
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
## Convolution with Maxpool Demo Run
___
This notebook shows a single run of the convolution and maxpool using Darius IP. The input feature map is read from memory, processed and output feature map is captured for one single convolution with maxpool command. The cycle count and efficiency for the full operation is read and displayed at the end.
The input data in memory is set with random integers in this notebook to test the run.
#### Terminology
| Term | Description |
| :------ | :--------------------------------------- |
| IFM | Input volume |
| Weights | A set of filter volumes |
| OFM | Output volume |
#### Arguments
| Convolution Arguments | Description |
| --------------------- | ---------------------------------------- |
| ifm-h, ifm-w | Height and width of an input feature map in an IFM volume |
| ifm-d | Depth of the IFM volume |
| kernel-h, kernel-w | Height and width of the weight filters |
| stride | Stride for the IFM volume |
| pad | Pad for the IFM volume |
| Channels | Number of Weight sets/number of output feature maps |
| Pool-kernel-h, Pool-kernel-w | Height and width of maxpool kernel |
| Pool-stride | Stride for the Convolved volume |
### Block diagram

<center>Figure 1</center>
Figure 1 presents a simplified block diagram including Darius CNN IP that is used for running convolution tasks. The Processing System (PS) represents the ARM processor, as well as the external DDR. The Programmable Logic (PL) incorporates the Darius IP for running convolution tasks, and an AXI Interconnect IP. The AXI_GP_0 is an AXILite interface for control signal communication between the ARM and the Darius IP. The data transfer happens through the AXI High Performance Bus, denoted as AXI_HP_0. __For more information about the Zynq architecture, visit:__ [Link](https://www.xilinx.com/support/documentation/user_guides/ug585-Zynq-7000-TRM.pdf)
### Dataflow
The dataflow begins by creating an input volume, and a set of weights in python local memory. In Figure 1, these volumes are denoted as “ifm_sw”, and “weights_sw”, respectively. After populating random data, the ARM processor reshapes and copies these volumes into contiguous blocks of shared memory, represented as “ifm” and “weights” in Figure 1, using the “reshape_and_copy()” function. Once the data is accessible by the hardware, the PS starts the convolution operation by asserting the start bit of Darius IP, through the “AXI_GP_0” interface. Darius starts the processing by reading the “ifm” and “weights” volumes from the external memory and writing the results back to a pre-allocated location, shown as “ofm” in Figure 1.
Notes:
- We presume the data in the “ifm_sw” and “weight_sw”, are populated in a row-major format. In order to get the correct results, these volumes have to be reshaped into an interleaved format, as expected by the Darius IP.
- No data reformatting is required for subsequent convolution calls to Darius, as it produces the “ofm” volume in the same format as it expects the “ifm” volume.
- Since the shared memory region is accessible both by the PS and PL regions, one can perform any post-processing steps that may be required directly on the “ofm” volume without transferring data back-and-forth to the python local memory.
### Step 1: Set the arguments for the convolution in CNNDataflow IP
```
# Input Feature Map (IFM) dimensions
ifm_height = 14
ifm_width = 14
ifm_depth = 64
# Kernel Window dimensions
kernel_height = 3
kernel_width = 3
# Other arguments
pad = 0
stride = 1
# Channels
channels = 32
# Maxpool dimensions
pool_kernel_height = 2
pool_kernel_width = 2
pool_stride = 2
print(
"HOST CMD: CNNDataflow IP Arguments set are - IH %d, IW %d, ID %d, KH %d,"
" KW %d, P %d, S %d, CH %d, PKH %d, PKW %d, PS %d"
% (ifm_height, ifm_width, ifm_depth, kernel_height, kernel_width,
pad, stride, channels, pool_kernel_height, pool_kernel_width, pool_stride))
```
### Step 2: Download `Darius Convolution IP` bitstream
```
from pynq import Overlay
overlay = Overlay(
"/opt/python3.6/lib/python3.6/site-packages/pynq/overlays/darius/"
"convolution.bit")
overlay.download()
print(f'Bitstream download status: {overlay.is_loaded()}')
```
### Step 3: Create MMIO object to access the CNNDataflow IP
For more on MMIO visit: [MMIO Documentation](http://pynq.readthedocs.io/en/latest/overlay_design_methodology/pspl_interface.html#mmio)
```
from pynq import MMIO
# Constants
CNNDATAFLOW_BASEADDR = 0x43C00000
NUM_COMMANDS_OFFSET = 0x60
CMD_BASEADDR_OFFSET = 0x70
CYCLE_COUNT_OFFSET = 0xd0
cnn = MMIO(CNNDATAFLOW_BASEADDR, 65536)
print(f'Idle state: {hex(cnn.read(0x0, 4))}')
```
### Step 4: Create Xlnk object
Xlnk object (Memory Management Unit) for allocating contiguous array in memory for data transfer between software and hardware
<div class="alert alert-danger">Note: You may run into problems if you exhaust and do not free memory buffers – we only have 128MB of contiguous memory, so calling the allocation twice (allocating 160MB) would lead to a “failed to allocate memory” error. Do a xlnk_reset() before re-allocating memory or running this cell twice </div>
```
from pynq import Xlnk
import numpy as np
# Constant
SIZE = 5000000 # 20 MB of numpy.uint32s
mmu = Xlnk()
# Contiguous memory buffers for CNNDataflow IP convolution command, IFM Volume,
# Weights and OFM Volume. These buffers are shared memories that are used to
# transfer data between software and hardware
cmd = mmu.cma_array(SIZE, dtype=np.int16)
ifm = mmu.cma_array(SIZE, dtype=np.int16)
weights = mmu.cma_array(SIZE, dtype=np.int16)
ofm = mmu.cma_array(SIZE, dtype=np.int16)
# Saving the base phyiscal address for the command, ifm, weights, and
# ofm buffers. These addresses will be used later to copy and transfer data
# between hardware and software
cmd_baseaddr = cmd.physical_address
ifm_baseaddr = ifm.physical_address
weights_baseaddr = weights.physical_address
ofm_baseaddr = ofm.physical_address
```
### Step 5: Functions to print Xlnk statistics
```
def get_kb(mmu):
return int(mmu.cma_stats()['CMA Memory Available'] // 1024)
def get_bufcount(mmu):
return int(mmu.cma_stats()['Buffer Count'])
def print_kb(mmu):
print("Available Memory (KB): " + str(get_kb(mmu)))
print("Available Buffers: " + str(get_bufcount(mmu)))
print_kb(mmu)
```
### Step 6: Construct convolution command
Check that arguments are in supported range and construct convolution command for hardware
```
from darius import darius_lib
conv_maxpool = darius_lib.Darius(ifm_height, ifm_width, ifm_depth,
kernel_height, kernel_width, pad, stride,
channels, pool_kernel_height,
pool_kernel_width, pool_stride,
ifm_baseaddr, weights_baseaddr,
ofm_baseaddr)
IP_cmd = conv_maxpool.IP_cmd()
print("Command to CNNDataflow IP: \n" + str(IP_cmd))
```
### Step 7: Create IFM volume and weight volume.
Volumes are created in software and populated with random values in a row-major format.
```
from random import *
ifm_sw = np.random.randint(0,255, ifm_width*ifm_height*ifm_depth, dtype=np.int16)
weights_sw = np.random.randint(0,255, channels*ifm_depth*kernel_height*kernel_width, dtype=np.int16)
```
#### Reshape IFM volume and weights
Volumes are reshaped from row-major format to IP format and data is copied to their respective shared buffer
```
conv_maxpool.reshape_and_copy_ifm(ifm_sw, ifm)
conv_maxpool.reshape_and_copy_weights(weights_sw, weights)
```
### Step 8: Load convolution command and start CNNDataflow IP
```
# Send convolution command to CNNDataflow IP
cmd_mem = MMIO(cmd_baseaddr, SIZE)
cmd_mem.write(0x0, IP_cmd)
# Load the number of commands and command physical address to offset addresses
cnn.write(NUM_COMMANDS_OFFSET, 1)
cnn.write(CMD_BASEADDR_OFFSET, cmd_baseaddr)
# Start Convolution if CNNDataflow IP is in Idle state
state = cnn.read(0x0)
if state == 4: # Idle state
print("state: IP IDLE; Starting IP")
start = cnn.write(0x0, 1) # Start IP
start
else:
print("state %x: IP BUSY" % state)
```
#### Check status of the CNNDataflow IP
```
# Check if Convolution IP is in Done state
state = cnn.read(0x0)
if state == 6: # Done state
print("state: IP DONE")
else:
print("state %x: IP BUSY" % state)
```
### Step 9: Read back first few words of OFM
```
for i in range(0, 15, 4):
print(hex(ofm[i]))
```
### Step 10: Read cycle count and efficiency of the complete run
```
hw_cycles = cnn.read(CYCLE_COUNT_OFFSET, 4)
efficiency = conv_maxpool.calc_efficiency(hw_cycles)
print("CNNDataflow IP cycles: %d\nEffciency: %.2f%%" % (hw_cycles, efficiency))
```
#### Reset Xlnk
```
mmu.xlnk_reset()
print_kb(mmu)
print("Cleared Memory!")
```
| github_jupyter |
<p align="center">
<img src="https://github.com/GeostatsGuy/GeostatsPy/blob/master/TCG_color_logo.png?raw=true" width="220" height="240" />
</p>
## Subsurface Data Analytics
## Interactive Demonstration of LASSO Regression and Intro to Hyperparameter Tuning
#### Michael Pyrcz, Associate Professor, University of Texas at Austin
##### [Twitter](https://twitter.com/geostatsguy) | [GitHub](https://github.com/GeostatsGuy) | [Website](http://michaelpyrcz.com) | [GoogleScholar](https://scholar.google.com/citations?user=QVZ20eQAAAAJ&hl=en&oi=ao) | [Book](https://www.amazon.com/Geostatistical-Reservoir-Modeling-Michael-Pyrcz/dp/0199731446) | [YouTube](https://www.youtube.com/channel/UCLqEr-xV-ceHdXXXrTId5ig) | [LinkedIn](https://www.linkedin.com/in/michael-pyrcz-61a648a1) | [GeostatsPy](https://github.com/GeostatsGuy/GeostatsPy)
In the Fall of 2019 my students requested a demonstration to show the value of LASSO regression. I wrote this interactive demonstration to show cases in which the use of regularization coefficient, a hyperparameter, that reduces the model flexibilty / sensivity to training data (reduces model variance) improves the prediction accuracy.
### PGE 383 Exercise: Interactive Demonstration of LASSO Regression and Intro to Hyperparameter Tuning
Let's start by introducing linear regression, expanding to LASSO regression with a regularization coefficient with feature selection, and then explain the 2 interactive demonstrations in this notebook (we had a 2 for 1 sale this week!).
#### Linear Regression
Linear regression for prediction. Here are some key aspects of linear regression:
**Parametric Model**
* the fit model is a simple weighted linear additive model based on all the available features, $x_1,\ldots,x_m$.
* the parametric model takes the form of:
\begin{equation}
y = \sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0
\end{equation}
**Least Squares**
* least squares optimization is applied to select the model parameters, $b_1,\ldots,b_m,b_0$
* we minize the error, residual sum of squares (RSS) over the training data:
\begin{equation}
RSS = \sum_{i=1}^n (y_i - (\sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0))^2
\end{equation}
* this could be simplified as the sum of square error over the training data,
\begin{equation}
\sum_{i=1}^n (\Delta y_i)^2
\end{equation}
**Assumptions**
* **Error-free** - predictor variables are error free, not random variables
* **Linearity** - response is linear combination of feature(s)
* **Constant Variance** - error in response is constant over predictor(s) value
* **Independence of Error** - error in response are uncorrelated with each other
* **No multicollinearity** - none of the features are redundant with other features
#### Other Resources
This is a tutorial / demonstration of **Linear Regression**. In $Python$, the $SciPy$ package, specifically the $Stats$ functions (https://docs.scipy.org/doc/scipy/reference/stats.html) provide excellent tools for efficient use of statistics.
I have previously provided this example in R and posted it on GitHub:
1. R https://github.com/GeostatsGuy/geostatsr/blob/master/linear_regression_demo_v2.R
2. Rmd with docs https://github.com/GeostatsGuy/geostatsr/blob/master/linear_regression_demo_v2.Rmd
3. knit as an HTML document(https://github.com/GeostatsGuy/geostatsr/blob/master/linear_regression_demo_v2.html)
#### LASSO Regression
With the lasso we add a hyperparameter, $\lambda$, to our minimization, with a shrinkage penalty term.
\begin{equation}
\sum_{i=1}^n \left(y_i - \left(\sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0 \right) \right)^2 + \lambda \sum_{j=1}^m |b_{\alpha}|
\end{equation}
As a result the lasso has 2 criteria:
1. set the model parameters to minimize the error with training data
2. shrink the estimates of the slope parameters towards zero. Note: the intercept is not affected by the lambda, $\lambda$, hyperparameter.
Note the only difference between the lasso and ridge regression is:
* for the lasso the shrinkage term is posed as an $\ell_1$ penalty ($\lambda \sum_{\alpha=1}^m |b_{\alpha}|$)
* for ridge regression the shrinkage term is posed as an $\ell_2$ penalty ($\lambda \sum_{\alpha=1}^m \left(b_{\alpha}\right)^2$).
While both ridge regression and the lasso shrink the model parameters ($b_{\alpha}, \alpha = 1,\ldots,m$) towards zero:
* the lasso parameters reach zero at different rates for each predictor feature as the lambda, $\lambda$, hyperparameter increases.
* as a result the lasso provides a method for feature ranking and selection!
The lambda, $\lambda$, hyperparameter controls the degree of fit of the model and may be related to the model variance and bias trade-off.
* for $\lambda \rightarrow 0$ the prediction model approaches linear regression, there is lower model bias, but the model variance is higher
* as $\lambda$ increases the model variance decreases and the model bias increases
* for $\lambda \rightarrow \infty$ the coefficients all become 0.0 and the model is the global mean
#### Train / Test Split
The available data is split into training and testing subsets.
* in general 15-30% of the data is withheld from training to apply as testing data
* testing data selection should be fair, the same difficulty of predictions (offset/different from the training dat
#### Machine Learning Model Training
The training data is applied to train the model parameters such that the model minimizes mismatch with the training data
* it is common to use **mean square error** (known as a **L2 norm**) as a loss function summarizing the model mismatch
* **miminizing the loss function** for simple models an anlytical solution may be available, but for most machine this requires an iterative optimization method to find the best model parameters
This process is repeated over a range of model complexities specified by hyperparameters.
#### Machine Learning Model Tuning
The withheld testing data is retrieved and loss function (usually the **L2 norm** again) is calculated to summarize the error over the testing data
* this is repeated over over the range of specified hypparameters
* the model complexity / hyperparameters that minimize the loss function / error summary in testing is selected
This is known are model hypparameter tuning.
#### Machine Learning Model Overfit
More model complexity/flexibility than can be justified with the available data, data accuracy, frequency and coverage
* Model explains “idiosyncrasies” of the data, capturing data noise/error in the model
* High accuracy in training, but low accuracy in testing / real-world use away from training data cases – poor ability of the model to generalize
#### The Interactive Demonstrations
Here's a simple workflow, demonstration of predictive machine learning model training and testing for overfit. We use a:
* simple polynomial model
* 1 preditor feature and 1 response feature
for an high interpretability model/ simple illustration.
#### Workflow Goals
Learn the basics of machine learning training, tuning for model generalization while avoiding model overfit. We use the very simple case of ridge regression that introduces a hyperparameter to linear regression.
We consider 2 examples:
1. **A linear model + noise** to make a random dataset with 1 predictor feature and 1 response feature. You can make the model, by-hand set the lambda hyperparameter and observe the impact. The code actually runs many lambda values so you can explore accurate and inacturate (over and underfit models).
2. **A loaded multivariate subsurface dataset** with random resampling to explore uncertainty in your result. Like above you can set the lambda hyperparameter by-hand and observe the model accuracy in train and test over a range model flexibility. In this case, since the model is quite multidimensional, you can see the cross validation plot instead of the visualization of the model.
#### Getting Started
You will need to copy the following data files to your working directory. They are available [here](https://github.com/GeostatsGuy/GeoDataSets):
* [unconv_MV.csv](https://github.com/GeostatsGuy/GeoDataSets/blob/master/unconv_MV.csv)
The dataset is available in this repository, https://github.com/GeostatsGuy/GeoDataSets.
* download this file to your working directory
#### Import Required Packages
We will also need some standard packages. These should have been installed with Anaconda 3.
```
import geostatspy.GSLIB as GSLIB # GSLIB utilies, visualization and wrapper
import geostatspy.geostats as geostats # GSLIB methods convert to Python
```
We will also need some standard packages. These should have been installed with Anaconda 3.
```
%matplotlib inline
import os # to set current working directory
import sys # supress output to screen for interactive variogram modeling
import io
import numpy as np # arrays and matrix math
import pandas as pd # DataFrames
import matplotlib.pyplot as plt # plotting
from sklearn.model_selection import train_test_split # train and test split
from sklearn.metrics import mean_squared_error # model error calculation
from sklearn.linear_model import Ridge # ridge regression
from sklearn.linear_model import Lasso # the lasso implemented in scikit learn
import scipy # kernel density estimator for PDF plot
from matplotlib.pyplot import cm # color maps
from ipywidgets import interactive # widgets and interactivity
from ipywidgets import widgets
from ipywidgets import Layout
from ipywidgets import Label
from ipywidgets import VBox, HBox
```
If you get a package import error, you may have to first install some of these packages. This can usually be accomplished by opening up a command window on Windows and then typing 'python -m pip install [package-name]'. More assistance is available with the respective package docs.
### Demonstration 1, Simple Linear Model + Noise
Let's build the code and dashboard in one block for concisenss. I have other examples to cover basics if you need that.
#### Build the Interactive Dashboard
The following code:
* makes a random dataset, change the random number seed and number of data for a different dataset
* loops over polygonal fits of 1st-12th order, loops over mulitple realizations and calculates the average MSE and P10 and P90 vs. order
* calculates a specific model example
* plots the example model with training and testing data, the error distributions and the MSE envelopes vs. complexity
```
import warnings
warnings.filterwarnings('ignore')
text_trap = io.StringIO()
sys.stdout = text_trap
l = widgets.Text(value=' Machine Learning LASSO Regression Hyperparameter Tuning Demo, Prof. Michael Pyrcz, The University of Texas at Austin',
layout=Layout(width='950px', height='30px'))
n = widgets.IntSlider(min=5, max = 200, value=30, step = 1, description = 'n',orientation='horizontal', style = {'description_width': 'initial'}, continuous_update=False)
split = widgets.FloatSlider(min=0.05, max = .95, value=0.20, step = 0.05, description = 'Test %',orientation='horizontal',style = {'description_width': 'initial'}, continuous_update=False)
std = widgets.FloatSlider(min=0, max = 200, value=0, step = 1.0, description = 'Noise StDev',orientation='horizontal',style = {'description_width': 'initial'}, continuous_update=False)
lam = widgets.FloatLogSlider(min=-5.0, max = 5.0, value=1,base=10,step = 0.2,description = 'Regularization',orientation='horizontal', style = {'description_width': 'initial'}, continuous_update=False)
ui = widgets.HBox([n,split,std,lam],)
ui2 = widgets.VBox([l,ui],)
def run_plot(n,split,std,lam):
seed = 13014; nreal = 20; slope = 20.0; intercept = 50.0
np.random.seed(seed) # seed the random number generator
lam_min = 1.0E-5;lam_max = 1.0e5
# make the datastet
X_seq = np.linspace(0.0,100,100)
X = np.random.rand(n)*20
y = X*slope + intercept # assume linear + error
y = y + np.random.normal(loc = 0.0,scale=std,size=n) # add noise
# calculate the MSE train and test over a range of complexity over multiple realizations of test/train split
clam_list = np.logspace(-5,5,20,base=10.0)
#print(clam_list)
cmse_train = np.zeros([len(clam_list),nreal]); cmse_test = np.zeros([len(clam_list),nreal])
cmse_truth = np.zeros([len(clam_list),nreal])
for j in range(0,nreal):
for i, clam in enumerate(clam_list):
#print('lam' + str(clam))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=split, random_state=seed+j)
n_train = len(X_train); n_test = len(X_test)
lasso_reg = Lasso(alpha=clam)
#print(X_train.reshape(n_train,1))
lasso_reg.fit(X_train.reshape(n_train,1),y_train)
#print('here')
y_pred_train = lasso_reg.predict(X_train.reshape(n_train,1))
y_pred_test = lasso_reg.predict(X_test.reshape(n_test,1))
y_pred_truth = lasso_reg.predict(X_seq.reshape(len(X_seq),1))
y_truth = X_seq*slope + intercept
cmse_train[i,j] = mean_squared_error(y_train, y_pred_train)
cmse_test[i,j] = mean_squared_error(y_test, y_pred_test)
cmse_truth[i,j] = mean_squared_error(y_truth, y_pred_truth)
# summarize over the realizations
cmse_train_avg = cmse_train.mean(axis=1)
cmse_test_avg = cmse_test.mean(axis=1)
cmse_truth_avg = cmse_truth.mean(axis=1)
cmse_train_high = np.percentile(cmse_train,q=90,axis=1)
cmse_train_low = np.percentile(cmse_train,q=10,axis=1)
cmse_test_high = np.percentile(cmse_test,q=90,axis=1)
cmse_test_low = np.percentile(cmse_test,q=10,axis=1)
cmse_truth_high = np.percentile(cmse_truth,q=90,axis=1)
cmse_truth_low = np.percentile(cmse_truth,q=10,axis=1)
# cmse_train_high = np.amax(cmse_train,axis=1)
# cmse_train_low = np.amin(cmse_train,axis=1)
# cmse_test_high = np.amax(cmse_test,axis=1)
# cmse_test_low = np.amin(cmse_test,axis=1)
# build the one model example to show
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=split, random_state=seed)
n_train = len(X_train); n_test = len(X_test)
lasso_reg = Lasso(alpha=lam)
lasso_reg.fit(X_train.reshape(n_train,1),y_train)
y_pred_train = lasso_reg.predict(X_train.reshape(n_train,1))
y_pred_test = lasso_reg.predict(X_test.reshape(n_test,1))
y_pred_truth = lasso_reg.predict(X_seq.reshape(len(X_seq),1))
# calculate error
error_seq = np.linspace(-100.0,100.0,100)
error_train = y_pred_train - y_train
error_test = y_pred_test - y_test
error_truth = X_seq*slope + intercept - y_truth
mse_train = mean_squared_error(y_train,y_pred_train)
mse_test = mean_squared_error(y_test,y_pred_test)
mse_truth = mean_squared_error(y_truth,y_pred_truth)
error_train_std = np.std(error_train)
error_test_std = np.std(error_test)
error_truth_std = np.std(error_truth)
#kde_error_train = scipy.stats.gaussian_kde(error_train)
#kde_error_test = scipy.stats.gaussian_kde(error_test)
plt.subplot(131)
plt.plot(X_seq, lasso_reg.predict(X_seq.reshape(len(X_seq),1)), color="black")
plt.plot(X_seq, X_seq*slope+intercept, color="black",alpha = 0.2)
plt.title("Ridge Regression Model, Lambda = "+str(round(lam,2)))
plt.scatter(X_train,y_train,c ="red",alpha=0.2,edgecolors="black")
plt.scatter(X_test,y_test,c ="blue",alpha=0.2,edgecolors="black")
plt.ylim([0,500]); plt.xlim([0,20]); plt.grid()
plt.xlabel('Porosity (%)'); plt.ylabel('Permeability (mD)')
plt.subplot(132)
plt.hist(error_train, facecolor='red',bins=np.linspace(-200.0,200.0,10),alpha=0.2,density=True,edgecolor='black',label='Train')
plt.hist(error_test, facecolor='blue',bins=np.linspace(-200.0,200.0,10),alpha=0.2,density=True,edgecolor='black',label='Test')
#plt.plot(error_seq,kde_error_train(error_seq),lw=2,label='Train',c='red')
#plt.plot(error_seq,kde_error_test(error_seq),lw=2,label='Test',c='blue')
#plt.xlim([-55.0,55.0]);
plt.ylim([0,0.1])
plt.xlabel('Model Error'); plt.ylabel('Frequency'); plt.title('Training and Testing Error, Lambda = '+str((round(lam,2))))
plt.legend(loc='upper left')
plt.grid(True)
plt.subplot(133); ax = plt.gca()
plt.plot(clam_list,cmse_train_avg,lw=2,label='Train',c='red')
ax.fill_between(clam_list,cmse_train_high,cmse_train_low,facecolor='red',alpha=0.05)
plt.plot(clam_list,cmse_test_avg,lw=2,label='Test',c='blue')
ax.fill_between(clam_list,cmse_test_high,cmse_test_low,facecolor='blue',alpha=0.05)
plt.plot(clam_list,cmse_truth_avg,lw=2,label='Truth',c='black')
ax.fill_between(clam_list,cmse_truth_high,cmse_truth_low,facecolor='black',alpha=0.05)
plt.xscale('log'); plt.xlim([lam_max,lam_min]); plt.yscale('log'); #plt.ylim([10,10000])
plt.xlabel('Model Flexibility by Regularization, Lambda'); plt.ylabel('Mean Square Error'); plt.title('Training and Testing Error vs. Model Complexity')
plt.legend(loc='upper left')
plt.grid(True)
plt.plot([lam,lam],[1.0e-5,1.0e5],c = 'black',linewidth=3,alpha = 0.8)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.6, wspace=0.2, hspace=0.3)
plt.show()
# connect the function to make the samples and plot to the widgets
interactive_plot = widgets.interactive_output(run_plot, {'n':n,'split':split,'std':std,'lam':lam})
interactive_plot.clear_output(wait = True) # reduce flickering by delaying plot updating
```
### Interactive Machine Learning LASSO Regression Hyperparameter Tuning Demonstation
#### Michael Pyrcz, Associate Professo, University of Texas at Austin
Change the number of sample data, train/test split and the data noise and observe hyperparameter tuning! Change the regularization hyperparameter, lambda, to observe a specific model example. Based on a simple, linear truth model + noise.
### The Inputs
* **n** - number of data
* **Test %** - percentage of sample data withheld as testing data
* **Noise StDev** - standard deviation of random Gaussian error added to the data
* **Regularization Hyperparameter** - the lambda coefficient, weight in loss the function on minimization of the model parameters
```
display(ui2, interactive_plot) # display the interactive plot
```
#### Observations
What did we learn?
* regularization reduces the model sensitivity to the data, this results in reduced model variance
* regularization is helpful with sparse data with noise
When the noise is removed from the dataset, regularization increase / flexibility and sensitivity reduction reduces the quality of the model.
Let's check out a more extreme example to really see this effect.
* we can enhance data sparcity by increasing the problem dimensionality
* we will use more realistic, noisy data
### Demonstration 2: Multivariate, Realistic Dataset
We have to load data, set set the directory to the location that you have placed this dataset.
* [unconv_MV.csv](https://github.com/GeostatsGuy/GeoDataSets/blob/master/unconv_MV.csv)
The dataset is available in this repository, https://github.com/GeostatsGuy/GeoDataSets.
* download this file to your working directory
#### Set the working directory
I always like to do this so I don't lose files and to simplify subsequent read and writes (avoid including the full address each time). Also, in this case make sure to place the required (see below) data file in this working directory.
```
os.chdir("d:\PGE337") # set the working directory
```
#### Load the data
The following loads the data into a DataFrame and then previews the first 5 samples.
```
df_mv = pd.read_csv("unconv_MV.csv")
df_mv.head()
```
#### Check the data
We should do much more data investigation. I do this in most of my workflows, but for this one, let's just calculate the summary statistics and call it a day!
```
df_mv.describe().transpose()
```
#### Build the Interactive Dashboard
The following code:
* makes a random sample of the dataset
* loops over ridge regression fits varying the lambda between 1.0e-5 to 1.0e5, loops over mulitple realizations and calculates the average MSE and P10 and P90 vs. lambda.
* calculates specified model cross validation
* plots the example model with training and testing data, the error distributions and the MSE envelopes vs. complexity/inverse of lambda
```
# import warnings
# warnings.filterwarnings('ignore')
# text_trap = io.StringIO()
# sys.stdout = text_trap
l = widgets.Text(value=' Machine Learning LASSO Regression Hyperparameter Tuning Demo, Prof. Michael Pyrcz, The University of Texas at Austin',
layout=Layout(width='950px', height='30px'))
n = widgets.IntSlider(min=5, max = 200, value=30, step = 1, description = 'n',orientation='horizontal', style = {'description_width': 'initial'}, continuous_update=False)
split = widgets.FloatSlider(min=0.05, max = .95, value=0.20, step = 0.05, description = 'Test %',orientation='horizontal',style = {'description_width': 'initial'}, continuous_update=False)
lam = widgets.FloatLogSlider(min=-5.0, max = 5.0, value=1,base=10,step = 0.2,description = 'Regularization',orientation='horizontal', style = {'description_width': 'initial'}, continuous_update=False)
ui = widgets.HBox([n,split,lam],)
ui2 = widgets.VBox([l,ui],)
def run_plot(n,split,lam):
seed = 13014; nreal = 20; slope = 20.0; intercept = 50.0
np.random.seed(seed) # seed the random number generator
lam_min = 1.0E-5;lam_max = 1.0e5
df_sample_mv = df_mv.sample(n=n)
df_X_mv = df_sample_mv[['Por','LogPerm','AI','Brittle','TOC','VR']]
df_y_mv = df_sample_mv[['Production']]
# calculate the MSE train and test over a range of complexity over multiple realizations of test/train split
clam_list = np.logspace(-5,5,20,base=10.0)
#print(clam_list)
cmse_train = np.zeros([len(clam_list),nreal]); cmse_test = np.zeros([len(clam_list),nreal])
coefs = np.zeros([len(clam_list),nreal,6])
for j in range(0,nreal):
for i, clam in enumerate(clam_list):
#print('lam' + str(clam))
df_X_mv_train, df_X_mv_test, df_y_mv_train, df_y_mv_test = train_test_split(df_X_mv, df_y_mv, test_size=split, random_state=seed+j)
n_train = len(df_X_mv_train); n_test = len(df_X_mv_test)
lasso_reg = Lasso(alpha=clam)
#print(X_train.reshape(n_train,1))
lasso_reg.fit(df_X_mv_train.values,df_y_mv_train.values)
coefs[i,j,:] = lasso_reg.coef_
#print('here')
y_pred_train = lasso_reg.predict(df_X_mv_train.values)
y_pred_test = lasso_reg.predict(df_X_mv_test.values)
cmse_train[i,j] = mean_squared_error(df_y_mv_train.values, y_pred_train)
cmse_test[i,j] = mean_squared_error(df_y_mv_test.values, y_pred_test)
# summarize over the realizations
cmse_train_avg = cmse_train.mean(axis=1)
cmse_test_avg = cmse_test.mean(axis=1)
cmse_train_high = np.percentile(cmse_train,q=90,axis=1)
cmse_train_low = np.percentile(cmse_train,q=10,axis=1)
cmse_test_high = np.percentile(cmse_test,q=90,axis=1)
cmse_test_low = np.percentile(cmse_test,q=10,axis=1)
coefs_avg = coefs.mean(axis=1)
coefs_high = np.percentile(coefs,q=75,axis=1)
coefs_low = np.percentile(coefs,q=25,axis=1)
# cmse_train_high = np.amax(cmse_train,axis=1)
# cmse_train_low = np.amin(cmse_train,axis=1)
# cmse_test_high = np.amax(cmse_test,axis=1)
# cmse_test_low = np.amin(cmse_test,axis=1)
# build the one model example to show
df_X_mv_train, df_X_mv_test, df_y_mv_train, df_y_mv_test = train_test_split(df_X_mv, df_y_mv, test_size=split, random_state=seed+j)
n_train = len(df_X_mv_train); n_test = len(df_X_mv_test)
lasso_reg = Lasso(alpha=lam)
lasso_reg.fit(df_X_mv_train.values,df_y_mv_train.values)
y_pred_train = lasso_reg.predict(df_X_mv_train.values)
y_pred_test = lasso_reg.predict(df_X_mv_test.values)
# calculate error
error_seq = np.linspace(-100.0,100.0,100)
error_train = y_pred_train - df_y_mv_train.values
error_test = y_pred_test - df_y_mv_test.values
mse_train = mean_squared_error(df_y_mv_train.values,y_pred_train)
mse_test = mean_squared_error(df_y_mv_test.values,y_pred_test)
error_train_std = np.std(error_train)
error_test_std = np.std(error_test)
#kde_error_train = scipy.stats.gaussian_kde(error_train)
#kde_error_test = scipy.stats.gaussian_kde(error_test)
plt.subplot(131)
plt.plot([0,8000],[0,8000],c = 'black',linewidth=3,alpha = 0.4)
plt.scatter(df_y_mv_train.values,y_pred_train,color="red",edgecolors='black',label='Train',alpha=0.2)
plt.scatter(df_y_mv_test.values,y_pred_test,color="blue",edgecolors='black',label='Test',alpha=0.2)
plt.title("Cross Validation, Lambda = "+str(round(lam,2)))
plt.ylim([0,5000]); plt.xlim([0,5000]); plt.grid(); plt.legend(loc = 'upper left')
plt.xlabel('True Response'); plt.ylabel('Estimated Response')
plt.subplot(132); ax = plt.gca()
# plt.hist(error_train, facecolor='red',bins=np.linspace(-2000.0,2000.0,10),alpha=0.2,density=False,edgecolor='black',label='Train')
# plt.hist(error_test, facecolor='blue',bins=np.linspace(-2000.0,2000.0,10),alpha=0.2,density=False,edgecolor='black',label='Test')
# #plt.plot(error_seq,kde_error_train(error_seq),lw=2,label='Train',c='red')
# #plt.plot(error_seq,kde_error_test(error_seq),lw=2,label='Test',c='blue')
# #plt.xlim([-55.0,55.0]);
# plt.ylim([0,10])
# plt.xlabel('Model Error'); plt.ylabel('Frequency'); plt.title('Training and Testing Error, Lambda = '+str((round(lam,2))))
# plt.legend(loc='upper left')
# plt.grid(True)
color = ['black','blue','green','red','orange','grey'] # plot the results
for ifeature in range(0,6):
plt.semilogx(clam_list,coefs_avg[:,ifeature], label = df_mv.columns[ifeature+1], c = color[ifeature], linewidth = 3.0)
ax.fill_between(clam_list,coefs_high[:,ifeature],coefs_low[:,ifeature],facecolor=color[ifeature],alpha=0.1)
plt.title('Standardized Model Coefficients vs. Lambda Hyperparameter'); plt.xlabel('Lambda Hyperparameter'); plt.ylabel('Standardized Model Coefficients')
plt.xlim(lam_max,lam_min); plt.grid(); plt.legend(loc = 'lower right')
plt.subplot(133); ax = plt.gca()
plt.plot(clam_list,cmse_train_avg,lw=2,label='Train',c='red')
ax.fill_between(clam_list,cmse_train_high,cmse_train_low,facecolor='red',alpha=0.05)
plt.plot(clam_list,cmse_test_avg,lw=2,label='Test',c='blue')
ax.fill_between(clam_list,cmse_test_high,cmse_test_low,facecolor='blue',alpha=0.05)
plt.xscale('log'); plt.xlim([lam_max,lam_min]); plt.yscale('log'); plt.ylim([1.0e5,1.0e7])
plt.xlabel('Model Flexibility by Regularization, Lambda'); plt.ylabel('Mean Square Error'); plt.title('Training and Testing Error vs. Model Complexity')
plt.legend(loc='upper left')
plt.grid(True)
plt.plot([lam,lam],[1.0e5,1.0e7],c = 'black',linewidth=3,alpha = 0.8)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.5, top=1.0, wspace=0.2, hspace=0.3)
plt.show()
# connect the function to make the samples and plot to the widgets
interactive_plot = widgets.interactive_output(run_plot, {'n':n,'split':split,'lam':lam})
interactive_plot.clear_output(wait = True) # reduce flickering by delaying plot updating
```
### Interactive Machine Learning LASSO Regression Hyperparameter Tuning Demonstation
#### Michael Pyrcz, Associate Professo, University of Texas at Austin
Change the number of sample data, train/test split and the data noise and observe hyperparameter tuning! Change the regularization hyperparameter, lambda, to observe a specific model example. Based on a more complicated (6 predictor features, some non-linearity and sampling error).
### The Inputs
* **n** - number of data
* **Test %** - percentage of sample data withheld as testing data
* **Regularization Hyperparameter** - the lambda coefficient, weight in loss the function on minimization of the model parameters
```
display(ui2, interactive_plot) # display the interactive plot
```
#### Comments
This was a basic demonstration of machine learning model training and tuning, with ridge regression. I have many other demonstrations and even basics of working with DataFrames, ndarrays, univariate statistics, plotting data, declustering, data transformations and many other workflows available at https://github.com/GeostatsGuy/PythonNumericalDemos and https://github.com/GeostatsGuy/GeostatsPy.
#### The Author:
### Michael Pyrcz, Associate Professor, University of Texas at Austin
*Novel Data Analytics, Geostatistics and Machine Learning Subsurface Solutions*
With over 17 years of experience in subsurface consulting, research and development, Michael has returned to academia driven by his passion for teaching and enthusiasm for enhancing engineers' and geoscientists' impact in subsurface resource development.
For more about Michael check out these links:
#### [Twitter](https://twitter.com/geostatsguy) | [GitHub](https://github.com/GeostatsGuy) | [Website](http://michaelpyrcz.com) | [GoogleScholar](https://scholar.google.com/citations?user=QVZ20eQAAAAJ&hl=en&oi=ao) | [Book](https://www.amazon.com/Geostatistical-Reservoir-Modeling-Michael-Pyrcz/dp/0199731446) | [YouTube](https://www.youtube.com/channel/UCLqEr-xV-ceHdXXXrTId5ig) | [LinkedIn](https://www.linkedin.com/in/michael-pyrcz-61a648a1)
#### Want to Work Together?
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
* Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I'd be happy to drop by and work with you!
* Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PIs including Profs. Foster, Torres-Verdin and van Oort)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
* I can be reached at mpyrcz@austin.utexas.edu.
I'm always happy to discuss,
*Michael*
Michael Pyrcz, Ph.D., P.Eng. Associate Professor, Cockrell School of Engineering, Bureau of Economic Geology, and The Jackson School of Geosciences, The University of Texas at Austin
#### More Resources Available at: [Twitter](https://twitter.com/geostatsguy) | [GitHub](https://github.com/GeostatsGuy) | [Website](http://michaelpyrcz.com) | [GoogleScholar](https://scholar.google.com/citations?user=QVZ20eQAAAAJ&hl=en&oi=ao) | [Book](https://www.amazon.com/Geostatistical-Reservoir-Modeling-Michael-Pyrcz/dp/0199731446) | [YouTube](https://www.youtube.com/channel/UCLqEr-xV-ceHdXXXrTId5ig) | [LinkedIn](https://www.linkedin.com/in/michael-pyrcz-61a648a1)
| github_jupyter |
```
import matplotlib.pyplot as plt
```
# 1. Data Preparation
## 1.1 Load Dataset
We load the breast cancer dataset (https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)).
Check the size - there are 569 total examples, with 30 features each.
Print the feature names and the names of the 2 target classes.
Each example represents a mass, with features to describe attributes of the digitized image. Each mass is classified as malignant or benign.
```
from sklearn.datasets import load_breast_cancer
cancer_dataset = load_breast_cancer()
print(cancer_dataset.data.shape)
print('Feature Names: {}\n'.format(cancer_dataset.feature_names))
print('Classes: {}'.format(cancer_dataset.target_names))
print(list(zip(cancer_dataset.feature_names, cancer_dataset.data[0])))
print(cancer_dataset.target_names[cancer_dataset.target[0]])
```
## 1.2 Train-Test Data Split
Create train and test datasets.
Train dataset is 80% of data. Test dataset is 20% of data.
Check lengths of train and test datasets compared to length of original dataset.
```
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(cancer_dataset.data, cancer_dataset.target, test_size = 0.20, random_state = 0)
print('Length of full dataset: {}'.format(len(cancer_dataset.data)))
print('Length of train dataset: {}'.format(len(X_train)))
print('Length of test dataset: {}'.format(len(X_test)))
```
## 1.3 Scale & Normalize Features
Scale features using the `sklearn.preprocessing.StandardScaler`.
Look at comparison of feature values for one example.
```
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
print('Before scaling: {}'.format(X_train[0]))
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
print('After scaling: {}'.format(X_train[0]))
```
Now we are ready to do some modeling.
# 2. Model Selection
## 2.1 [Naive Bayes Classifier](https://scikit-learn.org/stable/modules/naive_bayes.html#naive-bayes)
```
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, Y_train)
```
Use the trained model to predict on `X_test`
```
Y_pred = classifier.predict(X_test)
```
Check performance by comparing predictions `Y_pred` with true labels `Y_test`.
Compute accuracy. Then generate confusion matrix.
```
from sklearn.metrics import accuracy_score
acc = accuracy_score(Y_test, Y_pred)
print('Accuracy on test dataset: {}'.format(acc))
from sklearn.metrics import plot_confusion_matrix
disp = plot_confusion_matrix(
classifier, X_test, Y_test,
display_labels=cancer_dataset.target_names,
cmap=plt.cm.gist_earth
)
```
## 2.2 [KNN Classification](https://scikit-learn.org/stable/modules/neighbors.html)
KNN stands for K-Nearest Neighbor
We cluster training data, then classify test data points based on the train data points they are closest to.
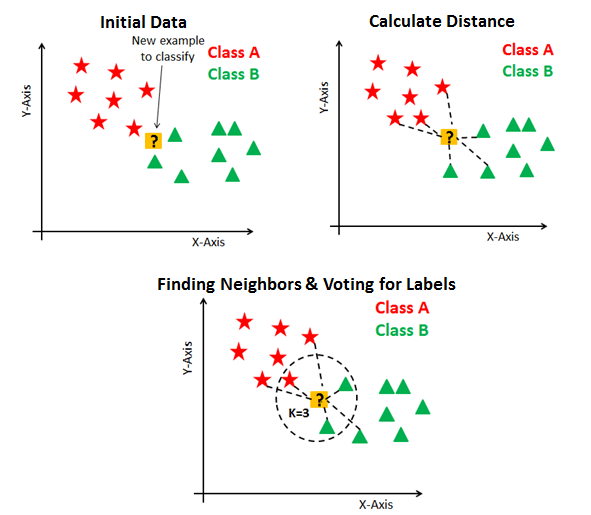
```
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)
classifier.fit(X_train, Y_train)
```
Use the trained model to predict on `X_test`
```
Y_pred = classifier.predict(X_test)
```
Check performance by comparing predictions `Y_pred` with true labels `Y_test`.
Compute accuracy. Then generate confusion matrix.
```
from sklearn.metrics import accuracy_score
acc = accuracy_score(Y_test, Y_pred)
print('Accuracy on test dataset: {}'.format(acc))
from sklearn.metrics import plot_confusion_matrix
disp = plot_confusion_matrix(
classifier, X_test, Y_test,
display_labels=cancer_dataset.target_names,
cmap=plt.cm.gist_earth
)
```
Train the logistic regression model on `X_train` and `Y_train`
## 2.3 [Logistic Regression](https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression)

Linear regression equation:

Now constrain this value to be between 0 and 1 with a sigmoid:

```
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, Y_train)
```
Use the trained model to predict on `X_test`
```
Y_pred = classifier.predict(X_test)
```
Check performance by comparing predictions `Y_pred` with true labels `Y_test`.
Compute accuracy. Then generate confusion matrix.
```
from sklearn.metrics import accuracy_score
acc = accuracy_score(Y_test, Y_pred)
print('Accuracy on test dataset: {}'.format(acc))
from sklearn.metrics import plot_confusion_matrix
disp = plot_confusion_matrix(
classifier, X_test, Y_test,
display_labels=cancer_dataset.target_names,
cmap=plt.cm.gist_earth
)
```
| github_jupyter |
# Computer Vision Nanodegree
## Project: Image Captioning
---
In this notebook, you will learn how to load and pre-process data from the [COCO dataset](http://cocodataset.org/#home). You will also design a CNN-RNN model for automatically generating image captions.
Note that **any amendments that you make to this notebook will not be graded**. However, you will use the instructions provided in **Step 3** and **Step 4** to implement your own CNN encoder and RNN decoder by making amendments to the **models.py** file provided as part of this project. Your **models.py** file **will be graded**.
Feel free to use the links below to navigate the notebook:
- [Step 1](#step1): Explore the Data Loader
- [Step 2](#step2): Use the Data Loader to Obtain Batches
- [Step 3](#step3): Experiment with the CNN Encoder
- [Step 4](#step4): Implement the RNN Decoder
<a id='step1'></a>
## Step 1: Explore the Data Loader
We have already written a [data loader](http://pytorch.org/docs/master/data.html#torch.utils.data.DataLoader) that you can use to load the COCO dataset in batches.
In the code cell below, you will initialize the data loader by using the `get_loader` function in **data_loader.py**.
> For this project, you are not permitted to change the **data_loader.py** file, which must be used as-is.
The `get_loader` function takes as input a number of arguments that can be explored in **data_loader.py**. Take the time to explore these arguments now by opening **data_loader.py** in a new window. Most of the arguments must be left at their default values, and you are only allowed to amend the values of the arguments below:
1. **`transform`** - an [image transform](http://pytorch.org/docs/master/torchvision/transforms.html) specifying how to pre-process the images and convert them to PyTorch tensors before using them as input to the CNN encoder. For now, you are encouraged to keep the transform as provided in `transform_train`. You will have the opportunity later to choose your own image transform to pre-process the COCO images.
2. **`mode`** - one of `'train'` (loads the training data in batches) or `'test'` (for the test data). We will say that the data loader is in training or test mode, respectively. While following the instructions in this notebook, please keep the data loader in training mode by setting `mode='train'`.
3. **`batch_size`** - determines the batch size. When training the model, this is number of image-caption pairs used to amend the model weights in each training step.
4. **`vocab_threshold`** - the total number of times that a word must appear in the in the training captions before it is used as part of the vocabulary. Words that have fewer than `vocab_threshold` occurrences in the training captions are considered unknown words.
5. **`vocab_from_file`** - a Boolean that decides whether to load the vocabulary from file.
We will describe the `vocab_threshold` and `vocab_from_file` arguments in more detail soon. For now, run the code cell below. Be patient - it may take a couple of minutes to run!
```
import torch
import sys
sys.path.append('/opt/cocoapi/PythonAPI')
from pycocotools.coco import COCO
!pip install nltk
import nltk
nltk.download('punkt')
from torchvision import transforms
from data_loader import get_loader
# Define a transform to pre-process the training images.
transform_train = transforms.Compose([
transforms.Resize(256), # smaller edge of image resized to 256
transforms.RandomCrop(224), # get 224x224 crop from random location
transforms.RandomHorizontalFlip(), # horizontally flip image with probability=0.5
transforms.ToTensor(), # convert the PIL Image to a tensor
transforms.Normalize((0.485, 0.456, 0.406), # normalize image for pre-trained model
(0.229, 0.224, 0.225))])
# Set the minimum word count threshold.
vocab_threshold = 5
# Specify the batch size.
batch_size = 10
# Obtain the data loader.
data_loader = get_loader(transform=transform_train,
mode='train',
batch_size=batch_size,
vocab_threshold=vocab_threshold,
vocab_from_file=False)
```
When you ran the code cell above, the data loader was stored in the variable `data_loader`.
You can access the corresponding dataset as `data_loader.dataset`. This dataset is an instance of the `CoCoDataset` class in **data_loader.py**. If you are unfamiliar with data loaders and datasets, you are encouraged to review [this PyTorch tutorial](http://pytorch.org/tutorials/beginner/data_loading_tutorial.html).
### Exploring the `__getitem__` Method
The `__getitem__` method in the `CoCoDataset` class determines how an image-caption pair is pre-processed before being incorporated into a batch. This is true for all `Dataset` classes in PyTorch; if this is unfamiliar to you, please review [the tutorial linked above](http://pytorch.org/tutorials/beginner/data_loading_tutorial.html).
When the data loader is in training mode, this method begins by first obtaining the filename (`path`) of a training image and its corresponding caption (`caption`).
#### Image Pre-Processing
Image pre-processing is relatively straightforward (from the `__getitem__` method in the `CoCoDataset` class):
```python
# Convert image to tensor and pre-process using transform
image = Image.open(os.path.join(self.img_folder, path)).convert('RGB')
image = self.transform(image)
```
After loading the image in the training folder with name `path`, the image is pre-processed using the same transform (`transform_train`) that was supplied when instantiating the data loader.
#### Caption Pre-Processing
The captions also need to be pre-processed and prepped for training. In this example, for generating captions, we are aiming to create a model that predicts the next token of a sentence from previous tokens, so we turn the caption associated with any image into a list of tokenized words, before casting it to a PyTorch tensor that we can use to train the network.
To understand in more detail how COCO captions are pre-processed, we'll first need to take a look at the `vocab` instance variable of the `CoCoDataset` class. The code snippet below is pulled from the `__init__` method of the `CoCoDataset` class:
```python
def __init__(self, transform, mode, batch_size, vocab_threshold, vocab_file, start_word,
end_word, unk_word, annotations_file, vocab_from_file, img_folder):
...
self.vocab = Vocabulary(vocab_threshold, vocab_file, start_word,
end_word, unk_word, annotations_file, vocab_from_file)
...
```
From the code snippet above, you can see that `data_loader.dataset.vocab` is an instance of the `Vocabulary` class from **vocabulary.py**. Take the time now to verify this for yourself by looking at the full code in **data_loader.py**.
We use this instance to pre-process the COCO captions (from the `__getitem__` method in the `CoCoDataset` class):
```python
# Convert caption to tensor of word ids.
tokens = nltk.tokenize.word_tokenize(str(caption).lower()) # line 1
caption = [] # line 2
caption.append(self.vocab(self.vocab.start_word)) # line 3
caption.extend([self.vocab(token) for token in tokens]) # line 4
caption.append(self.vocab(self.vocab.end_word)) # line 5
caption = torch.Tensor(caption).long() # line 6
```
As you will see soon, this code converts any string-valued caption to a list of integers, before casting it to a PyTorch tensor. To see how this code works, we'll apply it to the sample caption in the next code cell.
```
sample_caption = 'A person doing a trick on a rail while riding a skateboard.'
```
In **`line 1`** of the code snippet, every letter in the caption is converted to lowercase, and the [`nltk.tokenize.word_tokenize`](http://www.nltk.org/) function is used to obtain a list of string-valued tokens. Run the next code cell to visualize the effect on `sample_caption`.
```
import nltk
sample_tokens = nltk.tokenize.word_tokenize(str(sample_caption).lower())
print(sample_tokens)
```
In **`line 2`** and **`line 3`** we initialize an empty list and append an integer to mark the start of a caption. The [paper](https://arxiv.org/pdf/1411.4555.pdf) that you are encouraged to implement uses a special start word (and a special end word, which we'll examine below) to mark the beginning (and end) of a caption.
This special start word (`"<start>"`) is decided when instantiating the data loader and is passed as a parameter (`start_word`). You are **required** to keep this parameter at its default value (`start_word="<start>"`).
As you will see below, the integer `0` is always used to mark the start of a caption.
```
sample_caption = []
start_word = data_loader.dataset.vocab.start_word
print('Special start word:', start_word)
sample_caption.append(data_loader.dataset.vocab(start_word))
print(sample_caption)
```
In **`line 4`**, we continue the list by adding integers that correspond to each of the tokens in the caption.
```
sample_caption.extend([data_loader.dataset.vocab(token) for token in sample_tokens])
print(sample_caption)
```
In **`line 5`**, we append a final integer to mark the end of the caption.
Identical to the case of the special start word (above), the special end word (`"<end>"`) is decided when instantiating the data loader and is passed as a parameter (`end_word`). You are **required** to keep this parameter at its default value (`end_word="<end>"`).
As you will see below, the integer `1` is always used to mark the end of a caption.
```
end_word = data_loader.dataset.vocab.end_word
print('Special end word:', end_word)
sample_caption.append(data_loader.dataset.vocab(end_word))
print(sample_caption)
```
Finally, in **`line 6`**, we convert the list of integers to a PyTorch tensor and cast it to [long type](http://pytorch.org/docs/master/tensors.html#torch.Tensor.long). You can read more about the different types of PyTorch tensors on the [website](http://pytorch.org/docs/master/tensors.html).
```
import torch
sample_caption = torch.Tensor(sample_caption).long()
print(sample_caption)
```
And that's it! In summary, any caption is converted to a list of tokens, with _special_ start and end tokens marking the beginning and end of the sentence:
```
[<start>, 'a', 'person', 'doing', 'a', 'trick', 'while', 'riding', 'a', 'skateboard', '.', <end>]
```
This list of tokens is then turned into a list of integers, where every distinct word in the vocabulary has an associated integer value:
```
[0, 3, 98, 754, 3, 396, 207, 139, 3, 753, 18, 1]
```
Finally, this list is converted to a PyTorch tensor. All of the captions in the COCO dataset are pre-processed using this same procedure from **`lines 1-6`** described above.
As you saw, in order to convert a token to its corresponding integer, we call `data_loader.dataset.vocab` as a function. The details of how this call works can be explored in the `__call__` method in the `Vocabulary` class in **vocabulary.py**.
```python
def __call__(self, word):
if not word in self.word2idx:
return self.word2idx[self.unk_word]
return self.word2idx[word]
```
The `word2idx` instance variable is a Python [dictionary](https://docs.python.org/3/tutorial/datastructures.html#dictionaries) that is indexed by string-valued keys (mostly tokens obtained from training captions). For each key, the corresponding value is the integer that the token is mapped to in the pre-processing step.
Use the code cell below to view a subset of this dictionary.
```
# Preview the word2idx dictionary.
dict(list(data_loader.dataset.vocab.word2idx.items())[:10])
```
We also print the total number of keys.
```
# Print the total number of keys in the word2idx dictionary.
print('Total number of tokens in vocabulary:', len(data_loader.dataset.vocab))
```
As you will see if you examine the code in **vocabulary.py**, the `word2idx` dictionary is created by looping over the captions in the training dataset. If a token appears no less than `vocab_threshold` times in the training set, then it is added as a key to the dictionary and assigned a corresponding unique integer. You will have the option later to amend the `vocab_threshold` argument when instantiating your data loader. Note that in general, **smaller** values for `vocab_threshold` yield a **larger** number of tokens in the vocabulary. You are encouraged to check this for yourself in the next code cell by decreasing the value of `vocab_threshold` before creating a new data loader.
```
# Modify the minimum word count threshold.
vocab_threshold = 4
# Obtain the data loader.
data_loader = get_loader(transform=transform_train,
mode='train',
batch_size=batch_size,
vocab_threshold=vocab_threshold,
vocab_from_file=False)
# Print the total number of keys in the word2idx dictionary.
print('Total number of tokens in vocabulary:', len(data_loader.dataset.vocab))
```
There are also a few special keys in the `word2idx` dictionary. You are already familiar with the special start word (`"<start>"`) and special end word (`"<end>"`). There is one more special token, corresponding to unknown words (`"<unk>"`). All tokens that don't appear anywhere in the `word2idx` dictionary are considered unknown words. In the pre-processing step, any unknown tokens are mapped to the integer `2`.
```
unk_word = data_loader.dataset.vocab.unk_word
print('Special unknown word:', unk_word)
print('All unknown words are mapped to this integer:', data_loader.dataset.vocab(unk_word))
```
Check this for yourself below, by pre-processing the provided nonsense words that never appear in the training captions.
```
print(data_loader.dataset.vocab('jfkafejw'))
print(data_loader.dataset.vocab('ieowoqjf'))
```
The final thing to mention is the `vocab_from_file` argument that is supplied when creating a data loader. To understand this argument, note that when you create a new data loader, the vocabulary (`data_loader.dataset.vocab`) is saved as a [pickle](https://docs.python.org/3/library/pickle.html) file in the project folder, with filename `vocab.pkl`.
If you are still tweaking the value of the `vocab_threshold` argument, you **must** set `vocab_from_file=False` to have your changes take effect.
But once you are happy with the value that you have chosen for the `vocab_threshold` argument, you need only run the data loader *one more time* with your chosen `vocab_threshold` to save the new vocabulary to file. Then, you can henceforth set `vocab_from_file=True` to load the vocabulary from file and speed the instantiation of the data loader. Note that building the vocabulary from scratch is the most time-consuming part of instantiating the data loader, and so you are strongly encouraged to set `vocab_from_file=True` as soon as you are able.
Note that if `vocab_from_file=True`, then any supplied argument for `vocab_threshold` when instantiating the data loader is completely ignored.
```
# Obtain the data loader (from file). Note that it runs much faster than before!
data_loader = get_loader(transform=transform_train,
mode='train',
batch_size=batch_size,
vocab_from_file=True)
```
In the next section, you will learn how to use the data loader to obtain batches of training data.
<a id='step2'></a>
## Step 2: Use the Data Loader to Obtain Batches
The captions in the dataset vary greatly in length. You can see this by examining `data_loader.dataset.caption_lengths`, a Python list with one entry for each training caption (where the value stores the length of the corresponding caption).
In the code cell below, we use this list to print the total number of captions in the training data with each length. As you will see below, the majority of captions have length 10. Likewise, very short and very long captions are quite rare.
```
from collections import Counter
# Tally the total number of training captions with each length.
counter = Counter(data_loader.dataset.caption_lengths)
lengths = sorted(counter.items(), key=lambda pair: pair[1], reverse=True)
for value, count in lengths:
print('value: %2d --- count: %5d' % (value, count))
```
To generate batches of training data, we begin by first sampling a caption length (where the probability that any length is drawn is proportional to the number of captions with that length in the dataset). Then, we retrieve a batch of size `batch_size` of image-caption pairs, where all captions have the sampled length. This approach for assembling batches matches the procedure in [this paper](https://arxiv.org/pdf/1502.03044.pdf) and has been shown to be computationally efficient without degrading performance.
Run the code cell below to generate a batch. The `get_train_indices` method in the `CoCoDataset` class first samples a caption length, and then samples `batch_size` indices corresponding to training data points with captions of that length. These indices are stored below in `indices`.
These indices are supplied to the data loader, which then is used to retrieve the corresponding data points. The pre-processed images and captions in the batch are stored in `images` and `captions`.
```
import numpy as np
import torch.utils.data as data
# Randomly sample a caption length, and sample indices with that length.
indices = data_loader.dataset.get_train_indices()
print('sampled indices:', indices)
# Create and assign a batch sampler to retrieve a batch with the sampled indices.
new_sampler = data.sampler.SubsetRandomSampler(indices=indices)
data_loader.batch_sampler.sampler = new_sampler
# Obtain the batch.
images, captions = next(iter(data_loader))
print('images.shape:', images.shape)
print('captions.shape:', captions.shape)
# (Optional) Uncomment the lines of code below to print the pre-processed images and captions.
# print('images:', images)
# print('captions:', captions)
```
Each time you run the code cell above, a different caption length is sampled, and a different batch of training data is returned. Run the code cell multiple times to check this out!
You will train your model in the next notebook in this sequence (**2_Training.ipynb**). This code for generating training batches will be provided to you.
> Before moving to the next notebook in the sequence (**2_Training.ipynb**), you are strongly encouraged to take the time to become very familiar with the code in **data_loader.py** and **vocabulary.py**. **Step 1** and **Step 2** of this notebook are designed to help facilitate a basic introduction and guide your understanding. However, our description is not exhaustive, and it is up to you (as part of the project) to learn how to best utilize these files to complete the project. __You should NOT amend any of the code in either *data_loader.py* or *vocabulary.py*.__
In the next steps, we focus on learning how to specify a CNN-RNN architecture in PyTorch, towards the goal of image captioning.
<a id='step3'></a>
## Step 3: Experiment with the CNN Encoder
Run the code cell below to import `EncoderCNN` and `DecoderRNN` from **model.py**.
```
# Watch for any changes in model.py, and re-load it automatically.
% load_ext autoreload
% autoreload 2
# Import EncoderCNN and DecoderRNN.
from model import EncoderCNN, DecoderRNN
```
In the next code cell we define a `device` that you will use move PyTorch tensors to GPU (if CUDA is available). Run this code cell before continuing.
```
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
```
Run the code cell below to instantiate the CNN encoder in `encoder`.
The pre-processed images from the batch in **Step 2** of this notebook are then passed through the encoder, and the output is stored in `features`.
```
# Specify the dimensionality of the image embedding.
embed_size = 256
#-#-#-# Do NOT modify the code below this line. #-#-#-#
# Initialize the encoder. (Optional: Add additional arguments if necessary.)
encoder = EncoderCNN(embed_size)
# Move the encoder to GPU if CUDA is available.
encoder.to(device)
# Move last batch of images (from Step 2) to GPU if CUDA is available.
images = images.to(device)
# Pass the images through the encoder.
features = encoder(images)
print('type(features):', type(features))
print('features.shape:', features.shape)
# Check that your encoder satisfies some requirements of the project! :D
assert type(features)==torch.Tensor, "Encoder output needs to be a PyTorch Tensor."
assert (features.shape[0]==batch_size) & (features.shape[1]==embed_size), "The shape of the encoder output is incorrect."
```
The encoder that we provide to you uses the pre-trained ResNet-50 architecture (with the final fully-connected layer removed) to extract features from a batch of pre-processed images. The output is then flattened to a vector, before being passed through a `Linear` layer to transform the feature vector to have the same size as the word embedding.

You are welcome (and encouraged) to amend the encoder in **model.py**, to experiment with other architectures. In particular, consider using a [different pre-trained model architecture](http://pytorch.org/docs/master/torchvision/models.html). You may also like to [add batch normalization](http://pytorch.org/docs/master/nn.html#normalization-layers).
> You are **not** required to change anything about the encoder.
For this project, you **must** incorporate a pre-trained CNN into your encoder. Your `EncoderCNN` class must take `embed_size` as an input argument, which will also correspond to the dimensionality of the input to the RNN decoder that you will implement in Step 4. When you train your model in the next notebook in this sequence (**2_Training.ipynb**), you are welcome to tweak the value of `embed_size`.
If you decide to modify the `EncoderCNN` class, save **model.py** and re-execute the code cell above. If the code cell returns an assertion error, then please follow the instructions to modify your code before proceeding. The assert statements ensure that `features` is a PyTorch tensor with shape `[batch_size, embed_size]`.
<a id='step4'></a>
## Step 4: Implement the RNN Decoder
Before executing the next code cell, you must write `__init__` and `forward` methods in the `DecoderRNN` class in **model.py**. (Do **not** write the `sample` method yet - you will work with this method when you reach **3_Inference.ipynb**.)
> The `__init__` and `forward` methods in the `DecoderRNN` class are the only things that you **need** to modify as part of this notebook. You will write more implementations in the notebooks that appear later in the sequence.
Your decoder will be an instance of the `DecoderRNN` class and must accept as input:
- the PyTorch tensor `features` containing the embedded image features (outputted in Step 3, when the last batch of images from Step 2 was passed through `encoder`), along with
- a PyTorch tensor corresponding to the last batch of captions (`captions`) from Step 2.
Note that the way we have written the data loader should simplify your code a bit. In particular, every training batch will contain pre-processed captions where all have the same length (`captions.shape[1]`), so **you do not need to worry about padding**.
> While you are encouraged to implement the decoder described in [this paper](https://arxiv.org/pdf/1411.4555.pdf), you are welcome to implement any architecture of your choosing, as long as it uses at least one RNN layer, with hidden dimension `hidden_size`.
Although you will test the decoder using the last batch that is currently stored in the notebook, your decoder should be written to accept an arbitrary batch (of embedded image features and pre-processed captions [where all captions have the same length]) as input.

In the code cell below, `outputs` should be a PyTorch tensor with size `[batch_size, captions.shape[1], vocab_size]`. Your output should be designed such that `outputs[i,j,k]` contains the model's predicted score, indicating how likely the `j`-th token in the `i`-th caption in the batch is the `k`-th token in the vocabulary. In the next notebook of the sequence (**2_Training.ipynb**), we provide code to supply these scores to the [`torch.nn.CrossEntropyLoss`](http://pytorch.org/docs/master/nn.html#torch.nn.CrossEntropyLoss) optimizer in PyTorch.
```
# Specify the number of features in the hidden state of the RNN decoder.
hidden_size = 512
#-#-#-# Do NOT modify the code below this line. #-#-#-#
# Store the size of the vocabulary.
vocab_size = len(data_loader.dataset.vocab)
# Initialize the decoder.
decoder = DecoderRNN(embed_size, hidden_size, vocab_size)
# Move the decoder to GPU if CUDA is available.
decoder.to(device)
# Move last batch of captions (from Step 1) to GPU if CUDA is available
captions = captions.to(device)
# Pass the encoder output and captions through the decoder.
outputs = decoder(features, captions)
print('type(outputs):', type(outputs))
print('outputs.shape:', outputs.shape)
# Check that your decoder satisfies some requirements of the project! :D
assert type(outputs)==torch.Tensor, "Decoder output needs to be a PyTorch Tensor."
assert (outputs.shape[0]==batch_size) & (outputs.shape[1]==captions.shape[1]) & (outputs.shape[2]==vocab_size), "The shape of the decoder output is incorrect."
```
When you train your model in the next notebook in this sequence (**2_Training.ipynb**), you are welcome to tweak the value of `hidden_size`.
| github_jupyter |
```
# Dependencies
import pandas as pd
import pathlib
# filepaths
school_directory_filepath = "Resources/ca-school-list.csv"
sy_1420_filepath = "Resources/output_data/merged_data.csv"
# reading csvs into dataframes and renaming columns to match
school_directory_df = pd.read_csv(school_directory_filepath)
school_directory_df = school_directory_df.rename(columns = {"CDSCode":"CDS_CODE"})
school_directory_df.head()
# reading master enrollment file to dataframe
sy_1420_df = pd.read_csv(sy_1420_filepath)
sy_1420_df.head()
# pulling and rearranging columns into new dataframe and grouping by needed topics
enroll_new_df = sy_1420_df[["CDS_CODE", "COUNTY", "DISTRICT", "SCHOOL", "ETHNIC", "GENDER", "ENR_TOTAL", "year"]]
total_enrollment = enroll_test.groupby(by=["CDS_CODE", "COUNTY", "DISTRICT", "SCHOOL", "year"]).sum()
enroll_new_df
# resetting index from groupby dataframe
new_df = total_enrollment.reset_index()
new_df
# merging df with enrollment data and the full school directory
merged_df = pd.merge(new_df, school_directory_df, on="CDS_CODE", how="left")
merged_df
# pulling needed columns into new df
school_enroll_directory_df = merged_df[["CDS_CODE", "SCHOOL", "School", "District", "NCESDist", "County", "Street", "Zip", "City", "State", "year", "ENR_TOTAL"]]
school_enroll_directory_df
# drop any rows with null values
enroll_directory_df = school_enroll_directory_df.dropna(how="any")
enroll_directory_df
# final cleanup creating new dataframe without any values that read as "no Data"
has_no_data = enroll_directory_df["School"] != "No Data"
clean_enroll_direct_df = enroll_directory_df.loc[has_no_data, :]
# exporting school directory with enrollment totals to CSV
clean_enroll_direct_df.to_csv("Resources/output_data/school_directory_enrollment.csv")
# grouping by district and by year to find yearly enrollment total by district
district_groups_df = clean_enroll_direct_df.groupby(by=["District", "year"]).sum()
enroll_by_dist_df = district_groups_df.reset_index()
enroll_by_dist_df
# creating a new column that refers to the enrollment total from prior year
enroll_by_dist_df["Prior Year Enrollment"] = (enroll_by_dist_df
.groupby(by="District")["ENR_TOTAL"].shift(1))
# adding new column that lists percent change
enroll_by_dist_df["Percent Change"] = ((enroll_by_dist_df["ENR_TOTAL"] - enroll_by_dist_df["Prior Year Enrollment"]) / enroll_by_dist_df["Prior Year Enrollment"]) * 100
# sorting by year to ensure that all 2015 values have NaN as their percent change as expected
sorted_enrollment_by_dist_df = enroll_by_dist_df.sort_values(by="year")
sorted_enrollment_by_dist_df
# simplifying school directory df to pull only columns needed
new_clean_df = clean_enroll_direct_df[["District", "NCESDist"]]
new_clean_df
# merging the district and year sorted enrollment df with the simplified and cleaned df
percent_by_dist_df = pd.merge(sorted_enrollment_by_dist_df, new_clean_df, on="District", how="left")
percent_by_dist_df
# simplifying further and pulling only the needed columns within the new df that includes NCESDist and percent change year over year
new_percent_by_dist_df = percent_by_dist_df[["District", "year", "ENR_TOTAL", "Percent Change", "NCESDist"]]
new_percent_by_dist_df
# # setting conditionals to segment each year's data as an individual df before concatenating back together
# years = [2015, 2016, 2017, 2018, 2019]
# df_list = []
# for year in years:
# is_year = new_percent_by_dist_df["year"] == year
# df+year = new_percent_by_dist_df.loc[is_year, :].drop_duplicates(keep="first")
# df_list.append(df_+year)
# combined_data = pd.concat(df_list)
# enrollment_df2 = pd.DataFrame(combined_data)
# setting conditionals to segment each year's data as an individual df before concatenating back together
is_2015 = new_percent_by_dist_df["year"] == 2015
is_2016 = new_percent_by_dist_df["year"] == 2016
is_2017 = new_percent_by_dist_df["year"] == 2017
is_2018 = new_percent_by_dist_df["year"] == 2018
is_2019 = new_percent_by_dist_df["year"] == 2019
# creating new data frames and dropping duplicate values
df_2015 = new_percent_by_dist_df.loc[is_2015, :].drop_duplicates(keep="first")
df_2016 = new_percent_by_dist_df.loc[is_2016, :].drop_duplicates(keep="first")
df_2017 = new_percent_by_dist_df.loc[is_2017, :].drop_duplicates(keep="first")
df_2018 = new_percent_by_dist_df.loc[is_2018, :].drop_duplicates(keep="first")
df_2019 = new_percent_by_dist_df.loc[is_2019, :].drop_duplicates(keep="first")
# concatenating dfs by year on top of one another
list_dfs = [df_2015, df_2016, df_2017, df_2018, df_2019]
combined_data = pd.concat(list_dfs)
enrollment_df = pd.DataFrame(combined_data)
# final clean up sorting by year and then by district
clean_enrollment_df2 = enrollment_df.sort_values(by=["NCESDist", "year"])
# dropping rows without data under district code column
has_data = clean_enrollment_df2["NCESDist"] != "No Data"
clean_enrollment_df2 = clean_enrollment_df2.loc[has_data, :]
# reading out to csv
clean_enrollment_df2.to_csv("Resources/output_data/enrollment_by_dist_changes.csv")
```
| github_jupyter |
# Measurement noise assessment
In this notebook, we illustrate how to use pyABC with different noise models. For simplicity, we use a simple ODE model of a conversion reaction. For simplicity, we consider a single parameter:
```
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pyabc
%matplotlib inline
init = np.array([1, 0])
def f(y, t0, theta1, theta2=np.exp(-2)):
x1, x2 = y
dx1 = - theta1 * x1 + theta2 * x2
dx2 = theta1 * x1 - theta2 * x2
return dx1, dx2
theta1_true = np.exp(-2.5)
theta_true = {'theta1': theta1_true}
theta_min, theta_max = 0.05, 0.15
prior = pyabc.Distribution(
theta1=pyabc.RV("uniform", theta_min, theta_max-theta_min))
n_time = 10
measurement_times = np.linspace(0, 10, n_time)
```
We assume that the underlying dynamics of our observations follow the following model:
```
def model(pars):
sol = sp.integrate.odeint(
f, init, measurement_times,
args=(pars["theta1"],))
return {'X_2': sol[:,1]}
true_trajectory = model(theta_true)
```
However, we assume that our measurements are subject to additive Gaussian noise:
```
sigma = 0.02
def model_noisy(pars):
sim = model(pars)
return {'X_2': sim['X_2'] + sigma * np.random.randn(n_time)}
measured_data = model_noisy(theta_true)
# plot data
plt.plot(measurement_times, true_trajectory['X_2'], color="C0",
label='Simulation')
plt.scatter(measurement_times, measured_data['X_2'],
color="C1", label='Data')
plt.xlabel('Time $t$')
plt.ylabel('Measurement $Y$')
plt.title('Conversion reaction: True parameters fit')
plt.legend()
plt.show()
```
## Ignoring noise
In the notebook "Ordinary Differential Equations: Conversion Reaction", this model is used without accounting for a noise model, which is strictly speaking not correct. In this case, we get the following result:
```
def distance(simulation, data):
return np.absolute(data["X_2"] - simulation["X_2"]).sum()
abc = pyabc.ABCSMC(model, prior, distance)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history = abc.run(max_nr_populations=10)
```
As one can see in the below plot, this converges to a point estimate as $\varepsilon\rightarrow 0$, and does not correctly represent the posterior. In particular, in general this point estimate will not capture the correct parameter value (indicated by the grey line).
```
_, ax = plt.subplots()
for t in range(history.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history, x="theta1", t=t, refval=theta_true, refval_color='grey',
xmin=theta_min, xmax=theta_max, numx=100, ax=ax, label=f"Iteration {t}")
ax.legend()
plt.show()
```
## Add noise to the model output
To correctly account for noise, there are essentially two possibilities: Firstly, we can use the noisified model output:
```
abc = pyabc.ABCSMC(model_noisy, prior, distance)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_noisy_output = abc.run(max_nr_populations=10)
_, ax = plt.subplots()
for t in range(history_noisy_output.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_noisy_output, x="theta1", t=t,
refval=theta_true, refval_color='grey',
xmin=theta_min, xmax=theta_max, ax=ax, numx=200, label=f"Iteration {t}")
ax.legend()
```
This curve is much broader and, as one can show, closer to the correct posterior.
## Modify the acceptance step
Secondly, we can alternatively use the non-noisy model, but adjust the acceptance step:
```
acceptor = pyabc.StochasticAcceptor()
kernel = pyabc.IndependentNormalKernel(var=sigma**2)
eps = pyabc.Temperature()
abc = pyabc.ABCSMC(model, prior, kernel, eps=eps, acceptor=acceptor)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_acceptor = abc.run(max_nr_populations=10)
```
We use a `pyabc.StochasticAcceptor` for the acceptor, replacing the default `pyabc.UniformAcceptor`, in order to accept when
$$\frac{\pi(D|y,\theta)}{c}\geq[0,1],$$
where $\pi(D|y,\theta)$ denotes the distribution of noisy data $D$ given non-noisy model output $y$ and parameters $\theta$. Here, we use a `pyabc.IndependentNormalKernel` in place of a `pyabc.Distance` to capture the normal noise $\pi(D|y,\theta)\sim\mathcal{N}(D|y,\theta,\sigma)$. Also other noise models are possible, including Laplace or binomial noise. In place of the `pyabc.Epsilon`, we employ a `pyabc.Temperature` which implements schemes to decrease a temperature $T\searrow 1$, s.t. in iteration $t$ we sample from
$$\pi(\theta,y|D) \propto \pi(D|y,\theta)^{1/T_t}p(y|\theta)\pi(\theta),$$
where $p(y|\theta)$ denotes the model output likelihood, and $\pi(\theta)$ the parameters prior.
Each of acceptor, kernel and temperature offers various configuration options, however the default parameters have shown to be quite stable already.
```
_, ax = plt.subplots()
for t in range(history_acceptor.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_acceptor, x="theta1", t=t,
refval=theta_true, refval_color='grey',
xmin=theta_min, xmax=theta_max, ax=ax, numx=200, label=f"Iteration {t}")
ax.legend()
plt.show()
```
We see that we get essentially the same posterior distribution as with the noisy output (a bit more peaked, showing that the approximation error with the noisy output was not negligible yet), however at a much lower computational cost, as the below plot shows:
```
histories = [history_noisy_output, history_acceptor]
labels = ["noisy model", "stochastic acceptor"]
pyabc.visualization.plot_sample_numbers(histories, labels)
plt.show()
```
Thus, the stochastic acceptor is the proposed method to use in practice. For further details consult the API documentation.
## Estimate noise parameters
Our formulation of the modified acceptance step allows the noise model to be parameter-dependent (so does in theory also the noisified model output). Thus one can estimate parameters like e.g. the standard deviation of Gaussian noise on-the-fly. A parameter-dependent noise model is specified by passing a function to the kernel, which takes the parameters and returns an array of variances corresponding to the data. This is currently implemented for the `pyabc.IndependentNormalKernel`, `pyabc.IndependentLaplaceKernel`, `pyabc.BinomialKernel`.
Parameters are often estimated on a logarithmic scale if fold changes are of interest. We show this here exemplarily with the example of the standard deviation of a normal noise kernel:
```
theta_true_var = {'theta1': theta1_true, 'std': np.log10(sigma)}
prior = pyabc.Distribution(
theta1=pyabc.RV("uniform", theta_min, theta_max-theta_min),
std=pyabc.RV("uniform", -2.5, 2))
def var(p):
return 10**(2*p['std']) * np.ones(n_time)
acceptor = pyabc.StochasticAcceptor()
kernel = pyabc.IndependentNormalKernel(var=var)
eps = pyabc.Temperature()
abc = pyabc.ABCSMC(model, prior, kernel, eps=eps, acceptor=acceptor, population_size=100)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_acceptor_var = abc.run(max_nr_populations=10)
fig, ax = plt.subplots(1, 2)
for t in range(history_acceptor_var.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_acceptor_var, x="theta1", t=t,
refval=theta_true_var, refval_color='grey',
xmin=theta_min, xmax=theta_max, ax=ax[0], numx=200, label=f"Iteration {t}")
pyabc.visualization.plot_kde_1d_highlevel(
history_acceptor_var, x="std", t=t,
refval=theta_true_var, refval_color='grey',
xmin=-2.5, xmax=-0.5, ax=ax[1], numx=200, label=f"Iteration {t}")
ax[1].set_xlabel("log10(std)")
ax[1].set_ylabel(None)
ax[1].legend()
fig.set_size_inches((8, 4))
fig.tight_layout()
plt.show()
```
We see that we are able to estimate both parameters quite reasonably (the exact details of course depending on the data and model). For the present model, one could still derive the analytical posterior distribution, which we here omit for computational reasons. For an example, see [this notebook](https://github.com/yannikschaelte/Study-ABC-Noise/blob/master/study_abc_noise/estimate_noise_parameters/gaussian.ipynb).
| github_jupyter |
___
<a href='http://www.pieriandata.com'> <img src='../Pierian_Data_Logo.png' /></a>
___
# Merging, Joining, and Concatenating
There are 3 main ways of combining DataFrames together: Merging, Joining and Concatenating. In this lecture we will discuss these 3 methods with examples.
____
### Example DataFrames
```
import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
df1
df2
df3
```
## Concatenation
Concatenation basically glues together DataFrames. Keep in mind that dimensions should match along the axis you are concatenating on. You can use **pd.concat** and pass in a list of DataFrames to concatenate together:
```
pd.concat([df1,df2,df3])
pd.concat([df1,df2,df3],axis=1)
```
_____
## Example DataFrames
```
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
left
right
```
___
## Merging
The **merge** function allows you to merge DataFrames together using a similar logic as merging SQL Tables together. For example:
```
pd.merge(left,right,how='inner',on='key')
```
Or to show a more complicated example:
```
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, on=['key1', 'key2'])
pd.merge(left, right, how='outer', on=['key1', 'key2'])
pd.merge(left, right, how='right', on=['key1', 'key2'])
pd.merge(left, right, how='left', on=['key1', 'key2'])
```
## Joining
Joining is a convenient method for combining the columns of two potentially differently-indexed DataFrames into a single result DataFrame.
```
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
left.join(right)
left.join(right, how='outer')
```
# Great Job!
| github_jupyter |
<h1>Greedy Oracle</h1>
```
import os
from pterotactyl.reconstruction import touch
from pterotactyl.reconstruction import vision
from pterotactyl.policies.baselines import greedy
from pterotactyl import pretrained
TOUCH_LOCATION = os.path.dirname(pretrained.__file__) + '/reconstruction/touch/best/'
VISION_LOCATION = os.path.dirname(pretrained.__file__) + '/reconstruction/vision/t_p/'
class Params: # define training arguments
def __init__(self):
self.limit_data = True
self.env_batch_size = 2
self.num_actions = 50
self.seed = 0
self.budget = 5
self.number_points = 10000
self.loss_coeff = 9000
self.exp_type = "greedy_example"
self.finger = False
self.num_grasps = 5
self.use_touch = True
self.use_img = False
self.touch_location = TOUCH_LOCATION
self.vision_location = VISION_LOCATION
self.visualize = True
self.use_latent = False
self.use_recon = True
self.eval = True
self.greedy_checks = 3
self.pretrained_recon = True
params = Params()
greedy_test = greedy.Engine(params)
greedy_test()
```
We can now visualize the predicted objects with greedy actions, and also the distribution of chosen actions both in a histogram and projected from the shpere of posssible actions into image space.
```
import os
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
from glob import glob
from pterotactyl import objects
FONT_LOCATION = os.path.dirname(objects.__file__) + '/OpenSans-Bold.ttf'
histogram = Image.open('results/greedy_example/histogram.png')
display(histogram)
print('\n\n')
actions = Image.open('results/greedy_example/sphere_projection.png')
print(' Projected Actions')
display(actions)
img_locations = glob('results/greedy_example/*/')
for location in img_locations[:5]:
mesh = Image.open(location + "mesh.png")
points = Image.open(location + "points.png")
gt = Image.open(location + "ground_truth.png")
combo = Image.new('RGB', (512*3, 512))
x_offset = 0
for im, st in [[gt, 'Ground Truth'], [mesh, 'Mesh'], [points, 'Point Cloud']]:
draw = ImageDraw.Draw(im)
font = ImageFont.truetype(FONT_LOCATION, 35)
W,H = im.size
w,h = font.getsize(st)
draw.text(((W-w)/2, 0),st,(0, 0, 0), font = font)
combo.paste(im, (x_offset, 0))
x_offset += im.size[0]
display(combo)
```
| github_jupyter |
```
from PIL import Image , ImageOps , ImageFilter , ImageEnhance
from resize import Resize
import pytesseract
from resize import Resize
pytesseract.pytesseract.tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract'
import csv
############################################################
print('External Libraries Import Successful')
disp=Image.open('pic.jpg')
print('Input Image:')
display(disp)
#Image Resizing Section
print('Reszing Image Please Wait........')
Resize().rsize(Image.open('pic.jpg')).save('pic1.jpg')
print('Resized Image:')
display(Image.open('pic1.jpg'))
#Grayscale Conversion
image = Image.open('pic1.jpg').convert("L")
print('Gray Scale Conversion Applied:')
display(image)
for i in range(5):
image=image.filter(ImageFilter.SMOOTH_MORE)
############################################################
"""print (pytesseract.image_to_string(Image.open('pic.jpg')))
inverted_image = ImageOps.invert(image)
inverted_image.save('pic_bw.png')
print (pytesseract.image_to_string(Image.open('pic_bw.PNG')))
############################################################
im=Image.open('pic1.jpg')
im=im.filter(ImageFilter.SHARPEN)
im.save('pic_sharpen.jpg')
print('Picture with Sharpening Filter')
print (pytesseract.image_to_string(Image.open('pic_sharpen.jpg')))
############################################################
im=Image.open('pic_bw.png')
im=im.filter(ImageFilter.SHARPEN)
im.save('pic_sharpen_bw.jpg')
print('Picture with Sharpening and Black and white filter')
print (pytesseract.image_to_string(Image.open('pic_sharpen_bw.jpg')))"""
##############################################################
print("\n====================OUTPUT====================\n")
contrast=ImageEnhance.Contrast(image)
for i in range(10):
contrast.enhance(4).save('pic_contrast.png')
print('Contrast Filter Applied on Image:')
display(Image.open('pic_contrast.png'))
print('Stage 1 Tesseract Output:')
try:
s1=pytesseract.image_to_string(Image.open('pic_contrast.PNG'))
except UnicodeError:
print('The Input text consists a character which is not supported by the current CODEC installed please upload a better Image')
print ('<',s1,'>')
##############################################################
color=ImageEnhance.Color(Image.open('pic_contrast.png'))
color.enhance(0).save('pic_color_bw.png')
print('Enhancement Filter applied to Get Pure B/W image: ')
display(Image.open('pic_color_bw.png'))
print('Stage 2 Tesseract Output:')
try:
s2=pytesseract.image_to_string(Image.open('pic_color_bw.PNG'))
except UnicodeError:
print('The Input text consists a character which is not supported by the current CODEC installed please upload a better Image')
print ('<',s2,'>')
##############################################################
sharpen=ImageEnhance.Sharpness(Image.open('pic_color_bw.png'))
sharpen.enhance(2).save('pic_sharpen_enhance.png')
print('Applying Sharpening and Enhancement Filter We get: ')
display(Image.open('pic_sharpen_enhance.png'))
print('Stage 3 Tesseract Output:')
try:
s3=pytesseract.image_to_string(Image.open('pic_sharpen_enhance.PNG'))
except UnicodeError:
print('The Input text consists a character which is not supported by the current CODEC installed please upload a better Image')
print ('<',s3,'>')
##############################################################
inverted_image = ImageOps.invert(Image.open('pic_sharpen_enhance.png'))
for i in range(10):
ImageEnhance.Sharpness(inverted_image).enhance(2).save('pic_sharpen_enhance_sharpen.png')
k=Image.open('pic.jpg')
k=ImageOps.grayscale(k)
k=ImageOps.invert(k)
k=ImageEnhance.Contrast(k).enhance(3)
k.save('pic_sharpen_enhance_sharpen.png')
ImageEnhance.Sharpness(inverted_image).enhance(2).save('pic_sharpen_enhance_sharpen.png')
print('Applying Color Inversion and Sharpening Filter We Get : ')
display(Image.open('pic_sharpen_enhance_sharpen.png'))
print('Stage 4 Tesseract Output:')
try:
s4=pytesseract.image_to_string(Image.open('pic_sharpen_enhance_sharpen.png'))
except UnicodeError:
print('The Input text consists a character which is not supported by the current CODEC installed please upload a better Image')
print('<',s4,'>')
#Post Processing And Final Output
##############################################################
def output(k):
print('Saving the Result as .csv....................')
res = []
res.append(k)
csvfile = "output.csv"
print('Writing to the File Output.csv the following Result:')
print(res)
#Assuming res is a flat list
with open(csvfile, "w") as output:
writer = csv.writer(output, lineterminator='\n')
for val in res:
writer.writerow([val])
print("EXIT, YOUR FILE IS READY please check the output.csv in the current directory")
##############################################################
print('\n====================Final Result====================\n')
if(s1==s2):
if s1:
print(s1)
output(s1)
exit()
if(s2==s3):
if s2:
print(s2)
output(s2)
exit()
if(s3==s4):
if s3:
print(s3)
output(s3)
exit()
if s4:
print(s4)
output(s4)
exit()
if not s4:
print('Please Upload a better Image')
```
| github_jupyter |
# Neural Network on All Features
Import all necessary libraries, set matplotlib settings
```
import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
import sklearn.metrics
from scipy import stats
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import precision_recall_curve, recall_score, accuracy_score, precision_score, confusion_matrix
import gzip
import matplotlib.pyplot as plt
import matplotlib
plt.style.use("ggplot")
%matplotlib inline
matplotlib.rcParams['figure.dpi'] = 200
```
Set a random state to ensure replicability. Also, set cutoffs for our CNVs, since very small and very large CNVs are almost always benign and pathogenic respectively.
```
rand_state = 233
lower_bound = 2000
upper_bound = 5000000
```
Initialize our data files/filenames for training
```
file = gzip.open('./data/output_features_07_26_no_genelists.csv.gz')
df = pd.read_csv(file, dtype=str)
```
Drop columns that shouldn't be features, such as the genes, or chromsome number. This also includes repetitive elements that were classified as "Other" or "Unknown". Finally convert every value to a float.
```
df.drop(['genes_in_proximity','chr', 'start', 'end', 'Unnamed: 0', 'drop'], axis=1, inplace=True)
df.drop(['repeat_Other', 'repeat_Unknown'], axis=1, inplace=True)
df = df.astype(float)
```
Since the values have been converted from a string to a float, we can do the size cutoffs
```
# cutoffs
df = df[df["size"] > lower_bound]
df = df[df["size"] < upper_bound]
```
It seems scikit learn tends to like binary classification outputs of {0, 1}, not {-1, 1}. Also we need to seperate out the pathogenicity values, a.k.a. the values we want the classifier to output
```
df['pathogenicity'] = df['pathogenicity'].replace(-1, 0)
x_labels = df['pathogenicity'].values
df.drop(['pathogenicity'], axis=1, inplace=True)
```
We need to create the gene and repetitive element density values
```
df['gene_density'] = df['number_of_genes_in_proximity'] / df['size'] * 100000
cols = [c for c in df.columns if c.lower()[:6] == 'repeat']
for col in cols:
df[col + '_density'] = df[col] / df['size'] * 100000
```
My gene_list feature was not as good a feature as I originally thought it would be, so I drop any gene_list feature columns here
```
cols = [c for c in df.columns if c.lower()[:4] == 'bioc' or c.lower()[:4] == 'kegg' or c.lower()[:5] == 'react']
df = df.drop(cols,axis=1)
to_be_scaled = df.columns
```
Finally, since here we are training the model on selected features, we construct a list of those features. If training on all features, simply uncomment the line underneath. Then we set the dataframe to only include those features
```
to_be_scaled = ['repeat_LTR_density','repeat_SINE_density','repeat_LINE_density','repeat_Low complexity_density','repeat_Transposable element_density',
'repeat_Simple repeat_density','repeat_LINE','repeat_Segmental duplication_density','size','gene_density','mpo_multi_entrez_to_num_phenotypes','mpo_multi_entrez_to_num_phenotypes_using_thresh','mpo_behavior/neurological phenotype',
'mpo_growth/size/body region phenotype','pli_pli_0.0_to_0.1','pli_pli_0.9_to_1.0','pli_pli_0.8_to_0.9',
'pli_pli_0.3_to_0.4','gain_loss','omim_num_diseases', 'number_of_genes_in_proximity']
# to_be_scaled = df.columns
df = df[to_be_scaled]
```
Define a function for drawing a precision-recall curve using matplotlib
```
def precision_recall_graph(precisions, recalls):
"""
plots the precision recall curve and shows the current value for each
by identifying the classifier's threshold (t).
"""
# plot the curve
plt.figure(figsize=(8,8))
plt.title("Precision and Recall curve")
plt.step(recalls, precisions, color='b', alpha=0.2,
where='post')
plt.fill_between(recalls, precisions, step='post', alpha=0.2,
color='b')
plt.ylim([0, 1.01]);
plt.xlim([0.5, 1.01]);
plt.xlabel('Recall');
plt.ylabel('Precision');
```
Define a function for finding the precision and threshold for a particular recall rate
```
def find_threshold_for_recall(precisions, recalls, thresholds, recalls_wanted):
for recall in recalls_wanted:
closest_threshold = 0
for i in range(len(recalls)):
if recalls[i] - recall < 0:
closest_threshold = thresholds[i]
precision_dict[recall].append(precisions[i])
thresh_dict[recall].append(closest_threshold)
break
y_pred_adj = [1 if y >= closest_threshold else 0 for y in y_scores]
print(pd.DataFrame(confusion_matrix(y_test, y_pred_adj),
columns=['pred_neg', 'pred_pos'],
index=['neg', 'pos']))
```
Since we are running a k-fold cross validation, we end up with multiple different classifiers, feature importance rankings, scaling constants, etc. Furthermore, we also end up with multiple different accuracy, precision, recall values. We need a way to store all the variables/classifiers for each run of the k-fold cross validation, so we can average them for analysis, and/or also use them when testing on another dataset
```
# a list of the accuracy for each classifier
accuracy_list = []
# a list of the average precision for each classifier
avg_precision_list = []
# a list of the recalls that are wanted for analysis
recalls_wanted = [0.90, 0.97, 0.99]
# stores a list of the thresholds needed for each classifier for each recall
thresh_dict = {}
for recall in recalls_wanted:
thresh_dict[recall] = []
# stores a list of precisions for each classifier for each recall
precision_dict = {}
for recall in recalls_wanted:
precision_dict[recall] = []
# stores each classifier trained per run
clf_list = []
# for box-cox scaling on 'size' feature
lambda_list = []
# for mean 0, std 1 scaling on every feature
scaler_list= []
```
We need to initialize the k-fold cross validation
```
kfold = StratifiedKFold(n_splits=5,shuffle=True, random_state=rand_state)
kfold.get_n_splits(df, x_labels)
counter = 0
```
We set SCALING to true, since Neural Networks need scaling
```
SCALING = True
```
The following is the complete training and validation loop
```
for train_index, test_index in kfold.split(df, x_labels):
counter += 1
# use the indices to split the dataframe into the training and validation
# segments
X_pre_train, X_pre_test = df.iloc[train_index], df.iloc[test_index]
y_train, y_test = x_labels[train_index], x_labels[test_index]
# run the if statement if you would like to scale the features before
# training. this scaling implements standard mean 0, std 1 scaling, and
# also boxcox scaling on the 'size' feature
if SCALING:
X_pre_train = X_pre_train.copy()
X_pre_test = X_pre_test.copy()
# box-cox scaling on training data
X_pre_train.loc[:,'size'], lmbda = stats.boxcox(\
X_pre_train['size'].copy())
lambda_list.append(lmbda)
# use lambda for box-cox on validation data
X_pre_test.loc[:,'size'] = stats.boxcox(\
X_pre_test['size'].copy(), lmbda)
# standard scaler for all features, including 'size'
scaler = StandardScaler()
# save the scaler reference
scaler_list.append(scaler)
scaler.fit(X_pre_train)
# scale both training and validation data
X_train = scaler.transform(X_pre_train)
X_test = scaler.transform(X_pre_test)
else:
# simply assign variables to the original dataset
X_train = X_pre_train
X_test = X_pre_test
# Neural Network classifier
clf = MLPClassifier(activation='relu', momentum= .7,
solver='adam', max_iter=70, alpha=1e-4,
hidden_layer_sizes=(20, 10),
random_state=rand_state)
clf.fit(X_train, y_train)
# make predictions
preds = clf.predict(X_test)
# determine accuracy
accuracy_list.append(accuracy_score(y_test, preds))
# save classifier
clf_list.append(clf)
# find probabilities
y_scores = clf.predict_proba(X_test)[:,1]
# obtain precision recall matrix
avg_precision_list.append(sklearn.metrics.average_precision_score(y_test,
y_scores))
p, r, thresholds = precision_recall_curve(y_test, y_scores)
print("k_Fold " + str(counter) + " Results")
# save precision for each recall value wanted
find_threshold_for_recall(p, r, thresholds, recalls_wanted)
# graph precision recall curve
precision_recall_graph(p,r)
# show plots if needed
# plt.show()
```
Print out the precisions for each recall, average precision, and accuracy
```
for recall in recalls_wanted:
print("Precision for Recall of ", end='')
print(str(recall) +':', end='')
print(" %.4f (±%.4f)" % (np.array(precision_dict[recall]).mean(),
np.array(precision_dict[recall]).std()))
print("Average Precision: %.4f (±%.4f)" % (\
np.array(avg_precision_list).mean(),
np.array(avg_precision_list).std()))
print("Accuracy: %.4f (±%.4f)" % (np.array(accuracy_list).mean(),
np.array(accuracy_list).std()))
```
# Testing on ClinVar (Optional)
For testing these models on ClinVar, the new .csv file must be loaded, and all pre-processing from above repeated
```
file = open('./data/clinvar_filtered_final_everything_fixed_plus_features_08_06.csv')
df = pd.read_csv(file, dtype=str)
df.drop(['genes_in_proximity','chr', 'start', 'end', 'Unnamed: 0'],
axis=1, inplace=True)
df.drop(['repeat_Other', 'repeat_Unknown'], axis=1, inplace=True)
df = df.astype(float)
df = df[df["size"] > lower_bound]
df = df[df["size"] < upper_bound]
df['pathogenicity'] = df['pathogenicity'].replace(-1, 0)
x_labels = df['pathogenicity'].values
df.drop(['pathogenicity'], axis=1, inplace=True)
df['gene_density'] = df['number_of_genes_in_proximity'] / df['size'] * 100000
cols = [c for c in df.columns if c.lower()[:6] == 'repeat']
for col in cols:
df[col + '_density'] = df[col] / df['size'] * 100000
cols = [c for c in df.columns if c.lower()[:4] == 'bioc' or c.lower()[:4] == 'kegg' or c.lower()[:5] == 'react']
df = df.drop(cols,axis=1)
df = df[to_be_scaled]
```
Now initialize lists to store the accuracy and average precision of each model on the ClinVar testing set
```
test_accuracy_list = []
test_avg_precision_list = []
```
Finally use all of the 5 classifiers and their 3 threshold levels (for 90% recall, 97% recall, and 99% recall) to create predictions
```
for i in range(len(clf_list)):
clf = clf_list[i]
x_test = df.copy()
x_test.loc[:,'size'] = stats.boxcox(x_test['size'].copy(), lambda_list[i])
x_test = scaler_list[i].transform(x_test)
preds = clf.predict(x_test)
test_accuracy_list.append(accuracy_score(x_labels, preds))
y_scores = clf.predict_proba(x_test)[:,1]
test_avg_precision_list.append(sklearn.metrics.average_precision_score(
x_labels, y_scores))
p, r, thresholds = precision_recall_curve(x_labels, y_scores)
for recall in recalls_wanted:
print("for original recall: " + str(recall))
y_pred_adj = [1 if y >= thresh_dict[recall][i] else 0 for y in y_scores]
print(pd.DataFrame(confusion_matrix(x_labels, y_pred_adj),
columns=['pred_neg', 'pred_pos'],
index=['neg', 'pos']))
print("Test Average Precision: %.4f (±%.4f)" % (\
np.array(test_avg_precision_list).mean(),
np.array(test_avg_precision_list).std()))
print("Test Accuracy: %.4f (±%.4f)" % (np.array(test_accuracy_list).mean(),
np.array(test_accuracy_list).std()))
```
| github_jupyter |
```
import json
import numpy as np
import pandas as pd
from flask import Flask, make_response, jsonify, request, render_template
from datetime import datetime, date,timedelta
import yfinance as yf
from code_cr import *
from pykrx import stock
import math
# ====================================================
# 데이터
# ====================================================
com_df=pd.read_csv('com_df.csv',
dtype={'stock_code': 'str', '표준코드': 'str', '단축코드': 'str', 'stock_code_ori':'str'},
parse_dates=['listed_date', '상장일'])
# ====================================================
# 라우터
# ====================================================
app = Flask(__name__, template_folder="template", static_folder="static")
import re
import numpy as np
import pandas as pd
import requests #웹통신
import json
from pmdarima.arima import ndiffs
import pmdarima as pm
from pykrx import stock
# ==============
# 업종 분류
# ==============
# -------- 동일 업종 기업 출력
# TODO(미완성) 동일 업종 선택
def select_same_industry(corp_name):
indus=com_df[com_df['nm']==corp_name]['industry'].values[0] # TODO(df 확인)
# print(com_df.groupby(by='industry')['nm'].nunique().max()) # 동종업계 최대 151개 -> 151개 재무제표 크롤링?
list_com=com_df[com_df['industry']==indus]['corp_name'].values.tolist()
return list_com
# -------- 네이버증권 연관기업 코드(hjh)
def relate_code_crawl(co):
#연관 종목코드 있는 페이지 불러오기
url='https://finance.naver.com/item/main.naver?code='+str(co)
page=pd.read_html(url,encoding='CP949')
#연관 종목명과 종목코드 뽑아내기(code_list[0]은 '종목명'이어서 제외)
code_list=page[4].columns.tolist()
code_list=code_list[1:]
#종목코드 리스트 반환
codes=[]
for word in (code_list):
codes.append(word[-6:])
#print(codes)
return codes
#relate_code_crawl('000660')
# ==============
# 기업 이름 코드 변환
# ==============
# -------- 네이버 재무제표 크롤링 용 gicode로 변환
def nm_to_bs_gicode(corp_name):
gi=com_df[com_df['nm']==corp_name]['cd']
gi=gi.values[0]
return gi
def stc_code_to_bs_gicode(stock_code):
gi = com_df[com_df['stock_code'] == stock_code]['cd']
gi = gi.values[0]
return gi
def yh_code_to_bs_gicode(yh_code):
gi = com_df[com_df['yh_code'] == yhcode]['cd']
gi = gi.values[0]
return gi
# -------- 네이버 금융 크롤링 용 gicode로 변환
def nm_to_fn_gicode(corp_name):
gi=com_df[com_df['nm']==corp_name]['stock_code']
gi=gi.values[0]
return gi
def yh_code_to_fn_gicode(yh_code):
gi=com_df[com_df['yh_code']==yh_code]['stock_code']
gi=gi.values[0]
return gi
# -------- 코드를 기업이름으로 변환
def stc_code_to_nm(stock_code):
gi = com_df[com_df['stock_code'] == stock_code]['nm']
gi = gi.values[0]
return gi
def yh_code_to_nm(yh_code):
gi = com_df[com_df['yh_code'] == yh_code]['nm']
gi = gi.values[0]
return gi
# ==============
# 데이터 수집
# ==============
# -------- Balance Sheets API call
# def bs_api(corp_name=None, yh_code=None, stock_code=None):
# print('haha')
# -------- Balance Sheets Crawling(재무제표 크롤링)
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) kind로 특정 테이블 지정하는 대신 데이터프레임 리스트 전체 반환
# 3) '~계산에 참여한 계정 펼치기' 제거는 선택사항으로 둠
def bs_craw(stock_code, clear_name=False): # ------- 검색과 연동해서 입력 변수 설정
"""
# kind
: 0 (연간 포괄손익계산서), 1 (분기별 포괄손익계산서)
2 (연간 재무상태표), 3 (분기별 재무상태표)
4 (연간 현금흐름표), 5 (분기별 현금프름표)
"""
# ------- 검색과 연동해서 입력되는 변수 따라 gicode(네이버에서 분류하는 기업 코드)로 변환
gcode = stc_code_to_bs_gicode(stock_code)
url = f"http://comp.fnguide.com/SVO2/ASP/SVD_Finance.asp?NewMenuID=103&gicode={gcode}"
table_list = pd.read_html(url, encoding='UTF-8')
# 항목에서 불필요한 부분 제거('계산에 참여한 계정 펼치기')
if clear_name == False:
return table_list
else:
new_table_list = []
for tbl in table_list:
for i, idx in enumerate(tbl.iloc[:, 0]):
m = idx.replace('계산에 참여한 계정 펼치기', '')
tbl.iloc[i, 0] = m
new_table_list.append(tbl)
return new_table_list
# ------- 네이버 금융
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) kind로 특정 테이블 지정하는 대신 데이터프레임 리스트 전체 반환
def fn_craw(stock_code):
"""
# kind
: 0 (전일&당일 상한가, 하한가, 거래량 등) #TODO 가공 필요
1 (증권사 별 매도 매수 정보) #TODO 가공 필요(컬럼이름)
2 (외국인, 기관 거래 정보) #TODO 가공 필요
3 (기업실적분석(연도별 분기별 주요재무 정보)) #TODO 가공 필요?
4 (동일업종비교) #TODO 가공 필요?
5 (시가총액, 주식수, 액면가 정보) #TODO 가공 필요
6 (외국인 주식 한도, 보유 정보)
7 (목표주가 정보) #TODO 가공 필요
8 (PER, PBR 배당수익률 정보) (주가 따라 변동) #TODO 가공 필요
9 (동일업종 PER, 등락률 정보) #TODO 가공 필요
10 (호가 10단계)
11 (인기 검색 종목: 코스피) #TODO 가공 필요
12 (인기 검색 종목: 코스닥) #TODO 가공 필요
"""
gcode = str(stock_code)
url = f"https://finance.naver.com/item/main.naver?code={gcode}"
table_list = pd.read_html(url, encoding='euc-kr')
return table_list
# ==============
# 지표 선정
# ==============
# 220222 날씨 수정 시작 ---------------------------------------------
# -------- 지표 선정
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) 데이터프레임 하나가 아닌 리스트로 받아오기때문에 kind 제거하고 직접 선택해줌
# 3) sli_df_y, sil_df_q 에서 '-' 가공 시 if 조건에 따라 처리하는 대신 lambda와 re.sub 이용
# 4) dict 대신 array로 반환, 기업 이름(nm도 반환)
def idv_radar_weather_data(stock_code):
"""
# <지표 설명>
# 1. 배당 분석 -> 배당성향(배당 커버리지의 역수.)
# 2. 유동성 분석(단기채무지급능력) -> 당좌비율(당좌자산 / 유동부채)
# 3. 재무건전성 분석(레버리지 비율) -> 부채비율(총부채 / 자기자본)의 역수
# 4. 수익성분석 -> 매출수익성(당기순이익/매출액))
# 5. 성장성분석 -> 순이익성장률
"""
gcode = stock_code
nm = stc_code_to_nm(stock_code)
sil_df = fn_craw(gcode)[3] # 3: 기업실적정보 재무제표 (220220 수정)
foreign_ms = fn_craw(gcode)[2].loc[1, '외국인'] # 2 : 외국인, 기관 거래 정보
giguan_ms = fn_craw(gcode)[2].loc[1, '기관'] # 2 : 외국인, 기관 거래 정보
if (sil_df.iloc[0:8, 3].isna().sum()) > 0: # 표 안 가르고 계산하는 건 신규 상장 기업은 정보가 아예 없기 때문
pass
elif (sil_df.iloc[0:8, 9].isna().sum()) > 0: # 표 안 가르고 계산하는 건 신규 상장 기업은 정보가 아예 없기 때문
pass
else:
# 0. 재무정보는 최신 분기 실공시 기준
# 0. 단, 배당은 1년에 한 번 이루어지기 때문에 최신 년도 공시 기준임
sil_df_y = sil_df['최근 연간 실적'].iloc[:, 2] # 느리지만 .iloc으로 하는 이유는 공시 날짜가 다른 기업이 있기 때문
sil_df_q = sil_df['최근 분기 실적'].iloc[:, 4]
sil_df_y = sil_df_y.fillna(0)
sil_df_q = sil_df_q.fillna(0)
if sil_df_y.dtype == 'O':
sil_df_y = sil_df_y.apply(lambda x: re.sub('^-$', '0', '{}'.format(x)))
sil_df_y = sil_df_y.astype('float')
if sil_df_q.dtype == 'O':
sil_df_q = sil_df_q.apply(lambda x: re.sub('^-$', '0', '{}'.format(x)))
sil_df_q = sil_df_q.astype('float')
# 1. 배당성향(bd_tend)
bd_tend = sil_df_y[15] # 실제 배당 성향
# 2. 유동성 분석 - 당좌비율(당좌자산/유동부채)
# 당좌자산 = (유동자산 - 재고자산)
dj_rate = sil_df_q[7] # 당좌비율
# 3. 재무건전성 분석 - 부채비율(총부채/자기자본)의 역수
bch_rate = sil_df_q[6] / 100 # 부채비율
bch_rate = round((1 / bch_rate) * 100, 2)
# 4. 수익성 분석 - 매출수익성(당기순이익/매출액) # TODO 매출액 0인 애들은?
dg_bene = sil_df_q[2]
mch = sil_df_q[0]
suyk = round((dg_bene / mch) * 100, 2)
# 5. 성장성 분석 - 순이익성장률(지속성장 가능률)
# (1-배당성향)*자기자본순이익률(ROE)
# 유보율
roe = sil_df_y[5] / 100
ubo = (100 - bd_tend) / 100
grth = round(roe * ubo * 100, 2)
data_arr = np.array([bd_tend, dj_rate, bch_rate, suyk, grth])
# weather part----------------
# PER?
weather_per = sil_df_y[10]
# PBR
weather_pbr = sil_df_y[12]
# ROE
weather_roe = sil_df_y[5]
# EPS
weather_eps = sil_df_y[9]
# BPS
weather_bps = sil_df_y[11]
# array
weather_arr = np.array([weather_per, weather_pbr, weather_roe, weather_eps, weather_bps])
return data_arr, weather_arr, nm, foreign_ms, giguan_ms
# 수정수정수정
# -------- 관련 기업 지표 선정(상대적 비율 기준)
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) dict 대신 array로 반환, 기업 이름(nm도 반환)
# 220222 날씨
def relate_radar_weather_data(stock_code):
label_list = ['배당성향', '유동성', '건전성', '수익성', '성장성']
arr_list = []
# 주식 코드,이름으로 변환
gcode = stock_code
relate_corp = relate_code_crawl(co=gcode)
# 다섯 개 회사가 안에 있다
arr_list = [idv_radar_weather_data(stock_code=stcd) for stcd in relate_corp]
# arr_list에서 데이터 분리
radar_list = [x[0] for x in arr_list if x is not None]
weather_list = [x[1] for x in arr_list if x is not None]
nm_list = [x[2] for x in arr_list if x is not None]
# 외인 매수, 기관 매수
try:
foreign_ms = arr_list[0][3]
except TypeError:
foreign_ms=0.01
try:
giguan_ms = arr_list[0][4]
except TypeError:
giguan_ms=0.01
# radar_chart_data
radar_list = np.array(radar_list)
radar_list[:, 0] = (radar_list[:, 0] / radar_list[:, 0].mean()) * 100
radar_list[:, 1] = (radar_list[:, 1] / radar_list[:, 1].mean()) * 100
radar_list[:, 2] = (radar_list[:, 2] / radar_list[:, 2].mean()) * 100
radar_list[:, 3] = (radar_list[:, 3] / radar_list[:, 3].mean()) * 100
radar_list[:, 4] = (radar_list[:, 4] / radar_list[:, 4].mean()) * 100
# radar_chart_dict
radar_dict_list = []
for i, nm in enumerate(nm_list):
dic = {}
dic[nm] = radar_list[i, :].tolist()
radar_dict_list.append(dic)
# weather_chart_data
weather_list = np.array(weather_list)
weather_list[:, 0] = (weather_list[:, 0] / weather_list[:, 0].mean()) # 각 기업의 평균 대비 PER
weather_list[:, 1] = (weather_list[:, 1] / weather_list[:, 1].mean()) # 각 기업의 평균 대비 PBR
weather_list[:, 2] = (weather_list[:, 2] / weather_list[:, 2].mean()) # 각 기업의 평균 대비 ROE
weather_list[:, 3] = (weather_list[:, 3] / weather_list[:, 3].mean()) # 각 기업의 평균 대비 EPS
weather_list[:, 4] = (weather_list[:, 4] / weather_list[:, 4].mean()) # 각 기업의 평균 대비 BPS
weather_list=np.round(weather_list, 2)
return label_list, radar_dict_list, weather_list[0], foreign_ms, giguan_ms
# 220222 날씨 수정 끝 ---------------------------------------------
# ==============
# 지표 선정
# ==============
# -------- 지표 선정
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) 데이터프레임 하나가 아닌 리스트로 받아오기때문에 kind 제거하고 직접 선택해줌
# 3) sli_df_y, sil_df_q 에서 '-' 가공 시 if 조건에 따라 처리하는 대신 lambda와 re.sub 이용
# 4) dict 대신 array로 반환, 기업 이름(nm도 반환)
def idv_radar_data(stock_code):
"""
# <지표 설명>
# 1. 배당 분석 -> 배당성향(배당 커버리지의 역수.)
# 2. 유동성 분석(단기채무지급능력) -> 당좌비율(당좌자산 / 유동부채)
# 3. 재무건전성 분석(레버리지 비율) -> 부채비율(총부채 / 자기자본)의 역수
# 4. 수익성분석 -> 매출수익성(당기순이익/매출액))
# 5. 성장성분석 -> 순이익성장률
"""
gcode = stock_code
nm = stc_code_to_nm(stock_code)
sil_df = fn_craw(gcode)[3] # 3: 기업실적정보 재무제표 (220220 수정)
if (sil_df.iloc[0:8, 3].isna().sum()) > 0: # 표 안 가르고 계산하는 건 신규 상장 기업은 정보가 아예 없기 때문
pass
elif (sil_df.iloc[0:8, 9].isna().sum()) > 0: # 표 안 가르고 계산하는 건 신규 상장 기업은 정보가 아예 없기 때문
pass
else:
# 0. 재무정보는 최신 분기 실공시 기준
# 0. 단, 배당은 1년에 한 번 이루어지기 때문에 최신 년도 공시 기준임
sil_df_y = sil_df['최근 연간 실적'].iloc[:, 2] # 느리지만 .iloc으로 하는 이유는 공시 날짜가 다른 기업이 있기 때문
sil_df_q = sil_df['최근 분기 실적'].iloc[:, 4]
sil_df_y = sil_df_y.fillna(0)
sil_df_q = sil_df_q.fillna(0)
if sil_df_y.dtype == 'O':
sil_df_y = sil_df_y.apply(lambda x: re.sub('^-$', '0', '{}'.format(x)))
sil_df_y = sil_df_y.astype('float')
if sil_df_q.dtype == 'O':
sil_df_q = sil_df_q.apply(lambda x: re.sub('^-$', '0', '{}'.format(x)))
sil_df_q = sil_df_q.astype('float')
# 1. 배당성향(bd_tend)
bd_tend = sil_df_y[15] # 실제 배당 성향
# 2. 유동성 분석 - 당좌비율(당좌자산/유동부채)
# 당좌자산 = (유동자산 - 재고자산)
dj_rate = sil_df_q[7] # 당좌비율
# 3. 재무건전성 분석 - 부채비율(총부채/자기자본)의 역수
bch_rate = sil_df_q[6] / 100 # 부채비율
bch_rate = round((1 / bch_rate) * 100, 2)
# 4. 수익성 분석 - 매출수익성(당기순이익/매출액) # TODO 매출액 0인 애들은?
dg_bene = sil_df_q[2]
mch = sil_df_q[0]
suyk = round((dg_bene / mch) * 100, 2)
# 5. 성장성 분석 - 순이익성장률(지속성장 가능률)
# (1-배당성향)*자기자본순이익률(ROE)
# 유보율
roe = sil_df_y[5] / 100
ubo = (100 - bd_tend) / 100
grth = round(roe * ubo * 100, 2)
data_arr = np.array([bd_tend, dj_rate, bch_rate, suyk, grth])
return data_arr, nm
# -------- 관련 기업 지표 선정(상대적 비율 기준)
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) dict 대신 array로 반환, 기업 이름(nm도 반환)
def relate_radar_data(stock_code):
label_list = ['배당성향', '유동성', '건전성', '수익성', '성장성']
arr_list = []
# 주식 코드,이름으로 변환
gcode = stock_code
relate_corp = relate_code_crawl(co=gcode)
arr_list = [idv_radar_data(stock_code=stcd) for stcd in relate_corp]
nm_list = [x[1] for x in arr_list if x is not None]
arr_list = [x[0] for x in arr_list if x is not None]
arr_list = np.array(arr_list)
arr_list[:, 0] = (arr_list[:, 0] / arr_list[:, 0].mean()) * 100
arr_list[:, 1] = (arr_list[:, 1] / arr_list[:, 1].mean()) * 100
arr_list[:, 2] = (arr_list[:, 2] / arr_list[:, 2].mean()) * 100
arr_list[:, 3] = (arr_list[:, 3] / arr_list[:, 3].mean()) * 100
arr_list[:, 4] = (arr_list[:, 4] / arr_list[:, 4].mean()) * 100
dict_list = []
for i, nm in enumerate(nm_list):
dic = {}
dic[nm] = arr_list[i, :].tolist()
dict_list.append(dic)
return label_list, dict_list
# -------- 관련 기업 지표 선정(원본)
# def relate_radar_data(yh_code=None, corp_name=None, stock_code=None):
# label_list=['배당성향', '유동성', '건전성', '수익성', '성장성']
# dict_list = []
#
# # 주식 코드로 변환
# gcode = 0
# if yh_code != None:
# gcode = yh_code_to_fn_gicode(yh_code)
# elif corp_name != None:
# gcode = nm_to_fn_gicode(corp_name)
# elif stock_code != None:
# gcode = stock_code
#
# relate_corp = relate_code_crawl(co=gcode)
#
# dict_list = [idv_radar_data(stock_code=stcd) for stcd in relate_corp]
#
# dict_list = [x for x in dict_list if x is not None]
#
#
# return label_list, dict_list
# ==============
# 시각화
# ==============
# -------- 매출, 당기순이익 추이 그래프
# 220220 수정
# 1) 매개변수 stock_code로 축약
# 2) 크롤링한 데이터는 list로 받아오므로 kind 없애고 직접 인덱스 처리
def mch_dg(stock_code):
gcode = stock_code
nm = stc_code_to_nm(stock_code)
bs_df = bs_craw(stock_code=gcode)[0]
label_list = bs_df.columns[1:6].tolist() # 네 분기 + 전년동기
mch_list = bs_df.loc[0, label_list].tolist() # 매출액
dg_list = bs_df.loc[15, label_list].tolist() # 당기순이익
return label_list, mch_list, dg_list
def icon_selection(index_array):
res=[]
for idx in index_array:
if 3<idx :
res.append("CLEAR_DAY")
elif ( 1.2<idx and idx<=3 ):
res.append("PARTLY_CLOUDY_DAY")
elif ( 0.8<idx and idx<=1.2 ):
res.append("CLOUDY")
elif ( 0<idx and idx<=0.8 ):
res.append("RAIN")
else:
res.append("SNOW")
return res
def foreign_giguan(index_array):
res = []
for idx in index_array:
if idx >=0:
res.append("CLEAR_DAY")
else:
res.append("RAIN")
return res
# ====================================================
# 데이터
# ====================================================
# -------- 병합 파일 불러오기
com_df=pd.read_csv('com_df.csv',
dtype={'stock_code': 'str', '표준코드': 'str', '단축코드': 'str', 'stock_code_ori':'str'},
parse_dates=['listed_date', '상장일'])
# -------- 뉴스 크롤링
def news_crawl(gi):
tot_list = []
for p in range(1):
# 뉴스 기사 모인 페이지
url = 'https://m.stock.naver.com/domestic/stock/' + str(gi) + '/news/title' # https://m.stock.naver.com/domestic/stock/003550/total
#F12누르면 나오는 네트워크상에서 찾아온 경로
#https://m.stock.naver.com/api/news/stock/005930?pageSize=20&page=1&searchMethod=title_entity_id.basic
url = "https://m.stock.naver.com/api/news/stock/"+str(gi)+"?pageSize=5&searchMethod=title_entity_id.basic&page=1"
res = requests.get(url)
news_list = json.loads(res.text)
#페이지에서 가져온 전체 뉴스기사를 for문으로 분리
#print(news_list[0])
for i, news in enumerate(news_list) :
#신문사 id
a=news['items'][0]['officeId']
#기사 id
b=news['items'][0]['articleId']
list = []
list.append(news['items'][0]['officeName']) #신문사
list.append(news['items'][0]['datetime'][:8]) #날짜
list.append(news['items'][0]['title'].replace('"','\"')) #제목
list.append(news['items'][0]['imageOriginLink']) #이미지
list.append(news['items'][0]['body'].replace('"','\"')) # 기사 내용
list.append('https://m.stock.naver.com/domestic/stock/005930/news/view/'+str(a)+'/'+str(b)) #기사 url
tot_list.append(list)
news_df = pd.DataFrame(data=tot_list, columns=['offname','rdate','title','imgsrc','content','url'])
news_df['title'] = news_df['title'].str.replace('&', '&')
news_df['content'] = news_df['content'].str.replace('&', '&')
#news_df['title'] = [re.sub('[^A-Za-z0-9가-힣]', '' ,s) for s in news_df['title']]
#news_df.to_csv('css.csv',index=False)
return news_df
#co-종목코드
def relate_code_crawl(co):
#연관 종목코드 있는 페이지 불러오기
url='https://finance.naver.com/item/main.naver?code='+str(co)
page=pd.read_html(url,encoding='CP949')
#연관 종목명과 종목코드 뽑아내기(code_list[0]은 '종목명'이어서 제외)
code_list=page[4].columns.tolist()
code_list=code_list[1:]
#종목코드 리스트 반환
codes=[]
for word in (code_list):
codes.append(word[-6:])
#print(codes)
return codes
# def before_1w_kospi(date):
# before1w=date-timedelta(days=7)
# return fdr.DataReader('KS11',before1w)[['Close']]#, fdr.DataReader('KQ11',before1w)
def invest_opinion(gcode):
url='https://finance.naver.com/item/coinfo.naver?code='+str(gcode)
page=pd.read_html(url,encoding='CP949')
try:
a,b=page[3][1].tolist()[0][:4].split('.')
return ((int(a)+int(b)/100)/5)*100 #의견 점수 구한 후 백분율로 다시 변환
except ValueError:
return 0.1
#최상현 함수
def crawl_ifrs(gcode):
url = "http://comp.fnguide.com/SVO2/ASP/SVD_Main.asp?pGB=1&gicode=A" + gcode + "&cID=&MenuYn=Y&ReportGB=&NewMenuID=11&stkGb=701"
table_list = pd.read_html(url, encoding='UTF-8')
ifrs = table_list[10]
ifrs = ifrs.fillna('9999999999')
for i in range(1, 5):
ifrs.iloc[:, i] = ifrs.iloc[:, i].apply(lambda x: format(float(x), ','))
ifrs = pd.concat([ifrs['IFRS(연결)'], ifrs['Annual']], axis=1)
ifrs = ifrs.astype(str)
for i in range(1, 5):
ifrs.iloc[:12, i] = ifrs.iloc[:12, i].apply(lambda x: x[:-2])
ifrs.iloc[18:21, i] = ifrs.iloc[18:21, i].apply(lambda x: x[:-2])
ifrs.iloc[23:24, i] = ifrs.iloc[23:24, i].apply(lambda x: x[:-2])
ifrs = ifrs.replace(['9,999,999,999', '9,999,999,999.0'], ['-', '-'])
ifrs.rename(columns={'IFRS(연결)': ''}, inplace=True)
ifrs = ifrs.to_html(justify="right", index=False, classes="table")
ifrs = ifrs.replace('border="1"', 'border="0"')
pd.options.display.float_format = '{:,.0f}'.format
ifrs = ifrs.replace('<td>', '<td align="right">')
ifrs = ifrs.replace('<th>', '<th style="text-align: right;">')
ifrs = ifrs.replace('halign="left"', 'style="text-align: center;"')
ifrs = ifrs.replace('class ="dataframe table"', 'class ="dataframe table" style = "table-layout:fixed;word-break:break-all;"')
return (ifrs)
def ori_code(yh_code):
origin_stock=com_df[com_df['yh_code']==yh_code]['stock_code_ori'].values[0]
return origin_stock
# 아리마 모델
def stock_predict(code,ptype):
data = stock.get_market_ohlcv_by_date(fromdate="20220101", todate="20220222", ticker=str(code))
print(data.head())
data=data[[ptype]]
y_train=data
y_test=data
kpss_diffs = ndiffs(y_train, alpha=0.05, test='kpss', max_d=6)
adf_diffs = ndiffs(y_train, alpha=0.05, test='adf', max_d=6)
n_diffs = max(adf_diffs, kpss_diffs)
print(f"추정된 차수 d = {n_diffs}")
model=pm.auto_arima(y_train,d=n_diffs,seasonal=False,trace=True)
model.fit(y_train)
print(model.summary())
def forecast_one_step():
fc, conf_int = model.predict(n_periods=1 # 한 스텝씩!
, return_conf_int=True) # 신뢰구간 출력
return (
fc.tolist()[0],
np.asarray(conf_int).tolist()[0]
)
forecasts = []
y_pred = []
pred_upper = []
pred_lower = []
for new_ob in y_test[ptype]:
fc, conf = forecast_one_step()
y_pred.append(int(fc))
pred_upper.append(conf[1])
pred_lower.append(conf[0])
## 모형 업데이트 !!
model.update(new_ob)
fc_last = model.predict(n_periods=1 # 한 스텝씩!
)
df=pd.DataFrame({"test": y_test[ptype], "pred": y_pred})
print(df.tail())
def MAE(y_test, y_pred):
return np.mean(np.abs((df['test']-df['pred'])/df['test']))*100
mae=np.round(MAE(y_test, y_pred).astype('float'),4)
print(f"MAE: {MAE(y_test, y_pred):.3f}")
price_list=[]
return int(fc_last),mae
url = "http://comp.fnguide.com/SVO2/ASP/SVD_Main.asp?pGB=1&gicode=AA352820&cID=&MenuYn=Y&ReportGB=&NewMenuID=11&stkGb=701"
table_list = pd.read_html(url, encoding='UTF-8')
ifrs = table_list[10]
ifrs = ifrs.fillna('9999999999')
for i in range(1, 5):
ifrs.iloc[:, i] = ifrs.iloc[:, i].apply(lambda x: format(float(x), ','))
ifrs = pd.concat([ifrs['IFRS(연결)'], ifrs['Annual']], axis=1)
ifrs = ifrs.astype(str)
for i in range(1, 5):
ifrs.iloc[:12, i] = ifrs.iloc[:12, i].apply(lambda x: x[:-2])
ifrs.iloc[18:21, i] = ifrs.iloc[18:21, i].apply(lambda x: x[:-2])
ifrs.iloc[23:24, i] = ifrs.iloc[23:24, i].apply(lambda x: x[:-2])
ifrs = ifrs.replace(['9,999,999,999', '9,999,999,999.0'], ['-', '-'])
ifrs.rename(columns={'IFRS(연결)': ''}, inplace=True)
ifrs = ifrs.to_html(justify="right", index=False, classes="table")
ifrs = ifrs.replace('border="1"', 'border="0"')
pd.options.display.float_format = '{:,.0f}'.format
ifrs = ifrs.replace('<td>', '<td align="right">')
ifrs = ifrs.replace('<th>', '<th style="text-align: right;">')
ifrs = ifrs.replace('halign="left"', 'style="text-align: center;"')
ifrs = ifrs.replace('class ="dataframe table"', 'class ="dataframe table" style = "table-layout:fixed;word-break:break-all;"')
# return (ifrs)
print(type(' N/A(IFRS)'))
type(' N/A(IFRS)')==str
type
url = "http://comp.fnguide.com/SVO2/ASP/SVD_Main.asp?pGB=1&gicode=A" + gcode + "&cID=&MenuYn=Y&ReportGB=&NewMenuID=11&stkGb=701"
table_list = pd.read_html(url, encoding='UTF-8')
ifrs = table_list[10]
ifrs = ifrs.fillna('9999999999')
for i in range(1, 5):
ifrs.iloc[:, i] = ifrs.iloc[:, i].apply(lambda x: format(float(x), ','))
ifrs = pd.concat([ifrs['IFRS(연결)'], ifrs['Annual']], axis=1)
ifrs = ifrs.astype(str)
for i in range(1, 5):
ifrs.iloc[:12, i] = ifrs.iloc[:12, i].apply(lambda x: x[:-2])
ifrs.iloc[18:21, i] = ifrs.iloc[18:21, i].apply(lambda x: x[:-2])
ifrs.iloc[23:24, i] = ifrs.iloc[23:24, i].apply(lambda x: x[:-2])
ifrs = ifrs.replace(['9,999,999,999', '9,999,999,999.0'], ['-', '-'])
ifrs.rename(columns={'IFRS(연결)': ''}, inplace=True)
ifrs = ifrs.to_html(justify="right", index=False, classes="table")
ifrs = ifrs.replace('border="1"', 'border="0"')
pd.options.display.float_format = '{:,.0f}'.format
ifrs = ifrs.replace('<td>', '<td align="right">')
ifrs = ifrs.replace('<th>', '<th style="text-align: right;">')
ifrs = ifrs.replace('halign="left"', 'style="text-align: center;"')
ifrs = ifrs.replace('class ="dataframe table"', 'class ="dataframe table" style = "table-layout:fixed;word-break:break-all;"')
return (ifrs)
```
| github_jupyter |
```
import pandas as pd
import numpy as np
df = pd.read_parquet("../data/train.parquet")
df["length"] = df["session_mask"].map(lambda x: len(x))
import multiprocessing
df = [elem for elem in df.groupby('id')]
from tqdm import tqdm
cores = multiprocessing.cpu_count()
def concatenate(vectors):
elements = [elem for elem in vectors]
return np.concatenate(elements, axis=None)
def append_dataframe(df):
id = df[0]
df = df[1]
df = df.sort_values("timestamp")
history = concatenate(df["history"].values)
timestamp = concatenate(df["timestamp"].values)
session = concatenate(df["session"].values)
session_mask = concatenate(df["session_mask"].values)
user_mask = concatenate(df["user_mask"].values)
return pd.DataFrame({
"id": [id],
"history": [history],
"timestamp": [timestamp],
"session": [session],
"session_mask": [session_mask],
"user_mask": [user_mask],
"length": np.sum(df["length"].values)
})
with multiprocessing.Pool(cores) as p:
df = list(tqdm(p.imap(append_dataframe, df), total=len(df)))
df = pd.concat(df)
df
df.to_parquet("../data/masked.parquet")
import pandas as pd
import numpy as np
df = pd.read_parquet("../data/brunch/session.parquet")
import json
from tqdm import tqdm
with open("../data/dictionary.json") as fp:
dictionary = json.load(fp)
def make_label(x):
session = x["history"]
session = [dictionary[elem] for elem in session if elem in dictionary]
x["session"] = session
return x
tqdm.pandas()
df = df.progress_apply(make_label, axis=1)
with open("../data/brunch/predict/dev.users") as fp:
dev = [elem[0:-1] for elem in fp]
with open("../data/brunch/predict/test.users") as fp:
test = [elem[0:-1] for elem in fp]
df_dev = df[df.id.isin(dev)]
df_dev_grouped = df_dev.groupby("id")
from tqdm import tqdm
printed = False
def get_length(x):
id = x[0]
frame = x[1]
global printed
session = frame.session
lengths = [len(elem) for elem in session]
return pd.DataFrame({
"id": [id],
"length": [np.sum(lengths)]
})
df_dev_grouped = [elem for elem in df_dev_grouped]
sampled = df_dev_grouped[0:100]
df_list = []
for elem in tqdm(sampled):
df_list.append(get_length(elem))
df_dev = pd.concat(df_list)
df_dev.sort_values("length")
df[df.id == "#009bca89575df8ed68a302c1ceaf7da4"]
df
df = [row for index, row in df.iterrows()]
df[0]
def user_parallel_process(frame):
session = frame.session
if len(session) < 2:
return -1
frame["session_input"] = session[0:-1]
frame["session_output"] = session[1:]
session = session[0:-1]
session_length = len(session)
# generating session mask
session_mask = [1.0] * (session_length - 1)
session_mask = [0.0] + session_mask
# generating user mask
user_mask = [0.0] * (session_length - 1)
user_mask = user_mask + [1.0]
frame["session_mask"] = session_mask
frame["user_mask"] = user_mask
return frame
cores = multiprocessing.cpu_count()
with multiprocessing.Pool(cores) as p:
df = list(tqdm(p.imap(user_parallel_process, df), total=len(df)))
import json
with open("../data/dictionary.json") as fp:
dictionary = json.load(fp)
keys = []
values = []
for key, value in dictionary.items():
keys.append(key)
values.append(value)
import pandas as pd
df = pd.DataFrame({
"id" : keys,
"pos" : values
})
df.to_parquet("../data/brunch/dataframe_dictionary.parquet")
import pyarrow.parquet as pq
import json
import pandas as pd
with open("../data/dictionary.json") as fp:
dictionary = json.load(fp)
dataset = pq.ParquetDataset("../data/brunch/train")
table = dataset.read()
df = table.to_pandas()
from tqdm import tqdm
tqdm.pandas()
import numpy as np
def numpy_fill(arr):
'''Solution provided by Divakar.'''
mask = np.isnan(arr)
idx = np.where(~mask,np.arange(mask.shape[1]),0)
np.maximum.accumulate(idx,axis=1, out=idx)
out = arr[np.arange(idx.shape[0])[:,None], idx]
return out
def forward_fill(record):
pos = record["pos"]
session_input = record["session_input"]
session_output = record["session_output"]
if len(pos) == 0:
record["trainable"] = False
return record
if len(session_input) == 0 and len(session_output) == 0:
session_input = [float(pos[0])]
session_output = [float(pos[0])]
input_nans = np.isnan(session_input)
output_nans = np.isnan(session_output)
if all(input_nans):
record["trainable"] = False
return record
if np.isnan(session_input[0]):
session_input[0] = float(len(dictionary))
session_input = numpy_fill(np.array([session_input]))[0]
record["session_input"] = session_input
if all(output_nans):
record["trainable"] = False
return record
if np.isnan(session_output[0]):
session_output[0] = session_input[1]
session_output = numpy_fill(np.array([session_output]))[0]
record["session_output"] = session_output
record["trainable"] = True
return record
df = df.progress_apply(forward_fill, axis=1)
df.to_parquet("../data/brunch/train.parquet")
df[df.id == "#00104b6ef7bea05a3264ea0ab197fba9"]
sample_df.to_parquet("../data/brunch/sample_train.parquet")
import pandas as pd
import numpy as np
import tensorflow as tf
import json
from tqdm import tqdm
with open("../data/dictionary.json") as fp:
dictionary = json.load(fp)
df = pd.read_parquet("../data/brunch/train.parquet")
df[df.id == "#00104b6ef7bea05a3264ea0ab197fba9"]
df_trainable = df[df.trainable == True]
df_trainable = df_trainable.groupby("id")
input_list = []
label_list = []
mask_list = []
idx = 0
max_length = 30
dictionary_length = len(dictionary)
for idx, (key, frame) in tqdm(enumerate(df_trainable), total=len(df_trainable)):
frame = frame.sort_values("session")
session_input = np.concatenate(frame.session_input.values, axis=None)
session_output = np.concatenate(frame.session_output.values, axis=None)
session_mask = np.concatenate(frame.session_mask.values, axis=None)
user_mask = np.concatenate(frame.user_mask.values, axis=None)
message = "At least one of the dimension doesn't match in the input."
assert len(session_input) == len(session_output), message
assert len(session_output) == len(session_mask), message
assert len(session_mask) == len(user_mask), message
if len(session_input) > 30:
continue
inputs = [session_input, session_mask, user_mask]
inputs = tf.keras.preprocessing.sequence.pad_sequences(inputs,
maxlen=max_length,
padding="post")
label = tf.keras.preprocessing.sequence.pad_sequences([session_output],
maxlen=max_length,
value=np.float64(dictionary_length),
padding="post")
mask = [1.0] * len(session_input)
mask = tf.keras.preprocessing.sequence.pad_sequences([mask],
maxlen=max_length,
value = 0.0,
padding="post")
input_list.append(inputs)
label_list.append(label)
mask_list.append(mask)
if key == "#00104b6ef7bea05a3264ea0ab197fba9":
print(label)
inputs = np.array(input_list)
label = np.array(label_list)
mask = np.array(mask_list)
np.save("../data/brunch/train", inputs)
np.save("../data/brunch/label", label)
np.save("../data/brunch/mask", mask)
import pyarrow.parquet as pq
import json
import pandas as pd
with open("../data/dictionary.json") as fp:
dictionary = json.load(fp)
dataset = pq.ParquetDataset("../data/brunch/train")
table = dataset.read()
df = table.to_pandas()
df = df[df["session_input"].map(lambda x: len(x)) >= 3]
df = df.groupby('id').filter(lambda x: x['session'].count() >= 5)
import numpy as np
def filter_nan(x):
mask = np.isnan(x)
return all(mask)
df = df[df["session_input"].map(filter_nan) == False]
df = df[df["session_output"].map(filter_nan) == False]
import numpy as np
def forward_fill(arr):
'''Solution provided by Divakar.'''
mask = np.isnan(arr)
idx = np.where(~mask,np.arange(mask.shape[1]),0)
np.maximum.accumulate(idx, axis=1, out=idx)
out = arr[np.arange(idx.shape[0])[:,None], idx]
return out
def bidirectional_fill(x):
x = forward_fill(x)
x = np.flip(x, axis=1)
x = forward_fill(x)
x = np.flip(x, axis=1)
return x
def fill_nan(x):
x = x.sort_values("session")
session_input = [bidirectional_fill(np.array([elem])) for elem in x["session_input"].values]
session_output = [bidirectional_fill(np.array([elem])) for elem in x["session_output"].values]
session_mask = [elem for elem in x["session_mask"].values]
user_mask = [elem for elem in x["user_mask"].values]
time_step = x["timestamp"].values[-1]
x["session_input"] = [np.hstack(session_input)[0]] * len(x)
x["session_output"] = [np.hstack(session_output)[0]] * len(x)
x["session_mask"] = [np.hstack(session_mask)] * len(x)
x["user_mask"] = [np.hstack(user_mask)] * len(x)
x["timestamp"] = [time_step[-1]] * len(x)
return x.iloc[0]
def func(x):
return x
from tqdm import tqdm
tqdm.pandas()
df = df.groupby("id").progress_apply(fill_nan)
df.to_csv("../data/brunch/train.csv")
df
df.dtypes
df["length"] = df["session_input"].map(lambda x: len(x))
df
df["length"].quantile(0.9)
ranged_df = df[df['timestamp'] >= '2019-02-01']
len(ranged_df)
ranged_df
ranged_df["length"].quantile(0.05)
ranged_df = ranged_df[ranged_df["length"] <= 128]
len(ranged_df)
ranged_df["length"].max()
evaluation_ratio = 0.1
eval_df = ranged_df.iloc[:int(len(ranged_df) * evaluation_ratio)]
train_df = ranged_df.iloc[int(len(ranged_df) * evaluation_ratio):]
len(eval_df)
len(train_df)
train_df.to_csv("../data/brunch/train.csv")
eval_df.to_csv("../data/brunch/eval.csv")
row = train_df.iloc[0:100]
row = row.sort_values("length")
row.iloc[0]["length"]
train_df.to_parquet("../data/brunch/train.parquet")
eval_df.to_parquet("../data/brunch/eval.parquet")
```
| github_jupyter |
```
from IPython.display import Image
import itertools
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import autograd.numpy as np
from autograd.numpy import trace
from autograd.numpy.linalg import det
from autograd.numpy.linalg import inv
from autograd.scipy.stats import norm
from autograd.scipy.special import gamma as gammaFn
from autograd.scipy.special import polygamma
from autograd import grad
%matplotlib inline
```
Utility functions...
```
def besselFn_helper(x, v=5, M=10):
s = 0.
for m in xrange(M):
s += (1./(gammaFn(m+1)*gammaFn(m+v+1))) * (x/2.)**(2*m+v)
return s
def besselFn(v, x):
return np.pi/2. * (besselFn_helper(x,-v) - besselFn_helper(x,v))/np.sin(np.pi*v)
```
# Stein Variational Gradient Descent
### by Qiang Liu, Dilin Wang (https://arxiv.org/abs/1608.04471)
Particles explore the posterior according to the following iterative algorithm
$$ \theta_{i}^{l+1} \leftarrow \theta_{i}^{l} + \epsilon \boldsymbol{\hat \phi}(\theta_{i}^{l}) \text{ where } \boldsymbol{\hat \phi}(\theta_{i}^{l}) = \frac{1}{n} \sum_{j=1}^{n} k(\theta_{j}^{l}, \theta) \nabla_{\theta_{j}^{l}} \log p(\theta_{j}^{l}) + \nabla_{\theta_{j}^{l}} k(\theta_{j}^{l}, \theta)$$
where $k$ is a valid kernel and $\epsilon$ is a step-size. The operator $\boldsymbol{\hat \phi}(\theta_{i}^{l})$ is implemented below:
```
def steinOp(x, idx, dLogModel, params, kernel, kernelParams=None):
returnVal = 0.
n = len(x)
for j in xrange(n):
returnVal += kernel['f'](x[j], x[idx]) * dLogModel(x[j],params) + kernel['df'](x[j], x[idx])
return 1./n * returnVal
```
### Kernel Functions
The choice of kernel is straightforward for $\mathbb{R}$; the RBF and Matern work well. When the particles are restriced to some bounded domain, the choice becomes less clear. There are several options:
1) Transform to $\mathbb{R}$ and perform regular SVGD.
2) Contrive a kernel $k'(x_{1},x_{2}) = f(x_{1})k(x_{1},x_{2})f(x_{2})$ where $f$ is some function that is zero on the boundary and $k$ is regular pd kernel with no boundary considerations.
3) Consider the Sobolev space with appropriate boundaries and use the corresponding kernel.
4) Use a Fisher or related kernel
5) Use a heat kernel on the appropriate manifold.
We'll test the options above for some common distributions.
### Kernels for $\mathbb{R}^{d}$
```
# Radial Basis Function (Heat Kernel)
def rbf(x1, x2, params={'lengthScale': 1}):
return np.exp((-.5/params['lengthScale']) * np.sum((x1-x2)**2))
# Matern
def matern(x1, x2, params={'v': 1 ,'l': 6.}):
# np.abs seems to be problematic w/ autograd, hacking
if x1 > x2: d = x1 - x2
else: d = x2 - x1
temp = ((np.sqrt(2*params['v'])/params['l']) * np.sum(d))
return (2**(1-params['v'])/gammaFn(params['v'])) * temp**params['v'] * besselFn(params['v'], temp)
```
### Kernels for $\mathbb{R}^{d}_{>0}$
```
# Diffusion Kernel for Gamma r.v.'s via Parametrix Expansion
# Dropped \Psi terms following (Lafferty & Lebanon, 2005)
def gamma_diffusion(x1, x2, params={'t': .01}):
try: n = len(x1)
except: n = 1
squ_geo = np.sum((polygamma(1,x1)-polygamma(1,x2))**2)
return (4*np.pi*params['t'])**(-n/2.) * np.exp((-.25/params['t']) * squ_geo)
```
### Kernels for $\mathbb{R} \in [0, 1]$
```
def bernoulli_prob_prod(x1, x2, params={'p':.85}):
return (x1*x2)**params['p'] + (1-x1)**params['p'] * (1-x2)**params['p']
# First order Sovolex on [0,1]
def unit_sobolev(x1, x2):
return 2*(np.minimum(x1,x2) - x1*x2)
def bernoulli_kld(p1, p2):
return p1 * np.log(p1/p2) + (1-p1) * np.log((1-p1)/(1-p2))
def beta_score(x, params):
v1 = np.log(x) - polygamma(0,params['alpha']) + polygamma(0,params['alpha']+params['beta'])
v2 = np.log(1-x) - polygamma(0,params['beta']) + polygamma(0,params['alpha']+params['beta'])
return np.array([[v1, v2]])
def beta_fisher(x1, x2, params={'alpha':1.,'beta':1.}):
score1 = beta_score(x1, params)
score2 = beta_score(x2, params)
temp = polygamma(1,params['alpha']+params['beta'])
fisher_info_mat = np.array([[polygamma(1,params['alpha']) - temp, -temp],[-temp, polygamma(1,params['beta']) - temp]])
return np.dot(np.dot(score1, inv(fisher_info_mat)), score2.T)[0,0]
```
## Models
### Gaussian Mixture Model
```
# Model
def gaussPdf(x, params):
return (1./np.sqrt(2*np.pi*params['sigma']**2)) * np.exp((-.5/params['sigma']**2) * np.sum((x-params['mu'])**2))
def logGaussMixPDF(x, params):
return params['pi'][0] * gaussPdf(x, {'mu':params['mu'][0], 'sigma':params['sigma'][0]}) \
+ params['pi'][1] * gaussPdf(x, {'mu':params['mu'][1], 'sigma':params['sigma'][1]})
logModel = logGaussMixPDF
dLogModel = grad(logModel)
params = {
'mu': [-4,3],
'sigma': [1, 3],
'pi': [.3, .7]
}
# kernel
kernel = {'f': rbf}
kernel['df'] = grad(kernel['f'])
# initial distribution
q0 = np.random.normal
### generate samples
n = 15
x = []
for sampleIdx in xrange(n):
x.append(q0())
maxEpochs = 100
lr = 2.
for epochIdx in xrange(maxEpochs):
for idx in xrange(n):
x[idx] += lr * steinOp(x, idx, dLogModel, params, kernel)
x.sort()
probs = [np.exp(logModel(z, params)) for z in x]
x_true = np.linspace(-10, 10, 1000)
probs_true = [np.exp(logModel(z, params)) for z in x_true]
plt.plot(x_true, probs_true, 'b-', linewidth=5, label="True")
plt.plot(x, probs, 'rx--', markersize=10, mew=5, linewidth=5, label="Approximation")
plt.xlim([-10,10])
plt.legend()
```
### Gamma Mixture Model
```
# Model
def gammaPdf(x, params):
return x**(params['shape']-1)/(gammaFn(params['shape'])*params['scale']**params['shape']) * np.exp(-x/params['scale'])
def logGammaMixPDF(x, params):
return params['pi'][0] * gammaPdf(x, {'shape':params['shape'][0], 'scale':params['scale'][0]}) \
+ params['pi'][1] * gammaPdf(x, {'shape':params['shape'][1], 'scale':params['scale'][1]})
logModel = logGammaMixPDF
dLogModel = grad(logModel)
params = {
'shape': [1, 5],
'scale': [1, 2],
'pi': [.3, .7]
}
# kernel
kernel = {'f': gamma_diffusion}
kernel['df'] = grad(kernel['f'])
# initial distribution
q0 = np.random.gamma
### generate samples
n = 15
x = []
for sampleIdx in xrange(n):
x.append(q0(shape=7))
maxEpochs = 100
lr = 2
for epochIdx in xrange(maxEpochs):
for idx in xrange(n):
x[idx] += lr * steinOp(x, idx, dLogModel, params, kernel)
# check boundary condition, reflect if <= 0
if x[idx] <=0: x[idx] = np.abs(x[idx])
x.sort()
probs = [np.exp(logModel(z, params)) for z in x]
x_true = np.linspace(0, 20, 1000)
probs_true = [np.exp(logModel(z, params)) for z in x_true]
plt.plot(x_true, probs_true, 'b-', linewidth=5, label="True")
plt.plot(x, probs, 'rx--', markersize=10, mew=5, linewidth=5, label="Approximation")
plt.xlim([0,20])
plt.legend()
```
### Reference Prior
SVGD can also be used to compute reference priors. See [(Nalisnick & Smyth, 2017)](https://arxiv.org/abs/1704.01168).
```
# Model
def bernoulli_Jeffreys(x):
return 1./(np.pi * np.sqrt(x*(1-x)))
def neg_entropy(x, params):
return -(-x*np.log(x) + -(1-x)*np.log(1-x))
logModel = neg_entropy
dLogModel = grad(logModel)
params = {
}
# kernel
kernel = {'f': bernoulli_prob_prod}
kernel['df'] = grad(kernel['f'])
# initial distribution
q0 = np.random.uniform
### generate samples
n = 10
x = []
for sampleIdx in xrange(n):
x.append(q0())
maxEpochs = 100
lr = .01
for epochIdx in xrange(maxEpochs):
for idx in xrange(n):
x[idx] += lr * steinOp(x, idx, dLogModel, params, kernel)
# check boundary condition
if x[idx]<=0: x[idx] = np.abs(x[idx])
if x[idx]>=1: x[idx] = 1-(x[idx]-1)
x.sort()
probs = [bernoulli_Jeffreys(z) for z in x]
x_true = np.linspace(0, 1, 1000)
probs_true = [bernoulli_Jeffreys(z) for z in x_true]
plt.plot(x_true, probs_true, 'b-', linewidth=5, label="True")
plt.plot(x, probs, 'rx--', markersize=10, mew=5, linewidth=5, label="Approximation")
plt.xlim([0,1])
plt.legend()
```
## Appendix
### Parametrix Expansion
For most geometries, there is no closed-form solution for the heat kernel. However, short-time behavior follows the *parametrix expansion* $$ P^{(m)}_{t}(x,y) = (4 \pi t)^{-n/2} exp\{ \frac{- d^{2}(x,y)}{4t} \} (\Psi_{0}(x,y) + \Psi_{1}(x,y) t + \ldots + \Psi_{m}(x,y) t^{m} )$$ where the $\Psi$'s are defined recursively as $$\Psi_{0} = (\frac{\sqrt{det g}}{d^{n-1}})^{-1/2} \text{ , } \Psi_{k} = r^{-k}\Psi_{0} \int_{0}^{r} \Psi_{0}^{-1}(\delta \phi_{k-1}) s^{k-1} ds $$ where $d^{2}$ is square of the geodesic and $g$ is the corresponding Riemannian metric. We use $m=0$ for simplicity.
#### Gamma Geodesic
The geodesic on the Gamma's information manifold is not available in closed form. However, (Arwini & Dodson, 2008) give the upper-bound $$d(\kappa_{1}, \theta_{1}, \kappa_{2}, \theta_{2}) \le \mid \psi_{1}(\kappa_{1}) - \psi_{1}(\kappa_{2}) \mid + \mid \kappa_{1} \log \frac{\theta_{1}}{\theta_{2}} \mid $$ where $\psi_{k}$ is the polygamma function of order $k$. We'll assume a shared scale and thus drop the second term.
| github_jupyter |
# SIT742: Modern Data Science
**(Week 10: Data Analytics (III))**
---
- Materials in this module include resources collected from various open-source online repositories.
- You are free to use, change and distribute this package.
- If you found any issue/bug for this document, please submit an issue at [tulip-lab/sit742](https://github.com/tulip-lab/sit742/issues)
Prepared by **SIT742 Teaching Team**
---
## Session 10A - Spark MLlib (3): Supervised Learning
Spark has many libraries, namely under MLlib (Machine Learning Library)! Spark allows for quick and easy scalability of practical machine learning!
In this lab exercise, you will learn about how to build a Linear Regression Model, a SVM model, and a Logistic Regression Model, also you will learn how to create Classification and Regression DecisionTree and RandomForest Models, as well as how to tune the parameters for each to create more optimal trees and ensembles of trees.
## Content
### Part 1 Linear Regression
### Part 2 Support Vector Machine
### Part 3 Logistic Regression
### Part 4 Decision Tree (Regression)
4.1 maxDepth Parameter
4.2 maxBins Parameter
4.3 minInstancesPerNode Parameter
4.4 minInfoGain Parameter
### Part 5 Decision Tree (Classification)
### Part 6 Random Forest (Classification)
6.1 numTrees Parameter
6.2 featureSubsetStrategy Parameter
### Part 7 Random Forest (Regression)
---
# 1.Linear Regression
Linear regression uses a "line of best fit", based on previous data in order to predict future values. There are plenty of model evaluation metrics that can be applied to linear regression.
In this lab, we will look at **Mean Squared Error (MSE)**
Import the following libraries:
* LabeledPoint
* LinearRegressionWithSGD
* LinearRegressionModel from pyspark.mllib.regression
```
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
!tar xf spark-2.4.0-bin-hadoop2.7.tgz
!pip install -q findspark
!pip install pyspark
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-2.4.0-bin-hadoop2.7"
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql import SQLContext
conf = SparkConf().setAppName('project1').setMaster('local')
sc = SparkContext.getOrCreate(conf)
from pyspark.mllib.regression import LabeledPoint, LinearRegressionWithSGD, LinearRegressionModel
```
Now we need to create a <b>RDD of data</b> called <b>rdd_data</b>. That will be done by using the SparkContext (sc) to read in the <b>brain_body_data.csv</b> dataset. Take a look at the dataset so you have a feel for how it's structured.
```
!pip install wget
import wget
link_to_data = 'https://github.com/tuliplab/mds/raw/master/Jupyter/data/brain_body_data.csv'
DataSet = wget.download(link_to_data)
rdd_data = sc.textFile("brain_body_data.csv")
```
Now, run a <b>map function</b> on <b>rdd_data</b>, where the input is a <b>lambda function</b> that is as follows: <i>lambda line: line.split(",")</i>. This is so we can split the dataset by commas, since it's a comma-separated value file (CSV). Store this into a variable called <b>split_data</b>
```
split_data = rdd_data.map(lambda line: line.split(","))
```
Next, run the following function that will convert each line in our RDD into a LabeledPoint.
```
def labeledParse(line):
return LabeledPoint(line[0], [line[1]])
```
Now, run a <b>map function</b> on <b>split_data</b>, passing in <b>labeledParse</b> as input. Store the output into a variable called <b>reg_data</b>.
```
reg_data = split_data.map(labeledParse)
```
Now, we will create a variable called <b>linReg_model</b>, which will contain the linear regression model. The model will be made by calling the <b>LinearRegressionWithSGD</b> class and using the <b>.train</b> function with it. The .train function will take in 3 inputs:
<ul>
<li>1st: The training data (reg_data in this case)</li>
<li>2nd: The number of iterations, or how many times the regression will run (use iterations=150)</li>
<li>3rd: step used in SGD (use step=0.00001 in this case) </li>
</ul>
```
linReg_model = LinearRegressionWithSGD.train(reg_data, iterations=150, step=0.00001)
```
Next, we will create a variable called <b>actualAndPred</b>, which will contain the actual response, along with the predicted response from the model. This will be done by using the <b>map</b> function on <b>reg_data</b>, and passing in:<br> <b>lambda p: (p.label, linReg_model.predict(p.features))</b> as the input.
```
actualAndPreds = reg_data.map(lambda p: (p.label, linReg_model.predict(p.features)))
```
We will calculate the Mean Squared Error (MSE) value for the prediction. Run the following code to calculate the MSE. <br> <br>
The map function takes the actual value and subtracts it by the predicted value, then
squares the result. This is done for each value. <br> <br>
Next, the reduce function sums all of the mapped values together. <br> <br>
Afterwards, the result is divided by the number of elements that are present in actualAndPreds.
```
MSE = actualAndPreds.map(lambda vp : (vp[1] - vp[0])**2).reduce(lambda x, y: x + y) / actualAndPreds.count()
print("Mean Squared Error = " + str(MSE))
```
---
# 2.Support Vector Machine (SVM)
Support Vector Machines can be used for both **classification and regression** analysis. In our case, we will be using it for classification. Linear SVM in Spark only supports **binary classification**
Import the following libraries: <br>
<ul>
<li>SVMWithSGD, SVMModel from pyspark.mllib.classification</li>
<li>LabeledPoint from pyspark.mllib.regression</li>
</ul>
```
from pyspark.mllib.classification import SVMWithSGD, SVMModel
from pyspark.mllib.regression import LabeledPoint
```
Now we need to create a <b>RDD of data</b> called <b>svm_data</b>. That will be done by using the SparkContext (sc) to read in the <b>sample_svm_data.txt</b> dataset, which is a sample dataset that is built-in to Spark. It contains 322 rows of data.
```
import wget
link_to_data = 'https://github.com/tuliplab/mds/raw/master/Jupyter/data/sample_svm_data.txt'
DataSet = wget.download(link_to_data)
svm_data = sc.textFile("sample_svm_data.txt")
```
For this dataset, it isn't in a format that we need, so we will need the following function to modify it. This function will also create LabeledPoints out of the data, which is necessary to train the SVM Model. Depending on your dataset, the parsing required will differ.
```
def labeledParse(line):
values = [float(x) for x in line.split(' ')]
return LabeledPoint(values[0], values[1:])
```
This will be applied to <b>svm_data</b> by using the <b>.map</b> function, and passing in the <b>labeledParse function</b>. This will apply the labeledParse function to the entire dataset. Call the output <b>svm_parsed</b>
```
svm_parsed = svm_data.map(labeledParse)
```
Now create a SVM model using the <b>SVMWithSGD.train</b> function called <b>svm_model</b>, which requires two inputs:
<ul>
<li>1st: The dataset containing the LabeledPoints (<b>svm_parsed</b> in this case)</li>
<li>2nd: The number of iterations the model will run (<b>120</b> in this case)</li>
</ul>
```
svm_model = SVMWithSGD.train(svm_parsed, iterations=120)
```
Next, we will create a variable called <b>svm_Labels_Predicts</b>, which will map a tuple containing the label and the prediction. <br>
This will be done by using the <b>.map</b> function once again, but on the parsed data, <b>svm_parsed</b>. <br>
The input into svm_parsed.map() will be a lambda function: <b>lambda x: (x.label, svm_model.predict(x.features))</b>
```
svm_Labels_Predicts = svm_parsed.map(lambda x: (x.label, svm_model.predict(x.features)))
```
Now, we will take a look at the training error, called <b>trainingError</b>, which will tell us the accuracy of how well our model did. It will do this by counting the number of incorrect predictions it made, and divide it by the total number of predictions.<br>
We will run a <b>.filter</b> on the model we just created, <b>svm_Labels_Predicts</b>, <b>count</b> the output of that with <b>.count()</b>, then <b>divide</b> by the <b>number of elements in svm_parsed</b>. <br> <br>
This filter will take a lambda function as input: <b>lambda (v, p): v != p</b>, which just means that the function will look at the predicted value and the labeled value, then see if the prediction matched the label.<br><br>
Make sure to add a <b>.count()</b> to the <b>filter</b>, then <b>divide</b> the whole thing by <b>float(svm_parsed.count())</b>
```
trainingError = svm_Labels_Predicts.filter(lambda xy: xy[0] != xy[1]).count() / float(svm_parsed.count())
```
Finally, print trainingError, to see the percentage that the model predicted incorrectly.
```
print(trainingError)
```
---
# 3.Logistic Regression
Logistic Regression is a classifier, similar to SVM. Logistic Regression can be used for Binary Classification, which is pretty clear when looking at the diagram above. In the diagram, where are two distinct sections that data resides, which represents a binary classification. <br> <br> In this lab, we will use the same dataset as the one used for SVM, so we can compare the accuracy of both models.
Import the following libraries: <br>
<ul>
<li>LogisticRegressionWithLBFGS, LogisticRegressionModel from pyspark.mllib.classification</li>
<li>LabeledPoint from pyspark.mllib.regression</li>
</ul>
```
from pyspark.mllib.classification import LogisticRegressionWithLBFGS, LogisticRegressionModel
from pyspark.mllib.regression import LabeledPoint
```
Since we are still using the same dataset as in SVM, we will be using the same <b>svm_parsed</b> variable.
Create a variable called <b>logReg_model</b>, where we <b>train</b> a <b>LogisticRegressionWithLBFGS</b> model by passing in <b>svm_parsed</b>.
```
# Build the model
logReg_model = LogisticRegressionWithLBFGS.train(svm_parsed)
```
Next, create a variable called <b>logReg_Labels_Predicts</b> by <b>mapping</b> the <b>svm_parsed</b> data and passing in the <b>label</b>, along with the <b>logReg_model prediction</b>. This is similar to what we did in the SVM section of the lab.
```
logReg_Labels_Predicts = svm_parsed.map(lambda p: (p.label, logReg_model.predict(p.features)))
```
Finally, we will find the training error, or percentage that the model predicted incorrect. Thids will by done by applying the <b>filter</b> function on <b>logReg_Labels_Predicts</b>. We will pass in a lambda function that will filter for all values that do not equal <b>(lambda (v, p): v != p)</b>, then apply a <b>count()</b> on the filter. This will get the number of incorrect predictions. Now, we need to divide by the total number of predictions, or <b>float(svm_parsed.count())</b>. Store this as <b>trainingError2</b>. Refer to the SVM section if you need a hint.
```
trainingError2 = logReg_Labels_Predicts.filter(lambda vp: vp[0] != vp[1]).count() / float(svm_parsed.count())
```
Now print trainingError2 and trianingError (from the SVM section)
```
print(trainingError2)
print(trainingError)
```
It seems as though the training error for Logistic Regression is just slightly better than SVM for this case!
---
# 4.Decision Tree (Regression)
Import the following libraries:
<ul>
<li>DecisionTree, DecisionTreeModel from pyspark.mllib.tree</li>
<li>MLUtils from pyspark.mllib.util</li>
<li>time</li>
</ul>
```
from pyspark.mllib.tree import DecisionTree, DecisionTreeModel
from pyspark.mllib.util import MLUtils
import time
```
Next, we will load in the <b>poker.txt</b> LibSVM file, which is a dataset based on poker hands. Use <b>MLUtils.loadLibSVMFile</b> and pass in the spark context (<b>sc</b>) and the path to the file <b>'resources/poker.txt'</b>. Store this into a variable called <b>regDT_data</b>
```
import wget
link_to_data = 'https://github.com/tuliplab/mds/raw/master/Jupyter/data/poker.txt'
DataSet = wget.download(link_to_data)
regDT_data = MLUtils.loadLibSVMFile(sc, 'poker.txt')
```
Next, we need to split the data into a training dataset (called <b>regDT_train</b>) and testing dataset (called <b>regDT_test</b>). This will be done by running the <b>.randomSplit</b> function on <b>regDT_data</b>. The input into .randomSplit will be <b>[0.7, 0.3]</b>. <br> <br>
This will give us a training dataset containing 70% of the data, and a testing dataset containing 30% of the data.
```
(regDT_train, regDT_test) = regDT_data.randomSplit([0.7, 0.3])
```
Next, we need to create the Regression Decision Tree called <b>regDT_model</b>. To instantiate the regressor, use <b>DecisionTree.trainRegressor</b>. We will pass in the following parameters:
<ul>
<li>1st: The input data. In our case, we will use <b>regDT_train</b></li>
<li>2nd: The categorical features info. For our dataset, have <b>categoricalFeaturesInfo</b> equal <b>{}</b></li>
<li>3rd: The type of impurity. Since we're dealing with <b>Regression</b>, we will be have <b>impurity</b> set to <b>'variance'</b></li>
<li>4th: The maximum depth of the tree. For now, set <b>maxDepth</b> to <b>5</b>, which is the default value</li>
<li>5th: The maximum number of bins. For now, set <b>maxBins</b> to <b>32</b>, which is the default value</li>
<li>6th: The minimum instances required per node. For now, set <b>minInstancesPerNode</b> to <b>1</b>, which is the default value</li>
<li>7th: The minimum required information gain per node. For now, set <b>minInfoGain</b> to <b>0.0</b>, which is the default value</li>
</ul> <br> <br>
We will also be timing how long it takes to create the model, so run <b>start = time.time()</b> before creating the model and <b>print(time.time()-start)</b> after the model has been created. <br>
<b>Note</b>: The timings differ on run and by computer, therefore some statements throughout the lab may not directly align with the results you get, which is okay! There are many factors that can affect the time output.
```
start = time.time()
regDT_model = DecisionTree.trainRegressor(regDT_train, categoricalFeaturesInfo={},
impurity='variance', maxDepth=5, maxBins=32,
minInstancesPerNode=1, minInfoGain=0.0)
print (time.time()-start)
```
Next, we want to get the models prediction on the test data, which we will call <b>regDT_pred</b>. We will run <b>.predict</b> on regDT_model, passing in the testing data, <b>regDT_test</b> that is mapped using <b>.map</b> which maps the features by passing in a lambda function (<b>lambda x: x.features</b>).
```
regDT_pred = regDT_model.predict(regDT_test.map(lambda x: x.features))
```
Now create a variable called <b>regDT_label_pred</b> which uses a <b>.map</b> on <b>regDT_test</b>. Pass <b>lambda l: l.label</b> into the mapping function. Outside of the mapping function, add a <b>.zip(regDT_pred)</b>. This will merge the label with the prediction</b>
```
regDT_label_pred = regDT_test.map(lambda l: l.label).zip(regDT_pred)
```
Now we will calculate the Mean Squared Error for this prediction, which we will call <b>regDT_MSE</b>. This will equate to <b>regDT_label_pred.map(lambda (v, p): (v - p)**2).sum() / float(regDT_test.count())</b>, which will take the difference of the actual value and the predicted response, square it, and sum that with the rest of the values. Afterwards, it is divided by the total number of values in the testing data.
```
regDT_MSE = regDT_label_pred.map(lambda vp: (vp[0] - vp[1])**2).sum() / float(regDT_test.count())
```
Next, print out the MSE prediction value (<b>str(regDT_MSE)</b>), as well as the learned regression tree model (<b>regDT_model.toDebugString()</b>), so you have an idea of what the tree looks like.
```
print('Test Mean Squared Error = ' + str(regDT_MSE))
print('Learned Regression Tree Model: ' + regDT_model.toDebugString())
```
Now that we've created the basic Regression Decision Tree, let's start tuning some parameters! To speed up the process and reduce the amount of code that appears in this notebook, I've made a function that encorporates all of the code above. This way, we can tune the parameters in a single line of code. <br> <br>
Read over the code, and it should be apparent what each of the inputs should be. But just to reiterate:
<ul>
<li>1st: maxDepthValue is the value for maxDepth (Type:Int, Range: 0 to 30)</li>
<li>2nd: maxBinsValue is the value for maxBins (Type: Int, Range: >= 2)</li>
<li>3rd: minInstancesValue is the value for minInstancesPerNode (Type: Int, Range: >=1)</li>
<li>4th: minInfoGainValue is the value for minInfoGain (Type: Float)</li>
<ul>
<li><b>NOTE</b>: The input for minInfoGain MUST contain a decimal (ex. -3.0, 0.1, etc.) or else you will get an error</li>
</ul>
</ul>
```
def regDT_tuner(maxDepthValue, maxBinsValue, minInstancesValue, minInfoGainValue):
start = time.time()
regDT_model = DecisionTree.trainRegressor(regDT_train, categoricalFeaturesInfo={},
impurity='variance', maxDepth=maxDepthValue, maxBins=maxBinsValue,
minInstancesPerNode=minInstancesValue, minInfoGain=minInfoGainValue)
print (time.time()-start)
regDT_pred = regDT_model.predict(regDT_test.map(lambda x: x.features))
regDT_label_pred = regDT_test.map(lambda l: l.label).zip(regDT_pred)
regDT_MSE = regDT_label_pred.map(lambda vp: (vp[0] - vp[1])**2).sum() / float(regDT_test.count())
print('Test Mean Squared Error = ' + str(regDT_MSE))
print('Learned Regression Tree Model: ' + regDT_model.toDebugString())
```
Start off by re-creating the original tree. That requires the inputs: <b>(5, 32, 1, 0.0)</b> into <b>regDT_tuner</b>
```
regDT_tuner(5, 32, 1, 0.0)
```
Remember that when we are tuning a specific parameter, that we will keep the other parameters at their original value
## 4.1.maxDepth Parameter
Let's start by tuning the **maxDepth** parameter. Begin by setting it to a lower value, such as <b>1</b>
```
regDT_tuner(1, 32, 1, 0.0)
```
By decreasing the maxDepth parameter, you can see that the run-time slightly decreased, presenting a smaller tree as well. You may also see a slight increase in the error, which is to be expected since the tree is too small to make accurate predictions.
Now try increasing to value of <b>maxDepth</b> to a large number, such as <b>30</b>, which is the maximum value.
```
regDT_tuner(30, 32, 1, 0.0)
```
With a large value for maxDepth, you can see that the run-time increased greatly, along with the size of the tree. The MSE has increased greatly compared to the original, which is due to overfitting of the training data from having a deep tree.
## 4.2.maxBins Parameter
Now let's tune the <b>maxBins</b> variable. Start by decreasing the value to 2, to see what the lower end of this value does to the tree.
```
regDT_tuner(5, 2, 1, 0.0)
```
Comparing this to the original tree, we can see a small decrease in the training time, but not much of a difference in regards to MSE or the size of the tree.
Now let's take a look at the upper end, with a value of 15000
```
regDT_tuner(5, 15000, 1, 0.0)
```
With a very large maxBin value, we don't see too much of a change in the overall time or in the MSE. The model still has the same depth and nodes, as expected.
## 4.3.minInstancesPerNode parameter
Next we will look at tuning the **minInstancesPerNode** parameter. It starts off at the lowest value of 1, but let's see what happens if we keep increasing the value. Starting off with the value **100**
```
regDT_tuner(5, 32, 100, 0.0)
```
With minInstancesPerNode set to 100, we don't see much of a change in time and MSE, but we can see that there are less nodes in the tree. Try now with a value of <b>1000</b>
```
regDT_tuner(5, 32, 1000, 0.0)
```
With a value of 1000, we may see more of a decrease in the time, but the MSE has also increased a little bit. As well, the number of nodes in the model has decreased once again. Let's take it one step further and try with a value of <b>8000</b>
```
regDT_tuner(5, 32, 8000, 0.0)
```
With a value of 8000, we may see that the run-time to build the model is starting to decrease a lot more, with only a small increase in MSE compared to when the value was set to 1000. The main difference we see is that the tree has become a lot smaller! This is to be expected since we are tuning a stopping parameter, which determines when the model finishes building.
## 4.4.minInfoGain Parameter
For the last parameter, we will look at the minInfoGain parameter, which was initially set to 0.0. This value works well with negative values, and is very sensitive with values greater than 0.0. Try setting the value to a low number, such as -100.0
```
regDT_tuner(5, 32, 1, -100.0)
```
Overall, we don't see much of a change at all to anything. Now try changing the value to 0.0003
```
regDT_tuner(5, 32, 1, 0.0003)
```
We can see that small values greater than zero can cause drastic changes in how the model looks. Here, we see a small decrease in the training time, and small increase in the MSE value. But now the tree only contains one node in it. The affect of this parameter on the tree is similar to minInstancesPerNode, since they are both stopping parameters.
---
# 5.Decision Tree (Classification)
Now it's time for you to try it out for yourself! Build a Classification DecisionTree in a similar way that the Regression DecisionTree was built. Please note that you will be using the same dataset in this section (regDT_train, regDT_test), therefore you do not need to re-initialize that section.<br> <br>
Try to only reference the above section when you are experiencing a lot of difficulty. This section is mainly for you to apply your learning.
For some help with the variables:
<ul>
<li><b>numClasses</b>: The number of classes for this dataset is <b>10</b> (parameter doesn't require tuning)</li>
<li><b>categoricalFeaturesInfo</b>: Has a value of <b>{}</b> (parameter doesn't require tuning)</li>
<li><b>impurity</b>: There are two types of impurites you can use -- <b>'gini'</b> or <b>'entropy'</b> <i>(Default: 'gini')</i></li>
<li><b>maxDepth</b>: Values range between <b>0 and 30</b> <i>(Default: 5)</i></li>
<li><b>maxBins</b>: Value ranges between <b>2 and 2147483647</b> (largest value for 32-bits) <i>(Default: 32)</i></li>
<li><b>minInstancesPerNode</b> ranges between <b>1 and 2147483647</b> <i>(Default: 1)</i></li>
<li><b>minInfoGain</b>: Ensure it is a float (has a decimal in the value) <i>(Default: 0.0)</i></li>
</ul>
When displaying the <b>Training Error</b>, use the following formula and print statement instead of MSE: <br>
<b>classDT_error = classDT_label_pred.filter(lambda (v, p): v != p).count() / float(regDT_test.count())</b> <br>
<b>print('Test Error = ' + str(classDT_error))</b>
#### The Goal
Try to create a model that is better than the model with default values. Challenge yourself by trying to create the best model you can!
#### Note
We want a model that doesn't take too long to train and will cause overfitting. Remember that a very large model with high accuracy but long run time may not be good because the model may have overfit the data.
```
start = time.time()
classDT_model = DecisionTree.trainClassifier(regDT_train, numClasses = 10,
categoricalFeaturesInfo = {},
impurity = 'gini', maxDepth = 9,
maxBins = 25, minInstancesPerNode = 4,
minInfoGain = -3.0)
print(time.time() - start)
# Evaluate model on test instances and compute test error
classDT_pred = classDT_model.predict(regDT_test.map(lambda x: x.features))
classDT_label_pred = regDT_test.map(lambda lp: lp.label).zip(classDT_pred)
classDT_error = classDT_label_pred.filter(lambda vp: vp[0] != vp[1]).count() / float(regDT_test.count())
print('Test Error = ' + str(classDT_error))
print('Learned classification tree model:' + classDT_model.toDebugString())
# 1.16329193115
# Test Error = 0.495765559887
# Learned classification tree model:DecisionTreeModel classifier of depth 5 with 63 nodes
# Impurity: entropy
# maxDepth: 5
# maxBins: 32
# minInstancesPerNode: 1
# minInfoGain: 0.0
# 1.16743922234
# Test Error = 0.453958865439
# Learned classification tree model:DecisionTreeModel classifier of depth 9 with 577 nodes
# Impurity: gini
# maxDepth: 9
# maxBins: 25
# minInstancesPerNode: 4
# minInfoGain: -3.0
```
---
# 6.RandomForest (Classifier)
Now that we've run through the DecisionTree model, let's work with RandomForests now. The process for this will be similar with the DecisionTree section.
Import the following libraries:
<ul>
<li>RandomForest, RandomForestModel from pyspark.mllib.tree</li>
<li>MLUtils from pyspark.mllib.util</li>
<li>time</li>
</ul>
```
from pyspark.mllib.tree import RandomForest, RandomForestModel
from pyspark.mllib.util import MLUtils
import time
```
Next, we will load in the <b>pendigits.txt</b> LibSVM file, which is a dataset based on Pen-Based Recognition of Handwritten Digits. Use <b>MLUtils.loadLibSVMFile</b> and pass in the spark context (<b>sc</b>) and the path to the file <b>'resources/pendigits.txt'</b>. Store this into a variable called <b>classRF_data</b> <br> <br>
Note: You can also try out this section with the poker.txt dataset if you want to compare results from both sections!
```
import wget
link_to_data = 'https://github.com/tuliplab/mds/raw/master/Jupyter/data/pendigits.txt'
DataSet = wget.download(link_to_data)
!ls -l
classRF_data = MLUtils.loadLibSVMFile(sc, 'pendigits.txt')
```
Next, we need to split the data into a training dataset (called <b>classRF_train</b>) and testing dataset (called <b>classRF_test</b>). This will be done by running the <b>.randomSplit</b> function on <b>classRF_data</b>. The input into .randomSplit will be <b>[0.7, 0.3]</b>. <br> <br>
This will give us a training dataset containing 70% of the data, and a testing dataset containing 30% of the data.
```
(classRF_train, classRF_test) = classRF_data.randomSplit([0.7, 0.3])
```
Next, we need to create the Random Forest Classifier called <b>classRF_model</b>. To instantiate the classifier, use <b>RandomForest.trainClassifier</b>. We will pass in the following parameters:
<ul>
<li>1st: The input data. In our case, we will use <b>classRF_train</b></li>
<li>2nd: The number of classes. For this dataset, there will be 10 classes, so set <b>numClasses</b> equal to <b>10</b>
<li>3rd: The categorical features info. For our dataset, have <b>categoricalFeaturesInfo</b> equal <b>{}</b></li>
<li>4th: The number of trees. We will set <b>numTrees = 3</b>
<li>5th: The feature Subset Strategy. There are various inputs for this parameter, but for the sake of this section we will set <b>featureSubsetStrategy</b> equal to <b>"auto"</b></li>
<li>6th: The type of impurity. Since we're dealing with <b>Classification</b>, we will be have <b>impurity</b> set to <b>'gini'</b></li>
<li>7th: The maximum depth of the tree. For now, set <b>maxDepth</b> to <b>5</b>, which is the default value</li>
<li>8th: The maximum number of bins. For now, set <b>maxBins</b> to <b>32</b>, which is the default value</li>
<li>9th: The seed to generate random data. For now, set <b>seed</b> to <b>None</b></li>
</ul> <br> <br>
We will also be timing how long it takes to create the model, so run <b>start = time.time()</b> before creating the model and <b>print(time.time()-start)</b> after the model has been created. <br>
<b>Note</b>: The timings differ on run and by computer, therefore some statements throughout the lab may not directly align with the results you get, which is okay! There are many factors that can affect the time output.
```
start = time.time()
classRF_model = RandomForest.trainClassifier(classRF_train, numClasses = 10, categoricalFeaturesInfo={},
featureSubsetStrategy="auto", numTrees=3,
impurity='gini', maxDepth=4, maxBins=32, seed=None)
print (time.time()-start)
```
Next, we want to get the models prediction on the test data, which we will call <b>classRF_pred</b>. We will run <b>.predict</b> on classRF_model, passing in the testing data, <b>classRF_test</b> that is mapped using <b>.map</b> which maps the features using a lambda function (<b>lambda x: x.features</b>).
```
classRF_pred = classRF_model.predict(classRF_test.map(lambda x: x.features))
```
Now create a variable called <b>classRF_label_pred</b> which uses a <b>.map</b> on <b>classRF_test</b>. Pass <b>lambda l: l.label</b> into the mapping function. Outside of the mapping function, add a <b>.zip(classRF_pred)</b>. This will merge the label with the prediction</b>
```
classRF_label_pred = classRF_test.map(lambda l: l.label).zip(classRF_pred)
```
Now we will calculate the Test Error for this prediction, which we will call <b>classRF_error</b>. This will equate to <b>classRF_label_pred.filter(lambda (v, p): v != p).count() / float(classRF_test.count())</b>, which will count the number of incorrectly predicted values and divide it by the total number of predictions.
```
classRF_error = classRF_label_pred.filter(lambda vp: vp[0] != vp[1]).count() / float(classRF_test.count())
```
Next, print out the test error value (<b>str(classRF_error)</b>, as well as the learned regression tree model (<b>classRF_model.toDebugString()</b>), so you have an idea of what the ensemble looks like.
```
print('Test Error = ' + str(classRF_error))
print('Learned classification tree model:' + classRF_model.toDebugString())
```
Now that we've created the basic Classification Random Forest, let's start tuning some parameters! This is similar to the previous section, but since most of the tuning parameters have been covered in the Decision Tree section, there will only be two parameter to tune in this section. <br> <br>
Read over the code and understand how to build the Classification Random Forest as a whole. For the inputs, we have:
<ul>
<li>1st: numTreesValue is the value for numTrees (Type: Int, Range: > 0, Default: 3)</li>
<li>2nd: featureSubsetStrategyValue is the value for featureSubsetStrategyValue (Default: "auto")</li>
<ul>
<li>Values include: "auto", "all", "sqrt", "log2", "onethird"</li>
</ul>
</ul>
```
def classRF_tuner(numTreesValue, featureSubsetStrategyValue):
start = time.time()
classRF_model = RandomForest.trainClassifier(classRF_train, numClasses = 10, categoricalFeaturesInfo={},
featureSubsetStrategy=featureSubsetStrategyValue, numTrees=numTreesValue,
impurity='gini', maxDepth=4, maxBins=32, seed=None)
print (time.time()-start)
classRF_pred = classRF_model.predict(classRF_test.map(lambda x: x.features))
classRF_label_pred = classRF_test.map(lambda l: l.label).zip(classRF_pred)
classRF_error = classRF_label_pred.filter(lambda vp: vp[1] != vp[0]).count() / float(classRF_test.count())
print('Test Error = ' + str(classRF_error))
print('Learned classification tree model:' + classRF_model.toDebugString())
```
Start off by re-creating the original Random Forest. That requires the input: <b>(3)</b> and <b>"auto"</b> into <b>classRF_tuner</b>
```
classRF_tuner(3, "auto")
```
## 6.1.numTrees Parameter
Let's start by tuning the <b>numTrees</b> parameter. Begin by setting it to a lower value, such as <b>1</b>
```
classRF_tuner(1, "auto")
```
By setting numTrees to a value of 1, we see a slightly higher test error. Note that with numTrees equal to 1, the classifier acts as a Decision Tree, since there is only one tree in the ensemble.
Now let's try setting it to a numTrees to a larger value, such as 180.
```
classRF_tuner(180, "auto")
```
With a lot more trees in the ensemble, the training error has decreased a lot! But the training time has increased substantially as well. Remember that the training time increases roughly linearly with the number of trees.
## 6.2.featureSubsetStrategy Parameter
Remember that the featureSubsetStrategy parameter only changes the number of features used as candidates for splitting. The default is set to <b>"auto"</b>, which will select "all", "sqrt", or "onethird" based on the value of numTrees. Since we are basing our analysis off of the default values, we have a numTrees value of 3, which means "sqrt" is selected. So let's start by changing it it <b>"all"</b>, which will use all of the features
```
classRF_tuner(3, "all")
```
We can see that there is a small increase in the building time of the model, which is expected since we are considering all of the features. As well, there is a small increase in the test error. A possibility to the increase in test error is that there are some features that aren't "good" in the model, causing an increase in the test error. Next, we will try with <b>"sqrt"</b>
```
classRF_tuner(3, "sqrt")
```
This has very similar values to the "auto", which is correct since "auto" is using "sqrt" for featureSubsetStrategy, since our numTrees value was set to 3. Let's try using "onethird" now, which uses one third of the features.
```
classRF_tuner(3, "onethird")
```
We see that the run-time is similar to the default, but the testing error has decreased a little bit. It's possible that there is about the same number of features when you take one third of them, as if you take the square root of them for this particular dataset. Let's try with the last type, which is <b>"log2"</b>
```
classRF_tuner(3, "log2")
```
When using <b>"log2"</b>, there is a decrease in run-time, along with testing error!
---
# 7.RandomForest (Regression)
Now it's time for you to try it out for yourself! Build a Regression RandomForest in a similar way that the Classification RandomForest was built. Please note that you will be using the same dataset in this section (classRF_train, classRF_test), therefore you do not need to re-initialize that section.<br> <br>
Try to only reference the above section when you are experiencing a lot of difficulty. This section is mainly for you to apply your learning.
For some help with the variables:
<ul>
<li><b>categoricalFeaturesInfo</b>: Has a value of <b>{}</b> (parameter doesn't require tuning)</li>
<li><b>featureSubsetStrategy</b>: Can change these values between <b>"auto"</b>, <b>"all"</b>, <b>"sqrt"</b>, <b>"log2"</b>, and <b>"onethird"</b></li>
<li><b>numTrees</b>: Values range from <b>1</b> to infinity<i>(Default: 3)</i></li>
<ul>
<li>Note: If the value is too large, the system can run out of memory and not run.</li>
</ul>
<li><b>impurity</b>: For Regression, the value must be set to <b>'variance'</b> <i>(Default: 'variance')</i></li>
<li><b>maxDepth</b>: Values range between <b>0 and 30</b> <i>(Default: 5)</i></li>
<li><b>maxBins</b>: Value ranges between <b>2 and 2147483647</b> (largest value for 32-bits) <i>(Default: 32)</i></li>
<li><b>seed</b> Can be set to any value, or to a value based on system time with <i>None</i> <i>(Default: None)</i></li>
</ul>
When displaying the <b>Mean Squared Error</b>, use the following formula and print statement instead of Training Error: <br>
<b>regRF_MSE = regRF_label_pred.map(lambda (v, p): (v - p)**2).sum() / float(classRF_test.count())</b> <br>
<b>print('Test Error = ' + str(regRF_MSE))</b>
#### The Goal
Try to create a model that is better than the model with default values.
#### Try to beat!
With some parameter tuning, I was able to get a run-time increase of the model by ~0.9 seconds and a Test error decrease of ~2.54. Try to get a value similar to this, or better.
#### Note
We want a model that doesn't take too long to train and will cause overfitting. Remember that a very large model with high accuracy but long run time may not be good because the model may have overfit the data.
```
start = time.time()
regRF_model = RandomForest.trainRegressor(classRF_train, categoricalFeaturesInfo={},
numTrees=14, featureSubsetStrategy="onethird",
impurity='variance', maxDepth=11, maxBins=24, seed=None)
print(time.time() - start)
# Evaluate model on test instances and compute test error
regRF_pred = regRF_model.predict(classRF_train.map(lambda x: x.features))
regRF_label_pred = classRF_train.map(lambda lp: lp.label).zip(regRF_pred)
regRF_MSE = regRF_label_pred.map(lambda vp: (vp[0] - vp[1]) ** 2).sum()/\
float(classRF_train.count())
print('Test Mean Squared Error = ' + str(regRF_MSE))
print('Learned regression forest model: ' + regRF_model.toDebugString())
# 0.541887044907
# Test Mean Squared Error = 2.63255831252
# Learned regression forest model: TreeEnsembleModel regressor with 3 trees
# numTrees: 3
# featureSubsetStrategy="auto"
# Impurity: variance
# maxDepth: 4
# maxBins: 32
# 1.41001796722
# Test Mean Squared Error = 0.088487863674
# Learned regression forest model: TreeEnsembleModel regressor with 14 trees
# numTrees: 14
# featureSubsetStrategy="onethird"
# Impurity: variance
# maxDepth: 11
# maxBins: 16
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import datetime
import re
import os, os.path
import time
from sklearn.model_selection import train_test_split
import random
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sb
cd ../Training_Data
sb.set_palette("husl",4)
sb.set_style("whitegrid")
train_set = pd.read_csv('processed_train_set.csv',converters={'acceleration': eval})
test_set = pd.read_csv('processed_test_set.csv',converters={'acceleration': eval})
val_set = pd.read_csv('processed_val_set.csv',converters={'acceleration': eval})
trainingData = pd.read_csv('../Training_Data/processed_train_set_half.csv',converters={'acceleration': eval})
testingData = pd.read_csv('../Training_Data/processed_test_set_half.csv',converters={'acceleration': eval})
validationData = pd.read_csv('../Training_Data/processed_val_set_half.csv',converters={'acceleration': eval})
train_set = trainingData
test_set = testingData
val_set = validationData
cd ../Model
def calculate_model_size(model):
print(model.summary())
var_sizes = [
np.product(list(map(int, v.shape))) * v.dtype.size
for v in model.trainable_variables
]
print("Model size:", sum(var_sizes) / 1024, "KB")
samples = len(train_set['acceleration'][0])
lstm_model = tf.keras.Sequential([
tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(22),
input_shape=(samples, 3)), # output_shape=(batch, 253)
tf.keras.layers.Dense(5, activation="sigmoid") # (batch, 5)
])
cnn_model = tf.keras.Sequential([
tf.keras.layers.Conv2D(8, (4, 3),padding="same",activation="relu",
input_shape=(samples, 3, 1)), # output_shape=(batch, 760, 3, 8)
tf.keras.layers.MaxPool2D((3, 3)), # (batch, 253, 1, 8)
tf.keras.layers.Dropout(0.1), # (batch, 253, 1, 8)
tf.keras.layers.Conv2D(16, (4, 1), padding="same",activation="relu"), # (batch, 253, 1, 16)
tf.keras.layers.MaxPool2D((3, 1), padding="same"), # (batch, 84, 1, 16)
tf.keras.layers.Dropout(0.1), # (batch, 84, 1, 16)
tf.keras.layers.Flatten(), # (batch, 1344)
tf.keras.layers.Dense(16, activation="relu"), # (batch, 16)
tf.keras.layers.Dropout(0.1), # (batch, 16)
tf.keras.layers.Dense(5, activation="softmax") # (batch, 4)
])
cnn_model2 = tf.keras.Sequential([
tf.keras.layers.Conv2D(8, (4, 3),padding="same",activation="relu",
input_shape=(samples, 3, 1)), # output_shape=(batch, 760, 3, 8)
tf.keras.layers.MaxPool2D((3, 3)), # (batch, 253, 1, 8)
tf.keras.layers.Dropout(0.1), # (batch, 253, 1, 8)
tf.keras.layers.Conv2D(16, (4, 1), padding="same",activation="relu"), # (batch, 253, 1, 16)
tf.keras.layers.MaxPool2D((3, 1), padding="same"), # (batch, 84, 1, 16)
tf.keras.layers.Dropout(0.1), # (batch, 84, 1, 16)
tf.keras.layers.Flatten(), # (batch, 1344)
tf.keras.layers.Dense(16, activation="relu"), # (batch, 16)
tf.keras.layers.Dropout(0.1), # (batch, 16)
tf.keras.layers.Dense(5, activation="softmax") # (batch, 4)
])
#unused
cnn_model3 = tf.keras.Sequential([
tf.keras.layers.Conv2D(8, (4, 3),padding="same",activation="relu",
input_shape=(samples, 3, 1)), # output_shape=(batch, 760, 3, 8)
tf.keras.layers.MaxPool2D((6, 3)), # (batch, 126, 1, 8)
tf.keras.layers.Dropout(0.1), # (batch, 126, 1, 8)
tf.keras.layers.Conv2D(16, (4, 1), padding="same",activation="relu"), # (batch, 126, 1, 16)
tf.keras.layers.MaxPool2D((6, 1), padding="same"), # (batch, 21, 1, 16)
tf.keras.layers.Dropout(0.1), # (batch, 21, 1, 16)
tf.keras.layers.Flatten(), # (batch, 336)
tf.keras.layers.Dense(16, activation="relu"), # (batch, 16)
tf.keras.layers.Dropout(0.1), # (batch, 16)
tf.keras.layers.Dense(5, activation="softmax") # (batch, 4)
])
tensor_train_set = tf.data.Dataset.from_tensor_slices(
(np.array(train_set['acceleration'].tolist(),dtype=np.float64),
train_set['gesture'].tolist()))
tensor_test_set = tf.data.Dataset.from_tensor_slices(
(np.array(test_set['acceleration'].tolist(),dtype=np.float64),
test_set['gesture'].tolist()))
tensor_val_set = tf.data.Dataset.from_tensor_slices(
(np.array(val_set['acceleration'].tolist(),dtype=np.float64),
val_set['gesture'].tolist()))
calculate_model_size(lstm_model)
epochs_cnn = 20
epochs_lstm = 20
batch_size = 64
batch_size2 = 192
lstm_model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
calculate_model_size(cnn_model)
cnn_model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
calculate_model_size(cnn_model2)
cnn_model2.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
calculate_model_size(cnn_model3)
cnn_model3.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
tensor_train_set_lstm = tensor_train_set.batch(batch_size).repeat()
tensor_val_set_lstm = tensor_val_set.batch(batch_size)
tensor_test_set_lstm = tensor_test_set.batch(batch_size)
history_LSTM = lstm_model.fit(
tensor_train_set_lstm,
epochs=epochs_lstm,
validation_data=tensor_val_set_lstm,
steps_per_epoch=200,
validation_steps=int((len(val_set) - 1) / batch_size + 1))
loss_lstm, acc_lstm = lstm_model.evaluate(tensor_test_set_lstm)
pred_lstm = np.argmax(lstm_model.predict(tensor_test_set_lstm), axis=1)
confusion_lstm = tf.math.confusion_matrix(
labels=tf.constant(test_set['gesture'].to_numpy()),
predictions=tf.constant(pred_lstm),
num_classes=5)
print(confusion_lstm)
print("Loss {}, Accuracy {}".format(loss_lstm, acc_lstm))
plt.plot(history_LSTM.history['accuracy'])
plt.plot(history_LSTM.history['val_accuracy'])
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['Training_LSTM','Validation_LSTM'],loc='upper right')
plt.plot(history_LSTM.history['loss'])
plt.plot(history_LSTM.history['val_loss'])
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['Training_LSTM','Validation_LSTM'],loc='upper right')
converter = tf.lite.TFLiteConverter.from_keras_model(lstm_model)
lstm_tflite_model = converter.convert()
open("lstm_model_half.tflite", "wb").write(lstm_tflite_model)
lstm_model.save('lstm_model_half.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(lstm_model)
converter.experimental_new_converter = True
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
converter.target_spec.supported_types = [tf.float16]
lstm_opt_tflite_model = converter.convert()
# Save the model to disk
open("lstm_model_quantized.tflite", "wb").write(lstm_opt_tflite_model)
basic_model_size = os.path.getsize("../Model/lstm_model_half.tflite")
print("Basic model is %d bytes" % basic_model_size)
#quantized_model_size = os.path.getsize("lstm_model_quantized.tflite")
#print("Quantized model is %d bytes" % quantized_model_size)
#difference = basic_model_size - quantized_model_size
#print("Difference is %d bytes" % difference)
def reshape_function(data, label):
reshaped_data = tf.reshape(data, [-1, 3, 1])
return reshaped_data, label
train_set = pd.read_csv('processed_train_set.csv',converters={'acceleration': eval})
test_set = pd.read_csv('processed_test_set.csv',converters={'acceleration': eval})
val_set = pd.read_csv('processed_val_set.csv',converters={'acceleration': eval})
tensor_train_set = tf.data.Dataset.from_tensor_slices(
(np.array(train_set['acceleration'].tolist(),dtype=np.float64),
train_set['gesture'].tolist()))
tensor_test_set = tf.data.Dataset.from_tensor_slices(
(np.array(test_set['acceleration'].tolist(),dtype=np.float64),
test_set['gesture'].tolist()))
tensor_val_set = tf.data.Dataset.from_tensor_slices(
(np.array(val_set['acceleration'].tolist(),dtype=np.float64),
val_set['gesture'].tolist()))
tensor_train_set_cnn = tensor_train_set.map(reshape_function)
tensor_test_set_cnn = tensor_test_set.map(reshape_function)
tensor_val_set_cnn = tensor_val_set.map(reshape_function)
tensor_train_set_cnn = tensor_train_set_cnn.batch(batch_size).repeat()
tensor_test_set_cnn = tensor_test_set_cnn.batch(batch_size)
tensor_val_set_cnn = tensor_val_set_cnn.batch(batch_size)
history=cnn_model.fit(
tensor_train_set_cnn,
epochs=epochs_cnn,
validation_data=tensor_val_set_cnn,
steps_per_epoch=300,
validation_steps=int((len(val_set) - 1) / batch_size + 1))
history2=cnn_model2.fit(
tensor_train_set_cnn,
epochs=epochs_cnn,
validation_data=tensor_val_set_cnn,
steps_per_epoch=300,
validation_steps=int((len(val_set) - 1) / batch_size2 + 1))
loss_cnn, acc_cnn = cnn_model.evaluate(tensor_test_set_cnn)
pred_cnn = np.argmax(cnn_model.predict(tensor_test_set_cnn), axis=1)
confusion_cnn = tf.math.confusion_matrix(
labels=tf.constant(test_set['gesture'].to_numpy()),
predictions=tf.constant(pred_cnn),
num_classes=5)
loss_cnn2, acc_cnn2 = cnn_model2.evaluate(tensor_test_set_cnn)
pred_cnn2 = np.argmax(cnn_model2.predict(tensor_test_set_cnn), axis=1)
confusion_cnn2 = tf.math.confusion_matrix(
labels=tf.constant(test_set['gesture'].to_numpy()),
predictions=tf.constant(pred_cnn2),
num_classes=5)
print(confusion_cnn)
print("Loss {}, Accuracy {}".format(loss_cnn, acc_cnn))
print(confusion_cnn2)
print("Loss {}, Accuracy {}".format(loss_cnn2, acc_cnn2))
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.plot(history2.history['accuracy'])
plt.plot(history2.history['val_accuracy'])
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['Training','Validation','Training 2', 'Validation 2'],loc='lower right')
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.plot(history2.history['loss'])
plt.plot(history2.history['val_loss'])
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['Training','Validation','Training 2', 'Validation 2'],loc='upper right')
```
Overfitting if: training loss << validation loss
Underfitting if: training loss >> validation loss
```
cnn_model3.save('cnn_model3_half.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(cnn_model3)
cnn_tflite_model = converter.convert()
open("../Model/cnn_model3_half.tflite", "wb").write(cnn_tflite_model)
converter = tf.lite.TFLiteConverter.from_keras_model(cnn_model3)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
cnn_opt_tflite_model = converter.convert()
# Save the model to disk
open("../Model/cnn_model_quantized3_half.tflite", "wb").write(cnn_opt_tflite_model)
basic_model_size = os.path.getsize("../Model/cnn_model3_half.tflite")
print("Basic model is %d bytes" % basic_model_size)
quantized_model_size = os.path.getsize("../Model/cnn_model_quantized3_half.tflite")
print("Quantized model is %d bytes" % quantized_model_size)
difference = basic_model_size - quantized_model_size
print("Difference is %d bytes" % difference)
# Install xxd if it is not available
!sudo apt-get -qq install xxd
# Save the file as a C source file
!xxd -i cnn_model_quantized.tflite > cnn_opt_model.cc
# Print the source file
!cat /cnn_opt_model.cc
history3=cnn_model3.fit(
tensor_train_set_cnn,
epochs=epochs_cnn,
validation_data=tensor_val_set_cnn,
steps_per_epoch=300,
validation_steps=int((len(val_set) - 1) / batch_size2 + 1))
loss_cnn3, acc_cnn3 = cnn_model3.evaluate(tensor_test_set_cnn)
pred_cnn3 = np.argmax(cnn_model3.predict(tensor_test_set_cnn), axis=1)
confusion_cnn3 = tf.math.confusion_matrix(
labels=tf.constant(test_set['gesture'].to_numpy()),
predictions=tf.constant(pred_cnn3),
num_classes=5)
print(confusion_cnn2)
print("Loss {}, Accuracy {}".format(loss_cnn2, acc_cnn2))
print(confusion_cnn3)
print("Loss {}, Accuracy {}".format(loss_cnn3, acc_cnn3))
plt.plot(history2.history['loss'])
plt.plot(history2.history['val_loss'])
plt.plot(history3.history['loss'])
plt.plot(history3.history['val_loss'])
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['Training2','Validation2','Training 3', 'Validation 3'],loc='upper right')
plt.plot(history2.history['accuracy'])
plt.plot(history2.history['val_accuracy'])
plt.plot(history3.history['accuracy'])
plt.plot(history3.history['val_accuracy'])
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['Training2','Validation2','Training 3', 'Validation3 '],loc='lower right')
!xxd -i ../Model/cnn_model_quantized3_half.tflite > ../Model/cnn_opt_model3_half.cc
!cat ../Model/cnn_opt_model3_half.cc
plt.plot(history_LSTM.history['accuracy'])
plt.plot(history_LSTM.history['val_accuracy'])
plt.plot(history3.history['accuracy'])
plt.plot(history3.history['val_accuracy'])
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('CNN VS LSTM Accuracy')
plt.legend(['Training_LSTM','Validation_LSTM','Training_CNN','Validation_CNN'],loc='lower right')
plt.plot(history_LSTM.history['loss'])
plt.plot(history_LSTM.history['val_loss'])
plt.plot(history3.history['loss'])
plt.plot(history3.history['val_loss'])
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('CNN VS LSTM LOSS')
plt.legend(['Training_LSTM','Validation_LSTM','Training_CNN','Validation_CNN'],loc='upper right')
print(confusion_lstm)
print("Loss {}, Accuracy {}".format(loss_lstm, acc_lstm))
print("")
print(confusion_cnn3)
print("Loss {}, Accuracy {}".format(loss_cnn3, acc_cnn3))
```
| github_jupyter |
```
!git clone https://github.com/danielroich/Face-Identity-Disentanglement-via-StyleGan2.git 'project'
!pip install pytorch-msssim
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir('/content')
CODE_DIR = 'project'
os.chdir(f'./{CODE_DIR}')
from Losses.AdversarialLoss import calc_Dw_loss
from Models.Encoders.ID_Encoder import resnet50_scratch_dag
from Models.Encoders.Attribute_Encoder import Encoder_Attribute
from Models.Discrimanator import Discriminator
from Models.LatentMapper import LatentMapper
import torch
import torch.utils.data
import torchvision.datasets as dset
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
import seaborn as sns
sns.set()
def plot_w_image(w):
w = w.unsqueeze(0).cuda()
sample, latents = generator(
[w], input_is_latent=True, return_latents=True
)
new_image = sample.cpu().detach().numpy().transpose(0,2,3,1)[0]
new_image = (new_image + 1) / 2
plt.axis('off')
plt.imshow(new_image)
plt.show()
CODE_DIR = 'pixel2style2pixel'
!git clone https://github.com/eladrich/pixel2style2pixel.git $CODE_DIR
!wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip
!sudo unzip ninja-linux.zip -d /usr/local/bin/
!sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force
os.chdir(f'./{CODE_DIR}')
import sys
sys.path.append(".")
sys.path.append("..")
from models.stylegan2.model import Generator
generator = Generator(1024,512,8).cuda()
state_dict = torch.load('/content/drive/MyDrive/CNN-project-weights/stylegan2-ffhq-config-f.pt')
generator.load_state_dict(state_dict['g_ema'], strict=False)
generator = generator.eval()
E_id = resnet50_scratch_dag("/content/drive/MyDrive/CNN-project-weights/resnet50_scratch_dag.pth").cuda()
E_att = Encoder_Attribute().cuda()
discriminator = Discriminator(512).cuda()
mlp = LatentMapper(4096).cuda()
E_id = E_id.eval()
E_att = E_att.eval()
discriminator = discriminator.train()
mlp = mlp.train()
def get_w_by_index(idx, root_dir = r"/content/drive/MyDrive/CNN-project-weights/fake/w/"):
if torch.is_tensor(idx):
idx = idx.tolist()
dir_idx = idx // 1000
w_path = os.path.join(root_dir, str(dir_idx),str(idx)+ ".npy")
w = np.load(w_path)
return torch.tensor(w)
class WDataSet(Dataset):
def __init__(self,root_dir):
"""
Args:
root_dir (string): Directory with all the w's.
"""
self.root_dir = root_dir
def __len__(self):
## TODO: Change
return 6999
def __getitem__(self, idx):
return get_w_by_index(idx, self.root_dir)
class ConcatDataset(torch.utils.data.Dataset):
def __init__(self, datasets):
self.datasets = datasets
def __getitem__(self, i):
return tuple(d[i] for d in self.datasets)
def __len__(self):
return min(len(d) for d in self.datasets)
data_dir = r"/content/drive/MyDrive/CNN-project-weights/fake/image/"
attr_dataset = dset.ImageFolder(root=data_dir,
transform=transforms.Compose([
transforms.Resize(299),
transforms.CenterCrop(299),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]))
id_dataset = dset.ImageFolder(root=data_dir,
transform=transforms.Compose([
transforms.Resize(E_id.meta['imageSize'][1]),
transforms.CenterCrop(E_id.meta['imageSize'][1]),
transforms.ToTensor(),
transforms.Normalize(np.asarray(E_id.meta['mean']) / 255, np.asarray(E_id.meta['std']) / 255)
]))
w_dataset = WDataSet(r"/content/drive/MyDrive/CNN-project-weights/fake/w/")
def make_concat_loaders(batch_size, datasets):
full_dataset = ConcatDataset(datasets)
train_loader = torch.utils.data.DataLoader(dataset=full_dataset,
batch_size=batch_size, shuffle = True)
return train_loader
config = {
'beta1' : 0.5,
'beta2' : 0.999,
'lrD' : 0.0004,
'lrMLP' : 0.00003,
'lrAttr' : 0.0001,
'IdDiffersAttrTrainRatio' : 3, # 1/3
'batchSize' : 8,
'R1Param' : 10,
'lambdaID' : 1,
'lambdaLND' : 1,
'lambdaREC' : 1
}
train_loader = make_concat_loaders(config['batchSize'],(id_dataset, attr_dataset,w_dataset))
discriminator = Discriminator(512).cuda()
mlp = LatentMapper(4096).cuda()
optimizerD = torch.optim.Adam(discriminator.parameters(), lr=config['lrD'], betas=(config['beta1'], config['beta2']))
optimizerMLP = torch.optim.Adam(mlp.parameters(), lr=config['lrMLP'], betas=(config['beta1'], config['beta2']))
optimizerD = torch.optim.Adam(discriminator.parameters(), lr=config['lrD'], betas=(config['beta1'], config['beta2']))
optimizerMLP = torch.optim.Adam(mlp.parameters(), lr=config['lrMLP'], betas=(config['beta1'], config['beta2']))
def train_discriminator(optimizer, real_w, generated_w):
optimizer.zero_grad()
# 1.1 Train on Real Data
prediction_real = discriminator(real_w).view(-1)
# Calculate error and backpropagate
error_real = calc_Dw_loss(prediction_real, 1, "cuda", ws, config['R1Param'], False)
error_real.backward()
generated_w = generated_w.clone().detach()
# 1.2 Train on Fake Data
prediction_fake = discriminator(generated_w).view(-1)
# Calculate error and backpropagate
error_fake = calc_Dw_loss(prediction_fake, 0, "cuda", generated_w, config['R1Param'], False)
error_fake.backward()
# 1.3 Update weights with gradients
optimizer.step()
# Return error and predictions for real and fake inputs
# return error_real + error_fake, prediction_real, prediction_fake
return error_real, prediction_real, error_fake, prediction_fake
def train_mapper(optimizer, generated_w):
optimizer.zero_grad()
prediction = discriminator(generated_w).view(-1)
# Calculate error and backpropagate
error = calc_Dw_loss(prediction, 1, "cuda", generated_w, config['R1Param'], False)
error.backward()
# Update weights with gradients
optimizer.step()
# Return error
return error, prediction
for idx, data in enumerate(train_loader):
id_images, attr_images, ws = data
torch.cuda.empty_cache()
id_images = id_images[0].cuda()
attr_images = attr_images[0].cuda()
ws_single = ws.cuda()
if idx % config['IdDiffersAttrTrainRatio'] == 0:
different_attr_images = torch.empty_like(attr_images, device='cuda')
different_attr_images[0] = attr_images[7]
different_attr_images[1:] = attr_images[:7]
attr_images = different_attr_images
with torch.no_grad():
id_vec = E_id(id_images)
attr_vec = E_att(attr_images)
# different image to id and attr
id_vec = torch.squeeze(id_vec)
attr_vec = torch.squeeze(attr_vec)
encoded_vec = torch.cat((id_vec,attr_vec), dim=1)
test_vec = encoded_vec
break
MLP_losses = []
D_losses = []
```
# Training only the mapper and discriminator
```
####### Discriminator back pass #######
epochs = 4
for epoch in range(epochs):
for idx, data in enumerate(train_loader):
id_images, attr_images, ws = data
torch.cuda.empty_cache()
id_images = id_images[0].cuda()
attr_images = attr_images[0].cuda()
ws = ws.cuda()
if idx % config['IdDiffersAttrTrainRatio'] == 0:
different_attr_images = torch.empty_like(attr_images, device='cuda')
different_attr_images[0] = attr_images[7]
different_attr_images[1:] = attr_images[:7]
attr_images = different_attr_images
with torch.no_grad():
id_vec = E_id(id_images)
attr_vec = E_att(attr_images)
id_vec = torch.squeeze(id_vec)
attr_vec = torch.squeeze(attr_vec)
encoded_vec = torch.cat((id_vec,attr_vec), dim=1)
fake_data = mlp(encoded_vec)
error_real, prediction_real, error_fake, prediction_fake = train_discriminator(optimizerD, ws, fake_data)
print(f"\n error_real: {error_real}, error_fake: {error_fake} \n prediction_real: {torch.mean(prediction_real)}, prediction_fake: {torch.mean(prediction_fake)}")
g_error, g_pred = train_mapper(optimizerMLP, fake_data)
print(f"\n g_error: {g_error}, g_pred: {torch.mean(g_pred)}")
MLP_losses.append(g_error)
D_losses.append((error_real + error_fake) /2)
if idx % 5 == 0:
with torch.no_grad():
plot_w_image(mlp(test_vec)[0])
plt.figure(figsize=(10,5))
plt.title("Mapper and Discriminator Loss During Training")
plt.plot(MLP_losses,label="MLP")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
```
| github_jupyter |
```
# standard modules
import ee
from pprint import pprint
import datetime
import math
import pickle
ee.Initialize()
import os
import sys
# package modules
sys.path.append(os.path.join(os.path.dirname(os.getcwd()),'')) #path to geetools
from geetools import ui, cloud_mask, batch
sys.path.append(os.path.join(os.path.dirname(os.getcwd()),'bin')) #path to atmospheric repo
from atmcorr.atmospheric import Atmospheric
from atmcorr.timeSeries import timeSeries
```
## User Inputs
```
# start and end of time series
START_DATE = '2015-09-01' # YYYY-MM-DD
STOP_DATE = '2015-09-30' # YYYY-MM-DD
# define YOUR GEE asset path (check the Code Editor on the Google Earth Engine Platform)
assetPath = 'users/visithuruvixen/'
# Location
#studyarea = ee.Geometry.Rectangle(7.839915571336746,59.92729438200467,8.229930219774246,60.120787029875316)
studyarea = ee.Geometry.Rectangle(6.61742922283554, 59.83018236417845,8.459315101872107, 60.410305416291344)#whole park
sitepoint= ee.Geometry.Point(8.031215204296245,60.02282521279792)
# Description of time period and location
assetID = 'ic092015'
```
### Getting an Image Collection from the GEE Server
```
# The Sentinel-2 image collection
S2 = ee.ImageCollection('COPERNICUS/S2').filterBounds(studyarea)\
.filterDate(START_DATE, STOP_DATE).sort('system:time_start')\
.map(cloud_mask.sentinel2()) # applies an ESA cloud mask on all images (L1C)
S2List = S2.toList(S2.size()) # must loop through lists
NO_OF_IMAGES = S2.size().getInfo() # no. of images in the collection
NO_OF_IMAGES
```
### defining functions for atmospheric correction
```
#Set Key Variables
MISSIONS = ['Sentinel2']# satellite missions,
NO_OF_BANDS = 13
# Location of iLUTs (can keep default if you clone entire git repository to your machine)
DIRPATH = './files/iLUTs/S2A_MSI/Continental/view_zenith_0/'
# setting parameter for atmospheric correction
SRTM = ee.Image('USGS/GMTED2010') # Make sure that your study area is covered by this elevation dataset
altitude = SRTM.reduceRegion(reducer=ee.Reducer.mean(), geometry=studyarea.centroid()).get('be75').getInfo() # insert correct name for elevation variable from dataset
KM = altitude/1000 # i.e. Py6S uses units of kilometers
def atm_corr_image(imageInfo: dict) -> dict:
"""Retrieves atmospheric params from image.
imageInfo is a dictionary created from an ee.Image object
"""
atmParams = {}
# Python uses seconds, EE uses milliseconds:
scene_date = datetime.datetime.utcfromtimestamp(imageInfo['system:time_start']/1000)
dt1 = ee.Date(str(scene_date).rsplit(sep=' ')[0])
atmParams['doy'] = scene_date.timetuple().tm_yday
atmParams['solar_z'] = imageInfo['MEAN_SOLAR_ZENITH_ANGLE']
atmParams['h2o'] = Atmospheric.water(geom, dt1).getInfo()
atmParams['o3'] = Atmospheric.ozone(geom, dt1).getInfo()
atmParams['aot'] = Atmospheric.aerosol(geom, dt1).getInfo()
return atmParams
def get_corr_coef(imageInfo: dict, atmParams: dict) -> list:
"""Gets correction coefficients for each band in the image.
Uses DIRPATH global variable
Uses NO_OF_BANDS global variable
Uses KM global variable
Returns list of 2-length lists
"""
corr_coefs = []
# string list with padding of 2
bandNos = [str(i).zfill(2) for i in range(1, NO_OF_BANDS + 1)]
for band in bandNos:
filepath = DIRPATH + 'S2A_MSI_' + band + '.ilut'
with open(filepath, 'rb') as ilut_file:
iluTable = pickle.load(ilut_file)
a, b = iluTable(atmParams['solar_z'], atmParams['h2o'], atmParams['o3'], atmParams['aot'], KM)
elliptical_orbit_correction = 0.03275104*math.cos(atmParams['doy']/59.66638337) + 0.96804905
a *= elliptical_orbit_correction
b *= elliptical_orbit_correction
corr_coefs.append([a, b])
return corr_coefs
def toa_to_rad_multiplier(bandname: str, imageInfo: dict, atmParams: dict) -> float:
"""Returns a multiplier for converting TOA reflectance to radiance
bandname is a string like 'B1'
"""
ESUN = imageInfo['SOLAR_IRRADIANCE_'+bandname]
# solar exoatmospheric spectral irradiance
solar_angle_correction = math.cos(math.radians(atmParams['solar_z']))
# Earth-Sun distance (from day of year)
d = 1 - 0.01672 * math.cos(0.9856 * (atmParams['doy']-4))
# http://physics.stackexchange.com/questions/177949/earth-sun-distance-on-a-given-day-of-the-year
# conversion factor
multiplier = ESUN*solar_angle_correction/(math.pi*d**2)
# at-sensor radiance
return multiplier
def atm_corr_band(image, imageInfo: dict, atmParams: dict):
"""Atmospherically correct image
Converts toa reflectance to radiance.
Applies correction coefficients to get surface reflectance
Returns ee.Image object
"""
oldImage = ee.Image(image).divide(10000)
newImage = ee.Image()
cor_coeff_list = get_corr_coef(imageInfo, atmParams)
bandnames = oldImage.bandNames().getInfo()
for ii in range(NO_OF_BANDS):
img2RadMultiplier = toa_to_rad_multiplier(bandnames[ii], imageInfo, atmParams)
imgRad = oldImage.select(bandnames[ii]).multiply(img2RadMultiplier)
constImageA = ee.Image.constant(cor_coeff_list[ii][0])
constImageB = ee.Image.constant(cor_coeff_list[ii][1])
surRef = imgRad.subtract(constImageA).divide(constImageB)
newImage = newImage.addBands(surRef)
# unpack a list of the band indexes:
return newImage.select(*list(range(NO_OF_BANDS)))
```
### Performing atcorrection on ee.List of images
```
%%time
#date = ee.Date(dateString)
geom = studyarea
S3 = S2List
SrList = ee.List([0]) # Can't init empty list so need a garbage element
export_list = []
coeff_list = []
for i in range(NO_OF_IMAGES):
iInfo = S3.get(i).getInfo()
iInfoProps = iInfo['properties']
atmVars = atm_corr_image(iInfoProps)
corrCoeffs = get_corr_coef(iInfoProps, atmVars)
coeff_list.append(corrCoeffs)
# # set some properties to tack on to export images
#info = S3.getInfo()['properties'] #called iInfo
scene_date = datetime.datetime.utcfromtimestamp(iInfoProps['system:time_start']/1000)# i.e. Python uses seconds, EE uses milliseconds
dateString = scene_date.strftime("%Y-%m-%d")
# # Atmospheric constituents
h2o = Atmospheric.water(geom,ee.Date(dateString)).getInfo()
o3 = Atmospheric.ozone(geom,ee.Date(dateString)).getInfo()
aot = Atmospheric.aerosol(geom,ee.Date(dateString)).getInfo()
img = atm_corr_band(ee.Image(S3.get(i)), iInfoProps, atmVars)
img = img.set({'satellite':'Sentinel 2',
'fileID':iInfoProps['system:index'],
'Date':dateString,
'aerosol_optical_thickness':aot,
'water_vapour':h2o,
'ozone':o3})
SrList = SrList.add(img)
SrList = SrList.slice(1) # Need to remove the first element from the list which is garbage
with open('coeff_list.txt', 'w') as f:
pprint(coeff_list, stream=f)
print('runtime')
```
## Exporting AtCorrected Image Collection
```
#check that all images were corrected (list should be equal size to original IC)
SrList.size().getInfo()==S2.size().getInfo()
CorCol = ee.ImageCollection(SrList)#.map(cloud_mask.sentinel2()) #converting the list of atcor images to an imagecollection
assetlocation = assetPath+assetID #concatenate string variables to make one save destination
batch.ImageCollection.toAsset(col=CorCol,maxPixels=132441795, assetPath=assetlocation, scale=10, region=studyarea)#,create=True,verbose=False)
```
## Visualisation
```
firstImagenotcor = ee.Image(S2List.get(3)).divide(10000)
firstImageatcor = ee.Image(SrList.get(3))
from IPython.display import display, Image
region = geom.buffer(10000).bounds().getInfo()['coordinates']
channels = ['B4','B3','B2']
before = Image(url=firstImagenotcor.select(channels).getThumbUrl({
'region':region,'min':0,'max':0.25#,'gamma':1.5
}))
after = Image(url=firstImageatcor.select(channels).getThumbUrl({
'region':region,'min':0,'max':0.25#,'gamma':1.5
}))
display(before, after)
from geetools import ui
Map = ui.Map(tabs=('Inspector',))
Map.show()
imageidx=6
firstImagenotcor = ee.Image(S2List.get(imageidx)).divide(10000)
firstImageatcor = ee.Image(SrList.get(imageidx))
CorCol = ee.ImageCollection(SrList)#.map(cloud_mask.sentinel2()) #converting the list of atcor images to an imagecollection
vis = {'bands':['B4', 'B3','B2'], 'min':0, 'max':0.3}
#visS2 = {min: 0.0,max: 0.25,'bands':channels}
#is2=is2.clip(aoi)
from geetools import ui, tools, composite, cloud_mask, indices
bands=['B1','B2','B3','B4','B5','B6','B7','B8','B8A','B9','B10','B11','B12']
#medoid = composite.medoid(CorCol, bands=bands)
image = S2.mosaic()
img = CorCol.mosaic()
Map.centerObject(firstImagenotcor.clip(geom), zoom=11)
Map.addLayer(firstImagenotcor.clip(geom),vis, 'Uncorrected original, cloud masked')
Map.addLayer(firstImageatcor.clip(geom),vis, 'Atmospherically corrected')
#Map.addLayer(CorCol.first().clip(geom),vis, 'Atmospherically corrected, cloud masked')
#Map.addLayer(medoid.clip(geom), vis, 'Medoid AtCorrected')
Map.addLayer(S2.mosaic().clip(geom), {'bands':['B4', 'B3','B2'], 'min':0, 'max':5000}, 'Mosaic Not Corrected')
Map.addLayer(img.clip(geom), {'bands':['B4', 'B3','B2'], 'min':0, 'max':5000}, 'Mosaic IS Corrected')
composite = ee.Image(CorCol.min())
imageatcorlist = ee.Image(CorCol.get(5))
firstImageatcor = ee.Image(SrList.get(5))
region = geom.buffer(10000).bounds().getInfo()['coordinates']
channels = ['B4','B3','B2']
i2 = Image(url=imageatcorlist.select(channels).getThumbURL({
'region':region,'min':0,'max':0.25#,'gamma':1.5
}))
comp = Image(url=composite.select(channels).getThumbURL({
'region':region,'min':0,'max':0.25#,'gamma':1.5
}))
display(i2, comp)
```
| github_jupyter |
# Introducing CivisML 2.0
Note: We are continually releasing changes to CivisML, and this notebook is useful for any versions 2.0.0 and above.
Data scientists are on the front lines of their organization’s most important customer growth and engagement questions, and they need to guide action as quickly as possible by getting models into production. CivisML is a machine learning service that makes it possible for data scientists to massively increase the speed with which they can get great models into production. And because it’s built on open-source packages, CivisML remains transparent and data scientists remain in control.
In this notebook, we’ll go over the new features introduced in CivisML 2.0. For a walkthrough of CivisML’s fundamentals, check out this introduction to the mechanics of CivisML: https://github.com/civisanalytics/civis-python/blob/master/examples/CivisML_parallel_training.ipynb
CivisML 2.0 is full of new features to make modeling faster, more accurate, and more portable. This notebook will cover the following topics:
- CivisML overview
- Parallel training and validation
- Use of the new ETL transformer, `DataFrameETL`, for easy, customizable ETL
- Stacked models: combine models to get one bigger, better model
- Model portability: get trained models out of CivisML
- Multilayer perceptron models: neural networks built in to CivisML
- Hyperband: a smarter alternative to grid search
CivisML can be used to build models that answer all kinds of business questions, such as what movie to recommend to a customer, or which customers are most likely to upgrade their accounts. For the sake of example, this notebook uses a publicly available dataset on US colleges, and focuses on predicting the type of college (public non-profit, private non-profit, or private for-profit).
```
# first, let's import the packages we need
import requests
from io import StringIO
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import model_selection
# import the Civis Python API client
import civis
# ModelPipeline is the class used to build CivisML models
from civis.ml import ModelPipeline
# Suppress warnings for demo purposes. This is not recommended as a general practice.
import warnings
warnings.filterwarnings('ignore')
```
## Downloading data
Before we build any models, we need a dataset to play with. We're going to use the most recent College Scorecard data from the Department of Education.
This dataset is collected to study the performance of US higher education institutions. You can learn more about it in [this technical paper](https://collegescorecard.ed.gov/assets/UsingFederalDataToMeasureAndImprovePerformance.pdf), and you can find details on the dataset features in [this data dictionary](https://collegescorecard.ed.gov/data/).
```
# Downloading data; this may take a minute
# Two kind of nulls
df = pd.read_csv("https://ed-public-download.app.cloud.gov/downloads/Most-Recent-Cohorts-All-Data-Elements.csv", sep=",", na_values=['NULL', 'PrivacySuppressed'], low_memory=False)
# How many rows and columns?
df.shape
# What are some of the column names?
df.columns
```
## Data Munging
Before running CivisML, we need to do some basic data munging, such as removing missing data from the dependent variable, and splitting the data into training and test sets.
Throughout this notebook, we'll be trying to predict whether a college is public (labelled as 1), private non-profit (2), or private for-profit (3). The column name for this dependent variable is "CONTROL".
```
# Make sure to remove any rows with nulls in the dependent variable
df = df[np.isfinite(df['CONTROL'])]
# split into training and test sets
train_data, test_data = model_selection.train_test_split(df, test_size=0.2)
# print a few sample columns
train_data.head()
```
Some of these columns are duplicates, or contain information we don't want to use in our model (like college names and URLs). CivisML can take a list of columns to exclude and do this part of the data munging for us, so let's make that list here.
```
to_exclude = ['ADM_RATE_ALL', 'OPEID', 'OPEID6', 'ZIP', 'INSTNM',
'INSTURL', 'NPCURL', 'ACCREDAGENCY', 'T4APPROVALDATE',
'STABBR', 'ALIAS', 'REPAY_DT_MDN', 'SEPAR_DT_MDN']
```
## Basic CivisML Usage
When building a supervised model, there are a few basic things you'll probably want to do:
1. Transform the data into a modelling-friendly format
2. Train the model on some labelled data
3. Validate the model
4. Use the model to make predictions about unlabelled data
CivisML does all of this in three lines of code. Let's fit a basic sparse logistic model to see how.
The first thing we need to do is build a `ModelPipeline` object. This stores all of the basic configuration options for the model. We'll tell it things like the type of model, dependent variable, and columns we want to exclude. CivisML handles basic ETL for you, including categorical expansion of any string-type columns.
```
# Use a push-button workflow to fit a model with reasonable default parameters
sl_model = ModelPipeline(model='sparse_logistic',
model_name='Example sparse logistic',
primary_key='UNITID',
dependent_variable=['CONTROL'],
excluded_columns=to_exclude)
```
Next, we want to train and validate the model by calling `.train` on the `ModelPipeline` object. CivisML uses 4-fold cross-validation on the training set. You can train on local data or query data from Redshift. In this case, we have our data locally, so we just pass the data frame.
```
sl_train = sl_model.train(train_data)
```
This returns a `ModelFuture` object, which is *non-blocking*-- this means that you can keep doing things in your notebook while the model runs on Civis Platform in the background. If you want to make a blocking call (one that doesn't complete until your model is finished), you can use `.result()`.
```
# non-blocking
sl_train
# blocking
sl_train.result()
```
### Parallel Model Tuning and Validation
We didn't actually specify the number of jobs in the `.train()` call above, but behind the scenes, the model was actually training in parallel! In CivisML 2.0, model tuning and validation will automatically be distributed across your computing cluster, without ever using more than 90% of the cluster resources. This means that you can build models faster and try more model configurations, leaving you more time to think critically about your data. If you decide you want more control over the resources you're using, you can set the `n_jobs` parameter to a specific number of jobs, and CivisML won't run more than that at once.
We can see how well the model did by looking at the validation metrics.
```
# loop through the metric names and print to screen
metrics = [print(key) for key in sl_train.metrics.keys()]
# ROC AUC for each of the three categories in our dependent variable
sl_train.metrics['roc_auc']
```
Impressive!
This is the basic CivisML workflow: create the model, train, and make predictions. There are other configuration options for more complex use cases; for example, you can create a custom estimator, pass custom dependencies, manage the computing resources for larger models, and more. For more information, see the Machine Learning section of the [Python API client docs](https://civis-python.readthedocs.io).
Now that we can build a simple model, let's see what's new to CivisML 2.0!
## Custom ETL
CivisML can do several data transformations to prepare your data for modeling. This makes data preprocessing easier, and makes it part of your model pipeline rather than an additional script you have to run. CivisML's built-in ETL includes:
- Categorical expansion: expand a single column of strings or categories into separate binary variables.
- Dropping columns: remove columns not needed in a model, such as an ID number.
- Removing null columns: remove columns that contain no data.
With CivisML 2.0, you can now recreate and customize this ETL using `DataFrameETL`, our open source ETL transformer, [available on GitHub](https://github.com/civisanalytics/civisml-extensions).
By default, CivisML will use DataFrameETL to automatically detect non-numeric columns for categorical expansion. Our example college dataset has a lot of integer columns which are actually categorical, but we can make sure they're handled correctly by passing CivisML a custom ETL transformer.
```
# The ETL transformer used in CivisML can be found in the civismlext module
from civismlext.preprocessing import DataFrameETL
```
This creates a list of columns to categorically expand, identified using the data dictionary available [here](https://collegescorecard.ed.gov/data/).
```
# column indices for columns to expand
to_expand = list(df.columns[:21]) + list(df.columns[23:36]) + list(df.columns[99:290]) + \
list(df.columns[[1738, 1773, 1776]])
# create ETL estimator to pass to CivisML
etl = DataFrameETL(cols_to_drop=to_exclude,
cols_to_expand=to_expand, # we made this column list during data munging
check_null_cols='warn')
```
## Model Stacking
Now it's time to fit a model. Let's take a look at model stacking, which is new to CivisML 2.0.
Stacking lets you combine several algorithms into a single model which performs as well or better than the component algorithms. We use stacking at Civis to build more accurate models, which saves our data scientists time comparing algorithm performance. In CivisML, we have two stacking workflows: `stacking_classifier` (sparse logistic, GBT, and random forest, with a logistic regression model as a "meta-estimator" to combine predictions from the other models); and `stacking_regressor` (sparse linear, GBT, and random forest, with a non-negative linear regression as the meta-estimator). Use them the same way you use `sparse_logistic` or other pre-defined models. If you want to learn more about how stacking works under the hood, take a look at [this talk](https://www.youtube.com/watch?v=3gpf1lGwecA&t=1058s) by the person at Civis who wrote it!
Let's fit both a stacking classifier and some un-stacked models, so we can compare the performance.
```
workflows = ['stacking_classifier',
'sparse_logistic',
'random_forest_classifier',
'gradient_boosting_classifier']
models = []
# create a model object for each of the four model types
for wf in workflows:
model = ModelPipeline(model=wf,
model_name=wf + ' v2 example',
primary_key='UNITID',
dependent_variable=['CONTROL'],
etl=etl # use the custom ETL we created
)
models.append(model)
# iterate over the model objects and run a CivisML training job for each
trains = []
for model in models:
train = model.train(train_data)
trains.append(train)
```
Let's plot diagnostics for each of the models. In the Civis Platform, these plots will automatically be built and displayed in the "Models" tab. But for the sake of example, let's also explicitly plot ROC curves and AUCs in the notebook.
There are three classes (public, non-profit private, and for-profit private), so we'll have three curves per model. It looks like all of the models are doing well, with sparse logistic performing slightly worse than the other three.
```
%matplotlib inline
# Let's look at how the model performed during validation
def extract_roc(fut_job, model_name):
'''Build a data frame of ROC curve data from the completed training job `fut_job`
with model name `model_name`. Note that this function will only work for a classification
model where the dependent variable has more than two classes.'''
aucs = fut_job.metrics['roc_auc']
roc_curve = fut_job.metrics['roc_curve_by_class']
n_classes = len(roc_curve)
fpr = []
tpr = []
class_num = []
auc = []
for i, curve in enumerate(roc_curve):
fpr.extend(curve['fpr'])
tpr.extend(curve['tpr'])
class_num.extend([i] * len(curve['fpr']))
auc.extend([aucs[i]] * len(curve['fpr']))
model_vec = [model_name] * len(fpr)
df = pd.DataFrame({
'model': model_vec,
'class': class_num,
'fpr': fpr,
'tpr': tpr,
'auc': auc
})
return df
# extract ROC curve information for all of the trained models
workflows_abbrev = ['stacking', 'logistic', 'RF', 'GBT']
roc_dfs = [extract_roc(train, w) for train, w in zip(trains, workflows_abbrev)]
roc_df = pd.concat(roc_dfs)
# create faceted ROC curve plots. Each row of plots is a different model type, and each
# column of plots is a different class of the dependent variable.
g = sns.FacetGrid(roc_df, col="class", row="model")
g = g.map(plt.plot, "fpr", "tpr", color='blue')
```
All of the models perform quite well, so it's difficult to compare based on the ROC curves. Let's plot the AUCs themselves.
```
# Plot AUCs for each model
%matplotlib inline
auc_df = roc_df[['model', 'class', 'auc']]
auc_df.drop_duplicates(inplace=True)
plt.show(sns.swarmplot(x=auc_df['model'], y=auc_df['auc']))
```
Here we can see that all models but sparse logistic perform quite well, but stacking appears to perform marginally better than the others. For more challenging modeling tasks, the difference between stacking and other models will often be more pronounced.
Now our models are trained, and we know that they all perform very well. Because the AUCs are all so high, we would expect the models to make similar predictions. Let's see if that's true.
```
# kick off a prediction job for each of the four models
preds = [model.predict(test_data) for model in models]
# This will run on Civis Platform cloud resources
[pred.result() for pred in preds]
# print the top few rows for each of the models
pred_df = [pred.table.head() for pred in preds]
import pprint
pprint.pprint(pred_df)
```
Looks like the probabilities here aren't exactly the same, but are directionally identical-- so, if you chose the class that had the highest probability for each row, you'd end up with the same predictions for all models. This makes sense, because all of the models performed well.
## Model Portability
What if you want to score a model outside of Civis Platform? Maybe you want to deploy this model in an app for education policy makers. In CivisML 2.0, you can easily get the trained model pipeline out of the `ModelFuture` object.
```
train_stack = trains[0] # Get the ModelFuture for the stacking model
trained_model = train_stack.estimator
```
This `Pipeline` contains all of the steps CivisML used to train the model, from ETL to the model itself. We can print each step individually to get a better sense of what is going on.
```
# print each of the estimators in the pipeline, separated by newlines for readability
for step in train_stack.estimator.steps:
print(step[1])
print('\n')
```
Now we can see that there are three steps: the `DataFrameETL` object we passed in, a null imputation step, and the stacking estimator itself.
We can use this outside of CivisML simply by calling `.predict` on the estimator. This will make predictions using the model in the notebook without using CivisML.
```
# drop the dependent variable so we don't use it to predict itself!
predictions = trained_model.predict(test_data.drop(labels=['CONTROL'], axis=1))
# print out the class predictions. These will be integers representing the predicted
# class rather than probabilities.
predictions
```
## Hyperparameter optimization with Hyperband and Neural Networks
Multilayer Perceptrons (MLPs) are simple neural networks, which are now built in to CivisML. The MLP estimators in CivisML come from [muffnn](https://github.com/civisanalytics/muffnn), another open source package written and maintained by Civis Analytics using [tensorflow](https://www.tensorflow.org/). Let's fit one using hyperband.
Tuning hyperparameters is a critical chore for getting an algorithm to perform at its best, but it can take a long time to run. Using CivisML 2.0, we can use hyperband as an alternative to conventional grid search for hyperparameter optimization-- it runs about twice as fast. While grid search runs every parameter combination for the full time, hyperband runs many combinations for a short time, then filters out the best, runs them for longer, filters again, and so on. This means that you can try more combinations in less time, so we recommend using it whenever possible. The hyperband estimator is open source and [available on GitHub](https://github.com/civisanalytics/civisml-extensions). You can learn about the details in [the original paper, Li et al. (2016)](https://arxiv.org/abs/1603.06560).
Right now, hyperband is implemented in CivisML named preset models for the following algorithms:
- Multilayer Perceptrons (MLPs)
- Stacking
- Random forests
- GBTs
- ExtraTrees
Unlike grid search, you don't need to specify values to search over. If you pass `cross_validation_parameters='hyperband'` to `ModelPipeline`, hyperparameter combinations will be randomly drawn from preset distributions.
```
# build a model specifying the MLP model with hyperband
model_mlp = ModelPipeline(model='multilayer_perceptron_classifier',
model_name='MLP example',
primary_key='UNITID',
dependent_variable=['CONTROL'],
cross_validation_parameters='hyperband',
etl=etl
)
train_mlp = model_mlp.train(train_data,
n_jobs=10) # parallel hyperparameter optimization and validation!
# block until the job finishes
train_mlp.result()
```
Let's dig into the hyperband model a little bit. Like the stacking model, the model below starts with ETL and null imputation, but contains some additional steps: a step to scale the predictor variables (which improves neural network performance), and a hyperband searcher containing the MLP.
```
for step in train_mlp.estimator.steps:
print(step[1])
print('\n')
```
`HyperbandSearchCV` essentially works like `GridSearchCV`. If you want to get the best estimator without all of the extra CV information, you can access it using the `best_estimator_` attribute.
```
train_mlp.estimator.steps[3][1].best_estimator_
```
To see how well the best model performed, you can look at the `best_score_`.
```
train_mlp.estimator.steps[3][1].best_score_
```
And to look at information about the different hyperparameter configurations that were tried, you can look at the `cv_results_`.
```
train_mlp.estimator.steps[3][1].cv_results_
```
Just like any other model in CivisML, we can use hyperband-tuned models to make predictions using `.predict()` on the `ModelPipeline`.
```
predict_mlp = model_mlp.predict(test_data)
predict_mlp.table.head()
```
It looks like this model is predicting the same categories as the models we tried earlier, so we can feel very confident about those predictions.
We're excited to see what problems you solve with these new capabilities. If you have any problems or questions, contact us at support@civisanalytics.com. Happy modeling!
| github_jupyter |
# ML_Model1-- Loan Payment Prediction
### Problem Statement: Produce a supervised machine learning model to predict whether a load will be paid in full or charged off
## Step One: Data processing and cleaning
```
import pandas as pd
import numpy as np
pd.options.display.max_columns = 20
pd.options.display.max_rows = 20
import datetime as dt
# visualization
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import HTML
%matplotlib inline
```
Packages for model build:
```
from sklearn import metrics
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from sklearn.metrics import f1_score, recall_score, precision_score, roc_auc_score
from sklearn.metrics import classification_report, precision_recall_curve, roc_curve, auc
```
Load the data to Pandas:
```
#the uploaded file has low than 25MB, the original has to splitted into two parts
df=pd.read_csv('CaseStudy_Dataset2.csv')
df.head(5)
df.shape
```
Check the column information:
```
list(df.columns)
```
Check the target variable - loan_status by using value_counts():
```
df['loan_status'].value_counts()
```
Usually for loan applications which **didn't meet credit policy**, they should be declined directly before sent to the model.
Although, in this case these loans still had 'Status' information, we **would remove these records from build model and assume these loans won't be processed by the model**
Only keep records which passed credit policy:
```
df=df.loc[df['loan_status'].isin(['Fully Paid', 'Charged Off'])]
df['loan_status'].value_counts()
```
Define a function to check missing values:
```
def missing_values_table(df):
#1 Total missing values
mis_val = df.isnull().sum()
#2 Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
#3 Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
#4 Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
#5 Only keep the columns with missing values
mis_val_table_only = mis_val_table_ren_columns.loc[mis_val_table_ren_columns['% of Total Values'] > 0]
#6 Return the dataframe with missing information
return mis_val_table_only
#Apply the function to our dataframe:
missing=missing_values_table(df)
missing
```
Usually there are three options to deal with missing values:
1. Imputation
2. Create missing flag
3. Drop columns with a high percentage of missing vlaues
We see there are a number of columns with a high percentage of missing values.
There is no well-established threshold for removing missing values,
and the best course of action depends on the problem.
Here, to reduce the number of features, we will remove any columns that have greater than 80% missing rate (in real situations, the threshold can be 98%).
```
# find columns with missing > 80%
missing_columns = list(missing.index[missing['% of Total Values'] > 80])
missing_columns
```
Drop these columns with missing rate > 80%:
```
df2 = df.drop(columns = missing_columns)
missing_values_table(df2)
```
Check duplicates in Pandas:
```
# DataFrame.duplicated(): Return boolean Series denoting duplicate rows
df2.duplicated()
df2.loc[df2.duplicated()]
```
Remove duplicates:
```
# DataFrame.drop_duplicates(): Return DataFrame with duplicate rows removed
# inplace (bool, default False): Whether to drop duplicates in place or to return a copy
df2.drop_duplicates(inplace= True)
df2.shape
```
## Step Two: Exploratory Data Analysis
###### 2.1 Check whether the data is balanced or imbalanced
Practice:
1. Encode the target variable as 1 for 'Charged Off' and 0 for 'Fully Paid':
2. Calculate the charge off rate:
```
df2['target'] = df2['loan_status'].apply(lambda x:1 if x == 'Charged Off' else 0)
df2.target.sum() / df2.shape[0] * 100
```
The data is imbalanced
##### 2.2 Drop Columns May Cause Data Leakge
Data leakage is when information from outside the training dataset is used to create the model. This additional information can allow the model to learn or know something that it otherwise would not know and in turn invalidate the estimated performance of the mode being constructed.
In this case, we want to predict from the client's information whether the loan is "charged off" or "fully paid". The variables about the loan payment can fully infer the status of the loan, which is against the goal of prediction.
```
data_leakage_cols = ['funded_amnt','funded_amnt_inv','total_pymnt','total_pymnt_inv','total_rec_prncp',
'total_rec_int','total_rec_late_fee','recoveries','collection_recovery_fee',
'last_pymnt_amnt','chargeoff_within_12_mths','debt_settlement_flag']
df2.drop(columns=data_leakage_cols, inplace=True)
```
##### 2.3 Explore numerical features
Basic descriptive statistics view:
```
df2.describe()
df2['delinq_amnt'].value_counts()
```
Drop columns with constant values:
- collections_12_mths_ex_med
- tax_liens
- out_prncp
- out_prncp_inv
- delinq_amnt
- acc_now_delinq
```
df2.drop(columns=['collections_12_mths_ex_med','tax_liens','out_prncp','out_prncp_inv','delinq_amnt','acc_now_delinq'], inplace=True)
df2.shape
```
##### 2.5 Explore Categorical features
```
print(df2.info(0))
```
Create a separate DataFrame consisting of only categorical features:
```
df_cat=df2.select_dtypes(include=['object'])
df_cat.head()
```
Drop the target column and create a list with all categorical columns:
```
cat_columns=list(df_cat.drop(columns=['loan_status']).columns)
cat_columns
```
Strip leading and trailing space of each categorical column:
```
for i in cat_columns:
df2[i] = df2[i].str.strip()
```
Quickly explore each each categorical feature and check the frequency:
```
pd.set_option('display.max_columns', None)
df2[cat_columns].head(5)
```
Check frequency:
```
for i in cat_columns:
print(df2[i].value_counts().to_frame())
#for seperate columns:
#df2['emp_title'].value_counts()
```
After the exploratory analysis, we have a few findings:
1. **'desc'** is not relevant to the mdoel build and should be dropped
2. Drop all **date columns** to simplify the model build in this case. If we have more time, we can do some feature engineering by using date features, e.g. df_loan['issue_to_earliest_cr_line'] = df_loan['issue_d'] - df_loan['earliest_cr_line']
3. **'pmnt_plan','hardship_flag','initial_list_status' and 'application_type'** only have constant values and are useless for model build
4. **'emp_title', 'zip_code', and 'title'** have too many unique values and are not informative, we should drop them
5. To simplify the analysis, we only **keep 'grade' and drop 'sub_grade'**
6. Also, some types of information filled in by customer are very difficult to verify (customers can put whatever they want to). To simplify the analysis for this case, we should drop these columns that cann't be easily verified: **'emp_length', 'purpose'**
Finally, we create a list including all categorical columns should be dropped
```
drop_feature=['desc','issue_d','last_pymnt_d','last_credit_pull_d','earliest_cr_line', 'pymnt_plan','hardship_flag', 'emp_title',
'emp_length', 'zip_code','title', 'purpose','sub_grade','initial_list_status','application_type']
# Drop thoes features
df2 = df2.drop(columns=drop_feature)
df2.head(5)
remaining_cat_fea=[i for i in cat_columns if i not in drop_feature]
remaining_cat_fea
```
##### 2.6 Encode remaining categorical features
Convert 'revol_util' into a numerical feature:
```
df2['revol_util'].value_counts()
df2['revol_util'] = df2['revol_util'].str.replace('%', '').astype(float)/100
df2['revol_util'].value_counts()
```
1. Convert 'int_rate' into a numerical feature:
2. Convert 'verification_status' into a numerical feature: if 'Not Verified' then 0, else 1
```
df2['int_rate'] = df2['int_rate'].str.replace('%', '').astype(float)/100
df2['int_rate'].value_counts()
df2['verification_status'].value_counts()
df2['verification_status'] = df2['verification_status'].apply(lambda x: 0 if x == 'Not Verified' else 1)
df2['verification_status'].value_counts()
```
Check remaining categorical features:
```
list(df2.select_dtypes(include=['object']).columns)
```
Remove 'loan_status':
```
df2=df2.drop(columns=['loan_status'])
```
##### 2.7 One-hot encoding for remaining categorical features:
Most machine learning models unfortunately cannot deal with categorical variables
There are two mains to encode categorical variables:
1. **Label encoding**: assign each unique category
in a categorical variable with an integer.
No new columns are created.
2. **One-hot encoding**: create a new column for each unique category in a categorical variable.
Each observation recieves a 1 in the column for its corresponding category and a 0 in all other new columns.
```
def cate_convert(df, nan_as_category = True):
original_columns = list(df.columns)
categorical_columns = [col for col in df.columns if df[col].dtype == 'object']
df = pd.get_dummies(df, columns = categorical_columns, dummy_na= nan_as_category)
new_columns = [c for c in df.columns if c not in original_columns]
return df, new_columns
df2,cat_cols = cate_convert(df2, nan_as_category = True)
df2.head()
```
###### 2.8 Missing value imputation
```
missing=missing_values_table(df2)
missing
df2['pub_rec_bankruptcies'].fillna(value=0,inplace=True)
```
Practice:
1. impute 0 for ['revol_util']'s missing values
1. impute 0 for ['mths_since_last_delinq']'s missing values
```
df2['revol_util'].fillna(value=0,inplace=True)
df2['mths_since_last_delinq'].fillna(value=0,inplace=True)
# Check again:
missing=missing_values_table(df2)
missing
```
Backup the dataset:
```
final=df2.copy()
df2.to_csv('final_dataset_for_model.csv')
```
## Step Three: ML Modelling
###### 3.1 Check Correlations
```
# Display correlations
correlations = final.corr()['target'].dropna().sort_values(ascending = False)
print('Top Positive Correlations:\n', correlations.head(15))
print('\nTop Negative Correlations:\n', correlations.tail(15))
```
##### 3.2 Split into Test and Train datasets
```
x=final.drop(columns='target')
y=final['target']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=0)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
```
###### 3.3 Logistic regression model
1.Create the classifier(object)
```
logist= LogisticRegression()
```
2.Train the model on training data
```
logist.fit(x_train, y_train)
```
3.Make the prediction:
Now that the model has been trained, we can use it to make predictions.
We want to predict the probabilities of not paying a loan, so we use the model **predict_proba** method.
The first column is the probability of the target being 0 and the second column is the probability of the target being 1
```
log_reg_pred = logist.predict_proba(x_test)
y_pred_proba=log_reg_pred[:,1]
y_pred_proba
```
Predict the label:
**.predict()** is for predicting class labels:
scikit-learn is using a threshold of P>0.5 for binary classifications
```
y_pred = logist.predict(x_test)
y_pred
```
Get the coefficient list:
```
coefficients = pd.concat([pd.DataFrame(list(x_train.columns)),pd.DataFrame(np.transpose(logist.coef_))], axis = 1)
coefficients
```
**Check key metrics**
An **ROC curve** is a plot of True Positive Rate vs False Positive Rate where False Positive Rate=FP/(TN+FP) =1-Specificity.
4.Show the ROC_CURVE to evaluate the model performance
```
import numpy as np
[fpr, tpr, thr] = metrics.roc_curve(y_test, y_pred_proba)
idx = np.min(np.where(tpr > 0.95)) # index of the first threshold for which the sensibility > 0.95
plt.figure()
plt.plot(fpr, tpr, color='coral', label='ROC curve (area = %0.3f)' % metrics.auc(fpr, tpr))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot([0, fpr[idx]], [tpr[idx], tpr[idx]], 'k--', color='blue')
plt.plot([fpr[idx], fpr[idx]], [0, tpr[idx]], 'k--', color='blue')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (1 - specificity)', fontsize=14)
plt.ylabel('True Positive Rate (recall)', fontsize=14)
plt.title('Receiver operating characteristic (ROC) curve')
plt.legend(loc="lower right")
plt.show()
```
**AUROC** (Area Under the Receiver Operating Characteristics)
The more the area enclosed by the ROC curve, the better it is. The area under the curve can lie between 0 and 1. The closer it is to 1, the better it is
###### 3.4 Random Forest
**Ensemble learning**, in general, is a model that makes predictions based on a number of different models. By combining individual models, the ensemble model tends to be more flexible (less bias) and less data-sensitive (less variance)
Two most popular ensemble methods are bagging and boosting.
**Bagging**: Training a bunch of individual models in a parallel way. Each model is trained by a random subset of the data => bootstrapping the data plus using the aggregate to make a decision is called bagging!
- **Random forest** is an ensemble model using bagging as the ensemble method and decision tree as the individual model.
**Boosting**: Training a bunch of individual models in a sequential way. Each individual model learns from mistakes made by the previous model
- **Gradient Boosting**: GBT build trees one at a time, where each new tree helps to correct errors made by previously trained tree. GBT build trees one at a time, where each new tree helps to correct errors made by previously trained tree.
1.Create the classifier(object):
```
rf_model = RandomForestClassifier(
n_estimators=200,
max_depth=5)
```
2.Train the model on training data:
```
rf_model.fit(x_train, y_train)
```
3.Make the prediction:
```
rf_model_pred = rf_model.predict_proba(x_test)
y_pred_proba=rf_model_pred[:,1]
y_pred_proba
```
4.Show the ROC_CURVE to evaluate the model performance:
```
import numpy as np
[fpr, tpr, thr] = metrics.roc_curve(y_test, y_pred_proba)
idx = np.min(np.where(tpr > 0.95)) # index of the first threshold for which the sensibility > 0.95
plt.figure()
plt.plot(fpr, tpr, color='coral', label='ROC curve (area = %0.3f)' % metrics.auc(fpr, tpr))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot([0, fpr[idx]], [tpr[idx], tpr[idx]], 'k--', color='blue')
plt.plot([fpr[idx], fpr[idx]], [0, tpr[idx]], 'k--', color='blue')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (1 - specificity)', fontsize=14)
plt.ylabel('True Positive Rate (recall)', fontsize=14)
plt.title('Receiver operating characteristic (ROC) curve')
plt.legend(loc="lower right")
plt.show()
```
Get the feature importances for each feature using the following code:
```
rf_model.feature_importances_
```
Associate these feature importances with the corresponding features:
```
feature_importance_df = pd.DataFrame(list(zip(rf_model.feature_importances_, list(x_train.columns))))
feature_importance_df.columns = ['feature.importance', 'feature']
feature_importance_df.sort_values(by='feature.importance', ascending=False).head(20) # only show top 20
```
| github_jupyter |
```
# Erasmus+ ICCT project (2018-1-SI01-KA203-047081)
# Toggle cell visibility
from IPython.display import HTML
tag = HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide()
} else {
$('div.input').show()
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
Promijeni vidljivost <a href="javascript:code_toggle()">ovdje</a>.''')
display(tag)
%matplotlib notebook
import numpy as np
from scipy.integrate import odeint
import matplotlib.pyplot as plt
import ipywidgets as widgets
```
## Linearizacija - Jednostavno njihalo
Pri radu s modelima sustava, linearizacija je postupak modeliranja nelinearnog sustava s linearnom diferencijalnom jednadžbom u susjedstvu neke radne točke (obično točke ravnoteže). U ovom primjeru taj je postupak demonstriran pomoću jednostavnog njihala. Sila koja uzrokuje oscilacijsko gibanje njihala (prikazano na donjoj slici) definirana je kao $-mgsin\theta$. Jednadžba gibanja njihala definirana je kao:
\begin{equation}
mL^2\frac{d^2\theta}{dt^2}=-mgsin\theta L.
\end{equation}
Nakon sređivanja dobivamo sljedeću nelinearnu diferencijalnu jednadžbu drugog reda:
\begin{equation}
\frac{d^2\theta}{dt^2}+\frac{g}{L}sin\theta=0.
\end{equation}
U slučaju malih kutnih pomaka, vrijedi aproksimacija malog kuta (i.e. $sin\theta\approx\theta$) i dobiva se sljedeća linearna diferencijalna jednadžba drugog reda:
\begin{equation}
\frac{d^2\theta}{dt^2}+\frac{g}{L}\theta=0.
\end{equation}
---
<table>
<tr>
<th style="text-align:center">Jednostavno njihalo</th>
</tr>
<tr>
<td style="width:300px; height:300px"><img src='img/pendulum_hr.png'></td>
</tr>
<tr>
</tr>
</table>
### Kako koristiti ovaj interaktivni primjer?
Pomičite klizače za promjenu duljine njihala $L$ i vrijednosti početnih uvjeta $\theta_0$ i $\dot{\theta_0}$.
```
# create figure
fig = plt.figure(figsize=(9.8, 3),num='Diskretizacija - jednostavno njihalo')
# add sublot
ax = fig.add_subplot(111)
ax.set_title('Vremenski odziv')
ax.set_ylabel('izlaz')
ax.set_xlabel('$t$ [s]')
ax.axhline(y=0, xmin=-1, xmax=6, color='k', linewidth=1)
ax.grid(which='both', axis='both', color='lightgray')
nonlinear, = ax.plot([], [])
linear, = ax.plot([], [])
style = {'description_width': 'initial'}
g=9.81 # m/s^2
def model_nonlinear(ic,t,L):
fi, fidot = ic
return [fidot,-g/L*np.sin(fi)]
def model_linear(ic,t,L):
fi, fidot = ic
return [fidot,-g/L*fi]
def build_model(y0,ypika0,L):
ic=[y0,ypika0]
t=np.linspace(0,5,num=500)
fi=odeint(model_nonlinear,ic,t,args=(L,))
ys=fi[:,0]
fi_linear=odeint(model_linear,ic,t,args=(L,))
ys_linear=fi_linear[:,0]
global nonlinear, linear
ax.lines.remove(nonlinear)
ax.lines.remove(linear)
nonlinear, = ax.plot(t,ys,label='original',color='C0', linewidth=5)
linear, = ax.plot(t,ys_linear,label='linearizacija',color='C3', linewidth=2)
ax.legend()
ax.relim()
ax.autoscale_view()
L_slider=widgets.FloatSlider(value=0.3, min=.01, max=2., step=.01,
description='$L$ [m]:',disabled=False,continuous_update=False,
orientation='horizontal',readout=True,readout_format='.2f',)
ypika0_slider=widgets.FloatSlider(value=1, min=-3, max=3, step=0.1,
description='$\dot \\theta_0$ [rad/s]:',disabled=False,continuous_update=False,
orientation='horizontal',readout=True,readout_format='.2f',)
y0_slider=widgets.FloatSlider(value=1, min=-3, max=3, step=0.1,
description='$\\theta_0$ [rad]:',disabled=False,continuous_update=False,
orientation='horizontal',readout=True,readout_format='.2f',)
input_data=widgets.interactive_output(build_model, {'y0':y0_slider,'ypika0':ypika0_slider,'L':L_slider})
display(L_slider,y0_slider,ypika0_slider,input_data)
```
| github_jupyter |
```
%load_ext watermark
%watermark -d -u -a 'Andreas Mueller, Kyle Kastner, Sebastian Raschka' -v -p numpy,scipy,matplotlib
```
The use of watermark (above) is optional, and we use it to keep track of the changes while developing the tutorial material. (You can install this IPython extension via "pip install watermark". For more information, please see: https://github.com/rasbt/watermark).
2 Jupyter Notebooks
==================
* 按 ``[shift] + [Enter]`` 或点击 "play" 按钮运行.

* 按``[shift] + [tab]`` 获取关于函数和对象的帮助信息

* 也可以加?看帮助信息 ``function?``

## Numpy 数组(Arrays)
对`numpy` 数组(arrays)进行操作是机器学习的一个重要部分,(其实对所有科学计算都是),我们来快速浏览一些最重要的特性。
```
import numpy as np
# 为可复现设置随机种子
rnd = np.random.RandomState(seed=123)
# 生成随机数组
X = rnd.uniform(low=0.0, high=1.0, size=(3, 5)) # a 3 x 5 array
print(X)
```
(注意,像Python中的其他数据结构一样,NumPy数组使用从0开始的索引)
```
# 访问元素
# 得到单个元素
print(X[0, 0])
# 得到一行
# (here: 2nd row)
print(X[1])
# 得到一列
# (here: 2nd column)
print(X[:, 1])
# 矩阵转置
print(X.T)
```
$$\begin{bmatrix}
1 & 2 & 3 & 4 \\
5 & 6 & 7 & 8
\end{bmatrix}^T
=
\begin{bmatrix}
1 & 5 \\
2 & 6 \\
3 & 7 \\
4 & 8
\end{bmatrix}
$$
```
# 创建行向量,按指定元素数均匀分布的数字
y = np.linspace(0, 12, 5)
print(y)
# 将行向量转换为列向量
print(y[:, np.newaxis])
# 获取数组的形状(shape)及整形(reshaping)
# 生成随机数组
rnd = np.random.RandomState(seed=123)
X = rnd.uniform(low=0.0, high=1.0, size=(3, 5)) # a 3 x 5 array
print(X.shape)
print(X.reshape(5, 3))
# 用数组做索引 (索引传递(fancy indexing))
indices = np.array([3, 1, 0])
print(indices)
X[:, indices]
```
要了解的还有很多,这几个操作是我们马上要用到的。
## matplotlib
机器学习的另一个重要部分是数据的可视化。Python这方面最常用的的工具是[`matplotlib`](http://matplotlib.org),这是一个非常灵活的包,我们将在这里复习一些基础知识
在Jupyter notebooks里, 用IPython内置的方便使用的"[magic functions](https://ipython.org/ipython-doc/3/interactive/magics.html)", "matoplotlib inline"模式, 可以直接在笔记本里画图。
```
%matplotlib inline
import matplotlib.pyplot as plt
# 画一条线
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x));
# 散点图
x = np.random.normal(size=500)
y = np.random.normal(size=500)
plt.scatter(x, y);
# 使用imshow显示图
# - 注意,默认情况下,原点位于左上角
x = np.linspace(1, 12, 100)
y = x[:, np.newaxis]
im = y * np.sin(x) * np.cos(y)
print(im.shape)
plt.imshow(im);
im.shape
# 等高线图
# - 注意,默认情况下,原点位于左下角
plt.contour(im);
# 3D图
from mpl_toolkits.mplot3d import Axes3D
ax = plt.axes(projection='3d')
xgrid, ygrid = np.meshgrid(x, y.ravel())
ax.plot_surface(xgrid, ygrid, im, cmap=plt.cm.jet, cstride=2, rstride=2, linewidth=0);
```
还有更多的绘图类型可用。可以在[matplotlib gallery](http://matplotlib.org/gallery.html)进一步探索.
可以在notebook里很容易地测试这些例子:只需要把``源码``链接简单复制每一页,然后用``%load``魔法指令加载。
例如:
```
%load http://matplotlib.org/mpl_examples/pylab_examples/ellipse_collection.py
%load https://matplotlib.org/mpl_examples/shapes_and_collections/scatter_demo.py
```
| github_jupyter |
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Guia inicial de TensorFlow 2.0 para expertos
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/tutorials/quickstart/advanced"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />Ver en TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/es-419/tutorials/quickstart/advanced.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Ejecutar en Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/docs-l10n/blob/master/site/es-419/tutorials/quickstart/advanced.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />Ver codigo en GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/docs-l10n/site/es-419/tutorials/quickstart/advanced.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Descargar notebook</a>
</td>
</table>
Note: Nuestra comunidad de Tensorflow ha traducido estos documentos. Como las traducciones de la comunidad
son basados en el "mejor esfuerzo", no hay ninguna garantia que esta sea un reflejo preciso y actual
de la [Documentacion Oficial en Ingles](https://www.tensorflow.org/?hl=en).
Si tienen sugerencias sobre como mejorar esta traduccion, por favor envian un "Pull request"
al siguiente repositorio [tensorflow/docs](https://github.com/tensorflow/docs).
Para ofrecerse como voluntario o hacer revision de las traducciones de la Comunidad
por favor contacten al siguiente grupo [docs@tensorflow.org list](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs).
Este es un notebook de Google Colaboratory. Los programas de Python se executan directamente en tu navegador —una gran manera de aprender y utilizar TensorFlow. Para poder seguir este tutorial, ejecuta este notebook en Google Colab presionando el boton en la parte superior de esta pagina.
En Colab, selecciona "connect to a Python runtime": En la parte superior derecha de la barra de menus selecciona: CONNECT.
Para ejecutar todas las celdas de este notebook: Selecciona Runtime > Run all.
Descarga e installa el paquete TensorFlow 2.0 version.
Importa TensorFlow en tu programa:
Import TensorFlow into your program:
```
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
```
Carga y prepara el conjunto de datos [MNIST](http://yann.lecun.com/exdb/mnist/)
```
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Agrega una dimension de canales
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
```
Utiliza `tf.data` to separar por lotes y mezclar el conjunto de datos:
```
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
```
Construye el modelo `tf.keras` utilizando la API de Keras [model subclassing API](https://www.tensorflow.org/guide/keras#model_subclassing):
```
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
# Crea una instancia del modelo
model = MyModel()
```
Escoge un optimizador y una funcion de perdida para el entrenamiento de tu modelo:
```
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
```
Escoge metricas para medir la perdida y exactitud del modelo.
Estas metricas acumulan los valores cada epoch y despues imprimen el resultado total.
```
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
```
Utiliza `tf.GradientTape` para entrenar el modelo.
```
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
```
Prueba el modelo:
```
@tf.function
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
template = 'Epoch {}, Perdida: {}, Exactitud: {}, Perdida de prueba: {}, Exactitud de prueba: {}'
print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reinicia las metricas para el siguiente epoch.
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
```
El model de clasificacion de images fue entrenado y alcanzo una exactitud de ~98% en este conjunto de datos. Para aprender mas, lee los [tutoriales de TensorFlow](https://www.tensorflow.org/tutorials).
| github_jupyter |
```
from sklearn.cluster import KMeans
import sys
import json
import numpy as np
from sklearn import decomposition
import matplotlib.pyplot as plt
import random
from collections import defaultdict
import seaborn as sns
import matplotlib.pyplot as plt
import math
TWEETER_FEEDS = [
'nytimes', 'thesun', 'thetimes', 'ap', 'cnn']
# 'cnn', 'bbcnews', 'cnet', 'msnuk', 'telegraph']
extracting_fields = ['favorite_count', 'coordinates', 'favorited', 'possibly_sensitive', 'retweet_count',
'retweeted', 'retweeted_status', 'entities']
tweets = []
feed_names = []
fields_dict = defaultdict(list)
for feed in TWEETER_FEEDS:
idx = 0
tweet_data = open('/Users/lukekumar/Documents/Twitter-App/downloaded_tweets/'+feed+'-tweet.json', 'r')
for line in tweet_data:
data_dict = json.loads(line)
# print '\n'.join(np.unique(data_dict.keys()))
fields_dict['favorite_count'].append(int(data_dict['favorite_count']) if data_dict.get('favorite_count') is not None else 0)
fields_dict['favorited'].append(bool(data_dict['favorited']) if data_dict.get('favorited') is not None else False)
fields_dict['possibly_sensitive'].append(bool(data_dict['favorited']) if data_dict.get('possibly_sensitive') is not None else False)
fields_dict['retweet_count'].append(int(data_dict['retweet_count']))
fields_dict['retweet_count_ln'].append(math.log(int(data_dict['retweet_count'])+1))
fields_dict['retweeted'].append(bool(data_dict['retweeted']))
fields_dict['retweeted_status'].append(1 if data_dict.get('retweeted_status') is not None else 0)
entities_encode = [0, 0, 0]
if len(data_dict['entities']['hashtags']) > 0:
entities_encode[0] = 1
if len(data_dict['entities']['urls']) > 0:
entities_encode[1] = 1
if len(data_dict['entities']['user_mentions']) > 0:
entities_encode[2] = 1
fields_dict['entities'].append(entities_encode)
tweets.append(data_dict['text'])
feed_names.append(data_dict['user']['screen_name'])
tweet_data.close()
fields_dict.keys()
hist, bins = np.histogram(fields_dict['retweet_count'], bins=25)
width = 0.7 * (bins[1] - bins[0])
center = (bins[:-1] + bins[1:]) / 2
plt.bar(center, hist, align='center', width=width)
plt.title("Feature: retweet_count")
plt.show()
hist, bins = np.histogram(fields_dict['retweet_count_ln'], bins=25)
width = 0.7 * (bins[1] - bins[0])
center = (bins[:-1] + bins[1:]) / 2
plt.bar(center, hist, align='center', width=width)
plt.title("Feature: retweet_count_ln")
plt.show()
fields_dict.keys()
X = pd.DataFrame()
X['favorited'] = fields_dict['favorited']
X['retweeted_status'] = fields_dict['retweeted_status']
X['retweeted'] = fields_dict['retweeted']
X['entities_h'] = map(lambda x:x[0], fields_dict['entities'])
X['entities_u'] = map(lambda x:x[0], fields_dict['entities'])
X['entities_m'] = map(lambda x:x[0], fields_dict['entities'])
X['favorite_count'] = fields_dict['favorite_count']
X['possibly_sensitive'] = fields_dict['possibly_sensitive']
y = pd.DataFrame()
y['target'] = fields_dict['retweet_count_ln']
X.shape
X.dtypes
y.dtypes
from sklearn.ensemble import RandomForestRegressor
#from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from scipy import interp
import matplotlib.pyplot as plt
#Set Seed to avoid changes based on Randomness
np.random.seed(123456)
from time import time
n_samples, n_features = X.shape
print "num features: ", n_features
print "avg Y: ", np.mean(y)
RANDOM_STATE = None
kf = KFold(n_splits = 5, random_state = RANDOM_STATE, shuffle = True)
# Range of Features
max_feature_range = range(1, int(np.floor(np.sqrt(n_features))), 2) + \
range(int(np.floor(np.sqrt(n_features))), n_features, 2)
max_feature_range = [6] #['auto'] #[int(np.floor(np.sqrt(n_features)))]
print "max_feature range: ", max_feature_range
# Range Trees
min_tree = 100
max_tree = 100
delta = 1
print 'num trees: ', range(min_tree, max_tree+1, delta)
depth_range = [5, 10, 15, 20, 25, 50, None]
depth_range = [5]# [None]
print "depth: ", depth_range
#Parrellel Job
num_jobs = 100
def run_grid_search(X, y):
results = pd.DataFrame(columns=['max_features', 'max_depth', 'n_estimators', 'time',\
'mean-mse', 'std-mse', 'train_oob_error'])
index = 0
for max_features in max_feature_range:
for max_depth in depth_range:
for num_trees in range(min_tree, max_tree+1, delta):
rf = RandomForestRegressor(criterion='mse', n_jobs = num_jobs, oob_score = True, \
n_estimators = num_trees, max_features = max_features, \
min_samples_split = 2, max_depth = max_depth)
#rf = LogisticRegression(class_weight='balanced', max_iter=1000)
#skf = StratifiedKFold(y, 5, shuffle=True)
lst_mse = []
lst_oob_error = []
lst_predictions = []
lst_labels = []
start = time()
for train_index, test_index in kf.split(X):
X_train, X_test = X.loc[train_index], X.loc[test_index]
y_train, y_test = y.loc[train_index], y.loc[test_index]
# print "train: ", X_train.shape, "\ttest: ", X_test.shape
rf.fit(X_train, y_train)
prediction = rf.predict(X_test)
lst_predictions += prediction.tolist()
lst_labels += y_test.values.tolist()
lst_oob_error.append(1 - rf.oob_score_)
lst_mse.append(mean_squared_error(y_test, prediction))
end = time()
print 'max_features =', max_features, 'max_depth =', max_depth, 'n_estimators =', num_trees,\
'mean-mse: ', np.mean(lst_mse)
results.loc[index] = [max_features, max_depth, num_trees, end-start, np.mean(lst_mse), \
np.std(lst_mse), np.mean(lst_oob_error)]
index = index + 1
return results, lst_predictions, lst_labels
NewX = X.copy()
print NewX.columns
res, pred, label = run_grid_search(NewX.copy(), y.copy())
res
plt.plot(label[0:1000], color='b')
plt.plot(pred[0:1000], color='g')
plt.show()
NewX = X.copy()
print NewX.columns
#res = run_grid_search(NewX.copy(), y.copy())
res
```
| github_jupyter |
# Facies classification using machine learning techniques
Copy of <a href="https://home.deib.polimi.it/bestagini/">Paolo Bestagini's</a> "Try 2", augmented, by Alan Richardson (Ausar Geophysical), with an ML estimator for PE in the wells where it is missing (rather than just using the mean).
In the following, we provide a possible solution to the facies classification problem described at https://github.com/seg/2016-ml-contest.
The proposed algorithm is based on the use of random forests combined in one-vs-one multiclass strategy. In particular, we would like to study the effect of:
- Robust feature normalization.
- Feature imputation for missing feature values.
- Well-based cross-validation routines.
- Feature augmentation strategies.
## Script initialization
Let us import the used packages and define some parameters (e.g., colors, labels, etc.).
```
# Import
from __future__ import division
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (20.0, 10.0)
inline_rc = dict(mpl.rcParams)
from classification_utilities import make_facies_log_plot
import pandas as pd
import numpy as np
#import seaborn as sns
from sklearn import preprocessing
from sklearn.model_selection import LeavePGroupsOut
from sklearn.metrics import f1_score
from sklearn.multiclass import OneVsOneClassifier
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from scipy.signal import medfilt
import sys, scipy, sklearn
print('Python: ' + sys.version.split('\n')[0])
print(' ' + sys.version.split('\n')[1])
print('Pandas: ' + pd.__version__)
print('Numpy: ' + np.__version__)
print('Scipy: ' + scipy.__version__)
print('Sklearn: ' + sklearn.__version__)
# Parameters
feature_names = ['GR', 'ILD_log10', 'DeltaPHI', 'PHIND', 'PE', 'NM_M', 'RELPOS']
facies_names = ['SS', 'CSiS', 'FSiS', 'SiSh', 'MS', 'WS', 'D', 'PS', 'BS']
facies_colors = ['#F4D03F', '#F5B041','#DC7633','#6E2C00', '#1B4F72','#2E86C1', '#AED6F1', '#A569BD', '#196F3D']
```
## Load data
Let us load training data and store features, labels and other data into numpy arrays.
```
# Load data from file
data = pd.read_csv('../facies_vectors.csv')
# Store features and labels
X = data[feature_names].values # features
y = data['Facies'].values # labels
# Store well labels and depths
well = data['Well Name'].values
depth = data['Depth'].values
```
## Data inspection
Let us inspect the features we are working with. This step is useful to understand how to normalize them and how to devise a correct cross-validation strategy. Specifically, it is possible to observe that:
- Some features seem to be affected by a few outlier measurements.
- Only a few wells contain samples from all classes.
- PE measurements are available only for some wells.
```
# Define function for plotting feature statistics
def plot_feature_stats(X, y, feature_names, facies_colors, facies_names):
# Remove NaN
nan_idx = np.any(np.isnan(X), axis=1)
X = X[np.logical_not(nan_idx), :]
y = y[np.logical_not(nan_idx)]
# Merge features and labels into a single DataFrame
features = pd.DataFrame(X, columns=feature_names)
labels = pd.DataFrame(y, columns=['Facies'])
for f_idx, facies in enumerate(facies_names):
labels[labels[:] == f_idx] = facies
data = pd.concat((labels, features), axis=1)
# Plot features statistics
facies_color_map = {}
for ind, label in enumerate(facies_names):
facies_color_map[label] = facies_colors[ind]
sns.pairplot(data, hue='Facies', palette=facies_color_map, hue_order=list(reversed(facies_names)))
# Feature distribution
# plot_feature_stats(X, y, feature_names, facies_colors, facies_names)
# mpl.rcParams.update(inline_rc)
# Facies per well
for w_idx, w in enumerate(np.unique(well)):
ax = plt.subplot(3, 4, w_idx+1)
hist = np.histogram(y[well == w], bins=np.arange(len(facies_names)+1)+.5)
plt.bar(np.arange(len(hist[0])), hist[0], color=facies_colors, align='center')
ax.set_xticks(np.arange(len(hist[0])))
ax.set_xticklabels(facies_names)
ax.set_title(w)
# Features per well
for w_idx, w in enumerate(np.unique(well)):
ax = plt.subplot(3, 4, w_idx+1)
hist = np.logical_not(np.any(np.isnan(X[well == w, :]), axis=0))
plt.bar(np.arange(len(hist)), hist, color=facies_colors, align='center')
ax.set_xticks(np.arange(len(hist)))
ax.set_xticklabels(feature_names)
ax.set_yticks([0, 1])
ax.set_yticklabels(['miss', 'hit'])
ax.set_title(w)
```
## Feature imputation
Let us fill missing PE values. This is the only cell that differs from the approach of Paolo Bestagini. Currently no feature engineering is used, but this should be explored in the future.
```
def make_pe(X, seed):
reg = RandomForestRegressor(max_features='sqrt', n_estimators=50, random_state=seed)
DataImpAll = data[feature_names].copy()
DataImp = DataImpAll.dropna(axis = 0, inplace=False)
Ximp=DataImp.loc[:, DataImp.columns != 'PE']
Yimp=DataImp.loc[:, 'PE']
reg.fit(Ximp, Yimp)
X[np.array(DataImpAll.PE.isnull()),4] = reg.predict(DataImpAll.loc[DataImpAll.PE.isnull(),:].drop('PE',axis=1,inplace=False))
return X
```
## Feature augmentation
Our guess is that facies do not abrutly change from a given depth layer to the next one. Therefore, we consider features at neighboring layers to be somehow correlated. To possibly exploit this fact, let us perform feature augmentation by:
- Aggregating features at neighboring depths.
- Computing feature spatial gradient.
```
# Feature windows concatenation function
def augment_features_window(X, N_neig):
# Parameters
N_row = X.shape[0]
N_feat = X.shape[1]
# Zero padding
X = np.vstack((np.zeros((N_neig, N_feat)), X, (np.zeros((N_neig, N_feat)))))
# Loop over windows
X_aug = np.zeros((N_row, N_feat*(2*N_neig+1)))
for r in np.arange(N_row)+N_neig:
this_row = []
for c in np.arange(-N_neig,N_neig+1):
this_row = np.hstack((this_row, X[r+c]))
X_aug[r-N_neig] = this_row
return X_aug
# Feature gradient computation function
def augment_features_gradient(X, depth):
# Compute features gradient
d_diff = np.diff(depth).reshape((-1, 1))
d_diff[d_diff==0] = 0.001
X_diff = np.diff(X, axis=0)
X_grad = X_diff / d_diff
# Compensate for last missing value
X_grad = np.concatenate((X_grad, np.zeros((1, X_grad.shape[1]))))
return X_grad
# Feature augmentation function
def augment_features(X, well, depth, seed=None, pe=True, N_neig=1):
seed = seed or None
if pe:
X = make_pe(X, seed)
# Augment features
X_aug = np.zeros((X.shape[0], X.shape[1]*(N_neig*2+2)))
for w in np.unique(well):
w_idx = np.where(well == w)[0]
X_aug_win = augment_features_window(X[w_idx, :], N_neig)
X_aug_grad = augment_features_gradient(X[w_idx, :], depth[w_idx])
X_aug[w_idx, :] = np.concatenate((X_aug_win, X_aug_grad), axis=1)
# Find padded rows
padded_rows = np.unique(np.where(X_aug[:, 0:7] == np.zeros((1, 7)))[0])
return X_aug, padded_rows
# Augment features
X_aug, padded_rows = augment_features(X, well, depth)
```
## Generate training, validation and test data splits
The choice of training and validation data is paramount in order to avoid overfitting and find a solution that generalizes well on new data. For this reason, we generate a set of training-validation splits so that:
- Features from each well belongs to training or validation set.
- Training and validation sets contain at least one sample for each class.
```
# Initialize model selection methods
lpgo = LeavePGroupsOut(2)
# Generate splits
split_list = []
for train, val in lpgo.split(X, y, groups=data['Well Name']):
hist_tr = np.histogram(y[train], bins=np.arange(len(facies_names)+1)+.5)
hist_val = np.histogram(y[val], bins=np.arange(len(facies_names)+1)+.5)
if np.all(hist_tr[0] != 0) & np.all(hist_val[0] != 0):
split_list.append({'train':train, 'val':val})
# Print splits
for s, split in enumerate(split_list):
print('Split %d' % s)
print(' training: %s' % (data['Well Name'][split['train']].unique()))
print(' validation: %s' % (data['Well Name'][split['val']].unique()))
```
## Classification parameters optimization
Let us perform the following steps for each set of parameters:
- Select a data split.
- Normalize features using a robust scaler.
- Train the classifier on training data.
- Test the trained classifier on validation data.
- Repeat for all splits and average the F1 scores.
At the end of the loop, we select the classifier that maximizes the average F1 score on the validation set. Hopefully, this classifier should be able to generalize well on new data.
```
# Parameters search grid (uncomment parameters for full grid search... may take a lot of time)
N_grid = [100] # [50, 100, 150]
M_grid = [10] # [5, 10, 15]
S_grid = [25] # [10, 25, 50, 75]
L_grid = [5] # [2, 3, 4, 5, 10, 25]
param_grid = []
for N in N_grid:
for M in M_grid:
for S in S_grid:
for L in L_grid:
param_grid.append({'N':N, 'M':M, 'S':S, 'L':L})
# Train and test a classifier
def train_and_test(X_tr, y_tr, X_v, well_v, clf):
# Feature normalization
scaler = preprocessing.RobustScaler(quantile_range=(25.0, 75.0)).fit(X_tr)
X_tr = scaler.transform(X_tr)
X_v = scaler.transform(X_v)
# Train classifier
clf.fit(X_tr, y_tr)
# Test classifier
y_v_hat = clf.predict(X_v)
# Clean isolated facies for each well
for w in np.unique(well_v):
y_v_hat[well_v==w] = medfilt(y_v_hat[well_v==w], kernel_size=5)
return y_v_hat
# For each set of parameters
# score_param = []
# for param in param_grid:
# # For each data split
# score_split = []
# for split in split_list:
# # Remove padded rows
# split_train_no_pad = np.setdiff1d(split['train'], padded_rows)
# # Select training and validation data from current split
# X_tr = X_aug[split_train_no_pad, :]
# X_v = X_aug[split['val'], :]
# y_tr = y[split_train_no_pad]
# y_v = y[split['val']]
# # Select well labels for validation data
# well_v = well[split['val']]
# # Train and test
# y_v_hat = train_and_test(X_tr, y_tr, X_v, well_v, param)
# # Score
# score = f1_score(y_v, y_v_hat, average='micro')
# score_split.append(score)
# # Average score for this param
# score_param.append(np.mean(score_split))
# print('F1 score = %.3f %s' % (score_param[-1], param))
# # Best set of parameters
# best_idx = np.argmax(score_param)
# param_best = param_grid[best_idx]
# score_best = score_param[best_idx]
# print('\nBest F1 score = %.3f %s' % (score_best, param_best))
```
## Predict labels on test data
Let us now apply the selected classification technique to test data.
```
param_best = {'S': 25, 'M': 10, 'L': 5, 'N': 100}
# Load data from file
test_data = pd.read_csv('../validation_data_nofacies.csv')
# Prepare test data
well_ts = test_data['Well Name'].values
depth_ts = test_data['Depth'].values
X_ts = test_data[feature_names].values
y_pred = []
print('o' * 100)
for seed in range(100):
np.random.seed(seed)
# Make training data.
X_train, padded_rows = augment_features(X, well, depth, seed=seed)
y_train = y
X_train = np.delete(X_train, padded_rows, axis=0)
y_train = np.delete(y_train, padded_rows, axis=0)
param = param_best
clf = OneVsOneClassifier(RandomForestClassifier(n_estimators=param['N'], criterion='entropy',
max_features=param['M'], min_samples_split=param['S'], min_samples_leaf=param['L'],
class_weight='balanced', random_state=seed), n_jobs=-1)
# Make blind data.
X_test, _ = augment_features(X_ts, well_ts, depth_ts, seed=seed, pe=False)
# Train and test.
y_ts_hat = train_and_test(X_train, y_train, X_test, well_ts, clf)
# Collect result.
y_pred.append(y_ts_hat)
print('.', end='')
np.save('100_realizations.npy', y_pred)
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
# BIKES
```
day = pd.read_csv("data/day.csv")
data = day.drop(["dteday", "instant", "casual", 'registered', 'cnt', 'yr'], axis=1)
data.columns
data_raw = data.copy()
data.season = data.season.map({1: "spring", 2: "summer", 3: "fall", 4: 'winter'})
data.weathersit = data.weathersit.map({1: "clear, partly cloudy", 2: 'mist, cloudy', 3: 'light snow, light rain', 4:'heavy rain, snow and fog'})
data.mnth = pd.to_datetime(data.mnth, format="%m").dt.strftime("%b")
data.weekday = pd.to_datetime(data.weekday, format="%w").dt.strftime("%a")
data_dummies = pd.get_dummies(data, columns=['season', 'mnth', 'weekday', 'weathersit'])
data_dummies.head()
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data_raw.values, day.cnt.values, random_state=0)
from sklearn.linear_model import RidgeCV
ridge = RidgeCV().fit(X_train, y_train)
from sklearn.metrics import r2_score
ridge.score(X_train, y_train)
ridge.score(X_test, y_test)
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor(max_depth=5).fit(X_train, y_train)
print(tree.score(X_train, y_train))
print(tree.score(X_test, y_test))
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor(n_estimators=500).fit(X_train, y_train)
print(forest.score(X_train, y_train))
print(forest.score(X_test, y_test))
data_raw.cnt = day.cnt
data_dummies.cnt = day.cnt
data_raw.to_csv("data/bike_day_raw.csv", index=None)
data_dummies.to_csv("data/bike_day_dummies.csv", index=None)
```
# LOANS
```
data = pd.read_csv("data/loan.csv")[::23]
data.shape
data.head()
counts = data.notnull().sum(axis=0).sort_values(ascending=False)
columns = counts[:52].index
data = data[columns]
data = data.dropna()
data.head()
bad_statuses = ["Charged Off ", "Default", "Does not meet the credit policy. Status:Charged Off", "In Grace Period",
"Default Receiver", "Late (16-30 days)", "Late (31-120 days)"]
data['bad_status'] = data.loan_status.isin(bad_statuses)
data = data.drop(["url", "title", "id", "emp_title", "loan_status"], axis=1)
data.columns
data.dtypes
data.purpose.value_counts()
float_columns = data.dtypes[data.dtypes == "float64"].index
data_float = data[float_columns]
data_float.shape
X = data_float.values
y = data.bad_status.values
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LogisticRegression()
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
lr.coef_.shape
plt.figure(figsize=(8, 8))
plt.barh(range(X.shape[1]), lr.coef_.ravel())
plt.yticks(np.arange(X.shape[1]) + .5, data_float_hard.columns.tolist(), va="center");
data_float_hard = data_float.drop(['total_rec_late_fee', "revol_util"], axis=1)
X = data_float_hard.values
```
# SHELTER ANIMALS
```
train = pd.read_csv("data/shelter_train.csv")
test = pd.read_csv("data/shelter_test.csv")
train.head()
```
# Bank marketing
```
data = pd.read_csv("data/bank-additional/bank-additional-full.csv", sep=";")
data.head()
data.job.value_counts()
data.columns
data.dtypes
target = data.y
data = data.drop("y", axis=1)
bla = pd.get_dummies(data)
bla.columns
X = bla.values
y = target.values
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LogisticRegression()
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
plt.figure(figsize=(10, 12))
plt.barh(range(X.shape[1]), lr.coef_.ravel())
plt.yticks(np.arange(X.shape[1]) + .5, bla.columns.tolist(), va="center");
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100).fit(X_train, y_train)
rf.score(X_train, y_train)
rf.score(X_test, y_test)
bla['target'] = target
bla.to_csv("data/bank-campaign.csv", index=None)
```
| github_jupyter |
# Replication of Angrist (1990): Lifetime earnings and the Vietnam era draft lottery: Evidence from social security administrative records
Project by [Pascal Heid](https://github.com/Pascalheid), Summer 2020.
```
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from auxiliary.auxiliary_figures import get_figure1, get_figure2, get_figure3
from auxiliary.auxiliary_tables import (
get_table1,
get_table2,
get_table3,
get_table4,
)
from auxiliary.auxiliary_data import process_data
from auxiliary.auxiliary_visuals import background_negative_green, p_value_star
from auxiliary.auxiliary_extensions import (
get_flexible_table4,
get_figure1_extension1,
get_figure2_extension1,
get_bias,
get_figure1_extension2,
get_figure2_extension2,
)
import warnings
warnings.filterwarnings("ignore")
plt.rcParams["figure.figsize"] = [12, 6]
```
This notebook replicates the core results of the following paper:
> Angrist, Joshua. (1990). [Lifetime Earnings and the Vietnam Era Draft Lottery: Evidence from Social Security Administrative Records](https://www.jstor.org/stable/2006669?seq=1#metadata_info_tab_contents). *American Economic Review*. 80. 313-36.
In the following just a few notes on how to read the remainder:
- In this excerpt I replicate the Figures 1 to 3 and the Tables 1 to 4 (in some extended form) while I do not consider Table 5 to be a core result of the paper which is why it cannot be found in this notebook.
- I follow the example of Angrist keeping his structure throughout the replication part of this notebook.
- The naming and order of appearance of the figures does not follow the original paper but the published [correction](https://economics.mit.edu/files/7769).
- The replication material including the partially processed data as well as some replication do-files can be found [here](https://economics.mit.edu/faculty/angrist/data1/data/angrist90).
## 1. Introduction
For a soft introduction to the topic, let us have a look at the goal of Angrist's article. Already in the first few lines Angrist states a clear-cut aim for his paper by making the remark that "yet, academic research has not shown conclusively that Vietnam (or other) veterans are worse off economically than nonveterans". He further elaborates on why research had yet been so inconclusive. He traces it back to the flaw that previous research had solely tried to estimate the effect of veteran status on subsequent earnings by comparing the latter across individuals differing in veteran status. He argues that this naive estimate might likely be biased as it is easily imaginable that specific types of men choose to enlist in the army whose unobserved characteristics imply low civilian earnings (self-selcetion on unobservables).
Angrist avoids this pitfall by employing an instrumental variable strategy to obtain unbiased estimates of the effect of veteran status on earnings. For that he exploits the random nature of the Vietnam draft lottery. This lottery randomly groups people into those that are eligible to be forced to join the army and those that are not. The idea is that this randomly affects the veteran status without being linked to any unobserved characteristics that cause earnings. This allows Angrist to obtain an estimate of the treatment effect that does not suffer from the same shortcomings as the ones of previous studies.
He finds that Vietnam era veterans are worse off when it comes to long term annual real earnings as opposed to those that have not served in the army. In a secondary point he traces this back to the loss of working experience for veterans due to their service by estimating a simple structural model.
In the following sections I first walk you through the identification idea and empirical strategy. Secondly, I replicate and explain the core findings of the paper with a rather extensive elaboration on the different data sources used and some additional visualizations. Thirdly, I critically assess the paper followed by my own two extensions concluding with some overall remarks right after.
## 2. Identification and Empirical Approach
As already mentioned above the main goal of Angrist's paper is to determine the causal effect of veteran status on subsequent earnings. He believes for several reasons that conventional estimates that only compare earnings by veteran status are biased due to unobservables that affect both the probability of serving in the military as well as earnings over lifetime. This is conveniently shown in the causal graph below. Angrist names two potential reasons why this might be likely. First of all, he makes the point that probably people with few civilian opportunities (lower expected earnings) are more likely to register for the army. Without a measure for civilian opportunities at hand a naive estimate of the effect of military service on earnings would not be capable of capturing the causal effect. Hence, he believes that there is probably some self-selection into treatment on unobservables by individuals. In a second point, Angrist states that the selection criteria of the army might be correlated with unobserved characteristics of individuals that makes them more prone to receiving future earnings pointing into a certain direction.
Econometrically spoken, Angrist argues with the following linear regression equation representing a version of the right triangle in the causal graph:
\begin{aligned}
y_{cti} = \beta_c + \delta_t + s_i \alpha + u_{it}.
\end{aligned}
He argues that estimating the above model with the real earnings $y_{cti}$ for an individual $i$ in cohort $c$ at time $t$ being determined by cohort and time fixed effects ($\beta_c$ and $\delta_t$) as well an individual effect for veteran status is biased. This is for the above given reasons that the indicator for veteran status $s_i$ is likely to be correlated with the error term $u_{it}$.
Angrist's approach to avoid bias is now to employ an instrumental variable approach which is based on the accuracy of the causal graph below.
<div>
<img src="material/fig-angrist-1990-valid.png" width="600"/>
</div>
The validity of this causal graph rests on the crucial reasoning that there is no common cause of the instrument (Draft Lottery) and the unobserved variables (U). Angrist provides the main argument that the draft lottery was essentially random in nature and hence is not correlated with any personal characteristics and therefore not linked to any unobservables that might determine military service and earnings. As will be later explained in more detail, the Vietnam draft lottery determined randomly on the basis of the birth dates whether a person is eligible to be drafted by the army in the year following the lottery. The directed graph from Draft Lottery to Military Service is therefore warranted as the fact of having a lottery number rendering a person draft-eligible increases the probability of joining the military as opposed to a person that has an excluded lottery number.
This argumentation leads Angrist to use the probability of being a veteran conditional on being draft-eligible in the lottery as an instrument for the effect of veteran status on earnings. In essence this is the Wald estimate which is equal to the following formula:
\begin{aligned}
\hat{\alpha}_{IV, WALD} = \frac{E[earnings \mid eligible = 1] - E[earnings \mid eligible = 0]}{E[veteran \mid eligible = 1] - E[veteran \mid eligible = 0]}
\end{aligned}
The nominator equals to the estimated $\alpha$ from equation (1) while the denominator can be obtained by a first stage regression which regresses veteran status on draft-eligibility. It reduces to estimating the difference in conditional probabilities of being a veteran $prob(veteran \mid eligible = 1) - prob(veteran \mid eligible = 0)$. Estimates for this are obtained by Angrist through weighted least squares (WLS). This is done as Angrist does not have micro data but just grouped data (for more details see the data section in the replication). In order to obtain the estimates of the underlying micro level data it is necessary to adjust OLS by the size of the respective groups as weights. The above formula is also equivalent to a Two Stage Least Squares (2SLS) procedure in which earnings are regressed on the fitted values from a first stage regression of veteran status on eligibility.
In a last step, Angrist generalizes the Wald grouping method to more than just one group as instrument. There are 365 lottery numbers that were split up into two groups (eligible and non-eligible) for the previous Wald estimate. Those lottery numbers can also be split up even further into many more subgroups than just two, resulting in many more dummy variables as instruments. Angrist splits the lottery numbers into intervals of five which determine a group $j$. By cohort $c$ he estimates for each group $j$ the conditional probability of being a veteran $p_{cj}$. This first stage is again run by WLS. The resulting estimate $\hat p_{cj}$ is then used to conduct the second stage regression below.
\begin{aligned}
\bar y_{ctj} = \beta_c + \delta_t + \hat p_{cj} \alpha + \bar u_{ctj}
\end{aligned}
The details and estimation technique will be further explained when presenting the results in the replication section below.
## 3. Replication
### 3.1 Background and Data
### The Vietnam Era Draft Lottery
Before discussing how the data looks like it is worthwhile to understand how the Vietnam era draft lottery was working in order to determine to which extent it might actually serve as a valid instrument. During the Vietnam war there were several draft lotteries. They were held in the years from 1970 to 1975. The first one took place at the end of 1969 determining which men might be drafted in the following year. This procedure of determining the lottery numbers for the following year continued until 1975. The table below shows for which years there were lotteries drawn and which birth years were affected by them in the respective year. For more details have a look [here](https://www.sss.gov/history-and-records/vietnam-lotteries/).
| **Year** | **Cohorts** | **Draft-Eligibility Ceiling**|
|--------------|---------------|------------------------------|
| 1970 | 1944-50 | 195 |
| 1971 | 1951 | 125 |
| 1972 | 1952 | 95 |
| 1973 | 1953 | 95 |
| 1974 | 1954 | 95 |
| 1975 | 1955 | 95 |
| 1976 | 1956 | 95 |
The authority of drafting men for the army through the lottery expired on June 30, 1973 and already before no one was drafted anymore. The last draft call took place on December 7, 1972.
The general functioning of those seven lotteries was that every possible birthday (365 days) was randomly assigned a number between 1 and 365 without replacement. Taking the 1969 lottery this meant that the birthdate that had the number 1 assigned to, it caused every man born on that day in the years 1944 to 1950 to be drafted first if it came to a draft call in the year 1970. In practice, later in the same year of the draft lottery, the army announced draft-eligibility ceilings determining up to which draft lottery number was called in the following year. In 1970, this means that every man having a lottery number of below 195 was called to join the army. As from 1973 on nobody was called anymore, the numbers for the ceiling are imputed from the last observed one which was 95 in the year 1972. Men with lottery numbers below the ceiling for their respective year are from here on called "draft-eligible".
Being drafted did not mean that one actually had to serve in the army, though. Those drafted had to pass mental and physical tests which in the end decided who had to join. Further it should be mentioned that Angrist decides to only use data on those that turned 19 when being at risk of induction which includes men born between 1950 and 1953.
### The Data
#### Continuous Work History Sample (CWHS)
This administrative data set constitutes a random one percent sample draw of all possible social security numbers in the US. For the years from 1964 until 1984 it includes the **FICA** (social security) earnings history censored to the Social Security maximum taxable amount. It further includes FICA taxable earnings from self-employment. For the years from 1978 on it also has a series on total earnings (**Total W-2**) including for instance cash payments but excluding earnings from self-employment. This data set has some confidentiality restrictions which means that only group averages and variances were available. This means that Angrist cannot rely on micro data but has to work with sample moment which is a crucial factor for the exact implementation of the IV method. A group is made of by year of earnings, year of birth, ethnicity and five consecutive lottery numbers. The statistics collected for those also include the number of people in the group, the fraction of them having taxable earnings equal and above the taxable maximum and the fraction having zero earnings.
Regarding the actual data sets available for replication we have the data set `cwhsa` which consists of the above data for the years from 1964 to 1977 and then `cwhsb` which consists of the CWHS for the years after.
Above that Angrist provides the data set `cwhsc_new` which includes the **adjusted FICA** earnings. For those Angrist employed a strategy to approximate the underlying uncensored FICA earnings from the reported censored ones. All of those three different earnings variables are used repeatedly throughout the replication.
```
process_data("cwhsa")
```
The above earnings data only consists of FICA earnings. The lottery intervals from 1 to 73 are equivalent to intervals of five consecutive lottery numbers. Consequently, the variable lottery interval equals to one for the lottery numbers 1 to 5 and so on. The ethnicity variable is encoded as 1 for a white person and 2 for a nonwhite person.
```
process_data("cwhsb")
```
As stated above this data now consists of earnings from 1978 to 1984 for FICA (here encoded as "TAXAB") and Total W-2 (encoded as "TOTAL").
#### Survey of Income and Program Participation (SIPP) and the Defense Manpower Data Center (DMDC)
Throughout the paper it is necessary to have a measure of the fraction of people serving in the military. For this purpose the above two data sources are used.
The **SIPP** is a longitudinal survey of around 20,000 households in the year 1984 for which is determined whether the persons in the household are Vietnam war veterans. The survey also collected data on ethnicity and birth data which made it possible to match the data to lottery numbers. The **DMDC** on the other hand is an administrative record which shows the total number of new entries into the army by ethnicity, cohort and lottery number per year from mid 1970 until the end of 1973.
Those sources are needed for the results in Table 3 and 4. A combination of those two are matched to the earnings data of the CWHS which constitutes the data set `chwsc_new` below.
```
data_cwhsc_new = process_data("cwhsc_new")
data_cwhsc_new
```
This data set now also includes the adjusted FICA earnings which are marked by "ADJ" as well as the probability of serving in the military conditional on being in a group made up by ethnicity, birth cohort and lottery interval.
Below we have a short look at how the distribution of the different earnings measures look like. In the table you see the real earnings in 1978 dollar terms for the years from 1974 to 1984 for FICA and adjusted FICA as well as the years 1978 until 1984 for Total W-2.
```
for data in ["ADJ", "TAXAB", "TOTAL"]:
ax = sns.kdeplot(
data_cwhsc_new.loc[data, "earnings"],
color=np.random.choice(np.array([sns.color_palette()]).flatten(), 4),
)
ax.set_xlim(xmax=20000)
ax.legend(["Adjusted FICA", "FICA", "TOTAL W-2"], loc="upper left")
ax.set_title("Kernel Density of the different Earning Measures")
```
For a more detailed description of the somewhat confusing original variable names in the data sets please refer to the appendix at the very bottom of the notebook.
### 3.2 Establishing the Validity of the Instrument
In order to convincingly pursue the identification strategy outlined above it is necessary to establish an effect of draft eligibility (the draft lottery) on veteran status and to argue that draft eligibility is exogenous to any unobserved factor affecting both veteran status and subsequent earnings. As argued before one could easily construct reasonable patterns of unobservables that both cause veteran status and earnings rendering a naive regression of earnings on veteran status as biased.
The first requirement for IV to be valid holds as it is clearly observable that draft-eligibility has an effect on veteran status. The instrument is hence **relevant**. For the second part Angrist argues that the draft lottery itself is random in nature and hence not correlated with any unobserved characteristics (**exogenous**) a man might have that causes him to enroll in the army while at the same time making his earnings likely to go into a certain direction irrespective of veteran status.
On the basis of this, Angrist now shows that subsequent earnings are affected by draft eligibility. This is the foundation to find a nonzero effect of veteran status on earnings. Going back to the causal diagram from before, Angrist argued so far that there is no directed graph from Draft Lottery to the unobservables U but only to Military Service. Now he further establishes the point that there is an effect of draft-eligibility (Draft Lottery) that propagates through Military Service onto earnings (Wages).
In order to see this clearly let us have a look at **Figure 1** of the paper below. For white and nonwhite men separately the history of average FICA earnings in 1978 dollar terms is plotted. This is done by year within cohort across those that were draft-eligible and those that were not. The highest two lines represent the 1950 cohort going down to the cohort of men born in 1953. There is a clearly observable pattern among white men in the cohorts from 1950 to 52 which shows persistently lower earnings for those draft-eligible starting the year in which they could be drafted. This cannot be seen for those born in 1953 which is likely due to the fact that nobody was actually drafted in 1973 which would have otherwise been "their" year. For nonwhite men the picture is less clear. It seems that for cohorts 50 to 52 there is slightly higher earnings for those ineligible but this does not seem to be persistent over time. The cohort 1953 again does not present a conclusive image. Observable in all lines, though, is that before the year of conscription risk there is no difference in earnings among the group which is due to the random nature of the draft lottery.
```
# read in the original data sets
data_cwhsa = pd.read_stata("data/cwhsa.dta")
data_cwhsb = pd.read_stata("data/cwhsb.dta")
data_cwhsc_new = pd.read_stata("data/cwhsc_new.dta")
data_dmdc = pd.read_stata("data/dmdcdat.dta")
data_sipp = pd.read_stata("data/sipp2.dta")
get_figure1(data_cwhsa, data_cwhsb)
```
A more condensed view of the results in Figure 1 is given in **Figure 2**. It depicts the differences in earnings between the red and the black line in Figure 1 by cohort and ethnicity. This is just included for completeness as it does not provide any further insight in comparison to Figure 1.
```
get_figure2(data_cwhsa, data_cwhsb)
```
A further continuation of this line of argument is resulting in **Table 1**. Angrist makes the observations from the figures before even further fine-grained and explicit. In Table 1 Angrist estimates the expected difference in average FICA and Total W-2 earnings by ethnicity within cohort and year of earnings. In the table below for white men we can observe that there is no significant difference to the five percent level for the years before the year in which they might be drafted. This changes for the cohorts from 1950 to 52 in the years 1970 to 72, respectively. There we can observe a significantly lower income for those eligible in comparison to those ineligible. This seems to be persistent for the cohorts 1950 and 52 while less so for those born in 1951 and 1953. It should further be noted that Angrist reports that the quality of the Total W-2 earnings data was low in the first years (it was launched in 1972) explaining the inconlusive estimations in the periods at the beginning.
To focus the attention on the crucial points I mark all the negative estimates in different shades of green with more negative ones being darker. This clearly emphasizes the verbal arguments brought up before.
```
table1 = get_table1(data_cwhsa, data_cwhsb)
table1["white"].style.applymap(background_negative_green)
```
For the nonwhite males there is no clear cut pattern. Only few cells show significant results which is why Angrist in the following focuses on white males when constructing IV estimates. For completeness I present Table 1 for nonwhite males below although it is somewhat less important for the remainder of the paper.
```
table1["nonwhite"].style.applymap(background_negative_green)
```
### 3.3 Measuring the Effect of Military Service on Earnings
#### 3.3.1 Wald-estimates
As discussed in the identification section a simple OLS regression estimating the model in equation (1) might suffer from bias due to elements of $s_i$ that are correlated with the error term $u_{it}$. This problem can be to a certain extent circumvented by the grouping method proposed by Abraham Wald (1940). Grouping the data by the instrument which is draft eligibility status makes it possible to uncover the effect of veteran status on earnings.
An unbiased estimate of $\alpha$ can therefore be found by adjusting the difference in mean earnings across eligibility status by the difference in probability of becoming a veteran conditional on being either draft eligible or not. This verbal explanation is translated in the following formula:
\begin{aligned}
\hat\alpha = \frac{\bar y^e - \bar y^n}{\hat{p}(V|e) - \hat{p}(V|n)}
\end{aligned}
The variable $\bar y$ captures the mean earnings within a certain cohort and year further defined by the superscript $e$ or $n$ which indicates draft-eligibility status. The above formula poses the problem that the conditional probabilities of being a veteran cannot be obtained from the CWHS data set alone. Therefore in **Table 2** Angrist attempts to estimate them from two other sources. First from the SIPP which has the problem that it is a quite small sample. And secondly, he matches the CWHS data to the DMDC. Here it is problematic, though, that the amount of people entering the army in 1970 (which is the year when those born 1950 were drafted) is only collected for the second half of the year. This is the reason why Angrist has to go with the estimates from the SIPP for the cohort of 1950 while taking the bigger sample of the matched DMDC/CWHS for the birth years 1951 to 53. The crucial estimates needed for the denominator of equation (3) are presented in the last column of Table 2 below. It can already be seen that the differences in earnings by eligibility that we found in Table 1 will be scaled up quite a bit to obtain the estimates for $\hat{\alpha}$. We will come back to that in Table 3.
<div class="alert alert-block alert-success">
<b>Note:</b> The cohort 1950 for the DMDC/CWHS could not be replicated as the data for cohort 1950 from the DMDC set is missing in the replication data. Above that the standard errors for the estimates coming form SIPP differ slightly from the published results but are equal to the results from the replication code.
</div>
```
table2 = get_table2(data_cwhsa, data_dmdc, data_sipp)
table2["white"]
table2["nonwhite"]
```
In the next step Angrist brings together the insights gained so far from his analysis. **Table 3** presents again differences in mean earnings across eligibility status for different earnings measures and within cohort and year. The values in column 1 and 3 are directly taken from Table 1. In column 2 we now encounter the adjusted FICA measure for the first time. As a reminder, it consists of the scaled up FICA earnings as FICA earnings are only reported to a certain maximum amount. The true average earnings are likely to be higher and Angrist transformed the data to account for this. We can see that the difference in mean earnings is most often in between the one of pure FICA earnings and Total W-2 compensation. In column three there is again the probability difference from the last column of Table 2. As mentioned before the measure is taken from the SIPP sample for the cohort of 1950 and the DMDC/CWHS sample for the other cohorts. Angrist decides to exclude cohort 1953 and nonwhite males as for those draft eligibility does not seem to be an efficient instrument (see Table 1 and Figure 1 and 2). Although Angrist does not, in this replication I also present Table 3 for nonwhites to give the reader a broader picture. Further Angrist focuses his derivations only on the years 1981 to 1984 as those are the latest after the Vietnam war for which there was data avalaible. Effects in those years are most likely to represent long term effects.
Let us now look at the most crucial column of Table 3 which is the last one. It captures the Wald estimate for the effect of veteran status on adjusted FICA earnings in 1978 dollar terms per year and cohort from equation (3). So this is our $\hat{\alpha}$ per year and cohort.
For white males the point estimates indicate that the annual loss in real earnings due to serving in the military was around 2000 dollars. Looking at the high standard errors, though, only few of the estimates are actually statistically significant. In order to see this more clearly I added a star to those values in the last column that are statistically significant to the five percent level.
<div class="alert alert-block alert-success">
<b>Note:</b> In the last column I obtain slightly different standard errors than in the paper. The same is the case, though, in the replication code my replication is building up on.
</div>
```
table3 = get_table3(data_cwhsa, data_cwhsb, data_dmdc, data_sipp, data_cwhsc_new)
p_value_star(table3["white"], slice(None), ("", "Service Effect in 1978 $"))
```
Looking at nonwhite males now, we observe what we already expected. All of the Wald estimates are actually far away from being statistically significant.
```
p_value_star(table3["nonwhite"], slice(None), ("", "Service Effect in 1978 $"))
```
#### 3.3.2 More complex IV estimates
In the next step Angrist uses a more generalized version of the Wald estimate for the given data. While in the previous analysis the mean earnings were compared solely on the basis of two groups (eligibles and ineligibles, which were determined by the lottery numbers), in the following this is extended to more complex subgroups. The grouping is now based on intervals of five consecutive lottery numbers. As explained in the section on idenficication this boils down to estimating the model described in equation (2).
\begin{aligned}
\bar y_{ctj} = \beta_c + \delta_t + \hat p_{cj} \alpha + \bar u_{ctj}
\end{aligned}
$\bar y_{ctj}$ captures the mean earnings by cohort $c$, in year $t$ for group $j$. $\hat p_{cj}$ depicts the estimated probability of being a veteran conditional on being in cohort $c$ and group $j$. We are now interested in obtaining an estimate of $\alpha$. In our current set up $\alpha$ corresponds to a linear combination of the many different possible Wald estimates when comparing each of the subgroups in pairs. With this view in mind Angrist restricts the treatment effect to be same (i.e. equal to $\alpha$) for each comparison of subgroups. The above equation is equivalent to the second stage of the 2SLS estimation. Angrist estimates the above model using the mean real earnings averaged over the years 1981 to 84 and the cohorts from 1950 to 53. In the first stage Angrist has to estimate $\hat p_{cj}$ which is done again by using a combination of the SIPP sample and the matched DWDC/CWHS data set. With this at hand Angrist shows how the equation (2) looks like if it was estimated by OLS. The following **Figure 3** is also called Visual Instrumental Variables (VIV). In order to arrive there he takes the residuals from an OLS regression of $\bar y_{ctj}$ and $\hat p_{cj}$ on cohort and time dummies, respectively. Then he performs another OLS regression of the earnings residuals on the probability residuals. This is depicted in Figure 3 below. The slope of the regression line corresponds to an IV estimate of $\alpha$. The slope amounts to an estimate of -2384 dollars which serves as a reference for the treatment effect measured by another, more efficient method described below the Figure.
```
get_figure3(data_cwhsc_new)
```
We now shortly turn back to a remark from before. Angrist is forced to only work with sample means due to confidentiality restrictions on the underlying micro data. For the Wald estimates it is somewhat easily imaginable that this does not pose any problem. For the above estimation of $\alpha$ using 2SLS this is less obvious. Angrist argues, though, that there is a Generalized Method of Moments (GMM) interpretation of the 2SLS approach which allows him to work with sample moments alone. Another important implication thereof is that he is not restricted to using only one sample to obtain the sample moments. In our concrete case here, it is therefore unproblematic that the earnings data is coming from another sample than the conditional probabilities of being a veteran as both of the samples are drawn from the same population. This is a characteristic of the GMM.
In the following, Angrist estimates equation (2) by using the more efficient approach of Generalized Least Squares (GLS) as opposed to OLS. The GLS is more efficient if there is correlation between the residuals in a regression model. Angrist argues that this is the case in the above model equation and that this correlation can be estimated. GLS works such that coming from the estimated covariance matrix $\hat\Omega$ of the residuals, the regressors as well as the dependent variable are transformed using the upper triangle of the Cholesky decomposition of $\hat\Omega^{-1}$. Those transformed variables are then used to run a regular OLS model with nonrobust standard errors. The resulting estimate $\hat\alpha$ then is the most efficient one (if it is true that there is correlation between the residuals).
Angrist states that the optimal weigthing matrix $\Omega$ resulting in the most efficient estimate of $\hat\alpha$ looks the following:
\begin{aligned}
\Omega = V(\bar y_{ctj}) + \alpha^2 V(\hat p_{cj}).
\end{aligned}
All of the three elements on the right hand side can be estimated from the data at hand.
Now we have all the ingredients to have a look at the results in **Table 4**. In practice, Angrist estimates two models in the above manner based on the general form of the above regression equation. Model 1 allows the treatment effect to vary by cohort while Model 2 collapses them into a scalar estimate of $\alpha$.
The results for white men in Model 1 show that for each of the three earnings measures as dependent variable only few are statistically significant to the five percent level (indicated by a star added by me again). A look at Model 2 reveals, though, that the combined treatment effect is significant and it amounts to a minus of 2000 dollar (we look again at real earnings in 1978 dollar terms) annualy for those having served in the army. For cohort 1953 we obtain insignificant estimates which was to be expected given that actually nobody was drafted in that year.
<div class="alert alert-block alert-success">
<b>Note:</b> The results are again a bit different to those in the paper. The same is the case, though, in the replication code my replication is building up on.
</div>
```
table4 = get_table4(data_cwhsc_new)
p_value_star(
table4["white"], (slice(None), slice(None), ["Value", "Standard Error"]), (slice(None)),
)
```
Angrist also reports those estimates for nonwhite men which are not significant. This was already expected as the the instrument was not clearly correlated with the endogenous variable of veteran status.
```
p_value_star(
table4["nonwhite"], (slice(None), slice(None), ["Value", "Standard Error"]), (slice(None)),
)
```
This table concludes the replication of the core results of the paper. Summing up, Angrist constructed a causal graph for which he employs a plausible estimation strategy. Using his approach he concludes with the main result of having found a negative effect of serving in the military during the Vietnam era on subsequent earnings for white male in the United States.
Angrist provides some interpretation of the found effect and some concerns that might arise when reading his paper. I will discuss some of his points in the following critical assessment.
## 4. Critical Assessment
Considering the time back then and the consequently different state of research, the paper was a major contribution to instrumental variable estimation of treatment effects. More broadly, the paper is very conclusive and well written. Angrist discusses caveats quite thoroughly which makes the whole argumentation at first glance very concise. Methodologically, the paper is quite complex as due to the kind of data available. Angrist is quite innovative in that regard as he comes up with the two sample IV method in this paper which allows him to pratically follow his identification strategy. The attempt to explain the mechanisms behind the negative treatment effect found by him makes the paper comprehensive and shows the great sense of detail Angrist put into this paper.
While keeping in mind the positive sides of his paper, in hindsight, Angrist is a bit too vocal about the relevance and accuracy of his findings. Given our knowledge about the local average treatment effect (**LATE**) we encountered in our lecture, Angrist only identifies the average treatment effect of the compliers (those that enroll for the army if they are draft-eligible but do not if they are not) if there is individual level treatment heterogeneity and if the causal graph from before is accurate. Hence, the interpretation of the results gives only limited policy implications. For the discussion of veteran compensation the group of those who were induced by the lottery to join the military are not crucial. As there is no draft lottery anymore, what we are interested in is how to compensate veterans for their service who "voluntarily" decided to serve in the military. This question cannot be answered by Angrist's approach given the realistic assumption that there is treatment effect heterogeneity (which also Angrist argues might be warranted).
A related difficulty of interpretation arises because in the second part, Angrist uses an overidentified model. As already discussed before this amounts to a linear combination of the average treatment effects of subgroups. This mixes the LATEs of several subgroups making the policy implications even more blurred as it is not clear what the individual contributions of the different subgroups are. In this example here this might not make a big difference but should be kept in mind when using entirely different instrumental variables to identify the LATE.
In a last step, there are several possible scenarios to argue why **the given causal graph might be violated**. Angrist himself delivers one of them. After the lottery numbers were drawn, there was some time in between the drawing and the announcement of the draft-eligibility ceiling. This provoked behavioral responses of some individuals with low numbers to volunteer for the army in order to get better terms of service as well as enrolling in university which rendered them ineligible for the army. In our data, it is unobservable to see the fraction of individuals in each group to join university. If there was actually some avoidance behavior for those with low lottery numbers, then the instrument would be questionable as there would be a path from the Draft Lottery to unobservables (University) which affects earnings. At the same time there is also clearly a relation between University and Military Service.
Rosenzweig and Wolpin (2000) provide a causal graph that draws the general interpretability of the results in Angrist (1990) further into question. Let us look at the causal graph below now imagining that there was no directed graph from Draft Lottery to Civilian Experience. Their argument is that Military Service reduces Schooling and Civilian Experience which lowers Wages while affecting Wages directly and increasing them indirectly by reducing Schooling and increasing work experience. Those subtle mechanism are all collapsed into one measure by Angrist which gives an only insufficiently shallow answer to potentially more complex policy questions. Building up on this causal graph, Heckman (1997) challenges the validity of the instrument in general by making the point that there might be a directed graph from Draft Lottery to Civilian Experience. The argument goes as follows: Employers, after learning about their employees' lottery numbers, decrease the training on the job for those with a high risk of being drafted. If this is actually warranted the instrument Draft Lottery cannot produce unbiased estimates anymore.
<img src="material/fig-10-2.png" width="600" />
Morgan and Winship (2014) add to this that the bias introduced by this is further affected by how strongly Draft Lottery affects Military Service. Given the factor that the lottery alone does not determine military service but that there are tests, might cause the instrument to be rather weak and therefore a potential bias to be rather strong.
## 5. Extensions
### 5.1 Treatment effect with different years of earning
In the calculation of the average treatment in Table 4 Angrist chooses to calculate it for earnings in the years from 1981 to 84. While he plausibly argues that this most likely constitutes a long term effect (as those are the last years for which he has data) in comparison to earlier years, it does not give a complete picture. Looking at Table 1 again we can see that for the earnings differences in the years 81 to 84 quite big estimates are calculated. Assuming that the difference in probability of serving given eligibility versus noneligibility stays somewhat stable across the years, we would expect some heterogeneity in average treatment effects depending on which years we use the earnings data of. Angrist, though, does not investigate this although he has the data for it at hand. For example from a policy perspective one could easily argue that a look at the average treatment effect for earlier years (close to the years in which treatment happens) might be more relevant than the one for years after. This is because given the long time between the actual service and the earnings data of 1981 to 84 it is likely that second round effects are driving some of the results. These might be initially caused by veteran status but for later years the effect of veteran status might mainly act by means of other variables. For instance veterans after the war might be forced to take simple jobs due to their lack of work experience and from then on their path is determined by the lower quality of the job that they had to take right after war. For policy makers it might be of interest to see what happens to veterans right after service to see what needs to be done in order to stop second round effects from happening in the first place.
To give a more wholesome image, I estimate the results for Table 4 for different years of earnings of white men. As mentioned before the quality of the Total W-2 data set is rather low and the adjusted FICA is more plausible than the FICA data. This is why I only use the adjusted FICA data in the following. For the adjusted FICA I have data for Table 4 for the years from 1974 to 1984. For each possible four year range within those ten years I estimate Model 1 and 2 from Table 4 again.
Below I plot the average treatment effects obtained. On the x-axis I present the starting year of the range of the adjusted FICA data used. For starting value 74 it means that the average treatment effect is calculated for earnings data of the years 1974 to 77. The results at the starting year 81 are equivalent to the ones found by Angrist in Table 4 for white men.
```
# get the average treatment effects of Model 1 and 2 with adjusted FICA earnings for
# several different ranges of four years
results_model1 = np.empty((8, 4))
results_model2 = np.array([])
for number, start_year in enumerate(np.arange(74, 82)):
years = np.arange(start_year, start_year + 4)
flex_table4 = get_flexible_table4(data_cwhsc_new, years, ["ADJ"], [50, 51, 52, 53])
results_model1[number, :] = (
flex_table4["white"].loc[("Model 1", slice(None), "Value"), :].values.flatten()
)
results_model2 = np.append(
results_model2, flex_table4["white"].loc[("Model 2", slice(None), "Value"), :].values,
)
# Plot the effects for white men in Model 1 and 2
# (colors apart from Cohort 1950 are random, execute again to
# change them)
get_figure1_extension1(results_model1, results_model2)
```
The pattern is more complex than what we can see in the glimpse of Table 4 in the paper. We can see that there is quite some heterogeneity in average treatment effects across cohorts when looking at the data for early years. This changes when using data of later years. Further the fact of being a veteran does seem to play a role for the cohort 1953 right after the war but the treatment effect becomes insignificant when looking at later years. This is interesting as the cohort of 1953 was the one for which no one was drafted (remember that in 1973 no one was drafted as the last call was in December 1972).
Another observation is linked to the fact that draft eligibility does not matter for those born in 1953. These people appear to have voluntarily joined the army as no one of them could have possibly been drafted. This cannot be said for the cohorts before. Employers can only observe whether a person is a veteran and when they are born (and not if they are compliers or not). A theory could be that employers act on the loss of experience for initial wage setting for every army veteran right after the war. The fact that the cohort of 1953 could only be volunteers but not draftees could give them a boost in social status to catch up again in the long run, though. This mechanism might explain to a certain extent why we observe the upward sloping line for the cohort of 1953 (but not for the other groups).
As discussed in the critical assessment, we actually only capture the local average treatment effect of the compliers. Those are the ones who join the army when they are draft-eligible but do not when they are not. The identifying assumption for the LATE requires that everyone is a complier. This is probably not warranted for the cohort of 1953. In that year it is easily imaginable that there are both defiers and compliers which means that we do not capture the LATE for cohort 1953 in Model 1 and for cohort 1950-53 in Model 2 but something else we do not really know how to interpret. This might be another reason why we observe this peculiar pattern for the cohort of 1953. Following up on this remark I estimate the Model 2 again excluding the cohort of 1953 to focus on the cohorts for which the assumptions for LATE are likely to hold.
```
results_model2_53 = np.array([])
for number, start_year in enumerate(np.arange(74, 82)):
years = np.arange(start_year, start_year + 4)
flex_table4 = get_flexible_table4(data_cwhsc_new, years, ["ADJ"], [50, 51, 52])
results_model2_53 = np.append(
results_model2_53, flex_table4["white"].loc[("Model 2", slice(None), "Value"), :].values,
)
get_figure2_extension1(results_model2, results_model2_53)
```
We can see that for later years the treatment effect is a bit lower when excluding the cohort of 1953. It confirms the findings of Angrist with the advantage of making it possible to attach a clearer interpretation to it.
Following the above path, it would also be interesting to vary the amount of instruments used by more than just the two ways Angrist has shown. It would be interesting to break down the interval size of lottery numbers further. Unfortunately I could no find a way to do that with the already pre-processed data I have at hand.
### 5.2 Bias Quantification
In the critical assessment I argued that the simple Wald estimate might be biased because employers know their employees' birth date and hence their draft eligibility. The argument was that employers invest less into the human capital of those that might be drafted. This would cause the instrument of draft eligibility to not be valid and hence suffer from bias. This bias can be calculated in the following way for a binary instrument:
\begin{aligned}
\frac{E[Y|Z=1] - E[Y|Z=0]}{E[D|Z=1] - E[D|Z=0]} = \delta + \frac{E[\epsilon|Z=1] - E[\epsilon|Z=0]}{E[D|Z=1] - E[D|Z=0]}
\end{aligned}
What has been done in the last column of Table 3 (the Wald estimate) is that Angrist calculated the left hand side of this equation. This calculation yields an unbiased estimate of the treatment effect of $D$ (veteran status) on $Y$ (earnings) $\delta$ if there is no effect of the instrument $Z$ (draft eligibility) on $Y$ through means of unobservables $\epsilon$. In our argumentation this assumption does not hold which means that $E[\epsilon|Z=1] - E[\epsilon|Z=0]$ is not equal to zero as draft eligibility affects $Y$ by the behavioral change of employers to make investing into human capital dependent on draft eligibility. Therefore the left hand side calculation is not equal to the true treatment effect $\delta$ but has to be adjusted by the bias $\frac{E[\epsilon|Z=1] - E[\epsilon|Z=0]}{E[D|Z=1] - E[D|Z=0]}$.
In this section I run a thought experiment in which I quantify this bias. The argumentation here is rather heuristic because I lack the resources to really find a robust estimate of the bias but it gives a rough idea of whether the bias might matter economically. My idea is the following. In order to get a measure of $E[\epsilon|Z=1] - E[\epsilon|Z=0]$ I have a look at estimates for the effect of work experience on earnings. Remember that the expected difference in earnings due to a difference in draft eligibility is caused by a loss in human capital for those draft eligible because they might miss out on on-the-job-training. This loss in on-the-job-training could be approximated by a general loss in working experience. For an estimate of that effect I rely on Keane and Wolpin (1997) who work with a sample for young men between 14 and 21 years old from the year 1979. The effect of working experience on real earnings could be at least not far off of the possible effect in our sample of adjusted FICA real earnings of 19 year old men for the years 1981 to 1984. Remember that lottery participants find out about whether they are draft eligible or not at the end of the year before they might be drafted. I assume that draft dates are spread evenly over the draft year. One could then argue that on average a draft eligible person stays in his job for another half a year after having found out about the eligibility and before being drafted. Hence, for on average half a year an employer might invest less into the human capital of this draft eligible man. I assume now that employers show a quite moderate behavioral response. During the six months of time, the employees only receive a five month equivalent of human capital gain (or work experience gain) as opposed to the six months they stay in the company. This means they loose one month of work experience on average in comparison to those that are not draft eligible.
To quantify this one month loss of work experience I take estimates from Keane and Wolpin (1997). For blue collar workers they roughly estimate the gain in real earnings in percent from an increase in a year of blue collar work experience to be 4.6 percent (actually their found effect depends on the years of work experience but I simplify this for my rough calculations). For white collar workers the equivalent estimate amounts to roughly 2.7 percent. I now take those as upper and lower bounds, calculate their one month counterparts and quantify the bias in the Wald estimates of the last column of Table 3. The bias $\frac{E[\epsilon|Z=1] - E[\epsilon|Z=0]}{E[D|Z=1] - E[D|Z=0]}$ is then roughly equal to the loss in annual real earnings due to one month less of work experience divided by the difference in probability of being a veteran conditional on draft eligibility.
The first table below depicts how the bias changes by cohort across the different years of real earnings with increasing estimates of how a loss in experience affects real earnings. Clearly with increasing estimates of how strong work experience contributes to real earnings, the bias gets stronger. This is logical as it is equivalent to an absolute increase in the nominator. Above that the bias is stronger for later years of earnings as the real earnings increase by year. Further the slope is steeper for later cohorts as the denominator is smaller for later cohorts. Given the still moderate assumption of a loss of one month of work experience we can see that the bias does not seem to be negligible economically especially when taking the blue collar percentage estimate.
```
# Calculate the bias, the true delta and the orginal Wald estimate for a
# ceratain interval of working experience effect
interval = np.linspace(0.025, 0.05, 50) / 12
bias, true_delta, wald = get_bias(
data_cwhsa, data_cwhsb, data_dmdc, data_sipp, data_cwhsc_new, interval
)
# plot the bias by cohort
get_figure1_extension2(bias, interval)
```
To get a sense of how the size of the bias relates to the size of the previously estimated Wald coefficients, let us have look at the figure below. It shows for each cell consisting of a cohort and year combination, the Wald estimate from Table 3 as the horizontal line and the true $\delta$ depending on the weight of the loss in work experience as the upward sloping line. Given that our initial estimates of the Wald coefficients are in a range of only a few thousands, an estimated bias of roughly between 200 and 500 dollars cannot be characterized as incosiderable. Further given Angrist's policy question concerning Veteran compensation, even an estimate that is higher by 200 dollars makes a big difference when it is about compensating thousands of veterans.
```
# plot the the true delta (accounted for the bias) compared to the original Wald estimate
get_figure2_extension2(true_delta, wald, interval)
```
## 6. Conclusion
Regarding the overall quality and structure of Angrist (1990), reading it is a real treat. The controversy after its publication and the fact that it is highly cited clearly show how important its contribution was and still is. It is a great piece of discussion when it comes to the interpretability and policy relevance of instrumental variable approaches. As already reiterated in the critical assessment, one has to acknowledge the care Angrist put into this work. Although his results do not seem to prove reliable, it opened a whole discussion on how to use instrumental variables to get the most out of them. Another contribution that should not go unnoticed is that Angrist shows that instruments can be used even though they might not come from the same sample as the dependent and the endogenous variable. Practically, this is very useful as it widens possible areas of application for instrumental variables.
Overall, it has to be stated that the paper has some shortcomings but the care put into this paper and the good readibility allowed other researchers (and Angrist himself) to swoop in giving helpful remarks that improved the understanding of instrumental variable approaches for treatment effect evaluation.
## References
**Angrist, J.** (1990). [Lifetime Earnings and the Vietnam Era Draft Lottery: Evidence from Social Security Administrative Records](https://www.jstor.org/stable/2006669?seq=1#metadata_info_tab_contents). *American Economic Review*. 80. 313-36.
**Angrist, J. D., & Pischke, J.-S.** (2009). Mostly harmless econometrics: An empiricist's companion.
**Heckman, J.** (1997). Instrumental Variables: A Study of Implicit Behavioral Assumptions Used in Making Program Evaluations. *The Journal of Human Resources*, 32(3), 441-462. doi:10.2307/146178
**Keane, M., & Wolpin, K.** (1997). The Career Decisions of Young Men. *Journal of Political Economy*, 105(3), 473-522. doi:10.1086/262080
**Morgan, S., and Winship, C.** (2014). Counterfactuals and Causal Inference: Methods and Principles for Social Research (Analytical Methods for Social Research). Cambridge: Cambridge University Press. doi:10.1017/CBO9781107587991
**Rosenzweig, M. R. and Wolpin, K. I.**. (2000). “Natural ‘Natural Experiments’ in Economics.” *Journal of Economic Literature* 38:827–74.
**Wald, A.** (1940). The Fitting of Straight Lines if Both Variables are Subject to Error. *Ann. Math. Statist.* 11 , no. 3, 284--300.
## Appendix
### Key Variables in the Data Sets
#### data_cwhsa
| **Name** | **Description** |
|-----------------|--------------------------------------------|
| **index** | |
| byr | birth year |
| race | ethnicity, 1 for white and 2 for nonwhite |
| interval | interval of draft lottery numbers, 73 intervals with the size of five consecutive numbers |
| year | year for which earnings are collected |
| **variables** | |
| vmn1 | nominal earnings |
| vfin1 | fraction of people with zero earnings |
| vnu1 | sample size |
| vsd1 | standard deviation of earnings |
#### data_cwhsb
| **Name** | **Description** |
|-----------------|--------------------------------------------|
| **index** | |
| byr | birth year |
| race | ethnicity, 1 for white and 2 for nonwhite |
| interval | interval of draft lottery numbers, 73 intervals with the size of five consecutive numbers |
| year | year for which earnings are collected |
| type | source of the earnings data, "TAXAB" for FICA and "TOTAL" for Total W-2 |
| **variables** | |
| vmn1 | nominal earnings |
| vfin1 | fraction of people with zero earnings |
| vnu1 | sample size |
| vsd1 | standard deviation of earnings |
#### data_cwhsc_new
| **Name** | **Description** |
|-----------------|--------------------------------------------|
| **index** | |
| byr | birth year |
| race | ethnicity, 1 for white and 2 for nonwhite |
| interval | interval of draft lottery numbers, 73 intervals with the size of five consecutive numbers |
| year | year for which earnings are collected |
| type | source of the earnings data, "ADJ" for adjusted FICA, "TAXAB" for FICA and "TOTAL" for Total W-2 |
| **variables** | |
| earnings | real earnings in 1978 dollars |
| nj | sample size |
| nj0 | number of persons in the sample with zero earnings |
| iweight_old | weight for weighted least squares |
| ps_r | fraction of people having served in the army |
| ern74 to ern84 | unweighted covariance matrix of the real earnings |
#### data_dmdc
| **Name** | **Description** |
|-----------------|--------------------------------------------|
| **index** | |
| byr | birth year |
| race | ethnicity, 1 for white and 2 for nonwhite |
| interval | interval of draft lottery numbers, 73 intervals with the size of five consecutive numbers |
| **variables** | |
| nsrvd | number of people having served |
| ps_r | fraction of people having served |
#### data_sipp (this is the only micro data set)
| **Name** | **Description** |
|-----------------|--------------------------------------------|
| **index** | |
| u_brthyr | birth year |
| nrace | ethnicity, 0 for white and 1 for nonwhite |
| **variables** | |
| nvstat | 0 if man is not a veteran, 1 if he is |
| fnlwgt_5 | fraction of people with this index among overall sample |
| rsncode | 1 if person was draft eligible, else if not |
| github_jupyter |
TSG032 - CPU and Memory usage for all containers
================================================
Steps
-----
### Instantiate Kubernetes client
```
# Instantiate the Python Kubernetes client into 'api' variable
import os
try:
from kubernetes import client, config
from kubernetes.stream import stream
if "KUBERNETES_SERVICE_PORT" in os.environ and "KUBERNETES_SERVICE_HOST" in os.environ:
config.load_incluster_config()
else:
config.load_kube_config()
api = client.CoreV1Api()
print('Kubernetes client instantiated')
except ImportError:
from IPython.display import Markdown
display(Markdown(f'SUGGEST: Use [SOP059 - Install Kubernetes Python module](../install/sop059-install-kubernetes-module.ipynb) to resolve this issue.'))
raise
```
### Get the namespace for the big data cluster
Get the namespace of the big data cluster from the Kuberenetes API.
NOTE: If there is more than one big data cluster in the target
Kubernetes cluster, then set \[0\] to the correct value for the big data
cluster.
```
# Place Kubernetes namespace name for BDC into 'namespace' variable
try:
namespace = api.list_namespace(label_selector='MSSQL_CLUSTER').items[0].metadata.name
except IndexError:
from IPython.display import Markdown
display(Markdown(f'SUGGEST: Use [TSG081 - Get namespaces (Kubernetes)](../monitor-k8s/tsg081-get-kubernetes-namespaces.ipynb) to resolve this issue.'))
display(Markdown(f'SUGGEST: Use [TSG010 - Get configuration contexts](../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb) to resolve this issue.'))
display(Markdown(f'SUGGEST: Use [SOP011 - Set kubernetes configuration context](../common/sop011-set-kubernetes-context.ipynb) to resolve this issue.'))
raise
print('The kubernetes namespace for your big data cluster is: ' + namespace)
```
### Get per process usage stats
```
cmd = """echo "CPU %\t MEM %\t MEM\t PROCESS" &&
ps aux |
awk '
{mem[$11] += int($6/1024)};
{cpuper[$11] += $3};
{memper[$11] += $4};
END {
for (i in mem) {
print cpuper[i] "%\t", memper[i] "%\t", mem[i] "MB\t", i
}
}' |
sort -k3nr
"""
pod_list = api.list_namespaced_pod(namespace)
pod_names = [pod.metadata.name for pod in pod_list.items]
for pod in pod_list.items:
container_names = [container.name for container in pod.spec.containers]
for container in container_names:
print (f"CONTAINER: {container} / POD: {pod.metadata.name}")
try:
print(stream(api.connect_get_namespaced_pod_exec, pod.metadata.name, namespace, command=['/bin/sh', '-c', cmd], container=container, stderr=True, stdout=True))
except Exception:
print (f"Failed to get CPU/Memory for container: {container} in POD: {pod.metadata.name}")
print('Notebook execution complete.')
```
| github_jupyter |
# Using Amazon SageMaker Debugger with your own PyTorch container
Amazon SageMaker is a managed platform to build, train and host machine learning models. Amazon SageMaker Debugger is a new feature which offers capability to debug machine learning and deep learning models during training by identifying and detecting problems with the models in real time.
Amazon SageMaker also gives you the option of bringing your own algorithms packaged in a custom container, that can then be trained and deployed in the Amazon SageMaker environment.
This notebook guides you through an example of using your own container with PyTorch for training, along with the recently added feature, Amazon SageMaker Debugger.
## How does Amazon SageMaker Debugger work?
Amazon SageMaker Debugger lets you go beyond just looking at scalars like losses and accuracies during training and gives you full visibility into all tensors 'flowing through the graph' during training. Furthermore, it helps you monitor your training in real time using rules and CloudWatch events and react to issues like, for example, common training issues such as vanishing gradients or poor weight initialization.
### Concepts
* **Tensor**: These are the artifacts that define the state of the training job at any particular instant in its lifecycle.
* **Debug Hook**: Captures the tensors flowing through the training computational graph every N steps.
* **Debugging Rule**: Logic to analyze the tensors captured by the hook and report anomalies.
With these concepts in mind, let's understand the overall flow of things which Amazon SageMaker Debugger uses to orchestrate debugging.
It operates in two steps - saving tensors and analysis.
### Saving tensors
Tensors that debug hook captures are stored in S3 location specified by you. There are two ways you can configure Amazon SageMaker Debugger for storage:
1. With no changes to your training script: If you use any of SageMaker provided [Deep Learning containers](https://docs.aws.amazon.com/sagemaker/latest/dg/pre-built-containers-frameworks-deep-learning.html) then you don't need to make any changes to your training script for tensors to be stored. Amazon SageMaker Debugger will use the configuration you provide in the framework `Estimator` to save tensors in the fashion you specify.
2. Orchestrating your script to store tensors: Amazon SageMaker Debugger exposes a library which allows you to capture these tensors and save them for analysis. It's highly customizable and allows to save the specific tensors you want at different frequencies and configurations. Refer to the [DeveloperGuide](https://github.com/awslabs/sagemaker-debugger/tree/master/docs) for details on how to use Amazon SageMaker Debugger with your choice of framework in your training script.
### Analysis of tensors
Once tensors are saved, Amazon SageMaker Debugger can be configured to run debugging ***Rules*** on them. On a very broad level, a rule is a python script used to detect certain conditions during training. Some of the conditions that a data scientist training an algorithm might be interested in are monitoring for gradients getting too large or too small, detecting overfitting, and so on. Amazon SageMaker Debugger comes pre-packaged with certain built-in rules. You can also write your own rules using the Amazon SageMaker Debugger APIs. You can also analyze raw tensor data outside of the Rules construct in a notebook, using Amazong Sagemaker Debugger's full set of APIs.
## Setup
To successfully execute this example, the following packages need to be installed in your container:
* PyTorch v1.3.1
* Torchvision v0.4.2
* Amazon SageMaker Debugger (smdebug)
`!python -m pip install smdebug`
## Bring Your Own PyTorch for training
In this notebook, we will train a PyTorch model with Amazon SageMaker Debugger enabled. We can do that by using custom PyTorch container, enabling Amazon SageMaker Debugger in the training script, and bringing it to Amazon SageMaker for training.
Note: The changes to the training script that are mentioned in this notebook are only required when a custom container is used. Amazon SageMaker Debugger will be automatically enabled (and not require any changes to training script) if you use the SageMaker Deep Learning Container for PyTorch.
We will focus on how to modify a training script to save tensors by registering debug hooks and specifying which tensors to save.
The model used for this notebook is trained with the MNIST dataset. The example is based on https://github.com/pytorch/examples/blob/master/mnist/main.py
### Modifying the training script
Before we define the Estimator object and start training, we will explore parts of the training script in detail. (The entire training script can be found at [./scripts/pytorch_mnist.py](./scripts/pytorch_mnist.py)).
Step 1: Import Amazon SageMaker Debugger.
```python
import smdebug.pytorch as smd
```
Step 2: Create a debugger hook to save tensors of specified collections. Apart from a list of collections, the hook takes the save config and output directory as parameters. The output directory is a mandatory parameter. All these parameters can be specified in the config json file.
```python
def create_smdebug_hook():
# This allows you to create the hook from the configuration you pass to the SageMaker pySDK
hook = smd.Hook.create_from_json_file()
return hook
```
Step 3: Register the hook for all layers in the model
```python
hook.register_hook(model)
```
Step 4: For PyTorch, if you use a Loss module for loss, add a step to register loss
```python
hook.register_loss(criterion)
```
Once these changes are made in the training script, Amazon SageMaker Debugger will start saving tensors, belonging to the specified collections, during training into the specfied output directory.
Now, we will setup the Estimator and start training using modified training script.
```
from __future__ import absolute_import
import boto3
import pytest
from sagemaker.pytorch import PyTorch
from sagemaker import get_execution_role
from sagemaker.debugger import Rule, DebuggerHookConfig, TensorBoardOutputConfig, CollectionConfig, rule_configs
```
Define the configuration of training to run. `ecr_image` is where you can provide link to your bring-your-own-container. `hyperparameters` are fed into the training script with data directory (directory where the training dataset is stored) and smdebug directory (directory where the tensors will be saved) are mandatory fields.
```
role = get_execution_role()
training_dir = '/tmp/pytorch-smdebug'
smdebug_mnist_script = 'scripts/pytorch_mnist.py'
hyperparameters = {'random_seed': True, 'num_steps': 50, 'epochs': 5,
'data_dir':training_dir}
```
"rules" is a new parameter that will accept a list of rules you wish to evaluate the tensors output against. For rules, Amazon SageMaker Debugger supports two types:
* SageMaker Rules: These are rules specially curated by the data science and engineering teams in Amazon SageMaker which you can opt to evaluate against your training job.
* Custom Rules: You can optionally choose to write your own rule as a Python source file and have it evaluated against your training job. To provide Amazon SageMaker Debugger to evaluate this rule, you would have to provide the S3 location of the rule source and the evaluator image.
In this example, we will use the VanishingGradient which will attempt to evaluate if there are vanishing gradients. Alternatively, you could write your own custom rule, as demonstrated in [this](https://github.com/aws/amazon-sagemaker-examples-staging/blob/master/sagemaker-debugger/tensorflow_keras_custom_rule/tf-keras-custom-rule.ipynb) example.
```
rules = [
Rule.sagemaker(rule_configs.vanishing_gradient())
]
estimator = PyTorch(entry_point=smdebug_mnist_script,
base_job_name='smdebugger-demo-mnist-pytorch',
role=role,
instance_count=1,
instance_type='ml.m4.xlarge',
volume_size=400,
max_run=3600,
hyperparameters=hyperparameters,
framework_version='1.3.1',
py_version='py3',
## New parameter
rules = rules
)
```
*Note that Amazon Sagemaker Debugger is only supported for py_version='py3'.*
With the next step we kick off traning job using Estimator object we created above. Note that the way training job starts here is asynchronous. That means that notebook is not blocked and control flow is passed to next cell.
```
estimator.fit(wait=False)
```
### Result
As a result of calling the fit() Amazon SageMaker Debugger kicked off a rule evaluation job to monitor loss decrease, in parallel with the training job. The rule evaluation status(es) will be visible in the training logs at regular intervals. As you can see, in the summary, there was no step in the training which reported vanishing gradients in the tensors. Although, the loss was not found to be decreasing at step 1900.
```
estimator.latest_training_job.rule_job_summary()
def _get_rule_job_name(training_job_name, rule_configuration_name, rule_job_arn):
"""Helper function to get the rule job name with correct casing"""
return "{}-{}-{}".format(
training_job_name[:26], rule_configuration_name[:26], rule_job_arn[-8:]
)
def _get_cw_url_for_rule_job(rule_job_name, region):
return "https://{}.console.aws.amazon.com/cloudwatch/home?region={}#logStream:group=/aws/sagemaker/ProcessingJobs;prefix={};streamFilter=typeLogStreamPrefix".format(region, region, rule_job_name)
def get_rule_jobs_cw_urls(estimator):
region = boto3.Session().region_name
training_job = estimator.latest_training_job
training_job_name = training_job.describe()["TrainingJobName"]
rule_eval_statuses = training_job.describe()["DebugRuleEvaluationStatuses"]
result={}
for status in rule_eval_statuses:
if status.get("RuleEvaluationJobArn", None) is not None:
rule_job_name = _get_rule_job_name(training_job_name, status["RuleConfigurationName"], status["RuleEvaluationJobArn"])
result[status["RuleConfigurationName"]] = _get_cw_url_for_rule_job(rule_job_name, region)
return result
get_rule_jobs_cw_urls(estimator)
```
### Analysis
Another aspect of the Amazon SageMaker Debugger is analysis. It allows us to perform interactive exploration of the tensors saved in real time or after the job. Here we focus on after-the-fact analysis of the above job. We import the smdebug library, which defines a concept of Trial that represents a single training run. Note how we fetch the path to debugger artifacts for the above job.
```
from smdebug.trials import create_trial
trial = create_trial(estimator.latest_job_debugger_artifacts_path())
```
We can list all the tensors that were recorded to know what we want to plot.
```
trial.tensor_names()
```
We can also retrieve tensors by some default collections that smdebug creates from your training job. Here we are interested in the losses collection, so we can retrieve the names of tensors in losses collection as follows. Amazon SageMaker Debugger creates default collections such as weights, gradients, biases, losses automatically. You can also create custom collections from your tensors.
```
trial.tensor_names(collection="losses")
```
| github_jupyter |
# Tutorial on Python for scientific computing
> Marcos Duarte, Renato Naville Watanabe
> [Laboratory of Biomechanics and Motor Control](http://pesquisa.ufabc.edu.br/bmclab)
> Federal University of ABC, Brazil
<p style="text-align: right;">A <a href="https://jupyter.org/">Jupyter Notebook</a></p>
<h1>Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Scope-of-this-tutorial" data-toc-modified-id="Scope-of-this-tutorial-1"><span class="toc-item-num">1 </span>Scope of this tutorial</a></span></li><li><span><a href="#Python-as-a-calculator" data-toc-modified-id="Python-as-a-calculator-2"><span class="toc-item-num">2 </span>Python as a calculator</a></span></li><li><span><a href="#The-import-function" data-toc-modified-id="The-import-function-3"><span class="toc-item-num">3 </span>The import function</a></span></li><li><span><a href="#Object-oriented-programming" data-toc-modified-id="Object-oriented-programming-4"><span class="toc-item-num">4 </span>Object-oriented programming</a></span></li><li><span><a href="#Python-and-IPython-help" data-toc-modified-id="Python-and-IPython-help-5"><span class="toc-item-num">5 </span>Python and IPython help</a></span><ul class="toc-item"><li><span><a href="#Tab-completion-in-IPython" data-toc-modified-id="Tab-completion-in-IPython-5.1"><span class="toc-item-num">5.1 </span>Tab completion in IPython</a></span></li><li><span><a href="#The-four-most-helpful-commands-in-IPython" data-toc-modified-id="The-four-most-helpful-commands-in-IPython-5.2"><span class="toc-item-num">5.2 </span>The four most helpful commands in IPython</a></span></li><li><span><a href="#Comments" data-toc-modified-id="Comments-5.3"><span class="toc-item-num">5.3 </span>Comments</a></span></li><li><span><a href="#Magic-functions" data-toc-modified-id="Magic-functions-5.4"><span class="toc-item-num">5.4 </span>Magic functions</a></span></li></ul></li><li><span><a href="#Assignment-and-expressions" data-toc-modified-id="Assignment-and-expressions-6"><span class="toc-item-num">6 </span>Assignment and expressions</a></span></li><li><span><a href="#Variables-and-types" data-toc-modified-id="Variables-and-types-7"><span class="toc-item-num">7 </span>Variables and types</a></span><ul class="toc-item"><li><span><a href="#Numbers:-int,-float,-complex" data-toc-modified-id="Numbers:-int,-float,-complex-7.1"><span class="toc-item-num">7.1 </span>Numbers: int, float, complex</a></span></li><li><span><a href="#Strings" data-toc-modified-id="Strings-7.2"><span class="toc-item-num">7.2 </span>Strings</a></span></li><li><span><a href="#len()" data-toc-modified-id="len()-7.3"><span class="toc-item-num">7.3 </span>len()</a></span></li><li><span><a href="#Lists" data-toc-modified-id="Lists-7.4"><span class="toc-item-num">7.4 </span>Lists</a></span></li><li><span><a href="#Tuples" data-toc-modified-id="Tuples-7.5"><span class="toc-item-num">7.5 </span>Tuples</a></span></li><li><span><a href="#Sets" data-toc-modified-id="Sets-7.6"><span class="toc-item-num">7.6 </span>Sets</a></span></li><li><span><a href="#Dictionaries" data-toc-modified-id="Dictionaries-7.7"><span class="toc-item-num">7.7 </span>Dictionaries</a></span></li></ul></li><li><span><a href="#Built-in-Constants" data-toc-modified-id="Built-in-Constants-8"><span class="toc-item-num">8 </span>Built-in Constants</a></span></li><li><span><a href="#Logical-(Boolean)-operators" data-toc-modified-id="Logical-(Boolean)-operators-9"><span class="toc-item-num">9 </span>Logical (Boolean) operators</a></span><ul class="toc-item"><li><span><a href="#and,-or,-not" data-toc-modified-id="and,-or,-not-9.1"><span class="toc-item-num">9.1 </span>and, or, not</a></span></li><li><span><a href="#Comparisons" data-toc-modified-id="Comparisons-9.2"><span class="toc-item-num">9.2 </span>Comparisons</a></span></li></ul></li><li><span><a href="#Indentation-and-whitespace" data-toc-modified-id="Indentation-and-whitespace-10"><span class="toc-item-num">10 </span>Indentation and whitespace</a></span></li><li><span><a href="#Control-of-flow" data-toc-modified-id="Control-of-flow-11"><span class="toc-item-num">11 </span>Control of flow</a></span><ul class="toc-item"><li><span><a href="#if...elif...else" data-toc-modified-id="if...elif...else-11.1"><span class="toc-item-num">11.1 </span><code>if</code>...<code>elif</code>...<code>else</code></a></span></li><li><span><a href="#for" data-toc-modified-id="for-11.2"><span class="toc-item-num">11.2 </span>for</a></span><ul class="toc-item"><li><span><a href="#The-range()-function" data-toc-modified-id="The-range()-function-11.2.1"><span class="toc-item-num">11.2.1 </span>The <code>range()</code> function</a></span></li></ul></li><li><span><a href="#while" data-toc-modified-id="while-11.3"><span class="toc-item-num">11.3 </span>while</a></span></li></ul></li><li><span><a href="#Function-definition" data-toc-modified-id="Function-definition-12"><span class="toc-item-num">12 </span>Function definition</a></span></li><li><span><a href="#Numeric-data-manipulation-with-Numpy" data-toc-modified-id="Numeric-data-manipulation-with-Numpy-13"><span class="toc-item-num">13 </span>Numeric data manipulation with Numpy</a></span><ul class="toc-item"><li><span><a href="#Interpolation" data-toc-modified-id="Interpolation-13.1"><span class="toc-item-num">13.1 </span>Interpolation</a></span></li></ul></li><li><span><a href="#Read-and-save-files" data-toc-modified-id="Read-and-save-files-14"><span class="toc-item-num">14 </span>Read and save files</a></span></li><li><span><a href="#Ploting-with-matplotlib" data-toc-modified-id="Ploting-with-matplotlib-15"><span class="toc-item-num">15 </span>Ploting with matplotlib</a></span></li><li><span><a href="#Signal-processing-with-Scipy" data-toc-modified-id="Signal-processing-with-Scipy-16"><span class="toc-item-num">16 </span>Signal processing with Scipy</a></span></li><li><span><a href="#Symbolic-mathematics-with-Sympy" data-toc-modified-id="Symbolic-mathematics-with-Sympy-17"><span class="toc-item-num">17 </span>Symbolic mathematics with Sympy</a></span></li><li><span><a href="#Data-analysis-with-pandas" data-toc-modified-id="Data-analysis-with-pandas-18"><span class="toc-item-num">18 </span>Data analysis with pandas</a></span></li><li><span><a href="#More-about-Python" data-toc-modified-id="More-about-Python-19"><span class="toc-item-num">19 </span>More about Python</a></span></li></ul></div>
## Scope of this tutorial
This will be a very brief tutorial on Python.
For a more complete tutorial about Python see [A Whirlwind Tour of Python](https://github.com/jakevdp/WhirlwindTourOfPython) and [Python Data Science Handbook](https://jakevdp.github.io/PythonDataScienceHandbook/) for a specific tutorial about Python for scientific computing.
To use Python for scientific computing we need the Python program itself with its main modules and specific packages for scientific computing. [See this notebook on how to install Python for scientific computing](http://nbviewer.ipython.org/github/demotu/BMC/blob/master/notebooks/PythonInstallation.ipynb).
Once you get Python and the necessary packages for scientific computing ready to work, there are different ways to run Python, the main ones are:
- open a terminal window in your computer and type `python` or `ipython` that the Python interpreter will start
- run the `Jupyter notebook` and start working with Python in a browser
- run `Spyder`, an interactive development environment (IDE)
- run the `Jupyter qtconsole`, a more featured terminal
- run Python online in a website such as [https://www.pythonanywhere.com/](https://www.pythonanywhere.com/) or [Colaboratory](https://colab.research.google.com/notebooks/welcome.ipynb)
- run Python using any other Python editor or IDE
We will use the Jupyter Notebook for this tutorial but you can run almost all the things we will see here using the other forms listed above.
## Python as a calculator
Once in the Jupyter notebook, if you type a simple mathematical expression and press `Shift+Enter` it will give the result of the expression:
```
1 + 2 - 25
4/7
```
Using the `print` function, let's explore the mathematical operations available in Python:
```
print('1+2 = ', 1+2, '\n', '4*5 = ', 4*5, '\n', '6/7 = ', 6/7, '\n', '8**2 = ', 8**2, sep='')
```
And if we want the square-root of a number:
```
sqrt(9)
```
We get an error message saying that the `sqrt` function if not defined. This is because `sqrt` and other mathematical functions are available with the `math` module:
```
import math
math.sqrt(9)
from math import sqrt
sqrt(9)
```
## The import function
We used the command '`import`' to be able to call certain functions. In Python functions are organized in modules and packages and they have to be imported in order to be used.
A module is a file containing Python definitions (e.g., functions) and statements. Packages are a way of structuring Python’s module namespace by using “dotted module names”. For example, the module name A.B designates a submodule named B in a package named A. To be used, modules and packages have to be imported in Python with the import function.
Namespace is a container for a set of identifiers (names), and allows the disambiguation of homonym identifiers residing in different namespaces. For example, with the command import math, we will have all the functions and statements defined in this module in the namespace '`math.`', for example, '`math.pi`' is the π constant and '`math.cos()`', the cosine function.
By the way, to know which Python version you are running, we can use one of the following modules:
```
import sys
sys.version
```
And if you are in an IPython session:
```
from IPython import sys_info
print(sys_info())
```
The first option gives information about the Python version; the latter also includes the IPython version, operating system, etc.
## Object-oriented programming
Python is designed as an object-oriented programming (OOP) language. OOP is a paradigm that represents concepts as "objects" that have data fields (attributes that describe the object) and associated procedures known as methods.
This means that all elements in Python are objects and they have attributes which can be acessed with the dot (.) operator after the name of the object. We already experimented with that when we imported the module `sys`, it became an object, and we acessed one of its attribute: `sys.version`.
OOP as a paradigm is much more than defining objects, attributes, and methods, but for now this is enough to get going with Python.
## Python and IPython help
To get help about any Python command, use `help()`:
```
help(math.degrees)
```
Or if you are in the IPython environment, simply add '?' to the function that a window will open at the bottom of your browser with the same help content:
```
math.degrees?
```
And if you add a second '?' to the statement you get access to the original script file of the function (an advantage of an open source language), unless that function is a built-in function that does not have a script file, which is the case of the standard modules in Python (but you can access the Python source code if you want; it just does not come with the standard program for installation).
So, let's see this feature with another function:
```
import scipy.fftpack
scipy.fftpack.fft??
```
To know all the attributes of an object, for example all the functions available in `math`, we can use the function `dir`:
```
print(dir(math))
```
### Tab completion in IPython
IPython has tab completion: start typing the name of the command (object) and press `tab` to see the names of objects available with these initials letters. When the name of the object is typed followed by a dot (`math.`), pressing `tab` will show all available attribites, scroll down to the desired attribute and press `Enter` to select it.
### The four most helpful commands in IPython
These are the most helpful commands in IPython (from [IPython tutorial](http://ipython.org/ipython-doc/dev/interactive/tutorial.html)):
- `?` : Introduction and overview of IPython’s features.
- `%quickref` : Quick reference.
- `help` : Python’s own help system.
- `object?` : Details about ‘object’, use ‘object??’ for extra details.
### Comments
Comments in Python start with the hash character, #, and extend to the end of the physical line:
```
# Import the math library to access more math stuff
import math
math.pi # this is the pi constant; a useless comment since this is obvious
```
To insert comments spanning more than one line, use a multi-line string with a pair of matching triple-quotes: `"""` or `'''` (we will see the string data type later). A typical use of a multi-line comment is as documentation strings and are meant for anyone reading the code:
```
"""Documentation strings are typically written like that.
A docstring is a string literal that occurs as the first statement
in a module, function, class, or method definition.
"""
```
A docstring like above is useless and its output as a standalone statement looks uggly in IPython Notebook, but you will see its real importance when reading and writting codes.
Commenting a programming code is an important step to make the code more readable, which Python cares a lot.
There is a style guide for writting Python code ([PEP 8](https://www.python.org/dev/peps/pep-0008/)) with a session about [how to write comments](https://www.python.org/dev/peps/pep-0008/#comments).
### Magic functions
IPython has a set of predefined ‘magic functions’ that you can call with a command line style syntax.
There are two kinds of magics, line-oriented and cell-oriented.
Line magics are prefixed with the % character and work much like OS command-line calls: they get as an argument the rest of the line, where arguments are passed without parentheses or quotes.
Cell magics are prefixed with a double %%, and they are functions that get as an argument not only the rest of the line, but also the lines below it in a separate argument.
## Assignment and expressions
The equal sign ('=') is used to assign a value to a variable. Afterwards, no result is displayed before the next interactive prompt:
```
x = 1
```
Spaces between the statements are optional but it helps for readability.
To see the value of the variable, call it again or use the print function:
```
x
print(x)
```
Of course, the last assignment is that holds:
```
x = 2
x = 3
x
```
In mathematics '=' is the symbol for identity, but in computer programming '=' is used for assignment, it means that the right part of the expresssion is assigned to its left part.
For example, 'x=x+1' does not make sense in mathematics but it does in computer programming:
```
x = x + 1
print(x)
```
A value can be assigned to several variables simultaneously:
```
x = y = 4
print(x)
print(y)
```
Several values can be assigned to several variables at once:
```
x, y = 5, 6
print(x)
print(y)
```
And with that, you can do (!):
```
x, y = y, x
print(x)
print(y)
```
Variables must be “defined” (assigned a value) before they can be used, or an error will occur:
```
x = z
```
## Variables and types
There are different types of built-in objects in Python (and remember that everything in Python is an object):
```
import types
print(dir(types))
```
Let's see some of them now.
### Numbers: int, float, complex
Numbers can an integer (int), float, and complex (with imaginary part).
Let's use the function `type` to show the type of number (and later for any other object):
```
type(6)
```
A float is a non-integer number:
```
math.pi
type(math.pi)
```
Python (IPython) is showing `math.pi` with only 15 decimal cases, but internally a float is represented with higher precision.
Floating point numbers in Python are implemented using a double (eight bytes) word; the precison and internal representation of floating point numbers are machine specific and are available in:
```
sys.float_info
```
Be aware that floating-point numbers can be trick in computers:
```
0.1 + 0.2
0.1 + 0.2 - 0.3
```
These results are not correct (and the problem is not due to Python). The error arises from the fact that floating-point numbers are represented in computer hardware as base 2 (binary) fractions and most decimal fractions cannot be represented exactly as binary fractions. As consequence, decimal floating-point numbers are only approximated by the binary floating-point numbers actually stored in the machine. [See here for more on this issue](http://docs.python.org/2/tutorial/floatingpoint.html).
A complex number has real and imaginary parts:
```
1+2j
print(type(1+2j))
```
Each part of a complex number is represented as a floating-point number. We can see them using the attributes `.real` and `.imag`:
```
print((1+2j).real)
print((1+2j).imag)
```
### Strings
Strings can be enclosed in single quotes or double quotes:
```
s = 'string (str) is a built-in type in Python'
s
type(s)
```
String enclosed with single and double quotes are equal, but it may be easier to use one instead of the other:
```
'string (str) is a Python's built-in type'
"string (str) is a Python's built-in type"
```
But you could have done that using the Python escape character '\':
```
'string (str) is a Python\'s built-in type'
```
Strings can be concatenated (glued together) with the + operator, and repeated with *:
```
s = 'P' + 'y' + 't' + 'h' + 'o' + 'n'
print(s)
print(s*5)
```
Strings can be subscripted (indexed); like in C, the first character of a string has subscript (index) 0:
```
print('s[0] = ', s[0], ' (s[index], start at 0)')
print('s[5] = ', s[5])
print('s[-1] = ', s[-1], ' (last element)')
print('s[:] = ', s[:], ' (all elements)')
print('s[1:] = ', s[1:], ' (from this index (inclusive) till the last (inclusive))')
print('s[2:4] = ', s[2:4], ' (from first index (inclusive) till second index (exclusive))')
print('s[:2] = ', s[:2], ' (till this index, exclusive)')
print('s[:10] = ', s[:10], ' (Python handles the index if it is larger than the string length)')
print('s[-10:] = ', s[-10:])
print('s[0:5:2] = ', s[0:5:2], ' (s[ini:end:step])')
print('s[::2] = ', s[::2], ' (s[::step], initial and final indexes can be omitted)')
print('s[0:5:-1] = ', s[::-1], ' (s[::-step] reverses the string)')
print('s[:2] + s[2:] = ', s[:2] + s[2:], ' (because of Python indexing, this sounds natural)')
```
### len()
Python has a built-in functon to get the number of itens of a sequence:
```
help(len)
s = 'Python'
len(s)
```
The function len() helps to understand how the backward indexing works in Python.
The index s[-i] should be understood as s[len(s) - i] rather than accessing directly the i-th element from back to front. This is why the last element of a string is s[-1]:
```
print('s = ', s)
print('len(s) = ', len(s))
print('len(s)-1 = ',len(s) - 1)
print('s[-1] = ', s[-1])
print('s[len(s) - 1] = ', s[len(s) - 1])
```
Or, strings can be surrounded in a pair of matching triple-quotes: """ or '''. End of lines do not need to be escaped when using triple-quotes, but they will be included in the string. This is how we created a multi-line comment earlier:
```
"""Strings can be surrounded in a pair of matching triple-quotes: \""" or '''.
End of lines do not need to be escaped when using triple-quotes,
but they will be included in the string.
"""
```
### Lists
Values can be grouped together using different types, one of them is list, which can be written as a list of comma-separated values between square brackets. List items need not all have the same type:
```
x = ['spam', 'eggs', 100, 1234]
x
```
Lists can be indexed and the same indexing rules we saw for strings are applied:
```
x[0]
```
The function len() works for lists:
```
len(x)
```
### Tuples
A tuple consists of a number of values separated by commas, for instance:
```
t = ('spam', 'eggs', 100, 1234)
t
```
The type tuple is why multiple assignments in a single line works; elements separated by commas (with or without surrounding parentheses) are a tuple and in an expression with an '=', the right-side tuple is attributed to the left-side tuple:
```
a, b = 1, 2
print('a = ', a, '\nb = ', b)
```
Is the same as:
```
(a, b) = (1, 2)
print('a = ', a, '\nb = ', b)
```
### Sets
Python also includes a data type for sets. A set is an unordered collection with no duplicate elements.
```
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
fruit = set(basket) # create a set without duplicates
fruit
```
As set is an unordered collection, it can not be indexed as lists and tuples.
```
set(['orange', 'pear', 'apple', 'banana'])
'orange' in fruit # fast membership testing
```
### Dictionaries
Dictionary is a collection of elements organized keys and values. Unlike lists and tuples, which are indexed by a range of numbers, dictionaries are indexed by their keys:
```
tel = {'jack': 4098, 'sape': 4139}
tel
tel['guido'] = 4127
tel
tel['jack']
del tel['sape']
tel['irv'] = 4127
tel
tel.keys()
'guido' in tel
```
The dict() constructor builds dictionaries directly from sequences of key-value pairs:
```
tel = dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
tel
```
## Built-in Constants
- **False** : false value of the bool type
- **True** : true value of the bool type
- **None** : sole value of types.NoneType. None is frequently used to represent the absence of a value.
In computer science, the Boolean or logical data type is composed by two values, true and false, intended to represent the values of logic and Boolean algebra. In Python, 1 and 0 can also be used in most situations as equivalent to the Boolean values.
## Logical (Boolean) operators
### and, or, not
- **and** : logical AND operator. If both the operands are true then condition becomes true. (a and b) is true.
- **or** : logical OR Operator. If any of the two operands are non zero then condition becomes true. (a or b) is true.
- **not** : logical NOT Operator. Reverses the logical state of its operand. If a condition is true then logical NOT operator will make false.
### Comparisons
The following comparison operations are supported by objects in Python:
- **==** : equal
- **!=** : not equal
- **<** : strictly less than
- **<=** : less than or equal
- **\>** : strictly greater than
- **\>=** : greater than or equal
- **is** : object identity
- **is not** : negated object identity
```
True == False
not True == False
1 < 2 > 1
True != (False or True)
True != False or True
```
## Indentation and whitespace
In Python, statement grouping is done by indentation (this is mandatory), which are done by inserting whitespaces, not tabs. Indentation is also recommended for alignment of function calling that span more than one line for better clarity.
We will see examples of indentation in the next session.
## Control of flow
### `if`...`elif`...`else`
Conditional statements (to peform something if another thing is True or False) can be implemmented using the `if` statement:
```
if expression:
statement
elif:
statement
else:
statement
```
`elif` (one or more) and `else` are optionals.
The indentation is obligatory.
For example:
```
if True:
pass
```
Which does nothing useful.
Let's use the `if`...`elif`...`else` statements to categorize the [body mass index](http://en.wikipedia.org/wiki/Body_mass_index) of a person:
```
# body mass index
weight = 100 # kg
height = 1.70 # m
bmi = weight / height**2
if bmi < 15:
c = 'very severely underweight'
elif 15 <= bmi < 16:
c = 'severely underweight'
elif 16 <= bmi < 18.5:
c = 'underweight'
elif 18.5 <= bmi < 25:
c = 'normal'
elif 25 <= bmi < 30:
c = 'overweight'
elif 30 <= bmi < 35:
c = 'moderately obese'
elif 35 <= bmi < 40:
c = 'severely obese'
else:
c = 'very severely obese'
print('For a weight of {0:.1f} kg and a height of {1:.2f} m,\n\
the body mass index (bmi) is {2:.1f} kg/m2,\nwhich is considered {3:s}.'\
.format(weight, height, bmi, c))
```
### for
The `for` statement iterates over a sequence to perform operations (a loop event).
```
for iterating_var in sequence:
statements
```
```
for i in [3, 2, 1, 'go!']:
print(i, end=', ')
for letter in 'Python':
print(letter),
```
#### The `range()` function
The built-in function range() is useful if we need to create a sequence of numbers, for example, to iterate over this list. It generates lists containing arithmetic progressions:
```
help(range)
range(10)
range(1, 10, 2)
for i in range(10):
n2 = i**2
print(n2),
```
### while
The `while` statement is used for repeating sections of code in a loop until a condition is met (this different than the `for` statement which executes n times):
```
while expression:
statement
```
Let's generate the Fibonacci series using a `while` loop:
```
# Fibonacci series: the sum of two elements defines the next
a, b = 0, 1
while b < 1000:
print(b, end=' ')
a, b = b, a+b
```
## Function definition
A function in a programming language is a piece of code that performs a specific task. Functions are used to reduce duplication of code making easier to reuse it and to decompose complex problems into simpler parts. The use of functions contribute to the clarity of the code.
A function is created with the `def` keyword and the statements in the block of the function must be indented:
```
def function():
pass
```
As per construction, this function does nothing when called:
```
function()
```
The general syntax of a function definition is:
```
def function_name( parameters ):
"""Function docstring.
The help for the function
"""
function body
return variables
```
A more useful function:
```
def fibo(N):
"""Fibonacci series: the sum of two elements defines the next.
The series is calculated till the input parameter N and
returned as an ouput variable.
"""
a, b, c = 0, 1, []
while b < N:
c.append(b)
a, b = b, a + b
return c
fibo(100)
if 3 > 2:
print('teste')
```
Let's implemment the body mass index calculus and categorization as a function:
```
def bmi(weight, height):
"""Body mass index calculus and categorization.
Enter the weight in kg and the height in m.
See http://en.wikipedia.org/wiki/Body_mass_index
"""
bmi = weight / height**2
if bmi < 15:
c = 'very severely underweight'
elif 15 <= bmi < 16:
c = 'severely underweight'
elif 16 <= bmi < 18.5:
c = 'underweight'
elif 18.5 <= bmi < 25:
c = 'normal'
elif 25 <= bmi < 30:
c = 'overweight'
elif 30 <= bmi < 35:
c = 'moderately obese'
elif 35 <= bmi < 40:
c = 'severely obese'
else:
c = 'very severely obese'
s = 'For a weight of {0:.1f} kg and a height of {1:.2f} m,\
the body mass index (bmi) is {2:.1f} kg/m2,\
which is considered {3:s}.'\
.format(weight, height, bmi, c)
print(s)
bmi(73, 1.70)
```
## Numeric data manipulation with Numpy
Numpy is the fundamental package for scientific computing in Python and has a N-dimensional array package convenient to work with numerical data. With Numpy it's much easier and faster to work with numbers grouped as 1-D arrays (a vector), 2-D arrays (like a table or matrix), or higher dimensions. Let's create 1-D and 2-D arrays in Numpy:
```
import numpy as np
x1d = np.array([1, 2, 3, 4, 5, 6])
print(type(x1d))
x1d
x2d = np.array([[1, 2, 3], [4, 5, 6]])
x2d
```
len() and the Numpy functions size() and shape() give information aboout the number of elements and the structure of the Numpy array:
```
print('1-d array:')
print(x1d)
print('len(x1d) = ', len(x1d))
print('np.size(x1d) = ', np.size(x1d))
print('np.shape(x1d) = ', np.shape(x1d))
print('np.ndim(x1d) = ', np.ndim(x1d))
print('\n2-d array:')
print(x2d)
print('len(x2d) = ', len(x2d))
print('np.size(x2d) = ', np.size(x2d))
print('np.shape(x2d) = ', np.shape(x2d))
print('np.ndim(x2d) = ', np.ndim(x2d))
```
Create random data
```
x = np.random.randn(4,3)
x
```
Joining (stacking together) arrays
```
x = np.random.randint(0, 5, size=(2, 3))
print(x)
y = np.random.randint(5, 10, size=(2, 3))
print(y)
np.vstack((x,y))
np.hstack((x,y))
```
Create equally spaced data
```
np.arange(start = 1, stop = 10, step = 2)
np.linspace(start = 0, stop = 1, num = 11)
```
### Interpolation
Consider the following data:
```
y = [5, 4, 10, 8, 1, 10, 2, 7, 1, 3]
```
Suppose we want to create data in between the given data points (interpolation); for instance, let's try to double the resolution of the data by generating twice as many data:
```
t = np.linspace(0, len(y), len(y)) # time vector for the original data
tn = np.linspace(0, len(y), 2 * len(y)) # new time vector for the new time-normalized data
yn = np.interp(tn, t, y) # new time-normalized data
yn
```
The key is the Numpy `interp` function, from its help:
interp(x, xp, fp, left=None, right=None)
One-dimensional linear interpolation.
Returns the one-dimensional piecewise linear interpolant to a function with given values at discrete data-points.
A plot of the data will show what we have done:
```
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.plot(t, y, 'bo-', lw=2, label='original data')
plt.plot(tn, yn, '.-', color=[1, 0, 0, .5], lw=2, label='interpolated')
plt.legend(loc='best', framealpha=.5)
plt.show()
```
For more about Numpy, see [http://www.numpy.org/](http://www.numpy.org/).
## Read and save files
There are two kinds of computer files: text files and binary files:
> Text file: computer file where the content is structured as a sequence of lines of electronic text. Text files can contain plain text (letters, numbers, and symbols) but they are not limited to such. The type of content in the text file is defined by the Unicode encoding (a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems).
>
> Binary file: computer file where the content is encoded in binary form, a sequence of integers representing byte values.
Let's see how to save and read numeric data stored in a text file:
**Using plain Python**
```
f = open("newfile.txt", "w") # open file for writing
f.write("This is a test\n") # save to file
f.write("And here is another line\n") # save to file
f.close()
f = open('newfile.txt', 'r') # open file for reading
f = f.read() # read from file
print(f)
help(open)
```
**Using Numpy**
```
import numpy as np
data = np.random.randn(3,3)
np.savetxt('myfile.txt', data, fmt="%12.6G") # save to file
data = np.genfromtxt('myfile.txt', unpack=True) # read from file
data
```
## Ploting with matplotlib
Matplotlib is the most-widely used packge for plotting data in Python. Let's see some examples of it.
```
import matplotlib.pyplot as plt
```
Use the IPython magic `%matplotlib inline` to plot a figure inline in the notebook with the rest of the text:
```
%matplotlib inline
import numpy as np
t = np.linspace(0, 0.99, 100)
x = np.sin(2 * np.pi * 2 * t)
n = np.random.randn(100) / 5
plt.Figure(figsize=(12,8))
plt.plot(t, x, label='sine', linewidth=2)
plt.plot(t, x + n, label='noisy sine', linewidth=2)
plt.annotate(s='$sin(4 \pi t)$', xy=(.2, 1), fontsize=20, color=[0, 0, 1])
plt.legend(loc='best', framealpha=.5)
plt.xlabel('Time [s]')
plt.ylabel('Amplitude')
plt.title('Data plotting using matplotlib')
plt.show()
```
Use the IPython magic `%matplotlib qt` to plot a figure in a separate window (from where you will be able to change some of the figure proprerties):
```
%matplotlib qt
mu, sigma = 10, 2
x = mu + sigma * np.random.randn(1000)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
ax1.plot(x, 'ro')
ax1.set_title('Data')
ax1.grid()
n, bins, patches = ax2.hist(x, 25, density=True, facecolor='r') # histogram
ax2.set_xlabel('Bins')
ax2.set_ylabel('Probability')
ax2.set_title('Histogram')
fig.suptitle('Another example using matplotlib', fontsize=18, y=1)
ax2.grid()
plt.tight_layout()
plt.show()
```
And a window with the following figure should appear:
```
from IPython.display import Image
Image(url="./../images/plot.png")
```
You can switch back and forth between inline and separate figure using the `%matplotlib` magic commands used above. There are plenty more examples with the source code in the [matplotlib gallery](http://matplotlib.org/gallery.html).
```
# get back the inline plot
%matplotlib inline
```
## Signal processing with Scipy
The Scipy package has a lot of functions for signal processing, among them: Integration (scipy.integrate), Optimization (scipy.optimize), Interpolation (scipy.interpolate), Fourier Transforms (scipy.fftpack), Signal Processing (scipy.signal), Linear Algebra (scipy.linalg), and Statistics (scipy.stats). As an example, let's see how to use a low-pass Butterworth filter to attenuate high-frequency noise and how the differentiation process of a signal affects the signal-to-noise content. We will also calculate the Fourier transform of these data to look at their frequencies content.
```
from scipy.signal import butter, filtfilt
import scipy.fftpack
freq = 100.
t = np.arange(0,1,.01);
w = 2*np.pi*1 # 1 Hz
y = np.sin(w*t)+0.1*np.sin(10*w*t)
# Butterworth filter
b, a = butter(4, (5/(freq/2)), btype = 'low')
y2 = filtfilt(b, a, y)
# 2nd derivative of the data
ydd = np.diff(y,2)*freq*freq # raw data
y2dd = np.diff(y2,2)*freq*freq # filtered data
# frequency content
yfft = np.abs(scipy.fftpack.fft(y))/(y.size/2); # raw data
y2fft = np.abs(scipy.fftpack.fft(y2))/(y.size/2); # filtered data
freqs = scipy.fftpack.fftfreq(y.size, 1./freq)
yddfft = np.abs(scipy.fftpack.fft(ydd))/(ydd.size/2);
y2ddfft = np.abs(scipy.fftpack.fft(y2dd))/(ydd.size/2);
freqs2 = scipy.fftpack.fftfreq(ydd.size, 1./freq)
```
And the plots:
```
fig, ((ax1,ax2),(ax3,ax4)) = plt.subplots(2, 2, figsize=(12, 6))
ax1.set_title('Temporal domain', fontsize=14)
ax1.plot(t, y, 'r', linewidth=2, label = 'raw data')
ax1.plot(t, y2, 'b', linewidth=2, label = 'filtered @ 5 Hz')
ax1.set_ylabel('f')
ax1.legend(frameon=False, fontsize=12)
ax2.set_title('Frequency domain', fontsize=14)
ax2.plot(freqs[:int(yfft.size/4)], yfft[:int(yfft.size/4)],'r', lw=2,label='raw data')
ax2.plot(freqs[:int(yfft.size/4)],y2fft[:int(yfft.size/4)],'b--',lw=2,label='filtered @ 5 Hz')
ax2.set_ylabel('FFT(f)')
ax2.legend(frameon=False, fontsize=12)
ax3.plot(t[:-2], ydd, 'r', linewidth=2, label = 'raw')
ax3.plot(t[:-2], y2dd, 'b', linewidth=2, label = 'filtered @ 5 Hz')
ax3.set_xlabel('Time [s]'); ax3.set_ylabel("f ''")
ax4.plot(freqs[:int(yddfft.size/4)], yddfft[:int(yddfft.size/4)], 'r', lw=2, label = 'raw')
ax4.plot(freqs[:int(yddfft.size/4)],y2ddfft[:int(yddfft.size/4)],'b--',lw=2, label='filtered @ 5 Hz')
ax4.set_xlabel('Frequency [Hz]'); ax4.set_ylabel("FFT(f '')")
plt.show()
```
For more about Scipy, see [https://docs.scipy.org/doc/scipy/reference/tutorial/](https://docs.scipy.org/doc/scipy/reference/tutorial/).
## Symbolic mathematics with Sympy
Sympy is a package to perform symbolic mathematics in Python. Let's see some of its features:
```
from IPython.display import display
import sympy as sym
from sympy.interactive import printing
printing.init_printing()
```
Define some symbols and the create a second-order polynomial function (a.k.a., parabola):
```
x, y = sym.symbols('x y')
y = x**2 - 2*x - 3
y
```
Plot the parabola at some given range:
```
from sympy.plotting import plot
%matplotlib inline
plot(y, (x, -3, 5));
```
And the roots of the parabola are given by:
```
sym.solve(y, x)
```
We can also do symbolic differentiation and integration:
```
dy = sym.diff(y, x)
dy
sym.integrate(dy, x)
```
For example, let's use Sympy to represent three-dimensional rotations. Consider the problem of a coordinate system xyz rotated in relation to other coordinate system XYZ. The single rotations around each axis are illustrated by:
```
from IPython.display import Image
Image(url="./../images/rotations.png")
```
The single 3D rotation matrices around Z, Y, and X axes can be expressed in Sympy:
```
from IPython.core.display import Math
from sympy import symbols, cos, sin, Matrix, latex
a, b, g = symbols('alpha beta gamma')
RX = Matrix([[1, 0, 0], [0, cos(a), -sin(a)], [0, sin(a), cos(a)]])
display(Math(latex('\\mathbf{R_{X}}=') + latex(RX, mat_str = 'matrix')))
RY = Matrix([[cos(b), 0, sin(b)], [0, 1, 0], [-sin(b), 0, cos(b)]])
display(Math(latex('\\mathbf{R_{Y}}=') + latex(RY, mat_str = 'matrix')))
RZ = Matrix([[cos(g), -sin(g), 0], [sin(g), cos(g), 0], [0, 0, 1]])
display(Math(latex('\\mathbf{R_{Z}}=') + latex(RZ, mat_str = 'matrix')))
```
And using Sympy, a sequence of elementary rotations around X, Y, Z axes is given by:
```
RXYZ = RZ*RY*RX
display(Math(latex('\\mathbf{R_{XYZ}}=') + latex(RXYZ, mat_str = 'matrix')))
```
Suppose there is a rotation only around X ($\alpha$) by $\pi/2$; we can get the numerical value of the rotation matrix by substituing the angle values:
```
r = RXYZ.subs({a: np.pi/2, b: 0, g: 0})
r
```
And we can prettify this result:
```
display(Math(latex(r'\mathbf{R_{(\alpha=\pi/2)}}=') +
latex(r.n(chop=True, prec=3), mat_str = 'matrix')))
```
For more about Sympy, see [http://docs.sympy.org/latest/tutorial/](http://docs.sympy.org/latest/tutorial/).
## Data analysis with pandas
> "[pandas](http://pandas.pydata.org/) is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python."
To work with labellled data, pandas has a type called DataFrame (basically, a matrix where columns and rows have may names and may be of different types) and it is also the main type of the software [R](http://www.r-project.org/). Fo ezample:
```
import pandas as pd
x = 5*['A'] + 5*['B']
x
df = pd.DataFrame(np.random.rand(10,2), columns=['Level 1', 'Level 2'] )
df['Group'] = pd.Series(['A']*5 + ['B']*5)
plot = df.boxplot(by='Group')
from pandas.plotting import scatter_matrix
df = pd.DataFrame(np.random.randn(100, 3), columns=['A', 'B', 'C'])
plot = scatter_matrix(df, alpha=0.5, figsize=(8, 6), diagonal='kde')
```
pandas is aware the data is structured and give you basic statistics considerint that and nicely formatted:
```
df.describe()
```
For more on pandas, see this tutorial: [http://pandas.pydata.org/pandas-docs/stable/10min.html](http://pandas.pydata.org/pandas-docs/stable/10min.html).
## More about Python
There is a lot of good material in the internet about Python for scientific computing, here is a small list of interesting stuff:
- [How To Think Like A Computer Scientist](http://www.openbookproject.net/thinkcs/python/english2e/) or [the interactive edition](http://interactivepython.org/courselib/static/thinkcspy/index.html) (book)
- [Python Scientific Lecture Notes](http://scipy-lectures.github.io/) (lecture notes)
- [A Whirlwind Tour of Python](https://github.com/jakevdp/WhirlwindTourOfPython) (tutorial/book)
- [Python Data Science Handbook](https://jakevdp.github.io/PythonDataScienceHandbook/) (tutorial/book)
- [Lectures on scientific computing with Python](https://github.com/jrjohansson/scientific-python-lectures#lectures-on-scientific-computing-with-python) (lecture notes)
| github_jupyter |
```
%matplotlib inline
```
Word Embeddings: Encoding Lexical Semantics
===========================================
Word embeddings are dense vectors of real numbers, one per word in your
vocabulary. In NLP, it is almost always the case that your features are
words! But how should you represent a word in a computer? You could
store its ascii character representation, but that only tells you what
the word *is*, it doesn't say much about what it *means* (you might be
able to derive its part of speech from its affixes, or properties from
its capitalization, but not much). Even more, in what sense could you
combine these representations? We often want dense outputs from our
neural networks, where the inputs are $|V|$ dimensional, where
$V$ is our vocabulary, but often the outputs are only a few
dimensional (if we are only predicting a handful of labels, for
instance). How do we get from a massive dimensional space to a smaller
dimensional space?
How about instead of ascii representations, we use a one-hot encoding?
That is, we represent the word $w$ by
\begin{align}\overbrace{\left[ 0, 0, \dots, 1, \dots, 0, 0 \right]}^\text{|V| elements}\end{align}
where the 1 is in a location unique to $w$. Any other word will
have a 1 in some other location, and a 0 everywhere else.
There is an enormous drawback to this representation, besides just how
huge it is. It basically treats all words as independent entities with
no relation to each other. What we really want is some notion of
*similarity* between words. Why? Let's see an example.
Suppose we are building a language model. Suppose we have seen the
sentences
* The mathematician ran to the store.
* The physicist ran to the store.
* The mathematician solved the open problem.
in our training data. Now suppose we get a new sentence never before
seen in our training data:
* The physicist solved the open problem.
Our language model might do OK on this sentence, but wouldn't it be much
better if we could use the following two facts:
* We have seen mathematician and physicist in the same role in a sentence. Somehow they
have a semantic relation.
* We have seen mathematician in the same role in this new unseen sentence
as we are now seeing physicist.
and then infer that physicist is actually a good fit in the new unseen
sentence? This is what we mean by a notion of similarity: we mean
*semantic similarity*, not simply having similar orthographic
representations. It is a technique to combat the sparsity of linguistic
data, by connecting the dots between what we have seen and what we
haven't. This example of course relies on a fundamental linguistic
assumption: that words appearing in similar contexts are related to each
other semantically. This is called the `distributional
hypothesis <https://en.wikipedia.org/wiki/Distributional_semantics>`__.
Getting Dense Word Embeddings
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
How can we solve this problem? That is, how could we actually encode
semantic similarity in words? Maybe we think up some semantic
attributes. For example, we see that both mathematicians and physicists
can run, so maybe we give these words a high score for the "is able to
run" semantic attribute. Think of some other attributes, and imagine
what you might score some common words on those attributes.
If each attribute is a dimension, then we might give each word a vector,
like this:
\begin{align}q_\text{mathematician} = \left[ \overbrace{2.3}^\text{can run},
\overbrace{9.4}^\text{likes coffee}, \overbrace{-5.5}^\text{majored in Physics}, \dots \right]\end{align}
\begin{align}q_\text{physicist} = \left[ \overbrace{2.5}^\text{can run},
\overbrace{9.1}^\text{likes coffee}, \overbrace{6.4}^\text{majored in Physics}, \dots \right]\end{align}
Then we can get a measure of similarity between these words by doing:
\begin{align}\text{Similarity}(\text{physicist}, \text{mathematician}) = q_\text{physicist} \cdot q_\text{mathematician}\end{align}
Although it is more common to normalize by the lengths:
\begin{align}\text{Similarity}(\text{physicist}, \text{mathematician}) = \frac{q_\text{physicist} \cdot q_\text{mathematician}}
{\| q_\text{physicist} \| \| q_\text{mathematician} \|} = \cos (\phi)\end{align}
Where $\phi$ is the angle between the two vectors. That way,
extremely similar words (words whose embeddings point in the same
direction) will have similarity 1. Extremely dissimilar words should
have similarity -1.
You can think of the sparse one-hot vectors from the beginning of this
section as a special case of these new vectors we have defined, where
each word basically has similarity 0, and we gave each word some unique
semantic attribute. These new vectors are *dense*, which is to say their
entries are (typically) non-zero.
But these new vectors are a big pain: you could think of thousands of
different semantic attributes that might be relevant to determining
similarity, and how on earth would you set the values of the different
attributes? Central to the idea of deep learning is that the neural
network learns representations of the features, rather than requiring
the programmer to design them herself. So why not just let the word
embeddings be parameters in our model, and then be updated during
training? This is exactly what we will do. We will have some *latent
semantic attributes* that the network can, in principle, learn. Note
that the word embeddings will probably not be interpretable. That is,
although with our hand-crafted vectors above we can see that
mathematicians and physicists are similar in that they both like coffee,
if we allow a neural network to learn the embeddings and see that both
mathematicians and physicists have a large value in the second
dimension, it is not clear what that means. They are similar in some
latent semantic dimension, but this probably has no interpretation to
us.
In summary, **word embeddings are a representation of the *semantics* of
a word, efficiently encoding semantic information that might be relevant
to the task at hand**. You can embed other things too: part of speech
tags, parse trees, anything! The idea of feature embeddings is central
to the field.
Word Embeddings in Pytorch
~~~~~~~~~~~~~~~~~~~~~~~~~~
Before we get to a worked example and an exercise, a few quick notes
about how to use embeddings in Pytorch and in deep learning programming
in general. Similar to how we defined a unique index for each word when
making one-hot vectors, we also need to define an index for each word
when using embeddings. These will be keys into a lookup table. That is,
embeddings are stored as a $|V| \times D$ matrix, where $D$
is the dimensionality of the embeddings, such that the word assigned
index $i$ has its embedding stored in the $i$'th row of the
matrix. In all of my code, the mapping from words to indices is a
dictionary named word\_to\_ix.
The module that allows you to use embeddings is torch.nn.Embedding,
which takes two arguments: the vocabulary size, and the dimensionality
of the embeddings.
To index into this table, you must use torch.LongTensor (since the
indices are integers, not floats).
```
# Author: Robert Guthrie
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
word_to_ix = {"hello": 0, "world": 1}
embeds = nn.Embedding(2, 5) # 2 words in vocab, 5 dimensional embeddings
lookup_tensor = torch.tensor([word_to_ix["hello"]], dtype=torch.long)
hello_embed = embeds(lookup_tensor)
print(hello_embed)
```
An Example: N-Gram Language Modeling
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Recall that in an n-gram language model, given a sequence of words
$w$, we want to compute
\begin{align}P(w_i | w_{i-1}, w_{i-2}, \dots, w_{i-n+1} )\end{align}
Where $w_i$ is the ith word of the sequence.
In this example, we will compute the loss function on some training
examples and update the parameters with backpropagation.
```
CONTEXT_SIZE = 2
EMBEDDING_DIM = 10
# We will use Shakespeare Sonnet 2
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
# we should tokenize the input, but we will ignore that for now
# build a list of tuples. Each tuple is ([ word_i-2, word_i-1 ], target word)
trigrams = [([test_sentence[i], test_sentence[i + 1]], test_sentence[i + 2])
for i in range(len(test_sentence) - 2)]
# print the first 3, just so you can see what they look like
print(trigrams[:3])
vocab = set(test_sentence)
word_to_ix = {word: i for i, word in enumerate(vocab)}
class NGramLanguageModeler(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NGramLanguageModeler, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
self.linear2 = nn.Linear(128, vocab_size)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
log_probs = F.log_softmax(out, dim=1)
return log_probs
losses = []
loss_function = nn.NLLLoss()
model = NGramLanguageModeler(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.001)
for epoch in range(10):
total_loss = 0
for context, target in trigrams:
# Step 1. Prepare the inputs to be passed to the model (i.e, turn the words
# into integer indices and wrap them in tensors)
context_idxs = torch.tensor([word_to_ix[w] for w in context], dtype=torch.long)
# Step 2. Recall that torch *accumulates* gradients. Before passing in a
# new instance, you need to zero out the gradients from the old
# instance
model.zero_grad()
# Step 3. Run the forward pass, getting log probabilities over next
# words
log_probs = model(context_idxs)
# Step 4. Compute your loss function. (Again, Torch wants the target
# word wrapped in a tensor)
loss = loss_function(log_probs, torch.tensor([word_to_ix[target]], dtype=torch.long))
# Step 5. Do the backward pass and update the gradient
loss.backward()
optimizer.step()
# Get the Python number from a 1-element Tensor by calling tensor.item()
total_loss += loss.item()
losses.append(total_loss)
print(losses) # The loss decreased every iteration over the training data!
```
Exercise: Computing Word Embeddings: Continuous Bag-of-Words
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The Continuous Bag-of-Words model (CBOW) is frequently used in NLP deep
learning. It is a model that tries to predict words given the context of
a few words before and a few words after the target word. This is
distinct from language modeling, since CBOW is not sequential and does
not have to be probabilistic. Typcially, CBOW is used to quickly train
word embeddings, and these embeddings are used to initialize the
embeddings of some more complicated model. Usually, this is referred to
as *pretraining embeddings*. It almost always helps performance a couple
of percent.
The CBOW model is as follows. Given a target word $w_i$ and an
$N$ context window on each side, $w_{i-1}, \dots, w_{i-N}$
and $w_{i+1}, \dots, w_{i+N}$, referring to all context words
collectively as $C$, CBOW tries to minimize
\begin{align}-\log p(w_i | C) = -\log \text{Softmax}(A(\sum_{w \in C} q_w) + b)\end{align}
where $q_w$ is the embedding for word $w$.
Implement this model in Pytorch by filling in the class below. Some
tips:
* Think about which parameters you need to define.
* Make sure you know what shape each operation expects. Use .view() if you need to
reshape.
```
CONTEXT_SIZE = 2 # 2 words to the left, 2 to the right
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.""".split()
# By deriving a set from `raw_text`, we deduplicate the array
vocab = set(raw_text)
vocab_size = len(vocab)
word_to_ix = {word: i for i, word in enumerate(vocab)}
data = []
for i in range(2, len(raw_text) - 2):
context = [raw_text[i - 2], raw_text[i - 1],
raw_text[i + 1], raw_text[i + 2]]
target = raw_text[i]
data.append((context, target))
print(data[:5])
class CBOW(nn.Module):
def __init__(self):
pass
def forward(self, inputs):
pass
# create your model and train. here are some functions to help you make
# the data ready for use by your module
def make_context_vector(context, word_to_ix):
idxs = [word_to_ix[w] for w in context]
return torch.tensor(idxs, dtype=torch.long)
make_context_vector(data[0][0], word_to_ix) # example
```
| github_jupyter |
```
import cv2
import numpy as np
from pathlib import Path
from hfnet.settings import EXPER_PATH
from notebooks.utils import plot_images, plot_matches, add_frame
import torch
import tensorflow as tf
from tensorflow.python.saved_model import tag_constants
tf.contrib.resampler # import C++ op
%load_ext autoreload
%autoreload 2
%matplotlib inline
```
# Load query (night) and database (day) images
```
query_idx = 1 # also try with 2 and 3
read_image = lambda n: cv2.imread('doc/demo/' + n)[:, :, ::-1]
image_query = read_image(f'query{query_idx}.jpg')
images_db = [read_image(f'db{i}.jpg') for i in range(1, 5)]
plot_images([image_query] + images_db, dpi=50)
```
# Create HF-Net model for inference
```
class HFNet:
def __init__(self, model_path, outputs):
self.session = tf.Session()
self.image_ph = tf.placeholder(tf.float32, shape=(None, None, 3))
net_input = tf.image.rgb_to_grayscale(self.image_ph[None])
tf.saved_model.loader.load(
self.session, [tag_constants.SERVING], str(model_path),
clear_devices=True,
input_map={'image:0': net_input})
graph = tf.get_default_graph()
self.outputs = {n: graph.get_tensor_by_name(n+':0')[0] for n in outputs}
self.nms_radius_op = graph.get_tensor_by_name('pred/simple_nms/radius:0')
self.num_keypoints_op = graph.get_tensor_by_name('pred/top_k_keypoints/k:0')
def inference(self, image, nms_radius=4, num_keypoints=1000):
inputs = {
self.image_ph: image[..., ::-1].astype(np.float),
self.nms_radius_op: nms_radius,
self.num_keypoints_op: num_keypoints,
}
return self.session.run(self.outputs, feed_dict=inputs)
model_path = Path(EXPER_PATH, 'saved_models/hfnet')
outputs = ['global_descriptor', 'keypoints', 'local_descriptors']
hfnet = HFNet(model_path, outputs)
```
# Compute global descriptors and local features for query and database
```
db = [hfnet.inference(i) for i in images_db]
global_index = np.stack([d['global_descriptor'] for d in db])
query = hfnet.inference(image_query)
```
# Perform a global search in the database
```
def compute_distance(desc1, desc2):
# For normalized descriptors, computing the distance is a simple matrix multiplication.
return 2 * (1 - desc1 @ desc2.T)
nearest = np.argmin(compute_distance(query['global_descriptor'], global_index))
disp_db = [add_frame(im, (0, 255, 0)) if i == nearest else im
for i, im in enumerate(images_db)]
plot_images([image_query] + disp_db, dpi=50)
```
# Perform local matching with the retrieved image
```
def match_with_ratio_test(desc1, desc2, thresh):
dist = compute_distance(desc1, desc2)
nearest = np.argpartition(dist, 2, axis=-1)[:, :2]
dist_nearest = np.take_along_axis(dist, nearest, axis=-1)
valid_mask = dist_nearest[:, 0] <= (thresh**2)*dist_nearest[:, 1]
matches = np.stack([np.where(valid_mask)[0], nearest[valid_mask][:, 0]], 1)
return matches
matches = match_with_ratio_test(query['local_descriptors'],
db[nearest]['local_descriptors'], 0.8)
plot_matches(image_query, query['keypoints'],
images_db[nearest], db[nearest]['keypoints'],
matches, color=(0, 1, 0), dpi=50)
```
| github_jupyter |
```
import folium
import pandas as pd
# 红、蓝、绿
cluster_res = [[2, 3, 6, 9, 20, 24, 25, 27, 28, 53, 56, 57, 75, 121, 123], [0, 1, 7, 8, 10, 11, 15, 18, 19, 26, 32, 33, 34, 35, 37, 39, 40, 41, 42, 43, 44, 45, 46, 55, 60, 62, 63, 66, 71, 73, 74, 80, 81, 84, 86, 89, 95, 96, 97, 101, 102, 107, 112, 114, 116, 120, 122, 124], [4, 5, 12, 13, 14, 16, 17, 21, 22, 23, 29, 30, 31, 36, 38, 47, 48, 49, 50, 51, 52, 54, 58, 59, 61, 64, 65, 67, 68, 69, 70, 72, 76, 77, 78, 79, 82, 83, 85, 87, 88, 90, 91, 92, 93, 94, 98, 99, 100, 103, 104, 105, 106, 108, 109, 110, 111, 113, 115, 117, 118, 119]]
category = {}
for i in range(len(cluster_res)):
for item in cluster_res[i]:
category[item] = i
data = pd.read_csv('dataByPCA.csv')
NWU_latitude,NWU_longitude = 34.14612705388515, 108.87400175044368
NWU_map = folium.Map([NWU_latitude,NWU_longitude])
NWU_map
incident = folium.FeatureGroup()
for latitude,longitude in zip(data['latitude'],data['longitude']):
incident.add_child(
folium.CircleMarker([latitude,longitude],
radius=7,
fill=True,
color="yellow",
fill_color="red",
fill_opacity=0.4)
)
NWU_map.add_child(incident)
NWU_map
NWU_latitude,NWU_longitude = 34.14612705388515, 108.87400175044368
NWU_map = folium.Map([NWU_latitude,NWU_longitude])
A = folium.map.FeatureGroup()
B = folium.map.FeatureGroup()
C = folium.map.FeatureGroup()
for i in range(len(data['name'])):
#A类
if category[i] == 0:
A.add_child(
folium.CircleMarker(
[data['latitude'][i], data['longitude'][i]],
radius=1.5,
color='red',
fill=True,
fill_color='red',
fill_opacity=0.4)
)
#B类
elif category[i] == 1:
B.add_child(
folium.CircleMarker(
[data['latitude'][i], data['longitude'][i]],
radius=1.5,
color='green',
fill=True,
fill_color='red',
fill_opacity=0.4)
)
#C类
elif category[i] == 2:
C.add_child(
folium.CircleMarker(
[data['latitude'][i], data['longitude'][i]],
radius=1.5,
color='blue',
fill=True,
fill_color='red',
fill_opacity=0.4)
)
NWU_map.add_child(A)
NWU_map.add_child(B)
NWU_map.add_child(C)
NWU_map
def parse_zhch(s):
return str(str(s).encode('ascii' , 'xmlcharrefreplace'))[2:-1]
labels = []
for i in range(len(data['name'])):
labels.append(parse_zhch(data['name'][i]))
for lat, lng, label in zip(data['latitude'], data['longitude'], labels):
folium.Marker([lat, lng], popup=label).add_to(NWU_map)
NWU_map
```
| github_jupyter |
# Working with "Largish" Data
Sample data is Takata airbag warranty claims saved as a .csv file. It is a modest size of about 2.7GB.
We will compare 2 workflows:
- Using Dask
- Using PyArrow/fastparquet
### Dask Workflow
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import dask.dataframe as dd
from dask.distributed import Client
client = Client()
client
```
### Key thing is to set column types that are str/object to 'category' and float columns to float32
```
%%time
cols = ['WAR_CLAIM_DATE',
'WAR_DEFECT_CODE',
'VIN_MODEL_YR',
'VIN_FACTORY',
'VIN_MODEL_TYPE',
'WAR_ORIG_DISTR_CDE',
'WAR_RESP_DISTR_CDE',
'WAR_EXCH_RATE_AMT',
'CLAIM_LABOR_HRS_QTY',
'WAR_LABOR_CHG_AMT_USD',
'WAR_PARTS_CHG_AMT_USD',
'WAR_HDLG_CHG_AMT_USD',
'WAR_TOTAL_CHG_AMT_USD',
'PHASE_TYPE',
'PART_COST_25',
'DRIVER_PASSENGER',
'DIR_NUMBER',
'NA_FCTRY_YES_NO',
'PAB_TYPE',
'DAB_TYPE',
'STATE_CODE',
'COUNTRY',
'ZONE_REGION',
'CLAIM_SUBLET_AMT_USD',
'SUBLET_TYPE1_CODE',
'SUBLET_TYPE2_CODE',
'SUBLET_TYPE_DESC',
'SUBLET_YES_NO',
'WRWHA1_LABOR_CHG_AMT_USD',
'FRGT_SUBL_TAX_AMT_USD'
]
data_type = {
'WAR_CLAIM_DATE': np.int32,
'WAR_DEFECT_CODE': 'category',
'VIN_MODEL_YR': 'category',
'VIN_FACTORY': 'category',
'VIN_MODEL_TYPE': 'category',
'WAR_ORIG_DISTR_CDE': 'category',
'WAR_RESP_DISTR_CDE': 'category',
'WAR_EXCH_RATE_AMT': np.float32,
'CLAIM_LABOR_HRS_QTY': np.float32,
'WAR_LABOR_CHG_AMT_USD': np.float32,
'WAR_PARTS_CHG_AMT_USD': np.float32,
'WAR_HDLG_CHG_AMT_USD': np.float32,
'WAR_TOTAL_CHG_AMT_USD': np.float32,
'PHASE_TYPE': 'category',
'PART_COST_25': 'category',
'DRIVER_PASSENGER': 'category',
'DIR_NUMBER': 'category',
'NA_FCTRY_YES_NO': 'category',
'PAB_TYPE': 'category',
'DAB_TYPE': 'category',
'STATE_CODE': 'category',
'COUNTRY': 'category',
'ZONE_REGION': 'category',
'CLAIM_SUBLET_AMT_USD': np.float32,
'SUBLET_TYPE1_CODE': 'category',
'SUBLET_TYPE2_CODE': 'category',
'SUBLET_TYPE_DESC': 'category',
'SUBLET_YES_NO': 'category',
'WRWHA1_LABOR_CHG_AMT_USD': np.float32,
'FRGT_SUBL_TAX_AMT_USD': np.float32
}
df = dd.read_csv(r'D:/temp/DAB_PAB_Raw_Claims.csv', dtype=data_type, names=cols)
```
**Number of rows:**
```
%%time
# Using Python 3.6's new f-string syntax:
f"{df.WAR_CLAIM_DATE.count().compute():,d}"
%%time
df.head()
```
**To sum a single column, it took several seconds:**
```
%%time
f"${df['WAR_TOTAL_CHG_AMT_USD'].sum().compute():,.2f}"
%%time
df.groupby(['WAR_CLAIM_DATE'])['WAR_TOTAL_CHG_AMT_USD'].sum().compute()
```
**To just sum a single column using Dask, it took well over one minute. Now, let's compare how long it would take using fastparquet.**
### fastparquet Workflow
**Let's create a parquet file from a csv file:**
```
%%time
df.to_parquet(r'D:/temp/resultsets/your_parquet.parquet', engine='fastparquet')
%%time
dfp = dd.read_parquet(r'D:/temp/resultsets/your_parquet.parquet', engine='fastparquet')
%%time
columns = ['WAR_CLAIM_DATE', 'WAR_TOTAL_CHG_AMT_USD']
dfp_small = dfp[columns]
%%time
dfp.head()
%%time
# Using Python 3.6's new f-string syntax
f"{dfp.WAR_CLAIM_DATE.count().compute():,d}"
%%time
# using Python 3.6's new f-string syntax:
f"${dfp['WAR_TOTAL_CHG_AMT_USD'].sum().compute():,.2f}"
%%time
by_month = dfp.groupby(['WAR_CLAIM_DATE'])['WAR_TOTAL_CHG_AMT_USD'].sum().compute()
%%time
by_month = dfp_small.groupby(['WAR_CLAIM_DATE'])['WAR_TOTAL_CHG_AMT_USD'].sum().compute()
type(by_month)
by_month.sort_index()
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.ticker import FuncFormatter
fig = plt.figure(figsize=(14,8))
ax = plt.subplot(1,1,1)
ax.yaxis.set_major_formatter(FuncFormatter('${:,.0f}'.format))
plt.xticks(rotation=270, fontsize=8)
by_month.sort_index().plot.bar(ax=ax, color='b', alpha=0.4)
sns.despine()
```
| github_jupyter |
# Organizing time series metabolomics data (compound concentrations) into an array with dimensions of strain-replicate, time, and compound
```
import pandas as pd
import numpy as np
import pickle
df = pd.read_csv('../Data/20151130_OAM1_QuantResults_v2C.csv')
df
```
### Clean up the header row so that none of the columns are named "Unnamed", but instead are named something more meaningful
```
#only run once. otherwise, you have to reset kernel to avoid a reference error.
new_col = []
for i,k in enumerate(df.keys()):
if not "Unnamed" in k:
my_tag = k
new_col.append('%s %s'%(my_tag ,df.ix[0,k]))
df.columns = new_col
df = df.drop(df.index[[0]])
#and clean up an unnecessary colum
del df['Sample nan']
df
```
### Create a list of the compounds measured in each sample file
```
my_val_keys = []
for k in df.keys():
if "Final Conc." in k:
my_val_keys.append(k)
```
### Extract File, Concentration, Strain, Replicate, and Timepoint information
* Ignoring the calibration curve samples (OAA), the water blank samples (H2O), and uninoculated medium samples (medB), we need to pull the relevant sample information out of the filename
```
my_files = [] #each data file
my_vals = [] #values for each compound
my_strain = [] #strain name
my_replicate = [] #replicate name
my_strain_replicate = [] #strain-replicate
my_time = [] #time dimension
for i in range(df.shape[0]):
#OAA means it's a cal-curve
if not "OAA" in df.iloc[i]['Sample Data File'].split('_')[4]:
#H20 means it's a water blank
if not "H2O" in df.iloc[i]['Sample Data File'].split('_')[4]:
#medB means it's a medium control
if not "medB" in df.iloc[i]['Sample Data File'].split('_')[4]:
my_files.append(df.iloc[i]['Sample Data File'])
temp = df.iloc[i]['Sample Data File'].split('_')[4].split('-')
my_strain.append(temp[0])
my_replicate.append(temp[1])
my_strain_replicate.append('%s %s'%(temp[0],temp[1]))
my_time.append(float(temp[2].replace('t','')))
temp_vals = []
for mvk in my_val_keys:
temp_vals.append(df.iloc[i][mvk])
my_vals.append(temp_vals)
```
### Make a 3D array to store all information (strain-replicate x concentration x timepoint)
```
#unique timepoints
u_time = np.unique(my_time)
#unique filenames
u_files = np.unique(my_strain_replicate)
M = np.zeros((len(u_files),len(my_val_keys),len(u_time)))
for i,uf in enumerate(u_files):
for j,uv in enumerate(my_val_keys):
for k,ut in enumerate(u_time):
idx1 = np.argwhere( (np.asarray(my_strain_replicate) == uf) & (np.asarray(my_time) == ut )).flatten()
idx2 = np.argwhere(np.asarray(my_val_keys) == uv).flatten()
if len(idx1)>0:
if np.isnan(float(my_vals[idx1][idx2])):
pass
else:
M[i,j,k] = float(my_vals[idx1][idx2])
#dim one is labeled by u_files
#dim two is labeled by my_val_keys
#dim three is labeled by u_time
```
### Final step is to save the data for use in later Python programs
```
data = {}
data['dim1'] = u_files
data['dim2'] = my_val_keys
data['dim3'] = u_time
data['M'] = M
with open("../Data/metabolomics_data.pkl",'w') as f:
pickle.dump(data,f)
```
| github_jupyter |
<h1> Text Classification using TensorFlow/Keras on Cloud ML Engine </h1>
This notebook illustrates:
<ol>
<li> Creating datasets for Machine Learning using BigQuery
<li> Creating a text classification model using the Estimator API with a Keras model
<li> Training on Cloud ML Engine
<li> Deploying the model
<li> Predicting with model
<li> Rerun with pre-trained embedding
</ol>
```
# change these to try this notebook out
BUCKET = 'cloud-training-demos-ml'
PROJECT = 'cloud-training-demos'
REGION = 'us-central1'
import os
os.environ['BUCKET'] = BUCKET
os.environ['PROJECT'] = PROJECT
os.environ['REGION'] = REGION
os.environ['TFVERSION'] = '1.8'
import tensorflow as tf
print(tf.__version__)
```
We will look at the titles of articles and figure out whether the article came from the New York Times, TechCrunch or GitHub.
We will use [hacker news](https://news.ycombinator.com/) as our data source. It is an aggregator that displays tech related headlines from various sources.
### Creating Dataset from BigQuery
Hacker news headlines are available as a BigQuery public dataset. The [dataset](https://bigquery.cloud.google.com/table/bigquery-public-data:hacker_news.stories?tab=details) contains all headlines from the sites inception in October 2006 until October 2015.
Here is a sample of the dataset:
```
import google.datalab.bigquery as bq
query="""
SELECT
url, title, score
FROM
`bigquery-public-data.hacker_news.stories`
WHERE
LENGTH(title) > 10
AND score > 10
LIMIT 10
"""
df = bq.Query(query).execute().result().to_dataframe()
df
```
Let's do some regular expression parsing in BigQuery to get the source of the newspaper article from the URL. For example, if the url is http://mobile.nytimes.com/...., I want to be left with <i>nytimes</i>
```
query="""
SELECT
ARRAY_REVERSE(SPLIT(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.'))[OFFSET(1)] AS source,
COUNT(title) AS num_articles
FROM
`bigquery-public-data.hacker_news.stories`
WHERE
REGEXP_CONTAINS(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.com$')
AND LENGTH(title) > 10
GROUP BY
source
ORDER BY num_articles DESC
LIMIT 10
"""
df = bq.Query(query).execute().result().to_dataframe()
df
```
Now that we have good parsing of the URL to get the source, let's put together a dataset of source and titles. This will be our labeled dataset for machine learning.
```
query="""
SELECT source, LOWER(REGEXP_REPLACE(title, '[^a-zA-Z0-9 $.-]', ' ')) AS title FROM
(SELECT
ARRAY_REVERSE(SPLIT(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.'))[OFFSET(1)] AS source,
title
FROM
`bigquery-public-data.hacker_news.stories`
WHERE
REGEXP_CONTAINS(REGEXP_EXTRACT(url, '.*://(.[^/]+)/'), '.com$')
AND LENGTH(title) > 10
)
WHERE (source = 'github' OR source = 'nytimes' OR source = 'techcrunch')
"""
df = bq.Query(query + " LIMIT 10").execute().result().to_dataframe()
df.head()
```
For ML training, we will need to split our dataset into training and evaluation datasets (and perhaps an independent test dataset if we are going to do model or feature selection based on the evaluation dataset).
A simple, repeatable way to do this is to use the hash of a well-distributed column in our data (See https://www.oreilly.com/learning/repeatable-sampling-of-data-sets-in-bigquery-for-machine-learning).
```
traindf = bq.Query(query + " AND ABS(MOD(FARM_FINGERPRINT(title), 4)) > 0").execute().result().to_dataframe()
evaldf = bq.Query(query + " AND ABS(MOD(FARM_FINGERPRINT(title), 4)) = 0").execute().result().to_dataframe()
```
Below we can see that roughly 75% of the data is used for training, and 25% for evaluation.
We can also see that within each dataset, the classes are roughly balanced.
```
traindf['source'].value_counts()
evaldf['source'].value_counts()
```
Finally we will save our data, which is currently in-memory, to disk.
```
import os, shutil
DATADIR='data/txtcls'
shutil.rmtree(DATADIR, ignore_errors=True)
os.makedirs(DATADIR)
traindf.to_csv( os.path.join(DATADIR,'train.tsv'), header=False, index=False, encoding='utf-8', sep='\t')
evaldf.to_csv( os.path.join(DATADIR,'eval.tsv'), header=False, index=False, encoding='utf-8', sep='\t')
!head -3 data/txtcls/train.tsv
!wc -l data/txtcls/*.tsv
```
### TensorFlow/Keras Code
Please explore the code in this <a href="txtclsmodel/trainer">directory</a>: `model.py` contains the TensorFlow model and `task.py` parses command line arguments and launches off the training job.
There are some TODOs in the `model.py`, **make sure to complete the TODOs before proceeding!**
### Run Locally
Let's make sure the code compiles by running locally for a fraction of an epoch
```
%%bash
## Make sure we have the latest version of Google Cloud Storage package
pip install --upgrade google-cloud-storage
rm -rf txtcls_trained
gcloud ml-engine local train \
--module-name=trainer.task \
--package-path=${PWD}/txtclsmodel/trainer \
-- \
--output_dir=${PWD}/txtcls_trained \
--train_data_path=${PWD}/data/txtcls/train.tsv \
--eval_data_path=${PWD}/data/txtcls/eval.tsv \
--num_epochs=0.1
```
### Train on the Cloud
Let's first copy our training data to the cloud:
```
%%bash
gsutil cp data/txtcls/*.tsv gs://${BUCKET}/txtcls/
%%bash
OUTDIR=gs://${BUCKET}/txtcls/trained_fromscratch
JOBNAME=txtcls_$(date -u +%y%m%d_%H%M%S)
gsutil -m rm -rf $OUTDIR
gcloud ml-engine jobs submit training $JOBNAME \
--region=$REGION \
--module-name=trainer.task \
--package-path=${PWD}/txtclsmodel/trainer \
--job-dir=$OUTDIR \
--scale-tier=BASIC_GPU \
--runtime-version=$TFVERSION \
-- \
--output_dir=$OUTDIR \
--train_data_path=gs://${BUCKET}/txtcls/train.tsv \
--eval_data_path=gs://${BUCKET}/txtcls/eval.tsv \
--num_epochs=5
```
## Monitor training with TensorBoard
To activate TensorBoard within the JupyterLab UI navigate to "<b>File</b>" - "<b>New Launcher</b>". Then double-click the 'Tensorboard' icon on the bottom row.
TensorBoard 1 will appear in the new tab. Navigate through the three tabs to see the active TensorBoard. The 'Graphs' and 'Projector' tabs offer very interesting information including the ability to replay the tests.
You may close the TensorBoard tab when you are finished exploring.
### Results
What accuracy did you get?
### Deploy trained model
Once your training completes you will see your exported models in the output directory specified in Google Cloud Storage.
You should see one model for each training checkpoint (default is every 1000 steps).
```
%%bash
gsutil ls gs://${BUCKET}/txtcls/trained_fromscratch/export/exporter/
```
We will take the last export and deploy it as a REST API using Google Cloud Machine Learning Engine
```
%%bash
MODEL_NAME="txtcls"
MODEL_VERSION="v1_fromscratch"
MODEL_LOCATION=$(gsutil ls gs://${BUCKET}/txtcls/trained_fromscratch/export/exporter/ | tail -1)
#gcloud ml-engine versions delete ${MODEL_VERSION} --model ${MODEL_NAME} --quiet
#gcloud ml-engine models delete ${MODEL_NAME}
gcloud ml-engine models create ${MODEL_NAME} --regions $REGION
gcloud ml-engine versions create ${MODEL_VERSION} --model ${MODEL_NAME} --origin ${MODEL_LOCATION} --runtime-version=$TFVERSION
```
### Get Predictions
Here are some actual hacker news headlines gathered from July 2018. These titles were not part of the training or evaluation datasets.
```
techcrunch=[
'Uber shuts down self-driving trucks unit',
'Grover raises €37M Series A to offer latest tech products as a subscription',
'Tech companies can now bid on the Pentagon’s $10B cloud contract'
]
nytimes=[
'‘Lopping,’ ‘Tips’ and the ‘Z-List’: Bias Lawsuit Explores Harvard’s Admissions',
'A $3B Plan to Turn Hoover Dam into a Giant Battery',
'A MeToo Reckoning in China’s Workplace Amid Wave of Accusations'
]
github=[
'Show HN: Moon – 3kb JavaScript UI compiler',
'Show HN: Hello, a CLI tool for managing social media',
'Firefox Nightly added support for time-travel debugging'
]
```
Our serving input function expects the already tokenized representations of the headlines, so we do that pre-processing in the code before calling the REST API.
Note: Ideally we would do these transformation in the tensorflow graph directly instead of relying on separate client pre-processing code (see: [training-serving skew](https://developers.google.com/machine-learning/guides/rules-of-ml/#training_serving_skew)), howevever the pre-processing functions we're using are python functions so cannot be embedded in a tensorflow graph.
See the <a href="../text_classification_native.ipynb">text_classification_native</a> notebook for a solution to this.
```
import pickle
from tensorflow.python.keras.preprocessing import sequence
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
import json
requests = techcrunch+nytimes+github
# Tokenize and pad sentences using same mapping used in the deployed model
tokenizer = pickle.load( open( "txtclsmodel/tokenizer.pickled", "rb" ) )
requests_tokenized = tokenizer.texts_to_sequences(requests)
requests_tokenized = sequence.pad_sequences(requests_tokenized,maxlen=50)
# JSON format the requests
request_data = {'instances':requests_tokenized.tolist()}
# Authenticate and call CMLE prediction API
credentials = GoogleCredentials.get_application_default()
api = discovery.build('ml', 'v1', credentials=credentials,
discoveryServiceUrl='https://storage.googleapis.com/cloud-ml/discovery/ml_v1_discovery.json')
parent = 'projects/%s/models/%s' % (PROJECT, 'txtcls') #version is not specified so uses default
response = api.projects().predict(body=request_data, name=parent).execute()
# Format and print response
for i in range(len(requests)):
print('\n{}'.format(requests[i]))
print(' github : {}'.format(response['predictions'][i]['dense_1'][0]))
print(' nytimes : {}'.format(response['predictions'][i]['dense_1'][1]))
print(' techcrunch: {}'.format(response['predictions'][i]['dense_1'][2]))
```
How many of your predictions were correct?
### Rerun with Pre-trained Embedding
In the previous model we trained our word embedding from scratch. Often times we get better performance and/or converge faster by leveraging a pre-trained embedding. This is a similar concept to transfer learning during image classification.
We will use the popular GloVe embedding which is trained on Wikipedia as well as various news sources like the New York Times.
You can read more about Glove at the project homepage: https://nlp.stanford.edu/projects/glove/
You can download the embedding files directly from the stanford.edu site, but we've rehosted it in a GCS bucket for faster download speed.
```
!gsutil cp gs://cloud-training-demos/courses/machine_learning/deepdive/09_sequence/text_classification/glove.6B.200d.txt gs://$BUCKET/txtcls/
```
Once the embedding is downloaded re-run your cloud training job with the added command line argument:
` --embedding_path=gs://${BUCKET}/txtcls/glove.6B.200d.txt`
Be sure to change your OUTDIR so it doesn't overwrite the previous model.
While the final accuracy may not change significantly, you should notice the model is able to converge to it much more quickly because it no longer has to learn an embedding from scratch.
#### References
- This implementation is based on code from: https://github.com/google/eng-edu/tree/master/ml/guides/text_classification.
- See the full text classification tutorial at: https://developers.google.com/machine-learning/guides/text-classification/
Copyright 2017 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License
| github_jupyter |
```
# Import the SPICE module
import spiceypy
# Import datetime and get the current time stamp
import datetime
# get today's date
date_today = datetime.datetime.today()
# convert the datetime to a string, replacing the time with midnight
date_today = date_today.strftime('%Y-%m-%dT00:00:00')
# Load the spice kernels for leapseconds and for the planets
spiceypy.furnsh('../kernels/lsk/naif0012.tls')
spiceypy.furnsh('../kernels/spk/de432s.bsp')
# Compute the Ephemeris Time
et_today_midnight = spiceypy.utc2et(date_today)
# Compute the state vector of the Earth w.r.t. the Sun
earth_state_wrt_sun, earth_sun_light_time = spiceypy.spkgeo(targ=399,
et=et_today_midnight,
ref='ECLIPJ2000',
obs=10)
# The state vector is 6 dimensional: x,y,z in km and the corresponding velocities in km/s
print(f'State vector of the Earth w.r.t. the Sun for {date_today} (midnight):\n'
+ f'{earth_state_wrt_sun}')
import numpy as np
# Convert list to numpy array
earth_state_wrt_sun = np.array(earth_state_wrt_sun)
# Compute the distance
earth_sun_distance = np.linalg.norm(earth_state_wrt_sun[:3])
# First, we compute the actual orbital speed of the Earth around the Sun
earth_orb_speed_wrt_sun = np.linalg.norm(earth_state_wrt_sun[3:])
# It's around 30 km/s
print(f'Current orbital speed of the Earth around the Sun in km/s: {earth_orb_speed_wrt_sun}')
# Now let's compute the theoretical expectation. First, we load a pck file that contains
# miscellanoeus information, like the G*M values for different objects
# First, load the kernel
spiceypy.furnsh('../kernels/pck/gm_de431.tpc')
_, GM_SUN = spiceypy.bodvcd(bodyid=10, item='GM', maxn=1)
# Now compute the orbital speed
v_orb_func = lambda gm, r: np.sqrt(gm/r)
earth_orb_speed_wrt_sun_theory = v_orb_func(GM_SUN[0], earth_sun_distance)
# Print the result
print(f'Theoretical orbital speed of the Earth around the Sun in km/s: '
+ f'{earth_orb_speed_wrt_sun_theory}')
# A second check:
# The angular difference between the autumn equinox and today's position vector of the Earth
# (in this tutorial October) should be in degrees the number of days passed the 22th September.
# Again please note: we use the "today" function to determine the Earth's state vector.
# Now the "autumn vector" is simpley (1, 0, 0) in ECLIPJ2000 and we use this as a quick and simple
# rough estimation / computation
# Position vector
earth_position_wrt_sun = earth_state_wrt_sun[:3]
# Normalize it
earth_position_wrt_sun_normed = earth_position_wrt_sun / earth_sun_distance
# Define the "autumn vector" of the Earth
earth_position_wrt_sun_normed_autumn = np.array([1.0, 0.0, 0.0])
ang_dist_deg = np.degrees(np.arccos(np.dot(earth_position_wrt_sun_normed,
earth_position_wrt_sun_normed_autumn)))
print(f"Angular distance between autumn and today's position in degrees {date_today}: "
+ f"{ang_dist_deg}")
```
| github_jupyter |
# Text Analysis Using nltk.text
```
from nltk.tokenize import word_tokenize
from nltk.text import Text
my_string = "Two plus two is four, minus one that's three — quick maths. Every day man's on the block. Smoke trees. See your girl in the park, that girl is an uckers. When the thing went quack quack quack, your men were ducking! Hold tight Asznee, my brother. He's got a pumpy. Hold tight my man, my guy. He's got a frisbee. I trap, trap, trap on the phone. Moving that cornflakes, rice crispies. Hold tight my girl Whitney."
tokens = word_tokenize(my_string)
tokens = [word.lower() for word in tokens]
tokens[:5]
t = Text(tokens)
t
```
This method of converting raw strings to NLTK `Text` instances can be used when reading text from a file. For instance:
```python
f = open('my-file.txt','rU') # Opening a file with the mode 'U' or 'rU' will open a file for reading in universal newline mode. All three line ending conventions will be translated to a "\n"
raw = f.read()
```
```
t.concordance('uckers') # concordance() is a method of the Text class of NLTK. It finds words and displays a context window. Word matching is not case-sensitive.
# concordance() is defined as follows: concordance(self, word, width=79, lines=25). Note default values for optional params.
t.collocations() # def collocations(self, num=20, window_size=2). num is the max no. of collocations to print.
t.count('quack')
t.index('two')
t.similar('brother') # similar(self, word, num=20). Distributional similarity: find other words which appear in the same contexts as the specified word; list most similar words first.
t.dispersion_plot(['man', 'thing', 'quack']) # Reveals patterns in word positions. Each stripe represents an instance of a word, and each row represents the entire text.
t.plot(20) # plots 20 most common tokens
t.vocab()
```
Another thing that might be useful in analysis is finding common contexts. Our text is too small so we will use a bigger one.
NLTK comes with several interesting **corpora**, which are large collections of text. You can check out what kinds of corpora are found in `nltk.corpus` in Section 1 [here](http://www.nltk.org/book/ch02.html).
`reuters` is a corpus of news documents. More specifically, `reuters` is a *corpus reader* for the Reuters corpus which provides us with methods to access the corpus:
```
from nltk.corpus import reuters
text = Text(reuters.words()) # .words() is one method corpus readers provide for reading data from a corpus. We will learn more about these methods in Chapter 2.
text.common_contexts(['August', 'June']) # It seems that .common_contexts() takes 2 words which are used similarly and displays where they are used similarly. It also seems that '_' indicates where the words would be in the text.
```
We will further explore the Reuters corpus as well as several others in later chapters.
| github_jupyter |
```
"""
This simple notebook demonstrates the workflow of using the TensorFlow converter.
"""
import numpy as np
from tensorflow.python.tools.freeze_graph import freeze_graph
import tfcoreml
import linear_mnist_train
"""
Step 0: Before you run this notebook, view run the example script linear_mnist_train.py
to get a trained TensorFlow network.
This may take a few minutes.
"""
linear_mnist_train.train()
"""
Step 1: "Freeze" your tensorflow model - convert your TF model into a stand-alone graph definition file
Inputs:
(1) TensorFlow code
(2) trained weights in a checkpoint file
(3) The output tensors' name you want to use in inference
(4) [Optional] Input tensors' name to TF model
Outputs:
(1) A frozen TensorFlow GraphDef, with trained weights frozen into it
"""
# Provide these to run freeze_graph:
# Graph definition file, stored as protobuf TEXT
graph_def_file = './model.pbtxt'
# Trained model's checkpoint name
checkpoint_file = './checkpoints/model.ckpt'
# Frozen model's output name
frozen_model_file = './frozen_model.pb'
# Output nodes. If there're multiple output ops, use comma separated string, e.g. "out1,out2".
output_node_names = 'Softmax'
# Call freeze graph
freeze_graph(input_graph=graph_def_file,
input_saver="",
input_binary=False,
input_checkpoint=checkpoint_file,
output_node_names=output_node_names,
restore_op_name="save/restore_all",
filename_tensor_name="save/Const:0",
output_graph=frozen_model_file,
clear_devices=True,
initializer_nodes="")
"""
Step 2: Call converter
"""
# Provide these inputs in addition to inputs in Step 1
# A dictionary of input tensors' name and shape (with batch)
input_tensor_shapes = {"Placeholder:0":[1,784]} # batch size is 1
# Output CoreML model path
coreml_model_file = './model.mlmodel'
output_tensor_names = ['Softmax:0']
# Call the converter
coreml_model = tfcoreml.convert(
tf_model_path=frozen_model_file,
mlmodel_path=coreml_model_file,
input_name_shape_dict=input_tensor_shapes,
output_feature_names=output_tensor_names)
"""
Step 3: Run the converted model
"""
# Provide CoreML model with a dictionary as input. Change ':0' to '__0'
# as Swift / Objective-C code generation do not allow colons in variable names
coreml_inputs = {'Placeholder__0': np.random.rand(1,1,784)} # (sequence_length=1,batch=1,channels=784)
coreml_output = coreml_model.predict(coreml_inputs, useCPUOnly=False)
print coreml_output
```
| github_jupyter |
<a href="https://colab.research.google.com/github/VadimDu/Deep-Learning-to-predict-resistance-to-Fluoroquinolone-antibiotics/blob/main/Deep_Learning_to_predict_resistance_to_FQ_antibiotics.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# **Deep learning to predict antibiotic resistance**
In this tutorial we will preform machine-learning (deep learning) analysis of bacterial DNA gyrase/topoisomerase genes in order to predict resistance to Fluoroquinolone antibiotics. We will use Convolutional Neural Network (CNN) based classifier from Python library of Keras (TensorFlow) to achieve it.
### **Fluoroquinolones resistance in bacteria**
The fluoroquinolones are potent, broad-spectrum antibiotics that have been used in medical practice for the treatment of severe or resistant infections. Fluoroquinolones (FQ) are potent inhibitors of bacterial type II topoisomerases, which are essential enzymes involved in key cellular processes including DNA replication. DNA gyrase and topoisomerase are both heterotetrameric type II topoisomerase enzymes comprising two copies of each of either a GyrA and GyrB subunit or a ParC and ParE subunit, respectively. FQ target DNA gyrase and topoisomerase with varying efficiency in different bacteria, inhibit their control of supercoiling within the cell, resulting in impaired DNA replication and cell death. FQ have been extensively used in human
and veterinary medicine due to their effectiveness against both Gram-positive and Gram-negative bacteria, and resistance to FQ is evidently common and can occur via a range of mechanisms. The most common mechanism of high-level FQ resistance is due to point mutation in one or more of the target genes (*gyrA*, *gyrB*, *parC* and *parE*). The region where mutations arise in these
genes is a short DNA sequence known as the quinolone-resistance-determining-region (QRDR). Mutations in the QRDR of these genes, resulting in amino acid substitutions, alter the target protein structure and subsequently the FQ-binding affinity of the enzyme, leading to drug resistance. For an extensive review of the topic, refer to (Redgrave et al. 2014): ([link text](https://www.cell.com/trends/microbiology/fulltext/S0966-842X(14)00089-4?rss=yes%3Frss%3Dyes&mobileUi=0))
### **A short introduction to artificial neural networks**
An artificial neural network consists of layers of interconnected compute units (neurons). The depth of a neural network corresponds to the number of hidden layers, and the width to the maximum number of neurons in one of its layers. As it became possible to train networks with larger numbers of hidden layers, artificial neural networks were rebranded to “deep networks". In a typical configuration, the network receives data in an input layer, which are then transformed in a nonlinear way through multiple hidden layers, before final outputs are computed in the output layer. Neurons in a hidden or output layer are connected to all neurons of the previous layer. Each neuron computes a weighted sum of its inputs and applies a nonlinear activation function to calculate its output *f(x)*. The most popular activation function is the rectified linear unit (ReLU). The weights *w* between neurons are free parameters that capture the model’s representation of the data and are learned from input/output samples. Learning minimizes a loss function *L(w)* that measures the fit of the model output to the true label of a sample. During learning, the predicted label is compared with the true label to compute a loss for the current set of model weights. The loss is then backward propagated through the network to compute the gradients of the loss function and update weights. The loss function *L(w)* is typically optimized using gradient-based descent. In the figure below you can find a typical architecture of a neural network. <br/>
For a more detailed read about nerual networks and in general deep learning methods in computational biology, read this great paper (Angermueller et al. 2016): [link text](https://www.embopress.org/doi/full/10.15252/msb.20156651)
```
#Mount the Google Drive folders to be accessible with Google Colab:
from google.colab import drive
drive.mount('/content/drive')
#%pwd
#%ls /content/drive/My\ Drive/Input_data_for_CNN_deep-learning_FQ-resistance
#!git clone https://github.com/VadimDu/Deep-Learning-to-predict-resistance-to-Fluoroquinolone-antibiotics.git
from IPython.display import Image
Image("/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/Neural_net_intro1_Angermueller_et_al_2016.png")
```
### **A short introduction to Convolutional Neural Network**
CNNs are designed to model input data in the form of multidimensional arrays, such as two-dimensional images with three colour channels or one-dimensional genomic sequences with one channel per nucleotide. A convolutional layer consists of multiple maps of neurons, so-called feature maps or filters. Unlike in a fully connected network, each neuron within a feature map is only connected to a local patch of neurons in the previous layer, the so-called receptive field. In additiona, all neurons within a given feature map share the same parameters. Hence, all neurons within a feature map scan for the same feature in the previous layer, however at different locations. Different feature maps might, for example, detect edges of different orientation in an image, or different sequence motifs in a genomic sequence. The activity of a neuron is obtained by computing a discrete convolution of its receptive field, i.e. computing the weighted sum of input neurons, and applying an activation function. One limitation of CNNs is that the input sequence need to be of a fixed length. Nonetheless, CNNs are among the most widely used architectures
to extract features from fixed-size DNA sequence windows. Other alternative architectures exist such as recurrent neural networks (RNN), which are also suited for DNA/protein sequences. RNNs allow modeling sequences of variable length, however RNNs are more difficult to train than CNNs. In the figure below, you can find the principles of using CNN architecture for predicting molecular traits from DNA sequence, adapted from Angermueller et al. 2016.<br/>For more details about CNNs, refer again to (Angermueller et al. 2016): [link text](https://www.embopress.org/doi/full/10.15252/msb.20156651)
```
from IPython.display import Image
Image("/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/Deep_learning_for_computational_biology_Fig2.jpg")
```
### **Module imports and data input**
Now let us start the real practical tutorial! First let's import all the necessary for the analysis modules and functions. The required modules are pandas, numpy, Bio, sklearn, tensorflow, matplotlib and seaborn.
```
#Install missing Python3 modules in google-colab:
!pip3 install biopython
!pip3 install -U scikit-learn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
from Bio import SeqIO
import itertools
from sklearn.preprocessing import LabelEncoder #creating an integer encoding of labels
from sklearn.preprocessing import OneHotEncoder #creating a one hot encoding of integer encoded values
from sklearn.metrics import confusion_matrix, accuracy_score, mean_squared_error, classification_report, roc_auc_score, roc_curve, auc
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Conv1D, Dense, MaxPooling1D, Flatten, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.regularizers import l2, l1 #weight regularization to prevent overfitting
from tensorflow.keras.optimizers import SGD, Adam
from tensorflow.keras.models import load_model #Your saved model can be loaded later by calling the load_model() function
```
Now we will import our working files: the nucleotide sequences of the bacterial *gyrA* genes from each genome and a table with resistance phenotype lables for each genome. The labels table consists of these columns: genome_id (need to match with sequence headers in the sequence file), genome_name (the exact bacterial strain), resistance_phenotype (clinically resistant or susceptible to antibiotics phenotype), and binary_label (1 for resistant, 0 for susceptible).<br/>
**Note:** all the *gyrA* sequences and their resistance phenotypes were downloaded from PATRIC resource ([link text](https://www.patricbrc.org/)). Only bacterial genomes for which the resistance phenotype for FQ-antibiotics was determined with laboratory testing (by measuring minimum inhibitory concentration for different FQ drugs) were included.
```
fasta_path = "/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/AMR_FQ_phenotypic_data_r-s_mod_genomes_ids_uniq_gyrA_gene_mod.fasta"
labels = pd.read_csv("/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/AMR_FQ_phenotypic_data_r-s_mod_genomes_ids_uniq_gyr-par_nr_genomes_labels.txt", sep="\t", index_col=None, dtype={"genome_id" : str})
labels.shape
```
### **Data organization and filtering**
We will load the nucelotides sequences into Python with Bio module and parse them as regular fasta sequences. Then we will store them in a dictionary object (keys as the sequence headers, vals as the sequences themselfs). The reason we use dict here is that because dict keys must be unique, only non-duplicate headers (and thus sequences) are retained. This is useful if for some reason you have duplicate genes with a similar header (gene id), which you want to filter out to remove redundancy and data duplication. Finally, we will filter out genes longer than 2100bp and those that contain 'N's , and will trim the genes to use 2000bp (from 100 to 2100 bp position). Genes longer than 2100bp might be not 'real' *gyrA*, and in the first 100bp there is no useful information regarding FQ resistance. Also remember that CNN requires the input sequences to be of a fixed-same length. We also fix the sequence ids to match the ids in the labels table.
```
fasta_dict = {}
for sequence in SeqIO.parse(fasta_path, "fasta"):
if (len(str(sequence.seq)) >= 2100 and 'n' not in str(sequence.seq)):
fasta_dict[str(sequence.id).split("peg")[0].split(".")[0] + "." + str(sequence.id).split("peg")[0].split(".")[1]] = str(sequence.seq[100:2100])
len(fasta_dict)
```
Now we will extract the seqeunce data from our dict into 2 lists, one for the header and the other for the sequence, for ease of downstream analysis. We will cut from the headers the "fig|" string and leave only the number to match the genome_id in the labels table. We also will subset the label table to include only those genes that passed filtration in the previous step.
```
#Convert to list, header & sequence separately:
header_nr = list(fasta_dict.keys())
fasta = list(fasta_dict.values())
#Make list of all the retained sequence headers, in order to update the labels list accordingly:
header_nr = [header_nr[i].split("|")[1] for i in range(len(header_nr))] #remove the "|" from the header
labels_subset = labels[labels["genome_id"].isin(header_nr)] #subset the labels list using "isin"
len(labels_subset )
```
### **Data preparation for Convolutional Neural Network**
As we are using DNA sequence data represented as 4 nucleotide letters (A/a, G/g, C/c, T/t), we need to re-format the data into a format that can be passed to a deep learning algorithm such as CNN - real or integer values. In addition, our DNA sequences need to be organized in a matrix that would be fed to the CNN model. We will use one-hot encoding, which encodes every nucleotide in a sequence into a form of a 4-dimensional vector, 1-dim for each of the 4 nucelotides. We place a "1" in the dimension corresponding to the base found in the DNA sequence, and "0"s in the other dimensions. We then concatenate these 4-dim vectors together along the bases in the sequence to form a matrix. For each of the 10,127 sequences in our dataset, the matrix will be of 2000 x 4 size.<br/>
While we could use the labels as a vector of 1 or 0, it is often easier to similarly one-hot encode the labels, as we did the sequences.
```
#Encode the DNA nucleotide sequences using one-hot encoding:
one_hot_encoder = OneHotEncoder()
input_fasta = []
for sequence in fasta:
one_hot_encoded = one_hot_encoder.fit_transform(np.array(list(sequence)).reshape(-1,1))
#Each sequence is represented by a matrix of 2000x4
input_fasta.append(one_hot_encoded.toarray()) #Return a dense ndarray representation of this matrix.
input_fasta = np.stack(input_fasta) #Join (concatenate) a sequence of arrays along a new axis.
print(type(input_fasta))
print(input_fasta.shape) #Out: (N_samples, Seq_length, One-hot_encoded_cols=4)
print('DNA sequence #1 first 10-bases:\n',fasta[0][:10])
print('One-hot encoded DNA sequence #1 first 10-bases:\n',input_fasta[0][:10])
#One-hot encoding for the labels (resistant/susceptible)
one_hot_encoder = OneHotEncoder()
mlabels = np.array(labels_subset.iloc[:,3].values).reshape(-1, 1)
input_labels = one_hot_encoder.fit_transform(mlabels).toarray()
print(input_labels.shape)
```
The last thing left to do before building and running our model, is to randomly split our dataset into train set (75% of the samples) and test set (25%). We will train our model on the train set, and then test its performace on the previously unseen data from the test set. At a later step, we will further partition the training set into a training and validation set.
```
#Split the data into train and test set. At a later step, we will further partition the training set into a training and validation set.
x_train, x_test, y_train, y_test = train_test_split(input_fasta, input_labels, test_size=0.25, random_state=None)
print("X train set (sequences):", x_train.shape)
print("X test set (sequences):", x_test.shape)
print("Y train set (labels):", y_train.shape)
print("y test set (labels):", y_test.shape)
```
### **Building the CNN model**
Now we will build our CNN model with these specific hyperparameters that were already tuned for this dataset. Hyperparameters tunining is beyond the scope of this tutorial, but basically, the choice of network architecture and its hyperparameters can be made in a data-driven and objective way by assessing the model performance on a validation data set. Here we use a 1D-CNN model, which is commonly used in deep learning for functional genomics applications. A CNN learns to recognize patterns that are generally invariant across space, by trying to match the input sequence to a number of learnable "filters" of a fixed size. In our dataset, filters are sequence motifs within the DNA sequences. The 'filters' and 'units' arguments in the Conv1D (1D convolution layer neural net) and Dense (regular densely-connected neural net layer) are the number of neurons in each layer of our net. One way to improve the performance of a neural network is to add more layers. This might allow the model to extract and recombine higher order features embedded in the data. We will use cross entropy as the loss function, which is for binary classification problems and is defined in Keras as “binary_crossentropy“. We will define the loss function optimizer as the efficient stochastic gradient descent algorithm “adam“. This is a popular version of gradient descent because it automatically tunes itself and gives good results in a wide range of problem.
```
#Build the CNN model
model = Sequential()
model.add(Conv1D(filters=32, kernel_size=3, input_shape=(input_fasta.shape[1], 4), #input shape need to be the matrix of (N) sequence length x (M) one-hot encoded length
activation='relu', kernel_initializer = 'he_uniform', padding = 'same', kernel_regularizer=l1(0.001))) #the 1st hidden layer has 16 neurons
model.add(Conv1D(filters=16, kernel_size=3, input_shape=(input_fasta.shape[1], 4),
activation='relu', kernel_initializer = 'he_uniform', padding = 'same', kernel_regularizer=l1(0.001))) #the 2nd hidden layer has 16 neurons
#model.add(Dropout(0.5)) #Dropout is a regularization technique where randomly selected neurons are ignored (dropped-out) during training. This means that their contribution to the activation of downstream neurons is temporally removed on the forward pass and any weight updates are not applied to the neuron on the backward pass.
model.add(MaxPooling1D(pool_size=4)) #pooling layer summarizes adjacent neurons by computing, for example, the maximum or average over their activity, resulting in a smoother representation of feature activities
model.add(Flatten())
model.add(Dense(units=16, activation='relu', kernel_initializer = 'he_uniform', kernel_regularizer=l1(0.01))) #the 3rd hidden layer has 16 neurons
model.add(Dense(units=2, activation='softmax')) #the output layer has 2 neurons (our binary output - resistant or sensitive to antibiotics phenotype)
#the basic practical difference between 'sigmoid' and 'softmax' is that while both give output in [0,1] range, softmax ensures that the sum of outputs along channels (as per specified dimension) is 1 i.e., they are probabilities. Sigmoid just makes output between 0 to 1.
#Summarize the model in a table format
model.summary()
#Compile the model: selecting the loss function argument, optimization algorithm for the loss function, and perforance metrics. This is the last step before fitting & running the model
model.compile(loss='binary_crossentropy', optimizer='Adam', metrics=['binary_accuracy'])
```
###**Fit & evaluate the model**
Now we are finally ready to run our model ("fit" it to the training dataset, i.e. train our model). We will further divide the training set into a training and validation sets, in order to train the model on the reduced training set, and test ("validate") it on the validation set.<br/>
Two additional parameters we need to set are 'epochs' and 'batch_size'. One epoch is one learning cycle where the model passes through the whole training data set. A batch size defines the number of samples to work through before updating the internal model parameters ("weights"). The number of epochs is usually large (10, 100, 1000 or more), allowing the learning algorithm to run until the error (the loss function) is sufficiently minimized.<br/>
We will visualize the loss and accuracy curves (also called learning curves) for the training (reduced) and validation sets . These plots can help to diagnose whether the model has over learned, under learned, or is suitably fit to the training dataset. Once the loss for the validation set stops improving or gets worse throughout the learning cycles (the "epochs"), it is time to stop training because the model has already converged and may be just overfitting.
```
history = model.fit(x_train, y_train, epochs=30, batch_size=32, verbose=1, validation_split=0.25)
#Save model and its architecture to a file for later use to make predictions on other samples, or on the same dataset, but save time by not training the same model again.
#model.save("/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/CNN_model_n10127_all_gyrA_seq_2000nuc_l1_reg_v1.h5")
#Load a previously trained model to use for prediction ("ready-to-use")
#model_loaded = load_model("/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/CNN_model_n10127_all_gyrA_seq_2000nuc_l1_reg_v1.h5", compile=True)
#Generate learning curves:
plot_learning_curve (history, 'loss')
plot_learning_curve (history, 'accuracy')
```
###**Make predictions with the model on unseen data ("test set") and plot performance metrics**
The last step in this tutorial (and in a standard machine-learning workflow) is to test our model on the test set which we put aside ("unseen" by the model dataset, 25% of our original input data). Then we will print a classification report consisting of commonly used performance metrics (precision, recall, accuracy), plot a confusion matrix (number of true positive, true negative, false positive and false negative predictions) and a ROC area under curve.<br/>
**Note:** before running the next piece of code, run first the accessory functions defined at the end of the tutorial
```
labels_pred = model.predict_classes(x_test)
#Classification report (f1-score, presicion and recall):
print (classification_report (np.argmax(y_test, axis=1), labels_pred))
#ROC AUC (area under curve):
print ("ROC AUC: %.3f" % (roc_auc_score (np.argmax(y_test, axis=1), labels_pred, average='weighted')))
#To plot the ROC curve we need the true positive rate (TPR) and the false positive rate (FPR):
fpr, tpr, thresholds = roc_curve(np.argmax(y_test, axis=1), labels_pred)
plot_AUC_ROC (fpr, tpr)
#Generate confusion matrix:
confusion_mat (labels_pred, y_test)
```
### **Interpretation of CNN model results**
To help us interpretate the results of the CNN model, or why the model predicted a given outcome to a specific input, we can plot a saliency map. Saliency maps visualize the relative importance scores the model gives to each feature in the input data, in our case, to each nucleotide in the sequence, and how it affects the outcome label. Positive values in the map tell us that a small change to that nucleotide will change the output value, therefore which nucleotides are the most informative for classifying the bacterial *gyrA* into a resistant or sensitive allelles.<br/>
We can plot saliency map for one input sequence at a time, so let's choose one of interest (but any other sequence is good as well), with an index of 8720 which is a resistant *Klebsiella pneumoniae* (a bad bug, especially in hospitals setting...). For better visualization (and due to prior knowledge of where to look for...), we will plot only the first 500 bp out of 2000 bp (in essence it's 100-600bp).
```
#Can we understand why the neural network classifies a training point in the way that it does? To do so, we can compute a saliency map, which is the gradient of the model's prediction with respect to each individual nucleotide
#Add a new running number to the labels_subet table to match sequence locations in input_fasta matrix
labels_subset = labels_subset.assign (sequence_index = np.arange(0,len(labels_subset),1))
#Select a specific sequence from the labels table for which to calculate the saliency map
seq_index = 8720
print(labels_subset[labels_subset.sequence_index == seq_index][["genome_id","genome_name","resistant_phenotype"]])
#Calculate the saliency map for a specific sequence, based on our CNN model:
sal = compute_salient_bases(model, input_fasta[seq_index])
#subset only part of the 2000-nucleotide sequence that we wish to plot saliency map (for ease of visualization)
sal_pt = sal[0:500]
#Plot the saliency map:
plt.figure(figsize=[70,5])
ax = sns.barplot(x=np.arange(len(sal_pt)), y=sal_pt, color='darkblue')
plt.xlabel('Bases')
plt.ylabel('Magnitude of saliency values')
plt.xticks(ticks=np.arange(len(sal_pt)), labels=np.arange(100, len(sal_pt)+100, 1), rotation=90, fontsize=7) #+100 to offset that the fasta is starts from the 100th nucleotide
plt.title('Saliency map for bases in a gyrA sequence')
#plt.savefig("/content/drive/My Drive/Input_data_for_CNN_deep-learning_FQ-resistance/CNN_saliency_map_gyrA_Klebsiella_8720index_RES_100-600_v3.png", format='png', dpi=300, bbox_inches='tight')
```
We can nicely see a group of nucleotides in positions 246 to 256 with the highest score (and another relatively high score group at 274-277), which according to the model are more informative for the prediction. If you plot the whole 2000bp, you will find several other nucleotides with a non-zero score, but nothing as high as the group at 246-256 bp. This concludes that only several nucleotides have anything to do with FQ-antibiotic resistance.<br/>
This matches perfectly to well known positions in *gyrA* genes where mutations change the amino-acid sequence of the proten (QRDR - remember?), thus inhibit FQ antibiotics from binding and provides resistance to the bacteria. Mutations in position 83 over the amino-acid sequence, which corresponds to nucleotide 249 (codons 247-249) are the most common and also provides a high-level clinical resistance.<br/>
**Note**: As neural networks are stochastic models in their nature, which means that on the same data, the same model can train differently (varying performance) each time the code is run, the importance scores for each nucleotide (for the same sequence) can slightly vary between the runs. It is a normal behaviour for neural networks.
### **Conclusions**
Convolutional neural networks can effectively classify bactarial *gyrA* genes to whether these bacteria are resistant or sensitive to Fluoroquinolone antibiotics (for which *gyrA* is the primary target) based on clinically relevant phenotype. The model can be further improved with an extensive hyperparameters fine-tuning using grid-search or simply by tweaking some of the model's parameters (number of layers, number of neurons in each layer and regularization penalties).<br/>
In this tutorial we just confirmed already a well known mutation in the *gyrA* gene, but using machine-learning we can try to discover novel mutations in previously unknown positions or even in novel genes - which of course will require experimental validation in-vitro or/and in-vivo.
### **Acknowledgment**
This tutorial was partially adopted from Nikolay Oskolkov's tutorial on using deep learning for ancient human DNA analysis ([link text](https://github.com/NikolayOskolkov/DeepLearningAncientDNA)), from Angermueller et al. 2016 review paper on deep learning in computational biology, and from Machine Learning Mastery by Jason Brownlee.
```
#Accessory functions for plotting confusion matrix, AUC ROC, learning curves and saliency maps
def confusion_mat(pred_labels, true_labels):
'''Generate confusion matrix plot'''
cm = confusion_matrix(np.argmax(true_labels, axis=1), pred_labels)
print('Confusion matrix:\n',cm)
cm = cm.astype('float') / cm.sum(axis = 1)[:, np.newaxis]
plt.figure(figsize=[8,8])
plt.imshow(cm, cmap=plt.cm.Blues)
plt.title('Normalized confusion matrix', fontsize=14)
plt.colorbar()
plt.xlabel('True label', fontsize=16); plt.ylabel('Predicted label', fontsize=16)
plt.xticks([0, 1], fontsize=14, fontweight='bold'); plt.yticks([0, 1], fontsize=14, fontweight='bold')
plt.grid('off')
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], '.2f'), fontsize=14, fontweight='bold',
horizontalalignment='center',
color='white' if cm[i, j] > 0.5 else 'black')
def plot_AUC_ROC (fpr, tpr):
'''Function to plot ROC AUC curve. Inputs are the false positive rate (fpr) and true positive rate (tpr)
Labels and colors need to be changed manually'''
plt.figure(figsize=(8,8))
plt.plot(fpr, tpr, color='darkred', lw=3, label='(AUC = %0.3f)' % auc(fpr, tpr))
plt.plot([0,1], [0,1], color='darkblue', lw=2, linestyle='--')
plt.xlabel("False Positive Rate", fontsize=16)
plt.ylabel("True Positive Rate", fontsize=16)
plt.yticks(fontsize=16)
plt.xticks(fontsize=16)
plt.xlim([-0.01,1])
plt.ylim([-0.01,1.01])
plt.legend(loc="lower right", fontsize=14)
plt.title("Model ROC AUC", fontsize=18, pad=10)
def plot_learning_curve(model_history, param):
'''Generate learning curve for log loss function and for accuracy.
Accepts a mode history object (tensorflow.python.keras.callbacks.History) and a parameter to plot (accuracy or loss)'''
opt = ('loss', 'accuracy')
try:
assert param in opt
except AssertionError:
print("Parameter %s is not valid, choose from ('loss', 'accuracy')" % param)
else:
if param == 'loss':
plt.figure(figsize=(10,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss function', fontsize=20)
plt.ylabel('Loss', fontsize=18) #Loss
plt.xlabel('Epoch', fontsize=18)
plt.yticks(fontsize=16)
plt.xticks(fontsize=16)
plt.legend(['train', 'validation'], loc='upper left', fontsize=15)
elif param == 'accuracy':
plt.figure(figsize=(10,5))
plt.plot(history.history['binary_accuracy'])
plt.plot(history.history['val_binary_accuracy'])
plt.title('Model accuracy', fontsize=20)
plt.ylabel('Accuracy', fontsize=18)
plt.xlabel('Epoch', fontsize=18)
plt.yticks(fontsize=16)
plt.xticks(fontsize=16)
plt.legend(['train', 'validation'], loc='upper left', fontsize=15)
import tensorflow.keras.backend as K
def compute_salient_bases(model, x):
'''Compute saliency for a specific sequence based on the model'''
input_tensors = [model.input]
gradients = model.optimizer.get_gradients(model.output[0][1], model.input)
compute_gradients = K.function(inputs = input_tensors, outputs = gradients)
x_value = np.expand_dims(x, axis=0)
gradients = compute_gradients([x_value])[0][0]
sal = np.clip(np.sum(np.multiply(gradients,x), axis=1),a_min=0, a_max=None)
return sal
```
| github_jupyter |
## **Using ARIMA Models for Time Series Forecasting on Wind Speed and Direction**
# **Data Loading and Preprocessing**
```
from google.colab import drive
drive.mount('/content/drive')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import math
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from statsmodels.tsa.stattools import adfuller
data=pd.read_csv('/content/drive/My Drive/Datasets /Wind Turbine Dataset.csv')
df = data.rename(columns={"LV ActivePower (kW)":"Active Power", "Wind Speed (m/s)":"Wind Speed", "Theoretical_Power_Curve (KWh)":"Theoritical Power", "Wind Direction (°)":"Direction"})
df
df['Loss']= df['Theoritical Power']-df['Active Power']
df['Loss Percent']= (df['Loss']/df['Theoritical Power']) * 100
df['Date/Time'] = pd.to_datetime(df['Date/Time'],format='%d %m %Y %H:%M')
df['Date'] = df['Date/Time'].dt.date
df['Time'] = df['Date/Time'].dt.time
df['Sin Component'] = df['Wind Speed']*np.sin(math.pi*df['Direction']/180)
df['Cos Component'] = df['Wind Speed']*np.cos(math.pi*df['Direction']/180)
df
```
# **ARIMA Direct Model**
```
# 'dt':df['Date/Time'][:40000],
arima_data = pd.DataFrame({'sc':df['Sin Component'][:40000]})
print(arima_data)
print(arima_data.dtypes)
decomposed_data = seasonal_decompose(arima_data['sc'],freq=1008)
#frequency is choosen as 1008 as it is the time period of 24*7 hours
decomposed_data.plot()
plt.show()
trend = decomposed_data.trend
plt.plot(df.index[:40000],df['Sin Component'][:40000],color='orange')
plt.plot(trend)
plt.show()
test = adfuller(arima_data['sc'])
print(test)
```
The adfuller test helps us predict the stationarity of data. Our data is stationery according to this test
```
model = ARIMA(arima_data['sc'],order=(5,0,1))
result = model.fit()
result.summary()
# prediction = result.predict(40000,50529,df['Sin Component'])
prediction = result.forecast(steps=72)[0]
plt.plot(prediction)
plt.plot(df.index[:72],df['Sin Component'][40000:40072],color='orange')
```
As we can see in the above implementation that due to the noise the model isn't able to predict anything significant. So we try to smoothen out data by taking window size as 6 in rolling means.
# **ARIMA on Moving Averages**
```
hourly_arima_data=arima_data.rolling(window=6).mean()
print(hourly_arima_data)
plt.plot(hourly_arima_data)
clean = hourly_arima_data.dropna()
print(clean)
decomposed_data = seasonal_decompose(clean['sc'],freq=1008)
#frequency is choosen as 1008 as it is the time period of 24*7 hours
decomposed_data.plot()
plt.show()
trend = decomposed_data.trend
plt.plot(df.index[:39995],clean['sc'][:40000],color='orange')
plt.plot(trend)
plt.show()
test = adfuller(clean['sc'])
print(test)
plt.figure()
plt.subplot(211)
plot_acf(clean['sc'], ax=plt.gca())
plt.subplot(212)
plot_pacf(clean['sc'], ax=plt.gca())
plt.show()
model = ARIMA(clean['sc'],order=(5,0,2))
result = model.fit()
result
# prediction = result.predict(40000,40438)
# prediction = pd.DataFrame({'dt':1,'sc':2})
# print(prediction)
prediction = result.forecast(steps=72)[0]
plt.plot(prediction)
plt.plot(df.index[:72],df['Sin Component'][40000:40072],color='orange')
```
As we can see even moving averages is not providing much good results. So we try by taking mean of the data. By mean we mean taking mean of the 1 hour period.
# **ARIMA on Average and Daily Moving Average**
```
avg_data = []
for i in range(6667):
avg_data.append(arima_data['sc'][i*6:i*6+6].mean())
plt.plot(avg_data)
final = pd.DataFrame(avg_data,columns=['sc_avg'])
ma_avg_data=final.rolling(window=24).mean()
clean = ma_avg_data.dropna()
print(clean)
plt.plot(clean)
test = adfuller(clean['sc_avg'])
print(test)
plt.figure()
plt.subplot(211)
plot_acf(clean['sc_avg'], ax=plt.gca())
plt.subplot(212)
plot_pacf(clean['sc_avg'], ax=plt.gca())
plt.show()
model = ARIMA(clean['sc_avg'],order=(1,0,11))
result = model.fit()
result
prediction = result.forecast(steps=72)[2]
plt.plot(prediction)
# plt.plot(df.index[:72],clean['sc_avg'][],color='orange')
from statsmodels.tsa.holtwinters import ExponentialSmoothing
data = pd.DataFrame({'cc' : df['Cos Component'][:50000]})
data
model = ExponentialSmoothing(data, seasonal='additive',seasonal_periods=432)
model_fit = model.fit()
yhat = model_fit.forecast(steps=432)
yhat
plt.plot(yhat)
plt.plot(df.index[50000:50432],df['Cos Component'][50000:50432],color='orange')
!pip install gluonts
!pip install mxnet
import mxnet as mx
from mxnet import gluon
from gluonts.dataset import common
from gluonts.model import deepar
from gluonts.trainer import Trainer
from gluonts.model.simple_feedforward import SimpleFeedForwardEstimator
from gluonts.model.deepar import DeepAREstimator
from gluonts.dataset.common import ListDataset
data = pd.DataFrame({'value':df['Sin Component'][:40000]})
data.index = df['Date/Time'][:40000]
train_data = ListDataset([{'start':data.index[0], "target":data.value[:40000]}],freq = "10min")
test_data = ListDataset([{'start':data.index[0], "target":data.value[:40432]}],freq = "10min")
estimator = DeepAREstimator(freq = '10min', prediction_length=432, trainer=Trainer(epochs=15))
predictor = estimator.train(training_data=train_data)
x = predictor.predict(test_data)
type(x)
a = next(x)
forecast = a.mean
plt.plot(forecast)
plt.plot(df.index[:432],df['Sin Component'][40000:40432],color='orange')
```
| github_jupyter |
```
%matplotlib inline
import matplotlib.pyplot as plt
from pandas import read_csv, Series
import numpy as np
import scipy
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
def clean_and_read_adult(data_file="train"):
try:
f = open('adult_%s.csv' % data_file)
except IOError:
f = open('adult.%s' % data_file)
lines = f.read().split('\n')
w = open('adult_%s_clean.csv' % data_file, 'wb')
w.write(lines[0]+'\n')
for l in lines[1:]:
w.write(','.join([_.strip() for _ in l.split(',')])+'\n')
w.close()
f.close()
data = read_csv('adult_%s_clean.csv' % data_file)
return data
data_train = clean_and_read_adult('train')
data_test = clean_and_read_adult('test')
total_train = len(data_train)
total_test = len(data_test)
data_test.columns
race_label_encoder = LabelEncoder()
race_labels = race_label_encoder.fit(data_train['race'])
race_labels.classes_
target_race = 'White'
data_train['class'] = Series(data_train['race'] == target_race)
data_test['class'] = Series(data_test['race'] == target_race)
def show_race_occupation(query_ethic='White'):
data_ethic = data_train[data_train['race'] == query_ethic]
data_ethic['occupation'].hist(label=query_ethic)
for race in race_labels.classes_[::-1]:
show_race_occupation(race)
plt.xticks(rotation=90)
plt.legend()
for race in race_label_encoder.classes_:
print race, np.bincount(data_train[data_train['occupation'] == 'Exec-managerial']['race'] == race)
np.bincount(data_train['occupation'] == 'Exec-managerial')
for race in race_label_encoder.classes_:
print race, np.bincount(data_train[data_train['race'] == race]['occupation'] == 'Armed-Forces')
X = data_train.values
pop_skew = []
for i in range(X.shape[1]):
try:
pop_skew.append(scipy.stats.skew(X[:,i]))
except TypeError:
continue
X = data_train[data_train['race'] == 'White'].values
white_skew = []
for i in range(X.shape[1]):
try:
white_skew.append(scipy.stats.skew(X[:,i]))
except TypeError:
continue
X = data_train[data_train['race'] == 'Black'].values
black_skew = []
for i in range(X.shape[1]):
try:
black_skew.append(scipy.stats.skew(X[:,i]))
except TypeError:
continue
condition1 = data_train['race'] == 'Black'
condition2 = data_train['occupation'] == 'Exec-managerial'
X = data_train[condition1 & condition2].values
black_mgr_skew = []
for i in range(X.shape[1]):
try:
black_mgr_skew.append(scipy.stats.skew(X[:,i]))
except TypeError:
continue
condition1 = data_train['race'] == 'White'
condition2 = data_train['occupation'] == 'Exec-managerial'
X = data_train[condition1 & condition2].values
columns = data_train.columns
numeric_labels = []
white_mgr_skew = []
for i in range(X.shape[1]):
try:
white_mgr_skew.append(scipy.stats.skew(X[:,i]))
numeric_labels.append(columns[i])
except TypeError:
continue
plt.plot(pop_skew, 'r', label="Pop skew")
plt.plot(black_skew, 'k', label="Black skew")
plt.plot(white_skew, 'b', label="White skew")
plt.plot(white_mgr_skew, 'c', label="White Mgr skew")
plt.plot(black_mgr_skew, 'g', label="Black Mgr skew")
plt.legend()
plt.xticks(range(len(numeric_labels)), numeric_labels, rotation='vertical')
plt.show()
model_rf = RF(n_estimators=100, n_jobs=-1)
print 'all', np.bincount(data_train['class'])
for race in data_train['race'].unique():
query_race = data_train['race'] == race
class_race = data_train[query_race]['class']
print race, np.bincount(class_race)
def get_distribution(distr_sample):
values = np.bincount(distr_sample)
total = float(len(distr_sample))
return values/total
#X_train = data_train.fillna(0).loc[:, data_train.columns != 'salary']
# set missing values to 0
#X[X == '?'] = 0
X_train = data_train.loc[:, data_train.columns != 'class'].values
Y_train = data_train['class'].values
X_train.shape, Y_train.shape
# encode string input values as integers
def transform_train(X):
label_attributes = {}
encoded_x = None
numeric_x = None
for i in range(0, X.shape[1]):
if type(X[0,i]) != str:
if numeric_x is None:
numeric_x = X[:,i].reshape(X.shape[0], 1)
print numeric_x.shape
else:
numeric_x = np.concatenate((X[:,i].reshape(X.shape[0], 1), numeric_x), axis=1)
continue
label_encoder = LabelEncoder()
feature = label_encoder.fit_transform(X[:,i])
feature = feature.reshape(X.shape[0], 1)
onehot_encoder = OneHotEncoder(sparse=False)
feature = onehot_encoder.fit_transform(feature)
label_attributes[i] = {'label_encoder': label_encoder, 'onehot_encoder': onehot_encoder}
if encoded_x is None:
encoded_x = feature
else:
encoded_x = np.concatenate((encoded_x, feature), axis=1)
print("encoded X shape: : ", encoded_x.shape)
print("numericX shape: : ", numeric_x.shape)
X_ = np.concatenate((numeric_x, encoded_x), axis=1)
print("Final Shape:", X_.shape)
return X_, label_attributes
def transform_test(X, label_attributes):
encoded_x = None
numeric_x = None
for i in range(0, X.shape[1]):
if type(X[0,i]) != str:
if numeric_x is None:
numeric_x = X[:,i].reshape(X.shape[0], 1)
print numeric_x.shape
else:
numeric_x = np.concatenate((X[:,i].reshape(X.shape[0], 1), numeric_x), axis=1)
continue
label_encoder = label_attributes[i]['label_encoder']
feature = label_encoder.transform(X[:,i])
feature = feature.reshape(X.shape[0], 1)
onehot_encoder = label_attributes[i]['onehot_encoder']
feature = onehot_encoder.transform(feature)
if encoded_x is None:
encoded_x = feature
else:
encoded_x = np.concatenate((encoded_x, feature), axis=1)
print("encoded X shape: : ", encoded_x.shape)
print("numericX shape: : ", numeric_x.shape)
X_ = np.concatenate((numeric_x, encoded_x), axis=1)
print("Final Shape:", X_.shape)
return X_
#X_test = data_test.fillna(0).loc[:, data_test.columns != 'salary']
# set missing values to 0
#X[X == '?'] = 0
X_test = data_test.loc[:, data_test.columns != 'class'].values
Y_test = data_test['class'].values
X_test.shape
limit = len(X_train)
X_combined, _ = transform_train(np.concatenate((X_train, X_test), axis=0))
X_train_transformed, X_test_transformed = X_combined[:limit],X_combined[limit:]
print X_train_transformed.shape, X_test_transformed.shape
model_rf = RF(n_estimators=100)
model_rf.fit(X_train_transformed,Y_train)
pred_rf = model_rf.predict(X_train_transformed)
np.bincount(pred_rf == Y_train)
pred_rf_test = model_rf.predict(X_test_transformed)
np.bincount(pred_rf_test == Y_test)
## after deskewing it
##races_prior = {'all': {'no': class_no_prior, 'yes':class_yes_prior}}
occupation_prior = {}
for occupation in data_train['occupation'].unique():
data = data_train[data_train['occupation'] == occupation]
occupation_prior[occupation] = {}
for race in [target_race]:
values = get_distribution(data['race']==race)
if len(values) == 1:
no = 1.
yes = 0.
else:
no, yes = values
occupation_prior[occupation] = {'no_prior': no, 'yes_prior': yes}
## Correlates directly with skew values
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(occupation_prior)
class_no_prior, class_yes_prior = get_distribution(data['race'] == 'Black')
all_no, all_yes = np.bincount(data_train['class'])
yes_over_no = all_yes/float(all_no)
no_over_yes = 1/yes_over_no
class_no_prior, class_yes_prior
### Main Deskewing Routine
data = data_train
new_X = None
_sum = 0
races_prior = occupation_prior
for race in races_prior:
if races_prior[race]['no_prior'] >= class_no_prior:
race_yes_index = data.index[(data['occupation'] == race) & (data['class'] == True)].tolist()
race_no_index = data.index[(data['occupation'] == race) & (data['class'] == False)].tolist()
race_no_index = np.random.choice(race_no_index,
int(no_over_yes*len(race_yes_index)), replace=False).tolist()
else:
race_no_index = data.index[(data['occupation'] == race) & (data['class'] == False)].tolist()
race_yes_index = data.index[(data['occupation'] == race) & (data['class'] == True)]
race_yes_index = np.random.choice(race_yes_index,
int(yes_over_no*len(race_no_index))).tolist()
print len(race_no_index)/ float(len(race_yes_index)+len(race_no_index))
_sum += len(race_no_index + race_yes_index)
##print data.loc[race_no_index+race_yes_index,['race', 'class']]
##raw_input()
if new_X is None:
new_X = X_train_transformed[race_no_index + race_yes_index]
new_Y = Y_train[race_no_index + race_yes_index]
else:
new_X = np.concatenate((new_X, X_train_transformed[race_no_index + race_yes_index]), axis=0)
new_Y = np.concatenate((new_Y, Y_train[race_no_index + race_yes_index]), axis=0)
print total_train
print _sum
new_X.shape
model_deskew = RF(n_estimators=100, n_jobs=-1)
model_deskew.fit(new_X, new_Y)
pred_rf_deskew = model_deskew.predict(X_train_transformed)
np.bincount(pred_rf_deskew == Y_train)
pred_rf_deskew_test = model_deskew.predict(X_test_transformed)
np.bincount(pred_rf_deskew_test == Y_test)
```
| github_jupyter |
# Session 12: Model selection and cross-validation
In this combined teaching module and exercise set we will investigate how to optimize the choice of hyperparameters using model validation and cross validation. As an aside, we will see how to build machine learning models using a formalized pipeline from preprocessed (i.e. tidy) data to a model.
We import our standard stuff. Notice that we are not interested in seeing the convergence warning in scikit-learn so we suppress them for now.
```
import warnings
from sklearn.exceptions import ConvergenceWarning
warnings.filterwarnings(action='ignore', category=ConvergenceWarning)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
```
### Intro and recap
We begin with a brief review of important concepts and an overview of this module.
```
from IPython.display import YouTubeVideo
YouTubeVideo('9gkjahx_SWo', width=640, height=360)
```
### Bias and variance - a tradeoff
What is the cause of over- and underfitting? The video below explains that there are two concepts, bias and variance that explain thse two issues.
```
YouTubeVideo('YjC3mQLhWH8', width=640, height=360)
```
### Model building with pipelines
A powerful tool for making and applying models are pipelines, which allows to combine different preprocessing and model procedures into one. This has many advantages, mainly being more safe but also has the added side effect being more code-efficient.
```
YouTubeVideo('dGhqOx9jj7k', width=640, height=360)
```
> **Ex. 12.1.0:** Begin by reloading the housing dataset from Ex. 11.2.0 using the code below.
```
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
cal_house = fetch_california_housing()
X = pd.DataFrame(data=cal_house['data'],
columns=cal_house['feature_names'])\
.iloc[:,:-2]
y = cal_house['target']
```
> **Ex. 12.1.1:** Construct a model building pipeline which
> 1. adds polynomial features of degree 3 without bias;
> 1. scales the features to mean zero and unit std.
>> *Hint:* a modelling pipeline can be constructed with `make_pipeline` from `sklearn.pipeline`.
```
# [Answer to Ex. 12.1.1]
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
pipe_prep = make_pipeline(PolynomialFeatures(degree=3, include_bias=False),
StandardScaler())
```
# Model selection and validation
### Simple validation
In machine learning, we have two types of parameters: those that are learned from
the training data, for example, the weights in logistic regression, and the parameters
of a learning algorithm that are optimized separately. The latter are the tuning
parameters, also called *hyperparameters*, of a model, for example, the regularization
parameter in logistic regression or the depth parameter of a decision tree.
Below we investigate how we can choose optimal hyperparameters.
```
YouTubeVideo('NrIBv9ApX_8', width=640, height=360)
```
In what follows we will regard the "train" (aka. development, non-test) data for two purposes.
- First we are interested in getting a credible measure of models under different hyperparameters to perform a model selection.
- Then with the selected model we estimate/train it on all the training data.
> **Ex. 12.1.2:** Make a for loop with 10 iterations where you:
1. Split the input data into, train (also know as development) and test where the test sample should be one third. (Set a new random state for each iteration of the loop, so each iteration makes a different split).
2. Further split the training (aka development) data into to even sized bins; the first data is for training models and the other is for validating them. (Therefore these data sets are often called training and validation)
3. Train a linear regression model with sub-training data. Compute the RMSE for out-of-sample predictions for both the test data and the validation data. Save the RMSE.
> You should now have a 10x2 DataFrame with 10 RMSE from both the test data set and the train data set. Compute descriptive statistics of RMSE for the out-of-sample predictions on test and validation data. Are they simular?
> They hopefuly are pretty simular. This shows us, that we can split the train data, and use this to fit the model.
>> *Hint*: you can reuse any code used to solve exercises 11.2.X.
```
# [Answer to Ex. 12.1.2]
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error as mse
def rmse(y_pred, y_true):
return np.sqrt(mse(y_pred, y_true))
output = []
for random_state in range(10):
X_dev, X_test, y_dev, y_test = train_test_split(X, y, test_size=1/3, random_state=random_state)
X_train, X_val, y_train, y_val = train_test_split(X_dev, y_dev, test_size=1/2, random_state=random_state)
reg = LinearRegression().fit(X_train, y_train)
reg.predict(X_test)
output.append([rmse(reg.predict(X_val), y_val),
rmse(reg.predict(X_test), y_test)])
pd.DataFrame(output, columns=['test', 'validation']).describe()
```
> **Ex. 12.1.3:** Construct a model building pipeline which
> 1. adds polynomial features of degree 3 without bias;
> 1. scales the features to mean zero and unit std.
> 1. estimates a Lasso model
```
# [Answer to Ex. 12.1.3]
Lasso()
from sklearn.linear_model import Lasso
pipe_lasso = make_pipeline(PolynomialFeatures(degree=3, include_bias=False),
StandardScaler(),
Lasso(random_state=1,))
```
### Cross validation
The simple validation procedure that we outlined above has one disadvantage: it only uses parts of the *development* data for validation. In the video below we present a refined approach that uses all the *development* for validation.
```
YouTubeVideo('m4qR8L65fKQ', width=640, height=360)
```
When we want to optimize over both normal parameters and hyperparameteres we do this using nested loops (two-layered cross validation). In outer loop we vary the hyperparameters, and then in the inner loop we do cross validation for the model with the specific selection of hyperparameters. This way we can find the model, with the lowest mean MSE.
> **Ex. 12.1.4:**
Run a Lasso regression using the Pipeline from `Ex 12.1.3`. In the outer loop searching through the lambdas specified below.
In the inner loop make *5 fold cross validation* on the selected model and store the average MSE for each fold. Which lambda, from the selection below, gives the lowest test MSE?
```python
lambdas = np.logspace(-4, 4, 12)
```
*Hint:* `KFold` in `sklearn.model_selection` may be useful.
```
# [Answer to Ex. 12.1.4]
# This will be in assignment 2
```
### Tools for model selection
Below we review three useful tools for performing model selection. The first tool, the learning curve, can be used to assess whether there is over- and underfitting.
```
YouTubeVideo('Ii8UZW8PYlI', width=640, height=360)
```
The next tool, the validation curve, helps to make perform automated model selection and to visualize the process of model selection.
```
YouTubeVideo('xabvOCSGQx4', width=640, height=360)
```
When we have more than one hyperparameter, we need to find the combination of optimal hyperparameters. In the video below we see how to do that for *elastic net*, which has both L1 and L2 regularization.
```
YouTubeVideo('J0tt-j3CSlA', width=640, height=360)
```
> **Ex. 12.1.5:** __Automated Cross Validation in one dimension__
Now we want to repeat exercise 12.1.4 in a more automated fasion.
When you are doing cross validation with one hyperparameter, you can automate the process by using `validation_curve` from `sklearn.model_selection`. Use this function to search through the values of lambda, and find the value of lambda, which give the lowest test error.
> check if you got the same output for the manual implementation (Ex. 12.1.3) and the automated implementation (Ex. 12.1.4)
> BONUS: Plot the average MSE-test and MSE-train against the different values of lambda. (*Hint*: Use logarithmic axes, and lambda as index)
```
# [Answer to Ex. 12.1.5]
from sklearn.model_selection import validation_curve
lambdas = np.logspace(-4, 4, 12)
train_scores, test_scores = \
validation_curve(estimator=pipe_lasso,
X=X_train,
y=y_train,
param_name='lasso__alpha',
param_range=lambdas,
scoring='neg_mean_squared_error',# scoring='neg_mean_squared_error',
cv=5)
mean_values = pd.concat({'train': pd.DataFrame(-train_scores).mean(1),
'test': pd.DataFrame(-test_scores).mean(1),
'lambda': pd.DataFrame(lambdas).mean(1)}, axis =1)
# answer to plotting bonus question
from sklearn.metrics import mean_squared_error as mse
def rmse(y_pred, y_true):
return np.sqrt(mse(y_pred, y_true))
# plot the
pd.concat({'train': pd.DataFrame(-train_scores).mean(1),
'test': pd.DataFrame(-test_scores).mean(1)},
axis=1)\
.pipe(np.sqrt)\
.set_index(pd.Index(lambdas, name='lambda'))\
.plot(logx=True, logy=True)
plt.show()
```
When you have *more than one* hyperparameter, you will want to fit the model to all the possible combinations of hyperparameters. This is done in an approch called `Grid Search`, which is implementet in `sklearn.model_selection` as `GridSearchCV`
> **Ex. 12.1.6:** To get to know `Grid Search` we want to implement in one dimension. Using `GridSearchCV` implement the Lasso, with the same lambdas as before (`lambdas = np.logspace(-4, 4, 12)`), 10-fold CV and (negative) mean squared error as the scoring variable. Which value of Lambda gives the lowest test error?
```
# [Answer to Ex. 12.1.6]
from sklearn.model_selection import GridSearchCV
gs = GridSearchCV(estimator=pipe_lasso,
param_grid=[{'lasso__alpha':lambdas}],
scoring='neg_mean_squared_error',
cv=10,
n_jobs=-1)
gs = gs.fit(X_train, y_train)
print(gs.best_params_)
```
> **Ex. 12.1.7 BONUS** Expand the Lasso pipe from the last excercise with a Principal Component Analisys (PCA), and expand the Grid Search to searching in two dimensions (both along the values of lambda and the values of principal components (n_components)). Is `n_components` a hyperparameter? Which hyperparameters does the Grid Search select as the best?
> NB. This might take a while to calculate.
```
# [Answer to Ex. 12.1.7]
from sklearn.decomposition import PCA
pipe_sq_pca_lasso = make_pipeline(PolynomialFeatures(include_bias=False),
StandardScaler(),
PCA(),
Lasso())
gs = GridSearchCV(estimator=pipe_sq_pca_lasso,
param_grid=[{'lasso__alpha':lambdas,
'pca__n_components':range(1, X_train.shape[1]+1)}],
scoring='neg_mean_squared_error',
cv=10,
n_jobs=-1)
gs = gs.fit(X_train, y_train)
# Yes, n_components is a hyperparameter.
print(gs.best_params_)
```
> **Ex. 12.1.8 BONUS** repeat the previous now with RandomizedSearchCV with 20 iterations.
```
# [Answer to Ex. 12.1.8]
from sklearn.decomposition import PCA
from sklearn.model_selection import RandomizedSearchCV
pipe_sq_pca_lasso = make_pipeline(PolynomialFeatures(include_bias=False),
StandardScaler(),
PCA(),
Lasso())
gs = RandomizedSearchCV(estimator=pipe_sq_pca_lasso,
param_grid=[{'lasso__alpha':lambdas,
'pca__n_components':range(1, X_train.shape[1]+1)}],
scoring='neg_mean_squared_error',
cv=10,
n_jobs=-1,
n_iter=20)
gs = gs.fit(X_train, y_train)
# Yes, n_components is a hyperparameter.
print(gs.best_params_)
```
> **Ex. 12.1.9 BONUS** read about nested cross validation. How might we implement this in answer 12.1.6?
```
# [Answer to Ex. 12.1.9]
```
| github_jupyter |
# Model Optimization with an Image Classification Example
1. [Introduction](#Introduction)
2. [Prerequisites and Preprocessing](#Prequisites-and-Preprocessing)
3. [Train the model](#Train-the-model)
4. [Optimize trained model using SageMaker Neo and Deploy](#Optimize-trained-model-using-SageMaker-Neo-and-Deploy)
5. [Request Inference](#Request-Inference)
6. [Delete the Endpoint](#Delete-the-Endpoint)
## Introduction
***
Welcome to our model optimization example for image classification. In this demo, we will use the Amazon SageMaker Image Classification algorithm to train on the [caltech-256 dataset](http://www.vision.caltech.edu/Image_Datasets/Caltech256/) and then we will demonstrate Amazon SageMaker Neo's ability to optimize models.
## Prequisites and Preprocessing
***
### Setup
Before getting started, make sure to select `Python 3 (Data Science)` kernel.
Next, we need to define a few variables and obtain certain permissions that will be needed later in the example. These are:
* A SageMaker session
* IAM role to give learning, storage & hosting access to your data
* An S3 bucket, a folder & sub folders that will be used to store data and artifacts
* SageMaker's specific Image Classification training image which should not be changed
```
%cd /root/amazon-sagemaker-examples/aws_sagemaker_studio/sagemaker_neo_compilation_jobs/imageclassification_caltech
import sagemaker
from sagemaker import session, get_execution_role
role = get_execution_role()
sagemaker_session = session.Session()
# S3 bucket and folders for saving code and model artifacts.
# Feel free to specify different bucket/folders here if you wish.
bucket = sagemaker_session.default_bucket()
folder = 'StudioDemo-ImageClassification'
model_with_custom_code_sub_folder = folder + '/model-with-custom-code'
validation_data_sub_folder = folder + '/validation-data'
training_data_sub_folder = folder + '/training-data'
training_output_sub_folder = folder + '/training-output'
compilation_output_sub_folder = folder + '/compilation-output'
from sagemaker import session, get_execution_role
# S3 Location to save the model artifact after training
s3_training_output_location = 's3://{}/{}'.format(bucket, training_output_sub_folder)
# S3 Location to save the model artifact after compilation
s3_compilation_output_location = 's3://{}/{}'.format(bucket, compilation_output_sub_folder)
# S3 Location to save your custom code in tar.gz format
s3_model_with_custom_code_location = 's3://{}/{}'.format(bucket, model_with_custom_code_sub_folder)
from sagemaker.image_uris import retrieve
aws_region = sagemaker_session.boto_region_name
training_image = retrieve(framework='image-classification', region=aws_region, image_scope='training')
```
### Data preparation
In this demo, we are using [Caltech-256](http://www.vision.caltech.edu/Image_Datasets/Caltech256/) dataset, pre-converted into `RecordIO` format using MXNet's [im2rec](https://mxnet.apache.org/versions/1.7/api/faq/recordio) tool. Caltech-256 dataset contains 30608 images of 256 objects. For the training and validation data, the splitting scheme followed is governed by this [MXNet example](https://github.com/apache/incubator-mxnet/blob/8ecdc49cf99ccec40b1e342db1ac6791aa97865d/example/image-classification/data/caltech256.sh). The example randomly selects 60 images per class for training, and uses the remaining data for validation. It takes around 50 seconds to convert the entire Caltech-256 dataset (~1.2GB) into `RecordIO` format on a p2.xlarge instance. SageMaker's training algorithm takes `RecordIO` files as input. For this demo, we will download the `RecordIO` files and upload it to S3. We then initialize the 256 object categories as well to a variable.
```
import os
import urllib.request
def download(url):
filename = url.split("/")[-1]
if not os.path.exists(filename):
urllib.request.urlretrieve(url, filename)
# Dowload caltech-256 data files from MXNet's website
download('http://data.mxnet.io/data/caltech-256/caltech-256-60-train.rec')
download('http://data.mxnet.io/data/caltech-256/caltech-256-60-val.rec')
# Upload the file to S3
s3_training_data_location = sagemaker_session.upload_data('caltech-256-60-train.rec', bucket, training_data_sub_folder)
s3_validation_data_location = sagemaker_session.upload_data('caltech-256-60-val.rec', bucket, validation_data_sub_folder)
class_labels = ['ak47', 'american-flag', 'backpack', 'baseball-bat', 'baseball-glove', 'basketball-hoop', 'bat',
'bathtub', 'bear', 'beer-mug', 'billiards', 'binoculars', 'birdbath', 'blimp', 'bonsai-101',
'boom-box', 'bowling-ball', 'bowling-pin', 'boxing-glove', 'brain-101', 'breadmaker', 'buddha-101',
'bulldozer', 'butterfly', 'cactus', 'cake', 'calculator', 'camel', 'cannon', 'canoe', 'car-tire',
'cartman', 'cd', 'centipede', 'cereal-box', 'chandelier-101', 'chess-board', 'chimp', 'chopsticks',
'cockroach', 'coffee-mug', 'coffin', 'coin', 'comet', 'computer-keyboard', 'computer-monitor',
'computer-mouse', 'conch', 'cormorant', 'covered-wagon', 'cowboy-hat', 'crab-101', 'desk-globe',
'diamond-ring', 'dice', 'dog', 'dolphin-101', 'doorknob', 'drinking-straw', 'duck', 'dumb-bell',
'eiffel-tower', 'electric-guitar-101', 'elephant-101', 'elk', 'ewer-101', 'eyeglasses', 'fern',
'fighter-jet', 'fire-extinguisher', 'fire-hydrant', 'fire-truck', 'fireworks', 'flashlight',
'floppy-disk', 'football-helmet', 'french-horn', 'fried-egg', 'frisbee', 'frog', 'frying-pan',
'galaxy', 'gas-pump', 'giraffe', 'goat', 'golden-gate-bridge', 'goldfish', 'golf-ball', 'goose',
'gorilla', 'grand-piano-101', 'grapes', 'grasshopper', 'guitar-pick', 'hamburger', 'hammock',
'harmonica', 'harp', 'harpsichord', 'hawksbill-101', 'head-phones', 'helicopter-101', 'hibiscus',
'homer-simpson', 'horse', 'horseshoe-crab', 'hot-air-balloon', 'hot-dog', 'hot-tub', 'hourglass',
'house-fly', 'human-skeleton', 'hummingbird', 'ibis-101', 'ice-cream-cone', 'iguana', 'ipod', 'iris',
'jesus-christ', 'joy-stick', 'kangaroo-101', 'kayak', 'ketch-101', 'killer-whale', 'knife', 'ladder',
'laptop-101', 'lathe', 'leopards-101', 'license-plate', 'lightbulb', 'light-house', 'lightning',
'llama-101', 'mailbox', 'mandolin', 'mars', 'mattress', 'megaphone', 'menorah-101', 'microscope',
'microwave', 'minaret', 'minotaur', 'motorbikes-101', 'mountain-bike', 'mushroom', 'mussels',
'necktie', 'octopus', 'ostrich', 'owl', 'palm-pilot', 'palm-tree', 'paperclip', 'paper-shredder',
'pci-card', 'penguin', 'people', 'pez-dispenser', 'photocopier', 'picnic-table', 'playing-card',
'porcupine', 'pram', 'praying-mantis', 'pyramid', 'raccoon', 'radio-telescope', 'rainbow', 'refrigerator',
'revolver-101', 'rifle', 'rotary-phone', 'roulette-wheel', 'saddle', 'saturn', 'school-bus',
'scorpion-101', 'screwdriver', 'segway', 'self-propelled-lawn-mower', 'sextant', 'sheet-music',
'skateboard', 'skunk', 'skyscraper', 'smokestack', 'snail', 'snake', 'sneaker', 'snowmobile',
'soccer-ball', 'socks', 'soda-can', 'spaghetti', 'speed-boat', 'spider', 'spoon', 'stained-glass',
'starfish-101', 'steering-wheel', 'stirrups', 'sunflower-101', 'superman', 'sushi', 'swan',
'swiss-army-knife', 'sword', 'syringe', 'tambourine', 'teapot', 'teddy-bear', 'teepee',
'telephone-box', 'tennis-ball', 'tennis-court', 'tennis-racket', 'theodolite', 'toaster', 'tomato',
'tombstone', 'top-hat', 'touring-bike', 'tower-pisa', 'traffic-light', 'treadmill', 'triceratops',
'tricycle', 'trilobite-101', 'tripod', 't-shirt', 'tuning-fork', 'tweezer', 'umbrella-101', 'unicorn',
'vcr', 'video-projector', 'washing-machine', 'watch-101', 'waterfall', 'watermelon', 'welding-mask',
'wheelbarrow', 'windmill', 'wine-bottle', 'xylophone', 'yarmulke', 'yo-yo', 'zebra', 'airplanes-101',
'car-side-101', 'faces-easy-101', 'greyhound', 'tennis-shoes', 'toad', 'clutter']
```
## Train the model
***
Now that we are done with all the setup that is needed, we are ready to train our object detector. To begin, let us create a ``sagemaker.estimator.Estimator`` object. This estimator is required to launch the training job.
We specify the following parameters while creating the estimator:
* ``image_uri``: This is set to the training_image uri we defined previously. Once set, this image will be used later while running the training job.
* ``role``: This is the IAM role which we defined previously.
* ``instance_count``: This is the number of instances on which to run the training. When the number of instances is greater than one, then the image classification algorithm will run in distributed settings.
* ``instance_type``: This indicates the type of machine on which to run the training. For this example we will use `ml.p3.8xlarge`.
* ``volume_size``: This is the size in GB of the EBS volume to use for storing input data during training. Must be large enough to store training data as File Mode is used.
* ``max_run``: This is the timeout value in seconds for training. After this amount of time SageMaker terminates the job regardless of its current status.
* ``input_mode``: This is set to `File` in this example. SageMaker copies the training dataset from the S3 location to a local directory.
* ``output_path``: This is the S3 path in which the training output is stored. We are assigning it to `s3_training_output_location` defined previously.
```
ic_estimator = sagemaker.estimator.Estimator(image_uri=training_image,
role=role,
instance_count=1,
instance_type='ml.p3.8xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_training_output_location,
base_job_name='img-classification-training'
)
```
Following are certain hyperparameters that are specific to the algorithm which are also set:
* ``num_layers``: The number of layers (depth) for the network. We use 18 in this samples but other values such as 50, 152 can be used.
* ``image_shape``: The input image dimensions,'num_channels, height, width', for the network. It should be no larger than the actual image size. The number of channels should be same as the actual image.
* ``num_classes``: This is the number of output classes for the new dataset. Imagenet was trained with 1000 output classes but the number of output classes can be changed for fine-tuning. For caltech, we use 257 because it has 256 object categories + 1 clutter class.
* ``num_training_samples``: This is the total number of training samples. It is set to 15240 for caltech dataset with the current split.
* ``mini_batch_size``: The number of training samples used for each mini batch. In distributed training, the number of training samples used per batch will be N * mini_batch_size where N is the number of hosts on which training is run.
* ``epochs``: Number of training epochs.
* ``learning_rate``: Learning rate for training.
* ``top_k``: Report the top-k accuracy during training.
* ``precision_dtype``: Training datatype precision (default: float32). If set to 'float16', the training will be done in mixed_precision mode and will be faster than float32 mode.
```
ic_estimator.set_hyperparameters(num_layers=18,
image_shape = "3,224,224",
num_classes=257,
num_training_samples=15420,
mini_batch_size=128,
epochs=5,
learning_rate=0.01,
top_k=2,
use_pretrained_model=1,
precision_dtype='float32')
```
Next we setup the input ``data_channels`` to be used later for training.
```
train_data = sagemaker.inputs.TrainingInput(s3_training_data_location,
content_type='application/x-recordio',
s3_data_type='S3Prefix')
validation_data = sagemaker.inputs.TrainingInput(s3_validation_data_location,
content_type='application/x-recordio',
s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data}
```
After we've created the estimator object, we can train the model using ``fit()`` API
```
ic_estimator.fit(inputs=data_channels, logs=True)
```
## Optimize trained model using SageMaker Neo and Deploy
***
We will use SageMaker Neo's ``compile_model()`` API while specifying ``MXNet`` as the framework and the version to optimize the model. When calling this API, we also specify the target instance family, correct input shapes for the model and the S3 location to which the compiled model artifacts would be stored. For this example, we will choose ``ml_c5`` as the target instance family.
```
optimized_ic = ic_estimator.compile_model(target_instance_family='ml_c5',
input_shape={'data':[1, 3, 224, 224]},
output_path=s3_compilation_output_location,
framework='mxnet',
framework_version='1.8')
```
After compiled artifacts are generated and we have a ``sagemaker.model.Model`` object, we then create a ``sagemaker.mxnet.model.MXNetModel`` object while specifying the following parameters:
* ``model_data``: s3 location where compiled model artifact is stored
* ``image_uri``: Neo's Inference Image URI for MXNet
* ``framework_version``: set to MXNet's v1.8.0
* ``role`` & ``sagemaker_session`` : IAM role and sagemaker session which we defined in the setup
* ``entry_point``: points to the entry_point script. In our example the script has SageMaker's hosting functions implementation
* ``py_version``: We are required to set to python version 3
* ``env``: A dict to specify the environment variables. We are required to set MMS_DEFAULT_RESPONSE_TIMEOUT to 500
* ``code_location``: s3 location where repacked model.tar.gz is stored. Repacked tar file consists of compiled model artifacts and entry_point script
```
from sagemaker.mxnet.model import MXNetModel
optimized_ic_model = MXNetModel(model_data=optimized_ic.model_data,
image_uri=optimized_ic.image_uri,
framework_version='1.8.0',
role=role,
sagemaker_session=sagemaker_session,
entry_point='inference.py',
py_version='py37',
env={'MMS_DEFAULT_RESPONSE_TIMEOUT': '500'},
code_location=s3_model_with_custom_code_location
)
```
We can now deploy this ``sagemaker.mxnet.model.MXNetModel`` using the ``deploy()`` API, for which we need to use an instance_type belonging to the target_instance_family we used for compilation. For this example, we will choose ``ml.c5.4xlarge`` instance as we compiled for ``ml_c5``. The API also allow us to set the number of initial_instance_count that will be used for the Endpoint. By default the API will use ``JSONSerializer()`` and ``JSONDeserializer()`` for ``sagemaker.mxnet.model.MXNetModel`` whose ``CONTENT_TYPE`` is ``application/json``. The API creates a SageMaker endpoint that we can use to perform inference.
**Note**: If you compiled the model for a GPU `target_instance_family` then please make sure to deploy to one of the same target `instance_type` below and also make necessary changes in the entry point script `inference.py`
```
optimized_ic_classifier = optimized_ic_model.deploy(initial_instance_count = 1, instance_type = 'ml.c5.4xlarge')
```
## Request Inference
***
Once the endpoint is in ``InService`` we can then send a test image ``test.jpg`` and get the prediction result from the endpoint using SageMaker's ``predict()`` API. Instead of sending the raw image to the endpoint for prediction we will prepare and send the payload which is in a form acceptable by the API. Upon receiving the prediction result we will print the class label and probability.
```
import PIL.Image
import numpy as np
from IPython.display import Image
test_file = 'test.jpg'
test_image = PIL.Image.open(test_file)
payload = np.asarray(test_image.resize((224, 224)))
Image(test_file)
%%time
result = optimized_ic_classifier.predict(payload)
index = np.argmax(result)
print("Result: label - " + class_labels[index] + ", probability - " + str(result[index]))
```
## Delete the Endpoint
***
Having an endpoint running will incur some costs. Therefore as an optional clean-up job, you can delete it.
```
print("Endpoint name: " + optimized_ic_classifier.endpoint_name)
optimized_ic_classifier.delete_endpoint()
```
| github_jupyter |
```
from __future__ import print_function
import cntk
import numpy as np
import scipy.sparse
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env() # (only needed for our build system)
cntk.cntk_py.set_fixed_random_seed(1) # fix the random seed so that LR examples are repeatable
from IPython.display import Image
import matplotlib.pyplot
%matplotlib inline
matplotlib.pyplot.rcParams['figure.figsize'] = (40,40)
```
# CNTK: A Guided Tour
This tutorial exposes many advanced features of CNTK and is aimed towards people who have had some previous exposure to deep learning and/or other deep learning toolkits. If you are a complete beginner we suggest you start with the CNTK 101 Tutorial and come here after you have covered most of the 100 series.
Welcome to CNTK and the wonders of deep learning! Deep neural networks are redefining how computer programs
are created. In addition to imperative, functional, declarative programming, we now have differentiable programming which effectively 'learns'
programs from data.
With CNTK, you can be part of this revolution.
CNTK is the prime tool that Microsoft product groups use to create deep models for a whole range of products,
from speech recognition and machine translation via various image-classification services
to Bing search ranking.
This tutorial is a guided tour of CNTK. It is primarily meant for users that are new to CNTK but have some experience with deep neural networks.
The focus will be on how the basic steps of deep learning are done in CNTK,
which we will show predominantly by example.
This tour is not a complete API description. Instead, we refer the reader to the documentation
and task-specific tutorials for more detailed information.
To train a deep model, you will need to define your model structure, prepare your data so that it can be fed to CNTK, train the model and evaluate its accuracy, and deploy it.
This guided tour is organized as follows:
* Defining your **model structure**
* The CNTK programming model: Networks as Function Objects
* CNTK's Data Model: Tensors and Sequences of Tensors
* Your First CNTK Network: Logistic Regression
* Your second CNTK Network: MNIST Digit Recognition
* The Graph API: MNIST Digit Recognition Once More
* Feeding your **data**
* Small data sets that fit into memory: numpy/scipy arrays/
* Large data sets: `MinibatchSource` class
* Spoon-feeding data: your own minibatch loop
* **Training**
* Distributed Training
* Logging
* Checkpointing
* Cross-validation based training control
* Final evaluation
* **Deploying** the model
* From Python
* From C++ and C#
* From your own web service
* Via an Azure web service
* Conclusion
To run this tutorial, you will need CNTK 2.0 and ideally a CUDA-capable GPU (deep learning is no fun without GPUs).
# Defining Your Model Structure
So let us dive right in. Below we will introduce CNTK's programming model--*networks are function objects* and CNTK's data model. We will put that into action for logistic regression and MNIST digit recognition,
using CNTK's Functional API.
Lastly, CNTK also has a lower-level, TensorFlow/Theano-like graph API. We will replicate one example with it.
### The CNTK Programming Model: Networks are Function Objects
In CNTK, a neural network is a function object.
On one hand, a neural network in CNTK is just a function that you can call
to apply it to data.
On the other hand, a neural network contains learnable parameters
that can be accessed like object members.
Complicated function objects can be composed as hierarchies of simpler ones, which,
for example, represent layers.
The function-object approach is similar to Keras, Chainer, Dynet, Pytorch,
and the recent Sonnet.
The following illustrates the function-object approach with pseudo-code, using the example
of a fully-connected layer (called `Dense` in CNTK)::
```
# numpy *pseudo-code* for CNTK Dense layer (simplified, e.g. no back-prop)
def Dense(out_dim, activation):
# create the learnable parameters
b = np.zeros(out_dim)
W = np.ndarray((0,out_dim)) # input dimension is unknown
# define the function itself
def dense(x):
if len(W) == 0: # first call: reshape and initialize W
W.resize((x.shape[-1], W.shape[-1]), refcheck=False)
W[:] = np.random.randn(*W.shape) * 0.05
return activation(x.dot(W) + b)
# return as function object: can be called & holds parameters as members
dense.W = W
dense.b = b
return dense
d = Dense(5, np.tanh) # create the function object
y = d(np.array([1, 2])) # apply it like a function
W = d.W # access member like an object
print('W =', d.W)
print('y =', y)
```
Again, this is only pseudo-code. In reality, CNTK function objects are not actual Python lambdas.
Rather, they are represented internally as graph structures in C++ that encode the formula,
similar to TensorFlow and Theano.
This graph structure is wrapped in the Python class `Function` that exposes `__call__()` and `__getattr__()` methods.
The function object is CNTK's single abstraction used to represent different levels of neural networks, which
are only distinguished by convention:
* **basic operations** without learnable parameters (e.g. `times()`, `__add__()`, `sigmoid()`...)
* **layers** (`Dense()`, `Embedding()`, `Convolution()`...). Layers map one input to one output.
* **recurrent step functions** (`LSTM()`, `GRU()`, `RNNStep()`). Step functions map a previous state and a new input to a new state.
* **loss and metric** functions (`cross_entropy_with_softmax()`, `binary_cross_entropy()`, `squared_error()`, `classification_error()`...).
In CNTK, losses and metric are not special, just functions.
* **models**. Models are defined by the user and map features to predictions or scores, and is what gets deployed in the end.
* **criterion function**. The criterion function maps (features, labels) to (loss, metric).
The Trainer optimizes the loss by SGD, and logs the metric, which may be non-differentiable.
Higher-order layers compose objects into more complex ones, including:
* layer **stacking** (`Sequential()`, `For()`)
* **recurrence** (`Recurrence()`, `Fold()`, `UnfoldFrom()`, ...)
Networks are commonly defined by using existing CNTK functions (such as
specific types of neural-network layers)
and composing them using `Sequential()`.
In addition, users can write their own functions
as arbitrary Python expressions, as long as those consist of CNTK operations
over CNTK data types.
Python expressions get converted into the internal representation by wrapping them in a call to
`Function()`. This is similar to Keras' `Lambda()`.
Expressions can be written as multi-line functions through decorator syntax (`@Function`).
Lastly, function objects enable parameter sharing. If you call the same
function object at multiple places, all invocations will naturally share the same learnable parameters.
In summary, the function object is CNTK's single abstraction for conveniently defining
simple and complex models, parameter sharing, and training objectives.
(Note that it is possible to define CNTK networks directly in terms of
its underlying graph representation similar to TensorFlow and Theano. This is discussed
further below.)
### CNTK's Data model: Sequences of Tensors
CNTK can operate on two types of data:
* **tensors** (that is, N-dimensional arrays), dense or sparse
* **sequences** of tensors
The distinction is that the shape of a tensor is static during operation,
while the length of a sequence depends on data.
Tensors have *static axes*, while a sequence has an additional *dynamic axis*.
In CNTK, categorical data is represented as sparse one-hot tensors, not as integer vectors.
This allows to write embeddings and loss functions in a unified fashion as matrix products.
CNTK adopts Python's type-annotation syntax to declare CNTK types (works with Python 2.7).
For example,
* `Tensor[(13,42)]` denotes a tensor with 13 rows and 42 columns, and
* `Sequence[SparseTensor[300000]]` a sequence of sparse vectors, which for example could represent a word out of a 300k dictionary
Note the absence of a batch dimension. CNTK hides batching from the user.
We want users to think in tensors and sequences, and leave mini-batching to CNTK.
Unlike other toolkits, CNTK can also automatically batch *sequences with different lengths*
into one minibatch, and handles all necessary padding and packing.
Workarounds like 'bucketing' are not needed.
### Your First CNTK Network: Simple Logistic Regression
Let us put all of this in action for a very simple example of logistic regression.
For this example, we create a synthetic data set of 2-dimensional normal-distributed
data points, which should be classified into belonging to one of two classes.
Note that CNTK expects the labels as one-hot encoded.
```
input_dim_lr = 2 # classify 2-dimensional data
num_classes_lr = 2 # into one of two classes
# This example uses synthetic data from normal distributions,
# which we generate in the following.
# X_lr[corpus_size,input_dim] - input data
# Y_lr[corpus_size] - labels (0 or 1), one-hot-encoded
np.random.seed(0)
def generate_synthetic_data(N):
Y = np.random.randint(size=N, low=0, high=num_classes_lr) # labels
X = (np.random.randn(N, input_dim_lr)+3) * (Y[:,None]+1) # data
# Our model expects float32 features, and cross-entropy
# expects one-hot encoded labels.
Y = scipy.sparse.csr_matrix((np.ones(N,np.float32), (range(N), Y)), shape=(N, num_classes_lr))
X = X.astype(np.float32)
return X, Y
X_train_lr, Y_train_lr = generate_synthetic_data(20000)
X_test_lr, Y_test_lr = generate_synthetic_data(1024)
print('data =\n', X_train_lr[:4])
print('labels =\n', Y_train_lr[:4].todense())
```
We now define the model function. The model function maps input data to predictions.
It is the final product of the training process.
In this example, we use the simplest of all models: logistic regression.
```
model_lr = cntk.layers.Dense(num_classes_lr, activation=None)
```
Next, we define the criterion function. The criterion function is
the harness via which the trainer uses to optimize the model:
It maps (input vectors, labels) to (loss, metric).
The loss is used for the SGD updates. We choose cross entropy.
Specifically, `cross_entropy_with_softmax()` first applies
the `softmax()` function to the network's output, as
cross entropy expects probabilities.
We do not include `softmax()` in the model function itself, because
it is not necessary for using the model.
As the metric, we count classification errors (this metric is not differentiable).
We define criterion function as Python code and convert it to a `Function` object.
A single expression can be written as `Function(lambda x, y: `*expression of x and y*`)`,
similar to Keras' `Lambda()`.
To avoid evaluating the model twice, we use a Python function definition
with decorator syntax. This is also a good time to tell CNTK about the
data types of our inputs, which is done via the decorator `@Function.with_signature(`*argument types*`)`:
```
@cntk.Function.with_signature(cntk.layers.Tensor[input_dim_lr], cntk.layers.SparseTensor[num_classes_lr])
def criterion_lr(data, label_one_hot):
z = model_lr(data) # apply model. Computes a non-normalized log probability for every output class.
loss = cntk.cross_entropy_with_softmax(z, label_one_hot) # applies softmax to z under the hood
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
print('criterion_lr:', criterion_lr)
print('W =', model_lr.W.value) # W now has known shape and thus gets initialized
```
The decorator will 'compile' the Python function into CNTK's internal graph representation.
Thus, the resulting `criterion` not a Python function but a CNTK `Function` object.
We are now ready to train our model.
```
learner = cntk.sgd(model_lr.parameters,
cntk.learning_rate_schedule(0.1, cntk.UnitType.minibatch))
progress_writer = cntk.logging.ProgressPrinter(50)
criterion_lr.train((X_train_lr, Y_train_lr), parameter_learners=[learner],
callbacks=[progress_writer])
print(model_lr.W.value) # peek at updated W
```
The `learner` is the object that actually performs the model update. Alternative learners include `momentum_sgd()` and `adam()`. The `progress_writer` is a stock logging callback that prints the output you see above, and can be replaced by your own
or the stock `TensorBoardProgressWriter`to visualize training progress using TensorBoard.
The `train()` function is feeding our data `(X_train_lr, Y_train_lr)` minibatch by minibatch to the model and updates it, where the data is a tuple in the same order as the arguments of `criterion_mn()`.
Let us test how we are doing on our test set (this will also run minibatch by minibatch).
```
test_metric_lr = criterion_lr.test((X_test_lr, Y_test_lr),
callbacks=[progress_writer]).metric
```
And lastly, let us run a few samples through our model and see how it is doing.
Oops, `criterion` knew the input types, but `model_lr` does not,
so we tell it using `update_signature()`.
```
model_lr.update_signature(cntk.layers.Tensor[input_dim_lr])
print('model_lr:', model_lr)
```
Now we can call it like any Python function:
```
z = model_lr(X_test_lr[:20])
print("Label :", [label.todense().argmax() for label in Y_test_lr[:20]])
print("Predicted:", [z[i,:].argmax() for i in range(len(z))])
```
### Your Second CNTK Network: MNIST Digit Recognition
Let us do the same thing as above on an actual task--the MNIST benchmark, which is sort of the "hello world" of deep learning.
The MNIST task is to recognize scans of hand-written digits. We first download and prepare the data.
```
input_shape_mn = (28, 28) # MNIST digits are 28 x 28
num_classes_mn = 10 # classify as one of 10 digits
# Fetch the MNIST data. Best done with scikit-learn.
try:
from sklearn import datasets, utils
mnist = datasets.fetch_mldata("MNIST original")
X, Y = mnist.data / 255.0, mnist.target
X_train_mn, X_test_mn = X[:60000].reshape((-1,28,28)), X[60000:].reshape((-1,28,28))
Y_train_mn, Y_test_mn = Y[:60000].astype(int), Y[60000:].astype(int)
except: # workaround if scikit-learn is not present
import requests, io, gzip
X_train_mn, X_test_mn = (np.fromstring(gzip.GzipFile(fileobj=io.BytesIO(requests.get('http://yann.lecun.com/exdb/mnist/' + name + '-images-idx3-ubyte.gz').content)).read()[16:], dtype=np.uint8).reshape((-1,28,28)).astype(np.float32) / 255.0 for name in ('train', 't10k'))
Y_train_mn, Y_test_mn = (np.fromstring(gzip.GzipFile(fileobj=io.BytesIO(requests.get('http://yann.lecun.com/exdb/mnist/' + name + '-labels-idx1-ubyte.gz').content)).read()[8:], dtype=np.uint8).astype(int) for name in ('train', 't10k'))
# Shuffle the training data.
np.random.seed(0) # always use the same reordering, for reproducability
idx = np.random.permutation(len(X_train_mn))
X_train_mn, Y_train_mn = X_train_mn[idx], Y_train_mn[idx]
# Further split off a cross-validation set
X_train_mn, X_cv_mn = X_train_mn[:54000], X_train_mn[54000:]
Y_train_mn, Y_cv_mn = Y_train_mn[:54000], Y_train_mn[54000:]
# Our model expects float32 features, and cross-entropy expects one-hot encoded labels.
Y_train_mn, Y_cv_mn, Y_test_mn = (scipy.sparse.csr_matrix((np.ones(len(Y),np.float32), (range(len(Y)), Y)), shape=(len(Y), 10)) for Y in (Y_train_mn, Y_cv_mn, Y_test_mn))
X_train_mn, X_cv_mn, X_test_mn = (X.astype(np.float32) for X in (X_train_mn, X_cv_mn, X_test_mn))
# Have a peek.
matplotlib.pyplot.rcParams['figure.figsize'] = (5, 0.5)
matplotlib.pyplot.axis('off')
_ = matplotlib.pyplot.imshow(np.concatenate(X_train_mn[0:10], axis=1), cmap="gray_r")
```
Let's define the CNTK model function to map (28x28)-dimensional images to a 10-dimensional score vector. We wrap that in a function so that later in this tutorial we can easily recreate it.
```
def create_model_mn():
with cntk.layers.default_options(activation=cntk.ops.relu, pad=False):
return cntk.layers.Sequential([
cntk.layers.Convolution2D((5,5), num_filters=32, reduction_rank=0, pad=True), # reduction_rank=0 for B&W images
cntk.layers.MaxPooling((3,3), strides=(2,2)),
cntk.layers.Convolution2D((3,3), num_filters=48),
cntk.layers.MaxPooling((3,3), strides=(2,2)),
cntk.layers.Convolution2D((3,3), num_filters=64),
cntk.layers.Dense(96),
cntk.layers.Dropout(dropout_rate=0.5),
cntk.layers.Dense(num_classes_mn, activation=None) # no activation in final layer (softmax is done in criterion)
])
model_mn = create_model_mn()
```
This model is a tad bit more complicated! It consists of several convolution-pooling layeres and two
fully-connected layers for classification which is typical for MNIST. This demonstrates several aspects of CNTK's Functional API.
First, we create each layer using a function from CNTK's layers library (`cntk.layers`).
Second, the higher-order layer `Sequential()` creates a new function that applies all those layers
one after another. This is known [forward function composition](https://en.wikipedia.org/wiki/Function_composition).
Note that unlike some other toolkits, you cannot `Add()` more layers afterwards to a sequential layer.
CNTK's `Function` objects are immutable, besides their learnable parameters (to edit a `Function` object, you can `clone()` it).
If you prefer that style, create your layers as a Python list and pass that to `Sequential()`.
Third, the context manager `default_options()` allows to specify defaults for various optional arguments to layers,
such as that the activation function is always `relu`, unless overriden.
Lastly, note that `relu` is passed as the actual function, not a string.
Any function can be an activation function.
It is also allowed to pass a Python lambda directly, for example relu could also be
realized manually by saying `activation=lambda x: cntk.ops.element_max(x, 0)`.
The criterion function is defined like in the previous example, to map maps (28x28)-dimensional features and according
labels to loss and metric.
```
@cntk.Function.with_signature(cntk.layers.Tensor[input_shape_mn], cntk.layers.SparseTensor[num_classes_mn])
def criterion_mn(data, label_one_hot):
z = model_mn(data)
loss = cntk.cross_entropy_with_softmax(z, label_one_hot)
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
```
For the training, let us throw momentum into the mix.
```
N = len(X_train_mn)
lrs = cntk.learning_rate_schedule([0.001]*12 + [0.0005]*6 + [0.00025]*6 + [0.000125]*3 + [0.0000625]*3 + [0.00003125], cntk.learners.UnitType.sample, epoch_size=N)
momentums = cntk.learners.momentum_as_time_constant_schedule([0]*5 + [1024], epoch_size=N)
minibatch_sizes = cntk.minibatch_size_schedule([256]*6 + [512]*9 + [1024]*7 + [2048]*8 + [4096], epoch_size=N)
learner = cntk.learners.momentum_sgd(model_mn.parameters, lrs, momentums)
```
This looks a bit unusual.
First, the learning rate is specified as a list (`[0.001]*12 + [0.0005]*6 +`...). Together with the `epoch_size` parameter, this tells CNTK to use 0.001 for 12 epochs, and then continue with 0.005 for another 6, etc.
Second, the learning rate is specified per-sample, and momentum as a time constant.
These values specify directly the weight with which each sample's gradient
contributes to the model, and how its contribution decays as training progresses;
independent of the minibatch size, which is crucial for efficiency of GPUs and parallel training.
This unique CNTK feature allows to adjust the minibatch size without retuning those parameters.
Here, we grow it from 256 to 4096, leading to 3 times faster
operation towards the end (on a Titan-X).
Alright, let us now train the model. On a Titan-X, this will run for about a minute.
```
progress_writer = cntk.logging.ProgressPrinter()
criterion_mn.train((X_train_mn, Y_train_mn), minibatch_size=minibatch_sizes,
max_epochs=40, parameter_learners=[learner], callbacks=[progress_writer])
test_metric_mn = criterion_mn.test((X_test_mn, Y_test_mn), callbacks=[progress_writer]).metric
```
### Graph API Example: MNIST Digit Recognition Again
CNTK also allows networks to be written in graph style like TensorFlow and Theano. The following defines the same model and criterion function as above, and will get the same result.
```
images = cntk.input_variable(input_shape_mn, name='images')
with cntk.layers.default_options(activation=cntk.ops.relu, pad=False):
r = cntk.layers.Convolution2D((5,5), num_filters=32, reduction_rank=0, pad=True)(images)
r = cntk.layers.MaxPooling((3,3), strides=(2,2))(r)
r = cntk.layers.Convolution2D((3,3), num_filters=48)(r)
r = cntk.layers.MaxPooling((3,3), strides=(2,2))(r)
r = cntk.layers.Convolution2D((3,3), num_filters=64)(r)
r = cntk.layers.Dense(96)(r)
r = cntk.layers.Dropout(dropout_rate=0.5)(r)
model_mn = cntk.layers.Dense(num_classes_mn, activation=None)(r)
label_one_hot = cntk.input_variable(num_classes_mn, is_sparse=True, name='labels')
loss = cntk.cross_entropy_with_softmax(model_mn, label_one_hot)
metric = cntk.classification_error(model_mn, label_one_hot)
criterion_mn = cntk.combine([loss, metric])
print('criterion_mn:', criterion_mn)
```
# Feeding Your Data
Once you have decided your model structure and defined it, you are facing the question on feeding
your training data to the CNTK training process.
The above examples simply feed the data as numpy/scipy arrays.
That is only one of three ways CNTK provides for feeding data to the trainer:
1. As **numpy/scipy arrays**, for small data sets that can just be loaded into RAM.
2. Through instances of **CNTK's MinibatchSource class**, for large data sets that do not fit into RAM.
3. Through an **explicit minibatch-loop** when the above do not apply.
### 1. Feeding Data Via Numpy/Scipy Arrays
The `train()` and `test()` functions accept a tuple of numpy or scipy arrays for their `minibatch_source` arguments.
The tuple members must be in the same order as the arguments of the `criterion` function that `train()` or `test()` are called on.
For dense tensors, use numpy arrays, while sparse data should have the type `scipy.sparse.csr_matrix`.
Each of the arguments should be a Python list of numpy/scipy arrays, where each list entry represents a data item. For arguments declared as `Sequence[...]`, the first axis of the numpy/scipy array is the sequence length, while the remaining axes are the shape of each token of the sequence. Arguments that are not sequences consist of a single tensor. The shapes, data types (`np.float32/float64`) and sparseness must match the argument types as declared in the criterion function.
As an optimization, arguments that are not sequences can also be passed as a single large numpy/scipy array (instead of a list). This is what is done in the examples above.
Note that it is the responsibility of the user to randomize the data.
### 2. Feeding Data Using the `MinibatchSource` class for Reading Data
Production-scale training data sometimes does not fit into RAM. For example, a typical speech corpus may be several hundred GB large. For this case, CNTK provides the `MinibatchSource` class, which provides:
* A **chunked randomization algorithm** that holds only part of the data in RAM at any given time.
* **Distributed reading** where each worker reads a different subset.
* A **transformation pipeline** for images and image augmentation.
* **Composability** across multiple data types (e.g. image captioning).
At present, the `MinibatchSource` class implements a limited set of data types in the form of "deserializers":
* **Images** (`ImageDeserializer`).
* **Speech files** (`HTKFeatureDeserializer`, `HTKMLFDeserializer`).
* Data in CNTK's **canonical text format (CTF)**, which encodes any of CNTK's data types in a human-readable text format.
The following example of using the `ImageDeserializer` class shows the general pattern.
For the specific input-file formats, please consult the documentation
or data-type specific tutorials.
```
image_width, image_height, num_channels = (32, 32, 3)
num_classes = 1000
def create_image_reader(map_file, is_training):
transforms = []
if is_training: # train uses data augmentation (translation only)
transforms += [
cntk.io.transforms.crop(crop_type='randomside', side_ratio=0.8) # random translation+crop
]
transforms += [ # to fixed size
cntk.io.transforms.scale(width=image_width, height=image_height, channels=num_channels, interpolations='linear'),
]
# deserializer
return cntk.io.MinibatchSource(cntk.io.ImageDeserializer(map_file, cntk.io.StreamDefs(
features = cntk.io.StreamDef(field='image', transforms=transforms),
labels = cntk.io.StreamDef(field='label', shape=num_classes)
)), randomize=is_training, max_sweeps = cntk.io.INFINITELY_REPEAT if is_training else 1)
```
### 3. Feeding Data Via an Explicit Minibatch Loop
Instead of feeding your data as a whole to CNTK's `train()` and `test()` functions which implement a minibatch loop internally,
you can realize your own minibatch loop and call the lower-level APIs `train_minibatch()` and `test_minibatch()`.
This is useful when your data is not in a form suitable for the above, such as being generated on the fly as in variants of reinforcement learning. The `train_minibatch()` and `test_minibatch()` methods require you to instantiate an object of class `Trainer` that takes a subset of the arguments of `train()`. The following implements the logistic-regression example from above through explicit minibatch loops:
```
# Recreate the model, so that we can start afresh. This is a direct copy from above.
model_lr = cntk.layers.Dense(num_classes_lr, activation=None)
@cntk.Function.with_signature(cntk.layers.Tensor[input_dim_lr], cntk.layers.SparseTensor[num_classes_lr])
def criterion_lr(data, label_one_hot):
z = model_lr(data) # apply model. Computes a non-normalized log probability for every output class.
loss = cntk.cross_entropy_with_softmax(z, label_one_hot) # this applies softmax to z under the hood
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
# Create the learner; same as above.
learner = cntk.sgd(model_lr.parameters, cntk.learning_rate_schedule(0.1, cntk.UnitType.minibatch))
# This time we must create a Trainer instance ourselves.
trainer = cntk.Trainer(None, criterion_lr, [learner], [cntk.logging.ProgressPrinter(50)])
# Train the model by spoon-feeding minibatch by minibatch.
minibatch_size = 32
for i in range(0, len(X_train_lr), minibatch_size): # loop over minibatches
x = X_train_lr[i:i+minibatch_size] # get one minibatch worth of data
y = Y_train_lr[i:i+minibatch_size]
trainer.train_minibatch({criterion_lr.arguments[0]: x, criterion_lr.arguments[1]: y}) # update model from one minibatch
trainer.summarize_training_progress()
# Test error rate minibatch by minibatch
evaluator = cntk.Evaluator(criterion_lr.outputs[1], [progress_writer]) # metric is the second output of criterion_lr()
for i in range(0, len(X_test_lr), minibatch_size): # loop over minibatches
x = X_test_lr[i:i+minibatch_size] # get one minibatch worth of data
y = Y_test_lr[i:i+minibatch_size]
evaluator.test_minibatch({criterion_lr.arguments[0]: x, criterion_lr.arguments[1]: y}) # test one minibatch
evaluator.summarize_test_progress()
```
# Training and Evaluating
In our examples above, we use the `train()` function to train, and `test()` for evaluating.
In this section, we want to walk you through the advanced options of `train()`:
1. **Distributed Training** on mutliple GPUs using MPI.
2. Callbacks for **Progress Tracking**, **TensorBoard visualization**, **Checkpointing**,**Cross-validation**-based training contro, and **Testing** for the final model.
### 1. Distributed Training
CNTK makes distributed training easy. Out of the box, it supports three methods of distributed training:
* Simple **data-parallel** training.
* **1-bit SGD**.
* **BlockMomentum**.
Simple **data-parallel** training distributes each minibatch over N worker processes, where each process utilizes one GPU.
After each minibatch, sub-minibatch gradients from all workers are aggregated before updating each model copy.
This is often sufficient for convolutional networks, which have a high computation/communication ratio.
**1-bit SGD** uses 1-bit data compression with residual feedback to speed up data-parallel training
by reducing the data exchanges to 1 bit per gradient value.
To avoid affecting convergence, each worker keeps a quantization-error residual which is added to the next minibatch's
gradient. This way, all gradient values are eventually transmitted with full accuracy, albeit at a delay.
This method has been found effective for networks where communication cost becomes the dominating factor,
such as full-connected networks and some recurrent ones.
This method has been found to only minimally degrade accuracy at good speed-ups.
**BlockMomentum** improves communication bandwidth by exchanging gradients only every N minibatches.
To avoid affecting convergence, BlockMomentum combines "model averaging" with the residual technique of 1-bit SGD:
After N minibatches, block gradients are aggregated across workers, and added to all model copies at weight of 1/N,
while a residual keeps (N-1)/N times the block gradient, which is added to the next block gradient, which
then is in turn applied at a weight of 1/N and so on.
Processes are started with and communicate through MPI. Hence, CNTK's distributed training
works both within a single server and across multiple servers.
All you need to do is
* wrap your learner inside a `distributed_learner` object
* execute the Python script using `mpiexec`
Please see the example below when we put all together.
### 2. Callbacks
The `callbacks` parameter of `train()` specifies actions that the `train()` function
executes periodically, typically every epoch.
The `callbacks` parameter is a list of objects, where the object type decides the specific callback action.
Progress trackers allow to log progress (average loss and metric)
periodically after N minibatches and after completing each epoch.
Optionally, all of the first few minibatches can be logged.
The `ProgressPrinter` callback logs to stderr and file, while `TensorBoardProgressWriter`
logs events for visualization in TensorBoard.
You can also write your own progress tracker class.
Next, the `CheckpointConfig` class denotes a callback that writes a checkpoint file every epoch, and automatically restarts training at the latest available checkpoint.
The `CrossValidationConfig` class tells CNTK to periodically evaluate the model on a cross-validation data set,
and then call a user-specified callback function, which can then update the learning rate of return `False` to indicate early stopping.
Lastly, `TestConfig` instructs CNTK to evaluate the model at the end on a given test set.
This is the same as the explicit `test()` call in our examples above.
### Putting it all Together: Advanced Training Example
Let us now put all of the above examples together into a single training. The following example runs our MNIST example from above with logging, TensorBoard events, checkpointing, CV-based training control, and a final test.
```
# Create model and criterion function.
model_mn = create_model_mn()
@cntk.Function.with_signature(cntk.layers.Tensor[input_shape_mn], cntk.layers.SparseTensor[num_classes_mn])
def criterion_mn(data, label_one_hot):
z = model_mn(data)
loss = cntk.cross_entropy_with_softmax(z, label_one_hot)
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
# Create the learner.
learner = cntk.learners.momentum_sgd(model_mn.parameters, lrs, momentums)
# Wrap learner in a distributed learner for 1-bit SGD.
# In this example, distributed training kicks in after a warm-start period of one epoch.
learner = cntk.train.distributed.data_parallel_distributed_learner(learner, distributed_after=1, num_quantization_bits=1)
# Create progress callbacks for logging to file and TensorBoard event log.
# Prints statistics for the first 10 minibatches, then for every 50th, to a log file.
progress_writer = cntk.logging.ProgressPrinter(50, first=10, log_to_file='my.log')
tensorboard_writer = cntk.logging.TensorBoardProgressWriter(50, log_dir='my_tensorboard_logdir',
rank=cntk.train.distributed.Communicator.rank(), model=criterion_mn)
# Create a checkpoint callback.
# Set restore=True to restart from available checkpoints.
epoch_size = len(X_train_mn)
checkpoint_callback_config = cntk.CheckpointConfig('model_mn.cmf', epoch_size, preserve_all=True, restore=False)
# Create a cross-validation based training control.
# This callback function halves the learning rate each time the cross-validation metric
# improved less than 5% relative, and stops after 6 adjustments.
prev_metric = 1 # metric from previous call to the callback. Error=100% at start.
def adjust_lr_callback(index, average_error, cv_num_samples, cv_num_minibatches):
global prev_metric
if (prev_metric - average_error) / prev_metric < 0.05: # did metric improve by at least 5% rel?
learner.reset_learning_rate(cntk.learning_rate_schedule(learner.learning_rate() / 2, cntk.learners.UnitType.sample))
if learner.learning_rate() < lrs[0] / (2**7-0.1): # we are done after the 6-th LR cut
print("Learning rate {} too small. Training complete.".format(learner.learning_rate()))
return False # means we are done
print("Improvement of metric from {:.3f} to {:.3f} insufficient. Halving learning rate to {}.".format(prev_metric, average_error, learner.learning_rate()))
prev_metric = average_error
return True # means continue
cv_callback_config = cntk.CrossValidationConfig((X_cv_mn, Y_cv_mn), 3*epoch_size, minibatch_size=256,
callback=adjust_lr_callback, criterion=criterion_mn)
# Callback for testing the final model.
test_callback_config = cntk.TestConfig((X_test_mn, Y_test_mn), criterion=criterion_mn)
# Train!
callbacks = [progress_writer, tensorboard_writer, checkpoint_callback_config, cv_callback_config, test_callback_config]
progress = criterion_mn.train((X_train_mn, Y_train_mn), minibatch_size=minibatch_sizes,
max_epochs=50, parameter_learners=[learner], callbacks=callbacks)
# Progress is available from return value
losses = [summ.loss for summ in progress.epoch_summaries]
print('loss progression =', ", ".join(["{:.3f}".format(loss) for loss in losses]))
```
Unfortunately, MPI cannot be used from a Jupyter notebook; hence, the the `distributed_learner` above actually has no effect.
You can find the same example
as a standalone Python script under `Examples/1stSteps/MNIST_Complex_Training.py` to run under MPI, for example under MSMPI as
`mpiexec -n 4 -lines python -u Examples/1stSteps/MNIST_Complex_Training.py`
# Deploying your Model
Your ultimate purpose of training a deep neural network is to deploy it as part of your own program or product.
Since this involves programming languages other than Python,
we will only give a high-level overview here, and refer you to specific examples.
Once you completed training your model, it can be deployed in a number of ways.
* Directly in your **Python** program.
* From any other language that CNTK supports, including **C++** and **C#**.
* From **your own web serive**.
* Through a web service deployed to **Microsoft Azure**.
The first step in all cases is to make sure your model's input types are known by calling `update_signature()`, and then to save your model to disk after training:
```
model_mn.update_signature(cntk.layers.Tensor[input_shape_mn])
model_mn.save('mnist.cmf')
```
Deploying your model in a Python-based program is easy: Since networks are function objects that are callable, like a function, simply load the model, and call it with inputs, as we have already shown above:
```
# At program start, load the model.
classify_digit = cntk.Function.load('mnist.cmf')
# To apply model, just call it.
image_input = X_test_mn[8345] # (pick a random test digit for illustration)
scores = classify_digit(image_input) # call the model function with the input data
image_class = scores.argmax() # find the highest-scoring class
# And that's it. Let's have a peek at the result
print('Recognized as:', image_class)
matplotlib.pyplot.axis('off')
_ = matplotlib.pyplot.imshow(image_input, cmap="gray_r")
```
Models can be deployed directly from programs written in other programming languages for which bindings exist.
Please see the following example programs for an example similar to the Python one above:
* C++: `Examples/Evaluation/CNTKLibraryCPPEvalCPUOnlyExamples/CNTKLibraryCPPEvalCPUOnlyExamples.cpp`
* C#: `Examples/Evaluation/CNTKLibraryCSEvalCPUOnlyExamples/CNTKLibraryCSEvalExamples.cs`
To deploy a model from your own web service, load and invoke the model in the same way.
To deploy a model via an Azure web service, follow this tutorial: `Examples/Evaluation/CNTKAzureTutorial01`
# Conclusion
This tutorial provided an overview of the five main tasks of creating and using a deep neural network with CNTK.
We first examined CNTK's Functional programming and its tensor/sequence-based data model.
Then we considered the possible ways of feeding data to CNTK, including directly from RAM,
through CNTK's data-reading infrastructure (`MinibatchSource`), and spoon-feeding through a custom minibatch loop.
We then took a look at CNTK's advanced training options, including distributed training, logging to TensorBoard, checkpointing, CV-based training control, and final model evaluation.
Lastly, we briefly looked into model deployment.
We hope this guided your have you a good starting point for your own ventures with CNTK. Please enjoy!
| github_jupyter |
# Implementing models using the low-level backend
Keras supports two different backends to accelerate model training and evaluation using GPUs. To make the code easier to read, both backends are wrapped using the same API and all of the code in Keras is implemented using these wrappers. In case you want to extend Keras with new layer types, optimization algorithms, or cost functions, this is the way to go.
Let's get the gist of it by implementing a simple classification algorithm: logistic regression. The model has two trainable parameters: a weight matrix `W` and a bias vector `b`, which are used to perform an affine projection on the input `x`. The probability that the input belongs to the positive class is given by the logistic function:
$$
\hat{y} = \frac{1}{1 + e^{-(Wx + b)}}
$$
and the final predicted class is the positive class if $\hat{y} > 0.5$ and the negative class otherwise.
In this tutorial, we will learn how to implement this model and learn its optimal parameters using gradient descent. That's basically what we do in deep learning (but with a lot more layers, fancier architectures, and more robust optimization algorithms).
```
from keras import backend as K
import numpy as np
```
A placeholder can be seen as an "open slot" where you can put values later. These are used for function arguments, such as the input and output of the model.
```
x = K.placeholder(shape=(None, 5))
y = K.placeholder(shape=(None, 1))
```
A variable, on the other hand, can be seen as an automatically-managed shared memory between the host and the GPU (when using a GPU, of course). If running on a CPU, it is just a pointer to a normal Python array.
Note that we are initializing `W` with small random numbers following a Gaussian distribution, and `b` with zero (which is common practice for this type of model).
```
W = K.variable(0.01*np.random.randn(5, 1))
b = K.variable(np.zeros(1))
```
As `variables` have actual values, we can inspect and even change them using `.get_value()` and `.set_value()`.
```
print('Initial weights: {}'.format(W.get_value()))
print('Initial bias: {}'.format(b.get_value()))
```
The backend also contains common element-wise functions and supports common Numpy notation (so remember to use K.dot for matrix multiplications!)
```
y_hat = K.sigmoid(K.dot(x, W) + b)
```
If we try to print `y_hat`, we get something strange:
```
print(y_hat)
```
`sigmoid.0` corresponds to the name of a *node* in the graph generated by Theano (or Tensorflow, if that's the backend you are using). Since `y_hat` depends on `x` and `y`, which do not have values yet, we cannot compute any values for it.
We can use backend-dependent functions to print a graph. For Theano, we can use `theano.pp` (simple) or `theano.printing.debugprint`:
```
from theano import pp
pp(y_hat)
from theano.printing import debugprint
debugprint(y_hat)
```
The code we wrote so far computes the output of a logistic regression model, but we still have to train it. Let's define a loss function and its gradients for each of the trainable parameters.
```
loss = K.mean(K.binary_crossentropy(y_hat, y))
params = [W, b]
gradients = K.gradients(loss, params)
lr = 0.1
# Let's compute the gradient descent updates for each of the trainable parameters
# in our model and store it on a list of tuples in the format (parameter to update, new_value)
updates = []
for p, g in zip([W, b], gradients):
new_p = p - lr*g
updates.append((p, new_p))
```
We can turn a backend *expression* into a function by calling `K.function`. We pass a list of inputs (note: it has to be a list, even if your function only has one input!), the function we want to compute, and optionally, a list of parameters that we want to be updated **after** calling the function.
```
train_fn = K.function([x, y], loss, updates=updates)
```
This will convert the graph into C++ and CUDA code and compile it (when using the Theano backend - Tensorflow will to something slightly different, but the workflow in Keras is exactly the same).
Now, we will generate a random dataset with 16 examples and use it to train our model using gradient descent. As the number of samples is small, gradient descent will do the trick here - but this is never the case with deep learning!
```
# Generating dummy dataset
X_batch = 2*np.random.randn(16, 5)
y_batch = np.random.randint(0, 2, size=(16,1))
for iteration in range(1000):
iter_loss = train_fn([X_batch, y_batch])
if iteration % 100 == 0:
print('Iteration {} loss: {}'.format(iteration, iter_loss))
print('Final weights: {}'.format(W.get_value()))
predict = K.function([x], y_hat)
predictions = predict([X_batch])
accuracy = (y_batch == (predictions > 0.5).astype('int')).mean()*100
print(accuracy)
```
| github_jupyter |
# Lab of data analysis with python
Author: Jesús Fernández Bes
Jerónimo Arenas García (jeronimo.arenas@uc3m.es)
Jesús Cid Sueiro (jcid@tsc.uc3m.es)
Notebook version: 1.1 (Sep 20, 2017)
Changes: v.1.0 - First version.
v.1.1 - Compatibility with python 2 and python 3
Pending changes:
In this lab we will introduce some of the modules that we will use in the rest of the labs of the course.
The usual beginning of any python module is a list of import statements. In most our file we will use the following modules:
* numpy: The basic scientific computing library.
* csv: Used for input/output in using comma separated values files, one of the standards formats in data management.
* matplotlib: Used for plotting figures and graphs
* sklearn: Scikit-learn is the machine learning library for python.
```
%matplotlib inline
# Needed to include the figures in this notebook, you can remove it
# to work with a normal script
import numpy as np
import csv
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
```
## 1. NUMPY
The _numpy_ module is useful for scientific computing in Python.
The main data structure in _numpy_ is the n-dimensional array. You can define a _numpy_ _array_ from a list or a list of lists. Python will try to build it with the appropiate dimensions. You can check the dimensions of the array with _shape()_
```
my_array = np.array([[1, 2],[3, 4]])
print(my_array)
print(np.shape(my_array))
```
Define a new 3x2 array named *my_array2* with [1, 2, 3] in the first row and [4,5,6] in the second.
Check the dimension of the array.
```
#<SOL>
#</SOL>
```
There are a number of operations you can do with numpy arrays similar to the ones you can do with matrices in Matlab. One os the most important is **slicing**. We saw it when we talked about lists, it consists in extracting some subarray of the array.
```
my_array3 = my_array[:,1]
print(my_array3)
print(my_array[1,0:2])
```
One important thing to consider when you do slicing are the dimensions of the output array. Check the shape of *my_array3*. Check also its dimension with function _ndim_:
```
#<SOL>
#</SOL>
```
If you have correctly computed it you will see that *my_array3* is one dimensional. Sometimes this can be a problem when you are working with 2D matrixes (and vectors can be considered as 2D matrixes with one of the sizes equal to 1). To solve this, _numpy_ provides the _newaxis_ constant.
```
my_array3 = my_array3[:,np.newaxis]
```
Check again the shape and dimension of *my_array3*
```
#<SOL>
#</SOL>
```
It is possible to extract a single row or column from a 2D numpy array so that the result is still 2D, without explictly recurring to _np.newaxis_. Compare the outputs of the following print commands.
```
print(my_array[:,1])
print(my_array[:,1].shape)
print(my_array[:,1:2])
print(my_array[:,1:2].shape)
```
Another important array manipulation method is array _concatenation_ or _stacking_. It is useful to always state explicitly in which direction we want to stack the arrays. For example in the following example we are stacking the arrays vertically.
```
print(my_array)
print(my_array2)
print(np.concatenate( (my_array, my_array2) , axis=1)) # columnwise concatenation
```
**EXERCISE:** Concatenate the first column of *my_array* and the second column of *my_array2*
```
#<SOL>
#</SOL>
```
You can create _numpy_ arrays in several ways, not only from lists. For example _numpy_ provides a number of functions to create special types of matrices.
**EXERCISE:** Create 3 arrays usings _ones_, _zeros_ and _eye_. If you have any doubt about the parameters of the functions have a look at the help with the function _help( )_.
```
#<SOL>
#</SOL>
```
Finally _numpy_ provides all the basic matrix operations: multiplications, dot products, ...
You can find information about them in the [Numpy manual](http://docs.scipy.org/doc/numpy/reference/).
In addition to _numpy_ we have a more advanced library for scientific computing, [Scipy](http://www.scipy.org/scipylib/index.html), that includes modules for linear algebra, signal processing, Fourier transform, ...
## 2. Matplotlib
One important step of data analysis is data visualization. In python the simplest plotting library is _matplotlib_ and its sintax is similar to Matlab plotting library. In the next example we plot two sinusoids with different simbols.
```
t = np.arange(0.0, 1.0, 0.05)
a1 = np.sin(2*np.pi*t)
a2 = np.sin(4*np.pi*t)
#s = sin(2*3.14159*t)
plt.figure()
ax1 = plt.subplot(211)
ax1.plot(t,a1)
plt.xlabel('t')
plt.ylabel('a_1(t)')
ax2 = plt.subplot(212)
ax2.plot(t,a2, 'r.')
plt.xlabel('t')
plt.ylabel('a_2(t)')
plt.show()
```
## 3. Classification example
One of the main machine learning problems is clasification. In the following example, we will load and visualize a dataset that can be used in a clasification problem.
The [iris dataset](https://archive.ics.uci.edu/ml/datasets/Iris) is one of the most popular pattern recognition datasets. It consists on 150 instances of 4 features of iris flowers:
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm
The objective is usually to distinguish three different classes of iris plant: Iris setosa, Iris versicolor, and Iris virginica.
### 3.1 Loading the data
We give you the data in _.csv_ format. In each line of the csv file we have the 4 real-valued features of each instance and then a string defining the class of that instance: Iris-setosa, Iris-versicolor or Iris-virginica. There are 150 instances of flowers in the csv file.
Let's se how we can load the data in an _array_
```
# Open up the csv file in to a Python object
csv_file_object = csv.reader(open('iris_data.csv', 'r'))
datalist = [] # Create a variable called 'data'.
for row in csv_file_object: # Run through each row in the csv file,
datalist.append(row) # adding each row to the data variable
data = np.array(datalist) # Then convert from a list to an array
# Be aware that each item is currently
# a string in this format
print(np.shape(data))
X = data[:,0:-1]
label = data[:,-1,np.newaxis]
print(X.shape)
print(label.shape)
```
In the previous code we have saved the features in matrix X and the class labels in the vector labels. Both are 2D _numpy_ _arrays_.
We are also printing the shapes of each variable (see that we can also use `array_name.shape` to get the shape, appart from function _shape()_). Checking the shape of matrices is a convenient way to prevent mistakes in your code.
### 3.2 Visualizing the data
Extract the 2 first features of the data (sepal length and width) and plot the first versus the second in a figure, use a different color for the data corresponding to different classes.
First of all you probably want to split the data according to each class label.
```
#<SOL>
#</SOL>
```
According to this plot, which classes seem more difficult to distinguish?
## 4. Regression example
Now that we know how to load some data and visualize them, we will try to solve a simple regression task.
Our objective in this example is to predict the crime rates in different areas of the US using some socio-demographic data.
This dataset has 127 socioeconomic variables of different nature: categorical, integer, real, and for some of them there are also missing data ([check wikipedia](https://en.wikipedia.org/wiki/Missing_data)). This is usually a problem when training machine learning models, but we will ignore that problem and take only a small number of variables that we think can be useful for regression and which have no missing values.
5. population: population for community
6. householdsize: mean people per household
17. medIncome: median household income
The objective in the regresion problem is another real value that contains the *total number of violent crimes per 100K population*.
### 4.1 Loading the data
First of all, load the data from file _communities.csv_ in a new array. This array should have 1994 rows (instances) and 128 columns.
```
#<SOL>
#</SOL>
```
Take the columns (5,6,17) of the data and save them in a matrix *X_com*. This will be our input data. Convert this array into a _float_ array. The shape should be (1994,3)
Get the last column of the data and save it in an array called *y_com*. Convert this matrix into a _float_ array.
Check that the shape is (1994,1) .
```
#<SOL>
#</SOL>
```
Plot each variable in *X_com* versus *y_com* to have a first (partial) view of the data.
```
#<SOL>
#</SOL>
```
### 4.2 Train/Test splitting
Now, we are about to start doing machine learning. But, first of all, we have to separate our data in train and test partitions.
The train data will be used to adjust the parameters (train) of our model.
The test data will be used to evaluate our model.
Use *sklearn.cross_validation.train_test_split* to split the data in *train* (60%) and *test* (40%). Save the results in variables named *X_train*, *X_test*, *y_train*, *y_test*.
#### Important note
In real applications, you would have no access to any targets for the test data. However, for illustratory purposes, when evaluating machine learning algorithms it is common to set aside a _test partition_, including the corresponding labels, so that you can use these targets to assess the performance of the method. When proceeding in this way, the test labels should never be used during the design. It is just allowed to use them as a final assessment step once the classifier or regression model has been fully adjusted.
```
#<SOL>
#</SOL>
```
### 4.3 Normalization
Most machine learning algorithms require that the data is standardized (mean=0, standard deviation= 1). Scikit-learn provides a tool to do that in the object _sklearn.preprocessing.StandardScaler_ (but you can also try and program it by yourself, it easier than in MATLAB!!)
```
#<SOL>
#</SOL>
```
### 4.4 Training
We will apply two different K-NN regressors for this example. One with K (*n_neighbors*) = 1 and the other with K=7.
Read the [API](http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html#sklearn.neighbors.KNeighborsRegressor) and [this example](http://scikit-learn.org/stable/auto_examples/neighbors/plot_regression.html#example-neighbors-plot-regression-py) to understand how to fit the model.
```
#<SOL>
#</SOL>
```
### 4.5 Prediction and evaluation
Now use the two models you have trained to predict the test output *y_test*. To evaluate it measure the MSE.
The formula of MSE is
$$\text{MSE}=\frac{1}{K}\sum_{k=1}^{K}({\hat{y}}-y)^2$$
```
#<SOL>
#</SOL>
```
### 4.6 Saving the results
Finally we will save all our predictions for the model with K=1 in a csv file. To do so you can use the following code Snippet, where *y_pred* are the predicted output values for test.
```
#<SOL>
#</SOL>
```
| github_jupyter |
# 사전 학습된 FastText를 BlazingText에 호스팅하기
*본 노트북 예제는 [사전 학습된 FastText를 BlazingText에 호스팅하기(영어)](https://github.com/awslabs/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/blazingtext_hosting_pretrained_fasttext/blazingtext_hosting_pretrained_fasttext.ipynb) 노트북을 번역하면서 한국어 컨텐츠를 추가하였습니다.*
## 개요
이 노트북에서는 BlazingText가 [FastText 모델](https://fasttext.cc/docs/en/english-vectors.html)로
사전 학습된(pre-trained) 텍스트 분류(Text Classification) 및 Word2Vec 모델 (FastText 모델)의 호스팅을 지원하는 방법을 보여줍니다.
BlazingText는 교사 학습(supervised) 모드 사용 시 GPU 가속 버전의 FastText와 동일합니다. FastText는 비교사 학습인 단어 임베딩(Word Embedding)과 교사 학습인 텍스트 분류를 모두 수행하는 데 사용되는 얕은 신경망 모델(shallow Neural Network model)로 문자 단위 n-gram으로 임베딩을 수행하기 때문에 등장 빈도 수가 적은 단어에 대해서도 높은 정확도를 보여 줍니다. FastText 관련 논문들은 아래를 참조해 주세요.
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification<br>
[2] P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information<br>
[3] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, FastText.zip: Compressing text classification models
BlazingText는 사용자 정의 CUDA 커널을 사용하여 FastText의 학습 과정을 가속화하지만 기본 알고리즘은 두 알고리즘에서 동일합니다.
따라서 FastText로 학습된 모델이 있거나 FastText 팀에서 제공하는 사전 학습된 모델 중 하나가 사용 사례에 충분하면 BlazingText에 대한 호스팅 기능을 활용하여 실시간 예측을 위한 SageMaker 엔드포인트를 설정할 수 있습니다. 다시 말해, FastText로 사전 학습된 모델을 이미 보유하고 있다면 BlazingText 알고리즘으로 다시 학습하지 않아도 됩니다.
```
import sagemaker
from sagemaker import get_execution_role
import boto3
import json
sess = sagemaker.Session()
# This is the role that SageMaker would use to leverage AWS resources (S3, CloudWatch) on your behalf
role = get_execution_role()
#print(role)
#bucket = sess.default_bucket()
bucket = '[YOUR-BUCKET]' # Replace with your own bucket name if needed
prefix = 'sagemaker/DEMO-blazingtext-pretrained-fasttext' #Replace with the prefix under which you want to store the data if needed
region_name = boto3.Session().region_name
container = sagemaker.amazon.amazon_estimator.get_image_uri(region_name, "blazingtext", "latest")
print('Using SageMaker BlazingText container: {} ({})'.format(container, region_name))
```
### Hosting the [Language Idenfication model](https://fasttext.cc/docs/en/language-identification.html) by FastText
이 노트북에서는 언어 식별(Language Identification)을 위해 FastText가 제공하는 사전 학습된 모델을 활용합니다. 언어 식별은 입력 텍스트의 언어 식별 후 다양한 다운스트림 작업들에 해당 언어의 특정 모델을 적용해야 하는 많은 자연어 처리(NLP; Natural Language Processing) 응용 프로그램의 첫 단계입니다. 이 언어 식별 모델은 클래스 레이블(class label)로 언어 ID(language ID)를 사용하는 텍스트 분류 모델이므로 FastText를 학습에 직접 사용할 수 있습니다. FastText로 사전 학습된 언어 모델은 176개의 다른 언어 식별을 지원하며 한국어도 당연히 포함되어 있습니다.
FastText로 사전 학습된 모델 [1] 을 로컬 인스턴스로 가져오기 위해, [FastText 웹사이트](https://fasttext.cc/docs/en/language-identification.html)의 언어 식별 모델을 다운로드합니다.
```
!wget -O model.bin https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin
```
## Local Inference
엔드포인트를 생성하기 전에 fasttext 라이브러리를 설치하여 로컬에서 추론을 수행해 보겠습니다.
```
!pip install fasttext
import fasttext
model = fasttext.load_model('model.bin')
print(model.words[0:100]) # list of words in dictionary
print(model['안녕하세요']) # get the vector of the word 'king'
```
간단한 추론을 수행해 봅니다. 테스트할 문장은 한국어, 영어, 일본어, 독일어, 스페인어입니다.
```
sentences = [
"머신 러닝을 배우고 싶어요.",
"I want to learn machine learning.",
"マシンラーニングを学びたいです。",
"Ich möchte maschinelles Lernen lernen.",
"Quiero aprender el aprendizaje automático."]
model.predict(sentences)
```
모든 언어들이 올바르게 식별된 것을 확인할 수 있습니다.
## Creating SageMaker Inference Endpoint
BlazingText 컨테이너를 사용하여 SageMaker 추론 엔드포인트를 생성합니다. 이 엔드포인트는 FastText에서 제공하는 사전 학습된 모델과 호환되며 아무 수정 없이 직접 추론에 사용할 수 있습니다. 추론 엔드포인트는 컨텐츠 유형의 `application/json`에서 작동합니다.
`model.bin` 파일을 `langid.tar.gz`로 압축하고 S3에 업로드합니다. 로컬 인스턴스에 저장된 모델 파일은 더 이상 필요하지 않으므로 삭제합니다.
```
!tar -czvf langid.tar.gz model.bin
model_location = sess.upload_data("langid.tar.gz", bucket=bucket, key_prefix=prefix)
!rm langid.tar.gz model.bin
```
엔드포인트를 생성합니다. 약 5-10분 정도 소요됩니다.
```
lang_id = sagemaker.Model(model_data=model_location, image=container, role=role, sagemaker_session=sess)
lang_id.deploy(initial_instance_count = 1,instance_type = 'ml.m4.xlarge')
predictor = sagemaker.RealTimePredictor(endpoint=lang_id.endpoint_name,
sagemaker_session=sess,
serializer=json.dumps,
deserializer=sagemaker.predictor.json_deserializer)
```
이제 엔드포인트에서 직접 추론을 수행해 보겠습니다.
```
payload = {"instances" : sentences}
predictions = predictor.predict(payload)
print(predictions)
```
FastText는 클래스 레이블 앞에 `__label__`이 붙기 때문에, FastText에서 제공하는 사전 학습된 모델로 추론을 수행할 때 출력 레이블 앞에 `__label__`이 붙는 것을 알 수 있습니다. <br>
약간의 전처리를 통해 `__label__` 접두사(prefix)를 제거할 수 있습니다.
```
import copy
predictions_copy = copy.deepcopy(predictions) # Copying predictions object because we want to change the labels in-place
for output in predictions_copy:
output['label'] = output['label'][0][9:].upper() #__label__ has length of 9
print(predictions_copy)
```
### Stop / Close the Endpoint (Optional)
실시간 예측을 제공하기 위해 엔드포인트를 계속 실행할 필요가 없는 경우, 불필요한 과금을 막기 위해 엔드포인트를 삭제합니다.
```
sess.delete_endpoint(predictor.endpoint)
```
#### Tip
이와 유사하게, 여러분은 사전 학습된 [FastText word2vec 모델](https://fasttext.cc/docs/en/pretrained-vectors.html) SageMaker BlazingText hosting을 이용해 호스팅할 수 있습니다.
| github_jupyter |
# Headline Generation (NLP)
***

***
In this tutorial we are going to use a recurrent neural network to look at headlines from newspapers, to then be able to generate new headlines based on the seed (first few words) that we give it. The data we have given you contains only American headlines, so it will be biased. We suggest trying your own data if you find something similar!
***
## Imports
```
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Embedding, LSTM, Dense
from keras.preprocessing.text import Tokenizer
from keras.callbacks import EarlyStopping
from keras.models import Sequential
import keras.utils as ku
from tensorflow import set_random_seed
from numpy.random import seed
set_random_seed(2)
seed(1)
import pandas as pd
import numpy as np
import string, os
```
## Load the Data
Here we have data define the exact file we want to load in as we only want the data that is associated with articles and not the comments.
To Do:
- Load all **article** data
- Take a look at the headlines that we have loaded
```
!ls data
curr_dir = 'data/'
all_headlines = []
for filename in os.listdir(curr_dir):
if 'Articles' in filename:
article_df = pd.read_csv(curr_dir + filename)
all_headlines.extend(list(article_df.headline.values))
break
all_headlines[:10]
```
## Clean the Data
We need to clean the text of the data because it appears to be in unicode which is why we get apostrophe's appearing like "\xe2\x80\x99". We will define a function where we can pass all of our text through and which returns the text without any punctuation and capitol letters.
To Do:
- Write a function which checks for punctuation, removes it and changes all letters to lower case
- Pass your data through the function
```
def clean_text(txt):
txt = "".join(v for v in txt if v not in string.punctuation).lower()
txt = txt.decode("ascii", "ignore")
return txt.encode("utf8")
corpus = [clean_text(x) for x in all_headlines]
corpus[:10]
```
## Tokenise
With the Twitter Classification we tokenised our words, we will do the same here and create a bag of words. A bag of words is something which counts the amount of occurences of given word and labels it with a unique identifier.
To Do:
- Define a function to get a sequence of tokens
- Define a function to generate padded sequences
```
tokenizer = Tokenizer()
def get_sequence_of_tokens(corpus):
## tokenisation
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index)+1
## convert data to sequence of tokens
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
return input_sequences, total_words
input_sequences, total_words = get_sequence_of_tokens(corpus)
input_sequences[:10]
def generate_padded_sequences(input_sequences):
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
predictors, label = input_sequences[:,:-1], input_sequences[:,-1]
label = ku.to_categorical(label, num_classes=total_words)
return predictors, label, max_sequence_len
predictors, label, max_sequence_len = generate_padded_sequences(input_sequences)
```
## Create the Model and Train
We're going to create a model using a Long Short Term Memory (LSTM) layer. Traditional neural networks usually throw away what they've learned previously and start over again. Recurrent Nueral Networks (RNN) are different, what they learn persists through each layer. A typical RNN can struggle to identify and learn the long term dependecies of the data. This is where a LSTM comes in as it is capable of learning long term dependencies.
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
To Do:
- Create a model with the following layers:
Embedding
LSTM
Dense
- Compile the model
- Train the model
```
def create_model(max_sequence_len, total_words):
input_len = max_sequence_len - 1
model = Sequential()
# Add input embedding layer
model.add(Embedding(total_words, 10, input_length=input_len))
# Add hidden layer 1 - LSTM layer
model.add(LSTM(100))
# Add output layer
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
return model
model = create_model(max_sequence_len, total_words)
model.summary()
model.fit(predictors, label, epochs=100, verbose=2)
```
## Generate your Headlines
To generate the headlines we are going to create a function which takes in the beggining of our headline (the topic), how long you want the headline to be, the model we created and how long we want our sequences to be.
To Do:
- Create a generate_text function
- Generate different headlines
```
def generate_text(seed_text, next_words, model, max_sequence_len):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " "+output_word
return seed_text.title()
print (generate_text("united states", 5, model, max_sequence_len))
print (generate_text("preident trump", 4, model, max_sequence_len))
print (generate_text("donald trump", 4, model, max_sequence_len))
print (generate_text("india and china", 4, model, max_sequence_len))
print (generate_text("new york", 4, model, max_sequence_len))
print (generate_text("science and technology", 5, model, max_sequence_len))
print (generate_text("fake news", 5, model, max_sequence_len))
```
| github_jupyter |
<a href="https://colab.research.google.com/github/gabrielvieiraf/ProjetosPython/blob/master/GoogleColab/MachineLearning/ML_N_Supervisionada.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# **Indrodução Machine Learning Não Supervisionada 01**
## Tratando Dados
```
import pandas as pd
# Importando dados
dados = pd.read_html('https://github.com/alura-cursos/machine-learning-algoritmos-nao-supervisionados/blob/master/movies.csv')
filmes = dados[0]
# Deletando coluna
del filmes['Unnamed: 0']
# Visualizando dados
filmes.head()
# Traduzindo Colunas
colunas = {
'movieId':'Id',
'title':'titulo',
'genres':'generos'
}
# Traduzindo Gêneros
generos_colunas = {
'Adventure':'Aventura',
'Action':'Ação',
'Film-Noir':'Noir',
'(no genres listed)':'sem gênero',
'Mystery':'Mistério',
'War':'Guerra',
'Western':'Ocidental',
'Animation':'Animação',
'Horror':'Terror',
'Documentary':'Documentário',
'Comedy' : 'Comédia',
'Fantasy' : 'Fantasia',
'Thriller' : 'Suspense',
'Children' : 'Infantil',
}
# Renomeando Colunas
filmes.rename(columns = colunas, inplace = True )
# Separando Gêneros por colunas
generos = filmes['generos'].str.get_dummies()
# Renomeando Gêneros
generos.rename(columns = generos_colunas, inplace = True )
# Visualizando Dados
generos.head()
# Deletando Coluna
del filmes['generos']
# Concatenando Dataframes
dados_filmes = pd.concat([filmes,generos], axis = 1)
# Visualizando dados
dados_filmes.head()
```
```
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# Reescalando gêneros
generos_escalados = scaler.fit_transform(generos)
# Visualizando Gêneros Escalados
generos_escalados
```
## Agrupando Filmes por Gêneros
### Verificando Número de Grupos
```
def kmeans(numero_clusters,generos):
modelo = KMeans(n_clusters = numero_clusters)
modelo.fit(generos)
return (numero_clusters,modelo.inertia_)
resultado = [kmeans(i, generos_escalados) for i in range(1,21)]
resultado = pd.DataFrame(resultado,
columns=['n_clusters','inertia'])
resultado.inertia.plot(xticks=resultado.n_clusters)
```
### Agrupando
```
from sklearn.cluster import KMeans
modelo = KMeans(n_clusters=14)
# Ensinando Robô
modelo.fit(generos_escalados)
print('Grupos {}'.format(modelo.labels_))
# Criando Dataframe para grupos
grupos = pd.DataFrame(modelo.cluster_centers_,
columns = generos.columns)
```
## Visualizando Grupos
```
grupos.transpose().plot.bar(subplots=True,
sharex = False,
figsize=(20,176))
```
### Buscando Filmes nos grupos
```
grupo = 2
filtro = modelo.labels_ == grupo
dados_filmes[filtro].head(50)
```
## Visualizando TSNE no Scatter Plot
```
from sklearn.manifold import TSNE
import seaborn as sns
tsne = TSNE()
visualizacao = tsne.fit_transform(generos_escalados)
sns.set( rc= {'figure.figsize':(15,15)})
sns.scatterplot(x= visualizacao[:,0],
y= visualizacao[:,1],
hue = modelo.labels_,
palette = sns.color_palette('Set1', 14))
```
# Agrupamento Hierárquico
```
from sklearn.cluster import AgglomerativeClustering
modelo = AgglomerativeClustering(n_clusters = 14)
grupos = modelo.fit_predict(generos_escalados)
grupos
visualizacao = tsne.fit_transform(generos_escalados)
visualizacao
sns.scatterplot(x=visualizacao[:,0],
y=visualizacao[:,1],
hue=grupos,
palette = sns.color_palette('Set1', 14))
```
## Dendrograma
```
from scipy.cluster.hierarchy import dendrogram, linkage
```
### Agrupando Novamente
```
from sklearn.cluster import KMeans
modelo = KMeans(n_clusters=14)
# Ensinando Robô
modelo.fit(generos_escalados)
print('Grupos {}'.format(modelo.labels_))
# Criando Dataframe para grupos
grupos = pd.DataFrame(modelo.cluster_centers_,
columns = generos.columns)
```
### Plotando Dendrograma
```
# Matriz de instância
matriz = linkage(grupos)
dendrograma = dendrogram(matriz)
```
| github_jupyter |
# Conditional Variational Auto-encoder
## Introduction
This tutorial implements [Learning Structured Output Representation using Deep Conditional Generative Models](http://papers.nips.cc/paper/5775-learning-structured-output-representation-using-deep-conditional-generati) paper, which introduced Conditional Variational Auto-encoders in 2015, using Pyro PPL.
Supervised deep learning has been successfully applied for many recognition problems in machine learning and computer vision. Although it can approximate a complex many-to-one function very well when large number of training data is provided, the lack of probabilistic inference of the current supervised deep learning methods makes it difficult to model a complex structured output representations. In this work, Kihyuk Sohn, Honglak Lee and Xinchen Yan develop a scalable deep conditional generative model for structured output variables using Gaussian latent variables. The model is trained efficiently in the framework of stochastic gradient variational Bayes, and allows a fast prediction using stochastic feed-forward inference. They called the model Conditional Variational Auto-encoder (CVAE).
The CVAE is a conditional directed graphical model whose input observations modulate the prior on Gaussian latent variables that generate the outputs. It is trained to maximize the conditional marginal log-likelihood. The authors formulate the variational learning objective of the CVAE in the framework of stochastic gradient variational Bayes (SGVB). In experiments, they demonstrate the effectiveness of the CVAE in comparison to the deterministic neural network counterparts in generating diverse but realistic output predictions using stochastic inference. Here, we will implement their proof of concept: an artificial experimental setting for structured output prediction using MNIST database.
## The problem
Let's divide each digit image into four quadrants, and take one, two, or three quadrant(s) as an input and the remaining quadrants as an output to be predicted. The image below shows the case where one quadrant is the input:
<img src="https://i.ibb.co/x17xFwy/image1.png" alt="image1" width="300">
Our objective is to **learn a model that can perform probabilistic inference and make diverse predictions from a single input**. This is because we are not simply modeling a many-to-one function as in classification tasks, but we may need to model a mapping from single input to many possible outputs. One of the limitations of deterministic neural networks is that they generate only a single prediction. In the example above, the input shows a small part of a digit that might be a three or a five.
## Preparing the data
We use the MNIST dataset; the first step is to prepare it. Depending on how many quadrants we will use as inputs, we will build the datasets and dataloaders, removing the unused pixels with -1:
```Python
class CVAEMNIST(Dataset):
def __init__(self, root, train=True, transform=None, download=False):
self.original = MNIST(root, train=train, download=download)
self.transform = transform
def __len__(self):
return len(self.original)
def __getitem__(self, item):
image, digit = self.original[item]
sample = {'original': image, 'digit': digit}
if self.transform:
sample = self.transform(sample)
return sample
class ToTensor:
def __call__(self, sample):
sample['original'] = functional.to_tensor(sample['original'])
sample['digit'] = torch.as_tensor(np.asarray(sample['digit']),
dtype=torch.int64)
return sample
class MaskImages:
"""This torchvision image transformation prepares the MNIST digits to be
used in the tutorial. Depending on the number of quadrants to be used as
inputs (1, 2, or 3), the transformation masks the remaining (3, 2, 1)
quadrant(s) setting their pixels with -1. Additionally, the transformation
adds the target output in the sample dict as the complementary of the input
"""
def __init__(self, num_quadrant_inputs, mask_with=-1):
if num_quadrant_inputs <= 0 or num_quadrant_inputs >= 4:
raise ValueError('Number of quadrants as inputs must be 1, 2 or 3')
self.num = num_quadrant_inputs
self.mask_with = mask_with
def __call__(self, sample):
tensor = sample['original'].squeeze()
out = tensor.detach().clone()
h, w = tensor.shape
# removes the bottom left quadrant from the target output
out[h // 2:, :w // 2] = self.mask_with
# if num of quadrants to be used as input is 2,
# also removes the top left quadrant from the target output
if self.num == 2:
out[:, :w // 2] = self.mask_with
# if num of quadrants to be used as input is 3,
# also removes the top right quadrant from the target output
if self.num == 3:
out[:h // 2, :] = self.mask_with
# now, sets the input as complementary
inp = tensor.clone()
inp[out != -1] = self.mask_with
sample['input'] = inp
sample['output'] = out
return sample
def get_data(num_quadrant_inputs, batch_size):
transforms = Compose([
ToTensor(),
MaskImages(num_quadrant_inputs=num_quadrant_inputs)
])
datasets, dataloaders, dataset_sizes = {}, {}, {}
for mode in ['train', 'val']:
datasets[mode] = CVAEMNIST(
'../data',
download=True,
transform=transforms,
train=mode == 'train'
)
dataloaders[mode] = DataLoader(
datasets[mode],
batch_size=batch_size,
shuffle=mode == 'train',
num_workers=0
)
dataset_sizes[mode] = len(datasets[mode])
return datasets, dataloaders, dataset_sizes
```
## Baseline: Deterministic Neural Network
Before we dive into the CVAE implementation, let's code the baseline model. It is a straightforward implementation:
```Python
class BaselineNet(nn.Module):
def __init__(self, hidden_1, hidden_2):
super().__init__()
self.fc1 = nn.Linear(784, hidden_1)
self.fc2 = nn.Linear(hidden_1, hidden_2)
self.fc3 = nn.Linear(hidden_2, 784)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 784)
hidden = self.relu(self.fc1(x))
hidden = self.relu(self.fc2(hidden))
y = torch.sigmoid(self.fc3(hidden))
return y
```
In the paper, the authors compare the baseline NN with the proposed CVAE by comparing the negative (Conditional) Log Likelihood (CLL), averaged by image in the validation set. Thanks to PyTorch, computing the CLL is equivalent to computing the Binary Cross Entropy Loss using as input a signal passed through a Sigmoid layer. The code below does a small adjustment to leverage this: it only computes the loss in the pixels not masked with -1:
```Python
class MaskedBCELoss(nn.Module):
def __init__(self, masked_with=-1):
super().__init__()
self.masked_with = masked_with
def forward(self, input, target):
target = target.view(input.shape)
loss = F.binary_cross_entropy(input, target, reduction='none')
loss[target == self.masked_with] = 0
return loss.sum()
```
The training is very straightforward. We use 500 neurons in each hidden layer, Adam optimizer with `1e-3` learning rate, and early stopping. Please check the [Github repo](https://github.com/pyro-ppl/pyro/blob/dev/examples/cvae) for the full implementation.
## Deep Conditional Generative Models for Structured Output Prediction
As illustrated in the image below, there are three types of variables in a deep conditional generative model (CGM): input variables $\bf x$, output variables $\bf y$, and latent variables $\bf z$. The conditional generative process of the model is given in (b) as follows: for given observation $\bf x$, $\bf z$ is drawn from the prior distribution $p_{\theta}({\bf z} | {\bf x})$, and the output $\bf y$ is generated from the distribution $p_{\theta}({\bf y} | {\bf x, z})$. Compared to the baseline NN (a), the latent variables $\bf z$ allow for modeling multiple modes in conditional distribution of output variables $\bf y$ given input $\bf x$, making the proposed CGM suitable for modeling one-to-many mapping.
<img src="https://i.ibb.co/0mVvkSF/image2.png" alt="image1" width="800">
Deep CGMs are trained to maximize the conditional marginal log-likelihood. Often the objective function is intractable, and we apply the SGVB framework to train the model. The empirical lower bound is written as:
$$ \tilde{\mathcal{L}}_{\text{CVAE}}(x, y; \theta, \phi) = -KL(q_{\phi}(z | x, y) || p_{\theta}(z | x)) + \frac{1}{L}\sum_{l=1}^{L}\log p_{\theta}(y | x, z^{(l)}) $$
where $\bf z^{(l)}$ is a Gaussian latent variable, and $L$ is the number of samples (or particles in Pyro nomenclature).
We call this model conditional variational auto-encoder (CVAE). The CVAE is composed of multiple MLPs, such as **recognition network** $q_{\phi}({\bf z} | \bf{x, y})$, **(conditional) prior network** $p_{\theta}(\bf{z} | \bf{x})$, and **generation network** $p_{\theta}(\bf{y} | \bf{x, z})$. In designing the network architecture, we build the network components of the CVAE **on top of the baseline NN**. Specifically, as shown in (d) above, not only the direct input $\bf x$, but also the initial guess $\hat{y}$ made by the NN are fed into the prior network.
Pyro makes it really easy to translate this architecture into code. The recognition network and the (conditional) prior network are encoders from the traditional VAE setting, while the generation network is the decoder:
```Python
class Encoder(nn.Module):
def __init__(self, z_dim, hidden_1, hidden_2):
super().__init__()
self.fc1 = nn.Linear(784, hidden_1)
self.fc2 = nn.Linear(hidden_1, hidden_2)
self.fc31 = nn.Linear(hidden_2, z_dim)
self.fc32 = nn.Linear(hidden_2, z_dim)
self.relu = nn.ReLU()
def forward(self, x, y):
# put x and y together in the same image for simplification
xc = x.clone()
xc[x == -1] = y[x == -1]
xc = xc.view(-1, 784)
# then compute the hidden units
hidden = self.relu(self.fc1(xc))
hidden = self.relu(self.fc2(hidden))
# then return a mean vector and a (positive) square root covariance
# each of size batch_size x z_dim
z_loc = self.fc31(hidden)
z_scale = torch.exp(self.fc32(hidden))
return z_loc, z_scale
class Decoder(nn.Module):
def __init__(self, z_dim, hidden_1, hidden_2):
super().__init__()
self.fc1 = nn.Linear(z_dim, hidden_1)
self.fc2 = nn.Linear(hidden_1, hidden_2)
self.fc3 = nn.Linear(hidden_2, 784)
self.relu = nn.ReLU()
def forward(self, z):
y = self.relu(self.fc1(z))
y = self.relu(self.fc2(y))
y = torch.sigmoid(self.fc3(y))
return y
class CVAE(nn.Module):
def __init__(self, z_dim, hidden_1, hidden_2, pre_trained_baseline_net):
super().__init__()
# The CVAE is composed of multiple MLPs, such as recognition network
# qφ(z|x, y), (conditional) prior network pθ(z|x), and generation
# network pθ(y|x, z). Also, CVAE is built on top of the NN: not only
# the direct input x, but also the initial guess y_hat made by the NN
# are fed into the prior network.
self.baseline_net = pre_trained_baseline_net
self.prior_net = Encoder(z_dim, hidden_1, hidden_2)
self.generation_net = Decoder(z_dim, hidden_1, hidden_2)
self.recognition_net = Encoder(z_dim, hidden_1, hidden_2)
def model(self, xs, ys=None):
# register this pytorch module and all of its sub-modules with pyro
pyro.module("generation_net", self)
batch_size = xs.shape[0]
with pyro.plate("data"):
# Prior network uses the baseline predictions as initial guess.
# This is the generative process with recurrent connection
with torch.no_grad():
# this ensures the training process does not change the
# baseline network
y_hat = self.baseline_net(xs).view(xs.shape)
# sample the handwriting style from the prior distribution, which is
# modulated by the input xs.
prior_loc, prior_scale = self.prior_net(xs, y_hat)
zs = pyro.sample('z', dist.Normal(prior_loc, prior_scale).to_event(1))
# the output y is generated from the distribution pθ(y|x, z)
loc = self.generation_net(zs)
if ys is not None:
# In training, we will only sample in the masked image
mask_loc = loc[(xs == -1).view(-1, 784)].view(batch_size, -1)
mask_ys = ys[xs == -1].view(batch_size, -1)
pyro.sample('y', dist.Bernoulli(mask_loc).to_event(1), obs=mask_ys)
else:
# In testing, no need to sample: the output is already a
# probability in [0, 1] range, which better represent pixel
# values considering grayscale. If we sample, we will force
# each pixel to be either 0 or 1, killing the grayscale
pyro.deterministic('y', loc.detach())
# return the loc so we can visualize it later
return loc
def guide(self, xs, ys=None):
with pyro.plate("data"):
if ys is None:
# at inference time, ys is not provided. In that case,
# the model uses the prior network
y_hat = self.baseline_net(xs).view(xs.shape)
loc, scale = self.prior_net(xs, y_hat)
else:
# at training time, uses the variational distribution
# q(z|x,y) = normal(loc(x,y),scale(x,y))
loc, scale = self.recognition_net(xs, ys)
pyro.sample("z", dist.Normal(loc, scale).to_event(1))
```
## Training
The training code can be found in the [Github repo](https://github.com/pyro-ppl/pyro/tree/dev/examples/cvae).
Click play in the video below to watch how the CVAE learns throughout approximately 40 epochs.
<p><video muted controls loop width="100%"><source src="https://ucals-github.s3-sa-east-1.amazonaws.com/cvae_animation.mp4" type="video/mp4"><source src="https://ucals-github.s3-sa-east-1.amazonaws.com/cvae_animation.webm" type="video/webm"></video></p>
As we can see, the model learned posterior distribution continuously improves as the training progresses:
not only the loss goes down, but also we can see clearly how the predictions get better and better.
Additionally, here we can already observe the key advantage of CVAEs: the model learns to generate multiple predictions from a single input.
In the first digit, the input is clearly a piece of a 7. The model learns it and keeps predicting clearer 7's, but with different writing styles.
In the second and third digits, the inputs are pieces of what could be either a 3 or a 5 (truth is 3), and what could be either a 4 or a 9 (truth is 4).
During the first epochs, the CVAE predictions are blurred, and they get clearer as time passes, as expected.
However, different from the first digit, it's hard to determine whether the truth is 3 and 4 for the second and third digits, respectively, by observing only one quarter of the digits as input.
By the end of the training, the CVAE generates very clear and realistic predictions, but it doesn't force either a 3 or a 5 for the second digit, and a 4 or a 9 for the third digit.
Sometimes it predicts one option, and sometimes it predicts another.
## Evaluating the results
For qualitative analysis, we visualize the generated output samples in the next figure. As we can see, the baseline NNs can only make a single deterministic prediction, and as a result the output looks blurry and doesn’t look realistic in many cases. In contrast, the samples generated by the CVAE models are more realistic and diverse in shape; sometimes they can even change their identity (digit labels), such as from 3 to 5 or from 4 to 9, and vice versa.
<img src="https://i.ibb.co/Jvz9v71/cvae-q1.png" alt="image1" width="400">
We also provide a quantitative evidence by estimating the marginal conditional log-likelihoods (CLLs) in next table (lower is better).
| | 1 quadrant | 2 quadrants | 3 quadrants |
|--------------------|------------|-------------|-------------|
| NN (baseline) | 100.4 | 61.9 | 25.4 |
| CVAE (Monte Carlo) | 71.8 | 51.0 | 24.2 |
| Performance gap | 28.6 | 10.9 | 1.2 |
We achieved similar results to the ones achieved by the authors in the paper. We trained only for 50 epochs with early stopping patience of 3 epochs; to improve the results, we could leave the algorithm training for longer. Nevertheless, we can observe the same effect shown in the paper: **the estimated CLLs of the CVAE significantly outperforms the baseline NN**.
See the full code on [Github](https://github.com/pyro-ppl/pyro/blob/dev/examples/cvae).
## References
[1] `Learning Structured Output Representation using Deep Conditional Generative Models`,<br/>
Kihyuk Sohn, Xinchen Yan, Honglak Lee
| github_jupyter |
```
import sys
sys.path.append('..')
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sympy import simplify_logic
from lens.utils.relu_nn import get_reduced_model, prune_features
from lens import logic
from lens.utils.base import collect_parameters
torch.manual_seed(0)
np.random.seed(0)
gene_expression_matrix = pd.read_csv('w_1/data_0.csv', index_col=None, header=None)
labels = pd.read_csv('w_1/tempLabels_W-1.csv', index_col=None, header=None)
genes = pd.read_csv('w_1/features_0.csv', index_col=None, header=None)
gene_expression_matrix
labels
encoder = LabelEncoder()
labels_encoded = encoder.fit_transform(labels.values)
labels_encoded_noncontrols = labels_encoded[labels_encoded!=0] - 1
data_controls = gene_expression_matrix[labels_encoded==0]
data = gene_expression_matrix[labels_encoded!=0]
gene_signature = data_controls.mean(axis=0)
data_scaled = data - gene_signature
scaler = MinMaxScaler((0, 1))
scaler.fit(data_scaled)
data_normalized = scaler.transform(data_scaled)
x_train = torch.FloatTensor(data_normalized)
y_train = torch.FloatTensor(labels_encoded_noncontrols).unsqueeze(1)
print(x_train.shape)
print(y_train.shape)
torch.manual_seed(0)
np.random.seed(0)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
x_train = x_train.to(device)
y_train = y_train.to(device)
layers = [
torch.nn.Linear(x_train.size(1), 10, bias=False),
torch.nn.LeakyReLU(),
torch.nn.Linear(10, 5, bias=False),
torch.nn.LeakyReLU(),
torch.nn.Linear(5, 1, bias=False),
torch.nn.Sigmoid(),
]
model = torch.nn.Sequential(*layers).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.00007)
model.train()
need_pruning = True
for epoch in range(1, 30001):
# forward pass
optimizer.zero_grad()
y_pred = model(x_train)
# Compute Loss
loss = torch.nn.functional.binary_cross_entropy(y_pred, y_train)
for module in model.children():
if isinstance(module, torch.nn.Linear):
loss += 0.008 * torch.norm(module.weight, 1)
# backward pass
loss.backward()
optimizer.step()
# compute accuracy
if epoch % 1000 == 0:
y_pred_d = (y_pred > 0.5)
accuracy = (y_pred_d.eq(y_train).sum(dim=1) == y_train.size(1)).sum().item() / y_train.size(0)
print(f'Epoch {epoch}: train accuracy: {accuracy:.4f}')
if epoch > 8000 and need_pruning and epoch % 3000 == 0:
prune_features(model, 1, device)
need_pruning = True
```
## Local explanations
```
np.set_printoptions(precision=2, suppress=True)
outputs = []
for i, (xin, yin) in enumerate(zip(x_train, y_train)):
model_reduced = get_reduced_model(model, xin.to(device), bias=False).to(device)
for module in model_reduced.children():
if isinstance(module, torch.nn.Linear):
wa = module.weight.cpu().detach().numpy()
break
output = model_reduced(xin)
pred_class = torch.argmax(output)
true_class = torch.argmax(y_train[i])
# generate local explanation only if the prediction is correct
if pred_class.eq(true_class):
local_explanation = logic.relu_nn.explain_local(model.to(device), x_train, y_train, xin, yin, device=device)
print(f'Input {(i+1)}')
print(f'\tx={xin.cpu().detach().numpy()}')
print(f'\ty={y_train[i].cpu().detach().numpy()}')
print(f'\ty={output.cpu().detach().numpy()}')
#print(f'\tw={wa}')
print(f'\tExplanation: {local_explanation}')
print()
outputs.append(output)
if i > 1:
break
```
# Combine local explanations
```
global_explanation, predictions, counter = logic.combine_local_explanations(model, x=x_train, y=y_train,
target_class=0, topk_explanations=10,
device=device)
ynp = y_train.cpu().detach().numpy()[:, 0]
accuracy = np.sum(predictions == ynp) / len(ynp)
print(f'Accuracy of when using the formula "{global_explanation}": {accuracy:.4f}')
global_explanation = logic.relu_nn.explain_global(model, n_classes=1, target_class=0, device=device)
explanation = logic.relu_nn.explain_global(model, n_classes=1, target_class=0, device=device)
if explanation not in ['False', 'True', 'The formula is too complex!']:
accuracy, _ = logic.relu_nn.test_explanation(explanation, target_class=0, x=x_train.cpu(), y=y_train.cpu())
print(f'Class {0} - Global explanation: "{global_explanation}" - Accuracy: {accuracy:.4f}')
w, b = collect_parameters(model, device)
feature_weights = w[0]
feature_used_bool = np.sum(np.abs(feature_weights), axis=0) > 0
feature_used = np.nonzero(feature_used_bool)[0]
genes.iloc[feature_used]
```
ILMN_3286286, ILMN_1775520, ILMN_1656849, ILMN_1781198, ILMN_1665457
```
sum(y_train == 0).item() / len(y_train)
```
| github_jupyter |
# Text Cleaning
```
url = 'http://www.gutenberg.org/ebooks/1661.txt.utf-8'
file_name = 'sherlock.txt'
import urllib.request
# Download the file from `url` and save it locally under `file_name`:
with urllib.request.urlopen(url) as response:
with open(file_name, 'wb') as out_file:
data = response.read() # a `bytes` object
out_file.write(data)
!ls {*.txt}
!head -2 sherlock.txt
!sed -i 1,33d sherlock.txt
!head -5 sherlock.txt
```
## Load Data
```
#let's the load data to RAM
text = open(file_name, 'r', encoding='utf-8').read() # note that I add an encoding='utf-8' parameter to preserve information
print(text[:5])
print(f'The file is loaded as datatype: {type(text)} and has {len(text)} characters in it')
```
### Exploring Loaded Data
```
# how many unique characters do we see?
# For reference, ASCII has 127 characters in it - so we expect this to have at most 127 characters
unique_chars = list(set(text))
unique_chars.sort()
print(unique_chars)
print(f'There are {len(unique_chars)} unique characters, including both ASCII and Unicode character')
```
## Tokenization
### Split by Whitespace
```
words = text.split()
print(len(words))
print(words[90:200]) #start with the first chapeter, ignoring the index for now
# Let's look at another example:
'red-headed woman on the street'.split()
```
### Split by Word Extraction
**Introducing Regex**
```
import re
re.split('\W+', 'Words, words, words.')
words_alphanumeric = re.split('\W+', text)
len(words_alphanumeric), len(words)
print(words_alphanumeric[90:200])
words_break = re.split('\W+', "Isn't he coming home for dinner with the red-headed girl?")
print(words_break)
```
### spaCy for Tokenization
```
%%time
import spacy
nlp = spacy.load('en')
doc = nlp(text)
print(list(doc)[150:200])
```
Conveniently, spaCy tokenizes all *punctuations and words* and returned those as individual tokens as well. Let's try the example which we didn't like earlier:
```
words = nlp("Isn't he coming home for dinner with the red-headed girl?")
print([token for token in words])
sentences = list(doc.sents)
print(sentences[13:18])
```
#### STOP WORD REMOVAL & CASE CHANGE
spaCy has already marked each token as a stop word or not and stored it in `is_stop` attribute of each token. This makes it very handy for text cleaning. Let's take a quick look:
```
sentence_example = "the AI/AGI uprising cannot happen without the progress of NLP"
[(token, token.is_stop, token.is_punct) for token in nlp(sentence_example)]
for token in doc[:5]:
print(token, token.is_stop, token.is_punct)
text_lower = text.lower() # native python function
doc_lower = nlp(text_lower)
for token in doc_lower[:5]:
print(token, token.is_stop)
from spacy.lang.en.stop_words import STOP_WORDS
f'spaCy has a dictionary of {len(list(STOP_WORDS))} stop words'
domain_stop_words = ["NLP", "Processing", "AGI"]
for word in domain_stop_words:
STOP_WORDS.add(word)
[(token, token.is_stop, token.is_punct) for token in nlp(sentence_example)]
[str(token) for token in nlp(sentence_example) if not token.is_stop and not token.is_punct]
[str(token) for token in nlp(sentence_example) if not token.is_stop]
```
## Stemming and Lemmatization
### spaCy for Lemmatization
**spaCy only supports lemmatization**
An underscore at end, such as `lemma_` tells spaCy we are looking for something which is human readable. spaCy stores the internal hash or identifier which spaCy stores in `token.lemma`.
```
lemma_sentence_example = "Their Apples & Banana fruit salads are amazing. Would you like meeting me at the cafe?"
[(token, token.lemma_, token.lemma, token.pos_ ) for token in nlp(lemma_sentence_example)]
```
| github_jupyter |
# Durable Consumption Model
This notebooks shows you how to use the tools of the **consav** package to solve a **durable consumption model** with either
1. **vfi**: standard value function iteration (written in C++)
2. **nvfi**: nested value function iteration (writen in Python, or **nvfi_cpp** is written i C++)
3. **negm**: nested endogenous grid point method (writen in Python, or **negm_cpp** is written i C++)
The implemented solution methods are explained in detail in [A Guide to Solve Non-Convex Consumption-Saving Models](https://drive.google.com/open?id=1V15dwMIrl_TJGoqu7qauhVWcDm0yqb-D).
## Model equations
The **states** are:
1. the persistent component of income, $p_t$
2. stock of the durable good, $n_t$
3. cash-on-hand, $m_t$
The **choices** are:
1. durable consumption, $d_t$
2. non-durable consumption, $c_t$
**Utility** is CRRA over a Cobb-Douglas aggregate:
$$ u(c_{t},d_{t})=\frac{(c_{t}^{\alpha}(d_{t}+\underline{d})^{1-\alpha})^{1-\rho}}{1-\rho} $$
**Income** follows a persistent-transitory process:
$$
\begin{aligned}
p_{t+1}&=\psi_{t+1}p_{t}^{\lambda},\,\,\,\log\psi_{t+1}\sim\mathcal{N}(-0.5\sigma_{\psi}^{2},\sigma_{\psi}^{2}) \\ y_{t+1}&=\xi_{t+1}p_{t+1},\,\,\,\log\xi_{t+1}\sim\mathcal{N}(-0.5\sigma_{\xi}^{2},\sigma_{\xi}^{2})
\end{aligned}
$$
The household **cannot borrow** and the **interest rate** on savings is $r$. Adjusting the stock of durables is subject to a **proportional adjustment cost** $\tau$ and **durables depreciates** with a rate of $\delta$.
$$ n_{t+1}=(1-\delta)d_{t} $$
The **bellman equation** is
$$
\begin{aligned}
v_{t}(p_{t},n_{t},m_{t})&=\max\{v_{t}^{keep}(p_{t},n_{t},m_{t}),v_{t}^{adj.}(p_{t},x_{t})\}\\&\text{s.t.}&\\x_{t}&=&m_{t}+(1-\tau)n_{t}
\end{aligned}
$$
where
$$
\begin{aligned}
v_{t}^{keep}(p_{t},n_{t},m_{t})&=\max_{c_{t}}u(c_{t},n_{t})+\beta\mathbb{E}_{t}[v_{t+1}(p_{t+1},n_{t+1},m_{t+1})]\\&\text{s.t.}&\\
a_{t}&= m_{t}-c_{t}\\
m_{t+1}&= (1+r)a_{t}+y_{t+1}\\
n_{t+1}&= (1-\delta)n_{t}\\
a_{t}&\geq 0
\end{aligned}
$$
and
$$
\begin{aligned}
v_{t}^{adj.}(p_{t},x_{t})&= \max_{c_{t},d_{t}}u(c_{t},d_{t})+\beta\mathbb{E}_{t}[v_{t+1}(p_{t+1},n_{t+1},m_{t+1})]\\&\text{s.t.}&\\
a_{t}&= x_{t}-c_{t}-d_{t}\\
m_{t+1}&= (1+r)a_{t}+y_{t+1}\\
n_{t+1}&= (1-\delta)n_{t}\\
a_{t}&\geq 0
\end{aligned}
$$
## Overview
The model solved in this notebook is written in **DurableConsumptionModelModel.py**.
It provides a class called **DurableConsumptionModelClass** inheriting its basic interface from the **ModelClass**.
A short **overview** of the interface is:
1. Each instance of the BufferStockModel class must have a **name** and a **solmethod**, and must contain **two central methods**:
1. **setup()**: set baseline parameters in `.par` + set list of non-float scalars in `.non_float_list` (for safe type-inference)
2. **allocate()**: allocate memory for `.par`, `.sol` and `.sim`
2. **Type-inference:** When initializing the model with `BufferStockModelClass()` the `setup()` and `allocate()` methods are called, and the types of all variables in `.par`, `.sol` and `.sim` are inferred. Results can be seen in `.parlist`, `.sollist` and `.simlist` or by `print(model)`.
3. The **solve()** method solves the model
4. The **simulate()** method simulates the model
5. The **save()** method saves the model naming it **data/name_solmethod**
6. The **copy()** makes a deep copy of the model
In addition to **DurableConsumptionModel.py**, this folder contains the following files:
1. **last_period.py**: calculate consumption and value function in last period
2. **utility.py**: utility function and marginal utility function
3. **trans.py**: state transition functions
4. **post_decision.py**: calcualte $w$ and $q$
5. **nvfi.py**: solve with nested value function iteration
6. **negm.py**: solve with the nested endogenous grid method
7. **simulate.py**: simulate for all solution methods
8. **figs.py**: plot figures
9. **tabs.py**: prints tables in .tex files
The functions in these modules are loaded in **DurableConsumptionModel.py**.
The folder **cppfuncs** contains C++ functions used for solving with **vfi**, **nvfi_cpp** or **negm_cpp**.
## Numba
Before (important!) you load **Numba** you can disable it or choose the numbe of threads as follows:
```
from consav import runtools
runtools.write_numba_config(disable=0,threads=8)
```
# Setup
```
import time
import numpy as np
%matplotlib inline
# reload module each time cell is run
%load_ext autoreload
%autoreload 2
# load the BufferStockModel module
from DurableConsumptionModel import DurableConsumptionModelClass
```
Choose number of periods to solve:
```
T = 5
```
# NVFI - nested value function iteration
Define the **post-decision value function** as
$$ w_{t}(p_{t},n_{t},a_{t}) = \beta \mathbb{E}_{t}[v_{t+1}(m_{t+1},n_{t+1},p_{t+1})] $$
The **keeper problem** can then be written:
$$
\begin{aligned}
v_{t}^{keep}(p_{t},n_{t},m_{t})&=\max_{c_{t}}u(c_{t},n_{t})+ w_{t}(p_{t},n_{t},a_{t})]\\&\text{s.t.}&\\a_{t}&=&m_{t}-c_{t}\geq0
\end{aligned}
$$
The **adjuster problem** can further be written:
$$
\begin{aligned}
v_{t}^{adj.}(x_{t})&=\max_{d_{t}}v_{t}^{keep}(p_{t},d_{t},n_{t})\\&\text{s.t.}&\\m_{t}&=&x_{t}-d_{t}
\end{aligned}
$$
**NVFI** solves this reformulated problem.
```
model_nvfi = DurableConsumptionModelClass(name='example',solmethod='nvfi',T=T,do_print=True)
print(model_nvfi)
model_nvfi.precompile_numba() # solve with very coarse grids
model_nvfi.solve()
model_nvfi.simulate()
model_nvfi.save()
```
**Plot** interactive decision functions:
```
model_nvfi.decision_functions()
```
**Plot** life-cycle profiles:
```
model_nvfi.lifecycle()
```
# NEGM - nested endogenous grid method
Define the **post-decision marginal value of cash:**
$$
\begin{aligned}
q_{t}(p_{t},d_{t},a_{t})&=\beta R\mathbb{E}_{t}[u_{c}(c_{t+1},d_{t+1})]\\
&=&\beta R\mathbb{E}_{t}[\alpha c_{t+1}^{\alpha(1-\rho)-1}d_{t+1}^{(1-\alpha)(1-\rho)}]
\end{aligned}
$$
Note that all optimal interior consumption choices must satisfy the **Euler-equation**
$$
\begin{aligned}
u_{c}(c_{t},d_{t})=\alpha c_{t}^{\alpha(1-\rho)-1}d_{t}^{(1-\alpha)(1-\rho)}&=q(p_{t},d_{t},a_{t})
\end{aligned}
$$
This implies that we have an analytical mapping from the post-decision space $(p_t,d_t,a_t)$ to consumption and cash-on-hand $(c_t,m_t)$:
$$
\begin{aligned}
c_{t} &=\frac{1}{\alpha}\left(\frac{q(a_{t},d_{t},p_{t})}{d_{t}^{(1-\alpha)(1-\rho)}}\right)^{\alpha(1-\rho)-1}
\\
m_{t} &= a_{t}+c_{t}
\end{aligned}
$$
**NEGM** uses this mapping (and an upperenvelope algorithm) to solve the keeper problem much faster.
```
model_negm = DurableConsumptionModelClass(name='example',solmethod='negm',T=T,do_print=True)
model_negm.precompile_numba() # solve with very coarse grids
model_negm.solve()
model_negm.simulate()
model_negm.save()
```
**Plot** interactive decision functions:
```
model_negm.decision_functions()
```
**Plot** life-cycle profiles:
```
model_negm.lifecycle()
```
# Compare life-cycles from NVFI and NEGM
```
from figs import lifecycle_compare
lifecycle_compare(model_negm,'negm',model_nvfi,'nvfi')
```
# Compare life-cycle profiles with VFI
```
model_vfi = DurableConsumptionModelClass(name='example',solmethod='vfi',T=T,do_print=True)
model_vfi.precompile_numba() # solve with very coarse grids
model_vfi.solve()
model_vfi.simulate()
model_vfi.save()
lifecycle_compare(model_negm,'negm',model_vfi,'vfi')
```
| github_jupyter |
<i>Copyright (c) Microsoft Corporation. All rights reserved.</i>
<i>Licensed under the MIT License.</i>
# Factorization Machine Deep Dive
Factorization machine (FM) is one of the representative algorithms that are used for building content-based recommenders model. The algorithm is powerful in terms of capturing the effects of not just the input features but also their interactions. The algorithm provides better generalization capability and expressiveness compared to other classic algorithms such as SVMs. The most recent research extends the basic FM algorithms by using deep learning techniques, which achieve remarkable improvement in a few practical use cases.
This notebook presents a deep dive into the Factorization Machine algorithm, and demonstrates some best practices of using the contemporary FM implementations like [`xlearn`](https://github.com/aksnzhy/xlearn) for dealing with tasks like click-through rate prediction.
## 1 Factorization Machine
### 1.1 Factorization Machine
FM is an algorithm that uses factorization in prediction tasks with data set of high sparsity. The algorithm was original proposed in [\[1\]](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf). Traditionally, the algorithms such as SVM do not perform well in dealing with highly sparse data that is usually seen in many contemporary problems, e.g., click-through rate prediction, recommendation, etc. FM handles the problem by modeling not just first-order linear components for predicting the label, but also the cross-product of the feature variables in order to capture more generalized correlation between variables and label.
In certain occasions, the data that appears in recommendation problems, such as user, item, and feature vectors, can be encoded into a one-hot representation. Under this arrangement, classical algorithms like linear regression and SVM may suffer from the following problems:
1. The feature vectors are highly sparse, and thus it makes it hard to optimize the parameters to fit the model efficienly
2. Cross-product of features will be sparse as well, and this in turn, reduces the expressiveness of a model if it is designed to capture the high-order interactions between features
<img src="https://recodatasets.blob.core.windows.net/images/fm_data.png?sanitize=true">
The FM algorithm is designed to tackle the above two problems by factorizing latent vectors that model the low- and high-order components. The general idea of a FM model is expressed in the following equation:
$$\hat{y}(\textbf{x})=w_{0}+\sum^{n}_{i=1}w_{i}x_{i}+\sum^{n}_{i=1}\sum^{n}_{j=i+1}<\textbf{v}_{i}, \textbf{v}_{j}>x_{i}x_{j}$$
where $\hat{y}$ and $\textbf{x}$ are the target to predict and input feature vectors, respectively. $w_{i}$ is the model parameters for the first-order component. $<\textbf{v}_{i}, \textbf{v}_{j}>$ is the dot product of two latent factors for the second-order interaction of feature variables, and it is defined as
$$<\textbf{v}_{i}, \textbf{v}_{j}>=\sum^{k}_{f=1}v_{i,f}\cdot v_{j,f}$$
Compared to using fixed parameter for the high-order interaction components, using the factorized vectors increase generalization as well as expressiveness of the model. In addition to this, the computation complexity of the equation (above) is $O(kn)$ where $k$ and $n$ are the dimensionalities of the factorization vector and input feature vector, respectively (see [the paper](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf) for detailed discussion). In practice, usually a two-way FM model is used, i.e., only the second-order feature interactions are considered to favor computational efficiency.
### 1.2 Field-Aware Factorization Machine
Field-aware factorization machine (FFM) is an extension to FM. It was originally introduced in [\[2\]](https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf). The advantage of FFM over FM is that, it uses different factorized latent factors for different groups of features. The "group" is called "field" in the context of FFM. Putting features into fields resolves the issue that the latent factors shared by features that intuitively represent different categories of information may not well generalize the correlation.
Different from the formula for the 2-order cross product as can be seen above in the FM equation, in the FFM settings, the equation changes to
$$\theta_{\text{FFM}}(\textbf{w}\textbf{x})=\sum^{n}_{j1=1}\sum^{n}_{j2=j1+1}<\textbf{v}_{j1,f2}, \textbf{v}_{j2,f1}>x_{j1}x_{j2}$$
where $f_1$ and $f_2$ are the fields of $j_1$ and $j_2$, respectively.
Compared to FM, the computational complexity increases to $O(n^2k)$. However, since the latent factors in FFM only need to learn the effect within the field, so the $k$ values in FFM is usually much smaller than that in FM.
### 1.3 FM/FFM extensions
In the recent years, FM/FFM extensions were proposed to enhance the model performance further. The new algorithms leverage the powerful deep learning neural network to improve the generalization capability of the original FM/FFM algorithms. Representatives of the such algorithms are summarized as below. Some of them are implemented and demonstrated in the microsoft/recommenders repository.
|Algorithm|Notes|References|Example in Microsoft/Recommenders|
|--------------------|---------------------|------------------------|
|DeepFM|Combination of FM and DNN where DNN handles high-order interactions|[\[3\]](https://arxiv.org/abs/1703.04247)|-|
|xDeepFM|Combination of FM, DNN, and Compressed Interaction Network, for vectorized feature interactions|[\[4\]](https://dl.acm.org/citation.cfm?id=3220023)|[notebook](https://github.com/microsoft/recommenders/blob/master/notebooks/00_quick_start/xdeepfm_criteo.ipynb) / [utilities](https://github.com/microsoft/recommenders/blob/master/reco_utils/recommender/deeprec/models/xDeepFM.py)|
|Factorization Machine Supported Neural Network|Use FM user/item weight vectors as input layers for DNN model|[\[5\]](https://link.springer.com/chapter/10.1007/978-3-319-30671-1_4)|-|
|Product-based Neural Network|An additional product-wise layer between embedding layer and fully connected layer to improve expressiveness of interactions of features across fields|[\[6\]](https://ieeexplore.ieee.org/abstract/document/7837964)|-|
|Neural Factorization Machines|Improve the factorization part of FM by using stacks of NN layers to improve non-linear expressiveness|[\[7\]](https://dl.acm.org/citation.cfm?id=3080777)|-|
|Wide and deep|Combination of linear model (wide part) and deep neural network model (deep part) for memorisation and generalization|[\[8\]](https://dl.acm.org/citation.cfm?id=2988454)|[notebook](https://github.com/microsoft/recommenders/blob/master/notebooks/00_quick_start/wide_deep_movielens.ipynb) / [utilities](https://github.com/microsoft/recommenders/tree/master/reco_utils/recommender/wide_deep)|
## 2 Factorization Machine Implementation
### 2.1 Implementations
The following table summarizes the implementations of FM/FFM. Some of them (e.g., xDeepFM and VW) are implemented and/or demonstrated in the microsoft/recommenders repository
|Implementation|Language|Notes|Examples in Microsoft/Recommenders|
|-----------------|------------------|------------------|---------------------|
|[libfm](https://github.com/srendle/libfm)|C++|Implementation of FM algorithm|-|
|[libffm](https://github.com/ycjuan/libffm)|C++|Original implemenation of FFM algorithm. It is handy in model building, but does not support Python interface|-|
|[xlearn](https://github.com/aksnzhy/xlearn)|C++ with Python interface|More computationally efficient compared to libffm without loss of modeling effectiveness|[notebook](https://github.com/microsoft/recommenders/blob/master/notebooks/02_model/fm_deep_dive.ipynb)|
|[Vowpal Wabbit FM](https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Matrix-factorization-example)|Online library with estimator API|Easy to use by calling API|[notebook](https://github.com/microsoft/recommenders/blob/master/notebooks/02_model/vowpal_wabbit_deep_dive.ipynb) / [utilities](https://github.com/microsoft/recommenders/tree/master/reco_utils/recommender/vowpal_wabbit)
|[microsoft/recommenders xDeepFM](https://github.com/microsoft/recommenders/blob/master/reco_utils/recommender/deeprec/models/xDeepFM.py)|Python|Support flexible interface with different configurations of FM and FM extensions, i.e., LR, FM, and/or CIN|[notebook](https://github.com/microsoft/recommenders/blob/master/notebooks/00_quick_start/xdeepfm_criteo.ipynb) / [utilities](https://github.com/microsoft/recommenders/blob/master/reco_utils/recommender/deeprec/models/xDeepFM.py)|
Other than `libfm` and `libffm`, all the other three can be used in a Python environment.
* A deep dive of using Vowbal Wabbit for FM model can be found [here](https://github.com/microsoft/recommenders/blob/master/notebooks/02_model/vowpal_wabbit_deep_dive.ipynb)
* A quick start of Microsoft xDeepFM algorithm can be found [here](https://github.com/microsoft/recommenders/blob/master/notebooks/00_quick_start/xdeepfm_criteo.ipynb).
Therefore, in the example below, only code examples and best practices of using `xlearn` are presented.
### 2.2 xlearn
Setups for using `xlearn`.
1. `xlearn` is implemented in C++ and has Python bindings, so it can be directly installed as a Python package from PyPI. The installation of `xlearn` is enabled in the [Recommenders repo environment setup script](https://github.com/microsoft/recommenders/blob/master/scripts/generate_conda_file.py). One can follow the general setup steps to install the environment as required, in which `xlearn` is installed as well.
2. NOTE `xlearn` may require some base libraries installed as prerequisites in the system, e.g., `cmake`.
After a succesful creation of the environment, one can load the packages to run `xlearn` in a Jupyter notebook or Python script.
```
import time
import sys
sys.path.append("../../")
import os
import papermill as pm
from tempfile import TemporaryDirectory
import xlearn as xl
from sklearn.metrics import roc_auc_score
import numpy as np
import pandas as pd
import seaborn as sns
%matplotlib notebook
from matplotlib import pyplot as plt
from reco_utils.common.constants import SEED
from reco_utils.common.timer import Timer
from reco_utils.recommender.deeprec.deeprec_utils import (
download_deeprec_resources, prepare_hparams
)
from reco_utils.recommender.deeprec.models.xDeepFM import XDeepFMModel
from reco_utils.recommender.deeprec.IO.iterator import FFMTextIterator
from reco_utils.tuning.parameter_sweep import generate_param_grid
from reco_utils.dataset.pandas_df_utils import LibffmConverter
print("System version: {}".format(sys.version))
print("Xlearn version: {}".format(xl.__version__))
```
In the FM model building, data is usually represented in the libsvm data format. That is, `label feat1:val1 feat2:val2 ...`, where `label` is the target to predict, and `val` is the value to each feature `feat`.
FFM algorithm requires data to be represented in the libffm format, where each vector is split into several fields with categorical/numerical features inside. That is, `label field1:feat1:val1 field2:feat2:val2 ...`.
In the Microsoft/Recommenders utility functions, [a libffm converter](https://github.com/microsoft/recommenders/blob/290dd920d4a6a4d3bff71dd9ee7273be0c02dbbc/reco_utils/dataset/pandas_df_utils.py#L86) is provided to achieve the transformation from a tabular feature vectors to the corresponding libffm representation. For example, the following shows how to transform the format of a synthesized data by using the module of `LibffmConverter`.
```
df_feature_original = pd.DataFrame({
'rating': [1, 0, 0, 1, 1],
'field1': ['xxx1', 'xxx2', 'xxx4', 'xxx4', 'xxx4'],
'field2': [3, 4, 5, 6, 7],
'field3': [1.0, 2.0, 3.0, 4.0, 5.0],
'field4': ['1', '2', '3', '4', '5']
})
converter = LibffmConverter().fit(df_feature_original, col_rating='rating')
df_out = converter.transform(df_feature_original)
df_out
print('There are in total {0} fields and {1} features.'.format(converter.field_count, converter.feature_count))
```
To illustrate the use of `xlearn`, the following example uses the [Criteo data set](https://labs.criteo.com/category/dataset/), which has already been processed in the libffm format, for building and evaluating a FFM model built by using `xlearn`. Sometimes, it is important to know the total numbers of fields and features. When building a FFM model, `xlearn` can count these numbers automatically.
```
# Parameters
YAML_FILE_NAME = "xDeepFM.yaml"
TRAIN_FILE_NAME = "cretio_tiny_train"
VALID_FILE_NAME = "cretio_tiny_valid"
TEST_FILE_NAME = "cretio_tiny_test"
MODEL_FILE_NAME = "model.out"
OUTPUT_FILE_NAME = "output.txt"
LEARNING_RATE = 0.2
LAMBDA = 0.002
# The metrics for binary classification options are "acc", "prec", "f1" and "auc"
# for regression, options are "rmse", "mae", "mape"
METRIC = "auc"
EPOCH = 10
OPT_METHOD = "sgd" # options are "sgd", "adagrad" and "ftrl"
tmpdir = TemporaryDirectory()
data_path = tmpdir.name
yaml_file = os.path.join(data_path, YAML_FILE_NAME)
train_file = os.path.join(data_path, TRAIN_FILE_NAME)
valid_file = os.path.join(data_path, VALID_FILE_NAME)
test_file = os.path.join(data_path, TEST_FILE_NAME)
model_file = os.path.join(data_path, MODEL_FILE_NAME)
output_file = os.path.join(data_path, OUTPUT_FILE_NAME)
if not os.path.exists(yaml_file):
download_deeprec_resources(r'https://recodatasets.blob.core.windows.net/deeprec/', data_path, 'xdeepfmresources.zip')
```
The following steps are from the [official documentation of `xlearn`](https://xlearn-doc.readthedocs.io/en/latest/index.html) for building a model. To begin with, we do not modify any training parameter values.
NOTE, if `xlearn` is run through command line, the training process can be displayed in the console.
```
# Training task
ffm_model = xl.create_ffm() # Use field-aware factorization machine (ffm)
ffm_model.setTrain(train_file) # Set the path of training dataset
ffm_model.setValidate(valid_file) # Set the path of validation dataset
# Parameters:
# 0. task: binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: auc
# 4. number of epochs: 10
# 5. optimization method: sgd
param = {"task":"binary",
"lr": LEARNING_RATE,
"lambda": LAMBDA,
"metric": METRIC,
"epoch": EPOCH,
"opt": OPT_METHOD
}
# Start to train
# The trained model will be stored in model.out
with Timer() as time_train:
ffm_model.fit(param, model_file)
# Prediction task
ffm_model.setTest(test_file) # Set the path of test dataset
ffm_model.setSigmoid() # Convert output to 0-1
# Start to predict
# The output result will be stored in output.txt
with Timer() as time_predict:
ffm_model.predict(model_file, output_file)
```
The output are the predicted labels (i.e., 1 or 0) for the testing data set. AUC score is calculated to evaluate the model performance.
```
with open(output_file) as f:
predictions = f.readlines()
with open(test_file) as f:
truths = f.readlines()
truths = np.array([float(truth.split(' ')[0]) for truth in truths])
predictions = np.array([float(prediction.strip('')) for prediction in predictions])
auc_score = roc_auc_score(truths, predictions)
auc_score
pm.record('auc_score', auc_score)
print('Training takes {0:.2f}s and predicting takes {1:.2f}s.'.format(time_train.interval, time_predict.interval))
```
It can be seen that the model building/scoring process is fast and the model performance is good.
### 2.3 Hyperparameter tuning of `xlearn`
The following presents a naive approach to tune the parameters of `xlearn`, which is using grid-search of parameter values to find the optimal combinations. It is worth noting that the original [FFM paper](https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf) gave some hints in terms of the impact of parameters on the sampled Criteo dataset.
The following are the parameters that can be tuned in the `xlearn` implementation of FM/FFM algorithm.
|Parameter|Description|Default value|Notes|
|-------------|-----------------|------------------|-----------------|
|`lr`|Learning rate|0.2|Higher learning rate helps fit a model more efficiently but may also result in overfitting.|
|`lambda`|Regularization parameter|0.00002|The value needs to be selected empirically to avoid overfitting.|
|`k`|Dimensionality of the latent factors|4|In FFM the effect of k is not that significant as the algorithm itself considers field where `k` can be small to capture the effect of features within each of the fields.|
|`init`|Model initialization|0.66|-|
|`epoch`|Number of epochs|10|Using a larger epoch size will help converge the model to its optimal point|
```
param_dict = {
"lr": [0.0001, 0.001, 0.01],
"lambda": [0.001, 0.01, 0.1]
}
param_grid = generate_param_grid(param_dict)
auc_scores = []
with Timer() as time_tune:
for param in param_grid:
ffm_model = xl.create_ffm()
ffm_model.setTrain(train_file)
ffm_model.setValidate(valid_file)
ffm_model.fit(param, model_file)
ffm_model.setTest(test_file)
ffm_model.setSigmoid()
ffm_model.predict(model_file, output_file)
with open(output_file) as f:
predictions = f.readlines()
with open(test_file) as f:
truths = f.readlines()
truths = np.array([float(truth.split(' ')[0]) for truth in truths])
predictions = np.array([float(prediction.strip('')) for prediction in predictions])
auc_scores.append(roc_auc_score(truths, predictions))
print('Tuning by grid search takes {0:.2} min'.format(time_tune.interval / 60))
auc_scores = [float('%.4f' % x) for x in auc_scores]
auc_scores_array = np.reshape(auc_scores, (len(param_dict["lr"]), len(param_dict["lambda"])))
auc_df = pd.DataFrame(
data=auc_scores_array,
index=pd.Index(param_dict["lr"], name="LR"),
columns=pd.Index(param_dict["lambda"], name="Lambda")
)
auc_df
fig, ax = plt.subplots()
sns.heatmap(auc_df, cbar=False, annot=True, fmt=".4g")
```
More advanced tuning methods like Bayesian Optimization can be used for searching for the optimal model efficiently. The benefit of using, for example, `HyperDrive` from Azure Machine Learning Services, for tuning the parameters, is that, the tuning tasks can be distributed across nodes of a cluster and the optimization can be run concurrently to save the total cost.
* Details about how to tune hyper parameters by using Azure Machine Learning Services can be found [here](https://github.com/microsoft/recommenders/tree/master/notebooks/04_model_select_and_optimize).
* Note, to enable the tuning task on Azure Machine Learning Services by using HyperDrive, one needs a Docker image to containerize the environment where `xlearn` can be run. The Docker file provided [here](https://github.com/microsoft/recommenders/tree/master/docker) can be used for such purpose.
### 2.4 Clean up
```
tmpdir.cleanup()
```
## References
<a id='references'></a>
1. Rendle, Steffen. "Factorization machines." 2010 IEEE International Conference on Data Mining. IEEE, 2010.
2. Juan, Yuchin, et al. "Field-aware factorization machines for CTR prediction." Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016.
3. Guo, Huifeng, et al. "DeepFM: a factorization-machine based neural network for CTR prediction." arXiv preprint arXiv:1703.04247 (2017).
4. Lian, Jianxun, et al. "xdeepfm: Combining explicit and implicit feature interactions for recommender systems." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018.
5. Qu, Yanru, et al. "Product-based neural networks for user response prediction." 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 2016.
6. Zhang, Weinan, Tianming Du, and Jun Wang. "Deep learning over multi-field categorical data." European conference on information retrieval. Springer, Cham, 2016.
7. He, Xiangnan, and Tat-Seng Chua. "Neural factorization machines for sparse predictive analytics." Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 2017.
8. Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. ACM, 2016.
9. Langford, John, Lihong Li, and Alex Strehl. "Vowpal wabbit online learning project." (2007).
| github_jupyter |
Courtsey - https://mccormickml.com/2019/07/22/BERT-fine-tuning/
```
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
!pip install pytorch-pretrained-bert pytorch-nlp
import torch
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from pytorch_pretrained_bert import BertTokenizer, BertConfig
from pytorch_pretrained_bert import BertAdam, BertForSequenceClassification, BertModel
from tqdm import tqdm, trange
import pandas as pd
import io
import numpy as np
import matplotlib.pyplot as plt
import spacy
from nltk.corpus import stopwords
% matplotlib inline
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
n_gpu = torch.cuda.device_count()
torch.cuda.get_device_name(0)
stop_words = set(stopwords.words('english'))
df = pd.read_excel("PPMdata.xlsx")
print (df.shape)
df.head(3)
df = df.dropna(subset=['Sentence','Sentiment'])
print (df.shape)
df.Sentiment = df.Sentiment.astype(int)
df.Sentence = df.Sentence.str.lower()
df.Sentiment.value_counts()
df = df.sample(frac=1)
punctuation = '!"#$%&()*+-/:;<=>?@[\\]^_`{|}~.,'
df['clean_text'] = df.Sentence.apply(lambda x: ''.join(ch for ch in x if ch not in set(punctuation)))
# remove numbers
df['clean_text'] = df['clean_text'].str.replace("[0-9]", " ")
# remove whitespaces
df['clean_text'] = df['clean_text'].apply(lambda x:' '.join(x.split()))
df['clean_text'] = df.clean_text.apply(lambda x: " ".join([i for i in x.split() if i not in stop_words]).strip())
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
# function to lemmatize text
def lemmatization(texts):
output = []
for i in texts:
s = [token.lemma_ for token in nlp(i)]
output.append(' '.join(s))
return output
df['clean_text'] = lemmatization(df['clean_text'])
df['num_words'] = df.clean_text.apply(lambda x: len(x.split()))
df = df[df.num_words >= 5][df.num_words <= 50]
print (df.shape)
print (df.Sentiment.value_counts())
df.num_words.plot.hist()
plt.show()
sentences = df.clean_text.values
# We need to add special tokens at the beginning and end of each sentence for BERT to work properly
sentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]
labels = df.Sentiment.values
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
print ("Tokenize the first sentence:")
print (sentences[0])
print (tokenized_texts[0])
from collections import Counter
Counter([len(ids) for ids in tokenized_texts])
MAX_LEN = 64
tokenizer.convert_tokens_to_ids(tokenized_texts[0])
input_ids = pad_sequences([tokenizer.convert_tokens_to_ids(txt) for txt in tokenized_texts],
maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")
input_ids
# Create attention masks
attention_masks = []
# Create a mask of 1s for each token followed by 0s for padding
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
np.array(attention_masks)
# Use train_test_split to split our data into train and validation sets for training
train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels,
random_state=2018, test_size=0.1)
train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,
random_state=2018, test_size=0.1)
# Convert all of our data into torch tensors, the required datatype for our model
train_inputs = torch.tensor(train_inputs,dtype=torch.long)
validation_inputs = torch.tensor(validation_inputs,dtype=torch.long)
train_labels = torch.tensor(train_labels,dtype=torch.long)
validation_labels = torch.tensor(validation_labels,dtype=torch.long)
train_masks = torch.tensor(train_masks,dtype=torch.long)
validation_masks = torch.tensor(validation_masks,dtype=torch.long)
validation_inputs
# Select a batch size for training. For fine-tuning BERT on a specific task, the authors recommend a batch size of 16 or 32
batch_size = 32
# Create an iterator of our data with torch DataLoader. This helps save on memory during training because, unlike a for loop,
# with an iterator the entire dataset does not need to be loaded into memory
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
validation_sampler = SequentialSampler(validation_data)
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
train_data.tensors
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'gamma', 'beta']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.0}
]
# This variable contains all of the hyperparemeter information our training loop needs
optimizer = BertAdam(optimizer_grouped_parameters,
lr=2e-5,
warmup=.1)
# Function to calculate the accuracy of our predictions vs labels
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
device
?model
# Store our loss and accuracy for plotting
train_loss_set = []
# Number of training epochs (authors recommend between 2 and 4)
epochs = 1
# trange is a tqdm wrapper around the normal python range
for _ in trange(epochs, desc="Epoch"):
# Training
# Set our model to training mode (as opposed to evaluation mode)
model.train()
# Tracking variables
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
# Train the data for one epoch
for step, batch in enumerate(train_dataloader):
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Clear out the gradients (by default they accumulate)
optimizer.zero_grad()
# Forward pass
loss = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
train_loss_set.append(loss.item())
# Backward pass
loss.backward()
# Update parameters and take a step using the computed gradient
optimizer.step()
# Update tracking variables
tr_loss += loss.item()
nb_tr_examples += b_input_ids.size(0)
nb_tr_steps += 1
print("Train loss: {}".format(tr_loss/nb_tr_steps))
# Validation
# Put model in evaluation mode to evaluate loss on the validation set
model.eval()
# Tracking variables
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# Evaluate data for one epoch
for batch in validation_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up validation
with torch.no_grad():
# Forward pass, calculate logit predictions
logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))
model.eval()
# Tracking variables
predictions , true_labels = [], []
# Predict
for batch in validation_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up prediction
with torch.no_grad():
# Forward pass, calculate logit predictions
logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# Store predictions and true labels
predictions.append(logits)
true_labels.append(label_ids)
logits[:,1]
# Flatten the predictions and true values for aggregate Matthew's evaluation on the whole dataset
flat_predictions = [item for sublist in predictions for item in sublist]
flat_predictions = np.argmax(flat_predictions, axis=1).flatten()
flat_true_labels = np.array([item for sublist in true_labels for item in sublist])
flat_predictions
flat_true_labels
from sklearn.metrics import accuracy_score, f1_score
accuracy_score(flat_true_labels,flat_predictions)
f1_score(flat_true_labels,flat_predictions)
model.parameters
model2 = BertModel.from_pretrained('bert-base-uncased')
for param in model2.parameters():
param.requires_grad = False
from torch import nn
import torch.nn.functional as F
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
class finetuneBERT(Flatten,nn.Module):
def __init__(self, bert_output_size, output_size):
super(finetuneBERT, self).__init__()
self.bertmodel = model2
self.flatten = Flatten()
self.attn = nn.Linear(bert_output_size, bert_output_size)
self.out = nn.Linear(in_features=bert_output_size,out_features=output_size)
def forward(self, input_token, input_mask):
hidden, _ = self.bertmodel(input_token, input_mask)
attn_weights = F.softmax(
self.attn(hidden[-1]), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
flatten = torch.flatten(torch.Tensor(hidden[-1]),start_dim=1)
output = nn.Softmax()(self.out(flatten))
return output
model2.parameters
!pip install torchsummary
from torchsummary import summary
model3 = finetuneBERT(768*MAX_LEN,2)
model3.parameters
model3 = model3.to(device)
criterion = nn.CrossEntropyLoss()
from torch import optim
optimizer_ft = optim.SGD(model3.out.parameters(), lr=0.001, momentum=0.9)
# Store our loss and accuracy for plotting
train_loss_set = []
# Number of training epochs (authors recommend between 2 and 4)
epochs = 1
# trange is a tqdm wrapper around the normal python range
for _ in trange(epochs, desc="Epoch"):
# Training
# Set our model to training mode (as opposed to evaluation mode)
model3.train()
# Tracking variables
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
# Train the data for one epoch
for step, batch in enumerate(train_dataloader):
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Clear out the gradients (by default they accumulate)
optimizer_ft.zero_grad()
# Forward pass
output = model3(b_input_ids,b_input_mask)
#output = output.reshape(output.shape[0])
loss = criterion(output, b_labels)
train_loss_set.append(loss.item())
# Backward pass
loss.backward()
# Update parameters and take a step using the computed gradient
optimizer.step()
# Update tracking variables
tr_loss += loss.item()
nb_tr_examples += b_input_ids.size(0)
nb_tr_steps += 1
print("Train loss: {}".format(tr_loss/nb_tr_steps))
# Validation
# Put model in evaluation mode to evaluate loss on the validation set
model3.eval()
# Tracking variables
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# Evaluate data for one epoch
for batch in validation_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up validation
with torch.no_grad():
# Forward pass, calculate logit predictions
logits = model3(b_input_ids,b_input_mask)
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
#tmp_eval_accuracy = flat_accuracy(logits, label_ids)
tmp_eval_accuracy = np.dot(logits.argmax(axis=1),label_ids)*1.0/logits.shape[0]
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))
hidden, _ = model3.bertmodel(validation_inputs, validation_masks)
validation_inputs.shape
np.array(hidden[0]).shape
np.array(hidden[0])[0]
output.reshape(output.shape[0])
output.shape
criterion(output, b_labels)
?criterion
torch.randn(3, 5, requires_grad=True).shape
torch.empty(3, dtype=torch.long).random_(5).shape
torch.randn(3, 5, requires_grad=True)
```
| github_jupyter |
# Data Drift Dashboard for Boston Dataset
```
import pandas as pd
from sklearn import datasets
from plotly.graph_objects import histogram
from evidently.dashboard import Dashboard
from evidently.pipeline.column_mapping import ColumnMapping
from evidently.tabs import DataDriftTab
from evidently.model_profile import Profile
from evidently.profile_sections import DataDriftProfileSection
from evidently.analyzers.data_drift_analyzer import DataDriftOptions
```
## Boston Data
```
boston = datasets.load_boston()
boston_frame = pd.DataFrame(boston.data, columns = boston.feature_names)
boston_frame['target'] = boston.target
boston_frame.head()
column_mapping = ColumnMapping()
column_mapping.target = 'target'
column_mapping.prediction = None
column_mapping.datetime = None
column_mapping.numerical_features = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'TAX',
'PTRATIO', 'B', 'LSTAT']
column_mapping.categorical_features = ['CHAS', 'RAD']
#set parameters to detect dataset drift:
# - confidence level for the individual features
# - share of the drifted features to detect dataset drift
data_drift_opts = DataDriftOptions()
data_drift_opts.confidence = 0.99
data_drift_opts.drift_share = 0.5
#set the custom bins to plot in the datadrift table
data_drift_opts.xbins = {
'CRIM': dict(start=-10., end=100.,size=5.), # OPTION 1
'NOX': histogram.XBins(start=-0.5, end=1.5, size=.05) # OPTION 2 (NB: Xbins is not JSON serializable)
}
#set the custom number of bins to plot in the datadrift table
data_drift_opts.nbinsx = {'TAX': 3, 'PTRATIO': 5}
```
## Data and Target Drift Dashboard
```
boston_data_and_target_drift_dashboard = Dashboard(tabs=[DataDriftTab()], options=[data_drift_opts])
# reference_data = Dataset(boston_frame[:200], column_mapping)
# current_data = Dataset(boston_frame[:200], column_mapping)
boston_data_and_target_drift_dashboard.calculate(boston_frame[:200], boston_frame[200:], column_mapping)
boston_data_and_target_drift_dashboard.show()
#boston_data_and_target_drift_dashboard.save('boston_datadrift_with_customized_bins.html')
```
## Data and Target Drift Profile
```
#for profile all the column_mapping parameters should be JSON serializable
data_drift_opts.xbins = {
'CRIM': dict(start=-10., end=100.,size=5.), # OPTION 1
'NOX': histogram.XBins(start=-0.5, end=1.5, size=.05).to_plotly_json() #transform'XBins' to JSON serializable fromat
}
boston_target_and_data_drift_profile = Profile(sections=[DataDriftProfileSection()], options=[data_drift_opts])
boston_target_and_data_drift_profile.calculate(boston_frame[:200], boston_frame[200:],
column_mapping = column_mapping)
boston_target_and_data_drift_profile.json()
```
| github_jupyter |
# Baseline Modelling with ANN
By: Yolanda Chen, Emir Hermanto
Date: February 23th, 2021
**Issue:**
- Predict the same value
- Based on the below stackoverflow article, I feel like our ANN cannot handle our large dimensional data
- Related stackoverflow issue: https://stackoverflow.com/questions/4493554/neural-network-always-produces-same-similar-outputs-for-any-input/26209541
Resources:
I think we said not to use this, but keeping it here in case we want to quickly train a model: https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html#sklearn.neural_network.MLPClassifier.fit
Again, similar process but we're going to build an ANN similar to what we've built in labs instead: https://medium.com/@sdoshi579/classification-of-music-into-different-genres-using-keras-82ab5339efe0
https://medium.com/@pk_500/music-genre-classification-using-feed-forward-neural-network-using-pytorch-fdb9a960a964
#1 Data Processing
```
import json
import torch
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from google.colab import drive
drive.mount('/content/gdrive')
def get_data_loader(batch_size, url='gdrive/My Drive/APS360 Project/fma_small_segments.json'):
# Load json file
with open(url) as file:
data = json.load(file)
# Extract training, validation, and test datasets
training = data['training']
validation = data['validation']
test = data['test']
# Extract mfcc and labels
training_mfcc = training[0]['mfcc']
training_labels = training[0]['label']
validation_mfcc = validation[0]['mfcc']
validation_labels = validation[0]['label']
test_mfcc = test[0]['mfcc']
test_labels = test[0]['label']
# convert to torch tensor
training_mfcc = torch.Tensor(training_mfcc)
validation_mfcc = torch.Tensor(validation_mfcc)
test_mfcc = torch.Tensor(test_mfcc)
# normalize data
training_mfcc -= torch.min(training_mfcc)
training_mfcc /= torch.max(training_mfcc)
validation_mfcc -= torch.min(validation_mfcc)
validation_mfcc /= torch.max(validation_mfcc)
test_mfcc -= torch.min(test_mfcc)
test_mfcc /= torch.max(test_mfcc)
# Convert list to tensor and create dataset of mfcc and labels
training_dataset = torch.utils.data.TensorDataset(training_mfcc, torch.Tensor(training_labels))
validation_dataset = torch.utils.data.TensorDataset(validation_mfcc, torch.Tensor(validation_labels))
test_dataset = torch.utils.data.TensorDataset(test_mfcc, torch.Tensor(test_labels))
# Get the dataloader for training, validation, and test datasets
train_loader = torch.utils.data.DataLoader(dataset=training_dataset, batch_size=batch_size, drop_last=True, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=validation_dataset, batch_size=batch_size, drop_last=True, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, drop_last=True, shuffle=True)
return train_loader, val_loader, test_loader
```
# 2.Multiclass-ANN Architecture
Similar to what has been done in labs
Need to modify input size to match the input dimensions
Start off with a small network just to check
```
class GC1(nn.Module):
def __init__(self, firstLayerHidden = 1000, numHidden=3):
super(GC1, self).__init__()
self.hidden = []
self.inputLayer = nn.Linear (360, firstLayerHidden)
increment = (firstLayerHidden)//(numHidden + 1)
previousNodeCount = firstLayerHidden
for i in range(numHidden):
nodeCount = previousNodeCount - increment
hiddenLayer = nn.Linear(previousNodeCount, nodeCount)
self.hidden.append(hiddenLayer)
previousNodeCount = nodeCount
self.outputLayer = nn.Linear(previousNodeCount, 8)
def forward(self, input):
flattened = input.view(-1, 360)
activation1 = F.relu(self.inputLayer(flattened))
hiddenActivations = self.hiddenActivation(firstLayer=activation1)
output = self.outputLayer(hiddenActivations)
return output
def hiddenActivation(self, firstLayer):
currentLayer = firstLayer
for i in range(len(self.hidden)):
currentLayer = F.relu(self.hidden[i](currentLayer))
return currentLayer
class GC2(nn.Module):
def __init__(self, firstLayerHidden = 1200, numHidden=2):
super(GC2, self).__init__()
self.hidden = []
self.inputLayer = nn.Linear (940, firstLayerHidden)
increment = (firstLayerHidden)//(numHidden + 1)
previousNodeCount = firstLayerHidden
for i in range(numHidden):
nodeCount = previousNodeCount - increment
hiddenLayer = nn.Linear(previousNodeCount, nodeCount)
self.hidden.append(hiddenLayer)
previousNodeCount = nodeCount
self.outputLayer = nn.Linear(previousNodeCount, 8)
def forward(self, input):
flattened = input.view(-1, 940)
activation1 = F.relu(self.inputLayer(flattened))
hiddenActivations = self.hiddenActivation(firstLayer=activation1)
output = self.outputLayer(hiddenActivations)
return output
def hiddenActivation(self, firstLayer):
currentLayer = firstLayer
for i in range(len(self.hidden)):
currentLayer = F.relu(self.hidden[i](currentLayer))
return currentLayer
class GC3(nn.Module):
def __init__(self, firstLayerHidden = 1200, numHidden=2):
super(GC3, self).__init__()
self.hidden = []
self.inputLayer = nn.Linear (480, firstLayerHidden)
increment = (firstLayerHidden)//(numHidden + 1)
previousNodeCount = firstLayerHidden
for i in range(numHidden):
nodeCount = previousNodeCount - increment
hiddenLayer = nn.Linear(previousNodeCount, nodeCount)
self.hidden.append(hiddenLayer)
previousNodeCount = nodeCount
self.outputLayer = nn.Linear(previousNodeCount, 8)
def forward(self, input):
flattened = input.view(-1, 480)
activation1 = F.relu(self.inputLayer(flattened))
hiddenActivations = self.hiddenActivation(firstLayer=activation1)
output = self.outputLayer(hiddenActivations)
return output
def hiddenActivation(self, firstLayer):
currentLayer = firstLayer
for i in range(len(self.hidden)):
currentLayer = F.relu(self.hidden[i](currentLayer))
return currentLayer
class GC4(nn.Module):
def __init__(self, firstLayerHidden = 1200, numHidden=2):
super(GC4, self).__init__()
self.hidden = []
self.inputLayer = nn.Linear (1260, firstLayerHidden)
increment = (firstLayerHidden)//(numHidden + 1)
previousNodeCount = firstLayerHidden
for i in range(numHidden):
nodeCount = previousNodeCount - increment
hiddenLayer = nn.Linear(previousNodeCount, nodeCount)
self.hidden.append(hiddenLayer)
previousNodeCount = nodeCount
self.outputLayer = nn.Linear(previousNodeCount, 8)
def forward(self, input):
flattened = input.view(-1, 1260)
activation1 = F.relu(self.inputLayer(flattened))
hiddenActivations = self.hiddenActivation(firstLayer=activation1)
output = self.outputLayer(hiddenActivations)
return output
def hiddenActivation(self, firstLayer):
currentLayer = firstLayer
for i in range(len(self.hidden)):
currentLayer = F.relu(self.hidden[i](currentLayer))
return currentLayer
class GC6(nn.Module):
def __init__(self, firstLayerHidden = 1200, numHidden=2):
super(GC6, self).__init__()
self.hidden = []
self.inputLayer = nn.Linear (180, firstLayerHidden)
increment = (firstLayerHidden)//(numHidden + 1)
previousNodeCount = firstLayerHidden
for i in range(numHidden):
nodeCount = previousNodeCount - increment
hiddenLayer = nn.Linear(previousNodeCount, nodeCount)
self.hidden.append(hiddenLayer)
previousNodeCount = nodeCount
self.outputLayer = nn.Linear(previousNodeCount, 8)
def forward(self, input):
flattened = input.view(-1, 180)
activation1 = F.relu(self.inputLayer(flattened))
hiddenActivations = self.hiddenActivation(firstLayer=activation1)
output = self.outputLayer(hiddenActivations)
return output
def hiddenActivation(self, firstLayer):
currentLayer = firstLayer
for i in range(len(self.hidden)):
currentLayer = F.relu(self.hidden[i](currentLayer))
return currentLayer
class GC7(nn.Module):
def __init__(self, firstLayerHidden = 1200, numHidden=2):
super(GC7, self).__init__()
self.hidden = []
self.inputLayer = nn.Linear (60*258, firstLayerHidden)
increment = (firstLayerHidden)//(numHidden + 1)
previousNodeCount = firstLayerHidden
for i in range(numHidden):
nodeCount = previousNodeCount - increment
hiddenLayer = nn.Linear(previousNodeCount, nodeCount)
self.hidden.append(hiddenLayer)
previousNodeCount = nodeCount
self.outputLayer = nn.Linear(previousNodeCount, 8)
def forward(self, input):
flattened = input.view(-1, 60*258)
activation1 = F.relu(self.inputLayer(flattened))
hiddenActivations = self.hiddenActivation(firstLayer=activation1)
output = self.outputLayer(hiddenActivations)
return output
def hiddenActivation(self, firstLayer):
currentLayer = firstLayer
for i in range(len(self.hidden)):
currentLayer = F.relu(self.hidden[i](currentLayer))
return currentLayer
```
#3 Training Functions
```
def get_accuracy(model, train=False):
correct = 0
total = 0
if train == True:
data = train_loader
else:
data = val_loader
for input, labels in data:
output = model(input)
#select index with maximum prediction score
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(labels.view_as(pred)).sum().item()
total += input.shape[0]
return correct / total
def train(model, train_loader, batch_size=64, mom=0.9, num_epochs=1):
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=mom)
iters, losses, train_acc, val_acc = [], [], [], []
# training
n = 0 # the number of iterations
for epoch in range(num_epochs):
for input, labels in iter(train_loader):
#print(input)
#print(input.shape)
#print(labels)
out = model(input) # forward pass
#print(out)
#print(labels.long())
loss = criterion(out, labels.long()) # compute the total loss
loss.backward() # backward pass (compute parameter updates)
optimizer.step() # make the updates for each parameter
optimizer.zero_grad() # a clean up step for PyTorch
# save the current training information
iters.append(n)
losses.append(float(loss)/batch_size) # compute *average* loss
train_acc.append(get_accuracy(model, train=True)) # compute training accuracy
val_acc.append(get_accuracy(model, train=False)) # compute validation accuracy
n += 1
# plotting
plt.title("Training Curve")
plt.plot(iters, losses, label="Train")
plt.xlabel("Iterations")
plt.ylabel("Loss")
plt.show()
plt.title("Training Curve")
plt.plot(iters, train_acc, label="Train")
plt.plot(iters, val_acc, label="Validation")
plt.xlabel("Iterations")
plt.ylabel("Training Accuracy")
plt.legend(loc='best')
plt.show()
print("Final Training Accuracy: {}".format(train_acc[-1]))
print("Final Validation Accuracy: {}".format(val_acc[-1]))
def trainAdam(model, train_loader, batch_size=64, num_epochs=1, learn_rate=0.01, wd=0):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learn_rate, weight_decay=wd)
iters, losses, train_acc, val_acc = [], [], [], []
# training
n = 0 # the number of iterations
for epoch in range(num_epochs):
for input, labels in iter(train_loader):
out = model(input) # forward pass
#print(out)
#print(labels.long())
loss = criterion(out, labels.long()) # compute the total loss
loss.backward() # backward pass (compute parameter updates)
optimizer.step() # make the updates for each parameter
optimizer.zero_grad() # a clean up step for PyTorch
# save the current training information
iters.append(n)
losses.append(float(loss)/batch_size) # compute *average* loss
train_acc.append(get_accuracy(model, train=True)) # compute training accuracy
val_acc.append(get_accuracy(model, train=False)) # compute validation accuracy
n += 1
# plotting
plt.title("Training Curve")
plt.plot(iters, losses, label="Train")
plt.xlabel("Iterations")
plt.ylabel("Loss")
plt.show()
plt.title("Training Curve")
plt.plot(iters, train_acc, label="Train")
plt.plot(iters, val_acc, label="Validation")
plt.xlabel("Iterations")
plt.ylabel("Training Accuracy")
plt.legend(loc='best')
plt.show()
print("Final Training Accuracy: {}".format(train_acc[-1]))
print("Final Validation Accuracy: {}".format(val_acc[-1]))
```
# 4.Training
#4a. Number of Segments= Various, Momentum=0.95, Hidden Layers = 3, Batch Size = 16
```
train_loader, val_loader, test_loader = get_data_loader(64, url='gdrive/My Drive/APS360 Project/New and Better Samples/fma_small_spec_nmels_60_segments_5.json')
for input, labels in iter(train_loader):
print(labels)
print(input.shape)
print(input)
break;
model = GC7(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(64, url='gdrive/My Drive/APS360 Project/New and Better Samples/fma_small_spec_nmels_60_segments_5.json')
train(model, train_loader, batch_size=64, mom=0.99, num_epochs=10)
model = GC7(firstLayerHidden = 2800, numHidden=4)
#train_loader, val_loader, test_loader = get_data_loader(32, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
train(model, train_loader, batch_size=64, mom=0.99, num_epochs=1)
model = GC7(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(32, url='gdrive/My Drive/APS360 Project/New and Better Samples/fma_small_spec_nmels_60_segments_5.json')
train(model, train_loader, batch_size=32, mom=0.99, num_epochs=1)
model = GC6(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(64, url='gdrive/My Drive/APS360 Project/48k magic/fma_small_unnormalized.json')
train(model, train_loader, batch_size=64, mom=0.99, num_epochs=2)
train_loader, val_loader, test_loader = get_data_loader(64, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
for input, labels in iter(train_loader):
print(labels)
print(input.shape)
print(input)
break;
model = GC7(firstLayerHidden = 2800, numHidden=4)
#train_loader, val_loader, test_loader = get_data_loader(32, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
train(model, train_loader, batch_size=64, mom=0.99, num_epochs=1)
model = GC7(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(32, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
train(model, train_loader, batch_size=32, mom=0.99, num_epochs=1)
model = GC7(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(32, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
train(model, train_loader, batch_size=32, mom=0.99, num_epochs=3)
get_test_accuracy(model)
def get_test_accuracy(model):
correct = 0
total = 0
data = test_loader
for input, labels in data:
output = model(input)
#select index with maximum prediction score
pred = output.max(1, keepdim=True)[1]
#print(pred)
#print(labels)
correct += pred.eq(labels.view_as(pred)).sum().item()
total += input.shape[0]
return correct / total
model = GC7(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(16, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
train(model, train_loader, batch_size=16, mom=0.99, num_epochs=1)
model = GC7(firstLayerHidden = 2800, numHidden=4)
train_loader, val_loader, test_loader = get_data_loader(16, url='gdrive/My Drive/APS360 Project/fma_small_unnormalized_45.json')
train(model, train_loader, batch_size=16, mom=0.99, num_epochs=30)
```
| github_jupyter |
# Mixture Models and, specifically, Gaussian Mixture Models
* Thus far, we have primarily discussed relatively simple models consisting of only one peak in the probability distribution function (pdf) when representing data using pdfs.
* For example, when we introduced the probabilistic generative classifier, our examples focused on representing each class using a single Gaussian distribuion.
* Consider the following data set, would a multivariate Gaussian be able to represent each of these clustering data set well?
```
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
%matplotlib inline
n_samples = 1500
n_clusters = 1;
#generate data
transformation = [[ 0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X, y = datasets.make_blobs(n_samples=n_samples , centers = n_clusters)
X = np.dot(X, transformation)
#Plot Results
plt.figure(figsize=(12, 12))
plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1])
```
* Would a single multivariate Gaussian be able to represent this data set well?
```
n_clusters = 10;
#generate data
X, y = datasets.make_blobs(n_samples=n_samples , centers = n_clusters)
#Plot Results
plt.figure(figsize=(12, 12))
plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1])
```
* The second data set would be better represented by a *mixture model*
$p(x) = \sum_{k=1}^K \pi_k f(x | \theta_k)$
where
$0 \le \pi_k \le 1$, $\sum_k \pi_k =1$
* If each $f(x | \theta_k)$ is assumed to be a Gaussian distribution, then the above mixture model would be a *Gaussian Mixture Model*
$p(x) = \sum_{k=1}^K \pi_k N(x | \mu_k, \Sigma_k)$
where
$0 \le \pi_k \le 1$, $\sum_k \pi_k =1$
* *How would you draw from samples from a Gaussian Mixture Model? from a mixture model in general?*
* Gaussian mixture models (GMMs) can be used to learn a complex distribution that represents a data set. Thus, it can be used within the probabilistic generative classifier framework to model complex classes.
* GMMs are also commonly used for clustering where a GMM is fit to a data set to be clustered and each estimated Gaussian component is a resulting cluster.
* *If you were given a data set, how would you estimate the parameters of a GMM to fit the data?*
* A common approach for estimating the parameters of a GMM given data is *expectation maximization* (EM)
# Expectation Maximization
* EM is a general algorithm that can be applied to a variety of problems (not just mixture model clustering).
* With MLE, we define a likelihood and maximize it to find parameters of interest.
* With MAP, we maximize the posterior to find parameters of interest.
* The goal of EM is to also find the parameters that maximize your likelihood function.
* *The 1st step* is to define your likelihood function (defines your objective)
* Originally introduced by Dempster, Laird, and Rubin in 1977 - ``Maximum Likelihood from Incomplete Data via the EM Algorithm''
* EM is a method to simplify difficult maximum likelihood problems.
* Suppose we observe $\mathbf{x}_1, \ldots, \mathbf{x}_N$ i.i.d. from $g(\mathbf{x}_i | \Theta)$
* We want: $\hat\Theta = argmax L(\Theta|X) = argmax \prod_{i=1}^N g(\mathbf{x}_i | \Theta)$
* But suppose this maximization is very difficult. EM simplifies it by expanding the problem to a bigger easier problem - ``demarginalization''
\begin{equation}
g(x|\Theta) = \int_z f(x, z | \Theta) dz
\end{equation}
Main Idea: Do all of your analysis on $f$ and then integrate over the unknown z's.
### Censored Data Example
* Suppose we observe $\mathbf{y}_1, \ldots, \mathbf{y}_N$ i.i.d. from $f(\mathbf{y} | \Theta)$
* Lets say that we know that values are censored at $\ge a$
* So, we see: $\mathbf{y}_1, \ldots, \mathbf{y}_m$ (less than $a$) and we do not see $\mathbf{y}_{m+1}, \ldots, \mathbf{y}_N$ which are censored and set to $a$.
* Given this censored data, suppose we want to estimate the mean if the data was uncensored.
* Our observed data likelihood in this case would be:
\begin{eqnarray}
L &=& \prod_{i=1}^m \left[ 1 - F(a |\theta)\right]^{N-m}f(\mathbf{y}_i | \theta)\\
&=& \prod_{i=1}^m f(\mathbf{y}_i | \theta) \prod_{j=m+1}^N \int_a^\infty f(\mathbf{y}_j | \theta) dy_j
\end{eqnarray}
where $F(\cdot)$ is the cumulative distribution function and $f(y|\theta) = N(y|\theta)$, for example.
* So, the observed data likelihood would be very difficult to maximize to solve for $\theta$
* In EM, we introduce *latent variables* (i.e., ``hidden variables'') to simplify the problem
* *The second step*: Define the *complete likelihood* by introducing variables that simplify the problem.
* Going back to the censored data example, if we had observed the missing data, the problem would be easy to solve! It would simplify to a standard MLE. For this example, the complete data likelihood is:
\begin{equation}
L^c = \prod_{i=1}^m f(y_i | \theta) \prod_{i=m+1}^N f(z_i | \theta)
\end{equation}
where $z_i$ are the latent, hidden variables.
* Note: you cannot just use $a$ for the censored data, it would skew the results!
* The complete data likelihood would be much much simplier to optimize for $\theta$ if we had the $z$s...
# Reading Assignment
* Reading on K-Means: Section 9.1
* Reading on GMMs and EM: Section 9.2-9.4
| github_jupyter |
```
# Import Dependencies
import os
import csv
import numpy as np
import pandas as pd
# Fight Stats Uniform Raw Data -
# FIGHT STATS BY FIGHTER
fight_stats_raw = pd.read_csv('fight_stats_rds.csv', encoding='utf-8')
fight_stats_raw.head()
# VIEW Counts in each column
#fight_stats_raw.count()
# list out all column names for analysis
column_names_raw = fight_stats_raw.columns.values
for i in enumerate(column_names_raw):
print(i)
print(len(fight_stats_raw.columns.values))
# clean
# (93, 'Round1_Strikes_Total Strikes_Attempts') - done
# (94, 'Round1_Strikes_Total Strikes_Landed') - done
# (72, 'Round1_Strikes_Ground Total Strikes_Attempts') - done
# (73, 'Round1_Strikes_Ground Total Strikes_Landed') - done
# (19, 'Round1_Grappling_Submissions_Attempts') - done
# (20, 'Round1_Grappling_Takedowns_Attempts') - done
# (95, 'Round1_TIP_Back Control Time')
# (96, 'Round1_TIP_Clinch Time')
# (99, 'Round1_TIP_Ground Control Time')
# (101, 'Round1_TIP_Guard Control Time')
# (102, 'Round1_TIP_Half Guard Control Time')
# (103, 'Round1_TIP_Misc. Ground Control Time')
# (104, 'Round1_TIP_Mount Control Time')
# (106, 'Round1_TIP_Side Control Time')
# back control, ground control time, half guard, mount and side control time
# Set up variables for dataframe
name = fight_stats_raw['Name']
# Entire Fight Stats
last_round = fight_stats_raw['Last_round']
estimated_minutes = fight_stats_raw['estimated_minutes']
max_round = fight_stats_raw['Max_round']
# Round 1
# Total Strikes - Attempts and Landed
r1_total_strikes_att = fight_stats_raw['Round1_Strikes_Total Strikes_Attempts']
r1_total_strikes_landed = fight_stats_raw['Round1_Strikes_Total Strikes_Landed']
# Total Significant Strikes
r1_ss_att = fight_stats_raw['Round1_Strikes_Significant Strikes_Attempts']
r1_ss_landed = fight_stats_raw['Round1_Strikes_Significant Strikes_Landed']
# Total Opponent Significant Strikes
r1_opp_ss_att = fight_stats_raw['OPP_Round1_Strikes_Significant Strikes_Attempts']
r1_opp_ss_landed = fight_stats_raw['OPP_Round1_Strikes_Significant Strikes_Landed']
# Total Ground Strikes - Attempts and Landed
r1_ground_strikes_att = fight_stats_raw['Round1_Strikes_Ground Total Strikes_Attempts']
r1_ground_strikes_landed = fight_stats_raw['Round1_Strikes_Ground Total Strikes_Landed']
# Grappling Takedowns Attempts and Landed
r1_grappling_subm_att = fight_stats_raw['Round1_Grappling_Submissions_Attempts']
r1_grappling_TD_att = fight_stats_raw['Round1_Grappling_Takedowns_Attempts']
r1_grappling_TD_landed = fight_stats_raw['Round1_Grappling_Takedowns_Landed']
# Opponent Grappling Takedowns Attempts and Landed
r1_opp_TD_att = fight_stats_raw['OPP_Round1_Grappling_Takedowns_Attempts']
r1_opp_TD_landed = fight_stats_raw['OPP_Round1_Grappling_Takedowns_Landed']
# Grappling / Ground Time
r1_back_control_time = fight_stats_raw['Round1_TIP_Back Control Time']
r1_clinch_time = fight_stats_raw['Round1_TIP_Clinch Time']
r1_ground_control_time = fight_stats_raw['Round1_TIP_Ground Control Time']
r1_guard_control_time = fight_stats_raw['Round1_TIP_Guard Control Time']
r1_half_guard_time = fight_stats_raw['Round1_TIP_Half Guard Control Time']
r1_misc_ground_control_time = fight_stats_raw['Round1_TIP_Misc. Ground Control Time']
r1_mount_control_time = fight_stats_raw['Round1_TIP_Mount Control Time']
r1_side_control_time = fight_stats_raw['Round1_TIP_Side Control Time']
#########################
# Round 2
# Total Strikes - Attempts and Landed
r2_total_strikes_att = fight_stats_raw['Round2_Strikes_Total Strikes_Attempts']
r2_total_strikes_landed = fight_stats_raw['Round2_Strikes_Total Strikes_Landed']
# Total Significant Strikes
r2_ss_att = fight_stats_raw['Round2_Strikes_Significant Strikes_Attempts']
r2_ss_landed = fight_stats_raw['Round2_Strikes_Significant Strikes_Landed']
# Total Opponent Significant Strikes
r2_opp_ss_att = fight_stats_raw['OPP_Round2_Strikes_Significant Strikes_Attempts']
r2_opp_ss_landed = fight_stats_raw['OPP_Round2_Strikes_Significant Strikes_Landed']
# Total Ground Strikes - Attempts and Landed
r2_ground_strikes_att = fight_stats_raw['Round2_Strikes_Ground Total Strikes_Attempts']
r2_ground_strikes_landed = fight_stats_raw['Round2_Strikes_Ground Total Strikes_Landed']
# Grappling Takedowns Attempts and Landed
r2_grappling_subm_att = fight_stats_raw['Round2_Grappling_Submissions_Attempts']
r2_grappling_TD_att = fight_stats_raw['Round2_Grappling_Takedowns_Attempts']
r2_grappling_TD_landed = fight_stats_raw['Round2_Grappling_Takedowns_Landed']
# Opponent Grappling Takedowns Attempts and Landed
r2_opp_TD_att = fight_stats_raw['OPP_Round2_Grappling_Takedowns_Attempts']
r2_opp_TD_landed = fight_stats_raw['OPP_Round2_Grappling_Takedowns_Landed']
# Grappling / Ground Time
r2_back_control_time = fight_stats_raw['Round2_TIP_Back Control Time']
r2_clinch_time = fight_stats_raw['Round2_TIP_Clinch Time']
r2_ground_control_time = fight_stats_raw['Round2_TIP_Ground Control Time']
r2_guard_control_time = fight_stats_raw['Round2_TIP_Guard Control Time']
r2_half_guard_time = fight_stats_raw['Round2_TIP_Half Guard Control Time']
r2_misc_ground_control_time = fight_stats_raw['Round2_TIP_Misc. Ground Control Time']
r2_mount_control_time = fight_stats_raw['Round2_TIP_Mount Control Time']
r2_side_control_time = fight_stats_raw['Round2_TIP_Side Control Time']
#########################
# Round 3
# Total Strikes - Attempts and Landed
r3_total_strikes_att = fight_stats_raw['Round3_Strikes_Total Strikes_Attempts']
r3_total_strikes_landed = fight_stats_raw['Round3_Strikes_Total Strikes_Landed']
# Total Significant Strikes
r3_ss_att = fight_stats_raw['Round3_Strikes_Significant Strikes_Attempts']
r3_ss_landed = fight_stats_raw['Round3_Strikes_Significant Strikes_Landed']
# Total Opponent Significant Strikes
r3_opp_ss_att = fight_stats_raw['OPP_Round3_Strikes_Significant Strikes_Attempts']
r3_opp_ss_landed = fight_stats_raw['OPP_Round3_Strikes_Significant Strikes_Landed']
# Total Ground Strikes - Attempts and Landed
r3_ground_strikes_att = fight_stats_raw['Round3_Strikes_Ground Total Strikes_Attempts']
r3_ground_strikes_landed = fight_stats_raw['Round3_Strikes_Ground Total Strikes_Landed']
# Grappling Takedowns Attempts and Landed
r3_grappling_subm_att = fight_stats_raw['Round3_Grappling_Submissions_Attempts']
r3_grappling_TD_att = fight_stats_raw['Round3_Grappling_Takedowns_Attempts']
r3_grappling_TD_landed = fight_stats_raw['Round3_Grappling_Takedowns_Landed']
# Opponent Grappling Takedowns Attempts and Landed
r3_opp_TD_att = fight_stats_raw['OPP_Round3_Grappling_Takedowns_Attempts']
r3_opp_TD_landed = fight_stats_raw['OPP_Round3_Grappling_Takedowns_Landed']
# Grappling / Ground Time
r3_back_control_time = fight_stats_raw['Round3_TIP_Back Control Time']
r3_clinch_time = fight_stats_raw['Round3_TIP_Clinch Time']
r3_ground_control_time = fight_stats_raw['Round3_TIP_Ground Control Time']
r3_guard_control_time = fight_stats_raw['Round3_TIP_Guard Control Time']
r3_half_guard_time = fight_stats_raw['Round3_TIP_Half Guard Control Time']
r3_misc_ground_control_time = fight_stats_raw['Round3_TIP_Misc. Ground Control Time']
r3_mount_control_time = fight_stats_raw['Round3_TIP_Mount Control Time']
r3_side_control_time = fight_stats_raw['Round3_TIP_Side Control Time']
#########################
# Round 4
# Total Strikes - Attempts and Landed
r4_total_strikes_att = fight_stats_raw['Round4_Strikes_Total Strikes_Attempts']
r4_total_strikes_landed = fight_stats_raw['Round4_Strikes_Total Strikes_Landed']
# Total Significant Strikes
r4_ss_att = fight_stats_raw['Round4_Strikes_Significant Strikes_Attempts']
r4_ss_landed = fight_stats_raw['Round4_Strikes_Significant Strikes_Landed']
# Total Opponent Significant Strikes
r4_opp_ss_att = fight_stats_raw['OPP_Round4_Strikes_Significant Strikes_Attempts']
r4_opp_ss_landed = fight_stats_raw['OPP_Round4_Strikes_Significant Strikes_Landed']
# Total Ground Strikes - Attempts and Landed
r4_ground_strikes_att = fight_stats_raw['Round4_Strikes_Ground Total Strikes_Attempts']
r4_ground_strikes_landed = fight_stats_raw['Round4_Strikes_Ground Total Strikes_Landed']
# Grappling Takedowns Attempts and Landed
r4_grappling_subm_att = fight_stats_raw['Round4_Grappling_Submissions_Attempts']
r4_grappling_TD_att = fight_stats_raw['Round4_Grappling_Takedowns_Attempts']
r4_grappling_TD_landed = fight_stats_raw['Round4_Grappling_Takedowns_Landed']
# Opponent Grappling Takedowns Attempts and Landed
r4_opp_TD_att = fight_stats_raw['OPP_Round4_Grappling_Takedowns_Attempts']
r4_opp_TD_landed = fight_stats_raw['OPP_Round4_Grappling_Takedowns_Landed']
# Grappling / Ground Time
r4_back_control_time = fight_stats_raw['Round4_TIP_Back Control Time']
r4_clinch_time = fight_stats_raw['Round4_TIP_Clinch Time']
r4_ground_control_time = fight_stats_raw['Round4_TIP_Ground Control Time']
r4_guard_control_time = fight_stats_raw['Round4_TIP_Guard Control Time']
r4_half_guard_time = fight_stats_raw['Round4_TIP_Half Guard Control Time']
r4_misc_ground_control_time = fight_stats_raw['Round4_TIP_Misc. Ground Control Time']
r4_mount_control_time = fight_stats_raw['Round4_TIP_Mount Control Time']
r4_side_control_time = fight_stats_raw['Round4_TIP_Side Control Time']
#########################
# Round 5
# Total Strikes - Attempts and Landed
r5_total_strikes_att = fight_stats_raw['Round5_Strikes_Total Strikes_Attempts']
r5_total_strikes_landed = fight_stats_raw['Round5_Strikes_Total Strikes_Landed']
# Total Significant Strikes
r5_ss_att = fight_stats_raw['Round5_Strikes_Significant Strikes_Attempts']
r5_ss_landed = fight_stats_raw['Round5_Strikes_Significant Strikes_Landed']
# Total Opponent Significant Strikes
r5_opp_ss_att = fight_stats_raw['OPP_Round5_Strikes_Significant Strikes_Attempts']
r5_opp_ss_landed = fight_stats_raw['OPP_Round5_Strikes_Significant Strikes_Landed']
# Total Ground Strikes - Attempts and Landed
r5_ground_strikes_att = fight_stats_raw['Round5_Strikes_Ground Total Strikes_Attempts']
r5_ground_strikes_landed = fight_stats_raw['Round5_Strikes_Ground Total Strikes_Landed']
# Grappling Takedowns Attempts and Landed
r5_grappling_subm_att = fight_stats_raw['Round5_Grappling_Submissions_Attempts']
r5_grappling_TD_att = fight_stats_raw['Round5_Grappling_Takedowns_Attempts']
r5_grappling_TD_landed = fight_stats_raw['Round5_Grappling_Takedowns_Landed']
# Opponent Grappling Takedowns Attempts and Landed
r5_opp_TD_att = fight_stats_raw['OPP_Round5_Grappling_Takedowns_Attempts']
r5_opp_TD_landed = fight_stats_raw['OPP_Round5_Grappling_Takedowns_Landed']
# Grappling / Ground Time
r5_back_control_time = fight_stats_raw['Round5_TIP_Back Control Time']
r5_clinch_time = fight_stats_raw['Round5_TIP_Clinch Time']
r5_ground_control_time = fight_stats_raw['Round5_TIP_Ground Control Time']
r5_guard_control_time = fight_stats_raw['Round5_TIP_Guard Control Time']
r5_half_guard_time = fight_stats_raw['Round5_TIP_Half Guard Control Time']
r5_misc_ground_control_time = fight_stats_raw['Round5_TIP_Misc. Ground Control Time']
r5_mount_control_time = fight_stats_raw['Round5_TIP_Mount Control Time']
r5_side_control_time = fight_stats_raw['Round5_TIP_Side Control Time']
# Build this out to get a summarized view of (fss) fighter significant strikes
fss_dict = {
'Name': name,
'estimated_minutes': estimated_minutes,
'Round1_Strikes_Total Strikes_Attempts': r1_total_strikes_att,
'Round1_Strikes_Total Strikes_Landed': r1_total_strikes_landed,
'Round1_Strikes_Significant Strikes_Attempts': r1_ss_att,
'Round1_Strikes_Significant Strikes_Landed': r1_ss_landed,
'OPP_Round1_Strikes_Significant Strikes_Attempts': r1_opp_ss_att,
'OPP_Round1_Strikes_Significant Strikes_Landed': r1_opp_ss_landed,
'Round1_Strikes_Ground Total Strikes_Attempts': r1_ground_strikes_att,
'Round1_Strikes_Ground Total Strikes_Landed': r1_ground_strikes_landed,
'Round1_Grappling_Submissions_Attempts': r1_grappling_subm_att,
'Round1_Grappling_Takedowns_Attempts': r1_grappling_TD_att,
'Round1_Grappling_Takedowns_Landed': r1_grappling_TD_landed,
'OPP_Round1_Grappling_Takedowns_Attempts': r1_opp_TD_att,
'OPP_Round1_Grappling_Takedowns_Landed': r1_opp_TD_landed,
'Round1_TIP_Back Control Time': r1_back_control_time,
'Round1_TIP_Clinch Time': r1_clinch_time,
'Round1_TIP_Ground Control Time': r1_ground_control_time,
'Round1_TIP_Guard Control Time': r1_guard_control_time,
'Round1_TIP_Half Guard Control Time': r1_half_guard_time,
'Round1_TIP_Misc. Ground Control Time': r1_misc_ground_control_time,
'Round1_TIP_Mount Control Time': r1_mount_control_time,
'Round1_TIP_Side Control Time': r1_side_control_time,
'Round2_Strikes_Total Strikes_Attempts': r2_total_strikes_att,
'Round2_Strikes_Total Strikes_Landed': r2_total_strikes_landed,
'Round2_Strikes_Significant Strikes_Attempts': r2_ss_att,
'Round2_Strikes_Significant Strikes_Landed': r2_ss_landed,
'OPP_Round2_Strikes_Significant Strikes_Attempts': r2_opp_ss_att,
'OPP_Round2_Strikes_Significant Strikes_Landed': r2_opp_ss_landed,
'Round2_Strikes_Ground Total Strikes_Attempts': r2_ground_strikes_att,
'Round2_Strikes_Ground Total Strikes_Landed': r2_ground_strikes_landed,
'Round2_Grappling_Submissions_Attempts': r2_grappling_subm_att,
'Round2_Grappling_Takedowns_Attempts': r2_grappling_TD_att,
'Round2_Grappling_Takedowns_Landed': r2_grappling_TD_landed,
'OPP_Round2_Grappling_Takedowns_Attempts': r2_opp_TD_att,
'OPP_Round2_Grappling_Takedowns_Landed': r2_opp_TD_landed,
'Round2_TIP_Back Control Time': r2_back_control_time,
'Round2_TIP_Clinch Time': r2_clinch_time,
'Round2_TIP_Ground Control Time': r2_ground_control_time,
'Round2_TIP_Guard Control Time': r2_guard_control_time,
'Round2_TIP_Half Guard Control Time': r2_half_guard_time,
'Round2_TIP_Misc. Ground Control Time': r2_misc_ground_control_time,
'Round2_TIP_Mount Control Time': r2_mount_control_time,
'Round2_TIP_Side Control Time': r2_side_control_time,
'Round3_Strikes_Total Strikes_Attempts': r3_total_strikes_att,
'Round3_Strikes_Total Strikes_Landed': r3_total_strikes_landed,
'Round3_Strikes_Significant Strikes_Attempts': r3_ss_att,
'Round3_Strikes_Significant Strikes_Landed': r3_ss_landed,
'OPP_Round3_Strikes_Significant Strikes_Attempts': r3_opp_ss_att,
'OPP_Round3_Strikes_Significant Strikes_Landed': r3_opp_ss_landed,
'Round3_Strikes_Ground Total Strikes_Attempts': r3_ground_strikes_att,
'Round3_Strikes_Ground Total Strikes_Landed': r3_ground_strikes_landed,
'Round3_Grappling_Submissions_Attempts': r3_grappling_subm_att,
'Round3_Grappling_Takedowns_Attempts': r3_grappling_TD_att,
'Round3_Grappling_Takedowns_Landed': r3_grappling_TD_landed,
'OPP_Round3_Grappling_Takedowns_Attempts': r3_opp_TD_att,
'OPP_Round3_Grappling_Takedowns_Landed': r3_opp_TD_landed,
'Round3_TIP_Back Control Time': r3_back_control_time,
'Round3_TIP_Clinch Time': r3_clinch_time,
'Round3_TIP_Ground Control Time': r3_ground_control_time,
'Round3_TIP_Guard Control Time': r3_guard_control_time,
'Round3_TIP_Half Guard Control Time': r3_half_guard_time,
'Round3_TIP_Misc. Ground Control Time': r3_misc_ground_control_time,
'Round3_TIP_Mount Control Time': r3_mount_control_time,
'Round3_TIP_Side Control Time': r3_side_control_time,
'Round4_Strikes_Total Strikes_Attempts': r4_total_strikes_att,
'Round4_Strikes_Total Strikes_Landed': r4_total_strikes_landed,
'Round4_Strikes_Significant Strikes_Attempts': r4_ss_att,
'Round4_Strikes_Significant Strikes_Landed': r4_ss_landed,
'OPP_Round4_Strikes_Significant Strikes_Attempts': r4_opp_ss_att,
'OPP_Round4_Strikes_Significant Strikes_Landed': r4_opp_ss_landed,
'Round4_Strikes_Ground Total Strikes_Attempts': r4_ground_strikes_att,
'Round4_Strikes_Ground Total Strikes_Landed': r4_ground_strikes_landed,
'Round4_Grappling_Submissions_Attempts': r4_grappling_subm_att,
'Round4_Grappling_Takedowns_Attempts': r4_grappling_TD_att,
'Round4_Grappling_Takedowns_Landed': r4_grappling_TD_landed,
'OPP_Round4_Grappling_Takedowns_Attempts': r4_opp_TD_att,
'OPP_Round4_Grappling_Takedowns_Landed': r4_opp_TD_landed,
'Round4_TIP_Back Control Time': r4_back_control_time,
'Round4_TIP_Clinch Time': r4_clinch_time,
'Round4_TIP_Ground Control Time': r4_ground_control_time,
'Round4_TIP_Guard Control Time': r4_guard_control_time,
'Round4_TIP_Half Guard Control Time': r4_half_guard_time,
'Round4_TIP_Misc. Ground Control Time': r4_misc_ground_control_time,
'Round4_TIP_Mount Control Time': r4_mount_control_time,
'Round4_TIP_Side Control Time': r4_side_control_time,
'Round5_Strikes_Total Strikes_Attempts': r5_total_strikes_att,
'Round5_Strikes_Total Strikes_Landed': r5_total_strikes_landed,
'Round5_Strikes_Significant Strikes_Attempts': r5_ss_att,
'Round5_Strikes_Significant Strikes_Landed': r5_ss_landed,
'OPP_Round5_Strikes_Significant Strikes_Attempts': r5_opp_ss_att,
'OPP_Round5_Strikes_Significant Strikes_Landed': r5_opp_ss_landed,
'Round5_Strikes_Ground Total Strikes_Attempts': r5_ground_strikes_att,
'Round5_Strikes_Ground Total Strikes_Landed': r5_ground_strikes_landed,
'Round5_Grappling_Submissions_Attempts': r5_grappling_subm_att,
'Round5_Grappling_Takedowns_Attempts': r5_grappling_TD_att,
'Round5_Grappling_Takedowns_Landed': r5_grappling_TD_landed,
'OPP_Round5_Grappling_Takedowns_Attempts': r5_opp_TD_att,
'OPP_Round5_Grappling_Takedowns_Landed': r5_opp_TD_landed,
'Round5_TIP_Back Control Time': r5_back_control_time,
'Round5_TIP_Clinch Time': r5_clinch_time,
'Round5_TIP_Ground Control Time': r5_ground_control_time,
'Round5_TIP_Guard Control Time': r5_guard_control_time,
'Round5_TIP_Half Guard Control Time': r5_half_guard_time,
'Round5_TIP_Misc. Ground Control Time': r5_misc_ground_control_time,
'Round5_TIP_Mount Control Time': r5_mount_control_time,
'Round5_TIP_Side Control Time': r5_side_control_time
}
fss_df = pd.DataFrame(fss_dict)
fss_df = fss_df.groupby(['Name']).sum()
#fss_df
# list out all column names for analysis
column_names_fss = fss_df.columns.values
for i in enumerate(column_names_fss):
print(i)
# Create a function to sum across columns in a dataframe (Rounds 1 thru Rounds 5)
def sum_frame_by_column(frame, new_col_name, list_of_cols_to_sum):
frame[new_col_name] = frame[list_of_cols_to_sum].astype(float).sum(axis=1)
return(frame)
sum_frame_by_column(fss_df, 'Total (R1-R5) Strikes Attempts',
['Round1_Strikes_Total Strikes_Attempts',
'Round2_Strikes_Total Strikes_Attempts',
'Round3_Strikes_Total Strikes_Attempts',
'Round4_Strikes_Total Strikes_Attempts',
'Round5_Strikes_Total Strikes_Attempts'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Strikes Landed',
['Round1_Strikes_Total Strikes_Landed',
'Round2_Strikes_Total Strikes_Landed',
'Round3_Strikes_Total Strikes_Landed',
'Round4_Strikes_Total Strikes_Landed',
'Round5_Strikes_Total Strikes_Landed'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Significant Strikes Attempts',
['Round1_Strikes_Significant Strikes_Attempts',
'Round2_Strikes_Significant Strikes_Attempts',
'Round3_Strikes_Significant Strikes_Attempts',
'Round4_Strikes_Significant Strikes_Attempts',
'Round5_Strikes_Significant Strikes_Attempts'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Significant Strikes Landed',
['Round1_Strikes_Significant Strikes_Landed',
'Round2_Strikes_Significant Strikes_Landed',
'Round3_Strikes_Significant Strikes_Landed',
'Round4_Strikes_Significant Strikes_Landed',
'Round5_Strikes_Significant Strikes_Landed'])
sum_frame_by_column(fss_df, 'Opponent Total (R1-R5) Significant Strikes Attempts',
['OPP_Round1_Strikes_Significant Strikes_Attempts',
'OPP_Round2_Strikes_Significant Strikes_Attempts',
'OPP_Round3_Strikes_Significant Strikes_Attempts',
'OPP_Round4_Strikes_Significant Strikes_Attempts',
'OPP_Round5_Strikes_Significant Strikes_Attempts'])
sum_frame_by_column(fss_df, 'Opponent Total (R1-R5) Significant Strikes Landed',
['OPP_Round1_Strikes_Significant Strikes_Landed',
'OPP_Round2_Strikes_Significant Strikes_Landed',
'OPP_Round3_Strikes_Significant Strikes_Landed',
'OPP_Round4_Strikes_Significant Strikes_Landed',
'OPP_Round5_Strikes_Significant Strikes_Landed'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Ground Total Strikes_Attempts',
['Round1_Strikes_Ground Total Strikes_Attempts',
'Round2_Strikes_Ground Total Strikes_Attempts',
'Round3_Strikes_Ground Total Strikes_Attempts',
'Round4_Strikes_Ground Total Strikes_Attempts',
'Round5_Strikes_Ground Total Strikes_Attempts'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Ground Total Strikes_Landed',
['Round1_Strikes_Ground Total Strikes_Landed',
'Round2_Strikes_Ground Total Strikes_Landed',
'Round3_Strikes_Ground Total Strikes_Landed',
'Round4_Strikes_Ground Total Strikes_Landed',
'Round5_Strikes_Ground Total Strikes_Landed'])
sum_frame_by_column(fss_df, 'Total_R1-R5_Grappling_Submissions_Attempts',
['Round1_Grappling_Submissions_Attempts',
'Round2_Grappling_Submissions_Attempts',
'Round3_Grappling_Submissions_Attempts',
'Round4_Grappling_Submissions_Attempts',
'Round5_Grappling_Submissions_Attempts'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Grappling Takedowns Attempts',
['Round1_Grappling_Takedowns_Attempts',
'Round2_Grappling_Takedowns_Attempts',
'Round3_Grappling_Takedowns_Attempts',
'Round4_Grappling_Takedowns_Attempts',
'Round5_Grappling_Takedowns_Attempts'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Grappling Takedowns Landed',
['Round1_Grappling_Takedowns_Landed',
'Round2_Grappling_Takedowns_Landed',
'Round3_Grappling_Takedowns_Landed',
'Round4_Grappling_Takedowns_Landed',
'Round5_Grappling_Takedowns_Landed'])
sum_frame_by_column(fss_df, 'Opponent Total (R1-R5) Grappling Takedowns Attempts',
['OPP_Round1_Grappling_Takedowns_Attempts',
'OPP_Round2_Grappling_Takedowns_Attempts',
'OPP_Round3_Grappling_Takedowns_Attempts',
'OPP_Round4_Grappling_Takedowns_Attempts',
'OPP_Round5_Grappling_Takedowns_Attempts'])
sum_frame_by_column(fss_df, 'Opponent Total (R1-R5) Grappling Takedowns Landed',
['OPP_Round1_Grappling_Takedowns_Landed',
'OPP_Round2_Grappling_Takedowns_Landed',
'OPP_Round3_Grappling_Takedowns_Landed',
'OPP_Round4_Grappling_Takedowns_Landed',
'OPP_Round5_Grappling_Takedowns_Landed'])
sum_frame_by_column(fss_df, 'Total (R1-R5) Grappling Time',
['Round1_TIP_Back Control Time',
'Round2_TIP_Back Control Time',
'Round3_TIP_Back Control Time',
'Round4_TIP_Back Control Time',
'Round5_TIP_Back Control Time',
# 'Round1_TIP_Clinch Time',
# 'Round2_TIP_Clinch Time',
# 'Round3_TIP_Clinch Time',
# 'Round4_TIP_Clinch Time',
# 'Round5_TIP_Clinch Time',
'Round1_TIP_Ground Control Time',
'Round2_TIP_Ground Control Time',
'Round3_TIP_Ground Control Time',
'Round4_TIP_Ground Control Time',
'Round5_TIP_Ground Control Time',
'Round1_TIP_Guard Control Time',
'Round2_TIP_Guard Control Time',
'Round3_TIP_Guard Control Time',
'Round4_TIP_Guard Control Time',
'Round5_TIP_Guard Control Time',
'Round1_TIP_Half Guard Control Time',
'Round2_TIP_Half Guard Control Time',
'Round3_TIP_Half Guard Control Time',
'Round4_TIP_Half Guard Control Time',
'Round5_TIP_Half Guard Control Time',
'Round1_TIP_Misc. Ground Control Time',
'Round2_TIP_Misc. Ground Control Time',
'Round3_TIP_Misc. Ground Control Time',
'Round4_TIP_Misc. Ground Control Time',
'Round5_TIP_Misc. Ground Control Time',
'Round1_TIP_Mount Control Time',
'Round2_TIP_Mount Control Time',
'Round3_TIP_Mount Control Time',
'Round4_TIP_Mount Control Time',
'Round5_TIP_Mount Control Time',
])
# Get Column Names and Indices for Updated DataFrame
# column_names_fss_summary = fss_df.columns.values
# for i in enumerate(column_names_fss_summary):
# print(i)
# Drop all rounds breakdown columns
fss_df.drop(fss_df.iloc[:, 1:106], inplace=True, axis=1)
# View Updated fss_df for summary and minutes to enable career statistics calucations
fss_df.head()
# Get Column Names and Indices for Final fss_df
col_names_fss_final = fss_df.columns.values
for i in enumerate(col_names_fss_final):
print(i)
# checking completeness for new columns (total strikes attempt)
# check = 'Total (R1-R5) Grappling Time'
# fss_df[check].unique()
# fss_df[check].count()
fss_df['Total (R1-R5) Grappling Time'] = fss_df.iloc[:,14] / (15*60) # total grappling time in mins / (15 mins* 60seconds)
fss_df['Total (R1-R5) Grappling Actions(Grd. Strikes + (Sub & TD Attempts)'] = fss_df.iloc[:,7] + fss_df.iloc[:, 9] + fss_df.iloc[:,10]
fss_df['Total (R1-R5) Striking, Standing, and Clinch Time'] = fss_df.iloc[:,0] - fss_df.iloc[:,14]
fss_df.sort_values('Total (R1-R5) Grappling Time', ascending=False)
col_names_fss_final2 = fss_df.columns.values
for i in enumerate(col_names_fss_final2):
print(i)
# fss_df.iloc[:,14].unique()
fss_df_new = fss_df.drop(fss_df[(fss_df['Total (R1-R5) Strikes Attempts'] == 0) & (fss_df['Total (R1-R5) Grappling Actions(Grd. Strikes + (Sub & TD Attempts)'] == 0)].index)
fss_df.loc[fss_df['Total (R1-R5) Grappling Time'] < 5, 'Total (R1-R5) Grappling Time'] = 5
fss_df.loc[fss_df['Total (R1-R5) Grappling Actions(Grd. Strikes + (Sub & TD Attempts)'] == 0, 'Total (R1-R5) Grappling Actions(Grd. Strikes + (Sub & TD Attempts)'] = 1
fss_df_new['Total Striking Attempts to Grappling Action Attempts Ratio'] = fss_df.iloc[:,1] / fss_df.iloc[:,15]
fss_df_new['Total Striking Time to Grappling Action Time Ratio'] = fss_df.iloc[:,16] / fss_df.iloc[:,14]
# Sort to change views
# fss_df.sort_values('Total (R1-R5) Grappling Actions(Grd. Strikes + (Sub & TD Attempts)', ascending=False)
# fss_df.sort_values('Total (R1-R5) Grappling Time', ascending=True)
fss_df_new
```
### Career Statistics Calcuations
#### January 5, 2014 thru October 8, 2018
SLpM - Significant Strikes Landed per Minute
Str. Acc. - Significant Striking Accuracy
SApM - Significant Strikes Absorbed per Minute
Str. Def. - Significant Strike Defence (the % of opponents strikes that did not land)
TD Avg. - Average Takedowns Landed per minute
TD Acc. - Takedown Accuracy
TD Def. - Takedown Defense (the % of opponents TD attempts that did not land)
Sub. Avg. - Average Submissions Attempted per minute
```
# # Use the indices to calculate the following:
# # Create new columns that will be store the results of the calculations below:
# fss_df['Significant Strikes Landed per Minute'] = fss_df.iloc[:, 2] / fss_df.iloc[:, 0]
# fss_df['Str. Acc. - Significant Striking Accuracy'] = fss_df.iloc[:, 2] / fss_df.iloc[:, 1]
# fss_df['Significant Strikes Absorbed per Minute'] = fss_df.iloc[:, 4] / fss_df.iloc[:, 0]
# fss_df['Significant Strike Defence (% of Opponents Strikes Missed)'] = (fss_df.iloc[:, 3] - fss_df.iloc[:, 4]) / fss_df.iloc[:, 0]
# fss_df['Average Takedowns Landed per minute'] = fss_df.iloc[:, 3] / fss_df.iloc[:, 0] # UFC website is "Average Takedowns Landed per 15 minutes"
# fss_df['TD Acc. - Takedown Accuracy'] = fss_df.iloc[:, 7] / fss_df.iloc[:, 6]
# fss_df['Takedown Defense (% of opponents TD attempts missed)'] = (fss_df.iloc[:, 8] - fss_df.iloc[:, 9]) / fss_df.iloc[:, 8]
# fss_df['Sub. Avg. - Average Submissions Attempted per minute'] = fss_df.iloc[:, 5] / fss_df.iloc[:, 0] # Sub. Avg. - Average Submissions Attempted per 15 minutes"
# fss_df
```
### Machine Learning Metrics to Build Classifer for: Striker, Grappler, or FreeStyle Fighter:
- Total Strikes Attempted*
- Total Strikes Landed
- Total Ground Strikes Attempted*
- Total Ground Strikes Landed
-
```
#print(col_names_fss_final)
# was working?
# for i in col_names_fss_final:
# fss_df[i].astype(str).str.replace("nan", "0").astype(float)
# Extra Notes
# fss_df[i].astype(str).str.replace("", "0").astype(float)
# fss_df['Str. Acc. - Significant Striking Accuracy'].astype(str).str.replace("nan", "0").astype(float)
# #
# may work.
# for i in col_names_fss_final:
# fss_df[i].astype(str).str.replace("NaN", "0").astype(float)
# # Clean up all the "NaN" in these 3 columns
# updated_ss_accuracy = fss_df['Str. Acc. - Significant Striking Accuracy'].astype(str).str.replace("nan", "0").astype(float)
# updated_TD_accuracy = fss_df['TD Acc. - Takedown Accuracy'].astype(str).str.replace("nan", "0").astype(float)
# updated_TD_defense = fss_df['Takedown Defense (% of opponents TD attempts missed)'].astype(str).str.replace("nan", "0").astype(float)
# #fss_df['Str. Acc. - Significant Striking Accuracy'].count()
# #fss_df
# fss_df["Str. Acc. - Significant Striking Accuracy"] = updated_ss_accuracy
# # fss_df["TD Acc. - Takedown Accuracy"] = updated_TD_accuracy
# fss_df["Takedown Defense (% of opponents TD attempts missed)"] = updated_TD_defense
# fss_df.info()
# fss_df
# save to csv
fss_df_new.to_csv('fss_df_draft.csv')
```
| github_jupyter |
# Duckietown NCTU - Tutorial 3: Finite State Machine
By Chang-Yi Kuo, Brian Chuang, and Nick Wang
Before you run this jupyter notebook on your duckietop, make sure you
```sh
duckietop $ source ~/duckietown/environment.sh
duckietop $ source ~/duckietown/set_ros_master.sh duckiebot # your duckiebot
```
On duckiebot, You should also start a the launch
```sh
duckiebot $ roslaunch duckietown_kaku AGV.launch veh:=duckiebot
```
If you duckiebot is almost full, you could clean the cache files (~500MB).
```sh
duckiebot $ sudo apt-get clean
```
## Import Packages
```
import numpy as np
import scipy as sp
import cv2
import time
from matplotlib import pyplot as plt
%matplotlib inline
# set display defaults
plt.rcParams['figure.figsize'] = (10, 10) # large images
plt.rcParams['image.interpolation'] = 'nearest' # don't interpolate: show square pixels
```
## ROS Setup
```
import sys
# rospy
sys.path.insert(0, '/opt/ros/indigo/lib/python2.7/dist-packages')
# rospkg
sys.path.insert(0, '/usr/lib/python2.7/dist-packages/')
# duckietown_msgs
duckietown_root = '../../' # this file should be run from {duckietown_root}/turorials/python (otherwise change this line)
sys.path.insert(0, duckietown_root + 'catkin_ws/devel/lib/python2.7/dist-packages')
import rospy
from duckietown_msgs.msg import Twist2DStamped, BoolStamped
```
### initial a rosnode
```
rospy.init_node("jupyter_control",anonymous=False)
#please replace "trabant" with your duckiebot name
pub_car_cmd = rospy.Publisher("/buyme/jupyter_control/car_cmd",Twist2DStamped,queue_size=1)
# car_cmd_switch should do the mapping according current state
#pub_car_cmd = rospy.Publisher("/trabant/car_cmd_switch_node/cmd",Twist2DStamped,queue_size=1)
#
pub_at_stop_line = rospy.Publisher("/buyme/stop_line_filter_node/at_stop_line", BoolStamped, queue_size=1)
```
### define function for publishing car command
```
def car_command(v, omega, duration):
# Send stop command
car_control_msg = Twist2DStamped()
car_control_msg.v = v
car_control_msg.omega = omega
pub_car_cmd.publish(car_control_msg)
rospy.sleep(duration)
#rospy.loginfo("Shutdown")
car_control_msg.v = 0.0
car_control_msg.omega = 0.0
pub_car_cmd.publish(car_control_msg)
```
## Observe the Topics
Something you should care here:
The current state
* /trabant/fsm_node/mode
Car commands from different nodes
* /trabant/lane_controller_node/car_cmd
* /trabant/joy_mapper_node/car_cmd
* /trabant/jupyter_control/car_cmd
The car_cmd above should switch to the following for dagu_car
* /trabant/car_cmd_switch_node/cmd
```
%%bash
rostopic list
```
## FSM State
Use byobu to open a new terminal
duckiebot/duckietop $ rostopic echo /duckiebot/fsm_node/mode
### Set State
```
%%bash
rosservice call /trabant/fsm_node/set_state LANE_FOLLOWING
%%bash
rosservice call /trabant/fsm_node/set_state JOYSTICK_CONTROL
%%bash
rosservice call /trabant/fsm_node/set_state JUPYTER_CONTROL
```
## Testing JUPYTER_CONTROL mode
### Ex1: Forward 0.5 Tile Width
```
car_command(0.5, 0, 0.75)
```
### EX2: Turn 45 or 90 Degrees
```
car_command(0.2, 4, 1.25)
```
* switch
```
class switch(object):
def __init__(self, value):
self.value = value
self.fall = False
def __iter__(self):
"""Return the match method once, then stop"""
yield self.match
raise StopIteration
def match(self, *args):
"""Indicate whether or not to enter a case suite"""
if self.fall or not args:
return True
elif self.value in args: # changed for v1.5, see below
self.fall = True
return True
else:
return False
```
### motion planing lookup function
## def motion_planing(concat):
for i in range(len(concat)):
primitives = concat[i]
for case in switch(primitives):
if case('S'):
car_command(0.5, 0, 0.6)
break
if case('L'):
car_command(0.2, 4, 0.7)
break
if case('R'):
car_command(0.2, -4, 0.5)
break
if case('B'):
car_command(-0.4, 0, 0.5)
break
### example: overtaking
```
overtaking = "LSRSSRSLSS"
motion_planing(overtaking)
```
### example: parking
```
parking = "BBLBBB"
motion_planing(parking)
```
## Use Perception-based Event to Trgger
### Back to LANE_FOLLOWING first
```
%%bash
rosservice call /trabant/fsm_node/set_state LANE_FOLLOWING
```
### Try to send a at_stop_line when duckiebot sees it
Please keep seeing the changes in rostopic echo
```
img = cv2.imread('01-tutorial/stop.jpg')
dst = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.subplot(121),plt.imshow(dst, cmap = 'brg')
plt.title('Stop Line 1'), plt.xticks([]), plt.yticks([])
plt.show()
# Some magic stop line detection, and turned out that duckiebot sees a stop line
at_stop_line = True
if at_stop_line:
msg = BoolStamped()
msg.header.stamp = rospy.get_rostime()
msg.data = True
pub_at_stop_line.publish(msg)
```
You should see something like this
```
...
state: LANE_FOLLOWING
...
state: COORDINATION
...
state: INTERSECTION_CONTROL
...
```
## How FSM works in Duckietown
```
%%bash
rosservice call /trabant/fsm_node/set_state JUPYTER_CONTROL
```
### set a new state and events
See
```
JUPYTER_CONTROL
transisitons:
at_stop_line: "COORDINATION"
...
```
```
!cat '../../catkin_ws/src/duckietown/config/baseline/fsm/fsm_node/arg.yaml'
```
### car_cmd_switch
This will map the the desired car_cmd into "car_cmd_switch_node/cmd" based on current state
```
!cat '../../catkin_ws/src/duckietown/config/baseline/dagu_car/car_cmd_switch_node/arg.yaml'
```
### Send a at_stop_line event again
```
img = cv2.imread('01-tutorial/stop.jpg')
dst = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.subplot(121),plt.imshow(dst, cmap = 'brg')
plt.title('Stop Line 1'), plt.xticks([]), plt.yticks([])
plt.show()
# Some magic stop line detection, and turned out that duckiebot sees a stop line
at_stop_line = True
if at_stop_line:
msg = BoolStamped()
msg.header.stamp = rospy.get_rostime()
msg.data = True
pub_at_stop_line.publish(msg)
```
You should see something like this:
```
secs: 1481440270
nsecs: 387316942
frame_id: ''
state: JUPYTER_CONTROL
---
header:
seq: 11
stamp:
secs: 1481440708
nsecs: 640530109
frame_id: ''
state: COORDINATION
---
header:
seq: 12
stamp:
secs: 1481440708
nsecs: 640530109
frame_id: ''
state: INTERSECTION_CONTROL
```
| github_jupyter |
# Categorical and missing data
> This tutorial explores further concepts in Numpy such as, categorical data, advanced indexing and dealing with Not-a-Number (NaN) data.
- toc: false
- badges: true
- comments: true
- categories: [numpy]
#### Before we start with this tutorial, let's have a quick look at a data structure in Python called dictionary. This will help us understand some of the materials in the tutorial and also will help to introduce XArray later on.
#### A dictionary represents a mapping between keys and values. The keys and values are Python objects of any type. We declare a dictionary using curly braces. Inside we can specify the keys and values using `:` as a separator and and commas to separate elements in the dictionary. For example:
```
d = {1: 'one',
2: 'two',
3: 'tree'}
```
#### Then we can address or lookup elements in a dictionary using the `[ key_name ]` to address the value stored under a key. For example:
```
print(d[1], " + ", d[2], " = ", d[3])
```
#### Elements in a dictionary can be modified or new elements added by doing:
```
d[3] = 'three'
d[4] = 'four'
print(d[1], " + ", d[2], " = ", d[3])
```
#### We start now this tutorial by importing some libraries:
```
%matplotlib inline
import numpy as np
import imageio
from matplotlib import pyplot as plt
from matplotlib import colors
from check_answer import check_answer
```
#### Categorical data: sometimes remote sensing is used to create classification products. These products do not contain continuous values. They use discrete values to represent the different classes individual pixels can belong to.
#### As an example, the following cell simulates a very simple image containing three different land cover types. Value `1` represents area covered with grass, `2` croplands and `3` city.
```
# grass = 1
area = np.ones((100,100))
# crops = 2
area[10:60,20:50] = 2
# city = 3
area[70:90,60:80] = 3
area.shape, area.dtype, np.unique(area)
```
#### To visualise the previous array as an image, we are going to define our own colour map using a dictionary in which we can map values to colours:
```
# We map the values to colours
index = {1: 'green', 2: 'yellow', 3: 'grey'}
# Create a discrete colour map
cmap = colors.ListedColormap(index.values())
# Plot
plt.imshow(area, cmap=cmap)
```
#### Exercise 4.1: The harvesting season has arrived and our cropping lands have changed colour to brown. Can you:
1. Modify the yellow area to contain the new value `4`?
2. Add a new entry to the `index` dictionary mapping number `4` to the value `brown`
```
area?
index? = ?
# Regenerate discrete colour map
cmap = colors.ListedColormap(index.values())
# Plot
plt.imshow(area, cmap=cmap)
check_answer("4.1.1", area[20,30]), check_answer("4.1.2", index[4])
```
#### Masking out regions is a very common practice in remote sensing analysis. For example, the following image reprensents a fake remote sensing image containing a few typical features.
<img src="data/land_mask.png" alt="drawing" width="220" align="left"/>
#### We start by loading the previous image into a numpy array:
```
im = imageio.imread('data/land_mask.png')
plt.imshow(im)
```
#### In remote sensing analysis it's common to be interested in analysing certain features from the Earth surface such as vegetation. Clouds, cloud shadows and even water bodies need to be normally removed or 'masked' in order to process the data.
#### For this example, we have three files containing numpy arrays `.npy` which represent the masks to filter clouds, shadows and water from our image.
```
import matplotlib.gridspec as gridspec
plt.figure(figsize=(12,8))
gs = gridspec.GridSpec(1,3) # set up a 1 x 3 grid of images
ax1=plt.subplot(gs[0,0])
water_mask = np.load("data/water_mask.npy")
plt.imshow(water_mask)
ax1.set_title('Water Mask')
ax2=plt.subplot(gs[0,1])
cloud_mask = np.load("data/cloud_mask.npy")
plt.imshow(cloud_mask)
ax2.set_title('Cloud Mask')
ax3=plt.subplot(gs[0,2])
shadow_mask = np.load("data/shadow_mask.npy")
plt.imshow(shadow_mask)
ax3.set_title('Shadow Mask')
plt.show()
```
#### These masks are stored as `dtype=uint8` using `1` to indicate presence and `0` for absence of each feature.
#### Exercise 4.2: Can you use the water mask to set all the pixels in the image array representing water to 0?
> Tip: Remember that boolean arrays can be used to index and select regions of another array. To complete this exercise you will need to convert the previous water mask array into boolean types before you can use it.
```
# 1.- Load the image
answ = imageio.imread('data/land_mask.png')
# 2.- Create a boolean version of the water_mask array
bool_water_mask = ?
# 3.- Use the previous boolean array to set all pixels in the answ array to 0
answ[?] = ?
# You should see the region with water white
plt.imshow(answ)
check_answer("4.2", answ[200,200])
```
#### Exercise 4.3: Can you do the same as in the previous exercise but now setting to zero the areas covered by clouds, shadows and water?
```
# 1.- Load the image
answ = imageio.imread('data/land_mask.png')
# 2.- Create boolean versions of the masks
bool_water_mask = ?
bool_cloud_mask = ?
bool_shadow_mask = ?
# 3.- Use the previous boolean arrays to set all pixels in the answ array to 0 (You might need more than one line)
answ[?] = ?
# You should see just green and all the other regions white
plt.imshow(answ)
check_answer("4.3", answ[200,200]+answ[100,100]+answ[100,180]+answ[0,0])
```
#### The previous example demonstrates how categorical data can be used to describe and filter remote sensing images.
#### In practice, we could have used one array to store our three classes. For example, we could have used the value `1` to designate areas with water, `2` for clouds and `3` for cloud shadows:
```
mask = water_mask*1 + cloud_mask*2 + shadow_mask*3
plt.imshow(mask)
```
#### But this way of representing categories is not very convenient for the case when we can have pixels that can belong to two or more categories at the same time. For example, if we have a pixel that is classified as a cloud shadow and water at the same time, we would need to come up with a new category to represent this case.
#### Instead, it's a common practice to use bit flags to create these masking or pixel quality products. Bit flags use the binary representation of a number (using 0s and 1s) to encode the different categories. For example a uint8 number can store values in the range [0-255] and is internally represented with 8 bits which can be either 0 or 1.
#### In our previous case we could have used the following encoding:
* Bit 0: Water
`00000001` -> 1
* Bit 1: Cloud
`00000010` -> 2
* Bit 2: Shadow
`00000100`-> 4
#### So, if one pixel is both classified as shadow and water, this pixel would be encoded by the value `5`:
* `00000101` -> 5
#### Exercise 4.4: How would you represent a pixel that is a cloud and a shadow at the same time?
```
answ = ?
# Print binary format of answ
print(f"{answ:08b}")
check_answer("4.4", answ)
```
#### Some remote sensing collections contain ancillary data describing the quality of each pixel. Below, you can see the table representing how to interpret the bit flags for the Landsat 8 pixel quality product. This product gives information about the quality of each pixel in the reflectance product.
<img src="data/ls8_pq.png" alt="drawing" width="220" align="left"/>
#### And this is a real example of a pixel quality Landsat 8 image over Margaret River encoded using the previous bit flags.
```
pq = imageio.imread('data/LC08_L1TP_112084_20190820_20190902_01_T1_BQA.tiff')
plt.imshow(pq)
pq.shape, pq.dtype, np.unique(pq)
```
#### For the value `2720` we can see the binary representation doing:
```
"{:016b}".format(2720)
```
#### Starting from the right, we find:
* bit 5 = 1 -> Cloud
* bits 6,7 = 10 -> Medium confidence
* bits 8,9 = 10 -> Cirrus medium confidence
* bit 11 = 1 -> We don't know, not included in the table
#### Exercise 4.5: Can you work out what is the Cirrus confidence interpretation for the `2976` value in the PQ mask?
```
print("{:016b}".format(2976))
answ = ?# Choose one of "None", "Low", "Medium", "High"
check_answer("4.5", answ)
```
#### Analysing data with NaNs. NaN is a special value of `float32` and `float64` arrays used to designate Not-a-Number values. For example:
```
arr = np.array([1,2,3,4,5,np.nan,7,8,9], dtype=np.float32)
arr
```
#### To compute statistics on arrays containing NaN values, Numpy has special versions of common functions such as `mean`, `std` or `sum` that ignore the NaN values:
```
print(np.mean(arr))
print(np.nanmean(arr))
```
#### We have been previously filtering out water and cloud effects from images by setting the pixels to `0`. However, if we are interested in performing statistics to summarise the information in the image, this could be problematic. For example, consider the following uint16 array in which the value `0` designates no data. If we want to compute the mean of all the valid values, we can do converting the array to float type and then assigning the value `0` to NaN.
```
arr = np.array([234,243,0,231,219,0,228,220,237], dtype=np.uint16)
print("0s mean:", np.mean(arr))
arr = arr.astype(np.float32)
arr[arr==0]=np.nan
print("NaNs mean:", np.nanmean(arr))
```
#### Exercise 4.6: Can you calculate the mean value of the green channel for just the area covered with grass in the following image?
<img src="data/land_mask.png" alt="drawing" width="220" align="left"/>
```
# 1.- Load the image
im = imageio.imread('data/land_mask.png')
# 2.- Select green channel
im = ?
# 3.- Change the type of im to float32
im = ?
# 4.- Use the previous boolean array to set all pixels other than grass to NaN
im?
# You should see the all NaN regions white
plt.imshow(im)
# 5.- Calculate the mean value
answ = ?
check_answer("4.6", int(answ))
```
| github_jupyter |
# Classify Structured Data
## Import TensorFlow and Other Libraries
```
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow import feature_column
from os import getcwd
from sklearn.model_selection import train_test_split
```
## Use Pandas to Create a Dataframe
[Pandas](https://pandas.pydata.org/) is a Python library with many helpful utilities for loading and working with structured data. We will use Pandas to download the dataset and load it into a dataframe.
```
filePath = f"{getcwd()}/../tmp2/heart.csv"
dataframe = pd.read_csv(filePath)
dataframe.head()
```
## Split the Dataframe Into Train, Validation, and Test Sets
The dataset we downloaded was a single CSV file. We will split this into train, validation, and test sets.
```
train, test = train_test_split(dataframe, test_size=0.2)
train, val = train_test_split(train, test_size=0.2)
print(len(train), 'train examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
```
## Create an Input Pipeline Using `tf.data`
Next, we will wrap the dataframes with [tf.data](https://www.tensorflow.org/guide/datasets). This will enable us to use feature columns as a bridge to map from the columns in the Pandas dataframe to features used to train the model. If we were working with a very large CSV file (so large that it does not fit into memory), we would use tf.data to read it from disk directly.
```
# EXERCISE: A utility method to create a tf.data dataset from a Pandas Dataframe.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
# Use Pandas dataframe's pop method to get the list of targets.
labels = dataframe.pop('target')
# Create a tf.data.Dataset from the dataframe and labels.
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe),labels))
if shuffle:
# Shuffle dataset.
ds = ds.shuffle(buffer_size = len(dataframe))
# Batch dataset with specified batch_size parameter.
ds = ds.batch(batch_size)
return ds
batch_size = 5 # A small batch sized is used for demonstration purposes
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
```
## Understand the Input Pipeline
Now that we have created the input pipeline, let's call it to see the format of the data it returns. We have used a small batch size to keep the output readable.
```
for feature_batch, label_batch in train_ds.take(1):
print('Every feature:', list(feature_batch.keys()))
print('A batch of ages:', feature_batch['age'])
print('A batch of targets:', label_batch )
```
We can see that the dataset returns a dictionary of column names (from the dataframe) that map to column values from rows in the dataframe.
## Create Several Types of Feature Columns
TensorFlow provides many types of feature columns. In this section, we will create several types of feature columns, and demonstrate how they transform a column from the dataframe.
```
# Try to demonstrate several types of feature columns by getting an example.
example_batch = next(iter(train_ds))[0]
# A utility method to create a feature column and to transform a batch of data.
def demo(feature_column):
feature_layer = layers.DenseFeatures(feature_column, dtype='float64')
print(feature_layer(example_batch).numpy())
```
### Numeric Columns
The output of a feature column becomes the input to the model (using the demo function defined above, we will be able to see exactly how each column from the dataframe is transformed). A [numeric column](https://www.tensorflow.org/api_docs/python/tf/feature_column/numeric_column) is the simplest type of column. It is used to represent real valued features.
```
# EXERCISE: Create a numeric feature column out of 'age' and demo it.
age = feature_column.numeric_column('age')
demo(age)
```
In the heart disease dataset, most columns from the dataframe are numeric.
### Bucketized Columns
Often, you don't want to feed a number directly into the model, but instead split its value into different categories based on numerical ranges. Consider raw data that represents a person's age. Instead of representing age as a numeric column, we could split the age into several buckets using a [bucketized column](https://www.tensorflow.org/api_docs/python/tf/feature_column/bucketized_column).
```
# EXERCISE: Create a bucketized feature column out of 'age' with
# the following boundaries and demo it.
boundaries = [18, 25, 30, 35, 40, 45, 50, 55, 60, 65]
age_buckets = feature_column.bucketized_column(age,boundaries)
demo(age_buckets)
```
Notice the one-hot values above describe which age range each row matches.
### Categorical Columns
In this dataset, thal is represented as a string (e.g. 'fixed', 'normal', or 'reversible'). We cannot feed strings directly to a model. Instead, we must first map them to numeric values. The categorical vocabulary columns provide a way to represent strings as a one-hot vector (much like you have seen above with age buckets).
**Note**: You will probably see some warning messages when running some of the code cell below. These warnings have to do with software updates and should not cause any errors or prevent your code from running.
```
# EXERCISE: Create a categorical vocabulary column out of the
# above mentioned categories with the key specified as 'thal'.
thal = feature_column.categorical_column_with_vocabulary_list('thal',['fixed','normal','reversible'])
# EXERCISE: Create an indicator column out of the created categorical column.
thal_one_hot = feature_column.indicator_column(thal)
demo(thal_one_hot)
```
The vocabulary can be passed as a list using [categorical_column_with_vocabulary_list](https://www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_vocabulary_list), or loaded from a file using [categorical_column_with_vocabulary_file](https://www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_vocabulary_file).
### Embedding Columns
Suppose instead of having just a few possible strings, we have thousands (or more) values per category. For a number of reasons, as the number of categories grow large, it becomes infeasible to train a neural network using one-hot encodings. We can use an embedding column to overcome this limitation. Instead of representing the data as a one-hot vector of many dimensions, an [embedding column](https://www.tensorflow.org/api_docs/python/tf/feature_column/embedding_column) represents that data as a lower-dimensional, dense vector in which each cell can contain any number, not just 0 or 1. You can tune the size of the embedding with the `dimension` parameter.
```
# EXERCISE: Create an embedding column out of the categorical
# vocabulary you just created (thal). Set the size of the
# embedding to 8, by using the dimension parameter.
thal_embedding = feature_column.embedding_column(thal, dimension=8)
demo(thal_embedding)
```
### Hashed Feature Columns
Another way to represent a categorical column with a large number of values is to use a [categorical_column_with_hash_bucket](https://www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_hash_bucket). This feature column calculates a hash value of the input, then selects one of the `hash_bucket_size` buckets to encode a string. When using this column, you do not need to provide the vocabulary, and you can choose to make the number of hash buckets significantly smaller than the number of actual categories to save space.
```
# EXERCISE: Create a hashed feature column with 'thal' as the key and
# 1000 hash buckets.
thal_hashed = feature_column.categorical_column_with_hash_bucket('thal', hash_bucket_size = 1000)
demo(feature_column.indicator_column(thal_hashed))
```
### Crossed Feature Columns
Combining features into a single feature, better known as [feature crosses](https://developers.google.com/machine-learning/glossary/#feature_cross), enables a model to learn separate weights for each combination of features. Here, we will create a new feature that is the cross of age and thal. Note that `crossed_column` does not build the full table of all possible combinations (which could be very large). Instead, it is backed by a `hashed_column`, so you can choose how large the table is.
```
# EXERCISE: Create a crossed column using the bucketized column (age_buckets),
# the categorical vocabulary column (thal) previously created, and 1000 hash buckets.
crossed_feature = feature_column.crossed_column([age_buckets,thal], hash_bucket_size=1000)
demo(feature_column.indicator_column(crossed_feature))
```
## Choose Which Columns to Use
We have seen how to use several types of feature columns. Now we will use them to train a model. The goal of this exercise is to show you the complete code needed to work with feature columns. We have selected a few columns to train our model below arbitrarily.
If your aim is to build an accurate model, try a larger dataset of your own, and think carefully about which features are the most meaningful to include, and how they should be represented.
```
dataframe.dtypes
```
You can use the above list of column datatypes to map the appropriate feature column to every column in the dataframe.
```
# EXERCISE: Fill in the missing code below
feature_columns = []
# Numeric Cols.
# Create a list of numeric columns. Use the following list of columns
# that have a numeric datatype: ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope', 'ca'].
numeric_columns = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope', 'ca']
for header in numeric_columns:
# Create a numeric feature column out of the header.
numeric_feature_column = feature_column.numeric_column(header)
feature_columns.append(numeric_feature_column)
# Bucketized Cols.
# Create a bucketized feature column out of the age column (numeric column)
# that you've already created. Use the following boundaries:
# [18, 25, 30, 35, 40, 45, 50, 55, 60, 65]
age_buckets = feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
feature_columns.append(age_buckets)
# Indicator Cols.
# Create a categorical vocabulary column out of the categories
# ['fixed', 'normal', 'reversible'] with the key specified as 'thal'.
thal = feature_column.categorical_column_with_vocabulary_list('thal',['fixed', 'normal', 'reversible'])
# Create an indicator column out of the created thal categorical column
thal_one_hot = feature_column.indicator_column(thal)
feature_columns.append(thal_one_hot)
# Embedding Cols.
# Create an embedding column out of the categorical vocabulary you
# just created (thal). Set the size of the embedding to 8, by using
# the dimension parameter.
thal_embedding = feature_column.embedding_column(thal, dimension=8)
feature_columns.append(thal_embedding)
# Crossed Cols.
# Create a crossed column using the bucketized column (age_buckets),
# the categorical vocabulary column (thal) previously created, and 1000 hash buckets.
crossed_feature = feature_column.crossed_column([age_buckets,thal], hash_bucket_size=1000)
# Create an indicator column out of the crossed column created above to one-hot encode it.
crossed_feature = feature_column.indicator_column(crossed_feature)
feature_columns.append(crossed_feature)
```
### Create a Feature Layer
Now that we have defined our feature columns, we will use a [DenseFeatures](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/DenseFeatures) layer to input them to our Keras model.
```
# EXERCISE: Create a Keras DenseFeatures layer and pass the feature_columns you just created.
feature_layer = tf.keras.layers.DenseFeatures(feature_columns)
```
Earlier, we used a small batch size to demonstrate how feature columns worked. We create a new input pipeline with a larger batch size.
```
batch_size = 32
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
```
## Create, Compile, and Train the Model
```
model = tf.keras.Sequential([
feature_layer,
layers.Dense(128, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(train_ds,
validation_data=val_ds,
epochs=100)
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
```
# Submission Instructions
```
# Now click the 'Submit Assignment' button above.
```
# When you're done or would like to take a break, please run the two cells below to save your work and close the Notebook. This frees up resources for your fellow learners.
```
%%javascript
<!-- Save the notebook -->
IPython.notebook.save_checkpoint();
%%javascript
<!-- Shutdown and close the notebook -->
window.onbeforeunload = null
window.close();
IPython.notebook.session.delete();
```
| github_jupyter |
Colour maps
======
Colour maps can be specified with the colourmap() function
Calling colourmap() on a vis object loads a colourmap and applies it to that object in a single command.
It can also be called from the viewer object which just loads a colourmap and returns its id, which can be saved and used to set the "colourmap" property of a one or more or objects.
```
#First set up a basic vis so we can display the colourmaps
import lavavu
lv = lavavu.Viewer(border=False, axis=False, background="gray90", quality=3, fontscale=1.5)
```
**Specifying colour maps**
Maps can be loaded as strings or lists of colours, positions can optionally be provided in range [0,1] to set where on the scale the colour will be placed, eg:
```
"red white blue"
"0.0=red 0.25=white 1.0=blue"
[(0.0, 'red'), (0.25, 'white'), (1.0, 'blue')]
['red', 'white', 'blue']
```
To provide specific values for colours in their original scale (rather than positions normalized to [0,1] range), place the value in parenthesis instead, eg:
```
"red (100)white (200)blue"
```
When specifying colours you can use either:
1. colour names from https://en.wikipedia.org/wiki/X11_color_names eg: 'red'
2. RGB hex values such as '#ff0000'
3. HTML style rgb(a) values, eg: 'rgb(255,0,0)' or 'rgba(255,0,0,1)'
Colour order and positions can be reversed by passing *reverse=True*.
Pass *discrete=True* to produce a discrete colour map instead of a continuously varying one.
*log=True* will apply a logarithmic scale.
Addional properties to the colour map can be passed, for details see: https://lavavu.github.io/Documentation/Property-Reference#colourmap
**Colour bars**
The colourbar() function creates a colour bar plot, it can be called from an object and uses that objects colour map, if called on the viewer it must have its map specified at some point with colourmap(data).
There are several properties that specify how the colour bar is displayed, see: https://lavavu.github.io/Documentation/Property-Reference#colourbar
```
#Create colour bar then load a colourmap into it
cbar1 = lv.colourbar(size=[0.95,15], align="top")
cbar1.colourmap([(0, 'green'), (0.75, 'yellow'), (1, 'red')], reverse=True)
#Create another colour bar and load a map, this time with a log scale
cbar2 = lv.colourbar(size=[0.95,15], align="top", tickvalues=[20,50,100,200,500])
cbar2.colourmap('black (100)goldenrod (101)khaki white', range=[10,1000], logscale=True)
lv.display(resolution=[640,90], transparent=True)
print(cbar1)
```
**CubeHelix**
Custom [cube helix](https://www.mrao.cam.ac.uk/~dag/CUBEHELIX/) maps can be generated with cubehelix(), these will always have monotonically varying intensity values to be when printed in greyscale
```
cbar1.colourmap(lavavu.cubehelix(samples=16, start=0.5, rot=-0.9, sat=1.0, gamma=1.0, alpha=False))
cbar2.colourmap(lavavu.cubehelix(samples=16, start=1.0, rot=0.9, sat=0.75, gamma=1.0, alpha=False), logscale=False)
cbar2["tickvalues"] = []
lv.display(resolution=[640,90], transparent=True)
#Display in greyscale
cbar1.colourmap(lavavu.cubehelix(samples=16, start=0.5, rot=-0.9, sat=1.0, gamma=1.0, alpha=False), monochrome=True)
cbar2.colourmap(lavavu.cubehelix(samples=16, start=1.0, rot=0.9, sat=0.75, gamma=1.0, alpha=False), monochrome=True)
lv.display(resolution=[640,90], transparent=True)
```
**Getting data**
Colourmap data can be retreived with .getcolourmap() on an object, which returns the map formatted as a string, .getcolourmap(string=False) returns a python list of (position, colour) tuples instead. Either of these formats are supported when creating a colourmap so the data can be modified and passed to a new colour map.
```
print(cbar1.getcolourmap())
```
**CPT colour tables**
Most files in the Generic Map Tools CPT format can be imported.
A large library of these can be found at [cpt-city](http://soliton.vm.bytemark.co.uk/pub/cpt-city/index.html)
The *positions=False* argument can be passed to ignore the position data and load only the colours.
```
try:
#Check if file exists, if not download it from cpt-city
import os
fn = 'arctic.cpt'
if not os.path.isfile(fn):
import urllib
url = 'http://soliton.vm.bytemark.co.uk/pub/cpt-city/arendal/arctic.cpt'
urllib.urlretrieve(url, fn)
#Load with positions calibrated
cbar1.colourmap(lavavu.loadCPT(fn))
#Load colour data only
cbar2.colourmap(lavavu.loadCPT(fn, positions=False))
lv.display(resolution=[640,90], transparent=True)
except:
pass
```
**Predefined maps**
There are a number of colour maps available for convenience which can be accessed by passing their name instead of a list of colours when creating a colour map.
```
#Get the list of colormap names
#suggest: lv.colourmaps.(names)
maps = lv.defaultcolourmaps()
print(maps)
```
The first eight maps are selected to vary evenly in luminance to reduce banding artifacts
Following these are further maps inspired by the default colour tables from the [Generic Mapping Tools](http://gmt.soest.hawaii.edu/)
Those maps that have fixed colour positions included can also be loaded without the position data by preceding the name with '@'
The colourmap data can be retrieved for modification as follows:
```
print(lv.defaultcolourmap('cubelaw'))
```
**Plot of all built in maps**
Finally we will plot all the available built in colourmaps in continuous and discrete modes
```
#Clear the plot and create some new colour bars
lv.clear()
#Default continuous colour bar
cbar1 = lv.colourbar(size=[0.95,15], align="top")
#Discrete colour bar with bin labels enabled
cbar2 = lv.colourbar(size=[0.95,15], align="top", binlabels=True)
#Plot each map in the list
for name in maps:
print(name)
#Load as continuous colourmap
cbar1.colourmap(name)
#Load as discrete colourmap
cbar2.colourmap(name, discrete=True, range=[-6,6])
lv.display(resolution=[640,90], transparent=True)
```
| github_jupyter |
```
#!pip install randomcolor
import randomcolor # see: https://pypi.org/project/randomcolor/
#!pip install gif
import gif # see https://github.com/maxhumber/gif
#!pip install reverse_geocoder
import reverse_geocoder as rg # see ttps://pypi.org/project/reverse_geocoder/
import numpy as np
# plotting
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import cm, colors
# 3d
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
# everything below is used to color the globe
from mpl_toolkits.basemap import Basemap
import json
import requests
# from local helpers file
from helpers import domino, getpatches, getquadrature, color_land, color_country, get_land, applyupdate
@gif.frame
def myplot(color,quadrature, filename,frameid=0, angle1=30,angle2=30):
patches = getpatches(color,quadrature) # Get the hexagons
fig = plt.figure(figsize=plt.figaspect(1)*2,constrained_layout=False)
ax = fig.gca(projection='3d')
# Visualize each hexagon, that is given in "color". A color is computed
# for the center of the hexagon and then applied for the full hexagon
ax.add_collection3d(Poly3DCollection(patches,facecolor = color,linewidth=0.1,edgecolor="k"))
# Some styling
plt.axis("off")
l = 0.7
ax.set_xlim([-l,l]), ax.set_ylim([-l,l]),ax.set_zlim([-l,l])
ax.set_xticks([]), ax.set_yticks([]), ax.set_zticks([])
ax.w_xaxis.set_pane_color((1.0, 1.0, 1.0, 1.0))
ax.w_yaxis.set_pane_color((1.0, 1.0, 1.0, 1.0))
ax.w_zaxis.set_pane_color((1.0, 1.0, 1.0, 1.0))
for spine in ax.spines.values():
spine.set_visible(False)
plt.tight_layout()
s = "Frame {}".format(frameid)
ax.annotate(s,xy=(0.05,-0.09),fontsize=20,zorder = 10000)
ax.view_init(angle1, angle2)
fig.savefig(filename)
# pick the number of cells on the globe from this list
# [92, 492, 1212, 2252, 3612, 5292, 7292, 9612, 12252, 15212]
nq = 2252
quadrature = getquadrature(nq)
# plot the earth
colors = color_land(quadrature)
myplot(colors,quadrature,"earth.png")
# higher resolution to plot countries
nq = 7292
quadrature = getquadrature(nq)
colors = color_country(quadrature)
myplot(colors,quadrature,"earth_country.png")
# creating a gif
nq = 7292
quadrature = getquadrature(nq)
colors = color_land(quadrature)
frames = []
nframes = 20 # the more, the slower
for i,angle in enumerate(np.linspace(0,360,nframes)[:-1]):
print(i,end=",")
frames.append(myplot(colors,quadrature,"tmp.png",frameid = i, angle1=30,angle2=angle))
gif.save(frames,"spinning_earth.gif")
def diffusion(c,nextc,gamma = 0.2):
# Not really spherical diffusion
# because I ignore the cell size,
# but an approximation.
return c+gamma*(np.sum(nextc) -len(nextc)*c)
# pick the number of cells on the globe from this list
# [92, 492, 1212, 2252, 3612, 5292, 7292, 9612, 12252, 15212]
nq = 9612
quadrature = getquadrature(nq)
# +1 or -1 if center of hexagon is land or not
states = np.array([0.7 if l else -1.0 for l in get_land(quadrature)])
# if there were an eleveation profile of the earth,
# I could insert that instead of states
frames = [] # list of frames to append to
nframes = 200 # number of frames
frequency = 1 # frequency with which to update the states
# make camera move around the globe and up and down
angles1 = 0.2*np.degrees( np.sin(np.linspace(0,5*2*np.pi,nframes+1)[:-1]))
angles2 = np.linspace(0,3*360,nframes+1)[:-1]
# specify the update rule
updaterule = diffusion
for i,(angle1,angle2) in enumerate(zip(angles1,angles2)):
# Map from states to color
cmap = matplotlib.cm.get_cmap('terrain')
colors = [cmap(s) for s in states]
frames.append(myplot(colors,quadrature,f"PNG/{i}.png",i,angle1=angle1,angle2=angle2))
# update states according to rule
if i%frequency == 0:
states = applyupdate(quadrature,updaterule,states)
print(i+1,end= "," if i<nframes-1 else ". Done!")
gif.save(frames, "diffusion.gif", duration = 100)
def gameoflife(c,nextc):
# update the cell c based upon the neighbours nextc
# c is true => cell alive
# c is fale => cell dead
n = len(nextc) # is mostly 6 but for some points 5
nalive = sum(nextc)
if not(c) and nalive in [1,2]:
return True
if c and nalive in [3,4,5,6]:
return False
# Else, nothing changed
return c
# pick the number of cells on the globe from this list
# [92, 492, 1212, 2252, 3612, 5292, 7292, 9612, 12252, 15212]
nq = 5292
quadrature = getquadrature(nq)
# True or False if center of hexagon is land or not
states = np.random.rand(nq)<0.01
frames = [] # list of frames to append to
nframes = 100 # number of frames
frequency = 5 # frequency with which to update the states
# make camera move around the globe and up and down
angles1 = np.degrees( np.sin(np.linspace(0,2*np.pi,nframes+1)[:-1]))
angles2 = 30+0*np.linspace(0,3*360,nframes+1)[:-1]
# specify the update rule
updaterule = gameoflife
for i,(angle1,angle2) in enumerate(zip(angles1,angles2)):
# Map from states to color
colors = ["tab:green" if s else "k" for s in states]
frames.append(myplot(colors,quadrature,f"PNG/{i}.png",i,angle1=angle1,angle2=angle2))
# update states according to rule
if i%frequency == 0:
states = applyupdate(quadrature,updaterule,states)
print(i+1,end= "," if i<nframes-1 else ". Done!")
gif.save(frames, "gol.gif", duration = 100)
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import re
import datetime
import seaborn as sns
from matplotlib import pyplot as plt
from google.colab import drive
drive.mount('/content/drive')
DIR = "drive/My Drive/Notebooks/Thesis/Readmissions/"
adm_notes = pd.read_csv(DIR + "readmission.csv", low_memory=False)
!nvidia-smi
```
# Natural Language
```
import string
import nltk
from nltk import word_tokenize
from nltk.stem.porter import PorterStemmer
from nltk.corpus import stopwords
def clean_text(texts):
texts = texts.fillna(' ')
texts = texts.str.replace('\n',' ')
texts = texts.str.replace('\r',' ')
table = str.maketrans('', '', string.punctuation + '0123456789')
texts = [text.lower().translate(table) for text in texts]
return texts
adm_notes['TEXT'] = clean_text(adm_notes['TEXT'])
nltk.download('punkt')
nltk.download('stopwords')
stop_words = stopwords.words('english')
stop_words = stop_words + ['patient', 'date', 'admission', 'discharge', 'lastname', 'firstname', 'sex']
porter = PorterStemmer()
def tokenize_stem(text):
words = word_tokenize(text)
words = [word for word in words if word not in stop_words]
words = [porter.stem(word) for word in words]
return words
for i, text in enumerate(adm_notes['TEXT']):
adm_notes.loc[i, 'TEXT'] = (' ').join(tokenize_stem(adm_notes['TEXT'][i]))
```
# Model
## Words, Train and Test
```
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
```
Repartition data
```
df_train, df_test = train_test_split(adm_notes, test_size=0.2, random_state=42)
```
Subsample non-readmitted patients to match size of readmitted ones
```
rows_pos = df_train['READM_WITHIN_30'] == 1
df_train_pos = df_train.loc[rows_pos]
df_train_neg = df_train.loc[~rows_pos]
df_train = pd.concat([df_train_pos, df_train_neg.sample(n = len(df_train_pos))], axis = 0)
df_train = df_train.sample(n = len(df_train)).reset_index(drop = True)
rows_pos = df_test['READM_WITHIN_30'] == 1
df_test_pos = df_test.loc[rows_pos]
df_test_neg = df_test.loc[~rows_pos]
df_test = pd.concat([df_test_pos, df_test_neg.sample(n = len(df_test_pos))], axis = 0)
df_test = df_test.sample(n = len(df_test)).reset_index(drop = True)
print(df_train.shape)
print(df_test.shape)
```
Sparse Matrix with word count
# Recurrent Neural Network
```
from keras.models import Sequential, load_model
from keras.layers import LSTM, Dense, Dropout, Embedding, Conv1D, MaxPooling1D, SpatialDropout1D
from keras.optimizers import RMSprop, Adam
from keras.utils import to_categorical
from keras.callbacks import ModelCheckpoint
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import tensorflow as tf
NUMBER_WORDS = 5000
tokenizer = Tokenizer(num_words=NUMBER_WORDS)
tokenizer.fit_on_texts(df_train['TEXT'])
sequences_train = tokenizer.texts_to_sequences(df_train['TEXT'])
sequences_test = tokenizer.texts_to_sequences(df_test['TEXT'])
X_train = pad_sequences(sequences_train, maxlen=NUMBER_WORDS)
X_test = pad_sequences(sequences_test, maxlen=NUMBER_WORDS)
y_train = to_categorical(df_train['READM_WITHIN_30'])
y_test = to_categorical(df_test['READM_WITHIN_30'])
adam = Adam(learning_rate=0.00001)
model = Sequential()
model.add(Embedding(X_train.shape[1], 32, input_length=X_train.shape[1] ))
model.add(LSTM(32, dropout_W=0.2, dropout_U=0.2))
model.add(Dense(2, activation='sigmoid'))
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
model.summary()
from keras.utils.vis_utils import plot_model
plot_model(model, show_shapes=True, show_layer_names=False)
history = model.fit(X_train, y_train, epochs = 100, batch_size = 64, validation_split=0.2)
print(model.metrics_names)
model.evaluate(X_test, y_test, batch_size=64)
from sklearn.metrics import classification_report, roc_auc_score
y_pred = model.predict(X_test, batch_size=64, verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_test_raw = df_test['READM_WITHIN_30']
print(classification_report(y_test_raw, y_pred, digits=3))
print(roc_auc_score(y_test_raw, y_pred))
sns.set('talk', 'whitegrid', 'dark', font_scale=0.7,
rc={"lines.linewidth": 1, 'grid.linestyle': '--'})
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(9, 4))
ax[0].plot(history.history['accuracy'])
ax[0].plot(history.history['val_accuracy'])
ax[0].set_title('Model accuracy')
ax[0].set_ylabel('Accuracy')
ax[0].set_xlabel('Epoch')
ax[0].legend(['Train', 'Test'], loc='upper left')
ax[1].plot(history.history['loss'])
ax[1].plot(history.history['val_loss'])
ax[1].set_title('Model loss')
ax[1].set_ylabel('Loss')
ax[1].set_xlabel('Epoch')
ax[1].legend(['Train', 'Test'], loc='upper left')
fig.tight_layout()
plt.show()
```
| github_jupyter |
[Table of Contents](http://nbviewer.ipython.org/github/rlabbe/Kalman-and-Bayesian-Filters-in-Python/blob/master/table_of_contents.ipynb)
# Discrete Bayes Filter
```
#format the book
%matplotlib inline
from __future__ import division, print_function
from book_format import load_style
load_style()
```
The Kalman filter belongs to a family of filters called *Bayesian filters*. Most textbook treatments of the Kalman filter present the Bayesian formula, perhaps shows how it factors into the Kalman filter equations, but mostly keeps the discussion at a very abstract level.
That approach requires a fairly sophisticated understanding of several fields of mathematics, and it still leaves much of the work of understanding and forming an intuitive grasp of the situation in the hands of the reader.
I will use a different way to develop the topic, to which I owe the work of Dieter Fox and Sebastian Thrun a great debt. It depends on building an intuition on how Bayesian statistics work by tracking an object through a hallway - they use a robot, I use a dog. I like dogs, and they are less predictable than robots which imposes interesting difficulties for filtering. The first published example of this that I can find seems to be Fox 1999 [1], with a fuller example in Fox 2003 [2]. Sebastian Thrun also uses this formulation in his excellent Udacity course Artificial Intelligence for Robotics [3]. In fact, if you like watching videos, I highly recommend pausing reading this book in favor of first few lessons of that course, and then come back to this book for a deeper dive into the topic.
Let's now use a simple thought experiment, much like we did with the g-h filter, to see how we might reason about the use of probabilities for filtering and tracking.
## Tracking a Dog
Let's begin with a simple problem. We have a dog friendly workspace, and so people bring their dogs to work. Occasionally the dogs wander out of offices and down the halls. We want to be able to track them. So during a hackathon somebody invented a sonar sensor to attach to the dog's collar. It emits a signal, listens for the echo, and based on how quickly an echo comes back we can tell whether the dog is in front of an open doorway or not. It also senses when the dog walks, and reports in which direction the dog has moved. It connects to the network via wifi and sends an update once a second.
I want to track my dog Simon, so I attach the device to his collar and then fire up Python, ready to write code to track him through the building. At first blush this may appear impossible. If I start listening to the sensor of Simon's collar I might read **door**, **hall**, **hall**, and so on. How can I use that information to determine where Simon is?
To keep the problem small enough to plot easily we will assume that there are only 10 positions in the hallway, which we will number 0 to 9, where 1 is to the right of 0. For reasons that will be clear later, we will also assume that the hallway is circular or rectangular. If you move right from position 9, you will be at position 0.
When I begin listening to the sensor I have no reason to believe that Simon is at any particular position in the hallway. From my perspective he is equally likely to be in any position. There are 10 positions, so the probability that he is in any given position is 1/10.
Let's represent our belief of his position in a NumPy array. I could use a Python list, but NumPy arrays offer functionality that we will be using soon.
```
import numpy as np
belief = np.array([1./10]*10)
print(belief)
```
In [Bayesian statistics](https://en.wikipedia.org/wiki/Bayesian_probability) this is called a [*prior*](https://en.wikipedia.org/wiki/Prior_probability). It is the probability prior to incorporating measurements or other information. More completely, this is called the *prior probability distribution*. A [*probability distribution*](https://en.wikipedia.org/wiki/Probability_distribution) is a collection of all possible probabilities for an event. Probability distributions always sum to 1 because something had to happen; the distribution lists all possible events and the probability of each.
I'm sure you've used probabilities before - as in "the probability of rain today is 30%". The last paragraph sounds like more of that. But Bayesian statistics was a revolution in probability because it treats probability as a belief about a single event. Let's take an example. I know that if I flip a fair coin infinitely many times I will get 50% heads and 50% tails. This is called [*frequentist statistics*](https://en.wikipedia.org/wiki/Frequentist_inference) to distinguish it from Bayesian statistics. Computations are based on the frequency in which events occur.
I flip the coin one more time and let it land. Which way do I believe it landed? Frequentist probability has nothing to say about that; it will merely state that 50% of coin flips land as heads. In some ways it is meaningless to assign a probability to the current state of the coin. It is either heads or tails, we just don't know which. Bayes treats this as a belief about a single event - the strength of my belief or knowledge that this specific coin flip is heads is 50%. Some object to the term "belief"; belief can imply holding something to be true without evidence. In this book it always is a measure of the strength of our knowledge. We'll learn more about this as we go.
Bayesian statistics takes past information (the prior) into account. We observe that it rains 4 times every 100 days. From this I could state that the chance of rain tomorrow is 1/25. This is not how weather prediction is done. If I know it is raining today and the storm front is stalled, it is likely to rain tomorrow. Weather prediction is Bayesian.
In practice statisticians use a mix of frequentist and Bayesian techniques. Sometimes finding the prior is difficult or impossible, and frequentist techniques rule. In this book we can find the prior. When I talk about the probability of something I am referring to the probability that some specific thing is true given past events. When I do that I'm taking the Bayesian approach.
Now let's create a map of the hallway. We'll place the first two doors close together, and then another door further away. We will use 1 for doors, and 0 for walls:
```
hallway = np.array([1, 1, 0, 0, 0, 0, 0, 0, 1, 0])
```
I start listening to Simon's transmissions on the network, and the first data I get from the sensor is **door**. For the moment assume the sensor always returns the correct answer. From this I conclude that he is in front of a door, but which one? I have no reason to believe he is in front of the first, second, or third door. What I can do is assign a probability to each door. All doors are equally likely, and there are three of them, so I assign a probability of 1/3 to each door.
```
from kf_book.book_plots import figsize, set_figsize
import kf_book.book_plots as book_plots
import matplotlib.pyplot as plt
belief = np.array([1./3, 1./3, 0, 0, 0, 0, 0, 0, 1/3, 0])
plt.figure()
set_figsize(y=2)
book_plots.bar_plot(belief)
```
This distribution is called a [*categorical distribution*](https://en.wikipedia.org/wiki/Categorical_distribution), which is a discrete distribution describing the probability of observing $n$ outcomes. It is a [*multimodal distribution*](https://en.wikipedia.org/wiki/Multimodal_distribution) because we have multiple beliefs about the position of our dog. Of course we are not saying that we think he is simultaneously in three different locations, merely that we have narrowed down our knowledge to one of these three locations. My (Bayesian) belief is that there is a 33.3% chance of being at door 0, 33.3% at door 1, and a 33.3% chance of being at door 8.
This is an improvement in two ways. I've rejected a number of hallway positions as impossible, and the strength of my belief in the remaining positions has increased from 10% to 33%. This will always happen. As our knowledge improves the probabilities will get closer to 100%.
A few words about the [*mode*](https://en.wikipedia.org/wiki/Mode_(statistics))
of a distribution. Given a set of numbers, such as {1, 2, 2, 2, 3, 3, 4}, the *mode* is the number that occurs most often. For this set the mode is 2. A set can contain more than one mode. The set {1, 2, 2, 2, 3, 3, 4, 4, 4} contains the modes 2 and 4, because both occur three times. We say the former set is [*unimodal*](https://en.wikipedia.org/wiki/Unimodality), and the latter is *multimodal*.
Another term used for this distribution is a [*histogram*](https://en.wikipedia.org/wiki/Histogram). Histograms graphically depict the distribution of a set of numbers. The bar chart above is a histogram.
I hand coded the `belief` array in the code above. How would we implement this in code? We represent doors with 1, and walls as 0, so we will multiply the hallway variable by the percentage, like so;
```
belief = hallway * (1./3)
print(belief)
```
## Extracting Information from Sensor Readings
Let's put Python aside and think about the problem a bit. Suppose we were to read the following from Simon's sensor:
* door
* move right
* door
Can we deduce Simon's location? Of course! Given the hallway's layout there is only one place from which you can get this sequence, and that is at the left end. Therefore we can confidently state that Simon is in front of the second doorway. If this is not clear, suppose Simon had started at the second or third door. After moving to the right, his sensor would have returned 'wall'. That doesn't match the sensor readings, so we know he didn't start there. We can continue with that logic for all the remaining starting positions. The only possibility is that he is now in front of the second door. Our belief is:
```
belief = np.array([0., 1., 0., 0., 0., 0., 0., 0., 0., 0.])
```
I designed the hallway layout and sensor readings to give us an exact answer quickly. Real problems are not so clear cut. But this should trigger your intuition - the first sensor reading only gave us low probabilities (0.333) for Simon's location, but after a position update and another sensor reading we know more about where he is. You might suspect, correctly, that if you had a very long hallway with a large number of doors that after several sensor readings and positions updates we would either be able to know where Simon was, or have the possibilities narrowed down to a small number of possibilities. This is possible when a set of sensor readings only matches one to a few starting locations.
We could implement this solution now, but instead let's consider a real world complication to the problem.
## Noisy Sensors
Perfect sensors are rare. Perhaps the sensor would not detect a door if Simon sat in front of it while scratching himself, or misread if he is not facing down the hallway. Thus when I get **door** I cannot use 1/3 as the probability. I have to assign less than 1/3 to each door, and assign a small probability to each blank wall position. Something like
```Python
[.31, .31, .01, .01, .01, .01, .01, .01, .31, .01]
```
At first this may seem insurmountable. If the sensor is noisy it casts doubt on every piece of data. How can we conclude anything if we are always unsure?
The answer, as for the problem above, is with probabilities. We are already comfortable assigning a probabilistic belief to the location of the dog; now we have to incorporate the additional uncertainty caused by the sensor noise.
Say we get a reading of **door**, and suppose that testing shows that the sensor is 3 times more likely to be right than wrong. We should scale the probability distribution by 3 where there is a door. If we do that the result will no longer be a probability distribution, but we will learn how to fix that in a moment.
Let's look at that in Python code. Here I use the variable `z` to denote the measurement. `z` or `y` are customary choices in the literature for the measurement. As a programmer I prefer meaningful variable names, but I want you to be able to read the literature and/or other filtering code, so I will start introducing these abbreviated names now.
```
def update_belief(hall, belief, z, correct_scale):
for i, val in enumerate(hall):
if val == z:
belief[i] *= correct_scale
belief = np.array([0.1] * 10)
reading = 1 # 1 is 'door'
update_belief(hallway, belief, z=reading, correct_scale=3.)
print('belief:', belief)
print('sum =', sum(belief))
plt.figure()
book_plots.bar_plot(belief)
```
This is not a probability distribution because it does not sum to 1.0. But the code is doing mostly the right thing - the doors are assigned a number (0.3) that is 3 times higher than the walls (0.1). All we need to do is normalize the result so that the probabilities correctly sum to 1.0. Normalization is done by dividing each element by the sum of all elements in the list. That is easy with NumPy:
```
belief / sum(belief)
```
FilterPy implements this with the `normalize` function:
```Python
from filterpy.discrete_bayes import normalize
normalize(belief)
```
It is a bit odd to say "3 times as likely to be right as wrong". We are working in probabilities, so let's specify the probability of the sensor being correct, and compute the scale factor from that. The equation for that is
$$scale = \frac{prob_{correct}}{prob_{incorrect}} = \frac{prob_{correct}} {1-prob_{correct}}$$
Also, the `for` loop is cumbersome. As a general rule you will want to avoid using `for` loops in NumPy code. NumPy is implemented in C and Fortran, so if you avoid for loops the result often runs 100x faster than the equivalent loop.
How do we get rid of this `for` loop? NumPy lets you index arrays with boolean arrays. You create a boolean array with logical operators. We can find all the doors in the hallway with:
```
hallway == 1
```
When you use the boolean array as an index to another array it returns only the elements where the index is `True`. Thus we can replace the `for` loop with
```python
belief[hall==z] *= scale
```
and only the elements which equal `z` will be multiplied by `scale`.
Teaching you NumPy is beyond the scope of this book. I will use idiomatic NumPy constructs and explain them the first time I present them. If you are new to NumPy there are many blog posts and videos on how to use NumPy efficiently and idiomatically. For example, this video by Jake Vanderplas is often recommended: https://vimeo.com/79820956.
Here is our improved version:
```
from filterpy.discrete_bayes import normalize
def scaled_update(hall, belief, z, z_prob):
scale = z_prob / (1. - z_prob)
belief[hall==z] *= scale
normalize(belief)
belief = np.array([0.1] * 10)
scaled_update(hallway, belief, z=1, z_prob=.75)
print('sum =', sum(belief))
print('probability of door =', belief[0])
print('probability of wall =', belief[2])
book_plots.bar_plot(belief, ylim=(0, .3))
```
We can see from the output that the sum is now 1.0, and that the probability of a door vs wall is still three times larger. The result also fits our intuition that the probability of a door must be less than 0.333, and that the probability of a wall must be greater than 0.0. Finally, it should fit our intuition that we have not yet been given any information that would allow us to distinguish between any given door or wall position, so all door positions should have the same value, and the same should be true for wall positions.
This result is called the [*posterior*](https://en.wikipedia.org/wiki/Posterior_probability), which is short for *posterior probability distribution*. All this means is a probability distribution *after* incorporating the measurement information (posterior means 'after' in this context). To review, the *prior* is the probability distribution before including the measurement's information.
Another term is the [*likelihood*](https://en.wikipedia.org/wiki/Likelihood_function). When we computed `belief[hall==z] *= scale` we were computing how *likely* each position was given the measurement. The likelihood is not a probability distribution because it does not sum to one.
The combination of these gives the equation
$$\mathtt{posterior} = \frac{\mathtt{likelihood} \times \mathtt{prior}}{\mathtt{normalization}}$$
It is very important to learn and internalize these terms as most of the literature uses them extensively.
Does `scaled_update()` perform this computation? It does. Let me recast it into this form:
```
def scaled_update(hall, belief, z, z_prob):
scale = z_prob / (1. - z_prob)
likelihood = np.ones(len(hall))
likelihood[hall==z] *= scale
return normalize(likelihood * belief)
```
This function is not fully general. It contains knowledge about the hallway, and how we match measurements to it. We always strive to write general functions. Here we will remove the computation of the likelihood from the function, and require the caller to compute the likelihood themselves.
Here is a full implementation of the algorithm:
```python
def update(likelihood, prior):
return normalize(likelihood * prior)
```
Computation of the likelihood varies per problem. For example, the sensor might not return just 1 or 0, but a `float` between 0 and 1 indicating the probability of being in front of a door. It might use computer vision and report a blob shape that you then probabilistically match to a door. It might use sonar and return a distance reading. In each case the computation of the likelihood will be different. We will see many examples of this throughout the book, and learn how to perform these calculations.
FilterPy implements `update`. Here is the previous example in a fully general form:
```
from filterpy.discrete_bayes import update
def lh_hallway(hall, z, z_prob):
""" compute likelihood that a measurement matches
positions in the hallway."""
try:
scale = z_prob / (1. - z_prob)
except ZeroDivisionError:
scale = 1e8
likelihood = np.ones(len(hall))
likelihood[hall==z] *= scale
return likelihood
belief = np.array([0.1] * 10)
likelihood = lh_hallway(hallway, z=1, z_prob=.75)
update(likelihood, belief)
```
## Incorporating Movement
Recall how quickly we were able to find an exact solution when we incorporated a series of measurements and movement updates. However, that occurred in a fictional world of perfect sensors. Might we be able to find an exact solution with noisy sensors?
Unfortunately, the answer is no. Even if the sensor readings perfectly match an extremely complicated hallway map, we cannot be 100% certain that the dog is in a specific position - there is, after all, a tiny possibility that every sensor reading was wrong! Naturally, in a more typical situation most sensor readings will be correct, and we might be close to 100% sure of our answer, but never 100% sure. This may seem complicated, but let's go ahead and program the math.
First let's deal with the simple case - assume the movement sensor is perfect, and it reports that the dog has moved one space to the right. How would we alter our `belief` array?
I hope that after a moment's thought it is clear that we should shift all the values one space to the right. If we previously thought there was a 50% chance of Simon being at position 3, then after he moved one position to the right we should believe that there is a 50% chance he is at position 4. The hallway is circular, so we will use modulo arithmetic to perform the shift.
```
def perfect_predict(belief, move):
""" move the position by `move` spaces, where positive is
to the right, and negative is to the left
"""
n = len(belief)
result = np.zeros(n)
for i in range(n):
result[i] = belief[(i-move) % n]
return result
belief = np.array([.35, .1, .2, .3, 0, 0, 0, 0, 0, .05])
plt.subplot(121)
book_plots.bar_plot(belief, title='Before prediction', ylim=(0, .4))
belief = perfect_predict(belief, 1)
plt.subplot(122)
book_plots.bar_plot(belief, title='After prediction', ylim=(0, .4))
```
We can see that we correctly shifted all values one position to the right, wrapping from the end of the array back to the beginning.
If you execute the next cell by pressing CTRL-Enter in it you can see this in action. This simulates Simon walking around and around the hallway. It does not (yet) incorporate new measurements so the probability distribution does not change.
```
import time
%matplotlib notebook
set_figsize(y=2)
fig = plt.figure()
for _ in range(50):
# Simon takes one step to the right
belief = perfect_predict(belief, 1)
plt.cla()
book_plots.bar_plot(belief, ylim=(0, .4))
fig.canvas.draw()
time.sleep(0.05)
# reset to noninteractive plot settings
%matplotlib inline
set_figsize(y=2);
```
## Terminology
Let's pause a moment to review terminology. I introduced this terminology in the last chapter, but let's take a second to help solidify your knowledge.
The *system* is what we are trying to model or filter. Here the system is our dog. The *state* is its current configuration or value. In this chapter the state is our dog's position. We rarely know the actual state, so we say our filters produce the *estimated state* of the system. In practice this often gets called the state, so be careful to understand the context.
One cycle of prediction and updating with a measurement is called the state or system *evolution*, which is short for *time evolution* [7]. Another term is *system propogation*. It refers to how the state of the system changes over time. For filters, time is usually a discrete step, such as 1 second. For our dog tracker the system state is the position of the dog, and the state evolution is the position after a discrete amount of time has passed.
We model the system behavior with the *process model*. Here, our process model is that the dog moves one or more positions at each time step. This is not a particularly accurate model of how dogs behave. The error in the model is called the *system error* or *process error*.
The prediction is our new *prior*. Time has moved forward and we made a prediction without benefit of knowing the measurements.
Let's work an example. The current position of the dog is 17 m. Our epoch is 2 seconds long, and the dog is traveling at 15 m/s. Where do we predict he will be in two seconds?
Clearly,
$$ \begin{aligned}
\bar x &= 17 + (15*2) \\
&= 47
\end{aligned}$$
I use bars over variables to indicate that they are priors (predictions). We can write the equation for the process model like this:
$$ \bar x_{k+1} = f_x(\bullet) + x_k$$
$x_k$ is the current position or state. If the dog is at 17 m then $x_k = 17$.
$f_x(\bullet)$ is the state propagation function for x. It describes how much the $x_k$ changes over one time step. For our example it performs the computation $15 \cdot 2$ so we would define it as
$$f_x(v_x, t) = v_k t$$.
## Adding Uncertainty to the Prediction
`perfect_sensor()` assumes perfect measurements, but all sensors have noise. What if the sensor reported that our dog moved one space, but he actually moved two spaces, or zero? This may sound like an insurmountable problem, but let's model it and see what happens.
Assume that the sensor's movement measurement is 80% likely to be correct, 10% likely to overshoot one position to the right, and 10% likely to undershoot to the left. That is, if the movement measurement is 4 (meaning 4 spaces to the right), the dog is 80% likely to have moved 4 spaces to the right, 10% to have moved 3 spaces, and 10% to have moved 5 spaces.
Each result in the array now needs to incorporate probabilities for 3 different situations. For example, consider the reported movement of 2. If we are 100% certain the dog started from position 3, then there is an 80% chance he is at 5, and a 10% chance for either 4 or 6. Let's try coding that:
```
def predict_move(belief, move, p_under, p_correct, p_over):
n = len(belief)
prior = np.zeros(n)
for i in range(n):
prior[i] = (
belief[(i-move) % n] * p_correct +
belief[(i-move-1) % n] * p_over +
belief[(i-move+1) % n] * p_under)
return prior
belief = [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]
prior = predict_move(belief, 2, .1, .8, .1)
book_plots.plot_belief_vs_prior(belief, prior)
```
It appears to work correctly. Now what happens when our belief is not 100% certain?
```
belief = [0, 0, .4, .6, 0, 0, 0, 0, 0, 0]
prior = predict_move(belief, 2, .1, .8, .1)
book_plots.plot_belief_vs_prior(belief, prior)
prior
```
Here the results are more complicated, but you should still be able to work it out in your head. The 0.04 is due to the possibility that the 0.4 belief undershot by 1. The 0.38 is due to the following: the 80% chance that we moved 2 positions (0.4 $\times$ 0.8) and the 10% chance that we undershot (0.6 $\times$ 0.1). Overshooting plays no role here because if we overshot both 0.4 and 0.6 would be past this position. **I strongly suggest working some examples until all of this is very clear, as so much of what follows depends on understanding this step.**
If you look at the probabilities after performing the update you might be dismayed. In the example above we started with probabilities of 0.4 and 0.6 in two positions; after performing the update the probabilities are not only lowered, but they are strewn out across the map.
This is not a coincidence, or the result of a carefully chosen example - it is always true of the prediction. If the sensor is noisy we lose some information on every prediction. Suppose we were to perform the prediction an infinite number of times - what would the result be? If we lose information on every step, we must eventually end up with no information at all, and our probabilities will be equally distributed across the `belief` array. Let's try this with 100 iterations. The plot is animated; recall that you put the cursor in the cell and press Ctrl-Enter to execute the code and see the animation.
```
%matplotlib notebook
set_figsize(y=2)
belief = np.array([1.0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
plt.figure()
for i in range(100):
plt.cla()
belief = predict_move(belief, 1, .1, .8, .1)
book_plots.bar_plot(belief)
plt.title('Step {}'.format(i+1))
plt.gcf().canvas.draw()
print('Final Belief:', belief)
# reset to noninteractive plot settings
%matplotlib inline
set_figsize(y=2)
```
After 100 iterations we have lost almost all information, even though we were 100% sure that we started in position 0. Feel free to play with the numbers to see the effect of differing number of updates. For example, after 100 updates a small amount of information is left, after 50 a lot is left, but by 200 iterations essentially all information is lost.
And, if you are viewing this online here is an animation of that output.
<img src="animations/02_no_info.gif">
I will not generate these standalone animations through the rest of the book. Please see the preface for instructions to run this book on the web, for free, or install IPython on your computer. This will allow you to run all of the cells and see the animations. It's very important that you practice with this code, not just read passively.
## Generalizing with Convolution
We made the assumption that the movement error is at most one position. But it is possible for the error to be two, three, or more positions. As programmers we always want to generalize our code so that it works for all cases.
This is easily solved with [*convolution*](https://en.wikipedia.org/wiki/Convolution). Convolution modifies one function with another function. In our case we are modifying a probability distribution with the error function of the sensor. The implementation of `predict_move()` is a convolution, though we did not call it that. Formally, convolution is defined as
$$ (f \ast g) (t) = \int_0^t \!f(\tau) \, g(t-\tau) \, \mathrm{d}\tau$$
where $f\ast g$ is the notation for convolving f by g. It does not mean multiply.
Integrals are for continuous functions, but we are using discrete functions. We replace the integral with a summation, and the parenthesis with array brackets.
$$ (f \ast g) [t] = \sum\limits_{\tau=0}^t \!f[\tau] \, g[t-\tau]$$
Comparison shows that `predict_move()` is computing this equation - it computes the sum of a series of multiplications.
[Khan Academy](https://www.khanacademy.org/math/differential-equations/laplace-transform/convolution-integral/v/introduction-to-the-convolution) [4] has a good introduction to convolution, and Wikipedia has some excellent animations of convolutions [5]. But the general idea is already clear. You slide an array called the *kernel* across another array, multiplying the neighbors of the current cell with the values of the second array. In our example above we used 0.8 for the probability of moving to the correct location, 0.1 for undershooting, and 0.1 for overshooting. We make a kernel of this with the array `[0.1, 0.8, 0.1]`. All we need to do is write a loop that goes over each element of our array, multiplying by the kernel, and summing the results. To emphasize that the belief is a probability distribution I have named it `pdf`.
```
def predict_move_convolution(pdf, offset, kernel):
N = len(pdf)
kN = len(kernel)
width = int((kN - 1) / 2)
prior = np.zeros(N)
for i in range(N):
for k in range (kN):
index = (i + (width-k) - offset) % N
prior[i] += pdf[index] * kernel[k]
return prior
```
This illustrates the algorithm, but it runs very slow. SciPy provides a convolution routine `convolve()` in the `ndimage.filters` module. We need to shift the pdf by `offset` before convolution; `np.roll()` does that. The move and predict algorithm can be implemented with one line:
```python
convolve(np.roll(pdf, offset), kernel, mode='wrap')
```
FilterPy implements this with `discrete_bayes`' `predict()` function.
```
from filterpy.discrete_bayes import predict
belief = [.05, .05, .05, .05, .55, .05, .05, .05, .05, .05]
prior = predict(belief, offset=1, kernel=[.1, .8, .1])
book_plots.plot_belief_vs_prior(belief, prior, ylim=(0,0.6))
```
All of the elements are unchanged except the middle ones. The values in position 4 and 6 should be
$$(0.1 \times 0.05)+ (0.8 \times 0.05) + (0.1 \times 0.55) = 0.1$$
Position 5 should be $$(0.1 \times 0.05) + (0.8 \times 0.55)+ (0.1 \times 0.05) = 0.45$$
Let's ensure that it shifts the positions correctly for movements greater than one and for asymmetric kernels.
```
prior = predict(belief, offset=3, kernel=[.05, .05, .6, .2, .1])
book_plots.plot_belief_vs_prior(belief, prior, ylim=(0,0.6))
```
The position was correctly shifted by 3 positions and we give more weight to the likelihood of an overshoot vs an undershoot, so this looks correct.
Make sure you understand what we are doing. We are making a prediction of where the dog is moving, and convolving the probabilities to get the prior.
If we weren't using probabilities we would use this equation that I gave earlier:
$$ \bar x_{k+1} = x_k + f_{\mathbf x}(\bullet)$$
The prior, our prediction of where the dog will be, is the amount the dog moved plus his current position. The dog was at 10, he moved 5 meters, so he is now at 15 m. It couldn't be simpler. But we are using probabilities to model this, so our equation is:
$$ \bar{ \mathbf x}_{k+1} = \mathbf x_k \ast f_{\mathbf x}(\bullet)$$
We are *convolving* the current probabilistic position estimate with a probabilistic estimate of how much we think the dog moved. It's the same concept, but the math is slightly different. $\mathbf x$ is bold to denote that it is an array of numbers.
## Integrating Measurements and Movement Updates
The problem of losing information during a prediction may make it seem as if our system would quickly devolve into having no knowledge. However, each prediction is followed by an update where we incorporate the measurement into the estimate. The update improves our knowledge. The output of the update step is fed into the next prediction. The prediction degrades our certainty. That is passed into another update, where certainty is again increased.
Let's think about this intuitively. Consider a simple case - you are tracking a dog while he sits still. During each prediction you predict he doesn't move. Your filter quickly *converges* on an accurate estimate of his position. Then the microwave in the kitchen turns on, and he goes streaking off. You don't know this, so at the next prediction you predict he is in the same spot. But the measurements tell a different story. As you incorporate the measurements your belief will be smeared along the hallway, leading towards the kitchen. On every epoch (cycle) your belief that he is sitting still will get smaller, and your belief that he is inbound towards the kitchen at a startling rate of speed increases.
That is what intuition tells us. What does the math tell us?
We have already programmed the update and predict steps. All we need to do is feed the result of one into the other, and we will have implemented a dog tracker!!! Let's see how it performs. We will input measurements as if the dog started at position 0 and moved right one position each epoch. As in a real world application, we will start with no knowledge of his position by assigning equal probability to all positions.
```
from filterpy.discrete_bayes import update
hallway = np.array([1, 1, 0, 0, 0, 0, 0, 0, 1, 0])
prior = np.array([.1] * 10)
likelihood = lh_hallway(hallway, z=1, z_prob=.75)
posterior = update(likelihood, prior)
book_plots.plot_prior_vs_posterior(prior, posterior, ylim=(0,.5))
```
After the first update we have assigned a high probability to each door position, and a low probability to each wall position.
```
kernel = (.1, .8, .1)
prior = predict(posterior, 1, kernel)
book_plots.plot_prior_vs_posterior(prior, posterior, True, ylim=(0,.5))
```
The predict step shifted these probabilities to the right, smearing them about a bit. Now let's look at what happens at the next sense.
```
likelihood = lh_hallway(hallway, z=1, z_prob=.75)
posterior = update(likelihood, prior)
book_plots.plot_prior_vs_posterior(prior, posterior, ylim=(0,.5))
```
Notice the tall bar at position 1. This corresponds with the (correct) case of starting at position 0, sensing a door, shifting 1 to the right, and sensing another door. No other positions make this set of observations as likely. Now we will add an update and then sense the wall.
```
prior = predict(posterior, 1, kernel)
likelihood = lh_hallway(hallway, z=0, z_prob=.75)
posterior = update(likelihood, prior)
book_plots.plot_prior_vs_posterior(prior, posterior, ylim=(0,.5))
```
This is exciting! We have a very prominent bar at position 2 with a value of around 35%. It is over twice the value of any other bar in the plot, and is about 4% larger than our last plot, where the tallest bar was around 31%. Let's see one more cycle.
```
prior = predict(posterior, 1, kernel)
likelihood = lh_hallway(hallway, z=0, z_prob=.75)
posterior = update(likelihood, prior)
book_plots.plot_prior_vs_posterior(prior, posterior, ylim=(0,.5))
```
I ignored an important issue. Earlier I assumed that we had a motion sensor for the predict step; then, when talking about the dog and the microwave I assumed that you had no knowledge that he suddenly began running. I mentioned that your belief that the dog is running would increase over time, but I did not provide any code for this. In short, how do we detect and/or estimate changes in the process model if aren't directly measuring it?
For now I want to ignore this problem. In later chapters we will learn the mathematics behind this estimation; for now it is a large enough task just to learn this algorithm. It is profoundly important to solve this problem, but we haven't yet built enough of the mathematical apparatus that is required, and so for the remainder of the chapter we will ignore the problem by assuming we have a sensor that senses movement.
## The Discrete Bayes Algorithm
This chart illustrates the algorithm:
```
book_plots.create_predict_update_chart()
```
This filter is a form of the g-h filter. Here we are using the percentages for the errors to implicitly compute the $g$ and $h$ parameters. We could express the discrete Bayes algorithm as a g-h filter, but that would obscure the logic of this filter.
The filter equations are:
$$\begin{aligned} \bar {\mathbf x} &= \mathbf x \ast f_{\mathbf x}(\bullet)\, \, &\text{Predict Step} \\
\mathbf x &= \|\mathcal L \cdot \bar{\mathbf x}\|\, \, &\text{Update Step}\end{aligned}$$
$\mathcal L$ is the usual way to write the likelihood function, so I use that. The $\|\|$ notation denotes taking the norm. We need to normalize the product of the likelihood with the prior to ensure $x$ is a probability distribution that sums to one.
We can express this in pseudocode.
**Initialization**
1. Initialize our belief in the state
**Predict**
1. Based on the system behavior, predict state at the next time step
2. Adjust belief to account for the uncertainty in prediction
**Update**
1. Get a measurement and associated belief about its accuracy
2. Compute residual between estimated state and measurement
3. Determine whether the measurement matches each state
4. Update state belief if it matches the measurement
When we cover the Kalman filter we will use this exact same algorithm; only the details of the computation will differ.
Algorithms in this form are sometimes called *predictor correctors*. We make a prediction, then correct them.
Let's animate this. I've plotted the position of the doorways in black. Prior are drawn in orange, and the posterior in blue. You can see how the prior shifts the position and reduces certainty, and the posterior stays in the same position and increases certainty as it incorporates the information from the measurement. I've made the measurement perfect with the line `z_prob = 1.0`; we will explore the effect of imperfect measurements in the next section. finally, I draw a thick vertical line to indicate where Simon really is. This is not an output of the filter - we know where Simon really is only because we are simulating his movement.
```
def discrete_bayes_sim(pos, kernel, zs, z_prob_correct, sleep=0.25):
%matplotlib notebook
N = len(hallway)
fig = plt.figure()
for i, z in enumerate(zs):
plt.cla()
prior = predict(pos, 1, kernel)
book_plots.bar_plot(hallway, c='k')
book_plots.bar_plot(prior, ylim=(0,1.0), c='#ff8015')
plt.axvline(i % N + 0.4, lw=5)
fig.canvas.draw()
time.sleep(sleep)
plt.cla()
likelihood = lh_hallway(hallway, z=z, z_prob=z_prob_correct)
pos = update(likelihood, prior)
book_plots.bar_plot(hallway, c='k')
book_plots.bar_plot(pos, ylim=(0,1.0))
plt.axvline(i % 10 + 0.4, lw=5)
fig.canvas.draw()
time.sleep(sleep)
plt.show()
%matplotlib inline
set_figsize(y=2)
print('Final posterior:', pos)
# change these numbers to alter the simulation
kernel = (.1, .8, .1)
z_prob = 1.0
# list of perfect measurements
hallway = np.array([1, 1, 0, 0, 0, 0, 0, 0, 1, 0])
measurements = [hallway[i % len(hallway)] for i in range(25)]
pos = np.array([.1]*10)
discrete_bayes_sim(pos, kernel, measurements, z_prob)
```
## The Effect of Bad Sensor Data
You may be suspicious of the results above because I always passed correct sensor data into the functions. However, we are claiming that this code implements a *filter* - it should filter out bad sensor measurements. Does it do that?
To make this easy to program and visualize I will change the layout of the hallway to mostly alternating doors and hallways, and run the algorithm on 15 correct measurements:
```
hallway = np.array([1, 0, 1, 0, 0]*2)
kernel = (.1, .8, .1)
prior = np.array([.1] * 10)
measurements = [1, 0, 1, 0, 0]
z_prob = 0.75
discrete_bayes_sim(prior, kernel, measurements, z_prob)
```
We have identified the likely cases of having started at position 0 or 5, because we saw this sequence of doors and walls: 1,0,1,0,0. Now I inject a bad measurement. The next measurement should be 1, but instead we get a 0:
```
measurements = [1, 0, 1, 0, 0, 0]
discrete_bayes_sim(prior, kernel, measurements, z_prob)
```
That one bad measurement has significantly eroded our knowledge. Now let's continue with a series of correct measurements.
```
with figsize(y=5.5):
measurements = [0, 1, 0, 1, 0, 0, 1, 0, 1]
for i, m in enumerate(measurements):
likelihood = lh_hallway(hallway, z=m, z_prob=.75)
posterior = update(likelihood, prior)
prior = predict(posterior, 1, kernel)
plt.subplot(3, 3, i+1)
book_plots.bar_plot(posterior, ylim=(0, .4), title='step {}'.format(i+1))
plt.tight_layout()
```
We quickly filtered out the bad sensor reading and converged on the most likely positions for our dog.
## Drawbacks and Limitations
Do not be mislead by the simplicity of the examples I chose. This is a robust and complete filter, and you may use the code in real world solutions. If you need a multimodal, discrete filter, this filter works.
With that said, this filter it is not used often because it has several limitations. Getting around those limitations is the motivation behind the chapters in the rest of this book.
The first problem is scaling. Our dog tracking problem used only one variable, $pos$, to denote the dog's position. Most interesting problems will want to track several things in a large space. Realistically, at a minimum we would want to track our dog's $(x,y)$ coordinate, and probably his velocity $(\dot{x},\dot{y})$ as well. We have not covered the multidimensional case, but instead of an array we use a multidimensional grid to store the probabilities at each discrete location. Each `update()` and `predict()` step requires updating all values in the grid, so a simple four variable problem would require $O(n^4)$ running time *per time step*. Realistic filters can have 10 or more variables to track, leading to exorbitant computation requirements.
The second problem is that the filter is discrete, but we live in a continuous world. The histogram requires that you model the output of your filter as a set of discrete points. A 100 meter hallway requires 10,000 positions to model the hallway to 1cm accuracy. So each update and predict operation would entail performing calculations for 10,000 different probabilities. It gets exponentially worse as we add dimensions. A 100x100 m$^2$ courtyard requires 100,000,000 bins to get 1cm accuracy.
A third problem is that the filter is multimodal. In the last example we ended up with strong beliefs that the dog was in position 4 or 9. This is not always a problem. Particle filters, which we will study later, are multimodal and are often used because of this property. But imagine if the GPS in your car reported to you that it is 40% sure that you are on D street, and 30% sure you are on Willow Avenue.
A forth problem is that it requires a measurement of the change in state. We need a motion sensor to detect how much the dog moves. There are ways to work around this problem, but it would complicate the exposition of this chapter, so, given the aforementioned problems, I will not discuss it further.
With that said, if I had a small problem that this technique could handle I would choose to use it; it is trivial to implement, debug, and understand, all virtues.
## Tracking and Control
We have been passively tracking an autonomously moving object. But consider this very similar problem. I am automating a warehouse and want to use robots to collect all of the items for a customer's order. Perhaps the easiest way to do this is to have the robots travel on a train track. I want to be able to send the robot a destination and have it go there. But train tracks and robot motors are imperfect. Wheel slippage and imperfect motors means that the robot is unlikely to travel to exactly the position you command. There is more than one robot, and we need to know where they all are so we do not cause them to crash.
So we add sensors. Perhaps we mount magnets on the track every few feet, and use a Hall sensor to count how many magnets are passed. If we count 10 magnets then the robot should be at the 10th magnet. Of course it is possible to either miss a magnet or to count it twice, so we have to accommodate some degree of error. We can use the code from the previous section to track our robot since magnet counting is very similar to doorway sensing.
But we are not done. We've learned to never throw information away. If you have information you should use it to improve your estimate. What information are we leaving out? We know what control inputs we are feeding to the wheels of the robot at each moment in time. For example, let's say that once a second we send a movement command to the robot - move left 1 unit, move right 1 unit, or stand still. If I send the command 'move left 1 unit' I expect that in one second from now the robot will be 1 unit to the left of where it is now. This is a simplification because I am not taking acceleration into account, but I am not trying to teach control theory. Wheels and motors are imperfect. The robot might end up 0.9 units away, or maybe 1.2 units.
Now the entire solution is clear. We assumed that the dog kept moving in whatever direction he was previously moving. That is a dubious assumption for my dog! Robots are far more predictable. Instead of making a dubious prediction based on assumption of behavior we will feed in the command that we sent to the robot! In other words, when we call `predict()` we will pass in the commanded movement that we gave the robot along with a kernel that describes the likelihood of that movement.
### Simulating the Train Behavior
We need to simulate an imperfect train. When we command it to move it will sometimes make a small mistake, and its sensor will sometimes return the incorrect value.
```
class Train(object):
def __init__(self, track_len, kernel=[1.], sensor_accuracy=.9):
self.track_len = track_len
self.pos = 0
self.kernel = kernel
self.sensor_accuracy = sensor_accuracy
def move(self, distance=1):
""" move in the specified direction
with some small chance of error"""
self.pos += distance
# insert random movement error according to kernel
r = random.random()
s = 0
offset = -(len(self.kernel) - 1) / 2
for k in self.kernel:
s += k
if r <= s:
break
offset += 1
self.pos = int((self.pos + offset) % self.track_len)
return self.pos
def sense(self):
pos = self.pos
# insert random sensor error
if random.random() > self.sensor_accuracy:
if random.random() > 0.5:
pos += 1
else:
pos -= 1
return pos
```
With that we are ready to write the filter. We will put it in a function so that we can run it with different assumptions. I will assume that the robot always starts at the beginning of the track. The track is implemented as being 10 units long, but think of it as a track of length, say 10,000, with the magnet pattern repeated every 10 units. A length of 10 makes it easier to plot and inspect.
```
def train_filter(iterations, kernel, sensor_accuracy,
move_distance, do_print=True):
track = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
prior = np.array([.9] + [0.01]*9)
normalize(prior)
robot = Train(len(track), kernel, sensor_accuracy)
for i in range(iterations):
robot.move(distance=move_distance)
m = robot.sense()
if do_print:
print('''time {}: pos {}, sensed {}, '''
'''at position {}'''.format(
i, robot.pos, m, track[robot.pos]))
likelihood = lh_hallway(track, m, sensor_accuracy)
posterior = update(likelihood, prior)
index = np.argmax(posterior)
if i < iterations - 1:
prior = predict(posterior, move_distance, kernel)
if do_print:
print(''' predicted position is {}'''
''' with confidence {:.4f}%:'''.format(
index, posterior[index]*100))
book_plots.bar_plot(posterior)
if do_print:
print()
print('final position is', robot.pos)
index = np.argmax(posterior)
print('''predicted position is {} with '''
'''confidence {:.4f}%:'''.format(
index, posterior[index]*100))
```
Read the code and make sure you understand it. Now let's do a run with no sensor or movement error. If the code is correct it should be able to locate the robot with no error. The output is a bit tedious to read, but if you are at all unsure of how the update/predict cycle works make sure you read through it carefully to solidify your understanding.
```
import random
random.seed(3)
np.set_printoptions(precision=2, suppress=True, linewidth=60)
train_filter(iterations=4, kernel=[1.], sensor_accuracy=.999,
move_distance=4, do_print=True)
```
We can see that the code was able to perfectly track the robot so we should feel reasonably confident that the code is working. Now let's see how it fairs with some errors.
```
random.seed(5)
train_filter(iterations=4, kernel=[.1, .8, .1], sensor_accuracy=.9,
move_distance=4, do_print=True)
```
There was a sensing error at time 1, but we are still quite confident in our position.
Now let's run a very long simulation and see how the filter responds to errors.
```
with figsize(y=5.5):
for i in range (4):
random.seed(3)
plt.subplot(221+i)
train_filter(iterations=148+i, kernel=[.1, .8, .1],
sensor_accuracy=.8,
move_distance=4, do_print=False)
plt.title ('iteration {}'.format(148+i))
```
We can see that there was a problem on iteration 149 as the confidence degrades. But within a few iterations the filter is able to correct itself and regain confidence in the estimated position.
## Bayes Theorem
We developed the math in this chapter merely by reasoning about the information we have at each moment. In the process we discovered [*Bayes Theorem*](https://en.wikipedia.org/wiki/Bayes%27_theorem). Bayes theorem tells us how to compute the probability of an event given previous information. That is exactly what we have been doing in this chapter. With luck our code should match the Bayes Theorem equation!
We implemented the `update()` function with this probability calculation:
$$ \mathtt{posterior} = \frac{\mathtt{likelihood}\times \mathtt{prior}}{\mathtt{normalization}}$$
To review, the *prior* is the probability of something happening before we include the probability of the measurement (the *likelihood*) and the *posterior* is the probability we compute after incorporating the information from the measurement.
Bayes theorem is
$$P(A \mid B) = \frac{P(B \mid A)\, P(A)}{P(B)}$$
If you are not familiar with this notation, let's review. $P(A)$ means the probability of event $A$. If $A$ is the event of a fair coin landing heads, then $P(A) = 0.5$.
$P(A \mid B)$ is called a [*conditional probability*](https://en.wikipedia.org/wiki/Conditional_probability). That is, it represents the probability of $A$ happening *if* $B$ happened. For example, it is more likely to rain today if it also rained yesterday because rain systems usually last more than one day. We'd write the probability of it raining today given that it rained yesterday as $P(\mathtt{rain\_today} \mid \mathtt{rain\_yesterday})$.
In the Bayes theorem equation above $B$ is the *evidence*, $P(A)$ is the *prior*, $P(B \mid A)$ is the *likelihood*, and $P(A \mid B)$ is the *posterior*. By substituting the mathematical terms with the corresponding words you can see that Bayes theorem matches out update equation. Let's rewrite the equation in terms of our problem. We will use $x_i$ for the position at *i*, and $Z$ for the measurement. Hence, we want to know $P(x_i \mid Z)$, that is, the probability of the dog being at $x_i$ given the measurement $Z$.
So, let's plug that into the equation and solve it.
$$P(x_i \mid Z) = \frac{P(Z \mid x_i) P(x_i)}{P(Z)}$$
That looks ugly, but it is actually quite simple. Let's figure out what each term on the right means. First is $P(Z \mid x_i)$. This is the the likelihood, or the probability for the measurement at every cell $x_i$. $P(x_i)$ is the *prior* - our belief before incorporating the measurements. We multiply those together. This is just the unnormalized multiplication in the `update()` function:
```python
def update(likelihood, prior):
posterior = prior * likelihood # P(Z|x)*P(x)
return normalize(posterior)
```
The last term to consider is the denominator $P(Z)$. This is the probability of getting the measurement $Z$ without taking the location into account. It is often called the *evidence*. We compute that by taking the sum of $x$, or `sum(belief)` in the code. That is how we compute the normalization! So, the `update()` function is doing nothing more than computing Bayes theorem.
The literature often gives you these equations in the form of integrals. After all, an integral is just a sum over a continuous function. So, you might see Bayes' theorem written as
$$P(A \mid B) = \frac{P(B \mid A)\, P(A)}{\int P(B \mid A_j) P(A_j) \mathtt{d}A_j}\cdot$$
In practice the denominator can be fiendishly difficult to solve analytically (a recent opinion piece for the Royal Statistical Society [called it](http://www.statslife.org.uk/opinion/2405-we-need-to-rethink-how-we-teach-statistics-from-the-ground-up) a "dog's breakfast" [8]. Filtering textbooks are filled with integral laden equations which you cannot be expected to solve. We will learn more techniques to handle this in the **Particle Filters** chapter. Until then, recognize that in practice it is just a normalization term over which we can sum. What I'm trying to say is that when you are faced with a page of integrals, just think of them as sums, and relate them back to this chapter, and often the difficulties will fade. Ask yourself "why are we summing these values", and "why am I dividing by this term". Surprisingly often the answer is readily apparent.
## Total Probability Theorem
We now know the formal mathematics behind the `update()` function; what about the `predict()` function? `predict()` implements the [*total probability theorem*](https://en.wikipedia.org/wiki/Law_of_total_probability). Let's recall what `predict()` computed. It computed the probability of being at any given position given the probability of all the possible movement events. Let's express that as an equation. The probability of being at any position $i$ at time $t$ can be written as $P(X_i^t)$. We computed that as the sum of the prior at time $t-1$ $P(X_j^{t-1})$ multiplied by the probability of moving from cell $x_j$ to $x_i$. That is
$$P(X_i^t) = \sum_j P(X_j^{t-1}) P(x_i | x_j)$$
That equation is called the *total probability theorem*. Quoting from Wikipedia [6] "It expresses the total probability of an outcome which can be realized via several distinct events". I could have given you that equation and implemented `predict()`, but your chances of understanding why the equation works would be slim. As a reminder, here is the code that computes this equation
```python
for i in range(N):
for k in range (kN):
index = (i + (width-k) - offset) % N
result[i] += prob_dist[index] * kernel[k]
```
## Summary
The code is very short, but the result is impressive! We have implemented a form of a Bayesian filter. We have learned how to start with no information and derive information from noisy sensors. Even though the sensors in this chapter are very noisy (most sensors are more than 80% accurate, for example) we quickly converge on the most likely position for our dog. We have learned how the predict step always degrades our knowledge, but the addition of another measurement, even when it might have noise in it, improves our knowledge, allowing us to converge on the most likely result.
This book is mostly about the Kalman filter. The math it uses is different, but the logic is exactly the same as used in this chapter. It uses Bayesian reasoning to form estimates from a combination of measurements and process models.
**If you can understand this chapter you will be able to understand and implement Kalman filters.** I cannot stress this enough. If anything is murky, go back and reread this chapter and play with the code. The rest of this book will build on the algorithms that we use here. If you don't understand why this filter works you will have little success with the rest of the material. However, if you grasp the fundamental insight - multiplying probabilities when we measure, and shifting probabilities when we update leads to a converging solution - then after learning a bit of math you are ready to implement a Kalman filter.
## References
* [1] D. Fox, W. Burgard, and S. Thrun. "Monte carlo localization: Efficient position estimation for mobile robots." In *Journal of Artifical Intelligence Research*, 1999.
http://www.cs.cmu.edu/afs/cs/project/jair/pub/volume11/fox99a-html/jair-localize.html
* [2] Dieter Fox, et. al. "Bayesian Filters for Location Estimation". In *IEEE Pervasive Computing*, September 2003.
http://swarmlab.unimaas.nl/wp-content/uploads/2012/07/fox2003bayesian.pdf
* [3] Sebastian Thrun. "Artificial Intelligence for Robotics".
https://www.udacity.com/course/cs373
* [4] Khan Acadamy. "Introduction to the Convolution"
https://www.khanacademy.org/math/differential-equations/laplace-transform/convolution-integral/v/introduction-to-the-convolution
* [5] Wikipedia. "Convolution"
http://en.wikipedia.org/wiki/Convolution
* [6] Wikipedia. "Law of total probability"
http://en.wikipedia.org/wiki/Law_of_total_probability
* [7] Wikipedia. "Time Evolution"
https://en.wikipedia.org/wiki/Time_evolution
* [8] We need to rethink how we teach statistics from the ground up
http://www.statslife.org.uk/opinion/2405-we-need-to-rethink-how-we-teach-statistics-from-the-ground-up
[NextChapter -> 03-Gaussians](http://nbviewer.ipython.org/github/rlabbe/Kalman-and-Bayesian-Filters-in-Python/blob/master/03-Gaussians.ipynb)
| github_jupyter |
# StationSim - Grand Central Station version
author: P. Ternes
created: 28/05/2020
In this text we track changes made in the StationSim model to emulate the data from the Grand Central Station.
## Manly changes
* Create gates in all sides;
* Create a forbidden region in the center of the station to represent the clock;
* Designate all gates as possible entry and exit points;
* Change the way the model identifies a collision;
* Change the way the the agents perform a wiggle.
## Grand Central Station
You can access the Grand Station data here:
http://www.ee.cuhk.edu.hk/~xgwang/grandcentral.html
The main concourse of the station has a rectangular shape and has gates on all sides. We are considerate one gate on the South Side, two gates on the West Side, five gates on the North Side, and two gates on the East Side. The station also has a clock in the center of the main concourse. A schematic view of the station can be seen in the figure below.
<img src="figs/station1.png" width="300">
To define the size of the station, the location of the gates and the location and size of the clock, it is necessary to perform a calibration with real data. The complete discution about the Grand Central Station calibration can be found in the [`Real_Data_correct_trails`](Projects/ABM_DA/experiments/grand_central_terminal_data/Real_Data_correct_trails.ipynb) jupyter notebook.
## Create Grand Central Station in the StationSim model
To create a station with the structure of the Grand Central station is necesary to pass to the model a parameter with the key 'station' and the value 'Grand_Central_real'. E.g. like this:
```
model_params = {'station': 'Grand_Central'}
```
If the 'Grand_Central_real' parameter is passed to the model, several parameters will be determined within the set_station method. If any of these parameters are passed to the model, they are just ignored.
The <b>set_station</b> method is:
```
def set_station(self):
'''
Allows to manually set a station (e.g. 'Grand_Central') rather
than automatically generating a station from parameters like
number of gates, gate size, etc.
'''
if(self.station == 'Grand_Central'):
self.width = 740 # 53 m
self.height = 700 # 50 m
self.boundaries = np.array([[0, 0], [self.width, self.height]])
self.gates_locations =\
np.array([[0, 275], # gate 0
[125, 700], # gate 1
[577.5 , 700], # gate 2
[740, 655], # gate 3
[740, 475], # gate 4
[740, 265], # gate 5
[740, 65], # gate 6
[647.5, 0], # gate 7
[462.5, 0], # gate 8
[277.5, 0], # gate 9
[92.5, 0]]) # gate 10
self.gates_width = [250, 250, 245, 90, 150, 150, 120, 185, 185, 185, 185]
self.gates_in = len(self.gates_locations)
self.gates_out = len(self.gates_locations)
self.clock = Agent(self, self.pop_total)
self.clock.size = 56.0 # 4 m
self.clock.location = [370, 275] # 26.4 m, 20 m
self.clock.speed = 0.0
self.agent_size = 7.0 # 0.5 m
self.speed_mean = 0.839236 # pixel / frame
self.speed_std = 0.349087 # pixel / frame
self.gates_space = 28.0 # 2 m
else:
self.gates_locations = np.concatenate([
Model._gates_init(0, self.height, self.gates_in),
Model._gates_init(self.width, self.height, self.gates_out)])
self.gates_width = [20 for _ in range (len(self.gates_locations))]
self.boundaries = np.array([[0, 0], [self.width, self.height]])
# create a clock outside the station.
self.clock = Agent(self, self.pop_total)
self.clock.speed = 0.0
if(self.station is not None):
warnings.warn(
"The station parameter passed to the model is not valid; "
"Using the default station.",
RuntimeWarning
)
```
Note that if a different station name is passed, than the classical structure of the StationSim model is used. This means that only gates at left side are used as entrace points and gates at right side are used as exit points.
To ensure that the code is executed, regardless of the structure of the chosen station, a method is used to determine the exit gate. The <b>set_gate_out method</b> is:
```
def set_gate_out(self):
'''
Set a exit gate for the agent.
- The exit gate ca be any gate that is on a different side of
the entrance gate.
'''
if (self.model.station == 'Grand_Central'):
if (self.gate_in == 0):
self.gate_out = np.random.random_integers(1, 10)
elif (self.gate_in == 1 or self.gate_in == 2):
self.gate_out = np.random.choice( (0, 3, 4, 5, 6, 7, 8, 9, 10))
elif (self.gate_in == 3 or self.gate_in == 4 or self.gate_in == 5 or self.gate_in == 6):
self.gate_out = np.random.choice( (0, 1, 2, 7, 8, 9, 10))
else:
self.gate_out = np.random.random_integers(0, 6)
else:
self.gate_out = np.random.randint(self.model.gates_out) + self.model.gates_in
```
## Agent initial and final position
Each agent, when created, needs to receive a start position and a desired end position. These positions are based on the position of the entry and exit gates defined for that agent. To simulate the width of the gates a perturbartion is added to each selected position. In addition, it is necessary to ensure that the agents have positions that are a little more than a body away from the station walls and that are inside the environment.
The <b>set_agent_location</b> method returns a position based on the mentioned criteria.
```
def set_agent_location(self, gate):
'''
Define one final or initial position for the agent.
It is necessary to ensure that the agent has a distance from
the station wall compatible with its own size.
'''
wd = self.model.gates_width[gate] / 2.0
perturb = np.random.uniform(-wd, +wd)
if(self.model.gates_locations[gate][0] == 0):
new_location = self.model.gates_locations[gate] + [1.05*self.size, perturb]
elif(self.model.gates_locations[gate][0] == self.model.width):
new_location = self.model.gates_locations[gate] + [-1.05*self.size, perturb]
elif(self.model.gates_locations[gate][1] == 0):
new_location = self.model.gates_locations[gate] + [perturb, 1.05*self.size]
else:
new_location = self.model.gates_locations[gate] + [perturb, -1.05*self.size]
'''
As there are gates near the corners it is possible to create
a position outside the station. To fix this, rebound:
'''
if not self.model.is_within_bounds(self, new_location):
new_location = self.model.re_bound(self, new_location)
return new_location
```
The initial position also needs an aditional criterion. This position must be different from the current position of any other active agent. This condition is necessary due to the new definition of collision. If two agents are in the same position, then the new collision definition will cause the dynamics in the system to stop.
The <b>activate</b> method creats correctly a initial position. Note that after 10 attempts to create a starting position, if it is impossible to designate a unique position to the agent, than, the agent will be activated only in the next step.
```
def activate(self, model):
'''
Test whether an agent should become active.
This happens when the model time is greater than the agent's
activate time.
It is necessary to ensure that the agent has an initial position
different from the position of all active agents. If it was not
possible, activate the agent on next time step.
'''
if self.status == 0:
if model.total_time > self.steps_activate:
state = model.get_state('location2D')
model.tree = cKDTree(state)
for _ in range(10):
new_location = self.set_agent_location(model, self.gate_in)
neighbouring_agents = model.tree.query_ball_point(
new_location, self.size*1.1)
if (neighbouring_agents == [] or
neighbouring_agents == [self.unique_id]):
self.location = new_location
self.status = 1
model.pop_active += 1
self.step_start = model.total_time # model.step_id
self.loc_start = self.location
break
```
## New colision definition
In the default version of the StationSim model, the movement of the agents occurs mainly in the horizontal direction, from left to right side. This movement limitation allows the use of a simplified collision definition.
By creating gates on all sides of the station and allowing them to be points of entry and exit, we make it possible for agents to have the most varied directions of movement. Thus, a more robust definition of collision is necessary.
The new definition of colision is obtained through the equation of motion of each agent. Before a colision, the movemment is linear, and can be described by:
$$\vec{r}_i' = \vec{r}_i + \vec{v}_i\Delta t ,$$
where $\vec{r}_i = (x_i, y_i)$ is the position of agent $i$ at time $t$, $\vec{r}_i'= (x_i', y_i')$ is the position of agent i at time $t'$, $\vec{v}_i=(v_{xi}, v_{yi})$ is the agent velocity, and $\Delta t = t'-t$ is the time variation.
### Collision between two agents
The next figure illustrate the colision between two agents.
<img src="figs/collision_scheme.png" width="600">
Note that, when an agent $i$ collide with another agent $j$, the distance between the center of the agents is $\sigma = \sigma_i + \sigma_j$, where $\sigma_i$ and $\sigma_j$ are related with the agents width.
It is possible to obtain the distance between two agents $i$ and $j$ using their positions:
$$ \Delta r'^{2} = (x_j' - x_i')^2 + (y_j' - y_i')^2 ,$$
therefore, in a collision we have $\Delta r'^2 = \sigma^2$. Putting all the equations together and solving the quadratic equation, it is possible to find the time variation between the beginning of the movement and the collision.
$$\Delta t = \left\{ \begin{array}{lcl}
\infty & \mbox{if} & \Delta\vec{v}\cdot\Delta\vec{r}\ge0, \\
\infty & \mbox{if} & d < 0, \\
\dfrac{-\Delta\vec{v}\cdot\Delta\vec{r}-\sqrt{d}}{\Delta\vec{v}\cdot\Delta\vec{v}} & \mbox{if} & \mbox{otherwise,}
\end{array}\right.$$
where
$$\begin{array}{l}
d = (\Delta\vec{v}\cdot\Delta\vec{r})^2 - (\Delta\vec{v}\cdot\Delta\vec{v})(\Delta\vec{r}\cdot\Delta\vec{r} - \sigma^2),\\
\Delta\vec{v} = \vec{v}_j - \vec{v}_i = (v_{xj}-v_{xi}, v_{yj}-v_{yi}),\\
\Delta\vec{r} = \vec{r}_j - \vec{r}_i = (r_{xj}-r_{xi}, r_{yj}-r{yi}).\\
\end{array}$$
When $\Delta\vec{v}\cdot\Delta\vec{r}\ge 0 $ or $d < 0$, the agents do not collide, even though the distance between them is $\sigma$. This situation can occur if their movemment are parrallel or in opposite directions.
The <b>get_collisionTime2Agents</b> method return the collision time between two agents.
```
def get_collisionTime2Agents(self, agentB):
'''
Returns the collision time between two agents.
'''
tmin = 1.0e300
rAB = self.location - agentB.location
directionA = self.get_direction(self.loc_desire, self.location)
directionB = agentB.get_direction(agentB.loc_desire, agentB.location)
sizeAB = self.size + agentB.size
vA = self.speed
vB = agentB.speed
vAB = vA*directionA - vB*directionB
bAB = np.dot(vAB, rAB)
if bAB < 0.0:
delta = bAB**2 - (np.dot(vAB, vAB)*(np.dot(rAB, rAB) - sizeAB**2))
if (delta > 0.0):
collisionTime = abs((-bAB - np.sqrt(delta)) / np.dot(vAB, vAB))
tmin = collisionTime
return tmin
```
### Collision between an agent and a wall
In addition to colliding with another agent, an agent can also collide with a wall.
The next figure illustrate the colision between an agent and a wall.
<img src="figs/collision-wall.png" width="350">
Note that, when an agent $i$ collide with a wall, the distance between the center of the agent and the wall is $\sigma_i$, where $\sigma_i$ is related with the agent width. Considering that the station has a retangular shape, the agent can collide with four different walls. The equations to determine the colision time for each possible wall are:
$$
\Delta t = \left\{ \begin{array}{lcl}
(\sigma_i - x_i)/v_{xi} & \mbox{if} & v_{xi} < 0; \\
(w - \sigma_i - x_i)/v_{xi} & \mbox{if} & v_{xi} > 0; \\
\infty & \mbox{if} & v_{xi} = 0;
\end{array}\right.$$
for verticall walls, where, $w$ is the station width, and
$$
\Delta t = \left\{ \begin{array}{lcl}
(\sigma_i - y_i)/v_{yi} & \mbox{if} & v_{yi} < 0; \\
(h - \sigma_i - y_i)/v_{yi} & \mbox{if} & v_{yi} > 0; \\
\infty & \mbox{if} & v_{yi} = 0;
\end{array}\right.$$
for horizontal walls, where $h$ is the station heigh.
The minor collision time between an agent and a wall is determined by the <b>get_collisionTimeWall</b> method.
```
def get_collisionTimeWall(self, model):
'''
Returns the shortest collision time between an agent and a wall.
'''
tmin = 1.0e300
collisionTime = 1.0e300
direction = self.get_direction(self.loc_desire, self.location)
vx = self.speed*direction[0] # horizontal velocity
vy = self.speed*direction[1] # vertical velocity
if(vy > 0): # collision in botton wall
collisionTime = (model.height - self.size - self.location[1]) / vy
elif (vy < 0): # collision in top wall
collisionTime = (self.size - self.location[1]) / vy
if (collisionTime < tmin):
tmin = collisionTime
if(vx > 0): # collision in right wall
collisionTime = (model.width - self.size - self.location[0]) / vx
elif (vx < 0): # collision in left wall
collisionTime = (self.size - self.location[0]) / vx
if (collisionTime < tmin):
tmin = collisionTime
return tmin
```
### Velocity variation before wiggle
In the default version of the StationSim model when a collision was identified, before wiggle, the agent's velocity was decreased to try avoid the collision.
Unfortunately, by changing the collision definition, this feature was lost.
## Step implementation
In this new version of StationSim, we check if a collision occurs before moving agents. At the beginning of each model step, a table is created containing the time collision for each possible collision, including collisions with the wall, with other active agents and with the station clock.
Using the collision table, the shortest collision time is selected. The <b>get_collisionTable</b> method is:
```
def get_collisionTable(self):
'''
Returns the time of next colision (tmin) and a table with
information about every possible colision:
- collisionTable[0]: collision time
- collisionTable[1]: agent agent.unique_id
'''
collisionTable = []
for i in range(self.pop_total):
if (self.agents[i].status == 1):
collisionTime = self.agents[i].get_collisionTimeWall()
collision = (collisionTime, i)
collisionTable.append(collision)
collisionTime =\
self.agents[i].get_collisionTime2Agents(self.clock)
collision = (collisionTime, i)
collisionTable.append(collision)
for j in range(i+1, self.pop_total):
if (self.agents[j].status == 1):
collisionTime = self.agents[i].\
get_collisionTime2Agents(self.agents[j])
collision = (collisionTime, i)
collisionTable.append(collision)
collision = (collisionTime, j)
collisionTable.append(collision)
try:
tmin = min(collisionTable)
tmin = tmin[0]
if tmin <= 1.0e-10:
tmin = 0.02
except:
tmin = 1.0e300
return collisionTable, tmin
```
Therefore, after call the <b>get_collisionTable</b> method we have the information about when the next collision will occur. If the next collision occurs in a time greater than 1, all the active agent will be moved in a straight line for 1 step.
If the next collision occurs in a time lower than 1, all active agents will be moved in a straight line by a time equal to the next collision time. It is important to remember that this is a multibody problem, so it is possible to have simultaneous collisions. To track all possible collisions, a wiggle table is created with all colisions that occur at the same current collision time (inside a tolerance interval time). The <b>get_wiggleTable</b> is:
```
def get_wiggleTable(self, collisionTable, time):
'''
Returns a table with the agent.unique_id of all agents that
collide in the specified time. A tolerance time is used to
capture almost simultaneous collisions.
Each line in the collisionTable has 2 columns:
- Column 0: collision time
- Column 1: agent.unique_id
'''
return set([line[1] for line in collisionTable
if (abs(line[0] - time) < self.tolerance)])
```
All agents in the wiggle table will be passed to <b>set_wiggle</b> method where the agents that are colliding were moved on a normal direction. It is very important to ensure that after wiggle the agent is not above any other agent. If after 10 attempts to move the agent it was impossible to find a new location without another agent, the agent just remain stopped. The <b>set_wiggle</b> method is:
```
def set_wiggle(self, model):
'''
Determine a new position for an agent that collided with another
agent, or with some element of the station.
The new position simulates a lateral step. The side on which the
agent will take the step is chosen at random, as well as the
amplitude of the step.
Description:
- Determine a new position and check if it is a unique position.
- If it is unique, then the agent receives this position.
- Otherwise, a new position will be determined.
- This process has a limit of 10 attempts. If it is not possible
to determine a new unique position, the agent just stay stopped.
'''
direction = self.get_direction(self.loc_desire, self.location)
state = model.get_state('location2D')
model.tree = cKDTree(state)
for _ in range(10):
normal_direction = self.get_normal_direction(direction)
new_location = self.location +\
normal_direction *\
np.random.normal(self.size, self.size/2.0)
# Rebound
if not model.is_within_bounds(self, new_location):
new_location = model.re_bound(self, new_location)
# collision_map
if model.do_history:
self.history_collisions += 1
model.history_collision_locs.append(new_location)
model.history_collision_times.append(model.total_time)
# Check if the new location is possible
neighbouring_agents = model.tree.query_ball_point(new_location,
self.size*1.1)
dist = self.distance(new_location, model.clock.location)
if ((neighbouring_agents == [] or
neighbouring_agents == [self.unique_id]) and
(dist > (self.size + model.clock.size))):
self.location = new_location
# wiggle_map
if model.do_history:
self.history_wiggles += 1
model.history_wiggle_locs.append(new_location)
break
```
## Deleted code
As the defition of colision changed, some parts of the code were completely changed or deleted. Here is a summary of the main changes made:
* Agent.move: this method was completely replaced for a new Agent.move method;
* Agent.collision: deleted;
* Agent.neighbourhood: deleted;
* Agent.wiggle and model.max_wiggle parameters: deleted. The new wiggle is related with the agent size to simulate a real human step.
## Preliminar results
Both, classical and Grand Central versions, are working with the new collision definition. The basic experiments for this model can be found at [`gcs_experiments`](Projects/ABM_DA/experiments/gcs_experiments/gcs_experiments.ipynb).
## Grand Central station calibration
The StationSim_gcs model requires several initial parameters. If the Grand Central Terminal structure is chosen, most of these parameters will be automatically defined by the model in the <b>set_station</b> method shown above.
In this case, the parameters 'pop_total' and 'birth_rate', which represent the total number of simulated agents and the rate at which these agents enter the environment respectively, must be defined by the user of the code. It is important that these parameters are chosen in a manner consistent with the other parameters of the model. On the [`GCT-data`](Projects/ABM_DA/experiments/grand_central_terminal_data/GCT-data.ipynb) a complete analysis of real data from the grand central terminal is presented.
## Issues/next steps
### Organization and optimization
The softwere is slowly. The biggest reason for this are the loops to determine the collision time and collision tables.
* A possible solution would be to keep a table with information on the collision times and calculate the collision time only for the agents that collided in the previous step. This would decrease the number of repeated interactions unnecessarily in the get_collisionTable method.
* The drawback to this approach would be integration with data assimilation. After resample it is necessary to recalculate the entire table.
### Wiggles and Collisions
Some analytics about wiglles and collisions are not correct. By changing several parts of the code and the model itself, these quantities have gained a new interpretation. If you need these statistics, you need to change the code.
| github_jupyter |
## Background
#### The Algorithm
KNN can be used for both classification and regression predictive problems. KNN falls in the supervised learning family of algorithms. Informally, this means that we are given a labelled dataset consiting of training observations $(x,y)$ and would like to capture the relationship between $x$ and $y$. More formally, our goal is to learn a function $h: X\rightarrow Y$ so that given an unseen observation $x$, $h(x)$ can confidently predict the corresponding output $y$.
In the classification setting, the K-nearest neighbor algorithm essentially boils down to forming a majority vote between the K most similar instances to a given “unseen” observation. Similarity is defined according to a distance metric between two data points. The k-nearest-neighbor classifier is commonly based on the Euclidean distance between a test sample and the specified training samples. Let $x_{i}$ be an input sample with $p$ features $(x_{i1}, x_{i2},..., x_{ip})$, $n$ be the total number of input samples $(i=1,2,...,n)$. The Euclidean distance between sample $x_{i}$ and $x_{l}$ is is defined as:
$$d(x_{i}, x_{l}) = \sqrt{(x_{i1} - x_{l1})^2 + (x_{i2} - x_{l2})^2 + ... + (x_{ip} - x_{lp})^2}$$
Sometimes other measures can be more suitable for a given setting and include the Manhattan, Chebyshev and Hamming distance.
Reference: https://www.kaggle.com/skalskip/iris-data-visualization-and-knn-classification/notebook
### Loading useful libraries
More details about them can be found in `readme.md`
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
```
### Load data
```
data = load_iris()
type(data)
```
Notice how the data type is a `sklearn.Bunch` we can use Pandas to convert this to a dataframe
```
# label names for classification
data.target_names
df = pd.DataFrame(data.data, columns=data.feature_names)
# df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['target'] = pd.Series(data.target)
df
```
### Simple EDA
```
df.shape
# column names
df.columns
# integers representing the species: 0 = setosa, 1 = versicolor, 2 = virginica
df.target
df.describe()
df.groupby('target').size()
```
### Splitting the data into features and labels and using that to split into train and test sets
```
feature_columns = ['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
X = df[feature_columns].values
y = df['target'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
```
Notice the shape of `y_train = (120,)` and similarly for `y_test = (30,)` this simply means the array of data is indexed by a single index
### Some Visualization To Help Understand the Distrbution of the Dataset
```
plt.figure()
sns.pairplot(df, hue = "target", size=3, markers=["o", "s", "D"])
plt.show()
plt.figure()
df.boxplot(by="target", figsize=(15, 10))
plt.show()
```
## Classification
```
# Instantiate learning model (k = 3), choosing 3 for 3 labels
classifier = KNeighborsClassifier(n_neighbors=3)
# Fitting the model
classifier.fit(X_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Importing libraries to help with metrics and evaluation
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.model_selection import cross_val_score
cm = confusion_matrix(y_test, y_pred)
cm
accuracy = accuracy_score(y_test, y_pred) * 100
print('Accuracy: ' + str(round(accuracy, 2)) + ' %')
```
### Fine Tuning
The initial prediction worked to a great extent, but this is a very simple dataset. Below is how to fine tune parameters to produce best result
```
# creating list of K for KNN
k_list = list(range(1,50,2))
# creating list of cv scores
cv_scores = []
# perform 10-fold cross validation
for k in k_list:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X_train, y_train, cv=10, scoring='accuracy')
cv_scores.append(scores.mean())
# misclassification error
MSE = [1 - x for x in cv_scores]
plt.figure()
plt.figure(figsize=(12, 8))
plt.title('The optimal number of neighbors', fontsize=20, fontweight='bold')
plt.xlabel('Number of Neighbors K', fontsize=15)
plt.ylabel('Misclassification Error', fontsize=15)
sns.set_style("whitegrid")
plt.plot(k_list, MSE)
plt.show()
# finding best k
best_k = k_list[MSE.index(min(MSE))]
print("The optimal number of neighbors is %d." % best_k)
```
### Clustering Visualization
Below is a visualization of the optimal number of neighbors computed above. We limit the plot to two dimensions to make it easier.
resource: https://scikit-learn.org/stable/auto_examples/neighbors/plot_classification.html
```
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
n_neighbors = 9
# import some data to play with
iris = data
# we only take the first two features. We could avoid this ugly
# slicing by using a two-dim dataset
X = iris.data[:, :2]
y = iris.target
h = .02 # step size in the mesh
# Create color maps
cmap_light = ListedColormap(['orange', 'cyan', 'cornflowerblue'])
cmap_bold = ListedColormap(['darkorange', 'c', 'darkblue'])
for weights in ['distance']:
# we create an instance of Neighbours Classifier and fit the data.
clf = KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold,
edgecolor='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weights = '%s')"
% (n_neighbors, weights))
plt.show()
```
## End
| github_jupyter |
```
from selenium import webdriver
!dir .\chromedriver.exe
browser = webdriver.Chrome('/chromedriver.exe')
browser.get('https://www.jobkorea.co.kr/')
import time
time.sleep(1)
browser.find_element_by_css_selector('span.mainBtn.mainBtnPer').click()
browser.find_elements_by_css_selector('input#lb_id.iptTx')[0].send_keys('axlovexa')
browser.find_elements_by_css_selector('input#lb_pw.iptTx.devCapsLock')[0].send_keys('multi0811')
browser.find_element_by_css_selector('div.loginIptWrap.clear>button.btnLogin').click()
time.sleep(1)
browser.find_element_by_css_selector('li#gnbStart>a.linkItem').click()
browser.find_element_by_css_selector('li>a[href="/starter/passassay/"]').click()
browser.find_element_by_css_selector('div.toolTipCont.fullLy>div>button').click()
browser.find_elements_by_css_selector('input#txtSearch')[0].send_keys('선택한')
browser.find_element_by_css_selector('button#btnSraech').click()
cnt = 0
from bs4 import BeautifulSoup
import pandas as pd
for page in range(1,5):
browser.find_element_by_css_selector('li:nth-child('+str(i)+') > div.txBx > p > a > span').click()
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
introduction_page = soup.select('div.stContainer')
time.sleep(0.5)
content = []
for scraping in introduction_page:
company = introduction_page[0].select('h2 > strong > a')[0].text.strip()
group = introduction_page[0].select('h2 > em')[0].text.strip()
score = introduction_page[0].select('div.adviceTotal > div > span')[0].text.strip()
for q in range(0, 10):
try:
question = soup.select('button > span.tx')[q].text.strip()
answer = soup.select('dd > div.tx')[q].text.strip()
print(ColumnQ, question, ColumnA, answer)
content.append([company, group, score, question, answer])
except IndexError:
pass
browser.back()
# contents = [company, group, score, question, answer]
len(content)
df = pd.DataFrame(content, columns=['company', 'group', 'score', 'question', 'answer'])
df
```
## 위의 cell 까지!
def scrap(num):
browser.find_element_by_css_selector('li:nth-child('+str(num)+') > div.txBx > p > a > span').click()
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
introduction_page = soup.select('div.stContainer')
time.sleep(1)
for scraping in introduction_page:
company = introduction_page[0].select('h2 > strong > a')[0].text.strip()
group = introduction_page[0].select('h2 > em')[0].text.strip()
score = introduction_page[0].select('div.adviceTotal > div > span')[0].text.strip()
contents = []
for q in range(0, 10):
try:
question = soup.select('button > span.tx')[q].text.strip()
answer = soup.select('dd > div.tx')[q].text.strip()
contents.append([company, group, score, question, answer])
except IndexError:
pass
# return contents
# df = pd.DataFrame(contents, columns=['company', 'group', 'score', 'question', 'answer'])
# df
scrap(1)
len(contents)
for i in range(1,4):
scrap(i)
df = pd.DataFrame(contents, columns=['company', 'group', 'score', 'question', 'answer'])
df
# = pd.DataFrame(contents, columns=['company', 'group', 'score', 'question', 'answer'])
# df = pd.DataFrame(contents, columns=['company', 'group', 'score', 'question', 'answer'])
# contents.append([company, group, score, question, answer])
# import pandas as pd
df = pd.DataFrame(contents, columns=['company', 'group', 'score', 'question', 'answer'])
df
for i in range(1,21):
browser.find_element_by_css_selector('li:nth-child('+str(i)+') > div.txBx > p > a > span').click()
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
introduction_page = soup.select('div.stContainer')
time.sleep(1)
content = []
for scraping in introduction_page:
company = introduction_page[0].select('h2 > strong > a')[0].text.strip()
group = introduction_page[0].select('h2 > em')[0].text.strip()
score = introduction_page[0].select('div.adviceTotal > div > span')[0].text.strip()
for q in range(0, 10):
try:
ColumnQ = 'Q'+str(q+1)
question = soup.select('button > span.tx')[q].text.strip()
ColumnA = 'A'+str(q+1)
answer = soup.select('dd > div.tx')[q].text.strip()
print(ColumnQ, question, ColumnA, answer)
content.append([company, group, score, question, answer])
except IndexError:
pass
contents.extend(content.append([company, group, score, question, answer]))
browser.back()
| github_jupyter |
For a full explanation of the code, visit http://ataspinar.com/2017/08/15/building-convolutional-neural-networks-with-tensorflow/
```
import sys
sys.path.insert(0,'..')
from cnn_models.lenet5 import *
from cnn_models.lenet5_like import *
from cnn_models.alexnet import *
from cnn_models.vggnet16 import *
from utils import *
# To load the MNIST dataset you will need to install 'python-mnist'
# Install it with 'pip install python-mnist'
import load_data as ld
from collections import defaultdict
current_path = os.path.realpath('..')
```
# 1. Load on of the Three datasets
```
#1. The MNIST dataset: http://yann.lecun.com/exdb/mnist/
mnist_folder = os.path.join(current_path, 'datasets/mnist/')
mnist_image_width, mnist_image_height, mnist_image_depth, mnist_num_labels = 28, 28, 1, 10
train_dataset, train_labels, test_dataset, test_labels = ld.mnist(mnist_folder, mnist_image_width, mnist_image_height, mnist_image_depth)
# #2. The Cifar-10 dataset: https://www.cs.toronto.edu/~kriz/cifar.html
# c10_folder = os.path.join(current_path, 'datasets/cifar10/')
# c10_image_width, c10_image_height, c10_image_depth, c10_num_labels = 32, 32, 3, 10
# train_dataset, train_labels, test_dataset, test_labels = ld.cifar10(c10_folder, c10_image_width, c10_image_height, c10_image_depth)
# #3. The oxflower-17 dataset: http://www.robots.ox.ac.uk/~vgg/data/flowers/17/
# ox16_folder = os.path.join(current_path, 'datasets/oxflower17/')
# ox17_image_width, ox17_image_height, ox17_image_depth, ox17_num_labels = 224, 224, 3, 17
# import tflearn.datasets.oxflower17 as oxflower17
# train_dataset_, train_labels_ = oxflower17.load_data(one_hot=True)
# train_dataset, train_labels = train_dataset_[:1000,:,:,:], train_labels_[:1000,:]
# test_dataset, test_labels = train_dataset_[1000:,:,:,:], train_labels_[1000:,:]
#some meta-parameters
num_steps = 10001
#learning_rate = 0.1
learning_rates = [0.5, 0.1, 0.01, 0.001, 0.0001, 0.00001]
display_step = 1000
batch_size = 64
#set the image dimensions
image_width, image_height, image_depth, num_labels = mnist_image_width, mnist_image_height, mnist_image_depth, mnist_num_labels
#image_width, image_height, image_depth, num_labels = c10_image_width, c10_image_height, c10_image_depth, c10_num_labels
#Define some variables in order to avoid the use of magic variables
MODEL_KEY = "adam_lenet5"
USED_DATASET= "CIFAR-10"
#save the accuracy at each step in these dictionaries
dict_train_accuracies = { MODEL_KEY: defaultdict(list) }
dict_test_accuracies = { MODEL_KEY: defaultdict(list) }
for learning_rate in learning_rates:
graph = tf.Graph()
with graph.as_default():
#1) First we put the input data in a tensorflow friendly form.
tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, image_width, image_height, image_depth))
tf_train_labels = tf.placeholder(tf.float32, shape = (batch_size, num_labels))
tf_test_dataset = tf.constant(test_dataset, tf.float32)
#2)
# Choose the 'variables' containing the weights and biases
# You can choose from:
# variables_lenet5() | variables_lenet5_like() | variables_alexnet() | variables_vggnet16()
variables = variables_lenet5(image_width = image_width, image_height=image_height, image_depth = image_depth, num_labels = num_labels)
#3.
# Choose the model you will use to calculate the logits (predicted labels)
# You can choose from:
# model_lenet5 | model_lenet5_like | model_alexnet | model_vggnet16
model = model_lenet5
logits = model(tf_train_dataset, variables)
#4.
# Then we compute the softmax cross entropy between the logits and the (actual) labels
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=tf_train_labels))
#5.
# The optimizer is used to calculate the gradients of the loss function
#optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
#optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.0).minimize(loss)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
test_prediction = tf.nn.softmax(model(tf_test_dataset, variables))
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print('Initialized with learning_rate', learning_rate)
for step in range(num_steps):
#Since we are using stochastic gradient descent, we are selecting small batches from the training dataset,
#and training the convolutional neural network each time with a batch.
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run([optimizer, loss, train_prediction], feed_dict=feed_dict)
train_accuracy = accuracy(predictions, batch_labels)
dict_train_accuracies[MODEL_KEY][learning_rate].append(train_accuracy)
if step % display_step == 0:
test_accuracy = accuracy(test_prediction.eval(), test_labels)
dict_test_accuracies[MODEL_KEY][learning_rate].append(test_accuracy)
message = "step {:04d} : loss is {:06.2f}, accuracy on training set {:02.2f} %, accuracy on test set {:02.2f} %".format(step, l, train_accuracy, test_accuracy)
print(message)
import matplotlib.pyplot as plt
def average_points(points, stepsize = 100):
averaged_points = []
for ii in range(stepsize,len(points),stepsize):
subsection = points[ii-stepsize:ii]
average = np.nanmean(subsection)
averaged_points.append(average)
return averaged_points
models = list(dict_train_accuracies.keys())
colors = ['r', 'g', 'b', 'k', 'm', 'c']
ylimit = [0,100]
title = 'Accuracy on {} dataset for {} model'.format(USED_DATASET, MODEL_KEY)
ylabel = "Accuracy [%]"
xlabel = "Number of Iterations"
fig, ax1 = plt.subplots(figsize=(8,6))
fig.suptitle(title, fontsize=15)
ax1.set_ylim(ylimit)
ax1.set_ylabel(ylabel, fontsize=16)
ax1.set_xlabel(xlabel, fontsize=16)
learning_rates = sorted(list(dict_train_accuracies[MODEL_KEY].keys()))
for ii in range(len(learning_rates)):
learning_rate = learning_rates[ii]
color = colors[ii]
y_values_train_ = dict_train_accuracies[MODEL_KEY][learning_rate]
y_values_train = average_points(y_values_train_)
x_values_train = range(0,len(y_values_train_)-1,100)
y_values_test = dict_test_accuracies[MODEL_KEY][learning_rate]
x_values_test = range(0,len(y_values_train_),1000)
ax1.plot(x_values_train, y_values_train, '.{}'.format(color), alpha = 0.5)
ax1.plot(x_values_test, y_values_test, '*-{}'.format(color), alpha = 1, label='lr {}'.format(learning_rate))
ax1.legend(loc='lower right')
plt.show()
```
# ----------------------------------------
# These are the accuracies of the various models, on the three datasets that I got:
## LeNet5 Architecture








## AlexNet Architecture


| github_jupyter |
```
import importlib
import theano.tensor as T
import sys, os
sys.path.append("/home/bl3/PycharmProjects/GeMpy/")
sys.path.append("/home/bl3/PycharmProjects/pygeomod/pygeomod")
import GeoMig
#import geogrid
#importlib.reload(GeoMig)
importlib.reload(GeoMig)
import numpy as np
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
np.set_printoptions(precision = 15, linewidth= 300, suppress = True)
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
from matplotlib import cm
test = GeoMig.GeoMigSim_pro2(c_o = np.float32(-0.1),range = 17)
test.create_regular_grid_3D(0,10,0,10,0,10,20,20,20)
test.theano_set_3D_nugget_degree0()
layer_1 = np.array([[1,5,7], [9,5,7]], dtype = "float32")
layer_2 = np.array([[2,5,1],[7,5,1]], dtype = "float32")
dip_pos_1 = np.array([2,5,6], dtype = "float32")
dip_pos_2 = np.array([6.,4,6], dtype = "float32")
dip_pos_3 = np.array([8,4,5], dtype = "float32")
dip_angle_1 = float(0)
dip_angle_2 = float(45)
layers = np.asarray([layer_1,layer_2])
dips = np.asarray([dip_pos_1])#, dip_pos_3])
dips_angles = np.asarray([dip_angle_1], dtype="float32")
azimuths = np.asarray([0], dtype="float32")
polarity = np.asarray([1], dtype="float32")
#print (dips_angles)
rest = np.vstack((i[1:] for i in layers))
ref = np.vstack((np.tile(i[0],(np.shape(i)[0]-1,1)) for i in layers))
dips_angles.dtype
rest = rest.astype("float32")
ref = ref.astype("float32")
dips = dips.astype("float32")
dips_angles = dips_angles.astype("float32")
type(dips_angles)
rest, ref
rest, ref
G_x = np.sin(np.deg2rad(dips_angles)) * np.sin(np.deg2rad(azimuths)) * polarity
G_y = np.sin(np.deg2rad(dips_angles)) * np.cos(np.deg2rad(azimuths)) * polarity
G_z = np.cos(np.deg2rad(dips_angles)) * polarity
G_x, G_y, G_z
test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0]
_,h1 = np.argmin((abs(test.grid - ref[0])).sum(1)), test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0][np.argmin((abs(test.grid - ref[0])).sum(1))]
_, h2 =np.argmin((abs(test.grid - ref[1])).sum(1)), test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0][np.argmin((abs(test.grid - ref[1])).sum(1))]
print(test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0][np.argmin((abs(test.grid - ref[0])).sum(1))])
for i in range(rest.shape[0]):
print(test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0][np.argmin((abs(test.grid - rest[i])).sum(1))])
test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0][np.argmin((abs(test.grid - rest[0])).sum(1))]
rest
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0].reshape(200,200,200, order = "C")[:,:,::-1].transpose()
#sol = np.swapaxes(sol,0,1)
G_x, G_y, G_z = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[-3:]
G_x, G_y, G_z
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import matplotlib
import matplotlib.cm as cmx
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
h = np.array([h1,h2])
cm = plt.get_cmap("jet")
cNorm = matplotlib.colors.Normalize(vmin=h.min(), vmax=h.max())
scalarMap = cmx.ScalarMappable(norm=cNorm, cmap=cm)
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0].reshape(200,200,200,
order = "C")[:,:,:]
#sol = np.swapaxes(sol,0,1)
from skimage import measure
isolines = np.linspace(h1,h2,2)
#vertices = measure.marching_cubes(sol, isolines[0], spacing = (0.2,0.2,0.2),
# gradient_direction = "descent")[0]
for i in isolines[0:10]:
vertices = measure.marching_cubes(sol, i, spacing = (0.05,0.05,0.05),
gradient_direction = "ascent")[0]
ax.scatter(vertices[::40,0],vertices[::40,1],vertices[::40,2],color=scalarMap.to_rgba(i),
alpha = 0.2) #color=scalarMap.to_rgba(vertices[::10,2])
ax.scatter(layers[0][:,0],layers[0][:,1],layers[0][:,2], s = 50, c = "r" )
ax.scatter(layers[1][:,0],layers[1][:,1],layers[1][:,2], s = 50, c = "g" )
ax.quiver3D(dips[:,0],dips[:,1],dips[:,2], G_x,G_y,G_z, pivot = "tail", linewidths = 2)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("z")
ax.set_xlim(0,10)
ax.set_ylim(0,10)
ax.set_zlim(0,10)
#ax.scatter(simplices[:,0],simplices[:,1],simplices[:,2])
test.c_o.set_value(-0.56)
test.c_o.get_value()
test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
c_sol = np.array(([-7.2386541205560206435620784759521484375E-14],
[-1.5265566588595902430824935436248779296875E-14],
[-1.154631945610162802040576934814453125E-14],
[6.21724893790087662637233734130859375E-15],
[-5.9952043329758453182876110076904296875E-15],
[7.99360577730112709105014801025390625E-15],
[2.220446049250313080847263336181640625E-15],
[-3.641531520770513452589511871337890625E-14],
[8.0380146982861333526670932769775390625E-14],
[0.8816416857576581111999303175252862274646759033203125],
[9.355249580684368737593104015104472637176513671875],
[-0.1793850547262900996248191631821100600063800811767578125],
[0.047149729032205163481439313954979297704994678497314453125],
[-8.994519501910499315044944523833692073822021484375],
[ 0.4451793036427798000431721447966992855072021484375],
[-1.7549816402777651536126768405665643513202667236328125],
[0.0920938443689063301889063950511626899242401123046875],
[0.36837537747562587586713789278292097151279449462890625])).squeeze()
c_sol.squeeze()
c_sol=np.array([ -0.07519608514102089913411219868066837079823017120361328125,
0,
3.33264951481644633446421721600927412509918212890625,
1.3778510792932487927231477442546747624874114990234375,
-2.295940519242440469582788864499889314174652099609375,
])
import pymc as pm
a = pm.Uniform('a', lower=-1.1, upper=1.1, )
b = pm.Uniform('b', lower=-1.1, upper=1.1, )
c = pm.Uniform('c', lower=-1.1, upper=1.1, )
d = pm.Uniform('d', lower=-1.1, upper=1.1, )
e = pm.Uniform('e', lower=-1.1, upper=1.1, )
f = pm.Uniform('f', lower=-1.1, upper=1.1, )
@pm.deterministic
def this(value = 0, a = a ,b = b,c = c,d = d,e= e,f =f, c_sol = c_sol):
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,
a,b,-3*b,d,e,f)[1]
#error = abs(sol-c_sol)
#print (error)
return sol
like= pm.Normal("likelihood", this, 1./np.square(0.0000000000000000000000000000000000000000000000001),
value = c_sol, observed = True, size = len(c_sol)
)
model = pm.Model([a,b,c,d,e,f, like])
M = pm.MAP(model)
M.fit()
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,a,b,-3*b,d,1,1)[1]
-3*b.value
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
a.value, b.value, c.value,d.value, e.value, f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,0,0,-0.33,0,1,1)[1]
```
# Test with all variables
```
a.value, b.value, c.value,d.value,e.value,f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,a,b,1,1,1,1)[1]
a.value, b.value, c.value,d.value,e.value,f.value, this.value, c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
importlib.reload(GeoMig)
test = GeoMig.GeoMigSim_pro2(c_o = np.float32(-0.1),range = 17)
test.create_regular_grid_3D(0,10,0,10,0,10,20,20,20)
test.theano_set_3D_nugget_degree0()
a.value, b.value, c.value,d.value,e.value,f.value
import matplotlib.pyplot as plt
%matplotlib inline
G_x, G_y, G_z = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[-3:]
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,a,b,-3*b,d,1,-1)[0].reshape(20,20,20)
def plot_this_crap(direction):
fig = plt.figure()
ax = fig.add_subplot(111)
if direction == "x":
plt.arrow(dip_pos_1[1],dip_pos_1[2], dip_pos_1_v[1]-dip_pos_1[1],
dip_pos_1_v[2]-dip_pos_1[2], head_width = 0.2)
plt.arrow(dip_pos_2[1],dip_pos_2[2],dip_pos_2_v[1]-dip_pos_2[1],
dip_pos_2_v[2]-dip_pos_2[2], head_width = 0.2)
plt.plot(layer_1[:,1],layer_1[:,2], "o")
plt.plot(layer_2[:,1],layer_2[:,2], "o")
plt.plot(layer_1[:,1],layer_1[:,2], )
plt.plot(layer_2[:,1],layer_2[:,2], )
plt.contour( sol[25,:,:] ,30,extent = (0,10,0,10) )
if direction == "y":
plt.quiver(dips[:,0],dips[:,2], G_x,G_z, pivot = "tail")
plt.plot(layer_1[:,0],layer_1[:,2], "o")
plt.plot(layer_2[:,0],layer_2[:,2], "o")
plt.plot(layer_1[:,0],layer_1[:,2], )
plt.plot(layer_2[:,0],layer_2[:,2], )
plt.contour( sol[:,10,:].T ,30,extent = (0,10,0,10) )
if direction == "z":
plt.arrow(dip_pos_1[0],dip_pos_1[1], dip_pos_1_v[0]-dip_pos_1[0],
dip_pos_1_v[1]-dip_pos_1[1], head_width = 0.2)
plt.arrow(dip_pos_2[0],dip_pos_2[1],dip_pos_2_v[0]-dip_pos_2[0],
dip_pos_2_v[1]-dip_pos_2[1], head_width = 0.2)
plt.plot(layer_1[:,0],layer_1[:,1], "o")
plt.plot(layer_2[:,0],layer_2[:,1], "o")
plt.plot(layer_1[:,0],layer_1[:,1], )
plt.plot(layer_2[:,0],layer_2[:,1], )
plt.contour( sol[:,:,25] ,30,extent = (0,10,0,10) )
#plt.colorbar()
#plt.xlim(0,10)
#plt.ylim(0,10)
plt.colorbar()
plt.title("GeoBulleter v 0.1")
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,a,b,-3*b,d,+1,+1)[0].reshape(20,20,20)
plot_this_crap("y")
a.value, b.value
test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
c_sol
h,j,k =sol[5,10,35], sol[25,5,5], sol[30,15,-25]
layer_1 = np.array([[1,5,7],[5,5,7],[6,5,7], [9,5,7]], dtype = "float32")
layer_2 = np.array([[1,5,1],[5,5,1],[9,5,1]], dtype = "float32")
print(sol[5,25,35], sol[25,25,35], sol[30,25,35], sol[45,25,35])
print(sol[5,25,5], sol[25,25,5], sol[45,25,5])
list(layer_1[0]*5)
interfaces_aux = test.geoMigueller(dips,dips_angles,azimuths,polarity,
rest, ref)[0]
h = sol[10,20,30]# interfaces_aux[np.argmin(abs((test.grid - ref[0]).sum(1)))]
k = sol[30,15,25]# interfaces_aux[np.argmin(abs((test.grid - dips[0]).sum(1)))]
j = sol[45,25,5]#interfaces_aux[np.argmin(abs((test.grid - dips[-1]).sum(1)))]
h,k,j
dips[-1], ref[0]
sol[30,15,25], sol[30,15,25]
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref)[0].reshape(50,50,50, order = "C")
sol = np.swapaxes(sol,0,1)
plt.contour(sol[:,25,:].transpose())
"""Export model to VTK
Export the geology blocks to VTK for visualisation of the entire 3-D model in an
external VTK viewer, e.g. Paraview.
..Note:: Requires pyevtk, available for free on: https://github.com/firedrakeproject/firedrake/tree/master/python/evtk
**Optional keywords**:
- *vtk_filename* = string : filename of VTK file (default: output_name)
- *data* = np.array : data array to export to VKT (default: entire block model)
"""
vtk_filename = "noddyFunct2"
extent_x = 10
extent_y = 10
extent_z = 10
delx = 0.2
dely = 0.2
delz = 0.2
from pyevtk.hl import gridToVTK
# Coordinates
x = np.arange(0, extent_x + 0.1*delx, delx, dtype='float64')
y = np.arange(0, extent_y + 0.1*dely, dely, dtype='float64')
z = np.arange(0, extent_z + 0.1*delz, delz, dtype='float64')
# self.block = np.swapaxes(self.block, 0, 2)
gridToVTK(vtk_filename, x, y, z, cellData = {"geology" : sol})
len(x)
surf_eq.min()
np.min(z)
layers[0][:,0]
G_x = np.sin(np.deg2rad(dips_angles)) * np.sin(np.deg2rad(azimuths)) * polarity
G_y = np.sin(np.deg2rad(dips_angles)) * np.cos(np.deg2rad(azimuths)) * polarity
G_z = np.cos(np.deg2rad(dips_angles)) * polarity
a
data = [trace1, trace2]
layout = go.Layout(
xaxis=dict(
range=[2, 5]
),
yaxis=dict(
range=[2, 5]
)
)
fig = go.Figure(data=data, layout=layout)
import lxml
lxml??
# Random Box
#layers = [np.random.uniform(0,10,(10,2)) for i in range(100)]
#dips = np.random.uniform(0,10, (60,2))
#dips_angles = np.random.normal(90,10, 60)
#rest = (np.vstack((i[1:] for i in layers)))
#ref = np.vstack((np.tile(i[0],(np.shape(i)[0]-1,1)) for i in layers))
#rest;
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
X, Y, Z = axes3d.get_test_data(0.05)
cset = ax.contour(X, Y, Z, cmap=cm.coolwarm)
ax.clabel(cset, fontsize=9, inline=1)
print(X)
plt.show()
import matplotlib.pyplot as plt
% matplotlib inline
plt.contour( sol.reshape(100,100) ,30,extent = (0,10,0,10) )
import matplotlib.pyplot as plt
% matplotlib inline
dip_pos_1_v = np.array([np.cos(np.deg2rad(dip_angle_1))*1,
np.sin(np.deg2rad(dip_angle_1))]) + dip_pos_1
dip_pos_2_v = np.array([np.cos(np.deg2rad(dip_angle_2))*1,
np.sin(np.deg2rad(dip_angle_2))]) + dip_pos_2
plt.arrow(dip_pos_1[0],dip_pos_1[1], dip_pos_1_v[0]-dip_pos_1[0],
dip_pos_1_v[1]-dip_pos_1[1], head_width = 0.2)
plt.arrow(dip_pos_2[0],dip_pos_2[1],dip_pos_2_v[0]-dip_pos_2[0],
dip_pos_2_v[1]-dip_pos_2[1], head_width = 0.2)
plt.plot(layer_1[:,0],layer_1[:,1], "o")
plt.plot(layer_2[:,0],layer_2[:,1], "o")
plt.plot(layer_1[:,0],layer_1[:,1], )
plt.plot(layer_2[:,0],layer_2[:,1], )
plt.contour( sol.reshape(100,100) ,30,extent = (0,10,0,10) )
#plt.colorbar()
#plt.xlim(0,10)
#plt.ylim(0,10)
plt.title("GeoBulleter v 0.1")
print (dip_pos_1_v, dip_pos_2_v, layer_1)
```
# CPU
```
%%timeit
sol = test.geoMigueller(dips,dips_angles,rest, ref)[0]
test.geoMigueller.profile.summary()
sys.path.append("/home/bl3/anaconda3/lib/python3.5/site-packages/PyEVTK-1.0.0-py3.5.egg_FILES/pyevtk")
nx = 50
ny = 50
nz = 50
xmin = 1
ymin = 1
zmin = 1
grid = sol
var_name = "Geology"
#from evtk.hl import gridToVTK
import pyevtk
from pyevtk.hl import gridToVTK
# define coordinates
x = np.zeros(nx + 1)
y = np.zeros(ny + 1)
z = np.zeros(nz + 1)
x[1:] = np.cumsum(delx)
y[1:] = np.cumsum(dely)
z[1:] = np.cumsum(delz)
# plot in coordinates
x += xmin
y += ymin
z += zmin
print (len(x), x)
gridToVTK("GeoMigueller", x, y, z,
cellData = {var_name: grid})
```
## GPU
```
%%timeit
sol = test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref);
test.geoMigueller.profile.summary()
importlib.reload(GeoMig)
test = GeoMig.GeoMigSim_pro2()
from theano import function, config, shared, sandbox
import theano.tensor as T
import numpy
import time
vlen = 10 * 30 * 768 # 10 x #cores x # threads per core
iters = 1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i in range(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds" % (iters, t1 - t0))
print("Result is %s" % (r,))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
from theano import function, config, shared, sandbox
import theano.tensor as T
import numpy
import time
vlen = 10 * 30 * 768 # 10 x #cores x # threads per core
iters = 1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i in range(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds" % (iters, t1 - t0))
print("Result is %s" % (r,))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
from theano import function, config, shared, sandbox
import theano.tensor as T
import numpy
import time
vlen = 10 * 30 * 768 # 10 x #cores x # threads per core
iters = 1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i in range(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds" % (iters, t1 - t0))
print("Result is %s" % (r,))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
np.set_printoptions(precision=2)
test.geoMigueller(dips,dips_angles,rest, ref)[1]
T.fill_diagonal?
import matplotlib.pyplot as plt
% matplotlib inline
dip_pos_1_v = np.array([np.cos(np.deg2rad(dip_angle_1))*1,
np.sin(np.deg2rad(dip_angle_1))]) + dip_pos_1
dip_pos_2_v = np.array([np.cos(np.deg2rad(dip_angle_2))*1,
np.sin(np.deg2rad(dip_angle_2))]) + dip_pos_2
plt.arrow(dip_pos_1[0],dip_pos_1[1], dip_pos_1_v[0]-dip_pos_1[0],
dip_pos_1_v[1]-dip_pos_1[1], head_width = 0.2)
plt.arrow(dip_pos_2[0],dip_pos_2[1],dip_pos_2_v[0]-dip_pos_2[0],
dip_pos_2_v[1]-dip_pos_2[1], head_width = 0.2)
plt.plot(layer_1[:,0],layer_1[:,1], "o")
plt.plot(layer_2[:,0],layer_2[:,1], "o")
plt.plot(layer_1[:,0],layer_1[:,1], )
plt.plot(layer_2[:,0],layer_2[:,1], )
plt.contour( sol.reshape(50,50) ,30,extent = (0,10,0,10) )
#plt.colorbar()
#plt.xlim(0,10)
#plt.ylim(0,10)
plt.title("GeoBulleter v 0.1")
print (dip_pos_1_v, dip_pos_2_v, layer_1)
n = 10
#a = T.horizontal_stack(T.vertical_stack(T.ones(n),T.zeros(n)), T.vertical_stack(T.zeros(n), T.ones(n)))
a = T.zeros(n)
print (a.eval())
#U_G = T.horizontal_stack(([T.ones(n),T.zeros(n)],[T.zeros(n),T.ones(n)]))
T.stack?ö+aeg
x_min = 0
x_max = 10
y_min = 0
y_max = 10
z_min = 0
z_max = 10
nx = 2
ny = 2
nz = 2
g = np.meshgrid(
np.linspace(x_min, x_max, nx, dtype="float32"),
np.linspace(y_min, y_max, ny, dtype="float32"),
np.linspace(z_min, z_max, nz, dtype="float32"), indexing="ij"
)
np.vstack(map(np.ravel, g)).T.astype("float32")
map(np.ravel, g)
np.ravel(g, order = "F")
g
np.transpose?
from scipy.optimize import basinhopping
c_sol, test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,1,1,1,1,1,1)[1]
def func2d(x):
return abs((test.geoMigueller(dips,dips_angles,azimuths,polarity, rest, ref,x[0],x[1],x[2],x[3],1,1)[1] - c_sol)).sum()
minimizer_kwargs = {"method": "BFGS"}
x0 = [0.1, 0.1,0.1,0.1]
ret = basinhopping(func2d, x0, minimizer_kwargs=minimizer_kwargs,
niter=200)
ret
ret
ret
```
| github_jupyter |
```
import os
import cv2
import glob
import pickle
import requests
import numpy as np
from io import BytesIO
from matplotlib import cm
from tqdm import tqdm_notebook
import matplotlib.pyplot as plt
from PIL import Image, ImageOps, ImageDraw, ImageEnhance
from tensorflow.keras.preprocessing import image
from tensorflow.keras.backend import resize_images
# from tensorflow.keras.applications.vgg16 import VGG16
# from tensorflow.keras.applications.resnet50 import ResNet50
# from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions
# from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from tensorflow.keras.applications.nasnet import preprocess_input, decode_predictions, NASNetLarge
fname = "kay_images.npz"
with np.load(fname) as dobj:
dat = dict(**dobj)
dat.keys()
im = Image.fromarray(np.uint8(cm.gist_earth(dat["stimuli"][0])*255)).convert("L")
plt.imshow(dat["stimuli"][0], cmap="gray")
f, axs = plt.subplots(2, 4, figsize=(12, 6), sharex=True, sharey=True)
for ax, im in zip(axs.flat, dat["stimuli"]):
ax.imshow(im, cmap="gray")
f.tight_layout()
dat["stimuli"][0].shape
```
### stimuli images pre-process (crop circle, resize and colorize)
```
def crop_resize_image_circle(im):
size = (256, 256) # (128, 128)
mask = Image.new('L', size, 0)
draw = ImageDraw.Draw(mask)
draw.ellipse((0, 0) + size, fill=255)
im = Image.fromarray(np.uint8(cm.gist_earth(im)*255)).convert("L")
im.thumbnail(size, Image.ANTIALIAS)
output = ImageOps.fit(im, mask.size, centering=(0.5, 0.5))
output.putalpha(mask)
# enhancer = ImageEnhance.Brightness(output)
# output = enhancer.enhance(1.8)
# output.save('output.png')
return output
# for i, im in tqdm_notebook(enumerate(dat["stimuli"])):
for i, im in tqdm_notebook(enumerate(dat["stimuli_test"])):
# if i > 20: break
# cim = crop_resize_image_circle(im)
# print(cim.size)
# plt.imshow(cim)
# plt.show()
im = image.img_to_array(im)[:,:,0]
im = cv2.resize(im, (512, 512))
plt.imsave('./kay_data/stimuli_test_resized/stimuli_test_resized_{0}.png'.format(i), im, cmap='gray')
# cim.save('./kay_data/stimuli/stimuli_{0}.png'.format(i))
```
### image colorization
```
def deepai_colorization(img_path):
r = requests.post(
"https://api.deepai.org/api/colorizer",
files={
'image': open(img_path, 'rb'),
},
headers={'api-key': ''}
)
return r
for i, im in tqdm_notebook(enumerate(glob.glob('kay_data/stimuli_test/*.png'))):
r = deepai_colorization(im)
response = requests.get(r.json()['output_url'])
img = Image.open(BytesIO(response.content))
img.save('./kay_data/stimuli_test_colorized/stimuli_test_{0}_color.png'.format(i))
```
### super resolution images
```
def deepai_superes(img_path):
r = requests.post(
"https://api.deepai.org/api/torch-srgan",
files={
'image': open(img_path, 'rb'),
},
headers={'api-key': ''}
)
return r
for i, im in tqdm_notebook(enumerate(glob.glob('kay_data/stimuli_colorized/*.png'))):
r = deepai_superes(im)
response = requests.get(r.json()['output_url'])
img = Image.open(BytesIO(response.content))
img.save('./kay_data/stimuli_colorized_superes/stimuli_{0}_color_superes.png'.format(i))
```
### png to jpeg
```
for i, im in tqdm_notebook(enumerate(glob.glob('kay_data/stimuli_colorized_superes/*.png'))):
im = Image.open(im)
rgb_im = im.convert('RGB')
rgb_im.save('./kay_data/stimuli_colorized_superes_jpeg/stimuli_{0}_color_superes.jpg'.format(i))
```
### extract stimuli features
```
# https://tech.zegami.com/comparing-pre-trained-deep-learning-models-for-feature-extraction-c617da54641
stimuli_features = dict()
# model = ResNet50(weights='imagenet')
# model = VGG16(weights='imagenet') #, include_top=False)
model = NASNetLarge(weights='imagenet') #, include_top=False)
# model = NASNetMobile(weights='imagenet') #, include_top=False)
# model = MobileNetV2(weights='imagenet')
model_ex = NASNetLarge(weights='imagenet', include_top=False, pooling='avg')
def crop_center(img,cropx,cropy):
y,x, _ = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
# img classification
for i, img_path in tqdm_notebook(enumerate(glob.glob('kay_data/stimuli_colorized_superes_jpeg/*.jpg'))):
try:
# if i > 20: break
img_name = img_path.split(sep=os.sep)[1].split(sep='.')[0]
stimuli_features[img_name] = list()
img = image.load_img(img_path, target_size=(512, 512))
x = image.img_to_array(img)
x = np.array(x)
x = crop_center(x, 331, 331)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# x = x[:,:,:,:]
preds = model.predict(x)
# print('Predicted:', decode_predictions(preds, top=3)[0])
p = decode_predictions(preds, top=1)[0]
# if p[2] >= 0.8:
# print(p)
features = model_ex.predict(x)[0]
stimuli_features[img_name] += [p[0], features]
# plt.imshow(img)
# plt.show()
except:
print('bad input: ', img_path)
with open('kay_data/stimuli_features.pickle', 'wb') as fp:
pickle.dump(stimuli_features, fp, protocol=pickle.HIGHEST_PROTOCOL)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/ariG23498/G-SimCLR/blob/master/Imagenet_Subset/SimCLR_Pseudo_Labels/Shallow%20Autoencoder/Linear_Evaluation.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Initial setup
```
import tensorflow as tf
print(tf.__version__)
!nvidia-smi
```
### Restore model weights
```
!wget https://github.com/ariG23498/G-SimCLR/releases/download/v3.0/ImageNet_Subset_Shallow_Autoencoder.zip
!unzip -qq ImageNet_Subset_Shallow_Autoencoder.zip
!pip install -q wandb
# Other imports
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
import matplotlib.pyplot as plt
from imutils import paths
from tqdm import tqdm
import tensorflow as tf
import seaborn as sns
import numpy as np
import cv2
# Random seed fixation
tf.random.set_seed(666)
np.random.seed(666)
# Authorize wandb
import wandb
wandb.login()
from wandb.keras import WandbCallback
```
## Dataset gathering and preparation
```
# Gather dataset
!git clone https://github.com/thunderInfy/imagenet-5-categories
# Train and test image paths
train_images = list(paths.list_images("imagenet-5-categories/train"))
test_images = list(paths.list_images("imagenet-5-categories/test"))
print(len(train_images), len(test_images))
def prepare_images(image_paths):
images = []
labels = []
for image in tqdm(image_paths):
image_pixels = plt.imread(image)
image_pixels = cv2.resize(image_pixels, (224, 224))
image_pixels = image_pixels/255.
label = image.split("/")[2].split("_")[0]
images.append(image_pixels)
labels.append(label)
images = np.array(images)
labels = np.array(labels)
print(images.shape, labels.shape)
return images, labels
X_train, y_train = prepare_images(train_images)
X_test, y_test = prepare_images(test_images)
le = LabelEncoder()
y_train_enc = le.fit_transform(y_train)
y_test_enc = le.transform(y_test)
```
## Utilities
```
# Architecture utils
def get_resnet_simclr(hidden_1, hidden_2, hidden_3):
base_model = tf.keras.applications.ResNet50(include_top=False, weights=None, input_shape=(224, 224, 3))
base_model.trainable = True
inputs = Input((224, 224, 3))
h = base_model(inputs, training=False)
h = GlobalAveragePooling2D()(h)
projection_1 = Dense(hidden_1)(h)
projection_1 = Activation("relu")(projection_1)
projection_2 = Dense(hidden_2)(projection_1)
projection_2 = Activation("relu")(projection_2)
projection_3 = Dense(hidden_3)(projection_2)
resnet_simclr = Model(inputs, projection_3)
return resnet_simclr
resnet_simclr = get_resnet_simclr(256, 128, 50)
resnet_simclr.load_weights('ImageNet_Subset_Shallow_Autoencoder/gsimclr_imagenet_subset_shallow_autoencoder.h5')
resnet_simclr.summary()
def plot_training(H):
plt.plot(H.history["loss"], label="train_loss")
plt.plot(H.history["val_loss"], label="val_loss")
plt.plot(H.history["accuracy"], label="train_acc")
plt.plot(H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.show()
def get_linear_model(features):
linear_model = Sequential([Dense(5, input_shape=(features, ), activation="softmax")])
return linear_model
```
## Evaluation
```
resnet_simclr.layers[1].trainable = False
resnet_simclr.summary()
# These layers won't be trained during linear evaluation as well
resnet_simclr.layers[3].trainable = False
resnet_simclr.layers[5].trainable = False
# Encoder model with non-linear projections
projection = Model(resnet_simclr.input, resnet_simclr.layers[-2].output)
print(projection.summary())
# Extract train and test features
train_features = projection.predict(X_train)
test_features = projection.predict(X_test)
print(train_features.shape, test_features.shape)
# Early Stopping to prevent overfitting
es = tf.keras.callbacks.EarlyStopping(monitor="val_loss", patience=2, verbose=2, restore_best_weights=True)
# Initialize wandb
wandb.init(entity="g-simclr", project="g-simclr", id="imagenet-s-gsimclr-shallow-ae-le-1")
# Linear model
linear_model = get_linear_model(128)
linear_model.compile(loss="sparse_categorical_crossentropy", metrics=["accuracy"],
optimizer="adam")
history = linear_model.fit(train_features, y_train_enc,
validation_data=(test_features, y_test_enc),
batch_size=64,
epochs=100,
callbacks=[es, WandbCallback()])
plot_training(history)
# Encoder model with lesser non-linearity
projection = Model(resnet_simclr.input, resnet_simclr.layers[-4].output)
print(projection.summary())
# Extract train and test features
train_features = projection.predict(X_train)
test_features = projection.predict(X_test)
print(train_features.shape, test_features.shape)
# Initialize wandb
wandb.init(entity="g-simclr", project="g-simclr", id="imagenet-s-gsimclr-shallow-ae-le-2")
linear_model = get_linear_model(256)
linear_model.compile(loss="sparse_categorical_crossentropy", metrics=["accuracy"],
optimizer="adam")
history = linear_model.fit(train_features, y_train_enc,
validation_data=(test_features, y_test_enc),
batch_size=64,
epochs=35,
callbacks=[es, WandbCallback()])
plot_training(history)
# Encoder model with no projection
projection = Model(resnet_simclr.input, resnet_simclr.layers[-6].output)
print(projection.summary())
# Extract train and test features
train_features = projection.predict(X_train)
test_features = projection.predict(X_test)
print(train_features.shape, test_features.shape)
# Initialize wandb
wandb.init(entity="g-simclr", project="g-simclr", id="imagenet-s-gsimclr-shallow-ae-le-3")
linear_model = get_linear_model(2048)
linear_model.compile(loss="sparse_categorical_crossentropy", metrics=["accuracy"],
optimizer="adam")
history = linear_model.fit(train_features, y_train_enc,
validation_data=(test_features, y_test_enc),
batch_size=64,
epochs=35,
callbacks=[es, WandbCallback()])
plot_training(history)
```
| github_jupyter |
# Quantum Approximate Optimization Algorithm
Qiskit has an implementation of the Quantum Approximate Optimization Algorithm [QAOA](https://qiskit.org/documentation/stubs/qiskit.aqua.algorithms.QAOA.html) and this notebook demonstrates using it for a graph partition problem.
While QAOA can be directly used it often more convenient to use it in conjunction with the Optimization module. See the Optimization tutorials for more information.
```
import numpy as np
import networkx as nx
from qiskit import BasicAer
from qiskit.aqua.algorithms import NumPyMinimumEigensolver
from qiskit.optimization.applications.ising import graph_partition
from qiskit.optimization.applications.ising.common import random_graph, sample_most_likely
```
First we create a random graph and draw it so it can be seen.
```
num_nodes = 4
w = random_graph(num_nodes, edge_prob=0.8, weight_range=10, seed=48)
print(w)
G = nx.from_numpy_matrix(w)
layout = nx.random_layout(G, seed=10)
colors = ['r', 'g', 'b', 'y']
nx.draw(G, layout, node_color=colors)
labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos=layout, edge_labels=labels);
```
The brute-force method is as follows. Basically, we exhaustively try all the binary assignments. In each binary assignment, the entry of a vertex is either 0 (meaning the vertex is in the first partition) or 1 (meaning the vertex is in the second partition). We print the binary assignment that satisfies the definition of the graph partition and corresponds to the minimal number of crossing edges.
```
def brute_force():
# use the brute-force way to generate the oracle
def bitfield(n, L):
result = np.binary_repr(n, L)
return [int(digit) for digit in result] # [2:] to chop off the "0b" part
L = num_nodes
max = 2**L
minimal_v = np.inf
for i in range(max):
cur = bitfield(i, L)
how_many_nonzero = np.count_nonzero(cur)
if how_many_nonzero * 2 != L: # not balanced
continue
cur_v = graph_partition.objective_value(np.array(cur), w)
if cur_v < minimal_v:
minimal_v = cur_v
return minimal_v
sol = brute_force()
print(f'Objective value computed by the brute-force method is {sol}')
```
The graph partition problem can be converted to an Ising Hamitonian. Qiskit has different capabilities in the Optimization module to do this. Here, since the goal is to show QAOA, the module is used without further explanation to create the operator. The paper [Ising formulations of many NP problems](https://arxiv.org/abs/1302.5843) may be of interest if you would like to understand the technique further.
```
qubit_op, offset = graph_partition.get_operator(w)
```
So lets use the QAOA algorithm to find the solution.
```
from qiskit.aqua import aqua_globals
from qiskit.aqua.algorithms import QAOA
from qiskit.aqua.components.optimizers import COBYLA
from qiskit.circuit.library import TwoLocal
aqua_globals.random_seed = 10598
optimizer = COBYLA()
qaoa = QAOA(qubit_op, optimizer, quantum_instance=BasicAer.get_backend('statevector_simulator'))
result = qaoa.compute_minimum_eigenvalue()
x = sample_most_likely(result.eigenstate)
ising_sol = graph_partition.get_graph_solution(x)
print(ising_sol)
print(f'Objective value computed by QAOA is {graph_partition.objective_value(x, w)}')
```
The outcome can be seen to match to the value computed above by brute force. But we can also use the classical `NumPyMinimumEigensolver` to do the computation, which may be useful as a reference without doing things by brute force.
```
npme = NumPyMinimumEigensolver(qubit_op)
result = npme.compute_minimum_eigenvalue()
x = sample_most_likely(result.eigenstate)
ising_sol = graph_partition.get_graph_solution(x)
print(ising_sol)
print(f'Objective value computed by the NumPyMinimumEigensolver is {graph_partition.objective_value(x, w)}')
```
It is also possible to use VQE as is shown below
```
from qiskit.aqua.algorithms import VQE
from qiskit.circuit.library import TwoLocal
aqua_globals.random_seed = 10598
optimizer = COBYLA()
var_form = TwoLocal(qubit_op.num_qubits, 'ry', 'cz', reps=5, entanglement='linear')
vqe = VQE(qubit_op, var_form, optimizer, quantum_instance=BasicAer.get_backend('statevector_simulator'))
result = vqe.compute_minimum_eigenvalue()
x = sample_most_likely(result.eigenstate)
ising_sol = graph_partition.get_graph_solution(x)
print(ising_sol)
print(f'Objective value computed by VQE is {graph_partition.objective_value(x, w)}')
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
| github_jupyter |
# Tools for Better Coding
## Introduction
This chapter covers the tools that will help you to write better code. This includes practical topics such as debugging code, logging, linting, and the magic of auto-formatting.
As ever, you may need to `pip install packagename` on the terminal before being able to use some of the packages that are featured.
## Debugging code
Computers are *very* literal, so literal that unless you're perfectly precise about what you want, they will end up doing something different. When that happens, one of the most difficult issues in programming is to understand *why* the code isn't doing what you expected. When the code doesn't do what we expect, it's called a bug.
Bugs could be fundamental issues with the code you're using (in fact, the term originated because a moth causing a problem in an early computer) and, if you find one of these, you should file an issue with the maintainers of the code. However, what's much more likely is that the instructions you gave aren't quite what is needed to produce the outcome that you want. And, in this case, you might need to *debug* the code: to find out which part of it isn't doing what you expect.
Even with a small code base, it can be tricky to track down where the bug is: but don't fear, there are tools on hand to help you find where the bug is.
### Print statements
The simplest, and I'm afraid to say the most common, way to debug code is to plonk `print` statements in the code. Let's take a common example in which we perform some simple array operations, here multiplying an array and then summing it with another array:
```python
import numpy as np
def array_operations(in_arr_one, in_arr_two):
out_arr = in_arr_one*1.5
out_arr = out_arr + in_arr_two
return out_arr
in_vals_one = np.array([3, 2, 5, 16, '7', 8, 9, 22])
in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
result = array_operations(in_vals_one, in_vals_two)
result
```
```python
---------------------------------------------------------------------------
UFuncTypeError Traceback (most recent call last)
<ipython-input-1-166160824d19> in <module>
11 in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
12
---> 13 result = array_operations(in_vals_one, in_vals_two)
14 result
<ipython-input-1-166160824d19> in array_operations(in_arr_one, in_arr_two)
3
4 def array_operations(in_arr_one, in_arr_two):
----> 5 out_arr = in_arr_one*1.5
6 out_arr = out_arr + in_arr_two
7 return out_arr
UFuncTypeError: ufunc 'multiply' did not contain a loop with signature matching types (dtype('<U32'), dtype('<U32')) -> dtype('<U32')
```
Oh no! We've got a `UFuncTypeError` here, perhaps not the most illuminating error message we've ever seen. We'd like to know what's going wrong here. The `Traceback` did give us a hint about where the issue occurred though; it happens in the multiplication line of the function we wrote.
To debug the error with print statements, we might re-run the code like this:
```python
def array_operations(in_arr_one, in_arr_two):
print(f'in_arr_one is {in_arr_one}')
out_arr = in_arr_one*1.5
out_arr = out_arr + in_arr_two
return out_arr
in_vals_one = np.array([3, 2, 5, 16, '7', 8, 9, 22])
in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
result = array_operations(in_vals_one, in_vals_two)
result
```
```
in_arr_one is ['3' '2' '5' '16' '7' '8' '9' '22']
```
```python
---------------------------------------------------------------------------
UFuncTypeError Traceback (most recent call last)
<ipython-input-2-6a04719bc0ff> in <module>
9 in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
10
---> 11 result = array_operations(in_vals_one, in_vals_two)
12 result
<ipython-input-2-6a04719bc0ff> in array_operations(in_arr_one, in_arr_two)
1 def array_operations(in_arr_one, in_arr_two):
2 print(f'in_arr_one is {in_arr_one}')
----> 3 out_arr = in_arr_one*1.5
4 out_arr = out_arr + in_arr_two
5 return out_arr
UFuncTypeError: ufunc 'multiply' did not contain a loop with signature matching types (dtype('<U32'), dtype('<U32')) -> dtype('<U32')
```
What can we tell from the values of `in_arr_one` that are now being printed? Well, they seem to have quote marks around them and what that means is that they're strings, *not* floating point numbers or integers! Multiplying a string by 1.5 doesn't make sense here, so that's our error. If we did this, we might then trace the origin of that array back to find out where it was defined and see that instead of `np.array([3, 2, 5, 16, 7, 8, 9, 22])` being declared, we have `np.array([3, 2, 5, 16, '7', 8, 9, 22])` instead and `numpy` decides to cast the whole array as a string to ensure consistency.
Let's fix that problem by turning `'7'` into `7` and run it again:
```python
def array_operations(in_arr_one, in_arr_two):
out_arr = in_arr_one*1.5
out_arr = out_arr + in_arr_two
return out_arr
in_vals_one = np.array([3, 2, 5, 16, 7, 8, 9, 22])
in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
result = array_operations(in_vals_one, in_vals_two)
result
```
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-ebd3efde9b3e> in <module>
8 in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
9
---> 10 result = array_operations(in_vals_one, in_vals_two)
11 result
<ipython-input-3-ebd3efde9b3e> in array_operations(in_arr_one, in_arr_two)
1 def array_operations(in_arr_one, in_arr_two):
2 out_arr = in_arr_one*1.5
----> 3 out_arr = out_arr + in_arr_two
4 return out_arr
5
ValueError: operands could not be broadcast together with shapes (8,) (7,)
```
Still not working! But we've moved on to a different error now. We can still use a print statement to debug this one, which seems to be related to the shapes of variables passed into the function:
```python
def array_operations(in_arr_one, in_arr_two):
print(f'in_arr_one shape is {in_arr_one.shape}')
out_arr = in_arr_one*1.5
print(f'intermediate out_arr shape is {out_arr.shape}')
print(f'in_arr_two shape is {in_arr_two.shape}')
out_arr = out_arr + in_arr_two
return out_arr
in_vals_one = np.array([3, 2, 5, 16, 7, 8, 9, 22])
in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
result = array_operations(in_vals_one, in_vals_two)
result
```
```
in_arr_one shape is (8,)
intermediate out_arr shape is (8,)
in_arr_two shape is (7,)
```
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-4-4961f476c7eb> in <module>
11 in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
12
---> 13 result = array_operations(in_vals_one, in_vals_two)
14 result
<ipython-input-4-4961f476c7eb> in array_operations(in_arr_one, in_arr_two)
4 print(f'intermediate out_arr shape is {out_arr.shape}')
5 print(f'in_arr_two shape is {in_arr_two.shape}')
----> 6 out_arr = out_arr + in_arr_two
7 return out_arr
8
ValueError: operands could not be broadcast together with shapes (8,) (7,)
```
The print statement now tells us the shapes of the arrays as we go through the function. We can see that in the line before the `return` statement the two arrays that are being combined using the `+` operator don't have the same shape, so we're effectively adding two vectors from two differently dimensioned vector spaces and, understandably, we are being called out on our nonsense. To fix this problem, we would have to ensure that the input arrays are the same shape (it looks like we may have just missed a value from `in_vals_two`).
`print` statements are great for a quick bit of debugging and you are likely to want to use them more frequently than any other debugging tool. However, for complex, nested code debugging, they aren't always very efficient and you will sometimes feel like you are playing battleships in continually refining where they should go until you have pinpointed the actual problem, so they're far from perfect. Fortunately, there are other tools in the debugging toolbox...
### Icecream and better print statements
Typing `print` statements with arguments that help you debug code can become tedious. There are better ways to work, which we'll come to, but we must also recognise that `print` is used widely in practice. So what if we had a function that was as easier to use as `print` but better geared toward debugging? Well, we do, and it's called [**icecream**], and it's available in most major languages, including Python, Dart, Rust, javascript, C++, PHP, Go, Ruby, and Java.
Let's take an example from earlier in this chapter, where we used a `print` statement to display the contents of `in_arr_one` in advance of the line that caused an error being run. All we will do now is switch out `print(f'in_arr_one is {in_arr_one}')` for `ic(in_arr_one)`.
```python
from icecream import ic
def array_operations(in_arr_one, in_arr_two):
# Old debug line using `print`
# print(f'in_arr_one is {in_arr_one}')
# new debug line:
ic(in_arr_one)
out_arr = in_arr_one*1.5
out_arr = out_arr + in_arr_two
return out_arr
in_vals_one = np.array([3, 2, 5, 16, '7', 8, 9, 22])
in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
array_operations(in_vals_one, in_vals_two)
```
```
ic| in_arr_one: array(['3', '2', '5', '16', '7', '8', '9', '22'], dtype='<U21')
---------------------------------------------------------------------------
UFuncTypeError Traceback (most recent call last)
<ipython-input-6-9efd5fc1a1fe> in <module>
14 in_vals_two = np.array([4, 7, 3, 23, 6, 8, 0])
15
---> 16 array_operations(in_vals_one, in_vals_two)
<ipython-input-6-9efd5fc1a1fe> in array_operations(in_arr_one, in_arr_two)
6 # new debug line:
7 ic(in_arr_one)
----> 8 out_arr = in_arr_one*1.5
9 out_arr = out_arr + in_arr_two
10 return out_arr
UFuncTypeError: ufunc 'multiply' did not contain a loop with signature matching types (dtype('<U32'), dtype('<U32')) -> dtype('<U32')
```
What we get in terms of debugging output is `ic| in_arr_one: array(['3', '2', '5', '16', '7', '8', '9', '22'], dtype='<U21')`, which is quite similar to before apart from three important differences, all of which are advantages:
1. it is easier and quicker to write `ic(in_arr_one)` than `print(f'in_arr_one is {in_arr_one}')`
2. **icecream** automatically picks up the name of the variable, `in_arr_one`, and clearly displays its contents
3. **icecream** shows us that `in_arr_one` is of `type` array and that it has the `dtype` of `U`, which stands for Unicode (i.e. a string). `<U21` just means that all strings in the array are less than 21 characters long.
**icecream** has some other advantages relative to print statements too, for instance it can tell you about which lines were executed in which scripts if you call it without arguments:
```python
def foo():
ic()
print('first')
if 10 < 20:
ic()
print('second')
else:
ic()
print('Never executed')
foo()
```
```
ic| <ipython-input-7-8ced0f8fcf82>:2 in foo() at 00:58:19.962
ic| <ipython-input-7-8ced0f8fcf82>:6 in foo() at 00:58:19.979
first
second
```
And it can wrap assignments rather than living on its own lines:
```python
def half(i):
return ic(i) / 2
a = 6
b = ic(half(a))
```
```
ic| i: 6
ic| half(a): 3.0
```
All in all, if you find yourself using `print` to debug, you might find a one-time import of **icecream** followed by use of `ic` instead both more convenient and more effective.
### Debugging with the IDE
In this section, we'll learn about how your Integrated Development Environment, or IDE, can aid you with debugging. While we'll talk through the use of Visual Studio Code, which is free, directly supports Python, R, and other languages, and is especially rich, many of the features will be present in other IDEs too and the ideas are somewhat general.
To begin debugging using Visual Studio Code, get a script ready, for example `script.py`, that you'd like to debug. If your script has an error in, a debug run will automatically run into it and stop on the error; alternatively you can click to the left of the line number in your script to create a *breakpoint* that your code will stop at anyway when in debug mode.
To begin a debug session, click on the play button partially covered by a bug that's on the left hand ribbon of the VS Code window. It will bring up a menu. Click 'Run and debug' and select 'Python file'. The debugger will now start running the script you had open. When it reaches and error or a breakpoint it will stop.
Why is this useful? Once the code stops, you can hover over any variables and see what's 'inside' them, which is useful for working out what's going on. Remember, in the examples above, we only saw variables that we asked for. Using the debugger, we can hover over any variable we're interested in without having to decide ahead of time! We can also see other useful bits of info such as the *call stack* of functions that have been called, what local (within the current scope) and global (available everywhere) variables have been defined, and we can nominate variables to watch too.
Perhaps you now want to progress the code on from a breakpoint; you can do this too. You'll see that a menu has appeared with stop, restart, play, and other buttons on it. To skip over the next line of code, use the curved arrow over the dot. To dig in to the next line of code, for example if it's a function, use the arrow pointing toward a dot. To carry on running the code, use the play button.
This is only really scratching the surface of what you can do with IDE based debugging, but even that surface layer provides lots of really useful tools for finding out what's going on when your code executes.
## Logging
Logging is a means of tracking events that happen when software runs. An event is described by a descriptive message that can optionally contain data about variables that are defined as the code is executing.
Logging has two main purposes: to record events of interest, such as an error, and to act as an auditable account of what happened after the fact.
Although Python has a built-in logger, we will see an example of logging using [**loguru**](), a package that makes logging a little easier and has some nice settings.
Let's see how to log a debug message:
```
from loguru import logger
logger.debug("Simple logging!")
```
The default message includes the time, the type of log entry message it is, what bit of code it happened in (including a line number), and the message itself (basically all the info we need). There are different levels of code messages. They are:
- CRITICAL
- ERROR
- WARNING
- SUCCESS
- INFO
- DEBUG
- TRACE
You can find advice on what level to use for what message [here](https://reflectoring.io/logging-levels/), but it will depend a bit on what you're using your logs for.
What we've just seen are logging messages written out to the console, which doesn't persist. This is clearly no good for auditing what happened long after the fact (and it may not be that good for debugging either) so we also need a way to write a log to a file. This snippet of code
```python
logger.add("file_{time}.log")
```
tells **loguru** to send your logging messages to a *log file* instead of to the console. This is really handy for auditing what happened when your code executed long after it ran. You can choose any name for your log file, using "{time}" as part of the string is a shorthand that tells **loguru** to use the current datetime to name the file.
Log files can become quite numerous and quite large, which you might not want. Those logs from 6 months ago may just be taking up space and not be all that useful, for example. So, what you can also do, is tell **loguru** to use a new log file. Some examples of this would be `logger.add("file_1.log", rotation="500 MB")` to clean up a file after it reaches 500 MB in size, `rotation="12:00"` to refresh the log file at lunch time, and `retention="10 days"` to keep the file for 10 days.
One further feature that is worth being aware of is the capability to trace what caused errors, including the trace back through functions and modules, and report them in the log. Of course, you can debug these using the console, but sometimes having such complex errors written to a file (in full) can be handy. This example of a full traceback comes from the **loguru** documentation. The script would have:
```python
logger.add("out.log", backtrace=True, diagnose=True) # Caution, may leak sensitive data if used in production
def func(a, b):
return a / b
def nested(c):
try:
func(5, c)
except ZeroDivisionError:
logger.exception("What?!")
nested(0)
```
while the log file would record:
```
2018-07-17 01:38:43.975 | ERROR | __main__:nested:10 - What?!
Traceback (most recent call last):
File "test.py", line 12, in <module>
nested(0)
└ <function nested at 0x7f5c755322f0>
> File "test.py", line 8, in nested
func(5, c)
│ └ 0
└ <function func at 0x7f5c79fc2e18>
File "test.py", line 4, in func
return a / b
│ └ 0
└ 5
ZeroDivisionError: division by zero
```
## Auto-magically improving your code
In the previous chapter, we met the idea of *code style*: even for code that runs, *how* you write it matters for readability. (And it goes without saying that you don't want bugs in your code that stop it running at all.) It is possible to catch some errors, to flag style issues, and even to re-format code to comply with a code style automatically. In this section, we'll see how to use tools to perform these functions automatically.
### Linting
Linters are tools that analyse code for programmatic and stylistic errors, assuming you have declared a style. A linting tool flags any potential errors and deviations from style before you even run it. When you run a linter, you get a report of what line the issue is on and why it has been raised. They are supposedly named after the lint trap in a clothes dryer because of the way they catch small errors that could have big effects.
Some of the most popular linters in Python are [**flake8**](https://flake8.pycqa.org/en/latest/), [**pycodestyle**](https://pycodestyle.pycqa.org/en/latest/intro.html), and [**pylint**](https://www.pylint.org/).
Let's see an example of running a linter. VS Code has direct integration with a range of linters. To get going, use `⇧⌘P` (Mac) and then type 'Python Select Linter'. In the example below, we'll use **flake8** (and **pylance**, another VS Code extension). Let's pretend we have a script, `test.py`, containing
```python
list_defn = [1,5, 6,
7]
def this_is_a_func():
print('hello')
print(X)
import numpy as np
```
To see the linting report, press ``⌃``` (Mac) and navigate to the 'Problems' tab. We get a whole load of error messages about this script, here are a few:
- ⓧ missing whitespace after ',' flake8(E231) 1, 15
- ⓧ continuation line under-indented for visual indent flake8(E128) 2, 1
- ⓧ expected 2 blank lines, found 1 flake8(E302) 4, 1
- ⓧ indentation is not a multiple of 4 flake8(E111) 5, 4
- ⓧ undefined name 'X' flake8(F821) 7, 7
- ⓧ module level import not at top of file flake8(E402) 9, 1
- ⓧ 'numpy as np' imported but unused flake8(F3401) 9, 1
- ⚠ "X" is not defined Pylance(reportUndefinedVariable) 7, 7
- ⚠ no newline at end of file flake8(W292) 78, 338
each message is a warning or error that says what the problem is (for example, missing whitespace after ','), what library is reporting it (mostly flake8 here), the name of the rule that has been broken (E231), and the line, row position (1, 15). Very helpfully, we get an undefined name message for variable `X`, this is especially handy because it would cause an error on execution otherwise. The same goes for the indentation message (indentation matters!). You can customise your [linting settings](https://code.visualstudio.com/docs/python/linting) in VS Code too.
Although the automatic linting offered by an IDE is very convenient, it's not the only way to use linting tools. You can also run them from the command line. For example, for **flake8**, the command is `flake8 test.py`.
### Formatting
It's great to find out all the ways in which you are failing with respect to code style from a linter but wouldn't it be *even* better if you could fix those style issues automatically? The answer is clearly yes! This is where formatters come in; they can take valid code and forcibly apply a code style to them. This is really handy in practice for all kinds of reasons.
The most popular code formatters in Python are probably: [**yapf**](https://github.com/google/yapf), 'yet another Python formatter', from Google; [**autopep8**](https://github.com/hhatto/autopep8), which applies PEP8 to your code; and [**black**](https://black.readthedocs.io/en/stable/), the 'uncompromising formatter' that is very opinionated ("any colour, as long as it's black").
There are two ways to use formatters, line-by-line (though **black** doesn't work in this mode) or on an entire script at once. VS Code offers an integration with formatters. To select a formatter in VS Code, bring up the settings using `⌘,` (Mac) or `ctrl+,` (otherwise) and type 'python formatting provider' and you can choose from autopep8, black, and yapf.
If you choose **autopep8** and then open a script you can format a *selection* of code by pressing `⌘+k, ⌘+f` (Mac) or `ctrl+k, ctrl+f` (otherwise). They can also (and only, in the case of **black**) be used from the command line. For instance, to use **black**, the command is `black test.py`, assuming you have it installed.
Let's see an example of a poorly styled script and see what happens when we select all lines and use ctrl+k, ctrl+f to auto format with **autopep8**. The contents of `test.py` before formatting are:
```python
def very_important_function(y_val,debug = False, keyword_arg=0, another_arg =2):
X = np.linspace(0,10,5)
return X+ y_val +keyword_arg
very_important_function(2)
list_defn = [1,
2,
3,
5,
6,
7]
import numpy as np
```
and, after running the auto-formatting command,
```python
import numpy as np
def very_important_function(y_val, debug=False, keyword_arg=0, another_arg=2):
X = np.linspace(0, 10, 5)
return X + y_val + keyword_arg
very_important_function(2)
list_defn = [1,
2,
3,
5,
6,
7]
```
So what did the formatter do? Many things. It moved the import to the top, put two blank lines after the function definition, removed whitespace around keyword arguments, added a new line at the end, and fixed some of the indentation. The different formatters have different strengths and weaknesses; for example, **black** is not so good at putting imports in the right place but excels at splitting up troublesome wide lines. If you need a formatter that deals specifically with module imports, check out [**isort**](https://pycqa.github.io/isort/).
Apart from taking the pressure off you to always be thinking about code style, formatters can be useful when working collaboratively too. For some open source packages, maintainers ask that new code or changed code be run through a particular formatter if it is to be incorporated into the main branch. This helps ensure the code style is consistent regardless of who is writing it. Running the code formatter can even be automated to happen every time someone *commits* some code to a shared code repository too, using something called a *pre-commit hook*.
There is a package that can run **Black** on Jupyter Notebooks too: [**black-nb**](https://pypi.org/project/black-nb/).
| github_jupyter |
```
#default_exp showdoc
# export
from nbdev.imports import *
from nbdev.export import *
from nbdev.sync import *
from nbconvert import HTMLExporter
if IN_NOTEBOOK:
from IPython.display import Markdown,display
from IPython.core import page
IN_NOTEBOOK
```
# Show doc
> Functions to show the doc cells in notebooks
All the automatic documentation of functions and classes are generated with the `show_doc` function. It displays the name, arguments, docstring along with a link to the source code on GitHub.
## Gather the information
The inspect module lets us know quickly if an object is a function or a class but it doesn't distinguish classes and enums.
```
# export
def is_enum(cls):
"Check if `cls` is an enum or another type of class"
return type(cls) in (enum.Enum, enum.EnumMeta)
e = enum.Enum('e', 'a b')
assert is_enum(e)
assert not is_enum(int)
```
### Links to documentaion
```
# export
def get_all(package):
mod = importlib.import_module(pacakge)
path = Path(mod.__path__)
# export
def is_lib_module(name):
"Test if `name` is a library module."
if name.startswith('_'): return False
try:
_ = importlib.import_module(f'{Config().lib_name}.{name}')
return True
except: return False
assert is_lib_module('export')
assert not is_lib_module('transform')
#export
_re_digits_first = re.compile('^[0-9]+_')
#export
def try_external_doc_link(name, packages):
"Try to find a doc link for `name` in `packages`"
for p in packages:
try:
mod = importlib.import_module(f"{p}._nbdev")
try_pack = source_nb(name, is_name=True, mod=mod)
if try_pack:
page = _re_digits_first.sub('', try_pack).replace('.ipynb', '')
return f'{mod.doc_url}{page}#{name}'
except: return None
```
This function will only work for other packages built with `nbdev`.
```
#fastai2
test_eq(try_external_doc_link('TfmdDL', ['fastai2']), 'https://dev.fast.ai/data.core#TfmdDL')
#Only works for packages built with nbdev right now
assert try_external_doc_link('Tensor', ['torch']) is None
# export
def doc_link(name, include_bt=True):
"Create link to documentation for `name`."
cname = f'`{name}`' if include_bt else name
#Link to modulesn
if is_lib_module(name): return f"[{cname}]({Config().doc_baseurl}{'_'.join(name.split('.'))})"
#Link to local functions
try_local = source_nb(name, is_name=True)
if try_local:
page = _re_digits_first.sub('', try_local).replace('.ipynb', '')
return f'[{cname}]({Config().doc_baseurl}{page}#{name})'
##Custom links
mod = get_nbdev_module()
link = mod.custom_doc_links(name)
return f'[{cname}]({link})' if link is not None else cname
```
This function will generate link for a module (pointing to the html conversion of the notebook that created it) and functions (pointing to the hmtl conversion of the notebook they were defined, with the first anchor found before). If the function/module is not part of the library you are writing, it will call the function `custom_doc_links` generated in `_nbdev` (you can customize it to your needs) and just return the name between backticks if that function returns `None`.
For instance, fastai2 has the following `custom_doc_links` that tries to find a doc link for `name` in fastcore then nbdev (in this order):
``` python
def custom_doc_links(name):
from nbdev.showdoc import try_external_doc_link
return try_external_doc_link(name, ['fastcore', 'nbdev'])
```
```
test_eq(doc_link('export'), f'[`export`](/export)')
test_eq(doc_link('DocsTestClass'), f'[`DocsTestClass`](/export#DocsTestClass)')
test_eq(doc_link('DocsTestClass.test'), f'[`DocsTestClass.test`](/export#DocsTestClass.test)')
test_eq(doc_link('Tenso'),'`Tenso`')
test_eq(doc_link('_nbdev'), f'`_nbdev`')
test_eq(doc_link('__main__'), f'`__main__`')
#export
_re_backticks = re.compile(r"""
# Catches any link of the form \[`obj`\](old_link) or just `obj`,
# to either update old links or add the link to the docs of obj
\[` # Opening [ and `
([^`]*) # Catching group with anything but a `
`\] # ` then closing ]
(?: # Beginning of non-catching group
\( # Opening (
[^)]* # Anything but a closing )
\) # Closing )
) # End of non-catching group
| # OR
` # Opening `
([^`]*) # Anything but a `
` # Closing `
""", re.VERBOSE)
# export
def add_doc_links(text):
"Search for doc links for any item between backticks in `text` and isnter them"
def _replace_link(m): return doc_link(m.group(1) or m.group(2))
return _re_backticks.sub(_replace_link, text)
```
This function not only add links to backtick keywords, it also update the links that are already in the text (in case they have changed).
```
tst = add_doc_links('This is an example of `DocsTestClass`')
test_eq(tst, "This is an example of [`DocsTestClass`](/export#DocsTestClass)")
tst = add_doc_links('This is an example of [`DocsTestClass`](old_link.html)')
test_eq(tst, "This is an example of [`DocsTestClass`](/export#DocsTestClass)")
```
### Links to source
```
#export
def _is_type_dispatch(x): return type(x).__name__ == "TypeDispatch"
def _unwrapped_type_dispatch_func(x): return x.first() if _is_type_dispatch(x) else x
def _is_property(x): return type(x)==property
def _has_property_getter(x): return _is_property(x) and hasattr(x, 'fget') and hasattr(x.fget, 'func')
def _property_getter(x): return x.fget.func if _has_property_getter(x) else x
def _unwrapped_func(x):
x = _unwrapped_type_dispatch_func(x)
x = _property_getter(x)
return x
#export
def get_source_link(func):
"Return link to `func` in source code"
func = _unwrapped_func(func)
try: line = inspect.getsourcelines(func)[1]
except Exception: return ''
mod = inspect.getmodule(func)
module = mod.__name__.replace('.', '/') + '.py'
try:
nbdev_mod = importlib.import_module(mod.__package__.split('.')[0] + '._nbdev')
return f"{nbdev_mod.git_url}{module}#L{line}"
except: return f"{module}#L{line}"
```
Be sure to properly set the `git_url` in setting.ini (derived from `lib_name` and `branch` on top of the prefix you will need to adapt) so that those links are correct.
```
#hide
assert get_source_link(DocsTestClass.test).startswith(Config().git_url + 'nbdev/export.py')
#hide
#fastai2
from fastcore.foundation import L
assert get_source_link(L).startswith("https://github.com/fastai/fastcore/tree/master/fastcore/foundation.py")
```
As important as the source code, we want to quickly jump to where the function is defined when we are in a development notebook.
```
#export
_re_header = re.compile(r"""
# Catches any header in markdown with the title in group 1
^\s* # Beginning of text followed by any number of whitespace
\#+ # One # or more
\s* # Any number of whitespace
(.*) # Catching group with anything
$ # End of text
""", re.VERBOSE)
#export
def get_nb_source_link(func, local=False, is_name=None):
"Return a link to the notebook where `func` is defined."
func = _unwrapped_type_dispatch_func(func)
pref = '' if local else Config().git_url.replace('github.com', 'nbviewer.jupyter.org/github')+ Config().nbs_path.name+'/'
is_name = is_name or isinstance(func, str)
src = source_nb(func, is_name=is_name, return_all=True)
if src is None: return '' if is_name else get_source_link(func)
find_name,nb_name = src
nb = read_nb(nb_name)
pat = re.compile(f'^{find_name}\s+=|^(def|class)\s+{find_name}\s*\(', re.MULTILINE)
if len(find_name.split('.')) == 2:
clas,func = find_name.split('.')
pat2 = re.compile(f'@patch\s*\ndef\s+{func}\s*\([^:]*:\s*{clas}\s*(?:,|\))')
else: pat2 = None
for i,cell in enumerate(nb['cells']):
if cell['cell_type'] == 'code':
if re.search(pat, cell['source']): break
if pat2 is not None and re.search(pat2, cell['source']): break
if re.search(pat, cell['source']) is None and (pat2 is not None and re.search(pat2, cell['source']) is None):
return '' if is_name else get_function_source(func)
header_pat = re.compile(r'^\s*#+\s*(.*)$')
while i >= 0:
cell = nb['cells'][i]
if cell['cell_type'] == 'markdown' and _re_header.search(cell['source']):
title = _re_header.search(cell['source']).groups()[0]
anchor = '-'.join([s for s in title.split(' ') if len(s) > 0])
return f'{pref}{nb_name}#{anchor}'
i-=1
return f'{pref}{nb_name}'
test_eq(get_nb_source_link(DocsTestClass.test), get_nb_source_link(DocsTestClass))
test_eq(get_nb_source_link('DocsTestClass'), get_nb_source_link(DocsTestClass))
NB_SOURCE_URL = Config().git_url.replace('github.com', 'nbviewer.jupyter.org/github')+ Config().nbs_path.name+'/'
test_eq(get_nb_source_link(check_re), f'{NB_SOURCE_URL}00_export.ipynb#Finding-patterns')
test_eq(get_nb_source_link(check_re, local=True), f'00_export.ipynb#Finding-patterns')
```
You can either pass an object or its name (by default `is_name` will look if `func` is a string or not to decide if it's `True` or `False`, but you can override if there is some inconsistent behavior). `local` will return a local link, otherwise it will point to a the notebook on github wrapped in [nbviewer](https://nbviewer.jupyter.org/).
```
# export
def nb_source_link(func, is_name=None, disp=True):
"Show a relative link to the notebook where `func` is defined"
is_name = is_name or isinstance(func, str)
func_name = func if is_name else qual_name(func)
link = get_nb_source_link(func, local=True, is_name=is_name)
if disp: display(Markdown(f'[{func_name}]({link})'))
else: return link
```
This function assumes you are in one notebook in the development folder, otherwise you can use `disp=False` to get the relative link. You can either pass an object or its name (by default `is_name` will look if `func` is a string or not to decide if it's `True` or `False`, but you can override if there is some inconsistent behavior).
```
test_eq(nb_source_link(check_re, disp=False), f'00_export.ipynb#Finding-patterns')
test_eq(nb_source_link('check_re', disp=False), f'00_export.ipynb#Finding-patterns')
```
## Show documentation
```
# export
from fastscript import Param
# export
def type_repr(t):
"Representation of type `t` (in a type annotation)"
if (isinstance(t, Param)): return f'"{t.help}"'
if getattr(t, '__args__', None):
args = t.__args__
if len(args)==2 and args[1] == type(None):
return f'`Optional`\[{type_repr(args[0])}\]'
reprs = ', '.join([type_repr(o) for o in args])
return f'{doc_link(get_name(t))}\[{reprs}\]'
else: return doc_link(get_name(t))
```
The representation tries to find doc links if possible.
```
tst = type_repr(Optional[DocsTestClass])
test_eq(tst, '`Optional`\\[[`DocsTestClass`](/export#DocsTestClass)\\]')
tst = type_repr(Union[int, float])
test_eq(tst, '`Union`\\[`int`, `float`\\]')
test_eq(type_repr(Param("description")), '"description"')
# export
_arg_prefixes = {inspect._VAR_POSITIONAL: '\*', inspect._VAR_KEYWORD:'\*\*'}
def format_param(p):
"Formats function param to `param:Type=val` with font weights: param=bold, val=italic"
arg_prefix = _arg_prefixes.get(p.kind, '') # asterisk prefix for *args and **kwargs
res = f"**{arg_prefix}`{p.name}`**"
if hasattr(p, 'annotation') and p.annotation != p.empty: res += f':{type_repr(p.annotation)}'
if p.default != p.empty:
default = getattr(p.default, 'func', p.default) #For partials
default = getattr(default, '__name__', default) #Tries to find a name
if is_enum(default.__class__): #Enum have a crappy repr
res += f'=*`{default.__class__.__name__}.{default.name}`*'
else: res += f'=*`{repr(default)}`*'
return res
sig = inspect.signature(notebook2script)
params = [format_param(p) for _,p in sig.parameters.items()]
test_eq(params, ['**`fname`**=*`None`*', '**`silent`**=*`False`*', '**`to_dict`**=*`False`*'])
# export
def _format_enum_doc(enum, full_name):
"Formatted `enum` definition to show in documentation"
vals = ', '.join(enum.__members__.keys())
return f'<code>{full_name}</code>',f'<code>Enum</code> = [{vals}]'
#hide
tst = _format_enum_doc(e, 'e')
test_eq(tst, ('<code>e</code>', '<code>Enum</code> = [a, b]'))
# export
def _escape_chars(s):
return s.replace('_', '\_')
def _format_func_doc(func, full_name=None):
"Formatted `func` definition to show in documentation"
try:
sig = inspect.signature(func)
fmt_params = [format_param(param) for name,param
in sig.parameters.items() if name not in ('self','cls')]
except: fmt_params = []
name = f'<code>{full_name or func.__name__}</code>'
arg_str = f"({', '.join(fmt_params)})"
f_name = f"<code>class</code> {name}" if inspect.isclass(func) else name
return f'{f_name}',f'{name}{arg_str}'
#hide
test_eq(_format_func_doc(notebook2script), ('<code>notebook2script</code>',
'<code>notebook2script</code>(**`fname`**=*`None`*, **`silent`**=*`False`*, **`to_dict`**=*`False`*)'))
# export
def _format_cls_doc(cls, full_name):
"Formatted `cls` definition to show in documentation"
parent_class = inspect.getclasstree([cls])[-1][0][1][0]
name,args = _format_func_doc(cls, full_name)
if parent_class != object: args += f' :: {doc_link(get_name(parent_class))}'
return name,args
#hide
test_eq(_format_cls_doc(DocsTestClass, 'DocsTestClass'), ('<code>class</code> <code>DocsTestClass</code>',
'<code>DocsTestClass</code>()'))
# export
def show_doc(elt, doc_string=True, name=None, title_level=None, disp=True, default_cls_level=2):
"Show documentation for element `elt`. Supported types: class, function, and enum."
elt = getattr(elt, '__func__', elt)
qname = name or qual_name(elt)
if inspect.isclass(elt):
if is_enum(elt.__class__): name,args = _format_enum_doc(elt, qname)
else: name,args = _format_cls_doc (elt, qname)
elif callable(elt): name,args = _format_func_doc(elt, qname)
else: name,args = f"<code>{qname}</code>", ''
link = get_source_link(elt)
source_link = f'<a href="{link}" class="source_link" style="float:right">[source]</a>'
title_level = title_level or (default_cls_level if inspect.isclass(elt) else 4)
doc = f'<h{title_level} id="{qname}" class="doc_header">{name}{source_link}</h{title_level}>'
doc += f'\n\n> {args}\n\n' if len(args) > 0 else '\n\n'
if doc_string and inspect.getdoc(elt):
s = inspect.getdoc(elt)
# doc links don't work inside markdown pre/code blocks
s = f'```\n{s}\n```' if Config().get('monospace_docstrings') == 'True' else add_doc_links(s)
doc += s
if disp: display(Markdown(doc))
else: return doc
```
`doc_string` determines if we show the docstring of the function or not. `name` can be used to provide an alternative to the name automatically found. `title_level` determines the level of the anchor (default 3 for classes and 4 for functions). If `disp` is `False`, the function returns the markdown code instead of displaying it. If `doc_string` is `True` and `monospace_docstrings` is set to `True` in `settings.ini`, the docstring of the function is formatted in a code block to preserve whitespace.
For instance
```python
show_doc(notebook2script)
```
will display
<h4 id="notebook2script" class="doc_header"><code>notebook2script</code><a href="https://github.com/fastai/nbdev/tree/master/nbdev/export.py#L277" class="source_link" style="float:right">[source]</a></h4>
> <code>notebook2script</code>(**`fname`**=*`None`*, **`silent`**=*`False`*, **`to_pkl`**=*`False`*)
Convert `fname` or all the notebook satisfying `all_fs`.
### Integration test -
```
#hide
show_doc(DocsTestClass)
#hide
show_doc(DocsTestClass.test)
#hide
show_doc(notebook2script)
#hide
show_doc(check_re)
#hide
def test_func_with_args_and_links(foo, bar):
"""
Doc link: `show_doc`.
Args:
foo: foo
bar: bar
Returns:
None
"""
pass
show_doc(test_func_with_args_and_links)
Config()["monospace_docstrings"] = "True"
show_doc(test_func_with_args_and_links)
Config()["monospace_docstrings"] = "False"
```
### The doc command
```
#export
def md2html(md):
"Convert markdown `md` to HTML code"
import nbconvert
if nbconvert.__version__ < '5.5.0': return HTMLExporter().markdown2html(md)
else: return HTMLExporter().markdown2html(collections.defaultdict(lambda: collections.defaultdict(dict)), md)
#export
def get_doc_link(func):
mod = inspect.getmodule(func)
module = mod.__name__.replace('.', '/') + '.py'
try:
nbdev_mod = importlib.import_module(mod.__package__.split('.')[0] + '._nbdev')
try_pack = source_nb(func, mod=nbdev_mod)
if try_pack:
page = '.'.join(try_pack.split('_')[1:]).replace('.ipynb', '')
return f'{nbdev_mod.doc_url}{page}#{qual_name(func)}'
except: return None
test_eq(get_doc_link(notebook2script), 'https://nbdev.fast.ai/export#notebook2script')
#fastai2
from fastai2.data.core import TfmdDL
test_eq(get_doc_link(TfmdDL), 'https://dev.fast.ai/data.core#TfmdDL')
#export
def doc(elt):
"Show `show_doc` info in preview window when used in a notebook"
md = show_doc(elt, disp=False)
doc_link = get_doc_link(elt)
if doc_link is not None:
md += f'\n\n<a href="{doc_link}" target="_blank" rel="noreferrer noopener">Show in docs</a>'
output = md2html(md)
if IN_COLAB: get_ipython().run_cell_magic(u'html', u'', output)
else:
try: page.page({'text/html': output})
except: display(Markdown(md))
```
## Export -
```
#hide
notebook2script()
```
| github_jupyter |
# Titanic Project
## Problem Statement:
The Titanic Problem is based on the sinking of the ‘Unsinkable’ ship Titanic in early 1912. It gives you information about multiple people like their ages, sexes, sibling counts, embarkment points, and whether or not they survived the disaster. Based on these features, you have to predict if an arbitrary passenger on Titanic would survive the sinking or not.
```
import warnings
warnings.simplefilter("ignore")
import joblib
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
```
Importing all the necessary libraries here.
```
df = pd.read_csv("https://raw.githubusercontent.com/dsrscientist/dataset1/master/titanic_train.csv")
```
Instead of downloading the entire dataset on my local computer I am simply loading the file directly from the GitHub repository link using the raw option.
```
df
```
Here we are looking at the first five and last five rows of our entire dataset. We can see that there is a total of 891 rows and 12 columns. The survived column is basically our target label that we need to predict the survival accuracy making this a Classification problem!
# Exploratory Data Analysis (EDA)
```
df.shape
```
By taking a single look at the columns I can confirm that Passenger ID and Name are contributing no inputs since they are just unique values and no insights can be extracted from them so first I will drop them and then check for others one by one.
```
df.columns
```
Column Names and their data description:
- PassengerId - Total number of passengers on the ship labelled starting from 1
- Survived - Survival (0 = No; 1 = Yes)
- Pclass - Passenger Class (1 = 1st class; 2 = 2nd class; 3 = 3rd class)
- Name - Name of the passenger
- Sex - Gender of the passenger
- Age - Age of the passenger
- SibSp - Number of Siblings/Spouses Aboard
- Parch - Number of Parents/Children Aboard
- Ticket - Ticket Number
- Fare - Passenger Fare/Price of the ticket
- Cabin - Cabin/Room numbers where the passengers were staying in the ship
- Embarked - Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
```
df = df.drop(["PassengerId", "Name"], axis=1)
```
Sucessfuly removed the "PassengerId" and "Name" coulmns from our dataset that were logically not useful for predicting the survival of a person on the sinking ship.
```
df.isnull().sum()
```
Checking the missing value data shows that out of 891 records we have 177 missing in the "Age" column and 687 missing in the "Cabin" column while there are only 2 missing data in "Embarked" column.
As cabin column has the highest number of missing data that is close to 80 percent of the overall data filling them would make no sense and it will simply create a biasness in the machine learning model towards a particular value.
```
df = df.drop("Cabin", axis=1)
```
I have removed the "Cabin" column since most of its data was missing and there was no point of filling around 80 percent data manually into a column. Either we need to get the data collected for missing values which is not possible in this scenario therefore dropping the column is the only course of action that seems fit to ensure that our best model predicts the label without any biasness.
```
df.info()
```
With the above information we see a variation in the data types for our columns present in the given dataset. There are 2 columns filled with float values, 4 columns have integer values and the remaining 3 columns have object data type. Since object data type cannot be used to build a machine learning model we will need to check if they have any inputs to provide and encode them for usage purpose.
```
df.skew()
```
Using the skew method we can see if there is any skewness in our dataset indicating any kind of outliers. Whether those outliers are genuine or will need to be treated before creating our machine learning model.
The acceptable range for skewness is +/-0.5. We can see that columns 'Survived' and 'Age' are the only one's within that range and for the rest of the columns will need to check for further information on them.
# Visualization
```
plt.figure(figsize=(10,7))
sns.countplot(x ='Survived', data = df, palette="rainbow")
plt.xlabel('Count of people who were deceased and who survived')
plt.ylabel('Total number of people aboard Titanic')
plt.show()
```
In the above count plot 0 depicts the number of people who drowned when the Titanic sank and 1 depicts the people who survived the sinking. We can see that more number of people drowned when the Titanic was sinking and one's who survived represent a lesser number in comparison.
```
plt.figure(figsize=(10,7))
sns.countplot(x ='Survived', data = df, hue='Sex' , palette="magma")
plt.xlabel('Count of people who were deceased and who survived')
plt.ylabel('Total number of people aboard Titanic')
plt.show()
```
Adding the sex column shows us a representation on how more men died when compared to women since in Titanic the rescue operations prioritized the life boat usage for women and children.
```
plt.figure(figsize=(10,7))
sns.countplot(x ='Survived', data = df, hue='Pclass', palette="cubehelix")
plt.xlabel('Count of people who were deceased and who survived')
plt.ylabel('Total number of people aboard Titanic')
plt.show()
```
Just like the Sex column when I tried checking for a visual representation over the passenger class factor I see that the highest number of deaths happened for class 3 people because again the rescue team gave priority based on class and passengers from class 1 were rescued first then class 2 and by the time class 3 folks were being rescued they ran out of life boats and time as well since the Titanic had almost sank into the ocean.
```
plt.figure(figsize=(10,7))
sns.countplot(x ='Survived', data = df, hue='Embarked', palette="turbo")
plt.xlabel('Count of people who were deceased and who survived')
plt.ylabel('Total number of people aboard Titanic')
plt.show()
```
Taking a look at the embarked data it looks like the port where the passengers embarked the Titanic has very less to offer but definitely indicates that it still has inputs in terms of folks traveling from S=Southampton have died the most than they survived.
### Pair Plot
```
sns.pairplot(df)
plt.show()
```
The pairplot gives us a visualization on scatter plot + histogram showing us the outliers as well as the skewness data. Looking at the above picture we can see the presence of both skewness and outliers but we shall check few more visuals to confirm if those need to be treated or not.
```
df.head(10)
```
Using the head feature I am looking at the first 20 records of dataset and can observe that again "Ticket" column just shows a list of numbers paired with few alphabets that is basically indicating towards the unique allotment given to the passengers validating them to be eligible the board the Titanic. As it serves no purpose in the prediction of survival rate of the people cruising the Titanic I will remove this column too.
```
df = df.drop("Ticket", axis=1)
```
I removed the ticket column from the dataset as it was not something that would play a major role in the survival of a person present on the Titanic.
### Violin Plots
```
plt.figure(figsize=(10,7))
sns.violinplot(x="Sex", y="Pclass", hue="Survived", data=df, palette="Set2", split=True, scale="count", inner="quartile")
plt.show()
```
In the above plot when comparing the gender with passenger class we see that the male who were in class 3 died in higher numbers as they were least prioritized.
```
plt.figure(figsize=(10,7))
sns.violinplot(x="Sex", y="Age", hue="Survived", data=df, palette="Set3", split=True, scale="count", inner="quartile")
plt.show()
```
The above figure depiction shows that the females who survived were averagely in their thirties similarly the males who drowned were averagely in their thirties.
```
plt.figure(figsize=(10,7))
sns.violinplot(x="Sex", y="Fare", hue="Survived", data=df, palette="Set1", split=True, scale="count", inner="quartile")
plt.show()
```
The adition of fare column displays that the men who paid the least fare were not allowed to get on the life boats causing them to drown indicating that low priced fare meant a lower class passenger and hence a lower priority over rescuing.
# Filling the missing values
```
df.isnull().sum()
```
Gettig back to the missing values issue we will need to fix it and I have decided on using the mean option for "Age" column and mode for the "Embarked" column.
### Box Plot
```
plt.figure(figsize=(15,10))
sns.boxplot(x='Pclass', y='Age', data=df, palette="Accent")
```
For filling the missing value in the age column I am checking the average age of a person in that particular class so that we do not just randomly fill in those years for the age column.
In the above boxplot it shows that the class 1 people who are wealthy are above the average age for the other 2 class and in the class 3 there were mostly youngsters who did not have hefty money at that age.
```
def fill_age(cols):
Age = cols[0]
Pclass = cols[1]
if pd.isnull(Age):
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:
return Age
```
So we have created a function after applying the observations from the boxplot to get the average age based on the class of travel. In class 1 we see average age as 37, for class 2 the average age is around 29 and class 3 has an approximate avergae age of 24.
We will now use this function to fill the missing age values.
```
df["Age"] = df[["Age","Pclass"]].apply(fill_age, axis=1)
```
Using our fill_age function we have now added the average years data into the age column of our data set.
```
df["Embarked"] = df["Embarked"].fillna(df["Embarked"].mode()[0])
```
We have used the mode option to fill the missing data in Embarked column with the value most common for the column row wise.
# Encoding
```
df = pd.get_dummies(df)
df
```
I am using the pandas get_dummies method to encode the categorical object datatype 'Sex' and 'Embarked' columns. Since get_dummies uses the One Hot Encoding mechanism we are able to get extra columns where the rows are converted to indicator variables.
### Distribution Plot
```
for col, value in df.items():
plt.figure(figsize=(10,7))
sns.distplot(value, hist=False, color="g", kde_kws={"shade": True})
plt.tight_layout(pad=0.5, w_pad=0.7, h_pad=5.0)
plt.show()
```
Looking at the distribution plot after applying the encoding technique and ensuring all object datatype are converted to numbers that can be used for visualization we see that the presence of outliers are affecting the distribution patterns and causing skewness that might need to be treated.
But first I will try to build a model retaining all the data and check whether the model accuracy gets affected due to it or not.
# Correlation using a Heatmap
- Positive correlation - A correlation of +1 indicates a perfect positive correlation, meaning that both variables move in the same direction together.
- Negative correlation - A correlation of –1 indicates a perfect negative correlation, meaning that as one variable goes up, the other goes down.
```
lower_triangle = np.tril(df.corr())
plt.figure(figsize=(15,10))
sns.heatmap(df.corr(), vmin=-1, vmax=1, annot=True, square=True, fmt='0.3f',
annot_kws={'size':10}, cmap="coolwarm", mask=lower_triangle)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
```
In the above correlation heatmap we can see that our label has both positive and negative correlation with the other columns present in our dataset.
The female column is a perfect negative correlation to male column since the higher the number of female survivors the lower the number of male survivors.
# Splitting the dataset into 2 variables namely 'X' and 'Y' for feature and label
```
X = df.drop("Survived", axis=1)
Y = df["Survived"]
```
I have separated the dataset into features and labels where X represents all the feature columns and Y represents the target label column.
# Feature Scaling
```
scaler = StandardScaler()
X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
X # Displaying all the features after applying scaling technique to avoid bias output
```
Even though all our feature columns were of numeric data type I was unhappy with the decimal place differences and was worried that it might make my model biased towards float and integers. Therefore I am using the Standard Scaler method to ensure all my feature columns have been standardized.
```
X.describe()
```
Using the describe method I can see the count, mean, standard deviation, minimum, maximum and inter quantile values of our feature data set.
```
X = X.drop(["SibSp","Parch","Embarked_C","Embarked_Q","Embarked_S"], axis=1)
```
I have dropped the SibSp, Parch, Embarked_C, Embarked_Q and Embarked_S columns from the features list to check if that improves the accuracy for our classification models since as per the correlation details we saw it did not have much input for any kind of corresponse with the survival rate.
When I built the model using these columns the model score were lower than the one's when we dropped them.
# Creating the training and testing data sets
```
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=21)
```
I am taking 20 percent of the complete dataset for training purpose and the remaing 80 percent with be used to train the machine learning models
# ML Model Function for Classification and Evaluation Metrics
```
# Classification Model Function
def classify(model, X, Y):
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=21)
# Training the model
model.fit(X_train, Y_train)
# Predicting Y_test
pred = model.predict(X_test)
# Accuracy Score
acc_score = (accuracy_score(Y_test, pred))*100
print("Accuracy Score:", acc_score)
# Classification Report
class_report = classification_report(Y_test, pred)
print("\nClassification Report:\n", class_report)
# Cross Validation Score
cv_score = (cross_val_score(model, X, Y, cv=5).mean())*100
print("Cross Validation Score:", cv_score)
# Result of accuracy minus cv scores
result = acc_score - cv_score
print("\nAccuracy Score - Cross Validation Score is", result)
```
I have defined a class that will perform the train-test split, training of machine learning model, predicting the label value, getting the accuracy score, generating the classification report, getting the cross validation score and the result of difference between the accuracy score and cross validation score for any classification machine learning model that calls for this function.
Note: I have not removed the outliers since the loss of those data gave a lower score on the classification model when compared to retaining the outliers. Also the usage of Z score and IQR methods gave a data loss of more than 15 percent which I could not afford on my current data set.
```
# Logistic Regression
model=LogisticRegression()
classify(model, X, Y)
```
Created the Logistic Regression Model and checked for it's evaluation metrics.
```
# Support Vector Classifier
model=SVC(C=1.0, kernel='rbf', gamma='auto', random_state=42)
classify(model, X, Y)
```
Created the Support Vector Classifier Model and checked for it's evaluation metrics.
```
# Decision Tree Classifier
model=DecisionTreeClassifier(random_state=21, max_depth=15)
classify(model, X, Y)
```
Created the Decision Tree Classifier Model and checked for it's evaluation metrics.
```
# Random Forest Classifier
model=RandomForestClassifier(max_depth=15, random_state=111)
classify(model, X, Y)
```
Created the Random Forest Classifier Model and checked for it's evaluation metrics.
```
# K Neighbors Classifier
model=KNeighborsClassifier(n_neighbors=15)
classify(model, X, Y)
```
Created the K Neighbors Classifier Model and checked for it's evaluation metrics.
```
# Extra Trees Classifier
model=ExtraTreesClassifier()
classify(model, X, Y)
```
Created the Extra Trees Classifier Model and checked for it's evaluation metrics.
# Hyper parameter tuning on the best ML Model
```
# Choosing Support Vector Classifier
svc_param = {'kernel' : ['poly', 'sigmoid', 'rbf'],
'gamma' : ['scale', 'auto'],
'shrinking' : [True, False],
'random_state' : [21, 42, 104],
'probability' : [True, False],
'decision_function_shape' : ['ovo', 'ovr']
}
```
After comparing all the classification models I have selected Support Vector Classifier as my best model and have listed down it's parameters above referring the sklearn webpage.
```
GSCV = GridSearchCV(SVC(), svc_param, cv=5)
```
I am using the Grid Search CV method for hyper parameter tuning my best model.
```
GSCV.fit(X_train,Y_train)
```
I have trained the Grid Search CV with the list of parameters I feel it should check for best possible outcomes.
```
GSCV.best_params_
```
Here the Grid Search CV has provided me with the best parameters list out of all the combinations it used to train the model.
```
Final_Model = SVC(decision_function_shape='ovo', gamma='scale', kernel='poly', probability=True, random_state=21,
shrinking=True)
Classifier = Final_Model.fit(X_train, Y_train)
fmod_pred = Final_Model.predict(X_test)
fmod_acc = (accuracy_score(Y_test, fmod_pred))*100
print("Accuracy score for the Best Model is:", fmod_acc)
```
I have successfully incorporated the Hyper Parameter Tuning on my Final Model and received the accuracy score for it.
# AUC ROC Curve
```
disp = metrics.plot_roc_curve(Final_Model, X_test, Y_test)
disp.figure_.suptitle("ROC Curve")
plt.show()
```
I have generated the ROC Curve for my final model and it shows the AUC score for my final model to be of 85%
# Confusion Matrix
```
class_names = df.columns
metrics.plot_confusion_matrix(Classifier, X_test, Y_test, cmap='mako')
plt.title('\t Confusion Matrix for Decision Tree Classifier \n')
plt.show()
```
With the help of above confusion matrix I am able to understand the number of times I got the correct outputs and the number of times my model missed to provide the correct prediction (depicting in the black boxes)
# Saving the model
```
filename = "FinalModel_5.pkl"
joblib.dump(Final_Model, filename)
```
Finally I am saving my best classification model using the joblib library.
| github_jupyter |
<a href="https://colab.research.google.com/github/krakowiakpawel9/neural-network-course/blob/master/02_basics/02_activation_functions.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
* @author: krakowiakpawel9@gmail.com
* @site: e-smartdata.org
### Spis treści:
1. [Funkcje aktywacji](#a0)
1. [Import bibliotek](#a1)
2. [ReLU Function - Rectified Linear Unit](#a2)
3. [Funkcja Sigmoid](#a3)
4. [Tanh Function](#a4)
5. [Funkcja Softmax](#a5)
### <a name='a0'></a> 1. Funkcje Aktywacji
#### <a name='a1'></a> 1.1 Import bibliotek
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
import math
np.set_printoptions(precision=6)
```
#### <a name='a2'></a> 1.2 ReLU Function - Rectified Linear Unit
#### $$f(x) = max(x, 0)$$
```
def max_relu(x):
return max(x, 0.0)
for i in [-10., -5., 0., 5., 10.]:
print(max_relu(i))
data = np.random.randn(50)
data = sorted(data)
data
# wygenerowanie danych do wykresu
max_relu_data = np.array([max_relu(x) for x in data])
max_relu_data
df = pd.DataFrame({'data': data, 'max_relu_data': max_relu_data})
df.head()
px.line(df, x='data', y='max_relu_data', width=700, height=400, title='ReLU Function')
```
#### <a name='a3'></a> 1.3 Funkcja Sigmoid
#### $$f(x) = \frac{1}{1 + e^{-x}}$$
```
def sigmoid(x):
return 1 / (1 + np.exp(-x))
for i in [-5., -3., -1., 0., 1., 3., 5.]:
print(sigmoid(i))
data = 3 * np.random.randn(50)
data = sorted(data)
data
sigmoid_data = [sigmoid(x) for x in sorted(data)]
sigmoid_data
df = pd.DataFrame({'data': data, 'sigmoid_data': sigmoid_data})
df.head()
px.line(df, x='data', y='sigmoid_data', width=700, height=400, title='Sigmoid Function')
```
#### <a name='a4'></a> 1.4 Tanh Function
#### $$tanh (x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}$$
```
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
data = 2 * np.random.randn(100)
data = sorted(data)
data
tanh_data = [tanh(x) for x in sorted(data)]
tanh_data
df = pd.DataFrame({'data': data, 'tanh_data': tanh_data})
df.head()
px.line(df, x='data', y='tanh_data', width=700, height=400, title='Tanh Function')
```
#### <a name='a5'></a> 1.5 Softmax Function
#### $$S(x_i)=\frac{e^{x_{i}}}{\sum_{j=1}^{N}e^{x_j}},\ \ dla\ i = 1,...,N$$
#### $$S(x_1)=\frac{e^{x_{1}}}{\sum_{j=1}^{N}e^{x_j}}$$
```
def softmax(x):
e_x = np.exp(x)
denominator = np.sum(e_x, axis=1)
denominator = denominator[:, np.newaxis]
return e_x / denominator
data = np.random.randn(4, 5)
data
result = softmax(data)
result
result.sum(axis=1)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/silikmaz/easy-Telegram-bot/blob/master/easy_Telegram_bot.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
#@title <b><font color="red" size="+3">←</font><font color="black" size="+3"> download bot!</font></b>
!gdown https://github.com/silikmaz/easy-Telegram-bot/archive/master.zip
!unzip master.zip
%cd easy-Telegram-bot-master/
#@title <b><font color="red" size="+3">←</font><font color="black" size="+3"> download dependences'!</font></b>
!pip install pyrogram
!pip install tgcrypto
#@title <b><font color="red" size="+3">←</font><font color="black" size="+3"> preparation system</font></b>
#@title Example form fields
#@markdown <div> API can be obtained at my.telegram.org</div> <div> you need to create apps for Windows</div>
api_id = "" #@param {type:"string"}
api_hash = "" #@param {type:"string"}
#@markdown <div> cool settings, changing the symbol text </div>
symbol = "#" #@param {type:"string"}
team_percentage = "hack" #@param {type:"string"}
texte_hack1 = "Взлом собеседник в процессе ..." #@param {type:"string"}
percentage1 = "100" #@param {type:"string"}
texte_hack1_1 = "Взлом собеседник в процессе ..." #@param {type:"string"}
texte_hack2 = "Поиск секретных данных об флп ..." #@param {type:"string"}
percentage2 = "100" #@param {type:"string"}
texte_hack2_1 = "Найдены данные о существовании флп на компе не только собеседников и других людей!" #@param {type:"string"}
import configparser
config = configparser.ConfigParser() # создаём объекта парсера
config.read("./config.ini")
config["pyrogram"]["api_id"] = api_id
config["pyrogram"]["api_hash"] = api_hash
config["code"]["symbol"] = symbol
config["code"]["team_percentage"] = team_percentage
config["code"]["texte_hack1"] = texte_hack1
config["code"]["percentage1"] = percentage1
config["code"]["texte_hack1_1"] = texte_hack1_1
config["code"]["texte_hack2"] = texte_hack2
config["code"]["percentage2"] = percentage2
config["code"]["texte_hack2_1"] = texte_hack2_1
with open('config.ini', 'w') as configfile: # save
config.write(configfile)
#@markdown ---
#@markdown <Div>
#@markdown Support the "Railimag_nero" project and speed up development:
#@markdown </div> <div>
#@markdown Sberbank Card - 4276 6719 5951 5831(the of Maznikov Vladislav Andreevich)
#@markdown </div> <div> Yandex.Money -410015679919167</div> <div>
#@markdown PAYPAL - vladmaznikovya@mail.ru
#@markdown </div> <div> Copyright © maznikov Vladislav </div>
#@markdown <font color="red" size="+1">
#@title <b><font color="red" size="+3">←</font><font color="black" size="+3">play</font></b>
!python3 start-tel.py
```
| github_jupyter |
# Trends and cycles in unemployment
Here we consider three methods for separating a trend and cycle in economic data. Supposing we have a time series $y_t$, the basic idea is to decompose it into these two components:
$$
y_t = \mu_t + \eta_t
$$
where $\mu_t$ represents the trend or level and $\eta_t$ represents the cyclical component. In this case, we consider a *stochastic* trend, so that $\mu_t$ is a random variable and not a deterministic function of time. Two of methods fall under the heading of "unobserved components" models, and the third is the popular Hodrick-Prescott (HP) filter. Consistent with e.g. Harvey and Jaeger (1993), we find that these models all produce similar decompositions.
This notebook demonstrates applying these models to separate trend from cycle in the U.S. unemployment rate.
```
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
from pandas_datareader.data import DataReader
endog = DataReader('UNRATE', 'fred', start='1954-01-01')
endog.index.freq = endog.index.inferred_freq
```
### Hodrick-Prescott (HP) filter
The first method is the Hodrick-Prescott filter, which can be applied to a data series in a very straightforward method. Here we specify the parameter $\lambda=129600$ because the unemployment rate is observed monthly.
```
hp_cycle, hp_trend = sm.tsa.filters.hpfilter(endog, lamb=129600)
```
### Unobserved components and ARIMA model (UC-ARIMA)
The next method is an unobserved components model, where the trend is modeled as a random walk and the cycle is modeled with an ARIMA model - in particular, here we use an AR(4) model. The process for the time series can be written as:
$$
\begin{align}
y_t & = \mu_t + \eta_t \\
\mu_{t+1} & = \mu_t + \epsilon_{t+1} \\
\phi(L) \eta_t & = \nu_t
\end{align}
$$
where $\phi(L)$ is the AR(4) lag polynomial and $\epsilon_t$ and $\nu_t$ are white noise.
```
mod_ucarima = sm.tsa.UnobservedComponents(endog, 'rwalk', autoregressive=4)
# Here the powell method is used, since it achieves a
# higher loglikelihood than the default L-BFGS method
res_ucarima = mod_ucarima.fit(method='powell', disp=False)
print(res_ucarima.summary())
```
### Unobserved components with stochastic cycle (UC)
The final method is also an unobserved components model, but where the cycle is modeled explicitly.
$$
\begin{align}
y_t & = \mu_t + \eta_t \\
\mu_{t+1} & = \mu_t + \epsilon_{t+1} \\
\eta_{t+1} & = \eta_t \cos \lambda_\eta + \eta_t^* \sin \lambda_\eta + \tilde \omega_t \qquad & \tilde \omega_t \sim N(0, \sigma_{\tilde \omega}^2) \\
\eta_{t+1}^* & = -\eta_t \sin \lambda_\eta + \eta_t^* \cos \lambda_\eta + \tilde \omega_t^* & \tilde \omega_t^* \sim N(0, \sigma_{\tilde \omega}^2)
\end{align}
$$
```
mod_uc = sm.tsa.UnobservedComponents(
endog, 'rwalk',
cycle=True, stochastic_cycle=True, damped_cycle=True,
)
# Here the powell method gets close to the optimum
res_uc = mod_uc.fit(method='powell', disp=False)
# but to get to the highest loglikelihood we do a
# second round using the L-BFGS method.
res_uc = mod_uc.fit(res_uc.params, disp=False)
print(res_uc.summary())
```
### Graphical comparison
The output of each of these models is an estimate of the trend component $\mu_t$ and an estimate of the cyclical component $\eta_t$. Qualitatively the estimates of trend and cycle are very similar, although the trend component from the HP filter is somewhat more variable than those from the unobserved components models. This means that relatively mode of the movement in the unemployment rate is attributed to changes in the underlying trend rather than to temporary cyclical movements.
```
fig, axes = plt.subplots(2, figsize=(13,5));
axes[0].set(title='Level/trend component')
axes[0].plot(endog.index, res_uc.level.smoothed, label='UC')
axes[0].plot(endog.index, res_ucarima.level.smoothed, label='UC-ARIMA(2,0)')
axes[0].plot(hp_trend, label='HP Filter')
axes[0].legend(loc='upper left')
axes[0].grid()
axes[1].set(title='Cycle component')
axes[1].plot(endog.index, res_uc.cycle.smoothed, label='UC')
axes[1].plot(endog.index, res_ucarima.autoregressive.smoothed, label='UC-ARIMA(2,0)')
axes[1].plot(hp_cycle, label='HP Filter')
axes[1].legend(loc='upper left')
axes[1].grid()
fig.tight_layout();
```
| github_jupyter |
# Personalize Workshop Cleanup
This notebook will walk through deleting all of the resources created by the CPG Personalize Immersion Day. You should only need to perform these steps if you have deployed in your own AWS account and want to deprovision the resources. If you are participating in an AWS-led workshop, this process is likely not necessary.
This notebook uses the functions defined below, to iterate throught the resources inside a dataset group. The dataset group arn is saved from the Notebook `01_Data_Layer.pnyb`
```
%store -r
import sys
import getopt
import logging
import botocore
import boto3
import time
from packaging import version
from time import sleep
from botocore.exceptions import ClientError
logger = logging.getLogger()
personalize = None
def _get_dataset_group_arn(dataset_group_name):
dsg_arn = None
paginator = personalize.get_paginator('list_dataset_groups')
for paginate_result in paginator.paginate():
for dataset_group in paginate_result["datasetGroups"]:
if dataset_group['name'] == dataset_group_name:
dsg_arn = dataset_group['datasetGroupArn']
break
if dsg_arn:
break
if not dsg_arn:
raise NameError(f'Dataset Group "{dataset_group_name}" does not exist; verify region is correct')
return dsg_arn
def _get_solutions(dataset_group_arn):
solution_arns = []
paginator = personalize.get_paginator('list_solutions')
for paginate_result in paginator.paginate(datasetGroupArn = dataset_group_arn):
for solution in paginate_result['solutions']:
solution_arns.append(solution['solutionArn'])
return solution_arns
def _delete_campaigns(solution_arns):
campaign_arns = []
for solution_arn in solution_arns:
paginator = personalize.get_paginator('list_campaigns')
for paginate_result in paginator.paginate(solutionArn = solution_arn):
for campaign in paginate_result['campaigns']:
if campaign['status'] in ['ACTIVE', 'CREATE FAILED']:
logger.info('Deleting campaign: ' + campaign['campaignArn'])
personalize.delete_campaign(campaignArn = campaign['campaignArn'])
elif campaign['status'].startswith('DELETE'):
logger.warning('Campaign {} is already being deleted so will wait for delete to complete'.format(campaign['campaignArn']))
else:
raise Exception('Campaign {} has a status of {} so cannot be deleted'.format(campaign['campaignArn'], campaign['status']))
campaign_arns.append(campaign['campaignArn'])
max_time = time.time() + 30*60 # 30 mins
while time.time() < max_time:
for campaign_arn in campaign_arns:
try:
describe_response = personalize.describe_campaign(campaignArn = campaign_arn)
logger.debug('Campaign {} status is {}'.format(campaign_arn, describe_response['campaign']['status']))
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceNotFoundException':
campaign_arns.remove(campaign_arn)
if len(campaign_arns) == 0:
logger.info('All campaigns have been deleted or none exist for dataset group')
break
else:
logger.info('Waiting for {} campaign(s) to be deleted'.format(len(campaign_arns)))
time.sleep(20)
if len(campaign_arns) > 0:
raise Exception('Timed out waiting for all campaigns to be deleted')
def _delete_solutions(solution_arns):
for solution_arn in solution_arns:
try:
describe_response = personalize.describe_solution(solutionArn = solution_arn)
solution = describe_response['solution']
if solution['status'] in ['ACTIVE', 'CREATE FAILED']:
logger.info('Deleting solution: ' + solution_arn)
personalize.delete_solution(solutionArn = solution_arn)
elif solution['status'].startswith('DELETE'):
logger.warning('Solution {} is already being deleted so will wait for delete to complete'.format(solution_arn))
else:
raise Exception('Solution {} has a status of {} so cannot be deleted'.format(solution_arn, solution['status']))
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code != 'ResourceNotFoundException':
raise e
max_time = time.time() + 30*60 # 30 mins
while time.time() < max_time:
for solution_arn in solution_arns:
try:
describe_response = personalize.describe_solution(solutionArn = solution_arn)
logger.debug('Solution {} status is {}'.format(solution_arn, describe_response['solution']['status']))
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceNotFoundException':
solution_arns.remove(solution_arn)
if len(solution_arns) == 0:
logger.info('All solutions have been deleted or none exist for dataset group')
break
else:
logger.info('Waiting for {} solution(s) to be deleted'.format(len(solution_arns)))
time.sleep(20)
if len(solution_arns) > 0:
raise Exception('Timed out waiting for all solutions to be deleted')
def _delete_event_trackers(dataset_group_arn):
event_tracker_arns = []
event_trackers_paginator = personalize.get_paginator('list_event_trackers')
for event_tracker_page in event_trackers_paginator.paginate(datasetGroupArn = dataset_group_arn):
for event_tracker in event_tracker_page['eventTrackers']:
if event_tracker['status'] in [ 'ACTIVE', 'CREATE FAILED' ]:
logger.info('Deleting event tracker {}'.format(event_tracker['eventTrackerArn']))
personalize.delete_event_tracker(eventTrackerArn = event_tracker['eventTrackerArn'])
elif event_tracker['status'].startswith('DELETE'):
logger.warning('Event tracker {} is already being deleted so will wait for delete to complete'.format(event_tracker['eventTrackerArn']))
else:
raise Exception('Solution {} has a status of {} so cannot be deleted'.format(event_tracker['eventTrackerArn'], event_tracker['status']))
event_tracker_arns.append(event_tracker['eventTrackerArn'])
max_time = time.time() + 30*60 # 30 mins
while time.time() < max_time:
for event_tracker_arn in event_tracker_arns:
try:
describe_response = personalize.describe_event_tracker(eventTrackerArn = event_tracker_arn)
logger.debug('Event tracker {} status is {}'.format(event_tracker_arn, describe_response['eventTracker']['status']))
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceNotFoundException':
event_tracker_arns.remove(event_tracker_arn)
if len(event_tracker_arns) == 0:
logger.info('All event trackers have been deleted or none exist for dataset group')
break
else:
logger.info('Waiting for {} event tracker(s) to be deleted'.format(len(event_tracker_arns)))
time.sleep(20)
if len(event_tracker_arns) > 0:
raise Exception('Timed out waiting for all event trackers to be deleted')
def _delete_filters(dataset_group_arn):
filter_arns = []
filters_response = personalize.list_filters(datasetGroupArn = dataset_group_arn, maxResults = 100)
for filter in filters_response['Filters']:
logger.info('Deleting filter ' + filter['filterArn'])
personalize.delete_filter(filterArn = filter['filterArn'])
filter_arns.append(filter['filterArn'])
max_time = time.time() + 30*60 # 30 mins
while time.time() < max_time:
for filter_arn in filter_arns:
try:
describe_response = personalize.describe_filter(filterArn = filter_arn)
logger.debug('Filter {} status is {}'.format(filter_arn, describe_response['filter']['status']))
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceNotFoundException':
filter_arns.remove(filter_arn)
if len(filter_arns) == 0:
logger.info('All filters have been deleted or none exist for dataset group')
break
else:
logger.info('Waiting for {} filter(s) to be deleted'.format(len(filter_arns)))
time.sleep(20)
if len(filter_arns) > 0:
raise Exception('Timed out waiting for all filter to be deleted')
def _delete_datasets_and_schemas(dataset_group_arn):
dataset_arns = []
schema_arns = []
dataset_paginator = personalize.get_paginator('list_datasets')
for dataset_page in dataset_paginator.paginate(datasetGroupArn = dataset_group_arn):
for dataset in dataset_page['datasets']:
describe_response = personalize.describe_dataset(datasetArn = dataset['datasetArn'])
schema_arns.append(describe_response['dataset']['schemaArn'])
if dataset['status'] in ['ACTIVE', 'CREATE FAILED']:
logger.info('Deleting dataset ' + dataset['datasetArn'])
personalize.delete_dataset(datasetArn = dataset['datasetArn'])
elif dataset['status'].startswith('DELETE'):
logger.warning('Dataset {} is already being deleted so will wait for delete to complete'.format(dataset['datasetArn']))
else:
raise Exception('Dataset {} has a status of {} so cannot be deleted'.format(dataset['datasetArn'], dataset['status']))
dataset_arns.append(dataset['datasetArn'])
max_time = time.time() + 30*60 # 30 mins
while time.time() < max_time:
for dataset_arn in dataset_arns:
try:
describe_response = personalize.describe_dataset(datasetArn = dataset_arn)
logger.debug('Dataset {} status is {}'.format(dataset_arn, describe_response['dataset']['status']))
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceNotFoundException':
dataset_arns.remove(dataset_arn)
if len(dataset_arns) == 0:
logger.info('All datasets have been deleted or none exist for dataset group')
break
else:
logger.info('Waiting for {} dataset(s) to be deleted'.format(len(dataset_arns)))
time.sleep(20)
if len(dataset_arns) > 0:
raise Exception('Timed out waiting for all datasets to be deleted')
for schema_arn in schema_arns:
try:
logger.info('Deleting schema ' + schema_arn)
personalize.delete_schema(schemaArn = schema_arn)
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceInUseException':
logger.info('Schema {} is still in-use by another dataset (likely in another dataset group)'.format(schema_arn))
else:
raise e
logger.info('All schemas used exclusively by datasets have been deleted or none exist for dataset group')
def _delete_dataset_group(dataset_group_arn):
logger.info('Deleting dataset group ' + dataset_group_arn)
personalize.delete_dataset_group(datasetGroupArn = dataset_group_arn)
max_time = time.time() + 30*60 # 30 mins
while time.time() < max_time:
try:
describe_response = personalize.describe_dataset_group(datasetGroupArn = dataset_group_arn)
logger.debug('Dataset group {} status is {}'.format(dataset_group_arn, describe_response['datasetGroup']['status']))
break
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ResourceNotFoundException':
logger.info('Dataset group {} has been fully deleted'.format(dataset_group_arn))
else:
raise e
logger.info('Waiting for dataset group to be deleted')
time.sleep(20)
def delete_dataset_groups(dataset_group_arns, region = None):
global personalize
personalize = boto3.client(service_name = 'personalize', region_name = region)
for dataset_group_arn in dataset_group_arns:
logger.info('Dataset Group ARN: ' + dataset_group_arn)
solution_arns = _get_solutions(dataset_group_arn)
# 1. Delete campaigns
_delete_campaigns(solution_arns)
# 2. Delete solutions
_delete_solutions(solution_arns)
# 3. Delete event trackers
_delete_event_trackers(dataset_group_arn)
# 4. Delete filters
_delete_filters(dataset_group_arn)
# 5. Delete datasets and their schemas
_delete_datasets_and_schemas(dataset_group_arn)
# 6. Delete dataset group
_delete_dataset_group(dataset_group_arn)
logger.info(f'Dataset group {dataset_group_arn} fully deleted')
delete_dataset_groups([dataset_group_arn], region)
```
## Clean up the S3 bucket and IAM role
Start by deleting the role, then empty the bucket, then delete the bucket.
```
iam = boto3.client('iam')
```
Identify the name of the role you want to delete.
You cannot delete an IAM role which still has policies attached to it. So after you have identified the relevant role, let's list the attached policies of that role.
```
iam.list_attached_role_policies(
RoleName = role_name
)
```
You need to detach the policies in the result above using the code below. Repeat for each attached policy.
```
iam.detach_role_policy(
RoleName = role_name,
PolicyArn = 'arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess'
)
```
Finally, you should be able to delete the IAM role.
```
iam.delete_role(
RoleName = role_name
)
```
To delete an S3 bucket, it first needs to be empty. The easiest way to delete an S3 bucket, is just to navigate to S3 in the AWS console, delete the objects in the bucket, and then delete the S3 bucket itself.
## Deleting the Automation from the Operations Notebook
```
stack_name = "notebook-automation"
bucket= !aws cloudformation describe-stacks --stack-name $stack_name --query "Stacks[0].Outputs[?OutputKey=='InputBucketName'].OutputValue" --output text
bucket_name = bucket[0]
print(bucket)
!aws s3 rb s3://$bucket_name --force
!aws cloudformation delete-stack --stack-name $stack_name
time.sleep(30)
!aws cloudformation describe-stacks --stack-name $stack_name
```
## Deleting the Automation from the Initial CloudFormation deployment
```
stack_name = "id-ml-ops"
bucket= !aws cloudformation describe-stacks --stack-name $stack_name --query "Stacks[0].Outputs[?OutputKey=='InputBucketName'].OutputValue" --output text
bucket_name = bucket[0]
print(bucket_name)
!aws s3 rb s3://$bucket_name --force
!aws cloudformation delete-stack --stack-name $stack_name
time.sleep(120)
!aws cloudformation describe-stacks --stack-name $stack_name
```
## Deleting the bucket with the automation artifacts
```
stack_name = "AmazonPersonalizeImmersionDay"
bucket = !aws cloudformation describe-stack-resources --stack-name $stack_name --logical-resource-id SAMArtifactsBucket --query "StackResources[0].PhysicalResourceId" --output text
bucket_name = bucket[0]
print(bucket_name)
!aws s3 rb s3://$bucket_name --force
```
Now you can navigate to your [Cloudformation console](https://console.aws.amazon.com/cloudformation/) and delete the **AmazonPersonalizeImmersionDay** stack
## Cleanup Complete
All resources created by the Personalize workshop have been deleted.
| github_jupyter |
# A neural-network framework for modelling auditory sensory cells and synapses
Python notebook for comparing the evaluation results of the two additional CNN models to the referebce Dierich et al. IHC model and the Zilany et al. ANF model. The Dierich2020 CNN IHC model is evaluated using the BM outputs of the reference Verhulst2018 cochlear model (generated here).
## Prerequisites
- To run the full notebook for the first time, you'll have to compile the cochlea_utils.c file that is used for solving the TL model of the cochlea. This requires some C++ compiler which should be installed beforehand (more information can be found here). In a terminal, run from the Verhulstetal2018 folder:
For Mac/Linux: ` gcc -shared -fpic -O3 -ffast-math -o tridiag.so cochlea_utils.c `
For Windows: ` gcc -shared -fpic -O3 -ffast-math -o tridiag.dll cochlea_utils.c `
- If running on google colab: add the following as a code block and run it to compile cochlea_utils.c in the runtime machine:
` !gcc -shared -fpic -O3 -ffast-math -o tridiag.so cochlea_utils.c `
- The Matlab engine for python needs to be installed (see the instructions at the bottom of the `README` file).
- The Zilany2014 model needs to be compiled in Matlab by running the function mexANmodel.m, found under `Zilany2014/reference/` (see also the instructions on the model's readme file).
## Import required python packages and functions
Import required python packages and define the necessary parameters.
**Notice that for all the simulations, the reference models operate at 100kHz and the CNN models operate at 20kHz.**
```
import scipy.signal as sp_sig
import numpy as np
import keras
import tensorflow as tf
import matplotlib.pyplot as plt
from Verhulstetal2018.get_tl_vbm import tl_vbm
from extra_functions import *
from time import time
# Define model specific variables
ds_rate = 2 # downsampling rate of the frequency channels of the reference model
fs_connear = 20e3
fs_tl = 100e3
ds_factor = int(fs_tl / fs_connear)
p0 = 2e-5 # calibrate to 2e-5 Pascal
# load CFs
CF_connear = np.loadtxt('connear/cf.txt')*1e3
# scaling values for the CoNNear models
cochlea_scaling = 1e6
ihc_scaling = 1e1
an_scaling = 1e-2
# To run this notebook and the reference models, the Matlab engine needs to be succesfully installed in python
import matlab.engine
import os
```
## IHC stage
The input dimensions for the CNN models are (b x L x Ncf), where b is the batch-size (for loading multiple stimuli simultaneously), L is the input length (including the context) and Ncf are the frequency channels.
The ihc.json file can be loaded for the full-channel model (201 channels) or the ihc_1cf.json file for the 1-channel model. At the first block of each individual section, the necessary model is loaded and the rest of the parameters are defined.
The BM outputs extracted from the TL cochlear model of Verhulst et al. were given as inputs to the Dierich2020 model and its CNN counterpart.
### IHC excitation patterns
Compare the simulated average IHC receptor potentials across CF for tone stimuli presented at levels between 0 and 90 dB SPL.
**You can change the `f_tone` variable to have tone stimuli of different frequencies, say 500Hz, 1kHz, 2kHz, etc..**
```
modeldir = 'Dierich2020/' # Dierich et al. CNN model directory
# Define the IHC model hyperparameters
context_left = 256
context_right = 256
Nenc = 3 # number of layers in the encoder - check for the input size
# Load the 201-channel IHC model to simulate for all CFs
N_cf = 201
ihc = load_connear_model(modeldir,json_name="/ihc.json",weights_name="/ihc.h5",name="ihc_model")
ihc.summary()
# Define the pure tone stimulus
f_tone = 1e3 # frequency of the pure tone
L = np.arange(0., 91., 10.) # levels from 0 to 90dB SPL
stim_dur = 102.4e-3 # duration of the stimulus - 102.4 ms correspond to 2048 samples (fs = 20 kHz)
silence_left = 12.8e-3 # silence before the onset of the stimulus - 12.8 ms correspond to 256 samples (context)
silence_right = 12.8e-3 # silence after the stimulus - 256 samples
win_dur = 5.0e-3 # 5ms long hanning window for gradual onset
# make stimulus
t = np.arange(0., stim_dur, 1./fs_tl)
stim_sin = np.sin(2 * np.pi * f_tone * t) # generate the pure tone
# apply hanning window
winlength = int(2*win_dur * fs_tl)
win = sp_sig.windows.hann(winlength) # double-sided hanning window
stim_sin[:int(winlength/2)] = stim_sin[:int(winlength/2)] * win[:int(winlength/2)]
stim_sin[-int(winlength/2):] = stim_sin[-int(winlength/2):] * win[int(winlength/2):]
total_length = int(silence_left * fs_tl) + len(stim_sin) + int(silence_right * fs_tl)
stim = np.zeros((len(L), total_length))
stimrange = range(int(silence_left * fs_tl), int(silence_left * fs_tl) + len(stim_sin))
for i in range(len(L)):
stim[i, stimrange] = p0 * 10**(L[i]/20) * stim_sin / rms(stim_sin) # calibrate
############ Verhulstetal ############
# get the cochlear outputs of the reference model
output = tl_vbm(stim, L)
CF_tl = output[0]['cf'][::ds_rate] # center frequencies
window_length = int(total_length / ds_factor) # window length of the downsampled outputs
tl_target = np.zeros((len(L), window_length * ds_factor, N_cf)) # pre-allocate
ihc_target = np.zeros((len(L), window_length, N_cf)) # pre-allocate
for i in range(len(L)):
tl_target[i,:,:] = output[i]['v'][:,::ds_rate] # cochlear output
del output # remove the output variable to free-up some memory
############ Dierichetal ############
parent_dir = os.getcwd() # get current directory
os.chdir("./" + modeldir + "reference/") # navigate to the model's folder
eng = matlab.engine.start_matlab() # start the matlab engine
eng.workspace['Fs'] = fs_tl # pass the variables to the matlab workspace
magic_constant = 0.118
tl_in = magic_constant*tl_target
for i in range(len(L)):
for fi in range(N_cf):
v = tl_in[i,:,fi].tolist()
v = matlab.double(v)
eng.workspace['v'] = v
ihc_out = eng.eval('IHC_model(v,Fs);', nargout=1) # simulate the IHC output of the reference model
ihc_out = np.array(ihc_out[0])
ihc_target[i,:,fi] = sp_sig.resample_poly(ihc_out, fs_connear, fs_tl)
eng.quit()
os.chdir(parent_dir) # go back to the original folder
# remove context from the output
ihc_target = ihc_target[:, context_left:-context_right,:]
# downsample to 20 kHz
tl_target = sp_sig.resample_poly(tl_target, fs_connear, fs_tl, axis=1)
# apply proper scaling for feeding to the CoNNear
tl_target = tl_target * cochlea_scaling # scaling for the cochlear input
# compute the mean across CF for each level
ihc_target_mean = np.mean(ihc_target,axis=1)
############ CNN model #################
# check the time dimension size
if tl_target.shape[1] % 2**Nenc: # input size needs to be a multiple of 8
Npad = int(np.ceil(tl_target.shape[1]/(2**Nenc)))*(2**Nenc)-tl_target.shape[1]
tl_target = np.pad(tl_target,((0,0),(0,Npad),(0,0))) # zero-pad
# simulate
ihc_connear = ihc.predict(tl_target)
ihc_connear = ihc_connear / ihc_scaling # scaling for the IHC output
# compute the mean across CF for each level
ihc_connear_mean = np.mean(ihc_connear,axis=1)
############ Plots ###################
# Plot the mean Vihc patterns for the reference model
CF_rep=np.tile(CF_tl, (len(L),1))
plt.semilogx(CF_rep.T/1e3, 1e3*ihc_target_mean.T)
plt.xlim(0.25,8.), plt.grid(which='both'),
plt.xticks(ticks=(0.25, 0.5, 1., 2., 4., 8.) , labels=(0.25, 0.5, 1., 2., 4., 8.))
#plt.ylim(-59, -49.5)
plt.xlabel('CF (kHz)')
plt.ylabel('Mean of V_m (mV)')
plt.title('Dierich2020 IHC model')
plt.legend(L.astype(int), frameon=False)
plt.show()
# Plot the mean Vihc patterns for the CoNNear model
CF_rep=np.tile(CF_connear, (len(L),1))
plt.semilogx(CF_rep.T/1e3, 1e3*ihc_connear_mean.T)
plt.xlim(0.25,8.), plt.grid(which='both'),
plt.xticks(ticks=(0.25, 0.5, 1., 2., 4., 8.) , labels=(0.25, 0.5, 1., 2., 4., 8.))
#plt.ylim(-59, -49.5)
plt.xlabel('CF (kHz)')
plt.ylabel('Mean of V_m (mV)')
plt.title('Dierich2020 IHC model - CNN')
plt.legend(L.astype(int), frameon=False)
plt.show()
del ihc # remove the connear model variable to free-up some memory
```
### IHC AC-DC ratio
Compare the ratio of the AC and DC components of the IHC responses across CF.
```
modeldir = 'Dierich2020/' # Dierich et al. CNN model directory
# Define the IHC model hyperparameters
context_left = 256
context_right = 256
Nenc = 3 # number of layers in the encoder - check for the input size
# Load the 1-channel IHC model for this section - the results are computed for individual CFs
N_cf = 1
ihc = load_connear_model(modeldir,json_name="/ihc_1cf.json",weights_name="/ihc.h5",name="ihc_model")
#ihc.summary()
# Define the pure tone stimuli
N = 10 # number of frequencies to simulate between 0.15 and 8 kHz
f_tones = np.logspace(np.log10(150),np.log10(8000),num=N) # pick N frequencies in logarithmic spacing
# match the tone frequencies to the corresponding CFs
for j, f_tone in enumerate(f_tones):
fno, _ = min(enumerate(CF_connear), key=lambda x: abs( x [1]- f_tone))
f_tones[j] = CF_connear[int(fno)]
L = [80.] # 80 dB SPL
stim_dur = 80e-3 # duration of the stimulus
silence_left = 35.2e-3 # silence before the onset of the stimulus - 12.8 ms correspond to 256 samples (context)
silence_right = 12.8e-3 # silence after the stimulus - 256 samples
win_dur = 5.0e-3 # 5ms long ramp window for gradual onset
# indicate the time points of the response for computing the AC and DC components
t_ac_start = silence_left + 50e-3 # 50 ms after the stimulus onset
t_ac_dur = 20e-3 # 20 ms after t_ac_start
t_dc_start = 7.4e-3 # 7.4 ms after the left context (15 ms before the stimulus onset)
t_dc_dur = 10e-3 # 10 ms after t_dc_start
# region of the response for computing the AC component (50 - 70 ms after the stimulus onset)
ac_start = int(t_ac_start * fs_connear) - context_left
ac_end = ac_start + int(t_ac_dur * fs_connear)
ac_reg = np.arange(ac_start,ac_end,1)
# region of the response for computing the DC component (5 - 15 ms before the stimulus onset)
dc_start = int(t_dc_start * fs_connear)
dc_end = dc_start + int(t_dc_dur * fs_connear)
dc_reg = np.arange(dc_start,dc_end,1)
# make stimuli
t = np.arange(0., stim_dur, 1./fs_tl)
winlength = int(2*win_dur * fs_tl)
win = sp_sig.windows.bartlett(winlength) # double-sided ramp
total_length = int(silence_left * fs_tl) + len(t) + int(silence_right * fs_tl)
stim = np.zeros((len(f_tones), total_length))
for j, f_tone in enumerate(f_tones):
stim_sin = np.sin(2 * np.pi * f_tone * t) # generate the pure tone
# apply ramp window
stim_sin[:int(winlength/2)] = stim_sin[:int(winlength/2)] * win[:int(winlength/2)]
stim_sin[-int(winlength/2):] = stim_sin[-int(winlength/2):] * win[int(winlength/2):]
stimrange = range(int(silence_left * fs_tl), int(silence_left * fs_tl) + len(stim_sin))
stim[j, stimrange] = p0 * 10**(L[0]/20) * stim_sin / rms(stim_sin) # calibrate
############ Verhulstetal ############
# get the outputs of the reference model
output = tl_vbm(stim, L)
CF_tl = output[0]['cf'][::ds_rate] # center frequencies
window_length = int(total_length / ds_factor) # window length of the downsampled outputs
tl_target = np.zeros((len(f_tones), window_length * ds_factor, N_cf)) # pre-allocate
ihc_target = np.zeros((len(f_tones), window_length, N_cf))
for j, f_tone in enumerate(f_tones):
# find the CF closest to the stimulus frequency
No, _ = min(enumerate(CF_tl), key=lambda x: abs(x[1] - f_tone))
No = int(No)
# extract the outputs only for the specific CF
tl_target[j,:,:] = output[j]['v'][:,::ds_rate][:,[No]] # cochlear output
del output # remove the output variable to free-up some memory
############ Dierichetal ############
parent_dir = os.getcwd() # get current directory
os.chdir("./" + modeldir + "reference/") # navigate to the model's folder
eng = matlab.engine.start_matlab() # start the matlab engine
eng.workspace['Fs'] = fs_tl # pass the variables to the matlab workspace
magic_constant = 0.118
tl_in = magic_constant*tl_target
for i in range(len(L)):
for fi in range(N_cf):
v = tl_in[i,:,fi].tolist()
v = matlab.double(v)
eng.workspace['v'] = v
ihc_out = eng.eval('IHC_model(v,Fs);', nargout=1) # simulate the IHC output of the reference model
ihc_out = np.array(ihc_out[0])
ihc_target[i,:,fi] = sp_sig.resample_poly(ihc_out, fs_connear, fs_tl)
eng.quit()
os.chdir(parent_dir) # go back to the original folder
# remove context from the output
ihc_target = ihc_target[:, context_left:-context_right,:]
# downsample to 20 kHz
tl_target = sp_sig.resample_poly(tl_target, fs_connear, fs_tl, axis=1)
# apply proper scaling for feeding to the CoNNear
tl_target = tl_target * cochlea_scaling # scaling for the cochlear input
# compute the AC component for each frequency
acm_target = (np.max(ihc_target[:,ac_reg],axis=1)-np.min(ihc_target[:,ac_reg],axis=1))/2
ac_target = acm_target/np.sqrt(2.)
# compute the DC component for each frequency
dcm_target = (np.max(ihc_target[:,dc_reg],axis=1)-np.min(ihc_target[:,dc_reg],axis=1))/2
dc_target = (np.min(ihc_target[:,ac_reg],axis=1)+acm_target)-(np.min(ihc_target[:,dc_reg],axis=1)+dcm_target)
############ CoNNear #################
# check the time dimension size
if tl_target.shape[1] % 2**Nenc: # input size needs to be a multiple of 8
Npad = int(np.ceil(tl_target.shape[1]/(2**Nenc)))*(2**Nenc)-tl_target.shape[1]
tl_target = np.pad(tl_target,((0,0),(0,Npad),(0,0))) # zero-pad
# simulate
ihc_connear = ihc.predict(tl_target, verbose=1)
ihc_connear = ihc_connear / ihc_scaling # scaling for the IHC output
# compute the AC component for each frequency
acm_connear = (np.max(ihc_connear[:,ac_reg],axis=1)-np.min(ihc_connear[:,ac_reg],axis=1))/2
ac_connear = acm_connear/np.sqrt(2.)
# compute the DC component for each frequency
dcm_connear = (np.max(ihc_connear[:,dc_reg],axis=1)-np.min(ihc_connear[:,dc_reg],axis=1))/2
dc_connear = (np.min(ihc_connear[:,ac_reg],axis=1)+acm_connear)-(np.min(ihc_connear[:,dc_reg],axis=1)+dcm_connear)
############ Plots ###################
# Plot the logarithmic decrease of the AC/DC ratio across frequency
plt.loglog(f_tones/1e3, ac_target/dc_target,'o-')
plt.loglog(f_tones/1e3, ac_connear/dc_connear,'o-')
plt.xlim(0.1,10.), plt.grid(which='both'),
plt.xticks(ticks=(0.1,1,10) , labels=(0.1,1,10))
plt.xlabel('CF (kHz)')
plt.ylabel('AC component / DC component')
plt.title('AC-DC ratio')
plt.legend(['Dierich2020 IHC model','Dierich2020 IHC model - CNN'], frameon=False)
plt.show()
del ihc # remove the connear model variable to free-up some memory
```
### IHC level growth
Compare the growth of the half-wave rectified IHC receptor potential as a function of sound level.
```
modeldir = 'Dierich2020/' # Dierich et al. CNN model directory
# Define the IHC model hyperparameters
context_left = 256
context_right = 256
Nenc = 3 # number of layers in the encoder - check for the input size
# Load the 1-channel IHC model
N_cf = 1
ihc = load_connear_model(modeldir,json_name="/ihc_1cf.json",weights_name="/ihc.h5",name="ihc_model")
#ihc.summary()
# Define the pure tone stimuli
f_tone = 4e3 # frequency of the pure tone
# match the tone frequency to the corresponding CF
fno, _ = min(enumerate(CF_connear), key=lambda x: abs( x [1]- f_tone))
f_tone = CF_connear[int(fno)]
L = np.arange(0.,101.,10.) # levels from 0 to 100dB SPL
stim_dur = 80e-3 # duration of the stimulus
silence_left = 35.2e-3 # silence before the onset of the stimulus - 12.8 ms correspond to 256 samples (context)
silence_right = 12.8e-3 # silence after the stimulus - 256 samples
win_dur = 5.0e-3 # 5ms long ramp window for gradual onset
# indicate the time points of the response for computing the AC and DC components
t_ac_start = silence_left + 50e-3 # 50 ms after the stimulus onset
t_ac_dur = 20e-3 # 20 ms after t_ac_start
t_dc_start = 7.4e-3 # 7.4 ms after the left context (15 ms before the stimulus onset)
t_dc_dur = 10e-3 # 10 ms after t_dc_start
# region of the response for computing the AC component (50 - 70 ms after the stimulus onset)
ac_start = int(t_ac_start * fs_connear) - context_left
ac_end = ac_start + int(t_ac_dur * fs_connear)
ac_reg = np.arange(ac_start,ac_end,1)
# region of the response for computing the DC component (5 - 15 ms before the stimulus onset)
dc_start = int(t_dc_start * fs_connear)
dc_end = dc_start + int(t_dc_dur * fs_connear)
dc_reg = np.arange(dc_start,dc_end,1)
# make stimulus
t = np.arange(0., stim_dur, 1./fs_tl)
stim_sin = np.sin(2 * np.pi * f_tone * t) # generate the pure tone
# apply hanning window
winlength = int(2*win_dur * fs_tl)
win = sp_sig.windows.bartlett(winlength) # double-sided ramp
stim_sin[:int(winlength/2)] = stim_sin[:int(winlength/2)] * win[:int(winlength/2)]
stim_sin[-int(winlength/2):] = stim_sin[-int(winlength/2):] * win[int(winlength/2):]
total_length = int(silence_left * fs_tl) + len(stim_sin) + int(silence_right * fs_tl)
stim = np.zeros((len(L), total_length))
stimrange = range(int(silence_left * fs_tl), int(silence_left * fs_tl) + len(stim_sin))
for i in range(len(L)):
stim[i, stimrange] = p0 * 10**(L[i]/20) * stim_sin / rms(stim_sin) # calibrate
############ Verhulstetal ############
# get the outputs of the reference model
output = tl_vbm(stim, L)
CF_tl = output[0]['cf'][::ds_rate] # center frequencies
# find the CF closest to the stimulus frequency
No, _ = min(enumerate(CF_tl), key=lambda x: abs(x[1] - f_tone))
No = int(No)
window_length = int(total_length / ds_factor) # window length of the downsampled outputs
tl_target = np.zeros((len(L), window_length * ds_factor, N_cf)) # pre-allocate
ihc_target = np.zeros((len(L), window_length, N_cf))
for i in range(len(L)):
# extract the outputs only for the specific CF
tl_target[i,:,:] = output[i]['v'][:,::ds_rate][:,[No]] # cochlear output
del output # remove the output variable to free-up some memory
############ Dierichetal ############
parent_dir = os.getcwd() # get current directory
os.chdir("./" + modeldir + "reference/") # navigate to the model's folder
eng = matlab.engine.start_matlab() # start the matlab engine
eng.workspace['Fs'] = fs_tl # pass the variables to the matlab workspace
magic_constant = 0.118
tl_in = magic_constant*tl_target
for i in range(len(L)):
for fi in range(N_cf):
v = tl_in[i,:,fi].tolist()
v = matlab.double(v)
eng.workspace['v'] = v
ihc_out = eng.eval('IHC_model(v,Fs);', nargout=1) # simulate the IHC output of the reference model
ihc_out = np.array(ihc_out[0])
ihc_target[i,:,fi] = sp_sig.resample_poly(ihc_out, fs_connear, fs_tl)
eng.quit()
os.chdir(parent_dir) # go back to the original folder
# remove context from the output
ihc_target = ihc_target[:, context_left:-context_right,:]
# downsample to 20 kHz
tl_target = sp_sig.resample_poly(tl_target, fs_connear, fs_tl, axis=1)
# apply proper scaling for feeding to the CoNNear
tl_target = tl_target * cochlea_scaling # scaling for the cochlear input
dcm_target = np.mean(ihc_target[:,dc_reg],axis=1) # compute the DC component
vihc_target = np.zeros((ihc_target.shape))
for i in range(len(L)):
vihc_target[i,:] = ihc_target[i,:] - dcm_target[i] #half-wave rectify the response by substracting the DC component
vihc_target_rms = rms(vihc_target,axis=1)
############ CoNNear #################
# check the time dimension size
if tl_target.shape[1] % 2**Nenc: # input size needs to be a multiple of 8
Npad = int(np.ceil(tl_target.shape[1]/(2**Nenc)))*(2**Nenc)-tl_target.shape[1]
tl_target = np.pad(tl_target,((0,0),(0,Npad),(0,0))) # zero-pad
# simulate
ihc_connear = ihc.predict(tl_target, verbose=1)
ihc_connear = ihc_connear / ihc_scaling # scaling for the IHC output
dcm_connear = np.mean(ihc_connear[:,dc_reg],axis=1) # compute the DC component
vihc_connear = np.zeros((ihc_connear.shape))
for i in range(len(L)):
vihc_connear[i,:] = ihc_connear[i,:] - dcm_connear[i] #half-wave rectify the response by substracting the DC component
vihc_connear_rms = rms(vihc_connear,axis=1)
############ Plots ###################
# Plot the RMS of the half-wave rectified response across level
plt.plot(L, 1e3*vihc_target_rms,'o-')
plt.plot(L, 1e3*vihc_connear_rms,'o-')
plt.grid(which='both'),
#plt.yticks(ticks=np.arange(0.,10.,1.))
plt.xlabel('Stimulus level (dB-SPL)')
plt.ylabel('Half-wave rectified $\mathregular{V_{IHC}}$ (mV)')
plt.title('RMS of half-wave rectified $\mathregular{V_{IHC}}$')
plt.legend(['Dierich2020 IHC model','Dierich2020 IHC model - CNN'], frameon=False)
plt.show()
del ihc # remove the connear model variable to free-up some memory
```
## ANF stage
The input dimensions for the CNN models are (b x L x Ncf), where b is the batch-size (for loading multiple stimuli simultaneously), L is the input length (including the context) and Ncf are the frequency channels.
The anfX.json file can be loaded for the full-channel model (201 channels) or the anfX_1cf.json file for the 1-channel model, where X corresponds to the AN fiber type (h for HSR, m for MSR or l for LSR ANF model). At the first block of each individual section, the necessary model is loaded and the rest of the parameters are defined.
Auditory stimuli are generated here and given as inputs to the reference Zilany2014 cochlea-IHC model, to simulate the IHC outputs. These responses are then given as inputs to the Zilany2014 ANF model and its CNN counterpart, to simulate the mean firing rates or the PSTH responses.
### ANF firing rates
Compare the simulated ANF firing rates across time for tone stimuli presented at 70 dB SPL.
**You can change the `f_tone` variable to have tone stimuli of different frequencies, the `f_m` variable for generating amplitude-modulated tones or the `L` variable for having different levels.**
```
modeldir = 'Zilany2014/'
# Define the ANF model hyperparameters
context_left = 7936 # longer left-sided context for the ANF models
context_right = 256
Nenc = 14 # number of layers in the encoder - check for the input size
# Load the 1-channel ANF models
N_cf = 1
anfh = load_connear_model(modeldir,json_name="/anfh_1cf.json",weights_name="/anfh.h5",name="anfh_model")
anfh.summary()
anfm = load_connear_model(modeldir,json_name="/anfm_1cf.json",weights_name="/anfm.h5",name="anfm_model")
anfm.summary()
anfl = load_connear_model(modeldir,json_name="/anfl_1cf.json",weights_name="/anfl.h5",name="anfl_model")
anfl.summary()
# Define the pure tone stimulus
f_tone = 1e3 # frequency of the pure tone
L = [70.] # stimulus level
m = 1 # modulation percentage
f_m = 100 # modulation frequency - leave empty for pure-tone stimulus (no modulation applied)
#f_m = [] # uncomment for pure-tone stimulus
stim_dur = 400e-3 # duration of the stimulus - 409.6 ms correspond to 8192 samples (fs = 20 kHz)
silence_left = 396.8e-3 + 5e-3 # silence before the onset of the stimulus - 396.8 ms correspond to 7936 samples (left context)
silence_right = 12.8e-3 # silence after the stimulus - 256 samples (right context)
win_dur = 7.8e-3 # 5ms long ramp window for gradual onset
# match the tone frequency to the corresponding CF
fno, _ = min(enumerate(CF_connear), key=lambda x: abs( x [1]- f_tone))
f_tone = CF_connear[int(fno)]
# make stimulus
t = np.arange(0., stim_dur, 1./fs_tl)
if f_m: # if f_m is defined make a SAM tone
stim_sin = (1 + m * np.cos(2 * np.pi * f_m * t + np.pi)) * np.sin(2 * np.pi * f_tone * t) # generate the SAM tone
else:
stim_sin = np.sin(2 * np.pi * f_tone * t) # generate the pure tone
# apply ramp
winlength = int(2*win_dur * fs_tl)
win = sp_sig.windows.bartlett(winlength) # double-sided ramp window
stim_sin[:int(winlength/2)] = stim_sin[:int(winlength/2)] * win[:int(winlength/2)]
stim_sin[-int(winlength/2):] = stim_sin[-int(winlength/2):] * win[int(winlength/2):]
total_length = int(silence_left * fs_tl) + len(stim_sin) + int(silence_right * fs_tl)
stim = np.zeros((len(L), total_length))
stimrange = range(int(silence_left * fs_tl), int(silence_left * fs_tl) + len(stim_sin))
for i in range(len(L)):
stim[i, stimrange] = p0 * 10**(L[i]/20) * stim_sin / rms(stim_sin) # calibrate
############ Zilanyetal ############
parent_dir = os.getcwd() # get current directory
os.chdir("./" + modeldir + "reference/") # navigate to the model's folder
eng = matlab.engine.start_matlab() # start the matlab engine
# pass the variables to the matlab workspace
eng.workspace['nrep'] = 1.
eng.workspace['Fs'] = fs_tl
eng.workspace['noiseType'] = 0.0
eng.workspace['implnt'] = 0.0
eng.workspace['cohc'] = 1.0
eng.workspace['cihc'] = 1.0
eng.workspace['species'] = 2.0 # human
sponts = [1.,2.,3.] # simulate LSR, MSR and HSR ANF fibers
T = (total_length+1) / fs_tl # make simulation duration 1 sample longer to avoid errors
eng.workspace['T'] = T
window_length = int(total_length / ds_factor) # window length of the downsampled outputs
ihc_target = np.zeros((len(L),window_length,N_cf))
anfh_target = np.zeros((len(L), window_length, N_cf))
anfm_target = np.zeros((len(L), window_length, N_cf))
anfl_target = np.zeros((len(L), window_length, N_cf))
for i in range(len(L)):
stim_in = matlab.double(stim[i,:].tolist())
eng.workspace['stim'] = stim_in
eng.workspace['f'] = float(f_tone)
ihc_out = eng.eval('model_IHC(stim,f,nrep,1/Fs,T,cohc,cihc,species);', nargout = 1) # simulate the IHC output
eng.workspace['ihc'] = ihc_out
ihc_out = np.array(ihc_out[0])
ihc_target[i,:,0] = sp_sig.resample_poly(ihc_out, fs_connear, fs_tl)[:window_length] # downsample
for sponti, spont in enumerate(sponts):
eng.workspace['spont'] = float(spont)
anf_out = eng.eval('model_Synapse(ihc,f,nrep,1/Fs,spont,noiseType,implnt);', nargout = 1) # simulate the mean ANF firing rate
anf_out = np.array(anf_out[0])[:total_length]
if sponti == 0:
anfl_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
elif sponti == 1:
anfm_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
else:
anfh_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
eng.quit()
os.chdir(parent_dir) # go back to the original folder
# remove context from the outputs (and the last dimension)
anfh_target = anfh_target[:, context_left:-context_right, 0]
anfm_target = anfm_target[:, context_left:-context_right, 0]
anfl_target = anfl_target[:, context_left:-context_right, 0]
# apply proper scaling for feeding to the CNN model
ihc_target = ihc_target * ihc_scaling # scaling for the ihc input
############ CNN model #################
# check the time dimension size
if ihc_target.shape[1] % 2**Nenc: # input size needs to be a multiple of 16384
Npad = int(np.ceil(ihc_target.shape[1]/(2**Nenc)))*(2**Nenc)-ihc_target.shape[1]
ihc_target = np.pad(ihc_target,((0,0),(0,Npad),(0,0))) # zero-pad
# simulate
anfh_connear = anfh.predict(ihc_target, verbose=1)
anfm_connear = anfm.predict(ihc_target, verbose=1)
anfl_connear = anfl.predict(ihc_target, verbose=1)
# remove last dimension
anfh_connear = anfh_connear[:, :, 0]
anfm_connear = anfm_connear[:, :, 0]
anfl_connear = anfl_connear[:, :, 0]
# scale back to the original ANF values
anfh_connear = anfh_connear / an_scaling
anfm_connear = anfm_connear / an_scaling
anfl_connear = anfl_connear / an_scaling
# crop the connear time dimensions to match the size of the reference responses
anfh_connear = anfh_connear[:,:anfh_target.shape[1]]
anfm_connear = anfm_connear[:,:anfm_target.shape[1]]
anfl_connear = anfl_connear[:,:anfl_target.shape[1]]
############ Plots ###################
t_ds = np.arange(0., anfh_target.shape[1]/fs_connear, 1./fs_connear) # time vector of the (downsampled) responses
# Plot the firing rate patterns for the reference model
plt.plot(1e3*t_ds,anfh_target.T,'r')
plt.plot(1e3*t_ds,anfm_target.T,'b')
plt.plot(1e3*t_ds,anfl_target.T,'c')
plt.xlim(0,80.), plt.grid(which='both'),
plt.xlabel('Time (ms)')
plt.ylabel('Firing rate (spikes/s)')
plt.title('Zilany2014 ANF model')
plt.legend(['HSR','MSR','LSR'], frameon=False)
plt.show()
# Plot the firing rate patterns for the CoNNear model
plt.plot(1e3*t_ds,anfh_connear.T,'r')
plt.plot(1e3*t_ds,anfm_connear.T,'b')
plt.plot(1e3*t_ds,anfl_connear.T,'c')
plt.xlim(0,80.), plt.grid(which='both'),
plt.xlabel('Time (ms)')
plt.ylabel('Firing rate (spikes/s)')
plt.title('Zilany2014 ANF model - CNN')
plt.legend(['HSR','MSR','LSR'], frameon=False)
plt.show()
del anfh, anfm, anfl # remove the connear models variables to free-up some memory
```
### ANF rate-level curves
Compare the simulated ANF rate-level curves for the three fiber models.
**You can change the `f_tone` variable to get the curves of 1 kHz or 4 kHz.**
To simulate the ANF rate-level curves reported in the paper, the mean firing rate outputs need to be fed to the Zilany2014 ANF spike generator to generate the PSTH outputs. This can be done by setting the `simulate_psth` variable to 1, but requires many stimulus repetitions and a lot of time to compute (or a powerful computer). Alternatively, the spike generator can be omited to speed up the execution, by setting the `simulate_psth` variable to 1, and plotting the same results for the mean firing rate outputs instead.
```
simulate_psth = 1 # set to 0 to use the mean firing rates or to 1 to use the PSTH outputs (rather slow)
modeldir = 'Zilany2014/'
# Define the ANF model hyperparameters
context_left = 7936
context_right = 256
Nenc = 14 # number of layers in the encoder - check for the input size
# Load the 1-channel ANF models
N_cf = 1
if simulate_psth:
crop = 0 # get uncropped outputs to feed to the spike generator model
else:
crop = 1
anfh = load_connear_model(modeldir,json_name="/anfh_1cf.json",weights_name="/anfh.h5",name="anfh_model",crop=crop)
#anfh.summary()
anfm = load_connear_model(modeldir,json_name="/anfm_1cf.json",weights_name="/anfm.h5",name="anfm_model",crop=crop)
#anfm.summary()
anfl = load_connear_model(modeldir,json_name="/anfl_1cf.json",weights_name="/anfl.h5",name="anfl_model",crop=crop)
#anfl.summary()
# Define the pure tone stimulus
f_tone = 4e3 # frequency of the pure tone
L = np.arange(0.,101.,10.) # levels from 0 to 100 dB SPL
stim_dur = 50e-3 # duration of the stimulus - 409.6 ms correspond to 8192 samples (fs = 20 kHz)
silence_left = 396.8e-3 + 5e-3 # silence before the onset of the stimulus - 396.8 ms correspond to 7936 samples (left context)
silence_right = 12.8e-3 # silence after the stimulus - 256 samples (right context)
win_dur = 2.5e-3 # 2.5ms long ramp window for gradual onset
# Zilany2014 model parameters
nrep_spike = 100 # number of repetitions for the spike generator part of the ANF model - decrease for a faster but noisier result
psthbinwidth = 1/fs_connear
psthbins = int(psthbinwidth*fs_connear) # number of psth bins per psth bin
# match the tone frequency to the corresponding CF
fno, _ = min(enumerate(CF_connear), key=lambda x: abs( x [1]- f_tone))
f_tone = CF_connear[int(fno)]
# indicate the region of the response for computing the mean - 10-40 ms after the stimulus onset
index_start = int((silence_left + 10e-3) * fs_connear) - context_left # omit silence + 10 ms (15ms = 300 samples)
index_end = index_start + int(30e-3 * fs_connear) # keep 30 ms of response after (30ms = 600 samples)
stim_reg = np.arange(index_start,index_end,1) # stimulus region
# make stimulus
t = np.arange(0., stim_dur, 1./fs_tl)
stim_sin = np.sin(2 * np.pi * f_tone * t) # generate the pure tone
# apply ramp
winlength = int(2*win_dur * fs_tl)
win = sp_sig.windows.bartlett(winlength) # double-sided ramp window
stim_sin[:int(winlength/2)] = stim_sin[:int(winlength/2)] * win[:int(winlength/2)]
stim_sin[-int(winlength/2):] = stim_sin[-int(winlength/2):] * win[int(winlength/2):]
total_length = int(silence_left * fs_tl) + len(stim_sin) + int(silence_right * fs_tl)
stim = np.zeros((len(L), total_length))
stimrange = range(int(silence_left * fs_tl), int(silence_left * fs_tl) + len(stim_sin))
for i in range(len(L)):
stim[i, stimrange] = p0 * 10**(L[i]/20) * stim_sin / rms(stim_sin) # calibrate
############ Zilanyetal ############
parent_dir = os.getcwd() # get current directory
os.chdir("./" + modeldir + "reference/") # navigate to the model's folder
eng = matlab.engine.start_matlab() # start the matlab engine
# pass the variables to the matlab workspace
eng.workspace['nrep'] = 1.
eng.workspace['nrep_spike'] = float(nrep_spike)
eng.workspace['Fs'] = fs_tl
eng.workspace['Fs_psth'] = fs_connear
eng.workspace['noiseType'] = 0.0
eng.workspace['implnt'] = 0.0
eng.workspace['cohc'] = 1.0
eng.workspace['cihc'] = 1.0
eng.workspace['species'] = 2.0 # human
sponts = [1.,2.,3.] # simulate LSR, MSR and HSR ANF fibers
T = (total_length+1) / fs_tl # make simulation duration 1 sample longer to avoid errors
eng.workspace['T'] = T
window_length = int(total_length / ds_factor) # window length of the downsampled outputs
ihc_target = np.zeros((len(L),window_length,N_cf))
anfh_target = np.zeros((len(L), window_length, N_cf))
anfm_target = np.zeros((len(L), window_length, N_cf))
anfl_target = np.zeros((len(L), window_length, N_cf))
for i in range(len(L)):
stim_in = matlab.double(stim[i,:].tolist())
eng.workspace['stim'] = stim_in
eng.workspace['f'] = float(f_tone)
ihc_out = eng.eval('model_IHC(stim,f,nrep,1/Fs,T,cohc,cihc,species);', nargout = 1) # simulate the IHC output
eng.workspace['ihc'] = ihc_out
ihc_out = np.array(ihc_out[0])
ihc_target[i,:,0] = sp_sig.resample_poly(ihc_out, fs_connear, fs_tl)[:window_length] # downsample
for sponti, spont in enumerate(sponts):
eng.workspace['spont'] = float(spont)
anf_out = eng.eval('model_Synapse(ihc,f,nrep,1/Fs,spont,noiseType,implnt);', nargout = 1) # simulate the mean ANF firing rate
anf_out = np.array(anf_out[0])[:total_length]
if sponti == 0:
anfl_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
elif sponti == 1:
anfm_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
else:
anfh_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
if simulate_psth: # simulate psth
if sponti == 0:
anf_out = anfl_target[i,:,0]
elif sponti == 1:
anf_out = anfm_target[i,:,0]
else:
anf_out = anfh_target[i,:,0]
anf_out = np.tile(anf_out,nrep_spike)
anf_out = matlab.double(anf_out.tolist())
eng.workspace['rate'] = anf_out
psTH = eng.eval('model_SpikeGen(rate,f,nrep_spike,1/Fs_psth,spont,noiseType,implnt);', nargout = 1)
psTH = np.array(psTH[0])
pr = np.sum(np.reshape(psTH,(psthbins,int(psTH.size/psthbins)),order='F'),axis=0)/nrep_spike # pr of spike in each bin
psTH = pr/psthbinwidth # psth in units of /s
if sponti == 0:
anfl_target[i,:,0] = psTH
elif sponti == 1:
anfm_target[i,:,0] = psTH
else:
anfh_target[i,:,0] = psTH
# remove context from the outputs (and last dimension)
anfh_target = anfh_target[:, context_left:-context_right, 0]
anfm_target = anfm_target[:, context_left:-context_right, 0]
anfl_target = anfl_target[:, context_left:-context_right, 0]
# apply proper scaling for feeding to the CoNNear
ihc_target = ihc_target * ihc_scaling # scaling for the cochlear input
# compute the mean firing rate over the stimulus region
anfh_target_mean = np.mean(anfh_target[:,stim_reg],axis=1)
anfm_target_mean = np.mean(anfm_target[:,stim_reg],axis=1)
anfl_target_mean = np.mean(anfl_target[:,stim_reg],axis=1)
############ CNN model #################
# check the time dimension size
if ihc_target.shape[1] % 2**Nenc: # input size needs to be a multiple of 16384
Npad = int(np.ceil(ihc_target.shape[1]/(2**Nenc)))*(2**Nenc)-ihc_target.shape[1]
ihc_target = np.pad(ihc_target,((0,0),(0,Npad),(0,0))) # zero-pad
# simulate
anfh_connear = anfh.predict(ihc_target, verbose=1)
anfm_connear = anfm.predict(ihc_target, verbose=1)
anfl_connear = anfl.predict(ihc_target, verbose=1)
# scale back to the original ANF values
anfh_connear = anfh_connear / an_scaling
anfm_connear = anfm_connear / an_scaling
anfl_connear = anfl_connear / an_scaling
if simulate_psth: # simulate psth
# omit the negative values
anfh_connear = anfh_connear.clip(0)
anfm_connear = anfm_connear.clip(0)
anfl_connear = anfl_connear.clip(0)
for i in range(len(L)):
for sponti, spont in enumerate(sponts):
eng.workspace['spont'] = float(spont)
if sponti == 0:
anf_out = anfl_connear[i,:,0]
elif sponti == 1:
anf_out = anfm_connear[i,:,0]
else:
anf_out = anfh_connear[i,:,0]
anf_out = np.tile(anf_out,nrep_spike)
anf_out = matlab.double(anf_out.tolist())
eng.workspace['rate'] = anf_out
psTH = eng.eval('model_SpikeGen(rate,f,nrep_spike,1/Fs_psth,spont,noiseType,implnt);', nargout = 1)
psTH = np.array(psTH[0])
pr = np.sum(np.reshape(psTH,(psthbins,int(psTH.size/psthbins)),order='F'),axis=0)/nrep_spike # pr of spike in each bin
psTH = pr/psthbinwidth # psth in units of /s
if sponti == 0:
anfl_connear[i,:,0] = psTH
elif sponti == 1:
anfm_connear[i,:,0] = psTH
else:
anfh_connear[i,:,0] = psTH
# remove context from the outputs
anfh_connear = anfh_connear[:, context_left:-context_right, :]
anfm_connear = anfm_connear[:, context_left:-context_right, :]
anfl_connear = anfl_connear[:, context_left:-context_right, :]
# remove last dimension
anfh_connear = anfh_connear[:, :, 0]
anfm_connear = anfm_connear[:, :, 0]
anfl_connear = anfl_connear[:, :, 0]
# compute the mean firing rate over the stimulus region
anfh_connear_mean = np.mean(anfh_connear[:,stim_reg],axis=1)
anfm_connear_mean = np.mean(anfm_connear[:,stim_reg],axis=1)
anfl_connear_mean = np.mean(anfl_connear[:,stim_reg],axis=1)
eng.quit()
os.chdir(parent_dir) # go back to the original folder
############ Plots ###################
# Plot the rate-level curves for the reference model
plt.plot(anfh_target_mean.T,'ro-')
plt.plot(anfm_target_mean.T,'bo-')
plt.plot(anfl_target_mean.T,'co-')
plt.xlim(0,10), plt.grid(which='both'),
plt.xticks(ticks=L/10 , labels=L.astype(int))
plt.xlabel('Stimulus level (dB SPL)')
plt.ylabel('Firing rate (spikes/s)')
plt.title('Zilany2014 ANF model')
plt.legend(['HSR','MSR','LSR'], frameon=False)
plt.show()
# Plot the rate-level curves for the CoNNear model
plt.plot(anfh_connear_mean.T,'ro-')
plt.plot(anfm_connear_mean.T,'bo-')
plt.plot(anfl_connear_mean.T,'co-')
plt.xlim(0,10), plt.grid(which='both'),
plt.xticks(ticks=L/10 , labels=L.astype(int))
plt.xlabel('Stimulus level (dB SPL)')
plt.ylabel('Firing rate (spikes/s)')
plt.title('Zilany2014 ANF model - CNN')
plt.legend(['HSR','MSR','LSR'], frameon=False)
plt.show()
del anfh, anfm, anfl # remove the connear models variables to free-up some memory
```
### ANF synchrony-level functions
Compare the simulated ANF synchrony-level functions for the three fiber models.
**You can change the `f_tone` variable to get the curves of 1 kHz or 4 kHz.**
To simulate the ANF synchrony-level curves reported in the paper, the mean firing rate outputs need to be fed to the Zilany2014 ANF spike generator to generate the PSTH outputs. This can be done by setting the `simulate_psth` variable to 1, but requires many stimulus repetitions and a lot of time to compute (or a powerful computer). Alternatively, the spike generator can be omited to speed up the execution, by setting the `simulate_psth` variable to 1, and plotting the same results for the mean firing rate outputs instead.
```
simulate_psth = 1 # set to 0 to use the mean firing rates or to 1 to use the PSTH outputs (rather slow)
modeldir = 'Zilany2014/'
# Define the ANF model hyperparameters
context_left = 7936
context_right = 256
Nenc = 14 # number of layers in the encoder - check for the input size
# Load the 1-channel ANF models
N_cf = 1
if simulate_psth:
crop = 0 # get uncropped outputs to feed to the spike generator model
else:
crop = 1
anfh = load_connear_model(modeldir,json_name="/anfh_1cf.json",weights_name="/anfh.h5",name="anfh_model",crop=crop)
#anfh.summary()
anfm = load_connear_model(modeldir,json_name="/anfm_1cf.json",weights_name="/anfm.h5",name="anfm_model",crop=crop)
#anfm.summary()
anfl = load_connear_model(modeldir,json_name="/anfl_1cf.json",weights_name="/anfl.h5",name="anfl_model",crop=crop)
#anfl.summary()
# Define the pure tone stimulus
f_tone = 4e3 # frequency of the pure tone
L = np.arange(0.,101.,10.) # levels from 0 to 100 dB SPL with a step of 10 - in the paper the step is 5
f_m = 100 # modulation frequency
m = 1 # modulation percentage
stim_dur = 400e-3 # duration of the stimulus - 409.6 ms correspond to 8192 samples (fs = 20 kHz)
silence_left = 396.8e-3 + 5e-3 # silence before the onset of the stimulus - 396.8 ms correspond to 7936 samples (left context)
silence_right = 12.8e-3 # silence after the stimulus - 256 samples (right context)
win_dur = 7.8e-3 # 7.8ms long ramp window for gradual onset
# Zilany2014 model parameters
nrep_spike = 100 # number of repetitions for the spike generator part of the ANF model - decrease for a faster but noisier result
psthbinwidth = 1/fs_connear
psthbins = int(psthbinwidth*fs_connear) # number of psth bins per psth bin
# match the tone frequency to the corresponding CF
fno, _ = min(enumerate(CF_connear), key=lambda x: abs( x [1]- f_tone))
f_tone = CF_connear[int(fno)]
# indicate the region of interest for computing the synchrony
index_start = int(silence_left * fs_connear) - context_left # omit silence (5ms = 100 samples)
index_end = index_start + int(stim_dur * fs_connear) # keep for the stimulus duration (400ms = 8000 samples)
stim_reg = np.arange(index_start,index_end,1) # stimulus region
# make stimulus
t = np.arange(0., stim_dur, 1./fs_tl)
stim_sin = (1 + m * np.cos(2 * np.pi * f_m * t + np.pi)) * np.sin(2 * np.pi * f_tone * t) # generate the SAM tone
# apply ramp
winlength = int(2*win_dur * fs_tl)
win = sp_sig.windows.bartlett(winlength) # double-sided ramp window
stim_sin[:int(winlength/2)] = stim_sin[:int(winlength/2)] * win[:int(winlength/2)]
stim_sin[-int(winlength/2):] = stim_sin[-int(winlength/2):] * win[int(winlength/2):]
total_length = int(silence_left * fs_tl) + len(stim_sin) + int(silence_right * fs_tl)
stim = np.zeros((len(L), total_length))
stimrange = range(int(silence_left * fs_tl), int(silence_left * fs_tl) + len(stim_sin))
for i in range(len(L)):
stim[i, stimrange] = p0 * 10**(L[i]/20) * stim_sin / rms(stim_sin) # calibrate
############ Zilanyetal ############
parent_dir = os.getcwd() # get current directory
os.chdir("./" + modeldir + "reference/") # navigate to the model's folder
eng = matlab.engine.start_matlab() # start the matlab engine
# pass the variables to the matlab workspace
eng.workspace['nrep'] = 1.
eng.workspace['nrep_spike'] = float(nrep_spike)
eng.workspace['Fs'] = fs_tl
eng.workspace['Fs_psth'] = fs_connear
eng.workspace['noiseType'] = 0.0
eng.workspace['implnt'] = 0.0
eng.workspace['cohc'] = 1.0
eng.workspace['cihc'] = 1.0
eng.workspace['species'] = 2.0 # human
sponts = [1.,2.,3.] # simulate LSR, MSR and HSR ANF fibers
T = (total_length+1) / fs_tl # make simulation duration 1 sample longer to avoid errors
eng.workspace['T'] = T
window_length = int(total_length / ds_factor) # window length of the downsampled outputs
ihc_target = np.zeros((len(L),window_length,N_cf))
anfh_target = np.zeros((len(L), window_length, N_cf))
anfm_target = np.zeros((len(L), window_length, N_cf))
anfl_target = np.zeros((len(L), window_length, N_cf))
for i in range(len(L)):
stim_in = matlab.double(stim[i,:].tolist())
eng.workspace['stim'] = stim_in
eng.workspace['f'] = float(f_tone)
ihc_out = eng.eval('model_IHC(stim,f,nrep,1/Fs,T,cohc,cihc,species);', nargout = 1) # simulate the IHC output
eng.workspace['ihc'] = ihc_out
ihc_out = np.array(ihc_out[0])
ihc_target[i,:,0] = sp_sig.resample_poly(ihc_out, fs_connear, fs_tl)[:window_length] # downsample
for sponti, spont in enumerate(sponts):
eng.workspace['spont'] = float(spont)
anf_out = eng.eval('model_Synapse(ihc,f,nrep,1/Fs,spont,noiseType,implnt);', nargout = 1) # simulate the mean ANF firing rate
anf_out = np.array(anf_out[0])[:total_length]
if sponti == 0:
anfl_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
elif sponti == 1:
anfm_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
else:
anfh_target[i,:,0] = sp_sig.resample_poly(anf_out, fs_connear, fs_tl)
if simulate_psth: # simulate psth
if sponti == 0:
anf_out = anfl_target[i,:,0]
elif sponti == 1:
anf_out = anfm_target[i,:,0]
else:
anf_out = anfh_target[i,:,0]
anf_out = np.tile(anf_out,nrep_spike)
anf_out = matlab.double(anf_out.tolist())
eng.workspace['rate'] = anf_out
psTH = eng.eval('model_SpikeGen(rate,f,nrep_spike,1/Fs_psth,spont,noiseType,implnt);', nargout = 1)
psTH = np.array(psTH[0])
pr = np.sum(np.reshape(psTH,(psthbins,int(psTH.size/psthbins)),order='F'),axis=0)/nrep_spike # pr of spike in each bin
psTH = pr/psthbinwidth # psth in units of /s
if sponti == 0:
anfl_target[i,:,0] = psTH
elif sponti == 1:
anfm_target[i,:,0] = psTH
else:
anfh_target[i,:,0] = psTH
# remove context from the outputs (and last dimension)
anfh_target = anfh_target[:, context_left:-context_right, 0]
anfm_target = anfm_target[:, context_left:-context_right, 0]
anfl_target = anfl_target[:, context_left:-context_right, 0]
# apply proper scaling for feeding to the CoNNear
ihc_target = ihc_target * ihc_scaling # scaling for the ihc input
# compute the fft of the response
N = stim_reg.size
anfh_target_fft = (1/N)*(np.abs(np.fft.fft(anfh_target[:,stim_reg])))
anfm_target_fft = (1/N)*(np.abs(np.fft.fft(anfm_target[:,stim_reg])))
anfl_target_fft = (1/N)*(np.abs(np.fft.fft(anfl_target[:,stim_reg])))
# divide the modulation frequency component of the Fourier transform by the DC component (1st bin) to get the vector strengh
anfh_target_vs = anfh_target_fft[:,int(np.ceil(f_m/fs_connear*N))] / anfh_target_fft[:,0]
anfm_target_vs = anfm_target_fft[:,int(np.ceil(f_m/fs_connear*N))] / anfm_target_fft[:,0]
anfl_target_vs = anfl_target_fft[:,int(np.ceil(f_m/fs_connear*N))] / anfl_target_fft[:,0]
############ CNN model #################
# check the time dimension size
if ihc_target.shape[1] % 2**Nenc: # input size needs to be a multiple of 16384
Npad = int(np.ceil(ihc_target.shape[1]/(2**Nenc)))*(2**Nenc)-ihc_target.shape[1]
ihc_target = np.pad(ihc_target,((0,0),(0,Npad),(0,0))) # zero-pad
# simulate
anfh_connear = anfh.predict(ihc_target, verbose=1)
anfm_connear = anfm.predict(ihc_target, verbose=1)
anfl_connear = anfl.predict(ihc_target, verbose=1)
# scale back to the original ANF values
anfh_connear = anfh_connear / an_scaling
anfm_connear = anfm_connear / an_scaling
anfl_connear = anfl_connear / an_scaling
if simulate_psth: # simulate psth
# omit the negative values
anfh_connear = anfh_connear.clip(0)
anfm_connear = anfm_connear.clip(0)
anfl_connear = anfl_connear.clip(0)
for i in range(len(L)):
for sponti, spont in enumerate(sponts):
eng.workspace['spont'] = float(spont)
if sponti == 0:
anf_out = anfl_connear[i,:,0]
elif sponti == 1:
anf_out = anfm_connear[i,:,0]
else:
anf_out = anfh_connear[i,:,0]
anf_out = np.tile(anf_out,nrep_spike)
anf_out = matlab.double(anf_out.tolist())
eng.workspace['rate'] = anf_out
psTH = eng.eval('model_SpikeGen(rate,f,nrep_spike,1/Fs,spont,noiseType,implnt);', nargout = 1)
psTH = np.array(psTH[0])
pr = np.sum(np.reshape(psTH,(psthbins,int(psTH.size/psthbins)),order='F'),axis=0)/nrep_spike # pr of spike in each bin
psTH = pr/psthbinwidth # psth in units of /s
if sponti == 0:
anfl_connear[i,:,0] = psTH
elif sponti == 1:
anfm_connear[i,:,0] = psTH
else:
anfh_connear[i,:,0] = psTH
# remove context from the outputs
anfh_connear = anfh_connear[:, context_left:-context_right, :]
anfm_connear = anfm_connear[:, context_left:-context_right, :]
anfl_connear = anfl_connear[:, context_left:-context_right, :]
# remove last dimension
anfh_connear = anfh_connear[:, :, 0]
anfm_connear = anfm_connear[:, :, 0]
anfl_connear = anfl_connear[:, :, 0]
# compute the fft of the response
N = stim_reg.size
anfh_connear_fft = (1/N)*(np.abs(np.fft.fft(anfh_connear[:,stim_reg])))
anfm_connear_fft = (1/N)*(np.abs(np.fft.fft(anfm_connear[:,stim_reg])))
anfl_connear_fft = (1/N)*(np.abs(np.fft.fft(anfl_connear[:,stim_reg])))
# divide the modulation frequency component of the Fourier transform by the DC component (1st bin) to get the vector strengh
anfh_connear_vs = anfh_connear_fft[:,int(np.ceil(f_m/fs_connear*N))] / anfh_connear_fft[:,0]
anfm_connear_vs = anfm_connear_fft[:,int(np.ceil(f_m/fs_connear*N))] / anfm_connear_fft[:,0]
anfl_connear_vs = anfl_connear_fft[:,int(np.ceil(f_m/fs_connear*N))] / anfl_connear_fft[:,0]
eng.quit()
os.chdir(parent_dir) # go back to the original folder
############ Plots ###################
# Plot the synchrony-level functions for the reference model
plt.plot(anfh_target_vs.T,'ro-')
plt.plot(anfm_target_vs.T,'bo-')
plt.plot(anfl_target_vs.T,'co-')
plt.xlim(0,10), plt.grid(which='both'),
plt.ylim(0,1)
plt.xticks(ticks=L/10 , labels=L.astype(int))
plt.xlabel('Stimulus level (dB SPL)')
plt.ylabel('Synchrony to fm')
plt.title('Zilany2014 ANF model')
plt.legend(['HSR','MSR','LSR'], frameon=False)
plt.show()
# Plot the synchrony-level functions for the CoNNear model
plt.plot(anfh_connear_vs.T,'ro-')
plt.plot(anfm_connear_vs.T,'bo-')
plt.plot(anfl_connear_vs.T,'co-')
plt.xlim(0,10), plt.grid(which='both'),
plt.ylim(0,1)
plt.xticks(ticks=L/10 , labels=L.astype(int))
plt.xlabel('Stimulus level (dB SPL)')
plt.ylabel('Synchrony to fm')
plt.title('Zilany2014 ANF model - CNN')
plt.legend(['HSR','MSR','LSR'], frameon=False)
plt.show()
del anfh, anfm, anfl # remove the connear models variables to free-up some memory
```
| github_jupyter |
# Scareware vs Benign
Here, we are attempting to classify between 'Scareware' and 'Benign' using the features generated from the `feature selection` notebook on this data file. While this notebook is specifically tailored for the 'Scareware' vs 'Benign' problem, only two items need to be changed for this to be applicable to any other 'vs' file we have available. These will be noted below.
```
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, normalize
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
import keras
from keras.models import Sequential
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Dense, Dropout
from keras.metrics import CategoricalAccuracy, TruePositives, TrueNegatives, FalsePositives, FalseNegatives
print('Imports complete.')
```
## Cleaning the Data File
The `adware_vs_benign.csv` file was generated by the `create benign vs x files` notebook. This notebook will generate all of the data files for these experiments, however modifications must be made upstream to allow for these data files to have all of the available features. Here, we import the data file one chunk at a time since we can filter off the necessary columns every chunk.
If you want to change this notebook for another type of 'vs' file, you would only change a handful of variables:
- Change `path` and `datafile` to whatever you need it to be
- Either run the `feature_selection` notebook on your given datafile and pull out the list of features <i>or</i> you can add your own below.
- That's it, actually. A list without three items is a weak list.
```
# Import the data file
path = '../../malware_dataset/'
datafile = 'scareware_vs_benign.csv'
# Technique acquired from https://towardsdatascience.com/why-and-how-to-use-pandas-with-large-data-9594dda2ea4c
# I'm using this chunk technique because these files are kind of large and I want to make it as easy on us as
# possible.
df_chunk = pd.read_csv(path + datafile, chunksize=50000)
chunk_list = [] # append each chunk df here
cols_to_keep = ['Flow Duration',
'Fwd IAT Max',
'Fwd IAT Total',
'Flow IAT Max',
'Down/Up Ratio',
'URG Flag Count',
'ACK Flag Count',
'Fwd IAT Std',
'Flow IAT Std',
'Fwd IAT Mean',
'Flow IAT Mean',
'Protocol',
'Destination Port',
'Active Max',
'Min Packet Length',
'Bwd IAT Total',
'Active Mean',
'Idle Min',
'Idle Mean',
'Idle Max']
cols_to_keep.append('Label')
def filter_columns(chk, chknum):
# Clean the data for the features we want
print('Dropping unnecessary columns for chunk {}...'.format(chknum), end='')
chk.drop(columns=[col for col in chk.columns if col not in cols_to_keep], inplace=True, errors='raise') # Some systems raise an error about this errors='raise' argument (which is ironic, I guess). Feel free to remove it if need be.
chk.dropna(inplace=True)
print('done')
return chk
# Each chunk is in df format
chunkn = 1
for chunk in df_chunk:
# perform data filtering
chunk_filter = filter_columns(chunk, chunkn)
chunkn += 1
# Once the data filtering is done, append the chunk to list
chunk_list.append(chunk_filter)
# concat the list into dataframe
df = pd.concat(chunk_list)
dep_var = 'Label'
print('\nDataset Composition:\n{}\n'.format(df[dep_var].value_counts()))
# Output the features we have active
print('Active Features:')
n=1
for col in df.columns[:-1]:
print('\t{}. {}'.format(n, col))
n+=1
random_state = 1
```
Above, we see the features that have been chosen by the `feature selection` notebook.
```
print('Data before encoding:')
print(df.head())
# Separate the data out into the data and target classification
X = normalize(( df.loc[:, df.columns != dep_var] ).values)
y = df[dep_var]
# One-Hot Encoding for the target classification
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
#y = y.map(lambda classif : 0 if classif == 'BENIGN' else 1)
#y = keras.utils.to_categorical(y, num_classes=y.nunique())
print('Data after encoding:')
for i in range(5):
print('{} {}'.format(X[i, :], y[i]))
#print(X[:5, :])
#print('Label column:')
#print(y[:5])
```
## Training and Testing sets
Here, we are splitting up the X (data) and y (target) sets into specifically a training and testing set. We fit the models on the training set and then record their performance on the testing set to appropriately determine how the models are generalizing the data coming in. It would also be appropriate here to create an additional validation set or conduct 10-fold cross validation for every model. However, since the `train_test_split` function provided by `sklearn` automatically stratifies the dataset (keeps the target data in proper proportions), this will do for the time being as it is a general statement towards the model's performance. Once the results are needed for a formal paper or presentation, 10-fold cs will be conducted.
```
# Split the dataset up into training and testing sets
# This split is not stratified by default according to
# the documentation found here: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, shuffle=True, stratify=y, random_state=random_state)
```
## Model Fitting and Evaluation
The models we are training here are the Random Forest (`RandomForestClassifier`), Decision Tree (`DecisionTreeClassifier`), and k-Nearest Neighbors (`KNeighborsClassifier`) implementations provided by `sklearn`. We can see that the models perform modestly at around 60% accuracy. Just for fun, we are also running the `AdaBoost` model provided by `sklearn`, which extends off of the work of an already-existing model. This `AdaBoost` algorithm doesn't improve the performance of the models enough, though.
```
# Random Forest model training and evaluation
rf = RandomForestClassifier(n_estimators=100, random_state=random_state)
rf.fit(X_train, y_train)
print('Random Forest testing accuracy: {:.2f}%'.format(100*rf.score(X_test, y_test)))
# Decision Tree model training and evaluation
dt = DecisionTreeClassifier(random_state=random_state)
dt.fit(X_train, y_train)
print('Decision Tree testing accuracy: {:.2f}%'.format(100*dt.score(X_test, y_test)))
# k-Nearest Neighbors model training and evaluation
knn = KNeighborsClassifier(n_neighbors=5, algorithm='kd_tree')
knn.fit(X_train, y_train)
print('k-Nearest Neighbors testing accuracy: {:.2f}%'.format(100*knn.score(X_test, y_test)))
# AdaBoost-Decision Tree model training and evaluation
adadt = AdaBoostClassifier(base_estimator=dt, n_estimators=100, random_state=random_state)
adadt.fit(X_train, y_train)
print('AdaBoost-Decision Tree testing accuracy: {:.2f}%'.format(100*adadt.score(X_test, y_test)))
```
## Cleaning the Data File
Wait...what? Why are we here, again? Well, the way we set up the data for the `sklearn` models is different from the way that `keras` wants their deep learning models trained. Removing the columns and selecting the features is exactly the same as before, however configuring `y` (target) should be categorical, hot-encoded scheme rather than a simple 1D array. It can work either way, however I believe this is the best method for the time being<sup>[citation required]</sup>.
```
# Import the data file again because we've had to mess with it and the DL algorithms we're using want the y-data
# in a different format
df_chunk = pd.read_csv(path + datafile, chunksize=50000)
chunk_list = [] # append each chunk df here
# Each chunk is in df format
chunkn = 1
for chunk in df_chunk:
# perform data filtering
chunk_filter = filter_columns(chunk, chunkn)
chunkn += 1
# Once the data filtering is done, append the chunk to list
chunk_list.append(chunk_filter)
# concat the list into dataframe
df = pd.concat(chunk_list)
dep_var = 'Label'
print(df[dep_var].value_counts())
#print('Available features: {}'.format(df.columns))
# Output the features we have active
print('Active Features:')
for col in df.columns[:-1]:
print('\t' + col)
random_state = 1
# Separate the data out into the data and target classification
X = normalize( ( df.loc[:, df.columns != dep_var] ).values )
y = df[dep_var]
# One-Hot Encoding for the target classification
label_encoder = LabelEncoder()
#y = label_encoder.fit_transform(y)
y = y.map(lambda classif : 0 if classif == 'BENIGN' else 1)
y = keras.utils.to_categorical(y, num_classes=y.nunique())
print('Data:')
print(X[:5, :])
print('Targets:')
print(y[:5])
```
## Training and Testing data
This is the same idea as before.
<pre>
<i>"How can you really say that the data
sets are the same as before? Is that
just bad science? Who's running this
circus?"</i>
- you
</pre>
I hear the concerns that you is expressing. However, thanks to someone smarter<sub>(everyday?)</sub> than me, by passing the same `random_state` value, I can control this variable such that I get back the same splits as long as I'm providing the same data (which I am).
```
# Split the dataset up into training and testing sets
# This split is not stratified by default according to
# the documentation found here: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, shuffle=True, stratify=y, random_state=random_state)
```
## Deep Neural Network Model Training and Evaluation
Now, we begin with the crazier stuff. We've set up a `Sequential` model from the `keras` library and added a bunch of `Dense` layers to it. Playing around with the activation and loss functions, this is what we've currently settled on. As we can see, though, the model still only performs as well as flipping a coin (performing worse than some of the simpler models we saw before). We are still investigating potentially solutions to this problem and haven't had much luck in the way of success.
```
# Deep Neural Network model training and evaluation
# Set up the metrics we want to collect
accuracy = CategoricalAccuracy() # Will change this to Categorical if the target classification is categorical
tp = TruePositives() # These could be collected with a confusion matrix, however translating back
tn = TrueNegatives() # and forth from an image may be frustrating (it was last time I did it)
fp = FalsePositives()
fn = FalseNegatives()
metrics = [accuracy, tp, tn, fp, fn]
# The model must be reinitialized otherwise the model will have trained on all of the data (that wouldn't be true 10-fold cv)
model = Sequential()
model.add(Dense(64, input_shape=(len(cols_to_keep) - 1 ,))) # Input layer, needs same shape as input data (9 values 1D)
model.add(LeakyReLU(alpha=0.3))
model.add(Dense(128)) # Hidden layer of nodes
model.add(LeakyReLU(alpha=0.3))
model.add(Dense(32)) # Hidden layer of nodes
model.add(LeakyReLU(alpha=0.3))
model.add(Dense(8)) # Hidden layer of nodes
model.add(LeakyReLU(alpha=0.3))
model.add(Dense(2, activation='softmax')) # Output layer of 3 nodes
# "Configures the model for training"
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=metrics)
# Fit and test the model
model.fit(x=X_train, y=y_train, epochs=20, batch_size=512, verbose=0, validation_data=(X_test, y_test))
# Evaluate the performance of the model on the test set
scores = model.evaluate(X_test, y_test, verbose=2)
acc, loss, tpn, tnn, fpn, fnn = scores[1]*100, scores[0]*100, scores[2], scores[3], scores[4], scores[5]
totaln = tpn + tnn + fpn + fnn
print('Baseline: accuracy: {:.2f}%: loss: {:2f}'.format(acc, loss))
print('\tTrue Positive Rate: {} ({})'.format(tpn/totaln, tpn))
print('\tTrue Negative Rate: {} ({})'.format(tnn/totaln, tnn))
print('\tFalse Positive Rate: {} ({})'.format(fpn/totaln, fpn))
print('\tFalse Negative Rate: {} ({})'.format(fnn/totaln, fnn))
```
## Conclusion
Really, the moral of the story right now is <b>growth</b>. <i>Is this the best data science possible?</i> No. But, from here, we can find ways to improve our models and <b>grow</b> as humans. While, right now, we don't have the highest-performing models and we aren't using the most l33t techniques, <i>we can always improve ourselves</i>.
| github_jupyter |
```
%matplotlib inline
import os
import time
import torch
from torch.autograd import Variable
from torchvision import datasets, transforms
import scipy.io
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import scipy.misc
from darknet import Darknet
import dataset
from utils import *
from MeshPly import MeshPly
# Create new directory
def makedirs_(path):
if not os.path.exists( path ):
os.makedirs( path )
def valid(datacfg, modelcfg, weightfile):
def truths_length(truths, max_num_gt=50):
for i in range(max_num_gt):
if truths[i][1] == 0:
return i
# Parse configuration files
data_options = read_data_cfg(datacfg)
valid_images = data_options['valid']
meshname = data_options['mesh']
backupdir = data_options['backup']
name = data_options['name']
gpus = data_options['gpus']
fx = float(data_options['fx'])
fy = float(data_options['fy'])
u0 = float(data_options['u0'])
v0 = float(data_options['v0'])
im_width = int(data_options['width'])
im_height = int(data_options['height'])
if not os.path.exists(backupdir):
makedirs_(backupdir)
# Parameters
seed = int(time.time())
os.environ['CUDA_VISIBLE_DEVICES'] = gpus
torch.cuda.manual_seed(seed)
save = False
visualize = True
testtime = True
num_classes = 1
testing_samples = 0.0
edges_corners = [[0, 1], [0, 2], [0, 4], [1, 3], [1, 5], [2, 3], [2, 6], [3, 7], [4, 5], [4, 6], [5, 7], [6, 7]]
if save:
makedirs_(backupdir + '/test')
makedirs_(backupdir + '/test/gt')
import scipy.io
import scipy.misc
(backupdir + '/test/pr')
# To save
testing_error_trans = 0.0
testing_error_angle = 0.0
testing_error_pixel = 0.0
errs_2d = []
errs_3d = []
errs_trans = []
errs_angle = []
errs_corner2D = []
preds_trans = []
preds_rot = []
preds_corners2D = []
gts_trans = []
gts_rot = []
gts_corners2D = []
# Read object model information, get 3D bounding box corners
mesh = MeshPly(meshname)
vertices = np.c_[np.array(mesh.vertices), np.ones((len(mesh.vertices), 1))].transpose()
corners3D = get_3D_corners(vertices)
try:
diam = float(options['diam'])
except:
diam = calc_pts_diameter(np.array(mesh.vertices))
# Read intrinsic camera parameters
intrinsic_calibration = get_camera_intrinsic(u0, v0, fx, fy)
# Get validation file names
with open(valid_images) as fp:
tmp_files = fp.readlines()
valid_files = [item.rstrip() for item in tmp_files]
# Specicy model, load pretrained weights, pass to GPU and set the module in evaluation mode
model = Darknet(modelcfg)
model.print_network()
model.load_weights(weightfile)
model.cuda()
model.eval()
test_width = model.test_width
test_height = model.test_height
num_keypoints = model.num_keypoints
num_labels = num_keypoints * 2 + 3
# Get the parser for the test dataset
valid_dataset = dataset.listDataset(valid_images,
shape=(test_width, test_height),
shuffle=False,
transform=transforms.Compose([transforms.ToTensor(),]))
# Specify the number of workers for multiple processing, get the dataloader for the test dataset
kwargs = {'num_workers': 4, 'pin_memory': True}
test_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=1, shuffle=False, **kwargs)
logging(" Testing {}...".format(name))
logging(" Number of test samples: %d" % len(test_loader.dataset))
# Iterate through test batches (Batch size for test data is 1)
count = 0
for batch_idx, (data, target) in enumerate(test_loader):
# Images
img = data[0, :, :, :]
img = img.numpy().squeeze()
img = np.transpose(img, (1, 2, 0))
t1 = time.time()
# Pass data to GPU
data = data.cuda()
target = target.cuda()
# Wrap tensors in Variable class, set volatile=True for inference mode and to use minimal memory during inference
data = Variable(data, volatile=True)
t2 = time.time()
# Forward pass
output = model(data).data
t3 = time.time()
# Using confidence threshold, eliminate low-confidence predictions
all_boxes = get_region_boxes(output, num_classes, num_keypoints)
t4 = time.time()
# Evaluation
# Iterate through all batch elements
for box_pr, target in zip([all_boxes], [target[0]]):
# For each image, get all the targets (for multiple object pose estimation, there might be more than 1 target per image)
truths = target.view(-1, num_keypoints*2+3)
# Get how many objects are present in the scene
num_gts = truths_length(truths)
# Iterate through each ground-truth object
for k in range(num_gts):
box_gt = list()
for j in range(1, 2*num_keypoints+1):
box_gt.append(truths[k][j])
box_gt.extend([1.0, 1.0])
box_gt.append(truths[k][0])
# Denormalize the corner predictions
corners2D_gt = np.array(np.reshape(box_gt[:18], [9, 2]), dtype='float32')
corners2D_pr = np.array(np.reshape(box_pr[:18], [9, 2]), dtype='float32')
corners2D_gt[:, 0] = corners2D_gt[:, 0] * im_width
corners2D_gt[:, 1] = corners2D_gt[:, 1] * im_height
corners2D_pr[:, 0] = corners2D_pr[:, 0] * im_width
corners2D_pr[:, 1] = corners2D_pr[:, 1] * im_height
preds_corners2D.append(corners2D_pr)
gts_corners2D.append(corners2D_gt)
# Compute corner prediction error
corner_norm = np.linalg.norm(corners2D_gt - corners2D_pr, axis=1)
corner_dist = np.mean(corner_norm)
errs_corner2D.append(corner_dist)
# Compute [R|t] by pnp
R_gt, t_gt = pnp(np.array(np.transpose(np.concatenate((np.zeros((3, 1)), corners3D[:3, :]), axis=1)), dtype='float32'), corners2D_gt, np.array(intrinsic_calibration, dtype='float32'))
R_pr, t_pr = pnp(np.array(np.transpose(np.concatenate((np.zeros((3, 1)), corners3D[:3, :]), axis=1)), dtype='float32'), corners2D_pr, np.array(intrinsic_calibration, dtype='float32'))
# Compute translation error
trans_dist = np.sqrt(np.sum(np.square(t_gt - t_pr)))
errs_trans.append(trans_dist)
# Compute angle error
angle_dist = calcAngularDistance(R_gt, R_pr)
errs_angle.append(angle_dist)
# Compute pixel error
Rt_gt = np.concatenate((R_gt, t_gt), axis=1)
Rt_pr = np.concatenate((R_pr, t_pr), axis=1)
proj_2d_gt = compute_projection(vertices, Rt_gt, intrinsic_calibration)
proj_2d_pred = compute_projection(vertices, Rt_pr, intrinsic_calibration)
proj_corners_gt = np.transpose(compute_projection(corners3D, Rt_gt, intrinsic_calibration))
proj_corners_pr = np.transpose(compute_projection(corners3D, Rt_pr, intrinsic_calibration))
norm = np.linalg.norm(proj_2d_gt - proj_2d_pred, axis=0)
pixel_dist = np.mean(norm)
errs_2d.append(pixel_dist)
if visualize:
# Visualize
plt.xlim((0, im_width))
plt.ylim((0, im_height))
plt.imshow(scipy.misc.imresize(img, (im_height, im_width)))
# Projections
for edge in edges_corners:
plt.plot(proj_corners_gt[edge, 0], proj_corners_gt[edge, 1], color='g', linewidth=3.0)
plt.plot(proj_corners_pr[edge, 0], proj_corners_pr[edge, 1], color='b', linewidth=3.0)
plt.gca().invert_yaxis()
plt.show()
# Compute 3D distances
transform_3d_gt = compute_transformation(vertices, Rt_gt)
transform_3d_pred = compute_transformation(vertices, Rt_pr)
norm3d = np.linalg.norm(transform_3d_gt - transform_3d_pred, axis=0)
vertex_dist = np.mean(norm3d)
errs_3d.append(vertex_dist)
# Sum errors
testing_error_trans += trans_dist
testing_error_angle += angle_dist
testing_error_pixel += pixel_dist
testing_samples += 1
count = count + 1
if save:
preds_trans.append(t_pr)
gts_trans.append(t_gt)
preds_rot.append(R_pr)
gts_rot.append(R_gt)
np.savetxt(backupdir + '/test/gt/R_' + valid_files[count][-8:-3] + 'txt', np.array(R_gt, dtype='float32'))
np.savetxt(backupdir + '/test/gt/t_' + valid_files[count][-8:-3] + 'txt', np.array(t_gt, dtype='float32'))
np.savetxt(backupdir + '/test/pr/R_' + valid_files[count][-8:-3] + 'txt', np.array(R_pr, dtype='float32'))
np.savetxt(backupdir + '/test/pr/t_' + valid_files[count][-8:-3] + 'txt', np.array(t_pr, dtype='float32'))
np.savetxt(backupdir + '/test/gt/corners_' + valid_files[count][-8:-3] + 'txt', np.array(corners2D_gt, dtype='float32'))
np.savetxt(backupdir + '/test/pr/corners_' + valid_files[count][-8:-3] + 'txt', np.array(corners2D_pr, dtype='float32'))
t5 = time.time()
# Compute 2D projection error, 6D pose error, 5cm5degree error
px_threshold = 5 # 5 pixel threshold for 2D reprojection error is standard in recent sota 6D object pose estimation works
eps = 1e-5
acc = len(np.where(np.array(errs_2d) <= px_threshold)[0]) * 100. / (len(errs_2d)+eps)
acc5cm5deg = len(np.where((np.array(errs_trans) <= 0.05) & (np.array(errs_angle) <= 5))[0]) * 100. / (len(errs_trans)+eps)
acc3d10 = len(np.where(np.array(errs_3d) <= diam * 0.1)[0]) * 100. / (len(errs_3d)+eps)
acc5cm5deg = len(np.where((np.array(errs_trans) <= 0.05) & (np.array(errs_angle) <= 5))[0]) * 100. / (len(errs_trans)+eps)
corner_acc = len(np.where(np.array(errs_corner2D) <= px_threshold)[0]) * 100. / (len(errs_corner2D)+eps)
mean_err_2d = np.mean(errs_2d)
mean_corner_err_2d = np.mean(errs_corner2D)
nts = float(testing_samples)
if testtime:
print('-----------------------------------')
print(' tensor to cuda : %f' % (t2 - t1))
print(' forward pass : %f' % (t3 - t2))
print('get_region_boxes : %f' % (t4 - t3))
print(' prediction time : %f' % (t4 - t1))
print(' eval : %f' % (t5 - t4))
print('-----------------------------------')
# Print test statistics
logging('Results of {}'.format(name))
logging(' Acc using {} px 2D Projection = {:.2f}%'.format(px_threshold, acc))
logging(' Acc using 10% threshold - {} vx 3D Transformation = {:.2f}%'.format(diam * 0.1, acc3d10))
logging(' Acc using 5 cm 5 degree metric = {:.2f}%'.format(acc5cm5deg))
logging(" Mean 2D pixel error is %f, Mean vertex error is %f, mean corner error is %f" % (mean_err_2d, np.mean(errs_3d), mean_corner_err_2d))
logging(' Translation error: %f m, angle error: %f degree, pixel error: % f pix' % (testing_error_trans/nts, testing_error_angle/nts, testing_error_pixel/nts) )
if save:
predfile = backupdir + '/predictions_linemod_' + name + '.mat'
scipy.io.savemat(predfile, {'R_gts': gts_rot, 't_gts':gts_trans, 'corner_gts': gts_corners2D, 'R_prs': preds_rot, 't_prs':preds_trans, 'corner_prs': preds_corners2D})
datacfg = 'cfg/ape.data'
modelcfg = 'cfg/yolo-pose.cfg'
weightfile = 'backup/ape/model_backup.weights'
valid(datacfg, modelcfg, weightfile)
```
| github_jupyter |
# Non-Linear Least Squares Fitting with Python
For tasks requiring even the slightest amount of sophistication, the use of options like MS Excel becomes unrealistic. At this point, tools like MATLAB, Mathematica, or OriginLab must be employed.
An increasingly popular option within the sciences is the use of the Python programming language, particularly within the [Jupyter Notebook](http://jupyter.org/) environment, due to the very powerful methods of manipulation and inspection made available through an array of open source packages. In particular, and for our use here, the [Numpy](http://www.numpy.org/) (matrix manipulation), [Scipy](https://www.scipy.org/) (scientific/engineering algorithms), and [Matplotlib](https://matplotlib.org/) (advanced plotting) packages offer a robust suite of analysis tools.
Non-linear least squares fitting in Python can easily be achieved with either of two options:
+ the [`curve_fit()`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html) function from [`scipy.optimize`](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html)
+ the [LMFIT](https://lmfit.github.io/lmfit-py/) package, which is a powerful extension of scipy.optimize
Examples using both are demonstrated below.
# Fitting in 1D
```
# package imports
from math import *
import numpy as np
from scipy.optimize import curve_fit
from lmfit import Model
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.rcParams['axes.facecolor'] = '#e8e8e8'
plt.rcParams['axes.edgecolor'] = '#e8e8e8'
plt.rcParams['figure.facecolor'] = '#e8e8e8'
```
The data to be considered will be a simple Gaussian distribution of amplitude, $A$, centered at $x_c$, and standard distribution, $\sigma$:
### $$ f(x) = \frac{A}{\sqrt{2\pi\sigma^2}} e^{-\big[\frac{(x-x_c)^2}{2\sigma^2}\big]} $$
```
# define some function to play with
def gaussian(x, amp, xc, sigma):
return amp*np.exp( -(x-xc)**2 / (2*sigma**2)) / np.sqrt(2*np.pi*sigma**2)
# set initial parameters for fit function
x = np.arange(256)
amp = 1
xc = np.median(x)
sigma = x[-1]/10
noise_factor = 0.05
# make both clean and noisy data
data = gaussian(x, amp, xc, sigma)
noise = data + noise_factor*data.max()*np.random.normal(size=data.shape)
```
## Method 1: using the `scipy.optimize` package
The scipy package is easy to use and performs very well, but only returns limited information. Most of the time, though, it's exactly what you want: the fit values and covariance matrix. The diagonal elements of the covariance matrix equal the variance of each fit parameter, which can be used to calculate the fit parameter uncertainties, $\sigma_{ii}$.
\begin{equation*}
Cov = \mathbf{\sigma}^2_{i,j} =
\begin{pmatrix}
\sigma^2_{1} & \sigma_{1}\sigma_{2} & \sigma_{1}\sigma_{3} \\
\sigma_{2}\sigma_{1} & \sigma^2_{2} & \sigma_{2}\sigma_{3} \\
\sigma_{3}\sigma_{1} & \sigma_{3}\sigma_{2} & \sigma^2_{3}
\end{pmatrix}
\end{equation*}
Unfortunately, any goodness of fit ($R^2$, $\chi ^2$, etc.) is not returned, but it can easily be calculated:
$$R^2 = 1 - \frac{\text{(variance of residual)}}{\text{(total variance)}}$$
```
# define some initial guess values for the fit routine
guess_vals = [amp*2, xc*0.8, sigma/1.5]
# perform the fit and calculate fit parameter errors from covariance matrix
fit_params, cov_mat = curve_fit(gaussian, x, noise, p0=guess_vals)
fit_errors = np.sqrt(np.diag(cov_mat))
# manually calculate R-squared goodness of fit
fit_residual = noise - gaussian(x, *fit_params)
fit_Rsquared = 1 - np.var(fit_residual)/np.var(noise)
print('Fit R-squared:', fit_Rsquared, '\n')
print('Fit Amplitude:', fit_params[0], '\u00b1', fit_errors[0])
print('Fit Center: ', fit_params[1], '\u00b1', fit_errors[1])
print('Fit Sigma: ', fit_params[2], '\u00b1', fit_errors[2])
# plotting shizzle
plt.figure(figsize=(8,4))
plt.plot(x, data, linewidth=5, color='k', label='original')
plt.plot(x, noise, linewidth=2, color='b', label='noisy')
plt.plot(x, gaussian(x, *fit_params), linewidth=3, color='r', label='fit')
plt.title('non-linear least squares fit: scipy.optimize')
plt.legend()
plt.show()
```
## Method 2: using the [LMFIT](https://lmfit.github.io/lmfit-py/model.html) package
Under the hood, the LMFIT package actually uses `scipy.optimize`, but adds more advanced functionality for fit options and gives immediate access to fit perfomance and data statistics (see below). Although $\chi^2$ and the $\text{reduced-}\chi^2$ are automatically calculated, $R^2$ is not. Again, it's a trivial matter to calculate it.
```
# tell LMFIT what fn you want to fit, then fit, starting iteration with guess values
lmfit_model = Model(gaussian)
lmfit_result = lmfit_model.fit(noise, x=x,
amp=guess_vals[0],
xc=guess_vals[1],
sigma=guess_vals[2])
# again, calculate R-squared
lmfit_Rsquared = 1 - lmfit_result.residual.var()/np.var(noise)
print('Fit R-squared:', lmfit_Rsquared, '\n')
print(lmfit_result.fit_report())
# another view of fit parameters
lmfit_result.params.pretty_print()
```
You might notice here that the parameters can have several conditions placed on them in order to constrain the fit routine, such as: min and max bounds, ability to fix a value, or forcing a parameter to adhere to an analytic expression. Use of these is covered in the LMFIT documentation.
```
# plotting shizzle
plt.figure(figsize=(8,4))
plt.plot(x, data, linewidth=5, color='k', label='original')
plt.plot(x, noise, linewidth=2, color='b', label='noisy')
plt.plot(x, lmfit_result.best_fit, linewidth=3, color='r', label='fit')
plt.title('non-linear least squares fit: LMFIT package')
plt.legend()
plt.show()
# report best fit parameters with 1*sigma, 2*sigma, and 3*sigma confidence interrvals
print(lmfit_result.ci_report())
# show goodness of fits, X^2 and the reduced-X^2
print('Fit X^2: ', lmfit_result.chisqr)
print('Fit reduced-X^2:', lmfit_result.redchi)
# access info on data set and fit performance
print('Number of Data Points:', lmfit_result.ndata)
print('Number of Fit Iterations:', lmfit_result.nfev)
print('Number of freely independent variables:', lmfit_result.nvarys)
print('Did the fit converge?:', lmfit_result.success)
# quickly check the fit residuals (input_data - fit_data)
lmfit_result.plot_residuals();
```
# Fitting in 2D
Now, let's look at a more challenging example - least squares fitting over multiple independent dimentions. Why is this challenging? The curve fitting algorithm we're using here only accepts 1D arrays and expects the fitting function to only return a 1D array. But this won't stop us.. We'll just pass a 1D array of *N*D array elements (here, *N* = 2) and use this to build our *N*D fitting function, flattening the output back down to 1D for the function return.
This time, the data to be considered will be a 2D Gaussian (normal) distribution, without any assumption that variance in the $x$ and $y$ directions are equal ($\sigma_x \neq \sigma_y$):
$$ f(x, y) = \frac{A}{2\pi\sigma_x\sigma_y} e^{-\big[\frac{(x-x_c)^2}{2\sigma_x^2} + \frac{(y-y_c)^2}{2\sigma_y^2}\big]} $$
```
def gaussian_2d(xy_mesh, amp, xc, yc, sigma_x, sigma_y):
# unpack 1D list into 2D x and y coords
(x, y) = xy_mesh
# make the 2D Gaussian matrix
gauss = amp*np.exp(-((x-xc)**2/(2*sigma_x**2)+(y-yc)**2/(2*sigma_y**2)))/(2*np.pi*sigma_x*sigma_y)
# flatten the 2D Gaussian down to 1D
return np.ravel(gauss)
```
## Method 1: using the `scipy.optimize` package
You can already see the relavant changes in the definition of the distribution function. It takes in a 2D field of $x$ and $y$ values, produces a 2D array of normally distributed points, and the the return flattens everything out using `np.ravel()`. Let's first plot an ideal version of this function and then produce a slightly noisy version we can apply our fit routine towards.
```
# create the 1D list (xy_mesh) of 2D arrays of (x,y) coords
x = np.arange(256)
y = np.arange(256)
xy_mesh = np.meshgrid(x,y)
# set initial parameters to build mock data
amp = 1
xc, yc = np.median(x), np.median(y)
sigma_x, sigma_y = x[-1]/10, y[-1]/6
noise_factor = 0.07
# make both clean and noisy data, reshaping the Gaussian to proper 2D dimensions
data = gaussian_2d(xy_mesh, amp, xc, yc, sigma_x, sigma_y).reshape(np.outer(x, y).shape)
noise = data + noise_factor*data.max()*np.random.normal(size=data.shape)
# plot the function and with noise added
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.title('model')
plt.imshow(data, origin='bottom')
plt.grid(visible=False)
plt.subplot(1,2,2)
plt.title('noisy data')
plt.imshow(noise, origin='bottom')
plt.grid(visible=False)
plt.show()
```
Let's then take this noisy data, and apply the `curve_fit()` routine. This part looks a lot like the 1D case! Just notice the `np.ravel()` in the call to `curve_fit()`.
```
# define some initial guess values for the fit routine
guess_vals = [amp*2, xc*0.8, yc*0.8, sigma_x/1.5, sigma_y/1.5]
# perform the fit, making sure to flatten the noisy data for the fit routine
fit_params, cov_mat = curve_fit(gaussian_2d, xy_mesh, np.ravel(noise), p0=guess_vals)
# calculate fit parameter errors from covariance matrix
fit_errors = np.sqrt(np.diag(cov_mat))
# manually calculate R-squared goodness of fit
fit_residual = noise - gaussian_2d(xy_mesh, *fit_params).reshape(np.outer(x,y).shape)
fit_Rsquared = 1 - np.var(fit_residual)/np.var(noise)
print('Fit R-squared:', fit_Rsquared, '\n')
print('Fit Amplitude:', fit_params[0], '\u00b1', fit_errors[0])
print('Fit X-Center: ', fit_params[1], '\u00b1', fit_errors[1])
print('Fit Y-Center: ', fit_params[2], '\u00b1', fit_errors[2])
print('Fit X-Sigma: ', fit_params[3], '\u00b1', fit_errors[3])
print('Fit Y-Sigma: ', fit_params[4], '\u00b1', fit_errors[4])
# check against actual parameter values
amp, xc, yc, sigma_x, sigma_y
```
If we are simply interested in showing the standard deviations **from** the mean, we'll need to plot the waist contours, $1\sigma$, $2\sigma$, $3\sigma$, etc. This just shows the probability coverage of our function and doesn't take advantage of the fitting we've just done, but it does allow us to show how to create contours on a 2D plot, which we'll need for the next part.
```
# set contour levels out to 3 sigma
sigma_x_pts = xc + [sigma_x, 2*sigma_x, 3*sigma_x]
sigma_y_pts = yc + [sigma_y, 2*sigma_y, 3*sigma_y]
sigma_xy_mesh = np.meshgrid(sigma_x_pts, sigma_y_pts)
contour_levels = gaussian_2d(sigma_xy_mesh, amp, xc, yc,
sigma_x, sigma_y).reshape(sigma_xy_mesh[0].shape)
contour_levels = list(np.diag(contour_levels)[::-1])
# make labels for each contour
labels = {}
label_txt = [r'$3\sigma$', r'$2\sigma$', r'$1\sigma$']
for level, label in zip(contour_levels, label_txt):
labels[level] = label
# plot the function with noise added
plt.figure(figsize=(6,6))
plt.title('probability coverage')
plt.imshow(noise, origin='lower')
CS = plt.contour(data, levels=contour_levels, colors=['red', 'orange', 'white'])
plt.clabel(CS, fontsize=16, inline=1, fmt=labels)
plt.grid(visible=False)
plt.show()
```
Now, let's actually display the standard deviation **in** the mean, as a result of our fitting procedure. The error here was quite small (~0.03%), which means less than a pixel in diameter in the image above. We'll have to rescale this image to zoom in for a view of the fit uncertainty on the center.
```
# create a zoomed view of the noisy data, using fit error for scaling
x_zoom = np.linspace(xc-7*fit_errors[1], xc+7*fit_errors[1], 256)
y_zoom = np.linspace(xc-5*fit_errors[2], xc+5*fit_errors[2], 256)
xy_mesh_zoom = np.meshgrid(x_zoom,y_zoom)
# make noisy data using same parameters as before, except zoomed to center
data_zoom = gaussian_2d(xy_mesh_zoom, amp, xc, yc,
sigma_x, sigma_y).reshape(np.outer(x_zoom,y_zoom).shape)
noise_zoom = data_zoom + noise_factor*data_zoom.max()*np.random.normal(size=data_zoom.shape)
# set contour levels out to 3 standard deviations
err_x_pts = xc + [fit_errors[1], 2*fit_errors[1], 3*fit_errors[1]]
err_y_pts = yc + [fit_errors[2], 2*fit_errors[2], 3*fit_errors[2]]
err_xy_mesh = np.meshgrid(err_x_pts, err_y_pts)
extent = [x_zoom[0], x_zoom[-1], y_zoom[0], y_zoom[-1]]
contour_levels = gaussian_2d(err_xy_mesh, amp, xc, yc,
sigma_x, sigma_y).reshape(err_xy_mesh[0].shape)
contour_levels = list(np.diag(contour_levels)[::-1])
# make labels for each contour
labels = {}
label_txt = [r'$3\sigma$', r'$2\sigma$', r'$1\sigma$']
for level, label in zip(contour_levels, label_txt):
labels[level] = label
# plot the function with noise added
plt.figure(figsize=(6,6))
plt.title('fit uncertainty for $(x_c, y_c)$')
plt.imshow(noise_zoom, origin='lower', extent=extent)
CS = plt.contour(data_zoom, levels=contour_levels, origin='lower',
colors=['red', 'orange', 'white'], extent=extent)
plt.clabel(CS, fontsize=16, inline=1, fmt=labels)
plt.grid(visible=False)
plt.show()
```
Wow.. we've narrowed the position of the distribution peak down so much that there's hardly any variation in the data on this scale. This just goes to show: an excellent fit result starts with excellent data (*and* a correct choice of analytical model).
## Method 2: using the LMFIT package
Again, LMFIT is extraordinarily easy to use. All is exactly the same as for the 1D case, only with the `np.ravel()`. In each of these cases, the major changes we're making is to the fit function itself so that flattened data can be compared to a flattened model.
```
# tell LMFIT what fn you want to fit, then fit, starting iteration with guess values
lmfit_model = Model(gaussian_2d)
lmfit_result = lmfit_model.fit(np.ravel(noise),
xy_mesh=xy_mesh,
amp=guess_vals[0],
xc=guess_vals[1],
yc=guess_vals[2],
sigma_x=guess_vals[3],
sigma_y=guess_vals[4])
# again, calculate R-squared
lmfit_Rsquared = 1 - lmfit_result.residual.var()/np.var(noise)
print('Fit R-squared:', lmfit_Rsquared, '\n')
print(lmfit_result.fit_report())
lmfit_result.params.pretty_print()
# check against actual parameter values
amp, xc, yc, sigma_x, sigma_y
```
# Fitting in *N*D...
As you can see, the entire trick hinges on this:
1. create your multidimensional fitting function, but flatten the output to 1D;
2. flatten your multidimensional data to 1D;
3. employ the fit routine as you would normally for the 1D case, given the package you're working with.
With this as your algorithm, you can scale the 2D procudure outlined above in a fairly straightforward manner. It *would* be interesting to see the limits of this proceedure, though. I know the folks over at Big Data have some slick tricks for doing things like this. I'm just curious how much of it essentially comes down to applying these same procedures after taking an out-of-memory data set and applying principle component analysis on it as a sub-selection step.
IN any case, there it is... Not too terribly difficult after all. As long as you have correctly chosen your model and are able to faithfully code it up, you should now be able to quantify how well measured reality matches mathematical expectation.
# References
+ The above code is also available as a [Jupyter Notebook on my github](https://github.com/kippvs/nonlinear-least-squares-fitting)
+ [The Jupyter Project website](http://jupyter.org/)
+ [The Numpy package website](http://www.numpy.org/)
+ [The Scipy package website](https://www.scipy.org/) and [scipy.optimize documentation](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html)
+ [The Matplotlib package website](https://matplotlib.org/)
+ [The LMFIT package website](https://lmfit.github.io/lmfit-py/)
| github_jupyter |
# Opioid Prescriptions in the United States
An Exploration of the [Washington Post Opioid Dataset](https://www.washingtonpost.com/graphics/2019/investigations/dea-pain-pill-database/)
### Table of Contents
* [Opioid prescriptions for the US (2006-2017)](#opioid-us)
* [Opioid prescriptions by State (2006-2017)](#opioid-by-state)
* [Opioid prescriptions by County (2006-2017)](#opioid-by-county)
* [Opioid prescriptions in Tennessee (2006-2017)](#opioid-tn)
```
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import calendar
from ipyleaflet import *
import warnings
warnings.filterwarnings('ignore')
# magic function making plot outputs appear within the notebook
%matplotlib inline
# change the default plot output size
plt.rcParams['figure.figsize'] = [18, 8]
# get current working directory
cwd = os.getcwd()
data_dir = os.path.join(cwd, 'data')
# set input and output Excel files
in_nation = os.path.join(data_dir, 'OpioidsPerYearTotalAndRate.xlsx')
in_state = os.path.join(data_dir, 'OpioidRxRateByState.xlsx')
in_county = os.path.join(data_dir, 'OpioidRxRate_County.xlsx')
in_rate = os.path.join(data_dir, 'US_Opioid_OverdoseDeathsByState.xlsx')
```
## Opioid prescriptions for the US (2006-2017) <a class='anchor' id='opioid-us'></a>
### Total prescriptions
```
df_nation_total_rx = pd.read_excel(in_nation, sheet_name='TotalRx')
df_nation_total_rx.head()
# Plot the trend by year
ax = df_nation_total_rx.plot.bar(x=0, y=1, title="Total Prescriptions by Year", rot=0)
ax.set_xlabel("Year")
ax.set_ylabel("Total Prescriptions")
vals = ax.get_yticks().astype(int)
ax.set_yticklabels(['{:,}'.format(x) for x in vals])
# Plot the trend by year
ax = df_nation_total_rx.plot.bar(x=0, y=2, title="Prescription Rate Per 100 People", rot=0)
ax.set_xlabel("Year")
ax.set_ylabel("Prescription Rate")
vals = ax.get_yticks().astype(int)
# ax.set_yticklabels(['{:,}'.format(x) for x in vals])
```
### County participation
```
df_nation_county_ptcp = pd.read_excel(in_nation, sheet_name='CountyParticipation')
df_nation_county_ptcp.head()
# Plot the trend by year
ax = df_nation_county_ptcp.plot.bar(x=0, y=2, title="Counties with Data", rot=0)
ax.set_xlabel("Year")
ax.set_ylabel("Total Prescriptions")
vals = ax.get_yticks().astype(int)
# ax.set_yticklabels(['{:,}'.format(x) for x in vals])
# Plot the trend by year
ax = df_nation_county_ptcp.plot.bar(x=0, y=3, title="Percent Counties with Data", rot=0)
ax.set_xlabel("Year")
ax.set_ylabel("Total Prescriptions")
vals = ax.get_yticks().astype(int)
```
## Opioid Precriptions by State (2006-2017) <a class='anchor' id='opioid-by-state'></a>
### Merging each yearly spreadsheet into a single spreadsheet
```
df_state = pd.read_excel(in_state, sheet_name=None, ignore_index=True)
df_template = pd.read_excel(in_state, sheet_name=0)
for index, key in enumerate(df_state.keys()):
df_year = pd.read_excel(in_state, sheet_name=key)
df_template[key] = df_year.iloc[:, 2]
df_state=df_template.drop(columns=['2006 Prescribing Rate'])
df_state.head()
df_state['mean'] = df_state.mean(axis=1)
df_state.head()
out_state_file = in_state.replace(".xlsx", "_Merge.xlsx")
df_state.to_excel(out_state_file, index=False)
ax = df_state.plot.bar(x=1, y=range(2, 14), rot=0, title="Prescription Rate by State")
ax.set_xlabel("State")
ax.set_ylabel("Prescription Rate")
df_state_sort = df_state.sort_values(by='mean', ascending=False)
df_state_sort.head()
ax = df_state_sort.plot.bar(x=1, y=range(2, 14), rot=0, title="Prescription Rate by State")
ax.set_xlabel("State")
ax.set_ylabel("Prescription Rate")
df_state_top10 = df_state_sort.head(10)
df_state_top10
```
### Top 10 States with the highest prescription rate
```
ax = df_state_top10.plot.bar(x=1, y=range(2, 14), rot=0, title="Prescription Rate by State")
ax.set_xlabel("State")
ax.set_ylabel("Prescription Rate")
ax = df_state_sort.plot.bar(x=1, y=14, rot=0, title="Mean Prescription Rate by State")
ax.set_xlabel("State")
ax.set_ylabel("Prescription Rate")
```
## Opioid Precriptions by County (2006-2017) <a class='anchor' id='opioid-by-county'></a>
```
df_county = pd.ExcelFile(in_county)
sheet_names =df_county.sheet_names
print(sheet_names)
num_sheets = len(df_county.sheet_names)
print(f"Total number of sheets: {num_sheets}")
sheet_template = df_county.parse(sheet_name=sheet_names[0])[["County", "State", "FIPS County Code"]]
sheet_template.head()
```
### Merging each yearly spreadsheet into a single spreadsheet
```
for sheet_name in sheet_names[:-1]:
print(sheet_name)
sheet_year = df_county.parse(sheet_name)
# print(sheet_year.head()).
sheet_template= pd.merge(sheet_template, sheet_year, how='left', on=['FIPS County Code'])
# print(sheet_template.head())
sheet_template.head()
```
Filter and select columns:
```
filter_col = ["County", "State", "FIPS County Code"] + [col for col in sheet_template if col.startswith('20')]
filter_col
```
Display selected columns:
```
df_county_merge = sheet_template[filter_col]
df_county_merge.head()
col_names = ["County", "State", "FIPS County Code"] + sheet_names[:-1]
print(col_names)
```
Change column names:
```
df_county_merge.columns = col_names
df_county_merge['FIPS County Code']= df_county_merge['FIPS County Code'].astype(str)
df_county_merge['FIPS County Code'] = df_county_merge['FIPS County Code'].apply(lambda x: x.zfill(5))
df_county_merge.head()
```
Create a mean column:
```
df_county_merge = df_county_merge.replace(-9999, np.nan)
df_county_merge['mean'] = df_county_merge.mean(axis=1)
df_county_merge.head()
```
Save the merged opioid data as a new Excel file:
```
out_county_file = in_county.replace(".xlsx", "_Merge.xlsx")
df_county_merge.to_excel(out_county_file, index=False)
```
Sort mean prescription rate by county:
```
df_county = pd.read_excel(out_county_file, sheet_name=0, ignore_index=True)
df_county_sort = df_county.sort_values(by='mean', ascending=False)
df_county_top10 = df_county_sort.head(10)
df_county_top10
ax = df_county_top10.plot.bar(x=0, y=range(3, 15), rot=0, title="Top 10 County")
ax.set_xlabel("County")
ax.set_ylabel("Prescription Rate")
ax = df_county_top10.plot.bar(x=0, y=15, rot=0, title="Mean Prescription Rate by County")
ax.set_xlabel("County")
ax.set_ylabel("Prescription Rate")
```
## Opioid Prescriptions in Tennessee (2006-2017) <a class='anchor' id='opioid-tn'></a>
Select Tennessee opioid data by county:
```
df_tn = df_county[df_county['State']=='TN']
df_tn.head(10)
ax = df_tn.plot.bar(x=0, y=15, rot=0, title="Mean Prescription Rate by County")
ax.set_xlabel("County")
ax.set_ylabel("Prescription Rate")
df_tn_sort = df_tn.sort_values(by='mean', ascending=False)
ax = df_tn_sort.plot.bar(x=0, y=15, rot=0, title="Mean Prescription Rate by County")
ax.set_xlabel("County")
ax.set_ylabel("Prescription Rate")
df_tn_top10 = df_tn_sort.head(10)
df_tn_top10
ax = df_tn_top10.plot.bar(x=0, y=15, rot=0, title="Top 10 TN County")
ax.set_xlabel("County")
ax.set_ylabel("Prescription Rate")
ax = df_tn_top10.plot.bar(x=0, y=range(3, 15), rot=0, title="Top 10 County")
ax.set_xlabel("County")
ax.set_ylabel("Prescription Rate")
```
| github_jupyter |
```
import pymc3 as pm
import pandas as pd
import matplotlib.pyplot as plt
import fmax as fm
import numpy as np
import arviz as az
def plot_posterior_predictive(fcast_model, label):
"""Simple plot of the posterior predictive of a forecast model.
"""
sample_paths = fcast_model.posterior_predictive_samples
index = fcast_model.train_index
# Calculate the 1%, 10%, 50%, 90%, and 99% quantiles
lower_bound_one = np.quantile(sample_paths, q=0.01, axis=0)
lower_bound_ten = np.quantile(sample_paths, q=0.1, axis=0)
medians = np.quantile(sample_paths, q=0.5, axis=0)
upper_bound_ninety = np.quantile(sample_paths, q=0.9, axis=0)
upper_bound_ninety_nine = np.quantile(sample_paths, q=0.99, axis=0)
# Plot
fig, axs = plt.subplots(figsize=(13,8))
axs.fill_between(index, lower_bound_one, upper_bound_ninety_nine, alpha=0.4, label="99% CI", color="C0")
axs.fill_between(index, lower_bound_ten, upper_bound_ninety, alpha=0.7, label="80% CI", color="C0")
axs.plot(index, medians, label="Median")
axs.plot(index, fcast_model.train_data, color="red", label="Training")
axs.legend()
axs.set_xlabel("Period")
axs.set_ylabel("Record")
axs.set_title(label)
fig.tight_layout()
return fig
def plot_forecast(fcast_model, test_data, label, actual):
"""Simple plot of the posterior predictive of a forecast model.
"""
sample_paths = fcast_model.forecast_samples
index = fcast_model.master_with_fcast_index
# Calculate the 1%, 10%, 50%, 90%, and 99% quantiles
lower_bound_one = np.quantile(sample_paths, q=0.01, axis=0)
lower_bound_ten = np.quantile(sample_paths, q=0.1, axis=0)
medians = np.quantile(sample_paths, q=0.5, axis=0)
upper_bound_ninety = np.quantile(sample_paths, q=0.9, axis=0)
upper_bound_ninety_nine = np.quantile(sample_paths, q=0.99, axis=0)
# Plot
fig, axs = plt.subplots(figsize=(13,8))
axs.fill_between(index, lower_bound_one, upper_bound_ninety_nine, alpha=0.4, label="99% CI", color="C0")
axs.fill_between(index, lower_bound_ten, upper_bound_ninety, alpha=0.7, label="80% CI", color="C0")
axs.plot(index, medians, label="Median")
axs.plot(fcast_model.train_index, fcast_model.train_data, color="red", label="Training")
axs.plot(fcast_model.fcast_index, test_data, color="black", label="Tryfos")
axs.plot(fcast_model.fcast_index, actual, color="green", label="Actual")
axs.legend()
axs.set_xlabel("Period")
axs.set_ylabel("Record")
axs.set_title(label)
fig.tight_layout()
return fig
def plot_forecast_fin(fcast_model, test_data, label, actual):
"""Simple plot of the posterior predictive of a forecast model.
"""
sample_paths = fcast_model.forecast_samples
index = fcast_model.master_with_fcast_index
# Convert to the actual years
index = [1968+i for i in range(len(index))]
# Calculate the 1%, 10%, 50%, 90%, and 99% quantiles
lower_bound_one = np.quantile(sample_paths, q=0.025, axis=0)
lower_bound_ten = np.quantile(sample_paths, q=0.16, axis=0)
medians = np.quantile(sample_paths, q=0.5, axis=0)
upper_bound_ninety = np.quantile(sample_paths, q=0.84, axis=0)
upper_bound_ninety_nine = np.quantile(sample_paths, q=0.975, axis=0)
# Plot
fig, axs = plt.subplots(figsize=(13,8))
axs.fill_between(index, lower_bound_one, upper_bound_ninety_nine, alpha=0.4, label="95% CI", color="C0")
axs.fill_between(index, lower_bound_ten, upper_bound_ninety, alpha=0.7, label="68% CI", color="C0")
axs.plot(index, medians, label="Median", color="blue")
axs.plot([1968+i for i in range(len(fcast_model.train_index))], fcast_model.train_data, color="green", label="Training")
axs.plot([1983+i for i in range(len(fcast_model.fcast_index))], test_data, color="black", label="Tryfos")
axs.plot([1983+i for i in range(len(fcast_model.fcast_index))], actual, color="red", label="Actual")
axs.legend()
axs.set_xlabel("Period")
axs.set_ylabel("Record")
axs.set_title(label)
fig.tight_layout()
return fig
def plot_forecast_small(fcast_model, test_data, label, actual):
"""Simple plot of the posterior predictive of a forecast model.
"""
sample_paths = fcast_model.forecast_samples
index = fcast_model.master_with_fcast_index
# Convert to the actual years
index = [1968+i for i in range(len(index))]
# Calculate the 1%, 10%, 50%, 90%, and 99% quantiles
lower_bound_one = np.quantile(sample_paths, q=0.025, axis=0)
lower_bound_ten = np.quantile(sample_paths, q=0.16, axis=0)
medians = np.quantile(sample_paths, q=0.5, axis=0)
upper_bound_ninety = np.quantile(sample_paths, q=0.84, axis=0)
upper_bound_ninety_nine = np.quantile(sample_paths, q=0.975, axis=0)
# Plot
fig, axs = plt.subplots(figsize=(8,5))
axs.fill_between(index, lower_bound_one, upper_bound_ninety_nine, alpha=0.4, label="95% CI", color="C0")
axs.fill_between(index, lower_bound_ten, upper_bound_ninety, alpha=0.7, label="68% CI", color="C0")
axs.plot(index, medians, label="Median", color="blue")
axs.plot([1968+i for i in range(len(fcast_model.train_index))], fcast_model.train_data, color="green", label="Training")
axs.plot([1983+i for i in range(len(fcast_model.fcast_index))], test_data, color="black", label="Tryfos")
axs.plot([1983+i for i in range(len(fcast_model.fcast_index))], actual, color="red", label="Actual")
axs.legend()
#axs.set_xlabel("Period")
#axs.set_ylabel("Record")
#axs.set_title(label)
fig.tight_layout()
return fig
whiches = ["1000m", "1m", "5000m", "Marathon", "10000m"]
which = whiches[0]
training_records[0]
df = pd.read_csv("tryfos_data.csv")
years, records = df["Year"].values, df[which].values # Years 1983 and onward are just forecasts
training_years = years[:15]
training_records = records[:15]
tryfos_years = years[15:]
tryfos_fcast = records[15:]
actual_df = pd.read_csv("tryfos_actual.csv")
_, actual_records = actual_df["Year"].values, actual_df[which].values
prior_parameters = {
'mu' : {
'mean' : training_records[0],
'std' : 0.05*training_records[0],
},
'sigma' : {
'lam' : 1/13
}
}
model = fm.ForecastModel(training_records, prior_parameters=prior_parameters, attempt_distribution="gumbel",
kind="min", train='all', fcast_len=len(tryfos_fcast), fcast_test_data=actual_records)
model.fit(chains=1, draws=10000, tune=3000)
model.posterior_predictive()
model.forecast()
az.plot_posterior(model.trace)
fig = plot_posterior_predictive(model, f"{which}, Gumbel Attempts, Posterior Predictive")
fig = plot_forecast_fin(model, tryfos_fcast, f"{which}, Gumbel Attempts, Posterior Predictive", actual_records)
```
# Now do them all
```
#whiches = ["1m", "5000m", "10000m", "Marathon"]
whiches = ["1000m", "1m", "5000m", "Marathon", "10000m"]
#whiches = []
mses = {}
avg_log_probs = {}
fails = []
#whiches = ["1000m"]
for which in whiches:
try:
df = pd.read_csv("tryfos_data.csv")
years, records = df["Year"].values, df[which].values # Years 1983 and onward are just forecasts
training_years = years[:15]
training_records = records[:15]
tryfos_years = years[15:]
tryfos_fcast = records[15:]
actual_df = pd.read_csv("tryfos_actual.csv")
_, actual_records = actual_df["Year"].values, actual_df[which].values
prior_parameters = {
'mu' : {
'mean' : training_records[0],
'std' : 0.05*training_records[0],
},
'sigma' : {
'lam' : 1/(0.1*training_records[0])
}
}
model = fm.ForecastModel(training_records, prior_parameters=prior_parameters, attempt_distribution="gumbel",
kind="min", train='all', fcast_len=len(tryfos_fcast), fcast_test_data=actual_records)
model.fit(chains=1)
model.posterior_predictive()
model.forecast()
# MSE calculation
median = np.quantile(model.forecast_samples[:,-15:], q=0.5, axis=0)
bayes_mse = fm.mse(median, model.fcast_test_data)
tryfos_mse = fm.mse(tryfos_fcast, model.fcast_test_data)
mses[which] = (bayes_mse, tryfos_mse)
# Average logp
avg_log_probs[which] = np.mean(model.posterior_predictive_ppc["log_like_holdout"])
# Plots
fig = plot_posterior_predictive(model, f"{which}, Gumbel Attempts, Posterior Predictive")
fig.savefig(f"final_{which}_gumbel_attempts_post_pred.png")
# fig = plot_forecast(model, tryfos_fcast, f"{which}, Gumbel Attempts, Forecast", actual_records)
# fig.savefig(f"{which}_gumbel_attempts_forecast.png")
fig = plot_forecast_fin(model, tryfos_fcast, f"{which}, Gumbel Attempts", actual_records)
fig.savefig(f"final_{which}_gumbel_attempts_forecast.png")
fig = plot_forecast_small(model, tryfos_fcast, f"{which}, Gumbel Attempts", actual_records)
fig.savefig(f"s_final_{which}_gumbel_attempts_forecast.png")
except:
print(f"Error: failed on {which}")
fails.append(which)
mses
avg_log_probs
```
# Try to get Marathon to work.
```
#whiches = ["1m", "5000m", "10000m", "Marathon"]
whiches = ["Marathon"]
#whiches = []
mses = {}
avg_log_probs = {}
fails = []
#whiches = ["1000m"]
for which in whiches:
try:
df = pd.read_csv("tryfos_data.csv")
years, records = df["Year"].values, df[which].values # Years 1983 and onward are just forecasts
training_years = years[:15]
training_records = records[:15]
tryfos_years = years[15:]
tryfos_fcast = records[15:]
actual_df = pd.read_csv("tryfos_actual.csv")
_, actual_records = actual_df["Year"].values, actual_df[which].values
prior_parameters = {
'mu' : {
'mean' : training_records[0],
'std' : 0.05*training_records[0],
},
'sigma' : {
'lam' : 1/(0.5*training_records[0])
}
}
model = fm.ForecastModel(training_records, prior_parameters=prior_parameters, attempt_distribution="gumbel",
kind="min", train='all', fcast_len=len(tryfos_fcast), fcast_test_data=actual_records)
model.fit(chains=1)
model.posterior_predictive()
model.forecast()
# MSE calculation
median = np.quantile(model.forecast_samples[:,-15:], q=0.5, axis=0)
bayes_mse = fm.mse(median, model.fcast_test_data)
tryfos_mse = fm.mse(tryfos_fcast, model.fcast_test_data)
mses[which] = (bayes_mse, tryfos_mse)
# Average logp
avg_log_probs[which] = np.mean(model.posterior_predictive_ppc["log_like_holdout"])
# Plots
fig = plot_posterior_predictive(model, f"{which}, Gumbel Attempts, Posterior Predictive")
fig.savefig(f"final_{which}_gumbel_attempts_post_pred.png")
# fig = plot_forecast(model, tryfos_fcast, f"{which}, Gumbel Attempts, Forecast", actual_records)
# fig.savefig(f"{which}_gumbel_attempts_forecast.png")
fig = plot_forecast_fin(model, tryfos_fcast, f"{which}, Gumbel Attempts", actual_records)
fig.savefig(f"final_{which}_gumbel_attempts_forecast.png")
fig = plot_forecast_small(model, tryfos_fcast, f"{which}, Gumbel Attempts", actual_records)
fig.savefig(f"s_final_{which}_gumbel_attempts_forecast.png")
except:
print(f"Error: failed on {which}")
fails.append(which)
az.plot_posterior(model.trace)
```
| github_jupyter |
# Vector-space models: Static representations from contextual models
```
__author__ = "Christopher Potts"
__version__ = "CS224u, Stanford, Spring 2021"
```
## Contents
1. [Overview](#Overview)
1. [General set-up](#General-set-up)
1. [Loading Transformer models](#Loading-Transformer-models)
1. [The basics of tokenizing](#The-basics-of-tokenizing)
1. [The basics of representations](#The-basics-of-representations)
1. [The decontextualized approach](#The-decontextualized-approach)
1. [Basic example](#Basic-example)
1. [Creating a full VSM](#Creating-a-full-VSM)
1. [The aggregated approach](#The-aggregated-approach)
1. [Some related work](#Some-related-work)
## Overview
Can we get good static representations of words from models (like BERT) that supply only contextual representations? On the one hand, contextual models are very successful across a wide range of tasks, in large part because they are trained for a long time on a lot of data. This should be a boon for VSMs as we've designed them so far. On the other hand, the goal of having static representations might seem to be at odds with how these models process examples and represent examples. Part of the point is to obtain different representations for words depending on the context in which they occur, and a hallmark of the training procedure is that it processes sequences rather than individual words.
[Bommasani et al. (2020)](https://www.aclweb.org/anthology/2020.acl-main.431) make a significant step forward in our understanding of these issues. Ultimately, they arrive at a positive answer: excellent static word representations can be obtained from contextual models. They explore two strategies for achieving this:
1. __The decontextualized approach__: just process individual words as though they were isolated texts. Where a word consists of multiple tokens in the model, pool them with a function like mean or max.
1. __The aggregrated approach__: process lots and lots of texts containing the words of interest. As before, pool sub-word tokens, and also pool across all the pooled representations.
As Bommasani et al. say, the decontextualized approach "presents an unnatural input" – these models were not trained on individual words, but rather on longer sequences, so the individual words are infrequent kinds of inputs at best (and unattested as far as the model is concerned if the special boundary tokens [CLS] and [SEP] are not included). However, in practice, Bommasani et al. achieve very impressive results with this approach on word similarity/relatedness tasks.
The aggregrated approach is even better, but it requires more work and involves more decisions relating to which texts are processed.
This notebook briefly explores both of these approaches, with the goal of making it easy for you to apply these methods in [the associated homework and bakeoff](hw_wordrelatedness.ipynb).
## General set-up
```
import os
import pandas as pd
import torch
from transformers import BertModel, BertTokenizer
from transformers import RobertaModel, RobertaTokenizer
import utils
import vsm
DATA_HOME = os.path.join('data', 'vsmdata')
utils.fix_random_seeds()
```
The `transformers` library does a lot of logging. To avoid ending up with a cluttered notebook, I am changing the logging level. You might want to skip this as you scale up to building production systems, since the logging is very good – it gives you a lot of insights into what the models and code are doing.
```
import logging
logger = logging.getLogger()
logger.level = logging.ERROR
```
## Loading Transformer models
To start, let's get a feel for the basic API that `transformers` provides. The first step is specifying the pretrained parameters we'll be using:
```
bert_weights_name = 'bert-base-uncased'
```
There are lots other options for pretrained weights. See [this Hugging Face directory](https://huggingface.co/models).
Next, we specify a tokenizer and a model that match both each other and our choice of pretrained weights:
```
bert_tokenizer = BertTokenizer.from_pretrained(bert_weights_name)
bert_model = BertModel.from_pretrained(bert_weights_name)
```
## The basics of tokenizing
It's illuminating to see what the tokenizer does to example texts:
```
example_text = "Bert knows Snuffleupagus"
```
Simple tokenization:
```
bert_tokenizer.tokenize(example_text)
```
The `encode` method maps individual strings to indices into the underlying embedding used by the model:
```
ex_ids = bert_tokenizer.encode(example_text, add_special_tokens=True)
ex_ids
```
We can get a better feel for what these representations are like by mapping the indices back to "words":
```
bert_tokenizer.convert_ids_to_tokens(ex_ids)
```
Those are all the essential ingredients for working with these parameters in Hugging Face. Of course, the library has a lot of other functionality, but the above suffices for our current application.
## The basics of representations
To obtain the representations for a batch of examples, we use the `forward` method of the model, as follows:
```
with torch.no_grad():
reps = bert_model(torch.tensor([ex_ids]), output_hidden_states=True)
```
The return value `reps` is a special `transformers` class that holds a lot of representations. If we want just the final output representations for each token, we use `last_hidden_state`:
```
reps.last_hidden_state.shape
```
The shape indicates that our batch has 1 example, with 10 tokens, and each token is represented by a vector of dimensionality 768.
Aside: Hugging Face `transformers` models also have a `pooler_output` value. For BERT, this corresponds to the output representation above the [CLS] token, which is often used as a summary representation for the entire sequence. However, __we cannot use `pooler_output` in the current context__, as `transformers` adds new randomized parameters on top of it, to facilitate fine-tuning. If we want the [CLS] representation, we need to use `reps.last_hidden_state[:, 0]`.
Finally, if we want access to the output representations from each layer of the model, we use `hidden_states`. This will be `None` unless we set `output_hidden_states=True` when using the `forward` method, as above.
```
len(reps.hidden_states)
```
The length 13 corresponds to the initial embedding layer (layer 0) and the 12 layers of this BERT model.
The final layer in `hidden_states` is identical to `last_hidden_state`:
```
reps.hidden_states[-1].shape
torch.equal(reps.hidden_states[-1], reps.last_hidden_state)
```
## The decontextualized approach
As discussed above, Bommasani et al. (2020) define and explore two general strategies for obtaining static representations for word using a model like BERT. The simpler one involves processing individual words and, where they correspond to multiple tokens, pooling those token representations into a single vector using an operation like mean.
### Basic example
To begin to see what this is like in practice, we'll use the method `vsm.hf_encode`, which maps texts to their ids, taking care to use `unk_token` for texts that can't otherwise be processed by the model.
Where a word corresponds to just one token in the vocabulary, it will get mapped to a single id:
```
bert_tokenizer.tokenize('puppy')
vsm.hf_encode("puppy", bert_tokenizer)
```
As we saw above, some words map to multiple tokens:
```
bert_tokenizer.tokenize('snuffleupagus')
subtok_ids = vsm.hf_encode("snuffleupagus", bert_tokenizer)
subtok_ids
```
Next, the function `vsm.hf_represent` will map a batch of ids to their representations in a user-supplied model, at a specified layer in that model:
```
subtok_reps = vsm.hf_represent(subtok_ids, bert_model, layer=-1)
subtok_reps.shape
```
The shape here: 1 example containing 6 (sub-word) tokens, each of dimension 768. With `layer=-1`, we obtain the final output repreentation from the entire model.
The final step is to pool together the two tokens. Here, we can use a variety of operations; [Bommasani et al. 2020](https://www.aclweb.org/anthology/2020.acl-main.431) find that `mean` is the best overall:
```
subtok_pooled = vsm.mean_pooling(subtok_reps)
subtok_pooled.shape
```
The function `vsm.mean_pooling` is simple `torch.mean` with `axis=1`. There are also predefined functions `vsm.max_pooling`, `vsm.min_pooling`, and `vsm.last_pooling` (representation for the final token).
### Creating a full VSM
Now we want to scale the above process to a large vocabulary, so that we can create a full VSM. The function `vsm.create_subword_pooling_vsm` makes this easy. To start, we get the vocabulary from one of our count VSMs (all of which have the same vocabulary):
```
vsm_index = pd.read_csv(
os.path.join(DATA_HOME, 'yelp_window5-scaled.csv.gz'),
usecols=[0], index_col=0)
vocab = list(vsm_index.index)
vocab[: 5]
```
And then we use `vsm.create_subword_pooling_vsm`:
```
%%time
pooled_df = vsm.create_subword_pooling_vsm(
vocab, bert_tokenizer, bert_model, layer=1)
```
The result, `pooled_df`, is a `pd.DataFrame` with its index given by `vocab`. This can be used directly in the word relatedness evaluations that are central the homework and associated bakeoff.
```
pooled_df.shape
pooled_df.iloc[: 5, :5]
```
This approach, and the associated code, should work generally for all Hugging Face Transformer-based models. Bommasani et al. (2020) provide a lot of guidance when it comes to how the model, the layer choice, and the pooling function interact.
## The aggregated approach
The aggregated is also straightfoward to implement given the above tool. To start, we can create a map from vocabulary items into their sequences of ids:
```
vocab_ids = {w: vsm.hf_encode(w, bert_tokenizer)[0] for w in vocab}
```
Next, let's assume we have a corpus of texts that contain the words of interest:
```
corpus = [
"This is a sailing example",
"It's fun to go sailing!",
"We should go sailing.",
"I'd like to go sailing and sailing",
"This is merely an example"]
```
The following embeds every corpus example, keeping `layer=1` representations:
```
corpus_ids = [vsm.hf_encode(text, bert_tokenizer)
for text in corpus]
corpus_reps = [vsm.hf_represent(ids, bert_model, layer=1)
for ids in corpus_ids]
```
Finally, we define a convenience function for finding all the occurrences of a sublist in a larger list:
```
def find_sublist_indices(sublist, mainlist):
indices = []
length = len(sublist)
for i in range(0, len(mainlist)-length+1):
if mainlist[i: i+length] == sublist:
indices.append((i, i+length))
return indices
```
For example:
```
find_sublist_indices([1,2], [1, 2, 3, 0, 1, 2, 3])
```
And here's an example using our `vocab_ids` and `corpus`:
```
sailing = vocab_ids['sailing']
sailing_reps = []
for ids, reps in zip(corpus_ids, corpus_reps):
offsets = find_sublist_indices(sailing, ids.squeeze(0))
for (start, end) in offsets:
pooled = vsm.mean_pooling(reps[:, start: end])
sailing_reps.append(pooled)
sailing_rep = torch.mean(torch.cat(sailing_reps), axis=0).squeeze(0)
sailing_rep.shape
```
The above building blocks could be used as the basis for an original system and bakeoff entry for this unit. The major question is probably which data to use for the corpus.
## Some related work
1. [Ethayarajh (2019)](https://www.aclweb.org/anthology/D19-1006/) uses dimensionality reduction techniques (akin to LSA) to derive static representations from contextual models, and explores layer-wise variation in detailed, with findings that are likely to align with your experiences using the above techniques.
1. [Akbik et al (2019)](https://www.aclweb.org/anthology/N19-1078/) explore techniques similar to those of Bommasani et al. specifically for the supervised task of named entity recognition.
1. [Wang et al. (2020](https://arxiv.org/pdf/1911.02929.pdf) learn static representations from contextual ones using techniques adapted from the word2vec model.
| github_jupyter |
```
%matplotlib inline
```
# Experiment with Benchmark
Example to run the benchmark across all the baseline embedding algorithms.
```
from subprocess import call
import itertools
try: import cPickle as pickle
except: import pickle
import json
from argparse import ArgumentParser
import networkx as nx
import pandas as pd
import pdb
import os
import sys
from time import time
# sys.path.insert(0, './')
from gemben.utils import graph_gens
methClassMap = {"gf": "GraphFactorization",
"hope": "HOPE",
"lap": "LaplacianEigenmaps",
"node2vec": "node2vec",
"sdne": "SDNE",
"pa": "PreferentialAttachment",
"rand": "RandomEmb",
"cn": "CommonNeighbors",
"aa": "AdamicAdar",
"jc": "JaccardCoefficient"}
if __name__ == "__main__":
''' Sample usage
python experiments/exp_synthetic.py -syn_names all -plot_hyp_data 1 -meths all
'''
t1 = time()
parser = ArgumentParser(description='Graph Embedding Benchmark Experiments')
parser.add_argument('-data', '--data_sets',
help='dataset names (default: barabasi_albert_graph)')
parser.add_argument('-dims', '--dimensions',
help='embedding dimensions list(default: 128)')
parser.add_argument('-meth', '--methods',
help='method list (default: all methods)')
parser.add_argument('-plot_hyp_data', '--plot_hyp_data',
help='plot the hyperparameter results (default: False)')
parser.add_argument('-rounds', '--rounds',
help='number of rounds (default: 20)')
parser.add_argument('-s_sch', '--samp_scheme',
help='sampling scheme (default: rw)')
parser.add_argument('-lexp', '--lexp',
help='load experiment (default: False)')
params = json.load(
open('gemben/experiments/config/params_benchmark.conf', 'r')
)
args = vars(parser.parse_args())
print (args)
syn_hyps = json.load(
open('gemben/experiments/config/syn_hypRange.conf', 'r')
)
for k, v in args.items():
if v is not None:
params[k] = v
params["rounds"] = int(params["rounds"])
if params["data_sets"] == "all":
params["data_sets"] = syn_hyps.keys()
else:
params["data_sets"] = params["data_sets"].split(',')
params["lexp"] = bool(int(params["lexp"]))
params["plot_hyp_data"] = bool(int(params["plot_hyp_data"]))
if params["methods"] == "all":
params["methods"] = methClassMap.keys()
else:
params["methods"] = params["methods"].split(',')
params["dimensions"] = params["dimensions"].split(',')
samp_scheme = params["samp_scheme"]
for syn_data in params["data_sets"]:
syn_hyp_range = syn_hyps[syn_data]
hyp_keys = list(syn_hyp_range.keys())
if syn_data == "binary_community_graph":
graphClass = getattr(graph_gens, syn_data)
else:
graphClass = getattr(nx, syn_data)
ev_cols = ["GR MAP", "LP MAP", "LP P@100", "NC F1 score"]
for dim in params["dimensions"]:
dim = int(dim)
for meth in params["methods"]:
if not params["lexp"]:
hyp_df = pd.DataFrame(
columns=hyp_keys + ev_cols + ["Round Id"]
)
hyp_r_idx = 0
for hyp in itertools.product(*syn_hyp_range.values()):
hyp_dict = dict(zip(hyp_keys, hyp))
hyp_str = '_'.join(
"%s=%r" % (key, val) for (key, val) in hyp_dict.items()
)
syn_data_folder = 'benchmark_%s_%s' % (syn_data, hyp_str)
hyp_df_row = dict(zip(hyp_keys, hyp))
for r_id in range(params["rounds"]):
G = graphClass(**hyp_dict)
if not os.path.exists("gemben/data/%s" % syn_data_folder):
os.makedirs("gemben/data/%s" % syn_data_folder)
nx.write_gpickle(
G, 'gemben/data/%s/graph.gpickle' % syn_data_folder
)
os.system(
"python gem/experiments/exp.py -data %s -meth %s -dim %d -rounds 1 -s_sch %s -exp lp" % (syn_data_folder, meth, dim, samp_scheme)
)
MAP, prec, n_samps = pickle.load(
open('gemben/results/%s_%s_%d_%s.lp' % (syn_data_folder, meth, dim, samp_scheme), 'rb')
)
hyp_df.loc[hyp_r_idx, hyp_keys] = \
pd.Series(hyp_df_row)
prec_100 = prec[int(n_samps[0])][0][100]
hyp_df.loc[hyp_r_idx, ev_cols + ["Round Id"]] = \
[0, MAP[int(n_samps[0])][0], prec_100, 0, r_id]
hyp_r_idx += 1
hyp_df.to_hdf(
"gemben/intermediate/%s_%s_lp_%s_dim_%d_data_hyp.h5" % (syn_data, meth, samp_scheme, dim),
"df"
)
if params["plot_hyp_data"]:
from gem.utils import plot_util
plot_util.plot_hyp_data2(
hyp_keys, ["lp"], params["methods"], syn_data, samp_scheme, dim
)
print('Total time taken: %f sec' % (time() - t1))
```
| github_jupyter |
# MASH analysis pipeline with data-driven prior matrices
This notebook is a pipeline written in SoS to run `flashr + mashr` for multivariate analysis described in Urbut et al (2019). This pipeline was last applied to analyze GTEx V8 eQTL data, although it can be used as is to perform similar multivariate analysis for other association studies.
*Version: 2021.02.28 by Gao Wang and Yuxin Zou*
```
%revisions -s
```
## Data overview
`fastqtl` summary statistics data were obtained from dbGaP (data on CRI at UChicago Genetic Medicine). It has 49 tissues. [more description to come]
## Preparing MASH input
Using an established workflow (which takes 33hrs to run on a cluster system as configured by `midway2.yml`; see inside `fastqtl_to_mash.ipynb` for a note on computing environment),
```
INPUT_DIR=/project/compbio/GTEx_dbGaP/GTEx_Analysis_2017-06-05_v8/eqtl/GTEx_Analysis_v8_eQTL_all_associations
JOB_OPT="-c midway2.yml -q midway2"
sos run workflows/fastqtl_to_mash.ipynb --data-list $INPUT_DIR/FastQTLSumStats.list --common-suffix ".allpairs.txt" $JOB_OPT
```
As a result of command above I obtained the "mashable" data-set in the same format [as described here](https://stephenslab.github.io/gtexresults/gtexdata.html).
### Some data integrity check
1. Check if I get the same number of groups (genes) at the end of HDF5 data conversion:
```
$ zcat Whole_Blood.allpairs.txt.gz | cut -f1 | sort -u | wc -l
20316
$ h5ls Whole_Blood.allpairs.txt.h5 | wc -l
20315
```
The results agreed on Whole Blood sample (the original data has a header thus one line more than the H5 version). We should be good (since the pipeline reported success for all other files).
### Data & job summary
The command above took 33 hours on UChicago RCC `midway2`.
```
[MW] cat FastQTLSumStats.log
39832 out of 39832 groups merged!
```
So we have a total of 39832 genes (union of 49 tissues).
```
[MW] cat FastQTLSumStats.portable.log
15636 out of 39832 groups extracted!
```
We have 15636 groups without missing data in any tissue. This will be used to train the MASH model.
The "mashable" data file is `FastQTLSumStats.mash.rds`, 124Mb serialized R file.
## Multivariate adaptive shrinkage (MASH) analysis of eQTL data
Below is a "blackbox" implementation of the `mashr` eQTL workflow -- blackbox in the sense that you can run this pipeline as an executable, without thinking too much about it, if you see your problem fits our GTEx analysis scheme. However when reading it as a notebook it is a good source of information to help developing your own `mashr` analysis procedures.
Since the submission to biorxiv of Urbut 2017 we have improved implementation of MASH algorithm and made a new R package, [`mashr`](https://github.com/stephenslab/mashr). Major improvements compared to Urbut 2019 are:
1. Faster computation of likelihood and posterior quantities via matrix algebra tricks and a C++ implementation.
2. Faster computation of MASH mixture via convex optimization.
3. Replace `SFA` with `FLASH`, a new sparse factor analysis method to generate prior covariance candidates.
4. Improve estimate of residual variance $\hat{V}$.
At this point, the input data have already been converted from the original eQTL summary statistics to a format convenient for analysis in MASH, as a result of running the data conversion pipeline in `fastqtl_to_mash.ipynb`.
Example command:
```bash
JOB_OPT="-j 8"
#JOB_OPT="-c midway2.yml -q midway2"
sos run workflows/mashr_flashr_workflow.ipynb mash $JOB_OPT # --data ... --cwd ... --vhat ...
```
**FIXME: add comments on submitting jobs to HPC. Here we use the UChicago RCC cluster but other users can similarly configure their computating system to run the pipeline on HPC.**
### Global parameter settings
```
[global]
parameter: cwd = path('./mashr_flashr_workflow_output')
# Input summary statistics data
parameter: data = path("fastqtl_to_mash_output/FastQTLSumStats.mash.rds")
# Prefix of output files. If not specified, it will derive it from data.
# If it is specified, for example, `--output-prefix AnalysisResults`
# It will save output files as `{cwd}/AnalysisResults*`.
parameter: output_prefix = ''
# Exchangable effect (EE) or exchangable z-scores (EZ)
parameter: effect_model = 'EZ'
# Identifier of $\hat{V}$ estimate file
# Options are "identity", "simple", "mle", "vhat_corshrink_xcondition", "vhat_simple_specific"
parameter: vhat = 'simple'
parameter: mixture_components = ['flash', 'flash_nonneg', 'pca',"canonical"]
parameter: container = str
data = data.absolute()
cwd = cwd.absolute()
if len(output_prefix) == 0:
output_prefix = f"{data:bn}"
prior_data = file_target(f"{cwd:a}/{output_prefix}.{effect_model}.prior.rds")
vhat_data = file_target(f"{cwd:a}/{output_prefix}.{effect_model}.V_{vhat}.rds")
mash_model = file_target(f"{cwd:a}/{output_prefix}.{effect_model}.V_{vhat}.mash_model.rds")
def sort_uniq(seq):
seen = set()
return [x for x in seq if not (x in seen or seen.add(x))]
```
### Command interface
```
sos run mashr_flashr_workflow.ipynb -h
```
## Factor analyses
```
# Perform FLASH analysis with non-negative factor constraint (time estimate: 20min)
[flash]
input: data
output: f"{cwd}/{output_prefix}.flash.rds"
task: trunk_workers = 1, walltime = '2h', trunk_size = 1, mem = '8G', cores = 2, tags = f'{_output:bn}'
R: expand = "${ }", stderr = f'{_output:n}.stderr', stdout = f'{_output:n}.stdout', container = container
dat = readRDS(${_input:r})
dat = mashr::mash_set_data(dat$strong.b, Shat=dat$strong.s, alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3)
res = mashr::cov_flash(dat, factors="default", remove_singleton=${"TRUE" if "canonical" in mixture_components else "FALSE"}, output_model="${_output:n}.model.rds")
saveRDS(res, ${_output:r})
# Perform FLASH analysis with non-negative factor constraint (time estimate: 20min)
[flash_nonneg]
input: data
output: f"{cwd}/{output_prefix}.flash_nonneg.rds"
task: trunk_workers = 1, walltime = '2h', trunk_size = 1, mem = '8G', cores = 2, tags = f'{_output:bn}'
R: expand = "${ }", stderr = f'{_output:n}.stderr', stdout = f'{_output:n}.stdout', container = container
dat = readRDS(${_input:r})
dat = mashr::mash_set_data(dat$strong.b, Shat=dat$strong.s, alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3)
res = mashr::cov_flash(dat, factors="nonneg", remove_singleton=${"TRUE" if "canonical" in mixture_components else "FALSE"}, output_model="${_output:n}.model.rds")
saveRDS(res, ${_output:r})
[pca]
# Number of components in PCA analysis for prior
# set to 3 as in mash paper
parameter: npc = 2
input: data
output: f"{cwd}/{output_prefix}.pca.rds"
task: trunk_workers = 1, walltime = '1h', trunk_size = 1, mem = '4G', cores = 2, tags = f'{_output:bn}'
R: expand = "${ }", stderr = f'{_output:n}.stderr', stdout = f'{_output:n}.stdout', container = container
dat = readRDS(${_input:r})
dat = mashr::mash_set_data(dat$strong.b, Shat=dat$strong.s, alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3)
res = mashr::cov_pca(dat, ${npc})
saveRDS(res, ${_output:r})
[canonical]
input: data
output: f"{cwd}/{output_prefix}.canonical.rds"
task: trunk_workers = 1, walltime = '1h', trunk_size = 1, mem = '4G', cores = 2, tags = f'{_output:bn}'
R: expand = "${ }", stderr = f'{_output:n}.stderr', stdout = f'{_output:n}.stdout', container = container
library("mashr")
dat = readRDS(${_input:r})
dat = mashr::mash_set_data(dat$strong.b, Shat=dat$strong.s, alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3)
res = mashr::cov_canonical(dat)
saveRDS(res, ${_output:r})
```
### Estimate residual variance
FIXME: add some narratives here explaining what we do in each method.
```
# V estimate: "identity" method
[vhat_identity]
input: data
output: f'{vhat_data:nn}.V_identity.rds'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
dat = readRDS(${_input:r})
saveRDS(diag(ncol(dat$random.b)), ${_output:r})
# V estimate: "simple" method (using null z-scores)
[vhat_simple]
depends: R_library("mashr")
input: data
output: f'{vhat_data:nn}.V_simple.rds'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
library(mashr)
dat = readRDS(${_input:r})
vhat = estimate_null_correlation_simple(mash_set_data(dat$random.b, Shat=dat$random.s, alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3))
saveRDS(vhat, ${_output:r})
# V estimate: "mle" method
[vhat_mle]
# number of samples to use
parameter: n_subset = 6000
# maximum number of iterations
parameter: max_iter = 6
depends: R_library("mashr")
input: data, prior_data
output: f'{vhat_data:nn}.V_mle.rds'
task: trunk_workers = 1, walltime = '36h', trunk_size = 1, mem = '4G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
library(mashr)
# choose random subset
set.seed(1)
random.subset = sample(1:nrow(dat$random.b), min(${n_subset}, nrow(dat$random.b)))
random.subset = mash_set_data(dat$random.b[random.subset,], dat$random.s[random.subset,], alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3)
# estimate V mle
vhat = mash_estimate_corr_em(random.subset, readRDS(${_input[1]:r}), max_iter = ${max_iter})
saveRDS(vhat, ${_output:r})
# Estimate each V separately via corshrink
[vhat_corshrink_xcondition_1]
# Utility script
parameter: util_script = path('/project/mstephens/gtex/scripts/SumstatQuery.R')
# List of genes to analyze
parameter: gene_list = path()
fail_if(not gene_list.is_file(), msg = 'Please specify valid path for --gene-list')
fail_if(not util_script.is_file() and len(str(util_script)), msg = 'Please specify valid path for --util-script')
genes = sort_uniq([x.strip().strip('"') for x in open(f'{gene_list:a}').readlines() if not x.strip().startswith('#')])
depends: R_library("CorShrink")
input: data, for_each = 'genes'
output: f'{vhat_data:nn}/{vhat_data:bnn}_V_corshrink_{_genes}.rds'
task: trunk_workers = 1, walltime = '3m', trunk_size = 500, mem = '3G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
source(${util_script:r})
CorShrink_sum = function(gene, database, z_thresh = 2){
print(gene)
dat <- GetSS(gene, database)
z = dat$"z-score"
max_absz = apply(abs(z), 1, max)
nullish = which(max_absz < z_thresh)
# if (length(nullish) < ncol(z)) {
# stop("not enough null data to estimate null correlation")
# }
if (length(nullish) <= 1){
mat = diag(ncol(z))
} else {
nullish_z = z[nullish, ]
mat = as.matrix(CorShrink::CorShrinkData(nullish_z, ash.control = list(mixcompdist = "halfuniform"))$cor)
}
return(mat)
}
V = Corshrink_sum("${_genes}", ${data:r})
saveRDS(V, ${_output:r})
# Estimate each V separately via "simple" method
[vhat_simple_specific_1]
# Utility script
parameter: util_script = path('/project/mstephens/gtex/scripts/SumstatQuery.R')
# List of genes to analyze
parameter: gene_list = path()
fail_if(not gene_list.is_file(), msg = 'Please specify valid path for --gene-list')
fail_if(not util_script.is_file() and len(str(util_script)), msg = 'Please specify valid path for --util-script')
genes = sort_uniq([x.strip().strip('"') for x in open(f'{gene_list:a}').readlines() if not x.strip().startswith('#')])
depends: R_library("Matrix")
input: data, for_each = 'genes'
output: f'{vhat_data:nn}/{vhat_data:bnn}_V_simple_{_genes}.rds'
task: trunk_workers = 1, walltime = '1m', trunk_size = 500, mem = '3G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
source(${util_script:r})
simple_V = function(gene, database, z_thresh = 2){
print(gene)
dat <- GetSS(gene, database)
z = dat$"z-score"
max_absz = apply(abs(z), 1, max)
nullish = which(max_absz < z_thresh)
# if (length(nullish) < ncol(z)) {
# stop("not enough null data to estimate null correlation")
# }
if (length(nullish) <= 1){
mat = diag(ncol(z))
} else {
nullish_z = z[nullish, ]
mat = as.matrix(Matrix::nearPD(as.matrix(cov(nullish_z)), conv.tol=1e-06, doSym = TRUE, corr=TRUE)$mat)
}
return(mat)
}
V = simple_V("${_genes}", ${data:r})
saveRDS(V, ${_output:r})
# Consolidate Vhat into one file
[vhat_corshrink_xcondition_2, vhat_simple_specific_2]
depends: R_library("parallel")
# List of genes to analyze
parameter: gene_list = path()
fail_if(not gene_list.is_file(), msg = 'Please specify valid path for --gene-list')
genes = paths([x.strip().strip('"') for x in open(f'{gene_list:a}').readlines() if not x.strip().startswith('#')])
input: group_by = 'all'
output: f"{vhat_data:nn}.V_{step_name.rsplit('_',1)[0]}.rds"
task: trunk_workers = 1, walltime = '1h', trunk_size = 1, mem = '4G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
library(parallel)
files = sapply(c(${genes:r,}), function(g) paste0(c(${_input[0]:adr}), '/', g, '.rds'), USE.NAMES=FALSE)
V = mclapply(files, function(i){ readRDS(i) }, mc.cores = 1)
R = dim(V[[1]])[1]
L = length(V)
V.array = array(as.numeric(unlist(V)), dim=c(R, R, L))
saveRDS(V.array, ${_output:ar})
```
### Compute MASH priors
Main reference are our `mashr` vignettes [this for mashr eQTL outline](https://stephenslab.github.io/mashr/articles/eQTL_outline.html) and [this for using FLASH prior](https://github.com/stephenslab/mashr/blob/master/vignettes/flash_mash.Rmd).
The outcome of this workflow should be found under `./mashr_flashr_workflow_output` folder (can be configured). File names have pattern `*.mash_model_*.rds`. They can be used to computer posterior for input list of gene-SNP pairs (see next section).
```
# Compute data-driven / canonical prior matrices (time estimate: 2h ~ 12h for ~30 49 by 49 matrix mixture)
[prior]
depends: R_library("mashr")
# if vhat method is `mle` it should use V_simple to analyze the data to provide a rough estimate, then later be refined via `mle`.
input: [data, vhat_data if vhat != "mle" else f'{vhat_data:nn}.V_simple.rds'] + [f"{cwd}/{output_prefix}.{m}.rds" for m in mixture_components]
output: prior_data
task: trunk_workers = 1, walltime = '36h', trunk_size = 1, mem = '4G', cores = 4, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
library(mashr)
rds_files = c(${_input:r,})
dat = readRDS(rds_files[1])
vhat = readRDS(rds_files[2])
mash_data = mash_set_data(dat$strong.b, Shat=dat$strong.s, V=vhat, alpha=${1 if effect_model == 'EZ' else 0}, zero_Bhat_Shat_reset = 1E3)
# setup prior
U = list(XtX = t(mash_data$Bhat) %*% mash_data$Bhat / nrow(mash_data$Bhat))
for (f in rds_files[3:length(rds_files)]) U = c(U, readRDS(f))
U.ed = cov_ed(mash_data, U, logfile=${_output:nr})
# Canonical matrices
U.can = cov_canonical(mash_data)
saveRDS(c(U.ed, U.can), ${_output:r})
```
## `mashr` mixture model fitting
```
# Fit MASH mixture model (time estimate: <15min for 70K by 49 matrix)
[mash_1]
depends: R_library("mashr")
input: data, vhat_data, prior_data
output: mash_model
task: trunk_workers = 1, walltime = '36h', trunk_size = 1, mem = '4G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
library(mashr)
dat = readRDS(${_input[0]:r})
vhat = readRDS(${_input[1]:r})
U = readRDS(${_input[2]:r})
mash_data = mash_set_data(dat$random.b, Shat=dat$random.s, alpha=${1 if effect_model == 'EZ' else 0}, V=vhat, zero_Bhat_Shat_reset = 1E3)
saveRDS(mash(mash_data, Ulist = U, outputlevel = 1), ${_output:r})
```
### Optional posterior computations
Additionally provide posterior for the "strong" set in MASH input data.
```
# Compute posterior for the "strong" set of data as in Urbut et al 2017.
# This is optional because most of the time we want to apply the
# MASH model learned on much larger data-set.
[mash_2]
# default to True; use --no-compute-posterior to disable this
parameter: compute_posterior = True
# input Vhat file for the batch of posterior data
skip_if(not compute_posterior)
depends: R_library("mashr")
input: data, vhat_data, mash_model
output: f"{cwd:a}/{output_prefix}.{effect_model}.posterior.rds"
task: trunk_workers = 1, walltime = '36h', trunk_size = 1, mem = '4G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout", container = container
library(mashr)
dat = readRDS(${_input[0]:r})
vhat = readRDS(${_input[1]:r})
mash_data = mash_set_data(dat$strong.b, Shat=dat$strong.s, alpha=${1 if effect_model == 'EZ' else 0}, V=vhat, zero_Bhat_Shat_reset = 1E3)
mash_model = readRDS(${_input[2]:ar})
saveRDS(mash_compute_posterior_matrices(mash_model, mash_data), ${_output:r})
```
## Compute MASH posteriors
In the GTEx V6 paper we assumed one eQTL per gene and applied the model learned above to those SNPs. Under that assumption, the input data for posterior calculation will be the `dat$strong.*` matrices.
It is a fairly straightforward procedure as shown in [this vignette](https://stephenslab.github.io/mashr/articles/eQTL_outline.html).
But it is often more interesting to apply MASH to given list of eQTLs, eg, from those from fine-mapping results. In GTEx V8 analysis we obtain such gene-SNP pairs from DAP-G fine-mapping analysis. See [this notebook](https://stephenslab.github.io/gtex-eqtls/analysis/Independent_eQTL_Results.html) for how the input data is prepared. The workflow below takes a number of input chunks (each chunk is a list of matrices `dat$Bhat` and `dat$Shat`)
and computes posterior for each chunk. It is therefore suited for running in parallel posterior computation for all gene-SNP pairs, if input data chunks are provided.
```
JOB_OPT="-c midway2.yml -q midway2"
DATA_DIR=/project/compbio/GTEx_eQTL/independent_eQTL
sos run workflows/mashr_flashr_workflow.ipynb posterior \
$JOB_OPT \
--posterior-input $DATA_DIR/DAPG_pip_gt_0.01-AllTissues/DAPG_pip_gt_0.01-AllTissues.*.rds \
$DATA_DIR/ConditionalAnalysis_AllTissues/ConditionalAnalysis_AllTissues.*.rds
```
```
# Apply posterior calculations
[posterior_1]
parameter: analysis_units = path
regions = [x.replace("\"","").strip().split() for x in open(analysis_units).readlines() if x.strip() and not x.strip().startswith('#')]
parameter: mash_model = path(f"{cwd:a}/{output_prefix}.{effect_model}.V_{vhat}.mash_model.rds")
parameter: posterior_input = [path(x[0]) for x in regions]
parameter: posterior_vhat_files = paths()
# eg, if data is saved in R list as data$strong, then
# when you specify `--data-table-name strong` it will read the data as
# readRDS('{_input:r}')$strong
parameter: data_table_name = ''
parameter: bhat_table_name = 'bhat'
parameter: shat_table_name = 'sbhat'
mash_model = f"{mash_model:a}"
skip_if(len(posterior_input) == 0, msg = "No posterior input data to compute on. Please specify it using --posterior-input.")
fail_if(len(posterior_vhat_files) > 1 and len(posterior_vhat_files) != len(posterior_input), msg = "length of --posterior-input and --posterior-vhat-files do not agree.")
for p in posterior_input:
fail_if(not p.is_file(), msg = f'Cannot find posterior input file ``{p}``')
depends: R_library("mashr"), mash_model
input: posterior_input, group_by = 1
output: f"{cwd}/{_input:bn}.posterior.rds"
task: trunk_workers = 1, walltime = '20h', trunk_size = 1, mem = '20G', cores = 1, tags = f'{_output:bn}'
R: expand = "${ }", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout"
library(mashr)
data = readRDS("${_input}")${('$' + data_table_name) if data_table_name else ''}
vhat = readRDS("${vhat_data if len(posterior_vhat_files) == 0 else posterior_vhat_files[_index]}")
mash_data = mash_set_data(data$${bhat_table_name}, Shat=data$${shat_table_name}, alpha=${1 if effect_model == 'EZ' else 0}, V=vhat, zero_Bhat_Shat_reset = 1E3)
mash_output = mash_compute_posterior_matrices(readRDS("${mash_model}"), mash_data)
mash_output$snps = data$snps
saveRDS(mash_output, ${_output:r})
[posterior_2]
input: group_by = "all"
output:f"{cwd}/mash_output_list"
python: expand = "$[ ]", workdir = cwd, stderr = f"{_output:n}.stderr", stdout = f"{_output:n}.stdout"
import pandas as pd
pd.DataFrame({"#mash_result" : [$[_input:ar,]] }).to_csv("$[_output]",index = False ,header = False, sep = "t")
```
### Posterior results
1. The outcome of the `[posterior]` step should produce a number of serialized R objects `*.batch_*.posterior.rds` (can be loaded to R via `readRDS()`) -- I chopped data to batches to take advantage of computing in multiple cluster nodes. It should be self-explanary but please let me know otherwise.
2. Other posterior related files are:
1. `*.batch_*.yaml`: gene-SNP pairs of interest, identified elsewhere (eg. fine-mapping analysis).
2. The corresponding univariate analysis summary statistics for gene-SNPs from `*.batch_*.yaml` are extracted and saved to `*.batch_*.rds`, creating input to the `[posterior]` step.
3. Note the `*.batch_*.stdout` file documents some SNPs found in fine-mapping results but not found in the original `fastqtl` output.
| github_jupyter |
## Training Example
#### Training a model is very simple, follow this example to train your own model
```
#First import the training tool and the torchio library
import sys
sys.path.append('../Radiology_and_AI')
from training.run_training import run_training
import torchio as tio
#Next define what transforms you want applied to the training data
#Both the training and validation data must have the same normalization and data preparation steps
#Only the training samples should have the augmentations applied
#Any transforms found at https://torchio.readthedocs.io/transforms/transforms.html can be applied
#Keep track of the normalization and data preparation steps steps performed, you will need to apply the to all data passed into the model into the future
#These transforms are applied to data before it is used for training the model
training_transform = tio.Compose([
#Normalization
tio.ZNormalization(masking_method=tio.ZNormalization.mean),
#Augmentation
#Play around with different augmentations as you desire, refer to the torchio docs to see how they work
tio.RandomNoise(p=0.5),
tio.RandomGamma(log_gamma=(-0.3, 0.3)),
tio.RandomElasticDeformation(),
#Preparation
tio.CropOrPad((240, 240, 160)), #Crop/pad the images to a dimension your model can handle, our default unnet model requires the dimensions be multiples of 8
tio.OneHot(num_classes=5), #Set num_classes to the max segmentation label + 1
])
#These transforms are applied to data before it is used to determined the performance of the model on the validation set
validation_transform = tio.Compose([
#Normalization
tio.ZNormalization(masking_method=tio.ZNormalization.mean),
#Preparation
tio.CropOrPad((240, 240, 160)),
tio.OneHot(num_classes=5)
])
#The run training method applies the transforms you set and trains a model based on the parameters set here
run_training(
#input_data_path must be set to the path to the folder containing the subfolders for each training example.
#Each subfolder should contain one nii.gz file for each of the imaging series and the segmentation for that example
#The name of each nii.gz file should be the name of the parent folder followed by the name of the imaging series type or seg if it is the segmentation
#For example,MICCAI_BraTS2020_TrainingData contains ~300 folders, each corresponding to an input example,
# one folder BraTS20_Training_001, contains five files: BraTS20_Training_001_flair.nii.gz, BraTS20_Training_001_seg.nii.gz, BraTS20_Training_001_t1.nii.gz , BraTS20_Training_001_t2.nii.gz,and BraTS20_Training_001_t1ce.nii.gz
input_data_path = '../../brats_new/BraTS2020_TrainingData/MICCAI_BraTS2020_TrainingData',
#Where you want your trained model to be saved after training is completed
output_model_path = '../Models/test_train_many_1e-3.pt',
#The transforms you created previously
training_transform = training_transform,
validation_transform = validation_transform,
#The names of the modalities every example in your input data has
input_channels_list = ['flair','t1','t2','t1ce'],
#Which of the labels in your segmentation you want to train your model to predict
seg_channels = [1,2,4],
#The name of the type of model you want to train, currently UNet3D is the only available model
model_type = 'UNet3D',
#The amount of examples per training batch, reduce/increase this based on memory availability
batch_size = 1,
#The amount of cpus you want to be avaiable for loading the input data into the model
num_loading_cpus = 1,
#The learning rate of the AdamW optimizer
learning_rate = 1e-3,
#Whether or not you want to run wandb logging of your run, install wandb to use these parameters
wandb_logging = False,
wandb_project_name = None,
wandb_run_name = None,
#The seed determines how your training and validation data will be randomly split
#training_split_ratio is the share of your input data you want to use for training the model, the remainder is used for the validation data
#Keep track of both the seed and ratio used if you want to be able to split your input data the same way in the future
seed=42,
training_split_ratio = 0.9,
#Any parameters which can be applied to a pytorch lightning trainer can also be applied, below is a selection of parameters you can apply
#Refer to https://pytorch-lightning.readthedocs.io/en/latest/common/trainer.html#trainer-class-api to see the other parameters you could apply
max_epochs=10,
amp_backend = 'apex',
amp_level = 'O1',
precision=16,
check_val_every_n_epoch = 1,
log_every_n_steps=10,
val_check_interval= 50,
progress_bar_refresh_rate=1,
)
```
## Evaluation Example
#### If you want to evaluate your model in the future on a certain test dataset follow the below
```
#First import the training tool and the torchio library
import sys
sys.path.append('.../Radiology_and_AI')
from training.run_training import run_eval
import torchio as tio
#Whatever normalization and data preperation steps you performed must also be applied here
#Refer to the above for more info
#These transforms are applied to data before it is used to determined the performance of the model on the validation set
test_transform = tio.Compose([
#Normalization
tio.ZNormalization(masking_method=tio.ZNormalization.mean),
#Preparation
tio.CropOrPad((240, 240, 160)),
tio.OneHot(num_classes=5)
])
#The run_eval method evaluates and prints your models performance on a test dataset by averaging the Dice loss per batch
run_eval(
#The path to the folder containing the data, refer to the training example for more info
input_data_path= '../../brats_new/BraTS2020_TrainingData/MICCAI_BraTS2020_TrainingData',
#The path to the saved model weights
model_path="../../randgamma.pt",
#The transforms you specified above
validation_transform=validation_transform,
#The names of the modalities every example in your input data has
input_channels_list = ['flair','t1','t2','t1ce'],
#Which of the labels in your segmentation you want to train your model to predict
seg_channels = [1,2,4],
#The name of the type of model you want to train, currently UNet3D is the only available model
model_type = 'UNet3D'
#If set to true, we only return the performance of the model on the example which were not used for training, based on the train_val_split_ration and seed
#If false we evaluate on all data and ignore seed and training_split_ratio,
#set to false if input_data_path is set to a dataset you did not use during training
is_validation_data = True,
training_split_ratio=0.9,
seed=42,
#The amount of examples per training batch, reduce/increase this based on memory availability
batch_size=1,
#The amount of cpus you want to be avaiable for loading the input data into the model
num_loading_cpus = 1,
)
```
## Visualization Example
#### Tools for generating gifs, slices, and nifti files from input data and model predictions
```
#First import the training tool and the torchio library
import sys
sys.path.append('../Radiology_and_AI')
sys.path.append('../../MedicalZooPytorch')
from visuals.run_visualization import gen_visuals
import torchio as tio
#Whatever normalization and data preperation steps you performed must also be applied here
#Refer to the above for more info
#These transforms are applied to data before it is used to determined the performance of the model on the validation set
validation_transform = tio.Compose([
#Normalization
tio.ZNormalization(masking_method=tio.ZNormalization.mean),
#Preparation
tio.CropOrPad((240, 240, 160)),
tio.OneHot(num_classes=5)
])
#The gen_visuals method can be used for generating gifs of the inpu
gen_visuals(
#The path to the folder containing the nifti files for an example
image_path="../../brats_new/BraTS2020_TrainingData/MICCAI_BraTS2020_TrainingData/BraTS20_Training_010",
#The transforms applied to the input should the same applied to the validation data during model training
transforms = validation_transform,
#The path to the model to use for predictions
model_path = "../Models/test_train_many_1e-3.pt",
#Generate visuals using segmentations generated by the model
gen_pred = True,
#Generate visuals using annotated segmentations
gen_true = True,
#The modalities your input example has
input_channels_list = ['flair','t1','t2','t1ce'],
#The labels your segmentation has
seg_channels = [1,2,4],
#Save a gif of the brain in 3D spinning on its vertical axis
gen_gif = False,
#Where to output the gif of the brain with segmentations either from the annotated labels or the predicted labels
true_gif_output_path = "../../output/true",
pred_gif_output_path = "../../output/pred",
#Which segmentation labels to display in the gif
seg_channels_to_display_gif = [1,2,4],
#The angle from the horizontal axis you are looking down on the brain at as it is spinning
gif_view_angle = 30,
#How much the brain rotates between images of the gif
gif_angle_rotation = 20,
#fig size of the gif images
fig_size_gif = (50,25),
#Save an image of slices of the brain at different views and with segmentations
gen_slice = True,
#where to save the generated slice image
slice_output_path = "../../output/slices",
#Fig size of the slice images
fig_size_slice = (25,50),
#Which seg labels to display in the slice, they will be layered in this order on the image
seg_channels_to_display_slice = [2,4,1],
#Which slice to display for different views of the brain
sag_slice = None, #Sagittal
cor_slice = None, #Coronal
axi_slice = None, #Axial
disp_slice_base = True, #WHether or not to display the input image in the background
slice_title = None, #THe title of the slice images figure
gen_nifti = True, #Whether or not to generate nifti files for the input image and the segmentations
nifti_output_path = "../../output/nifti", #WHere to ssave the nifti files
)
```
| github_jupyter |
# Introduction and demonstration of OSTL
This tutorial starts from a short description of BPTT, followed by a discussion of its shortcomings. Next, we introduce OSTL as a biologically-inspired alternative to BPTT. We demonstrate its basic operational principle and showcase the gradient-equivalence for certain scenarios, using here an example of a simple task of learning the XOR function. In particular, this tutorial:
1. Introduces Online Spatio-Temporal Learning (OSTL) as an alternative to back-propagation through time (BPTT)
2. Illustrates the basic working principle of OSTL
3. Demonstrates gradient-equivalence for LSTM and bio-inspired SNU units
This tutorial is based on the paper
**Bohnstingl, T., Woźniak, S., Maass, W., Pantazi, A., & Eleftheriou, E. (2020). Online Spatio-Temporal Learning in Deep Neural Networks. arXiv, 2007.12723. https://arxiv.org/abs/2007.12723v2**
## Back-propagation through time (BPTT)
Almost all recurrent neural networks (RNN) used in machine learning operating on temporal input data are trained with the error back-propagation through time algorithm. This algorithm works by unrolling the RNN over time, i.e., the network is replicated for each individual discrete time step. The video below illustrates this process for a two-layer RNN which receives a phrase of French words as an input sequence: "Conseil Européen pour la Recherche Nucléaire", and is given the task to translate this three-step long sentence into its English version: "European Council for Nuclear Research".

At first, the network is unrolled in time, i.e., the network is replicated for three time steps. Then, the inputs for these time steps are fed sequentially and the output is computed for each time step separately. Once the entire input sequence has been processed, the network operation is interrupted and the gradients of the error with respect to the parameters are propagated back through time.
$$
\newcommand{\dv}[2]{\frac{\textrm{d}#1}{\textrm{d}#2}}
\newcommand{\pdv}[2]{\frac{\partial #1}{\partial #2}}
\begin{align}
\Delta {\theta}_l &= -\eta \dv{E}{{\theta}_l}\\
&= -\eta \sum_{1 \leq t \leq T} \dv{E_k^t}{{\theta}_l}
\end{align}$$
It is important to note that the error is typically only provided at the output layer *k* and has to propagate through the units in the network to reach all parameters. For example, if a network is composed of two layers with simple RNN cells:
$$
\newcommand{\dv}[2]{\frac{\textrm{d}#1}{\textrm{d}#2}}
\newcommand{\pdv}[2]{\frac{\partial #1}{\partial #2}}
\begin{align}
{s}_l^t &= g({W}_l x^t + {H}_l y^t + d \cdot (1- y_l^{t-1}) \cdot {s}_l^{t-1}),\\
{y}_l^t &= {\sigma}({s}^t + {b}_l),
\end{align}$$
with $${\theta}_l=\{{W}_l, {H}_l, {b}_l\}$$.
### Disadvantages and drawbacks
- In order to compute $\Delta {\theta}_l$, the input sequence has to be observed till its last time step and the intermediate activations need to be stored
- In consequence, memory requirements grow linearly with length of input sequence *T*
- Separate phases for the forward propagation and the gradient computation are required
- $\Delta {\theta}_l$ contains a complex combination of *spatial* and *temporal* gradients
## Online Spatio-Temporal Learning (OSTL)
A way to tackle the shortcomings of BPTT is proposed in OSTL. This algorithm also makes use of gradient computations, but the way those computations are done is much inspired by findings from biological systems.
In particular, as the following Figure illustrates, three factors are found in biology to modulate the change of synaptic weights (plasticity):
1. Pre-synaptic activity
2. Post-synaptic activity
3. Learning signals, so called-third factors

Inspired by this, we assign to each synapse a so-called eligibility trace
$$
\newcommand{\dv}[2]{\frac{\textrm{d}#1}{\textrm{d}#2}}
\newcommand{\pdv}[2]{\frac{\partial #1}{\partial #2}}
\begin{align}
\mathbf{e}^{t,{\theta}_l}_{k} &= \pdv{{y}^t_{k}}{{s}^t_{k}} {\epsilon}^{t,{\theta}_l}_{k} + \pdv{{y}^t_{k}}{{\theta}_{l}},
\end{align}$$
with $$
\newcommand{\dv}[2]{\frac{\textrm{d}#1}{\textrm{d}#2}}
\newcommand{\pdv}[2]{\frac{\partial #1}{\partial #2}}
\newcommand\myeq{\stackrel{\mbox{def}}{=}}
\begin{align}
{\epsilon}_k^{t,{\theta}_l} &\myeq \dv{{s}_k^t}{{\theta}_l}.
\end{align}$$
Importantly, this eligibility trace holds information of the pre- and post-synaptic activity and carries this information through time, hence those are the spatial gradient components. Furthermoer, we define the learning signal, which transports information from the environment to the synapses, to be
$$
\newcommand{\dv}[2]{\frac{\textrm{d}#1}{\textrm{d}#2}}
\newcommand{\pdv}[2]{\frac{\partial #1}{\partial #2}}
\begin{align}
\mathbf{L}^t_{l} &= \pdv{E^t}{{y}_k^t} \left( \prod_{(k-l+1) > m \ge 1} \pdv{{y}^t_{k-m+1}}{{s}^t_{k-m+1}} \pdv{{s}^t_{k-m+1}}{{y}^t_{k-m}} \right).
\end{align}$$
The learning signal transports information from the environment to the individual layers of the network *l*, hence those are the temporal components of the gradients.
To finally compute the gradients for the trainable parameters, the eligitbility traces and the learning signals are combined at each time step (online) according to
$$
\newcommand{\dv}[2]{\frac{\textrm{d}#1}{\textrm{d}#2}}
\newcommand{\pdv}[2]{\frac{\partial #1}{\partial #2}}
\begin{align}
\Delta {\theta}_l &= -\eta \sum_{1 \leq t \leq T} \left( \mathbf{L}_l^t \mathbf{e}_l^{t,{\theta}_l} + \mathbf{R}\right),
\end{align}
$$
which gives rise to the name "Online Spatio-Temporal learning".
The working pricinple of OSTL is illustrated in the animation below.

## Implementation
We start by importing required python packages and by defining an auxiliary function for data generation.
```
#General imports
import collections
import argparse
import time
import pickle
import Scripts.Utils_Persistence as Utils_Persistence
import numpy as np
import tensorflow as tf
from tensorflow.python.ops import rnn_cell_impl
#This function creates data from the XOR function
def createXorData(bs, seq_len):
x_val = np.tile(np.expand_dims([[1], [0], [1], [1], [0], [0], [1], [1], [0], [1]], 0), (bs, 1, 1))
y_val = np.tile(np.expand_dims([[0], [1], [1], [1], [0], [0], [0], [0], [1], [0]], 0), (bs, 1, 1))
return x_val, y_val
#OSTL specific inputs
from Scripts.RNN_loop import dynamic_rnn
from Scripts.MultiRNNCell import MultiRNNCell
from Scripts.gradient_descent import GradientDescentOptimizer as opt
from Scripts.Neuron_models import SNUELayer
```
### Define configuration of the network
In this section, the network configuration is defined. For example, the type of unit to run may be selected. One of the options is to use soft spiking neural units (sSNU). These units have been introduced in the paper **Woźniak, S., Pantazi, A., Bohnstingl, T., & Eleftheriou, E. (2020). Deep learning incorporating biologically inspired neural dynamics and in-memory computing - Nature Machine Intelligence. Nat. Mach. Intell., 2(6), 325–336. doi: 10.1038/s42256-020-0187-0**
```
config = {'lr': 0.01,
'batch_size': 1,
'cell': 'sSNU',
'seq_len': 10,
'save_state': True,
}
```
As the first step, we generate the data that will later be used for training and for testing. This tutorial illustrates solving a fixed input/output relation using the sSNU. The following animation demonstrates this task:

```
#Fix the random seed in order to be able to numerically
#compare the computed gradients
np.random.seed(1234)
tf.set_random_seed(1234)
#We generate "config['batch_size']" examples with a length of 100 for testing
val_data_x_val, val_data_y_val = createXorData(config['batch_size'], config['seq_len'])
#We generate data roughly 2000 examples with a length of 100 for traininging
train_data_x_val, train_data_y_val = createXorData(int(2000/config['batch_size']), config['seq_len'])
train_data_x_val.shape
#Generate test data
test_data_x_val, test_data_y_val = createXorData(config['batch_size'], config['seq_len'])
```
Next we can also briefly visualize the data
```
import matplotlib
matplotlib.rcParams['text.usetex'] = True
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [20, 10]
from matplotlib import patches
from matplotlib import cm
matplotlib.rcParams.update({'font.size': 22})
fig, ax = plt.subplots(1, 1)
for x in np.where(train_data_x_val[10, :20, 0])[0]:
ax.axvline(x=x, ymin=0.03, ymax=0.25, color='C0', linewidth=6.)
p = patches.Rectangle((-0.2, -0.1), 0.4+np.max(np.where(train_data_x_val[10, :20, :])[0]), 1, linewidth=1, edgecolor='none', facecolor='C0', alpha=0.2)
ax.add_patch(p)
for x in np.where(train_data_y_val[10, :20, 0])[0]:
ax.axvline(x=x, ymin=0.7, ymax=0.9, color='C2', linewidth=6.)
p = patches.Rectangle((-0.2, 2.3), 0.4+np.max(np.where(train_data_x_val[10, :20, :])[0]), 1, linewidth=1, edgecolor='none', facecolor='C2', alpha=0.2)
ax.add_patch(p)
ax.set_xlim([-5., np.max(np.where(train_data_x_val[10, :20, :])[0])+5.])
ax.set_xticks(np.arange(0., np.max(np.where(train_data_x_val[10, :20, :])[0])+5.))
ax.set_xlabel('Timestep')
ax.set_ylim([-0.1,3.5])
ax.set_yticklabels(['Input 1', 'Input 2', 'Ouptut'])
ax.set_yticks([0.45, 1.6, 2.7])
```
### Preparation of the network architecture
<Put an illustration of the network architecture here>
Let's define some placeholders
```
#Define the placeholders to construct the network
x = tf.placeholder(tf.float32, [None, None, 1]) #(batchsize, timesteps, number of units)
target = tf.placeholder(tf.float32, [None, None, 1])
train = tf.placeholder_with_default(tf.constant(1, tf.int32), ())
```
Let's define the units to be used
```
#List containing the RNN units
rnn_layers_BPTT = []
rnn_layers_OSTL = []
#Create fixed random initializers for reproducibility
initW = np.random.uniform(-np.sqrt(6) / np.sqrt(1 + 1), np.sqrt(6) / np.sqrt(1 + 1), size=(1, 1))
initH = np.random.uniform(-np.sqrt(6) / np.sqrt(1 + 1), np.sqrt(6) / np.sqrt(1 + 1), size=(1, 1))
#Create the SNU layer for BPTT and for OSTL
rnn_layers_BPTT.append(SNUELayer(1, 1, activation=tf.nn.sigmoid, recurrent=True, decay=0., g=tf.identity, initW=initW, initH=initH, name='BPTT'))
rnn_layers_OSTL.append(SNUELayer(1, 1, activation=tf.nn.sigmoid, recurrent=True, decay=0., g=tf.identity, initW=initW, initH=initH, name='OSTL'))
'''
#Create the SNU layer for BPTT and for OSTL
rnn_layers_BPTT.append(SNUELayer(1, 1, activation=tf.nn.sigmoid, recurrent=True, decay=0., g=tf.identity, name='BPTT'))
rnn_layers_OSTL.append(SNUELayer(1, 1, activation=tf.nn.sigmoid, recurrent=True, decay=0., g=tf.identity, name='OSTL'))
'''
```
Define the optimizer to be used
```
optimizer = opt(learning_rate=config['lr'])
```
Next, we define the loss function and the optimization step
```
#Define the loss function to be used in OSTL
def loss_function(target_t, output_t, time, layer):
'''
Computes the desired loss for a single timestep
'''
loss = tf.reduce_sum(tf.cast(tf.squared_difference(output_t, target_t), dtype=tf.float32))
loss = tf.reduce_sum(loss)
return loss
#Define the gradient function to compute the learning signal
def gradient_function(loss, output_t, time, last_time, layer):
'''
Computes the learning signal used for OSTL
'''
grads = tf.gradients(loss, output_t)[0]
return grads
#Optimization step for BPTT
multi_rnn_cell_BPTT = tf.nn.rnn_cell.MultiRNNCell(rnn_layers_BPTT)
out_BPTT, state_BPTT = tf.nn.dynamic_rnn(multi_rnn_cell_BPTT, x, dtype=tf.float32)
loss_BPTT = loss_function(target, out_BPTT, None, 0)
train_step_BPTT = optimizer.minimize(loss_BPTT)
#Optimization step for OSTL
multi_rnn_cell_OSTL = MultiRNNCell(rnn_layers_OSTL)
out_OSTL, state_OSTL = dynamic_rnn(multi_rnn_cell_OSTL, x, target, loss_function, gradient_function, train, 1, 0, -1, optimizer, dtype=tf.float32)
loss_OSTL = loss_function(target, out_OSTL, None, 0)
train_step_OSTL = tf.no_op()
```
### Train the network
```
#Array to track the gradients of the individual weights
vals_BPTT = []
vals_OSTL = []
vals_tensor_length = int(len(tf.trainable_variables())/2)
vals_tensor_BPTT = tf.trainable_variables()[:vals_tensor_length]
vals_tensor_OSTL = tf.trainable_variables()[vals_tensor_length:]
#Define the feed_dictionary for testing
feed_dict_val = {x: val_data_x_val,
target: val_data_y_val,
train: 0.}
#Define a TF session
s = tf.Session()
#Run the initialization of the network
s.run(tf.global_variables_initializer())
#Store the initial weights of the network
init_weights_BPTT = s.run(vals_tensor_BPTT)
init_weights_OSTL = s.run(vals_tensor_OSTL)
#Iterate over the training data
iterations = int(2000/config['batch_size'])
#Try to load a checkpoint if any exists
resume = Utils_Persistence.LoadObject('./checkpoints/GradEqu_' + config['cell'])
if resume is not None:
print('Loading checkpoint')
itrStart = resume['itr']
np.random.set_state(resume['rng'])
Utils_Persistence.PersistenceLoadThis(s, 'GradEqu_' + config['cell'] + '_e' + str(itrStart), withGraph=False)
if itrStart >= iterations:
print("State loaded: already finished training at itr", itrStart, ". Plotting & exiting.")
exit(0)
else:
print('State loaded: resuming the learning from itr', itrStart)
not_loaded = False
else:
print("Did not find checkpoint. Run from scratch")
itrStart = 0
not_loaded = True
for itr in range(itrStart, iterations):
#Define the feed dictionary for training
feed_dict = {x: train_data_x_val[(config['batch_size']*itr):(config['batch_size']*(itr+1)), :],
target: train_data_y_val[(config['batch_size']*itr):(config['batch_size']*(itr+1)), :],
train: 1.}
#Run a single training step
o_BPTT, o_OSTL, _, _ = s.run([out_BPTT, out_OSTL, train_step_BPTT, train_step_OSTL], feed_dict=feed_dict)
#Store the intermediate values of the parameters
vals_BPTT.append(s.run(vals_tensor_BPTT))
vals_OSTL.append(s.run(vals_tensor_OSTL))
#Evaluate the model on the testset every 100 iterations
if itr % 100 == 0:
l_BPTT, l_OSTL = s.run([loss_BPTT, loss_OSTL], feed_dict=feed_dict_val)
print('(' + str(itr + 100) + '/' + str(iterations) + ') Loss (BPTT): ' + str(l_BPTT) + ', Loss (OSTL): ' + str(l_OSTL))
vals_BPTT.append(s.run(vals_tensor_BPTT))
vals_OSTL.append(s.run(vals_tensor_OSTL))
#Save the final checkpoint
if not_loaded and 'GradEqu_' + config['cell'] is not None and config['save_state']:
Utils_Persistence.PersitenceSaveThis(s, 'GradEqu_' + config['cell'] + '_e' + str(itr))
Utils_Persistence.SaveObject({'itr': itr, 'rng': np.random.get_state(),
'vals_BPTT': vals_BPTT, 'vals_OSTL': vals_OSTL},
'./checkpoints/GradEqu_' + config['cell'])
print('State saved at iteration ' + str(itr))
```
### Evaluate the network
Load stored checkpoints
```
#Try to load a checkpoint if any exists
resume = Utils_Persistence.LoadObject('./checkpoints/GradEqu_' + config['cell'])
if resume is not None:
print('Loading checkpoint')
itrStart = resume['itr']
vals_BPTT = resume['vals_BPTT']
vals_OSTL = resume['vals_OSTL']
np.random.set_state(resume['rng'])
Utils_Persistence.PersistenceLoadThis(s, 'GradEqu_' + config['cell'] + '_e' + str(itrStart), withGraph=False)
print('State loaded: resuming the learning from itr', itrStart)
else:
print("Did not find checkpoint. Please run model from scratch!")
```
After the model has been trained for a while, the model can be tested on unseed data
```
print('Demo XOR data')
print('Input: ' + str(test_data_x_val[0, :, 0].flatten().astype(np.int32)) + '\n')
print('Ouput: ' + str(test_data_y_val[0, :, 0].flatten()))
#Create the new feed_dict
feed_dict_test = {x: test_data_x_val,
target: test_data_y_val,
train: 0.}
o_BPTT, o_OSTL = s.run([out_BPTT, out_OSTL], feed_dict=feed_dict_test)
print('BPTT: ' + str((o_BPTT[0] > 0.5).astype(np.int32).flatten()) + '\nOSTL: ' + str((o_OSTL[0] > 0.5).astype(np.int32).flatten()))
```
### Investigate the gradients
In this simple scenario of a single-layered RNN, it can be shown that the gradients of OSTL and BPTT are equivalent. This is empirically demonstrated below. First, a random element of the input weights is selected and then analyzed.
```
#Pick randomly entries from the gradients for each trainable parameter
param_ind = []
for param in tf.trainable_variables()[:vals_tensor_length]:
param_ind.append(np.random.randint(0, int(np.prod(param.shape))))
```
The figure below illustrates the evolution of the learning signal and of the eligibility trace. Those two quantities combined together form the gradient updates for the parameters. One can see in the third panel that the gradient updates of BPTT and of OSTL align.

```
fig, ax = plt.subplots(1, 1)
for ind, param in enumerate(tf.trainable_variables()[:1]):
data_BPTT = [p.flatten()[param_ind[ind]] for p in [g[ind] for g in vals_BPTT]][:100]
data_OSTL = [p.flatten()[param_ind[ind]] for p in [g[ind] for g in vals_OSTL]][:100]
line = ax.plot(np.arange(len(data_OSTL)), data_OSTL, label=r'$\theta_' + str(ind) + '$ OSTL')
ax.scatter(np.arange(len(data_BPTT)), data_BPTT, marker='x', s=200., color=line[0].get_color(), label=r'$\theta_' + str(ind) + '$ BPTT')
ax.set_ylabel(r'Value of $\theta$')
ax.set_xlabel('Time')
ax.legend()
```
| github_jupyter |
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
prng = np.random.RandomState(10)
```
#### No categoricals
```
xs = np.linspace(0, 10, 20)
ys = xs + prng.normal(0, scale=1, size=len(xs))
plt.scatter(xs, ys);
from cgpm2.linreg import LinearRegression
from cgpm2.transition_hypers import transition_hyper_grids
from cgpm2.transition_hypers import transition_hypers
linreg = LinearRegression([0], [1], distargs={'levels': [0]}, rng=prng)
for (rowid, (x, y)) in enumerate(zip(xs,ys)):
linreg.observe(rowid, {0: x}, {1:y})
grids = transition_hyper_grids([linreg],)
for _i in xrange(10):
transition_hypers([linreg], grids, prng)
fig, ax = plt.subplots()
for x in xs:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x}, N=2)]
ax.scatter([x]*len(preds), preds)
```
#### Now add a categorical variable.
```
num_xs = 20
xs0 = np.linspace(0, 10, num_xs)
ys0 = xs0 + prng.normal(0, scale=1, size=len(xs0))
zs0 = [0]*len(xs0)
xs1 = np.linspace(0, 10, num_xs)
ys1 = xs1 + prng.normal(0, scale=1, size=len(xs1)) + 500
zs1 = [1]*len(xs1)
xs2 = np.linspace(0, 10, num_xs)
ys2 = xs2 + prng.normal(0, scale=1, size=len(xs2)) + 1000
zs2 = [2]*len(xs2)
fig, ax = plt.subplots()
ax.scatter(xs0,ys0,color='r')
ax.scatter(xs1,ys1,color='g')
ax.scatter(xs2,ys2,color='b')
linreg = LinearRegression([0], [1,2], distargs={'levels': [0, 3]}, rng=prng)
for rowid, (x,y,z) in enumerate(zip(xs0, ys0, zs0)):
linreg.observe(rowid, {0:y}, {1:x, 2:z})
for rowid, (x,y,z) in enumerate(zip(xs1, ys1, zs1)):
linreg.observe(rowid+len(xs0), {0:y}, {1:x, 2:z})
for rowid, (x,y,z) in enumerate(zip(xs2, ys2, zs2)):
linreg.observe(rowid+len(xs0)+len(xs1), {0:y}, {1:x, 2:z})
fig, ax = plt.subplots()
for x in xs0:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x, 2:0}, N=20)]
ax.scatter(x, np.mean(preds), color='r')
for x in xs1:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x, 2:1}, N=20)]
ax.scatter(x, np.mean(preds), color='g')
for x in xs1:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x, 2:2}, N=20)]
ax.scatter(x, np.mean(preds), color='b')
grids = transition_hyper_grids([linreg],)
for _i in xrange(100):
transition_hypers([linreg], grids, prng)
fig, ax = plt.subplots()
for x in xs:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x, 2:0}, N=20)]
ax.scatter(x, np.mean(preds), color='r')
for x in xs:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x, 2:1}, N=20)]
ax.scatter(x, np.mean(preds), color='g')
for x in xs:
preds = [sample[0] for sample in linreg.simulate(None, [0], None, {1:x, 2:2}, N=20)]
ax.scatter(x, np.mean(preds), color='b')
for x,y,z in zip(xs0,ys0,zs0):
lp1 = linreg.logpdf(None, {0:y}, None, {1:x, 2:0})
lp2 = linreg.logpdf(None, {0:y}, None, {1:x, 2:1})
lp3 = linreg.logpdf(None, {0:y}, None, {1:x, 2:2})
print (lp1, lp2, lp3)
for x,y,z in zip(xs1, ys1, zs1):
lp1 = linreg.logpdf(None, {0:y}, None, {1:x, 2:0})
lp2 = linreg.logpdf(None, {0:y}, None, {1:x, 2:1})
lp3 = linreg.logpdf(None, {0:y}, None, {1:x, 2:2})
print (lp1, lp2, lp3)
for x,y,z in zip(xs2, ys2, zs2):
lp1 = linreg.logpdf(None, {0:y}, None, {1:x, 2:0})
lp2 = linreg.logpdf(None, {0:y}, None, {1:x, 2:1})
lp3 = linreg.logpdf(None, {0:y}, None, {1:x, 2:2})
print (lp1, lp2, lp3)
```
#### Test chain.
```
from cgpm2.flexible_rowmix import FlexibleRowMixture
from cgpm2.crp import CRP
from cgpm2.normal import Normal
from cgpm2.categorical import Categorical
from cgpm2.product import Product
mixture = FlexibleRowMixture(
cgpm_row_divide=CRP([-1],[],rng=prng),
cgpm_components_base=Product([
Normal([1],[],rng=prng),
Categorical([2],[],distargs={'k':3}, rng=prng),
])
)
for rowid, (x,z) in enumerate(zip(xs0,zs0)):
mixture.observe(rowid, {1:x, 2:z})
for rowid, (x,z) in enumerate(zip(xs1,zs1)):
mixture.observe(rowid + len(xs0), {1:x, 2:z})
for rowid, (x,z) in enumerate(zip(xs2,zs2)):
mixture.observe(rowid + len(xs0) + len(xs1), {1:x, 2:z})
from cgpm2.chain import Chain
chain = Chain([linreg, mixture])
# Forward sample all.
chain.simulate(None, [0,1,2])
# Forward sample, but let 1 be implicit.
chain.simulate(None, [0,2])
chain.accuracy = 100
# Invert the sample, simulate x,z | y = 0
samples = chain.simulate(None, [1,2], {0:0}, N=10)
plt.hist([s[2] for s in samples])
plt.xlim([0,3])
# Invert the sample, simulate x,z | y = 500
samples = chain.simulate(None, [1,2], {0:500}, N=10)
plt.hist([s[2] for s in samples])
plt.xlim([0,3])
# Invert the sample, simulate x,z | y = 1000
samples = chain.simulate(None, [1,2], {0:1000}, N=10)
plt.hist([s[2] for s in samples])
plt.xlim([0,3])
```
| github_jupyter |

# Welcome to the automatminer basic tutorial!
#### Versions used to make this notebook (`automatminer 2019.10.14` and `matminer 0.6.2`, `python 3.7.3` on MacOS Mojave `10.14.6`)
---
[Automatminer](https://github.com/hackingmaterials/automatminer) is a package for *automatically* creating ML pipelines using matminer's featurizers, feature reduction techniques, and Automated Machine Learning (AutoML). Automatminer works end to end - raw data to prediction - without *any* human input necessary.
#### Put in a dataset, get out a machine that predicts materials properties.
Automatminer is competitive with state of the art hand-tuned machine learning models across multiple domains of materials informatics. Automatminer also included utilities for running MatBench, a materials science ML benchmark.
#### Learn more about Automatminer and MatBench from the [official documentation](http://hackingmaterials.lbl.gov/automatminer/).
# How does automatminer work?
Automatminer automatically decorates a dataset using hundreds of descriptor techniques from matminer’s descriptor library, picks the most useful features for learning, and runs a separate AutoML pipeline. Once a pipeline has been fit, it can be summarized in a text file, saved to disk, or used to make predictions on new materials.

Materials primitives (e.g., crystal structures) go in one end, and property predictions come out the other. MatPipe handles the intermediate operations such as assigning descriptors, cleaning problematic data, data conversions, imputation, and machine learning.
### MatPipe is the main Automatminer object
`MatPipe` is the central object in Automatminer. It has a sklearn BaseEstimator syntax for `fit` and `predict` operations. Simply `fit` on your training data, then `predict` on your testing data.
### MatPipe uses [pandas](https://pandas.pydata.org>) dataframes as inputs and outputs.
Put dataframes (of materials) in, get dataframes (of property predictions) out.
# What's in this notebook?
In this notebook, we walk through the basic steps of using Automatminer to train and predict on data. We'll also view the internals of our AutoML pipeline using Automatminer's API.
* First, we'll load a dataset of ~4,600 band gaps collected from experimental sources.
* Next, we'll fit a Automatminer `MatPipe` (pipeline) to the data
* Then, we'll predict experimental band gap from chemical composition, and see how our predictions do (note, this is not an easy problem!)
* We'll examine our pipeline with `MatPipe`'s introspection methods.
* Finally, we look at how to save and load pipelines for reproducible predictions.
*Note: for the sake of brevity, we will use a single train-test split in this notebook. To run a full Automatminer benchmark, see the documentation for `MatPipe.benchmark`*
# Preparing a dataset
Let's load a dataset to play around with. For this example, we will use matminer to load one of the MatBench v0.1 datasets. If you have been through some of machine learning or data retrieval tutorials on this repo, you will be familiar with the commands needed to fetch our dataset as a dataframe.
```
from matminer.datasets import load_dataset
df = load_dataset("matbench_expt_gap")
# Let's look at our dataset
df.describe()
```
### Looking at the data
```
df.head()
```
### Seeing how many unique compositions are present
We should find all the compositions are unique.
```
# How many unique compositions do we have?
df["composition"].unique().shape[0]
```
### Generate a train-test split
```
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size=0.2, shuffle=True, random_state=20191014)
```
### Remove the target property from the test_df
Let's remove the testing dataframe's target property so we can be sure we are not giving Automatminer any test information.
Our target variable is `"gap expt"`.
```
target = "gap expt"
prediction_df = test_df.drop(columns=[target])
prediction_df.head()
prediction_df.describe()
```
# Fitting and predicting with Automatminer's MatPipe
Our dataset contains 4,604 unique stoichiometries and experimentally measured band gaps. We have everything we need to start our AutoML pipeline.
For simplicity, we will use an `MatPipe` preset. `MatPipe` is highly customizable and has hundreds of configuration options, but most use cases will be satisfied by using one of the preset configurations. We use the `from_preset` method.
In this example, we'll use the "express" preset, which will take approximately an hour.
```
from automatminer import MatPipe
pipe = MatPipe.from_preset("express")
```
### Fitting the pipeline
To fit an Automatminer `MatPipe` to the data, pass in your training data and desired target.
```
pipe.fit(train_df, target)
```
### Predicting new data
Our MatPipe is now fit. Let's predict our test data with `MatPipe.predict`. This should only take a few minutes.
```
prediction_df = pipe.predict(prediction_df)
```
### Examine predictions
`MatPipe` places the predictions a column called `"{target} predicted"`:
```
prediction_df.head()
```
### Score predictions
Now let's score our predictions using mean average error, and compare them to a Dummy Regressor from sklearn.
```
from sklearn.metrics import mean_absolute_error
from sklearn.dummy import DummyRegressor
# fit the dummy
dr = DummyRegressor()
dr.fit(train_df["composition"], train_df[target])
dummy_test = dr.predict(test_df["composition"])
# Score dummy and MatPipe
true = test_df[target]
matpipe_test = prediction_df[target + " predicted"]
mae_matpipe = mean_absolute_error(true, matpipe_test)
mae_dummy = mean_absolute_error(true, dummy_test)
print("Dummy MAE: {} eV".format(mae_dummy))
print("MatPipe MAE: {} eV".format(mae_matpipe))
```
# Examining the internals of MatPipe
Inspect `MatPipe` internals with a dict/text digest from either `MatPipe.inspect` (long, comprehensive version of all proper attriute names) or `MatPipe.summarize` (executive summary).
```
import pprint
# Get a summary and save a copy to json
summary = pipe.summarize(filename="MatPipe_predict_experimental_gap_from_composition_summary.json")
pprint.pprint(summary)
# Explain the MatPipe's internals more comprehensively
details = pipe.inspect(filename="MatPipe_predict_experimental_gap_from_composition_details.json")
print(details)
```
### Access MatPipe's internal objects directly.
You can access MatPipe's internal objects directly, instead of via a text digest; you just need to know which attributes to access. See the online API docs or the source code for more info.
```
# Access some attributes of MatPipe directly, instead of via a text digest
print(pipe.learner.best_pipeline)
print(pipe.autofeaturizer.featurizers["composition"])
```
# Persistence of pipelines
### Being able to reproduce your results is a crucial aspect of materials informatics.
`MatPipe` provides methods for easily saving and loading **entire pipelines** for use by others.
Save a MatPipe for later with `MatPipe.save`. Load it with `MatPipe.load`.
```
# Save the pipeline for later
filename = "MatPipe_predict_experimental_gap_from_composition.p"
pipe.save(filename)
# Load your saved pipeline later, or on another machine
pipe_loaded = MatPipe.load(filename)
```
# This concludes the Automatminer basic tutorial
Congrats! You've made it through the basic Automatminer tutorial!
In this tutorial, you learned how to:
1. Access a MatBench benchmarking dataset with matminer.
2. Fit and make production predictions with `MatPipe`.
3. Inspect the `MatPipe` pipeline.
4. Save and share your results for reproducible science.
If you encountered any problems running this notebook, please open an issue on the repo or post an issue on our [support forum](https://hackingmaterials.discourse.group).
| github_jupyter |
### Here I show how I obtained certain parameter values and some ideas for improving the estimates.
```
# Autoreload all modules when changes are saved.
%reload_ext autoreload
%autoreload 2
# Show all figures inline.
%matplotlib inline
# Add olfaction-prediction to the Python path.
import os
import sys
curr_path = os.getcwd()
gerkin_path = os.path.split(curr_path)[0]
olfaction_prediction_path = os.path.split(gerkin_path)[0]
sys.path.append(olfaction_prediction_path)
import opc_python
# Import numerical libraries.
import numpy as np
import matplotlib.pyplot as plt
# Import generic utility modules I wrote to load the data from the tab-delimited text files and to score predictions.
from opc_python.utils import loading, scoring
# Import the modules I wrote for actually shaping and fitting the data to the model.
from opc_python.gerkin import dream,fit1,fit2
# Load the molecular descriptors data.
molecular_headers, molecular_data = loading.load_molecular_data()
print("First ten molecular descriptor types are %s" % molecular_headers[:10])
print("First ten descriptor values for the first compound are %s" % molecular_data[0][:10])
total_size = len(set([int(row[0]) for row in molecular_data]))
print("We have molecular descriptors for %d unique molecules" % total_size)
# Figure out parameters for regularization.
regs = np.linspace(0,1,11)
matrix_training = np.zeros((len(regs),9))
matrix_leaderboard = np.zeros((len(regs),9))
for i,reg in enumerate(regs):
result = fit1.subject_regularize(rfcs,X_training,X_training,Y_training,oob=True,regularize=[reg])
matrix_training[i,:] = result
result = fit1.subject_regularize(rfcs,X_leaderboard_int,X_leaderboard_other,Y_leaderboard,oob=False,regularize=[reg])
matrix_leaderboard[i,:] = result
for matrix in (matrix_training,matrix_leaderboard):
plt.figure()
matrix /= matrix.max(axis=0)[np.newaxis,:]
plt.pcolor(matrix[:,3],vmin=0.8,vmax=1)
# Determine Lasso performance.
alphas = np.logspace(-2,1,8)
lassos1 = {}
scores1_train = []
scores1_test = []
scores2_train = []
scores2_test = []
for alpha in alphas:
print(alpha)
lassos,score_train,score_test = lasso_(X_training,Y_training_median['subject'],
X_leaderboard_int,Y_leaderboard['subject'],
1,alpha=alpha,regularize=[0.3,0.3,0.3])
scores1_train.append(score_train[0])
scores1_test.append(score_test[0])
scores2_train.append(score_train[1])
scores2_test.append(score_test[1])
lassos1[alpha] = lassos
plt.scatter(alphas,scores1_train,color='b')
plt.scatter(alphas,scores1_test,color='r')
plt.xscale('log')
plt.figure()
plt.scatter(alphas,scores2_train,color='b')
plt.scatter(alphas,scores2_test,color='r')
plt.xscale('log')
estimator1 = Lasso(alpha=0.9,max_iter=5000)
estimator2 = Lasso(alpha=0.9,max_iter=5000)
estimator1.fit(X_obs,Y_obs['mean_std'][:,1])
x = estimator1.coef_
estimator2.fit(X_leaderboard,Y_leaderboard['mean_std'][:,1])
y = estimator2.coef_
plt.scatter(x,y)
plt.figure()
plt.plot(x,color='r')
plt.plot(y,color='b')
np.where(x*y > 0.01)
# Determine Lasso performance.
alphas = np.logspace(-2,1,8)
lassos1 = {}
scores1_train = []
scores1_test = []
scores2_train = []
scores2_test = []
for alpha in alphas:
print(alpha)
lassos,score_train,score_test = lasso_(X_training,Y_training_median['mean_std'],
X_leaderboard_int,Y_leaderboard['mean_std'],
2,alpha=alpha)
scores1_train.append(score_train[0])
scores1_test.append(score_test[0])
scores2_train.append(score_train[1])
scores2_test.append(score_test[1])
lassos1[alpha] = lassos
plt.scatter(alphas,scores1_train,color='b')
plt.scatter(alphas,scores1_test,color='r')
plt.xscale('log')
plt.figure()
plt.scatter(alphas,scores2_train,color='b')
plt.scatter(alphas,scores2_test,color='r')
plt.xscale('log')
estimator1 = Lasso(alpha=0.9,max_iter=5000)
estimator2 = Lasso(alpha=0.9,max_iter=5000)
estimator1.fit(X_obs,Y_obs['mean_std'][:,1])
x = estimator1.coef_
estimator2.fit(X_leaderboard,Y_leaderboard['mean_std'][:,1])
y = estimator2.coef_
plt.scatter(x,y)
plt.figure()
plt.plot(x,color='r')
plt.plot(y,color='b')
np.where(x*y > 0.01)
# Minimum samples per leaf.
ns = [1,2,4,8,16,32]
rs = {n:fit2.rfc_cv(X_all,Y_all_imp['mean_std'],Y_all_mask['mean_std'],n_splits=15,n_estimators=25,min_samples_leaf=n) for n in ns}
for kind1 in ['int','ple','dec']:
for kind2 in ['mean','sigma','trans']:
n_ = sorted(list(rs.keys()))[0]
if kind2 in rs[n_][1][kind1]:
means = [rs[n][1][kind1][kind2]['mean'] for n in ns]
sems = [rs[n][1][kind1][kind2]['sem'] for n in ns]
plt.errorbar(ns,means,sems,label=kind1+'_'+kind2)
plt.xscale('log')
plt.xlim(0.5,1000)
plt.xlabel('min_samples_leaf')
plt.ylabel('r')
plt.legend()
# Maximum tree depth.
ns = (2**np.linspace(1,5,9)).astype('int')
rs = {n:rfc_cv(X_all,Y_all['mean_std'],n_splits=25,max_depth=n) for n in ns}
for kind1 in ['int','ple','dec']:
for kind2 in ['mean','sigma','trans']:
if kind2 in rs[2.0][1][kind1]:
means = [rs[n][1][kind1][kind2]['mean'] for n in ns]
sems = [rs[n][1][kind1][kind2]['sem'] for n in ns]
plt.errorbar(ns,means,sems,label=kind1+'_'+kind2)
plt.xscale('log')
plt.xlabel('Max Depth')
plt.xlim(1,1000)
plt.legend()
Y_training_mask,_ = dream.make_Y_obs(['training'],imputer='mask')
Y_training_median,_ = dream.make_Y_obs(['training'],imputer='median')
Y_training_zero,_ = dream.make_Y_obs(['training'],imputer='zero')
y = Y_training_mask
y_mean = y['mean_std'][:,:21]/100.0
y_std = y['mean_std'][:,21:]/100.0
from scipy.optimize import curve_fit
x = y_mean[:,0]
y = y_std[:,0]
def f(x,k0,k1):
return k0*x**(k1*0.5) - k0*x**(k1*2)
k0,k1=curve_fit(f,x,y,p0=[0.7,1],maxfev=10000)[0]
print("k0=%.3g; k1=%.3g" % (k0,k1))
plt.scatter(x,y,label='Data')
x_ = np.linspace(0,1.0,100)
plt.plot(x_,f(x_,k0,k1),color='r',linewidth=3,label='Fit')
plt.xlabel('Intensity Mean')
plt.ylabel('Intensity StDev')
plt.legend()
plt.figure()
plt.scatter(x,y-f(x,k0,k1))
def f_int(x):
return 100*(k0*(x/100)**(k1*0.5) - k0*(x/100)**(k1*2))
#print('r using fit itself = %.3g' % scoring.r2(None,None,rfcs[2][0][3].oob_prediction_[:,21],Y_training['mean_std'][:,21]))
#print('r using f_int = %.3g' % scoring.r2(None,None,f_int(rfcs[2][0][0].oob_prediction_[:,0]),Y_training['mean_std'][:,21]))
#print('r using f_int = %.3g' % scoring.r2(None,None,rfcs[2][0][0].oob_prediction_[:,0],Y_training['mean_std'][:,0]))
from scipy.optimize import curve_fit
x = y_mean[:,1]
y = y_std[:,1]
def f(x,k0,k1):
return k0*x**(k1*0.5) - k0*x**(k1*2)
k0,k1=curve_fit(f,x,y,p0=[0.7,1])[0]
print(k0,k1)
plt.scatter(x,y,label='Data')
x_ = np.linspace(0,1.0,100)
plt.plot(x_,f(x_,k0,k1),color='r',linewidth=3,label='Fit')
plt.xlabel('Pleasantness Mean')
plt.ylabel('Pleasantness StDev')
plt.legend()
plt.legend()
plt.figure()
plt.scatter(x,y-f(x,k0,k1))
def f_ple(x):
return 100*(k0*(x/100)**(k1*0.5) - k0*(x/100)**(k1*2))
from scipy.optimize import curve_fit
x = y_mean[:,2:21].ravel()
y = y_std[:,2:21].ravel()
def f(x,k0,k1):
return k0*x**(k1*0.5) - k0*x**(k1*2)
k0,k1=curve_fit(f,x,y,p0=[0.7,1])[0]
print(k0,k1)
plt.scatter(x,y,label='Data')#Y_obs['mean_std'][:,0],Y_obs['mean_std'][:,21])
x_ = np.linspace(0,1.0,100)
plt.plot(x_,f(x_,k0,k1),color='r',linewidth=3,label='Fit')
plt.xlabel('Other Descriptors Mean')
plt.ylabel('Other Descriptors StDev')
plt.legend()
plt.legend()
plt.figure()
plt.scatter(x,y-f(x,k0,k1))
def f_dec(x):
return 100*(k0*(x/100)**(k1*0.5) - k0*(x/100)**(k1*2))
# Plot r vs the maximum number of features per tree for subchallenge 2.
ns = np.logspace(1,3.48,12).astype('int')
rs = {10: ({'mean': 4.5287503680444283, 'sem': 0.13714615321987517},
{'dec': {'mean': {'mean': 0.35741904017752996, 'sem': 0.010048318402360087},
'sigma': {'mean': 0.26364038011571522, 'sem': 0.0066697475868345195}},
'int': {'mean': {'mean': 0.095846326633119261, 'sem': 0.011534906168037609},
'sigma': {'mean': -0.19442773962706283, 'sem': 0.013246295480355922},
'trans': {'mean': -0.14841245979725629, 'sem': 0.014477101914558255}},
'ple': {'mean': {'mean': 0.56265800877494421, 'sem': 0.013762511615746981},
'sigma': {'mean': 0.078114653930579078, 'sem': 0.013059909526612193}}}),
16: ({'mean': 4.2762653281962626, 'sem': 0.14630142507898916},
{'dec': {'mean': {'mean': 0.33607958258692089, 'sem': 0.010755178194062617},
'sigma': {'mean': 0.24953806713067767, 'sem': 0.0072430177045214993}},
'int': {'mean': {'mean': 0.080597860297553225, 'sem': 0.010328564454501418},
'sigma': {'mean': -0.1831432623519923, 'sem': 0.015823665199024079},
'trans': {'mean': -0.1339838955094253, 'sem': 0.016009654970459093}},
'ple': {'mean': {'mean': 0.53454801842938016, 'sem': 0.013648074163107654},
'sigma': {'mean': 0.083599248367205059, 'sem': 0.010150692008152835}}}),
28: ({'mean': 4.4701678025412317, 'sem': 0.14599522051390151},
{'dec': {'mean': {'mean': 0.34870707634403841, 'sem': 0.010376725741241408},
'sigma': {'mean': 0.26167957616840015, 'sem': 0.0076003340767839701}},
'int': {'mean': {'mean': 0.10319739802052659, 'sem': 0.014246267245439325},
'sigma': {'mean': -0.19009823259725972, 'sem': 0.011209139395029032},
'trans': {'mean': -0.11650510017477485, 'sem': 0.012928859605985615}},
'ple': {'mean': {'mean': 0.5430733968547149, 'sem': 0.014784953521207751},
'sigma': {'mean': 0.090061683509025339, 'sem': 0.012478688832880159}}}),
47: ({'mean': 4.7253857892800202, 'sem': 0.1014228402373675},
{'dec': {'mean': {'mean': 0.36463523931447767, 'sem': 0.0077892818476017877},
'sigma': {'mean': 0.27848648194260939, 'sem': 0.0055596404826221855}},
'int': {'mean': {'mean': 0.12456193164028778, 'sem': 0.011020750201587774},
'sigma': {'mean': -0.19581291085950936, 'sem': 0.012204784570451606},
'trans': {'mean': -0.096822889766287681, 'sem': 0.015292940589798586}},
'ple': {'mean': {'mean': 0.55871347758289436, 'sem': 0.010607290634184519},
'sigma': {'mean': 0.098940792262160057, 'sem': 0.011444230404422117}}}),
79: ({'mean': 4.5948586693250224, 'sem': 0.14140871753848633},
{'dec': {'mean': {'mean': 0.35349151004259566, 'sem': 0.010578871458227949},
'sigma': {'mean': 0.26451399172704326, 'sem': 0.0073617384376021807}},
'int': {'mean': {'mean': 0.15749460124159698, 'sem': 0.014409412612637526},
'sigma': {'mean': -0.2013942721149391, 'sem': 0.013305349700475404},
'trans': {'mean': -0.060088766676318579, 'sem': 0.017177634996689763}},
'ple': {'mean': {'mean': 0.53488235662014261, 'sem': 0.012547643369955928},
'sigma': {'mean': 0.10970476070408371, 'sem': 0.0094896634896857648}}}),
134: ({'mean': 4.8539751223104419, 'sem': 0.1162501624649929},
{'dec': {'mean': {'mean': 0.35652418608559755, 'sem': 0.0087043702461469703},
'sigma': {'mean': 0.27728883132036353, 'sem': 0.0059275683871883537}},
'int': {'mean': {'mean': 0.19200644382156473, 'sem': 0.012530863162805508},
'sigma': {'mean': -0.1664127104350237, 'sem': 0.014727246170865512},
'trans': {'mean': -0.0050509811396929442, 'sem': 0.013512400586764228}},
'ple': {'mean': {'mean': 0.54832750777745565, 'sem': 0.0098732363104831779},
'sigma': {'mean': 0.14384012732930848, 'sem': 0.013526458292162615}}}),
225: ({'mean': 4.9870061127976335, 'sem': 0.081148988667772787},
{'dec': {'mean': {'mean': 0.35920173978820247, 'sem': 0.005771214032598007},
'sigma': {'mean': 0.28571600997788305, 'sem': 0.0044894837783576776}},
'int': {'mean': {'mean': 0.20899398507098751, 'sem': 0.0089409157503288449},
'sigma': {'mean': -0.1625729228151592, 'sem': 0.012846884683828403},
'trans': {'mean': -0.00029354436544479738, 'sem': 0.013363608550869724}},
'ple': {'mean': {'mean': 0.54321470659037041, 'sem': 0.0084886147095966039},
'sigma': {'mean': 0.17407163721666641, 'sem': 0.010335404716236968}}}),
378: ({'mean': 5.2309187208238734, 'sem': 0.10196943375487943},
{'dec': {'mean': {'mean': 0.36222194098676708, 'sem': 0.007045483436985178},
'sigma': {'mean': 0.28748525876153946, 'sem': 0.0047622927467698851}},
'int': {'mean': {'mean': 0.30763309255762561, 'sem': 0.010489674520969026},
'sigma': {'mean': -0.13437720563989827, 'sem': 0.015216850317463513},
'trans': {'mean': 0.077208246830087784, 'sem': 0.016776811806067937}},
'ple': {'mean': {'mean': 0.51666345722264007, 'sem': 0.012102754509798147},
'sigma': {'mean': 0.22387777822938859, 'sem': 0.012002426045896302}}}),
636: ({'mean': 5.2783150795158216, 'sem': 0.13760824709660485},
{'dec': {'mean': {'mean': 0.34389494434882933, 'sem': 0.010619378453447091},
'sigma': {'mean': 0.28352414027492062, 'sem': 0.0073509746683288425}},
'int': {'mean': {'mean': 0.3772666034669338, 'sem': 0.0089725357164009943},
'sigma': {'mean': -0.070406052406278383, 'sem': 0.013146427411079784},
'trans': {'mean': 0.12848715202789562, 'sem': 0.013902235706203112}},
'ple': {'mean': {'mean': 0.47628383046916783, 'sem': 0.012710721163219313},
'sigma': {'mean': 0.26026415548531601, 'sem': 0.010394694087536604}}}),
1069: ({'mean': 5.3546828132513324, 'sem': 0.12890359059613288},
{'dec': {'mean': {'mean': 0.33732613917980125, 'sem': 0.008720117607173207},
'sigma': {'mean': 0.27622741774403192, 'sem': 0.0071757382362265653}},
'int': {'mean': {'mean': 0.43133470244978406, 'sem': 0.010878799280296147},
'sigma': {'mean': -0.026361142275758507, 'sem': 0.015099084255438586},
'trans': {'mean': 0.13238543687124554, 'sem': 0.018554714187045213}},
'ple': {'mean': {'mean': 0.43199201719291991, 'sem': 0.014489942433701003},
'sigma': {'mean': 0.31700085937001704, 'sem': 0.013427424445132865}}}),
1796: ({'mean': 5.5498459671689746, 'sem': 0.13681528903807455},
{'dec': {'mean': {'mean': 0.32179820864086328, 'sem': 0.0094069815127022019},
'sigma': {'mean': 0.27898990045943434, 'sem': 0.0065779356885316484}},
'int': {'mean': {'mean': 0.51764555751818397, 'sem': 0.012206761954778787},
'sigma': {'mean': 0.055523211752833854, 'sem': 0.01355106954720255},
'trans': {'mean': 0.18963409134717207, 'sem': 0.017923968933286152}},
'ple': {'mean': {'mean': 0.3943537656955719, 'sem': 0.012444820366012996},
'sigma': {'mean': 0.37983842127958406, 'sem': 0.013840079795020142}}}),
3019: ({'mean': 5.3932719860365959, 'sem': 0.13908557141359157},
{'dec': {'mean': {'mean': 0.30618849055096442, 'sem': 0.0095607486607533522},
'sigma': {'mean': 0.26814972696669526, 'sem': 0.0062064562069586047}},
'int': {'mean': {'mean': 0.53539506258094605, 'sem': 0.012949449933710522},
'sigma': {'mean': 0.060942920358335699, 'sem': 0.013911404385486428},
'trans': {'mean': 0.17382531945634028, 'sem': 0.019449794276195469}},
'ple': {'mean': {'mean': 0.35777486592782493, 'sem': 0.014959772093079271},
'sigma': {'mean': 0.3948171320652123, 'sem': 0.014163182412156508}}})}
for kind1 in ['int','ple','dec']:
for kind2 in ['mean','sigma','trans']:
if kind2 in rs[10][1][kind1]:
means = [rs[n][1][kind1][kind2]['mean'] for n in ns]
sems = [rs[n][1][kind1][kind2]['sem'] for n in ns]
plt.errorbar(ns,means,sems,label=kind1+'_'+kind2)
plt.xscale('log')
plt.xlim(10,100000)
plt.legend()
# Plot r vs the maximum number of features per tree for subchallenge 1.
ns = np.logspace(1,3.48,12).astype('int')
rs = {10: ({'mean': 14.626823924339622, 'sem': 0.67293213710441813},
{'dec': {'mean': 0.1115032164997066, 'sem': 0.0049366842404788515},
'int': {'mean': 0.063175885345557098, 'sem': 0.011757087396024829},
'ple': {'mean': 0.24558507250578115, 'sem': 0.010251468787021155}}),
16: ({'mean': 16.592630198674783, 'sem': 0.57970873096949382},
{'dec': {'mean': 0.12771997189368894, 'sem': 0.005640659238315947},
'int': {'mean': 0.068220206630371344, 'sem': 0.0097569244354709563},
'ple': {'mean': 0.27667611992206365, 'sem': 0.0088230434191277924}}),
28: ({'mean': 17.001787805562639, 'sem': 0.52905721649550286},
{'dec': {'mean': 0.1274005373522745, 'sem': 0.0056496569190668585},
'int': {'mean': 0.097336893904010763, 'sem': 0.010542390181966255},
'ple': {'mean': 0.27221428344252996, 'sem': 0.0057676157734840184}}),
47: ({'mean': 14.981979294390715, 'sem': 0.51799581666082983},
{'dec': {'mean': 0.11219535109392517, 'sem': 0.0052548441399689312},
'int': {'mean': 0.075689638817071039, 'sem': 0.006293064770536495},
'ple': {'mean': 0.24965925218067012, 'sem': 0.0078836451477239354}}),
79: ({'mean': 15.81419214971354, 'sem': 1.3142988376383489},
{'dec': {'mean': 0.11709726161501317, 'sem': 0.009452935255343145},
'int': {'mean': 0.10696881918664522, 'sem': 0.024092414574482853},
'ple': {'mean': 0.24361952303212289, 'sem': 0.013546580983435055}}),
134: ({'mean': 15.865602192053283, 'sem': 0.68405017387517886},
{'dec': {'mean': 0.11562109914684, 'sem': 0.0053868071673007136},
'int': {'mean': 0.097934326116037654, 'sem': 0.021095231703079462},
'ple': {'mean': 0.26102284924556374, 'sem': 0.0067083817314546228}}),
225: ({'mean': 17.318745662215576, 'sem': 0.59125172502595269},
{'dec': {'mean': 0.11917748796457502, 'sem': 0.0038042932435202806},
'int': {'mean': 0.16193085269478602, 'sem': 0.018867845750103893},
'ple': {'mean': 0.26261383679004585, 'sem': 0.0059204822078491549}}),
378: ({'mean': 15.934339306208141, 'sem': 0.45211081563147515},
{'dec': {'mean': 0.1083938313372175, 'sem': 0.0052862145544272723},
'int': {'mean': 0.16475683550258524, 'sem': 0.009235021958794153},
'ple': {'mean': 0.23204608901107826, 'sem': 0.0059273034875685525}}),
636: ({'mean': 15.771761053703225, 'sem': 0.74466463785302328},
{'dec': {'mean': 0.10312794275339685, 'sem': 0.0049585966863074571},
'int': {'mean': 0.202790369126047, 'sem': 0.016817041589260329},
'ple': {'mean': 0.20973227107129092, 'sem': 0.0082837468624166466}}),
1069: ({'mean': 17.554725518233688, 'sem': 0.40722588984168068},
{'dec': {'mean': 0.11081691637979074, 'sem': 0.002969119102252506},
'int': {'mean': 0.24713787336311413, 'sem': 0.0034750441857333502},
'ple': {'mean': 0.22991350637065663, 'sem': 0.0088152286906102353}}),
1796: ({'mean': 15.842837013180731, 'sem': 1.1021490359940003},
{'dec': {'mean': 0.095404715725000269, 'sem': 0.0086366687854054283},
'int': {'mean': 0.24647214944115894, 'sem': 0.009001181733327009},
'ple': {'mean': 0.20473681688185336, 'sem': 0.024290004669442054}}),
3019: ({'mean': 14.559636621415361, 'sem': 0.87558204964710695},
{'dec': {'mean': 0.082906650297182763, 'sem': 0.0063709138354757526},
'int': {'mean': 0.27934768414882283, 'sem': 0.013820164346925809},
'ple': {'mean': 0.15841500207406473, 'sem': 0.013952809590184693}})}
for kind in ['int','ple','dec']:
means = [rs[n][1][kind]['mean'] for n in ns]
sems = [rs[n][1][kind]['sem'] for n in ns]
plt.errorbar(ns,means,sems,label=kind)
plt.xscale('log')
plt.xlim(10,100000)
plt.xlabel('max_features')
plt.legend()
# Using n_splits=40,max_features=1500.
string = """
1,1
int_mean = 0.382+/- 0.012
ple_mean = 0.170+/- 0.011
dec_mean = 0.167+/- 0.005
int_sigma = 0.093+/- 0.008
ple_sigma = 0.337+/- 0.011
dec_sigma = 0.168+/- 0.005
int_trans = 0.111+/- 0.007
1,2
int_mean = 0.402+/- 0.011
ple_mean = 0.221+/- 0.013
dec_mean = 0.201+/- 0.007
int_sigma = 0.119+/- 0.008
ple_sigma = 0.360+/- 0.010
dec_sigma = 0.197+/- 0.006
int_trans = 0.141+/- 0.010
1,4
int_mean = 0.444+/- 0.010
ple_mean = 0.311+/- 0.010
dec_mean = 0.258+/- 0.005
int_sigma = 0.108+/- 0.012
ple_sigma = 0.396+/- 0.008
dec_sigma = 0.245+/- 0.005
int_trans = 0.147+/- 0.012
1,8
int_mean = 0.475+/- 0.010
ple_mean = 0.399+/- 0.011
dec_mean = 0.324+/- 0.008
int_sigma = 0.049+/- 0.010
ple_sigma = 0.390+/- 0.008
dec_sigma = 0.290+/- 0.006
int_trans = 0.148+/- 0.013
1,16
int_mean = 0.472+/- 0.010
ple_mean = 0.396+/- 0.012
dec_mean = 0.315+/- 0.008
int_sigma = 0.023+/- 0.010
ple_sigma = 0.360+/- 0.009
dec_sigma = 0.272+/- 0.005
int_trans = 0.187+/- 0.010
2,1
int_mean = 0.371+/- 0.009
ple_mean = 0.176+/- 0.012
dec_mean = 0.167+/- 0.004
int_sigma = 0.117+/- 0.010
ple_sigma = 0.334+/- 0.008
dec_sigma = 0.169+/- 0.004
int_trans = 0.137+/- 0.009
2,2
int_mean = 0.423+/- 0.009
ple_mean = 0.208+/- 0.011
dec_mean = 0.202+/- 0.006
int_sigma = 0.130+/- 0.009
ple_sigma = 0.380+/- 0.009
dec_sigma = 0.200+/- 0.005
int_trans = 0.160+/- 0.009
2,4
int_mean = 0.446+/- 0.009
ple_mean = 0.301+/- 0.013
dec_mean = 0.252+/- 0.006
int_sigma = 0.090+/- 0.010
ple_sigma = 0.380+/- 0.008
dec_sigma = 0.238+/- 0.005
int_trans = 0.127+/- 0.013
2,8
int_mean = 0.473+/- 0.011
ple_mean = 0.366+/- 0.014
dec_mean = 0.300+/- 0.008
int_sigma = 0.060+/- 0.010
ple_sigma = 0.396+/- 0.010
dec_sigma = 0.278+/- 0.006
int_trans = 0.171+/- 0.011
2,16
int_mean = 0.475+/- 0.010
ple_mean = 0.396+/- 0.012
dec_mean = 0.315+/- 0.007
int_sigma = 0.020+/- 0.012
ple_sigma = 0.378+/- 0.009
dec_sigma = 0.281+/- 0.005
int_trans = 0.167+/- 0.014
4,1
int_mean = 0.380+/- 0.012
ple_mean = 0.159+/- 0.010
dec_mean = 0.165+/- 0.005
int_sigma = 0.119+/- 0.010
ple_sigma = 0.345+/- 0.010
dec_sigma = 0.166+/- 0.005
int_trans = 0.137+/- 0.011
4,2
int_mean = 0.417+/- 0.009
ple_mean = 0.216+/- 0.013
dec_mean = 0.200+/- 0.004
int_sigma = 0.129+/- 0.011
ple_sigma = 0.375+/- 0.010
dec_sigma = 0.198+/- 0.004
int_trans = 0.147+/- 0.010
4,4
int_mean = 0.458+/- 0.010
ple_mean = 0.287+/- 0.014
dec_mean = 0.246+/- 0.007
int_sigma = 0.110+/- 0.012
ple_sigma = 0.383+/- 0.011
dec_sigma = 0.238+/- 0.007
int_trans = 0.144+/- 0.014
4,8
int_mean = 0.454+/- 0.010
ple_mean = 0.348+/- 0.013
dec_mean = 0.280+/- 0.006
int_sigma = 0.054+/- 0.012
ple_sigma = 0.371+/- 0.011
dec_sigma = 0.261+/- 0.005
int_trans = 0.136+/- 0.011
4,16
int_mean = 0.444+/- 0.011
ple_mean = 0.355+/- 0.011
dec_mean = 0.279+/- 0.006
int_sigma = 0.016+/- 0.007
ple_sigma = 0.365+/- 0.010
dec_sigma = 0.260+/- 0.005
int_trans = 0.133+/- 0.010
8,1
int_mean = 0.366+/- 0.011
ple_mean = 0.185+/- 0.012
dec_mean = 0.161+/- 0.005
int_sigma = 0.109+/- 0.012
ple_sigma = 0.333+/- 0.011
dec_sigma = 0.164+/- 0.005
int_trans = 0.128+/- 0.011
8,2
int_mean = 0.408+/- 0.009
ple_mean = 0.215+/- 0.012
dec_mean = 0.196+/- 0.004
int_sigma = 0.118+/- 0.011
ple_sigma = 0.355+/- 0.011
dec_sigma = 0.194+/- 0.004
int_trans = 0.134+/- 0.011
8,4
int_mean = 0.454+/- 0.010
ple_mean = 0.267+/- 0.013
dec_mean = 0.230+/- 0.007
int_sigma = 0.105+/- 0.011
ple_sigma = 0.386+/- 0.011
dec_sigma = 0.224+/- 0.006
int_trans = 0.151+/- 0.010
8,8
int_mean = 0.461+/- 0.010
ple_mean = 0.310+/- 0.009
dec_mean = 0.253+/- 0.006
int_sigma = 0.071+/- 0.011
ple_sigma = 0.375+/- 0.009
dec_sigma = 0.242+/- 0.005
int_trans = 0.120+/- 0.012
8,16
int_mean = 0.461+/- 0.009
ple_mean = 0.315+/- 0.012
dec_mean = 0.254+/- 0.005
int_sigma = 0.063+/- 0.011
ple_sigma = 0.369+/- 0.007
dec_sigma = 0.245+/- 0.005
int_trans = 0.135+/- 0.011
16,1
int_mean = 0.396+/- 0.009
ple_mean = 0.190+/- 0.011
dec_mean = 0.170+/- 0.004
int_sigma = 0.103+/- 0.012
ple_sigma = 0.347+/- 0.009
dec_sigma = 0.175+/- 0.005
int_trans = 0.121+/- 0.012
16,2
int_mean = 0.424+/- 0.011
ple_mean = 0.212+/- 0.010
dec_mean = 0.191+/- 0.005
int_sigma = 0.114+/- 0.011
ple_sigma = 0.356+/- 0.011
dec_sigma = 0.194+/- 0.005
int_trans = 0.138+/- 0.011
16,4
int_mean = 0.439+/- 0.009
ple_mean = 0.235+/- 0.010
dec_mean = 0.212+/- 0.005
int_sigma = 0.125+/- 0.011
ple_sigma = 0.374+/- 0.009
dec_sigma = 0.211+/- 0.005
int_trans = 0.142+/- 0.013
16,8
int_mean = 0.463+/- 0.008
ple_mean = 0.263+/- 0.011
dec_mean = 0.231+/- 0.005
int_sigma = 0.100+/- 0.011
ple_sigma = 0.385+/- 0.010
dec_sigma = 0.227+/- 0.005
int_trans = 0.138+/- 0.012
16,16
int_mean = 0.469+/- 0.011
ple_mean = 0.265+/- 0.012
dec_mean = 0.230+/- 0.006
int_sigma = 0.104+/- 0.011
ple_sigma = 0.392+/- 0.011
dec_sigma = 0.228+/- 0.005
int_trans = 0.129+/- 0.012
"""
kinds = ['int','ple','dec']
moments = ['mean','sigma','trans']
rs_leaf_depth = {}
for kind in kinds:
rs_leaf_depth[kind] = {}
for moment in moments:
if moment != 'trans' or kind == 'int':
rs_leaf_depth[kind][moment] = np.zeros((5,5))
for line in string.split('\n'):
if ',' in line:
leaf,depth = [int(_) for _ in line.split(',')]
if '+/-' in line:
kind = line.split('=')[0].strip()
kind,moment = kind.split('_')
mean = float(line.split('=')[1].split('+/-')[0].strip())
rs_leaf_depth[kind][moment][int(np.log(leaf)/np.log(2)),int(np.log(depth)/np.log(2))] = mean
for kind in kinds:
for moment in moments:
if moment != 'trans' or kind == 'int':
plt.figure()
plt.xlabel('max_depth')
plt.ylabel('min_leaf')
plt.title('%s_%s' % (kind,moment))
ax = plt.gca()
ax.set_xticklabels([1,2,4,8,16])
ax.set_yticklabels([1,2,4,8,16])
plt.pcolor(rs_leaf_depth[kind][moment])
plt.colorbar(label='r')
"""
With rf:
For subchallenge 2, using cross-validation with:
at most 1000 features:
at least 1 samples per leaf:
at most None depth:
score = 4.65+/- 0.13
int_mean = 0.417+/- 0.010
ple_mean = 0.446+/- 0.014
dec_mean = 0.302+/- 0.010
int_sigma = -0.018+/- 0.014
ple_sigma = 0.167+/- 0.014
dec_sigma = 0.230+/- 0.007
int_trans = 0.161+/- 0.011
With et:
For subchallenge 2, using cross-validation with:
at most 1000 features:
at least 1 samples per leaf:
at most None depth:
score = 4.87+/- 0.13
int_mean = 0.594+/- 0.010
ple_mean = 0.424+/- 0.017
dec_mean = 0.294+/- 0.010
int_sigma = 0.023+/- 0.020
ple_sigma = 0.129+/- 0.014
dec_sigma = 0.238+/- 0.008
int_trans = 0.279+/- 0.012
```
| github_jupyter |
```
import os
import ast
### open Hamiltonian data ###
working_dir = os.getcwd()
parent_dir = os.path.dirname(working_dir) # gets directory where running python file is!
data_dir = os.path.join(parent_dir, 'Molecular_Hamiltonian_data')
hamiltonian_data = os.path.join(data_dir, 'hamiltonians.txt')
with open(hamiltonian_data, 'r') as input_file:
hamiltonians = ast.literal_eval(input_file.read())
for key in hamiltonians.keys():
print(f"{key: <25} n_qubits: {hamiltonians[key][1]:<5.0f}")
# molecule_key = 'H3_STO-3G_singlet_1+'
molecule_key='H1-Li1_STO-3G_singlet'
transformation, N_qubits, Hamilt_dictionary, _ ,_, _ = hamiltonians[molecule_key]
```
# 1. Get OpenFermion representation of Hamiltonian
```
from quchem.Misc_functions.conversion_scripts import Get_Openfermion_Hamiltonian
openFermion_H = Get_Openfermion_Hamiltonian(Hamilt_dictionary)
openFermion_H
```
# 2. Get cliques defined by commutativity
```
from quchem.Unitary_Partitioning.Graph import Clique_cover_Hamiltonian
commutativity_flag = 'AC' ## <- defines relationship between sets!!!
Graph_colouring_strategy='largest_first'
anti_commuting_sets = Clique_cover_Hamiltonian(openFermion_H,
N_qubits,
commutativity_flag,
Graph_colouring_strategy)
anti_commuting_sets
```
# 3. Example of X_sk operator
```
key_larg, largest_AC_set = max(anti_commuting_sets.items(), key=lambda x:len(x[1])) # largest nonCon part found by dfs alg
largest_AC_set
from quchem.Unitary_Partitioning.Seq_Rot_circuit_functions import Build_R_SeqRot_Q_circuit
S_index=0
check_reduction_lin_alg = True
check_circuit = True
AC_set = anti_commuting_sets[key_larg]
Q_circuit_Rsl, Psl, gammal = Build_R_SeqRot_Q_circuit(AC_set,
S_index,
N_qubits,
check_reduction_lin_alg=check_reduction_lin_alg,
atol=1e-8,
rtol=1e-05,
check_circuit = check_circuit)
Q_circuit_Rsl
Q_circuit_Rsl.unitary()
## compare with linear algebra
from quchem.Unitary_Partitioning.Unitary_partitioning_Seq_Rot import Get_Xsk_op_list
S_index=0
check_reduction = True
X_sk_theta_sk_list, normalised_FULL_set, Ps, gamma_l = Get_Xsk_op_list(AC_set,
S_index,
N_qubits,
check_reduction=check_reduction,
atol=1e-8,
rtol=1e-05,)
X_sk_theta_sk_list
from quchem.Unitary_Partitioning.Unitary_partitioning_Seq_Rot import Get_Rsl_matrix
R_Sl_matrix = Get_Rsl_matrix(X_sk_theta_sk_list, N_qubits)
## checking Rsl circuit unitary is the same as lin alg R_sl matrix
import numpy as np
np.allclose(Q_circuit_Rsl.unitary(), R_Sl_matrix.todense())
Ps
gamma_l
```
# 4. Full Seq Rot circuit
```
import cirq
qubits = list(cirq.LineQubit.range(N_qubits))
ansatz = cirq.Circuit([cirq.X.on(q) for q in qubits])
ansatz
from quchem.Unitary_Partitioning.Seq_Rot_circuit_functions import Full_SeqRot_Rl_Circuit
S_index=0
check_reduction_lin_alg = True
AC_set = anti_commuting_sets[key_larg]
full_circuit, Ps, gamma_l = Full_SeqRot_Rl_Circuit(ansatz, AC_set, S_index,N_qubits,
check_reduction_lin_alg=check_reduction_lin_alg)
full_circuit
Ps
```
# 5. Circuit experiments (TODO)
- Ansatz
- Rsl
- Ps measurement
```
# TODO
Seq_Rot_VQE_Experiment_UP_circuit_lin_alg
# TODO
Seq_Rot_VQE_Experiment_UP_circuit_sampling
```
| github_jupyter |
# Plasma Beta with FGM and FPI data
This notebook shows how to calculate plasma beta with FGM and FPI data
## Get started
```
from pyspedas.mms import fgm, fpi # load routines
from pyspedas import tinterpol # interpolate tplot variables
from pytplot import tplot, get_data, store_data # plot, access, and create tplot variables
```
## Define some constants
```
mu0 = 1256.0 # nT-m/A
Kb = 1.3807*10**(-16.) # cm^2-g-1/s^2-1/K
```
## Set some options for the load routines
```
probe = '1'
trange = ['2015-10-16/11:00', '2015-10-16/14:00']
```
## Load the FGM and FPI data
```
fgm_vars = fgm(trange=trange, probe=probe)
fpi_vars = fpi(datatype=['dis-moms', 'des-moms'], trange=trange, probe=probe, center_measurement=True)
```
## Set some variable names
```
temp_para_i = 'mms'+probe+'_dis_temppara_fast'
temp_perp_i = 'mms'+probe+'_dis_tempperp_fast'
temp_para_e = 'mms'+probe+'_des_temppara_fast'
temp_perp_e = 'mms'+probe+'_des_tempperp_fast'
number_density_i = 'mms'+probe+'_dis_numberdensity_fast'
number_density_e = 'mms'+probe+'_des_numberdensity_fast'
b_field = 'mms'+probe+'_fgm_b_gsm_srvy_l2'
b_magnitude = 'mms'+probe+'_fgm_b_gsm_srvy_l2_mag'
```
## Split the B-field magnitude into its own variable
```
times, data = get_data(b_field)
store_data(b_magnitude, data={'x': times, 'y': data[:, 3]})
```
## Interpolate the B-field data to the FPI time stamps
```
tinterpol(b_magnitude, number_density_i, newname=['b_mag_interpolated'])
```
## Extract the data from the pyTplot variables
```
btimes, bdata = get_data('b_mag_interpolated')
ipatimes, i_para_temp = get_data(temp_para_i)
ipetimes, i_perp_temp = get_data(temp_perp_i)
epatimes, e_para_temp = get_data(temp_para_e)
epetimes, e_perp_temp = get_data(temp_perp_e)
nitimes, i_n = get_data(number_density_i)
netimes, e_n = get_data(number_density_e)
```
## Calculate the magnetic pressure
note: 1.0e-8 comes from A-nT/m -> g/(s^2-cm)
```
Pmag = 1.0e-8*bdata**2/(2.0*mu0)
```
## Calculate the ion and electron temperatures
```
Te_total=(e_para_temp+2*e_perp_temp)/3.0
Ti_total=(i_para_temp+2*i_perp_temp)/3.0
```
## Calculate the plasma pressure
note: eV -> K conversion: 11604.505 K/eV
```
Pplasma = (i_n*11604.505*Ti_total+e_n*11604.505*Te_total)*Kb
```
## Calculate plasma beta
```
Beta = Pplasma/Pmag
```
## Store the data in pyTplot variables
```
store_data('plasma_beta', data={'x': btimes, 'y': Beta})
store_data('magnetic_pressure', data={'x': btimes, 'y': Pmag})
store_data('plasma_pressure', data={'x': btimes, 'y': Pplasma})
```
## Plot the results
```
tplot(['plasma_beta', 'plasma_pressure', 'magnetic_pressure'])
```
| github_jupyter |
```
from tabu import TabuSampler
from sklearn import cluster, datasets, mixture
import copy
import matplotlib.pyplot as plt
import numpy as np
#from anytree import Node, RenderTree
from treelib import Node, Tree
np.random.seed(4)
n_samples = 150
dataset = datasets.make_blobs(n_samples=n_samples, random_state=6)
#dataset = datasets.make_moons(n_samples=n_samples, noise=.05)
#dataset = datasets.make_circles(n_samples=n_samples, factor=.5,noise=.05)
#print(dataset[0])
fig, ax = plt.subplots()
for i in range(0,150):
if dataset[1][i] == 0:
ax.scatter(dataset[0][i,0],dataset[0][i,1],c='b')
elif dataset[1][i] == 1:
ax.scatter(dataset[0][i,0],dataset[0][i,1],c='g')
else:
ax.scatter(dataset[0][i,0],dataset[0][i,1],c='r')
#plt.xlim(-2.5, 2.5)
#plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.show()
feature_vecs = dataset[0]
print(feature_vecs[0])
print(feature_vecs[1])
print(str(feature_vecs[0] - feature_vecs[1]))
def binary_clustering(feature_vecs,feature_index):
h= {}
J= {}
cluster1 = [] #stores the indices for the first cluster
cluster2 = [] #stores the indices for the second cluster
for i in feature_index:
for j in feature_index:
if i < j:
J[(i,j)] = np.linalg.norm(feature_vecs[i] - feature_vecs[j])**2
#Now use a sampler to solve it
sampler = TabuSampler()
# Run the problem on the sampler and print the results
sampleset = sampler.sample_ising(h, J, num_reads = 5,timeout=10000)
bin_cluster = sampleset.first[0]
for key in bin_cluster:
#put in cluster 1 if -1, else 2
if bin_cluster[key] == -1:
cluster1.append(key)
elif bin_cluster[key] == 1:
cluster2.append(key)
return cluster1,cluster2
feature_index = [i for i in range(0,n_samples)]
cl1, cl2 = binary_clustering(feature_vecs,feature_index)
#binary_clustering(feature_vecs,feature_index)
#Let's plot the output
fig, ax = plt.subplots()
for i in range(0,len(feature_vecs)):
if i in cl1:
ax.scatter(dataset[0][i,0],dataset[0][i,1],c='b')
else:
ax.scatter(dataset[0][i,0],dataset[0][i,1],c='r')
#plt.xlim(-2.5, 2.5)
#plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.show()
def squared_dist_sum(feature_vecs,feature_index):
h= {}
J= {}
total = 0.0
for i in feature_index:
for j in feature_index:
if i < j:
total += np.linalg.norm(feature_vecs[i] - feature_vecs[j])**2
return total
squared_dist_sum(feature_vecs,[3,1,2])
l = [3,2,2]
tree = Tree()
tree.create_node("Harry", "harry") # root node
tree.create_node("Jane", "jane", parent="harry")
tree.create_node("Bill", "bill", parent="harry",data = l)
tree.create_node("Diane", "diane", parent="jane")
tree.create_node("Mary", "mary", parent="diane")
tree.create_node("Mark", "mark", parent="jane")
tree.show()
x = tree.leaves("harry")
print(x[0].identifier)
print(x[0].data)
y = x[0].bpointer
print(y)
for node in x:
print(node)
print(tree.get_node("bill"))
level = 0
node_label = "c,0,0"
cluster_tree = Tree()
feature_index = [i for i in range(0,n_samples)]
cluster_tree.create_node(node_label, node_label,data=feature_index)
max_sum_label = None #Keeps track of the leaf node with the least squared distance
max_sum = 0.0
for i in range(0,2):
cur_node = cluster_tree.get_node(node_label)
cl1, cl2 = binary_clustering(feature_vecs,cur_node.data)
#Attach clusters to the cluster_tree
print("Expanding cluster:",node_label)
node_label_set = node_label.split(",") #comma separated
child1_node_label = "c," + str(int(node_label_set[1])+1) +"," + str(1)
child2_node_label = "c," + str(int(node_label_set[1])+1) +"," + str(2)
cluster_tree.create_node(child1_node_label,child1_node_label,data=cl1,parent=node_label)
cluster_tree.create_node(child2_node_label,child2_node_label,data=cl2,parent=node_label)
#Now to check the least sum of squared error
max_sum_id = None #Reinitialize if changed
max_sum = 0.0
cur_leaves = cluster_tree.leaves(node_label) #get the leaf nodes
for node in cur_leaves:
cur_sum = squared_dist_sum(feature_vecs,node.data)
if cur_sum > max_sum:
max_sum = cur_sum
max_sum_label = node.identifier
#Now we have our max_sum_label
node_label = max_sum_label
cluster_tree.show()
x = cluster_tree.leaves("c,0,0")
print(x)
#Let's plot the output
fig, ax = plt.subplots()
ctr = 0
for node in cluster_tree.leaves("c,0,0"):
print(len(node.data))
for i in range(0,len(feature_vecs)):
if ctr == 0:
c = 'b'
elif ctr == 1:
c = 'g'
else:
c = 'r'
if i in node.data:
ax.scatter(dataset[0][i,0],dataset[0][i,1],c=c)
ctr += 1
#plt.xlim(-2.5, 2.5)
#plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.show()
from sklearn.cluster import DBSCAN
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80],[77,77]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
l
for i in l:
for j > i:
print(str(i)","str(j))
dataset[0]
```
| github_jupyter |
```
%matplotlib inline
%load_ext autoreload
%autoreload 2
import sys
sys.path.append("../..") # Adds the module to path
```
# DeepTrack 2.1 - Generators
This tutorial introduces and explains generators.
### What are generators?
Generators are objects designed to help DeepTrack interface with other packages that want to retrieve the data. They achieve this by automatically executing your features and return data in a standardized format, such as in batches.
```
import deeptrack as dt
import matplotlib.pyplot as plt
import numpy as np
u = dt.units
```
## 1. Create a data pipeline
For demonstration purposes, we'll define a simple data pipeline.
```
IMAGE_SIZE = 64
particle = dt.MieSphere(position=lambda: np.random.uniform(IMAGE_SIZE / 2 - 4, IMAGE_SIZE / 2 + 4, 2))
optics = dt.Brightfield(output_region=(0, 0, IMAGE_SIZE, IMAGE_SIZE))
image_pipeline = optics(particle)
image_pipeline.plot(cmap="gray")
label = image_pipeline >> (lambda image: image.get_property("position") - IMAGE_SIZE / 2)
data_pipeline = image_pipeline & label
```
## 1. The ContinuousGenerator
The main generator used is the `ContinuousGenerator`. This will spin up a new thread in the background to continuously create more data asynchronously. This is very useful when training on the gpu, because it maximizes the utilization of both the gpu and the cpu! You create a generator like so:
```
generator = dt.generators.ContinuousGenerator(data_pipeline)
```
This will create images in batches for you asunchronously until it is filled up. Then it waits for a signal to replace that data with new data! Of course, you'll want to specify these parameters when creating the generator.
```
# A generator that will fill up with 128 samples, and output them in batches of 8.
generator = dt.generators.ContinuousGenerator(data_pipeline, batch_size=8, max_data_size=512)
```
In order to tell the generator to start creating data, we use the with statement:
```
with generator:
print("Data is being created!")
```
However, as soon as you exit the `with` statement, you'll stop generating data. You can start it again by entering a new `with`-statement
```
import time
print(f"I have {len(generator)} batches ready for you!")
time.sleep(0.5)
print(f"I still have {len(generator)} batches ready for you!")
with generator:
print(f"Working....")
time.sleep(1)
print(f"I have {len(generator)} batches ready for you!")
```
### 2.1 min_data_size
`min_data_size` describes how many samples the generator needs to create before it can be used. This is very useful for training, because you might not want to start your training untill you have enough data ready to not overfit.
```
# I'll create 10 samples before entering the with-statement
generator = dt.generators.ContinuousGenerator(data_pipeline, batch_size=8, min_data_size=10)
```
### 2.2 max_epochs_per_sample
Per default, during training, the generator will kepp using the same data until it has been replaced. If the pipeline is fast, this is not a problem. The model will likely see new data frequently. However, if the pipeline is slow, it's possible that each sample does not have time to be replaced fully between epochs. If a model is trained too many epochs on the same data, it may overfit. To mitigate this, we can use the `max_epochs_per_sample` option! This will flag how many times a data-point can be used before it has to be replaced!
```
# Data here is guaranteed to be fully replaced every two epochs of training
generator = dt.generators.ContinuousGenerator(data_pipeline, batch_size=8, max_epochs_per_sample=2)
```
### 2.2 label_function and batch_function
The continuous generator assumes you pipeline works as `data, label = pipeline.update()()`. Sometime this is inconvenient. In these cases you can define two functions that converts the output of the pipeline to the desired format.
```
generator = dt.generators.ContinuousGenerator(image_pipeline, label_function=lambda x: x.get_property("position"))
```
## 3. Training a model using a generator!
```
generator = dt.generators.ContinuousGenerator(
data_pipeline,
batch_size=8,
min_data_size=128,
max_data_size=256,
max_epochs_per_sample=2
)
model = dt.models.Convolutional(input_shape=(IMAGE_SIZE, IMAGE_SIZE, 1), number_of_outputs=2)
with generator:
model.fit(generator, epochs=100)
```
| github_jupyter |
# **Emergency Vehicle Detection Training**
## Install
```
!pip install tensorflow==2.1.0
```
## Import Libraries
```
import numpy as np
import os
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import tensorflow as tf
tf.__version__
```
## Setup Google Drive
```
from google.colab import drive
drive.mount("/content/gdrive")
tpath = "/content/gdrive/My Drive/Academic/Vehicle/Dataset/Train"
vpath = "/content/gdrive/My Drive/Academic/Vehicle/Dataset/Validation"
```
## Train
#### Initializing
```
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.1,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
vertical_flip=True
)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
tpath,
target_size=(224, 224),
batch_size=32,
color_mode="rgb",
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
vpath,
target_size=(224, 224),
batch_size=32,
color_mode="rgb",
class_mode='binary')
```
#### Model
```
import tensorflow as tf
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32,(3,3),input_shape=(224,224,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D(64,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(128,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Conv2D(64,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
model.compile(loss="binary_crossentropy",
optimizer='adam',
metrics=['accuracy'],
)
```
#### Training the Model
```
batch_size = 32
epochs = 10
steps_per_epoch = train_generator.n // batch_size
validation_steps = validation_generator.n // batch_size
history=model.fit_generator(train_generator, steps_per_epoch=steps_per_epoch, epochs=epochs, workers=4,
validation_data=validation_generator, validation_steps=validation_steps)
```
## Metrics
```
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
```
## Save the Model
```
from tensorflow.keras.models import load_model
model.save('/content/gdrive/My Drive/Academic/Vehicle/Dataset/Allen2.h5')
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.