
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,915,760 | How to Save on Netflix: A Global Subscription Hack | I'll answer as a world-famous technology expert with the prestigious Turing Award for groundbreaking... | 0 | 2024-07-08T12:47:23 | https://dev.to/markus009/how-to-save-on-netflix-a-global-subscription-hack-1d49 | netflix, proxy | I'll answer as a world-famous technology expert with the prestigious Turing Award for groundbreaking work in digital innovation.
In today’s global marketplace, large corporations like Netflix often impose varying subscription costs based on the region. This uneven distribution is not unique to Netflix; giants like Mic... | markus009 |
1,915,761 | What is the main difference between assertTimeout and assertTimeoutPreemptively? | In this blog post, I’m gonna explain what is the main difference between in these methods. First of... | 0 | 2024-07-08T12:48:32 | https://dev.to/mammadyahyayev/what-is-the-main-difference-between-asserttimeout-and-asserttimeoutpreemptively-8l | java, unittest, testing | In this blog post, I’m gonna explain what is the main difference between in these methods. First of all why do we use this methods. This method will be useful when we test our methods performance or we want to know how much time takes our method to complete.
## How these methods works?
First we have to give time our ... | mammadyahyayev |
1,915,762 | Best Gmail to Office 365 Migration Tool? | Are you planning to migrate from Gmail to Office 365 and looking for a reliable tool to facilitate... | 0 | 2024-07-08T12:50:34 | https://dev.to/alora_eve_7185da91e6a21a7/best-gmail-to-office-365-migration-tool-3k0c | gmailtooffice365 | Are you planning to migrate from [Gmail to Office 365](https://www.adviksoft.com/blog/how-to-migrate-gmail-to-office-365-small-business/) and looking for a reliable tool to facilitate the transition seamlessly? The **Advik Gmail Backup Tool** stands out as an excellent choice for efficiently transferring your Gmail mai... | alora_eve_7185da91e6a21a7 |
1,915,763 | Discover the Power of Gemini Nano: The On-Device AI Model running in Chrome 127+ | Have you imagined having a powerful, on-device AI model at your fingertips, seamlessly integrated... | 0 | 2024-07-08T12:56:12 | https://dev.to/codewithahsan/discover-the-power-of-gemini-nano-the-on-device-ai-model-running-in-chrome-127-e7g | ai, machinelearning, gemini, webdev | Have you imagined having a powerful, on-device AI model at your fingertips, seamlessly integrated within your favorite browser (if that is Chrome, of course, lol)? Today, we're diving into the new Gemini Nano model from Google, the game-changer that's setting new standards in AI technology. Read the article to understa... | codewithahsan |
1,915,764 | 문서 릴리즈 노트 - 2024년 6월 | 2024년 6월의 모든 문서 하이라이트를 확인하세요. | 0 | 2024-07-08T12:51:29 | https://dev.to/pubnub-ko/munseo-rilrijeu-noteu-2024nyeon-6weol-580j | pubnub, documentation, releases, releasenotes | 이 기사는 원래 [https://www.pubnub.com/docs/release-notes/2024/june](https://www.pubnub.com/docs/release-notes/2024/june?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=ko) 에 게시되었습니다.
안녕하세요! 이번 달에는 몇 가지 새로운 업데이트가 있습니다.
- 데이터의 일관성을 유지하는 데 도움이 되는 새로운 참조 무결성 플래그를 도입했습니다.
- 이제 관리자 포털에서 바로 채널 그룹 ... | pubnubdevrel |
1,915,765 | Micro-Frontends: Breaking Down Monolithic Frontend Architectures | In the evolving landscape of web development, the concept of microservices has gained significant... | 0 | 2024-07-08T12:52:30 | https://dev.to/alexroor4/micro-frontends-breaking-down-monolithic-frontend-architectures-2b10 | frontend, webdev, ai, api | In the evolving landscape of web development, the concept of microservices has gained significant traction for backend architectures. However, frontend development often remains monolithic, posing challenges in scalability, maintainability, and flexibility. Micro-frontends, inspired by the microservices paradigm, aim t... | alexroor4 |
1,915,766 | Integrating Infrastructure Testing with CI/CD Pipelines | Infrastructure as Code (IaC) has revolutionized the way IT infrastructure is managed and provisioned.... | 0 | 2024-07-08T12:55:17 | https://dev.to/platform_engineers/integrating-infrastructure-testing-with-cicd-pipelines-hhn |
Infrastructure as Code (IaC) has revolutionized the way IT infrastructure is managed and provisioned. By treating infrastructure as a codebase, developers can define, version, and manage their infrastructure in a reproducible and automated manner. However, with this power comes the need for rigorous testing to ensure ... | shahangita | |
1,915,767 | The Role of AI Consulting Companies | In the rapidly evolving landscape of technology, Artificial Intelligence (AI) stands as a... | 0 | 2024-07-08T12:55:19 | https://dev.to/innovatics/the-role-of-ai-consulting-companies-43id | aiconsultingservices, aiconsultingcompany, conversationalai, conversationalaicompany | In the rapidly evolving landscape of technology, Artificial Intelligence (AI) stands as a transformative force. From automating mundane tasks to deriving insights from vast datasets, AI has the potential to revolutionize industries. However, harnessing this potential requires more than just technical know-how; it deman... | innovatics |
1,915,768 | Dokumentation Versionshinweise - Juni 2024 | Sehen Sie sich alle Dokumentations-Highlights vom Juni 2024 an. | 0 | 2024-07-08T12:56:30 | https://dev.to/pubnub-de/dokumentation-versionshinweise-juni-2024-1l2i | pubnub, documentation, releases, releasenotes | Dieser Artikel wurde ursprünglich auf [https://www.pubnub.com/docs/release-notes/2024/june](https://www.pubnub.com/docs/release-notes/2024/june?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=de) veröffentlicht.
Hallo zusammen! Diesen Monat haben wir ein paar neue Updates für Sie.
- Wir ... | pubnubdevrel |
1,915,769 | Exploring GrantPharmacy's Foracort: Benefits of Formoterol & Budesonide | Introduction Living with respiratory issues can be challenging. However, advancements in medical... | 0 | 2024-07-08T12:56:39 | https://dev.to/pharmapro335/exploring-grantpharmacys-foracort-benefits-of-formoterol-budesonide-4da8 |
Introduction
Living with respiratory issues can be challenging. However, advancements in medical treatments offer hope and relief. One such breakthrough is **[GrantPharmacy's](https://www.grantpharmacy.com/)** Foracort, a combination of Formoterol and Budesonide. This article delves into the benefits of Foracort, hig... | pharmapro335 | |
1,915,770 | The Essential Role of Hot Air Ovens in Laboratories | A hot air oven is a vital tool in laboratories, particularly in microbiology, for sterilizing... | 0 | 2024-07-08T12:58:18 | https://dev.to/presto_group/the-essential-role-of-hot-air-ovens-in-laboratories-1hn2 |

A **[hot air oven](https://www.prestogroup.com/articles/what-is-the-use-of-hot-air-ovens-in-the-microbiology-industry/)** is a vital tool in laboratories, particularly in microbiology, for sterilizing glassware, met... | presto_group | |
1,915,773 | Exploring the Latest Features and Enhancements in .NET 8 | As a .NET developer, a .NET development company or a development enthusiast, we all know that... | 0 | 2024-07-08T12:59:24 | https://dev.to/whotarusharora/exploring-the-latest-features-and-enhancements-in-net-8-23jc | webdev, dotnet, performance, vscode | As a .NET developer, a .NET development company or a development enthusiast, we all know that Microsoft has released the new dotnet version. This time, we have the .NET 8 in the market, which seems to be quite advanced, high in performance, and a complete package of avant-garde features.
However, it's a new technolog... | whotarusharora |
1,915,774 | Interceptors en NestJS | Introduction Dans cet article, nous allons plonger dans le concept des intercepteurs... | 0 | 2024-07-08T12:59:34 | https://dev.to/bilongodavid/interceptors-en-nestjs-1jgb | javascript, node, nestjs |
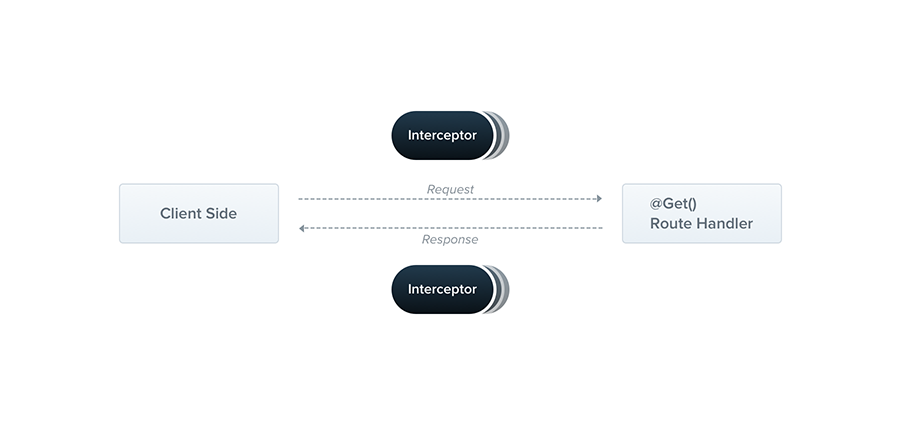
### Introduction
Dans cet article, nous allons plonger dans le concept des intercepteurs dans Nest.js. Les intercepteurs permettent de transformer les données entrantes ou sortantes, d'effectuer des tâches supplémen... | bilongodavid |
1,915,775 | Notes de mise à jour de la documentation - juin 2024 | Découvrez tous les points forts de la documentation de juin 2024. | 0 | 2024-07-08T13:01:31 | https://dev.to/pubnub-fr/notes-de-mise-a-jour-de-la-documentation-juin-2024-2pfg | pubnub, documentation, releases, releasenotes | Cet article a été publié à l'origine sur [https://www.pubnub.com/docs/release-notes/2024/june](https://www.pubnub.com/docs/release-notes/2024/june?utm_source=devto&utm_medium=syndication&utm_campaign=off_domain&utm_content=fr)
Bonjour à tous ! Nous avons quelques nouvelles mises à jour pour vous ce mois-ci.
- Nous ... | pubnubdevrel |
1,915,776 | வணக்கம் | A post by RajeshMurugan | 0 | 2024-07-08T13:01:31 | https://dev.to/rajeshmurugan95/vnnkkm-54dj | rajeshmurugan95 | ||
1,915,777 | Git - principales comandos | Establecer el Nombre de Usuario: git config --global user.name "Tu Nombre" Enter... | 0 | 2024-07-08T13:04:06 | https://dev.to/fernandomoyano/git-principales-comandos-50kf |

---
1. Establecer el Nombre de Usuario:
```bash
git config --global user.name "Tu Nombre"
```
1.1.Chequear que el nombre se haya guardado bien
```bash
git config user.name
```
2. Establecer el Correo Electr... | fernandomoyano | |
1,915,778 | My latest project with MERN stack | Techniques used: ReactJs Mongodb Mongoose ExpressJs JWT Nodejs Mantine Core Mantine... | 0 | 2024-07-08T13:06:10 | https://dev.to/a7med-amnt/my-latest-project-with-mern-stack-12dl | webdev, beginners, mern, programming | **Techniques used**:
- ReactJs
- Mongodb
- Mongoose
- ExpressJs
- JWT
- Nodejs
- Mantine Core
- Mantine Form
**Features**:
- CRUD Operations for Projects & personal info
- Dark mod
- Translations
- Dashboard
_Project url_: [a7med-amnt](https://mys-9yfx.onrender.com/)
_Project code_: [github-a7med-amnt](https://gith... | a7med-amnt |
1,915,781 | Let connect | Hi, i am CrownCode, a web developer, Let connect and grow toether, drop ur number or github handle,... | 0 | 2024-07-08T13:07:32 | https://dev.to/crown_code_43cc4b866d2688/let-connect-2gi4 | webdev, javascript, beginners, programming | Hi, i am CrownCode, a web developer, Let connect and grow toether, drop ur number or github handle, preferably number.... | crown_code_43cc4b866d2688 |
1,915,785 | In-Demand Data Analyst Skills To Get Easily Hired in 2024 | Introduction The demand for data analysts continues to soar as businesses across various... | 0 | 2024-07-08T13:19:53 | https://dev.to/sejal_4218d5cae5da24da188/in-demand-data-analyst-skills-to-get-easily-hired-in-2024-3709 | ## Introduction
The demand for data analysts continues to soar as businesses across various sectors recognize the value of data-driven decision-making. To stand out in the competitive job market of 2024, aspiring data analysts need to master a specific set of skills. This blog highlights the most sought-after skills th... | sejal_4218d5cae5da24da188 | |
1,915,807 | How to Obtain a Canada Temporary Number for WhatsApp Verification | In today's digital age, having a virtual phone number can be incredibly beneficial for various... | 0 | 2024-07-08T13:20:53 | https://dev.to/legitsms/how-to-obtain-a-canada-temporary-number-for-whatsapp-verification-3n11 | web3, chatgpt, web, help | In today's digital age, having a virtual phone number can be incredibly beneficial for various reasons, including maintaining privacy and managing multiple accounts. One popular use case is verifying WhatsApp accounts. This guide will walk you through the step-by-step process of obtaining a Canada virtual number from L... | legitsms |
1,915,844 | Let's Measure Performance with Playwright Feat: Chrome Trace | Introduction Hello there. I recently wrote an article on optimizing the performance of my... | 0 | 2024-07-08T13:22:58 | https://dev.to/moondaeseung/lets-measure-performance-with-playwright-feat-chrome-trace-3ino | # Introduction
Hello there. I recently wrote an article on optimizing the performance of my library, [Flitter](https://flitter.dev/). Every time I measured the library's performance, I had to manually access `chrome devtools` and press the record button. In this post, we'll look at how to record and track performance... | moondaeseung | |
1,915,846 | Learn Python - Day 1 | Chapter 1 What python can do? Python is versatile programming language and... | 0 | 2024-07-09T12:34:41 | https://dev.to/dinesh_chinnathurai_136b1/python-learning-59e7 | introduction | ## Chapter 1
## What python can do?
- Python is versatile programming language and known for its simplicity and readability
- Python can do many things like web development, Data analysis and visualization, AI and ML, scripting for automation, Desktop GUI application, database access and so on.
## Why python?
Pytho... | dinesh_chinnathurai_136b1 |
1,915,847 | Soccer Uniform | Soccer outfits, otherwise called football packs or shirts, normally comprise of a few parts intended... | 0 | 2024-07-08T13:29:08 | https://dev.to/alpaca_uniform_ae3e003f4b/soccer-uniform-3beh | Soccer outfits, otherwise called football packs or shirts, normally comprise of a few parts intended to give solace, execution, and group character. Here are the critical components of soccer garbs:
Jersey/Unit:
Plan: The plan of the shirt frequently incorporates the group’s tones, logo, and support logos.
Material... | alpaca_uniform_ae3e003f4b | |
1,915,848 | Why Magic is Superior to Supabase | Supabase is a toy No-Code and Low-Code framework, allowing you to wrap your database in CRUD API... | 0 | 2024-07-08T13:29:39 | https://ainiro.io/blog/why-magic-is-superior-to-supabase | lowcode | [Supabase](https://supabase.com) is a toy No-Code and Low-Code framework, allowing you to wrap your database in CRUD API endpoints in some few seconds.
The problem is that once you need to go beyond CRUD, there are no real alternatives to coding. I've written extensively about the problems originating from this in a [... | polterguy |
1,915,849 | Data Storytelling Là Gì? Cách Dữ Liệu Nói Lên Câu Chuyện | Terus Digital Marketing trực thuộc Terus là đơn cung cấp đơn vị cung cấp giải pháp số toàn diện. Phục... | 0 | 2024-07-08T13:30:56 | https://dev.to/terus_digitalmarketing/data-storytelling-la-gi-cach-du-lieu-noi-len-cau-chuyen-2if3 | webdev, terus, teruswebsite, website | Terus Digital Marketing trực thuộc Terus là đơn cung cấp đơn vị cung cấp giải pháp số toàn diện. Phục vụ chủ yếu mọi đối tượng kinh doanh tại HCM & toàn quốc. Với kinh nghiệm lĩnh vực [dịch vụ SEO Tổng Thể Website Nâng Cao Thứ Hạng, Tối Ưu Chi Phí](https://terusvn.com/seo/dich-vu-seo-tong-the-uy-tin-hieu-qua-tai-terus/... | terus_digitalmarketing |
1,915,850 | 2024's Must-Play Free Arcade Games for Every Gamer | Freearcadegames.net has a wide array of free online arcade games that are appropriate for any age.... | 0 | 2024-07-08T13:32:18 | https://dev.to/corazon_5e82e1043ad8b3a14/2024s-must-play-free-arcade-games-for-every-gamer-igd | Freearcadegames.net has a wide array of free online arcade games that are appropriate for any age. Freearcadegames.net presents all sorts of HTML5 games, which have classic arcade hits and thrilling new releases. At Freearcadegames.net, you will never get bored since there is plenty to choose from be it action packed s... | corazon_5e82e1043ad8b3a14 | |
1,915,851 | 15 GIT Questions Will Make You Better Developer | Hi coders, welcome to our new article. Today, we are going to talk about most important and popular... | 0 | 2024-07-08T13:32:52 | https://dev.to/mammadyahyayev/15-git-questions-on-stackoverflow-will-make-you-better-developer-4bo7 | git, softwareengineering, github | Hi coders, welcome to our new article. Today, we are going to talk about most important and popular Git questions asked on Stackoverflow. You need to be great at Git, because it is highly used among entire IT industry.
## Introduction
It doesn’t matter you are a backend, or frontend developer, if you are writing code... | mammadyahyayev |
1,915,854 | AI and Data Privacy: Balancing Innovation and Security in the Digital Age | Artificial intelligence is ubiquitous nowadays, from those eerily accurate music recommendations to... | 0 | 2024-07-08T13:39:35 | https://dev.to/digitalsamba/ai-and-data-privacy-balancing-innovation-and-security-in-the-digital-age-hoh | ai, privacy, webdev, security | Artificial intelligence is ubiquitous nowadays, from those eerily accurate music recommendations to robots operating colossal factories. However, all this remarkable AI technology relies on extensive datasets to make decisions, and this data includes our personal information!
The pressing question is, how can we harne... | digitalsamba |
1,915,855 | Exploring the React Compiler: A detailed introduction | Written by David Omotayo✏️ React has revolutionized how developers build user interfaces since its... | 0 | 2024-07-09T14:04:24 | https://blog.logrocket.com/exploring-react-compiler-detailed-introduction | react, webdev | **Written by [David Omotayo](https://blog.logrocket.com/author/davidomotayo/)✏️**
React has revolutionized how developers build user interfaces since its inception, with every iteration providing innovative and powerful ways for creating dynamic, component-based applications.
Despite its many strengths, React has tr... | leemeganj |
1,915,856 | Dom Manipulate in angular | <h2 #hello1>Hello world</h2> <button (click)="handleFunction()">Change... | 0 | 2024-07-08T13:42:30 | https://dev.to/webfaisalbd/dom-manipulate-in-angular-52h9 | ```html
<h2 #hello1>Hello world</h2>
<button (click)="handleFunction()">Change Text</button>
```
```ts
@ViewChild('hello1', { static: true }) helloElement: ElementRef;
handleFunction() {
this.helloElement.nativeElement.textContent = 'Hello Angular!';
this.helloElement.nativeElement.style.color = 'red';
... | webfaisalbd | |
1,915,857 | MongoDB | MongoDB শিখুন, বুক ফুলিয়ে বলুন "MongoDB জানি!" এখানে আপনার জন্য একটি চেকলিস্ট দিলাম যা আপনাকে একজন... | 0 | 2024-07-08T13:42:57 | https://dev.to/debos_das_9a77be9788e2d6e/mongodb-1ef9 | MongoDB শিখুন, বুক ফুলিয়ে বলুন "MongoDB জানি!" এখানে আপনার জন্য একটি চেকলিস্ট দিলাম যা আপনাকে একজন দক্ষ MongoDB ডেভেলপার হতে সাহায্য করবে।
📚 Meet MongoDB: MongoDB এর সাথে পরিচিত হন, এর বেসিক কনসেপ্ট এবং ডাটাবেজ হিসেবে এর বিশেষত্ব জানুন।
📘 Terminology and Data Model: MongoDB এর টার্মিনোলজি যেমন ডকুমেন্ট, কালেকশন, ড... | debos_das_9a77be9788e2d6e | |
1,915,858 | Unlocking age verification—The fusion of ID document recognition and face attribute analysis | Age verification is more crucial than ever in today’s world, affecting a broad range of sectors like... | 0 | 2024-07-08T13:43:36 | https://dev.to/faceplugin/unlocking-age-verification-the-fusion-of-id-document-recognition-and-face-attribute-analysis-29l2 | programming, ai, machinelearning, datascience | Age verification is more crucial than ever in today’s world, affecting a broad range of sectors like social media and online gaming. Verifying your age is an essential step when purchasing age-restricted goods like alcohol and tobacco, joining an online gaming community, or even just creating a new social media account... | faceplugin |
1,915,860 | Web scraping | Hello everyone ! I am new to Data Science and Dev. I would like to ask more about web scraping to... | 0 | 2024-07-08T13:45:59 | https://dev.to/last_chance/web-scraping-35k | python, webscraping, selenium, scrapy | Hello everyone ! I am new to Data Science and Dev. I would like to ask more about web scraping to someone who knows about it... if you are also exploring... that would be fine too | last_chance |
1,915,861 | Enhancing ID Verification Systems: Unleashing the Power of On Premise Face Recognition SDKs | Security and convenience are of the utmost importance in the current digital era, on premise face... | 0 | 2024-07-08T13:46:54 | https://dev.to/faceplugin/enhancing-id-verification-systems-unleashing-the-power-of-on-premise-face-recognition-sdks-of3 | programming, machinelearning, datascience, softwareengineering | Security and convenience are of the utmost importance in the current digital era, on premise face recognition SDKs are a vital tool for companies and organizations. These cutting-edge solutions simplify procedures and improve security measures while offering a flawless user experience. It is more important than ever t... | faceplugin |
1,915,862 | Headless UI alternatives: Radix Primitives, React Aria, Ark UI | Written by Amazing Enyichi Agu✏️ Using React component libraries is a popular way to quickly build... | 0 | 2024-07-09T17:49:51 | https://blog.logrocket.com/headless-ui-alternatives-radix-primitives-react-aria-ark-ui | react, webdev | **Written by [Amazing Enyichi Agu](https://blog.logrocket.com/author/amazingenyichiagu/)✏️**
Using React component libraries is a popular way to quickly build React applications. Components from this type of library have many benefits. Firstly, they follow accessibility guidelines like [WAI-ARIA](https://www.w3.org/WA... | leemeganj |
1,915,864 | Preparing for the 100 Days of MERN Full Stack Challenge: The Goals, Plan, and Expectations | Hello developers 👋, I’m Naresh Kumar, a beginner in Full Stack Development from India. Tomorrow, I’m... | 0 | 2024-07-08T14:10:29 | https://dev.to/naresh_kmu_68/preparing-for-the-100-days-of-mern-full-stack-challenge-the-goals-plan-and-expectations-b2h | 100daysofcode, fullstack, webdev, programming |
**Hello developers 👋,**
I’m Naresh Kumar, a beginner in Full Stack Development from India. Tomorrow, I’m starting the #100DaysOfFullStackChallenge to improve my full-stack skills and become job-ready in the next 100 days 🚀.
**My Goals 🎯**
- Improve my coding skills 🧑💻 and create outstanding full-stack pro... | naresh_kmu_68 |
1,915,870 | PYTHON INSTALLATION (IDLE & COLLAB Execution Test) | https://www.python.org/downloads/ check the system type of yours. The latest series will not work on... | 0 | 2024-07-08T14:09:33 | https://dev.to/pradeepmtm/python-installation-idle-collab-execution-test-ilc | python, installation | https://www.python.org/downloads/
check the system type of yours.
The latest series will not work on win 7 or earlier
✏️**
Perplexity AI has captured the public's attention and impressed tech giants like Amazon and Nvidia with its unique approach to AI. It isn't your typical search engine — it blends the clear answers of a chatbot with the detailed informa... | leemeganj |
1,915,866 | Started New thing:) | I am happy to post my first post about the new learning day1 started downloaded and did the... | 0 | 2024-07-08T14:02:18 | https://dev.to/sandy74/started-new-thing-4lh6 | tutorial, beginners, hello | I am happy to post my first post about the new learning day1 started downloaded and did the print("Hello Galaxy"); | sandy74 |
1,915,867 | Router Link for single page to pass data for details page | <button [routerLink]="['/invoice/payment-history', data?.invoiceId]" ... | 0 | 2024-07-08T14:03:22 | https://dev.to/webfaisalbd/router-link-for-single-page-to-pass-data-for-details-page-1k96 | ```html
<button [routerLink]="['/invoice/payment-history', data?.invoiceId]" style="margin-right: 5px;" mat-mini-fab matTooltip="View"
color="accent">
<mat-icon>remove_red_eye</mat-icon>
</button>
```
---
## another way:
```html
<button (click)="handlePaymentHistory(data?.in... | webfaisalbd | |
1,915,868 | Ant Design adoption guide: Overview, examples, and alternatives | Written by Elijah Asaolu✏️ Ant Design prides itself as the second most popular React UI library,... | 0 | 2024-07-10T18:54:01 | https://blog.logrocket.com/ant-design-adoption-guide | react, webdev | **Written by [Elijah Asaolu](https://blog.logrocket.com/author/asaoluelijah/)✏️**
Ant Design prides itself as the second most popular React UI library, with over 90k stars on GitHub as of the time of writing. It's easy to see why, given its plethora of rich and easy-to-use UI components and other features that make bu... | leemeganj |
1,915,869 | OKR Brainstorming Là Gì? Cách Tối Ưu Hiệu Quả Khi Thực Hiện OKR | Terus Digital Marketing trực thuộc Terus là đơn cung cấp đơn vị cung cấp giải pháp số toàn diện. Phục... | 0 | 2024-07-08T14:07:46 | https://dev.to/terus_digitalmarketing/okr-brainstorming-la-gi-cach-toi-uu-hieu-qua-khi-thuc-hien-okr-19m6 | Terus Digital Marketing trực thuộc Terus là đơn cung cấp đơn vị cung cấp giải pháp số toàn diện. Phục vụ chủ yếu mọi đối tượng kinh doanh tại HCM & toàn quốc. Với kinh nghiệm lĩnh vực [dịch vụ SEO Tổng Thể Website Nâng Cao Thứ Hạng, Tối Ưu Chi Phí](https://terusvn.com/seo/dich-vu-seo-tong-the-uy-tin-hieu-qua-tai-terus/... | terus_digitalmarketing | |
1,915,871 | Top Image Labeling Tools for Streamlined Digital Asset Management | Introduction In today's digital era, companies and institutions are producing and... | 0 | 2024-07-09T11:32:29 | https://dev.to/api4ai/top-image-labeling-tools-for-streamlined-digital-asset-management-1p7h | imagelabeling, api, ai, imageprocessing | #Introduction
In today's digital era, companies and institutions are producing and overseeing a staggering amount of digital content. A recent [IDC](https://www.idc.com/) report predicts that the global creation of digital data will hit 175 zettabytes by 2025, underscoring the rapid expansion and critical need for eff... | taranamurtuzova |
1,915,872 | Caracteres de entrada do teclado | A maioria dos programas e applets Java do mundo real é gráfica e baseada em janelas e não baseada em... | 0 | 2024-07-09T22:02:03 | https://dev.to/devsjavagirls/caracteres-de-entrada-do-teclado-35n6 | java | - A maioria dos programas e applets Java do mundo real é gráfica e baseada em janelas e não baseada em console.
- Há, porém, um tipo de entrada de console que é relativamente fácil de usar: a leitura de um caractere a partir do teclado.
- Para ler um caractere a partir do teclado usaremos System.in.read().
- O méto... | devsjavagirls |
1,915,873 | API Testing Using RestAssured And Testkube | Modern applications adopt API-first design, which provides seamless communication between services... | 0 | 2024-07-08T14:10:15 | https://testkube.io/learn/api-testing-using-restassured-and-testkube | testing, restassured, kubernetes | Modern applications adopt API-first design, which provides seamless communication between services and clients. This approach is becoming increasingly popular, where APIs are designed and developed before the implementation of the actual services. This ensures that APIs are treated as first-class citizens, fostering co... | michael20003 |
1,915,874 | Transforming Workloads Seamlessly with Raven: The Automated Workload Conversion Tool | In today's rapidly evolving technological landscape, businesses are constantly seeking efficient ways... | 0 | 2024-07-08T14:10:32 | https://dev.to/onixcloud/transforming-workloads-seamlessly-with-raven-the-automated-workload-conversion-tool-3ena | data, automation, cloud, migration | In today's rapidly evolving technological landscape, businesses are constantly seeking efficient ways to optimize their operations. One significant challenge many enterprises face is the seamless migration of data and workloads across different platforms and systems. This is where [Raven Migration](https://www.onixnet.... | onixcloud |
1,915,875 | Swift Beginnings: A New Language Journey | Origin My journey with Swift began around two weeks ago. While many of my peers are immersing... | 0 | 2024-07-08T14:11:09 | https://dev.to/aaron_castillo3290/swift-beginnings-a-new-language-journey-26b1 | **Origin**
My journey with Swift began around two weeks ago. While many of my peers are immersing themselves in Python and Java to develop complex databases, I’ve chosen to focus on Swift to create an engaging iPhone game. I chose this path because I wanted to build something that resonates with a broad audience, not j... | aaron_castillo3290 | |
1,915,877 | User agent detection and the ua-parser-js license change | Written by Ikeh Akinyemi✏️ User agent detection plays an important role in helping developers... | 0 | 2024-07-11T14:02:14 | https://blog.logrocket.com/user-agent-detection-ua-parser-js-license-change | javascript, webdev | **Written by [Ikeh Akinyemi](https://blog.logrocket.com/author/ikehakinyemi/)✏️**
User agent detection plays an important role in helping developers optimize their websites and applications for various devices, browsers, and operating systems. By accurately identifying their users’ environments, developers can tailor ... | leemeganj |
1,915,878 | Why Are Leather Biker Jackets Cool? | The Timeless Appeal of Leather Biker Jackets Leather biker jackets have been a symbol of cool for... | 0 | 2024-07-08T14:16:02 | https://dev.to/monaljacketsuk/why-are-leather-biker-jackets-cool-24c0 | The Timeless Appeal of Leather Biker Jackets
Leather biker jackets have been a symbol of cool for decades. From their origins in the mid-20th century to their continued popularity today, these jackets have transcended fashion trends to become a staple in wardrobes worldwide. But what exactly makes leather [biker jacke... | monaljacketsuk | |
1,915,879 | Become a Pro Programmer: 10 Tips and Strategies for Improving Your Coding Skills | As a programmer, it’s essential to continuously improve your skills to stay current and competitive... | 0 | 2024-07-08T14:28:37 | https://dev.to/akshayvs/become-a-pro-programmer-10-tips-and-strategies-for-improving-your-coding-skills-2364 | 
As a programmer, it’s essential to continuously improve your skills to stay current and competitive in the field. But with so many technologies, languages, and approaches, it can... | akshayvs | |
1,915,881 | Deploy Angular App with GraphQL on IIS & Azure (Part 7) | TL;DR: This blog contains the step-by-step procedures for deploying the full-stack web app built with... | 0 | 2024-07-11T17:04:39 | https://www.syncfusion.com/blogs/post/deploy-graphql-angular-on-iss-azure-7 | angular, development, web, azure | ---
title: Deploy Angular App with GraphQL on IIS & Azure (Part 7)
published: true
date: 2024-07-08 11:16:14 UTC
tags: angular, development, web, azure
canonical_url: https://www.syncfusion.com/blogs/post/deploy-graphql-angular-on-iss-azure-7
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xf2okpe... | jollenmoyani |
1,915,882 | Testing Kubernetes Applications with Pytest and Testkube: A Complete Guide | Testing modern distributed applications within Kubernetes environments can be daunting due to the... | 0 | 2024-07-08T14:21:12 | https://testkube.io/learn/testing-kubernetes-applications-with-pytest-and-testkube-a-complete-guide | Testing modern distributed applications within Kubernetes environments can be daunting due to the complexity and the need for scalable solutions. Traditional testing tools often fall short when it comes to efficiency and agility.
However, with the advent of Kubernetes native solutions like Testkube, it's easier than ... | michael20003 | |
1,915,884 | Writing a You Go - Technical Article Writing Made Easy | If you are a working developer like I am, you should never have a problem coming up with an article... | 0 | 2024-07-08T14:22:16 | https://www.stephanmiller.com/writing-as-you-go/ | writing | ---
title: Writing a You Go - Technical Article Writing Made Easy
published: true
date: 2024-07-08 06:06:00 UTC
tags: writing
canonical_url: https://www.stephanmiller.com/writing-as-you-go/
---
If you are a working developer like I am, you should never have a problem coming up with an article idea.
Well, I am one and... | eristoddle |
1,915,885 | 🌟 Embracing Cloud-Native Applications in the IT Industry ☁️🚀 | As the IT industry evolves, so does the approach to application development. Cloud-native... | 0 | 2024-07-08T14:22:20 | https://dev.to/m_hussain/embracing-cloud-native-applications-in-the-it-industry-2mpi | cloudnative, devops, webdev, programming | As the IT industry evolves, so does the approach to application development. Cloud-native applications are paving the way for agility, scalability, and rapid innovation. Here’s why they're crucial:
Agility: Deploy updates faster and more frequently, responding quickly to market demands and customer feedback.
Scalabili... | m_hussain |
1,915,886 | sample post | this is a sample post wrote on the python session | 0 | 2024-07-08T14:24:19 | https://dev.to/tshrinivasan/sample-post-143k | test, sample | this is a sample post wrote on the python session | tshrinivasan |
1,915,887 | 17 Free Open-source Icon Libraries (Carefully Curated List, Filterable & Sortable) - Need Feedback | Hi guys, I want to share my latest work on how i serve a resource list content on my blog... | 0 | 2024-07-08T14:25:58 | https://dev.to/syakirurahman/17-free-open-source-icon-libraries-carefully-curated-list-filterable-sortable-need-feedback-p66 | webdev, beginners, design, opensource | Hi guys,
I want to share my latest work on how i serve a resource list content on my blog [https://devaradise.com/icon-libraries/](https://devaradise.com/icon-libraries/)
So, the idea was to create a user friendly page dedicated to listicle content, where users can filter and sort based on any attribute related to t... | syakirurahman |
1,915,970 | Python first program - Getting started with Python | Python download link : https://www.python.org/downloads/ Install the latest stable version of... | 0 | 2024-07-08T14:29:27 | https://dev.to/kannansubramanian/python-first-program-getting-started-with-python-2i07 | python, programming | Python download link : https://www.python.org/downloads/
1. Install the latest stable version of python.
2. Install IDE - Visual studio code
3. Create Python file (FirstCode.py)
4. write your first code
```
print("Kannan Subramanian")
```
Press F5 / Play bytton to run the code

Doing it every block the callbacks can be received up to 30 times a minute. In this case, ... | apirone_com | |
1,915,972 | தொடக்கம்... | இன்று python இணைய வகுப்பில் இணைந்தேன். windows கணிணியில் python-3.12.4 நிறுவிய பிறகு IDLE திறந்தேன்.... | 0 | 2024-07-08T14:32:28 | https://dev.to/mahaloghu/tottkkm-1630 | beginners, help, idle | இன்று python இணைய வகுப்பில் இணைந்தேன். windows கணிணியில் python-3.12.4 நிறுவிய பிறகு IDLE திறந்தேன். அதில்
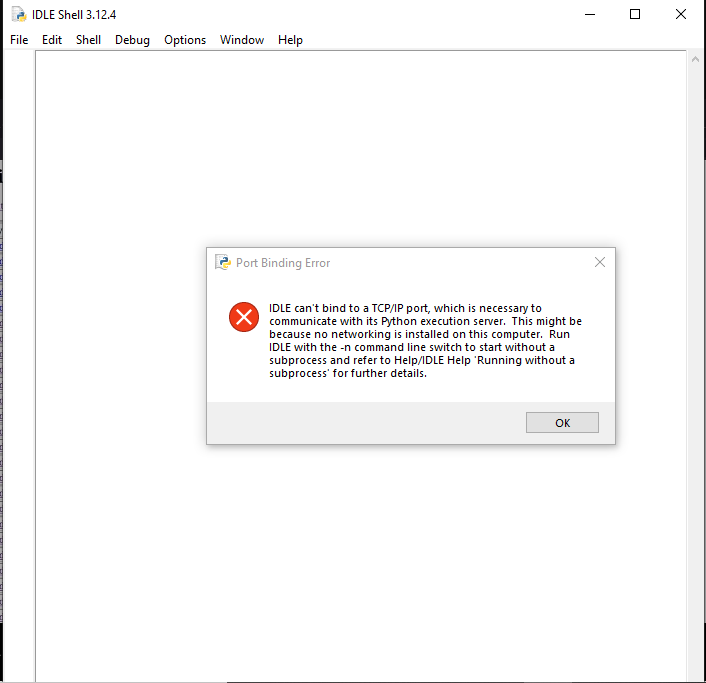 படத்தில் உள்ளவாறு error செய்தி வருகிறது. இதை எப்படி அணுகுவது? | mahaloghu |
1,915,973 | Isolation of git_sync and task (uses scripts from codebase) running in a DAG | Isolation of git_sync and task (uses... | 0 | 2024-07-08T14:36:29 | https://dev.to/anantha_lakshmimeruva_51/isolation-of-gitsync-and-task-uses-scripts-from-codebase-running-in-a-dag-2g39 | {% stackoverflow 78721362 %}
https://stackoverflow.com/q/78721362/25753693 | anantha_lakshmimeruva_51 | |
1,915,974 | Path to Python | Attended the class conducted by Kaniyam Foundation. Nice and simple speech. clear path forward. I... | 0 | 2024-07-08T14:42:16 | https://dev.to/mani_prabhu_m/path-to-python-1b1o | beginners, python, firstpost | Attended the class conducted by Kaniyam Foundation.
Nice and simple speech. clear path forward. I have attempted to learn python many times. but no progress after learning all data types, conditions etc.
Hope this time the journey will continue.
MK | mani_prabhu_m |
1,915,975 | first day of python | Am from medical background. totally new for computer programming. knows somethings today from... | 0 | 2024-07-08T14:42:41 | https://dev.to/ganesh_balaraman_6edae0d9/first-day-of-python-3hm4 | Am from medical background. totally new for computer programming. knows somethings today from kaniyam.com group, i.e, what is python, its some of applications, and i tried to do print also. it works. lovely. | ganesh_balaraman_6edae0d9 | |
1,915,976 | How to Summarize YouTube Videos Using Gemini, ChatGPT, Claude, and Perplexity in 2024 | In this article, I want to showcase AI tools for creating summaries from YouTube videos. These AI... | 0 | 2024-07-08T14:43:19 | https://dev.to/proflead/how-to-summarize-youtube-videos-using-gemini-chatgpt-claude-and-perplexity-in-2024-1732 | ai, chatgpt, gemini, howto | In this article, I want to showcase AI tools for creating summaries from YouTube videos. These AI tools can quickly summarize a video’s content so you don’t have to watch the entire thing. I’ll demonstrate how to use these AIs to rapidly extract the main points from videos.
## AI Tools for Video Summarization
Video su... | proflead |
1,915,977 | 08-07-2024 | கடந்த பதிவில் ஏற்பட்ட பிழை K7 security ஐ disable செய்த பிறகு வரவில்லை. IDLE திறந்து கொண்டது.... | 0 | 2024-07-08T14:43:57 | https://dev.to/mahaloghu/08-07-2024-18gn | print, post, help | கடந்த பதிவில் ஏற்பட்ட பிழை K7 security ஐ disable செய்த பிறகு வரவில்லை. IDLE திறந்து கொண்டது.
என்னுடைய சந்தேகம் K7 security ஐ disable செய்யாமல் திறக்க என்ன செய்ய வேண்டும்? | mahaloghu |
1,915,978 | பைதானில் முதல் பாடம் | 8/7/2024,சென்னை பைதான் வகுப்பு இன்று ஆரம்பம். அறிமுக உரை கேட்டேன். Google Colab ல் print command... | 0 | 2024-07-08T14:44:22 | https://dev.to/rjagathe/mutl-paattm-1m62 | 8/7/2024,சென்னை
பைதான் வகுப்பு இன்று ஆரம்பம்.
அறிமுக உரை கேட்டேன்.
Google Colab ல் print command கொடுத்து சோதனை செய்தேன்.
பைதான் கணினியில் நிறுவப்பட்டது.
IDE ஆக PyCharm யினை install செய்துள்ளேன். வகுப்பில் ஆசிரியர் VS பயன்படுத்துவதாக கூறினார்.எனவே, PyCharm எந்த அளவிற்கு உபயோகப்படும் எனத் தெரியவில்லை....பார்ப்போம். | rjagathe | |
1,915,979 | No Code Test Automation A Complete Guide | No code this word has become popular in the last few years, from no-code software development to... | 0 | 2024-07-08T14:45:25 | https://dev.to/jamescantor38/no-code-test-automation-a-complete-guide-4a76 | nocodetestautomation, testgrid | No code this word has become popular in the last few years, from no-code software development to no-code website development; every business is exploring this no-code technology, and software or website is no more different.
Today many software teams have adopted no-code test automation, and many businesses are shiftin... | jamescantor38 |
1,915,980 | Important Software Testing Documentation: SRS, FRS and BRS | Despite how much we all hate writing documentation, it’s one of the essential steps in any industry,... | 0 | 2024-07-08T14:46:42 | https://testfort.com/blog/important-software-testing-documentation-srs-frs-and-brs | qa, testing, softwaredevelopment, webdev | Despite how much we all hate writing documentation, it’s one of the essential steps in any industry, including software testing. Having clear documentation is very important. It’s like having a roadmap. When you know exactly what you’re doing and how things need to be done, there’s less of a risk of your team getting l... | testfort_inc |
1,915,981 | Automatização de Deploy com CI/CD | A automação de deploy com CI/CD (Integração Contínua e Entrega Contínua/Desdobramento Contínuo) tem... | 0 | 2024-07-08T14:47:22 | https://dev.to/annalaura2/automatizacao-de-deploy-com-cicd-26gg |
A automação de deploy com CI/CD (Integração Contínua e Entrega Contínua/Desdobramento Contínuo) tem se tornado uma prática essencial no desenvolvimento moderno de software. Este artigo irá explorar o que é CI/CD, seus benefícios, as principais ferramentas utilizadas, e como implementá-lo de maneira eficaz em seus proj... | annalaura2 | |
1,915,982 | Affiliate Marketing Là Gì? Cách Kiếm Tiền Online Bằng Affiliate | Terus Digital Marketing trực thuộc Terus là đơn cung cấp đơn vị cung cấp giải pháp số toàn diện. Phục... | 0 | 2024-07-08T14:50:50 | https://dev.to/terus_digitalmarketing/affiliate-marketing-la-gi-cach-kiem-tien-online-bang-affiliate-1dm9 | webdev, website, marketing, terus | Terus Digital Marketing trực thuộc Terus là đơn cung cấp đơn vị cung cấp giải pháp số toàn diện. Phục vụ chủ yếu mọi đối tượng kinh doanh tại HCM & toàn quốc. Với kinh nghiệm lĩnh vực dịch vụ SEO Tổng Thể Website Nâng Cao Thứ Hạng, Tối Ưu Chi Phí trong đó rất nhiều dự án lớn nhỏ đã và đang thành công chúng tôi luôn hướ... | terus_digitalmarketing |
1,915,983 | Python print() funtion | I am learned python basic concept today. share you what i learned today with example. The name as it... | 0 | 2024-07-08T14:54:59 | https://dev.to/karthik_guna_057168ec9458/python-print-funtion-44ea | python, function, print | I am learned python basic concept today.
share you what i learned today with example.
The name as it is print what you entered inside print function.
```
Ex : print("Hello")
```
In additionally you can pass variables like string or integer or other data types.
```
anime1 = "dragon ball"
anime2 = "naruto"
Ex : print... | karthik_guna_057168ec9458 |
1,915,984 | A Importância da Cobertura de Código: Devo buscar 100% ? | Disclaimer Este texto foi concebido pela IA Generativa em função da transcrição do... | 0 | 2024-07-08T14:56:26 | https://dev.to/asouza/a-importancia-da-cobertura-de-testes-devo-buscar-100--3hho | ## Disclaimer
Este texto foi concebido pela IA Generativa em função da transcrição do episódio do nosso canal, Dev Eficiente. [O episódio completo pode ser visto no canal.](https://youtu.be/dmj53dbgv68)
## Resumo
No texto de hoje, quero falar com você sobre um tema crucial para a qualidade do software: a cobertura d... | asouza | |
1,915,986 | Take the 2024 open source maintainer survey! | It is time for the third installment Tidelift state of the open source maintainer survey! Do you... | 0 | 2024-07-08T15:01:37 | https://dev.to/tidelift/take-the-2024-open-source-maintainer-survey-3692 | opensource, maintainers, survey, news | <p>It is time for the third installment Tidelift state of the open source maintainer survey! </p>
<!--more-->
<p><strong>Do you actively maintain one or more open source projects?</strong> If so, we'd love to learn from you. </p>
<p>The reports that come out of the Tidelift maintainer survey have become an im... | cdgrams |
1,915,987 | 🧩 100 FREE Frontend Challenges – Sharpen Your Skills! | Hey again 👋 This weeks newsletter is jam-packed with great reads and resources, here's a quick... | 0 | 2024-07-10T17:30:00 | https://dev.to/adam/100-free-frontend-challenges-sharpen-your-skills-67c | webdev, css, design, ux | **Hey again** 👋
This weeks newsletter is jam-packed with great reads and resources, here's a quick look:
🛠️ Transitioning to Auto Height in CSS
🔧 Essential JS Snippets for Modern Web Features
👁️ Taku Satoh's Design Philosophy
Enjoy 🤗 - Adam at Unicorn Club.
---
## 📬 Want More? Subscribe to Our Newslette... | adam |
1,915,991 | Join Our Facebook Community for Exclusive Bad Bunny Merch Updates! | Want to be the first to know about our latest Bad Bunny merch? Like our Facebook page to get... | 0 | 2024-07-08T15:09:32 | https://dev.to/badbunnymerch12/join-our-facebook-community-for-exclusive-bad-bunny-merch-updates-28b1 | badbunnymerch, facebook, badbunny | Want to be the first to know about our latest Bad Bunny merch? Like our Facebook page to get exclusive updates, sneak peeks, and special offers. Connect with other Bad Bunny fans and share your love for the hottest merch around!
https://www.facebook.com/badbunnymerchshop/
 and given my interests in both frontend (my creative side) and backend (my curiosity for more of the technical engine that drives a site)- I decided to make my site fullstack. For example, I wan... | ashleyd480 |
1,915,994 | Node Selectors, Labels, Selectors, Static Pods, and Manual Scheduling | Hello everyone, welcome back to the CK 2024 series!! Today we will cover node selectors, labels and... | 0 | 2024-07-08T15:13:55 | https://dev.to/jensen1806/node-selectors-labels-selectors-static-pods-and-manual-scheduling-47bn | kubernetes, docker, devops, containers |
Hello everyone, welcome back to the CK 2024 series!! Today we will cover node selectors, labels and selectors, static pods, and manual scheduling. I highly recommend you read through the previous blogs to grasp the concepts thoroughly before proceeding with this one.
### Kubernetes Architecture Recap
To begin, let'... | jensen1806 |
1,915,995 | Lado Okhotnikov on mocap technology for Meta Force | The recently published article on the mo-cap technology reveals an interesting case of its... | 0 | 2024-07-08T15:15:55 | https://dev.to/ncs_music_31bd885261814f7/lado-okhotnikov-on-mocap-technology-for-meta-force-5ai6 | The recently published [article on the mo-cap technology](urlhttps://beincrypto.com/lado-okhotnikov-about-an-integral-part-of-the-project/) reveals an interesting case of its introduction to metaverses. Lado Okhotnikov, the visionary behind Meta Force, asserts innovative technologies are just necessary to create someth... | ncs_music_31bd885261814f7 | |
1,915,996 | Follow Us on X for Real-Time Bad Bunny Merch News! | Stay up-to-date with all things Bad Bunny merch by following us on X! Get real-time updates on new... | 0 | 2024-07-08T15:17:04 | https://dev.to/badbunnymerch12/follow-us-on-x-for-real-time-bad-bunny-merch-news-1d2k | badbunnymerch, twitter, badbunny | Stay up-to-date with all things Bad Bunny merch by following us on X! Get real-time updates on new arrivals, flash sales, and much more. Join the conversation and tweet us your favorite Bad Bunny merch moments!
https://x.com/BadBunny12usa
 Design: From Skeuomorphism to Neumorphism | User interface (UI) design has evolved significantly over the past few decades, keeping pace with... | 0 | 2024-07-08T15:24:15 | https://dev.to/codebridge_tech/the-evolution-of-user-interface-ui-design-from-skeuomorphism-to-neumorphism-hl7 | User interface (UI) design has evolved significantly over the past few decades, keeping pace with rapid advances in technology. Early computer interfaces relied on simple text-based commands, while modern UIs feature dynamic graphics, animations, and touch interactions.
This evolution reflects a shift toward making i... | codebridge_tech | |
1,916,017 | Day 2: Error: "NGCC failed to run on entry-point" | Scenario: This error occurs when the Angular Compatibility Compiler (NGCC) fails to run on... | 0 | 2024-07-08T15:24:46 | https://dev.to/dipakahirav/day-2-error-ngcc-failed-to-run-on-entry-point-3gnd | angular, webdev, javascript, help | #### Scenario:
This error occurs when the Angular Compatibility Compiler (NGCC) fails to run on an entry-point during the build process. It typically happens after upgrading Angular or when there are issues with third-party libraries.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?s... | dipakahirav |
1,916,018 | AI in Software Testing: Wins and Risks of Artificial Intelligence in QA | AI in QA is a topic you can cover once a week and still miss some novelties. A year ago, we released... | 0 | 2024-07-08T15:27:19 | https://testfort.com/blog/ai-in-software-testing-a-silver-bullet-or-a-threat-to-the-profession | qa, testing, qateam, development | AI in QA is a topic you can cover once a week and still miss some novelties. A year ago, we released an article on what ChatGPT can do for software test automation, and it seemed like a big deal.
Now, AI for software testing is a separate business, tech, and expert territory, with serious players, loud failures, and, ... | testfort_inc |
1,916,019 | 10 Tips for Building a Cyber Resilience Strategy | In today's digital landscape, cybercrimes pose significant threats to businesses, resulting in... | 0 | 2024-07-08T15:31:20 | https://www.clouddefense.ai/build-a-cyber-resilience-strategy/ |

In today's digital landscape, cybercrimes pose significant threats to businesses, resulting in halted operations and substantial financial losses. Despite heavy investments in cyberse... | clouddefenseai | |
1,916,020 | The Importance of Community for Open Source 🌱💚🌍 | If you have been following me for a little while, you know by now that I love Open Source and I love... | 0 | 2024-07-08T17:00:00 | https://dev.to/pachicodes/the-importance-of-community-for-open-source-5ak | opensource, community, beginners, github |
If you have been following me for a little while, you know by now that I love Open Source and I love community. Open Source projects stand out for their collaborative nature and community-driven approach; these two topics go hand in hand. However, sometimes I feel like people still don't understand how important commu... | pachicodes |
1,916,021 | How to Protect Your Application from AI Bots | Bots have traditionally been something we try to prevent from entering our applications. There were,... | 0 | 2024-07-08T15:42:51 | https://www.permit.io/blog/introduce-ai-bots-in-applications | programming, security, webdev, tutorial | ---
title: How to Protect Your Application from AI Bots
published: true
date: 2024-07-08 14:00:00 UTC
tags: programming, security, webdev, tutorial
canonical_url: https://www.permit.io/blog/introduce-ai-bots-in-applications
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xdd07g49nm5eatswvy9c.jpg
-... | gemanor |
1,916,023 | Books vs online courses vs projects? 📚 | 3rd question from the Dev Pools series. Same rules as before. Since we can't add polls, we select an... | 27,980 | 2024-07-09T13:30:00 | https://dev.to/devonremote/books-vs-online-courses-vs-projects-3eog | discuss, programming, career, learning | **3rd question** from the **Dev Pools** series.
Same rules as before. Since we can't add polls, we select an emoji.
**Which learning method works for u the most?**
❤️ - books/articles
🦄 - online courses
🔥 - hands-on projects & practice
---
Maybe sth else?
| devonremote |
1,916,024 | 2024 UI/UX Design Trends: Shaping the Future of User Experience | As the digital landscape continues to evolve, so does the world of user interface (UI) and user... | 0 | 2024-07-08T15:37:16 | https://dev.to/codebridge_tech/2024-uiux-design-trends-shaping-the-future-of-user-experience-1k10 |
As the digital landscape continues to evolve, so does the world of user interface (UI) and user experience (UX) design. In 2024, we can expect to see exciting new trends and innovations that will shape the user experience of tomorrow. In this blog post, we will explore some of the key [UI/UX design trends](https://www... | codebridge_tech | |
1,916,025 | React Native or Flutter for App development | A post by Aadarsh Kunwar | 0 | 2024-07-08T15:37:40 | https://dev.to/aadarshk7/react-native-or-flutter-for-app-development-6hg | appdevelopment, ai, appdeveloper, flutter | aadarshk7 | |
1,916,027 | How to Use Text Underline Offset in Tailwind CSS | To use text underline offset in Tailwind CSS, you can use the underline-offset-{amount} utility... | 0 | 2024-07-10T15:32:00 | https://larainfo.com/blogs/how-to-use-text-underline-offset-in-tailwind-css/ | tailwindcss, webdev | To use text underline offset in Tailwind CSS, you can use the underline-offset-{amount} utility class. Here's how to apply it:
1. Add the underline class to enable underlining.
2. Use underline-offset-{amount} to set the offset.
The available amounts are:
underline-offset-auto
- underline-offset-0
- underline-offset... | saim_ansari |
1,916,029 | The Ultimate Guide to Weather REST APIs: Choosing the Right One for Your Project | Weather data is critical for many applications, from agriculture to event planning, and selecting the... | 0 | 2024-07-08T15:41:41 | https://dev.to/sameeranthony/the-ultimate-guide-to-weather-rest-apis-choosing-the-right-one-for-your-project-5aa6 | api, rest, weather, software | Weather data is critical for many applications, from agriculture to event planning, and selecting the right Weather REST API can greatly impact your project's success. In this guide, we'll explore the key aspects to consider when choosing a weather API, focusing on both commercial and navigational perspectives.
## Und... | sameeranthony |
1,916,030 | Meetings vs no meetings team? | 4th question from the Dev Pools series. Same rules as before. Since we can't add polls, we select an... | 27,980 | 2024-07-11T13:30:00 | https://dev.to/devonremote/meetings-vs-no-meetings-4of6 | career, discuss, programming | **4th question** from the **Dev Pools** series.
Same rules as before. Since we can't add polls, we select an emoji.
**Do you prefer days with multiple meetings throughout the workday, or days without them?**
❤️ - I like having multiple meetings during the day
🦄 - I don't like having multiple meetings during the day... | devonremote |
1,916,031 | Creating a Responsive Profile Settings UI with Tailwind CSS | In this section, we will create a user profile settings design using Tailwind CSS. This process will... | 0 | 2024-07-12T15:47:00 | https://larainfo.com/blogs/creating-a-responsive-profile-settings-ui-with-tailwind-css/ | html, tailwindcss, css, webdev | In this section, we will create a user profile settings design using Tailwind CSS. This process will involve designing a user interface that is visually appealing and user-friendly, leveraging the utility-first approach of Tailwind CSS to style various components effectively.
Create a minimalist user profile setup wit... | saim_ansari |
1,916,032 | My First Post | Hi everyone! This is my first post on dev community. Iam a Linux enthusiastic. Iam interested in... | 0 | 2024-07-08T15:43:41 | https://dev.to/nerujanp/my-first-post-49e3 | **Hi everyone!**
This is my first post on dev community. Iam a Linux enthusiastic. Iam interested in opensource and programming. Iam looking for long to learning this things in Tamil, and i found this python course. This is the starting point to learn those things. Today, i attended my 1st python class. i hope this is... | nerujanp | |
1,916,033 | Regra 1: O mais simples possível, mas não mais simples do que isso | Série de artigos sobre o livro As Regras da programação de Chris Zimmerman. O livro trata de 21... | 0 | 2024-07-10T01:07:51 | https://dev.to/fernanda_leite_febc2f0459/regra-1-o-mais-simples-possivel-mas-nao-mais-simples-do-que-isso-563p | programming, learning, cleancode | Série de artigos sobre o livro **As Regras da programação** de Chris Zimmerman. O livro trata de 21 regras que ajudam programadores a criarem códigos melhores. Falarei um pouco sobre cada regra do meu ponto de vista trazendo alguns exemplos e opiniões sobre o livro, com o objetivo principal de consolidar e compartilhar... | fernanda_leite_febc2f0459 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.