
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,916,127 | O laço for | A forma geral do laço for para repetir uma única instrução. Inicialização: Configura o valor... | 0 | 2024-07-09T22:03:07 | https://dev.to/devsjavagirls/o-laco-for-3ii8 | java | - A forma geral do laço for para repetir uma única instrução.

- Inicialização: Configura o valor inicial da variável de controle do laço.
- Condição: Uma expressão booleana que decide se o laço continua ou não.
-... | devsjavagirls |
1,916,034 | 🐦JSON vs. BSON🐦 | What's the Difference? Hey, Devs! 👋 Let's talk about two popular data formats: JSON and... | 0 | 2024-07-08T15:46:19 | https://dev.to/gadekar_sachin/json-vs-bson-4o5c | development, javascript, beginners, programming |
## What's the Difference?
Hey, Devs! 👋 Let's talk about two popular data formats: JSON and BSON. Understanding their differences can help you choose the right one for your projects. Ready? Let's dive in!
### 1. JSON (JavaScript Object Notation)
📝 **What is JSON?**
- Lightweight data interchange format.
- Easy t... | gadekar_sachin |
1,916,035 | Automating EC2 Instance Management with AWS Lambda and EventBridge Using Terraform | Introduction: EC2 instances are virtual servers for running applications on the AWS infrastructure.... | 0 | 2024-07-08T15:47:16 | https://dev.to/mohanapriya_s_1808/automating-ec2-instance-management-with-aws-lambda-and-eventbridge-using-terraform-38jm | **Introduction:**
_EC2 instances are virtual servers for running applications on the AWS infrastructure. It is crucial for providing scalable computing capacity, allowing users to deploy and manage applications efficiently in the cloud. EC2 instances are widely used for hosting websites, running databases, and handlin... | mohanapriya_s_1808 | |
1,916,037 | Unlocking the Potential of React AI Assistants with Sista AI | Integrating AI with React: A Comprehensive Guide Integrating AI into a React app can seem daunting,... | 27,994 | 2024-07-08T15:51:40 | https://dev.to/sista-ai/unlocking-the-potential-of-react-ai-assistants-with-sista-ai-3npo | ai, react, javascript, typescript | <h2>Integrating AI with React: A Comprehensive Guide</h2><p>Integrating AI into a React app can seem daunting, especially for those without extensive machine learning experience. However, with the right tools and pre-trained models, it can be achieved with relative ease.</p><p>This article will explore how to combine A... | sista-ai |
1,916,038 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-07-08T15:51:03 | https://dev.to/favoy64573/buy-verified-cash-app-account-3476 | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | favoy64573 |
1,916,039 | Next.js with Shadcn UI Progress Bar Example | In this tutorial, we will learn how to use a progress bar in Next.js with Shadcn UI. Before using... | 0 | 2024-07-08T15:54:54 | https://frontendshape.com/post/next-13-with-shadcn-ui-progress-bar-example | nextjs, webdev, shadcnui | In this tutorial, we will learn how to use a progress bar in Next.js with Shadcn UI.
Before using the progress bar in Next.js 13 with Shadcn UI, you need to install it by running `npx shadcn-ui@latest` add progress.
```
npx shadcn-ui@latest add progress
# or
npx shadcn-ui@latest add
```
1. Create a progress bar in Ne... | aaronnfs |
1,916,040 | Building a Basic Auth System With Go and MySQL | Go is one of the few languages that have caught my attention in the past. So in our quest to do more,... | 0 | 2024-07-09T06:18:31 | https://dev.to/kalashin1/building-an-auth-system-with-go-and-mysql-1i5h | go, mysql, backend | [Go](https://go.dev/) is one of the few languages that have caught my attention in the past. So in our quest to do more, we will build a simple auth system using Go. I am starting to like writing Go because the syntax is quite elegant and helps to reduce the overall amount of code I have to write.
Go is also very fas... | kalashin1 |
1,916,041 | How to Use Icons in Shadcn UI with Next.js | In this section, we'll see how to use icons in Next.js with ShadCN UI. ShadCN UI includes... | 0 | 2024-07-10T15:33:00 | https://frontendshape.com/post/how-to-use-icon-in-shadcn-ui-with-next-js-13 | nextjs, webdev, shadcnui | In this section, we'll see how to use icons in Next.js with ShadCN UI. ShadCN UI includes Lucide-React icons by default, and you also have the option to incorporate SVG icons from [Heroicons](https://heroicons.com/).
```
npm install lucide-react
# yarn
yarn add lucide-react
```
Next.js with Shadcn UI Icons: Small, Medi... | aaronnfs |
1,916,043 | Best Comic Book Store | Check out One of the best places online for comic books. They have a wide variety of comics and... | 0 | 2024-07-08T16:02:44 | https://dev.to/khadija_fahad_151c2358fb8/best-comic-book-store-4o5e | Check out [](https://onlinecomicbookstore.com)
One of the best places online for comic books. They have a wide variety of comics and graphic novels for every fan. Whether you collect comics or just love to read them, this site has something for you. Explore the selection and find your next favorite comic book! | khadija_fahad_151c2358fb8 | |
1,916,044 | Building Ollama Cloud - Scaling Local Inference to the Cloud | Ollama is primarily a wrapper around llama.cpp, designed for local inference tasks. It's not... | 0 | 2024-07-08T16:43:56 | https://dev.to/samyfodil/building-ollama-cloud-scaling-local-inference-to-the-cloud-2i1a | cloudcomputing, rag, webassembly, go |
Ollama is primarily a wrapper around `llama.cpp`, designed for local inference tasks. It's not typically your first choice if you're looking for cutting-edge performance or features, but it has its uses, especially in environments where external dependencies are a concern.
#### Local AI Development
When using Ollama... | samyfodil |
1,916,045 | Create File Upload UI in Next.js with Shadcn UI | In this tutorial, we will create a file upload feature in Next.js using Shadcn UI. Before use file... | 0 | 2024-07-12T15:32:00 | https://frontendshape.com/post/create-file-upload-in-nextjs-13-with-shadcn-ui | webdev, nextjs, shadcnui | In this tutorial, we will create a file upload feature in Next.js using Shadcn UI.
Before use file upload in next js 13 with shadcn ui you need to install npx shadcn-ui add input.
```
npx shadcn-ui add input
# or
npx shadcn-ui@latest add
```
1.Create a File Upload Feature in Next.js Using Shadcn UI's Input and Label C... | aaronnfs |
1,916,046 | Building a Hybrid Sign-Up/Subscribe Form with Stripe Elements | I had a user reach out to me on X asking if there was any way to integrate a Stripe credit card entry... | 0 | 2024-07-08T16:13:16 | https://clerk.com/blog/building-a-hybrid-sign-up-and-subscribe-form-with-stripe | clerk, stripe, nextjs, saas | I had a user reach out to me on X asking if there was any way to integrate a Stripe credit card entry field with Clerk's sign-up forms.
{% embed https://twitter.com/koslib/status/1788611782598131950 %}
Kostas is building a Chrome extension that uses AI to let users write responses to LinkedIn posts directly from thei... | brianmmdev |
1,916,047 | Gaining a Competitive Edge: The Vital Role of Competitive Market Intelligence | In today's rapidly changing business environment, surpassing the competition across various metrics... | 0 | 2024-07-08T16:13:14 | https://dev.to/linda0609/gaining-a-competitive-edge-the-vital-role-of-competitive-market-intelligence-46ch | strtegyconsultingservices, competitivemarketintelligence | In today's rapidly changing business environment, surpassing the competition across various metrics is essential for long-term success. Consequently, [competitive market intelligence (CMI)](https://www.sganalytics.com/market-research/market-intelligence/) has become increasingly vital. CMI involves gathering, analyzing... | linda0609 |
1,916,048 | Adding Tailwind CSS to Django | The quickest way to get started with Tailwind in CSS is by using Django tailwind. We'll walk you... | 0 | 2024-07-09T03:22:58 | https://dev.to/paul_freeman/adding-tailwind-css-to-django-14a | django, tailwindcss | The quickest way to get started with Tailwind in CSS is by using
[Django tailwind](https://github.com/timonweb/django-tailwind).
We'll walk you through the Django-tailwind setup.
First, you need to install the django-tailwind package. You can do this using pip
```
pip install django-tailwind
```
Then add django-tail... | paul_freeman |
1,916,049 | Day 8 of 90 DevOps Project: Creating a Private Kubernetes Cluster on AWS EKS with Public Jump Server Access | Hey Everyone, Welcome Back! I'm excited to share my latest project, part of my 90-day DevOps... | 0 | 2024-07-08T16:31:20 | https://dev.to/arbythecoder/day-8-of-90-devops-project-creating-a-private-kubernetes-cluster-on-aws-eks-with-public-jump-server-access-57pf | devops, kubernetes, aws, beginners | #
Hey Everyone, Welcome Back!
I'm excited to share my latest project, part of my 90-day DevOps journey. I know there's been a delay in delivering this article, and I want to be transparent about the reasons. AWS charges led me to close my previous account and open a new one after my free tier expired. Unfortunately,... | arbythecoder |
1,916,050 | 40 Days Of Kubernetes (13/40) | Day 13/40 Static Pods, Manual Scheduling, Labels, and Selectors in... | 0 | 2024-07-11T16:59:12 | https://dev.to/sina14/40-days-of-kubernetes-1340-45gf | kubernetes, 40daysofkubernetes | ## Day 13/40
# Static Pods, Manual Scheduling, Labels, and Selectors in Kubernetes
[Video Link](https://www.youtube.com/watch?v=6eGf7_VSbrQ)
@piyushsachdeva
[Git Repository](https://github.com/piyushsachdeva/CKA-2024/)
[My Git Repo](https://github.com/sina14/40daysofkubernetes)
In this part, `node` selector, `label`... | sina14 |
1,916,076 | Generic DB Manager in .net C# | Simplify Your .NET Project with DbManager.EFCore Git Hub : dbmanager DbManager is a... | 0 | 2024-07-08T16:22:25 | https://dev.to/internet_traffic_6ced875e/generic-db-manager-in-net-c-18go | netcore, efcore, csharp | ## **Simplify Your .NET Project with DbManager.EFCore**
Git Hub : [dbmanager](https://github.com/ony19161/dbmanager)
DbManager is a powerful package that simplifies the integration of CRUD (Create, Read, Update, Delete) operations in your .NET projects. Currently it supports two database systems MS SQL Server and MyS... | internet_traffic_6ced875e |
1,916,077 | A Personalized News Summary AI Tool with me. | Have you wished to read like top 5 latest articles all at once on a single page and in just a few... | 0 | 2024-07-11T22:56:30 | https://dev.to/sababu_/a-personalized-news-summary-ai-tool-with-me-79g | Have you wished to read like top 5 latest articles all at once on a single page and in just a few minutes instead of turning pages 🤔? Nowadays, everything is fast, there are many things to read, from newsletters we subscribed to, flooding into our email inbox every morning to articles we come across shared with us or ... | sababu_ | |
1,916,079 | Unlocking Innovation: The Future of Low-Code Development | Introduction Low-code development platforms have revolutionized the way applications are built,... | 0 | 2024-07-08T16:23:47 | https://dev.to/engkerollosadel/unlocking-innovation-the-future-of-low-code-development-48o | **Introduction**
Low-code development platforms have revolutionized the way applications are built, enabling developers to create software with minimal hand-coding. This evolution has opened up new opportunities for businesses to innovate quickly and efficiently. As we move forward, the next generation of low-code capa... | engkerollosadel | |
1,916,080 | Erecept | Wegovy to skuteczny lek, który zdobył znaczną popularność w leczeniu otyłości i nadwagi. FlexTouch to... | 0 | 2024-07-08T16:24:12 | https://dev.to/receptax07/erecept-51h | Wegovy to skuteczny lek, który zdobył znaczną popularność w leczeniu otyłości i nadwagi. FlexTouch to zaawansowany device iniekcji leku Wegovy opracowany przez firmę Novo Nordisk, który pozwala na precyzyjne podawanie leku. W tym artykule omówimy działanie leku Wegovy FlexTouch, jego zastosowanie, dawkowanie, skutki ub... | receptax07 | |
1,916,081 | Day 3: Continuous Integration Explained: How to Integrate Code Efficiently | Introduction to Continuous Integration (CI) Continuous Integration (CI) is a cornerstone... | 0 | 2024-07-08T16:27:43 | https://dev.to/dipakahirav/day-3-continuous-integration-explained-how-to-integrate-code-efficiently-2ohh | devops, cicd, learning, beginners | #### Introduction to Continuous Integration (CI)
Continuous Integration (CI) is a cornerstone of modern software development practices. It involves the regular merging of code changes into a shared repository, followed by automated builds and tests. This process helps identify and fix issues early, ensuring that the c... | dipakahirav |
1,916,082 | I launched a real-time telegram tracker for crypto communities. | The Problems We're Solving: *1. Information Overload: * - Crypto and Web3 enthusiasts often need to... | 0 | 2024-07-08T16:28:07 | https://dev.to/tonyfuchs112/i-launched-a-real-time-telegram-tracker-for-crypto-communities-1fle | javascript, python, cryptocurrency | The Problems We're Solving:
**1. Information Overload:
** - Crypto and Web3 enthusiasts often need to monitor dozens or even hundreds of communities across Telegram and Discord.
- Real-life example: Our platform allows you to track these communities without cluttering your personal Telegram with spam-filled chats. You... | tonyfuchs112 |
1,916,085 | Lightroom Premium APK for iOS | Adobe Lightroom is a powerful tool for photographers, offering a wide array of features for photo... | 0 | 2024-07-08T16:29:58 | https://dev.to/shams_uddin_54a750943f8e2/lightroom-premium-apk-for-ios-3e2e | learning, mobile, software | Adobe Lightroom is a powerful tool for photographers, offering a wide array of features for photo editing and management. While the official app is available on the Apple App Store, some users seek out modified versions like Lightroom Premium APK to access premium features for free. However, this practice comes with ri... | shams_uddin_54a750943f8e2 |
1,916,086 | What are your goals for week 28 of 2024? | It's week 28 of 2024. What are your goals for the week? What are you building? What... | 19,128 | 2024-07-08T17:05:58 | https://dev.to/jarvisscript/what-are-your-goals-for-week-28-of-2024-jil | discuss, motivation | It's week 28 of 2024.
## What are your goals for the week?
- What are you building?
- What will be a good result by week's end?
- What events are happening this week?
* any suggestions for in person or virtual events?
- Any special goals for the quarter?
### Last Week's Goals
Last week was a short week, no ... | jarvisscript |
1,916,087 | Deploying a Discord Bot to AWS EC2 Using Terraform | Prerequisites Install Terraform: Ensure that Terraform is installed on your local... | 0 | 2024-07-08T16:32:13 | https://dev.to/aisquare/deploying-a-discord-bot-to-aws-ec2-using-terraform-in5 | ## Prerequisites
1. **Install Terraform**: Ensure that Terraform is installed on your local machine. You can download it from the [Terraform website](https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli).
2. **AWS CLI**: Install and configure the AWS CLI with your credentials. Follow the [AW... | aisquare | |
1,916,088 | Tooth Whitening | https://maps.google.com/maps?cid=17481504403585659126 | 0 | 2024-07-08T16:32:23 | https://dev.to/tooth-whitening/tooth-whitening-e8d | [https://maps.google.com/maps?cid=17481504403585659126](https://maps.google.com/maps?cid=17481504403585659126) | tooth-whitening | |
1,916,089 | Node.js is Not Single-Threaded | Node.js is known as a blazingly fast server platform with its revolutionary single-thread... | 0 | 2024-07-08T18:40:39 | https://dev.to/evgenytk/nodejs-is-not-single-threaded-29o1 | node, javascript, webdev, programming | Node.js is known as a blazingly fast server platform with its revolutionary single-thread architecture, utilizing server resources more efficiently. But is it actually possible to achieve that amazing performance using only one thread? The answer might surprise you.
In this article we will reveal all the secrets and m... | evgenytk |
1,916,090 | Using NgModule vs Standalone components | I have been studying Angular from a free YouTube course by Procademy. We are working on different dev... | 0 | 2024-07-08T16:35:04 | https://dev.to/yash_saxena_/using-ngmodule-vs-standalone-components-8d8 | I have been studying Angular from a free YouTube course by Procademy. We are working on different dev versions(node - 18.19.1 npm-10.8.1 ng-18.0.6). The creator created a sample project and there was an app.module.ts file by default but when I created the project it wasn't there. I started by creating components and us... | yash_saxena_ | |
1,916,091 | Best Surrogacy Centres in Panaji - Ekmifertility | Ekmifertility is the best surrogacy centres in Goa . Contact us now, to know more about surrogacy... | 0 | 2024-07-08T16:35:06 | https://dev.to/nikhil_kumarsingh_214aef/best-surrogacy-centres-in-panaji-ekmifertility-7f1 | Ekmifertility is the best surrogacy centres in Goa . Contact us now, to know more about surrogacy treatment options. Surrogacy is a widely known process where another woman has to carry your child in her womb until birth. Ekmi Fertility, being the best surrogacy centre in Panaji has a large pool of surrogate mothers wh... | nikhil_kumarsingh_214aef | |
1,916,092 | Python Introduction Course with Kaniyam | Day1 Introduction to Python and its usages How to install python in windows, Linux and MacOS How to... | 0 | 2024-07-08T16:43:18 | https://dev.to/mansoor_hussain_24fa27251/python-introduction-course-with-kaniyam-5b5i | python, kaniyam, week1 | Day1
1. Introduction to Python and its usages
2. How to install python in windows, Linux and MacOS
3. How to raise questions
- Use Google search
- Connect with online forums - https://forums.tamillinuxcommunity.org/
- Class chat - Whatsapp channel/Class Channel
4. How to check python version
- Open python console... | mansoor_hussain_24fa27251 |
1,916,093 | What are Usna and Arwa Rice and their Health Benefits | Rice is consumed as a primary food source around the world, and comes in different varieties to... | 0 | 2024-07-08T16:43:38 | https://dev.to/veeroverseas_fc6c8680453a/what-are-usna-and-arwa-rice-and-their-health-benefits-5dme | basmati, news | Rice is consumed as a primary food source around the world, and comes in different varieties to choose from. Rice comes in two different options: Arwa and Usna rice. Arwa rice Vs Usna rice can pull out an interesting debate among rice lovers. If you’re planning a family get together, but confused between Usna and Arwa ... | veeroverseas_fc6c8680453a |
1,916,094 | Unleashing the Potential of JS Voice User Interface with Sista AI | Unleash the potential of JS Voice User Interface with Sista AI! Explore how AI can transform user interactions and revolutionize engagement 🚀 | 27,994 | 2024-07-08T16:45:34 | https://dev.to/sista-ai/unleashing-the-potential-of-js-voice-user-interface-with-sista-ai-bb6 | ai, react, javascript, typescript | <h2>Unlocking the Power of Voice User Interfaces with Sista AI</h2><p>Sista AI, an end-to-end AI integration platform, revolutionizes user interactions by seamlessly integrating AI voice assistants into apps within minutes, enhancing user engagement and accessibility. With cutting-edge solutions like conversational AI ... | sista-ai |
1,916,095 | Why ‘Screw Optimization’ is My New Mantra | Before the LeetCoders jump in, let me clarify: I’m not advocating for sloppy algorithms. Instead, I’m... | 0 | 2024-07-11T15:15:00 | https://dev.to/nmiller15/why-screw-optimization-is-my-new-mantra-1lip | productivity, programming, learning, career | Before the LeetCoders jump in, let me clarify: I’m not advocating for sloppy algorithms. Instead, I’m challenging the obsession with finding the perfect solution before taking any action.
### **The Perfectionist’s Dilemma**
For the past two months, I’ve been telling myself to stop obsessing over the optimal solution ... | nmiller15 |
1,916,096 | A instrução if e else | A forma completa da instrução if é: A cláusula else é opcional. Se a expressão condicional for... | 0 | 2024-07-09T22:02:21 | https://dev.to/devsjavagirls/a-instrucao-if-e-else-j8c | java | - A forma completa da instrução if é:
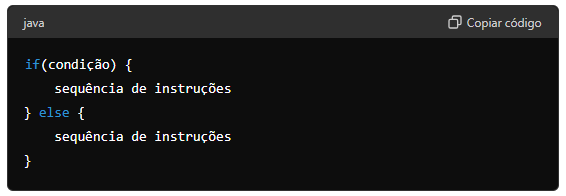
- A cláusula else é opcional.
- Se a expressão condicional for verdadeira, as instruções dentro do if será executado. Caso contrário, se houver, as instruções do else será exec... | devsjavagirls |
1,916,097 | Sahipro controls for Automation testing | Hi All, Today I learn about sahipro for automation testing Text input... | 0 | 2024-07-08T16:48:34 | https://dev.to/karthick_ravi/sahipro-controls-for-automation-testing-2dkn | automaton, selenium, testing | Hi All,
Today I learn about sahipro for automation testing
Text input
_setValue(_textbox("fieldloc"),"Test1")
_selectWindow()
_lockWindow()
| karthick_ravi |
1,916,098 | How to connect keycloak and Nuxt | While working in an internal project, I got the task of getting the connection between keycloak and... | 0 | 2024-07-08T16:51:06 | https://dev.to/leamsigc/how-to-connect-keycloak-and-nuxt-3blc | nuxt, vue, tutorial |
While working in an internal project, I got the task of getting the connection between keycloak and our nuxt application.
After an hour of research, I found two feasible options to get this working fast and easy.
→ Using the `keycloak-js`
1. manage the keycloak manually
```vue
<script setup>
import Keycloa... | leamsigc |
1,916,099 | 🚀 Launching FidForward! 🚀 | Today, Bernardo and I are excited to launch FidForward in private beta! We're looking for companies... | 0 | 2024-07-08T16:54:15 | https://dev.to/rbatista19/launching-fidforward-54gc | react, node | Today, Bernardo and I are excited to launch FidForward in private beta!
We're looking for companies with 10-50 employees willing to pilot the next generation of performance management.
With two pilot programs already running successfully (achieving a 30-50% improvement in eNPS), we’re eager to expand FidForward to mo... | rbatista19 |
1,916,100 | A instrução switch | A segunda instrução de seleção Java é switch. A instrução switch fornece uma ramificação com vários... | 0 | 2024-07-09T22:02:40 | https://dev.to/devsjavagirls/a-instrucao-switch-5bed | java | - A segunda instrução de seleção Java é switch.
- A instrução switch fornece uma ramificação com vários caminhos, permitindo ao programa fazer uma seleção entre várias alternativas.
- Embora uma série de instruções if aninhadas possa executar testes com vários caminhos, em muitas situações, switch é uma abordagem mai... | devsjavagirls |
1,916,101 | Complete Guide to the Django Services and Repositories Design Pattern with the Django REST Framework | Introduction to the Django Services and Repositories Design Pattern with Django REST... | 0 | 2024-07-08T16:59:18 | https://mateoramirezr.hashnode.dev/django-services-and-repositories-design-pattern-with-rest-api | webdev, django, backend, api | ## Introduction to the Django Services and Repositories Design Pattern with Django REST Framework
[**You can find the complete code and structure of the project in the following GitHub link:** *<mark>Click</mark>*](https://github.com/MateoRamirezRubio1/mini-blog-rest-api).
In the world of software development, code o... | mateoramirezr |
1,916,102 | Common Lisp VS C: a testimony | I like testimonies. Here's one on Lisp vs C. About execution time, speed of development, length of... | 0 | 2024-07-08T16:58:40 | https://dev.to/vindarel/common-lisp-vs-c-a-testimony-42ga | lisp, commonlisp, c, programming | _I like testimonies. Here's one on Lisp vs C. About execution time, speed of development, length of programs, ease of development._
---
I find SBCL produces highly performant code, and is even faster with a small number of well-placed type declarations. I have a Lisp vs C story: I'm a mathematician and was doing some... | vindarel |
1,916,103 | Evotto: Drive Your Dreams - Transforming Journeys into Unforgettable Adventures | Embarking on the journey of "Evotto" -an evolution to automobile , offers an opportunity to connect... | 0 | 2024-07-08T17:00:01 | https://dev.to/evotto_official/evotto-drive-your-dreams-transforming-journeys-into-unforgettable-adventures-jg2 | Embarking on the journey of "Evotto" -an evolution to automobile , offers an opportunity to connect with transport readers by making them feel the freedom and excitement of exploring new destinations in the comfort of our rental vehicles. We engage our audience by sharing vivid ways, highlighting unique vehicle feature... | evotto_official | |
1,916,104 | Tente isso 3-1 : Construa um sistema de ajuda | Este projeto constrói um sistema de ajuda simples que exibe a sintaxe das instruções de controle... | 0 | 2024-07-09T22:02:55 | https://dev.to/devsjavagirls/tente-isso-3-1-construa-um-sistema-de-ajuda-45ng | java | Este projeto constrói um sistema de ajuda simples que exibe a sintaxe das instruções de controle Java. O programa exibe um menu contendo as instruções de controle e então espera que uma seja selecionada. Após a seleção, a sintaxe da instrução é exibida. Nessa primeira versão do programa, só há ajuda disponível para as ... | devsjavagirls |
1,916,105 | Gin and router example | Install Gin with the following command: go get -u github.com/gin-gonic/gin Enter... | 0 | 2024-07-08T17:34:09 | https://dev.to/hieunguyendev/gin-and-router-example-2939 | go, gin, beginners, backend |

- Install Gin with the following command:
```
go get -u github.com/gin-gonic/gin
```
- After installation, we proceed to code in the “main.go” file with a simple function as follows:
```
package main
import (
... | hieunguyendev |
1,916,107 | Python_In_Tamil-001 | Dear All, I am Govindarajan from Thanjavur. I teach Basic Python through OnLine. I am a PCEP and... | 0 | 2024-07-08T17:06:10 | https://dev.to/govi1964/pythonintamil-001-54f | python, learning, programming, basic | Dear All,
I am Govindarajan from Thanjavur. I teach Basic Python through OnLine. I am a PCEP and PCAP.
Ok, let us start learning Basic Python.
1. Install python from python.org as per your computer system.
2. In windows, in the search bar, type cmd, cmd page will get opened. Write python at the cursor location and pre... | govi1964 |
1,916,108 | Git User Credentials | So i always wondered why i do a git push to a certain repository but notice that i see a different... | 0 | 2024-07-08T17:09:21 | https://dev.to/debuggingrabbit/git-credentials-23fc | So i always wondered why i do a git push to a certain repository but notice that i see a different user as the committer, and not the account i cloned from. so the problem is this - i clone from repo A with username A1, but while doing a git push i noticed that the commit done was from username B1, even though they all... | debuggingrabbit | |
1,916,109 | Dockerizing a Laravel App: Nginx, MySql, PhpMyAdmin, and Php-8.2 | What is Docker? Docker is an open-source platform that enables developers to automate the... | 0 | 2024-07-08T18:13:47 | https://dev.to/kamruzzaman/dockerizing-a-laravel-app-nginx-mysql-phpmyadmin-and-php-82-43ne | laravel, nginx, mysql, phpmyadmin |

**What is Docker?**
Docker is an open-source platform that enables developers to automate the deployment, scaling, and management of applications using containerization. Containers package an application and its de... | kamruzzaman |
1,916,115 | Internal Error: No such file or directory @ rb_sysopen - /box/script.js when using Judge0 API | I'm encountering an issue while trying to execute code using the Judge0 API. The response I receive... | 0 | 2024-07-08T17:21:52 | https://dev.to/nischal_kshaj_f2c1d595ea/internal-error-no-such-file-or-directory-rbsysopen-boxscriptjs-when-using-judge0-api-2la4 | I'm encountering an issue while trying to execute code using the Judge0 API. The response I receive from the API is as follows:
json
Copy code
{
"stdout": null,
"time": null,
"memory": null,
"stderr": null,
"token": "4957159e-0921-44fa-82a6-b9d4b202f276",
"compile_output": null,
"message": "No such file ... | nischal_kshaj_f2c1d595ea | |
1,916,116 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash app... | 0 | 2024-07-08T17:22:13 | https://dev.to/gomon87305/buy-verified-cash-app-account-5b2g | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | gomon87305 |
1,916,117 | Architecting a Secure and Scalable Network with AWS VPCs and Subnets | Building a secure and scalable network in the cloud is critical for any organization that leverages... | 0 | 2024-07-08T17:22:18 | https://dev.to/harshana_vivekanandhan_88/architecting-a-secure-and-scalable-network-with-aws-vpcs-and-subnets-3kcc | webdev, aws, cloudcomputing | Building a secure and scalable network in the cloud is critical for any organization that leverages cloud services. AWS Virtual Private Cloud (VPC) and its associated subnets provide the foundational infrastructure to achieve these goals. This blog post will guide you through the process of architecting a secure and sc... | harshana_vivekanandhan_88 |
1,916,118 | python learning-D1 | hi day 1 '''python print(welcome)''' | 0 | 2024-07-08T17:22:22 | https://dev.to/perumal_s_9a6d79a633d63d4/python-learning-d1-mal | hi
day 1
'''python
print(welcome)''' | perumal_s_9a6d79a633d63d4 | |
1,916,119 | Git Dual Boot Files Modified Solution | So there is a problem that you might face which is if you use dual boot or switched from windows to... | 0 | 2024-07-08T17:23:26 | https://dev.to/abdulmateenzwl/git-dual-boot-files-modified-solution-32ee | git, linux, microsoft, dualboot | So there is a problem that you might face which is if you use dual boot or switched from windows to linux or vice versa That the files in your git are shown as modified but when you try to pull it says already uptodate.
This issue often occurs due to differences in how Windows and Linux handle line endings in text fi... | abdulmateenzwl |
1,916,120 | Transmute negative emotions into personal growth | I had a bad day at work today. Corporate games, lazy management, and unmeaningful work is what got... | 0 | 2024-07-08T22:46:43 | https://dev.to/dellboyan/transmute-negative-emotions-into-personal-growth-4c1p | productivity, learning, programming | I had a bad day at work today. Corporate games, lazy management, and unmeaningful work is what got me. There's no need to go into details but this situation left me with a lot of anger. It did help that I was biking from work so a lot of that steam went out, but it also got me thinking, what's the point of this state? ... | dellboyan |
1,916,121 | Unlock the Power of Cryptography with the 'Polybius Square Encryption in Python' Project | The article is about the 'Polybius Square Encryption in Python' project, a captivating programming practice course offered on LabEx. It delves into the intricacies of the Polybius square encryption algorithm, guiding readers through its implementation in Python. The article highlights the key skills learners will acqui... | 27,678 | 2024-07-08T17:28:19 | https://dev.to/labex/unlock-the-power-of-cryptography-with-the-polybius-square-encryption-in-python-project-57n4 | labex, programming, course, python |
Embark on an exciting journey into the world of cryptography with the 'Polybius Square Encryption in Python' project on [LabEx](https://labex.io/courses/project-chessboard-encryption). This captivating programming practice course will equip you with the knowledge and skills to implement the Polybius square encryption ... | labby |
1,916,122 | Deep Dive into PandApache3: Code de lancement | A post by Mary 🇪🇺 🇷🇴 🇫🇷 | 0 | 2024-07-08T17:30:41 | https://dev.to/pykpyky/deep-dive-into-pandapache3-code-de-lancement-3chm | webdev, csharp, dotnet | pykpyky | |
1,916,123 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-07-08T17:31:51 | https://dev.to/gomon87305/buy-verified-paxful-account-58e9 | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | gomon87305 |
1,916,125 | Python class first day | Hi all, Today I joined the python class run by Kaniyam Foundation. First day of class today they... | 0 | 2024-07-08T17:36:06 | https://dev.to/mahesh_s_369d8f0b1ccd1b9e/python-class-first-day-4o9c | python | Hi all,
Today I joined the python class run by Kaniyam Foundation. First day of class today they taught basic installation and instructions and how to create blogs. It was very useful for me. And they taught basic Python programming.
Basic program
👇👇👇
```
Print("hello world")
```
I will write about the daily act... | mahesh_s_369d8f0b1ccd1b9e |
1,916,126 | Deep Dive into PandApache3: Code de lancement | Vous êtes-vous déjà demandé a quoi ressemble un serveur web de l’intérieur ? Avez-vous déjà rêvé d'en... | 0 | 2024-07-08T17:36:14 | https://dev.to/pykpyky/deep-dive-into-pandapache3-code-de-lancement-327n | webdev, csharp, dotnet, development | Vous êtes-vous déjà demandé a quoi ressemble un serveur web de l’intérieur ? Avez-vous déjà rêvé d'en créer un vous-même ? Vous êtes au bon endroit !
Bienvenue dans ce premier article technique consacré au développement de PandApache3.
Cet article et les suivants ont pour ambition de vous décrire le fonctionnement i... | pykpyky |
1,916,129 | Buy Negative Google Reviews | https://dmhelpshop.com/product/buy-negative-google-reviews/ Buy Negative Google Reviews Negative... | 0 | 2024-07-08T17:41:46 | https://dev.to/gomon87305/buy-negative-google-reviews-1ecg | javascript, webdev, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-negative-google-reviews/\n\n\nBuy Negative Google Reviews\nNegative reviews on Google are detrimental critiques that expose customers’ unfavorable experiences with a business. These reviews can significantly damage a company’s reputation, presenting challenges in both attracting new customers and retaining current ones. If you are considering purchasing negative Google reviews from dmhelpshop.com, we encourage you to reconsider and instead focus on providing exceptional products and services to ensure positive feedback and sustainable success.\n\nWhy Buy Negative Google Reviews from dmhelpshop\nWe take pride in our fully qualified, hardworking, and experienced team, who are committed to providing quality and safe services that meet all your needs. Our professional team ensures that you can trust us completely, knowing that your satisfaction is our top priority. With us, you can rest assured that you’re in good hands.\n\nIs Buy Negative Google Reviews safe?\nAt dmhelpshop, we understand the concern many business persons have about the safety of purchasing Buy negative Google reviews. We are here to guide you through a process that sheds light on the importance of these reviews and how we ensure they appear realistic and safe for your business. Our team of qualified and experienced computer experts has successfully handled similar cases before, and we are committed to providing a solution tailored to your specific needs. Contact us today to learn more about how we can help your business thrive.\n\nBuy Google 5 Star Reviews\nReviews represent the opinions of experienced customers who have utilized services or purchased products from various online or offline markets. These reviews convey customer demands and opinions, and ratings are assigned based on the quality of the products or services and the overall user experience. Google serves as an excellent platform for customers to leave reviews since the majority of users engage with it organically. When you purchase Buy Google 5 Star Reviews, you have the potential to influence a large number of people either positively or negatively. Positive reviews can attract customers to purchase your products, while negative reviews can deter potential customers.\n\nIf you choose to Buy Google 5 Star Reviews, people will be more inclined to consider your products. However, it is important to recognize that reviews can have both positive and negative impacts on your business. Therefore, take the time to determine which type of reviews you wish to acquire. Our experience indicates that purchasing Buy Google 5 Star Reviews can engage and connect you with a wide audience. By purchasing positive reviews, you can enhance your business profile and attract online traffic. Additionally, it is advisable to seek reviews from reputable platforms, including social media, to maintain a positive flow. We are an experienced and reliable service provider, highly knowledgeable about the impacts of reviews. Hence, we recommend purchasing verified Google reviews and ensuring their stability and non-gropability.\n\nLet us now briefly examine the direct and indirect benefits of reviews:\nReviews have the power to enhance your business profile, influencing users at an affordable cost.\nTo attract customers, consider purchasing only positive reviews, while negative reviews can be acquired to undermine your competitors. Collect negative reports on your opponents and present them as evidence.\nIf you receive negative reviews, view them as an opportunity to understand user reactions, make improvements to your products and services, and keep up with current trends.\nBy earning the trust and loyalty of customers, you can control the market value of your products. Therefore, it is essential to buy online reviews, including Buy Google 5 Star Reviews.\nReviews serve as the captivating fragrance that entices previous customers to return repeatedly.\nPositive customer opinions expressed through reviews can help you expand your business globally and achieve profitability and credibility.\nWhen you purchase positive Buy Google 5 Star Reviews, they effectively communicate the history of your company or the quality of your individual products.\nReviews act as a collective voice representing potential customers, boosting your business to amazing heights.\nNow, let’s delve into a comprehensive understanding of reviews and how they function:\nGoogle, with its significant organic user base, stands out as the premier platform for customers to leave reviews. When you purchase Buy Google 5 Star Reviews , you have the power to positively influence a vast number of individuals. Reviews are essentially written submissions by users that provide detailed insights into a company, its products, services, and other relevant aspects based on their personal experiences. In today’s business landscape, it is crucial for every business owner to consider buying verified Buy Google 5 Star Reviews, both positive and negative, in order to reap various benefits.\n\nWhy are Google reviews considered the best tool to attract customers?\nGoogle, being the leading search engine and the largest source of potential and organic customers, is highly valued by business owners. Many business owners choose to purchase Google reviews to enhance their business profiles and also sell them to third parties. Without reviews, it is challenging to reach a large customer base globally or locally. Therefore, it is crucial to consider buying positive Buy Google 5 Star Reviews from reliable sources. When you invest in Buy Google 5 Star Reviews for your business, you can expect a significant influx of potential customers, as these reviews act as a pheromone, attracting audiences towards your products and services. Every business owner aims to maximize sales and attract a substantial customer base, and purchasing Buy Google 5 Star Reviews is a strategic move.\n\nAccording to online business analysts and economists, trust and affection are the essential factors that determine whether people will work with you or do business with you. However, there are additional crucial factors to consider, such as establishing effective communication systems, providing 24/7 customer support, and maintaining product quality to engage online audiences. If any of these rules are broken, it can lead to a negative impact on your business. Therefore, obtaining positive reviews is vital for the success of an online business\n\nWhat are the benefits of purchasing reviews online?\nIn today’s fast-paced world, the impact of new technologies and IT sectors is remarkable. Compared to the past, conducting business has become significantly easier, but it is also highly competitive. To reach a global customer base, businesses must increase their presence on social media platforms as they provide the easiest way to generate organic traffic. Numerous surveys have shown that the majority of online buyers carefully read customer opinions and reviews before making purchase decisions. In fact, the percentage of customers who rely on these reviews is close to 97%. Considering these statistics, it becomes evident why we recommend buying reviews online. In an increasingly rule-based world, it is essential to take effective steps to ensure a smooth online business journey.\n\nBuy Google 5 Star Reviews\nMany people purchase reviews online from various sources and witness unique progress. Reviews serve as powerful tools to instill customer trust, influence their decision-making, and bring positive vibes to your business. Making a single mistake in this regard can lead to a significant collapse of your business. Therefore, it is crucial to focus on improving product quality, quantity, communication networks, facilities, and providing the utmost support to your customers.\n\nReviews reflect customer demands, opinions, and ratings based on their experiences with your products or services. If you purchase Buy Google 5-star reviews, it will undoubtedly attract more people to consider your offerings. Google is the ideal platform for customers to leave reviews due to its extensive organic user involvement. Therefore, investing in Buy Google 5 Star Reviews can significantly influence a large number of people in a positive way.\n\nHow to generate google reviews on my business profile?\nFocus on delivering high-quality customer service in every interaction with your customers. By creating positive experiences for them, you increase the likelihood of receiving reviews. These reviews will not only help to build loyalty among your customers but also encourage them to spread the word about your exceptional service. It is crucial to strive to meet customer needs and exceed their expectations in order to elicit positive feedback. If you are interested in purchasing affordable Google reviews, we offer that service.\n\n\n\n\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | gomon87305 |
1,916,130 | Glue work makes the dream work | Glue (Verb): To integrate different parts of a system together that would otherwise be... | 0 | 2024-07-08T17:42:05 | https://dev.to/ajparadith/glue-work-makes-the-dream-work-4g6n | womenintech, testing, career | Glue (Verb): To integrate different parts of a system together that would otherwise be incompatible.
**Glue is complex**
Being the Glue can be a lot of different things, from Coding, design or just being the human being amongst it all. People are not always rewarded for doing it well. It’s testing or Quality Engineer... | ajparadith |
1,916,131 | Deep Dive into PandApache3: Launch Code | Have you ever wondered what a web server looks like from the inside? Have you ever dreamt of creating... | 0 | 2024-07-08T17:44:58 | https://dev.to/pykpyky/deep-dive-into-pandapache3-launch-code-43mh | webdev, csharp, dotnet, development |
Have you ever wondered what a web server looks like from the inside? Have you ever dreamt of creating one yourself? You've come to the right place!
Welcome to this first technical article dedicated to the development of PandApache3.
This article and the following ones aim to describe the internal workings of PandApa... | pykpyky |
1,916,132 | Pergunte ao especialista - If/else ou switch | Sob que condições devo usar uma escada if-else-if em vez de um switch ao codificar uma ramificação... | 0 | 2024-07-09T22:03:19 | https://dev.to/devsjavagirls/pergunte-ao-especialista-ifelse-ou-switch-c71 | java | Sob que condições devo usar uma escada if-else-if em vez de um switch ao codificar uma ramificação com vários caminhos?
Resposta:
Em geral, use uma escada if-else-if quando as condições que controlam o processo de seleção não dependerem de um único valor.
Exemplo:
if(x < 10) // ...
else if(y != 0) // ...
else if... | devsjavagirls |
1,916,133 | Navigating Common Git Errors: A Guide for Developers | As developers, we often encounter various errors when using Git. One such error involves attempting... | 0 | 2024-07-08T17:49:57 | https://dev.to/saint_vandora/navigating-common-git-errors-a-guide-for-developers-35bk | webdev, javascript, git, github | As developers, we often encounter various errors when using Git. One such error involves attempting to fetch all branches or create a new branch in a directory that is not a Git repository. In this article, we will explore a common scenario and provide a step-by-step guide on how to resolve it.
## The Scenario
You ar... | saint_vandora |
1,916,134 | Building 100% reusable UI kits | Hey devs :) Introduction With 15+ years of UI kit building & design systems, my team is... | 0 | 2024-07-08T17:51:19 | https://dev.to/joshua_mcmillan_3e37d7136/building-100-reusable-ui-kits-1nj6 | javascript, webdev, react, programming | Hey devs :)
**Introduction**
With 15+ years of UI kit building & design systems, my team is launching a platform (free beta access) that allows developers to build consistent & fully functional UI kits / design systems in days, instead of months. Giving you best practices with the most advanced system design/system d... | joshua_mcmillan_3e37d7136 |
1,916,135 | Building the Foundation: Your Pathway to Mastery in Prompt Engineering. | Building the Foundation: Your Pathway to Mastery in Prompt Engineering Greetings, courageous... | 27,995 | 2024-07-08T17:51:27 | https://dev.to/ameet/building-the-foundation-your-pathway-to-mastery-in-prompt-engineering-oh3 | aws, promptengineering, genai, anthropic | **Building the Foundation: Your Pathway to Mastery in Prompt Engineering**
Greetings, courageous adventurer! You are about to embark on an intriguing journey through the domain of AI prompt engineering, poised to
learn, experiment, and innovate. This series serves as your compass, a powerful guide that will navigate ... | ameet |
1,916,137 | Crafting an Effective Cover Letter 📨💯🚀 | Hello, everyone! ⭐ Today, we are diving into a topic that is a bit outside from my usual... | 27,996 | 2024-07-09T13:00:00 | https://dev.to/pachicodes/crafting-an-effective-cover-letter-2mj9 | career, beginners, discuss |
Hello, everyone! ⭐
Today, we are diving into a topic that is a bit outside from my usual discussions.
While technical skills are crucial, understanding the nuances of the job application process, specifically the creation of a compelling cover letter, is equally important, so today I want to share a bit of what work... | pachicodes |
1,916,138 | What a W.I.T.C.H! | Exploratory testing using a Witch. Erm - pardon? I love a heuristic. Does not mean I... | 0 | 2024-07-08T17:53:05 | https://dev.to/ajparadith/what-a-witch-5gmp | testing, exploratorytesting, webdev | ## Exploratory testing using a Witch.
Erm - pardon?
I love a heuristic. Does not mean I always remember them, so take my advice — i’m not using it.
Here’s an exploratory testing heuristic using the acronym W.I.T.C.H.
## **W.I.T.C.H Heuristic**
**W — Workflows**
- Explore common and edge workflows: Identify typ... | ajparadith |
1,916,139 | Say Goodbye to Solo Coding 👋: Collaborate with Others on SocialCode 🤝 | We Are Live 🚀: Announcing the Launch of SocialCode We are thrilled to announce that... | 0 | 2024-07-08T17:55:53 | https://dev.to/socialcodeclub/say-goodbye-to-solo-coding-collaborate-with-others-on-socialcode-4ip7 | coding, collaboration, learning, startup | ## We Are Live 🚀: Announcing the Launch of SocialCode
We are thrilled to announce that SocialCode is now live! After many long days of hard work and dedication, we are excited to introduce a platform **designed to help developers collaborate, create, and connect**. SocialCode is more than just a tool; it’s a communit... | socialcodeclub |
1,916,140 | Funções de escopo no Kotlin | As funções de escopo do no Kotlin é um recurso poderoso que nos permite melhor a legibilidade dos... | 0 | 2024-07-08T19:04:53 | https://dev.to/renatocardosoalves/funcoes-de-escopo-no-kotlin-2i1a | kotlin, programming | As funções de escopo do no Kotlin é um recurso poderoso que nos permite melhor a legibilidade dos nossos códigos. Elas facilitam a execução de blocos de código em um contexto específico, eliminando a necessidade de variáveis temporarias. As cinco principais funções de escopo são: **'let'**, **'run'**, **'with'**, **'ap... | renatocardosoalves |
1,916,141 | What’s the Difference Between Kubernetes Namespaces and VCluster? | There are several options when it comes to containerized application orchestration and management.... | 0 | 2024-07-08T18:03:55 | https://dev.to/signadot/whats-the-difference-between-kubernetes-namespaces-and-vcluster-5d6n | kubernetes, microservices, containerorchestration, virtualclusters | There are several options when it comes to containerized application orchestration and management. Two of the most popular are Kubernetes namespaces and virtual clusters. But which is better for your use case? In this blog, we’ll be comparing the differences and similarities between these two solutions so you can make ... | signadot |
1,916,143 | Hello World | Today, I joined a free online course on Python by the Kaniyam Foundation. And, this blog is to... | 0 | 2024-07-08T18:01:26 | https://dev.to/amotbeli/hello-world-9hp | programming, python, beginners, learning | Today, I joined a free online course on Python by the Kaniyam Foundation. And, this blog is to document my progress throughout the course.
In the first live session this evening, a lot of course details were shared. Helpful information was provided regarding the installation of Python on our machines. As is customary,... | amotbeli |
1,916,144 | Introducing CurlDock: Simplify API Testing with Docker and Curl | Hey Dev.to community! I'm excited to share CurlDock, a lightweight open-source tool I've been... | 0 | 2024-07-08T18:26:33 | https://dev.to/ietxaniz/introducing-curldock-simplify-api-testing-with-docker-and-curl-5ajo | curl, api, docker, devtools | Hey Dev.to community!
I'm excited to share CurlDock, a lightweight open-source tool I've been working on to simplify API testing and curl script management.
## What is CurlDock?
CurlDock combines the power of curl with the convenience of Docker, offering a user-friendly interface for creating, editing, and executing... | ietxaniz |
1,916,145 | Animated text underline in CSS only | .animated-underline { position: relative; text-decoration:... | 0 | 2024-07-08T18:06:57 | https://dev.to/nureon22/animated-text-underline-in-css-only-4joo | css, web |

```css
.animated-underline {
position: relative;
text-decoration: none;
}
.animated-underline::after {
content: "";
position: absolute;
left: 50%;
top: 100%;
width: 100%;
height: 0... | nureon22 |
1,916,147 | Unleashing the Ultimate Style with Purple Brand: Hoodies, Shirts, and Jeans | In the ever-evolving world of fashion, Purple Brand has emerged as a beacon of style and quality.... | 0 | 2024-07-08T18:08:08 | https://dev.to/ayshanoor445/unleashing-the-ultimate-style-with-purple-brand-hoodies-shirts-and-jeans-3bec | react | In the ever-evolving world of fashion, [Purple Brand](https://purplebrandofficial.com/) has emerged as a beacon of style and quality. Renowned for its unique designs and impeccable craftsmanship, Purple Brand offers a range of clothing that caters to fashion enthusiasts who seek to make a statement. This article delves... | ayshanoor445 |
1,916,148 | 1823. Find the Winner of the Circular Game | 1823. Find the Winner of the Circular Game Medium There are n friends that are playing a game. The... | 27,523 | 2024-07-08T18:09:43 | https://dev.to/mdarifulhaque/1823-find-the-winner-of-the-circular-game-5aa2 | php, leetcode, algorithms, programming | 1823\. Find the Winner of the Circular Game
Medium
There are `n` friends that are playing a game. The friends are sitting in a circle and are numbered from `1` to `n` in **clockwise order**. More formally, moving clockwise from the <code>i<sup>th</sup></code> friend brings you to the <code>(i+1)<sup>th</sup></code> f... | mdarifulhaque |
1,916,149 | Python Introduction Course In Tamil By Kaniyam | Today's introductory Python class was great. Mr. Syed explained very clearly what we are going to... | 0 | 2024-07-08T18:14:10 | https://dev.to/rajeshmurugan95/python-introduction-course-in-tamil-by-kaniyam-g22 | python, kaniyam, learning, beginners | Today's introductory Python class was great. Mr. Syed explained very clearly what we are going to learn in the upcoming classes. Mr. Shrini also gave excellent clarification of many doubts. Thanks to them for taking the time to share their knowledge. | rajeshmurugan95 |
1,916,150 | 3 Amazing Productivity Apps for Linux | I use Ubuntu 24.04 as my daily driver on my main laptop and these are some of the best native Linux... | 0 | 2024-07-08T18:59:20 | https://dev.to/syedumaircodes/3-amazing-productivity-apps-for-linux-pac | linux, ubuntu, productivity, beginners | I use Ubuntu 24.04 as my daily driver on my main laptop and these are some of the best native Linux apps that I use on a daily basis.
## 1. Iotas
Iotas is a note taking application for Linux distributions that is available in the Ubuntu repositories or as a Flatpak that you can download from Flathub.
It's the Linux e... | syedumaircodes |
1,916,178 | Process kill commands | Kill PID ;kill process by process id Kill -9 PID ; kill forcefully a process Kill -15 ; kill... | 0 | 2024-07-08T18:20:43 | https://dev.to/m_abdullah/process-kill-commands-2k10 | redhat, centos, linux, processkillin | Kill PID ;kill process by process id
Kill -9 PID ; kill forcefully a process
Kill -15 ; kill gracefully a process
pkill NAMEOFProcess ; kill by name of process | m_abdullah |
1,916,213 | Understanding Proprietary and Open Source Software | Introduction: Software plays a crucial role in our daily lives, but not all software is the same.... | 0 | 2024-07-08T18:26:50 | https://dev.to/jakvel/understanding-proprietary-and-open-source-software-4m6 | beginners, opensource | Introduction:
Software plays a crucial role in our daily lives, but not all software is the same. There are two main types: proprietary software and open source software. Each has its own characteristics, benefits, and limitations. This blog will explain what these types of software are, their differences, and why th... | jakvel |
1,916,214 | The Ultimate Guide to Yoga Stretches for Improved Flexibility | Flexibility is a vital component of overall health and fitness, and yoga is one of the most effective... | 0 | 2024-07-08T18:27:11 | https://dev.to/samer_samer_5201fdb838bce/the-ultimate-guide-to-yoga-stretches-for-improved-flexibility-56c3 | Flexibility is a vital component of overall health and fitness, and yoga is one of the most effective methods to enhance it. This ultimate guide to yoga stretches will help you understand how yoga can improve your flexibility, reduce tension, and contribute to a more balanced and healthy lifestyle. Whether you are a be... | samer_samer_5201fdb838bce | |
1,916,216 | Showing more Article info on Daily.dev | Daily.dev is a very good extension that helps us aggregate news from several sources. When... | 0 | 2024-07-08T18:31:50 | https://dev.to/jacktt/showing-more-article-info-on-dailydev-5351 | 
Daily.dev is a very good extension that helps us aggregate news from several sources.
When browsing news, I usually scan the `Title -> Thumbnail -> Description`. However, the current view of Daily.dev has only `Tit... | jacktt | |
1,916,218 | Creating a DynamoDB Table and Setting Up IAM Access Control | Introduction to DynamoDB Tables Amazon DynamoDB is a fully managed NoSQL database service provided by... | 0 | 2024-07-08T18:33:40 | https://dev.to/rashmitha_v_d0cfc20ba7152/creating-a-dynamodb-table-and-setting-up-iam-access-control-4f1k | **_Introduction to DynamoDB Tables_**
Amazon DynamoDB is a fully managed NoSQL database service provided by AWS (Amazon Web Services). It offers high performance, seamless scalability, and low latency for applications needing consistent, single-digit millisecond response times. DynamoDB is particularly well-suited for ... | rashmitha_v_d0cfc20ba7152 | |
1,916,221 | Colecciones y bases de dinámicas en base a campos de tipo fecha | En algunas ocasiones deseamos generar bases de datos y colecciones dinámicas en base a una... | 0 | 2024-07-08T19:38:13 | https://dev.to/avbravo/colecciones-y-bases-de-dinamicas-en-base-a-campos-de-tipo-fecha-45d6 | En algunas ocasiones deseamos generar bases de datos y colecciones dinámicas en base a una fecha.
Por ejemplo generar una base datos para cada año y las colecciones por mes y por cada empresa. De manera que contamos con una mejor clasificación de los documentos , lo que genera un mejor desempeño de la aplicación al di... | avbravo | |
1,916,222 | Step-by-Step to AI Engineering Mastery | Hey there, your boy Nomadev is back with another AI blog. I've been away for a bit, but now I'm here... | 0 | 2024-07-08T18:38:41 | https://dev.to/thenomadevel/step-by-step-to-ai-engineering-mastery-1mpn | webdev, javascript, ai, rag | Hey there, your boy Nomadev is back with another AI blog. I've been away for a bit, but now I'm here to stay with regular updates on all things AI!
Generative AI is the buzzword these days, heralding a new era in technology. Its transformative potential is reshaping our interactions with digital systems and opening up... | thenomadevel |
1,916,224 | Data Science? Never Heard Of It. | So, the truth is, last year when I first picked up Data Science, I had no idea what it was. I always... | 0 | 2024-07-12T13:00:00 | https://dev.to/cyrildotexe/data-science-never-heard-of-it-4epf | datascience, beginners | So, the truth is, last year when I first picked up Data Science, I had no idea what it was.
I always wanted to take programming more seriously. I tried a little HTML and CSS a few years back but stopped and I did some simple robotics coding during secondary (high) school.
Anyway, last year I had some time on my hands... | cyrildotexe |
1,916,226 | Desvendando os Segredos dos Pré-Processadores CSS: Domine a Arte da Estilização Web com Sass | Introdução No dinâmico mundo do desenvolvimento web, estilizar com CSS é fundamental para criar... | 0 | 2024-07-08T18:44:59 | https://dev.to/dienik/desvendando-os-segredos-dos-pre-processadores-css-domine-a-arte-da-estilizacao-web-com-sass-5bn7 |
**Introdução**
No dinâmico mundo do desenvolvimento web, estilizar com CSS é fundamental para criar interfaces atraentes e funcionais. Mas e se você pudesse ir além do CSS puro e explorar novas possibilidades com pré-processadores? Nesta palestra, vamos explorar o Sass, um dos pré-processadores mais populares e pode... | dienik | |
1,916,227 | Automação de Coleta de Dados de CNPJ com Python utilizando ReceitaWS | Neste artigo, vamos explorar como automatizar a coleta de dados de CNPJ usando Python. Utilizaremos a... | 0 | 2024-07-08T18:45:34 | https://dev.to/madrade1472/automacao-de-coleta-de-dados-de-cnpj-com-python-utilizando-receitaws-5e39 | Neste artigo, vamos explorar como automatizar a coleta de dados de CNPJ usando Python. Utilizaremos a API da ReceitaWS para obter informações detalhadas sobre cada CNPJ e armazenaremos esses dados em um arquivo CSV. Este guia é voltado para desenvolvedores que desejam automatizar a extração e armazenamento de informaçõ... | madrade1472 | |
1,916,234 | Understanding Docker Architecture: A Beginner's Guide | For most beginners, Docker's architecture is hard to understand. In this blog post, you will learn... | 0 | 2024-07-08T18:50:48 | https://dev.to/rakibtweets/understanding-docker-architecture-a-beginners-guide-fi1 | docker, dockerarchitecture, devops, containerization | For most beginners, Docker's architecture is hard to understand. In this blog post, you will learn everything about Docker architecture and how it works, as easily as possible, with proper visual aids.
### What is Docker?
> Docker is a platform for building, running and shipping application in consistent manners. Doc... | rakibtweets |
1,916,235 | ntegrating SignalR with Angular for Seamless Video Calls: A Step-by-Step Guide | Hi everyone! Today, we'll explore how to create a simple video call web app using WebRTC, Angular,... | 0 | 2024-07-08T18:52:51 | https://dev.to/abdullah_khrais_97a2c908d/ntegrating-signalr-with-angular-for-seamless-video-calls-a-step-by-step-guide-mdh | signalr, api, angular, videocall | Hi everyone! Today, we'll explore how to create a simple video call web app using WebRTC, Angular, and ASP.NET Core. This guide will walk you through the basics of setting up a functional application with these technologies. WebRTC enables peer-to-peer video, voice, and data communication, while SignalR will handle the... | abdullah_khrais_97a2c908d |
1,916,243 | help | https://idx.google.com/majalah-5125170 | 0 | 2024-07-08T18:57:42 | https://dev.to/yayan/help-48fd | https://idx.google.com/majalah-5125170 | yayan | |
1,916,245 | Building an Angular E-commerce App: A Step-by-Step Guide to Understanding and Refining Requirements | Introduction Imagine you're tasked with building a web application. The project manager... | 28,006 | 2024-07-08T19:28:56 | https://dev.to/cezar-plescan/building-an-angular-e-commerce-app-a-step-by-step-guide-to-understanding-and-refining-requirements-hoe | ## Introduction
Imagine you're tasked with building a web application. The project manager hands you a list of requirements, but some of them are a bit... fuzzy. What do you do? Panic? Start coding blindly? Or maybe, you take a step back and start asking questions. In this series of articles, we'll follow the journey ... | cezar-plescan | |
1,916,250 | Top-Rated Physiotherapy Clinic in Toronto | Experience unparalleled physiotherapy clinic toronto care at Toronto's leading physiotherapy clinic,... | 0 | 2024-07-08T19:03:55 | https://dev.to/brett_wyman_845b6cb9a8c82/top-rated-physiotherapy-clinic-in-toronto-4hni | Experience unparalleled [physiotherapy clinic toronto](https://www.bodydynamics.ca/physiotherapy/) care at Toronto's leading physiotherapy clinic, where our expert team is dedicated to your recovery and wellness. | brett_wyman_845b6cb9a8c82 | |
1,916,254 | Apparently everyone speaks English here | That's a great skill, I am planning to break down here every step and what I did to become fluent (I... | 0 | 2024-07-08T19:05:24 | https://dev.to/ocelotmocha93/apparently-everyone-speaks-english-here-4dje | That's a great skill, I am planning to break down here every step and what I did to become fluent (I said fluent, not master) in English.
| ocelotmocha93 | |
1,916,255 | Trying Kotlin Multiplatform for the First Time: Step by Step Building an App with KMP | After getting inspired by KotlinConf, I decided to try Kotlin Multiplatform (KMP) for the first time... | 0 | 2024-07-08T19:06:27 | https://dev.to/gadipuranto/trying-kotlin-multiplatform-for-the-first-time-step-by-step-building-an-app-with-kmp-5845 | kotlin, kmp, android, mobile | After getting inspired by KotlinConf, I decided to try Kotlin Multiplatform (KMP) for the first time and build an app with this technology. KMP is a technology developed by JetBrains that allows developers to write code together for various platforms using the Kotlin programming language. The main goal is to reduce cod... | gadipuranto |
1,916,256 | Trying Kotlin Multiplatform for the First Time: Step by Step Building an App with KMP | After getting inspired by KotlinConf, I decided to try Kotlin Multiplatform (KMP) for the first time... | 0 | 2024-07-08T19:06:27 | https://dev.to/gadipuranto/trying-kotlin-multiplatform-for-the-first-time-step-by-step-building-an-app-with-kmp-91 | kotlin, kmp, android, mobile | After getting inspired by KotlinConf, I decided to try Kotlin Multiplatform (KMP) for the first time and build an app with this technology. KMP is a technology developed by JetBrains that allows developers to write code together for various platforms using the Kotlin programming language. The main goal is to reduce cod... | gadipuranto |
1,916,260 | Automate Github Pull Requests With NodeJS API | Integrating with the GitHub API using Node.js, TypeScript, and NestJS involves several steps. Here's... | 0 | 2024-07-08T19:07:42 | https://dev.to/redbonzai/automate-github-pull-requests-with-nodejs-api-48gj | nextjs, javascript, programming, typescript | Integrating with the GitHub API using Node.js, TypeScript, and NestJS involves several steps. Here's a detailed guide to achieve this:
### 1. Set Up a New NestJS Project
First, create a new NestJS project if you don't have one already:
```bash
npm i -g @nestjs/cli
nest new github-pr-automation
cd github-pr-automatio... | redbonzai |
1,916,263 | Trying Kotlin Multiplatform for the First Time: Step by Step Building an App with KMP | After getting inspired by KotlinConf, I decided to try Kotlin Multiplatform (KMP) for the first time... | 0 | 2024-07-08T19:14:17 | https://dev.to/adeeplearn/trying-kotlin-multiplatform-for-the-first-time-step-by-step-building-an-app-with-kmp-459a | kotlin, kmp, android, mobile | After getting inspired by KotlinConf, I decided to try Kotlin Multiplatform (KMP) for the first time and build an app with this technology. KMP is a technology developed by JetBrains that allows developers to write code together for various platforms using the Kotlin programming language. The main goal is to reduce cod... | adeeplearn |
1,916,439 | Custom hook for Api calls(Reactjs) | I'm sure during developing complex and big react applications, everybody will struggle with code... | 0 | 2024-07-08T19:32:22 | https://dev.to/a8rts/custom-hook-for-api-callsreactjs-4bnn | webdev, javascript, programming, react | I'm sure during developing complex and big react applications, everybody will struggle with code reusability. One approach is this(custom hook for api calls). Let's go for creating them.
First of all i'm sorry about my bad writing, my language is not originally English :)
Of course we have to get data from the server... | a8rts |
1,916,264 | The Best 5 Free IP Geolocation APIs for Programmers | Free IP geolocation APIs play a crucial role in enabling developers to integrate location-based... | 0 | 2024-07-08T19:15:28 | https://dev.to/sameeranthony/the-best-5-free-ip-geolocation-apis-for-programmers-l39 | api, geolocation, programmer | Free IP geolocation APIs play a crucial role in enabling developers to integrate location-based services into their applications effortlessly. These APIs provide accurate geographical information based on IP addresses, making them invaluable for a variety of applications, from targeted advertising to fraud prevention. ... | sameeranthony |
1,916,434 | Why Jenkins is still MVP among CI/CD tools? | Jenkins is a powerful, open-source automation server used for continuous integration and continuous... | 0 | 2024-07-08T19:20:53 | https://dev.to/mcieciora/why-jenkins-is-still-mvp-among-cicd-tools-2npn | devops, cicd, jenkins |
Jenkins is a powerful, open-source automation server used for continuous integration and continuous delivery. It allows developers to automate the building, testing, and deployment of applications, facilitating rapid development cycles. Jenkins supports a vast array of plugins, making it highly customizable and adapta... | mcieciora |
1,916,435 | Fixed Window Counter: Under the Hood of express-rate-limit | To ensure a single user or a client cannot overwhelm the system with too many requests in a short... | 0 | 2024-07-08T19:21:47 | https://dev.to/dkn1ght23/fixed-window-counter-express-rate-limit-280 | javascript, node, express, systemdesign | To ensure a single user or a client cannot overwhelm the system with too many requests in a short period of time, we use rate limiting. [express-rate-limit](https://www.npmjs.com/package/express-rate-limit) is popular among developers due to its ease of implementation and understanding. But how does it work under the h... | dkn1ght23 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.