing/nguyen-ly-thi-giac-la-gi-ung-dung-trong-thiet-ke-website-27b9 | Nguyên tắc trực quan (Visual principles) là những quy tắc, nguyên lý cơ bản liên quan đến cách con người nhìn và cảm nhận thông tin thông qua thị giác. Khi áp dụng các nguyên tắc này vào thiết kế, chúng giúp tạo ra các sản phẩm trực quan hài hòa, dễ hiểu và thu hút người dùng. Các nguyên tắc trực quan chính bao gồm:
1... | terus_digitalmarketing | |
1,915,682 | Deploying a Web-app with Elastic Beanstalk | So a few months ago I made an E-commerce store as a personal project. I'll be deploying it today... | 0 | 2024-07-08T11:43:45 | https://dev.to/aktran321/deploying-a-web-app-with-elastic-beanstalk-37hb | So a few months ago I made an E-commerce store as a personal project. I'll be deploying it today (again) with Elastic Beanstalk and documenting the process.
## 1. Elastic Beanstalk
For my MacOs machine, I have to install Homebrew. Once installed, run commands:
* brew update
* brew install awsebcli
* eb --version
Cr... | aktran321 | |
1,915,654 | Widgets Là Gì? Thông Tin Cần Biết Về Widgets WordPress | Widgets là những phần tử linh hoạt và dễ sử dụng trong hệ thống WordPress, cho phép bạn thêm các... | 0 | 2024-07-08T11:22:03 | https://dev.to/terus_technique/widgets-la-gi-thong-tin-can-biet-ve-widgets-wordpress-4518 | website, digitalmarketing, seo, terus |

Widgets là những phần tử linh hoạt và dễ sử dụng trong hệ thống WordPress, cho phép bạn thêm các chức năng, nội dung và [tùy chỉnh giao diện website một cách đơn giản](https://terusvn.com/thiet-ke-website-tai-hcm/).... | terus_technique |
1,915,655 | Dive into Cutting-Edge Machine Learning Techniques with LabEx 🚀 | The article is about a collection of five cutting-edge machine learning tutorials curated by the LabEx platform. The labs cover a diverse range of topics, including Gaussian Mixture Model selection, handwritten digit classification, Independent Component Analysis, nonlinear data regression, and feature selection using ... | 27,933 | 2024-07-08T11:22:32 | https://dev.to/labex/dive-into-cutting-edge-machine-learning-techniques-with-labex-296b | sklearn, coding, programming, tutorial |
Are you ready to explore the frontiers of machine learning? LabEx, a premier platform for hands-on coding tutorials, has curated a collection of five captivating labs that will take you on a journey through the latest advancements in the field. From mastering Gaussian Mixture Models to delving into Independent Compone... | labby |
1,915,656 | Dokumentation Versionshinweise - Mai 2024 | Sehen Sie sich alle Dokumentations-Highlights vom Mai 2024 an. | 0 | 2024-07-08T11:22:42 | https://dev.to/pubnub-de/dokumentation-versionshinweise-mai-2024-43je | pubnub, documentation, releases, releasenotes | Dieser Artikel wurde ursprünglich auf [https://www.pubnub.com/docs/release-notes/2024/may](https://www.pubnub.com/docs/release-notes/2024/may?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) veröffentlicht.
Willkommen zu den Versionshinweisen dieses Monats! PubNub bringt Ihnen ein Bündel... | pubnubdevrel |
1,915,657 | Improve Data Accuracy with Automated Data Lineage | Manta-Prolifics Microsoft Purview Connector (MPP) Today’s hybrid workspaces require data to be... | 0 | 2024-07-08T11:23:06 | https://dev.to/kalyaniprolific/improve-data-accuracy-with-automated-data-lineage-2e9f | ##

[Manta-Prolifics Microsoft Purview Connector](https://prolifics.com/us/expertise/data-ai/manta-prolifics-purview-connector) (MPP)
Today’s hybrid workspaces require data to be accessed from a plethora of devices,... | kalyaniprolific | |
1,915,658 | How I Launch a Site Every 2 Days | Launching a website every three days involves a rapid development cycle driven by efficiency and... | 0 | 2024-07-08T11:23:18 | https://dev.to/roc_c_75b7658dd4def6b500a/how-i-launch-a-site-every-2-days-48i3 | webdev, beginners, ai, productivity |
Launching a website every three days involves a rapid development cycle driven by efficiency and quick deployment strategies. This article explores the motivations and methodologies behind this fast-paced approach, f... | roc_c_75b7658dd4def6b500a |
1,915,659 | Source Code Là Gì? Các Thông Tin Cần Biết Về Source Code | Source code, hay mã nguồn, là thành phần căn bản của bất kỳ phần mềm máy tính nào. Nó bao gồm những... | 0 | 2024-07-08T11:25:27 | https://dev.to/terus_technique/source-code-la-gi-cac-thong-tin-can-biet-ve-source-code-4o0i | website, digitalmarketing, seo, terus |

Source code, hay mã nguồn, là thành phần căn bản của bất kỳ phần mềm máy tính nào. Nó bao gồm những dòng mã lệnh, được các lập trình viên viết bằng các ngôn ngữ lập trình, tạo thành chức năng và tính năng của một ứ... | terus_technique |
1,915,660 | How Pubrica's Expertise Converts Your Manuscript into an Engaging Abstract | Pubrica Expertise: Convert Your Manuscript into Abstract Service Abstracts provide a sneak peek into... | 0 | 2024-07-08T11:26:20 | https://dev.to/pubrica_healthcare_9a6f31/how-pubricas-expertise-converts-your-manuscript-into-an-engaging-abstract-10n2 | Pubrica Expertise: Convert Your Manuscript into Abstract Service
Abstracts provide a sneak peek into a research paper, offering a brief overview of the study's goals, methods, outcomes, and conclusions. They are often the first, and sometimes the only, part of the manuscript that readers, reviewers, and editors evaluat... | pubrica_healthcare_9a6f31 | |
1,915,661 | Top App Development Company in Houston | App Development Services Houston | Transform Your Ideas into Reality with the Leading App Development Company in Houston, USA! Unlock... | 0 | 2024-07-08T11:27:04 | https://dev.to/mobisoftinfotech/top-app-development-company-in-houston-app-development-services-houston-hae | mobile, development, softwaredevelopment |

Transform Your Ideas into Reality with the Leading App Development Company in Houston, USA! Unlock the Power of Custom Apps with Mobisoft Infotech – Houston's Best App Developers!For more details do visit us here: h... | mobisoftinfotech |
1,915,662 | learn web development | https://www.udemy.com/course/learn-html-css-and-javascript-for-absolute-beginners/?referralCode=7533F... | 0 | 2024-07-08T11:27:33 | https://dev.to/shimwa_bonheur_0b955afb80/learn-web-development-8g8 | https://www.udemy.com/course/learn-html-css-and-javascript-for-absolute-beginners/?referralCode=7533F13615E4EFA586B2 | shimwa_bonheur_0b955afb80 | |
1,915,721 | Bitpower’s revolutionary innovation | Blockchain technology is one of the revolutionary innovations in the field of financial technology... | 0 | 2024-07-08T12:17:25 | https://dev.to/pings_iman_934c7bc4590ba4/bitpowers-revolutionary-innovation-1i9b |

Blockchain technology is one of the revolutionary innovations in the field of financial technology in recent years, which has greatly changed the traditional financial model. As an innovator in the blockchain field... | pings_iman_934c7bc4590ba4 | |
1,915,663 | Notes de mise à jour de la documentation - mai 2024 | Découvrez tous les points forts de la documentation de mai 2024. | 0 | 2024-07-08T11:27:43 | https://dev.to/pubnub-fr/notes-de-mise-a-jour-de-la-documentation-mai-2024-1ekp | pubnub, documentation, releases, releasenotes | Cet article a été publié à l'origine sur [https://www.pubnub.com/docs/release-notes/2024/may](https://www.pubnub.com/docs/release-notes/2024/may?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
Bienvenue dans les notes de version de ce mois-ci ! PubNub vous apporte un ensemble de mises à... | pubnubdevrel |
1,915,664 | Parallax Là Gì? Lợi Ích Khi Thiết Kế Website Parallax | Parallax là một hiệu ứng trực quan được sử dụng trong thiết kế website, trong đó các đối tượng trên... | 0 | 2024-07-08T11:28:13 | https://dev.to/terus_technique/parallax-la-gi-loi-ich-khi-thiet-ke-website-parallax-23m4 | website, digitalmarketing, seo, terus |

Parallax là một hiệu ứng trực quan được sử dụng trong [thiết kế website](https://terusvn.com/thiet-ke-website-tai-hcm/), trong đó các đối tượng trên trang web, như hình ảnh và văn bản, di chuyển ở tốc độ khác nhau k... | terus_technique |
1,915,665 | eCommerce Website Design Tips to Increase Sales | Creating an effective eCommerce website involves more than just a visually appealing design. It’s... | 0 | 2024-07-08T11:28:51 | https://dev.to/makemaya_usa/ecommerce-website-design-tips-to-increase-sales-5g31 | Creating an effective eCommerce website involves more than just a visually appealing design. It’s about providing a seamless user experience that drives conversions and increases sales. Here are some essential eCommerce website design tips to boost your online store’s performance:
Mobile Optimization: With the majorit... | makemaya_usa | |
1,915,666 | What Are Some Good Books on Research Methodology | No research can be considered comprehensive without reliable information. The data gathered for... | 0 | 2024-07-08T11:29:14 | https://dev.to/phd_assistance_f71ddf2d25/what-are-some-good-books-on-research-methodology-5758 | researchmethods, booksonresearchmethods |
No research can be considered comprehensive without reliable information. The data gathered for research serves not only to deepen insights into the field but also to produce substantial research material, theses, or... | phd_assistance_f71ddf2d25 |
1,915,667 | Mulesoft Certification Strategies for Exam Success | Mulesoft Certification Improve your project management skills with Mulesoft training Enhancing your... | 0 | 2024-07-08T11:29:19 | https://dev.to/mulesoftcertfication/mulesoft-certification-strategies-for-exam-success-4nc9 | <a href="https://dumpsarena.com/mulesoft-certification/mulesoft-certification/">Mulesoft Certification</a> Improve your project management skills with Mulesoft training
Enhancing your project management skills is crucial for career advancement, and Mulesoft training offers a unique opportunity to achieve this. Mulesoft... | mulesoftcertfication | |
1,915,668 | How to Use Terraform Providers | What are Terraform Providers A key feature of Terraform is the ability to manage... | 0 | 2024-07-08T12:30:00 | https://www.env0.com/blog/how-to-use-terraform-providers | terraform, devops, kubernetes, aws | What are Terraform Providers
----------------------------
A key feature of [Terraform](https://www.env0.com/blog/terraform-tutorial) is the ability to manage infrastructure on virtually any platform. But how does Terraform know how to interact with infrastructure services as diverse as AWS, Kubernetes, and GitHub? Tha... | env0team |
1,915,669 | Summer launch week hackathon with the PXCI stack | We’re excited to invite you to join our summer hackathon in collaboration with our friends at Prisma,... | 0 | 2024-07-08T11:35:15 | https://xata.io/blog/summer-launch-pxci-hackathon | ai, database, javascript, hackathon | We’re excited to invite you to join our summer hackathon in collaboration with our friends at [Prisma](https://www.prisma.io/), [Clerk](https://clerk.com/) and [Inngest](https://www.inngest.com/)!
Over the past year, we’ve noticed that many of our customers were using the PXCI (Prisma, Xata, Clerk and Inngest) stack a... | cezz |
1,915,670 | STACK OF | My ultimate startup codex/recipe for growing http://microlaunch.net - product analytics: posthog -... | 0 | 2024-07-08T11:30:27 | https://dev.to/ishaan_singhal_f3b6b687f3/stack-of-4b19 | My ultimate startup codex/recipe for growing [http://microlaunch.net](https://t.co/7uMrMk7NTD)  - product analytics: posthog - web analytics + domains: cloudflare - SEO: ... | ishaan_singhal_f3b6b687f3 | |
1,915,671 | Angular Là Gì? Tầm Quan Trọng Trong Xây Dựng Website | Angular là một framework JavaScript mạnh mẽ và phổ biến được phát triển bởi Google. Nó được sử dụng... | 0 | 2024-07-08T11:31:40 | https://dev.to/terus_technique/angular-la-gi-tam-quan-trong-trong-xay-dung-website-53j8 | website, digitalmarketing, seo, terus |

Angular là một framework JavaScript mạnh mẽ và phổ biến được phát triển bởi Google. Nó được sử dụng để [xây dựng các ứng dụng web và ứng dụng di động hiện đại](https://terusvn.com/thiet-ke-website-tai-hcm/), đặc bi... | terus_technique |
1,915,672 | Now I know why NVIDIA stocks are high | I was curious when I was constantly getting notifications that NVIDIA stocks were high, but I didn't... | 0 | 2024-07-10T13:58:32 | https://dev.to/rajai_kumar/now-i-know-why-nvidia-stocks-are-high-403n | machinelearning, datascience, computerscience, tensorflow |
I was curious when I was constantly getting notifications that NVIDIA stocks were high, but I didn't pay attention to it for a very long time (I knew subconsciously it had something to do with chip making. That's it.).
Finally, when I did that, I learned about GPGPU. And I shared my findings with you guys in the last... | rajai_kumar |
1,915,673 | Bridge Là Gì? Những Ưu, Nhược Điểm Khi Dùng Bridge | Bridge là một thiết bị mạng được sử dụng để kết nối hai hoặc nhiều mạng LAN (Local Area Network)... | 0 | 2024-07-08T11:34:01 | https://dev.to/terus_technique/bridge-la-gi-nhung-uu-nhuoc-diem-khi-dung-bridge-2laa | website, digitalmarketing, seo, terus |
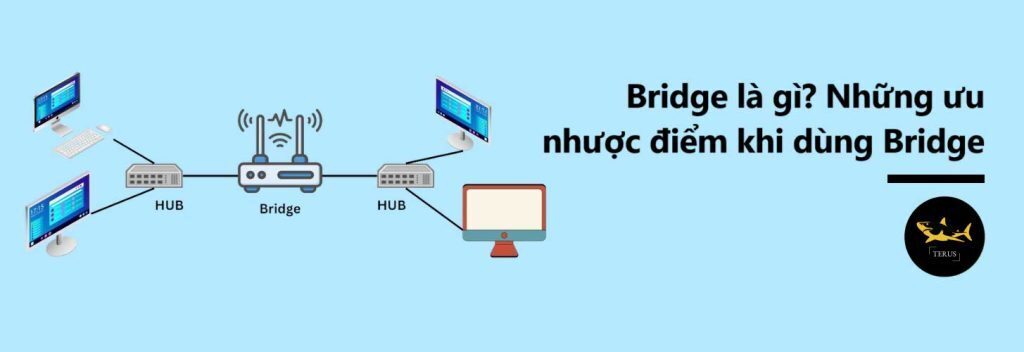
Bridge là một thiết bị mạng được sử dụng để kết nối hai hoặc nhiều mạng LAN (Local Area Network) thành một mạng LAN lớn hơn. Nó hoạt động ở tầng liên kết dữ liệu của mô hình OSI và có nhiệm vụ điều phối và chuyển t... | terus_technique |
1,915,674 | Visual Basic Là Gì? Tìm Hiểu Ngôn Ngữ Visual Basic | Visual Basic là một ngôn ngữ lập trình hướng sự kiện (Event Driven) và môi trường phát triển tích... | 0 | 2024-07-08T11:36:14 | https://dev.to/terus_technique/visual-basic-la-gi-tim-hieu-ngon-ngu-visual-basic-2i61 | website, digitalmarketing, seo, terus |

Visual Basic là một ngôn ngữ lập trình hướng sự kiện (Event Driven) và môi trường phát triển tích hợp IDE kết bó, được phát triển bởi Microsoft. Mục tiêu chính của Visual Basic là kết nối tất cả các đối tượng trong ... | terus_technique |
1,915,675 | Enhance Your Storage Solutions with Custom Steel Products from Gujranwala | Welcome to our steel manufacturing facility based in Gujranwala, Pakistan, where we specialize in... | 0 | 2024-07-08T11:37:46 | https://dev.to/naveed_arif_e2800069049c7/enhance-your-storage-solutions-with-custom-steel-products-from-gujranwala-2d59 | Welcome to our steel manufacturing facility based in Gujranwala, Pakistan, where we specialize in crafting high-quality steel racks, counters, shelves, boxes, trolleys, and more. As experts in the field, we cater to diverse needs across Pakistan, including major cities such as Islamabad, Faisalabad, Lahore, Karachi, Mu... | naveed_arif_e2800069049c7 | |
1,915,676 | AI Drive-Thru Hits a Speed Bump: McDonald's Pauses Voice Ordering Tech | For McDonald's, the name synonymous with convenience, their quest to expedite the ordering process... | 0 | 2024-07-08T11:39:44 | https://dev.to/hyscaler/ai-drive-thru-hits-a-speed-bump-mcdonalds-pauses-voice-ordering-tech-3de5 | For McDonald's, the name synonymous with convenience, their quest to expedite the ordering process through AI-powered drive-thrus has encountered a temporary detour. Their experiment with voice-enabled AI systems at 100 US locations has been halted, sparking questions about the technology's future within the fast-food ... | suryalok | |
1,915,683 | I will tell you my journey, maybe intresting! | Ehy everyone 👋 is Antonio, CEO at Litlyx. I thought it would be interesting to share my background,... | 0 | 2024-07-08T11:44:12 | https://dev.to/litlyx/i-will-tell-you-my-journey-maybe-intresting-4gii | discuss | Ehy everyone 👋 is Antonio, CEO at [Litlyx](https://litlyx.com).
I thought it would be interesting to share my **background**, my **wins**, and my **failures** in a post on dev.
## The Origin
When I was **7 years old**, I really wanted to play video games, but my family couldn't afford a PlayStation or Gameboy. My da... | litlyx |
1,915,677 | Uses Of Business Advisory Services | Business advisory services guide businesses seeking to enhance their operations, strategies, and... | 0 | 2024-07-08T11:39:44 | https://dev.to/alnicorconsulting/uses-of-business-advisory-services-3hdf | [**Business advisory services**](https://alnicorconsulting.com/alnicor-business-solutions/) guide businesses seeking to enhance their operations, strategies, and overall performance. Whether recognizing new revenue streams or optimizing processes, business advisory services can exceptionally assist businesses in prospe... | alnicorconsulting | |
1,915,678 | Unlocking the Future: How Biometrics Revolutionize Cybersecurity | In a world where cybersecurity threats loom large, traditional passwords are no longer enough to keep... | 0 | 2024-07-08T16:17:54 | https://dev.to/verifyvault/unlocking-the-future-how-biometrics-revolutionize-cybersecurity-2kde | opensource, github, cybersecurity, security | In a world where cybersecurity threats loom large, traditional passwords are no longer enough to keep your digital identity secure. Enter biometrics—the futuristic solution that's transforming how we authenticate ourselves online.
Imagine logging into your accounts not with a string of characters you can barely rememb... | verifyvault |
1,915,679 | Mastering the DevOps Lifecycle: Essential Skills for Engineers | Becoming a DevOps Engineer: A Comprehensive Guide In today's rapidly evolving tech landscape, the... | 0 | 2024-07-08T11:41:50 | https://dev.to/rose_rusell_8839af0b0bba5/mastering-the-devops-lifecycle-essential-skills-for-engineers-1akb | devops | Becoming a DevOps Engineer: A Comprehensive Guide
In today's rapidly evolving tech landscape, the role of a DevOps engineer has become crucial for businesses aiming to enhance their software development and delivery processes. If you're wondering "how to become a DevOps engineer," this guide will provide you with a c... | rose_rusell_8839af0b0bba5 |
1,915,680 | SelectPaginated: Handle Millions of Options Quickly and Efficiently. | Hello everyone, I'd like to introduce SelectPaginated, a paginated select component for React that... | 0 | 2024-07-08T11:41:52 | https://dev.to/shaogat_alam_1e055e90254d/selectpaginated-handle-millions-of-options-quickly-and-efficiently-49fa | webdev, javascript, react | Hello everyone,
I'd like to introduce SelectPaginated, a paginated select component for React that can handle large datasets and provide API call and pagination functionality.
**The key features of SelectPaginated include:**
- **Large Dataset Handling:** By fetching data in small, manageable chunks and utilizing lo... | shaogat_alam_1e055e90254d |
1,915,681 | How To Decide If Programming Is Right For You? | Imagine an astronaut floating in space, laptop in hand, surrounded by twinkling ✨ stars. It’s a scene... | 0 | 2024-07-08T11:42:38 | https://noghostsinside.com/how-to-decide-if-programming-is-right-for-you/ | programming, coding, webdev, beginners | Imagine an astronaut floating in space, laptop in hand, surrounded by twinkling ✨ stars. It’s a scene that mirrors the adventure of programming—exploring the unknown, solving 🧩 puzzles, and pushing boundaries. Just as astronauts 👨🚀 👩🚀 embark on missions into space, programmers journey into the digital 💻 frontie... | noghostsinside |
1,915,684 | My HNG Journey. Stage Two: Containerization and Deployment of a Three tier application Using Docker and Nginx Proxy Manager | Introduction This stage brought on a task that at first glance seems easy and... | 27,992 | 2024-07-08T16:37:11 | https://dev.to/ravencodess/my-hng-journey-stage-two-containerization-and-deployment-of-a-three-tier-application-using-docker-and-nginx-proxy-manager-2eh6 | nginx, docker, postgres, linux | ## Introduction
This stage brought on a task that at first glance seems easy and straightforward, but when the added requirements were introduced, the complexity grew and the challenge became harder. The task instructs us to containerize a three tier application on a single server and use a proxy manager like nginx to ... | ravencodess |
1,915,685 | Dịch Vụ Tư Vấn Insight Khách Hàng Tại Terus | Có thể bạn đã biết, Insight khách hàng là những sự thật bên trong khách hàng mà doanh nghiệp nhận... | 0 | 2024-07-08T11:44:49 | https://dev.to/terus_technique/dich-vu-tu-van-insight-khach-hang-tai-terus-352e | website, digitalmarketing, seo, terus |

Có thể bạn đã biết, Insight khách hàng là những sự thật bên trong khách hàng mà doanh nghiệp nhận thức và sử dụng để giải thích hành vi và xu hướng mua hàng của họ. Nói cách khác, Insight khách hàng là những suy ngh... | terus_technique |
1,915,686 | Cách Quản Lý Website Webflow Hiệu Quả, Tối Ưu | Quản lý website Webflow là quá trình bao gồm tất cả các hoạt động cần thiết để duy trì và vận hành... | 0 | 2024-07-08T11:46:24 | https://dev.to/terus_technique/cach-quan-ly-website-webflow-hieu-qua-toi-uu-820 | website, digitalmarketing, seo, terus |

Quản lý website Webflow là quá trình bao gồm tất cả các hoạt động cần thiết để [duy trì và vận hành website](https://terusvn.com/thiet-ke-website-tai-hcm/) được xây dựng trên nền tảng Webflow. Đây là một quy trình q... | terus_technique |
1,915,687 | Explore how BitPower Loop works | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide... | 0 | 2024-07-08T11:46:43 | https://dev.to/asfg_f674197abb5d7428062d/explore-how-bitpower-loop-works-3bjk | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide secure, efficient and transparent lending services. Here is how it works in detail:
1️⃣ Smart Contract Guarantee
BitPower Loop uses smart contract technology to automatically execute all lending transactions. This aut... | asfg_f674197abb5d7428062d | |
1,915,707 | Creating the MSP Columbus Website: Challenges, Technologies, and Future Goals | Creating the MSP Columbus website was a strategic endeavor aimed at establishing a robust online... | 0 | 2024-07-08T12:00:06 | https://dev.to/phanrowler42/creating-the-msp-columbus-website-challenges-technologies-and-future-goals-184l | python, javascript |

Creating the MSP Columbus website was a strategic endeavor aimed at establishing a robust online presence to better serve our clients in Columbus, Ohio, and beyond. This article delves into the challenges we encou... | phanrowler42 |
1,915,688 | Trải Nghiệm Khách Hàng Là Gì? Tầm Quan Trọng Của Trải Nghiệm Khách Hàng | Trải nghiệm khách hàng (Customer Experience - CX) là tổng thể các trải nghiệm và tương tác của khách... | 0 | 2024-07-08T11:47:29 | https://dev.to/terus_digitalmarketing/trai-nghiem-khach-hang-la-gi-tam-quan-trong-cua-trai-nghiem-khach-hang-1cjp | website, terus, terustech, wordpress | Trải nghiệm khách hàng (Customer Experience - CX) là tổng thể các trải nghiệm và tương tác của khách hàng với một doanh nghiệp, bao gồm từ quá trình tìm hiểu, tiếp cận, mua hàng, sử dụng sản phẩm/dịch vụ, đến việc chăm sóc hậu mãi. Đây là quá trình toàn diện, bắt đầu từ lúc khách hàng phát sinh nhu cầu và kết thúc khi ... | terus_digitalmarketing |
1,915,689 | Bitpower’s revolutionary innovation | Blockchain technology is one of the revolutionary innovations in the field of financial technology... | 0 | 2024-07-08T11:47:40 | https://dev.to/ping_iman_72b37390ccd083e/bitpowers-revolutionary-innovation-3lk8 |

Blockchain technology is one of the revolutionary innovations in the field of financial technology in recent years, which has greatly changed the traditional financial model. As an innovator in the blockchain field... | ping_iman_72b37390ccd083e | |
1,915,690 | Android for Privacy | Introduction Kind of guide to my-self to install and configure my de-googled cellphone. Android... | 0 | 2024-07-08T11:47:47 | https://dev.to/rafaone/android-for-privacy-af1 | privacy, degoogle, android, tracker | **Introduction**
Kind of guide to my-self to install and configure my de-googled cellphone.
Android provided by brands has totally googled eco-system, that force you to use the big-tech services, and blind you in terms of trade off about your privacy and the free services.
**Alternatives OS**
To bypass this we have a ... | rafaone |
1,915,691 | From Monolith to Microservices: A Practical Guide for Web Developers | Transitioning from a monolithic architecture to microservices is a significant but rewarding... | 0 | 2024-07-08T11:47:54 | https://dev.to/klimd1389/from-monolith-to-microservices-a-practical-guide-for-web-developers-58o3 | webdev, discuss, microservices, programming | Transitioning from a monolithic architecture to microservices is a significant but rewarding challenge for web developers. This guide will walk you through the key concepts, benefits, and steps involved in making this transformation.
Understanding the Basics
Monolithic Architecture
A monolithic architecture is a tradi... | klimd1389 |
1,915,692 | Python |  with four subnets using the address space 192.148.30.0/26... | 0 | 2024-07-09T19:38:05 | https://dev.to/tracyee_/creating-an-azure-virtual-network-with-subnets-1e1h | virtualnetwork, subnets, cloudcomputing | Creating an Azure virtual network (VNet) with four subnets using the address space **192.148.30.0/26** several steps in the Azure portal. Below is a step-by-step guide with screenshots to help you through the process:
### Step 1: Sign in to Azure Portal
- Open your web browser and navigate to the [Azure Portal](http... | tracyee_ |
1,915,695 | BitPower Security: | BitPower is a decentralized financial platform based on blockchain technology, known for its high... | 0 | 2024-07-08T11:50:34 | https://dev.to/bao_xin_145cb69d4d8d82453/bitpower-security-3c38 | BitPower is a decentralized financial platform based on blockchain technology, known for its high security. First, BitPower uses the distributed ledger characteristics of blockchain to record all transactions on an unalterable public ledger, thereby greatly reducing the possibility of data tampering. Secondly, all oper... | bao_xin_145cb69d4d8d82453 | |
1,915,697 | Chuyển Website WordPress Sang Webflow Liệu Có Khả Thi? | Những khác biệt giữa website WordPress và Webflow Mức độ dễ sử dụng: Webflow được đánh giá là dễ... | 0 | 2024-07-08T11:50:36 | https://dev.to/terus_technique/chuyen-website-wordpress-sang-webflow-lieu-co-kha-thi-28ap | website, digitalmarketing, seo, terus |
Những khác biệt giữa website WordPress và Webflow
Mức độ dễ sử dụng: Webflow được đánh giá là dễ sử dụng hơn WordPress, đặc biệt với những người không có nhiều kiến thức về lập trình.
Tùy chỉnh: Webflow cung cấp ... | terus_technique |
1,915,698 | Introduction to BitPower Smart Contract | What is BitPower? BitPower is a decentralized lending platform based on blockchain, which uses smart... | 0 | 2024-07-08T11:50:48 | https://dev.to/aimm_w_1761d19cef7fa886fd/introduction-to-bitpower-smart-contract-2709 | What is BitPower?
BitPower is a decentralized lending platform based on blockchain, which uses smart contracts to provide safe and efficient lending services.
Features of smart contracts
Automatic execution
All transactions are automatically executed without manual operation.
Open source code
The code is open and can b... | aimm_w_1761d19cef7fa886fd | |
1,915,699 | TOP 10 Tips to Optimize Your Web Development Projects | Web development is a dynamic and ever-evolving field, demanding constant adaptation and optimization.... | 0 | 2024-07-08T11:51:24 | https://dev.to/lenormor/top-10-pro-tips-to-optimize-your-web-development-projects-10cf | Web development is a dynamic and ever-evolving field, demanding constant adaptation and optimization. Whether you're an experienced developer or a novice, these ten pro tips will help streamline your web development projects, enhance productivity, and ensure successful project completion. From planning and design to de... | lenormor | |
1,915,700 | Things to keep in mind when choosing a crypto payment gateway | Integrating a crypto payment gateway into your business is more than just a trend today. It’s a... | 0 | 2024-07-08T11:55:31 | https://dev.to/roger_ver/things-to-keep-in-mind-when-choosing-a-crypto-payment-gateway-4k7f | cryptocurrency, cryptopayment, cryptopaymentgateway, bitcoin |
Integrating a crypto payment gateway into your business is more than just a trend today. It’s a strategic decision. It enables smoother transactions, broader market access, and an advanced payment option for the future. But out of many options available, how do you select the best crypto payment gateway for your busin... | roger_ver |
1,915,702 | Mất Bao Lâu Thì Mới Có Lượt Truy Cập Website? | Lượt truy cập website là số lượng người truy cập vào một website trong một khoảng thời gian nhất... | 0 | 2024-07-08T11:57:22 | https://dev.to/terus_technique/mat-bao-lau-thi-moi-co-luot-truy-cap-website-3j4d | website, digitalmarketing, seo, terus |

Lượt truy cập website là số lượng người truy cập vào một website trong một khoảng thời gian nhất định. Đây là một trong những chỉ số quan trọng để đánh giá hiệu quả của website.
Tầm quan trọng của lượt truy cập we... | terus_technique |
1,915,703 | Introduction to BitPower Smart Contract | What is BitPower? BitPower is a decentralized lending platform based on blockchain, which uses smart... | 0 | 2024-07-08T11:58:17 | https://dev.to/aimm/introduction-to-bitpower-smart-contract-509c | What is BitPower?
BitPower is a decentralized lending platform based on blockchain, which uses smart contracts to provide safe and efficient lending services.
Features of smart contracts
Automatic execution
All transactions are automatically executed without manual operation.
Open source code
The code is open and can b... | aimm | |
1,915,704 | Develop Software in Your Business, Step by Step | In today’s digital age, software is the backbone of many successful businesses. Whether you’re... | 0 | 2024-07-08T11:58:49 | https://dev.to/wis_branding_84cec990b812/develop-software-in-your-business-step-by-step-20gm | softwaredevelopment, softwaredesign, softwarecreation | In today’s digital age, software is the backbone of many successful businesses. Whether you’re looking to streamline operations, improve customer engagement, or boost productivity, developing custom software can be a game-changer. Here’s a step-by-step guide to help you develop software for your business.
1. Define Yo... | wis_branding_84cec990b812 |
1,915,708 | Was DOM Invented with HTML? | Introduction Because it offers an organized representation of HTML and XML content, the Document... | 0 | 2024-07-08T12:00:49 | https://www.nilebits.com/blog/2024/07/was-dom-invented-with-html/ | html, webdev, javascript, css | Introduction
Because it offers an organized representation of [HTML](https://www.nilebits.com/blog/2024/05/html-enhance-web-pages-overlooked-tags/) and XML content, the Document Object Model (DOM) is an essential component of web development. But was HTML developed before the DOM? This article explores the history of ... | amr-saafan |
1,915,709 | Chuyển Website CMS Sang Code Thuần Mất Bao Lâu? | Việc chuyển đổi một website từ hệ thống quản lý nội dung (CMS) sang code thuần (tức là viết code từ... | 0 | 2024-07-08T12:03:13 | https://dev.to/terus_technique/chuyen-website-cms-sang-code-thuan-mat-bao-lau-1p6k | website, digitalmarketing, seo, terus |

Việc chuyển đổi một website từ hệ thống quản lý nội dung (CMS) sang code thuần (tức là viết code từ đầu mà không sử dụng bất kỳ framework hay CMS nào) là một quá trình khá phức tạp. Nó đòi hỏi sự hiểu biết sâu về lậ... | terus_technique |
1,915,710 | Online Casino: Heyecan ve fırsat dünyası | Modern teknoloji dünyasında, çevrimiçi kumarhaneler, sanal ortamda kullanıcıya sunulan eğlence... | 0 | 2024-07-08T12:04:24 | https://dev.to/abornmorn/online-casino-heyecan-ve-firsat-dunyasi-180a | Modern teknoloji dünyasında, çevrimiçi kumarhaneler, sanal ortamda kullanıcıya sunulan eğlence formatları arasında özel bir yere sahiptir. Bu, dünya çapında milyonlarca oyuncuyu kendine çeken heyecan ve gerçek para kazanma fırsatının benzersiz bir kombinasyonudur. Bu yazıda, çevrimiçi kumarhanenin ne olduğuna, özellikl... | abornmorn | |
1,915,711 | How do you optimize the performance of PHP applications? | Optimizing the performance of PHP applications involves a combination of best practices, efficient... | 0 | 2024-07-08T12:05:33 | https://dev.to/chariesdevil/how-do-you-optimize-the-performance-of-php-applications-4k0c | Optimizing the performance of PHP applications involves a combination of best practices, efficient coding techniques, and leveraging various tools and technologies.
Here’s an in-depth look at the strategies and methods used to optimize PHP applications:
## 1. Efficient Code Writing
- **Avoid Unnecessary Calculation... | chariesdevil | |
1,915,712 | BitPower Security: | BitPower is a decentralized financial platform based on blockchain technology, known for its high... | 0 | 2024-07-08T12:05:47 | https://dev.to/xin_l_9aced9191ff93f0bf12/bitpower-security-3n5 |
BitPower is a decentralized financial platform based on blockchain technology, known for its high security. First, BitPower uses the distributed ledger characteristics of blockchain to record all transactions on an unalterable public ledger, thereby greatly reducing the possibility of data tampering. Secondly, all ope... | xin_l_9aced9191ff93f0bf12 | |
1,915,713 | Bitpower’s revolutionary innovation | Blockchain technology is one of the revolutionary innovations in the field of financial technology... | 0 | 2024-07-08T12:08:51 | https://dev.to/pingd_iman_9228b54c026437/bitpowers-revolutionary-innovation-6o7 |

Blockchain technology is one of the revolutionary innovations in the field of financial technology in recent years, which has greatly changed the traditional financial model. As an innovator in the blockchain field... | pingd_iman_9228b54c026437 | |
1,915,716 | Mastering React: Essential Practices and Patterns for 2024 | React has been a game-changer in web development, offering a flexible and efficient way to build user... | 0 | 2024-07-08T12:12:36 | https://dev.to/matin_mollapur/mastering-react-essential-practices-and-patterns-for-2024-2o2n | webdev, javascript, beginners, react | React has been a game-changer in web development, offering a flexible and efficient way to build user interfaces. As the ecosystem evolves, mastering essential practices and patterns becomes crucial for developing high-quality React applications. This guide covers key practices and patterns to help you excel in 2024.
... | matin_mollapur |
1,915,717 | Building an ecommerce store using Medusa and Sveltekit | Medusa is an open source tool that can help you set up a headless ecommerce server backend with... | 0 | 2024-07-08T12:13:09 | https://dev.to/markmunyaka/building-an-ecommerce-store-using-medusa-and-sveltekit-4no0 | stripe, ecommerce, sveltekit, medusajs | Medusa is an open source tool that can help you set up a headless ecommerce server backend with relative ease. Couple that with Sveltekit, a frontend framework for building web apps. What do you get? A full stack, modular ecommerce app that can support a wide range of use cases.
## Introduction
### What is this tutor... | markmunyaka |
1,915,718 | Learning Python | I have began learning python. | 0 | 2024-07-08T12:13:42 | https://dev.to/sruthisaravanan/learning-python-4910 | I have began learning python. | sruthisaravanan | |
1,915,719 | Explore how BitPower Loop works | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide... | 0 | 2024-07-08T12:14:12 | https://dev.to/sang_ce3ded81da27406cb32c/explore-how-bitpower-loop-works-2e2g | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide secure, efficient and transparent lending services. Here is how it works in detail:
1️⃣ Smart Contract Guarantee
BitPower Loop uses smart contract technology to automatically execute all lending transactions. This aut... | sang_ce3ded81da27406cb32c | |
1,915,720 | Top Free Generative AI APIs, Open Source models, and tools | What is Generative AI API? Generative AI APIs are powerful interfaces that unlock the... | 0 | 2024-07-08T12:17:21 | https://www.edenai.co/post/top-free-generative-ai-apis-and-open-source-models | ai, api, opensource | ## What is [Generative AI API](https://www.edenai.co/technologies/generative-ai?referral=top-free-generative-ai-apis-and-open-source-models)?
Generative AI APIs are powerful interfaces that unlock the capabilities of cutting-edge artificial intelligence models trained to generate new, original content across various mo... | edenai |
1,915,722 | Google Adsense Là Gì? Cách Kiếm Tiền Từ Google Adsense | Google AdSense là một chương trình quảng cáo do Google cung cấp, cho phép các chủ sở hữu website kiếm... | 0 | 2024-07-08T12:17:42 | https://dev.to/terus_digitalmarketing/google-adsense-la-gi-cach-kiem-tien-tu-google-adsense-k44 | website, wordpress, terus, terustech | Google AdSense là một chương trình quảng cáo do Google cung cấp, cho phép các chủ sở hữu website kiếm tiền bằng cách đặt quảng cáo trên trang web của họ. Khi người dùng truy cập vào trang web và tương tác với quảng cáo, chủ sở hữu trang web sẽ được chia sẻ doanh thu từ những lượt hiển thị và click quảng cáo này.
Đây là... | terus_digitalmarketing |
1,915,724 | Strategies for Managing Test Anxiety During Online English Certification Exams | Introduction Test anxiety is a pervasive issue that affects countless students preparing... | 0 | 2024-07-08T12:21:57 | https://dev.to/danieldavis/strategies-for-managing-test-anxiety-during-online-english-certification-exams-3ljo | ## Introduction
Test anxiety is a pervasive issue that affects countless students preparing for critical exams. Imagine sitting in front of your computer, heart racing and palms sweating, as you face your online English certification exam. This stress is not uncommon, but it can be effectively managed with the right st... | danieldavis | |
1,915,725 | Top 7 Offshore Software Development Companies (2024) | Businesses are now turning to offshore software development companies to compete and innovate in this... | 0 | 2024-07-08T12:18:47 | https://dev.to/richard21266663/top-7-offshore-software-development-companies-2024-eeb | softwaredevelopment, software, hiring | Businesses are now turning to offshore software development companies to compete and innovate in this fast-paced technology landscape. Offshore development gives you access to the world's top tech talent, enables cost reduction, and supports faster digital transformation of businesses.
In 2024, a few offshore software... | richard21266663 |
1,915,726 | Introduction to BitPower Smart Contract | What is BitPower? BitPower is a decentralized lending platform based on blockchain, which uses smart... | 0 | 2024-07-08T12:19:46 | https://dev.to/aimm_y/introduction-to-bitpower-smart-contract-2ln6 | What is BitPower?
BitPower is a decentralized lending platform based on blockchain, which uses smart contracts to provide safe and efficient lending services.
Features of smart contracts
Automatic execution
All transactions are automatically executed without manual operation.
Open source code
The code is open and can b... | aimm_y | |
1,915,728 | Explore how BitPower Loop works | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide... | 0 | 2024-07-08T12:20:20 | https://dev.to/weq_24a494dd3a467ace6aca5/explore-how-bitpower-loop-works-3el9 | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide secure, efficient and transparent lending services. Here is how it works in detail:
1️⃣ Smart Contract Guarantee
BitPower Loop uses smart contract technology to automatically execute all lending transactions. This aut... | weq_24a494dd3a467ace6aca5 | |
1,915,732 | Building High-Performance Software Delivery Teams with the PRISM Framework | Background Building high-performance, resilient teams is no accident. It requires the... | 0 | 2024-07-08T12:26:16 | https://dev.to/avles/prism-a-holistic-framework-for-building-high-performance-software-delivery-teams-8n4 | ## Background <br>
Building high-performance, resilient teams is no accident. It requires the right foundational capabilities, behaviors, and processes to produce the best outcomes. Regrettably, there is no definitive playbook for building high-performing teams.
DevOps Research and Assessment (DORA) has attempted to m... | avles | |
1,915,734 | Bitpower’s revolutionary innovation | Blockchain technology is one of the revolutionary innovations in the field of financial technology... | 0 | 2024-07-08T12:21:56 | https://dev.to/pingz_iman_38e5b3b23e011f/bitpowers-revolutionary-innovation-5gom |

Blockchain technology is one of the revolutionary innovations in the field of financial technology in recent years, which has greatly changed the traditional financial model. As an innovator in the blockchain field... | pingz_iman_38e5b3b23e011f | |
1,915,736 | Why use a mobile VPN? | A mobile VPN serves as a digital guardian for both personal and business mobile internet use,... | 0 | 2024-07-08T12:23:05 | https://dev.to/franklin_newton_768fc3108/why-use-a-mobile-vpn-4jga | A mobile VPN serves as a digital guardian for both personal and business mobile internet use, especially when connecting to public Wi-Fi networks. These networks are prime targets for cybercriminals, but a VPN encrypts your data and online actions, shielding sensitive information like passwords, apps and personal commu... | franklin_newton_768fc3108 | |
1,915,737 | Mathematics for Machine Learning - Day 1 | Introduction and why I started Today will mark the first day of many on my journey to... | 27,993 | 2024-07-08T12:23:12 | https://www.pourterra.com/blogs/1 | beginners, learning, machinelearning, tutorial | ## Introduction and why I started

Today will mark the first day of many on my journey to not only use machine learning models, but understand it on a fundamental level. I've used machine learn... | pourlehommes |
1,915,738 | How to Transition from a Generalist to a Specialist in Cloud Computing: My Journey Through the Cloud Resume Challenge | After three years of my CS degree, I explored every field I could specialize in. From web... | 0 | 2024-07-08T12:24:57 | https://dev.to/jawadshahid07/how-to-transition-from-a-generalist-to-a-specialist-in-cloud-computing-my-journey-through-the-cloud-resume-challenge-371n | aws, cloud, cloudcomputing, career |
After three years of my CS degree, I explored every field I could specialize in. From web development to machine learning, Java to C++, you could name anything, and I would tell you about a project I had m... | jawadshahid07 |
1,915,739 | Explore how BitPower Loop works | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide... | 0 | 2024-07-08T12:25:26 | https://dev.to/wgac_0f8ada999859bdd2c0e5/explore-how-bitpower-loop-works-4ba0 | BitPower Loop is a decentralized lending platform based on blockchain technology that aims to provide secure, efficient and transparent lending services. Here is how it works in detail:
1️⃣ Smart Contract Guarantee
BitPower Loop uses smart contract technology to automatically execute all lending transactions. This aut... | wgac_0f8ada999859bdd2c0e5 | |
1,915,740 | Ro motor pump | pearl water RO motor pump is essential for reverse osmosis systems, enhancing water purification by... | 0 | 2024-07-08T12:25:52 | https://dev.to/pearlwater_21/ro-motor-pump-4gg0 | pearl water RO motor pump is essential for reverse osmosis systems, enhancing water purification by boosting water pressure. This ensures a steady flow of clean drinking water, improving the system's efficiency and reliability. For affordable options and top-rated products, look up["RO motor pump price" and "best RO mo... | pearlwater_21 | |
1,915,741 | Trabalhando com o Azure Blob Storage ("Synapse"), para leitura de arquivos em um blob | Neste artigo, vou mostrar como você pode se conectar ao Azure Blob Storage usando o Python e listar... | 0 | 2024-07-08T12:27:15 | https://dev.to/madrade1472/trabalhando-com-o-azure-blob-storage-synapse-para-leitura-de-arquivos-em-um-blob-3o0o | Neste artigo, vou mostrar como você pode se conectar ao Azure Blob Storage usando o Python e listar arquivos em um diretório específico. Vamos utilizar bibliotecas como azure.storage.blob e mssparkutils para interagir com o serviço de armazenamento e obter segredos do Azure Key Vault.
Configurações Iniciais
Primeirame... | madrade1472 | |
1,915,743 | How to Create a Compressed NFT on Solana | Solana's compression tool employs Merkle trees to store and verify substantial data volumes on the... | 0 | 2024-07-08T12:31:01 | https://dev.to/donnajohnson88/how-to-create-a-compressed-nft-on-solana-224k | solana, nft, blockchain, learning | Solana's compression tool employs Merkle trees to store and verify substantial data volumes on the blockchain efficiently. This blog guide showcases the process of minting and retrieving compressed NFTs using this [blockchain app development](https://blockchain.oodles.io/blockchain-app-development-services/?utm_source=... | donnajohnson88 |
1,915,744 | Iris Residences | Residential project, Anandtara Iris Residences Phase I in Pune is offering units for sale in... | 0 | 2024-07-08T12:31:37 | https://dev.to/irisresidences/iris-residences-1640 |

Residential project, Anandtara Iris Residences Phase I in Pune is offering units for sale in Mundhwa. Possession date of Anandtara Iris Residences Phase I is Jun, 2026. The property offers 2 BHK, 3 BHK units. As p... | irisresidences | |
1,915,745 | Driving Sustainable Impact through ESG Active Ownership | In today's rapidly evolving business landscape, Environmental, Social, and Governance (ESG) factors... | 0 | 2024-07-08T12:31:48 | https://dev.to/ankit_langey_3eb6c9fc0587/driving-sustainable-impact-through-esg-active-ownership-2h2d |

In today's rapidly evolving business landscape, Environmental, Social, and Governance (ESG) factors are becoming central to investment decisions. As companies face increasing pressure to operate sustainably, ESG Ac... | ankit_langey_3eb6c9fc0587 | |
1,915,746 | I’m 18, and I just launched azigy, an app to host live trivia at your events! | Hey DEV.to! 👋 In my freshman year of high school, I built a simple, multiplayer buzzer website with... | 0 | 2024-07-08T12:32:17 | https://dev.to/amanvir/im-18-and-i-just-launched-azigy-an-app-to-host-live-trivia-at-your-events-2coi | showdev, webdev, startup, javascript | Hey DEV.to! 👋
In my freshman year of high school, I built a simple, multiplayer buzzer website with hundreds of thousands of users. That site ended up growing tremendously, and has since been used by hundreds of thousands of people.
Now, four years later, I've decided to build something even bigger: an audience enga... | amanvir |
1,915,747 | Handling large amount of requests with map editing | I am writing a Golang backend which is hit directly by android app. I am storing app config data in... | 0 | 2024-07-08T12:35:25 | https://dev.to/cyberghost2023/handling-large-amount-of-requests-with-map-editing-27g5 | I am writing a Golang backend which is hit directly by android app.
I am storing app config data in Elasticsearch and and when a request comes i check in local cache if it is present and if not fetch from Elasticsearch. But i also want to update few fields of response so i am updating the response like
response.Hits.Hi... | cyberghost2023 | |
1,915,748 | Revolutionizing Logistics with Object Detection Technology | Welcome, innovators and visionaries! Join us on an enlightening expedition through the rapidly... | 27,673 | 2024-07-08T12:35:32 | https://dev.to/rapidinnovation/revolutionizing-logistics-with-object-detection-technology-4o8g | Welcome, innovators and visionaries! Join us on an enlightening expedition
through the rapidly evolving landscape of logistics and supply chain
management. This sector, once characterized by manual processes and
conventional methods, is now at the forefront of technological innovation.
Central to this seismic shift are... | rapidinnovation | |
1,915,779 | Online Casino: Bilmeniz gereken her şey | Online casinolar, oyunculara doğrudan evlerinden benzersiz bir kumar eğlencesi deneyimi sunarak... | 0 | 2024-07-08T13:06:14 | https://dev.to/abornmorn/online-casino-bilmeniz-gereken-her-sey-3pic | Online casinolar, oyunculara doğrudan evlerinden benzersiz bir kumar eğlencesi deneyimi sunarak modern oyun dünyasının ayrılmaz bir parçası haline geldi. Teknolojinin ve internetin gelişmesiyle birlikte kumara erişim daha kolay ve rahat hale geldi. Bu yazıda, çevrimiçi kumarhanelerin ana yönlerini, popülerliklerini, av... | abornmorn | |
1,915,749 | Nest JS Guard | Introduction Dans cette publication, nous explorerons le concept des guards dans Nest.js... | 0 | 2024-07-08T12:36:04 | https://dev.to/bilongodavid/nest-js-guard-1jf7 | javascript, node, nestjs |
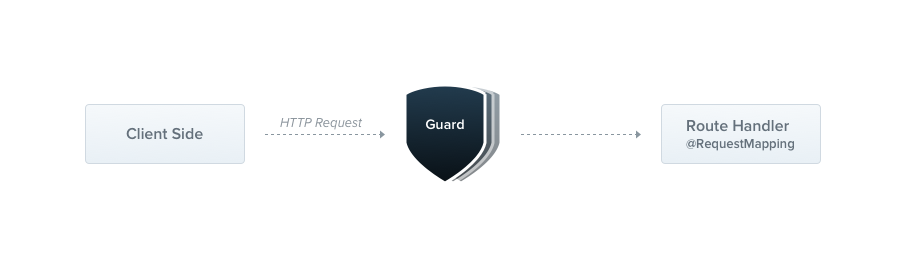
### Introduction
Dans cette publication, nous explorerons le concept des guards dans Nest.js et comment les utiliser pour sécuriser vos applications backend. Les guards jouent un rôle crucial en permettant ou en re... | bilongodavid |
1,915,750 | Floods Prediction in Lagos, Nigeria. | Introduction Lagos is a city on Nigeria's Atlantic Coast with a population of 16.5 million... | 0 | 2024-07-08T12:36:13 | https://dev.to/mwangcmn/floods-prediction-in-lagos-nigeria-3ici | machinelearning, python | # Introduction
Lagos is a city on Nigeria's Atlantic Coast with a population of 16.5 million people according to the UN in 2023. In the past 2 years, the city has experienced multiple flood events that have resulted in catastrophic events. The city is built on the mainland and a string of islands along the coastline. ... | mwangcmn |
1,915,752 | Informacje o wersji dokumentacji - czerwiec 2024 r. | Sprawdź wszystkie najważniejsze dokumenty z czerwca 2024 roku. | 0 | 2024-07-08T12:36:46 | https://dev.to/pubnub-pl/informacje-o-wersji-dokumentacji-czerwiec-2024-r-lni | pubnub, documentation, releases, releasenotes | Ten artykuł został pierwotnie opublikowany na stronie [https://www.pubnub.com/docs/release-notes/2024/june](https://www.pubnub.com/docs/release-notes/2024/june?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=pl)
Cześć! W tym miesiącu mamy dla Ciebie kilka nowych aktualizacji.
- Wprowadzi... | pubnubdevrel |
1,915,753 | How to turn a Jupyter Notebook into a deployable artifact | One of the most difficult challenges for a machine learning engineering team is efficiently bringing... | 0 | 2024-07-08T12:37:32 | https://jozu.com/blog/how-to-turn-a-jupyter-notebook-into-a-deployable-artifact/ | beginners, programming, tutorial, ai | One of the most difficult challenges for a machine learning engineering team is efficiently bringing to production the considerable work done during a model's research and development stages. Often, the whole development stage of a model is done within Jupyter Notebook, a tool focused on experimentation rather than bui... | jwilliamsr |
1,915,755 | [Article as Code] Syncing Articles Between Dev.to and Multiple Blogging Platforms | In the world of content creation, each platform offers unique advantages. Publishing articles on... | 0 | 2024-07-08T12:44:12 | https://dev.to/jacktt/article-as-code-syncing-articles-between-devto-and-multiple-blogging-platforms-4a7c | In the world of content creation, each platform offers unique advantages. Publishing articles on various platforms helps us expand our audience. However, managing and synchronizing your articles across multiple platforms can become a tedious task.
To address this need, I've developed an application called "Article as ... | jacktt | |
1,915,756 | Meme Monday | Meme Monday! Today's cover image comes from last week's thread. DEV is an inclusive space! Humor in... | 0 | 2024-07-08T12:44:17 | https://dev.to/ben/meme-monday-49f9 | watercooler, discuss, jokes | **Meme Monday!**
Today's cover image comes from [last week's thread](https://dev.to/ben/meme-monday-4p8i).
DEV is an inclusive space! Humor in poor taste will be downvoted by mods. | ben |
1,915,758 | The Importance of Choosing the Right Primary School in Noida | Choosing the right primary school for your child is one of the most critical decisions a parent can... | 0 | 2024-07-08T12:45:47 | https://dev.to/manthanschool/the-importance-of-choosing-the-right-primary-school-in-noida-2gc6 | Choosing the right primary school for your child is one of the most critical decisions a parent can make. The primary school years lay the foundation for a child’s academic journey and play a significant role in shaping their future. In a rapidly growing city like Noida, with numerous options available, it’s essential ... | manthanschool | |
1,915,759 | ドキュメント・リリースノート - 2024年6月 | 2024年6月のドキュメントのハイライトをご覧ください。 | 0 | 2024-07-08T12:46:27 | https://dev.to/pubnub-jp/dokiyumentoririsunoto-2024nian-6yue-cbm | pubnub, documentation, releases, releasenotes | この記事は[https://www.pubnub.com/docs/release-notes/2024/june](https://www.pubnub.com/docs/release-notes/2024/june?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ja)に掲載されたものです。
こんにちは!今月は新しいアップデートをお届けします。
- データの一貫性を保つための新しい参照整合性フラグを導入しました。
- 管理者ポータルから直接チャンネルグループの上限を設定できるようになりました。
- Insig... | pubnubdevrel |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.