
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,900,704 | @Resource: The Versatile Bean Injection Annotation for Jakarta EE and Spring | This annotation does bean injection, like the @Autowired and @Inject annotations. This annotation... | 27,602 | 2024-06-26T22:30:00 | http://springmasteryhub.com/?p=224 | java, springboot, spring, programming |
This annotation does bean injection, like the `@Autowired` and `@Inject` annotations.
This annotation is packaged with Jakarta EE and will work on your Spring projects.
You can use this annotation almost in the same way you use the other annotations used to inject dependencies.
Using in-field injection and set met... | tiuwill |
1,901,793 | Gecko: Making a programming language is hard 😮💨 | Seemingly every programmer has a dream, making a programming language. It's not a bad idea, really,... | 0 | 2024-06-26T22:07:19 | https://dev.to/neutrino2211/gecko-making-a-programming-language-is-hard-4g0a | go, projects, programming |
Seemingly every programmer has a dream, making a programming language. It's not a bad idea, really, making a programming language fuelled by your ideas of what makes the 'perfect language' is exciting but... the process is not for the faint at heart.
## The Idea
I first thought of making a programming language back ... | neutrino2211 |
1,901,888 | Webview em QML (Qt Modeling Language) | Introdução O código a seguir é um exemplo de uma aplicação básica em QML (Qt Modeling... | 0 | 2024-06-26T22:06:05 | https://dev.to/moprius/webview-em-qml-qt-modeling-language-67k | qml, webview, website, qt | ## Introdução
O código a seguir é um exemplo de uma aplicação básica em QML (Qt Modeling Language) que cria uma janela de aplicação que incorpora um visualizador de web (WebEngineView) para exibir a página do Google. Ele inclui funcionalidades como um menu de contexto, ícone de bandeja do sistema (SystemTrayIcon), e um... | moprius |
1,901,885 | ACCELERATING DEVOPS TESTING: Advanced Parallel Testing Techniques with Python | Parallel Testing: Parallel Testing in DevOps is a technique where different tests are executed at... | 0 | 2024-06-26T21:58:51 | https://dev.to/davidbosah/accelerating-devops-testing-advanced-parallel-testing-techniques-with-python-6ka | webdev, devops, python, beginners |
**Parallel Testing:**
Parallel Testing in DevOps is a technique where different tests are executed at the same time thereby improving efficiency. Parallel testing in DevOps with Python involves using frameworks and libraries from python to execute different tests at the same time.
_Frame works/Tools used ... | davidbosah |
1,901,886 | Day 979 : Run | liner notes: Professional : Not a bad day. Had a couple of meetings. Responded to some community... | 0 | 2024-06-26T21:57:47 | https://dev.to/dwane/day-979-run-3el4 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Not a bad day. Had a couple of meetings. Responded to some community questions. I even finished a draft of the blog post I've been writing for a new feature and sent it to some folks for a technical review to make sure what I wrote is technically correct.
- Personal : Last night, I went... | dwane |
1,901,884 | The Magic of Guitar: A Journey Through Strings and Melodies | Introduction The guitar is more than just a musical instrument; it is a universal language that... | 0 | 2024-06-26T21:51:24 | https://dev.to/ronny_odhiambo_dfd50cf0ee/the-magic-of-guitar-a-journey-through-strings-and-melodies-g59 | **Introduction**
The guitar is more than just a musical instrument; it is a universal language that transcends cultures, genres, and generations. From the soulful strums of blues to the electrifying riffs of rock, the guitar has woven its way into the fabric of music history. Whether you're a seasoned musician or a nov... | ronny_odhiambo_dfd50cf0ee | |
1,901,882 | Pure CSS Pixar lamp | Check out this Pen I made! | 0 | 2024-06-26T21:44:53 | https://dev.to/mhjwbymhmd/pure-css-pixar-lamp-5a07 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/amit_sheen/pen/WNBdRqm %} | mhjwbymhmd |
1,901,881 | Pure CSS Pixar lamp | Check out this Pen I made! | 0 | 2024-06-26T21:44:49 | https://dev.to/mhjwbymhmd/pure-css-pixar-lamp-198b | codepen | Check out this Pen I made!
{% codepen https://codepen.io/amit_sheen/pen/WNBdRqm %} | mhjwbymhmd |
1,901,879 | Understanding Array Data Structures | In computer science, an array is a data structure consisting of a collection of elements (values or... | 0 | 2024-06-26T21:40:19 | https://dev.to/m__mdy__m/understanding-array-data-structures-8do | javascript, programming, beginners, tutorial | In computer science, an array is a data structure consisting of a collection of elements (values or variables) of the same memory size, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simple... | m__mdy__m |
1,901,877 | Memory management and other weird blobs | I always felt confused by the terms “Blob, Buffer, ArrayBuffer, Uint8Array.” Everyone has their own... | 0 | 2024-06-26T21:39:59 | https://dev.to/artiumws/memory-management-and-other-weird-blobs-36bj | webdev, javascript, programming, tutorial | I always felt confused by the terms “Blob, Buffer, ArrayBuffer, Uint8Array.”
Everyone has their own definition, but no one can clearly define them. It always ends up in a nonsensical technical explanation.
Today, I’ll put a human-readable definition on these terms. This will help my future self and other engineers to... | artiumws |
1,901,878 | 🎯 Elevate Your TypeScript Skills with `type-guards-ts`! | After the success of our last article on mastering type guards, I decided to create an NPM library to... | 0 | 2024-06-26T21:35:24 | https://dev.to/geraldhamiltonwicks/elevate-your-typescript-skills-with-type-guards-ts-36k7 | typescript, javascript | After the success of our last article on mastering type guards, I decided to create an NPM library to help streamline the process. Introducing `type-guards-ts`, a comprehensive library designed to enhance your TypeScript projects with advanced type guard techniques!
Ready to master TypeScript type guards? Dive into th... | geraldhamiltonwicks |
1,901,876 | Introdução às linguagens de programação | Introdução No mundo da programação, entender as diferenças entre linguagens de baixo... | 0 | 2024-06-26T21:31:07 | https://dev.to/moprius/introducao-a-linguagens-de-programacao-4j90 | programming, cpp, rust, python | ## Introdução
No mundo da programação, entender as diferenças entre linguagens de baixo nível, médio nível e alto nível é essencial para qualquer desenvolvedor. As linguagens de baixo nível, como código da máquina e Assembly, proporcionam controle direto sobre o hardware, permitindo otimizações precisas de desempenho,... | moprius |
1,901,875 | Новая нейросеть | О существовании нейросетей общественность узнала недавно, но они быстро проникли в различные сферы... | 0 | 2024-06-26T21:30:54 | https://dev.to/tutuev_aleksandar/novaia-nieirosiet-2p2p | О существовании нейросетей общественность узнала недавно, но они быстро проникли в различные сферы жизни — от медицины до развлечений. Сегодня они способны обрабатывать огромные объемы данных, распознавать объекты и генерировать тексты и изображения. Последние тренды нейросетей включают метаобучение, обработку естестве... | tutuev_aleksandar | |
1,901,873 | A musical lesson on learning hard things, and a polite game of tic-tac-toe | I have a programming nemesis: Python dictionaries. I don’t know why, but for some reason they never... | 0 | 2024-06-26T21:27:01 | https://dev.to/codingtitan/a-musical-lesson-on-learning-hard-things-and-a-polite-game-of-tic-tac-toe-4m87 | I have a programming nemesis: Python dictionaries. I don’t know why, but for some reason they never clicked for me. Lists, no problem. Tuples, sure. Even more complex stuff like classes - you got it, pal.
But dictionaries, for some reason, are the ungodly spawn of all my bad karma. I just can’t wrap my head around the... | codingtitan | |
1,901,871 | Let's talk about CSSBattles | Recently I discovered a great website to exercise my CSS skills in a different way daily. CSSBattle... | 0 | 2024-06-26T21:22:53 | https://dev.to/thaisavieira/lets-talk-about-cssbattles-1cgo | css, learning | Recently I discovered a great website to exercise my CSS skills in a different way daily. [CSSBattle](https://cssbattle.dev/) offers every day a different "target", a design you should make as close as possible with CSS. I highly recommend it cause it helps me to get more familiar with CSS proprieties like margin, padd... | thaisavieira |
1,901,828 | Unlocking the Power of Utility Functions and Custom Hooks in React | Diving into utility functions and custom hooks can transform your React projects, let's learn by... | 0 | 2024-06-26T21:13:36 | https://dev.to/trisogene/unlocking-the-power-of-utility-functions-and-custom-hooks-in-react-3mlb | customhook, react, reusable, cleancode | Diving into utility functions and custom hooks can transform your React projects, let's learn by watching some examples!
## 🛠 Utility functions
- Can be used outside of react component
- Provide reusability and reduce code length
```js
// utils.js
export const capitalizeWords = (str) => {
if (!str) return "";
... | trisogene |
1,901,824 | The Magic of SAP: A Comprehensive Guide for Begginers | In the process of our IT life, each of us will surely encounter the word SAP one day. But what is... | 0 | 2024-06-26T21:10:50 | https://dev.to/sramek5/the-magic-of-sap-a-comprehensive-guide-for-begginers-19jc | sap, erp, architecture |
In the process of our IT life, each of us will surely encounter the word SAP one day. But what is actually SAP and how does it actually work? The official vendor documentation is clear on this and defines SAP as following: `SAP is one of the world’s leading producers of software for the management of business processe... | sramek5 |
1,901,819 | Building a basic HTTP server with Go | Go or Go lang as it’s commonly referred to is a wannabe system’s programming language originally... | 0 | 2024-06-26T21:10:47 | https://dev.to/kalashin1/building-a-basic-http-server-with-go-387m | go, api, learning, backend | Go or Go lang as it’s commonly referred to is a wannabe system’s programming language originally designed and developed at Google, it’s aim was to be the ultimate replacement for C/C++. Go incorporates modern programming language features like type inference and generics while presenting itself in an effortless and min... | kalashin1 |
1,901,821 | How can I set up an SMTP email relay on a debian server? | I am trying to set up an SMTP email relay. Does anyone know any guides for doing that? | 0 | 2024-06-26T21:07:38 | https://dev.to/lauralaura/how-can-i-set-up-an-smtp-email-relay-on-a-debian-server-12n1 | emai, debian, smtp | I am trying to set up an SMTP email relay. Does anyone know any guides for doing that? | lauralaura |
1,901,820 | Azure Cost Optimization: Your Guide to Smart Cloud Spending | Microsoft Azure offers a robust and scalable cloud platform for businesses of all sizes. However, the... | 0 | 2024-06-26T20:58:09 | https://dev.to/unicloud/azure-cost-optimization-your-guide-to-smart-cloud-spending-ep7 | azure | Microsoft Azure offers a robust and scalable cloud platform for businesses of all sizes. However, the flexibility and power of Azure can sometimes lead to unexpected costs if not managed strategically. [Azure cost optimization](https://unicloud.co/blog/azure-cost-optimization-strategies-to-maximize-your-cloud-savings/)... | unicloud |
1,901,795 | AWS - A brief introduction | Okay, everybody knows that "DevOps" is the new "thing" in the IT area, the reason for that is mainly... | 0 | 2024-06-26T20:51:41 | https://dev.to/pokkan70/aws-a-brief-introduction-46ai | aws, cloud, devops, cloudpractitioner | Okay, everybody knows that "DevOps" is the new "thing" in the IT area, the reason for that is mainly because of the huge popularity of many cloud providers, and that popularity has a good reason:
Nobody wants anymore to host an entire data center inside of a company building, okay maybe you could see some companies do... | pokkan70 |
1,901,817 | useMemo Hook | useMemo is a hook that allows you to memoize expensive calculations to avoid unnecessary... | 0 | 2024-06-26T20:50:39 | https://dev.to/geetika_bajpai_a654bfd1e0/usememo-hook-ne8 | `useMemo` is a hook that allows you to memoize expensive calculations to avoid unnecessary re-computations on every render.
## Explanation of the Code
This React component, MemoTutorial, demonstrates how to use the useMemo hook to optimize performance by memoizing the result of a function that computes the longest nam... | geetika_bajpai_a654bfd1e0 | |
1,901,816 | 10 Slack emojis that developers should use | ALL of the companies that I've worked at so far used Slack. When I was entering the workforce, I... | 0 | 2024-06-26T20:50:24 | https://dev.to/gabrielpineda/10-slack-emojis-that-developers-should-use-387c | slack, productivity, development, softwaredevelopment |

ALL of the companies that I've worked at so far used Slack. When I was entering the workforce, I always dreaded communicating in Slack - it was too formal! But that was until my coworkers and myself added emojis to... | gabrielpineda |
1,900,673 | Micro Models - How to Build Using This Concept | In my last article (Developing for Scale and Quality with AI Micro-Models), I introduced the concept... | 0 | 2024-06-26T20:50:18 | https://dev.to/eletroswing/micro-models-how-to-build-using-this-concept-266n | ai, openai, opensource, chatgpt | In my last article (Developing for Scale and Quality with AI Micro-Models), I introduced the concept of micro-models for efficient AI model development. This time, we'll delve deeper into how to find micro-models, how to use them, and the benefits and trade-offs in terms of development time and efficiency. Let's get st... | eletroswing |
1,895,977 | sddfgb | A post by Aasuyadav1 | 0 | 2024-06-26T18:30:00 | https://dev.to/aasuyadav1/sddfgb-c47 | beginners, programming, df, javascript | aasuyadav1 | |
1,901,815 | 🤯PEPE holders realize over $18 million in gains in ten days, wipe out nearly 4% in value | 🤑 PEPE Down Nearly 4% Pepe (PEPE) is trading at $0.00001248, down almost 4% on Wednesday. The... | 0 | 2024-06-26T20:50:05 | https://dev.to/irmakork/pepe-holders-realize-over-18-million-in-gains-in-ten-days-wipe-out-nearly-4-in-value-52jn |
🤑 PEPE Down Nearly 4%
Pepe (PEPE) is trading at $0.00001248, down almost 4% on Wednesday. The frog-themed meme coin has seen consistent profit-taking by traders over the past ten days.
📉 Selling Pressure
Consistent profit-taking increases selling pressure, likely pushing prices lower. On-chain data shows a spike i... | irmakork | |
1,901,814 | 🔥Bitcoin price wobbles at $61K as US gov sends 4K BTC to Coinbase | 📈 Bitcoin Back at $61,000 Bitcoin price returned to $61,000 on June 26, as news emerged of an... | 0 | 2024-06-26T20:49:48 | https://dev.to/irmakork/bitcoin-price-wobbles-at-61k-as-us-gov-sends-4k-btc-to-coinbase-3b56 |
📈 Bitcoin Back at $61,000
Bitcoin price returned to $61,000 on June 26, as news emerged of an incoming BTC sale by the U.S. government.
⚠️ State Selling Risk
BTC price faced uncertainty as coins from a U.S. government wallet were sent to Coinbase. According to Arkham, the total involved was 3,940 BTC ($240 million).... | irmakork | |
1,901,813 | 💥Bitcoin price must end June above $56.5K to defend uptrend — Analysis | ⚠️ Potential BTC Volatility A deluge of potential BTC price volatility triggers is due this week,... | 0 | 2024-06-26T20:49:30 | https://dev.to/irmakork/bitcoin-price-must-end-june-above-565k-to-defend-uptrend-analysis-mdb |
⚠️ Potential BTC Volatility
A deluge of potential BTC price volatility triggers is due this week, with participants eyeing the crucial support zone.
📉 Key Support Level
Bitcoin risks losing its uptrend if it ends June below $56,500, warns trading resource Material Indicators. BTC hit its lowest levels since early Ma... | irmakork | |
1,901,812 | 👀Here's How Bitcoin And Altcoins Will Behave 'Until Fed Cuts Rates,' According To Veteran Crypto Analyst | 📊 Bitcoin Dominance to Increase Crypto analyst Benjamin Cowen predicts Bitcoin’s dominance will rise... | 0 | 2024-06-26T20:49:13 | https://dev.to/irmakork/heres-how-bitcoin-and-altcoins-will-behave-until-fed-cuts-rates-according-to-veteran-crypto-analyst-18lb |
📊 Bitcoin Dominance to Increase
Crypto analyst Benjamin Cowen predicts Bitcoin’s dominance will rise further despite recent market fluctuations.
📉 Recent Speculation
Cowen addressed speculation that Bitcoin dominance has peaked after a sharper BTC decline compared to altcoins recently. He believes Bitcoin dominance... | irmakork | |
1,901,811 | 💥Here’s when Ethereum will reach $6,000, according to analysts | 🚀 Ethereum Up Nearly 50% in 2024 Ethereum (ETH) has surged nearly 50% since January 1, surpassing... | 0 | 2024-06-26T20:48:53 | https://dev.to/irmakork/heres-when-ethereum-will-reach-6000-according-to-analysts-429a |
🚀 Ethereum Up Nearly 50% in 2024
Ethereum (ETH) has surged nearly 50% since January 1, surpassing $4,000 in March, but has faced an 11% decline over the past 30 days.
📈 Optimistic Forecast
Crypto analyst degentrading predicts Ethereum will reach $6,000 by September 2024, despite skepticism from Andrew Kang of Mecha... | irmakork | |
1,432,159 | How to Save TikTok Videos without Watermark or Logo | For many people, after liking a video on TikTok, they want to save it to watch it again later.... | 0 | 2023-04-11T01:18:17 | https://dev.to/snaptikappme/how-to-download-tiktok-video-h5k | For many people, after liking a video on TikTok, they want to save it to watch it again later. However, when saving videos on the TikTok app, the video usually comes with a watermark, TikTok logo, and the ID of the poster (username). This can reduce your viewing experience. Therefore, to download TikTok videos without ... | snaptikappme | |
1,901,810 | 🚀Bitcoin price analysis | Bitcoin bulls are striving to keep the price above the crucial support level of $56,552. 🐻 Bears... | 0 | 2024-06-26T20:48:32 | https://dev.to/irmakork/bitcoin-price-analysis-1f4j |
Bitcoin bulls are striving to keep the price above the crucial support level of $56,552.
🐻 Bears Push Below $60,000
On June 24, bears pushed the price below $60,000, but the long tail on the candlestick indicates strong buying at lower levels. Expect bulls to stay active in the $60,000 to $56,552 zone for the next f... | irmakork | |
1,901,809 | 🔥Ether price analysis | 📉 Ether Slips Toward $3,000 Support Ether (ETH) has been gradually declining towards the key support... | 0 | 2024-06-26T20:48:17 | https://dev.to/irmakork/ether-price-analysis-ndh |
📉 Ether Slips Toward $3,000 Support
Ether (ETH) has been gradually declining towards the key support level at $3,000. Bulls bought the dip to $3,240 on June 24 but are struggling to push the price to the 20-day EMA ($3,506).
🐻 Bears Eye $3,200
If the price turns down from the current level, bears will attempt to si... | irmakork | |
1,901,808 | 🚀Solana price analysis | 📈 Solana Recovers to $137 Solana (SOL) rebounded sharply from $122 on June 24 and re-entered the... | 0 | 2024-06-26T20:48:00 | https://dev.to/irmakork/solana-price-analysis-38c0 |
📈 Solana Recovers to $137
Solana (SOL) rebounded sharply from $122 on June 24 and re-entered the descending channel pattern on June 25.
🐻 Bears Target 20-day EMA
Bears will try to halt the relief rally at the 20-day EMA ($143). If the price turns down sharply from this level, the SOL/USDT pair could tumble to cruc... | irmakork | |
1,901,807 | 🚀XRP price analysis | 📉 XRP Bounces to $0.47 XRP bounced off the $0.46 support on June 24, but bulls are struggling to... | 0 | 2024-06-26T20:47:43 | https://dev.to/irmakork/xrp-price-analysis-4e0d |
📉 XRP Bounces to $0.47
XRP bounced off the $0.46 support on June 24, but bulls are struggling to extend the recovery.
🐻 Bears in Control
Both moving averages are sloping down, and the relative strength index (RSI) is in negative territory, indicating bears are in control. Sellers will again try to push the price be... | irmakork | |
1,901,806 | 💥Dogecoin price analysis | 🐕 Dogecoin Rebounds to $0.12 Dogecoin (DOGE) broke and closed below the $0.12 support on June 24, but... | 0 | 2024-06-26T20:47:25 | https://dev.to/irmakork/dogecoin-price-analysis-1e4f |
🐕 Dogecoin Rebounds to $0.12
Dogecoin (DOGE) broke and closed below the $0.12 support on June 24, but bulls started a recovery and pushed the price back above this level on June 25.
📈 Key Resistance Level
Bulls need to propel the price above the 20-day EMA ($0.13) to signal a robust recovery. If successful, the DOG... | irmakork | |
1,901,796 | Using AI with Structured Prompts: A Guide to Enhanced Productivity | In the rapidly evolving landscape of artificial intelligence, the way we interact with AI systems is... | 0 | 2024-06-26T20:47:02 | https://dev.to/oussama_errafif/using-ai-with-structured-prompts-a-guide-to-enhanced-productivity-f5o | ai, promptengineering, chatgpt, machinelearning | In the rapidly evolving landscape of artificial intelligence, the way we interact with AI systems is becoming increasingly sophisticated. To maximize the potential of AI tools, it’s crucial to use well-structured prompts. Structured prompts not only help in obtaining precise and actionable outputs but also streamline t... | oussama_errafif |
1,901,805 | 💵Shiba Inu price analysis | 📉 Shiba Inu (SHIB) Struggles Below $0.000017 Shiba Inu (SHIB) plunged below the 78.6% Fibonacci... | 0 | 2024-06-26T20:47:01 | https://dev.to/irmakork/shiba-inu-price-analysis-3m4m |
📉 Shiba Inu (SHIB) Struggles Below $0.000017
Shiba Inu (SHIB) plunged below the 78.6% Fibonacci retracement level of $0.000017 on June 24, firmly placing bears in control.
🐻 Bearish Momentum
Despite an attempted recovery on June 25, bullish momentum remains weak. Bears are poised to push the price below $0.000017 ... | irmakork | |
1,901,804 | 🚀Avalanche price analysis | 📉 Avalanche (AVAX) Faces Downtrend Avalanche (AVAX) resumed its downtrend after breaking below the... | 0 | 2024-06-26T20:46:42 | https://dev.to/irmakork/avalanche-price-analysis-4eff |
📉 Avalanche (AVAX) Faces Downtrend
Avalanche (AVAX) resumed its downtrend after breaking below the strong support at $29 on June 17.
🐻 Bearish Indicators
Downward sloping moving averages and an RSI near oversold territory indicate bears are currently dominant. Bulls are attempting a relief rally, likely encounterin... | irmakork | |
1,901,803 | 🤯$6.6B in Bitcoin Options and $3.4B in Ethereum Options Expiring Soon, Will Prices Hit Max Pain Point? | 📊 Bitcoin and Ethereum Options Expiry Insight This week, crypto traders are closely monitoring the... | 0 | 2024-06-26T20:46:25 | https://dev.to/irmakork/66b-in-bitcoin-options-and-34b-in-ethereum-options-expiring-soon-will-prices-hit-max-pain-point-4hoi |
📊 Bitcoin and Ethereum Options Expiry Insight
This week, crypto traders are closely monitoring the upcoming options expiry for Bitcoin and Ethereum scheduled for Friday, June 28. A substantial $6.6 billion in Bitcoin options and $3.5 billion in Ethereum options are set to expire, heightening market volatility.
🔍 Bi... | irmakork | |
1,901,802 | 🤔 When Is Bitcoin (BTC) Price Likely To Reach $100,000? | 📉 Bitcoin and Ethereum in Recent Decline Recent weeks have seen Bitcoin and Ethereum experience... | 0 | 2024-06-26T20:46:04 | https://dev.to/irmakork/when-is-bitcoin-btc-price-likely-to-reach-100000-52h8 |
📉 Bitcoin and Ethereum in Recent Decline
Recent weeks have seen Bitcoin and Ethereum experience significant declines, sparking concerns among investors. Despite a bullish start to the year, both leading cryptocurrencies have faced considerable selling pressure in June. This has raised questions about whether the curr... | irmakork | |
1,901,801 | 💥Dogwifhat price breakout signals potential rally above $2.1 resistance | 📈 Dogwifhat (WIF) Breaks Out and Shows Potential Dogwifhat (WIF) price surged above $2 on Wednesday... | 0 | 2024-06-26T20:45:45 | https://dev.to/irmakork/dogwifhat-price-breakout-signals-potential-rally-above-21-resistance-4dlg |
📈 Dogwifhat (WIF) Breaks Out and Shows Potential
Dogwifhat (WIF) price surged above $2 on Wednesday after breaking out from a descending trendline on Tuesday. On-chain data reveals that the largest whale has accumulated 2.3 million tokens valued at $4.67 million, signaling potential for an upcoming rally.
🐋 Whale A... | irmakork | |
1,901,800 | 💥Bears stall Notcoin’s rally: Is $0.0101 next for NOT? | 📈 Notcoin (NOT) has recently shown gains despite Bitcoin (BTC) struggling to hold above $61,000. 📅... | 0 | 2024-06-26T20:45:18 | https://dev.to/irmakork/bears-stall-notcoins-rally-is-00101-next-for-not-55p9 |
📈 Notcoin (NOT) has recently shown gains despite Bitcoin (BTC) struggling to hold above $61,000.
📅 On June 16th, AMBCrypto noted bullish social sentiment and short-term price optimism for Notcoin.
📉 However, recent price action has reinforced a bearish trend, with a brief upturn observed in the past 24 hours like... | irmakork | |
1,901,798 | 🚀BONK gains 17%: Is this the beginning of a bull run? | 🚀 Bonk (BONK) saw a significant surge on June 25th, with its price rising by 17% in the past 24 hours... | 0 | 2024-06-26T20:44:59 | https://dev.to/irmakork/bonk-gains-17-is-this-the-beginning-of-a-bull-run-31g |
🚀 Bonk (BONK) saw a significant surge on June 25th, with its price rising by 17% in the past 24 hours due to heightened trading activity.
☁️ Currently, BONK is trading above the Ichimoku Cloud, indicating a strong bullish trend supported by the cloud. As long as the price remains above the cloud, the bullish momentu... | irmakork | |
1,901,797 | 💥FLOKI: These historical trends point to a 100% price rise | 📈 Floki (FLOKI) has surged by 10.12% over the past 24 hours, trading at $0.00017, indicating... | 0 | 2024-06-26T20:44:27 | https://dev.to/irmakork/floki-these-historical-trends-point-to-a-100-price-rise-451o |
📈 Floki (FLOKI) has surged by 10.12% over the past 24 hours, trading at $0.00017, indicating potential for further gains.
📊 The MVRV ratio, which compares market value to realized value, currently stands at -36.34% for FLOKI. This suggests that holders bought at a higher average price recently, making selling at cur... | irmakork | |
1,901,794 | 💥Can AVAX hold the $25 support? Insights from key indicators | 📉 Avalanche (AVAX) has breached its January low at $27.3 and is currently testing critical support at... | 0 | 2024-06-26T20:44:10 | https://dev.to/irmakork/can-avax-hold-the-25-support-insights-from-key-indicators-5hc7 |
📉 Avalanche (AVAX) has breached its January low at $27.3 and is currently testing critical support at $25.5 amid a volatile cryptocurrency market.
📉 Since May 22nd, AVAX has declined by over 40%, with a recent 3% surge sparking concerns of either a deeper collapse or a potential reversal. As of now, AVAX is trading... | irmakork | |
1,901,792 | ChatGPT: Más que un Asistente, un Confidente en la Era Digital | ¿A qué se debe el éxito de ChatGPT? 🚀 Muchos suponen que se trata de la mayor innovación y... | 0 | 2024-06-26T20:39:59 | https://dev.to/jzchannel03/chatgpt-mas-que-un-asistente-un-confidente-en-la-era-digital-555 | chatgpt, ai, productivity, programming | ### ¿A qué se debe el éxito de ChatGPT? 🚀
Muchos suponen que se trata de la mayor innovación y revolución traída al mercado de la IA, la cual se sentía un poco estancada, y eso trajo consigo su gran boom. _¿Pero, hay algo más que eso?_ _¿No huele a… algo más…? 🤔_
¡Es momento de arriar las velas! ¡Vamos más allá en ... | jzchannel03 |
1,901,790 | Looking for somebody learning Kotlin/Android | this is what I am looking for: somebody who has maybe just started to write in kotlin or also java.... | 0 | 2024-06-26T20:37:32 | https://dev.to/laurenz_holzhausen_d0dc5f/looking-for-somebody-learning-kotlinandroid-40c8 | android, kotlin | this is what I am looking for:
somebody who has maybe just started to write in kotlin or also java. The person is needed for the android side of an app update.
The app already exists, have a look here: https://apps.apple.com/gb/app/trazycarantulas/id1590680699
If you want to gain some experience with this project... | laurenz_holzhausen_d0dc5f |
1,864,041 | 6 Reasons Your Documentation Efforts Might Be a Waste of Time (And How to Fix It) | Technical documentation is a cornerstone of effective software development, providing a roadmap for... | 0 | 2024-06-26T20:34:42 | https://dev.to/ifrah/6-reasons-your-documentation-efforts-might-be-a-waste-of-time-and-how-to-fix-it-aol | productivity, documentation, programming | Technical documentation is a cornerstone of effective software development, providing a roadmap for users and developers alike. However, there are common pitfalls that can render even the most well-intentioned documentation efforts useless. Let's explore these pitfalls and how to avoid them.
## 1. 100% AI-Generated C... | ifrah |
1,901,789 | Demasiados frameworks de JS, pero por qué? | A menudo se puede pensar que ya es repugnante la cantidad de frameworks que hay en el mercado, o... | 0 | 2024-06-26T20:30:49 | https://dev.to/jzchannel03/demasiados-frameworks-de-js-pero-por-que-25n6 | frameworks, webdev, javascript, astro | A menudo se puede pensar que ya es repugnante la cantidad de frameworks que hay en el mercado, o pensar que algunas personas han quedado fuera del tren de la tecnología y están en camino de quedarse sin trabajo pronto.
_¿Por qué cada día nace una nueva tecnología que cambia el método y la forma de trabajar con las int... | jzchannel03 |
1,901,788 | Mastering Contrast in UI Design: Enhancing User Experience Through Visual Dynamics | 👋 Hello, Dev Community! I'm Prince Chouhan, continuing my exploration into UI/UX design. Today,... | 0 | 2024-06-26T20:29:13 | https://dev.to/prince_chouhan/mastering-contrast-in-ui-design-enhancing-user-experience-through-visual-dynamics-1njh | ui, uidesign, ux, uxdesign | 👋 Hello, Dev Community!
I'm Prince Chouhan, continuing my exploration into UI/UX design. Today, let's delve into the essential topic of Contrast!
🗓️ Day 9 Topic: Contrast in UI Design
📚 Today's Learning Highlights:
Contrast Overview:
Contrast in UI design extends beyond color differences—it encompasses visual di... | prince_chouhan |
1,901,787 | So many JS frameworks, but why? | We can often think that it’s already disgusting how many frameworks there are on the market, or think... | 0 | 2024-06-26T20:24:45 | https://dev.to/jzchannel03/so-many-js-frameworks-but-why-1aka | frameworks, webdev, javascript, astro | We can often think that it’s already disgusting how many frameworks there are on the market, or think that some people have been left off the technology train and are on their way to being out of a job soon.
_Why is it that every day a new technology is born that changes the method and way of working with web interfac... | jzchannel03 |
1,901,770 | Test Observability for AWS Lambda with Grafana Tempo and OpenTelemetry Layers | I got great feedback from my Pulitzer award-winning blog post, "Testing AWS Lambda & Serverless... | 0 | 2024-06-26T20:18:38 | https://tracetest.io/blog/test-observability-for-aws-lambda-with-grafana-tempo-and-opentelemetry-layers | tracetest, tempo, opentelemetry, tracebasedtesting | I got great feedback from my Pulitzer award-winning blog post, "[Testing AWS Lambda & Serverless with OpenTelemetry](https://tracetest.io/blog/testing-aws-lambda-serverless-with-opentelemetry)". The community wanted a guide on using the official OpenTelemetry Lambda layers instead of a custom TypeScript wrapper. 😄
I ... | xoscar |
1,901,769 | Announcing Swiftide, blazing fast data pipelines for RAG | While working with other Python-based tooling, frustrations arose around performance, stability, and... | 0 | 2024-06-26T20:15:29 | https://dev.to/timonv/announcing-swiftide-blazing-fast-data-pipelines-for-rag-4onb | llm, rust, ai, data | While working with other Python-based tooling, frustrations arose around performance, stability, and ease of use.
Excited to announce Swiftide, blazing fast data pipelines for Retrieval Augmented Generation written in Rust. Python bindings soon!
Check it out at https://swiftide.rs
```rust
IngestionPipeline::from_lo... | timonv |
1,901,767 | LeetCode Meditations — Chapter 12: Dynamic Programming | Dynamic programming (DP) is one of those concepts that is a bit intimidating when you hear it for the... | 26,418 | 2024-06-26T20:13:09 | https://rivea0.github.io/blog/leetcode-meditations-chapter-12-dynamic-programming | computerscience, algorithms, typescript, javascript | Dynamic programming (DP) is one of those concepts that is a bit intimidating when you hear it for the first time, but the crux of it is simply <mark>breaking problems down into smaller parts and solving them, also storing those solutions so that we don't have to compute them again.</mark>
Breaking problems down into ... | rivea0 |
1,901,765 | Vision Loss People application | I have been asked to provide a solution as Fullstack java developer to design the application so... | 0 | 2024-06-26T20:12:28 | https://dev.to/codekiller/vision-loss-people-application-oci | I have been asked to provide a solution as Fullstack java developer to design the application so that vision loss people also can use it.As part my Health industry.Any suggestions are welcome. | codekiller | |
1,901,762 | 🚀 Invitation to Test and Review: AutoCAD Points Import Plugin 🚀 | Hey everyone! I'm excited to announce the release of my AutoCAD Points Import Plugin! 🎉 This plugin... | 0 | 2024-06-26T20:11:14 | https://dev.to/dzt/invitation-to-test-and-review-autocad-points-import-plugin-43db | autocad, csharp, beginners, tutorial | Hey everyone!
I'm excited to announce the release of my AutoCAD Points Import Plugin! 🎉 This plugin simplifies the process of importing point data from text files into AutoCAD drawings, streamlining your workflow and enhancing productivity.
Key Features:
Effortless Import: Directly import points from structured tex... | dzt |
1,901,759 | How to Send Emails With Google App Script | If you’re a beginner like me and have spent hours unsuccessfully searching for the right piece of... | 0 | 2024-06-26T20:10:13 | https://mailtrap.io/blog/google-scripts-send-email/ | If you’re a beginner like me and have spent hours unsuccessfully searching for the right piece of content or GitHub page that covers how to use Google App Script to send email, you’re in the right place!
In this article, I will take you step by step through the process of sending emails via Google Scripts.
So hold ti... | dzenanakajtaz | |
1,901,702 | 🌐 How to Change Time Zone in Google Chrome to Test Different Timezones | Have you ever wondered how your website or app behaves in different time zones? Maybe you’ve got... | 0 | 2024-06-26T20:09:12 | https://dev.to/enszrlu/how-to-change-time-zone-in-google-chrome-to-test-different-timezones-2j18 | webdev, testing, debug, timezone | Have you ever wondered how your website or app behaves in different time zones? Maybe you’ve got users all around the globe, and you need to ensure everything works perfectly no matter where they are. Or you deployed your application and the time does not show as it is supposed to, even though it works locally. Then yo... | enszrlu |
1,901,752 | From Pods to Projects: Mastering Task Management the Whale-some Way | As I delved further into the project management process, I discovered an intriguing parallel: we can... | 0 | 2024-06-26T20:08:24 | https://dev.to/rasyidf/from-pods-to-projects-mastering-task-management-the-whale-some-way-5gad | management, projectmanagement, learning | As I delved further into the project management process, I discovered an intriguing parallel: we can learn a lot from how whales manage their pods. Here's my journey into this oceanic analogy.
In the vast ocean of project management, tracking progress can feel as daunting as navigating the deep blue sea. However, adop... | rasyidf |
1,901,756 | SHOPIFY HELP SUPPORT | Do you need assistance with a Shopify store? I can assist you in designing your Shopify store with... | 0 | 2024-06-26T20:08:15 | https://dev.to/haastrup/shopify-help-support-9oe | Do you need assistance with a Shopify store?
I can assist you in designing your Shopify store with the features you've asked to increase sales.
I'm excited to hear more about your needs and work with you to continue talking about your project and how I can support you.
Reach out to me right now
| haastrup | |
1,901,754 | The Ultimate 9-Week Anti-Procrastination Challenge 🚀 | The Ultimate 9-Week Anti-Procrastination Challenge 🚀 Are you tired of endless scrolling and putting... | 0 | 2024-06-26T20:04:49 | https://dev.to/newme/the-ultimate-9-week-anti-procrastination-challenge-2485 | procrastination, productivity | The Ultimate 9-Week Anti-Procrastination Challenge 🚀
Are you tired of endless scrolling and putting things off? It’s time to change that and embrace productivity! Join our 9-week Anti-Procrastination Challenge and see how much you can accomplish. Each week, we’ll provide you with actionable tips to help you stay focus... | newme |
1,894,873 | Understanding Object Destructuring in Javascript. | Introduction In the world of modern JavaScript development, efficiency and readability are... | 0 | 2024-06-26T20:02:52 | https://dev.to/zache_niyokwizera_3ea666/understanding-object-destructuring-in-javascript-53m1 | javascript, webdev, beginners, programming |
## Introduction
In the world of modern JavaScript development, efficiency and readability are crucial. Object destructuring is a feature that significantly enhances both by allowing developers to unpack values from objects and arrays into distinct variables. This makes the code more concise and easier to understand a... | zache_niyokwizera_3ea666 |
1,901,751 | Steenstrips | Wandpanelen, ook wel wandpanelen genoemd, worden steeds populairder vanwege hun vermogen om het... | 0 | 2024-06-26T19:51:39 | https://dev.to/dodecoay09/steenstrips-2joj | Wandpanelen, ook wel wandpanelen genoemd, worden steeds populairder vanwege hun vermogen om het uiterlijk en de functionaliteit van een binnen- of buitenruimte te transformeren. Of het nu gaat om het toevoegen van een esthetisch tintje, het verbeteren van de akoestiek of zelfs het bieden van een praktische oplossing vo... | dodecoay09 | |
1,901,747 | Studying for the AWS SAA | With countless posts on the internet explaining the "best" way to study for the AWS Solutions... | 0 | 2024-06-26T19:34:38 | https://dev.to/tklevits/studying-for-the-aws-saa-4000 | aws, solutionsarchitect | With countless posts on the internet explaining the "best" way to study for the AWS Solutions Architect Associate exam, I thought I would add my own experience to the mix.
**TLDR**:
- Adrian Cantrill's SAA course
- Tutorial Dojo's practice exams: One question on the exam exactly matched Review Set 7. Many services li... | tklevits |
1,901,746 | React Server Component is perfect for Backends-for-Frontends | By now, you should be familiar with React Server Components (RSC) or at least have heard about them.... | 0 | 2024-06-26T19:30:20 | https://dev.to/yaodingyd/react-server-component-is-perfect-for-backends-for-frontends-123n | react, webdev, javascript | By now, you should be familiar with React Server Components (RSC) or at least have heard about them. RSC is the latest addition to React's feature set, offering significant benefits such as reduced client-side JavaScript bundles, improved user experience by eliminating extra network roundtrips, and the ability to run s... | yaodingyd |
1,901,745 | A Disposable Firefox Instance | Making a Disposable Firefox Instance We want to make a disposable firefox instance. Why... | 0 | 2024-06-26T19:30:08 | https://dev.to/terminaldweller/a-disposable-firefox-instance-3p03 | ## Making a Disposable Firefox Instance
We want to make a disposable firefox instance.<br/>
Why firefox? well the only other choice is chromium really. Mozilla are no choir boys either. Basically we are choosing between the lesser of two evils here. There is also the whole google killing off manifest v2.<br/>
Qutebrow... | terminaldweller | |
1,901,743 | RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale | RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale | 0 | 2024-06-26T19:25:40 | https://aimodels.fyi/papers/arxiv/res-q-evaluating-code-editing-large-language | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [RES-Q: Evaluating Code-Editing Large Language Model Systems at the Repository Scale](https://aimodels.fyi/papers/arxiv/res-q-evaluating-code-editing-large-language). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newslet... | mikeyoung44 |
1,901,742 | WARP: On the Benefits of Weight Averaged Rewarded Policies | WARP: On the Benefits of Weight Averaged Rewarded Policies | 0 | 2024-06-26T19:25:05 | https://aimodels.fyi/papers/arxiv/warp-benefits-weight-averaged-rewarded-policies | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [WARP: On the Benefits of Weight Averaged Rewarded Policies](https://aimodels.fyi/papers/arxiv/warp-benefits-weight-averaged-rewarded-policies). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.... | mikeyoung44 |
1,901,741 | Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data | Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data | 0 | 2024-06-26T19:24:30 | https://aimodels.fyi/papers/arxiv/generative-ai-misuse-taxonomy-tactics-insights-from | machinelearning, ai, beginners, datascience | *This is a Plain English Papers summary of a research paper called [Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data](https://aimodels.fyi/papers/arxiv/generative-ai-misuse-taxonomy-tactics-insights-from). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsle... | mikeyoung44 |
1,901,740 | Interior Design in Dubai: Elevating Standards of Design and Construction Excellence | Interior design in Dubai, known for its towering skyscrapers, luxurious lifestyle, and innovative... | 0 | 2024-06-26T19:24:03 | https://dev.to/sam_butt_e48888c74a1cd121/interior-design-in-dubai-elevating-standards-of-design-and-construction-excellence-1n07 | busines, interiordesign, blog | **[Interior design in Dubai](https://wdfitout.com/)**, known for its towering skyscrapers, luxurious lifestyle, and innovative architecture, has become a global hub for interior design. The city’s commitment to excellence in design and construction is evident in its awe-inspiring buildings and interiors that blend trad... | sam_butt_e48888c74a1cd121 |
1,901,739 | Next.js starter template | Hi, I created a starter template for next.js, it also contains typescript, tailwind, shadcn/ui. I... | 0 | 2024-06-26T19:23:53 | https://dev.to/michalskolak/nextjs-starter-template-7be | webdev, react, nextjs, tailwindcss | Hi,
I created a starter template for next.js, it also contains typescript, tailwind, shadcn/ui. I have already written about it here, but I have added some new functionalities such as: Next-auth, Prisma, React-hook-form, T3-env.
If you liked the project, I will appreciate if you leave a star. 🌟
[https://github.com/Sk... | michalskolak |
1,901,738 | React Context API | Why do we need context API. In React, passing props is a fundamental concept that... | 0 | 2024-06-26T19:19:42 | https://dev.to/geetika_bajpai_a654bfd1e0/react-context-api-4ig8 | ## Why do we need context API.
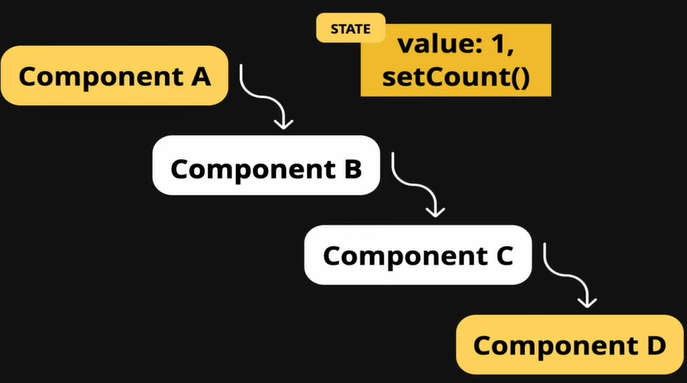
In React, passing props is a fundamental concept that enables a parent component to share data with its child components as well as other components within an application.
## Prop Dr... | geetika_bajpai_a654bfd1e0 | |
1,873,369 | Styling in React | Introduction Styling is a crucial aspect of web development that ensures your applications... | 27,559 | 2024-06-26T19:17:00 | https://dev.to/suhaspalani/styling-in-react-1534 | webdev, css, react, programming | #### Introduction
Styling is a crucial aspect of web development that ensures your applications are visually appealing and user-friendly. React offers several approaches to styling components, from traditional CSS and Sass to modern CSS-in-JS solutions like Styled-Components. This week, we'll dive into these methods an... | suhaspalani |
1,901,737 | React Component or Example for Comparison View | Can someone help me with a good react example where i want to show previous and current table rows... | 0 | 2024-06-26T19:14:29 | https://dev.to/java_development_0653df7f/react-component-or-example-for-comparison-view-5hfd | Can someone help me with a good react example where i want to show previous and current table rows differences ?
Assume a person know the difference between employee record of v1 and v2
Looking for a good design and a nice react example or component. Please advise | java_development_0653df7f | |
1,901,736 | Unleashing Imagination: The Best Children's Book Illustration Services in the UK | Children's books are a gateway to the world of imagination, adventure, and learning. Behind every... | 0 | 2024-06-26T19:07:47 | https://dev.to/craft2publish/unleashing-imagination-the-best-childrens-book-illustration-services-in-the-uk-1d50 | webdev, javascript, beginners, programming | Children's books are a gateway to the world of imagination, adventure, and learning. Behind every captivating story lies a powerful visual journey crafted by talented illustrators. In the UK, the field of children's [book illustration in uk](https://craft2publish.com/childrens-book-illustration/) is thriving, with prof... | craft2publish |
1,901,734 | What is Behavior Driven Development (BDD)? | Introduction What is bdd ? Behavior Driven Development (BDD) is an agile software development... | 0 | 2024-06-26T18:48:51 | https://dev.to/keploy/what-is-behavior-driven-development-bdd-10ca | webdev, javascript, beginners, programming |
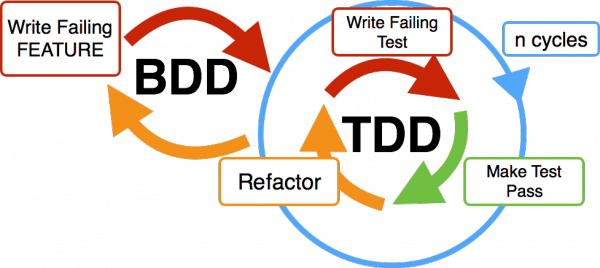
Introduction
[What is bdd](https://keploy.io/docs/concepts/reference/glossary/behaviour-driven-development/) ?
Behavior Driven Development (BDD) is an agile software development methodology that emphasizes collabora... | keploy |
1,901,726 | Database Transactions : Concurrency Control | The number of users who can use the database engine concurrently is a significant criteria for... | 27,868 | 2024-06-26T18:47:41 | https://dev.to/aharmaz/database-transactions-concurrency-control-1h6i | database, transaction, concurrenc, performance | The number of users who can use the database engine concurrently is a significant criteria for classifying the database management systems. A DBMS is single-user if at most one user at a time can use the engine and it is multiuser if many users can use it concurrently. Most of the DBMSs need to be multiuser, for exampl... | aharmaz |
1,901,733 | Prestige Golf Cars | Prestige Golf Cars Address: 1085 W Pioneer Blvd ste 160, Mesquite, NV 89027 Phone: (725)... | 0 | 2024-06-26T18:44:58 | https://dev.to/snzbn/prestige-golf-cars-3lcc | prestage, golf, carts | Prestige Golf Cars
Address: 1085 W Pioneer Blvd ste 160, Mesquite, NV 89027
Phone: (725) 296-2862
Email: sales@prestigegolfcars.com
Website: https://prestigegolfcars.com
GMB Profile: https://www.google.com/maps?cid=15050115738512877032
Prestige Golf Cars, nestled at 1085 W Pioneer Blvd ste 160, Mesquite, NV 89027, Uni... | snzbn |
1,901,732 | Mastering SOLID Principles ✅ | The SOLID principles are design principles in object-oriented programming that help developers create... | 0 | 2024-06-26T18:44:02 | https://dev.to/alisamirali/mastering-solid-principles-1aa6 | solidprinciples, javascript, softwaredevelopment, softwareengineering | The SOLID principles are design principles in object-oriented programming that help developers create more understandable, flexible, and maintainable software.
Let's dive into each principle and see how they can be applied using JavaScript.
---
##📌 1. Single Responsibility Principle (SRP)
**Definition:** A class ... | alisamirali |
1,901,724 | AI Environmental Bot Creation: A Step-by-Step Guide with Twilio, Node.js, Gemini, and Render | Hello 👋 In this blog, we will explore how to build a WhatsApp bot using Twilio, Node.js, Typescript,... | 0 | 2024-06-26T18:40:35 | https://imkarthikeyans.hashnode.dev/ai-environmental-bot-creation-a-step-by-step-guide-with-twilio-nodejs-gemini-and-render | webdev, javascript, beginners, twilio | Hello 👋
In this blog, we will explore how to build a WhatsApp bot using Twilio, Node.js, Typescript, Render, and Gemini.
**Pre-requisites :**
* Have a Twilio account. If you don’t have one, you can register for a [trial account](https://www.twilio.com/try-twilio)
* Install [Ngrok](https://ngrok.com/) and make ... | imkarthikeyan |
1,901,730 | Innovate Trading Strategies and Algorithms Together | Are you a passionate developer or programmer with a keen interest in the forex market? Do you thrive... | 0 | 2024-06-26T18:40:18 | https://dev.to/siddharthdholu/innovate-trading-strategies-and-algorithms-together-4jo | programming, trading, algorithms, forex | Are you a passionate developer or programmer with a keen interest in the forex market? Do you thrive on the challenge of creating cutting-edge strategies and algorithms? If so, we want you to join our exciting new initiative!
**About Us**
We are building a vibrant community of developers who share a common goal: to re... | siddharthdholu |
1,901,725 | Ingesting Data to Parseable Using Pandas | A Step-by-Step Guide Managing and deriving insights from vast amounts of historical data... | 0 | 2024-06-26T18:40:04 | https://dev.to/parseable/ingesting-data-to-parseable-using-pandas-pm1 | database, monitoring, devops, python | ## A Step-by-Step Guide
Managing and deriving insights from vast amounts of historical data is not just a challenge but a necessity. Imagine your team grappling with numerous log files, trying to pinpoint issues. But, because logs are stored as files, it is very inefficient to search through them. This scenario is all... | jenwikehuger |
1,901,896 | Formação Em Desenvolvimento Front-end + React + VUE Gratuita | A Vai na Web está oferecendo uma formação online e gratuita em Desenvolvimento Front-end, com foco em... | 0 | 2024-06-28T13:38:00 | https://guiadeti.com.br/formacao-desenvolvimento-front-end-react-vue/ | cursogratuito, css, cursosgratuitos, frontend | ---
title: Formação Em Desenvolvimento Front-end + React + VUE Gratuita
published: true
date: 2024-06-26 18:36:02 UTC
tags: CursoGratuito,css,cursosgratuitos,frontend
canonical_url: https://guiadeti.com.br/formacao-desenvolvimento-front-end-react-vue/
---
A Vai na Web está oferecendo uma formação online e gratuita em ... | guiadeti |
1,901,727 | Differences between Asp.net and Asp.net Core | ASP.NET and ASP.NET Core are both frameworks for building web applications and services, but they... | 0 | 2024-06-26T18:34:54 | https://dev.to/pains_arch/differences-between-aspnet-and-aspnet-core-23o7 | aspdotnet, aspnet, development, csharp | **ASP.NET and ASP.NET Core are both frameworks for building web applications and services, but they have several key differences. Here are the main distinctions between the two:**
## 1. Cross-Platform Support
* **ASP.NET:** Primarily designed to run on Windows. It can run on Windows Server and Internet Information Se... | pains_arch |
1,890,422 | Top 5 Must-Ask Questions About Your Career in IT | Navigating the labyrinth of an IT career can sometimes feel like decoding the most complex algorithm.... | 0 | 2024-06-26T18:27:06 | https://dev.to/usulpro/top-5-must-ask-questions-about-your-career-in-it-2245 | career, careerdevelopment, mentorship, beginners | Navigating the labyrinth of an IT career can sometimes feel like decoding the most complex algorithm. But hey, who said challenges aren’t fun? Every question about your career can be a stepping stone to your next big achievement. With IT continually evolving, maintaining a laser focus on career progression, honing in-d... | usulpro |
1,901,723 | Buy verified cash app account | Buy verified cash app account Cash app has emerged as a dominant force in the realm of mobile banking... | 0 | 2024-06-26T18:25:25 | https://dev.to/rvukpinty37/buy-verified-cash-app-account-3n5m | webdev, javascript, beginners, programming | Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with ... | rvukpinty37 |
1,901,721 | DevOps for Financial Services: A Guide for Entrepreneurs | The world of finance is changing. FinTech startups are disrupting the traditional landscape with... | 0 | 2024-06-26T18:23:56 | https://dev.to/marufhossain/devops-for-financial-services-a-guide-for-entrepreneurs-4ojn | The world of finance is changing. FinTech startups are disrupting the traditional landscape with innovative apps and services. But building a successful FinTech startup requires more than just a brilliant idea. Streamlined operations and a robust IT infrastructure are crucial for survival in this fast-paced industry. T... | marufhossain | |
1,901,720 | 1382. Balance a Binary Search Tree | 1382. Balance a Binary Search Tree Medium Given the root of a binary search tree, return a balanced... | 27,523 | 2024-06-26T18:23:16 | https://dev.to/mdarifulhaque/1382-balance-a-binary-search-tree-1bj8 | php, leetcode, algorithms, programming | 1382\. Balance a Binary Search Tree
Medium
Given the `root` of a binary search tree, return _a **balanced** binary search tree with the same node values_. If there is more than one answer, return **any of them**.
A binary search tree is **balanced** if the depth of the two subtrees of every node never differs by mor... | mdarifulhaque |
1,901,684 | Running pgAdmin to Manage a PostgreSQL Cluster on Kubernetes | Let’s say you need to do something in PostgreSQL in Kubernetes, and it is inconvenient to work with... | 0 | 2024-06-26T18:14:16 | https://dev.to/dbazhenov/running-pgadmin-to-manage-a-postgresql-cluster-in-kubernetes-616 | percona, kubernetes, postgres, database | Let’s say you need to do something in PostgreSQL in Kubernetes, and it is inconvenient to work with the database in the terminal, or you need to become more familiar with PostgreSQL or SQL commands. In that case, this article comes in handy.
I explain how to run pgAdmin in a Kubernetes cluster to manage PostgreSQL dat... | dbazhenov |
1,901,704 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-26T18:13:18 | https://dev.to/younwary818/buy-verified-cash-app-account-596b | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | younwary818 |
1,893,900 | Orchestrating Serverless Workflows with Ease using AWS Step Functions | When we talk about running serverless workloads on AWS (disclaimer: serverless doesn’t mean there are... | 0 | 2024-06-26T18:10:42 | https://dev.to/aws-builders/orchestrating-serverless-workflows-with-ease-using-aws-step-functions-3mok | aws, orchestration, stepfunctions | When we talk about running serverless workloads on AWS (disclaimer: serverless doesn’t mean there are no servers, it just means you don’t have to worry about provisioning and managing them), the service that immediately comes to mind is definitely AWS Lambda. This serverless compute service allows developers to run the... | brandondamue |
1,901,701 | Write | Check out this Pen I made! | 0 | 2024-06-26T18:07:50 | https://dev.to/afzalqwe/write-4ki6 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Afzal-hosen-Tipu/pen/eYaXYeb %} | afzalqwe |
1,901,699 | How to Analyze a Crypto White Paper | Introduction Understanding a white paper is crucial in crypto. It shows the project's... | 0 | 2024-06-26T18:06:24 | https://dev.to/cryptoavigdor/how-to-analyze-a-crypto-white-paper-542f | cryptocurrency, whitepaper, crypto, presale | ## Introduction
Understanding a white paper is crucial in crypto. It shows the project's goals, technology, and plans. Here's a simple guide on how to analyze a white paper.
## What is a White Paper?
A white paper explains a crypto project's details. It includes the problem, solution, and roadmap. It helps investors d... | cryptoavigdor |
1,901,698 | Betfair India - Betfair Betting and Casino Site in India | Betfair, founded in 2000, revolutionized the betting industry by introducing the world’s first... | 0 | 2024-06-26T18:02:37 | https://dev.to/sower9/betfair-india-betfair-betting-and-casino-site-in-india-e4k | Betfair, founded in 2000, revolutionized the betting industry by introducing the world’s first peer-to-peer betting exchange. This innovative platform allows users to bet against each other, rather than against a traditional bookmaker, offering better odds and greater flexibility. By leveraging cutting-edge technology,... | sower9 | |
1,901,696 | Unraid: Das ultimative Tool für deine Heimserver 🚀 | Entdecke Unraid: Flexibles Betriebssystem für Heimserver, unterstützt Docker & VMs. Einfach zu... | 0 | 2024-06-26T18:00:10 | https://blog.disane.dev/unraid-dein-heim-server/ | unraid, homelab, server, nas | Entdecke Unraid: Flexibles Betriebssystem für Heimserver, unterstützt Docker & VMs. Einfach zu installieren, kosteneffizient und perfekt für deine Datenverwaltung. 🚀
---
In der heutigen digitalen Ära, in der Daten und Medieninhalt... | disane |
1,901,694 | Intro to JavaScript Testing: Frameworks, Tools, and Practices | Testing is a super important element of the software development lifecycle, making sure our code is... | 0 | 2024-06-26T17:58:38 | https://dev.to/buildwebcrumbs/intro-to-javascript-testing-frameworks-tools-and-practices-167i | javascript, beginners, testing, webdev | Testing is a super important element of the software development lifecycle, making sure our code is reliable and functional.
Having a flexible approach to testing can significantly better the quality and maintainability of applications.
In this article, we will explore essential testing types, prominent tools and fra... | pachicodes |
1,901,693 | Cricket Gloves Market by Type, segmentation, growth and forecast 2024-2031 | Cricket Gloves Market The Cricket Gloves Market is expected to grow from USD 1800 Million in 2023 to... | 0 | 2024-06-26T17:56:40 | https://dev.to/reportprime23/cricket-gloves-market-by-type-segmentation-growth-and-forecast-2024-2031-10kf | Cricket Gloves Market
The Cricket Gloves Market is expected to grow from USD 1800 Million in 2023 to USD 2800 Million by 2031, at a CAGR of 4.3% during the forecast period.
Get Sample Report: https://www.reportprime.com/enquiry/sample-report/17961
Cricket Gloves Market Size
Cricket gloves are protective gear worn by... | reportprime23 | |
1,901,692 | Windows 11 unsuckifying guide | Here's an incomplete list of tips, tools, and settings to help make Windows 11 suck less. Biggest... | 0 | 2024-06-26T17:53:32 | https://dev.to/thejaredwilcurt/windows-11-unsuckifying-guide-1oc5 | windows, windows11, guide, tutorial | Here's an incomplete list of tips, tools, and settings to help make Windows 11 suck less.
**Biggest pro-tip:** If you are installing Windows 11 fresh, use English-Global instead of English US. This skips installing TikTok, Disney+, LinkedIn, Spotify, etc paid-promotional links everywhere. Also turns off MS Store by de... | thejaredwilcurt |
1,901,689 | Ratatui Audio with Rodio: Sound FX for Rust Text-based UI | Ratatui audio with Rodio 🔊 adding sound effects to a 🦀 Rust Text-based user interface or Terminal app using the Rodio crate. | 0 | 2024-06-26T17:47:13 | https://rodneylab.com/ratatui-audio-with-rodio/ | rust, gamedev, tui | ---
title: "Ratatui Audio with Rodio: Sound FX for Rust Text-based UI"
published: "true"
description: "Ratatui audio with Rodio 🔊 adding sound effects to a 🦀 Rust Text-based user interface or Terminal app using the Rodio crate."
tags: "rust, gamedev, tui"
canonical_url: "https://rodneylab.com/ratatui-audio-with-rodio... | askrodney |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.