
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
```
from __future__ import absolute_import
from __future__ import print_function
import numpy as np
import numpy
import PIL
from PIL import Image
np.random.seed(1337) # for reproducibility
import random
from keras.datasets import mnist
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Input, Lambda
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Flatten
from keras.optimizers import RMSprop
from keras import backend as K
from keras.layers import Concatenate, Dense, LSTM, Input, concatenate
def euclidean_distance(x, y):
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
def eucl_dist_output_shape(shapes):
shape1, shape2 = shapes
return (shape1[0], 1)
def conc(vects):
x, y = vects
conc1 = concatenate([x,y])
return conc1
def conc_shape(shapes):
shape1, shape2 = shapes
return (shape1[0],256)
def kl_div(p,q):
return K.sum((p*K.abs(K.log(p)-K.log(q)))/K.max((p*K.abs(K.log(p)-K.log(q)))
, axis=1, keepdims=True),axis=1, keepdims=True)
def contrastive_loss(y_true, y_pred):
'''Contrastive loss from Hadsell-et-al.'06
http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
'''
x = y_pred[:,0:128]
y = y_pred[:,128:268]
y_pred1 = euclidean_distance(x,y)
p = x
q = y
p = K.clip(p, K.epsilon(), 1)
q = K.clip(q, K.epsilon(), 1)
#y_true1 = y_true[:,0]
#y_true1 = K.reshape(y_true1,(-1,))
#print(y_true1)
#tr_same = y_true[:,1]
#tr_same = K.reshape(tr_same, (-1,))
y_true1 = y_true
tr_same = K.round(y_true/3)
margin = 1
test = 0.01*kl_div(p,q)
contra = (y_true1 * K.square(y_pred1) + (1 - y_true1) * K.square(K.maximum(margin - y_pred1, 0)))
return K.mean((1-tr_same)*contra
+ (tr_same)*test)
def create_pairs(x, y, digit_indices):
'''Positive and negative pair creation.
Alternates between positive and negative pairs.
'''
pairs = []
labels = []
n = min([len(digit_indices[d]) for d in range(10)]) - 1
for d in range(10):
for i in range(n):
z1, z2 = digit_indices[d][i], digit_indices[d][i + 1]
pairs += [[x[z1], x[z2]]]
inc = random.randrange(1, 10)
dn = (d + inc) % 10
z1, z2 = digit_indices[d][i], digit_indices[dn][i]
pairs += [[x[z1], x[z2]]]
labels += [1, 0]
for i in range(0,3000):
k1 = random.randrange(0,x.shape[0])
k2 = random.randrange(0, y.shape[0])
pairs+= [[x[k1],y[k2]]]
labels += [3]
return np.array(pairs), np.array(labels)
def create_base_network():
'''Base network to be shared (eq. to feature extraction).
'''
seq = Sequential()
seq.add(Conv2D(30, (5, 5), input_shape=(28, 28,1), activation='relu'))
seq.add(MaxPooling2D(pool_size=(2, 2)))
seq.add(Dropout(0.2))
seq.add(Flatten())
seq.add(Dense(128, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(128, activation='relu'))
return seq
def compute_accuracy(predictions, labels):
'''Compute classification accuracy with a fixed threshold on distances.
'''
return labels[predictions.ravel() < 0.5].mean()
seed=7
numpy.random.seed(seed)
X_test=[]
for i in range(0,10):
for j in range(1,201):
img = PIL.Image.open("/home/aniruddha/Documents/USPSdataset/%d/%d.jpg" %(i,j)).convert("L")
arr = np.array(img)
# ravel to convert 28x28 to 784 1D array
arr=arr.ravel()
X_test.append(arr)
X_test=np.array(X_test)
#X_train=X_train.reshape(2000,784)
X_test=X_test.astype('float32')
print(X_test.shape)
y_test=[]
for i in range(0,10):
for j in range(1,201):
y_test.append(i)
y_test=np.array(y_test)
num_classes = 10
print(y_test.shape)
X_train= []
for i in range(0,10):
for j in range(201,1801):
img = PIL.Image.open("/home/aniruddha/Documents/USPSdataset/%d/%d.jpg" %(i,j)).convert("L")
arr = np.array(img)
# ravel to convert 28x28 to 784 1D array
arr=arr.ravel()
X_train.append(arr)
X_train=np.array(X_train)
#X_train=X_train.reshape(19000,784)
X_train=X_train.astype('float32')
print(X_train.shape)
#X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
#X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32')
print(X_train.shape)
print(X_test.shape)
X_train=X_train/255
X_test=X_test/255
y_train=[]
for i in range(0,10):
for j in range(201,1801):
y_train.append(i)
y_train=np.array(y_train)
num_classes = 10
print(y_train.shape)
print(y_test.shape)
print(y_train)
print(y_test)
input_dim = 784
nb_epoch = 5
(X1_train,y1_train), (X1_test, y1_test) = mnist.load_data()
X1_train=X1_train/255
X1_test=X1_test/255
X1_train = X1_train.astype('float32')
X1_test = X1_test.astype('float32')
X1_train = X1_train.reshape(-1,784)
X1_test = X1_test.reshape(-1,784)
# create training+test positive and negative pairs
digit_indices = [np.where(y_train == i)[0] for i in range(10)]
tr_pairs, tr_y = create_pairs(X_train, X1_train, digit_indices)
digit_indices = [np.where(y_test == i)[0] for i in range(10)]
te_pairs, te_y = create_pairs(X_test, X1_test, digit_indices)
base_network = create_base_network()
X_temp=X_train.reshape(-1,28,28,1)
input_dim = X_temp.shape[1:]
print(input_dim)
# network definition
base_network = create_base_network()
input_a = Input(shape=input_dim)
input_b = Input(shape=input_dim)
#input_a=K.reshape(input_a,(28,28,1))
#input_b=K.reshape(input_b,(28,28,1))
# because we re-use the same instance `base_network`,
# the weights of the network
# will be shared across the two branches
print(input_b.shape)
processed_a = base_network(input_a)
processed_b = base_network(input_b)
distance = Lambda(conc, output_shape=conc_shape)([processed_a, processed_b])
model = Model(input=[input_a, input_b], output=distance)
print(distance.shape)
r = distance
r = K.reshape(r, (-1,256))
print(r.shape)
test_model = Model(input = input_a, output = processed_a)
tr_pairs1=tr_pairs.reshape(-1,2,28,28,1)
te_pairs1=te_pairs.reshape(-1,2,28,28,1)
print(tr_pairs1.shape)
print(te_pairs1.shape)
print(tr_pairs1[:,0].shape)
print(tr_pairs[:, 1])
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model).create(prog='dot', format='svg'))
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(base_network).create(prog='dot', format='svg'))
nb_epoch=5
# train
rms = RMSprop()
model.compile(loss=contrastive_loss, optimizer=rms)
model.fit([tr_pairs1[:,0], tr_pairs1[:, 1]], tr_y,
validation_data=([te_pairs1[:,0], te_pairs1[:, 1]], te_y),
batch_size=128,
nb_epoch=nb_epoch)
(X_train1,y_train1),(X_test1,y_test1)=mnist.load_data()
X_test1 = X_test1/255
X_test1 = X_test1.astype('float32')
X_test1 = X_test1.reshape(-1,28,28,1)
print(X_test1.shape)
%matplotlib inline
from time import time
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import offsetbox
from sklearn import manifold, datasets, decomposition, ensemble, discriminant_analysis, random_projection
def plot_embedding(mu, Y, title=None):
num_class = 1000 # data points per class
# x_min, x_max = np.min(mu, 0), np.max(mu, 0)
# mu = (mu - x_min) / (x_max - x_min)
# classes = [0, 1, 2, 3, 4, 6, 7, 8, 9, 10, 11, 12, 15, 16, 18, 19,
# 20, 21, 22, 25, 26, 27, 28, 29, 30, 31, 32, 34, 35, 36, 37, 39, 40, 42, 43, 44, 45, 46, 48, 49]
classes = [0,1,2,3,4,5,6,7,8,9]
data = [[] for i in classes]
for i, y in enumerate(Y):
data[classes.index(y)].append(np.array(mu[i]))
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'olive', 'orange', 'mediumpurple']
l = [i for i in range(10)]
alphas = 0.3 * np.ones(10)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_aspect(1)
font_size = 13
for i in range(10):
temp = np.array(data[i])
l[i] = plt.scatter(temp[:num_class, 0], temp[:num_class, 1], s = 5, c = colors[i], edgecolors = 'face', alpha=alphas[i])
leg = plt.legend((l[0],l[1],l[2],l[3],l[4],l[5],l[6],l[7],l[8],l[9]),
('0','1','2','3','4','5','6','7','8','9'), loc='center left', bbox_to_anchor=(1, 0.5), fontsize=font_size)
leg.get_frame().set_linewidth(0.0)
plt.xticks(fontsize=font_size)
plt.yticks(fontsize=font_size)
X_test1=X_test1.reshape(-1,28,28,1)
processed=test_model.predict(X_test1)
X_train = X_train.reshape(-1,28,28,1)
processed=test_model.predict(X_train)
print(processed.shape)
#latest model
#new
#tsne of test - mnist dataset
print("Computing t-SNE embedding")
tsne_pred = manifold.TSNE(n_components=2, init='pca', random_state=0)
t0 = time()
X_tsne_pred = tsne_pred.fit_transform(processed)
plot_embedding(X_tsne_pred, y_train,
"t-SNE embedding of the digits (time %.2fs)" %
(time() - t0))
#new
#tsne of test - mnist dataset
print("Computing t-SNE embedding")
tsne_pred = manifold.TSNE(n_components=2, init='pca', random_state=0)
t0 = time()
X_tsne_pred = tsne_pred.fit_transform(processed)
plot_embedding(X_tsne_pred, y_test1,
"t-SNE embedding of the digits (time %.2fs)" %
(time() - t0))
X_train11=X_train.reshape(-1,28,28,1)
X_test11=X_test.reshape(-1,28,28,1)
processed_train=test_model.predict(X_train11)
processed_test=test_model.predict(X_test11)
num_pixels = 128
processed_train = processed_train.reshape(processed_train.shape[0], num_pixels).astype('float32')
processed_test = processed_test.reshape(processed_test.shape[0], num_pixels).astype('float32')
print(num_pixels)
print(processed_train.shape)
print(processed_test.shape)
from keras.utils import np_utils
y_train1 = np_utils.to_categorical(y_train)
y_test1 = np_utils.to_categorical(y_test)
num_classes = 10
# define baseline model
def baseline_model1():
# create model
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer='normal', activation='relu'))
model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# build the model
model1 = baseline_model1()
# Fit the model
model1.fit(processed_train, y_train1, validation_data=(processed_test, y_test1), epochs=10, batch_size=200, verbose=1)
# Final evaluation of the model
scores_test = model1.evaluate(processed_test, y_test1, verbose=1)
scores_train = model1.evaluate(processed_train, y_train1, verbose=1)
#scores_train=scores_train/1.0
#scores_test=scores_test/1.0
print('* Accuracy on training set: %0.2f%%' % (100 * scores_train[1]))
print('* Accuracy on test set: %0.2f%%' % (100 * scores_test[1]))
from keras.utils import np_utils
y_test1 = np_utils.to_categorical(y_test1)
num_classes = 10
scores_test_USPS=model1.evaluate(processed, y_test1, verbose=1)
print('* Accuracy on test USPS set: %0.2f%%' % (100 * scores_test_USPS[1]))
```
| github_jupyter |
(algorythmic_complexity)=
# Algorithmic complexity
``` {index} Algorithmic Complexity
```
In order to make our programs efficient (or, at least, not horribly inefficient), we can consider how the execution time varies depending on the input size \\(n\\). Let us define a measure of this efficiency as a function \\( T(n)\\). Of course, the time it takes to execute a code will vary largely depending on the processor, compiler or disk speed. \\( T(n)\\) goes around this variance by measuring *asymptotic* complexity. In this case, only (broadly defined) *steps* will determine the time it takes to execute an algorithm.
Now, say we want to add two \\(n\\)-bit binary digits. One way to do this is to go bit by bit and add the two. We can see that \\(n\\) operations are involved.
\\[T(n) = c*n\\]
where \\(c\\) is the time it takes to add two bits on a machine. On different machines, the value of \\(c\\) may vary, but the linearity of this function is the common factor. Our aim is to abstract away from the details of implementation and think about the fundamental usage of computing resources.
## Big O notation
The mathematical definiton of this concept can be found [here](https://primer-computational-mathematics.github.io/book/c_mathematics/mathematical_notation/Big_O_notation.html). In simple terms, we say that:
\\[f(n) = O(g(n))\\]
if there exists \\(c>0\\) and \\(n_0>0\\) such that
\\[f(n) \leq c * g(n), \quad \text{for all} \ n \geq n_0.\\]
\\(g(n)\\) can be thought of as an *upper bound* of \\(f(n)\\) as \\(n \to \infty\\). In some publications *big Theta* notation is used. \\(\Theta(n)\\) can be considered the *least upper bound*, in algorithm analysis we ofter use both notations interchangeably.
Here are a couple of examples:
\\[ 3n + 4 = O(n)\\]
\\[ n^2 + 17n = O(n^2)\\]
\\[2^n = O(2^n)\\]
\\[42 = O(1)\\]
but also:
\\[log(n) = O(n)\\]
\\[n = O(n^2)\\]
We will now consider different time complexities of algorithms.
----------------
### Constant time \\(O(1)\\)
An algorithm is said to run in *constant* time if its complexity is \\(O(1)\\). This is usually considered the *fastest* case (which is true but only in the *asymptotic* sense). No matter what the input size is, the program will take the same amount of time to terminate. Let us consider some examples:
* ```Hello World!```:
```
def f(n):
print("Hello World!")
```
No matter what ```n``` is, the function does the same thing, which takes the same time. Therefore its complexity is constant.
* Checking if an integer is odd or not:
```
import time
def f(n):
return n & 1 == 1
print(f(7))
print(f(2349017324987123948729382))
```
In this case, we only need to check if the zeroth bit of the binary representation is set to 1. The number of operations does not depend on the value or the size of the input number.
* Searching a dictionary:
```
d = {}
d['A'] = 1
d['B'] = 2
d['C'] = 3
print(d['B'])
```
Dictionaries are data structures which can be queried in constant time. If we have a key, we can retrieve an element instantaneously.
----------------
### Linear time \\(O(n)\\)
This complexity appears in real-life problems much more frequently than constant time. The program is said to run in *linear* time if the time it takes is proportional to the input size:
* Finding a maximum in an unsorted list:
```
def f(l):
_max = l[0]
for i in l:
if i > _max:
_max = i
return _max
print(f([1,4,7,4,3,9,0,4,-3]))
```
As we do not know anything about the order of elements in this list, we need to check every element in order to *see* if it is not the greatest. The longer the list, the more such checks are needed. In general, when we need to go trough some data structure a constant number of times, we are dealing with linear time.
----------------
### Quadratic time \\(O(n^2)\\)
The *quadratic* time complexity is also a very popular case. It often might not be the most efficient solution and can point to better complexities such as \\(O(n*log(n))\\). However, there are problems in which such traversal is necessary.
* **Selection sort**:
```
def swap(i,j,l):
temp = l[i]
l[i] = l[j]
l[j] = temp
def selectionSort(l):
i = 0
while i < len(l)-1:
swap(i,i+l[i:].index(min(l[i:])),l)
i+=1
return l
print(selectionSort([3,4,5,6,7,8,9,3,2]))
```
The algorithm works as follows:
1) Find the minimum of the list and swap it with the first element.
2) Now consider all elements behind the first index
3) Find the minimum of this sublist and swap it with the first element (of the sublist)S
A diagram says more than a 1000 words:
```{figure} algo_images/SelectionSort.png
:width: 60%
```
If we calculate the sum of operations (arithmetic series) we get \\(\frac{n*(n+1)}{2} = O(n^2)\\). Selection Sort is considered a rather inefficient sorting algorithm.
* Adding Matrices:
```
# Adds two square matrices of the same size
def addMatrix(A,B):
res = []
for i in range(len(A)):
temp = []
for j in range(len(A[i])):
temp.append(A[i][j] + B[i][j])
res.append(temp)
return res
print(addMatrix([[1,2,3],[1,2,3],[1,2,3]],[[3,2,1],[3,2,1],[3,2,1]]))
```
When we want to add two \\(n \times n\\) matrices, we have to perform the addition element-wise, therefore we perform \\(n^2\\) additions.
------------------
## Different complexities
Apart from the three complexities above, there are many more which show up quite often. The most notable ones are (we will discuss some of them later):
1) Logarithmic \\(O(log(n))\\) - present in e.g. Binary Search.
2) Loglinear \\(O(n*log(n))\\) - e.g. Merge Sort.
3) Multi-variable \\(O(n*k)\\) - e.g. searching for a substring of length \\(k\\) in a string of length \\(n\\).
4) Exponential \\(O(a^n)\\), \\(a > 1\\) - this is bad.
5) Factorial \\(O(n!)\\) - even worse (producing all permutations of a string).
----------------
## Best, worst and average case runtimes
While analyzing algorithms, it is worth considering how the program behaves based on different inputs.
* Best-case runtime complexity is a function defined by the minimum number of steps taken on any input.
* Worst-case runtime complexity considers the maximum number of steps taken by the algorithm.
* Average case runtime complexity is probably the most accurate measure of the performance of an algorithm and takes into account the behaviour of the program when fed with an *average* input.
In production, both worst and average runtime complexities are considered (imagine an algorithm with an average \\(O(n^2)\\) and worst-case \\(O(n!)\\) - that could be easily exploited!)
Let us now perform an analysis on a simple search algorithm which finds the number \\(x\\) in a list \\(l\\)
```
def simpleSearch(x,l):
for i in range(len(l)):
if x == l[i]:
return i
return -1
print(simpleSearch(1,[3,4,5,6,7,1,23,4]))
```
Our assumption is that \\(x\\) is in the list and that the probability that it is at a particular index is uniform.
1) Best-case: \\(O(1)\\) - in is the zeroth cell
2) Worst-case: \\(O(n)\\) - have to go through the whole list
3) Average case: \\(O(\frac{n}{2}) = O(n)\\) - the element will be *somewhere in the middle*
In this case, we can predict that the program will run in linear time.
------------
## Exercises
* **Which Big O** category do these functions fall into (least upper bound):
1) \\( 4n^3 + 2n\\)
2) \\(\sum_{i=0}^{n} i^2\\)
3) \\(log(log(n))\\)
4) 34562
```{admonition} Answers
:class: dropdown
1) \\(O(n^3)\\)
2) \\(O(n^3)\\)
3) \\(O(log(log(n))\\)
4) \\(O(1)\\)
```
------
* **Multiplying Matrices** We want to multiply two square matrices of side length \\(n\\) of the same size using the following code:
```
def mulMatrix(A,B):
C = [([0]*len(A)) for i in range(len(A))]
for i in range(len(A)):
for j in range(len(A)):
for k in range(len(A)):
C[i][j] += (A[i][k]*B[k][j])
return C
print(mulMatrix([[1,1,1],[2,2,2],[3,3,3]],
[[1,2,3],[1,2,3],[1,2,3]]))
```
**What is the algorythmic complexity of this algorithm?**
```{admonition} Answer
:class: dropdown
The function `mulMatrix` in its innermost loop does two operations: one multiplication and one addition. It does this \\(n^3\\) times because there are three nested `for` loops, each one iterating `n` times.
Therefore \\(O(n^3)\\).
```
----------
* **Insertion Sort** algorithm works according to the steps:
1) Take the minimum element from the list and swap it with the first element.
2) Now elements before index 1 are sorted
3) Take the minimum element from the unsorted portion of the list and put it at an appropriate position in the sorted portion.
4) Repeat until the whole list is sorted.
The following GIF should be helpful:
<img src="https://upload.wikimedia.org/wikipedia/commons/9/9c/Insertion-sort-example.gif" width="80%">
Source: [Wikimedia Commons](https://upload.wikimedia.org/wikipedia/commons/9/9c/Insertion-sort-example.gif)
**What is the algorythmic complexity of this algorithm?**
```{admonition} Answer
:class: dropdown
\\(O(n^2)\\)
```
-------
## References
* Victor S.Adamchik, CMU, 2009 [Algorythmic Complexity](https://www.cs.cmu.edu/~adamchik/15-121/lectures/Algorithmic%20Complexity/complexity.html)
* Adrian Mejia, Medium, 2018 [8 time complexity examples that every programmer should know](https://medium.com/@amejiarosario/8-time-complexity-examples-that-every-programmer-should-know-171bd21e5ba)
| github_jupyter |
# Análise de redes
_Rede_ (_network_) é uma forma de organizar e representar dados discretos. Elas diferem da forma tabular, em que linhas e colunas são as estruturas fundamentais, e funcionam com base em dois conceitos:
1. _entidades_, ou _atores_, ou ainda _nós_, e
2. _relacionamentos_, ou _links_, ou _arcos_, ou ainda, _conexões_.
Casualmente, o conceito de _rede_ se confunde com o conceito matemático de _grafo_, para o qual as entidades são chamadas _vértices_ e os relacionamentos _arestas_. Usa-se a notação $G(V,E)$ para designar um grafo genérico $G$ com um conjunto $V$ de vértices e um conjunto $E$ de arestas. A Fig. {numref}`random-graph` esboça um grafo genérico.
```{figure} ../figs/17/random-graph.png
---
width: 500px
name: random-graph
---
Grafo genérico contendo 6 vértices e 13 arestas.
```
## Redes complexas
Com o barateamento dos recursos de computação no final do século XX, a _análise de redes complexas_ (do inglês _complex network analysis_, ou CNA) evoluiu como uma área de pesquisa independente. Desde então, tornou-se possível mapear bancos de dados enormes e extrair conhecimento a partir de um emaranhado complexo de interligações.
No século XXI, percebemos um interesse explosivo em CNA. Algumas aplicações modernas incluem, mas não se limitam a:
- transporte, para planejamento de malhas ferroviárias, rodovias e conexões entre cidades;
- sociologia, para entender pessoas, seu comportamento, interação em redes sociais, orientações de pensamento e preferências;
- energia, para sistematizar linhas de transmissão de energia elétrica;
- biologia, para modelar redes de transmissão de doenças infecciosas;
- ciência, para encontrar os núcleos de pesquisa mais influentes do mundo em um determinado campo do conhecimento.
## O módulo `networkx`
Neste capítulo, introduziremos alguns conceitos relacionados à CNA, tais como componentes conexas, medidades de centralidade e visualização de grafos usando o módulo Python `networkx`. Este módulo tornou-se popular pela sua versatilidade. Alguns de seus pontos positivos são:
- facilidade de instalação;
- ampla documentação no [site oficial](https://networkx.org);
- extenso conjunto de funções e algoritmos;
- versatilidade para lidar com redes de até 100.000 nós.
```{note}
Algumas ferramentas com potencial similar ao `networkx` são [`igraph`](https://igraph.org) e [`graph-tool`](https://graph-tool.skewed.de). Especificamente para visualização, você poderá se interessar pelo [`Graphviz`](https://www.graphviz.org) ou pelo [`Gephi`](https://gephi.org).
```
Vamos praticar um pouco com este módulo para entender conceitos fundamentais. Em seguida, faremos uma aplicação. Supondo que você já tenha instalado o `networkx`, importe-o:
```
import networkx as nx
```
### Criação de grafos não dirigidos
Em seguida vamos criar um grafo $G$ _não dirigido_. Isso significa que o sentido da aresta é irrelevante. Contudo, vale comentar que há situações em que o sentido da aresta importa. Neste caso, diz-se que o grafo é _dirigido_.
```
# cria grafo não dirigido com 4 vértices
# inicializa
G = nx.Graph()
# adiciona arestas explicitamente
G.add_edge(1,2)
G.add_edge(1,3)
G.add_edge(2,3)
G.add_edge(3,4)
```
Em seguida, visualizamos o grafo com `draw_networkx`.
```
nx.draw_networkx(G)
```
### Adição e deleção de nós e arestas
Podemos adicionar nós indvidualmente ou por meio de uma lista, bem como usar _strings_ como nome.
```
G.add_node('A')
G.add_nodes_from(['p',99,'Qq'])
G.add_node('Mn') # nó adicionado por engano
nx.draw_networkx(G)
```
Podemos fazer o mesmo com arestas sobre nós existentes ou não existentes.
```
G.add_edge('A','p') # aresta individual
G.add_edges_from([(1,99),(4,'A')]) # aresta por lista (origem, destino)
G.add_edge('Mn','no') # 'no' não existente
nx.draw_networkx(G)
```
Nós e arestas podem ser removidos de maneira similar.
```
G.remove_node('no')
G.remove_nodes_from(['Qq',99,'p'])
nx.draw_networkx(G)
G.remove_edge(1,2)
G.remove_edges_from([('A',4),(1,3)])
nx.draw_networkx(G)
```
Para remover todas os nós e arestas do grafo, mas mantê-lo criado, usamos `clear`.
```
G.clear()
```
Verificamos que não há nós nem arestas:
```
len(G.nodes()), len(G.edges)
```
Para deletá-lo completamente, podemos fazer:
```
del G
```
### Criação de grafos aleatórios
Podemos criar um grafo aleatório de diversas formas. Com `random_geometric_graph`, o grafo de _n_ nós uniformemente aleatórios fica restrito ao "cubo" unitário de dimensão `dim` e conecta quaisquer dois nós _u_ e _v_ cuja distância entre eles é no máximo `raio`.
```
# 30 nós com raio de conexão 0.2
n = 30
raio = 0.2
G = nx.random_geometric_graph(n,raio,dim=2)
nx.draw_networkx(G)
# 30 nós com raio de conexão 5
n = 30
raio = 5
G = nx.random_geometric_graph(n,raio,dim=2)
nx.draw_networkx(G)
# 12 nós com raio de conexão 1.15
n = 12
raio = 1.15
G = nx.random_geometric_graph(n,raio,dim=2)
nx.draw_networkx(G)
# 12 nós com raio de conexão 0.4
n = 12
raio = 0.4
G = nx.random_geometric_graph(n,raio,dim=2)
nx.draw_networkx(G)
```
### Impressão de listas de nós e de arestas
Podemos acessar a lista de nós ou de arestas com:
```
G.nodes()
G.edges()
```
Notemos que as arestas são descritas por meio de tuplas (_origem_,_destino_).
Se especificarmos `data=True`, atributos adicionais são impressos. Para os nós, vemos `pos` como a posição espacial.
```
print(G.nodes(data=True))
```
No caso das arestas, nenhum atributo existe para este grafo. Contudo, em grafos mais complexos, é comum ter _capacidade_ e _peso_ como atributos. Ambas são relevantes em estudos de _fluxo_, em que se associa a arestas uma "capacidade" de transporte e um "peso" de relevância.
```
print(G.edges(data=True))
```
### Criação de redes a partir de arquivos
Um modo conveniente de criar redes é ler diretamente um arquivo contendo informações sobre a conectividade. O _dataset_ que usaremos a partir deste ponto em diante corresponde a uma rede representando a amizade entre usuários reais do Facebook. Cada usuário é representado por um vértice e um vínculo de amizade por uma aresta. Os dados são anônimos.
Carregamos o arquivo _.txt_ com `networkx.read_edgelist`.
```
fb = nx.read_edgelist('../database/fb_data.txt')
len(fb.nodes), len(fb.edges)
```
Vemos que esta rede possui 4039 usuários e 88234 vínculos de amizade. Você pode plotar o grafo para visualizá-lo, porém pode demorar um pouco...
## Propriedades relevantes
Vejamos algumas propriedades de interesse de redes e grafos.
### Grau
O _grau_ de um nó é o número de arestas conectadas a ele. Assim, o grau médio da rede do Facebook acima pode ser calculado por:
```
fb.number_of_edges()/fb.number_of_nodes()
```
ou
```
fb.size()/fb.order()
```
Ambos os resultados mostram que cada usuário nesta rede tem pelo menos 21 amizades.
### Caminho
_Caminho_ é uma sequencia de nós conectados por arestas contiguamente. O _caminho mais curto_ em uma rede é o menor número de arestas a serem visitadas partindo de um nó de origem _u_ até um nó de destino _v_.
A seguir, plotamos um caminho formado por 20 nós.
```
Gpath = nx.path_graph(20)
nx.draw_networkx(Gpath)
```
### Componente
Um grafo é _conexo_ se para todo par de nós, existe um caminho entre eles. Uma _componente conexa_, ou simplesmente _componente_ de um grafo é um subconjunto de seus nós tal que cada nó no subconjunto tem um caminho para todos os outros.
Podemos encontrar todas as componentes da rede do Facebook usando `connected_componentes`. Entretanto, o resultado final é um objeto _generator_. Para acessarmos as componentes, devemos usar um iterador.
```
cc = nx.connected_components(fb)
# varre componentes e imprime os primeiros 5 nós
for c in cc:
print(list(c)[0:5])
```
Uma vez que há apenas uma lista impressa, temos que a rede do Facebook, na verdade, é uma componente única. De outra forma,
```
# há apenas 1 componente conexa, a própria rede
nx.number_connected_components(fb)
```
### Subgrafo
_Subgrafo_ é um subconjunto dos nós de um grafo e todas as arestas que os conectam. Para selecionarmos um _subgrafo_ da rede Facebook, usamos `subgraph`. Os argumentos necessários são: o grafo original e uma lista dos nós de interesse. Abaixo, geramos uma lista aleatória de `ng` nós.
```
from numpy.random import randint
# número de nós do subgrafo
ng = 40
# identifica nós (nomes são strings)
nodes_to_get = randint(1,fb.number_of_nodes(),ng).astype(str)
# extrai subgrafo
fb_sub = nx.subgraph(fb,nodes_to_get)
# plota
nx.draw_networkx(fb_sub)
```
Se fizermos alguma alteração no grafo original, pode ser que o número de componentes se altere. Vejamos:
```
# copia grafo
fb_less = fb.copy()
# remove o nó '0'
fb_less.remove_node('0')
# novas componentes
nx.number_connected_components(fb_less)
```
Neste exemplo, a retirada de apenas um nó do grafo original resultou em 19 componentes, com número variável de elementos.
```
ncs = []
for c in nx.connected_components(fb_less):
ncs.append(len(c))
# número de componentes em ordem
sorted(ncs,reverse=True)
```
## Métricas de centralidade
A _centralidade_ de um nó mede a sua importância relativa no grafo. Em outras palavras, nós mais "centrais" tendem a ser considerados os mais influentes, privilegiados ou comunicativos.
Em uma rede social, por exemplo, um usuário com alta centralidade pode ser um _influencer_, um político, uma celebridade, ou até mesmo um malfeitor. Há diversas _métricas de centralidade_ disponíveis. Aqui veremos as 4 mais corriqueiras:
- _centralidade de grau_ (_degree centrality_): definida pelo número de arestas de um nó;
- _centralidade de intermediação_(_betweeness centrality_): definida pelo número de vezes em que o nó é visitado ao tomarmos o caminho mais curto entre um par de nós distintos deste. Esta centralidade pode ser imaginada como uma "ponte" ou "pedágio".
- _centralidade de proximidade_ (_closeness centrality_): definida pelo inverso da soma das distâncias do nó de interesse a todos os outros do grafo. Ela quão "próximo" o nó é de todos os demais. Um nó com alta centralidade é aquele que, grosso modo, "dista por igual" dos demais.
- _centralidade de autovetor_ (_eigenvector centrality_): definida pelo escore relativo para um nó tomando por base suas conexões. Conexões com nós de alta centralidade aumentam seu escore, ao passo que conexões com nós de baixa centralidade reduzem seu escore. De certa forma, ela mede como um nó está conectado a nós influentes.
Em particular, um nó com alta centralidade de proximidade e alta centralidade de intermediação é chamado de _hub_.
Vamos calcular as centralidades de um subgrafo da rede do Facebook. Primeiro, extraímos um subgrafo menor.
```
# número de nós do subgrafo
ng = 400
# identifica nós (nomes são strings)
nodes_to_get = randint(1,fb.number_of_nodes(),ng).astype(str)
# extrai subgrafo
fb_sub_c = nx.subgraph(fb,nodes_to_get)
import matplotlib.pyplot as plt
# centralidade de grau
deg = nx.degree_centrality(fb_sub_c)
nx.draw_networkx(fb_sub_c,
with_labels=False,
node_color=list(deg.values()),
alpha=0.6,
cmap=plt.cm.afmhot)
# centralidade de intermediação
bet = nx.betweenness_centrality(fb_sub_c)
nx.draw_networkx(fb_sub_c,
with_labels=False,
node_color=list(bet.values()),
alpha=0.6,
cmap=plt.cm.afmhot)
# centralidade de proximidade
cln = nx.closeness_centrality(fb_sub_c)
nx.draw_networkx(fb_sub_c,
with_labels=False,
node_color=list(cln.values()),
alpha=0.6,
cmap=plt.cm.afmhot)
# centralidade de autovetor
eig = nx.eigenvector_centrality(fb_sub_c)
nx.draw_networkx(fb_sub_c,
with_labels=False,
node_color=list(eig.values()),
alpha=0.6,
cmap=plt.cm.afmhot)
```
## Layouts de visualização
Podemos melhorar a visualização das redes alterando os layouts. O exemplo a seguir dispõe o grafo em um layout melhor, chamado de `spring`. Este layout acomoda a posição dos nós iterativamente por meio de um algoritmo especial. Além disso, a centralidade de grau está normalizada no intervalo [0,1] e escalonada.
Com o novo plot, é possível distinguir "comunidades", sendo os maiores nós os mais centrais.
```
from numpy import array
pos_fb = nx.spring_layout(fb_sub_c,iterations = 50)
nsize = array([v for v in deg.values()])
nsize = 500*(nsize - min(nsize))/(max(nsize) - min(nsize))
nodes = nx.draw_networkx_nodes(fb_sub_c, pos = pos_fb, node_size = nsize)
edges = nx.draw_networkx_edges(fb_sub_c, pos = pos_fb, alpha = .1)
```
Um layout aleatório pode ser plotado da seguinte forma:
```
pos_fb = nx.random_layout(fb_sub_c)
nx.draw_networkx(fb_sub_c,pos_fb,with_labels=False,alpha=0.5)
```
| github_jupyter |
What is the Merge Sort Algorithm?
It is a divide and conquer algorithm to solve and unorgainzed array into a sequence, ordered array
It splits into 2 halves, sorts them, and merges the sorted halves.
Ex.
43 2 24 65 34 1 67 35
Splits [Step 1]
(1) 43 2 24 65
(2) 34 1 67 35
Divide by 2 [Step 2]
43 2
24 65
34 1
67 35
Organize pairs [Step 3]
(By lowest to highest)
2, 43
24, 65
1, 34
35, 67
Classify Pairs [Step 4]
2, 43 a
24, 65 b
1, 34 c
35, 67 d
Merge a & b and c & d [Step 5]
ab 2, 24, 43, 65
cd 1, 34, 35, 67
Merge ab & cd
(Do this by comparing ab[0] to cd[0], etc...
1, 2, 24, 34, 35, 43, 65, 67
```
#Python code
array1 = [56, 39, 66, 8, 37, 57, 15, 30, 27, 77]
#Step 1 -- Split into 2
def ms_step1():
middle = len(array1) / 2
middle = int(middle)
group1a = array1[:middle]
group2a = array1[middle:]
ms_step1()
#Step 2 -- Group
def ms_step2():
if len(group1a) % 2 == 1:
#Odd
group1b = group1a[:3]
group2b = group1a[3:]
group3b = group2a[:3]
group4b = group2a[3:]
else:
#Even
group1b = group1a[:2]
group2b = group1a[2:]
group3b = group2a[:2]
group4b = group2a[2:]
ms_step2()
#Step 3 -- Organize Pairs
#Step 4 -- Classify Pairs
#Use sort function
def ms_step3a4():
group1b.sort()
group2b.sort()
group3b.sort()
group4b.sort()
ms_step3a4()
# Step 5 -- Merge Lists by comparing
def ms_step5():
bin1 = group1b + group2b
bin2 = group3b + group4b
bin1.sort()
bin2.sort()
solution = bin1 + bin2
solution.sort()
print(solution)
ms_step5()
array1 = [56, 39, 66, 8, 37, 57, 15, 30, 27, 77]; print(array1)
ms_step1()
ms_step2()
ms_step3a4()
ms_step5()
#Code written by Will Zou
def merge_sort():
array1 = [56, 39, 66, 8, 37, 57, 15, 30, 27, 77]
#step 1
middle = len(array1) / 2
middle = int(middle)
group1a = array1[:middle]
group2a = array1[middle:]
#step 2
if len(group1a) % 2 == 1:
#Odd
group1b = group1a[:3]
group2b = group1a[3:]
group3b = group2a[:3]
group4b = group2a[3:]
else:
#Even
group1b = group1a[:2]
group2b = group1a[2:]
group3b = group2a[:2]
group4b = group2a[2:]
#step 3 and 4
group1b.sort()
group2b.sort()
group3b.sort()
group4b.sort()
#step 5
bin1 = group1b + group2b
bin2 = group3b + group4b
bin1.sort()
bin2.sort()
solution = bin1 + bin2
solution.sort()
print(array1)
print(solution)
merge_sort()
```
https://www.geeksforgeeks.org/merge-sort/
https://github.com/william-zou21/MergeSortAlgorithm
| github_jupyter |
# Testing the effect of *Dropout Rates* with Different Layers
*This notebook uses the **Dog or Cat** data set available [here](http://files.fast.ai/data/dogscats.zip)*
```
# Put these at the top of every notebook, to get automatic reloading and inline plotting
%reload_ext autoreload
%autoreload 2
%matplotlib inline
# This file contains all the main external libs we'll use
from fastai.imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
# Using the same data set as Deep Learning Part 1 - lesson 1
PATH = "data/dogscats/"
# Select an image model
arch=resnet50
# Set to the number of CPU Cores you have
workers=8
# this is an array we will iterate through to test each one
dropouts = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
bestdrop = 0.2 # established in previous notebook so it will be our static dropout rate
# these variables are used for capturing results
los1 = []
acc1 = []
los2 = []
acc2 = []
sz=64 # unchanged
bs=512 # batch size
learnrate = 1e-1 #0.1
tfms = tfms_from_model(arch, sz)
data = ImageClassifierData.from_paths(PATH, tfms=tfms, bs=bs, num_workers=workers)
```
## Dropout Layers in Model
```
learn = ConvLearner.pretrained(arch, data, precompute=False, ps=bestdrop)
learn
```
## Learning Rate
```
learn = ConvLearner.pretrained(arch, data, precompute=False, ps=[0,bestdrop])
# Finding the learning rate
lrf=learn.lr_find()
# Plotting the learning rate
learn.sched.plot()
learn = ConvLearner.pretrained(arch, data, precompute=False, ps=[bestdrop,0])
# Finding the learning rate
lrf=learn.lr_find()
# Plotting the learning rate
learn.sched.plot()
```
## Run Tests
```
#### Dropout change in first layer only ####
#loop through all entries in the dropouts array
for dropout in dropouts:
learn = ConvLearner.pretrained(arch, data, precompute=False, ps=[dropout,bestdrop])
print('Dropout Rates: ',dropout,',',bestdrop)
# Make sure we have enough cycles and due to dropout variability, let's make sure we are mixing things up a bit
%time fit_array = learn.fit(learnrate, 3, cycle_len=1, cycle_mult=2)
# learn.fit actually returns an array that looks like this: [[0.1983260258436203],0.9185000009536743]
# it includes that last val_loss and accuracy values
accuracy = fit_array[1]
loss = fit_array[0][0]
# add them to our arrays for charting later
acc1.append(accuracy)
los1.append(loss)
#### Dropout change in second layer only ####
#loop through all entries in the dropouts array
for dropout in dropouts:
learn = ConvLearner.pretrained(arch, data, precompute=False, ps=[bestdrop,dropout])
print('Dropout Rates: ',bestdrop,',',dropout)
# Make sure we have enough cycles and due to dropout variability, let's make sure we are mixing things up a bit
%time fit_array = learn.fit(learnrate, 3, cycle_len=1, cycle_mult=2)
# learn.fit actually returns an array that looks like this: [[0.1983260258436203],0.9185000009536743]
# it includes that last val_loss and accuracy values
accuracy = fit_array[1]
loss = fit_array[0][0]
# add them to our arrays for charting later
acc2.append(accuracy)
los2.append(loss)
print(dropouts)
# dropout changes in first layer
print(acc1)
print(los1)
# dropout changes in second layer
print(acc2)
print(los2)
#cheatsheet of results
#acc1 =
#acc2 =
```
## Interpreting Results
```
width = 0.05 # bar width
# Get current size
fig_size = plt.rcParams["figure.figsize"]
# Set new size (0=width,1=height)
fig_size[0] = 10
fig_size[1] = 6
plt.rcParams["figure.figsize"] = fig_size
plt.bar(dropouts, acc1, width, align='center')
plt.tick_params(axis='x', which='major', labelsize=10)
plt.tick_params(axis='y', which='major', labelsize=15)
xrange = np.arange(0,1,.1)
plt.xticks(xrange, dropouts)
plt.ylim(.85,.95)
plt.xlabel('Dropout X,0.2', size = 20)
plt.ylabel('Accuracy',size = 20)
plt.show()
plt.bar(dropouts, acc2, width, align='center')
plt.tick_params(axis='x', which='major', labelsize=10)
plt.tick_params(axis='y', which='major', labelsize=15)
xrange = np.arange(0,1,.1)
plt.xticks(xrange, dropouts)
plt.ylim(.85,.95)
plt.xlabel('Dropout 0.2,X', size = 20)
plt.ylabel('Accuracy',size = 20)
plt.show()
```
| github_jupyter |
This notebook uses code from `VHA.ipynb`. It's much more concise and doesn't do VQE; we just get the ground state so I can quickly analyze its properties.
### Get ground state
```
import numpy as np
import scipy.linalg
from tools.utils import *
tol = 0.005
# Define lattice and model
from openfermion.utils import HubbardSquareLattice
# HubbardSquareLattice parameters
x_n = 8
y_n = 1
n_dofs = 1 # 1 degree of freedom for spin, this might be wrong. Having only one dof means ordered=False.
periodic = 0 # Not sure what this is, periodic boundary conditions?
spinless = 0 # Has spin
lattice = HubbardSquareLattice(x_n, y_n, n_dofs=n_dofs, periodic=periodic, spinless=spinless)
from openfermion.hamiltonians import FermiHubbardModel
from openfermion.utils import SpinPairs
tunneling = [('neighbor', (0, 0), 1.)] # Not sure if this is right
interaction = [('onsite', (0, 0), 6., SpinPairs.DIFF)] # Not sure if this is right
potential = [(0, 0.)]
# potential = None
mag_field = 0.
particle_hole_sym = False # Not sure if this is right
hubbard = FermiHubbardModel(lattice , tunneling_parameters=tunneling, interaction_parameters=interaction,
potential_parameters=potential, magnetic_field=mag_field,
particle_hole_symmetry=particle_hole_sym)
# Get ground state and energy
from openfermion import get_sparse_operator, get_ground_state
hub_sparse = get_sparse_operator(hubbard.hamiltonian())
genergy, gstate = get_ground_state(hub_sparse)
print("Ground state energy: ", genergy)
# w, v = scipy.sparse.linalg.eigsh(hub_sparse, k=200, which='SA')
# gstate=v[:, 199]
```
### Analyze ground state
```
# Get average measurement of each qubit
from cirq import measure_state_vector
measurements = [measure_state_vector(gstate, range(2 * x_n * y_n))[0] for _ in range(10000)]
np.mean(measurements, axis=0)
```
In Scalettar notes, magnetization $m$ is defined as $$m = \frac{\rho_\uparrow - \rho_\downarrow}{\rho_\uparrow + \rho_\downarrow}$$
```
# Calculate density
sum(np.mean(measurements, axis=0)) / (x_n * y_n)
# Check spin balance
up_spins = 0
down_spins = 0
unequal = 0
for trial in measurements:
up_spins += sum(trial[:x_n * y_n])
down_spins += sum(trial[x_n * y_n:])
if up_spins != down_spins:
unequal += 1
print("m =", (up_spins - down_spins) / (up_spins + down_spins))
unequal
pos = 0
neg = 0
for trial in measurements:
up_spins = sum(trial[:x_n * y_n])
down_spins = sum(trial[x_n * y_n:])
m = (up_spins - down_spins) / (up_spins + down_spins)
if np.abs(m) > tol:
if m > 0:
pos += 1
else:
neg += 1
pos
neg
```
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Objectives" data-toc-modified-id="Objectives-1"><span class="toc-item-num">1 </span>Objectives</a></span></li><li><span><a href="#Data-Types" data-toc-modified-id="Data-Types-2"><span class="toc-item-num">2 </span>Data Types</a></span><ul class="toc-item"><li><span><a href="#Data-Types" data-toc-modified-id="Data-Types-2.1"><span class="toc-item-num">2.1 </span>Data Types</a></span></li><li><span><a href="#How-can-we-check-types?" data-toc-modified-id="How-can-we-check-types?-2.2"><span class="toc-item-num">2.2 </span>How can we check types?</a></span></li><li><span><a href="#String-methods" data-toc-modified-id="String-methods-2.3"><span class="toc-item-num">2.3 </span>String methods</a></span></li><li><span></span></li></ul></li><li><span><a href="#Data-Structures" data-toc-modified-id="Data-Structures-3"><span class="toc-item-num">3 </span>Data Structures</a></span><ul class="toc-item"><li><span><a href="#List" data-toc-modified-id="List-3.1"><span class="toc-item-num">3.1 </span>List</a></span><ul class="toc-item"><li><span><a href="#List-Indexing" data-toc-modified-id="List-Indexing-3.1.1"><span class="toc-item-num">3.1.1 </span>List Indexing</a></span></li><li><span><a href="#List-Methods" data-toc-modified-id="List-Methods-3.1.2"><span class="toc-item-num">3.1.2 </span>List Methods</a></span></li></ul></li><li><span><a href="#Dictionaries" data-toc-modified-id="Dictionaries-3.2"><span class="toc-item-num">3.2 </span>Dictionaries</a></span><ul class="toc-item"><li><span><a href="#Accessing-elements-of-the-dictionary" data-toc-modified-id="Accessing-elements-of-the-dictionary-3.2.1"><span class="toc-item-num">3.2.1 </span>Accessing elements of the dictionary</a></span></li></ul></li></ul></li><li><span><a href="#Control-Flow" data-toc-modified-id="Control-Flow-4"><span class="toc-item-num">4 </span>Control Flow</a></span><ul class="toc-item"><li><span><a href="#If-Statements" data-toc-modified-id="If-Statements-4.1"><span class="toc-item-num">4.1 </span>If Statements</a></span><ul class="toc-item"><li><span><a href="#Ternary-Operator" data-toc-modified-id="Ternary-Operator-4.1.1"><span class="toc-item-num">4.1.1 </span>Ternary Operator</a></span></li></ul></li><li><span><a href="#for-loop-and-while-loops" data-toc-modified-id="for-loop-and-while-loops-4.2"><span class="toc-item-num">4.2 </span>for loop and while loops</a></span><ul class="toc-item"><li><span><a href="#for-Loops" data-toc-modified-id="for-Loops-4.2.1"><span class="toc-item-num">4.2.1 </span><code>for</code> Loops</a></span></li><li><span><a href="#while-Loops" data-toc-modified-id="while-Loops-4.2.2"><span class="toc-item-num">4.2.2 </span><code>while</code> Loops</a></span></li><li><span><a href="#🎵I-want-to-break-free!!!-🎵" data-toc-modified-id="🎵I-want-to-break-free!!!-🎵-4.2.3"><span class="toc-item-num">4.2.3 </span><em>🎵I want to break free!!! 🎵</em></a></span></li></ul></li></ul></li></ul></div>
# Objectives
You will be able to:
* Identify data types - strings, numbers, bool
* Identify data structures - lists, dictionaries
* Define use case for different control flow tools - if, for, while
# Data Types
## Data Types
```
string = 'What is the meaning of life?'
string2 = '525,600 minutes'
number = 42.0
another_num = 42
_bool = False
n = None
str(another_num)
int(number)
string1 = 'What is the meaning of life?'
string1
```
## How can we check types?
```
type(number)
```
## String methods
* .upper()
* .lower()
* .capitalize()
* .title()
```
string.title()
string.upper()
var = 'hello'
var1= 'python'
var2 = 'course!'
var.capitalize()
var2.capitalize()
var1.capitalize()
string.capitalize()
```
# Data Structures
* lists - []
* dictionaries - {'key':'value'/value, }
* tuple
## List
### List Indexing
```
top_travel_cities = ['Solta', 'Buenos Aires', 'Los Cabos', 'Walla Walla Valley', 'Marakesh', 'Albuquerque', 'Archipelago Sea', 'Iguazu Falls', 'Salina Island', 'Toronto', 'Pyeongchang']
top_travel_cities
type(top_travel_cities)
top_travel_cities[0:5]
len(top_travel_cities)
top_travel_cities[:4]
top_travel_cities[::-2]
```
### List Methods
* .pop() - remove last element added
* .append() - add element to end of list
* .insert() - inserts new element
* .remove() - remove element from list
* .extend() - extends one list with elements from another
```
#top_travel_cities.insert()
a = [1, 2, 3]
b = ['one', 'two', 'three']
a.pop()
print(a)
# .extend() exercise
print('a', a)
print('b', b)
a.extend(b)
print('new a', a)
a.remove(2)
print(a)
a.insert(2,5)
print(a)
```
You can also add lists together to create larger lists
```
c = a + b + [1000,100] + [1]
print(c)
```
You can also create lists of lists (nested lists)
```
a = [[10,11,22],3,4,a]
a
```
## Dictionaries
You should think of these as key-value pairs (they don't have order). In other languages, these are nearly equivalent to a **hash map**.
```
d = {'str_key':'str_val', 'other key':1, 10: 5}
# Getting the value via key
d['other key']
```
Safe way of getting a value (what if the key isn't there)
```
d['not a key'] # Gives error
print(d.get('not a key'))
d.get('not a key', 0) # Allows for a default value
```
### Accessing elements of the dictionary
```
d = {'str_key':'str_val', 'other key':1, 10: 5}
len(d)
d.keys()
d.values()
d.items()
```
## Tuple
```
roles = ("Admin", "Operator", "User")
# Or following line will create the same Tuple
# roles = "Admin", "Operator", "User"
print(roles[0])
roles = ("Admin", "Operator", "User")
roles[2] = "Customer"
permissions = (("Admin", "Operator", "Customer"), ("Developer", "Tester"), [1, 2, 3], {"Stage": "Development"})
print(permissions[2])
```
<b>Tuple unpacking
```
numbers = (1, 2, 3)
a, b, c = numbers
print(a)
print(b)
print(c)
```
# Control Flow
* for loop
* while loop
* if statement
## If Statements
```
# if statements
if condition_statement:
output (print_statement, return_statement, operation)
elif:
output alternate
else:
output last possibility
```
### Ternary Operator
This can be really useful when you want to shorten your code and make it more readable. These are especially common in list comprehnesions and lambda functions.
```
flag = False
x = 1 if flag else 0
print(x)
y = 10
z = 20
x = y if y < z else z
print(x)
y = 10
z = 20
if y < z:
print('Smaller value')
else:
print('None')
```
## for loop and while loops
* for loop - iterate through a set
* while loop - iterate through a condition
### `for` Loops
These act a little different from other typical languages. In Python, you are always looping over an [_iterable_](https://docs.python.org/3/glossary.html#term-iterable)
```
# for memeber in a_set:
# operation
fruits = ["Apple", "Orange", "Pineapple", "Grape"]
# Lets make juice with these fruits
for fruit in fruits:
print(fruit + " Juice!")
# start with 5 and ends with 10
for i in range(5, 10):
print(i)
for letter in 'Python': # Here "Python" acts like a list of characters
print(letter)
```
### `while` Loops
`while` loops will keep going until a condition is met or the "brakes are pumped" with a `break` statement (See next subsection).
```
# while condition(>,<.>=,<=,==):
# operation
stop_number = 4
while stop_number > 0:
print(stop_number)
stop_number -= 1
print("The stop_number reached", stop_number, "so the while loop's condition became False and stopped execution")
```
### _🎵I want to break free!!! 🎵_
You can add more control in these loops with `continue` and `break`. They are usually part of an if-else block to find certain situations.
```
i = 0
while(i<10):
print(i)
if i == 5:
print('Break freee!!!')
break
i += 1
i = 0
counter = 0
while(i<10):
i += 1
counter += 1
if counter % 2 == 0:
continue
# This won't be reached if even
print(i,'After the continue')
```
| github_jupyter |
# Training Keras models with TensorFlow Cloud
**Author:** [Jonah Kohn](https://jonahkohn.com)<br>
**Date created:** 2020/08/11<br>
**Last modified:** 2020/08/11<br>
**Description:** In-depth usage guide for TensorFlow Cloud.
## Introduction
[TensorFlow Cloud](https://github.com/tensorflow/cloud) is a Python package that
provides APIs for a seamless transition from local debugging to distributed training
in Google Cloud. It simplifies the process of training TensorFlow models on the
cloud into a single, simple function call, requiring minimal setup and no changes
to your model. TensorFlow Cloud handles cloud-specific tasks such as creating VM
instances and distribution strategies for your models automatically. This guide
will demonstrate how to interface with Google Cloud through TensorFlow Cloud,
and the wide range of functionality provided within TensorFlow Cloud. We'll start
with the simplest use-case.
## Setup
We'll get started by installing TensorFlow Cloud, and importing the packages we
will need in this guide.
```
!pip install -q tensorflow_cloud
import tensorflow as tf
import tensorflow_cloud as tfc
from tensorflow import keras
from tensorflow.keras import layers
```
## API overview: a first end-to-end example
Let's begin with a Keras model training script, such as the following CNN:
```python
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
model = keras.Sequential(
[
keras.Input(shape=(28, 28)),
# Use a Rescaling layer to make sure input values are in the [0, 1] range.
layers.experimental.preprocessing.Rescaling(1.0 / 255),
# The original images have shape (28, 28), so we reshape them to (28, 28, 1)
layers.Reshape(target_shape=(28, 28, 1)),
# Follow-up with a classic small convnet
layers.Conv2D(32, 3, activation="relu"),
layers.MaxPooling2D(2),
layers.Conv2D(32, 3, activation="relu"),
layers.MaxPooling2D(2),
layers.Conv2D(32, 3, activation="relu"),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10),
]
)
model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=keras.metrics.SparseCategoricalAccuracy(),
)
model.fit(x_train, y_train, epochs=20, batch_size=128, validation_split=0.1)
```
To train this model on Google Cloud we just need to add a call to `run()` at
the beginning of the script, before the imports:
```python
tfc.run()
```
You don't need to worry about cloud-specific tasks such as creating VM instances
and distribution strategies when using TensorFlow Cloud.
The API includes intelligent defaults for all the parameters -- everything is
configurable, but many models can rely on these defaults.
Upon calling `run()`, TensorFlow Cloud will:
- Make your Python script or notebook distribution-ready.
- Convert it into a Docker image with required dependencies.
- Run the training job on a GCP GPU-powered VM.
- Stream relevant logs and job information.
The default VM configuration is 1 chief and 0 workers with 8 CPU cores and
1 Tesla T4 GPU.
## Google Cloud configuration
In order to facilitate the proper pathways for Cloud training, you will need to
do some first-time setup. If you're a new Google Cloud user, there are a few
preliminary steps you will need to take:
1. Create a GCP Project;
2. Enable AI Platform Services;
3. Create a Service Account;
4. Download an authorization key;
5. Create a Cloud Storage bucket.
Detailed first-time setup instructions can be found in the
[TensorFlow Cloud README](https://github.com/tensorflow/cloud#setup-instructions),
and an additional setup example is shown on the
[TensorFlow Blog](https://blog.tensorflow.org/2020/08/train-your-tensorflow-model-on-google.html).
## Common workflows and Cloud storage
In most cases, you'll want to retrieve your model after training on Google Cloud.
For this, it's crucial to redirect saving and loading to Cloud Storage while
training remotely. We can direct TensorFlow Cloud to our Cloud Storage bucket for
a variety of tasks. The storage bucket can be used to save and load large training
datasets, store callback logs or model weights, and save trained model files.
To begin, let's configure `fit()` to save the model to a Cloud Storage, and set
up TensorBoard monitoring to track training progress.
```
def create_model():
model = keras.Sequential(
[
keras.Input(shape=(28, 28)),
layers.experimental.preprocessing.Rescaling(1.0 / 255),
layers.Reshape(target_shape=(28, 28, 1)),
layers.Conv2D(32, 3, activation="relu"),
layers.MaxPooling2D(2),
layers.Conv2D(32, 3, activation="relu"),
layers.MaxPooling2D(2),
layers.Conv2D(32, 3, activation="relu"),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10),
]
)
model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=keras.metrics.SparseCategoricalAccuracy(),
)
return model
```
Let's save the TensorBoard logs and model checkpoints generated during training
in our cloud storage bucket.
```
import datetime
import os
# Note: Please change the gcp_bucket to your bucket name.
gcp_bucket = "keras-examples"
checkpoint_path = os.path.join("gs://", gcp_bucket, "mnist_example", "save_at_{epoch}")
tensorboard_path = os.path.join( # Timestamp included to enable timeseries graphs
"gs://", gcp_bucket, "logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
)
callbacks = [
# TensorBoard will store logs for each epoch and graph performance for us.
keras.callbacks.TensorBoard(log_dir=tensorboard_path, histogram_freq=1),
# ModelCheckpoint will save models after each epoch for retrieval later.
keras.callbacks.ModelCheckpoint(checkpoint_path),
# EarlyStopping will terminate training when val_loss ceases to improve.
keras.callbacks.EarlyStopping(monitor="val_loss", patience=3),
]
model = create_model()
```
Here, we will load our data from Keras directly. In general, it's best practice
to store your dataset in your Cloud Storage bucket, however TensorFlow Cloud can
also accomodate datasets stored locally. That's covered in the Multi-file section
of this guide.
```
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
```
The [TensorFlow Cloud](https://github.com/tensorflow/cloud) API provides the
`remote()` function to determine whether code is being executed locally or on
the cloud. This allows for the separate designation of `fit()` parameters for
local and remote execution, and provides means for easy debugging without overloading
your local machine.
```
if tfc.remote():
epochs = 100
callbacks = callbacks
batch_size = 128
else:
epochs = 5
batch_size = 64
callbacks = None
model.fit(x_train, y_train, epochs=epochs, callbacks=callbacks, batch_size=batch_size)
```
Let's save the model in GCS after the training is complete.
```
save_path = os.path.join("gs://", gcp_bucket, "mnist_example")
if tfc.remote():
model.save(save_path)
```
We can also use this storage bucket for Docker image building, instead of your local
Docker instance. For this, just add your bucket to the `docker_image_bucket_name` parameter.
```
# docs_infra: no_execute
tfc.run(docker_image_bucket_name=gcp_bucket)
```
After training the model, we can load the saved model and view our TensorBoard logs
to monitor performance.
```
# docs_infra: no_execute
model = keras.models.load_model(save_path)
!#docs_infra: no_execute
!tensorboard dev upload --logdir "gs://keras-examples-jonah/logs/fit" --name "Guide MNIST"
```
## Large-scale projects
In many cases, your project containing a Keras model may encompass more than one
Python script, or may involve external data or specific dependencies. TensorFlow
Cloud is entirely flexible for large-scale deployment, and provides a number of
intelligent functionalities to aid your projects.
### Entry points: support for Python scripts and Jupyter notebooks
Your call to the `run()` API won't always be contained inside the same Python script
as your model training code. For this purpose, we provide an `entry_point` parameter.
The `entry_point` parameter can be used to specify the Python script or notebook in
which your model training code lives. When calling `run()` from the same script as
your model, use the `entry_point` default of `None`.
### `pip` dependencies
If your project calls on additional `pip` dependencies, it's possible to specify
the additional required libraries by including a `requirements.txt` file. In this
file, simply put a list of all the required dependencies and TensorFlow Cloud will
handle integrating these into your cloud build.
### Python notebooks
TensorFlow Cloud is also runnable from Python notebooks. Additionally, your specified
`entry_point` can be a notebook if needed. There are two key differences to keep
in mind between TensorFlow Cloud on notebooks compared to scripts:
- When calling `run()` from within a notebook, a Cloud Storage bucket must be specified
for building and storing your Docker image.
- GCloud authentication happens entirely through your authentication key, without
project specification. An example workflow using TensorFlow Cloud from a notebook
is provided in the "Putting it all together" section of this guide.
### Multi-file projects
If your model depends on additional files, you only need to ensure that these files
live in the same directory (or subdirectory) of the specified entry point. Every file
that is stored in the same directory as the specified `entry_point` will be included
in the Docker image, as well as any files stored in subdirectories adjacent to the
`entry_point`. This is also true for dependencies you may need which can't be acquired
through `pip`
For an example of a custom entry-point and multi-file project with additional pip
dependencies, take a look at this multi-file example on the
[TensorFlow Cloud Repository](https://github.com/tensorflow/cloud/tree/master/src/python/tensorflow_cloud/core/tests/examples/multi_file_example).
For brevity, we'll just include the example's `run()` call:
```python
tfc.run(
docker_image_bucket_name=gcp_bucket,
entry_point="train_model.py",
requirements="requirements.txt"
)
```
## Machine configuration and distributed training
Model training may require a wide range of different resources, depending on the
size of the model or the dataset. When accounting for configurations with multiple
GPUs, it becomes critical to choose a fitting
[distribution strategy](https://www.tensorflow.org/guide/distributed_training).
Here, we outline a few possible configurations:
### Multi-worker distribution
Here, we can use `COMMON_MACHINE_CONFIGS` to designate 1 chief CPU and 4 worker GPUs.
```python
tfc.run(
docker_image_bucket_name=gcp_bucket,
chief_config=tfc.COMMON_MACHINE_CONFIGS['CPU'],
worker_count=2,
worker_config=tfc.COMMON_MACHINE_CONFIGS['T4_4X']
)
```
By default, TensorFlow Cloud chooses the best distribution strategy for your machine
configuration with a simple formula using the `chief_config`, `worker_config` and
`worker_count` parameters provided.
- If the number of GPUs specified is greater than zero, `tf.distribute.MirroredStrategy` will be chosen.
- If the number of workers is greater than zero, `tf.distribute.experimental.MultiWorkerMirroredStrategy` or `tf.distribute.experimental.TPUStrategy` will be chosen based on the accelerator type.
- Otherwise, `tf.distribute.OneDeviceStrategy` will be chosen.
### TPU distribution
Let's train the same model on TPU, as shown:
```python
tfc.run(
docker_image_bucket_name=gcp_bucket,
chief_config=tfc.COMMON_MACHINE_CONFIGS["CPU"],
worker_count=1,
worker_config=tfc.COMMON_MACHINE_CONFIGS["TPU"]
)
```
### Custom distribution strategy
To specify a custom distribution strategy, format your code normally as you would
according to the
[distributed training guide](https://www.tensorflow.org/guide/distributed_training)
and set `distribution_strategy` to `None`. Below, we'll specify our own distribution
strategy for the same MNIST model.
```python
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = create_model()
if tfc.remote():
epochs = 100
batch_size = 128
else:
epochs = 10
batch_size = 64
callbacks = None
model.fit(
x_train, y_train, epochs=epochs, callbacks=callbacks, batch_size=batch_size
)
tfc.run(
docker_image_bucket_name=gcp_bucket,
chief_config=tfc.COMMON_MACHINE_CONFIGS['CPU'],
worker_count=2,
worker_config=tfc.COMMON_MACHINE_CONFIGS['T4_4X'],
distribution_strategy=None
)
```
## Custom Docker images
By default, TensorFlow Cloud uses a
[Docker base image](https://hub.docker.com/r/tensorflow/tensorflow/)
supplied by Google and corresponding to your current TensorFlow version. However,
you can also specify a custom Docker image to fit your build requirements, if necessary.
For this example, we will specify the Docker image from an older version of TensorFlow:
```python
tfc.run(
docker_image_bucket_name=gcp_bucket,
base_docker_image="tensorflow/tensorflow:2.1.0-gpu"
)
```
## Additional metrics
You may find it useful to tag your Cloud jobs with specific labels, or to stream
your model's logs during Cloud training.
It's good practice to maintain proper labeling on all Cloud jobs, for record-keeping.
For this purpose, `run()` accepts a dictionary of labels up to 64 key-value pairs,
which are visible from the Cloud build logs. Logs such as epoch performance and model
saving internals can be accessed using the link provided by executing `tfc.run` or
printed to your local terminal using the `stream_logs` flag.
```python
job_labels = {"job": "mnist-example", "team": "keras-io", "user": "jonah"}
tfc.run(
docker_image_bucket_name=gcp_bucket,
job_labels=job_labels,
stream_logs=True
)
```
## Putting it all together
For an in-depth Colab which uses many of the features described in this guide,
follow along
[this example](https://github.com/tensorflow/cloud/blob/master/src/python/tensorflow_cloud/core/tests/examples/dogs_classification.ipynb)
to train a state-of-the-art model to recognize dog breeds from photos using feature
extraction.
| github_jupyter |
```
# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir( os.path.join('..', 'notebook_format') )
from formats import load_style
load_style()
os.chdir(path)
# 1. magic to print version
# 2. magic so that the notebook will reload external python modules
%load_ext watermark
%load_ext autoreload
%autoreload 2
%watermark -a 'Ethen' -d -t -v
```
# Logging
Once your application grows beyond a basic project, having good logging as oppose to just print statement is going to allow us to look at behaviors and errors over time and give us a better overall picture of what's going on.
There are 5 different kinds of logging levels. Levels allow us to to specify exactly what we want to log by separating them into categories. The description of each of these is as follows:
- DEBUG: Detailed debugrmation, typically of interest only when diagnosing problems
- INFO: Confirmation that things are working as expected
- WARNING: An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected
- ERROR: Due to a more serious problem, the software has not been able to perform some function
- CRITICAL: A serious error, indicating that the program itself may be unable to continue running
The default level is WARNING, meaning that it will capture anything that is a warning or above, and ignore the DEBUG and debug level. we can change this behavior using the basicConfig method.
```
import logging
from imp import reload
# jupyter notebook already uses logging, thus we reload the module to make it work in notebooks
# http://stackoverflow.com/questions/18786912/get-output-from-the-logging-module-in-ipython-notebook
reload(logging)
# In the following not only did we change the logging level, but
# also specify a logging file to write the log in, and the format.
# the format we specified here is simply the time, the level name
# and the message that we'll later specify, for more information
# about what format we can specify, refer to the following webpage
# https://docs.python.org/3/library/logging.html#logrecord-attributes
logging.basicConfig(filename = 'test.log', level = logging.DEBUG,
format = '%(asctime)s:%(levelname)s:%(message)s')
def add(x, y):
"""Add Function"""
return x + y
def subtract(x, y):
"""Subtract Function"""
return x - y
def multiply(x, y):
"""Multiply Function"""
return x * y
def divide(x, y):
"""Divide Function"""
return x / y
num_1 = 20
num_2 = 10
# add logging debugrmation instead of print statement
# to record what was going on, note that if we were to
# run it for multiple
add_result = add(num_1, num_2)
logging.debug('Add: {} + {} = {}'.format(num_1, num_2, add_result))
sub_result = subtract(num_1, num_2)
logging.debug('Sub: {} - {} = {}'.format(num_1, num_2, sub_result))
mul_result = multiply(num_1, num_2)
logging.debug('Mul: {} * {} = {}'.format(num_1, num_2, mul_result))
div_result = divide(num_1, num_2)
logging.debug('Div: {} / {} = {}'.format(num_1, num_2, div_result))
```
After running the code, we should a logging file in the same directory as the notebook. And it should something along the lines of:
```
2017-03-16 13:55:32,075:DEBUG:Add: 20 + 10 = 30
2017-03-16 13:55:32,076:DEBUG:Sub: 20 - 10 = 10
2017-03-16 13:55:32,076:DEBUG:Mul: 20 * 10 = 200
2017-03-16 13:55:32,076:DEBUG:Div: 20 / 10 = 2.0
```
The code chunk logs the information in the root logger. If we have multiple scripts that does the logging, they will get logged to the same place, which might not be ideal. Thus we can create a separate logger for each module.
```
import logging
# then specify the module's logger, the logger's level
# and add the handler to the logger
logger = logging.getLogger(__name__)
logger.setLevel(logging.ERROR)
# boiler plate, set the format using Formatter,
# and set the file to log to with FileHandler
formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(message)s')
file_handler = logging.FileHandler('math.log')
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
# note that we do not need to reload the logging
# module this time, as it will not have conflict
# with jupyter notebook's logging behavior
def add(x, y):
"""Add Function"""
return x + y
def subtract(x, y):
"""Subtract Function"""
return x - y
def multiply(x, y):
"""Multiply Function"""
return x * y
def divide(x, y):
"""Divide Function"""
try:
result = x / y
except ZeroDivisionError:
# by calling .exception it will produce the traceback,
# which is helpful for knowing where the bug occurred
logger.exception('Tried to divide by 0')
else:
return result
num_1 = 20
num_2 = 0
# note that we'll use the logger we explicitly created
# to log to message as oppose to logging in the last example
add_result = add(num_1, num_2)
logger.info('Add: {} + {} = {}'.format(num_1, num_2, add_result))
sub_result = subtract(num_1, num_2)
logger.info('Sub: {} - {} = {}'.format(num_1, num_2, sub_result))
mul_result = multiply(num_1, num_2)
logger.info('Mul: {} * {} = {}'.format(num_1, num_2, mul_result))
div_result = divide(num_1, num_2)
logger.info('Div: {} / {} = {}'.format(num_1, num_2, div_result))
```
```
2017-03-16 15:02:58,144:ERROR:Tried to divide by 0
Traceback (most recent call last):
File "<ipython-input-7-573995498bac>", line 37, in divide
result = x / y
ZeroDivisionError: division by zero
```
# Reference
- [Youtube: Python Tutorial: Logging Basics - Logging to Files, Setting Levels, and Formatting](https://www.youtube.com/watch?v=-ARI4Cz-awo)
- [Toutube: Python Tutorial: Logging Advanced - Loggers, Handlers, and Formatters](https://www.youtube.com/watch?v=jxmzY9soFXg&feature=youtu.be)
| github_jupyter |
# Jelly roll model
In this notebook we show how to set up and solve the "two-potential" model from "Homogenisation of spirally-wound high-contrast layered materials", S. Psaltis, R. Timms, C.P. Please, S.J. Chapman, SIAM Journal on Applied Mathematics, 2020.
We consider a spirally-wound cell, such as the common 18650 lithium-ion cell. In practice these cells are constructed by rolling a sandwich of layers containing the active cathode, positive current collector, active cathode, separator, active anode, negative current collector, active anode, and separator. The "two-potential" model consists of an equation for the potential $\phi^\pm$ in each current collector. The potential difference drives a current $I$ through the electrode/separator/electrode sandwich (which we refer to as the "active material" in the original paper). Thus, in non-dimensional form, the model is
$$ \frac{\delta^+\sigma^+}{2\pi^2}\frac{1}{r}\frac{\mathrm{d}}{\mathrm{d}r}\left(\frac{1}{r}\frac{\mathrm{d}\phi^+}{\mathrm{d}r}\right) + 2I(\phi^+-\phi^-) = 0,$$
$$ \frac{\delta^-\sigma^-}{2\pi^2}\frac{1}{r}\frac{\mathrm{d}}{\mathrm{d}r}\left(\frac{1}{r}\frac{\mathrm{d}\phi^-}{\mathrm{d}r}\right) - 2I(\phi^+-\phi^-) = 0,$$
with boundary conditions
$$ \frac{\mathrm{d}\phi^+}{\mathrm{d}r}(r=r_0) = 0, \quad \phi^+(r=1) = 1, \quad \phi^-(r=0) = 0, \quad \frac{\mathrm{d}\phi^-}{\mathrm{d}r}(r=1) = 0.$$
For a complete description of the model and parameters, please refer to the original paper.
It can be shown that the active material can be modelled using any 1D battery model we like to describe the electrochemical/thermal behaviour in the electrode/separator/electrode sandwich. Such functionality will be added to PyBaMM in a future release and will enable efficient simulations of jelly roll cells.
## Two-potential resistor model
In this section we consider a simplified model in which we ignore the details of the anode, cathode and separator, and treat them as a single region of active material, modelled as an Ohmic conductor, with two such regions per winding. In this case the model becomes
$$ \frac{\delta^+\sigma^+}{2\pi^2}\frac{1}{r}\frac{\mathrm{d}}{\mathrm{d}r}\left(\frac{1}{r}\frac{\mathrm{d}\phi^+}{\mathrm{d}r}\right) + \frac{2\sigma^{a}(\phi^--\phi^+)}{l\epsilon^4} = 0,$$
$$ \frac{\delta^-\sigma^-}{2\pi^2}\frac{1}{r}\frac{\mathrm{d}}{\mathrm{d}r}\left(\frac{1}{r}\frac{\mathrm{d}\phi^-}{\mathrm{d}r}\right) - \frac{2\sigma^{a}(\phi^--\phi^+)}{l\epsilon^4} = 0,$$
along with the same boundary conditions.
We begin by importing PyBaMM along with some other useful packages
```
%pip install pybamm -q # install PyBaMM if it is not installed
import pybamm
import numpy as np
from numpy import pi
import matplotlib.pyplot as plt
```
First we will define the parameters in the model. Note the model is posed in non-dimensional form.
```
N = pybamm.Parameter("Number of winds")
r0 = pybamm.Parameter("Inner radius")
eps = (1 - r0) / N # ratio of sandwich thickness to cell radius
delta = pybamm.Parameter("Current collector thickness")
delta_p = delta # assume same thickness
delta_n = delta # assume same thickness
l = 1/2 - delta_p - delta_n # active material thickness
sigma_p = pybamm.Parameter("Positive current collector conductivity")
sigma_n = pybamm.Parameter("Negative current collector conductivity")
sigma_a = pybamm.Parameter("Active material conductivity")
```
Next we define our geometry and model
```
# geometry
r = pybamm.SpatialVariable("radius", domain="cell", coord_sys="cylindrical polar")
geometry = {"cell": {r: {"min": r0, "max": 1}}}
# model
model = pybamm.BaseModel()
phi_p = pybamm.Variable("Positive potential", domain="cell")
phi_n = pybamm.Variable("Negative potential", domain="cell")
A_p = (2 * sigma_a / eps ** 4 / l) / (delta_p * sigma_p / 2 / pi ** 2)
A_n = (2 * sigma_a / eps ** 4 / l) / (delta_n * sigma_n / 2 / pi ** 2)
model.algebraic = {
phi_p: pybamm.div((1 / r ** 2) * pybamm.grad(phi_p)) + A_p * (phi_n - phi_p),
phi_n: pybamm.div((1 / r ** 2) * pybamm.grad(phi_n)) - A_n * (phi_n - phi_p),
}
model.boundary_conditions = {
phi_p: {
"left": (0, "Neumann"),
"right": (1, "Dirichlet"),
},
phi_n: {
"left": (0, "Dirichlet"),
"right": (0, "Neumann"),
}
}
model.initial_conditions = {phi_p: 1, phi_n: 0} # initial guess for solver
model.variables = {"Negative potential": phi_n, "Positive potential": phi_p}
```
Next we provide values for our parameters, and process our geometry and model, thus replacing the `Parameter` symbols with numerical values
```
params = pybamm.ParameterValues(
{
"Number of winds":20,
"Inner radius": 0.25,
"Current collector thickness": 0.05,
"Positive current collector conductivity": 5e6,
"Negative current collector conductivity": 5e6,
"Active material conductivity": 1,
}
)
params.process_geometry(geometry)
params.process_model(model)
```
We choose to discretise in space using the Finite Volume method on a uniform grid
```
# mesh
submesh_types = {"cell": pybamm.Uniform1DSubMesh}
var_pts = {r: 100}
mesh = pybamm.Mesh(geometry, submesh_types, var_pts)
# method
spatial_methods = {"cell": pybamm.FiniteVolume()}
# discretise
disc = pybamm.Discretisation(mesh, spatial_methods)
disc.process_model(model);
```
We can now solve the model
```
# solver
solver = pybamm.CasadiAlgebraicSolver()
solution = solver.solve(model)
```
The model gives the homogenised potentials in the negative a positive current collectors. Interestingly, the solid potential has microscale structure, varying linearly in the active material. In order to see this we need to post-process the solution and plot the potential as a function of radial position, being careful to capture the spiral geometry.
```
# extract numerical parameter values
# Note: this overrides the definition of the `pybamm.Parameter` objects
N = params.evaluate(N)
r0 = params.evaluate(r0)
eps = params.evaluate(eps)
delta = params.evaluate(delta)
# post-process homogenised potential
phi_n = solution["Negative potential"]
phi_p = solution["Positive potential"]
def alpha(r):
return 2 * (phi_n(x=r) - phi_p(x=r))
def phi_am1(r, theta):
# careful here - phi always returns a column vector so we need to add a new axis to r to get the right shape
return alpha(r) * (r[:,np.newaxis]/eps - r0/eps - delta - theta / 2 / pi) / (1 - 4*delta) + phi_p(x=r)
def phi_am2(r, theta):
# careful here - phi always returns a column vector so we need to add a new axis to r to get the right shape
return alpha(r) * (r0/eps + 1 - delta + theta / 2 / pi - r[:,np.newaxis]/eps) / (1 - 4*delta) + phi_p(x=r)
# define spiral
spiral_pos_inner = lambda t : r0 - eps * delta + eps * t / (2 * pi)
spiral_pos_outer = lambda t : r0 + eps * delta + eps * t / (2 * pi)
spiral_neg_inner = lambda t : r0 - eps * delta + eps/2 + eps * t / (2 * pi)
spiral_neg_outer = lambda t : r0 + eps * delta + eps/2 + eps * t / (2 * pi)
spiral_am1_inner = lambda t : r0 + eps * delta + eps * t / (2 * pi)
spiral_am1_outer = lambda t : r0 - eps * delta + eps/2 + eps * t / (2 * pi)
spiral_am2_inner = lambda t : r0 + eps * delta + eps/2 + eps * t / (2 * pi)
spiral_am2_outer = lambda t : r0 - eps * delta + eps + eps * t / (2 * pi)
# Setup fine mesh with nr points per layer
nr = 10
rr = np.linspace(r0, 1, nr)
tt = np.arange(0, (N+1)*2*pi, 2*pi)
# N+1 winds of pos c.c.
r_mesh_pos = np.zeros((len(tt),len(rr)))
for i in range(len(tt)):
r_mesh_pos[i,:] = np.linspace(spiral_pos_inner(tt[i]), spiral_pos_outer(tt[i]), nr)
# N winds of neg, am1, am2
r_mesh_neg = np.zeros((len(tt)-1, len(rr)))
r_mesh_am1 = np.zeros((len(tt)-1, len(rr)))
r_mesh_am2 = np.zeros((len(tt)-1, len(rr)))
for i in range(len(tt)-1):
r_mesh_am2[i,:] = np.linspace(spiral_am2_inner(tt[i]), spiral_am2_outer(tt[i]), nr)
r_mesh_neg[i,:] = np.linspace(spiral_neg_inner(tt[i]), spiral_neg_outer(tt[i]), nr)
r_mesh_am1[i,:] = np.linspace(spiral_am1_inner(tt[i]), spiral_am1_outer(tt[i]), nr)
# Combine and sort
r_total_mesh = np.vstack((r_mesh_pos,r_mesh_neg,r_mesh_am1, r_mesh_am2))
r_total_mesh = np.sort(r_total_mesh,axis=None)
# plot homogenised potential
fig, ax = plt.subplots(1, 1, figsize=(8,6))
ax.plot(r_total_mesh, phi_n(x=r_total_mesh), 'b', label=r"$\phi^-$")
ax.plot(r_total_mesh, phi_p(x=r_total_mesh), 'r', label=r"$\phi^+$")
for i in range(len(tt)):
ax.plot(r_mesh_pos[i,:], phi_p(x=r_mesh_pos[i,:]), 'k', label=r"$\phi$" if i ==0 else "")
for i in range(len(tt)-1):
ax.plot(r_mesh_neg[i,:], phi_n(x=r_mesh_neg[i,:]), 'k')
ax.plot(r_mesh_am1[i,:], phi_am1(r_mesh_am1[i,:], tt[i]), 'k')
ax.plot(r_mesh_am2[i,:], phi_am2(r_mesh_am2[i,:], tt[i]), 'k')
ax.set_xlabel(r"$r$")
ax.set_ylabel(r"$\phi$")
ax.legend();
```
## References
The relevant papers for this notebook are:
```
pybamm.print_citations()
```
| github_jupyter |
```
import plaidml.keras
plaidml.keras.install_backend()
import os
os.environ["KERAS_BACKEND"] = "plaidml.keras.backend"
# Importing useful libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional, Conv1D, Flatten, MaxPooling1D
from keras.optimizers import SGD
import math
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from keras import optimizers
import time
```
### Data Processing
```
df = pd.read_csv('../data/num_data.csv')
dataset = df
dataset.shape
def return_rmse(test,predicted):
rmse = math.sqrt(mean_squared_error(test, predicted))
return rmse
data_size = dataset.shape[0]
train_size=int(data_size * 0.6)
test_size = 100
valid_size = data_size - train_size - test_size
test_next_day = [12, 24, 48]
training_set = dataset[:train_size].iloc[:,4:16].values
valid_set = dataset[train_size:train_size+valid_size].iloc[:,4:16].values
test_set = dataset[data_size-test_size:].iloc[:,4:16].values
y = dataset.iloc[:,4].values
y = y.reshape(-1,1)
n_feature = training_set.shape[1]
y.shape
# Scaling the dataset
sc = MinMaxScaler(feature_range=(0,1))
training_set_scaled = sc.fit_transform(training_set)
valid_set_scaled = sc.fit_transform(valid_set)
test_set_scaled = sc.fit_transform(test_set)
sc_y = MinMaxScaler(feature_range=(0,1))
y_scaled = sc_y.fit_transform(y)
# split a multivariate sequence into samples
position_of_target = 4
def split_sequences(sequences, n_steps_in, n_steps_out):
X_, y_ = list(), list()
for i in range(len(sequences)):
# find the end of this pattern
end_ix = i + n_steps_in
out_end_ix = end_ix + n_steps_out-1
# check if we are beyond the dataset
if out_end_ix > len(sequences):
break
# gather input and output parts of the pattern
seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix-1:out_end_ix, position_of_target]
X_.append(seq_x)
y_.append(seq_y)
return np.array(X_), np.array(y_)
n_steps_in = 12
n_steps_out = 12
X_train, y_train = split_sequences(training_set_scaled, n_steps_in, n_steps_out)
X_valid, y_valid = split_sequences(valid_set_scaled, n_steps_in, n_steps_out)
X_test, y_test = split_sequences(test_set_scaled, n_steps_in, n_steps_out)
GRU_LSTM_reg = Sequential()
GRU_LSTM_reg.add(GRU(units=50, return_sequences=True, input_shape=(X_train.shape[1],n_feature), activation='tanh'))
GRU_LSTM_reg.add(LSTM(units=50, activation='tanh'))
GRU_LSTM_reg.add(Dense(units=n_steps_out))
DFS_2LSTM = Sequential()
DFS_2LSTM.add(Conv1D(filters=64, kernel_size=6, activation='tanh', input_shape=(X_train.shape[1],n_feature)))
DFS_2LSTM.add(MaxPooling1D(pool_size=4))
DFS_2LSTM.add(Dropout(0.2))
DFS_2LSTM.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1],n_feature), activation='tanh'))
DFS_2LSTM.add(LSTM(units=50, activation='tanh'))
DFS_2LSTM.add(Dropout(0.190 + 0.0025 * n_steps_in))
DFS_2LSTM.add(Dense(units=n_steps_out))
# Compiling the RNNs
adam = optimizers.Adam(lr=0.01)
GRU_LSTM_reg.compile(optimizer=adam,loss='mean_squared_error')
DFS_2LSTM.compile(optimizer=adam,loss='mean_squared_error')
RnnModelDict = {'DFS_2LSTM': DFS_2LSTM}
rmse_df = pd.DataFrame(columns=['Model', 'train_rmse', 'valid_rmse', 'train_time'])
# RnnModelDict = {'LSTM_GRU': LSTM_GRU_reg}
for model in RnnModelDict:
regressor = RnnModelDict[model]
print('training start for', model)
start = time.process_time()
regressor.fit(X_train,y_train,epochs=50,batch_size=1024)
train_time = round(time.process_time() - start, 2)
print('results for training set')
y_train_pred = regressor.predict(X_train)
# plot_predictions(y_train,y_train_pred)
train_rmse = return_rmse(y_train,y_train_pred)
print('results for valid set')
y_valid_pred = regressor.predict(X_valid)
# plot_predictions(y_valid,y_valid_pred)
valid_rmse = return_rmse(y_valid,y_valid_pred)
# print('results for test set - 24 hours')
# y_test_pred24 = regressor.predict(X_test_24)
# plot_predictions(y_test_24,y_test_pred24)
# test24_rmse = return_rmse(y_test_24,y_test_pred24)
one_df = pd.DataFrame([[model, train_rmse, valid_rmse, train_time]],
columns=['Model', 'train_rmse', 'valid_rmse', 'train_time'])
rmse_df = pd.concat([rmse_df, one_df])
# save the rmse results
# rmse_df.to_csv('../rmse_24h_plus_time.csv')
history = regressor.fit(X_train, y_train, epochs=50, batch_size=1024, validation_data=(X_valid, y_valid),
verbose=2, shuffle=False)
# plot history
plt.figure(figsize=(30, 15))
plt.plot(history.history['loss'], label='Training')
plt.plot(history.history['val_loss'], label='Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Transform back and plot
y_train_origin = y[:train_size-46]
y_valid_origin = y[train_size:train_size+valid_size]
y_train_pred = regressor.predict(X_train)
y_train_pred_origin = sc_y.inverse_transform(y_train_pred)
y_valid_pred = regressor.predict(X_valid)
y_valid_pred_origin = sc_y.inverse_transform(y_valid_pred)
_y_train_pred_origin = y_train_pred_origin[:, 0:1]
_y_valid_pred_origin = y_valid_pred_origin[:, 0:1]
plt.figure(figsize=(20, 8));
plt.plot(pd.to_datetime(valid_original.index), valid_original,
alpha=0.5, color='red', label='Actual PM2.5 Concentration',)
plt.plot(pd.to_datetime(valid_original.index), y_valid_pred_origin[:,0:1],
alpha=0.5, color='blue', label='Predicted PM2.5 Concentation')
plt.title('PM2.5 Concentration Prediction')
plt.xlabel('Time')
plt.ylabel('PM2.5 Concentration')
plt.legend()
plt.show()
sample = 500
plt.figure(figsize=(20, 8));
plt.plot(pd.to_datetime(valid_original.index[-500:]), valid_original[-500:],
alpha=0.5, color='red', label='Actual PM2.5 Concentration',)
plt.plot(pd.to_datetime(valid_original.index[-500:]), y_valid_pred_origin[:,11:12][-500:],
alpha=0.5, color='blue', label='Predicted PM2.5 Concentation')
plt.title('PM2.5 Concentration Prediction')
plt.xlabel('Time')
plt.ylabel('PM2.5 Concentration')
plt.legend()
plt.show()
```
| github_jupyter |
# Python для анализа данных
*Татьяна Рогович, НИУ ВШЭ*
## Интерактивные визуализации в Plotly
```
!pip install plotly==4.2.1
import plotly
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import pandas as pd
import numpy as np
```
Мы будем использовать оффлайн версию. Если вы хотите хранить графики в облаке, используйте
https://plot.ly/python/getting-started/#chart-studio-support
Вам понадобится регистрация и создание своего API ключа.
## Простые графики в Plotly
Синтаксис plotly несколько отличается от того, что мы уже видели в matplotlib.
Здесь мы передаем данные для графиков функция из библиотеки plotly.graph_objects, которую мы импортировали как go, и потом эти графики передаем функции go.Figure, которая собственно рендерит наш график.
```
our_data = [2, 3, 1] # задаем данные
our_bar = go.Bar(y = our_data) # передаем данные объекту Bar, говорим, что наши данные, это величина категории по шкале y
# layout = dict(height = 500)
fig = go.Figure(data = our_bar) # передаем наш бар объекту Figure, который уже рисует график (ура, что-то знакомое!)
fig.show() # выводим график
```
А теперь давайте представим, что наши данные разбиты по какой-то категориальной переменной.
```
trace0 = go.Bar(y = [2, 3, 1])
trace1 = go.Bar(y = [4, 7, 3])
our_data = [trace0, trace1] # когда объектов больше одного - передаем их списком
fig = go.Figure(data = our_data)
fig.show()
```
Теперь попробуем построить что-то с координатами x и y. Такой график уже будет Scatter - у каждого нашего наблюдения есть координаты x и y.
```
trace0 = go.Scatter(
x=[1, 2, 3, 4],
y=[10, 15, 13, 17]
)
trace1 = go.Scatter(
x=[1, 2, 3, 4],
y=[16, 5, 11, 9]
)
our_data = [trace0, trace1]
fig = go.Figure(data = our_data)
fig.show()
```
Давайте теперь попробуем построить пару уже знакомых нам графиков для обитателей леса.
```
forest = pd.read_csv('https://raw.githubusercontent.com/pileyan/Data/master/data/populations.txt', sep = '\t')
forest.head()
trace0 = go.Bar(
x=forest.year,
y=forest.hare+forest.carrot+forest.lynx
)
trace1 = go.Bar(
x=forest.year,
y=forest.lynx
)
our_data = [trace0, trace1]
fig = go.Figure(data = our_data)
fig.show()
```
### Упражнения
1. Постройте график, который сравнивает популяции зайцев и морковки за все годы.
2. Постройте столбчатый график, который сравнивает общую популяцию (зайцы, рыси и морковки) с популяцией рысей по годам.
```
# упражнение 1
trace_hare = go.Bar(
x=forest.year,
y=forest.hare
)
trace_carrot = go.Scatter(
x=forest.year,
y=forest.carrot
)
our_data = [trace_hare, trace_carrot]
fig = go.Figure(data = our_data)
fig.show()
# упражнение
trace_all = go.Bar(
x=forest.year,
y=forest.hare + forest.lynx + forest.carrot
)
trace_lynx = go.Bar(
x=forest.year,
y=forest.lynx
)
our_data = [trace_all, trace_lynx]
# fig = go.Figure(data = our_data)
# fig.add_trace(trace_all)
fig.show()
```
А теперь давайте построим эти два графика рядом.
Обратите внимание, plotly считает с 1, а не с 0, как мы привыкли.
```
type(trace_carrot)
fig = make_subplots(rows=2, cols=1)
fig.add_trace(trace_carrot, row=1, col=1)
fig.add_trace(trace_hare, row=1, col=1)
fig.add_trace(trace_all, row=2, col=1)
fig.add_trace(trace_lynx, row=2, col=1)
```
В plotly за данные внутри оси координаты и всю "красоту" (подписи, шкалы, фон, сетка и т.д.) отвечают два разных объекта - data и layout.
'fig = go.Figure(data = our_data)'
Здесь объект data принимает данные, из которых figure построит нам график. Как мы увидим ниже, аттрибуты данных тоже настраиваются объекте данных (например, цвет или размер точек).
За внешний вид этого графика отвечает layout - там довольно много параметров, которые можно настроить, которые задаются через словари, где ключ - параметр, а значение - то, как мы хотим его изменить (текст, числовое значение и т.д.).
https://plot.ly/python/reference/ - здесь можно посмотреть, какие типы графиков вообще есть и какие параметры можно настраивать в каждом из них.
В объект layout мы передаем словарь, где ключ - ключевое слово, а значение - то, что мы ему присваиваем. Обратите внимание, в синтаксе ниже показаны три варианта, как это можно записать. Все они эквивалентны.
```
trace0 = go.Scatter(
x=[1, 2, 3, 4],
y=[10, 15, 13, 17]
)
our_data = [trace0]
our_layout = dict(title = 'A simple line')
# our_layout = {'title' : 'A simple line'}
# our_layout = go.Layout(title = 'A simple line')
# после того, как создали отдельно объекты и для data, и для layout, передаем их функции go.Figure()
fig = go.Figure(data=our_data,
layout=our_layout)
fig.show()
```
Как уже говорилось, все находящееся внутри осей координат и касающееся данных настраивается внутри объекта, относящимся к данным.
Так в объекте go.Scatter (который по сути создает словарь, вообще почти все в plotly построено на синтаксисе словарей) мы можем прописать тип, цвет и размер маркеров, всплывающий текст и т.д.). В layout подписываем шкалы x и y - обратите внимание, что внутри словаря некторые параметры в свою очередь тоже словари :)
```
trace0 = go.Scatter(
x=[1, 2, 3, 4],
y=[10, 15, 13, 17],
marker={'color': 'red',
'symbol': 101,
'size': 10}, # атрибуты маркера - цвет, код символа, размер
mode = 'lines+markers', # атрибуты графика. Здесь можно задать просто линию или маркеры, например
text = ['one', 'two', 'three'], # подписи к точкам
name = 'Red Trace' # имя в легенде
)
our_data = [trace0]
our_layout = go.Layout(
title="First Plot",
xaxis={'title':'x axis'}, # заголовки шкал
yaxis={'title':'y axis'},
height = 400,
width = 700)
# после того, как создали отдельно объекты и для data, и для layout, передаем их функции go.Figure()
fig = go.Figure(data=our_data, layout=our_layout)
fig.show()
```
Давайте посмотрим, как наши объекты выглядят внутри
```
# словари словарей!
our_data
# при желании мы даже можем обратиться к объектам внутри по индексу
our_data[0]['marker']['color']
our_layout
```
## Упражнение
1. Постройте на одном графике кол-во обитателей живущих в лесу (зайцы, рыси, морковки). Подпишите шкалы, поменяйте цвет всех линий, задайте название графика для легенды.
```
trace_hare = go.Scatter(
x=forest.year,
y=forest.hare,
marker={'color': 'grey'},
name = 'Hares'
)
trace_carrot = go.Scatter(
x=forest.year,
y=forest.carrot,
marker={'color': 'orange'},
name = 'Carrots'
)
trace_lynx = go.Scatter(
x=forest.year,
y=forest.lynx,
marker={'color': 'teal'},
name = 'Lynxes'
)
our_data = [trace_hare, trace_carrot, trace_lynx]
our_layout = go.Layout(
title="Who lives in the forest?",
xaxis={'title':'years'},
yaxis={'title':'population'})
fig = go.Figure(data = our_data, layout = our_layout)
fig.show()
```
## Упражнение
1. Вернемся к еще одному знакомому набору данных: постройте график рассеяния для данных по преступности в США, где по шкале x будет количество убийств (murder), по y - ограбления (burglary). За размер будет отвечать количество людей в штате (возможно, нуждается в масшатабировании), а за цвет - количество угнанных автомобилей. При наведении курсора на точку должно выводиться названия штата (обратите внимание на атрибут текст в примерах выше).
Цвет, размер, прозрачность и цветовая схема указываются в словаре аттрибутов маркера (size, color, opacity, colorscale, showscale).
```
s = '<b>%{text}</b>' +'<br><i>Murders per capita</i>: %{x}'
s
crimes = pd.read_csv('https://raw.githubusercontent.com/pileyan/Data/master/data/crimeRatesByState2005.tsv', sep='\t')
crimes.head()
trace0 = go.Scatter(
x = crimes['murder'],
y = crimes['burglary'],
mode = 'markers',
marker = dict(size = crimes['population']/500000,
color = crimes['motor_vehicle_theft'],
opacity = 0.7,
colorscale ='Electric',
showscale =True),
text = crimes['state'],
# pop = crimes['population'],
hovertemplate =
'<b>%{text}</b>' +
'<br><i>Murders per capita</i>: %{x}' +
'<br><i>Burglary per capita</i>: %{y}' +
'<br><i>Motor Vehicle Theft per capita</i>: %{marker.color}' +
'<br><i>Population</i>: %{marker.size}'
) # Показатели, которые мы уложим в описание каждой точки
layout= go.Layout(
title= 'Crime in the USA',
hovermode= 'closest',
xaxis= dict(
title= 'Murder rate (number per 100,000 population)',
ticklen= 5,
zeroline= False,
gridwidth= 1,
),
yaxis=dict(
title= 'Burglary rate (number per 100,000 population)',
ticklen= 5,
gridwidth= 2,
),
showlegend= False
)
fig = go.Figure(data = [trace0], layout = layout)
fig
```
## Упражнение
Сделайте график рассеяния для данных gapminder.
1. Преобразуйте ВВП с помощью логарифма.
2. Отфильтруйте данные только для одного года (например, 1972)
3. ВВП по шкале X, продолжительность жизни по Y.
4. За цвет маркера отвечают континенты (не забудьте перевести переменную в категориальную).
5. За размер - население.
```
gapminder = pd.read_csv('https://raw.githubusercontent.com/pileyan/Data/master/data/gapminderData.csv')
gapminder.head()
gapminder['log_gdpPercap'] = np.log(gapminder['gdpPercap'])
gapminder['continent'] = pd.Categorical(gapminder['continent'])
gapminder.head()
gapminder_1972 = gapminder[gapminder['year'] == 1972]
trace0 = go.Scatter(
x = gapminder_1972['log_gdpPercap'],
y = gapminder_1972['lifeExp'],
mode = 'markers',
marker = dict(
size = gapminder_1972['pop']/5000000,
color = gapminder_1972['continent'].cat.codes,
opacity = 0.7,
colorscale ='Viridis',
showscale =False),
text = gapminder_1972['country'],
hovertemplate =
'<b>%{text}</b>' +
'<br><i>GDP per Capita</i>: %{x}' +
'<br><i>Life Expectancy</i>: %{y}',
)
layout = go.Layout(
title='Life Expectancy v. Per Capita GDP in 1972',
hovermode='closest',
xaxis=dict(
title='GDP per capita',
ticklen=5,
zeroline=False,
gridwidth=2,
),
yaxis=dict(
title='Life Expectancy (years)',
ticklen=5,
gridwidth=2,
),
)
fig = go.Figure(data = [trace0], layout = layout)
fig
```
На самом деле ценность данных gapminder в том, что их здорово использовать для создания анимаций. В традиционном синтаксе Plotly это можно сделать, но сейчас мы воспользуемся библиотекой plotly.express.
https://plot.ly/python/plotly-express/
Это библиотека, которая специально была сделана для "быстрых" визуализаций. Я думаю, вы заметили, что синтаксис plotly достаточно громоздкий по сравнению с matplotlib. Но он и более гибкий. Plotly.express больше похожа на matplotlib, и анимацию мы сделаем именно в ней, потому что здесь это сильно проще.
Ниже ссылку, как делать анимации в традиционном plotly
https://plot.ly/python/v3/gapminder-example/#create-frames
```
import plotly.express as px
# какая переменная отвечает за анимацию?
px.scatter(gapminder, x="gdpPercap", y="lifeExp", animation_frame="year",
size="pop", color="continent", hover_name="country",
log_x=True, size_max=55, range_x=[100,100000], range_y=[25,90])
```
Также в plotly можно создавать интерактивные тепловые карты. Для этого используем функцию Choropleth.
Параметр location mode принимает значения, которые будут отвечать за географические данные, а locations - уже собственно переменную. Если у вас есть набор данных, где колонка с географическими словарями совпадает с внутренним словарем plotly, то даже почти ничего не нужно делать, все распознается автоматически.
Параметр z - данные, которые наносим на тепловую шкалу.
Почитать больше про тепловые карты: https://plot.ly/python/choropleth-maps/
И про все виды интерактивных карт в plotly: https://plot.ly/python/maps/
```
trace0 = go.Choropleth(
locationmode = 'country names',
locations = gapminder_1972['country'],
text = gapminder_1972['country'],
z = gapminder_1972['lifeExp']
)
fig = go.Figure(data = [trace0])
fig
```
## Упражнение
Постройте график для ирисов. Каждый тип ирисов должен быть отдельным графиком, объединенными в один. Длина чашелистика (sepal) - шкала x, длина лепестка (petal) - шкала y, размер маркера - ширина лепестка, цвет - тип ирисов.
```
iris = pd.read_csv('https://raw.githubusercontent.com/pileyan/Data/master/data/iris.csv', header = 0)
iris.head()
iris.species.unique()
setosa = iris[iris.species == 'setosa']
versicolor = iris[iris.species == 'versicolor']
virginica = iris[iris.species == 'virginica']
trace1 = go.Scatter(
x = setosa['petal_length'],
y = setosa['petal_width'],
mode = 'markers',
marker = dict(size = setosa["petal_length"]*10,
color = '#FF0000'),
name = 'iris setosa'
)
trace2 = go.Scatter(
x = versicolor['petal_length'],
y = versicolor['petal_width'],
mode = 'markers',
marker = dict(size = versicolor["petal_length"]*10,
color = '#009900'),
name = 'iris versicolor'
)
trace3 = go.Scatter(
x = virginica['petal_length'],
y = virginica['petal_width'],
mode = 'markers',
marker = dict(size = virginica["petal_length"]*10,
color = '#3333FF'),
name ='iris virginica'
)
layout= go.Layout(
title= 'Iris clustering',
hovermode= 'closest',
xaxis= dict(
title= 'petal Length (in cm)',
ticklen= 5,
zeroline= False,
gridwidth= 2,
),
yaxis=dict(
title= 'petal width (in cm)',
ticklen= 5,
gridwidth= 2,
),
showlegend= True
)
data = [trace1, trace2, trace3]
fig = go.Figure(data=data, layout=layout)
fig.show()
iris.groupby('species').mean()
```
## Карты с координатами в Plotly
```
import plotly
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import pandas as pd
import numpy as np
```
В прошлый раз мы посмотрели, как создавать тепловую карту. В плотли можно также создать и карту с координатами. Для построения некоторых карт нужно будет зарегистрироваться на сервисе mapbox (именно он предоставляет plotly интерфейс карты, на которую мы наносим наши данные). Но часть карт open source и не требуют токена.
https://www.mapbox.com/
https://plot.ly/python/scattermapbox/
```
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/Nuclear%20Waste%20Sites%20on%20American%20Campuses.csv')
df.head()
site_lat = df.lat
site_lon = df.lon
locations_name = df.text
data = [
go.Scattermapbox(
lat=site_lat,
lon=site_lon,
mode='markers',
marker=dict(
size=17,
color='rgb(255, 0, 0)',
opacity=0.7
),
text=locations_name,
hoverinfo='text'
),
go.Scattermapbox(
lat=site_lat,
lon=site_lon,
mode='markers',
marker=dict(
size=8,
color='rgb(242, 177, 172)',
opacity=0.7
),
hoverinfo='none'
)]
layout = go.Layout(
title='Nuclear Waste Sites on Campus',
autosize=True,
hovermode='closest',
showlegend=False,
mapbox=dict(
style="open-street-map",
bearing=0,
center=dict(
lat=38,
lon=-94
),
pitch=0,
zoom=3,
),
)
fig = go.Figure(data = data, layout = layout)
fig.show()
```
| github_jupyter |
### Nonlinear time evolution and the GPE
This notebook shows how to use QuSpin to study time evolution. Below we show three examples:
* imaginary time evolution to find the lowest energy state of the GPE
* real time evolution with a user-defined function for a non-linear ODE
* unitary quantum evolution
The Gross-Pitaevskii equation (GPE) describes the physics of weakly-interacting bosonic systems, and is given by
$$ i\partial_t\psi_j(t) = -J\left[ \psi_{j-1}(t) + \psi_{j+1}(t)\right] + \frac{1}{2}\kappa_i(j-j_0)^2\psi_j(t) + U|\psi_j(t)|^2\psi_j(t) $$
where $J$ is the hopping matrix element, $\kappa_i$ is the harmonic trap 'frequency' [we use the subindex $i$ to indicate an initial value which will play a role later on], and $U$ -- the interaction strength. The lattice sites are labelled by $j=0,\dots,L-1$, and $j_0$ is the centre of the 1d chain. We set the lattice constant to unity, and use open boundary conditions.
It will prove useful to define the GPE in vectorised form. Let $\vec \psi$ be the vector whose elements are the magnitude of the function $\psi_j$ on every site. The GPE then reduces to
$$ i\partial_t\vec{\psi}(t) = H_\mathrm{sp}\vec{\psi}(t) + U \vec{\psi}^*(t)\circ \vec{\psi}(t)\circ \vec{\psi}(t)$$
where $H_\mathrm{sp}$ is a single-particle Hailtonian which contains the hopping term and the armonic potential, and the simbol $\circ$ defines element-wise multiplication: $(\vec\psi\circ\vec\phi)_j = \psi_j\phi_j$.
We start by constructing the single-particle Hamiltonian $H_\mathrm{sp}$. For the sake of saving code, it would be advantageous to view this Hamiltonian as the $t=0$ limit of a more-generic time-dependent Hamiltonian $H_\mathrm{sp}(t)$, which is defined by
$$ H_\mathrm{sp}(t) = -J\sum_{j=0}^{L-2} (a^\dagger_{j+1}a_j + \mathrm{h.c.}) + \frac{1}{2}\kappa_\mathrm{trap}(t)\sum_{j=0}^{L-1}(j-j_0)^2n_j $$
$$\kappa_\mathrm{trap}(t)=(\kappa_f-\kappa_i)t/t_\mathrm{ramp}+ \kappa_i $$
In the limit $t=0$, we have $\kappa_\mathrm{trap}(0) = \kappa_i $.
First, we load the required libraries and define the model parameters
```
from quspin.operators import hamiltonian # Hamiltonians and operators
from quspin.basis import boson_basis_1d # Hilbert space boson basis
from quspin.tools.evolution import evolve
import numpy as np # generic math functions
from six import iteritems # loop over elements of dictionary
import matplotlib.pyplot as plt
#
##### define model parameters #####
L=300 # system size
# calculate centre of chain
if L%2==0:
j0 = L//2-0.5 # centre of chain
else:
j0 = L//2 # centre of chain
sites=np.arange(L)-j0 # centred chain sites around zero
# static parameters
J=1.0 # hopping
U=1.0 # Bose-Hubbard interaction strength
# dynamic parameters
kappa_trap_i=0.001 # initial chemical potential
kappa_trap_f=0.0001 # final chemical potential
t_ramp=40.0/J # set total ramp time
# ramp protocol
def ramp(t,kappa_trap_i,kappa_trap_f,t_ramp):
return (kappa_trap_f - kappa_trap_i)*t/t_ramp + kappa_trap_i
# ramp protocol parameters
ramp_args=[kappa_trap_i,kappa_trap_f,t_ramp]
```
where we defined the function `ramp()` as the protocol $\kappa_\mathrm{trap}(t)$. Pay special attention to its arguments: the first argument must necessarily be the time $t$, followerd by all optional arguments (the parameters). These same parameters are then stored in the variable `ramp_args`.
Defining the static part of the Hamiltonian is straightforward and proceeds as before. However, due to the time dependence of $H_\mathrm{sp}(t)$, we now use a non-empty `dynamic` list. The structure of `dynamic` lists is similar to that of `static` lists: first comes the operator string, then the corresponding site-coupling list. The new thing is that we also need to parse the time-dependent function `ramp`, and its arguments `ramp_args`.
```
##### construct single-particle Hamiltonian #####
# define site-coupling lists
hopping=[[-J,i,(i+1)%L] for i in range(L-1)]
trap=[[0.5*(i-j0)**2,i] for i in range(L)]
# define static and dynamic lists
static=[["+-",hopping],["-+",hopping]]
dynamic=[['n',trap,ramp,ramp_args]] # <-- definition of dyamic lists
# define basis
basis = boson_basis_1d(L,Nb=1,sps=2)
# build Hamiltonian
Hsp=hamiltonian(static,dynamic,basis=basis,dtype=np.float64)
E,V=Hsp.eigsh(time=0.0,k=1,which='SA')
```
#### Imaginary Time Evolution
Let us set $t=0$ and consider the GPE for the initial trap parameter $\kappa_i=\kappa_\mathrm{trap}(0)$. The ground state of the single-particle Hamiltonian $H_\mathrm{sp}(t=0)$ is squeezed due to the trap. However, repulsive interactions have an opposite effect trying to push the particles apart. Thus, the true state of the system is a compromise of hte two effects.
Our first goal is to find the GS of the GPE, which is formally defined as the state of minimal energy:
$$\vec\psi_\mathrm{GS} = \inf_{\vec{\psi}} \bigg( \vec{\psi}^t H_\mathrm{sp}(t=0)\vec{\psi} + \frac{U}{2}\sum_{j=0}^{L-1}|\psi_j|^4\bigg)$$
One way to find the configuration $\vec\psi_\mathrm{GS}$, is to solve the GPE in imaginary time ($it\to \tau$), which induces exponential decay in all modes of the system, except for the lowest-energy state. In doing so, we keep the norm of the solution fixed:
$$\partial_{\tau}\vec\varphi(\tau) = -\bigg[H_\mathrm{sp}(0)\vec\varphi(\tau) + U \vec\varphi^*(\tau)\circ \vec\varphi(\tau)\circ \vec\varphi(\tau)\bigg],\qquad ||\vec\varphi(\tau)||=\mathrm{const.}$$
$$\vec{\psi}_\mathrm{GS} = \lim_{\tau\to\infty}\vec\varphi(\tau)$$
Any initial value problem requires us to pick an initial state. In the case of imaginary evolution, this state can often be arbitrary, but needs to possess the same symmetries as the true GPE ground state. Here, we choose the ground state of the single-particle Hamiltonian for an initial state, and normalise it to one particle per site. We also define the imaginary time vector `tau`. This array has to contain sufficiently long times so that we make sure we obtain the long imaginary time limit $\tau\to\infty$. Since imaginary time evolution is not unitary, QuSpin will be normalising the vector every $\tau$-step. Thus, one also needs to make sure these steps are small enough to avoid convergence problems of the ODE solver.
Performing imaginary time evolution is done using the `evolve()` method of the `measurements` tool. This function accepts an initial state `phi0`, initial time `tau[0]`, and a time vector `tau` and solves the user-defined ODE `GPE_imag_time`. The first two arguments of this user-defined ODE function must be the time variable and the state. The parameters of the ODE are passed using the keyword argument `f_params=GPE_params`. To ensure the normalisation of the state at each $\tau$-step we use the flag `imag_time=True`. Real-valued output can be specified by `real=True`. Last, we request `evolve()` to create a generator object using the keyword argument `iterate=True`. Many of the keyword arguments of `evolve()` are the same as in the `H.evolve()` method of the `hamiltonian class`: for instance, one can choose a specific SciPy solver and its arguments, or the solver's absolute and relative tolerance.
Last, looping over the generator `phi_tau` we have access to the solution, which we display in a form of a movie:
```
#########################################################
##### imaginary-time evolution to compute GS of GPE #####
################################################### ######
def GPE_imag_time(tau,phi,Hsp,U):
"""
This function solves the real-valued GPE in imaginary time:
$$ -\dot\phi(\tau) = Hsp(t=0)\phi(\tau) + U |\phi(\tau)|^2 \phi(\tau) $$
"""
return -( Hsp.dot(phi,time=0) + U*np.abs(phi)**2*phi )
# define ODE parameters
GPE_params = (Hsp,U)
# define initial state to flow to GS from
phi0=V[:,0]*np.sqrt(L) # initial state normalised to 1 particle per site
# define imaginary time vector
tau=np.linspace(0.0,35.0,71)
# evolve state in imaginary time
psi_tau = evolve(phi0,tau[0],tau,GPE_imag_time,f_params=GPE_params,imag_time=True,real=True,iterate=True)
#
# display state evolution
for i,psi0 in enumerate(psi_tau):
# compute energy
E_GS=(Hsp.matrix_ele(psi0,psi0,time=0) + 0.5*U*np.sum(np.abs(psi0)**4) ).real
print('$J\\tau=%0.2f,\\ E_\\mathrm{GS}(\\tau)=%0.4fJ$'%(tau[i],E_GS) )
```
#### Real Time Evolution with User-Specified ODE
Next, we use our GPE ground state, to time-evolve it in real time according to the trap widening protocol $\kappa_\mathrm{trap}(t)$ hard-coded into the single-particle Hamiltonian $H_\mathrm{sp}(t)$. We proceed analogously -- first we define the real-time GPE and the time vector. In defining the GPE function, we split the ODE into a time-independent static part and a time-dependent dynamic part. The single-particle Hamiltonian for the former is accessed using the `hamiltonian` attribute `Hsp.static` which returns a sparse matrix. We can then manually add the non-linear cubic mean-field interaction term. In order to access the time-dependent part of the Hamiltonian, and evaluate it, we loop over the dynamic list `Hsp.dynamic`, reading off the corresponding sparse matrix `Hd` together with the time-dependent function `f` which multiplies it, and its arguments `f_args`. Last, we multiply the final output vector by the Schr\"odinger $-i$, which ensures the unitarity of for real-time evolution.
To perform real-time evolution we once again use the `evolve()` function. This time, however, since the solution of the GPE is anticipated to be complex-valued, and because we do not do imaginary time, we do not need to pass the flags `real` and `imag_time`. Instead, we decided to show the flags for the relative and absolute tolerance of the solver.
```
#########################################################
############## real-time evolution of GPE ###############
#########################################################
def GPE(time,psi):
"""
This function solves the complex-valued time-dependent GPE:
$$ i\dot\psi(t) = Hsp(t)\psi(t) + U |\psi(t)|^2 \psi(t) $$
"""
# solve static part of GPE
psi_dot = Hsp.static.dot(psi) + U*np.abs(psi)**2*psi
# solve dynamic part of GPE
for f,Hd in iteritems(Hsp.dynamic):
psi_dot += f(time)*Hd.dot(psi)
return -1j*psi_dot
# define real time vector
t=np.linspace(0.0,t_ramp,101)
# time-evolve state according to GPE
psi_t = evolve(psi0,t[0],t,GPE,iterate=True,atol=1E-12,rtol=1E-12)
#
# display state evolution
for i,psi in enumerate(psi_t):
# compute energy
E=(Hsp.matrix_ele(psi,psi,time=t[i]) + 0.5*U*np.sum(np.abs(psi)**4) ).real
print('$Jt=%0.2f,\\ E(t)-E_\\mathrm{GS}=%0.4fJ$'%(t[i],E-E_GS) )
```
#### Real Time Evolution under a Hamiltonian
The last example we show demonstrates how to use the `hamiltonian` class method `evolve()`, which is almost the same as the measurement function `evolve()`. The idea behind it is that any Hamiltonian, defins a unique unitary evolution through the Schroedinger equation.
Suppose we put aside the GPE altogether, setting $U=0$. We ask the question how does the GPE GS (obtained via imaginary time evolution) evolve under the free Hamiltonian $H_\mathrm{sp}(t)$ which widens thr trap.
Below, we show how to evolve the GPE ground state under the single-particle Hamiltonian, which des not know about the interactions. This can be though of as quenching the interaction strength $U$ to zero and observing the time evolution of the state in a slowly changing harmonic trap. More precisely, we want to solve the linear initial value problem
$$ i\partial_t\vec{\psi}(t) = H_\mathrm{sp}(t)\vec{\psi}(t),\ \ \ \vec \psi(0) = \vec\psi_\mathrm{GS} $$
This time, there is no need for a user-defined function for the ODE -- Schroedinger's equation (in real and imaginary time) is provided in QuSpin by default.
```
#######################################################################################
##### quantum real time evolution from GS of GPE with single-particle Hamiltonian #####
#######################################################################################
# define real time vector
t=np.linspace(0.0,2*t_ramp,101)
# time-evolve state according to linear Hamiltonian Hsp (no need to define a GPE)
psi_sp_t = Hsp.evolve(psi0,t[0],t,iterate=True,atol=1E-12,rtol=1E-12)
#
# display state evolution
for i,psi in enumerate(psi_sp_t):
# compute energy
E=Hsp.matrix_ele(psi,psi,time=t[i]).real
print('$Jt=%0.2f,\\ E(t)-E_\\mathrm{GS}=%0.4fJ$'%(t[i],E-E_GS) )
```
| github_jupyter |
# T81-558: Applications of Deep Neural Networks
**Module 2: Python for Machine Learning**
* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)
* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).
# Module 2 Material
Main video lecture:
* Part 2.1: Introduction to Pandas [[Video]](https://www.youtube.com/watch?v=bN4UuCBdpZc&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_1_python_pandas.ipynb)
* Part 2.2: Categorical Values [[Video]](https://www.youtube.com/watch?v=4a1odDpG0Ho&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_2_pandas_cat.ipynb)
* **Part 2.3: Grouping, Sorting, and Shuffling in Python Pandas** [[Video]](https://www.youtube.com/watch?v=YS4wm5gD8DM&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_3_pandas_grouping.ipynb)
* Part 2.4: Using Apply and Map in Pandas for Keras [[Video]](https://www.youtube.com/watch?v=XNCEZ4WaPBY&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_4_pandas_functional.ipynb)
* Part 2.5: Feature Engineering in Pandas for Deep Learning in Keras [[Video]](https://www.youtube.com/watch?v=BWPTj4_Mi9E&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_02_5_pandas_features.ipynb)
# Part 2.3: Grouping, Sorting, and Shuffling
### Shuffling a Dataset
The following code is used to shuffle and reindex a data set. A random seed can be used to produce a consistent shuffling of the data set.
```
import os
import pandas as pd
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA', '?'])
#np.random.seed(42) # Uncomment this line to get the same shuffle each time
df = df.reindex(np.random.permutation(df.index))
df.reset_index(inplace=True, drop=True)
display(df[0:10])
```
### Sorting a Data Set
Data sets can also be sorted. This code sorts the MPG dataset by name and displays the first car.
```
import os
import pandas as pd
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA', '?'])
df = df.sort_values(by='name', ascending=True)
print(f"The first car is: {df['name'].iloc[0]}")
display(df[0:5])
```
### Grouping a Data Set
Grouping is a common operation on data sets. In SQL, this operation is referred to as "GROUP BY". Grouping is used to summarize data. Because of this summarization the row could will either stay the same or more likely shrink after a grouping is applied.
The Auto MPG dataset is used to demonstrate grouping.
```
import os
import pandas as pd
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA', '?'])
display(df[0:5])
```
The above data set can be used with group to perform summaries. For example, the following code will group cylinders by the average (mean). This code will provide the grouping. In addition to mean, other aggregating functions, such as **sum** or **count** can be used.
```
g = df.groupby('cylinders')['mpg'].mean()
g
```
It might be useful to have these **mean** values as a dictionary.
```
d = g.to_dict()
d
```
This allows you to quickly access an individual element, such as to lookup the mean for 6 cylinders. This is used in target encoding, which is presented in this module.
```
d[6]
```
The code below shows how to count the number of rows that match each cylinder count.
```
df.groupby('cylinders')['mpg'].count().to_dict()
```
# Part 2.4: Apply and Map
The **apply** and **map** functions can also be applied to Pandas **dataframes**.
### Using Map with Dataframes
```
import os
import pandas as pd
import numpy as np
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA', '?'])
display(df[0:10])
df['origin_name'] = df['origin'].map({1: 'North America', 2: 'Europe', 3: 'Asia'})
display(df[0:50])
```
### Using Apply with Dataframes
If the **apply** function is directly executed on the data frame, the lambda function is called once per column or row, depending on the value of axis. For axis = 1, rows are used.
The following code calculates a series called **efficiency** that is the **displacement** divided by **horsepower**.
```
effi = df.apply(lambda x: x['displacement']/x['horsepower'], axis=1)
display(effi[0:10])
```
### Feature Engineering with Apply and Map
In this section we will see how to calculate a complex feature using map, apply, and grouping. The data set is the following CSV:
* https://www.irs.gov/pub/irs-soi/16zpallagi.csv
This is US Government public data for "SOI Tax Stats - Individual Income Tax Statistics". The primary website is here:
* https://www.irs.gov/statistics/soi-tax-stats-individual-income-tax-statistics-2016-zip-code-data-soi
Documentation describing this data is at the above link.
For this feature, we will attempt to estimate the adjusted gross income (AGI) for each of the zipcodes. The data file contains many columns; however, you will only use the following:
* STATE - The state (e.g. MO)
* zipcode - The zipcode (e.g. 63017)
* agi_stub - Six different brackets of annual income (1 through 6)
* N1 - The number of tax returns for each of the agi_stubs
Note, the file will have 6 rows for each zipcode, for each of the agi_stub brackets. You can skip zipcodes with 0 or 99999.
We will create an output CSV with these columns; however, only one row per zip code. Calculate a weighted average of the income brackets. For example, the following 6 rows are present for 63017:
|zipcode |agi_stub | N1 |
|--|--|-- |
|63017 |1 | 4710 |
|63017 |2 | 2780 |
|63017 |3 | 2130 |
|63017 |4 | 2010 |
|63017 |5 | 5240 |
|63017 |6 | 3510 |
We must combine these six rows into one. For privacy reasons, AGI's are broken out into 6 buckets. We need to combine the buckets and estimate the actual AGI of a zipcode. To do this, consider the values for N1:
* 1 = \$1 to \$25,000
* 2 = \$25,000 to \$50,000
* 3 = \$50,000 to \$75,000
* 4 = \$75,000 to \$100,000
* 5 = \$100,000 to \$200,000
* 6 = \$200,000 or more
The median of each of these ranges is approximately:
* 1 = \$12,500
* 2 = \$37,500
* 3 = \$62,500
* 4 = \$87,500
* 5 = \$112,500
* 6 = \$212,500
Using this you can estimate 63017's average AGI as:
```
>>> totalCount = 4710 + 2780 + 2130 + 2010 + 5240 + 3510
>>> totalAGI = 4710 * 12500 + 2780 * 37500 + 2130 * 62500 + 2010 * 87500 + 5240 * 112500 + 3510 * 212500
>>> print(totalAGI / totalCount)
88689.89205103042
```
```
import pandas as pd
df=pd.read_csv('https://www.irs.gov/pub/irs-soi/16zpallagi.csv')
```
First, we trim all zipcodes that are either 0 or 99999. We also select the three fields that we need.
```
df=df.loc[(df['zipcode']!=0) & (df['zipcode']!=99999),['STATE','zipcode','agi_stub','N1']]
df
```
We replace all of the **agi_stub** values with the correct median values with the **map** function.
```
medians = {1:12500,2:37500,3:62500,4:87500,5:112500,6:212500}
df['agi_stub']=df.agi_stub.map(medians)
df
```
Next the dataframe is grouped by zip code.
```
groups = df.groupby(by='zipcode')
```
A lambda is applied across the groups and the AGI estimate is calculated.
```
df = pd.DataFrame(groups.apply(lambda x:sum(x['N1']*x['agi_stub'])/sum(x['N1']))).reset_index()
df
```
The new agi_estimate column is renamed.
```
df.columns = ['zipcode','agi_estimate']
display(df[0:10])
```
We can also see that our zipcode of 63017 gets the correct value.
```
df[ df['zipcode']==63017 ]
```
# Part 2.5: Feature Engineering
Feature engineering is a very important part of machine learning. Later in this course we will see some techniques for automatic feature engineering.
## Calculated Fields
It is possible to add new fields to the dataframe that are calculated from the other fields. We can create a new column that gives the weight in kilograms. The equation to calculate a metric weight, given a weight in pounds is:
$ m_{(kg)} = m_{(lb)} \times 0.45359237 $
This can be used with the following Python code:
```
import os
import pandas as pd
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/auto-mpg.csv",
na_values=['NA', '?'])
df.insert(1, 'weight_kg', (df['weight'] * 0.45359237).astype(int))
df
```
## Google API Keys
Sometimes you will use external API's to obtain data. The following examples show how to use the Google API keys to encode addresses for use with neural networks. To use these, you will need your own Google API key. The key I have below is not a real key, you need to put your own in there. Google will ask for a credit card, but unless you use a very large number of lookups, there will be no actual cost. YOU ARE NOT required to get an Google API key for this class, this only shows you how. If you would like to get a Google API key, visit this site and obtain one for **geocode**.
[Google API Keys](https://developers.google.com/maps/documentation/embed/get-api-key)
```
GOOGLE_KEY = 'INSERT_YOUR_KEY'
```
# Other Examples: Dealing with Addresses
Addresses can be difficult to encode into a neural network. There are many different approaches, and you must consider how you can transform the address into something more meaningful. Map coordinates can be a good approach. [Latitude and longitude](https://en.wikipedia.org/wiki/Geographic_coordinate_system) can be a useful encoding. Thanks to the power of the Internet, it is relatively easy to transform an address into its latitude and longitude values. The following code determines the coordinates of [Washington University](https://wustl.edu/):
```
import requests
address = "1 Brookings Dr, St. Louis, MO 63130"
response = requests.get('https://maps.googleapis.com/maps/api/geocode/json?key={}&address={}'.format(GOOGLE_KEY,address))
resp_json_payload = response.json()
if 'error_message' in resp_json_payload:
print(resp_json_payload['error_message'])
else:
print(resp_json_payload['results'][0]['geometry']['location'])
```
If latitude and longitude are simply fed into the neural network as two features, they might not be overly helpful. These two values would allow your neural network to cluster locations on a map. Sometimes cluster locations on a map can be useful. Consider the percentage of the population that smokes in the USA by state:

The above map shows that certain behaviors, like smoking, can be clustered by global region.
However, often you will want to transform the coordinates into distances. It is reasonably easy to estimate the distance between any two points on Earth by using the [great circle distance](https://en.wikipedia.org/wiki/Great-circle_distance) between any two points on a sphere:
The following code implements this formula:
$\Delta\sigma=\arccos\bigl(\sin\phi_1\cdot\sin\phi_2+\cos\phi_1\cdot\cos\phi_2\cdot\cos(\Delta\lambda)\bigr)$
$d = r \, \Delta\sigma$
```
from math import sin, cos, sqrt, atan2, radians
# Distance function
def distance_lat_lng(lat1,lng1,lat2,lng2):
# approximate radius of earth in km
R = 6373.0
# degrees to radians (lat/lon are in degrees)
lat1 = radians(lat1)
lng1 = radians(lng1)
lat2 = radians(lat2)
lng2 = radians(lng2)
dlng = lng2 - lng1
dlat = lat2 - lat1
a = sin(dlat / 2)**2 + cos(lat1) * cos(lat2) * sin(dlng / 2)**2
c = 2 * atan2(sqrt(a), sqrt(1 - a))
return R * c
# Find lat lon for address
def lookup_lat_lng(address):
response = requests.get('https://maps.googleapis.com/maps/api/geocode/json?key={}&address={}'.format(GOOGLE_KEY,address))
json = response.json()
if len(json['results']) == 0:
print("Can't find: {}".format(address))
return 0,0
map = json['results'][0]['geometry']['location']
return map['lat'],map['lng']
# Distance between two locations
import requests
address1 = "1 Brookings Dr, St. Louis, MO 63130"
address2 = "3301 College Ave, Fort Lauderdale, FL 33314"
lat1, lng1 = lookup_lat_lng(address1)
lat2, lng2 = lookup_lat_lng(address2)
print("Distance, St. Louis, MO to Ft. Lauderdale, FL: {} km".format(
distance_lat_lng(lat1,lng1,lat2,lng2)))
```
Distances can be useful to encode addresses as. You must consider what distance might be useful for your dataset. Consider:
* Distance to major metropolitan area
* Distance to competitor
* Distance to distribution center
* Distance to retail outlet
The following code calculates the distance between 10 universities and washu:
```
# Encoding other universities by their distance to Washington University
schools = [
["Princeton University, Princeton, NJ 08544", 'Princeton'],
["Massachusetts Hall, Cambridge, MA 02138", 'Harvard'],
["5801 S Ellis Ave, Chicago, IL 60637", 'University of Chicago'],
["Yale, New Haven, CT 06520", 'Yale'],
["116th St & Broadway, New York, NY 10027", 'Columbia University'],
["450 Serra Mall, Stanford, CA 94305", 'Stanford'],
["77 Massachusetts Ave, Cambridge, MA 02139", 'MIT'],
["Duke University, Durham, NC 27708", 'Duke University'],
["University of Pennsylvania, Philadelphia, PA 19104", 'University of Pennsylvania'],
["Johns Hopkins University, Baltimore, MD 21218", 'Johns Hopkins']
]
lat1, lng1 = lookup_lat_lng("1 Brookings Dr, St. Louis, MO 63130")
for address, name in schools:
lat2,lng2 = lookup_lat_lng(address)
dist = distance_lat_lng(lat1,lng1,lat2,lng2)
print("School '{}', distance to wustl is: {}".format(name,dist))
```
# Module 2 Assignment
You can find the first assignment here: [assignment 2](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/assignments/assignment_yourname_class2.ipynb)
| github_jupyter |
# Plotting with categorical data
```
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid", color_codes=True)
np.random.seed(sum(map(ord, "categorical")))
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
iris = sns.load_dataset("iris")
```
```
sns.stripplot(x="day", y="total_bill", data=tips);
```
```
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True);
```
```
sns.swarmplot(x="day", y="total_bill", data=tips);
```
```
sns.swarmplot(x="day", y="total_bill", hue="sex", data=tips);
```
```
sns.swarmplot(x="size", y="total_bill", data=tips);
```
```
sns.swarmplot(x="total_bill", y="day", hue="time", data=tips);
```
```
sns.boxplot(x="day", y="total_bill", hue="time", data=tips);
```
```
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.boxplot(x="day", y="total_bill", hue="weekend", data=tips, dodge=False);
```
```
sns.violinplot(x="total_bill", y="day", hue="time", data=tips);
```
```
sns.violinplot(x="total_bill", y="day", hue="time", data=tips,
bw=.1, scale="count", scale_hue=False);
```
```
sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True);
```
```
sns.violinplot(x="day", y="total_bill", hue="sex", data=tips,
split=True, inner="stick", palette="Set3");
```
```
sns.violinplot(x="day", y="total_bill", data=tips, inner=None)
sns.swarmplot(x="day", y="total_bill", data=tips, color="w", alpha=.5);
```
```
sns.barplot(x="sex", y="survived", hue="class", data=titanic);
```
```
sns.countplot(x="deck", data=titanic, palette="Greens_d");
```
```
sns.countplot(y="deck", hue="class", data=titanic, palette="Greens_d");
```
```
sns.pointplot(x="sex", y="survived", hue="class", data=titanic);
```
```
sns.pointplot(x="class", y="survived", hue="sex", data=titanic,
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"]);
```
```
sns.boxplot(data=iris, orient="h");
```
```
sns.violinplot(x=iris.species, y=iris.sepal_length);
```
```
f, ax = plt.subplots(figsize=(7, 3))
sns.countplot(y="deck", data=titanic, color="c");
```
```
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips);
```
```
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips, kind="bar");
```
```
sns.factorplot(x="day", y="total_bill", hue="smoker",
col="time", data=tips, kind="swarm");
```
```
sns.factorplot(x="time", y="total_bill", hue="smoker",
col="day", data=tips, kind="box", size=4, aspect=.5);
```
```
g = sns.PairGrid(tips,
x_vars=["smoker", "time", "sex"],
y_vars=["total_bill", "tip"],
aspect=.75, size=3.5)
g.map(sns.violinplot, palette="pastel");
```
| github_jupyter |
<a href="https://colab.research.google.com/github/joanby/python-ml-course/blob/master/notebooks/T10%20-%203%20-%20Plotly%20para%20dibujar-Colab.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Clonamos el repositorio para obtener los dataSet
```
!git clone https://github.com/joanby/python-ml-course.git
```
# Damos acceso a nuestro Drive
```
from google.colab import drive
drive.mount('/content/drive')
# Test it
!ls '/content/drive/My Drive'
from google.colab import files # Para manejar los archivos y, por ejemplo, exportar a su navegador
import glob # Para manejar los archivos y, por ejemplo, exportar a su navegador
from google.colab import drive # Montar tu Google drive
```
# Gráficos con PlotLy
```
!pip install chart_studio
import chart_studio.plotly as py
import plotly.graph_objects as go
from chart_studio import tools as tls
tls.set_credentials_file(username='JuanGabriel', api_key='6mEfSXf8XNyIzpxwb8z7')
import plotly
plotly.__version__
help(plotly)
import numpy as np
help(np.random)
```
# Scatter Plots sencillos
```
N = 2000
random_x = np.random.randn(N)
random_y = np.random.randn(N)
trace = go.Scatter(x = random_x, y = random_y, mode = "markers")
py.iplot([trace], filename = "basic-scatter")
plot_url = py.plot([trace], filename = "basic-scatter-inline")
plot_url
```
# Gráficos combinados
```
N = 200
rand_x = np.linspace(0,1, N)
rand_y0 = np.random.randn(N) + 3
rand_y1 = np.random.randn(N)
rand_y2 = np.random.randn(N) - 3
trace0 = go.Scatter(x = rand_x, y = rand_y0, mode="markers", name="Puntos")
trace1 = go.Scatter(x = rand_x, y = rand_y1, mode="lines", name="Líneas")
trace2 = go.Scatter(x = rand_x, y = rand_y2, mode="lines+markers", name="Puntos y líneas")
data = [trace0, trace1, trace2]
py.iplot(data, filename = "scatter-line-plot")
```
# Estilizado de gráficos
```
trace = go.Scatter(x = random_x, y = random_y, name = "Puntos de estilo guay", mode="markers",
marker = dict(size = 12, color = "rgba(140,20,20,0.8)", line = dict(width=2, color="rgb(10,10,10)")))
layout = dict(title = "Scatter Plot Estilizado", xaxis = dict(zeroline = False), yaxis = dict(zeroline=False))
fig = dict(data = [trace], layout = layout)
py.iplot(fig)
trace = go.Scatter(x = random_x, y = random_y, name = "Puntos de estilo guay", mode="markers",
marker = dict(size = 8, color = "rgba(10,80,220,0.25)", line = dict(width=1, color="rgb(10,10,80)")))
fig = dict(data = [trace], layout = layout)
py.iplot(fig)
trace = go.Histogram(x = random_x, name = "Puntos de estilo guay")
fig = dict(data = [trace], layout = layout)
py.iplot(fig)
trace = go.Box(x = random_x, name = "Puntos de estilo guay", fillcolor = "rgba(180,25,95,0.6)")
fig = dict(data = [trace], layout = layout)
py.iplot(fig, filename = "basic-scatter-inline")
help(go.Box)
```
# Información al hacer Hover
```
import pandas as pd
data = pd.read_csv("/content/python-ml-course/datasets/usa-population/usa_states_population.csv")
data
N = 53
c = ['hsl('+str(h)+', 50%, 50%)' for h in np.linspace(0,360,N)]
l = []
y = []
for i in range(int(N)):
y.append((2000+i))
trace0 = go.Scatter(
x = data["Rank"],
y = data["Population"]+ i*1000000,
mode = "markers",
marker = dict(size = 14, line = dict(width=1), color = c[i], opacity = 0.3),
name = data["State"]
)
l.append(trace0)
layout = go.Layout(title = "Población de los estados de USA",
hovermode = "closest",
xaxis = dict(title="ID", ticklen=5, zeroline=False, gridwidth=2),
yaxis = dict(title="Población", ticklen=5, gridwidth=2),
showlegend = False)
fig = go.Figure(data = l, layout = layout)
py.iplot(fig, filename = "basic-scatter-inline")
trace = go.Scatter(y = np.random.randn(1000),
mode = "markers", marker = dict(size = 16, color = np.random.randn(1000),
colorscale = "Viridis", showscale=True))
py.iplot([trace], filename = "basic-scatter-inline")
```
# Datasets muy grandes
```
N = 100000
trace = go.Scattergl(x = np.random.randn(N), y = np.random.randn(N), mode = "markers",
marker = dict(color="#BAD5FF", line = dict(width=1)))
py.iplot([trace], filename = "basic-scatter-inline")
```
| github_jupyter |
# Signed field
```
from konfoo import Index, Byteorder, Signed, Signed8, Signed16, Signed24, Signed32, Signed64
```
## Item
Item type of the `field` class.
```
Signed.item_type
```
Checks if the `field` class is a `bit` field.
```
Signed.is_bit()
```
Checks if the `field` class is a `boolean` field.
```
Signed.is_bool()
```
Checks if the `field` class is a `decimal` number field.
```
Signed.is_decimal()
```
Checks if the `field` class is a `floating point` number field.
```
Signed.is_float()
```
Checks if the `field` class is a `pointer` field.
```
Signed.is_pointer()
```
Checks if the `field` class is a `stream` field.
```
Signed.is_stream()
```
Checks if the `field` class is a `string` field.
```
Signed.is_string()
```
## Field
```
signed = Signed(bit_size=32, align_to=None, byte_order='auto')
signed = Signed(32)
```
### Field view
```
signed
str(signed)
repr(signed)
```
### Field name
```
signed.name
```
### Field index
```
signed.index
```
Byte `index` of the `field` within the `byte stream`.
```
signed.index.byte
```
Bit offset relative to the byte `index` of the `field` within the `byte stream`.
```
signed.index.bit
```
Absolute address of the `field` within the `data source`.
```
signed.index.address
```
Base address of the `byte stream` within the `data source`.
```
signed.index.base_address
```
Indexes the `field` and returns the `index` after the `field`.
```
signed.index_field(index=Index())
```
### Field alignment
```
signed.alignment
```
Byte size of the `field group` which the `field` is *aligned* to.
```
signed.alignment.byte_size
```
Bit offset of the `field` within its *aligned* `field group`.
```
signed.alignment.bit_offset
```
### Field size
```
signed.bit_size
```
### Field byte order
```
signed.byte_order
signed.byte_order.value
signed.byte_order.name
signed.byte_order = 'auto'
signed.byte_order = Byteorder.auto
```
### Field value
Checks if the decimal `field` is signed or unsigned.
```
signed.signed
```
Maximal decimal `field` value.
```
signed.max()
```
Minimal decimal `field` value.
```
signed.min()
```
Returns the decimal `field` value as an integer number.
```
signed.value
```
Returns the decimal `field` value *aligned* to its `field group` as a number of bytes.
```
bytes(signed)
bytes(signed).hex()
```
Returns the decimal `field` value as an integer number.
```
int(signed)
```
Returns the decimal `field` value as an floating point number.
```
float(signed)
```
Returns the decimal `field` value as a lowercase hexadecimal string prefixed with `0x`.
```
hex(signed)
```
Returns the decimal `field` value as a binary string prefixed with `0b`.
```
bin(signed)
```
Returns the decimal `field` value as an octal string prefixed with `0o`.
```
oct(signed)
```
Returns the decimal `field` value as a boolean value.
```
bool(signed)
```
Returns the decimal `field` value as a signed integer number.
```
signed.as_signed()
```
Returns the decimal `field` value as an unsigned integer number.
```
signed.as_unsigned()
```
### Field metadata
Returns the ``meatadata`` of the ``field`` as an ordered dictionary.
```
signed.describe()
```
### Deserialize
```
signed.deserialize(bytes.fromhex('00010000'), byte_order='little')
signed.value
bytes(signed)
bytes(signed).hex()
int(signed)
float(signed)
hex(signed)
bin(signed)
oct(signed)
bool(signed)
```
### Serialize
```
buffer = bytearray()
signed.value = 256
signed.value = 256.0
signed.value = 0x100
signed.value = 0b100000000
signed.value = 0o400
signed.value = False
signed.value = 256
signed.serialize(buffer, byte_order='little')
buffer.hex()
bytes(signed).hex()
```
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Python-正则表达式操作指南" data-toc-modified-id="Python-正则表达式操作指南-1"><span class="toc-item-num">1 </span>Python 正则表达式操作指南</a></span><ul class="toc-item"><li><span><a href="#简介" data-toc-modified-id="简介-1.1"><span class="toc-item-num">1.1 </span>简介</a></span></li><li><span><a href="#简单模式" data-toc-modified-id="简单模式-1.2"><span class="toc-item-num">1.2 </span>简单模式</a></span><ul class="toc-item"><li><span><a href="#字符匹配" data-toc-modified-id="字符匹配-1.2.1"><span class="toc-item-num">1.2.1 </span>字符匹配</a></span></li><li><span><a href="#重复" data-toc-modified-id="重复-1.2.2"><span class="toc-item-num">1.2.2 </span>重复</a></span></li></ul></li><li><span><a href="#使用正则表达式" data-toc-modified-id="使用正则表达式-1.3"><span class="toc-item-num">1.3 </span>使用正则表达式</a></span><ul class="toc-item"><li><span><a href="#编译正则表达式" data-toc-modified-id="编译正则表达式-1.3.1"><span class="toc-item-num">1.3.1 </span>编译正则表达式</a></span></li><li><span><a href="#反斜杠" data-toc-modified-id="反斜杠-1.3.2"><span class="toc-item-num">1.3.2 </span>反斜杠</a></span></li><li><span><a href="#执行匹配" data-toc-modified-id="执行匹配-1.3.3"><span class="toc-item-num">1.3.3 </span>执行匹配</a></span></li><li><span><a href="#编译标志" data-toc-modified-id="编译标志-1.3.4"><span class="toc-item-num">1.3.4 </span>编译标志</a></span></li></ul></li><li><span><a href="#更多模式功能" data-toc-modified-id="更多模式功能-1.4"><span class="toc-item-num">1.4 </span>更多模式功能</a></span><ul class="toc-item"><li><span><a href="#更多的元字符" data-toc-modified-id="更多的元字符-1.4.1"><span class="toc-item-num">1.4.1 </span>更多的元字符</a></span></li><li><span><a href="#分组" data-toc-modified-id="分组-1.4.2"><span class="toc-item-num">1.4.2 </span>分组</a></span></li><li><span><a href="#无捕获组和命名组" data-toc-modified-id="无捕获组和命名组-1.4.3"><span class="toc-item-num">1.4.3 </span>无捕获组和命名组</a></span></li><li><span><a href="#前向界定符" data-toc-modified-id="前向界定符-1.4.4"><span class="toc-item-num">1.4.4 </span>前向界定符</a></span></li></ul></li><li><span><a href="#修改字符串" data-toc-modified-id="修改字符串-1.5"><span class="toc-item-num">1.5 </span>修改字符串</a></span><ul class="toc-item"><li><span><a href="#将字符串分片" data-toc-modified-id="将字符串分片-1.5.1"><span class="toc-item-num">1.5.1 </span>将字符串分片</a></span></li><li><span><a href="#搜索和替换" data-toc-modified-id="搜索和替换-1.5.2"><span class="toc-item-num">1.5.2 </span>搜索和替换</a></span></li></ul></li><li><span><a href="#常见问题" data-toc-modified-id="常见问题-1.6"><span class="toc-item-num">1.6 </span>常见问题</a></span><ul class="toc-item"><li><span><a href="#使用字符串方式" data-toc-modified-id="使用字符串方式-1.6.1"><span class="toc-item-num">1.6.1 </span>使用字符串方式</a></span></li><li><span><a href="#match()-vs-search()" data-toc-modified-id="match()-vs-search()-1.6.2"><span class="toc-item-num">1.6.2 </span><code>match() vs search()</code></a></span></li><li><span><a href="#贪婪-vs-不贪婪" data-toc-modified-id="贪婪-vs-不贪婪-1.6.3"><span class="toc-item-num">1.6.3 </span>贪婪 vs 不贪婪</a></span></li><li><span><a href="#使用-re.VERBOSE" data-toc-modified-id="使用-re.VERBOSE-1.6.4"><span class="toc-item-num">1.6.4 </span>使用 <code>re.VERBOSE</code></a></span></li></ul></li></ul></li><li><span><a href="#笔记" data-toc-modified-id="笔记-2"><span class="toc-item-num">2 </span>笔记</a></span></li></ul></div>
# Python 正则表达式操作指南
## 简介
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在 Python 中,并通过 re 模块实现。
使用这个小型语言,你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。
然后你可以问诸如“这个字符串匹配该模式吗?”或“在这个字符串中是否有部分匹配该模式呢?”。
你也可以使用 RE 以各种方式来修改或分割字符串。
## 简单模式
### 字符匹配
- 大多数字母和字符一般都会和自身匹配。
- 元字符:`. ^ $ * + ? { [ ] \ | ( )`
- 元字符是"[" 和 "]"。它们常用来指定一个字符类别,所谓字符类别就是你想匹配的一个字符集。字符可以单个列出,也可以用“-”号分隔的两个给定字符来表示一个字符区间。
- 元字符在类别里并不起作用。例如,`[akm$]` 将匹配字符"a", "k", "m", 或 "`$`" 中的任意一个;"`$`"通常用作元字符,但在字符类别里,其特性被除去,恢复成普通字符。
- 可以用补集来匹配不在区间范围内的字符。其做法是把"^"作为类别的**首个字符**;其它地方的"^"只会简单匹配 "^"字符本身。例如,`[^5]` 将匹配除 "5" 之外的任意字符。
- 最重要的元字符是反斜杠"\"。 做为 Python 中的字符串字母,反斜杠后面可以加不同的字符以表示不同特殊意义。它也可以用于取消所有的元字符,这样你就可以在模式中匹配它们了。举个例子,如果你需要匹配字符 "[" 或 "\",你可以在它们之前用反斜杠来取消它们的特殊意义: `\[` 或 `\\`。
- `\d` 匹配任何十进制数;它相当于类 `[0-9]`。
- `\D` 匹配任何非数字字符;它相当于类 `[^0-9]`。
- `\s` 匹配任何空白字符;它相当于类 `[ \t\n\r\f\v]`。
- `\S` 匹配任何非空白字符;它相当于类 `[^ \t\n\r\f\v]`。
- `\w` 匹配任何字母数字字符;它相当于类 `[a-zA-Z0-9_]`。
- `\W` 匹配任何非字母数字字符;它相当于类 `[^a-zA-Z0-9_]`。
- 元字符 `.` 。它匹配除了换行字符外的任何字符,在 alternate 模式(`re.DOTALL`)下它甚至可以匹配换行。"`.`" 通常被用于你想匹配“任何字符”的地方。
### 重复
- `*` 匹配零或更多次,所以可以根本就不出现
- `+` 则要求至少出现一次
- `?` 匹配一次或零次,可以认为它用于标识某事物是可选的
- `{m,n}`(注意m,n之间不能有空格),其中 m 和 n 是十进制整数。该限定符的意思是至少有 m 个重复,至多到 n 个重复
考虑表达式 `a[bcd]*b`。它匹配字母 "a",零个或更多个来自类 `[bcd]` 中的字母,最后以 "b" 结尾。现在想一想该 RE 对字符串 "abcbd" 的匹配。
匹配引擎一开始会尽其所能进行匹配(贪婪匹配),如果没有匹配然后就逐步退回并反复尝试 RE 剩下来的部分。直到它退回尝试匹配 [bcd] 到零次为止,如果随后还是失败,那么引擎就会认为该字符串根本无法匹配 RE 。
Step| Matched| Explanation|
----|----|---
1 |a |a 匹配模式
2 |abcbd| 引擎匹配 `[bcd]*`,并尽其所能匹配到字符串的结尾
3 |Failure| 引擎尝试匹配 b,但当前位置已经是字符的最后了,所以失败
4 |abcb| 退回,[bcd]`*` 尝试少匹配一个字符。
5 |Failure| 再次尝次 b,但在当前最后一位字符是 "d"。
6 |abc |再次退回,`[bcd]*`只匹配 "bc"。
7 |abcb |再次尝试 b ,这次当前位上的字符正好是 "b"
## 使用正则表达式
### 编译正则表达式
REs 被处理成字符串是因为正则表达式不是 Python 语言的核心部分,也没有为它创建特定的语法。(应用程序根本就不需要 REs,因此没必要包含它们去使语言说明变得臃肿不堪。)而 re 模块则只是以一个 C 扩展模块的形式来被 Python 包含,就象 socket 或 zlib 模块一样。将 REs 作为字符串以保证 Python 语言的简洁。
```
import re
p = re.compile('ab*')
p = re.compile('ab*', re.IGNORECASE)
print (p)
```
### 反斜杠
为了匹配一个反斜杠,不得不在 RE 字符串中写 '`\\\\`',因为正则表达式中必须是 "`\\`",而每个反斜杠在常规的 Python 字符串实值中必须表示成 "`\\`"。在 REs 中反斜杠的这个重复特性会导致大量重复的反斜杠,而且所生成的字符串也很难懂。
解决的办法就是为正则表达式使用 Python 的 raw 字符串表示;在字符串前加个 "r" 反斜杠就不会被任何特殊方式处理,所以 `r"\n"` 就是包含 "`\`" 和 "n" 的两个字符,而 "`\n`" 则是一个字符,表示一个换行。正则表达式通常在 Python 代码中都是用这种 raw 字符串表示。
常规字符串| Raw 字符串
---------|--------
"`ab*`" |r"`ab*`"
"`\\\\section`"| r"`\\section`"
"`\\w+\\s+\\1`"| r"`\w+\s+\1`"
### 执行匹配
方法/属性| 作用
--------|-------
match() |决定 RE 是否在字符串刚开始的位置匹配
search()| 扫描字符串,找到这个 RE 匹配的位置
findall()| 找到 RE 匹配的所有子串,并把它们作为一个列表返回
finditer()| 找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
如果没有匹配到的话,match() 和 search() 将返回 None。如果成功的话,就会返回一个 `MatchObject` 实例,其中有这次匹配的信息:它是从哪里开始和结束,它所匹配的子串等等。
findall() 在它返回结果时不得不创建一个列表。在 Python 2.2中,也可以用 finditer() 方法。
MatchObject 实例也有几个方法和属性;最重要的那些如下所示:
方法/属性| 作用
--------|------
group() |返回被 RE 匹配的字符串
start() |返回匹配开始的位置
end() |返回匹配结束的位置
span() |返回一个元组包含匹配 (开始,结束) 的位置
在实际程序中,最常见的作法是将 `MatchObject` 保存在一个变量里,然後检查它是否为 None,通常如下所示:
```
p = re.compile('[a-z]+')
m = p.match( 'tempo')
print(m)
if m:
print ('Match found: ', m.group())
else:
print ('No match')
m.group()
m.start(), m.end()
m.span()
iterator = p.finditer('12 drummers drumming, 11 ... 10 ...')
for match in iterator:
print(match.group())
print(match.span())
```
### 编译标志
编译标志让你可以修改正则表达式的一些运行方式。在 re 模块中标志可以使用两个名字,一个是全名如 IGNORECASE,一个是缩写,一字母形式如 I。(如果你熟悉 Perl 的模式修改,一字母形式使用同样的字母;例如 re.VERBOSE的缩写形式是 re.X。)
多个标志可以通过按位 OR-ing 它们来指定。如 `re.I | re.M` 被设置成 I 和 M 标志:
- LOCALE 影响 \w, \W, \b, 和 \B,这取决于当前的本地化设置。
locales 是 C 语言库中的一项功能,是用来为需要考虑不同语言的编程提供帮助的。举个例子,如果你正在处理法文文本,你想用 \w+ 来匹配文字,但 \w 只匹配字符类 [A-Za-z];它并不能匹配 "é" 或 "ç"。如果你的系统配置适当且本地化设置为法语,那么内部的 C 函数将告诉程序 "é" 也应该被认为是一个字母。当在编译正则表达式时使用 LOCALE 标志会得到用这些 C 函数来处理 \w 后的编译对象;这会更慢,但也会象你希望的那样可以用 \w+ 来匹配法文文本。
- VERBOSE
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。当该标志被指定时,在 RE 字符串中的空白符被忽略,除非该空白符在字符类中或在反斜杠之后;这可以让你更清晰地组织和缩进 RE。它也可以允许你将注释写入 RE,这些注释会被引擎忽略;注释用 "#"号 来标识,不过该符号不能在字符串或反斜杠之后。
标志 |含义
------|----
DOTALL, S |使 `.` 匹配包括换行在内的所有字符
IGNORECASE, I |使匹配对大小写不敏感
LOCALE, L |做本地化识别(locale-aware)匹配
MULTILINE, M |多行匹配,影响 `^` 和 `$`,`^` 和 `$` 不会被解释
VERBOSE, X |能够使用 REs 的 verbose 状态,使之被组织得更清晰易懂
## 更多模式功能
### 更多的元字符
剩下来要讨论的一部分元字符是零宽界定符(zero-width assertions)。它们并不会使引擎在处理字符串时更快;相反,它们根本就没有对应任何字符,只是简单的成功或失败。举个例子,\b 是一个在单词边界定位当前位置的界定符(assertions),这个位置根本就不会被 \b 改变。这意味着零宽界定符(zero-width assertions)将永远不会被重复,因为如果它们在给定位置匹配一次,那么它们很明显可以被匹配无数次。
- `|`
- 可选项,或者 "or" 操作符。如果 A 和 B 是正则表达式,A|B 将匹配任何匹配了 "A" 或 "B" 的字符串。| 的优先级非常低,是为了当你有多字符串要选择时能适当地运行。Crow|Servo 将匹配 "Crow" 或 "Servo", 而不是 "Cro", 一个 "w" 或 一个 "S", 和 "ervo"。
- 为了匹配字母 "|",可以用 `\|`,或将其包含在字符类中,如 `[|]`。
- `^`
- 匹配行首。除非设置 MULTILINE 标志,它只是匹配字符串的开始。在 MULTILINE 模式里,它也可以直接匹配字符串中的每个换行。
- `$`
- 匹配行尾,**行尾被定义为要么是字符串尾,要么是一个换行字符后面的任何位置**。
- 匹配一个 "`$`",使用 `\$` 或将其包含在字符类中,如 `[$]`。
- `\A`
- 只匹配字符串首。
- 当不在 MULTILINE 模式,`\A` 和 `^` 实际上是一样的。
- 然而,在 MULTILINE 模式里它们是不同的;`\A` 只是匹配字符串首,而 `^` 还可以匹配在换行符之后字符串的任何位置。
- `\Z`
- Matches only at the end of the string.
- 只匹配字符串尾。
- `\b`
- 单词边界。
- 这是个零宽界定符(zero-width assertions)只用以匹配单词的词首和词尾。
- 单词被定义为一个字母数字序列,因此词尾就是用空白符或非字母数字符来标示的。
- `\B`
- 另一个零宽界定符(zero-width assertions),它正好同 \b 相反,只在当前位置不在单词边界时匹配。
```
p = re.compile(r'\bclass\b')
print (p.search('no class at all'))
print (p.search('the declassified algorithm'))
print (p.search('one subclass is'))
```
当用这个特殊序列时你应该记住这里有两个微妙之处。第一个是 Python 字符串和正则表达式之间最糟的冲突。在 Python 字符串里,"\b" 是反斜杠字符,ASCII值是8。如果你没有使用 raw 字符串时,那么 Python 将会把 "\b" 转换成一个回退符,你的 RE 将无法象你希望的那样匹配它了。下面的例子看起来和我们前面的 RE 一样,但在 RE 字符串前少了一个 "r" 。
```
p = re.compile('\bclass\b')
print (p.search('no class at all'))
print (p.search('\b' + 'class' + '\b'))
```
第二个在字符类中,这个限定符(assertion)不起作用,\b 表示回退符,以便与 Python 字符串兼容。
### 分组
- 组是通过 "(" 和 ")" 元字符来标识的。 "(" 和 ")" 有很多在数学表达式中相同的意思;它们一起把在它们里面的表达式组成一组。举个例子,你可以用重复限制符,象 `*, +, ?, 和 {m,n}`,来重复组里的内容,比如说 `(ab)*` 将匹配零或更多个重复的 "ab"。
- 小组是从左向右计数的,从1开始。组可以被嵌套。计数的数值可以通过从左到右计算打开的括号数来确定。
- `The groups()` 方法返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
- 模式中的逆向引用允许你指定先前捕获组的内容,该组也必须在字符串当前位置被找到。举个例子,如果组 1 的内容能够在当前位置找到的话,\1 就成功否则失败。记住 Python 字符串也是用反斜杠加数据来允许字符串中包含任意字符的,所以当在 RE 中使用逆向引用时确保使用 raw 字符串。
- 象这样只是搜索一个字符串的逆向引用并不常见 -- 用这种方式重复数据的文本格式并不多见 -- 但你不久就可以发现它们用在字符串替换上非常有用。
```
p = re.compile('(ab)*')
print (p.match('ababababab').span())
p = re.compile('(a)b')
m = p.match('ab')
print(m.group())
print(m.group(0))
p = re.compile('(a(b)c)d')
m = p.match('abcd')
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.group(2,1))
m.groups()
p = re.compile(r'(\b\w+)\s+\1')
p.findall('Paris in the the the spring')
#p.search('Paris in the the the spring').group()
```
### 无捕获组和命名组
- Python 新增了一个扩展语法到 Perl 扩展语法中。如果在问号后的第一个字符是 "P",你就可以知道它是针对 Python 的扩展。目前有两个这样的扩展:
- `(?P<name>...)` 定义一个命名组
- `(?P=name)` 则是对命名组的逆向引用
- 首先,有时你想用一个组去收集正则表达式的一部分,但又对组的内容不感兴趣。你可以用一个无捕获组: `(?:...)` 来实现这项功能,这样你可以在括号中发送任何其他正则表达式。
- 除了捕获匹配组的内容之外,无捕获组与捕获组表现完全一样;
- 你可以在其中放置任何字符,可以用重复元字符如 "`*`" 来重复它,可以在其他组(无捕获组与捕获组)中嵌套它。
- `(?:...)` 对于修改已有组尤其有用,因为你可以不用改变所有其他组号的情况下添加一个新组。
- 捕获组和无捕获组在搜索效率方面也没什么不同,没有哪一个比另一个更快。
- 其次,更重要和强大的是命名组;与用数字指定组不同的是,它可以用名字来指定。
- 命令组的语法是 Python 专用扩展之一: `(?P<name>...)`。名字很明显是组的名字。
- 除了该组有个名字之外,命名组也同捕获组是相同的。`MatchObject` 的方法处理捕获组时接受的要么是表示组号的整数,要么是包含组名的字符串。命名组也可以是数字,所以你可以通过两种方式来得到一个组的信息。
- 命名组是便于使用的,因为它可以让你使用容易记住的名字来代替不得不记住的数字。
- 因为逆向引用的语法,象 `(...)\1` 这样的表达式所表示的是组号,这时用组名代替组号自然会有差别。
- 还有一个 Python 扩展:`(?P=name)`,它可以使叫 name 的组内容再次在当前位置发现。
- 正则表达式为了找到重复的单词,`(\b\w+)\s+\1` 也可以被写成 `(?P<word>\b\w+)\s+(?P=word)`
```
m = re.match("([abc])+", "abc")
print(m.groups())
('c',)
m = re.match("(?:[abc])+", "abc")
print(m.groups())
p = re.compile(r'(?P<word>\b\w+\b)')
m = p.search( '(((( Lots of punctuation )))' )
print(m.groups('word'))
print(m.group(1))
p = re.compile(r'(?P<word>\b\w+)\s+(?P=word)')
p.search('Paris in the the spring').group()
```
### 前向界定符
另一个零宽界定符(zero-width assertion)是前向界定符。前向界定符包括前向肯定界定符和前项否定界定符,如下所示:
- `(?=...)`
前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。
- `(?!...)`
前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功
考虑一个简单的模式用于匹配一个文件名,并将其通过 "." 分成基本名和扩展名两部分。如在 "news.rc" 中,"news" 是基本名,"rc" 是文件的扩展名。
- 匹配模式非常简单:`.*[.].*$`
- 注意 "`.`" 需要特殊对待,因为它是一个元字符;我把它放在一个字符类中。另外注意后面的 `$`;
- 添加这个是为了确保字符串所有的剩余部分必须被包含在扩展名中。
- 这个正则表达式匹配 "foo.bar"、"autoexec.bat"、 "sendmail.cf" 和 "printers.conf"。
现在,考虑把问题变得复杂点;如果你想匹配的扩展名不是 "bat" 的文件名?
- `.*[.](?!bat$).*$`
- 前向的意思:如果表达式 bat 在这里没有匹配,尝试模式的其余部分;如果 `bat$` 匹配,整个模式将失败。
- 后面的 `$` 被要求是为了确保象 "sample.batch" 这样扩展名以 "bat" 开头的会被允许。
- 将另一个文件扩展名排除在外现在也容易;简单地将其做为可选项放在界定符中。下面的这个模式将以 "bat" 或 "exe" 结尾的文件名排除在外。`.*[.](?!bat$|exe$).*$`
```
import re
twitter = re.compile(
'''(?<=@)([\w\d_]+)''',re.UNICODE | re.VERBOSE)
text = '''This text includes two Twitter handles.
One for @ThePSF, and one for the author, @doughellmann.
'''
print (text)
for match in twitter.findall(text):
print ('Handle:', match)
# 前向
# Isaac 前面有 Asimov 才能匹配
test = re.compile(r'Isaac(?=Asimov)')
test.findall("IsaacAsimov")
#test.findall("AsimovIsaac")
# 前向
# Isaac 前面有 Asimov 不能匹配
test = re.compile(r'Isaac(?!Asimov)')
test.findall("IsaacAsimov")
# test.findall("AsimovIsaac")
# 后向
# Isaac 后面有 Asimov 才能匹配
test = re.compile(r'(?<=Asimov)Isaac')
test.findall("AsimovIsaac")
#test.findall("IsaacAsimov")
# 后向
# Isaac 后面有 Asimov 不能匹配
test = re.compile(r'(?<!Asimov)Isaac')
test.findall("AsimovIsaac")
#test.findall("IsaacAsimov")
# 后向
m = re.search('(?<=abc)def', 'abcdef')
m.group(0)
# 后向
m = re.search('(?<=-)\w+', 'spam-egg')
m.group(0)
```
## 修改字符串
方法/属性| 作用
--------|------
`split()` |将字符串在 RE 匹配的地方分片并生成一个列表,
`sub()` |找到 RE 匹配的所有子串,并将其用一个不同的字符串替换
`subn()`|与 `sub()` 相同,但返回新的字符串和替换次数
- `re.compile().split(text, num)`: num 非 0 时,最多分成 num 段
- `p2 = re.compile(r'(\W+)')`: 打印出定界符,如果不需要则为:`p = re.compile(r'\W+')`
### 将字符串分片
```
p = re.compile(r'\W+')
p.split('This is a test, short and sweet, of split().')
# 最多分出 3 段(0 开始数)
p.split('This is a test, short and sweet, of split().', 3)
p = re.compile(r'\W+')
p2 = re.compile(r'(\W+)')
p.split('This... is a test.')
p2.split('This... is a test.')
re.split('[\W]+', 'Words, words, words.')
re.split('([\W]+)', 'Words, words, words.')
re.split('[\W]+', 'Words, words, words.', 1)
```
### 搜索和替换
`sub(replacement, string[, count = 0])`
- 返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。
- 可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
- `subn()` 方法作用一样,但返回的是包含新字符串和替换执行次数的两元组。
- 空匹配只有在它们没有紧挨着前一个匹配时才会被替换掉。
- 还可以指定用 `(?P<name>...)` 语法定义的命名组。"`\g<name>`" 将通过组名 "name" 用子串来匹配,并且 "`\g<number>`" 使用相应的组号。所以 "`\g<2>`" 等于 "`\2`",但能在替换字符串里含义不清,如 "`\g<2>0`"。("`\20`" 被解释成对组 20 的引用,而不是对后面跟着一个字母 "0" 的组 2 的引用。)
- 替换也可以是一个甚至给你更多控制的函数。如果替换是个函数,该函数将会被模式中每一个不重复的匹配所调用。在每次调用时,函数会被传入一个 `MatchObject` 的对象作为参数,因此可以用这个对象去计算出替换字符串并返回它。
```
p = re.compile('(blue|white|red)')
p.sub( 'colour', 'blue socks and red shoes')
p.sub('colour', 'blue socks and red shoes', count=1)
p = re.compile('x*')
p.sub('-', 'abxd')
p = re.compile('section{ ( [^}]* ) }', re.VERBOSE)
p = re.compile('section{(\w+)}')
p.sub(r'subsection{\1}','section{First} section{second}')
p = re.compile('section{ (?P<name> [^}]* ) }', re.VERBOSE)
p = re.compile('section{ (?P<name> \w+) }', re.VERBOSE)
p.sub(r'subsection{\1}','section{First}')
p.sub(r'subsection{\g<1>}','section{First}')
p.sub(r'subsection{\g<name>}','section{First}')
def hexrepl( match ):
... "Return the hex string for a decimal number"
... value = int( match.group() )
... return hex(value)
...
p = re.compile(r'\d+')
p.sub(hexrepl, 'Call 65490 for printing, 49152 for user code.')
```
## 常见问题
### 使用字符串方式
用一个固定字符串替换另一个 的例子,如:你可以把 "deed" 替换成 "word"。re.sub() 似乎正是胜任这个工作的函数,但还是考虑考虑 replace() 方法吧。注意 replace() 也可以在单词里面进行替换,可以把 "swordfish" 变成 "sdeedfish"。
另一个常见任务是从一个字符串中删除单个字符或用另一个字符来替代它。你也许可以用 re.sub('\n',' ', s) 这样来实现,但 translate() 能够实现这两个任务,而且比任何正则表达式操作起来更快。 (translate 需要配合 string.maketrans 使用。例如:import string 后 'a1b3'.translate(string.maketrans('ab', 'cd')) )
### `match() vs search()`
match() 函数只检查 RE 是否在字符串开始处匹配,而 search() 则是扫描整个字符串。
### 贪婪 vs 不贪婪
不贪婪的限定符 `*?、+?、?? 或 {m,n}?`,尽可能匹配小的文本。
### 使用 `re.VERBOSE`
# 笔记
- 大多数字母和字符一般都会和自身匹配
- 元字符在类别里(`[]` 里)并不起作用
- 可以用补集来匹配不在区间范围内的字符。其做法是把"^"作为**类别**的**首个字符**;其它地方的"^"只会简单匹配 "^"字符本身
- 在字符串前加个 "r" 反斜杠就不会被任何特殊方式处理
- 如果没有匹配到的话,match() 和 search() 将返回 None。如果成功的话,就会返回一个 `MatchObject` 实例,其中有这次匹配的信息:它是从哪里开始和结束,它所匹配的子串等等。findall() 在它返回结果时不得不创建一个列表。在 Python 2.2中,也可以用 finditer() 方法。
- 多个标志可以通过按位 OR-ing 它们来指定。如 `re.I | re.M` 被设置成 I 和 M 标志
- 组可以被嵌套。计数的数值可以通过从左到右计算打开的括号数来确定。`The groups()` 方法返回一个包含所有小组字符串的元组,从 **1** 到 所含的小组号。
- 模式中的逆向引用允许你指定先前捕获组的内容,该组也必须在字符串当前位置被找到。举个例子,如果组 1 的内容能够在当前位置找到的话,\1 就成功否则失败。
- 无捕获组和命名组
- `(?P<name>...)` 定义一个命名组,`(?P=name)` 则是对命名组的逆向引用;除了用数字指定组,它可以用名字来指定,如:`(\b\w+)\s+\1` 也可以被写成 `(?P<word>\b\w+)\s+(?P=word)`
- 无捕获组: `(?:...)` ,对于修改已有组尤其有用,因为你可以不用改变所有其他组号的情况下添加一个新组。
- 前向界定符
- `(?=...)` 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。
- `(?!...)` 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功,匹配不是 bat 或 exe 后缀的:`.*[.](?!bat$|exe$).*$`
- `split(string [, maxsplit = 0])`
- `re.compile().split(text, num)`: num 非 0 时,最多分成 num 段
- `p2 = re.compile(r'(\W+)')`: 打印出定界符,如果不需要则为:`p = re.compile(r'\W+')`
- `sub(replacement, string[, count = 0])`
- 可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
- 空匹配只有在它们没有紧挨着前一个匹配时才会被替换掉。
- 还可以指定用 `(?P<name>...)` 语法定义的命名组。"`\g<name>`" 将通过组名 "name" 用子串来匹配,并且 "`\g<number>`" 使用相应的组号。
- 替换也可以是一个函数,该函数将会被模式中每一个不重复的匹配所调用。
- 更快的替换:`replace`
- 从一个字符串中删除单个字符或用另一个字符来替代它
- 可以用 `re.sub('\n',' ', s)` 这样来实现,但 `translate()` 能够实现这两个任务,而且比任何正则表达式操作起来更快。
- `translate` 需要配合` string.maketrans` 使用。例如:`import string` 后 `'a1b3'.translate(string.maketrans('ab', 'cd'))`
| github_jupyter |
# Get your data ready for training
This module defines the basic [`DataBunch`](/basic_data.html#DataBunch) object that is used inside [`Learner`](/basic_train.html#Learner) to train a model. This is the generic class, that can take any kind of fastai [`Dataset`](https://pytorch.org/docs/stable/data.html#torch.utils.data.Dataset) or [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). You'll find helpful functions in the data module of every application to directly create this [`DataBunch`](/basic_data.html#DataBunch) for you.
```
from fastai.gen_doc.nbdoc import *
from fastai.basic_data import *
show_doc(DataBunch, doc_string=False)
```
Bind together a `train_dl`, a `valid_dl` and optionally a `test_dl`, ensures they are on `device` and apply to them `tfms` as batch are drawn. `path` is used internally to store temporary files, `collate_fn` is passed to the pytorch `Dataloader` (replacing the one there) to explain how to collate the samples picked for a batch. By default, it applies data to the object sent (see in [`vision.image`](/vision.image.html#vision.image) why this can be important).
An example of `tfms` to pass is normalization. `train_dl`, `valid_dl` and optionally `test_dl` will be wrapped in [`DeviceDataLoader`](/basic_data.html#DeviceDataLoader).
```
show_doc(DataBunch.create, doc_string=False)
```
Create a [`DataBunch`](/basic_data.html#DataBunch) from `train_ds`, `valid_ds` and optionally `test_ds`, with batch size `bs` and by using `num_workers`. `tfms` and `device` are passed to the init method.
```
show_doc(DataBunch.show_batch)
show_doc(DataBunch.dl)
show_doc(DataBunch.add_tfm)
```
Adds a transform to all dataloaders.
```
show_doc(DeviceDataLoader, doc_string=False)
```
Put the batches of `dl` on `device` after applying an optional list of `tfms`. `collate_fn` will replace the one of `dl`. All dataloaders of a [`DataBunch`](/basic_data.html#DataBunch) are of this type.
### Factory method
```
show_doc(DeviceDataLoader.create, doc_string=False)
```
Create a [`DeviceDataLoader`](/basic_data.html#DeviceDataLoader) on `device` from a `dataset` with batch size `bs`, `num_workers`processes and a given `collate_fn`. The dataloader will `shuffle` the data if that flag is set to True, and `tfms` are passed to the init method. All `kwargs` are passed to the pytorch [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) class initialization.
### Methods
```
show_doc(DeviceDataLoader.one_batch)
show_doc(DeviceDataLoader.add_tfm)
```
Add a transform (i.e. same as `self.tfms.append(tfm)`).
```
show_doc(DeviceDataLoader.remove_tfm)
```
Remove a transform.
```
show_doc(DatasetType, doc_string=False)
```
Internal enumerator to name the training, validation and test dataset/dataloader.
## Undocumented Methods - Methods moved below this line will intentionally be hidden
```
show_doc(DeviceDataLoader.proc_batch)
```
## New Methods - Please document or move to the undocumented section
| github_jupyter |
[](https://colab.research.google.com/github/eirasf/GCED-AA2/blob/main/lab4/lab4_parte2.ipynb)
# Práctica 4: Redes neuronales usando Keras con Regularización
## Parte 2. Penalización basada en la norma de los parámetros
En esta segunda parte analizaremos cómo realizar una regularización basada en la norma de los parámetros tanto L2 como L1.
## Pre-requisitos. Instalar paquetes
Para la primera parte de este Laboratorio 4 necesitaremos TensorFlow, TensorFlow-Datasets y otros paquetes para inicializar la semilla y poder reproducir los resultados.
```
import tensorflow as tf
import tensorflow_datasets as tfds
import os
import numpy as np
import random
#Fijamos la semilla para poder reproducir los resultados
seed=1234
os.environ['PYTHONHASHSEED']=str(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
random.seed(seed)
```
Además, cargamos también APIs que vamos a emplear para que el código quede más legible
```
from matplotlib import pyplot
from tensorflow import keras
from keras.models import Sequential
from keras.layers import InputLayer
from keras.layers import Dense
```
##Cargamos el conjunto de datos
Cargamos el conjunto *german_credit_numeric* tal y como hicimos en la parte 1 de este laboratorio.
```
# Cargamos el conjunto de datos
ds_train = tfds.load('german_credit_numeric', split='train[:50%]', as_supervised=True).batch(128)
ds_test = tfds.load('german_credit_numeric', split='train[50%:]', as_supervised=True).batch(128)
```
También vamos a establecer la función de pérdida, el algoritmo que vamos a emplear para el entrenamiento y la métrica que nos servirá para evaluar el rendimiento del modelo entrenado.
```
fn_perdida = tf.keras.losses.BinaryCrossentropy()
optimizador = tf.keras.optimizers.Adam(0.001)
metrica = tf.keras.metrics.AUC()
```
## Creamos un modelo *Sequential*
Creamos un modelo *Sequential* tal y como se ha hecho en la primera parte de este laboratorio. Pero incluiremos un término de regularización en las capas *Dense*. En Keras tenemos varias opciones para incluirlo:
- *kernel_regularizer* actúa sobre los pesos ($W$)
- *bias_regularizer* actúa sobre el sesgo ($b$)
- *activity_regularizer* intenta reducir la salida de la capa $y$, por lo tanto, reducirá los pesos y ajustará el sesgo.
Normalmente se aplica *kernel_regularizer* (tal y como se ha visto en clase de teoría) para evitar que la red se sobreajuste, para introducirlo en Keras solo hace falta indicarlo en la capa correspondiente, indicando el valor del hiperparámetro de regularización $\alpha$ (por defecto, su valor es 0.01).
Existen varias opciones para calcular este término regularizador, aunque las más empleadas (y vistas en teoría son):
1. L1, el término regularización se calcula usando el valor absoluto de los pesos, $||\mathbf{W}||_{1}$ .
1. L2, la más utilizada, donde el término de regularización se calcula usando el cuadrado de los pesos, $\frac{1}{2}||\mathbf{W}||^2$
**TO-DO**: Prueba diferentes términos de regularización e hiperparámetros. Fijate en la diferencia de resultado entre entrenamiento y test.
```
#Descomentar el término regularizador que se vaya a emplear
from tensorflow.keras.regularizers import l2
#from tensorflow.keras.regularizers import l1
tamano_entrada = 24
#TODO- Varía el valor de alpha para ajustar la regularización
alpha=0.01
h0_size = 20
h1_size = 10
h2_size = 5
#TODO - define el modelo Sequential
model = ...
#TODO - incluye la capa de entrada
model.add(...)
#TODO - incluye las unidades de la primera capa Dense
model.add( Dense(units=..., kernel_regularizer=l2(alpha),activation='relu'))
#TODO - incluye las otras 3 capas Dense con el término de regularización
model.add(...)
model.add(...)
model.add(...)
#Construimos el modelo y mostramos
model.build()
print(model.summary())
```
Completar el método *compile*.
```
#TODO - indicar los parametros del método compile
model.compile(...)
```
Completar el método *fit* tal y como hemos hecho en los laboratorios anteriores.
```
num_epochs = 1000
#TODO - entrenar el modelo
history = model.fit(...)
# plot training history
pyplot.plot(history.history['loss'], label='train')
pyplot.legend()
pyplot.show()
```
Evaluación sobre el conjunto de test (no usado para el entrenamiento).
```
#TODO - llamar a evaluate usando el conjunto de test
result = model.evaluate(...)
print(model.metrics_names)
print(result)
```
| github_jupyter |
<img src="../../../images/qiskit-heading.gif" alt="Note: In order for images to show up in this jupyter notebook you need to select File => Trusted Notebook" width="500 px" align="left">
# _*Qiskit Aqua: Generating Random Variates*_
The latest version of this notebook is available on https://github.com/Qiskit/qiskit-tutorials.
***
### Contributors
Albert Akhriev<sup>[1]</sup>, Jakub Marecek<sup>[1]</sup>
### Affliation
- <sup>[1]</sup>IBMQ
## Introduction
While classical computers use only pseudo-random routines, quantum computers
can generate true random variates.
For example, the measurement of a quantum superposition is intrinsically random,
as suggested by Born's rule.
Consequently, some of the
best random-number generators are based on such quantum-mechanical effects. (See the
Further, with a logarithmic amount of random bits, quantum computers can produce
linearly many more bits, which is known as
randomness expansion protocols.
In practical applications, one wishes to use random variates of well-known
distributions, rather than random bits.
In this notebook, we illustrate ways of generating random variates of several popular
distributions on IBM Q.
## Random Bits and the Bernoulli distribution
It is clear that there are many options for generating random bits (i.e., Bernoulli-distributed scalars, taking values either 0 or 1). Starting from a simple circuit such as a Hadamard gate followed by measurement, one can progress to vectors of Bernoulli-distributed elements. By addition of such random variates, we could get binomial distributions. By multiplication we could get geometric distributions, although perhaps leading to a circuit depth that may be impratical at the moment, though.
Let us start by importing the basic modules and creating a quantum circuit for generating random bits:
```
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sys, math, time
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from qiskit import BasicAer
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute
# In this example we use 'qasm_simulator' backend.
glo_backend = BasicAer.get_backend("qasm_simulator")
```
In the next step we create a quantum circuit, which will be used for generation:
```
# Number of qubits utilised simultaneously.
glo_num_qubits = 5
def create_circuit(num_target_qubits: int) -> QuantumCircuit:
"""
Creates and returns quantum circuit for random variate generation.
:param num_target_qubits: number of qubits to be used.
:return: quantum curcuit.
"""
assert isinstance(num_target_qubits, int) and num_target_qubits > 0
q = QuantumRegister(num_target_qubits)
c = ClassicalRegister(num_target_qubits)
circuit = QuantumCircuit(q, c)
circuit.h(q)
circuit.barrier()
circuit.measure(q, c)
return circuit
# Create and plot generating quantum circuit.
circuit = create_circuit(glo_num_qubits)
#print(circuit)
circuit.draw(output='mpl')
```
## Uniformly-distributed scalars and vectors
It is clear that there are many options for approximating uniformly-distributed scalars by the choice of an integer from a finite range uniformly at random, e.g., by a binary-code construction from the Bernoulli-distributed vectors. In the following snippet, we generate random bits, which we then convert using the binary-code construction, up to the machine precision of a classical computer.
```
def uniform_rand_float64(circuit: QuantumCircuit, num_target_qubits: int,
size: int, vmin: float, vmax: float) -> np.ndarray:
"""
Generates a vector of random float64 values in the range [vmin, vmax].
:param circuit: quantum circuit for random variate generation.
:param num_target_qubits: number of qubits to be used.
:param size: length of the vector.
:param vmin: lower bound.
:param vmax: upper bound.
:return: vector of random values.
"""
assert sys.maxsize == np.iinfo(np.int64).max # sizeof(int) == 64 bits
assert isinstance(size, int) and size > 0
assert isinstance(vmin, float) and isinstance(vmax, float) and vmin <= vmax
nbits = 7 * 8 # nbits > mantissa of float64
bit_str_len = (nbits * size + num_target_qubits - 1) // num_target_qubits
job = execute(circuit, glo_backend, shots=bit_str_len, memory=True)
bit_str = ''.join(job.result().get_memory())
scale = float(vmax - vmin) / float(2**nbits - 1)
return np.array([vmin + scale * float(int(bit_str[i:i+nbits], 2))
for i in range(0, nbits * size, nbits)], dtype=np.float64)
def uniform_rand_int64(circuit: QuantumCircuit, num_target_qubits: int,
size: int, vmin: int, vmax: int) -> np.ndarray:
"""
Generates a vector of random int64 values in the range [vmin, vmax].
:param circuit: quantum circuit for random variate generation.
:param num_target_qubits: number of qubits to be used.
:param size: length of the vector.
:param vmin: lower bound.
:param vmax: upper bound.
:return: vector of random values.
"""
assert sys.maxsize == np.iinfo(np.int64).max # sizeof(int) == 64 bits
assert isinstance(size, int) and size > 0
assert isinstance(vmin, int) and isinstance(vmax, int) and vmin <= vmax
assert abs(vmin) <= 2**52 and abs(vmax) <= 2**52 # 52 == mantissa of float64
return np.rint(uniform_rand_float64(circuit, num_target_qubits,
size, float(vmin), float(vmax))).astype(np.int64)
```
### Uniform distribution over floating point numbers.
In this example we draw a random vector of floating-point values uniformly distributed within some arbitrary selected interval:
```
# Draw a sample from uniform distribution.
start_time = time.time()
sample = uniform_rand_float64(circuit, glo_num_qubits, size=54321, vmin=-7.67, vmax=19.52)
sampling_time = time.time() - start_time
# Print out some details.
print("Uniform distribution over floating point numbers:")
print(" sample type:", type(sample), ", element type:", sample.dtype, ", shape:", sample.shape)
print(" sample min: {:.4f}, max: {:.4f}".format(np.amin(sample), np.amax(sample)))
print(" sampling time: {:.2f} secs".format(sampling_time))
# Plotting the distribution.
plt.hist(sample.ravel(),
bins=min(int(np.ceil(np.sqrt(sample.size))), 100),
density=True, facecolor='b', alpha=0.75)
plt.xlabel("value", size=12)
plt.ylabel("probability", size=12)
plt.title("Uniform distribution over float64 numbers in [{:.2f} ... {:.2f}]".format(
np.amin(sample), np.amax(sample)), size=12)
plt.grid(True)
# plt.savefig("uniform_distrib_float.png", bbox_inches="tight")
plt.show()
```
### Uniform distribution over integers.
Our next example is similar to the previous one, but here we generate a random vector of integers:
```
# Draw a sample from uniform distribution.
start_time = time.time()
sample = uniform_rand_int64(circuit, glo_num_qubits, size=54321, vmin=37, vmax=841)
sampling_time = time.time() - start_time
# Print out some details.
print("Uniform distribution over bounded integer numbers:")
print(" sample type:", type(sample), ", element type:", sample.dtype, ", shape:", sample.shape)
print(" sample min: {:d}, max: {:d}".format(np.amin(sample), np.amax(sample)))
print(" sampling time: {:.2f} secs".format(sampling_time))
# Plotting the distribution.
plt.hist(sample.ravel(),
bins=min(int(np.ceil(np.sqrt(sample.size))), 100),
density=True, facecolor='g', alpha=0.75)
plt.xlabel("value", size=12)
plt.ylabel("probability", size=12)
plt.title("Uniform distribution over int64 numbers in [{:d} ... {:d}]".format(
np.amin(sample), np.amax(sample)), size=12)
plt.grid(True)
# plt.savefig("uniform_distrib_int.png", bbox_inches="tight")
plt.show()
```
## Normal distribution
To generate random variates with a standard normal distribution using two independent
samples $u_1, u_2$ of the uniform distribution on the unit interval [0, 1], one can
consider the Box-Muller transform to obtain a 2-vector:
\begin{align}
\begin{bmatrix}
%R\cos(\Theta )=
{\sqrt {-2\ln u_{1}}}\cos(2\pi u_{2}) \\
% R\sin(\Theta )=
{\sqrt {-2\ln u_{1}}}\sin(2\pi u_{2})
\end{bmatrix},
\end{align}
wherein we have two independent samples of the standard normal distribution.
In IBM Q, this is implemented as follows:
```
def normal_rand_float64(circuit: QuantumCircuit, num_target_qubits: int,
size: int, mu: float, sigma: float) -> np.ndarray:
"""
Draws a sample vector from the normal distribution given the mean and standard
deviation, using the Box-Muller method.
"""
TINY = np.sqrt(np.finfo(np.float64).tiny)
assert isinstance(size, int) and size > 0
rand_vec = np.zeros((size,), dtype=np.float64)
# Generate array of uniformly distributed samples, factor 1.5 longer that
# actually needed.
n = (3 * size) // 2
x = np.reshape(uniform_rand_float64(circuit, num_target_qubits,
2*n, 0.0, 1.0), (-1, 2))
x1 = 0.0 # first sample in a pair
c = 0 # counter
for d in range(size):
r2 = 2.0
while r2 >= 1.0 or r2 < TINY:
# Regenerate array of uniformly distributed samples upon shortage.
if c >= n:
c = 0
n = max(size // 10, 1)
x = np.reshape(uniform_rand_float64(circuit, num_target_qubits,
2*n, 0.0, 1.0), (-1, 2))
x1 = 2.0 * x[c, 0] - 1.0 # first sample in a pair
x2 = 2.0 * x[c, 1] - 1.0 # second sample in a pair
r2 = x1 * x1 + x2 * x2
c += 1
f = np.sqrt(np.abs(-2.0 * np.log(r2) / r2))
rand_vec[d] = f * x1
return (rand_vec * sigma + mu)
```
The following example demonstrates how to draw a random vector of normally distributed variates:
```
# Mean and standard deviation.
mu = 2.4
sigma = 5.1
# Draw a sample from the normal distribution.
start_time = time.time()
sample = normal_rand_float64(circuit, glo_num_qubits, size=4321, mu=mu, sigma=sigma)
sampling_time = time.time() - start_time
# Print out some details.
print("Normal distribution (mu={:.3f}, sigma={:.3f}):".format(mu, sigma))
print(" sample type:", type(sample), ", element type:", sample.dtype, ", shape:", sample.shape)
print(" sample min: {:.4f}, max: {:.4f}".format(np.amin(sample), np.amax(sample)))
print(" sampling time: {:.2f} secs".format(sampling_time))
# Plotting the distribution.
x = np.linspace(mu - 4.0 * sigma, mu + 4.0 * sigma, 1000)
analyt = np.exp(-0.5 * ((x - mu) / sigma)**2) / (sigma * math.sqrt(2.0 * math.pi))
plt.hist(sample.ravel(),
bins=min(int(np.ceil(np.sqrt(sample.size))), 100),
density=True, facecolor='r', alpha=0.75)
plt.plot(x, analyt, '-b', lw=1)
plt.xlabel("value", size=12)
plt.ylabel("probability", size=12)
plt.title("Normal distribution: empirical vs analytic", size=12)
plt.grid(True)
# plt.savefig("normal_distrib.png", bbox_inches="tight")
plt.show()
```
There is a substantial amount of further work needed to either certify the quality of the source of random numbers (cf. NIST SP 800-90B, Recommendation for the Entropy Sources Used for Random Bit Generation) or to use random variates within quantum algorithms (cf. <a href="https://github.com/Qiskit/qiskit-aqua/tree/master/qiskit/aqua/components/uncertainty_models">uncertainty_models</a> within Qiskit Aqua).
| github_jupyter |
# Visualizing Models, Data and Traning with Tensorboard
In this tutorial, we'll learn how to:
1. Read in data and with appropriate transforms
2. Set up TensorBoard
3. Write to TensorBoard
4. Inspect a model architecutre using TensorBoard
5. Use TensorBoard to create interactive versions of the visualizations we created in last tutorial.
Specially, on point 5, we'll see:
* A couple of ways to insepect our training data
* How to track our model's performance as it trains
* How to assess our model's performance once it is trained
```
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# dataset
trainset = torchvision.datasets.FashionMNIST(
'./data', download=True, train=True,
transform=transform)
testset = torchvision.datasets.FashionMNIST(
'./data', download=True, train=False,
transform=transform)
# dataloader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False)
# constant for classes
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')
# helper function to show an image
def matplotlib_imshow(img, one_channel=False):
if one_channel:
img = img.mean(dim=0)
img = img / 2 + 0.5 # unnormlize
npimg = img.numpy()
if one_channel:
plt.imshow(npimg, cmap='Greys')
else:
plt.imshow(np.transpose(npimg, (1, 2, 0)))
```
We'll define a similar model architecutre from that tutorial, making only minor modifications to account for the fact that the images are now one channel instead of three and 28*28 instead of 32*32.
```
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16*4*4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
```
We'll define the same `optimizer` and `criterion` from before:
```
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)
```
## TensorBord setup
Now we'll set up TensorBoard, importing `tensorboard` from `torch.utils` and defining a `SummaryWriter`, our key object for writing information to TensorBoard.
```
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('runs/fashion_mnist_experiment_1')
```
## Writing to TensorBoard
```
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# create grid of images
img_grid = torchvision.utils.make_grid(images)
# show images
matplotlib_imshow(img_grid, one_channel=True)
# write to tensorboard
writer.add_image('four_fashion_mnist_images', img_grid)
```

## Inspect the model using TensorBoard
One of TensorBoad's strenghts is its ability to visualize model structures. Let's visualize the model we built.
```
writer.add_graph(net, images)
writer.close()
```

Go ahead and double click on `Net` to see it expand, seeing a detailed view of the individual operations that make up the model.
## Adding a "Projector" to TensorBoard
We can visualize the lower dimensional representation of higher dimensional data via the `add_embedding` method.
```
def select_n_random(data, labels, n=100):
"""
Select n random datapoints and their corresponding lables from
a dataset.
"""
assert len(data) == len(labels)
perm = torch.randperm(len(data))
return data[perm][:n], labels[perm][:n]
# select random iamges and their target indices
images, labels = select_n_random(trainset.data, trainset.targets)
# get the class labels for each image
class_labels = [classes[lab] for lab in labels]
# log embedding
features = images.view(-1, 28*28)
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
writer.close()
images.shape, labels.shape
```
## Tracking model training with TensorBoard
```
# help functions
def images_to_probs(net, images):
"""
Generates predictions adn corresonding probabilities from a
trained network and a list of images.
"""
output = net(images)
# convert output probilities to predicted class
_, pred_tensor = torch.max(output, 1)
preds = np.squeeze(pred_tensor.numpy())
return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)]
def plot_classes_preds(net, images, labels):
"""
Generates matplotlib Figure using a trained network, along with
images and labels from a batch, that shows the network's top
prediction along with its probability, alongnside the actual
label, coloring this information based on wheterh the prediction
was correct or not.
Uses the "iamgess_to_probs" function.
"""
preds, probs = images_to_probs(net, images)
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(12, 48))
for idx in np.arange(4):
ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[])
matplotlib_imshow(images[idx], one_channel=True)
ax.set_title("{0}, {1:.1f}%\n(label: {2})".format(
classes[preds[idx]],
probs[idx] * 100.0,
classes[labels[idx]]),
color=("green" if preds[idx]==labels[idx].item() else "red"))
return fig
running_loss = 0.0
for epoch in range(1):
for i, data in enumerate(trainloader, 0):
# get the inputs, data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outpus = net(inputs)
loss = criterion(outpus, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 99:
# log the running loss
writer.add_scalar('training loass',
running_loss / 1000,
epoch * len(trainloader) + i)
writer.add_figure('predictions vs. actuals',
plot_classes_preds(net, inputs, labels),
global_step=epoch*len(trainloader) + i)
running_loss = 0.0
print('Finishing Training')
```
| github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.
# Handwritten Digit Classification (MNIST) using ONNX Runtime on Azure ML
This example shows how to deploy an image classification neural network using the Modified National Institute of Standards and Technology ([MNIST](http://yann.lecun.com/exdb/mnist/)) dataset and Open Neural Network eXchange format ([ONNX](http://aka.ms/onnxdocarticle)) on the Azure Machine Learning platform. MNIST is a popular dataset consisting of 70,000 grayscale images. Each image is a handwritten digit of 28x28 pixels, representing number from 0 to 9. This tutorial will show you how to deploy a MNIST model from the [ONNX model zoo](https://github.com/onnx/models), use it to make predictions using ONNX Runtime Inference, and deploy it as a web service in Azure.
Throughout this tutorial, we will be referring to ONNX, a neural network exchange format used to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools (CNTK, PyTorch, Caffe, MXNet, TensorFlow) and choose the combination that is best for them. ONNX is developed and supported by a community of partners including Microsoft AI, Facebook, and Amazon. For more information, explore the [ONNX website](http://onnx.ai) and [open source files](https://github.com/onnx).
[ONNX Runtime](https://aka.ms/onnxruntime-python) is the runtime engine that enables evaluation of trained machine learning (Traditional ML and Deep Learning) models with high performance and low resource utilization.
#### Tutorial Objectives:
- Describe the MNIST dataset and pretrained Convolutional Neural Net ONNX model, stored in the ONNX model zoo.
- Deploy and run the pretrained MNIST ONNX model on an Azure Machine Learning instance
- Predict labels for test set data points in the cloud using ONNX Runtime and Azure ML
## Prerequisites
### 1. Install Azure ML SDK and create a new workspace
Please follow [Azure ML configuration notebook](https://github.com/Azure/MachineLearningNotebooks/blob/master/00.configuration.ipynb) to set up your environment.
### 2. Install additional packages needed for this tutorial notebook
You need to install the popular plotting library `matplotlib`, the image manipulation library `opencv`, and the `onnx` library in the conda environment where Azure Maching Learning SDK is installed.
```sh
(myenv) $ pip install matplotlib onnx opencv-python
```
**Debugging tip**: Make sure that you run the "jupyter notebook" command to launch this notebook after activating your virtual environment. Choose the respective Python kernel for your new virtual environment using the `Kernel > Change Kernel` menu above. If you have completed the steps correctly, the upper right corner of your screen should state `Python [conda env:myenv]` instead of `Python [default]`.
### 3. Download sample data and pre-trained ONNX model from ONNX Model Zoo.
In the following lines of code, we download [the trained ONNX MNIST model and corresponding test data](https://github.com/onnx/models/tree/master/mnist) and place them in the same folder as this tutorial notebook. For more information about the MNIST dataset, please visit [Yan LeCun's website](http://yann.lecun.com/exdb/mnist/).
```
# urllib is a built-in Python library to download files from URLs
# Objective: retrieve the latest version of the ONNX MNIST model files from the
# ONNX Model Zoo and save it in the same folder as this tutorial
import urllib.request
onnx_model_url = "https://www.cntk.ai/OnnxModels/mnist/opset_7/mnist.tar.gz"
urllib.request.urlretrieve(onnx_model_url, filename="mnist.tar.gz")
# the ! magic command tells our jupyter notebook kernel to run the following line of
# code from the command line instead of the notebook kernel
# We use tar and xvcf to unzip the files we just retrieved from the ONNX model zoo
!tar xvzf mnist.tar.gz
```
## Deploy a VM with your ONNX model in the Cloud
### Load Azure ML workspace
We begin by instantiating a workspace object from the existing workspace created earlier in the configuration notebook.
```
# Check core SDK version number
import azureml.core
print("SDK version:", azureml.core.VERSION)
from azureml.core import Workspace
ws = Workspace.from_config()
print(ws.name, ws.resource_group, ws.location, sep = '\n')
```
### Registering your model with Azure ML
```
model_dir = "mnist" # replace this with the location of your model files
# leave as is if it's in the same folder as this notebook
from azureml.core.model import Model
model = Model.register(workspace = ws,
model_path = model_dir + "/" + "model.onnx",
model_name = "mnist_1",
tags = {"onnx": "demo"},
description = "MNIST image classification CNN from ONNX Model Zoo",)
```
### Optional: Displaying your registered models
This step is not required, so feel free to skip it.
```
models = ws.models
for name, m in models.items():
print("Name:", name,"\tVersion:", m.version, "\tDescription:", m.description, m.tags)
```
### ONNX MNIST Model Methodology
The image classification model we are using is pre-trained using Microsoft's deep learning cognitive toolkit, [CNTK](https://github.com/Microsoft/CNTK), from the [ONNX model zoo](http://github.com/onnx/models). The model zoo has many other models that can be deployed on cloud providers like AzureML without any additional training. To ensure that our cloud deployed model works, we use testing data from the famous MNIST data set, provided as part of the [trained MNIST model](https://github.com/onnx/models/tree/master/mnist) in the ONNX model zoo.
***Input: Handwritten Images from MNIST Dataset***
***Task: Classify each MNIST image into an appropriate digit***
***Output: Digit prediction for input image***
Run the cell below to look at some of the sample images from the MNIST dataset that we used to train this ONNX model. Remember, once the application is deployed in Azure ML, you can use your own images as input for the model to classify!
```
# for images and plots in this notebook
import matplotlib.pyplot as plt
from IPython.display import Image
# display images inline
%matplotlib inline
Image(url="http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png", width=200, height=200)
```
### Specify our Score and Environment Files
We are now going to deploy our ONNX Model on AML with inference in ONNX Runtime. We begin by writing a score.py file, which will help us run the model in our Azure ML virtual machine (VM), and then specify our environment by writing a yml file. You will also notice that we import the onnxruntime library to do runtime inference on our ONNX models (passing in input and evaluating out model's predicted output). More information on the API and commands can be found in the [ONNX Runtime documentation](https://aka.ms/onnxruntime).
### Write Score File
A score file is what tells our Azure cloud service what to do. After initializing our model using azureml.core.model, we start an ONNX Runtime inference session to evaluate the data passed in on our function calls.
```
%%writefile score.py
import json
import numpy as np
import onnxruntime
import sys
import os
from azureml.core.model import Model
import time
def init():
global session, input_name, output_name
model = Model.get_model_path(model_name = 'mnist_1')
session = onnxruntime.InferenceSession(model, None)
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
def run(input_data):
'''Purpose: evaluate test input in Azure Cloud using onnxruntime.
We will call the run function later from our Jupyter Notebook
so our azure service can evaluate our model input in the cloud. '''
try:
# load in our data, convert to readable format
data = np.array(json.loads(input_data)['data']).astype('float32')
start = time.time()
r = session.run([output_name], {input_name: data})[0]
end = time.time()
result = choose_class(r[0])
result_dict = {"result": [result],
"time_in_sec": [end - start]}
except Exception as e:
result_dict = {"error": str(e)}
return json.dumps(result_dict)
def choose_class(result_prob):
"""We use argmax to determine the right label to choose from our output"""
return int(np.argmax(result_prob, axis=0))
```
### Write Environment File
This step creates a YAML environment file that specifies which dependencies we would like to see in our Linux Virtual Machine.
```
from azureml.core.conda_dependencies import CondaDependencies
myenv = CondaDependencies.create(pip_packages=["numpy", "onnxruntime", "azureml-core"])
with open("myenv.yml","w") as f:
f.write(myenv.serialize_to_string())
```
### Create the Container Image
This step will likely take a few minutes.
```
from azureml.core.image import ContainerImage
image_config = ContainerImage.image_configuration(execution_script = "score.py",
runtime = "python",
conda_file = "myenv.yml",
description = "MNIST ONNX Runtime container",
tags = {"demo": "onnx"})
image = ContainerImage.create(name = "onnximage",
# this is the model object
models = [model],
image_config = image_config,
workspace = ws)
image.wait_for_creation(show_output = True)
```
In case you need to debug your code, the next line of code accesses the log file.
```
print(image.image_build_log_uri)
```
We're all done specifying what we want our virtual machine to do. Let's configure and deploy our container image.
### Deploy the container image
```
from azureml.core.webservice import AciWebservice
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'demo': 'onnx'},
description = 'ONNX for mnist model')
```
The following cell will likely take a few minutes to run as well.
```
from azureml.core.webservice import Webservice
aci_service_name = 'onnx-demo-mnist'
print("Service", aci_service_name)
aci_service = Webservice.deploy_from_image(deployment_config = aciconfig,
image = image,
name = aci_service_name,
workspace = ws)
aci_service.wait_for_deployment(True)
print(aci_service.state)
if aci_service.state != 'Healthy':
# run this command for debugging.
print(aci_service.get_logs())
# If your deployment fails, make sure to delete your aci_service or rename your service before trying again!
# aci_service.delete()
```
### Success!
If you've made it this far, you've deployed a working VM with a handwritten digit classifier running in the cloud using Azure ML. Congratulations!
Let's see how well our model deals with our test images.
## Testing and Evaluation
### Load Test Data
These are already in your directory from your ONNX model download (from the model zoo).
Notice that our Model Zoo files have a .pb extension. This is because they are [protobuf files (Protocol Buffers)](https://developers.google.com/protocol-buffers/docs/pythontutorial), so we need to read in our data through our ONNX TensorProto reader into a format we can work with, like numerical arrays.
```
# to manipulate our arrays
import numpy as np
# read in test data protobuf files included with the model
import onnx
from onnx import numpy_helper
# to use parsers to read in our model/data
import json
import os
test_inputs = []
test_outputs = []
# read in 3 testing images from .pb files
test_data_size = 3
for i in np.arange(test_data_size):
input_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'input_0.pb')
output_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'output_0.pb')
# convert protobuf tensors to np arrays using the TensorProto reader from ONNX
tensor = onnx.TensorProto()
with open(input_test_data, 'rb') as f:
tensor.ParseFromString(f.read())
input_data = numpy_helper.to_array(tensor)
test_inputs.append(input_data)
with open(output_test_data, 'rb') as f:
tensor.ParseFromString(f.read())
output_data = numpy_helper.to_array(tensor)
test_outputs.append(output_data)
if len(test_inputs) == test_data_size:
print('Test data loaded successfully.')
```
### Show some sample images
We use `matplotlib` to plot 3 test images from the dataset.
```
plt.figure(figsize = (16, 6))
for test_image in np.arange(3):
plt.subplot(1, 15, test_image+1)
plt.axhline('')
plt.axvline('')
plt.imshow(test_inputs[test_image].reshape(28, 28), cmap = plt.cm.Greys)
plt.show()
```
### Run evaluation / prediction
```
plt.figure(figsize = (16, 6), frameon=False)
plt.subplot(1, 8, 1)
plt.text(x = 0, y = -30, s = "True Label: ", fontsize = 13, color = 'black')
plt.text(x = 0, y = -20, s = "Result: ", fontsize = 13, color = 'black')
plt.text(x = 0, y = -10, s = "Inference Time: ", fontsize = 13, color = 'black')
plt.text(x = 3, y = 14, s = "Model Input", fontsize = 12, color = 'black')
plt.text(x = 6, y = 18, s = "(28 x 28)", fontsize = 12, color = 'black')
plt.imshow(np.ones((28,28)), cmap=plt.cm.Greys)
for i in np.arange(test_data_size):
input_data = json.dumps({'data': test_inputs[i].tolist()})
# predict using the deployed model
r = json.loads(aci_service.run(input_data))
if "error" in r:
print(r['error'])
break
result = r['result'][0]
time_ms = np.round(r['time_in_sec'][0] * 1000, 2)
ground_truth = int(np.argmax(test_outputs[i]))
# compare actual value vs. the predicted values:
plt.subplot(1, 8, i+2)
plt.axhline('')
plt.axvline('')
# use different color for misclassified sample
font_color = 'red' if ground_truth != result else 'black'
clr_map = plt.cm.gray if ground_truth != result else plt.cm.Greys
# ground truth labels are in blue
plt.text(x = 10, y = -30, s = ground_truth, fontsize = 18, color = 'blue')
# predictions are in black if correct, red if incorrect
plt.text(x = 10, y = -20, s = result, fontsize = 18, color = font_color)
plt.text(x = 5, y = -10, s = str(time_ms) + ' ms', fontsize = 14, color = font_color)
plt.imshow(test_inputs[i].reshape(28, 28), cmap = clr_map)
plt.show()
```
### Try classifying your own images!
Create your own handwritten image and pass it into the model.
```
# Preprocessing functions take your image and format it so it can be passed
# as input into our ONNX model
import cv2
def rgb2gray(rgb):
"""Convert the input image into grayscale"""
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
def resize_img(img):
"""Resize image to MNIST model input dimensions"""
img = cv2.resize(img, dsize=(28, 28), interpolation=cv2.INTER_AREA)
img.resize((1, 1, 28, 28))
return img
def preprocess(img):
"""Resize input images and convert them to grayscale."""
if img.shape == (28, 28):
img.resize((1, 1, 28, 28))
return img
grayscale = rgb2gray(img)
processed_img = resize_img(grayscale)
return processed_img
# Replace this string with your own path/test image
# Make sure your image is square and the dimensions are equal (i.e. 100 * 100 pixels or 28 * 28 pixels)
# Any PNG or JPG image file should work
your_test_image = "<path to file>"
# e.g. your_test_image = "C:/Users/vinitra.swamy/Pictures/handwritten_digit.png"
import matplotlib.image as mpimg
if your_test_image != "<path to file>":
img = mpimg.imread(your_test_image)
plt.subplot(1,3,1)
plt.imshow(img, cmap = plt.cm.Greys)
print("Old Dimensions: ", img.shape)
img = preprocess(img)
print("New Dimensions: ", img.shape)
else:
img = None
if img is None:
print("Add the path for your image data.")
else:
input_data = json.dumps({'data': img.tolist()})
try:
r = json.loads(aci_service.run(input_data))
result = r['result'][0]
time_ms = np.round(r['time_in_sec'][0] * 1000, 2)
except Exception as e:
print(str(e))
plt.figure(figsize = (16, 6))
plt.subplot(1, 15,1)
plt.axhline('')
plt.axvline('')
plt.text(x = -100, y = -20, s = "Model prediction: ", fontsize = 14)
plt.text(x = -100, y = -10, s = "Inference time: ", fontsize = 14)
plt.text(x = 0, y = -20, s = str(result), fontsize = 14)
plt.text(x = 0, y = -10, s = str(time_ms) + " ms", fontsize = 14)
plt.text(x = -100, y = 14, s = "Input image: ", fontsize = 14)
plt.imshow(img.reshape(28, 28), cmap = plt.cm.gray)
```
## Optional: How does our ONNX MNIST model work?
#### A brief explanation of Convolutional Neural Networks
A [convolutional neural network](https://en.wikipedia.org/wiki/Convolutional_neural_network) (CNN, or ConvNet) is a type of [feed-forward](https://en.wikipedia.org/wiki/Feedforward_neural_network) artificial neural network made up of neurons that have learnable weights and biases. The CNNs take advantage of the spatial nature of the data. In nature, we perceive different objects by their shapes, size and colors. For example, objects in a natural scene are typically edges, corners/vertices (defined by two of more edges), color patches etc. These primitives are often identified using different detectors (e.g., edge detection, color detector) or combination of detectors interacting to facilitate image interpretation (object classification, region of interest detection, scene description etc.) in real world vision related tasks. These detectors are also known as filters. Convolution is a mathematical operator that takes an image and a filter as input and produces a filtered output (representing say edges, corners, or colors in the input image).
Historically, these filters are a set of weights that were often hand crafted or modeled with mathematical functions (e.g., [Gaussian](https://en.wikipedia.org/wiki/Gaussian_filter) / [Laplacian](http://homepages.inf.ed.ac.uk/rbf/HIPR2/log.htm) / [Canny](https://en.wikipedia.org/wiki/Canny_edge_detector) filter). The filter outputs are mapped through non-linear activation functions mimicking human brain cells called [neurons](https://en.wikipedia.org/wiki/Neuron). Popular deep CNNs or ConvNets (such as [AlexNet](https://en.wikipedia.org/wiki/AlexNet), [VGG](https://arxiv.org/abs/1409.1556), [Inception](http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf), [ResNet](https://arxiv.org/pdf/1512.03385v1.pdf)) that are used for various [computer vision](https://en.wikipedia.org/wiki/Computer_vision) tasks have many of these architectural primitives (inspired from biology).
### Convolution Layer
A convolution layer is a set of filters. Each filter is defined by a weight (**W**) matrix, and bias ($b$).

These filters are scanned across the image performing the dot product between the weights and corresponding input value ($x$). The bias value is added to the output of the dot product and the resulting sum is optionally mapped through an activation function. This process is illustrated in the following animation.
```
Image(url="https://www.cntk.ai/jup/cntk103d_conv2d_final.gif", width= 200)
```
### Model Description
The MNIST model from the ONNX Model Zoo uses maxpooling to update the weights in its convolutions, summarized by the graphic below. You can see the entire workflow of our pre-trained model in the following image, with our input images and our output probabilities of each of our 10 labels. If you're interested in exploring the logic behind creating a Deep Learning model further, please look at the [training tutorial for our ONNX MNIST Convolutional Neural Network](https://github.com/Microsoft/CNTK/blob/master/Tutorials/CNTK_103D_MNIST_ConvolutionalNeuralNetwork.ipynb).
#### Max-Pooling for Convolutional Neural Nets

#### Pre-Trained Model Architecture

```
# remember to delete your service after you are done using it!
# aci_service.delete()
```
## Conclusion
Congratulations!
In this tutorial, you have:
- familiarized yourself with ONNX Runtime inference and the pretrained models in the ONNX model zoo
- understood a state-of-the-art convolutional neural net image classification model (MNIST in ONNX) and deployed it in Azure ML cloud
- ensured that your deep learning model is working perfectly (in the cloud) on test data, and checked it against some of your own!
Next steps:
- Check out another interesting application based on a Microsoft Research computer vision paper that lets you set up a [facial emotion recognition model](https://github.com/Azure/MachineLearningNotebooks/tree/master/onnx/onnx-inference-emotion-recognition.ipynb) in the cloud! This tutorial deploys a pre-trained ONNX Computer Vision model in an Azure ML virtual machine.
- Contribute to our [open source ONNX repository on github](http://github.com/onnx/onnx) and/or add to our [ONNX model zoo](http://github.com/onnx/models)
| github_jupyter |
#### New to Plotly?
Plotly's Python library is free and open source! [Get started](https://plot.ly/python/getting-started/) by downloading the client and [reading the primer](https://plot.ly/python/getting-started/).
<br>You can set up Plotly to work in [online](https://plot.ly/python/getting-started/#initialization-for-online-plotting) or [offline](https://plot.ly/python/getting-started/#initialization-for-offline-plotting) mode, or in [jupyter notebooks](https://plot.ly/python/getting-started/#start-plotting-online).
<br>We also have a quick-reference [cheatsheet](https://images.plot.ly/plotly-documentation/images/python_cheat_sheet.pdf) (new!) to help you get started!
#### Imports
The tutorial below imports [NumPy](http://www.numpy.org/), [Pandas](https://plot.ly/pandas/intro-to-pandas-tutorial/), [SciPy](https://www.scipy.org/) and [PeakUtils](http://pythonhosted.org/PeakUtils/).
```
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.tools import FigureFactory as FF
import numpy as np
import pandas as pd
import scipy
import peakutils
```
#### Import Data
To start detecting peaks, we will import some data on milk production by month:
```
milk_data = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/monthly-milk-production-pounds.csv')
time_series = milk_data['Monthly milk production (pounds per cow)']
time_series = time_series.tolist()
df = milk_data[0:15]
table = FF.create_table(df)
py.iplot(table, filename='milk-production-dataframe')
```
#### Original Plot
```
trace = go.Scatter(
x = [j for j in range(len(time_series))],
y = time_series,
mode = 'lines'
)
data = [trace]
py.iplot(data, filename='milk-production-plot')
```
#### With Peak Detection
We need to find the x-axis indices for the peaks in order to determine where the peaks are located.
```
cb = np.array(time_series)
indices = peakutils.indexes(cb, thres=0.02/max(cb), min_dist=0.1)
trace = go.Scatter(
x=[j for j in range(len(time_series))],
y=time_series,
mode='lines',
name='Original Plot'
)
trace2 = go.Scatter(
x=indices,
y=[time_series[j] for j in indices],
mode='markers',
marker=dict(
size=8,
color='rgb(255,0,0)',
symbol='cross'
),
name='Detected Peaks'
)
data = [trace, trace2]
py.iplot(data, filename='milk-production-plot-with-peaks')
```
#### Only Highest Peaks
We can attempt to set our threshold so that we identify as many of the _highest peaks_ that we can.
```
cb = np.array(time_series)
indices = peakutils.indexes(cb, thres=0.678, min_dist=0.1)
trace = go.Scatter(
x=[j for j in range(len(time_series))],
y=time_series,
mode='lines',
name='Original Plot'
)
trace2 = go.Scatter(
x=indices,
y=[time_series[j] for j in indices],
mode='markers',
marker=dict(
size=8,
color='rgb(255,0,0)',
symbol='cross'
),
name='Detected Peaks'
)
data = [trace, trace2]
py.iplot(data, filename='milk-production-plot-with-higher-peaks')
from IPython.display import display, HTML
display(HTML('<link href="//fonts.googleapis.com/css?family=Open+Sans:600,400,300,200|Inconsolata|Ubuntu+Mono:400,700" rel="stylesheet" type="text/css" />'))
display(HTML('<link rel="stylesheet" type="text/css" href="http://help.plot.ly/documentation/all_static/css/ipython-notebook-custom.css">'))
! pip install git+https://github.com/plotly/publisher.git --upgrade
import publisher
publisher.publish(
'python-Peak-Finding.ipynb', 'python/peak-finding/', 'Peak Finding | plotly',
'Learn how to find peaks and valleys on datasets in Python',
title='Peak Finding in Python | plotly',
name='Peak Finding',
language='python',
page_type='example_index', has_thumbnail='false', display_as='peak-analysis', order=3,
ipynb= '~notebook_demo/120')
```
| github_jupyter |
```
%matplotlib inline
```
# Matplotlib logo
This example generates the current matplotlib logo.
```
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import matplotlib.font_manager
from matplotlib.patches import Circle, Rectangle, PathPatch
from matplotlib.textpath import TextPath
import matplotlib.transforms as mtrans
MPL_BLUE = '#11557c'
def get_font_properties():
# The original font is Calibri, if that is not installed, we fall back
# to Carlito, which is metrically equivalent.
if 'Calibri' in matplotlib.font_manager.findfont('Calibri:bold'):
return matplotlib.font_manager.FontProperties(family='Calibri',
weight='bold')
if 'Carlito' in matplotlib.font_manager.findfont('Carlito:bold'):
print('Original font not found. Falling back to Carlito. '
'The logo text will not be in the correct font.')
return matplotlib.font_manager.FontProperties(family='Carlito',
weight='bold')
print('Original font not found. '
'The logo text will not be in the correct font.')
return None
def create_icon_axes(fig, ax_position, lw_bars, lw_grid, lw_border, rgrid):
"""
Create a polar axes containing the matplotlib radar plot.
Parameters
----------
fig : matplotlib.figure.Figure
The figure to draw into.
ax_position : (float, float, float, float)
The position of the created Axes in figure coordinates as
(x, y, width, height).
lw_bars : float
The linewidth of the bars.
lw_grid : float
The linewidth of the grid.
lw_border : float
The linewidth of the Axes border.
rgrid : array-like
Positions of the radial grid.
Returns
-------
ax : matplotlib.axes.Axes
The created Axes.
"""
with plt.rc_context({'axes.edgecolor': MPL_BLUE,
'axes.linewidth': lw_border}):
ax = fig.add_axes(ax_position, projection='polar')
ax.set_axisbelow(True)
N = 7
arc = 2. * np.pi
theta = np.arange(0.0, arc, arc / N)
radii = np.array([2, 6, 8, 7, 4, 5, 8])
width = np.pi / 4 * np.array([0.4, 0.4, 0.6, 0.8, 0.2, 0.5, 0.3])
bars = ax.bar(theta, radii, width=width, bottom=0.0, align='edge',
edgecolor='0.3', lw=lw_bars)
for r, bar in zip(radii, bars):
color = *cm.jet(r / 10.)[:3], 0.6 # color from jet with alpha=0.6
bar.set_facecolor(color)
ax.tick_params(labelbottom=False, labeltop=False,
labelleft=False, labelright=False)
ax.grid(lw=lw_grid, color='0.9')
ax.set_rmax(9)
ax.set_yticks(rgrid)
# the actual visible background - extends a bit beyond the axis
ax.add_patch(Rectangle((0, 0), arc, 9.58,
facecolor='white', zorder=0,
clip_on=False, in_layout=False))
return ax
def create_text_axes(fig, height_px):
"""Create an axes in *fig* that contains 'matplotlib' as Text."""
ax = fig.add_axes((0, 0, 1, 1))
ax.set_aspect("equal")
ax.set_axis_off()
path = TextPath((0, 0), "matplotlib", size=height_px * 0.8,
prop=get_font_properties())
angle = 4.25 # degrees
trans = mtrans.Affine2D().skew_deg(angle, 0)
patch = PathPatch(path, transform=trans + ax.transData, color=MPL_BLUE,
lw=0)
ax.add_patch(patch)
ax.autoscale()
def make_logo(height_px, lw_bars, lw_grid, lw_border, rgrid, with_text=False):
"""
Create a full figure with the Matplotlib logo.
Parameters
----------
height_px : int
Height of the figure in pixel.
lw_bars : float
The linewidth of the bar border.
lw_grid : float
The linewidth of the grid.
lw_border : float
The linewidth of icon border.
rgrid : sequence of float
The radial grid positions.
with_text : bool
Whether to draw only the icon or to include 'matplotlib' as text.
"""
dpi = 100
height = height_px / dpi
figsize = (5 * height, height) if with_text else (height, height)
fig = plt.figure(figsize=figsize, dpi=dpi)
fig.patch.set_alpha(0)
if with_text:
create_text_axes(fig, height_px)
ax_pos = (0.535, 0.12, .17, 0.75) if with_text else (0.03, 0.03, .94, .94)
ax = create_icon_axes(fig, ax_pos, lw_bars, lw_grid, lw_border, rgrid)
return fig, ax
```
A large logo:
```
make_logo(height_px=110, lw_bars=0.7, lw_grid=0.5, lw_border=1,
rgrid=[1, 3, 5, 7])
```
A small 32px logo:
```
make_logo(height_px=32, lw_bars=0.3, lw_grid=0.3, lw_border=0.3, rgrid=[5])
```
A large logo including text, as used on the matplotlib website.
```
make_logo(height_px=110, lw_bars=0.7, lw_grid=0.5, lw_border=1,
rgrid=[1, 3, 5, 7], with_text=True)
plt.show()
```
| github_jupyter |
# HER2 One Scanner - Hamamatsu2
- 5-Fold (80/20) split, No Holdout Set
- Truth = Categorical from Mean of 7 continuous scores
- Epoch at automatic Stop when loss<.001 change
- LeNet model, 10 layers, Dropout (0.7)
```
import numpy as np
import pandas as pd
import random
from keras.callbacks import EarlyStopping
from PIL import Image
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, Lambda
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
from sklearn.cross_validation import train_test_split
from sklearn.metrics import roc_curve, auc, classification_report
import csv
import cv2
import scipy
import os
%matplotlib inline
import matplotlib.pyplot as plt
#For single scanner
BASE_PATH = '/home/diam/Desktop/HER2_data_categorical/Hamamatsu2/'
#BASE PATH for working from home:
#BASE_PATH = '/home/OSEL/Desktop/HER2_data_categorical/'
#epochs = 10
batch_size = 32
num_classes = 3
#epochs = 35
```
## Get Data - Practice
```
#This is the version from Ravi's code:
#FDA
#X_FDA = []
#idx_FDA = []
#for index, image_filename in list(enumerate(BASE_PATH)):
# img_file = cv2.imread(BASE_PATH + '/' + image_filename)
# if img_file is not None:
#img_file = smisc.imresize(arr = img_file, size = (600,760,3))
# img_file = smisc.imresize(arr = img_file, size = (120,160,3))
# img_arr = np.asarray(img_file)
# X_FDA.append(img_arr)
# idx_FDA.append(index)
#X_FDA = np.asarray(X_FDA)
#idx_FDA = np.asarray(idx_FDA)
#random.seed(rs)
#random_id = random.sample(idx_FDA, len(idx_FDA)/2)
#random_FDA = []
#for i in random_id:
# random_FDA.append(X_FDA[i])
#random_FDA = np.asarray(random_FDA)
```
## Get Data - Real
```
def get_data(folder):
X = []
y = []
filenames = []
for hclass in os.listdir(folder):
if not hclass.startswith('.'):
if hclass in ["1"]:
label = 1
else: #label must be 1 or 2
if hclass in ["2"]:
label = 2
else:
label = 3
for image_filename in os.listdir(folder + hclass):
filename = folder + hclass + '/' + image_filename
img_file = cv2.imread(folder + hclass + '/' + image_filename)
if img_file is not None:
img_file = scipy.misc.imresize(arr=img_file, size=(120, 160, 3))
img_arr = np.asarray(img_file)
X.append(img_arr)
y.append(label)
filenames.append(filename)
X = np.asarray(X)
y = np.asarray(y)
z = np.asarray(filenames)
return X,y,filenames
print(z)
X, y, z = get_data(BASE_PATH)
#print(X)
#print(y)
#print(z)
print(len(X))
print(len(y))
print(len(z))
#INTEGER ENCODE
#https://machinelearningmastery.com/how-to-one-hot-encode-sequence-data-in-python/
encoder = LabelEncoder()
y_cat = np_utils.to_categorical(encoder.fit_transform(y))
print(y_cat)
```
### Old Code
```
#encoder = LabelEncoder()
#encoder.fit(y)
#X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
#encoded_y_train = encoder.transform(y_train)
#encoded_y_test = encoder.transform(y_test)
#y_train = np_utils.to_categorical(encoded_y_train)
#y_test = np_utils.to_categorical(encoded_y_test)
#X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
```
## Fit Model with K-Fold X-Val
```
kf = KFold(n_splits = 2, random_state=5, shuffle=True)
print(kf.get_n_splits(y_cat))
print(kf)
#for train_index, test_index in kf.split(y):
# X_train, X_test = X[train_index], X[test_index]
# print(train_index, test_index)
oos_y = []
oos_pred = []
fold = 0
for train, test in kf.split(y_cat):
fold+=1
print("fold #{}".format(fold))
X_train = X[train]
y_train = y_cat[train]
#z_train = z[train]
X_test = X[test]
y_test = y_cat[test]
#z_test = z[test]
#encoder = LabelEncoder()
#encoder.fit(y_test)
#y_train = np_utils.to_categorical(encoder.transform(y_train))
#y_test = np_utils.to_categorical(encoder.transform(y_test))
model = Sequential()
model.add(Lambda(lambda x: x * 1./255., input_shape=(120, 160, 3), output_shape=(120, 160, 3)))
model.add(Conv2D(32, (3, 3), input_shape=(120, 160, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.7))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-3, patience=25, verbose=1, mode='auto')
model.fit(
X_train,
y_train,
validation_data=(X_test,y_test),
callbacks=[monitor],
shuffle=True,
batch_size=batch_size,
verbose=0,
epochs=1000)
pred = model.predict(X_test)
oos_y.append(y_test)
pred = np.argmax(pred,axis=1)
oos_pred.append(pred)
#measure the fold's accuracy
y_compare = np.argmax(y_test,axis=1) #for accuracy calculation
score = metrics.accuracy_score(y_compare, pred)
print("Fold Score (accuracy): {}".format(score))
print(y_test)
print(test)
```
| github_jupyter |
<a href="http://landlab.github.io"><img style="float: left" src="../../../landlab_header.png"></a>
For more Landlab tutorials, click here: https://landlab.readthedocs.io/en/latest/user_guide/tutorials.html
**Application of the flow__distance utility on a Sicilian basin**
This notebook illustrates how to run the flow**__**distance utility on a digital elevation model (DEM) that represents a real basin in Sicily. First, a watershed will be extracted from the input DEM by using the watershed utility. Then, the distances from each node to the watershed's outlet will be obtained with the flow**__**distance utility. Flow is routed using the D8 algorithm.
First, import what we'll need:
```
from landlab.io import read_esri_ascii
from landlab.components import FlowAccumulator
from landlab.plot import imshow_grid
from matplotlib.pyplot import figure
%matplotlib inline
from landlab.utils import watershed
import numpy as np
from landlab.utils.flow__distance import calculate_flow__distance
```
Import a square DEM that includes the watershed:
```
(mg, z) = read_esri_ascii('nocella_resampled.txt',
name='topographic__elevation')
```
Run the FlowAccumulator and the DepressionFinderAndRouter components to find depressions, to route the flow across them and to calculate flow direction and drainage area:
```
fr = FlowAccumulator(mg,
flow_director='D8',
depression_finder='DepressionFinderAndRouter')
fr.run_one_step()
```
Set the id of the outlet. The value indicated here is the node id of the entire watershed's outlet:
```
outlet_id = 15324
```
Run the watershed utility and show the watershed mask:
```
ws_mask = watershed.get_watershed_mask(mg, outlet_id)
figure()
imshow_grid(mg, ws_mask, allow_colorbar=False)
```
Run the flow**__**distance utility:
```
flow__distance = calculate_flow__distance(mg, add_to_grid=True, clobber=True)
```
Mask the flow**__**distance to the watershed mask. This operation has to be done because the flow**__**distance utility is applied to the entire grid that contains other streams not connected with our stream network and, for this reason, not belonging to our watershed.
```
flow_distance = np.zeros(mg.number_of_nodes)
flow_distance[ws_mask] = flow__distance[ws_mask] - flow__distance[outlet_id]
```
Add the flow**__**distance field to the grid and show the spatial distribution of the distances from each node to the watershed's outlet:
```
mg.add_field('flow_distance', flow_distance, at='node', clobber=True)
figure()
imshow_grid(mg,
mg.at_node['flow_distance'],
colorbar_label='flow distance (m)')
```
| github_jupyter |
<a href="https://colab.research.google.com/github/helenksouza/Data-Science/blob/main/api_twitter.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Importar bibliotecas e definir constantes
```
### K: Documentação: https://docs.tweepy.org/en/stable/
import tweepy #implementa api do tt
import pandas as pd #lendo dados
pd.set_option('display.width', 1000) #s/ quebrar linhas
pd.set_option('display.max_columns', None)
```
## Configurar credenciais e instanciar objetos
```
consumer_key = 'a0UFrEDs31mP3QveZ04CSv407'
consumer_secret = 'flLj85BkLxBWvpLnAzoM4hMChOQ8OIVJeuF2tIk6kEBdk33jUH'
access_token = '1031714872927690758-YylDk440S0Vs3iIG2HUcvzHqFVhZUL'
access_token_secret = 'l3EDLYG71tao3Q15Nzicyv9iq9TOpwdrccHtkR2haSlVm'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret) #identificando quem esta requisitando
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
### K: https://docs.tweepy.org/en/stable/api.html#api-reference
```
## Obter tweets da forma mais simples
```
user_id = 'BarackObama'
tweets = api.user_timeline(screen_name=user_id,
count=10, #qtd de tweets ### K: Max 200.
include_rts=False,
tweet_mode='extended' #mais de 140 caracteres
)
print ('Tweets do {}\n'.format(user_id))
for tweet in tweets[:5]: #1° tweets
print('ID: {}'.format(tweet.id))
print(tweet.created_at)
print(tweet.full_text, '\n')
```
## Obter tweets de múltiplos usuários e escrever em um arquivo
```
def retrieve_tweets_from_account(account):
cursor = tweepy.Cursor(api.user_timeline, id=account,
tweet_mode='extended').items(10)
return pd.DataFrame([dict({'created_at':i.created_at, #dicionario
'tweet': i.full_text,
'author': i.author.screen_name, #nome de tela
'retweeted': i.retweeted,
'source': i.source,
'retweet_count': i.retweet_count,
'favorite_count': i.favorite_count,
'in_reply_to': i.in_reply_to_screen_name,
'coordinates': i.coordinates
}) for i in cursor])
account_set = ['OneTweetTony',
'TheSeanLock',
'BarackObama']
df_tweets = pd.DataFrame()
for account in account_set:
new_tweets = retrieve_tweets_from_account(account)
df_tweets = df_tweets.append(new_tweets, ignore_index=True)
df_tweets.to_excel('tweets.xlsx')
df_tweets.to_csv('tweets.csv', index=False)
print (df_tweets[:15])
```

```
```
| github_jupyter |
# Load
## Import
```
%reload_ext autoreload
%autoreload 2
%reload_ext cython
%reload_ext line_profiler
import os,sys
sys.path.insert(1, os.path.join(sys.path[0], '..', 'module'))
import wiki
import dill
import scipy as sp
import numpy as np
import pandas as pd
import networkx as nx
from ipywidgets import interact, widgets, Layout
import plotly.express as px
import plotly.graph_objs as go
import plotly.figure_factory as ff
```
## Networks
```
topics = ['anatomy', 'biochemistry', 'cognitive science', 'evolutionary biology',
'genetics', 'immunology', 'molecular biology', 'chemistry', 'biophysics',
'energy', 'optics', 'earth science', 'geology', 'meteorology',
'philosophy of language', 'philosophy of law', 'philosophy of mind',
'philosophy of science', 'economics', 'accounting', 'education',
'linguistics', 'law', 'psychology', 'sociology', 'electronics',
'software engineering', 'robotics',
'calculus', 'geometry', 'abstract algebra',
'Boolean algebra', 'commutative algebra', 'group theory', 'linear algebra',
'number theory', 'dynamical systems and differential equations']
import wiki
path_saved = '/Users/harangju/Developer/data/wiki/graphs/dated'
networks = {}
for topic in topics:
print(topic, end=' ')
networks[topic] = wiki.Net(path_graph=os.path.join(path_saved, topic + '.pickle'),
path_barcodes=os.path.join(path_saved, topic + '.barcode'))
```
## Models
| Run | ID | Notes |
|:---:|:--------------|:------|
| 1 | 20200422_1318 | |
| 2 | 20200520_2057 | |
| 3 | 20200708_1221 | 10 runs per subject |
```
simulation = '20200422_1318'
simulation = '20200520_2057'
simulation = '20200820_1919'
base_dir = os.path.join('/', 'Users', 'harangju', 'Developer', 'data', 'wiki', 'simulations')
session_dir = os.path.join(base_dir, simulation)
filenames = sorted(os.listdir(session_dir))
filenames[:3]
filenames[-3:]
model_topics = list(set(
[filename.split('_')[1] for filename in filenames
if filename.split('_')[0]=='model']
))
model_topics[:3]
# models = {topic: [dill.load(open(os.path.join(session_dir, filename), 'rb'))
# for filename in filenames
# if filename.split('_')[1]==topic]
# for topic in model_topics}
model_paths = {
topic: [
os.path.join(session_dir, filename)
for filename in filenames[:-1]
if (filename.split('_')[0]=='model') and (filename.split('_')[1]==topic)
]
for topic in model_topics
}
{topic: model_paths[topic] for topic in model_topics[:1]}
```
# Basic network statistics
```
import bct
import pickle
from networkx.algorithms.cluster import clustering
from networkx.algorithms import betweenness_centrality
from networkx.convert_matrix import to_numpy_array
```
## Model
```
measures = {'indegree': lambda g: [x[1] for x in g.in_degree],
'outdegree': lambda g: [x[1] for x in g.out_degree],
'clustering': lambda g: list(clustering(g).values()),
'centrality': lambda g: list(betweenness_centrality(g).values()),
'modularity': lambda g: g.graph['modularity'],
'coreness': lambda g: g.graph['coreness_be']}
df_model = pd.DataFrame()
for topic in model_paths.keys():
print(topic)
network = networks[topic]
for i, model_path in enumerate(model_paths[topic]):
print(i, end=' ')
model = dill.load(open(model_path, 'rb'))
df_model = pd.concat(
[df_model] + [pd.DataFrame([[topic, i, measure, func(model.graph)]],
columns=['topic','model','measure','value'])
for measure, func in measures.items()],
ignore_index=True)
print('')
df_model
```
## Save
```
path_analysis = '/Users/harangju/Developer/data/wiki/analysis/'
pickle.dump(df_model, open(os.path.join(path_analysis,f"stats_model_{simulation}.pickle"),'wb'))
```
## Load
```
import pickle
import pandas as pd
path_analysis = '/Users/harangju/Developer/data/wiki/analysis/'
df = pickle.load(open(path_analysis+'stats.pickle', 'rb'))
df_expand = pickle.load(open(path_analysis+'stats_expand.pickle', 'rb'))
df.topic = df.topic.astype('object')
df.measure = df.measure.astype('object')
df_expand.topic = df_expand.topic.astype('object')
df_expand.measure = df_expand.measure.astype('object')
df_mean = df_expand\
.groupby(['topic', 'measure'], as_index=False)\
.mean()\
.pivot(index='topic', columns='measure', values='value')\
.reset_index()
df_model = pickle.load(open(os.path.join(path_analysis,f"stats_model_{simulation}.pickle"),'rb'))
df_model_expand = df_model\
.drop('model', axis=1)\
.value\
.apply(pd.Series)\
.merge(df_model, left_index=True, right_index=True)\
.drop('value', axis=1)\
.melt(id_vars=['topic','measure'])\
.drop('variable', axis=1)\
.dropna()
df_model_mean = df_model_expand\
.groupby(['topic', 'measure'], as_index=False)\
.mean()\
.pivot(index='topic', columns='measure', values='value')
```
## Plot
```
import plotly.subplots as sb
import plotly.graph_objects as go
import plotly.express as px
fig = px.colors.qualitative.swatches()
# fig.show()
path_result = os.path.join(
'/','Users','harangju','Box Sync','Research','my papers','wikipedia','results'
)
```
### Growth
```
first_n_nodes = 10
start_date = 0
path_plot = '3 model growth'
if not os.path.isdir(os.path.join(path_result, path_plot)):
os.mkdir(os.path.join(path_result, path_plot))
if not os.path.isdir(os.path.join(path_result, path_plot, simulation)):
os.mkdir(os.path.join(path_result, path_plot, simulation))
save_fig = True
for topic in model_paths.keys():
fig = sb.make_subplots(1, 2)
network = networks[topic]
fig.add_trace(
go.Histogram(
x=[d for _,d in network.graph.degree], nbinsx=30, name='empirical'
),
row=1, col=1
)
fig.update_yaxes(title_text='number of edges', row=1, col=1)
fig.update_xaxes(title_text='degree', row=1, col=1)
fig.add_trace(
go.Scatter(
x=sorted([network.graph.nodes[n]['year'] for n in network.graph.nodes]),
y=list(range(1,len(network.graph.nodes)+1)),
mode='lines', name='empirical', showlegend=False,
line={'color': px.colors.qualitative.Plotly[0]}
),
row=1, col=2
)
fig.update_yaxes(title_text='number of nodes', row=1, col=2)
fig.update_xaxes(title_text='year', row=1, col=2)
fig.update_layout(title=topic, template='plotly_white')
for i, model_path in enumerate(model_paths[topic]):
model = dill.load(open(model_path, 'rb'))
fig.add_trace(
go.Histogram(
x=[d for _,d in model.graph.degree], nbinsx=30,
name=f"model {i}", marker_color=px.colors.qualitative.Plotly[1+i]
),
row=1, col=1
)
fig.add_trace(
go.Scatter(
x=sorted([model.graph.nodes[n]['year'] for n in model.graph.nodes]),
y=list(range(1,len(model.graph.nodes)+1)),
mode='lines', name=f"model {i}", showlegend=False,
line={'color': px.colors.qualitative.Plotly[1+i]}
),
row=1, col=2
)
fig.add_trace(
go.Scatter(
x=[start_date, start_date],
y=[0, max(len(model.graph.nodes), len(network.graph.nodes))],
mode='lines',
name='model start',
line={'color': 'black', 'dash': 'dash'}
),
row=1, col=2
)
fig.show()
if save_fig:
fig.write_image(os.path.join(path_result, path_plot, simulation, topic+'.pdf'))
```
### Static
```
path_plot = '3 model static'
save_fig = True
if not os.path.isdir(os.path.join(path_result, path_plot)):
os.mkdir(os.path.join(path_result, path_plot))
if not os.path.isdir(os.path.join(path_result, path_plot, simulation)):
os.mkdir(os.path.join(path_result, path_plot, simulation))
df_mean = df_mean.sort_values('topic', ascending=True, ignore_index=True)
df_model_mean = df_model_mean.sort_values('topic', ascending=True, ignore_index=True)
ranges = {'clustering': [0,0.3],
'centrality': [0,0.04],
'indegree': [0,10],
'outdegree': [0,10],
'coreness': [0,2],
'modularity': [0,1]}
dticks = {'clustering': 0.1,
'centrality': 0.01,
'indegree': 1,
'outdegree': 1,
'coreness': .5,
'modularity': .5}
for measure in ['clustering','centrality','indegree','outdegree','coreness','modularity']:
fig = go.Figure()
fig.add_trace(go.Scatter(x=df_mean[measure],
y=df_model_mean[measure],
mode='markers',
marker={'color': '#2A3F5F'},
hovertext=df_mean.topic,
showlegend=False))
fig.add_trace(go.Scatter(x=ranges[measure], y=ranges[measure],
mode='lines',
line={'dash': 'dash',
'color': '#2A3F5F'},
showlegend=False))
fig.update_layout(template='plotly_white',
width=500, height=500,
title=measure,
xaxis={'title': 'real',
'range': ranges[measure],
'dtick': dticks[measure]},
yaxis={'title': 'model',
'range': ranges[measure],
'dtick': dticks[measure]})
fig.show()
if save_fig:
fig.write_image(os.path.join(path_result, path_plot, simulation, f"summary_{measure}.pdf"))
```
# Persistent homology
## Real networks
```
barcodes = pd.concat(
[
network.barcodes.assign(topic=topic)\
.assign(type='real')\
.assign(null=0)
for topic, network in networks.items()
],
ignore_index=True,
sort=False
)
```
## Model
```
barcodes_models = pd.DataFrame()
for topic in model_paths.keys():
print(topic)
for i, model_path in enumerate(model_paths[topic]):
print(i, end=' ')
model = dill.load(open(model_path, 'rb'))
barcodes_models = pd.concat(
[barcodes_models] +\
[model.barcodes\
.assign(topic=topic)\
.assign(type='model')\
.assign(model=i)],
ignore_index=True
)
print('')
```
## Save
```
path_analysis = os.path.join('/','Users','harangju','Developer','data','wiki','analysis')
pickle.dump(
barcodes_models,
open(os.path.join(path_analysis, f"barcodes_models_{simulation}.pickle"), 'wb')
)
```
## Load
```
import pickle
path_analysis = os.path.join('/','Users','harangju','Developer','data','wiki','analysis')
barcodes = pickle.load(open(os.path.join(path_analysis, 'barcodes.pickle'),'rb'))
barcodes_models = pickle.load(open(os.path.join(path_analysis, 'barcodes_models.pickle'),'rb'))
```
## Compute
```
barcodes_models = barcodes_models[barcodes_models.lifetime!=0]
```
## Plot
```
save_fig = True
path_result = os.path.join(
'/','Users','harangju','Box Sync','Research','my papers','wikipedia','results'
)
```
### Finite lifetimes
```
import scipy as sp
lifetime = pd.DataFrame()
for topic in topics:
t_models, p_models = sp.stats.ttest_ind(
barcodes[
(barcodes.topic==topic) &
(barcodes.lifetime!=np.inf) &
(barcodes.lifetime!=0)]['lifetime'].values,
barcodes_models[
(barcodes_models.topic==topic) &
(barcodes_models.lifetime!=np.inf) &
(barcodes_models.lifetime!=0)]['lifetime'].values,
)
lifetime = pd.concat(
[lifetime, pd.DataFrame(
[[t_models, p_models]],
columns=['t (targets)','p (targets)']
)], ignore_index=True
)
barcodes_mean = barcodes[
(barcodes.lifetime!=np.inf) & (barcodes.lifetime!=0)]\
.groupby(['topic', 'type'], as_index=False)\
.mean()\
.drop(['dim','birth','death','null'], axis=1)\
.sort_values('topic')
barcodes_mean
barcodes_models_mean = barcodes_models[
(barcodes_models.lifetime!=np.inf) & (barcodes_models.lifetime!=0)]\
.groupby(['topic'], as_index=False)\
.mean()\
.drop(['dim','birth','death','model'], axis=1)\
.sort_values('topic')
barcodes_models_mean
path_plot = '3 model lifetimes'
if not os.path.isdir(os.path.join(path_result, path_plot)):
os.mkdir(os.path.join(path_result, path_plot))
if not os.path.isdir(os.path.join(path_result, path_plot, simulation)):
os.mkdir(os.path.join(path_result, path_plot, simulation))
fig = go.Figure()
max_lifetime = max(np.max(barcodes_mean.lifetime),
np.max(barcodes_models_mean.lifetime)) + 10
fig.add_trace(
go.Scatter(
x=[0,max_lifetime],
y=[0,max_lifetime],
mode='lines',
line=dict(dash='dash'),
name='1:1'
)
)
fig.add_trace(
go.Scatter(
x=barcodes_models_mean.lifetime,
y=barcodes_mean[barcodes_mean.type=='real'].lifetime,
mode='markers',
name='model',
hovertext=barcodes_models_mean.topic
)
)
fig.update_layout(
template='plotly_white',
title='Lifetimes (finite)',
width=500, height=500,
xaxis={'title': 'years (null)',
'range': [0,max_lifetime+100],
'dtick': 1000},
yaxis={'title': 'years (real)',
'range': [0,max_lifetime+100],
'scaleanchor': 'x',
'scaleratio': 1,
'dtick': 1000}
)
fig.show()
if save_fig:
fig.write_image(os.path.join(path_result, path_plot, simulation, 'finite.pdf'))
```
### Infinite lifetimes
```
import scipy as sp
reals = []
models = []
for topic in topics:
reals.append(barcodes[(barcodes.lifetime==np.inf) &
(barcodes.topic==topic) &
(barcodes.type=='real')].shape[0])
models.append(barcodes_models[(barcodes_models.lifetime==np.inf) &
(barcodes_models.topic==topic)].shape[0])
t_models, p_models = sp.stats.ttest_ind(reals, models)
t_models, p_models
import plotly.figure_factory as ff
import os
path_plot = '3 model lifetimes'
if not os.path.exists(os.path.join(path_result, path_plot)):
os.mkdir(os.path.join(path_result, path_plot))
fig = ff.create_distplot([models, reals],
['models', 'real'],
bin_size=300, show_curve=False,
colors=['#d62728','#1f77b4'])
#colors=['#2ca02c', '#d62728', '#1f77b4'])
fig.update_layout(template='plotly_white',
title_text='Lifetimes (infinite)',
xaxis={'title': 'count'},
yaxis={'title': 'probability'})
fig.show()
if save_fig:
fig.write_image(os.path.join(path_result, path_plot, simulation, 'infinite.pdf'))
```
### Dimensionality
```
combined = pd.concat(
[
barcodes[barcodes.type=='real'],
barcodes_models.assign(null=barcodes_models.model).drop('model', axis=1)
],
ignore_index=True
)
counts = combined[(combined.lifetime!=0)]\
.assign(count=1)\
.groupby(['type','topic','dim'], as_index=False)['count']\
.sum()\
.sort_values('type', axis=0, ascending=True)
counts
nulls = barcodes_models[barcodes_models.lifetime!=0]\
.groupby(['topic'], as_index=False)['model'].max()
nulls.model = nulls.model + 1
nulls
nulls = pd.merge(nulls, counts,
how='left', left_on=['topic'], right_on=['topic'])
nulls['count'] = nulls['count'] / nulls.model
nulls
path_plot = '3 model dimensionality'
if not os.path.exists(os.path.join(path_result, path_plot)):
os.mkdir(os.path.join(path_result, path_plot))
if not os.path.exists(os.path.join(path_result, path_plot, simulation)):
os.mkdir(os.path.join(path_result, path_plot, simulation))
fig = px.box(nulls, x='dim', y='count', color='type')
fig.update_layout(template='plotly_white',
title_text='Dimensionality',
yaxis={'range': [0,2000]})
fig.update_traces(marker={'size': 4})
fig.show()
if save_fig:
fig.write_image(os.path.join(path_result, path_plot, simulation, 'dimensionality.pdf'))
```
| github_jupyter |
```
import pandas as pd
import numpy as np
pd.__version__
```
# Understanding Pandas Indexes, Access, and Joins

Carl Kadie
## Introduction
The Python Pandas library is a great tool for data manipulation. However, it is only efficient if you understand Pandas indexing. Pandas Indexing is the key to accessing & joining rows in seconds instead of minute or hours.
The Pandas documentation says that indexes are like mathematical sets. We'll see in this notebook; however, they are not like mathematical sets! Indexes are, instead, a kind of list. This notebook will show that, with this insight, you can understand and be productive with Pandas indexing.
This notebook will cover:
*Background*
* Pandas
* Accessing Rows & Columns
*Indexes*
* Understanding Indexes
* Creating Indexes
* Multi-Level Indexes
* Index Trick: Inputing an index into other function.
* Joining
* Grouping and Sorting
* Deleting Rows
## Pandas
__[Pandas](https://pandas.pydata.org/)__ is one of the most popular __[Python](https://docs.python.org/3/)__ libraries. You can think of Pandas as an in-memory database. Alternatively, you can think of it as a spreadsheet that, instead of having a graphical user interface, is controlled via Python. Like a database or spreadsheet, Pandas organizes data in rows and columns. It easily works with one million rows. Indeed, if you have enough memory, it can work with 100 million rows.
## Row Access
Pandas provides three main ways to access rows. We'll summerize them and then look at examples.
* ``.iloc[...]`` -- for position-based access (that is, accessing by row number)
* Inputs: Integer, list of integers, slice of integers, (also, bool array or function)
* Outputs: single-value inputs return a series, list-like inputs returns a dataframe
* Note this uses square brackets. If you use round parentheses, you'll get a confusing error message.
* ``.loc[...]`` -- for label-based access (that is, via a string or other hashable value). Inputs:
* Single label
* List of labels
* Slice of labels (unlike rest of Python, includes stop)
* (also, bool array or function)
* ``[...]`` is ambiguous (may be position based or label based)
* Always one input
* Accepts a column name or a list of columns
* Slicing (or bool array) selects rows
Let's create an example dataframe.
```
df = pd.DataFrame([['a',2,True],
['b',3,False],
['c',1,False]],columns=['alpha','num','class'])
df
```
Now, we access it using ``.iloc`` and the integer ``0``, meaning that we want the row in position 0. *Note the square brackets, not parentheses*. Because we passed it a value, it returns a series representing the first row.
```
df.iloc[0]
```
Next, we pass it a list of integers telling which row positions we want. It returns a dataframe.
```
df.iloc[[0,2]]
```
We can use Python's slice notation to ask from rows from position 0 to position 2 (but not including 2).
```
df.iloc[0:2]
```
We can turn the column named ``alpha`` into an index named ``alpha``. (We'll talk more about creating indexes, later.)
```
df.set_index(['alpha'],inplace=True)
df
```
With this is index, we can use ``.loc[]`` to access the row with label ``b``.
```
df.loc['b'] # returns row 'b' as a series
```
By giving ``.loc[]`` a list of labels, we can access a set of rows. The result is returned as a new dataframe.
```
print(df)
df.loc[['b','a']] # returns rows 'b' and 'a' as a dataframe
```
We can also use Python slice notation to access from ``a`` to ``b``. Surprisingly, an unlike the usual Python convention, the result includes the ``b`` row.
```
df.loc['a':'b']
```
If we leave off the ``.iloc`` or ``.loc``, we can only access rows via slicing (or via a bool array). Here we slice by label:
```
df['a':'b']
```
We can slice by position number.
```
df[0:2]
```
## Column Access
Pandas provides four main ways to access columns. We'll summarize them here and then look at examples.
Column Access:
* Add a second position input to ``.iloc``
* Add a second label input to ``.loc`` (the labels in this context will be the columns names)
* Give a string or list of strings to ``[]``
* (if unambiguous) use ``.COLNAME``
Here is our example dataframe from above.
```
df
```
We tell it that we want the rows at position 0 and 2 *and* the columns at position 1 and 0 (in that order).
```
df.iloc[[0,2],[1,0]]
```
Here is how we tell it we want all rows *and* the columns at position 1 and 0. (``:`` is Python slice notation for 'all.')
```
df.iloc[:,[1,0]]
```
Using single integers with ``.iloc``, returns a single value, in this case, the number at row position 0 and column position 0.
```
print(df)
df.iloc[0,0]
```
Switching to ``.loc``, we can give it lists of labels as input.
```
df.loc[['c','a'],['class','num']]
```
If we give a single label for the row and the name of a single column, we'll get a single value, in this case, a number.
```
df.loc['c','num']
```
We can use ``:`` to get all rows and selected columns.
```
df.loc[:,['num']]
```
If we leave of the ``.iloc`` and ``.loc`` and just use bare ``[]``, a list of labels will be assumed to be column names.
```
df[['class','num']]
```
A single input string will return a column as a series.
```
df['num']
```
Where there is no conflicting methods or properties, we can access a column with '.COLNAME'.
```
df.num # Same as df['num']
```
What if you want to access rows by their _position_ and _columns_ by their label? You have to do it in two steps.
```
#These three lines all do the same thing.
step1 = df.iloc[0:2];step1[['class']]
(df.iloc[0:2])[['class']]
df.iloc[0:2][['class']]
```
## Understanding Indexes
Indexes let us efficiently access rows by label. But how should we think of them? The Pandas documentation says an index is
> Immutable ndarray implementing an ordered, sliceable __set__ (*emphasis added*)
Recall that in mathematics a __set__ has these two important properties:
* No repeated elements
* Elements are unordered
But, as we'll see presently, a Pandas index these two properties:
* Elements may be repeated
* Elements are ordered
In other words, contrary to the Pandas documentation, an Pandas index is not a mathematical set. Instead, it is a kind of __list__. Specifically, an index is
* A (kind of) list of hashable elements, where
* the position(s) of element(s) can be found quickly.
Keep this in mind while we next look a creating and using Pandas indexes.
## Creating Indexes
Here is a summary of the methods and properties used to create indexes. The list is followed by examples.
* ``.set_index(...)`` -- turn column(s) into index(s)
* ``.reset_index(...)`` -- turn index(s) into column(s)
* ``.index`` -- see the index
* ``.index.values`` -- the elements of an index, in order.
* ``.index.get_loc(...)`` -- given a label, return its position(s)
* ``.index.names`` -- the name(s) of an index.
Let's first create dataframe ``df0``. It starts with no index, except the default, nameless one.
```
df0 = pd.DataFrame([['x',2,True],
['y',3,False],
['x',1,False]],columns=['alpha','num','class'])
df0
```
We can ask to see the index. It doesn't tell us much, but we know this is some data structure that represents a list of elements where the position of elements can be quickly found.
```
df0.index
```
We can ask to see the elements of the index, in order.
```
df0.index.values
```
Here is how we convert column ``alpha`` into index ``alpha``. Note that ``x`` appears twice. That is OK. (In this example, we create a new dataframe. Alternatively, we could have used ``inplace=True`` to change the original dataframe.)
```
print('df0:')
print(df0)
df1 = df0.set_index(['alpha'])
df1
```
Now if we ask to see the index we get different datastructure. It still represents a list of elements whose positions can quickly be found.
```
df1.index
```
We can ask to see the elements of the index, in order.
```
df1.index.values
```
We can ask to see the position of ``y`` in the index.
```
print(df1)
df1.index.get_loc('y')
```
If we ask to see the positions of ``x`` in the index, it returns a bool array. That is its way to tell us the two positions that contain ``x``.
```
df1.index.get_loc('x')
```
Just as we turned a column into an index, we can turn an index into a column. All these lines do the same thing.
```
#All four do the same
df1.reset_index(['alpha'])
df1.reset_index('alpha')
df1.reset_index()
df1.reset_index(level=0)
```
We can use the ``.index.names`` property to see and set index's names.
```
print(df1)
df1.index.names
df1.index.names = ['new_index_name']
df1
```
Although indexes are not required to have names, I strongly recommend that you always give them names.
## Multi-Level Indexes
Indexes can have multiple levels. Here is a summary of the main methods and properties for this. It will be followed by examples.
* ``.set_index(``*list_of_columns_names*``)`` -- turn multiple columns into an index
* ``.index.values`` -- the pairs (or, more generally, tuples) of labels that make up the index
* ``.reset_index(``*index_name, list_of_index_names or level*``)`` -- turned the named parts of the index back to columns.
* ``.loc[``*tuple_of_labels*``]`` or left part of tuple -- the rows with these labels
To create a multi-level index, use ``.set_index`` followed by a list of column names. The columns will be turned into a multi-level index.
```
df0 = pd.DataFrame([['x',2,True],
['y',3,False],
['x',1,False]],columns=['alpha','num','class']
)
df2 = df0.set_index(['alpha','num'])
df2
```
You can list the pairs (or, more generally, tuples) of labels that make up the index.
```
df2.index.values
```
Your can turn part (or all) of an index back into a column. The lines below all do the same thing, namely remove part of the multi-level index and return a new dataframe.
```
#all these are the same
df2.reset_index(['num'])
df2.reset_index('num')
df2.reset_index(level=1)
```
The lines above returned a new dataframe, so ``df2`` remains unchanged. (If you wanted to change ``df2`` you could add ``inplace=True``.)
```
df2
```
You can append to an index.
```
df2.set_index('class',append=True)
```
Again ``df2`` didn't change. We can access rows by giving a tuple of values that make up a label.
```
print(df2)
df2.loc[[('x',2)]]
```
I was suprised to discover that you can also just give the left part of a tuple.
```
# These lines are the same
df2.loc[[('x')]]
df2.loc[['x']]
```
## Index Trick: Giving an Index to ``.loc`` and set operations
Recall that
* the ``.loc`` method can take a list of labels
* an index *is* a list of labels
So, a ``.loc`` can take an index as input. (The index can even be from another dataframe.)
Also, even though indexes are not mathematical sets, Pandas does define some set-inspired operators on them.
Here are some interesting methods and operators on indexes related to this. After the list, we'll look at examples.
* ``unique`` -- remove duplicate labels
* ``union`` (``&``) -- set union
* ``intersection`` (``|``) -- set intersection
* ``difference`` (``-``) -- set difference
* ``symmetric_difference`` (``^``) -- set symmetric difference
To see this in action, let's create a new example dataframe.
```
df0 = pd.DataFrame([['x',2,True],
['y',3,False],
['x',1,False]],columns=['alpha','num','class'])
df_num = df0.set_index(['num'])
df_num
```
As expected, if we feed a dataframe's index into that dataframe's ``.loc`` method, we get an identical dataframe back.
```
print(df_num.index)
df_num.loc[df_num.index]
```
But what happens if give ``.loc`` an index with repeated values. First, here is dataframe with such an index.
```
df_alpha = df0.set_index(['alpha'])
df_alpha
```
Next, we feed the dataframe's index into the dataframe's ``.loc`` ...
```
print(df_alpha.index)
df_alpha.loc[df_alpha.index]
```
We get a dataframe with duplicates of the duplicates! (Here is what happened. First, it asked for the row(s) indexed by label ``x``. That returned two rows. Then it asked for the row(s) indexed by label ``y``. That return one row. Then it asked for the row(s) indexed by label ``x`` again. And, again, that returned two rows.)
We can use the ``.unique()`` method to return a list of labels without duplicates.
```
print(df_alpha.index.unique())
df_alpha.loc[df_alpha.index.unique()]
```
Here is an example of applying a set-inspired method. In this case, we take the intersection of the index and the list ``['y','z']``. The result is an index containing just ``y``. When we give this to the ``.loc`` method, the result is a dataframe containing just the ``y`` row.
```
print(df_alpha.index)
print(df_alpha.index.intersection(['y','z']))
# These lines are the same
df_alpha.loc[df_alpha.index.intersection(['y','z'])]
df_alpha.loc[df_alpha.index & ['y','z']]
```
## Joining
Join two dataframes with ``.join``.
* The left dataframe does not need to be indexed, but the right one does
* In the ``on``, put the name of the left column(s) of interest.
In this example, we use ``join`` to add a score to a dataframe based on column ``alpha``. Here is the left dataframe. It isn't indexed.
```
df_left = pd.DataFrame([['x',2,True],
['y',3,False],
['x',1,False]],columns=['alpha','num','class'])
df_left
```
The right dataframe needs an index, but index can be named anything. Here we call it ``alpha2``.
```
df_right = pd.DataFrame([['x',.99],
['b',.88],
['z',.66]],columns=['alpha2','score'])
df_right.set_index(['alpha2'],inplace=True)
df_right
```
We combine the two dataframes with a left join. We use column ``alpha`` from the first dataframe and whatever is indexed in the second data frame. The result is a new dataframe with a score column.
```
df_left.join(df_right,on=['alpha'],how='left')
```
## Grouping and Sorting
You might think that the ``.groupby`` and ``.sort_values`` methods would be faster with index. In fact, however, they can be thought of as providing their own indexing and, thus, don't need any indexing help from us.
Let see this by first creating a dataframe with 1,000,000 rows and 4 columns. Each column contains a random number from 0 to 9 (inclusive).
```
import numpy as np
random_state = np.random.RandomState(seed=92933) #Create a random state with a known seed
df_mil = pd.DataFrame(random_state.randint(0,10,size=(1*1000*1000, 4)), columns=list('ABCD'))
df_mil.tail() #Display the last rows
```
The ``.groupby`` method has many sub-methods. Let's look at just one: ``.groupby(...).size()``. We can use this to give us a count of the rows where A=0 and B=0, then where A=0 and B=1, etc.
```
df_mil.groupby(['A','B']).size().iloc[:15] #.iloc[:15] Display the first 15 rows
```
Notice that we didn't pre-index the dataframe. Even without a dataframe, however, ``.groupby(...).size()`` runs quickly. Also, interestingly, it creates a result that is indexed.
Sorting is also fast, even without an index.
```
df_mil.sort_values(['A','B']).tail() #.tail() shows the last rows of the result
```
But what if want to sort indexes? As an example, consider this dataframe with 1 million rows, 4 columns, and random values from 0 to 9999. It is indexed on ``A`` and ``B``.
```
random_state = np.random.RandomState(seed=2) #Create a random state with a known seed
df_mil2 = pd.DataFrame(random_state.randint(0,1000,size=(1*1000*1000, 4)), columns=list('ABCD')).set_index(['A','B'])
df_mil2.iloc[:5] #Show first 5 rows
```
With Pandas version 0.19.0, we must first turn the indexes into columns, sort, and then restore the indexes. Like this:
df_mil2s = df_mil2.reset_index().sort_values(['A','B','C','D']).set_index(['A','B'])
df_mil2s.head(10) #Display the first rows
With Pandas version 0.23.0, we can sort indexes and columns together. Like this:
```
df_mil2.sort_values(['A','B','C','D']).iloc[:5] #Show first 5 rows
```
## Deleting Rows
As our final topic, let's look at deleting rows via a list of labels.
We actually already have all the tools needed to do this, so you can treat this as a challenge problem. Before stating the challenge problem, let's create the inputs. Dataframe ``df_mil3`` has a million rows and is indexed.
```
random_state = np.random.RandomState(seed=2) #Create a random state with a known seed
df_mil3 = pd.DataFrame(random_state.randint(0,1000,size=(1*1000*1000, 4)), columns=list('ABCD')).sort_values(['A','B','C','D']).set_index(['A','B'])
df_mil3.head() #Display the first rows
```
Dataframe ``df_delete`` has 300,000 rows and is also indexed.
```
random_state = np.random.RandomState(seed=4183) #Create a random state with a known seed
df_delete = pd.DataFrame(random_state.randint(0,1000,size=(300*1000, 2)), columns=list('AB')).sort_values(['A','B']).set_index(['A','B'])
df_delete.head() # Display first rows
```
*Challenge Problem* : Create a new dataframe where rows labeled in ``df_delete`` are deleted from ``df_mil3``. For example,
* A=0,B=0 is in ``df_delete``, so all the four A=0,B=0 rows in ``df_mil3`` should be removed.
* A=0,B=1 is in ``df_delete``, but not in ``df_mil3``, so no action is needed.
* A=0,B=2 is *not* in ``df_delete`` and is in ``df_mil3``, so those rows should remain in ``df_mil3``.
Think about this challenge problem yourself, if you like. When you're ready, keep reading for three solutions.
#### Solution #1
First, we use the set-like index method ``.difference`` to create ``keep_index``, an index of the labels we want to keep.
```
keep_index = df_mil3.index.difference(df_delete.index)
keep_index.values[:10] #Display the first 10 labels that we want to keep
```
Then, we give ``keep_index`` to ``.loc`` to access the desired rows.
```
df_mil3.loc[keep_index].head() #Display only the first rows of the result
```
#### Solution \#2
First, use Python's ``set`` class and ``sorted`` function to create a list of labels we want to keep.
```
keep_label_list = sorted(set(df_mil3.index) - set(df_delete.index))
keep_label_list[:10] #Display only the first 10 labels that we want to keep
```
Then, again, use ``.loc`` to access those rows.
```
df_mil3.loc[keep_label_list].head() #Display only the first rows of the result
```
#### Method \#3
First, create a list of the labels to drop, using the index intersection operator, ``&``.
```
drop_index = df_mil3.index & df_delete.index
drop_index.values[:10] #Display just the first 10 labels that we want to drop
```
Then, apply the (not previouslly mentioned) built-in ``.drop`` method.
```
df_mil3.drop(drop_index).head() #Display the the first rows of the result
```
We can draw two lessons from there being three solution methods. First, we've learned enough to solve many problems without learning new functions. Second, in Pandas there often is a new-to-you function that does (almost) exactly what you want.
## Summary
We have seen that
* You can access the rows of a Pandas dataframe either by position(s) or by label(s).
* Label access uses an index, making it fast.
* A Pandas index is a kind of list with fast element search. (It is not mathematical-set-like.)
* Indexes can (and should) be named. They can be multi-level. They are easily set and reset.
* To join two dataframes, you first index the second dataframe, then do the join.
* The ``groupby(...)' and '.sort_values(...)`` methods are fast without using indexes.
* Rows can be deleted, among other ways, with the ``.drop`` method.
| github_jupyter |
# 6.8 长短期记忆(LSTM)
## 6.8.2 读取数据集
```
import tensorflow as tf
from tensorflow import keras
import time
import math
import numpy as np
import sys
sys.path.append("..")
import d2lzh_tensorflow2 as d2l
(corpus_indices, char_to_idx, idx_to_char,vocab_size) = d2l.load_data_jay_lyrics()
```
## 6.8.3 从零开始实现
### 6.8.3.1 初始化模型参数
```
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
def get_params():
def _one(shape):
return tf.Variable(tf.random.normal(shape=shape,stddev=0.01,mean=0,dtype=tf.float32))
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
tf.Variable(tf.zeros(num_hiddens), dtype=tf.float32))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = tf.Variable(tf.zeros(num_outputs), dtype=tf.float32)
return [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]
```
## 6.8.4 定义模型
```
def init_lstm_state(batch_size, num_hiddens):
return (tf.zeros(shape=(batch_size, num_hiddens)),
tf.zeros(shape=(batch_size, num_hiddens)))
def lstm(inputs, state, params):
W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q = params
(H, C) = state
outputs = []
for X in inputs:
X=tf.reshape(X,[-1,W_xi.shape[0]])
I = tf.sigmoid(tf.matmul(X, W_xi) + tf.matmul(H, W_hi) + b_i)
F = tf.sigmoid(tf.matmul(X, W_xf) + tf.matmul(H, W_hf) + b_f)
O = tf.sigmoid(tf.matmul(X, W_xo) + tf.matmul(H, W_ho) + b_o)
C_tilda = tf.tanh(tf.matmul(X, W_xc) + tf.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * tf.tanh(C)
Y = tf.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
```
### 6.8.4.1 训练模型并创作歌词
```
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
```
## 6.8.5 简洁实现
```
lr = 1e-2 # 注意调整学习率
lstm_layer = keras.layers.LSTM(num_hiddens,time_major=True,return_sequences=True,return_state=True)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_keras(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
```
| github_jupyter |
I am exploring the data that was posted in the paper [Increases in COVID-19 are unrelated to levels of vaccination across 68 countries and 2947 counties in the United States](https://dx.doi.org/10.1007%2Fs10654-021-00808-7) it provides some plots showing the relationship between the percent of population vaccinated and the cases if COVID-19 infections. They conclude that the data show that there is no negative relationship between vaccination rates and infection rates.
This strikes me as counter to most of the research that shows a vaccine efficacy. So, here I pull the same data to replicate the results and perhaps explore further.
The paper reports getting their data from the Our World in Data database for the cross-country data. They take the data for the 7 days preceeding September 3 (when they pulled the data). I pulled [this version of the data](https://github.com/owid/covid-19-data/blob/b0bde8fa460b94938c47295880130a844e281539/public/data/owid-covid-data.xlsx) on October 30, 2021.
```
import yaml
import numpy
import pandas
import toyplot.svg
print("yaml version: ", yaml.__version__)
print("numpy version: ", numpy.__version__)
print("pandas version: ", pandas.__version__)
print("toyplot version: ", toyplot.__version__)
full_data = pandas.read_excel('owid-covid-data.xlsx')
```
This data contains samples from Feburary 2020 to October 29 2021. We need to narrow the data to the range from August 28 to September 3 (the range used in the paper).
We going to drop any entry that has no continent information (suggesting that the entry is for a continent, not a country). We are also dropping entries that have not case information or population information as this is what was done in the paper. (It was probably invalid information anyway.)
```
full_data['datestamp'] = pandas.to_datetime(full_data['date'])
narrow_data = full_data[
(full_data['datestamp'] >= pandas.Timestamp('2021-08-28')) &
(full_data['datestamp'] <= pandas.Timestamp('2021-09-03'))]
narrow_data = narrow_data.dropna(
subset=['continent', 'new_cases_per_million', 'population'],
how='any')
```
Sum up the case counts for all data within this range.
```
case_summation = pandas.pivot_table(
narrow_data,
index='location',
values=[
'new_cases_per_million',
'new_tests_per_thousand',
],
aggfunc='sum',
)
case_summation
case_summation.loc['Israel']
```
A couple of observations here. First, we have over triple the values in this table as were reported in the paper. This is because (I believe) the paper removed any entries that did not have an update 3 days prior to September 3 when pulled on September 3. However, since then there have clearly been many updates to the tables for those countries that are slower at reporting. As a double-check, here is a quick check to show that countries have an entry on September 3.
```
date_check = pandas.pivot_table(
narrow_data,
index='location',
values=['datestamp'],
aggfunc='max',
)
date_check[date_check['datestamp'] != pandas.Timestamp('2021-09-03')]
```
This brings me to the other difference. If you look at the values that are available in the paper, the case rates I have are larger. I believe this is for the same reason. At September 3, the data was not yet updated for all the values in this range. In the 2 months from then to now, all the reporting has completed, and we have a fuller (and more accurate) account.
So now with fuller data, let's continue. Let's pull the vaccination rate. I don't see where the paper specified which vaccination rate was picked (at the beginning or end of the week). I also found that the vaccination rate was not always posted and is missing in this particular range for some countries. So, I'll take the max reported at any time prior to the start since vaccines given during the week would not have any effect on the infection rate.
```
vac_summary = pandas.pivot_table(
full_data[(full_data['datestamp'] <= pandas.Timestamp('2021-08-28'))],
index='location',
values=[
'people_fully_vaccinated_per_hundred',
],
aggfunc='max',
)
vac_summary
```
Once again, my numbers don't match up with the paper. The values in the paper are greater. I think they did some averaging. I don't know what the point of that is.
Anyway, let's combine the data. Some of the countries are missing vaccination information, so we also have to remove those.
```
plot_data = pandas.DataFrame({
'cases_per_million': case_summation['new_cases_per_million'],
'vac_percent': vac_summary['people_fully_vaccinated_per_hundred'],
'tests_per_thousand': case_summation['new_tests_per_thousand'],
}).dropna()
plot_data
```
Finally, let's recreate the plot.
```
plot_data[plot_data['cases_per_million'] > 7300]
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Population Fully Vaccinated (%)',
ylabel='COVID-19 Cases per Million People in 7 Days',
)
x = plot_data['vac_percent']
y = plot_data['cases_per_million']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
axes.scatterplot(x, y)
axes.text(
plot_data['vac_percent']['Israel'],
plot_data['cases_per_million']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
toyplot.svg.render(canvas, 'vaccinated-vs-cases.svg')
```
This looks pretty similar to the table given in the paper.
A hypothesis I have is that the reason you are getting fewer cases with low vaccination rates is simply that more infections are going unreported. A reason for that might be that fewer tests are being adminsistered. Out of curiosity, lets color the points by the number of tests administered. (Many are reported as 0, probably because those countries did not report the number of tests.)
```
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Population Fully Vaccinated (%)',
ylabel='COVID-19 Cases per Million People in 7 Days',
)
x = plot_data['vac_percent']
y = plot_data['cases_per_million']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
colors = numpy.log(numpy.array(plot_data['tests_per_thousand']) + 1)
colormap = toyplot.color.brewer.map(
"BlueGreenYellow", domain_max=0, domain_min=numpy.max(colors))
axes.scatterplot(x, y, color=(colors, colormap))
axes.text(
plot_data['vac_percent']['Israel'],
plot_data['cases_per_million']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
```
Let's take a closer look at the relationship between the vaccinated population and the number of tests. To be fair, we will throw away all countries that do not report any tests.
```
plot_data = plot_data[plot_data['tests_per_thousand'] > 0]
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Population Fully Vaccinated (%)',
ylabel='Tests per Thousand People',
)
x = plot_data['vac_percent']
y = plot_data['tests_per_thousand']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
axes.scatterplot(x, y)
axes.text(
plot_data['vac_percent']['Israel'],
plot_data['tests_per_thousand']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
toyplot.svg.render(canvas, 'vaccinated-vs-tests.svg')
```
So, we see a positive correlation between the number of vaccinations and the number of tests. That is not surprising. A country with the wherewithal and desire to vaccinate a high proportion of people are also those that are more willing and able to adminster more tests.
It would also make sense if the number of tests affected the number of positive cases. After all, a person cannot test positive if that person is not tested in the first place. Let's check that hypothesis to see if, ignoring the vaccination rate, more tests is correlated with more _reported_ infections.
```
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Tests per Thousand People',
ylabel='COVID-19 Cases per Million People in 7 Days',
)
x = plot_data['tests_per_thousand']
y = plot_data['cases_per_million']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
axes.scatterplot(x, y)
axes.text(
plot_data['tests_per_thousand']['Israel'],
plot_data['cases_per_million']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
toyplot.svg.render(canvas, 'tests-vs-cases.svg')
```
Yes, there is a correlation here, too. No surprise here.
So, to return to the original conclusion of the paper, it is wrong to say that "there appears to be no discernable relationship between percentage of population fully vaccinated and new COVID-19 cases." The key here is that the data are the number of _reported_ cases, not the number of _actual_ cases. What the data are actually showing is the obvious correlations of vaccination to the number of tests and number of tests to infections discovered.
But let's not stop there. Let's try to dive a little deeper. Rather than look at the number of cases _reported_, let's look at the number of deaths attributed to COVID-19. A dealth is more likely to be investigated and reported than someone who is not seriously ill. Granted, some nations will be more vigilent than others, but an established health care system should catch most of them. This is probably why the [CDC uses hospitalizations and deaths as an indicator of vaccination efficacy](https://covid.cdc.gov/covid-data-tracker/#vaccine-effectiveness) rather than infection.
Let's repeat this experiment using deaths instead of infections.
```
case_summation = pandas.pivot_table(
narrow_data,
index='location',
values=[
'new_cases_per_million',
'new_tests_per_thousand',
'new_deaths_per_million',
],
aggfunc='sum',
)
case_summation
plot_data = pandas.DataFrame({
'cases_per_million': case_summation['new_cases_per_million'],
'deaths_per_million': case_summation['new_deaths_per_million'],
'vac_percent': vac_summary['people_fully_vaccinated_per_hundred'],
'tests_per_thousand': case_summation['new_tests_per_thousand'],
}).dropna()
plot_data
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Population Fully Vaccinated (%)',
ylabel='COVID-19 Deaths per Million People in 7 Days',
)
x = plot_data['vac_percent']
y = plot_data['deaths_per_million']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
axes.scatterplot(x, y)
axes.text(
plot_data['vac_percent']['Israel'],
plot_data['deaths_per_million']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
```
This looks different than the comparison of reported infections. In particular, where before Israel was an anomaly (high vaccination high infections), it is now closer to the norm (high vaccination low deaths). The correlation is ever so slightly down, but not enough to really draw conclusions.
But notice that clump in the lower left of the graph. There are lots of countries with low population rates and reporting low death rates. Once again, we need to remind our self that we are dealing with the number of COVID-19 deaths _reported_, not those that actually happened. Although most "first world countries" are likely to check and report all deaths that are likely caused by COVID, a country with a very poor healthcare infrastructure is likely to be unable to investigate causes of death.
If we look closer, we see many rows in the data that report 0 deaths, many of which also have a high infection rate.
```
pandas.set_option('display.max_rows', None)
plot_data[plot_data['deaths_per_million'] == 0]
```
many of the reports of 0 death seem suspicious. How do we correct for that? Well, we could just remove them. But what about countries like Liechtenstein and Luxembourg? These countries should be able to accurately report deaths, but are probably so small that there just happened to be no deaths that week. We don't want to skew our data for these cases.
However, what if we look at the number of hospital beds per capita? Shouldn't that be a good indication of the availability of healthcare (and therefore the likelyhood of a COVID-19 death being detected). What happens if we limit the plot to countries that have more than 1 bed for every thousand people.
```
vac_summary = pandas.pivot_table(
full_data[(full_data['datestamp'] <= pandas.Timestamp('2021-08-28'))],
index='location',
values=[
'people_fully_vaccinated_per_hundred',
'hospital_beds_per_thousand',
],
aggfunc='max',
).dropna()
vac_summary = vac_summary[vac_summary['hospital_beds_per_thousand'] > 1]
pandas.set_option('display.max_rows', 10)
plot_data = pandas.DataFrame({
'cases_per_million': case_summation['new_cases_per_million'],
'deaths_per_million': case_summation['new_deaths_per_million'],
'vac_percent': vac_summary['people_fully_vaccinated_per_hundred'],
'tests_per_thousand': case_summation['new_tests_per_thousand'],
'beds': vac_summary['hospital_beds_per_thousand'],
}).dropna()
plot_data
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Population Fully Vaccinated (%)',
ylabel='COVID-19 Deaths per Million People in 7 Days',
)
x = plot_data['vac_percent']
y = plot_data['deaths_per_million']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
axes.scatterplot(x, y)
axes.text(
plot_data['vac_percent']['Israel'],
plot_data['deaths_per_million']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
```
Although there still is a clump of countries in the lower left corner that is probably under-reporting deaths, we have managed to filter many of them out. Here we see that yes in fact there is a negative correlation between COVID-19 deaths and vaccinations.
I noticed that the dataset also has some information about excess mortality. Although this metric is not perfect, it is a bit less dependent on accurately determining whether or not deaths are caused by COVID-19.
```
vac_summary = pandas.pivot_table(
full_data[(full_data['datestamp'] <= pandas.Timestamp('2021-08-28'))],
index='location',
values=[
'people_fully_vaccinated_per_hundred',
'hospital_beds_per_thousand',
'excess_mortality',
],
aggfunc='max',
).dropna()
plot_data = pandas.DataFrame({
'cases_per_million': case_summation['new_cases_per_million'],
'deaths_per_million': case_summation['new_deaths_per_million'],
'vac_percent': vac_summary['people_fully_vaccinated_per_hundred'],
'tests_per_thousand': case_summation['new_tests_per_thousand'],
'beds': vac_summary['hospital_beds_per_thousand'],
'excess_mortality': vac_summary['excess_mortality'],
}).dropna()
canvas = toyplot.Canvas(width='400px', height='400px')
axes = canvas.cartesian(
xlabel='Population Fully Vaccinated (%)',
ylabel='Excess Mortality (%)',
)
x = plot_data['vac_percent']
y = plot_data['excess_mortality']
fit_coef = numpy.polyfit(x, y, 1)
fit_x = numpy.array([numpy.min(x), numpy.max(x)])
fit_y = fit_x*fit_coef[0] + fit_coef[1]
axes.plot(fit_x, fit_y, color='#BBBBBB')
axes.scatterplot(x, y)
axes.text(
plot_data['vac_percent']['Israel'],
plot_data['excess_mortality']['Israel'],
'Israel',
style={'text-anchor':'start',
'-toyplot-anchor-shift':'5pt'}
)
```
| github_jupyter |
```
import warnings
warnings.filterwarnings("ignore")
import sys
import os
import tensorflow as tf
# sys.path.append("../libs")
sys.path.insert(1, '../')
from libs import input_data
from libs import models
from libs import trainer
from libs import freeze
flags=tf.app.flags
flags=tf.app.flags
#Important Directories
flags.DEFINE_string('data_dir','..\\..\\_inputs\\raw','Train Data Folder')
flags.DEFINE_string('summaries_dir','..\\..\\summaries','Summaries Folder')
flags.DEFINE_string('train_dir','..\\..\\logs&checkpoint','Directory to write event logs and checkpoint')
flags.DEFINE_string('models_dir','..\\..\\models','Models Folder')
#Task Specific Parameters
flags.DEFINE_string('wanted_words','yes,no,up,down,left,right,on,off,stop,go','Wanted Words')
flags.DEFINE_float('validation_percentage',10,'Validation Percentage')
flags.DEFINE_float('testing_percentage',10,'Testing Percentage')
flags.DEFINE_integer('sample_rate',16000,'Sample Rate')
flags.DEFINE_integer('clip_duration_ms',1000,'Clip Duration in ms')
flags.DEFINE_float('window_size_ms',20,'How long each spectogram timeslice is')
flags.DEFINE_float('window_stride_ms',10.0,'How far to move in time between frequency windows.')
flags.DEFINE_integer('dct_coefficient_count',257,'How many bins to use for the MFCC fingerprint')
flags.DEFINE_float('time_shift_ms',100.0,'Range to randomly shift the training audio by in time.')
FLAGS=flags.FLAGS
model_architecture='ds_cnn_spec'
start_checkpoint=None
logging_interval=10
eval_step_interval=500
save_step_interval=2000
silence_percentage=10.0
unknown_percentage=12.0
background_frequency=0.8
background_volume=0.2
learning_rate='0.0005,0.0001' #Always seperated by comma, trains with each of the learning rate for the given number of iterations
train_steps='10000,20000' #Declare the training steps for which the learning rates will be used
batch_size=100
model_size_info=[6 ,276 ,10 ,4 ,2 ,1 ,276 ,3 ,3 ,2 ,2 ,276 ,3 ,3 ,1 ,1 ,276 ,3 ,3 ,1 ,1 ,276 ,3 ,3 ,1 ,1 ,276 ,3 ,3 ,1 ,1 ]
remaining_args = FLAGS([sys.argv[0]] + [flag for flag in sys.argv if flag.startswith("--")])
assert(remaining_args == [sys.argv[0]])
train_dir=os.path.join(FLAGS.data_dir,'train','audio')
model_settings = models.prepare_model_settings(
len(input_data.prepare_words_list(FLAGS.wanted_words.split(','))),
FLAGS.sample_rate, FLAGS.clip_duration_ms, FLAGS.window_size_ms,
FLAGS.window_stride_ms, FLAGS.dct_coefficient_count)
audio_processor = input_data.AudioProcessor(
train_dir, silence_percentage, unknown_percentage,
FLAGS.wanted_words.split(','), FLAGS.validation_percentage,
FLAGS.testing_percentage, model_settings,use_silence_folder=True,use_spectrogram=True)
def get_train_data(args):
sess=args
time_shift_samples = int((FLAGS.time_shift_ms * FLAGS.sample_rate) / 1000)
train_fingerprints, train_ground_truth = audio_processor.get_data(
batch_size, 0, model_settings,background_frequency,
background_volume, time_shift_samples, 'training', sess)
return train_fingerprints,train_ground_truth
def get_val_data(args):
'''
Input: (sess,offset)
'''
sess,i=args
validation_fingerprints, validation_ground_truth = (
audio_processor.get_data(batch_size, i, model_settings, 0.0,
0.0, 0, 'validation', sess))
return validation_fingerprints,validation_ground_truth
# def get_test_data(args):
# '''
# Input: (sess,offset)
# '''
# sess,i=args
# test_fingerprints, test_ground_truth = audio_processor.get_data(
# batch_size, i, model_settings, 0.0, 0.0, 0, 'testing', sess)
# return test_fingerprints,test_ground_truth
def main(_):
sess=tf.InteractiveSession()
# Placeholders
fingerprint_size = model_settings['fingerprint_size']
label_count = model_settings['label_count']
fingerprint_input = tf.placeholder(
tf.float32, [None, fingerprint_size], name='fingerprint_input')
ground_truth_input = tf.placeholder(
tf.float32, [None, label_count], name='groundtruth_input')
set_size = audio_processor.set_size('validation')
label_count = model_settings['label_count']
# Create Model
logits, dropout_prob = models.create_model(
fingerprint_input,
model_settings,
model_architecture,
model_size_info=model_size_info,
is_training=True)
#Start Training
extra_args=(dropout_prob,label_count,batch_size,set_size)
trainer.train(sess,logits,fingerprint_input,ground_truth_input,get_train_data,
get_val_data,train_steps,learning_rate,eval_step_interval, logging_interval=logging_interval,
start_checkpoint=start_checkpoint,checkpoint_interval=save_step_interval,
model_name=model_architecture,train_dir=FLAGS.train_dir,
summaries_dir=FLAGS.summaries_dir,args=extra_args)
tf.app.run(main=main)
# save_checkpoint='../logs&checkpoint/ds_cnn/ckpt-50000'
# save_path=os.path.join(FLAGS.models_dir,model_architecture,'%s.pb'%os.path.basename(save_checkpoint))
# freeze.freeze_graph(FLAGS,model_architecture,save_checkpoint,save_path,model_size_info=model_size_info)
# save_path=os.path.join(FLAGS.models_dir,model_architecture,'%s-batched.pb'%os.path.basename(save_checkpoint))
# freeze.freeze_graph(FLAGS,model_architecture,save_checkpoint,save_path,batched=True,model_size_info=model_size_info)
```
| github_jupyter |
```
# enable auto reload of modules
%load_ext autoreload
%autoreload 2
# This part ensures that we can later import loca return torch.tensor(0.) l functions
# from a module in another directory with relative imports
import os
from os import listdir
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
from glob import glob
import logging
import matplotlib.pyplot as plt
import argparse
import socket
import time
from datetime import datetime
from tqdm import tqdm
import numpy as np
from scipy import sparse
from scipy import ndimage
import copy
import torch
import torch.nn as nn #Dice coeff
from torch import optim
from torch.utils.data import Dataset
from torchvision import datasets, models, transforms
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader, random_split, WeightedRandomSampler
# from src.models.unet import UNet
from src.models.unet import UNet
from src.data.maya_dataset import MayaDataset, MayaTransform
from src.visualization.visualize import visualize_output_of_dataloader, plot_img_and_mask
from src.models.train_model import train_net
from src.models.eval_model import eval_net
from src.models.predict_model import predict_img
# https://docs.opencv.org/3.4/d3/dc0/group__imgproc__shape.html#gada4437098113fd8683c932e0567f47ba
class PolygonizedMayaDataset(Dataset):
def __init__(self, mayadataset: MayaDataset, set = 'test') -> None:
self.dataset = mayadataset
self.set = set
self.st = [[1,1,1],[1,1,1], [1,1,1]]
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
s = self.dataset[index]
sample = copy.deepcopy(s)
for k in s.keys():
if 'ori_mask' in k:
if self.set == 'test':
labeled, num_features = ndimage.label(sample[k][0])
else:
labeled, num_features = ndimage.label( (1 - (sample[k]/255))[0] )
sample[f'labeled_{k}'] = labeled
return sample
# Data loaders
dir_img_root = '../data/processed/'
batch_size=2
dataset = MayaDataset(dir_img_root, split="train", transform = MayaTransform(use_augmentations=False))
poly_dataset = PolygonizedMayaDataset(dataset, set = 'train')
n = len(poly_dataset)
# loader = DataLoader(poly_dataset, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
poly_dataset[0].keys()
def collate(dt):
s = {}
for k in dt[0].keys():
print(k)
for i in range(len(dt)):
if k not in s:
s[k] = [dt[i][k]]
else:
s[k].append(dt[i][k])
for k in s:
t = s[k]
if isinstance(s[k][0], torch.Tensor):
t = [ i.numpy() for i in s[k]]
s[k] = np.array(t)
return s
cl = collate(poly_dataset)
def get_all_structure(mask):
st = []
for i in range(mask.shape[0]):
for j in range(1, mask[i].max()+1):
st.append(mask[i] ==j)
return np.array(st)
sta = get_all_structure(cl['labeled_ori_mask_aguada'])
stb = get_all_structure(cl['labeled_ori_mask_building'])
stp = get_all_structure(cl['labeled_ori_mask_platform'])
sb = np.count_nonzero(stb, axis=(1,2))
minval = np.argmin(sb[np.nonzero(sb)])
maxval = np.argmax(sb[np.nonzero(sb)])
minval, maxval
plt.imshow(stb[268])
print(np.unique(stb[268], return_counts=True))
print(np.where(stb[268]))
plt.imshow(stb[268][250:260,470:])
sp = np.count_nonzero(stp, axis=(1,2))
minval = np.min(sp[np.nonzero(sp)])
maxval = np.max(sp[np.nonzero(sp)])
minval, maxval
sa = np.count_nonzero(sta, axis=(1,2))
minval = np.min(sa[np.nonzero(sa)])
maxval = np.max(sa[np.nonzero(sa)])
minval, maxval
```
| github_jupyter |
```
#Mount the google drive
from google.colab import drive
drive.mount('/content/drive')
# direct to the folder where the data located, change the folder path here if needed
%cd '/content/drive/MyDrive/CSCE 638 NLP Project/LOL_Data/'
!ls
import pandas as pd
import numpy as np
import sklearn
from sklearn.model_selection import GroupKFold
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
# import tensorflow_hub as hub
import tensorflow as tf
# import bert_tokenization as tokenization
import tensorflow.keras.backend as K
from tensorflow import keras
import os
from scipy.stats import spearmanr
from math import floor, ceil
!pip install transformers
!pip install sentencepiece
from transformers import *
import seaborn as sns
import string
import re #for regex
np.set_printoptions(suppress=True)
print(tf.__version__)
```
# Prep / tokenizer
#### 1. Read data and tokenizer
Read tokenizer and data, as well as defining the maximum sequence length that will be used for the input to Bert (maximum is usually 512 tokens)
```
training_sample_count = 8000
dev_count = 1000
test_count = 1000
running_folds = 1
MAX_SENTENCE_LENGTH = 20 # max number of words in a sentence
MAX_SENTENCES = 5 # max number of sentences to encode in a text
MAX_LENGTH = 100 # max words in a text as whole sentences
```
### load dataset
```
df_train = pd.read_csv('train8000.csv')
df_train = df_train[:training_sample_count*running_folds]
df_train = df_train[df_train['is_humor']==1]
print(df_train.describe())
display(df_train.head())
df_train.to_csv('train4932.csv')
# load augmented training data via backtranslation
df_train_aug = pd.read_csv('aug_train_4932.tsv', sep = '\t')
print(df_train_aug.describe())
display(df_train_aug.head())
# debug the translated aug_text, sometimes missing quotes will cause problems
print(len(df_train))
print(len(df_train_aug))
'''
print(df_train_aug.info())
print(df_train_aug.iloc[4926,:])
ct = 0
for i in range(len(df_train)):
if df_train.iloc[i,0] != df_train_aug.iloc[i,0]:
print(i, df_train.iloc[i,0], df_train_aug.iloc[i,0])
ct += 1
if ct == 10:
stop
'''
# concatenate two dataframe
df_train = pd.concat([df_train, df_train_aug], ignore_index = True)
print(df_train.describe())
df_dev = pd.read_csv('dev1000.csv')
df_dev = df_dev[:dev_count*running_folds]
df_dev = df_dev[df_dev['is_humor']==1]
print(df_dev.describe())
df_test = pd.read_csv('test1000.csv')
df_test = df_test[:test_count]
display(df_test.head(3))
output_categories = list(df_train.columns[[4]]) # humor controversy
input_categories = list(df_train.columns[[1]]) # text
TARGET_COUNT = len(output_categories)
print('\ninput categories:\n\t', input_categories)
print('\noutput categories:\n\t', output_categories)
print('\noutput TARGET_COUNT:\n\t', TARGET_COUNT)
```
## 2. Preprocessing functions
These are some functions that will be used to preprocess the raw text data into useable Bert inputs.<br>
```
from transformers import BertTokenizer
MODEL_TYPE = 'bert-large-uncased'
tokenizer = BertTokenizer.from_pretrained(MODEL_TYPE)
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
def return_id(str1, str2, truncation_strategy, length):
inputs = tokenizer.encode_plus(str1, str2,
add_special_tokens=True,
max_length=length,
truncation_strategy=truncation_strategy)
input_ids = inputs["input_ids"] #token indices, numerical representations of tokens building the sequences that will be used as input by the model
input_masks = [1] * len(input_ids) # indicate the ids should be attended
input_segments = inputs["token_type_ids"] #BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying the two types of sequence in the model.
padding_length = length - len(input_ids)
padding_id = tokenizer.pad_token_id
input_ids = input_ids + ([padding_id] * padding_length)
input_masks = input_masks + ([0] * padding_length)
input_segments = input_segments + ([0] * padding_length)
return [input_ids, input_masks, input_segments]
def compute_input_arrays(df, columns, tokenizer):
model_input = []
for xx in range((MAX_SENTENCES*3)+3): # +3 for the whole sentences
model_input.append([])
for _, row in tqdm(df[columns].iterrows()):
#print(type(row))
#print(row)
#print(row.text)
#print(type(row.text))
#stop
i = 0
# sent
sentences = sent_tokenize(row.text) # separate a long text into sentences
for xx in range(MAX_SENTENCES): # MAX_SENTENCES = 5
s = sentences[xx] if xx<len(sentences) else ''
ids_q, masks_q, segments_q = return_id(s, None, 'longest_first', MAX_SENTENCE_LENGTH) #MAX_SENTENCE_LENGTH = 20
model_input[i].append(ids_q)
i+=1
model_input[i].append(masks_q)
i+=1
model_input[i].append(segments_q)
i+=1
# full row
ids_q, masks_q, segments_q = return_id(row.text, None, 'longest_first', MAX_LENGTH) # MAX_LENGTH = 100
model_input[i].append(ids_q)
i+=1
model_input[i].append(masks_q)
i+=1
model_input[i].append(segments_q)
for xx in range((MAX_SENTENCES*3)+3):
model_input[xx] = np.asarray(model_input[xx], dtype=np.int32)
print(model_input[0].shape)
return model_input
inputs = compute_input_arrays(df_train, input_categories, tokenizer)
dev_inputs = compute_input_arrays(df_dev, input_categories, tokenizer)
test_inputs = compute_input_arrays(df_test, input_categories, tokenizer)
# check the tokenized sentences
print(len(inputs), len(inputs[0]), len(inputs[0][0]))
# check out input for 7th row
xx = 7
print(df_train.iloc[xx,1])
print(sent_tokenize(df_train.iloc[xx,1]))
inputs[0][xx], inputs[3][xx], inputs[6][xx], inputs[15][xx]
def compute_output_arrays(df, columns):
return np.asarray(df[columns])
outputs = compute_output_arrays(df_train, output_categories)
dev_outputs = compute_output_arrays(df_dev, output_categories)
```
## 3. Create model
```
#config = BertConfig() # print(config) to see settings
#config.output_hidden_states = False # Set to True to obtain hidden states
#bert_model = TFBertModel.from_pretrained('bert-large-uncased', config=config)
bert_model = TFBertModel.from_pretrained("bert-large-uncased")
#config
def create_model():
# model structure
# takes q_ids [max=20*MAX_SENTENCES] and a_ids [max=200]
import gc
model_inputs = []
f_inputs=[]
for i in range(MAX_SENTENCES):
# bert embeddings
q_id = tf.keras.layers.Input((MAX_SENTENCE_LENGTH,), dtype=tf.int32)
q_mask = tf.keras.layers.Input((MAX_SENTENCE_LENGTH,), dtype=tf.int32)
q_atn = tf.keras.layers.Input((MAX_SENTENCE_LENGTH,), dtype=tf.int32)
q_embedding = bert_model(q_id, attention_mask=q_mask, token_type_ids=q_atn)[0]
q = tf.keras.layers.GlobalAveragePooling1D()(q_embedding)
# internal model
hidden1 = keras.layers.Dense(32, activation="relu")(q)
hidden2 = keras.layers.Dropout(0.3)(hidden1)
hidden3 = keras.layers.Dense(8, activation='relu')(hidden2)
f_inputs.append(hidden3)
model_inputs.extend([q_id, q_mask, q_atn])
# whole sentence
a_id = tf.keras.layers.Input((MAX_LENGTH,), dtype=tf.int32)
a_mask = tf.keras.layers.Input((MAX_LENGTH,), dtype=tf.int32)
a_atn = tf.keras.layers.Input((MAX_LENGTH,), dtype=tf.int32)
a_embedding = bert_model(a_id, attention_mask=a_mask, token_type_ids=a_atn)[0]
a = tf.keras.layers.GlobalAveragePooling1D()(a_embedding)
print(a.shape)
# internal model
hidden1 = keras.layers.Dense(256, activation="relu")(a)
hidden2 = keras.layers.Dropout(0.2)(hidden1)
hidden3 = keras.layers.Dense(64, activation='relu')(hidden2)
f_inputs.append(hidden3)
model_inputs.extend([a_id, a_mask, a_atn])
# final classifier
concat_ = keras.layers.Concatenate()(f_inputs)
hiddenf1 = keras.layers.Dense(512, activation='relu')(concat_)
hiddenf2 = keras.layers.Dropout(0.2)(hiddenf1)
hiddenf3 = keras.layers.Dense(256, activation='relu')(hiddenf2)
output = keras.layers.Dense(TARGET_COUNT, activation='sigmoid')(hiddenf3) # softmax
model = keras.Model(inputs=model_inputs, outputs=[output] )
gc.collect()
return model
model = create_model()
model.summary()
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='./Results/ColBERT_Task1c_Large_model_plot.png', show_shapes=True, show_layer_names=True)
```
## 5. Training, validation and testing
Loops over the folds in gkf and trains each fold for 3 epochs --- with a learning rate of 3e-5 and batch_size of 6. A simple binary crossentropy is used as the objective-/loss-function.
```
# Evaluation Metrics
import sklearn
def print_evaluation_metrics(y_true, y_pred, label='', is_regression=True, label2=''):
print('==================', label2)
### For regression
if is_regression:
print("Regression task returns: MSE")
print('mean_absolute_error',label,':', sklearn.metrics.mean_absolute_error(y_true, y_pred))
print('mean_squared_error',label,':', sklearn.metrics.mean_squared_error(y_true, y_pred))
print('r2 score',label,':', sklearn.metrics.r2_score(y_true, y_pred))
# print('max_error',label,':', sklearn.metrics.max_error(y_true, y_pred))
return sklearn.metrics.mean_squared_error(y_true, y_pred)
else:
### FOR Classification
# print('balanced_accuracy_score',label,':', sklearn.metrics.balanced_accuracy_score(y_true, y_pred))
# print('average_precision_score',label,':', sklearn.metrics.average_precision_score(y_true, y_pred))
# print('balanced_accuracy_score',label,':', sklearn.metrics.balanced_accuracy_score(y_true, y_pred))
# print('accuracy_score',label,':', sklearn.metrics.accuracy_score(y_true, y_pred))
print("Classification returns: Acc")
print('f1_score',label,':', sklearn.metrics.f1_score(y_true, y_pred))
matrix = sklearn.metrics.confusion_matrix(y_true, y_pred)
print(matrix)
TP,TN,FP,FN = matrix[1][1],matrix[0][0],matrix[0][1],matrix[1][0]
Accuracy = (TP+TN)/(TP+FP+FN+TN)
Precision = TP/(TP+FP)
Recall = TP/(TP+FN)
F1 = 2*(Recall * Precision) / (Recall + Precision)
print('Acc', Accuracy, 'Prec', Precision, 'Rec', Recall, 'F1',F1)
return sklearn.metrics.accuracy_score(y_true, y_pred)
# test
print_evaluation_metrics([1,0], [0.9,0.1], '', True)
print_evaluation_metrics([1,0], [1,1], '', False)
```
### Loss function selection
Regression problem between 0 and 1, so binary_crossentropy and mean_absolute_error seem good.
Here are the explanations: https://www.dlology.com/blog/how-to-choose-last-layer-activation-and-loss-function/
```
training_epochs = 1
min_acc = 100
min_test = []
dev_preds = []
test_preds = []
best_model = False
for BS in [6]:
LR = 1e-5
print('>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>')
print('LR=', LR)
gkf = GroupKFold(n_splits=2).split(X=df_train.text, groups=df_train.text)
for fold, (train_idx, valid_idx) in enumerate(gkf):
if fold not in range(running_folds):
continue
train_inputs = [(inputs[i][:])[:training_sample_count] for i in range(len(inputs))]
train_outputs = (outputs[:])[:training_sample_count]
#train_inputs = [(inputs[i][train_idx])[:training_sample_count] for i in range(len(inputs))]
#train_outputs = (outputs[train_idx])[:training_sample_count]
#valid_inputs = [inputs[i][valid_idx] for i in range(len(inputs))]
#valid_outputs = outputs[valid_idx]
#print(len(train_idx), len(train_outputs))
model = create_model()
K.clear_session()
optimizer = tf.keras.optimizers.Adam(learning_rate=LR)
model.compile(loss='binary_crossentropy', optimizer=optimizer)
print('model compiled')
model.fit(train_inputs, train_outputs, epochs=training_epochs, batch_size=BS, verbose=1,
# validation_split=0.2,
# validation_data=(x_val, y_val)
)
# model.save_weights(f'bert-{fold}.h5')
# valid_preds.append(model.predict(valid_inputs))
#test_preds.append(model.predict(test_inputs))
dev_preds.append(model.predict(dev_inputs))
acc = print_evaluation_metrics(np.array(dev_outputs), np.array(dev_preds[-1]))
if acc < min_acc:
print('new acc >> ', acc)
min_acc = acc
best_model = model
```
## Regression submission
```
# check the dev set results
min_test = best_model.predict(dev_inputs)
df_dev['humor_controversy_pred'] = min_test
print_evaluation_metrics(df_dev['humor_controversy'], df_dev['humor_controversy_pred'], '', True)
df_dev.head()
```
## Binary submission
```
for split in np.arange(0.1, 0.99, 0.1).tolist():
df_dev['humor_controversy_pred_bi'] = (df_dev['humor_controversy_pred'] > split)
print_evaluation_metrics(df_dev['humor_controversy'], df_dev['humor_controversy_pred_bi'], '', False, 'SPLIT on '+str(split))
df_dev.head()
# use optimal split
split = 0.4
df_dev['humor_controversy_pred_bi'] = (df_dev['humor_controversy_pred'] > split)
print_evaluation_metrics(df_dev['humor_controversy'], df_dev['humor_controversy_pred_bi'], '', False, 'SPLIT on '+str(split))
df_dev.head()
df_dev[df_dev['humor_controversy_pred_bi']!=df_dev['humor_controversy']]
```
### Get Test Set Results for Submission
```
min_test = best_model.predict(test_inputs)
df_test['humor_controversy'] = min_test
df_test['humor_controversy'] = (df_test['humor_controversy'] > split)
print(df_test.head())
df_test['humor_controversy'] = df_test['humor_controversy'].astype(int)
print(df_test.head())
# drop the text column for submission
df_sub = df_test.drop('text',axis = 1)
print(df_sub.head())
df_sub.to_csv('./Results/ColBERT_LargeUncased_Task1c.csv', index=False)
```
| github_jupyter |
##### Copyright 2020 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# TensorFlow basics
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/guide/basics"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/guide/basics.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/docs/blob/master/site/en/guide/basics.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/docs/site/en/guide/basics.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
</table>
This guide provides a quick overview of _TensorFlow basics_. Each section of this doc is an overview of a larger topic—you can find links to full guides at the end of each section.
TensorFlow is an end-to-end platform for machine learning. It supports the following:
* Multidimensional-array based numeric computation (similar to <a href="https://numpy.org/" class="external">NumPy</a>.)
* GPU and distributed processing
* Automatic differentiation
* Model construction, training, and export
* And more
## Tensors
TensorFlow operates on multidimensional arrays or _tensors_ represented as `tf.Tensor` objects. Here is a two-dimensional tensor:
```
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
print(x)
print(x.shape)
print(x.dtype)
```
The most important attributes of a `tf.Tensor` are its `shape` and `dtype`:
* `Tensor.shape`: tells you the size of the tensor along each of its axes.
* `Tensor.dtype`: tells you the type of all the elements in the tensor.
TensorFlow implements standard mathematical operations on tensors, as well as many operations specialized for machine learning.
For example:
```
x + x
5 * x
x @ tf.transpose(x)
tf.concat([x, x, x], axis=0)
tf.nn.softmax(x, axis=-1)
tf.reduce_sum(x)
```
Running large calculations on CPU can be slow. When properly configured, TensorFlow can use accelerator hardware like GPUs to execute operations very quickly.
```
if tf.config.list_physical_devices('GPU'):
print("TensorFlow **IS** using the GPU")
else:
print("TensorFlow **IS NOT** using the GPU")
```
Refer to the [Tensor guide](tensor.ipynb) for details.
## Variables
Normal `tf.Tensor` objects are immutable. To store model weights (or other mutable state) in TensorFlow use a `tf.Variable`.
```
var = tf.Variable([0.0, 0.0, 0.0])
var.assign([1, 2, 3])
var.assign_add([1, 1, 1])
```
Refer to the [Variables guide](variable.ipynb) for details.
## Automatic differentiation
<a href="https://en.wikipedia.org/wiki/Gradient_descent" class="external">_Gradient descent_</a> and related algorithms are a cornerstone of modern machine learning.
To enable this, TensorFlow implements automatic differentiation (autodiff), which uses calculus to compute gradients. Typically you'll use this to calculate the gradient of a model's _error_ or _loss_ with respect to its weights.
```
x = tf.Variable(1.0)
def f(x):
y = x**2 + 2*x - 5
return y
f(x)
```
At `x = 1.0`, `y = f(x) = (1**2 + 3 - 5) = -2`.
The derivative of `y` is `y' = f'(x) = (2*x + 2) = 4`. TensorFlow can calculate this automatically:
```
with tf.GradientTape() as tape:
y = f(x)
g_x = tape.gradient(y, x) # g(x) = dy/dx
g_x
```
This simplified example only takes the derivative with respect to a single scalar (`x`), but TensorFlow can compute the gradient with respect to any number of non-scalar tensors simultaneously.
Refer to the [Autodiff guide](autodiff.ipynb) for details.
## Graphs and tf.function
While you can use TensorFlow interactively like any Python library, TensorFlow also provides tools for:
* **Performance optimization**: to speed up training and inference.
* **Export**: so you can save your model when it's done training.
These require that you use `tf.function` to separate your pure-TensorFlow code from Python.
```
@tf.function
def my_func(x):
print('Tracing.\n')
return tf.reduce_sum(x)
```
The first time you run the `tf.function`, although it executes in Python, it captures a complete, optimized graph representing the TensorFlow computations done within the function.
```
x = tf.constant([1, 2, 3])
my_func(x)
```
On subsequent calls TensorFlow only executes the optimized graph, skipping any non-TensorFlow steps. Below, note that `my_func` doesn't print _tracing_ since `print` is a Python function, not a TensorFlow function.
```
x = tf.constant([10, 9, 8])
my_func(x)
```
A graph may not be reusable for inputs with a different _signature_ (`shape` and `dtype`), so a new graph is generated instead:
```
x = tf.constant([10.0, 9.1, 8.2], dtype=tf.float32)
my_func(x)
```
These captured graphs provide two benefits:
* In many cases they provide a significant speedup in execution (though not this trivial example).
* You can export these graphs, using `tf.saved_model`, to run on other systems like a [server](https://www.tensorflow.org/tfx/serving/docker) or a [mobile device](https://www.tensorflow.org/lite/guide), no Python installation required.
Refer to [Intro to graphs](intro_to_graphs.ipynb) for more details.
## Modules, layers, and models
`tf.Module` is a class for managing your `tf.Variable` objects, and the `tf.function` objects that operate on them. The `tf.Module` class is necessary to support two significant features:
1. You can save and restore the values of your variables using `tf.train.Checkpoint`. This is useful during training as it is quick to save and restore a model's state.
2. You can import and export the `tf.Variable` values _and_ the `tf.function` graphs using `tf.saved_model`. This allows you to run your model independently of the Python program that created it.
Here is a complete example exporting a simple `tf.Module` object:
```
class MyModule(tf.Module):
def __init__(self, value):
self.weight = tf.Variable(value)
@tf.function
def multiply(self, x):
return x * self.weight
mod = MyModule(3)
mod.multiply(tf.constant([1, 2, 3]))
```
Save the `Module`:
```
save_path = './saved'
tf.saved_model.save(mod, save_path)
```
The resulting SavedModel is independent of the code that created it. You can load a SavedModel from Python, other language bindings, or [TensorFlow Serving](https://www.tensorflow.org/tfx/serving/docker). You can also convert it to run with [TensorFlow Lite](https://www.tensorflow.org/lite/guide) or [TensorFlow JS](https://www.tensorflow.org/js/guide).
```
reloaded = tf.saved_model.load(save_path)
reloaded.multiply(tf.constant([1, 2, 3]))
```
The `tf.keras.layers.Layer` and `tf.keras.Model` classes build on `tf.Module` providing additional functionality and convenience methods for building, training, and saving models. Some of these are demonstrated in the next section.
Refer to [Intro to modules](intro_to_modules.ipynb) for details.
## Training loops
Now put this all together to build a basic model and train it from scratch.
First, create some example data. This generates a cloud of points that loosely follows a quadratic curve:
```
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['figure.figsize'] = [9, 6]
x = tf.linspace(-2, 2, 201)
x = tf.cast(x, tf.float32)
def f(x):
y = x**2 + 2*x - 5
return y
y = f(x) + tf.random.normal(shape=[201])
plt.plot(x.numpy(), y.numpy(), '.', label='Data')
plt.plot(x, f(x), label='Ground truth')
plt.legend();
```
Create a model:
```
class Model(tf.keras.Model):
def __init__(self, units):
super().__init__()
self.dense1 = tf.keras.layers.Dense(units=units,
activation=tf.nn.relu,
kernel_initializer=tf.random.normal,
bias_initializer=tf.random.normal)
self.dense2 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
# For Keras layers/models, implement `call` instead of `__call__`.
x = x[:, tf.newaxis]
x = self.dense1(x)
x = self.dense2(x)
return tf.squeeze(x, axis=1)
model = Model(64)
plt.plot(x.numpy(), y.numpy(), '.', label='data')
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Untrained predictions')
plt.title('Before training')
plt.legend();
```
Write a basic training loop:
```
variables = model.variables
optimizer = tf.optimizers.SGD(learning_rate=0.01)
for step in range(1000):
with tf.GradientTape() as tape:
prediction = model(x)
error = (y-prediction)**2
mean_error = tf.reduce_mean(error)
gradient = tape.gradient(mean_error, variables)
optimizer.apply_gradients(zip(gradient, variables))
if step % 100 == 0:
print(f'Mean squared error: {mean_error.numpy():0.3f}')
plt.plot(x.numpy(),y.numpy(), '.', label="data")
plt.plot(x, f(x), label='Ground truth')
plt.plot(x, model(x), label='Trained predictions')
plt.title('After training')
plt.legend();
```
That's working, but remember that implementations of common training utilities are available in the `tf.keras` module. So consider using those before writing your own. To start with, the `Model.compile` and `Model.fit` methods implement a training loop for you:
```
new_model = Model(64)
new_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.optimizers.SGD(learning_rate=0.01))
history = new_model.fit(x, y,
epochs=100,
batch_size=32,
verbose=0)
model.save('./my_model')
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylim([0, max(plt.ylim())])
plt.ylabel('Loss [Mean Squared Error]')
plt.title('Keras training progress');
```
Refer to [Basic training loops](basic_training_loops.ipynb) and the [Keras guide](https://www.tensorflow.org/guide/keras) for more details.
| github_jupyter |
```
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '3'
with open('../Malaya-Dataset/dependency/gsd-ud-train.conllu.txt') as fopen:
corpus = fopen.read().split('\n')
with open('../Malaya-Dataset/dependency/gsd-ud-test.conllu.txt') as fopen:
corpus.extend(fopen.read().split('\n'))
with open('../Malaya-Dataset/dependency/gsd-ud-dev.conllu.txt') as fopen:
corpus.extend(fopen.read().split('\n'))
import bert
from bert import run_classifier
from bert import optimization
from bert import tokenization
from bert import modeling
import tensorflow as tf
import numpy as np
import unicodedata
import six
from functools import partial
SPIECE_UNDERLINE = '▁'
def preprocess_text(inputs, lower=False, remove_space=True, keep_accents=False):
if remove_space:
outputs = ' '.join(inputs.strip().split())
else:
outputs = inputs
outputs = outputs.replace("``", '"').replace("''", '"')
if six.PY2 and isinstance(outputs, str):
outputs = outputs.decode('utf-8')
if not keep_accents:
outputs = unicodedata.normalize('NFKD', outputs)
outputs = ''.join([c for c in outputs if not unicodedata.combining(c)])
if lower:
outputs = outputs.lower()
return outputs
def encode_pieces(sp_model, text, return_unicode=True, sample=False):
# return_unicode is used only for py2
# note(zhiliny): in some systems, sentencepiece only accepts str for py2
if six.PY2 and isinstance(text, unicode):
text = text.encode('utf-8')
if not sample:
pieces = sp_model.EncodeAsPieces(text)
else:
pieces = sp_model.SampleEncodeAsPieces(text, 64, 0.1)
new_pieces = []
for piece in pieces:
if len(piece) > 1 and piece[-1] == ',' and piece[-2].isdigit():
cur_pieces = sp_model.EncodeAsPieces(
piece[:-1].replace(SPIECE_UNDERLINE, ''))
if piece[0] != SPIECE_UNDERLINE and cur_pieces[0][0] == SPIECE_UNDERLINE:
if len(cur_pieces[0]) == 1:
cur_pieces = cur_pieces[1:]
else:
cur_pieces[0] = cur_pieces[0][1:]
cur_pieces.append(piece[-1])
new_pieces.extend(cur_pieces)
else:
new_pieces.append(piece)
# note(zhiliny): convert back to unicode for py2
if six.PY2 and return_unicode:
ret_pieces = []
for piece in new_pieces:
if isinstance(piece, str):
piece = piece.decode('utf-8')
ret_pieces.append(piece)
new_pieces = ret_pieces
return new_pieces
def encode_ids(sp_model, text, sample=False):
pieces = encode_pieces(sp_model, text, return_unicode=False, sample=sample)
ids = [sp_model.PieceToId(piece) for piece in pieces]
return ids
import sentencepiece as spm
sp_model = spm.SentencePieceProcessor()
sp_model.Load('bert-base/sp10m.cased.v4.model')
with open('bert-base/sp10m.cased.v4.vocab') as fopen:
v = fopen.read().split('\n')[:-1]
v = [i.split('\t') for i in v]
v = {i[0]: i[1] for i in v}
class Tokenizer:
def __init__(self, v):
self.vocab = v
pass
def tokenize(self, string):
return encode_pieces(sp_model, string, return_unicode=False, sample=False)
def convert_tokens_to_ids(self, tokens):
return [sp_model.PieceToId(piece) for piece in tokens]
def convert_ids_to_tokens(self, ids):
return [sp_model.IdToPiece(i) for i in ids]
tokenizer = Tokenizer(v)
tag2idx = {'PAD': 0, 'X': 1}
tag_idx = 2
def process_corpus(corpus, until = None):
global word2idx, tag2idx, char2idx, word_idx, tag_idx, char_idx
sentences, words, depends, labels, pos, sequences = [], [], [], [], [], []
temp_sentence, temp_word, temp_depend, temp_label, temp_pos = [], [], [], [], []
first_time = True
for sentence in corpus:
try:
if len(sentence):
if sentence[0] == '#':
continue
if first_time:
print(sentence)
first_time = False
sentence = sentence.split('\t')
if sentence[7] not in tag2idx:
tag2idx[sentence[7]] = tag_idx
tag_idx += 1
temp_word.append(sentence[1])
temp_depend.append(int(sentence[6]) + 1)
temp_label.append(tag2idx[sentence[7]])
temp_sentence.append(sentence[1])
temp_pos.append(sentence[3])
else:
if len(temp_sentence) < 2 or len(temp_word) != len(temp_label):
temp_word = []
temp_depend = []
temp_label = []
temp_sentence = []
temp_pos = []
continue
bert_tokens = ['<cls>']
labels_ = [0]
depends_ = [0]
seq_ = []
for no, orig_token in enumerate(temp_word):
labels_.append(temp_label[no])
depends_.append(temp_depend[no])
t = tokenizer.tokenize(orig_token)
bert_tokens.extend(t)
labels_.extend([1] * (len(t) - 1))
depends_.extend([0] * (len(t) - 1))
seq_.append(no + 1)
bert_tokens.append('<sep>')
labels_.append(0)
depends_.append(0)
words.append(tokenizer.convert_tokens_to_ids(bert_tokens))
depends.append(depends_)
labels.append(labels_)
sentences.append(bert_tokens)
pos.append(temp_pos)
sequences.append(seq_)
temp_word = []
temp_depend = []
temp_label = []
temp_sentence = []
temp_pos = []
except Exception as e:
print(e, sentence)
return sentences[:-1], words[:-1], depends[:-1], labels[:-1], pos[:-1], sequences[:-1]
sentences, words, depends, labels, _, _ = process_corpus(corpus)
import json
with open('../Malaya-Dataset/dependency/augmented-dependency.json') as fopen:
augmented = json.load(fopen)
text_augmented, depends_augmented, labels_augmented = [], [], []
for a in augmented:
text_augmented.extend(a[0])
depends_augmented.extend(a[1])
labels_augmented.extend((np.array(a[2]) + 1).tolist())
def parse_XY(texts, depends, labels):
outside, sentences, outside_depends, outside_labels = [], [], [], []
for no, text in enumerate(texts):
temp_depend = depends[no]
temp_label = labels[no]
s = text.split()
sentences.append(s)
bert_tokens = ['<cls>']
labels_ = [0]
depends_ = [0]
for no, orig_token in enumerate(s):
labels_.append(temp_label[no])
depends_.append(temp_depend[no])
t = tokenizer.tokenize(orig_token)
bert_tokens.extend(t)
labels_.extend([1] * (len(t) - 1))
depends_.extend([0] * (len(t) - 1))
bert_tokens.append('<sep>')
labels_.append(0)
depends_.append(0)
outside.append(tokenizer.convert_tokens_to_ids(bert_tokens))
outside_depends.append(depends_)
outside_labels.append(labels_)
return outside, sentences, outside_depends, outside_labels
outside, _, outside_depends, outside_labels = parse_XY(text_augmented,
depends_augmented,
labels_augmented)
words.extend(outside)
depends.extend(outside_depends)
labels.extend(outside_labels)
idx2tag = {v:k for k, v in tag2idx.items()}
from sklearn.model_selection import train_test_split
words_train, words_test, depends_train, depends_test, labels_train, labels_test \
= train_test_split(words, depends, labels, test_size = 0.2)
len(words_train), len(words_test)
train_X = words_train
train_Y = labels_train
train_depends = depends_train
test_X = words_test
test_Y = labels_test
test_depends = depends_test
epoch = 30
batch_size = 32
warmup_proportion = 0.1
num_train_steps = int(len(train_X) / batch_size * epoch)
num_warmup_steps = int(num_train_steps * warmup_proportion)
bert_config = modeling.BertConfig.from_json_file('bert-base/bert_config.json')
class BiAAttention:
def __init__(self, input_size_encoder, input_size_decoder, num_labels):
self.input_size_encoder = input_size_encoder
self.input_size_decoder = input_size_decoder
self.num_labels = num_labels
self.W_d = tf.get_variable("W_d", shape=[self.num_labels, self.input_size_decoder],
initializer=tf.contrib.layers.xavier_initializer())
self.W_e = tf.get_variable("W_e", shape=[self.num_labels, self.input_size_encoder],
initializer=tf.contrib.layers.xavier_initializer())
self.U = tf.get_variable("U", shape=[self.num_labels, self.input_size_decoder, self.input_size_encoder],
initializer=tf.contrib.layers.xavier_initializer())
def forward(self, input_d, input_e, mask_d=None, mask_e=None):
batch = tf.shape(input_d)[0]
length_decoder = tf.shape(input_d)[1]
length_encoder = tf.shape(input_e)[1]
out_d = tf.expand_dims(tf.matmul(self.W_d, tf.transpose(input_d, [0, 2, 1])), 3)
out_e = tf.expand_dims(tf.matmul(self.W_e, tf.transpose(input_e, [0, 2, 1])), 2)
output = tf.matmul(tf.expand_dims(input_d, 1), self.U)
output = tf.matmul(output, tf.transpose(tf.expand_dims(input_e, 1), [0, 1, 3, 2]))
output = output + out_d + out_e
if mask_d is not None:
d = tf.expand_dims(tf.expand_dims(mask_d, 1), 3)
e = tf.expand_dims(tf.expand_dims(mask_e, 1), 2)
output = output * d * e
return output
class BiLinear:
def __init__(self, left_features, right_features, out_features):
self.left_features = left_features
self.right_features = right_features
self.out_features = out_features
self.U = tf.get_variable("U-bi", shape=[out_features, left_features, right_features],
initializer=tf.contrib.layers.xavier_initializer())
self.W_l = tf.get_variable("Wl", shape=[out_features, left_features],
initializer=tf.contrib.layers.xavier_initializer())
self.W_r = tf.get_variable("Wr", shape=[out_features, right_features],
initializer=tf.contrib.layers.xavier_initializer())
def forward(self, input_left, input_right):
left_size = tf.shape(input_left)
output_shape = tf.concat([left_size[:-1], [self.out_features]], axis = 0)
batch = tf.cast(tf.reduce_prod(left_size[:-1]), tf.int32)
input_left = tf.reshape(input_left, (batch, self.left_features))
input_right = tf.reshape(input_right, (batch, self.right_features))
tiled = tf.tile(tf.expand_dims(input_left, axis = 0), (self.out_features,1,1))
output = tf.transpose(tf.reduce_sum(tf.matmul(tiled, self.U), axis = 2))
output = output + tf.matmul(input_left, tf.transpose(self.W_l))\
+ tf.matmul(input_right, tf.transpose(self.W_r))
return tf.reshape(output, output_shape)
class Model:
def __init__(
self,
learning_rate,
hidden_size_word,
training = True,
cov = 0.0):
self.words = tf.placeholder(tf.int32, (None, None))
self.heads = tf.placeholder(tf.int32, (None, None))
self.types = tf.placeholder(tf.int32, (None, None))
self.switch = tf.placeholder(tf.bool, None)
self.mask = tf.cast(tf.math.not_equal(self.words, 0), tf.float32)
self.maxlen = tf.shape(self.words)[1]
self.lengths = tf.count_nonzero(self.words, 1)
mask = self.mask
heads = self.heads
types = self.types
self.arc_h = tf.layers.Dense(hidden_size_word)
self.arc_c = tf.layers.Dense(hidden_size_word)
self.attention = BiAAttention(hidden_size_word, hidden_size_word, 1)
self.type_h = tf.layers.Dense(hidden_size_word)
self.type_c = tf.layers.Dense(hidden_size_word)
self.bilinear = BiLinear(hidden_size_word, hidden_size_word, len(tag2idx))
model = modeling.BertModel(
config=bert_config,
is_training=training,
input_ids=self.words,
use_one_hot_embeddings=False)
output_layer = model.get_sequence_output()
arc_h = tf.nn.elu(self.arc_h(output_layer))
arc_c = tf.nn.elu(self.arc_c(output_layer))
type_h = tf.nn.elu(self.type_h(output_layer))
type_c = tf.nn.elu(self.type_c(output_layer))
out_arc = tf.squeeze(self.attention.forward(arc_h, arc_c, mask_d=self.mask,
mask_e=self.mask), axis = 1)
self.out_arc = out_arc
batch = tf.shape(out_arc)[0]
max_len = tf.shape(out_arc)[1]
sec_max_len = tf.shape(out_arc)[2]
batch_index = tf.range(0, batch)
decode_arc = out_arc + tf.linalg.diag(tf.fill([max_len], -np.inf))
minus_mask = tf.expand_dims(tf.cast(1 - mask, tf.bool), axis = 2)
minus_mask = tf.tile(minus_mask, [1, 1, sec_max_len])
decode_arc = tf.where(minus_mask, tf.fill(tf.shape(decode_arc), -np.inf), decode_arc)
self.decode_arc = decode_arc
self.heads_seq = tf.argmax(decode_arc, axis = 1)
self.heads_seq = tf.identity(self.heads_seq, name = 'heads_seq')
t = tf.cast(tf.transpose(self.heads_seq), tf.int32)
broadcasted = tf.broadcast_to(batch_index, tf.shape(t))
concatenated = tf.transpose(tf.concat([tf.expand_dims(broadcasted, axis = 0),
tf.expand_dims(t, axis = 0)], axis = 0))
type_h = tf.gather_nd(type_h, concatenated)
out_type = self.bilinear.forward(type_h, type_c)
self.tags_seq = tf.argmax(out_type, axis = 2)
self.tags_seq = tf.identity(self.tags_seq, name = 'tags_seq')
log_likelihood, transition_params = tf.contrib.crf.crf_log_likelihood(
out_type, self.types, self.lengths
)
crf_loss = tf.reduce_mean(-log_likelihood)
self.logits, _ = tf.contrib.crf.crf_decode(
out_type, transition_params, self.lengths
)
self.logits = tf.identity(self.logits, name = 'logits')
batch = tf.shape(out_arc)[0]
max_len = tf.shape(out_arc)[1]
batch_index = tf.range(0, batch)
t = tf.transpose(heads)
broadcasted = tf.broadcast_to(batch_index, tf.shape(t))
concatenated = tf.transpose(tf.concat([tf.expand_dims(broadcasted, axis = 0),
tf.expand_dims(t, axis = 0)], axis = 0))
type_h = tf.gather_nd(type_h, concatenated)
out_type = self.bilinear.forward(type_h, type_c)
minus_inf = -1e8
minus_mask = (1 - mask) * minus_inf
out_arc = out_arc + tf.expand_dims(minus_mask, axis = 2) + tf.expand_dims(minus_mask, axis = 1)
loss_arc = tf.nn.log_softmax(out_arc, dim=1)
loss_type = tf.nn.log_softmax(out_type, dim=2)
loss_arc = loss_arc * tf.expand_dims(mask, axis = 2) * tf.expand_dims(mask, axis = 1)
loss_type = loss_type * tf.expand_dims(mask, axis = 2)
num = tf.reduce_sum(mask) - tf.cast(batch, tf.float32)
child_index = tf.tile(tf.expand_dims(tf.range(0, max_len), 1), [1, batch])
t = tf.transpose(heads)
broadcasted = tf.broadcast_to(batch_index, tf.shape(t))
concatenated = tf.transpose(tf.concat([tf.expand_dims(broadcasted, axis = 0),
tf.expand_dims(t, axis = 0),
tf.expand_dims(child_index, axis = 0)], axis = 0))
loss_arc = tf.gather_nd(loss_arc, concatenated)
loss_arc = tf.transpose(loss_arc, [1, 0])
t = tf.transpose(types)
broadcasted = tf.broadcast_to(batch_index, tf.shape(t))
concatenated = tf.transpose(tf.concat([tf.expand_dims(broadcasted, axis = 0),
tf.expand_dims(child_index, axis = 0),
tf.expand_dims(t, axis = 0)], axis = 0))
loss_type = tf.gather_nd(loss_type, concatenated)
loss_type = tf.transpose(loss_type, [1, 0])
cost = (tf.reduce_sum(-loss_arc) / num) + (tf.reduce_sum(-loss_type) / num)
self.cost = tf.cond(self.switch, lambda: cost + crf_loss, lambda: cost)
self.optimizer = optimization.create_optimizer(self.cost, learning_rate,
num_train_steps, num_warmup_steps, False)
mask = tf.sequence_mask(self.lengths, maxlen = self.maxlen)
self.prediction = tf.boolean_mask(self.logits, mask)
mask_label = tf.boolean_mask(self.types, mask)
correct_pred = tf.equal(tf.cast(self.prediction, tf.int32), mask_label)
correct_index = tf.cast(correct_pred, tf.float32)
self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
self.prediction = tf.cast(tf.boolean_mask(self.heads_seq, mask), tf.int32)
mask_label = tf.boolean_mask(self.heads, mask)
correct_pred = tf.equal(self.prediction, mask_label)
correct_index = tf.cast(correct_pred, tf.float32)
self.accuracy_depends = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
tf.reset_default_graph()
sess = tf.InteractiveSession()
learning_rate = 2e-5
hidden_size_word = 128
model = Model(learning_rate, hidden_size_word)
sess.run(tf.global_variables_initializer())
var_lists = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope = 'bert')
saver = tf.train.Saver(var_list = var_lists)
saver.restore(sess, 'bert-base/model.ckpt')
from tensorflow.keras.preprocessing.sequence import pad_sequences
batch_x = train_X[:5]
batch_x = pad_sequences(batch_x,padding='post')
batch_y = train_Y[:5]
batch_y = pad_sequences(batch_y,padding='post')
batch_depends = train_depends[:5]
batch_depends = pad_sequences(batch_depends,padding='post')
sess.run([model.accuracy, model.accuracy_depends, model.cost],
feed_dict = {model.words: batch_x,
model.types: batch_y,
model.heads: batch_depends,
model.switch: False})
sess.run([model.accuracy, model.accuracy_depends, model.cost],
feed_dict = {model.words: batch_x,
model.types: batch_y,
model.heads: batch_depends,
model.switch: True})
tags_seq, heads = sess.run(
[model.logits, model.heads_seq],
feed_dict = {
model.words: batch_x,
},
)
tags_seq[0], heads[0], batch_depends[0]
from tqdm import tqdm
epoch = 20
for e in range(epoch):
train_acc, train_loss = [], []
test_acc, test_loss = [], []
train_acc_depends, test_acc_depends = [], []
pbar = tqdm(
range(0, len(train_X), batch_size), desc = 'train minibatch loop'
)
for i in pbar:
index = min(i + batch_size, len(train_X))
batch_x = train_X[i: index]
batch_x = pad_sequences(batch_x,padding='post')
batch_y = train_Y[i: index]
batch_y = pad_sequences(batch_y,padding='post')
batch_depends = train_depends[i: index]
batch_depends = pad_sequences(batch_depends,padding='post')
acc_depends, acc, cost, _ = sess.run(
[model.accuracy_depends, model.accuracy, model.cost, model.optimizer],
feed_dict = {
model.words: batch_x,
model.types: batch_y,
model.heads: batch_depends,
model.switch: False
},
)
train_loss.append(cost)
train_acc.append(acc)
train_acc_depends.append(acc_depends)
pbar.set_postfix(cost = cost, accuracy = acc, accuracy_depends = acc_depends)
pbar = tqdm(
range(0, len(test_X), batch_size), desc = 'test minibatch loop'
)
for i in pbar:
index = min(i + batch_size, len(test_X))
batch_x = test_X[i: index]
batch_x = pad_sequences(batch_x,padding='post')
batch_y = test_Y[i: index]
batch_y = pad_sequences(batch_y,padding='post')
batch_depends = test_depends[i: index]
batch_depends = pad_sequences(batch_depends,padding='post')
acc_depends, acc, cost = sess.run(
[model.accuracy_depends, model.accuracy, model.cost],
feed_dict = {
model.words: batch_x,
model.types: batch_y,
model.heads: batch_depends,
model.switch: False
},
)
test_loss.append(cost)
test_acc.append(acc)
test_acc_depends.append(acc_depends)
pbar.set_postfix(cost = cost, accuracy = acc, accuracy_depends = acc_depends)
print(
'epoch: %d, training loss: %f, training acc: %f, training depends: %f, valid loss: %f, valid acc: %f, valid depends: %f\n'
% (e, np.mean(train_loss),
np.mean(train_acc),
np.mean(train_acc_depends),
np.mean(test_loss),
np.mean(test_acc),
np.mean(test_acc_depends)
))
from tqdm import tqdm
epoch = 5
for e in range(epoch):
train_acc, train_loss = [], []
test_acc, test_loss = [], []
train_acc_depends, test_acc_depends = [], []
pbar = tqdm(
range(0, len(train_X), batch_size), desc = 'train minibatch loop'
)
for i in pbar:
index = min(i + batch_size, len(train_X))
batch_x = train_X[i: index]
batch_x = pad_sequences(batch_x,padding='post')
batch_y = train_Y[i: index]
batch_y = pad_sequences(batch_y,padding='post')
batch_depends = train_depends[i: index]
batch_depends = pad_sequences(batch_depends,padding='post')
acc_depends, acc, cost, _ = sess.run(
[model.accuracy_depends, model.accuracy, model.cost, model.optimizer],
feed_dict = {
model.words: batch_x,
model.types: batch_y,
model.heads: batch_depends,
model.switch: True
},
)
train_loss.append(cost)
train_acc.append(acc)
train_acc_depends.append(acc_depends)
pbar.set_postfix(cost = cost, accuracy = acc, accuracy_depends = acc_depends)
pbar = tqdm(
range(0, len(test_X), batch_size), desc = 'test minibatch loop'
)
for i in pbar:
index = min(i + batch_size, len(test_X))
batch_x = test_X[i: index]
batch_x = pad_sequences(batch_x,padding='post')
batch_y = test_Y[i: index]
batch_y = pad_sequences(batch_y,padding='post')
batch_depends = test_depends[i: index]
batch_depends = pad_sequences(batch_depends,padding='post')
acc_depends, acc, cost = sess.run(
[model.accuracy_depends, model.accuracy, model.cost],
feed_dict = {
model.words: batch_x,
model.types: batch_y,
model.heads: batch_depends,
model.switch: True
},
)
test_loss.append(cost)
test_acc.append(acc)
test_acc_depends.append(acc_depends)
pbar.set_postfix(cost = cost, accuracy = acc, accuracy_depends = acc_depends)
print(
'epoch: %d, training loss: %f, training acc: %f, training depends: %f, valid loss: %f, valid acc: %f, valid depends: %f\n'
% (e, np.mean(train_loss),
np.mean(train_acc),
np.mean(train_acc_depends),
np.mean(test_loss),
np.mean(test_acc),
np.mean(test_acc_depends)
))
saver = tf.train.Saver(tf.trainable_variables())
saver.save(sess, 'bert-base-dependency/model.ckpt')
tf.reset_default_graph()
sess = tf.InteractiveSession()
learning_rate = 2e-5
hidden_size_word = 128
model = Model(learning_rate, hidden_size_word, training = False)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.trainable_variables())
saver.restore(sess, 'bert-base-dependency/model.ckpt')
def pred2label(pred):
out = []
for pred_i in pred:
out_i = []
for p in pred_i:
out_i.append(idx2tag[p])
out.append(out_i)
return out
def evaluate(heads_pred, types_pred, heads, types, lengths,
symbolic_root=False, symbolic_end=False):
batch_size, _ = heads_pred.shape
ucorr = 0.
lcorr = 0.
total = 0.
ucomplete_match = 0.
lcomplete_match = 0.
corr_root = 0.
total_root = 0.
start = 1 if symbolic_root else 0
end = 1 if symbolic_end else 0
for i in range(batch_size):
ucm = 1.
lcm = 1.
for j in range(start, lengths[i] - end):
total += 1
if heads[i, j] == heads_pred[i, j]:
ucorr += 1
if types[i, j] == types_pred[i, j]:
lcorr += 1
else:
lcm = 0
else:
ucm = 0
lcm = 0
if heads[i, j] == 0:
total_root += 1
corr_root += 1 if heads_pred[i, j] == 0 else 0
ucomplete_match += ucm
lcomplete_match += lcm
return ucorr / total, lcorr / total, corr_root / total_root
arcs, types, roots = [], [], []
real_Y, predict_Y = [], []
for i in tqdm(range(0, len(test_X), batch_size)):
index = min(i + batch_size, len(test_X))
batch_x = test_X[i: index]
batch_x = pad_sequences(batch_x,padding='post')
batch_y = test_Y[i: index]
batch_y = pad_sequences(batch_y,padding='post')
batch_depends = test_depends[i: index]
batch_depends = pad_sequences(batch_depends,padding='post')
tags_seq, heads = sess.run(
[model.logits, model.heads_seq],
feed_dict = {
model.words: batch_x,
},
)
arc_accuracy, type_accuracy, root_accuracy = evaluate(heads - 1, tags_seq, batch_depends - 1, batch_y,
np.count_nonzero(batch_x, axis = 1))
arcs.append(arc_accuracy)
types.append(type_accuracy)
roots.append(root_accuracy)
predicted = pred2label(tags_seq)
real = pred2label(batch_y)
predict_Y.extend(predicted)
real_Y.extend(real)
temp_real_Y = []
for r in real_Y:
temp_real_Y.extend(r)
temp_predict_Y = []
for r in predict_Y:
temp_predict_Y.extend(r)
from sklearn.metrics import classification_report
print(classification_report(temp_real_Y, temp_predict_Y, digits = 5))
print('arc accuracy:', np.mean(arcs))
print('types accuracy:', np.mean(types))
print('root accuracy:', np.mean(roots))
strings = ','.join(
[
n.name
for n in tf.get_default_graph().as_graph_def().node
if ('Variable' in n.op
or 'Placeholder' in n.name
or '_seq' in n.name
or 'alphas' in n.name
or 'logits' in n.name
or 'self/Softmax' in n.name)
and 'Adam' not in n.name
and 'beta' not in n.name
and 'global_step' not in n.name
and 'adam' not in n.name
and 'gradients/bert' not in n.name
]
)
strings.split(',')
def freeze_graph(model_dir, output_node_names):
if not tf.gfile.Exists(model_dir):
raise AssertionError(
"Export directory doesn't exists. Please specify an export "
'directory: %s' % model_dir
)
checkpoint = tf.train.get_checkpoint_state(model_dir)
input_checkpoint = checkpoint.model_checkpoint_path
absolute_model_dir = '/'.join(input_checkpoint.split('/')[:-1])
output_graph = absolute_model_dir + '/frozen_model.pb'
clear_devices = True
with tf.Session(graph = tf.Graph()) as sess:
saver = tf.train.import_meta_graph(
input_checkpoint + '.meta', clear_devices = clear_devices
)
saver.restore(sess, input_checkpoint)
output_graph_def = tf.graph_util.convert_variables_to_constants(
sess,
tf.get_default_graph().as_graph_def(),
output_node_names.split(','),
)
with tf.gfile.GFile(output_graph, 'wb') as f:
f.write(output_graph_def.SerializeToString())
print('%d ops in the final graph.' % len(output_graph_def.node))
freeze_graph('bert-base-dependency', strings)
string = 'husein makan ayam'
import re
def entities_textcleaning(string, lowering = False):
"""
use by entities recognition, pos recognition and dependency parsing
"""
string = re.sub('[^A-Za-z0-9\-\/() ]+', ' ', string)
string = re.sub(r'[ ]+', ' ', string).strip()
original_string = string.split()
if lowering:
string = string.lower()
string = [
(original_string[no], word.title() if word.isupper() else word)
for no, word in enumerate(string.split())
if len(word)
]
return [s[0] for s in string], [s[1] for s in string]
def parse_X(left):
bert_tokens = ['<cls>']
for no, orig_token in enumerate(left):
t = tokenizer.tokenize(orig_token)
bert_tokens.extend(t)
bert_tokens.append("<sep>")
return tokenizer.convert_tokens_to_ids(bert_tokens), bert_tokens
sequence = entities_textcleaning(string)[1]
parsed_sequence, bert_sequence = parse_X(sequence)
def merge_sentencepiece_tokens_tagging(x, y):
new_paired_tokens = []
n_tokens = len(x)
rejected = ['<cls>', '<sep>']
i = 0
while i < n_tokens:
current_token, current_label = x[i], y[i]
if not current_token.startswith('▁') and current_token not in rejected:
previous_token, previous_label = new_paired_tokens.pop()
merged_token = previous_token
merged_label = [previous_label]
while (
not current_token.startswith('▁')
and current_token not in rejected
):
merged_token = merged_token + current_token.replace('▁', '')
merged_label.append(current_label)
i = i + 1
current_token, current_label = x[i], y[i]
merged_label = merged_label[0]
new_paired_tokens.append((merged_token, merged_label))
else:
new_paired_tokens.append((current_token, current_label))
i = i + 1
words = [
i[0].replace('▁', '')
for i in new_paired_tokens
if i[0] not in ['<cls>', '<sep>']
]
labels = [i[1] for i in new_paired_tokens if i[0] not in ['<cls>', '<sep>']]
return words, labels
def load_graph(frozen_graph_filename):
with tf.gfile.GFile(frozen_graph_filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def)
return graph
g = load_graph('bert-base-dependency/frozen_model.pb')
x = g.get_tensor_by_name('import/Placeholder:0')
heads_seq = g.get_tensor_by_name('import/heads_seq:0')
tags_seq = g.get_tensor_by_name('import/logits:0')
test_sess = tf.InteractiveSession(graph = g)
h, t = test_sess.run([heads_seq, tags_seq],
feed_dict = {
x: [parsed_sequence],
},
)
h = h[0] - 1
t = [idx2tag[d] for d in t[0]]
merged_h = merge_sentencepiece_tokens_tagging(bert_sequence, h)
merged_t = merge_sentencepiece_tokens_tagging(bert_sequence, t)
print(list(zip(merged_h[0], merged_h[1])))
print(list(zip(merged_t[0], merged_t[1])))
import boto3
bucketName = 'huseinhouse-storage'
Key = 'bert-base-dependency/frozen_model.pb'
outPutname = "v30/dependency/bert-base-dependency.pb"
s3 = boto3.client('s3',
aws_access_key_id='',
aws_secret_access_key='')
s3.upload_file(Key,bucketName,outPutname)
```
| github_jupyter |
```
# -*- coding: utf-8 -*-
#@author: Renan Silva
#@Github: https://github.com/rfelipesilva
#@Python 3.8.7
import basedosdados as bd
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
```
# Análise - deputados federais
Usando a base eleições da base dos dados para analisar diferença entre generos nas eleições brasileiras de 1990 até os dias de hoje (Fevereiro, 2022) para cargos de deputados(a) federais.
Vale ressaltar que o escopo dessa analise foca somente em analisar a informação de gênero dos cadidatos, não levando em consideração raça, situação da candidatura, ou instrução.
- Acesso aos dados
- Exploração dos dados
- Fortamação dos dados
- Visualização dos dados - Responder perguntas:
- Qual o total de candidaturas e candidaturas eleitas por homens e mulheres?
- Qual a distribuição de candidaturas por gênero ao longo dos anos?
- Qual a distribuição de candidaturas por gênero por partido?
- Repostas que podemos extrair:
- Ano que tivemos recorde de candidatas mulheres
- Partido que mais indicou mulheres como candidatas
- Referências
## Acesso aos dados
Aqui estamos usando duas tabelas do dataset de eleições brasileiras da brilhante [Base dos Dados](https://basedosdados.org/).
Para saber como criar seu token e como acessar essa e outras tabelas/conjunto de dados, basta acessar o site.
```
df_candidates = bd.read_sql(query="SELECT * FROM basedosdados.br_tse_eleicoes.candidatos WHERE ano IN (1990, 1994, 1998, 2002, 2006, 2010, 2014, 2018)",
billing_project_id='<YOUR PROJECT ID>')
df_candidates.head()
df_result_candidates = bd.read_sql(query="SELECT * FROM basedosdados.br_tse_eleicoes.resultados_candidato WHERE ano IN (1990, 1994, 1998, 2002, 2006, 2010, 2014, 2018)",
billing_project_id='<YOUR PROJECT ID>')
df_result_candidates.head()
```
***
## Exploração dos dados
Para começar, vamos definir quais informações(colunas) vamos utilizar de cada dataframe e entender como essas informações estão em relação a complitude do dado (valores ausentes):
- df_candidate -> desse dataframe iremos utilizar as colunas:
- ano
- id_candidato_bd
- sigla_partido
- cargo
- genero
- df_result_candidates -> desse dataframe iremos utilizar as seguintes colunas:
- id_candidato_bd
- resultado
- votos
- cargo
- ano
Antes de entender valores nulos ou ausentes, vamos filtrar somente as colunas que vamos trabalhar e então explorar valores nulos por coluna no dataframe **df_candidate**:
```
df_candidates = df_candidates[['ano', 'id_candidato_bd', 'sigla_partido', 'cargo', 'genero']] #FILTRANDO COLUNAS
df_candidates['genero'].fillna('não informado', inplace=True) #PREENCHENDO VALORES NULLOS COMO "não informado" NA COLUNA DE "genero"
df_candidates['cargo'].fillna('não informado', inplace=True) #PREENCHENDO VALORES NULLOS COMO "não informado" NA COLUNA DE "cargo"
```
As colunas ***cargo*** e ***genero*** do dataframe **df_candidates** são as que receberão atenção agora, portanto podemos ignorar as outras colunas (serão usadas depois para juntar as tabelas).
```
df_candidates.cargo.value_counts() #VALORES TOTAIS POR CARGO
df_candidates.genero.value_counts() #VALORES TOTAIS POR GÊNERO
```
Já temos valores para analisar, mas podemos facilitar o entendimento através de simples gráficos de distribuição:
```
df_candidates.cargo.value_counts().plot(kind='bar', figsize=(15,5)).grid(axis='y', linestyle='--', linewidth=1)
plt.xticks(rotation=25)
plt.title('Distribuição de candidatos por cargo')
plt.show()
df_candidates.genero.value_counts().plot(kind='bar').grid(axis='y', linestyle='--', linewidth=1)
plt.xticks(rotation=0)
plt.title('Distribuição de candidatos por gênero informado')
plt.show()
```
Sobre os dataframes:
- df_candidates:
- o dataset trás dados para de todos os cargos como *Presidente*, *Deputado federal* e etc. No nosso caso vamos trabalhar somente com dados de **Deputado Federal**
- o dataset contém valores nulos quando olhamos para a variável **gênero** (porém já foram tratados do nosso lado)
Vemos que, com simples gráficos não tão elaborados, agora temos uma percepção melhor dos dados do dataframe **df_cadidates** e principalmente das variáveis que vamos trabalhar.
Vamos fazer a mesma coisa mas agora para o dataframe **df_result_candidates**:
```
df_result_candidates = df_result_candidates[['ano', 'id_candidato_bd', 'resultado', 'votos', 'cargo']] #FILTRANDO COLUNAS
df_result_candidates.head()
```
Vemos que no dataframe **df_result_candidates** temos algunas valores nulos para o id do candidato(a), vamos aproveitar e entender se temos mais valores nulos nas outras colunas:
```
df_result_candidates.isnull().sum()
```
Nesse caso só temos valores nulos para a coluna **id_candidato_bd**, isso deve ser levado em consideração depois na hora de juntar informações entre os dois dataframes.
Por agora isso já basta na exploração dos dados, temos tudo que precisamos e sabemos tudo que devemos levar em consideração na análise.
***
## Formatação dos dados
Para começarmos a analisar a questão de gênero, precisamos juntar informações dos dois dataframes:
- df_candidate -> contém informação de gênero de qualquer candidato (OS DADOS ESTÃO SENDO USADOS CONFORME FORMATAÇÃO DO DATASET, NÃO FOI ALTERADO NENHUM REGISTRO DO DADO)
- df_result_candidates -> contém informações de resultados das eleições (por exemplo Votos)
Nesse momento estaremos priorizando o dataframe **df_result_candidates** já com os resultados pós eleições para depois contarmos votos.
Para juntar os dataframes, iremos utilizar como valor chave entre eles a coluna ***id_candidato_bd*** e também vamos filtrar ambos para trabalhar somente com o cargo de **Deputado Federal**, lembrando que alguns desses valores estão nulos conforme analisado durante a fase de exploração dos dados.
Vamos lidar com a junção dos dados da seguinte forma:
1. Limpar **id_candidato_bd** nulos de ambos dataframes, pois esses podem trazer mais ruídos do que ajudar a análise.
2. Filtrar somente pelo cargo deputado federal, já que ambos dataframes contém dados de todos os cargos.
3. Também vamos criar um novo dataframe com valores únicos em relação a **id_candidato_bd** e **genero**, com isso na hora de juntar as tabelas teremos um dataframe mais limpo para simular a análise.
```
#1. LIMPANDO DADOS NULOS
df_candidates = df_candidates[df_candidates['id_candidato_bd'].isnull() == False]
df_result_candidates = df_result_candidates[df_result_candidates['id_candidato_bd'].isnull() == False]
#2. FILTRANDO DADOS POR DEPUTADO(a) FEDERAL
df_congressperson = df_candidates[df_candidates['cargo'] == 'deputado federal']
df_result_congressperson = df_result_candidates[df_result_candidates['cargo'] == 'deputado federal']
#3. CRIANDO NOVO DATAFRAME COM INFORMAÇÕES UNICAS DE GENERO POR CANDIDATO(a)
df_candidates_genre = df_congressperson[['id_candidato_bd','genero']].drop_duplicates()
```
Agora podemos seguir com a junção das tabelas e então seguir para a visualização dos dados:
```
#JUNTANDO TABELAS PARA TRAZER INFORMAÇÃO DE GÊNERO e VOTOS
df_merged = df_result_congressperson.merge(df_candidates_genre,
left_on='id_candidato_bd',
right_on='id_candidato_bd',
how='left')
#BREVE VISUALIZAÇÃO DO NOVO DATAFRAME
df_merged.head()
```
***
# Visualização dos dados
Agora é hora de responder algumas perguntas através da visualização dos dados, vamos começar por:
### Qual o total de candidaturas e candidaturas eleitas por homens e mulheres?
```
congressperson_candidates_labels = df_merged.genero.value_counts().index
congressperson_candidates_values = df_merged.genero.value_counts().values
congressperson_elected_labels = df_merged[df_merged['resultado'] == 'eleito'].genero.value_counts().index
congressperson_elected_values = df_merged[df_merged['resultado'] == 'eleito'].genero.value_counts().values
explode_candidates = (0, 0.1, 0.3)
explode_elected = (0, 0.2)
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols= 2, figsize=(20,5))
ax1.pie(congressperson_candidates_values, explode=explode_candidates, labels=congressperson_candidates_labels, shadow=True,
autopct= lambda x: '{:.0f}'.format(x*congressperson_candidates_values.sum()/100))
ax1.set_title('Total de candidatos por gênero')
ax1.axis('equal')
ax2.pie(congressperson_elected_values, explode=explode_elected, labels=congressperson_elected_labels, shadow=True,
autopct= lambda x: '{:.0f}'.format(x*congressperson_elected_values.sum()/100))
ax2.set_title('Total de candidatos eleitos por gênero')
ax2.axis('equal')
ax1.legend(title='Gênero',
loc='lower left')
plt.show()
```
### Qual a porcentagem de candidaturas e candidaturas eleitas por homens e mulheres?
```
congressperson_candidates_perc_labels = df_merged.genero.value_counts(normalize=True).index
congressperson_candidates_perc_values = df_merged.genero.value_counts(normalize=True).values
congressperson_elected_perc_labels = df_merged[df_merged['resultado'] == 'eleito'].genero.value_counts(normalize=True).index
congressperson_elected_perc_values = df_merged[df_merged['resultado'] == 'eleito'].genero.value_counts(normalize=True).values
fig_perc, (ax1_perc, ax2_perc) = plt.subplots(nrows=1, ncols= 2, figsize=(20,5))
ax1_perc.pie(congressperson_candidates_perc_values, explode=explode_candidates, labels=congressperson_candidates_perc_labels, shadow=True,
autopct='%1.1f%%')
ax1_perc.set_title('Porcentagem de candidatos por gênero')
ax1_perc.axis('equal')
ax2_perc.pie(congressperson_elected_perc_values, explode=explode_elected, labels=congressperson_elected_perc_labels, shadow=True,
autopct='%1.1f%%')
ax2_perc.set_title('Porcentagem de candidatos eleitos por gênero')
ax2_perc.axis('equal')
ax1_perc.legend(title='Gênero',
loc='lower left')
plt.show()
```
### Qual a quantidade de candidaturas por gênero ao longo dos anos?
```
#FORMATANDO DF PARA PLOTAR O GRÁFICO
df_candidates_by_year = df_merged.groupby(['ano','genero']).size().reset_index(name='counts').pivot('ano','genero','counts').reset_index()[['ano','feminino','masculino',]]
#COLOCANDO VALOR 0 QUANDO FOR Null
df_candidates_by_year.fillna(0, inplace=True)
#DEFININDO VALORES DO GRÁFICO
labels = list(df_candidates_by_year['ano'].values)
men = list(df_candidates_by_year['masculino'].values)
women = list(df_candidates_by_year['feminino'].values)
x = np.arange(len(labels)) # LOCALIZAÇÃO DAS BARRAS
width = 0.35 # TAMANHO DAS BARRAS
fig, ax = plt.subplots(figsize=(15,5))
rects1 = ax.bar(x - width/2, men, width, label='Masculino')
rects2 = ax.bar(x + width/2, women, width, label='Feminino')
# FORMATANDO LEGENDA DO GRÁFICO
ax.set_ylabel('Total')
ax.set_title('Total de candidaturas por gênero ao longo dos anos')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.set_xlabel('Anos')
ax.legend()
plt.grid(axis='y', linestyle='--', linewidth=1)
def autolabel(rects):
"""Coloca o valor correspondente em cima de cada barra"""
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(int(height)),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 ALINHAMENTO VERTICAL
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
fig.tight_layout()
plt.ylim(0, max(men)+1000)
plt.show()
```
### Qual a distribuição de candidaturas por gênero por partido?
```
df_candidates_by_party = df_candidates.groupby(['sigla_partido','genero']).size().reset_index(name='counts').pivot('sigla_partido','genero','counts').reset_index()[['sigla_partido','feminino','masculino',]]
#COLOCANDO VALOR 0 QUANDO FOR Null
df_candidates_by_party.fillna(0, inplace=True)
#DEFININDO VALORES DO GRÁFICO
labels = list(df_candidates_by_party['sigla_partido'].values)
men = list(df_candidates_by_party['masculino'].values)
women = list(df_candidates_by_party['feminino'].values)
ind = np.arange(len(df_candidates_by_party))
width = 0.4
fig, ax = plt.subplots(figsize=(25,50))
ax.barh(ind, df_candidates_by_party['masculino'], width, color='tab:blue', label='Masculino')
ax.barh(ind + width, df_candidates_by_party['feminino'], width, color='tab:orange', label='Feminino')
ax.set(yticks=ind + width, yticklabels=df_candidates_by_party['sigla_partido'], ylim=[2*width - 1, len(df_candidates_by_party)])
ax.set_ylabel('Partidos')
ax.set_xlabel('Total')
ax.legend()
def autolabel(rects):
"""Coloca o valor correspondente em cima de cada barra"""
for rect in rects.patches:
y_value = rect.get_width()
x_value = rect.get_y() + rect.get_height() / 4
space = 1
label = int(y_value)
plt.annotate(label,
(y_value, x_value + 0.2),
xytext=(15, space),
textcoords='offset points',
ha='center',
va='bottom',
size=10)
autolabel(rects1)
autolabel(rects2)
plt.grid(axis='x', linestyle='--', linewidth=1)
plt.xlim(0, max(men)+500)
plt.title('Distribuição de candidaturas por gênero por partido')
plt.show()
```
Assim finalizamos a parte de visualização dos dados, na seção a seguir fica fácil responder as questões mencionadas no começo dessa análise, não é?
***
# Repostas que podemos extrair
Quando visualizamos como os dados se comportam, fica bem mais legal e intuitivo iterpretar e tomar decisões. Sendo assim, gostaria de levantar duas perguntas que rapidamente podem ser respondidas:
1. Ano que tivemos recorde de candidatas mulheres:
- De acordo com a visualização, podemos afirmar que o ano em que tivemos mais candidatas foi: 2018
2. Partido que mais indicou mulheres como candidatas:
- De acordo com a visualização, podemos afirmar que o partido que mais indicou candidatas foi: PT com 1777
Bom, isso é tudo por agora, pesosal!
Agradeço pela leitura caso tenha chegado até aqui e fique a vontade para me enviar melhorias e comentários.
***
# Referências
- **Base dos Dados** -> https://basedosdados.org/
- **Pandas** -> https://pandas.pydata.org/
- **Matplotlib** -> https://matplotlib.org/
| github_jupyter |
# Contrasts Overview
```
import numpy as np
import statsmodels.api as sm
```
This document is based heavily on this excellent resource from UCLA http://www.ats.ucla.edu/stat/r/library/contrast_coding.htm
A categorical variable of K categories, or levels, usually enters a regression as a sequence of K-1 dummy variables. This amounts to a linear hypothesis on the level means. That is, each test statistic for these variables amounts to testing whether the mean for that level is statistically significantly different from the mean of the base category. This dummy coding is called Treatment coding in R parlance, and we will follow this convention. There are, however, different coding methods that amount to different sets of linear hypotheses.
In fact, the dummy coding is not technically a contrast coding. This is because the dummy variables add to one and are not functionally independent of the model's intercept. On the other hand, a set of *contrasts* for a categorical variable with `k` levels is a set of `k-1` functionally independent linear combinations of the factor level means that are also independent of the sum of the dummy variables. The dummy coding is not wrong *per se*. It captures all of the coefficients, but it complicates matters when the model assumes independence of the coefficients such as in ANOVA. Linear regression models do not assume independence of the coefficients and thus dummy coding is often the only coding that is taught in this context.
To have a look at the contrast matrices in Patsy, we will use data from UCLA ATS. First let's load the data.
#### Example Data
```
import pandas as pd
url = 'https://stats.idre.ucla.edu/stat/data/hsb2.csv'
hsb2 = pd.read_table(url, delimiter=",")
hsb2.head(10)
```
It will be instructive to look at the mean of the dependent variable, write, for each level of race ((1 = Hispanic, 2 = Asian, 3 = African American and 4 = Caucasian)).
```
hsb2.groupby('race')['write'].mean()
```
#### Treatment (Dummy) Coding
Dummy coding is likely the most well known coding scheme. It compares each level of the categorical variable to a base reference level. The base reference level is the value of the intercept. It is the default contrast in Patsy for unordered categorical factors. The Treatment contrast matrix for race would be
```
from patsy.contrasts import Treatment
levels = [1,2,3,4]
contrast = Treatment(reference=0).code_without_intercept(levels)
print(contrast.matrix)
```
Here we used `reference=0`, which implies that the first level, Hispanic, is the reference category against which the other level effects are measured. As mentioned above, the columns do not sum to zero and are thus not independent of the intercept. To be explicit, let's look at how this would encode the `race` variable.
```
hsb2.race.head(10)
print(contrast.matrix[hsb2.race-1, :][:20])
pd.get_dummies(hsb2.race.values, drop_first=False)
```
This is a bit of a trick, as the `race` category conveniently maps to zero-based indices. If it does not, this conversion happens under the hood, so this will not work in general but nonetheless is a useful exercise to fix ideas. The below illustrates the output using the three contrasts above
```
from statsmodels.formula.api import ols
mod = ols("write ~ C(race, Treatment)", data=hsb2)
res = mod.fit()
print(res.summary())
```
We explicitly gave the contrast for race; however, since Treatment is the default, we could have omitted this.
### Simple Coding
Like Treatment Coding, Simple Coding compares each level to a fixed reference level. However, with simple coding, the intercept is the grand mean of all the levels of the factors. Patsy does not have the Simple contrast included, but you can easily define your own contrasts. To do so, write a class that contains a code_with_intercept and a code_without_intercept method that returns a patsy.contrast.ContrastMatrix instance
```
from patsy.contrasts import ContrastMatrix
def _name_levels(prefix, levels):
return ["[%s%s]" % (prefix, level) for level in levels]
class Simple(object):
def _simple_contrast(self, levels):
nlevels = len(levels)
contr = -1./nlevels * np.ones((nlevels, nlevels-1))
contr[1:][np.diag_indices(nlevels-1)] = (nlevels-1.)/nlevels
return contr
def code_with_intercept(self, levels):
contrast = np.column_stack((np.ones(len(levels)),
self._simple_contrast(levels)))
return ContrastMatrix(contrast, _name_levels("Simp.", levels))
def code_without_intercept(self, levels):
contrast = self._simple_contrast(levels)
return ContrastMatrix(contrast, _name_levels("Simp.", levels[:-1]))
hsb2.groupby('race')['write'].mean().mean()
contrast = Simple().code_without_intercept(levels)
print(contrast.matrix)
mod = ols("write ~ C(race, Simple)", data=hsb2)
res = mod.fit()
print(res.summary())
```
### Sum (Deviation) Coding
Sum coding compares the mean of the dependent variable for a given level to the overall mean of the dependent variable over all the levels. That is, it uses contrasts between each of the first k-1 levels and level k In this example, level 1 is compared to all the others, level 2 to all the others, and level 3 to all the others.
```
from patsy.contrasts import Sum
contrast = Sum().code_without_intercept(levels)
print(contrast.matrix)
mod = ols("write ~ C(race, Sum)", data=hsb2)
res = mod.fit()
print(res.summary())
```
This corresponds to a parameterization that forces all the coefficients to sum to zero. Notice that the intercept here is the grand mean where the grand mean is the mean of means of the dependent variable by each level.
```
hsb2.groupby('race')['write'].mean().mean()
```
### Backward Difference Coding
In backward difference coding, the mean of the dependent variable for a level is compared with the mean of the dependent variable for the prior level. This type of coding may be useful for a nominal or an ordinal variable.
```
from patsy.contrasts import Diff
contrast = Diff().code_without_intercept(levels)
print(contrast.matrix)
mod = ols("write ~ C(race, Diff)", data=hsb2)
res = mod.fit()
print(res.summary())
```
For example, here the coefficient on level 1 is the mean of `write` at level 2 compared with the mean at level 1. Ie.,
```
res.params["C(race, Diff)[D.1]"]
hsb2.groupby('race').mean()["write"][2] - \
hsb2.groupby('race').mean()["write"][1]
```
### Helmert Coding
Our version of Helmert coding is sometimes referred to as Reverse Helmert Coding. The mean of the dependent variable for a level is compared to the mean of the dependent variable over all previous levels. Hence, the name 'reverse' being sometimes applied to differentiate from forward Helmert coding. This comparison does not make much sense for a nominal variable such as race, but we would use the Helmert contrast like so:
```
from patsy.contrasts import Helmert
contrast = Helmert().code_without_intercept(levels)
print(contrast.matrix)
mod = ols("write ~ C(race, Helmert)", data=hsb2)
res = mod.fit()
print(res.summary())
```
To illustrate, the comparison on level 4 is the mean of the dependent variable at the previous three levels taken from the mean at level 4
```
grouped = hsb2.groupby('race')
grouped.mean()["write"][4] - grouped.mean()["write"][:3].mean()
```
As you can see, these are only equal up to a constant. Other versions of the Helmert contrast give the actual difference in means. Regardless, the hypothesis tests are the same.
```
k = 4
1./k * (grouped.mean()["write"][k] - grouped.mean()["write"][:k-1].mean())
k = 3
1./k * (grouped.mean()["write"][k] - grouped.mean()["write"][:k-1].mean())
```
### Orthogonal Polynomial Coding
The coefficients taken on by polynomial coding for `k=4` levels are the linear, quadratic, and cubic trends in the categorical variable. The categorical variable here is assumed to be represented by an underlying, equally spaced numeric variable. Therefore, this type of encoding is used only for ordered categorical variables with equal spacing. In general, the polynomial contrast produces polynomials of order `k-1`. Since `race` is not an ordered factor variable let's use `read` as an example. First we need to create an ordered categorical from `read`.
```
hsb2['readcat'] = np.asarray(pd.cut(hsb2.read, bins=3))
hsb2.groupby('readcat').mean()['write']
from patsy.contrasts import Poly
levels = hsb2.readcat.unique().tolist()
contrast = Poly().code_without_intercept(levels)
print(contrast.matrix)
mod = ols("write ~ C(readcat, Poly)", data=hsb2)
res = mod.fit()
print(res.summary())
```
As you can see, readcat has a significant linear effect on the dependent variable `write` but not a significant quadratic or cubic effect.
| github_jupyter |
# CNTK 103: Part B - Feed Forward Network with MNIST
We assume that you have successfully completed CNTK 103 Part A.
In this tutorial we will train a fully connected network on MNIST data.
## Introduction
**Problem** (recap from the CNTK 101):
The MNIST data comprises of hand-written digits with little background noise.tient.
<img src="http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png", width=200, height=200>
**Goal**:
Our goal is to train a classifier that will identify the digits in the MNIST dataset.
**Approach**:
The same 5 stages we have used in the previous tutorial are applicable: Data reading, Data preprocessing, Creating a model, Learning the model parameters and Evaluating (a.k.a. testing/prediction) the model.
- Data reading: We will use the CNTK Text reader
- Data preprocessing: Covered in part A (suggested extension section).
Rest of the steps are kept identical to CNTK 102.
```
# Import the relevant components
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import sys
import os
# from cntk import Trainer, cntk_device, StreamConfiguration, text_format_minibatch_source
from cntk import Trainer, StreamConfiguration, text_format_minibatch_source
from cntk.initializer import glorot_uniform
from cntk.learner import sgd
from cntk.ops import *
%matplotlib inline
```
## Data reading
In this section, we will read the data generated in CNTK 103 Part B.
```
#Ensure we always get the same amount of randomness
np.random.seed(0)
# Define the data dimensions
input_dim = 784
num_output_classes = 10
```
### Input and Labels
In this tutorial we are generating synthetic data using `numpy` library. In real world problems, one would use a reader, that would read feature values (`features`: *age* and *tumor size*) corresponding to each obeservation (patient). Note, each observation can reside in a higher dimension space (when more features are available) and will be represented as a tensor in CNTK. More advanced tutorials shall introduce the handling of high dimensional data.
```
# Ensure the training data is generated and available for this tutorial
train_file = "data/Train-28x28_cntk_text.txt"
if os.path.isfile(train_file):
path = train_file
else:
print("Please generate the data by completing CNTK 103 Part A")
feature_stream_name = 'features'
labels_stream_name = 'labels'
mb_source = text_format_minibatch_source(path, [
StreamConfiguration(feature_stream_name, input_dim),
StreamConfiguration(labels_stream_name, num_output_classes)])
features_si = mb_source[feature_stream_name]
labels_si = mb_source[labels_stream_name]
print("Training data from file {0} successfully read.".format(path))
```
<a id='#Model Creation'></a>
## Model Creation
Our feed forward network will be relatively simple with 2 hidden layers (`num_hidden_layers`) with each layer having 200 hidden nodes (`hidden_layers_dim`).
<img src="http://cntk.ai/jup/feedforward_network.jpg",width=200, height=200>
If you are not familiar with the terms *hidden_layer* and *number of hidden layers*, please refere back to CNTK 102 tutorial.
For this tutorial: The number of green nodes (refer to picture above) in each hidden layer is set to 200 and the number of hidden layers (refer to the number of layers of green nodes) is 2. Fill in the following values:
- num_hidden_layers
- hidden_layers_dim
Note: In this illustration, we have not shown the bias node (introduced in the logistic regression tutorial). Each hidden layer would have a bias node.
```
num_hidden_layers = 2
hidden_layers_dim = 400
```
Network input and output:
- **input** variable (a key CNTK concept):
>An **input** variable is a container in which we fill different observations (data point or sample, equivalent to a blue/red dot in our example) during model learning (a.k.a.training) and model evaluation (a.k.a testing). Thus, the shape of the `input_variable` must match the shape of the data that will be provided. For example, when data are images each of height 10 pixels and width 5 pixels, the input feature dimension will be two (representing image height and width). Similarly, in our examples the dimensions are age and tumor size, thus `input_dim` = 2). More on data and their dimensions to appear in separate tutorials.
**Question** What is the input dimension of your chosen model? This is fundamental to our understanding of variables in a network or model representation in CNTK.
```
# The input variable (representing 1 observation, in our example of age and size) $\bf{x}$ which in this case
# has a dimension of 2.
# The label variable has a dimensionality equal to the number of output classes in our case 2.
input = input_variable((input_dim), np.float32)
label = input_variable((num_output_classes), np.float32)
```
## Feed forward network setup
If you are not familiar with the feedforward network, please refer to CNTK 102. In this tutorial we are using the same network.
```
# Define a fully connected feedforward network
def linear_layer(input_var, output_dim):
input_dim = input_var.shape[0]
times_param = parameter(shape=(input_dim, output_dim), init=glorot_uniform())
bias_param = parameter(shape=(output_dim))
t = times(input_var, times_param)
return bias_param + t
def dense_layer(input, output_dim, nonlinearity):
r = linear_layer(input, output_dim)
r = nonlinearity(r)
return r;
def fully_connected_classifier_net(input, num_output_classes, hidden_layer_dim, num_hidden_layers, nonlinearity):
h = dense_layer(input, hidden_layer_dim, nonlinearity)
for i in range(1, num_hidden_layers):
h = dense_layer(h, hidden_layer_dim, nonlinearity)
r = linear_layer(h, num_output_classes)
return r
```
Network output: `z` will be used to represent the output of a network across.
We introduced sigmoid function in CNTK 102, this tutorial we will suggest that you try different activation functions. You may choose to do this right away and take a peek into the performance later in the tutorial or run the preset tutorial and then choose to performa the suggested activity
** Suggested Activity **
- Record the training error you get with `sigmoid` as the activation function
- Now change to `relu` as the activation fucntion and see if you can improve your training error
*Quiz*: Different supported activation functions can be [found here][]. Which activation function gives the least training error?
[found here]: https://github.com/Microsoft/CNTK/wiki/Activation-Functions
```
# Create the fully connected classfier but first we scale the input to 0-1 range by dividing each pixel by 256.
scaled_input = element_times(constant(0.00390625), input)
z = fully_connected_classifier_net(scaled_input, num_output_classes, hidden_layers_dim, num_hidden_layers, relu)
```
### Learning model parameters
Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function][] and other [activation][] functions).
[softmax function]: http://lsstce08:8000/cntk.ops.html#cntk.ops.softmax
[activation]: https://github.com/Microsoft/CNTK/wiki/Activation-Functions
## Training
Similar to CNTK 102, we use minimize the cross-entropy between the label and predicted probability by the network. If this terminology sounds strange to you, please refer to the CNTK 102 for a refresher.
```
loss = cross_entropy_with_softmax(z, label)
```
#### Evaluation
In order to evaluate the classification, one can compare the output of the network which for each observation emits a vector of evidences (can be converted into probabilities using `softmax` functions) with dimension equal to number of classes.
```
label_error = classification_error(z, label)
```
### Configure training
The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent][] (`sgd`) being one of the most popular one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent][] generate a new set model parameters in a single iteration.
The aforementioned model parameter update using a single observation at a time is attractive since it does not require the entire data set (all observation) to be loaded in memory and also requires gradient computation over fewer datapoints, thus allowing for training on large data sets. However, the updates generated using a single observation sample at a time can vary wildly between iterations. An intermediate ground is to load a small set of observations and use an average of the `loss` or error from that set to update the model parameters. This subset is called a *minibatch*.
With minibatches we often sample observation from the larger training dataset. We repeat the process of model parameters update using different combination of training samples and over a period of time minimize the `loss` (and the error). When the incremental error rates are no longer changing significantly or after a preset number of maximum minibatches to train, we claim that our model is trained.
One of the key parameter for optimization is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial.
With this information, we are ready to create our trainer.
[optimization]: https://en.wikipedia.org/wiki/Category:Convex_optimization
[Stochastic Gradient Descent]: https://en.wikipedia.org/wiki/Stochastic_gradient_descent
[gradient-decent]: http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html
```
# Instantiate the trainer object to drive the model training
learning_rate_per_sample = 0.003125
learner = sgd(z.parameters, lr=learning_rate_per_sample)
trainer = Trainer(z, loss, label_error, [learner])
```
First lets create some helper functions that will be needed to visualize different functions associated with training.
```
from cntk.utils import get_train_eval_criterion, get_train_loss
# Define a utiltiy function to compute moving average sum (
# More efficient implementation is possible with np.cumsum() function
def moving_average(a, w=5) :
if len(a) < w:
return a[:] #Need to send a copy of the array
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
# Defines a utility that prints the training progress
def print_training_progress(trainer, mb, frequency, verbose=1):
training_loss = "NA"
eval_error = "NA"
if mb%frequency == 0:
training_loss = get_train_loss(trainer)
eval_error = get_train_eval_criterion(trainer)
if verbose: print ("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error*100))
return mb, training_loss, eval_error
```
<a id='#Run the trainer'></a>
### Run the trainer
We are now ready to train our fully connected neural net. We want to decide what data we need to feed into the training engine.
In this example, each iteration of the optimizer will work on `minibatch_size` sized samples. We would like to train on all 60000 observations. Additionally we will make multiple passes through the data specified by the variable `num_sweeps_to_train_with`. With these parameters we can proceed with training our simple feed forward network.
```
#Initialize the parameters for the trainer
minibatch_size = 64
num_samples_per_sweep = 60000
num_sweeps_to_train_with = 10
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
#Run the trainer on and perform model training
training_progress_output_freq = 100
plotdata = {"batchsize":[], "loss":[], "error":[]}
for i in range(0, int(num_minibatches_to_train)):
mb = mb_source.next_minibatch(minibatch_size)
# Specify the mapping of input variables in the model to actual minibatch data to be trained with
arguments = {input: mb[features_si],
label: mb[labels_si]}
trainer.train_minibatch(arguments)
batchsize, loss, error = print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
if not (loss == "NA" or error =="NA"):
plotdata["batchsize"].append(batchsize)
plotdata["loss"].append(loss)
plotdata["error"].append(error)
```
Let us plot the errors over the different training minibatches. Note that as we iterate the training loss decreases though we do see some intermediate bumps.
Hence, we use smaller minibatches and using `sgd` enables us to have a great scalability while being performant for large data sets. There are advanced variants of the optimizer unique to CNTK that enable harnessing computational efficiency for real world data sets and will be introduced in advanced tutorials.
```
#Compute the moving average loss to smooth out the noise in SGD
plotdata["avgloss"] = moving_average(plotdata["loss"])
plotdata["avgerror"] = moving_average(plotdata["error"])
#Plot the training loss and the training error
import matplotlib.pyplot as plt
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss ')
plt.show()
plt.subplot(212)
plt.plot(plotdata["batchsize"], plotdata["avgerror"], 'r--')
plt.xlabel('Minibatch number')
plt.ylabel('Label Prediction Error')
plt.title('Minibatch run vs. Label Prediction Error ')
plt.show()
```
## Evaluation / Testing
Now that we have trained the network, let us evaluate the trained network on the test data. This is done using `trainer.test_minibatch`.
```
# Ensure the training data is read and available for this tutorial
test_file = "data/Test-28x28_cntk_text.txt"
if os.path.isfile(test_file):
path = test_file
else:
print("Please generate the data by completing CNTK 103 Part A")
feature_stream_name = 'features'
labels_stream_name = 'labels'
test_mb_source = text_format_minibatch_source(path, [
StreamConfiguration(feature_stream_name, input_dim),
StreamConfiguration(labels_stream_name, num_output_classes)])
features_si = mb_source[feature_stream_name]
labels_si = mb_source[labels_stream_name]
print("Test data from file {0} successfully read", path)
# Test data for trained model
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples / test_minibatch_size
test_result = 0.0
for i in range(0, int(num_minibatches_to_test)):
mb = test_mb_source.next_minibatch(test_minibatch_size)
# Specify the mapping of input variables in the model to actual
# minibatch data to be tested with
arguments = {input: mb[features_si],
label: mb[labels_si]}
eval_error = trainer.test_minibatch(arguments)
test_result = test_result + eval_error
# Average of evaluation errors of all test minibatches
print("Average errors of all test minibaches: {0:.2f}%".format(test_result*100 / num_minibatches_to_test))
```
Note, this error is very comparable to our training error indicating that our model has good "out of sample" error a.k.a generalization error. This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid the phenomenon of overfitting.
We have so far been dealing with aggregate measures of error. Lets now get the probabilities associated with individual data points. For each observation, the `eval` function returns the probability distribution across all the classes. The classifer is trained to recognize digits, hence has 10 classes. First let us route the network output through a `softmax` function. This maps the aggregated activations across the netowrk to probabilities across the 10 classes.
```
out = softmax(z)
```
Lets a small minibatch sample from the test data.
```
mb = test_mb_source.next_minibatch(test_minibatch_size)
predicted_label_prob =out.eval({input : mb[features_si]})
#orig_label=np.array(mb[labels_si].m_data.data().to_numpy())
orig_label = np.asarray(mb[labels_si].m_data)
#Find the index with the maximum value for both predicted as well as the ground truth
pred = [np.argmax(predicted_label_prob[i,:,:]) for i in range(0,predicted_label_prob.shape[0])]
gtlabel = [np.argmax(orig_label[i,:,:]) for i in range(0, orig_label.shape[0])]
print("Label :", gtlabel[:25])
print("Predicted:", pred[:25])
```
Lets visualize some of the results
```
# Plot a random image
sample_number = 5
#img_data = mb[features_si].m_data.data().to_numpy()
img_data = mb[features_si].value
plt.imshow(img_data[sample_number,:,:].reshape(28,28), cmap="gray_r")
plt.axis('off')
img_gt, img_pred = gtlabel[sample_number], pred[sample_number]
print("Image Label: ", img_pred)
```
**Exploration Suggestion**
- Try exploring how the classifier behaves with different parameters - suggest changing the `minibatch_size` parameter from 25 to say 64 or 128. What happens to the error rate? How does the error compare to the logistic regression classifier?
- Suggest trying to increase the number of sweeps
- Can you change the network to reduce the training error rate? When do you see *overfitting* happening?
#### Code link
If you want to try running the tutorial from python command prompt. Please run the [FeedForwardNet.py][] example.
[FeedForwardNet.py]: https://github.com/Microsoft/CNTK/blob/master/bindings/python/examples/NumpyInterop/FeedForwardNet.py
| github_jupyter |
# Homework 3: Functional file parsing
---
## Topic areas
* Functions
* I/O operations
* String operations
* Data structures
---
## Background
[ClinVar][1] is a freely accessible, public archive of reports of the relationships among human variations and phenotypes, with supporting evidence.
For this assignment, you will be working with a Variant Call Format (VCF) file. Below are the necessary details regarding this assignment, but consider looking [here][2] for a more detailed description of the file format. The purpose of the VCF format is to store gene sequence variations in a plain-text form.
The data you will be working with (`clinvar_20190923_short.vcf`) contains several allele frequencies from different databases. The one to look for in this assignment is from ExAC database. More information about the database can be found [here][3].
### The file format
The beginning of every VCF file contains various sets of information:
* Meta-information (details about the experiment or configuration) lines start with **`##`**
* These lines are helpful in understanding specialized keys found in the `INFO` column. It is in these sections that one can find:
* The description of the key
* The data type of the values
* The default value of the values
* Header lines (column names) start with **`#`**
From there on, each line is made up of tab (`\t`) separated values that make up eight (8) columns. Those columns are:
1. CHROM (chromosome)
2. POS (base pair position of the variant)
3. ID (identifier if applicable; `.` if not applicable/missing)
4. REF (reference base)
5. ALT (alternate base(s): comma (`,`) separated if applicable)
6. QUAL (Phred-scaled quality score; `.` if not applicable/missing)
7. FILTER (filter status; `.` if not applicable/missing)
8. INFO (any additional information about the variant)
* Semi-colon (`;`) separated key-value pairs
* Key-value pairs are equal sign (`=`) separated (key on the left, value on the right)
* If a key has multiple values, the values are comma (`,`) separated
#### Homework specific information
The given data (`clinvar_20190923_short.vcf`) is a specialized form of the VCF file. As such, there are some additional details to consider when parsing for this assignment. You will be expected to consider two (2) special types of keys:
1. The `AF_EXAC` key that describes the allele frequencies from the ExAC database
> `##INFO=<ID=AF_EXAC,Number=1,Type=Float,Description="allele frequencies from ExAC">`
* The data included are `float`ing point numbers
2. The `CLNDN` key that gives all the names the given variant is associated with
> `##INFO=<ID=CLNDN,Number=.,Type=String,Description="ClinVar's preferred disease name for the concept specified by disease identifiers in CLNDISDB">`
* The data are`str`ings. **However**, if there are multiple diseases associated with a given variant, the diseases are pipe (`|`) separated (there are 178 instances of this case)
---
[1]: https://www.ncbi.nlm.nih.gov/clinvar/intro/
[2]: https://samtools.github.io/hts-specs/VCFv4.3.pdf
[3]: http://exac.broadinstitute.org
## Instructions
It is safe to assume that this homework will take a considerable amount of string operations to complete. But, it is important to note that this skill is _incredibly_ powerful in bioinformatics. Many dense, plain-text files exist in the bioinformatic domain, and mastering the ability to parse them is integral to many people's research. While the format we see here has a very clinical use case, other formats exist that you will likely encounter: CSV, TSV, SAM, GFF3, etc.
Therefore, we <u>***STRONGLY ENCOURAGE***</u> you to:
* Come to office hours
* Schedule one-on-one meetings
* Post to GitHub
* Ask a friend
Ensure you _truly_ understand the concepts therein. The concepts here are not esoteric, but very practical. Also, **ask early, ask often**.
That said, on to the instructions for the assignment.
### Expectations
You are expected to:
1. Move the `clinvar_20190923_short.vcf` to the same folder as this notebook
1. Write a function called `parse_line` that:
1. Takes a `str`ing as an argument
2. Extract the `AF_EXAC` data to determine the rarity of the variant
1. If the disease is rare:
* `return` an a `list` of associated diseases
2. If the disease is not rare:
* `return` an empty `list`
2. Write another function called `read_file` that:
1. Takes a `str`ing as an argument representing the file to be opened
2. Open the file
3. Read the file _line by line_.
* **Note**: You are expected to do this one line at a time. The reasoning is that if the file is sufficiently large, you may not have the memory available to hold it. So, **do not** use `readlines()`!
* If you do, your grade will be reduced
4. Passes the line to `parse_line`
5. Use a dictionary to count the results given by `parse_line` to keep a running tally (or count) of the number of times a specific disease is observed
6. `return` that dictionary
3. `print` the results from `read_file` when it is complete
4. Each function must have its own cell
5. The code to run all of your functions must have its own cell
---
## Academic Honor Code
In accordance with Rackham's Academic Misconduct Policy; upon submission of your assignment, you (the student) are indicating acceptance of the following statement:
> “I pledge that this submission is solely my own work.”
As such, the instructors reserve the right to process any and all source code therein contained within the submitted notebooks with source code plagiarism detection software.
Any violations of the this agreement will result in swift, sure, and significant punishment.
---
## Due date
This assignment is due **October 7th, 2019 by Noon (12 PM)**
---
## Submission
> `<uniqname>_hw3.ipynb`
### Example
> `mdsherm_hw3.ipynb`
We will *only* grade the most recent submission of your exam.
---
## Late Policy
Each submission will receive a **10%** penalty per day (up to three days) that the assignment is late.
After that, the student will receive a **0** for your homework.
---
## Good luck and code responsibly!
---
```
# Define your parse_line function here
# Define your read_file function here
```
---
```
# DO NOT MODIFY THIS CELL!
# If your code works as expected, this cell should print the results
from pprint import pprint
pprint(read_file('clinvar_20190923_short.vcf'))
```
| github_jupyter |
# DeepDreaming with TensorFlow
### Rule of thumb for increasing/decreasing accuracy and processing speeds
```
t_obj_filter: 0-144 available. This does not affect timing
iter_n: Iterations to run deep dream. Lower is faster
step: TODO
octave_n: Number of field of views to split apart the picture, Lower is faster
octave_scale: I think this is the amount of overlap, higher is faster
```
### Import in the video stream
```
# boilerplate code
from __future__ import print_function
import os
from io import BytesIO
import numpy as np
from functools import partial
import PIL.Image
from IPython.display import clear_output, Image, display, HTML
import tensorflow as tf
#Added imports
import time
import uuid
#Use CPU only --> Temporary Flag
os.environ['CUDA_VISIBLE_DEVICES']=""
#Set the absolute fil path towards the images to work on
os.environ['DD_STREAM']=os.path.join(os.getenv('HOME'), 'src/DeepDream_Streaming_Video')
image_dir= os.path.join(os.getenv('DD_STREAM'), 'data', 'trains_to_classify')
print (image_dir)
image_files = [f for f in os.listdir(image_dir) if os.path.isfile(os.path.join(image_dir, f))]
#!wget https://storage.googleapis.com/download.tensorflow.org/models/inception5h.zip && unzip inception5h.zip
```
### Create the deep dream conversion class
```
class DeepDream(object):
"""
TODO: Add docstring
"""
def __init__(self,
model_fn='tensorflow_inception_graph.pb',
layer='mixed4d_3x3_bottleneck_pre_relu'):
self.load_graph(model_fn)
self.k5x5=self.setup_k()
self.layer=layer
def load_graph(self, model_fn='tensorflow_inception_graph.pb'):
# creating TensorFlow session and loading the model
self.graph = tf.Graph()
self.sess = tf.InteractiveSession(graph=self.graph)
with tf.gfile.FastGFile(model_fn, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
self.t_input = tf.placeholder(np.float32, name='input') # define the input tensor
# Unclear why imagenet_mean variable standard in deep dream
imagenet_mean = 117.0
t_preprocessed = tf.expand_dims(self.t_input-imagenet_mean, 0)
tf.import_graph_def(graph_def, {'input':t_preprocessed})
def setup_k(self):
k = np.float32([1,4,6,4,1])
k = np.outer(k, k)
return k[:,:,None,None]/k.sum()*np.eye(3, dtype=np.float32)
def showarray(self, a, fmt='jpeg'):
a = np.uint8(np.clip(a, 0, 1)*255)
f = BytesIO()
PIL.Image.fromarray(a).save(f, fmt)
display(Image(data=f.getvalue()))
def visstd(self, a, s=0.1):
'''Normalize the image range for visualization'''
return (a-a.mean())/max(a.std(), 1e-4)*s + 0.5
def T(self, layer):
'''Helper for getting layer output tensor'''
return self.graph.get_tensor_by_name("import/%s:0"%self.layer)
def tffunc(self, *argtypes):
'''
Helper that transforms TF-graph generating function into a regular one.
See "resize" function below.
'''
placeholders = list(map(tf.placeholder, argtypes))
def wrap(f):
out = f(*placeholders)
def wrapper(*args, **kw):
return out.eval(dict(zip(placeholders, args)), session=kw.get('session'))
return wrapper
return wrap
# Helper function that uses TF to resize an image
def resize(self, img, size):
img = tf.expand_dims(img, 0)
return tf.image.resize_bilinear(img, size)[0,:,:,:]
def calc_grad_tiled(self, img, t_grad, tile_size=512):
'''Compute the value of tensor t_grad over the image in a tiled way.
Random shifts are applied to the image to blur tile boundaries over
multiple iterations.'''
sz = tile_size
h, w = img.shape[:2]
sx, sy = np.random.randint(sz, size=2)
img_shift = np.roll(np.roll(img, sx, 1), sy, 0)
grad = np.zeros_like(img)
for y in range(0, max(h-sz//2, sz),sz):
for x in range(0, max(w-sz//2, sz),sz):
sub = img_shift[y:y+sz,x:x+sz]
g = self.sess.run(t_grad, {self.t_input:sub})
grad[y:y+sz,x:x+sz] = g
return np.roll(np.roll(grad, -sx, 1), -sy, 0)
def lap_split(self, img):
'''Split the image into lo and hi frequency components'''
with tf.name_scope('split'):
lo = tf.nn.conv2d(img, self.k5x5, [1,2,2,1], 'SAME')
lo2 = tf.nn.conv2d_transpose(lo, self.k5x5*4, tf.shape(img), [1,2,2,1])
hi = img-lo2
return lo, hi
def lap_split_n(self, img, n):
'''Build Laplacian pyramid with n splits'''
levels = []
for i in range(n):
img, hi = self.lap_split(img)
levels.append(hi)
levels.append(img)
return levels[::-1]
def lap_merge(self, levels):
'''Merge Laplacian pyramid'''
img = levels[0]
for hi in levels[1:]:
with tf.name_scope('merge'):
img = tf.nn.conv2d_transpose(img, self.k5x5*4, tf.shape(hi), [1,2,2,1]) + hi
return img
def normalize_std(self, img, eps=1e-10):
'''Normalize image by making its standard deviation = 1.0'''
with tf.name_scope('normalize'):
std = tf.sqrt(tf.reduce_mean(tf.square(img)))
return img/tf.maximum(std, eps)
def lap_normalize(self, img, scale_n=4):
'''Perform the Laplacian pyramid normalization.'''
img = tf.expand_dims(img,0)
tlevels = sel.flap_split_n(img, scale_n)
tlevels = list(map(self.normalize_std, tlevels))
out = self.lap_merge(tlevels)
return out[0,:,:,:]
def render_deepdream(self,t_obj, img0,
iter_n=10, step=1.5,
octave_n=4, octave_scale=1.4,
show_image=False):
t_score = tf.reduce_mean(t_obj) # defining the optimization objective
t_grad = tf.gradients(t_score, self.t_input)[0] # behold the power of automatic differentiation!
# split the image into a number of octaves
img = img0
octaves = []
for i in range(octave_n-1):
hw = img.shape[:2]
lo = self.resize(img, np.int32(np.float32(hw)/octave_scale))
hi = img-self.resize(lo, hw)
#img = lo
img = lo.eval(session=self.sess)
octaves.append(hi)
# generate details octave by octave
for octave in range(octave_n):
if octave>0:
hi = octaves[-octave]
img = (self.resize(img, hi.shape[:2])+hi).eval(session=self.sess)
for i in range(iter_n):
g = self.calc_grad_tiled(img, t_grad)
img += g*(step / (np.abs(g).mean()+1e-7))
print('.',end = ' ')
clear_output()
#Added as a flag to not have to show the image every iteration
if show_image == True:
self.showarray(img/255.0)
return img/255.0
def load_parameters_run_deep_dream_return_image(self,
image,
name=uuid.uuid4(),
t_obj_filter= 139,
iter_n=10,
step=1.5,
octave_n=4,
octave_scale=1.4,
show_image=False):
'''
Image must be an np_float32 datatype
'''
assert isinstance(image,np.ndarray)
start_time=time.time()
output_image=self.render_deepdream(
self.T(self.layer)[:,:,:,t_obj_filter],
image,
iter_n=int(iter_n),
step=int(step),
octave_n=int(octave_n),
octave_scale=float(octave_scale),
show_image=show_image)
print ('Processing time:',time.time()-start_time)
return output_image
def load_image_into_memory_from_file(filename='pilatus800.jpg',show_image=False):
'''
Load an image into memory as a numpy.ndarray
'''
img0 = PIL.Image.open(filename)
img = np.float32(img0)
if show_image==True:
self.showarray(img)
return img
deepdream = DeepDream(model_fn='tensorflow_inception_graph.pb',
layer='mixed4d_3x3_bottleneck_pre_relu')
img=load_image_into_memory_from_file(filename='pilatus800.jpg',show_image=False)
output_image=deepdream.load_parameters_run_deep_dream_return_image(img,octave_n=4,show_image=True)
```
| github_jupyter |
```
# future
from __future__ import print_function
# third party
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torchvision import datasets
from torchvision import transforms
# let's prepare parameters
class Args():
def __init__(self):
super(Args, self).__init__()
self.batch_size = 64
# self.epochs = 3
self.epochs = 14
self.lr = 1.0
self.gamma = 0.7
self.no_cuda = False
self.dry_run = False
self.seed = 42
self.log_interval = 100
self.save_model = True
self.test_batch_size = 1000
args = Args()
# check it
args.test_batch_size
# we use cuda
use_cuda = True
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
```
## datasets
```
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
dataset1 = datasets.MNIST("../data", train=True, download=True, transform=transform)
dataset2 = datasets.MNIST("../data", train=False, transform=transform)
len(dataset1), len(dataset2)
# add some other params for dataloaders
train_kwargs = {"batch_size": args.batch_size}
test_kwargs = {"batch_size": args.test_batch_size}
if use_cuda:
cuda_kwargs = {"num_workers": 1, "pin_memory": True, "shuffle": True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
train_kwargs
# prepare data loader
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
```
## architecture
```
# architecture
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
```
## training loop
```
# training loop
for epoch in range(1, args.epochs + 1):
# train(args, model, device, train_loader, optimizer, epoch)
# training
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print(
"Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch,
batch_idx * len(data),
len(train_loader.dataset),
100.0 * batch_idx / len(train_loader),
loss.item(),
)
)
if args.dry_run:
break
# test(model, device, test_loader)
# validation
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(
output, target, reduction="sum"
).item() # sum up batch loss
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100.0 * correct / len(test_loader.dataset),
)
)
# update
scheduler.step()
# save model
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
# load and use it
```
## How to train a model with MY DATA!
```
#
# https://github.com/myleott/mnist_png
# from torchaudio.datasets.utils import walk_files
from typing import Any, Iterable, List, Optional, Tuple, Union
def walk_files(root: str,
suffix: Union[str, Tuple[str]],
prefix: bool = False,
remove_suffix: bool = False) -> Iterable[str]:
"""List recursively all files ending with a suffix at a given root
Args:
root (str): Path to directory whose folders need to be listed
suffix (str or tuple): Suffix of the files to match, e.g. '.png' or ('.jpg', '.png').
It uses the Python "str.endswith" method and is passed directly
prefix (bool, optional): If true, prepends the full path to each result, otherwise
only returns the name of the files found (Default: ``False``)
remove_suffix (bool, optional): If true, removes the suffix to each result defined in suffix,
otherwise will return the result as found (Default: ``False``).
"""
root = os.path.expanduser(root)
for dirpath, dirs, files in os.walk(root):
dirs.sort()
# `dirs` is the list used in os.walk function and by sorting it in-place here, we change the
# behavior of os.walk to traverse sub directory alphabetically
# see also
# https://stackoverflow.com/questions/6670029/can-i-force-python3s-os-walk-to-visit-directories-in-alphabetical-order-how#comment71993866_6670926
files.sort()
for f in files:
if f.endswith(suffix):
if remove_suffix:
f = f[: -len(suffix)]
if prefix:
f = os.path.join(dirpath, f)
yield f
import os
walker = walk_files(
"/disk2/data/mnist_png/mnist_png/training",
suffix="png",
prefix=True,
remove_suffix=False
)
_walker = list(walker)
# _walker
from torch.utils.data import Dataset
# check datasets1
dataset1[0][0].shape, dataset1[0][1]
from PIL import Image
# transform = transforms.Compose(
# [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
# )
class MyDataset(Dataset):
def __init__(self, data_list):
"""
MyDataset based on Dataset
"""
super(MyDataset, self).__init__()
self.data_list = data_list
self.toTensor = transforms.ToTensor()
self.normalize = transforms.Normalize((0.1307,), (0.3081,))
def __getitem__(self, index):
# get path
_path = self.data_list[index]
# get label
_label = _path.split("/")[-2]
# read image
img = Image.open(_path)
# apply transforms
img = self.toTensor(img)
img = self.normalize(img)
return img, int(_label)
def __len__(self):
return len(self.data_list)
my_dataset = MyDataset(_walker)
len(my_dataset)
my_dataset[0][0].shape, my_dataset[0][1]
my_train_loader = torch.utils.data.DataLoader(my_dataset, **train_kwargs)
# train block
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print(
"Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch,
batch_idx * len(data),
len(train_loader.dataset),
100.0 * batch_idx / len(train_loader),
loss.item(),
)
)
if args.dry_run:
break
# test block
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(
output, target, reduction="sum"
).item() # sum up batch loss
pred = output.argmax(
dim=1, keepdim=True
) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100.0 * correct / len(test_loader.dataset),
)
)
# training loop
for epoch in range(1, args.epochs + 1):
train(args, model, device, my_train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
```
| github_jupyter |
## Outline of the problem
This goal with building this model is to create a model which would give our sponsors predictive power on the configuration of an eports tournament which give a minimum threshold of required viewers chosen to be 10K (hypothetically cost effective). This variable was chosen as these sponsors will expect a minimum threshold of viewers which running these tournament for it to be cost effective. By incorperating useful predicitors into our model such as, days to run the tournament for, the prize pool amount, location and the month the tournament should be run. By incorporating these predictors it would allow stakeholders to use the model to investigate tournament configurations that would produce a gain in revenue that they might not of otherwise thought of while also ensuring that expected returns are being continued to be met.
## Module Import
```
#Import all required modules
import pandas as pd
from sklearn.model_selection import train_test_split
import statsmodels.formula.api as smf
from sklearn.preprocessing import StandardScaler
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from statsmodels.graphics import gofplots as sm
import numpy as np
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from scipy import stats
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
import missingno as msno
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import plot_confusion_matrix
import statsmodels.api as sm
from sklearn.tree import _tree
from scipy.stats import loguniform
```
## Data Import
```
CSdf = pd.read_csv('Data/CSGO.csv')
Dotadf = pd.read_csv('Data/Dota_2.csv')
PUBGdf = pd.read_csv('Data/PUBG.csv')
R6df = pd.read_csv('Data/R6.csv')
RLdf = pd.read_csv('Data/RL.csv')
tournament_df = pd.read_json('tour2.json')
T7df = pd.read_csv('Data/T7.csv')
gamedfs = [CSdf, Dotadf, PUBGdf, R6df, RLdf, T7df]
game_names = ['CSGO', 'D2', 'PUBG', 'R6', 'RL', 'T7' ]
```
## Dataframe preproccessing
```
def df_clean(dfs,game_str):
final_games = pd.DataFrame()
for df, g_str in zip(dfs, game_str):
df['DateTime'] = pd.to_datetime(df['DateTime'])
df = df.drop(columns=['Flags', 'Players Trend'], errors='ignore' )
df = df.dropna(axis=0)
df.reset_index(drop=True, inplace=True)
df['Game_gain'] = df['Players'] - df['Players'].shift(1)
df['Twitch_gain'] = df['Twitch Viewers'] - df['Twitch Viewers'].shift(1)
df['Game:'] = g_str
df['Prev_views'] = df['Twitch Viewers'].shift(1)
df['Prev_players'] = df['Players'].shift(1)
final_games = final_games.append(df,sort=False)
final_games.reset_index(drop=True, inplace=True)
return final_games
figuresdf = df_clean(gamedfs,game_names)
tournament_df = tournament_df.drop(columns=['Currency:', 'Exchange Rate:'], errors='ignore')
tournament_df['Start Date'] = tournament_df['Date:'].str[:10]
tournament_df['End Date'] = tournament_df['Date:'].str[-10:]
tournament_df['Prize Pool'] = tournament_df['Prize Pool:'].apply(lambda x: str(x).split('(')[-1] )
tournament_df['Location:'] = tournament_df['Location:'].apply(lambda x: str(x).split(',')[-1] )
tournament_df['Location:'] = tournament_df['Location:'].str.strip()
tournament_df['Prize Pool'] = tournament_df['Prize Pool'].str.replace(r'\D+', '')
tournament_df = tournament_df.drop(columns=['Date:', 'Prize Pool:'])
tournament_df['End Date'] = pd.to_datetime(tournament_df['End Date'])
tournament_df['Start Date'] = pd.to_datetime(tournament_df['Start Date'])
tournament_df['Prize Pool'] = tournament_df['Prize Pool'].astype(float)
tournament_df['Tour_days'] = (tournament_df['End Date'] - tournament_df['Start Date']).dt.days
drop_tour_locs = {'Offline', 'N/A', 'Asia', 'Southeast Asia', 'South USA', 'Europe', 'Middle East', 'USAs', 'Latin USA', 'Americas', 'Latin America', 'South America', 'Americas'}
tournament_df.drop(tournament_df.loc[tournament_df['Location:'] == drop_tour_locs].index, inplace=True)
game_title_replace = {'Counter-Strike: Global Offensive' : 'CSGO', 'Dota 2' : 'D2', 'PLAYERUNKNOWN’S BATTLEGROUNDS' : 'PUBG', 'Rocket League' : 'RL', 'Tekken 7' : 'T7'}
tournament_df['Game:'] = tournament_df['Game:'].replace(game_title_replace)
tournament_df.drop(tournament_df[tournament_df['Tour_days'] >= 5].index, inplace=True)
tournament_df['Tour_days'] = (tournament_df['Tour_days'] + 1)
tournament_df['DATE'] = [pd.date_range(s, e, freq='d') for s, e in
zip(pd.to_datetime(tournament_df['Start Date']), pd.to_datetime(tournament_df['End Date']))]
tournament_df = tournament_df.explode('DATE')
tournament_df.drop_duplicates(inplace=True)
#Merge the tournaments data frames and
final_frame = pd.merge(tournament_df, figuresdf, left_on=['Game:','DATE'], right_on=['Game:','DateTime'], how='inner',copy=False)
#Cleaning up of the location data in the dataframe to group countries into one variable for a given country instead or many.
rename_locs = {'Germay' : 'Germany', 'Online (Twitch)' : 'Online','online' : 'Online', 'South Africa' : 'SouthA', 'Taipei City': 'Taipei', 'Unites States' : 'USA', 'Europe/Americas/OCE' : 'drop', 'United Kingdom' : 'UK', 'United States' : 'USA', 'United Arab Emirates' : 'UAE', 'Texas' : 'USA', 'Madrid' : 'Spain', '(Spain)' : 'Spain', 'Hong Kong' : 'China', 'America' : 'USA','Philadelphia' : 'USA', 'Sydney' : 'Australia', 'Toronto' : 'USA', 'AMERICAS' : 'USA', 'North America' : 'USA'}
rename_city = {'TX' : 'USA', 'Parc des Expositions de la porte de Versailles' : 'France', 'Dominican Republic' : 'DomPublic', 'Madrid (Spain)' : 'Spain', 'Fresno' : 'USA', 'Al Khobar' : 'Saudi Arabia', 'IL' : 'USA', 'Taipei' : 'Taiwan', 'Taiwan City' : 'Taiwan', 'Chantilly' : 'France', 'Spain Spain' : 'Spain' , 'Kettering' : 'UK', 'Macao' : 'China', 'Berlin' : 'Germany', 'Fersno' : 'USA' , 'Wien' : 'Austria', 'Québec' : 'Canada', 'Saudi arabia' : 'Saudi Arabia', 'Bogotá' : 'Columbia', 'Fukuoka' : 'Japan', 'China (offline)' : 'China', 'NV' : 'USA', 'North USA' : 'USA', 'Colmar' : 'France', 'La Rochelle' : 'France', 'Brussels' : 'Belgium' , 'Copenhagen' : 'Denmark', 'Fredericia' : 'Denmark', 'Seoul' : 'SK', 'South Korea' : 'SK', 'Korea' : 'SK', 'Rome' : 'Italy', 'São Paulo': 'Brazil', 'Dublin' : 'Ireland', 'Jakarta' : 'Indonesia', 'NJ' : 'USA', 'Poitiers' : 'France', 'New Jersey' : 'USA', 'Seattle' : 'USA', 'Santa Ana' : 'USA', 'Dallas' : 'USA', 'CA' : 'USA', 'CT': 'USA', 'Bangkok' : 'Thailand', 'Richmond' : 'USA', 'Tokyo' : 'Japan', 'Sweden.' : 'Sweden', 'MA' : 'USA', 'San Jose' : 'USA', 'MaCanadao' : 'Canada', 'SC' : 'USA', 'Changsha' : 'China', 'Riyadh' : 'Saudi Arabia', 'Florida' : 'USA', 'London' : 'UK' , 'Stockholm Sweden.' : 'Sweden' , 'BC' : 'USA', 'Oslo' : 'Norway', 'MaCanadao' : 'Canada', 'Dubai' : 'UAE' ,'China (offline)' : 'China', 'Birmingham' : 'UK', 'Munich' : 'Germany', 'Pennsylvania' : 'USA' , 'Moscow': 'Russia', 'Elmhurst' : 'USA', 'NA' : 'USA' , 'FL' : 'USA', 'Montreal' : 'Canada', 'Ghent' : 'Belgium' , 'Tennessee' : 'USA' , 'Barcelona' : 'Spain', 'Shanghai' : 'China', 'California' : 'USA' , 'Zürich' : "Switzerland", 'Mechelen' : 'Belgium', 'GA' : 'Georgia', 'Paris' : 'France', 'Manila' : 'Philippines', 'Chiba': 'Japan', 'Lille' : 'France', 'Flordia' : 'USA', 'Bern' : 'Switzerland', 'Los Angeles' : 'USA', 'San Francisco' : 'USA', 'MaCanadau' : 'Canada' , 'MaCanadao' : 'Canada', 'MaCanadau' : 'Canada', 'Kyiv' : 'Ukraine' , 'ca' : 'Canada'}
final_frame['Location:'] = final_frame['Location:'].replace(rename_locs)
final_frame['Location:'] = final_frame['Location:'].replace(rename_city)
final_frame.drop(final_frame.loc[final_frame['Location:'] == 'drop'].index, inplace=True)
final_frame.drop(final_frame.loc[final_frame['Location:'] == 'Europe'].index, inplace=True)
final_frame.drop(final_frame.loc[final_frame['Location:'] == 'Americas'].index, inplace=True)
final_frame.drop(final_frame.loc[final_frame['Location:'] == 'Offline'].index, inplace=True)
try:
final_frame = final_frame.groupby(['T,o,u,r'], as_index=False).agg({ 'DateTime' : 'first', 'Tour_days' : 'first','Location:': 'first', 'Game:' : 'first', 'Prize Pool' : 'first', 'Players' : 'first', 'Twitch Viewers' : 'first', 'Game_gain' : 'sum', 'Twitch_gain' : 'sum', 'Prev_views' : 'first', 'Prev_players' : 'first'})
except:
pass
# compute the mean of negative viewers under 10k and over for use in the fm function to calculate the cost of the function
neg_twitch_mean = np.mean(final_frame.loc[final_frame['Twitch_gain'] < 10000, 'Twitch_gain'])
pos_twitch_mean = np.mean(final_frame.loc[final_frame['Twitch_gain'] >= 10000, 'Twitch_gain'])
print(pos_twitch_mean, neg_twitch_mean)
#Encode the twtich gain column with a binary representation as our taget variables for values over 10k viewers.
final_frame.loc[final_frame['Twitch_gain'] < 10000,'Twitch_gain' ] = 0
final_frame.loc[final_frame['Twitch_gain'] >= 10000, 'Twitch_gain'] = 1
final_frame.drop(columns=['T,o,u,r'], inplace=True, errors='ignore')
# covert dates to month value as it would be a useful predictor in our model
final_frame['DateTime'] = final_frame['DateTime'].dt.month
```
## Exploratory Date Analyse (EDA)
```
msno.matrix(final_frame, labels=True)
```
We can see that there are no missing values in your data so no issues there. Next we can split the data into categorical and numerical data for further analysis.
```
#Split columns into categorical and Numerical data.
Category_columns = [ 'Tour_days', 'Twitch_gain', 'DateTime']
Numerical_columns = ['Prize Pool', 'Players', 'Twitch Viewers', 'Game_gain', 'Prev_views', 'Prev_players']
final_frame.hist(column = Category_columns, figsize=(10,10), ylabelsize=10, xlabelsize = 10)
```
For Datetime we have the expected values of the months within the 1-12 range and more tournaments occuring near the end of the year and in January which is to be expected.
With Twitch gain we have an rougly even distribution of tournaments providing a gain of 10000 viewers and less than 10000 viewers. This would lend itself well to using accuracy as the predictive metric in our model as the dataset is balanced.
Tour dates we have an obvious trends with longer tournaments being less favourable which is to be expected as they cost more money and tend to be run for only major events which there is fewer of.
```
final_frame.hist(column = Numerical_columns, figsize=(30,10), ylabelsize=10, xlabelsize = 10)
```
All columns apart from Game_gain are all skewed left so I will try to apply a transform to the data to have it more normally ditributed which could lead to better results in our model. Prev_views and Prev_players look like they are represting quite similar date so I would be suprised to see a strong correlation there and so one might have to be dropped.
```
#performing some transforms on the data to get a more normal distribution for the data which may lead to a perfomance increase in the model
stats.boxcox(final_frame['Prize Pool'])[0]
final_frame.hist(column = Numerical_columns, figsize=(30,10), ylabelsize=10, xlabelsize = 10)
final_frame.describe()
```
Here we can see that Twitch Viewers has an empty viewer count on some days as min = 0 which I highly doubt is a true value for a game steaming on twitch so will need to be removed.
```
final_frame.drop(final_frame.loc[final_frame['Twitch Viewers'] == 0].index, inplace=True)
final_frame.describe()
```
After removing the values we get a more appropriate minimum viewer count of 117 which is reasonable as it could be for one of the less popular games on a quite month.
```
for col in Numerical_columns:
sns.boxplot(y = final_frame['Twitch_gain'].astype('category'), x = col, data=final_frame, showfliers=False)
plt.show()
```
From the box plots we can see that prev_players and players are quite evenly distributed between the twitch gain target meaning they likely won't be good predictors and so those columns will be dropped. All over values look like they may have enough variationin the data to become good predictors. Prev_views also although have some variation in data there isn't a great amount so it might not lead to being a good predictor.
```
#Drop the two unrequired columns
final_frame.drop(columns=['Prev_players', 'Players'], inplace=True)
#create category plots for Games and Locations to further investigate the data.
for col in final_frame.select_dtypes(include='object'):
category_graph = sns.catplot(x = col, kind='count', col ='Twitch_gain', data=final_frame, height=13, sharey=False)
category_graph.set_xticklabels(rotation=60)
```
For the country categorical data there seems to be good variation in all the country apart from the USA and Online tournament which may lead to them being oversampled when creating the model this might be solved later on with varaible reduction.
The Game categories seem to have a better spread of the values which seems to suggest that games might be a good predictor.
```
#final_frame['Location:'] = final_frame['Location:'].astype('category').cat.codes
game_dum = pd.get_dummies(final_frame['Game:'], prefix='Game' , dtype=float)
loc_dum = pd.get_dummies(final_frame['Location:'], prefix='Loc' , dtype=float)
final_frame = pd.concat([final_frame, game_dum], axis=1)
final_frame = pd.concat([final_frame, loc_dum], axis=1)
final_frame.drop(columns=['Game:', 'Location:'], inplace=True)
```
We will be one hot encoding the Location and Game variables for use when training our final mode, did try label encoding the countries but seemed to get better results with one hot encoding.
```
#Convert the remaning columns all to floats for use in the model.
Int_cols = ['DateTime', 'Tour_days']
final_frame[Int_cols] = final_frame[Int_cols].astype(float)
#Create our heatmap to check for correlation between variables.
cor = final_frame.corr()
plt.figure(figsize = (20,10))
sns.heatmap(cor.iloc[0:12,0:12], annot = True, cmap='Blues')
```
Here we can see a strong correlation between Twitch Viewers and Prev_views and from previous analyse from the box plots previous views will be dropped as it had less variation in it's data so is likely a worse predictor.
```
final_frame.drop(columns=['Prev_views'], inplace=True)
cor = final_frame.corr()
plt.figure(figsize = (20,10))
sns.heatmap(cor.iloc[0:12,0:12], annot = True, cmap='Blues')
```
Our model seems to have much more reasonable levels of correlation in its data now, though there is quite a strong correlation between Twitch Viewers and Prize Pool = 0.56 and Prize Pool and Tour days = 0.58. These varaibles will be important predictors for the stakeholders when deciding where to base tournaments so I will leave them in at the moment. If this leads to overfitting of the model then dropped some of these values will need to be revisited.
```
def reduce_variables(dataframe, target):
final_frame.columns = final_frame.columns.str.replace(' ', '_')
target_string = target + " ~ "
all_columns = dataframe.columns.tolist()
all_columns.remove(target)
variables = " + ".join(all_columns)
full_string = target_string + variables
model_fit = smf.ols(full_string, data=dataframe).fit()
pvalues = model_fit.pvalues
pvalues = pvalues.drop("Intercept")
max_p = pvalues.idxmax()
alpha = 0.05
while pvalues.max() > alpha:
max_p = pvalues.idxmax()
all_columns.remove(max_p)
variables = " + ".join(all_columns)
full_string = target_string + variables
model = smf.ols(full_string, data=dataframe).fit()
pvalues = model.pvalues
pvalues = pvalues.drop("Intercept")
return model, full_string
final_model, complete_string = reduce_variables(final_frame, 'Twitch_gain')
print(complete_string)
print(final_model.summary())
#Create our final dataframe for creating the model with the required variables.
model_frame = final_frame[['Twitch_gain', 'Tour_days', 'Prize_Pool', 'Twitch_Viewers', 'Game_PUBG']].copy()
#Pop our target column for creating our model
y = model_frame.pop('Twitch_gain')
```
Next we will need to predict our cost values for the fm scoring funtion, I have taken £1.33 gain in revenue per twitch viewer gained as a hypotheical value as there is no direct data online to be found on the ROI of a twitch advertisment. The cost associated wtih each cost are as follows:
- Cost of false negative = Cost of a false negative would be the loss of viewers that could have been gained if the tournament had been run at the correct time and place but monetary loss to the company would be 0.
- Cost of false positive = Cost of a false positive would be that a tournament that shouldn't have been run but did get run instead resulting in a potential loss of viewers, meaning a loss in revenue. To get this cost I will take the mean twitch viewers under the expected value of 10k multipied by the loss of each viewers £1.33.
- Cost of true positive = Would be the gain in viewership from running the tournament which would add revenue to the sponsors, this will be calculated taking the mean of the viewers above the 10k threshold multiplied by the gain of each viewer.
- Cost of true negative = Cost of a true negative wouldn't really have a cost associated with it as the tournament just wouldn't take place so setting this to 0.
```
# Define a fucntion for calculating the fm score for each threshold of our logistic model which returns the fm score.
def calculate_fm_score(y_value, y_pred_value):
tn, fp, fn, tp = confusion_matrix(y_value, y_pred_value).ravel()
Condition_pos = tp + fn
Condition_neg = tn + fp
Total_pop = tp + fp + tn + fn
Prevalence = Condition_pos/Total_pop
m = ((1-Prevalence)/Prevalence)*((neg_twitch_mean*1.33) - 0)/(0 - (pos_twitch_mean*1.33))
Tpr = tp / Condition_pos
Fpr = fp / Condition_neg
fm = Tpr - (m*Fpr)
return fm
# split the data into the train and test sets before training and testing the model.
X_train, X_test, Y_train, Y_test = train_test_split(model_frame, y, test_size=0.3, random_state=10)
X_test, X_val, Y_test, Y_val = train_test_split(X_test, Y_test, test_size=0.5, random_state=10)
#intialise scaler to standardize the data was we have columns with a large range of different values
scaler = StandardScaler()
# scale our data using the standardisation our data has a large variation in its data ranges.
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
X_val - scaler.transform(X_val)
```
Now with the data split into train, test and validation sets and the data scaled with our standard scaler we can begin searching for the appropriate model for our final model.
```
#intialise the scaler and logistic regression model.
log_mod = LogisticRegression(random_state=2)
log_mod.fit(X_train, Y_train)
y_pred = log_mod.predict(X_train)
print(f'Accuracy score is : {metrics.accuracy_score(Y_train, y_pred)}')
# create our decision tree classifier
dec_tree = DecisionTreeClassifier()
#initailise the k-fold object for use on hyperparameter search and cross validation
cv = KFold(n_splits=5, shuffle=True, random_state=2)
#set the parameters to used in a gridsearch for the decsion tree
param_dict = {"criterion":['gini','entropy'],
"max_depth":range(1,5),
"min_samples_split":range(2,5),
"min_samples_leaf":range(1,5)
}
#run the grid search to predict the best parameters for our model.
dec_grid = GridSearchCV(dec_tree, param_grid=param_dict, cv=cv, verbose=1, n_jobs=1, scoring='accuracy', refit=True)
dec_grid.fit(X_train, Y_train)
#print the best hyperparameters giving the best decision tree results.
print(f'Best Hyperparameters are : {dec_grid.best_params_}')
print(f'Best accuracy score is : {dec_grid.best_score_}')
```
The decision tree model seems to perform the best here and so will be chosen for the final model predictions and with threshold selection from the fm score.
```
dec_tree = DecisionTreeClassifier(**dec_grid.best_params_)
dec_tree.fit(X_train,Y_train)
ns_probs = [0 for _ in range(len(Y_train))]
Y_train_pred = dec_tree.predict_proba(X_train)
Y_train_pred = Y_train_pred[:, 1]
ns_auc = roc_auc_score(Y_train, ns_probs)
lr_auc = roc_auc_score(Y_train, Y_train_pred)
print('No Skill: ROC AUC=%.3f' % (ns_auc))
print('Logistic: ROC AUC=%.3f' % (lr_auc))
ns_fpr, ns_tpr, _ = roc_curve(Y_train, ns_probs)
lr_fpr, lr_tpr, thresholds = roc_curve(Y_train, Y_train_pred)
plt.plot(ns_fpr, ns_tpr, linestyle='--', label='No Skill')
plt.plot(lr_fpr, lr_tpr, marker='.', label='Logistic test set')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend()
# show the plot
plt.show()
```
With a ROC curve score of ROC AUC=0.795 the model does seem to predicting some signal in the data this might make for a good model.
```
#save our predicted probabilites into a dataframe before applying our threshold.
pred_proba_df = pd.DataFrame(dec_tree.predict_proba(X_train))
best_FM = 0
#run the threshold for the decision tree using the
for threshold in thresholds:
#set the prediction values to 1 or leave as 0 based on the current threshold value.
Y_train_pred = pred_proba_df.applymap(lambda x: 1 if x > threshold else 0)
test_accuracy = metrics.accuracy_score(Y_train.to_numpy().reshape(Y_train.to_numpy().size,1),
Y_train_pred.iloc[:,1].to_numpy().reshape(Y_train_pred.iloc[:,1].to_numpy().size,1))
y_hat_train = (Y_train_pred.iloc[:,1].to_numpy().reshape(Y_train_pred.iloc[:,1].to_numpy().size,1))
#calcualte the fm scoring function
FM = calculate_fm_score(Y_train, y_hat_train)
#If the fm score is increase from the previous score then update the best_FM variable to keep the best current fm score.
#Also save the threshold and accuracy for that given fm score.
if FM > best_FM:
best_FM= FM
Current_best_threshold = threshold
Current_acc_score = test_accuracy
best_y_hat = y_hat_train
plot_confusion_matrix(dec_tree, X_train, y_hat_train)
print(f"The greatest fm score acheieved was: {best_FM} at a threshold of {Current_best_threshold} returning an accuracy of {Current_acc_score}")
```
Not that the threshold has been found that maximises our fm function then we can apply this threshold in the testing and validation stages of determine the effect of this threshold on the accuracy of the model.
```
pred_proba_df = pd.DataFrame(dec_tree.predict_proba(X_val))
Y_val_pred = pred_proba_df.applymap(lambda x: 1 if x > Current_best_threshold else 0)
test_accuracy = metrics.accuracy_score(Y_val.to_numpy().reshape(Y_val.to_numpy().size,1),
Y_val_pred.iloc[:,1].to_numpy().reshape(Y_val_pred.iloc[:,1].to_numpy().size,1))
plot_confusion_matrix(dec_tree, X_val, Y_val)
print('Our testing accuracy on the test dataset with updated threshold is {}'.format(test_accuracy))
```
Our accuracy score with the update threshold for validation is much different from our training score which seems to indicate overfitting of the model.
```
pred_proba_df = pd.DataFrame(dec_tree.predict_proba(X_test))
Y_test_pred = pred_proba_df.applymap(lambda x: 1 if x > Current_best_threshold else 0)
test_accuracy = metrics.accuracy_score(Y_test.to_numpy().reshape(Y_test.to_numpy().size,1),
Y_test_pred.iloc[:,1].to_numpy().reshape(Y_test_pred.iloc[:,1].to_numpy().size,1))
plot_confusion_matrix(dec_tree, X_test, Y_test)
print('Our testing accuracy on the test dataset with updated threshold is {}'.format(test_accuracy))
```
Again the accuracy score is quite different from our validation scoring seems like the model is overfitting due to randomness in the data possiibly.
```
logistic_regression = sm.Logit(y,sm.add_constant(model_frame))
result = logistic_regression.fit()
print(result.summary())
```
For our coefficents of the Logistic Regression model these can be expressed as:
Tour_days: For an increase of 1 tour day we can expect a 0.458% increased likelyhood of getting the required 10k viewers holding all other values constant.
Interestingly in crease in twitch viewers from the previous years and prize pool actually decrease the likelyhood of gaining the 10k viewers but only by a small margin. This points to previous years twitch viewers and the prize pool not being as impactful an indicator as I previously expected.
Prize Pool and Twitch Viewer coefficient numbers are very small and so a change in them seems to not have much of an effect on whether we would get the required amount of viewers. This is suprising I expected an increased prize pool to correlate with an increased lieklyhood af gaining the amount of viewersabove the threshold. Previous years twitch viewers I expected might not have a great effect on wether the threshold was reached as I didn't expect the numbers to grow or have much loss from year to year.
Hosting the game Pub G seems to decrease the likelyhood of gaining the 10k viewers by -1% given all other variables are kept constant which is
negligible.
## Recommendation
- Due to the amount of money involved a loss of 20k for getting the wrong tournament and the overfitting of the model which I can't seem to correct even after using different solvers and applying different types of regularisation to model.
- I then can't recommend the model for prediction of esports tournaments, as the results are too unreliable due to overfitting of the model.
- Next steps would be to try differnt variable selection to see if that could correct the overfitting and also checking the data more closely for outliers which may be impacting the results.
| github_jupyter |
# Ecuaciones diferenciales ordinarias
Erwin Renzo Franco Diaz
Las ecuaciones diferenciales son parte fundamental de la física. Muchas leyes físicas como la segunda ley de Newton o las ecuaciones de Maxwell se expresan de esta manera, por lo que aprender resolverlas es de suma importancia. En esta sesión aprenderemos algunos métodos simbólicos y numéricos que ofrecen ciertos paquetes en Python para poder obtener la solución a ecuaciones diferenciales ordinarias. Primero veremos como resolverlas de manera simbólica usando el paquete $\texttt{sympy}$.
## Decaimiento radioactivo
Los núcleos radioactivos decaen de acuerdo a la ley
$$
\frac{dN}{dt} = - \lambda N
$$
donde $N$ es la concentración de los nucleidos en el tiempo $t$.
La solución a esta ecuación es una exponencial que decae. Si en $t = 0$ se tiene una concentración inicial $N(0) = N_0$
$$
N = N_0 e^{-\lambda t}.
$$
```
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
t = sp.symbols('t', real = True)
N = sp.Function('N', real = True, positive = True)(t)
l = sp.symbols('lambda', real = True, positive = True)
#sin condiciones iniciales
eq = sp.Eq(sp.diff(N), -l*N)
eq
sol = sp.dsolve(eq, N)
sol
#con condiciones iniciales
N_0 = sp.symbols('N_0', positive = True)
sol_ci = sp.dsolve(eq, N, ics = {N.subs(t, 0): N_0})
sol_ci
#hacemos que N sea una funcion numerica para graficarla
l_num = 0.2
N0_num = 1.0e5
N_num = sp.lambdify(t, sol_ci.subs([(l, l_num), (N_0, N0_num)]).rhs, 'numpy')
t_plot = np.linspace(0, 50, 1000)
N_plot = N_num(t_plot)/N0_num
plt.plot(t_plot, N_plot)
```
# Oscilador armónico
## Oscilador armónico simple
Una de los sistemas más importantes de la física, si es que no es el más importante, es el oscilador armónico cuya realización más simple es una partícula en un resorte. De la segunda ley de Newton y la ley de Hooke, la ecuación de movimiento que describe el oscilador armónico está dada por
$$
\frac{d^2 x}{dt^2} + \omega^2 x = 0
$$
donde $x$ es la posición de la partícula y $\omega$ es su frecuencia. La solución general a esta ecuación está dada por
$$
x(t) = C_1 \cos(\omega t) + C_2 \sin(\omega t) = A\cos(\omega t + \phi)
$$
donde $C_1$ y $C_2$, u $\omega$ y $\phi$ dependen de las condiciones iniciales $x(0) = x_0$ y $\dot{x} (0) = \dot{x}_0$
```
x = sp.Function('x', real = True)(t)
w = sp.symbols('omega', real = True, positive = True)
eq_simple = sp.Eq(sp.diff(x, (t, 2)) + w**2*x, 0)
sol_simple = sp.dsolve(eq_simple, x)
sol_simple
x0 = sp.symbols('x_0', real = True)
x0dot = sp.symbols('\dot{x_0}', real = True)
sol_simple_ci = sp.dsolve(eq_simple, x, ics = {x.subs(t, 0): x0, sp.diff(x, t).subs(t, 0): x0dot})
sol_simple_ci
w_num = 0.5
x0_num = 5
x0dot_num = 10
x_simple_num = sp.lambdify(t, sol_simple_ci.subs([(w, w_num), (x0, x0_num), (x0dot, x0dot_num)]).rhs, 'numpy')
x_simple_plot = x_simple_num(t_plot)
plt.plot(t_plot, x_simple_plot)
plt.title('un clasico')
plt.show()
```
## Oscilador armónico amortiguado
Consideremos el caso en el que además se tiene una fuerza de resistencia proporcional a la velocidad de la partícula. La ecuación de movimiento será ahora
$$
\frac{d^2 x}{dt^2} + \gamma \dot{x}+ \omega^2 x = 0
$$
cuya solución depende de los valores de $\gamma$ y $\omega$.
```
g = sp.symbols('gamma', real = True, positive = True)
eq_damped = sp.Eq(sp.diff(x, (t, 2)) + g*sp.diff(x, t) + w**2*x, 0)
eq_damped
```
### Sobreamortiguado
```
#sobreamortiguado
g_sobre = 2.5*2*w
CI = {x.subs(t, 0): x0, sp.diff(x, t).subs(t, 0): x0dot}
eq_damped_sobre = eq_damped.subs(g, g_sobre)
sol_sobre = sp.simplify(sp.dsolve(eq_damped_sobre, x, ics = CI))
sol_sobre
sol_sobre = sp.dsolve(eq_damped_sobre, x, ics = CI)
x_sobre_num = sp.lambdify(t, sol_sobre.subs([(w, w_num), (x0, x0_num), (x0dot, x0dot_num)]).rhs, 'numpy')
x_sobre_plot = x_sobre_num(t_plot)
plt.plot(t_plot, x_sobre_plot)
```
### Amortiguamiento crítico
```
#amortiguamiento critico
g_crit = 2*w
eq_damped_crit = eq_damped.subs(g, g_crit)
sol_crit = sp.dsolve(eq_damped_crit, x, ics = CI)
sol_crit
x_crit_num = sp.lambdify(t, sol_crit.subs([(w, w_num), (x0, x0_num), (x0dot, x0dot_num)]).rhs, 'numpy')
x_crit_plot = x_crit_num(t_plot)
plt.plot(t_plot, x_sobre_plot, t_plot, x_crit_plot)
plt.legend(['sobreamortiguado', 'critico'])
```
### Subamortiguamiento
```
#subamortiguado
g_sub = 0.2*2*w
eq_damped_sub = eq_damped_crit.subs(g_crit, g_sub)
sol_sub = sp.dsolve(eq_damped_sub, x, ics=CI)
sol_sub = sol_sub
sol_sub
#ploteando
x_sub_num = sp.lambdify(t, sol_sub.subs([(w, w_num), (x0, x0_num), (x0dot, x0dot_num)]).rhs, 'numpy')
x_sub_plot = x_sub_num(t_plot)
plt.plot(t_plot, x_sobre_plot, t_plot, x_crit_plot, t_plot, x_sub_plot)
plt.legend(['sobreamortiguado', 'critico', 'subamortiguado'])
```
# Sistema de ecuaciones diferenciales
En una serie radioactiva con dos nucleidos diferentes con concentraciones $N_1(t)$ y $N_2(t)$, se tiene
\begin{align}
\frac{dN_1}{dt} &= -\lambda_1 N_1 \\
\frac{dN_2}{dt} &= \lambda_1 N_1 - \lambda_2 N_2\\
\end{align}
En $t = 0$, $N_1(0) = N_0$ y $N_2(0) = 0$
```
N1= sp.Function('N_1', real = True)(t)
N2= sp.Function('N_2', real = True)(t)
#l1, l2 = sp.symbols('lambda_1, lambda_2', real = True, positive = True)
l1_num = 0.5
l2_num = 0.7
eq1 = sp.Eq(sp.diff(N1), -l1_num*N1)
eq2 = sp.Eq(sp.diff(N2), l1_num*N1 - l2_num*N2)
eqs = [eq1, eq2]
N1_sol, N2_sol = sp.dsolve(eqs, [N1, N2], ics = {N1.subs(t, 0): N_0, N2.subs(t, 0): 0})
N2_sol
N1_num = sp.lambdify(t, N1_sol.subs(N_0, N0_num).rhs, 'numpy')
N2_num = sp.lambdify(t, N2_sol.subs(N_0, N0_num).rhs, 'numpy')
N1_plot = N1_num(t_plot)
N2_plot = N2_num(t_plot)
plt.plot(t_plot, N1_plot, t_plot, N2_plot)
plt.legend(['$N_1$', '$N_2$'])
plt.yscale('log')
plt.show()
```
| github_jupyter |
# Multi GPU
Keras 2.0.9 makes it really easy to use multiple GPUs for Data-parallel training. Let's see how it's done!
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import fashion_mnist
from keras.utils import to_categorical
```
## Load data
We use the newly added Fashion Mnist dataset from Zalando Research
https://github.com/zalandoresearch/fashion-mnist
Label Description
0 T-shirt/top
1 Trouser
2 Pullover
3 Dress
4 Coat
5 Sandal
6 Shirt
7 Sneaker
8 Bag
9 Ankle boot
```
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train = np.expand_dims(X_train.astype("float"), -1)
X_test = np.expand_dims(X_test.astype("float"), -1)
Y_train = to_categorical(y_train)
Y_test = to_categorical(y_test)
X_train.shape
plt.figure(figsize=(12,4))
for i in range(1, 10):
plt.subplot(1, 10, i)
plt.imshow(X_train[i].reshape(28, 28), cmap='gray')
plt.title(y_train[i])
# apply mean subtraction to the data
mean = np.mean(X_train, axis=0)
X_train -= mean
X_test -= mean
```
## Data Generator
to augment the data
```
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
fill_mode="nearest")
```
## Convolutional Model
```
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D
from keras.layers import Activation, Dropout, Flatten, Dense
def create_conv_model(input_shape=(28, 28, 1),
n_classes=10,
activation='relu',
kernel_initializer='glorot_normal'):
model = Sequential()
model.add(Conv2D(32, (3, 3),
padding='same',
input_shape=input_shape,
kernel_initializer=kernel_initializer,
activation=activation))
model.add(Conv2D(32, (3, 3),
activation=activation,
kernel_initializer=kernel_initializer))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3),
padding='same',
activation=activation,
kernel_initializer=kernel_initializer))
model.add(Conv2D(64, (3, 3),
activation=activation,
kernel_initializer=kernel_initializer))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512,
activation=activation,
kernel_initializer=kernel_initializer))
model.add(Dense(n_classes,
activation='softmax',
kernel_initializer=kernel_initializer))
return model
```
## Multi GPU
```
from keras.utils.training_utils import multi_gpu_model
import tensorflow as tf
gpus = 1
```
if more than one GPU is present on the machine we need to create a copy of the model on each GPU and sync them on the CPU
```
if gpus <= 1:
model = create_conv_model()
else:
with tf.device("/cpu:0"):
model = create_conv_model()
model = multi_gpu_model(model, gpus=gpus)
```
## Train
We will use a `LearningRateScheduler` callback to adjust the learning rate of SGD
```
n_epochs = 30
initial_lr = 5e-3
def poly_decay(epoch):
max_epochs = n_epochs
lr = initial_lr
power = 1.0
alpha = lr * (1 - (epoch / float(max_epochs))) ** power
return alpha
epochs = []
lrs = []
for i in range(n_epochs):
epochs.append(i)
lrs.append(poly_decay(i))
plt.plot(epochs, lrs)
from keras.callbacks import LearningRateScheduler
from keras.optimizers import SGD
opt = SGD(lr=initial_lr, momentum=0.9)
callbacks = [LearningRateScheduler(poly_decay)]
model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=["accuracy"])
batch_size = 1024
history = model.fit_generator(
datagen.flow(X_train, Y_train, batch_size=batch_size * gpus),
validation_data=(X_test, Y_test),
steps_per_epoch=len(X_train) // (batch_size * gpus),
epochs=n_epochs,
callbacks=callbacks, verbose=1)
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Accuracy')
plt.legend(['train', 'test'])
plt.xlabel('Epochs')
```
## Exercise 1
your machine has 4 GPUs.
- compare the training time with 1 GPU VS 2 GPUs VS 4 GPUs. Is the training time the same? Is is larger or smaller?
- try to max out the gpu memory by increasing the batch size. Can you do it?
- is the model overfitting? experiment with the model architechture. Try to reduce overfitting by:
- adding more layers
- changing the filter size
- adding more dropout
- adding regularization
- adding batch normalization
*Copyright © 2017 Francesco Mosconi & CATALIT LLC. All rights reserved.*
| github_jupyter |
# Anchor explanations for ImageNet
```
import tensorflow as tf
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input, decode_predictions
from alibi.datasets import load_cats
from alibi.explainers import AnchorImage
```
### Load InceptionV3 model pre-trained on ImageNet
```
model = InceptionV3(weights='imagenet')
```
### Load and pre-process sample images
The *load_cats* function loads a small sample of images of various cat breeds.
```
image_shape = (299, 299, 3)
data, labels = load_cats(target_size=image_shape[:2], return_X_y=True)
print(f'Images shape: {data.shape}')
```
Apply image preprocessing, make predictions and map predictions back to categories. The output label is a tuple which consists of the class name, description and the prediction probability.
```
images = preprocess_input(data)
preds = model.predict(images)
label = decode_predictions(preds, top=3)
print(label[0])
```
### Define prediction function
```
predict_fn = lambda x: model.predict(x)
```
### Initialize anchor image explainer
The segmentation function will be used to generate superpixels. It is important to have meaningful superpixels in order to generate a useful explanation. Please check scikit-image's [segmentation methods](http://scikit-image.org/docs/dev/api/skimage.segmentation.html) (*felzenszwalb*, *slic* and *quickshift* built in the explainer) for more information.
In the example, the pixels not in the proposed anchor will take the average value of their superpixel. Another option is to superimpose the pixel values from other images which can be passed as a numpy array to the *images_background* argument.
```
segmentation_fn = 'slic'
kwargs = {'n_segments': 15, 'compactness': 20, 'sigma': .5}
explainer = AnchorImage(predict_fn, image_shape, segmentation_fn=segmentation_fn,
segmentation_kwargs=kwargs, images_background=None)
```
### Explain a prediction
The explanation of the below image returns a mask with the superpixels that constitute the anchor.
```
i = 0
plt.imshow(data[i]);
```
The *threshold*, *p_sample* and *tau* parameters are also key to generate a sensible explanation and ensure fast enough convergence. The *threshold* defines the minimum fraction of samples for a candidate anchor that need to lead to the same prediction as the original instance. While a higher threshold gives more confidence in the anchor, it also leads to longer computation time. *p_sample* determines the fraction of superpixels that are changed to either the average value of the superpixel or the pixel value for the superimposed image. The pixels in the proposed anchors are of course unchanged. The parameter *tau* determines when we assume convergence. A bigger value for *tau* means faster convergence but also looser anchor restrictions.
```
image = images[i]
np.random.seed(0)
explanation = explainer.explain(image, threshold=.95, p_sample=.5, tau=0.25)
```
Superpixels in the anchor:
```
plt.imshow(explanation.anchor);
```
A visualization of all the superpixels:
```
plt.imshow(explanation.segments);
```
| github_jupyter |
# Spleen 3D segmentation with MONAI
This tutorial shows how to integrate MONAI into an existing PyTorch medical DL program.
And easily use below features:
1. Transforms for dictionary format data.
1. Load Nifti image with metadata.
1. Add channel dim to the data if no channel dimension.
1. Scale medical image intensity with expected range.
1. Crop out a batch of balanced images based on positive / negative label ratio.
1. Cache IO and transforms to accelerate training and validation.
1. 3D UNet model, Dice loss function, Mean Dice metric for 3D segmentation task.
1. Sliding window inference method.
1. Deterministic training for reproducibility.
The Spleen dataset can be downloaded from http://medicaldecathlon.com/.

Target: Spleen
Modality: CT
Size: 61 3D volumes (41 Training + 20 Testing)
Source: Memorial Sloan Kettering Cancer Center
Challenge: Large ranging foreground size
[](https://colab.research.google.com/github/Project-MONAI/tutorials/blob/master/3d_segmentation/spleen_segmentation_3d.ipynb)
## Setup environment
```
!python -c "import monai" || pip install -q "monai-weekly[gdown, nibabel, tqdm, ignite]"
!python -c "import aim" || pip install -q aim
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
from monai.utils import first, set_determinism
from monai.transforms import (
AsDiscrete,
AsDiscreted,
EnsureChannelFirstd,
Compose,
CropForegroundd,
LoadImaged,
Orientationd,
RandCropByPosNegLabeld,
SaveImaged,
ScaleIntensityRanged,
Spacingd,
EnsureTyped,
EnsureType,
Invertd,
)
from monai.handlers.utils import from_engine
from monai.networks.nets import UNet
from monai.networks.layers import Norm
from monai.metrics import DiceMetric
from monai.losses import DiceLoss
from monai.inferers import sliding_window_inference
from monai.data import CacheDataset, DataLoader, Dataset, decollate_batch
from monai.config import print_config
from monai.apps import download_and_extract
import aim
from aim.pytorch import track_gradients_dists, track_params_dists
import torch
import matplotlib.pyplot as plt
import tempfile
import shutil
import os
import glob
```
## Setup imports
```
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
print_config()
```
## Setup data directory
You can specify a directory with the `MONAI_DATA_DIRECTORY` environment variable.
This allows you to save results and reuse downloads.
If not specified a temporary directory will be used.
```
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(root_dir)
```
## Download dataset
Downloads and extracts the dataset.
The dataset comes from http://medicaldecathlon.com/.
```
resource = "https://msd-for-monai.s3-us-west-2.amazonaws.com/Task09_Spleen.tar"
md5 = "410d4a301da4e5b2f6f86ec3ddba524e"
compressed_file = os.path.join(root_dir, "Task09_Spleen.tar")
data_dir = os.path.join(root_dir, "Task09_Spleen")
if not os.path.exists(data_dir):
download_and_extract(resource, compressed_file, root_dir, md5)
```
## Set MSD Spleen dataset path
```
train_images = sorted(
glob.glob(os.path.join(data_dir, "imagesTr", "*.nii.gz")))
train_labels = sorted(
glob.glob(os.path.join(data_dir, "labelsTr", "*.nii.gz")))
data_dicts = [
{"image": image_name, "label": label_name}
for image_name, label_name in zip(train_images, train_labels)
]
train_files, val_files = data_dicts[:-9], data_dicts[-9:]
```
## Set deterministic training for reproducibility
```
set_determinism(seed=0)
```
## Setup transforms for training and validation
Here we use several transforms to augment the dataset:
1. `LoadImaged` loads the spleen CT images and labels from NIfTI format files.
1. `AddChanneld` as the original data doesn't have channel dim, add 1 dim to construct "channel first" shape.
1. `Spacingd` adjusts the spacing by `pixdim=(1.5, 1.5, 2.)` based on the affine matrix.
1. `Orientationd` unifies the data orientation based on the affine matrix.
1. `ScaleIntensityRanged` extracts intensity range [-57, 164] and scales to [0, 1].
1. `CropForegroundd` removes all zero borders to focus on the valid body area of the images and labels.
1. `RandCropByPosNegLabeld` randomly crop patch samples from big image based on pos / neg ratio.
The image centers of negative samples must be in valid body area.
1. `RandAffined` efficiently performs `rotate`, `scale`, `shear`, `translate`, etc. together based on PyTorch affine transform.
1. `EnsureTyped` converts the numpy array to PyTorch Tensor for further steps.
```
train_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image", "label"]),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(keys=["image", "label"], pixdim=(
1.5, 1.5, 2.0), mode=("bilinear", "nearest")),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
RandCropByPosNegLabeld(
keys=["image", "label"],
label_key="label",
spatial_size=(96, 96, 96),
pos=1,
neg=1,
num_samples=4,
image_key="image",
image_threshold=0,
),
# user can also add other random transforms
# RandAffined(
# keys=['image', 'label'],
# mode=('bilinear', 'nearest'),
# prob=1.0, spatial_size=(96, 96, 96),
# rotate_range=(0, 0, np.pi/15),
# scale_range=(0.1, 0.1, 0.1)),
EnsureTyped(keys=["image", "label"]),
]
)
val_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image", "label"]),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(keys=["image", "label"], pixdim=(
1.5, 1.5, 2.0), mode=("bilinear", "nearest")),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
EnsureTyped(keys=["image", "label"]),
]
)
```
## Check transforms in DataLoader
```
check_ds = Dataset(data=val_files, transform=val_transforms)
check_loader = DataLoader(check_ds, batch_size=1)
check_data = first(check_loader)
image, label = (check_data["image"][0][0], check_data["label"][0][0])
print(f"image shape: {image.shape}, label shape: {label.shape}")
# plot the slice [:, :, 80]
plt.figure("check", (12, 6))
plt.subplot(1, 2, 1)
plt.title("image")
plt.imshow(image[:, :, 80], cmap="gray")
plt.subplot(1, 2, 2)
plt.title("label")
plt.imshow(label[:, :, 80])
plt.show()
```
## Define CacheDataset and DataLoader for training and validation
Here we use CacheDataset to accelerate training and validation process, it's 10x faster than the regular Dataset.
To achieve best performance, set `cache_rate=1.0` to cache all the data, if memory is not enough, set lower value.
Users can also set `cache_num` instead of `cache_rate`, will use the minimum value of the 2 settings.
And set `num_workers` to enable multi-threads during caching.
If want to to try the regular Dataset, just change to use the commented code below.
```
train_ds = CacheDataset(
data=train_files, transform=train_transforms,
cache_rate=1.0, num_workers=4)
# train_ds = monai.data.Dataset(data=train_files, transform=train_transforms)
# use batch_size=2 to load images and use RandCropByPosNegLabeld
# to generate 2 x 4 images for network training
train_loader = DataLoader(train_ds, batch_size=2, shuffle=True, num_workers=4)
val_ds = CacheDataset(
data=val_files, transform=val_transforms, cache_rate=1.0, num_workers=4)
# val_ds = Dataset(data=val_files, transform=val_transforms)
val_loader = DataLoader(val_ds, batch_size=1, num_workers=4)
```
## Create Model, Loss, Optimizer
```
# standard PyTorch program style: create UNet, DiceLoss and Adam optimizer
device = torch.device("cuda:0")
UNet_meatdata = dict(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH
)
model = UNet(**UNet_meatdata).to(device)
loss_function = DiceLoss(to_onehot_y=True, softmax=True)
loss_type = "DiceLoss"
optimizer = torch.optim.Adam(model.parameters(), 1e-4)
dice_metric = DiceMetric(include_background=False, reduction="mean")
Optimizer_metadata = {}
for ind, param_group in enumerate(optimizer.param_groups):
optim_meta_keys = list(param_group.keys())
Optimizer_metadata[f'param_group_{ind}'] = {key: value for (key, value) in param_group.items() if 'params' not in key}
```
## Execute a typical PyTorch training process
```
max_epochs = 600
val_interval = 10
best_metric = -1
best_metric_epoch = -1
epoch_loss_values = []
metric_values = []
post_pred = Compose([EnsureType(), AsDiscrete(argmax=True, to_onehot=2)])
post_label = Compose([EnsureType(), AsDiscrete(to_onehot=2)])
# initialize a new Aim Run
aim_run = aim.Run()
# log model metadata
aim_run['UNet_meatdata'] = UNet_meatdata
# log optimizer metadata
aim_run['Optimizer_metadata'] = Optimizer_metadata
slice_to_track = 80
for epoch in range(max_epochs):
print("-" * 10)
print(f"epoch {epoch + 1}/{max_epochs}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step += 1
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f"{step}/{len(train_ds) // train_loader.batch_size}, "
f"train_loss: {loss.item():.4f}")
# track batch loss metric
aim_run.track(loss.item(), name="batch_loss", context={'type':loss_type})
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
# track epoch loss metric
aim_run.track(epoch_loss, name="epoch_loss", context={'type':loss_type})
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
if (epoch + 1) % val_interval * 2 == 0:
# track model params and gradients
track_params_dists(model,aim_run)
# THIS SEGMENT TAKES RELATIVELY LONG (Advise Against it)
track_gradients_dists(model, aim_run)
model.eval()
with torch.no_grad():
for index, val_data in enumerate(val_loader):
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
roi_size = (160, 160, 160)
sw_batch_size = 4
val_outputs = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model)
# tracking input, label and output images with Aim
output = torch.argmax(val_outputs, dim=1)[0, :, :, slice_to_track].float()
aim_run.track(aim.Image(val_inputs[0, 0, :, :, slice_to_track], \
caption=f'Input Image: {index}'), \
name='validation', context={'type':'input'})
aim_run.track(aim.Image(val_labels[0, 0, :, :, slice_to_track], \
caption=f'Label Image: {index}'), \
name='validation', context={'type':'label'})
aim_run.track(aim.Image(output, caption=f'Predicted Label: {index}'), \
name = 'predictions', context={'type':'labels'})
val_outputs = [post_pred(i) for i in decollate_batch(val_outputs)]
val_labels = [post_label(i) for i in decollate_batch(val_labels)]
# compute metric for current iteration
dice_metric(y_pred=val_outputs, y=val_labels)
# aggregate the final mean dice result
metric = dice_metric.aggregate().item()
# track val metric
aim_run.track(metric, name="val_metric", context={'type':loss_type})
# reset the status for next validation round
dice_metric.reset()
metric_values.append(metric)
if metric > best_metric:
best_metric = metric
best_metric_epoch = epoch + 1
torch.save(model.state_dict(), os.path.join(
root_dir, "best_metric_model.pth"))
best_model_log_message = f"saved new best metric model at the {epoch+1}th epoch"
aim_run.track(aim.Text(best_model_log_message), name='best_model_log_message', epoch=epoch+1)
print(best_model_log_message)
message1 = f"current epoch: {epoch + 1} current mean dice: {metric:.4f}"
message2 = f"\nbest mean dice: {best_metric:.4f} "
message3 = f"at epoch: {best_metric_epoch}"
aim_run.track(aim.Text(message1 +"\n" + message2 + message3), name='epoch_summary', epoch=epoch+1)
print(message1, message2, message3)
# finalize Aim Run
aim_run.close()
print(
f"train completed, best_metric: {best_metric:.4f} "
f"at epoch: {best_metric_epoch}")
```
## Run Aim UI to deeply explore tracked insights
```
%load_ext aim
%aim up
```
Once the above cell is executed, you will see the Aim UI running in output cell
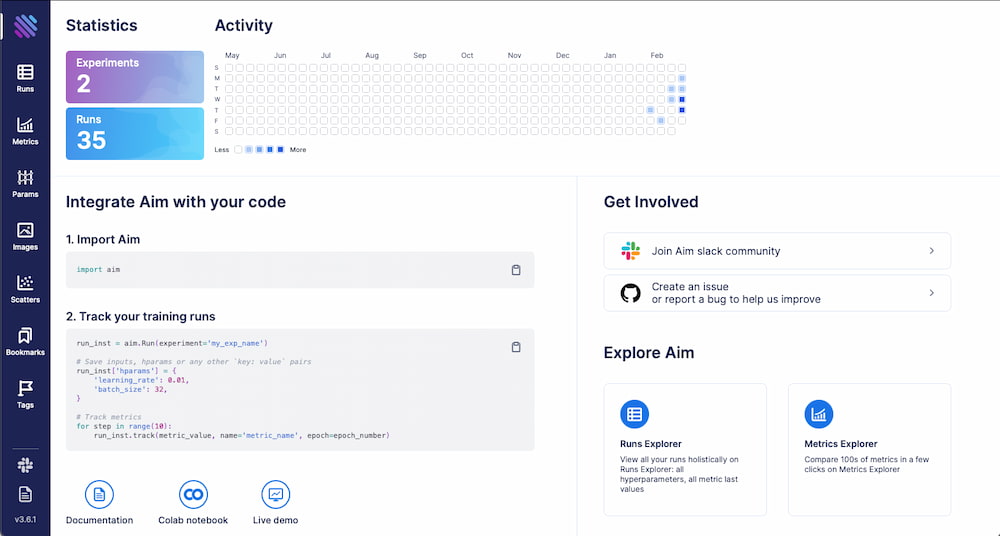
## Explore the loss and metric
Compare metrics curves with Metrics Explorer - group and aggregate by any hyperparameter to easily compare training runs
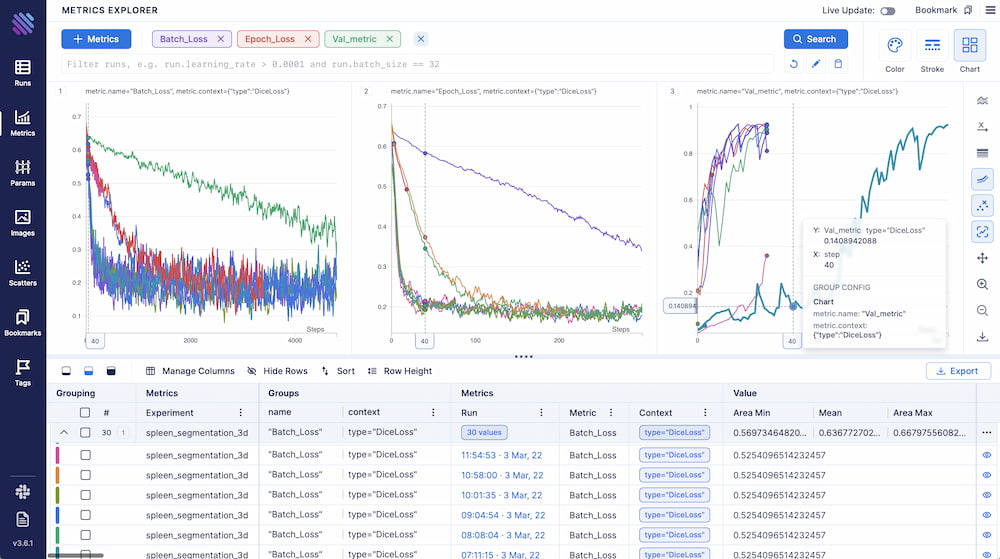
## Compare and analyze model outputs
Compare models of different runs with input images and labels
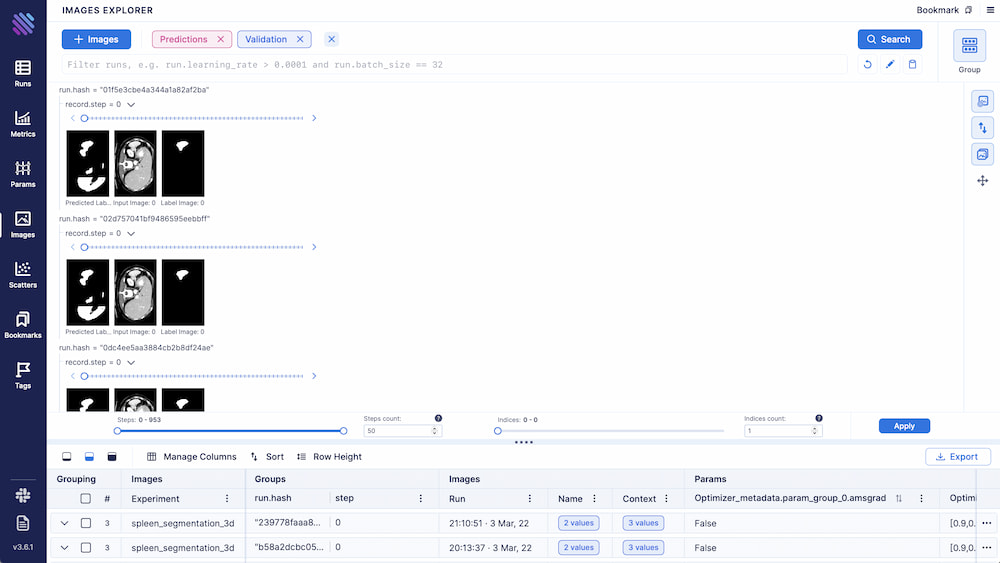
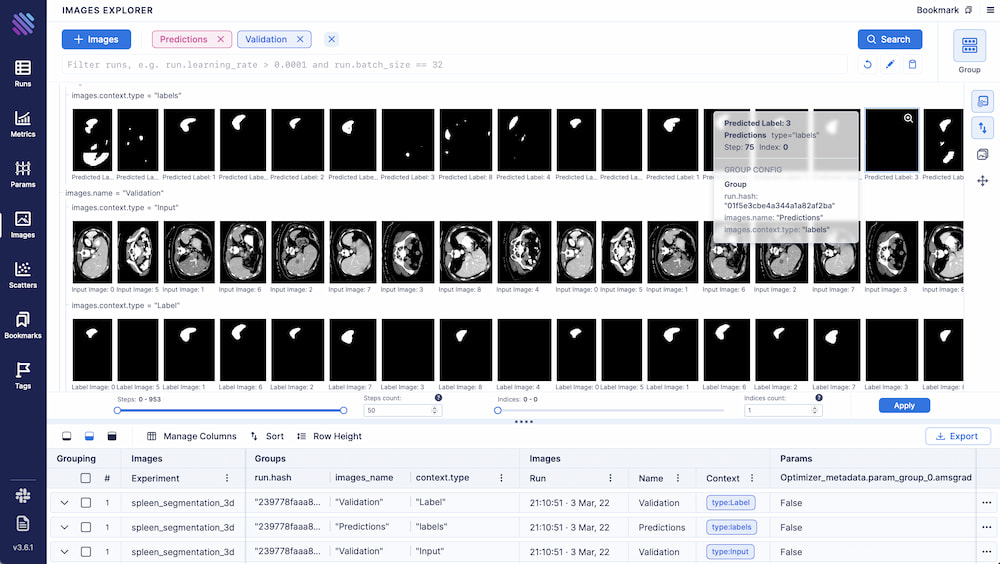
## Evaluation on original image spacings
```
val_org_transforms = Compose(
[
LoadImaged(keys=["image", "label"]),
EnsureChannelFirstd(keys=["image", "label"]),
Spacingd(keys=["image"], pixdim=(
1.5, 1.5, 2.0), mode="bilinear"),
Orientationd(keys=["image"], axcodes="RAS"),
ScaleIntensityRanged(
keys=["image"], a_min=-57, a_max=164,
b_min=0.0, b_max=1.0, clip=True,
),
CropForegroundd(keys=["image"], source_key="image"),
EnsureTyped(keys=["image", "label"]),
]
)
val_org_ds = Dataset(
data=val_files, transform=val_org_transforms)
val_org_loader = DataLoader(val_org_ds, batch_size=1, num_workers=4)
post_transforms = Compose([
EnsureTyped(keys="pred"),
Invertd(
keys="pred",
transform=val_org_transforms,
orig_keys="image",
meta_keys="pred_meta_dict",
orig_meta_keys="image_meta_dict",
meta_key_postfix="meta_dict",
nearest_interp=False,
to_tensor=True,
),
AsDiscreted(keys="pred", argmax=True, to_onehot=2),
AsDiscreted(keys="label", to_onehot=2),
])
model.load_state_dict(torch.load(
os.path.join(root_dir, "best_metric_model.pth")))
model.eval()
with torch.no_grad():
for val_data in val_org_loader:
val_inputs = val_data["image"].to(device)
roi_size = (160, 160, 160)
sw_batch_size = 4
val_data["pred"] = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model)
val_data = [post_transforms(i) for i in decollate_batch(val_data)]
val_outputs, val_labels = from_engine(["pred", "label"])(val_data)
# compute metric for current iteration
dice_metric(y_pred=val_outputs, y=val_labels)
# aggregate the final mean dice result
metric_org = dice_metric.aggregate().item()
# reset the status for next validation round
dice_metric.reset()
print("Metric on original image spacing: ", metric_org)
```
## Cleanup data directory
Remove directory if a temporary was used.
```
if directory is None:
shutil.rmtree(root_dir)
```
| github_jupyter |
[](https://www.pythonista.io)
# Validación de formularios.
## Validación de campos.
A lo largo del tiempo, los desarrolladores de aplicaciones basadas en *Flask* han identificado ciertos patrones que pueden ser útiles. Uno de ellos corresponde a un macro en *Jinja* que despliega los mensajes de error de validación de cada campo. Puede saber más al respecto en la siguiente liga:
https://flask.palletsprojects.com/en/2.0.x/patterns/wtforms/
## El patrón ```_form_helpers.html```.
El código de este patrón es el siguiente y se ha guardado en el archivo [```templates/_formhelpers.html```](templates/_formhelpers.html).
``` html
{% macro render_field(field) %}
<dt>{{ field.label }}
<dd>{{ field(**kwargs)|safe }}
{% if field.errors %}
<ul class=errors>
{% for error in field.errors %}
<li>{{ error }}</li>
{% endfor %}
</ul>
{% endif %}
</dd>
{% endmacro %}
```
El macro ```render_field()``` desplegará los errores de validación de cada campo al presionar el botón de envío.
**Ejemplo:**
Se creará el archivo [```templates/datos_alumno.html```](templates/datos_alumno.html) que incluye el siguiente código, que es similar a la plantilla ```templates/pantilla_formularios.html```, pero importando y aplicando el macro ```render_field()```.
``` html
<!DOCTYPE html>
<html>
<head>
<title>Datos del alumno</title>
</head>
<body>
<h1>Datos personales del alumno.</h1>
{% from "_formhelpers.html" import render_field %}
<form method="POST">
{{ form.hidden_tag() }}
{{ render_field(form.nombre) }}
{{ render_field(form.primer_apellido) }}
{{ render_field(form.segundo_apellido) }}
{{ render_field(form.carrera)}}
{{ render_field(form.semestre)}}
{{ render_field(form.promedio)}}
{{ render_field(form.al_corriente)}}
<p>
{{ form.enviar }}
</form>
</body>
</html>
```
**Advertencia:** Una vez ejecutada la siguiente celda, es necesario interrumpir el kernel de Jupyter para poder ejecutar el resto de las celdas de la notebook.
```
from flask import Flask, render_template, abort
from flask_wtf import FlaskForm
from wtforms.validators import DataRequired, ValidationError
from wtforms.fields import SelectField, BooleanField, SubmitField, StringField
carreras = ("Sistemas",
"Derecho",
"Actuaría",
"Arquitectura",
"Administración")
campos = ('nombre',
'primer_apellido',
'segundo_apellido',
'carrera',
'semestre',
'promedio',
'al_corriente')
def valida_promedio(form, field):
try:
numero = float(field.data)
except:
raise ValidationError('Debe de ingresar un número')
if numero < 0 or numero > 10:
raise ValidationError('Debe de ingresar un número entre 0 y 10')
class DatosEstudiante(FlaskForm):
nombre = StringField('Nombre', [DataRequired()], default = '')
primer_apellido = StringField('Primer apellido', [DataRequired()], default = '')
segundo_apellido = StringField('Segundo apellido', default = '')
carrera = SelectField('Carrera', [DataRequired()], choices = carreras)
semestre = SelectField('Semestre', [DataRequired()], choices = [(str(x), str(x)) for x in range(1, 50)])
promedio = StringField('Promedio', [DataRequired(), valida_promedio], default = '0')
al_corriente = BooleanField('Al corriente de pagos')
enviar = SubmitField('Enviar')
app = Flask(__name__)
app.config['SECRET_KEY'] ="Pyth0n15t4"
@app.route('/', methods=['GET', 'POST'])
def index():
forma = DatosEstudiante()
if forma.validate_on_submit():
for campo in campos:
print(forma[campo].data)
else:
print('Datos incorrectos.')
return render_template('datos_alumno.html', form=forma)
#Si no se define el parámetro host, flask sólo será visible desde localhost
# app.run(host='localhost')
app.run('0.0.0.0')
```
http://localhost:5000
<p style="text-align: center"><a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Licencia Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/80x15.png" /></a><br />Esta obra está bajo una <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Licencia Creative Commons Atribución 4.0 Internacional</a>.</p>
<p style="text-align: center">© José Luis Chiquete Valdivieso. 2022.</p>
| github_jupyter |
# Metrics for prediction model based on 1h resolution
This notebook contains metric definition for Prediction model.
Model score is calculated using the following formula:
* For each day in year 2017
* Build model based on data before given day
* Predict given day
* Calculate prediction error for given day
* Report 95th percentile as model score
```
import datetime
import calendar
import time
import json
import numpy as np
import pandas as pd
from sklearn import tree
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['figure.figsize'] = 12, 4
```
# Load project
Load rainfall and flow data from the files and clean it by:
* Resampling to 5 minutes
* Slice to the common range
* Fill NaNs
```
PROJECT_FOLDER = '../../datasets/radon-medium/'
flow = pd.read_csv(PROJECT_FOLDER + 'flow1.csv', parse_dates=['time'])
flow = flow.set_index('time').flow
flow = flow.resample('1H').mean()
rainfall = pd.read_csv(PROJECT_FOLDER + 'rainfall1.csv', parse_dates=['time'])
rainfall = rainfall.set_index('time').rainfall
rainfall = rainfall.resample('1H').mean()
data_frame = pd.concat([flow, rainfall], axis=1).fillna(0)
data_frame['day'] = data_frame.index.map(lambda x: x.date())
data_frame = data_frame['2015-01-01':'2018-07-05']
print(data_frame.isna().sum())
print(data_frame.head())
print(data_frame.tail())
```
## Prepare functions for calculating model score
The basic prediction model uses daily pattern as a prediction
```
class PredictionModel:
def fit(self, flow, rain):
pass
def predict(self, day, rain):
return np.zeros(24)
def loss(y_hat, y):
"""
https://en.wikipedia.org/wiki/Mean_absolute_percentage_error
"""
return 100.0 * np.sum(np.abs((y-y_hat) / y)) / y.shape[0]
def split_data(flow, split_day):
"""Get all data up to given day"""
end_day = split_day - pd.Timedelta('1 min')
return flow[:end_day]
def evaluate_day(model, flow, rain, day):
"""Evaluate data for single day"""
xs = split_data(flow, day)
y = flow[day: day+pd.Timedelta('1439 min')]
model.fit(xs, rain)
y_hat = model.predict(day, rain)
return loss(y_hat, y)
def evaluate_model(model, flow, rain, start_day):
"""
Evaluate model on all days starting from the split_day.
Returns 95th percentile error as model score
"""
last_day = flow.index[-1] - pd.Timedelta(1, 'D')
split_day = start_day
costs = []
while split_day < last_day:
cost = evaluate_day(model, flow, rain, split_day)
costs.append(cost)
split_day += pd.Timedelta(1, 'D')
return np.percentile(costs, 95), costs
error = evaluate_day(PredictionModel(), flow, rainfall, pd.Timestamp('2017-11-10'))
print('Error: {:.2f}%'.format(error))
```
# Evaluate some models for year 2018
## Mean model
```
class MeanModel:
def fit(self, flow, rain):
self.mean = np.mean(flow.values)
def predict(self, day, rain):
return np.ones(24) * self.mean
start_time = time.time()
score, costs = evaluate_model(MeanModel(), data_frame.flow, data_frame.rainfall, pd.Timestamp('2018-01-01'))
print('MeanModel 95th percentile error: {:.2f}%'.format(score))
print("Calculated in {:.3f} seconds".format(time.time() - start_time))
```
## Daily pattern model
```
class DailyPatternModel:
def fit(self, flow, rain):
""" Use daily pattern """
df = flow.to_frame().reset_index()
self.daily_pattern = df.groupby(by=[df.time.map(lambda x : x.hour)]).flow.mean().values
def predict(self, day, rain):
return self.daily_pattern
start_time = time.time()
score, costs = evaluate_model(DailyPatternModel(), data_frame.flow, data_frame.rainfall, pd.Timestamp('2017-01-01'))
print('DailyPatternModel 95th percentile error: {:.2f}%'.format(score))
print("Calculated in {:.3f} seconds".format(time.time() - start_time))
```
## Last day model
```
class LastDayModel(PredictionModel):
def fit(self, flow, rain):
self.y = flow.values[-24:]
def predict(self, day, rain):
return self.y
score, costs = evaluate_model(LastDayModel(), data_frame.flow, data_frame.rainfall, pd.Timestamp('2017-01-01'))
print('LastDayModel 95th percentile error: {:.2f}%'.format(score))
```
| github_jupyter |
### Load the train dataset.
```
import os
import random
import pandas as pd
news = []
for directory in os.listdir("1150haber/raw_texts/"):
for filename in os.listdir("1150haber/raw_texts/" + directory):
f = open("1150haber/raw_texts/" + directory + "/" + filename, "r", encoding="windows-1254")
new = f.read().replace("\n", " ")
new = new.lower()
news.append(new)
random.shuffle(news)
print(len(news))
data = {"Haber": news}
df_train = pd.DataFrame(data)
df_train["Haber"] = df_train["Haber"].apply(str)
df_train.sample(20)
```
### Load the test dataset.
```
import os
import random
import pandas as pd
news = []
labels = []
filenames = []
i = 0
for directory in os.listdir("1150haber/test/"):
i += 1
for filename in os.listdir("1150haber/test/" + directory):
f = open("1150haber/test/" + directory + "/" + filename, "r", encoding="windows-1254")
new = f.read().replace("\n", " ")
new = new.lower()
news.append(new)
labels.append(i)
print(len(news))
data = {"Haber": news, "Sınıf": labels}
df_test = pd.DataFrame(data)
df_test["Haber"] = df_test["Haber"].apply(str)
df_test = df_test.sample(frac = 1).reset_index(drop=True)
df_test.sample(230).sort_index()
```
### Background for labeling functions
```
para = ["lira", "dolar", "döviz", "faiz"]
ekonomi_kavramlar = ["cari", "enflasyon", "merkez bankası", "imf", "kredi", "yatırım"]
sayi_birimleri = ["milyon", "milyar", "bin", "trilyon", "katrilyon"]
magazin_kavramlar = ["ünlü", "tatil", "bodrum", "konser", "sevgili", "yakışıklı", "aşk"]
magazin_meslekler = ["manken", "oyuncu", "aktör"]
magazin_kisiler = ["hülya avşar", "beren saat", "ajda pekkan", "demet akalın", "mehmet ali erbil"]
vucut_bolumleri = ["kalp", "diş", "göz", "damar", "ağız", "cilt", "vücut", "yağ", "böbrek", "kan", "tırnak", "bağırsak", "baş"]
saglik_kavramlar = ["tedavi", "bilim", "ilaç", "teşhis", "hasta", "tıp", "ameliyat", "ssk", "hastane"]
hastaliklar = ["kanser", "şeker", "yağ", "hastalık", "doğum", "anne", "görme", "tansiyon"]
siyasi_rutbeler = ["genel başkanı", "milletvekili", "bakan", "başbakan", "cumhurbaşkanı", "dışişleri"]
siyasi_kavramlar = ["abd", "erdoğan", "kılıçdaroğlu", "demirtaş", "bahçeli", "akşener", "avrupa", "büyükşehir", "anayasa", "abd"]
siyasi_partiler = ["akp", "chp", "mhp", "hdp"]
spor_kavramlar = ["teknik", "milli", "gol", "takım", "maç", "transfer", "forma", "uefa", "direktör", "terim"]
takimlar = ["fenerbahçe", "galatasaray", "beşiktaş", "trabzonspor", "barcelona", "arjantin", "kocaelispor"]
dallar = ["futbolcu", "kupa", "saha", "hakem", "lig", "rakip", "şampiyon", "deplasman", "futbol", "basketbol", "penaltı"]
EKONOMI = 1
MAGAZIN = 2
SAGLIK = 3
SIYASI = 4
SPOR = 5
BELIRSIZ = -1
```
### Labeling functions.
```
from snorkel.labeling import labeling_function
import re
@labeling_function()
def para_iceriyor(sample_new):
for para_tipi in para:
if re.search(para_tipi, sample_new.Haber):
return EKONOMI
return BELIRSIZ
@labeling_function()
def ekonomik_kavram_iceriyor(sample_new):
for ekonomik_kavram in ekonomi_kavramlar:
if re.search(ekonomik_kavram, sample_new.Haber):
return EKONOMI
return BELIRSIZ
@labeling_function()
def sayi_birimi_iceriyor(sample_new):
for sayi_birimi in sayi_birimleri:
if re.search(sayi_birimi, sample_new.Haber):
return EKONOMI
return BELIRSIZ
@labeling_function()
def magazin_kavrami_iceriyor(sample_new):
for magazin_kavrami in magazin_kavramlar:
if re.search(magazin_kavrami, sample_new.Haber):
return MAGAZIN
return BELIRSIZ
@labeling_function()
def magazin_meslegi_iceriyor(sample_new):
for magazin_meslegi in magazin_meslekler:
if re.search(magazin_meslegi, sample_new.Haber):
return MAGAZIN
return BELIRSIZ
@labeling_function()
def magazin_kisiler_iceriyor(sample_new):
for magazin_kisisi in magazin_kisiler:
if re.search(magazin_kisisi, sample_new.Haber):
return MAGAZIN
return BELIRSIZ
@labeling_function()
def vucut_bolumu_iceriyor(sample_new):
for vucut_bolumu in vucut_bolumleri:
if re.search(vucut_bolumu, sample_new.Haber):
return SAGLIK
return BELIRSIZ
@labeling_function()
def saglik_kavramlari_iceriyor(sample_new):
for saglik_kavrami in saglik_kavramlar:
if re.search(saglik_kavrami, sample_new.Haber):
return SAGLIK
return BELIRSIZ
@labeling_function()
def hastalik_iceriyor(sample_new):
for hastalik in hastaliklar:
if re.search(hastalik, sample_new.Haber):
return SAGLIK
return BELIRSIZ
@labeling_function()
def siyasi_rutbe_iceriyor(sample_new):
for siyasi_rutbe in siyasi_rutbeler:
if re.search(siyasi_rutbe, sample_new.Haber):
return SIYASI
return BELIRSIZ
@labeling_function()
def siyasi_kavram_iceriyor(sample_new):
for siyasi_kavram in siyasi_kavramlar:
if re.search(siyasi_kavram, sample_new.Haber):
return SIYASI
return BELIRSIZ
@labeling_function()
def siyasi_parti_iceriyor(sample_new):
for siyasi_parti in siyasi_partiler:
if re.search(siyasi_parti, sample_new.Haber):
return SIYASI
return BELIRSIZ
@labeling_function()
def spor_kavramlar_iceriyor(sample_new):
for spor_kavrami in spor_kavramlar:
if re.search(spor_kavrami, sample_new.Haber):
return SPOR
return BELIRSIZ
@labeling_function()
def takimlar_iceriyor(sample_new):
for takim in takimlar:
if re.search(takim, sample_new.Haber):
return SPOR
return BELIRSIZ
@labeling_function()
def spor_dallari_iceriyor(sample_new):
for spor_dali in dallar:
if re.search(spor_dali, sample_new.Haber):
return SPOR
return BELIRSIZ
from snorkel.labeling import PandasLFApplier
lfs = [para_iceriyor, ekonomik_kavram_iceriyor, sayi_birimi_iceriyor, magazin_kavrami_iceriyor, magazin_meslegi_iceriyor,
magazin_kisiler_iceriyor, vucut_bolumu_iceriyor, saglik_kavramlari_iceriyor, hastalik_iceriyor, siyasi_rutbe_iceriyor,
siyasi_kavram_iceriyor, siyasi_parti_iceriyor, spor_kavramlar_iceriyor, takimlar_iceriyor, spor_dallari_iceriyor]
applier = PandasLFApplier(lfs=lfs)
L_train = applier.apply(df=df_train)
L_test = applier.apply(df=df_test)
from snorkel.labeling import LFAnalysis
LFAnalysis(L=L_train, lfs=lfs).lf_summary()
L_train.shape
```
### Convert the labels from LFs into a single noise-aware probabilistic label per data point
```
from snorkel.labeling.model import MajorityLabelVoter
majority_model = MajorityLabelVoter(6)
preds_train = majority_model.predict(L=L_train)
from snorkel.labeling.model import LabelModel
label_model = LabelModel(cardinality=6, verbose=True)
label_model.fit(L_train=L_train, n_epochs=500, log_freq=100, seed=123)
Y_test = df_test.Sınıf.values
majority_acc = majority_model.score(L=L_test, Y=Y_test, tie_break_policy="random")[
"accuracy"
]
print(f"{'Majority Vote Accuracy:':<25} {majority_acc * 100:.1f}%")
label_model_acc = label_model.score(L=L_test, Y=Y_test, tie_break_policy="random")[
"accuracy"
]
print(f"{'Label Model Accuracy:':<25} {label_model_acc * 100:.1f}%")
```
The **majority vote model** or more **sophisticated LabelModel** could in principle be used directly as a classifier if the outputs of our labeling functions were made available at test time. However, these models (i.e. these re-weighted combinations of our labeling function's votes) will *abstain on the data points that our labeling functions don't cover* (and additionally, may require slow or unavailable features to execute at test time).
```
from snorkel.labeling import filter_unlabeled_dataframe
probs_train = label_model.predict_proba(L=L_train)
df_train_filtered, probs_train_filtered = filter_unlabeled_dataframe(
X=df_train, y=probs_train, L=L_train
)
probs_train.shape
df_train.size
```
## Training a Classifier
```
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(ngram_range=(1, 5))
X_train = vectorizer.fit_transform(df_train_filtered.Haber.tolist())
X_test = vectorizer.transform(df_test.Haber.tolist())
from snorkel.utils import probs_to_preds
preds_train_filtered = probs_to_preds(probs=probs_train_filtered)
preds_train_filtered.shape
```
### Logistic Regression
```
from sklearn.linear_model import LogisticRegression
sklearn_model = LogisticRegression(C=1e3, solver="liblinear")
sklearn_model.fit(X=X_train, y=preds_train_filtered)
print(f"Test Accuracy: {sklearn_model.score(X=X_test, y=Y_test) * 100:.1f}%")
```
### Naive Bayes
```
from sklearn.metrics import accuracy_score
from sklearn import naive_bayes
# fit the training dataset on the NB classifier
Naive = naive_bayes.MultinomialNB()
Naive.fit(X_train, preds_train_filtered)
# predict the labels on validation dataset
predictions_NB = Naive.predict(X_test)
# Use accuracy_score function to get the accuracy
print("Naive Bayes Accuracy Score -> ", accuracy_score(predictions_NB, Y_test)*100)
```
### SVM
```
from sklearn import svm
# Classifier - Algorithm - SVM
# fit the training dataset on the classifier
SVM = svm.SVC(C=1.0, kernel='linear', degree=3, gamma='auto')
SVM.fit(X_train, preds_train_filtered)
# predict the labels on validation dataset
predictions_SVM = SVM.predict(X_test)
# Use accuracy_score function to get the accuracy
print("SVM Accuracy Score -> ", accuracy_score(predictions_SVM, Y_test)*100)
```
| github_jupyter |
# Prerequisites
```
# path to the root directory from the Google Drive root
GD_DATA_ROOT_PATH = 'UoB Project/training_data'
# data directory name in the <GD_DATA_ROOT_PATH>
# NOTE: in the dir, there should be one zip file
# that contain all the required data files including images to configuration
GD_DATA_DIR_NAME = 'd5_i321_c4_r416_sd64'
# Yolo v4 configuration data
SUBDIVISIONS = '64'
YOLO_WIDTH = '416'
YOLO_HEIGHT = '416'
!/usr/local/cuda/bin/nvcc --version
# define helper functions
def imShow(path):
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread(path)
height, width = image.shape[:2]
resized_image = cv2.resize(image,(3*width, 3*height), interpolation = cv2.INTER_CUBIC)
fig = plt.gcf()
fig.set_size_inches(18, 10)
plt.axis("off")
plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB))
plt.show()
# use this to upload files
def upload():
from google.colab import files
uploaded = files.upload()
for name, data in uploaded.items():
with open(name, 'wb') as f:
f.write(data)
print ('saved file', name)
# use this to download a file
def download(path):
from google.colab import files
files.download(path)
```
# Building Darknet
```
!git clone https://github.com/AlexeyAB/darknet
%cd /content/darknet
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
!make
!ln -s /content/darknet/darknet /usr/bin
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
!darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/person.jpg
imShow('predictions.jpg')
```
# Setting up Google Drive
```
from google.colab import drive
drive.mount('/content/drive')
!ln -s "/content/drive/My Drive/{GD_DATA_ROOT_PATH}" /data
%cd /content/darknet
!unzip "/data/{GD_DATA_DIR_NAME}/*.zip" -d training
!cp cfg/yolov4.cfg training/obj.cfg
%cd /content/darknet/training
n_classes = !echo -e $(sed -n /class/p obj.data | cut -d'=' -f2)
n_classes = int(n_classes[0])
print('No of classes::' + str(n_classes))
!sed -i 's/backup = backup\//backup = \/data\/{GD_DATA_DIR_NAME}\/backup\//' obj.data
!sed -i 's/subdivisions=8/subdivisions={SUBDIVISIONS}/' obj.cfg
!sed -i 's/width=608/width={YOLO_WIDTH}/' obj.cfg
!sed -i 's/height=608/height={YOLO_HEIGHT}/' obj.cfg
max_batches = n_classes * 2000
steps1 = int(max_batches / 100 * 80)
steps2 = int(max_batches / 100 * 90)
filters = (n_classes + 5) * 3
!sed -i 's/max_batches = 500500/max_batches = {max_batches}/' obj.cfg
!sed -i 's/steps=400000,450000/steps={steps1},{steps2}/' obj.cfg
!sed -i 's/classes=80/classes={n_classes}/' obj.cfg
!sed -i 's/filters=255/filters={filters}/' obj.cfg
%cd /content/darknet
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137
assert False
import os.path
%cd /content/darknet
backup_path = '/data/{}/backup'.format(GD_DATA_DIR_NAME)
backup_weights_path = '{}/obj_last.weights'.format(backup_path)
backup_log_path = '{}/output.txt'.format(backup_path)
backup_cfg_path = '{}/obj.cfg'.format(backup_path)
backup_data_path = '{}/obj.data'.format(backup_path)
backup_names_path = '{}/obj.names'.format(backup_path)
config_path = 'training/obj.cfg'
data_path = 'training/obj.data'
names_path = 'training/obj.names'
weights_path = 'yolov4.conv.137'
# copy the required files to drive
!mkdir -p "{backup_path}"
!touch -a "{backup_log_path}"
!cp "{config_path}" "{backup_cfg_path}"
!cp "{data_path}" "{backup_data_path}"
!cp "{names_path}" "{backup_names_path}"
if os.path.isfile(backup_weights_path):
print("Backup weight file found!")
print("Starting from last weight!")
!darknet detector train "{data_path}" "{config_path}" "{backup_weights_path}" -dont_show &>> "{backup_log_path}"
else:
print("Backup weight NOT found!")
print("Starting from scratch")
!darknet detector train "{data_path}" "{config_path}" "{weights_path}" -dont_show &> "{backup_log_path}"
!ls /data/d1_321_c4/backup/
# show chart.png of how custom object detector did with training
imShow('chart.png')
```
| github_jupyter |
# 7. Temporal Difference Learning Introduction
We are now going to look at a third method for solving MDPs, _**Temporal Difference Learning**_. TD is one of the most important ideas in RL, and we will see how it combines ideas from the first two techniques, Dynamic Programming and Monte Carlo.
Recall that one of the disadvantages of DP was that it requires a full model of environment, and never learns from experience. On the other hand, we saw that MC does learn from experience, and we will shortly see that TD learns from experience as well.
With the Monte Carlo method, we saw that we could only update the value function after completing an episode. On the other hand, DP uses bootstrapping and was able to improve its estimates based on existing estimates. We will see that TD learning also uses bootstrapping, and furthermore is fully online, so we don't need to wait for an episode to finish before we start updating our value estimates.
In this section we will take our standard approach:
> 1. First we will look at the prediction problem, aka finding the value function given a policy.
2. Second we will look at the control problem. We will look at 2 different ways of approaching the control problem: **SARSA** and **Q-Learning**.
---
# 2. Prediction Problem - `TD(0)`
We are now going to look at how to apply TD to the prediction problem, aka finding the value function. The reason that there is a 0 in the name is because there are other TD learning methods such as `TD(1)` and `TD(`${\lambda}$`)`, but they are outside the scope of this course. They are similar, but not necessary to understand _Q-learning_ and _Approximation methods_, which is what we eventually want to get to.
## 2.1 Monte Carlo Disadvantage
One big disadvantage of Monte Carlo was that we needed to wait until the episode is finished before we can calculate the returns, since the return depends on all future rewards. Also, recall that the MC method is to average the returns, and that earlier in the course we looked at different ways of calculating averages.
## 2.2 `TD(0)`
In particular, we can look at the method that does not require us to store all of the returns: _the moving average_.
$$Y_t = (1 - \alpha)Y_{t-1} + \alpha X_t$$
$$Y_t = Y_{t-1} - \alpha Y_{t-1} + \alpha X_t$$
$$Y_t = Y_{t-1} + \alpha ( X_t - Y_{t-1})$$
Recall that $\alpha$ can be constant or decay with time. So, if we use this formula it would be an alternative way of caculating the average reward for a state.
$$V(S_t) \leftarrow V(S_t) + \alpha \big[G(t) - V(S_t)\big]$$
Annotated:
<img src="https://drive.google.com/uc?id=1j1uV3Fl04qjSPfURVMn5QB32K4nrykP3">
In this case we have chosen to not multiply the previous value by $1 - \alpha$, and we have chosen to have $\alpha$ be constant (instead of slowly get smaller over time).
Now recall the definition of $V$; it is the expected value of the return, given a state:
$$V(s) = E \big[G(t) \mid S_t = s\big]$$
But, remember that we can also define it recursively:
$$V(s) = E \big[R(t+1) + \lambda V(S_{t+1}) \mid S_t =s\big]$$
So, it is reasonable to ask if we can just replace the return in the update equation with this recursive definition of $V$! What we get from this, is the `TD(0)` method:
$$V(S_t) = V(S_t) + \alpha \big[R(t+1) + \lambda V(S_{t+1}) - V(S_t)\big]$$
<span style="color:#0000cc">$$\text{TD(0)} \rightarrow V(s) = V(s) + \alpha \big[r + \lambda V(s') - V(s)\big]$$</span>
We can also see how this is fully online! We are not calculating $G$, the full return. Instead, we are just using another $V$ estimate, in particular the $V$ for the next state. What this also tells us is that we cannot update $V(s)$ until we know $V(s')$. So, rather than waiting for the entire episode to finish, we just need to wait until we reach the next state to update the value for the current state.
## 2.3 Sources of Randomness
It is helpful to examine how these estimates work, and what the sources of randomness are.
> * With MC, the randomness came from the fact that each episode could play out in a different way. So, the return for a state would be different if all the later state transitions had some randomness.
* With **`TD(0)`** we have yet another source of randomness. In particular, we don't even know the return, so instead we use $r + \gamma V(s')$ to estimate the return $G$.
## 2.4 Summary
We just looked at why `TD(0)` is advantageous in comparison to MC/DP.
> * Unlike DP, we do not require a full model of the environment, we learn from experience, and only update V for states we visit.
* Unlike MC, we don't need to wait for an episode to finish before we can start learning. This is advantageous in situations where we have very long episodes. We can improve our performance during the episode itself, rather than having to wait until the next episode.
* It can even be used for continuous tasks, in which there are no episodes at all.
---
# 3. `TD(0)` in Code
```
import numpy as np
from common import standard_grid, negative_grid, print_policy, print_values
SMALL_ENOUGH = 10e-4
GAMMA = 0.9
ALPHA = 0.1 # Learning Rate
ALL_POSSIBLE_ACTIONS = ('U', 'D', 'L', 'R')
# NOTE: This is only policy evaluation, not optimization
def random_action (a, eps=0.1):
"""Adding randomness to ensure that all states are visited. We will use epsilon-soft
to ensure that all states are visited. What happens if you don't do this? i.e. eps = 0"""
p = np.random.random()
if p < (1 - eps):
return a
else:
return np.random.choice(ALL_POSSIBLE_ACTIONS)
def play_game(grid, policy):
"""Much simpler than MC version, because we don't need to calculate any returns. All
we need to do is return a list of states and rewards."""
s = (2, 0)
grid.set_state(s)
states_and_rewards = [(s, 0)] # list of tuples of (state, reward)
while not grid.game_over():
a = policy[s]
a = random_action(a)
r = grid.move(a)
s = grid.current_state()
states_and_rewards.append((s, r))
return states_and_rewards
if __name__ == '__main__':
# Use standard grid so that we can compare to iterative policy evaluation
grid = standard_grid()
# print rewards
print("rewards:")
print_values(grid.rewards, grid)
# state -> action
policy = {
(2, 0): 'U',
(1, 0): 'U',
(0, 0): 'R',
(0, 1): 'R',
(0, 2): 'R',
(1, 2): 'R',
(2, 1): 'R',
(2, 2): 'R',
(2, 3): 'U',
}
# Initialize V(s) and returns to 0. This occurs outside of for loop. The entire purpose
# of the for loop is to converge onto V(s)! Remember, V(s) is a function, but since
# the number of states are enumerable, relatively small, and discrete, we can find
# the approximate value for each state. We don't need to solve for a continuous equation!
states = grid.all_states()
V = {v: 0 for v in states}
# Repeat until convergence
for it in range(1000):
# Generate an episode using pi
states_and_rewards = play_game(grid, policy)
# the first (s, r) tuple is the state we start in and 0
# (since we don't get a reward) for simply starting the game
# the last (s, r) tuple is the terminal state and the final reward
# the value for the terminal state is by definition 0, so we don't
# care about updating it.
# Once we have our states and rewards, we loop through them and do the TD(0) update
# which is the equation from the theory we discussed. Notice that here we have
# generated a full episode and then are making our V(s) updates. We could have done
# them inline, but this allows for them to be cleaner and easier to follow.
# This is where our update equation is implemented
for t in range(len(states_and_rewards) - 1):
s, _ = states_and_rewards[t]
s2, r = states_and_rewards[t + 1]
# We will update V(s) AS we experience the episode
update = V[s] + ALPHA * (r + GAMMA * V[s2] - V[s])
V[s] = update
print("values:")
print_values(V, grid)
print("policy:")
print_policy(policy, grid)
```
---
# 3. SARSA
We are now going to look at how to apply the `TD(0)` algorithm to the control problem. We are going to apply `TD(0)` to _policy iteration_. In particular, we are going to use the value iteration method, where we continually update $Q$ based on itself. We are going to do it in place, and any actions we take are always greedy with respect to our current estimate of $Q$. So, we will be skipping the part where we do a full policy evaluation, and just immediately going to the more efficient form.
Recall from the Monte Carlo section, that the reason we want to use $Q$ is because it allows us to choose an action based on the argmax of $Q$. We are not able to do this with $V$ because it is only indexed by the state. Since $Q$ has the same recursive form, we can apply the same update equation as before:
$$Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha \Big[R(t+1) + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)\Big]$$
$$Q(s, a) \leftarrow Q(s, a) + \alpha \Big[r + \gamma Q(s', a') - Q(s,a)\Big]$$
Notice that we have the same limitation as we did with MC; since $Q$ is indexed by both state and action, we need many more iterations to gather enough data for convergence. Because the update depends on the 5-tuple (s,a,r,s',a') this method is called _**SARSA**_.
## 3.1 What Policy to use?
Since SARSA requires us to know $Q(s,a)$ for all the possible actions $a$ in state $s$, so that we can accurately chose the argmax, we have the same problem as we did with MC. Recall, the problem was that if you follow a deterministic policy, you will only ever do $\frac{1}{|A|}$ of the possible actions, which will leave most of $Q$ undefined. To fix this we either have to use exploring starts, or a policy that allows for exploration, like epsilon-greedy. Since we know that exploring starts is not realistic, we are going to use epsilon greedy.
## 3.2 Pseudocode
```
Q(s,a) = artibtrary, Q(terminal, a) = 0
for t=1..N:
# Start a game
s = start_state, a = epsilon_greedy_from(Q(s))
while not game_over:
s', r = do_action(a)
a' = epsilon_greedy_from(Q(s'))
Q(s,a) = Q(s,a) + alpha*[r + gamma*Q(s', a') - Q(s,a)]
s = s', a = a'
```
We can see that our pseudocode functions as follows:
> * We initialize $Q$ arbitrarily, and set it to 0 for any terminal state.
* We then enter an infinite loop
* Inside the loop we start a game
* We get the first state and select the first action based on epsilon greedy and the current $Q$. This is our tuple (s, a)
* Inside this loop we start another loop that ends when the game is over
* We do the action $a$ to get to the state $s'$ and get the reward $r$
* We then choose the next state based on epsilon greedy and the current $Q$. We'll call this $a'$
* Then we do our update for $Q(s,a)$, which depends on $Q(s,a)$ itself, $r$, and $Q(s',a')$
* Next, we update s to be s', and we update a to be a'
An interesting fact about SARSA is that a convergence proof has never been published. However, it has been stated that SARSA will converge if the policy converges to a greedy policy. One way to achieve this is to let $\epsilon = \frac{1}{t}$, where $t$ represents time.
## 3.3 Learning Rate
Recall that we can also have a decaying learning rate. There is a problem with using a $\alpha = \frac{1}{t}$ decay though. Only one state action pair will be updated in $Q$. Therefore, the learning rate will decay for values of $Q$ that have never been updated before. You could try to remedy this by only decaying the learning rate once per episode, but you still have the same problem. Only a subset of the full set of states are going to be visited in the episode, and only one of the possible actions per state are going to be taken. So, even if you decay the learning rate once per episode, you will still be decaying the learning rate for parts of $Q$ that have never been updated before.
To solve this, we take inspiration from deep learning; in particular the AdaGrad and RMSprop algorithms, which are both adaptive learning rates. Recall, what makes these unique is that the effective learning rates decrease more when past gradients have been large. In other words, the more something has changed in the past, the more we will decrease the learning rate in the future.
Our version will be simpler than these techniques, but the idea is the same. We are going to keep a count of how many times we have seen a state action pair (s, a). We will set $\alpha$ to be the original $\alpha$ divided by this count:
$$\alpha(s,a) = \frac{\alpha_0}{count(s,a)}$$
Equivalently:
$$\alpha(s,a) = \frac{\alpha_0}{k + m*count(s,a)}$$
Every state action pair now has its own alpha, and so each will have its own individually decaying learning rate.
---
# 4. SARSA in Code
```
import numpy as np
import matplotlib.pyplot as plt
from common import standard_grid, negative_grid, print_policy, print_values, max_dict
GAMMA = 0.9
ALPHA = 0.1 # Effective Alpha will be derived from this initial alpha
ALL_POSSIBLE_ACTIONS = ('U', 'D', 'L', 'R')
# Notice this in this script there is no play_game function. That is because with SARSA
# playing the games and performing the updates cannot be separate. We have to do the
# updates while playing the game. So, TD methods are fully online!
if __name__ == '__main__':
# NOTE: if we use the standard grid, there's a good chance we will end up with
# suboptimal policies
# e.g.
# ---------------------------
# R | R | R | |
# ---------------------------
# R* | | U | |
# ---------------------------
# U | R | U | L |
# since going R at (1,0) (shown with a *) incurs no cost, it's OK to keep doing that.
# we'll either end up staying in the same spot, or back to the start (2,0), at which
# point we whould then just go back up, or at (0,0), at which point we can continue
# on right.
# instead, let's penalize each movement so the agent will find a shorter route.
grid = negative_grid(step_cost=-0.1)
# print rewards
print("rewards:")
print_values(grid.rewards, grid)
# Initialize Q(s,a)
Q = {
state: {
a: 0
for a in ALL_POSSIBLE_ACTIONS
}
for state in states
}
# Create 2 update counts dictionaries. update_counts is to see what proportion of time
# we spend in each state. update_counts_sa is for the adaptive learning rate.
update_counts = {}
update_counts_sa = {}
for s in states:
update_counts_sa[s] = {}
for a in ALL_POSSIBLE_ACTIONS:
update_counts_sa[s][a] = 1.0
# Repeat until convergence
t = 1.0 # Using t for epsilon greedy. Only increases every 100 steps, by small amount.
deltas = []
for it in range(10000):
if it % 100 == 0:
t += 1e-2
if it % 2000 == 0:
print("it:", it)
# Instead of 'generating' an epsiode, we will PLAY an episode within this loop
s = (2, 0) # start state
grid.set_state(s)
# the first (s, r) tuple is the state we start in and 0 (since we don't get a
# reward) for simply starting the game. The last (s, r) tuple is the terminal
# state and the final reward the value for the terminal state is by definition 0,
# so we don't care about updating it.
a = max_dict(Q[s])[0]
a = random_action(a, eps=0.5/t)
biggest_change = 0
# Enter the game loop
while not grid.game_over():
# Do action to find reward and next state
r = grid.move(a)
s2 = grid.current_state()
# Find next action based on epsilon greedy. We need the next action as well since
# Q(s,a) depends on Q(s',a'). If s2 not in policy then its a terminal state, where
# all Q are 0
a2 = max_dict(Q[s2])[0]
a2 = random_action(a2, eps=0.5/t) # eps not constant, instead decaying with time
# Calculate alpha -> Initial alpha / Count
alpha = ALPHA / update_counts_sa[s][a]
update_counts_sa[s][a] += 0.005 # Update count, only by small amount
old_qsa = Q[s][a] # Keeping track of deltas. Want to know how Q changes as we learn
# Q update!
Q[s][a] = Q[s][a] + alpha*(r + GAMMA*Q[s2][a2] - Q[s][a])
biggest_change = max(biggest_change, np.abs(old_qsa - Q[s][a]))
# Update update_counts dictionary - want to know how often Q(s) has been updated
update_counts[s] = update_counts.get(s,0) + 1
# Set s and a to new s and a (s' and a'). Next state becomes current state.
s = s2
a = a2
deltas.append(biggest_change)
plt.plot(deltas)
plt.show()
# Since we want to print the policy, we need to find it by taking the argmax of Q
# determine the policy from Q*
# find V* from Q*
policy = {}
V = {}
for s in grid.actions.keys():
a, max_q = max_dict(Q[s])
policy[s] = a
V[s] = max_q
# what's the proportion of time we spend updating each part of Q?
print("update counts:")
total = np.sum(list(update_counts.values()))
for k, v in update_counts.items():
update_counts[k] = float(v) / total
print_values(update_counts, grid)
print("values:")
print_values(V, grid)
print("policy:")
print_policy(policy, grid)
```
---
# 5. Q-Learning
We are now going to discuss _**Q-Learning**_. This is different from the strategy that we have been taking so far. The main theme so far behind each of the control algorithms that we have studied so far has been generalized policy iteration. We always alternate between:
> * Policy evaluation
* Policy improvement (choosing an action greedily based on the current value function estimate)
All of these control algorithms are referred to as _**on-policy**_ methods. That means that we are playing the game using the current best policy. What is unique about Q-learning is that it is an _**off-policy**_ method. This means that the actions you take can be completely random, and yet you still end up being able to calculate the optimal policy.
## 5.1 Q-Learning Theory
So, how does Q-Learning actually work? Well, it actually looks a lot like SARSA. The idea is, instead of choosing $a'$ based on the argmax of $Q$, we instead update $Q$ based on the max over all actions.
$$Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha \Big[R(t+1) + \gamma max_{a'} Q(S_{t+1}, a') - Q(S_t, A_t)\Big]$$
$$Q(s, a) \leftarrow Q(s, a) + \alpha \Big[r + \gamma max_{a'} Q(s', a') - Q(s,a)\Big]$$
Now you think yourself: isn't that exactly the same thing? If we choose $a'$ as the argmax of $Q$, then the thing beside $\gamma$ will be $Q(s',a')$, which is maxed over $a'$.
The difference is, that Q-Learning is _off-policy_. With Q-Learning, remember that it is an off policy method. So, $Q(s',a')$ might be the max over all $a'$, but this doesn't necessarily mean that $a'$ has to be our next action. That is the difference. We update $Q(s,a)$ using the max of $Q(s',a')$, even if we don't end up doing the action $a'$ in the next step. What this suggests is that it doesn't really matter what policy we follow; we can choose actions randomly and still get the same answer. In reality, if we do take purely random actions, your agent will act suboptimally very often and that will make your episodes last longer.
## 5.2 Key Difference
So, the key difference to remember:
> It doesn't matter what policy we use to play the game. It is reasonable to ask then, under what circumstances is Q-Learning equivalent to SARSA? If the policy you use during Q-Learning is a greedy policy, meaning that you always choose the argmax over $Q$, then your $Q(s',a')$ will correspond to the next action you take. In that case, you will be doing SARSA, but also Q-Learning.
---
# 6. Q-Learning in Code
```
GAMMA = 0.9
ALPHA = 0.1
ALL_POSSIBLE_ACTIONS = ('U', 'D', 'L', 'R')
if __name__ == '__main__':
# NOTE: if we use the standard grid, there's a good chance we will end up with
# suboptimal policies
# e.g.
# ---------------------------
# R | R | R | |
# ---------------------------
# R* | | U | |
# ---------------------------
# U | R | U | L |
# since going R at (1,0) (shown with a *) incurs no cost, it's OK to keep doing that.
# we'll either end up staying in the same spot, or back to the start (2,0), at which
# point we whould then just go back up, or at (0,0), at which point we can continue
# on right.
# instead, let's penalize each movement so the agent will find a shorter route.
#
# grid = standard_grid()
grid = negative_grid(step_cost=-0.1)
# print rewards
print("rewards:")
print_values(grid.rewards, grid)
# no policy initialization, we will derive our policy from most recent Q
# initialize Q(s,a)
Q = {}
states = grid.all_states()
for s in states:
Q[s] = {}
for a in ALL_POSSIBLE_ACTIONS:
Q[s][a] = 0
# let's also keep track of how many times Q[s] has been updated
update_counts = {}
update_counts_sa = {}
for s in states:
update_counts_sa[s] = {}
for a in ALL_POSSIBLE_ACTIONS:
update_counts_sa[s][a] = 1.0
# repeat until convergence
t = 1.0
deltas = []
for it in range(10000):
if it % 100 == 0:
t += 1e-2
if it % 2000 == 0:
print("it:", it)
# instead of 'generating' an epsiode, we will PLAY
# an episode within this loop
s = (2, 0) # start state
grid.set_state(s)
# the first (s, r) tuple is the state we start in and 0
# (since we don't get a reward) for simply starting the game
# the last (s, r) tuple is the terminal state and the final reward
# the value for the terminal state is by definition 0, so we don't
# care about updating it.
a, _ = max_dict(Q[s])
biggest_change = 0
while not grid.game_over():
a = random_action(a, eps=0.5/t) # epsilon-greedy
# Can also perform uniform random action also works, but it is slower since you
# can bump into walls
# a = np.random.choice(ALL_POSSIBLE_ACTIONS)
r = grid.move(a)
s2 = grid.current_state()
# Adaptive learning rate
alpha = ALPHA / update_counts_sa[s][a]
update_counts_sa[s][a] += 0.005
# We will update Q(s,a) AS WE EXPERIENCE the episode
old_qsa = Q[s][a]
# The difference between SARSA and Q-Learning is with Q-Learning we will use this
# max[a']{ Q(s',a') } in our update. Even if we do not end up taking this action
# in our next step
a2, max_q_s2a2 = max_dict(Q[s2])
Q[s][a] = Q[s][a] + alpha * (r + GAMMA*max_q_s2a2 - Q[s][a])
biggest_change = max(biggest_change, np.abs(old_qsa - Q[s][a]))
# We want to know how often Q(s) has been updated too
update_counts[s] = update_counts.get(s,0) + 1
# Next state becomes current state. Go back to top of while loop, and we can see
# that we call `a = random_action(a, eps=0.5/t)`. This means that the `a` we
# chose here may not actually be used. `a2` was used to update our value function
# `Q`, but it may not be used in the next iteration. If we were following a purely
# greedy policy then it would be used, and that is identical to SARSA.
s = s2
a = a2
deltas.append(biggest_change)
plt.plot(deltas)
plt.show()
# determine the policy from Q*
# find V* from Q*
policy = {}
V = {}
for s in grid.actions.keys():
a, max_q = max_dict(Q[s])
policy[s] = a
V[s] = max_q
# what's the proportion of time we spend updating each part of Q?
print("update counts:")
total = np.sum(list(update_counts.values()))
for k, v in update_counts.items():
update_counts[k] = float(v) / total
print_values(update_counts, grid)
print("values:")
print_values(V, grid)
print("policy:")
print_policy(policy, grid)
```
---
# 7. Temporal Difference Learning Summary
Temporal Difference learning combines aspects from both Monte Carlo and Dynamic Programming. From Monte Carlo we incorporate ideas like learning from experience, meaning we actually play the game. We also learn how to generalize this idea of taking the sample mean from the returns (based on what we learned in the multi-armed bandit section). The problem of MC is that it is not fully online.
We also incorporated ideas from Dynamic Programming such as bootstrapping, and using the recursive form of the value function to estimate the return.
When we put these two together, we get `TD(0)`, where instead of taking the sample mean of returns, we take sample mean of estimated returns, based on the current reward, $r$, and the next state value, $V(s')$.
For the **control** problem, we saw that again we needed to use the action value function instead of the state-value function, for the same reason as Monte Carlo Estimation. We derived the SARSA algorithm which combines ideas from value iteration, and `TD(0)`. We then discussed the difference between on-policy and off-policy algorithms and we determined in hindsight that all of the control solutions that we have seen have been _on-policy_, until now. At this point we learned about an _off-policy_ control solution, Q-Learning (which has gained traction recently, in part due to deep Q-Learning).
One disadvantage of _all_ of these methods, is that they require us to estimate $Q$. As we learned early on, the state space can easily become infeasible to enumerate, and then on top of that for every state you need to enumerate all of the possible actions as well. So, in real world problems it is very possible that $Q$ does not even fit into memory! The method of measuring $Q(s,a)$ and storing it as a dictionary is called the _tabular method_. In fact, all of the methods we have learned about so far have been tabular methods. As you may imagine, tabular methods are only practical for small problems. In the next section, we will learn a new technique that helps us get around this problem, using _function approximation_. This will allow us to compress the amount of space that we need to represent $Q$.
| github_jupyter |
```
import cv2
import os
import tensorflow as tf
from tensorflow.keras import metrics
from tensorflow.keras.layers import Dense, Conv2D, BatchNormalization, Activation, MaxPooling2D, UpSampling2D
from tensorflow.keras.layers import AveragePooling2D, Input, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler
from tensorflow.keras.callbacks import ReduceLROnPlateau
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.regularizers import l2
from tensorflow.keras import backend as K
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Model
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import os
import cv2
import h5py
# 自動增長 GPU 記憶體用量
physical_devices = tf.config.list_physical_devices('GPU')
print(physical_devices)
tf.config.experimental.set_memory_growth(physical_devices[0], True)
from tensorflow.python.framework.ops import disable_eager_execution
disable_eager_execution()
# Training parameters
batch_size = 32 # orig paper trained all networks with batch_size=128
epochs = 200
data_augmentation = True
num_classes = 10
n = 3
# Model version
# Orig paper: version = 1 (ResNet v1), Improved ResNet: version = 2 (ResNet v2)
version = 1
# Computed depth from supplied model parameter n
if version == 1:
depth = n * 6 + 2
elif version == 2:
depth = n * 9 + 2
# Model name, depth and version
model_type = 'CIFAR10_ResNet%dv%d' % (depth, version)
# Load the CIFAR10 data.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# Input image dimensions.
input_shape = x_train.shape[1:]
# Normalize data.
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
subtract_pixel_mean = True
# If subtract pixel mean is enabled
if subtract_pixel_mean:
x_train_mean = np.mean(x_train, axis=0)
x_train -= x_train_mean
x_test -= x_train_mean
def resnet_layer(inputs,
num_filters=16,
kernel_size=3,
strides=1,
activation='relu',
kernel_regularizer=l2(1e-4),
batch_normalization=True,
conv_first=True):
"""2D Convolution-Batch Normalization-Activation stack builder
# Arguments
inputs (tensor): input tensor from input image or previous layer
num_filters (int): Conv2D number of filters
kernel_size (int): Conv2D square kernel dimensions
strides (int): Conv2D square stride dimensions
activation (string): activation name
batch_normalization (bool): whether to include batch normalization
conv_first (bool): conv-bn-activation (True) or
bn-activation-conv (False)
# Returns
x (tensor): tensor as input to the next layer
"""
conv = Conv2D(num_filters,
kernel_size=kernel_size,
strides=strides,
padding='same',
kernel_initializer='he_normal',
kernel_regularizer=kernel_regularizer)
x = inputs
if conv_first:
x = conv(x)
if batch_normalization:
x = BatchNormalization()(x)
if activation is not None:
x = Activation(activation)(x)
else:
if batch_normalization:
x = BatchNormalization()(x)
if activation is not None:
x = Activation(activation)(x)
x = conv(x)
return x
def resnet_v1(input_shape, depth, num_classes=10, kernel_regularizer=l2(1e-4)):
"""ResNet Version 1 Model builder [a]
Stacks of 2 x (3 x 3) Conv2D-BN-ReLU
Last ReLU is after the shortcut connection.
At the beginning of each stage, the feature map size is halved (downsampled)
by a convolutional layer with strides=2, while the number of filters is
doubled. Within each stage, the layers have the same number filters and the
same number of filters.
Features maps sizes:
stage 0: 32x32, 16
stage 1: 16x16, 32
stage 2: 8x8, 64
The Number of parameters is approx the same as Table 6 of [a]:
ResNet20 0.27M
ResNet32 0.46M
ResNet44 0.66M
ResNet56 0.85M
ResNet110 1.7M
# Arguments
input_shape (tensor): shape of input image tensor
depth (int): number of core convolutional layers
num_classes (int): number of classes (CIFAR10 has 10)
# Returns
model (Model): Keras model instance
"""
if (depth - 2) % 6 != 0:
raise ValueError('depth should be 6n+2 (eg 20, 32, 44 in [a])')
# Start model definition.
num_filters = 16
num_res_blocks = int((depth - 2) / 6)
inputs = Input(shape=input_shape)
x = resnet_layer(inputs=inputs, kernel_regularizer=kernel_regularizer)
# Instantiate the stack of residual units
for stack in range(3):
for res_block in range(num_res_blocks):
strides = 1
if stack > 0 and res_block == 0: # first layer but not first stack
strides = 2 # downsample
y = resnet_layer(inputs=x,
num_filters=num_filters,
kernel_regularizer=kernel_regularizer,
strides=strides)
y = resnet_layer(inputs=y,
num_filters=num_filters,
kernel_regularizer=kernel_regularizer,
activation=None)
if stack > 0 and res_block == 0: # first layer but not first stack
# linear projection residual shortcut connection to match
# changed dims
x = resnet_layer(inputs=x,
num_filters=num_filters,
kernel_size=1,
strides=strides,
activation=None,
kernel_regularizer=kernel_regularizer,
batch_normalization=False)
x = tf.keras.layers.add([x, y])
x = Activation('relu')(x)
num_filters *= 2
# Add classifier on top.
# v1 does not use BN after last shortcut connection-ReLU
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
# Instantiate model.
model = Model(inputs=inputs, outputs=outputs)
return model
def resnet_v2(input_shape, depth, num_classes=10, kernel_regularizer=l2(1e-4)):
"""ResNet Version 2 Model builder [b]
Stacks of (1 x 1)-(3 x 3)-(1 x 1) BN-ReLU-Conv2D or also known as
bottleneck layer
First shortcut connection per layer is 1 x 1 Conv2D.
Second and onwards shortcut connection is identity.
At the beginning of each stage, the feature map size is halved (downsampled)
by a convolutional layer with strides=2, while the number of filter maps is
doubled. Within each stage, the layers have the same number filters and the
same filter map sizes.
Features maps sizes:
conv1 : 32x32, 16
stage 0: 32x32, 64
stage 1: 16x16, 128
stage 2: 8x8, 256
# Arguments
input_shape (tensor): shape of input image tensor
depth (int): number of core convolutional layers
num_classes (int): number of classes (CIFAR10 has 10)
# Returns
model (Model): Keras model instance
"""
if (depth - 2) % 9 != 0:
raise ValueError('depth should be 9n+2 (eg 56 or 110 in [b])')
# Start model definition.
num_filters_in = 16
num_res_blocks = int((depth - 2) / 9)
inputs = Input(shape=input_shape)
# v2 performs Conv2D with BN-ReLU on input before splitting into 2 paths
x = resnet_layer(inputs=inputs,
num_filters=num_filters_in,
kernel_regularizer=kernel_regularizer,
conv_first=True)
# Instantiate the stack of residual units
for stage in range(3):
for res_block in range(num_res_blocks):
activation = 'relu'
batch_normalization = True
strides = 1
if stage == 0:
num_filters_out = num_filters_in * 4
if res_block == 0: # first layer and first stage
activation = None
batch_normalization = False
else:
num_filters_out = num_filters_in * 2
if res_block == 0: # first layer but not first stage
strides = 2 # downsample
# bottleneck residual unit
y = resnet_layer(inputs=x,
num_filters=num_filters_in,
kernel_size=1,
strides=strides,
activation=activation,
batch_normalization=batch_normalization,
kernel_regularizer=kernel_regularizer,
conv_first=False)
y = resnet_layer(inputs=y,
num_filters=num_filters_in,
kernel_regularizer=kernel_regularizer,
conv_first=False)
y = resnet_layer(inputs=y,
num_filters=num_filters_out,
kernel_regularizer=kernel_regularizer,
kernel_size=1,
conv_first=False)
if res_block == 0:
# linear projection residual shortcut connection to match
# changed dims
x = resnet_layer(inputs=x,
num_filters=num_filters_out,
kernel_size=1,
strides=strides,
activation=None,
kernel_regularizer=kernel_regularizer,
batch_normalization=False)
x = tf.keras.layers.add([x, y])
num_filters_in = num_filters_out
# Add classifier on top.
# v2 has BN-ReLU before Pooling
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
# Instantiate model.
model = Model(inputs=inputs, outputs=outputs)
return model
# Convert class vectors to binary class matrices.
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
def lr_schedule(epoch):
"""Learning Rate Schedule
Learning rate is scheduled to be reduced after 80, 120, 160, 180 epochs.
Called automatically every epoch as part of callbacks during training.
# Arguments
epoch (int): The number of epochs
# Returns
lr (float32): learning rate
"""
lr = 1e-3
if epoch > 180:
lr *= 0.5e-3
elif epoch > 160:
lr *= 1e-3
elif epoch > 120:
lr *= 1e-2
elif epoch > 80:
lr *= 1e-1
print('Learning rate: ', lr)
return lr
if version == 2:
model = resnet_v2(input_shape=input_shape, depth=depth, num_classes=num_classes, kernel_regularizer=l2(1e-4))
else:
model = resnet_v1(input_shape=input_shape, depth=depth, num_classes=num_classes, kernel_regularizer=l2(1e-4))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=lr_schedule(0)),
metrics=['accuracy'])
model.summary()
print(model_type)
lr_scheduler = LearningRateScheduler(lr_schedule)
lr_reducer = ReduceLROnPlateau(factor=np.sqrt(0.1),
cooldown=0,
patience=5,
min_lr=0.5e-6)
# Prepare model model saving directory.
save_dir = os.path.join(os.getcwd(), 'saved_models')
import datetime as dt
model_name = 'pmon_%s_%s_model.{epoch:03d}.h5' % (model_type, dt.datetime.now().strftime("%Y%m%d%H"))
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
filepath = os.path.join(save_dir, model_name)
# Prepare callbacks for model saving and for learning rate adjustment.
checkpoint = ModelCheckpoint(filepath=filepath,
monitor='val_acc',
verbose=1,
save_best_only=False)
callbacks = [checkpoint, lr_reducer, lr_scheduler]
# Run training, with or without data augmentation.
if not data_augmentation:
print('Not using data augmentation.')
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True,
callbacks=callbacks)
else:
print('Using real-time data augmentation.')
# This will do preprocessing and realtime data augmentation:
datagen = ImageDataGenerator(
# set input mean to 0 over the dataset
featurewise_center=False,
# set each sample mean to 0
samplewise_center=False,
# divide inputs by std of dataset
featurewise_std_normalization=False,
# divide each input by its std
samplewise_std_normalization=False,
# apply ZCA whitening
zca_whitening=False,
# epsilon for ZCA whitening
zca_epsilon=1e-06,
# randomly rotate images in the range (deg 0 to 180)
rotation_range=0,
# randomly shift images horizontally
width_shift_range=0.1,
# randomly shift images vertically
height_shift_range=0.1,
# set range for random shear
shear_range=0.,
# set range for random zoom
zoom_range=0.,
# set range for random channel shifts
channel_shift_range=0.,
# set mode for filling points outside the input boundaries
fill_mode='nearest',
# value used for fill_mode = "constant"
cval=0.,
# randomly flip images
horizontal_flip=True,
# randomly flip images
vertical_flip=False,
# set rescaling factor (applied before any other transformation)
rescale=None,
# set function that will be applied on each input
preprocessing_function=None,
# image data format, either "channels_first" or "channels_last"
data_format=None,
# fraction of images reserved for validation (strictly between 0 and 1)
validation_split=0.0)
# Compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied).
datagen.fit(x_train)
# Fit the model on the batches generated by datagen.flow().
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
validation_data=(x_test, y_test),
epochs=epochs, verbose=1, workers=1,
callbacks=callbacks)
```
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
train_datagen.fit(x_train)
validation_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
validation_datagen.fit(x_test)
```
model.save_weights('./saved_models/pmon_%s_%s_model.%s.final.h5' % (model_type, dt.datetime.now().strftime("%Y%m%d%H"), '22.2e-4')) # The third string parameter is the suffix string
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import matplotlib.cbook as cbook
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
# Score trained model.
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
```
| github_jupyter |
```
import pandas as pd
import spacy
import os
import scispacy
from spacy import displacy
from tqdm.notebook import tqdm
sentences = df[df["sentence"].str.contains("population") | (df["sentence"].str.contains("sample") & df["sentence"].str.contains("size")]["sentence"]
sentences.reset_index(drop=True,inplace=True)
nlp = spacy.load("en_core_sci_lg")
doc = nlp(sentences[0])
displacy.serve(doc, style="dep")
subject = doc[7]
subject = doc[7]
a = [i.dep_ for i in subject.lefts]
b = [i for i in subject.lefts]
c = [i for i in doc[2].ancestors]
vec_df.fillna("[]",inplace=True)
npr = list(set(vec_df[vec_df["sentence"].str.contains("not peer")]["paper_id"].to_list()))
len(npr)
import pandas as pd
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import os
def bulk_index(df, index_name):
# This method will process rows of a given dataframe
# into dicts indexable by ES. Those are then indexed.
es = Elasticsearch()
helpers.bulk(es, doc_generator(df, index_name))
def doc_generator(df, index_name):
# This function creates documents from dataframe rows, and then
# indexes those documents in ElasticSearch
df_iter = df.iterrows()
for index, document in df_iter:
yield {
"_index": index_name,
"article": document.to_dict(),
}
return True
directory = "/home/acorn/Documents/covid/v6/v6_text/"
vec_df = pd.concat([pd.read_pickle(directory + f, compression="gzip") for f in os.listdir(directory)])
v7 = pd.read_json("/home/acorn/Documents/covid/v7/v7_text.json", orient="records")
if "sentenc_id" in v7.columns:
v7.rename(columns={"sentenc_id": "sentence_id"}, inplace=True)
df = pd.concat([vec_df, v7])
del v7
del vec_df
#df = pd.read_pickle("v6-7bySection.pkl", compression="gzip")
#bulk_index(df, index_name="cordv7sections")
del df
print("Sections done.")
df = pd.read_pickle("v6-7bySentence.pkl",compression="gzip")
bulk_index(df, index_name="cord19sentences")
del df
print("Sentences done")
#df.fillna("[]", inplace=True)
column_remap = {'lemma':'sum',
'UMLS':'sum',
'GGP':'sum',
'SO':'sum',
'TAXON':'sum',
'CHEBI':'sum',
'GO':'sum',
'CL':'sum',
'DNA':'sum',
'CELL_TYPE':'sum',
'CELL_LINE':'sum',
'RNA':'sum',
'PROTEIN':'sum',
'DISEASE':'sum',
'CHEMICAL':'sum',
'CANCER':'sum',
'ORGAN':'sum',
'TISSUE':'sum',
'ORGANISM':'sum',
'CELL':'sum',
'AMINO_ACID':'sum',
'GENE_OR_GENE_PRODUCT':'sum',
'SIMPLE_CHEMICAL':'sum',
'ANATOMICAL_SYSTEM':'sum',
'IMMATERIAL_ANATOMICAL_ENTITY':'sum',
'MULTI-TISSUE_STRUCTURE':'sum',
'DEVELOPING_ANATOMICAL_STRUCTURE':'sum',
'ORGANISM_SUBDIVISION':'sum',
'CELLULAR_COMPONENT':'sum',
'PATHOLOGICAL_FORMATION':'sum',
'ORGANISM_SUBSTANCE':'sum'}
#for col in tqdm(column_remap.keys()):
# df[col] = [i.split("~") if isinstance(i, str) else i for i in df[col].to_list()]
df.to_pickle("v6-7bySection.pkl",compression="gzip")
df.fillna("[]", inplace=True)
sentences = df.groupby(['paper_id','section'])['sentence'].apply(' '.join).reset_index()["sentence"].to_list()
print("Made sentences")
df = df.groupby(['paper_id','section']).agg(column_remap)
print("Grouped and aggregated.")
df["sentence"] = sentences
print("Assigned column")
df.to_pickle("v6-7bySection.pkl", compression="gzip")
df = pd.read_pickle("v6-7bySection.pkl", compression="gzip")
sentence_id = [df.iloc[i]["paper_id"][0:5] + str(i) + df.iloc[i]["paper_id"][-5:] for i in df.index]
li1 = [i[:5] for i in df["paper_id"].to_list()]
li2 = [i for i in df.index]
li3 = [i[-5:] for i in df["paper_id"].to_list()]
sentence_id = [x + str(y) + z for x,y,z in zip(li1, li2, li3)]
x = []
for i in df.index:
x.append(i[0][0:5] + i[1].replace(" ","").replace("'","").replace('"',"").replace("[]","None"))
df["section_id"] = x
df2 = df[0:5]
bulk_index(df, "cord19sections")
df
```
| github_jupyter |
# Fully Bayesian GPs - Sampling Hyperparamters with NUTS
In this notebook, we'll demonstrate how to integrate GPyTorch and NUTS to sample GP hyperparameters and perform GP inference in a fully Bayesian way.
The high level overview of sampling in GPyTorch is as follows:
1. Define your model as normal, extending ExactGP and defining a forward method.
2. For each parameter your model defines, you'll need to register a GPyTorch prior with that parameter, or some function of the parameter. If you use something other than a default closure (e.g., by specifying a parameter or transformed parameter name), you'll need to also specify a setting_closure: see the docs for `gpytorch.Module.register_prior`.
3. Define a pyro model that has a sample site for each GP parameter. For your convenience, we define a `pyro_sample_from_prior` method on `gpytorch.Module` that returns a copy of the module where each parameter has been replaced by the result of a `pyro.sample` call.
4. Run NUTS (or HMC etc) on the pyro model you just defined to generate samples. Note this can take quite a while or no time at all depending on the priors you've defined.
5. Load the samples in to the model, converting the model from a simple GP to a batch GP (see our example notebook on simple batch GPs), where each GP in the batch corresponds to a different hyperparameter sample.
6. Pass test data through the batch GP to get predictions for each hyperparameter sample.
```
import math
import torch
import gpytorch
import pyro
from pyro.infer.mcmc import NUTS, MCMC, HMC
from matplotlib import pyplot as plt
%matplotlib inline
%load_ext autoreload
%autoreload 2
# Training data is 11 points in [0,1] inclusive regularly spaced
train_x = torch.linspace(0, 1, 4)
# True function is sin(2*pi*x) with Gaussian noise
train_y = torch.sin(train_x * (2 * math.pi)) + torch.randn(train_x.size()) * 0.2
# We will use the simplest form of GP model, exact inference
class ExactGPModel(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super(ExactGPModel, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean()
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
```
## Running Sampling
The next cell is the first piece of code that differs substantially from other work flows. In it, we create the model and likelihood as normal, and then register priors to each of the parameters of the model. Note that we directly can register priors to transformed parameters (e.g., "lengthscale") rather than raw ones (e.g., "raw_lengthscale"). This is useful, **however** you'll need to specify a prior whose support is fully contained in the domain of the parameter. For example, a lengthscale prior must have support only over the positive reals or a subset thereof.
```
# this is for running the notebook in our testing framework
import os
smoke_test = ('CI' in os.environ)
num_samples = 2 if smoke_test else 100
warmup_steps = 2 if smoke_test else 100
from gpytorch.priors import LogNormalPrior, NormalPrior, UniformPrior
# Use a positive constraint instead of usual GreaterThan(1e-4) so that LogNormal has support over full range.
likelihood = gpytorch.likelihoods.GaussianLikelihood(noise_constraint=gpytorch.constraints.Positive())
model = ExactGPModel(train_x, train_y, likelihood)
model.mean_module.register_prior("mean_prior", UniformPrior(-1, 1), "constant")
model.covar_module.base_kernel.register_prior("lengthscale_prior", UniformPrior(0.01, 0.5), "lengthscale")
model.covar_module.register_prior("outputscale_prior", UniformPrior(1, 2), "outputscale")
likelihood.register_prior("noise_prior", UniformPrior(0.01, 0.5), "noise")
mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)
def pyro_model(x, y):
with gpytorch.settings.fast_computations(False, False, False):
sampled_model = model.pyro_sample_from_prior()
output = sampled_model.likelihood(sampled_model(x))
pyro.sample("obs", output, obs=y)
return y
nuts_kernel = NUTS(pyro_model)
mcmc_run = MCMC(nuts_kernel, num_samples=num_samples, warmup_steps=warmup_steps, disable_progbar=smoke_test)
mcmc_run.run(train_x, train_y)
```
## Loading Samples
In the next cell, we load the samples generated by NUTS in to the model. This converts `model` from a single GP to a batch of `num_samples` GPs, in this case 100.
```
model.pyro_load_from_samples(mcmc_run.get_samples())
model.eval()
test_x = torch.linspace(0, 1, 101).unsqueeze(-1)
test_y = torch.sin(test_x * (2 * math.pi))
expanded_test_x = test_x.unsqueeze(0).repeat(num_samples, 1, 1)
output = model(expanded_test_x)
```
## Plot Mean Functions
In the next cell, we plot the first 25 mean functions on the samep lot. This particular example has a fairly large amount of data for only 1 dimension, so the hyperparameter posterior is quite tight and there is relatively little variance.
```
with torch.no_grad():
# Initialize plot
f, ax = plt.subplots(1, 1, figsize=(4, 3))
# Plot training data as black stars
ax.plot(train_x.numpy(), train_y.numpy(), 'k*', zorder=10)
for i in range(min(num_samples, 25)):
# Plot predictive means as blue line
ax.plot(test_x.numpy(), output.mean[i].detach().numpy(), 'b', linewidth=0.3)
# Shade between the lower and upper confidence bounds
# ax.fill_between(test_x.numpy(), lower.numpy(), upper.numpy(), alpha=0.5)
ax.set_ylim([-3, 3])
ax.legend(['Observed Data', 'Sampled Means'])
```
## Simulate Loading Model from Disk
Loading a fully Bayesian model from disk is slightly different from loading a standard model because the process of sampling changes the shapes of the model's parameters. To account for this, you'll need to call `load_strict_shapes(False)` on the model before loading the state dict. In the cell below, we demonstrate this by recreating the model and loading from the state dict.
Note that without the `load_strict_shapes` call, this would fail.
```
state_dict = model.state_dict()
model = ExactGPModel(train_x, train_y, likelihood)
# Load parameters without standard shape checking.
model.load_strict_shapes(False)
model.load_state_dict(state_dict)
```
| github_jupyter |
# Interpreting Nodes and Edges by Saliency Maps in GAT
This demo shows how to use integrated gradients in graph attention networks to obtain accurate importance estimations for both the nodes and edges. The notebook consists of three parts:
setting up the node classification problem for Cora citation network
training and evaluating a GAT model for node classification
calculating node and edge importances for model's predictions of query ("target") nodes.
```
import networkx as nx
import pandas as pd
import numpy as np
from scipy import stats
import os
import time
import sys
import stellargraph as sg
from copy import deepcopy
from stellargraph.mapper import FullBatchNodeGenerator
from stellargraph.layer import GAT, GraphAttention
from tensorflow.keras import layers, optimizers, losses, metrics, models, Model
from sklearn import preprocessing, feature_extraction, model_selection
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
%matplotlib inline
```
### Loading the CORA network
**Downloading the CORA dataset:**
The dataset used in this demo can be downloaded from https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz
The following is the description of the dataset:
> The Cora dataset consists of 2708 scientific publications classified into one of seven classes.
> The citation network consists of 5429 links. Each publication in the dataset is described by a
> 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary.
> The dictionary consists of 1433 unique words. The README file in the dataset provides more details.
Download and unzip the cora.tgz file to a location on your computer and set the `data_dir` variable to
point to the location of the dataset (the directory containing "cora.cites" and "cora.content").
```
data_dir = os.path.expanduser("~/data/cora")
```
Load the graph from edgelist
```
edgelist = pd.read_csv(os.path.join(data_dir, "cora.cites"), header=None, names=["source", "target"], sep='\t')
edgelist["label"] = "cites"
Gnx = nx.from_pandas_edgelist(edgelist, edge_attr="label")
nx.set_node_attributes(Gnx, "paper", "label")
```
Load the features and subject for the nodes
```
feature_names = ["w_{}".format(ii) for ii in range(1433)]
column_names = feature_names + ["subject"]
node_data = pd.read_csv(os.path.join(data_dir, "cora.content"), header=None, names=column_names, sep='\t')
```
### Splitting the data
For machine learning we want to take a subset of the nodes for training, and use the rest for validation and testing. We'll use scikit-learn again to do this.
Here we're taking 140 node labels for training, 500 for validation, and the rest for testing.
```
train_data, test_data = model_selection.train_test_split(node_data, train_size=140, test_size=None, stratify=node_data['subject'])
val_data, test_data = model_selection.train_test_split(test_data, train_size=500, test_size=None, stratify=test_data['subject'])
from collections import Counter
Counter(train_data['subject'])
```
### Converting to numeric arrays
For our categorical target, we will use one-hot vectors that will be fed into a soft-max Keras layer during training. To do this conversion ...
```
target_encoding = feature_extraction.DictVectorizer(sparse=False)
train_targets = target_encoding.fit_transform(train_data[["subject"]].to_dict('records'))
val_targets = target_encoding.transform(val_data[["subject"]].to_dict('records'))
test_targets = target_encoding.transform(test_data[["subject"]].to_dict('records'))
node_ids = node_data.index
all_targets = target_encoding.transform(
node_data[["subject"]].to_dict("records")
)
```
We now do the same for the node attributes we want to use to predict the subject. These are the feature vectors that the Keras model will use as input. The CORA dataset contains attributes 'w_x' that correspond to words found in that publication. If a word occurs more than once in a publication the relevant attribute will be set to one, otherwise it will be zero.
```
node_features = node_data[feature_names]
```
### Creating the GAT model in Keras
Now create a StellarGraph object from the NetworkX graph and the node features and targets. It is StellarGraph objects that we use in this library to perform machine learning tasks on.
```
G = sg.StellarGraph(Gnx, node_features=node_features)
print(G.info())
```
To feed data from the graph to the Keras model we need a generator. Since GAT is a full-batch model, we use the `FullBatchNodeGenerator` class to feed node features and graph adjacency matrix to the model.
```
generator = FullBatchNodeGenerator(G, method='gat',sparse=False)
```
For training we map only the training nodes returned from our splitter and the target values.
```
train_gen = generator.flow(train_data.index, train_targets)
```
Now we can specify our machine learning model, we need a few more parameters for this:
* the `layer_sizes` is a list of hidden feature sizes of each layer in the model. In this example we use two GAT layers with 8-dimensional hidden node features at each layer.
* `attn_heads` is the number of attention heads in all but the last GAT layer in the model
* `activations` is a list of activations applied to each layer's output
* Arguments such as `bias`, `in_dropout`, `attn_dropout` are internal parameters of the model, execute `?GAT` for details.
To follow the GAT model architecture used for Cora dataset in the original paper [Graph Attention Networks. P. Velickovic et al. ICLR 2018 https://arxiv.org/abs/1803.07294], let's build a 2-layer GAT model, with the 2nd layer being the classifier that predicts paper subject: it thus should have the output size of `train_targets.shape[1]` (7 subjects) and a softmax activation.
```
gat = GAT(
layer_sizes=[8, train_targets.shape[1]],
attn_heads=8,
generator=generator,
bias=True,
in_dropout=0,
attn_dropout=0,
activations=["elu","softmax"],
normalize=None,
saliency_map_support=True
)
# Expose the input and output tensors of the GAT model for node prediction, via GAT.node_model() method:
x_inp, predictions = gat.node_model()
```
### Training the model
Now let's create the actual Keras model with the input tensors `x_inp` and output tensors being the predictions `predictions` from the final dense layer
```
model = Model(inputs=x_inp, outputs=predictions)
model.compile(
optimizer=optimizers.Adam(lr=0.005),
loss=losses.categorical_crossentropy,
weighted_metrics=["acc"],
)
```
Train the model, keeping track of its loss and accuracy on the training set, and its generalisation performance on the validation set (we need to create another generator over the validation data for this)
```
val_gen = generator.flow(val_data.index, val_targets)
```
Train the model
```
N = len(node_ids)
history = model.fit_generator(train_gen, validation_data=val_gen, shuffle=False, epochs=10, verbose=2)
import matplotlib.pyplot as plt
%matplotlib inline
def remove_prefix(text, prefix):
return text[text.startswith(prefix) and len(prefix):]
def plot_history(history):
metrics = sorted(set([remove_prefix(m, "val_") for m in list(history.history.keys())]))
for m in metrics:
# summarize history for metric m
plt.plot(history.history[m])
plt.plot(history.history['val_' + m])
plt.title(m)
plt.ylabel(m)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()
plot_history(history)
```
Evaluate the trained model on the test set
```
test_gen = generator.flow(test_data.index, test_targets)
test_metrics = model.evaluate_generator(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
```
Check serialization
```
# Save model
model_json = model.to_json()
model_weights = model.get_weights()
# Load model from json & set all weights
model2 = models.model_from_json(
model_json, custom_objects={"GraphAttention": GraphAttention}
)
model2.set_weights(model_weights)
model2_weights = model2.get_weights()
pred2 = model2.predict_generator(test_gen)
pred1 = model.predict_generator(test_gen)
print(np.allclose(pred1,pred2))
```
# Node and link importance via saliency maps
Now we define the importances of node features, nodes, and links in the target node's neighbourhood (ego-net), and evaluate them using our library.
Node feature importance: given a target node $t$ and the model's prediction of $t$'s class, for each node $v$ in its ego-net, feature importance of feature $f$ for node $v$ is defined as the change in the target node's predicted score $s(c)$ for the winning class $c$ if feature $f$ of node $v$ is perturbed.
The overall node importance for node $v$ is defined here as the sum of all feature importances for node $v$, i.e., it is the amount by which the target node's predicted score $s(c)$ would change if we set all features of node $v$ to zeros.
Link importance for link $e=(u, v)$ is defined as the change in target node $t$'s predicted score $s(c)$ if the link $e$ is removed from the graph. Links with high importance (positive or negative) affect the target node prediction more than links with low importance.
Node and link importances can be used to assess the role of neighbour nodes and links in model's predictions for the node(s) of interest (the target nodes). For datasets like CORA-ML, the features and edges are binary, vanilla gradients may not perform well so we use integrated gradients to compute them (https://arxiv.org/pdf/1703.01365.pdf).
```
from stellargraph.utils.saliency_maps import IntegratedGradientsGAT
from stellargraph.utils.saliency_maps import GradientSaliencyGAT
```
Select the target node whose prediction is to be interpreted.
```
graph_nodes = list(G.nodes())
all_gen = generator.flow(graph_nodes)
target_idx = 7
target_nid = graph_nodes[target_idx]
target_gen = generator.flow([target_nid])
```
Node id of the target node:
```
y_true = all_targets[target_idx] # true class of the target node
```
Extract adjacency matrix and feature matrix
```
y_pred = model.predict_generator(target_gen).squeeze()
class_of_interest = np.argmax(y_pred)
print("target node id: {}, \ntrue label: {}, \npredicted label: {}".format(target_nid, y_true, y_pred.round(2)))
```
Get the node feature importance by using integrated gradients
```
int_grad_saliency = IntegratedGradientsGAT(model, train_gen, generator.node_list)
saliency = GradientSaliencyGAT(model, train_gen)
```
Get the ego network of the target node.
```
G_ego = nx.ego_graph(Gnx, target_nid, radius=len(gat.activations))
```
Compute the link importance by integrated gradients.
```
integrate_link_importance = int_grad_saliency.get_link_importance(target_nid, class_of_interest, steps=25)
print('integrated_link_mask.shape = {}'.format(integrate_link_importance.shape))
integrated_node_importance = int_grad_saliency.get_node_importance(target_nid, class_of_interest, steps=25)
print('\nintegrated_node_importance', integrated_node_importance.round(2))
print('integrated self-importance of target node {}: {}'.format(target_nid, integrated_node_importance[target_idx].round(2)))
print("\nEgo net of target node {} has {} nodes".format(target_nid, G_ego.number_of_nodes()))
print("Number of non-zero elements in integrated_node_importance: {}".format(np.count_nonzero(integrated_node_importance)))
```
Get the ranks of the edge importance values.
```
sorted_indices = np.argsort(integrate_link_importance.flatten().reshape(-1))
sorted_indices = np.array(sorted_indices)
integrated_link_importance_rank = [(int(k/N), k%N) for k in sorted_indices[::-1]]
topk = 10
print('Top {} most important links by integrated gradients are {}'.format(topk, integrated_link_importance_rank[:topk]))
#print('Top {} most important links by integrated gradients (for potential edges) are {}'.format(topk, integrated_link_importance_rank_add[-topk:]))
```
In the following, we plot the link and node importance (computed by integrated gradients) of the nodes within the ego graph of the target node.
For nodes, the shape of the node indicates the positive/negative importance the node has. 'round' nodes have positive importance while 'diamond' nodes have negative importance. The size of the node indicates the value of the importance, e.g., a large diamond node has higher negative importance.
For links, the color of the link indicates the positive/negative importance the link has. 'red' links have positive importance while 'blue' links have negative importance. The width of the link indicates the value of the importance, e.g., a thicker blue link has higher negative importance.
```
nx.set_node_attributes(G_ego, values={x[0]:{'subject': x[1]} for x in node_data['subject'].items()})
node_size_factor = 1e2
link_width_factor = 4
nodes = list(G_ego.nodes())
colors = pd.DataFrame([v[1]['subject'] for v in G_ego.nodes(data=True)],
index=nodes, columns=['subject'])
colors = np.argmax(target_encoding.transform(colors.to_dict('records')), axis=1) + 1
fig, ax = plt.subplots(1, 1, figsize=(15, 10));
pos = nx.spring_layout(G_ego)
# Draw ego as large and red
node_sizes = [integrated_node_importance[graph_nodes.index(k)] for k in G_ego.nodes()]
node_shapes = ['o' if integrated_node_importance[graph_nodes.index(k)] > 0
else 'd' for k in G_ego.nodes()]
positive_colors, negative_colors = [], []
positive_node_sizes, negative_node_sizes = [], []
positive_nodes, negative_nodes = [], []
#node_size_sclae is used for better visualization of nodes
node_size_scale = node_size_factor/np.max(node_sizes)
for k in range(len(node_shapes)):
if list(nodes)[k] == target_nid:
continue
if node_shapes[k] == 'o':
positive_colors.append(colors[k])
positive_nodes.append(list(nodes)[k])
positive_node_sizes.append(node_size_scale*node_sizes[k])
else:
negative_colors.append(colors[k])
negative_nodes.append(list(nodes)[k])
negative_node_sizes.append(node_size_scale*abs(node_sizes[k]))
cmap = plt.get_cmap('jet', np.max(colors)-np.min(colors)+1)
nc = nx.draw_networkx_nodes(G_ego, pos, nodelist=positive_nodes,
node_color=positive_colors, cmap=cmap,
node_size=positive_node_sizes, with_labels=False,
vmin=np.min(colors)-0.5, vmax=np.max(colors)+0.5, node_shape='o')
nc = nx.draw_networkx_nodes(G_ego, pos, nodelist=negative_nodes,
node_color=negative_colors, cmap=cmap,
node_size=negative_node_sizes, with_labels=False,
vmin=np.min(colors)-0.5, vmax=np.max(colors)+0.5, node_shape='d')
# Draw the target node as a large star colored by its true subject
nx.draw_networkx_nodes(G_ego, pos, nodelist=[target_nid],
node_size=50*abs(node_sizes[nodes.index(target_nid)]), node_shape='*',
node_color=[colors[nodes.index(target_nid)]],
cmap=cmap, vmin=np.min(colors)-0.5, vmax=np.max(colors)+0.5, label="Target")
edges = G_ego.edges()
#link_width_scale is used for better visualization of links
weights = [integrate_link_importance[graph_nodes.index(u),list(Gnx.nodes()).index(v)] for u,v in edges]
link_width_scale = link_width_factor/np.max(weights)
edge_colors = ['red' if integrate_link_importance[graph_nodes.index(u),list(Gnx.nodes()).index(v)] > 0 else 'blue' for u,v in edges]
ec = nx.draw_networkx_edges(G_ego, pos, edge_color=edge_colors,
width = [link_width_scale*w for w in weights])
plt.legend()
plt.colorbar(nc, ticks=np.arange(np.min(colors),np.max(colors)+1))
plt.axis('off')
plt.show()
```
We then remove the node or edge in the ego graph one by one and check how the prediction changes. By doing so, we can obtain the ground truth importance of the nodes and edges. Comparing the following figure and the above one can show the effectiveness of integrated gradients as the importance approximations are relatively consistent with the ground truth.
```
[X,_,A], y_true_all = all_gen[0]
N = A.shape[-1]
X_bk = deepcopy(X)
edges = [(graph_nodes.index(u),graph_nodes.index(v)) for u,v in G_ego.edges()]
nodes = [list(Gnx.nodes()).index(v) for v in G_ego.nodes()]
selected_nodes = np.array([[target_idx]], dtype='int32')
clean_prediction = model.predict([X, selected_nodes, A]).squeeze()
predict_label = np.argmax(clean_prediction)
groud_truth_edge_importance = np.zeros((N, N), dtype = 'float')
groud_truth_node_importance = []
for node in nodes:
if node == target_idx:
groud_truth_node_importance.append(0)
continue
X = deepcopy(X_bk)
#we set all the features of the node to zero to check the ground truth node importance.
X[0, node, :] = 0
predict_after_perturb = model.predict([X, selected_nodes, A]).squeeze()
prediction_change = clean_prediction[predict_label] - predict_after_perturb[predict_label]
groud_truth_node_importance.append(prediction_change)
node_shapes = ['o' if groud_truth_node_importance[k] > 0 else 'd' for k in range(len(nodes))]
positive_colors, negative_colors = [], []
positive_node_sizes, negative_node_sizes = [], []
positive_nodes, negative_nodes = [], []
#node_size_scale is used for better visulization of nodes
node_size_scale = node_size_factor/max(groud_truth_node_importance)
for k in range(len(node_shapes)):
if nodes[k] == target_idx:
continue
if node_shapes[k] == 'o':
positive_colors.append(colors[k])
positive_nodes.append(graph_nodes[nodes[k]])
positive_node_sizes.append(node_size_scale*groud_truth_node_importance[k])
else:
negative_colors.append(colors[k])
negative_nodes.append(graph_nodes[nodes[k]])
negative_node_sizes.append(node_size_scale*abs(groud_truth_node_importance[k]))
X = deepcopy(X_bk)
for edge in edges:
original_val = A[0, edge[0], edge[1]]
if original_val == 0:
continue
#we set the weight of a given edge to zero to check the ground truth link importance
A[0, edge[0], edge[1]] = 0
predict_after_perturb = model.predict([X, selected_nodes, A]).squeeze()
groud_truth_edge_importance[edge[0], edge[1]] = (predict_after_perturb[predict_label] - clean_prediction[predict_label])/(0 - 1)
A[0, edge[0], edge[1]] = original_val
# print(groud_truth_edge_importance[edge[0], edge[1]])
fig, ax = plt.subplots(1, 1, figsize=(15, 10));
cmap = plt.get_cmap('jet', np.max(colors)-np.min(colors)+1)
# Draw the target node as a large star colored by its true subject
nx.draw_networkx_nodes(G_ego, pos, nodelist=[target_nid], node_size=50*abs(node_sizes[nodes.index(target_idx)]), node_color=[colors[nodes.index(target_idx)]], cmap=cmap,
node_shape='*', vmin=np.min(colors)-0.5, vmax=np.max(colors)+0.5, label="Target")
# Draw the ego net
nc = nx.draw_networkx_nodes(G_ego, pos, nodelist=positive_nodes, node_color=positive_colors, cmap=cmap, node_size=positive_node_sizes, with_labels=False,
vmin=np.min(colors)-0.5, vmax=np.max(colors)+0.5, node_shape='o')
nc = nx.draw_networkx_nodes(G_ego, pos, nodelist=negative_nodes, node_color=negative_colors, cmap=cmap, node_size=negative_node_sizes, with_labels=False,
vmin=np.min(colors)-0.5, vmax=np.max(colors)+0.5, node_shape='d')
edges = G_ego.edges()
#link_width_scale is used for better visulization of links
link_width_scale = link_width_factor/np.max(groud_truth_edge_importance)
weights = [link_width_scale*groud_truth_edge_importance[graph_nodes.index(u),list(Gnx.nodes()).index(v)] for u,v in edges]
edge_colors = ['red' if groud_truth_edge_importance[graph_nodes.index(u),list(Gnx.nodes()).index(v)] > 0 else 'blue' for u,v in edges]
ec = nx.draw_networkx_edges(G_ego, pos, edge_color=edge_colors, width = weights)
plt.legend()
plt.colorbar(nc, ticks=np.arange(np.min(colors),np.max(colors)+1))
plt.axis('off')
plt.show()
```
| github_jupyter |
# Practical example
## Importing the relevant libraries
```
# For this practical example we will need the following libraries and modules
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import seaborn as sns
sns.set()
```
## Loading the raw data
```
# Load the data from a .csv in the same folder
raw_data = pd.read_csv('1.04. Real-life example.csv')
# Let's explore the top 5 rows of the df
raw_data.head()
```
## Preprocessing
### Exploring the descriptive statistics of the variables
```
# Descriptive statistics are very useful for initial exploration of the variables
# By default, only descriptives for the numerical variables are shown
# To include the categorical ones, you should specify this with an argument
raw_data.describe(include='all')
# Note that categorical variables don't have some types of numerical descriptives
# and numerical variables don't have some types of categorical descriptives
```
### Determining the variables of interest
```
# For these several lessons, we will create the regression without 'Model'
# Certainly, when you work on the problem on your own, you could create a regression with 'Model'
data = raw_data.drop(['Model'],axis=1)
# Let's check the descriptives without 'Model'
data.describe(include='all')
```
### Dealing with missing values
```
# data.isnull() # shows a df with the information whether a data point is null
# Since True = the data point is missing, while False = the data point is not missing, we can sum them
# This will give us the total number of missing values feature-wise
data.isnull().sum()
# Let's simply drop all missing values
# This is not always recommended, however, when we remove less than 5% of the data, it is okay
data_no_mv = data.dropna(axis=0)
# Let's check the descriptives without the missing values
data_no_mv.describe(include='all')
```
### Exploring the PDFs
```
# A great step in the data exploration is to display the probability distribution function (PDF) of a variable
# The PDF will show us how that variable is distributed
# This makes it very easy to spot anomalies, such as outliers
# The PDF is often the basis on which we decide whether we want to transform a feature
sns.distplot(data_no_mv['Price'])
```
### Dealing with outliers
```
# Obviously there are some outliers present
# Without diving too deep into the topic, we can deal with the problem easily by removing 0.5%, or 1% of the problematic samples
# Here, the outliers are situated around the higher prices (right side of the graph)
# Logic should also be applied
# This is a dataset about used cars, therefore one can imagine how $300,000 is an excessive price
# Outliers are a great issue for OLS, thus we must deal with them in some way
# It may be a useful exercise to try training a model without removing the outliers
# Let's declare a variable that will be equal to the 99th percentile of the 'Price' variable
q = data_no_mv['Price'].quantile(0.99)
# Then we can create a new df, with the condition that all prices must be below the 99 percentile of 'Price'
data_1 = data_no_mv[data_no_mv['Price']<q]
# In this way we have essentially removed the top 1% of the data about 'Price'
data_1.describe(include='all')
# We can check the PDF once again to ensure that the result is still distributed in the same way overall
# however, there are much fewer outliers
sns.distplot(data_1['Price'])
# We can treat the other numerical variables in a similar way
sns.distplot(data_no_mv['Mileage'])
q = data_1['Mileage'].quantile(0.99)
data_2 = data_1[data_1['Mileage']<q]
# This plot looks kind of normal, doesn't it?
sns.distplot(data_2['Mileage'])
# The situation with engine volume is very strange
# In such cases it makes sense to manually check what may be causing the problem
# In our case the issue comes from the fact that most missing values are indicated with 99.99 or 99
# There are also some incorrect entries like 75
sns.distplot(data_no_mv['EngineV'])
# A simple Google search can indicate the natural domain of this variable
# Car engine volumes are usually (always?) below 6.5l
# This is a prime example of the fact that a domain expert (a person working in the car industry)
# may find it much easier to determine problems with the data than an outsider
data_3 = data_2[data_2['EngineV']<6.5]
# Following this graph, we realize we can actually treat EngineV as a categorical variable
# Even so, in this course we won't, but that's yet something else you may try on your own
sns.distplot(data_3['EngineV'])
# Finally, the situation with 'Year' is similar to 'Price' and 'Mileage'
# However, the outliers are on the low end
sns.distplot(data_no_mv['Year'])
# I'll simply remove them
q = data_3['Year'].quantile(0.01)
data_4 = data_3[data_3['Year']>q]
# Here's the new result
sns.distplot(data_4['Year'])
# When we remove observations, the original indexes are preserved
# If we remove observations with indexes 2 and 3, the indexes will go as: 0,1,4,5,6
# That's very problematic as we tend to forget about it (later you will see an example of such a problem)
# Finally, once we reset the index, a new column will be created containing the old index (just in case)
# We won't be needing it, thus 'drop=True' to completely forget about it
data_cleaned = data_4.reset_index(drop=True)
# Let's see what's left
data_cleaned.describe(include='all')
```
## Checking the OLS assumptions
```
# Here we decided to use some matplotlib code, without explaining it
# You can simply use plt.scatter() for each of them (with your current knowledge)
# But since Price is the 'y' axis of all the plots, it made sense to plot them side-by-side (so we can compare them)
f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharey=True, figsize =(15,3)) #sharey -> share 'Price' as y
ax1.scatter(data_cleaned['Year'],data_cleaned['Price'])
ax1.set_title('Price and Year')
ax2.scatter(data_cleaned['EngineV'],data_cleaned['Price'])
ax2.set_title('Price and EngineV')
ax3.scatter(data_cleaned['Mileage'],data_cleaned['Price'])
ax3.set_title('Price and Mileage')
plt.show()
# From the subplots and the PDF of price, we can easily determine that 'Price' is exponentially distributed
# A good transformation in that case is a log transformation
sns.distplot(data_cleaned['Price'])
```
### Relaxing the assumptions
```
# Let's transform 'Price' with a log transformation
log_price = np.log(data_cleaned['Price'])
# Then we add it to our data frame
data_cleaned['log_price'] = log_price
data_cleaned
# Let's check the three scatters once again
f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharey=True, figsize =(15,3))
ax1.scatter(data_cleaned['Year'],data_cleaned['log_price'])
ax1.set_title('Log Price and Year')
ax2.scatter(data_cleaned['EngineV'],data_cleaned['log_price'])
ax2.set_title('Log Price and EngineV')
ax3.scatter(data_cleaned['Mileage'],data_cleaned['log_price'])
ax3.set_title('Log Price and Mileage')
plt.show()
# The relationships show a clear linear relationship
# This is some good linear regression material
# Alternatively we could have transformed each of the independent variables
# Since we will be using the log price variable, we can drop the old 'Price' one
data_cleaned = data_cleaned.drop(['Price'],axis=1)
```
### Multicollinearity
```
# Let's quickly see the columns of our data frame
data_cleaned.columns.values
# sklearn does not have a built-in way to check for multicollinearity
# one of the main reasons is that this is an issue well covered in statistical frameworks and not in ML ones
# surely it is an issue nonetheless, thus we will try to deal with it
# Here's the relevant module
# full documentation: http://www.statsmodels.org/dev/_modules/statsmodels/stats/outliers_influence.html#variance_inflation_factor
from statsmodels.stats.outliers_influence import variance_inflation_factor
# To make this as easy as possible to use, we declare a variable where we put
# all features where we want to check for multicollinearity
# since our categorical data is not yet preprocessed, we will only take the numerical ones
variables = data_cleaned[['Mileage','Year','EngineV']]
# we create a new data frame which will include all the VIFs
# note that each variable has its own variance inflation factor as this measure is variable specific (not model specific)
vif = pd.DataFrame()
# here we make use of the variance_inflation_factor, which will basically output the respective VIFs
vif["VIF"] = [variance_inflation_factor(variables.values, i) for i in range(variables.shape[1])]
# Finally, I like to include names so it is easier to explore the result
vif["Features"] = variables.columns
# Let's explore the result
vif
# Since Year has the highest VIF, I will remove it from the model
# This will drive the VIF of other variables down!!!
# So even if EngineV seems with a high VIF, too, once 'Year' is gone that will no longer be the case
data_no_multicollinearity = data_cleaned.drop(['Year'],axis=1)
```
## Create dummy variables
```
# To include the categorical data in the regression, let's create dummies
# There is a very convenient method called: 'get_dummies' which does that seemlessly
# It is extremely important that we drop one of the dummies, alternatively we will introduce multicollinearity
data_with_dummies = pd.get_dummies(data_no_multicollinearity, drop_first=True)
# Here's the result
data_with_dummies.head()
```
### Rearrange a bit
```
# To make our data frame more organized, we prefer to place the dependent variable in the beginning of the df
# Since each problem is different, that must be done manually
# We can display all possible features and then choose the desired order
data_with_dummies.columns.values
# To make the code a bit more parametrized, let's declare a new variable that will contain the preferred order
# If you want a different order, just specify it here
# Conventionally, the most intuitive order is: dependent variable, indepedendent numerical variables, dummies
cols = ['log_price', 'Mileage', 'EngineV', 'Brand_BMW',
'Brand_Mercedes-Benz', 'Brand_Mitsubishi', 'Brand_Renault',
'Brand_Toyota', 'Brand_Volkswagen', 'Body_hatch', 'Body_other',
'Body_sedan', 'Body_vagon', 'Body_van', 'Engine Type_Gas',
'Engine Type_Other', 'Engine Type_Petrol', 'Registration_yes']
# To implement the reordering, we will create a new df, which is equal to the old one but with the new order of features
data_preprocessed = data_with_dummies[cols]
data_preprocessed.head()
```
## Linear regression model
### Declare the inputs and the targets
```
# The target(s) (dependent variable) is 'log price'
targets = data_preprocessed['log_price']
# The inputs are everything BUT the dependent variable, so we can simply drop it
inputs = data_preprocessed.drop(['log_price'],axis=1)
```
### Scale the data
```
# Import the scaling module
from sklearn.preprocessing import StandardScaler
# Create a scaler object
scaler = StandardScaler()
# Fit the inputs (calculate the mean and standard deviation feature-wise)
scaler.fit(inputs)
# Scale the features and store them in a new variable (the actual scaling procedure)
inputs_scaled = scaler.transform(inputs)
```
### Train Test Split
```
# Import the module for the split
from sklearn.model_selection import train_test_split
# Split the variables with an 80-20 split and some random state
# To have the same split as mine, use random_state = 365
x_train, x_test, y_train, y_test = train_test_split(inputs_scaled, targets, test_size=0.2, random_state=365)
```
### Create the regression
```
# Create a linear regression object
reg = LinearRegression()
# Fit the regression with the scaled TRAIN inputs and targets
reg.fit(x_train,y_train)
# Let's check the outputs of the regression
# I'll store them in y_hat as this is the 'theoretical' name of the predictions
y_hat = reg.predict(x_train)
# The simplest way to compare the targets (y_train) and the predictions (y_hat) is to plot them on a scatter plot
# The closer the points to the 45-degree line, the better the prediction
plt.scatter(y_train, y_hat)
# Let's also name the axes
plt.xlabel('Targets (y_train)',size=18)
plt.ylabel('Predictions (y_hat)',size=18)
# Sometimes the plot will have different scales of the x-axis and the y-axis
# This is an issue as we won't be able to interpret the '45-degree line'
# We want the x-axis and the y-axis to be the same
plt.xlim(6,13)
plt.ylim(6,13)
plt.show()
# Another useful check of our model is a residual plot
# We can plot the PDF of the residuals and check for anomalies
sns.distplot(y_train - y_hat)
# Include a title
plt.title("Residuals PDF", size=18)
# In the best case scenario this plot should be normally distributed
# In our case we notice that there are many negative residuals (far away from the mean)
# Given the definition of the residuals (y_train - y_hat), negative values imply
# that y_hat (predictions) are much higher than y_train (the targets)
# This is food for thought to improve our model
# Find the R-squared of the model
reg.score(x_train,y_train)
# Note that this is NOT the adjusted R-squared
# in other words... find the Adjusted R-squared to have the appropriate measure :)
```
### Finding the weights and bias
```
# Obtain the bias (intercept) of the regression
reg.intercept_
# Obtain the weights (coefficients) of the regression
reg.coef_
# Note that they are barely interpretable if at all
# Create a regression summary where we can compare them with one-another
reg_summary = pd.DataFrame(inputs.columns.values, columns=['Features'])
reg_summary['Weights'] = reg.coef_
reg_summary
# Check the different categories in the 'Brand' variable
data_cleaned['Brand'].unique()
# In this way we can see which 'Brand' is actually the benchmark
```
## Testing
```
# Once we have trained and fine-tuned our model, we can proceed to testing it
# Testing is done on a dataset that the algorithm has never seen
# Luckily we have prepared such a dataset
# Our test inputs are 'x_test', while the outputs: 'y_test'
# We SHOULD NOT TRAIN THE MODEL ON THEM, we just feed them and find the predictions
# If the predictions are far off, we will know that our model overfitted
y_hat_test = reg.predict(x_test)
# Create a scatter plot with the test targets and the test predictions
# You can include the argument 'alpha' which will introduce opacity to the graph
plt.scatter(y_test, y_hat_test, alpha=0.2)
plt.xlabel('Targets (y_test)',size=18)
plt.ylabel('Predictions (y_hat_test)',size=18)
plt.xlim(6,13)
plt.ylim(6,13)
plt.show()
# Finally, let's manually check these predictions
# To obtain the actual prices, we take the exponential of the log_price
df_pf = pd.DataFrame(np.exp(y_hat_test), columns=['Prediction'])
df_pf.head()
# We can also include the test targets in that data frame (so we can manually compare them)
df_pf['Target'] = np.exp(y_test)
df_pf
# Note that we have a lot of missing values
# There is no reason to have ANY missing values, though
# This suggests that something is wrong with the data frame / indexing
# After displaying y_test, we find what the issue is
# The old indexes are preserved (recall earlier in that code we made a note on that)
# The code was: data_cleaned = data_4.reset_index(drop=True)
# Therefore, to get a proper result, we must reset the index and drop the old indexing
y_test = y_test.reset_index(drop=True)
# Check the result
y_test.head()
# Let's overwrite the 'Target' column with the appropriate values
# Again, we need the exponential of the test log price
df_pf['Target'] = np.exp(y_test)
df_pf
# Additionally, we can calculate the difference between the targets and the predictions
# Note that this is actually the residual (we already plotted the residuals)
df_pf['Residual'] = df_pf['Target'] - df_pf['Prediction']
# Since OLS is basically an algorithm which minimizes the total sum of squared errors (residuals),
# this comparison makes a lot of sense
# Finally, it makes sense to see how far off we are from the result percentage-wise
# Here, we take the absolute difference in %, so we can easily order the data frame
df_pf['Difference%'] = np.absolute(df_pf['Residual']/df_pf['Target']*100)
df_pf
# Exploring the descriptives here gives us additional insights
df_pf.describe()
# Sometimes it is useful to check these outputs manually
# To see all rows, we use the relevant pandas syntax
pd.options.display.max_rows = 999
# Moreover, to make the dataset clear, we can display the result with only 2 digits after the dot
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# Finally, we sort by difference in % and manually check the model
df_pf.sort_values(by=['Difference%'])
```
| github_jupyter |
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.svm import SVC
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn import metrics
from keras.models import Sequential
from keras.layers import Dense, Dropout, regularizers
from keras.layers import LSTM
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
import warnings
import numpy as np
from collections import OrderedDict
import os
from lob_data_utils import lob, db_result, gdf_pca, model
from lob_data_utils.svm_calculation import lob_svm
from lob_data_utils.keras_metrics import matthews_correlation, auc_roc
sns.set_style('whitegrid')
warnings.filterwarnings('ignore')
data_length = 24000
stock = '9062'
gdf_filename_pattern = 'gdf_{}_r{}_s{}_K50'
gdf_parameters = [(0.1, 0.1), (0.01, 0.1), (0.1, 0.5), (0.01, 0.5), (0.25, 0.25)]
df_log = pd.read_csv('../../gdf_pca/res_log_que.csv')
df_log = df_log[df_log['stock'] == int(stock)]
columns = [c for c in df_log.columns if 'matthews' in c or 'roc_auc' in c]
df_log[columns]
gdf_dfs = []
for r, s in gdf_parameters:
gdf_dfs.append(gdf_pca.SvmGdfResults(
stock, r=r, s=s, data_length=data_length, data_dir='../../../data_gdf',
gdf_filename_pattern=gdf_filename_pattern))
gdf_dfs[0].df.columns
df = gdf_dfs[2].df
df_test = gdf_dfs[2].df_test
n_components = gdf_dfs[2].get_pca('pca_n_gdf_que_prev').n_components_
class_weights = gdf_dfs[2].get_classes_weights()
print(n_components, class_weights)
df[[c for c in df.columns if 'gdf' in c]].boxplot(figsize=(16, 4))
X_train = df[[gdf for gdf in df.columns if 'gdf' in gdf or 'queue' in gdf]].values
y_train = df['mid_price_indicator'].values
print(n_components)
pca = PCA(n_components=n_components)
pca.fit(X_train)
X_train = pca.transform(X_train)
X_test = df_test[[gdf for gdf in df_test.columns if 'gdf' in gdf or 'queue' in gdf]].values
y_test = df_test['mid_price_indicator'].values
X_test = pca.transform(X_test)
print(X_train.shape)
print(X_test.shape)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
max_features = 1024
model = Sequential()
# model.add(LSTM(6))
model.add(Dense(8, activation='tanh'))
model.add(Dense(16, activation='tanh'))
model.add(Dense(32, activation='tanh'))
model.add(Dropout(rate=0.25))
model.add(Dense(64, activation='tanh'))
model.add(Dropout(rate=0.25))
model.add(Dense(128, activation='tanh'))
model.add(Dropout(rate=0.5))
model.add(Dense(256, activation='tanh'))
model.add(Dropout(rate=0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[auc_roc])
model.fit(X_train, y_train, shuffle=False,
epochs=4, batch_size=50, class_weight=class_weights)
print(model.summary())
pred_test = model.predict_classes(X_test)
pred = model.predict_classes(X_train)
print(metrics.roc_auc_score(y_test, pred_test), metrics.roc_auc_score(y_train, pred))
print(metrics.matthews_corrcoef(y_test, pred_test), metrics.matthews_corrcoef(y_train, pred))
model = Sequential()
model.add(LSTM(6))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[auc_roc])
epochs = 3
batch_size = 10
score = gdf_dfs[2].train_lstm(
model, feature_name='que', plot_name='here.png',
fit_kwargs={'epochs': epochs, 'batch_size': batch_size, 'verbose': 1, 'shuffle': False},
class_weight=class_weights,
compile_kwargs= { 'loss': 'binary_crossentropy', 'optimizer': 'adam', 'metrics': [auc_roc]})
score
# More time steps
def split_sequences(sequences, labels, n_steps):
X, y = list(), list()
for i in range(len(sequences)):
end_ix = i + n_steps
# check if we are beyond the dataset
if end_ix > len(sequences):
break
# gather input and output parts of the pattern
seq_x = sequences[i:end_ix]
lab = labels[end_ix-1]
X.append(seq_x)
y.append(lab)
return np.array(X), np.array(y)
X_train = df[[gdf for gdf in df.columns if 'gdf' in gdf or 'queue' in gdf]].values
y_train = df['mid_price_indicator'].values
pca = PCA(n_components=n_components)
pca.fit(X_train)
X_train = pca.transform(X_train)
X_test = df_test[[gdf for gdf in df_test.columns if 'gdf' in gdf or 'queue' in gdf]].values
y_test = df_test['mid_price_indicator'].values
X_test = pca.transform(X_test)
X_train, y_train = split_sequences(X_train, y_train, n_steps=5)
X_test, y_test = split_sequences(X_test, y_test, n_steps=5)
#X_test= np.reshape(X_test, (X_test.shape[0], 1, 3))
#X_train = np.reshape(X_train, (X_train.shape[0], 1, 3))
print(X_train.shape)
print(X_test.shape)
max_features = 1024
model = Sequential()
model.add(LSTM(128, input_shape=(5, 3)))
model.add(Dense(64, activation='tanh'))
model.add(Dense(32, activation='tanh'))
model.add(Dense(16, activation='tanh'))
model.add(Dense(8, activation='tanh'))
model.add(Dense(4, activation='tanh'))
model.add(Dense(2, activation='tanh'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[auc_roc])
model.fit(X_train, y_train, shuffle=False,
epochs=7, batch_size=50, class_weight=class_weights)
print(model.summary())
pred_test = model.predict_classes(X_test)
pred = model.predict_classes(X_train)
print(metrics.roc_auc_score(y_test, pred_test), metrics.roc_auc_score(y_train, pred))
print(metrics.matthews_corrcoef(y_test, pred_test), metrics.matthews_corrcoef(y_train, pred))
## With validation
model = Sequential()
model.add(LSTM(512, input_shape=(2, 2)))
model.add(Dropout(rate=0.5))
model.add(Dense(256, activation='tanh'))
model.add(Dense(128, activation='tanh'))
model.add(Dense(64, activation='tanh'))
model.add(Dense(32, activation='tanh'))
model.add(Dense(16, activation='tanh'))
model.add(Dense(8, activation='tanh'))
model.add(Dense(4, activation='tanh'))
model.add(Dense(2, activation='tanh'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[auc_roc])
epochs = 3
batch_size = 25
score = gdf_dfs[0].train_lstm(
model, feature_name='pca_n_gdf_que_prev', plot_name='here.png', n_steps=2,
fit_kwargs={'epochs': epochs, 'batch_size': batch_size, 'verbose': 1, 'shuffle': False},
class_weight=class_weights,
compile_kwargs= { 'loss': 'binary_crossentropy', 'optimizer': 'adam', 'metrics': [auc_roc]})
score['matthews'], score['test_matthews'], score['roc_auc'], score['test_roc_auc']
model = Sequential()
model.add(LSTM(8, input_shape=(2, 1)))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[auc_roc])
epochs = 3
batch_size = 25
score = gdf_dfs[1].train_lstm(
model, feature_name='pca_n_gdf_que', plot_name='here.png', n_steps=2,
fit_kwargs={'epochs': epochs, 'batch_size': batch_size, 'verbose': 1, 'shuffle': False},
class_weight=class_weights,
compile_kwargs= { 'loss': 'binary_crossentropy', 'optimizer': 'adam', 'metrics': [auc_roc]})
score['matthews'], score['test_matthews'], score['roc_auc'], score['test_roc_auc']
score = {**score, 'arch': model.to_json(), 'batch_size': batch_size, 'n_steps': 2, 'epochs': epochs,
'r': gdf_dfs[1].r, 's': gdf_dfs[1].s}
pd.DataFrame([score]).to_csv(
'../gdf_pca/res_lstm_weird/res_lstm_pca_que_{}_len24000_r{}_s{}.csv'.format(stock, gdf_dfs[1].r, gdf_dfs[1].s))
```
| github_jupyter |
# pandapower WLS State Estimation
This is an introduction into the usage of the pandapower state estimation module. It shows how to
create measurements for a pandapower network and how to perform a state estimation with the weighted least squares (WLS) algorithm.
## Example Network
We will be using the reference network from the book "Power System State Estimation" by Ali Abur and Antonio Gómez Expósito.
It contains 3 buses with connecting lines between buses 1-2, 1-3 and 2-3. 8 measurements of different types enable WLS state estimation.
We first create this network in pandapower.
```
import pandapower as pp
net = pp.create_empty_network()
b1 = pp.create_bus(net, name="bus 1", vn_kv=1., index=1)
b2 = pp.create_bus(net, name="bus 2", vn_kv=1., index=2)
b3 = pp.create_bus(net, name="bus 3", vn_kv=1., index=3)
pp.create_ext_grid(net, 1) # set the slack bus to bus 1
l1 = pp.create_line_from_parameters(net, 1, 2, 1, r_ohm_per_km=.01, x_ohm_per_km=.03, c_nf_per_km=0., max_i_ka=1)
l2 = pp.create_line_from_parameters(net, 1, 3, 1, r_ohm_per_km=.02, x_ohm_per_km=.05, c_nf_per_km=0., max_i_ka=1)
l3 = pp.create_line_from_parameters(net, 2, 3, 1, r_ohm_per_km=.03, x_ohm_per_km=.08, c_nf_per_km=0., max_i_ka=1)
net
```
Now we can add our measurements, which are valid for one point in time.
We add two voltage magnitude measurements on buses 1 / 2 with voltage magnitude of 1.006 pu / 0.968 pu and a standard deviation of 0.004 pu each:
## Adding Measurements
Measurements are defined via the pandapower *create_measurement* function.
The physical properties which can be measured are set with the *type* argument and can be one of the following: "p" for active power, "q" for reactive power, "v" for voltage and "i" for electrical current.
The element is set with the *element_type* argument, it can be either "bus", "line" or "transformer".
Power is measured in kW / kVar, voltage in per unit and current in A. Bus power injections are positive if power is generated at the bus and negative if it is consumed.
```
pp.create_measurement(net, "v", "bus", 1.006, .004, b1) # V at bus 1
pp.create_measurement(net, "v", "bus", 0.968, .004, b2) # V at bus 2
net.measurement
```
We add bus injection measurements on bus 2 with P=-501 kW and Q=-286kVar and standard deviations of 10kVA:
```
pp.create_measurement(net, "p", "bus", -501, 10, b2) # P at bus 2
pp.create_measurement(net, "q", "bus", -286, 10, b2) # Q at bus 2
net.measurement
```
Finally, we add line measurements for lines 0 and 1, both placed at the side of bus 1. The bus parameter defines the bus at which the line measurement is positioned, the line argument is the index of the line.
```
pp.create_measurement(net, "p", "line", 888, 8, bus=b1, element=l1) # Pline (bus 1 -> bus 2) at bus 1
pp.create_measurement(net, "p", "line", 1173, 8, bus=b1, element=l2) # Pline (bus 1 -> bus 3) at bus 1
pp.create_measurement(net, "q", "line", 568, 8, bus=b1, element=l1) # Qline (bus 1 -> bus 2) at bus 1
pp.create_measurement(net, "q", "line", 663, 8, bus=b1, element=l2) # Qline (bus 1 -> bus 3) at bus 1
net.measurement
```
## Performing the State Estimation
The measurements are now set. We have to initialize the starting voltage magnitude and voltage angles for the state estimator. In continous operation, this can be the result of the last state estimation. In our case, we set flat start conditions: 1.0 p.u. for voltage magnitude, 0.0 degree for voltage angles. This is easily done with the parameter "init", which we define as "flat".
And now run the state estimation. Afterwards, the result will be stored in the table res_bus_est.
```
from pandapower.estimation import estimate
success = estimate(net, init='flat')
print(success)
```
## Handling of Bad Data
The state estimation class allows additionally the removal of bad data, especially single or non-interacting false measurements. For detecting bad data the Chi-squared distribution is used to identify the presence of them. Afterwards follows the largest normalized residual test that identifys the actual measurements which will be removed at the end.
To test this function we will add a single false measurement to the network (active power flow of line 1 at bus 3):
```
pp.create_measurement(net, "p", "line", 1000, 8, bus=b3, element=l1) # Pline (bus 1 -> bus 2) at bus 3
net.measurement
```
The next step is the call of the largest normalized residual test's wrapper function *remove_bad_data* that handles the removal of the added false measurement, and returns a identication of success of the state estimation. The argument structure of this function is similiar to the *estimate* function (compare above). It only provides further adjustments according to the maximum allowed normalized residual ("rn_max_threshold"), and the probability of false required by the chi-squared test ("chi2_prob_false").
```
from pandapower.estimation import remove_bad_data
import numpy as np
success_rn_max = remove_bad_data(net, init='flat', rn_max_threshold=3.0, chi2_prob_false=0.05)
print(success_rn_max)
```
The management of results will be the same like for the *estimate* function (see following section).
## Working with Results
We can show the voltage magnitude and angles directly:
```
net.res_bus_est.vm_pu
net.res_bus_est.va_degree
```
The results match exactly with the results from the book: Voltages 0.9996, 0.9742, 0.9439; Voltage angles 0.0, -1.2475, -2.7457). Nice!
Let's look at the bus power injections, which are available in res_bus_est as well
```
net.res_bus_est.p_kw
net.res_bus_est.q_kvar
```
We can also compare the resulting line power flows with the measurements.
```
net.res_line_est.p_from_kw
net.res_line_est.q_from_kvar
```
Again, this values do match the estimated values from our reference book.
This concludes the small tutorial how to perform state estimation with a pandapower network.
| github_jupyter |
# SageMaker End to End Solutions: Fraud Detection for Automobile Claims
<a id='overview-0'></a>
## [Overview](./0-AutoClaimFraudDetection.ipynb)
* **[Notebook 0 : Overview, Architecture, and Data Exploration](./0-AutoClaimFraudDetection.ipynb)**
* **[Business Problem](#business-problem)**
* **[Technical Solution](#nb0-solution)**
* **[Solution Components](#nb0-components)**
* **[Solution Architecture](#nb0-architecture)**
* **[DataSets and Exploratory Data Analysis](#nb0-data-explore)**
* **[Exploratory Data Science and Operational ML workflows](#nb0-workflows)**
* **[The ML Life Cycle: Detailed View](#nb0-ml-lifecycle)**
* [Notebook 1: Data Prep, Process, Store Features](./1-data-prep-e2e.ipynb)
* Architecture
* Getting started
* DataSets
* SageMaker Feature Store
* Create train and test datasets
* [Notebook 2: Train, Check Bias, Tune, Record Lineage, and Register a Model](./2-lineage-train-assess-bias-tune-registry-e2e.ipynb)
* Architecture
* Train a model using XGBoost
* Model lineage with artifacts and associations
* Evaluate the model for bias with Clarify
* Deposit Model and Lineage in SageMaker Model Registry
* [Notebook 3: Mitigate Bias, Train New Model, Store in Registry](./3-mitigate-bias-train-model2-registry-e2e.ipynb)
* Architecture
* Develop a second model
* Analyze the Second Model for Bias
* View Results of Clarify Bias Detection Job
* Configure and Run Clarify Explainability Job
* Create Model Package for second trained model
* [Notebook 4: Deploy Model, Run Predictions](./4-deploy-run-inference-e2e.ipynb)
* Architecture
* Deploy an approved model and Run Inference via Feature Store
* Create a Predictor
* Run Predictions from Online FeatureStore
* [Notebook 5 : Create and Run an End-to-End Pipeline to Deploy the Model](./5-pipeline-e2e.ipynb)
* Architecture
* Create an Automated Pipeline
* Clean up
## Overview, Architecture, and Data Exploration
In this overview notebook, we will address business problems regarding auto insurance fraud, technical solutions, explore dataset, solution architecture, and scope the machine learning (ML) life cycle.
<a id='business-problem'> </a>
## Business Problem
[overview](#overview-0)
<i> "Auto insurance fraud ranges from misrepresenting facts on insurance applications and inflating insurance claims to staging accidents and submitting claim forms for injuries or damage that never occurred, to false reports of stolen vehicles.
Fraud accounted for between 15 percent and 17 percent of total claims payments for auto insurance bodily injury in 2012, according to an Insurance Research Council (IRC) study. The study estimated that between $\$5.6$ billion and $\$7.7$ billion was fraudulently added to paid claims for auto insurance bodily injury payments in 2012, compared with a range of $\$4.3$ billion to $\$5.8$ billion in 2002. </i>" [source: Insurance Information Institute](https://www.iii.org/article/background-on-insurance-fraud)
In this example, we will use an *auto insurance domain* to detect claims that are possibly fraudulent.
more precisley we address the use-case: <i> "what is the likelihood that a given autoclaim is fraudulent?" </i>, and explore the technical solution.
As you review the [notebooks](#nb0-notebooks) and the [architectures](#nb0-architecture) presented at each stage of the ML life cycle, you will see how you can leverage SageMaker services and features to enhance your effectiveness as a data scientist, as a machine learning engineer, and as an ML Ops Engineer.
We will then do [data exploration](#nb0-data-explore) on the synthetically generated datasets for Customers and Claims.
Then, we will provide an overview of the technical solution by examining the [Solution Components](#nb0-components) and the [Solution Architecture](#nb0-architecture).
We will be motivated by the need to accomplish new tasks in ML by examining a [detailed view of the Machine Learning Life-cycle](#nb0-ml-lifecycle), recognizing the [separation of exploratory data science and operationalizing an ML worklfow](#nb0-workflows).
### Car Insurance Claims: Data Sets and Problem Domain
The inputs for building our model and workflow are two tables of insurance data: a claims table and a customers table. This data was synthetically generated is provided to you in its raw state for pre-processing with SageMaker Data Wrangler. However, completing the Data Wragnler step is not required to continue with the rest of this notebook. If you wish, you may use the `claims_preprocessed.csv` and `customers_preprocessed.csv` in the `data` directory as they are exact copies of what Data Wragnler would output.
<a id ='nb0-solution'> </a>
## Technical Solution
[overview](#overview-0)
In this introduction, you will look at the technical architecture and solution components to build a solution for predicting fraudulent insurance claims and deploy it using SageMaker for real-time predictions. While a deployed model is the end-product of this notebook series, the purpose of this guide is to walk you through all the detailed stages of the [machine learning (ML) lifecycle](#ml-lifecycle) and show you what SageMaker servcies and features are there to support your activities in each stage.
**Topics**
- [Solution Components](#nb0-components)
- [Solution Architecture](#nb0-architecture)
- [Code Resources](#nb0-code)
- [ML lifecycle details](#nb0-ml-lifecycle)
- [Manual/exploratory and automated workflows](#nb0-workflows)
<a id ='nb0-components'> </a>
## Solution Components
[overview](#overview-0)
The following [SageMaker](https://sagemaker.readthedocs.io/en/stable/v2.html) Services are used in this solution:
1. [SageMaker DataWrangler](https://aws.amazon.com/sagemaker/data-wrangler/) - [docs](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler.html)
1. [SageMaker Processing](https://aws.amazon.com/blogs/aws/amazon-sagemaker-processing-fully-managed-data-processing-and-model-evaluation/) - [docs](https://sagemaker.readthedocs.io/en/stable/amazon_sagemaker_processing.html)
1. [SageMaker Feature Store](https://aws.amazon.com/sagemaker/feature-store/)- [docs](https://sagemaker.readthedocs.io/en/stable/amazon_sagemaker_featurestore.html)
1. [SageMaker Clarify](https://aws.amazon.com/sagemaker/clarify/)- [docs](https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-processing-job-run.html)
1. [SageMaker Training with XGBoost Algorithm and Hyperparameter Optimization](https://sagemaker.readthedocs.io/en/stable/frameworks/xgboost/using_xgboost.html)- [docs](https://sagemaker.readthedocs.io/en/stable/frameworks/xgboost/index.html)
1. [SageMaker Model Registry](https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html)- [docs](https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry-deploy.html#model-registry-deploy-api)
1. [SageMaker Hosted Endpoints]()- [predictors - docs](https://sagemaker.readthedocs.io/en/stable/api/inference/predictors.html)
1. [SageMaker Pipelines]()- [docs](https://sagemaker.readthedocs.io/en/stable/workflows/pipelines/index.html)

<a id ='nb0-data-explore'> </a>
## DataSets and Exploratory Visualizations
[overview](#overview-0)
The dataset is synthetically generated and consists of <font color='green'> customers and claims </font> datasets.
Here we will load them and do some exploratory visualizations.
```
!pip install seaborn==0.11.1
# Importing required libraries.
import pandas as pd
import numpy as np
import seaborn as sns # visualisation
import matplotlib.pyplot as plt # visualisation
%matplotlib inline
sns.set(color_codes=True)
df_claims = pd.read_csv("./data/claims_preprocessed.csv", index_col=0)
df_customers = pd.read_csv("./data/customers_preprocessed.csv", index_col=0)
print(df_claims.isnull().sum().sum())
print(df_customers.isnull().sum().sum())
```
This should return no null values in both of the datasets.
```
# plot the bar graph customer gender
df_customers.customer_gender_female.value_counts(normalize=True).plot.bar()
plt.xticks([0, 1], ["Male", "Female"]);
```
The dataset is heavily weighted towards male customers.
```
# plot the bar graph of fraudulent claims
df_claims.fraud.value_counts(normalize=True).plot.bar()
plt.xticks([0, 1], ["Not Fraud", "Fraud"]);
```
The overwhemling majority of claims are legitimate (i.e. not fraudulent).
```
# plot the education categories
educ = df_customers.customer_education.value_counts(normalize=True, sort=False)
plt.bar(educ.index, educ.values)
plt.xlabel("Customer Education Level");
# plot the total claim amounts
plt.hist(df_claims.total_claim_amount, bins=30)
plt.xlabel("Total Claim Amount")
```
Majority of the total claim amounts are under $25,000.
```
# plot the number of claims filed in the past year
df_customers.num_claims_past_year.hist(density=True)
plt.suptitle("Number of Claims in the Past Year")
plt.xlabel("Number of claims per year")
```
Most customers did not file any claims in the previous year, but some filed as many as 7 claims.
```
sns.pairplot(
data=df_customers, vars=["num_insurers_past_5_years", "months_as_customer", "customer_age"]
);
```
Understandably, the `months_as_customer` and `customer_age` are correlated with each other. A younger person have been driving for a smaller amount of time and therefore have a smaller potential for how long they might have been a customer.
We can also see that the `num_insurers_past_5_years` is negatively correlated with `months_as_customer`. If someone frequently jumped around to different insurers, then they probably spent less time as a customer of this insurer.
```
df_combined = df_customers.join(df_claims)
sns.lineplot(x="num_insurers_past_5_years", y="fraud", data=df_combined);
```
Fraud is positively correlated with having a greater number of insurers over the past 5 years. Customers who switched insurers more frequently also had more prevelance of fraud.
```
sns.boxplot(x=df_customers["months_as_customer"]);
sns.boxplot(x=df_customers["customer_age"]);
```
Our customers range from 18 to 75 years old.
```
df_combined.groupby("customer_gender_female").mean()["fraud"].plot.bar()
plt.xticks([0, 1], ["Male", "Female"])
plt.suptitle("Fraud by Gender");
```
Fraudulent claims come disproportionately from male customers.
```
# Creating a correlation matrix of fraud, gender, months as customer, and number of different insurers
cols = [
"fraud",
"customer_gender_male",
"customer_gender_female",
"months_as_customer",
"num_insurers_past_5_years",
]
corr = df_combined[cols].corr()
# plot the correlation matrix
sns.heatmap(corr, annot=True, cmap="Reds");
```
Fraud is correlated with having more insurers in the past 5 years, and negatively correlated with being a customer for a longer period of time. These go hand in hand and mean that long time customers are less likely to commit fraud.
### Combined DataSets
We have been looking at the indivudual datasets, now let's look at their combined view (join).
```
import pandas as pd
df_combined = pd.read_csv("./data/claims_customer.csv")
df_combined = df_combined.loc[:, ~df_combined.columns.str.contains("^Unnamed: 0")]
# get rid of an unwanted column
df_combined.head()
df_combined.describe()
```
Let's explore any unique, missing, or large percentage category in the combined dataset.
```
combined_stats = []
for col in df_combined.columns:
combined_stats.append(
(
col,
df_combined[col].nunique(),
df_combined[col].isnull().sum() * 100 / df_combined.shape[0],
df_combined[col].value_counts(normalize=True, dropna=False).values[0] * 100,
df_combined[col].dtype,
)
)
stats_df = pd.DataFrame(
combined_stats,
columns=["feature", "unique_values", "percent_missing", "percent_largest_category", "datatype"],
)
stats_df.sort_values("percent_largest_category", ascending=False)
import matplotlib.pyplot as plt
import numpy as np
sns.set_style("white")
corr_list = [
"customer_age",
"months_as_customer",
"total_claim_amount",
"injury_claim",
"vehicle_claim",
"incident_severity",
"fraud",
]
corr_df = df_combined[corr_list]
corr = round(corr_df.corr(), 2)
fix, ax = plt.subplots(figsize=(15, 15))
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
ax = sns.heatmap(corr, mask=mask, ax=ax, annot=True, cmap="OrRd")
ax.set_xticklabels(ax.xaxis.get_ticklabels(), fontsize=10, ha="right", rotation=45)
ax.set_yticklabels(ax.yaxis.get_ticklabels(), fontsize=10, va="center", rotation=0)
plt.show()
```
<a id ='nb0-architecture'> </a>
## Solution Architecture
[overview](#overview-0)
We will go through 5 stages of ML and explore the solution architecture of SageMaker. Each of the sequancial notebooks will dive deep into corresponding ML stage.
<a id ='nb0-data-prep'> </a>
### [Notebook 1](./1-data-prep-e2e.ipynb): Data Preparation, Ingest, Transform, Preprocess, and Store in SageMaker Feature Store
[overview](#nb0-solution)

<a id ='nb0-train-store'> </a>
### [Notebook 2](./2-lineage-train-assess-bias-tune-registry-e2e.ipynb) and [Notebook 3](./3-mitigate-bias-train-model2-registry-e2e.ipynb) : Train, Tune, Check Pre- and Post- Training Bias, Mitigate Bias, Re-train, and Deposit the Best Model to SageMaker Model Registry
[overview](#nb0-solution)

<a id ='nb0-deploy-predict'> </a>
### [Notebooks 4](./4-deploy-run-inference-e2e.ipynb) : Load the Best Model from Registry, Deploy it to SageMaker Hosted Endpoint, and Make Predictions
[overview](#nb0-solution)

<a id ='nb0-pipeline'> </a>
### [Notebooks 5](./5-pipeline-e2e.ipynb): End-to-End Pipeline - MLOps Pipeline to run an end-to-end automated workflow with all the design decisions made during manual/exploratory steps in previous notebooks.
[overview](#nb0-solution)

<a id ='nb0-code'> </a>
## Code Resources
[overview](#nb0-solution)
### Stages
Our solution is split into the following stages of the [ML Lifecycle](#nb0-ml-lifecycle), and each stage has it's own notebook:
* [Use-case and Architecture](./0-AutoClaimFraudDetection.ipynb): We take a high-level look at the use-case, solution components and architecture.
* [Data Prep and Store](./1-data-prep-e2e.ipynb): We prepare a dataset for machine learning using SageMaker DataWrangler, create and deposit the datasets in a SageMaker FeatureStore. [--> Architecture](#nb0-data-prep)
* [Train, Assess Bias, Establish Lineage, Register Model](./2-lineage-train-assess-bias-tune-registry-e2e.ipynb): We detect possible pre-training and post-training bias, train and tune a XGBoost model using Amazon SageMaker, record Lineage in the Model Registry so we can later deploy it. [--> Architecture](#nb0-train-store)
* [Mitigate Bias, Re-train, Register New Model](./3-mitigate-bias-train-model2-registry-e2e.ipynb): We mitigate bias, retrain a less biased model, store it in a Model Registry. [--> Architecture](#nb0-train-store)
* [Deploy and Serve](./4-deploy-run-inference-e2e.ipynb): We deploy the model to a Amazon SageMaker Hosted Endpoint and run realtime inference via the SageMaker Online Feature Store . [--> Architecture](#nb0-deploy-predict)
* [Create and Run an MLOps Pipeline](./5-pipeline-e2e.ipynb): We then create a SageMaker Pipeline that ties together everything we have done so far, from outputs from Data Wrangler, Feature Store, Clarify , Model Registry and finally deployment to a SageMaker Hosted Endpoint. [--> Architecture](#nb0-pipeline)
* [Conclusion](./6-conclusion-e2e.ipynb): We wrap things up and discuss how to clean up the solution.
<a id ='nb0-workflows'> </a>
## The Exploratory Data Science and ML Ops Workflows
[overview](#overview-0)
### Exploratory Data Science and Scalable MLOps
Note that there are typically two workflows: a manual exploratory workflow and an automated workflow.
The *exploratory, manual data science workflow* is where experiments are conducted and various techniques and strategies are tested.
After you have established your data prep, transformations, featurizations and training algorithms, testing of various hyperparameters for model tuning, you can start with the automated workflow where you *rely on MLOps or the ML Engineering part of your team* to streamline the process, make it more repeatable and scalable by putting it into an automated pipeline.

<a id ='nb0-ml-lifecycle'></a>
## The ML Life Cycle: Detailed View
[overview](#overview-0)

The Red Boxes and Icons represent comparatively newer concepts and tasks that are now deemed important to include and execute, in a production-oriented (versus research-oriented) and scalable ML lifecycle.
These newer lifecycle tasks and their corresponding, supporting AWS Services and features include:
1. [*Data Wrangling*](): AWS Data Wrangler for cleaning, normalizing, transforming and encoding data, as well as join ing datasets. The outputs of Data Wrangler are code generated to work with SageMaker Processing, SageMaker Pipelines, SageMaker Feature Store or just a plain old python script with pandas,
1. Feature Engineering has always been done, but now with AWS Data Wrangler we can use a GUI based tool to do so and generate code for the next phases of the life-cycle.
2. [*Detect Bias*](): Using AWS Clarify, in Data Prep or in Training we can detect pre-training and post-training bias, and eventually at Inference time provide Interpretability / Explainability of the inferences (e.g., which factors were most influential in coming up with the prediction)
3. [*Feature Store [Offline]*](): Once we have done all of our feature engineering, the encoding and transformations, we can then standardize features, offline in AWS Feature Store, to be used as input features for training models.
4. [*Artifact Lineage*](): Using AWS SageMaker’s Artifact Lineage features we can associate all the artifacts (data, models, parameters, etc.) with a trained model to produce meta data that can be stored in a Model Registry.
5. [*Model Registry*](): AWS Model Registry stores the meta data around all artifacts that you have chosen to include in the process of creating your models, along with the model(s) themselves in a Model Registry. Later a human approval can be used to note that the model is good to be put into production. This feeds into the next phase of deploy and monitor .
6. [*Inference and the Online Feature Store*](): For realtime inference, we can leverage a online AWS Feature Store we have created to get us single digit millisecond low latency and high throughput for serving our model with new incoming data.
7. [*Pipelines*](): Once we have experimented and decided on the various options in the lifecycle (which transforms to apply to our features, imbalance or bias in the data, which algorithms to choose to train with, which hyper-parameters are giving us the best performance metrics, etc.) we can now automate the various tasks across the lifecycle using SageMaker Pipelines.
1. In this blog, we will show a pipeline that starts with the outputs of AWS Data Wrangler and ends with storing trained models in the Model Registry.
2. Typically, you could have a pipeline for data prep, one for training until model registry (which we are showing in the code associated with this blog) , one for inference, and one for re-training using SageMaker Monitor to detect model drift and data drift and trigger a re-training using , say an AWS Lambda function.
[overview](#overview-0)
___
### Next Notebook: [Data Preparation, Process, and Store Features](./1-data-prep-e2e.ipynb)
| github_jupyter |
# 単変量線形回帰の信頼区間
```
import numpy as np
from scipy import stats
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
```
# 真の回帰直線
* $y = x + 1$
# 観測値
* $x = 0.0, 0.5. 1.0, \dots, 10.0$
* サンプル数: 21
* $Y_i = x_i + 1 + \varepsilon, \varepsilon \sim N(0, 0.5^2)$
```
# 実験設定
SAMPLE_SIZE = 21
SIGMA = 0.5
# 実験を管理するクラス
class Experiment:
def __init__(self, random_seed, sigma, sample_size):
np.random.seed(random_seed)
# 実験設定
self.sigma = sigma
self.sample_size = sample_size
# サンプルを生成
self.x_train = np.array([0.5 * i for i in range(sample_size)])
self.y_true = self.x_train + 1
self.y_train = self.y_true + np.random.normal(0.0, sigma, sample_size)
# 回帰係数を算出
self.x_mean = np.mean(self.x_train)
self.s_xx = np.sum((self.x_train - self.x_mean) ** 2)
self.y_mean = np.mean(self.y_train)
self.s_xy = np.sum((self.x_train - self.x_mean) * (self.y_train - self.y_mean))
# 回帰係数
self.coef = self.s_xy / self.s_xx
self.intercept = self.y_mean - self.coef * self.x_mean
# 不偏標本分散
s2 = np.sum((self.y_train - self.intercept - self.coef * self.x_train) ** 2) / (sample_size - 2)
self.s = np.sqrt(s2)
# t分布(自由度N-2)の上側2.5%点
self.t = stats.t.ppf(1-0.025, df=sample_size-2)
# 予測
def predict(self, x):
return self.intercept + self.coef * x
# 真の値
def calc_true_value(self, x):
return x + 1
# 95%信頼区間
def calc_confidence(self, x):
band = self.t * self.s * np.sqrt(1 / self.sample_size + (x - self.x_mean)**2 / self.s_xx)
upper_confidence = self.predict(x) + band
lower_confidence = self.predict(x) - band
return (lower_confidence, upper_confidence)
# 観測値, 95%信頼区間, 真の回帰直線を描画する
def plot(self):
# 学習データ
plt.scatter(self.x_train, self.y_train, color='royalblue', alpha=0.2)
# 回帰直線
y_pred = self.predict(self.x_train)
plt.plot(self.x_train, y_pred, color='royalblue', label='y_fitted')
# 信頼区間
lower_confidence, upper_confidence = self.calc_confidence(self.x_train)
plt.plot(self.x_train, upper_confidence, color='royalblue', linestyle='dashed', label='95% confidence interval')
plt.plot(self.x_train, lower_confidence, color='royalblue', linestyle='dashed')
x_max = max(self.x_train)
plt.xlim([0, x_max])
plt.ylim([0.5, x_max + 1.5])
plt.legend();
# あるxにおける信頼区間と真の値を描画する
def plot_at_x(self, x):
plt.xlim([x-0.5, x+0.5])
plot_x = np.array([x-0.5, x, x+0.5])
plot_y = self.predict(plot_x)
# 信頼区間
lb, ub = self.calc_confidence(x)
error = (ub - lb) / 2
plt.errorbar(plot_x[1], plot_y[1], fmt='o', yerr=error, capsize=5, color='royalblue', label='95% confidence interval')
plt.plot(plot_x, plot_y, alpha=0.2, color='royalblue')
# 真の値
y_true = x + 1
plt.scatter(x, y_true, color='orange', label='true value')
plt.xlim([x-0.5, x+0.5])
plt.legend();
```
# 実験
```
# 観測した標本から回帰直線と95%信頼区間を求める
random_seed = 27
experiment = Experiment(random_seed, SIGMA, SAMPLE_SIZE)
experiment.plot()
```
## 信頼区間に真の値が含まれるケース
```
x = 8
experiment.plot_at_x(x)
```
## 信頼区間に真の値が含まれないケース
```
x = 0
experiment.plot_at_x(x)
```
# 実験を1万回繰り返す
* 信頼区間に真の値が含まれる割合を計測する
```
experiment_count = 10000
count = 0
for i in range(experiment_count):
experiment = Experiment(i, SIGMA, SAMPLE_SIZE)
x = np.random.uniform(0, 10, 1)[0]
y_true = experiment.calc_true_value(x)
lb, ub = experiment.calc_confidence(x)
# 信頼区間に真の値が含まれるかチェック
count += 1 if (lb <= y_true and y_true <= ub) else 0
print('信頼区間に真の値が含まれる割合: {:.1f}%'.format(100 * count / experiment_count))
```
| github_jupyter |
# A Simulation Study for Time-varying coefficients
```
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import math
from scipy import stats
from math import pi
from scipy.spatial.distance import cdist
import time
from orbit.models.ktrx import KTRXFull, KTRXAggregated
from orbit.models.ktrlite import KTRLiteMAP
from orbit.estimators.pyro_estimator import PyroEstimatorVI, PyroEstimatorMAP
from orbit.estimators.stan_estimator import StanEstimatorMAP
from orbit.diagnostics.metrics import smape
from orbit.utils.features import make_fourier_series_df, make_fourier_series
from orbit.diagnostics.plot import plot_predicted_data
plt.style.use('fivethirtyeight')
%load_ext autoreload
%autoreload 2
```
# Data Simulation Modules
```
def sim_data_seasonal(n, RS):
""" coefficients curve are sine-cosine like
"""
np.random.seed(RS)
# make the time varing coefs
tau = np.arange(1, n+1)/n
data = pd.DataFrame({
'tau': tau,
'date': pd.date_range(start='1/1/2018', periods=n),
'beta1': 2 * tau,
'beta2': 1.01 + np.sin(2*pi*tau),
'beta3': 1.01 + np.sin(4*pi*(tau-1/8)),
# 'x1': stats.chi2.rvs(4, size=n),
# 'x2': stats.t.rvs(2, size=n),
# 'x3': stats.t.rvs(2, size=n),
'x1': np.random.normal(0, 10, size=n),
'x2': np.random.normal(0, 10, size=n),
'x3': np.random.normal(0, 10, size=n),
'trend': np.cumsum(np.concatenate((np.array([1]), np.random.normal(0, 0.1, n-1)))),
'error': np.random.normal(0, 1, size=n) #stats.t.rvs(30, size=n),#
})
# add error to the data
#err_cov = np.exp(-cdist(data.tau.values.reshape(n, -1), data.tau.values.reshape(n, -1), 'euclid')/10)
#L = np.linalg.cholesky(err_cov).T
#data['error2'] = L.dot(stats.chi2.rvs(100, size=n))
data['y'] = data.x1 * data.beta1 + data.x2 * data.beta2 + data.x3 * data.beta3 + data.error
#data['y2'] = data.x1 * data.beta1 + data.x2 * data.beta2 + data.x3 * data.beta3 + data.error2
#data['y3'] = data.trend + data.x1 * data.beta1 + data.x2 * data.beta2 + data.x3 * data.beta3 + data.error
return data
def sim_data_rw(n, RS, p=3):
""" coefficients curve are sine-cosine like
"""
np.random.seed(RS)
# initializing coefficients at zeros, simulate all coefficient values
lev = np.cumsum(np.concatenate((np.array([5.0]), np.random.normal(0, 0.01, n-1))))
beta = np.concatenate(
[np.random.uniform(0.05, 0.12, size=(1,p)),
np.random.normal(0.0, 0.01, size=(n-1,p))],
axis=0)
beta = np.cumsum(beta, 0)
# simulate regressors
covariates = np.random.normal(0, 10, (n, p))
# observation with noise
y = lev + (covariates * beta).sum(-1) + 0.3 * np.random.normal(0, 1, n)
regressor_col = ['x{}'.format(pp) for pp in range(1, p+1)]
data = pd.DataFrame(covariates, columns=regressor_col)
beta_col = ['beta{}'.format(pp) for pp in range(1, p+1)]
beta_data = pd.DataFrame(beta, columns=beta_col)
data = pd.concat([data, beta_data], axis=1)
data['y'] = y
data['date'] = pd.date_range(start='1/1/2018', periods=len(y))
return data
seas_data = sim_data_seasonal(n=1000, RS=8888)
seas_data.head(10)
rw_data = sim_data_rw(n=300, RS=8888, p=3)
rw_data.head(10)
```
In following section, let's start with random walk type of simulation.
# Random Walk Simulation Study
## KTRLite
**KTRLite** is used to learn the trend. We will use a default to do that.
```
p = 3
# define stuff
regressor_col = ['x{}'.format(pp) for pp in range(1, p+1)]
response_col = 'y'
# run the model
# run lite first
ktr_lite = KTRLiteMAP(
response_col=response_col,
date_col='date',
seed=2020,
estimator_type=StanEstimatorMAP,
)
ktr_lite.fit(df=rw_data)
level_knot_scale = ktr_lite.level_knot_scale
level_knots_stan = ktr_lite._aggregate_posteriors['map']['lev_knot'][0]
level_knot_dates = ktr_lite._level_knot_dates
level_knots_stan = np.array([0] * len(level_knot_dates))
```
## Hierarchical structure with neutral sign assumption
Each coefficient follow Normal dist. with a latent mean which also follows a Normal dist.
```
%%time
ktrx_neutral = KTRXFull(
response_col=response_col,
date_col='date',
level_knot_scale=level_knot_scale,
level_knot_dates=level_knot_dates,
level_knots=level_knots_stan,
regressor_col=regressor_col,
regressor_init_knot_loc=[0] * len(regressor_col),
regressor_init_knot_scale=[1.0] * len(regressor_col),
regressor_knot_scale=[0.5] * len(regressor_col),
span_coefficients=0.1,
rho_coefficients=0.05,
prediction_percentiles=[2.5, 97.5],
seed=2020,
num_steps=501,
num_sample=1000,
learning_rate=0.2,
learning_rate_total_decay=0.05,
verbose=True,
message=50,
n_bootstrap_draws=-1,
estimator_type=PyroEstimatorVI,
# new setting we want to test
mvn=0,
flat_multiplier=True,
geometric_walk=False,
min_residuals_sd=1.0,
)
ktrx_neutral.fit(df=rw_data)
idx = 3
coef_mid, coef_lower, coef_upper = ktrx_neutral.get_regression_coefs(include_ci=True, coefficient_method='empirical')
x = np.arange(coef_mid.shape[0])
plt.plot(x, coef_mid['x{}'.format(idx)], label='est', alpha=0.5)
plt.fill_between(x, coef_lower['x{}'.format(idx)], coef_upper['x{}'.format(idx)], label='est', alpha=0.5)
plt.scatter(x, rw_data['beta{}'.format(idx)], label='truth', s=10, alpha=0.5)
plt.legend()
_ = ktrx_neutral.plot_regression_coefs(with_knot=True, figsize=(16, 8))
```
## Hierarchical structure with positive sign assumption
Most of setting are similar to previous setting. However, this time we turn on sign as positive which implies all coefficient distribution are replaced by folded normal.
```
%%time
ktrx_pos = KTRXFull(
response_col=response_col,
date_col='date',
level_knot_scale=level_knot_scale,
level_knot_dates=level_knot_dates,
level_knots=level_knots_stan,
regressor_col=regressor_col,
regressor_init_knot_loc=[0] * len(regressor_col),
regressor_init_knot_scale=[1.0] * len(regressor_col),
regressor_knot_scale=[0.5] * len(regressor_col),
# this is the only change fromp previous setting
regressor_sign=['+'] * len(regressor_col),
span_coefficients=0.1,
rho_coefficients=0.05,
prediction_percentiles=[2.5, 97.5],
seed=2020,
num_steps=501,
num_sample=1000,
learning_rate=0.2,
learning_rate_total_decay=0.05,
verbose=True,
message=50,
n_bootstrap_draws=-1,
estimator_type=PyroEstimatorVI,
# new setting we want to test
mvn=0,
flat_multiplier=True,
geometric_walk=False,
min_residuals_sd=1.0,
)
ktrx_pos.fit(df=rw_data)
idx = 3
coef_mid, coef_lower, coef_upper = ktrx_pos.get_regression_coefs(include_ci=True, coefficient_method='empirical')
x = np.arange(coef_mid.shape[0])
plt.plot(x, coef_mid['x{}'.format(idx)], label='est', alpha=0.5)
plt.fill_between(x, coef_lower['x{}'.format(idx)], coef_upper['x{}'.format(idx)], label='est', alpha=0.5)
plt.scatter(x, rw_data['beta{}'.format(idx)], label='truth', s=10, alpha=0.5)
plt.legend()
_ = ktrx_pos.plot_regression_coefs(with_knot=True, figsize=(16, 8))
```
## Gemetric random walk structure with positive sign assumption and
Most of setting are similar to previous setting. However, this time we turn on sign as positive which implies all coefficient distribution are replaced by folded normal.
```
%%time
ktrx_grw = KTRXFull(
response_col=response_col,
date_col='date',
level_knot_scale=level_knot_scale,
level_knot_dates=level_knot_dates,
level_knots=level_knots_stan,
regressor_col=regressor_col,
regressor_init_knot_loc=[0] * len(regressor_col),
# since we turn geometric_walk to true, this setting also need to be changed from previous
# i.e. scale parameter is interpreted differently
regressor_init_knot_scale=[1.0] * len(regressor_col),
regressor_knot_scale=[0.5] * len(regressor_col),
regressor_sign=['+'] * len(regressor_col),
span_coefficients=0.1,
rho_coefficients=0.05,
prediction_percentiles=[2.5, 97.5],
seed=2020,
num_steps=501,
num_sample=1000,
learning_rate=0.2,
learning_rate_total_decay=0.05,
verbose=True,
message=50,
n_bootstrap_draws=-1,
estimator_type=PyroEstimatorVI,
# new setting we want to test
mvn=0,
flat_multiplier=True,
geometric_walk=True,
min_residuals_sd=1.0,
)
ktrx_grw.fit(df=rw_data)
idx = 3
coef_mid, coef_lower, coef_upper = ktrx_grw.get_regression_coefs(include_ci=True, coefficient_method='empirical')
x = np.arange(coef_mid.shape[0])
plt.plot(x, coef_mid['x{}'.format(idx)], label='est', alpha=0.5)
plt.fill_between(x, coef_lower['x{}'.format(idx)], coef_upper['x{}'.format(idx)], label='est', alpha=0.5)
plt.scatter(x, rw_data['beta{}'.format(idx)], label='truth', s=10, alpha=0.5)
plt.legend()
_ = ktrx_grw.plot_regression_coefs(with_knot=True, figsize=(16, 8))
```
# Sine-cosine coefficients Simulation Study
## KTRLite
**KTRLite** is used to learn the trend. We will use a default to do that.
```
p = 3
# define stuff
regressor_col = ['x{}'.format(pp) for pp in range(1, p+1)]
response_col = 'y'
# run the model
# run lite first
ktr_lite = KTRLiteMAP(
response_col=response_col,
date_col='date',
seed=2020,
estimator_type=StanEstimatorMAP,
)
ktr_lite.fit(df=seas_data)
level_knot_scale = ktr_lite.level_knot_scale
level_knots_stan = ktr_lite._aggregate_posteriors['map']['lev_knot'][0]
level_knot_dates = ktr_lite._level_knot_dates
level_knots_stan = np.array([0] * len(level_knot_dates))
```
## Hierarchical structure with neutral sign assumption
Each coefficient follow Normal dist. with a latent mean which also follows a Normal dist.
```
%%time
ktrx_neutral = KTRXFull(
response_col=response_col,
date_col='date',
level_knot_scale=level_knot_scale,
level_knot_dates=level_knot_dates,
level_knots=level_knots_stan,
regressor_col=regressor_col,
regressor_init_knot_loc=[0] * len(regressor_col),
regressor_init_knot_scale=[10.0] * len(regressor_col),
regressor_knot_scale=[2.0] * len(regressor_col),
span_coefficients=0.1,
rho_coefficients=0.05,
prediction_percentiles=[2.5, 97.5],
seed=2020,
num_steps=501,
num_sample=1000,
learning_rate=0.2,
learning_rate_total_decay=0.05,
verbose=True,
message=50,
n_bootstrap_draws=-1,
estimator_type=PyroEstimatorVI,
# new setting we want to test
mvn=0,
flat_multiplier=True,
geometric_walk=False,
min_residuals_sd=1.0,
)
ktrx_neutral.fit(df=seas_data)
idx = 3
coef_mid, coef_lower, coef_upper = ktrx_neutral.get_regression_coefs(include_ci=True, coefficient_method='empirical')
x = np.arange(coef_mid.shape[0])
plt.plot(x, coef_mid['x{}'.format(idx)], label='est', alpha=0.5)
plt.fill_between(x, coef_lower['x{}'.format(idx)], coef_upper['x{}'.format(idx)], label='est', alpha=0.5)
plt.scatter(x, seas_data['beta{}'.format(idx)], label='truth', s=10, alpha=0.5)
plt.legend()
_ = ktrx_neutral.plot_regression_coefs(with_knot=True, figsize=(16, 8))
```
## Hierarchical structure with positive sign assumption
Most of setting are similar to previous setting. However, this time we turn on sign as positive which implies all coefficient distribution are replaced by folded normal.
```
%%time
ktrx_pos = KTRXFull(
response_col=response_col,
date_col='date',
level_knot_scale=level_knot_scale,
level_knot_dates=level_knot_dates,
level_knots=level_knots_stan,
regressor_col=regressor_col,
regressor_init_knot_loc=[0] * len(regressor_col),
regressor_init_knot_scale=[10.0] * len(regressor_col),
regressor_knot_scale=[2.0] * len(regressor_col),
# this is the only change fromp previous setting
regressor_sign=['+'] * len(regressor_col),
span_coefficients=0.1,
rho_coefficients=0.05,
prediction_percentiles=[2.5, 97.5],
seed=2020,
num_steps=501,
num_sample=1000,
learning_rate=0.2,
learning_rate_total_decay=0.05,
verbose=True,
message=50,
n_bootstrap_draws=-1,
estimator_type=PyroEstimatorVI,
# new setting we want to test
mvn=0,
flat_multiplier=True,
geometric_walk=False,
min_residuals_sd=1.0,
)
ktrx_pos.fit(df=seas_data)
idx = 3
coef_mid, coef_lower, coef_upper = ktrx_pos.get_regression_coefs(include_ci=True, coefficient_method='empirical')
x = np.arange(coef_mid.shape[0])
plt.plot(x, coef_mid['x{}'.format(idx)], label='est', alpha=0.5)
plt.fill_between(x, coef_lower['x{}'.format(idx)], coef_upper['x{}'.format(idx)], label='est', alpha=0.5)
plt.scatter(x, seas_data['beta{}'.format(idx)], label='truth', s=10, alpha=0.5)
plt.legend()
_ = ktrx_pos.plot_regression_coefs(with_knot=True, figsize=(16, 8))
```
## Gemetric random walk structure with positive sign assumption and
Most of setting are similar to previous setting. However, this time we turn on sign as positive which implies all coefficient distribution are replaced by folded normal.
```
%%time
ktrx_grw = KTRXFull(
response_col=response_col,
date_col='date',
level_knot_scale=level_knot_scale,
level_knot_dates=level_knot_dates,
level_knots=level_knots_stan,
regressor_col=regressor_col,
regressor_init_knot_loc=[0] * len(regressor_col),
# since we turn geometric_walk to true, this setting also need to be changed from previous
# i.e. scale parameter is interpreted differently
regressor_init_knot_scale=[10.0] * len(regressor_col),
regressor_knot_scale=[0.2] * len(regressor_col),
regressor_sign=['+'] * len(regressor_col),
span_coefficients=0.1,
rho_coefficients=0.05,
prediction_percentiles=[2.5, 97.5],
seed=2020,
num_steps=501,
num_sample=1000,
learning_rate=0.2,
learning_rate_total_decay=0.05,
verbose=True,
message=50,
n_bootstrap_draws=-1,
estimator_type=PyroEstimatorVI,
# new setting we want to test
mvn=0,
flat_multiplier=True,
geometric_walk=True,
min_residuals_sd=1.0,
)
ktrx_grw.fit(df=seas_data)
idx = 3
coef_mid, coef_lower, coef_upper = ktrx_grw.get_regression_coefs(include_ci=True, coefficient_method='empirical')
x = np.arange(coef_mid.shape[0])
plt.plot(x, coef_mid['x{}'.format(idx)], label='est', alpha=0.5)
plt.fill_between(x, coef_lower['x{}'.format(idx)], coef_upper['x{}'.format(idx)], label='est', alpha=0.5)
plt.scatter(x, seas_data['beta{}'.format(idx)], label='truth', s=10, alpha=0.5)
plt.legend()
_ = ktrx_grw.plot_regression_coefs(with_knot=True, figsize=(16, 8))
# def multiple_test(N, n, sim_type):
# out = pd.DataFrame()
# out['index'] = range(0, N)
# # for hte model fit
# out['time_1'] = 0.0
# out['time_2'] = 0.0
# out['SSE_1'] = 0.0
# out['SSE_2'] = 0.0
# out['RMSE_1'] = 0.0
# out['RMSE_2'] = 0.0
# out['max_error_1'] = 0.0
# out['max_error_2'] = 0.0
# # for the true values
# out['SSE_beta1_1'] = 0.0
# out['SSE_beta1_2'] = 0.0
# out['SSE_beta2_1'] = 0.0
# out['SSE_beta2_2'] = 0.0
# out['SSE_beta3_1'] = 0.0
# out['SSE_beta3_2'] = 0.0
# for i in range(0, N):
# # simulate the data
# if sim_type == 'sea':
# data = sim_data_seasonal(n = n, RS = 1000+i)
# if sim_type == 'rw':
# data = sim_data_rw(n = n, RS = 1000+i, p=3)
# #print(data.head())
# # define stuff
# regressor_col=['x1', 'x2', 'x3']
# response_col = 'y'
# # run the model
# # run lite first
# ktr_lite = KTRLiteMAP(
# response_col=response_col,
# date_col='date',
# level_knot_scale=1,
# seed=2000+i,
# span_level= .1,
# estimator_type=StanEstimatorMAP,
# )
# ktr_lite.fit(df=data)
# level_knot_scale = ktr_lite.level_knot_scale
# level_knots_stan = ktr_lite._aggregate_posteriors['map']['lev_knot'][0]
# level_knot_dates = ktr_lite._level_knot_dates
# level_knots_stan = np.array([0] * len(level_knot_dates))
# ktrx1 = KTRXFull(
# response_col=response_col,
# date_col='date',
# degree_of_freedom=30,
# level_knot_scale=level_knot_scale,
# level_knot_dates=level_knot_dates,
# level_knots=level_knots_stan,
# regressor_col=regressor_col,
# regressor_knot_pooling_loc=[0] * len(regressor_col),
# regressor_knot_pooling_scale=[1] * len(regressor_col),
# # regressor_knot_scale=[1.0] * len(regressor_col),
# span_coefficients=0.1,
# rho_coefficients=0.1,
# prediction_percentiles=[2.5, 97.5],
# seed=2000+i,
# num_steps=1000,
# num_sample=3000,
# verbose=False,
# message=100,
# n_bootstrap_draws=-1,
# estimator_type=PyroEstimatorVI,
# mvn=1
# )
# ktrx2 = KTRXFull(
# response_col=response_col,
# date_col='date',
# degree_of_freedom=30,
# level_knot_scale=level_knot_scale,
# level_knot_dates=level_knot_dates,
# level_knots=level_knots_stan,
# regressor_col=regressor_col,
# regressor_knot_pooling_loc=[0] * len(regressor_col),
# regressor_knot_pooling_scale=[1] * len(regressor_col),
# regressor_knot_scale=[1.0] * len(regressor_col),
# span_coefficients=0.1,
# rho_coefficients=0.1,
# prediction_percentiles=[2.5, 97.5],
# seed=2000+i,
# num_steps=1000,
# num_sample=3000,
# verbose=False,
# message=100,
# n_bootstrap_draws=-1,
# estimator_type=PyroEstimatorVI,
# )
# # fit the models and recod the times
# start_time = time.time()
# ktrx1.fit(df=data)
# time_1 = time.time() - start_time
# start_time = time.time()
# ktrx2.fit(df=data)
# time_2 = time.time() - start_time
# # get the predictions
# predicted_df_1 = ktrx1.predict(df=data)
# predicted_df_2 = ktrx2.predict(df=data)
# # compare to observations
# SSE_1 = sum((predicted_df_1['prediction'] - data['y'])**2.0 )
# SSE_2 = sum((predicted_df_2['prediction'] - data['y'])**2.0 )
# max_misfit_1 = max(abs(predicted_df_1['prediction'] - data['y']) )
# max_misfit_2 = max(abs(predicted_df_2['prediction'] - data['y']) )
# out.at[i, 'time_1'] = time_1
# out.at[i, 'time_2'] = time_2
# out.at[i, 'SSE_1'] = SSE_1
# out.at[i, 'SSE_2'] = SSE_2
# out.at[i, 'RMSE_1'] = (SSE_1/n)**(0.5)
# out.at[i, 'RMSE_2'] = (SSE_2/n)**(0.5)
# out.at[i, 'max_error_1'] = max_misfit_1
# out.at[i, 'max_error_2'] = max_misfit_2
# #compare to true values
# coef_df_1= ktrx1.get_regression_coefs(
# aggregate_method='median',
# include_ci=False)
# coef_df_2= ktrx2.get_regression_coefs(
# aggregate_method='median',
# include_ci=False)
# SSE_beta1_1 = sum((coef_df_1['x1']-data['beta1'])**2.0)
# SSE_beta2_1 = sum((coef_df_1['x2']-data['beta2'])**2.0)
# SSE_beta3_1 = sum((coef_df_1['x3']-data['beta3'])**2.0)
# SSE_beta1_2 = sum((coef_df_2['x1']-data['beta1'])**2.0)
# SSE_beta2_2 = sum((coef_df_2['x2']-data['beta2'])**2.0)
# SSE_beta3_2 = sum((coef_df_2['x3']-data['beta3'])**2.0)
# out.at[i,'SSE_beta1_1'] = SSE_beta1_1
# out.at[i,'SSE_beta2_1'] = SSE_beta2_1
# out.at[i,'SSE_beta3_1'] = SSE_beta3_1
# out.at[i,'SSE_beta1_2'] = SSE_beta1_2
# out.at[i,'SSE_beta2_2'] = SSE_beta2_2
# out.at[i,'SSE_beta3_2'] = SSE_beta3_2
# return out
# out = multiple_test(N=2, n=300, sim_type='sea')
# multiple_test(N=3, n=300, sim_type='rw')
```
| github_jupyter |
### Prior and Posterior
$$A \sim \cal{N}(0,s I)$$
$$q(A) =\cal{N}(\mu_A, \Lambda_A)$$
### Likelihood
$$Y|A,X = Y|\prod_c A_c^T X_c$$
```
import tensorflow as tf
import os
import numpy as np
from tqdm import tqdm
from matplotlib import pyplot as plt
from matplotlib import cm
tf.logging.set_verbosity(tf.logging.ERROR)
np.random.seed(10)
```
## Simulating synthetic data
```
#lik = 'Poisson'
lik = 'Gaussian'
assert lik in ['Poisson','Gaussian']
#---------------------------------------------------
# Declaring additive model parameters
N =1000
D = 20 # number of covariates
R = 1 # number of trials
A = np.random.randn(D,1)
indices = [np.arange(0,int(D/3)).tolist(),
np.arange(int(D/3),int(2*D/3)).tolist(),
np.arange(int(2*D/3),D).tolist()]
print(indices)
#---------------------------------------------------
# Simulating data
np_link,tf_link = np.exp, tf.exp
xmin,xmax=-1,1
X_np = np.random.uniform(xmin,xmax,(N,D))
A_tile = np.tile(np.expand_dims(A,0),[N,1,R])
X_tile = np.tile(np.expand_dims(X_np,-1),[1,1,R])
proj_np = X_tile*A_tile
pred_np = proj_np[:,indices[0],:].sum(axis=1)
for i in range(1,len(indices)):
pred_np *= proj_np[:,indices[i],:].sum(axis=1)
if lik == 'Gaussian':
Y_np = pred_np + np.random.rand(N,R)*.1
elif lik=='Poisson':
link = np.exp
rate = np.tile(link(pred_np),[1,R])
Y_np = np.random.poisson(rate,size=(N,R))
print(A.shape)
print(proj_np.shape,pred_np.shape,Y_np.shape)
```
## Constructing tensorflow model
```
import sys
sys.path.append('../MFVI')
from likelihoods import Gaussian, Poisson, Gaussian_with_link
from settings import np_float_type,int_type
from model import MFVI, MFVI2
#---------------------------------------------------
# Constructing tensorflow model
X = tf.placeholder(tf.float32,[N,D])
Y = tf.placeholder(tf.float32,[N,R])
with tf.variable_scope("likelihood") as scope:
if lik=='Gaussian':
likelihood = Gaussian(variance=1)
elif lik == 'Poisson':
likelihood = Poisson()
with tf.variable_scope("model") as scope:
m= MFVI2(X,Y,likelihood,indices=indices)
vars_opt = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='model/inference')
vars_opt += tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='likelihood')
```
## Running inference and learning
```
#---------------------------------------------------
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # reset values to wrong
# declare loss
loss = -m.build_likelihood()
opt_global = tf.train.AdamOptimizer(1e-2).minimize(loss,var_list=vars_opt)
init = tf.global_variables_initializer()
sess.run(init) # reset values to wrong
feed_dic = {Y:Y_np, X:X_np}
#---------------------------------------------------
print('Running Optimization...')
nit = 5000
loss_array = np.zeros((nit,))
for it in tqdm(range( nit)):
sess.run(opt_global,feed_dict=feed_dic)
loss_array[it]= float(sess.run(loss, feed_dic))
#if it%1000==0:
# print( 'iteration %d'%it)
# print( sess.run(m.s))
# print( sess.run(m.q_A_sqrt).T)
p_mean = sess.run(tf.reduce_mean(m.sample_predictor(X),-1), feed_dic)
q_A_mu = sess.run(m.q_A_mu, feed_dic)
q_A_sqrt = sess.run(m.q_A_sqrt, feed_dic)
sess.close()
print('Done')
fig,axarr = plt.subplots(1,2,figsize=(8,4))
ax=axarr[0]
ax.plot(loss_array[:it], linewidth=3, color='blue')
ax.set_xlabel('iterations',fontsize=20)
ax.set_ylabel('Variational Objective',fontsize=20)
ax=axarr[1]
ax.plot(pred_np, p_mean,'.', color='blue')
ax.set_xlabel('true predictor',fontsize=20)
ax.set_ylabel('predicted predictor',fontsize=20)
fig.tight_layout()
plt.show()
plt.close()
fig,ax = plt.subplots(1,figsize=(5,5))
ax.plot(A,'r',label='true')
ax.errorbar(range(D),y=q_A_mu[:,0],yerr=q_A_sqrt[:,0],label='inferred')
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
ax.set_xlabel('weight index',fontsize=20)
ax.set_xticks(np.arange(0,D,3))
ax.set_xticklabels(np.arange(0,D,3))
fig.tight_layout()
plt.show()
```
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Logistic-Regression" data-toc-modified-id="Logistic-Regression-1"><span class="toc-item-num">1 </span>Logistic Regression</a></span><ul class="toc-item"><li><span><a href="#Important-considerations" data-toc-modified-id="Important-considerations-1.1"><span class="toc-item-num">1.1 </span>Important considerations</a></span><ul class="toc-item"><li><span><a href="#Can-we-build-a-model-that-will-predict-the-contents-of-one-of-those-categorical-columns-with-NAs?" data-toc-modified-id="Can-we-build-a-model-that-will-predict-the-contents-of-one-of-those-categorical-columns-with-NAs?-1.1.1"><span class="toc-item-num">1.1.1 </span>Can we build a model that will predict the contents of one of those categorical columns with NAs?</a></span></li><li><span><a href="#Recursive-Feature-Elimination" data-toc-modified-id="Recursive-Feature-Elimination-1.1.2"><span class="toc-item-num">1.1.2 </span>Recursive Feature Elimination</a></span></li></ul></li><li><span><a href="#Building-the-model" data-toc-modified-id="Building-the-model-1.2"><span class="toc-item-num">1.2 </span>Building the model</a></span><ul class="toc-item"><li><span><a href="#P-Values-and-feature-selection" data-toc-modified-id="P-Values-and-feature-selection-1.2.1"><span class="toc-item-num">1.2.1 </span>P-Values and feature selection</a></span></li><li><span><a href="#The-Logit-model" data-toc-modified-id="The-Logit-model-1.2.2"><span class="toc-item-num">1.2.2 </span>The Logit model</a></span></li><li><span><a href="#ROC-Curve" data-toc-modified-id="ROC-Curve-1.2.3"><span class="toc-item-num">1.2.3 </span>ROC Curve</a></span></li><li><span><a href="#Explore-logit-predictions" data-toc-modified-id="Explore-logit-predictions-1.2.4"><span class="toc-item-num">1.2.4 </span>Explore logit predictions</a></span></li></ul></li><li><span><a href="#Default-Dataset" data-toc-modified-id="Default-Dataset-1.3"><span class="toc-item-num">1.3 </span>Default Dataset</a></span></li><li><span><a href="#Next-steps" data-toc-modified-id="Next-steps-1.4"><span class="toc-item-num">1.4 </span>Next steps</a></span></li></ul></li></ul></div>
# Logistic Regression
Logistic Regression is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable. In logistic regression, the dependent variable is a binary variable that contains data coded as 1 (yes, success, etc.) or 0 (no, failure, etc.). In other words, the logistic regression model predicts P(Y=1) as a function of X.
It works very much the same way Linear Regression does, except that the optimization function is not OLS but [_maximum likelihood_](https://en.wikipedia.org/wiki/Maximum_likelihood_estimation).
## Important considerations
- We use logistic regression to train a model to predict between 2-classes: Yes/No, Black/White, True/False. If we need to predict more than two classes, we need to build some artifacts in logistic regression that will be explained at the end of this notebook.
- No dependent variables should be among the set of features. Study the correlation between all the features separatedly.
- Scaled, norm'd and centered input variables.
The output from a logistic regression is always the log of the odds. We will explore this concept further along the exercise.
```
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import statsmodels.api as sm
from sklearn import metrics
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, LabelBinarizer
from sklearn.pipeline import make_pipeline
from sklearn_pandas import DataFrameMapper
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.metrics import roc_auc_score, roc_curve, accuracy_score
from matplotlib.gridspec import GridSpec
data = pd.read_csv('./data/houseprices_prepared.csv.gz')
data.head()
```
Lets build a dataframe that will contain the type and number of NAs that each feature contains. We will use it to decide what variables to select. We will now from there what features are numerical and categorical, and how many contain NAs.
```
def dataframe_metainformation(df):
meta = dict()
descr = pd.DataFrame({'dtype': df.dtypes, 'NAs': df.isna().sum()})
categorical_features = descr.loc[descr['dtype'] == 'object'].index.values.tolist()
numerical_features = descr.loc[descr['dtype'] != 'object'].index.values.tolist()
numerical_features_na = descr.loc[(descr['dtype'] != 'object') & (descr['NAs'] > 0)].index.values.tolist()
categorical_features_na = descr.loc[(descr['dtype'] == 'object') & (descr['NAs'] > 0)].index.values.tolist()
complete_features = descr.loc[descr['NAs'] == 0].index.values.tolist()
meta['description'] = descr
meta['categorical_features'] = categorical_features
meta['categorical_features'] = categorical_features
meta['categorical_features_na'] = categorical_features_na
meta['numerical_features'] = numerical_features
meta['numerical_features_na'] = numerical_features_na
meta['complete_features'] = complete_features
return meta
def print_metainformation(meta):
print('Available types:', meta['description']['dtype'].unique())
print('{} Features'.format(meta['description'].shape[0]))
print('{} categorical features'.format(len(meta['categorical_features'])))
print('{} numerical features'.format(len(meta['numerical_features'])))
print('{} categorical features with NAs'.format(len(meta['categorical_features_na'])))
print('{} numerical features with NAs'.format(len(meta['numerical_features_na'])))
print('{} Complete features'.format(len(meta['complete_features'])))
meta = dataframe_metainformation(data)
print_metainformation(meta)
```
### Can we build a model that will predict the contents of one of those categorical columns with NAs?
Let's try! I will start with `FireplaceQu` that presents a decent amount of NAs.
Define **target** and **features** to hold the variable we want to predict and the features I can use (those with no NAs). We remove the `Id` from the list of features to be used by our model. Finally, we establish what is the source dataset, by using only those rows from `data` that are not equal to NA.
Lastly, we will encode all categorical features (but the target) to have a proper setup for running the logistic regression. To encode, we'll use OneHotEncoding by calling `get_dummies`. The resulting dataset will have all numerical features.
```
target = 'FireplaceQu'
features = meta['complete_features']
features.remove('Id')
print('Selecting {} features'.format(len(features)))
data_complete = data.filter(features + [target])
data_complete = data_complete[data_complete[target].notnull()]
meta_complete = dataframe_metainformation(data_complete)
print_metainformation(meta_complete)
dummy_columns = meta_complete['categorical_features']
dummy_columns.remove(target)
data_encoded = pd.get_dummies(data_complete, columns=dummy_columns)
data_encoded.head(3)
```
How many occurences do we have from each class of the target variable?
```
sns.countplot(x='FireplaceQu', data=data_encoded);
plt.show();
```
Since we've very few occurences of classes `Ex`, `Fa` and `Po`, we will remove them from the training set, and we will train our model to learn to classify only between `TA` or `Gd`.
```
data_encoded = data_encoded[(data_encoded[target] != 'Ex') &
(data_encoded[target] != 'Fa') &
(data_encoded[target] != 'Po')]
data_encoded[target] = data_encoded[target].map({'TA':0, 'Gd':1})
sns.countplot(x='FireplaceQu', data=data_encoded);
```
Set the list of features prepared
```
features = list(data_encoded)
features.remove(target)
```
### Recursive Feature Elimination
Recursive Feature Elimination (RFE) is based on the idea to repeatedly construct a model and choose either the best or worst performing feature, setting the feature aside and then repeating the process with the rest of the features. This process is applied until all features in the dataset are exhausted. The goal of RFE is to select features by recursively considering smaller and smaller sets of features.
```
from sklearn.exceptions import ConvergenceWarning
import warnings
warnings.filterwarnings(action='ignore', category=ConvergenceWarning)
X = data_encoded.loc[:, features]
y = data_encoded.loc[:, target]
logreg = LogisticRegression(solver='lbfgs', max_iter=250)
rfe = RFE(logreg, 15)
rfe = rfe.fit(X, y)
print('Selected features: {}'.format(list(data_encoded.loc[:, rfe.support_])))
```
## Building the model
Set the variables $X$ and $Y$ to the contents of the dataframe I want to use, and fit a `Logit` model. Print a summary to check the results. We're using the `statmodels` package because we want easy access to all the statistical indicators that logistic regression can lead to.
```
X = data_encoded.loc[:, list(data_encoded.loc[:, rfe.support_])]
y = data_encoded.loc[:, target]
logit_model=sm.Logit(y, X)
result=logit_model.fit(method='bfgs')
print(result.summary2())
```
### P-Values and feature selection
Remove those predictors with _p-values_ above 0.05
Mark those features with a p-value higher thatn 0.05 (or close) to be removed from $X$, and run the logistic regression again to re-.check the p-values. From that point we'll be ready to run the model properly in sklearn.
```
to_remove = result.pvalues[result.pvalues > 0.05].index.tolist()
X.drop(to_remove, inplace=True, axis=1)
logit_model=sm.Logit(y, X)
result=logit_model.fit(method='bfgs')
print(result.summary2())
```
### The Logit model
Here we train the model and evaluate on the test set. The interpretation of the results obtained by calling the `classification_report` are as follows:
The **precision** is the ratio tp / (tp + fp) where tp is the number of true positives and fp the number of false positives. The precision is intuitively the ability of the classifier to not label a sample as positive if it is negative.
The **recall** is the ratio tp / (tp + fn) where tp is the number of true positives and fn the number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples.
The **F-beta** score can be interpreted as a weighted harmonic mean of the precision and recall, where an F-beta score reaches its best value at 1 and worst score at 0.
The F-beta score weights the recall more than the precision by a factor of beta. beta = 1.0 means recall and precision are equally important.
The **support** is the number of occurrences of each class in y_test.
```
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=0)
logreg = LogisticRegression(solver='lbfgs')
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
print('Accuracy on test: {:.2f}'.format(logreg.score(X_test, y_test)))
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
```
### ROC Curve
The receiver operating characteristic (ROC) curve is another common tool used with binary classifiers. The dotted line represents the ROC curve of a purely random classifier; a good classifier stays as far away from that line as possible (toward the top-left corner).
```
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
```
Plot the FPR vs. TPR, and the diagonal line representing the null model.
```
def plot_roc(fpr, tpr, logit_roc_auc):
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.05])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend(loc="lower right")
# plt.savefig('Log_ROC')
plt.show();
plot_roc(fpr, tpr, logit_roc_auc)
```
The results are very poor, and what we've got shouldn't be used in production. The proposal from this point is:
1. to know more about how the predictions are made in logistic regression
2. apply a logit to predict if the price of a house will be higher or lower than a given value
### Explore logit predictions
What you've seen is that we irectly call the method `predict` in `logit`, which will tell me to which class each sample is classified: 0 or 1. To accomplish this, the model produces two probabilities
```
pred_proba_df = pd.DataFrame(logreg.predict_proba(X_test))
threshold_list = np.arange(0.05, 1.0, 0.05)
accuracy_list = np.array([])
for threshold in threshold_list:
y_test_pred = pred_proba_df.applymap(lambda prob: 1 if prob > threshold else 0)
test_accuracy = accuracy_score(y_test.values,
y_test_pred[1].values.reshape(-1, 1))
accuracy_list = np.append(accuracy_list, test_accuracy)
```
And the plot of the array of accuracy values got from each of the probabilities.
```
plt.plot(range(accuracy_list.shape[0]), accuracy_list, 'o-', label='Accuracy')
plt.title('Accuracy for different threshold values')
plt.xlabel('Threshold')
plt.ylabel('Accuracy')
plt.xticks([i for i in range(1, accuracy_list.shape[0], 2)],
np.round(threshold_list[1::2], 1))
plt.grid()
plt.show();
```
## Default Dataset
A simulated data set containing information on ten thousand customers. The aim here is to predict which customers will default on their credit card debt. A data frame with 10000 observations on the following 4 variables.
`default`
A factor with levels No and Yes indicating whether the customer defaulted on their debt
`student`
A factor with levels No and Yes indicating whether the customer is a student
`balance`
The average balance that the customer has remaining on their credit card after making their monthly payment
`income`
Income of customer
```
data = pd.read_csv('data/default.csv', sep=';')
data.head()
```
Let's build a class column with the proper values on it (0 and 1) instead of the strings with Yes and No.
```
data.default = data.default.map({'No': 0, 'Yes': 1})
data.student = data.student.map({'No': 0, 'Yes': 1})
data.head()
```
We are interested in predicting whether an individual will default on his or her credit card payment, on the basis of annual income and monthly credit card balance.
It is worth noting that figure below displays a very pronounced relationship between the predictor balance and the response default. In most real applications, the relationship between the predictor and the response will not be nearly so strong.
```
def plot_descriptive(data):
fig = plt.figure(figsize=(9, 4))
gs = GridSpec(1, 3, width_ratios=[3, 1, 1])
ax0 = plt.subplot(gs[0])
ax0 = plt.scatter(data.balance[data.default==0],
data.income[data.default==0],
label='default=No',
marker='.', c='red', alpha=0.5)
ax0 = plt.scatter(data.balance[data.default==1],
data.income[data.default==1],
label='default=Yes',
marker='+', c='green', alpha=0.7)
ax0 = plt.xlabel('balance')
ax0 = plt.ylabel('income')
ax0 = plt.legend(loc='best')
ax0 = plt.subplot(gs[1])
ax1 = sns.boxplot(x="default", y="balance", data=data)
ax0 = plt.subplot(gs[2])
ax2 = sns.boxplot(x="default", y="income", data=data)
plt.tight_layout()
plt.show()
plot_descriptive(data)
```
Consider again the Default data set, where the response `default` falls into one of two categories, Yes or No. Rather than modeling this response $Y$ directly, logistic regression models the probability that $Y$ belongs to a particular category.
For example, the probability of default given balance can be written as
$$Pr(default = Yes|balance)$$
The values of $Pr(default = Yes|balance)$ –$p(balance)$–, will range between 0 and 1. Then for any given value of `balance`, a prediction can be made for `default`. For example, one might predict `default = Yes` for any individual for whom $p(balance) > 0.5$.
```
def plot_classes(show=True):
plt.scatter(data.balance[data.default==0],
data.default[data.default==0],
marker='o', color='red', alpha=0.5)
plt.scatter(data.balance[data.default==1],
data.default[data.default==1],
marker='+', color='green', alpha=0.7)
plt.xlabel('Balance')
plt.ylabel('Probability of default')
plt.yticks([0, 1], [0, 1])
if show is True:
plt.show();
plot_classes()
```
Build the model, and keep it on `logreg`.
```
X_train, X_test, y_train, y_test = train_test_split(data.balance,
data.default,
test_size=0.3,
random_state=0)
logreg = LogisticRegression(solver='lbfgs')
logreg.fit(X_train.values.reshape(-1, 1), y_train)
y_pred = logreg.predict(X_test.values.reshape(-1, 1))
acc_test = logreg.score(X_test.values.reshape(-1, 1), y_test)
print('Accuracy on test: {:.2f}'.format(acc_test))
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
```
And now represent where is the model setting the separation function between the two classes.
```
def plot_sigmoid():
plt.figure(figsize=(10,4))
plt.subplot(1, 2, 1)
plot_classes(show=False)
plt.plot(sigm.x.values, sigm.y.values, color='black', linewidth=3);
plt.title('Sigmoid')
plt.subplot(1, 2, 2)
plot_classes(show=False)
plt.plot(sigm.x.values, sigm.y.values, color='black', linewidth=3);
plt.xlim(1925, 1990)
plt.title('Zooming the Sigmoid')
plt.tight_layout()
plt.show()
def model(x):
return 1 / (1 + np.exp(-x))
y_func = model(X_test.values * logreg.coef_ + logreg.intercept_).ravel()
sigm = pd.DataFrame({'x': list(X_test.values), 'y': list(y_pred)}).\
sort_values(by=['x'])
plot_sigmoid()
```
## Next steps
- Explore multinomial logistic regression with sklearn
- Explore SKLearn pipelines to find the optimal parameters of Logit
- Explore Lasso and Ridge Regression with Linear Regression problems
- Continue reading by exploring GLM (Generalized Linear Models).
| github_jupyter |
This notebook was prepared by [Donne Martin](https://github.com/donnemartin). Source and license info is on [GitHub](https://github.com/donnemartin/interactive-coding-challenges).
# Challenge Notebook
## Problem: Find the longest absolute file path.
See the [LeetCode](https://leetcode.com/problems/longest-absolute-file-path/) problem page.
<pre>
Suppose we abstract our file system by a string in the following manner:
The string "dir\n\tsubdir1\n\tsubdir2\n\t\tfile.ext" represents:
dir
subdir1
subdir2
file.ext
The directory dir contains an empty sub-directory subdir1 and a sub-directory subdir2 containing a file file.ext.
The string "dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext" represents:
dir
subdir1
file1.ext
subsubdir1
subdir2
subsubdir2
file2.ext
The directory dir contains two sub-directories subdir1 and subdir2. subdir1 contains a file file1.ext and an empty second-level sub-directory subsubdir1. subdir2 contains a second-level sub-directory subsubdir2 containing a file file2.ext.
We are interested in finding the longest (number of characters) absolute path to a file within our file system. For example, in the second example above, the longest absolute path is "dir/subdir2/subsubdir2/file2.ext", and its length is 32 (not including the double quotes).
Given a string representing the file system in the above format, return the length of the longest absolute path to file in the abstracted file system. If there is no file in the system, return 0.
Note:
The name of a file contains at least a . and an extension.
The name of a directory or sub-directory will not contain a .
Time complexity required: O(n) where n is the size of the input string.
Notice that a/aa/aaa/file1.txt is not the longest file path, if there is another path aaaaaaaaaaaaaaaaaaaaa/sth.png.
</pre>
* [Constraints](#Constraints)
* [Test Cases](#Test-Cases)
* [Algorithm](#Algorithm)
* [Code](#Code)
* [Unit Test](#Unit-Test)
* [Solution Notebook](#Solution-Notebook)
## Constraints
* Is the input a string?
* Yes
* Can we assume the input is valid?
* No
* Will there always be a file in the input?
* Yes
* Is the output an int?
* Yes
* Can we assume this fits memory?
* Yes
## Test Cases
* None -> TypeError
* '' -> 0
* 'dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext' -> 32
## Algorithm
Refer to the [Solution Notebook](). If you are stuck and need a hint, the solution notebook's algorithm discussion might be a good place to start.
## Code
```
class Solution(object):
def length_longest_path(self, file_system):
# TODO: Implement me
pass
```
## Unit Test
**The following unit test is expected to fail until you solve the challenge.**
```
# %load test_length_longest_path.py
import unittest
class TestSolution(unittest.TestCase):
def test_length_longest_path(self):
solution = Solution()
self.assertRaises(TypeError, solution.length_longest_path, None)
self.assertEqual(solution.length_longest_path(''), 0)
file_system = 'dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext'
expected = 32
self.assertEqual(solution.length_longest_path(file_system), expected)
print('Success: test_length_longest_path')
def main():
test = TestSolution()
test.test_length_longest_path()
if __name__ == '__main__':
main()
```
## Solution Notebook
Review the [Solution Notebook]() for a discussion on algorithms and code solutions.
| github_jupyter |
Sebastian Raschka, 2015
# Python Machine Learning Essentials
# Chapter 7 - Combining Different Models for Ensemble Learning
Note that the optional watermark extension is a small IPython notebook plugin that I developed to make the code reproducible. You can just skip the following line(s).
```
%load_ext watermark
%watermark -a 'Sebastian Raschka' -u -d -v -p numpy,pandas,matplotlib,scipy,scikit-learn
# to install watermark just uncomment the following line:
#%install_ext https://raw.githubusercontent.com/rasbt/watermark/master/watermark.py
```
<br>
<br>
### Sections
- [Learning with ensembles](#Learning-with-ensembles)
- [Implementing a simple majority vote classifier](#Implementing-a-simple-majority-vote-classifier)
- [Combining different algorithms for classification with majority vote](#Combining-different-algorithms-for-classification-with-majority-vote)
- [Evaluating and tuning the ensemble classifier](#Evaluating-and-tuning-the-ensemble-classifier)
- [Bagging -- Building an ensemble of classifiers from bootstrap samples](#Bagging----Building-an-ensemble-of-classifiers-from-bootstrap-samples)
- [Leveraging weak learners via adaptive boosting](#Leveraging-of-weak-learners-via-adaptive-boosting)
<br>
<br>
# Learning with ensembles
[[back to top](#Sections)]
```
from scipy.misc import comb
import math
def ensemble_error(n_classifier, error):
k_start = math.ceil(n_classifier / 2.0)
probs = [comb(n_classifier, k) * error**k *
(1-error)**(n_classifier - k)
for k in range(k_start, n_classifier + 1)]
return sum(probs)
ensemble_error(n_classifier=11, error=0.25)
import numpy as np
error_range = np.arange(0.0, 1.01, 0.01)
ens_errors = [ensemble_error(n_classifier=11,
error=error)
for error in error_range]
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(error_range,
ens_errors,
label='Ensemble error',
linewidth=2)
plt.plot(error_range,
error_range,
linestyle='--',
label='Base error',
linewidth=2)
plt.xlabel('Base error')
plt.ylabel('Base/Ensemble error')
plt.legend(loc='upper left')
plt.grid()
plt.tight_layout()
# plt.savefig('./figures/ensemble_err.png', dpi=300)
plt.show()
```
<br>
<br>
# Implementing a simple majority vote classifier
[[back to top](#Sections)]
```
import numpy as np
np.argmax(np.bincount([0, 0, 1],
weights=[0.2, 0.2, 0.6]))
ex = np.array([[0.9, 0.1],
[0.8, 0.2],
[0.4, 0.6]])
p = np.average(ex,
axis=0,
weights=[0.2, 0.2, 0.6])
p
np.argmax(p)
from sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.preprocessing import LabelEncoder
from sklearn.externals import six
from sklearn.base import clone
from sklearn.pipeline import _name_estimators
import numpy as np
import operator
class MajorityVoteClassifier(BaseEstimator,
ClassifierMixin):
""" A majority vote ensemble classifier
Parameters
----------
classifiers : array-like, shape = [n_classifiers]
Different classifiers for the ensemble
vote : str, {'classlabel', 'probability'} (default='label')
If 'classlabel' the prediction is based on the argmax of
class labels. Else if 'probability', the argmax of
the sum of probabilities is used to predict the class label
(recommended for calibrated classifiers).
weights : array-like, shape = [n_classifiers], optional (default=None)
If a list of `int` or `float` values are provided, the classifiers
are weighted by importance; Uses uniform weights if `weights=None`.
"""
def __init__(self, classifiers, vote='classlabel', weights=None):
self.classifiers = classifiers
self.named_classifiers = {key: value for key, value
in _name_estimators(classifiers)}
self.vote = vote
self.weights = weights
def fit(self, X, y):
""" Fit classifiers.
Parameters
----------
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Matrix of training samples.
y : array-like, shape = [n_samples]
Vector of target class labels.
Returns
-------
self : object
"""
if self.vote not in ('probability', 'classlabel'):
raise ValueError("vote must be 'probability' or 'classlabel'"
"; got (vote=%r)"
% vote)
if self.weights and len(self.weights) != len(self.classifiers):
raise ValueError('Number of classifiers and weights must be equal'
'; got %d weights, %d classifiers'
% (len(self.weights), len(self.classifiers)))
# Use LabelEncoder to ensure class labels start with 0, which
# is important for np.argmax call in self.predict
self.lablenc_ = LabelEncoder()
self.lablenc_.fit(y)
self.classes_ = self.lablenc_.classes_
self.classifiers_ = []
for clf in self.classifiers:
fitted_clf = clone(clf).fit(X, self.lablenc_.transform(y))
self.classifiers_.append(fitted_clf)
return self
def predict(self, X):
""" Predict class labels for X.
Parameters
----------
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Matrix of training samples.
Returns
----------
maj_vote : array-like, shape = [n_samples]
Predicted class labels.
"""
if self.vote == 'probability':
maj_vote = np.argmax(self.predict_proba(X), axis=1)
else: # 'classlabel' vote
# Collect results from clf.predict calls
predictions = np.asarray([clf.predict(X)
for clf in self.classifiers_]).T
maj_vote = np.apply_along_axis(
lambda x:
np.argmax(np.bincount(x,
weights=self.weights)),
axis=1,
arr=predictions)
maj_vote = self.lablenc_.inverse_transform(maj_vote)
return maj_vote
def predict_proba(self, X):
""" Predict class probabilities for X.
Parameters
----------
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
Returns
----------
avg_proba : array-like, shape = [n_samples, n_classes]
Weighted average probability for each class per sample.
"""
probas = np.asarray([clf.predict_proba(X)
for clf in self.classifiers_])
avg_proba = np.average(probas, axis=0, weights=self.weights)
return avg_proba
def get_params(self, deep=True):
""" Get classifier parameter names for GridSearch"""
if not deep:
return super(MajorityVoteClassifier, self).get_params(deep=False)
else:
out = self.named_classifiers.copy()
for name, step in six.iteritems(self.named_classifiers):
for key, value in six.iteritems(step.get_params(deep=True)):
out['%s__%s' % (name, key)] = value
return out
```
<br>
<br>
## Combining different algorithms for classification with majority vote
[[back to top](#Sections)]
```
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
iris = datasets.load_iris()
X, y = iris.data[50:, [1, 2]], iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.5,
random_state=1)
from sklearn.cross_validation import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
import numpy as np
clf1 = LogisticRegression(penalty='l2',
C=0.001,
random_state=0)
clf2 = DecisionTreeClassifier(max_depth=1,
criterion='entropy',
random_state=0)
clf3 = KNeighborsClassifier(n_neighbors=1,
p=2,
metric='minkowski')
pipe1 = Pipeline([['sc', StandardScaler()],
['clf', clf1]])
pipe3 = Pipeline([['sc', StandardScaler()],
['clf', clf3]])
clf_labels = ['Logistic Regression', 'Decision Tree', 'KNN']
print('10-fold cross validation:\n')
for clf, label in zip([pipe1, clf2, pipe3], clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
# Majority Rule (hard) Voting
mv_clf = MajorityVoteClassifier(
classifiers=[pipe1, clf2, pipe3])
clf_labels += ['Majority Voting']
all_clf = [pipe1, clf2, pipe3, mv_clf]
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
```
<br>
<br>
## Evaluating and tuning the ensemble classifier
[[back to top](#Sections)]
```
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
colors = ['black', 'orange', 'blue', 'green']
linestyles = [':', '--', '-.', '-']
for clf, label, clr, ls \
in zip(all_clf,
clf_labels, colors, linestyles):
# assuming the label of the positive class is 1
y_pred = clf.fit(X_train,
y_train).predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_true=y_test,
y_score=y_pred)
roc_auc = auc(x=fpr, y=tpr)
plt.plot(fpr, tpr,
color=clr,
linestyle=ls,
label='%s (auc = %0.2f)' % (label, roc_auc))
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1],
linestyle='--',
color='gray',
linewidth=2)
plt.xlim([-0.1, 1.1])
plt.ylim([-0.1, 1.1])
plt.grid()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.tight_layout()
# plt.savefig('./figures/roc.png', dpi=300)
plt.show()
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
from itertools import product
all_clf = [pipe1, clf2, pipe3, mv_clf]
x_min = X_train_std[:, 0].min() - 1
x_max = X_train_std[:, 0].max() + 1
y_min = X_train_std[:, 1].min() - 1
y_max = X_train_std[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=2, ncols=2,
sharex='col',
sharey='row',
figsize=(7, 5))
for idx, clf, tt in zip(product([0, 1], [0, 1]),
all_clf, clf_labels):
clf.fit(X_train_std, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.3)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train==0, 0],
X_train_std[y_train==0, 1],
c='blue',
marker='^',
s=50)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train==1, 0],
X_train_std[y_train==1, 1],
c='red',
marker='o',
s=50)
axarr[idx[0], idx[1]].set_title(tt)
plt.text(-3.5, -4.5,
s='Sepal width [standardized]',
ha='center', va='center', fontsize=12)
plt.text(-10.5, 4.5,
s='Petal length [standardized]',
ha='center', va='center',
fontsize=12, rotation=90)
plt.tight_layout()
# plt.savefig('./figures/voting_panel', bbox_inches='tight', dpi=300)
plt.show()
mv_clf.get_params()
from sklearn.grid_search import GridSearchCV
params = {'decisiontreeclassifier__max_depth': [1, 2],
'pipeline-1__clf__C': [0.001, 0.1, 100.0]}
grid = GridSearchCV(estimator=mv_clf,
param_grid=params,
cv=10,
scoring='roc_auc')
grid.fit(X_train, y_train)
for params, mean_score, scores in grid.grid_scores_:
print("%0.3f+/-%0.2f %r"
% (mean_score, scores.std() / 2, params))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
```
<br>
<br>
# Bagging -- Building an ensemble of classifiers from bootstrap samples
[[back to top](#Sections)]
```
import pandas as pd
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
# drop 1 class
df_wine = df_wine[df_wine['Class label'] != 1]
y = df_wine['Class label'].values
X = df_wine[['Alcohol', 'Hue']].values
from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import train_test_split
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.40,
random_state=1)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=None)
bag = BaggingClassifier(base_estimator=tree,
n_estimators=500,
max_samples=1.0,
max_features=1.0,
bootstrap=True,
bootstrap_features=False,
n_jobs=1,
random_state=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f'
% (tree_train, tree_test))
bag = bag.fit(X_train, y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train, y_train_pred)
bag_test = accuracy_score(y_test, y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f'
% (bag_train, bag_test))
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,
sharex='col',
sharey='row',
figsize=(8, 3))
for idx, clf, tt in zip([0, 1],
[tree, bag],
['Decision Tree', 'Bagging']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],
X_train[y_train==0, 1],
c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],
X_train[y_train==1, 1],
c='red', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.text(10.2, -1.2,
s='Hue',
ha='center', va='center', fontsize=12)
plt.tight_layout()
#plt.savefig('./figures/bagging_region.png',
# dpi=300,
# bbox_inches='tight')
plt.show()
```
<br>
<br>
# Leveraging of weak learners via adaptive boosting
[[back to top](#Sections)]
```
from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=1)
ada = AdaBoostClassifier(base_estimator=tree,
n_estimators=500,
learning_rate=0.1,
random_state=0)
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f'
% (tree_train, tree_test))
ada = ada.fit(X_train, y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train, y_train_pred)
ada_test = accuracy_score(y_test, y_test_pred)
print('AdaBoost train/test accuracies %.3f/%.3f'
% (ada_train, ada_test))
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(1, 2, sharex='col', sharey='row', figsize=(8, 3))
for idx, clf, tt in zip([0, 1],
[tree, ada],
['Decision Tree', 'AdaBoost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],
X_train[y_train==0, 1],
c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],
X_train[y_train==1, 1],
c='red', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.text(10.2, -1.2,
s='Hue',
ha='center', va='center', fontsize=12)
plt.tight_layout()
#plt.savefig('./figures/adaboost_region.png',
# dpi=300,
# bbox_inches='tight')
plt.show()
```
<br>
<br>
<br>
<br>
| github_jupyter |
```
import torchdyn
import torch
from torch.autograd import grad
import torch.nn as nn
import matplotlib.pyplot as plt
from torchdyn.core import ODEProblem
import torchdiffeq
import time
%load_ext autoreload
%autoreload 2
f = nn.Sequential(nn.Linear(1, 32), nn.SELU(), nn.Linear(32, 32), nn.SELU(), nn.Linear(32, 1))
prob = ODEProblem(f, solver='dopri5', sensitivity='adjoint', atol=1e-4, rtol=1e-4)
```
### Learning `T` from a target (3)
```
# torchdyn
x = torch.randn(1, 1, requires_grad=True)
t0 = torch.zeros(1)
T = torch.ones(1).requires_grad_(True)
opt = torch.optim.Adam((T,), lr=1e-2)
for i in range(2000):
t_span = torch.cat([t0, T])
t_eval, traj = prob(x, t_span)
loss = ((t_span[-1:] - torch.tensor([5]))**2).mean()
print(f'{loss}, {t_span}', end='\r')
loss.backward(); opt.step(); opt.zero_grad()
# torchdiffeq
# we have to wrap for torchdiffeq
class VectorField(nn.Module):
def __init__(self, f):
super().__init__()
self.f = f
def forward(self, t, x):
return self.f(x)
sys = VectorField(f)
x = torch.randn(1, 1, requires_grad=True)
t0 = torch.zeros(1)
T = torch.ones(1).requires_grad_(True)
opt = torch.optim.Adam((T,), lr=1e-2)
for i in range(2000):
t_span = torch.cat([t0, T])
traj = torchdiffeq.odeint_adjoint(sys, x, t_span, method='dopri5', atol=1e-4, rtol=1e-4)
loss = ((t_span[-1:] - torch.tensor([5]))**2).mean()
print(f'{loss}, {t_span}', end='\r')
loss.backward(); opt.step(); opt.zero_grad()
```
#### Explicit loss on `T`, gradcheck
```
t_span = torch.cat([t0, T])
t_eval, traj = prob(x, t_span)
l = ((t_span[-1:] - torch.tensor([5]))**2).mean()
dldt_torchdyn = grad(l, T)[0]
t_span = torch.cat([t0, T])
traj = torchdiffeq.odeint_adjoint(sys, x, t_span, method='dopri5', atol=1e-4, rtol=1e-4)
l = ((t_span[-1:] - torch.tensor([5]))**2).mean()
dldt_torchdiffeq = grad(l, T)[0]
dldt_torchdyn - dldt_torchdiffeq
```
#### Explicit loss on `t0`, gradcheck
```
t0 = torch.zeros(1).requires_grad_(True)
T = torch.ones(1).requires_grad_(True)
t_span = torch.cat([t0, T])
t_eval, traj = prob(x, t_span)
l = ((t_span[:1] - torch.tensor([5]))**2).mean()
dldt_torchdyn = grad(l, t0)[0]
t_span = torch.cat([t0, T])
traj = torchdiffeq.odeint_adjoint(sys, x, t_span, method='dopri5', atol=1e-4, rtol=1e-4)
l = ((t_span[:1] - torch.tensor([5]))**2).mean()
dldt_torchdiffeq = grad(l, t0)[0]
dldt_torchdyn - dldt_torchdiffeq
```
#### Learning `xT` by stretching `T` (fixed vector field)
Note: vec field is always positive so we are sure to hit the target
```
f = nn.Sequential(nn.Linear(1, 32), nn.SELU(), nn.Linear(32, 1), nn.Softplus())
prob = ODEProblem(f, solver='dopri5', sensitivity='adjoint', atol=1e-4, rtol=1e-4)
# torchdyn
x = torch.zeros(1, 1, requires_grad=True) + 0.5
t0 = torch.zeros(1)
T = torch.ones(1).requires_grad_(True)
opt = torch.optim.Adam((T,), lr=1e-2)
for i in range(1000):
t_span = torch.cat([t0, T])
t_eval, traj = prob(x, t_span)
loss = ((traj[-1] - torch.tensor([2]))**2).mean()
print(f'L: {loss.item():.2f}, T: {t_span[-1].item():.2f}, xT: {traj[-1].item():.2f}', end='\r')
loss.backward(); opt.step(); opt.zero_grad()
class VectorField(nn.Module):
def __init__(self, f):
super().__init__()
self.f = f
def forward(self, t, x):
return self.f(x)
sys = VectorField(f)
x = torch.zeros(1, 1, requires_grad=True) + 0.5
t0 = torch.zeros(1)
T = torch.ones(1).requires_grad_(True)
opt = torch.optim.Adam((T,), lr=1e-2)
for i in range(1000):
t_span = torch.cat([t0, T])
traj = torchdiffeq.odeint_adjoint(sys, x, t_span, method='dopri5', atol=1e-4, rtol=1e-4)
loss = ((traj[-1] - torch.tensor([2]))**2).mean()
print(f'L: {loss.item():.2f}, T: {t_span[-1].item():.2f}, xT: {traj[-1].item():.2f}', end='\r')
loss.backward(); opt.step(); opt.zero_grad()
x = torch.zeros(1, 1, requires_grad=True) + 0.5
t_span = torch.cat([t0, T])
t_eval, traj = prob(x, t_span)
l = ((traj[-1] - torch.tensor([5]))**2).mean()
dldt_torchdyn = grad(l, T)[0]
t_span = torch.cat([t0, T])
traj = torchdiffeq.odeint_adjoint(sys, x, t_span, method='dopri5', atol=1e-4, rtol=1e-4)
l = ((traj[-1] - torch.tensor([5]))**2).mean()
dldt_torchdiffeq = grad(l, T)[0]
dldt_torchdyn, dldt_torchdiffeq
```
| github_jupyter |
```
import pickle
import datetime as dt
import matplotlib.pyplot as plt
import calendar
import collections
import numpy as np
import pandas as pd
# load your dataset here! it should be formatted as this notebook assumes,
# and things should run without too much wrangling on your part!
d = pickle.load(open('reddit_info_dict_final.pkl', 'rb'))
# unpacking the data we saved earlier
dt_created = d['dt_created']
authors = d['authors']
num_comments_all = d['num_comments_all']
upvote_ratios = d['upvote_ratios']
scores = d['scores']
titles = d['titles']
texts = d['texts']
comment_texts_all = d['comment_texts_all']
comment_authors_all = d['comment_authors_all']
# let's look at posting over time!
# convert to a python datetime object
ts_created = [dt.datetime.fromtimestamp(d) for d in dt_created]
# get the minimum timestamp, so we can track days since the beginning of the dataset
min_ts = min(ts_created)
# this is a list of days since the beginning of the dataset
ts_created_days = [(d - min_ts).days for d in ts_created]
# now we want the range of days so that we can make a proper histogram.
range_of_days = max(ts_created_days) - min(ts_created_days)
# make this larger - it's going to be a big timeline!
plt.rcParams["figure.figsize"] = (200,50)
# how does posting change over time? let's take a look:
plt.xticks(ticks=[r for r in range(range_of_days)][::10], labels=[dt.datetime.strftime((min_ts + dt.timedelta(days=r)), '%Y%m%d') for r in range(range_of_days)][::20])
plt.hist(ts_created_days, bins=range_of_days)
# absent some context or aggregation of data, this likely doesn't really show much!
# so let's try something different:
ts_created_dayofweek = [d.weekday() for d in ts_created]
ts_created_dayofmonth = [d.day for d in ts_created]
ts_created_month = [d.month for d in ts_created]
# wow! a blob!
plt.hist(ts_created_dayofweek, bins=7)
def plot_a_range_of_values(list_of_values, n_bins, labels, zero_index=True):
"""
Given a list of values (say, day of week or month of year) for a bunch of events,
plots a histogram of their values, given by n_bins.
Ideally n_bins is the number of possible values found in our list of values.
inputs:
list_of_values: list of integer values (e.g. day of week or month of year) for a bunch of events.
n_bins: number of bins we are using. integer; should be the number of possible values in list_of_values.
labels: the labels we want to see on our x-axis (names of days/months, days of a month). list of str or ints.
if the string 'auto', we let matplotlib set its own labels.
zero_index: if True (e.g. months, days of week), we assume our bins start at 0.
if False (e.g. day of month), our bins start at 1.
"""
if labels == 'auto':
plt.hist(list_of_values, bins=n_bins, rwidth=0.75, align='left')
else:
if zero_index:
ticks_min = 0
ticks_max = n_bins
else:
ticks_min = 1
ticks_max = n_bins + 1
plt.xticks(ticks=range(ticks_min, ticks_max), labels=labels)
plt.hist(list_of_values, bins=range(ticks_min, ticks_max + 1), rwidth=0.75, align='left')
# let's do better - let's look at weekly posting patterns to start.
plt.rcParams["figure.figsize"] = (20,10)
# does this look like what you expected? why or why not?
labels = [calendar.day_name[i] for i in range(7)]
plot_a_range_of_values(ts_created_dayofweek, 7, labels)
# ok, now let's look at day of month:
# does this look like what you expected? why or why not?
plot_a_range_of_values(ts_created_dayofmonth, 31, [r for r in range(1, 32)], zero_index=False)
# and now month of year.
labels = [calendar.month_name[i] for i in range(1, 13)]
plot_a_range_of_values(ts_created_month, 12, labels, zero_index=False)
# so we have some time-based data. what else can we explore?
# let's look at users - can we get the number of posts each user has made?
# collections.Counter will count the number of times each value appears in a list.
# this is super handy for figuring out how often someone shows up in a dataset, for example.
author_counts_by_name = collections.Counter(authors)
# is the subreddit dominated by a small set of posters, or does everyone post about the same amount?
author_post_count = author_counts_by_name.values()
# look! it's an old friend!
# this time we're not going to be predicting our own labels though!
plot_a_range_of_values(author_post_count, 20, labels='auto', zero_index=True)
# if your data is like my data, you're probably going to see a huge spike at 1, and not much else.
# let's figure out how to zoom in on the long tail.
plot_a_range_of_values([a for a in author_post_count if a > 1], 20, labels='auto', zero_index=True)
# or, even more simply:
print(collections.Counter(author_counts_by_name.values()))
# can you think of a better way to visualize your result?
# now for a little bit of natural language processing and pandas!
keyword = 'gme'
df = pd.DataFrame({'title': titles, 'texts': texts, 'ts': ts_created})
df.head(5)
# lil dataframe!!
# we want to make sure we can do keyword search fairly well!
# keep in mind that searching like this might be slower for large datasets;
# you may want to look into solutions like elasticsearch or parallel computing if your dataset is huge!
# lambda expressions are like little mini functions.
# they're really handy when you want to do a function on a column and get a column back that aligns with your previous column.
df['combined_text_lowercase'] = df.apply(lambda x: x.title.lower() + x.texts.lower(), axis=1)
df['{}_present'.format(keyword)] = df['combined_text_lowercase'].apply(lambda x: keyword in x)
# wow, more columns!
df.head(5)
# let's try another small task: how often is your keyword mentioned over time?
# if we plot it right now, what will happen?
plt.plot(df['ts'], df['gme_present'])
# not quite what we wanted, right?
# let's group by day - that's a manageable grouping.
# first, let's round to the nearest day.
df['date_ts'] = df['ts'].apply(lambda b: b.date())
# now we need to group.
grouped_by_date_ts = df.groupby('date_ts')
dates = []
num_keyword_mentions = []
for date_ts, gr in grouped_by_date_ts:
num_keyword_mentions.append(gr['{}_present'.format(keyword)].sum())
dates.append(date_ts)
plt.plot(dates, num_keyword_mentions)
# what does this tell us about trends in the subreddit? what happens if we superimpose two lines?
# can you make a function that does all the stuff we just did?
keyword2 = 'facebook'
df['{}_present'.format(keyword2)] = df['combined_text_lowercase'].apply(lambda x: keyword2 in x)
dates = []
num_keyword_mentions = []
num_keyword2_mentions = []
grouped_by_date_ts = df.groupby('date_ts')
for date_ts, gr in grouped_by_date_ts:
num_keyword_mentions.append(gr['{}_present'.format(keyword)].sum())
num_keyword2_mentions.append(gr['{}_present'.format(keyword2)].sum())
dates.append(date_ts)
plt.plot(dates, num_keyword_mentions, color='orange', label='gme')
plt.plot(dates, num_keyword2_mentions, color='blue', label='facebook')
plt.legend()
grouped_by_date_ts = df.groupby('date_ts')
# maybe traffic was just up on a day that you saw a spike - how can we remedy that?
# fraction of posts!
num_keyword_mentions_fractional = []
num_keyword2_mentions_fractional = []
dates = []
for date_ts, gr in grouped_by_date_ts:
num_keyword_mentions_fractional.append(gr['{}_present'.format(keyword)].sum() / gr['{}_present'.format(keyword)].count())
num_keyword2_mentions_fractional.append(gr['{}_present'.format(keyword2)].sum() / gr['{}_present'.format(keyword2)].count())
dates.append(date_ts)
plt.plot(dates, num_keyword_mentions_fractional, color='orange', label='gme')
plt.plot(dates, num_keyword2_mentions_fractional, color='blue', label='facebook')
plt.legend()
# let's make another dataframe of authors & how many posts they made!
author_df = pd.DataFrame({'author': author_counts_by_name.keys(), 'post_counts': author_counts_by_name.values()})
print(author_df.head(5))
df['author'] = authors
df['author'] = df['author'].astype('str')
author_df['author'] = author_df['author'].astype('str')
print(df.head(5))
# now what happens if we join this to our existing dataframe?
df_merged = df.merge(author_df, how='left', on='author')
df_merged['post_counts'].value_counts()
# what kind of user makes up most of the posts?
# what else do you want to know about your data?
```
| github_jupyter |
# Tutorial 02: Exploratory Model Analysis
*Authors: Zach del Rosario*
---
This is a tutorial on using grama to do *exploratory model analysis*; to evaluate the model to generate data, then use that data to understand the model.
**Learning Goals**: By completing this notebook, you will learn:
1. How to use the verbs `gr.eval_monte_carlo` and `gr.eval_sinews`
1. How to use `gr.plot_auto`
1. Common grama arguments and defaults
**Prerequisites**:
- Familiarity with the Python programming language
- [Tutorial 01: Introduction]()
**Table of Contents**:
1. [Initialize](#s1)
2. [Monte Carlo Simulation](#s2)
3. [Sweeps](#s3)
## Initialize <a id="s1"></a>
In order to perform model analysis, we first need to construct the model. For this exercise we'll use a pre-built model: the cantilever beam model.
#### __Q1: Initialize grama__
Import grama and the cantilever beam model.
*Hint*: We initialized grama in the previous notebook; feel free to copy and paste from there.
```
###
# TASK: Set up grama
# TODO: Import grama, make the cantilever_beam model
###
# TODO: Import grama
# TODO: Assign the cantilever_beam model to `md`
# -- NO NEED TO MODIFY BELOW ----
md.printpretty()
```
## Monte Carlo Simulation <a id="s2"></a>
---
#### __Q2: Monte Carlo__
Perform a Monte Carlo simulation on model `md` with `gr.eval_monte_carlo`. Draw `100` samples, and use the nominal settings for the deterministic variables. Determine which arguments are required, and which are optional.
*Hint*: In Jupyter, click-selecting a function and pressing `Shift + Tab` will bring up the documentation. Use this to investigate the arguments.
```
###
# TASK: Perform a monte carlo simulation (MCS)
# TODO: Use gr.eval_monte_carlo, determine which arguments you need to set
###
# TODO: Perform MCS, assign results to `df_mc`
# -- NO NEED TO MODIFY BELOW ----
df_mc.describe()
```
#### __Q3: Random Seeds__
Run the code cell above a few times, and note how the results change. Then add the `seed` keyword argument with your favorite integer, and try again.
Random seeds are useful when debugging Monte Carlo results, as they ensure the same "random" results on repeated execution. As a rough rule of thumb you should systematically use multiple seeds when testing algorithms, but fix one seed when studying a model.
#### __Q4: Skip evaluation__
Modify your code above, and use the `skip` keyword to skip evaluating the functions. Take the results of `gr.eval_monte_carlo` and pass them to `gr.plot_auto`.
```
###
# TASK: Skip evaluation
# TODO: Use gr.eval_monte_carlo with the skip keyword
###
# TODO: Perform MCS with skipped evaluation, assign results to `df_skip`
gr.plot_auto(df_skip)
```
Using the autoplotter with skipped evaluation provides a visualization of the *design of experiment* (DOE), or sampling plan. Note that `gr.eval_monte_carlo` also provides an estimate of the runtime of the DOE paired with the chosen model---this is only possible when the model as runtime estimates available. When studying more expensive models, running a `skip` check first to inspect the design is often a good idea: This practice can help you catch errors before using a lot of compute resources.
#### __Q5: Autoplot evaluation__
Modify your code above to evaluate the model functions. Take the results of `gr.eval_monte_carlo` and pass them to `gr.plot_auto`. Use the same seed as you used above when setting `skip=True`. Interpret the resulting histograms.
```
###
# TASK: Autoplot MCS
# TODO: Use gr.eval_monte_carlo with gr.plot_auto
###
# TODO: Perform MCS and visualize with gr.plot_auto
```
Based on the MCS output histograms, you should be able to see that `c_area` is unaffected by the random variables, while `g_stress` and `g_disp` have a small faction of cases which lead to negative values. Since we used the same `seed` for the skipped and evaluated cases, we can guarantee the input design above matches the output results here.
## Sweeps <a id="s3"></a>
---
Monte Carlo Simulation is very useful for estimating distributions and probabilities. However, sometimes we want a more qualitative understanding of the random variables' impact on model outputs. In this last section we will use *sweeps* to gain some qualitative understanding.
#### __Q6: Sinew Design__
Use the verb `gr.eval_sinews` to construct a sinew DOE. Visualize the design without evaluating. Describe the DOE in words.
*Hint*: Use the same patterns we used for `gr.eval_monte_carlo` above.
```
###
# TASK: Sinew design
# TODO: Use gr.eval_sinews to generate a design
###
# TODO: Generate a sinew design but do not evaluate the model functions
```
#### __Q7: Sinew Study__
Use the verb `gr.eval_sinews` to evaluate the model. Visualize and interpret the results.
*Hint*: Use the same patterns we used for `gr.eval_monte_carlo` above.
```
###
# TASK: Sinew evaluation
# TODO: Use gr.eval_sinews to evaluate the model
###
# TODO: Generate, evaluate, and visualize a sinew design
```
# Next Steps
When you are done, please take [this survey](https://docs.google.com/forms/d/e/1FAIpQLSc1OgMrImpZNMr5a9n5HUrSj1ZIu3kZj6Ooa7jTd-lGs2J9SA/viewform?entry.923399158=4088579) about the exercise.
When you're ready, move on to [Tutorial 03: Model Building](https://github.com/zdelrosario/py_grama/blob/master/tutorials/t03_building_assignment.ipynb).
| github_jupyter |
Universidade Federal do Rio Grande do Sul (UFRGS)
Programa de Pós-Graduação em Engenharia Civil (PPGEC)
# PEC00025: Introduction to Vibration Theory
### Class 08 - Vibration analysis in frequency domain
[1. Frequency preservation theorem](#section_1)
[2. Reological models](#section_2)
[2.1. General linear model](#section_21)
[2.2. The Kevin-Voigt model](#section_22)
[2.3. The Maxwell model](#section_23)
[2.4. The standard model](#section_24)
[3. Equilibrium in frequency domain](#section_3)
[4. Assignment](#section_4)
---
_Prof. Marcelo M. Rocha, Dr.techn._ [(ORCID)](https://orcid.org/0000-0001-5640-1020)
_Porto Alegre, RS, Brazil_
```
# Importing Python modules required for this notebook
# (this cell must be executed with "shift+enter" before any other Python cell)
import numpy as np
import matplotlib.pyplot as plt
from MRPy import MRPy
```
## 1. Frequency preservation theorem <a name="section_1"></a>
Let us assume now that our idealized single degree of freedom system is subjected to a harmonic
(sinusoidal) loading with frequency $f_0$:
$$ F(t) = F_{\rm max} \sin(2\pi f_0 t + \theta_F) $$
with $F_{\rm max}$ being the force function amplitude and $\theta$ some phase angle.
<img src="images/singleDOF.png" alt="SDOF system" width="240px"/>
Recalling the convolution theorem for Fourier Transform presented in last class we anticipate that,
in the same way as with Laplace Transform, the system response can calculated as:
$$ u(t) = f(t) * h(t) = \int_{-\infty}^{\infty} {f(t - \tau}) h(\tau) \, \; d\tau $$
with $f(t) = F(t)/m$. Deriving now the displacement twice we got the acceleration:
$$ \ddot{u}(t) = \int_{-\infty}^{\infty} {\ddot{f}(t - \tau}) h(\tau) \, \; d\tau $$
but replacing the sinusoidal function we get:
$$ \ddot{u}(t) = -(2\pi f_0)^2 \int_{-\infty}^{\infty} {f(t - \tau}) h(\tau) \, \; d\tau $$
Replacing now the integral in the expression above by $u(t)$ we arrive at:
$$ \ddot{u}(t) + (2\pi f_0)^2 u(t) = 0 $$
what is a homogeneous differential equation with solution:
$$ u(t) = u_{\rm max} \sin(2\pi f_0 t + \theta_u) $$
This solution states that _a linear system responds to a harmonic excitation preserving
the same excitation frequency_. On the other hand, whenever a system is subjected
to a harmonic excitation and the excitation frequency is not exclusivelly preserved
in the system response, this will be a strong indication that _the system is not linear_.
This theorem is demonstrated below with a excitation frequency $f_0 = 1$Hz applied to a linear
system with natural frequency $f_{\rm n} = 2$Hz. The system equation is solved with
the ```MRPy``` method ```sdof_Fourier()``` which assumes that the loading is periodic and
hence no initial conditions are required. How this method works will be explained in
the following sections.
```
f0 = 1.0 # excitation frequency (kg)
F0 = 1.0 # excitation amplitude (N)
m = 1.0 # system mass (kg)
fn = 2.0 # system natural frequency (Hz)
zt = 0.01 # system damping ratio (nondim)
F = F0*MRPy.harmonic(NX=1, N=1024, Td=8, f0=1, phi=0) # MRPy harmonic function
F = (F + 2*F0)**1.05 - 2*F0
u = F.sdof_Fourier(fn, 0.01)/m # frequency domain solution
f0 = F.plot_time(0, figsize=(8,2), axis_t=(0, 8, -1.50, 1.50 ))
f1 = u.plot_time(1, figsize=(8,2), axis_t=(0, 8, -0.02, 0.02 ))
f2 = u.plot_freq(2, figsize=(8,2), axis_f=(0, 8, 0.00, 0.0004))
```
## 2. Reological models <a name="section_2"></a>
### 2.1. The general linear model <a name="section_21"></a>
The damped spring-mass system depicted at the beginning of this notebook, with a single spring in parallel
with a single damper, is one amongst many possible models for the reological behavior of linear systems.
In general, the equilibrium equation may be written as:
$$ m \ddot{u} + r(u, t) = F(t) $$
where $r(u, t)$ is a time function abridging both _restitutive_ and _reactive_ forces, which obviously
depend on the system response itself, $u(t)$. In general, it can be stated that a linear reological model
is the solution of the equation:
$$ \left(a_0 + a_1\frac{\partial}{\partial t} + a_2\frac{\partial^2}{\partial t^2} + \dots \right) r(t) =
\left(b_0 + b_1\frac{\partial}{\partial t} + b_2\frac{\partial^2}{\partial t^2} + \dots \right) u(t) $$
If we apply a Fourier Transform to this equation, with $\mathscr{F} \left\{ r(t) \right\} = R(\omega)$
and $\mathscr{F} \left\{ u(t) \right\} = U(\omega)$, after some algebraic manipulation we arrive
at the following general relation:
$$ R(\omega) = K(\omega) \left[ 1 + i\mu(\omega) \right] U(\omega)$$
what in short means that there will be an _in phase_ and an _out of phase_ force to displacement response.
Each reological models will have its own $K(\omega)$ and $\mu(\omega)$ functions.
It is important to observe the importance of the Fourier Transform approach here,
which makes possible the solution of equilibrium equation in frequency domain without
the need of solving an integral-differential equation in time domain.
### 2.2. The Kevin-Voigt model <a name="section_22"></a>
The parallel spring-damper system, commonly used for elastic structures in
Civil Engineering, is known as _Kelvin-Voigt_ model.
<img src="images/Kelvin_Voigt_diagram.svg" alt="Kelvin-Voigt" width="160px"/>
In time domain the model is formulated as:
$$ r(t) = c\dot{u}(t) + ku(t) $$
while its properties are:
\begin{align*}
K(\omega) &= k \\
\mu(\omega) &= -\frac{c\omega}{k}
\end{align*}
We will be always using this model, unless otherwise explicitly stated.
### 2.3. The Maxwell model <a name="section_23"></a>
The series spring-damper system, the most basic representation of a viscous
material, is known as _Maxwell_ model.
<img src="images/Maxwell_diagram.svg" alt="Maxwell" width="240px"/>
In time domain the model is stated as:
$$ r(t) + \frac{c}{k} \; \dot{r}(t) = c\dot{u}(t)$$
while its properties are:
\begin{align*}
K(\omega) &= \frac{c^2 k}{c^2 \omega^2 + k^2} \omega^2 \\
\mu(\omega) &= -\frac{k}{c\omega}
\end{align*}
Observe that this model implies the possibility (almost a certainty)
of a system non-zero final response. Furthermore, for zero excitation frequency
(what means a static load) the displacement will become infinity.
### 2.3. The Zener (standard) model <a name="section_24"></a>
A more complex reological model is known as the Zener (or standard) model.
There are two versions for these model, as illustrated below.
<table align="center">
<tr>
<td align="center"><img src="images/Zener_Maxwell_diagram.svg" alt="Zener-Maxwell" width="200px"/></td>
<td align="center"><img src="images/Zener_Kelvin_diagram.svg" alt="Zener-Kelvin" width="180px"/></td>
</tr>
<tr>
<td align="center"> The Zener model (Maxwell version) </td>
<td align="center"> The Zener model (Kelvin version) </td>
</tr>
</table> <br>
The time domain equation for the Maxwell version of Zener model is:
$$ r(t) + \frac{c}{k_2} \; \dot{r}(t) = k_1 u(t) + \frac{c(k_1 + k_2)}{k_2} \; \dot{u}(t) $$
while the equation for the Kelvin version is:
$$ r(t) + \frac{c}{k_1 + k_2} \; \dot{r}(t) = \frac{k_1 k_2}{k_1 + k_2} \; u(t) + \frac{c k_1}{k_1 + k_2} \; \dot{u}(t) $$
As an exercise, it is suggested the derivation of frequency domain functions, $K(\omega)$ and $\mu(\omega)$
for these two Zener model versions.
## 3. Equilibrium in frequency domain <a name="section_3"></a>
After choosing a suitable reological model, we may now go back to the linear dynamic equilibrium equation:
$$ m \ddot{u} + r(u, t) = F(t) $$
and apply a Fourier transform to both sides of equation:
$$ -\omega^2 U(\omega) + \frac{1}{m} \; R(\omega) = F(\omega) $$
where $\mathscr{F} \left\{ F(t)/m \right\} = F(\omega)$.
After replacing the expression for the choosen $R(\omega)$, the system response $U(\omega)$ can be
calculated as a function of excitation $F(\omega)$, and transformed back to time domain (if required).
One must be aware that this is complex algebra and the solution will have both an _in phase_ and
an _out of phase_ components.
In the following we will do the math for the most used Kevin-Voigt model. The equilibrium in
frequency domain is:
$$ -\omega^2 U(\omega) + \frac{k}{m} \; \left( 1 - i\frac{c\omega}{k} \right) U(\omega) = F(\omega) $$
Now we isolate $U(\omega)$ and recall that $\omega_{\rm n}^2 = k/m$ and that $\zeta = c/(2m\omega_{\rm n}) $, what gives:
$$ U(\omega) = H(\omega) F(\omega) $$
where:
$$ H(\omega) = \frac{1}{\omega_{\rm n}^2} \; \left[ \frac{1}{(1 - \beta^2) - i(2\zeta\beta)} \right]$$
is called the _system mechanical admittance_, with $\beta = \omega / \omega_{\rm n}$ being
a nondimensional frequency.
These expressions allow a straightforward solution of the equilibrium equation in time domain
(although its complex algebra). The mechanical admittance can be understood as a frequency
dependent flexibility, for as the excitation frequency goes to zero (static condition) the
admittance goes to $1/\omega_{\rm n}^2$, which is the flexibility coefficient
(inverse of the stiffness coefficient, $\omega_{\rm n}^2$) with unity mass.
In the expression above it can also be observed that for undamped systems, $\zeta = 0$, the
admittance, and consequently the system response, will rise to infinity when the excitation
frequency equals the system natural frequency, $\omega = \omega_{\rm n}$. This condition is
called _resonance_, and must be always avoided in structural systems design.
The class ``MRPy`` has a method ``sdof_Fourier()`` that is an implementation of this
solution in frequency domain (for Kevin-Voigt model). It requires no inicial condition,
for in Fourier analysis the numerical approach (where signals must have a finite duration)
assumes the signal is always periodic.
The example below compares the solutions with ``sdof_Fourier()`` and ``sdof_Duhamel()``
for a linear system subject to a harmonic load. Observe the difference due to
the initial conditions in time domain approach. The two responses become the same
after some acceleration time in the solution with Duhamel. This difference between
the two solution methods is exactly the system response to some initial conditions.
```
m = 1.0 # system mass (kg)
fn = 1.0 # system natural frequency (Hz)
zt = 0.01 # system damping ratio (nondim)
F = MRPy.white_noise(1, 2048, Td=32) # 32 seconds white noise
F = (F - F.mean())/F.std() # unit variance
# Uncomment the following line for padding zeros to force same result
# F = F.double().double()
uF = F.sdof_Fourier(1, 0.01)/m # 1Hz, 1% damping, 1kg mass
uD = F.sdof_Duhamel(1, 0.01, 0, 0)/m # zero initial conditions
uE = uF - uD # solutions difference
f2 = F.plot_time(2, figsize=(8,2), axis_t=(0, 32, -4.0, 4.0))
f3 = uF.plot_time(3, figsize=(8,2), axis_t=(0, 32, -0.2, 0.2))
f4 = uD.plot_time(4, figsize=(8,2), axis_t=(0, 32, -0.2, 0.2))
f5 = uE.plot_time(5, figsize=(8,2), axis_t=(0, 32, -0.2, 0.2))
```
There are many areas in engineering analysis where design codes define dynamic loads as power spectra.
For instance, surface irregularities in pavements, earthquake accelerations, wind speeds, etc.
In these cases, the equation:
$$ U(\omega) = H(\omega) F(\omega) $$
which preserve phase information, is replaced by:
$$ S_U(\omega) = \lvert H(\omega) \rvert^2 S_F(\omega) $$
where, instead of the complex Fourier transforms, the (real) spectral densities are used.
In this new equation, the absolute squared mechanical admittance becomes:
$$ \lvert H(\omega) \rvert^2 = \frac{1}{\omega_{\rm n}^4} \; \left[ \frac{1}{(1 - \beta^2)^2 + (2\zeta\beta)^2} \right]$$
with $\beta = \omega/\omega_{\rm n}$.
The square root of the expression between brackets is also called _dynamic amplification factor_, $A(\beta, \zeta)$:
$$ A(\beta, \zeta) = \sqrt{\frac{1}{(1 - \beta^2)^2 + (2\zeta\beta)^2}} $$
plotted below for some typical values of the damping ratio.
```
bt = np.linspace(0, 3, 200)
zt = [0.20, 0.10, 0.05, 0.01]
plt.figure(6, figsize=(8,4))
for z in zt:
A = np.sqrt(1/((1 - bt**2)**2 + (2*z*bt)**2))
f6 = plt.semilogy(bt, A)
plt.legend(zt)
plt.axis([0, 3, 0.1, 100])
plt.ylabel('Dynamic Amplification (nondim)')
plt.xlabel('Normalized frequency')
plt.grid(True)
```
The most important features of the dynamic amplification factor are:
* The factor represents the dynamic response increase with respect to the static response to a harmonic loading: <br> <br> $$ F(t) = F_{\rm max} \sin(\omega t + \theta) $$ <br> such that <br> $$ u_{\rm max} = A(\beta, \zeta) \; \frac{F_{\rm max}}{m \omega_{\rm n}^2} $$ <br> where we recall that $m \omega_{\rm n}^2$ is the stiffness coefficient and the phase information is lost.
* For very low frequencies the amplification becomes $A(\beta, \zeta) = 1$, what means static response.
* For $\beta \approx 1$ the amplification attains its maximum, which is approximatelly $A(1, \zeta) = 1/(2\zeta)$. This means, for instance, that for a typical damping ratio, $\zeta = 1$%, the dynamic response is amplified approximately 50 times with respect to the static response.
Lets take a look at this theory by running an example.
```
m = 1.0 # system mass (kg)
fn = 1.0 # system natural frequency (Hz)
zt = 0.01 # system damping ratio (nondim)
k = m*(2*np.pi*fn)**2 # implied stiffness
Td = 32 # load duration (s)
fs = 32 # sampling rate (Hz)
N = Td*fs # signal length
f0 = 1.0 # excitation frequency (Hz)
F0 = 1.0 # excitation amplitude (N)
phi = 0.0 # phase angle (rad)
F = F0*MRPy.harmonic(1, N, fs, f0=f0, phi=phi) # harmonic loading
ue = F0/k # static response
ud = F.sdof_Fourier(fn, zt)/m # dynamic response
up = ud[0].max() # peak response
f7 = F.plot_time(7, figsize=(8,2), axis_t=(0,32,-1.5,1.5))
f8 = ud.plot_time(8, figsize=(8,2), axis_t=(0,32,-1.5,1.5))
print('Static displacement would be: {0:6.3f}m'.format(ue))
print('Peak of dynamic displacement: {0:6.3f}m'.format(up))
print('Amplification factor is: {0:4.1f} '.format(up/ue))
```
## 4. Example of application <a name="section_4"></a>
The aerodynamic force over a bluff body due to wind speed turbulence
can be calculated as:
$$ F(z, t) = \frac{1}{2} \rho V^2(z, t) C_{\rm D} A $$
where $z$ is the height above ground, $\rho$ is the air density, $V(z,t)$
is the wind speed at height $z$, and the product $C_{\rm D} A$ refers
to the aerodynamic characteristics of the body.
It can be shown that the spectral density of this aerodynamic force
is related to the spectral density of the (fluctuating part) of the wind
speed through:
$$ S_F(z, f) = \left [
\frac{2\bar{F}(z)}{\bar{V}(z)} \right ]^2 S_v(z, f)$$
where $f$ is the frequency, $\bar{F}(z)$ is the mean force at height $z$,
and $\bar{V}(z)$ is the mean wind speed at height $z$.
The wind speed turbulence, $v(t)$, may be modelled according to Harris' spectral density, $S_V(f)$:
$$ \frac{f S_V(f)}{\sigma_V^2} = \frac{0.6 Y}{\left( 2 + Y^2 \right)^{5/6}}$$
with:
\begin{align*}
Y &= 1800 f \;/\; \bar{V}_{10} \\
\sigma_V^2 &= 6.66 \; c_{\rm as} \; \bar{V}_{10}^2
\end{align*}
where $\sigma_V^2$ is the wind speed variance, $c_{\rm as}$ is the surface drag coefficient and $\bar{V}_{10}$ is the mean wind speed at 10m height.
```
cas = 6.5e-3 # NBR-6123 category II
V10 = 20. # mean speed at 10m (m/s)
sV2 = 6.66*cas*(V10**2) # wind speed variance
fs = 64. # samplig rate
N = 8192 # length of sample
M = N//2 + 1 # length of periodogram
df = fs/M # frequency step
f = np.linspace(0, fs/2, M) # frequency axis
Y = 1800*f[1:]/V10 # avoiding zero division
SV0 = np.zeros((2, M))
SV0[0,1:] = 0.6*sV2*Y/((2 + Y**2)**(5/6))/f[1:]
SV0[1,1:] = SV0[0,1:] # (replicating)
plt.figure(6, figsize=(8, 3))
plt.loglog(f[1:], SV0[0,1:]);
plt.grid(True)
```
## 5. Assignment <a name="section_5"></a>
1. Calcular as funções $K(\omega)$ e $\mu(\omega)$ para o modelo reológico de Zener (escolha uma das
duas versões, Maxwell ou Kelvin).
2. Aplique as funções acima na equação de equilíbrio dinâmico no domínio da frequência e deduza
a correspondente função de admitância mecânica.
3. Plote esta admitância em função da frequência adimensionalizada.
4. Apresente a expressão da frequência natural de vibração livre para este modelo.
4. Relatório com deduções, gráficos e resultados (nome do arquivo T6_xxxxxxxx.ipynb).
Prazo: 03 de junho de 2020.
| github_jupyter |
# 1. Lecture des données
```
# -*- coding: utf-8 -*-
import numpy as np
from math import *
from pylab import *
def read_file ( filename ):
"""
Lit le fichier contenant les données du geyser Old Faithful
"""
# lecture de l'en-tête
infile = open ( filename, "r" )
for ligne in infile:
if ligne.find ( "eruptions waiting" ) != -1:
break
# ici, on a la liste des temps d'éruption et des délais d'irruptions
data = []
for ligne in infile:
nb_ligne, eruption, waiting = [ float (x) for x in ligne.split () ]
data.append ( eruption )
data.append ( waiting )
infile.close ()
# transformation de la liste en tableau 2D
data = np.asarray ( data )
data.shape = ( int ( data.size / 2 ), 2 )
return data
data = read_file ( "./data/2015_tme4_faithful.txt" )
math.log(math.e)
```
# 2. Loi normale bidimensionnelle
```
def normale_bidim( x,z,quintuplet) :
import math
u_x,u_z,sigma_x,sigma_z,p = quintuplet
return 1/(2*math.pi*sigma_x * sigma_z * math.sqrt(1-p**2) )*math.exp(-1/(2*(1-p**2))*(((x-u_x)/sigma_x)**2-2*p*(( (x-u_x)*(z-u_z) )/(sigma_x*sigma_z))+((z-u_z)/sigma_z)**2))
normale_bidim ( 1, 2, (1.0,2.0,3.0,4.0,0) )
normale_bidim ( 1, 0, (1.0,2.0,1.0,2.0,0.7) )
import matplotlib.pyplot as plt
def dessine_1_normale ( params ):
# récupération des paramètres
mu_x, mu_z, sigma_x, sigma_z, rho = params
# on détermine les coordonnées des coins de la figure
x_min = mu_x - 2 * sigma_x
x_max = mu_x + 2 * sigma_x
z_min = mu_z - 2 * sigma_z
z_max = mu_z + 2 * sigma_z
# création de la grille
x = np.linspace ( x_min, x_max, 100 )
z = np.linspace ( z_min, z_max, 100 )
X, Z = np.meshgrid(x, z)
# calcul des normales
norm = X.copy ()
for i in range ( x.shape[0] ):
for j in range ( z.shape[0] ):
norm[i,j] = normale_bidim ( x[i], z[j], params )
# affichage
fig = plt.figure ()
plt.contour ( X, Z, norm, cmap=cm.autumn )
plt.show ()
dessine_1_normale ( (-3.0,-5.0,3.0,2.0,0.7) )
dessine_1_normale ( (-3.0,-5.0,3.0,2.0,0.2) )
```
# 4. Visualisation des données du Old Faithful
```
def dessine_normales ( data, params, weights, bounds, ax ):
# récupération des paramètres
mu_x0, mu_z0, sigma_x0, sigma_z0, rho0 = params[0]
mu_x1, mu_z1, sigma_x1, sigma_z1, rho1 = params[1]
# on détermine les coordonnées des coins de la figure
x_min = bounds[0]
x_max = bounds[1]
z_min = bounds[2]
z_max = bounds[3]
# création de la grille
nb_x = nb_z = 100
x = np.linspace ( x_min, x_max, nb_x )
z = np.linspace ( z_min, z_max, nb_z )
X, Z = np.meshgrid(x, z)
# calcul des normales
norm0 = np.zeros ( (nb_x,nb_z) )
for j in range ( nb_z ):
for i in range ( nb_x ):
norm0[j,i] = normale_bidim ( x[i], z[j], params[0] )# * weights[0]
norm1 = np.zeros ( (nb_x,nb_z) )
for j in range ( nb_z ):
for i in range ( nb_x ):
norm1[j,i] = normale_bidim ( x[i], z[j], params[1] )# * weights[1]
# affichages des normales et des points du dataset
ax.contour ( X, Z, norm0, cmap=cm.winter, alpha = 0.5 )
ax.contour ( X, Z, norm1, cmap=cm.autumn, alpha = 0.5 )
for point in data:
ax.plot ( point[0], point[1], 'k+' )
def find_bounds ( data, params ):
# récupération des paramètres
mu_x0, mu_z0, sigma_x0, sigma_z0, rho0 = params[0]
mu_x1, mu_z1, sigma_x1, sigma_z1, rho1 = params[1]
# calcul des coins
x_min = min ( mu_x0 - 2 * sigma_x0, mu_x1 - 2 * sigma_x1, data[:,0].min() )
x_max = max ( mu_x0 + 2 * sigma_x0, mu_x1 + 2 * sigma_x1, data[:,0].max() )
z_min = min ( mu_z0 - 2 * sigma_z0, mu_z1 - 2 * sigma_z1, data[:,1].min() )
z_max = max ( mu_z0 + 2 * sigma_z0, mu_z1 + 2 * sigma_z1, data[:,1].max() )
return ( x_min, x_max, z_min, z_max )
# affichage des données : calcul des moyennes et variances des 2 colonnes
mean1 = data[:,0].mean ()
mean2 = data[:,1].mean ()
std1 = data[:,0].std ()
std2 = data[:,1].std ()
# les paramètres des 2 normales sont autour de ces moyennes
params = np.array ( [(mean1 - 0.2, mean2 - 1, std1, std2, 0),
(mean1 + 0.2, mean2 + 1, std1, std2, 0)] )
weights = np.array ( [0.4, 0.6] )
bounds = find_bounds ( data, params )
# affichage de la figure
fig = plt.figure ()
ax = fig.add_subplot(111)
dessine_normales ( data, params, weights, bounds, ax )
plt.show ()
```
# 5. EM : l'étape E
```
def Q_i ( data, current_params, current_weights ):
[[mu_x_0, mu_z_0, sigma_x_0, sigma_z_0, rho_0],[mu_x_1, mu_z_1, sigma_x_1, sigma_z_1, rho_1]] = current_params
[pi_0,pi_1] = current_weights
t = list()
for d in data:
[x,z] = d
a_0 = pi_0 * normale_bidim(x,z,(mu_x_0, mu_z_0, sigma_x_0, sigma_z_0, rho_0))
a_1 = pi_1 * normale_bidim(x,z,(mu_x_1, mu_z_1, sigma_x_1, sigma_z_1, rho_1))
Q_y0 = a_0/(a_0+a_1)
Q_y1 = a_1/(a_0+a_1)
t.append(np.array([Q_y0,Q_y1]))
return np.array(t)
#current_params = np.array ( [(mu_x, mu_z, sigma_x, sigma_z, rho), # params 1ère loi normale
# (mu_x, mu_z, sigma_x, sigma_z, rho)] ) # params 2ème loi normale
current_params = np.array([[ 3.28778309, 69.89705882, 1.13927121, 13.56996002, 0. ],
[ 3.68778309, 71.89705882, 1.13927121, 13.56996002, 0. ]])
# current_weights = np.array ( [ pi_0, pi_1 ] )
current_weights = np.array ( [ 0.5, 0.5 ] )
T = Q_i ( data, current_params, current_weights )
print(T)
current_params = np.array([[ 3.2194684, 67.83748075, 1.16527301, 13.9245876, 0.9070348 ],
[ 3.75499261, 73.9440348, 1.04650191, 12.48307362, 0.88083712]])
current_weights = np.array ( [ 0.49896815, 0.50103185] )
T = Q_i ( data, current_params, current_weights )
print(T)
```
# 6. EM : l'étape M
```
math.sqrt(4)
def M_step (data, Q, current_params, current_weights ):
pi_0 = Q[:,0].sum() / (Q[:,0].sum()+Q[:,1].sum())
mu_x0 = (Q[:,0]*data[:,0]).sum()/Q[:,0].sum()
mu_z0 = (Q[:,0]*data[:,1]).sum()/Q[:,0].sum()
sigma_x0 = math.sqrt((Q[:,0]*((data[:,0]-mu_x0)**2)).sum()/Q[:,0].sum())
sigma_z0 = math.sqrt((Q[:,0]*((data[:,1]-mu_z0)**2)).sum()/Q[:,0].sum() )
p_0 = ((((data[:,0]-mu_x0)*(data[:,1]-mu_z0))/(sigma_x0*sigma_z0))*(Q[:,0])).sum()/Q[:,0].sum()
##############################################################################################
pi_1 = Q[:,1].sum() / (Q[:,0].sum()+Q[:,1].sum())
mu_x1 = (Q[:,1]*data[:,0]).sum()/Q[:,1].sum()
mu_z1 = (Q[:,1]*data[:,1]).sum()/Q[:,1].sum()
sigma_x1 = math.sqrt((Q[:,1]*((data[:,0]-mu_x1)**2)).sum()/Q[:,1].sum())
sigma_z1 = math.sqrt((Q[:,1]*((data[:,1]-mu_z1)**2)).sum()/Q[:,1].sum() )
p_1 = ((((data[:,0]-mu_x1)*(data[:,1]-mu_z1))/(sigma_x1*sigma_z1))*(Q[:,1])).sum()/Q[:,1].sum()
return np.array([np.array([mu_x0,mu_z0,sigma_x0,sigma_z0,p_0]),np.array([mu_x1,mu_z1,sigma_x1,sigma_z1,p_1])]),np.array([pi_0,pi_1])
current_params = array([(2.51460515, 60.12832316, 0.90428702, 11.66108819, 0.86533355),
(4.2893485, 79.76680985, 0.52047055, 7.04450242, 0.58358284)])
current_weights = array([ 0.45165145, 0.54834855])
Q = Q_i ( data, current_params, current_weights )
n = M_step ( data, Q, current_params, current_weights )
n
mean1 = data[:,0].mean ()
mean2 = data[:,1].mean ()
std1 = data[:,0].std ()
std2 = data[:,1].std ()
params = np.array ( [(mean1 - 0.2, mean2 - 1, std1, std2, 0),
(mean1 + 0.2, mean2 + 1, std1, std2, 0)] )
weights = np.array ( [ 0.5, 0.5 ] )
res_EM = list()
for i in range(0,20):
res_EM.append((params,weights))
T = Q_i ( data, params, weights )
params,weights = M_step ( data, T, params, weights )
plt.rcParams['animation.ffmpeg_path'] = u'/home/ghiles/anaconda3/envs/breakout/bin/ffmpeg'
import matplotlib.animation as manimation; manimation.writers.list()
# calcul des bornes pour contenir toutes les lois normales calculées
def find_video_bounds ( data, res_EM ):
bounds = np.asarray ( find_bounds ( data, res_EM[0][0] ) )
for param in res_EM:
new_bound = find_bounds ( data, param[0] )
for i in [0,2]:
bounds[i] = min ( bounds[i], new_bound[i] )
for i in [1,3]:
bounds[i] = max ( bounds[i], new_bound[i] )
return bounds
bounds = find_video_bounds ( data, res_EM )
import matplotlib.animation as animation
# création de l'animation : tout d'abord on crée la figure qui sera animée
fig = plt.figure ()
ax = fig.gca (xlim=(bounds[0], bounds[1]), ylim=(bounds[2], bounds[3]))
# la fonction appelée à chaque pas de temps pour créer l'animation
def animate ( i ):
ax.cla ()
dessine_normales (data, res_EM[i][0], res_EM[i][1], bounds, ax)
ax.text(5, 40, 'step = ' + str ( i ))
print ("step animate = %d" % ( i ))
# exécution de l'animation
anim = animation.FuncAnimation(fig, animate,frames = len(res_EM), interval=1000 )
writer = animation.FFMpegWriter(fps=15, metadata=dict(artist='Me'), bitrate=1800)
# éventuellement, sauver l'animation dans une vidéo
anim.save('old_faithful.mp4', writer=writer)
```
| github_jupyter |
# Relativistic kinematics
<h3>Learning goals</h3>
<ul>
<li>Relativistic kinematics.
<li>Standard model particles.
</ul>
<b>Background</b>
If you know the mass of a particle, most of the time you know <i>what that particle is</i>. However, there is no way to just build a single detector that gives you the mass. You need to be clever and make use of Special relativity, specifically <a href="http://en.wikipedia.org/wiki/Relativistic_mechanics">relativistic kinematics</a>.
To determine the mass ($m$) of a particle you need to know the 4-momenta of the particles ($\mathbf{P}$) that are detected after the collision: the energy ($E$), the momentum in the x direction ($p_x$), the momentum in the y direction ($p_y$), the momentum in the z direction ($p_z$).
$$\mathbf{P} = (E,p_x,p_y,p_z)$$
\begin{equation*} m = \sqrt{E^2-(p_x^2+p_y^2 + p_z^2)} \end{equation*}
<b>Let's code!</b>
Here is some sample code that reads in data from a small sample file from the <a href = "https://cms.cern">CMS experiment</a>. It loops over data from many different proton-proton collisions.
If you haven't already, you will want to go through the [data model](https://github.com/particle-physics-playground/playground/blob/master/activities/codebkg_DataInterfacing.ipynb) (also included when you cloned this directory) exercise so you know how to pull out the relevant information.
For each collision, you can get the 4-momenta of the jets, muons, electrons, and photons produced in these collisions.
```
# Import standard libraries #
import numpy as np
import matplotlib.pylab as plt
%matplotlib notebook
# Import custom tools #
import h5hep
import pps_tools as pps
# Download the file #
file = 'dimuons_1000_collisions.hdf5'
pps.download_drive_file(file)
print("Reading in the data....")
# Read the data in as a list #
infile = '../data/dimuons_1000_collisions.hdf5'
collisions = pps.get_collisions(infile,experiment='CMS',verbose=False)
print(len(collisions))
```
<h2><font color="red">Challenge!</font></h2>
Copy this sample code and use it to calculate the mass of the muons. Make a histogram of this quantity.
<i>Hint!</i>
Make sure you do this for all the muons! Each collision can produce differing numbers of muons, so take care when you code this up.
Your histogram should look something like the following sketch, though the peak will be at different values.
The value of the peak, should be the mass of the particle <a href="http://en.wikipedia.org/wiki/Muon">Check your answer!</a>
You should also make histograms of the energy and magnitude of momentum ($|p|$). You should see a pretty wide range of values for these, and yet the mass is a very specific number.
```
from IPython.display import Image
Image(filename='images/muons_sketch.jpeg')
# Your code here
```
Suppose we didn't know anything about special relativity and we tried calculating the mass from what we know about classical physics.
$$KE = \frac{1}{2}mv^2 \qquad KE = \frac{p^2}{2m} \qquad m = \frac{p^2}{2KE}$$
Let's interpret the energy from the CMS data as the kinetic energy ($KE$). Use classical mechanics then to calculate the mass of the muon, given the energy/KE and the momentum. What does <b>that</b> histogram look like?
*Your histogram should not look like the last one! We know that the Classical description of kinematics is not accurate for particle moving at high energies, so don't worry if the two histograms are different. That's the point! :)*
```
# Your code here
```
| github_jupyter |
```
import keras
from keras.models import Sequential, Model, load_model
from keras.layers import Dense, Dropout, Activation, Flatten, Input, Lambda
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, Conv1D, MaxPooling1D, LSTM, ConvLSTM2D, GRU, CuDNNLSTM, CuDNNGRU, BatchNormalization, LocallyConnected2D, Permute, TimeDistributed, Bidirectional
from keras.layers import Concatenate, Reshape, Softmax, Conv2DTranspose, Embedding, Multiply
from keras.callbacks import ModelCheckpoint, EarlyStopping, Callback
from keras import regularizers
from keras import backend as K
from keras.utils.generic_utils import Progbar
from keras.layers.merge import _Merge
import keras.losses
from functools import partial
from collections import defaultdict
import tensorflow as tf
from tensorflow.python.framework import ops
import isolearn.keras as iso
import numpy as np
import tensorflow as tf
import logging
logging.getLogger('tensorflow').setLevel(logging.ERROR)
import pandas as pd
import os
import pickle
import numpy as np
import scipy.sparse as sp
import scipy.io as spio
import matplotlib.pyplot as plt
import isolearn.io as isoio
import isolearn.keras as isol
from sequence_logo_helper_protein import plot_protein_logo as plot_protein_logo_scrambler
from sequence_logo_helper_protein import plot_importance_scores
import pandas as pd
from keras.backend.tensorflow_backend import set_session
from adam_accumulate_keras import *
def contain_tf_gpu_mem_usage() :
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
set_session(sess)
contain_tf_gpu_mem_usage()
class EpochVariableCallback(Callback) :
def __init__(self, my_variable, my_func) :
self.my_variable = my_variable
self.my_func = my_func
def on_epoch_begin(self, epoch, logs={}) :
K.set_value(self.my_variable, self.my_func(K.get_value(self.my_variable), epoch))
class IdentityEncoder(iso.SequenceEncoder) :
def __init__(self, seq_len, channel_map) :
super(IdentityEncoder, self).__init__('identity', (seq_len, len(channel_map)))
self.seq_len = seq_len
self.n_channels = len(channel_map)
self.encode_map = channel_map
self.decode_map = {
val : key for key, val in channel_map.items()
}
def encode(self, seq) :
encoding = np.zeros((self.seq_len, self.n_channels))
for i in range(len(seq)) :
if seq[i] in self.encode_map :
channel_ix = self.encode_map[seq[i]]
encoding[i, channel_ix] = 1.
return encoding
def encode_inplace(self, seq, encoding) :
for i in range(len(seq)) :
if seq[i] in self.encode_map :
channel_ix = self.encode_map[seq[i]]
encoding[i, channel_ix] = 1.
def encode_inplace_sparse(self, seq, encoding_mat, row_index) :
raise NotImplementError()
def decode(self, encoding) :
seq = ''
for pos in range(0, encoding.shape[0]) :
argmax_nt = np.argmax(encoding[pos, :])
max_nt = np.max(encoding[pos, :])
if max_nt == 1 :
seq += self.decode_map[argmax_nt]
else :
seq += self.decode_map[-1]
return seq
def decode_sparse(self, encoding_mat, row_index) :
encoding = np.array(encoding_mat[row_index, :].todense()).reshape(-1, 4)
return self.decode(encoding)
class NopTransformer(iso.ValueTransformer) :
def __init__(self, n_classes) :
super(NopTransformer, self).__init__('nop', (n_classes, ))
self.n_classes = n_classes
def transform(self, values) :
return values
def transform_inplace(self, values, transform) :
transform[:] = values
def transform_inplace_sparse(self, values, transform_mat, row_index) :
transform_mat[row_index, :] = np.ravel(values)
from seqprop_protein_utils import *
from seqprop_rosetta_kl_helper import _get_kl_divergence_numpy, _get_smooth_kl_divergence_numpy, _get_smooth_circular_kl_divergence_numpy
from seqprop_rosetta_kl_helper import _get_kl_divergence_keras, _get_smooth_kl_divergence_keras, _get_smooth_circular_kl_divergence_keras
from basinhopping_rosetta import *
from trrosetta_single_model_no_msa_batched_simpler_1d_features_2 import load_saved_predictor, InstanceNormalization, msa2pssm, reweight, fast_dca, keras_collect_features, pssm_func
dataset_name = "hallucinated_0685"
fig_name = dataset_name
def make_a3m(seqs) :
alphabet = np.array(list("ARNDCQEGHILKMFPSTWYV-"), dtype='|S1').view(np.uint8)
msa = np.array([list(s) for s in seqs], dtype='|S1').view(np.uint8)
for i in range(alphabet.shape[0]):
msa[msa == alphabet[i]] = i
msa[msa > 20] = 20
return msa
a3m = ["GHYVIKISYEFDKDDLSEEQLMQWLTRRVQAALNEAGMDFHLTSLKVERSPSNGKYKITVTVTLNPGNPHFAQRAARAISDYLRDEYPGIKDFKVTAVPL"]
msa_one_hot = np.expand_dims(one_hot_encode_msa(make_a3m(a3m)), axis=0)[:, :1, ...]
print(msa_one_hot.shape)
#Create test data
x_test = msa_one_hot[:, :1, :, :20]
print(x_test.shape)
x_train = np.transpose(msa_one_hot[:, ..., :20], (1, 0, 2, 3))
print(x_train.shape)
#Initialize sequence encoder
seq_length = x_test.shape[2]
residues = list("ARNDCQEGHILKMFPSTWYV")
residue_map = {
residue : residue_ix
for residue_ix, residue in enumerate(residues)
}
encoder = IdentityEncoder(seq_length, residue_map)
#Define sequence templates
sequence_template = '$' * seq_length
sequence_mask = np.array([1 if sequence_template[j] == '$' else 0 for j in range(len(sequence_template))])
#Calculate background distribution
x_mean = np.tile(np.array([0.07892653, 0.04979037, 0.0451488 , 0.0603382 , 0.01261332,
0.03783883, 0.06592534, 0.07122109, 0.02324815, 0.05647807,
0.09311339, 0.05980368, 0.02072943, 0.04145316, 0.04631926,
0.06123779, 0.0547427 , 0.01489194, 0.03705282, 0.0691271 ]).reshape(1, -1), (seq_length, 1))
x_mean_logits = np.log(x_mean)
plot_protein_logo_scrambler(residue_map, np.copy(x_mean), sequence_template=sequence_template, figsize=(12, 1), logo_height=1.0, plot_start=0, plot_end=seq_length)
#Calculate mean test seqeunce kl-divergence against background
x_test_clipped = np.clip(np.copy(x_test[:, 0, :, :]), 1e-8, 1. - 1e-8)
kl_divs = np.sum(x_test_clipped * np.log(x_test_clipped / np.tile(np.expand_dims(x_mean, axis=0), (x_test_clipped.shape[0], 1, 1))), axis=-1) / np.log(2.0)
x_mean_kl_divs = np.sum(kl_divs * sequence_mask, axis=-1) / np.sum(sequence_mask)
x_mean_kl_div = np.mean(x_mean_kl_divs)
print("Mean KL Div against background (bits) = " + str(x_mean_kl_div))
from tensorflow.python.framework import ops
#Stochastic Binarized Neuron helper functions (Tensorflow)
#ST Estimator code adopted from https://r2rt.com/beyond-binary-ternary-and-one-hot-neurons.html
#See Github https://github.com/spitis/
def st_sampled_softmax(logits):
with ops.name_scope("STSampledSoftmax") as namescope :
nt_probs = tf.nn.softmax(logits)
onehot_dim = logits.get_shape().as_list()[1]
sampled_onehot = tf.one_hot(tf.squeeze(tf.multinomial(logits, 1), 1), onehot_dim, 1.0, 0.0)
with tf.get_default_graph().gradient_override_map({'Ceil': 'Identity', 'Mul': 'STMul'}):
return tf.ceil(sampled_onehot * nt_probs)
def st_hardmax_softmax(logits):
with ops.name_scope("STHardmaxSoftmax") as namescope :
nt_probs = tf.nn.softmax(logits)
onehot_dim = logits.get_shape().as_list()[1]
sampled_onehot = tf.one_hot(tf.argmax(nt_probs, 1), onehot_dim, 1.0, 0.0)
with tf.get_default_graph().gradient_override_map({'Ceil': 'Identity', 'Mul': 'STMul'}):
return tf.ceil(sampled_onehot * nt_probs)
@ops.RegisterGradient("STMul")
def st_mul(op, grad):
return [grad, grad]
#Gumbel Distribution Sampler
def gumbel_softmax(logits, temperature=0.5) :
gumbel_dist = tf.contrib.distributions.RelaxedOneHotCategorical(temperature, logits=logits)
batch_dim = logits.get_shape().as_list()[0]
onehot_dim = logits.get_shape().as_list()[1]
return gumbel_dist.sample()
#PWM Masking and Sampling helper functions
def mask_pwm(inputs) :
pwm, onehot_template, onehot_mask = inputs
return pwm * onehot_mask + onehot_template
def sample_pwm_st(pwm_logits) :
n_sequences = K.shape(pwm_logits)[0]
seq_length = K.shape(pwm_logits)[2]
flat_pwm = K.reshape(pwm_logits, (n_sequences * seq_length, 20))
sampled_pwm = st_sampled_softmax(flat_pwm)
return K.reshape(sampled_pwm, (n_sequences, 1, seq_length, 20))
def sample_pwm_gumbel(pwm_logits) :
n_sequences = K.shape(pwm_logits)[0]
seq_length = K.shape(pwm_logits)[2]
flat_pwm = K.reshape(pwm_logits, (n_sequences * seq_length, 20))
sampled_pwm = gumbel_softmax(flat_pwm, temperature=0.5)
return K.reshape(sampled_pwm, (n_sequences, 1, seq_length, 20))
#Generator helper functions
def initialize_sequence_templates(generator, encoder, sequence_templates, background_matrices, model_suffix='') :
embedding_templates = []
embedding_masks = []
embedding_backgrounds = []
for k in range(len(sequence_templates)) :
sequence_template = sequence_templates[k]
onehot_template = encoder(sequence_template).reshape((1, len(sequence_template), 20))
for j in range(len(sequence_template)) :
if sequence_template[j] not in ['$', '@'] :
nt_ix = np.argmax(onehot_template[0, j, :])
onehot_template[:, j, :] = -4.0
onehot_template[:, j, nt_ix] = 10.0
onehot_mask = np.zeros((1, len(sequence_template), 20))
for j in range(len(sequence_template)) :
if sequence_template[j] == '$' :
onehot_mask[:, j, :] = 1.0
embedding_templates.append(onehot_template.reshape(1, -1))
embedding_masks.append(onehot_mask.reshape(1, -1))
embedding_backgrounds.append(background_matrices[k].reshape(1, -1))
embedding_templates = np.concatenate(embedding_templates, axis=0)
embedding_masks = np.concatenate(embedding_masks, axis=0)
embedding_backgrounds = np.concatenate(embedding_backgrounds, axis=0)
generator.get_layer('template_dense' + model_suffix).set_weights([embedding_templates])
generator.get_layer('template_dense' + model_suffix).trainable = False
generator.get_layer('mask_dense' + model_suffix).set_weights([embedding_masks])
generator.get_layer('mask_dense' + model_suffix).trainable = False
generator.get_layer('background_dense' + model_suffix).set_weights([embedding_backgrounds])
generator.get_layer('background_dense' + model_suffix).trainable = False
#Generator construction function
def build_sampler(batch_size, seq_length, n_classes=1, n_samples=1, sample_mode='st', model_suffix='') :
#Initialize Reshape layer
reshape_layer = Reshape((1, seq_length, 20))
#Initialize background matrix
onehot_background_dense = Embedding(n_classes, seq_length * 20, embeddings_initializer='zeros', name='background_dense' + model_suffix)
#Initialize template and mask matrices
onehot_template_dense = Embedding(n_classes, seq_length * 20, embeddings_initializer='zeros', name='template_dense' + model_suffix)
onehot_mask_dense = Embedding(n_classes, seq_length * 20, embeddings_initializer='ones', name='mask_dense' + model_suffix)
#Initialize Templating and Masking Lambda layer
masking_layer = Lambda(mask_pwm, output_shape = (1, seq_length, 20), name='masking_layer' + model_suffix)
background_layer = Lambda(lambda x: x[0] + x[1], name='background_layer' + model_suffix)
#Initialize PWM normalization layer
pwm_layer = Softmax(axis=-1, name='pwm' + model_suffix)
#Initialize sampling layers
sample_func = None
if sample_mode == 'st' :
sample_func = sample_pwm_st
elif sample_mode == 'gumbel' :
sample_func = sample_pwm_gumbel
upsampling_layer = Lambda(lambda x: K.tile(x, [n_samples, 1, 1, 1]), name='upsampling_layer' + model_suffix)
sampling_layer = Lambda(sample_func, name='pwm_sampler' + model_suffix)
permute_layer = Lambda(lambda x: K.permute_dimensions(K.reshape(x, (n_samples, batch_size, 1, seq_length, 20)), (1, 0, 2, 3, 4)), name='permute_layer' + model_suffix)
def _sampler_func(class_input, raw_logits) :
#Get Template and Mask
onehot_background = reshape_layer(onehot_background_dense(class_input))
onehot_template = reshape_layer(onehot_template_dense(class_input))
onehot_mask = reshape_layer(onehot_mask_dense(class_input))
#Add Template and Multiply Mask
pwm_logits = masking_layer([background_layer([raw_logits, onehot_background]), onehot_template, onehot_mask])
#Compute PWM (Nucleotide-wise Softmax)
pwm = pwm_layer(pwm_logits)
#Tile each PWM to sample from and create sample axis
pwm_logits_upsampled = upsampling_layer(pwm_logits)
sampled_pwm = sampling_layer(pwm_logits_upsampled)
sampled_pwm = permute_layer(sampled_pwm)
sampled_mask = permute_layer(upsampling_layer(onehot_mask))
return pwm_logits, pwm, sampled_pwm, onehot_mask, sampled_mask
return _sampler_func
#Scrambler network definition
def load_scrambler_network(seq_length, model_suffix='') :
#Discriminator network definition
seed_input = Lambda(lambda x: K.zeros((1, 1), dtype=tf.int32))
mask_dense = Embedding(1, seq_length, embeddings_initializer='glorot_normal', name='scrambler_mask_dense' + model_suffix)
mask_reshape = Reshape((1, seq_length, 1))
mask_norm = BatchNormalization(axis=-1, name='scrambler_mask_norm' + model_suffix)
mask_act = Activation('softplus')
onehot_to_logits = Lambda(lambda x: 2. * x - 1., name='scrambler_onehot_to_logits' + model_suffix)
scale_logits = Lambda(lambda x: x[1] * K.tile(x[0], (1, 1, 1, 20)), name='scrambler_logit_scale' + model_suffix)
def _scrambler_func(sequence_input) :
#Final conv out
final_conv_out = mask_act(mask_norm(mask_reshape(mask_dense(seed_input(sequence_input))), training=True))
#final_conv_out = mask_act(mask_reshape(mask_dense(seed_input(sequence_input))))
#Scale inputs by importance scores
scaled_inputs = scale_logits([final_conv_out, onehot_to_logits(sequence_input)])
return scaled_inputs, final_conv_out
return _scrambler_func
#Keras loss functions
def get_margin_entropy_ame_masked(pwm_start, pwm_end, pwm_background, max_bits=1.0) :
def _margin_entropy_ame_masked(pwm, pwm_mask) :
conservation = pwm[:, 0, pwm_start:pwm_end, :] * K.log(K.clip(pwm[:, 0, pwm_start:pwm_end, :], K.epsilon(), 1. - K.epsilon()) / K.constant(pwm_background[pwm_start:pwm_end, :])) / K.log(2.0)
conservation = K.sum(conservation, axis=-1)
mask = K.max(pwm_mask[:, 0, pwm_start:pwm_end, :], axis=-1)
n_unmasked = K.sum(mask, axis=-1)
mean_conservation = K.sum(conservation * mask, axis=-1) / n_unmasked
margin_conservation = K.switch(mean_conservation > K.constant(max_bits, shape=(1,)), mean_conservation - K.constant(max_bits, shape=(1,)), K.zeros_like(mean_conservation))
return margin_conservation
return _margin_entropy_ame_masked
def get_target_entropy_sme_masked(pwm_start, pwm_end, pwm_background, target_bits=1.0) :
def _target_entropy_sme_masked(pwm, pwm_mask) :
conservation = pwm[:, 0, pwm_start:pwm_end, :] * K.log(K.clip(pwm[:, 0, pwm_start:pwm_end, :], K.epsilon(), 1. - K.epsilon()) / K.constant(pwm_background[pwm_start:pwm_end, :])) / K.log(2.0)
conservation = K.sum(conservation, axis=-1)
mask = K.max(pwm_mask[:, 0, pwm_start:pwm_end, :], axis=-1)
n_unmasked = K.sum(mask, axis=-1)
mean_conservation = K.sum(conservation * mask, axis=-1) / n_unmasked
return (mean_conservation - target_bits)**2
return _target_entropy_sme_masked
def get_weighted_loss(loss_coeff=1.) :
def _min_pred(y_true, y_pred) :
return loss_coeff * y_pred
return _min_pred
#Initialize Encoder and Decoder networks
batch_size = 1
#seq_length = 81
n_samples = 4
sample_mode = 'gumbel'
#Load scrambler
scrambler = load_scrambler_network(seq_length)
#Load sampler
sampler = build_sampler(batch_size, seq_length, n_classes=1, n_samples=n_samples, sample_mode=sample_mode)
#Load trRosetta predictor
def _tmp_load_model(model_path) :
saved_model = load_model(model_path, custom_objects = {
'InstanceNormalization' : InstanceNormalization,
'reweight' : reweight,
'wmin' : 0.8,
'msa2pssm' : msa2pssm,
'tf' : tf,
'fast_dca' : fast_dca,
'keras_collect_features' : pssm_func#keras_collect_features
})
return saved_model
#Specfiy file path to pre-trained predictor network
save_dir = os.path.join(os.getcwd(), '../../../seqprop/examples/rosetta/trRosetta/network/model2019_07')
#model_name = 'model.xaa_batched_no_drop_2.h5' #Without drop
model_name = 'model.xaa_batched.h5' #With drop
model_path = os.path.join(save_dir, model_name)
predictor = _tmp_load_model(model_path)
predictor.trainable = False
predictor.compile(
loss='mse',
optimizer=keras.optimizers.SGD(lr=0.1)
)
predictor.inputs
predictor.outputs
#Test predictor on sequence
save_figs = True
pd, pt, pp, po = predictor.predict(x=[x_test[:, 0, :, :], np.concatenate([x_test, np.zeros((1, 1, x_test.shape[2], 1))], axis=-1)], batch_size=1)
f, ax_list = plt.subplots(1, 4, figsize=(12, 3))
p_list = [
[pd, 'distance', ax_list[0]],
[pt, 'theta', ax_list[1]],
[pp, 'phi', ax_list[2]],
[po, 'omega', ax_list[3]]
]
for p_keras, p_name, p_ax in p_list :
p_keras_vals = np.argmax(p_keras[0, ...], axis=-1)
p_ax.imshow(np.max(p_keras_vals) - p_keras_vals, cmap="Reds", vmin=0, vmax=np.max(p_keras_vals))
p_ax.set_title(p_name, fontsize=14)
p_ax.set_xlabel("Position", fontsize=14)
p_ax.set_ylabel("Position", fontsize=14)
plt.sca(p_ax)
plt.xticks([0, p_keras_vals.shape[0]], [0, p_keras_vals.shape[0]], fontsize=14)
plt.yticks([0, p_keras_vals.shape[1]], [0, p_keras_vals.shape[1]], fontsize=14)
plt.tight_layout()
if save_figs :
plt.savefig(fig_name + '_p_distribs.png', transparent=True, dpi=150)
plt.savefig(fig_name + '_p_distribs.svg')
plt.savefig(fig_name + '_p_distribs.eps')
plt.show()
#Build scrambler model
scrambler_class = Input(shape=(1,), name='scrambler_class')
scrambler_input = Input(shape=(1, seq_length, 20), name='scrambler_input')
scrambled_pwm, importance_scores = scrambler(scrambler_input)
pwm_logits, pwm, sampled_pwm, _, sampled_mask = sampler(scrambler_class, scrambled_pwm)
scrambler_model = Model([scrambler_input, scrambler_class], [pwm, importance_scores])
#Initialize Sequence Templates and Masks
initialize_sequence_templates(scrambler_model, encoder, [sequence_template], [x_mean_logits])
scrambler_model.compile(
optimizer=keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999),
loss='mean_squared_error'
)
def _get_kl_divergence_keras(p_dist, p_theta, p_phi, p_omega, t_dist, t_theta, t_phi, t_omega) :
kl_dist = K.mean(K.sum(t_dist * K.log(t_dist / p_dist), axis=-1), axis=(-1, -2))
kl_theta = K.mean(K.sum(t_theta * K.log(t_theta / p_theta), axis=-1), axis=(-1, -2))
kl_phi = K.mean(K.sum(t_phi * K.log(t_phi / p_phi), axis=-1), axis=(-1, -2))
kl_omega = K.mean(K.sum(t_omega * K.log(t_omega / p_omega), axis=-1), axis=(-1, -2))
return K.mean(kl_dist + kl_theta + kl_phi + kl_omega, axis=1)
#Build Auto-scrambler pipeline
#Define model inputs
ae_scrambler_class = Input(batch_shape=(1, 1), name='ae_scrambler_class')
ae_scrambler_input = Input(batch_shape=(1, 1, seq_length, 20), name='ae_scrambler_input')
scrambled_in, importance_scores = scrambler(ae_scrambler_input)
#Run encoder and decoder
_, scrambled_pwm, scrambled_sample, pwm_mask, sampled_mask = sampler(ae_scrambler_class, scrambled_in)
#Define layer to deflate sample axis
deflate_scrambled_sample = Lambda(lambda x: K.reshape(x, (batch_size * n_samples, 1, seq_length, 20)), name='deflate_scrambled_sample')
#Deflate sample axis
scrambled_sample_deflated = deflate_scrambled_sample(scrambled_sample)
#Make reference prediction on non-scrambled input sequence
collapse_input_layer_non_scrambled = Lambda(lambda x: x[:, 0, :, :], output_shape=(seq_length, 20))
create_msa_layer_non_scrambled = Lambda(lambda x: K.concatenate([x, K.zeros((x.shape[0], x.shape[1], x.shape[2], 1))], axis=-1), output_shape=(1, seq_length, 21))
collapsed_in_non_scrambled = collapse_input_layer_non_scrambled(ae_scrambler_input)
collapsed_in_non_scrambled_msa = create_msa_layer_non_scrambled(ae_scrambler_input)
p_dist_non_scrambled_deflated, p_theta_non_scrambled_deflated, p_phi_non_scrambled_deflated, p_omega_non_scrambled_deflated = predictor([collapsed_in_non_scrambled, collapsed_in_non_scrambled_msa])
#Make prediction on scrambled sequence samples
collapse_input_layer = Lambda(lambda x: x[:, 0, :, :], output_shape=(seq_length, 20))
create_msa_layer = Lambda(lambda x: K.concatenate([x, K.zeros((x.shape[0], x.shape[1], x.shape[2], 1))], axis=-1), output_shape=(1, seq_length, 21))
collapsed_in = collapse_input_layer(scrambled_sample_deflated)
collapsed_in_msa = create_msa_layer(scrambled_sample_deflated)
p_dist_scrambled_deflated, p_theta_scrambled_deflated, p_phi_scrambled_deflated, p_omega_scrambled_deflated = predictor([collapsed_in, collapsed_in_msa])
#Define layer to inflate sample axis
inflate_dist_target = Lambda(lambda x: K.expand_dims(x, axis=1), name='inflate_dist_target')
inflate_theta_target = Lambda(lambda x: K.expand_dims(x, axis=1), name='inflate_theta_target')
inflate_phi_target = Lambda(lambda x: K.expand_dims(x, axis=1), name='inflate_phi_target')
inflate_omega_target = Lambda(lambda x: K.expand_dims(x, axis=1), name='inflate_omega_target')
inflate_dist_prediction = Lambda(lambda x: K.reshape(x, (batch_size, n_samples, seq_length, seq_length, 37)), name='inflate_dist_prediction')
inflate_theta_prediction = Lambda(lambda x: K.reshape(x, (batch_size, n_samples, seq_length, seq_length, 25)), name='inflate_theta_prediction')
inflate_phi_prediction = Lambda(lambda x: K.reshape(x, (batch_size, n_samples, seq_length, seq_length, 13)), name='inflate_phi_prediction')
inflate_omega_prediction = Lambda(lambda x: K.reshape(x, (batch_size, n_samples, seq_length, seq_length, 25)), name='inflate_omega_prediction')
#Inflate sample axis
p_dist_non_scrambled = inflate_dist_target(p_dist_non_scrambled_deflated)
p_theta_non_scrambled = inflate_theta_target(p_theta_non_scrambled_deflated)
p_phi_non_scrambled = inflate_phi_target(p_phi_non_scrambled_deflated)
p_omega_non_scrambled = inflate_omega_target(p_omega_non_scrambled_deflated)
p_dist_scrambled = inflate_dist_prediction(p_dist_scrambled_deflated)
p_theta_scrambled = inflate_theta_prediction(p_theta_scrambled_deflated)
p_phi_scrambled = inflate_phi_prediction(p_phi_scrambled_deflated)
p_omega_scrambled = inflate_omega_prediction(p_omega_scrambled_deflated)
#Cost function parameters
pwm_start = 0
pwm_end = seq_length
target_bits = 1.0
#NLL cost
nll_loss_func = _get_kl_divergence_keras
#Conservation cost
conservation_loss_func = get_target_entropy_sme_masked(pwm_start=pwm_start, pwm_end=pwm_end, pwm_background=x_mean, target_bits=1.8)
#Entropy cost
entropy_loss_func = get_target_entropy_sme_masked(pwm_start=pwm_start, pwm_end=pwm_end, pwm_background=x_mean, target_bits=target_bits)
#entropy_loss_func = get_margin_entropy_ame_masked(pwm_start=pwm_start, pwm_end=pwm_end, pwm_background=x_mean, max_bits=target_bits)
#Define annealing coefficient
anneal_coeff = K.variable(0.0)
#Execute NLL cost
nll_loss = Lambda(lambda x: nll_loss_func(x[0], x[1], x[2], x[3], x[4], x[5], x[6], x[7]), name='nll')([
p_dist_non_scrambled,
p_theta_non_scrambled,
p_phi_non_scrambled,
p_omega_non_scrambled,
p_dist_scrambled,
p_theta_scrambled,
p_phi_scrambled,
p_omega_scrambled
])
#Execute conservation cost
conservation_loss = Lambda(lambda x: anneal_coeff * conservation_loss_func(x[0], x[1]), name='conservation')([scrambled_pwm, pwm_mask])
#Execute entropy cost
entropy_loss = Lambda(lambda x: (1. - anneal_coeff) * entropy_loss_func(x[0], x[1]), name='entropy')([scrambled_pwm, pwm_mask])
loss_model = Model(
[ae_scrambler_class, ae_scrambler_input],
[nll_loss, conservation_loss, entropy_loss]
)
#Initialize Sequence Templates and Masks
initialize_sequence_templates(loss_model, encoder, [sequence_template], [x_mean_logits])
opt = AdamAccumulate(lr=0.01, beta_1=0.5, beta_2=0.9, accum_iters=2)
loss_model.compile(
optimizer=opt,
loss={
'nll' : get_weighted_loss(loss_coeff=1.0),
'conservation' : get_weighted_loss(loss_coeff=1.0),
'entropy' : get_weighted_loss(loss_coeff=10.0)
}
)
scrambler_model.summary()
loss_model.summary()
#Training configuration
#Define number of training epochs
n_iters = 500 * 2
#Define experiment suffix (optional)
experiment_suffix = "_kl_divergence_per_example_gradacc_2_native_bg"
model_name = "autoscrambler_rosetta_" + dataset_name + "_n_iters_" + str(n_iters) + "_n_samples_" + str(n_samples) + "_target_bits_" + str(target_bits).replace(".", "") + experiment_suffix
print("Model save name = " + model_name)
#(Re-)Initialize scrambler mask
def reset_generator(scrambler_model, verbose=False) :
session = K.get_session()
for layer in scrambler_model.layers :
if 'scrambler' in layer.name :
for v in layer.__dict__:
v_arg = getattr(layer, v)
if hasattr(v_arg,'initializer'):
initializer_method = getattr(v_arg, 'initializer')
initializer_method.run(session=session)
if verbose :
print('reinitializing layer {}.{}'.format(layer.name, v))
#(Re-)Initialize Optimizer
def reset_optimizer(opt, verbose=False) :
session = K.get_session()
for v in opt.__dict__:
v_arg = getattr(opt, v)
if hasattr(v_arg,'initializer'):
initializer_method = getattr(v_arg, 'initializer')
initializer_method.run(session=session)
if verbose :
print('reinitializing optimizer parameter {}'.format(v))
#Reset mask
reset_generator(scrambler_model, verbose=True)
reset_generator(loss_model, verbose=True)
reset_optimizer(opt, verbose=True)
#Execute training procedure
class LossHistory(keras.callbacks.Callback) :
def on_train_begin(self, logs={}):
self.nll_losses = []
self.entropy_losses = []
self.conservation_losses = []
def on_batch_end(self, batch, logs={}) :
self.nll_losses.append(logs.get('nll_loss'))
self.entropy_losses.append(logs.get('entropy_loss'))
self.conservation_losses.append(logs.get('conservation_loss'))
s_test = np.zeros((1, 1))
pwm_test = []
importance_scores_test = []
train_histories = []
for data_ix in range(x_test.shape[0]) :
if data_ix % 100 == 0 :
print("Optimizing example " + str(data_ix) + "...")
train_history = LossHistory()
# train the autoscrambler
_ = loss_model.fit(
[s_test, x_test[data_ix:data_ix+1]],
[s_test, s_test, s_test],
epochs=1,
steps_per_epoch=n_iters,
callbacks=[train_history]
)
temp_pwm, temp_importance_scores = scrambler_model.predict_on_batch(x=[x_test[data_ix:data_ix+1], s_test])
pwm_test.append(temp_pwm)
importance_scores_test.append(temp_importance_scores)
train_histories.append(train_history)
#Reset mask
reset_generator(scrambler_model)
reset_generator(loss_model)
reset_optimizer(opt)
save_figs = True
def _rolling_average(x, window=1) :
x_avg = []
for j in range(x.shape[0]) :
j_min = max(j - window + 1, 0)
x_avg.append(np.mean(x[j_min:j+1]))
return np.array(x_avg)
train_history = train_histories[0]
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(2 * 4, 3))
n_epochs_actual = len(train_history.nll_losses)
nll_rolling_window = 50
entropy_rolling_window = 1
ax1.plot(np.arange(1, n_epochs_actual + 1), _rolling_average(np.array(train_history.nll_losses), window=nll_rolling_window), linewidth=3, color='green')
plt.sca(ax1)
plt.xlabel("Epochs", fontsize=14)
plt.ylabel("NLL", fontsize=14)
plt.xlim(1, n_epochs_actual)
plt.xticks([1, n_epochs_actual], [1, n_epochs_actual], fontsize=12)
plt.yticks(fontsize=12)
ax2.plot(np.arange(1, n_epochs_actual + 1), _rolling_average(np.array(train_history.entropy_losses), window=entropy_rolling_window), linewidth=3, color='orange')
plt.sca(ax2)
plt.xlabel("Epochs", fontsize=14)
plt.ylabel("Entropy Loss", fontsize=14)
plt.xlim(1, n_epochs_actual)
plt.xticks([1, n_epochs_actual], [1, n_epochs_actual], fontsize=12)
plt.yticks(fontsize=12)
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_losses.png', transparent=True, dpi=150)
plt.savefig(model_name + '_losses.eps')
plt.show()
#Visualize a reconstructed sequence pattern
save_figs = True
for plot_i in range(0, 1) :
print("Test sequence " + str(plot_i) + ":")
subtracted_logits_test = (2. * np.array(x_test[plot_i:plot_i+1], dtype=np.float64) - 1.) * np.maximum(np.array(importance_scores_test[plot_i], dtype=np.float64), 1e-7)
subtracted_pwm_test = np.exp(subtracted_logits_test) / np.expand_dims(np.sum(np.exp(subtracted_logits_test), axis=-1), axis=-1)
plot_protein_logo_scrambler(residue_map, x_test[plot_i, 0, :, :], sequence_template=sequence_template, figsize=(12, 1), plot_start=0, plot_end=seq_length, save_figs=save_figs, fig_name=model_name + "_orig_sequence")
plot_protein_logo_scrambler(residue_map, pwm_test[plot_i][0, 0, :, :], sequence_template=sequence_template, figsize=(12, 1), plot_start=0, plot_end=seq_length, save_figs=save_figs, fig_name=model_name + "_scrambled_pwm")
plot_protein_logo_scrambler(residue_map, subtracted_pwm_test[0, 0, :, :], sequence_template=sequence_template, figsize=(12, 1), plot_start=0, plot_end=seq_length, save_figs=save_figs, fig_name=model_name + "_scrambled_pwm_no_bg")
importance_scores = np.concatenate(importance_scores_test, axis=0)
#Visualize importance scores
save_figs = True
f = plt.figure(figsize=(4, 1))
plt.imshow(importance_scores.reshape(1, -1), aspect='auto', cmap="hot", vmin=0, vmax=np.max(importance_scores))
plt.xticks([], [])
plt.yticks([], [])
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_p_vis1.png', transparent=True, dpi=150)
plt.savefig(model_name + '_p_vis1.svg')
plt.savefig(model_name + '_p_vis1.eps')
plt.show()
f = plt.figure(figsize=(4, 4))
p_keras_vals = np.argmax(pd[0, ...], axis=-1)
plt.imshow(np.max(p_keras_vals) - p_keras_vals, cmap="Reds", vmin=0, vmax=np.max(p_keras_vals))
plt.xticks([], [])
plt.yticks([], [])
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_p_vis2.png', transparent=True, dpi=150)
plt.savefig(model_name + '_p_vis2.svg')
plt.savefig(model_name + '_p_vis2.eps')
plt.show()
#Test reconstructive ability on scrambled samples
scrambled_pwm = pwm_test[0][0, 0, :, :]
n_test_samples = 512
nts = np.arange(20)
test_samples = np.zeros((n_test_samples, 1, scrambled_pwm.shape[0], scrambled_pwm.shape[1]))
for sample_ix in range(n_test_samples) :
for j in range(scrambled_pwm.shape[0]) :
rand_nt = np.random.choice(nts, p=scrambled_pwm[j, :])
test_samples[sample_ix, 0, j, rand_nt] = 1.
test_samples_msa = np.concatenate([
test_samples,
np.zeros((test_samples.shape[0], test_samples.shape[1], test_samples.shape[2], 1))
], axis=-1)
#Test predictor on scrambled sequences
pd_scrambled, pt_scrambled, pp_scrambled, po_scrambled = predictor.predict(x=[test_samples[:, 0, :, :], test_samples_msa], batch_size=4)
#Calculate KL-divergences to unscrambled distributions
def _get_kl_divergence_numpy(p_dist, p_theta, p_phi, p_omega, t_dist, t_theta, t_phi, t_omega) :
kl_dist = np.mean(np.sum(t_dist * np.log(t_dist / p_dist), axis=-1), axis=(-2, -1))
kl_theta = np.mean(np.sum(t_theta * np.log(t_theta / p_theta), axis=-1), axis=(-2, -1))
kl_phi = np.mean(np.sum(t_phi * np.log(t_phi / p_phi), axis=-1), axis=(-2, -1))
kl_omega = np.mean(np.sum(t_omega * np.log(t_omega / p_omega), axis=-1), axis=(-2, -1))
return kl_dist + kl_theta + kl_phi + kl_omega
save_figs = True
kl_divs = _get_kl_divergence_numpy(pd_scrambled, pt_scrambled, pp_scrambled, po_scrambled, pd, pt, pp, po)
print("Mean KL Div = " + str(round(np.mean(kl_divs), 3)))
print("Median KL Div = " + str(round(np.median(kl_divs), 3)))
kl_x_min = 0.0
kl_x_max = 9.0#3.0
n_bins = 50
kl_divs_histo, bin_edges = np.histogram(kl_divs, bins=n_bins, range=[kl_x_min, kl_x_max], density=True)
f = plt.figure(figsize=(6, 4))
plt.bar(bin_edges[:-1], kl_divs_histo, width=(kl_x_max - kl_x_min) / n_bins, edgecolor='black', color='orange', linewidth=2)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.xlabel("KL Divergence", fontsize=12)
plt.ylabel("Sample Density", fontsize=12)
plt.xlim(kl_x_min, kl_x_max)
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_kl_hist.png', transparent=True, dpi=150)
plt.savefig(model_name + '_kl_hist.eps')
plt.show()
#Compute mean distributions for plotting
pd_scrambled_mean = np.mean(pd_scrambled, axis=0, keepdims=True)
pt_scrambled_mean = np.mean(pt_scrambled, axis=0, keepdims=True)
pp_scrambled_mean = np.mean(pp_scrambled, axis=0, keepdims=True)
po_scrambled_mean = np.mean(po_scrambled, axis=0, keepdims=True)
f, ax_list = plt.subplots(1, 4, figsize=(12, 3))
p_list = [
[pd_scrambled_mean, 'distance', ax_list[0]],
[pt_scrambled_mean, 'theta', ax_list[1]],
[pp_scrambled_mean, 'phi', ax_list[2]],
[po_scrambled_mean, 'omega', ax_list[3]]
]
for p_keras, p_name, p_ax in p_list :
p_keras_vals = np.argmax(p_keras[0, ...], axis=-1)
p_ax.imshow(np.max(p_keras_vals) - p_keras_vals, cmap="Reds", vmin=0, vmax=np.max(p_keras_vals))
p_ax.set_title(p_name, fontsize=14)
p_ax.set_xlabel("Position", fontsize=14)
p_ax.set_ylabel("Position", fontsize=14)
plt.sca(p_ax)
plt.xticks([0, p_keras_vals.shape[0]], [0, p_keras_vals.shape[0]], fontsize=14)
plt.yticks([0, p_keras_vals.shape[1]], [0, p_keras_vals.shape[1]], fontsize=14)
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_p_mean_distribs.png', transparent=True, dpi=150)
plt.savefig(model_name + '_p_mean_distribs.eps')
plt.show()
kl_divs_argsort = np.argsort(kl_divs)[::-1]
qt = 0.95
qt_ix = kl_divs_argsort[int(qt * kl_divs_argsort.shape[0])]
pd_scrambled_qt = pd_scrambled[qt_ix:qt_ix+1]
pt_scrambled_qt = pt_scrambled[qt_ix:qt_ix+1]
pp_scrambled_qt = pp_scrambled[qt_ix:qt_ix+1]
po_scrambled_qt = po_scrambled[qt_ix:qt_ix+1]
f, ax_list = plt.subplots(1, 4, figsize=(12, 3))
p_list = [
[pd_scrambled_qt, 'distance', ax_list[0]],
[pt_scrambled_qt, 'theta', ax_list[1]],
[pp_scrambled_qt, 'phi', ax_list[2]],
[po_scrambled_qt, 'omega', ax_list[3]]
]
for p_keras, p_name, p_ax in p_list :
p_keras_vals = np.argmax(p_keras[0, ...], axis=-1)
p_ax.imshow(np.max(p_keras_vals) - p_keras_vals, cmap="Reds", vmin=0, vmax=np.max(p_keras_vals))
p_ax.set_title(p_name, fontsize=14)
p_ax.set_xlabel("Position", fontsize=14)
p_ax.set_ylabel("Position", fontsize=14)
plt.sca(p_ax)
plt.xticks([0, p_keras_vals.shape[0]], [0, p_keras_vals.shape[0]], fontsize=14)
plt.yticks([0, p_keras_vals.shape[1]], [0, p_keras_vals.shape[1]], fontsize=14)
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_p_qt_' + str(qt).replace(".", "") + '_distribs.png', transparent=True, dpi=150)
plt.savefig(model_name + '_p_qt_' + str(qt).replace(".", "") + '_distribs.eps')
plt.show()
kl_divs_argsort = np.argsort(kl_divs)[::-1]
qt = 0.99
qt_ix = kl_divs_argsort[int(qt * kl_divs_argsort.shape[0])]
pd_scrambled_qt = pd_scrambled[qt_ix:qt_ix+1]
pt_scrambled_qt = pt_scrambled[qt_ix:qt_ix+1]
pp_scrambled_qt = pp_scrambled[qt_ix:qt_ix+1]
po_scrambled_qt = po_scrambled[qt_ix:qt_ix+1]
f, ax_list = plt.subplots(1, 4, figsize=(12, 3))
p_list = [
[pd_scrambled_qt, 'distance', ax_list[0]],
[pt_scrambled_qt, 'theta', ax_list[1]],
[pp_scrambled_qt, 'phi', ax_list[2]],
[po_scrambled_qt, 'omega', ax_list[3]]
]
for p_keras, p_name, p_ax in p_list :
p_keras_vals = np.argmax(p_keras[0, ...], axis=-1)
p_ax.imshow(np.max(p_keras_vals) - p_keras_vals, cmap="Reds", vmin=0, vmax=np.max(p_keras_vals))
p_ax.set_title(p_name, fontsize=14)
p_ax.set_xlabel("Position", fontsize=14)
p_ax.set_ylabel("Position", fontsize=14)
plt.sca(p_ax)
plt.xticks([0, p_keras_vals.shape[0]], [0, p_keras_vals.shape[0]], fontsize=14)
plt.yticks([0, p_keras_vals.shape[1]], [0, p_keras_vals.shape[1]], fontsize=14)
plt.tight_layout()
if save_figs :
plt.savefig(model_name + '_p_qt_' + str(qt).replace(".", "") + '_distribs.png', transparent=True, dpi=150)
plt.savefig(model_name + '_p_qt_' + str(qt).replace(".", "") + '_distribs.eps')
plt.show()
#Save importance scores
np.save(model_name + "_importance_scores", importance_scores)
```
| github_jupyter |
```
import os
from pygromos.files.gromos_system.ff.forcefield_system import forcefield_system
from pygromos.files.gromos_system.gromos_system import Gromos_System
from pygromos.simulations.hvap_calculation.hvap_calculation import Hvap_calculation
from pygromos.data.simulation_parameters_templates import template_sd
pygro_env={'SHELL': '/bin/bash', 'LIBGL_ALWAYS_INDIRECT': '1', 'CONDA_EXE': '/home/mlehner/anaconda3/bin/conda', '_CE_M': '', 'WSL_DISTRO_NAME': 'Ubuntu-20.04', 'NAME': 'MarcSurface', 'GSETTINGS_SCHEMA_DIR': '/home/mlehner/anaconda3/envs/pygro/share/glib-2.0/schemas', 'LOGNAME': 'mlehner', 'CONDA_PREFIX': '/home/mlehner/anaconda3/envs/pygro', 'GSETTINGS_SCHEMA_DIR_CONDA_BACKUP': '', 'HOME': '/home/mlehner', 'LANG': 'C.UTF-8', 'WSL_INTEROP': '/run/WSL/451_interop', 'CONDA_PROMPT_MODIFIER': '(pygro) ', 'PERL5LIB': '/home/mlehner/anaconda3/envs/pygro/lib/perl/mm_pbsa', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', 'TERM': 'xterm-256color', '_CE_CONDA': '', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'USER': 'mlehner', 'CONDA_SHLVL': '2', 'AMBERHOME': '/home/mlehner/anaconda3/envs/pygro', 'DISPLAY': '172.21.240.1:0', 'SHLVL': '1', 'CONDA_PYTHON_EXE': '/home/mlehner/anaconda3/bin/python', 'CONDA_DEFAULT_ENV': 'pygro', 'WSLENV': '', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'PATH': '/home/mlehner/anaconda3/envs/pygro/bin:/home/mlehner/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/mnt/c/Program Files/WindowsApps/CanonicalGroupLimited.Ubuntu20.04onWindows_2004.2021.222.0_x64__79rhkp1fndgsc:/mnt/c/WINDOWS/system32:/mnt/c/WINDOWS:/mnt/c/WINDOWS/System32/Wbem:/mnt/c/WINDOWS/System32/WindowsPowerShell/v1.0:/mnt/c/WINDOWS/System32/OpenSSH:/mnt/c/Program Files/NVIDIA Corporation/NVIDIA NvDLISR:/mnt/c/Program Files (x86)/NVIDIA Corporation/PhysX/Common:/mnt/c/Program Files/Wolfram Research/WolframScript:/mnt/c/Users/thier/AppData/Local/Microsoft/WindowsApps:/mnt/c/Users/thier/AppData/Local/Programs/Microsoft VS Code/bin:/mnt/c/Users/thier/AppData/Local/GitHubDesktop/bin:/snap/bin:/usr/local/gromacs/bin/GMXRC', 'HOSTTYPE': 'x86_64', 'CONDA_PREFIX_1': '/home/mlehner/anaconda3', '_': '/home/mlehner/anaconda3/envs/pygro/bin/python3'}
work_dir=os.getcwd()+"/example_files/Hvap_files/"
gromosXX_path=None #"/home/mlehner/gromosXX/gromosXX/BUILD/program/"
gromosPP_path=None# "/home/mlehner/gromosPlsPls/gromos++/BUILD/programs/"
ff = forcefield_system(name="54A7")
ff.mol_name = "H2O"
groSys = Gromos_System(work_folder=work_dir+"init/", system_name="Hvap_test", in_smiles="O", auto_convert=True, Forcefield=ff, in_imd_path=template_sd, in_gromosPP_bin_dir=gromosPP_path, in_gromosXX_bin_dir=gromosXX_path)
hvap_sys=Hvap_calculation(input_system=groSys, work_folder=work_dir+"hvap", forcefield=ff, system_name="test")
hvap_sys.submissonSystem._enviroment = pygro_env
hvap_sys.create_liq()
hvap_sys.run_gas()
hvap_sys.run_liq()
hvap_sys.calc_hvap()
```
| github_jupyter |
# Diseño de software para cómputo científico
----
## Unidad 3: HDF5
### Agenda de la Unidad 3
---
#### Clase 1
- Lectura y escritura de archivos.
- Persistencia de binarios en Python (pickle).
- Archivos INI/CFG, CSV, JSON, XML y YAML
#### Clase 2
- Bases de datos relacionales y SQL.
### Clase 3
- Breve repaso de bases de datos No relacionales.
- **Formato HDF5.**
## Hierarchical Data Format 5 (HDF5)
- El formato HDF5 está diseñado para abordar algunas de las limitaciones de la biblioteca HDF4 y para satisfacer los requisitos actuales y anticipados de los sistemas y aplicaciones modernos.
- HDF5 simplifica la estructura de archivos para incluir solo dos tipos principales de objetos:
- **Datasets**, que son matrices multidimensionales de tipo homogéneo
- **Groups**, que son estructuras de contenedor que pueden contener conjuntos de datos y otros grupos
- Es formato de datos verdaderamente jerárquico similar a un sistema de archivos.
- Se puede acceder a los recursos en un archivo HDF5 utilizando la sintaxis '/ruta/a/recurso' similar a POSIX. - Soporta metadatos.
- Las API de almacenamiento más complejas que representan imágenes y tablas se pueden construir utilizando conjuntos de datos, grupos y atributos.
## HDF5 - Críticas
- Es monolítico y su especificación es muy larga
- HDF5 no exige el uso de UTF-8, por lo que las aplicaciones del cliente pueden esperar ASCII en la mayoría de los lugares.
- Los datos de un dataset no se pueden liberar del disco sin generar una copia de archivo utilizando una herramienta externa (*h5repack*)
## HDF5: un sistema de archivos en un archivo

Trabajar con grupos y miembros de grupos es similar a trabajar con directorios y archivos en UNIX.
- `/` grupo raíz (cada archivo HDF5 tiene un grupo raíz)
- `/foo` miembro del grupo raíz llamado foo
- `/foo/bar` miembro del grupo foo llamado bar
## HDF5 en el stack científico de Python

## Pandas + HDF5
```
!rm hdf5/ -rf
!mkdir hdf5
import numpy as np
import pandas as pd # pip install tables
hdf = pd.HDFStore('hdf5/storage.h5')
hdf.info()
df = pd.DataFrame(np.random.rand(5,3), columns=('A','B','C'))# put the dataset in the storage
hdf.put('d1', df, format='table', data_columns=True)
hdf['d1'].shape
hdf.append('d1', pd.DataFrame(np.random.rand(5,3),
columns=('A','B','C')),
format='table', data_columns=True)
hdf.close() # closes the file
```
## Pandas + HDF5
Hay muchas formas de abrir un almacenamiento hdf5, podríamos usar nuevamente el constructor de la clase `HDFStorage`, pero la función `read_hdf()` también nos permite consultar los datos:
```
# this query selects the columns A and B# where the values of A is greather than 0.5
df = pd.read_hdf('hdf5/storage.h5','d1',where=['A>.5'], columns=['A','B'])
df
```
## Pandas + HDF5
- En este punto, tenemos un almacenamiento que contiene un único conjunto de datos.
- La estructura del almacenamiento se puede organizar mediante grupos.
- En el siguiente ejemplo, agregamos tres conjuntos de datos diferentes al archivo hdf5, dos en el mismo grupo y otro en uno diferente:
```
hdf = pd.HDFStore('hdf5/storage.h5')
hdf.put('tables/t1', pd.DataFrame(np.random.rand(20,5)))
hdf.put('tables/t2', pd.DataFrame(np.random.rand(10,3)))
hdf.put('new_tables/t1', pd.DataFrame(np.random.rand(15,2)), format="fixed")
print(hdf.info())
hdf.close()
```
## HDF5 Command line tools
Re comendable instalar
```bash
$ sudo apt install hdf5-tools
...
$
h52gif h5debug h5dump h5jam h5mkgrp h5redeploy h5repart h5unjam
h5copy h5diff h5import h5ls h5perf_serial h5repack h5stat
```
Documentación: https://support.hdfgroup.org/products/hdf5_tools/#h5dist
## HDF5 Command line tools
### List content
```
!h5ls hdf5/storage.h5/d1/_i_table
```
### Copy
```
!h5copy -i hdf5/storage.h5 -s tables/t1 -o hdf5/out.h5 -d copy
!h5ls hdf5/out.h5
```
## HDF5 Command line tools
### Stats
```
!h5stat hdf5/storage.h5
```
## GUI tool
- La mejor herramienta es vitables (`pip install ViTables`).
- Instalenla con la misma version de h5py y pytables que usaron para crear los archivos.
```
!vitables hdf5/storage.h5
```
## Referencias
- https://github.com/jackdbd/hdf5-pydata-munich"
- https://en.wikipedia.org/wiki/Hierarchical_Data_Format
- https://dzone.com/articles/quick-hdf5-pandas
| github_jupyter |
```
%load_ext autoreload
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
from sklearn.utils import shuffle
from torchsample.initializers import Uniform
from torchsample.modules import ModuleTrainer
from torchsample.metrics import CategoricalAccuracy
%aimport torchsample.modules
%matplotlib inline
use_cuda = False
batch_size = 64
```
## Setup
We're going to download the collected works of Nietzsche to use as our data for this class.
```
from keras.utils.data_utils import get_file
path = get_file('nietzsche.txt', origin="https://s3.amazonaws.com/text-datasets/nietzsche.txt")
text = open(path).read()
print('corpus length:', len(text))
chars = sorted(list(set(text)))
chars.insert(0, "\0")
vocab_size = len(chars)
print('total chars:', vocab_size)
```
Sometimes it's useful to have a zero value in the dataset, e.g. for padding
```
''.join(chars)
```
Map from chars to indices and back again
```
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
```
idx will be the data we use from now own - it simply converts all the characters to their index (based on the mapping above)
```
idx = [char_indices[c] for c in text]
idx[:10]
''.join(indices_char[i] for i in idx[:70])
```
## 3 char model
### Create inputs
Create a list of every 4th character, starting at the 0th, 1st, 2nd, then 3rd characters
```
cs=3
c1_dat = [idx[i] for i in range(0, len(idx)-1-cs, cs)]
c2_dat = [idx[i+1] for i in range(0, len(idx)-1-cs, cs)]
c3_dat = [idx[i+2] for i in range(0, len(idx)-1-cs, cs)]
c4_dat = [idx[i+3] for i in range(0, len(idx)-1-cs, cs)]
x1 = np.stack(c1_dat)
x2 = np.stack(c2_dat)
x3 = np.stack(c3_dat)
x3.shape
```
Our output
```
y = np.stack(c4_dat)
y.shape
```
The first 4 inputs and outputs
```
x1[:4], x2[:4], x3[:4]
y[:4]
x1.shape, y.shape
```
### Create and train model
The number of latent factors to create (i.e. the size of the embedding matrix). Pick a size for our hidden state
```
n_fac = 42
n_hidden = 256
import torch.nn as nn
import torch.nn.functional as F
seq_len = 3
def tensor(from_int):
return torch.from_numpy(np.array(from_int)).long()
class SimpleRnn3Chars(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(vocab_size, n_fac)
self.dense_in_lin = nn.Linear(n_fac, n_hidden)
self.dense_hidden_lin = nn.Linear(n_hidden, n_hidden)
self.dense_out = nn.Linear(n_hidden, vocab_size)
self.init()
# print(self.embedding(Variable(tensor([10]))))
# print(self.dense_in_lin.bias)
def dense_in(self, x):
x = x.view(x.size(0), -1)
x = self.dense_in_lin(x)
x = F.relu(x, True)
return x
def dense_hidden(self, x):
x = self.dense_hidden_lin(x)
x = F.tanh(x)
return x
def forward(self, c1, c2, c3):
c1_in = self.embedding(c1) # x => torch.Size([B, 3, n_fac])
c2_in = self.embedding(c2)
c3_in = self.embedding(c3)
c1_hidden = self.dense_in(c1_in)
c2_dense = self.dense_in(c2_in)
hidden_2 = self.dense_hidden(c1_hidden)
c2_hidden = c2_dense + hidden_2
c3_dense = self.dense_in(c3_in)
hidden_3 = self.dense_hidden(c2_hidden)
c3_hidden = c3_dense + hidden_3
c4_out = self.dense_out(c3_hidden)
return c4_out
def init(self):
torch.nn.init.uniform(self.embedding.weight, a=-0.05, b=0.05)
torch.nn.init.xavier_uniform(self.dense_in_lin.weight)
torch.nn.init.constant(self.dense_in_lin.bias, val=0.0)
torch.nn.init.eye(self.dense_hidden_lin.weight)
torch.nn.init.constant(self.dense_hidden_lin.bias, val=0.0)
torch.nn.init.xavier_uniform(self.dense_out.weight)
torch.nn.init.constant(self.dense_out.bias, val=0.0)
%autoreload 2
criterion = nn.CrossEntropyLoss()
model = SimpleRnn3Chars()
if(use_cuda):
model.cuda()
criterion.cuda()
trainer = ModuleTrainer(model)
trainer.set_optimizer(optim.Adam, lr=1e-3)
trainer.set_loss(criterion)
model
trainer.fit([tensor(x1), tensor(x2), tensor(x3)], tensor(y), nb_epoch=4, batch_size=batch_size, shuffle=True)
```
### Test model
```
def get_next(inp):
idxs = [char_indices[c] for c in inp]
arrs = [tensor([i]) for i in idxs]
p = trainer.predict(arrs)
# torch doesn't have an argmax function. See https://discuss.pytorch.org/t/argmax-with-pytorch/1528
v, i = torch.max(p, 1) # i is the result Tensor with the index locations of the maximum values
i = torch.max(i.data) # find any index (they are all max)
return chars[i]
get_next('phi')
get_next(' th')
get_next(' an')
```
## Our first RNN!
### Create inputs
This is the size of our unrolled RNN.
```
cs=8
```
For each of 0 through 7, create a list of every 8th character with that starting point. These will be the 8 inputs to out model.
```
c_in_dat = [[idx[i+n] for i in range(0, len(idx)-1-cs, cs)]
for n in range(cs)]
len(c_in_dat), len(c_in_dat[0])
```
Then create a list of the next character in each of these series. This will be the labels for our model.
```
c_out_dat = [idx[i+cs] for i in range(0, len(idx)-1-cs, cs)]
xs = [np.stack(c) for c in c_in_dat]
len(xs), xs[0].shape
y = np.stack(c_out_dat)
```
So each column below is one series of 8 characters from the text.
```
[xs[n][:cs] for n in range(cs)]
```
...and this is the next character after each sequence.
```
y[:cs]
```
### Create and train model
```
import torch.nn as nn
import torch.nn.functional as F
def each_tensor(items):
return [tensor(item) for item in items]
class RnnMultiChar(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(vocab_size, n_fac)
self.dense_in_lin = nn.Linear(n_fac, n_hidden)
self.dense_hidden_lin = nn.Linear(n_hidden, n_hidden)
self.dense_out = nn.Linear(n_hidden, vocab_size)
self.init()
def dense_in(self, x):
x = x.view(x.size(0), -1)
x = self.dense_in_lin(x)
x = F.relu(x, True)
return x
def dense_hidden(self, x):
x = self.dense_hidden_lin(x)
x = F.relu(x)
return x
def forward(self, *c):
c_in = self.embedding(c[0])
hidden = self.dense_in(c_in)
for i in range(1,cs):
c_in = self.embedding(c[i]) # x => torch.Size([B, 1, n_fac])
c_dense = self.dense_in(c_in)
hidden = self.dense_hidden(hidden)
hidden.add_(c_dense)
c_out = self.dense_out(hidden)
return c_out
def init(self):
torch.nn.init.uniform(self.embedding.weight, a=-0.05, b=0.05)
torch.nn.init.xavier_uniform(self.dense_in_lin.weight)
torch.nn.init.constant(self.dense_in_lin.bias, val=0.0)
torch.nn.init.eye(self.dense_hidden_lin.weight)
torch.nn.init.constant(self.dense_hidden_lin.bias, val=0.0)
torch.nn.init.xavier_uniform(self.dense_out.weight)
torch.nn.init.constant(self.dense_out.bias, val=0.0)
%autoreload 2
criterion = nn.CrossEntropyLoss()
model = RnnMultiChar()
if(use_cuda):
model.cuda()
criterion.cuda()
trainer = ModuleTrainer(model)
trainer.set_optimizer(optim.Adam, lr=1e-3)
trainer.set_loss(criterion)
model
trainer.fit(each_tensor(xs), tensor(y), nb_epoch=4, batch_size=batch_size, shuffle=True)
```
### Test model
```
get_next('for ther')
get_next('part of ')
get_next('queens a')
```
## Our first RNN with PyTorch!
The SimpleRNN layer does not exist in PyTorch (yet?)
```
n_hidden, n_fac, cs, vocab_size
```
This is nearly exactly equivalent to the RNN we built ourselves in the previous section.
```
import torch.nn as nn
import torch.nn.functional as F
class RnnMultiCharPytorch(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(vocab_size, n_fac)
self.rnn = nn.RNNCell(input_size=n_fac, hidden_size=n_hidden, nonlinearity='relu')
self.dense_out = nn.Linear(n_hidden, vocab_size)
self.init()
def forward(self, *c):
batch_size = c[0].size(0)
hidden = Variable(torch.zeros(batch_size, n_hidden))
# F.relu(F.linear(input, w_ih, b_ih)
for ci in c:
c_in = self.embedding(ci)
c_in = c_in.view(c_in.size(0), -1) # torch.Size([64, 42])
hidden = self.rnn(c_in, hidden)
c_out = self.dense_out(hidden)
return c_out
def init(self):
torch.nn.init.uniform(self.embedding.weight, a=-0.05, b=0.05)
torch.nn.init.xavier_uniform(self.rnn.weight_ih)
torch.nn.init.constant(self.rnn.bias_ih, val=0.0)
torch.nn.init.eye(self.rnn.weight_hh)
torch.nn.init.constant(self.rnn.bias_hh, val=0.0)
torch.nn.init.xavier_uniform(self.dense_out.weight)
torch.nn.init.constant(self.dense_out.bias, val=0.0)
%autoreload 2
criterion = nn.CrossEntropyLoss()
model = RnnMultiCharPytorch()
if(use_cuda):
model.cuda()
criterion.cuda()
trainer = ModuleTrainer(model)
trainer.set_optimizer(optim.Adam, lr=1e-3)
trainer.set_loss(criterion)
model
trainer.fit(each_tensor(xs), tensor(y), nb_epoch=4, batch_size=batch_size, shuffle=True)
get_next('for ther')
get_next('part of ')
get_next('queens a')
```
## Returning sequences
## Create inputs
To use a sequence model, we can leave our input unchanged - but we have to change our output to a sequence (of course!)
Here, c_out_dat is identical to c_in_dat, but moved across 1 character.
```
#c_in_dat = [[idx[i+n] for i in range(0, len(idx)-1-cs, cs)]
# for n in range(cs)]
c_out_dat = [[idx[i+n] for i in range(1, len(idx)-cs, cs)]
for n in range(cs)]
ys = [np.stack(c) for c in c_out_dat]
len(ys), ys[0].shape
```
Reading down each column shows one set of inputs and outputs.
```
[xs[n][:cs] for n in range(cs)]
len(xs), xs[0].shape
[ys[n][:cs] for n in range(cs)]
len(ys), ys[0].shape
```
### Create and train model
```
import torch.nn as nn
import torch.nn.functional as F
class RnnMultiOutput(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(vocab_size, n_fac)
self.dense_in_lin = nn.Linear(n_fac, n_hidden)
self.dense_hidden_lin = nn.Linear(n_hidden, n_hidden)
self.dense_out = nn.Linear(n_hidden, vocab_size)
self.init()
def dense_in(self, x):
x = x.view(x.size(0), -1)
x = self.dense_in_lin(x)
x = F.relu(x, True)
return x
def dense_hidden(self, x):
x = self.dense_hidden_lin(x)
x = F.relu(x)
return x
def forward(self, *c):
c_in = self.embedding(c[0])
hidden = self.dense_in(c_in)
out = [self.dense_out(hidden)]
for i in range(1,cs):
c_in = self.embedding(c[i]) # x => torch.Size([B, 1, n_fac])
c_dense = self.dense_in(c_in)
hidden = self.dense_hidden(hidden)
hidden.add_(c_dense)
out.append(self.dense_out(hidden))
return out
def init(self):
torch.nn.init.uniform(self.embedding.weight, a=-0.05, b=0.05)
torch.nn.init.xavier_uniform(self.dense_in_lin.weight)
torch.nn.init.constant(self.dense_in_lin.bias, val=0.0)
torch.nn.init.eye(self.dense_hidden_lin.weight)
torch.nn.init.constant(self.dense_hidden_lin.bias, val=0.0)
torch.nn.init.xavier_uniform(self.dense_out.weight)
torch.nn.init.constant(self.dense_out.bias, val=0.0)
%autoreload 2
criterion = nn.CrossEntropyLoss()
model = RnnMultiOutput()
if(use_cuda):
model.cuda()
criterion.cuda()
trainer = ModuleTrainer(model)
trainer.set_optimizer(optim.Adam, lr=1e-3)
trainer.set_loss(criterion)
# Bug in torchsample?
trainer._has_multiple_loss_fns = False
model
# TODO print each loss separately
trainer.fit(each_tensor(xs), each_tensor(ys), nb_epoch=4, batch_size=batch_size, shuffle=True)
```
### Test model
```
%autoreload 2
def char_argmax(p):
# print(p.size())
v, i = torch.max(p, 0) # i is the result Tensor with the index locations of the maximum values
i = torch.max(i.data) # find any index (they are all max)
return chars[i]
def get_nexts_multiple(inp):
idxs = [char_indices[c] for c in inp]
arrs = [tensor([i]) for i in idxs]
ps = trainer.predict(arrs)
print(list(inp))
return [char_argmax(p[0]) for p in ps]
get_nexts_multiple(' this is')
get_nexts_multiple(' part of')
```
## Sequence model with PyTorch
```
n_hidden, n_fac, cs, vocab_size
```
To convert our previous PyTorch model into a sequence model, simply return multiple outputs instead of a single one
```
import torch.nn as nn
import torch.nn.functional as F
class RnnCellMultiOutput(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(vocab_size, n_fac)
self.rnn = nn.RNNCell(input_size=n_fac, hidden_size=n_hidden, nonlinearity='relu')
self.dense_out = nn.Linear(n_hidden, vocab_size)
self.init()
def forward(self, *c):
batch_size = c[0].size(0)
hidden = Variable(torch.zeros(batch_size, n_hidden))
out = []
for ci in c:
c_in = self.embedding(ci)
c_in = c_in.view(c_in.size(0), -1)
hidden = self.rnn(c_in, hidden)
out.append(self.dense_out(hidden))
return out
def init(self):
torch.nn.init.uniform(self.embedding.weight, a=-0.05, b=0.05)
torch.nn.init.xavier_uniform(self.rnn.weight_ih)
torch.nn.init.constant(self.rnn.bias_ih, val=0.0)
torch.nn.init.eye(self.rnn.weight_hh)
torch.nn.init.constant(self.rnn.bias_hh, val=0.0)
torch.nn.init.xavier_uniform(self.dense_out.weight)
torch.nn.init.constant(self.dense_out.bias, val=0.0)
%autoreload 2
criterion = nn.CrossEntropyLoss()
model = RnnCellMultiOutput()
if(use_cuda):
model.cuda()
criterion.cuda()
trainer = ModuleTrainer(model)
trainer.set_optimizer(optim.Adam, lr=1e-3)
trainer.set_loss(criterion)
# Bug in torchsample?
trainer._has_multiple_loss_fns = False
model
# TODO print each loss separately
trainer.fit(each_tensor(xs), each_tensor(ys), nb_epoch=4, batch_size=batch_size, shuffle=True)
get_nexts_multiple(' this is')
```
## Stateful model with Pytorch
```
# TODO
```
| github_jupyter |
<img src="images/usm.jpg" width="480" height="240" align="left"/>
# MAT281 - Laboratorio N°02
## Objetivos del laboratorio
* Reforzar conceptos básicos de clasificación.
## Contenidos
* [Problema 01](#p1)
<a id='p1'></a>
## I.- Problema 01
<img src="https://www.xenonstack.com/wp-content/uploads/xenonstack-credit-card-fraud-detection.png" width="360" height="360" align="center"/>
El conjunto de datos se denomina `creditcard.csv` y consta de varias columnas con información acerca del fraude de tarjetas de crédito, en donde la columna **Class** corresponde a: 0 si no es un fraude y 1 si es un fraude.
En este ejercicio se trabajará el problemas de clases desbalancedas. Veamos las primeras cinco filas dle conjunto de datos:
```
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,accuracy_score,recall_score,precision_score,f1_score
from sklearn.dummy import DummyClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
%matplotlib inline
sns.set_palette("deep", desat=.6)
sns.set(rc={'figure.figsize':(11.7,8.27)})
# cargar datos
df = pd.read_csv(os.path.join("data","creditcard.csv"), sep=";")
df.head()
```
Analicemos el total de fraudes respecto a los casos que nos son fraudes:
```
# calcular proporciones
df_count = pd.DataFrame()
df_count["fraude"] =["no","si"]
df_count["total"] = df["Class"].value_counts()
df_count["porcentaje"] = 100*df_count["total"] /df_count["total"] .sum()
df_count
```
Se observa que menos del 1% corresponde a registros frudulentos. La pregunta que surgen son:
* ¿ Cómo deben ser el conjunto de entrenamiento y de testeo?
* ¿ Qué modelos ocupar?
* ¿ Qué métricas ocupar?
Por ejemplo, analicemos el modelos de regresión logística y apliquemos el procedimiento estándar:
```
# datos
y = df.Class
X = df.drop('Class', axis=1)
# split dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=27)
# Creando el modelo
lr = LogisticRegression(solver='liblinear').fit(X_train, y_train)
# predecir
lr_pred = lr.predict(X_test)
# calcular accuracy
accuracy_score(y_test, lr_pred)
```
En general el modelo tiene un **accuracy** del 99,9%, es decir, un podría suponer que el modelo predice casi perfectamente, pero eso esta lejos de ser así. Para ver por qué es necesario seguir los siguientes pasos:
### 1. Cambiar la métrica de rendimiento
El primer paso es comparar con distintas métricas, para eso ocupemos las 4 métricas clásicas abordadas en el curso:
* accuracy
* precision
* recall
* f-score
En este punto deberá poner las métricas correspondientes y comentar sus resultados.
```
# metrics
y_true = list(y_test)
y_pred = list(lr.predict(X_test))
print('\nMatriz de confusion:\n ')
print(confusion_matrix(y_true,y_pred))
print('\nMetricas:\n ')
print('accuracy: ',accuracy_score(y_test, lr_pred))
print('recall: ',recall_score(y_test, lr_pred))
print('precision: ',precision_score(y_test, lr_pred))
print('f-score: ',f1_score(y_test, lr_pred))
print("")
```
Podemos ver que la métrica de accuary es muy alta, pero otras que quizas para el contexto en el que estamos son más utiles como la de precisión no es tan alta, además podemos ver en la matriz de confusión que hay 16 falsos positivos, lo cual quizas con otros modelos se pueda mejorar, así que viendo las otras métricas y la matriz se podría decir que se puede mejorar mucho más cambiando de modelo quizas.
### 2. Cambiar algoritmo
El segundo paso es comparar con distintos modelos. Debe tener en cuenta que el modelo ocupado resuelva el problema supervisado de clasificación.
En este punto deberá ajustar un modelo de **random forest**, aplicar las métricas y comparar con el modelo de regresión logística.
```
# train model
rfc = RandomForestClassifier(max_depth=5, n_estimators=100, max_features=1).fit(X_train, y_train)
# metrics
y_true = list(y_test)
y_pred = list(rfc.predict(X_test)) # predicciones con random forest
print('\nMatriz de confusion:\n ')
print(confusion_matrix(y_true,y_pred))
print('\nMetricas:\n ')
print('accuracy: ',accuracy_score(y_true,y_pred))
print('recall: ',recall_score(y_true,y_pred))
print('precision: ',precision_score(y_true,y_pred))
print('f-score: ',f1_score(y_true,y_pred))
print("")
```
Comparando el modelo random forest con el de regresión logística, vemos en primero lugar que el modelo random forest no tienen falsos positivos en su matriz de confusión, lo cual para nuestro contexto es algo bueno debido a que no pasaría por alto ningun fraude, por otro lado el modelo de regresión logística si tiene falsos positivos en la matriz de confusión, lo cual para nuestro contexto no es algo bueno, además podemos ver que la precisión del modelo random forest tiene un valor 1, es decir, es un modelo muy preciso, por lo cual este modelo es mejor que el de regresión logística.
### 3. Técnicas de remuestreo: sobremuestreo de clase minoritaria
El tercer paso es ocupar ténicas de remuestreo, pero sobre la clase minoritaria. Esto significa que mediantes ténicas de remuestreo trataremos de equiparar el número de elementos de la clase minoritaria a la clase mayoritaria.
```
from sklearn.utils import resample
# concatenar el conjunto de entrenamiento
X = pd.concat([X_train, y_train], axis=1)
# separar las clases
not_fraud = X[X.Class==0]
fraud = X[X.Class==1]
# remuestrear clase minoritaria
fraud_upsampled = resample(fraud,
replace=True, # sample with replacement
n_samples=len(not_fraud), # match number in majority class
random_state=27) # reproducible results
# recombinar resultados
upsampled = pd.concat([not_fraud, fraud_upsampled])
# chequear el número de elementos por clases
upsampled.Class.value_counts()
# datos de entrenamiento sobre-balanceados
y_train = upsampled.Class
X_train = upsampled.drop('Class', axis=1)
```
Ocupando estos nuevos conjunto de entrenamientos, vuelva a aplicar el modelos de regresión logística y calcule las correspondientes métricas. Además, justifique las ventajas y desventjas de este procedimiento.
```
upsampled = LogisticRegression(solver='liblinear').fit(X_train, y_train)
# metrics
y_true = list(y_test)
y_pred = list(upsampled.predict(X_test))
print('\nMatriz de confusion:\n ')
print(confusion_matrix(y_true,y_pred))
print('\nMetricas:\n ')
print('accuracy: ',accuracy_score(y_true,y_pred))
print('recall: ',recall_score(y_true,y_pred))
print('precision: ',precision_score(y_true,y_pred))
print('f-score: ',f1_score(y_true,y_pred))
print("")
```
Podemos ver que claramente este conjunto que intenta equiparar la clase minoritaria resulta ser peor que el conjunto inicial, ya que se puede ver en la matriz de confusión que existen 287 falsos positivos, lo cual significa para nuestro contexto que más fraudes dan positivos que negativos, siendo esto peor que el conjunto inicial, por otro lado podemos ver que la precisión disminuyo considerablemente comparado con el conjunto inicial, en conclusión este nuevo conjunto de entrenamiento tiene muchas desventajas con respecto al inicial, una ventaja que no compensa es que son muy pocos los falsos negativos, es decir, que la mayoria de las transacciones legitimas son validadas y muy pocas son catalogadas como fraude.
### 4. Técnicas de remuestreo - Ejemplo de clase mayoritaria
El cuarto paso es ocupar ténicas de remuestreo, pero sobre la clase mayoritaria. Esto significa que mediantes ténicas de remuestreo trataremos de equiparar el número de elementos de la clase mayoritaria a la clase minoritaria.
```
# remuestreo clase mayoritaria
not_fraud_downsampled = resample(not_fraud,
replace = False, # sample without replacement
n_samples = len(fraud), # match minority n
random_state = 27) # reproducible results
# recombinar resultados
downsampled = pd.concat([not_fraud_downsampled, fraud])
# chequear el número de elementos por clases
downsampled.Class.value_counts()
# datos de entrenamiento sub-balanceados
y_train = downsampled.Class
X_train = downsampled.drop('Class', axis=1)
```
Ocupando estos nuevos conjunto de entrenamientos, vuelva a aplicar el modelos de regresión logística y calcule las correspondientes métricas. Además, justifique las ventajas y desventjas de este procedimiento.
```
undersampled = LogisticRegression(solver='liblinear').fit(X_train, y_train)
# metrics
y_true = list(y_test)
y_pred = list(undersampled.predict(X_test))
print('\nMatriz de confusion:\n ')
print(confusion_matrix(y_true,y_pred))
print('\nMetricas:\n ')
print('accuracy: ',accuracy_score(y_true,y_pred))
print('recall: ',recall_score(y_true,y_pred))
print('precision: ',precision_score(y_true,y_pred))
print('f-score: ',f1_score(y_true,y_pred))
print("")
```
Al igual que el remuestreo anterior, podemos ver que este nuevo conjunto de datos solo logra que la precisión disminuya, lo que para el contexto en que trabajamos es algo negativo, porque se dejan pasar muchos fraudes como transacciones legitimas, por lo tanto este nuevo conjunto de datos, al igual que el anterior, tiene muchas desventajas, mientras que la única ventaja que se puede observar es que disminuye la cantidad de falsos negativos, pero para un universo de más de 1200 datos de entrenamiento, pasar de 33 a 16 no resulta ser muy relevante.
### 5. Conclusiones
Para finalizar el laboratorio, debe realizar un análisis comparativo con los disintos resultados obtenidos en los pasos 1-4. Saque sus propias conclusiones del caso.
Por lo que se pudo ver en los diferentes pasos, el mejor conjunto de entrenamiento es el incial que se utilizó, ya que viendo como se comportaron los otros conjuntos de entrenamiento, ya sea haciendo un remuestreo de la clase minoritaria o la clase mayoritaria, resultaron ser un fracaso para el contexto en el que estamos, debido a que en vez de mejorar las métricas, lo único que hacian era agregar falsos positivos a la matriz de confusión. Por otro lado se pudo ver que con el modelo de random forest se logró una muy buena precisión, obteniendo 0 falsos positivos, lo cual para nuestro contexto es ideal, por lo que podemos concluir que este modelo es mucho mejor que el de regresión logística para este caso.
| github_jupyter |
### Lab 04
Labs in general are for you to solve short programming challenges in class. In contrast, homework assignments will involve more challenging and lengthy problems.
Feel free to ask the TAs for help if there is anything you do not understand. The TAs will go through suggested solutions in the last 15 minutes of the lab - typically by solving them in a live demo. **Your midterm exams will be like this, so it is highly beneficial for you to attend these labs**.
The second lab is to gain basic familiarity with handling vectors, matrices and basic linear algebra.
- You can import any Python standard library module you need
- Do this lab without using the web to search for solutions
```
import numpy as np
import scipy.linalg as la
np.random.seed(123)
m = 10
n = 10
A = np.random.normal(0, 1, (m, n))
b = np.random.normal(0, 1,(n, 1))
```
**1**.
Perform an LU decomposition to solve $Ax = b$
- Using `lu_factor` and `solve_triangular`
- Using `lu` and `solve_triangular`
- Check that your answer is correct using `np.allclose` in each case
```
lu, pv = la.lu_factor(A)
x = la.lu_solve((lu, pv), b)
np.allclose(A@x, b)
P, L, U = la.lu(A)
y = la.solve_triangular(L, P.T@b, lower=True)
x = la.solve_triangular(U, y)
np.allclose(A@x, b)
```
**2**.
Calculate the Gram matrix $S = A^TA$. Use the same $A$ and $b$ from the previous question.
- Solve $Sx = b$ using Cholesky decomposition
- Check that your answer is correct using `np.allclose`
```
S = A.T @ A
x = la.cho_solve(la.cho_factor(S), b)
np.allclose(S@x, b)
```
**3**.
- Diagonalize the matrix $S$ by finding its eigenvalues and eigenvectors
- Check that your answer is correct using `np.allclose`
```
lam, V = la.eigh(S)
np.allclose(V @ np.diag(lam) @ V.T, S)
```
**4**.
- Perform a singular value decomposition (SVD) of the matrix $A$.
- Use the singular values to calculate the $L_\text{Frobenius}$ and $L_2$ norms of $A$
- Check your answers using `la.norm` and `np.allclose`
- Express the eigenvalues of $S$ in terms of the singular values $\sigma$
- Check your answers using `np.allclose`
```
U, sigma, Vt = la.svd(A)
l2 = sigma[0]
lF = np.sqrt((sigma**2).sum())
np.allclose(l2, la.norm(A, ord=2))
np.allclose(lF, la.norm(A, ord='fro'))
np.allclose(sorted(np.sqrt(lam), reverse=True), sigma)
```
**5**.
Suppose a vector $v$ has coordinates $b$ when expressed as a linear combination of the columns of $A$. What are the new coordinates of $v$ when expressed as a linear combination of the (normalized) eigenvectors of $A$?
```
V @ np.diag(lam) @ V @ b
```
| github_jupyter |
# Unsupervised outliers detection (event detection)
```
import drama as drm
import numpy as np
import matplotlib.pylab as plt
from matplotlib import gridspec
%matplotlib inline
```
## Signal synthesis
```
i_sig = 1
n_ftrs = 3000
noise = 0.2
# noise = 0.0
scl = 0.01
sft = 0.01
# x = np.tile(np.linspace(0,1,n_ftrs),2)
X, y = drm.synt_event(i_sig, n_ftrs,n_inlier=500,n_outlier=50,
sigma = noise,n1 = scl,n2 = sft,n3 = scl,n4 = sft,
mu=[0.75,0.76],amp=[0.2,0.3],sig=[0.005,0.01])
gs = gridspec.GridSpec(1, 2)
plt.figure(figsize=(8,3))
ax1 = plt.subplot(gs[0, 0])
ax2 = plt.subplot(gs[0, 1])
ax1.set_title('Inliers')
ax2.set_title('Outliers')
inliers = X[y==0]
outliers = X[y==1]
for i in range(10):
ax1.plot(inliers[i],'b')
ax2.plot(outliers[i],'r')
# plt.savefig('Huge_data.jpg')
```
## Outlier detection
```
n_try = 5
result = []
for i in range(n_try):
auc,mcc,rws,conf = drm.grid_run_drama(X,y)
arr = np.stack([auc,mcc,rws],axis=-1)
result.append(arr)
result = np.array(result)
drts = np.unique(conf[:,1])
metrs = np.unique(conf[:,2])
res = result.reshape(n_try,5,10,-1)
drm.plot_table(np.mean(res,axis=0),drts,metrs)
lof_all = np.zeros((n_try,3))
ifr_all = np.zeros((n_try,3))
df = drm.sk_check(X,X,y,[1])
for i in range(n_try):
for j,scr in enumerate(['AUC','MCC','RWS']):
lof_all[i,j] = df[scr][0]
ifr_all[i,j] = df[scr][1]
auc = np.sum((res[:, :, :, 0].T>lof_all[:, 0]) & (res[:, :, :, 0].T>ifr_all[:, 0]),axis=-1).T
mcc = np.sum((res[:, :, :, 1].T>lof_all[:, 1]) & (res[:, :, :, 1].T>ifr_all[:, 1]),axis=-1).T
rws = np.sum((res[:, :, :, 2].T>lof_all[:, 2]) & (res[:, :, :, 2].T>ifr_all[:, 2]),axis=-1).T
fig = plt.figure(figsize=(20,10))
plt.clf()
ax = fig.add_subplot(111)
ax.set_aspect('auto')
ax.imshow(auc, cmap=plt.cm.jet,interpolation='nearest')
width, height = auc.shape
for x in range(width):
for y in range(height):
ax.annotate('AUC: {:d}\n MCC: {:d}\n RWS: {:d}'.format(auc[x][y],mcc[x][y],rws[x][y]), xy=(y, x),
horizontalalignment='center',
verticalalignment='center',fontsize=18);
plt.xticks(range(10),metrs,fontsize=15)
plt.yticks(range(5), drts,fontsize=15)
plt.title('Number of successes (LOF and i-forest) out of 20 data set',fontsize=25)
plt.annotate('** Colors depend on AUC.', (0,0), (0, -30), xycoords='axes fraction',
textcoords='offset points', va='top',fontsize=15)
# plt.savefig('AND_success.jpg',dpi=150,bbox_inches='tight')
```
| github_jupyter |
```
import os
import sys
from pathlib import Path
import torch
import torch.utils.data
from torchvision import transforms, datasets
import numpy as np
import matplotlib.pyplot as plt
import pvi
from pvi.models import ClassificationBNNLocalRepam
from pvi.clients import Client
from pvi.servers import SequentialServer
from pvi.distributions import MeanFieldGaussianDistribution, MeanFieldGaussianFactor
from pvi.utils.training_utils import EarlyStopping
data_dir = Path("/Users/matt/projects/datasets")
cache_dir = Path("/Users/matt/projects/pvi/rough/experiments/femnist")
```
## Define various functions for splitting data and recording performance metrics.
```
# Data splitting functions.
def homogeneous_split(data, num_clients=100, seed=42):
# Set numpy's random seed.
np.random.seed(seed)
perm = np.random.permutation(len(data["x"]))
client_data = []
for i in range(num_clients):
client_idx = perm[i::num_clients]
client_data.append({"x": data["x"][client_idx], "y": data["y"][client_idx]})
return client_data
# Performance metric function.
def performance_metrics(client, data, batch_size=512):
dataset = torch.utils.data.TensorDataset(data["x"], data["y"])
loader = torch.utils.data.DataLoader(dataset, batch_size=512, shuffle=False)
device = client.config["device"]
if device == "cuda":
loader.pin_memory = True
preds, mlls = [], []
for (x_batch, y_batch) in loader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
pp = client.model_predict(x_batch)
preds.append(pp.component_distribution.probs.mean(1).cpu())
mlls.append(pp.log_prob(y_batch).cpu())
mll = torch.cat(mlls).mean()
preds = torch.cat(preds)
acc = sum(torch.argmax(preds, dim=-1) == loader.dataset.tensors[1]) / len(
loader.dataset.tensors[1]
)
return {"mll": mll, "acc": acc}
```
## Data preprocessing
```
transform_train = transforms.Compose([transforms.ToTensor()])
transform_test = transforms.Compose([transforms.ToTensor()])
train_set = datasets.MNIST(root=data_dir, train=True, download=True, transform=transform_train)
test_set = datasets.MNIST(root=data_dir, train=False, download=True, transform=transform_test)
train_data = {
"x": ((train_set.data - 0) / 255).reshape(-1, 28 * 28),
"y": train_set.targets,
}
test_data = {
"x": ((test_set.data - 0) / 255).reshape(-1, 28 * 28),
"y": test_set.targets,
}
# Get client splits.
client_data = homogeneous_split(train_data, 10, seed=42)
```
## Define configuration for server and clients
```
model_config = {
"input_dim": 784,
"latent_dim": 200,
"output_dim": 10,
"num_layers": 1,
"num_predictive_samples": 100,
"prior_var": 1.0,
}
client_config = {
"damping_factor": 1.0,
"optimiser": "Adam",
"optimiser_params": {"lr": 2e-3},
"sigma_optimiser_params": {"lr": 2e-3},
"early_stopping": EarlyStopping(5, score_name="elbo", stash_model=True),
"performance_metrics": performance_metrics,
"batch_size": 512,
"epochs": 2000,
"print_epochs": np.inf,
"num_elbo_samples": 10,
"valid_factors": False,
"device": "cpu",
"init_var": 1e-3,
"verbose": True,
}
server_config = {
**client_config,
"max_iterations": 100,
}
```
## Set up model etc.
```
device = server_config["device"]
model = ClassificationBNNLocalRepam(config=model_config)
# Initial parameters.
init_q_std_params = {
"loc": torch.zeros(size=(model.num_parameters,)).to(device).uniform_(-0.1, 0.1),
"scale": torch.ones(size=(model.num_parameters,)).to(device)
* client_config["init_var"] ** 0.5,
}
prior_std_params = {
"loc": torch.zeros(size=(model.num_parameters,)).to(device),
"scale": model_config["prior_var"] ** 0.5
* torch.ones(size=(model.num_parameters,)).to(device),
}
init_factor_nat_params = {
"np1": torch.zeros(model.num_parameters).to(device),
"np2": torch.zeros(model.num_parameters).to(device),
}
p = MeanFieldGaussianDistribution(
std_params=prior_std_params, is_trainable=False
)
init_q = MeanFieldGaussianDistribution(
std_params=init_q_std_params, is_trainable=False
)
clients = []
for i in range(10):
data_i = client_data[i]
t_i = MeanFieldGaussianFactor(nat_params=init_factor_nat_params)
clients.append(
Client(
data=data_i,
model=model,
t=t_i,
config=client_config,
val_data=test_data
)
)
server = SequentialServer(model=model, p=p, clients=clients, config=server_config, init_q=init_q, data=train_data, val_data=test_data)
```
## Run PVI!
```
i = 0
while not server.should_stop():
server.tick()
# Obtain performance metrics.
metrics = server.log["performance_metrics"][-1]
print("Iterations: {}.".format(i))
print("Time taken: {:.3f}.".format(metrics["time"]))
print(
"Test mll: {:.3f}. Test acc: {:.3f}.".format(
metrics["val_mll"], metrics["val_acc"]
)
)
print(
"Train mll: {:.3f}. Train acc: {:.3f}.\n".format(
metrics["train_mll"], metrics["train_acc"]
)
)
i += 1
```
| github_jupyter |
# Building a Multilayer Convolutional Network
the previous tutorial is using softmax regression to recognize MNIST digits.
The tutorial for this notebook is here:
[Building a Multilayer Convolutional Network](https://www.tensorflow.org/versions/r0.10/tutorials/mnist/pros/index.html#deep-mnist-for-experts#content)
```
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1, 28, 28, 1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
sess = tf.InteractiveSession()
%%time
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.initialize_all_variables())
for i in range(10000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
%%time
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images[:250], y_: mnist.test.labels[:250], keep_prob: 1.0}))
```
| github_jupyter |
# Classifying images of everyday objects using a neural network
The ability to try many different neural network architectures to address a problem is what makes deep learning really powerful, especially compared to shallow learning techniques like linear regression, logistic regression etc.
In this assignment, you will:
1. Explore the CIFAR10 dataset: https://www.cs.toronto.edu/~kriz/cifar.html
2. Set up a training pipeline to train a neural network on a GPU
2. Experiment with different network architectures & hyperparameters
As you go through this notebook, you will find a **???** in certain places. Your job is to replace the **???** with appropriate code or values, to ensure that the notebook runs properly end-to-end. Try to experiment with different network structures and hypeparameters to get the lowest loss.
You might find these notebooks useful for reference, as you work through this notebook:
- https://jovian.ml/aakashns/04-feedforward-nn
- https://jovian.ml/aakashns/fashion-feedforward-minimal
```
# Uncomment and run the commands below if imports fail
# !conda install numpy pandas pytorch torchvision cpuonly -c pytorch -y
# !pip install matplotlib --upgrade --quiet
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
%matplotlib inline
# Project name used for jovian.commit
project_name = '03-cifar10-feedforward'
```
## Exploring the CIFAR10 dataset
```
dataset = CIFAR10(root='data/', download=True, transform=ToTensor())
test_dataset = CIFAR10(root='data/', train=False, transform=ToTensor())
```
**Q: How many images does the training dataset contain?**
```
dataset_size = len(dataset)
dataset_size
```
**Q: How many images does the training dataset contain?**
```
test_dataset_size = len(test_dataset)
test_dataset_size
```
**Q: How many output classes does the dataset contain? Can you list them?**
Hint: Use `dataset.classes`
```
classes = dataset.classes
classes
num_classes = len(classes)
num_classes
```
**Q: What is the shape of an image tensor from the dataset?**
```
img, label = dataset[0]
img_shape = img.shape
img_shape
```
Note that this dataset consists of 3-channel color images (RGB). Let us look at a sample image from the dataset. `matplotlib` expects channels to be the last dimension of the image tensors (whereas in PyTorch they are the first dimension), so we'll the `.permute` tensor method to shift channels to the last dimension. Let's also print the label for the image.
```
img, label = dataset[0]
plt.imshow(img.permute((1, 2, 0)))
print('Label (numeric):', label)
print('Label (textual):', classes[label])
```
**(Optional) Q: Can you determine the number of images belonging to each class?**
Hint: Loop through the dataset.
```
img_class_count = {}
for tensor, index in dataset:
x = classes[index]
if x not in img_class_count:
img_class_count[x] = 1
else:
img_class_count[x] += 1
print(img_class_count)
```
Let's save our work to Jovian, before continuing.
```
!pip install jovian --upgrade --quiet
import jovian
jovian.commit(project=project_name, environment=None)
```
## Preparing the data for training
We'll use a validation set with 5000 images (10% of the dataset). To ensure we get the same validation set each time, we'll set PyTorch's random number generator to a seed value of 43.
```
torch.manual_seed(43)
val_size = 5000
train_size = len(dataset) - val_size
```
Let's use the `random_split` method to create the training & validation sets
```
train_ds, val_ds = random_split(dataset, [train_size, val_size])
len(train_ds), len(val_ds)
```
We can now create data loaders to load the data in batches.
```
batch_size=128
train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size*2, num_workers=4, pin_memory=True)
```
Let's visualize a batch of data using the `make_grid` helper function from Torchvision.
```
for images, _ in train_loader:
print('images.shape:', images.shape)
plt.figure(figsize=(16,8))
plt.axis('off')
plt.imshow(make_grid(images, nrow=16).permute((1, 2, 0)))
break
```
Can you label all the images by looking at them? Trying to label a random sample of the data manually is a good way to estimate the difficulty of the problem, and identify errors in labeling, if any.
## Base Model class & Training on GPU
Let's create a base model class, which contains everything except the model architecture i.e. it wil not contain the `__init__` and `__forward__` methods. We will later extend this class to try out different architectures. In fact, you can extend this model to solve any image classification problem.
```
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
with torch.no_grad():
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc} # detached loss function
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['val_loss'], result['val_acc']))
```
We can also use the exact same training loop as before. I hope you're starting to see the benefits of refactoring our code into reusable functions.
```
def evaluate(model, val_loader):
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
model.epoch_end(epoch, result)
history.append(result)
return history
```
Finally, let's also define some utilities for moving out data & labels to the GPU, if one is available.
```
torch.cuda.is_available()
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
device = get_default_device()
device
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
```
Let us also define a couple of helper functions for plotting the losses & accuracies.
```
def plot_losses(history):
losses = [x['val_loss'] for x in history]
plt.plot(losses, '-x')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Loss vs. No. of epochs');
def plot_accuracies(history):
accuracies = [x['val_acc'] for x in history]
plt.plot(accuracies, '-x')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Accuracy vs. No. of epochs');
```
Let's move our data loaders to the appropriate device.
```
train_loader = DeviceDataLoader(train_loader, device)
val_loader = DeviceDataLoader(val_loader, device)
test_loader = DeviceDataLoader(test_loader, device)
```
## Training the model
We will make several attempts at training the model. Each time, try a different architecture and a different set of learning rates. Here are some ideas to try:
- Increase or decrease the number of hidden layers
- Increase of decrease the size of each hidden layer
- Try different activation functions
- Try training for different number of epochs
- Try different learning rates in every epoch
What's the highest validation accuracy you can get to? **Can you get to 50% accuracy? What about 60%?**
```
input_size = 3*32*32
output_size = 10
```
**Q: Extend the `ImageClassificationBase` class to complete the model definition.**
Hint: Define the `__init__` and `forward` methods.
```
class CIFAR10Model(ImageClassificationBase):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(input_size, 512)
self.linear2 = nn.Linear(512, 256)
self.linear3 = nn.Linear(256, 128)
self.linear4 = nn.Linear(128, output_size)
def forward(self, xb):
# Flatten images into vectors
out = xb.view(xb.size(0), -1)
# Apply layers & activation functions
# linear layer 1
out = self.linear1(out)
# activation layer 1
out = F.relu(out)
# linear layer 2
out = self.linear2(out)
# activation layer 2
out = F.relu(out)
# linear layer 3
out = self.linear3(out)
# activation layer 3
out = F.relu(out)
# linear layer 4
out = self.linear4(out)
return out
```
You can now instantiate the model, and move it the appropriate device.
```
model = to_device(CIFAR10Model(), device)
```
Before you train the model, it's a good idea to check the validation loss & accuracy with the initial set of weights.
```
history = [evaluate(model, val_loader)]
history
```
**Q: Train the model using the `fit` function to reduce the validation loss & improve accuracy.**
Leverage the interactive nature of Jupyter to train the model in multiple phases, adjusting the no. of epochs & learning rate each time based on the result of the previous training phase.
```
history += fit(10, 1e-1, model, train_loader, val_loader)
history += fit(10, 1e-2, model, train_loader, val_loader)
history += fit(10, 1e-3, model, train_loader, val_loader)
history += fit(20, 1e-5, model, train_loader, val_loader)
```
Plot the losses and the accuracies to check if you're starting to hit the limits of how well your model can perform on this dataset. You can train some more if you can see the scope for further improvement.
```
plot_losses(history)
plot_accuracies(history)
```
Finally, evaluate the model on the test dataset report its final performance.
```
evaluate(model, test_loader)
```
Are you happy with the accuracy? Record your results by completing the section below, then you can come back and try a different architecture & hyperparameters.
## Recoding your results
As your perform multiple experiments, it's important to record the results in a systematic fashion, so that you can review them later and identify the best approaches that you might want to reproduce or build upon later.
**Q: Describe the model's architecture with a short summary.**
E.g. `"3 layers (16,32,10)"` (16, 32 and 10 represent output sizes of each layer)
```
arch = repr(model)
arch
```
**Q: Provide the list of learning rates used while training.**
```
lrs = [1e-1, 1e-2, 1e-3, 1e-5]
```
**Q: Provide the list of no. of epochs used while training.**
```
epochs = [10, 20]
```
**Q: What were the final test accuracy & test loss?**
```
res = evaluate(model, val_loader)
test_acc = res['val_acc']
test_loss = res['val_loss']
print(res)
```
Finally, let's save the trained model weights to disk, so we can use this model later.
```
torch.save(model.state_dict(), 'cifar10-feedforward.pth')
```
The `jovian` library provides some utility functions to keep your work organized. With every version of your notebok, you can attach some hyperparameters and metrics from your experiment.
```
# Clear previously recorded hyperparams & metrics
jovian.reset()
jovian.log_hyperparams(arch=arch,
lrs=lrs,
epochs=epochs)
jovian.log_metrics(test_loss=test_loss, test_acc=test_acc)
```
Finally, we can commit the notebook to Jovian, attaching the hypeparameters, metrics and the trained model weights.
```
jovian.commit(project=project_name, outputs=['cifar10-feedforward.pth'], environment=None)
```
Once committed, you can find the recorded metrics & hyperprameters in the "Records" tab on Jovian. You can find the saved model weights in the "Files" tab.
## Continued experimentation
Now go back up to the **"Training the model"** section, and try another network architecture with a different set of hyperparameters. As you try different experiments, you will start to build an undestanding of how the different architectures & hyperparameters affect the final result. Don't worry if you can't get to very high accuracy, we'll make some fundamental changes to our model in the next lecture.
Once you have tried multiple experiments, you can compare your results using the **"Compare"** button on Jovian.

## (Optional) Write a blog post
Writing a blog post is the best way to further improve your understanding of deep learning & model training, because it forces you to articulate your thoughts clearly. Here'are some ideas for a blog post:
- Report the results given by different architectures on the CIFAR10 dataset
- Apply this training pipeline to a different dataset (it doesn't have to be images, or a classification problem)
- Improve upon your model from Assignment 2 using a feedfoward neural network, and write a sequel to your previous blog post
- Share some Strategies for picking good hyperparameters for deep learning
- Present a summary of the different steps involved in training a deep learning model with PyTorch
- Implement the same model using a different deep learning library e.g. Keras ( https://keras.io/ ), and present a comparision.
| github_jupyter |
<h1><div align="center">Natural Language Processing From Scratch</div></h1>
<div align="center">Bruno Gonçalves</div>
<div align="center"><a href="http://www.data4sci.com/">www.data4sci.com</a></div>
<div align="center">@bgoncalves, @data4sci</div>
# Lesson IV - Applications
```
import string
import gzip
from collections import Counter
import numpy as np
import pandas as pd
import pickle
from sklearn.metrics.pairwise import cosine_similarity, euclidean_distances
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from sklearn.preprocessing import normalize
from pprint import pprint
%matplotlib inline
```
# word2vec embeddings
We start by loading a well trained set of word embeddings from project polyglot: https://sites.google.com/site/rmyeid/projects/polyglot
```
word_list, embeddings = pd.read_pickle('data/polyglot-en.pkl')
embeddings = normalize(embeddings)
word_list = np.array(word_list)
word_dict = dict(zip(word_list, range(embeddings.shape[0])))
print(embeddings.shape)
```
# Find the most similar words
```
def most_similar(word, embeddings, dictionary, reverse_dictionary, top_k=8):
valid_word = dictionary[word]
similarity = cosine_similarity(embeddings, embeddings[valid_word, :].reshape(1, -1))
nearest = (-similarity).argsort(axis=0)[1:top_k + 1].flatten()
return reverse_dictionary[nearest]
most_similar("king", embeddings, word_dict, word_list)
```
# Analogies
Question task set downloaded from: http://download.tensorflow.org/data/questions-words.txt
```
questions = pd.read_table('data/questions-words.txt', comment=':', sep=' ', header=None)
print(questions.shape)
```
Let us now define a function to automatically evaluate this specific type of analogy. We simply look up the embeddings for each of the four words in the question and perform the necessary vector algebra. To be safe, we enclose the entire function into a try/except block to catch the exceptions thrown when we try to use a word that is not part of our vocabulary (included in the embeddings)
```
def evaluate_analogy(question):
word1, word2, word3, word4 = question
if word1 not in word_dict or \
word2 not in word_dict or \
word3 not in word_dict or \
word4 not in word_dict:
return None
key1 = word_dict[word1]
key2 = word_dict[word2]
key3 = word_dict[word3]
key4 = word_dict[word4]
vec1 = embeddings[key1, :]
vec2 = embeddings[key2, :]
vec3 = embeddings[key3, :]
vec4 = embeddings[key4, :]
predict = vec2-vec1+vec3
sim = np.matmul(predict, embeddings.T)
nearest = np.argsort(-sim)[:10]
return word4 in word_list[nearest]
results = [evaluate_analogy(questions.iloc[i]) for i in range(1000)]
clean_results = [res for res in results if res is not None]
accuracy = np.mean(clean_results)
print(accuracy)
```
We this simple approach we achieve ~53% accuracy. Our results are penalized by the fact that our embeddings weren't generated specifically for this purpose and are missing some of the words used in the analogies.
# Visualization
```
plt.figure(figsize=(15, 5))
plt.imshow(embeddings.T, aspect=300, cmap=cm.jet)
plt.xlabel("vocabulary")
plt.ylabel("embeddings dimensions")
```
# Visualizing the embedding space
Using a dimensionality reduction algorithm like t-SNE we are able to project our word embeddings into a two dimensional space for visualization purposes. While the details of how t-SNE does its magic are beyond the scope of this course, the fundamental idea is the same of algorithms like PCA or the matrix decomposition methods we explored. Project the dataset into a latent, and lower dimensional, space in a smart way. t-SNE became popular in recent year due to its hability to make projections into 2D space in a way that preserves as much of the higher dimensional structure as possible resulting in beautiful and useful visualizations.
The start implementation of t-SNE is that that comes bundled with **sklearn**. Here we simply call it to generate the plot we saw in the slides.
```
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000, method='exact')
plot_only = 500 # Plot only 500 words
low_dim_embs = tsne.fit_transform(np.array(embeddings)[:plot_only, :])
labels = [word_list[i] for i in range(plot_only)]
plt.figure(figsize=(18, 18)) # in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
```
# Word co-occurences
GloVe relies on the word co-occurences matrix. Let's take a look in detail on how to calculate it. For convenience, we'll use the same nursery rhyme we looked at in Lesson I. To save time we'll just load the data from a file
```
data = pickle.load(open("data/mary.pickle", "rb"))
mary_word_list = data['word_list']
mary_word_dict = data['word_dict']
text_words = data['text_words']
```
Let's check that everything looks ok
```
for word in mary_word_dict:
if mary_word_list[mary_word_dict[word]] != word:
print("ERROR!")
```
And that we got the right text
```
print(text_words)
```
And now we're ready to define a function that calculates the cooccurence matrix
```
def cooccurence_matrix(word_dict, text_words, window_size=1):
vocabulary_size = len(word_dict)
matrix = np.zeros((vocabulary_size, vocabulary_size), dtype='int')
for i in range(window_size+1, len(text_words)-window_size):
word_id = word_dict[text_words[i]]
for j in range(i-window_size, i+window_size+1):
if j == i:
continue
context_id = word_dict[text_words[j]]
matrix[word_id, context_id] += 1
return matrix
```
Let's take a look at what this matrix looks like
```
matrix = cooccurence_matrix(mary_word_dict, text_words)
pprint(matrix)
```
While it might appear symmetrical, that is actually not true, as we can easily see:
```
np.sum(np.abs(matrix-matrix.T))
```
or more directly
```
print(matrix[mary_word_dict['a'], mary_word_dict['had']])
print(matrix[mary_word_dict['had'], mary_word_dict['a']])
```
The most common implementations of GloVe scale the contribution of each context word by its distance to the center word. In this way, nearer words contribute more than more distant ones. Using this unweighted definition, we can also calculate the conditional probability $P(w|C)$:
```
Prob = matrix/matrix.sum(axis=0)
```
A simple example will confirm that this is correct:
```
Prob[mary_word_dict['mary'], mary_word_dict['had']]
```
This implies that 1/3. of the occurences of the word mary are next to the word 'had'. Let's confirm it explicitly
```
for i in range(len(text_words)):
if text_words[i] == 'mary':
if i != 0:
print(text_words[i-1], text_words[i], text_words[i+1])
else:
print(None, text_words[i], text_words[i+1])
```
Naturally, the complementary probability $P(had|mary)$ is different
```
Prob[mary_word_dict['had'], mary_word_dict['mary']]
```
As we saw, GloVe relies on this coocurrence matrix to define its embeddings. We can also easily see how more complex language models of the form $P(word|word1,word_2, \cdots)$ can be obtained by changing the way in which the columns are defined (and increasing their number significantly).
Surprisingly, in 2014, it was shown by O. Levy and Y. Goldberg in a highly cited [NIPS paper](https://papers.nips.cc/paper/5477-neural-word-embedding-as-implicit-matrix-factorization) that some variations of word2vec are equivalent to factorizing a word-context matrix. These two approches for obtaining word embeddings aren't so differnet after all.
# Language Detection
We start by building a vector of character distributions for each language. Due to the total size of the google books dataset, we include only a partial file in the data directory. The interested student is encouraged to download all teh files and use the code below to build hers or his own language detector.
```
characters = sorted(set(string.ascii_letters.lower()))
dict_char = dict(zip(characters, range(len(characters))))
counts = np.zeros(len(characters), dtype='uint64')
line_count = 0
filename = "data/googlebooks-eng-all-1gram-20120701-a.gz"
for line in gzip.open(filename, "rt"):
fields = line.lower().strip().split()
line_count += 1
if line_count % 100000 == 0:
print(filename, line_count)
break
count = int(fields[2])
word = fields[0]
if "_" in word:
continue
letters = [char for char in word if char in characters]
if len(letters) != len(word):
continue
for letter in letters:
if letter not in dict_char:
continue
counts[dict_char[letter]] += count
total = np.sum(counts)
list_char = list(dict_char.items())
list_char.sort(key=lambda x: x[1])
for key, value in enumerate(list_char):
print(value[0], counts[key]/total)
```
Not surprisingly, the most common character is the letter *a*. This is an artifact of the fact that we are using the datafile containing only words that start with the letter *a*. If you were to run it on the entire dataset, the resutls shown in the slides would be found.
For simplicity, I've also included the complete table for all 5 languages in the repository. This is the datset that we will used to build our language detector.
# Visualization
Let's start by making a quick visualization of the probabiltity distributions for each language. THe first step is to load up the language character frequency from the file:
```
P_letter_lang = pd.read_csv('data/table_langs.dat', sep=' ', header=0, index_col = 0)
plt.plot(range(26), pd.np.array(P_letter_lang["eng"]), '-')
plt.plot(range(26), pd.np.array(P_letter_lang["fre"]), '-')
plt.plot(range(26), pd.np.array(P_letter_lang["ger"]), '-')
plt.plot(range(26), pd.np.array(P_letter_lang["ita"]), '-')
plt.plot(range(26), pd.np.array(P_letter_lang["spa"]), '-')
plt.xticks(list(range(26)), P_letter_lang.index)
plt.legend(["English", "French", "German", "Italian", "Spanish"])
plt.xlabel("letter")
plt.ylabel("P(letter)")
```
As we can see, there definitely some common trends (the letters *q* and *j* are underrepreented across all languages), there are also some significant peaks that will help us discriminate between one language and the next.
## The detector
Based on this table of data it is extremely simple to build a Naive Bayes classifier. To do so, one must just calculte the correct set of log likelihoods so that we may use them later on.
```
def process_data(P_letter_lang):
langs = list(P_letter_lang.columns)
P_letter = P_letter_lang.mean(axis=1)
P_letter /= P_letter.sum()
P_lang_letter = np.array(P_letter_lang)/(P_letter_lang.shape[1]*P_letter.T[:,None])
L_lang_letter = np.log(P_lang_letter.T)
return langs, P_letter, L_lang_letter
langs, P_letter, L_lang_letter = process_data(P_letter_lang)
```
Finally, we have all the tools we need to write down our mini detector:
```
def detect_lang(langs, P_letter, L_lang_letter, text):
counts = np.zeros(26, dtype='int')
pos = dict(zip(P_letter.index, range(26)))
text_counts = Counter(text).items()
for letter, count in text_counts:
if letter in pos:
counts[pos[letter]] += count
L_text = np.dot(L_lang_letter, counts)
index = np.argmax(L_text)
lang_text = langs[index]
prob = np.exp(L_text[index])/np.sum(np.exp(L_text))*100
return lang_text, prob, L_text
```
And that's all there is to it. So now let's test our detector with a few past headlines from Google News:
```
texts = {}
texts["eng"] = "North Korea’s Test of Nuclear Bomb Amplifies a Global Crisis".lower()
texts["ita"] = "Nucleare, Onu riunisce consiglio sicurezza. E Seul simula attacco alle basi di Kim".lower()
texts["fre"] = "Corée du Nord : les Etats-Unis prêts à utiliser leurs capacités nucléaires".lower()
texts["spa"] = "Estados Unidos amenaza con una “respuesta militar masiva” a Corea del Norte".lower()
texts["ger"] = "Überraschung".lower()
texts["ita2"] = "Wales lancia la Wikipedia delle news. Contro il fake in campo anche Google".lower()
for lang in texts:
text = texts[lang]
lang_text, prob, L_text = detect_lang(langs, P_letter, L_lang_letter, text)
print(lang, lang_text, prob, text)
```
Overall we do a pretty good job. We get 5/6 correct and the only one we are missing is a specific case where there are a surprising number of English words in the middle of an Italian headline.
| github_jupyter |
# Deep Reinforcement Learning <em> in Action </em>
## N-Armed Bandits
### Chapter 2
```
import numpy as np
import torch as th
from torch.autograd import Variable
from matplotlib import pyplot as plt
import random
%matplotlib inline
```
This defines the main contextual bandit class we'll be using as our environment/simulator to train a neural network.
```
class ContextBandit:
def __init__(self, arms=10):
self.arms = arms
self.init_distribution(arms)
self.update_state()
def init_distribution(self, arms):
# Num states = Num Arms to keep things simple
self.bandit_matrix = np.random.rand(arms,arms)
#each row represents a state, each column an arm
def reward(self, prob):
reward = 0
for i in range(self.arms):
if random.random() < prob:
reward += 1
return reward
def get_state(self):
return self.state
def update_state(self):
self.state = np.random.randint(0,self.arms)
def get_reward(self,arm):
return self.reward(self.bandit_matrix[self.get_state()][arm])
def choose_arm(self, arm):
reward = self.get_reward(arm)
self.update_state()
return reward
```
Here we define our simple neural network model using PyTorch
```
def softmax(av, tau=1.12):
n = len(av)
probs = np.zeros(n)
for i in range(n):
softm = ( np.exp(av[i] / tau) / np.sum( np.exp(av[:] / tau) ) )
probs[i] = softm
return probs
def one_hot(N, pos, val=1):
one_hot_vec = np.zeros(N)
one_hot_vec[pos] = val
return one_hot_vec
arms = 10
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 1, arms, 100, arms
model = th.nn.Sequential(
th.nn.Linear(D_in, H),
th.nn.ReLU(),
th.nn.Linear(H, D_out),
th.nn.ReLU(),
)
loss_fn = th.nn.MSELoss(size_average=False)
env = ContextBandit(arms)
```
Next we define the training function, which accepts an instantiated ContextBandit object.
```
def train(env):
epochs = 5000
#one-hot encode current state
cur_state = Variable(th.Tensor(one_hot(arms,env.get_state())))
reward_hist = np.zeros(50)
reward_hist[:] = 5
runningMean = np.average(reward_hist)
learning_rate = 1e-2
optimizer = th.optim.Adam(model.parameters(), lr=learning_rate)
plt.xlabel("Plays")
plt.ylabel("Mean Reward")
for i in range(epochs):
y_pred = model(cur_state) #produce reward predictions
av_softmax = softmax(y_pred.data.numpy(), tau=2.0) #turn reward distribution into probability distribution
av_softmax /= av_softmax.sum() #make sure total prob adds to 1
choice = np.random.choice(arms, p=av_softmax) #sample an action
cur_reward = env.choose_arm(choice)
one_hot_reward = y_pred.data.numpy().copy()
one_hot_reward[choice] = cur_reward
reward = Variable(th.Tensor(one_hot_reward))
loss = loss_fn(y_pred, reward)
if i % 50 == 0:
runningMean = np.average(reward_hist)
reward_hist[:] = 0
plt.scatter(i, runningMean)
reward_hist[i % 50] = cur_reward
optimizer.zero_grad()
# Backward pass: compute gradient of the loss with respect to model
# parameters
loss.backward()
# Calling the step function on an Optimizer makes an update to its
# parameters
optimizer.step()
cur_state = Variable(th.Tensor(one_hot(arms,env.get_state())))
train(env)
```
| github_jupyter |
# JSS'19 - Gkortzis et al. - Data Collection
This notebook describes and performs the following steps necessary to collect all data used in the study:
1. [Requirements](#requirements)
1. [Download projects from GitHub](#download)
2. [Detect Maven root directories](#detect_root_dirs)
3. [Compile and install Maven projects](#install)
4. [Retrieve projects' dependencies](#dependencies)
5. [Run Spotbugs](#spotbugs)
6. [Extract metrics and create analysis dataset](#metrics)
<a id="requirements"></a>
## Requirements
The external tools required to run the analysis can be automatically obtained by executing the ```download-vendor-tools.sh``` script in the __analysis/tooling__ directory. The follwoing runtime environments and tools shoudl also be available in your system:
1. Open-jdk 8 & open-jdk 11 (some projects can be build with version 1.8 only)
2. Python3
3. Unzip
<a id="download"></a>
## Download Projects from GitHub
With a list of Github Maven repositories, the first step is to clone these reposirotories locally. This is the task that the github_downloader script performs.
The execute_downloader requires three parameters:
1. `credentials` : `String`. The github credentials in a specific format (`github_username:github_token`)
2. `repository_list` : `Filepath`. The list of repositories to clone locally
3. `download_directory` : `Directory`. The fullpath of the directory where the repositories will be cloned
Additionally, there is an optional parameter:
4. `Boolean`. That can be used to update (perform a git pull) on an already existing repository.
```
import github_downloader
credentials = "github_username:github_token" # replace this value with your personal credentials
repository_list = "../maven_starred_sorted_all.csv"
download_directory = "/media/agkortzis/Data/maven_repos" # replace this value
github_downloader.execute_downloader(credentials, repository_list, download_directory)
# github_downloader.execute_downloader(credentials, repoInputFile, repoStoreRoot, update_existing=True)
```
<a id="detect_root_dirs"></a>
## Detect Maven root directories
```
import repository_path_retriever
repositories_root_directories_file = "../repositories_root_directories.csv" # the file that will store the repositories with their detected maven root direcotry
repositories_alternative_directories_file = "../repositories_alternative_directories_file.csv" # the file that stores the paths for repositories with more than one maven parent projects
repository_path_retriever.detect_configuration_file(download_directory,repositories_root_directories_file,repositories_alternative_directories_file)
```
<a id="install"></a>
## Compile and install Maven projects
The next step after downloading the projects is to perform a maven install. This process will collect the projects dependencies and generate the `.jar` file. Both, the `.jar` file and the dependencies will be stored in the `.m2` directory under each project's direcoty.
This `.m2` root directory is, by default, located under the users folder (`/home/user/.m2`).
The `execute_mvn_install` requires one argument:
1. `root_directory` : `Directory`. The full path of the directory in which all repositories (downloaded by the previous step) are located.
Users can also define the following two optional parametes:
2. `Boolean`. Perform a mvn clean on each repository before compiling it again, and
3. `Datetime`. Checkout each repository to a specific date. Date shoud be formatted as `YYYY-MM-DD` (example `2018-12-25`)
```
import project_installer
root_directory = download_directory # replace this value
repositories_sucessfully_build_list = "../sucessfully_built_repositories.csv" #
project_installer.install_all_repositories(root_directory,repositories_root_directories_file,repositories_sucessfully_build_list)
#project_installer.install_all_repositories(root_directory, repository_list, build_list_file, clean_repository_before_install, skip_maven, skip_gradle)
```
<a id="dependencies"></a>
## Retrieve project dependencies
Having a local copy of each maven reporitory we proceed with retrieving their dependency tree. Each tree will be stored in a separate file (with `.trees` suffix) for further analysis as we describe on the next [step](#spotbugs). If a project consist of more than one modules, a seperate tree of each module will be stored in the `.trees` file.
This step requires two parameters:
1. `root_directory` : `Directory`. The full path of the directory that stores the repositories
2. `output_directory` : `Directory`. The full path of the directory that will store the `.trees` files.
```
import os
import dependency_extractor
os.chdir('/home/agkortzis/git_repos/ICSR19/analysis/tooling')
os.getcwd()
root_directory = f"/media/agkortzis/Data/maven_repos/" # replace this value
output_directory = "/home/agkortzis/git_repos/ICSR19/analysis/data/" # replace this value
#repositories_sucessfully_build_list = repositories_sucessfull_build_list # from step "Compile and install Maven projects"
repositories_sucessfully_build_list = "../successfuly_built_maven_repos_part2.txt" # from step "Compile and install Maven projects"
repositories_root_directories_file = "../downloaded_repos_with_maven_rootpaths.txt" # from step "Detect Maven root directories"
dependency_extractor.execute(root_directory, output_directory, repositories_sucessfully_build_list, repositories_root_directories_file)
```
<a id="spotbugs"></a>
## Run SpotBugs
With the installed projects, the next step is to run SpotBugs.
For that, we use the `.trees` files, which contain the dependency tree for each module built for the project.
Thus, for each project (i.e., each `.trees` files), the next sub-steps are:
1. Parse the `.trees` file
2. Ignore modules that are not Java source code (not `.jar` nor `.war`)
3. For each remaining tree (i.e., for each `.jar`/`.war` module):
1. Select relevant dependencies (i.e., compile dependencies)
2. Verify if main package and dependencies are installed in the `.m2` local repository
3. Run SpotBugs for the set **[module] + [dependencies]**
```
import os
import logging
import datetime
import maven
import spotbugs
logging.basicConfig(level=logging.INFO)
os.chdir('/home/agkortzis/git_repos/ICSR19/analysis/tooling')
os.getcwd()
path_to_data = os.path.abspath('../repositories_data') #TODO: replace with relative
path_to_m2_directory = '/media/agkortzis/Data/m2'
def run_spotbugs(file_project_trees, output_file, path_to_m2_directory=os.path.expanduser('~/.m2')):
trees = maven.get_compiled_modules(file_project_trees)
if not trees:
logging.info(f'No modules to analyze: {file_project_trees}.')
return
pkg_paths = []
for t in trees:
pkg_paths.extend([a.artifact.get_m2_path(path_to_m2_directory) for a in t])
pkg_paths = list(set(pkg_paths))
spotbugs.analyze_project(pkg_paths, output_file)
currentDT = datetime.datetime.now()
print ("Started at :: {}".format(str(currentDT)))
projects_tress = [f for f in os.listdir(path_to_data) if f.endswith('.trees')]
counter = 1
total = len(projects_tress)
for f in projects_tress:
filepath = path_to_data + os.path.sep + f
output_file = f'{os.path.splitext(filepath)[0]}.xml'
logging.info("{}/{}".format(counter,total))
run_spotbugs(filepath, output_file, path_to_m2_directory)
counter = counter + 1
currentDT = datetime.datetime.now()
print ("Finished at :: {}".format(str(currentDT)))
```
<a id="metrics"></a>
## Extract metrics and create analysis dataset
*[Describe steps]*
```
import csv
import os
import itertools
import logging
import datetime
import maven as mvn
import spotbugs as sb
import sloc
logging.basicConfig(level=logging.INFO)
def count_vulnerabilities(spotbugs_xml, classes_sloc, class_sets, class_dict): # {'uv': project_classes, 'dv': dep_classes}
vdict = sb.collect_vulnerabilities(spotbugs_xml, class_dict)
dataset_info = {}
for k in class_dict.keys():
dataset_info[k] = {}
dataset_info[k]["classes"] = [sb.get_main_classname(b) for c in vdict[k] for r in c for b in r]
dataset_info[k]["classes"] = list(set(dataset_info[k]["classes"]))
dataset_info[k]["count"] = [len(r) for c in vdict[k] for r in c]
dataset_info[k]["sloc"] = 0
dataset_info[k]["classes_sloc"] = 0
try:
dataset_info[k]["sloc"] = sum([int(classes_sloc.get(c,0)) for c in sloc.get_roots(class_dict[k])])
dataset_info[k]["classes_sloc"] = sum([int(classes_sloc.get(c,0)) for c in sloc.get_roots(dataset_info[k]["classes"])])
except Exception as e:
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_dep_classes.txt', 'w') as log:
for entry in sloc.get_roots(class_dict[k]):
log.write("{}\n".format(entry))
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_dep_original.txt', 'w') as log:
for entry in class_dict[k]:
log.write("{}\n".format(entry))
raise e
logging.error("Error while calculating metrics\n{}".format(e))#angor
return [len(class_dict[k]) for k in class_sets] + [len(dataset_info[k]["classes"]) for k in class_sets] + [dataset_info[k]["sloc"] for k in class_sets] + [dataset_info[k]["classes_sloc"] for k in class_sets] + [count for k in class_sets for count in dataset_info[k]["count"]] # e.g., #uv_p1_r1 | #uv_p1_r2 ... | #dv_p3_r3 | #dv_p3_r4
def project_level_metrics(trees, spotbugs_xml, path_to_m2_directory=os.path.expanduser('~/.m2')):
modules = [m.artifact for m in trees]
dep_modules = [m.artifact for t in trees for m in t.deps if m.artifact not in modules]
dep_modules = list(set(dep_modules)) # remove duplicates
metrics = {}
# Collect SLOC info
classes_sloc = {}
for m in (modules + dep_modules):
classes_sloc.update(sloc.retrieve_SLOC(m.get_m2_path(path_to_m2_directory))[0])
# Collect classes from user code
project_classes = [c for m in modules for c in m.get_class_list(path_to_m2_directory)]
# Collect classes from dependencies
## Original dataset
try:
dep_classes = [c for m in dep_modules for c in m.get_class_list(path_to_m2_directory)]
except Exception as e:#angor
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_modules.txt', 'w') as log:
log.write("{}\n".format(spotbugs_xml))
for entry in dep_modules:
log.write("{}\n".format(entry.get_m2_path(path_to_m2_directory)))
raise e
metrics['general'] = count_vulnerabilities(spotbugs_xml, classes_sloc, ['uv', 'dv'], {'uv': project_classes, 'dv': dep_classes})
## Enterprise dataset (compare enterprise vs. non-enterprise dependencies)
dm_enterprise = [m for m in dep_modules if m.groupId in enterprise_group_ids]
dm_not_enterprise = [m for m in dep_modules if m.groupId not in enterprise_group_ids]
try:
dc_enterprise = [c for m in dm_enterprise for c in m.get_class_list(path_to_m2_directory)]
dc_not_enterprise = [c for m in dm_not_enterprise for c in m.get_class_list(path_to_m2_directory)]
except Exception as e:#angor
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_modules-enterprise.txt', 'w') as log:
log.write("{}\n".format(spotbugs_xml))
for entry in dep_modules:
log.write("{}\n".format(entry.get_m2_path(path_to_m2_directory)))
raise e
metrics['enterprise'] = count_vulnerabilities(spotbugs_xml, classes_sloc, ['uv', 'dve', 'dvne'], {'uv': project_classes, 'dve': dc_enterprise, 'dvne': dc_not_enterprise})
## Well-known projects (compare well-known community projects vs. non-well-known projects dependencies)
dm_known = [m for m in dep_modules if m.groupId in wellknown_group_ids]
dm_not_known = [m for m in dep_modules if m.groupId not in wellknown_group_ids]
try:
dc_known = [c for m in dm_known for c in m.get_class_list(path_to_m2_directory)]
dc_not_known = [c for m in dm_not_known for c in m.get_class_list(path_to_m2_directory)]
except Exception as e:#angor
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_modules-wellknown.txt', 'w') as log:
log.write("{}\n".format(spotbugs_xml))
for entry in dep_modules:
log.write("{}\n".format(entry.get_m2_path(path_to_m2_directory)))
raise e
metrics['wellknown'] = count_vulnerabilities(spotbugs_xml, classes_sloc, ['uv', 'dvw', 'dvnw'], {'uv': project_classes, 'dvw': dc_known, 'dvnw': dc_not_known})
return metrics
def collect_sp_metrics(file_project_trees, output_file, append_to_file=True, path_to_m2_directory=os.path.expanduser('~/.m2')):
trees = mvn.get_compiled_modules(file_project_trees)
spotbugs_xml = f'{os.path.splitext(file_project_trees)[0]}.xml'
proj_name = os.path.basename(os.path.splitext(file_project_trees)[0])
logging.info("Project :: {}".format(proj_name))
if not trees:
logging.warning(f'No modules to analyze: {file_project_trees}.')
return
if not os.path.exists(spotbugs_xml):
logging.warning(f'SpotBugs XML not found: {spotbugs_xml}.')
return
metrics = project_level_metrics(trees, spotbugs_xml, path_to_m2_directory)
for dataset in metrics.keys():
if append_to_file:
with open(output_file+dataset+'.csv', 'a') as f:
f.write(','.join([proj_name] + [str(m) for m in metrics[dataset]]) + os.linesep)
else:
with open(output_file+dataset+'.csv', 'w') as f:
f.write(','.join([proj_name] + [str(m) for m in metrics[dataset]]) + os.linesep)
logging.debug(f'{dataset}||' + ','.join([proj_name] + [str(m) for m in metrics[dataset]]) + os.linesep)
def create_headers(class_sets):
proj_info = [f'#{k}{h}' for h in ['_classes', 'v_classes', '_sloc', 'v_classes_sloc'] for k in class_sets]
vcount = [f'#{k}v_p{p}_r{r}' for k in class_sets for p in range(1,4) for r in range(1,5)]
return ['project'] + proj_info + vcount
currentDT = datetime.datetime.now()
print ("Started at :: {}".format(str(currentDT)))
os.chdir('/home/agkortzis/git_repos/ICSR19/analysis/tooling')
os.getcwd()
path_to_m2_directory = '/media/agkortzis/2TB_EX_STEREO/m2'
path_to_data = os.path.abspath('../repositories_data')
projects_dataset = os.path.abspath('../jss_revised_dataset.csv')
projects_escope_dataset = os.path.abspath('../dependencies_groupids_enterprise_info.csv')
with open(projects_escope_dataset) as escope_csv:
enterprise_group_ids = set()
wellknown_group_ids = set()
rows = csv.reader(escope_csv, delimiter=';')
for r in rows:
if r[2] == '1':
enterprise_group_ids.add(r[1])
# logging.info("Entreprise id = {}".format(r[1]))
if r[6] == '1':
wellknown_group_ids.add(r[1])
# logging.info("Well known id = {}".format(r[1]))
#
with open(projects_dataset+'general.csv', 'w') as f:
class_sets = ['u', 'd']
f.write(','.join(create_headers(class_sets)) + os.linesep)
with open(projects_dataset+'enterprise.csv', 'w') as f:
class_sets = ['u', 'de', 'dne']
f.write(','.join(create_headers(class_sets)) + os.linesep)
with open(projects_dataset+'wellknown.csv', 'w') as f:
class_sets = ['u', 'dw', 'dnw']
f.write(','.join(create_headers(class_sets)) + os.linesep)
projects_tress = [f for f in os.listdir(path_to_data) if f.endswith('.trees')]
number_of_projects = len(projects_tress)
for index, f in enumerate(projects_tress):
logging.info("{}/{} --> {}".format(index,number_of_projects,f))
filepath = path_to_data + os.path.sep + f
collect_sp_metrics(filepath, projects_dataset, path_to_m2_directory)
currentDT = datetime.datetime.now()
print ("Finished at :: {}".format(str(currentDT)))
import os
import itertools
import logging
import datetime
import maven as mvn
import spotbugs as sb
import sloc
logging.basicConfig(level=logging.INFO)
os.chdir('/home/agkortzis/git_repos/ICSR19/analysis/tooling')
os.getcwd()
path_to_m2_directory = '/media/agkortzis/2TB_EX_STEREO/m2'
path_to_data = os.path.abspath('../repositories_data')
projects_dataset = os.path.abspath('../jss_revised_dataset.csv')
def project_level_metrics(trees, spotbugs_xml, path_to_m2_directory=os.path.expanduser('~/.m2')):
modules = [m.artifact for m in trees]
dep_modules = [m.artifact for t in trees for m in t.deps if m.artifact not in modules]
dep_modules = list(set(dep_modules)) # remove duplicates
# Collect classes from user code
project_classes = [c for m in modules for c in m.get_class_list(path_to_m2_directory)]
try:
# Collect classes from dependencies
dep_classes = [c for m in dep_modules for c in m.get_class_list(path_to_m2_directory)]
except Exception as e:#angor
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_modules.txt', 'w') as log:
log.write("{}\n".format(spotbugs_xml))
for entry in dep_modules:
log.write("{}\n".format(entry.get_m2_path(path_to_m2_directory)))
raise e
# Collect SLOC info
classes_sloc = {}
for m in (modules + dep_modules):
classes_sloc.update(sloc.retrieve_SLOC(m.get_m2_path(path_to_m2_directory))[0])
vdict = sb.collect_vulnerabilities(spotbugs_xml, {'uv': project_classes, 'dv': dep_classes})
uv_classes = [sb.get_main_classname(b) for c in vdict['uv'] for r in c for b in r]
uv_classes = list(set(uv_classes))
dv_classes = [sb.get_main_classname(b) for c in vdict['dv'] for r in c for b in r]
dv_classes = list(set(dv_classes))
uv_count = [len(r) for c in vdict['uv'] for r in c]
dv_count = [len(r) for c in vdict['dv'] for r in c]
u_sloc, d_sloc, uv_classes_sloc, dv_classes_sloc = 0, 0, 0, 0 #angor
try:#angor
u_sloc = sum([int(classes_sloc.get(c,0)) for c in sloc.get_roots(project_classes)])
d_sloc = sum([int(classes_sloc.get(c,0)) for c in sloc.get_roots(dep_classes)])
uv_classes_sloc = sum([int(classes_sloc.get(c,0)) for c in sloc.get_roots(uv_classes)])
dv_classes_sloc = sum([int(classes_sloc.get(c,0)) for c in sloc.get_roots(dv_classes)])
except Exception as e:#angor
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_dep_classes.txt', 'w') as log:
for entry in sloc.get_roots(dep_classes):
log.write("{}\n".format(entry))
with open ('/home/agkortzis/git_repos/ICSR19/analysis/log_dep_original.txt', 'w') as log:
for entry in dep_classes:
log.write("{}\n".format(entry))
raise e#angor
logging.error("Error while calculating metrics\n{}".format(e))#angor
return [
len(project_classes), # #u_classes
len(dep_classes), # #d_classes
len(uv_classes), # #uv_classes
len(dv_classes), # #dv_classes
u_sloc, # #u_sloc
d_sloc, # #d_sloc
uv_classes_sloc , # #uv_classes_sloc
dv_classes_sloc # #dv_classes_sloc
] + uv_count + dv_count # #uv_p1_r1 | #uv_p1_r2 ... | #dv_p3_r3 | #dv_p3_r4
def collect_sp_metrics(file_project_trees, output_file, append_to_file=True, path_to_m2_directory=os.path.expanduser('~/.m2')):
trees = mvn.get_compiled_modules(file_project_trees)
spotbugs_xml = f'{os.path.splitext(file_project_trees)[0]}.xml'
proj_name = os.path.basename(os.path.splitext(file_project_trees)[0])
logging.info("Project :: {}".format(proj_name))
if not trees:
logging.warning(f'No modules to analyze: {file_project_trees}.')
return
if not os.path.exists(spotbugs_xml):
logging.warning(f'SpotBugs XML not found: {spotbugs_xml}.')
return
metrics = project_level_metrics(trees, spotbugs_xml, path_to_m2_directory)
if append_to_file:
with open(output_file, 'a') as f:
f.write(','.join([proj_name] + [str(m) for m in metrics]) + os.linesep)
else:
with open(output_file, 'w') as f:
f.write(','.join([proj_name] + [str(m) for m in metrics]) + os.linesep)
logging.debug(','.join([proj_name] + [str(m) for m in metrics]) + os.linesep)
currentDT = datetime.datetime.now()
print ("Started at :: {}".format(str(currentDT)))
metrics_header = ['#u_classes', '#d_classes', '#uv_classes', '#dv_classes',
'#u_sloc', '#d_sloc', '#uv_classes_sloc', '#dv_classes_sloc',
'#uv_p1_r1', '#uv_p1_r2', '#uv_p1_r3', '#uv_p1_r4',
'#uv_p2_r1', '#uv_p2_r2', '#uv_p2_r3', '#uv_p2_r4',
'#uv_p3_r1', '#uv_p3_r2', '#uv_p3_r3', '#uv_p3_r4',
'#dv_p1_r1', '#dv_p1_r2', '#dv_p1_r3', '#dv_p1_r4',
'#dv_p2_r1', '#dv_p2_r2', '#dv_p2_r3', '#dv_p2_r4',
'#dv_p3_r1', '#dv_p3_r2', '#dv_p3_r3', '#dv_p3_r4', ]
with open(projects_dataset, 'w') as f:
f.write(','.join((['project'] + metrics_header)) + os.linesep)
projects_tress = [f for f in os.listdir(path_to_data) if f.endswith('.trees')]
number_of_projects = len(projects_tress)
for index, f in enumerate(projects_tress):
logging.info("{}/{} --> {}".format(index,number_of_projects,f))
filepath = path_to_data + os.path.sep + f
collect_sp_metrics(filepath, projects_dataset, path_to_m2_directory)
currentDT = datetime.datetime.now()
print ("Finished at :: {}".format(str(currentDT)))
```
| github_jupyter |
**Notas para contenedor de docker:**
Comando de docker para ejecución de la nota de forma local:
nota: cambiar `dir_montar` por la ruta de directorio que se desea mapear a `/datos` dentro del contenedor de docker.
```
dir_montar=<ruta completa de mi máquina a mi directorio>#aquí colocar la ruta al directorio a montar, por ejemplo:
#dir_montar=/Users/erick/midirectorio.
```
Ejecutar:
```
$docker run --rm -v $dir_montar:/datos --name jupyterlab_prope_r_kernel_tidyverse -p 8888:8888 -d palmoreck/jupyterlab_prope_r_kernel_tidyverse:3.0.16
```
Ir a `localhost:8888` y escribir el password para jupyterlab: `qwerty`
Detener el contenedor de docker:
```
docker stop jupyterlab_prope_r_kernel_tidyverse
```
Documentación de la imagen de docker `palmoreck/jupyterlab_prope_r_kernel_tidyverse:3.0.16` en [liga](https://github.com/palmoreck/dockerfiles/tree/master/jupyterlab/prope_r_kernel_tidyverse).
---
Para ejecución de la nota usar:
[docker](https://www.docker.com/) (instalación de forma **local** con [Get docker](https://docs.docker.com/install/)) y ejecutar comandos que están al inicio de la nota de forma **local**.
O bien dar click en alguno de los botones siguientes:
[](https://mybinder.org/v2/gh/palmoreck/dockerfiles-for-binder/jupyterlab_prope_r_kernel_tidyerse?urlpath=lab/tree/Propedeutico/Python/clases/1_introduccion/2_core_python.ipynb) esta opción crea una máquina individual en un servidor de Google, clona el repositorio y permite la ejecución de los notebooks de jupyter.
[](https://repl.it/languages/python3) esta opción no clona el repositorio, no ejecuta los notebooks de jupyter pero permite ejecución de instrucciones de *Python* de forma colaborativa con [repl.it](https://repl.it/). Al dar click se crearán nuevos ***repl*** debajo de sus users de ***repl.it***.
# Revisar y ejecutar los ejemplos de la sección 1.2 del libro de texto "Numerical Methods in Engineering with Python3" de J. Kiusalaas
Temas:
* Variables, *strings*, tuples, listas.
* Operadores aritméticos y operadores de comparación.
* Condicionales.
* Loops.
* Conversión de tipo.
* Funciones matemáticas.
* Input/Output.
* Abrir/Cerrar un archivo.
* Control de errores.
## *Strings*
```
string = "Un día soleado como hoy :)"
string
string2 = "así es!"
string3 = "".join([string,"\n", string2])
string3
print(string3)
print("-"*20)
```
**Seleccionando posiciones:**
```
string[0:5]
string[:5]
string[0:10]
string[0:10:1]
string[0:10:4]
string[0:10:3]
string[1:10:4]
print(string3)
print("-"*20)
```
**Usando tres dobles commilas y salto de línea"**
```
string4 = """Un día soleado como hoy :)
así es!
"""
string4
print(string4)
string4.splitlines()
string4.split()
k = 0
for linea in string4.splitlines():
print(linea)
print(k)
k+=1
```
## Tuplas
Una tupla en Python es una estructura de datos y puede crearse como sigue:
```
(1,2,3)
mytuple = (1, 2, 3)
mytuple[0]
mytuple[1]
mytuple[2]
```
Otra forma es directamente con la función `tuple`:
```
mytuple2 = tuple((1, "Hola", "mundo!"))
mytuple2[1] + mytuple2[2]
mytuple2[1] + " " + mytuple2[2]
```
Podemos acceder al último elemento de una tupla con:
```
mytuple2[-1]
```
**Una característica importante de una tupla es que no pueden modificarse sus elementos, no es mutable**.
```
mytuple[0]
mytuple[0] = -1
```
Otra forma de crear una lista es vía *list comprehension* ver [liga](https://realpython.com/list-comprehension-python/)
```
a = [(-1)**k for k in range(4)]
a
```
## Listas
Una lista en Python es una estructura de datos y puede crearse como sigue:
```
a = [1, "string1", 2]
a[0]
a[1]
a[2]
```
Una lista es similar a una tupla pero **tiene la característica de ser mutable**:
```
a[0] = -1
a
```
Otra forma de crear una lista es vía *list comprehension* ver [liga](https://realpython.com/list-comprehension-python/)
```
a = [(-1)**k for k in range(4)]
a
```
---
**Observación**
Si se utiliza un *statement* de la forma `a = ((-1)**k for k in range(4))` lo que obtenemos es un [generator](https://wiki.python.org/moin/Generators)
---
```
a = ((-1)**k for k in range(4))
for n in a:
print(n)
```
## Diccionarios
Creamos un diccionario con: `{}` o `dict()`
```
dic = {'llave1': 1,'llave2':'string1'}
print(dic)
dic2 = dict([('key1', -1), ('key2', 'mistring')])
print(dic2)
#podemos acceder a los valores
#guardados en cada llave como sigue:
print('valor guardado en la llave1:', dic['llave1'])
print('valor guardado en la llave2:',dic['llave2'])
print('valor guardado en la key1:', dic2['key1'])
print('valor guardado en la key2:', dic2['key2'])
#imprimimos las llaves
print('llaves del diccionario:',dic.keys())
#imprimimos los valores:
print('valores del diccionario:', dic.values())
print('llaves del diccionario:',dic2.keys())
print('valores del diccionario:', dic2.values())
for k,v in dic.items():
print("llave:")
print(k)
print("valor:")
print(v)
#añadimos entradas a un diccionario
#con:
dic['llave3'] = -34
print('añadiendo pareja llave-valor al diccionario: \n',dic)
dic2['key3'] = 'mistring2'
print('añadiendo pareja llave-valor al diccionario: \n',dic2)
#podemos remover la llave-valor del diccionario con pop
valor=dic.pop('llave1')
print(valor)
print('el diccionario:', dic)
valor2=dic2.pop('key3')
print(valor2)
print('el diccionario2:', dic2)
{x: x**2 for x in (2, 4, 6)}
```
## Referencias
* Estructuras de datos: https://docs.python.org/3/tutorial/datastructures.html
* [generator](https://wiki.python.org/moin/Generators)
| github_jupyter |
# Densely Connected Networks (DenseNet)
ResNet significantly changed the view of how to parametrize the functions in deep networks. *DenseNet* (dense convolutional network) is to some extent the logical extension of this :cite:`Huang.Liu.Van-Der-Maaten.ea.2017`.
To understand how to arrive at it, let us take a small detour to mathematics.
## From ResNet to DenseNet
Recall the Taylor expansion for functions. For the point $x = 0$ it can be written as
$$f(x) = f(0) + f'(0) x + \frac{f''(0)}{2!} x^2 + \frac{f'''(0)}{3!} x^3 + \ldots.$$
The key point is that it decomposes a function into increasingly higher order terms. In a similar vein, ResNet decomposes functions into
$$f(\mathbf{x}) = \mathbf{x} + g(\mathbf{x}).$$
That is, ResNet decomposes $f$ into a simple linear term and a more complex
nonlinear one.
What if we want to capture (not necessarily add) information beyond two terms?
One solution was
DenseNet :cite:`Huang.Liu.Van-Der-Maaten.ea.2017`.

:label:`fig_densenet_block`
As shown in :numref:`fig_densenet_block`, the key difference between ResNet and DenseNet is that in the latter case outputs are *concatenated* (denoted by $[,]$) rather than added.
As a result, we perform a mapping from $\mathbf{x}$ to its values after applying an increasingly complex sequence of functions:
$$\mathbf{x} \to \left[
\mathbf{x},
f_1(\mathbf{x}),
f_2([\mathbf{x}, f_1(\mathbf{x})]), f_3([\mathbf{x}, f_1(\mathbf{x}), f_2([\mathbf{x}, f_1(\mathbf{x})])]), \ldots\right].$$
In the end, all these functions are combined in MLP to reduce the number of features again. In terms of implementation this is quite simple:
rather than adding terms, we concatenate them. The name DenseNet arises from the fact that the dependency graph between variables becomes quite dense. The last layer of such a chain is densely connected to all previous layers. The dense connections are shown in :numref:`fig_densenet`.

:label:`fig_densenet`
The main components that compose a DenseNet are *dense blocks* and *transition layers*. The former define how the inputs and outputs are concatenated, while the latter control the number of channels so that it is not too large.
## [**Dense Blocks**]
DenseNet uses the modified "batch normalization, activation, and convolution"
structure of ResNet (see the exercise in :numref:`sec_resnet`).
First, we implement this convolution block structure.
```
from mxnet import np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
def conv_block(num_channels):
blk = nn.Sequential()
blk.add(nn.BatchNorm(),
nn.Activation('relu'),
nn.Conv2D(num_channels, kernel_size=3, padding=1))
return blk
```
A *dense block* consists of multiple convolution blocks, each using the same number of output channels. In the forward propagation, however, we concatenate the input and output of each convolution block on the channel dimension.
```
class DenseBlock(nn.Block):
def __init__(self, num_convs, num_channels, **kwargs):
super().__init__(**kwargs)
self.net = nn.Sequential()
for _ in range(num_convs):
self.net.add(conv_block(num_channels))
def forward(self, X):
for blk in self.net:
Y = blk(X)
# Concatenate the input and output of each block on the channel
# dimension
X = np.concatenate((X, Y), axis=1)
return X
```
In the following example,
we [**define a `DenseBlock` instance**] with 2 convolution blocks of 10 output channels.
When using an input with 3 channels, we will get an output with $3+2\times 10=23$ channels. The number of convolution block channels controls the growth in the number of output channels relative to the number of input channels. This is also referred to as the *growth rate*.
```
blk = DenseBlock(2, 10)
blk.initialize()
X = np.random.uniform(size=(4, 3, 8, 8))
Y = blk(X)
Y.shape
```
## [**Transition Layers**]
Since each dense block will increase the number of channels, adding too many of them will lead to an excessively complex model. A *transition layer* is used to control the complexity of the model. It reduces the number of channels by using the $1\times 1$ convolutional layer and halves the height and width of the average pooling layer with a stride of 2, further reducing the complexity of the model.
```
def transition_block(num_channels):
blk = nn.Sequential()
blk.add(nn.BatchNorm(), nn.Activation('relu'),
nn.Conv2D(num_channels, kernel_size=1),
nn.AvgPool2D(pool_size=2, strides=2))
return blk
```
[**Apply a transition layer**] with 10 channels to the output of the dense block in the previous example. This reduces the number of output channels to 10, and halves the height and width.
```
blk = transition_block(10)
blk.initialize()
blk(Y).shape
```
## [**DenseNet Model**]
Next, we will construct a DenseNet model. DenseNet first uses the same single convolutional layer and maximum pooling layer as in ResNet.
```
net = nn.Sequential()
net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3),
nn.BatchNorm(), nn.Activation('relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))
```
Then, similar to the four modules made up of residual blocks that ResNet uses,
DenseNet uses four dense blocks.
Similar to ResNet, we can set the number of convolutional layers used in each dense block. Here, we set it to 4, consistent with the ResNet-18 model in :numref:`sec_resnet`. Furthermore, we set the number of channels (i.e., growth rate) for the convolutional layers in the dense block to 32, so 128 channels will be added to each dense block.
In ResNet, the height and width are reduced between each module by a residual block with a stride of 2. Here, we use the transition layer to halve the height and width and halve the number of channels.
```
# `num_channels`: the current number of channels
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
for i, num_convs in enumerate(num_convs_in_dense_blocks):
net.add(DenseBlock(num_convs, growth_rate))
# This is the number of output channels in the previous dense block
num_channels += num_convs * growth_rate
# A transition layer that halves the number of channels is added between
# the dense blocks
if i != len(num_convs_in_dense_blocks) - 1:
num_channels //= 2
net.add(transition_block(num_channels))
```
Similar to ResNet, a global pooling layer and a fully-connected layer are connected at the end to produce the output.
```
net.add(nn.BatchNorm(),
nn.Activation('relu'),
nn.GlobalAvgPool2D(),
nn.Dense(10))
```
## [**Training**]
Since we are using a deeper network here, in this section, we will reduce the input height and width from 224 to 96 to simplify the computation.
```
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
```
## Summary
* In terms of cross-layer connections, unlike ResNet, where inputs and outputs are added together, DenseNet concatenates inputs and outputs on the channel dimension.
* The main components that compose DenseNet are dense blocks and transition layers.
* We need to keep the dimensionality under control when composing the network by adding transition layers that shrink the number of channels again.
## Exercises
1. Why do we use average pooling rather than maximum pooling in the transition layer?
1. One of the advantages mentioned in the DenseNet paper is that its model parameters are smaller than those of ResNet. Why is this the case?
1. One problem for which DenseNet has been criticized is its high memory consumption.
1. Is this really the case? Try to change the input shape to $224\times 224$ to see the actual GPU memory consumption.
1. Can you think of an alternative means of reducing the memory consumption? How would you need to change the framework?
1. Implement the various DenseNet versions presented in Table 1 of the DenseNet paper :cite:`Huang.Liu.Van-Der-Maaten.ea.2017`.
1. Design an MLP-based model by applying the DenseNet idea. Apply it to the housing price prediction task in :numref:`sec_kaggle_house`.
[Discussions](https://discuss.d2l.ai/t/87)
| github_jupyter |
# Reading data with pandas
## Use the Pandas library to do statistics on tabular data.
* Pandas is a widely-used Python library for statistics, particularly on tabular data.
* Borrows many features from R's dataframes.
* A 2-dimensional table whose columns have names
and potentially have different data types.
* Load it with `import pandas as pd`. The alias pd is commonly used for Pandas.
* Read a Comma Separate Values (CSV) data file with `pd.read_csv`.
* Argument is the name of the file to be read.
* Assign result to a variable to store the data that was read.
```
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv')
print(data)
```
* The columns in a dataframe are the observed variables, and the rows are the observations.
* Pandas uses backslash `\` to show wrapped lines when output is too wide to fit the screen.
```{warning}
## File Not Found
Our lessons store their data files in a `data` sub-directory, which is why the path to the file is `data/gapminder_gdp_oceania.csv`.
If you forget to include `data/`, or if you include it but your copy of the file is somewhere else, you will get a runtime error
```
## Use `index_col` to specify that a column's values should be used as row headings.
* Row headings are numbers (0 and 1 in this case).
* Really want to index by country.
* Pass the name of the column to `read_csv` as its `index_col` parameter to do this.
```
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
print(data)
```
## Use the `DataFrame.info()` method to find out more about a dataframe.
```
data.info()
```
* This is a `DataFrame`
* Two rows named `'Australia'` and `'New Zealand'`
* Twelve columns, each of which has two actual 64-bit floating point values.
* We will talk later about null values, which are used to represent missing observations.
* Uses 208 bytes of memory.
## The `DataFrame.columns` variable stores information about the dataframe's columns.
* Note that this is data, *not* a method. (It doesn't have parentheses.)
* Like `math.pi`.
* So do not use `()` to try to call it.
* Called a *member variable*, or just *member*.
```
print(data.columns)
```
## Use `DataFrame.T` to transpose a dataframe.
* Sometimes want to treat columns as rows and vice versa.
* Transpose (written `.T`) doesn't copy the data, just changes the program's view of it.
* Like `columns`, it is a member variable.
```
print(data.T)
```
## Use `DataFrame.describe()` to get summary statistics about data.
`DataFrame.describe()` gets the summary statistics of only the columns that have numerical data.
All other columns are ignored, unless you use the argument `include='all'`.
```
print(data.describe())
```
* Not particularly useful with just two records,
but very helpful when there are thousands.
```{admonition} Exercise: Reading Other Data
Read the data in `gapminder_gdp_americas.csv`,(which should be in the same directory as `gapminder_gdp_oceania.csv`) into a variable called `americas` and display its summary statistics.
```
:::{admonition} See Solution
:class: tip, dropdown
To read in a CSV, we use `pd.read_csv` and pass the filename 'data/gapminder_gdp_americas.csv' to it. We also once again pass the column name 'country' to the parameter `index_col` in order to index by country:
```python
americas = pd.read_csv('data/gapminder_gdp_americas.csv', index_col='country')
```
:::
```{admonition} Exercise: Inspecting Data
After reading the data for the Americas, use `help(americas.head)` and `help(americas.tail)` to find out what `DataFrame.head` and `DataFrame.tail` do.
1. What method call will display the first three rows of this data?
2. What method call will display the last three columns of this data?
(Hint: you may need to change your view of the data.)
```
:::{admonition} See Solution
:class: tip, dropdown
1. We can check out the first five rows of `americas` by executing `americas.head()` (allowing us to view the head of the DataFrame). We can specify the number of rows we wish to see by specifying the parameter `n` in our call to `americas.head()`. To view the first three rows, execute:
```python
americas.head(n=3)
```
2. To check out the last three rows of `americas`, we would use the command, `americas.tail(n=3)`, analogous to `head()` used above. However, here we want to look at the last three columns so we need to change our view and then use `tail()`. To do so, we create a new DataFrame in which rows and columns are switched:
```python
americas_flipped = americas.T
```
We can then view the last three columns of `americas` by viewing the last three rows of `americas_flipped`:
```python
americas_flipped.tail(n=3)
```
:::
| github_jupyter |
# Generating synthetic sequences with embedded regulatory grammars for RNA-binding proteins
In this notebook, we will generate synthetic sequences with implanted regulatory grammars, i.e. set of motifs. Each regulatory grammar is defined by a set of motifs that are separated in space a specific distance. In this simple dataset, only a single regulatory grammar is embedded within each sequence, which basically means that there is no useless motifs implanted, i.e. only sampling noise from the position weight matrices. In addition, the start position of the regulatory grammar can be implanted in random locations on the seuqence, albeit the spacing between the motifs are conserved. Details of the simulation procedure is outlined below.
```
import os, sys, h5py
import numpy as np
import pandas as pd
np.random.seed(22) # for reproducibility
```
## Process JASPAR pfm and convert to pwm
First we need to download the JASPAR motifs:
! wget http://jaspar.genereg.net/html/DOWNLOAD/JASPAR_CORE/pfm/nonredundant/pfm_vertebrates.txt -O ../data/synthetic_TF_dataset/pfm_vertebrates.txt
If this doesn't work, then you can download it manually from the link and place it in the ../data/synthetic_TF_dataset directory.
Next, we need to load and parse the JASPAR motifs and generate a pool of core motifs for CTCF, GABPA, SP1, SRF, and YY1, and a generic pool of motifs from which we will randomly sample from.
```
def get_jaspar_motifs(file_path):
def get_motif(f):
line = f.readline()
name = line.strip().split()[1]
pfm = []
for i in range(4):
line = f.readline()
if len(line.split()[1]) > 1:
pfm.append(np.asarray(np.hstack([line.split()[1][1:], line.split()[2:-1]]), dtype=float))
else:
pfm.append(np.asarray(line.split()[2:-1], dtype=float))
pfm = np.vstack(pfm)
sum_pfm = np.sum(pfm, axis=0)
pwm = pfm/np.outer(np.ones(4), sum_pfm)
line = f.readline()
return name, pwm
num_lines = sum(1 for line in open(file_path))
num_motifs = int(num_lines/6)
f = open(file_path)
tf_names = []
tf_motifs = []
for i in range(num_motifs):
name, pwm = get_motif(f)
tf_names.append(name)
tf_motifs.append(pwm)
return tf_motifs, tf_names
# parse JASPAR motifs
savepath = '../../data'
file_path = os.path.join(savepath, 'pfm_vertebrates.txt')
motif_set, motif_names = get_jaspar_motifs(file_path)
# get a subset of core motifs
core_names = ['SP1', 'Gabpa', 'CEBPB', 'MAX', 'YY1']
strand_motifs = []
core_index = []
for name in core_names:
index = motif_names.index(name)
strand_motifs.append(motif_set[index])
core_index.append(index)
# generate reverse compliments
core_motifs = []
for pwm in strand_motifs:
core_motifs.append(pwm)
reverse = pwm[:,::-1]
core_motifs.append(reverse[::-1,:])
# randomly select background sequences which include core motifs
num_background = 65
motif_index = np.random.permutation(len(motif_set))[0:num_background]
motif_index = motif_index
background_motifs = []
for index in motif_index:
pwm = motif_set[index]
background_motifs.append(pwm)
```
### Filter background motifs that look like core motifs
```
duplicate_index = [4, 5, 12, 15, 17, 18, 20, 36, 42, 60]
motif_index = set(motif_index) - set(duplicate_index)
# randomly select background sequences which include core motifs
background_motifs = []
for motif in core_motifs:
background_motifs.append(motif)
for index in list(motif_index)[:50]:
pwm = motif_set[index]
background_motifs.append(pwm)
reverse = pwm[:,::-1]
background_motifs.append(reverse[::-1,:])
```
# Simulation overview
We define a regulatory grammar, $G$, as a the interactions of specific motifs spaced in specific spatial positions. Each grammar consists of a position weight matrix (PWM) with implanted motifs from which a synthetic sequence is generated from. In this synthetic dataset, each simulated sequence is generated from a given grammar that is randomly translated, but the motifs and spatial positions between motifs within the grammar are conserved.
To generate each regulatory grammar, we first create a model which consists of a subset of motifs and their spatial distances with respect to one another. We limit the pool of possible motifs to $M$ motifs to include all of the core motifs and a subset of motifs (num_motif total motifs) which are randomly sampled from the pool of JASPAR database (under the list tf_motifs). For a given grammar, the number of motifs is determined by sampling an exponential distribution (parameterized by interaction_rate). Then, the minimum is taken between this value and the max_motif, which imposes the constraint of a maximum number of motifs for a given grammar.
The motifs are randomly sampled from the pool of available motifs and the distance between each motif is determined by randomly sampling an exponential distribution (parameterized by distance_scale) plus a minimum distance between motifs (distance_offset). The motifs are placed along a PWM in locations determined by the distances between motifs. For simplicity, we will use a uniform distribution for the PWMs for all 'non-motif' nucleotides, i.e. $p = 1/4$.
This constitutes the regulatory grammar model, from which synthetic sequences can be simulated from. Moreover, each regulatory grammar is associated to a given class.
Note that here we elect not to include alternative regulatory codes for a given class directly. Since we are sampling from a smaller pool, we assume alternative codes will give rise to a different phenotype, specified by a different class. Also, we do not alter the spacing between the motifs or include noisy motifs in the grammar model. All of the noise comes from random sampling in generating the sequence and the translation of the grammar.
```
def generate_model(core_motifs, min_interactions, max_interactions, seq_length):
num_motif = len(core_motifs)
cum_dist = np.cumsum([0, 0, 0.5, 0.25, 0.17, .05, 0.3])
# sample core motifs for each grammar
valid_sim = False
while not valid_sim:
# determine number of core motifs in a given grammar model
num_interactions = np.where(np.random.rand() > cum_dist)[0][-1]+2 #np.random.randint(min_interactions, max_interactions)
# randomly sample motifs
sim_motifs = np.random.randint(num_motif, size=num_interactions)
num_sim_motifs = len(sim_motifs)
#sim_motifs = sim_motifs[np.random.permutation(num_sim_motifs)]
# verify that distances aresmaller than sequence length
distance = 0
for i in range(num_sim_motifs):
distance += core_motifs[sim_motifs[i]].shape[1]
if seq_length > distance > 0:
valid_sim = True
# simulate distances between motifs + start
valid_dist = False
while not valid_dist:
remainder = seq_length - distance
sep = np.random.uniform(0, 2, size=num_sim_motifs+1)
sep = np.round(sep/sum(sep)*remainder).astype(int)
if np.sum(sep) == remainder:
valid_dist = True
# build a PWM for each regulatory grammar
pwm = np.ones((4,sep[0]))/4
for i in range(num_sim_motifs):
pwm = np.hstack([pwm, core_motifs[sim_motifs[i]], np.ones((4,sep[i+1]))/4])
return pwm
def simulate_sequence(sequence_pwm):
"""simulate a sequence given a sequence model"""
nucleotide = 'ACGT'
# sequence length
seq_length = sequence_pwm.shape[1]
# generate uniform random number for each nucleotide in sequence
Z = np.random.uniform(0,1,seq_length)
# calculate cumulative sum of the probabilities
cum_prob = sequence_pwm.cumsum(axis=0)
# go through sequence and find bin where random number falls in cumulative
# probabilities for each nucleotide
one_hot_seq = np.zeros((4, seq_length))
for i in range(seq_length):
index=[j for j in range(4) if Z[i] < cum_prob[j,i]][0]
one_hot_seq[index,i] = 1
return one_hot_seq
```
# Simulation overview
The number of sequences for each grammar is determined by a randomly sampled population fraction (pop_fraction). For a each grammar model, the total number of sequences simulated is then, $N$ times its population fraction. For each sequence, the grammar model is randomly translated according to a Gaussian distribution, but with constraints to make sure the entire grammar is contained within the sequence. Then, the cumulative sum at each nucleotide position of the translated model is calculated. A uniform random number from 0 to 1 is generated and the bin with which it falls with respect to the the cumulative proprabilities specifies the simulated nucleotide value. THis is done for each nucleotide position to simulate the entire sequence of length $S$.
After all of the the synthetic sequences are generated, i.e. the sequence model (translated grammar), and an indicator vector of length $G$ specifying which grammar generated the sequence, the dataset is split into training, cross-validation, and a test set. Then each dataset is stored in a hdf5 file.
```
# dataset parameters
num_seq = 20000 # number of sequences
seq_length = 200 # length of sequence
min_interactions = 3 # exponential rate of number of motifs for each grammar
max_interactions = 5
# generate sythetic sequences as a one-hot representation
seq_pwm = []
seq_model = []
num_sim = int(num_seq/2)
for j in range(num_sim):
signal_pwm = generate_model(core_motifs, min_interactions, max_interactions, seq_length)
seq_pwm.append(simulate_sequence(signal_pwm))
seq_model.append(signal_pwm)
# simulate a background sequence
for j in range(num_sim):
background_pwm = generate_model(background_motifs, 2, max_interactions, seq_length)
seq_pwm.append(simulate_sequence(background_pwm))
seq_model.append(background_pwm)
# generate labels
seq_label = np.vstack([np.ones((num_sim,1)), np.zeros((num_sim, 1))])
def split_data(data, label, model, split_size):
"""split data into train set, cross-validation set, and test set"""
def subset_data(data, label, model, sub_index):
"""returns a subset of the data and labels based on sub_index"""
num_sub = len(sub_index)
sub_set_label = []
sub_set_seq = []
sub_set_model = []
for index in sub_index:
sub_set_seq.append([data[index]])
sub_set_label.append(label[index])
sub_set_model.append([model[index]])
sub_set_seq = np.vstack(sub_set_seq)
sub_set_label = np.vstack(sub_set_label)
sub_set_model = np.vstack(sub_set_model)
return (sub_set_seq, sub_set_label, sub_set_model)
# determine indices of each dataset
N = len(data)
cum_index = np.cumsum(np.multiply([0, split_size[0], split_size[1], split_size[2]],N)).astype(int)
# shuffle data
shuffle = np.random.permutation(N)
# training dataset
train_index = shuffle[range(cum_index[0], cum_index[1])]
cross_validation_index = shuffle[range(cum_index[1], cum_index[2])]
test_index = shuffle[range(cum_index[2], cum_index[3])]
# create subsets of data based on indices
print('Generating training data')
train = subset_data(data, label, model, train_index)
print('Generating cross-validation data')
cross_validation = subset_data(data, label, model, cross_validation_index)
print('Generating test data')
test = subset_data(data, label, model, test_index)
return train, cross_validation, test
def save_dataset(savepath, train, valid, test):
f = h5py.File(savepath, "w")
dset = f.create_dataset("X_train", data=train[0], compression="gzip")
dset = f.create_dataset("Y_train", data=train[1], compression="gzip")
dset = f.create_dataset("model_train", data=train[2], compression="gzip")
dset = f.create_dataset("X_valid", data=valid[0], compression="gzip")
dset = f.create_dataset("Y_valid", data=valid[1], compression="gzip")
dset = f.create_dataset("model_valid", data=valid[2], compression="gzip")
dset = f.create_dataset("X_test", data=test[0], compression="gzip")
dset = f.create_dataset("Y_test", data=test[1], compression="gzip")
dset = f.create_dataset("model_test", data=test[2], compression="gzip")
f.close()
# split into training, cross-validation, and test sets
print("Splitting dataset into train, cross-validation, and test")
train_size = 0.7
cross_validation_size = 0.1
test_size = 0.2
split_size = [train_size, cross_validation_size, test_size]
train, valid, test = split_data(seq_pwm, seq_label, seq_model, split_size)
# save to file
filename = 'synthetic_code_dataset.h5'
file_path = os.path.join(savepath, filename)
print('Saving to: ' + file_path)
save_dataset(file_path, train, valid, test)
```
| github_jupyter |
# Introduction to Python coding
*TODO*:Perhaps recognize to the students that I know they know the simple conditional and looping statements. The goal here is to get them retrained from birth so to speak to properly understand these operations in context. I'd like to show them how to think about these things. We never just decide to stick in another loop because we haven't done one in a while or randomly insert a conditional statement. Either here or somewhere else, we need to really stress the difference between atomic element assignment like numbers and assignment between references. Students had their minds blown in the linked list stuff later. Emphasize that functions can change lists that come in also.
Now that we've studied a problem-solving process and learned the common programming patterns using pseudocode, it's finally time to express ourselves using actual Python programming language syntax. Keep in mind that, to implement any program, we should follow the problem-solving process and write things out in pseudocode first. Then, coding is a simple matter of translating pseudocode to Python.
Let's review our computation model. Our basic raw ingredient is data (numbers or text strings) that lives on our disk typically (or SSDs nowadays). Note: we might have to go get that data with code; see MSAN692. The disk is very large but cannot serve up data fast enough for the processor, which is many orders of magnitude faster than the disk. Consequently, our first act in an analytics program is often to load some data from the disk into temporary memory. The memory is faster than the disk but smaller and disappears when the power goes off or your program terminates. The processor is still much faster than the memory but we have lots of tricks to increase the speed of communication between the processor and memory (e.g., caches).
The processor is where all of the action occurs because it is the entity that executes the statements in a program. The operations in a program boil down to one of these fundamental instructions within the processor:
* load small chunks of data from memory into the CPU
* perform arithmetic computations on data in the CPU
* store small chunks of data back to memory
* conditionally perform computations
* repeat operations
In [Model of Computation](computation.md), we studied pseudocode that maps to one or more of these fundamental instructions. We saw how some of the [higher-level programming patterns](operations.md) map down to pseudocode chosen from these fundamental instructions. We finished up by looking at some of the [low-level programming patterns](combinations.md) that combine fundamental instructions to do useful things like filtering and image processing.
The act of translating a pseudocode operation into Python code involves choosing the right Python construct, just like programming involves choosing the right pattern to solve a piece of a real-world problem. Then, it's a matter of shoehorning our free-form pseudocode into the straitjacket of programming language syntax. Before we get to those details, however, let's look at the big picture and a general strategy for writing programs.
## Coding is similar to writing a paper
Writing and executing a program are remarkably similar to writing and reading a paper or report. Just as with our program work plan, we begin writing a paper by clearly identifying a thesis or problem statement. Analogous to identifying input-output pairs, we might identify the target audience and what we hope readers will come away with after reading the paper. With this in mind, we should write an outline of the paper, which corresponds to identifying the processing steps in the program work plan. Sections and chapters in a paper might correspond to functions and packages in the programming world.
When reading a paper, we read the sections and paragraphs in order, like a processor executes a program. The paper text can ask the reader to jump temporarily to a figure or different section and return. This is analogous to a program calling a function and returning, possibly with some information. When reading a paper, we might also encounter conditional sections, such as "*If you've studied quantum physics, you can skip this section*." There can even be loops in a paper, such as "*Now's a good time to reread the background section on linear algebra*."
The point is that, if you've been taught how to properly write a paper, the process of writing code should feel very familiar. To simplify the process of learning to code in Python, we're going to restrict ourselves to a subset of the language and follow a few templates that will help us organize our programs.
## A small introductory Python subset
While I was in graduate school, I worked in Paris for six months (building an industrial robot control language). A friend, who didn't speak French, came over to work as well and got a tutor. The tutor started him out with just the present tense, four verbs, and a few key nouns like *café* and *croissant*. Moreover, the tutor gave him simple sentence templates in the French equivalent of these English templates:
`_______ go _______.`
and
`I am _________.`
that he could fill in with subjects and objects (nouns, pronouns).
That's also an excellent approach for learning to code in a programming language. We're going to start out playing around in a small sandbox, picking a simple subset of python that lets us do some interesting things.
The "nouns" in this subset are numbers like `34` and `3.4`, strings like `parrt`, and lists of nouns like `[3,1.5,4]`. We can name these values using *variables* just as we use names like Mary to refer to a specific human being. The "verbs", which act on nouns, are arithmetic operators like `cost + tax`, relational operators like `quantity<10`, and some built-in functions like `len(names)`. We'll also use some sentence templates for conditional statements and loops. Finally, we'll also need the ability to pull in (`import`) code written by other programmers to help us out. It's like opening a cookbook that lets us refer to existing recipes.
### Values and variables
The atomic elements in python, so to speak, are numbers and strings of text. We distinguish between integer and real numbers, which we call floating-point numbers, because computers represent the two internally in a different way. Here's where the *data type* comes back into play. Numbers like `34`, `-9`, and `0` are said to have type `int` whereas `3.14159` and `0.123` are type `float`. These values are called int or float *literals*. Strings of text are just a sequence of characters in single quotes (there are more quoting options but we can ignore that for now) and have type `string`. For example, `'parrt'` and `'May 25, 1999'`. Note that the string representation of `'207'` is very different than the integer `207`. The former is a sequence, which we can think of as a list, with three characters and the latter is a numeric value that we could, say, multiply by 10.
Let's look at our first python program!
```
print 'hi'
```
That code is a kind of *statement* that instructs the computer to print the specified value to the computer screen (the console).
**Exercise**: Try that statement out yourself. Using PyCharm, we see an editor window and the results of running the one-line program using the Run menu:
<img src="images/hi-pycharm.png" style="width: 400px">
You can also try things out interactively using the interactive Python *console* (also called a Python *shell*) without actually creating a Python file containing the code. After typing the print statement and hitting the newline (return) key, the console looks like:
<img src="images/hi-pycharm-console.png" style="width: 400px">
So here is our first statement template:
`print ___________`
We can fill that hole with any kind of *expression*; right now, we only know about values (the simplest expressions) so we can do things like:
```
print 34
print 3.14159
```
Notice the order of execution. The processor is executing one statement after the other.
Instead of printing values to the screen, let's store values into memory through variable assignment statements. The assignment statement template looks like:
*variablename* `= __________`
For example, we can store the value one into a variable called `count` and then reference that variable to load the data back from memory for use by a print statement:
```
count = 1
print count
```
Again, the sequence matters. Putting the `print` before the assignment will cause an error because `count` is not defined as a variable until after the assignment.
To see how things are stored in memory, let's look at three assignments.
```
count = 1
name = 'iPhone'
price = 699.99
```
We can visualize the state of computer memory after executing that program using [pythontutor.com](https://goo.gl/5kLND1). It shows a snapshot of memory like this:
<img src="images/assign-python-tutor.png" style="width: 100px">
(fyi, the "Global frame" holds what we call *global variables*. For now, everything will be globally visible and so we can just call them variables.)
**Exercise**: Type in those assignments yourself and then print each variable.
Another important thing about variables in a program, is that we can reassign variables to new values. For example, programs tend to count things and so you will often see assignments that looks like `count = count + 1`. Here's a contrived example:
```
count = 0
count = count + 1
print count
```
From a mathematical point of view, it looks weird/nonsensical to say that a value is equal to itself plus something else. Programmers don't mean that the two are equal; we are assigning a value to a variable, which just happens to be the same variable referenced on the right-hand side. The act of assignment corresponds to the fundamental processor "store to memory" operation we discussed earlier. The Python language differentiates between assignment, `=`, and equality, `==`, using two different operators.
### Lists of values
Just as we use columns of data in spreadsheets frequently, we also use lists of values a lot in Python coding. A list is just an ordered sequence of elements. The simplest list has numbers or strings as elements. For example, `[2, 4, 8]` is a list with three numbers in it. We call this a *list literal* just like `4` is an integer literal. Of course, we can also associate a name with a list:
```
values = [2, 4, 8]
print values
```
Python tutor shows the following snapshot of memory. Notice how indexing of the list, the numbers in grey, start from zero. In other words, the element in the 1st position has index 0, the element in the second position has index 1, etc... The last valid index in a list has the length of the list - 1.
<img src="images/list-python-tutor.png" style="width:250px">
Here's an example list with string elements:
```
names = ['Xue', 'Mary', 'Bob']
print names
```
**Exercise**: Try printing the result of adding 2 list literals together using the `+` operator. E.g., `[34,99]` and `[1,3,7]`.
The list elements don't all have to be of the same type. For example, we might group the name and enrollment of a course in the same list:
```
course = ['msan692', 51]
```
This list might be a single row in a table with lots of courses. Because a table is a list of rows, a table is a list of lists. For example, a table like this:
<img src="images/courses-table.png" style="width:100px">
could be associated with variable `courses` using this python list of row lists.
```
courses = [
['msan501', 51],
['msan502', 32],
['msan692', 101]
]
```
Python tutor gives a snapshot of memory that looks like this:
<img src="images/table-python-tutor.png" style="width:330px">
This example code also highlights an important python characteristic. Assignment and print statements must be completed on the same line *unless* we break the line in a `[...]` construct (or `(...)` for future reference). For example, if we finish the line with the `=` symbol, we get a syntax error from python:
```python
badcourses =
[
['msan501', 51],
['msan502', 32],
['msan692', 101]
]
```
yields error:
```python
File "<ipython-input-17-55e90f1fbebb>", line 1
badcourses =
^
SyntaxError: invalid syntax
```
Besides creating lists, we need to *access the elements*, which we do using square brackets and an index value. For example, to get the first course at index 0 from this list, we would use `courses[0]`:
```
print courses[0] # print the first one
print courses[1] # print the 2nd one
```
Because this is a list of lists, we use two-step array indexing like `courses[i][j]` to access row `i` and column `j`.
**Exercise**: Try printing out the `msan502` and `32` values using array index notation.
We can also set list values by using the array indexing notation on the left-hand side of an assignment statement:
```
print courses[2][1]
courses[2][1] = 99
print courses[2]
```
This indexing notation also works to access the elements of a string (but you cannot assign to individual characters in a string because strings are immutable):
```
name = 'parrt'
print name[0]
print name[1]
```
### References
Looking at the python tutor representation of our `courses` list, we can see that Python definitely represents that table as a list of lists in memory. Also notice that variable `courses` *refers* to the list, meaning that `courses` is a variable that points at some memory space organized into a list. For example, if we assign another variable to `courses`, then they *both* point at the same organized chunk of memory:
```
courses = [
['msan501', 51],
['msan502', 32],
['msan692', 101]
]
mycourses = courses
```
Python tutor illustrates [this](https://goo.gl/BSMY6y) nicely:
While the python tutor does not illustrate it this way, variables assigned to strings also refer to them with the same pointer concept. After executing the following two assignments, variables `name` and `myname` refer to the same sequence of characters in memory.
```
name = 'parrt'
myname = name
```
The general rule is that assignment only makes copies of numbers, not strings or lists. We'll learn more about this later.
### Expressions
So far, we've seen the assignment and print statements, both of which have "holes" where we can stick in values. More generally, we can insert *expressions*. An expression is just a combination of values and operators, corresponding to nouns and verbs in natural language. We use arithmetic operators (`+`, `-`, `*`, `/`) and parentheses for computing values:
```
price = 50.00
cost = price * 1.10 + 4 # add 10% tax and 4$ for shipping
print cost
```
The expression is `price * 1.10 + 4` and it follows the normal operator precedence rules that multiplies are done before additions. For example, `4 + price * 1.10` gives the same result:
```
price = 50.00
cost = 4 + price * 1.10 # add 10% tax and 4$ for shipping
print cost
```
There is another kind of expression called a *conditional expression* or *Boolean expression* that is a combination of values and relational operators (`<`, `>`, `<=`, `>=`, `==` equal, `!=` not equal). These are primarily used in conditional statements and loops, which we'll see next.
### Conditional statements
Ok, we've now got a basic understanding of how to compute and print values, and we have seen that the processor execute statements one after the other. Processors can also execute statements conditionally so let's see how to express that in python. The basic template for a conditional statement looks like:
```
if _____: _______
```
if there is one conditional statement or
```
if _____:
_____
_____
...
```
if there is more than one conditional statement.
<img src="images/redbang.png" style="width:30px" align="left"> Please note that any statements associated with this `if` are **indented** from the starting column of the `if` keyword. Indentation is how python groups statements and associates statements with conditionals and loops. All statements starting at the same column number are grouped together. The exception is when we associate a single statement with a conditional or loop on the same line (the first `if` template).
Here's a simple example that tests whether the temperature is greater than 90 degrees (Fahrenheit, let's say).
```
temp = 95
if temp>90: print 'hot!'
```
The processor executes the assignment first then tests the value of variable `temp` against value `90`. The result of that conditional expression has type boolean (`bool`). If the result is true, the processor executes the print statement guarded by the conditional. If the result is false, the processor skips the print statement.
As always, the sequence of operations is critical to proper program execution. It's worth pointing out that this `if` statement is different than what we might find in a recipe meant for humans. For example, the `if` statement above evaluates `temp>90` at a very specific point in time, directly after the previous assignment statement executes. In a recipe, however, we might see something like "*if the cream starts to boil, turn down the heat.*" What this really means is that if the cream **ever** starts to boil, turn down the heat. In most programming languages, there is no direct way to express this real-world functionality. Just keep in mind that Python `if` statements execute only when the processor reaches it. The `if` statement is not somehow constantly and repeatedly evaluating `temp>90`.
In [Model of Computation](computation.md), we also saw and if-else type conditional statement. We can also directly expressed this in python. The template looks like:
```
if _____:
_____
_____
...
else:
_____
_____
...
```
Continuing with our previous example, we might use the `else` clause like this:
```
temp = 95
if temp>90:
print 'hot!'
else:
print 'nice'
temp = 75
if temp>90:
print 'hot!'
else:
print 'nice'
```
### Loop statements
Our model of computation also allows us to repeat statements using a variety of loops. The most general loop tested a condition expression and has a template that looks like this:
```
while _____:
_____
_____
...
```
where one of the statements within the `while` loop must change the conditions of the test to avoid an infinite loop.
Let's translate this simple pseudocode program:
*init a counter to 1*<br>
*while counter <= 5*:<br>
*print "hi"*<br>
*add 1 to counter*<br>
to Python:
```
count = 0
while count <= 5:
print "hi"
count = count + 1
```
**Exercise**: Using the same coding template, alter the loop so that it prints out the `count` variable each time through the loop instead of `hi`.
Another kind of loop we saw is the for-each loop, which has the template:
```
for x in _____:
_____
_____
...
```
where `x` can be any variable name we want. For example,We can print each name from a list on a line by itself:
```
names = ['Xue', 'Mary', 'Bob']
for name in names:
print name
```
Similarly, we can print out the rows of our courses table like this:
```
for course in courses:
print course
```
When we need to loop through multiple lists simultaneously, we use indexed loops following this template:
```
n = _____ # n is the length of the lists (should be same length)
for i in range(n):
_____
_____
...
```
The `range(n)` function returns a range from 0 to n-1 or $[0..n)$ in math notation.
Here is an indexed loop that is equivalent of the for-each loop:
```
names = ['msan501', 'msan502', 'msan692']
enrollment = [51, 32, 101]
n = 3
for i in range(n):
print names[i], enrollment[i] # print the ith element of names and enrollment lists
```
Usually we don't know the length of the list (3 in this case) and so we must ask python to compute it using the commonly-used `len(...)` function. Rewriting the example to be more general, we'd see:
```
n = len(names)
for i in range(n):
print names[i], enrollment[i]
```
As a shorthand, programmers often combine the `range` and `len` as follows:
```
for i in range(len(courses)):
print names[i], enrollment[i]
```
## Importing libraries
We've seen the use of some predefined functions, such as `range` and `len`, but those are available without doing anything special in your Python program. Now let's take a look at importing a library of code and data. Because there are perhaps millions of libraries out there and Python can't automatically load them all into memory (slow and they wouldn't fit), we must explicitly `import` the libraries we want to use. This is like opening a specific cookbook.
For example, let's say we need the value of π, which I can only remember to five decimal points. If we type `pi` in the Python console, we get an error because that variable is not defined:
```
print pi
```
However, the Python `math` library has that variable and much more, so let's import it.
```
import math
```
That tells Python to bring in the `math` library and so now we can access the stuff inside. A crude way to ask Python for the list of stuff in a package is to use the `dir` function, similar to the Windows commandline `dir` command.
```
print dir(math)
```
It's better to use the [online math documentation](https://docs.python.org/2/library/math.html), but sometimes that command is helpful if you just can't remember the name of something.
Anyway, now we can finally get the value of `pi`:
```
print math.pi
```
We can access anything we want by prefixing it with the name of the library followed by the dot operator which is kind of like an "access" operator. `pi` is a variable but there are also functions such as `sqrt`:
```
print math.sqrt(100)
```
## Summary
Take a look back at the summary in [Model of Computation](computation.md). You'll notice that the high level pseudocode operations look remarkably like the actual python equivalent. Great news! Let's review all of our python statement templates as it defines the basic "sentence structure" we'll use going forward to write some real programs.
<ul>
<li>Values: integers, floating-point numbers, strings; lists of values in square brackets.</li>
<li>Assignments:<br><i>varname</i> <b><tt>=</tt></b> <i>expression</i></li>
<li>Printing to console:<br><b><tt>print</tt> <i>expression</i></b></li>
<li>Conditional statements:<br><b><tt>if</tt> <i>expression</i><tt>:</tt><br> <i>statement(s)</i></b><br>
Or with <tt>else</tt> clause:,<br>
<b><tt>if</tt> <i>expression</i><tt>:</tt><br> <i>statement(s)</i><br><tt>else:</tt><br> <i>statement(s)</i></b></li>
<li>Basic loop:<br><b><tt>while</tt> <i>expression</i><tt>:</tt><br> <i>statement(s)</i></b></li>
<li>For-each loop:<br><b><tt>for</tt> <i>varname</i> <tt>in</tt> <i>expression</i><tt>:</tt><br> <i>statement(s)</i></b></li>
<li>Indexed loop:<br><b><tt>for i in range(len(</tt><i>listvarname</i><tt>)):</tt><br> <i>statement(s)</i></b></li>
</ul>
We import packages with `import` and can refer to the elements using the dot `.` operator.
| github_jupyter |
```
from didatictests import Didatic_test
def the_function(arg):
inp = input("One number, please: ")
total = arg + int(inp)
print(total)
return total
test3 = Didatic_test(
fn = the_function,
args = Dt.parse_args('forty'),
keyboard_inputs = ('two'),
test_name = 'Error demo',
expected_output = 42,
expected_prints = '42\n',
run_prints_test = True,
run_output_test = True,
verbose=True
)
test3.run()
pass
```
# Redefinindo funções para simular entradas do usuário e evitar de ficar redigitando toda hora
Imagine que uma etapa do seu projeto atual é fazer um questionário e depois usar as respostas em outras partes do seu programa.
Você cria uma função para fazer o questionário, mas percebe que dá muito trabalho ficar digitando as respostas novamente toda vez que for desenvolver/testar as partes do programa que usam essa sua função.
Isso pode ser contornado de várias formas, mas a mais prática deve ser 'auto-redefinir' sua função para que ela rode uma vez, memorize todos os seus inputs e depois passe a simular eles como entrada
Se você quiser um outro conjunto de entradas diferentes, basta recrear e 'auto-redefinir' ela novamente
```
def fazer_questionario():
questionario = {
'nome': 'Informe o seu nome: ',
'idade': 'Informe sua idade: ',
'peso': 'Informe o seu peso: ',
'altura': 'Informe a sua altura: ',
'nascimento': 'Informe sua data de nascimento: ',
'cor_vavorita': 'Sua cor favorita é: '
}
respostas = {}
for atr, pergunta in questionario.items():
respostas[atr] = input(pergunta)
return respostas
fazer_questionario = Dt.auto_redefine(fazer_questionario, input_verbose=True)
```
Com isso a função acaba sendo chamada 1 vez logo apos ser definida e todos os inputs do usuário ficam salvos internamente para serem repetidos automaticamente em todas as chamadas seguintes. Se quiser usar um novo conjunto de entradas, basta rodar a célular acima outra vez e informar os novos inputs.
```
fazer_questionario()
```
Outra maneira é já deixar definido no código a sequencia de inputs simulados pelo usuário em vez de rodar o programa uma vez para capturar e salvar as entradas:
```
def fazer_questionario():
questionario = {
'nome': 'Informe o seu nome: ',
'idade': 'Informe sua idade: ',
'peso': 'Informe o seu peso: ',
'altura': 'Informe a sua altura: ',
'nascimento': 'Informe sua data de nascimento: ',
'cor_vavorita': 'Sua cor favorita é: '
}
respostas = {}
for atr, pergunta in questionario.items():
respostas[atr] = input(pergunta)
return respostas
fazer_questionario = Dt.redefine(fazer_questionario, ('Makoto', '27', '82', '1.85', '25/06/1994', 'azul'), input_verbose=True)
fazer_questionario()
def args_plus_inputs(*args, x, y, z):
input_1 = int(input("Choose the first number: "))
input_2 = int(input("Choose the second number: "))
print(f"Computing {input_1} + {input_2} + {x} + {y} + {z} + {args}")
return input_1 + input_2 + x + y + z + sum(args)
args_plus_inputs = Dt.auto_redefine(args_plus_inputs, input_verbose=True)
def soma_inputs_e_printa(n=0):
print("O n informado foi:", n)
a = int(input("Digite um número: "))
b = int(input("Digite outro número: "))
print(a+b+n)
test = Dt(soma_inputs_e_printa, keyboard_inputs=('1','2'), verbose=True)
test.just_run()
Dt.redefine
nova = Dt.redefine(soma_inputs_e_printa,('5','7'))
nova()
nova()
Dt.input_interceptor(soma_inputs_e_printa)
auto_nova = Dt.auto_redefine(soma_inputs_e_printa, input_verbose=True)
auto_nova(75)
def tuplefy(thing:list):
"""
redefine(fn, keyboard_inputs,input_verbose=False)
Return a new function that will use the 'keyboard_inputs' tuple\
as simulated inputs, but will work as fn otherwise
ex.: call_menu = redefine(call_menu,('lorem ipsum','25','y','n'))
Parameters
----------
fn: The function that will be copied but will use \
the simulated inputs
keyboard_inputs: The inputs that will be simulated
Returns
-------
refedined_fn: Return a fn copy that will always \
use the 'keyboard_inputs' as input simulation
"""
return thing if type(thing) is tuple else (thing,)
print(tuplefy.__code__)
print(tuplefy.__doc__)
print(tuplefy.__name__)
print(tuplefy.__annotations__)
def soma_diferente(x):
y=int(input("Digite um número: "))
z=int(input("Digite um número: "))
print("A soma é: ",x+y+z)
return x+y+z,7
from didatictests import Didatic_test as Dt
test_str = Dt.generate_test(soma_diferente, Dt.parse_args(5), 'teste 1', False, True, False)
test_str
Dt(soma_diferente, Dt.parse_args(5), 'teste 1', ('123', '456'), (584, 7), '', False, True, False).run()
test.run()
test = Dt(soma_diferente, Dt.parse_args(5), 'teste 1', False, True, False)
def print_args(args):
pos_args = args.get('pos_inputs',())
key_args = args.get('key_inputs',())
pos_args_str = str(pos_args).replace('(','').replace(')','')
key_args_str = ', '.join([f'{key}={value}' for key,value in key_args.items()])
args_str = ', '.join([pos_args_str,key_args_str]).strip(', ')
print(f"({args_str})")
print_args(Dt.parse_args({'a':5},[2,3,4],3,x=12,y=5))
1+1
print_args(Dt.parse_args(1,2,3))
```
----
```
from didatictests import Didatic_test as Dt
import builtins
inputs = []
input_fn_backup = builtins.input
builtins.input = Dt.intercepted_input_fn(inputs,True,'[I]: ')
nome = input("Digite o seu nome: ")
idade = input("Digite a sua idade: ")
altura = input("Digite a sua altura: ")
peso = input("Digite o seu peso: ")
print([nome,idade,altura,peso])
print(inputs)
from didatictests import Didatic_test as Dt
import builtins
prints = []
print_fn_backup = builtins.print
builtins.print = Dt.intercepted_print_fn(prints,True,'[P]: ')
print("Digite o seu nome: ")
print("Digite a sua idade: ")
print("Digite a sua altura: ")
print("Digite o seu peso: ")
builtins.print = print_fn_backup
print(prints)
def fn(*args,**kwargs):
print(args)
print(kwargs)
fn(1,'a',True,x=0,y=False,z=[])
from didatictests import Didatic_test as Dt
def soma(a,b,c,d,e,jota):
print('iniciando a função')
x = int(input("Digite o valor de x"))
y = int(input("Digite o valor de y"))
z = int(input("Digite o valor de z"))
soma = sum([a,b,c,x,y,z])
print('total:', soma)
return soma,d,e
interceptions = {}
soma_interceptada = Dt.intercepted_fn(soma, interceptions, True, '[i]: ','[p]: ')
soma_interceptada(1,2,3,d=0,e=-1,jota="aaaaa")
interceptions
from didatictests import Didatic_test
def soma(a,b,c,d=0,e=7):
print('iniciando a função')
x = int(input("Digite o valor de x"))
y = int(input("Digite o valor de y"))
z = int(input("Digite o valor de z"))
soma = sum([a,b,c,x,y,z])
print('total:', soma)
return soma,d,e
Didatic_test.generate_test(soma,Didatic_test.parse_args(1,2,3,e=5,d=15),"Teste-1",True,True,True,False)
Didatic_test(soma, Didatic_test.parse_args(1, 2, 3, e=5, d=15), 'Teste-1', ['582', '693', '471'], (1752, 15, 5), 'iniciando a função\ntotal: 1752\n', False, True, True).run()
```
----
```
from didatictests import Didatic_test
def soma(a,b,c,d=0,e=7):
print('iniciando a função')
x = int(input("Digite o valor de x"))
y = int(input("Digite o valor de y"))
z = int(input("Digite o valor de z"))
soma = sum([a,b,c,x,y,z])
print('total:', soma)
return soma,d,e
soma2 = Didatic_test.auto_redefine(soma,Didatic_test.parse_args(1,2,3,e=5,d=15),False)
soma2(1,2,3,d=4,e=5)
soma2(1,2,3,d=4,e=5)
```
---
```
from didatictests import Didatic_test
def soma(a,b,c,d=0,e=7):
print('iniciando a função')
x = int(input("Digite o valor de x"))
y = int(input("Digite o valor de y"))
z = int(input("Digite o valor de z"))
soma = sum([a,b,c,x,y,z])
print('total:', soma)
return soma,d,e
soma2 = Didatic_test.redefine2(soma,['7','8','9'],False)
soma2(1,2,3,d=4,e=5)
soma2(1,2,3,d=4,e=5)
```
-----
```
x = ['a','b','c']
x.remove('a')
x
```
| github_jupyter |
# Azure Form Recognizer
Azure Form Recognizer is a cognitive service that uses machine learning technology to identify and extract key-value pairs and table data from form documents. It then outputs structured data that includes the relationships in the original file.

### Overview
*Safety Incident Reports Dataset*: Raw unstructured data is fed into the pipeline in the form of electronically generated PDFs. These reports contain information about injuries that occurred at 5 different factories belonging to a company. This data provides information on injury reports, including the nature, description, date, source and the name of the establishment where it happened.
### Notebook Organization
+ Fetch the injury report PDF files from a container under an azure storage account.
+ Convert the PDF files to JSON by querying the azure trained form recognizer model using the REST API.
+ Preprocess the JSON files to extract only relevant information.
+ Push the JSON files to a container under an azure storage account.
## Importing Relevant Libraries
```
# Please install this specific version of azure storage blob compatible with this notebook.
!pip install azure-storage-blob==2.1.0
# Import the required libraries
import json
import time
import requests
import os
from azure.storage.blob import BlockBlobService
import pprint
from os import listdir
from os.path import isfile, join
import shutil
import pickle
```
## Create Local Folders
```
# Create local directories if they don't exist
# *input_forms* contains all the pdf files to be converted to json
if (not os.path.isdir(os.getcwd()+"/input_forms")):
os.makedirs(os.getcwd()+"/input_forms")
# *output_json* will contain all the converted json files
if (not os.path.isdir(os.getcwd()+"/output_json")):
os.makedirs(os.getcwd()+"/output_json")
```
## Downloading the PDF forms from a container in azure storage
- Downloads all PDF forms from a container named *incidentreport* to a local folder *input_forms*
```
%%time
# Downloading pdf files from a container named *incidentreport* to a local folder *input_forms*
# Importing user defined config
import config
# setting up blob storage configs
STORAGE_ACCOUNT_NAME = config.STORAGE_ACCOUNT_NAME
STORAGE_ACCOUNT_ACCESS_KEY = config.STORAGE_ACCOUNT_ACCESS_KEY
STORAGE_CONTAINER_NAME = "incidentreport"
# Instantiating a blob service object
blob_service = BlockBlobService(STORAGE_ACCOUNT_NAME, STORAGE_ACCOUNT_ACCESS_KEY)
blobs = blob_service.list_blobs(STORAGE_CONTAINER_NAME)
# Downloading pdf files from the container *incidentreport* and storing them locally to *input_forms* folder
for blob in blobs:
# Check if the blob.name is already present in the folder input_forms. If yes then continue
try:
with open('merged_log','rb') as f:
merged_files = pickle.load(f)
except FileNotFoundError:
merged_files = set()
# If file is already processed then continue to next file
if (blob.name in merged_files):
continue
download_file_path = os.path.join(os.getcwd(), "input_forms", blob.name)
blob_service.get_blob_to_path(STORAGE_CONTAINER_NAME, blob.name ,download_file_path)
merged_files.add(blob.name)
# Keep trace of all the processed files at the end of your script (to keep track later)
with open('merged_log', 'wb') as f:
pickle.dump(merged_files, f)
# Total number of forms to be converted to JSON
files = [f for f in listdir(os.getcwd()+"/input_forms") if isfile(join(os.getcwd()+"/input_forms", f))]
```
## Querying the custom trained form recognizer model (PDF -> JSON)
- Converts PDF -> JSON by querying the trained custom model.
- Preprocess the JSON file and extract only the relevant information.
```
%%time
# Importing user defined config
import config
# Endpoint parameters for querying the custom trained form-recognizer model to return the processed JSON
# Processes PDF files one by one and return CLEAN JSON files
endpoint = config.FORM_RECOGNIZER_ENDPOINT
# Change if api key is expired
apim_key = config.FORM_RECOGNIZER_APIM_KEY
# This model is the one trained on 5 forms
model_id =config.FORM_RECOGNIZER_MODEL_ID
post_url = endpoint + "/formrecognizer/v2.0/custom/models/%s/analyze" % model_id
files = [f for f in listdir(os.getcwd()+"/input_forms") if isfile(join(os.getcwd()+"/input_forms", f))]
params = {"includeTextDetails": True}
headers = {'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key}
local_path = os.path.join(os.getcwd(), "input_forms//")
output_path = os.path.join(os.getcwd(), "output_json//")
for file in files:
try:
with open('json_log','rb') as l:
json_files = pickle.load(l)
except FileNotFoundError:
json_files = set()
if (file in json_files):
continue
else:
with open(local_path+file, "rb") as f:
data_bytes = f.read()
try:
resp = requests.post(url = post_url, data = data_bytes, headers = headers, params = params)
print('resp',resp)
if resp.status_code != 202:
print("POST analyze failed:\n%s" % json.dumps(resp.json()))
quit()
print("POST analyze succeeded:\n%s" % resp.headers)
get_url = resp.headers["operation-location"]
except Exception as e:
print("POST analyze failed:\n%s" % str(e))
quit()
n_tries = 15
n_try = 0
wait_sec = 5
max_wait_sec = 60
while n_try < n_tries:
try:
resp = requests.get(url = get_url, headers = {"Ocp-Apim-Subscription-Key": apim_key})
resp_json = resp.json()
if resp.status_code != 200:
print("GET analyze results failed:\n%s" % json.dumps(resp_json))
quit()
status = resp_json["status"]
if status == "succeeded":
print("Analysis succeeded:\n%s" % file[:-4])
allkeys = resp_json['analyzeResult']['documentResults'][0]['fields'].keys()
new_dict = {}
for i in allkeys:
if resp_json['analyzeResult']['documentResults'][0]['fields'][i] != None:
key = i.replace(" ", "_")
new_dict[key] = resp_json['analyzeResult']['documentResults'][0]['fields'][i]['valueString']
else:
key = i.replace(" ", "_")
new_dict[key] = None
# Appending form url to json
new_dict['form_url'] = 'https://stcognitivesearch0001.blob.core.windows.net/formupload/' + file
with open(output_path+file[:-4]+".json", 'w') as outfile:
json.dump(new_dict, outfile)
# Change the encoding of file in case of spanish forms. It will detected random characters.
with open(output_path+file[:-4]+".json", 'w', encoding='utf-8') as outfile:
json.dump(new_dict, outfile, ensure_ascii=False)
# Once JSON is saved log it otherwise don't log it.
json_files.add(file)
with open('json_log', 'wb') as f:
pickle.dump(json_files, f)
break
if status == "failed":
print("Analysis failed:\n%s" % json.dumps(resp_json))
quit()
# Analysis still running. Wait and retry.
time.sleep(wait_sec)
n_try += 1
wait_sec = min(2*wait_sec, max_wait_sec)
except Exception as e:
msg = "GET analyze results failed:\n%s" % str(e)
print(msg)
quit()
```
## Upload the JSON files to a cotainer
- Upload JSON files from local folder *output_json* to the container *formrecogoutput*
```
# Total number of converted JSON
files = [f for f in listdir(os.getcwd()+"/output_json") if isfile(join(os.getcwd()+"/output_json", f))]
%%time
# Importing user defined config
import config
# Connect to the container for uploading the JSON files
# Set up configs for blob storage
STORAGE_ACCOUNT_NAME = config.STORAGE_ACCOUNT_NAME
STORAGE_ACCOUNT_ACCESS_KEY = config.STORAGE_ACCOUNT_ACCESS_KEY
# Upload the JSON files in this container
STORAGE_CONTAINER_NAME = "formrecogoutput"
# Instantiating a blob service object
blob_service = BlockBlobService(STORAGE_ACCOUNT_NAME, STORAGE_ACCOUNT_ACCESS_KEY)
%%time
# Upload JSON files from local folder *output_json* to the container *formrecogoutput*
local_path = os.path.join(os.getcwd(), "output_json")
# print(local_path)
for files in os.listdir(local_path):
# print(os.path.join(local_path,files))
blob_service.create_blob_from_path(STORAGE_CONTAINER_NAME, files, os.path.join(local_path,files))
```
| github_jupyter |
```
import json
import numpy as np
import torch
import re
from nltk.tokenize import word_tokenize
def clean_replace(s, r, t, forward=True, backward=False):
def clean_replace_single(s, r, t, forward, backward, sidx=0):
idx = s[sidx:].lower().find(r.lower())
if idx == -1:
return s, -1
idx += sidx
idx_r = idx + len(r)
if backward:
while idx > 0 and s[idx - 1]:
idx -= 1
elif idx > 0 and s[idx - 1] != ' ':
return s, -1
if forward:
while idx_r < len(s) and (s[idx_r].isalpha() or s[idx_r].isdigit()):
idx_r += 1
elif idx_r != len(s) and (s[idx_r].isalpha() or s[idx_r].isdigit()):
return s, -1
return s[:idx] + t + s[idx_r:], idx_r
sidx = 0
while sidx != -1:
s, sidx = clean_replace_single(s, r, t, forward, backward, sidx)
return s
def value_key_map(db_data):
requestable_keys = ['address', 'name', 'phone', 'postcode', 'food', 'area', 'pricerange']
value_key = {}
for db_entry in db_data:
for k, v in db_entry.items():
if k in requestable_keys:
value_key[v] = k
return value_key
def db_search(db, constraints):
"""when doing matching, remember to lower case"""
match_results = []
for entry in db:
entry_values = ' '.join(entry.values()).lower()
match = True
for c in constraints:
if c.lower() not in entry_values:
match = False
break
if match:
match_results.append(entry)
return match_results
def replace_entity(response, vk_map, constraint):
response = re.sub('[cC][., ]*[bB][., ]*\d[., ]*\d[., ]*\w[., ]*\w', '<postcode_SLOT>', response)
response = re.sub('\d{5}\s?\d{6}', '<phone_SLOT>', response)
constraint_str = ' '.join(constraint)
for v, k in sorted(vk_map.items(), key=lambda x: -len(x[0])):
start_idx = response.lower().find(v.lower())
if start_idx == -1 \
or (start_idx != 0 and response[start_idx - 1] != ' ') \
or (v in constraint_str):
continue
if k not in ['name', 'address']:
response = clean_replace(response, v, '<' + k + '_SLOT>', forward=True, backward=False)
else:
response = clean_replace(response, v, '<' + k + '_SLOT>', forward=False, backward=False)
return response
with open("../CamRest676/CamRest676.json", "r") as f:
raw_data = json.loads(f.read())
# read database
with open("../CamRest676/CamRestDB.json", "r") as f:
db_data = json.loads(f.read())
vk_map = value_key_map(db_data)
all_data = []
for dial_id, dial in enumerate(raw_data):
one_dialog = []
for turn in dial['dial']:
turn_num = turn['turn']
constraint = []
requested = []
for slot in turn['usr']['slu']:
if slot['act'] == 'inform':
s = slot['slots'][0][1]
if s not in ['dontcare', 'none']:
constraint.extend(word_tokenize(s))
else:
requested.extend(word_tokenize(slot['slots'][0][1]))
degree = len(db_search(db_data, constraint))
if degree > 6:
degree = 6
constraint.insert(0, '[inform]')
requested.insert(0, '[request]')
user = turn['usr']['transcript']
real_response = turn['sys']['sent']
replaced_response = replace_entity(real_response, vk_map, constraint)
one_dialog.append({
'dial_id': dial_id,
'turn_num': turn_num,
'user': user,
'real_response': real_response,
'replaced_response': replaced_response,
'degree': degree,
'bspan_inform': constraint,
'bspan_request': requested,
})
all_data.append(one_dialog)
indices = np.arange(len(all_data))
# np.random.shuffle(indices)
train_data = indices[:408]
val_data = indices[408:544]
test_data = indices[544:]
train_data = [all_data[idx] for idx in train_data]
val_data = [all_data[idx] for idx in val_data]
test_data = [all_data[idx] for idx in test_data]
torch.save(train_data, "train_data.pkl")
torch.save(val_data, "val_data.pkl")
torch.save(test_data, "test_data.pkl")
train_data[0]
```
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Goal" data-toc-modified-id="Goal-1"><span class="toc-item-num">1 </span>Goal</a></span></li><li><span><a href="#Var" data-toc-modified-id="Var-2"><span class="toc-item-num">2 </span>Var</a></span></li><li><span><a href="#Init" data-toc-modified-id="Init-3"><span class="toc-item-num">3 </span>Init</a></span></li><li><span><a href="#DM-run" data-toc-modified-id="DM-run-4"><span class="toc-item-num">4 </span>DM run</a></span></li><li><span><a href="#Communites" data-toc-modified-id="Communites-5"><span class="toc-item-num">5 </span>Communites</a></span><ul class="toc-item"><li><span><a href="#n1000_r3" data-toc-modified-id="n1000_r3-5.1"><span class="toc-item-num">5.1 </span>n1000_r3</a></span></li><li><span><a href="#n1000_r30" data-toc-modified-id="n1000_r30-5.2"><span class="toc-item-num">5.2 </span>n1000_r30</a></span></li></ul></li><li><span><a href="#Estimated-coverage" data-toc-modified-id="Estimated-coverage-6"><span class="toc-item-num">6 </span>Estimated coverage</a></span></li><li><span><a href="#Feature-tables" data-toc-modified-id="Feature-tables-7"><span class="toc-item-num">7 </span>Feature tables</a></span><ul class="toc-item"><li><span><a href="#n1000_r3" data-toc-modified-id="n1000_r3-7.1"><span class="toc-item-num">7.1 </span>n1000_r3</a></span><ul class="toc-item"><li><span><a href="#MetaQUAST-classifications" data-toc-modified-id="MetaQUAST-classifications-7.1.1"><span class="toc-item-num">7.1.1 </span>MetaQUAST classifications</a></span></li><li><span><a href="#SNPs-~-coverage" data-toc-modified-id="SNPs-~-coverage-7.1.2"><span class="toc-item-num">7.1.2 </span>SNPs ~ coverage</a></span></li></ul></li><li><span><a href="#n1000_r30" data-toc-modified-id="n1000_r30-7.2"><span class="toc-item-num">7.2 </span>n1000_r30</a></span><ul class="toc-item"><li><span><a href="#Number-of-contigs" data-toc-modified-id="Number-of-contigs-7.2.1"><span class="toc-item-num">7.2.1 </span>Number of contigs</a></span></li><li><span><a href="#Misassembly-types" data-toc-modified-id="Misassembly-types-7.2.2"><span class="toc-item-num">7.2.2 </span>Misassembly types</a></span></li><li><span><a href="#SNPs-~-coverage" data-toc-modified-id="SNPs-~-coverage-7.2.3"><span class="toc-item-num">7.2.3 </span>SNPs ~ coverage</a></span></li></ul></li></ul></li><li><span><a href="#sessionInfo" data-toc-modified-id="sessionInfo-8"><span class="toc-item-num">8 </span>sessionInfo</a></span></li></ul></div>
# Goal
* evaluate the results of the training dataset run
# Var
```
# location of all training dataset runs
work_dir = '/ebio/abt3_projects/databases_no-backup/DeepMAsED/train_runs/'
# 1000 ref genomes, 3 metagenomes
n1000_r3_dir = file.path(work_dir, 'n1000_r3')
# 1000 ref genomes, 30 metagenomes
n1000_r30_dir = file.path(work_dir, 'n1000_r30')
```
# Init
```
library(dplyr)
library(tidyr)
library(ggplot2)
library(data.table)
source('/ebio/abt3_projects/software/dev/DeepMAsED/bin/misc_r_functions/init.R')
```
# DM run
```
# pipeline run config files
cat_file(file.path(n1000_r3_dir, 'config.yaml'))
# pipeline run config files
cat_file(file.path(n1000_r30_dir, 'config.yaml'))
```
# Communites
* Simulated abundances of each ref genome
## n1000_r3
```
comm_files = list.files(file.path(n1000_r3_dir, 'MGSIM'), 'comm_wAbund.txt', full.names=TRUE, recursive=TRUE)
comm_files
comms = list()
for(F in comm_files){
df = read.delim(F, sep='\t')
df$Rep = basename(dirname(F))
comms[[F]] = df
}
comms = do.call(rbind, comms)
rownames(comms) = 1:nrow(comms)
comms %>% dfhead
comms$Perc_rel_abund %>% summary %>% print
p = comms %>%
group_by(Taxon) %>%
mutate(mean_Rank = mean(Rank)) %>%
ungroup() %>%
mutate(Taxon = reorder(Taxon, mean_Rank)) %>%
ggplot(aes(Taxon, Perc_rel_abund, color=Rep)) +
geom_point(size=0.5, alpha=0.4) +
scale_y_log10() +
labs(y='% abundance') +
theme_bw() +
theme(
axis.text.x = element_blank()
)
dims(10,3)
plot(p)
p = comms %>%
mutate(Perc_rel_abund = ifelse(Perc_rel_abund == 0, 1e-5, Perc_rel_abund)) %>%
group_by(Taxon) %>%
summarize(mean_perc_abund = mean(Perc_rel_abund),
sd_perc_abund = sd(Perc_rel_abund)) %>%
ungroup() %>%
mutate(neg_sd_perc_abund = mean_perc_abund - sd_perc_abund,
pos_sd_perc_abund = mean_perc_abund + sd_perc_abund,
neg_sd_perc_abund = ifelse(neg_sd_perc_abund <= 0, 1e-5, neg_sd_perc_abund)) %>%
mutate(Taxon = Taxon %>% reorder(-mean_perc_abund)) %>%
ggplot(aes(Taxon, mean_perc_abund)) +
geom_linerange(aes(ymin=neg_sd_perc_abund, ymax=pos_sd_perc_abund),
size=0.3, alpha=0.3) +
geom_point(size=0.5, alpha=0.4, color='red') +
labs(y='% abundance') +
theme_bw() +
theme(
axis.text.x = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.minor.y = element_blank()
)
dims(10,2.5)
plot(p)
dims(10,2.5)
plot(p + scale_y_log10())
```
## n1000_r30
```
comm_files = list.files(file.path(n1000_r30_dir, 'MGSIM'), 'comm_wAbund.txt', full.names=TRUE, recursive=TRUE)
comm_files %>% length %>% print
comm_files %>% head
comms = list()
for(F in comm_files){
df = read.delim(F, sep='\t')
df$Rep = basename(dirname(F))
comms[[F]] = df
}
comms = do.call(rbind, comms)
rownames(comms) = 1:nrow(comms)
comms %>% dfhead
p = comms %>%
mutate(Perc_rel_abund = ifelse(Perc_rel_abund == 0, 1e-5, Perc_rel_abund)) %>%
group_by(Taxon) %>%
summarize(mean_perc_abund = mean(Perc_rel_abund),
sd_perc_abund = sd(Perc_rel_abund)) %>%
ungroup() %>%
mutate(neg_sd_perc_abund = mean_perc_abund - sd_perc_abund,
pos_sd_perc_abund = mean_perc_abund + sd_perc_abund,
neg_sd_perc_abund = ifelse(neg_sd_perc_abund <= 0, 1e-5, neg_sd_perc_abund)) %>%
mutate(Taxon = Taxon %>% reorder(-mean_perc_abund)) %>%
ggplot(aes(Taxon, mean_perc_abund)) +
geom_linerange(aes(ymin=neg_sd_perc_abund, ymax=pos_sd_perc_abund),
size=0.3, alpha=0.3) +
geom_point(size=0.5, alpha=0.4, color='red') +
labs(y='% abundance') +
theme_bw() +
theme(
axis.text.x = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.minor.y = element_blank()
)
dims(10,2.5)
plot(p)
dims(10,2.5)
plot(p + scale_y_log10())
```
# Estimated coverage
* Coverage estimated with nonpareil
```
F = file.path(n1000_r3_dir, 'coverage', 'nonpareil', 'all_summary.txt')
cov = read.delim(F, sep='\t')
cov %>% summary %>% print
F = file.path(n1000_r30_dir, 'coverage', 'nonpareil', 'all_summary.txt')
cov = read.delim(F, sep='\t')
cov %>% summary %>% print
```
# Feature tables
* feature tables for ML model training/testing
## n1000_r3
```
feat_files = list.files(file.path(n1000_r3_dir, 'map'), 'features.tsv.gz', full.names=TRUE, recursive=TRUE)
feat_files %>% length %>% print
feat_files %>% head
feats = list()
for(F in feat_files){
cmd = glue::glue('gunzip -c {F}', F=F)
df = fread(cmd, sep='\t') %>%
distinct(contig, assembler, Extensive_misassembly)
df$Rep = basename(dirname(dirname(F)))
feats[[F]] = df
}
feats = do.call(rbind, feats)
rownames(feats) = 1:nrow(feats)
feats %>% dfhead
```
### MetaQUAST classifications
```
p = feats %>%
mutate(Extensive_misassembly = ifelse(Extensive_misassembly == '', 'None',
Extensive_misassembly)) %>%
group_by(Extensive_misassembly, assembler, Rep) %>%
summarize(n = n()) %>%
ungroup() %>%
ggplot(aes(Extensive_misassembly, n, color=assembler)) +
geom_boxplot() +
scale_y_log10() +
labs(x='metaQUAST extensive mis-assembly', y='Count') +
coord_flip() +
theme_bw() +
theme(
axis.text.x = element_text(angle=45, hjust=1)
)
dims(7,4)
plot(p)
```
### SNPs ~ coverage
```
# loading files; just checking first million lines (should be sufficient)
feats = list()
for(F in feat_files){
cmd = glue::glue('gunzip -c {F} | head -n 1000000', F=F)
df = fread(cmd, sep='\t')
df$Rep = basename(dirname(dirname(F)))
feats[[F]] = df
}
feats = do.call(rbind, feats)
rownames(feats) = 1:nrow(feats)
feats %>% dfhead
# general summary
feats %>% summary
# should not have more SNPs than coverage
feats %>%
filter(num_SNPs > coverage) %>%
nrow %>% print
# sum(num_query_*) should equal coverage
feats %>%
filter(num_query_A + num_query_C + num_query_G + num_query_T != coverage) %>%
nrow %>% print
```
## n1000_r30
```
feat_files = list.files(file.path(n1000_r30_dir, 'map'), 'features.tsv.gz', full.names=TRUE, recursive=TRUE)
feat_files %>% length %>% print
feat_files %>% head
feats = list()
for(F in feat_files){
cmd = glue::glue('gunzip -c {F}', F=F)
df = fread(cmd, sep='\t') %>%
distinct(contig, assembler, Extensive_misassembly)
df$Rep = basename(dirname(dirname(F)))
feats[[F]] = df
}
feats = do.call(rbind, feats)
rownames(feats) = 1:nrow(feats)
feats %>% dfhead
```
### Number of contigs
```
feats_s = feats %>%
group_by(assembler, Rep) %>%
summarize(n_contigs = n_distinct(contig)) %>%
ungroup
feats_s$n_contigs %>% summary
```
### Misassembly types
```
p = feats %>%
mutate(Extensive_misassembly = ifelse(Extensive_misassembly == '', 'None',
Extensive_misassembly)) %>%
group_by(Extensive_misassembly, assembler, Rep) %>%
summarize(n = n()) %>%
ungroup() %>%
ggplot(aes(Extensive_misassembly, n, color=assembler)) +
geom_boxplot() +
scale_y_log10() +
labs(x='metaQUAST extensive mis-assembly', y='Count') +
coord_flip() +
theme_bw() +
theme(
axis.text.x = element_text(angle=45, hjust=1)
)
dims(7,4)
plot(p)
```
### SNPs ~ coverage
```
# loading files; just checking first million lines (should be sufficient)
feats = list()
for(F in feat_files){
cmd = glue::glue('gunzip -c {F} | head -n 1000000', F=F)
df = fread(cmd, sep='\t')
df$Rep = basename(dirname(dirname(F)))
feats[[F]] = df
}
feats = do.call(rbind, feats)
rownames(feats) = 1:nrow(feats)
feats %>% dfhead
# general summary
feats %>% summary
# should not have more SNPs than coverage
feats %>%
filter(num_SNPs > coverage) %>%
nrow %>% print
# sum(num_query_*) should equal coverage
feats %>%
filter(num_query_A + num_query_C + num_query_G + num_query_T != coverage) %>%
nrow %>% print
```
# sessionInfo
```
sessionInfo()
```
| github_jupyter |
```
!pip install -U scikit-learn
import sys
sys.path.append('../SPIE2019_COURSE/')
import os
import glob
import time
from random import shuffle
import numpy as np
import pandas as pd
import json
import uuid
import gc
from sklearn.model_selection import ParameterGrid
import SimpleITK as sitk
import registration_gui as rgui
import utilities
from downloaddata import fetch_data as fdata
from ipywidgets import interact, fixed
import matplotlib.pyplot as plt
%matplotlib inline
# Path to data
source_path = './data'
# Directory of images inside source_path
images_dir = '/images'
# Directory of masks inside source_path
mask_dir = '/masks'
# Directory of landmarks inside source_path
landmarks_dir = '/landmarks'
# Path to the results
results_path = './results'
# Directory of the images registration results
registration_results_dir = '/registration'
# Directory of the hyperparameters seach results
hp_search_results_dir = '/hp_results'
# Identifier of the current param grids
params_grid_id = '02'
# Number of patients
n_patients = 6
patient_ids = range(1, n_patients + 1)
# Grid of the hyperparameters search
params_grid = {
'grid_physical_spacing': [10.0, 20.0, 30.0],
'similarity_function': ['mean_squares', 'mattes_mutual_information', 'correlation', 'joint_histogram_mutual_information'],
'optimizer': ['lbfgs2'],
'max_optimizer_iterations': [5000],
'scale_parameter_and_smoothing_sigma_max_power': [1, 2, 3],
'interpolator': ['linear', 'bspline']
}
# Computing a list with all combinations and shuffle it
grid = list(ParameterGrid(params_grid))
shuffle(grid)
print('Total combinations: {}'.format(len(grid)))
time_per_config = 0.2
est_time = len(grid) * time_per_config * 6
print('Estimated time {:.2f}h'.format(est_time))
'''
If the kernel deads or the laptop runs out of memory, load the already computed combinations and
remove it from the param_grid.
'''
# Load the previously computed parameters
files_to_load = glob.glob(os.path.join(results_path + hp_search_results_dir, params_grid_id) + '/*.json')
data = []
for file in files_to_load:
with open(file, 'r') as fp:
data.append(eval(json.load(fp)))
df_data = pd.DataFrame(data)
params_ls = [row['params'] for idx, row in df_data.iterrows()]
# Get the parameters combination that have not been computed yet
grid = [x for x in grid if x not in params_ls]
del df_data, params_ls
gc.collect()
print('Total combinations: {}'.format(len(grid)))
time_per_config = 0.2
est_time = len(grid) * time_per_config * 6
print('Estimated time {:.2f}h'.format(est_time))
def save_results(path_to_save, file_name, results):
'''
Save in JSON format the results for every parameters combination
Args:
- path_to_save (string): Path to save the JSON file.
- file_name (string): Name of the JSON file.
- results (dict): Dictionary with the results.
Returns:
- None
'''
# Check if the directory exists, if not create one
if not os.path.exists(path_to_save):
os.makedirs(path_to_save)
# Save resutls as JSON file
with open(os.path.join(path_to_save, file_name), 'w') as fp:
json.dump(str(results), fp)
gc.collect()
return None
def save_transform(path_to_save, file_name, transform):
'''
Save in TFM format the final transform
Args:
- path_to_save (string): Path to save the TFM file.
- file_name (string): Name of the TFM file.
- transform (SimpleITK.SimpleITK.Transform): SimpleITK transform to save.
Returns:
- None
'''
# Check if the directory exists, if not create one
if not os.path.exists(path_to_save):
os.makedirs(path_to_save)
# Save tranformation as TFM file
sitk.WriteTransform(transform, os.path.join(path_to_save, file_name + '.tfm'))
gc.collect()
return None
def iteration_callback_ffd(filter):
# Define a simple callback which allows us to monitor registration progress.
print('\rRegistration progress -> {0:.2f}'.format(filter.GetMetricValue()), end='')
def free_form_deformation_registration(images, masks, params):
'''
Computes the free form deformation algorithm for the registration of the images.
Args:
- images (list(SimpleITK.Image)): Images to feed the registration algorithm.
- masks (list(SimpleITK.Image)): Masks to feed the registration algorithm.
- params (dict): Dictionary with the parameters to use in the algorithm.
Returns:
- final_transformation (SimpleITK.Transform)
- stop_condition (str)
'''
fixed_index = 0
moving_index = 1
fixed_image = images[fixed_index]
fixed_image_mask = masks[fixed_index] == 1
moving_image = images[moving_index]
moving_image_mask = masks[moving_index] == 1
registration_method = sitk.ImageRegistrationMethod()
# Determine the number of BSpline control points using the physical
# spacing we want for the finest resolution control grid.
grid_physical_spacing = [params['grid_physical_spacing'], params['grid_physical_spacing'], params['grid_physical_spacing']] # A control point every grid_physical_spacingmm
image_physical_size = [size*spacing for size,spacing in zip(fixed_image.GetSize(), fixed_image.GetSpacing())]
mesh_size = [int(image_size/grid_spacing + 0.5) \
for image_size,grid_spacing in zip(image_physical_size,grid_physical_spacing)]
# The starting mesh size will be 1/4 of the original, it will be refined by
# the multi-resolution framework.
mesh_size = [int(sz/4 + 0.5) for sz in mesh_size]
initial_transform = sitk.BSplineTransformInitializer(image1 = fixed_image,
transformDomainMeshSize = mesh_size, order=3)
# Instead of the standard SetInitialTransform we use the BSpline specific method which also
# accepts the scaleFactors parameter to refine the BSpline mesh. In this case we start with
# the given mesh_size at the highest pyramid level then we double it in the next lower level and
# in the full resolution image we use a mesh that is four times the original size.
registration_method.SetInitialTransformAsBSpline(initial_transform,
inPlace=False,
scaleFactors=[1,2,4])
# Selecting similarity fuction
if params['similarity_function'] == 'mean_squares':
registration_method.SetMetricAsMeanSquares()
elif params['similarity_function'] == 'mattes_mutual_information':
registration_method.SetMetricAsMattesMutualInformation()
elif params['similarity_function'] == 'correlation':
registration_method.SetMetricAsCorrelation()
elif params['similarity_function'] == 'ants_neighborhood_correlation':
registration_method.SetMetricAsANTSNeighborhoodCorrelation(radius=1)
elif params['similarity_function'] == 'joint_histogram_mutual_information':
registration_method.SetMetricAsJointHistogramMutualInformation()
else:
raise ValueError('Invalid similarity function')
registration_method.SetMetricSamplingStrategy(registration_method.RANDOM)
registration_method.SetMetricSamplingPercentage(0.01)
registration_method.SetMetricFixedMask(fixed_image_mask)
registration_method.SetShrinkFactorsPerLevel(shrinkFactors=[2 ** i for i in range(params['scale_parameter_and_smoothing_sigma_max_power'] - 1, -1, -1)])
registration_method.SetSmoothingSigmasPerLevel(smoothingSigmas=[2 ** i for i in range(params['scale_parameter_and_smoothing_sigma_max_power'] - 2, -1, -1)] + [0])
registration_method.SmoothingSigmasAreSpecifiedInPhysicalUnitsOn()
# Selecting interpolator
if params['interpolator'] == 'linear':
registration_method.SetInterpolator(sitk.sitkLinear)
elif params['interpolator'] == 'bspline':
registration_method.SetInterpolator(sitk.sitkBSpline)
else:
raise ValueError('Invalid interpolator')
# Selecting optimizer
if params['optimizer'] == 'amoeba':
registration_method.SetOptimizerAsAmoeba(simplexDelta=0.1, numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'one_plus_one':
registration_method.SetOptimizerAsOnePlusOneEvolutionary(numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'powell':
registration_method.SetOptimizerAsPowell(numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'step_gradient_descent':
registration_method.SetOptimizerAsRegularStepGradientDescent(learningRate=0.1, minStep=0.1, numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'gradient_line_search':
registration_method.SetOptimizerAsConjugateGradientLineSearch(learningRate=0.01, numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'gradient_descent':
registration_method.SetOptimizerAsGradientDescent(learningRate=0.01, numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'dradient_descent_line_search':
registration_method.SetOptimizerAsGradientDescentLineSearch(learningRate=0.01, numberOfIterations=params['max_optimizer_iterations'])
elif params['optimizer'] == 'lbfgs2':
registration_method.SetOptimizerAsLBFGS2(numberOfIterations=params['max_optimizer_iterations'])
else:
raise ValueError('Invalid optimization function')
registration_method.AddCommand(sitk.sitkIterationEvent, lambda: iteration_callback_ffd(registration_method))
final_transformation = registration_method.Execute(fixed_image, moving_image)
stop_condition = registration_method.GetOptimizerStopConditionDescription()
print('\nOptimizer\'s stopping condition, {0}'.format(stop_condition))
return final_transformation, stop_condition
def registration(original_images_path, original_masks_path, transformed_files_path, patient_id, params):
'''
Load the images and compute the registration of the images for each patient. The available methods are
free form deformation and demons based registration algorithms.
Args:
- original_images_path (str): Path to the original images.
- original_masks_path (str): Path to the original masks.
- transformed_files_path (str): Path to save the transformed files.
- patient_id (int): Id of the patient.
- params (dict): Dictionary with the parameters to use in the algorithm.
Returns:
- stop_condition (str)
'''
# Load images and masks
images = []
masks = []
for i in [0, 5]:
image_file_name = original_images_path + '/0' + str(patient_id) + '/{}0.mhd'.format(i)
mask_file_name = original_masks_path + '/0' + str(patient_id) + '/{}0.mhd'.format(i)
images.append(sitk.ReadImage(image_file_name, sitk.sitkFloat32))
masks.append(sitk.ReadImage(mask_file_name))
# Compute the registration
final_transform, stop_condition = free_form_deformation_registration(images, masks, params)
# Save the final transform
save_transform(transformed_files_path + '/0' + str(patient_id), 'final_transform', final_transform)
gc.collect()
return stop_condition
def evaluate_registration(images_files_path, mask_files_path, landmark_files_path, transformed_files_path, patient_id):
'''
Evaluates the performance of the registration computing different metrics.
Args:
- images_files_path (str): Path to the image files.
- mask_files_path (str): Path to the mask files.
- landmark_files_path (str): Path to the landmarks files.
- transformed_files_path (str): Path to the transformed files.
- patient_id (int): Id of the patient.
Returns:
- results (dict): Dictionary with all the evaluation metrics.
'''
# Load images, masks and landmarks
images = []
masks = []
landmarks = []
for i in [0, 5]:
image_file_name = images_files_path + '/0' + str(patient_id) + '/{}0.mhd'.format(i)
mask_file_name = mask_files_path + '/0' + str(patient_id) + '/{}0.mhd'.format(i)
landmarks_file_name = landmark_files_path + '/0' + str(patient_id) + '/{}0.pts.txt'.format(i)
images.append(sitk.ReadImage(image_file_name, sitk.sitkFloat32))
masks.append(sitk.ReadImage(mask_file_name))
landmarks.append(utilities.read_POPI_points(landmarks_file_name))
# Load transformation
transformation = sitk.ReadTransform(transformed_files_path + '/0' + str(patient_id) + '/final_transform.tfm')
# Create dictionary to store all the relevant information
results = {}
# Define fixed and moving index
fixed_index = 0
moving_index = 1
# Compute the evaluation criteria with landmarks
final_TRE = utilities.target_registration_errors(transformation, landmarks[fixed_index], landmarks[moving_index])
# Save TRE
results['TRE'] = final_TRE
# Transfer the segmentation via the estimated transformation.
# Nearest Neighbor interpolation so we don't introduce new labels.
transformed_labels = sitk.Resample(masks[moving_index],
images[fixed_index],
transformation,
sitk.sitkNearestNeighbor,
0.0,
masks[moving_index].GetPixelID())
# Specify reference masks
reference_segmentation = masks[fixed_index]
# Segmentations after registration ensure that it is the correct label
seg = transformed_labels == 1
# Compute the evaluation criteria with masks
# Note that for the overlap measures filter, because we are dealing with a single label we
# use the combined, all labels, evaluation measures without passing a specific label to the methods.
overlap_measures_filter = sitk.LabelOverlapMeasuresImageFilter()
hausdorff_distance_filter = sitk.HausdorffDistanceImageFilter()
# Use the absolute values of the distance map to compute the surface distances (distance map sign, outside or inside
# relationship, is irrelevant)
label = 1
reference_distance_map = sitk.Abs(sitk.SignedMaurerDistanceMap(reference_segmentation, squaredDistance=False))
reference_surface = sitk.LabelContour(reference_segmentation)
statistics_image_filter = sitk.StatisticsImageFilter()
# Get the number of pixels in the reference surface by counting all pixels that are 1.
statistics_image_filter.Execute(reference_surface)
num_reference_surface_pixels = int(statistics_image_filter.GetSum())
# Overlap measures
overlap_measures_filter.Execute(reference_segmentation, seg)
results['JI'] = overlap_measures_filter.GetJaccardCoefficient()
results['DC'] = overlap_measures_filter.GetDiceCoefficient()
results['VS'] = overlap_measures_filter.GetVolumeSimilarity()
# Hausdorff distance
hausdorff_distance_filter.Execute(reference_segmentation, seg)
results['HD'] = hausdorff_distance_filter.GetHausdorffDistance()
# Symmetric surface distance measures
segmented_distance_map = sitk.Abs(sitk.SignedMaurerDistanceMap(seg, squaredDistance=False))
segmented_surface = sitk.LabelContour(seg)
# Multiply the binary surface segmentations with the distance maps. The resulting distance
# maps contain non-zero values only on the surface (they can also contain zero on the surface)
seg2ref_distance_map = reference_distance_map*sitk.Cast(segmented_surface, sitk.sitkFloat32)
ref2seg_distance_map = segmented_distance_map*sitk.Cast(reference_surface, sitk.sitkFloat32)
# Get the number of pixels in the segmented surface by counting all pixels that are 1.
statistics_image_filter.Execute(segmented_surface)
num_segmented_surface_pixels = int(statistics_image_filter.GetSum())
# Get all non-zero distances and then add zero distances if required.
seg2ref_distance_map_arr = sitk.GetArrayViewFromImage(seg2ref_distance_map)
seg2ref_distances = list(seg2ref_distance_map_arr[seg2ref_distance_map_arr!=0])
seg2ref_distances = seg2ref_distances + \
list(np.zeros(num_segmented_surface_pixels - len(seg2ref_distances)))
ref2seg_distance_map_arr = sitk.GetArrayViewFromImage(ref2seg_distance_map)
ref2seg_distances = list(ref2seg_distance_map_arr[ref2seg_distance_map_arr!=0])
ref2seg_distances = ref2seg_distances + \
list(np.zeros(num_reference_surface_pixels - len(ref2seg_distances)))
all_surface_distances = seg2ref_distances + ref2seg_distances
results['SD'] = all_surface_distances
results['R'] = 0.2*np.mean(results['TRE'])+0.3*np.mean(results['HD'])+0.5*100*np.abs(results['VS'])
return results
def statistical_info_from_results(results):
'''
Compute some statistical information from the results of all patients
Args:
- results (dict): Dictionary with the all the results.
Returns:
- results (dict): Dictionary with the all the results and the statistical info.
'''
JI_ls = [results['patient_0' + str(patient_id)]['JI'] for patient_id in patient_ids]
results['JI_mean'] = np.mean(JI_ls)
results['JI_median'] = np.median(JI_ls)
results['JI_std'] = np.std(JI_ls)
DC_ls = [results['patient_0' + str(patient_id)]['DC'] for patient_id in patient_ids]
results['DC_mean'] = np.mean(DC_ls)
results['DC_median'] = np.median(DC_ls)
results['DC_std'] = np.std(DC_ls)
SD_ls = [np.mean(results['patient_0' + str(patient_id)]['SD']) for patient_id in patient_ids]
results['SD_mean'] = np.mean(SD_ls)
results['SD_median'] = np.median(SD_ls)
results['SD_std'] = np.std(SD_ls)
TRE_ls = [np.mean(results['patient_0' + str(patient_id)]['TRE']) for patient_id in patient_ids]
results['TRE_mean'] = np.mean(TRE_ls)
results['TRE_median'] = np.median(TRE_ls)
results['TRE_std'] = np.std(TRE_ls)
HD_ls = [results['patient_0' + str(patient_id)]['HD'] for patient_id in patient_ids]
results['HD_mean'] = np.mean(HD_ls)
results['HD_median'] = np.median(HD_ls)
results['HD_std'] = np.std(HD_ls)
VS_ls = [results['patient_0' + str(patient_id)]['VS'] for patient_id in patient_ids]
results['VS_mean'] = np.mean(VS_ls)
results['VS_median'] = np.median(VS_ls)
results['VS_std'] = np.std(VS_ls)
R_ls = [results['patient_0' + str(patient_id)]['R'] for patient_id in patient_ids]
results['R_mean'] = np.mean(R_ls)
results['R_median'] = np.median(R_ls)
results['R_std'] = np.std(R_ls)
return results
# Print the output on the terminal
#sys.stdout = open('/dev/stdout', 'w')
for idx, params in enumerate(grid):
t_start = time.time()
# Create an unique id for the parameters combination
params_id = uuid.uuid4()
print('parameters {}, id: {}, params: {}'.format(idx, params_id, params))
# Save all the important data in the results dict
results = {}
results['id'] = str(params_id)
results['params'] = params
# Compute the registration for each patient
for patient_id in patient_ids:
print('params_id: {}, patient: {}'.format(params_id, patient_id))
stop_condition = registration(source_path + images_dir,
source_path + mask_dir,
os.path.join(results_path + registration_results_dir, params_grid_id, str(params_id)),
patient_id, params)
registration_evaluation_results = evaluate_registration(source_path + images_dir,
source_path + mask_dir,
source_path + landmarks_dir,
os.path.join(results_path + registration_results_dir, params_grid_id, str(params_id)),
patient_id)
# Store the results for each patient
results['patient_0' + str(patient_id) + '_stop_cond'] = stop_condition
results['patient_0' + str(patient_id)] = registration_evaluation_results
gc.collect()
# Compute some statistical information from the results
results = statistical_info_from_results(results)
t_end = time.time()
results['computation_time_min'] = (t_end - t_start) / 60
# Save the results of this parameters combination to a file
path_to_save = os.path.join(results_path + hp_search_results_dir, params_grid_id)
file_name = str(params_id) + '.json'
save_results(path_to_save, file_name, results)
gc.collect()
print('\n')
```
| github_jupyter |
```
import pandas as pd
import sqlite3
```
# NYC Dog Licensing Dataset (ETL): Extract
```
#pull and save NYC Dog Licensing Dataset from NYC Open Data
dogs = pd.read_csv("../Data/NYC_Dog_Licensing_Dataset.csv")
print(dogs.shape)
dogs.head()
```
# NYC Dog Licensing Dataset (ETL): Transform
```
#drop extraneous columns of dataset
dogs = dogs.drop(['RowNumber',
'AnimalBirthMonth',
'CommunityDistrict',
'CensusTract2010',
'NTA',
'CityCouncilDistrict',
'CongressionalDistrict',
'StateSenatorialDistrict'], axis=1)
#drop records with missing data
dogs = dogs.dropna()
print(dogs.shape)
#extract license issued and expired years
dogs['LicenseIssuedYear'] = pd.DatetimeIndex(dogs['LicenseIssuedDate']).year
dogs['LicenseExpiredYear'] = pd.DatetimeIndex(dogs['LicenseExpiredDate']).year
#drop license issued and expired date columns of dataset
dogs = dogs.drop(['LicenseIssuedDate', 'LicenseExpiredDate'], axis=1)
#set integer types
dogs.ZipCode = dogs.ZipCode.astype(int)
dogs.LicenseIssuedYear = dogs.LicenseIssuedYear.astype(int)
dogs.LicenseExpiredYear = dogs.LicenseExpiredYear.astype(int)
#review cleaned dataset
dogs.head()
#check data types of dataset
dogs.info()
#statistical description of dataset
#first license issued year = 2014
dogs.describe()
```
# NYC Dog Licensing Dataset (ETL): Load
```
#creating SQL connection
conn = sqlite3.connect('../Data/pet_care_industry.db')
c = conn.cursor()
#function to create table
def create_table(query):
c.execute(query)
#function to close connection
def close_c_conn():
c.close()
conn.close()
#create dogs table
create_query = """CREATE TABLE dogs
(id INTEGER PRIMARY KEY,
AnimalName TEXT,
AnimalGender TEXT,
BreedName TEXT,
Borough TEXT,
ZipCode INTEGER,
LicenseIssuedYear INTEGER,
LicenseExpiredYear INTEGER);"""
c.execute('DROP TABLE IF EXISTS dogs')
create_table(create_query)
#function to insert dogs into table
def insert_dogs(dogs):
for i in range(len(dogs.index)):
c.execute("""INSERT INTO dogs
(id,
AnimalName,
AnimalGender,
BreedName,
Borough,
ZipCode,
LicenseIssuedYear,
LicenseExpiredYear)
VALUES
(?,?,?,?,?,?,?,?)""",
(i,
dogs.iloc[i]['AnimalName'],
dogs.iloc[i]['AnimalGender'],
dogs.iloc[i]['BreedName'],
dogs.iloc[i]['Borough'],
int(dogs.iloc[i]['ZipCode']),
int(dogs.iloc[i]['LicenseIssuedYear']),
int(dogs.iloc[i]['LicenseExpiredYear'])))
conn.commit()
#insert dogs into table
insert_dogs(dogs)
#check SQL dogs table
dogs = pd.read_sql_query("SELECT * FROM dogs;", conn)
dogs = dogs.set_index('id')
dogs
#close connection
close_c_conn()
```
| github_jupyter |
# 1D-CNN Model for ECG Classification
- The model used has 2 Conv. layers and 2 FC layers.
- This code repeat running the training process and produce all kinds of data which can be given, such as data needed for drawing loss and accuracy graph through epochs, and maximum test accuracy for each run.
## Get permission of Google Drive access
```
from google.colab import drive
drive.mount('/content/gdrive')
root_path = 'gdrive/My Drive/Colab Notebooks'
```
## File name settings
```
data_dir = 'mitdb'
train_name = 'train_ecg.hdf5'
test_name = 'test_ecg.hdf5'
all_name = 'all_ecg.hdf5'
model_dir = 'model'
model_name = 'conv2'
model_ext = '.pth'
csv_dir = 'csv'
csv_ext = '.csv'
csv_name = 'conv2'
csv_accs_name = 'accs_conv2'
```
## Import required packages
```
import os
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.optim import Adam
import numpy as np
import pandas as pd
import h5py
import matplotlib.pyplot as plt
```
## GPU settings
```
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
if torch.cuda.is_available():
print(torch.cuda.get_device_name(0))
```
## Define `ECG` `Dataset` class
```
class ECG(Dataset):
def __init__(self, mode='train'):
if mode == 'train':
with h5py.File(os.path.join(root_path, data_dir, train_name), 'r') as hdf:
self.x = hdf['x_train'][:]
self.y = hdf['y_train'][:]
elif mode == 'test':
with h5py.File(os.path.join(root_path, data_dir, test_name), 'r') as hdf:
self.x = hdf['x_test'][:]
self.y = hdf['y_test'][:]
elif mode == 'all':
with h5py.File(os.path.join(root_path, data_dir, all_name), 'r') as hdf:
self.x = hdf['x'][:]
self.y = hdf['y'][:]
else:
raise ValueError('Argument of mode should be train, test, or all.')
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return torch.tensor(self.x[idx], dtype=torch.float), torch.tensor(self.y[idx])
```
## Make Batch Generator
### Batch size
You can change it if you want.
```
batch_size = 32
```
### `DataLoader` for batch generating
`torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False)`
```
train_dataset = ECG(mode='train')
test_dataset = ECG(mode='test')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
```
### Size check for single batch
```
x_train, y_train = next(iter(train_loader))
print(x_train.size())
print(y_train.size())
```
### Number of total batches
```
total_batch = len(train_loader)
print(total_batch)
```
## Pytorch layer modules for **Conv1D** Network
### `Conv1d` layer
- `torch.nn.Conv1d(in_channels, out_channels, kernel_size)`
### `MaxPool1d` layer
- `torch.nn.MaxPool1d(kernel_size, stride=None)`
- Parameter `stride` follows `kernel_size`.
### `ReLU` layer
- `torch.nn.ReLU()`
### `Linear` layer
- `torch.nn.Linear(in_features, out_features, bias=True)`
### `Softmax` layer
- `torch.nn.Softmax(dim=None)`
- Parameter `dim` is usually set to `1`.
## Construct 1D CNN ECG classification model
```
class ECGConv1D(nn.Module):
def __init__(self):
super(ECGConv1D, self).__init__()
self.conv1 = nn.Conv1d(1, 16, 7, padding=3) # 128 x 16
self.relu1 = nn.LeakyReLU()
self.pool1 = nn.MaxPool1d(2) # 64 x 16
self.conv2 = nn.Conv1d(16, 16, 5, padding=2) # 64 x 16
self.relu2 = nn.LeakyReLU()
self.pool2 = nn.MaxPool1d(2) # 32 x 16
self.linear3 = nn.Linear(32 * 16, 128)
self.relu3 = nn.LeakyReLU()
self.linear4 = nn.Linear(128, 5)
self.softmax4 = nn.Softmax(dim=1)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = x.view(-1, 32 * 16)
x = self.linear3(x)
x = self.relu3(x)
x = self.linear4(x)
x = self.softmax4(x)
return x
ecgnet = ECGConv1D()
ecgnet.to(device)
```
## Training process settings
```
run = 10
epoch = 400
lr = 0.001
```
## Traning function
```
def train(nrun, model):
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=lr)
train_losses = list()
train_accs = list()
test_losses = list()
test_accs = list()
best_test_acc = 0 # best test accuracy
for e in range(epoch):
print("Epoch {} - ".format(e+1), end='')
# train
train_loss = 0.0
correct, total = 0, 0
for _, batch in enumerate(train_loader):
x, label = batch # get feature and label from a batch
x, label = x.to(device), label.to(device) # send to device
optimizer.zero_grad() # init all grads to zero
output = model(x) # forward propagation
loss = criterion(output, label) # calculate loss
loss.backward() # backward propagation
optimizer.step() # weight update
train_loss += loss.item()
correct += torch.sum(output.argmax(dim=1) == label).item()
total += len(label)
train_losses.append(train_loss / len(train_loader))
train_accs.append(correct / total)
print("loss: {:.4f}, acc: {:.2f}%".format(train_losses[-1], train_accs[-1]*100), end=' / ')
# test
with torch.no_grad():
test_loss = 0.0
correct, total = 0, 0
for _, batch in enumerate(test_loader):
x, label = batch
x, label = x.to(device), label.to(device)
output = model(x)
loss = criterion(output, label)
test_loss += loss.item()
correct += torch.sum(output.argmax(dim=1) == label).item()
total += len(label)
test_losses.append(test_loss / len(test_loader))
test_accs.append(correct / total)
print("test_loss: {:.4f}, test_acc: {:.2f}%".format(test_losses[-1], test_accs[-1]*100))
# save model that has best validation accuracy
if test_accs[-1] > best_test_acc:
best_test_acc = test_accs[-1]
torch.save(model.state_dict(), os.path.join(root_path, model_dir, '_'.join([model_name, str(nrun), 'best']) + model_ext))
# save model for each 10 epochs
if (e + 1) % 10 == 0:
torch.save(model.state_dict(), os.path.join(root_path, model_dir, '_'.join([model_name, str(nrun), str(e+1)]) + model_ext))
return train_losses, train_accs, test_losses, test_accs
```
## Training process
### Repeat for 10 times
```
best_test_accs = list()
for i in range(run):
print('Run', i+1)
ecgnet = ECGConv1D() # init new model
train_losses, train_accs, test_losses, test_accs = train(i, ecgnet.to(device)) # train
best_test_accs.append(max(test_accs)) # get best test accuracy
best_test_acc_epoch = np.array(test_accs).argmax() + 1
print('Best test accuracy {:.2f}% in epoch {}.'.format(best_test_accs[-1]*100, best_test_acc_epoch))
print('-' * 100)
df = pd.DataFrame({ # save model training process into csv file
'loss': train_losses,
'test_loss': test_losses,
'acc': train_accs,
'test_acc': test_accs
})
df.to_csv(os.path.join(root_path, csv_dir, '_'.join([csv_name, str(i+1)]) + csv_ext))
df = pd.DataFrame({'best_test_acc': best_test_accs}) # save best test accuracy of each run
df.to_csv(os.path.join(root_path, csv_dir, csv_accs_name + csv_ext))
```
## Print the best test accuracy of each run
```
for i, a in enumerate(best_test_accs):
print('Run {}: {:.2f}%'.format(i+1, a*100))
```
| github_jupyter |
```
from doctest import run_docstring_examples
from datetime import datetime
```
# Day 1: Report Repair
Tipp: diese Aufgabe kann u.A. mit zwei bzw. drei verschachtelten For-Schleifen gelöst werden.
Quelle: https://adventofcode.com/2020/day/1
## Part One
After saving Christmas five years in a row, you've decided to take a vacation at a nice resort on a tropical island. Surely, Christmas will go on without you.
The tropical island has its own currency and is entirely cash-only. The gold coins used there have a little picture of a starfish; the locals just call them stars. None of the currency exchanges seem to have heard of them, but somehow, you'll need to find fifty of these coins by the time you arrive so you can pay the deposit on your room.
To save your vacation, you need to get all fifty stars by December 25th.
Collect stars by solving puzzles. Two puzzles will be made available on each day in the Advent calendar; the second puzzle is unlocked when you complete the first. Each puzzle grants one star. Good luck!
Before you leave, the Elves in accounting just need you to fix your expense report (your puzzle input); apparently, something isn't quite adding up.
Specifically, they need you to find the two entries that sum to 2020 and then multiply those two numbers together.
For example, suppose your expense report contained the following:
1721
979
366
299
675
1456
In this list, the two entries that sum to 2020 are 1721 and 299. Multiplying them together produces 1721 * 299 = 514579, so the correct answer is 514579.
Of course, your expense report is much larger. Find the two entries that sum to 2020; what do you get if you multiply them together?
Your puzzle answer was 1020084.
```
def report_repair_p1(expenses, zielsumme=2020):
"""
Findet die zwei Zahlen aus einer Liste von Zahlen, die addiert "zielsumme" ergeben und gibt das Produkt zurück.
Tests:
1721 * 299 = 514579
>>> print(report_repair_p1([1721, 979, 366, 299, 675, 1456], 2020))
514579
"""
n = len(expenses)
resultat = None
for i in range(n-1):
for j in range(i+1, n):
summe = expenses[i] + expenses[j]
if summe == zielsumme:
resultat = expenses[i] * expenses[j]
break
return resultat
run_docstring_examples(report_repair_p1, locals())
```
## Part Two
The Elves in accounting are thankful for your help; one of them even offers you a starfish coin they had left over from a past vacation. They offer you a second one if you can find three numbers in your expense report that meet the same criteria.
Using the above example again, the three entries that sum to 2020 are 979, 366, and 675. Multiplying them together produces the answer, 241861950.
In your expense report, what is the product of the three entries that sum to 2020?
Your puzzle answer was 295086480.
```
def report_repair_p2(expenses, zielsumme=2020):
"""
Findet die drei Zahlen aus einer Liste von Zahlen, die addiert "zielsumme" ergeben und gibt das Produkt zurück.
Tests:
979 + 366 + 675 = 2020
979 * 366 * 675 = 241861950
>>> print(report_repair_p2([1721, 979, 366, 299, 675, 1456], 2020))
241861950
"""
n = len(expenses)
resultat = None
for i in range(n-2):
for j in range(i+1, n-1):
teilsumme = expenses[i] + expenses[j]
for k in range(j+1, n):
if teilsumme + expenses[k] == zielsumme:
resultat = expenses[i] * expenses[j] * expenses[k]
break
return resultat
run_docstring_examples(report_repair_p2, locals())
```
## Testdaten laden
```
with open('../inputs/2020_01.csv') as f:
input_data = [int(line.rstrip()) for line in f]
```
## Solution
```
def check_solution(fun, input_data, solution=0):
start = datetime.now()
result = fun(input_data)
dauer = datetime.now() - start
nachricht = "Ergebnis: {} Rechenzeit: {}"
print(nachricht.format(result, dauer))
assert result == solution
check_solution(report_repair_p1, input_data, 1020084)
check_solution(report_repair_p2, input_data, 295086480)
```
| github_jupyter |
##### Copyright 2018 The TensorFlow Authors.
Licensed under the Apache License, Version 2.0 (the "License").
# DCGAN: An example with tf.keras and eager
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/">
<img src="https://www.tensorflow.org/images/tf_logo_32px.png" />
View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/dcgan.ipynb">
<img src="https://www.tensorflow.org/images/colab_logo_32px.png" />
Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/generative_examples/dcgan.ipynb">
<img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />
View source on GitHub</a>
</td>
</table>
This notebook demonstrates how to generate images of handwritten digits using [tf.keras](https://www.tensorflow.org/programmers_guide/keras) and [eager execution](https://www.tensorflow.org/programmers_guide/eager). To do so, we use Deep Convolutional Generative Adverserial Networks ([DCGAN](https://arxiv.org/pdf/1511.06434.pdf)).
This model takes about ~30 seconds per epoch (using tf.contrib.eager.defun to create graph functions) to train on a single Tesla K80 on Colab, as of July 2018.
Below is the output generated after training the generator and discriminator models for 150 epochs.

```
# to generate gifs
!pip install imageio
```
## Import TensorFlow and enable eager execution
```
from __future__ import absolute_import, division, print_function
# Import TensorFlow >= 1.10 and enable eager execution
import tensorflow as tf
tf.enable_eager_execution()
import os
import time
import numpy as np
import glob
import matplotlib.pyplot as plt
import PIL
import imageio
from IPython import display
```
## Load the dataset
We are going to use the MNIST dataset to train the generator and the discriminator. The generator will then generate handwritten digits.
```
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
# We are normalizing the images to the range of [-1, 1]
train_images = (train_images - 127.5) / 127.5
BUFFER_SIZE = 60000
BATCH_SIZE = 256
```
## Use tf.data to create batches and shuffle the dataset
```
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
```
## Write the generator and discriminator models
* **Generator**
* It is responsible for **creating convincing images that are good enough to fool the discriminator**.
* It consists of Conv2DTranspose (Upsampling) layers. We start with a fully connected layer and upsample the image 2 times so as to reach the desired image size (mnist image size) which is (28, 28, 1).
* We use **leaky relu** activation except for the **last layer** which uses **tanh** activation.
* **Discriminator**
* **The discriminator is responsible for classifying the fake images from the real images.**
* In other words, the discriminator is given generated images (from the generator) and the real MNIST images. The job of the discriminator is to classify these images into fake (generated) and real (MNIST images).
* **Basically the generator should be good enough to fool the discriminator that the generated images are real**.
```
class Generator(tf.keras.Model):
def __init__(self):
super(Generator, self).__init__()
self.fc1 = tf.keras.layers.Dense(7*7*64, use_bias=False)
self.batchnorm1 = tf.keras.layers.BatchNormalization()
self.conv1 = tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(1, 1), padding='same', use_bias=False)
self.batchnorm2 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv2DTranspose(32, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.batchnorm3 = tf.keras.layers.BatchNormalization()
self.conv3 = tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False)
def call(self, x, training=True):
x = self.fc1(x)
x = self.batchnorm1(x, training=training)
x = tf.nn.relu(x)
x = tf.reshape(x, shape=(-1, 7, 7, 64))
x = self.conv1(x)
x = self.batchnorm2(x, training=training)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.batchnorm3(x, training=training)
x = tf.nn.relu(x)
x = tf.nn.tanh(self.conv3(x))
return x
class Discriminator(tf.keras.Model):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same')
self.conv2 = tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')
self.dropout = tf.keras.layers.Dropout(0.3)
self.flatten = tf.keras.layers.Flatten()
self.fc1 = tf.keras.layers.Dense(1)
def call(self, x, training=True):
x = tf.nn.leaky_relu(self.conv1(x))
x = self.dropout(x, training=training)
x = tf.nn.leaky_relu(self.conv2(x))
x = self.dropout(x, training=training)
x = self.flatten(x)
x = self.fc1(x)
return x
generator = Generator()
discriminator = Discriminator()
# Defun gives 10 secs/epoch performance boost
generator.call = tf.contrib.eager.defun(generator.call)
discriminator.call = tf.contrib.eager.defun(discriminator.call)
```
## Define the loss functions and the optimizer
* **Discriminator loss**
* The discriminator loss function takes 2 inputs; **real images, generated images**
* real_loss is a sigmoid cross entropy loss of the **real images** and an **array of ones (since these are the real images)**
* generated_loss is a sigmoid cross entropy loss of the **generated images** and an **array of zeros (since these are the fake images)**
* Then the total_loss is the sum of real_loss and the generated_loss
* **Generator loss**
* It is a sigmoid cross entropy loss of the generated images and an **array of ones**
* The discriminator and the generator optimizers are different since we will train them separately.
```
def discriminator_loss(real_output, generated_output):
# [1,1,...,1] with real output since it is true and we want
# our generated examples to look like it
real_loss = tf.losses.sigmoid_cross_entropy(multi_class_labels=tf.ones_like(real_output), logits=real_output)
# [0,0,...,0] with generated images since they are fake
generated_loss = tf.losses.sigmoid_cross_entropy(multi_class_labels=tf.zeros_like(generated_output), logits=generated_output)
total_loss = real_loss + generated_loss
return total_loss
def generator_loss(generated_output):
return tf.losses.sigmoid_cross_entropy(tf.ones_like(generated_output), generated_output)
discriminator_optimizer = tf.train.AdamOptimizer(1e-4)
generator_optimizer = tf.train.AdamOptimizer(1e-4)
```
## Checkpoints (Object-based saving)
```
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
```
## Training
* We start by iterating over the dataset
* The generator is given **noise as an input** which when passed through the generator model will output a image looking like a handwritten digit
* The discriminator is given the **real MNIST images as well as the generated images (from the generator)**.
* Next, we calculate the generator and the discriminator loss.
* Then, we calculate the gradients of loss with respect to both the generator and the discriminator variables (inputs) and apply those to the optimizer.
## Generate Images
* After training, its time to generate some images!
* We start by creating noise array as an input to the generator
* The generator will then convert the noise into handwritten images.
* Last step is to plot the predictions and **voila!**
```
EPOCHS = 150
noise_dim = 100
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement of the gan.
random_vector_for_generation = tf.random_normal([num_examples_to_generate,
noise_dim])
def generate_and_save_images(model, epoch, test_input):
# make sure the training parameter is set to False because we
# don't want to train the batchnorm layer when doing inference.
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def train(dataset, epochs, noise_dim):
for epoch in range(epochs):
start = time.time()
for images in dataset:
# generating noise from a uniform distribution
noise = tf.random_normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
generated_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(generated_output)
disc_loss = discriminator_loss(real_output, generated_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
if epoch % 1 == 0:
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
random_vector_for_generation)
# saving (checkpoint) the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time taken for epoch {} is {} sec'.format(epoch + 1,
time.time()-start))
# generating after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
random_vector_for_generation)
train(train_dataset, EPOCHS, noise_dim)
```
## Restore the latest checkpoint
```
# restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
```
## Display an image using the epoch number
```
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)
```
## Generate a GIF of all the saved images.
<!-- TODO(markdaoust): Remove the hack when Ipython version is updated -->
```
with imageio.get_writer('dcgan.gif', mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
last = -1
for i,filename in enumerate(filenames):
frame = 2*(i**0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
# this is a hack to display the gif inside the notebook
os.system('cp dcgan.gif dcgan.gif.png')
display.Image(filename="dcgan.gif.png")
```
To downlod the animation from Colab uncomment the code below:
```
#from google.colab import files
#files.download('dcgan.gif')
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.