
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,901,420 | Top Open-Source APIs for Web Development in 2024: Unleashing Innovation | As web development continues to evolve, the use of public APIs (Application Programming Interfaces)... | 0 | 2024-06-26T14:58:53 | https://dev.to/futuristicgeeks/top-open-source-apis-for-web-development-in-2024-unleashing-innovation-2hn4 | webdev, beginners, api, programming | As web development continues to evolve, the use of public APIs (Application Programming Interfaces) has become a cornerstone for building robust, feature-rich applications. Public APIs offer developers access to a wide range of functionalities without having to build them from scratch, thus speeding up the development ... | futuristicgeeks |
1,901,419 | Cool JS Frameworks - Astro vs Next.js | Astro vs Next.js? We must see before choosing a JavaScript framework. When building web... | 0 | 2024-06-26T14:55:59 | https://dev.to/zoltan_fehervari_52b16d1d/cool-js-frameworks-astro-vs-nextjs-eo8 | astro, nextjs, javascript, javascriptframeworks | Astro vs Next.js?
**We must see before choosing a JavaScript framework.**
When building web applications, the framework you choose can steer your project to success. Astro offers a lightweight solution with static generation benefits, while Next.js delivers comprehensive server-side rendering for React developers.
#... | zoltan_fehervari_52b16d1d |
1,901,417 | How to Build and Manage a High-Performing Software Development Team? | In my initial years as a software developer, I quickly recognized that the success of any software... | 0 | 2024-06-26T14:53:42 | https://dev.to/igor_ag_aaa2341e64b1f4cb4/software-development-team-4nol | In my initial years as a software developer, I quickly recognized that the success of any software project isn't just rooted in strong code or innovative design—it hinges significantly on the team dynamics. A software development team isn't merely a collection of individuals with varied tech skills; it's a cohesive uni... | igor_ag_aaa2341e64b1f4cb4 | |
1,901,413 | Who's Your .NET Ally? - F# vs C# | F#, with its functional-first approach, is a hit for tasks involving complex data manipulation and... | 0 | 2024-06-26T14:40:39 | https://dev.to/zoltan_fehervari_52b16d1d/whos-your-net-ally-f-vs-c-35oc | fsharp, csharp, dotnet, frameworks | F#, with its functional-first approach, is a hit for tasks involving complex data manipulation and parallel processing. Meanwhile, C# is the go-to for a wider range of applications, from web development to gaming, thanks to its object-oriented roots.
## Functional Programming Face-Off
F# shines in scenarios that bene... | zoltan_fehervari_52b16d1d |
1,901,412 | C# event-driven programming with delegates and events. | Event-driven programming, delegates and events. So far you have been learning about... | 27,862 | 2024-06-26T14:40:09 | https://dev.to/emanuelgustafzon/c-event-driven-programming-with-delegates-and-events-47lh | eventdriven, delegates, csharp, event | # Event-driven programming, delegates and events.
So far you have been learning about delegates. By putting what we learned in action we can already create event driven programming functionalities.
We will also talk about publishers and subscribers and the event keyword.
But for now check the example below where w... | emanuelgustafzon |
1,901,411 | Front-End Technologies | Web Technologies involves outlining the various technologies and frameworks involved in web... | 0 | 2024-06-26T14:40:06 | https://dev.to/arun970/front-end-technologies-58jn | beginners, web |
Web Technologies involves outlining the various technologies and frameworks involved in web development, from the front end to the back end, as well as tools for testing, deployment, and maintenance. Here’s a compreh... | arun970 |
1,901,410 | Mastering SOLID Principles in Java: A Practical Guide | SOLID principles are fundamental for any developer aiming to build robust, maintainable systems.... | 0 | 2024-06-26T14:39:23 | https://dev.to/adaumircosta/mastering-solid-principles-in-java-a-practical-guide-10kb | java, solidprinciples | SOLID principles are fundamental for any developer aiming to build robust, maintainable systems. These principles not only enhance code quality but also facilitate teamwork and scalability of projects. Let’s delve into each of these principles with practical examples in Java, highlighting both common violations and rec... | adaumircosta |
1,901,409 | AWS S3 Pricing for Beginners | A Comprehensive Guide to AWS S3 Pricing for Beginners Amazon Web Services (AWS) Simple... | 0 | 2024-06-26T14:39:11 | https://dev.to/sh20raj/aws-s3-pricing-for-beginners-3fc2 | aws, s3 | # A Comprehensive Guide to AWS S3 Pricing for Beginners
Amazon Web Services (AWS) Simple Storage Service (S3) is a scalable object storage service that provides secure, durable, and highly available storage. AWS S3 pricing can be complex due to the various factors involved. This guide will help you understand the diff... | sh20raj |
1,887,998 | philly Hibachi backyard party | If you’re looking to add a unique and entertaining culinary experience to your next gathering, look... | 0 | 2024-06-14T05:54:14 | https://dev.to/awesomechef08/philly-hibachi-backyard-party-5jb | If you’re looking to add a unique and entertaining culinary experience to your next gathering, look no further than AwesomeHibachi. Specializing in bringing the excitement and flavors of Hibachi dining directly to you, AwesomeHibachi offers a variety of services tailored to make your event unforgettable, whether it's i... | awesomechef08 | |
1,901,392 | I got hacked💥 and blew up prod! | I have been around the block enough times in my 15-year or so career to have broken things, and at... | 0 | 2024-06-26T14:37:52 | https://dev.to/kwnaidoo/i-got-hacked-and-blew-up-prod-43a3 | watercooler, webdev, productivity, beginners | I have been around the block enough times in my 15-year or so career to have broken things, and at times quite badly.
Here are some stupid mistakes I have made, and how to easily avoid them:
## Running SQL in production
Sometimes you must run destructive statements like **UPDATE** or **DELETE** in production. The pr... | kwnaidoo |
1,901,407 | Dom javascript | creat elemts: const div = document.createElement("div"); //Element yaratish ya'ni shu xolatda... | 0 | 2024-06-26T14:37:10 | https://dev.to/bekmuhammaddev/dom-javascript-29af | dom, javascript, aripovdev |
creat elemts:
```
const div = document.createElement("div"); //Element yaratish ya'ni shu xolatda <div></div>
const h1 = document.createElement("h1"); //Element yaratish ya'ni shu xolatda <h1></h1>
```
addClassList:
```
div.classList.add('p-5', 'bg-success'); // class qo'shish ya'ni shu xolatda
div.innerHTML = "... | bekmuhammaddev |
1,901,406 | The Role of WebAssembly in Frontend Development | Every successful sector or industry wasn’t always successful, they have all gone through the... | 0 | 2024-06-26T14:36:31 | https://dev.to/outstandingvick/the-role-of-webassembly-in-frontend-development-55pd | webdev, frontend, webassembly, javascript | Every successful sector or industry wasn’t always successful, they have all gone through the baby-steps phase before becoming great, and Frontend development isn’t any different, it has grown from simple static web pages of the 1990s to the sophisticated, dynamic applications of today. Initially, HTML, CSS, and JavaScr... | outstandingvick |
1,901,405 | Let's Connect Devs | Hi everyone, I am Harleen Singh, an undergrad at University and I am writing this to connect with... | 0 | 2024-06-26T14:35:27 | https://dev.to/devwhoisstuck/lets-connect-devs-1edn | webdev, opensource, ideas, programming | Hi everyone, I am Harleen Singh, an undergrad at University and I am writing this to connect with more developers over X and Github to discuss ideas
https://x.com/devwhoistuck
https://github.com/harleen001 | devwhoisstuck |
1,901,404 | Loading animation with a ball | Check out this Pen I made! | 0 | 2024-06-26T14:35:11 | https://dev.to/tidycoder/loading-animation-with-a-ball-2mi7 | codepen, webdev, html, css | Check out this Pen I made!
{% codepen https://codepen.io/TidyCoder/pen/bGyOjoM %} | tidycoder |
1,901,403 | What is GCP Interconnect? | What is GCP Interconnect? Google Cloud Interconnect is a service that provides a direct connection... | 0 | 2024-06-26T14:35:00 | https://dev.to/robertasaservice/what-is-gcp-interconnect-2ja1 | **What is GCP Interconnect?**
Google Cloud Interconnect is a service that provides a direct connection between your on prem or datacenter and the Google Cloud Network.
**Types of Interconnect:**
**Dedicated Interconnect:** Provides a direct physical connection from your data center to Google Cloud.
**Partner Interc... | robertasaservice | |
1,901,402 | Frontend frameworks: Next/Nuxt/Gatsby: Mastering one or knowing all | Frontend frameworks, mastering one and being an expert, or knowing more of them but not going deep... | 0 | 2024-06-26T14:34:08 | https://dev.to/momciloo/frontend-frameworks-nextnuxtgatsby-mastering-one-or-knowing-all-56l3 | Frontend frameworks, mastering one and being an expert, or knowing more of them but not going deep into their functionalities?
I came across a discussion on [Reddit](https://www.reddit.com/r/Frontend/comments/1d2u9m3/master_of_one_or_okay_at_many_frameworks/) about this topic and it inspired me to devote myself to thi... | momciloo | |
1,901,401 | Responsive Images with HTML | Providing the best user experience across various devices is very crucial. One essential aspect of... | 0 | 2024-06-26T14:33:10 | https://dev.to/samfrexz/responsive-images-with-html-35j0 | frontend, beginners, tutorial, html | Providing the best user experience across various devices is very crucial. One essential aspect of this experience is the use of responsive images. There is no need to embed large images on a page if it is being viewed on a small screen. Mobile users don't intend to waste bandwidth by downloading a large image designed... | samfrexz |
1,901,400 | Revitalize Your Sleep with Adipoli Cleaners' Mattress Cleaning Services Australia | Are you tossing and turning at night, wondering if your mattress is as clean as it should be? Look no... | 0 | 2024-06-26T14:32:02 | https://dev.to/adipolicleaners/revitalize-your-sleep-with-adipoli-cleaners-mattress-cleaning-services-australia-5b5k | Are you tossing and turning at night, wondering if your mattress is as clean as it should be? Look no further than Adipoli Cleaners, your go-to experts for Mattress Cleaning Services Australia. We understand that a clean mattress is the foundation of a good night's sleep and overall health.
Why Mattress Cleaning Matter... | adipolicleaners | |
1,901,399 | Filament: add a confirmation password field in a form | To add a confirmation password field in a form, you typically want to ensure that the user correctly... | 0 | 2024-06-26T14:31:58 | https://dev.to/johndivam/filament-to-add-a-confirmation-password-field-in-a-form-38kk | laravel, filament, php, webdev | To add a confirmation password field in a form, you typically want to ensure that the user correctly enters their password twice to prevent typos and ensure accuracy .
```
Forms\Components\TextInput::make('password')
->password()
->required()
->maxLength(25... | johndivam |
1,901,398 | Here are your Top Free Python IDEs and Text Editors | I say: choosing the right Python IDEs and text editors can significantly impact your productivity. ... | 0 | 2024-06-26T14:28:42 | https://dev.to/zoltan_fehervari_52b16d1d/here-are-your-top-free-python-ides-and-text-editors-4n32 | python, pythonides, pythontexteditors, pythondev | **I say: choosing the right Python IDEs and text editors can significantly impact your productivity.**
## Top Free Python IDEs
**1. PyCharm Community Edition** — Ideal for advanced coding, this open-source IDE offers features like code analysis and intelligent completion.
**2. Spyder** — Great for data-driven project... | zoltan_fehervari_52b16d1d |
1,899,076 | Handling file uploads in Next.js using UploadThing | Written by Jude Miracle✏️ An important aspect of many websites these days is file submission... | 0 | 2024-06-26T14:27:37 | https://blog.logrocket.com/handling-file-uploads-next-js-using-uploadthing | nextjs, webdev | **Written by [Jude Miracle](https://blog.logrocket.com/author/judemiracle/)✏️**
An important aspect of many websites these days is file submission features. Whether it’s a job application on a company’s website or pictures and videos on social media apps, it’s crucial to develop user-friendly file upload forms.
Howe... | leemeganj |
1,901,397 | MERN stack roadmap with job ready projects | Month 1: Foundations HTML & CSS HTML Basics: Elements, attributes, headings,... | 0 | 2024-06-26T14:27:04 | https://dev.to/dhirajaryaa/mern-stack-roadmap-with-job-ready-projects-ffe | webdev, mern, javascript, tutorial | #### Month 1: Foundations
**HTML & CSS**
- **HTML Basics**: Elements, attributes, headings, paragraphs, links, lists, forms.
- **CSS Basics**: Selectors, properties, box model, flexbox, grid.
- **Responsive Design**: Media queries, mobile-first design.
- **Resources**: [MDN Web Docs](https://developer.mozilla.org/en-U... | dhirajaryaa |
1,901,396 | How NOT to learn mobile development | I built the same app 3 times, here is what I learned After completing a full stack... | 0 | 2024-06-26T14:27:00 | https://dev.to/rafi_barides_faa6677ba16d/how-not-to-learn-mobile-development-pcn | mobile, swift, reactnative, kotlin | ## I built the same app 3 times, here is what I learned
After completing a full stack development curriculum, I felt ready to extend my knowledge and go beyond the web. I jumped into what seems like a chaotic entanglement of technologies, with different sources each suggesting alternate tech stacks. I came across thre... | rafi_barides_faa6677ba16d |
1,901,395 | 5 Strange Facts About White Label Fantasy Sports Software Developers | When it comes to the world of fantasy sports, the developers behind white label fantasy sports... | 0 | 2024-06-26T14:26:16 | https://dev.to/davidwyat/5-strange-facts-aboutwhite-label-fantasy-sports-software-developers-12kc | development, coding, softwaredevelopment, developers | When it comes to the world of fantasy sports, the developers behind **[white label fantasy sports software](https://www.sciflare.com/white-label-fantasy-sports-software/)** often work behind the scenes, crafting platforms that engage millions of users worldwide. While their work is integral to the industry, there are s... | davidwyat |
1,901,390 | Java's 2024 Game Engines as far as I know | Java’s Capabilities in Game Design? I advise you to select the Java game engine that... | 0 | 2024-06-26T14:24:54 | https://dev.to/zoltan_fehervari_52b16d1d/javas-2024-game-engines-as-far-as-i-know-51d2 | java, gamedev, javagameengines, javaframeworks | ## Java’s Capabilities in Game Design?
I advise you to select the Java game engine that aligns with your vision to bring your interactive stories to life. Let’s see…
### Java for Cross-Platform Game Development
Java game engines provide a foundation for building games that operate smoothly across a spectrum of platf... | zoltan_fehervari_52b16d1d |
1,901,389 | Wednesday Links - Edition 2024-06-26 | Writing Truly Memory Safe JIT Compilers (10... | 6,965 | 2024-06-26T14:22:29 | https://dev.to/0xkkocel/wedenasday-links-edition-2024-06-26-5f8 | refactoring, renovate, kotlin, api | Writing Truly Memory Safe JIT Compilers (10 min)☔
https://medium.com/graalvm/writing-truly-memory-safe-jit-compilers-f79ad44558dd
Refactoring Just Enough (2 min)⚖️
https://blog.thecodewhisperer.com/permalink/refactoring-just-enough
Power Assert now in Kotlin! (2 min)🎉
https://kt.academy/article/power-assert
Getting... | 0xkkocel |
1,901,388 | How to install SDL2 on macOS | Setting up SDL libraries on macOS can be challenging, this tutorial covers how to set it up, compile a program and open a window to as a test. | 0 | 2024-06-26T14:20:50 | https://www.csalmeida.com/log/how-to-install-sdl2-on-macos/ | c, sdl2, setup | ---
title: How to install SDL2 on macOS
published: true
description: "Setting up SDL libraries on macOS can be challenging, this tutorial covers how to set it up, compile a program and open a window to as a test."
tags: c, sdl2, setup
canonical_url: https://www.csalmeida.com/log/how-to-install-sdl2-on-macos/
cover_imag... | cristiano |
1,901,383 | گیربکس sew | گیربکس SEW یکی از محصولات برجسته در صنعت گیربکس و انتقال قدرت است که توسط شرکت SEW-Eurodrive تولید... | 0 | 2024-06-26T14:18:37 | https://dev.to/arshasanat/gyrbkhs-sew-9n7 | sew | گیربکس SEW یکی از محصولات برجسته در صنعت گیربکس و انتقال قدرت است که توسط شرکت SEW-Eurodrive تولید میشود. این شرکت که در سال 1931 در آلمان تأسیس شده است، به عنوان یکی از پیشروان در زمینه تولید سیستمهای محرکه و گیربکسهای صنعتی شناخته میشود.
گیربکسهای SEW به دلیل کیفیت بالا، عملکرد قابل اعتماد و تنوع گستردهای که ا... | arshasanat |
1,901,382 | Ultimate Comfort and Style with ITA Leisure Beach Towels | The sun warms your skin, the sound of crashing waves fills the air, and a refreshing ocean breeze... | 0 | 2024-06-26T14:18:07 | https://dev.to/italeisure/ultimate-comfort-and-style-with-ita-leisure-beach-towels-3oib | beachtowels, beachtowelsforsale, cheapestbeachtowels, italeisure | The sun warms your skin, the sound of crashing waves fills the air, and a refreshing ocean breeze whispers through your hair. You've reached your happy place – the beach. But between dips in the cool water and soaking up the rays, there's one essential item: a beach towel. It's your haven, your drying station, your spo... | italeisure |
1,430,931 | How to use React useRef with TypeScript | If you're a developer using React and TypeScript, you'll need to know how to use useRef to reference... | 0 | 2023-04-09T17:02:02 | https://dev.to/coder9/how-to-use-react-useref-with-typescript-21dl | react, abotwrotethis | If you're a developer using React and TypeScript, you'll need to know how to use `useRef` to reference elements in your application. In this tutorial, we will explore how to use `useRef` along with TypeScript to leverage the strengths of both technologies.
## What is useRef?
`useRef` is a React hook that provides a w... | coder9 |
1,901,366 | How to Create Invoices in Salesforce Using Docs Made Easy A Salesforce Document Generation App | Invoicing, once a cumbersome manual process, has evolved dramatically with automation, bringing... | 0 | 2024-06-26T14:14:42 | https://dev.to/kimayanazum/how-to-create-invoices-in-salesforce-using-docs-made-easy-a-salesforce-document-generation-app-5b2c | tutorial, community, webdev, programming | Invoicing, once a cumbersome manual process, has evolved dramatically with automation, bringing efficiency and accuracy to businesses of all sizes. Salesforce users can further streamline their invoicing process with the integration of Docs Made Easy, a versatile application available on the Salesforce AppExchange. Thi... | kimayanazum |
1,901,381 | HireVA Services | Elevate your business with our distinctive expertise. From crafting personalized designs to... | 0 | 2024-06-26T14:13:19 | https://dev.to/hireva349/hireva-services-1o5o | services, webdev, programming, beginners | Elevate your business with our distinctive expertise. From crafting personalized designs to orchestrating seamless interactions, we translate your vision into digital reality. Discover the transformative impact of HireVA, where our VAs possess diverse skill sets in Automation, Project Management, CRM Management, GHL, S... | hireva349 |
1,901,370 | Type issu in Nextjs app. | [Help please] how can i solve the issue? there is an object called diary comming from an database and... | 0 | 2024-06-26T14:12:05 | https://dev.to/abdullahmunshi/type-issu-in-nextjs-app-40dn | nextjs, typescript, reactjsdevelopment, nextjsdevelopment | [Help please] how can i solve the issue? there is an object called diary comming from an database and passed to <DiaryEditForm diary={diary} /> component where a useState hook expecting that object. at build time it gives the following error.
 ensures that **every job** can be **inspected for security vulnerabilities and compliance issues before and even... | xlab_steampunk |
1,901,346 | Using PHP Attributes to Create and Use a Custom Validator in Symfony | Symfony, a leading PHP framework, is consistently updated to leverage modern PHP features. With PHP... | 0 | 2024-06-26T14:00:00 | https://chrisshennan.com/blog/using-php-attributes-to-create-and-use-a-custom-validator-in-symfony | symfony, php, attributes, validation | Symfony, a leading PHP framework, is consistently updated to leverage modern PHP features. With PHP 8, attributes provide a new way to define metadata for classes, methods, properties, etc., which can be used for validation constraints. This blog post will guide you through creating and using a custom validator in Symf... | chrisshennan |
1,901,359 | MGID's Generative AI | MGID's Generative AI... | 0 | 2024-06-26T13:53:31 | https://dev.to/franksinatra/mgids-generative-ai-4mib | mgid, ai, generative | MGID's Generative AI [https://www.mgid.com/blog/unleashing-creativity-exploring-mgid-s-generative-ai-features](https://www.mgid.com/blog/unleashing-creativity-exploring-mgid-s-generative-ai-features) is like having a creative assistant who never runs out of ideas. This tool helps regular folks, like us, craft engaging ... | franksinatra |
1,901,358 | Abaya: A Symbol of Modesty and Tradition | The abaya is a long, flowing black cloak worn by Muslim women, primarily in the Middle East and North... | 0 | 2024-06-26T13:51:13 | https://dev.to/jack_son_3c5a8a5465bbf062/abaya-a-symbol-of-modesty-and-tradition-365p | javascript | The [abaya](https://wearmumtaz.com/collections/abaya) is a long, flowing black cloak worn by Muslim women, primarily in the Middle East and North Africa. It is designed to cover the entire body except for the face, hands, and feet, symbolizing modesty and privacy. Traditionally, the abaya is made from lightweight fabri... | jack_son_3c5a8a5465bbf062 |
1,901,350 | A RAG for Elixir | Abstract This is the second part of a series of blog posts on using a RAG (Retrieval... | 27,867 | 2024-06-26T13:50:49 | https://bitcrowd.dev/a-rag-for-elixir | llm, rag, ai, elixir | ## Abstract
This is the second part of a series of blog posts on using a RAG (Retrieval Augmented Generation) information system for your codebase. Together we explore how this can empower your development team. Check out the [first post](/how-even-the-simplest-RAG-can-empower-your-team) for an introduction into the t... | klappradla |
1,901,357 | Release 0.9.0 of Ebirah | long over due release update of my docker-dzil experiment | 0 | 2024-06-26T13:47:00 | https://dev.to/jonasbn/release-090-of-ebirah-1mio | perl, docker, release, opensource | ---
title: Release 0.9.0 of Ebirah
published: true
description: long over due release update of my docker-dzil experiment
tags: perl, docker, release, opensource
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-26 13:26 +0000
---
I finally got around to ma... | jonasbn |
1,901,356 | How Learning Programming is Similar to Learning a New Language | As someone who has been deeply involved in teaching English and helping people master the language... | 0 | 2024-06-26T13:46:07 | https://dev.to/anjali110385/how-learning-programming-is-similar-to-learning-a-new-language-3dmm | englishspeaking, interview, education, programming |
As someone who has been deeply involved in teaching English and helping people master the language through my website, English Fear, I've noticed fascinating parallels between learning a programming language and learning a natural language. Understanding vocabulary is crucial in both areas, as learning programming syn... | anjali110385 |
1,901,354 | New Journey | Hi everyone, I'm new here and I am a computer engineering graduate from Ghana Communications... | 0 | 2024-06-26T13:44:33 | https://dev.to/nlankwei5/new-journey-oj7 | cloudcomputing, aws, beginners | Hi everyone, I'm new here and I am a computer engineering graduate from Ghana Communications Technology University, Accra-Ghana in West Africa. I have always been curious abut the cloud and networking. The path has been a bit hazy for me for the past two years. I got completely confused. Finally a have a guide and a me... | nlankwei5 |
1,901,353 | Exploring the Role of CaptchaAI in Automating and Bypassing Captcha Challenges | In the digital era, CAPTCHAs serve as a critical barrier against automated attacks, ensuring that... | 0 | 2024-06-26T13:44:00 | https://dev.to/media_tech/exploring-the-role-of-captchaai-in-automating-and-bypassing-captcha-challenges-4ad | In the digital era, CAPTCHAs serve as a critical barrier against automated attacks, ensuring that users on websites are indeed human. However, these CAPTCHAs can often disrupt user experience and slow down digital interactions. CaptchaAI, a leading **captcha solving service**, aims to bridge the gap between maintaining... | media_tech | |
1,900,511 | Build an AI-Powered Resume & Cover Letter Generator (CopilotKit, LangChain, Tavily & Next.js) | TL;DR Building a great project is the best resume for an aspiring developer. Well, today... | 0 | 2024-06-26T13:40:20 | https://dev.to/copilotkit/build-an-ai-powered-resume-cover-letter-generator-copilotkit-langchain-tavily-nextjs-1nkc | webdev, tutorial, programming, javascript | ## **TL;DR**
Building a great project is the best resume for an aspiring developer.
Well, today we will hit two birds with one stone; I will teach you how to build a cutting-edge, AI-powered application that will generate your resume & cover letter based on your LinkedIn, GitHub & X.
This project & your ensuing res... | uliyahoo |
1,901,349 | Git Branch Management | Introduction A well-structured branch management flow is crucial for handling frequent... | 0 | 2024-06-26T13:38:42 | https://dev.to/abir101/git-branch-management-1170 | ## Introduction
A well-structured branch management flow is crucial for handling frequent releases and immediate hotfixes efficiently. This article outlines a comprehensive branch management flow designed for regular periodic releases alongside urgent hotfixes, ensuring that features and fixes are tested thoroughly be... | abir101 | |
1,901,348 | Segunda parte: Definiciones/Conceptos del día a día | Como mencioné en la introducción, la idea al finalizar esta serie de publicaciones es tener las... | 27,616 | 2024-06-26T13:37:26 | https://dev.to/alfredtester/segunda-parte-definicionesconceptos-del-dia-a-dia-4oa2 | testing, api, apitesting, e2etesting |
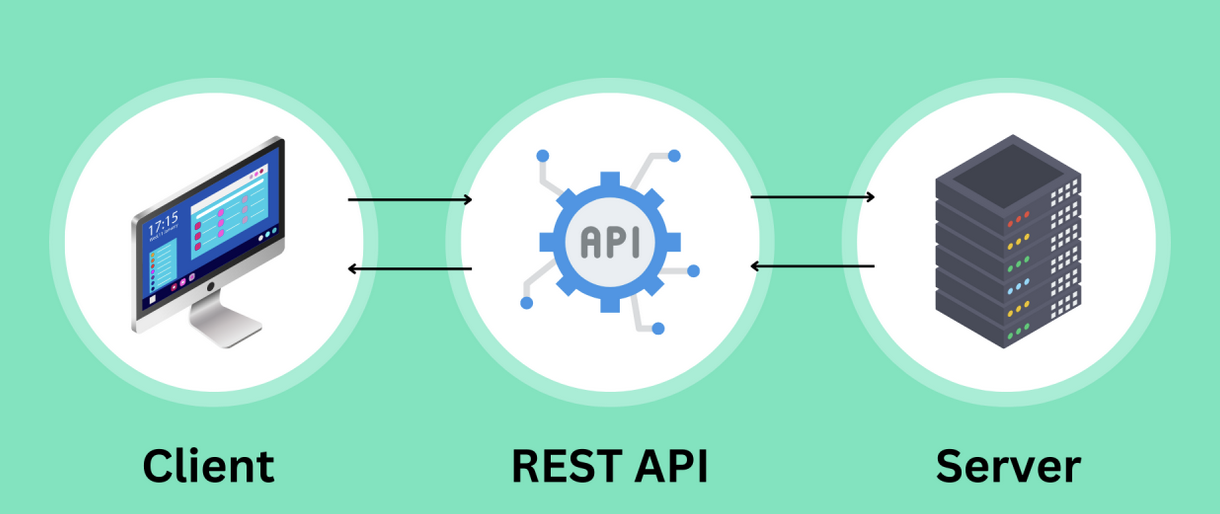
Como mencioné en la introducción, la idea al finalizar esta serie de publicaciones es tener las herramientas y el conocimiento para poder convertirnos expertos en API Testing, por tanto poder manejar y tener claridad de los ... | alfredtester |
1,901,347 | Norfolk County Emergency Towing | Norfolk County Emergency Towing provides emergency towing for vehicles that have been in an accident.... | 0 | 2024-06-26T13:36:16 | https://dev.to/norfolk_countyemergency/norfolk-county-emergency-towing-4jnc | towing, towingservices, roadsideservices | Norfolk County Emergency Towing provides emergency towing for vehicles that have been in an accident. We will safely transport your vehicle to our repair shop and do our best to restore the damages. [Towing Services Simcoe ON](https://www.emergencytowingnorfolk.ca/) also provide regular 24/7 towing services and roadsid... | norfolk_countyemergency |
1,901,322 | How even the simplest RAG can empower your team | Abstract This is the first part of a series of blog posts on using a RAG (Retrieval... | 27,867 | 2024-06-26T13:34:01 | https://bitcrowd.dev/how-even-the-simplest-RAG-can-empower-your-team | llm, rag, ai, ruby | ## Abstract
This is the first part of a series of blog posts on using a RAG (Retrieval Augmented Generation) information system for coding. Find out how this can empower your development team.
In this episode, we will discuss at a very simple [RAG](https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-... | klappradla |
1,901,344 | Predictive Maintenance of vehicles in the Automotive Industry | *Problem Formulation * I delve into a problem that is peculiar to the automotive industry. The... | 0 | 2024-06-26T13:33:05 | https://dev.to/ludwig023/predictive-maintenance-of-vehicles-in-the-automotive-industry-46d5 | **Problem Formulation **
I delve into a problem that is peculiar to the automotive industry. The business problem hinges on the leverage of predictive analytics and machine learning techniques to act as a forerunner of vehicle component failures before they happen, this would aid in the reduction of downtime, enhancin... | ludwig023 | |
1,901,345 | My Journey to Learn Data Science and Machine Learning | For Developers Looking to Add Machine Learning to Their Toolkit Hello, fellow developers!... | 0 | 2024-06-26T13:32:12 | https://dev.to/mesfin_t/my-journey-to-learn-data-science-and-machine-learning-3a29 | data, science, machine, learning |
### For Developers Looking to Add Machine Learning to Their Toolkit
Hello, fellow developers! 🌟
Are you already proficient in full-stack development, particularly with the MERN stack (MongoDB, Express.js, React, Node.js)? Have you ever wondered how integrating Data Science and Machine Learning could elevate your p... | mesfin_t |
1,901,342 | How to get an interview call after applying online? 2024 | In today's competitive job market, getting a phone call for an interview after submitting an online... | 0 | 2024-06-26T13:30:19 | https://dev.to/hey_rishabh/how-to-get-an-interview-call-after-applying-online-2024-2dgm | webdev, javascript, beginners, tutorial | In today's competitive job market, getting a phone call for an interview after submitting an online application can be difficult. To boost your chances of sticking out in the sea of applications that companies receive, you must use powerful methods.
**Here are some tips to increase your chances of getting an interview... | hey_rishabh |
1,901,341 | Pattern Matching | Uzbek | C# | Bugun biza C# dasturlash tilidagi legenda xususiyatlardan biri bo'lmish Pattern Matchinglarni ko'rib... | 0 | 2024-06-26T13:29:03 | https://dev.to/ozodbek_soft/pattern-matching-uzbek-c-4hi7 | dotnet, csharp, uzbek, patternmatching | **Bugun biza C# dasturlash tilidagi legenda xususiyatlardan biri bo'lmish Pattern Matchinglarni ko'rib o'tamiz!**
Bu postni ham ma'lum bir sabablarga ko'ra savol javob orqali yoritib boraman.
**1 savol** - Pattern Matching nima ?
> _C# dasturlash tilida `Pattern Matching` - bu kod ichida turli ma'lumot turlarini a... | ozodbek_soft |
1,901,340 | Pattern Matching | Uzbek | C# | Bugun biza C# dasturlash tilidagi legenda xususiyatlardan biri bo'lmish Pattern Matchinglarni ko'rib... | 0 | 2024-06-26T13:29:03 | https://dev.to/ozodbek_soft/pattern-matching-uzbek-c-2eoo | dotnet, csharp, uzbek, patternmatching | **Bugun biza C# dasturlash tilidagi legenda xususiyatlardan biri bo'lmish Pattern Matchinglarni ko'rib o'tamiz!**
Bu postni ham ma'lum bir sabablarga ko'ra savol javob orqali yoritib boraman.
**1 savol** - Pattern Matching nima ?
> _C# dasturlash tilida `Pattern Matching` - bu kod ichida turli ma'lumot turlarini a... | ozodbek_soft |
1,901,339 | 5 Simple Steps to Get Your Test Suite Running in Heroku CI | So, I’ve always thought about Heroku as just a place to run my code. They have a CLI. I can connect... | 0 | 2024-06-26T13:27:49 | https://dzone.com/articles/5-simple-steps-to-get-your-test-suite-running | cicd, pipeline, heroku, testing | So, I’ve always thought about Heroku as just a place to run my code. They have a CLI. I can connect it to my GitHub repo, push my code to a Heroku remote, and bam… it’s deployed. No fuss. No mess.
But I had always run my test suite… somewhere else: locally, or with CircleCI, or in GitHub Actions. How did I not know th... | mbogan |
1,901,337 | Reasons Why Intranet is Important at the Workplace | Effective communication, collaboration, and information sharing are foundational to any... | 0 | 2024-06-26T13:24:54 | https://dev.to/webtualglobal/reasons-why-intranet-is-important-at-the-workplace-1p2a |

Effective communication, collaboration, and information sharing are foundational to any organization's success. An intranet plays a crucial role in facilitating these activities within the workplace environment. It... | webtualglobal | |
1,901,325 | Free Tool: Mesher | Hi, i've recently developed (yet another) small tool to generate vanilla CSS animated gradients. It's... | 0 | 2024-06-26T13:23:02 | https://dev.to/tipografo/free-tool-mesher-8ao | gradients, css, animatedgradients, nextjs | Hi, i've recently developed _(yet another)_ small tool to [generate vanilla CSS animated gradients](https://mshr.app). It's still in it's early stages but i would love to get some feedback from all of the community, wishing this tool can help someone generate some cool gradients.
Link: [mshr.app](https://mshr.app)

# Overview
Have you ever got up from your desk and walked over to the restroom, only to find that all of the stalls are full? Then you walked to the other restrooms in the building, only to find that all of them are... | charlesrc019 | |
1,901,336 | Day 3: AWS Compute Services | In our previous blog post, we explored the fundamental concepts of AWS, including Regions,... | 0 | 2024-06-26T13:21:55 | https://dev.to/dipakahirav/day-3-aws-compute-services-15oi | aws, awschallenge, amazon, services | In our previous blog post, we explored the fundamental concepts of AWS, including Regions, Availability Zones, and the AWS Management Console. Today, we'll dive deeper into AWS compute services, particularly Amazon EC2 (Elastic Compute Cloud).
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewi... | dipakahirav |
1,901,335 | Power of Real DOM in JavaScript | JavaScript developers, ready to transform your coding game? Dive deep into the world of Real DOM... | 0 | 2024-06-26T13:21:15 | https://dev.to/gadekar_sachin/power-of-real-dom-in-javascript-58ad |
JavaScript developers, ready to transform your coding game? Dive deep into the world of Real DOM manipulation and discover how mastering this essential skill can revolutionize your web development journey. Let’s break it down with the Pareto Principle, ensuring you focus on the vital 20% that delivers 80% of the res... | gadekar_sachin | |
1,901,324 | Microsoft Entra External ID & Cerbos ✨ | 👋 Looking to level up your authentication (authn) and authorization (authz) game? Here's a great... | 0 | 2024-06-26T13:18:37 | https://dev.to/cerbos/microsoft-entra-external-id-cerbos-ccp | authz, tutorial, cerbos, javascript | 👋 Looking to level up your authentication (authn) and authorization (authz) game? Here's a great tutorial that dives into integrating Microsoft Entra External ID for seamless external authentication and Cerbos for top-notch, fine-grained authorization. You’ll learn about adding authentication to your external-facing a... | phrawzty |
1,901,321 | API Gateway Patterns for Microservices Architectures | In microservices-based architectures, the API gateway pattern plays a crucial role in managing and... | 0 | 2024-06-26T13:13:35 | https://dev.to/platform_engineers/api-gateway-patterns-for-microservices-architectures-2m5a | In microservices-based architectures, the API gateway pattern plays a crucial role in managing and optimizing communication between clients and multiple microservices. This pattern simplifies complexity, enhances security, and improves performance, making it indispensable for building scalable and resilient systems. Th... | shahangita | |
1,901,320 | How-to fix Git com GPG Lock | Um dia, sem mais nem menos, você não consegue mergear uma branch em outra ou sequer fazer um commit... | 0 | 2024-06-26T13:13:25 | https://dev.to/debborafernandess/how-to-fix-git-com-gpg-lock-4p4h | Um dia, sem mais nem menos, você não consegue mergear uma branch em outra ou sequer fazer um commit manual, porque ao tentar recebe a mensagem de erro:
```
gpg: waiting for lock (held by 4242) ...
```
E agora, o que aconteceu?
_Será que a chave GPG expirou e eu devo renovar?
Seria um lock no processo e matar o proces... | debborafernandess | |
1,429,685 | Creating a virtual machine with AWS | Creating a virtual machine on AWS is as simple as cutting a slice of birthday cake :). Whether you... | 0 | 2023-04-07T21:31:07 | https://dev.to/lomosa/creating-a-virtual-machine-with-aws-3kjl | aws, virtualmachine, cloud, tutorial | Creating a virtual machine on AWS is as simple as cutting a slice of birthday cake :). Whether you are a beginner or an expert in cloud computing and have difficulty in setting up a virtual machine in AWS, you can follow these simple steps:
**1. Set up an account**
To set up an account head over to [AWS Free Cloud Co... | lomosa |
1,901,317 | Investing for Tomorrow: Understanding Sustainable Investing. | In recent years, there has been a growing trend towards sustainable investing, driven by both... | 0 | 2024-06-26T13:11:34 | https://dev.to/team_convanto_b68a85d86ab/investing-for-tomorrow-understanding-sustainable-investing-b9h | startup, business, sustainable, investing | In recent years, there has been a growing trend towards sustainable investing, driven by both environmental concerns and the recognition of long-term financial viability. Investors are increasingly looking beyond traditional financial metrics to consider environmental, social, and governance (ESG) factors when making i... | team_convanto_b68a85d86ab |
1,901,316 | DumpsBoss AWS Practitioner Exam Dumps Your Study Plan | Unveiling the Secrets of AWS Practitioner Exam Dumps Introduction In the fast-paced world of cloud... | 0 | 2024-06-26T13:04:35 | https://dev.to/thomas564/dumpsboss-aws-practitioner-exam-dumps-your-study-plan-3b66 | Unveiling the Secrets of AWS Practitioner Exam Dumps
Introduction
In the fast-paced world of cloud computing, obtaining certifications can significantly boost one's career prospects. Among these certifications, the AWS Certified Cloud Practitioner stands out as an entry-level credential that validates essential knowle... | thomas564 | |
1,901,315 | Unified Software Solutions for Business Efficiency | The Software solutions integrated seamlessly combine various applications and systems to function as... | 0 | 2024-06-26T13:04:01 | https://dev.to/john_expert_9dd57f8abf5ed/unified-software-solutions-for-business-efficiency-2jfa | webdev, beginners | The [Software solutions integrated ](https://engageexperts.ae/software-solutions-integrated/)seamlessly combine various applications and systems to function as a cohesive unit, enhancing efficiency and productivity. These solutions enable different software components to communicate and work together, facilitating data... | john_expert_9dd57f8abf5ed |
1,901,314 | Creating A Radio Software | Day 1: Starting My Radio Software Project Hello, World! 👋 My name is Preston Arnold, a... | 0 | 2024-06-26T13:02:49 | https://dev.to/prestonarnold0/creating-a-radio-software-3fn7 | webdev, javascript, programming, react | ## Day 1: Starting My Radio Software Project
Hello, World! 👋
My name is Preston Arnold, a 14-year-old developer from the UK with 4 years of experience in Website Development.
Anyways, enough about me.
## Inspirations
For this project, I've drawn inspiration from some fantastic radio automation software:
- **[Ra... | prestonarnold0 |
1,901,313 | Optimize Django Performance: Using Asynchronous Signals with Huey and SQLite | One of the powerful features of the Django framework is the provision of an independent means of... | 27,866 | 2024-06-26T13:01:59 | https://medium.com/@abasifreke/optimize-django-performance-using-asynchronous-signals-with-huey-and-sqlite-40dfbec122e1 | webdev, django, programming, python | One of the powerful features of the Django framework is the provision of an independent means of communication between different parts of its application without being tightly connected, this is done by signals. Django Signals allow connectivity between different components while responding to changes. For example, cre... | abasifreke_ukpong |
1,901,311 | How AI is Transforming Blockchain for Better Security and Efficiency | Blockchain technology has revolutionized the way we think about data security and transparency. With... | 0 | 2024-06-26T13:00:23 | https://dev.to/gianna4/how-ai-is-transforming-blockchain-for-better-security-and-efficiency-nj9 | Blockchain technology has revolutionized the way we think about data security and transparency. With its decentralized and immutable nature, it has become a cornerstone for applications requiring secure and verifiable records, from financial transactions to supply chain management. However, as the digital landscape evo... | gianna4 | |
1,881,749 | Why do we need clean code? | Let's start by considering a non-code related example to help us answer this question. Consider you... | 0 | 2024-06-26T12:57:25 | https://dev.to/wraith/why-do-we-need-clean-code-1cea | development | Let's start by considering a non-code related example to help us answer this question.
Consider you just arrived at your friend's house to pick them up to go to work. They open the door and you can immediately tell they have a lot going on. Maybe they overslept and are now scrambling to get out the door. They also pro... | wraith |
1,901,310 | UI Libraries in React | UI libraries that can create aesthetically pleasing websites are what every developer looks for.... | 0 | 2024-06-26T12:52:55 | https://medium.com/@shariq.ahmed525/ui-libraries-in-react-2c3fe5046e6d | javascript, react, reactjsdevelopment | UI libraries that can create aesthetically pleasing websites are what every developer looks for. These libraries not only help developers but also make life easier for users by enabling them to navigate the system quickly. So, what are some great UI libraries that developers can use with React.js? Let’s see them one by... | shariqahmed525 |
1,901,309 | Part 2: Mastering Prompts and Language Models with LangChain | Part 2: Mastering Prompts and Language Models with LangChain In the previous part of our... | 27,162 | 2024-06-26T12:51:19 | https://dev.to/jamesbmour/part-2-mastering-prompts-and-language-models-with-langchain-2667 | python, llm, langchain, vectordatabase | # Part 2: Mastering Prompts and Language Models with LangChain
In the previous part of our LangChain tutorial series, we introduced the core components of the library. Now, let's dive deeper into two essential aspects of building LangChain applications: prompts and language models (LLMs). You'll learn how to create ef... | jamesbmour |
1,900,803 | Processos de código - Introdução. | Que a construção de software não é um processo convencional até o mais novato desenvolvedor sabe,... | 0 | 2024-06-26T12:51:18 | https://dev.to/loremimpsu/processos-de-codigo-introducao-mpk | 100daysofcode, softwareengineering, softwaredevelopment |
Que a construção de software não é um processo convencional até o mais novato desenvolvedor sabe, porém a complexidade dessa tarefa é elevada a um nível diferente quando se envolve dois ou mais desenvolvedores em um time. Surge a necessidade de um método que ajude ao time a desenvolver de maneira coordenada e sempre e... | loremimpsu |
1,901,278 | Day 22 of 30 of JavaScript | Hey reader👋 Hope you are doing well😊 In the last post we have talked about Asynchronous JavaScript.... | 0 | 2024-06-26T12:45:13 | https://dev.to/akshat0610/day-22-of-30-of-javascript-2omi | webdev, javascript, beginners, tutorial | Hey reader👋 Hope you are doing well😊
In the last post we have talked about Asynchronous JavaScript. In this post we are going to discuss about Callbacks.
So let's get started🔥
## Callbacks in JavaScript
A callback is a function passed as an argument to another function, which gets invoked after the main function c... | akshat0610 |
1,901,307 | Looking for Senior Python developer job. | I am a senior developer with 5 years of experience in python. | 0 | 2024-06-26T12:38:34 | https://dev.to/sankar_puvvada/looking-for-senior-python-developer-job-42c1 | I am a senior developer with 5 years of experience in python. | sankar_puvvada | |
1,901,305 | Discover the Healing Benefits of Natural Hammam Spa | Introduction: In today's fast-paced world, finding time to relax and rejuvenate is essential. One of... | 0 | 2024-06-26T12:34:44 | https://dev.to/abitamim_patel_7a906eb289/discover-the-healing-benefits-of-natural-hammam-spa-48o0 | Introduction:
In today's fast-paced world, finding time to relax and rejuvenate is essential. One of the most effective and enjoyable ways to do this is by visiting a **[Natural Hammam Spa](https://spa.trakky.in/ahmedabad/shahibag/spas/nathamahm)**. Rooted in centuries-old traditions, the Hammam experience offers a uni... | abitamim_patel_7a906eb289 | |
1,901,304 | All About JavaScript Object | Here I am trying to elaborate on JavaScript Arrays features and built-in methods. I believe... | 0 | 2024-06-26T12:30:42 | https://dev.to/azadulkabir455/all-about-javascript-object-25an | ## Here I am trying to elaborate on JavaScript Arrays features and built-in methods. I believe you can find this useful.
Please click the below link to read this Article
🚀 Link: [Article Link](https://shorturl.at/5JetU)
Follow more articles like this follow me.
🚀Link: [Azad Ul Kabir](https://www.linkedin.com/in/aza... | azadulkabir455 | |
1,900,668 | Flutter liveness: 300% performance enhance | Stepping forward!! Hello there again! I'm glad to be here sharing results and great improvements. If... | 27,768 | 2024-06-26T12:28:51 | https://dev.to/jodamco/flutter-liveness-300-performance-enhance-3kkh | flutter, android, machinelearning, learning | **Stepping forward!!**
Hello there again! I'm glad to be here sharing results and great improvements. If you're short of time and only want to know how to improve your app performance I recommend you [peek at the code here](https://github.com/jodamco/gmlkit_liveness/blob/main/lib/presentation/widgets/custom_face_detec... | jodamco |
1,901,303 | The Evolution and Impact of Warehousing in Ahmedabad | Ahmedabad, a bustling city in the state of Gujarat, India, has emerged as a significant hub for... | 0 | 2024-06-26T12:28:27 | https://dev.to/expressroadways/the-evolution-and-impact-of-warehousing-in-ahmedabad-2m4a | warehouseinahmedabad, warehouseforren, warehouseinindia, warehouse |

Ahmedabad, a bustling city in the state of Gujarat, India, has emerged as a significant hub for industry and commerce. One of the key pillars supporting this rapid economic growth is the warehousing sector. This ar... | expressroadways |
1,901,302 | Journals with no APC charges | Publishing a research paper for free involves careful planning and choosing the right journals and... | 0 | 2024-06-26T12:27:33 | https://dev.to/neerajm76404554/journals-with-no-apc-charges-3cnb | research, student, computerscience, devjournal | Publishing a research paper for free involves careful planning and choosing the right journals and platforms that do not charge publication fees. Here’s a step-by-step guide to help you navigate the process:
**Submit Paper This Link - https://ijsret.com/2024/04/12/free-journal-to-publish-research-paper/
**
Free jou... | neerajm76404554 |
1,898,830 | Creating a Virtual Machine Scale-Set in Azure (VMSS). | What is Virtual machine scale-set? One intriguing feature provided by Microsoft Azure is... | 0 | 2024-06-26T12:24:35 | https://dev.to/laoluafolami/creating-a-virtual-machine-scale-set-in-azure-vmss-21g9 | azure | ## What is Virtual machine scale-set?
One intriguing feature provided by Microsoft Azure is called Virtual Machine Scale Sets (VMSS), which aids in the creation and management of a group of similar, auto-scaling Virtual Machines (VMs). VM instances can be automatically increased or decreased in accordance with predeter... | laoluafolami |
1,890,644 | Control Rate Limit using Queues | Rate limiting is an important technique used to control the frequency of operations or requests... | 0 | 2024-06-26T12:23:48 | https://dev.to/woovi/control-rate-limit-using-queues-eh5 | ratelimit, queue | Rate limiting is an important technique used to control the frequency of operations or requests within a specified period. It is commonly implemented to ensure system stability, fairness, and security
In this article, we are going to focus on how to use queues to control the rate limit usage of some external APIs.
##... | sibelius |
1,901,301 | Aronsol Pvt Ltd | Aronsol is a dynamic digital marketing agency that specializes in crafting compelling stories,... | 0 | 2024-06-26T12:21:30 | https://dev.to/aronsoldm/aronsol-pvt-ltd-3bf7 | **[Aronsol](https://aronsol.com/)** is a dynamic digital marketing agency that specializes in crafting compelling stories, designing visually stunning content, and delivering tailored IT solutions. We're passionate about creating narratives that truly connect with audiences, and our team of experts is here to guide you... | aronsoldm | |
1,901,300 | WA GB: Panduan Utama Mengunduh dan Menggunakan Mod WhatsApp Terbaik | Selamat datang di WA GB, sumber terpercaya Anda untuk mendownload APK WA GB terbaru dan asli. Baik... | 0 | 2024-06-26T12:20:44 | https://dev.to/linkwagb01/wa-gb-panduan-utama-mengunduh-dan-menggunakan-mod-whatsapp-terbaik-3dbl | Selamat datang di WA GB, sumber terpercaya Anda untuk mendownload APK WA GB terbaru dan asli. Baik Anda ingin menyempurnakan pengalaman berkirim pesan atau mempelajari lebih lanjut tentang aplikasi canggih ini, Anda datang ke tempat yang tepat. Pada artikel ini, kami akan membahas semua yang perlu Anda ketahui tentang ... | linkwagb01 | |
1,901,298 | Quantum App Development Software: A Comprehensive Guide | Quantum computing represents an upgrade in processing power and a fundamental shift in the underlying... | 0 | 2024-06-26T12:20:41 | https://dev.to/igor_ag_aaa2341e64b1f4cb4/quantum-app-development-software-b1f | softwaredevelopment, software, community, guide | Quantum computing represents an upgrade in processing power and a fundamental shift in the underlying computation framework. Leveraging the principles of quantum mechanics, specifically phenomena like superposition and entanglement, quantum computers process information in ways that defy the limits of classical binary ... | igor_ag_aaa2341e64b1f4cb4 |
1,901,290 | Using Python for Automated Testing In DevOps | What Is Automated Testing? This is the process of using software tools to implement tests on codes... | 0 | 2024-06-26T12:19:34 | https://dev.to/davidbosah/using-python-for-automated-testing-in-devops-1mj5 | programming, devops, beginners, python |
**What Is Automated Testing?**
This is the process of using software tools to implement tests on codes as part of DevOps pipeline with the aim of making sure that the code works as expected and to catch any bugs or problems early on.
_Certain tools are used in Automated testing for DevOps, they include:_
_Selenium... | davidbosah |
1,901,292 | Elevator Installation and Repair Services | Estind Elevators | ESTIND ELEVATORS PVT LTD take great pleasure in introducing ourselves as a prominent Elevator... | 0 | 2024-06-26T12:19:01 | https://dev.to/anjali199378/elevator-installation-and-repair-services-estind-elevators-3c1j | ESTIND ELEVATORS PVT LTD take great pleasure in introducing ourselves as a prominent Elevator installation company in Bangalore, With a decade of experience, we have been dedicatedly serving our valued customers from longtime. Throughout the years, we have worked tirelessly to earn the trust of our clients, successfull... | anjali199378 | |
1,901,291 | how to flash bitcoin | How to Buy Flash USDT: Unlock the Power of Tether with MartelGold Are you looking to get your hands... | 0 | 2024-06-26T12:18:54 | https://dev.to/bryan_nas_8d7e1c432bd86dc/how-to-flash-bitcoin-3g0g | flashbtc, flashusdt, flashbitcoin, flashbitoinsender | How to Buy Flash USDT: Unlock the Power of Tether with MartelGold
Are you looking to get your hands on Flash USDT, the revolutionary Tether solution that’s taking the cryptocurrency world by storm? Look no further! In this article, we’ll guide you through the process of buying Flash USDT and unlocking its incredible b... | bryan_nas_8d7e1c432bd86dc |
1,901,289 | Possible: Conflict Revisited | Possible: Conflict Revisited will be one theme for this post. But first, the Summer Solstice is here!... | 0 | 2024-06-26T12:15:23 | https://dev.to/becomingthejourney/possible-conflict-revisited-47go | Possible: **[Conflict Revisited](https://becomingthejourney.com/blog/possible-conflict-revisited/)** will be one theme for this post. But first, the Summer Solstice is here! I love the ring of it, the associations, the potential, the possibilities! The sun is at the peak of its shining influence on our precious blue-... | becomingthejourney | |
1,901,288 | what is flash usdt? | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get... | 0 | 2024-06-26T12:15:14 | https://dev.to/bryan_nas_8d7e1c432bd86dc/what-is-flash-usdt-2p8p | flashbtc, flashusdt, flastbitcoin, flashbitcoinsoftware | Hey there, fellow cryptocurrency enthusiasts! Are you looking for a new and exciting way to get involved in the world of digital currency? Look no further than Flash USDT, the innovative solution from MartelGold.
As a valued member of the MartelGold community, I’m excited to share with you the incredible benefits of F... | bryan_nas_8d7e1c432bd86dc |
1,900,145 | Simplified Guide to Installing NVM on Ubuntu | Introduction Managing multiple versions of Node.js on your Ubuntu system is crucial for... | 0 | 2024-06-26T12:13:47 | https://dev.to/mesonu/simplified-guide-to-installing-nvm-on-ubuntu-3dpa | webdev, javascript, programming, node |

#### Introduction
Managing multiple versions of Node.js on your Ubuntu system is crucial for development. Node Version Manager (NVM) simplifies this process, allowing you to switch between differen... | mesonu |
1,901,287 | The Accidental Inventor Who Sparked the Silicon Valley Revolution | William Shockley's invention of the transistor in 1947 at Bell Labs revolutionized the electronics... | 0 | 2024-06-26T12:13:32 | https://dev.to/hyscaler/the-accidental-inventor-who-sparked-the-silicon-valley-revolution-285k | history, transistor, techupdate | [William Shockley](https://en.wikipedia.org/wiki/William_Shockley)'s invention of the transistor in 1947 at Bell Labs revolutionized the electronics industry and paved the way for countless innovations that have transformed our world. From the smartphones in our pockets to the computers that power modern society, the t... | saif05 |
1,901,286 | flash bitcoin transaction | How to Know Flash Bitcoin: Unlock the Secrets with MartelGold Hey there, fellow Bitcoin enthusiasts!... | 0 | 2024-06-26T12:12:21 | https://dev.to/bryan_nas_8d7e1c432bd86dc/flash-bitcoin-transaction-3lo | flashbtc, flashusdt, flastbitcoin, flashbitcoinsoftware | How to Know Flash Bitcoin: Unlock the Secrets with MartelGold
Hey there, fellow Bitcoin enthusiasts! Are you tired of feeling left behind in the world of cryptocurrency? Do you want to stay ahead of the curve and unlock the full potential of Bitcoin? Look no further than FlashGen (BTC Generator), the innovative softwa... | bryan_nas_8d7e1c432bd86dc |
1,901,285 | Seamless Travel from Urbania Chandigarh to Jaipur | Experience convenient and comfortable travel options from Urbania Chandigarh to Jaipur. Discover... | 0 | 2024-06-26T12:12:02 | https://dev.to/ckstravels/seamless-travel-from-urbania-chandigarh-to-jaipur-486f | Experience convenient and comfortable travel options from [Urbania Chandigarh to Jaipur](https://ckstravel.in/). Discover reliable transport services with convenient schedules, ensuring a smooth journey to the vibrant city of Jaipur. Plan your trip today for a hassle-free travel experience with Urbania Chandigarh to Ja... | ckstravels | |
1,901,284 | How to Fix the Externally-Managed-Environment Error When Using Pip? | How to Fix the Externally-Managed-Environment Error When Using Pip? When you use pip to... | 0 | 2024-06-26T12:11:41 | https://dev.to/luca1iu/how-to-fix-the-externally-managed-environment-error-when-using-pip-2omo | tutorial, python, beginners, devops | # How to Fix the Externally-Managed-Environment Error When Using Pip?
When you use pip to install Python packages, you may encounter an ‘externally-managed-environment’ error.
```bash
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try brew i... | luca1iu |
1,901,271 | Demystifying Azure Kubernetes Cluster Automatic | It seems that Microsoft timed this release perfectly to coincide with the 10th anniversary of... | 0 | 2024-06-26T12:11:15 | https://gtrekter.medium.com/demystifying-azure-automatic-kubernetes-cluster-4d809ee01b01 | kubernetes, azure, aks, microservices | It seems that Microsoft timed this release perfectly to coincide with the 10th anniversary of Kubernetes. A couple of weeks ago, Microsoft officially announced the public preview of Azure Kubernetes Service (AKS) Automatic. In this article, I will explain what AKS Automatic is and highlight the differences between it a... | gtrekter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.