
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,916,437 | Understanding Composition API vs Options API in Vue.js: Which One to Choose? | Vue.js offers two powerful APIs for building components: the Options API and the Composition API.... | 0 | 2024-07-08T19:27:21 | https://dev.to/haseebmirza/understanding-composition-api-vs-options-api-in-vuejs-which-one-to-choose-1bl4 | javascript, vue, frontend | Vue.js offers two powerful APIs for building components: the Options API and the Composition API. While both serve the same purpose, they offer different approaches to managing your component's logic and state. In this post, we'll dive into the key differences, pros, cons, and use cases of each API to help you make an ... | haseebmirza |
1,916,438 | Vue 3 para Iniciantes: Dicas que Gostaria de Ter Sabido ao Começar com a Composition API e TypeScript | Introdução Quando comecei a usar o Vue 3 com a Composition API e TypeScript, encontrei... | 0 | 2024-07-08T19:31:28 | https://dev.to/dienik/vue-3-para-iniciantes-dicas-que-gostaria-de-ter-sabido-ao-comecar-com-a-composition-api-e-typescript-kc | typescript, vue, compositionapi, javascript |
## Introdução
Quando comecei a usar o Vue 3 com a Composition API e TypeScript, encontrei algumas dificuldades, mas também descobri várias dicas e truques que fizeram toda a diferença. Se você está começando agora, essas são as dicas que gostaria de ter conhecido desde o início.
## O que é a Composition API e seus... | dienik |
1,916,441 | 12 Free Figma Screens Hero Section Templates | Struggling to create a captivating hero section for your next project? Look no further than... | 0 | 2024-07-08T19:34:59 | https://neattemplate.com/figma-templates/12-free-figma-screens-hero-section-templates | webdev, ui, ux, figma | Struggling to create a captivating hero section for your next project? Look no further than Peterdraw's generous offer of 12 FREE Figma hero section templates!
These templates are not only visually stunning, but also completely customizable, allowing you to tailor them perfectly to your brand identity. Whether you're ... | faisalgg |
1,916,442 | Bubble Sort: Given an Array of Unsorted Items, Return A Sorted Array | While most modern languages have built-in sorting methods for operations like this, it is still... | 0 | 2024-07-08T19:36:38 | https://dev.to/redbonzai/bubble-sort-given-an-array-of-unsorted-items-return-a-sorted-array-e63 | While most modern languages have built-in sorting methods for operations like this, it is still important to understand some of the common basic approaches and learn how they can be implemented.
The bubble sort method starts at the beginning of an unsorted array and 'bubbles up' unsorted values towards the end, iterat... | redbonzai | |
1,916,443 | Free Figma Brand Book Template 100+ Slides | Are you looking to create an amazing brand book for your company or are you a brand designer in the... | 0 | 2024-07-11T15:39:00 | https://neattemplate.com/figma-ui-kits/free-figma-brand-book-template-100-slides | webdev, ui, ux, figma | Are you looking to create an amazing brand book for your company or are you a brand designer in the process of designing a brand book for one of your clients? Look no further! Brix Templates offers a free brand book kit Figma template that can save you hours in design time.
brand book kit features 100 slides that you ... | faisalgg |
1,916,444 | Website in your pocket. Turn your Android phone into a web server! 🚀 | Hosting a website is simple right? Let us do something cooler insted. How about hosting a website... | 0 | 2024-07-08T19:45:55 | https://dev.to/ghoshbishakh/website-in-your-pocket-turn-your-android-phone-into-a-web-server-53gb | webdev, iot, android, tutorial | Hosting a website is simple right? Let us do something cooler insted. How about hosting a website from your Android device? Do not worry, we need not root/jailbreak your phone.
## 🚀 Let's Get Started!
### Tools You'll Need:
1. **Termux:** [Termux](https://termux.dev/en/) is an Android terminal emulator for running ... | ghoshbishakh |
1,916,448 | خرید عمده لباس زنانه از تولیدی پوشاک زنانه گلساران | *تولیدی پوشاک زنانه *گلساران یکی از برجستهترین تولیدکنندگان لباسهای زنانه در ایران است که با تمرکز... | 0 | 2024-07-08T19:44:08 | https://dev.to/victory2009/khryd-mdh-lbs-znnh-z-twlydy-pwshkh-znnh-glsrn-1hfa | **تولیدی پوشاک زنانه **گلساران یکی از برجستهترین تولیدکنندگان لباسهای زنانه در ایران است که با تمرکز بر طراحیهای مدرن و استفاده از بهترین مواد اولیه، محصولاتی باکیفیت و متنوع را به بازار عرضه میکند. این تولیدی با بهرهگیری از تیمی مجرب و حرفهای، همواره در تلاش است تا نیازهای مختلف مشتریان را به خوبی شناسایی و برآو... | victory2009 | |
1,916,449 | Prefer utility types over model changes in TypeScript | Generally, in software, a model is an abstraction or a way to represent a system, process, or object... | 0 | 2024-07-08T19:49:39 | https://dev.to/jabreuar/prefer-utility-types-over-model-changes-in-typescript-61a | typescript, javascript, webdev, programming | Generally, in software, a model is an abstraction or a way to represent a system, process, or object in the real world. Modeling is the process of creating these abstractions to facilitate understanding, analysis, and design of system.
TypeScript provides several utility types to facilitate common type transformation... | jabreuar |
1,916,451 | Implementing Selection Sort in Javascript | Selection sort works by selecting the minimum value in a list and swapping it with the first value in... | 0 | 2024-07-08T20:02:00 | https://dev.to/redbonzai/implementing-selection-sort-in-javascript-53ke | Selection sort works by selecting the minimum value in a list and swapping it with the first value in the list. It then starts at the second position, selects the smallest value in the remaining list, and swaps it with the second element. It continues iterating through the list and swapping elements until it reaches t... | redbonzai | |
1,916,452 | Navigating Medical Billing Services: A Guide to Understanding and Choosing Wisely | Medical billing services play a crucial role in the healthcare industry, ensuring that healthcare... | 0 | 2024-07-08T20:01:32 | https://dev.to/med_loopus_439d423ea79b8d/navigating-medical-billing-services-a-guide-to-understanding-and-choosing-wisely-5f7c | medicalbilling, health, medicalbillingservices | Medical billing services play a crucial role in the healthcare industry, ensuring that healthcare providers receive timely and accurate reimbursement for services rendered. For many healthcare practices, managing billing in-house can be overwhelming and time-consuming. Outsourcing medical billing services has become a ... | med_loopus_439d423ea79b8d |
1,916,456 | Mastering BK8KHPlay02: A Comprehensive Guide to Online Betting Success | BK8KHPLAY02 is a prominent online betting platform that has garnered a significant user base due to... | 0 | 2024-07-08T20:06:21 | https://dev.to/guh_add_ce89570ee959c8ff2/mastering-bk8khplay02-a-comprehensive-guide-to-online-betting-success-4d61 |
BK8KHPLAY02 is a prominent online betting platform that has garnered a significant user base due to its diverse offerings and user-friendly interface. Whether you're a seasoned bettor or a newcomer, understanding the... | guh_add_ce89570ee959c8ff2 | |
1,916,458 | One Line of Code that Cost Me An HOUR to Fix | Hello developers. In today’s article, I am going to share story of how one line of code cost me an... | 0 | 2024-07-10T07:03:00 | https://dev.to/mammadyahyayev/one-line-of-code-that-cost-me-an-hour-to-fix-1b5e | java, softwaredevelopment, logging |

Hello developers. I... | mammadyahyayev |
1,916,459 | Kdash - a true opensource K8s micro IDE | KDash v0.2.0 - a true opensource K8s micro IDE KDash v0.2.0 (MacOs oriented... | 0 | 2024-07-08T20:16:02 | https://dev.to/target-ops/kdash-a-true-opensource-k8s-micro-ide-500h | productivity, beginners, kdash | ---
title: Kdash - a true opensource K8s micro IDE
published: true
tags:
- productivity
- beginners
- KDash
---
KDash v0.2.0 - a true opensource K8s micro IDE
==============================================
[ | HTML attributes provide additional information about HTML elements. They enhance the functionality... | 0 | 2024-07-08T20:53:44 | https://dev.to/ridoy_hasan/html-attributes-a-to-z--mho | webdev, beginners, learning, html |
HTML attributes provide additional information about HTML elements. They enhance the functionality and interactivity of elements, allowing for greater control and customization. This guide will explore the most common HTML attributes, their purposes, and practical examples to demonstrate their usage.
#### What Are H... | ridoy_hasan |
1,916,492 | Aegis AV Elevating Home Entertainment Systems | Aegis AV is a premier provider of high-quality audio video cabinets designed to enhance and organize... | 0 | 2024-07-08T21:15:42 | https://dev.to/aegisav/aegis-av-elevating-home-entertainment-systems-52jm | Aegis AV is a premier provider of high-quality audio video cabinets designed to enhance and organize your home entertainment setup. Based in San Angelo, Texas,[ Aegis AV](https://aegisav.com/) has established itself as a leader in the industry, known for its innovative designs and superior craftsmanship.
Product Range
... | aegisav | |
1,916,483 | shadcn-ui/ui codebase analysis: How does shadcn-ui CLI work? — Part 2.8 | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the... | 0 | 2024-07-08T20:55:30 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-does-shadcn-ui-cli-work-part-28-28kg | javascript, opensource, shadncui, nextjs | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the shadcn-ui/ui CLI.
In part 2.7, we looked at function isTypescriptProject this function checks if the cwd (current working directory) has a tsconfig.json file.
Let’s move on to the next line of code.

 and [Arindam](https://x.com/Arindam_1729). The title was "**How to Successfully Launch on Product Hunt 🚀**".
If you're interested in listening to the space while you read this post, you can chec... | elliezub |
1,916,510 | பைத்தானுடன் எனது அறிமுகம் | 08-07-2027 வணக்கம் நண்பர்களே, நான் எந்த விதமான கணினி துறை சார்ந்தவனும் கிடையாது. ஆனாலும் எனக்கு வலை... | 0 | 2024-07-08T21:42:12 | https://dev.to/jothilingam88/paittaannnuttnnn-ennntu-arrimukm-3lpb | python, kaniyam, jopy | **08-07-2027**
வணக்கம் நண்பர்களே,
நான் எந்த விதமான கணினி துறை சார்ந்தவனும் கிடையாது. ஆனாலும் எனக்கு வலை தளங்கள் வடிவமைப்பில் ஓர் ஆர்வம் வெகு நாளாக இருந்தது. இணைய தளங்கள் வழியாக கொஞ்சம் கற்றுக் கொண்டேன்.இதன் மூலம் கணினி நிரல் மொழி பற்றிய அடிப்படை அறிவினை சிறிது கற்று அறிமுகம் ஆகிக் கொண்டேன்.
மேலும் தற்போது பங்குசந்தை... | jothilingam88 |
1,916,511 | Array Sort Methods in JavaScript.! | JavaScriptda Arraylarni saralash usullari.!! Alifbo tartibida saralash.! Array sort() Array... | 0 | 2024-07-08T21:24:56 | https://dev.to/samandarhodiev/array-sort-methods-in-javascript-1840 | **JavaScriptda Arraylarni saralash usullari.!!**
**Alifbo tartibida saralash.!**
`Array sort()
Array reverse()
Array toSorted()
Array toReversed()`
**Raqamli saralash.!**
`Numeric Sort
Random Sort
Math.min()
Math.max()
Home made Min()
Home made Max()`
<u>1.`sort()`</u>
Ushbu metod Array elementlarini alif... | samandarhodiev | |
1,916,512 | Installed Python | I am very curious to learn python. Installed python already in my laptop. | 0 | 2024-07-08T21:25:30 | https://dev.to/rajkannan_rajagopal/installed-python-1dh9 | I am very curious to learn python. Installed python already in my laptop. | rajkannan_rajagopal | |
1,916,517 | CSS: Learning box model with analogies | Introduction If you're studying CSS, you may have already encountered the term box model.... | 0 | 2024-07-08T21:29:31 | https://dev.to/fhmurakami/css-learning-box-model-with-analogies-20jj | css, learning, beginners, frontend | ## Introduction
If you're studying CSS, you may have already encountered the term _box model_. If not, don't worry; we'll address this topic in this article.
Every element in a web page is a rectangle called _box_; that's where the _box model_ name came from. Understanding how this model works is the basis for creatin... | fhmurakami |
1,916,521 | Mastering Asynchronous Form Submissions in React: A Step-by-Step Guide | Handling asynchronous operations in React can sometimes feel like navigating a maze. One common... | 0 | 2024-07-09T14:59:34 | https://dev.to/abbaraees/mastering-asynchronous-form-submissions-in-react-a-step-by-step-guide-3maj | react, webdev, javascript |
Handling asynchronous operations in React can sometimes feel like navigating a maze. One common challenge is ensuring that form submissions only proceed when all validation checks have successfully completed.
In this post, we'll dive deep into a robust solution for managing asynchronous form submissions in React. We'... | abbaraees |
1,916,522 | The importance of semantic HTML for SEO and accessibility. | Introduction In the digital error, creating websites isn't just about elegancy. Its about ensuring... | 0 | 2024-07-09T09:29:22 | https://dev.to/elijah_mengo_927f1447d4c8/the-importance-of-semantic-html-for-seo-and-accessibility-197n | webdev, seo, html | **<u>Introduction</u>**
In the <u>digital error</u>, creating websites isn't just about elegancy. Its about ensuring content is accessible and easily understood by all users and search engines. Semantics HTML plays a vital role in achieving this by providing clear structure and meaning to web content.
This report exp... | elijah_mengo_927f1447d4c8 |
1,916,523 | Array Iteration Methods in JavaScript.! | recently... | 0 | 2024-07-08T21:43:06 | https://dev.to/samandarhodiev/array-iteration-methods-in-javascript-56p6 | recently... | samandarhodiev | |
1,916,524 | JavaScript Array Const.! | recently... | 0 | 2024-07-08T21:44:48 | https://dev.to/samandarhodiev/javascript-array-const-2ah | recently... | samandarhodiev | |
1,916,525 | Reverse engineering Perplexity AI: prompt injection tricks to reveal its system prompts and speed secrets | I've been working on creating an open-source alternative to Perplexity AI. If you’re curious, check... | 0 | 2024-07-08T21:52:21 | https://dev.to/paka/reverse-engineering-perplexity-ai-prompt-injection-tricks-to-reveal-its-system-prompts-and-speed-secrets-16ce | llm, rag, promptengineering | I've been working on creating an open-source alternative to Perplexity AI. If you’re curious, check out my project on [GitHub Sensei Search](https://github.com/jjleng/sensei). Spoiler: making something that matches Perplexity's quality is no weekend hackathon!
First off, huge respect to the Perplexity team. I’ve seen ... | paka |
1,916,531 | JavaScript Fundamentals | Here are some of the basic fundamentals and concepts of JavaScript I have learned so far.... | 0 | 2024-07-08T22:13:52 | https://dev.to/joebush4466/javascript-fundamentals-34h7 | javascript, learning, beginners, newbie | Here are some of the basic fundamentals and concepts of JavaScript I have learned so far.
1. Everything within JavaScript is a form of data type except for the common operators and symbols (+,%,!,etc.)
2. There are seven basic data types
- Numbers
- Strings
- Booleans
- Objects
- Arrays
- Null
- Undefined
I wil... | joebush4466 |
1,916,534 | Access Portal: My first Ruby Program! | This is my first Ruby program, EVER! Pretty much, you are greeted by a robot that needs your help to... | 0 | 2024-07-08T22:21:13 | https://dev.to/annavi11arrea1/access-portal-my-first-ruby-program-51oc | ruby, beginners, webdev, programming | This is my first Ruby program, EVER! Pretty much, you are greeted by a robot that needs your help to open doors to advance through the game. Player must decipher a code at every gate. So far, I have created two gates with intermittent activities. That took me the whole day, and it was a learning experience. Two gates d... | annavi11arrea1 |
1,916,535 | 🚀 Boost Your Laravel Performance with Real-Time Laravel N+1 Query Detection! 🛠️ | Sure! Here's a revised version tailored specifically for dev.to: 🚀 Boost Your Laravel... | 0 | 2024-07-08T22:23:08 | https://dev.to/scaleupsaas/boost-your-laravel-performance-with-real-time-laravel-n1-query-detection-2j8n | laravel, database, opensource, github | Sure! Here's a revised version tailored specifically for dev.to:
---
## 🚀 Boost Your Laravel Performance with Real-Time N+1 Query Detection! 🛠️
As Laravel developers, we've all faced the dreaded N+1 query problem at some point. It's a silent performance killer that can turn a blazing-fast application into a sluggi... | scaleupsaas |
1,916,536 | Using Streams in Node.js: Efficiency in Data Processing and Practical Applications | Introduction We've all heard about the power of streams in Node.js and how they excel at... | 0 | 2024-07-08T22:34:48 | https://dev.to/george_ferreira/using-streams-in-nodejs-efficiency-in-data-processing-and-practical-applications-2jig | node, javascript, performance, beginners | ## Introduction
We've all heard about the power of streams in Node.js and how they excel at processing large amounts of data in a highly performant manner, with minimal memory resources, almost magically. If not, here's a brief description of what streams are.
Node.js has a package/library called `node:stream`. This ... | george_ferreira |
1,916,537 | Building a Rick and Morty Character Explorer with HTMX and Express.js | Wubba lubba dub dub, developers! Have you ever wondered what it would be like to explore the vast... | 0 | 2024-07-10T10:29:17 | https://dev.to/mikeyny_zw/building-a-rick-and-morty-character-explorer-with-htmx-and-expressjs-12n3 | webdev, javascript, htmx, rickandmorty |
Wubba lubba dub dub, developers! Have you ever wondered what it would be like to explore the vast multiverse of Rick and Morty through the lens of web development? Well, grab your portal guns and get ready, because today we'll do just that – we're going to build a Rick and Morty Character Explorer using HTMX and Expr... | mikeyny_zw |
1,916,543 | 3 Tips to Speed Up Your Website | A fast-loading website is crucial for providing a great user experience and improving your search... | 0 | 2024-07-08T22:40:20 | https://dev.to/codebyten/3-tips-to-speed-up-your-website-38pe | webdev, javascript, beginners, programming | A fast-loading website is crucial for providing a great user experience and improving your search engine rankings. Here are three quick and effective tips to speed up your website:
**Tip 1: Optimize Images**
Images are often the largest files on a webpage, and large image files can significantly slow down your site's ... | codebyten |
1,916,538 | Aumenta la disponibilidad de tus sistemas Legacy | Muchos de nosotros trabajamos con servicios legacy o bien servicios que no son capaces de escalar... | 28,000 | 2024-07-09T07:00:00 | https://dev.to/aws-espanol/aumenta-la-disponibilidad-de-tus-sistemas-legacy-4ip3 | aws, legacy, serverless, availability | Muchos de nosotros trabajamos con servicios legacy o bien servicios que no son capaces de escalar correctamente, ya sea por problemas de diseño o por requerimientos técnicos. Estos sistemas que tienen esas dificultad para escalar son mas propensos a sufrir paradas de servicio, lo que supone un gran problema, sobre todo... | jvimora |
1,916,539 | Elevate Your Dubai Trip Experience With Renting A Cadillac | Take your Dubai experience to the next level with a Cadillac car rental. With its garish aesthetic... | 0 | 2024-07-08T22:28:51 | https://dev.to/elon01/elevate-your-dubai-trip-experience-with-renting-a-cadillac-28i2 | Take your Dubai experience to the next level with a Cadillac car rental. With its garish aesthetic and burly performance, Cadillac renders a driving experience that is both sophisticated and thrilling. Opt for affordable [**One and Only rent Cadillac**](https://oneandonlycarsrental.com/product-category/rent-cadillac-in... | elon01 | |
1,916,540 | Boost Your Vocabulary Effortlessly with Vocabulary Booster 🎓🚀 | Boost Your Vocabulary Effortlessly with Vocabulary Booster 🎓🚀 Hey dev.to community! 🌟 I am excited... | 0 | 2024-07-08T22:29:29 | https://dev.to/huseyn0w/boost-your-vocabulary-effortlessly-with-vocabulary-booster-2p7k | webdev, showdev, productivity, opensource | Boost Your Vocabulary Effortlessly with [Vocabulary Booster](https://github.com/huseyn0w/vocabularify) 🎓🚀
Hey dev.to community! 🌟
I am excited to introduce [Vocabulary Booster](https://github.com/huseyn0w/vocabularify), a desktop application designed to help you expand your vocabulary effortlessly. Unlike most lan... | huseyn0w |
1,916,541 | Top Crypto-Friendly Countries in 2022 | Cryptocurrency has revolutionized finance and investment, and its influence is set to grow. However,... | 27,673 | 2024-07-08T22:34:50 | https://dev.to/rapidinnovation/top-crypto-friendly-countries-in-2022-21oj | Cryptocurrency has revolutionized finance and investment, and its influence is
set to grow. However, not all countries are equally welcoming to crypto. Some
have stringent regulations, while others are more lenient. Curious about which
jurisdictions offer the best conditions for crypto projects? Read on to
discover the... | rapidinnovation | |
1,916,542 | Git Commands for Software Engineers | Introduction Git is an essential tool for software engineers, enabling efficient version... | 0 | 2024-07-08T22:39:32 | https://dev.to/iamcymentho/git-commands-for-software-engineers-51n8 | webdev, softwaredevelopment, github, githubactions | ## Introduction
Git is an essential tool for software engineers, enabling efficient version control, collaboration, and project management. Whether you're working on a solo project or part of a large team, mastering Git commands is crucial for streamlining your development workflow. This guide covers the most common Gi... | iamcymentho |
1,916,544 | Props Drilling 🛠️ | What ? Passing data from a parent component down through multiple levels of nested child... | 26,254 | 2024-07-08T22:43:42 | https://dev.to/jorjishasan/props-drilling-2df7 | react, webdev, learning, beginners | ## What ?
Passing data from a parent component down through multiple levels of nested child components via props is called **props drilling**. This can make the code hard to manage and understand as the application grows. It's not a topic but a problem. How it's a problem?
In react, Data flows from top to bottom compo... | jorjishasan |
1,916,545 | Building Reusable List Components in React | Introduction In React development, it's common to encounter scenarios where you need to display lists... | 0 | 2024-07-08T22:48:32 | https://dev.to/nouarsalheddine/building-reusable-list-components-in-react-249l | javascript, beginners, programming, react | **Introduction**
In React development, it's common to encounter scenarios where you need to display lists of similar components with varying styles or content. For instance, you might have a list of authors, each with different information like name, age, country, and books authored. To efficiently handle such cases, w... | nouarsalheddine |
1,916,547 | Day 986 : Desire | liner notes: Saturday : Did the radio show. Had a good time as usual. Did a little coding after the... | 0 | 2024-07-08T23:07:30 | https://dev.to/dwane/day-986-desire-18i5 | hiphop, code, coding, lifelongdev | _liner notes_:
- Saturday : Did the radio show. Had a good time as usual. Did a little coding after the show and watched some anime. The recording of this week's show is at https://kNOwBETTERHIPHOP.com
![Radio show episode image of an AI generated image of a barber's chair behind prison bars with the words July 6th 20... | dwane |
1,916,549 | Website Navigation: Is a 'Home' Link Necessary in the Main Menu? | Should websites include a "Home" link in the main menu? Traditionally, this has been a common... | 0 | 2024-07-09T21:58:12 | https://dev.to/jennavisions/website-navigation-is-a-home-link-necessary-in-the-main-menu-4ja | discuss, webdev, a11y |
**Should websites include a "Home" link in the main menu?**
Traditionally, this has been a common practice on many websites.
However, some may argue that having a separate menu item for 'Home' might be redundant or unnecessary as the logo often being a direct link to the homepage.
_**Pros of Including a "Home" Link:... | jennavisions |
1,916,592 | Iterating Over a Visual Editor Compiler | The Visual Editor When it comes to creating visual editors for workflows, React Flow... | 0 | 2024-07-10T20:15:25 | https://dev.to/eletroswing/iterating-over-a-visual-editor-compiler-51l9 | node, typescript, react, web | ## The Visual Editor
When it comes to creating visual editors for workflows, React Flow stands out as an ideal choice. It offers robust performance, is highly customizable, and facilitates document export. With it, you can build everything from chatbots to complex backends.
## Compiling the Visual
Directly exporting t... | eletroswing |
1,916,593 | Test-driven API Development in Go | This article explores TDD and provides a step-by-step example for implementing it at the API-level in Go | 0 | 2024-07-08T23:36:15 | https://dev.to/calvinmclean/test-driven-api-development-in-go-1fb8 | go, testing, tutorial, tdd | ## Introduction
Test-driven development is an effective method for ensuring well-tested and refactorable code. The basic idea is that you start development by writing tests. These tests clearly document expectations and create a rubric for a successful implementation. When done properly, you can clearly define the exp... | calvinmclean |
1,916,594 | [Game of Purpose] Day 51 - Splines | Today I learned about Splines. They are just Bezier Curves connected together. Along them you can... | 27,434 | 2024-07-08T23:36:22 | https://dev.to/humberd/game-of-purpose-day-51-splines-3mkd | gamedev | Today I learned about Splines. They are just Bezier Curves connected together. Along them you can render static meshes.
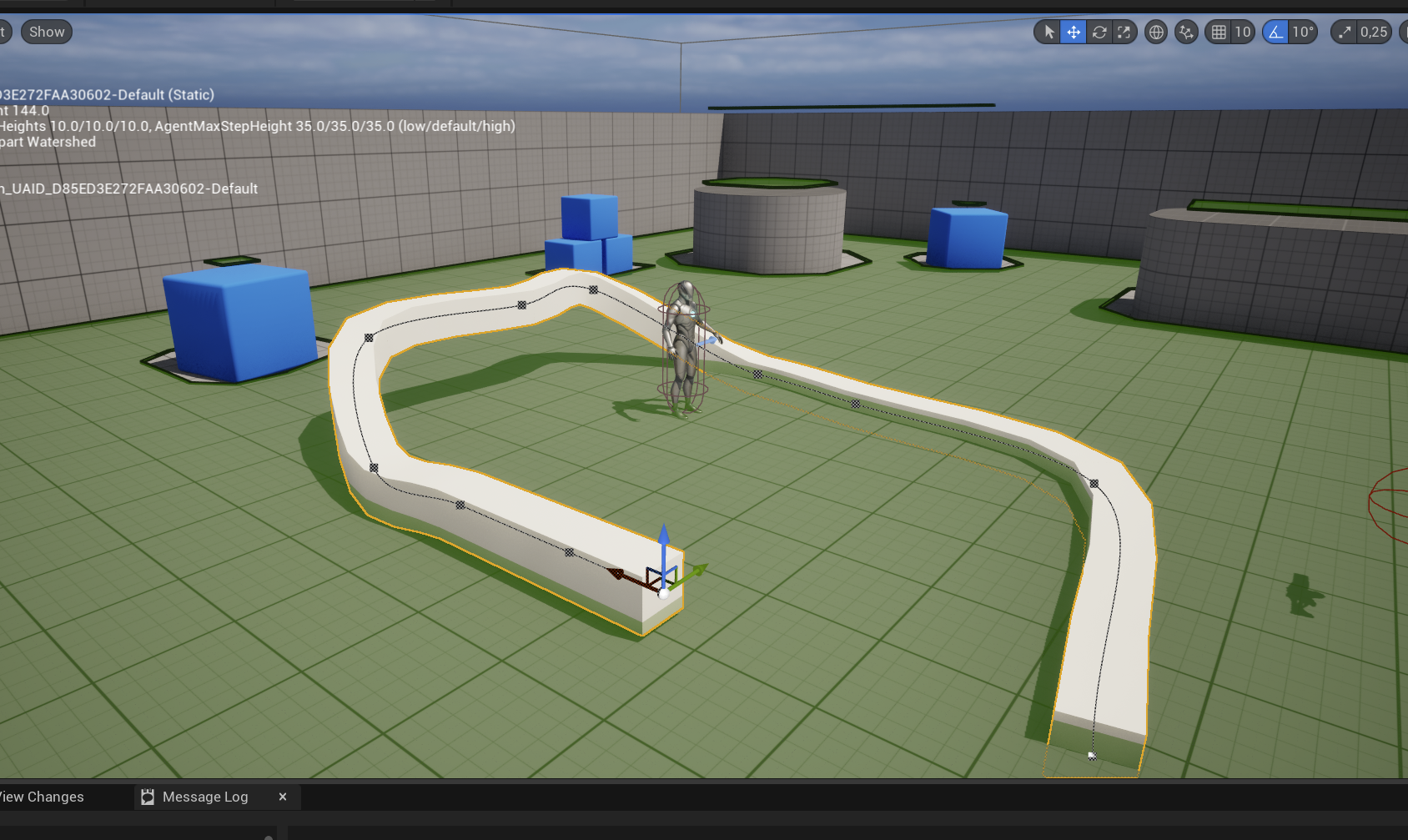
| humberd |
1,916,596 | The Power of Custom Merchandise: 4 Ways to Elevate Your Brand Identity | Importance of Brand identity When it comes to the role a company’s brand plays in its... | 0 | 2024-07-08T23:53:37 | https://chrissycodes.hashnode.dev/the-power-of-custom-merchandise-4-ways-to-elevate-your-brand-identity | business, branding, companies, technology | ---
title: The Power of Custom Merchandise: 4 Ways to Elevate Your Brand Identity
published: true
date: 2024-07-08 04:48:01 UTC
tags: business,branding,Companies,technology
canonical_url: https://chrissycodes.hashnode.dev/the-power-of-custom-merchandise-4-ways-to-elevate-your-brand-identity
---

Daily.dev is a very good extension that helps us aggregate news from several sources.
When browsing news, I usually scan the `Title -> Thumbnail -> Description`. However, the current view of Daily.dev has only `Tit... | jacktt | |
1,916,598 | Send Slack Notifications with Go AWS Lambda Functions | Introduction In this article, we will discuss how to create an AWS lambda function to send... | 0 | 2024-07-08T23:51:53 | https://dev.to/audu97/send-slack-notifications-with-go-aws-lambda-functions-1ci5 | aws, go, cloud, devops | ### Introduction
In this article, we will discuss how to create an AWS lambda function to send Slack notifications when the CPU utilization of an AWS instance reaches 50%.
AWS Lambda is a serverless compute service offered by Amazon Web Services (AWS). It lets you run code without having to provision or manage servers... | audu97 |
1,916,600 | Lo que costó mi escritorio | Mi escritorio ha sido un fiel compañero por varios años, 8 nomás. Es un testigo de mi crecimiento y... | 0 | 2024-07-08T23:55:34 | https://dev.to/viistorrr/lo-que-costo-mi-escritorio-2acn | Mi escritorio ha sido un fiel compañero por varios años, 8 nomás. Es un testigo de mi crecimiento y aunque podría venderlo a buen precio hoy, su valor va más allá de lo que me puedan dar en monedas.
En una de esas rutinas de limpieza me puse a pensar sobre cuánto he crecido desde que lo tengo y decidí hacer el ejercic... | viistorrr | |
1,916,605 | An easy way to start with Dart Spotify! | Hey! Today I'd like to my experience working with Dart Spotify SDK. If you didn't know, Spotify API... | 0 | 2024-07-09T00:23:16 | https://dev.to/rockyondabeat/an-easy-way-to-start-with-dart-spotify-193j | Hey!
Today I'd like to my experience working with Dart Spotify SDK.
If you didn't know, Spotify API is free to use! (But apparently not totally since you need a Premium account). So you can build your own apps using it.
Spotify API was really hard for to use so I searched for an SDK that would make my life easier. A... | rockyondabeat | |
1,916,607 | Understanding Git Stashes | Stash is something stored or hidden away for later use. Why would i want to use git stash in the... | 0 | 2024-07-09T00:27:42 | https://dev.to/debuggingrabbit/understanding-git-stashes-12l | Stash is something stored or hidden away for later use.
Why would i want to use git stash in the first place.
let's say i'm working on the sign up button for a client but he needs work done on the login feature immediately regardless of the urgency for the signup feature, i can quickly stash my signup as work in prog... | debuggingrabbit | |
1,916,608 | Caravane du Grand Erg / Morocco Private Desert Tours | Caravane Du Grand Erg is a professional tour operator located in Zagora, southern Morocco. We... | 0 | 2024-07-09T00:31:35 | https://dev.to/caravane_dugranderg_246/caravane-du-grand-erg-morocco-private-desert-tours-34di | **[Caravane Du Grand Erg](https://caravanedugranderg.com/)** is a professional tour operator located in Zagora, southern **Morocco**. We specialize in [Morocco desert tours](https://caravanedugranderg.com/) from north to south.
Our team has deep knowledge of local life, traditions, and customs. We offer private trave... | caravane_dugranderg_246 | |
1,916,609 | Introduction to Bioinformatics with Python | Introduction: Bioinformatics is a rapidly growing field that combines biology, computer science, and... | 0 | 2024-07-09T00:33:33 | https://dev.to/kartikmehta8/introduction-to-bioinformatics-with-python-4jl5 | Introduction:
Bioinformatics is a rapidly growing field that combines biology, computer science, and mathematics to analyze and interpret biological data. With the vast amount of biological data being generated, the need for efficient computational tools has become crucial. This is where Python, a popular programming l... | kartikmehta8 | |
1,916,610 | Leveraging Google Cloud Platform Consulting For Optimal Cloud Solutions | Google Cloud Platform Consulting: Unlocking the Full Potential of Cloud Services Google Cloud... | 0 | 2024-07-09T00:42:30 | https://dev.to/saumya27/leveraging-google-cloud-platform-consulting-for-optimal-cloud-solutions-4ihh | **Google Cloud Platform Consulting: Unlocking the Full Potential of Cloud Services**
Google Cloud Platform (GCP) offers a suite of cloud computing services that run on the same infrastructure that Google uses internally for its end-user products. Organizations looking to leverage GCP for their cloud needs often turn t... | saumya27 | |
1,916,611 | Essential Linux Utilities and Tools for DevOps Engineers : Day 2 of 50 days DevOps Tools Series | Introduction Linux is the operating system of choice for many DevOps engineers due to its... | 0 | 2024-07-09T00:50:56 | https://dev.to/shivam_agnihotri/essential-linux-utilities-and-tools-for-devops-engineers-day-2-of-50-days-devops-tools-series-40p2 | devops, linux, automaton, developer | ## Introduction
Linux is the operating system of choice for many DevOps engineers due to its stability, flexibility, and powerful command-line interface. Mastering Linux utilities and tools is essential for effective DevOps practices, as they streamline processes, enhance productivity, and enable robust automation. In... | shivam_agnihotri |
1,916,612 | Migrating from MySQL to PostgreSQL | Migrating a database from MySQL to Postgres is a challenging process. While MySQL and Postgres do a... | 0 | 2024-07-11T05:00:00 | https://dev.to/mrpercival/migrating-from-mysql-to-postgresql-1oh7 | postgressql, postgres, mysql, perl | Migrating a database from MySQL to Postgres is a challenging process.
While MySQL and Postgres do a similar job, there are some fundamental differences between them and those differences can create issues that need addressing for the migration to be successful.
## Where to start?
[Pg Loader](https://pgloader.io) ... | mrpercival |
1,916,615 | Join Our Threads Community for Exclusive Bad Bunny Merch Discussions! | Stay up-to-date with all things Bad Bunny merch by following us on X! Get real-time updates on new... | 0 | 2024-07-09T00:58:31 | https://dev.to/badbunnymerch12/join-our-threads-community-for-exclusive-bad-bunny-merch-discussions-5ffm | badbunnymerch, threads, badbunny | Stay up-to-date with all things Bad Bunny merch by following us on X! Get real-time updates on new arrivals, flash sales, and much more. Join the conversation and tweet us your favorite Bad Bunny merch moments!
https://www.threads.net/@badbunny39f

| manikandan_k_b1ec5439286b | |
1,916,638 | Why HTMX is far superior to React and NextJs | On Anuntech we have the challenge to create an ERP, and for the ones that already worked with it,... | 0 | 2024-07-09T01:48:21 | https://henriqueleite42.hashnode.dev/why-htmx-is-far-superior-to-react-and-nextjs | htmx, javascript, website, webdev | On Anuntech we have the challenge to create an ERP, and for the ones that already worked with it, know that ERP can be one of the more complex types of software to create (and use, god have mercy of SAP users).
To avoid the complexity to use, we wanted something similar to PlayStore: You have an infinity of modules to... | henriqueleite42 |
1,916,639 | Creating a Symmetrical Star Pattern in Dart | Hey everyone! I recently worked on a fun coding challenge to generate a symmetrical star pattern... | 0 | 2024-07-09T01:49:16 | https://dev.to/ahzem/creating-a-symmetrical-star-pattern-in-dart-57kj | Hey everyone!
I recently worked on a fun coding challenge to generate a symmetrical star pattern using Dart. Here's the pattern I wanted to create:
```
*
**
***
****
*****
******
*******
********
*********
**********
*********
********
***... | ahzem | |
1,916,640 | Case (III) - KisFlow-Golang Stream Real- Application of KisFlow in Multi-Goroutines | Github: https://github.com/aceld/kis-flow Document:... | 0 | 2024-07-09T01:53:20 | https://dev.to/aceld/case-iii-kisflow-golang-stream-real-application-of-kisflow-in-multi-goroutines-4m7g | go |
<img width="150px" src="https://github.com/aceld/kis-flow/assets/7778936/8729d750-897c-4ba3-98b4-c346188d034e" />
Github: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framewor... | aceld |
1,916,641 | Using Localstack for Component tests | The Ask? I was always wondering if I could test Cloud Services locally without the hassle... | 0 | 2024-07-09T01:58:03 | https://dev.to/vinay_madan/using-localstack-for-component-tests-36b9 | node, docker, localstack, aws | ### The Ask?
I was always wondering if I could test Cloud Services locally without the hassle and expense of provisioning cloud services using one of the providers like AWS, Azure, or GCP then I found LocalStack, an open-source project that allows us to emulate multiple AWS cloud services, such as SQS, EC2, and CloudFo... | vinay_madan |
1,916,643 | What is JavaScript scope & the scope chain? | Scope is a fancy term to determine where a variable or function is available to be accessed or used.... | 0 | 2024-07-09T02:37:26 | https://dev.to/finalgirl321/what-is-javascript-scope-the-scope-chain-bbl | Scope is a fancy term to determine where a variable or function is available to be accessed or used. We have four types in JS - global, function, module (not discussed here) and block.
The global scope is when you define something outside of any functions.
```
var name = "meg"
function sayHello() {
...more... | finalgirl321 | |
1,916,676 | Jenkins a powerful open-source automation server | Jenkins leverages plugins to transform from a basic automation server into a powerful tool for... | 0 | 2024-07-09T02:52:16 | https://dev.to/mibii/jenkins-a-powerful-open-source-automation-server-9ei | jenkins | Jenkins leverages plugins to transform from a basic automation server into a powerful tool for managing your entire software delivery lifecycle. By exploring and utilizing the right plugins, you can automate various tasks, improve development efficiency, and ensure consistent and reliable deployments.
Jenkins its... | mibii |
1,916,644 | Mr.Bones - Comida y snacks naturales para perros y gatos | Natural snacks for pets are increasingly gaining popularity among pet owners who are keen on... | 0 | 2024-07-09T02:06:04 | https://dev.to/mrbones24/mrbones-comida-y-snacks-naturales-para-perros-y-gatos-2k88 | webdev, javascript, beginners, programming | Natural snacks for pets are increasingly gaining popularity among pet owners who are keen on providing their dogs and cats with the best nutrition possible. Unlike commercial snacks that often contain artificial additives, preservatives, and low-quality ingredients, natural snacks are made from wholesome, organic ingre... | mrbones24 |
1,916,646 | Leetcode Day 8: Remove Element Explained | The problem is as follows: Given an integer array nums and an integer val, remove all occurrences of... | 0 | 2024-07-09T02:10:40 | https://dev.to/simona-cancian/leetcode-day-8-remove-element-explained-212a | python, leetcode, beginners, codenewbie | **The problem is as follows:**
Given an integer array `nums` and an integer `val`, remove all occurrences of `val` in `nums` _in-place_. The order of the elements may be changed. Then return the _number of elements in `nums` which are not equal to `val`_.
Consider the number of elements in `nums` which are not equal ... | simona-cancian |
1,916,648 | Localization Made Easy with Python and DeepL | Today, I was working on a project and needed to find a way to localize some JSON files. I speak... | 0 | 2024-07-09T02:18:19 | https://dev.to/mattdark/localization-made-easy-with-python-and-deepl-1l1e | tutorial, python | Today, I was working on a project and needed to find a way to localize some JSON files. I speak English as my second language and have some previous experience participating in localization projects, so there wouldn't have been any problem on localizing those files from Spanish to English, but how do you optimize the p... | mattdark |
1,916,668 | My first Blog | Hello Guys! Hardwork beats talent when talent didn't work hard Thanks for reading my blog😊 | 0 | 2024-07-09T02:22:16 | https://dev.to/nishanthi_a_02e5ab1a72d22/my-first-blog-3p4 | Hello Guys!
* Hardwork beats talent when talent didn't work hard
Thanks for reading my blog😊
| nishanthi_a_02e5ab1a72d22 | |
1,916,669 | From Prototype to Production: The Limits of Low-Code/No-Code Platforms | What is Low-Code? Low-code development platforms enable the rapid creation and deployment of... | 0 | 2024-07-09T02:27:58 | https://dev.to/madia/from-prototype-to-production-the-limits-of-low-codeno-code-platforms-24ah | **What is Low-Code?**
Low-code development platforms enable the rapid creation and deployment of applications with minimal hand-coding. These platforms offer a visual development environment where developers can drag and drop components to build applications, reducing the need for extensive coding knowledge. This appro... | madia | |
1,916,708 | Hola Mundo | A post by ALVARO ANTONIO ROJAS FLOREZ | 0 | 2024-07-09T03:44:30 | https://dev.to/alvaro_antoniorojasflor/hola-mundo-3n6i | alvaro_antoniorojasflor | ||
1,916,671 | Understanding Google AI for Website Rankings on Search Pages | You might have heard of the Google algorithm, but what exactly is it? Simply put, the Google... | 0 | 2024-07-09T02:30:45 | https://dev.to/juddiy/understanding-google-ai-for-website-rankings-on-search-pages-37ao | google, website, seo | You might have heard of the Google algorithm, but what exactly is it? Simply put, the Google algorithm is a complex set of rules and formulas that determine which web pages rank higher in search results. Every time you search on Google, these algorithms quickly analyze billions of web pages to find the most relevant re... | juddiy |
1,916,672 | Create a Next.js AI Chatbot App with Vercel AI SDK | The recent advancements in Artificial Intelligence have propelled me (and probably many in the... | 0 | 2024-07-12T02:13:00 | https://dev.to/milu_franz/create-a-nextjs-ai-chatbot-app-with-vercel-ai-sdk-42je | openai, nextjs, beginners, ai | The recent advancements in Artificial Intelligence have propelled me (and probably many in the Software Engineering community) to delve deeper into this field. Initially I wasn't sure where to start, so I enrolled in the [Supervised Machine Learning Coursera class](https://www.coursera.org/learn/machine-learning) to le... | milu_franz |
1,916,673 | Avoiding the Trap: Recognizing When Low-Code/No-Code Solutions Need an Upgrade | What is Low-Code? Low-code development platforms enable the rapid creation and deployment of... | 0 | 2024-07-09T02:33:58 | https://dev.to/madia/avoiding-the-trap-recognizing-when-low-codeno-code-solutions-need-an-upgrade-3ba0 | lowcode, nocode, saas | **What is Low-Code?**
Low-code development platforms enable the rapid creation and deployment of applications with minimal hand-coding. These platforms offer a visual development environment where developers can drag and drop components to build applications, reducing the need for extensive coding knowledge. This appro... | madia |
1,916,674 | Python: print method | Hello All today im learn about how to install python software and print statement. and the way of... | 0 | 2024-07-09T02:38:33 | https://dev.to/aravind_p_8c2c1f5d858ba36/python-print-method-3ef9 | Hello All
today im learn about how to install python software and print statement. and the way of teaching session is easy and intresting
```python
print("hello all")
| aravind_p_8c2c1f5d858ba36 | |
1,916,675 | Building a .NET TWAIN Document Scanner Application for Windows and macOS using MAUI | Dynamsoft used to offer both the .NET TWAIN SDK and the Dynamic Web TWAIN SDK. However, the .NET... | 0 | 2024-07-09T02:45:18 | https://www.dynamsoft.com/codepool/dotnet-twain-maui-desktop-document-scanner.html | dotnet, maui, document, scanner | Dynamsoft used to offer both the .NET TWAIN SDK and the Dynamic Web TWAIN SDK. However, the .NET TWAIN SDK is no longer maintained, and the focus has shifted to the web-based Dynamic Web TWAIN SDK. Despite this shift, you can still build a desktop document scanner application in .NET by leveraging the REST API provided... | yushulx |
1,916,678 | Understand Just-in-Time provisioning | Just-in-Time provisioning is a process used in identity and access management systems to create user... | 0 | 2024-07-09T02:52:39 | https://blog.logto.io/jit-provisioning/ | webdev, saas, identity, opensource | Just-in-Time provisioning is a process used in identity and access management systems to create user accounts on the fly as they sign in to a system for the first time. This article explains the basics of Just-in-Time provisioning and answers common questions about its implementation.
---
Before we discuss Just-in-Tim... | palomino |
1,916,679 | Building an Amazon Clone with Html, Css & javascript | Introduction I am excited to share the journey of building an Amazon clone, a React Native... | 0 | 2024-07-09T02:55:50 | https://dev.to/billsparkx/building-an-amazon-clone-with-html-css-javascript-250 |
_**Introduction**_
I am excited to share the journey of building an Amazon clone, a React Native application developed as a portfolio project. This project was a collaborative effort with Mensah Bernard and Bill Nyamekye Mensah. The project kicked off on July 4, 2024, and had to be completed by July 11, 2024. Our go... | billsparkx | |
1,916,680 | Which broker is best for trading in UAE? | Which broker is best for trading in UAE? No doubt Axiory Global is a respected forex broker in the... | 0 | 2024-07-09T02:57:37 | https://dev.to/corey_johnson_61fe0bcade5/which-broker-is-best-for-trading-in-uae-291o | uae | Which broker is best for trading in UAE? No doubt **[Axiory Global](https://goglb.axiory.com/afs/come.php?cid=5513&ctgid=1043&atype=1&brandid=7)** is a respected forex broker in the UAE and worldwide, IT IS best for trading in UAE:
| trading |
1,916,681 | Adding custom video player to website | Adding a custom video player to your website can enhance user experience, improve branding, and... | 0 | 2024-07-09T03:01:36 | https://dev.to/sh20raj/adding-custom-video-player-to-website-6l0 | video, player, webdev, javascript | Adding a custom video player to your website can enhance user experience, improve branding, and provide more control over video playback features. Here's a step-by-step guide to help you create and integrate a custom video player into your website.
### Step 1: Choose the Right Tools
1. **HTML5 Video**: The HTML5 `<vi... | sh20raj |
1,916,682 | Leverage a Bitcoin Loan: Risks and Rewards of Boosting Your Crypto Returns | Bitcoin's price volatility presents a double-edged sword for traders. While it offers the potential... | 0 | 2024-07-09T03:02:18 | https://dev.to/epakconsultant/leverage-a-bitcoin-loan-risks-and-rewards-of-boosting-your-crypto-returns-4m44 | Bitcoin's price volatility presents a double-edged sword for traders. While it offers the potential for significant profits, it also amplifies potential losses. Bitcoin loans emerge as a strategy to potentially magnify gains, but it's crucial to understand the inherent risks before diving in.
The Leverage Lure:
Imagi... | epakconsultant |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.