
text stringlengths 2.5k 6.39M | kind stringclasses 3
values |
|---|---|
```
import scipy.stats as stats
import matplotlib
import matplotlib.patches as mpatches
import math
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
```
*** Read the csv file ***
```
image_data =pd.read_csv("cata_for_image_reso_and_size.csv")
image_data.head()
```
*** Seperated the data based on the resolution. image_300 contains all the images with 300 resolution. image_96 contains all the images with 96 resolution. ***
```
image_300 = image_data.loc[image_data['resolution(DPI)'] == 300]
image_300.head()
image_96 = image_data.loc[image_data['resolution(DPI)'] == 96]
image_96.head()
```
*** Calculating the mean of image size between 300 and 96 resolution ***
```
image_300_size_mean = image_300["size(MB)"].mean()
print("300 resolution image size mean: " + str(image_300_size_mean))
image_96_size_mean = image_96["size(MB)"].mean()
print("96 resolution image size mean: " + str(image_96_size_mean))
```
*** Calculating the standard deviation of image size between 300 and 96 resolution ***
```
image_300_size_SD = image_300["size(MB)"].std()
print("300 resolution image size SD: " + str(image_300_size_SD))
image_96_size_SD = image_96["size(MB)"].std()
print("96 resolution image size SD: " + str(image_96_size_SD))
```
*** Calculating the image size mean, median, variance, and standard deviation ***
```
size_mean = image_data["size(MB)"].mean()
size_median = image_data["size(MB)"].median()
size_variance = image_data["size(MB)"].var()
size_SD = image_data["size(MB)"].std()
print("size mean: " + str(size_mean))
print("size median: " + str(size_median))
print("size variance: " + str(size_variance))
print("size SD: " + str(size_SD))
```
*** Calculating the image resolution mean, median, variance, and standard deviation ***
```
resolution_mean = image_data["resolution(DPI)"].mean()
resolution_median = image_data["resolution(DPI)"].median()
resolution_variance = image_data["resolution(DPI)"].var()
resolution_SD = image_data["resolution(DPI)"].std()
print("resolution mean: " + str(resolution_mean))
print("resolution median: " + str(resolution_median))
print("resolution variance: " + str(resolution_variance))
print("resolution SD: " + str(resolution_SD))
```
***Two sample T- test***
*** Null Hypothesis: Image size mean is same between 300 and 96 resolution Images. ***
*** Ploting the 300 resolution image size and 96 resolution image size together. Also ploting the mean as well to see the difference. ***
```
plt.figure(figsize=(12,8))
plt.hist(image_300["size(MB)"], bins=20, edgecolor='k', alpha=0.5, label='300 resolution')
plt.hist(image_96["size(MB)"], bins=20, edgecolor='k', alpha=0.5, label='96 resolution')
plt.axvline(image_300_size_mean, color='r', linewidth=2, label='300 reso Mean')
plt.axvline(image_96_size_mean, color='y', linewidth=2, label='96 reso Mean')
plt.legend(loc='upper right')
plt.savefig('images_size_hyto_test.png', dpi = 100)
```
*** Calculating the T-Test within the data to find the P-value ***
```
stats.ttest_ind(a= image_300["size(MB)"],
b= image_96["size(MB)"],
equal_var=False)
```
*** The T-test gives p-value of 0.008 ***
*** Using 95% confidence level we reject the null hypothesis. Since the p-value is smaller than the corresponding significance level of 5%. ( 𝛼 < 0.05 ) ***
*** Ploting the histogram for image size ***
```
matplotlib.rc('axes', labelsize=12)
matplotlib.rc('axes', titlesize=12)
pd.DataFrame(image_data).hist(column="size(MB)", bins=15, ec='red')
plt.xlabel("Size(MB)")
plt.ylabel( "Number of Images")
plt.title("Sample size = " + str(image_data.shape[0]+1) + str())
plt.savefig('images_size_hist.png', dpi = 100)
```
*** Ploting the density curve for the image size using seaborn ***
```
matplotlib.rc('axes', labelsize=12)
matplotlib.rc('axes', titlesize=12)
sns.distplot(image_data['size(MB)'], hist=True, kde=True,
bins=15, color = 'green',
hist_kws={'edgecolor':'red'},
kde_kws={'linewidth': 2})
plt.savefig('images_size_density.png', dpi = 100)
```
*** Ploting the histogram for image resolution ***
```
matplotlib.rc('axes', labelsize=12)
matplotlib.rc('axes', titlesize=12)
pd.DataFrame(image_data).hist(column="resolution(DPI)", bins=15, ec='red')
plt.xlabel("Resolution(DPI)")
plt.ylabel( "Number of Images")
plt.title("Sample size = " + str(image_data.shape[0]+1) + str())
plt.savefig('images_reso_hist.png', dpi = 100)
```
*** Ploting the density curve for the image resolution using seaborn ***
```
# seaborn histogram and density plot
matplotlib.rc('axes', labelsize=12)
matplotlib.rc('axes', titlesize=12)
sns.distplot(image_data['resolution(DPI)'], hist=True, kde=True,
bins=15, color = 'green',
hist_kws={'edgecolor':'red'},
kde_kws={'linewidth': 2})
plt.savefig('images_reso_density.png', dpi = 100)
```
*** Using the T-critical value to find the confidence interval for image size ***
```
sample_size = 500
for sample in range(25):
sample = np.random.choice(a=image_data["size(MB)"], size = sample_size)
sample_mean = sample.mean()
t_critical = stats.t.ppf(q = 0.975, df=24) # Get the t-critical value
sigma = size_SD/math.sqrt(sample_size) # Standard deviation estimate
margin_of_error = t_critical * sigma
confidence_interval = (sample_mean - margin_of_error,
sample_mean + margin_of_error)
print("T-critical value: " + str(t_critical))
print("Confidence interval for size: " + str(confidence_interval))
```
*** Used the T-critical value to fidn the confidence interval for resolution ***
```
sample_size = 500
for sample in range(25):
sample = np.random.choice(a=image_data["resolution(DPI)"], size = sample_size)
sample_mean = sample.mean()
t_critical = stats.t.ppf(q = 0.975, df=24) # Get the t-critical value
sigma = resolution_SD/math.sqrt(sample_size) # Standard deviation estimate
margin_of_error = t_critical * sigma
confidence_interval = (sample_mean - margin_of_error,
sample_mean + margin_of_error)
print("T-critical value: " + str(t_critical))
print("Confidence interval for resolution: " + str(confidence_interval))
```
*** Calculating the covariance and correlation between image size and resolution ***
```
print('Covariance of size and resolution: %.2f'%np.cov(image_data["size(MB)"], image_data["resolution(DPI)"])[0, 1])
print('Correlation of size and resolution: %.2f'%np.corrcoef(image_data["size(MB)"], image_data["resolution(DPI)"])[0, 1])
```
*** Ploting the image size and resolution to see the correlation between them ***
```
matplotlib.rc('axes', labelsize=19)
matplotlib.rc('axes', titlesize=12)
m, b = np.polyfit(image_data["resolution(DPI)"], image_data["size(MB)"], 1)
plt.figure(figsize=(12,10))
plt.scatter(image_data["resolution(DPI)"], image_data["size(MB)"])
plt.xlabel('resolution')
plt.ylabel('size')
plt.plot(image_data["resolution(DPI)"], m*image_data["resolution(DPI)"] + b, 'r-')
plt.savefig('images_correlation.png', dpi = 100)
```
| github_jupyter |
### Retrieve Frequency Domain and Time Domain Data
```
def readFile(file):
"""
Reads a file in memory
Arguments:
file (string): file to be read in
Returns:
Python list containing file data points
"""
data = []
infile = open(file,"r")
s = infile.read()
numbers = [eval(x) for x in s.split()]
for number in numbers:
data.append(number)
infile.close() # Close the file
return data
```
#### Training Set
```
# Set 1
music_nv_1_time = readFile('Data/Training/Set 1/y1.txt')
music_v_1_time = readFile('Data/Training/Set 1/y2.txt')
speech_1_time = readFile('Data/Training/Set 1/y3.txt')
speech_bkg_music_1_time = readFile('Data/Training/Set 1/y4.txt')
# Set 2
music_nv_2_time = readFile('Data/Training/Set 2/y1.txt')
music_v_2_time = readFile('Data/Training/Set 2/y2.txt')
speech_2_time = readFile('Data/Training/Set 2/y3.txt')
speech_bkg_music_2_time = readFile('Data/Training/Set 2/y4.txt')
```
#### Testing Set
```
# Set 3
music_nv_3_time = readFile('Data/Testing/Set 3/y1.txt')
music_v_3_time = readFile('Data/Testing/Set 3/y2.txt')
speech_3_time = readFile('Data/Testing/Set 3/y3.txt')
speech_bkg_music_3_time = readFile('Data/Testing/Set 3/y4.txt')
# Set 4
music_nv_4_time = readFile('Data/Testing/Set 4/y1.txt')
music_v_4_time = readFile('Data/Testing/Set 4/y2.txt')
speech_4_time = readFile('Data/Testing/Set 4/y3.txt')
speech_bkg_music_4_time = readFile('Data/Testing/Set 4/y4.txt')
```
### Feature Selection
### Calculate Time Domain Signal Mean Value (Weighted)
```
def meanValue(aList):
"""
Calculates the mean value of the absolute signal
Arguments:
aList (array): 1-D array containing values to be averaged
Returns:
Average of values
"""
listSum = 0
count = 0
for value in aList:
listSum = listSum + abs(value)
# The sample frequency is 22050 Hz
# Therefore, the data points in a 5 s recording are 110250
mean = listSum / 110250
return mean
```
#### Training Set
```
# Set 1
music_nv_1_time_mean = meanValue(music_nv_1_time)
music_v_1_time_mean = meanValue(music_v_1_time)
speech_1_time_mean = meanValue(speech_1_time)
speech_bkg_music_1_time_mean = meanValue(speech_bkg_music_1_time)
# Set 2
music_nv_2_time_mean = meanValue(music_nv_2_time)
music_v_2_time_mean = meanValue(music_v_2_time)
speech_2_time_mean = meanValue(speech_2_time)
speech_bkg_music_2_time_mean = meanValue(speech_bkg_music_2_time)
```
#### Testing Set
```
# Set 3
music_nv_3_time_mean = meanValue(music_nv_3_time)
music_v_3_time_mean = meanValue(music_v_3_time)
speech_3_time_mean = meanValue(speech_3_time)
speech_bkg_music_3_time_mean = meanValue(speech_bkg_music_3_time)
# Set 4
music_nv_4_time_mean = meanValue(music_nv_4_time)
music_v_4_time_mean = meanValue(music_v_4_time)
speech_4_time_mean = meanValue(speech_4_time)
speech_bkg_music_4_time_mean = meanValue(speech_bkg_music_4_time)
```
### Calculate Percentage of Signal Below Mean [Feature #2]
```
def maxCount(aList, mean, scaling_factor):
"""
Calculates the maximum number of consecutive low amplitude points
Arguments:
aList (array): 1-D array containing values to be iterated
mean (float): The calculated absolute value average
scaling_factor (float): Calculates 'null point' relative to signal mean
Returns:
Number of low amplitude (null) points
"""
count = 0
max_count = 0
for i in range(len(aList)-1):
if abs(aList[i]) < (mean*scaling_factor) and abs(aList[i+1]) < (mean*scaling_factor):
count = count + 1
else:
count = 0
if count > max_count:
max_count = count
return max_count
```
### Scaling Factor of 0.5
#### Training Set
```
# Set 1
music_nv_1_null_time_0_5 = maxCount(music_nv_1_time, music_nv_1_time_mean, 0.5)
music_v_1_null_time_0_5 = maxCount(music_v_1_time, music_v_1_time_mean, 0.5)
speech_1_null_time_0_5 = maxCount(speech_1_time, speech_1_time_mean, 0.5)
speech_bkg_music_1_null_time_0_5 = maxCount(speech_bkg_music_1_time, speech_bkg_music_1_time_mean, 0.5)
# Set 2
music_nv_2_null_time_0_5 = maxCount(music_nv_2_time, music_nv_2_time_mean, 0.5)
music_v_2_null_time_0_5 = maxCount(music_v_2_time, music_v_2_time_mean, 0.5)
speech_2_null_time_0_5 = maxCount(speech_2_time, speech_2_time_mean, 0.5)
speech_bkg_music_2_null_time_0_5 = maxCount(speech_bkg_music_2_time, speech_bkg_music_2_time_mean, 0.5)
```
#### Testing Set
```
# Set 3
music_nv_3_null_time_0_5 = maxCount(music_nv_3_time, music_nv_3_time_mean, 0.5)
music_v_3_null_time_0_5 = maxCount(music_v_3_time, music_v_3_time_mean, 0.5)
speech_3_null_time_0_5 = maxCount(speech_3_time, speech_3_time_mean, 0.5)
speech_bkg_music_3_null_time_0_5 = maxCount(speech_bkg_music_3_time, speech_bkg_music_3_time_mean, 0.5)
# Set 4
music_nv_4_null_time_0_5 = maxCount(music_nv_4_time, music_nv_4_time_mean, 0.5)
music_v_4_null_time_0_5 = maxCount(music_v_4_time, music_v_4_time_mean, 0.5)
speech_4_null_time_0_5 = maxCount(speech_4_time, speech_4_time_mean, 0.5)
speech_bkg_music_4_null_time_0_5 = maxCount(speech_bkg_music_4_time, speech_bkg_music_4_time_mean, 0.5)
```
### Data Partitioning
There are currently four sound categories we are working with:
- music with no vocals
- music with vocals
- speech
- speech with background music
At this point we have worked enough through the time domain statistics to gather a sufficient set of traits to run the system through.
We will take the following strategy to pin point the exact class the test data points to.
#### Project: Diverge from the sound basis
Is the sound speech-oriented or music-oriented?
The music-oriented category in this case consists of:
- music with no vocals
- music with vocals
The main message being transmitted is the rhythm, instrumentation, and/or vocalisation of the musical material.
The speech-oriented category in this case consists of:
- speech
- speech with background music
The main message being transmitted is the speaker's words.
```
import numpy as np
```
#### Training Set
```
# Using training set 1 and 2, populate the training arrays with % time below 0.5 * mean
# ~ Class 0 = speech based
# ~ Class 1 = music based
speach_music_train = np.array([speech_1_null_time_0_5,
speech_2_null_time_0_5,
speech_bkg_music_1_null_time_0_5,
speech_bkg_music_2_null_time_0_5,
music_nv_1_null_time_0_5,
music_nv_2_null_time_0_5,
music_v_1_null_time_0_5,
music_v_2_null_time_0_5])
label_sm_train = np.array([0, 0, 0, 0, 1, 1, 1, 1])
```
#### Testing Set
```
# Using testing set 3 and 4, populate the testing arrays with % time below 0.5 * mean
# ~ Class 0 = speech
# ~ Class 1 = music
speach_music_test = np.array([speech_3_null_time_0_5,
speech_4_null_time_0_5,
speech_bkg_music_3_null_time_0_5,
speech_bkg_music_4_null_time_0_5,
music_nv_3_null_time_0_5,
music_nv_4_null_time_0_5,
music_v_3_null_time_0_5,
music_v_4_null_time_0_5])
label_sm_test = np.array([0, 0, 0, 0, 1, 1, 1, 1])
```
#### Data Visualisation
```
import matplotlib.pyplot as plt
plt.plot(label_sm_train[0:4], speach_music_train[0:4], 'ro')
plt.plot(label_sm_train[4:8], speach_music_train[4:8], 'bo')
plt.xlabel('Class Number')
plt.ylabel('Maximum Consecutive Null Points')
plt.title('Maximum Consecutive Null Points')
plt.grid(True)
plt.show()
```
The graphs above might be a little misleading. The quantity of interest is plotted along the **verical axis**, the horizontal axis merely benefits the reader by making the points more discernable.
The kNN algorithm will; therefore, be **adapted** to measure vertical distance between points as the distance metric - the horizontal (and hypotenuse) distance is irrelevant to our analysis.
### Establish a Definition for our kNN algorithm
#### Distance Between Two Points
```
def verticalDistance(y_a, y_b):
"""
Calculates the vertical distance between two points (1 feature)
Arguments:
y_a (float): 1-D array containing values to be iterated
y_b (float): The calculated absolute value average
Returns:
Distance between two points
"""
return abs(y_a - y_b)
```
#### Calculate List of Distances
```
def listOfDistances(x_test, X_in):
"""
Calculates a list of distances from a test point to each
member of an input array
Arguments:
x_test (float): Test point
X_in (array): 1-D array containing values to be iterated
Returns:
List of distances between test point and input array
"""
distance_list = []
length = len(X_in)
while length > 0:
distance_list.insert(0,verticalDistance(x_test, X_in[length-1]))
length = length-1
return distance_list
y_test = 1.0
Y_in = np.array([2.0, -1.5, -2, 0])
listOfDistances(y_test, Y_in)
```
#### Determine k Nearest Neighbours
#### Sorting the distances and returning indices
```
def kNearestIndices(distance_list, k):
"""
Calculates a list of the nearest indices to the test point
Arguments:
distance_list (array): 1-D array containing list of distances
k (int): Number of nearest points desired
Returns:
List of the k-nearest indices to the test point
"""
# Step 1: Create an empty numpy array
arr_empty = np.array([])
# Step 2: Append the distance_list python array
arr_append = np.append (arr_empty, distance_list)
# Step 3: Sort the array elements in ascending order
arr_sort = np.argsort(arr_append)
# Step 4: Retain first k elements
k_nearest_indices = arr_sort[:k]
return k_nearest_indices
# Test Cell
print(kNearestIndices([5.0, 3.5, 2.5, 1.0], 3))
```
#### Returning the Values at the K-Nearest Indeces
```
def kNearestNeighbours(k_nearest_indices, X_in, Y_in):
"""
Calculates a list of the nearest neighbours to the test point
Arguments:
k_nearest_indices (array): 1-D array containing list of distances
X_in (array): 1-D array containing data array points
Y_in (array): 1-D array containing label points
Returns:
List of the k-nearest neighbours to the test point
"""
# Step 1: Create two Python lists
X = []
Y = []
# Step 2: Identify how many nearest neighbours
# are to be used
length = len(k_nearest_indices)
# Step 3: Place the nearest neighbour in the created
# Python list, head first
while length > 0:
X.insert(0, X_in[k_nearest_indices[length - 1]])
Y.insert(0, Y_in[k_nearest_indices[length - 1]])
length = length - 1
# Step 4: Use the Python lists to create ceooresponding
#. numpy arrays
X_k = np.array (X)
Y_k = np.array (Y)
return X_k, Y_k
# Test Cell
X_train_grade = np.array([1, 2, 3, 4, 5, 6, 7, 8])
Y_train_grade = np.array([0, 0, 0, 0, 1, 1, 1, 0])
X_k_grade, Y_k_grade = kNearestNeighbours([0, 1, 3], X_train_grade, Y_train_grade)
print(X_k_grade)
print(Y_k_grade)
from scipy import stats
```
#### Predict Category
```
def predict(x_test, X_in, Y_in, k):
"""
Determine the most likely identity of the test point
Arguments:
x_test (array): 1-D array containing test point
X_in (array): 1-D array containing data array points
Y_in (array): 1-D array containing label points
k (int): Number of nearest points desired
Returns:
Most likely identity of test point
"""
# Step 1: Task 2 - Calculate list of distances
distance_list = []
distance_list = listOfDistances(x_test, X_in)
# print(distance_list)
# Step 2: Task 3.1 - Determine k Nearest Indices
k_nearest_indices = kNearestIndices(distance_list, k)
# print(k_nearest_indices)
# Step 3: Task 3.2 - Determine k Nearest Neighbours
X_k, Y_k = kNearestNeighbours(k_nearest_indices, X_in, Y_in)
# print(Y_k)
# Step 4: Determine mode of classes
prediction = np.array(stats.mode(Y_k))
# print(prediction)
# Step 5: Return only the class member
return prediction[0]
# Test Cell
X_train_grade = np.array([1, 2, 3, 4, 5, 6, 7, 8])
Y_train_grade = np.array([0, 0, 0, 0, 1, 1, 1, 0])
x1_grade = np.array([0])
k_grade = 3
print(predict(x1_grade, X_train_grade, Y_train_grade, k_grade))
```
#### Predict for an entire batch of test examples
```
def predictBatch(X_t, X_in, Y_in, k):
"""
Determine the most likely identities of the test point list
Arguments:
X_t (array): 1-D array containing test point list
X_in (array): 1-D array containing data array points
Y_in (array): 1-D array containing label points
k (int): Number of nearest points desired
Returns:
Most likely identity of test point list values
"""
length = len(X_t)
predictions_py = []
while (length > 0):
# Step 1: Identify the prediction for the last index
prediction = predict(X_t[length-1], X_in, Y_in, k)
# Step 2: Concatenate the index to the head of the list
predictions_py = [*prediction, *predictions_py]
length = length - 1
predictions = np.array(predictions_py)
return predictions
# Test Cell
X_train_grade = np.array([1, 2, 3, 4, 15, 16, 17, 5])
Y_train_grade = np.array([0, 0, 0, 0, 1, 1, 1, 0])
X_test_grade = np.array([1, 2, 3, 14])
Y_test_grade = np.array([0, 0, 0, 1])
k_grade=1
print(predictBatch(X_test_grade, X_train_grade, Y_train_grade, k=k_grade))
```
#### Accuracy Metric
```
def accuracy(Y_pred, Y_test):
"""
Determine the accuracy of the prediction with respect
to the true value (label)
Arguments:
Y_pred (array): 1-D array containing prediction point list
Y_test (array): 1-D array containing label point list
Returns:
Accuracy of prediction
"""
length = len(Y_pred)
correct = 0
while length > 0:
# Step 1: Identify if the array alements are equal
if np.equal(Y_pred[length - 1], Y_test[length - 1]):
# Step 2: If equal increment correct
correct = correct + 1
length = length - 1
accuracy = correct / len(Y_pred)
return accuracy
# Test Cell
Y_test_grade = np.array([0, 0, 0, 1])
Y_pred_grade = np.array([0, 0, 0, 1])
print(accuracy(Y_pred_grade, Y_test_grade))
```
#### Single Method Implementation
```
def run(X_train, X_test, Y_train, Y_test, k):
"""
Defines the kNN algortithm in one method
Arguments:
X_train (array): 1-D array containing training data points
X_test (array): 1-D array containing testing data points
Y_train (array): 1-D array containing training label points
Y_test (array): 1-D array containing testing label points
k (int): Number of nearest points desired
Returns:
Accuracy of prediction
"""
# Step 1: Task 5 - Predict for an entire batch of test examples
Y_pred = predictBatch(X_test, X_train, Y_train, k)
# Step 2: Task 6 - Accuracy metric
test_accuracy = accuracy(Y_pred, Y_test)
return test_accuracy
# Test Cell
X_train_grade = np.array([1, 2, 3, 4, 15, 16, 17, 5])
Y_train_grade = np.array([0, 0, 0, 0, 1, 1, 1, 0])
X_test_grade = np.array([1, 2, 3, 14])
Y_test_grade = np.array([0, 0, 0, 1])
k_grade=3
print("Accuracy Test:")
print(f'{run(X_train_grade, X_test_grade, Y_train_grade, Y_test_grade, k_grade)}')
```
## Project: Diverge from the sound basis
```
k = 1
print("kNN algorithm accuracy:")
print(f'{run(speach_music_train, speach_music_test, label_sm_train, label_sm_test, k)}')
```
Thank you for reading through to the end of this notebook
### Fin
| github_jupyter |
<center>
# How to transform your data
</center>
***
```
import datetime
print('Last updated: {}'.format(datetime.date.today().strftime('%d %B, %Y')))
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## Outline:
This tutorial demonstrates how to use the following functions to transform a sample dataset in various ways. The tutorial covers the following steps:
1. Importing the brightwind library and loading some sample data
1. Using the `scale_wind_speed()` function
2. Using the `average_data_by_period()` function
1. Using the `adjust_slope_offset()` function
1. Using the `offset_wind_direction()` function
1. Using the `offset_timestamps()` function
1. Using the `selective_avg()` function
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 1. Importing the brightwind library and loading some sample data
```
import brightwind as bw
```
The following commands will load the exisiting dataset and show the first few timestamps.
```
# load existing sample dataset
data = bw.load_csv(bw.datasets.demo_data)
# show first few rows of dataframe
data.head(5)
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 2. Using the `scale_wind_speed()` function
The following commands specify an arbitrary scale factor and apply this to one of the speed variables.
```
# specify scale factor
scale_factor = 1.03
# apply scale factor to Spd80mN variable
Spd80mN_scaled = bw.scale_wind_speed(data.Spd80mN, scale_factor)
# print first 5 rows of result
Spd80mN_scaled.head(5)
```
Now we'll repeat the same step, this time saving the resulting data in the existing dataframe. The new variable appears as the last column on the right hand side of the returned dataframe.
```
# apply scale factor to Spd80mN variable, creating a new variable in the existing dataframe
data['Spd80mN_scaled'] = bw.scale_wind_speed(data.Spd80mN, scale_factor)
# show first few rows of updated dataframe, scaled wind speed is included in the last column
data.head(5)
```
Finally, we can compare the mean values of the scaled and unscaled speed time series. The ratio of these mean values is shown to equal the intended scale factor.
```
# print unscaled mean speed
print('The unscaled mean speed is: \t {} m/s'.format(round(data.Spd80mN.mean(),2)))
# print scaled mean speed
print('The scaled mean speed is: \t {} m/s'.format(round(data.Spd80mN_scaled.mean(),2)))
# calculate ratio of mean values
ratio = data.Spd80mN_scaled.mean()/data.Spd80mN.mean()
# print ratio of mean values
print('The ratio of these values is: \t {}'.format(round(ratio,2)))
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 3. Using the `average_data_by_period()` function
This function can be used to apply a window average to data, using a window which can be specified as any number of minutes ('min'), hours ('H'), days ('D'), weeks ('W'). '1M' and '1AS' can also used for monthly and annual averages respectively. The output is created within a new series.
```
# then derive monthly averages
data_monthly = bw.average_data_by_period(data.Spd80mN, period='1M')
# show monthly averaged data for first 5 months
data_monthly.head(5)
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 4. Using the `adjust_slope_offset()` function
Now, let's imagine that data from the northern anemometer at 80 m was logged with standard slope and offset values of 0.765 and 0.35, and we need to rescale this data considering slope and offset values from a calibration certificate which is specific to this anemometer. The following command can be used to do this, once again adding a new variable to the dataframe.
```
# Apply slope and offset adjustments
data['Spd80mN_adj'] = bw.adjust_slope_offset(data.Spd80mN,0.765, 0.35, 0.7642, 0.352)
```
Now let's view the raw and adjusted speed values side-by-side.
```
# concatenate raw and adjusted variables
summary = data[['Spd80mN', 'Spd80mN_adj']]
# show first few values
summary.head(5)
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 5. Using the `offset_wind_direction()` function
Similarly, the following function can be used to apply a scalar offset to direction data from a given wind vane.
```
# apply directional offset
data['Dir38mS_adj'] = bw.offset_wind_direction(data.Dir38mS, -10)
# concatenate raw and adjusted variables
summary = data[['Dir38mS', 'Dir38mS_adj']]
# show first few values
summary.head(5)
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 6. Using the `offset_timestamps()` function
This function can be used to apply an offset to the timestamps within a dataset. A few examples are provided below, first, let's print the first timestamp of the raw data for comparison.
```
# print first timestamp
print(data.index[0])
```
Now we'll add 1 hour and 30 minutes to the timestamps of the data and print the first timestamp once again.
```
# add 90 minutes to timestamps
data = bw.offset_timestamps(data, '1.5H')
# print first timestamp
print(data.index[0])
```
Negative offsets can also be applied.
```
# subtract 2 hours from timestamps
data = bw.offset_timestamps(data, '-2H')
# print first timestamp
print(data.index[0])
```
Offsets can also be applied in minutes (positive or negative).
```
# add 7 minutes to timestamps
data = bw.offset_timestamps(data, '7min', overwrite=True)
# print first timestamp
print(data.index[0])
```
Time offsets can also be restricted to a certain time period during the record using the following extra arguments. In this case we can see that the final adjustment has just been applied from the 2nd to the 4th timestamps.
```
# subtract 7 minutes from timestamps between the datetime range below
data = bw.offset_timestamps(data, '-7min', date_from='2016-01-09 15:17:00', date_to='2016-01-09 16:47:00')
# show all data for first 5 timestamps
data.head(5)
```
If the timestamp is adjustment is large enough to overlap the unadjusted data before/after the 'date_from'/'date_to', by default the function will not overwrite the unadjusted data. The argument 'overwrite=True' can be specified to change this default and overwrite the neighbouring timestamps.
Finally, note that the adjusted timestamps can be allocated to a completely new dataframe, leaving the input dataset unchanged.
```
# create new dataset with 6H added to the original timestamps
data_adj = bw.offset_timestamps(data, '6H')
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
## 7. Using the `selective_avg()` function
This function can be used to create a time series of wind speed using data from two anemometers mounted at the same height, along with one wind vane. For each timestamp in the dataset, the function either averages the two wind speed values or only includes the upstream wind speed value if the other is in the wake of the mast. The wake is defined by winds approaching the mast from the opposite site of the boom within a directional sector of a given size (in this case 60 degrees).
```
# derive selective average variable based on two 80 m anemeters and 78 m wind vane
data['sel_avg_80m'] = bw.selective_avg(data.Spd80mN, data.Spd80mS, wdir=data.Dir78mS, boom_dir_1=0, boom_dir_2=180, sector_width=60)
# concatenate inputs and new output variable
summary = data[['Spd80mN', 'Spd80mS', 'Dir78mS','sel_avg_80m']]
# show the first 5 entries, none of which include waked anemometers
summary.head(5)
```
***
<div style='margin-top: 3em; margin-bottom: 3em;'>
</div>
| github_jupyter |
```
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \
-O /tmp/horse-or-human.zip
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip \
-O /tmp/validation-horse-or-human.zip
import os
import zipfile
local_zip = '/tmp/horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/horse-or-human')
local_zip = '/tmp/validation-horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/validation-horse-or-human')
zip_ref.close()
# Directory with our training horse pictures
train_horse_dir = os.path.join('/tmp/horse-or-human/horses')
# Directory with our training human pictures
train_human_dir = os.path.join('/tmp/horse-or-human/humans')
# Directory with our training horse pictures
validation_horse_dir = os.path.join('/tmp/validation-horse-or-human/horses')
# Directory with our training human pictures
validation_human_dir = os.path.join('/tmp/validation-horse-or-human/humans')
import tensorflow as tf
model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image 300x300 with 3 bytes color
# This is the first convolution
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# The second convolution
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The third convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fourth convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fifth convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
# Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('horses') and 1 for the other ('humans')
tf.keras.layers.Dense(1, activation='sigmoid')
])
from tensorflow.keras.optimizers import RMSprop
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['acc'])
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1/255)
# Flow training images in batches of 128 using train_datagen generator
train_generator = train_datagen.flow_from_directory(
'/tmp/horse-or-human/', # This is the source directory for training images
target_size=(300, 300), # All images will be resized to 150x150
batch_size=128,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow training images in batches of 128 using train_datagen generator
validation_generator = validation_datagen.flow_from_directory(
'/tmp/validation-horse-or-human/', # This is the source directory for training images
target_size=(300, 300), # All images will be resized to 150x150
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=8,
epochs=100,
verbose=1,
validation_data = validation_generator,
validation_steps=8)
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'r', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
```
| github_jupyter |
# Grouping your data
```
import warnings
warnings.simplefilter('ignore', FutureWarning)
import matplotlib
matplotlib.rcParams['axes.grid'] = True # show gridlines by default
%matplotlib inline
import pandas as pd
```
## Experimenting with Split-Apply-Combine – Summary reports
In the last module, you downloaded data from Comtrade that could be described
as ‘heterogenous’ or mixed in some way. For example, the same dataset contained
information relating to both imports and exports.
To find the partner countries with the largest trade value in terms of exports means filtering
the dataset to obtain just the rows containing export data and then ranking those. Finding
the largest import partner requires a sort on just the import data.
But what if you wanted to find out even more refined information? For example:
- the total value of exports of product X from the UK to those countries on a year by
year basis (group the information by year and then find the total for each year)
- the total value of exports of product X from the UK to each of the partner countries by
year (group the information by country and year and then find the total for each
country/year pairing)
- the average value of exports across all the countries on a month by month basis
(group by month, then find the average value per month)
- the average value of exports across each country on a month by month basis (group
by month and country, then find the average value over each country/month pairing)
- the difference month on month between the value of imports from, or exports to, each
particular country over the five year period (group by country, order by month and
year, then find the difference between consecutive months).
In each case, the original dataset needs to be separated into several subsets, or groups of
data rows, and then some operation performed on those rows. To generate a single, final
report would then require combining the results of those operations in a new or extended
dataframe.
This sequence of operations is common enough for it to have been described as the ‘split-
apply-combine’ pattern. The sequence is to:
- ‘split’ an appropriately shaped dataset into several components
- ‘apply’ an operator to the rows contained within a component
- ‘combine’ the results of applying to operator to each component to return a single
combined result.
Having learned how to group data using the `groupby()` method, You will see how to make use of this pattern using pandas and start to put those groups to work.
## Splitting a dataset by grouping
‘Grouping’ refers to the process of splitting a dataset into sets of rows, or ‘groups’, on the
basis of one or more criteria associated with each data row.
Grouping is often used to split a dataset into one or more distinct groups. Each row in the
dataset being grouped around can be assigned to one, and only one, of the derived
groups. The rows associated with a particular group may be accessed by reference to the
group or the same processing or reporting operation may be applied to the rows contained
in each group on a group by group basis.

The rows do not have to be ‘grouped’ together in the original dataset – they could appear
in any order in the original dataset (for example, a commodity A row, followed by a two
commodity B rows, then another commodity A row, and so on). However, the order in
which each row appears in the original dataset will typically be reflected by the order in
which the rows appear in each subgroup.
Let’s see how to do that in pandas. Create a simple dataframe that looks like the full table
in the image above:
```
data=[['A',10],['A',15],['A',5],['A',20],
['B',10],['B',10],['B',5],
['C',20],['C',30]]
df = pd.DataFrame(data=data, columns=["Commodity","Amount"])
df
```
Next, use the `groupby()` method to group the dataframe into separate groups of rows
based on the values contained within one or more specified ‘key’ columns. For example,
group the rows according to what sort of commodity each row corresponds to as specified
by the value taken in the ‘Commodity’ column.
```
grouped = df.groupby('Commodity')
```
The number and ‘names’ of the groups that are identified correspond to the unique values
that can be found within the column or columns (which will be referred to as the ‘key
columns’) used to identify the groups.
You can see what groups are available with the following method call:
```
grouped.groups.keys()
```
The `get_group()` method can be used to grab just the rows associated with a particular
group.
```
grouped.get_group('B')
```
Datasets can also be grouped against multiple columns. For example, if there was an
extra ‘Year’ column in the above table, you could group against just the commodity,
exactly as above, to provide access to rows by commodity; just the year, setting `grouped
= df.groupby( 'Year' )`; or by both commodity and year, passing in the two grouping
key columns as a list:
```
grouped = df.groupby( ['Commodity','Year'])
```
The list of keys associated with the groups might then look like [(‘A’, 2015), (‘A’, 2014),
(‘B’, 2015), (‘B’, 2014)]. The rows associated with the group corresponding to commodity
A in 2014 could then be retrieved using the command:
```
grouped.get_group( ('A',2014) )
```
This may seem to you like a roundabout way of filtering the dataframe as you did before; but you’ll see that the ability to automatically group rows sets up the possibility of
then processing those rows as separate ‘mini-dataframes’ and then combining the results
back together.
**Task: Grouping data**
- As you complete the tasks, think about these questions:
- For your particular dataset, how did you group the data and what questions did
you ask of it?
- Which countries were the major partners of your reporter country for
the different groupings?
- With the ability to group data so easily, what other sorts of questions would you
like to be able to ask?
| github_jupyter |
```
import keras
from keras.models import Sequential, Model, load_model
from keras.layers import Dense, Dropout, Activation, Flatten, Input, Lambda
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, Conv1D, MaxPooling1D, LSTM, ConvLSTM2D, GRU, CuDNNLSTM, CuDNNGRU, BatchNormalization, LocallyConnected2D, Permute, TimeDistributed, Bidirectional
from keras.layers import Concatenate, Reshape, Softmax, Conv2DTranspose, Embedding, Multiply
from keras.callbacks import ModelCheckpoint, EarlyStopping, Callback
from keras import regularizers
from keras import backend as K
from keras.utils.generic_utils import Progbar
from keras.layers.merge import _Merge
import keras.losses
from functools import partial
from collections import defaultdict
import tensorflow as tf
from tensorflow.python.framework import ops
import isolearn.keras as iso
import numpy as np
import tensorflow as tf
import logging
logging.getLogger('tensorflow').setLevel(logging.ERROR)
import pandas as pd
import os
import pickle
import numpy as np
import scipy.sparse as sp
import scipy.io as spio
import matplotlib.pyplot as plt
import isolearn.io as isoio
import isolearn.keras as isol
from sequence_logo_helper_protein import plot_protein_logo
import pandas as pd
from keras.backend.tensorflow_backend import set_session
def contain_tf_gpu_mem_usage() :
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
set_session(sess)
contain_tf_gpu_mem_usage()
class EpochVariableCallback(Callback) :
def __init__(self, my_variable, my_func) :
self.my_variable = my_variable
self.my_func = my_func
def on_epoch_begin(self, epoch, logs={}) :
K.set_value(self.my_variable, self.my_func(K.get_value(self.my_variable), epoch))
class IdentityEncoder(iso.SequenceEncoder) :
def __init__(self, seq_len, channel_map) :
super(IdentityEncoder, self).__init__('identity', (seq_len, len(channel_map)))
self.seq_len = seq_len
self.n_channels = len(channel_map)
self.encode_map = channel_map
self.decode_map = {
val : key for key, val in channel_map.items()
}
def encode(self, seq) :
encoding = np.zeros((self.seq_len, self.n_channels))
for i in range(len(seq)) :
if seq[i] in self.encode_map :
channel_ix = self.encode_map[seq[i]]
encoding[i, channel_ix] = 1.
return encoding
def encode_inplace(self, seq, encoding) :
for i in range(len(seq)) :
if seq[i] in self.encode_map :
channel_ix = self.encode_map[seq[i]]
encoding[i, channel_ix] = 1.
def encode_inplace_sparse(self, seq, encoding_mat, row_index) :
raise NotImplementError()
def decode(self, encoding) :
seq = ''
for pos in range(0, encoding.shape[0]) :
argmax_nt = np.argmax(encoding[pos, :])
max_nt = np.max(encoding[pos, :])
if max_nt == 1 :
seq += self.decode_map[argmax_nt]
else :
seq += self.decode_map[-1]
return seq
def decode_sparse(self, encoding_mat, row_index) :
encoding = np.array(encoding_mat[row_index, :].todense()).reshape(-1, 4)
return self.decode(encoding)
class NopTransformer(iso.ValueTransformer) :
def __init__(self, n_classes) :
super(NopTransformer, self).__init__('nop', (n_classes, ))
self.n_classes = n_classes
def transform(self, values) :
return values
def transform_inplace(self, values, transform) :
transform[:] = values
def transform_inplace_sparse(self, values, transform_mat, row_index) :
transform_mat[row_index, :] = np.ravel(values)
#Re-load cached dataframe (shuffled)
dataset_name = "coiled_coil_binders"
experiment = "baker_big_set_5x_negatives"
pair_df = pd.read_csv("pair_df_" + experiment + "_in_shuffled.csv", sep="\t")
print("len(pair_df) = " + str(len(pair_df)))
print(pair_df.head())
#Generate training and test set indexes
valid_set_size = 0.0005
test_set_size = 0.0995
data_index = np.arange(len(pair_df), dtype=np.int)
train_index = data_index[:-int(len(pair_df) * (valid_set_size + test_set_size))]
valid_index = data_index[train_index.shape[0]:-int(len(pair_df) * test_set_size)]
test_index = data_index[train_index.shape[0] + valid_index.shape[0]:]
print('Training set size = ' + str(train_index.shape[0]))
print('Validation set size = ' + str(valid_index.shape[0]))
print('Test set size = ' + str(test_index.shape[0]))
#Sub-select smaller dataset
n_train_pos = 20000
n_train_neg = 20000
n_test_pos = 2000
n_test_neg = 2000
orig_n_train = train_index.shape[0]
orig_n_valid = valid_index.shape[0]
orig_n_test = test_index.shape[0]
train_index_pos = np.nonzero((pair_df.iloc[train_index]['interacts'] == 1).values)[0][:n_train_pos]
train_index_neg = np.nonzero((pair_df.iloc[train_index]['interacts'] == 0).values)[0][:n_train_neg]
train_index = np.concatenate([train_index_pos, train_index_neg], axis=0)
np.random.shuffle(train_index)
test_index_pos = np.nonzero((pair_df.iloc[test_index]['interacts'] == 1).values)[0][:n_test_pos] + orig_n_train + orig_n_valid
test_index_neg = np.nonzero((pair_df.iloc[test_index]['interacts'] == 0).values)[0][:n_test_neg] + orig_n_train + orig_n_valid
test_index = np.concatenate([test_index_pos, test_index_neg], axis=0)
np.random.shuffle(test_index)
print('Training set size = ' + str(train_index.shape[0]))
print('Test set size = ' + str(test_index.shape[0]))
#Calculate sequence lengths
pair_df['amino_seq_1_len'] = pair_df['amino_seq_1'].str.len()
pair_df['amino_seq_2_len'] = pair_df['amino_seq_2'].str.len()
pair_df.head()
#Initialize sequence encoder
seq_length = 81
residue_map = {'D': 0, 'E': 1, 'V': 2, 'K': 3, 'R': 4, 'L': 5, 'S': 6, 'T': 7, 'N': 8, 'H': 9, 'A': 10, 'I': 11, 'G': 12, 'P': 13, 'Q': 14, 'Y': 15, 'W': 16, 'M': 17, 'F': 18, '#': 19}
encoder = IdentityEncoder(seq_length, residue_map)
#Construct data generators
class CategoricalRandomizer :
def __init__(self, case_range, case_probs) :
self.case_range = case_range
self.case_probs = case_probs
self.cases = 0
def get_random_sample(self, index=None) :
if index is None :
return self.cases
else :
return self.cases[index]
def generate_random_sample(self, batch_size=1, data_ids=None) :
self.cases = np.random.choice(self.case_range, size=batch_size, replace=True, p=self.case_probs)
def get_amino_seq(row, index, flip_randomizer, homodimer_randomizer, max_seq_len=seq_length) :
is_flip = True if flip_randomizer.get_random_sample(index=index) == 1 else False
is_homodimer = True if homodimer_randomizer.get_random_sample(index=index) == 1 else False
amino_seq_1, amino_seq_2 = row['amino_seq_1'], row['amino_seq_2']
if is_flip :
amino_seq_1, amino_seq_2 = row['amino_seq_2'], row['amino_seq_1']
if is_homodimer and row['interacts'] < 0.5 :
amino_seq_2 = amino_seq_1
return amino_seq_1, amino_seq_2
flip_randomizer = CategoricalRandomizer(np.arange(2), np.array([0.5, 0.5]))
homodimer_randomizer = CategoricalRandomizer(np.arange(2), np.array([0.95, 0.05]))
batch_size = 32
data_gens = {
gen_id : iso.DataGenerator(
idx,
{ 'df' : pair_df },
batch_size=(idx.shape[0] // batch_size) * batch_size,
inputs = [
{
'id' : 'amino_seq_1',
'source_type' : 'dataframe',
'source' : 'df',
#'extractor' : lambda row, index, flip_randomizer=flip_randomizer, homodimer_randomizer=homodimer_randomizer: (get_amino_seq(row, index, flip_randomizer, homodimer_randomizer)[0] + "#" * seq_length)[:seq_length],
'extractor' : lambda row, index, flip_randomizer=flip_randomizer, homodimer_randomizer=homodimer_randomizer: get_amino_seq(row, index, flip_randomizer, homodimer_randomizer)[0],
'encoder' : IdentityEncoder(seq_length, residue_map),
'dim' : (1, seq_length, len(residue_map)),
'sparsify' : False
},
{
'id' : 'amino_seq_2',
'source_type' : 'dataframe',
'source' : 'df',
#'extractor' : lambda row, index, flip_randomizer=flip_randomizer, homodimer_randomizer=homodimer_randomizer: (get_amino_seq(row, index, flip_randomizer, homodimer_randomizer)[1] + "#" * seq_length)[:seq_length],
'extractor' : lambda row, index, flip_randomizer=flip_randomizer, homodimer_randomizer=homodimer_randomizer: get_amino_seq(row, index, flip_randomizer, homodimer_randomizer)[1],
'encoder' : IdentityEncoder(seq_length, residue_map),
'dim' : (1, seq_length, len(residue_map)),
'sparsify' : False
},
{
'id' : 'amino_seq_1_len',
'source_type' : 'dataframe',
'source' : 'df',
'extractor' : lambda row, index, flip_randomizer=flip_randomizer, homodimer_randomizer=homodimer_randomizer: len(get_amino_seq(row, index, flip_randomizer, homodimer_randomizer)[0]),
'encoder' : lambda t: t,
'dim' : (1,),
'sparsify' : False
},
{
'id' : 'amino_seq_2_len',
'source_type' : 'dataframe',
'source' : 'df',
'extractor' : lambda row, index, flip_randomizer=flip_randomizer, homodimer_randomizer=homodimer_randomizer: len(get_amino_seq(row, index, flip_randomizer, homodimer_randomizer)[1]),
'encoder' : lambda t: t,
'dim' : (1,),
'sparsify' : False
}
],
outputs = [
{
'id' : 'interacts',
'source_type' : 'dataframe',
'source' : 'df',
'extractor' : lambda row, index: row['interacts'],
'transformer' : NopTransformer(1),
'dim' : (1,),
'sparsify' : False
}
],
randomizers = [flip_randomizer, homodimer_randomizer],
shuffle = True
) for gen_id, idx in [('train', train_index), ('valid', valid_index), ('test', test_index)]
}
#Load data matrices
[x_1_train, x_2_train, l_1_train, l_2_train], [y_train] = data_gens['train'][0]
[x_1_test, x_2_test, l_1_test, l_2_test], [y_test] = data_gens['test'][0]
print("x_1_train.shape = " + str(x_1_train.shape))
print("x_2_train.shape = " + str(x_2_train.shape))
print("x_1_test.shape = " + str(x_1_test.shape))
print("x_2_test.shape = " + str(x_2_test.shape))
print("l_1_train.shape = " + str(l_1_train.shape))
print("l2_train.shape = " + str(l_2_train.shape))
print("l_1_test.shape = " + str(l_1_test.shape))
print("l2_test.shape = " + str(l_2_test.shape))
print("y_train.shape = " + str(y_train.shape))
print("y_test.shape = " + str(y_test.shape))
#Define sequence templates
sequence_templates = [
'$' * i + '@' * (seq_length - i)
for i in range(seq_length+1)
]
sequence_masks = [
np.array([1 if sequence_templates[i][j] == '$' else 0 for j in range(len(sequence_templates[i]))])
for i in range(seq_length+1)
]
#Calculate background distributions
x_means = []
x_mean_logits = []
for i in range(seq_length + 1) :
x_means.append(np.ones((x_1_train.shape[2], x_1_train.shape[3])) * 0.05)
x_mean_logits.append(np.zeros((x_1_train.shape[2], x_1_train.shape[3])))
#Visualize a few background sequence distributions
visualize_len = 67
plot_protein_logo(residue_map, np.copy(x_means[visualize_len]), sequence_template=sequence_templates[visualize_len], figsize=(12, 1), logo_height=1.0, plot_start=0, plot_end=81)
visualize_len = 72
plot_protein_logo(residue_map, np.copy(x_means[visualize_len]), sequence_template=sequence_templates[visualize_len], figsize=(12, 1), logo_height=1.0, plot_start=0, plot_end=81)
visualize_len = 81
plot_protein_logo(residue_map, np.copy(x_means[visualize_len]), sequence_template=sequence_templates[visualize_len], figsize=(12, 1), logo_height=1.0, plot_start=0, plot_end=81)
#Calculate mean training set kl-divergence against background
mean_kl_divs = []
for i in range(seq_length + 1) :
x_train_len = x_1_train[np.ravel(l_1_train) == i, ...]
if x_train_len.shape[0] > 0 :
x_train_clipped_len = np.clip(np.copy(x_train_len[:, 0, :, :]), 1e-8, 1. - 1e-8)
kl_divs = np.sum(x_train_clipped_len * np.log(x_train_clipped_len / np.tile(np.expand_dims(x_means[i], axis=0), (x_train_clipped_len.shape[0], 1, 1))), axis=-1) / np.log(2.0)
x_mean_kl_divs = np.sum(kl_divs * sequence_masks[i], axis=-1) / np.sum(sequence_masks[i])
x_mean_kl_div = np.mean(x_mean_kl_divs)
mean_kl_divs.append(x_mean_kl_div)
print("[Length = " + str(i) + "] Mean KL Div against background (bits) = " + str(x_mean_kl_div))
else :
mean_kl_divs.append(0)
#PWM Masking and Sampling helper functions
def mask_pwm(inputs) :
pwm, onehot_template, onehot_mask = inputs
return pwm * onehot_mask + onehot_template
#Generator helper functions
def initialize_sequence_templates(generator, encoder, sequence_templates, background_matrices) :
embedding_templates = []
embedding_masks = []
embedding_backgrounds = []
for k in range(len(sequence_templates)) :
sequence_template = sequence_templates[k]
onehot_template = encoder(sequence_template).reshape((1, len(sequence_template), 20))
for j in range(len(sequence_template)) :
if sequence_template[j] not in ['$', '@'] :
nt_ix = np.argmax(onehot_template[0, j, :])
onehot_template[:, j, :] = 0.0
onehot_template[:, j, nt_ix] = 1.0
onehot_mask = np.zeros((1, len(sequence_template), 20))
for j in range(len(sequence_template)) :
if sequence_template[j] == '$' :
onehot_mask[:, j, :] = 1.0
embedding_templates.append(onehot_template.reshape(1, -1))
embedding_masks.append(onehot_mask.reshape(1, -1))
embedding_backgrounds.append(background_matrices[k].reshape(1, -1))
embedding_templates = np.concatenate(embedding_templates, axis=0)
embedding_masks = np.concatenate(embedding_masks, axis=0)
embedding_backgrounds = np.concatenate(embedding_backgrounds, axis=0)
generator.get_layer('template_dense').set_weights([embedding_templates])
generator.get_layer('template_dense').trainable = False
generator.get_layer('mask_dense').set_weights([embedding_masks])
generator.get_layer('mask_dense').trainable = False
#Generator construction function
def build_sampler(batch_size, seq_length, n_classes=1) :
#Initialize Reshape layer
reshape_layer = Reshape((1, seq_length, 20))
#Initialize background matrix
onehot_background_dense = Embedding(n_classes, seq_length * 20, embeddings_initializer='zeros', name='background_dense')
#Initialize template and mask matrices
onehot_template_dense = Embedding(n_classes, seq_length * 20, embeddings_initializer='zeros', name='template_dense')
onehot_mask_dense = Embedding(n_classes, seq_length * 20, embeddings_initializer='ones', name='mask_dense')
#Initialize Templating and Masking Lambda layer
masking_layer = Lambda(mask_pwm, output_shape = (1, seq_length, 20), name='masking_layer')
def _sampler_func(class_input, scaled_pwm, scale) :
#Get Template and Mask
onehot_background = reshape_layer(onehot_background_dense(class_input))
onehot_template = reshape_layer(onehot_template_dense(class_input))
onehot_mask = reshape_layer(onehot_mask_dense(class_input))
#Add Template and Multiply Mask
pwm = masking_layer([scaled_pwm, onehot_template, onehot_mask])
return pwm, onehot_mask
return _sampler_func
#Scrambler network definition
def make_resblock(n_channels=64, window_size=8, dilation_rate=1, group_ix=0, layer_ix=0, drop_rate=0.0) :
#Initialize res block layers
batch_norm_0 = BatchNormalization(name='scrambler_resblock_' + str(group_ix) + '_' + str(layer_ix) + '_batch_norm_0')
relu_0 = Lambda(lambda x: K.relu(x, alpha=0.0))
conv_0 = Conv2D(n_channels, (1, window_size), dilation_rate=dilation_rate, strides=(1, 1), padding='same', activation='linear', kernel_initializer='glorot_normal', name='scrambler_resblock_' + str(group_ix) + '_' + str(layer_ix) + '_conv_0')
batch_norm_1 = BatchNormalization(name='scrambler_resblock_' + str(group_ix) + '_' + str(layer_ix) + '_batch_norm_1')
relu_1 = Lambda(lambda x: K.relu(x, alpha=0.0))
conv_1 = Conv2D(n_channels, (1, window_size), dilation_rate=dilation_rate, strides=(1, 1), padding='same', activation='linear', kernel_initializer='glorot_normal', name='scrambler_resblock_' + str(group_ix) + '_' + str(layer_ix) + '_conv_1')
skip_1 = Lambda(lambda x: x[0] + x[1], name='scrambler_resblock_' + str(group_ix) + '_' + str(layer_ix) + '_skip_1')
drop_1 = None
if drop_rate > 0.0 :
drop_1 = Dropout(drop_rate)
#Execute res block
def _resblock_func(input_tensor) :
batch_norm_0_out = batch_norm_0(input_tensor)
relu_0_out = relu_0(batch_norm_0_out)
conv_0_out = conv_0(relu_0_out)
batch_norm_1_out = batch_norm_1(conv_0_out)
relu_1_out = relu_1(batch_norm_1_out)
if drop_rate > 0.0 :
conv_1_out = drop_1(conv_1(relu_1_out))
else :
conv_1_out = conv_1(relu_1_out)
skip_1_out = skip_1([conv_1_out, input_tensor])
return skip_1_out
return _resblock_func
def load_scrambler_network(n_groups=1, n_resblocks_per_group=4, n_channels=32, window_size=8, dilation_rates=[1], drop_rate=0.0) :
#Discriminator network definition
conv_0 = Conv2D(n_channels, (1, 1), strides=(1, 1), padding='same', activation='linear', kernel_initializer='glorot_normal', name='scrambler_conv_0')
skip_convs = []
resblock_groups = []
for group_ix in range(n_groups) :
skip_convs.append(Conv2D(n_channels, (1, 1), strides=(1, 1), padding='same', activation='linear', kernel_initializer='glorot_normal', name='scrambler_skip_conv_' + str(group_ix)))
resblocks = []
for layer_ix in range(n_resblocks_per_group) :
resblocks.append(make_resblock(n_channels=n_channels, window_size=window_size, dilation_rate=dilation_rates[group_ix], group_ix=group_ix, layer_ix=layer_ix, drop_rate=drop_rate))
resblock_groups.append(resblocks)
last_block_conv = Conv2D(n_channels, (1, 1), strides=(1, 1), padding='same', activation='linear', kernel_initializer='glorot_normal', name='scrambler_last_block_conv')
skip_add = Lambda(lambda x: x[0] + x[1], name='scrambler_skip_add')
final_conv = Conv2D(1, (1, 1), strides=(1, 1), padding='same', activation='sigmoid', kernel_initializer='glorot_normal', name='scrambler_final_conv')
scale_inputs = Lambda(lambda x: x[1] * K.tile(x[0], (1, 1, 1, 20)), name='scrambler_input_scale')
def _scrambler_func(sequence_input) :
conv_0_out = conv_0(sequence_input)
#Connect group of res blocks
output_tensor = conv_0_out
#Res block group execution
skip_conv_outs = []
for group_ix in range(n_groups) :
skip_conv_out = skip_convs[group_ix](output_tensor)
skip_conv_outs.append(skip_conv_out)
for layer_ix in range(n_resblocks_per_group) :
output_tensor = resblock_groups[group_ix][layer_ix](output_tensor)
#Last res block extr conv
last_block_conv_out = last_block_conv(output_tensor)
skip_add_out = last_block_conv_out
for group_ix in range(n_groups) :
skip_add_out = skip_add([skip_add_out, skip_conv_outs[group_ix]])
#Final conv out
final_conv_out = final_conv(skip_add_out)
#Scale inputs by importance scores
scaled_inputs = scale_inputs([final_conv_out, sequence_input])
return scaled_inputs, final_conv_out
return _scrambler_func
#Keras loss functions
def get_sigmoid_kl_divergence() :
def _kl_divergence(y_true, y_pred) :
y_true = K.clip(y_true, K.epsilon(), 1.0 - K.epsilon())
y_pred = K.clip(y_pred, K.epsilon(), 1.0 - K.epsilon())
return K.mean(y_true * K.log(y_true / y_pred) + (1.0 - y_true) * K.log((1.0 - y_true) / (1.0 - y_pred)), axis=-1)
return _kl_divergence
def get_margin_entropy_ame_masked(pwm_start, pwm_end) :
def _margin_entropy_ame_masked(pwm, pwm_mask, pwm_background, max_bits) :
conservation = pwm[:, 0, pwm_start:pwm_end, :] * K.log(K.clip(pwm[:, 0, pwm_start:pwm_end, :], K.epsilon(), 1. - K.epsilon()) / pwm_background[:, 0, pwm_start:pwm_end, :]) / K.log(2.0)
conservation = K.sum(conservation, axis=-1)
mask = K.max(pwm_mask[:, 0, pwm_start:pwm_end, :], axis=-1)
n_unmasked = K.sum(mask, axis=-1)
mean_conservation = K.sum(conservation * mask, axis=-1) / n_unmasked
margin_conservation = K.switch(mean_conservation > K.constant(max_bits[:, 0], shape=(1,)), mean_conservation - K.constant(max_bits, shape=(1,)), K.zeros_like(mean_conservation))
return margin_conservation
return _margin_entropy_ame_masked
def get_target_entropy_sme_masked(pwm_start, pwm_end) :
def _target_entropy_sme_masked(pwm, pwm_mask, pwm_background, target_bits) :
conservation = pwm[:, 0, pwm_start:pwm_end, :] * K.log(K.clip(pwm[:, 0, pwm_start:pwm_end, :], K.epsilon(), 1. - K.epsilon()) / pwm_background[:, 0, pwm_start:pwm_end, :]) / K.log(2.0)
conservation = K.sum(conservation, axis=-1)
mask = K.max(pwm_mask[:, 0, pwm_start:pwm_end, :], axis=-1)
n_unmasked = K.sum(mask, axis=-1)
mean_conservation = K.sum(conservation * mask, axis=-1) / n_unmasked
return (mean_conservation - target_bits[:, 0])**2
return _target_entropy_sme_masked
def get_weighted_loss(loss_coeff=1.) :
def _min_pred(y_true, y_pred) :
return loss_coeff * y_pred
return _min_pred
#Initialize Encoder and Decoder networks
batch_size = 32
seq_length = 81
#Resnet parameters
resnet_n_groups = 5
resnet_n_resblocks_per_group = 4
resnet_n_channels = 48
resnet_window_size = 3
resnet_dilation_rates = [1, 2, 4, 2, 1]
resnet_drop_rate = 0.0
#Load scrambler
scrambler = load_scrambler_network(
n_groups=resnet_n_groups,
n_resblocks_per_group=resnet_n_resblocks_per_group,
n_channels=resnet_n_channels, window_size=resnet_window_size,
dilation_rates=resnet_dilation_rates,
drop_rate=resnet_drop_rate
)
#Load sampler
sampler = build_sampler(batch_size, seq_length, n_classes=seq_length+1)
#Load predictor
predictor_path = 'saved_models/ppi_rnn_baker_big_set_5x_negatives_classifier_symmetric_drop_25_5x_negatives_balanced_partitioned_data_epoch_10.h5'
predictor = load_model(predictor_path, custom_objects={ 'sigmoid_nll' : get_sigmoid_kl_divergence() })
predictor.trainable = False
predictor.compile(loss='mean_squared_error', optimizer=keras.optimizers.SGD(lr=0.1))
#Build scrambler model
scrambler_class = Input(shape=(1,), name='scrambler_class')
scrambler_input = Input(shape=(1, seq_length, 20), name='scrambler_input')
scrambled_pwm, importance_scores = scrambler(scrambler_input)
pwm, pwm_mask = sampler(scrambler_class, scrambled_pwm, importance_scores)
zeropad_layer = Lambda(lambda x: x[0] * x[1], name='zeropad')
sampled_pwm_zeropad = zeropad_layer([pwm, pwm_mask])
scrambler_model = Model([scrambler_input, scrambler_class], [pwm, importance_scores])
#Initialize Sequence Templates and Masks
initialize_sequence_templates(scrambler_model, encoder, sequence_templates, x_means)
scrambler_model.compile(
optimizer=keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999),
loss='mean_squared_error'
)
#Set target bits
conservation_target_bits = np.zeros(seq_length+1)
conservation_target_bits[:] = 0.5
conservation_target_bits = conservation_target_bits.tolist()
entropy_target_bits = np.zeros(seq_length+1)
entropy_target_bits[:] = 0.5
entropy_target_bits = entropy_target_bits.tolist()
#Helper function for setting sequence-length-specific parameters
def initialize_sequence_length_params(model, background_matrix_list, conservation_target_bits_list, entropy_target_bits_list) :
flat_background_matrix_list = []
flat_conservation_target_bits_list = []
flat_entropy_target_bits_list = []
for k in range(len(background_matrix_list)) :
flat_background_matrix_list.append(background_matrix_list[k].reshape(1, -1))
flat_conservation_target_bits_list.append(np.array([conservation_target_bits_list[k]]).reshape(1, -1))
flat_entropy_target_bits_list.append(np.array([entropy_target_bits_list[k]]).reshape(1, -1))
flat_background_matrix_list = np.concatenate(flat_background_matrix_list, axis=0)
flat_conservation_target_bits_list = np.concatenate(flat_conservation_target_bits_list, axis=0)
flat_entropy_target_bits_list = np.concatenate(flat_entropy_target_bits_list, axis=0)
model.get_layer('x_mean_dense').set_weights([flat_background_matrix_list])
model.get_layer('x_mean_dense').trainable = False
model.get_layer('conservation_target_bits_dense').set_weights([flat_conservation_target_bits_list])
model.get_layer('conservation_target_bits_dense').trainable = False
model.get_layer('entropy_target_bits_dense').set_weights([flat_entropy_target_bits_list])
model.get_layer('entropy_target_bits_dense').trainable = False
#Build Auto-scrambler pipeline
#Define model inputs
ae_scrambler_class_1 = Input(shape=(1,), name='ae_scrambler_class_1')
ae_scrambler_input_1 = Input(shape=(1, seq_length, 20), name='ae_scrambler_input_1')
ae_scrambler_class_2 = Input(shape=(1,), name='ae_scrambler_class_2')
ae_scrambler_input_2 = Input(shape=(1, seq_length, 20), name='ae_scrambler_input_2')
#ae_label_input = Input(shape=(1,), name='ae_label_input')
scrambled_in_1, importance_scores_1 = scrambler(ae_scrambler_input_1)
scrambled_in_2, importance_scores_2 = scrambler(ae_scrambler_input_2)
#Run encoder and decoder
scrambled_pwm_1, pwm_mask_1 = sampler(ae_scrambler_class_1, scrambled_in_1, importance_scores_1)
scrambled_pwm_2, pwm_mask_2 = sampler(ae_scrambler_class_2, scrambled_in_2, importance_scores_2)
zeropad_layer_1 = Lambda(lambda x: x[0] * x[1], name='zeropad_1')
zeropad_layer_2 = Lambda(lambda x: x[0] * x[1], name='zeropad_2')
scrambled_pwm_1_zeropad = zeropad_layer_1([scrambled_pwm_1, pwm_mask_1])
scrambled_pwm_2_zeropad = zeropad_layer_2([scrambled_pwm_2, pwm_mask_2])
#Make reference prediction on non-scrambled input sequence
collapse_input_layer_non_scrambled = Lambda(lambda x: x[:, 0, :, :], output_shape=(seq_length, 20))
collapsed_in_1_non_scrambled = collapse_input_layer_non_scrambled(ae_scrambler_input_1)
collapsed_in_2_non_scrambled = collapse_input_layer_non_scrambled(ae_scrambler_input_2)
y_pred_non_scrambled = predictor([collapsed_in_1_non_scrambled, collapsed_in_2_non_scrambled])#ae_label_input
#Make prediction on scrambled sequence samples
collapse_input_layer = Lambda(lambda x: x[:, 0, :, :], output_shape=(seq_length, 20))
collapsed_in_1 = collapse_input_layer(scrambled_pwm_1_zeropad)
collapsed_in_2 = collapse_input_layer(scrambled_pwm_2_zeropad)
y_pred_scrambled = predictor([collapsed_in_1, collapsed_in_2])
#Cost function parameters
pwm_start = 0
pwm_end = 81
#Define background matrix embeddings and target bits
seq_reshape_layer = Reshape((1, seq_length, 20))
flatten_bit_layer = Reshape((1,))
x_mean_dense = Embedding(seq_length+1, seq_length * 20, embeddings_initializer='zeros', name='x_mean_dense')
conservation_target_bits_dense = Embedding(seq_length+1, 1, embeddings_initializer='zeros', name='conservation_target_bits_dense')
entropy_target_bits_dense = Embedding(seq_length+1, 1, embeddings_initializer='zeros', name='entropy_target_bits_dense')
x_mean_len_1 = seq_reshape_layer(x_mean_dense(ae_scrambler_class_1))
x_mean_len_2 = seq_reshape_layer(x_mean_dense(ae_scrambler_class_2))
conservation_target_bits_len_1 = flatten_bit_layer(conservation_target_bits_dense(ae_scrambler_class_1))
conservation_target_bits_len_2 = flatten_bit_layer(conservation_target_bits_dense(ae_scrambler_class_2))
entropy_target_bits_len_1 = flatten_bit_layer(entropy_target_bits_dense(ae_scrambler_class_1))
entropy_target_bits_len_2 = flatten_bit_layer(entropy_target_bits_dense(ae_scrambler_class_2))
#NLL cost
nll_loss_func = get_sigmoid_kl_divergence()
#Conservation cost
conservation_loss_func = get_target_entropy_sme_masked(pwm_start=pwm_start, pwm_end=pwm_end)
#Entropy cost
entropy_loss_func = get_target_entropy_sme_masked(pwm_start=pwm_start, pwm_end=pwm_end)
#entropy_loss_func = get_margin_entropy_ame_masked(pwm_start=pwm_start, pwm_end=pwm_end)
#Define annealing coefficient
anneal_coeff = K.variable(1.0)
#Execute NLL cost
nll_loss = Lambda(lambda x: nll_loss_func(x[0], x[1]), name='nll')([
y_pred_non_scrambled,
y_pred_scrambled
])
#Execute conservation cost
conservation_loss = Lambda(lambda x: anneal_coeff * (0.5 * conservation_loss_func(x[0], x[1], x[2], x[3]) + 0.5 * conservation_loss_func(x[4], x[5], x[6], x[7])), name='conservation')([
scrambled_pwm_1,
pwm_mask_1,
x_mean_len_1,
conservation_target_bits_len_1,
scrambled_pwm_2,
pwm_mask_2,
x_mean_len_2,
conservation_target_bits_len_2
])
#Execute entropy cost
entropy_loss = Lambda(lambda x: (1. - anneal_coeff) * (0.5 * entropy_loss_func(x[0], x[1], x[2], x[3]) + 0.5 * entropy_loss_func(x[4], x[5], x[6], x[7])), name='entropy')([
scrambled_pwm_1,
pwm_mask_1,
x_mean_len_1,
entropy_target_bits_len_1,
scrambled_pwm_2,
pwm_mask_2,
x_mean_len_2,
entropy_target_bits_len_2
])
loss_model = Model(
[ae_scrambler_class_1, ae_scrambler_input_1, ae_scrambler_class_2, ae_scrambler_input_2], #ae_label_input
[nll_loss, conservation_loss, entropy_loss]
)
#Initialize Sequence Templates and Masks
initialize_sequence_templates(loss_model, encoder, sequence_templates, x_means)
#Initialize Sequence Length Parameters
initialize_sequence_length_params(loss_model, x_means, conservation_target_bits, entropy_target_bits)
loss_model.compile(
optimizer=keras.optimizers.Adam(lr=0.0001, beta_1=0.5, beta_2=0.9),
loss={
'nll' : get_weighted_loss(loss_coeff=1.0),
'conservation' : get_weighted_loss(loss_coeff=1.0),
'entropy' : get_weighted_loss(loss_coeff=10.0)
}
)
scrambler_model.summary()
loss_model.summary()
#Training configuration
#Define number of training epochs
n_epochs = 20
#Define experiment suffix (optional)
experiment_suffix = "_kl_divergence_zeropad_continuous_no_bg"
#Define anneal function
def _anneal_func(val, epoch, n_epochs=n_epochs) :
if epoch in [0] :
return 1.0
return 0.0
architecture_str = "resnet_" + str(resnet_n_groups) + "_" + str(resnet_n_resblocks_per_group) + "_" + str(resnet_n_channels) + "_" + str(resnet_window_size) + "_" + str(resnet_drop_rate).replace(".", "")
model_name = "autoscrambler_dataset_" + dataset_name + "_" + architecture_str + "_n_epochs_" + str(n_epochs) + "_target_bits_" + str(entropy_target_bits[0]).replace(".", "") + experiment_suffix
print("Model save name = " + model_name)
#Execute training procedure
callbacks =[
#ModelCheckpoint("model_checkpoints/" + model_name + "_epoch_{epoch:02d}.hdf5", monitor='val_loss', mode='min', period=10, save_weights_only=True),
EpochVariableCallback(anneal_coeff, _anneal_func)
]
s_train = np.zeros((x_1_train.shape[0], 1))
s_test = np.zeros((x_1_test.shape[0], 1))
# train the autoencoder
train_history = loss_model.fit(
[l_1_train, x_1_train, l_2_train, x_2_train], #y_train
[s_train, s_train, s_train],
shuffle=True,
epochs=n_epochs,
batch_size=batch_size,
validation_data=(
[l_1_test, x_1_test, l_2_test, x_2_test], #y_test
[s_test, s_test, s_test]
),
callbacks=callbacks
)
f, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(3 * 4, 3))
n_epochs_actual = len(train_history.history['nll_loss'])
ax1.plot(np.arange(1, n_epochs_actual + 1), train_history.history['nll_loss'], linewidth=3, color='green')
ax1.plot(np.arange(1, n_epochs_actual + 1), train_history.history['val_nll_loss'], linewidth=3, color='orange')
plt.sca(ax1)
plt.xlabel("Epochs", fontsize=14)
plt.ylabel("NLL", fontsize=14)
plt.xlim(1, n_epochs_actual)
plt.xticks([1, n_epochs_actual], [1, n_epochs_actual], fontsize=12)
plt.yticks(fontsize=12)
ax2.plot(np.arange(1, n_epochs_actual + 1), train_history.history['entropy_loss'], linewidth=3, color='green')
ax2.plot(np.arange(1, n_epochs_actual + 1), train_history.history['val_entropy_loss'], linewidth=3, color='orange')
plt.sca(ax2)
plt.xlabel("Epochs", fontsize=14)
plt.ylabel("Entropy Loss", fontsize=14)
plt.xlim(1, n_epochs_actual)
plt.xticks([1, n_epochs_actual], [1, n_epochs_actual], fontsize=12)
plt.yticks(fontsize=12)
ax3.plot(np.arange(1, n_epochs_actual + 1), train_history.history['conservation_loss'], linewidth=3, color='green')
ax3.plot(np.arange(1, n_epochs_actual + 1), train_history.history['val_conservation_loss'], linewidth=3, color='orange')
plt.sca(ax3)
plt.xlabel("Epochs", fontsize=14)
plt.ylabel("Conservation Loss", fontsize=14)
plt.xlim(1, n_epochs_actual)
plt.xticks([1, n_epochs_actual], [1, n_epochs_actual], fontsize=12)
plt.yticks(fontsize=12)
plt.tight_layout()
plt.show()
# Save model and weights
save_dir = 'saved_models'
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name + '.h5')
scrambler_model.save(model_path)
print('Saved scrambler model at %s ' % (model_path))
#Load models
save_dir = 'saved_models'
#model_name = "autoscrambler_dataset_coiled_coil_binders_inverted_scores_sample_mode_st_n_samples_32_resnet_5_4_48_3_00_n_epochs_20_target_bits_24_kl_divergence_log_prob"
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name + '.h5')
scrambler_model = load_model(model_path, custom_objects={
})
print('Loaded scrambler model %s ' % (model_path))
#Visualize a few reconstructed sequence patterns
pwm_test, importance_scores = scrambler_model.predict_on_batch(x=[x_1_test[:32], l_1_test[:32]])
subtracted_pwm_test = x_1_test[:32] * importance_scores
for plot_i in range(0, 5) :
print("Test sequence " + str(plot_i) + ":")
plot_protein_logo(residue_map, x_1_test[plot_i, 0, :, :], sequence_template=sequence_templates[l_1_test[plot_i, 0]], figsize=(12, 1), plot_start=0, plot_end=96)
plot_protein_logo(residue_map, pwm_test[plot_i, 0, :, :], sequence_template=sequence_templates[l_1_test[plot_i, 0]], figsize=(12, 1), plot_start=0, plot_end=96)
plot_protein_logo(residue_map, subtracted_pwm_test[plot_i, 0, :, :], sequence_template=sequence_templates[l_1_test[plot_i, 0]], figsize=(12, 1), plot_start=0, plot_end=96)
#Binder DHD_154
#seq_1 = ("TAEELLEVHKKSDRVTKEHLRVSEEILKVVEVLTRGEVSSEVLKRVLRKLEELTDKLRRVTEEQRRVVEKLN" + "#" * seq_length)[:81]
#seq_2 = ("DLEDLLRRLRRLVDEQRRLVEELERVSRRLEKAVRDNEDERELARLSREHSDIQDKHDKLAREILEVLKRLLERTE" + "#" * seq_length)[:81]
seq_1 = "TAEELLEVHKKSDRVTKEHLRVSEEILKVVEVLTRGEVSSEVLKRVLRKLEELTDKLRRVTEEQRRVVEKLN"[:81]
seq_2 = "DLEDLLRRLRRLVDEQRRLVEELERVSRRLEKAVRDNEDERELARLSREHSDIQDKHDKLAREILEVLKRLLERTE"[:81]
print("Seq 1 = " + seq_1)
print("Seq 2 = " + seq_2)
encoder = IdentityEncoder(81, residue_map)
test_onehot_1 = np.tile(np.expand_dims(np.expand_dims(encoder(seq_1), axis=0), axis=0), (batch_size, 1, 1, 1))
test_onehot_2 = np.tile(np.expand_dims(np.expand_dims(encoder(seq_2), axis=0), axis=0), (batch_size, 1, 1, 1))
test_len_1 = np.tile(np.array([[len(seq_1)]]), (batch_size, 1))
test_len_2 = np.tile(np.array([[len(seq_2)]]), (batch_size, 1))
pred_interacts = predictor.predict(x=[test_onehot_1[:, 0, ...], test_onehot_2[:, 0, ...]])[0, 0]
print("Predicted interaction prob = " + str(round(pred_interacts, 4)))
#Visualize a few reconstructed sequence patterns
save_figs = False
pair_name = "DHD_154"
pwm_test_1, importance_scores_1 = scrambler_model.predict_on_batch(x=[test_onehot_1, test_len_1])
pwm_test_2, importance_scores_2 = scrambler_model.predict_on_batch(x=[test_onehot_2, test_len_2])
scrambled_pred_interacts = predictor.predict(x=[pwm_test_1[:, 0, ...], pwm_test_2[:, 0, ...]])[:, 0]
print("Scrambler predictions = " + str(np.round(scrambled_pred_interacts[:10], 2)))
subtracted_pwm_test_1 = test_onehot_1 * importance_scores_1
subtracted_pwm_test_2 = test_onehot_2 * importance_scores_2
print("Binder 1:")
plot_protein_logo(residue_map, test_onehot_1[0, 0, :, :], sequence_template=sequence_templates[test_len_1[0, 0]], figsize=(12, 1), plot_start=0, plot_end=96, save_figs=save_figs, fig_name=model_name + "_original_example_" + pair_name + "_binder_1")
plot_protein_logo(residue_map, pwm_test_1[0, 0, :, :], sequence_template=sequence_templates[test_len_1[0, 0]], figsize=(12, 1), plot_start=0, plot_end=96, save_figs=save_figs, fig_name=model_name + "_scrambled_example_" + pair_name + "_binder_1")
plot_protein_logo(residue_map, subtracted_pwm_test_1[0, 0, :, :], sequence_template=sequence_templates[test_len_1[0, 0]], figsize=(12, 1), plot_start=0, plot_end=96, save_figs=save_figs, fig_name=model_name + "_subtracted_example_" + pair_name + "_binder_1")
print("Binder 2:")
plot_protein_logo(residue_map, test_onehot_2[0, 0, :, :], sequence_template=sequence_templates[test_len_2[0, 0]], figsize=(12, 1), plot_start=0, plot_end=96, save_figs=save_figs, fig_name=model_name + "_original_example_" + pair_name + "_binder_2")
plot_protein_logo(residue_map, pwm_test_2[0, 0, :, :], sequence_template=sequence_templates[test_len_2[0, 0]], figsize=(12, 1), plot_start=0, plot_end=96, save_figs=save_figs, fig_name=model_name + "_scrambled_example_" + pair_name + "_binder_2")
plot_protein_logo(residue_map, subtracted_pwm_test_2[0, 0, :, :], sequence_template=sequence_templates[test_len_2[0, 0]], figsize=(12, 1), plot_start=0, plot_end=96, save_figs=save_figs, fig_name=model_name + "_subtracted_example_" + pair_name + "_binder_2")
#Re-load cached dataframe (shuffled)
dataset_name = "coiled_coil_binders"
experiment = "coiled_coil_binders_alyssa"
data_df = pd.read_csv(experiment + ".csv", sep="\t")
print("len(data_df) = " + str(len(data_df)))
test_df = data_df.copy().reset_index(drop=True)
batch_size = 32
test_df = test_df.iloc[:(len(test_df) // batch_size) * batch_size].copy().reset_index(drop=True)
print("len(test_df) = " + str(len(test_df)))
print(test_df.head())
#Construct test data
batch_size = 32
test_gen = iso.DataGenerator(
np.arange(len(test_df), dtype=np.int),
{ 'df' : test_df },
batch_size=(len(test_df) // batch_size) * batch_size,
inputs = [
{
'id' : 'amino_seq_1',
'source_type' : 'dataframe',
'source' : 'df',
#'extractor' : lambda row, index: (row['amino_seq_1'] + "#" * seq_length)[:seq_length],
'extractor' : lambda row, index: row['amino_seq_1'],
'encoder' : IdentityEncoder(seq_length, residue_map),
'dim' : (1, seq_length, len(residue_map)),
'sparsify' : False
},
{
'id' : 'amino_seq_2',
'source_type' : 'dataframe',
'source' : 'df',
#'extractor' : lambda row, index: row['amino_seq_2'] + "#" * seq_length)[:seq_length],
'extractor' : lambda row, index: row['amino_seq_2'],
'encoder' : IdentityEncoder(seq_length, residue_map),
'dim' : (1, seq_length, len(residue_map)),
'sparsify' : False
},
{
'id' : 'amino_seq_1_len',
'source_type' : 'dataframe',
'source' : 'df',
'extractor' : lambda row, index: len(row['amino_seq_1']),
'encoder' : lambda t: t,
'dim' : (1,),
'sparsify' : False
},
{
'id' : 'amino_seq_2_len',
'source_type' : 'dataframe',
'source' : 'df',
'extractor' : lambda row, index: len(row['amino_seq_2']),
'encoder' : lambda t: t,
'dim' : (1,),
'sparsify' : False
}
],
outputs = [
{
'id' : 'interacts',
'source_type' : 'dataframe',
'source' : 'df',
'extractor' : lambda row, index: row['interacts'],
'transformer' : NopTransformer(1),
'dim' : (1,),
'sparsify' : False
}
],
randomizers = [],
shuffle = False
)
#Load data matrices
[x_1_test, x_2_test, l_1_test, l_2_test], [y_test] = test_gen[0]
print("x_1_test.shape = " + str(x_1_test.shape))
print("x_2_test.shape = " + str(x_2_test.shape))
print("l_1_test.shape = " + str(l_1_test.shape))
print("l_2_test.shape = " + str(l_2_test.shape))
print("y_test.shape = " + str(y_test.shape))
#Predict on test set
pwm_test_1, importance_scores_1 = scrambler_model.predict(x=[x_1_test, l_1_test], batch_size=32, verbose=True)
pwm_test_2, importance_scores_2 = scrambler_model.predict(x=[x_2_test, l_2_test], batch_size=32, verbose=True)
unscrambled_preds = predictor.predict(x=[x_1_test[:, 0, ...], x_2_test[:, 0, ...]], batch_size=32, verbose=True)[:, 0]
scrambled_preds = []
for i in range(pwm_test_1.shape[0]) :
if i % 100 == 0 :
print("Predicting scrambled samples for sequence " + str(i) + "...")
scrambled_pred_sample = predictor.predict(x=[pwm_test_1[i, ...], pwm_test_2[i, ...]], batch_size=32, verbose=False)[0, 0]
scrambled_preds.append(scrambled_pred_sample)
scrambled_preds = np.array(scrambled_preds)
min_val = 0.0
max_val = 1.0
max_y_val = 8
n_bins = 25
save_figs = False
figsize = (6, 4)
measurements = [
unscrambled_preds,
scrambled_preds
]
colors = [
'green',
'red'
]
labels = [
'Unscrambled',
'Scrambled'
]
x_label = 'Prediction'
y_label = 'Density'
min_hist_val = np.min(measurements[0])
max_hist_val = np.max(measurements[0])
for i in range(1, len(measurements)) :
min_hist_val = min(min_hist_val, np.min(measurements[i]))
max_hist_val = max(max_hist_val, np.max(measurements[i]))
if min_val is not None :
min_hist_val = min_val
if max_val is not None :
max_hist_val = max_val
hists = []
bin_edges = []
means = []
for i in range(len(measurements)) :
hist, b_edges = np.histogram(measurements[i], range=(min_hist_val, max_hist_val), bins=n_bins, density=True)
hists.append(hist)
bin_edges.append(b_edges)
means.append(np.mean(measurements[i]))
bin_width = bin_edges[0][1] - bin_edges[0][0]
#Compare Log Likelihoods
f = plt.figure(figsize=figsize)
for i in range(len(measurements)) :
plt.bar(bin_edges[i][1:] - bin_width/2., hists[i], width=bin_width, linewidth=2, alpha=0.5, edgecolor='black', color=colors[i], label=labels[i])
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.xlim(min_hist_val, max_hist_val)
if max_y_val is not None :
plt.ylim(0, max_y_val)
plt.xlabel(x_label, fontsize=14)
plt.ylabel(y_label, fontsize=14)
for i in range(len(measurements)) :
plt.axvline(x=means[i], linewidth=2, color=colors[i], linestyle="--")
plt.legend(fontsize=14, loc='upper left')
plt.tight_layout()
if save_figs :
fig_name = experiment + "_model_" + model_name + "_pos_hist"
plt.savefig(fig_name + ".png", dpi=300, transparent=True)
plt.savefig(fig_name + ".eps")
plt.show()
#Store unscrambled and scrambled binding predictions
test_df['pred_interacts'] = np.round(unscrambled_preds, 2)
test_df['pred_interacts_scrambled'] = np.round(scrambled_preds, 2)
flat_importance_scores_1 = importance_scores_1[:, 0, :, 0]
flat_importance_scores_2 = importance_scores_2[:, 0, :, 0]
short_model_name = "inclusion_target_bits_" + str(entropy_target_bits[0]).replace(".", "") + "_epochs_" + str(n_epochs) + experiment_suffix
test_df.to_csv(experiment + "_model_" + short_model_name + "_testset.csv", sep="\t", index=False)
np.save(experiment + "_model_" + short_model_name + "_testset_importance_scores_1", flat_importance_scores_1)
np.save(experiment + "_model_" + short_model_name + "_testset_importance_scores_2", flat_importance_scores_2)
```
| github_jupyter |
# REINFORCE in TensorFlow (3 pts)¶
This notebook implements a basic reinforce algorithm a.k.a. policy gradient for CartPole env.
It has been deliberately written to be as simple and human-readable.
Authors: [Practical_RL](https://github.com/yandexdataschool/Practical_RL) course team
```
%env THEANO_FLAGS = 'floatX=float32'
import os
if type(os.environ.get("DISPLAY")) is not str or len(os.environ.get("DISPLAY")) == 0:
!bash ../xvfb start
%env DISPLAY = : 1
```
The notebook assumes that you have [openai gym](https://github.com/openai/gym) installed.
In case you're running on a server, [use xvfb](https://github.com/openai/gym#rendering-on-a-server)
```
import gym
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
env = gym.make("CartPole-v0")
# gym compatibility: unwrap TimeLimit
if hasattr(env, 'env'):
env = env.env
env.reset()
n_actions = env.action_space.n
state_dim = env.observation_space.shape
plt.imshow(env.render("rgb_array"))
```
# Building the network for REINFORCE
For REINFORCE algorithm, we'll need a model that predicts action probabilities given states.
For numerical stability, please __do not include the softmax layer into your network architecture__.
We'll use softmax or log-softmax where appropriate.
```
import tensorflow as tf
# create input variables. We only need <s,a,R> for REINFORCE
states = tf.placeholder('float32', (None,)+state_dim, name="states")
actions = tf.placeholder('int32', name="action_ids")
cumulative_rewards = tf.placeholder('float32', name="cumulative_returns")
<define network graph using raw tf or any deep learning library >
logits = <linear outputs(symbolic) of your network >
policy = tf.nn.softmax(logits)
log_policy = tf.nn.log_softmax(logits)
# utility function to pick action in one given state
def get_action_proba(s): return policy.eval({states: [s]})[0]
```
#### Loss function and updates
We now need to define objective and update over policy gradient.
Our objective function is
$$ J \approx { 1 \over N } \sum _{s_i,a_i} \pi_\theta (a_i | s_i) \cdot G(s_i,a_i) $$
Following the REINFORCE algorithm, we can define our objective as follows:
$$ \hat J \approx { 1 \over N } \sum _{s_i,a_i} log \pi_\theta (a_i | s_i) \cdot G(s_i,a_i) $$
When you compute gradient of that function over network weights $ \theta $, it will become exactly the policy gradient.
```
# get probabilities for parti
indices = tf.stack([tf.range(tf.shape(log_policy)[0]), actions], axis=-1)
log_policy_for_actions = tf.gather_nd(log_policy, indices)
# policy objective as in the last formula. please use mean, not sum.
# note: you need to use log_policy_for_actions to get log probabilities for actions taken.
J = <YOUR CODE>
# regularize with entropy
entropy = <compute entropy. Don't forget the sign!>
# all network weights
all_weights = <a list of all trainable weights in your network >
# weight updates. maximizing J is same as minimizing -J. Adding negative entropy.
loss = -J - 0.1*entropy
update = tf.train.AdamOptimizer().minimize(loss, var_list=all_weights)
```
### Computing cumulative rewards
```
def get_cumulative_rewards(rewards, # rewards at each step
gamma=0.99 # discount for reward
):
"""
take a list of immediate rewards r(s,a) for the whole session
compute cumulative rewards R(s,a) (a.k.a. G(s,a) in Sutton '16)
R_t = r_t + gamma*r_{t+1} + gamma^2*r_{t+2} + ...
The simple way to compute cumulative rewards is to iterate from last to first time tick
and compute R_t = r_t + gamma*R_{t+1} recurrently
You must return an array/list of cumulative rewards with as many elements as in the initial rewards.
"""
<your code here >
return < array of cumulative rewards >
assert len(get_cumulative_rewards(range(100))) == 100
assert np.allclose(get_cumulative_rewards([0, 0, 1, 0, 0, 1, 0], gamma=0.9), [
1.40049, 1.5561, 1.729, 0.81, 0.9, 1.0, 0.0])
assert np.allclose(get_cumulative_rewards(
[0, 0, 1, -2, 3, -4, 0], gamma=0.5), [0.0625, 0.125, 0.25, -1.5, 1.0, -4.0, 0.0])
assert np.allclose(get_cumulative_rewards(
[0, 0, 1, 2, 3, 4, 0], gamma=0), [0, 0, 1, 2, 3, 4, 0])
print("looks good!")
def train_step(_states, _actions, _rewards):
"""given full session, trains agent with policy gradient"""
_cumulative_rewards = get_cumulative_rewards(_rewards)
update.run({states: _states, actions: _actions,
cumulative_rewards: _cumulative_rewards})
```
### Playing the game
```
def generate_session(t_max=1000):
"""play env with REINFORCE agent and train at the session end"""
# arrays to record session
states, actions, rewards = [], [], []
s = env.reset()
for t in range(t_max):
# action probabilities array aka pi(a|s)
action_probas = get_action_proba(s)
a = <pick random action using action_probas >
new_s, r, done, info = env.step(a)
# record session history to train later
states.append(s)
actions.append(a)
rewards.append(r)
s = new_s
if done:
break
train_step(states, actions, rewards)
return sum(rewards)
s = tf.InteractiveSession()
s.run(tf.global_variables_initializer())
for i in range(100):
rewards = [generate_session() for _ in range(100)] # generate new sessions
print("mean reward:%.3f" % (np.mean(rewards)))
if np.mean(rewards) > 300:
print("You Win!")
break
```
### Results & video
```
# record sessions
import gym.wrappers
env = gym.wrappers.Monitor(gym.make("CartPole-v0"),
directory="videos", force=True)
sessions = [generate_session() for _ in range(100)]
env.close()
# show video
from IPython.display import HTML
import os
video_names = list(
filter(lambda s: s.endswith(".mp4"), os.listdir("./videos/")))
HTML("""
<video width="640" height="480" controls>
<source src="{}" type="video/mp4">
</video>
""".format("./videos/"+video_names[-1])) # this may or may not be _last_ video. Try other indices
# That's all, thank you for your attention!
```
| github_jupyter |
# Installing Neurokernel on Amazon Compute Cloud GPU Instances
In this notebook, we show step by step how to run Neurokernel on Amazon Elastic Compute Cloud (Amazon EC2) GPU instances. This notebook assumes that you have already setup an account on Amazon Web Services (AWS) and that you are able to start an Amazon EC2 Linux Instance. For detailed tutorial on starting an Linux Instance, see [Getting Started with Amazon EC2 Linux Instances](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EC2_GetStarted.html). AWS currently provide free tier for new users for one year on t2.micro instances. If you have not used AWS before, you can try starting an linux instance free of charge to familiarize yourself with the cloud computing service.
**Important**: GPU instances on Amazon EC2 always incur charges. Please be sure that you understand pricing structure on Amazon EC2. Pricing information can be found [here](http://aws.amazon.com/ec2/pricing/).
## Setting up with Amazon EC2
We provide here a few links to [Amazon EC2 Documentation](http://aws.amazon.com/documentation/ec2/) to help you set up with Amazon EC2. If you have already set up with Amazon EC2, you can skip to the next section.
- General information about Amazon EC2 can be found [here](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html).
- To sign up for AWS and prepare for launching an instance, follow the documentation [here](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/get-set-up-for-amazon-ec2.html).
- To start an Amazon EC2 Linux instance, follow [these steps](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EC2_GetStarted.html).
- Make sure to check out these [best practice guides](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-best-practices.html) to better manage your instances.
If you follow these steps, the setup time usually takes 1-2 hours. Note that there is an up to two-hour verification time after you sign up for AWS.
## Using Preloaded Neurokernel Amazon Machine Image
We made available a public Amazon Machine Image (AMI) in which all packages required by Neurokernel are preloaded.
The AMI is only available in US East Region currently, and you must launch the AMI in this region. If you wish to run Neurokernel in another region, you can copy the AMI to that region.
AMI is preloaded with the latest CUDA 7.5. We will update the AMI from time to time as newer version of packages are released. Please follow the steps below to launch an GPU instance using the AMI.
First, change your region to US East and search in the public images for Neurokernel. Click on the one with AMI ID: ami-3776735d. Then click Launch button on the top.
<img src='files/files/ec2-ami-1.png' />
You will be prompted to Step 2 of instance setup.
Here, choose either g2.2xlarge for an instance with 1 GPU or g2.8xlarge for one with 4 GPUs.
<img src='files/files/ec2-launch-step2.png' />
In step 3: leave the default setting for instance details, or customize it according to your needs. You can also request a [spot instance](https://aws.amazon.com/ec2/spot/), which can significantly lower your cost (but the instance can be taken down once the current price is higher than your maximum bid price). For example, you can bid your price and launch the instance in a specific subnet that corresponds to the one having the lowest cost.
<img src='files/files/ec2-launch-step3.png' />
In step 4, add storage with at least 8 GiB size. If you wish to keep the root storage, uncheck "Delete on Termination" box. Add additional storage as you need.
<img src='files/files/ec2-launch-step4.png' />
In step 5, you can leave it as is or create a new tag for you instance.
In step 6, select an existing security group. Then, review and launch the instance. You can log into your instance.
Once you are logged in, actviate the Neurokernel environment by:
```
source activate NK
```
You can now start using Neurokernel in ~/neurokernel. To update neurokernel to the latest
```
cd ~/neurokernel
git pull
cd ~/neurodriver
git pull
```
You can then try the intro example:
```
cd ~/neurodriver/examples/intro/data
python gen_generic_lpu.py -s 0 -l lpu_0 generic_lpu_0.gexf.gz generic_lpu_0_input.h5
python gen_generic_lpu.py -s 1 -l lpu_1 generic_lpu_1.gexf.gz generic_lpu_1_input.h5
cd ../
python intro_demo.py --gpu_dev 0 0 --log file
```
Now, you can use Neurokernel on the EC2 instance.
# The following is intended for more advanced users, and is not required to run Neurokernel on EC2
## Install Neurokernel from Scratch
If you wish to install NVIDIA Driver, CUDA and Neurokernel from scratch, you can following the guide below. These are the steps that were used to create the AMI mentioned above.
### Starting a GPU Instance
In your EC2 dashboard, click on "instance" on the navigation bar on the left and then click on the "Launch Instance" button.
In step 1, choose Ubuntu Server 14.04 LTS (HVM), SSD Volume Type - ami-d05e75b8 (The AMI number may differ, as they are frequently updated).
<img src='files/files/ec2-launch-step1.png' />
In step 2, choose either g2.2xlarge for an instance with 1 GPU or g2.8xlarge for one with 4 GPUs.
<img src='files/files/ec2-launch-step2.png' />
In step 3, leave the default setting for instance details, or customize it according to your needs.
In step 4, add storage with at least 8 GiB size. If you wish to keep the root storage, uncheck "Delete on Termination" box. Add additional storage as you need.
<img src='files/files/ec2-launch-step4.png' />
In step 5, you can leave it as is or create a new tag for you instance.
In step 6, select an existing security group. Then, review and launch the instance.
### Installing NVIDIA Drivers and CUDA
The Ubuntu AMI does not come with GPU driver installed. After you have launched the GPU instance, the first thing to do is to install NVIDIA drivers. This requires a series of commands. The following commands install 340.46 driver and CUDA 7.0. In principle, latest NVIDIA driver and CUDA library can be installed.
**Important Note**: At various point, you will be prompted to answer [Y/n] when executing some of the following commands. Please make sure that you have installed all packages by answering "y" and make sure that you DO NOT see "Abort" at the end of output of each command. The best way to avoid this is to execute the commands one line at a time.
```
sudo apt-get update
sudo apt-get upgrade
```
To this point, you may be prompted "What would you like to do about menu.lst?". Select: "keep the local version currently installed". Wait until the upgrade is finished and execute the following commands
```
sudo apt-get install build-essential
sudo apt-get install linux-image-extra-virtual
```
You may be prompted again with "What would you like to do about menu.lst?". Select again: "keep the local version currently installed". Wait until the end of the installation and execute the following commands
```
echo -e "blacklist nouveau\nblacklist lbm-nouveau\noptions nouveau modeset=0\nalias nouveau off\nalias lbm-nouveau off" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
sudo update-initramfs -u
sudo reboot
```
The server will reboot. Log in after it is up again, execute the following commands
```
sudo apt-get install linux-source
sudo apt-get install linux-headers-`uname -r`
```
Now we are ready to install NVIDIA Driver
```
mkdir packages
cd packages
wget http://us.download.nvidia.com/XFree86/Linux-x86_64/361.28/NVIDIA-Linux-x86_64-361.28.run
chmod u+x NVIDIA-Linux-x86_64-361.28.run
sudo ./NVIDIA-Linux-x86_64-361.28.run
```
Installation of GPU driver starts here. Accept the license agreement. "OK" throughout the installation process. When prompted "Would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver will be used when you restart X?", choose "no".
Now, we install CUDA by the following commands
```
sudo modprobe nvidia
wget http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run
chmod u+x cuda_7.5.18_linux.run
./cuda_7.5.18_linux.run -extract=`pwd`
sudo ./cuda-linux64-rel-7.5.18-19867135.run
```
When the license agreement appears, press "q" so you don't have to scroll down. Type in "accept" to accept the license agreement. Press Enter to use the default path. Enter "no" when asked to add desktop menu shortcuts. Enter "yes" for creating a symbolic link.
Finally, update your path variable by
```
echo -e "export PATH=/usr/local/cuda-7.5/bin:\$PATH\nexport LD_LIBRARY_PATH=/usr/local/cuda-7.5/lib64:\$LD_LIBRARY_PATH" | tee -a ~/.bashrc
source ~/.bashrc
```
### Installing Neurokernel
The simplest way to install Neurokernel on Ubuntu is to use conda. We first install miniconda
```
wget https://repo.continuum.io/miniconda/Miniconda-latest-Linux-x86_64.sh
chmod u+x Miniconda-latest-Linux-x86_64.sh
./Miniconda-latest-Linux-x86_64.sh
```
When prompt, accept the license agreement and choose default path for installing miniconda. Answer "yes" when asked "Do you wish the installer to prepend the Miniconda2 install location
to PATH in your /home/ubuntu/.bashrc ?". After installation is complete, edit ~/.condarc file by
```
echo -e "channels:\n- https://conda.binstar.org/neurokernel/channel/ubuntu1404\n- defaults" > ~/.condarc
```
You can then create a new conda environment containing the packages required by Neurokernel by the following command
```
sudo apt-get install libibverbs1 libnuma1 libpmi0 libslurm26 libtorque2 libhwloc-dev git
source ~/.bashrc
conda create -n NK neurokernel_deps
```
Clone the Neurokernel repository
```
cd
rm -rf packages
git clone https://github.com/neurokernel/neurokernel.git
git clone https://github.com/neurokernel/neurodriver.git
source activate NK
cd ~/neurokernel
python setup.py develop
cd ~/neurodriver
python setup.py develop
```
Test by running intro example:
```
cd ~/neurodriver/examples/intro/data
python gen_generic_lpu.py -s 0 -l lpu_0 generic_lpu_0.gexf.gz generic_lpu_0_input.h5
python gen_generic_lpu.py -s 1 -l lpu_1 generic_lpu_1.gexf.gz generic_lpu_1_input.h5
cd ../
python intro_demo.py --gpu_dev 0 0 --log file
```
Inspect the log "neurokernel.log" to ensure that no error has occured during execution. If this is the case, the installation is complete.
| github_jupyter |
## Setup
```
!pip install tflite-support
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from scipy import stats
from sklearn import metrics
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
# Check if GPU is available
if tf.test.gpu_device_name():
print('Default GPU Device: {}'.format(tf.test.gpu_device_name()))
else:
print("Please install GPU version of TF")
```
## Loading and preparing train and test data
We use "Sensors Activity Dataset" by Shoaib et al. which is available for download from [here](https://www.utwente.nl/en/eemcs/ps/research/dataset/).
There are 7 activities in this dataset: Biking, Downstairs, Jogging, Sitting, Standing, Upstairs, Walking.
There were ten participants involved in data collection experiment who performed each of these activities for 3-4 minutes.
All ten participants were male, between the ages of 25 and 30.
Each of these participants was equipped with five smartphones on five body positions:
1. One in their right jean’s pocket.
2. One in their left jean’s pocket.
3. One on belt position towards the right leg using a belt clipper.
4. One on the right upper arm.
5. One on the right wrist.
The data was collected for an accelerometer, a gyroscope, a magnetometer, and a linear acceleration sensor.
Each csv file contains data for each participant's seven physical activities for all five positions.
Notation in these files:
Accelerometer ( Ax = x-axis, Ay = y-axis, Az= Z-aixs)
Linear Acceleration Sensor ( Lx = x-axis, Ly = y axis, Lz= Z-aixs)
Gyroscope ( Gx = x-axis, Gy = y-axis, Gz= Z-aixs)
Magnetometer ( Mx = x-axis, My = y-axis, Mz= Z-aixs)
```
# Download dataset
! wget https://www.utwente.nl/en/eemcs/ps/dataset-folder/sensors-activity-recognition-dataset-shoaib.rar -P ../data/
# Extract dataset using unrar
!pip install unrar
!unrar e ../data/sensors-activity-recognition-dataset-shoaib.rar ../data/
```
## Loading and preparing train and test data
We load all 10 participants data into a single dataframe:
```
df = pd.DataFrame()
for i in range(10):
df_tmp = pd.read_csv('../data/Participant_' + str(i+1) + '.csv', header=1)
df = pd.concat([df, df_tmp])
# View top 5 rows of dataframe
df.head()
```
Now we split data into train and test sets (80% train, 20% test):
```
split_point = int(len(df) * 0.8)
train_data = df.iloc[:split_point, :]
test_data = df.iloc[split_point:, :]
print("Number of train spamples: ", len(train_data))
print("Number of test spamples: ", len(test_data))
```
As we only use right pocket's and left pocket's data, we should concatenate those into a single data frame:
```
def concat(data):
# Select left pocket data
left_pocket = data.iloc[:,1:10]
#Square root of sum of squares of accelerometer, linear acceleration and gyroscope data
left_pocket["MA"] = np.sqrt(np.square(left_pocket['Ax']) + np.square(left_pocket['Ay']) + np.square(left_pocket['Az']))
left_pocket["ML"] = np.sqrt(np.square(left_pocket['Lx']) + np.square(left_pocket['Ly']) + np.square(left_pocket['Lz']))
left_pocket["MG"] = np.sqrt(np.square(left_pocket['Gx']) + np.square(left_pocket['Gy']) + np.square(left_pocket['Gz']))
# Select right pocket data
right_pocket = data.iloc[:,15:24]
right_pocket.columns=['Ax', 'Ay', 'Az', 'Lx', 'Ly', 'Lz', 'Gx', 'Gy', 'Gz']
#Square root of sum of squares of accelerometer, linear acceleration and gyroscope data
right_pocket["MA"] = np.sqrt(np.square(right_pocket['Ax']) + np.square(right_pocket['Ay']) + np.square(right_pocket['Az']))
right_pocket["ML"] = np.sqrt(np.square(right_pocket['Lx']) + np.square(right_pocket['Ly']) + np.square(right_pocket['Lz']))
right_pocket["MG"] = np.sqrt(np.square(right_pocket['Gx']) + np.square(right_pocket['Gy']) + np.square(right_pocket['Gz']))
# Extract labels
labels = data.iloc[:, 69]
labels = labels.to_frame()
labels.columns=['Activity_Label']
labels = pd.concat([labels]*2, ignore_index=True)
#replace typo 'upsatirs' with upstairs!
labels.loc[(labels['Activity_Label'] == 'upsatirs')] = 'upstairs'
#Concatenate left pocket and right pocket data into a single data frame (we only use left pocket and right pocket data)
frames = [left_pocket, right_pocket]
df = pd.concat(frames)
return df, labels
# Generate input data and labels
train_X, train_y = concat(train_data)
test_X, test_y = concat(test_data)
train_X.head()
train_y.head()
```
Next we use sliding window mechanism to generate data segments.
We use Accelerometer, Linear acceleration and Gyroscope features and their sum of squares roots:
```
lx = x['Lx'].values[i: i + n_time_steps]
ly = x['Ly'].values[i: i + n_time_steps]
lz = x['Lz'].values[i: i + n_time_steps]
gx = x['Gx'].values[i: i + n_time_steps]
gy = x['Gy'].values[i: i + n_time_steps]
gz = x['Gz'].values[i: i + n_time_steps]
MA = x['MA'].values[i: i + n_time_steps]
ML = x['ML'].values[i: i + n_time_steps]
MG = x['MG'].values[i: i + n_time_steps]
, lx, ly, lz, gx, gy, gz, MA, ML, MG
```
```
N_TIME_STEPS = 100 #sliding window length
STEP = 50 #Sliding window step size
N_FEATURES = 12
def generate_sequence(x, y, n_time_steps, step):
segments = []
labels = []
for i in range(0, len(x) - n_time_steps, step):
ax = x['Ax'].values[i: i + n_time_steps]
ay = x['Ay'].values[i: i + n_time_steps]
az = x['Az'].values[i: i + n_time_steps]
lx = x['Lx'].values[i: i + n_time_steps]
ly = x['Ly'].values[i: i + n_time_steps]
lz = x['Lz'].values[i: i + n_time_steps]
gx = x['Gx'].values[i: i + n_time_steps]
gy = x['Gy'].values[i: i + n_time_steps]
gz = x['Gz'].values[i: i + n_time_steps]
MA = x['MA'].values[i: i + n_time_steps]
ML = x['ML'].values[i: i + n_time_steps]
MG = x['MG'].values[i: i + n_time_steps]
label = stats.mode(y['Activity_Label'][i: i + n_time_steps])[0][0]
segments.append([ax, ay, az, lx, ly, lz, gx, gy, gz, MA, ML, MG])
labels.append(label)
return segments, labels
train_X, train_y = generate_sequence(train_X, train_y, N_TIME_STEPS, STEP)
test_X, test_y = generate_sequence(test_X, test_y, N_TIME_STEPS, STEP)
# reshape input segments and one-hot encode labels
def reshape_segments(x, y, n_time_steps, n_features):
x_reshaped = np.asarray(x, dtype= np.float32).reshape(-1, n_time_steps, n_features)
y_reshaped = np.asarray(pd.get_dummies(y), dtype = np.float32)
return x_reshaped, y_reshaped
X_train, y_train = reshape_segments(train_X, train_y, N_TIME_STEPS, N_FEATURES)
X_test, y_test = reshape_segments(test_X, test_y, N_TIME_STEPS, N_FEATURES)
```
## Building the model
```
Sequential = tf.keras.Sequential
LSTM = tf.keras.layers.LSTM
Flatten = tf.keras.layers.Flatten
Dense = tf.keras.layers.Dense
l2 = tf.keras.regularizers.L2
Adam = tf.keras.optimizers.Adam
N_CLASSES = 7
N_HIDDEN_UNITS = 32
L2 = 0.000001
model=Sequential(name='sequential_1')
model.add(LSTM(N_HIDDEN_UNITS, return_sequences=True, input_shape=(N_TIME_STEPS, N_FEATURES),
kernel_initializer='orthogonal', kernel_regularizer=l2(L2), recurrent_regularizer=l2(L2),
bias_regularizer=l2(L2), name="LSTM_1"))
#model.add(LSTM(N_HIDDEN_UNITS,
# kernel_regularizer=l2(L2), recurrent_regularizer=l2(L2),
# bias_regularizer=l2(L2), name="LSTM_2"))
model.add(Flatten(name='Flatten'))
model.add(Dense(N_HIDDEN_UNITS, activation='relu',
kernel_regularizer=l2(L2), bias_regularizer=l2(L2), name="Dense_1"))
model.add(Dense(N_CLASSES, activation='softmax',
kernel_regularizer=l2(L2), bias_regularizer=l2(L2), name="Output"))
model.summary()
```
## Training & Evaluation
```
#compile
LR = 0.0001
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=LR), metrics=['accuracy'])
# prepare callbacks
from keras.callbacks import ModelCheckpoint
callbacks= [ModelCheckpoint('model.h5', save_weights_only=False, save_best_only=True, verbose=1)]
BATCH_SIZE = 1024
N_EPOCHS = 30
model.fit(X_train, y_train,
batch_size=BATCH_SIZE, epochs=N_EPOCHS,
validation_data=(X_test, y_test), callbacks=callbacks)
model.save('model_lastest.h5')
```
## Confusion Matrix
```
y_pred_ohe = model.predict(X_test)
y_pred_labels = np.argmax(y_pred_ohe, axis=1)
y_true_labels = np.argmax(y_test, axis=1)
confusion_matrix = metrics.confusion_matrix(y_true=y_true_labels, y_pred=y_pred_labels)
LABELS = ['Biking' ,' Downstairs', 'Jogging', 'Sitting', 'Standing', 'Upstairs', 'Walking']
plt.figure(figsize=(16, 14))
sns.set(style='whitegrid', palette='muted', font_scale=1.5)
sns.heatmap(confusion_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show();
```
## Exporting the model
a fused TFLite LSTM model
```
run_model = tf.function(lambda x: model(x))
# This is important, let's fix the input size.
BATCH_SIZE = 1
STEPS = 100
INPUT_SIZE = 12
concrete_func = run_model.get_concrete_function(
tf.TensorSpec([BATCH_SIZE, STEPS, INPUT_SIZE], model.inputs[0].dtype))
# model directory.
MODEL_DIR = "keras_lstm"
model.save(MODEL_DIR, save_format="tf", signatures=concrete_func)
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_DIR)
tflite_model = converter.convert()
# Save the model.
with open('model_LSTM.tflite', 'wb') as f:
f.write(tflite_model)
# Save the model.
with open('model_LSTM_Metadata.tflite', 'wb') as f:
f.write(tflite_model)
```
**Adding metadata to TensorFlow Lite models**
```
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "Human Activity Recognition"
model_meta.description = ("input[None, 100, 3] "
"is Sensor "
"output['Biking' ,' Downstairs', 'Jogging', 'Sitting', 'Standing', 'Upstairs', 'Walking']")
model_meta.version = "v3.100.3"
model_meta.author = "phuoctan4141"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
input_meta.name = 'inputSensor'
input_meta.description = (
"Input is array data from sensor with 100steps".format(100, 3))
input_stats = _metadata_fb.StatsT()
input_meta.stats = input_stats
labelmap_file = '/content/labelmap.txt'
export_model_path = '/content/model_LSTM_Metadata.tflite'
import os
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 7 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename(labelmap_file)
label_file.description = "Labels for activities that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
# Pack metadata and associated files into the model
populator = _metadata.MetadataPopulator.with_model_file(export_model_path)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files([labelmap_file])
populator.populate()
```
TEST TFLITE
```
# X_train,X_test, y_train,y_test
# Run the model with TensorFlow to get expected results.
TEST_CASES = 10
# Run the model with TensorFlow Lite
interpreter = tf.lite.Interpreter(model_content=tflite_model)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
for i in range(TEST_CASES):
expected = model.predict(X_test[i:i+1])
interpreter.set_tensor(input_details[0]["index"], X_test[i:i+1, :, :])
interpreter.invoke()
result = interpreter.get_tensor(output_details[0]["index"])
# Assert if the result of TFLite model is consistent with the TF model.
np.testing.assert_almost_equal(expected, result, decimal=5)
print("Done. The result of TensorFlow matches the result of TensorFlow Lite.")
# Please note: TfLite fused Lstm kernel is stateful, so we need to reset
# the states.
# Clean up internal states.
interpreter.reset_all_variables()
```
| github_jupyter |
```
#ignore
from IPython.core.display import HTML,Image
import sys
sys.path.append('/anaconda/')
import config
HTML('<style>{}</style>'.format(config.CSS))
```
Markets are, in my view, mostly random. However, they're not _completely_ random. Many small inefficiencies and patterns exist in markets which can be identified and used to gain slight edge on the market.
These edges are rarely large enough to trade in isolation - transaction costs and overhead can easily exceed the expected profits offered. But when we are able to combine many such small edges together, the rewards can be great.
In this article, I'll present a framework for blending together outputs from multiple models using a type of ensemble modeling known as _stacked generalization_. This approach excels at creating models which "generalize" well to unknown future data, making them an excellent choice for the financial domain, where overfitting to past data is a major challenge.
This post is the sixth and final installment in my tutorial series on applying machine learning to financial time series data. If you haven't already read the prior articles, you may want to do that before starting this one.
* [Data management](ML_data_management.html)
* [Feature engineering](feature_engineering.html)
* [Feature selection](feature_selection.html)
* [Walk-forward modeling](walk_forward_model_building.html)
* [Model evaluation](model_evaluation.html)
### Ensemble Learning
_Ensemble learning_ is a powerful - and widely used - technique for improving model performance (especially it's _generalization_) by combining predictions made by multiple different machine learning models. The idea behind ensemble learning is not dissimilar from the concept ["wisdom of the crowd"](https://en.wikipedia.org/wiki/Wisdom_of_the_crowd), which posits that the aggregated/consensus answer of several diverse, well-informed individuals is typically better than any one individual within the group.
In the world of machine learning, this concept of combining multiple models takes many forms. The first form appears _within_ a number of commonly used algorithms such as [Random Forests](https://en.wikipedia.org/wiki/Random_forest), [Bagging](https://en.wikipedia.org/wiki/Bootstrap_aggregating), and [Boosting](https://en.wikipedia.org/wiki/Boosting_(machine_learning) (though this one works somewhat differently). Each of these algorithms takes a single base model (e.g., a decision tree) and trains many versions of that single algorithm on differing sets of features or samples. The resulting collection of trained models are often more robust out of sample because they're likely to be less overfitted to certain features or samples in the training data.
A second form of ensembling methods involves aggregating across multiple _different model types_ (e.g., an SVM, a logistic regression, and a decision tree) - or with _different hyperparameters_. Since each learning algorithm or set of hyperparameters tends to have different biases, it will tend to make different prediction errors - and extract different signals - from the same set of data. Assuming all models are reasonably good - and that the errors are reasonably uncorrelated to one another - they will partially cancel each other out and the aggregated predictions will be more useful than any single model's predictions.
One particularly flexible approach to this latter type of ensemble modeling is "stacked generalization", or "stacking". In this post, I will walk through a simple example of stacked generalization applied to time series data. If you'd like to replicate and experiment with the below code, _you can download the source notebook for this post by right-clicking on the below button and choosing "save link as"_
<a style="text-align: center;" href="https://github.com/convergenceIM/alpha-scientist/blob/master/content/06_Ensemble_Modeling.ipynb"><img src="images/button_ipynb-notebook.png" title="download ipynb" /></a>
### Overview of Stacked Generalization
The "stacked generalization" framework was initially proposed by Wolpert in a [1992 academic paper](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.56.1533). Since it was first proposed, stacked generalization (aka "stacking") has received a modest but consistent amount of attention from the ML research community.
Stacked generalization is an ensemble modeling technique. The core concept of stacked generalization is to generate a single, optimally robust prediction for a regression or classification task by (a) building multiple different models (with varying learning algorithms, varying hyperparameters, and/or different features) to make predictions then (b) training a "meta-model" or "blending model" to determine how to combine the predictions of each of these multiple models.
A nice way to visualize this (borrowed from documentation for Sebastian Rashka's excellent [mlxtend package](http://rasbt.github.io/mlxtend/user_guide/regressor/StackingRegressor/)) is shown below. Each model R<sub>1</sub> thru R<sub>m</sub> is trained on historical data and used to make predictions P<sub>1</sub> thru P<sub>m</sub>. Those predictions then become the features used to train a meta-model to determine how to combine these predictions.
<img src="http://rasbt.github.io/mlxtend/user_guide/regressor/StackingRegressor_files/stackingregression_overview.png" width="400">
I think of this using an analogy. Imagine that there is a team of investment analysts whose manager has asked each of them to make earnings forecasts for the same set of companies across many quarters. The manager "learns" which analysts have historically been most accurate, somewhat accurate, and inaccurate. When future predictions are needed, the manager can assign greater and lesser (and in some cases, zero) weighting to each analyst's prediction.
It's clear why it's referred to as "stacked". But why "generalization"? The principal motivation for applying this technique is to achieve greater "generalization" of models to out-of-sample (i.e., unseen) data by de-emphasizing models which appear to be overfitted to the data. This is achieved by allowing the meta-model to learn which of the base models' predictions have held up well (and poorly) out-of-sample and to weight models appropriately.
### Motivations
In my view, stacked generalization is perfectly suited to the challenges we face when making predictions in noisy, non-stationary, regime-switching financial markets. When properly implemented (see next section), stacking help to defend against the scourge of overfitting - something which virtually all practitioners of investing ML will agree is a major challenge.
Better yet, stacking allows us to blend together relatively weak (but orthogonal and additive) signals together in a way that doesn't get drowned out by stronger signals.
To illustrate, consider a canonical trend-following strategy which is predicated on 12 month minus 1 month price change. Perhaps we also believe that month-of-year or recent IBIS earnings trend have a weak, but still useful effect on price changes. If we were to train a model that lumped together dominant features (12 minus 1 momentum) and weaker features (seasonality or IBIS trend), our model may miss the subtle information because the dominant features overshadow them.
A stacked model, which has one component (i.e., a base model) focused on solely momentum features, another component focused on solely seasonality features, and a third one focused on analyst revisions features can capture and use the more subtle effects alongside the more dominant momentum effect.
### Keys to Success
Stacked generalization is sometimes referred to as a "black art" and there is truth to that view. However, there are also two concrete principles that will get you a long way towards robust results.
__1. Out of Sample Training__
First, it's _absolutely critical_ that the predictions P<sub>1</sub> thru P<sub>m</sub> used to train the meta-model are exclusively _out of sample_ predictions. Why? Because in order to determine which models are likely to generalize best to out of sample (ie those with least overfit), we must judge that based on past predictions which were themselves made out-of-sample.
Imagine that you trained two models using different algorithms, say logistic regression and decision trees. Both could be very useful (out of sample) but decision trees have a greater tendency to overfit training data. If we used in-sample predictions as features to our meta-learner, we'd likely give much more weight to the model with a tendancy to overfit the most.
Several methods can be used for this purpose. Some advise splitting training data into Train<sub>1</sub> and Train<sub>2</sub> sets so base models can be trained on Train<sub>1</sub> and then can make predictions on Train<sub>2</sub> data for use in training the ensemble model. Predictions of the ensemble model must, of course, be evaluated on yet another dataset.
Others use K-fold cross-validation prediction (such as scikit's `cross_val_predict`) on base models to simulate out-of-sample(ish) predictions to feed into the ensemble layer.
However, in my view, the best method for financial time series data is to use walk-forward training and prediction on the base models, as described in my [Walk-forward modeling](walk_forward_model_building.html) post. In addition to ensuring that every base prediction is true out-of-sample, it simulates the impact of non-stationarity (a.k.a. regime change) over time.
__2. Non-Negativity__
Second - and this is less of a hard-and-fast rule - is to constrain the meta-model to learning non-negative coefficients only, using an algorithm like ElasticNet or lasso which allows non-negativity constraints.
This technique is important because quite often (and sometimes by design) there will be very high collinearity of the "features" fed into the meta-model (P<sub>1</sub> thru P<sub>m</sub>). In periods of high collinearity, learning algorithms can do funky things, such as finding a slightly better fit to past data by assigning a high positive coefficient to one model and a large negative coefficient to another. This is rarely what we really want.
Call me crazy, but if a model is useful only in that it consistently predicts the wrong outcome, it's probably not a model I want to trust.
### Further Reading
That's enough (too much?) background for now. Those interested in more about the theory and practice of stacked generalization should check out the below research papers:
* [Wolpert, 1992](http://www.machine-learning.martinsewell.com/ensembles/stacking/Wolpert1992.pdf)
* [Ting and Witten, 1997](https://pdfs.semanticscholar.org/fd97/e40ef6c310213fae017fdbf328c8bdf5cb68.pdf)
* [Ting and Witten, 1999](https://arxiv.org/pdf/1105.5466.pdf)
* [Breiman, 1996](https://link.springer.com/content/pdf/10.1007/BF00117832.pdf)
* [Sigletos et al, 2005](http://www.jmlr.org/papers/volume6/sigletos05a/sigletos05a.pdf)
* [Why do stacked ensemble models win data science competitions?](https://blogs.sas.com/content/subconsciousmusings/2017/05/18/stacked-ensemble-models-win-data-science-competitions/)
## Preparing the Data
For this simple example, I will create synthetic data rather than using real market prices to remove the ambiguity about what features and transformations may be necessary to extract maximum value from the model.
Note: to make the dataset more realistic, I will extract an _index_ from actual stock prices using quandl's API, but all features and target values will be constructed below.
With index in hand, we will generate four "hidden factors". These are the non-random drivers of the target variable, and are the "signal" we ideally want to learn.
To ensure that these factors are meaningful, we will _create the target variable (`y`) using combinations of these factors_. The first two hidden factors have a __linear__ relationship to the target. The second two hidden factors have a more complex relationship involving interaction effects between variables. Lastly, we will add a noise component to make our learners work for it.
Finally, we'll create several features that are each related to one or more hidden factors, including generous amounts of noise and bias.
Key point: we've created X and y data which we know is related by several different linkages, some of which are linear and some of which aren't. This is what our modeling will seek to learn.
```
import numpy as np
import pandas as pd
pd.core.common.is_list_like = pd.api.types.is_list_like # remove once updated pandas-datareader issue is fixed
# https://github.com/pydata/pandas-datareader/issues/534
import pandas_datareader.data as web
%matplotlib inline
from IPython.core.display import HTML,Image
HTML('<style>{}</style>'.format(config.CSS))
def get_symbols(symbols,data_source, begin_date=None,end_date=None):
out = pd.DataFrame()
for symbol in symbols:
df = web.DataReader(symbol, data_source,begin_date, end_date)[['AdjOpen','AdjHigh','AdjLow','AdjClose','AdjVolume']].reset_index()
df.columns = ['date','open','high','low','close','volume'] #my convention: always lowercase
df['symbol'] = symbol # add a new column which contains the symbol so we can keep multiple symbols in the same dataframe
df = df.set_index(['date','symbol'])
out = pd.concat([out,df],axis=0) #stacks on top of previously collected data
return out.sort_index()
idx = get_symbols(['AAPL','CSCO','MSFT','INTC'],data_source='quandl',begin_date='2012-01-01',end_date=None).index
# note, we're only using quandl prices to generate a realistic multi-index of dates and symbols
num_obs = len(idx)
split = int(num_obs*.80)
## First, create factors hidden within feature set
hidden_factor_1 = pd.Series(np.random.randn(num_obs),index=idx)
hidden_factor_2 = pd.Series(np.random.randn(num_obs),index=idx)
hidden_factor_3 = pd.Series(np.random.randn(num_obs),index=idx)
hidden_factor_4 = pd.Series(np.random.randn(num_obs),index=idx)
## Next, generate outcome variable y that is related to these hidden factors
y = (0.5*hidden_factor_1 + 0.5*hidden_factor_2 + # factors linearly related to outcome
hidden_factor_3 * np.sign(hidden_factor_4) + hidden_factor_4*np.sign(hidden_factor_3)+ # factors with non-linear relationships
pd.Series(np.random.randn(num_obs),index=idx)).rename('y') # noise
## Generate features which contain a mix of one or more hidden factors plus noise and bias
f1 = 0.25*hidden_factor_1 + pd.Series(np.random.randn(num_obs),index=idx) + 0.5
f2 = 0.5*hidden_factor_1 + pd.Series(np.random.randn(num_obs),index=idx) - 0.5
f3 = 0.25*hidden_factor_2 + pd.Series(np.random.randn(num_obs),index=idx) + 2.0
f4 = 0.5*hidden_factor_2 + pd.Series(np.random.randn(num_obs),index=idx) - 2.0
f5 = 0.25*hidden_factor_1 + 0.25*hidden_factor_2 + pd.Series(np.random.randn(num_obs),index=idx)
f6 = 0.25*hidden_factor_3 + pd.Series(np.random.randn(num_obs),index=idx) + 0.5
f7 = 0.5*hidden_factor_3 + pd.Series(np.random.randn(num_obs),index=idx) - 0.5
f8 = 0.25*hidden_factor_4 + pd.Series(np.random.randn(num_obs),index=idx) + 2.0
f9 = 0.5*hidden_factor_4 + pd.Series(np.random.randn(num_obs),index=idx) - 2.0
f10 = hidden_factor_3 + hidden_factor_4 + pd.Series(np.random.randn(num_obs),index=idx)
## From these features, create an X dataframe
X = pd.concat([f1.rename('f1'),f2.rename('f2'),f3.rename('f3'),f4.rename('f4'),f5.rename('f5'),
f6.rename('f6'),f7.rename('f7'),f8.rename('f8'),f9.rename('f9'),f10.rename('f10')],axis=1)
```
### Exploratory Data Analysis
We'll avoid going too deeply into exploratory data analysis (refer to [Feature engineering](feature_engineering.html) for more exploration of that topic). I will, however, plot three simple views:
1. Distributions of the features and target variables.
2. Simple univariate regressions for each of the ten features vs. the target variable.
3. A clustermap showing correlations between the features (see [Feature selection](feature_selection.html) for more on this technique):
```
## Distribution of features and target
X.plot.kde(legend=True,xlim=(-5,5),color=['green']*5+['orange']*5,title='Distributions - Features and Target')
y.plot.kde(legend=True,linestyle='--',color='red') # target
## Univariate Regressions
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="dark")
# Set up the matplotlib figure
fig, axes = plt.subplots(4, 3, figsize=(8, 6), sharex=True, sharey=True)
# Rotate the starting point around the cubehelix hue circle
for ax, s in zip(axes.flat, range(10)):
cmap = sns.cubehelix_palette(start=s, light=1, as_cmap=True)
x = X.iloc[:,s]
sns.regplot(x, y,fit_reg = True, marker=',', scatter_kws={'s':1},ax=ax,color='salmon')
ax.set(xlim=(-5, 5), ylim=(-5, 5))
ax.text(x=0,y=0,s=x.name.upper(),color='black',
**{'ha': 'center', 'va': 'center', 'family': 'sans-serif'},fontsize=20)
fig.tight_layout()
fig.suptitle("Univariate Regressions for Features", y=1.05,fontsize=20)
## Feature correlations
from scipy.cluster import hierarchy
from scipy.spatial import distance
corr_matrix = X.corr()
correlations_array = np.asarray(corr_matrix)
linkage = hierarchy.linkage(distance.pdist(correlations_array), \
method='average')
g = sns.clustermap(corr_matrix,row_linkage=linkage,col_linkage=linkage,\
row_cluster=True,col_cluster=True,figsize=(5,5),cmap='Greens',center=0.5)
plt.setp(g.ax_heatmap.yaxis.get_majorticklabels(), rotation=0)
plt.show()
label_order = corr_matrix.iloc[:,g.dendrogram_row.reordered_ind].columns
```
## Making Base Models
The first step in a stacked generalization system is to generate the "base models", meaning the models which are learning from our input features. We'll create two base models to use in our ensemble:
1. A collection of simple linear regression models
2. A collection of tree models - in this case, using the ExtraTrees algorithm
As described above _it's absolutely critical_ to build models which provide realistic _out-of-sample_ predictions, I am going to apply the methodology presented in [Walk-forward modeling](walk_forward_model_building.html). In short, this will retrain at the end of each calendar quarter, using only data which would have been available at that time. Predictions are made using the most recently trained model.
To make this easier to follow, I'll define a simple function called `make_walkforward_model` that trains a series of models at various points in time and generates out of sample predictions using those trained models.
```
from sklearn.base import clone
from sklearn.linear_model import LinearRegression
def make_walkforward_model(features,outcome,algo=LinearRegression()):
recalc_dates = features.resample('Q',level='date').mean().index.values[:-1]
## Train models
models = pd.Series(index=recalc_dates)
for date in recalc_dates:
X_train = features.xs(slice(None,date),level='date',drop_level=False)
y_train = outcome.xs(slice(None,date),level='date',drop_level=False)
#print(f'Train with data prior to: {date} ({y_train.count()} obs)')
model = clone(algo)
model.fit(X_train,y_train)
models.loc[date] = model
begin_dates = models.index
end_dates = models.index[1:].append(pd.to_datetime(['2099-12-31']))
## Generate OUT OF SAMPLE walk-forward predictions
predictions = pd.Series(index=features.index)
for i,model in enumerate(models): #loop thru each models object in collection
#print(f'Using model trained on {begin_dates[i]}, Predict from: {begin_dates[i]} to: {end_dates[i]}')
X = features.xs(slice(begin_dates[i],end_dates[i]),level='date',drop_level=False)
p = pd.Series(model.predict(X),index=X.index)
predictions.loc[X.index] = p
return models,predictions
```
To create a series of walk-forward models, simply pass in X and y data along with a scikit estimator object. It returns a series of models and a series of predictions. Here, we'll create two base models on all features, one using linear regression and one with extra trees.
```
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import ExtraTreesRegressor
linear_models,linear_preds = make_walkforward_model(X,y,algo=LinearRegression())
tree_models,tree_preds = make_walkforward_model(X,y,algo=ExtraTreesRegressor())
```
Note that no predictions can be made prior to the first trained model, so it's important to `dropna()` on predictions prior to use.
```
print("Models:")
print(linear_models.head())
print()
print("Predictions:")
print(linear_preds.dropna().head())
```
It can be instructive to see how the linear model coefficients evolve over time:
```
pd.DataFrame([model.coef_ for model in linear_models],
columns=X.columns,index=linear_models.index).plot(title='Weighting Coefficients for \nLinear Model')
```
Next, I'll create a simple function to evaluate multiple model performance metrics, called `calc_scorecard`. Further detail on this method of model evaluation is provided in the earlier post [Model evaluation](model_evaluation.html).
```
from sklearn.metrics import r2_score,mean_absolute_error
def calc_scorecard(y_pred,y_true):
def make_df(y_pred,y_true):
y_pred.name = 'y_pred'
y_true.name = 'y_true'
df = pd.concat([y_pred,y_true],axis=1).dropna()
df['sign_pred'] = df.y_pred.apply(np.sign)
df['sign_true'] = df.y_true.apply(np.sign)
df['is_correct'] = 0
df.loc[df.sign_pred * df.sign_true > 0 ,'is_correct'] = 1 # only registers 1 when prediction was made AND it was correct
df['is_incorrect'] = 0
df.loc[df.sign_pred * df.sign_true < 0,'is_incorrect'] = 1 # only registers 1 when prediction was made AND it was wrong
df['is_predicted'] = df.is_correct + df.is_incorrect
df['result'] = df.sign_pred * df.y_true
return df
df = make_df(y_pred,y_true)
scorecard = pd.Series()
# building block metrics
scorecard.loc['RSQ'] = r2_score(df.y_true,df.y_pred)
scorecard.loc['MAE'] = mean_absolute_error(df.y_true,df.y_pred)
scorecard.loc['directional_accuracy'] = df.is_correct.sum()*1. / (df.is_predicted.sum()*1.)*100
scorecard.loc['edge'] = df.result.mean()
scorecard.loc['noise'] = df.y_pred.diff().abs().mean()
# derived metrics
scorecard.loc['edge_to_noise'] = scorecard.loc['edge'] / scorecard.loc['noise']
scorecard.loc['edge_to_mae'] = scorecard.loc['edge'] / scorecard.loc['MAE']
return scorecard
calc_scorecard(y_pred=linear_preds,y_true=y).rename('Linear')
```
Since we are concerned about not only average performance but also period-to-period consistency, I'll create a simple wrapper function which recalculates our metrics by quarter.
```
def scores_over_time(y_pred,y_true):
df = pd.concat([y_pred,y_true],axis=1).dropna().reset_index().set_index('date')
scores = df.resample('A').apply(lambda df: calc_scorecard(df[y_pred.name],df[y_true.name]))
return scores
scores_by_year = scores_over_time(y_pred=linear_preds,y_true=y)
print(scores_by_year.tail(3).T)
scores_by_year['edge_to_mae'].plot(title='Prediction Edge vs. MAE')
```
## Making the Ensemble Model
Now that we've trained base models and generated out-of-sample predictions, it's time to train the stacked generalization ensemble model.
Training the ensemble model simply requires feeding in the base models' predictions in as the X dataframe. To clean up the data and ensure the X and y are of compatible dimensions, I've created a short data preparation function.
Here, we'll use Lasso to train the ensemble becuase it is one of a few linear models which can be constrained to `positive = True`. This will ensure that the ensemble will assign either a positive or zero weight to each model, for reasons described above.
```
from sklearn.linear_model import LassoCV
def prepare_Xy(X_raw,y_raw):
''' Utility function to drop any samples without both valid X and y values'''
Xy = X_raw.join(y_raw).replace({np.inf:None,-np.inf:None}).dropna()
X = Xy.iloc[:,:-1]
y = Xy.iloc[:,-1]
return X,y
X_ens, y_ens = prepare_Xy(X_raw=pd.concat([linear_preds.rename('linear'),tree_preds.rename('tree')],
axis=1),y_raw=y)
ensemble_models,ensemble_preds = make_walkforward_model(X_ens,y_ens,algo=LassoCV(positive=True))
ensemble_preds = ensemble_preds.rename('ensemble')
print(ensemble_preds.dropna().head())
```
Note that the ensemble's predictions don't begin until July, since the earliest trained ensemble model isn't available until end of Q2. This is necessary to make sure the ensemble model is trained on out of sample data - and that its predictions are _also_ out of sample.
Again, we can look at the coefficients over time of the ensemble model. Keep in mind that the coefficients of the ensemble model represents how much weight is being given to each base model. In this case, it appears that our tree model is much more useful relative to the linear model, though the linear model is gradually catching up.
```
pd.DataFrame([model.coef_ for model in ensemble_models],
columns=X_ens.columns,index=ensemble_models.index).plot(title='Weighting Coefficients for \nSimple Two-Model Ensemble')
```
## Performance of Ensemble vs. Base Models
Now that we have predictions from both the base models and ensemble model, we can explore how the ensemble performs relative to base models. Is the whole really more than the sum of the parts?
```
# calculate scores for each model
score_ens = calc_scorecard(y_pred=ensemble_preds,y_true=y_ens).rename('Ensemble')
score_linear = calc_scorecard(y_pred=linear_preds,y_true=y_ens).rename('Linear')
score_tree = calc_scorecard(y_pred=tree_preds,y_true=y_ens).rename('Tree')
scores = pd.concat([score_linear,score_tree,score_ens],axis=1)
scores.loc['edge_to_noise'].plot.bar(color='grey',legend=True)
scores.loc['edge'].plot(color='green',legend=True)
scores.loc['noise'].plot(color='red',legend=True)
plt.show()
print(scores)
```
```
fig,[[ax1,ax2],[ax3,ax4]] = plt.subplots(2,2,figsize=(9,6))
metric = 'RSQ'
scores_over_time(y_pred=ensemble_preds.rename('ensemble'),y_true=y)[metric].rename('Ensemble').\
plot(title=f'{metric.upper()} over time',legend=True,ax=ax1)
scores_over_time(y_pred=linear_preds.rename('linear'),y_true=y)[metric].rename('Linear').\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax1)
scores_over_time(y_pred=tree_preds.rename('tree'),y_true=y)[metric].rename("Tree").\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax1)
metric = 'edge'
scores_over_time(y_pred=ensemble_preds.rename('ensemble'),y_true=y)[metric].rename('Ensemble').\
plot(title=f'{metric.upper()} over time',legend=True,ax=ax2)
scores_over_time(y_pred=linear_preds.rename('linear'),y_true=y)[metric].rename('Linear').\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax2)
scores_over_time(y_pred=tree_preds.rename('tree'),y_true=y)[metric].rename("Tree").\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax2)
metric = 'noise'
scores_over_time(y_pred=ensemble_preds.rename('ensemble'),y_true=y)[metric].rename('Ensemble').\
plot(title=f'{metric.upper()} over time',legend=True,ax=ax3)
scores_over_time(y_pred=linear_preds.rename('linear'),y_true=y)[metric].rename('Linear').\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax3)
scores_over_time(y_pred=tree_preds.rename('tree'),y_true=y)[metric].rename("Tree").\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax3)
metric = 'edge_to_noise'
scores_over_time(y_pred=ensemble_preds.rename('ensemble'),y_true=y)[metric].rename('Ensemble').\
plot(title=f'{metric.upper()} over time',legend=True,ax=ax4)
scores_over_time(y_pred=linear_preds.rename('linear'),y_true=y)[metric].rename('Linear').\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax4)
scores_over_time(y_pred=tree_preds.rename('tree'),y_true=y)[metric].rename("Tree").\
plot(title=f'{metric.upper()} over time',legend=True, alpha = 0.5, linestyle='--',ax=ax4)
plt.tight_layout()
plt.show()
```
### Observations:
* We can see that the ensemble is fairly consistently more effective than either of the base models.
* All models seem to be getting better over time (and as they have more data on which to train).
* The ensemble also appears to be a bit more consistent over time. Much like a diversified portfolio of stocks should be less volatile than the individual stocks within it, an ensemble of diverse models will often perform more consistently across time
## Next Steps
The stacked generalization methodology is highly flexible. There are countless directions you can take this, including:
* __More model types__: add SVMs, deep learning models, regularlized regressions, and dimensionality reduction models to the mix
* __More hyperparameter combinations__: try multiple sets of hyperparameters on a particular algorithm.
* __Orthogonal feature sets__: try training base models on different subsets of features. Avoid the "curse of dimensionality" by limiting each base model to an appropriately small number of features.
## Summary
This final post, combined with the five previous posts, presents an end-to-end framework for applying supervised machine learning techniques to financial time series data, in a way which helps mitigate the several unique challenges of this domain.
* [Data management](ML_data_management.html)
* [Feature engineering](feature_engineering.html)
* [Feature selection](feature_selection.html)
* [Walk-forward modeling](walk_forward_model_building.html)
* [Model evaluation](model_evaluation.html)
Please feel free to add to the comment section with your comments and questions on this post. I'm also interested in ideas for future posts.
Going forward, I plan to shift gears from tutorials to research on market anomalies and trading opportunities.
## One more thing...
If you've found this post useful, please consider subscribing to the email list to be notified of future posts (email addresses will only be used for this purpose...).
You can also follow me on [twitter](https://twitter.com/data2alpha) and forward to a friend or colleague who may find this topic interesting.
| github_jupyter |
```
pd.options.display.max_rows = 9999
pd.options.display.max_columns = 9999
import sys
import missingno as msno
import matplotlib.pyplot as plt
from matplotlib import rc
import seaborn as sns
from PIL import Image
from functools import reduce
%matplotlib inline
rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False
import requests
#parameter
code, page_size, page = "KOSPI", 20, 1
url = "https://m.stock.naver.com/api/json/sise/dailySiseIndexListJson.nhn?code={}&pageSize={}&page={}".format(code, page_size, page)
url
response = requests.get(url)
response
#json(str) -> dict(parsing) : df
datas = response.json()['result']['siseList']
kospi_df = pd.DataFrame(datas)
kospi_df.tail()
def get_stock_data(code="KOSPI", page_size=20, page=1):
url = "https://m.stock.naver.com/api/json/sise/dailySiseIndexListJson.nhn?code={}&pageSize={}&page={}".format(code, page_size, page)
response = requests.get(url)
return pd.DataFrame(response.json()['result']['siseList'])
kospi_df = get_stock_data(page_size=100)
kosdaq_df = get_stock_data("KOSDAQ",100)
kosdaq_df.head()
#1. URL
code, page_size, page = "FX_USDKRW", 100, 1
url = 'https://m.stock.naver.com/api/json/marketindex/marketIndexDay.nhn?marketIndexCd={}&pageSize={}&page={}'.format(code, page_size, page)
#2. req, rep : JSON
headers = {"cookie":"NRTK=ag#all_gr#1_ma#-2_si#0_en#0_sp#0; NNB=CMA7YWP7P2XF4; NaverSuggestUse=use%26unuse; _ga=GA1.2.773807485.1590195174; nx_ssl=2; ASID=6af24fe600000172b0e8cca30000004c; nid_inf=-1496171055; NID_AUT=a7ughWicWlJrQTgQ+CkwmRvaHq2c+nJiMy95GX28FJjCEWQSG4047DBrmGx+Zr2D; NID_JKL=Pho2PdQOZrILUyf3OTEukiPzNn5qauR7NiyKzzZH8uU=; NID_SES=AAABgZqF2SnQbopTDmPcdqJi8W1dMFUfKwJfpkciWTHO8Vr3kZOpSrL7G4o2BwfEk3JUOEBbcMVxmzfNCek4hsnTlHZlZevt5fEZP5JjiOX593U3l1dCBIW7Ma348+M5R+t43tMfUgMuXTjQ2q0vlCxjYu1F8egvoky8VMI9WbDPW5ysZaeB7fbombvBgzo8hyjAa4DFVmIzj2wNor9FAGRiu0+b4BSc7BDboNn50ZFSvoiiEAYKLFlSMm8FBUAPaJa2A7jFY1mI4irXlROPCvG9aOMm/AKIz+sAkJ/8RinVuLMyqMcLoq6vsJZTP+l5CDiunfQFArdCfrQ6ZlJkUXyv09FqkWsmGKteYaWjrIM6qXISoWhA3xex9OZx60+fb3tP8DAjQS0YPnsqFK2fDcFW3FNRNITrdANJFti+FUa0cl2pNkPJk3qOgUty5CiZQKWG7PgNLcWiAOukAljuthffph3jhuhfd1OXvuFfrnqU2NevcAiR4uo2BqABg02T8nT95WRCER6eiPIudknQCcFCEkM=; naver_mobile_stock_codeList=102280%7C; XSRF-TOKEN=0dd911ec-40af-4411-83e9-514bb9769403; JSESSIONID=E5FBDAD1347E6CEB95935D2807A127A4; BMR="}
response = requests.get(url, headers = headers)
response.text
#3. JSON > DF
datas = response.json()["result"]["marketIndexDay"]
usd_df = pd.DataFrame(datas)
usd_df.tail()
from sklearn import preprocessing
# 그래프 그리기
plt.figure(figsize=(20,5))
data1 = preprocessing.minmax_scale(kospi_df["ncv"][::-1])
data2 = preprocessing.minmax_scale(kosdaq_df["ncv"][::-1])
data3 = preprocessing.minmax_scale(usd_df["nv"][::-1])
plt.plot(kospi_df["dt"], data1, "r*:", label="kospi")
plt.plot(kosdaq_df["dt"], data2, "b^:", label="kosdaq")
plt.plot(usd_df["dt"], data3, "go-", label = "usd")
step = len(kospi_df) // 10
plt.xticks(kospi_df[::step]["dt"][::-1])
plt.show()
np.corrcoef(data1, data2)[0,1]**2, np.corrcoef(data1, data3)[0,1]**2
```
### HTML
```
keyword = "삼성전자"
url = "https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query={}".format(keyword)
print(url)
response = requests.get(url)
response
response.text
from bs4 import BeautifulSoup
dom = BeautifulSoup(response.content, "html.parser")
type(dom)
selector = "#nx_related_keywords > dl > dd.lst_relate._related_keyword_list > ul>li"
elements = dom.select(selector)
keywords = [element.text.strip() for element in elements]
df = pd.DataFrame({"keyword": keywords})
df
```
### xpath
### xpath 문법
- "//*[@id="nx_related_keywords"]/dl/dd[1]/ul/li"
- '//' : 가장 상위 엘리먼트
- '*' : 모든 하위 엘리먼트에서 찾음.
- '[@id="nx_related_keywords"]' : 속성값의 키 : id, 밸류 : nx_rerlated_keywords를 선택
- '/' : 한단계 하위 엘리먼트에서 찾음
- '[]'
- 속성값으로 엘리먼트 찾기
- 숫자가 오면 몇 번째 엘리먼트를 의미
```
import scrapy
from scrapy.http import TextResponse
keyword = "삼성전자"
url = "https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query={}".format(keyword)
response = requests.get(url)
tr_obj = TextResponse(response.url, body=response.text, encoding = "utf-8")
tr_obj
selector = '//*[@id="nx_related_keywords"]/dl/dd[1]/ul/li'
datas = tr_obj.xpath(selector)
len(datas)
datas[0]
datas[0].xpath('a/text()').extract()
datas = tr_obj.xpath('//*[@id="nx_related_keywords"]/dl/dd[1]/ul/li/a/text()').extract()
datas
```
| github_jupyter |
# Introduction to Data Science
# Lecture 8: Temporal data analysis and applications to stock analysis
*COMP 5360 / MATH 4100, University of Utah, http://datasciencecourse.net/*
In this lecture, we'll cover
* temporal data analysis
* importing stock data using the pandas_datareader python package
* visualizing time series
* rolling means
* time-domain vs frequency-domain analysis
Parts of this lecture were adapted from a [previous lecture by *Curtis Miller*](https://github.com/datascience-course/2019-datascience-lectures/tree/master/08-time-series)
and a [lecture on Time Series and Spectral Analysis by James Holland Jones](http://web.stanford.edu/class/earthsys214/notes/series.html).
Further reading:
+ Yves Hilpisch, Python for Finance, O'Reilly, (2014) [link](http://proquest.safaribooksonline.com.ezproxy.lib.utah.edu/book/programming/python/9781491945360).
For a more complete treatment, take Math 5075 (Time Series Analysis).
## Temporal data analysis
A *time series* is a series of data points indexed by time, $x_i = x(t_i)$, for $i=1,\ldots,n$. Examples frequently occur in
* weather forecasting,
* mathematical finance (stocks),
* electricity demand in a power grid,
* keystrokes on a computer, and
* any applied science and engineering which involves temporal measurements
*Temporal data analysis* or *time series analysis* is just the study of such data.
As a first example of time series data, we'll consider stocks and *mathematical finance*.
## Mathematical finance
Prior to the 1980s, banking and finance were well-known for being "boring"; investment banking was distinct from commercial banking and the primary role of the industry was handling "simple" (at least in comparison to today) financial instruments, such as loans. Deregulation under the Regan administration, coupled with an influx of mathematics and computing power have transformed the industry from the "boring" business of banking to what it is today.
* Advanced mathematics, such as analysis of the [Black-Scholes model](https://en.wikipedia.org/wiki/Black%E2%80%93Scholes_model), is now essential to finance.
* Algorithms are now responsible for making split-second decisions. In fact, [the speed at which light travels is a limitation when designing trading systems](http://www.nature.com/news/physics-in-finance-trading-at-the-speed-of-light-1.16872).
* [Machine learning and data mining techniques are popular](http://www.ft.com/cms/s/0/9278d1b6-1e02-11e6-b286-cddde55ca122.html#axzz4G8daZxcl) in the financial sector. For example, **high-frequency trading (HFT)** is a branch of algorithmic trading where computers make thousands of trades in short periods of time, engaging in complex strategies such as statistical arbitrage and market making. HFT was responsible for phenomena such as the [2010 flash crash](https://en.wikipedia.org/wiki/2010_Flash_Crash) and a [2013 flash crash](http://money.cnn.com/2013/04/24/investing/twitter-flash-crash/) prompted by a hacked [Associated Press tweet](http://money.cnn.com/2013/04/23/technology/security/ap-twitter-hacked/index.html?iid=EL) about an attack on the White House.
### Installing `pandas_datareader`
We will use a package not included in the Anaconda distribution, [**pandas_datareader**](https://pydata.github.io/pandas-datareader/), that can be installed via the command prompt:
pip install pandas_datareader
```
#imports and setup
import numpy as np
import pandas as pd
import pandas_datareader.data as web
from datetime import datetime
from scipy.signal import periodogram
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (10, 6)
```
## Getting and Visualizing Stock Data
### The `pandas_datareader` package
From the `pandas_datareader` documentation:
Functions from `pandas_datareader.data` and `pandas_datareader.wb` extract data from various internet sources into a pandas DataFrame. Currently the following sources are supported:
* Tiingo
* IEX* Alpha Vantage
* Enigma
* Quandl
* St.Louis FED (FRED)
* Kenneth French’s data library
* World Bank
* OECD
* Eurostat
* Thrift Savings Plan
* Nasdaq Trader symbol definitions
* Stooq
* MOEX
We will use the function
df = pandas_datareader.data.DataReader(name, data_source=None, start=None, end=None, retry_count=3, pause=0.1, session=None, api_key=None)
to import stock data as a pandas DataFrame. The arguments that we'll use are
name : str or list of strs
the name of the dataset. Some data sources (IEX, fred) will
accept a list of names.
data_source: {str, None}
the data source ("iex", "fred", "ff")
start : string, int, date, datetime, Timestamp
left boundary for range (defaults to 1/1/2010)
end : string, int, date, datetime, Timestamp
right boundary for range (defaults to today)
As usual, you can type
help(pandas_datareader.data.DataReader)
to see the documentation of a python function.
Now let's get some data.
```
start = datetime(2010, 1, 29)
end = datetime(2020, 1, 29)
AAPL = web.DataReader(name="AAPL", data_source="yahoo", start=start, end=end)
AAPL.tail()
```
What does this data mean?
* **high** is the highest price of the stock on that trading day,
* **low** the lowest price of the stock on that trading day,
* **Open** is the price of the stock at the beginning of the trading day (it need not be the closing price of the previous trading day)
* **close** the price of the stock at closing time
* **Volume** indicates how many stocks were traded
* **Adj Closed** is the price of the stock after adjusting for corporate actions. While stock prices are considered to be set mostly by traders, *stock splits* (when the company makes each extant stock worth two and halves the price) and *dividends* (payout of company profits per share) also affect the price of a stock and should be accounted for.
### Visualizing Stock Data
Now that we have stock data we can visualize it using the `matplotlib` package, called using a convenience method, `plot()` in pandas.
```
AAPL["Adj Close"].plot(grid = True); # Plot the adjusted closing price of AAPL
```
### Plotting multiple stocks together
For a variety of reasons, we may wish to plot multiple financial instruments together including:
* we may want to compare stocks
* compare them to the market or other securities such as [exchange-traded funds (ETFs)](https://en.wikipedia.org/wiki/Exchange-traded_fund).
Here, we plot the adjusted close for several stocks together.
```
MSFT, GOOG = (web.DataReader(name=s, data_source="yahoo", start=start, end=end) for s in ["MSFT", "GOOG"])
# Below I create a DataFrame consisting of the adjusted closing price of these stocks, first by making a list of these objects and using the join method
adj_close = pd.DataFrame({ "AAPL": AAPL["Adj Close"],
"MSFT": MSFT["Adj Close"],
"GOOG": GOOG["Adj Close"]})
adj_close.head()
adj_close.plot(grid = True);
```
**Q:** Why is this plot difficult to read?
It plots the *absolute price* of stocks with time. While absolute price is important, frequently we are more concerned about the *relative change* of an asset rather than its absolute price. Also, Google stock is much more expensive than Apple or Microsoft stock, and this difference makes Apple and Microsoft stock appear less volatile than they truly are (that is, their price appears not to vary as much with time).
One solution is to use two different scales when plotting the data; one scale will be used by Apple and Microsoft stocks, and the other by Google.
```
adj_close.plot(secondary_y = ["AAPL", "MSFT"], grid = True);
```
But, this solution clearly has limitations. We only have two sides of the plot to add more labels!
A "better" solution is to plot the information we actually want. One option is to plot the *stock returns since the beginning of the period of interest*:
$$
\text{return}_{t,0} = \frac{\text{price}_t}{\text{price}_0}
$$
This requires transforming the data, which we do using a *lambda function*.
```
# df.apply(arg) will apply the function arg to each column in df, and return a DataFrame with the result
# Recall that lambda x is an anonymous function accepting parameter x; in this case, x will be a pandas Series object
stock_return = adj_close.apply(lambda x: x / x[0])
stock_return.head()
stock_return.plot(grid = True).axhline(y = 1, color = "black", lw = 1);
```
This is a much more useful plot! Note:
* We can now see how profitable each stock was since the beginning of the period.
* Furthermore, we see that these stocks are highly correlated; they generally move in the same direction, a fact that was difficult to see in the other charts.
Alternatively, we could plot the change of each stock per day. One way to do so would be to use the *percentage increase of a stock*:
$$
\text{increase}_t = \frac{\text{price}_{t} - \text{price}_{t-1}}{\text{price}_t}
$$
or the *log difference*.
$$
\text{change}_t = \log\left( \frac{\text{price}_{t}}{\text{price}_{t - 1}} \right) = \log(\text{price}_{t}) - \log(\text{price}_{t - 1})
$$
Here, $\log$ is the natural log. Log difference has a desirable property: the sum of the log differences can be interpreted as the total change (as a percentage) over the period summed. Log differences also more cleanly correspond to how stock prices are modeled in continuous time.
We can obtain and plot the log differences of the data as follows.
```
stock_change = adj_close.apply(lambda x: np.log(x) - np.log(x.shift(1))) # shift moves dates back by 1.
stock_change.head()
stock_change.plot(grid = True).axhline(y = 0, color = "black", lw = 1);
```
Do you prefer to plot stock return or log difference?
* Looking at returns since the beginning of the period make the overall trend of the securities apparent.
* Log difference, however, emphasizes changes between days.
### Comparing stocks to the overall market
We often want to compare the performance of stocks to the performance of the overall market.
[SPY](https://finance.yahoo.com/quote/SPY/) is the ticker symbol for the SPDR S&P 500 exchange-traded mutual fund (ETF), which is a fund that has roughly the stocks in the [S&P 500 stock index](https://finance.yahoo.com/quote/%5EGSPC?p=^GSPC).
This serves as one measure for the overal market.
```
SPY = web.DataReader(name="SPY", data_source="yahoo", start=start, end=end)
SPY.tail()
adj_close['SPY'] = SPY["Adj Close"]
adj_close.head()
stock_return['SPY'] = adj_close[['SPY']].apply(lambda x: x / x[0])
stock_return.head()
stock_return.plot(grid = True).axhline(y = 1, color = "black", lw = 1);
stock_change['SPY'] = adj_close[['SPY']].apply(lambda x: np.log(x) - np.log(x.shift(1))) # shift moves dates back by 1.
stock_change.head()
stock_change.plot(grid = True).axhline(y = 0, color = "black", lw = 1);
```
### Moving Averages
For a time series $x_t$, the *$q$-day moving average at time $t$*, denoted $MA^q_t$, is the average of $x_t$ over the past $q$ days,
$$
MA^q_t = \frac{1}{q} \sum_{i = 0}^{q-1} x_{t - i}
$$
The [`rolling`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.rolling.html) function in Pandas provides functionality for computing moving averages. We'll use it to create a 20-day moving average for Apple stock data and plot it alongside the stock price.
```
AAPL["20d"] = AAPL["Adj Close"].rolling(window = 20, center = False).mean()
AAPL.head(30)
```
Notice how late the rolling average begins. It cannot be computed until twenty days have passed. Note that this becomes more severe for slower moving averages.
```
AAPL[["Adj Close", "20d"]].tail(300).plot(grid = True);
```
Notice that the moving averages "smooths" the time series. This can sometimes make it easier to identify trends. The larger $q$, the less responsive a moving average is to fast fluctuations in the series $x_t$.
So, if these fast fluctuations are considered "noise", a moving average will identify the "signal".
* *Fast moving averages* have smaller $q$ and more closely follow the time series.
* *Slow moving averages* have larger $q$ and respond less to the fluctuations of the stock.
Let's compare the 20-day, 50-day, and 200-day moving averages.
```
AAPL["50d"] = AAPL["Adj Close"].rolling(window = 50, center = False).mean()
AAPL["200d"] = AAPL["Adj Close"].rolling(window = 200, center = False).mean()
AAPL[["Adj Close", "20d", "50d", "200d"]].tail(500).plot(grid = True);
```
The 20-day moving average is the most sensitive to fluctuations, while the 200-day moving average is the least sensitive.
### Trading strategies and backtesting
**Trading** is the practice of buying and selling financial assets for the purpose of making a profit. Traders develop **trading strategies** that a computer can use to make trades. Sometimes, these can be very complicated, but other times traders make decisions based on finding patterns or trends in charts.
One example is called the [moving average crossover strategy](http://www.investopedia.com/university/movingaverage/movingaverages4.asp).
This strategy is based on two moving averages, a "fast" one and a "slow" one. The strategy is:
* Trade the asset when the fast moving average crosses over the slow moving average.
* Exit the trade when the fast moving average crosses over the slow moving average again.
A trade will be prompted when the fast moving average crosses from below to above the slow moving average, and the trade will be exited when the fast moving average crosses below the slow moving average later.
This is the outline of a complete strategy and we already have the tools to get a computer to automatically implement the strategy.
But before we decide if we want to use it, we should first evaluate the quality of the strategy. The usual means for doing this is called **backtesting**, which is looking at how profitable the strategy is on historical data.
You could now write python code that could implement and backtest a trading strategy. There are also lots of python packages for this:
* [**pyfolio**](https://quantopian.github.io/pyfolio/) (for analytics)
* [**zipline**](http://www.zipline.io/beginner-tutorial.html) (for backtesting and algorithmic trading), and
* [**backtrader**](https://www.backtrader.com/) (also for backtesting and trading).
# Time-domain vs frequency-domain analysis
So far, we have thought about a time series $x(t)$ in the "time domain". But, for some time series, it is easier to describe them in terms of the "frequency domain".
For example, a good way to describe the function
$$
x(t) = \cos\left( 2 \pi f t \right)
$$
is as a oscillating function with frequency $f$ (or period $1/f$).
According to [Fourier analysis](https://en.wikipedia.org/wiki/Fourier_transform), we can decompose any signal into its frequency components,
$$
x(t) = \sum_{n=-\infty}^\infty \hat{x}(n) \ e^{2 \pi i n t}
\qquad \qquad t \in [0,1]
$$
or
$$
x(t) = \int_{-\infty}^\infty \hat{x}(f) \ e^{2 \pi i f t} \ df
\qquad \qquad t \in [-\infty,\infty].
$$
The
[*power spectral density* or *periodogram*](https://en.wikipedia.org/wiki/Spectral_density)
$S_{xx}(f) \approx |\hat x(f) |^2$
of a time series $x(t)$ describes the distribution of power into the frequency components that compose that signal.
There are lots of time-dependent signals that are periodic or at least some of the signal is periodic. Examples:
* [sunspots](https://en.wikipedia.org/wiki/Sunspot) follow an 11 year cycle. So if $x(t)$ was a time series representing the "strength" of the sunspot, we would have that $|\hat{x}(f)|^2$ would be large at $f = 1/11$. (Remember period = 1/frequency.)
* The temperature in SLC. Here, we can decompose the temperature into a part that is varying over the course of a year, the part that varies over the day, and the "remaining" part.
* $\ldots$
We can compute the power spectral density using the scipy function
[`periodogram`](https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.signal.periodogram.html).
To illustrate this, we'll follow the
[course notes of James Holland Jones on Time Series and Spectral Analysis](http://web.stanford.edu/class/earthsys214/notes/series.html)
and consider
[historical measles data from New York City posted by Ben Bolker](https://ms.mcmaster.ca/~bolker/measdata.html).
### Measles data
We can download the monthly measles data from New York City between 1928 and 1964.
```
df = pd.read_csv("nycmeas.dat", sep=" ", names=["date","cases"],index_col=0)
df.head()
df["cases"].plot(grid = True);
```
Looking at the plot, we observe that the series is very regular with "periodically occuring" spikes. It appears that approximately once a year, there is a significant measles outbreak. By computing the power spectrum, we can see which frequencies make up this time series.
```
cases = df["cases"].values
f, Pxx_den = periodogram(cases, fs=12, window="hamming")
plt.plot(f, Pxx_den);
```
Since there are 12 months per year, we set the measurement frequency argument in `periodogram` as fs=12.
Clearly, the dominant frequency in this signal is 1 year. Why?
**Q:** Is it useful to look at the power spectrum of stock data?
**Exercise:** try it for the Apple stock data over the previous 10 years.
| github_jupyter |
<a href="https://colab.research.google.com/github/shahd1995913/Tahalf-Mechine-Learning-DS3/blob/main/Tasks/ML1_S5_Assignment.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# ML1-S5 (Assignment)
----
## Problem 1: Logistic Regression
---
- Mention 2 types of regularization used to overcome the overfitting problem and what is the difference between them.
- Using the data below in X,y. Build a **`logistic model`** to predict the output and evaluate the model with a confusion matrix.
# Common causes for overfitting are :
1. When the model is complex enough that it starts modeling the noise in the training data.
2. When the training data is relatively small and is an insufficient representation of the underlying distribution that it is sampled from, the model fails to learn a generalizable mapping.
---
## Lasso(also known as L1) and Ridge(also known as L2) regression are two popular regularization techniques that are used to avoid overfitting of data.
## These methods are used to penalize the coefficients to find the optimum solution and reduce complexity.
## The difference between L1 and L2 regularization techniques lies in the nature of this regularization term. In general, the addition of this regularization term causes the values of the weight matrices to reduce, leading simpler models.
---
# L2 and L1 Regularization : LASSO vs Ridge
1. Lasso regression
- Lasso regression is a regularization technique used to reduce model complexity.
- It is also known as L1 regularization.
- Lasso stands for Least Absolute Shrinkage and Selector Operator.
- The Lasso regression works by penalizing the sum of the absolute values of the coefficients.
2. Ridge regression
- Ridge regression refers to a type of linear regression where in order to get better predictions in the long term, we introduce a small amount of bias.
- It is also known as L2 regularization.
- In Ridge or L2 regression, the penalty function is determined by the sum of the squares of the coefficients.
- In ridge regression, we have the same loss function with a slight alteration in the penalty term.
```
### Put Your Answer Here ####
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Dataset
X = np.arange(15).reshape(-1, 1)
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1])
X
y
x_train, x_test, y_train, y_test =train_test_split(X, y, test_size=0.2, random_state=0)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
model = LogisticRegression(solver='liblinear', C=0.05, multi_class='ovr',
random_state=0)
model.fit(x_train, y_train)
model.predict_proba(x_train)
x_test = scaler.transform(x_test)
y_pred = model.predict(x_test)
print(model.score(x_train, y_train))
print(model.score(x_test, y_test))
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
confusion_matrix(y_test, y_pred)
print(classification_report(y_test, y_pred))
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
# ax = plt.subplot()
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(cm)
ax.grid(False)
sns.set(font_scale=3.0) #edited as suggested
sns.heatmap(cm, annot=True, ax=ax, cmap="Blues", fmt="g"); # annot=True to annotate cells
# labels, title and ticks
ax.set_xlabel('Predicted outputs');
ax.set_ylabel('Actual outputs');
ax.set_title('Confusion Matrix');
ax.xaxis.set_ticklabels(['False', 'True']);
ax.yaxis.set_ticklabels(['Flase', 'True']);
plt.show()
```
## Problem 2: KNN + metrics
---
Build a classification model based on KNN to classify the [Iris Dataset](https://archive.ics.uci.edu/ml/datasets/iris) , report the training and testing `accuracy` ,`f1score` , `recall` , `percision`.
```
import pandas as pd
import numpy as np
import math
import operator
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score , precision_score , roc_auc_score ,roc_curve
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore") #to remove unwanted warnings
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report, confusion_matrix
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
#Import knearest neighbors Classifier model
from sklearn.neighbors import KNeighborsClassifier
#Loading the Data
iris= load_iris()
# Split X and Y
#======================
X= iris.data
Y= iris.target
X_train, X_test, y_train, y_test= train_test_split(X, Y, test_size= 0.3,random_state=32)
print(f'training set size: {X_train.shape[0]} samples \ntest set size: {X_test.shape[0]} samples')
#Create KNN Classifier
knn = KNeighborsClassifier(n_neighbors=3)
#Train the model using the training sets
knn.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = knn.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy when number of neighbors 3 :===>",metrics.accuracy_score(y_test, y_pred))
custom_model_score = accuracy_score(y_test,y_pred)
print(custom_model_score)
print(classification_report(y_test,y_pred))
```
## Problem 3: Naive Bayes
---
- Build a gaussian naive bayes model on [Iris Dataset](https://archive.ics.uci.edu/ml/datasets/iris) , you can load the data using sklearn , split the data to train 70% and test 30%.
- If we have a discrete data which type of naive bayes should we use?
- Create a dataset with 0 and 1 ,the training data will have 1000 instance and each instance will have 8 features , the testing data will have 100 instance and build a naive bayes model on it .
```
### Start Your Code Here ####
#Loading the Data
iris= load_iris()
# Split X and Y
#======================
Naive_X= iris.data
Naive_y= iris.target
Naive_X_train, Naive_X_test, Naive_y_train, Naive_y_test = train_test_split(Naive_X, Naive_y, test_size = 0.3)
print(f'training set size: {Naive_X_train.shape[0]} samples \ntest set size: {Naive_X_test.shape[0]} samples')
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
Naive_X_train = sc.fit_transform(Naive_X_train)
Naive_X_test = sc.transform(Naive_X_test)
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(Naive_X_train, Naive_y_train)
Naive_y_pred = classifier.predict(Naive_X_test)
Naive_y_pred
from sklearn.metrics import confusion_matrix
cm1 = confusion_matrix(Naive_y_test, Naive_y_pred)
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(Naive_y_test, Naive_y_pred))
print("----------------------------------------------------------")
custom_model_score_naive = accuracy_score(Naive_y_test,Naive_y_pred)
print("Accuracy :",custom_model_score_naive)
print(classification_report(Naive_y_test,y_pred))
print("----------------------------------------------------------")
# print(cm1)
cm_df = pd.DataFrame(cm1,
index = ['setosa','versicolor','virginica'],
columns = ['setosa','versicolor','virginica'])
sns.heatmap(cm_df, annot=True)
plt.title('Accuracy using Naive Bayes:{0:.3f}'.format(accuracy_score(Naive_y_test, Naive_y_pred)))
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.show()
dfNaive_ = pd.DataFrame({'Real Values':Naive_y_test, 'Predicted Values':Naive_y_pred})
dfNaive_
```
# - If we have a discrete data which type of naive bayes should we use?
---
## Sol --> Bernoulli Naive Bayes
### if you have discrete features in 1s and 0s that represent the presence or absence of a feature.
### In that case, the features will be binary and we will use Bernoulli Naive Bayes.
---
### - Create a dataset with 0 and 1 ,the training data will have 1000 instance and each instance will have 8 features , the testing data will have 100 instance and build a naive bayes model on it
---
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
Bayes_x,Bayes_Y=make_classification(n_samples= 1000,n_features=8,n_informative=8,n_redundant=0,n_repeated=0,n_classes=2,random_state=14)
# If the test_size was 0.1 then that mean 100 instance
Bayes_x_train, Bayes_X_test, Bayes_y_train, Bayes_y_test= train_test_split(Bayes_x, Bayes_Y, test_size= 0.1, random_state=32)
sc= StandardScaler()
sc.fit(Bayes_x_train)
Bayes_x_train= sc.transform(Bayes_x_train)
sc. fit(Bayes_X_test)
Bayes_X_test= sc.transform(Bayes_X_test)
Bayes_x.shape
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(Bayes_x_train, Bayes_y_train)
Bayes_y_pred = classifier.predict(Bayes_X_test)
Bayes_y_pred
from sklearn.metrics import confusion_matrix
cm1 = confusion_matrix(Bayes_y_test, Bayes_y_pred)
from sklearn.metrics import accuracy_score
print ("Accuracy : ", accuracy_score(Bayes_y_test, Bayes_y_pred))
print("----------------------------------------------------------")
custom_model_score_Bayes = accuracy_score(Bayes_y_test,Bayes_y_pred)
print("Accuracy :",custom_model_score_Bayes)
print(classification_report(Bayes_y_test,Bayes_y_pred))
print("----------------------------------------------------------")
# print(cm1)
cm_df = pd.DataFrame(cm1)
sns.heatmap(cm_df, annot=True)
plt.title('Accuracy using Naive Bayes:{0:.3f}'.format(accuracy_score(Bayes_y_test, Bayes_y_pred)))
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.show()
```
## How can I choose the best K in KNN ??
1. KNN --> K number of neighbors .
- If the value of K is small then it lead to -- >overfitting of the model.
- if K is very large then i--> underfitting of the model.
2. KNN when be a odd value provide a good result.
--- > To choose the best K in KNN --- > we can also split the entire data set into train set and test set. then preform the KNN algorithm into training set and cross validate, we can use k with a cross validate to take the best result and we well repet until find a good result.
| github_jupyter |
# Building MANN in Tensorflow
Now, we will see how to implement MANN in tensorflow
First, let us import all the required libraries,
```
import warnings
warnings.filterwarnings('ignore')
import tensorflow as tf
import numpy as np
class MANNCell():
def __init__(self, rnn_size, memory_size, memory_vector_dim, head_num, gamma=0.95,
reuse=False):
#initialize all the variables
self.rnn_size = rnn_size
self.memory_size = memory_size
self.memory_vector_dim = memory_vector_dim
self.head_num = head_num
self.reuse = reuse
self.step = 0
self.gamma = gamma
#initialize controller as the basic rnn cell
self.controller = tf.nn.rnn_cell.BasicRNNCell(self.rnn_size)
def __call__(self, x, prev_state):
prev_read_vector_list = prev_state['read_vector_list']
controller_input = tf.concat([x] + prev_read_vector_list, axis=1)
#next we pass the controller, which is the RNN cell, the controller_input and prev_controller_state
with tf.variable_scope('controller', reuse=self.reuse):
controller_output, controller_state = self.controller(controller_input, prev_controller_state)
num_parameters_per_head = self.memory_vector_dim + 1
total_parameter_num = num_parameters_per_head * self.head_num
#Initiliaze weight matrix and bias and compute the parameters
with tf.variable_scope("o2p", reuse=(self.step > 0) or self.reuse):
o2p_w = tf.get_variable('o2p_w', [controller_output.get_shape()[1], total_parameter_num],
initializer=tf.random_uniform_initializer(minval=-0.1, maxval=0.1))
o2p_b = tf.get_variable('o2p_b', [total_parameter_num],
initializer=tf.random_uniform_initializer(minval=-0.1, maxval=0.1))
parameters = tf.nn.xw_plus_b(controller_output, o2p_w, o2p_b)
head_parameter_list = tf.split(parameters, self.head_num, axis=1)
#previous read weight vector
prev_w_r_list = prev_state['w_r_list']
#previous memory
prev_M = prev_state['M']
#previous usage weight vector
prev_w_u = prev_state['w_u']
#previous index and least used weight vector
prev_indices, prev_w_lu = self.least_used(prev_w_u)
#read weight vector
w_r_list = []
#write weight vector
w_w_list = []
#key vector
k_list = []
#now, we will initialize some of the important parameters that we use for addressing.
for i, head_parameter in enumerate(head_parameter_list):
with tf.variable_scope('addressing_head_%d' % i):
#key vector
k = tf.tanh(head_parameter[:, 0:self.memory_vector_dim], name='k')
#sig_alpha
sig_alpha = tf.sigmoid(head_parameter[:, -1:], name='sig_alpha')
#read weights
w_r = self.read_head_addressing(k, prev_M)
#write weights
w_w = self.write_head_addressing(sig_alpha, prev_w_r_list[i], prev_w_lu)
w_r_list.append(w_r)
w_w_list.append(w_w)
k_list.append(k)
#usage weight vector
w_u = self.gamma * prev_w_u + tf.add_n(w_r_list) + tf.add_n(w_w_list)
#update the memory
M_ = prev_M * tf.expand_dims(1. - tf.one_hot(prev_indices[:, -1], self.memory_size), dim=2)
#write operation
M = M_
with tf.variable_scope('writing'):
for i in range(self.head_num):
w = tf.expand_dims(w_w_list[i], axis=2)
k = tf.expand_dims(k_list[i], axis=1)
M = M + tf.matmul(w, k)
#read opearion
read_vector_list = []
with tf.variable_scope('reading'):
for i in range(self.head_num):
read_vector = tf.reduce_sum(tf.expand_dims(w_r_list[i], dim=2) * M, axis=1)
read_vector_list.append(read_vector)
#controller output
NTM_output = tf.concat([controller_output] + read_vector_list, axis=1)
state = {
'controller_state': controller_state,
'read_vector_list': read_vector_list,
'w_r_list': w_r_list,
'w_w_list': w_w_list,
'w_u': w_u,
'M': M,
}
self.step += 1
return NTM_output, state
#weight vector for read operation
def read_head_addressing(self, k, prev_M):
"content based cosine similarity"
k = tf.expand_dims(k, axis=2)
inner_product = tf.matmul(prev_M, k)
k_norm = tf.sqrt(tf.reduce_sum(tf.square(k), axis=1, keep_dims=True))
M_norm = tf.sqrt(tf.reduce_sum(tf.square(prev_M), axis=2, keep_dims=True))
norm_product = M_norm * k_norm
K = tf.squeeze(inner_product / (norm_product + 1e-8))
K_exp = tf.exp(K)
w = K_exp / tf.reduce_sum(K_exp, axis=1, keep_dims=True)
return w
#weight vector for write operation
def write_head_addressing(sig_alpha, prev_w_r_list, prev_w_lu):
return sig_alpha * prev_w_r + (1. - sig_alpha) * prev_w_lu
#least used weight vector
def least_used(w_u):
_, indices = tf.nn.top_k(w_u, k=self.memory_size)
w_lu = tf.reduce_sum(tf.one_hot(indices[:, -self.head_num:], depth=self.memory_size), axis=1)
return indices, w_lu
#next we define the function called zero state for initializing all the states -
#controller state, read vector, weights and memory
def zero_state(self, batch_size, dtype):
one_hot_weight_vector = np.zeros([batch_size, self.memory_size])
one_hot_weight_vector[..., 0] = 1
one_hot_weight_vector = tf.constant(one_hot_weight_vector, dtype=tf.float32)
with tf.variable_scope('init', reuse=self.reuse):
state = {
'controller_state': self.controller.zero_state(batch_size, dtype),
'read_vector_list': [tf.zeros([batch_size, self.memory_vector_dim])
for _ in range(self.head_num)],
'w_r_list': [one_hot_weight_vector for _ in range(self.head_num)],
'w_u': one_hot_weight_vector,
'M': tf.constant(np.ones([batch_size, self.memory_size, self.memory_vector_dim]) * 1e-6, dtype=tf.float32)
}
return state
```
| github_jupyter |
# <center>Complex System & Networks : Introductory</center>
## *Sample Introduction Programs*
**Example 1(a):** PRINT statement.
```
# PROG 1(a): PRINT HELLO
print("Welcome to Complex System and Networks.")
```
**Example 1(b):** Understanding basic algebra in Python3.
```
# PROG 1(b):
a=5
b=29
c=6
d=54
sum=a+b+c+d
print("sum =",sum)
alpha=a-b
beta=c-d
```
*The values assigned to a, b, c and d in the previous cell have been used to calculate alpha and beta.*
```
print(alpha)
a=7
sum=a+b+d
print("new sum =",sum)
```
*Variable a has been assigned a new value and the new value is used in calculating the sum, while the values of b and d remain the same.*
**Example 2:** Understanding matplot in Python3 (plotting and saving).
```
# Example 2: Use of PLOT command
# to plot, we will use matplotlib.pyplot library
# say we want to plot the data set with x and y values as follows
# x= [1,2,3,4,5] and y= [1,4,9,16,25]
# here “y” is nothing but square of corresponding “x”
import matplotlib.pyplot as plt
x=[1,2,3,4,5]
y=[1,4,9,16,25]
plt.plot(x,y) # this will plot x vs y
plt.savefig('square.png') # this will save the figure in same folder where the program is saved
```
**EXERCISE 1:** FIND OUT AND EXECUTE INSTRUCTIONS ON HOW TO LABEL THE AXES AND MODIFY THE PLOT ATTRIBUTES (marker type, marker size, marker color,etc.)
```
# Example 2: Use of PLOT command
# plotting with different plot attributes
import matplotlib.pyplot as plt
x=[1,2,3,4,5]
y=[1,4,9,16,25]
plt.xlabel("Value of X", size=14)
plt.ylabel("Value of Y",size=14)
plt.title("Simple Integers Square Plot",size=16)
plt.plot(x,y, color='red', marker='o', linestyle='dashed',linewidth=2, markersize=12)
```
**Example 3:** Plotting an undirected graph.
```
# Example 3: Plotting an undirected graph
# to plot a graph, we will use networkx library
# A node can be string or number
# part 3(A) is with numbers and 3(B) is with string
# Part 3(A)
import networkx as nx
import matplotlib.pyplot as plt
G=nx.Graph()
nodes=[1,2,3,4,5] # list of nodes
edges=[(1,2),(3,4),(4,5),(2,3),(5,1)] # list of edges
G.add_nodes_from(nodes)
G.add_edges_from(edges)
nx.draw(G,with_labels= True)
# plt.show()
plt.savefig('number_as_nodes.png') # fig saved in same folder where the program is saved
plt.plot()
```
**EXERCISE 2:** FIND OUT AND EXECUTE INSTRUCTIONS ON HOW TO MODIFY THE GRAPH ATTRIBUTES (node type, node size, node color, etc.)
```
# Example 3: Plotting an undirected graph Part 3(A)
import networkx as nx
import matplotlib.pyplot as plt
G= nx.Graph()
nodes=[1,2,3,4,5] # list of nodes
edges=[(1,2),(3,4),(4,5),(2,3),(5,1)] # list of edges
G.add_nodes_from(nodes)
G.add_edges_from(edges)
#adding graph attributes
options = {
'node_color': 'red',
'node_size': 1000,
'width': 2,
'edge_color': 'blue'
}
nx.draw(G,**options,with_labels= True) ##added attribute option
plt.show()
# Example 3: Plotting an undirected graph
# to plot a graph, we will use networkx library
# A node can be string or number
# part 3(A) is with numbers and 3(B) is with string
#Part 3(B)
import networkx as nx
import matplotlib.pyplot as plt
G=nx.Graph()
nodes2=['A','B','C']
edges2=[('A','B'),('B','C'),('C','A')]
G.add_nodes_from(nodes2)
G.add_edges_from(edges2)
nx.draw(G,with_labels= True)
# plt.show()
plt.savefig('string_as_nodes.png')
plt.plot()
```
**Example 4:** Plotting an directed graph.
```
# Example 4: plotting a Directed graph
import networkx as nx
import matplotlib.pyplot as plt
G=nx.DiGraph() # for directed graph
nodes=[1,2,3,4,5] # list of nodes
edges=[(1,2),(3,4),(4,5),(2,3),(5,1)] # list of edges
G.add_nodes_from(nodes)
G.add_edges_from(edges)
nx.draw(G,with_labels= True)
# plt.show()
plt.savefig('Directed_graph.png')
plt.plot()
```
| github_jupyter |
```
from bs4 import BeautifulSoup
import requests
# Here, we're just importing both Beautiful Soup and the Requests library
page_link = 'https://www.sec.gov/cgi-bin/current?q1=5&q2=4&q3='
# this is the url that we've already determined is safe and legal to scrape from.
page_response = requests.get(page_link, timeout=5)
# here, we fetch the content from the url, using the requests library
page_content = BeautifulSoup(page_response.content, "html.parser")
#we use the html parser to parse the url content and store it in a variable.
```
## extract and clean links pages
```
page_new = []
page_content.find_all("a")
for i in page_content.find_all("a"):
if "8-K" in i:
page_new.append(i)
page_new1 = []
for i in page_new:
page_new1.append(i.get('href'))
page_new2 = []
for i in page_new1:
i = "http://www.sec.gov" + i
page_new2.append(i)
page_new2
page_link_2 = "https://www.sec.gov/Archives/edgar/data/1591890/0001493152-19-013299-index.html"
page_response_2 = requests.get(page_link_2,timeout=5)
page_content_2 = BeautifulSoup(page_response_2.content,"html.parser")
file_links = []
for table in page_content_2.findAll('table', {'class': "tableFile"}):
for tr in table.findAll('tr'):
for td in table.findAll('td'):
for a in td.findAll('a'):
file_links.append(a.get('href'))
```
## Extract company names
```
page_fill_text = []
for i in page_content.find_all("pre"):
print(i.text)
company_names = []
for i in page_new2:
page_link_3 = i
page_response_3 = requests.get(page_link_3,timeout=5)
page_content_3 = BeautifulSoup(page_response_3.content,"html.parser")
company = page_content_3.find_all('span', attrs = {"class": "companyName"})[0].text.split('(Filer)')[0]
company_names.append(company)
company_names
import pandas as pd
data_company = {"Companies":company_names}
company_df = pd.DataFrame(data_company)
company_df.to_csv("Companies.csv")
page_content_2.find_all('span', attrs = {"class": "companyName"})[0].text.split('(Filer)')[0]
```
## Extract date filled
```
date_heading = []
date_value = []
for div in page_content_2.findAll('div',{'class':"formGrouping"}):
for div in div.findAll('div',{"class":"infoHead"}):
date_heading.append(div.text)
for div in page_content_2.findAll('div',{'class':"formGrouping"}):
for div in div.findAll('div',{"class":"info"}):
date_value.append(div.text)
date_heading[0:5]
date_value[0:5]
```
## Extract 8K files href
```
link_list = []
for table in page_content_2.findAll('table', {'class': "tableFile"}):
for tr in table.findAll('tr'):
for td in tr.findAll('td'):
for a in td.findAll('a'):
link_list.append(a.get('href'))
```
## Extract 8K files info
```
info_list = []
for table in page_content_2.findAll('table', {'class': "tableFile"}):
for tr in table.findAll('tr'):
for td in tr.findAll('td'):
info_list.append(td.text)
for i in page_content_2.findAll('div', {'id': "formHeader"}):
for ir in i.findAll('div',{'id':'secNum'}):
print(ir.text)
info_list[0:5]
link_list[0:5]
```
## Looping through all the pages
```
link_list_1 = []
info_list_1 = []
for link in page_new2:
page_link_3 = link
page_response_3 = requests.get(page_link_3,timeout=5)
page_content_3 = BeautifulSoup(page_response_3.content,"html.parser")
for table in page_content_3.findAll('table', {'class': "tableFile"}):
for tr in table.findAll('tr'):
for td in tr.findAll('td'):
info_list_1.append(td.text)
for table in page_content_3.findAll('table', {'class': "tableFile"}):
for tr in table.findAll('tr'):
for td in tr.findAll('td'):
for a in td.findAll('a'):
link_list_1.append(a.get('href'))
print(link_list_1[0:5])
print(info_list_1[0:5])
import re
def cleanhtml(raw_html):
cleanr = re.compile('<.*?>')
cleanr1 = re.compile('(\n|\xa0)')
cleantext = re.sub(cleanr, '', raw_html)
cleantext1 = re.sub(cleanr1, '', cleantext)
cleantext1 = cleantext1.strip()
return cleantext1
page_new1 = []
for i in page_new:
k = cleanhtml()
page_new1.append(k)
```
# Scrapping 8K forms
```
import pandas as pd
df = pd.read_csv(r"finance_CIK_2.csv")
df.head()
ek_url = df["8k_url"].values.tolist()
# Here, we're just importing both Beautiful Soup and the Requests library
page_link_e = str(ek_url[0])
# this is the url that we've already determined is safe and legal to scrape from.
page_response_e = requests.get(page_link_e, timeout=5)
# here, we fetch the content from the url, using the requests library
page_content_e = BeautifulSoup(page_response_e.content, "html.parser")
#we use the html parser to parse the url content and store it in a variable.
text_label = []
text_a = []
text_text = []
for table in page_content_e.findAll('table', {'class': "tableFile2"}):
for tr in table.findAll('tr'):
for td in table.findAll('td', {'nowrap':'nowrap'}):
text_label.append(td.text)
for table in page_content_e.findAll('table', {'class': "tableFile2"}):
for tr in table.findAll('tr'):
for td in table.findAll('td', {'nowrap':'nowrap'}):
for a in td.findAll('a', {'id':'documentsbutton'}):
text_a.append(a)
for table in page_content_e.findAll('table', {'class': "tableFile2"}):
for tr in table.findAll('tr'):
for td in table.findAll('td'):
text_text.append(td.text)
text_label
import re
for i in text_text:
dates = [x for x in i if re.match(r'd{4}-d{2}-d{2}',x)]
dates
text_label_8 = []
for i in text_label:
if i == "8-K":
text_label_8.append(i)
print(len(text_label_8))
print(len(text_a))
text_a
def extract_text_pre_link():
text_label = []
text_a = []
for i in ek_url:
# Here, we're just importing both Beautiful Soup and the Requests library
page_link_e = str(i)
# this is the url that we've already determined is safe and legal to scrape from.
page_response_e = requests.get(page_link_e, timeout=5)
# here, we fetch the content from the url, using the requests library
page_content_e = BeautifulSoup(page_response_e.content, "html.parser")
#we use the html parser to parse the url content and store it in a variable.
for table in page_content_e.findAll('table', {'class': "tableFile2"}):
for tr in table.findAll('tr'):
for td in table.findAll('td', {'nowrap':'nowrap'}):
for a in td.findAll('a', {'id':'documentsbutton'}):
text_a.append(a.get('href'))
return text_a
text_a = extract_text_pre_link()
len(text_a)
text_a
data = {"links":text_a}
df_pre_links = pd.DataFrame(data)
df_pre_links.to_csv("pre_links.csv")
# Here, we're just importing both Beautiful Soup and the Requests library
p_link = "http://www.sec.gov" + "/Archives/edgar/data/799033/000109230604000729/0001092306-04-000729-index.htm"
page_link_p = p_link
# this is the url that we've already determined is safe and legal to scrape from.
page_response_p = requests.get(page_link_p, timeout=5)
# here, we fetch the content from the url, using the requests library
page_content_p = BeautifulSoup(page_response_p.content, "html.parser")
#we use the html parser to parse the url content and store it in a variable.
table = page_content_p.find('table', attrs={'class':'tableFile'})
table_rows = table.find_all('tr')
l = []
a_list = []
for tr in table_rows:
td = tr.find_all('td')
row = [tr.text for tr in td]
l.append(row)
df_ext = pd.DataFrame(l, columns=["A", "B", "C","D","E"])
#df_ext = df_ext[df_ext["D"] == "8-K"]
for tr in table_rows:
for td in tr.findAll('td'):
for a in td.findAll('a'):
a_list.append(a.get('href'))
df_ext
# Get names of indexes for which column Age has value 30
#indexNames = df_ext[df_ext['B'] == "None"].index
#Delete these row indexes from dataFrame
df_ext = df_ext.drop([0])
df_ext
df_main = pd.DataFrame(columns=["A","B","C","D","E"])
df_main = pd.concat([df_main,df_ext])
df_main
def extract_df_pre():
df_main = pd.DataFrame(columns=["A","B","C","D","E"])
for i in text_a:
# Here, we're just importing both Beautiful Soup and the Requests library
p_link = "http://www.sec.gov" + str(i)
page_link_p = p_link
# this is the url that we've already determined is safe and legal to scrape from.
page_response_p = requests.get(page_link_p, timeout=5)
# here, we fetch the content from the url, using the requests library
page_content_p = BeautifulSoup(page_response_p.content, "html.parser")
#we use the html parser to parse the url content and store it in a variable.
table = page_content_p.find('table', attrs={'class':'tableFile'})
table_rows = table.find_all('tr')
l = []
a_list = []
for tr in table_rows:
td = tr.find_all('td')
row = [tr.text for tr in td]
l.append(row)
df_ext = pd.DataFrame(l, columns=["A", "B", "C","D","E"])
#df_ext = df_ext[df_ext["D"] == "8-K"]
for tr in table_rows:
for td in tr.findAll('td'):
for a in td.findAll('a'):
a_list.append(a.get('href'))
df_ext = df_ext.drop([0])
df_main = pd.concat([df_main,df_ext])
return df_main
df_main = extract_df_pre()
df_main.head(20)
df_main.to_csv("df_main_pre.csv")
```
| github_jupyter |
The notebook outlines the steps to setup a random search experiment using the [Keras Tuner](https://github.com/keras-team/keras-tuner/).
```
# Install TensorFlow 2.0.0-beta0
!pip install tensorflow-gpu==2.0.0-beta0
# Installation of Keras Tuner
%%bash
git clone https://github.com/keras-team/keras-tuner.git
cd keras-tuner
git checkout refactor
pip3 install .
# Packages
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import numpy as np
import time
from sklearn.model_selection import train_test_split
np.random.seed(666)
# Tuner used to search for the best model
from kerastuner.tuners import RandomSearch
```
The [Pima Indians' Diabetes dataset](https://www.kaggle.com/uciml/pima-indians-diabetes-database
) which is known to have missing values.
```
data = pd.read_csv("https://raw.githubusercontent.com/sayakpaul/TF-2.0-Hacks/master/Keras_tuner_with_TF_2_0/diabetes.csv")
data.sample(5)
# Inspecting the missing values
(data.iloc[:, 0:5] == 0).sum()
# Mark zero values as missing or NaN
data.iloc[:, 0:5] = data.iloc[:, 0:5].replace(0, np.NaN)
# Count the number of NaN values in each column
print(data.isnull().sum())
# Fill missing values with mean column values
data.fillna(data.mean(), inplace=True)
# Count the number of NaN values in each column
print(data.isnull().sum())
# Split dataset into features and targets
values = data.values
X = values[:,0:8]
y = values[:,8]
# Train and test splits - 80:20
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=666)
def build_model(hp):
# Converting a model to a tunable model is as simple as replacing static
# values with the hyper parameters variables
model = keras.Sequential()
model.add(layers.Dense(12, input_shape=(X_train.shape[1],)))
for i in range(hp.Range('num_layers', 2, 20)):
model.add(layers.Dense(units=hp.Range('units_' + str(i), 10, 16, 2),
activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# Compiles the model with the set of learning rates
model.compile(
optimizer=keras.optimizers.Adam(
hp.Choice('learning_rate', [1e-2, 1e-3, 1e-4])),
loss='binary_crossentropy',
metrics=['accuracy'])
return model
# Initialize the hypertuner by passing the model function (model_fn)
# and specifying key search constraints: maximize val_acc (objective)
tuner = RandomSearch(
build_model,
objective='val_accuracy',
max_trials=3,
executions_per_trial=3,
directory='test_dir')
# Perform the model search
start = time.time()
tuner.search(x=X_train,
y=y_train,
epochs=5,
validation_data=(X_test, y_test))
print('The process took {} seconds'.format(time.time() - start))
# Show the best models, their hyperparameters, and the resulting metrics
tuner.results_summary()
```
## References:
- https://github.com/keras-team/keras-tuner/tree/refactor
- https://github.com/keras-team/keras-tuner/blob/refactor/tutorials/helloworld/helloworld.py
| github_jupyter |
# ML Project
This is an example of an ML Project that you could do on this dataset, that we scraped earlier, saved and exported to a dataset.
## Importing packages and dataset
```
import copy
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
pd.options.mode.chained_assignment = None
df = pd.read_csv('data/comment_data.csv', usecols=['score', 'text'])
```
## Preparing the dataset
```
def prepare_data(df):
# Remove everything except alphanumeric characters
df.text = df.text.str.replace('[^a-zA-Z\s]', '')
# Get only numbers, but allow minus in front
df.score = df.score.str.extract('(^-?[0-9]*\S+)')
# Remove rows with None as string
df.score = df.score.replace('None', np.nan)
# Remove all None
df = df.dropna()
# Convert score feature from string to float
score = df.score.astype(float)
df.score = copy.deepcopy(score)
return df
df = prepare_data(df)
```
## Converting score to percentile rating
```
def score_to_percentile(df):
second = df.score.quantile(0.50) # Average
third = df.score.quantile(0.75) # Good
fourth = df.score.quantile(0.95) # exceptional
new_score = []
for i, row in enumerate(df.score):
if row > fourth:
new_score.append('exceptional')
elif row > third:
new_score.append('good')
elif row > second:
new_score.append('average')
else:
new_score.append('bad')
df.score = new_score
return df
df = score_to_percentile(df)
```
## Split the data for training and testing
```
def df_split(df):
y = df[['score']]
X = df.drop(['score'], axis=1)
content = [' ' + comment for comment in X.text.values]
X = CountVectorizer().fit_transform(content).toarray()
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = df_split(df)
```
## Train and Test Logistic Regression Model
Note: This accuracy score is not that great, but this is an example project, to provide a baseline. If you are reading this, try to optimize the accuracy further.
```
lr = LogisticRegression(C=0.05, solver='lbfgs', multi_class='multinomial')
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
score = accuracy_score(y_test, pred)
print ("Accuracy: {0}".format(score))
```
| github_jupyter |
```
library(dplyr)
library(MASS) # for negative binomial regression
library(readr) # read csv file
```
### <div class='info-circle alert alert-block alert-info'> Load combined data</div>
```
reg_df <- read_csv('Data/combined_data.csv')
dim(reg_df)
head(reg_df)
# Filter Wuhan
reg_df <-
reg_df %>%
filter(city != 'Wuhan')
```
### <div class="alert alert-block alert-danger">Outbreak Estimates</div>
* COVID-19 outbreak in different areas
#### Outbreak case Prediction using Negative Binomial Model
1. For the outbreak in Wuhan, a Binomial regression model is fitted first;
2. When the outbreak area changes, the corresponding predictors (e.g., human flow from and the distance to the outbreak city) also vary with the change;
3. Assuming that the spatial spread pattern of COVID-19 remains unchanged (which is a very strong assumption);
4. Based on the adjusted predictors, estimations are then made based on the fitted model.
Formula:
cumulative_cases ~ exp(log_local_flow + log_population + log_distance + mean_intensity)
1. local_flow: human flow from the outbreak city to each city (vary with the outbreak area)
2. population: the population of each city (unchanged)
3. distance: distance from each city to the outbreak city (vary with the outbreak area)
4. mean_intensity: mean intra-city activity intensity (unchanged)
---
#### step 1: model fit
```
# negative Binomial model
# in the MASS package
# cases on '2020-02-09'
reg_df$cumulative_cases <- reg_df$date_0209
reg_df <- reg_df %>%
mutate(log_local_flow = log(local_flow + 1)) %>%
mutate(log_population = log(population)) %>%
mutate(log_distance = log(distance + 1))
negb_model <- glm.nb(cumulative_cases ~
log_local_flow +
log_population +
log_distance +
mean_intensity,
data = reg_df
)
summary(negb_model)
1/negb_model$theta
```
---
#### step 2: model prediciton when the outbreak city changes
##### case for Chengdu
```
# case example
city <- 'Chengdu'
nb_predict_base_df = read.csv(paste0('Data/outbreak_base_data/nb_base_', city, '_for_prediction.csv'))
head(nb_predict_base_df)
#
# the human flow from Chengdu to Beijing is: 237.216012
# the distance from Beijing to Chengdu is: 1518.037
nb_predict_base_df <- nb_predict_base_df %>%
mutate(log_local_flow = log(local_flow + 1)) %>%
mutate(log_population = log(population)) %>%
mutate(log_distance = log(distance + 1))
predicted_cases <- predict(negb_model, nb_predict_base_df, type = "response")
# excluding NA: the outbreak city itsself and cities with missing values
raw_predicted = sum(predicted_cases, na.rm=TRUE)
round_predicted = sum(round(predicted_cases), na.rm=TRUE)
cat(city, ', ', raw_predicted, ', ', round_predicted, '\n')
```
##### multiple cities
```
cities <- c('Beijing', 'Shanghai', 'Tianjin', 'Chongqing',
'Zhengzhou', 'Changsha', 'Hefei', 'Guangzhou',
'Shenzhen', 'Nanchang', 'Nanjing', 'Hangzhou',
'Shenyang', 'Suzhou', 'Xian', 'Chengdu')
cities_cn <- c('北京市', '上海市', '天津市', '重庆市',
'郑州市', '长沙市', '合肥市', '广州市',
'深圳市', '南昌市', '南京市', '杭州市',
'沈阳市', '苏州市', '西安市', '成都市')
raw_predicts <- c()
round_predicts <- c()
for (city in cities)
{
nb_predict_base_df = read.csv(paste0('Data/outbreak_base_data/nb_base_',
city, '_for_prediction.csv'))
nb_predict_base_df <- nb_predict_base_df %>%
mutate(log_local_flow = log(local_flow + 1)) %>%
mutate(log_population = log(population)) %>%
mutate(log_distance = log(distance + 1))
predicted_cases <- predict(negb_model, nb_predict_base_df, type = "response")
raw_predicted = sum(predicted_cases, na.rm=TRUE)
round_predicted = sum(round(predicted_cases), na.rm=TRUE)
cat(city, ', ', raw_predicted, ', ', round_predicted, '\n')
# cities <- rbind(cities, city)
raw_predicts <- rbind(raw_predicts, raw_predicted)
round_predicts <- rbind(round_predicts, round_predicted)
}
# cities_cn
# cities
# raw_predicts
# round_predicts
predicted <-
data.frame(city_cn=cities_cn, city=cities,
raw_predict=raw_predicts, predicted_cumulative_cases=round_predicts)
rownames(predicted) = 1:nrow(predicted)
predicted
# results to file
file_path = file.path(paste0("Data/", "negb_predicted_outbreak_size_by_area.csv"))
# write.csv(predicted, file = file_path, row.names = FALSE, fileEncoding = "UTF-8")
```
| github_jupyter |
# Benchmarks
In this chapter, we provide rudimentary benchmarks of the Python bindings to fftwpp. The timings reported in the plot where produced on a Intel® Core™ i9-9880H CPU @ 2.30GHz with 32 Go of RAM. No particular precautions were taken regarding the load of the machine.
```
import timeit
import numpy as np
import matplotlib.pyplot as plt
import pyfftwpp
from pyfftwpp import PlanFactory
plt.rcParams["figure.figsize"] = (8, 6)
```
This function should be called if you intend to use the multi-threaded implementation of FFTW.
```
pyfftwpp.init_threads();
```
## NumPy vs. FFTW: 1D benchmark
We consider 1D transforms of increasing size and compare NumPy and FFTW (single thread)
```
rng = np.random.default_rng(202103271821)
rank = 1
sizes = [1 << k for k in range(14)]
timeit_params = {"repeat": 10, "number": 100000}
# - row 0: size of 1D fft
# - row 1: average time, numpy implementation
# - row 2: standard deviation, numpy implementation
# - row 3: average time, fftw
# - row 4: standard deviation, fftw
data = np.empty((len(sizes), 5), dtype=np.float64)
pyfftwpp.plan_with_nthreads(1)
factory = PlanFactory().set_measure()
for i, size in enumerate(sizes):
data[i, 0] = size
real = rng.random(size=rank * (size,), dtype=np.float64)
imag = rng.random(size=real.shape, dtype=real.dtype)
a = real + 1j * imag
t = timeit.repeat("np.fft.fft(a)", globals=globals(), **timeit_params)
data[i, 1:3] = np.mean(t), np.std(t)
x = np.empty_like(a)
y = np.empty_like(a)
plan = factory.create_plan(1, x, y)
x[:] = a
t = timeit.repeat("plan.execute()", globals=globals(), **timeit_params)
data[i, 3:] = np.mean(t), np.std(t)
const = 0.7 * data[-1, 3] / (data[-1, 0] * np.log(data[-1, 0]))
plt.loglog(sizes, data[:, 1], "o-", label="NumPy")
plt.loglog(sizes, data[:, 3], "o-", label="FFTW")
plt.loglog(
sizes, sizes * np.log(sizes) * const, "-", label=r"$\mathrm{const.}\,N\log N$"
)
plt.legend()
plt.ylim(1e-2, 1e1)
plt.xlabel("Size of input")
plt.ylabel("Time [μs]")
plt.title("1D, complex-to-complex FFT")
```
Both NumPy and FFTW exhibit the expected $\mathcal O(N\log N)$ complexity. The single-threaded implementation of FFTW is already significantly faster than NumPy.
```
np.savetxt("numpy_vs_fftw_1d.csv", data)
```
## Scaling of the multithreaded version: 3D transforms
We now consider 3D transforms of size 81 (we avoid powers of 2 here) and increase the number of threads.
```
rank = 3
size = 81
timeit_params = {"repeat": 10, "number": 1000}
# - row 0: number of threads
# - row 0: average time, numpy implementation
# - row 1: standard deviation, numpy implementation
data2 = []
factory = PlanFactory().set_measure()
for i, num_threads in enumerate(range(1, 17)):
real = rng.random(size=rank * (size,), dtype=np.float64)
imag = rng.random(size=real.shape, dtype=real.dtype)
a = real + 1j * imag
x = np.empty_like(a)
y = np.empty_like(a)
pyfftwpp.plan_with_nthreads(num_threads)
plan = factory.create_plan(1, x, y)
x[:] = a
t = timeit.repeat("plan.execute()", globals=globals(), **timeit_params)
data2.append((num_threads, np.mean(t), np.std(t)))
data2 = np.array(data2, dtype=np.float64)
plt.loglog(data2[:, 0], data2[:, 1], "o-")
plt.loglog(data2[:, 0], data2[0, 0] / data2[:, 0] * data2[0, 1])
plt.xlabel("Number of threads")
plt.ylabel("Time [μs]")
plt.title(f"{rank * (size,)}, complex-to-complex, multithreaded, FFT")
```
We observe almost perfect scaling up to 7 threads, which appears to be the optimum for this machine.
```
np.savetxt(f"fftw_openmp_{size}_{rank}d.csv", data2)
```
| github_jupyter |
```
import numpy as np
import os
import pandas as pd
import scipy.interpolate
import sklearn.metrics
import sys
sys.path.append("../src")
import localmodule
from matplotlib import pyplot as plt
%matplotlib inline
# Define constants.
dataset_name = localmodule.get_dataset_name()
models_dir = localmodule.get_models_dir()
units = localmodule.get_units()
n_units = len(units)
n_thresholds = 221
n_trials = 10
n_eval_trials = 5
# Initialize dictionary.
reports = {}
model_names = [
"icassp-convnet",
# "icassp-ntt-convnet",
# "icassp-add-convnet",
"pcen-convnet",
# "pcen-ntt-convnet",
"pcen-add-convnet"
]
# Loop over models.
for model_name in model_names:
# Initialize dictionary.
report = {}
# Loop over augmentations.
for aug_kind_str in ["none", "all-but-noise", "all"]:
# Initialize dictionaries.
aug_report = {
"validation": {},
"test-CV-F": {},
}
# Initialize precisions, recalls, and F1 scores.
val_precisions = np.zeros((n_units, n_trials))
val_recalls = np.zeros((n_units, n_trials))
val_f1_scores = np.zeros((n_units, n_trials))
val_thresholds = np.zeros((n_units, n_trials))
val_threshold_ids = np.zeros((n_units, n_trials))
val_auprcs = np.zeros((n_units, n_trials))
# Define thresholds.
thresholds = 1.0 - np.concatenate((
np.logspace(-9, -2, 141), np.delete(np.logspace(-2, 0, 81), 0)
))
n_thresholds = len(thresholds)
# Define model directory.
if not aug_kind_str == "none":
aug_model_name = "_".join([model_name, "aug-" + aug_kind_str])
else:
aug_model_name = model_name
model_dir = os.path.join(models_dir, aug_model_name)
# Loop over test units.
for test_unit_id in range(n_units):
# Define directory for test unit.
test_unit_str = units[test_unit_id]
test_unit_dir = os.path.join(model_dir, test_unit_str)
# Retrieve fold such that unit_str is in the test set.
folds = localmodule.fold_units()
fold = [f for f in folds if test_unit_str in f[0]][0]
test_units = fold[0]
validation_units = fold[2]
# Loop over trials.
for trial_id in range(n_trials):
trial_str = "trial-" + str(trial_id)
trial_dir = os.path.join(test_unit_dir, trial_str)
break_switch = False
# Loop over validation units.
for predict_unit_str in validation_units:
val_metrics_name = "_".join([
dataset_name,
aug_model_name,
"test-" + test_unit_str,
trial_str,
"predict-" + predict_unit_str,
"full-audio-metrics.csv"
])
val_metrics_path = os.path.join(trial_dir, val_metrics_name)
val_tp = np.zeros((n_thresholds,))
val_fp = np.zeros((n_thresholds,))
val_fn = np.zeros((n_thresholds,))
try:
val_metrics_df = pd.read_csv(val_metrics_path)
val_tp = val_tp + np.array(val_metrics_df["True positives"])
val_fp = val_fp + np.array(val_metrics_df["False positives"])
val_fn = val_fn + np.array(val_metrics_df["False negatives"])
except:
break_switch = True
break
if break_switch:
val_auprc = 0.0
val_p = np.zeros((n_thresholds,))
val_r = np.zeros((n_thresholds,))
val_f = np.zeros((n_thresholds,))
val_threshold_id = 0
else:
val_p = val_tp / (np.finfo(float).eps + val_tp + val_fp)
val_r = val_tp / (np.finfo(float).eps + val_tp + val_fn)
val_f = 2*val_p*val_r / (np.finfo(float).eps+(val_p+val_r))
val_threshold_id = np.argmax(val_f)
val_p_ = np.array([1.0] + list(val_p) + [0.0])
val_r_ = np.array([0.0] + list(val_r) + [1.0])
val_auprc = sklearn.metrics.auc(val_r_, val_p_, reorder=True)
val_precisions[test_unit_id, trial_id] = val_p[val_threshold_id]
val_recalls[test_unit_id, trial_id] = val_r[val_threshold_id]
val_f1_scores[test_unit_id, trial_id] = val_f[val_threshold_id]
val_thresholds[test_unit_id, trial_id] = thresholds[val_threshold_id]
val_threshold_ids[test_unit_id, trial_id] = val_threshold_id
val_auprcs[test_unit_id, trial_id] = val_auprc
aug_report["validation"]["P"] = val_precisions
aug_report["validation"]["R"] = val_recalls
aug_report["validation"]["F"] = val_f1_scores
aug_report["validation"]["AUPRC"] = val_auprcs
aug_report["validation"]["threshold"] = val_thresholds
aug_report["validation"]["threshold_ids"] = val_threshold_ids
aug_report["validation"]["trials_F"] = np.argsort(val_f1_scores, axis=1)
aug_report["validation"]["trials_AUPRC"] = np.argsort(val_auprcs, axis=1)
# Initialize precisions, recalls, and F1 scores.
F_trials = aug_report["validation"]["trials_F"]
test_precisions = np.zeros((n_units, n_trials))
test_recalls = np.zeros((n_units, n_trials))
test_f1_scores = np.zeros((n_units, n_trials))
test_bools = np.ones((n_units, n_trials), dtype=bool)
# Loop over test units.
for test_unit_id in range(n_units):
test_unit_str = units[test_unit_id]
test_unit_dir = os.path.join(model_dir, test_unit_str)
# Loop over trials.
for eval_trial_id in range(n_trials):
trial_id = F_trials[test_unit_id, eval_trial_id]
trial_str = "trial-" + str(trial_id)
trial_dir = os.path.join(test_unit_dir, trial_str)
# Load test predictions.
test_metrics_name = "_".join([
dataset_name,
aug_model_name,
"test-" + test_unit_str,
trial_str,
"predict-" + test_unit_str,
"full-audio-metrics.csv"
])
test_metrics_path = os.path.join(trial_dir, test_metrics_name)
threshold_id = int(val_threshold_ids[test_unit_id, trial_id])
try:
test_metrics_df = pd.read_csv(test_metrics_path)
test_tp = np.array(test_metrics_df["True positives"])
test_tp = test_tp[threshold_id]
test_fp = np.array(test_metrics_df["False positives"])
test_fp = test_fp[threshold_id]
test_fn = np.array(test_metrics_df["False negatives"])
test_fn = test_fn[threshold_id]
test_p = test_tp / (test_tp+test_fp)
test_r = test_tp /(test_tp+test_fn)
test_f1_score = (2*test_p*test_r) / (test_p+test_r)
test_precisions[test_unit_id, trial_id] = test_p
test_recalls[test_unit_id, trial_id] = test_r
test_f1_scores[test_unit_id, trial_id] = test_f1_score
except:
test_bools[test_unit_id, trial_id] = False
aug_report["test-CV-F"]["P"] = test_precisions
aug_report["test-CV-F"]["R"] = test_recalls
aug_report["test-CV-F"]["F"] = test_f1_scores
aug_report["test-CV-F"]["is_valid"] = test_bools
report[aug_kind_str] = aug_report
reports[model_name] = report
import datetime
import matplotlib.pylab
import mir_eval
import numpy as np
import peakutils
thresholds = 1.0 - np.concatenate((
np.logspace(-9, -2, 141), np.delete(np.logspace(-2, 0, 81), 0)
))
n_thresholds = len(thresholds)
tolerance = 0.5 # in seconds
n_hours = 11
bin_hop = 30 # in minutes
n_bins = int(np.round(n_hours * (60/bin_hop)))
bins = (3600 * np.linspace(0, n_hours, 1 + n_bins)).astype('int')
data_dir = localmodule.get_data_dir()
dataset_name = localmodule.get_dataset_name()
test_unit_id = 0
# Define directory for annotations.
annotations_name = "_".join([dataset_name, "annotations"])
annotations_dir = os.path.join(data_dir, annotations_name)
model_pairs = [
["icassp-convnet", "all"],
["pcen-convnet", "all-but-noise"],
["pcen-add-convnet", "all-but-noise"]
]
plt.figure(figsize=(5, 3))
for model_pair_id, model_pair in enumerate(model_pairs):
model_name = model_pair[0]
aug_kind_str = model_pair[1]
if aug_kind_str == "none":
aug_model_name = model_name
else:
aug_model_name = "_".join([
model_name, "aug-" + aug_kind_str])
model_dir = os.path.join(models_dir, aug_model_name)
model_report = reports[model_name][aug_kind_str]
thrush_Fs = []
tseep_Fs = []
thrush_Rs = []
tseep_Rs = []
# We do not include unit10 in the visualization because
# it is shorter (6 hours) than the other recordings (10 hours).
for test_unit_id in range(n_units)[:-1]:
# Define directory for trial.
trial_id = model_report[
"validation"]["trials_AUPRC"][test_unit_id, -1]
trial_str = "trial-" + str(trial_id)
test_unit_str = units[test_unit_id]
test_unit_dir = os.path.join(model_dir, test_unit_str)
trial_dir = os.path.join(test_unit_dir, trial_str)
# Load predictions.
predictions_name = "_".join([
dataset_name,
aug_model_name,
"test-" + test_unit_str,
trial_str,
"predict-" + test_unit_str,
"full-predictions.csv"
])
prediction_path = os.path.join(trial_dir, predictions_name)
prediction_df = pd.read_csv(prediction_path)
odf = np.array(prediction_df["Predicted probability"])
timestamps = np.array(prediction_df["Timestamp"])
# Load threhold.
threshold_id = int(model_report[
"validation"]["threshold_ids"][test_unit_id, -1])
threshold = thresholds[threshold_id]
# Select peaks.
threshold = thresholds[threshold_id]
if model_name == "pcen-add-convnet":
peak_locations = peakutils.indexes(odf, thres=threshold)
else:
peak_locations = peakutils.indexes(odf, thres=threshold, min_dist=3)
selected = timestamps[peak_locations]
# Load annotation.
annotation_path = os.path.join(annotations_dir,
test_unit_str + ".txt")
annotation = pd.read_csv(annotation_path, '\t')
begin_times = np.array(annotation["Begin Time (s)"])
end_times = np.array(annotation["End Time (s)"])
relevant = 0.5 * (begin_times + end_times)
relevant = np.sort(relevant)
high_freqs = np.array(annotation["High Freq (Hz)"])
low_freqs = np.array(annotation["Low Freq (Hz)"])
mid_freqs = 0.5 * (high_freqs + low_freqs)
n_relevant = len(relevant)
# Filter by frequency ranges.
thrush_low = 1000.0
thrush_high = 5000.0
thrush_relevant = relevant[(thrush_low < mid_freqs) & (mid_freqs < thrush_high)]
tseep_low = 5000.0
tseep_high = 10000.0
tseep_relevant = relevant[(tseep_low < mid_freqs) & (mid_freqs < tseep_high)]
# Match events for all calls.
selected_relevant = mir_eval.util.match_events(relevant, selected, tolerance)
tp_relevant_ids = list(zip(*selected_relevant))[0]
tp_relevant_times = [relevant[i] for i in tp_relevant_ids]
tp_selected_ids = list(zip(*selected_relevant))[1]
tp_selected_times = [selected[i] for i in tp_selected_ids]
# Compute number of false positives through time.
fp_times = [selected[i] for i in range(len(selected)) if i not in tp_selected_ids]
fp_x, fp_y = np.histogram(fp_times, bins=bins);
# Match events for Thrush calls. Get number of true positives through time.
thrush_selected_relevant = mir_eval.util.match_events(
thrush_relevant, selected, tolerance)
thrush_tp_relevant_ids = list(zip(*thrush_selected_relevant))[0]
thrush_tp_relevant_times = [thrush_relevant[i] for i in thrush_tp_relevant_ids]
thrush_tp_selected_ids = list(zip(*thrush_selected_relevant))[1]
thrush_tp_selected_times = [selected[i] for i in thrush_tp_selected_ids]
thrush_tp_x, thrush_tp_y = np.histogram(thrush_tp_relevant_times, bins=bins);
# Get number of false negatives for Thrush.
thrush_fn_times = [thrush_relevant[i] for i in range(len(thrush_relevant))
if i not in thrush_tp_relevant_ids]
thrush_fn_x, thrush_fn_y = np.histogram(thrush_fn_times, bins=n_bins);
# Get Thrush precision through time.
thrush_P = thrush_tp_x / (np.finfo(float).eps + thrush_tp_x + fp_x)
thrush_R = thrush_tp_x / (np.finfo(float).eps + thrush_tp_x + thrush_fn_x)
thrush_F = (2*thrush_P*thrush_R) / (np.finfo(float).eps + thrush_P + thrush_R)
# Match events for Thrush calls. Get number of true positives through time.
tseep_selected_relevant = mir_eval.util.match_events(
tseep_relevant, selected, tolerance)
tseep_tp_relevant_ids = list(zip(*tseep_selected_relevant))[0]
tseep_tp_relevant_times = [tseep_relevant[i] for i in tseep_tp_relevant_ids]
tseep_tp_selected_ids = list(zip(*tseep_selected_relevant))[1]
tseep_tp_selected_times = [selected[i] for i in tseep_tp_selected_ids]
tseep_tp_x, tseep_tp_y = np.histogram(tseep_tp_relevant_times, bins=bins);
# Get number of false negatives for Tseep.
tseep_fn_times = [tseep_relevant[i] for i in range(len(tseep_relevant))
if i not in tseep_tp_relevant_ids]
tseep_fn_x, tseep_fn_y = np.histogram(tseep_fn_times, bins=n_bins);
# Get Tseep precision through time.
tseep_P = tseep_tp_x / (np.finfo(float).eps + tseep_tp_x + fp_x)
tseep_R = tseep_tp_x / (np.finfo(float).eps + tseep_tp_x + tseep_fn_x)
tseep_F = (2*tseep_P*tseep_R) / (np.finfo(float).eps + tseep_P + tseep_R)
thrush_Fs.append(thrush_F)
tseep_Fs.append(tseep_F)
thrush_Rs.append(thrush_R)
tseep_Rs.append(tseep_R)
print(trial_id, threshold, model_report["validation"]["AUPRC"][test_unit_id, -1])
utc_timestamp = 1443065462
utc_datetime = datetime.datetime.fromtimestamp(utc_timestamp)
utc_offset =\
utc_datetime.hour +\
utc_datetime.minute / 60 +\
utc_datetime.second / 3600
local_offset = utc_offset - 4
first_hour = 20
thrush_R_Q1 = np.percentile(np.stack(thrush_Rs), 25, axis=0)
thrush_R_med = np.percentile(np.stack(thrush_Rs), 50, axis=0)
thrush_R_Q3 = np.percentile(np.stack(thrush_Rs), 75, axis=0)
thrush_F_Q1 = np.percentile(np.stack(thrush_Fs), 25, axis=0)
thrush_F_med = np.percentile(np.stack(thrush_Fs), 50, axis=0)
thrush_F_Q3 = np.percentile(np.stack(thrush_Fs), 75, axis=0)
tseep_R_Q1 = np.percentile(np.stack(tseep_Rs), 25, axis=0)
tseep_R_med = np.percentile(np.stack(tseep_Rs), 50, axis=0)
tseep_R_Q3 = np.percentile(np.stack(tseep_Rs), 75, axis=0)
tseep_F_Q1 = np.percentile(np.stack(tseep_Fs), 25, axis=0)
tseep_F_med = np.percentile(np.stack(tseep_Fs), 50, axis=0)
tseep_F_Q3 = np.percentile(np.stack(tseep_Fs), 75, axis=0)
plt.figure(figsize=(5, 2.5))
fig = plt.gcf()
ax1 = plt.gca()
ax1.fill_between(
thrush_tp_y[1:] / 3600 + local_offset,
100 * thrush_R_Q1[:],
100 * thrush_R_Q3[:],
color = "#0040FF",
alpha = 0.33)
ax1.plot(
thrush_tp_y[1:] / 3600 + local_offset,
100 * thrush_R_med[:],
"-o",
color = "#0040FF",
linewidth = 2.0)
ax1.fill_between(
tseep_tp_y[1:] / 3600 + local_offset,
100 * tseep_R_Q1[:],
100 * tseep_R_Q3[:],
color = "#FFB800",
alpha = 0.33)
ax1.plot(
tseep_tp_y[1:] / 3600 + local_offset,
100 * tseep_R_med[:],
"-o",
color = "#FFB800",
linewidth = 2.0)
ax1.legend(["Thrushes (0-5 kHz)", "Warblers and sparrows (5-10 kHz)"],
loc=2, prop={'family':'serif'})
ax1.set_xticks(range(first_hour, first_hour+n_hours+1)[::2])
ax1.set_xticklabels([str(np.mod(n, 24))
for n in range(first_hour, first_hour+n_hours+1)][::2], family="serif")
ax1.set_xticks(
np.linspace(first_hour, first_hour+n_hours - 0.5, n_hours * 2),
minor=True)
ax1.set_xlabel("Local time (hours)", family="serif")
ax1.set_ylim(0, 100)
ax1.set_ylabel("Recall (%)", family="serif")
ax1.set_yticks(np.linspace(0, 100, 5))
ax1.set_yticks(np.linspace(0, 100, 25), minor=True)
ax1.grid(color='k', linestyle='--', linewidth=1.0, alpha=0.25, which="major")
ax1.grid(color='k', linestyle='-', linewidth=0.5, alpha=0.1, which="minor")
ax1.set_axisbelow(True)
if aug_model_name == "icassp-convnet":
plt.title("CNN baseline (previous state of the art) [57]", family="serif")
elif aug_model_name == "pcen-convnet":
plt.title("CNN with PCEN", family="serif")
elif aug_model_name == "pcen-add-convnet":
plt.title("CNN with PCEN and context adaptation", family="serif")
plt.savefig("spl_recall-time_" + aug_model_name + ".png", dpi=500, bbox_inches="tight")
plt.savefig("spl_recall-time_" + aug_model_name + ".svg", bbox_inches="tight")
plt.figure(figsize=(5, 2.5))
fig = plt.gcf()
ax1 = plt.gca()
ax1.fill_between(
thrush_tp_y[1:] / 3600 + local_offset,
100 * thrush_F_Q1[:],
100 * thrush_F_Q3[:],
color = "#0040FF",
alpha = 0.33)
ax1.plot(
thrush_tp_y[1:] / 3600 + local_offset,
100 * thrush_F_med[:],
"-o",
color = "#0040FF",
linewidth = 2.0)
ax1.fill_between(
tseep_tp_y[1:] / 3600 + local_offset,
100 * tseep_F_Q1[:],
100 * tseep_F_Q3[:],
color = "#FFB800",
alpha = 0.33)
ax1.plot(
tseep_tp_y[1:] / 3600 + local_offset,
100 * tseep_F_med[:],
"-o",
color = "#FFB800",
linewidth = 2.0)
ax1.legend(["Thrushes (0-5 kHz)", "Warblers and sparrows (5-10 kHz)"],
loc=2, prop={'family':'serif'})
ax1.set_xticks(range(first_hour, first_hour+n_hours+1)[::2])
ax1.set_xticklabels([str(np.mod(n, 24))
for n in range(first_hour, first_hour+n_hours+1)][::2], family="serif")
ax1.set_xticks(
np.linspace(first_hour, first_hour+n_hours - 0.5, n_hours * 2),
minor=True)
ax1.set_xlabel("Local time (hours)", family="serif")
ax1.set_ylim(0, 100)
ax1.set_ylabel("F1 score (%)", family="serif")
ax1.set_yticks(np.linspace(0, 100, 5))
ax1.set_yticks(np.linspace(0, 100, 25), minor=True)
ax1.grid(color='k', linestyle='--', linewidth=1.0, alpha=0.25, which="major")
ax1.grid(color='k', linestyle='-', linewidth=0.5, alpha=0.1, which="minor")
ax1.set_axisbelow(True)
if aug_model_name == "icassp-convnet":
plt.title("CNN baseline (previous state of the art) [57]", family="serif")
elif aug_model_name == "pcen-convnet":
plt.title("CNN with PCEN", family="serif")
elif aug_model_name == "pcen-add-convnet":
plt.title("CNN with PCEN and context adaptation", family="serif")
plt.savefig("spl_f1score-time_" + aug_model_name + ".png", dpi=500, bbox_inches="tight")
plt.savefig("spl_f1score-time_" + aug_model_name + ".svg", bbox_inches="tight")
np.savez("spl_f1-time_" + aug_model_name + ".npz",
model_name = model_name,
aug_kind_str = aug_kind_str,
first_hour = first_hour,
n_hours = n_hours,
local_offset = local_offset,
tseep_Rs = tseep_Rs,
tseep_Fs = tseep_Fs)
7 0.9943765867480965 0.6421072032234718
7 0.8741074588205833 0.5529593765052065
2 0.9992056717652757 0.5243307930059488
0 0.99 0.7839739012056433
3 0.9910874906186625 0.32893297284136014
0 0.999999999 0.7175532691008519
6 0.999999999 0.0
0 0.999999999 0.5779149051768301
7 0.800473768503112 0.0
5 0.999999999 0.0
7 0.9998415106807539 0.0
1 0.9996837722339832 0.7393552544924215
first_hour = 20
# Loop over units.
unit_id = 1
unit_str = units[unit_id]
annotation_path = os.path.join(annotations_dir,
unit_str + ".txt")
annotation = pd.read_csv(annotation_path, '\t')
begin_times = np.array(annotation["Begin Time (s)"])
end_times = np.array(annotation["End Time (s)"])
relevant = 0.5 * (begin_times + end_times)
relevant = np.sort(relevant)
high_freqs = np.array(annotation["High Freq (Hz)"])
low_freqs = np.array(annotation["Low Freq (Hz)"])
mid_freqs = 0.5 * (high_freqs + low_freqs)
n_relevant = len(relevant)
thrush_low = 0.0
thrush_high = 5000.0
thrush_relevant = relevant[(thrush_low < mid_freqs) & (mid_freqs < thrush_high)]
thrush_x, thrush_y = np.histogram(thrush_relevant, bins=bins)
thrush_x = np.maximum(thrush_x, 15.0)
tseep_low = 5000.0
tseep_high = 10000.0
tseep_relevant = relevant[(tseep_low < mid_freqs) & (mid_freqs < tseep_high)]
tseep_x, tseep_y = np.histogram(tseep_relevant, bins=bins)
tseep_x = np.maximum(tseep_x, 15.0)
fig, ax2 = plt.subplots(1, 1, sharex=True, figsize=(5, 2.5))
ax2.plot(
thrush_y[1:] / 3600 + local_offset,
np.log10(thrush_x / bin_hop),
"-o",
color = "#0040FF")
ax2.plot(
tseep_y[1:] / 3600 + local_offset,
np.log10(tseep_x / bin_hop),
"-o",
color = "#FFB800")
ax2.set_xticks(1.0 + np.array(range(first_hour, first_hour+n_hours+1)[::2]))
ax2.set_xticklabels([str(np.mod(n, 24))
for n in range(1+first_hour, first_hour+n_hours+1)][::2], family="serif")
ax2.set_xticks(
0.5 + np.linspace(first_hour, first_hour+n_hours, n_hours * 2),
minor=True)
ax2.set_xlabel("Local time (hours)", family="serif")
yticks = [ 0.5, 1, 2, 5, 10, 20, 50, 100]
ax2.set_yticks(np.log10(yticks), minor=True)
ax2.set_yticks(np.log10([1, 10, 100]))
ax2.set_yticklabels(map(str, [1, 10, 100]), family="serif");
ax2.set_ylabel("Flight calls per minute", family="serif")
ax2.grid(color='k', linestyle='--', linewidth=1.0, alpha=0.25, which="major")
ax2.grid(color='k', linestyle='-', linewidth=0.5, alpha=0.1, which="minor")
ax2.set_axisbelow(True)
ax2.legend(["Thrushes (0-5 kHz)", "Warblers and sparrows (5-10 kHz)"],
loc=2, prop={'family':'serif'})
plt.savefig("spl_flight-call-density.png", dpi=500, bbox_inches="tight")
plt.savefig("spl_flight-call-density.svg", dpi=500, bbox_inches="tight")
bin_hop
import sys
sys.path.append('../src')
import localmodule
import h5py
import os
import librosa
import numpy as np
from matplotlib import pyplot as plt
data_dir = localmodule.get_data_dir()
dataset_name = localmodule.get_dataset_name()
test_unit_str = "unit03"
bin_hop = 30 # in minutes
n_hours = 11
n_bins = int(np.round(n_hours * (60/bin_hop)))
thrush_low = 2000.0
thrush_high = 2500.0
tseep_low = 4000.0
tseep_high = 5000.0
full_logmelspec_name = "_".join([dataset_name, "full-logmelspec"])
full_logmelspec_dir = os.path.join(data_dir, full_logmelspec_name)
logmelspec_path = os.path.join(full_logmelspec_dir, test_unit_str + ".hdf5")
logmelspec_file = h5py.File(logmelspec_path)
lms_fmin = logmelspec_file["logmelspec_settings"]["fmax"].value
lms_fmax = logmelspec_file["logmelspec_settings"]["fmin"].value
lms_sr = logmelspec_file["logmelspec_settings"]["sr"].value
lms_hop_length = logmelspec_file["logmelspec_settings"]["hop_length"].value
lms_hop_duration = lms_hop_length / lms_sr
n_hops_per_bin = int(bin_hop * 60 / lms_hop_duration)
mel_f = librosa.core.mel_frequencies(
logmelspec_file["logmelspec_settings"]["n_mels"].value + 2,
fmin=logmelspec_file["logmelspec_settings"]["fmin"].value,
fmax=logmelspec_file["logmelspec_settings"]["fmax"].value,
htk=False)
thrush_mel_start = np.argmin(np.abs(thrush_low - mel_f))
thrush_mel_stop = np.argmin(np.abs(thrush_high - mel_f))
tseep_mel_start = np.argmin(np.abs(tseep_low - mel_f))
tseep_mel_stop = np.argmin(np.abs(tseep_high - mel_f))
thrush_percentiles = []
tseep_percentiles = []
for bin_id in range(n_bins):
print(bin_id)
bin_start = bin_id * n_hops_per_bin
bin_stop = bin_start + n_hops_per_bin
thrush_fragment = logmelspec_file["logmelspec"][
thrush_mel_start:thrush_mel_stop, bin_start:bin_stop]
thrush_percentiles.append(np.percentile(thrush_fragment, [25, 50, 75]))
tseep_fragment = logmelspec_file["logmelspec"][
tseep_mel_start:tseep_mel_stop, bin_start:bin_stop]
tseep_percentiles.append(np.percentile(tseep_fragment, [25, 50, 75]))
logmelspec_file.close()
thrush_percentiles = np.stack(thrush_percentiles)
tseep_percentiles = np.stack(tseep_percentiles)
fig, ax = plt.subplots(1, 1, sharex=True, figsize=(4, 4))
ax.scatter(
np.log10((thrush_tp_x + thrush_fn_x) / bin_hop),
100 * thrush_F_med[:],
c = "#0040FF")
ax.scatter(
np.log10((tseep_tp_x + tseep_fn_x) / bin_hop),
100 * tseep_F_med[:],
c = "#FFB800")
ax.legend(
["Thrushes", "Warblers and sparrows"],
loc=2,
prop={'family':'serif','weight':'roman'})
xticks = [0.2, 0.5, 1, 2, 5, 10, 20, 50]
ax.set_xticks(np.log10(xticks))
ax.set_xticklabels([str(xtick) for xtick in xticks], family="serif")
ax.set_xlabel("Flight calls per minute", family="serif")
ax.set_ylim(0, 100);
ax.set_ylabel("F1 score (%)", family="serif")
ax.set_yticks(np.linspace(0, 100, 6))
ax.set_yticklabels(
[str(F) for F in np.linspace(0, 100, 6).astype('int')],
family="serif")
mixed_log10_x = np.concatenate([np.log10(thrush_tp_x + thrush_fn_x), np.log10(tseep_tp_x + tseep_fn_x)])
mixed_y = np.concatenate([100 * thrush_F_med[:], 100 * tseep_F_med[:]])
mixed_R, mixed_p = scipy.stats.pearsonr(mixed_log10_x, mixed_y)
print("R = {:3.2f}, p = {:1.0e} ; n = {}".format(mixed_R, mixed_p, len(mixed_y)))
fig, ax = plt.subplots(1, 1, sharex=True, figsize=(4, 4))
thrush_med_noise = thrush_percentiles[:, 1]
thrush_med_noise = thrush_med_noise - np.mean(thrush_med_noise)
thrush_med_noise = thrush_med_noise / np.std(thrush_med_noise)
tseep_med_noise = tseep_percentiles[:, 1]
ax.scatter(
thrush_med_noise,
100 * thrush_F_med[:],
c = "#0040FF")
ax.scatter(
tseep_med_noise,
100 * tseep_F_med[:],
c = "#FFB800")
ax.legend(
["Thrushes (2-6 kHz)", "Warblers and sparrows (6-10 kHz)"],
loc=1,
prop={'family':'serif'})
xticks = [-30.0, -28.5, -27.0, -25.5, -24.0]
ax.set_xticks(xticks)
ax.set_xticklabels([str(xtick) for xtick in xticks], family="serif")
ax.set_xlabel("Sound pressure level (dB)", family="serif")
ax.set_ylim(0, 100);
ax.set_ylabel("F1 score (%)", family="serif")
ax.set_yticks(np.linspace(0, 100, 6))
ax.set_yticklabels(
[str(F) for F in np.linspace(0, 100, 6).astype('int')],
family="serif")
thrush_noise_R, thrush_noise_p = scipy.stats.pearsonr(thrush_med_noise, 100*thrush_F_med[:])
print("Thrushes. R = {:3.2f} ; p = {:1.0e} ; n = {}".format(thrush_noise_R, thrush_noise_p, len(thrush_med_noise)))
tseep_noise_R, tseep_noise_p = scipy.stats.pearsonr(tseep_med_noise, 100*tseep_F_med[:])
print("Warblers and sparrows. R = {:3.2f} ; p = {:1.0e} ; n = {}".format(tseep_noise_R, tseep_noise_p, len(tseep_med_noise)))
tseep_tp_y
first_hour + np.linspace(0, n_hours, tseep_percentiles.shape[0])
from matplotlib import pyplot as plt
import numpy as np
import datetime
%matplotlib inline
utc_timestamp = 1443065462
utc_datetime = datetime.datetime.fromtimestamp(utc_timestamp)
utc_offset =\
utc_datetime.hour +\
utc_datetime.minute / 60 +\
utc_datetime.second / 3600
local_offset = utc_offset - 4
first_hour = 20
fig, ax3 = plt.subplots(1, 1, sharex=True, figsize=(5, 2.5))
n_hours = 10.5
tseep_tp_y = first_hour + np.linspace(0, n_hours, tseep_percentiles.shape[0])
thrush_tp_y = first_hour + np.linspace(0, n_hours, thrush_percentiles.shape[0])
ax3.fill_between(
thrush_tp_y,
thrush_percentiles[:, 0],
thrush_percentiles[:, 2],
color = "#80007F",
alpha = 0.33);
ax3.plot(
thrush_tp_y,
thrush_percentiles[:, 1],
"-o",
color = "#80007F",
linewidth = 2.0)
ax3.fill_between(
tseep_tp_y,
tseep_percentiles[:, 0],
tseep_percentiles[:, 2],
color = "#008000",
alpha = 0.2);
ax3.plot(
tseep_tp_y,
tseep_percentiles[:, 1],
"-o",
color = "#008000",
linewidth = 2.0)
ax3.set_xticks(range(first_hour, first_hour+1)[::2], minor=True)
ax3.set_xticklabels([str(np.mod(n, 24))
for n in range(first_hour, first_hour+13)][::2], family="serif")
#ax3.set_xticks(
# np.linspace(first_hour, first_hour+ 11 - 0.5, n_hours * 2),
# minor=True)
ax3.set_xlabel("Local time (hours)", family="serif")
ydBs = [-33, -30, -27, -24, -21, -18, -15]
ax3.set_yticks(ydBs[::2])
ax3.set_yticks(ydBs, minor=True)
ax3.set_yticklabels([str(ydB) for ydB in ydBs[::2]], family="serif");
ax3.set_ylabel("Sound pressure level (dB)", family="serif")
ax3.grid(color='k', linestyle='--', linewidth=1.0, alpha=0.25, which="major")
#ax3.grid(color='k', linestyle='-', linewidth=0.5, alpha=0.1, which="minor")
ax3.set_axisbelow(True)
ax3.legend(["Insects (2-2.5 kHz)", "Insects (4-5 kHz)"],
loc=1, prop={'family':'serif'})
plt.savefig("spl_fig_db.png", dpi=500, bbox_inches="tight")
plt.savefig("spl_fig_db.svg", dpi=500, bbox_inches="tight")
utc_timestamp = 1443065462
utc_datetime = datetime.datetime.fromtimestamp(utc_timestamp)
utc_offset =\
utc_datetime.hour +\
utc_datetime.minute / 60 +\
utc_datetime.second / 3600
local_offset = utc_offset - 4
first_hour = 20
fig, ax1 = plt.subplots(1, 1, sharex=True, figsize=(5, 2.5))
thrush_R_Q1 = np.sort(np.stack(thrush_Rs), axis=0)[1]
thrush_R_med = np.sort(np.stack(thrush_Rs), axis=0)[2]
thrush_R_Q3 = np.sort(np.stack(thrush_Rs), axis=0)[3]
thrush_F_Q1 = np.sort(np.stack(thrush_Fs), axis=0)[1]
thrush_F_med = np.sort(np.stack(thrush_Fs), axis=0)[2]
thrush_F_Q3 = np.sort(np.stack(thrush_Fs), axis=0)[3]
ax1.fill_between(
thrush_tp_y[1:] / 3600 + local_offset,
100 * thrush_F_Q1[:],
100 * thrush_F_Q3[:],
color = "#0040FF",
alpha = 0.33)
ax1.plot(
thrush_tp_y[1:] / 3600 + local_offset,
100 * thrush_F_med[:],
"-o",
color = "#0040FF",
linewidth = 2.0)
tseep_R_Q1 = np.sort(np.stack(tseep_Rs), axis=0)[1]
tseep_R_med = np.sort(np.stack(tseep_Rs), axis=0)[2]
tseep_R_Q3 = np.sort(np.stack(tseep_Rs), axis=0)[3]
tseep_F_Q1 = np.sort(np.stack(tseep_Fs), axis=0)[1]
tseep_F_med = np.sort(np.stack(tseep_Fs), axis=0)[2]
tseep_F_Q3 = np.sort(np.stack(tseep_Fs), axis=0)[3]
ax1.fill_between(
tseep_tp_y[1:] / 3600 + local_offset,
100 * tseep_F_Q1[:],
100 * tseep_F_Q3[:],
color = "#FFB800",
alpha = 0.33)
ax1.plot(
tseep_tp_y[1:] / 3600 + local_offset,
100 * tseep_F_med[:],
"-o",
color = "#FFB800",
linewidth = 2.0)
ax1.legend(["Thrushes (0-5 kHz)", "Warblers and sparrows (5-10 kHz)"],
loc=2, prop={'family':'serif'})
ax1.set_xticks(range(first_hour, first_hour+n_hours+1)[::2])
ax1.set_xticklabels([str(np.mod(n, 24))
for n in range(first_hour, first_hour+n_hours+1)][::2], family="serif")
ax1.set_xticks(
np.linspace(first_hour, first_hour+n_hours - 0.5, n_hours * 2),
minor=True)
ax1.set_xlabel("Local time (hours)", family="serif")
ax1.set_ylim(0, 100)
ax1.set_ylabel("Recall (%)", family="serif")
ax1.set_yticks(np.linspace(0, 100, 5))
ax1.set_yticklabels(np.linspace(0, 100, 5).astype('int'), family="serif")
ax1.set_yticks(np.linspace(0, 100, 25), minor=True)
ax1.grid(color='k', linestyle='--', linewidth=1.0, alpha=0.25, which="major")
ax1.grid(color='k', linestyle='-', linewidth=0.5, alpha=0.1, which="minor")
ax1.set_axisbelow(True)
plt.savefig("icassp_fig_recall-time_a.png", dpi=500, bbox_inches="tight")
plt.savefig("icassp_fig_recall-time_a.svg", bbox_inches="tight")
```
| github_jupyter |
# How to further train a pre-trained model
We will demonstrate how to freeze some or all of the layers of a pre-trained model and continue training using a new fully-connected set of layers and data with a different format.
Adapted from the Tensorflow 2.0 [transfer learning tutorial](https://www.tensorflow.org/tutorials/images/transfer_learning).
## Imports & Settings
```
%matplotlib inline
from sklearn.datasets import load_files
import numpy as np
import pandas as pd
from pathlib import Path
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import seaborn as sns
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Dense, Flatten, Dropout, GlobalAveragePooling2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
import tensorflow_datasets as tfds
gpu_devices = tf.config.experimental.list_physical_devices('GPU')
if gpu_devices:
print('Using GPU')
tf.config.experimental.set_memory_growth(gpu_devices[0], True)
else:
print('Using CPU')
results_path = Path('results', 'transfer_learning')
if not results_path.exists():
results_path.mkdir(parents=True)
sns.set_style('whitegrid')
```
## Load TensorFlow Cats vs Dog Dataset
TensorFlow includes a large number of built-in dataset:
```
tfds.list_builders()
```
We will use a set of cats and dog images for binary classification.
```
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
split=[
tfds.Split.TRAIN.subsplit(tfds.percent[:80]),
tfds.Split.TRAIN.subsplit(tfds.percent[80:90]),
tfds.Split.TRAIN.subsplit(tfds.percent[90:])
],
with_info=True,
as_supervised=True,
data_dir='../data/tensorflow'
)
print('Raw train:\t', raw_train)
print('Raw validation:\t', raw_validation)
print('Raw test:\t', raw_test)
```
### Show sample images
```
get_label_name = metadata.features['label'].int2str
for image, label in raw_train.take(2):
plt.figure()
plt.imshow(image)
plt.title(get_label_name(label))
plt.grid(False)
plt.axis('off')
```
## Preprocessing
All images will be resized to 160x160:
```
IMG_SIZE = 160
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
for image_batch, label_batch in train_batches.take(1):
pass
image_batch.shape
```
## Load the VGG-16 Bottleneck Features
We use the VGG16 weights, pre-trained on ImageNet with the much smaller 32 x 32 CIFAR10 data. Note that we indicate the new input size upon import and set all layers to not trainable:
```
vgg16 = VGG16(input_shape=IMG_SHAPE, include_top=False, weights='imagenet')
vgg16.summary()
feature_batch = vgg16(image_batch)
feature_batch.shape
```
## Freeze model layers
```
vgg16.trainable = False
vgg16.summary()
```
## Add new layers to model
### Using the Sequential model API
```
global_average_layer = GlobalAveragePooling2D()
dense_layer = Dense(64, activation='relu')
dropout = Dropout(0.5)
prediction_layer = Dense(1, activation='sigmoid')
seq_model = tf.keras.Sequential([vgg16,
global_average_layer,
dense_layer,
dropout,
prediction_layer])
seq_model.compile(loss = tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = 'Adam',
metrics=["accuracy"])
seq_model.summary()
```
### Using the Functional model API
We use Keras’ functional API to define the vgg16 output as input into a new set of fully-connected layers like so:
```
#Adding custom Layers
x = vgg16.output
x = GlobalAveragePooling2D()(x)
x = Dense(64, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(1, activation='sigmoid')(x)
```
We define a new model in terms of inputs and output, and proceed from there on as before:
```
transfer_model = Model(inputs = vgg16.input,
outputs = predictions)
transfer_model.compile(loss = tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = 'Adam',
metrics=["accuracy"])
transfer_model.summary()
```
### Compute baseline metrics
```
initial_epochs = 10
validation_steps=20
initial_loss, initial_accuracy = transfer_model.evaluate(validation_batches, steps = validation_steps)
print(f'Initial loss: {initial_loss:.2f} | initial_accuracy accuracy: {initial_accuracy:.2%}')
```
## Train VGG16 transfer model
```
history = transfer_model.fit(train_batches,
epochs=initial_epochs,
validation_data=validation_batches)
```
### Plot Learning Curves
```
def plot_learning_curves(df):
fig, axes = plt.subplots(ncols=2, figsize=(15, 4))
df[['loss', 'val_loss']].plot(ax=axes[0], title='Cross-Entropy')
df[['accuracy', 'val_accuracy']].plot(ax=axes[1], title='Accuracy')
for ax in axes:
ax.legend(['Training', 'Validation'])
sns.despine()
fig.tight_layout();
metrics = pd.DataFrame(history.history)
plot_learning_curves(metrics)
```
## Fine-tune VGG16 weights
### Unfreeze selected layers
```
vgg16.trainable = True
```
How many layers are in the base model:
```
f'Number of layers in the base model: {len(vgg16.layers)}'
# Fine-tune from this layer onwards
start_fine_tuning_at = 12
# Freeze all the layers before the `fine_tune_at` layer
for layer in vgg16.layers[:start_fine_tuning_at]:
layer.trainable = False
base_learning_rate = 0.0001
transfer_model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate / 10),
metrics=['accuracy'])
```
### Define callbacks
```
early_stopping = EarlyStopping(monitor='val_accuracy', patience=10)
transfer_model.summary()
```
### Continue Training
And now we proceed to train the model:
```
fine_tune_epochs = 50
total_epochs = initial_epochs + fine_tune_epochs
history_fine_tune = transfer_model.fit(train_batches,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_batches,
callbacks=[early_stopping])
metrics_tuned = metrics.append(pd.DataFrame(history_fine_tune.history), ignore_index=True)
fig, axes = plt.subplots(ncols=2, figsize=(15, 4))
metrics_tuned[['loss', 'val_loss']].plot(ax=axes[1], title='Cross-Entropy Loss')
metrics_tuned[['accuracy', 'val_accuracy']].plot(ax=axes[0], title=f'Accuracy (Best: {metrics_tuned.val_accuracy.max():.2%})')
axes[0].yaxis.set_major_formatter(FuncFormatter(lambda y, _: '{:.0%}'.format(y)))
axes[0].set_ylabel('Accuracy')
axes[1].set_ylabel('Loss')
for ax in axes:
ax.axvline(10, ls='--', lw=1, c='k')
ax.legend(['Training', 'Validation', 'Start Fine Tuning'])
ax.set_xlabel('Epoch')
sns.despine()
fig.tight_layout()
fig.savefig(results_path / 'transfer_learning');
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import pickle
import markovify
import os
```
# Hidden Markov Model development
This notebook attempts to develop HMM for generating beat map sequences in a realistic manner. Goals include:
- Process note data into "words" that can be read by markovify
- Train HMMs for each difficulty level
- Generate new sequences
```
with open('../level_df/17e9_expert.pkl', 'rb') as f:
df = pickle.load(f)
df
df_notes = df.iloc[:, 13:]
df_notes.drop(index = df_notes[(df_notes == 999).all(axis = 1)].index, axis = 0, inplace = True)
df_notes.reset_index(drop = True, inplace = True)
seq = []
for index, row in df_notes.iterrows():
values = {}
for x in df_notes.columns:
values.update({x: int(row[x])})
if 'notes_type_3' not in list(values.keys()):
values.update({'notes_type_3': 999})
values.update({'notes_lineIndex_3': 999})
values.update({'notes_lineLayer_3': 999})
values.update({'notes_cutDirection_3': 999})
word = f"{values['notes_type_0']},{values['notes_lineIndex_0']},{values['notes_lineLayer_0']},{values['notes_cutDirection_0']},{values['notes_type_1']},{values['notes_lineIndex_1']},{values['notes_lineLayer_1']},{values['notes_cutDirection_1']},{values['notes_type_3']},{values['notes_lineIndex_3']},{values['notes_lineLayer_3']},{values['notes_cutDirection_3']}"
seq.append(word)
def make_sequence(df):
"""Returns a sequence of 'words' that describe the placement and type of blocks for use in a HMM generator."""
df_notes = df.iloc[:, 13:]
df_notes.drop(index = df_notes[(df_notes == 999).all(axis = 1)].index, axis = 0, inplace = True)
df_notes.reset_index(drop = True, inplace = True)
seq = []
for index, row in df_notes.iterrows():
values = {}
for x in df_notes.columns:
values.update({x: int(row[x])})
if 'notes_type_3' not in list(values.keys()):
values.update({'notes_type_3': 999})
values.update({'notes_lineIndex_3': 999})
values.update({'notes_lineLayer_3': 999})
values.update({'notes_cutDirection_3': 999})
elif 'notes_type_0' not in list(values.keys()):
values.update({'notes_type_0': 999})
values.update({'notes_lineIndex_0': 999})
values.update({'notes_lineLayer_0': 999})
values.update({'notes_cutDirection_0': 999})
elif 'notes_type_1' not in list(values.keys()):
values.update({'notes_type_1': 999})
values.update({'notes_lineIndex_1': 999})
values.update({'notes_lineLayer_1': 999})
values.update({'notes_cutDirection_1': 999})
word = f"{values['notes_type_0']},{values['notes_lineIndex_0']},{values['notes_lineLayer_0']},{values['notes_cutDirection_0']},{values['notes_type_1']},{values['notes_lineIndex_1']},{values['notes_lineLayer_1']},{values['notes_cutDirection_1']},{values['notes_type_3']},{values['notes_lineIndex_3']},{values['notes_lineLayer_3']},{values['notes_cutDirection_3']}"
seq.append(word)
return seq
def generate_corpus(difficulty):
corpus = []
filelist = [f for f in os.listdir('../level_df')]
for f in filelist:
if f.endswith(f"{difficulty}.pkl"):
with open(f"../level_df/{f}", 'rb') as d:
df = pickle.load(d)
seq = make_sequence(df)
corpus.append(seq)
return corpus
def train_HMM(corpus):
MC = markovify.Chain(corpus, 5)
return MC
def HMM(difficulty):
corpus = generate_corpus(difficulty)
MC = train_HMM(corpus)
return MC
difficulties = ['easy', 'normal', 'hard', 'expert', 'expertPlus']
for difficulty in difficulties:
MC = HMM(difficulty)
with open(f"../models/HMM_{difficulty}_v2.pkl", 'wb') as f:
pickle.dump(MC, f)
MC_hard = HMM('hard')
walk = MC_hard.walk()
def walk_to_df(walk):
sequence = []
for step in walk:
sequence.append(step.split(","))
constant = ['notes_type_0', 'notes_lineIndex_0', 'notes_lineLayer_0',
'notes_cutDirection_0', 'notes_type_1', 'notes_lineIndex_1', 'notes_lineLayer_1',
'notes_cutDirection_1', 'notes_type_3', 'notes_lineIndex_3',
'notes_lineLayer_3', 'notes_cutDirection_3']
df = pd.DataFrame(sequence, columns = constant)
return df
sequence = []
for step in walk:
sequence.append(step.split(","))
sequence
constant = ['notes_type_0', 'notes_lineIndex_0', 'notes_lineLayer_0',
'notes_cutDirection_0', 'notes_type_1', 'notes_lineIndex_1', 'notes_lineLayer_1',
'notes_cutDirection_1', 'notes_type_3', 'notes_lineIndex_3',
'notes_lineLayer_3', 'notes_cutDirection_3']
pd.DataFrame(sequence, columns = constant)
```
| github_jupyter |
```
import json
d = [
{'Tag': 'OTHER', 'Description': 'other'},
{'Tag': 'ADDRESS', 'Description': 'Address of physical location.'},
{'Tag': 'PERSON', 'Description': 'People, including fictional.'},
{
'Tag': 'NORP',
'Description': 'Nationalities or religious or political groups.',
},
{
'Tag': 'FAC',
'Description': 'Buildings, airports, highways, bridges, etc.',
},
{
'Tag': 'ORG',
'Description': 'Companies, agencies, institutions, etc.',
},
{'Tag': 'GPE', 'Description': 'Countries, cities, states.'},
{
'Tag': 'LOC',
'Description': 'Non-GPE locations, mountain ranges, bodies of water.',
},
{
'Tag': 'PRODUCT',
'Description': 'Objects, vehicles, foods, etc. (Not services.)',
},
{
'Tag': 'EVENT',
'Description': 'Named hurricanes, battles, wars, sports events, etc.',
},
{'Tag': 'WORK_OF_ART', 'Description': 'Titles of books, songs, etc.'},
{'Tag': 'LAW', 'Description': 'Named documents made into laws.'},
{'Tag': 'LANGUAGE', 'Description': 'Any named language.'},
{
'Tag': 'DATE',
'Description': 'Absolute or relative dates or periods.',
},
{'Tag': 'TIME', 'Description': 'Times smaller than a day.'},
{'Tag': 'PERCENT', 'Description': 'Percentage, including "%".'},
{'Tag': 'MONEY', 'Description': 'Monetary values, including unit.'},
{
'Tag': 'QUANTITY',
'Description': 'Measurements, as of weight or distance.',
},
{'Tag': 'ORDINAL', 'Description': '"first", "second", etc.'},
{
'Tag': 'CARDINAL',
'Description': 'Numerals that do not fall under another type.',
},
]
d = [d['Tag'] for d in d]
d = ['PAD', 'X'] + d
import numpy as np
with open('processed-train-ontonotes5.json') as fopen:
data = json.load(fopen)
seq_len = 50
skip = 4
def iter_seq(x):
return [x[i: i+seq_len] for i in range(0, len(x)-seq_len, skip)]
def to_train_seq(*args):
return [iter_seq(x) for x in args]
from collections import defaultdict
entities = defaultdict(list)
for i in data:
entities['text'].append(i[0])
entities['label'].append(i[1])
train_X_seq, train_Y_seq = to_train_seq(entities['text'], entities['label'])
len(train_X_seq), len(train_Y_seq)
with open('processed-test-ontonotes5.json') as fopen:
data = json.load(fopen)
entities = defaultdict(list)
for i in data:
entities['text'].append(i[0])
entities['label'].append(i[1])
test_X_seq, test_Y_seq = to_train_seq(entities['text'], entities['label'])
len(test_X_seq), len(test_Y_seq)
with open('ontonotes5-train-test.json', 'w') as fopen:
json.dump({'train_X': train_X_seq, 'train_Y': train_Y_seq,
'test_X': test_X_seq, 'test_Y': test_Y_seq}, fopen)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/aswit3/Start_Your_NLP_Career/blob/master/spam_classification.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from google.colab import drive
drive.mount('/content/drive')
import tensorflow as tf
import tensorflow_hub as hub
import pandas as pd
from sklearn import preprocessing
import keras
import numpy as np
!unzip drive/My\ Drive/datasets/sms-spam-collection-dataset.zip
option = 2
if option == 1:
url = "https://tfhub.dev/google/elmo/2"
embed = hub.Module(url)
elif option == 2:
url = "https://tfhub.dev/google/universal-sentence-encoder-large/3"
embed = hub.Module(url)
data = pd.read_csv('spam.csv', encoding='latin-1')
data.head()
y = list(data['v1'])
x = list(data['v2'])
le = preprocessing.LabelEncoder()
le.fit(y)
def encode(le, labels):
enc = le.transform(labels)
return keras.utils.to_categorical(enc)
def decode(le, one_hot):
dec = np.argmax(one_hot, axis=1)
return le.inverse_transform(dec)
test = encode(le, ['ham', 'spam', 'ham', 'ham'])
untest = decode(le, test)
x_enc = x
y_enc = encode(le, y)
x_train = np.asarray(x_enc[:5000])
y_train = np.asarray(y_enc[:5000])
x_test = np.asarray(x_enc[5000:])
y_test = np.asarray(y_enc[5000:])
from keras.layers import Input, Lambda, Dense
from keras.models import Model
import keras.backend as K
input_text = Input(shape=(1,), dtype=tf.string)
if option == 1:
def ELMoEmbedding(x):
return embed(tf.squeeze(tf.cast(x, tf.string)), signature="default", as_dict=True)["default"]
embedding = Lambda(ELMoEmbedding, output_shape=(1024, ))(input_text)
elif option == 2:
def UniversalEmbedding(x):
return embed(tf.squeeze(tf.cast(x, tf.string)))
embedding = Lambda(UniversalEmbedding, output_shape=(512, ))(input_text)
#embedding = Lambda(ELMoEmbedding, output_shape=(1024, ))(input_text)
dense = Dense(256, activation='relu')(embedding)
pred = Dense(2, activation='softmax')(dense)
model = Model(inputs=[input_text], outputs=pred)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
with tf.Session() as session:
K.set_session(session)
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
history = model.fit(x_train, y_train, epochs=1, batch_size=32)
model.save_weights('./model.h5')
with tf.Session() as session:
K.set_session(session)
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
model.load_weights('./model.h5')
predicts = model.predict(x_test, batch_size=32)
y_test = decode(le, y_test)
y_preds = decode(le, predicts)
from sklearn import metrics
print(metrics.confusion_matrix(y_test, y_preds))
print(metrics.classification_report(y_test, y_preds))
```
| github_jupyter |
# Winding Creation and Analysis
This document describes methods to create windings either from BCH/BATCH files or from scratch.
```
import femagtools.bch
import femagtools.plot
import femagtools.windings
import matplotlib.pyplot as plt
```
Load a BATCH file and create the winding:
```
bch = femagtools.bch.read('PM_270_L8_001.BATCH')
w = femagtools.windings.Winding(bch)
w.windings
```
Plot the magnetomotive force (in ampere-turns/ampere/turns)
```
f=w.mmf()
title = f"Q={w.Q}, p={w.p}"
femagtools.plot.mmf(f, title)
```
Plot the MMF harmonics
```
femagtools.plot.mmf_fft(f)
femagtools.plot.winding_factors(w, 8)
```
Show the winding properties:
```
w.windings
```
Show the slots of phase 3:
```
w.slots(2)
```
Show the slots and the winding directions of all phases and layers:
```
w.zoneplan()
```
Plot the zone plan:
```
femagtools.plot.zoneplan(w)
```
Plot the diagram using matplotlib:
```
femagtools.plot.winding(w)
```
Show the diagram as SVG document:
```
from IPython.display import SVG
SVG(w.diagram())
```
Create a single layer 3-phase winding with 12 slots, 2 pole pairs from scratch:
```
w1 = femagtools.windings.Winding({'Q':12, 'p':2, 'm':3})
```
Show the winding properties and note the default radius and winding turns values:
```
w1.windings
w1.slots(3)
```
Plot the magnetomotive force:
```
femagtools.plot.mmf(w1.mmf(), '')
```
Show the zoneplan:
```
w1.zoneplan()
```
This is a 2-layer, 3-phase winding with 90 slots and 12 pole pairs:
```
w2 = femagtools.windings.Winding({'Q':90, 'p':4, 'm':3, 'l':2})
femagtools.plot.mmf(w2.mmf())
femagtools.plot.mmf_fft(w2.mmf())
femagtools.plot.winding_factors(w2, 8)
femagtools.plot.zoneplan(w2)
```
Draw the coil diagram:
```
plt.figure(figsize=(12,4))
femagtools.plot.winding(w2)
```
Winding factor
```
w2.kw()
```
A 2-layer winding with coil width:
```
plt.figure(figsize=(12,2))
w3 = femagtools.windings.Winding({'Q':90, 'p':4, 'm':3, 'l':2,
'yd':10})
femagtools.plot.zoneplan(w3)
femagtools.plot.mmf(w3.mmf())
femagtools.plot.winding_factors(w3, 8)
```
This is another example with 168 slots from a BATCH file:
```
bch = femagtools.bch.read('xxx.BCH')
w4 = femagtools.windings.Winding(bch)
femagtools.plot.zoneplan(w4)
plt.figure(figsize=(12,4))
femagtools.plot.winding(w4)
w4.yd
SVG(w4.diagram())
w4.zoneplan()
femagtools.plot.mmf(w4.mmf())
```
The same example created directly:
```
w5 = femagtools.windings.Winding(dict(Q=168, p=7, m=3, l=2, yd=10))
femagtools.plot.zoneplan(w5)
plt.figure(figsize=(16,4))
femagtools.plot.winding(w5)
```
Here is another example:
```
bch = femagtools.bch.read('PM_130_L10.BATCH')
w6 = femagtools.windings.Winding(bch)
f = w6.mmf()
femagtools.plot.mmf(f)
femagtools.plot.mmf_fft(f)
femagtools.plot.zoneplan(w6)
plt.figure(figsize=(12,4))
femagtools.plot.winding(w6)
SVG(w6.diagram())
```
| github_jupyter |
```
import numpy as np
import matplotlib.pyplot as plt
from sympy import Symbol, integrate
%matplotlib notebook
```
### Smooth local paths
We will use cubic spirals to generate smooth local paths. Without loss of generality, as $\theta$ smoothly changes from 0 to 1, we impose a condition on the curvature as follows
$\kappa = f'(\theta) = K(\theta(1-\theta))^n $
This ensures curvature vanishes at the beginning and end of the path. Integrating, the yaw changes as
$\theta = \int_0^x f'(\theta)d\theta$
With $n = 1$ we get a cubic spiral, $n=2$ we get a quintic spiral and so on. Let us use the sympy package to find the family of spirals
1. Declare $x$ a Symbol
2. You want to find Integral of $f'(x)$
3. You can choose $K$ so that all coefficients are integers
Verify if $\theta(0) = 0$ and $\theta(1) = 1$
```
K = 30 #choose for cubic/quintic
n = 2 #choose for cubic/ quintic
x = Symbol('x') #declare as Symbol
print(integrate(K*(x*(1-x))**n, x)) # complete the expression
x = np.linspace(0,1,num=100)
thetas = -2*x**3 + 3*x**2
plt.figure()
plt.plot(x,thetas,'.')
thetas = 6*x**5 - 15*x**4 + 10*x**3
plt.plot(x,thetas,'.')
#write function to compute a cubic spiral
#input/ output can be any theta
def cubic_spiral(theta_i, theta_f, n=10):
x = np.linspace(0, 1, num=n)
# -2*x**3 + 3*x**2
return (theta_f - theta_i)*(-2*x**3 + 3*x**2) + theta_i
def quintic_spiral(theta_i, theta_f, n=10):
x = np.linspace(0, 1, num=n)
# 6*x**5 - 15*x**4 + 10*x**3
return (theta_f - theta_i)*(6*x**5 - 15*x**4 + 10*x**3) + theta_i
```
### Plotting
Plot cubic, quintic spirals along with how $\theta$ will change when moving in a circular arc. Remember circular arc is when $\omega $ is constant
```
num_pts = 100
plt.figure()
plt.plot(np.pi/2*(1-np.linspace(0,1,num_pts)), label='Circular')
plt.plot(cubic_spiral(np.pi/2, 0,num_pts), label='Cubic')
plt.plot(quintic_spiral(np.pi/2, 0,num_pts),label='Quintic')
plt.grid()
plt.legend()
```
## Trajectory
Using the spirals, convert them to trajectories $\{(x_i,y_i,\theta_i)\}$. Remember the unicycle model
$dx = v\cos \theta dt$
$dy = v\sin \theta dt$
$\theta$ is given by the spiral functions you just wrote. Use cumsum() in numpy to calculate {}
What happens when you change $v$?
```
num_pts = 50
v = 1
dt = 0.1
# cubic
theta = cubic_spiral(np.pi/2, np.pi, num_pts)
x = np.cumsum(v*np.cos(theta)*dt)
y = np.cumsum(v*np.sin(theta)*dt)
# quintic
theta = quintic_spiral(np.pi/2, np.pi, num_pts)
xq = np.cumsum(v*np.cos(theta)*dt)
yq = np.cumsum(v*np.sin(theta)*dt)
# circular
theta = np.pi/2*(1+np.linspace(0,1,num_pts-2))
xc = np.cumsum(v*np.cos(theta)*dt)
yc = np.cumsum(v*np.sin(theta)*dt)
# plot trajectories for circular/ cubic/ quintic
plt.figure()
plt.plot(x,y, label='cubic')
plt.plot(xq,yq, label='quintic')
plt.plot(xc,yc, label='circular')
plt.legend()
plt.grid()
```
## Symmetric poses
We have been doing only examples with $|\theta_i - \theta_f| = \pi/2$.
What about other orientation changes? Given below is an array of terminal angles (they are in degrees!). Start from 0 deg and plot the family of trajectories
```
dt = 0.1
thetas = np.deg2rad([15, 30, 45, 60, 90, 120, 150, 180]) #convert to radians
plt.figure()
for tf in thetas:
t = cubic_spiral(0, tf,50)
x = np.cumsum(np.cos(t)*dt)
y = np.cumsum(np.sin(t)*dt)
plt.plot(x, y)
# On the same plot, move from 180 to 180 - theta
thetas = np.pi - np.deg2rad([15, 30, 45, 60, 90, 120, 150, 180])
for tf in thetas:
t = cubic_spiral(np.pi, tf, 50)
x = np.cumsum(np.cos(t)*dt)
y = np.cumsum(np.sin(t)*dt)
plt.plot(x, y)
plt.grid()
```
Modify your code to print the following for the positive terminal angles $\{\theta_f\}$
1. Final x, y position in corresponding trajectory: $x_f, y_f$
2. $\frac{y_f}{x_f}$ and $\tan \frac{\theta_f}{2}$
What do you notice?
What happens when $v$ is doubled?
```
dt = 0.1
v = 0.5
thetas = np.deg2rad([15, 30, 45, 60, 90, 120, 150, 180]) #convert to radians
plt.figure()
for tf in thetas:
t = cubic_spiral(0, tf,50)
x = np.cumsum(v*np.cos(t)*dt)
y = np.cumsum(v*np.sin(t)*dt)
print(f"tf:{np.rad2deg(tf):0.1f} xf:{x[-1]:0.3f} yf:{y[-1]:0.3f} yf/xf:{y[-1]/x[-1]:0.3f} tan(theta/2):{np.tan(tf/2):0.3f}")
```
These are called *symmetric poses*. With this spiral-fitting approach, only symmetric poses can be reached.
In order to move between any 2 arbitrary poses, you will have to find an intermediate pose that is pair-wise symmetric to the start and the end pose.
What should be the intermediate pose? There are infinite possibilities. We would have to formulate it as an optimization problem. As they say, that has to be left for another time!
```
```
| github_jupyter |
<a href="https://colab.research.google.com/github/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_04_2_multi_class.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# T81-558: Applications of Deep Neural Networks
**Module 4: Training for Tabular Data**
* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)
* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).
# Module 4 Material
* Part 4.1: Encoding a Feature Vector for Keras Deep Learning [[Video]](https://www.youtube.com/watch?v=Vxz-gfs9nMQ&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_04_1_feature_encode.ipynb)
* **Part 4.2: Keras Multiclass Classification for Deep Neural Networks with ROC and AUC** [[Video]](https://www.youtube.com/watch?v=-f3bg9dLMks&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_04_2_multi_class.ipynb)
* Part 4.3: Keras Regression for Deep Neural Networks with RMSE [[Video]](https://www.youtube.com/watch?v=wNhBUC6X5-E&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_04_3_regression.ipynb)
* Part 4.4: Backpropagation, Nesterov Momentum, and ADAM Neural Network Training [[Video]](https://www.youtube.com/watch?v=VbDg8aBgpck&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_04_4_backprop.ipynb)
* Part 4.5: Neural Network RMSE and Log Loss Error Calculation from Scratch [[Video]](https://www.youtube.com/watch?v=wmQX1t2PHJc&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_04_5_rmse_logloss.ipynb)
# Google CoLab Instructions
The following code ensures that Google CoLab is running the correct version of TensorFlow.
```
try:
%tensorflow_version 2.x
COLAB = True
print("Note: using Google CoLab")
except:
print("Note: not using Google CoLab")
COLAB = False
```
# Part 4.2: Keras Multiclass Classification for Deep Neural Networks with ROC and AUC
* **Binary Classification** - Classification between two possibilities (positive and negative). Common in medical testing, does the person have the disease (positive) or not (negative).
* **Classification** - Classification between more than 2. The iris dataset (3-way classification).
* **Regression** - Numeric prediction. How many MPG does a car get? (covered in next video)
In this class session we will look at some visualizations for all three.
It is important to evaluate the level of error in the results produced by a neural network. In this part we will look at how to evaluate error for both classification and regression neural networks.
Binary classification is used to create a model that classifies between only two classes. These two classes are often called "positive" and "negative". Consider the following program that uses the [wcbreast_wdbc dataset](https://github.com/jeffheaton/t81_558_deep_learning/blob/master/datasets_wcbc.ipynb) to classify if a breast tumor is cancerous (malignant) or not (benign).
```
import pandas as pd
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/wcbreast_wdbc.csv",
na_values=['NA','?'])
display(df[0:5])
```
### ROC Curves
ROC curves can be a bit confusing. However, they are very common. It is important to know how to read them. Even their name is confusing. Do not worry about their name, it comes from electrical engineering (EE).
Binary classification is common in medical testing. Often you want to diagnose if someone has a disease. This can lead to two types of errors, know as false positives and false negatives:
* **False Positive** - Your test (neural network) indicated that the patient had the disease; however, the patient did not have the disease.
* **False Negative** - Your test (neural network) indicated that the patient did not have the disease; however, the patient did have the disease.
* **True Positive** - Your test (neural network) correctly identified that the patient had the disease.
* **True Negative** - Your test (neural network) correctly identified that the patient did not have the disease.
Types of errors:

Neural networks classify in terms of probability of it being positive. However, at what probability do you give a positive result? Is the cutoff 50%? 90%? Where you set this cutoff is called the threshold. Anything above the cutoff is positive, anything below is negative. Setting this cutoff allows the model to be more sensitive or specific:
More info on Sensitivity vs Specificity: [Khan Academy](https://www.youtube.com/watch?v=Z5TtopYX1Gc)
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import math
mu1 = -2
mu2 = 2
variance = 1
sigma = math.sqrt(variance)
x1 = np.linspace(mu1 - 5*sigma, mu1 + 4*sigma, 100)
x2 = np.linspace(mu2 - 5*sigma, mu2 + 4*sigma, 100)
plt.plot(x1, stats.norm.pdf(x1, mu1, sigma)/1,color="green")
plt.plot(x2, stats.norm.pdf(x2, mu2, sigma)/1,color="red")
plt.axvline(x=-2,color="black")
plt.axvline(x=0,color="black")
plt.axvline(x=+2,color="black")
plt.text(-2.7,0.55,"Sensitive")
plt.text(-0.7,0.55,"Balanced")
plt.text(1.7,0.55,"Specific")
plt.ylim([0,0.53])
plt.xlim([-5,5])
plt.legend(['Negative','Positive'])
plt.yticks([])
#plt.set_yticklabels([])
plt.show()
from scipy.stats import zscore
# Prepare data - apply z-score to ALL x columns
# Only do this if you have no categoricals (and are sure you want to use z-score across the board)
x_columns = df.columns.drop('diagnosis').drop('id')
for col in x_columns:
df[col] = zscore(df[col])
# Convert to numpy - Regression
x = df[x_columns].values
y = df['diagnosis'].map({'M':1,"B":0}).values # Binary classification, M is 1 and B is 0
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
# Plot a confusion matrix.
# cm is the confusion matrix, names are the names of the classes.
def plot_confusion_matrix(cm, names, title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(names))
plt.xticks(tick_marks, names, rotation=45)
plt.yticks(tick_marks, names)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# Plot an ROC. pred - the predictions, y - the expected output.
def plot_roc(pred,y):
fpr, tpr, _ = roc_curve(y, pred)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
plt.show()
```
### ROC Chart Example
```
# Classification neural network
import numpy as np
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
# Split into train/test
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=42)
model = Sequential()
model.add(Dense(100, input_dim=x.shape[1], activation='relu',kernel_initializer='random_normal'))
model.add(Dense(50,activation='relu',kernel_initializer='random_normal'))
model.add(Dense(25,activation='relu',kernel_initializer='random_normal'))
model.add(Dense(1,activation='sigmoid',kernel_initializer='random_normal'))
model.compile(loss='binary_crossentropy',
optimizer=tensorflow.keras.optimizers.Adam(),
metrics =['accuracy'])
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-3,
patience=5, verbose=1, mode='auto', restore_best_weights=True)
model.fit(x_train,y_train,validation_data=(x_test,y_test),callbacks=[monitor],verbose=2,epochs=1000)
pred = model.predict(x_test)
plot_roc(pred,y_test)
```
### Multiclass Classification Error Metrics
The following sections will examine several metrics for evaluating classification error. The following classification neural network will be used to evaluate.
```
import pandas as pd
from scipy.stats import zscore
# Read the data set
df = pd.read_csv(
"https://data.heatonresearch.com/data/t81-558/jh-simple-dataset.csv",
na_values=['NA','?'])
# Generate dummies for job
df = pd.concat([df,pd.get_dummies(df['job'],prefix="job")],axis=1)
df.drop('job', axis=1, inplace=True)
# Generate dummies for area
df = pd.concat([df,pd.get_dummies(df['area'],prefix="area")],axis=1)
df.drop('area', axis=1, inplace=True)
# Missing values for income
med = df['income'].median()
df['income'] = df['income'].fillna(med)
# Standardize ranges
df['income'] = zscore(df['income'])
df['aspect'] = zscore(df['aspect'])
df['save_rate'] = zscore(df['save_rate'])
df['age'] = zscore(df['age'])
df['subscriptions'] = zscore(df['subscriptions'])
# Convert to numpy - Classification
x_columns = df.columns.drop('product').drop('id')
x = df[x_columns].values
dummies = pd.get_dummies(df['product']) # Classification
products = dummies.columns
y = dummies.values
# Classification neural network
import numpy as np
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
# Split into train/test
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=42)
model = Sequential()
model.add(Dense(100, input_dim=x.shape[1], activation='relu',kernel_initializer='random_normal'))
model.add(Dense(50,activation='relu',kernel_initializer='random_normal'))
model.add(Dense(25,activation='relu',kernel_initializer='random_normal'))
model.add(Dense(y.shape[1],activation='softmax',kernel_initializer='random_normal'))
model.compile(loss='categorical_crossentropy',
optimizer=tensorflow.keras.optimizers.Adam(),
metrics =['accuracy'])
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-3, patience=5,
verbose=1, mode='auto', restore_best_weights=True)
model.fit(x_train,y_train,validation_data=(x_test,y_test),callbacks=[monitor],verbose=2,epochs=1000)
```
### Calculate Classification Accuracy
Accuracy is the number of rows where the neural network correctly predicted the target class. Accuracy is only used for classification, not regression.
$ accuracy = \frac{c}{N} $
Where $c$ is the number correct and $N$ is the size of the evaluated set (training or validation). Higher accuracy numbers are desired.
As we just saw, by default, Keras will return the percent probability for each class. We can change these prediction probabilities into the actual iris predicted with **argmax**.
```
pred = model.predict(x_test)
pred = np.argmax(pred,axis=1) # raw probabilities to chosen class (highest probability)
```
Now that we have the actual iris flower predicted, we can calculate the percent accuracy (how many were correctly classified).
```
from sklearn import metrics
y_compare = np.argmax(y_test,axis=1)
score = metrics.accuracy_score(y_compare, pred)
print("Accuracy score: {}".format(score))
```
### Calculate Classification Log Loss
Accuracy is like a final exam with no partial credit. However, neural networks can predict a probability of each of the target classes. Neural networks will give high probabilities to predictions that are more likely. Log loss is an error metric that penalizes confidence in wrong answers. Lower log loss values are desired.
The following code shows the output of predict_proba:
```
from IPython.display import display
# Don't display numpy in scientific notation
np.set_printoptions(precision=4)
np.set_printoptions(suppress=True)
# Generate predictions
pred = model.predict(x_test)
print("Numpy array of predictions")
display(pred[0:5])
print("As percent probability")
print(pred[0]*100)
score = metrics.log_loss(y_test, pred)
print("Log loss score: {}".format(score))
pred = np.argmax(pred,axis=1) # raw probabilities to chosen class (highest probability)
```
[Log loss](https://www.kaggle.com/wiki/LogarithmicLoss) is calculated as follows:
$ \mbox{log loss} = -\frac{1}{N}\sum_{i=1}^N {( {y}_i\log(\hat{y}_i) + (1 - {y}_i)\log(1 - \hat{y}_i))} $
The log function is useful to penalizing wrong answers. The following code demonstrates the utility of the log function:
```
%matplotlib inline
from matplotlib.pyplot import figure, show
from numpy import arange, sin, pi
#t = arange(1e-5, 5.0, 0.00001)
#t = arange(1.0, 5.0, 0.00001) # computer scientists
t = arange(0.0, 1.0, 0.00001) # data scientists
fig = figure(1,figsize=(12, 10))
ax1 = fig.add_subplot(211)
ax1.plot(t, np.log(t))
ax1.grid(True)
ax1.set_ylim((-8, 1.5))
ax1.set_xlim((-0.1, 2))
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.set_title('log(x)')
show()
import numpy as np
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
# Compute confusion matrix
cm = confusion_matrix(y_compare, pred)
np.set_printoptions(precision=2)
print('Confusion matrix, without normalization')
print(cm)
plt.figure()
plot_confusion_matrix(cm, products)
# Normalize the confusion matrix by row (i.e by the number of samples
# in each class)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print('Normalized confusion matrix')
print(cm_normalized)
plt.figure()
plot_confusion_matrix(cm_normalized, products, title='Normalized confusion matrix')
plt.show()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/shahd1995913/Tahalf-Mechine-Learning-DS3/blob/main/Tasks/ML1_S3_Assignment.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# ML1-S3 (Assignment)
----
## Problem 1: Polynomial Regression
---
You want to buy huge amount of chocolates to build a chocolate house, every room in this chocolate house should be made of different types of high quality chocolates. There is only one place to buy this amount of chocolate, the "Chocolate City" of 1000 different factories and famous for its cheating prices. Chocolate Merchants Association has provided a price sheet `chocolate_data.csv` to beat the deception for 10 types of quality, the prices are per kg, but there are quality types in the market that are not mentioned in the sheet. Build a **`regression model`** that predicts the price per kilogram, and says if you want 1000kg with a quality type called "3.5" what is the price?
```
# Import required libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# to make sure all students have the same results
random_val = 123
#import the train test split function
from sklearn.model_selection import train_test_split
#import the linear regression function
from sklearn.linear_model import LinearRegression
#import metrics
from sklearn import metrics
dataset_path = '/content/data.csv'
df = pd.read_csv(dataset_path)
df.head()
df.price
df.describe()
#Setting the value for X and Y
x = df[['quality', 'chocolate']]
y = df['price']
#Splitting the dataset
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 10)
#Fitting the Multiple Linear Regression model
mlr = LinearRegression()
mlr.fit(x_train, y_train)
#Intercept and Coefficient
print("Intercept: ", mlr.intercept_)
print("Coefficients:")
list(zip(x, mlr.coef_))
# Regression Equation: Price = 2731.756756756756+ ( -424.099099099099 * quality) + ( 424.09909909909913* chocolate)
#Prediction of test set
y_pred_mlr= mlr.predict(x_test)
#Predicted values
print("Prediction for test set: {}".format(y_pred_mlr))
#Actual value and the predicted value
mlr_diff = pd.DataFrame({'Actual value': y_test, 'Predicted value': y_pred_mlr})
mlr_diff.head()
#Model Evaluation
from sklearn import metrics
meanAbErr = metrics.mean_absolute_error(y_test, y_pred_mlr)
meanSqErr = metrics.mean_squared_error(y_test, y_pred_mlr)
rootMeanSqErr = np.sqrt(metrics.mean_squared_error(y_test, y_pred_mlr))
print('R squared: {:.2f}'.format(mlr.score(x,y)*100))
print('Mean Absolute Error:', meanAbErr)
print('Mean Square Error:', meanSqErr)
print('Root Mean Square Error:', rootMeanSqErr)
new_df=df.copy()
x = new_df['quality']
y = new_df['price']
print(new_df.head())
def linear_regression(x, y):
N = len(x)
x_mean = x.mean()
y_mean = y.mean()
B1_num = ((x - x_mean) * (y - y_mean)).sum()
B1_den = ((x - x_mean)**2).sum()
B1 = B1_num / B1_den
B0 = y_mean - (B1*x_mean)
reg_line = 'y = {} + {}β'.format(B0, round(B1, 3))
return (B0, B1, reg_line)
N = len(x)
x_mean = x.mean()
y_mean = y.mean()
B1_num = ((x - x_mean) * (y - y_mean)).sum()
B1_den = ((x - x_mean)**2).sum()
B1 = B1_num / B1_den
B0 = y_mean - (B1 * x_mean)
def corr_coef(x, y):
N = len(x)
num = (N * (x*y).sum()) - (x.sum() * y.sum())
den = np.sqrt((N * (x**2).sum() - x.sum()**2) * (N * (y**2).sum() - y.sum()**2))
R = num / den
return R
B0, B1, reg_line = linear_regression(x, y)
print('Regression Line: ', reg_line)
R = corr_coef(x, y)
print('Correlation Coef.: ', R)
print('"Goodness of Fit": ', R**2)
plt.figure(figsize=(12,5))
plt.scatter(x, y, s=300, linewidths=1, edgecolor='black')
plt.title('How quality Affects Price')
plt.xlabel('quality', fontsize=15)
plt.ylabel('Price', fontsize=15)
plt.plot(x, B0 + B1*x, c = 'r', linewidth=5, alpha=.5, solid_capstyle='round')
plt.scatter(x=x.mean(), y=y.mean(), marker='*', s=10**2.5, c='r')
import numpy as np
import matplotlib.pyplot as plt
def estimate_coef(x, y):
# number of observations/points
n = np.size(x)
# mean of x and y vector
m_x = np.mean(x)
m_y = np.mean(y)
# calculating cross-deviation and deviation about x
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_x
# calculating regression coefficients
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return (b_0, b_1)
def plot_regression_line(x, y, b):
# plotting the actual points as scatter plot
plt.scatter(x, y, color = "m",
marker = "o", s = 30)
# predicted response vector
y_pred = b[0] + b[1]*x
# plotting the regression line
plt.plot(x, y_pred, color = "g")
# putting labels
plt.xlabel('quality')
plt.ylabel('price')
# function to show plot
plt.show()
def main():
# observations / data
x = np.array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
y = np.array([450, 500, 600, 800, 1100, 1500, 2000, 3000, 5000, 10000])
# estimating coefficients
b = estimate_coef(x, y)
print("Estimated coefficients:\nb0 = {} \
\nb1 = {}".format(b[0], b[1]))
print("Estimated eqution: Price = {} + \
quality* {}".format(b[0], b[1]))
# plotting regression line
quality=(int(input("Please Enter the quality ??")))
price= 6943.333333333333 +(-808.7878787878788*quality)
print("price is :",price )
plot_regression_line(x, y, b)
if __name__ == "__main__":
main()
```
## Problem 2: SVR
---
Build **`SVR model`** on the chocolate dataset `chocolate_data.csv` and provide the output graph showing the predictions of prices vs quality levels.
```
### Start Your Code Here ####
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
### End Your Code Here ####
dataset = pd.read_csv('/content/data.csv')
X = dataset.iloc[:,1:2].values.astype(float)
y = dataset.iloc[:,2:3].values.astype(float)
#3 Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
#4 Fitting the Support Vector Regression Model to the dataset
# Create your support vector regressor here
from sklearn.svm import SVR
# most important SVR parameter is Kernel type. It can be #linear,polynomial or gaussian SVR. We have a non-linear condition #so we can select polynomial or gaussian but here we select RBF(a #gaussian type) kernel.
regressor = SVR(kernel='rbf')
regressor.fit(X,y)
#5 Predicting a new result
y_pred = regressor.predict(6)
#6 Visualising the Support Vector Regression results
plt.scatter(X, y, color = 'magenta')
plt.plot(X, regressor.predict(X), color = 'green')
plt.title('Truth or Bluff (Support Vector Regression Model)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
#3 Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
#5 Predicting a new result
y_pred = sc_y.inverse_transform ((regressor.predict (sc_X.transform(np.array([[6.5]])))))
import numpy as np
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
dataset = pd.read_csv('/content/data.csv')
X = dataset.iloc[:, 1:2].values.reshape(1,-1)
y = dataset.iloc[:, 2].values.reshape(1,-1)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
#1 Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#2 Importing the dataset
dataset = pd.read_csv('/content/data.csv')
X = dataset.iloc[:,1:2].values.astype(float)
y = dataset.iloc[:,2:3].values.astype(float)
#3 Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
#4 Fitting the Support Vector Regression Model to the dataset
# Create your support vector regressor here
from sklearn.svm import SVR
# most important SVR parameter is Kernel type. It can be #linear,polynomial or gaussian SVR. We have a non-linear condition #so we can select polynomial or gaussian but here we select RBF(a #gaussian type) kernel.
regressor = SVR(kernel='rbf')
regressor.fit(X,y)
#5 Predicting a new result
# y_pred = regressor.predict(6.5)
# y_pred = regressor.predict(np.array([6.5]))
y_pred = sc_y.inverse_transform(regressor.predict(sc_X.transform([[6.5]])).reshape(1,-1))
#6 Visualising the Support Vector Regression results
plt.scatter(X, y, color = 'magenta')
plt.plot(X, regressor.predict(X), color = 'green')
plt.title('Truth or Bluff (Support Vector Regression Model)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
#3 Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(X)
y = sc_y.fit_transform(y)
#5 Predicting a new result
# y_pred = sc_y.inverse_transform ((regressor.predict (sc_X.transform(np.array([[6.5]])))))
# Predicting a new result
# some_data_array=1
# y_pred = regressor.predict(some_data_array)
y_pred = sc_y.inverse_transform(regressor.predict(sc_X.transform([[6.5]])).reshape(1,-1))
#6 Visualising the Regression results (for higher resolution and #smoother curve)
X_grid = np.arange(min(X), max(X), 0.1)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = "red")
plt.plot(X_grid, regressor.predict(X_grid), color = "blue")
plt.title("Truth or Bluff (Support Vector Regression Model(High Resolution))")
plt.xlabel("Position level")
plt.ylabel("Salary")
plt.show()
```
| github_jupyter |
Loan Sarazin & Anna Marizy
# Mise en oeuvre de l'algorithme EM
## Calcul de la valeur de la densité de probabilité d'un mélange de gaussienne en un point
### Les paramétres de la fonction gm_pdf
<ul>
<li>x : le point où l'on calcule la valeur de la densitè</li>
<li>mu : le vecteur des moyennes des gaussiennes</li>
<li>sigma : le vecteur des écart-types des gaussiennes</li>
<li>p : le vecteur des probabilitès de la loi multinomiale associèe</li>
</ul>
```
import numpy as np
import pandas as pd
from scipy.stats import norm
from scipy.stats import uniform
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
def gm_pdf(x, mu, sigma, p):
#Initialisation de la variable de sortie
resultat = 0.0
#Contrôle de la cohérence des paramètres d'entrée
#Le vecteur de moyenne doit avoir la même longueur que le vecteur p
if len(mu) != len(p):
print('Erreur de dimension sur la moyenne')
# Le vecteur des écart-types doit avoir la même longueur que le vecteur p
elif len(sigma) != len(p):
print('Erreur de dimension sur les écarts-types')
else:
# Calcul de la valeur de la densité
for i in range(0, len(p)):
resultat = resultat + p[i] * norm.pdf(x, mu[i], sigma[i])
return resultat
```
## Génération de nombre aléatoire suivant un mélange de gaussienne
Dans un mélange de gaussienne chaque densité de probabilité correspondant à une loi normale est pondérée par un coefficient plus petit que un.
La somme de tous ces coefficients est égale à un. Une variable aléatoire qui suit une loi normale suit donc une des lois normales du mélange avec une probabilité égale au coefficient de pondération de cette même loi normale. Pour générer un échantillon suivant une loi normale, il faut donc procéder en deux étapes :
<ol>
<li>Tirer aléatoirement un nombre entre 1 et N (le nombre de gaussiennes du mélange) suivant une loi mumltinomiale définie par les coefficients du mélange.</li>
<li>Une fois ce nombre obtenu, on génère le nombre suivant la loi normale associée.</li>
</ol>
### Les paramètres de la fonction gm_rnd
<ul>
<li>mu : le vecteur des moyennes des gaussiennes</li>
<li>sigma : le vecteur des écart-types des gaussiennes</li>
<li>p : le vecteur des probabilités de la loi multinomiale associée</li>
</ul>
```
def gm_rnd(mu, sigma, p):
# Initialisation de la variable de sortie
resultat = 0.0
#Contrôle de la cohérence des paramètres d'entrée
#Le vecteur de moyenne doit avoir la même longueur que le vecteur p
if len(mu) != len(p):
print('Erreur de dimension sur la moyenne')
# Le vecteur des écart-types doit avoir la même longueur que le vecteur p
elif len(sigma) != len(p):
print('Erreur de dimension sur sur les écarts-types')
else:
#Génération de l'échantillon
# On échantillonne suivant une loi uniforme sur [0,1]
u = uniform.rvs(loc = 0.0, scale = 1.0, size = 1)
# % Chaque test suivant permet de définir un intervalle sur lequel la
# probabilité d'appartenance de la variable uniforme est égale à l'une des
# probabilités définie dans le vecteur p. Lorsque u appartient à l'un de
# ces intervalles, c'est équivalent à avoir générer une variable aléatoire
# suivant l'un des éléments de p. Par exemple, pour le premier test
# ci-dessous, la probabilité que u appartienne à l'intervalle [0,p[0][ est
# égale à p[0] puisque u suit une loi uniforme. Donc si u appartient à
# [0,p[0][ cela est équivalent à avoir tirer suivant l'événement de probabilité p[0].
if u < p[0]: # On test si on a généré un événement de probabilité p[0]
resultat = sigma[0] * norm.rvs(loc = 0, scale = 1, size = 1) + mu[0]
# Pour générer suivant une loi normale quelconque, il suffit de multiplier
# une variable normale centrée réduite (moyenne nulle et écart-type égal à 1)
# par l'écart-type désité et d'additionner la moyenne désirée au produit précédent.
for i in range(1, len(p)):
if (u > np.sum(p[0:i])) and (u <= np.sum(p[0:i+1])): # On test si on a généré
# un événement de probabilité p[i]
resultat = sigma[i] * norm.rvs(loc = 0.0, scale = 1.0, size = 1) + mu[i]
# Pour générer suivant une loi normale quelconque, il suffit de multiplier
# une variable normale centrée réduite (moyenne nulle et écart-type égal à 1)
# par l'écart-type désité et d'additionner la moyenne désirée au produit précédent.
return resultat
```
### Les paramètres de la densité de mélange de gaussienne
```
p = np.array([0.2, 0.5, 0.3])
mu = np.array([-5.0, 0.0, 6.0])
sigma = np.array([1.0, 0.5, 1.0])
```
### Calcul de la densité de probabilité du mélange de gaussienne
```
x = np.arange(-20,20, 0.001)
pointPdf = gm_pdf(x, mu, sigma, p)
```
### Tracé de la densité de probabilité du mélange de gaussienne
```
plt.plot(x, pointPdf, 'r-')
plt.title('Densite de melange')
plt.xlabel('x')
plt.ylabel('pdf')
plt.grid()
plt.show()
```
### Génération d'échantillons suivant densité de probabilité du mélange de gaussienne
```
nbEchantillon = 1000
donnees = np.array(nbEchantillon*[0],dtype = float)
for i in range(0, nbEchantillon, 1):
donnees[i] = gm_rnd(mu, sigma, p)
```
### Tracé des échantillons
```
plt.plot(donnees, 'b')
plt.title('Melange de gausiennes')
plt.xlabel('Index')
plt.ylabel('Donnees')
plt.grid()
plt.show()
```
### Tracé des échantillons
```
plt.plot(donnees, 'g.')
plt.title('Melange de gausiennes')
plt.xlabel('Index')
plt.ylabel('Donnees')
plt.grid()
plt.show()
```
### Tracé de l'histogramme des échantillons
```
plt.hist(donnees, bins = 30, density = False, edgecolor = "red")
plt.title('Melange de gausiennes')
plt.xlabel('Donnees')
plt.ylabel('Index')
plt.show()
```
### Tracé de l'histogramme des échantillons
```
plt.hist(donnees, bins = 30, density = True, color = 'yellow', edgecolor = "red")
plt.title('Melange de gausiennes')
plt.xlabel('Donnees')
plt.ylabel('Index')
plt.show()
```
### L'algorithme EM
```
nbMaxIterations = 40
mu_em = np.array([-0.0156, -4.9148, 5.9692])
sigma_em = np.array([1.3395, 1.3395, 1.3395])
alpha_em = np.array([0.4800, 0.2200, 0.3000])
def EM_algorithm(nbMaxIterations, mu_em, sigma_em, alpha_em, donnees):
nbIteration = 1 #Initialisation de la variable d'arrêt
nbComposante = len(alpha_em) #Nombre de composantes du mélange
nbDonnees = len(donnees) #Nombre de données
p = np.zeros(shape=(nbComposante, nbDonnees))
#Déclaration et initialisation de la matrice qui va contenir les probabilités
#p(k|x,theta_courant)
alpha_em_new = alpha_em
sigma_em_carre_new = sigma_em
mu_em_new = mu_em
donneesP = np.zeros(shape=(nbEchantillon))
while nbIteration < nbMaxIterations:
#Création d'un array avec les lois à postériori
for n in range(0, nbDonnees, 1):
for k in range(0, nbComposante, 1):
p[k, n] = alpha_em[k] * norm.pdf(x = donnees[n], loc = mu_em[k], scale = sigma_em[k])
p[:, n] = p[:, n] / np.sum(p[:, n])
for k in range(0, nbComposante, 1):
alpha_em_new[k] = np.sum(p[k,:]) / nbDonnees #Moyenne de la loi de la gaussienne k
for n in range(0, nbDonnees, 1):
donneesP[n] = donnees[n] * p[k, n]
mu_em_new[k] = np.sum(donneesP) / np.sum(p[k, :])
for n in range(nbDonnees):
donneesP[n] = ((donnees[n] - mu_em_new[k]) ** 2) * p[k, n]
sigma_em_carre_new[k] = np.sum(donneesP) / np.sum(p[k, :])
mu_em = mu_em_new
sigma_em = np.sqrt(sigma_em_carre_new)
alpha_em = alpha_em_new
nbIteration = nbIteration + 1
return mu_em, sigma_em, alpha_em
mu_em, sigma_em, alpha_em = EM_algorithm(nbMaxIterations, mu_em, sigma_em, alpha_em, donnees)
print('Les paramètres estimés sont : ')
print('Moyennes des composantes du mélange', mu_em)
print('Ecrat type des composantes du mélange', sigma_em)
print('Probabilités des composantes du mélange', alpha_em)
print('La somme des probabilités des composantes du mélange vaut : ', np.sum(alpha_em))
plt.plot(x, pointPdf, 'r-', label = 'Originale')
plt.title('Densite de melange')
plt.xlabel('x')
plt.ylabel('pdf')
pointPdfEstime = gm_pdf(x, mu_em, sigma_em, alpha_em)
plt.plot(x, pointPdfEstime, 'b-', label = 'Estimée')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.show()
#Comparaison en faisant varier les valeurs d'initialisation
plt.plot(x, pointPdf, 'r-', label = 'Originale')
plt.title('Densite de melange')
plt.xlabel('x')
plt.ylabel('pdf')
pointPdfEstime = gm_pdf(x, mu_em, sigma_em, alpha_em)
plt.plot(x, pointPdfEstime, 'b-', label = 'Estimée init')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
mu_1 = np.array([0, -5, 6])
sigma_1 = np.array([1.3395, 1.3395, 1.3395])
alpha_1 = np.array([0.4800, 0.2200, 0.3000])
mu_1, sigma_1, alpha_1 = EM_algorithm(nbMaxIterations, mu_1, sigma_1, alpha_1, donnees)
pointPdfEstime = gm_pdf(x, mu_1, sigma_1, alpha_1)
plt.plot(x, pointPdfEstime, 'b-', label = 'Estimée 1')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.show()
#Comparaison en faisant varier les valeurs d'initialisation - nombre d'itérations
#Conservation des moyennes arrondies
mu_1 = np.array([0, -5, 6])
sigma_1 = np.array([1.3395, 1.3395, 1.3395])
alpha_1 = np.array([0.4800, 0.2200, 0.3000])
mu_2, sigma_2, alpha_2 = EM_algorithm(10, mu_1, sigma_1, alpha_1, donnees)
mu_3, sigma_3, alpha_3 = EM_algorithm(50, mu_1, sigma_1, alpha_1, donnees)
plt.figure(figsize = (10, 5))
plt.plot(x, pointPdf, 'r-', label = 'Originale')
plt.title('Densite de melange')
plt.xlabel('x')
plt.ylabel('pdf')
pointPdfEstime = gm_pdf(x, mu_2, sigma_2, alpha_2)
plt.plot(x, pointPdfEstime, label = 'Itérations = 10')
pointPdfEstime = gm_pdf(x, mu_3, sigma_3, alpha_3)
plt.plot(x, pointPdfEstime, label = 'Itérations = 40')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.show()
#Comparaison en faisant varier les valeurs d'initialisation - nombre d'itérations
#Retour aux valeurs initiales des moyennes
mu_1 = np.array([-0.0156, -4.9148, 5.9692])
sigma_1 = np.array([1.3395, 1.3395, 1.3395])
alpha_1 = np.array([0.4800, 0.2200, 0.3000])
mu_2, sigma_2, alpha_2 = EM_algorithm(10, mu_1, sigma_1, alpha_1, donnees)
mu_3, sigma_3, alpha_3 = EM_algorithm(50, mu_1, sigma_1, alpha_1, donnees)
plt.figure(figsize = (10, 5))
plt.plot(x, pointPdf, 'r-', label = 'Originale')
plt.title('Densite de melange')
plt.xlabel('x')
plt.ylabel('pdf')
pointPdfEstime = gm_pdf(x, mu_2, sigma_2, alpha_2)
plt.plot(x, pointPdfEstime, label = 'Itérations = 10')
pointPdfEstime = gm_pdf(x, mu_3, sigma_3, alpha_3)
plt.plot(x, pointPdfEstime, label = 'Itérations = 40')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.show()
```
### Conclusion
On peut voir qu'en faisant varier très légèrement les paramètres d'initialisation, les estimations diffèrent beaucoup.
Le nombre d'itérations a une influence négligeable lorsque les paramètres sont optimaux. En revanche, si les paramètres d'initialisation sont légèrement modifiés, et donc ne sont plus optimaux, le nombre d'itérations a une influence forte sur les résultats d'estimation.
# Algorithme EM avec les données Galaxy
```
data = pd.read_excel('2122_Galaxy.xlsx', header = None)
donnees = data.to_numpy()
plt.hist(donnees, bins = 30, density = False, edgecolor = "red")
plt.title('Données Galaxy')
plt.xlabel('Donnees')
plt.ylabel('Vitesse')
plt.show()
nb_vel = donnees.size
mu, sigma = np.mean(donnees), np.var(donnees)
print("La moyenne des vitesses vaut : {:.2f}".format(mu))
print("La variance des vitesses vaut : {:.2f}".format(sigma))
vel_min = donnees.min()
vel_max = donnees.max()
donnees.shape
```
## Tracé des vitesses
```
plt.figure()
plt.plot(donnees, '.')
```
## Détermination du nombre de gaussiennes
Utilisation de la fonction gaussian Mixture
```
#3 gaussiennes
gm = GaussianMixture(n_components=3).fit(donnees)
# la méthode fit de GaussianMixture utilise l'algorithme EM.
mu = gm.means_.ravel()
alpha = gm.weights_
sigma = np.sqrt(gm.covariances_)
print("Les moyennes des Gaussiennes composantes sont les suivantes : \n")
print(mu)
print("\nLes poids alpha sont les suivants : \n")
print(alpha)
x = np.arange(9000,35000, 1000)
pointPdfEstime = gm_pdf(x, mu, sigma, alpha)
plt.figure()
plt.hist(donnees, bins = 30, density = True, edgecolor = "red")
plt.plot(x, pointPdfEstime.T, 'b-', label = 'Estimation')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.show()
#2 Gaussiennes
gm = GaussianMixture(n_components=4, covariance_type='full').fit(donnees.reshape(-1, 1))
nbMaxIterations = 40
mu_em_mod = np.round(gm.means_.ravel(), 4)
sigma_em_mod = np.round(np.sqrt(gm.covariances_.T.ravel()), 4)
alpha_em_mod = gm.weights_
print('Les paramètres estimés sont : ')
print('Moyennes des composantes du mélange', mu_em_mod)
print('Ecart type des composantes du mélange', sigma_em_mod)
print('Probabilités des composantes du mélange', alpha_em_mod)
pointPdf = gm_pdf(x, mu_em_mod, sigma_em_mod, alpha_em_mod)
plt.figure
plt.hist(donnees, bins = 40, density = True, color='skyblue', edgecolor = "red", label = 'Vitesses')
plt.plot(x, pointPdf, 'b-', label = 'Estimée')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.xlabel('Donnees')
plt.ylabel('pdf')
plt.title('Melange de gausiennes')
plt.show()
```
## Comparaison des résultats en fonction du nombre de Gaussiennes
```
x = np.arange(vel_min-100, vel_max+100, 5)
nb_gauss = [2, 3, 4, 5,6]
plt.figure(figsize = (15, 8))
plt.hist(donnees, bins = 40, density = True, color='skyblue', edgecolor = "red", label = 'Vitesses')
for i in nb_gauss:
gm = GaussianMixture(n_components=i, covariance_type='full', n_init = 10).fit(donnees.reshape(-1, 1))
nbMaxIterations = 40
mu_em_mod = np.round(gm.means_.ravel(), 4)
sigma_em_mod = np.round(np.sqrt(gm.covariances_.T.ravel()), 4)
alpha_em_mod = gm.weights_
pointPdf = gm_pdf(x, mu_em_mod, sigma_em_mod, alpha_em_mod)
plt.plot(x, pointPdf, label = f'Estimée, {i} gaussiennes', linewidth = 3)
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.xlabel('Donnees')
plt.ylabel('pdf')
plt.title('Melange de gausiennes')
plt.show()
```
On peut voir sur la graphique ci-dessus que si on augmente trop le nombre de gaussiennes, on donne un poids très important à des données qui sont non significatives. Par exemple, avec 6 gaussiennes, on obtient un pic principal autour d'une valeur concentrant peu de données.
Quand on utilise un nombre faible de gaussiennes, l'estimation est très proche de la réalité pour la majorité des données. Cependant, l'estimation ne prend pas en compte les données extrêmes ou les petits groupes de données.
Il s'agit donc de trouver un compromis. D'après le graphique ci-dessus, on pourrait conclure que le nombre idéal de Gaussiennes à utiliser est de quatre. En effet, à partir de 5 gaussiennes, un pic se créé autour d'un petit groupe de données. Inversement, en dessous de 4 gaussiennes, l'estimation s'éloigne de la réalité pour les données 'centrales' (c'est-à-dire le plus gros groupe de données) en faisant disparaître les deux groupes de données.
## Algorithme EM appliqué aux données Galaxy
```
#Détermination des paramètres d'initialisation de manière empirique (lecture histogramme et exécution de l'algorithme EM)
moy_em_emp = np.array([9000, 20000, 23000, 33000])
sum_moy = np.sum(moy_em_emp)
ecart_type_em_emp = np.array([400, 1000, 1000, 400])
alpha_em_emp =moy_em_emp/sum_moy
#Algo EM du TP pour les paramètres définis ci-dessus
mu_emp, ecart_type_emp, alpha_emp = EM_algorithm(40, moy_em_emp, ecart_type_em_emp, alpha_em_emp, donnees)
#Gaussian mixture pour 4 gaussiennes
gm = GaussianMixture(n_components=4, covariance_type='full').fit(donnees.reshape(-1, 1))
nbMaxIterations = 40
mu_em_mod = np.round(gm.means_.ravel(), 4)
sigma_em_mod = np.round(np.sqrt(gm.covariances_.T.ravel()), 4)
alpha_em_mod = gm.weights_
pointPdf = gm_pdf(x, mu_em_mod, sigma_em_mod, alpha_em_mod)
plt.figure(figsize = (15, 8))
plt.hist(donnees, bins = 40, density = True, color='skyblue', edgecolor = "red", label = 'Vitesses')
plt.title('Densite de melange')
plt.xlabel('x')
plt.ylabel('pdf')
pointPdfEstime = gm_pdf(x, mu_emp, ecart_type_emp, alpha_emp)
plt.plot(x, pointPdfEstime, label = 'Itérations = 40')
plt.plot(x, pointPdf, 'b-', label = 'Estimation "optimale" Gaussian mixture')
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
plt.show()
```
Nous avons rencontré des problèmes de stabilité lors de l'éxécution de l'algorithme EM. Cela pourrait provenir notamment du fait ques les paramètres d'initialisation sont déterminés empiriquement et ne sont pas du tout optimaux. D'autre part, nous avons finalement assez peu de données, 81 valeurs, contrairement au premier exemple qui en contenait 1000 et pour laquelle nous n'avions pas rencontré ce type de problème.
En effet, on a parfois une seule gaussienne sans changer les paramètres ou les itérations.
## Conclusion du TP
L'algorithme EM mis en oeuvre dans la fonction Gaussian Mixture permet d'estimer les données sans avoir de connaissances à priori. Or, nous avons vu que ces connaissances sont très difficiles à obtenir. Une piste pour les déterminer serait de séparer les groupes de données apparents et calculer séparement moyenne et écart-type. Cependant, certains groupes de données sont très proches, comme dans le jeu de données Galaxy, ce qui peut compliquer le processus de séparation.
| github_jupyter |
```
from pathlib import Path
import math
from itertools import combinations_with_replacement, islice
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.ticker
import matplotlib.colors
import matplotlib.cm
from tqdm.auto import tqdm
import numpy as np
import numpy
import torch
import torch.nn as nn
```
# MNIST tanh
```
BINS = 8
LAYERS = [(25, 6), (6, 6), (6, 6), (6, 5)]
ACTIVATION = nn.Tanh()
RUNS = 3
FREQUENCY = 20 # epochs per measurement
EPOCHS = 500
BATCH_SIZE = 50
print("Total Measurements: {}".format(EPOCHS / FREQUENCY))
top_str = ""
for i, l in enumerate(LAYERS):
if i == len(LAYERS)-1:
in_w = l[0]
out_w = l[1]
top_str += f"{in_w}-{out_w}"
else:
in_w = l[0]
out_w = l[1]
top_str += f"{in_w}-"
exp_dir = Path('/home/eric/Code/deep-ei-private/runs/absolute-final/mnist25-6-6-6-5tanh')
run_folders = [exp_dir / f"run{i}-frames" for i in range(1, RUNS+1)]
# run_folders = [here / "run1-frames"]
runs_frames = [list(run.glob('*.frame')) for run in run_folders]
print(run_folders)
all(d.exists() for d in run_folders)
def get_measures(path_to_frame):
frame = torch.load(path_to_frame)
measure_names = [
'batches',
'epochs',
'training_loss',
'testing_loss',
'training_accuracy',
'testing_accuracy',
'model'
]
for i in range(len(LAYERS)):
start_i = end_i = i
# for (start_i, end_i) in combinations_with_replacement(range(len(LAYERS)), 2):
measure_names.append(f"pairwise-ei:{start_i}-{end_i}")
measure_names.append(f"pairwise-sensitivity:{start_i}-{end_i}")
measure_names.append(f"vector-ei:{start_i}-{end_i}")
measures = {}
for name in measure_names:
if type(frame[name]) is torch.Tensor:
measures[name] = frame[name].item()
else:
measures[name] = frame[name]
return measures
runs_datapoints = [[get_measures(path) for path in run_frames] for run_frames in runs_frames]
for run_datapoints in runs_datapoints:
run_datapoints.sort(key=lambda f: f['batches'])
ltl = {
0: 'X',
1: 'T1',
2: 'T2',
3: 'T3',
4: 'Y'
}
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 2, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.text(0.5, -0.45, "(c)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax.set_title("MNIST", fontsize=8)
ax = plt.subplot(1, 2, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"vector-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI$ (bits)',fontsize=8)
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.yaxis.labelpad = 0
ax.set_title("MNIST", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(d)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/mnist-ei-whole-timeseries.pdf', dpi=100)
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 2, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.set_title("MNIST", fontsize=8)
ax.text(0.5, -0.45, "(c)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 2, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"pairwise-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI_{parts}$ (bits)',fontsize=8)
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.yaxis.labelpad = 0
ax.set_title("MNIST", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(d)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/mnist-ei-parts-timeseries.pdf', dpi=100)
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 3, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.yaxis.labelpad = 0
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.set_title("MNIST", fontsize=8)
ax.text(0.5, -0.45, "(c)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 3, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"pairwise-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI_{parts}$ (bits)',fontsize=8)
ax.set_ylim(0, 11)
ax.yaxis.labelpad = -5.5
ax.legend(loc='upper right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.set_title("MNIST", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(d)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 3, 3)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"vector-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI$ (bits)',fontsize=8)
ax.set_ylim(0, 11)
ax.yaxis.labelpad = -5.5
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.set_title("MNIST", fontsize=8)
plt.subplots_adjust(wspace=0.35, bottom=0.3, left=0.1, right=0.99)
ax.text(0.5, -0.45, "(e)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/mnist-ei-parts-and-whole-timeseries.pdf', dpi=100)
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 2, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.set_title("MNIST", fontsize=8)
ax.text(0.5, -0.45, "(a)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 2, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_parts_layer = np.array([f[f"pairwise-ei:{l}-{l}"] for f in run])
ei_whole_layer = np.array([f[f"vector-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_whole_layer - ei_parts_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$\phi_{feedforward}$ (bits)',fontsize=8)
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.yaxis.labelpad = 0
ax.set_title("MNIST", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(b)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/mnist-ii-timeseries.pdf', dpi=100)
```
# IRIS
```
########### PARAMS ############
BINS = 256
LAYERS = [(4, 5), (5, 5), (5, 3)]
ACTIVATION = nn.Sigmoid()
RUNS = 3
FREQUENCY = 40 # epochs per measurement
EPOCHS = 4000
# BATCH_SIZE = 10 this is fixed
top_str = "sigmoid"
for i, l in enumerate(LAYERS):
if i == len(LAYERS)-1:
in_w = l[0]
out_w = l[1]
top_str += f"{in_w}-{out_w}"
else:
in_w = l[0]
out_w = l[1]
top_str += f"{in_w}-"
here = Path('/home/eric/Code/deep-ei-private/runs/iris/fourth/sigmoid-fixed-longer')
run_folders = list(here.glob("run*-frames"))
runs_frames = [list(run.glob('*.frame')) for run in run_folders]
print(run_folders)
all(d.exists() for d in run_folders)
def get_measures(path_to_frame):
frame = torch.load(path_to_frame)
measure_names = [
'batches',
'epochs',
'training_loss',
'testing_loss',
'training_accuracy',
'testing_accuracy',
]
for (start_i, end_i) in combinations_with_replacement(range(len(LAYERS)), 2):
measure_names.append(f"pairwise-ei:{start_i}-{end_i}")
measure_names.append(f"pairwise-sensitivity:{start_i}-{end_i}")
measure_names.append(f"vector-ei:{start_i}-{end_i}")
measures = {}
for name in measure_names:
if type(frame[name]) is torch.Tensor:
measures[name] = frame[name].item()
else:
measures[name] = frame[name]
return measures
runs_datapoints = [[get_measures(path) for path in run_frames] for run_frames in runs_frames]
for run_datapoints in runs_datapoints:
run_datapoints.sort(key=lambda f: f['batches'])
ltl = {
0: 'X',
1: 'T1',
2: 'T2',
3: 'Y'
}
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 2, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.set_title("IRIS", fontsize=8)
ax.text(0.5, -0.45, "(a)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 2, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"vector-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI$ (bits)',fontsize=8)
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.yaxis.labelpad = 0
ax.set_title("IRIS", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(b)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/iris-ei-whole-timeseries.pdf', dpi=100)
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 2, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.text(0.5, -0.45, "(a)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax.set_title("IRIS", fontsize=8)
ax = plt.subplot(1, 2, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"pairwise-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI_{parts}$ (bits)',fontsize=8)
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.yaxis.labelpad = 0
ax.set_title("IRIS", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(b)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/iris-ei-parts-timeseries.pdf', dpi=100)
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 3, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"IRIS: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.yaxis.labelpad = 0
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.set_title("IRIS", fontsize=8)
ax.text(0.5, -0.45, "(a)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 3, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"pairwise-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI_{parts}$ (bits)',fontsize=8)
ax.set_ylim(0, 6.5)
ax.yaxis.labelpad = 0
ax.legend(loc='upper right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.set_title("IRIS", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(b)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 3, 3)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_layer = np.array([f[f"vector-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$EI$ (bits)',fontsize=8)
ax.set_ylim(0, 6.5)
ax.yaxis.labelpad = 0
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.set_title("IRIS", fontsize=8)
plt.subplots_adjust(wspace=0.35, bottom=0.3, left=0.1, right=0.99)
ax.text(0.5, -0.45, "(c)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/iris-ei-parts-and-whole-timeseries.pdf', dpi=100)
plt.figure(figsize=(5.5, 2.0))
ax = plt.subplot(1, 2, 1)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
training_losses = [f['training_loss'] for f in run]
testing_losses = [f['testing_loss'] for f in run]
if i == 2:
plt.plot(epochs, training_losses, color='purple', label='training', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', label='testing', alpha=0.4 + 0.3*i)
else:
plt.plot(epochs, training_losses, color='purple', alpha=0.4 + 0.3*i)
plt.plot(epochs, testing_losses, color='orange', alpha=0.4 + 0.3*i)
# plt.title(f"mnist: {top_str}", fontsize=15)
ax.set_xlabel('Epoch', fontsize=8)
ax.set_ylabel('MSE Loss', fontsize=8)
ax.tick_params(axis='both',which='major',labelsize=8)
plt.legend(loc='upper right', prop={'size':6})
plt.yscale('log')
ax.set_title("IRIS", fontsize=8)
ax.text(0.5, -0.45, "(c)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
ax = plt.subplot(1, 2, 2)
for i, run in enumerate(runs_datapoints):
batches = [f['batches'] for f in run]
epochs = [f['epochs'] for f in run]
for l in range(len(LAYERS)):
ei_parts_layer = np.array([f[f"pairwise-ei:{l}-{l}"] for f in run])
ei_whole_layer = np.array([f[f"vector-ei:{l}-{l}"] for f in run])
line, = ax.plot(epochs, ei_whole_layer - ei_parts_layer, c=matplotlib.cm.viridis(l/3), alpha=0.4 + 0.3*i)
if i == 2:
line.set_label(f"{ltl[l]} → {ltl[l+1]}")
#ax.set_xlabel('Epoch',fontsize=15)
ax.set_xlabel('Epoch', fontsize = 8)
ax.set_ylabel('$\phi_{feedforward}$ (bits)',fontsize=8)
ax.legend(loc='lower right', prop={'size': 6})
ax.tick_params(axis='both',which='major',labelsize=8)
ax.yaxis.labelpad = 0
ax.set_title("IRIS", fontsize=8)
plt.subplots_adjust(wspace=0.3, bottom=0.3)
ax.text(0.5, -0.45, "(d)", size=9, ha="center", weight="bold",
transform=ax.transAxes)
plt.savefig('figures/iris-ii-timeseries.pdf', dpi=100)
```
| github_jupyter |
When benchmarking you **MUST**
1. close all applications
2. close docker
3. close all but this Web windows
4. all pen editors other than jupyter-lab (this notebook)
```
import os
from cloudmesh.common.Shell import Shell
from pprint import pprint
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import pandas as pd
from tqdm.notebook import tqdm
from cloudmesh.common.util import readfile
from cloudmesh.common.util import writefile
from cloudmesh.common.StopWatch import StopWatch
from cloudmesh.common.systeminfo import systeminfo
import ipywidgets as widgets
sns.set_theme(style="whitegrid")
info = systeminfo()
user = info["user"]
node = info["uname.node"]
processors = 4
# Parameters
user = "gregor"
node = "i5"
processors = 3
p = widgets.IntSlider(
value=processors,
min=2,
max=64,
step=1,
description='Processors:',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d'
)
u = widgets.Text(value=user, placeholder='The user name', description='User:', disabled=False)
n = widgets.Text(value=node, placeholder='The computer name', description='Computer:', disabled=False)
display(p)
display(u)
display(n)
processors = p.value
user = u.value
node = n.value
print (processors, user, node)
experiments = 10
maximum = 1024 * 100000
intervals = 10
label = f"{user}-{node}-{processors}"
output = f"benchmark/{user}"
delta = int(maximum / intervals)
totals = [64] + list(range(0,maximum, delta))[1:]
points = [int(t/processors) for t in totals]
print (totals)
print(points)
os.makedirs(output, exist_ok=True)
systeminfo = StopWatch.systeminfo({"user": user, "uname.node": node})
writefile(f"{output}/{label}-sysinfo.log", systeminfo)
print (systeminfo)
df = pd.DataFrame(
{"Size": points}
)
df = df.set_index('Size')
experiment_progress = tqdm(range(0, experiments), desc ="Experiment")
experiment = -1
for experiment in experiment_progress:
exoeriment = experiment + 1
log = f"{output}/{label}-{experiment}-log.log"
os.system(f"rm {log}")
name = points[experiment]
progress = tqdm(range(0, len(points)),
desc =f"Benchmark {name}",
bar_format="{desc:<30} {total_fmt} {r_bar}")
i = -1
for state in progress:
i = i + 1
n = points[i]
#if linux, os:
command = f"mpiexec -n {processors} python count-click.py " + \
f"--n {n} --max_number 10 --find 8 --label {label} " + \
f"--user {user} --node={node} " + \
f"| tee -a {log}"
#if windows:
#command = f"mpiexec -n {processors} python count-click.py " + \
# f"--n {n} --max_number 10 --find 8 --label {label} " + \
# f"--user {user} --node={node} " + \
# f">> {log}"
os.system (command)
content = readfile(log).splitlines()
lines = Shell.cm_grep(content, "csv,Result:")
# print(lines)
values = []
times = []
for line in lines:
msg = line.split(",")[7]
t = line.split(",")[4]
total, overall, trials, find, label = msg.split(" ")
values.append(int(overall))
times.append(float(t))
# print (t, overall)
#data = pd.DataFrame(values, times, columns=["Values", "Time"])
#print (data.describe())
#sns.lineplot(data=data, palette="tab10", linewidth=2.5)
# df["Size"] = values
df[f"Time_{experiment}"] = times
# print(df)
df = df.rename_axis(columns="Time")
df
sns.lineplot(data=df, markers=True);
plt.savefig(f'{output}/{label}-line.png');
plt.savefig(f'{output}/{label}-line.pdf');
dfs = df.stack().reset_index()
dfs = dfs.set_index('Size')
dfs = dfs.drop(columns=['Time'])
dfs = dfs.rename(columns={0:'Time'})
dfs
sns.scatterplot(data=dfs, x="Size", y="Time");
plt.savefig(f"{output}/{label}-scatter.pdf")
plt.savefig(f"{output}/{label}-scatter.png")
sns.relplot(x="Size", y="Time", kind="line", data=dfs);
plt.savefig(f"{output}/{label}-relplot.pdf")
plt.savefig(f"{output}/{label}-relplot.png")
df.to_pickle(f"{output}/{label}-df.pkl")
```
| github_jupyter |
<a href="https://colab.research.google.com/github/ashwinvaswani/Generative-Modelling-of-Images-from-Speech/blob/master/src/TIP.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
!pip install pydub
!pip install pytube==9.5.1
!pip install mtcnn
!pip install keras-vggface
!pip install youtube-dl
# Importing Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import cv2
import os
import sys
import moviepy.editor as mp
import pickle
import math
from math import ceil
from math import floor
import time
from pydub import AudioSegment
from pytube import YouTube
################# TEMP ####################
import youtube_dl
###########################################
import shutil
import IPython.display as ipd
import librosa
import librosa.display
import dlib
from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
from numpy import expand_dims
from matplotlib import pyplot
from PIL import Image
from numpy import asarray
from keras_vggface.vggface import VGGFace
from keras_vggface.utils import preprocess_input
from keras_vggface.utils import decode_predictions
from google.colab import drive
drive.mount('/content/drive')
PATH = './drive/My Drive/TIP/Dataset/'
PATH_TO_MAIN = './drive/My Drive/TIP/'
YT_LINK = 'http://www.youtube.com/watch?v='
column_names = ['YouTube_ID', 'start_segment', 'end_segment', 'X_coordinate', 'Y_coordinate']
train_df = pd.read_csv(PATH + 'avspeech_train.csv',names = column_names)
test_df = pd.read_csv(PATH + 'avspeech_test.csv',names = column_names)
train_df.head()
test_df.head()
YT_LINK + train_df.iloc[4]["YouTube_ID"]
# yt = YouTube('www.youtube.com/watch?v=AvWWVOgaMlk')
def dwl_vid(zxt):
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
ydl.download([zxt])
# shutil.rmtree('Images')
# shutil.rmtree('Audio')
# shutil.rmtree('Videos')
shutil.rmtree(PATH_TO_MAIN + 'Face_Images/')
os.mkdir("Images")
os.mkdir("Audio")
os.mkdir("Videos")
os.mkdir(PATH_TO_MAIN + 'Face_Images/')
len_train = train_df.shape[0]
count_unsuccessful = 0
dict_audio = {}
to_remove = []
for i in range(1,150):
if(True):
print(i)
print(YT_LINK + train_df.iloc[i]["YouTube_ID"])
try:
# yt = YouTube(YT_LINK + train_df.iloc[i]["YouTube_ID"])
# stream = yt.streams.first()
# stream.download(output_path = 'Videos/',filename = train_df.iloc[i]["YouTube_ID"])
################# TEMP ####################
ydl_opts = {'outtmpl':'Videos/'+train_df.iloc[i]["YouTube_ID"]}
link = YT_LINK + train_df.iloc[i]["YouTube_ID"]
dl_input = link.strip()
dwl_vid(dl_input)
###########################################
cap = cv2.VideoCapture("Videos/" + train_df.iloc[i]["YouTube_ID"] + '.mkv')
fps = cap.get(cv2.CAP_PROP_FPS)
if fps == 0:
print("0 fps")
continue
count = 0
dir_name = train_df.iloc[i]["YouTube_ID"]
print("FPS is : " + str(fps))
start_cnt = train_df.iloc[i]["start_segment"]
end_cnt = train_df.iloc[i]["end_segment"]
while(1):
ret,frame = cap.read()
if ret == 1:
count += 1
(h, w) = frame.shape[:2]
if (((start_cnt + end_cnt)*fps)/2) - 16 < count < (((start_cnt + end_cnt)*fps)/2) + 16:
dnnFaceDetector = dlib.cnn_face_detection_model_v1( PATH_TO_MAIN + "Face_detection/mmod_human_face_detector.dat")
faceRects = dnnFaceDetector(frame, 0)
print(faceRects)
if len(faceRects) == 0:
to_remove.append(dir_name)
continue
for faceRect in faceRects:
x1 = faceRect.rect.left()
y1 = faceRect.rect.top()
x2 = faceRect.rect.right()
y2 = faceRect.rect.bottom()
img = frame[y1:y2, x1:x2]
print("About to crop")
print(count)
img = cv2.resize(img, (224,224), interpolation = cv2.INTER_AREA)
cv2.imwrite('Images/' +dir_name + '.png', img)
cv2.imwrite(PATH_TO_MAIN + 'Face_Images/' +dir_name + '.png', img)
break
if count > int(end_cnt*fps):
break
k = cv2.waitKey(1)
if k == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
time.sleep(60)
except:
print("###########################################")
print("SORRY!!! The video is unavailable")
print("###########################################")
time.sleep(120)
count_unsuccessful += 1
continue
try:
clip = mp.VideoFileClip("Videos/" + train_df.iloc[i]["YouTube_ID"] + '.mkv').subclip(start_cnt,end_cnt)
clip.audio.write_audiofile("Audio/" + train_df.iloc[i]["YouTube_ID"] +'.mp3')
print("before dict")
dict_audio[train_df.iloc[i]["YouTube_ID"]] = end_cnt - start_cnt
except:
print("###########################################")
print("Error with audio")
print("###########################################")
continue
cnt = 0
list_aud = []
list_img = []
for elem in sorted(os.listdir(PATH_TO_MAIN + 'Face_Images/')):
list_img.append(elem)
cnt += 1
for elem in sorted(os.listdir('./Audio')):
list_aud.append(elem)
cnt += 1
for i in range(len(list_aud)):
print(list_aud[i],list_img[i])
print(cnt)
# Preparing y_train for encoder and x_train for decoder
def get_embeddings(filenames):
faces = []
for f in filenames:
img = cv2.imread(f)
face_arr = asarray(img)
faces.append(face_arr)
samples = asarray(faces,'float32')
samples = preprocess_input(samples,version=2)
model = VGGFace(model='resnet50',include_top=False,input_shape=(224,224,3),pooling='avg')
yhat = model.predict(samples)
return yhat
face_list = []
for elem in os.listdir('./Images'):
face_list.append('./Images/' + elem)
y_train_encoder = get_embeddings(face_list)
x_train_decoder = get_embeddings(face_list)
y_train_encoder.shape
# Using y_train to create decoder
# Input is y_train and output is images from Images folder
# Augmenting Audio
# shutil.rmtree('Processed_Audio')
os.mkdir('Processed_Audio')
temp_dict = dict_audio.copy()
for elem in os.listdir('./Audio'):
sound = AudioSegment.from_mp3('./Audio/' + elem)
sound_new = sound
while temp_dict[elem[:-4]] < 6:
print("here")
sound_new += sound
temp = temp_dict[elem[:-4]]
temp_dict[elem[:-4]] = 2*temp
sound = sound_new
extract = sound[0:6*1000]
extract.export('Processed_Audio/' + elem, format="mp3")
# # to_remove = ['2f32XSMYlDk']
# for elem in to_remove:
# os.remove('Processed_Audio/' + elem + '.mp3')
# Preparing x_train
# shutil.rmtree('Spectograms')
os.mkdir('Spectograms')
for filename in os.listdir("./Processed_Audio"):
audio_path = './Processed_Audio/' + filename
x , sr = librosa.load(audio_path,sr = 15925)
print(audio_path)
print(type(x), type(sr))
print(x.shape, sr)
ipd.Audio(audio_path)
window_size = 25
window = np.hanning(window_size)
h1 = 160
print(h1)
stft = librosa.core.spectrum.stft(x, n_fft=512, hop_length=h1,win_length=window_size, window=window)
out = 2 * np.abs(stft) / np.sum(window_size)
with open('./Spectograms/' + filename[:-4] + '.pkl','wb') as f:
pickle.dump(stft,f)
# librosa.display.waveplot(x, sr=sr)
# mfccs = librosa.feature.mfcc(x, sr=sr)
# print(mfccs.shape)
# librosa.display.specshow(mfccs, sr=sr, x_axis='time')
# print()
stft.shape
# for elem in stft:
# print(elem)
# Todo: For all pickle files in spectogram
def get_encoder_network_input(k):
shape_x = k.shape[0]
shape_y = k.shape[1]
mod = np.zeros((shape_x,shape_y))
for i in range(shape_x):
for j in range(shape_y):
mod[i][j] = np.abs(k[i][j])
theta_ = np.zeros((shape_x,shape_y))
for i in range(shape_x):
for j in range(shape_y):
theta_[i][j] = np.angle(k[i][j])
real = np.zeros((shape_x,shape_y))
complex_ = np.zeros((shape_x,shape_y))
for i in range(shape_x):
for j in range(shape_y):
temp = mod[i][j]
real[i][j] = temp * math.cos(complex_[i][j])
complex_[i][j] = temp * math.sin(complex_[i][j])
real = np.expand_dims(real,axis = 0)
complex_ = np.expand_dims(complex_,axis = 0)
combined = np.concatenate((real,complex_))
return combined
encoder_input = []
for elem in os.listdir('./Spectograms/'):
with open('./Spectograms/' + elem,'rb') as f:
print('./Spectograms/' + elem)
k = pickle.load(f)
print(k.shape)
encoder_input.append(np.transpose(get_encoder_network_input(k)))
len(encoder_input)
# For encoder
# Input : encoder input as np array
# Output : y_train_encoder
# FOr decoder
# Input : y_pred_encoder
# Output : Images from Images folder
x_enc_train = np.asarray(encoder_input)
x_enc_train.shape
y_train_encoder.shape
with open(PATH_TO_MAIN + 'Pickles/encoder_trainX_81.pkl','wb') as f:
pickle.dump(x_enc_train,f)
with open(PATH_TO_MAIN + 'Pickles/encoder_trainY_81.pkl','wb') as f:
pickle.dump(y_train_encoder,f)
from google.colab import files
files.download(PATH_TO_MAIN + 'Pickles/encoder_trainX_81.pkl')
!nvidia-smi
```
| github_jupyter |
```
# Inserting Liberaaries !!!
%matplotlib inline
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
import random
import datetime
import statistics
import scipy
from scipy import stats
# Reading and loading the data
df = pd.read_csv('trip.csv')
df
```
Check the lenght of the data
```
length = len(df)
length
```
Univariate Analysis to determine the time range of data set<br>
We sort the data frame by `starttime`<br>
what sorting did was to change the position of records within the data frame, and hence the change in positions disturbed the arrangement of the indexes which were earlier in an ascending order. Hence, considering this, we decided to reset the indexes so that the ordered data frame now has indexes in an ascending order. Finally, we printed the date range that started from the first value of starttime and ended with the last value of stoptime
```
df2 = df.sort('starttime')
df2
df2.reset_index(inplace=True)
df2
print("Data Range is from: ",'[',df2.loc[1,'starttime'],']',' to ','[',df2.loc[len(df2)-1,'stoptime'],']')
```
There are two insights. One is that the data ranges from October 2014 up till September 2016 (i.e., three years of data). Moreover, it seems like the cycle sharing service is usually operational beyond the standard 9 to 5 business hours.
new users would be short-term pass holders however once they try out the service and become satisfied would ultimately avail the membership to receive the perks and benefits offered<br>
plot a bar graph of trip frequencies by user type
groupby groups the data by a given field, that is, usertype, in the current situation<br>
size counts trips falling within each of the grouped usertypes
```
fre_usr_stat = df2.groupby('usertype').size()
fre_usr_stat
fre_usr_stat.plot.barh(figsize=(5,5),title='FREQUENCY-USER-GRAPH')
```
You may want know more about her target customers to whom to company’s marketing message will be targetted to<br>
Find out the gender and age groups that are most likely to ride a cycle or the ones that are more prone to avail the service.<br>
Fing out the distribution of gender and birth years
```
gender_stat = df2.groupby('gender').size()
gender_stat
gender_stat.plot.barh(figsize=(10,5),title='GENDER GRAPH')
birth_stat = df2.groupby('birthyear').size()
birth_stat
birth_stat.plot.bar(figsize=(15,5),title='BIRTH-YEAR-GRAPH')
```
millenials are supposed to make a conscious decision, a decision they will remain loyal to for a long period. Hence we mat assume that the most millennials would be members rather than short-term pass holders. Based on data below, it appeared to be valid, and we can make sure that the brand engaged millennials as part of the marketing plan.
```
mill_stat = df2.groupby('usertype')['birthyear'].size()
mill_stat
mill_stat.plot.barh(figsize=(10,5))
```
### Multivariate Analysis
Multivariate analysis refers to incorporation of multiple exploratory variables to understand the behavior of a response variable. This seems to be the most feasible and realistic approach considering the fact that entities within this world are usually interconnected. Thus the variability in response variable might be affected by the variability in the interconnected exploratory variables<br>
Who completed more trips male or female. Draw a stacked bar graph (i.e., a bar graph for birth year, but each bar having two colors, one for each gender)
We at first transformed the data frame by **unstacking**, that is, splitting, the gender column into three columns, that is, Male, Female, and Other. This meant that for each of the birth years we had the trip count for all three gender types. Finally, a stacked bar graph was created by using this transformed data frame.
```
birth_gen_stat = df2.groupby(['birthyear', 'gender'])['birthyear'].count()
birth_gen_stat = birth_gen_stat.unstack('gender')
birth_gen_stat = birth_gen_stat.fillna(0)
birth_gen_stat
birth_gen_stat[['Male','Female','Other']].plot.bar(figsize=(15,5),stacked=True,title='BIRTH-YEAR-GENDER-GRAPH')
```
It seemed as if males were dominating the distribution. It made sense as well. No? Well, it did; as seen earlier, that majority of the trips were availed by males, hence this skewed the distribution in favor of males. However, subscribers born in 1947 were all females. Moreover, those born in 1964 and 1994 were dominated by females as wel
what the distribution of user type was for the other age generations. Is it that the majority of people in the other age generations were short-term pass holders?
```
birth_usr_stat = df2.groupby(['birthyear', 'usertype'])['birthyear'].count()
birth_usr_stat = birth_usr_stat.unstack('usertype')
birth_usr_stat = birth_usr_stat.fillna(0)
birth_usr_stat
birth_usr_stat[['Member']].plot.bar(figsize=(15,5),title='BIRTH-YEAR-USER-GRAPH')
```
The graph shows the distribution of only one user type and not two (i.e., membership and short-term pass holders)? Does this mean that birth year information was only present for only one user type?
Validation If We Don’t Have Birth Year Available for Short-Term Pass Holders
```
df2[df2['usertype'] == ('Short-Term Pass Holder')]['birthyear'].isnull().values.all()
```
We first sliced the data frame to consider only short-term pass holders. Then we went forward to find out if all the values in birth year are missing (i.e., null) for this slice. Members have to provide details like birth year when applying for the membership, something which is not a prerequisite for short-term pass holders. WE decided to test this deduction by checking if gender is available for short-term pass holders or not
```
df2[df2['usertype'] == ('Short-Term Pass Holder')]['gender'].isnull().values.all()
```
how the frequency of trips vary across date and time (i.e., a time series analysis). Trip start time is given with the data, but to make a time series plot, we had to transform the date from string to date time format. Split the datetime into date components (i.e., year, month, day, and hour )
At first we converted start time column of the dataframe into a list. Next we converted the string dates into python datetime objects. We then converted the list into a series object and converted the dates from datetime object to pandas date object. The time components of year, month, day and hour were derived from the list with the datetime objects.
```
List_ = list(df2['starttime'])
List_ = [datetime.datetime.strptime(x, "%m/%d/%Y %H:%M") for x in List_]
df2['starttime_mod'] = pd.Series(List_,index=df2.index)
df2['starttime_date'] = pd.Series([x.date() for x in List_],index=df2.index)
df2['starttime_year'] = pd.Series([x.year for x in List_],index=df2.index)
df2['starttime_month'] = pd.Series([x.month for x in List_],index=df2.index)
df2['starttime_day'] = pd.Series([x.day for x in List_],index=df2.index)
df2['starttime_hour'] = pd.Series([x.hour for x in List_],index=df2.index)
df2.groupby('starttime_date')['tripduration'].mean().plot.bar(title = 'Distribution of Trip duration by date', figsize = (20,5))
```
Determining the measures of centers using the statistics package will require us to transform the input data structure to a list type.
```
trip_duration = list(df2['tripduration'])
station_from = list(df2['from_station_name'])
print ('Mean of trip duration: %f'%statistics.mean(trip_duration))
print ('Median of trip duration: %f'%statistics.median(trip_duration))
print ('Mode of station originating from: %s'%statistics.mode(station_from))
```
The output revealed that most trips originated from Pier 69/Alaskan Way & Clay St station. Hence this was the ideal location for running promotional campaigns targeted to existing customers. Moreover, the output showed the mean to be greater than that of the mean.<br>
why the average (i.e., mean) is greater than the central value (i.e., median).<br>
this might be either due to some extreme values after the median or due to the majority of values lying after the median.<br> plot a distribution of the trip durations in order to determine which premise holds true .
```
df2['tripduration'].plot.hist(bins=100,title='Frequency distribution of Trip duration',figsize=(5,5))
```
The distribution has only one peak (i.e., mode). The distribution is not symmetric and has majority of values toward the right-hand side of the mode. These extreme values toward the right are negligible in quantity, but their extreme nature tends to pull the mean toward themselves. Thus the reason why the mean is greater than the median<br>
The distribution is referred to as a **normal distribution.**
Find out whether outliers exist within our dataset—more precisely in the tripduration feature. For that first create a box plot by writing code to see the outliers visually and then checked the same by applying the interval calculation method
```
box = df2.boxplot(column=['tripduration'])
```
See a huge number of outliers in trip duration from the box plot. She asked Eric if he could determine the proportion of trip duration values which are outliers. She wanted to know if outliers are a tiny or majority portion of the dataset
```
q75, q25 = np.percentile(trip_duration, [75 ,25])
iqr = q75 - q25
print ('Proportion of values as outlier: %f percent'%(
(len(df2) - len([x for x in trip_duration if q75+(1.5*iqr) >=x>= q25-(1.5*iqr)]))*100/float(len(df2))))
```
Q3 refers to the 75th percentile and Q1 refers to the 25th percentile. Hence we use the numpy.percentile() method to determine the values for Q1 and Q3. Next we compute the IQR by subtracting both of them. Then we determine the subset of values by applying the interval. We then used the formula to get the number of outliers.
In our code, len(data) determines Length of all values and Length of all non outliers values is determined by `len([x for x in trip_duration if q75+(1.5*iqr) >=x>= q25-(1.5*iqr)]))`
Considering the time series nature of the dataset, removing these outliers wouldn’t be an option. The only option we could rely on was to apply transformation to these outliers to negate their extreme nature. However, we are interested in observing the mean of the non-outlier values of trip duration. This we can compare with the mean of all values calculated earlier
```
mean_trip = np.mean([x for x in trip_duration if q75+(1.5*iqr) >=x>= q25-(1.5*iqr)])
upper_whisker = q75+(1.5*iqr)
print('Mean of trip duration: %f'%mean_trip)
```
The mean of non-outlier trip duration values in (i.e., approximately 712) is considerably lower than that calculated in the presence of outliers in Listing 1-15 (i.e., approximately 1,203). This best describes the notion that mean is highly affected by the presence of outliers in the dataset.
upper_whisker is the maximum value of the right (i.e., positive) whisker i.e. boundary uptill which all values are valid and any value greater than that is considered as an outlier
WE are interested to see the outcome statistics once the outliers were transformed into valid value sets. Hence we decided to start with a simple outlier transformation to the mean of valid values
```
def transform_tripduration(x):
if x > upper_whisker:
return mean_trip_duration
return x
df2['tripduration_mean'] = df2['tripduration'].apply(lambda x: transform_tripduration(x))
print(df2['tripduration_mean'])
df2['tripduration_mean'].plot.hist(bins=100, title='Frequency distribution of mean transformed Trip duration')
plt.show()
```
We initialized a function by the name of transform_tripduration . The function will check if a trip duration value is greater than the upper whisker boundary value, and if that is the case it will replace it with the mean. Next we add tripduration_mean as a new column to the data frame. We did so by custom modifying the already existing tripduration column by applying the transform_tripduration function.
the skewness has now decreased to a great extent after the transformation. Moreover, the majority of the observations have a tripduration of 712 primarily because all values greater than the upper whisker boundary are now converted into the mean of the non-outlier values calculated. We are now interested in understanding how the center of measures appear for this transformed distribution. Hence we came up with the code
```
print('Mean of trip duration: %f'%df2['tripduration_mean'].mean())
print('Standard deviation of trip duration: %f'%df2['tripduration_mean'].std())
print('Median of trip duration: %f'%df2['tripduration_mean'].median())
```
We were expecting the mean to appear the same as previous because of the mean transformation of the outlier values. WE knew that the hike at 711.7 is the mode, which meant that after the transformation the mean is the same as that of the mode. The thing that surprised the most was that the median is approaching the mean, which means that the positive skewness we saw in is not that strong.
Pearson R correlation into practice and decided to make a scatter plot between the two quantities for them to see the relationship visually.
```
pd.set_option('display.width', 100)
pd.set_option('precision', 3)
df2['age'] = df2['starttime_year'] - df2['birthyear']
correlations = df2[['tripduration','age']].corr(method='pearson')
print(correlations)
df2 = df2.dropna()
sns.pairplot(df2, vars=['age', 'tripduration'], kind='reg')
plt.show()
for cat in ['gender','usertype']:
print ('Category: %s\n'%cat)
groupby_category = df2.groupby(['starttime_date', cat])['starttime_date'].count().unstack(cat)
groupby_category = groupby_category.dropna()
category_names = list(groupby_category.columns)
for comb in [(category_names[i],category_names[j]) for i in range(len(category_names)) for j in range(i+1, len(category_names))]:
print ('%s %s'%(comb[0], comb[1]))
t_statistics = stats.ttest_ind(list(groupby_category[comb[0]]), list(groupby_category[comb[1]]))
print ('Statistic: %f, P value: %f'%(t_statistics.statistic, t_statistics.pvalue))
print ('\n')
"""SUMMERY"""
"""
At first we added some liberaries. Next we added the data file. Check its length and sort it by a column starttime and after it we print the range of
data.
After it we print the number of members and short-term pass holders and plot their graph.
We find the gender of all customer which is male, female or others. And then we plot a graph showing th gender of patients.
Next we get the birthyear of the costomer and plot the graph for that.
Aftr it we did some analysis and form graphs according to user type, birthyear and gender , birth year.
Next we converted the string dates into python datetime objects. We then converted the list into a series object and converted the dates from datetime
object to pandas date object. The time components of year, month, day and hour were derived from the list with the datetime objects.
Next we did some statistics on the trip duration column from the main data. And made some graphs to easily compare the data.
Next we determine the proportion of trip duration values which are outliers.
Next we see the outcome statistics once the outliers were transformed into valid value sets. Hence we decided to start with a simple outlier
transformation to the mean of valid values
We are now interested in understanding how the center of measures appear for this transformed distribution. Hence we came up with the code to do so.
Next we make Pearson R correlation into practice and decided to make a scatter plot between the two quantities for them to see the relationship visually.
"""
```
"""
So now after analyzing the whole Project we can say that this project should be launched near
""REI / Yale Ave N & John St""
"""
```
"""ありがとう"""
```
| github_jupyter |
# Farm Household Models
Most economics textbooks typically present the decisions of firms in separate chapters from the decisions of households. In this artificial but useful dichotomy the firm organizes production and hires factors of production while households own the factors of production (and ownership shares in firms). Households earn incomes from supplying these factors to firms and use that income to purchase products from the firms.
Many households in developing countries however may operate small farms, garden plots, stores or other types of businesses, and may also at the same time sell or hire labor in the labor market. In fact a large literature suggests that one defining characteristic of developing countries labor markets is the very large fraction of its labor force that are self-employed 'own account' workers and the many who run small businesses alongside wage labor jobs (Gollin, 2008).
For this reasin it will be useful to build models that allow households to both utilize labor and other factors as potential producers who may also choose to sell or hire these factors on factor markets. Here we offer stylized representations of the so called 'farm household model' or 'agricultural household model' (Singh, Squire, Strauss, 1986).
In these models the household acts both as a consumption unit, maximizing utility over consumption and 'leisure' choices and as a production unit, deciding how to allocate factors of production to the household farm or business.
A key question in this literature is whether the household's production decisions (such as its choice of labor and other inputs and the scale of production) are *separable* or not from its preferences and endowments (e.g. consumer preferences, household demographic composition and ownership of land and other resources). For example, will a rural farm household with more working age adults run a larger farm compared to a neighboring household that is otherwise similar and has access to the same technology but has fewer working-age adults? If the households decisions are non-separable then the answer might be yes: the larger household uses of its larger labor force to run a larger farm.
When households are embedded in well functioning competitive markets however we tend to expect the household's decisions to become separable:
- **Household as a profit-maximizing firm:** acting as a profit-maximizing firm the household first optimally chooses labor and other input allocations to extract maximum profit income from the farm.
- **Household as a consumption unit:** the household makes optimal choices over consumption and leisure subject to its income budget which includes income from selling its labor endowment and maximized profits from the household as a firm.
In the simple example above of two otherwise identical households the separable farm household model would predict that both households run farms of similar size and use wage labor markets to equalize land-labor ratios and hence marginal products of labor across farms. The larger household would be a net seller of labor on the market compared to the smaller household.
Without the separation property the common approach of many studies to separately estimate consumer demand from output supply functions is no longer valid.
Another way to state the separation hypothesis is that if they have access to markets the marginal production decisions of farms (and firms more generally) should not depend on their owners' ownership of tradable factors (except in so far as it might raise their overal income) or their preferences in consumption. When markets are complete then production decisions will be separable, the price mechanism will equalize the marginal products of factors across uses, and the initial distribution of tradable factors should not matter for allocative efficiency (the first and second welfare theorems). Much of modern micro-development since at least the mid 1960s however is concerned with how transactions costs, asymmetric information, conflict and costly enforcement can lead to market frictions and imperfections that make production decisions non-separable, which then means that the initial distribution of property rights (over land and other tradable factors) may in fact well matter for determining the patterns of production organization and its efficiency in general equilibrium. A good example of such analysis is Eswaran and Kotwal (1986) paper on "Access to Capital and Agrarian production organization," which explores how the combination of transaction costs in labor hiring and in access to capital can lead to a theory of endogenous class structure or occupational choice which can change dramatically depending on the initial distribution of property rights.
### The Chayanovian Household
We'll start with a non-separable model, inspired by the work of the Russian agronomist Alexander Chayanov whose early 20th century ideas and writings on "the peasant economy" became widely influential in anthropology, economics, and other fields. Chayanov played a role in the Soviet agrarian reforms but his focus on the importance of the household economy led him to be (presciently) skeptical of the appropriateness and efficiency of large-scale Soviet farms. He was arrested, sent to a labor camp and later executed.
The following model is not anywhere as rich as Chayanov's description of the peasant household economy but instead a stripped down version close in spirit to Amartya Sen's (1966) adaptation.
Farm household $i$ has land and labor endowment $(\bar T_i, \bar L_i )$. We can assume that it can buy and sell the agricultural product at a market price $p$ but in practice we will model the household as self-sufficient and cut off from the market for land and labor. The household (which we treat as a single decision-making unit for now) allocates labor maximizes utility over consumption and leisure
$$\max_{c_i,l_i} U(c_i,l_i)$$
Although we haven't included it above, we think of the utility function $U(c_i,l_i;A)$ as depending on 'preference shifters' $A$ which might include such things as the household's demographic composition or things that affect it's preference for leisure over consumption).
The household maximizes this utility subject to the constraints that consumption $c_i$ not exceed output and that the sum of hours in production $L_i$ plus hours in leisure $l_i$ not exceed the household's labor endowment $\bar L_i$
$$c_i \leq F(\bar T_i, L_i) $$
$$L_i + l_i \leq \bar L_i$$
Substituting the constraints into the objective allows one to redefine the problem as one of choosing the right allocation of labor to production:
$$\max_{L_i} U(F(\bar T_i, L_i),\bar L_i - L_i)$$
From the first order necessary conditions we obtain
$$U_c \cdot F_L = U_l$$
which states that the farm household should allocated labor to farm production up to the point where the marginal utility benefit of additional consumption $U_c \cdot F_L$ equals the opportunity cost of leisure.
Since the household sets the marginal product of labor (or shadow price of labor) equal to the marginal rate of substitution between leisure and consumption $F_L = U_l/U_c$ and the latter is clearly affected by 'preference shifters' $A$ and also by the household's land endowment. The shadow price of labor will hence differ across households that are otherwise similar (say in their access to production technology and farming skill). For example households with a larger endowment of labor will run larger farms.
It will be useful to draw things in leisure-consumption space. Leisure is measured on the horizontal from left to right which then means that labor $L$ allocated to production can be measured from right to left with an origin starting at the endowment point $\bar L_i$
To fix ideas with a concrete example assume farm household $i$ has Cobb-Douglas preferences over consumption and leisure:
$$U(c,l) = c^\beta l^{1-\beta}$$
and its production technology is a simple constant returns to scale Cobb-Douglas production function of the form:
$$F(\bar T_i,L_i)=\bar T_i^\alpha L_i^{1-\alpha}$$
The marginal product of labor $F_L$ which the literature frequently refers to as the shadow price of labor will be given by:
$$F_L (\bar T_i,L_i) = (1-\alpha) \left [ {\frac{\bar T_i}{L_i}} \right ]^\alpha$$
The first order necessary condition can therefore be solved for and for these Cobb-Douglas forms we get a rather simple and tidy solution to the optimal choice of leisure
$$l^* = \frac{a \cdot \bar L}{1+a} $$
where $a=\frac{1-\beta}{\beta \cdot (1-\alpha)}$
### Graphical analysis
To modify and interact with plots below run code in [Code Section](#Code-Section)
```
chayanov(TBAR,LBAR,0.5,0.5)
```
### Inverse farm size productivity relationship
In this non-separable household with no market for land or labor, each household farms as much land as it owns.
We find the well-known inverse** farm size-productivity relationship**: output per hectare is higher on smaller (more land-constrained) farms. Households with larger farms have more land and the marginal products of labor is consequently higher (so the shadow price of labor is higher on larger farms).
These two relationships can be seen below on this two-axis plot.
```
invfsplot()
```
If you are running this notebook in interactive mode you can play with the sliders:
```
interact(chayanov,Tbar=(50,200,1),Lbar=(24,100,1),alpha=(0.1,0.9,0.1),beta=(0.1,0.9,0.1));
```
## The Separable Farm Household
Consider now the case of the household that participates in markets. It can buy and sell the consumption good at market price $p$ and buy or sell labor at market wage $w$. Hired labor and own household labor are assumed to be perfect substitutes.
To keep the analysis a little bit simpler and fit everything on a single graph we'll assume that the market for land leases remains closed. However it is easy to show that for a linear homogenous production function this will not matter for allocative efficiency -- it will be enough to have a working competitive labor market for the marginal product of land and labor to equalize across farms.
When the farm household is a price-taker on markets like this, farm production decisions become 'separable' from farm consumption decisions. The farm household can make its optimal decisions as a profit-maximizing farm and then separately choose between consumption and leisure subject to an income constraint.
So the household's problem can be boiled down to:
$$\max_{c,l} U(c,l)$$
s.t.
$$p \cdot c \leq pF(\bar T_i,L^*) + w \cdot (\bar L_i - l)$$
This last constraint states that what the household spends on consumption cannot exceed the value of farm sales at a profit maximizing optimum plus wage income from labor sold to the market. This last constraint can also be rewritten as:
$$p \cdot c + w \cdot l \leq \Pi (T_i,w,p) + w \cdot \bar L_i $$
where $\Pi (T_i,w,p) = p \cdot F(T_i,L^*_i) - w \cdot L^*_i$ is the maximized value of farm profits and $L^*_i$ is the optimal quantity of labor that achieves that maximum.
In other words the farm household can be thought of as maximizing profits by choosing an optimal labor input into the farm $L^*_i$ which will be satisfied with own and/or hired labor. The household then maximizes utility from consumption and leisure subject to the constraint that it not spend more on consumption and leisure as its income which is made up of farm profits (a return to land) and the market value of it's labor endowment.
In this last description the household is thought of as buying leisure at its market wage opportunity cost.
#### The efficient competitive farm
As a production enterprise the farm acts to maximize farm profits $pF(\bar T_i,L_i) - w \cdot L_i $. The first-order necessary condition for an interior optimum is:
$$p \cdot F_L (\bar T_i,L) = w$$
The separation property is immediately apparent from this first order condition, as this equation alone is enough to determine the farm's optimum labor demand which depends only on the production technology and the market wage, and not at all on household preferences. While the quantity of labor demanded here does depend on the households' ownership of land, with a functioning labor market the number of workers per unit land will be the same across all farms and hence also independent of household land endowment.
For the Cobb-Douglas production function, optimal labor demand can then be solved to be:
$$ L_i^* = \bar T_i \cdot \left [ {\frac{p(1-\alpha)}{w}} \right ]^\frac{1}{\alpha}$$
Substituting this value into the profit function we can find an expression for farm profits $\Pi (T_i,w,p)$ as a function of the market product price and wage and the farm's land holding. If we had allowed for hiring on both land and labor markets we would have found zero profits with this linear homogenous technology so in this context where there is no working land market, profits are just like a competitively determined rent to non-traded land (equal in value to what the same household would have earned on its land endowment had the land market been open).
Note how the optimal allocation of labor to the farm is independent of the size of the household $\bar L_i$ and household preferences. If we had allowed for a competitive land market the labor allocation would also have been independent of the household's
Household demand for consumption and leisure is very simple given this Cobb-Douglas utility:
$$c^*(w) = \beta \cdot I $$
$$l^*(w) = (1-\beta) \cdot \frac{I}{w} $$
where household income $I$ is given by the sum of farm profits and the market value of the factor endowment:
$$I = \Pi(w,\bar T) + w \cdot \bar L$$
In what follows we shall normalize the product price $p$ to unity. This is without loss of generality as all that matters for real allocations is the relative price of labor (or leisure) relative to output, or the real wage $\frac{w}{p}$. So in all the expressions that follow when we see $w$ it should be thought of as $\frac{w}{p}$
### Example: Household that works own farm *and* sells labor to the market
```
W = 1
fig, ax = plt.subplots(figsize=(10,8))
plot_production(TBAR,LBAR,W)
plot_farmconsumption(TBAR, LBAR, W)
ax.set_title("The Separable Household Model")
ax.set_xlim(0,LBAR+20)
ax.set_ylim(0,F(TBAR,LBAR)+20)
plt.show()
```
Here is the same household when facing a much lower wage (55% of the wage above). They will want to expand output on their own farm and cut back on labor sold to the market (expand leisure). This household will on net hire workers to operate their farm.
### Example: HH that hires labor
Compared to the last diagram we'll set a lower wage. This both leads the farm to expand labor hiring and leads the household to supply less labor.
```
fig, ax = plt.subplots(figsize=(10,8))
plot_production(TBAR,LBAR, W*0.55)
plot_farmconsumption(TBAR, LBAR, W*0.55)
ax.set_title("The Separable Household Model")
ax.set_xlim(0,LBAR+20)
ax.set_ylim(0,F(TBAR,LBAR)+20)
plt.show()
```
### No Inverse farm size productivity relationship
Since every farm takes the market wage as given the marginal product of labor will be equalized across farms. The shadow price of labor will equal the market wage on all farms, regardless of their land size. The land labor ratio and hence also the marginal product of land will also equalize across farms so output per unit land will also remain constant.
The next section describes some empirical tests of the separation hypothesis as well as models with 'selective-separability' where missing markets and/or transactions costs end up determining that, depending on their initial ownership of assets, some households may face different factor shadow prices depending on whether they are buyers or sellers or non-participants on factor markets.
This last example should drive home the point that when the farm household's optimization problem is separable the farm's optimal choice of inputs will be independent of both household characteristics *and* it's endownment of *tradable* factors such as land and labor.
In this last example when we shut down the labor market and introduce a transaction wedge on the market for land we create a non-separable region of autarkic or non-transacting households (shaded above). A framework such as this would generate data that displays the classic inverse farm-size productivity relationship. Farms that lease in land are smaller and have higher output per hectare than larger farms that lease land out and within the autarky zone farm size is increasing in the size of the land endowment and the shadow price (and hence output per unit land) falling.
## Code Section
Run code below and then return to start of [Graphical analysis](#Graphical-analysis)
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from ipywidgets import interact
ALPHA = 0.5
BETA = 0.7
TBAR = 100
LBAR = 100
def F(T,L,alpha=ALPHA):
return (T**alpha)*(L**(1-alpha))
def FL(T,L,alpha=ALPHA):
"""Shadow price of labor"""
return (1-alpha)*F(T,L,alpha=ALPHA)/L
def FT(T,L,alpha=ALPHA):
"""Shadow price of labor"""
return alpha*F(T,L,alpha=ALPHA)/T
def U(c, l, beta=BETA):
return (c**beta)*(l**(1-beta))
def indif(l, ubar, beta=BETA):
return ( ubar/(l**(1-beta)) )**(1/beta)
def leisure(Lbar,alpha=ALPHA, beta=BETA):
a = (1-alpha)*beta/(1-beta)
return Lbar/(1+a)
def HH(Tbar,Lbar,alpha=ALPHA, beta=BETA):
"""Household optimum leisure, consumption and utility"""
a = (1-alpha)*beta/(1-beta)
leisure = Lbar/(1+a)
output = F(Tbar,Lbar-leisure, alpha)
utility = U(output, leisure, beta)
return leisure, output, utility
def chayanov(Tbar,Lbar,alpha=ALPHA, beta=BETA):
leis = np.linspace(0.1,Lbar,num=100)
q = F(Tbar,Lbar-leis,alpha)
l_opt, Q, U = HH(Tbar, Lbar, alpha, beta)
print("Leisure, Consumption, Utility =({:5.2f},{:5.2f},{:5.2f})"
.format(l_opt, Q, U))
print("shadow price labor:{:5.2f}".format(FL(Tbar,Lbar-l_opt,beta)))
c = indif(leis,U,beta)
fig, ax = plt.subplots(figsize=(8,8))
ax.plot(leis, q, lw=2.5)
ax.plot(leis, c, lw=2.5)
ax.plot(l_opt,Q,'ob')
ax.vlines(l_opt,0,Q, linestyles="dashed")
ax.hlines(Q,0,l_opt, linestyles="dashed")
ax.set_xlim(0, 110)
ax.set_ylim(0, 150)
ax.set_xlabel(r'$l - leisure$', fontsize=16)
ax.set_ylabel('$c - consumption$', fontsize=16)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.grid()
ax.set_title("Chayanovian Household Optimum")
plt.show()
```
** Inverse Farm Size plot **
```
def invfsplot():
Tb = np.linspace(1,LBAR)
le, q, _ = HH(Tb,LBAR)
fig, ax1 = plt.subplots(figsize=(6,6))
ax1.plot(q/Tb,label='output per unit land')
ax1.set_title("Chayanov -- Inverse Farm Size Productivity")
ax1.set_xlabel('Farm Size '+r'$\bar T$')
ax1.set_ylabel('Output per unit land')
ax1.grid()
ax2 = ax1.twinx()
ax2.plot(FL(Tb,LBAR-le),'k--',label='shadow price labor')
ax2.set_ylabel('Shadow Price of Labor')
legend = ax1.legend(loc='upper left', shadow=True)
legend = ax2.legend(loc='upper right', shadow=True)
plt.show()
invfsplot()
def farm_optimum(Tbar, w, alpha=ALPHA, beta=BETA):
"""returns optimal labor demand and profits"""
LD = Tbar * ((1-alpha)/w)**(1/alpha)
profit = F(Tbar, LD) - w*LD
return LD, profit
def HH_optimum(Tbar, Lbar, w, alpha=ALPHA, beta=BETA):
"""returns optimal consumption, leisure and utility.
Simple Cobb-Douglas choices from calculated income """
_, profits = farm_optimum(Tbar, w, alpha)
income = profits + w*Lbar
consumption = beta * income
leisure = (1-beta) * income/w
utility = U(consumption, leisure, beta)
return consumption, leisure, utility
def plot_production(Tbar,Lbar,w):
lei = np.linspace(1, Lbar)
q = F(Tbar, Lbar-lei)
ax.plot(lei, q, lw=2.5)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
def plot_farmconsumption(Tbar, Lbar, w, alpha=ALPHA, beta=BETA):
lei = np.linspace(1, Lbar)
LD, profits = farm_optimum(Tbar, w)
q_opt = F(Tbar,LD)
yline = profits + w*Lbar - w*lei
c_opt, l_opt, u_opt = HH_optimum(Tbar, Lbar, w)
ax.plot(Lbar-LD,q_opt,'ob')
ax.plot(lei, yline)
ax.plot(lei, indif(lei,u_opt, beta),'k')
ax.plot(l_opt, c_opt,'ob')
ax.vlines(l_opt,0,c_opt, linestyles="dashed")
ax.hlines(c_opt,0,l_opt, linestyles="dashed")
ax.vlines(Lbar - LD,0,q_opt, linestyles="dashed")
ax.hlines(profits,0,Lbar, linestyles="dashed")
ax.vlines(Lbar,0,F(Tbar,Lbar))
ax.hlines(q_opt,0,Lbar, linestyles="dashed")
ax.text(Lbar+1,profits,r'$\Pi ^*$',fontsize=16)
ax.text(Lbar+1,q_opt,r'$F(\bar T, L^{*})$',fontsize=16)
ax.text(-6,c_opt,r'$c^*$',fontsize=16)
ax.annotate('',(Lbar-LD,2),(Lbar,2),arrowprops={'arrowstyle':'->'})
ax.text((2*Lbar-LD)/2,3,r'$L^{*}$',fontsize=16)
ax.text(l_opt/2,8,'$l^*$',fontsize=16)
ax.annotate('',(0,7),(l_opt,7),arrowprops={'arrowstyle':'<-'})
```
| github_jupyter |
```
import seaborn as sns
from adaptive.compute import collect
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from scipy.stats import norm
from time import time
from glob import glob
import scipy.stats as stats
from IPython.display import display, HTML
from adaptive.saving import *
import dill as pickle
from pickle import UnpicklingError
import copy
from itertools import compress
import scipy.stats as stats
from plot_utils import *
import os
sns.set(font_scale=1.2)
%matplotlib inline
%reload_ext autoreload
%autoreload 2
```
# Sequential classification with bandit feedback
$85$ multi-class classification from OpenML(https://www.openml.org), see below for the list of darasets
### Policies:
1. __optimal contextual policy__ that assigns each covariate to its correct label;
2. __best fixed_arm policy__ that always assigns each covariates to the label with most samples;
3. __contrast__ between the above policies.
We demonstrate the contrast estimation here.
### Compared estimation methods:
- DM: direct method;
- DR: doubly-robust method with weight $h_t=1$;
- non-contextual `MinVar` $h_t = 1/E[\sum_w\frac{\pi^2(x,w)}{e_t(x,w)}]$
- non-contextual `StableVar` $h_t = 1/\sqrt{E[\sum_w\frac{\pi^2(x,w)}{e_t(x,w)}]}$
- contextual `MinVar` $h_t(x) = 1/\sum_w\frac{\pi^2(x,w)}{e_t(x,w)}$
- contextual `StableVar` $h_t(x) = 1/\sum_w\frac{\pi^2(x,w)}{e_t(x,w)}$
## Read saving results
```
def read_data(name):
results = read_files(f'{name}*')
print(len(results))
if os.path.exists(f"{name}_stats.csv"):
df_stats = pd.read_csv(f"{name}_stats.csv")
else:
df_stats, _, _ = generate_data_frames(results)
df_stats.to_csv(f"{name}_stats.csv")
return df_stats
df_stats = read_data("results/classification")
df_lite = merge_dataset_df(df_stats)
df_lite['dgp'].unique()
```
## Analyze characteristics of datasets: #classes, #features, #observations
```
analyze_characteristics(df_lite)
```
## Plots
### Use DR as a baseline and compare it with other methods; evaluating contrast
Every subplot corresponds to an estimation method, wherein each point denotes a dataset, and its $(x,y)$ coordinates are bias and standard error normalized by RMSE of DR estimate on the same dataset.
```
plot_radius(df_lite, 'uniform', 'optimal-best_arm')
```
### Compare contextual weighting versus non-contextual weighting; evaluating contrast
In the left panel, each point denotes a dataset, and its $(x,y)$ coordinates are bias and standard error of contextual `MinVar` normalized by RMSE of non-contextual `MinVar` on the same dataset. Same visualization is applied to contextual and non-contextual `StableVar` in the right panel.
```
plot_radius_comparison(df_lite, 'optimal-best_arm')
```
### Compare MinVar versus StableVar; evaluating contrast
Each point corresponds to a dataset. The $(x,y)$ coordinates are bias and standard error of `MinVar` normalized by its `StableVar` counterpart in forms of both noncontextual weighting (left panel) and contextual weighting (right panel).
```
plot_radius_comparison_2(df_lite, 'optimal-best_arm')
```
| github_jupyter |
# DisCoPy v0.3.3 - new features
[1. Classical-quantum maps and mixed circuits](#1.-Classical-quantum-maps-and-mixed-circuits)
- `discopy.quantum.cqmap` implements Bob and Aleks' classical-quantum maps.
- Now `discopy.quantum.circuit` diagrams have two generating objects: `bit` and `qubit`.
- New boxes `Discard`, `Measure` and `ClassicalGate` can be simulated with `cqmap` or sent to `pytket`.
[2. ZX diagrams and PyZX interface](#2.-ZX-diagrams-and-PyZX-interface)
- `discopy.quantum.zx` implements diagrams with spiders, swaps and Hadamard boxes.
- `to_pyzx` and `from_pyzx` methods can be used to turn diagrams into graphs, simplify then back.
[3. Parametrised diagrams, formal sums and automatic gradients](#3.-Parametrised-diagrams,-formal-sums-and-automatic-gradients)
- We can use `sympy.Symbols` as variables in our diagrams (tensor, circuit or ZX).
- We can take formal sums of diagrams. `TensorFunctor` sends formal sums to concrete sums.
- Given a diagram (tensor, circuit or ZX) with a free variable, we can compute its gradient as a sum.
[4. Learning functors, diagrammatically](#4.-Learning-functors,-diagrammatically)
- We can use automatic gradients to learn functors (classical and/or quantum) from data.
## 1. Classical-quantum maps and mixed circuits
```
from discopy.quantum import *
circuit = H @ X >> CX >> Measure() @ Id(qubit)
circuit.draw()
circuit.eval()
circuit.init_and_discard().draw()
circuit.init_and_discard().eval()
circuit.to_tk()
from pytket.backends.ibm import AerBackend
backend = AerBackend()
circuit.eval(backend)
postprocess = ClassicalGate('postprocess', n_bits_in=2, n_bits_out=0, array=[1, 0, 0, 0])
postprocessed_circuit = Ket(0, 0) >> H @ X >> CX >> Measure() @ Measure() >> postprocess
postprocessed_circuit.draw(aspect='auto')
postprocessed_circuit.to_tk()
postprocessed_circuit.eval(backend)
```
## 2. ZX diagrams and PyZX interface
```
from discopy.quantum.zx import *
from pyzx import draw
bialgebra = Z(1, 2, .25) @ Z(1, 2, .75) >> Id(1) @ SWAP @ Id(1) >> X(2, 1) @ X(2, 1, .5)
bialgebra.draw(aspect='equal')
draw(bialgebra.to_pyzx())
from pyzx import generate, simplify
graph = generate.cliffordT(2, 5)
print("From DisCoPy:")
Diagram.from_pyzx(graph).draw()
print("To PyZX:")
draw(graph)
simplify.full_reduce(graph)
draw(graph)
print("And back!")
Diagram.from_pyzx(graph).draw()
```
## 3. Parametrised diagrams, formal sums and automatic gradients
```
from sympy.abc import phi
from discopy import drawing
from discopy.quantum import *
circuit = sqrt(2) @ Ket(0, 0) >> H @ Rx(phi) >> CX >> Bra(0, 1)
drawing.equation(circuit, circuit.subs(phi, .5), symbol="|-->")
gradient = scalar(1j) @ (circuit >> circuit[::-1]).grad(phi)
gradient.draw()
import numpy as np
x = np.arange(0, 1, 0.05)
y = np.array([circuit.subs(phi, i).measure() for i in x])
dy = np.array([gradient.subs(phi, i).eval().array for i in x])
from matplotlib import pyplot as plt
plt.subplot(2, 1, 1)
plt.plot(x, y)
plt.ylabel("Amplitude")
plt.subplot(2, 1, 2)
plt.plot(x, dy)
plt.ylabel("Gradient")
```
## 4. Learning functors, diagrammatically
```
from discopy import *
s, n = Ty('s'), Ty('n')
Alice, loves, Bob = Word("Alice", n), Word("loves", n.r @ s @ n.l), Word("Bob", n)
grammar = Cup(n, n.r) @ Id(s) @ Cup(n.l, n)
parsing = {
"{} {} {}".format(subj, verb, obj): subj @ verb @ obj >> grammar
for subj in [Alice, Bob] for verb in [loves] for obj in [Alice, Bob]}
pregroup.draw(parsing["Alice loves Bob"], aspect='equal')
print("Our favorite toy dataset:")
corpus = {
"{} {} {}".format(subj, verb, obj): int(obj != subj)
for subj in [Alice, Bob] for verb in [loves] for obj in [Alice, Bob]}
for sentence, scalar in corpus.items():
print("'{}' is {}.".format(sentence, "true" if scalar else "false"))
from sympy import symbols
parameters = symbols("a0 a1 b0 b1 c00 c01 c10 c11")
F = TensorFunctor(
ob={s: 1, n: 2},
ar={Alice: symbols("a0 a1"),
Bob: symbols("b0 b1"),
loves: symbols("c00 c01 c10 c11")})
gradient = F(parsing["Alice loves Bob"]).grad(*parameters)
gradient
gradient.subs(list(zip(parameters, 8 * [0])))
from discopy.quantum import *
gates = {
Alice: ClassicalGate('Alice', 0, 1, symbols("a0 a1")),
Bob: ClassicalGate('Bob', 0, 1, symbols("b0 b1")),
loves: ClassicalGate('loves', 0, 2, symbols("c00 c01 c10 c11"))}
F = CircuitFunctor(ob={s: Ty(), n: bit}, ar=gates)
F(parsing["Alice loves Bob"]).draw()
F(parsing["Alice loves Alice"]).grad(symbols("a0")).draw()
F(parsing["Alice loves Alice"]).grad(symbols("a0")).eval()
```
| github_jupyter |
<a href=https://pythonista.io><img src="img/pythonista.png" width="100px"></a>
# Introducción a DevOps.
# ¿Qué es DevOps?
* "DevOps" es un término que está de moda y en ocasiones pierde sentido.
* Muchas personas y organizaciones tienen su propias definiciones sobre "DevOps".
* Es una contracción de "Operaciones de Desarrollo".
# Definición de "DevOps".
"Conjunto de prácticas enfocadas a reducir el tiempo entre el registro de un cambio en un sistema y el momento en el que el cambio es puesto en un entrono de producción garantizando la calidad de éste".
# DevOps puede considerarse como una 'cultura'.
Una cultura en la que las organizaciones de desarrollo de TI se enfocan en crear grupos de trabajo mutidisciplinarios que facilitan la comunicacion, control, seguridad, calidad y agilidad del ciclo de vida del software.
# ¿Conceptos ligados a DevOps?
* Desarrollo ágil.
* Cómputo en la nube.
* Infraestructura como software.
* Microservicios.
* "Full stack" developer.
# Desarrollo ágil.
Aún cuando es posible hacer DevOps con metodologías más convencionales, el desarrollo ágil es muy compatible con DevOps.
* Se basa en ciclos de desarrollo cortos con objetivos y entregables especificos.
* El producto (software) evoluciona conforme los ciclos avanzan.
* Los grupos de trabajo son multidisciplinarios y por lo general autogestionados.
* Es una opción a metodologías más rigurosas.
* Sin embargo, DevOps puede funcionar con otras metodologías.
# ¿Cuál es la promesa de DevOps?
## Autoservicio.
## Autogestión.
## Entrega e integración continua.
## Colaboración.
## Escalabilidad.
# La cadena de DevOps.

Fuente: [Wikipedia](https://en.wikipedia.org/wiki/DevOps#/media/File:Devops-toolchain.svg)
# Componentes en el desarrollo (ágil) de un producto de software.
* Control de versiones.
* Gestión y aprovisionamiento de entornos.
* Automatización.
* Pruebas y QA.
* Integración.
* Entrega/Despliegue.
* Comunicación.
# Control de versiones.
## Herramientas de control de versiones.
* [Apache Subversion](https://subversion.apache.org/).
* [Mercurial](https://www.mercurial-scm.org/).
* [Git](https://git-scm.com/).
## Servicios de control de versiones.
* [Github](https://github.com/).
* [GitLab](https://about.gitlab.com/).
* [BitBucket](https://bitbucket.org/).
* [SourceForge](https://sourceforge.net/).
# Gestión de entornos.
* [Heroku](https://www.heroku.com/).
* [OpenShift](https://www.openshift.com/).
* [Docker Cloud](https://cloud.docker.com/).
* [Dokku](http://dokku.viewdocs.io/dokku/).
* [Zeit](https://zeit.co/).
* [Elastick Beanstalk.](https://aws.amazon.com/es/elasticbeanstalk/)
* [Google App Engine.](https://cloud.google.com/appengine/)
* [Microsoft Azure.](https://azure.microsoft.com/es-mx/)
# Automatización.
* [Salt](https://saltstack.com/).
* [Chef](https://www.chef.io/).
* [Puppet](https://puppet.com/).
* [Ansible](https://www.ansible.com/).
# Pruebas, aseguramiento de calidad, integración y entrega.
## ¿Qué probamos/validamos?
* Componentes.
* Funcionalidad.
* Seguridad.
* Integración.
## Herramientas.
* [Jenkins](https://jenkins.io/).
* [Travis CI](https://travis-ci.org/).
* [Buildbot](http://buildbot.net/).
* [Selenium](http://www.seleniumhq.org/).
* [Bugzilla](https://www.bugzilla.org/).
* [Sahi](http://sahipro.com/sahi-open-source/).
# Infraestructura como código (IaC).
El objetivo de DevOps no estaría completo si no fuera posible proveer los recursos de infraestructura necesarios para que un proyecto de desarrollo se lleve a cabo correctamente.
Actualmente la virtualización no sólo de unidades de cómputo sino de redes y almacenamiento permiten consolidar estos recursos y permitir desplegar infraestructura especializada.
* [Terraform.](https://www.terraform.io/)
# Comunicaciones y comunidades.
* [Slack](https://slack.com).
* [Stack Overflow](https://stackoverflow.com/).
* IRC, Correo, Groupware, Whatsapp, etc.
# ¿De aquí a dónde?
[Stackshare](https://stackshare.io/)
<a href=https://pythonista.io><img src="img/pythonista.png" width="100px"></a>
<p style="text-align: center"><a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Licencia Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/80x15.png" /></a><br />Esta obra está bajo una <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Licencia Creative Commons Atribución 4.0 Internacional</a>.</p>
<p style="text-align: center">© José Luis Chiquete Valdivieso. 2019.</p>
| github_jupyter |
# T1055.004 - Process Injection: Asynchronous Procedure Call
Adversaries may inject malicious code into processes via the asynchronous procedure call (APC) queue in order to evade process-based defenses as well as possibly elevate privileges. APC injection is a method of executing arbitrary code in the address space of a separate live process.
APC injection is commonly performed by attaching malicious code to the APC Queue (Citation: Microsoft APC) of a process's thread. Queued APC functions are executed when the thread enters an alterable state.(Citation: Microsoft APC) A handle to an existing victim process is first created with native Windows API calls such as <code>OpenThread</code>. At this point <code>QueueUserAPC</code> can be used to invoke a function (such as <code>LoadLibrayA</code> pointing to a malicious DLL).
A variation of APC injection, dubbed "Early Bird injection", involves creating a suspended process in which malicious code can be written and executed before the process' entry point (and potentially subsequent anti-malware hooks) via an APC. (Citation: CyberBit Early Bird Apr 2018) AtomBombing (Citation: ENSIL AtomBombing Oct 2016) is another variation that utilizes APCs to invoke malicious code previously written to the global atom table.(Citation: Microsoft Atom Table)
Running code in the context of another process may allow access to the process's memory, system/network resources, and possibly elevated privileges. Execution via APC injection may also evade detection from security products since the execution is masked under a legitimate process.
## Atomic Tests
```
#Import the Module before running the tests.
# Checkout Jupyter Notebook at https://github.com/cyb3rbuff/TheAtomicPlaybook to run PS scripts.
Import-Module /Users/0x6c/AtomicRedTeam/atomics/invoke-atomicredteam/Invoke-AtomicRedTeam.psd1 - Force
```
### Atomic Test #1 - Process Injection via C#
Process Injection using C#
reference: https://github.com/pwndizzle/c-sharp-memory-injection
Excercises Five Techniques
1. Process injection
2. ApcInjectionAnyProcess
3. ApcInjectionNewProcess
4. IatInjection
5. ThreadHijack
Upon successful execution, cmd.exe will execute T1055.exe, which exercises 5 techniques. Output will be via stdout.
**Supported Platforms:** windows
#### Attack Commands: Run with `command_prompt`
```command_prompt
PathToAtomicsFolder\T1055.004\bin\T1055.exe
```
```
Invoke-AtomicTest T1055.004 -TestNumbers 1
```
## Detection
Monitoring Windows API calls indicative of the various types of code injection may generate a significant amount of data and may not be directly useful for defense unless collected under specific circumstances for known bad sequences of calls, since benign use of API functions may be common and difficult to distinguish from malicious behavior. Windows API calls such as <code>SuspendThread</code>/<code>SetThreadContext</code>/<code>ResumeThread</code>, <code>QueueUserAPC</code>/<code>NtQueueApcThread</code>, and those that can be used to modify memory within another process, such as <code>VirtualAllocEx</code>/<code>WriteProcessMemory</code>, may be used for this technique.(Citation: Endgame Process Injection July 2017)
Analyze process behavior to determine if a process is performing actions it usually does not, such as opening network connections, reading files, or other suspicious actions that could relate to post-compromise behavior.
| github_jupyter |
<a href="https://colab.research.google.com/github/lsuhpchelp/lbrnloniworkshop2020/blob/master/day5/keras_mnist_v2_5layer_fc.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# MNIST handwritten digits classification with 5-layer softmax regression model.
Ref: https://github.com/CSCfi/machine-learning-scripts
In the second step, we'll 5 fully connected layer model to classify MNIST digits using Keras (using Tensorflow as the compute backend) as shown in the slides.
Note that we want you to ignore the initialization part which could be environment/platform dependent, however, focus more on the part that is related to the structure of the neural network (NN) to understand how the full connected layers are implemented in Keras.
```
# initialization of the environment using keras
%matplotlib inline
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten, MaxPooling2D
from keras.layers.convolutional import Conv2D
from keras.utils import np_utils
from keras import backend as K
from distutils.version import LooseVersion as LV
from keras import __version__
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
print('Using Keras version:', __version__, 'backend:', K.backend())
assert(LV(__version__) >= LV("2.0.0"))
```
Let's load the MNIST or Fashion-MNIST dataset.
```
from keras.datasets import mnist, fashion_mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# if you want to use the fashion_mnist data
#(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
nb_classes = 10
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# one-hot encoding:
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
print()
print('MNIST data loaded: train:',len(X_train),'test:',len(X_test))
print('X_train:', X_train.shape)
print('y_train:', y_train.shape)
print('Y_train:', Y_train.shape)
```
We'll have to do a bit of tensor manipulations, depending on the used backend (Theano or Tensorflow).
```
# input image dimensions
img_rows, img_cols = 28, 28
if K.common.image_dim_ordering() == 'th':
X_train_disp = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test_disp = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
# Note how do we flatten the images
X_train = X_train.reshape(X_train.shape[0], img_rows*img_cols)
X_test = X_test.reshape(X_test.shape[0], img_rows*img_cols)
input_shape = (img_rows*img_cols,)
else:
X_train_disp = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test_disp = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
# Note how do we flatten the images
X_train = X_train.reshape(X_train.shape[0], img_rows*img_cols)
X_test = X_test.reshape(X_test.shape[0], img_rows*img_cols)
input_shape = (img_rows*img_cols,)
print('X_train:', X_train.shape)
print('X_test:', X_test.shape)
```
## Initialization
Build the 5 layer full connected softmax regression NN model
```
nb_classes = 10
model = Sequential()
# using the relu activation function
act_func='relu'
model.add(Dense(200,activation=act_func,input_shape=input_shape))
model.add(Dense(100,activation=act_func))
model.add(Dense( 60,activation=act_func))
model.add(Dense( 30,activation=act_func))
#build the softmax regression layer
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
# using the cross-entropy loss function (objective)
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
print(model.summary())
# uncomment the below line to visualize the neural network structure
#SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
```
## Learning
Now let's train the one layer linear softmax regression model. This is a relatively simple model, training is very fast.
```
%%time
epochs = 50 # one epoch finishes in 1-2 seconds
history = model.fit(X_train,
Y_train,
epochs=epochs,
batch_size=128,
verbose=2,
# note the use of validation data
validation_data=(X_test, Y_test))
# You should see a typical sign of overfitting based on the loss and accuracy
# curves, see our version 3 for a solution.
# plot the training and validation loss
plt.figure(figsize=(5,4))
plt.plot(history.epoch,history.history['loss'],label='training loss',color='blue')
plt.plot(history.epoch,history.history['val_loss'],label='test loss',color='red')
plt.legend()
plt.title('loss')
# plot the training and validation accuracy
plt.figure(figsize=(5,4))
plt.plot(history.epoch,history.history['accuracy'],label='training acc',color='blue')
plt.plot(history.epoch,history.history['val_accuracy'],label='test acc',color='red')
plt.legend()
plt.title('accuracy');
```
## Inference
With enough training epochs, the test accuracy should be around 98%, much higher that the linear regression model.
You can compare your result with the state-of-the art [here](http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html). Even more results can be found [here](http://yann.lecun.com/exdb/mnist/).
```
%%time
scores = model.evaluate(X_test, Y_test, verbose=2)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
```
We can again take a closer look on the results. Let's begin by defining
a helper function to show the failure cases of our classifier.
```
def show_failures(predictions, trueclass=None, predictedclass=None, maxtoshow=10):
rounded = np.argmax(predictions, axis=1)
errors = rounded!=y_test
print('Showing max', maxtoshow, 'first failures. '
'The predicted class is shown first and the correct class in parenthesis.')
ii = 0
plt.figure(figsize=(maxtoshow, 1))
for i in range(X_test.shape[0]):
if ii>=maxtoshow:
break
if errors[i]:
if trueclass is not None and y_test[i] != trueclass:
continue
if predictedclass is not None and predictions[i] != predictedclass:
continue
plt.subplot(1, maxtoshow, ii+1)
plt.axis('off')
if K.common.image_dim_ordering() == 'th':
plt.imshow(X_test_disp[i,0,:,:], cmap="gray")
else:
plt.imshow(X_test_disp[i,:,:,0], cmap="gray")
plt.title("%d (%d)" % (rounded[i], y_test[i]))
ii = ii + 1
```
Here are the first 10 test digits the CNN classified to a wrong class:
```
predictions = model.predict(X_test)
show_failures(predictions)
```
We can use `show_failures()` to inspect failures in more detail. For example, here are failures in which the true class was "6":
```
show_failures(predictions, trueclass=6)
```
# Question
We used the above 5 layer deep neural network, this is a kind of arbitrary decision, try to modify the structure of the neural network, e.g., try different number of layers (using 3/6/10 layers?), different number of neurons at each layer (100/300/500/1000??), will this make a big difference in the shape of the loss and accuracy curve?
| github_jupyter |
```
# from google.colab import drive
# drive.mount('/content/drive')
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from matplotlib import pyplot as plt
import copy
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=10, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=10, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
foreground_classes = {'plane', 'car', 'bird'}
#foreground_classes = {'bird', 'cat', 'deer'}
background_classes = {'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'}
#background_classes = {'plane', 'car', 'dog', 'frog', 'horse','ship', 'truck'}
fg1,fg2,fg3 = 0,1,2
dataiter = iter(trainloader)
background_data=[]
background_label=[]
foreground_data=[]
foreground_label=[]
batch_size=10
for i in range(5000):
images, labels = dataiter.next()
for j in range(batch_size):
if(classes[labels[j]] in background_classes):
img = images[j].tolist()
background_data.append(img)
background_label.append(labels[j])
else:
img = images[j].tolist()
foreground_data.append(img)
foreground_label.append(labels[j])
foreground_data = torch.tensor(foreground_data)
foreground_label = torch.tensor(foreground_label)
background_data = torch.tensor(background_data)
background_label = torch.tensor(background_label)
def create_mosaic_img(bg_idx,fg_idx,fg):
"""
bg_idx : list of indexes of background_data[] to be used as background images in mosaic
fg_idx : index of image to be used as foreground image from foreground data
fg : at what position/index foreground image has to be stored out of 0-8
"""
image_list=[]
j=0
for i in range(9):
if i != fg:
image_list.append(background_data[bg_idx[j]])#.type("torch.DoubleTensor"))
j+=1
else:
image_list.append(foreground_data[fg_idx])#.type("torch.DoubleTensor"))
label = foreground_label[fg_idx]- fg1 # minus fg1 because our fore ground classes are fg1,fg2,fg3 but we have to store it as 0,1,2
#image_list = np.concatenate(image_list ,axis=0)
image_list = torch.stack(image_list)
return image_list,label
desired_num = 30000
mosaic_list_of_images =[] # list of mosaic images, each mosaic image is saved as list of 9 images
fore_idx =[] # list of indexes at which foreground image is present in a mosaic image i.e from 0 to 9
mosaic_label=[] # label of mosaic image = foreground class present in that mosaic
for i in range(desired_num):
np.random.seed(i)
bg_idx = np.random.randint(0,35000,8)
fg_idx = np.random.randint(0,15000)
fg = np.random.randint(0,9)
fore_idx.append(fg)
image_list,label = create_mosaic_img(bg_idx,fg_idx,fg)
mosaic_list_of_images.append(image_list)
mosaic_label.append(label)
class MosaicDataset(Dataset):
"""MosaicDataset dataset."""
def __init__(self, mosaic_list_of_images, mosaic_label, fore_idx):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.mosaic = mosaic_list_of_images
self.label = mosaic_label
self.fore_idx = fore_idx
def __len__(self):
return len(self.label)
def __getitem__(self, idx):
return self.mosaic[idx] , self.label[idx], self.fore_idx[idx]
batch = 250
msd = MosaicDataset(mosaic_list_of_images, mosaic_label , fore_idx)
train_loader = DataLoader( msd,batch_size= batch ,shuffle=True)
class Focus(nn.Module):
def __init__(self):
super(Focus, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=0)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=0)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=0)
self.conv4 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=0)
self.conv5 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=0)
self.conv6 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.batch_norm1 = nn.BatchNorm2d(32,track_running_stats=False)
self.batch_norm2 = nn.BatchNorm2d(64,track_running_stats=False)
self.batch_norm3 = nn.BatchNorm2d(256,track_running_stats=False)
self.dropout1 = nn.Dropout2d(p=0.05)
self.dropout2 = nn.Dropout2d(p=0.1)
self.fc1 = nn.Linear(256,64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 10)
self.fc4 = nn.Linear(10, 1)
def forward(self,z): #y is avg image #z batch of list of 9 images
y = torch.zeros([batch,64, 12,12], dtype=torch.float64)
x = torch.zeros([batch,9],dtype=torch.float64)
ftr = torch.zeros([batch,9,64,12,12])
y = y.to("cuda")
x = x.to("cuda")
ftr = ftr.to("cuda")
for i in range(9):
out,ftrs = self.helper(z[:,i])
#print(out.shape)
x[:,i] = out
ftr[:,i] = ftrs
log_x = F.log_softmax(x,dim=1) # log_alpha
x = F.softmax(x,dim=1)
for i in range(9):
x1 = x[:,i]
y = y + torch.mul(x1[:,None,None,None],ftr[:,i])
return x,log_x, y #alpha, log_alpha, avg_data
def helper(self, x):
#x1 = x
#x1 =x
x = self.conv1(x)
x = F.relu(self.batch_norm1(x))
x = (F.relu(self.conv2(x)))
x = self.pool(x)
x = self.conv3(x)
x1 = F.tanh(x)
x = F.relu(self.batch_norm2(x))
x = (F.relu(self.conv4(x)))
x = self.pool(x)
x = self.dropout1(x)
x = self.conv5(x)
x = F.relu(self.batch_norm3(x))
x = self.conv6(x)
#x1 = F.tanh(x)
x = F.relu(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.dropout2(x)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.dropout2(x)
x = F.relu(self.fc3(x))
x = self.fc4(x)
x = x[:,0]
#print(x.shape)
return x,x1
torch.manual_seed(1237)
focus_net = Focus().double()
focus_net = focus_net.to("cuda")
for params in focus_net.parameters():
params.requires_grad =True
class Classification(nn.Module):
def __init__(self):
super(Classification, self).__init__()
self.conv1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1)
self.conv6 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2,padding=1)
self.batch_norm1 = nn.BatchNorm2d(128,track_running_stats=False)
self.batch_norm2 = nn.BatchNorm2d(256,track_running_stats=False)
self.batch_norm3 = nn.BatchNorm2d(512,track_running_stats=False)
self.dropout1 = nn.Dropout2d(p=0.05)
self.dropout2 = nn.Dropout2d(p=0.1)
self.global_average_pooling = nn.AvgPool2d(kernel_size=2)
self.fc1 = nn.Linear(512,128)
# self.fc2 = nn.Linear(128, 64)
# self.fc3 = nn.Linear(64, 10)
self.fc2 = nn.Linear(128, 3)
def forward(self, x):
x = self.conv1(x)
x = F.relu(self.batch_norm1(x))
x = (F.relu(self.conv2(x)))
x = self.pool(x)
x = self.conv3(x)
x = F.relu(self.batch_norm2(x))
x = (F.relu(self.conv4(x)))
x = self.pool(x)
x = self.dropout1(x)
x = self.conv5(x)
x = F.relu(self.batch_norm3(x))
x = (F.relu(self.conv6(x)))
x = self.pool(x)
#print(x.shape)
x = self.global_average_pooling(x)
x = x.squeeze()
#x = x.view(x.size(0), -1)
#print(x.shape)
x = self.dropout2(x)
x = F.relu(self.fc1(x))
#x = F.relu(self.fc2(x))
#x = self.dropout2(x)
#x = F.relu(self.fc3(x))
x = self.fc2(x)
return x
torch.manual_seed(1237)
classify = Classification().double()
classify = classify.to("cuda")
for params in classify.parameters():
params.requires_grad = True
test_images =[] #list of mosaic images, each mosaic image is saved as laist of 9 images
fore_idx_test =[] #list of indexes at which foreground image is present in a mosaic image
test_label=[] # label of mosaic image = foreground class present in that mosaic
for i in range(10000):
np.random.seed(i+30000)
bg_idx = np.random.randint(0,35000,8)
fg_idx = np.random.randint(0,15000)
fg = np.random.randint(0,9)
fore_idx_test.append(fg)
image_list,label = create_mosaic_img(bg_idx,fg_idx,fg)
test_images.append(image_list)
test_label.append(label)
test_data = MosaicDataset(test_images,test_label,fore_idx_test)
test_loader = DataLoader( test_data,batch_size= batch ,shuffle=False)
import torch.optim as optim
# criterion_classify = nn.CrossEntropyLoss()
optimizer_focus = optim.SGD(focus_net.parameters(), lr=0.01, momentum=0.9)
optimizer_classify = optim.SGD(classify.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
def my_cross_entropy(x, y,alpha,log_alpha,k):
loss = criterion(x,y)
b = -1.0* alpha * log_alpha
b = torch.mean(torch.sum(b,dim=1))
closs = loss
entropy = b
loss = (1-k)*loss + ((k)*b)
return loss,closs,entropy
col1=[]
col2=[]
col3=[]
col4=[]
col5=[]
col6=[]
col7=[]
col8=[]
col9=[]
col10=[]
col11=[]
col12=[]
col13=[]
correct = 0
total = 0
count = 0
flag = 1
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
with torch.no_grad():
for data in train_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels , fore_idx = inputs.to("cuda"),labels.to("cuda"), fore_idx.to("cuda")
alphas, _ ,avg_images = focus_net(inputs)
outputs = classify(avg_images)
_, predicted = torch.max(outputs.data, 1)
for j in range(labels.size(0)):
count += 1
focus = torch.argmax(alphas[j])
if alphas[j][focus] >= 0.5 :
argmax_more_than_half += 1
else:
argmax_less_than_half += 1
if(focus == fore_idx[j] and predicted[j] == labels[j]):
focus_true_pred_true += 1
elif(focus != fore_idx[j] and predicted[j] == labels[j]):
focus_false_pred_true += 1
elif(focus == fore_idx[j] and predicted[j] != labels[j]):
focus_true_pred_false += 1
elif(focus != fore_idx[j] and predicted[j] != labels[j]):
focus_false_pred_false += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 30000 train images: %d %%' % ( 100 * correct / total))
print("total correct", correct)
print("total train set images", total)
print("focus_true_pred_true %d =============> FTPT : %d %%" % (focus_true_pred_true , (100 * focus_true_pred_true / total) ) )
print("focus_false_pred_true %d =============> FFPT : %d %%" % (focus_false_pred_true, (100 * focus_false_pred_true / total) ) )
print("focus_true_pred_false %d =============> FTPF : %d %%" %( focus_true_pred_false , ( 100 * focus_true_pred_false / total) ) )
print("focus_false_pred_false %d =============> FFPF : %d %%" % (focus_false_pred_false, ( 100 * focus_false_pred_false / total) ) )
print("argmax_more_than_half ==================> ",argmax_more_than_half)
print("argmax_less_than_half ==================> ",argmax_less_than_half)
print(count)
print("="*100)
col1.append(0)
col2.append(argmax_more_than_half)
col3.append(argmax_less_than_half)
col4.append(focus_true_pred_true)
col5.append(focus_false_pred_true)
col6.append(focus_true_pred_false)
col7.append(focus_false_pred_false)
correct = 0
total = 0
count = 0
flag = 1
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
with torch.no_grad():
for data in test_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels , fore_idx = inputs.to("cuda"),labels.to("cuda"), fore_idx.to("cuda")
alphas,_, avg_images = focus_net(inputs)
outputs = classify(avg_images)
_, predicted = torch.max(outputs.data, 1)
for j in range(labels.size(0)):
focus = torch.argmax(alphas[j])
if alphas[j][focus] >= 0.5 :
argmax_more_than_half += 1
else:
argmax_less_than_half += 1
if(focus == fore_idx[j] and predicted[j] == labels[j]):
focus_true_pred_true += 1
elif(focus != fore_idx[j] and predicted[j] == labels[j]):
focus_false_pred_true += 1
elif(focus == fore_idx[j] and predicted[j] != labels[j]):
focus_true_pred_false += 1
elif(focus != fore_idx[j] and predicted[j] != labels[j]):
focus_false_pred_false += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
print("total correct", correct)
print("total train set images", total)
print("focus_true_pred_true %d =============> FTPT : %d %%" % (focus_true_pred_true , (100 * focus_true_pred_true / total) ) )
print("focus_false_pred_true %d =============> FFPT : %d %%" % (focus_false_pred_true, (100 * focus_false_pred_true / total) ) )
print("focus_true_pred_false %d =============> FTPF : %d %%" %( focus_true_pred_false , ( 100 * focus_true_pred_false / total) ) )
print("focus_false_pred_false %d =============> FFPF : %d %%" % (focus_false_pred_false, ( 100 * focus_false_pred_false / total) ) )
print("argmax_more_than_half ==================> ",argmax_more_than_half)
print("argmax_less_than_half ==================> ",argmax_less_than_half)
col8.append(argmax_more_than_half)
col9.append(argmax_less_than_half)
col10.append(focus_true_pred_true)
col11.append(focus_false_pred_true)
col12.append(focus_true_pred_false)
col13.append(focus_false_pred_false)
nos_epochs = 60
k = 0.01
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
for epoch in range(nos_epochs): # loop over the dataset multiple times
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
running_loss = 0.0
running_cross_entropy = 0.0
running_entropy = 0.0
cnt=0
iteration = desired_num // batch
epoch_loss = []
epoch_ce = []
epoch_entropy = []
#training data set
for i, data in enumerate(train_loader):
inputs , labels , fore_idx = data
inputs = inputs.double()
inputs, labels = inputs.to("cuda"), labels.to("cuda")
# zero the parameter gradients
optimizer_focus.zero_grad()
optimizer_classify.zero_grad()
alphas,log_alpha, avg_images = focus_net(inputs)
outputs = classify(avg_images)
# outputs, alphas, avg_images = classify(inputs)
_, predicted = torch.max(outputs.data, 1)
# print(outputs)
# print(outputs.shape,labels.shape , torch.argmax(outputs, dim=1))
#loss = criterion_classify(outputs, labels)
loss,c_e,entropy = my_cross_entropy(outputs, labels,alphas,log_alpha,k)
loss.backward()
optimizer_focus.step()
optimizer_classify.step()
running_loss += loss.item()
running_cross_entropy += c_e.item()
running_entropy += entropy.item()
mini = 60
if cnt % mini == mini-1: # print every 40 mini-batches
print('[%d, %5d] loss: %.3f cross_entropy: %.3f entropy: %.3f' %(epoch + 1, cnt + 1, running_loss / mini,running_cross_entropy/mini,running_entropy/mini))
epoch_loss.append(running_loss/mini)
epoch_ce.append(running_cross_entropy/mini)
epoch_entropy.append(running_entropy/mini)
running_loss = 0.0
running_cross_entropy = 0.0
running_entropy = 0.0
cnt=cnt+1
if epoch % 5 == 0:
for j in range (batch):
focus = torch.argmax(alphas[j])
if(alphas[j][focus] >= 0.5):
argmax_more_than_half +=1
else:
argmax_less_than_half +=1
if(focus == fore_idx[j] and predicted[j] == labels[j]):
focus_true_pred_true += 1
elif(focus != fore_idx[j] and predicted[j] == labels[j]):
focus_false_pred_true +=1
elif(focus == fore_idx[j] and predicted[j] != labels[j]):
focus_true_pred_false +=1
elif(focus != fore_idx[j] and predicted[j] != labels[j]):
focus_false_pred_false +=1
if epoch % 5 == 0:
col1.append(epoch+1)
col2.append(argmax_more_than_half)
col3.append(argmax_less_than_half)
col4.append(focus_true_pred_true)
col5.append(focus_false_pred_true)
col6.append(focus_true_pred_false)
col7.append(focus_false_pred_false)
#************************************************************************
#testing data set
with torch.no_grad():
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
for data in test_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels = inputs.to("cuda"), labels.to("cuda")
alphas, _,avg_images = focus_net(inputs)
outputs = classify(avg_images)
#outputs, alphas, avg_images = classify(inputs)
_, predicted = torch.max(outputs.data, 1)
for j in range (batch):
focus = torch.argmax(alphas[j])
if(alphas[j][focus] >= 0.5):
argmax_more_than_half +=1
else:
argmax_less_than_half +=1
if(focus == fore_idx[j] and predicted[j] == labels[j]):
focus_true_pred_true += 1
elif(focus != fore_idx[j] and predicted[j] == labels[j]):
focus_false_pred_true +=1
elif(focus == fore_idx[j] and predicted[j] != labels[j]):
focus_true_pred_false +=1
elif(focus != fore_idx[j] and predicted[j] != labels[j]):
focus_false_pred_false +=1
col8.append(argmax_more_than_half)
col9.append(argmax_less_than_half)
col10.append(focus_true_pred_true)
col11.append(focus_false_pred_true)
col12.append(focus_true_pred_false)
col13.append(focus_false_pred_false)
if(np.mean(epoch_loss) <= 0.02):
break;
print('Finished Training')
torch.save(focus_net.state_dict(),"/content/weights_focus_3.pt")
torch.save(classify.state_dict(),"/content/weights_classify_3.pt")
columns = ["epochs", "argmax > 0.5" ,"argmax < 0.5", "focus_true_pred_true", "focus_false_pred_true", "focus_true_pred_false", "focus_false_pred_false" ]
df_train = pd.DataFrame()
df_test = pd.DataFrame()
len(col1)
df_train[columns[0]] = col1
df_train[columns[1]] = col2
df_train[columns[2]] = col3
df_train[columns[3]] = col4
df_train[columns[4]] = col5
df_train[columns[5]] = col6
df_train[columns[6]] = col7
df_test[columns[0]] = col1
df_test[columns[1]] = col8
df_test[columns[2]] = col9
df_test[columns[3]] = col10
df_test[columns[4]] = col11
df_test[columns[5]] = col12
df_test[columns[6]] = col13
df_train
# plt.figure(12,12)
plt.plot(col1,col2, label='argmax > 0.5')
plt.plot(col1,col3, label='argmax < 0.5')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("training data")
plt.title("On Training set")
plt.show()
plt.figure(figsize=(6,6))
plt.plot(col1,col4, label ="focus_true_pred_true ")
plt.plot(col1,col5, label ="focus_false_pred_true ")
plt.plot(col1,col6, label ="focus_true_pred_false ")
plt.plot(col1,col7, label ="focus_false_pred_false ")
plt.title("On Training set")
#plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("training data")
plt.savefig("train_3.png",bbox_inches="tight")
plt.savefig("train_3.pdf",bbox_inches="tight")
plt.show()
df_test
# plt.figure(12,12)
plt.plot(col1,col8, label='argmax > 0.5')
plt.plot(col1,col9, label='argmax < 0.5')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("Testing data")
plt.title("On Testing set")
plt.show()
plt.figure(figsize=(6,6))
plt.plot(col1,col10, label ="focus_true_pred_true ")
plt.plot(col1,col11, label ="focus_false_pred_true ")
plt.plot(col1,col12, label ="focus_true_pred_false ")
plt.plot(col1,col13, label ="focus_false_pred_false ")
plt.title("On Testing set")
#plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("Testing data")
plt.savefig("test_3.png",bbox_inches="tight")
plt.savefig("test_3.pdf",bbox_inches="tight")
plt.show()
correct = 0
total = 0
count = 0
flag = 1
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
focus_net.eval()
classify.eval()
with torch.no_grad():
for data in train_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels , fore_idx = inputs.to("cuda"),labels.to("cuda"), fore_idx.to("cuda")
alphas,_, avg_images = focus_net(inputs)
outputs = classify(avg_images)
_, predicted = torch.max(outputs.data, 1)
for j in range(labels.size(0)):
count += 1
focus = torch.argmax(alphas[j])
if alphas[j][focus] >= 0.5 :
argmax_more_than_half += 1
else:
argmax_less_than_half += 1
if(focus == fore_idx[j] and predicted[j] == labels[j]):
focus_true_pred_true += 1
elif(focus != fore_idx[j] and predicted[j] == labels[j]):
focus_false_pred_true += 1
elif(focus == fore_idx[j] and predicted[j] != labels[j]):
focus_true_pred_false += 1
elif(focus != fore_idx[j] and predicted[j] != labels[j]):
focus_false_pred_false += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 30000 train images: %d %%' % ( 100 * correct / total))
print("total correct", correct)
print("total train set images", total)
print("focus_true_pred_true %d =============> FTPT : %d %%" % (focus_true_pred_true , (100 * focus_true_pred_true / total) ) )
print("focus_false_pred_true %d =============> FFPT : %d %%" % (focus_false_pred_true, (100 * focus_false_pred_true / total) ) )
print("focus_true_pred_false %d =============> FTPF : %d %%" %( focus_true_pred_false , ( 100 * focus_true_pred_false / total) ) )
print("focus_false_pred_false %d =============> FFPF : %d %%" % (focus_false_pred_false, ( 100 * focus_false_pred_false / total) ) )
print("argmax_more_than_half ==================> ",argmax_more_than_half)
print("argmax_less_than_half ==================> ",argmax_less_than_half)
print(count)
print("="*100)
correct = 0
total = 0
count = 0
flag = 1
focus_true_pred_true =0
focus_false_pred_true =0
focus_true_pred_false =0
focus_false_pred_false =0
argmax_more_than_half = 0
argmax_less_than_half =0
focus_net.eval()
classify.eval()
with torch.no_grad():
for data in test_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels , fore_idx = inputs.to("cuda"),labels.to("cuda"), fore_idx.to("cuda")
alphas, _,avg_images = focus_net(inputs)
outputs = classify(avg_images)
_, predicted = torch.max(outputs.data, 1)
for j in range(labels.size(0)):
focus = torch.argmax(alphas[j])
if alphas[j][focus] >= 0.5 :
argmax_more_than_half += 1
else:
argmax_less_than_half += 1
if(focus == fore_idx[j] and predicted[j] == labels[j]):
focus_true_pred_true += 1
elif(focus != fore_idx[j] and predicted[j] == labels[j]):
focus_false_pred_true += 1
elif(focus == fore_idx[j] and predicted[j] != labels[j]):
focus_true_pred_false += 1
elif(focus != fore_idx[j] and predicted[j] != labels[j]):
focus_false_pred_false += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
print("total correct", correct)
print("total train set images", total)
print("focus_true_pred_true %d =============> FTPT : %d %%" % (focus_true_pred_true , (100 * focus_true_pred_true / total) ) )
print("focus_false_pred_true %d =============> FFPT : %d %%" % (focus_false_pred_true, (100 * focus_false_pred_true / total) ) )
print("focus_true_pred_false %d =============> FTPF : %d %%" %( focus_true_pred_false , ( 100 * focus_true_pred_false / total) ) )
print("focus_false_pred_false %d =============> FFPF : %d %%" % (focus_false_pred_false, ( 100 * focus_false_pred_false / total) ) )
print("argmax_more_than_half ==================> ",argmax_more_than_half)
print("argmax_less_than_half ==================> ",argmax_less_than_half)
correct = 0
total = 0
focus_net.eval()
classify.eval()
with torch.no_grad():
for data in train_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels = inputs.to("cuda"), labels.to("cuda")
alphas,_, avg_images = focus_net(inputs)
outputs = classify(avg_images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 30000 train images: %d %%' % ( 100 * correct / total))
print("total correct", correct)
print("total train set images", total)
correct = 0
total = 0
focus_net.eval()
classify.eval()
with torch.no_grad():
for data in test_loader:
inputs, labels , fore_idx = data
inputs = inputs.double()
inputs, labels = inputs.to("cuda"), labels.to("cuda")
alphas, _,avg_images = focus_net(inputs)
outputs = classify(avg_images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total))
print("total correct", correct)
print("total train set images", total)
```
| github_jupyter |
# Practical 1: word2vec
Repo: https://github.com/oxford-cs-deepnlp-2017/practical-1
XML data [link](https://github.com/oxford-cs-deepnlp-2017/practical-1/blob/master/ted_en-20160408.xml)
```
# !jt -t onedork -T -N -kl -f fira
# !jt -t onedork -fs 95 -f fira -altp -tfs 11 -nfs 115 -cellw 88% -T
# !jt -t onedork -f firacode -fs 100 -nf roboto -nfs 95 -tf ptsans -tfs 105 -T -altmd -lineh 150
import re
import zipfile
from pathlib import Path
from random import shuffle
import lxml.etree
import urllib.request as ureq
import numpy as np
from bokeh.models import ColumnDataSource, LabelSet
from bokeh.plotting import figure, show, output_file
from bokeh.io import output_notebook
output_notebook()
```
### Retrieve and/or load data
```
# Get XML data
output_freq: int = 100
def raw_hooker(chunk, max_size, total_size = -1):
"""Output streaming info about download object."""
total_chunks: int = round((total_sz / max_sz) + 0.5)
chunk_denom: int = (total_chunks + 1) // output_freq
if chunk % chunk_denom == 0:
print(chunk, max_sz, total_sz)
xml_raw_url: str = "https://github.com/oxford-cs-deepnlp-2017/practical-1/blob/master/ted_en-20160408.xml?raw=true"
res = re.search(r"^.+/(.+)\?.+$", xml_raw_url)
xml_filename: str = ""
if res:
xml_filename = res.group(1)
print(xml_filename)
xml_local_path = Path().joinpath(xml_filename)
if not xml_local_path.is_file():
_fn, _hdr = ureq.urlretrieve(xml_raw_url, filename = xml_filename, reporthook=raw_hooker)
if xml_local_path.is_file():
print(f"Filename: {_fn}\nHeader data: {_hdr}")
# Retain only the subtitle test of the dataset.
xml_doc = lxml.etree.parse(xml_filename)
input_text = "\n".join(xml_doc.xpath("//content/text()"))
del xml_doc
```
### Preprocess data
```
idx = input_text.find("Hyowon Gweon: See this?")
if idx:
print(idx)
print(input_text[idx-20:idx+150])
# Remove parenthesized strings
clean_input = re.sub(r"\([^\)]*\)", "", input_text)
idx = clean_input.find("Hyowon Gweon: See this?")
clean_input[idx-20:idx+150]
# --- Remove names of speaking characters the occur at the beginning of a line.
dialog_pattern: str = r"^([a-z ]+?:\s*)"
comp_dialog = re.compile(dialog_pattern, flags = re.I | re.M)
cleaner_input = comp_dialog.sub("", clean_input)
# --- Split into sentence chunks and/or just create a single string of all sentances without the fluff.
enumlist = lambda iterable: {k:v for k, v in enumerate(iterable)}
lines = re.split(r".\n+", cleaner_input)
print(f"No. lines: {len(lines):,}\n")
print("\n".join([f"{i}: {line}" for i, line in enumlist(lines[:5]).items()]))
# --- Remove non-alphanumeric characters and split by whitespace.
# re.split(re.sub(r"([\W]+)", " ", lines[0]), " ")
s_dict = {}
for i, line in enumlist(lines).items():
s_dict[i] = re.split(r"\s+", re.sub(r"([^\w]+)", " ", line.lower()))
# sentences.append(re.split(r"\s+", re.sub(r"([^\w]+)", " ", line)))
print(f"Dictionary length: {len(s_dict):,}\n")
# --- Get Top 1000 words by frequency
sort_dict_by_values = lambda d, rev = False: dict(sorted(d.items(), key = lambda q: q[1], reverse=rev))
def frequencies(iterable):
tmp_dict = dict()
if iterable.keys():
for k in iterable:
for w in iterable[k]:
if len(w) > 0:
if not w in tmp_dict:
tmp_dict[w] = 1
else:
tmp_dict[w] += 1
return sort_dict_by_values(tmp_dict)
freq_dict = frequencies(s_dict)
# unique_counts = sorted(list(set(freq_dict.values())), reverse = True)
# unique_values = list(set(freq_dict.values()))
# value_rnk = {i:v for i, v in enumerate(sorted(unique_values, reverse=True))}
# word_rnk = {word:ct for i,(word, ct) in enumerate(freq_dict.items()) if i < TOPN}
# print(("\n".join([f"{k}: {word_rnk[k]}" for k in word_rnk if word_rnk[k] < 20]))
# print("\n".join([f"{k}: {freq_dict[k]}" for k in freq_dict if freq_dict[k] < 20]))
TOPN: int = 100
def top_n_words(d: dict):
__w_dict: dict = dict(word=[], word_len=[], freq=[])
ddict= dict(sorted(d.items(), key = lambda q: q[1], reverse = True))
for i, (k, v) in enumerate(ddict.items(), start=1):
if i > TOPN:
break
__w_dict[k] = v
# __w_dict["word"].append(k)
# __w_dict["freq"].append(v)
return __w_dict
top_n_dict = top_n_words(freq_dict)
max_width = max([len(w) for w in top_n_dict.keys()])
print(max_width)
def print_word_rank(d: dict):
# If limit is -1, print all results.
max_w = max([len(w) for w in d.keys()])
# max_w += int(max_w * 0.2)
items = [f"{i:<5}\t{k:<{max_w}}\t{v[i]}" for i, (k, v) in enumerate(d.items(), start=1)]
print("{a:<5}\t{b:<{w}}\t{c}".format(a="Index", b="Word", c="Count", w= max_w))
print("\n".join(items))
print_word_rank(top_n_dict)
# print_top_n(word_rnk, 10)
# print("\n".join([f"{i}: {k} - {word_rnk[k]}" for k in word_rnk if word_rnk[k] < 20]))
# print_top_n(word_rnk, TOPN)
# unique_counts = sorted(list(set(freq_dict.values())), reverse = True)
# max_count = max(freq_dict.values())
# mean_count = sum(freq_dict.values()) / len(freq_dict)
# print(max_count, "\n", f"{mean_count:.3f}")
max(map(len, freq_dict.keys()))
# --- Clean up some unnecessary objects.
if clean_input:
del clean_input
if input_text:
del input_text
```
| github_jupyter |
# Reusable and modular code with functions
## Instructor notes
*Estimated teaching time:* 30 min
*Estimated challenge time:* 0 min
*Key questions:*
*Learning objectives:*
- "Build reusable code in Python."
- "Write functions using conditional statements (if, then, else)"
---
## Functions
Functions wrap up reusable pieces of code - they help you apply the _Do Not Repeat Yourself_ (DRY) principle.
```
def square(x):
# The body of the function is indicated by indenting by 4 spaces.
return x**2
square(4)
def hyphenate(a, b):
# return statements immediately return a value (or None if no value is given)
return a + '-' + b
# Any code in the function after the return statement does not get executed.
print("We will never get here")
hyphenate('python', 'esque')
```
Suppose that separating large data files into individual yearly files is a task that we frequently have to perform. We could write a `for` loop like the one above every time we needed to do it but that would be time consuming and error prone. A more elegant solution would be to create a reusable tool that performs this task with minimum input from the user. To do this, we are going to turn the code we’ve already written into a function.
Functions are reusable, self-contained pieces of code that are called with a single command. They can be designed to accept arguments as input and return values, but they don’t need to do either. Variables declared inside functions only exist while the function is running and if a variable within the function (a local variable) has the same name as a variable somewhere else in the code, the local variable hides but doesn’t overwrite the other.
Every method used in Python (for example, `print`) is a function, and the libraries we import (say, `pandas`) are a collection of functions. We will only use functions that are housed within the same code that uses them, but it’s also easy to write functions that can be used by different programs.
Functions are declared following this general structure:
```python
def this_is_the_function_name(input_argument1, input_argument2):
# The body of the function is indented
# This function prints the two arguments to screen
print('The function arguments are:', input_argument1, input_argument2, '(this is done inside the function!)')
# And returns their product
return input_argument1 * input_argument2
```
The function declaration starts with the word `def`, followed by the function name and any arguments in parenthesis, and ends in a colon. The body of the function is indented just like loops are. If the function returns something when it is called, it includes a return statement at the end.
Let's rewrite this function with shorter (but still informative) names so we don't need to type as much:
```
def product(a, b):
print('The function arguments are:', a, b, '(this is done inside the function!)')
return a * b
```
This is how we call the function:
```
product_of_inputs = product(2, 5)
print('Their product is:', product_of_inputs, '(this is done outside the function!)')
```
## Challenge - Functions
1. Change the values of the input arguments in the function and check its output.
2. Try calling the function by giving it the wrong number of arguments (not 2) or not assigning the function call to a variable (no `product_of_inputs =`).
### Bonus challenges
3. Declare a variable inside the function and test to see where it exists (Hint: can you print it from outside the function?).
4. Explore what happens when a variable both inside and outside the function have the same name. What happens to the global variable when you change the value of the local variable?
## Solutions - Functions
```
# Challenge part 1
product_of_inputs = product(2, 6)
print(product_of_inputs)
```
Challenge part 2:
```python
product(2, 6, "nope")
```
```python
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-fe9d9cd35fe2> in <module>()
1 # 2
----> 2 this_is_the_function_name(2, 6, "nope")
TypeError: this_is_the_function_name() takes 2 positional arguments but 3 were given
```
Challenge part 3:
```python
def product(a, b):
inside_fun = "existential crisis"
print('The function arguments are:', a, b, '(this is done inside the function!)')
return a * b
product(2, 5)
print(inside_fun)
```
```python
The function arguments are: 2 5 (this is done inside the function!)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-13-e7a0563b00a6> in <module>()
12
13 this_is_the_function_name(2, 5)
---> 14 print(inside_fun)
NameError: name 'inside_fun' is not defined
```
```
# Challenge part 4
outside = "unchanged"
def product(a, b):
outside = "I'm being manipulated"
print('The function arguments are:', a, b, '(this is done inside the function!)')
return a * b
product(2, 5)
print(outside)
```
Say we had some code for taking our `survey.csv` data and splitting it out into one file for each year:
```python
# First let's make sure we've read the survey data into a pandas DataFrame.
import pandas as pd
all_data = pd.read_csv("surveys.csv")
this_year = 2002
# Select data for just that year
surveys_year = all_data[all_data.year == this_year]
# Write the new DataFrame to a csv file
filename = 'surveys' + str(this_year) + '.csv'
surveys_year.to_csv(filename)
```
There are many different "chunks" of this code that we can turn into functions, and we can even create functions that call other functions inside them. Let’s first write a function that separates data for just one year and saves that data to a file:
```
def year_to_csv(year, all_data):
"""
Writes a csv file for data from a given year.
year --- year for which data is extracted
all_data --- DataFrame with multi-year data
"""
# Select data for the year
surveys_year = all_data[all_data.year == year]
# Write the new DataFrame to a csv file
filename = 'function_surveys' + str(year) + '.csv'
surveys_year.to_csv(filename)
```
The text between the two sets of triple double quotes is called a _docstring_ and contains the documentation for the function. It does nothing when the function is running and is therefore not necessary, but it is good practice to include docstrings as a reminder of what the code does. Docstrings in functions also become part of their ‘official’ documentation:
```
?year_to_csv
```
**Signature:** `year_to_csv(year, all_data)`
***Docstring:***
```
Writes a csv file for data from a given year.
year --- year for which data is extracted
all_data --- DataFrame with multi-year data
```
***File:*** `~/devel/python-workshop-base/workshops/docs/modules/notebooks/<ipython-input-16-978149c5937c>`
***Type:*** `function`
```
# Read the survey data into a pandas DataFrame.
# (if you are jumping in to just this lesson and don't yet have the surveys.csv file yet,
# see the "Data analysis in Python with Pandas" `working_with_data` module)
import pandas as pd
surveys_df = pd.read_csv("surveys.csv")
year_to_csv(2002, surveys_df)
```
### Aside - listing files and the `os` module
Google Collaboratory and Juypter Notebooks have a built-in file browser, however, you can list the files and directories in the current directory ("folder") with Python code like:
```python
import os
print(os.listdir())
```
You'll see a Python list, a bit like:
```
['surveys.csv','function_surveys2002.csv']
```
(you may have additional files listed here, generated in previous lessons)
The [os](https://docs.python.org/3/library/os.html) module contains, among other things, a bunch of useful functions for working with the filesystem and file paths.
Two other useful examples (hint - these might help in a upcoming challenge):
```python
# This returns True if the file or directory specified exists
os.path.exists('surveys.csv')
```
```python
# This creates empty (nested) directories based on a path (eg in a 'path' each directory is separated by slashes)
os.makedirs('data/csvs/')
```
If a directory already exists, `os.makedirs` fails and produces an error message (in Python terminology we might say it 'raises an exception' ).
We can avoid this by using `os.path.exists` and `os.makedirs` together like:
```python
if not os.path.exists('data/csvs/'):
os.makedirs('data/csvs/')
```
What we really want to do, though, is create files for multiple years without having to request them one by one. Let’s write another function that uses a `for` loop over a sequence of years and repeatedly calls the function we just wrote, `year_to_csv`:
```
def create_csvs_by_year(start_year, end_year, all_data):
"""
Writes separate CSV files for each year of data.
start_year --- the first year of data we want
end_year --- the last year of data we want
all_data --- DataFrame with multi-year data
"""
# "end_year" is the last year of data we want to pull, so we loop to end_year+1
for year in range(start_year, end_year+1):
year_to_csv(year, all_data)
```
Because people will naturally expect that the end year for the files is the last year with data, the `for` loop inside the function ends at `end_year + 1`. By writing the entire loop into a function, we’ve made a reusable tool for whenever we need to break a large data file into yearly files. Because we can specify the first and last year for which we want files, we can even use this function to create files for a subset of the years available. This is how we call this function:
```
# Create CSV files, one for each year in the given range
create_csvs_by_year(1977, 2002, surveys_df)
```
## Challenge - More Functions
1. How could you use the function `create_csvs_by_year` to create a CSV file for only one year ? (Hint: think about the syntax for range)
2. Modify `year_to_csv` so that it has two additional arguments, `output_path` (the path of the directory where the files will be written) and `filename_prefix` (a prefix to be added to the start of the file name). Name your new function `year_to_csv_at_path`. Eg, `def year_to_csv_at_path(year, all_data, output_path, filename_prefix):`. Call your new function to create a new file with a different name in a different directory. ... **Hint:** You could manually create the target directory before calling the function using the Collaboratory / Jupyter file browser, *or* for bonus points you could do it in Python inside the function using the `os` module.
3. Create a new version of the `create_csvs_by_year` function called `create_csvs_by_year_at_path` that also takes the additional arguments `output_path` and `filename_prefix`. Internally `create_csvs_by_year_at_path` should pass these values to `year_to_csv_at_path`. Call your new function to create a new set of files with a different name in a different directory.
4. Make these new functions return a list of the files they have written. There are many ways you can do this (and you should try them all!): you could make the function print the filenames to screen, or you could use a `return` statement to make the function produce a list of filenames, or you can use some combination of the two. You could also try using the `os` library to list the contents of directories.
## Solutions - More Functions
```
# Solution - part 1
create_csvs_by_year(2002, 2002, surveys_df)
# Solution - part 2 and 3
import os
def year_to_csv_at_path(year, all_data, output_path, filename_prefix):
"""
Writes a csv file for data from a given year.
year --- year for which data is extracted
all_data --- DataFrame with multi-year data
output_path --- The output path for the generated file
filename_prefix --- Output filename will be of the form "{filename_prefix}{year}.csv"
"""
# Select data for the year
surveys_year = all_data[all_data.year == year]
# Create directories if required
if not os.path.exists(output_path):
os.makedirs(output_path)
# Write the new DataFrame to a csv file
filename = output_path + '/' + filename_prefix + str(year) + '.csv'
surveys_year.to_csv(filename)
def create_csvs_by_year_at_path(start_year, end_year, all_data, output_path, filename_prefix):
"""
Writes separate CSV files for each year of data.
start_year --- the first year of data we want
end_year --- the last year of data we want
all_data --- DataFrame with multi-year data
output_path --- The output path for the generated file
filename_prefix --- Output filename will be of the form "{filename_prefix}{year}.csv"
"""
# "end_year" is the last year of data we want to pull, so we loop to end_year+1
for year in range(start_year, end_year+1):
year_to_csv_at_path(year, all_data, output_path, filename_prefix)
# Solution - part 4
def year_to_csv_return_filenames(year, all_data):
# Select data for the year
surveys_year = all_data[all_data.year == year]
# Write the new DataFrame to a csv file
filename = 'function_surveys' + str(year) + '.csv'
surveys_year.to_csv(filename)
# We could just print the filename. We can see the result, but won't capture the value
# print(filename)
# It's often more useful to return data rather than print it, so we can do something with it
return filename
def create_csvs_by_year_return_filenames(start_year, end_year, all_data):
generated_files = []
for year in range(start_year, end_year+1):
fn = year_to_csv_return_filenames(year, all_data)
generated_files.append(fn)
return generated_files
print(create_csvs_by_year_return_filenames(2000, 2002, surveys_df))
```
The functions we wrote demand that we give them a value for every argument. Ideally, we would like these functions to be as flexible and independent as possible. Let’s modify the function `create_csvs_by_year` so that the `start_year` and `end_year` default to the full range of the data if they are not supplied by the user.
Arguments can be given default values with an equal sign in the function declaration - we call these **'keyword'** arguments. Any argument in the function without a default value (here, `all_data`) is a required argument - we call these **'positional'** arguments. Positional arguements MUST come before any keyword arguments. Keyword arguments are optional - if you don't include them when calling the function, the default value is used.
```
def keyword_arg_test(all_data, start_year = 1977, end_year = 2002):
"""
A simple function to demonstrate the use of keyword arguments with defaults !
start_year --- the first year of data we want --- default: 1977
end_year --- the last year of data we want --- default: 2002
all_data --- DataFrame with multi-year data - not actually used
"""
return start_year, end_year
start,end = keyword_arg_test(surveys_df, 1988, 1993)
print('Both optional arguments:\t', start, end)
start,end = keyword_arg_test(surveys_df)
print('Default values:\t\t\t', start, end)
```
The `\t` in the print statements are tabs, used to make the text align and be easier to read.
What if our dataset doesn’t start in 1977 and end in 2002? We can modify the function so that it looks for the ealiest and latest years in the dataset if those dates are not provided. Let's redefine `csvs_by_year`:
```
def csvs_by_year(all_data, start_year = None, end_year = None):
"""
Writes separate CSV files for each year of data. The start year and end year can
be optionally provided, otherwise the earliest and latest year in the dataset are
used as the range.
start_year --- the first year of data we want --- default: None - check all_data
end_year --- the last year of data we want --- default: None - check all_data
all_data --- DataFrame with multi-year data
"""
if start_year is None:
start_year = min(all_data.year)
if end_year is None:
end_year = max(all_data.year)
return start_year, end_year
start,end = csvs_by_year(surveys_df, 1988, 1993)
print('Both optional arguments:\t', start, end)
start,end = csvs_by_year(surveys_df)
print('Default values:\t\t\t', start, end)
```
The default values of the `start_year` and `end_year` arguments in this new version of the `csvs_by_year` function are now `None`. This is a built-in constant in Python that indicates the absence of a value - essentially, that the variable exists in the namespace of the function (the directory of variable names) but that it doesn’t correspond to any existing object.
## Challenge - Experimenting with keyword arguments
1. What type of object corresponds to a variable declared as `None` ? (Hint: create a variable set to None and use the function `type()`)
2. Compare the behavior of the function `csvs_by_year` when the keyword arguments have `None` as a default vs. calling the function by supplying (non-default) values to the keyword arguments
3. What happens if you only include a value for `start_year` in the function call? Can you write the function call with only a value for `end_year` ? (Hint: think about how the function must be assigning values to each of the arguments - this is related to the need to put the arguments without default values before those with default values in the function definition!)
## Solutions - Experimenting with keyword arguments
```
# Challenge 1
the_void = None
type(the_void)
# Challenge 2
print(csvs_by_year(surveys_df))
print(csvs_by_year(surveys_df, start_year=1999, end_year=2001))
# Challenge 3
print(csvs_by_year(surveys_df, start_year=1999))
# Keyword args are taken in order if there is no keyword used
# Doing this is a bit dangerous (what if you later decide to add more keyword args to the function ?)
print(csvs_by_year(surveys_df, 1999))
print(csvs_by_year(surveys_df, 1999, end_year=2001))
# But keyword args must always come last - this throws an error
# print(csvs_by_year(surveys_df, start_year=1999, 2001))
# We don't need to specify all keyword args, nor do they need to be in order
print(csvs_by_year(surveys_df, end_year=1999))
print(csvs_by_year(surveys_df, end_year=2001, start_year=1999))
```
## Conditionals - `if` statements
The body of the test function now has two conditionals (`if` statements) that check the values of `start_year` and `end_year`. `if` statements execute a segment of code when some condition is met. They commonly look something like this:
```
a = 5
if a < 0: # Meets first condition?
# if a IS less than zero
print('a is a negative number')
elif a > 0: # Did not meet first condition. meets second condition?
# if a ISN'T less than zero and IS more than zero
print('a is a positive number')
else: # Met neither condition
# if a ISN'T less than zero and ISN'T more than zero
print('a must be zero!')
```
Change the value of `a` to see how this function works. The statement `elif` means “else if”, and all of the conditional statements must end in a colon.
The `if` statements in the function `csvs_by_year` check whether there is an object associated with the variable names `start_year` and `end_year`. If those variables are `None`, the `if` statements return the boolean `True` and execute whatever is in their body. On the other hand, if the variable names are associated with some value (they got a number in the function call), the `if` statements return `False` and do not execute. The opposite conditional statements, which would return `True` if the variables were associated with objects (if they had received value in the function call), would be `if start_year` and `if end_year`.
As we’ve written it so far, the function `csvs_by_year` associates values in the function call with arguments in the function definition just based in their order. If the function gets only two values in the function call, the first one will be associated with `all_data` and the second with `start_year`, regardless of what we intended them to be. We can get around this problem by calling the function using keyword arguments, where each of the arguments in the function definition is associated with a keyword and the function call passes values to the function using these keywords:
```
start,end = csvs_by_year(surveys_df)
print('Default values:\t\t\t', start, end)
start,end = csvs_by_year(surveys_df, 1988, 1993)
print('No keywords:\t\t\t', start, end)
start,end = csvs_by_year(surveys_df, start_year = 1988, end_year = 1993)
print('Both keywords, in order:\t', start, end)
start,end = csvs_by_year(surveys_df, end_year = 1993, start_year = 1988)
print('Both keywords, flipped:\t\t', start, end)
start,end = csvs_by_year(surveys_df, start_year = 1988)
print('One keyword, default end:\t', start, end)
start,end = csvs_by_year(surveys_df, end_year = 1993)
print('One keyword, default start:\t', start, end)
```
## Multiple choice challenge
What output would you expect from the `if` statement (try to figure out the answer without running the code):
```python
pod_bay_doors_open = False
dave_want_doors_open = False
hal_insanity_level = 2001
if not pod_bay_doors_open:
print("Dave: Open the pod bay doors please HAL.")
dave_wants_doors_open = True
elif pod_bay_doors_open and hal_insanity_level >= 95:
print("HAL: I'm closing the pod bay doors, Dave.")
if dave_wants_doors_open and not pod_bay_doors_open and hal_insanity_level >= 95:
print("HAL: I’m sorry, Dave. I’m afraid I can’t do that.")
elif dave_wants_doors_open and not pod_bay_doors_open:
print("HAL: I'm opening the pod bay doors, welcome back Dave.")
else:
print("... silence of space ...")
```
**a)** "HAL: I'm closing the pod bay doors, Dave.", "... silence of space ..."
**b)** "Dave: Open the pod bay doors please HAL.", "HAL: I’m sorry, Dave. I’m afraid I can’t do that."
**c)** "... silence of space ..."
**d)** "Dave: Open the pod bay doors please HAL.", HAL: "I'm opening the pod bay doors, welcome back Dave."
**Option (b)**
## Bonus Challenge - Modifying functions
1. Rewrite the `year_to_csv` and `csvs_by_year` functions to have keyword arguments with default values.
2. Modify the functions so that they don’t create yearly files if there is no data for a given year and display an alert to the user (Hint: use conditional statements to do this. For an extra challenge, use `try` statements !).
3. The code below checks to see whether a directory exists and creates one if it doesn’t. Add some code to your function that writes out the CSV files, to check for a directory to write to.
```python
import os
if 'dir_name_here' in os.listdir():
print('Processed directory exists')
else:
os.mkdir('dir_name_here')
print('Processed directory created')
```
`4.` The code that you have written so far to loop through the years is good, however it is not necessarily reproducible with different datasets. For instance, what happens to the code if we have additional years of data in our CSV files? Using the tools that you learned in the previous activities, make a list of all years represented in the data. Then create a loop to process your data, that begins at the earliest year and ends at the latest year using that list.
_HINT:_ you can create a loop with a list as follows: `for years in year_list:`
## Solutions - Modifying functions
```
# Solution - part 1
def year_to_csv(year=None, all_data=None):
"""
Writes a csv file for data from a given year.
year --- year for which data is extracted
all_data --- DataFrame with multi-year data
"""
if all_data is None:
all_data = pd.read_csv("surveys.csv")
if year is None:
year = min(all_data.year)
# Select data for the year
surveys_year = all_data[all_data.year == year]
# Write the new DataFrame to a csv file
filename = 'function_surveys' + str(year) + '.csv'
surveys_year.to_csv(filename)
def csvs_by_year(start_year=None, end_year=None, all_data=None):
"""
Writes separate CSV files for each year of data.
start_year --- the first year of data we want
end_year --- the last year of data we want
all_data --- DataFrame with multi-year data
"""
if all_data is None:
all_data = pd.read_csv("surveys.csv")
if start_year is None:
start_year = min(all_data.year)
if end_year is None:
end_year = max(all_data.year)
# "end_year" is the last year of data we want to pull, so we loop to end_year+1
for year in range(start_year, end_year+1):
year_to_csv(year, all_data)
# Solution - part 2
def csvs_by_year(start_year=None, end_year=None, all_data=None):
"""
Writes separate CSV files for each year of data.
start_year --- the first year of data we want
end_year --- the last year of data we want
all_data --- DataFrame with multi-year data
"""
if all_data is None:
all_data = pd.read_csv("surveys.csv")
if start_year is None:
start_year = min(all_data.year)
if end_year is None:
end_year = max(all_data.year)
# "end_year" is the last year of data we want to pull, so we loop to end_year+1
for year in range(start_year, end_year+1):
# print(len(all_data[all_data.year == year]))
if len(all_data[all_data.year == year]) > 0:
year_to_csv(year, all_data)
else:
print("Skipping: ", year, " - no data points for this year.")
surveys_df = pd.read_csv("surveys.csv")
csvs_by_year(1977, 2002, surveys_df)
import os
# Solution - part 3
def year_to_csv(year=None, all_data=None, output_dir='output'):
"""
Writes a csv file for data from a given year.
year --- year for which data is extracted
all_data --- DataFrame with multi-year data
output_dir --- the output directory when CSV files will be written
"""
if all_data is None:
all_data = pd.read_csv("surveys.csv")
if year is None:
year = min(all_data.year)
# Select data for the year
surveys_year = all_data[all_data.year == year]
if output_dir in os.listdir('.'):
print('Processed directory exists: ', output_dir)
else:
os.mkdir(output_dir)
print('Processed directory created: ', output_dir)
# Write the new DataFrame to a csv file
filename = output_dir + '/' + 'function_surveys' + str(year) + '.csv'
# The more correct way to create paths is:
# filename = os.path.join(output_dir, 'function_surveys' + str(year) + '.csv')
surveys_year.to_csv(filename)
year_to_csv(2002, surveys_df)
# Solution - part 4
def csvs_by_year(all_data):
"""
Writes separate CSV files for each year of data.
all_data --- DataFrame with multi-year data
"""
# We could do this, but missing years will be included in the 'range'
# start_year = min(all_data.year)
# end_year = max(all_data.year)
# year_list = range(start_year, end_year+1)
# Instead, we create an empty list, then loop over all the rows, adding years
# we haven't seen yet to the list.
year_list = []
for year in surveys_df.year:
if year not in year_list:
year_list.append(year)
# An elegant alternative is to use a 'set' object.
# A 'set' is a collection where every value is unique - no duplicates.
# This ensures no repeated years and has the advantage of also skipping missing years.
# year_list = set(surveys_df.year)
# "end_year" is the last year of data we want to pull, so we loop to end_year+1
for year in year_list:
year_to_csv(year, all_data)
# The 'list' of years from each row contains duplicates (we just list the first 20 here)
print(list(surveys_df.year)[0:20])
print()
# Making it a 'set' removes duplicates
print(list(set(surveys_df.year)))
```
| github_jupyter |
```
%pylab inline
pylab.rcParams['figure.figsize'] = (16.0, 8.0)
```
# Propagating samples through the model function
Assume the measurement model, i.e. the relation between the input quantities and the measurand, to be given as
$$ Y = f(X_1,X_2,\ldots,X_N) $$
with joint PDF associated with the input quantities given as $g_{\mathbf{X}}(\mathbf{\xi})$.
The aim of the Monte Carlo method is the propagation of samples from the PDF $g_{\mathbf{X}}(\mathbf{\xi})$ through the measurement model $f()$ as a means to calculate samples from the PDF $g_{Y}(\eta)$.
Basically, two types of implementation have to be considered: for-loops and vectorisation.
#### Monte Carlo using for-loops
This is the most easiest way of implementing Monte Carlo for a given function $f()$.
``` python
Y = np.zeros(number_of_runs)
X1,X2,...,XN = draw_from_gX(number_of_runs)
for k in range(number_of_runs):
Y[k] = model_function(X1[k],X2[k],...,XN[k])
```
#### Monte Carlo using vectorisation
For scripting languages, such as Python, Matlab or LabView, a for-loop is often very inefficient. Instead, a vectorisation of the model function should be considered.
For instance, let the model function be
$$ Y = X_1 \sin (2\pi X_2) - X_3^2 $$
The vectorized Monte Carlo method for this model is given as
``` python
X1,X2,X3 = draw_from_gX(number_of_runs)
Y = X1*np.sin(2*np.pi*X2) - X3**2
```
### Exercise 3.1
Carry out a Monte Carlo propagation of samples through the model
$$ Y = \frac{X_2^2}{\sqrt{1-X_1^2}}$$
with knowledge about the input quantities given as
* The value of $X_1$ satisfies $-0.8 \leq x_1 \leq 0.8$
* $X_2$ has best estimate $x_2 = 3.4$ with associated standard uncertainty $\sigma=0.5$ determined from 12 repeated measurements
```
from scipy.stats import uniform, t
X1dist = uniform(loc=-0.8, scale=1.6)
X2dist = t(11, loc=3.4, scale=0.5)
draws = 10000
X1 = X1dist.rvs(draws)
X2 = X2dist.rvs(draws)
Y = X2**2 / (sqrt(1-X1**2))
hist(Y, bins=100, edgecolor="none");
y = mean(Y)
uy = std(Y)
ys = sort(Y)
q = int(len(Y)*0.95)
l = int(0.5*(len(Y)-q))
r = int(l + q)
yl = ys[l]
yr = ys[r]
print("best estimate %g"%y)
print("standard uncertainty %g"%uy)
print("95%% coverage interval [%g, %g]"%(yl, yr))
```
### Exercise 3.2
Carry out a Monte Carlo propagation for the following parameter estimation problem.
For a measurement device under test, a parametrised calibration curve is to be determined by means of a non-linear least-squares fit to a set of measured pairs $(t_i, x_i)$ assuming as functional relationship
$$ x_i = f(t_i) = a\cdot\exp (-b t_i)\cdot \sin (c t_i) $$
The measurement data is assumed to be disturbed by white noise with a standard deviation of $\sigma=0.3$. The values $x_i$ are all assumed to be obtained independently, i.e. to be uncorrelated.
For the fitting of the parameters use
``` python
from scipy.optimize import curve_fit
noise = sigma*ones_like(x)
phat,cphat = curve_fit(modelfun, t, x, sigma=noise)
```
```
data = loadtxt("test_data.txt",delimiter=",")
t = data[:,0]
x = data[:,1]
# alternatively: t = linspace(0,5,25); x = 5.0 * exp(-0.5*t) * sin(2*pi*t) + random.randn(len(t))*0.3
sigma = 0.3
errorbar(t,x,sigma*ones_like(t),fmt="o-");
from scipy.optimize import curve_fit
noise_std = 0.2
noise = full_like(t, noise_std)
modelfun = lambda ti,a,b,c: a*exp(-b*ti)*sin(c*ti)
# linearization result (à la GUM)
phat,uphat = curve_fit(modelfun, t, x, sigma=noise)
draws = 1000
pMC = zeros((draws, 3))
success= []
failed = []
for k in range(draws):
xMC = x + random.randn(len(x))*sigma
try:
pMC[k,:] = curve_fit(modelfun, t, xMC, sigma=noise)[0]
success.append(k)
except RuntimeError:
failed.append(k)
phatMC = mean(pMC[success],axis=0)
uphatMC= cov(pMC[success],rowvar=0)
figure(figsize=(16,8))
errorbar(arange(1,4)-0.1, phat, sqrt(diag(uphat)), fmt="o", label="linearization result")
errorbar(arange(1,4)+0.1, phatMC, sqrt(diag(uphatMC)), fmt="s", label="Monte Carlo result")
legend()
xlim(0,4)
xticks([1,2,3], ["a", "b", "c"]);
tick_params(which="both",labelsize=20)
time = linspace(t[0], t[-1], 500)
XMC = zeros((len(time), len(success)))
for k in range(len(success)):
XMC[:,k] = modelfun(time, *pMC[success[k]])
figure(figsize=(16,6))
errorbar(t, x, sigma*ones_like(x),fmt="o", label="measured")
plot(time, modelfun(time, *phatMC), "g", label="modelled")
legend()
plot(time, XMC,color="g", alpha=0.01);
```
| github_jupyter |
# Cross Validation and Bootsrapping
```
%matplotlib inline
import tellurium as te
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
```
## Cross Validation Codes
```
def foldGenerator(num_points, num_folds):
"""
:param int num_points:
:param int num_folds:
:return array, array: training indices, test indices
"""
indices = range(num_points)
for remainder in range(num_folds):
test_indices = []
for idx in indices:
if idx % num_folds == remainder:
test_indices.append(idx)
train_indices = np.array(list(set(indices).difference(test_indices)))
test_indices = np.array(test_indices)
yield train_indices, test_indices
#
generator = foldGenerator(10, 5)
for g in generator:
print(g)
```
## Set up data
```
# Detailed simulation model
COLUMN_NAMES = ["[%s]" % x for x in ['A', 'B', 'C']]
def getSimulationData():
te.setDefaultPlottingEngine('matplotlib')
model = """
model test
species A, B, C;
J0: -> A; v0
A -> B; ka*A;
B -> C; kb*B;
J1: C ->; C*kc
ka = 0.4;
v0 = 10
kb = 0.8*ka
kc = ka
end
"""
r = te.loada(model)
return r.simulate(0, 50, 100)
result = getSimulationData()
for col in COLUMN_NAMES:
plt.plot(result['time'], result[col])
plt.xlabel("Time")
plt.ylabel("Concentration")
plt.legend(COLUMN_NAMES)
# Set-up the data
if True:
STD = 5
result = getSimulationData()
length = len(result)
XV = result['time']
XV = XV.reshape(length, 1)
ERRORS = np.array(np.random.normal(0, STD, length))
YV_PURE = result['[B]']
YV = YV_PURE + ERRORS
YV_PURE = YV_PURE.reshape(length, 1)
YV = YV.reshape(length, 1)
```
## Cross Validation
```
# Does a polynomial regression of the specified order
def buildMatrix(xv, order):
"""
:param array-of-float xv:
:return matrix:
"""
length = len(xv)
xv = xv.reshape(length)
constants = np.repeat(1, length)
constants = constants.reshape(length)
data = [constants]
for n in range(1, order+1):
data.append(xv*data[-1])
mat = np.matrix(data)
return mat.T
def regress(xv, yv, train, test, order=1):
"""
:param array-of-float xv: predictor values
:param array-of-float yv: response values
:param array-of-int train: indices of training data
:param array-of-int test: indices of test data
:param int order: Order of the polynomial regression
return float, array-float, array-float: R2, y_test, y_preds
"""
regr = linear_model.LinearRegression()
# Train the model using the training sets
mat_train = buildMatrix(xv[train], order)
regr.fit(mat_train, yv[train])
mat_test = buildMatrix(XV[test], order)
y_pred = regr.predict(mat_test)
rsq = r2_score(YV[test], y_pred)
return rsq, yv[test], y_pred, regr.coef_
generator = foldGenerator(100, 4)
for train, test in generator:
rsq, yv_test, yv_pred, coef_ = regress(XV, YV, train, test, order=3)
plt.figure()
plt.scatter(test, yv_pred, color = 'b')
plt.scatter(test, yv_test, color = 'r')
plt.title("RSQ: %2.4f" % rsq)
```
## Bootstrapping
```
# Compute residuals
train = range(len(XV))
test = range(len(XV))
rsq, yv_test, yv_pred, _ = regress(XV, YV, train, test, order=3)
residuals = yv_test - yv_pred
plt.scatter(test, residuals)
_ = plt.title("%2.4f" % rsq)
# Generate synthetic data from residuals
def generateData(y_obs, y_fit):
"""
:param np.array y_obs
:param np.array y_fit
:return np.array: bootstrap data
"""
residuals = y_obs - y_fit
length = len(y_obs)
residuals = residuals.reshape(length)
samples = np.random.randint(0, length, length)
result = y_fit + residuals[samples]
result = result.reshape(length)
return result
y_obs = np.array([1, 2, 3])
y_fit = np.array([.9, 2.4, 3.2])
for _ in range(4):
print (generateData(y_obs, y_fit))
train = range(len(XV))
rsq, yv_test, yv_pred, _ = regress(XV, YV, train, train, order=3)
plt.scatter(YV, generateData(YV, yv_pred))
plt.title("Original")
for _ in range(4):
plt.figure()
plt.scatter(YV, generateData(YV, yv_pred))
# Estimate the parameters for each random data set
train = range(len(XV))
coefs = []
_, _, y_fit, _ = regress(XV, YV, train, train, order=3)
for _ in range(10):
yv = generateData(YV, y_fit)
_, _, _, coef_ = regress(XV, yv, train, train, order=3)
coefs.append(coef_)
coefs
```
| github_jupyter |
# Multivariate SuSiE and ENLOC model
## Aim
This notebook aims to demonstrate a workflow of generating posterior inclusion probabilities (PIPs) from GWAS summary statistics using SuSiE regression and construsting SNP signal clusters from global eQTL analysis data obtained from multivariate SuSiE models.
## Methods overview
This procedure assumes that molecular phenotype summary statistics and GWAS summary statistics are aligned and harmonized to have consistent allele coding (see [this module](../../misc/summary_stats_merger.html) for implementation details). Both molecular phenotype QTL and GWAS should be fine-mapped beforehand using mvSusiE or SuSiE. We further assume (and require) that molecular phenotype and GWAS data come from the same population ancestry. Violations from this assumption may not cause an error in the analysis computational workflow but the results obtained may not be valid.
## Input
1) GWAS Summary Statistics with the following columns:
- chr: chromosome number
- bp: base pair position
- a1: effect allele
- a2: other allele
- beta: effect size
- se: standard error of beta
- z: z score
2) eQTL data from multivariate SuSiE model with the following columns:
- chr: chromosome number
- bp: base pair position
- a1: effect allele
- a2: other allele
- pip: posterior inclusion probability
3) LD correlation matrix
## Output
Intermediate files:
1) GWAS PIP file with the following columns
- var_id
- ld_block
- snp_pip
- block_pip
2) eQTL annotation file with the following columns
- chr
- bp
- var_id
- a1
- a2
- annotations, in the format: `gene:cs_num@tissue=snp_pip[cs_pip:cs_total_snps]`
Final Outputs:
1) Enrichment analysis result prefix.enloc.enrich.rst: estimated enrichment parameters and standard errors.
2) Signal-level colocalization result prefix.enloc.sig.out: the main output from the colocalization analysis with the following format
- column 1: signal cluster name (from eQTL analysis)
- column 2: number of member SNPs
- column 3: cluster PIP of eQTLs
- column 4: cluster PIP of GWAS hits (without eQTL prior)
- column 5: cluster PIP of GWAS hits (with eQTL prior)
- column 6: regional colocalization probability (RCP)
3) SNP-level colocalization result prefix.enloc.snp.out: SNP-level colocalization output with the following form at
- column 1: signal cluster name
- column 2: SNP name
- column 3: SNP-level PIP of eQTLs
- column 4: SNP-level PIP of GWAS (without eQTL prior)
- column 5: SNP-level PIP of GWAS (with eQTL prior)
- column 6: SNP-level colocalization probability
4) Sorted list of colocalization signals
Takes into consideration 3 situations:
1) "Major" and "minor" alleles flipped
2) Different strand but same variant
3) Remove variants with A/T and C/G alleles due to ambiguity
## Minimal working example
```
sos run mvenloc.ipynb merge \
--cwd output \
--eqtl-sumstats .. \
--gwas-sumstats ..
sos run mvenloc.ipynb eqtl \
--cwd output \
--sumstats-file .. \
--ld-region ..
sos run mvenloc.ipynb gwas \
--cwd output \
--sumstats-file .. \
--ld-region ..
sos run mvenloc.ipynb enloc \
--cwd output \
--eqtl-pip .. \
--gwas-pip ..
```
### Summary
```
head enloc.enrich.out
head enloc.sig.out
head enloc.snp.out
```
## Command interface
```
sos run mvenloc.ipynb -h
```
## Implementation
```
[global]
parameter: cwd = path
parameter: container = ""
```
### Step 0: data formatting
#### Extract common SNPS between the GWAS summary statistics and eQTL data
```
[merger]
# eQTL summary statistics as a list of RData
parameter: eqtl_sumstats = path
# GWAS summary stats in gz format
parameter: gwas_sumstats = path
input: eqtl_sumstats, gwas_sumstats
output: f"{cwd:a}/{eqtl_sumstats:bn}.standardized.gz", f"{cwd:a}/{gwas_sumstats:bn}.standardized.gz"
R: expand = "${ }"
###
# functions
###
allele.qc = function(a1,a2,ref1,ref2) {
# a1 and a2 are the first data-set
# ref1 and ref2 are the 2nd data-set
# Make all the alleles into upper-case, as A,T,C,G:
a1 = toupper(a1)
a2 = toupper(a2)
ref1 = toupper(ref1)
ref2 = toupper(ref2)
# Strand flip, to change the allele representation in the 2nd data-set
strand_flip = function(ref) {
flip = ref
flip[ref == "A"] = "T"
flip[ref == "T"] = "A"
flip[ref == "G"] = "C"
flip[ref == "C"] = "G"
flip
}
flip1 = strand_flip(ref1)
flip2 = strand_flip(ref2)
snp = list()
# Remove strand ambiguous SNPs (scenario 3)
snp[["keep"]] = !((a1=="A" & a2=="T") | (a1=="T" & a2=="A") | (a1=="C" & a2=="G") | (a1=="G" & a2=="C"))
# Remove non-ATCG coding
snp[["keep"]][ a1 != "A" & a1 != "T" & a1 != "G" & a1 != "C" ] = F
snp[["keep"]][ a2 != "A" & a2 != "T" & a2 != "G" & a2 != "C" ] = F
# as long as scenario 1 is involved, sign_flip will return TRUE
snp[["sign_flip"]] = (a1 == ref2 & a2 == ref1) | (a1 == flip2 & a2 == flip1)
# as long as scenario 2 is involved, strand_flip will return TRUE
snp[["strand_flip"]] = (a1 == flip1 & a2 == flip2) | (a1 == flip2 & a2 == flip1)
# remove other cases, eg, tri-allelic, one dataset is A C, the other is A G, for example.
exact_match = (a1 == ref1 & a2 == ref2)
snp[["keep"]][!(exact_match | snp[["sign_flip"]] | snp[["strand_flip"]])] = F
return(snp)
}
# Extract information from RData
eqtl.split = function(eqtl){
rows = length(eqtl)
chr = vector(length = rows)
pos = vector(length = rows)
a1 = vector(length = rows)
a2 = vector(length = rows)
for (i in 1:rows){
split1 = str_split(eqtl[i], ":")
split2 = str_split(split1[[1]][2], "_")
chr[i]= split1[[1]][1]
pos[i] = split2[[1]][1]
a1[i] = split2[[1]][2]
a2[i] = split2[[1]][3]
}
eqtl.df = data.frame(eqtl,chr,pos,a1,a2)
}
remove.dup = function(df){
df = df %>% arrange(PosGRCh37, -N)
df = df[!duplicated(df$PosGRCh37),]
return(df)
}
###
# Code
###
# gene regions:
# 1 = ENSG00000203710
# 2 = ENSG00000064687
# 3 = ENSG00000203710
# eqtl
gene.name = scan(${_input[0]:r}, what='character')
# initial filter of gwas variants that are in eqtl
gwas = gwas_sumstats
gwas_filter = gwas[which(gwas$id %in% var),]
# create eqtl df
eqtl.df = eqtl.split(eqtl$var)
# allele flip
f_gwas = gwas %>% filter(chr %in% eqtl.df$chr & PosGRCh37 %in% eqtl.df$pos)
eqtl.df.f = eqtl.df %>% filter(pos %in% f_gwas$PosGRCh37)
# check if there are duplicate pos
length(unique(f_gwas$PosGRCh37))
# multiple snps with same pos
dup.pos = f_gwas %>% group_by(PosGRCh37) %>% filter(n() > 1)
f_gwas = remove.dup(f_gwas)
qc = allele.qc(f_gwas$testedAllele, f_gwas$otherAllele, eqtl.df.f$a1, eqtl.df.f$a2)
keep = as.data.frame(qc$keep)
sign = as.data.frame(qc$sign_flip)
strand = as.data.frame(qc$strand_flip)
# sign flip
f_gwas$z[qc$sign_flip] = -1 * f_gwas$z[qc$sign_flip]
f_gwas$testedAllele[qc$sign_flip] = eqtl.df.f$a1[qc$sign_flip]
f_gwas$otherAllele[qc$sign_flip] = eqtl.df.f$a2[qc$sign_flip]
f_gwas$testedAllele[qc$strand_flip] = eqtl.df.f$a1[qc$strand_flip]
f_gwas$otherAllele[qc$strand_flip] = eqtl.df.f$a2[qc$strand_flip]
# remove ambigiuous
if ( sum(!qc$keep) > 0 ) {
eqtl.df.f = eqtl.df.f[qc$keep,]
f_gwas = f_gwas[qc$keep,]
}
```
#### Extract common SNPS between the summary statistics and LD
```
[eqtl_1, gwas_1 (filter LD file and sumstat file)]
parameter: sumstat_file = path
# LD and region information: chr, start, end, LD file
paramter: ld_region = path
input: sumstat_file, for_each = 'ld_region'
output: f"{cwd:a}/{sumstat_file:bn}_{region[0]}_{region[1]}_{region[2]}.z.rds",
f"{cwd:a}/{sumstat_file:bn}_{region[0]}_{region[1]}_{region[2]}.ld.rds"
R:
# FIXME: need to filter both ways for sumstats and for LD
# lds filtered
eqtl_id = which(var %in% eqtl.df.f$eqtl)
ld_f = ld[eqtl_id, eqtl_id]
# ld missing
miss = which(is.na(ld_f), arr.ind=TRUE)
miss_r = unique(as.data.frame(miss)$row)
miss_c = unique(as.data.frame(miss)$col)
total_miss = unique(union(miss_r,miss_c))
# FIXME: LD should not have missing data if properly processed by our pipeline
# In the future we should throw an error when it happens
if (length(total_miss)!=0){
ld_f2 = ld_f[-total_miss,]
ld_f2 = ld_f2[,-total_miss]
dim(ld_f2)
}else{ld_f2 = ld_f}
f_gwas.f = f_gwas %>% filter(id %in% eqtl_id.f$eqtl)
```
### Step 1: fine-mapping
```
[eqtl_2, gwas_2 (finemapping)]
# FIXME: RDS file should have included region information
output: f"{_input[0]:nn}.susieR.rds", f"{_input[0]:nn}.susieR_plot.rds"
R:
susie_results = susieR::susie_rss(z = f_gwas.f$z,R = ld_f2, check_prior = F)
susieR::susie_plot(susie_results,"PIP")
susie_results$z = f_gwas.f$z
susieR::susie_plot(susie_results,"z_original")
```
### Step 2: fine-mapping results processing
#### Construct eQTL annotation file using eQTL SNP PIPs and credible sets
```
[eqtl_3 (create signal cluster using CS)]
output: f"{_input[0]:nn}.enloc_annot.gz"
R:
cs = eqtl[["sets"]][["cs"]][["L1"]]
o_id = which(var %in% eqtl_id.f$eqtl)
pip = eqtl$pip[o_id]
eqtl_annot = cbind(eqtl_id.f, pip) %>% mutate(gene = gene.name,cluster = -1, cluster_pip = 0, total_snps = 0)
for(snp in cs){
eqtl_annot$cluster[snp] = 1
eqtl_annot$cluster_pip[snp] = eqtl[["sets"]][["coverage"]]
eqtl_annot$total_snps[snp] = length(cs)
}
eqtl_annot1 = eqtl_annot %>% filter(cluster != -1)%>%
mutate(annot = sprintf("%s:%d@=%e[%e:%d]",gene,cluster,pip,cluster_pip,total_snps)) %>%
select(c(chr,pos,eqtl,a1,a2,annot))
# FIXME: repeats whole process (extracting+fine-mapping+cs creation) 3 times before this next step
eqtl_annot_comb = rbind(eqtl_annot3, eqtl_annot1, eqtl_annot2)
# FIXME: write to a zip file
write.table(eqtl_annot_comb, file = "eqtl.annot.txt", col.names = T, row.names = F, quote = F)
```
#### Export GWAS PIP
```
[gwas_3 (format PIP into enloc GWAS input)]
output: f"{_input[0]:nn}.enloc_gwas.gz"
R:
gwas_annot1 = f_gwas.f %>% mutate(pip = susie_results$pip)
# FIXME: repeat whole process (extracting common snps + fine-mapping) 3 times before the next steps
gwas_annot_comb = rbind(gwas_annot3, gwas_annot1, gwas_annot2)
gwas_loc_annot = gwas_annot_comb %>% select(id, chr, PosGRCh37,z)
write.table(gwas_loc_annot, file = "loc.gwas.txt", col.names = F, row.names = F, quote = F)
bash:
perl format2torus.pl loc.gwas.txt > loc2.gwas.txt
R:
loc = data.table::fread("loc2.gwas.txt")
loc = loc[["V2"]]
gwas_annot_comb2 = gwas_annot_comb %>% select(id, chr, PosGRCh37,pip)
gwas_annot_comb2 = cbind(gwas_annot_comb2, loc) %>% select(id, loc, pip)
write.table(gwas_annot_comb2, file = "gwas.pip.txt", col.names = F, row.names = F, quote = F)
bash:
perl format2torus.pl gwas.pip.txt | gzip --best > gwas.pip.gz
```
### Step 3: Colocalization with FastEnloc
```
[enloc]
# eQTL summary statistics as a list of RData
# FIXME: to replace later
parameter: eqtl_pip = path
# GWAS summary stats in gz format
parameter: gwas_pip = path
input: eqtl_pip, gwas_pip
output: f"{cwd:a}/{eqtl_pip:bnn}.{gwas_pip:bnn}.xx.gz"
bash:
fastenloc -eqtl eqtl.annot.txt.gz -gwas gwas.pip.txt.gz
sort -grk6 prefix.enloc.sig.out | gzip --best > prefix.enloc.sig.sorted.gz
rm -f prefix.enloc.sig.out
```
| github_jupyter |
## DL3
Follow this notebook only if you're new to DeepLearing and Transfer learning. This is a extension of the Startet kit given [here](https://github.com/shubham3121/DL-3/blob/master/DL%233_EDA.ipynb). I'll try to keep it simple. Please ignore the typos :)
### Why to use Mobilenet architecture?
You might have seen multiple tutorials on the VGG16 based transfer learning but here I'm going to use Mobilenet because of the following reasons
<ul>
<li> No. of parameters to train in Mobilenet is quite less in compare to the VGG16
<li> Having fewer parameters will make your training time less and you'll be able to do more experiment and your chances of wining becames higher.
<li> On top of above reasons Mobile net has similar performance on the ImageNet dataset as VGG16
</ul>
Having said that let move on to the imorting important libs
```
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import GlobalAveragePooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.applications import MobileNet
from keras import optimizers
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.models import Model
from sklearn.model_selection import train_test_split
import pandas as pd
from tqdm import tqdm
import gc
import cv2 as cv
import numpy as np
import tensorflow as tf
import random as rn
# The below is necessary in Python 3.2.3 onwards to
# have reproducible behavior for certain hash-based operations.
# See these references for further details:
# https://docs.python.org/3.4/using/cmdline.html#envvar-PYTHONHASHSEED
# https://github.com/keras-team/keras/issues/2280#issuecomment-306959926
import os
os.environ['PYTHONHASHSEED'] = '0'
# The below is necessary for starting Numpy generated random numbers
# in a well-defined initial state.
np.random.seed(42)
# The below is necessary for starting core Python generated random numbers
# in a well-defined state.
rn.seed(12345)
# Force TensorFlow to use single thread.
# Multiple threads are a potential source of
# non-reproducible results.
# For further details, see: https://stackoverflow.com/questions/42022950/which-seeds-have-to-be-set-where-to-realize-100-reproducibility-of-training-res
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
from keras import backend as K
# The below tf.set_random_seed() will make random number generation
# in the TensorFlow backend have a well-defined initial state.
# For further details, see: https://www.tensorflow.org/api_docs/python/tf/set_random_seed
tf.set_random_seed(1234)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
```
I'm going to use 128x128 images. You can change that if you wish.
My folder structure is as follow
<ul>
<li> DL3</li>
<ul>
<li> starter_kit</li>
<ul>
<li> this_notebook</li>
</ul>
<li> data</li>
<ul>
<li> train_img</li>
<li> test_img</li>
</ul>
</ul>
</ul>
```
img_width, img_height = (128, 128)
train_data_dir = '../data/train_img/'
test_data_dir = '../data/test_img/'
epochs = 10
batch_size = 128
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
Mobile_model = MobileNet(include_top=False, input_shape=input_shape)
def get_model():
# add a global spatial average pooling layer
x = Mobile_model.output
x = GlobalAveragePooling2D()(x)
predictions = Dense(85, activation='sigmoid')(x)
model = Model(inputs=Mobile_model.input, outputs=predictions)
return model
model = get_model()
```
We'll start with training the head(last layer) only as that layer is initialized randomaly and we don't want to affect the other layers weights as while backpropogation.
```
#train only last layer
for layer in model.layers[:-1]:
layer.trainable = False
model.summary()
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(width_shift_range=0.2, height_shift_range=0.2,
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True, rotation_range = 20)
val_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train = pd.read_csv('../train.csv', index_col=0)
test = pd.read_csv('../test.csv')
attributes = pd.read_csv('../attributes.txt', delimiter='\t', header=None, index_col=0)
classes = pd.read_csv('../classes.txt', delimiter='\t', header=None, index_col=0)
def get_imgs(src, df, labels = False):
if labels == False:
imgs = []
files = df['Image_name'].values
for file in tqdm(files):
im = cv.imread(os.path.join(src, file))
im = cv.resize(im, (img_width, img_height))
imgs.append(im)
return np.array(imgs)
else:
imgs = []
labels = []
files = os.listdir(src)
for file in tqdm(files):
im = cv.imread(os.path.join(src, file))
im = cv.resize(im, (img_width, img_height))
imgs.append(im)
labels.append(df.loc[file].values)
return np.array(imgs), np.array(labels)
train_imgs, train_labels = get_imgs(train_data_dir, train, True)
#train val split
X_tra, X_val, y_tra, y_val = train_test_split(train_imgs, train_labels, test_size = 3000, random_state = 222)
gc.collect()
train_datagen.fit(X_tra)
val_datagen.fit(X_val)
def fmeasure(y_true, y_pred):
def recall(y_true, y_pred):
"""Recall metric.
Only computes a batch-wise average of recall.
Computes the recall, a metric for multi-label classification of
how many relevant items are selected.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
"""Precision metric.
Only computes a batch-wise average of precision.
Computes the precision, a metric for multi-label classification of
how many selected items are relevant.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2*((precision*recall)/(precision+recall))
```
We're going to train our model with SGD and very low learning rate
```
early_stp = EarlyStopping(patience=3)
model_ckpt = ModelCheckpoint('mobilenet_1_layer.h5', save_weights_only=True)
opt = optimizers.SGD(lr=0.001, decay = 1e-6, momentum = 0.9, nesterov = True)
model.compile(opt, loss = 'binary_crossentropy', metrics=['accuracy', fmeasure])
model.fit_generator(train_datagen.flow(X_tra, y_tra, batch_size=batch_size),
steps_per_epoch=len(X_tra) / batch_size, epochs=5,
validation_data=val_datagen.flow(X_val, y_val, batch_size=batch_size),
validation_steps = len(X_val)/batch_size, callbacks=[early_stp, model_ckpt], workers = 10, max_queue_size=20)
model = get_model()
#train only last 10 layer
for layer in model.layers:
layer.trainable = True
opt = optimizers.SGD(lr=0.001, decay = 1e-6, momentum = 0.9, nesterov = True)
model.compile(opt, loss = 'binary_crossentropy', metrics=['accuracy', fmeasure])
model.summary()
early_stp = EarlyStopping(patience=3)
model_ckpt = ModelCheckpoint('mobilenet_all_layers.h5', save_weights_only=True)
model.load_weights('mobilenet_1_layer.h5')
model.fit_generator(train_datagen.flow(X_tra, y_tra, batch_size=batch_size),
steps_per_epoch=len(X_tra) / batch_size, epochs=10,
validation_data=val_datagen.flow(X_val, y_val, batch_size=batch_size),
validation_steps = len(X_val)/batch_size, callbacks=[early_stp, model_ckpt], workers = 10, max_queue_size=20)
test_imgs = get_imgs(test_data_dir, test)
test_datagen.fit(test_imgs)
pred = model.predict_generator(test_datagen.flow(test_imgs, batch_size=512, shuffle=False), verbose=1, workers=8)
sub = pd.read_csv('../sample_submission.csv')
sub.iloc[:, 1:] = pred.round().astype(int)
sub.head()
sub.to_csv('submission.csv', index=False)
sub.shape
```
## Final Thoughts
This submission should get you around $\approx$0.80 on the LB. and if you've noticed that our last epochs val_fmeasure is the same so it means that our val set is represantion of the test set and you can train for many epochs with EarlyStopping without worring about overfitting on val or train set.
### How to improve from here?
You can change many things which will let you get higher LB score. Following is a small list
<ul>
<li> Change the Image size to bigger number </li>
<li> Increse the number of epoch in the fully trainable network($2^{nd}$ training) </li>
<li> Use diffrent architechure. you'll get more info on that [here](keras.io/applications/)</li>
<li> If nothing works ensemble is your best friend </li>
</ul>
I'll try to keep improving this notebook. Feel free to contribuite.
Thanks
| github_jupyter |
# Lagrangian mechanics
> Marcos Duarte
> Laboratory of Biomechanics and Motor Control ([http://demotu.org/](http://demotu.org/))
> Federal University of ABC, Brazil
## The development of the laws of motion of bodies
> *"The theoretical development of the laws of motion of bodies is a problem of such interest and importance that it has engaged the attention of all the most eminent mathematicians since the invention of dynamics as a mathematical science by Galileo, and especially since the wonderful extension which was given to that science by Newton.
> Among the successors of those illustrious men, Lagrange has perhaps done more than any other analyst to give extent and harmony to such deductive researches, by showing that the most varied consequences respecting the motions of systems of bodies may be derived from one radical formula; the beauty of the methods so suiting the dignity of the results as to make of his great work a kind of scientific poem."*
— Hamilton, 1834 (apud Taylor, 2005).
The [Lagrangian mechanics](https://en.wikipedia.org/wiki/Lagrangian_mechanics) is a formulation of [classical mechanics](https://en.wikipedia.org/wiki/Classical_mechanics) where the [equations of motion](https://en.wikipedia.org/wiki/Equations_of_motion) are obtained from the [kinetic](https://en.wikipedia.org/wiki/Kinetic_energy) and [potential](https://en.wikipedia.org/wiki/Potential_energy) energy of the system (<a href="https://en.wikipedia.org/wiki/Scalar_(physics)">scalar</a> quantities) represented in [generalized coordinates](https://en.wikipedia.org/wiki/Generalized_coordinates) instead of using [Newton's laws of motion](https://en.wikipedia.org/wiki/Newton's_laws_of_motion) to deduce the equations of motion from the [forces](https://en.wikipedia.org/wiki/Force) on the system ([vector](https://en.wikipedia.org/wiki/Euclidean_vector) quantities) represented in [Cartesian coordinates](https://en.wikipedia.org/wiki/Cartesian_coordinate_system). Lagrangian mechanics was introduced by [Joseph-Louis Lagrange](https://en.wikipedia.org/wiki/Joseph-Louis_Lagrange) in the late 18th century.
Let's deduce the Lagrange equations, but first let's review the basics of the Newtonian approach.
## Description of motion
One can describe the motion of a particle by specifying its position with respect to a frame of reference in the three-dimensional space as a function of time:
\begin{equation}
x(t),\, y(t),\, z(t) \quad \equiv \quad x_i(t) \quad i=1,\dotsc,3
\label{eq1}
\end{equation}
A system of $N$ particles will require $3N$ equations to describe their motion.
The basic problem in classical mechanics is to find ways to determine functions such as these, also known as equations of motion, capable of specifying the position of objects over time, for any mechanical situation. Assuming as known the meaning of $x_i(t)$, one can define the components of velocity, $v_i$, and acceleration, $a_i$, at time $t$, as:
\begin{equation} \begin{array}{rcl}
v_i(t) = \dfrac{\mathrm d x_i(t)}{\mathrm d t} = \dot{x}_i(t) \\
a_i(t) = \dfrac{\mathrm d^2 x_i(t)}{\mathrm d t^2} = \dot{v}_i(t)
\label{eq3}
\end{array} \end{equation}
Where we used the Newton's notation for differentiation (also called the dot notation), a dot over the dependent variable. Of note, [Joseph Louis Lagrange](https://pt.wikipedia.org/wiki/Joseph-Louis_Lagrange) introduced the prime mark to denote a derivative: $x'(t)$. Read more about the different notations for differentiation at [Wikipedia](https://en.wikipedia.org/wiki/Notation_for_differentiation).
### Laws of motion
The [Newton's laws of motion](https://en.wikipedia.org/wiki/Newton's_laws_of_motion) laid the foundation for classical mechanics. They describe the relationship between the motion of a body and the possible forces acting upon it.
In Newtonian mechanics, the body's linear momentum is defined as:
\begin{equation}
\mathbf{p} = m\mathbf{v}
\label{eq5}
\end{equation}
If the mass of the body is constant, remember that Newton's second law can be expressed by:
\begin{equation}
\mathbf{F} = \frac{\mathrm d \mathbf{p}}{\mathrm d t}=\frac{\mathrm d \big(m\mathbf{v}\big)}{\mathrm d t} = m\mathbf{a}
\label{eq6}
\end{equation}
Using Newton's second law, to determine the position of the body we will have to solve the following second order ordinary differential equation:
\begin{equation}
\frac{\mathrm d^2 x_i(t)}{\mathrm d t^2} = \frac{\mathbf{F}}{m}
\label{eqa7}
\end{equation}
Which has the general solution:
\begin{equation}
\mathbf{x}(t) = \int\!\bigg(\int\frac{\mathbf{F}}{m} \mathrm{d}t\bigg)\mathrm{d}t
\label{eq8}
\end{equation}
### Mechanical energy
A related physical quantity is the mechanical energy, which is the sum of kinetic and potential energies.
The kinetic energy, $T$ of a particle is given by:
\begin{equation}
T = \frac{1}{2}mv^2
\label{eq9}
\end{equation}
The kinetic energy of a particle can be expressed in terms of its linear momentum:
\begin{equation}
T = \frac{p^2}{2m}
\label{eq10}
\end{equation}
And for a given coordinate of the particle's motion, its linear momentum can be obtained from its kinetic energy by:
\begin{equation}
p_i = \frac{\partial T}{\partial v_i}
\label{eq11}
\end{equation}
The potential energy, $V$ is the stored energy of a particle and its formulation is dependent on the force acting on the particle. For example, for a conservative force dependent solely on the particle position, such as due to the gravitational field near the Earth surface or due to a linear spring, force and potential energy are related by:
\begin{equation}
\mathbf{F} = - \frac{\partial \mathbf{V}}{\partial x}
\label{eq12}
\end{equation}
## Lagrange's equation in Cartesian Coordinates
The Lagrangian mechanics can be formulated independent of the Newtonian mechanics and Cartesian coordinates; in fact Joseph-Louis Lagrange this new formalism from the [principle of least action](http://nbviewer.jupyter.org/github/BMClab/bmc/blob/master/notebooks/principle_of_least_action.ipynb).
For simplicity, let's first deduce the Lagrange's equation for a particle in Cartesian Coordinates and from Newton's second law.
Because we want to deduce the laws of motion based on the mechanical energy of the particle, one can see that the time derivative of the expression for the linear momentum as a function of the kinetic energy, cf. Eq. (\ref{eq11}), is equal to the force acting on the particle and we can substitute the force in Newton's second law by this term:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\bigg(\frac{\partial T}{\partial \dot x}\bigg) = m\ddot x
\label{eq13}
\end{equation}
We saw that a conservative force can also be expressed in terms of the potential energy of the particle, cf. Eq. (\ref{eq12}); substituting the right side of the equation above by this expression, we have:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\bigg(\frac{\partial T}{\partial \dot x}\bigg) = -\frac{\partial V}{\partial x}
\label{eq14}
\end{equation}
Using the fact that:
\begin{equation}
\frac{\partial T}{\partial x} = 0 \quad and \quad \frac{\partial V}{\partial \dot x} = 0
\label{eq15}
\end{equation}
We can write:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\bigg(\frac{\partial (T-V)}{\partial \dot x}\bigg) - \frac{\partial (T-V)}{\partial x} = 0
\label{eq16}
\end{equation}
Defining the Lagrange or Lagrangian function, $\mathcal{L}$, as the difference between the kinetic and potential energy in the system:
\begin{equation}
\mathcal{L}(x,\dot x, t) = T - V
\label{eq17}
\end{equation}
We have the Lagrange's equation in Cartesian Coordinates for a conservative force acting on a particle:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\bigg(\frac{\partial \mathcal{L}}{\partial \dot x}\bigg) - \frac{\partial \mathcal{L}}{\partial x} = 0
\label{eq18}
\end{equation}
Once all derivatives of the Lagrangian function are calculated, this equation will be the equation of motion for the particle. If there are $N$ independent particles in a three-dimensional space, there will be $3N$ equations for the system.
The set of equations above for a system are known as Euler–Lagrange equations, or Lagrange's equations of the second kind.
Let's see some simple examples of the Lagrange's equation in Cartesian Coordinates just to consolidate what was deduced above. The real application of Lagrangian mechanics is in generalized coordinates, what will see after these examples.
### Example 1: Particle moving under the influence of a conservative force
Let's deduce the equation of motion using the Lagrangian mechanics for a particle with mass $m$ moving in the 3D space under the influence of a [conservative force](https://en.wikipedia.org/wiki/Conservative_force).
The Lagrangian $(\mathcal{L} = T - V)$ of the particle is:
\begin{equation}
\mathcal{L}(x,y,z,\dot x,\dot y,\dot z, t) = \frac{1}{2}m(\dot x^2(t) + \dot y^2(t) + \dot z^2(t)) - V(x(t),y(t),z(t))
\end{equation}
The equations of motion for the particle are found by applying the Lagrange's equation for each coordinate.
For the x coordinate:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\left( {\frac{\partial \mathcal{L}}{\partial \dot{x}}}
\right) = \frac{\partial \mathcal{L}}{\partial x }
\end{equation}
And the derivatives of $\mathcal{L}$ are given by:
\begin{equation} \begin{array}{rcl}
&\dfrac{\partial \mathcal{L}}{\partial x} &=& -\dfrac{\partial \mathbf{V}}{\partial x} \\
&\dfrac{\partial \mathcal{L}}{\partial \dot{x}} &=& m\dot{x} \\
&\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{x}}} \right) &=& m\ddot{x}
\end{array} \end{equation}
hence:
\begin{equation}
m\ddot{x} = -\frac{\partial \mathbf{V}}{\partial x}
\end{equation}
and similarly for the $y$ and $z$ coordinates.
For instance, if the conservative force is due to the gravitational field near Earth's surface $(\mathbf{V}=[0, mgy, 0])$, the Lagrange's equations (the equations of motion) are:
\begin{equation} \begin{array}{rcl}
m\ddot{x} &=& -\dfrac{\partial (0)}{\partial x} = 0 \\
m\ddot{y} &=& -\dfrac{\partial (mgy)}{\partial y} = -mg \\
m\ddot{z} &=& -\dfrac{\partial (0)}{\partial z} = 0
\end{array} \end{equation}
### Example 2: Ideal mass-spring system
<figure><img src="./../images/massspring_lagrange.png" width="220" alt="mass spring" style="float:right;margin: 0px 20px 10px 20px;"/></figure>
Consider a system with a mass $m$ attached to an ideal spring (massless) with spring constant $k$ at the horizontal direction $x$. If the system is perturbed (a force is momentarily applied to the mass), we know the mass will oscillate around the rest position of the spring. Let's deduce the equation of motion for this system using the Lagrangian mechanics.
The Lagrangian $(\mathcal{L} = T - V)$ of the system is:
\begin{equation}
\mathcal{L}(x,\dot x, t) = \frac{1}{2}m\dot x^2(t) - \frac{1}{2}kx^2(t)
\end{equation}
The derivatives of $L$ are given by:
\begin{equation} \begin{array}{rcl}
&\dfrac{\partial \mathcal{L}}{\partial x} &=& -kx \\
&\dfrac{\partial \mathcal{L}}{\partial \dot{x}} &=& m\dot{x} \\
&\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{x}}} \right) &=& m\ddot{x}
\end{array} \end{equation}
And the Lagrange's equation (the equation of motion) is:
\begin{equation}
m\ddot{x} + kx = 0
\end{equation}
## Generalized coordinates
The direct application of Newton's laws to mechanical systems results in a set of equations of motion in terms of Cartesian coordinates of each of the particles that make up the system. In many cases, this is not the most convenient coordinate system to solve the problem or describe the movement of the system. For example, in problems involving many particles, it may be convenient to choose a system that includes the coordinate of the center of mass. Another example is a serial chain of rigid links, such as a member of the human body or from a robot manipulator, it may be simpler to describe the positions of each link by the angles between links.
Coordinate systems such as these are referred as [generalized coordinates](https://en.wikipedia.org/wiki/Generalized_coordinates). Generalized coordinates uniquely specify the positions of the particles in a system. Although there may be several generalized coordinates to describe a system, usually a judicious choice of generalized coordinates provides the minimum number of independent coordinates that define the configuration of a system (which is the number of <a href="https://en.wikipedia.org/wiki/Degrees_of_freedom_(mechanics)">degrees of freedom</a> of the system), turning the problem simpler to solve.
Being a little more technical, according to [Wikipedia](https://en.wikipedia.org/wiki/Configuration_space_(physics)):
"In classical mechanics, the parameters that define the configuration of a system are called generalized coordinates, and the vector space defined by these coordinates is called the configuration space of the physical system. It is often the case that these parameters satisfy mathematical constraints, such that the set of actual configurations of the system is a manifold in the space of generalized coordinates. This manifold is called the configuration manifold of the system."
In problems where it is desired to use generalized coordinates, one can write Newton's equations of motion in terms of Cartesian coordinates and then transform them into generalized coordinates. However, it would be desirable and convenient to have a general method that would directly establish the equations of motion in terms of a set of convenient generalized coordinates. In addition, general methods for writing, and perhaps solving, the equations of motion in terms of any coordinate system would also be desirable. The [Lagrangian mechanics](https://en.wikipedia.org/wiki/Lagrangian_mechanics) is such a method.
### Lagrange's equation in generalized coordinates
We have deduced the Lagrange's equation in Cartesian Coordinates from the Newton's law just because it was a simple form of getting to the final equations. But, by no means the Lagrangian Mechanics should be viewed as a consequence of Newton's laws and specific to Cartesian Coordinates. The Lagrangian Mechanics could be deduced completely independent of Newton's law.
The Lagrange's equation can be expressed in terms of generalized coordinates what makes the Lagrangian formalism even more powerful. In fact, we will have the same equation as we deduced before (the only explicit difference will be that we will use $q_i$ instead of the Cartesian coordinate).
See [this notebook](http://nbviewer.jupyter.org/github/BMClab/bmc/blob/master/notebooks/lagrangian_mechanics_generalized.ipynb) for a deduction of the Lagrange's equation in generalized coordinates.
Defining the Lagrange or Lagrangian function of a system with $N$ generalized coordinates:
\begin{equation}
\mathcal{L} \equiv \mathcal{L}(q_1,\dotsc,q_{N} ,\dot{q}_1,\dotsc,\dot{q}_{N} ) = T - V
\label{eq46}
\end{equation}
We have the Lagrange's equation:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\left( {\frac{\partial \mathcal{L}}{\partial \dot{q}_i }}
\right)-\frac{\partial \mathcal{L}}{\partial q_i } = Q_{NCi} \quad i=1,\dotsc,N
\label{eq47}
\end{equation}
Where $Q_{NCi}$ is the generalized force due to a non-conservative force, any force that can't be expressed in terms of a potential.
Once all derivatives of the Lagrangian function are calculated, this equation will be the equation of motion for each particle. If there are $N$ generalized coordinates to define the configuration of a system, there will be $N$ equations for the system.
The set of equations above for a system are known as Euler–Lagrange equations, or Lagrange's equations of the second kind.
### Example 3: Simple pendulum under the influence of gravity
<figure><img src="./../images/simplependulum_lagrange.png" width="220" alt="simple pendulum" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a pendulum with a massless rod of length $d$ and a mass $m$ at the extremity swinging in a plane forming the angle $\theta$ with vertical, $g=10 m/s^2$ and the origin of the coordinate system at the point of the pendulum suspension.
Although the pendulum moves at the plane, it only has one degree of freedom, which can be described by the angle $\theta$, the generalized coordinate. It is not difficult to find the equation of motion using Newton's law, but let's find it using the Lagrangian mechanics.
The kinetic energy is:
\begin{equation}
T = \frac{1}{2}md^2\dot\theta^2
\end{equation}
And the potential energy is:
\begin{equation}
V = -mgd\cos\theta
\end{equation}
The Lagrangian function is:
\begin{equation}
\mathcal{L}(\theta, \dot\theta, t) = \frac{1}{2}md^2\dot\theta^2(t) + mgd\cos\theta(t)
\end{equation}
And the derivatives are given by:
\begin{equation} \begin{array}{rcl}
&\dfrac{\partial \mathcal{L}}{\partial \theta} &=& -mgd\sin\theta \\
&\dfrac{\partial \mathcal{L}}{\partial \dot{\theta}} &=& md^2\dot{\theta} \\
&\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{\theta}}} \right) &=& md^2\ddot{\theta}
\end{array} \end{equation}
Finally, the Lagrange's equation (the equation of motion) is:
\begin{equation}
md^2\ddot\theta + mgd\sin\theta = 0
\end{equation}
#### Example 3a: Numerical solution of the equation of motion for the simple pendulum
A classical approach to solve the equation of motion for the simple pendulum is to consider the motion for small angles where $\sin\theta \approx \theta$ and the differential equation is linearized to $d\ddot\theta + g\theta = 0$. This equation has an analytical solution of the type $\theta(t) = A \sin(\omega t + \phi)$, where $\omega = \sqrt{g/d}$ and $A$ and $\phi$ are constants related to the initial position and velocity.
Let's solve the differential equation for the pendulum numerically using the [Euler’s method](https://nbviewer.jupyter.org/github/demotu/BMC/blob/master/notebooks/OrdinaryDifferentialEquation.ipynb#Euler-method).
Remember that we have to (1) transform the second-order ODE into two coupled first-order ODEs, (2) approximate the derivative of each variable by its discrete first order difference and (3) write equation to calculate the variable in a recursive way, updating its value with an equation based on the first order difference.
In Python:
```
import numpy as np
def pendulum_euler(T, y0, v0, h):
"""
Two coupled first-order ODEs for the pendulum (y=theta and v is a new variable):
dydt = v
dvdt = -g/d * y
Two equations to update the values of the variables based on first-order difference:
y[n+1] = y[n] + h*v[n]
v[n+1] = v[n] + h*dvdt[n]
"""
N = int(np.ceil(T/h))
y, v = np.zeros(N), np.zeros(N)
y[0], v[0] = y0, v0
d = 2 # length of the pendulum in m
g = 10 # acceleration of gravity in m/s2
for i in range(N-1):
y[i+1] = y[i] + h*v[i]
v[i+1] = v[i] + h*(-g/d*y[i])
t = np.linspace(0, T, N, endpoint=False)
return t, y, v
%matplotlib notebook
import matplotlib.pyplot as plt
def plot(t, y, v):
"""
Plot data
"""
fig, ax = plt.subplots(1, 1, figsize=(8, 3))
ax.plot(t, y, 'b', label='Position')
ax.plot(t, v, 'r', label='Velocity')
ax.legend()
plt.show()
T, y0, v0, h = 10, 45*np.pi/180, 0, .001
t, theta, vtheta = pendulum_euler(T, y0, v0, h)
plot(t, theta, vtheta)
```
### Example 4: Simple pendulum on moving cart
<figure><img src="./../images/masspend_lagrange.png" width="250" alt="cart pendulum" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a simple pendulum with massless rod of length $d$ and mass $m$ at the extremity of the rod forming an angle $\theta$ with the vertical direction under the action of gravity and $g=10 m/s^2$. The pendulum swings freely from a cart with mass $M$ that moves at the horizontal direction pushed by a force $F_x$.
Let's use the Lagrangian mechanics to derive the equations of motion for the system.
From the figure on the right, because of the constraints introduced by the constant length of the rod and the motion the cart can perform, good generalized coordinates to describe the configuration of the system are $x$ and $\theta$. Let's use these coordinates.
The positions of the cart (c) and of the pendulum tip (p) are:
$ x_c = x $
$ y_c = 0 $
$ x_p = x + d \sin \theta $
$ y_p = -d \cos \theta $
The velocities of the cart and of the pendulum are:
$ \dot{x}_c = \dot{x} $
$ \dot{y}_c = 0 $
$ \dot{x}_p = \dot{x} + d \dot{\theta} \cos \theta $
$ \dot{y}_p = d \dot{\theta} \sin \theta $
The kinetic energy of the system is:
\begin{equation}
T = \frac{1}{2} M \big(\dot x_c^2 + \dot y_c^2 \big) + \frac{1}{2}m\,\big( \dot x_p^2 + \dot y_p^2 \big)
\end{equation}
And the potential energy of the system is:
\begin{equation}
V = M g y_c + m g y_p
\end{equation}
The Lagrangian function is:
\begin{equation}\begin{array}{rcl}
\mathcal{L} &=& \frac{1}{2} M \dot x^2 + \frac{1}{2}m\,\bigg[ \big(\dot{x} + d \dot{\theta} \cos\theta \big)^2 + \big(d \dot{\theta} \sin \theta \big)^2 \bigg] + m g d \cos \theta \\
&=& \frac{1}{2} (M+m) \dot x^2 + m\dot{x}d\dot{\theta}\cos\theta + \frac{1}{2}md^2\dot{\theta}^2 + m g d \cos \theta
\end{array}\end{equation}
The derivatives w.r.t. $x$ are:
\begin{equation}\begin{array}{rcl}
\dfrac{\partial \mathcal{L}}{\partial x} &=& 0 \\
\dfrac{\partial \mathcal{L}}{\partial \dot{x}} &=& (M+m) \dot{x} + m d \dot{\theta} \cos \theta \\
\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{x}}} \right) &=& (M+m)\ddot{x} + m d \ddot{\theta} \cos \theta - m d \dot{\theta}^2 \sin \theta
\end{array}\end{equation}
The derivatives w.r.t. $\theta$ are:
\begin{equation}\begin{array}{rcl}
\dfrac{\partial \mathcal{L}}{\partial \theta} &=& -m\dot{x}d\dot{\theta}\sin\theta - mgd\sin\theta \\
\dfrac{\partial \mathcal{L}}{\partial \dot{\theta}} &=& m\dot{x}d\cos\theta + md^2\dot{\theta} \\
\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{\theta}}} \right) &=& m\ddot{x}d\cos\theta - m\dot{x}d\dot{\theta}\sin\theta + md^2\ddot{\theta}
\end{array}\end{equation}
Finally, the Lagrange's equations (the equations of motion) are:
\begin{equation}\begin{array}{rcl}
(M+m)\ddot{x} + md\big(\ddot{\theta} \cos\theta - \dot{\theta}^2 \sin\theta\big) = F_x \\
\ddot{\theta} + \dfrac{\ddot{x}}{d}\cos\theta + \dfrac{g}{d}\sin\theta = 0
\end{array}\end{equation}
### Example 5: Double pendulum under the influence of gravity
<figure><img src="./../images/doublependulum_lagrange.png" width="200" alt="double pendulum" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a double pendulum (one pendulum attached to another) with massless rods of length $d_1$ and $d_2$ and masses $m_1$ and $m_2$ at the extremities of each rod swinging in a plane forming the angles $\theta_1$ and $\theta_2$ with vertical and $g=10 m/s^2$.
This case could be solved using Newtonian mechanics, but it's not simple (e.g., see [this link](http://www.myphysicslab.com/pendulum/double-pendulum/double-pendulum-en.html)). Instead, let's use the Lagrangian mechanics to derive the equations of motion for each pendulum.
The system has two degrees of freedom and we need two generalized coordinates ($\theta_1, \theta_2$) to describe the system's configuration.
The position of masses $m_1$ and $m_2$ are:
$x_1 = d_1\sin\theta_1$
$y_1 = -d_1\cos\theta_1$
$x_2 = d_1\sin\theta_1 + d_2\sin\theta_2$
$y_2 = -d_1\cos\theta_1 - d_2\cos\theta_2$
The kinetic and potential energies of the system are:
$ T = \frac{1}{2}m_1(\dot x_1^2 + \dot y_1^2) + \frac{1}{2}m_2(\dot x_2^2 + \dot y_2^2) $
$ V = m_1gy_1 + m_2gy_2 $
Let's use Sympy to help us; in fact we could solve this problem entirely in Sympy, see [Lagrange’s method in Sympy](http://docs.sympy.org/latest/modules/physics/mechanics/lagrange.html), but for now let's do just the derivatives.
Let's import Sympy libraries and define some variables:
```
from sympy import Symbol, symbols, cos, sin, Matrix, simplify, Eq, latex
from sympy.physics.mechanics import dynamicsymbols, mlatex, init_vprinting
init_vprinting()
from IPython.display import display, Math
t = Symbol('t')
d1, d2, m1, m2, g = symbols('d1 d2 m1 m2 g', positive=True)
a1, a2 = dynamicsymbols('theta1 theta2')
```
The positions and velocities of masses $m_1$ and $m_2$ are:
```
x1, y1 = d1*sin(a1), -d1*cos(a1)
x2, y2 = d1*sin(a1) + d2*sin(a2), -d1*cos(a1) - d2*cos(a2)
x1d, y1d = x1.diff(t), y1.diff(t)
x2d, y2d = x2.diff(t), y2.diff(t)
display(Math(r'x_1=' + mlatex(x1) + r'\quad \text{and} \quad \dot{x}_1=' + mlatex(x1d)))
display(Math(r'y_1=' + mlatex(y1) + r'\quad \text{and} \quad \dot{y}_1=' + mlatex(y1d)))
display(Math(r'x_2=' + mlatex(x2) + r'\quad \text{and} \quad \dot{x}_2=' + mlatex(x2d)))
display(Math(r'y_2=' + mlatex(y2) + r'\quad \text{and} \quad \dot{y}_2=' + mlatex(y2d)))
```
The kinetic and potential energies of the system are:
```
T = m1*(x1d**2 + y1d**2)/2 + m2*(x2d**2 + y2d**2)/2
V = m1*g*y1 + m2*g*y2
display(Math(r'T=' + mlatex(simplify(T))))
display(Math(r'V=' + mlatex(simplify(V))))
```
The Lagrangian function is:
```
L = T - V
display(Math(r'\mathcal{L}=' + mlatex(simplify(L))))
```
And the derivatives are (let's write a function to automate this process):
```
def lagrange_terms(L, *q, show=True):
"""Calculate terms of Lagrange equations given the Lagrangian and q's.
"""
Lterms = []
for qi in q:
dLdqi = simplify(L.diff(qi))
Lterms.append(dLdqi)
dLdqdi = simplify(L.diff(qi.diff(t)))
Lterms.append(dLdqdi)
dtdLdqdi = simplify(dLdqdi.diff(t))
Lterms.append(dtdLdqdi)
if show:
display(Math(r'w.r.t.\;%s:'%latex(qi.func)))
display(Math(r'\dfrac{\partial\mathcal{L}}{\partial %s}='
%latex(qi.func) + mlatex(dLdqi)))
display(Math(r'\dfrac{\partial\mathcal{L}}{\partial\dot{%s}}='
%latex(qi.func) + mlatex(dLdqdi)))
display(Math(r'\dfrac{\mathrm d}{\mathrm{dt}}\left({\dfrac{'+
r'\partial\mathcal{L}}{\partial\dot{%s}}}\right)='
%latex(qi.func) + mlatex(dtdLdqdi)))
return Lterms
Lterms = lagrange_terms(L, a1, a2)
```
Finally, the Lagrange's equations (the equations of motion) are:
```
for i in range(int(len(Lterms)/3)):
display(Eq(simplify(Lterms[3*i+2]-Lterms[3*i]), 0))
```
The motion of a double pendulum is very interesting; most of times it presents a chaotic behavior, see for example [https://www.myphysicslab.com/pendulum/double-pendulum-en.html](https://www.myphysicslab.com/pendulum/double-pendulum-en.html).
#### Example 5a: Numerical solution of the equation of motion for the double pendulum
In order to solve numerically the ODEs for the double pendulum we will transform each equation above into two first ODEs. As the two variables $\ddot{\theta_1}$ and $\ddot{\theta_2}$ appear in both equations, first we have to rearrange the equations to find expressions for $\ddot{\theta_1}$ and $\ddot{\theta_2}$. Second, we define two variables and then we can use these equations as we did for the single pendulum.
But we should avoid to use the Euler's method because of the non-negligible error in the numerical integration in this case; more accurate methods such as [Runge-Kutta](https://en.wikipedia.org/wiki/Runge%E2%80%93Kutta_methods) should be employed.
### Example 6: Double compound pendulum under the influence of gravity
<figure><img src="./../images/pendula_lagrange.png" width="200" alt="double pendulum" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider the double compound pendulum shown on the the right with length $d$ and mass $m$ of each rod swinging in a plane forming the angles $\theta_1$ and $\theta_2$ with vertical and $g=10 m/s^2$.
The system has two degrees of freedom and we need two generalized coordinates ($\theta_1, \theta_2$) to describe the system's configuration.
Let's use the Lagrangian mechanics to derive the equations of motion for each pendulum.
To calculate the potential and kinetic energy of the system, we will need to calculate the position and velocity of each pendulum. Now each pendulum is a rod with distributed mass and we will have to calculate the moment of rotational inertia of the rod. In this case, the kinetic energy of each pendulum will be given as the kinetic energy due to rotation of the pendulum plus the kinetic energy due to the speed of the center of mass of the pendulum, such that the total kinetic energy of the system is:
$ T = \overbrace{\underbrace{\frac{1}{2}I_{cm}\dot\theta_1^2}_{\text{rotation}} + \underbrace{\frac{1}{2}m(\dot x_{1,cm}^2 + \dot y_{1,cm}^2)}_{\text{translation}}}^{\text{pendulum 1}} + \overbrace{\underbrace{\frac{1}{2}I_{cm}\dot\theta_2^2}_{\text{rotation}} + \underbrace{\frac{1}{2}m(\dot x_{2,cm}^2 + \dot y_{2,cm}^2)}_{\text{translation}}}^{\text{pendulum 2}} $
And the potential energy of the system is:
$ V = mg\big(y_{1,cm} + y_{2,cm}\big) $
Let's use Sympy once again.
The position and velocity of the center of mass of the rods $1$ and $2$ are:
```
d, m, g = symbols('d m g', positive=True)
a1, a2 = dynamicsymbols('theta1 theta2')
I = m*d*d/12
x1, y1 = d*sin(a1)/2, -d*cos(a1)/2
x2, y2 = d*sin(a1) + d*sin(a2)/2, -d*cos(a1) - d*cos(a2)/2
x1d, y1d = x1.diff(t), y1.diff(t)
x2d, y2d = x2.diff(t), y2.diff(t)
display(Math(r'x_1=' + mlatex(x1) + r'\quad \text{and} \quad \dot{x}_1=' + mlatex(x1d)))
display(Math(r'y_1=' + mlatex(y1) + r'\quad \text{and} \quad \dot{y}_1=' + mlatex(y1d)))
display(Math(r'x_2=' + mlatex(x2) + r'\quad \text{and} \quad \dot{x}_2=' + mlatex(x2d)))
display(Math(r'y_2=' + mlatex(y2) + r'\quad \text{and} \quad \dot{y}_2=' + mlatex(y2d)))
```
The kinetic and potential energies of the system are:
```
T = I/2*(a1.diff(t))**2 + m*(x1d**2+y1d**2)/2 + I/2*(a2.diff(t))**2 + m*(x2d**2+y2d**2)/2
V = m*g*y1 + m*g*y2
display(Math(r'T=' + mlatex(simplify(T))))
display(Math(r'V=' + mlatex(simplify(V))))
```
The Lagrangian function is:
```
L = T - V
display(Math(r'\mathcal{L}=' + mlatex(simplify(L))))
```
And the derivatives are (let's write a function to automate this process):
```
Lterms = lagrange_terms(L, a1, a2)
```
Finally, the Lagrange's equations (the equations of motion) are:
```
for i in range(int(len(Lterms)/3)):
display(Eq(simplify(Lterms[3*i+2]-Lterms[3*i]), 0))
```
### Example 7: Two masses and two springs under the influence of gravity
<figure><img src="./../images/springs_masses_g.png" width="200" alt="double pendulum" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a system composed by two masses and two springs attached in series with massless springs under gravity and a force on $m_2$ and $g=10 m/s^2$ as shown in the figure.
The system has two degrees of freedom and we need two generalized coordinates to describe the system's configuration, for example, ${y_1, y_2}$, the positions of masses $m_1, m_2$ w.r.t. the ceiling (the origin).
(We could also have used ${z_1, z_2}$, the position of mass $m_1$ w.r.t. the ceiling and the position of mass $m_2$ w.r.t. the mass $m_1$. But the first set of coordinates would be the only choice if we were solving the problem using Newtonian mechanics because we can only apply Newton's second law to an inertial frame of reference.)
The kinetic energy of the system is:
$ T = \frac{1}{2}m_1\dot y_1^2 + \frac{1}{2}m_2\dot y_2^2 $
The potential energy of the system is:
$ V = \frac{1}{2}k_1 (y_1-\ell_1)^2 + \frac{1}{2}k_2 ((y_2-y_1)-\ell_2)^2 - m_1gy_1 - m_2g y_2 $
Where $\ell_1, \ell_2$ are the resting lengths (constants) of the two springs because the elastic potential energy is proportional to the deformation of the spring. For simplicity, let's ignore the resting position of each spring, so:
$ V = \frac{1}{2}k_1 y_1^2 + \frac{1}{2}k_2 (y_2-y_1)^2 - m_1gy_1 - m_2g y_2 $
Sympy is our friend:
```
from sympy import Symbol, symbols, cos, sin, Matrix, simplify, Eq, latex
from sympy.physics.mechanics import dynamicsymbols, mlatex, init_vprinting
init_vprinting()
from IPython.display import display, Math
t = Symbol('t')
m1, m2, g, k1, k2 = symbols('m1 m2 g k1 k2', positive=True)
y1, y2, F = dynamicsymbols('y1 y2 F')
```
The Lagrangian function is:
```
y1d, y2d = y1.diff(t), y2.diff(t)
T = (m1*y1d**2)/2 + (m2*y2d**2)/2
V = (k1*y1**2)/2 + (k2*(y2-y1)**2)/2 - m1*g*y1 - m2*g*y2
#display(Math(r'T=' + mlatex(simplify(T))))
#display(Math(r'V=' + mlatex(simplify(V))))
L = T - V
display(Math(r'\mathcal{L}=' + mlatex(simplify(L))))
```
And the derivatives are (using the function we wrote before to automate this process):
```
Lterms = lagrange_terms(L, y1, y2)
```
Finally, the Lagrange's equations (the equations of motion) are:
```
display(Eq(simplify(Lterms[2]-Lterms[0]), 0))
display(Eq(simplify(Lterms[5]-Lterms[3]), F))
```
**Same problem, but with the other set of coordinates**
Using ${z_1, z_2}$ as the position of mass $m_1$ w.r.t. the ceiling and the position of mass $m_2$ w.r.t. the mass $m_1$, the solution is:
```
z1, z2 = dynamicsymbols('z1 z2')
z1d, z2d = z1.diff(t), z2.diff(t)
T = (m1*z1d**2)/2 + (m2*(z1d + z2d)**2)/2
V = (k1*z1**2)/2 + (k2*z2**2)/2 - m1*g*z1 - m2*g*(z1+z2)
display(Math(r'T=' + mlatex(simplify(T))))
display(Math(r'V=' + mlatex(simplify(V))))
L = T - V
display(Math(r'\mathcal{L}=' + mlatex(simplify(L))))
Lterms = lagrange_terms(L, z1, z2)
```
Finally, the Lagrange's equations (the equations of motion) are:
```
display(Eq(simplify(Lterms[2]-Lterms[0]), F))
display(Eq(simplify(Lterms[5]-Lterms[3]), F))
```
The solutions using the two sets of coordinates seem different; the reader is invited to verify that in fact they are the same (remember that $y_1 = z_1,\, y_2 = z_1+z_2,\, \ddot{y}_2 = \ddot{z}_1+\ddot{z}_2$).
**Same problem, but considering the spring resting length**
And here is the solution considering the rest length of the spring:
```
t = Symbol('t')
m1, m2, g, k1, k2 = symbols('m1 m2 g k1 k2', positive=True)
y1, y2, l1, l2, F = dynamicsymbols('y1 y2 ell1 ell2 F')
y1d, y2d = y1.diff(t), y2.diff(t)
T = (m1*y1d**2)/2 + (m2*y2d**2)/2
V = (k1*(y1-l1)**2)/2 + (k2*((y2-y1)-l2)**2)/2 - m1*g*y1 - m2*g*y2
L = T - V
display(Math(r'\mathcal{L}=' + mlatex(simplify(L))))
Lterms = lagrange_terms(L, y1, y2, show=False)
display(Eq(simplify(Lterms[2]-Lterms[0]), 0))
display(Eq(simplify(Lterms[5]-Lterms[3]), F))
```
## Non-conservative forces
The dissipation energy of a non-conservative system with a non-conservative force (e.g., the viscous force from a damper, which is proportional to velocity) can be expressed as:
\begin{equation}
D_i = \frac{1}{2}C \, \dot{q}_i^2
\label{dissipation}
\end{equation}
And the Lagrange's equation can be extended to include such non-conservative force in the following way:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\left( {\frac{\partial \mathcal{L}}{\partial \dot{q}_i }}
\right)-\frac{\partial \mathcal{L}}{\partial q_i } + \frac{\partial D_i}{\partial \dot{q}_i }= 0
\label{lagrange_dissip}
\end{equation}
### Example 8: Mass-spring-damper system
<figure><img src="./../images/mass_spring_damper.png" width="200" alt="mass-spring-damper system" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a mass-spring-damper system with an external force acting on the mass.
The massless spring has a stiffness coefficient $k$ and length at rest $x_0$.
The massless damper has a damping coefficient $b$.
For simplicity, consider that the system starts at the resting position of the spring ($x=0$ at $x_0$).
The system has one degree of freedom and we need only one generalized coordinate ($x$) to describe the system's configuration.
Let's use the Lagrangian mechanics to derive the equations of motion for the system.
The kinetic energy of the system is:
\begin{equation}
T = \frac{1}{2} m \dot x^2
\end{equation}
The potential energy of the system is:
\begin{equation}
V = \frac{1}{2} k x^2
\end{equation}
The Lagrangian function is:
\begin{equation}
\mathcal{L} = \frac{1}{2} m \dot x^2 - \frac{1}{2} k x^2
\end{equation}
The dissipation energy of the system is:
\begin{equation}
D = \frac{1}{2} b \dot x^2
\end{equation}
Calculating all the terms in the Lagrange's equation for a dissipative process (cf. Eq. (\ref{lagrange_dissip})), the classical equation for a mass-spring-damper system can be found:
\begin{equation}
m\ddot{x} + b\dot{x} + kx = F(t)
\end{equation}
### Example 9: Mass-spring-damper system with gravity
<figure><img src="./../images/mass_spring_damper_gravity.png" width="220" alt="mass-spring-damper system" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a mass-spring-damper system under the action of the gravitational force ($g=10 m/s^2$) and an external force acting on the mass.
The massless spring has a stiffness coefficient $k$ and length at rest $y_0$.
The massless damper has a damping coefficient $b$.
The gravitational force acts downwards and it is negative (see figure).
For simplicity, consider that the system starts at the resting position of the spring ($y=0$ at $y_0$).
The system has one degree of freedom and we need only one generalized coordinate ($y$) to describe the system's configuration.
Let's use the Lagrangian mechanics to derive the equations of motion for the system.
The kinetic energy of the system is:
\begin{equation}
T = \frac{1}{2} m \dot y^2
\end{equation}
The potential energy of the system is:
\begin{equation}
V = \frac{1}{2} k y^2 + m g y
\end{equation}
The Lagrangian function is:
\begin{equation}
\mathcal{L} = \frac{1}{2} m \dot y^2 - \frac{1}{2} k y^2 - m g y
\end{equation}
The dissipation energy of the system is:
\begin{equation}
D = \frac{1}{2} b \dot y^2
\end{equation}
The derivatives of the Lagrangian w.r.t. $y$ and $t$ are:
\begin{equation}\begin{array}{rcl}
\dfrac{\partial \mathcal{L}}{\partial y} &=& -ky - mg \\
\dfrac{\partial \mathcal{L}}{\partial \dot{y}} &=& m \dot{y} \\
\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{y}}} \right) &=& m\ddot{y}
\end{array}\end{equation}
The derivative of the dissipation energy w.r.t. $\dot{y}$ is:
\begin{equation}
\frac{\partial D_i}{\partial \dot{y}_i } = b \dot y
\end{equation}
Substituting all these terms in the Lagrange's equation:
\begin{equation}
\frac{\mathrm d }{\mathrm d t}\left( {\frac{\partial \mathcal{L}}{\partial \dot{q}_i }}
\right)-\frac{\partial \mathcal{L}}{\partial q_i } + \frac{\partial D_i}{\partial \dot{q}_i } = Q_{NCi}
\label{lagrange_dissip2}
\end{equation}
Results in:
\begin{equation}
m\ddot{y} + b\dot{y} + ky + mg = F_0 \cos(\omega t)
\end{equation}
#### Example 9a: Numerical solution of the equation of motion for mass-spring-damper system
Let's solve the differential equation for the pendulum numerically using the [Euler’s method](https://nbviewer.jupyter.org/github/demotu/BMC/blob/master/notebooks/OrdinaryDifferentialEquation.ipynb#Euler-method).
Remember that we have to (1) transform the second-order ODE into two coupled first-order ODEs, (2) approximate the derivative of each variable by its discrete first order difference and (3) write equation to calculate the variable in a recursive way, updating its value with an equation based on the first order difference.
In Python:
```
import numpy as np
def msdg_euler(T, y0, v0, h):
"""
Two coupled first-order ODEs for the pendulum (v is a new variable):
dydt = v
dvdt = (F0*np.cos(omega*t) - b*v - k*y - m*g)/m
Two equations to update the values of the variables based on first-order difference:
y[n+1] = y[n] + h*v[n]
v[n+1] = v[n] + h*dvdt[n]
"""
N = int(np.ceil(T/h))
y, v = np.zeros(N), np.zeros(N)
y[0], v[0] = y0, v0
m = 1 # mass, kg
k = 100 # spring coefficient, N/m
b = 2 # damping coefficient, N/m/s
F0 = 1 # external force, N
w = 1 # angular frequency, Hz
g = 10 # acceleration of gravity, m/s2
t = np.linspace(0, T, N, endpoint=False)
F = F0*np.cos(w*t)
for i in range(N-1):
y[i+1] = y[i] + h*v[i]
v[i+1] = v[i] + h*((F[i] - b*v[i] - k*y[i] - m*g)/m)
return t, y, v
%matplotlib notebook
import matplotlib.pyplot as plt
def plot(t, y, v):
"""
Plot data
"""
fig, ax1 = plt.subplots(1, 1, figsize=(8, 3))
ax1.set_title('Simulation of mass-spring-damper system under gravity and external force')
ax1.plot(t, y, 'b', label='Position')
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('Position (m)', color='b')
ax1.tick_params('y', colors='b')
ax2 = ax1.twinx()
ax2.plot(t, v, 'r', label='Velocity')
ax2.set_ylabel('Velocity (m/s)', color='r')
ax2.tick_params('y', colors='r')
plt.tight_layout()
plt.show()
T, y0, v0, h = 10, .1, 0, .01
t, y, v = msdg_euler(T, y0, v0, h)
plot(t, y, v)
```
## Forces of constraint
The fact the Lagrangian formalism uses generalized coordinates means that in a system with constraints we typically have fewer coordinates (in turn, fewer equations of motion) and we don't need to worry about forces of constraint that we would have to consider in the Newtonian formalism.
However, when we do want to determine a force of constraint, using Lagrangian formalism in fact will be disadvantageous! Let's see now one way of determining a force of constraint using Lagrangian formalism. The trick is to postpone the consideration that there is a constraint in the system; this will increase the number of generalized coordinates but will allow the determination of a force of constraint.
Let's exemplify this approach determining the tension at the rod in the simple pendulum under the influence of gravity we saw earlier.
### Example 10: Force of constraint in a simple pendulum under the influence of gravity
<figure><img src="./../images/simplependulum_lagrange.png" width="220" alt="simple pendulum" style="float:right;margin: 10px 50px 10px 50px;"/></figure>
Consider a pendulum with a massless rod of length $d$ and a mass $m$ at the extremity swinging in a plane forming the angle $\theta$ with vertical and $g=10 m/s^2$.
Although the pendulum moves at the plane, it only has one degree of freedom, which can be described by the angle $\theta$, the generalized coordinate. But because we want to determine the force of constraint tension at the rod, let's also consider for now the variable $r$ for the 'varying' length of the rod (instead of the constant $d$).
In this case, the kinetic energy of the system will be:
\begin{equation}
T = \frac{1}{2}mr^2\dot\theta^2 + \frac{1}{2}m\dot r^2
\end{equation}
And for the potential energy we will also have to consider the constraining potential, $V_r(r(t))$:
\begin{equation}
V = -mgr\cos\theta + V_r(r(t))
\end{equation}
The Lagrangian function is:
\begin{equation}
\mathcal{L}(\theta, \dot\theta, t) = \frac{1}{2}m(\dot r^2(t) + r^2(t)\,\dot\theta^2(t)) + mgr(t)\cos\theta(t) - V_r(r(t))
\end{equation}
The derivatives w.r.t. $\theta$ are:
\begin{equation} \begin{array}{rcl}
&\dfrac{\partial \mathcal{L}}{\partial \theta} &=& -mgr\sin\theta \\
&\dfrac{\partial \mathcal{L}}{\partial \dot{\theta}} &=& mr^2\dot{\theta} \\
&\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{\theta}}} \right) &=& 2mr\dot{r}\dot{\theta} + mr^2\ddot{\theta}
\end{array} \end{equation}
The derivatives w.r.t. $r$ are:
\begin{equation} \begin{array}{rcl}
&\dfrac{\partial \mathcal{L}}{\partial r} &=& mr \dot\theta^2 + mg\cos\theta - \dot{V}_r(r) \\
&\dfrac{\partial \mathcal{L}}{\partial \dot{r}} &=& m\dot r \\
&\dfrac{\mathrm d }{\mathrm d t}\left( {\dfrac{\partial \mathcal{L}}{\partial \dot{r}}} \right) &=& m\ddot{r}
\end{array} \end{equation}
The Lagrange's equations (the equations of motion) are:
\begin{equation} \begin{array}{rcl}
&2mr\dot{r}\dot{\theta} + mr^2\ddot{\theta} + mgr\sin\theta &=& 0 \\
&m\ddot{r} - mr \dot\theta^2 - mg\cos\theta + \dot{V}_r(r) &=& 0 \\
\end{array} \end{equation}
Now, we will apply the constraint condition, $r(t)=d$. This means that $\dot{r}=\ddot{r}=0$.
With this constraint applied, the first Lagrange's equation is the equation for the simple pendulum:
\begin{equation}
md^2\ddot{\theta} + mgd\sin\theta = 0
\end{equation}
The second equation yields:
\begin{equation}
-\dfrac{\mathrm d V_r}{\mathrm d r}\bigg{\rvert}_{r=d} = - md \dot\theta^2 - mg\cos\theta
\end{equation}
But the tension force, $F_T$, is by definition equal to the gradient of the constraining potential, so:
\begin{equation}
F_T = - md \dot\theta^2 - mg\cos\theta
\end{equation}
As expected, the tension at the rod is proportional to the centripetal and the gravitational forces.
## Considerations on the Lagrangian mechanics
The Lagrangian mechanics does not constitute a new theory in classical mechanics; the results of a Lagrangian or Newtonian analysis must be the same for any mechanical system, only the method used to obtain the results is different.
We are accustomed to think of mechanical systems in terms of vector quantities such as force, velocity, angular momentum, torque, etc., but in the Lagrangian formalism the equations of motion are obtained entirely in terms of the kinetic and potential energies (scalar operations) in the configuration space. Another important aspect of the force vs. energy analogy is that in situations where it is not possible to make explicit all the forces acting on the body, it is still possible to obtain expressions for the kinetic and potential energies.
In fact, the concept of force does not enter into Lagrangian mechanics. This is an important property of the method. Since energy is a scalar quantity, the Lagrangian function for a system is invariant for coordinate transformations. Therefore, it is possible to move from a certain configuration space (in which the equations of motion can be somewhat complicated) to a space that can be chosen to allow maximum simplification of the problem.
## Convention to report the equations of motion
There is an elegant form to display the equations of motion using generalized coordinates $q_i$ grouping the terms proportional to common quantities in matrices, see for example, Craig (2005, page 180), Pandy (2001), and Zatsiorsky (2002, page 383):
\begin{equation}
\quad M(q_i)\ddot{q_i} + C(q_i,\dot{q}_i) + G(q_i) = Q(q_i,\dot{q}_i)
\label{}
\end{equation}
Where, for a system with $N$ generalized coordinates:
- $M$ is the inertia matrix ($NxN$);
- $\ddot{q_i}$ is a matrix ($Nx1$ of generalized accelerations);
- $C$ is a matrix ($Nx1$) of [centripetal](http://en.wikipedia.org/wiki/Centripetal_force) and [Coriolis](http://en.wikipedia.org/wiki/Coriolis_effect) generalized forces;
- $G$ is a matrix ($Nx1$) of gravitational generalized forces;
- $Q$ is a matrix ($Nx1$) of external generalized forces.
The reader is invited to express the equations of motion from the examples above in this form.
## Problems
1. Derive the Lagrange's equation (the equation of motion) for a mass-spring system where the spring is attached to the ceiling and the mass in hanging in the vertical.
<figure><img src="./../images/springgravity.png" width="200" alt="mass-spring with gravity"/></figure>
2. Derive the Lagrange's equation for an inverted pendulum in the vertical.
<figure><img src="./../images/invpendulum2.png" width="200" alt="inverted pendulum"/></figure>
3. Derive the Lagrange's equation for the following system:
<figure><img src="./../images/massessprings_lagrange.png" width="280" alt="two masses and two springs"/></figure>
4. Derive the Lagrange's equation for a spring pendulum, a simple pendulum where a mass $m$ is attached to a massless spring with spring constant $k$ and length at rest $d_0$.
<figure><img src="./../images/pendulumspring.png" width="200" alt="mass-spring pendulum"/></figure>
5. Derive the Lagrange's equation for the system shown below.
<figure><img src="./../images/pendulumramp.png" width="250" alt="pendulum on a ramp"/></figure>
6. Derive the Lagrange's equation for the following Atwood machine (consider that $m_1 > m_2$, i.e., the pulley will rotate counter-clockwise, and that moving down is in the positive direction):
<figure><img src="./../images/atwood_machine.png" width="125" alt="Atwood machine"/></figure>
7. Write computer programs (in Python!) to solve numerically the equations of motion from the problems above.
## References
- Marion JB (1970) [Classical Dynamics of particles and systems](https://books.google.com.br/books?id=Ss43BQAAQBAJ), 2nd ed., Academic Press.
- Synge JL (1949) [Principles of Mechanics](https://books.google.com.br/books?id=qsYfENCRG5QC), 2nd ed., McGraw-hill.
- Taylor J (2005) [Classical Mechanics](https://archive.org/details/JohnTaylorClassicalMechanics). University Science Books.
| github_jupyter |
```
import numpy as np
import xmltodict
import pandas as pd
import json
import gzip
import pickle
import csv
df = pd.read_hdf('papers.h5','table')
unique_names = pickle.load(open('big_names.pkl','rb'))
uniqie_confs = pickle.load(open('confs.pkl','rb'))
#big_names = np.unique(np.concatenate(df.name))
unique_names = pickle.load(open('big_names.pkl','rb'))
unique_confs = pickle.load(open('confs.pkl','rb'))
faculty_affil = pd.read_csv('faculty-affiliations.csv')
ranks = pd.read_csv('ranks.csv')
def csv2dict_str_str(fname):
with open(fname, mode='r') as infile:
rdr = csv.reader(infile)
d = {rows[0].strip(): rows[1].strip() for rows in rdr}
return d
aliasdict = csv2dict_str_str('dblp-aliases.csv')
df.shape, unique_names.shape, unique_confs.shape,faculty_affil.shape, ranks.shape
#unique_names = [str(_) for _ in unique_names]
#np.savetxt('names.txt',unique_names,encoding='utf-8',fmt='%s')
conf_idx = {}
name_idx = {}
for i in range(unique_names.shape[0]):
authorName = unique_names[i]
realName = aliasdict.get(authorName, authorName)
name_idx[realName] = i
name_idx[authorName] = i
for i in range(unique_confs.shape[0]):
confName = unique_confs[i]
conf_idx[confName] = i
if False:
for name in faculty_affil.affiliation.unique():
if name in list(ranks.uni):
print(',',end='')
else: #print(name)
print(name)
print('.',end='')
for name in faculty_affil.name:
if name in unique_names:
print(',',end='')
else:
print(name)
print('.',end='')
ranks[ranks.index < 16]
min_year = df.year.min()
max_year = df.year.max()
span_years = max_year - min_year
year_blocks = 8
offset_years = [(i-min_year)//year_blocks for i in range(min_year,max_year+1)]
year_ind = max(offset_years)+1
conf_idx = pickle.load(open('conf_idx.pkl','rb'))
name_idx = pickle.load(open('name_idx.pkl','rb'))
offset_years
import scipy.sparse
X = scipy.sparse.dok_matrix((len(unique_names),year_ind*unique_confs.shape[0]))
xdict = {}
auth_years = np.ones((len(unique_names),2)) * np.array([3000,1000])
#y = np.zeros(len(unique_names))#scipy.sparse.dok_matrix((1,len(unique_names)))
for row in df.itertuples():
paper_year = row[10]
#if row['year'] < 2005:
# continue
#print(row)
#if row['conf'] == 'CoRR':
# continue
conf = row[2]
n = row[4]
authors = row[3]
j = year_ind*conf_idx[conf] + (paper_year-min_year)//year_blocks
for a in authors:
i = name_idx[a]
if conf != 'CoRR':
xdict[(i,j)] = 1/n + xdict.get((i,j),0)
auth_years[i,0] = min(auth_years[i,0],paper_year)
auth_years[i,1] = max(auth_years[i,1],paper_year)
X._update(xdict)
#pickle.dump(X,open('x.pkl','wb'))
#pickle.dump(conf_idx,open('conf_idx.pkl','wb'))
#pickle.dump(name_idx,open('name_idx.pkl','wb'))
#X_dup = np.copy(X)
#for i in range(5):
# j = year_ind*conf_idx['CoRR'] + (i-min_year)//year_blocks
# X[:,j] = 0
settings = [-6,'hinge',15,0]
settings = [-6, 'hinge', 20, 0.15]
#settings = [-8.548444243014805, 'hinge', 25, 0.8315610452033819]
#settings = [-8.053796519336224, 'log', 15, 0.04885118622350815]
#settings = [-8.305486025332591, 'hinge', 70, 0.8854278179436874]
#settings = [-8.475194214243022, 'modified_huber', 11, 0.01707933834322717,0.1]
#settings = [-8.403912963838302, 'modified_huber', 10, 0.7195030417696724,0.1] #15, .8,4
#settings = [-8.57, 'modified_huber',22, 0.78, 0.07]
#settings = [-7.687656839233525, 'modified_huber', 106, 0.8035188318995535,0.1] # 27, .7. 1
#settings = [-8.438322018202042, 'modified_huber', 34, 0.746304732399994,0.1] # 23 .77 2
settings = [-4.228109135925832, 'modified_huber', 31, 0.919015912687292, 0.7758551488895429] # good ranking, bad acc
#settings = [-8.778235592882929, 'modified_huber', 11, 0.5720682745534834, 0.8463472302623746] # good acc, bad ranking
settings = [-4.502004811792925, 'modified_huber', 9, 0.9680926337835235, 0.6488148993147007] # maybe balance
settings = [-5.323680251147268,'modified_huber',9,0.9873050198822073,0.4352589129929476] # 1 error and 85 acc, it says
settings = [-4.228109135925832,'modified_huber',31, 0.919015912687292,0.7758551488895429] # no errors but little acc
#settings =[-6.013005893126464, 'modified_huber', 30, 0.9485296659531548, 0.683735528500138] # errors but acc
#settings = [-5.3,'modified_huber',31,0.98,0.6] # my own model
y = np.zeros(len(unique_names))
for i in range(settings[2]): #40?
uni_name = ranks.iloc[i]['uni']
uni_faculty = faculty_affil[faculty_affil.affiliation == uni_name]
uni_names = np.array(uni_faculty.name)
for name in set([aliasdict.get(n, n) for n in uni_names]):
if name in name_idx:
y[name_idx[name]] = 1
else:
pass
#print(name)
#X.shape,y.reshape((-1,))
from sklearn.linear_model import SGDClassifier
X = scipy.sparse.csr_matrix(X)
print(X.shape,y.shape)
clf = SGDClassifier(settings[1],average=False,verbose=1,warm_start=True,tol=1e-5,max_iter=1,alpha=10 ** settings[0],penalty='elasticnet',l1_ratio=settings[3],epsilon=settings[4])
clf.fit(X,y)
for i in range(25):
minv = clf.coef_[clf.coef_ > 0].min()
maxv = clf.coef_[clf.coef_ > 0].max()
#clf.coef_ = np.maximum(minv,clf.coef_)
clf = clf.partial_fit(X,y)
print(minv,maxv)
#minv = clf.coef_[clf.coef_ > 0].min()
#clf.coef_ = np.maximum(minv,clf.coef_)
X = scipy.sparse.csr_matrix(X)
import csv
with open('pairwise_tiers.csv','rt') as csvfile:
filereader = csv.reader(csvfile)
conf_pairs = [[t.strip('\ufeff') for t in _ if len(t)!=0] for _ in filereader]
if False:
best_cost = 1000
best_params = []
for itr in range(1000):
alpha = np.random.uniform(-6.5,-3)
hinge_log = 'hinge' if np.random.rand() < 0.5 else 'modified_huber'
uni_rank = int(round(np.exp(np.random.uniform(np.log(5),np.log(50)))))
l1r = np.random.uniform(0.2,1)
eps = np.random.uniform(0.1,1)
y = np.zeros(len(unique_names))
for i in range(uni_rank): #40?
uni_name = ranks.iloc[i]['uni']
uni_faculty = faculty_affil[faculty_affil.affiliation == uni_name]
uni_names = np.array(uni_faculty.name)
for name in set([aliasdict.get(n, n) for n in uni_names]):
if name in name_idx:
y[name_idx[name]] = 1
else:
pass
#print(name)
#X.shape,y.reshape((-1,))
from sklearn.linear_model import SGDClassifier
clf = SGDClassifier(hinge_log,average=True,verbose=0,tol=1e-5,max_iter=1,alpha= 10 ** alpha,penalty='elasticnet',l1_ratio=l1r,epsilon=eps)
clf.fit(X,y)
for i in range(25):
clf.coef_ = np.maximum(0,clf.coef_)
clf = clf.partial_fit(X,y)
clf.coef_ = np.maximum(0,clf.coef_)
classifier_cost = 0
conf_ord = np.argsort(np.squeeze(clf.coef_))
conf_rank_dict = {}
conf_elem = len(unique_confs)*year_ind
for i in range(len(unique_confs)*year_ind):
idx = conf_ord[-(i+1)]
conf_name = unique_confs[idx//year_ind]
conf_score = clf.coef_[0,idx]
if idx%year_ind < 3:
continue
if conf_score == 0:
conf_rank_dict[conf_name] = num_elem
else:
conf_rank_dict[conf_name] = i
pair_len = len(conf_pairs)//2
neg_top = 0
for i in range(pair_len):
better = conf_pairs[2*i]
worse = conf_pairs[2*i+1]
#print(better,worse)
for b in better:
neg_top += clf.coef_[0,conf_idx[b]*year_ind+4] < 0
for w in worse:
classifier_cost += conf_rank_dict[w] < conf_rank_dict[b]
#if conf_rank_dict[w] < conf_rank_dict[b]:
# print(w,conf_rank_dict[w],'\t',b,conf_rank_dict[b])
all_choices = clf.decision_function(X)
frac_correct = (all_choices[y.astype(np.bool)] > 0).sum()
print(classifier_cost,[alpha,hinge_log,uni_rank,l1r,eps],frac_correct/y.sum(),neg_top,clf.coef_[0,5570])
if classifier_cost < best_cost:
best_cost = classifier_cost
best_params = [alpha,hinge_log,uni_rank,l1r,eps]
#print(best_cost,best_params)
#8 [-3.5003506670165976, 'log', 21]
#10 [-3.0421236321136265, 'log', 47]
#11 [-3.954162400006843, 'log', 109]
else:
classifier_cost = 0
conf_ord = np.argsort(np.squeeze(clf.coef_))
conf_rank_dict = {}
num_elem = len(unique_confs)*year_ind
for i in range(num_elem):
idx = conf_ord[-(i+1)]
conf_name = unique_confs[idx//year_ind]
conf_score = clf.coef_[0,idx]
if idx%year_ind < 3:
continue
if conf_score == 0:
conf_rank_dict[conf_name] = num_elem
else:
conf_rank_dict[conf_name] = i
pair_len = len(conf_pairs)//2
for i in range(pair_len):
better = conf_pairs[2*i]
worse = conf_pairs[2*i+1]
#print(better,worse)
for b in better:
for w in worse:
classifier_cost += (conf_rank_dict[w] < conf_rank_dict[b])
if conf_rank_dict[w] < conf_rank_dict[b]:
print(w,conf_rank_dict[w],'\t',b,conf_rank_dict[b])
all_choices = clf.decision_function(X)
frac_correct = (all_choices[y.astype(np.bool)] > 0).sum()
print(classifier_cost,settings,frac_correct/y.sum())
(all_choices > 0).sum(),y.sum(),(all_choices[y.astype(np.bool)] > 0).sum()
conf_choice = ['SIGGRAPH','NIPS','3DV','HRI','ECCV (8)','ECCV (1)','Comput. Graph. Forum','Shape Modeling International','Symposium on Geometry Processing',' Computer Aided Geometric Design','ICLR','NIPS','AAAI','I. J. Robotics Res.','CVPR','International Journal of Computer Vision','Robotics: Science and Systems','ICRA','WACV','ICML','AISTATS','CoRR','SIGGRAPH Asia','ECCV','ICCV','ISER','Humanoids','3DV','IROS','CoRL','Canadian Conference on AI','ACCV ','Graphics Interface','CRV','BMVC']
ri_confs = np.zeros(len(unique_confs)*year_ind)
print(clf.intercept_)
ms = clf.coef_.mean()
ss = clf.coef_.std()
for i in range(len(unique_confs)*year_ind):
idx = conf_ord[-(i+1)]
conf_name = unique_confs[idx//year_ind]
conf_score = clf.coef_[0,idx]
if conf_name in conf_choice:
ri_confs[idx] = 1
if conf_name in conf_choice and (idx%year_ind)==5:
#if 'ICCV' in conf_name and (idx%year_ind)==4:
start_year = offset_years.index(idx%year_ind) + 1970
end_year = len(offset_years) - 1 - offset_years[::-1].index(idx%year_ind) + 1970
print_name =conf_name + '_' + str(start_year)[-2:] +'t' + str(end_year)[-2:]
print('{:20s}\t{:.0f}\t{:.1f}'.format(print_name[:20],100*conf_score,(conf_score-ms)/ss))
ri_confs.shape,ri_confs.sum(),X.shape
scores = clf.decision_function(X)
years_working = (1+auth_years[:,1]-auth_years[:,0])
value_scores = scores - clf.intercept_[0]
norm_scores = (value_scores)/years_working
ri_filter_mat = scipy.sparse.diags(ri_confs)
ri_scores = clf.decision_function(X.dot(ri_filter_mat))-clf.intercept_[0]
ri_norm_scores = ri_scores/years_working
prev_cand = ['Pulkit Agrawal',
'Joydeep Biswas',
'Katherine L. Bouman',
'David Braun',
'Jia Deng',
'Naomi T. Fitter',
'David F. Fouhey',
'Saurabh Gupta',
'Judy Hoffman',
'Hanbyul Joo',
'Honglak Lee',
'Changliu Liu',
'Petter Nilsson',
"Matthew O'Toole",
'Alessandro Roncone',
'Alanson P. Sample',
'Manolis Savva',
'Adriana Schulz',
'Amy Tabb',
'Fatma Zeynep Temel',
'Long Wang',
'Cathy Wu',
'Ling-Qi Yan']
print('{:20s}\t{:4s}\t{:4s}\t{:4s}\t{}'.format('name','rate','total','ri','years'))
for ns, name in sorted([(value_scores[name_idx[ni]],ni) for ni in prev_cand],reverse=True):
ni = name_idx[name]
print('{:20s}\t{:.2f}\t{:.2f}\t{:.2f}\t{:.0f}'.format(name,norm_scores[ni],value_scores[ni],ri_scores[ni],years_working[ni]))
print('')
curious_names = ['Xiaolong Wang 0004','Kumar Shaurya Shankar',
'Nicholas Rhinehart',
'Humphrey Hu',
'David F. Fouhey',
'Lerrel Pinto',
'Justin Johnson',
'Amir Roshan Zamir',
'Brian Okorn']
print('{:20s}\t{:4s}\t{:4s}\t{:4s}\t{}'.format('name','rate','total','ri','years'))
for name in curious_names:
ni = name_idx[name]
print('{:20s}\t{:.2f}\t{:.2f}\t{:.2f}\t{:.0f}'.format(name,norm_scores[ni],value_scores[ni],ri_scores[ni],years_working[ni]))
if False:
uni_faculty = faculty_affil[faculty_affil.affiliation == 'Carnegie Mellon University'] #Carnegie Mellon University
uni_names = np.array(uni_faculty.name)
uni_names = list(uni_names) + ['Jacob Walker','Lerrel Pinto','Brian Okorn','Leonid Keselman','Siddharth Ancha']
cmu_scores = []
for name in set([aliasdict.get(n, n) for n in uni_names]):
if name in name_idx:
#if ri_scores[name_idx[name]] < 2.5:
# continue
score = scores[name_idx[name]]
cmu_scores.append((score,name))
else:
pass
#print(name)
for s,p in sorted(cmu_scores,reverse=True):
print('{:20s}\t{:.1f}'.format(p,s))
print('\nvalue based!\n')
cmu_scores = []
for name in set([aliasdict.get(n, n) for n in uni_names]):
if name in name_idx:
#print(name,auth_years[name_idx[name]])
score = (scores[name_idx[name]]-clf.intercept_)[0]/(1+auth_years[name_idx[name],1]-auth_years[name_idx[name],0])
#if ri_scores[name_idx[name]] < 2.5:
# continue
cmu_scores.append((score, value_scores[name_idx[name]] ,name))
else:
pass
#print(name)
for s,rs,p in sorted(cmu_scores,reverse=True):
print('{:20s}\t{:.1f}\t{:.1f}'.format(p,rs,s))
if True:
print('\n best overall \n')
cmu_scores = []
best_scores = np.argsort(value_scores)[::-1]
#print(best_scores.shape,unique_names[best_scores[0]])
fa_list = list(faculty_affil.name)
fa_a_list = list(faculty_affil.affiliation)
uni_names = [unique_names[i] for i in best_scores[:20000]]
for name in set([aliasdict.get(n, n) for n in uni_names]):
if name in name_idx:
uni = 'unknown'
if name in fa_list:
uni = fa_a_list[fa_list.index(name)]
if name not in ['Jacob Walker','Justin Johnson','Pieter Abbeel','Martial Hebert','Jessica K. Hodgins','Abhinav Gupta','Christopher G. Atkeson','Tom M. Mitchell','Matthew T. Mason']:
if years_working[name_idx[name]] < 3:
continue
if years_working[name_idx[name]] > 8:
continue
#if ri_scores[name_idx[name]] < 5:
# continue
if auth_years[name_idx[name],1] < 2016:
continue
#if (np.array(X[name_idx[name],:].todense()) * ri_confs).sum() == 0:
# continue
#print(name,auth_years[name_idx[name]])
score = norm_scores[name_idx[name]]
ri_vscore = ri_norm_scores[name_idx[name]]
vscore = value_scores[name_idx[name]]
cmu_scores.append((score,ri_scores[name_idx[name]],vscore,uni,name,auth_years[name_idx[name]]))
else:
pass
#print(name)
print('{:22s}\t{:15s}\t{:5s}\t{:3s}\t{:4s}\t{} {}'.format('name','uni','rate','RI-t','total','start','end'))
for s,ris,vs,u,p,yrs in sorted(cmu_scores,reverse=True):
print('{:22s}\t{:15s}\t{:.3f}\t{:.1f}\t{:.2f}\t{} {}'.format(p[:22],u[:15],s,ris,vs,int(yrs[0]),int(yrs[1])))
if False:
gz = gzip.GzipFile('dblp.xml.gz')
names = set()
places = set()
papers = []
def handle_article(_, article):
try:
if 'author' not in article:
return True
if type(article['author']) != list:
authors = [article['author']]
else:
authors = article['author']
if 'booktitle' in article:
venue = article['booktitle']
elif 'journal' in article:
venue = article['journal']
else:
return True
names = names.union(set(authors))
places.add(venue)
except:
print(sys.exc_info()[0])
failures += 1
raise
return True
xmltodict.parse(gz, item_depth=2, item_callback=handle_article)
ls *.pkl
pickle.dump(clf.coef_,open('clf_faculty_neg_pos_light_reg.pkl','wb'))
```
| github_jupyter |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import pickle
from subprocess import call, check_output
!python --version
```
# Check correlation between predictions
# Prepare submission for the test sample
Read the sample submission
```
submission = pd.read_csv('/home/mlisovyi/.kaggle/competitions/house-prices-advanced-regression-techniques/sample_submission.csv')
# config of inputs
out_dir = 'data'
out_v = 'v0'
opt_features = ['raw', 'pca_quat', 'raw_StandardScaler']
opt_models = ['LGB_depth7_cols06', 'LinRegL2_10', 'knn5_p1', 'LGB_depthINF_cols06_nleaves5']
#which models to average over
average_models = ['raw_LGB_depth7_cols01',
'raw_LGB_depth7_cols06',
'raw_LGB_depthINF_cols06_nleaves5',
'pca_quat_LinRegL2_001',
'pca_quat_LinRegL2_10',
'raw_RandomF_maxF03']#,
#'raw_StandardScaler_knn5_p1']
average_models_2 = [ 'raw_LGB_depthINF_cols06_nleaves5',
'pca_quat_LinRegL2_10']#,
#'raw_StandardScaler_knn5_p1']
# the actual predictions
preds = pickle.load(open( "{}/pred_{}.pickle".format(out_dir, out_v), "rb" ))
preds.keys()
for feat in opt_features:
for model in opt_models:
submission['SalePrice'] = np.expm1(preds['{}_{}'.format(feat, model)])
fout = '{}/subm_{}_{}_{}.csv'.format(out_dir, out_v, feat, model)
submission.to_csv(fout, index=False)
print('!kaggle competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_{}_{}'.format(fout, out_v, feat, model))
submission['SalePrice'] = np.zeros(submission['SalePrice'].shape)
for m in average_models:
submission['SalePrice'] += np.expm1(preds[m])
submission['SalePrice'] *= 1./len(average_models)
fout = '{}/subm_{}_avePrice.csv'.format(out_dir, out_v)
submission.to_csv(fout, index=False)
print('!kaggle competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_avePrice'.format(fout, out_v))
#check_output(['kaggle', 'competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_avePrice'.format(fout, out_v)])
submission['SalePrice'] = np.zeros(submission['SalePrice'].shape)
for m in average_models:
submission['SalePrice'] += preds[m]
submission['SalePrice'] *= 1./len(average_models)
submission['SalePrice'] = np.expm1(submission['SalePrice'])
fout = '{}/subm_{}_aveLogPrice.csv'.format(out_dir, out_v)
submission.to_csv(fout, index=False)
print('!kaggle competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_aveLogPrice'.format(fout, out_v))
#check_output(['kaggle', 'competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_avePrice'.format(fout, out_v)])
submission['SalePrice'] = np.zeros(submission['SalePrice'].shape)
for m in average_models_2:
submission['SalePrice'] += preds[m]
submission['SalePrice'] *= 1./len(average_models_2)
submission['SalePrice'] = np.expm1(submission['SalePrice'])
fout = '{}/subm_{}_aveLogPrice_2.csv'.format(out_dir, out_v)
submission.to_csv(fout, index=False)
print('!kaggle competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_aveLogPrice_2'.format(fout, out_v))
#check_output(['kaggle', 'competitions submit -c house-prices-advanced-regression-techniques -f {} -m {}_avePrice'.format(fout, out_v)])
!kaggle competitions submit -c house-prices-advanced-regression-techniques -f data/subm_v0_aveLogPrice_2.csv -m v0_aveLogPrice_2
```
| github_jupyter |
<a href="https://colab.research.google.com/github/MUYang99/NOx-Time-Series-Prediction-Based-on-Deep-Learning/blob/main/SVM.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
from math import sqrt
from numpy import concatenate
import numpy as np
import pandas as pd
from pandas import read_csv
from pandas import DataFrame
from pandas import concat
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.svm import SVR
from matplotlib import pyplot
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
# load dataset
dataset = pd.read_excel('d1.xlsx')
dataset.columns = ['Date', 'NOx']
dataset = dataset.dropna(subset=['NOx'])
dataset = dataset[dataset.Date < '20151231']
# normalise features
scaler = MinMaxScaler(feature_range=(0,1))
nox = dataset.NOx.values
nox = nox.reshape(len(nox), 1)
scaled = scaler.fit_transform(nox)
# frame as supervised learning
n_mins = 5
n_features = 1
reframed = series_to_supervised(scaled, n_mins, 1)
# drop columns we don't want to predict
print(reframed.shape)
# split into train and test sets
values = reframed.values
n_val_quarters = 144
train = values[:-n_val_quarters, :]
test = values[-n_val_quarters:, :]
# split into input and outputs
n_obs = n_mins * n_features
train_X, train_y = train[:, :n_obs], train[:, -1]
test_X, test_y =test[:, :n_obs], test[:,-1]
print(train_y,test_y)
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
# design svm model
clf = SVR()
# fit model
clf.fit(train_X,train_y)
# make a prediction
predict_y = clf.predict(test_X)
yhat = predict_y.reshape(predict_y.shape[0],1)
test_X = test_X.reshape((test_X.shape[0],n_mins*n_features))
print(yhat.shape,test_X.shape)
# invert scaling for forecast
inv_yhat = concatenate((test_X[:, -24:-1], yhat), axis=1)
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:,-1]
# invert scaling for actual
test_y = test_y.reshape((len(test_y), 1))
inv_y = concatenate((test_X[:, -24:-1], test_y), axis=1)
inv_y = scaler.inverse_transform(inv_y)
inv_y = inv_y[:,-1]
# plot
fig, ax = pyplot.subplots(figsize=(15,5), dpi = 300)
ax.plot([x for x in range(1, inv_yhat.shape[0]+1)], inv_yhat, linewidth=2.0, label = "predict")
ax.plot([x for x in range(1, inv_y.shape[0]+1)], inv_y, linewidth=2.0, label = "true")
ax.legend(loc=2);
pyplot.grid(linestyle='-.')
pyplot.show()
# calculate RMSE
rmse = sqrt(mean_squared_error(inv_y, inv_yhat))
print('Test RMSE: %.3f' % rmse)
# calculate MAE
MAE = mean_absolute_error(inv_y, inv_yhat)
print('Test MAE: %.3f' %MAE)
```
| github_jupyter |
Updated Notebook from Practical Business Python.
Original article had a model that did not work correctly. This notebook is for the [updated article](http://pbpython.com/amortization-model-revised.html).
Many thanks to the individuals that helped me fix the errors. The solution below is based heavily on this [gist](https://gist.github.com/sjmallon/e1ca2aee4574d5517b8d31c93832222a) and comments on [reddit](https://www.reddit.com/r/Python/comments/5e3xab/building_a_financial_model_with_pandas/?st=iwjk8alv&sh=d721fcd7).
```
import pandas as pd
from datetime import date
import numpy as np
from collections import OrderedDict
from dateutil.relativedelta import *
import matplotlib.pyplot as plt
from IPython.core.pylabtools import figsize
```
Build a payment schedule using a generator that can be easily read into a pandas dataframe for additional analysis and plotting
```
def amortize(principal, interest_rate, years, pmt, addl_principal, start_date, annual_payments):
"""
Calculate the amortization schedule given the loan details.
:param principal: Amount borrowed
:param interest_rate: The annual interest rate for this loan
:param years: Number of years for the loan
:param pmt: Payment amount per period
:param addl_principal: Additional payments to be made each period.
:param start_date: Start date for the loan.
:param annual_payments: Number of payments in a year.
:return:
schedule: Amortization schedule as an Ortdered Dictionary
"""
# initialize the variables to keep track of the periods and running balances
p = 1
beg_balance = principal
end_balance = principal
while end_balance > 0:
# Recalculate the interest based on the current balance
interest = round(((interest_rate/annual_payments) * beg_balance), 2)
# Determine payment based on whether or not this period will pay off the loan
pmt = min(pmt, beg_balance + interest)
principal = pmt - interest
# Ensure additional payment gets adjusted if the loan is being paid off
addl_principal = min(addl_principal, beg_balance - principal)
end_balance = beg_balance - (principal + addl_principal)
yield OrderedDict([('Month',start_date),
('Period', p),
('Begin Balance', beg_balance),
('Payment', pmt),
('Principal', principal),
('Interest', interest),
('Additional_Payment', addl_principal),
('End Balance', end_balance)])
# Increment the counter, balance and date
p += 1
start_date += relativedelta(months=1)
beg_balance = end_balance
```
Wrapper function to call `amortize`.
This function primarily cleans up the table and provides summary stats so it is easy to compare various scenarios.
```
def amortization_table(principal, interest_rate, years,
addl_principal=0, annual_payments=12, start_date=date.today()):
"""
Calculate the amortization schedule given the loan details as well as summary stats for the loan
:param principal: Amount borrowed
:param interest_rate: The annual interest rate for this loan
:param years: Number of years for the loan
:param annual_payments (optional): Number of payments in a year. DEfault 12.
:param addl_principal (optional): Additional payments to be made each period. Default 0.
:param start_date (optional): Start date. Default first of next month if none provided
:return:
schedule: Amortization schedule as a pandas dataframe
summary: Pandas dataframe that summarizes the payoff information
"""
# Payment stays constant based on the original terms of the loan
payment = -round(np.pmt(interest_rate/annual_payments, years*annual_payments, principal), 2)
# Generate the schedule and order the resulting columns for convenience
schedule = pd.DataFrame(amortize(principal, interest_rate, years, payment,
addl_principal, start_date, annual_payments))
schedule = schedule[["Period", "Month", "Begin Balance", "Payment", "Interest",
"Principal", "Additional_Payment", "End Balance"]]
# Convert to a datetime object to make subsequent calcs easier
schedule["Month"] = pd.to_datetime(schedule["Month"])
#Create a summary statistics table
payoff_date = schedule["Month"].iloc[-1]
stats = pd.Series([payoff_date, schedule["Period"].count(), interest_rate,
years, principal, payment, addl_principal,
schedule["Interest"].sum()],
index=["Payoff Date", "Num Payments", "Interest Rate", "Years", "Principal",
"Payment", "Additional Payment", "Total Interest"])
return schedule, stats
```
Example showing how to call the function
```
df, stats = amortization_table(700000, .04, 30, addl_principal=200, start_date=date(2016, 1,1))
stats
df.head()
df.tail()
```
Make multiple calls to compare scenarios
```
schedule1, stats1 = amortization_table(100000, .04, 30, addl_principal=50, start_date=date(2016,1,1))
schedule2, stats2 = amortization_table(100000, .05, 30, addl_principal=200, start_date=date(2016,1,1))
schedule3, stats3 = amortization_table(100000, .04, 15, addl_principal=0, start_date=date(2016,1,1))
pd.DataFrame([stats1, stats2, stats3])
```
Make some plots to show scenarios
```
%matplotlib inline
plt.style.use('ggplot')
fig, ax = plt.subplots(1, 1)
schedule1.plot(x='Month', y='End Balance', label="Scenario 1", ax=ax)
schedule2.plot(x='Month', y='End Balance', label="Scenario 2", ax=ax)
schedule3.plot(x='Month', y='End Balance', label="Scenario 3", ax=ax)
plt.title("Pay Off Timelines");
def make_plot_data(schedule, stats):
"""Create a dataframe with annual interest totals, and a descriptive label"""
y = schedule.set_index('Month')['Interest'].resample("A").sum().reset_index()
y["Year"] = y["Month"].dt.year
y.set_index('Year', inplace=True)
y.drop('Month', 1, inplace=True)
label="{} years at {}% with additional payment of ${}".format(stats['Years'], stats['Interest Rate']*100, stats['Additional Payment'])
return y, label
y1, label1 = make_plot_data(schedule1, stats1)
y2, label2 = make_plot_data(schedule2, stats2)
y3, label3 = make_plot_data(schedule3, stats3)
y = pd.concat([y1, y2, y3], axis=1)
figsize(7,5)
fig, ax = plt.subplots(1, 1)
y.plot(kind="bar", ax=ax)
plt.legend([label1, label2, label3], loc=1, prop={'size':10})
plt.title("Interest Payments");
additional_payments = [0, 50, 200, 500]
fig, ax = plt.subplots(1, 1)
for pmt in additional_payments:
result, _ = amortization_table(100000, .04, 30, addl_principal=pmt, start_date=date(2016,1,1))
ax.plot(result['Month'], result['End Balance'], label='Addl Payment = ${}'.format(str(pmt)))
plt.title("Pay Off Timelines")
plt.ylabel("Balance")
ax.legend();
```
| github_jupyter |
# Metagenomics Bioinformatics Course - EBI MGnify 2021
## MGnify Genomes resource - Metagenomic Assembled Genomes Catalogues - Practical exercise
### Aims
In this exercise, we will learn how to use the [Genomes resource within MGnify](https://www.ebi.ac.uk/metagenomics/browse#genomes).
- Discover the available data on the MGnify website
- Use two search mechanisms (search by _gene_ and search by _genome_)
- Learn how to use the MGnify API to fetch data using scripts or analysis notebooks
- Use the _genome_ search mechanism via the API, to compare your own MAGs against a MGnify catalogue and see whether they are novel
### How this works
This file is a [Jupyter Notebook](https://jupyter.org).
It has instructions, and also code cells. The code cells are connected to Python, and you can run all of the code in a cell by pressing Play (▶) icon in the top bar, or pressing `shift + return`.
The code libraries you should need are already installed.
# Import packages
[pandas](https://pandas.pydata.org/docs/reference/index.html#api) is a data analysis library with a huge list of features. It is very good at holding and manipulating table data. It is almost always short-handed to `pd`
```
import pandas as pd
```
[jsonapi-client](https://pypi.org/project/jsonapi-client/) is a library to get formatted data from web services into python code
```
from jsonapi_client import Session as APISession
```
[matplotlib](https://matplotlib.org) is the go-to package for making plots and charts. It is almost always short-handed to `plt`.
```
import matplotlib.pyplot as plt
```
`pathlib` is part of the Python standard library. We use it to find files and directories.
```
from pathlib import Path
```
`time` is part of the Python standard library. We will use it to wait for results from the API.
```
import time
```
`tarfile` is part of the Python standard library. We will use it to extract compressed files from a `.tar.gz` file that the API gives us.
```
import tarfile
```
**We will also import some extra package later. `sourmash` and `requests` will be used for specialised tasks and explained at the time.**
# The MGnify API (recap from [day 2](<./Day 2 - Service API Practical.ipynb>))
<span style="background-color:#ffaaaa; padding: 8px">Saw all this on Day 2? [⇓ Skip to new tasks](#Task-1---list-Genome-Catalogues).</span>
## Core concepts
An [API](https://en.wikipedia.org/wiki/API "Application programming interface") is how your scripts (e.g. Python or R) can talk to the MGnify database.
The MGnify API uses [JSON](https://en.wikipedia.org/wiki/JSON "Javascript Object Notation") to transfer data in a systematic way. This is human-readable and computer-readable.
The particular format we use is a standard called [JSON:API](https://jsonapi.org).
There is a Python package ([`jsonapi_client`](https://pypi.org/project/jsonapi-client/)) to make consuming this data easy. We're using it here.
The MGnify API has a "browsable interface", which is a human-friendly way of exploring the API. The URLs for the browsable API are exactly the same as you'd use in a script or code; but when you open those URLs in a browser you see a nice interface. Find it here: [https://www.ebi.ac.uk/metagenomics/api/v1/](https://www.ebi.ac.uk/metagenomics/api/v1/).
The MGnify API is "paginated", i.e. when you list some data you are given it in multiple pages. This is because there can sometimes by thousands of results. Thankfully `jsonapi_client` handles this for us.
## Example
The MGnify website has a list of ["Super Studies"](https://www.ebi.ac.uk/metagenomics/browse) (collections of studies that together represent major research efforts or collaborations).
What the website is actually showing, is the data from an API endpoint (i.e. specific resource within the API) that lists those. It's here: [api/v1/super-studies](https://www.ebi.ac.uk/metagenomics/api/v1/super-studies). Have a look.
Here is an example of some Python code, using two popular packages that let us write a short tidy piece of code:
 **Click into the next cell, and press `shift + return` (or click the ▶ icon on the menubar at the top) to run it.**
```
endpoint = 'super-studies'
with APISession("https://www.ebi.ac.uk/metagenomics/api/v1") as mgnify:
resources = map(lambda r: r.json, mgnify.iterate(endpoint))
resources = pd.json_normalize(resources)
resources.to_csv(f"{endpoint}.csv")
resources
```
## Line by line explanation
```python
### The packages were already imported, but if you wanted to use this snippet on it's own as a script you would import them like this:
from jsonapi_client import Session as APISession
import pandas as pd
###
endpoint = 'super-studies'
# An "endpoint" is the specific resource within the API which we want to get data from.
# It is the a URL relative to the "server base URL" of the API, which for MGnify is https://www.ebi.ac.uk/metagenomics/api/v1.
# You can find the endpoints in the API Docs https://www.ebi.ac.uk/metagenomics/api/docs/
with APISession("https://www.ebi.ac.uk/metagenomics/api/v1") as mgnify:
# Calling "APISession" is enabling a connection to the MGnify API, that can be used multiple times.
# The `with...as mgnify` syntax is a Python "context".
# Everything inside the `with...` block (i.e. indented below it) can use the `APISession` which we've called `mgnify` here.
# When the `with` block closes (the indentation stops), the connection to the API is nicely cleaned up for us.
resources = map(lambda r: r.json, mgnify.iterate(endpoint))
# `map` applies a function to every element of an iterable - so do something to each thing in a list.
# Remember we said the API is paginated?
# `mgnify.iterate(endpoint)` is a very helpful function that loops over as many pages of results as there are.
# `lambda r: r.json` is grabbing the JSON attribute from each Super Study returned from the API.
# All together, this makes `resources` be a bunch of JSON representations we could loop through, each containing the data of a Super Study.
resources = pd.json_normalize(resources)
# `pd` is the de-facto shorthand for the `pandas` package - you'll see it anywhere people are using pandas.
# The `json_normalize` function takes "nested" data and does its best to turn it into a table.
# You can throw quite strange-looking data at it and it usually does something sensible.
resources.to_csv(f"{endpoint}.csv")
# Pandas has a built-in way of writing CSV (or TSV, etc) files, which is helpful for getting data into other tools.
# This writes the table-ified Super Study list to a file called `super-studies.csv`.
resources
# In a Jupyter notebook, you can just write a variable name in a cell (or the last line of a long cell), and it will print it.
# Jupyter knows how to display Pandas tables (actually called "DataFrames", because they are More Than Just Tables ™) in a pretty way.
```
# Day 4 Tasks
## Task 1 - list Genome Catalogues
 **In the cell below, complete the Python code to fetch the list of [Genome Catalogues from the MGnify API](https://www.ebi.ac.uk/metagenomics/api/v1/genome-catalogues), and show them in a table.**
(Note that there may only be one catalogue in the list right now, that is correct)
```
# In case we skipped the API recap, make sure packages are imported
import pandas as pd
from jsonapi_client import Session as APISession
import time
import tarfile
import matplotlib.pyplot as plt
from pathlib import Path
# Complete this code
endpoint =
with APISession("https://www.ebi.ac.uk/metagenomics/api/v1") as mgnify:
catalogues =
catalogues
```
### Solution
Unhide these cells to see a solution
```
endpoint = 'genome-catalogues'
with APISession("https://www.ebi.ac.uk/metagenomics/api/v1") as mgnify:
catalogues = map(lambda r: r.json, mgnify.iterate(endpoint))
catalogues = pd.json_normalize(catalogues)
catalogues
```
## Task 2 - list Genomes
Each catalogue contains a much larger list of Genomes.
 **In the cell below, complete the Python code to fetch the list of [Genomes from the MGnify API](https://www.ebi.ac.uk/metagenomics/api/v1/genome-catalogues), and show them in a table.**
(Note that there are quite a lot of pages of data, so this will take a minute to run)
```
catalogue_id = catalogues.id[0]
endpoint = f'genome-catalogues/{catalogue_id}/genomes' # a Python f-string inserts the value of a variable into the string where that variable name appears inside {..}
with as mgnify:
genomes =
genomes
```
### Solution
Unhide these cells to see a solution
```
catalogue_id = catalogues.id[0]
endpoint = f'genome-catalogues/{catalogue_id}/genomes' # a Python f-string inserts the value of a variable into the string where that variable name appears inside {..}
with APISession("https://www.ebi.ac.uk/metagenomics/api/v1") as mgnify:
genomes = map(lambda r: r.json, mgnify.iterate(endpoint))
genomes = pd.json_normalize(genomes)
genomes
```
## Task 3 - search Genome Catalogues using the website
[MGnify Genomes](https://www.ebi.ac.uk/metagenomics/browse#genomes) offers two ways to search for Genomes in a MAG Catalogues.
### Search using a gene
1.  Go to [the MGnify Genomes webpage](https://www.ebi.ac.uk/metagenomics/browse#genomes) and open the latest version of the Human Gut catalogue.
2. Imagine you've got some sequence of interest and want to see whether it is in the Gut Genome Catalogue.
*  **Use the following sequence, and the "Search by gene" tool** to discover whether is it likely to from a species in the gut.
```
GGAGTGCGGCGGAAAGTTAACCTATGCCGGACCCTGCGGGAATCCAGCTGCGTTCGAACAAGCAACCAACATATATATCTGAATTTGGATGTGGTGGGCACTTTGT
TGTTAGGCGCTTTGAGGTGCGAGTGACACTTTGGGGTGCGCGGAGCCCTGGGTTGGGTCGATGATTTGGGATGAGCTTCTTACTTAGGTGAAGAGGGGCTTTATGG
CTGAGAGGTAGTCTTTGGCTACGTCGGCTTTATCTGCTTGGAAATTGTGCCAGGCCCACCATTGGACCATTCCTACGAAGCTTGAGGCTATGTGGTGTAGTAGGAA
GCTTCGGTCCATGGTGGCGGCGGGGCCGTTTGGGTCGGTAGGGACGGTTTCGGCTGCTCGGGCCATGATGGTCTTGCGGAGGCTGTCGGCGAAGACGCGTGAACCG
GCGCCGGCTACCAGTGCCCGTACACCCTGACGGCGCTCCCAGAGGTTGTTGAGGATATGCTCGACCTGTACGAGTGGGTCATCGAGGGGCGTACCGTCATCGTCGA
GGGCATGGGTGCAGATATCGCGCACGAGCTCAGCGAGCAGGTCATCTTTGCTTTTGAAGAGGCCGTAGAACGTGGCCCGACCCACATGGGCGCGAGCGATGATGTC
GCCGACGGTGATCTTGCCGTAGTCCTCTTCGCGCAGCAGCTCGGAGAACGCCGCGACGATCGCGGCGCGGCTTTTGGCCTTGCGGGCATCCATGGCTATGCGTCCG
CGTCAACGAGCAGACAGCGGAGCGTCCCGGAGCAGCCCTCGTAGGGGCGCTTGCCGGCGCCGTAGCCGACGGCTTCGATGCGGTAGCGTGAGGGCAGTTGGTCGGA
CGTGCGCAGAGCAGTGACGATGGCGGCGCCCGTGGGCGTCACGAGCTCGCCGGCGACCGGTGCAGGCGTGAGGGCGATATTGCCCGCCTGGCACAGGTTGACGACA
GCGGGGACGGGAATGGGCATGAGGCCGTGGGCGCAGCGAATGGCGCCGTGGCCCTCGAAAAGCGAC
```
*  This search compares [k-mers](https://en.wikipedia.org/wiki/K-mer) of length 31, from your search sequence to every genome in the catalogue. Look at the `% Kmers found` column in the results, and the BLAST score *p* values. **Do you think the top hit is a certain match?**
*  Click the Genome Accession of the top hit. Browse the available information for that Genome. What do you think the role of this species is in the human gut?
### Search using a genome
For the last couple of tasks, you will need your binned MAGs generated on Day 3 of the course.
If you didn't finish that practical, then you can copy some we made from the `penelopeprime` shared drive.
1.  Put your binned MAG fasta files in the folder `/home/training/mags`.
* If you don't have them, run this command in a Terminal: `cp -r /media/penelopeprime/Metagenomics-Nov21/Day4/day4-example-mag-bins/* ~/mags`
2.  Go back to [the MGnify Genomes webpage](https://www.ebi.ac.uk/metagenomics/browse#genomes) and open the latest version of the Human Gut catalogue.
3.  Pick one of your binned MAGs, and use its FASTA file with the "Search by MAG" tool on the website to see whether your MAG is similar to any of those in the catalogue.
* The query might take a couple of minutes to be queued and run.
* Once it finishes, look at the results table.
* This search uses [sourmash](https://sourmash.readthedocs.io/en/latest/) to find how much of your query metagenome is contained by target genomes in the MAG catalogue.
* A result where the best match shows "60% query covered" means 60% of the query MAG's partitions were found in the best matching catalogue MAG.
* Download the CSV file of all the matches (there is an icon in the results table).
* The [Sourmash documentation](https://sourmash.readthedocs.io/en/latest/classifying-signatures.html#appendix-a-how-sourmash-gather-works) explains the columns in this table.
4.  Calculate the total ammount (i.e. the `sum`) of your query MAG that is covered by MAGs from the catalogue, by fixing the second half of code snippet (adding a calculation).
```
##### FIX ME #####
downloaded_csv_file = '/home/training/downloads/ .csv'
##################
sourmash_results = pd.read_csv(downloaded_csv_file)
display(sourmash_results) # this shows the CSV table, loaded into a Pandas dataframe, in a pretty format. `display` is a special Jupyter function, that won't work in a regular python script.
query_contained_by_best_match = sourmash_results.f_unique_to_query.max()
print(f'The best matching MAG contained {query_contained_by_best_match * 100}% of the query’s k-mers.')
##### FIX ME #####
query_contained_by_all_matches =
print(f'All matching MAGs together contained {query_contained_by_all_matches * 100}% of the query’s k-mers.')
##################
```
 Do you think this containment fraction means your MAG is novel, or is it well-represented by genomes in the MGnify catalogue? How complete and contaminated do you think your MAGs are? How would a low completeness (say 50%) affect the threshold you’d be looking for to consider your MAG represented by the catalogue?
### Solution
Unhide these cells to see a solution.
```
import os
downloaded_csv_file = max(Path('/home/training/Downloads').glob('*.csv'), key=os.path.getctime)
sourmash_results = pd.read_csv(downloaded_csv_file)
display(sourmash_results) # this shows the CSV table, loaded into a Pandas dataframe, in a pretty format. `display` is a special Jupyter function, that won't work in a regular python script.
query_contained_by_best_match = sourmash_results.f_unique_to_query.max()
print(f'The best matching MAG contained {query_contained_by_best_match * 100}% of the query’s k-mers.')
query_contained_by_all_matches = sourmash_results.f_unique_to_query.sum()
print(f'All matching MAGs together contained {query_contained_by_all_matches * 100}% of the query’s k-mers.')
```
## Task 4 - Find out whether your MAGs are novel, using the API
In this final task, we will combine the API skills you’ve gained with your knowledge of the MAG search mechanism.
Imagine you created more than a couple of MAGs, following the process of Day 3 but using a big dataset and a high performance computing cluster. Now, you want to see if any of them are novel or are they well covered by a catalogue on the MGnify resource. It will be a pain to do all that by hand! You can upload a directory of a few MAGs on the website, but for 100s or 1000s, you need to use the API.
Follow along and fill in the missing pieces of code to do this.
We need to compute a "sketch" for each Genome, using Sourmash. On the website this happens in your browser. To use the API, we do it using the [sourmash](https://sourmash.readthedocs.io/en/latest/) package. We will also use [Biopython’s SeqIO](https://biopython.org/wiki/SeqRecord) package to read the FASTA files in Python code.
**Most of the code here is completed for you, because it would take some time to learn how to put it all together. You can follow the code comments, or just press `shift + enter` in each cell to run it and come back to study it later.**
### Load up our MAGs
```
# If you didn't have these packages installed, you'd need to run "pip install pandas biopython sourmash"
import sourmash
from Bio import SeqIO
```
We’ll find the filepath for all of our "new" MAGs.
 Edit the value of `my_mags_folder` if you put your MAGs somewhere different.
```
my_mags_folder = Path('/home/training/mags')
# pathlib is a handy standard Python library for finding files and directories
my_mags_files = list(my_mags_folder.glob('*.fa*'))
my_mags_files
```
### Calculate sourmash "sketches" to search against the MGnify catalogue
We’ll compute a sourmash sketch for each MAG. A sketch goes into a signature, that we will use for searching. The signature is a sort of collection of hashes that are well suited for calculating the *containment* of your MAGs within the catalogue's MAGs.
```
for mag_file in my_mags_files:
# the sourmash parameters are chosen to match those used within MGnify
sketch = sourmash.MinHash(n=0, ksize=31, scaled=1000)
# a fasta file may have multiple records in it. add them all to the sourmash signature.
for index, record in enumerate(SeqIO.parse(mag_file, 'fasta')):
sketch.add_sequence(str(record.seq))
# save the sourmash sketch as a "signature" file
sig = sourmash.SourmashSignature(sketch, name=record.name or mag_file.stem)
with open(mag_file.stem + '.sig', 'wt') as fp:
sourmash.save_signatures([sig], fp)
# check what signature files we've created.
# using ! in Jupyter lets you run a shell command. It is handy for quick things like pwd and ls.
!ls *.sig
```
### Submit a search job to the MGnify API
We’ll call the MGnify API with all of our sketches.
There is an endpoint for this (the same one used by the website).
In this case, we need to **send** data to the API (not just fetch it). This is called "POST"ing data in the API world.
This part of the API is quite specialized and so is not a formal JSON:API, so we use the more flexible [requests](https://docs.python-requests.org/en/master/) Python package to communicate with it.
```
import requests
endpoint = 'https://www.ebi.ac.uk/metagenomics/api/v1/genomes-search/gather'
catalogue_id = 'human-gut-v1-0' # You could change this to any other catalogue ID from the MGnify website, if you use this in the future.
# Create a list of file uploads, and attach them to the API request
signatures = [open(mag.stem + '.sig', 'rb') for mag in my_mags_files]
sketch_uploads = [('file_uploaded', signature) for signature in signatures]
# Send the API request - it specifies which catalogue to search against and attaches all of the signature files.
submitted_job = requests.post(endpoint, data={'mag_catalog': catalogue_id}, files=sketch_uploads).json()
map(lambda fp: fp.close(), signatures) # tidy up open file pointers
print(submitted_job)
```
### Wait for our results to be ready
As you can see in the printed `submitted_job` above, a `status_URL` was returned in the response from submitting the job via the API.
Since the job will be in a queue, we must poll this `status_URL` to wait for our job to be completed.
We’ll check every 2 seconds until ALL of the jobs are finished.
```
job_done = False
while not job_done:
print('Checking status...')
status = requests.get(submitted_job['data']['status_URL'])
# the status_URL is just another API endpoint that's unique for our search job
queries_done = {sig['job_id']: sig['status'] for sig in status.json()['data']['signatures']}
job_done = all(map(lambda q: q == 'SUCCESS', queries_done.values()))
if not job_done:
print('Still waiting for jobs to complete. Current status of jobs')
print(queries_done)
print('Will check again in 2 seconds')
time.sleep(2)
print('All finished!')
```
### Download all of the search results
Now, we need to fetch the results. We can grab these all at once, as a compressed archive (a `.tgz` file), via the top level `results_url` from the `status` endpoint's response.
```
results_endpoint = status.json()['data']['results_url']
print(f'Will fetch results from {results_endpoint}')
results_response = requests.get(results_endpoint, stream=True)
assert results_response.status_code == 200
with open('mag_novelty_results.tgz', 'wb') as tarball:
tarball.write(results_response.raw.read())
!ls *.tgz
```
### Make a table with our search results
The tarball we just downloaded contains `.csv` files – one for each query, so one for each of your MAGs.
We can load them all up and put them into a single Pandas dataframe:
```
# we'll make an array of all the tables and concatenate them using pandas
results_tables = []
# We need to translate the Job IDs (assigned by the MGnify API) back to the name of the each MAG.
# This just creates that map, so in the combined table we know what result applies to what MAG.
job_to_mag_filename = {sig['job_id']: sig['filename'].rstrip('.sig') for sig in status.json()['data']['signatures']}
# Python has built-in support for tarfiles, so we can pull the CSVs from it straight into Pandas.
with tarfile.open('mag_novelty_results.tgz', 'r:gz') as tarball:
for results_csv in tarball.getmembers():
results_table = pd.read_csv(tarball.extractfile(results_csv))
# add a column to the table with the MAG filename on every row
job_id = results_csv.name.rstrip('.csv')
results_table['query_mag'] = job_to_mag_filename[job_id]
results_tables.append(results_table)
# Stick all the tables together (same columns, so we're stacking the rows here)
mag_novelty_results = pd.concat(results_tables, ignore_index=True)
mag_novelty_results
```
### Compute statistics on the search results
We can find the number of matches for each MAG by grouping and counting the table rows.
We will use Pandas [groupby](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html) for this. GroupBy lets you calculate an "aggregate" statistic on each group of rows, where the groups are usually defined by having the same value of some column. In our case, we're grouping by the `query_mag` column.
```
mag_novelty_results.groupby('query_mag').count()
```
 **Calculate the apparent novelty of each of your MAGs**.
Use a `groupby`, and remember you’re trying to find out how much of each MAG is contained by ALL of the matches from the catalogue.
That is the `f_unique_to_query` column.
```
mag_novelty_results.groupby(
```
#### Solution
Unhide these cells to see a solution.
```
mag_novelty_results.groupby('query_mag').sum().sort_values('f_unique_to_query')
# We've added the .sort_values() for bonus points! This just orders the table by that column.
```
### Examine properties of matched MAGs, using data from the MGnify FTP
Finally, let’s look at the matched catalogue genomes for one of our MAGs.
Since we're looking at *containment* of your MAGs within a catalogue, the sourmash search looks at **all** genomes in the MGnify catalogue, not just the cluster/species representatives that are browsable on the website and accessible by the API.
The [EBI FTP site for MGnify](http://ftp.ebi.ac.uk/pub/databases/metagenomics/mgnify_genomes/) lets you access the full catalogue dataset.
There is a file for each catalogue (`genomes-all_metadata.tsv`) with some basic information about all of the genomes. This file also contains the mapping of each genome to its Species Representative (as shown on the website and API).
We’ve downloaded it to the shared drive (`penelopeprime`) to save you a few minutes waiting for it.
For this task we will:
- find which of your MAGs has the most matches from the sourmash search
- extract the ID of those matches, from the search results
- find the corresponding rows in the big metadata table we fetched from the FTP
- plot statistics about the matched MGnify genomes
 **Explore, and complete, the code in the following cells to do this**
```
all_genomes_metadata = pd.read_csv('/media/penelopeprime/Metagenomics-Nov21/Day4/genomes-all_metadata.tsv', sep='\t', index_col='Genome')
# the (big) file was downloaded from http://ftp.ebi.ac.uk/pub/databases/metagenomics/mgnify_genomes/human-gut/v1.0/genomes-all_metadata.tsv
all_genomes_metadata
# Find the mag with most matches (use a .groupby() and an aggregate statistic that counts the rows of each group)
# .f_unique_to_query.idxmax() finds the INDEX (label) corresponding to the maximum vaule of the f_unique_to_query column.
# Note that any column would do since we're just counting!
# We want mag_with_most_matches to be something like "bin.2".
########################################### COMPLETE ME ###########################################
mag_with_most_matches = mag_novelty_results. .f_unique_to_query.idxmax()
###################################################################################################
print(f'{mag_with_most_matches} has the most matches')
# Pull out the matched genome name from the filepath that's returned in the results
mag_novelty_results['match_genome_name'] = mag_novelty_results.apply(lambda result: result['name'].split('/')[-1].rstrip('.fa'), axis=1)
# Select the search results for the MAG we're interested in – the one with the most matches
matches_of_interest = mag_novelty_results[mag_novelty_results.query_mag==mag_with_most_matches]
# Use the newly created "match_genome_name" as the table index
# we can do this because it is now unique (the same MGnify genome can't match twice for the same query)
matches_of_interest.set_index('match_genome_name', inplace=True)
matches_of_interest
# Pandas has a powerful "join" feature. Since we now have two tables of data indexed by the MGnify genome IDs, we can join their columns together
matches_of_interest = matches_of_interest.join(all_genomes_metadata)
matches_of_interest
# Let’s see the completeness of the MGnify genomes that seem to contain our most-matched MAG
plt.hist(matches_of_interest.Completeness)
plt.xlabel('Completeness \ %')
plt.ylabel('Number of genomes')
plt.title(f'Completeness histogram for MGnify Genomes matching {mag_with_most_matches}');
# Make a plot of the contamination fraction of each of the genomes that match our MAG.
# Note that you can call `matches_of_interest.columns` to see a list of all the columns in the table.
########################################### COMPLETE ME ###########################################
plt.
plt.xlabel('Contamination \ %')
plt.ylabel
plt.title
###################################################################################################
# Make a chart showing the which continents had how many samples matching your MAG
########################################### COMPLETE ME ###########################################
###################################################################################################
```
#### Solution
Unhide these cells to see a solution
```
import matplotlib.pyplot as plt
all_genomes_metadata = pd.read_csv('/media/penelopeprime/Metagenomics-Nov21/Day4/genomes-all_metadata.tsv', sep='\t', index_col='Genome')
# the (big) file was downloaded from http://ftp.ebi.ac.uk/pub/databases/metagenomics/mgnify_genomes/human-gut/v1.0/genomes-all_metadata.tsv
mag_with_most_matches = mag_novelty_results.groupby('query_mag').count().f_unique_to_query.idxmax()
print(f'{mag_with_most_matches} has the most matches')
# Pull out the matched genome name from the filepath that's returned in the results
mag_novelty_results['match_genome_name'] = mag_novelty_results.apply(lambda result: result['name'].split('/')[-1].rstrip('.fa'), axis=1)
# Select the search results for the MAG we're interested in – the one with the most matches
matches_of_interest = mag_novelty_results[mag_novelty_results.query_mag==mag_with_most_matches]
# Use the newly created "match_genome_name" as the table index
# we can do this because it is now unique (the same MGnify genome can't match twice for the same query)
matches_of_interest.set_index('match_genome_name', inplace=True)
# Pandas has a powerful "join" feature. Since we now have two tables of data indexed by the MGnify genome IDs, we can join their columns together
matches_of_interest = matches_of_interest.join(all_genomes_metadata)
# Let’s see the completeness of the MGnify genomes that seem to contain our most-matched MAG
plt.figure(0)
plt.hist(matches_of_interest.Completeness)
plt.xlabel('Completeness \ %')
plt.ylabel('Number of genomes')
plt.title(f'Completeness histogram for MGnify Genomes matching {mag_with_most_matches}');
plt.figure(1)
plt.hist(matches_of_interest.Contamination)
plt.xlabel('Contamination \ %')
plt.ylabel('Number of genomes')
plt.title(f'Contamination histogram for MGnify Genomes matching {mag_with_most_matches}');
plt.figure(2)
matches_of_interest.Continent.hist()
plt.xlabel('Continent where sample was collected')
plt.ylabel('Number of samples')
plt.title(f'Geographical spread of samples for MGnify Genomes matching {mag_with_most_matches}');
```
| github_jupyter |
# Time Series Prediction
**Objectives**
1. Build a linear, DNN and CNN model in keras to predict stock market behavior.
2. Build a simple RNN model and a multi-layer RNN model in keras.
3. Combine RNN and CNN architecture to create a keras model to predict stock market behavior.
In this lab we will build a custom Keras model to predict stock market behavior using the stock market dataset we created in the previous labs. We'll start with a linear, DNN and CNN model
Since the features of our model are sequential in nature, we'll next look at how to build various RNN models in keras. We'll start with a simple RNN model and then see how to create a multi-layer RNN in keras. We'll also see how to combine features of 1-dimensional CNNs with a typical RNN architecture.
We will be exploring a lot of different model types in this notebook. To keep track of your results, record the accuracy on the validation set in the table here. In machine learning there are rarely any "one-size-fits-all" so feel free to test out different hyperparameters (e.g. train steps, regularization, learning rates, optimizers, batch size) for each of the models. Keep track of your model performance in the chart below.
| Model | Validation Accuracy |
|----------|:---------------:|
| Baseline | 0.295 |
| Linear | -- |
| DNN | -- |
| 1-d CNN | -- |
| simple RNN | -- |
| multi-layer RNN | -- |
| RNN using CNN features | -- |
| CNN using RNN features | -- |
## Load necessary libraries and set up environment variables
```
import os
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from google.cloud import bigquery
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (Dense, DenseFeatures,
Conv1D, MaxPool1D,
Reshape, RNN,
LSTM, GRU, Bidirectional)
from tensorflow.keras.callbacks import TensorBoard, ModelCheckpoint
from tensorflow.keras.optimizers import Adam
# To plot pretty figures
%matplotlib inline
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# For reproducible results.
from numpy.random import seed
seed(1)
tf.random.set_seed(2)
PROJECT = "your-gcp-project-here" # REPLACE WITH YOUR PROJECT NAME
BUCKET = "your-gcp-bucket-here" # REPLACE WITH YOUR BUCKET
REGION = "us-central1" # REPLACE WITH YOUR BUCKET REGION e.g. us-central1
%env
PROJECT = PROJECT
BUCKET = BUCKET
REGION = REGION
```
## Explore time series data
We'll start by pulling a small sample of the time series data from Big Query and write some helper functions to clean up the data for modeling. We'll use the data from the `percent_change_sp500` table in BigQuery. The `close_values_prior_260` column contains the close values for any given stock for the previous 260 days.
```
%%time
bq = bigquery.Client(project=PROJECT)
bq_query = '''
#standardSQL
SELECT
symbol,
Date,
direction,
close_values_prior_260
FROM
`stock_market.eps_percent_change_sp500`
LIMIT
100
'''
df_stock_raw = bq.query(bq_query).to_dataframe()
df_stock_raw.head()
```
The function `clean_data` below does three things:
1. First, we'll remove any inf or NA values
2. Next, we parse the `Date` field to read it as a string.
3. Lastly, we convert the label `direction` into a numeric quantity, mapping 'DOWN' to 0, 'STAY' to 1 and 'UP' to 2.
```
def clean_data(input_df):
"""Cleans data to prepare for training.
Args:
input_df: Pandas dataframe.
Returns:
Pandas dataframe.
"""
df = input_df.copy()
# TF doesn't accept datetimes in DataFrame.
df['Date'] = pd.to_datetime(df['Date'], errors='coerce')
df['Date'] = df['Date'].dt.strftime('%Y-%m-%d')
# TF requires numeric label.
df['direction_numeric'] = df['direction'].apply(lambda x: {'DOWN': 0,
'STAY': 1,
'UP': 2}[x])
return df
df_stock = clean_data(df_stock_raw)
df_stock.head()
```
## Read data and preprocessing
Before we begin modeling, we'll preprocess our features by scaling to the z-score. This will ensure that the range of the feature values being fed to the model are comparable and should help with convergence during gradient descent.
```
STOCK_HISTORY_COLUMN = 'close_values_prior_260'
COL_NAMES = ['day_' + str(day) for day in range(0, 260)]
LABEL = 'direction_numeric'
def _scale_features(df):
"""z-scale feature columns of Pandas dataframe.
Args:
features: Pandas dataframe.
Returns:
Pandas dataframe with each column standardized according to the
values in that column.
"""
avg = df.mean()
std = df.std()
return (df - avg) / std
def create_features(df, label_name):
"""Create modeling features and label from Pandas dataframe.
Args:
df: Pandas dataframe.
label_name: str, the column name of the label.
Returns:
Pandas dataframe
"""
# Expand 1 column containing a list of close prices to 260 columns.
time_series_features = df[STOCK_HISTORY_COLUMN].apply(pd.Series)
# Rename columns.
time_series_features.columns = COL_NAMES
time_series_features = _scale_features(time_series_features)
# Concat time series features with static features and label.
label_column = df[LABEL]
return pd.concat([time_series_features,
label_column], axis=1)
df_features = create_features(df_stock, LABEL)
df_features.head()
```
Let's plot a few examples and see that the preprocessing steps were implemented correctly.
```
ix_to_plot = [0, 1, 9, 5]
fig, ax = plt.subplots(1, 1, figsize=(15, 8))
for ix in ix_to_plot:
label = df_features['direction_numeric'].iloc[ix]
example = df_features[COL_NAMES].iloc[ix]
ax = example.plot(label=label, ax=ax)
ax.set_ylabel('scaled price')
ax.set_xlabel('prior days')
ax.legend()
```
### Make train-eval-test split
Next, we'll make repeatable splits for our train/validation/test datasets and save these datasets to local csv files. The query below will take a subsample of the entire dataset and then create a 70-15-15 split for the train/validation/test sets.
```
def _create_split(phase):
"""Create string to produce train/valid/test splits for a SQL query.
Args:
phase: str, either TRAIN, VALID, or TEST.
Returns:
String.
"""
floor, ceiling = '2002-11-01', '2010-07-01'
if phase == 'VALID':
floor, ceiling = '2010-07-01', '2011-09-01'
elif phase == 'TEST':
floor, ceiling = '2011-09-01', '2012-11-30'
return '''
WHERE Date >= '{0}'
AND Date < '{1}'
'''.format(floor, ceiling)
def create_query(phase):
"""Create SQL query to create train/valid/test splits on subsample.
Args:
phase: str, either TRAIN, VALID, or TEST.
sample_size: str, amount of data to take for subsample.
Returns:
String.
"""
basequery = """
#standardSQL
SELECT
symbol,
Date,
direction,
close_values_prior_260
FROM
`stock_market.eps_percent_change_sp500`
"""
return basequery + _create_split(phase)
bq = bigquery.Client(project=PROJECT)
for phase in ['TRAIN', 'VALID', 'TEST']:
# 1. Create query string
query_string = create_query(phase)
# 2. Load results into DataFrame
df = bq.query(query_string).to_dataframe()
# 3. Clean, preprocess dataframe
df = clean_data(df)
df = create_features(df, label_name='direction_numeric')
# 3. Write DataFrame to CSV
if not os.path.exists('../data'):
os.mkdir('../data')
df.to_csv('../data/stock-{}.csv'.format(phase.lower()),
index_label=False, index=False)
print("Wrote {} lines to {}".format(
len(df),
'../data/stock-{}.csv'.format(phase.lower())))
ls -la ../data
```
## Modeling
For experimentation purposes, we'll train various models using data we can fit in memory using the `.csv` files we created above.
```
N_TIME_STEPS = 260
N_LABELS = 3
Xtrain = pd.read_csv('../data/stock-train.csv')
Xvalid = pd.read_csv('../data/stock-valid.csv')
ytrain = Xtrain.pop(LABEL)
yvalid = Xvalid.pop(LABEL)
ytrain_categorical = to_categorical(ytrain.values)
yvalid_categorical = to_categorical(yvalid.values)
```
To monitor training progress and compare evaluation metrics for different models, we'll use the function below to plot metrics captured from the training job such as training and validation loss or accuracy.
```
def plot_curves(train_data, val_data, label='Accuracy'):
"""Plot training and validation metrics on single axis.
Args:
train_data: list, metrics obtrained from training data.
val_data: list, metrics obtained from validation data.
label: str, title and label for plot.
Returns:
Matplotlib plot.
"""
plt.plot(np.arange(len(train_data)) + 0.5,
train_data,
"b.-", label="Training " + label)
plt.plot(np.arange(len(val_data)) + 1,
val_data, "r.-",
label="Validation " + label)
plt.gca().xaxis.set_major_locator(mpl.ticker.MaxNLocator(integer=True))
plt.legend(fontsize=14)
plt.xlabel("Epochs")
plt.ylabel(label)
plt.grid(True)
```
### Baseline
Before we begin modeling in keras, let's create a benchmark using a simple heuristic. Let's see what kind of accuracy we would get on the validation set if we predict the majority class of the training set.
```
sum(yvalid == ytrain.value_counts().idxmax()) / yvalid.shape[0]
```
Ok. So just naively guessing the most common outcome `UP` will give about 29.5% accuracy on the validation set.
### Linear model
We'll start with a simple linear model, mapping our sequential input to a single fully dense layer.
**Lab Task #1a:** In the cell below, create a linear model using the [keras sequential API](https://www.tensorflow.org/api_docs/python/tf/keras/Sequential) which maps the sequential input to a single dense fully connected layer.
```
# TODO 1a
model = Sequential()
model.add( # TODO: Your code goes here.
model.compile( # TODO: Your code goes here.
history = model.fit( # TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
```
The accuracy seems to level out pretty quickly. To report the accuracy, we'll average the accuracy on the validation set across the last few epochs of training.
```
np.mean(history.history['val_accuracy'][-5:])
```
### Deep Neural Network
The linear model is an improvement on our naive benchmark. Perhaps we can do better with a more complicated model. Next, we'll create a deep neural network with keras. We'll experiment with a two layer DNN here but feel free to try a more complex model or add any other additional techniques to try an improve your performance.
**Lab Task #1b:** In the cell below, create a deep neural network in keras to model `direction_numeric`. Experiment with different activation functions or add regularization to see how much you can improve performance.
```
#TODO 1b
model = Sequential()
# TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
np.mean(history.history['val_accuracy'][-5:])
```
### Convolutional Neural Network
The DNN does slightly better. Let's see how a convolutional neural network performs.
A 1-dimensional convolutional can be useful for extracting features from sequential data or deriving features from shorter, fixed-length segments of the data set. Check out the documentation for how to implement a [Conv1d in Tensorflow](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv1D). Max pooling is a downsampling strategy commonly used in conjunction with convolutional neural networks. Next, we'll build a CNN model in keras using the `Conv1D` to create convolution layers and `MaxPool1D` to perform max pooling before passing to a fully connected dense layer.
**Lab Task #1b:** Create 1D Convolutional network in keras. You can experiment with different numbers of convolutional layers, filter sizes, kernals sizes and strides, pooling layers etc. After passing through the convolutional layers, flatten the result and pass through a deep neural network to complete the model.
```
#TODO 1c
model = Sequential()
# Convolutional layer(s)
# TODO: Your code goes here.
# Flatten the result and pass through DNN.
# TODO: Your code goes here.
# Compile your model and train
# TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
np.mean(history.history['val_accuracy'][-5:])
```
### Recurrent Neural Network
RNNs are particularly well-suited for learning sequential data. They retain state information from one iteration to the next by feeding the output from one cell as input for the next step. In the cell below, we'll build a RNN model in keras. The final state of the RNN is captured and then passed through a fully connected layer to produce a prediction.
**Lab Task #2a:** Create an RNN model in keras. You can try different types of RNN cells like [LSTMs](https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM),
[GRUs](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GRU) or basic [RNN cell](https://www.tensorflow.org/api_docs/python/tf/keras/layers/SimpleRNN). Experiment with different cell sizes, activation functions, regularization, etc.
```
#TODO 2a
model = Sequential()
# Reshape inputs to pass through RNN layer.
# TODO: Your code goes here.
# Compile your model and train
# TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
np.mean(history.history['val_accuracy'][-5:])
```
### Multi-layer RNN
Next, we'll build multi-layer RNN. Just as multiple layers of a deep neural network allow for more complicated features to be learned during training, additional RNN layers can potentially learn complex features in sequential data. For a multi-layer RNN the output of the first RNN layer is fed as the input into the next RNN layer.
**Lab Task #2b:** Now that you've seen how to build a sinlge layer RNN, create an deep, multi-layer RNN model. Look into how you should set the `return_sequences` variable when instantiating the layers of your RNN.
```
#TODO 2b
model = Sequential()
# Reshape inputs to pass through RNN layers.
# TODO: Your code goes here.
# Compile your model and train
# TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
np.mean(history.history['val_accuracy'][-5:])
```
### Combining CNN and RNN architecture
Finally, we'll look at some model architectures which combine aspects of both convolutional and recurrant networks. For example, we can use a 1-dimensional convolution layer to process our sequences and create features which are then passed to a RNN model before prediction.
**Lab Task #3a:** Create a model that first passes through a 1D-Convolution then passes those sequential features through an sequential recurrent layer. You can experiment with different hyperparameters of the CNN and the RNN to see how much you can improve performance of your model.
```
#TODO 3a
model = Sequential()
# Reshape inputs for convolutional layer
# TODO: Your code goes here.
# Pass the convolutional features through RNN layer
# TODO: Your code goes here.
# Compile your model and train
# TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
np.mean(history.history['val_accuracy'][-5:])
```
We can also try building a hybrid model which uses a 1-dimensional CNN to create features from the outputs of an RNN.
**Lab Task #3b:** Lastly, create a model that passes through the recurrant layer of an RNN first before applying a 1D-Convolution. As before, the result of the CNN is then flattened and passed through the fully connected layer(s).
```
#TODO 3b
model = Sequential()
# Reshape inputs and pass through RNN layer.
# TODO: Your code goes here.
# Apply 1d convolution to RNN outputs.
# TODO: Your code goes here.
# Flatten the convolution output and pass through DNN.
# TODO: Your code goes here.
# Compile your model and train
# TODO: Your code goes here.
plot_curves(history.history['loss'],
history.history['val_loss'],
label='Loss')
plot_curves(history.history['accuracy'],
history.history['val_accuracy'],
label='Accuracy')
np.mean(history.history['val_accuracy'][-5:])
```
## Extra Credit
1. The `eps_percent_change_sp500` table also has static features for each example. Namely, the engineered features we created in the previous labs with aggregated information capturing the `MAX`, `MIN`, `AVG` and `STD` across the last 5 days, 20 days and 260 days (e.g. `close_MIN_prior_5_days`, `close_MIN_prior_20_days`, `close_MIN_prior_260_days`, etc.). Try building a model which incorporates these features in addition to the sequence features we used above. Does this improve performance?
2. The `eps_percent_change_sp500` table also contains a `surprise` feature which captures information about the earnings per share. Try building a model which uses the `surprise` feature in addition to the sequence features we used above. Does this improve performance?
Copyright 2019 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License
| github_jupyter |
# Introduction
Impressive... you've finished the first part of this workshop!\
It's time to apply what you've learned previously.\
You'll learn new things too, don't worry.
In this part of the workshop, you will learn how to analyze a dataset of raw data in order to draw conclusions.\
You will have access to a dataset that contains information from over 15,000 video games.
In this workshop:
- Reading a dataset
- Data analysis
- Data cleaning
- Data visualizations
For this we will use the pandas library : [pandas](https://pandas.pydata.org/)\
we will also use seaborn to visualize our analysis : [seaborn](https://seaborn.pydata.org/)
```
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
```
## I) Reading dataset
The routine ... create a dataframe with the pandas function that reads a csv.\
Then use the head method on the dataframe to display the first rows of the dataset.
**Exercice :**\
create a dataframe with the pandas function that reads a csv.\
use the head method on the dataframe to display the first rows of the dataset.
```
#read the file video_games.csv and display head of dataframe
```
**Expected output:**\
<img src="./image/head.png"/>
The [info](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.info.html) method will allow you to retrieve the information related to the dataframe.\
It allows you to better understand the data, which will allow you to act accordingly.
```
#display informations about the dataframe
```
**Expected output:**\
<class 'pandas.core.frame.DataFrame'>\
RangeIndex: 16719 entries, 0 to 16718\
Data columns (total 16 columns):\
\# Column Non-Null Count Dtype \
\--- ------ -------------- -----
0 Name 16717 non-null object \
1 Platform 16719 non-null object \
2 Year_of_Release 16450 non-null float64\
3 Genre 16717 non-null object\
4 Publisher 16665 non-null object\
5 NA_Sales 16719 non-null float64\
6 EU_Sales 16719 non-null float64\
7 JP_Sales 16719 non-null float64\
8 Other_Sales 16719 non-null float64\
9 Global_Sales 16719 non-null float64\
10 Critic_Score 8137 non-null float64\
11 Critic_Count 8137 non-null float64\
12 User_Score 10015 non-null object\
13 User_Count 7590 non-null float64\
14 Developer 10096 non-null object\
15 Rating 9950 non-null object \
dtypes: float64(9), object(7)\
memory usage: 2.0+ MB
You will notice that the info() method informs you that your object is a dataframe.\
We also get the names of the columns and the number of values defined for each of them.
You will notice that there are several functions that allow you to get information about a dataframe.\
In Data Science, it is a reflex to take, when you work with datasets we start by seeing how the data is composed.
To continue in this direction there is an attribute that contains the names of all the columns.
**Exercice :**\
Find and display the attribute that contains the names of the different columns.
```
#display the name of columns
```
**Expected output:** Index(\['Name', 'Platform', 'Year_of_Release', 'Genre', 'Publisher', 'NA_Sales',
'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales', 'Critic_Score',
'Critic_Count', 'User_Score', 'User_Count', 'Developer', 'Rating'],
dtype='object')
## II) Data Analysis
You have observed that the dataset contains several columns of data.
However, a fairly common problem in Data Science is undefined data (NaN values).\
It is important to know how much undefined data a dataset contains.
**Exercice :**\
Display the percentage of missing data for each column.
```
# display the percentage of data missing
```
**Expected output:**\
Name 0.011962\
Platform 0.000000\
Year_of_Release 1.608948\
Genre 0.011962\
Publisher 0.322986\
NA_Sales 0.000000\
EU_Sales 0.000000\
JP_Sales 0.000000\
Other_Sales 0.000000\
Global_Sales 0.000000\
Critic_Score 51.330821\
Critic_Count 51.330821\
User_Score 40.098092\
User_Count 54.602548\
Developer 39.613613\
Rating 40.486871\
dtype: float64
You have obtained the percentages of missing values for each column.\
It may be interesting to see our analyses in different forms
**Exercice :**\
Display the number of missing values for each column.
```
# display the count of data missing
```
**Expected output:**\
Name 2\
Platform 0\
Year_of_Release 269\
Genre 2\
Publisher 54\
NA_Sales 0\
EU_Sales 0\
JP_Sales 0\
Other_Sales 0\
Global_Sales 0\
Critic_Score 8582\
Critic_Count 8582\
User_Score 6704\
User_Count 9129\
Developer 6623\
Rating 6769\
dtype: int64
We observe that some columns contain a lot of undefined data.\
These columns are : ```Critic_Score```, ```Critic_Count```, ```User_Score```, ```User_Count```, ```Developer```, ```Rating```.
We will deal with this problem later.
When analyzing data, one of the first things to do is to look at the correlations between the different columns.\
To do this, we use a heatmap that displays all the correlations of a dataframe.
Obviously when we talk about correlations, we are talking about columns that have numerical values.
**Exercice :**\
Select the numerical values of the dataframe.
```
#select numerical values
```
**Expected output:** Index(\['Year_of_Release', 'NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales',
'Global_Sales', 'Critic_Score', 'Critic_Count', 'User_Count'],
dtype='object')
Now that we have selected the numerical data from the dataframe,\
we would like to use a heatmap to display the different correlations.
For this, we will use [Seaborn](https://seaborn.pydata.org/), a library based on Matplotlib and which allows to visualize all kinds of analysis.
**Exercice :**\
Display a heatmap of correlation of the numerical values of the dataframe.
```
#display heatmap thanks to seaborn
```
**Expected output:**\
<img src="./image/heatmap.png"/>
## III) Data Cleaning
You will remember that during our analysis we noticed that some columns were infested with undefined values.\
When a column contains too much undefined data, it is not usable.
**Exerice :**\
Remove the columns from the dataset: ```Critic_Score```, ```Critic_Count```, ```User_Score```, ```User_Count```, ```Developer```, ```Rating```.
```
df = pd.read_csv('video_games.csv')
print('Before ', df.shape)
#Remove columns: Critic_Score, Critic_Count, User_Score, User_Count, Developer, Rating.
print('After ', df.shape)
```
**Expected Result:**\
Before (16719, 16)\
After (16719, 10)
When we have a column that contains few undefined values and to be able to work with it anyway it is frequent to replace the defined values by the mode.\
The mode is the value that appears most in the column.\
Be careful, this technique must be used sparingly or the results may be strongly biased.
**Exercice :**\
Replace the undefined values in the ```Genre``` column with the mode.
```
# Filling NaN values in Genre with the mode
```
When a column that contains unique values also contains undefined values, we prefer to delete the rows that have undefined values.\
This method is used for proper names, or ids for example.
**Exerice :**\
Delete the rows that have an undefined ```Name``` value.
```
# Removing the 2 missing rows from Name
print('Before ', df.shape)
# code here ->
print('After ', df.shape)
```
**Expected Result:**\
Before (16719, 10)\
After (16717, 10)
**Exercice :**\
Perform the same task for the undefined values in the column : ```Year_of_Release```.
```
# Droping 269 missing rows from Year_of_Release
print('Before ', df.shape)
# code here ->
print('After ', df.shape)
```
**Expected Result:**\
Before (16717, 10)\
After (16448, 10)
**Exercice :**\
Perform the same task for the undefined values in the column : ```Publisher```.
```
# Removing the 54 missing rows from Publisher
print('Before ', df.shape)
# code here ->
print('After ', df.shape)
print('-'*20)
print(df.isna().sum())
```
**Expected output:**\
Before (16448, 10)\
After (16416, 10)\
--------------------\
Name 0\
Platform 0\
Year_of_Release 0\
Genre 0\
Publisher 0\
NA_Sales 0\
EU_Sales 0\
JP_Sales 0\
Other_Sales 0\
Global_Sales 0\
dtype: int64
## IV) Data Visualization
We now have clean data that can be analyzed.\
The previous steps are very important for our analysis to be relevant, that's the job of a data scientist.
Now we will perform an analysis on the global sales of video games.
**Exercice :**\
Get the 10 best-selling games with their ```Global_sales``` and their ```name```.
```
# Top 10 Games by Global Sales
```
**Expected output:**\
<img src="./image/games_per_gs.png"/>
We have a dataframe that contains the 10 best selling games in history.\
It's good but it's not very visual, in general to present data analysis work, a part of data visualization is done in order to render our results in graphical form.
To realize data visualization, there are several interesting libraries and notably Seaborn a library based on the matplotlib library.
**Exercice :**\
Display a graph to see the 10 best selling games in history.
```
# Graph top 10 games by global sales.
```
**Expected output:**\
<img src="./image/graph.png"/>
# Congratz !
During this workshop, we were able to draw conclusions from the data, such as which games were the most sold.\
But all of this required a first understanding of the data, and then a cleaning of the data.\
Who knows what impertinent results we would have had if we had not cleaned the data?
Thank you for attending this workshop.\
Good job, your job is done for now.\
You got way above our expectation, and you're entirely ready to do Data Analysis in any other mission.
| github_jupyter |
# Image features exercise
*Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the [assignments page](http://vision.stanford.edu/teaching/cs231n/assignments.html) on the course website.*
We have seen that we can achieve reasonable performance on an image classification task by training a linear classifier on the pixels of the input image. In this exercise we will show that we can improve our classification performance by training linear classifiers not on raw pixels but on features that are computed from the raw pixels.
All of your work for this exercise will be done in this notebook.
```
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
from __future__ import print_function
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# for auto-reloading extenrnal modules
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
```
## Load data
Similar to previous exercises, we will load CIFAR-10 data from disk.
```
from cs231n.features import color_histogram_hsv, hog_feature
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000):
# Load the raw CIFAR-10 data
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# Subsample the data
mask = list(range(num_training, num_training + num_validation))
X_val = X_train[mask]
y_val = y_train[mask]
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
return X_train, y_train, X_val, y_val, X_test, y_test
X_train, y_train, X_val, y_val, X_test, y_test = get_CIFAR10_data()
```
## Extract Features
For each image we will compute a Histogram of Oriented
Gradients (HOG) as well as a color histogram using the hue channel in HSV
color space. We form our final feature vector for each image by concatenating
the HOG and color histogram feature vectors.
Roughly speaking, HOG should capture the texture of the image while ignoring
color information, and the color histogram represents the color of the input
image while ignoring texture. As a result, we expect that using both together
ought to work better than using either alone. Verifying this assumption would
be a good thing to try for the bonus section.
The `hog_feature` and `color_histogram_hsv` functions both operate on a single
image and return a feature vector for that image. The extract_features
function takes a set of images and a list of feature functions and evaluates
each feature function on each image, storing the results in a matrix where
each column is the concatenation of all feature vectors for a single image.
```
from cs231n.features import *
num_color_bins = 10 # Number of bins in the color histogram
feature_fns = [hog_feature, lambda img: color_histogram_hsv(img, nbin=num_color_bins)]
X_train_feats = extract_features(X_train, feature_fns, verbose=True)
X_val_feats = extract_features(X_val, feature_fns)
X_test_feats = extract_features(X_test, feature_fns)
# Preprocessing: Subtract the mean feature
mean_feat = np.mean(X_train_feats, axis=0, keepdims=True)
X_train_feats -= mean_feat
X_val_feats -= mean_feat
X_test_feats -= mean_feat
# Preprocessing: Divide by standard deviation. This ensures that each feature
# has roughly the same scale.
std_feat = np.std(X_train_feats, axis=0, keepdims=True)
X_train_feats /= std_feat
X_val_feats /= std_feat
X_test_feats /= std_feat
# Preprocessing: Add a bias dimension
X_train_feats = np.hstack([X_train_feats, np.ones((X_train_feats.shape[0], 1))])
X_val_feats = np.hstack([X_val_feats, np.ones((X_val_feats.shape[0], 1))])
X_test_feats = np.hstack([X_test_feats, np.ones((X_test_feats.shape[0], 1))])
```
## Train SVM on features
Using the multiclass SVM code developed earlier in the assignment, train SVMs on top of the features extracted above; this should achieve better results than training SVMs directly on top of raw pixels.
```
# Use the validation set to tune the learning rate and regularization strength
from cs231n.classifiers.linear_classifier import LinearSVM
'''learning_rates = [1e-9, 1e-8, 1e-7]
regularization_strengths = [1e5, 1e6, 1e7]
learning_rates = [1e-9, 2.5e-9, 5e-9]
regularization_strengths = [i*1e7 for i in range(10)]'''
learning_rates = [(1+i*0.1)*1e-9 for i in range(6)]
regularization_strengths = [(1+i*0.1)*4e7 for i in range(6)]
results = {}
best_val = -1
best_svm = None
pass
################################################################################
# TODO: #
# Use the validation set to set the learning rate and regularization strength. #
# This should be identical to the validation that you did for the SVM; save #
# the best trained classifer in best_svm. You might also want to play #
# with different numbers of bins in the color histogram. If you are careful #
# you should be able to get accuracy of near 0.44 on the validation set. #
################################################################################
#pass
for lr in learning_rates:
for reg in regularization_strengths:
svm = LinearSVM()
svm.train(X_train_feats, y_train, lr, reg, num_iters=2000)
y_train_pred = svm.predict(X_train_feats)
train_acc = np.mean(y_train == y_train_pred)
y_val_pred = svm.predict(X_val_feats)
val_acc = np.mean(y_val == y_val_pred)
if val_acc > best_val:
best_val = val_acc
best_svm = svm
results[(lr, reg)] = train_acc, val_acc
################################################################################
# END OF YOUR CODE #
################################################################################
# Print out results.
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
# Evaluate your trained SVM on the test set
y_test_pred = best_svm.predict(X_test_feats)
test_accuracy = np.mean(y_test == y_test_pred)
print(test_accuracy)
# An important way to gain intuition about how an algorithm works is to
# visualize the mistakes that it makes. In this visualization, we show examples
# of images that are misclassified by our current system. The first column
# shows images that our system labeled as "plane" but whose true label is
# something other than "plane".
examples_per_class = 8
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for cls, cls_name in enumerate(classes):
idxs = np.where((y_test != cls) & (y_test_pred == cls))[0]
idxs = np.random.choice(idxs, examples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt.subplot(examples_per_class, len(classes), i * len(classes) + cls + 1)
plt.imshow(X_test[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls_name)
plt.show()
```
### Inline question 1:
Describe the misclassification results that you see. Do they make sense?
## Neural Network on image features
Earlier in this assigment we saw that training a two-layer neural network on raw pixels achieved better classification performance than linear classifiers on raw pixels. In this notebook we have seen that linear classifiers on image features outperform linear classifiers on raw pixels.
For completeness, we should also try training a neural network on image features. This approach should outperform all previous approaches: you should easily be able to achieve over 55% classification accuracy on the test set; our best model achieves about 60% classification accuracy.
```
print(X_train_feats.shape)
from cs231n.classifiers.neural_net import TwoLayerNet
input_dim = X_train_feats.shape[1]
hidden_dim = 500
num_classes = 10
net = TwoLayerNet(input_dim, hidden_dim, num_classes)
best_net = None
################################################################################
# TODO: Train a two-layer neural network on image features. You may want to #
# cross-validate various parameters as in previous sections. Store your best #
# model in the best_net variable. #
################################################################################
results = {}
best_val = -1
'''learning_rates = [1e-2, 5e-2, 1e-1, 5e-1]
regularization_strengths = [1e-3, 1e-2, 1e-1]'''
learning_rates = [(1+i*0.1)*5e-1 for i in range(6)]
regularization_strengths = [(1+i*0.1)*1e-3 for i in range(6)]
for lr in learning_rates:
for reg in regularization_strengths:
stats = net.train(X_train_feats, y_train, X_val_feats, y_val,
learning_rate=lr, learning_rate_decay=0.95,
reg=reg, num_iters=1500, batch_size=200, verbose=False)
y_train_pred = net.predict(X_train_feats)
train_acc = np.mean(y_train == y_train_pred)
y_val_pred = net.predict(X_val_feats)
val_acc = np.mean(y_val == y_val_pred)
if val_acc > best_val:
best_val = val_acc
best_net = net
results[(lr, reg)] = train_acc, val_acc
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
################################################################################
# END OF YOUR CODE #
################################################################################
# Run your neural net classifier on the test set. You should be able to
# get more than 55% accuracy.
test_acc = (net.predict(X_test_feats) == y_test).mean()
print(test_acc)
```
# Bonus: Design your own features!
You have seen that simple image features can improve classification performance. So far we have tried HOG and color histograms, but other types of features may be able to achieve even better classification performance.
For bonus points, design and implement a new type of feature and use it for image classification on CIFAR-10. Explain how your feature works and why you expect it to be useful for image classification. Implement it in this notebook, cross-validate any hyperparameters, and compare its performance to the HOG + Color histogram baseline.
# Bonus: Do something extra!
Use the material and code we have presented in this assignment to do something interesting. Was there another question we should have asked? Did any cool ideas pop into your head as you were working on the assignment? This is your chance to show off!
| github_jupyter |
# Introduction to Feature Columns
**Learning Objectives**
1. Load a CSV file using [Pandas](https://pandas.pydata.org/)
2. Create an input pipeline using tf.data
3. Create multiple types of feature columns
## Introduction
In this notebook, you classify structured data (e.g. tabular data in a CSV file) using [feature columns](https://www.tensorflow.org/guide/feature_columns). Feature columns serve as a bridge to map from columns in a CSV file to features used to train a model. In a subsequent lab, we will use [Keras](https://www.tensorflow.org/guide/keras) to define the model.
Each learning objective will correspond to a __#TODO__ in this student lab notebook -- try to complete this notebook first and then review the [solution notebook](../solutions/feat.cols_tf.data.ipynb).
## The Dataset
We will use a small [dataset](https://archive.ics.uci.edu/ml/datasets/heart+Disease) provided by the Cleveland Clinic Foundation for Heart Disease. There are several hundred rows in the CSV. Each row describes a patient, and each column describes an attribute. We will use this information to predict whether a patient has heart disease, which in this dataset is a binary classification task.
Following is a [description](https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/heart-disease.names) of this dataset. Notice there are both numeric and categorical columns.
>Column| Description| Feature Type | Data Type
>------------|--------------------|----------------------|-----------------
>Age | Age in years | Numerical | integer
>Sex | (1 = male; 0 = female) | Categorical | integer
>CP | Chest pain type (0, 1, 2, 3, 4) | Categorical | integer
>Trestbpd | Resting blood pressure (in mm Hg on admission to the hospital) | Numerical | integer
>Chol | Serum cholestoral in mg/dl | Numerical | integer
>FBS | (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false) | Categorical | integer
>RestECG | Resting electrocardiographic results (0, 1, 2) | Categorical | integer
>Thalach | Maximum heart rate achieved | Numerical | integer
>Exang | Exercise induced angina (1 = yes; 0 = no) | Categorical | integer
>Oldpeak | ST depression induced by exercise relative to rest | Numerical | float
>Slope | The slope of the peak exercise ST segment | Numerical | integer
>CA | Number of major vessels (0-3) colored by flourosopy | Numerical | integer
>Thal | 3 = normal; 6 = fixed defect; 7 = reversable defect | Categorical | string
>Target | Diagnosis of heart disease (1 = true; 0 = false) | Classification | integer
## Import TensorFlow and other libraries
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import tensorflow as tf
from tensorflow import feature_column
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
print("TensorFlow version: ",tf.version.VERSION)
```
## Lab Task 1: Use Pandas to create a dataframe
[Pandas](https://pandas.pydata.org/) is a Python library with many helpful utilities for loading and working with structured data. We will use Pandas to download the dataset from a URL, and load it into a dataframe.
```
URL = 'https://storage.googleapis.com/download.tensorflow.org/data/heart.csv'
dataframe = pd.read_csv(URL)
dataframe.head()
dataframe.info()
```
## Split the dataframe into train, validation, and test
The dataset we downloaded was a single CSV file. As a best practice, Complete the below TODO by splitting this into train, validation, and test sets.
```
# TODO 1a
# TODO: Your code goes here
print(len(train), 'train examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
```
## Lab Task 2: Create an input pipeline using tf.data
Next, we will wrap the dataframes with [tf.data](https://www.tensorflow.org/guide/datasets). This will enable us to use feature columns as a bridge to map from the columns in the Pandas dataframe to features used to train a model. If we were working with a very large CSV file (so large that it does not fit into memory), we would use tf.data to read it from disk directly. That is not covered in this lab.
Complete the `TODOs` in the below cells using `df_to_dataset` function.
```
# A utility method to create a tf.data dataset from a Pandas Dataframe
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop('target')
ds = # TODO 2a: Your code goes here
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
return ds
batch_size = 5 # A small batch sized is used for demonstration purposes
# TODO 2b
train_ds = # Your code goes here
val_ds = # Your code goes here
test_ds = # Your code goes here
```
## Understand the input pipeline
Now that we have created the input pipeline, let's call it to see the format of the data it returns. We have used a small batch size to keep the output readable.
```
for feature_batch, label_batch in train_ds.take(1):
print('Every feature:', list(feature_batch.keys()))
print('A batch of ages:', feature_batch['age'])
print('A batch of targets:', label_batch)
```
## Lab Task 3: Demonstrate several types of feature column
TensorFlow provides many types of feature columns. In this section, we will create several types of feature columns, and demonstrate how they transform a column from the dataframe.
```
# We will use this batch to demonstrate several types of feature columns
example_batch = next(iter(train_ds))[0]
# A utility method to create a feature column
# and to transform a batch of data
def demo(feature_column):
feature_layer = layers.DenseFeatures(feature_column)
print(feature_layer(example_batch).numpy())
```
### Numeric columns
The output of a feature column becomes the input to the model. A [numeric column](https://www.tensorflow.org/api_docs/python/tf/feature_column/numeric_column) is the simplest type of column. It is used to represent real valued features. When using this column, your model will receive the column value from the dataframe unchanged.
```
age = feature_column.numeric_column("age")
tf.feature_column.numeric_column
print(age)
```
### Let's have a look at the output:
#### key='age'
A unique string identifying the input feature. It is used as the column name and the dictionary key for feature parsing configs, feature Tensor objects, and feature columns.
#### shape=(1,)
In the heart disease dataset, most columns from the dataframe are numeric. Recall that tensors have a rank. "Age" is a "vector" or "rank-1" tensor, which is like a list of values. A vector has 1-axis, thus the shape will always look like this: shape=(3,), where 3 is a scalar (or single number) and with 1-axis.
#### default_value=None
A single value compatible with dtype or an iterable of values compatible with dtype which the column takes on during tf.Example parsing if data is missing. A default value of None will cause tf.io.parse_example to fail if an example does not contain this column. If a single value is provided, the same value will be applied as the default value for every item. If an iterable of values is provided, the shape of the default_value should be equal to the given shape.
#### dtype=tf.float32
defines the type of values. Default value is tf.float32. Must be a non-quantized, real integer or floating point type.
#### normalizer_fn=None
If not None, a function that can be used to normalize the value of the tensor after default_value is applied for parsing. Normalizer function takes the input Tensor as its argument, and returns the output Tensor. (e.g. lambda x: (x - 3.0) / 4.2). Please note that even though the most common use case of this function is normalization, it can be used for any kind of Tensorflow transformations.
```
demo(age)
```
### Bucketized columns
Often, you don't want to feed a number directly into the model, but instead split its value into different categories based on numerical ranges. Consider raw data that represents a person's age. Instead of representing age as a numeric column, we could split the age into several buckets using a [bucketized column](https://www.tensorflow.org/api_docs/python/tf/feature_column/bucketized_column). Notice the one-hot values below describe which age range each row matches.
```
age_buckets = tf.feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
demo(____) # TODO 3a: Replace the blanks with a correct value
```
### Categorical columns
In this dataset, thal is represented as a string (e.g. 'fixed', 'normal', or 'reversible'). We cannot feed strings directly to a model. Instead, we must first map them to numeric values. The categorical vocabulary columns provide a way to represent strings as a one-hot vector (much like you have seen above with age buckets). The vocabulary can be passed as a list using [categorical_column_with_vocabulary_list](https://www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_vocabulary_list), or loaded from a file using [categorical_column_with_vocabulary_file](https://www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_vocabulary_file).
```
thal = tf.feature_column.categorical_column_with_vocabulary_list(
'thal', ['fixed', 'normal', 'reversible'])
thal_one_hot = tf.feature_column.indicator_column(thal)
demo(thal_one_hot)
```
In a more complex dataset, many columns would be categorical (e.g. strings). Feature columns are most valuable when working with categorical data. Although there is only one categorical column in this dataset, we will use it to demonstrate several important types of feature columns that you could use when working with other datasets.
### Embedding columns
Suppose instead of having just a few possible strings, we have thousands (or more) values per category. For a number of reasons, as the number of categories grow large, it becomes infeasible to train a neural network using one-hot encodings. We can use an embedding column to overcome this limitation. Instead of representing the data as a one-hot vector of many dimensions, an [embedding column](https://www.tensorflow.org/api_docs/python/tf/feature_column/embedding_column) represents that data as a lower-dimensional, dense vector in which each cell can contain any number, not just 0 or 1. The size of the embedding (8, in the example below) is a parameter that must be tuned.
Key point: using an embedding column is best when a categorical column has many possible values. We are using one here for demonstration purposes, so you have a complete example you can modify for a different dataset in the future.
```
# Notice the input to the embedding column is the categorical column
# we previously created
thal_embedding = tf.feature_column.embedding_column(thal, dimension=8)
demo(thal_embedding)
```
### Hashed feature columns
Another way to represent a categorical column with a large number of values is to use a [categorical_column_with_hash_bucket](https://www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_hash_bucket). This feature column calculates a hash value of the input, then selects one of the `hash_bucket_size` buckets to encode a string. When using this column, you do not need to provide the vocabulary, and you can choose to make the number of hash_buckets significantly smaller than the number of actual categories to save space.
Key point: An important downside of this technique is that there may be collisions in which different strings are mapped to the same bucket. In practice, this can work well for some datasets regardless.
```
thal_hashed = tf.feature_column.categorical_column_with_hash_bucket(
'thal', hash_bucket_size=1000)
demo(tf.feature_column.indicator_column(thal_hashed))
```
### Crossed feature columns
Combining features into a single feature, better known as [feature crosses](https://developers.google.com/machine-learning/glossary/#feature_cross), enables a model to learn separate weights for each combination of features. Here, we will create a new feature that is the cross of age and thal. Note that `crossed_column` does not build the full table of all possible combinations (which could be very large). Instead, it is backed by a `hashed_column`, so you can choose how large the table is.
```
crossed_feature = tf.feature_column.crossed_column([age_buckets, thal], hash_bucket_size=1000)
demo(tf.feature_column.indicator_column(crossed_feature))
```
## Choose which columns to use
We have seen how to use several types of feature columns. Now we will use them to train a model. The goal of this tutorial is to show you the complete code (e.g. mechanics) needed to work with feature columns. We have selected a few columns to train our model below arbitrarily.
Key point: If your aim is to build an accurate model, try a larger dataset of your own, and think carefully about which features are the most meaningful to include, and how they should be represented.
```
feature_columns = []
# numeric cols
for header in ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope', 'ca']:
feature_columns.append(feature_column.numeric_column(header))
# bucketized cols
age_buckets = feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
feature_columns.append(age_buckets)
# indicator cols
thal = feature_column.categorical_column_with_vocabulary_list(
'thal', ['fixed', 'normal', 'reversible'])
thal_one_hot = feature_column.indicator_column(thal)
feature_columns.append(thal_one_hot)
# embedding cols
thal_embedding = feature_column.embedding_column(thal, dimension=8)
feature_columns.append(thal_embedding)
# crossed cols
crossed_feature = feature_column.crossed_column([age_buckets, thal], hash_bucket_size=1000)
crossed_feature = feature_column.indicator_column(crossed_feature)
feature_columns.append(crossed_feature)
```
### How to Input Feature Columns to a Keras Model
Now that we have defined our feature columns, we now use a [DenseFeatures](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/DenseFeatures) layer to input them to a Keras model. Don't worry if you have not used Keras before. There is a more detailed video and lab introducing the Keras Sequential and Functional models.
```
feature_layer = tf.keras.layers.DenseFeatures(feature_columns)
```
Earlier, we used a small batch size to demonstrate how feature columns worked. We create a new input pipeline with a larger batch size.
```
batch_size = 32
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
```
## Create, compile, and train the model
```
model = tf.keras.Sequential([
feature_layer,
layers.Dense(128, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_ds,
validation_data=val_ds,
epochs=5)
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
```
### Visualize the model loss curve
Next, we will use Matplotlib to draw the model's loss curves for training and validation. A line plot is also created showing the accuracy over the training epochs for both the train (blue) and test (orange) sets.
```
def plot_curves(history, metrics):
nrows = 1
ncols = 2
fig = plt.figure(figsize=(10, 5))
for idx, key in enumerate(metrics):
ax = fig.add_subplot(nrows, ncols, idx+1)
plt.plot(history.history[key])
plt.plot(history.history['val_{}'.format(key)])
plt.title('model {}'.format(key))
plt.ylabel(key)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left');
plot_curves(history, ['loss', 'accuracy'])
```
You can see that accuracy is at 77% for both the training and validation data, while loss bottoms out at about .477 after four epochs.
Key point: You will typically see best results with deep learning with much larger and more complex datasets. When working with a small dataset like this one, we recommend using a decision tree or random forest as a strong baseline. The goal of this tutorial is not to train an accurate model, but to demonstrate the mechanics of working with structured data, so you have code to use as a starting point when working with your own datasets in the future.
## Next steps
The best way to learn more about classifying structured data is to try it yourself. We suggest finding another dataset to work with, and training a model to classify it using code similar to the above. To improve accuracy, think carefully about which features to include in your model, and how they should be represented.
Copyright 2020 Google Inc.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| github_jupyter |
# Compute Project Stats
* This notebook uses the GitHub [GraphQL API](https://developer.github.com/v4/) to compute the number of open and
closed bugs pertaining to Kubeflow GitHub Projects
* Stats are broken down by labels
* Results are plotted using [plotly](https://plot.ly)
* Plots are currently published on plot.ly for sharing; they are publicly vieable by anyone
## Setup GitHub
* You will need a GitHub personal access token in order to use the GitHub API
* See these [instructions](https://help.github.com/articles/creating-a-personal-access-token-for-the-command-line/) for creating a personal access token
* You will need the scopes:
* repo
* read:org
* Set the environment variable `GITHUB_TOKEN` to pass your token to the code
## Setup Plot.ly Online
* In order to use plot.ly to publish the plot you need to create a plot.ly account and get an API key
* Follow plot.ly's [getting started guide](https://plot.ly/python/getting-started/)
* Store your API key in `~/.plotly/.credentials `
```
# Use plotly cufflinks to plot data frames
# https://plot.ly/ipython-notebooks/cufflinks/
# instructions for offline plotting
# https://plot.ly/python/getting-started/#initialization-for-offline-plotting
#
# Follow the instructions for online plotting:
# https://plot.ly/python/getting-started/
# You will need to setup an account
import plotly
import plotly.plotly as py
import plotly.graph_objs as go
import cufflinks as cf
#from importlib import reload
import itertools
import project_stats
#reload(project_stats)
c = project_stats.ProjectStats(project="0.6.0")
#c = project_stats.ProjectStats(project="0.7.0")
c.main()
```
Make plots showing different groups of labels
* Columns are multi level indexes
* See [here](https://pandas.pydata.org/pandas-docs/stable/user_guide/advanced.html) for instructions on multilevel indexes
* We specify a list of tuples where each tuple specifies the item to select at the corresponding level in the index
```
counts = ["open", "total"]
#labels = ["cuj/build-train-deploy", "cuj/multi-user", "area/katib"]
labels = ["priority/p0", "priority/p1", "priority/p2"]
columns = [(a,b) for (a,b) in itertools.product(counts, labels)]
import datetime
start=datetime.datetime(2019, 1, 1)
i = c.stats.index > start
#c.stats.iloc[i]
c.stats.loc[i, columns].iplot(kind='scatter', width=5, filename='project-stats', title='{0} Issue Count'.format(c.project))
c.stats.iloc[-1][columns]
import datetime
start=datetime.datetime(2019, 1, 1)
i = c.stats.index > start
c.stats.iloc[i]
```
| github_jupyter |
# Tutorial 17: Self-Supervised Contrastive Learning with SimCLR

**Filled notebook:**
[](https://github.com/phlippe/uvadlc_notebooks/blob/master/docs/tutorial_notebooks/tutorial17/SimCLR.ipynb)
[](https://colab.research.google.com/github/phlippe/uvadlc_notebooks/blob/master/docs/tutorial_notebooks/tutorial17/SimCLR.ipynb)
**Pre-trained models:**
[](https://github.com/phlippe/saved_models/tree/main/tutorial17)
[](https://drive.google.com/drive/folders/1BmisSPs5BXQKpolyHp5X4klSAhpDx479?usp=sharing)
**Recordings:**
[](https://youtu.be/waVZDFR-06U)
[](https://youtu.be/o3FktysLLd4)
**Author:** Phillip Lippe
In this tutorial, we will take a closer look at self-supervised contrastive learning. Self-supervised learning, or also sometimes called unsupervised learning, describes the scenario where we have given input data, but no accompanying labels to train in a classical supervised way. However, this data still contains a lot of information from which we can learn: how are the images different from each other? What patterns are descriptive for certain images? Can we cluster the images? And so on. Methods for self-supervised learning try to learn as much as possible from the data alone, so it can quickly be finetuned for a specific classification task.
The benefit of self-supervised learning is that a large dataset can often easily be obtained. For instance, if we want to train a vision model on semantic segmentation for autonomous driving, we can collect large amounts of data by simply installing a camera in a car, and driving through a city for an hour. In contrast, if we would want to do supervised learning, we would have to manually label all those images before training a model. This is extremely expensive, and would likely take a couple of months to manually label the same amount of data. Further, self-supervised learning can provide an alternative to transfer learning from models pretrained on ImageNet since we could pretrain a model on a specific dataset/situation, e.g. traffic scenarios for autonomous driving.
Within the last two years, a lot of new approaches have been proposed for self-supervised learning, in particular for images, that have resulted in great improvements over supervised models when few labels are available. The subfield that we will focus on in this tutorial is contrastive learning. Contrastive learning is motivated by the question mentioned above: how are images different from each other? Specifically, contrastive learning methods train a model to cluster an image and its slightly augmented version in latent space, while the distance to other images should be maximized. A very recent and simple method for this is [SimCLR](https://arxiv.org/abs/2006.10029), which is visualized below (figure credit - [Ting Chen et al.](https://simclr.github.io/)).
<center width="100%"><img src="simclr_contrastive_learning.png" width="500px"></center>
The general setup is that we are given a dataset of images without any labels, and want to train a model on this data such that it can quickly adapt to any image recognition task afterward. During each training iteration, we sample a batch of images as usual. For each image, we create two versions by applying data augmentation techniques like cropping, Gaussian noise, blurring, etc. An example of such is shown on the left with the image of the dog. We will go into the details and effects of the chosen augmentation techniques later. On those images, we apply a CNN like ResNet and obtain as output a 1D feature vector on which we apply a small MLP. The output features of the two augmented images are then trained to be close to each other, while all other images in that batch should be as different as possible. This way, the model has to learn to recognize the content of the image that remains unchanged under the data augmentations, such as objects which we usually care about in supervised tasks.
We will now implement this framework ourselves and discuss further details along the way. Let's first start with importing our standard libraries below:
```
## Standard libraries
import os
from copy import deepcopy
## Imports for plotting
import matplotlib.pyplot as plt
plt.set_cmap('cividis')
%matplotlib inline
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf') # For export
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.set()
## tqdm for loading bars
from tqdm.notebook import tqdm
## PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
## Torchvision
import torchvision
from torchvision.datasets import STL10
from torchvision import transforms
# PyTorch Lightning
try:
import pytorch_lightning as pl
except ModuleNotFoundError: # Google Colab does not have PyTorch Lightning installed by default. Hence, we do it here if necessary
!pip install --quiet pytorch-lightning>=1.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
# Import tensorboard
%load_ext tensorboard
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = "../data"
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = "../saved_models/tutorial17"
# In this notebook, we use data loaders with heavier computational processing. It is recommended to use as many
# workers as possible in a data loader, which corresponds to the number of CPU cores
NUM_WORKERS = os.cpu_count()
# Setting the seed
pl.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print("Device:", device)
print("Number of workers:", NUM_WORKERS)
```
As in many tutorials before, we provide pre-trained models. Note that those models are slightly larger as normal (~100MB overall) since we use the default ResNet-18 architecture. If you are running this notebook locally, make sure to have sufficient disk space available.
```
import urllib.request
from urllib.error import HTTPError
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial17/"
# Files to download
pretrained_files = ["SimCLR.ckpt", "ResNet.ckpt",
"tensorboards/SimCLR/events.out.tfevents.SimCLR",
"tensorboards/classification/ResNet/events.out.tfevents.ResNet"]
pretrained_files += [f"LogisticRegression_{size}.ckpt" for size in [10, 20, 50, 100, 200, 500]]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name)
if "/" in file_name:
os.makedirs(file_path.rsplit("/",1)[0], exist_ok=True)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print(f"Downloading {file_url}...")
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print("Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n", e)
```
## SimCLR
We will start our exploration of contrastive learning by discussing the effect of different data augmentation techniques, and how we can implement an efficient data loader for such. Next, we implement SimCLR with PyTorch Lightning, and finally train it on a large, unlabeled dataset.
### Data Augmentation for Contrastive Learning
To allow efficient training, we need to prepare the data loading such that we sample two different, random augmentations for each image in the batch. The easiest way to do this is by creating a transformation that, when being called, applies a set of data augmentations to an image twice. This is implemented in the class `ContrastiveTransformations` below:
```
class ContrastiveTransformations(object):
def __init__(self, base_transforms, n_views=2):
self.base_transforms = base_transforms
self.n_views = n_views
def __call__(self, x):
return [self.base_transforms(x) for i in range(self.n_views)]
```
The contrastive learning framework can easily be extended to have more _positive_ examples by sampling more than two augmentations of the same image. However, the most efficient training is usually obtained by using only two.
Next, we can look at the specific augmentations we want to apply. The choice of the data augmentation to use is the most crucial hyperparameter in SimCLR since it directly affects how the latent space is structured, and what patterns might be learned from the data. Let's first take a look at some of the most popular data augmentations (figure credit - [Ting Chen and Geoffrey Hinton](https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html)):
<center width="100%"><img src="simclr_data_augmentations.png" width="800px" style="padding-top: 10px; padding-bottom: 10px"></center>
All of them can be used, but it turns out that two augmentations stand out in their importance: crop-and-resize, and color distortion. Interestingly, however, they only lead to strong performance if they have been used together as discussed by [Ting Chen et al.](https://arxiv.org/abs/2006.10029) in their SimCLR paper. When performing randomly cropping and resizing, we can distinguish between two situations: (a) cropped image A provides a local view of cropped image B, or (b) cropped images C and D show neighboring views of the same image (figure credit - [Ting Chen and Geoffrey Hinton](https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html)).
<center width="100%"><img src="crop_views.svg" width="400px" style="padding-top: 20px; padding-bottom: 0px"></center>
While situation (a) requires the model to learn some sort of scale invariance to make crops A and B similar in latent space, situation (b) is more challenging since the model needs to recognize an object beyond its limited view. However, without color distortion, there is a loophole that the model can exploit, namely that different crops of the same image usually look very similar in color space. Consider the picture of the dog above. Simply from the color of the fur and the green color tone of the background, you can reason that two patches belong to the same image without actually recognizing the dog in the picture. In this case, the model might end up focusing only on the color histograms of the images, and ignore other more generalizable features. If, however, we distort the colors in the two patches randomly and independently of each other, the model cannot rely on this simple feature anymore. Hence, by combining random cropping and color distortions, the model can only match two patches by learning generalizable representations.
Overall, for our experiments, we apply a set of 5 transformations following the original SimCLR setup: random horizontal flip, crop-and-resize, color distortion, random grayscale, and gaussian blur. In comparison to the [original implementation](https://github.com/google-research/simclr), we reduce the effect of the color jitter slightly (0.5 instead of 0.8 for brightness, contrast, and saturation, and 0.1 instead of 0.2 for hue). In our experiments, this setting obtained better performance and was faster and more stable to train. If, for instance, the brightness scale highly varies in a dataset, the original settings can be more beneficial since the model can't rely on this information anymore to distinguish between images.
```
contrast_transforms = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(size=96),
transforms.RandomApply([
transforms.ColorJitter(brightness=0.5,
contrast=0.5,
saturation=0.5,
hue=0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
```
After discussing the data augmentation techniques, we can now focus on the dataset. In this tutorial, we will use the [STL10 dataset](https://cs.stanford.edu/~acoates/stl10/), which, similarly to CIFAR10, contains images of 10 classes: airplane, bird, car, cat, deer, dog, horse, monkey, ship, truck. However, the images have a higher resolution, namely $96\times 96$ pixels, and we are only provided with 500 labeled images per class. Additionally, we have a much larger set of $100,000$ unlabeled images which are similar to the training images but are sampled from a wider range of animals and vehicles. This makes the dataset ideal to showcase the benefits that self-supervised learning offers.
Luckily, the STL10 dataset is provided through torchvision. Keep in mind, however, that since this dataset is relatively large and has a considerably higher resolution than CIFAR10, it requires more disk space (~3GB) and takes a bit of time to download. For our initial discussion of self-supervised learning and SimCLR, we will create two data loaders with our contrastive transformations above: the `unlabeled_data` will be used to train our model via contrastive learning, and `train_data_contrast` will be used as a validation set in contrastive learning.
```
unlabeled_data = STL10(root=DATASET_PATH, split='unlabeled', download=True,
transform=ContrastiveTransformations(contrast_transforms, n_views=2))
train_data_contrast = STL10(root=DATASET_PATH, split='train', download=True,
transform=ContrastiveTransformations(contrast_transforms, n_views=2))
```
Finally, before starting with our implementation of SimCLR, let's look at some example image pairs sampled with our augmentations:
```
# Visualize some examples
pl.seed_everything(42)
NUM_IMAGES = 6
imgs = torch.stack([img for idx in range(NUM_IMAGES) for img in unlabeled_data[idx][0]], dim=0)
img_grid = torchvision.utils.make_grid(imgs, nrow=6, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(10,5))
plt.title('Augmented image examples of the STL10 dataset')
plt.imshow(img_grid)
plt.axis('off')
plt.show()
plt.close()
```
We see the wide variety of our data augmentation, including randomly cropping, grayscaling, gaussian blur, and color distortion. Thus, it remains a challenging task for the model to match two, independently augmented patches of the same image.
### SimCLR implementation
Using the data loader pipeline above, we can now implement SimCLR. At each iteration, we get for every image $x$ two differently augmented versions, which we refer to as $\tilde{x}_i$ and $\tilde{x}_j$. Both of these images are encoded into a one-dimensional feature vector, between which we want to maximize similarity which minimizes it to all other images in the batch. The encoder network is split into two parts: a base encoder network $f(\cdot)$, and a projection head $g(\cdot)$. The base network is usually a deep CNN as we have seen in e.g. [Tutorial 5](https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial5/Inception_ResNet_DenseNet.html) before, and is responsible for extracting a representation vector from the augmented data examples. In our experiments, we will use the common ResNet-18 architecture as $f(\cdot)$, and refer to the output as $f(\tilde{x}_i)=h_i$. The projection head $g(\cdot)$ maps the representation $h$ into a space where we apply the contrastive loss, i.e., compare similarities between vectors. It is often chosen to be a small MLP with non-linearities, and for simplicity, we follow the original SimCLR paper setup by defining it as a two-layer MLP with ReLU activation in the hidden layer. Note that in the follow-up paper, [SimCLRv2](https://arxiv.org/abs/2006.10029), the authors mention that larger/wider MLPs can boost the performance considerably. This is why we apply an MLP with four times larger hidden dimensions, but deeper MLPs showed to overfit on the given dataset. The general setup is visualized below (figure credit - [Ting Chen et al.](https://arxiv.org/abs/2006.10029)):
<center width="100%"><img src="simclr_network_setup.svg" width="350px"></center>
After finishing the training with contrastive learning, we will remove the projection head $g(\cdot)$, and use $f(\cdot)$ as a pretrained feature extractor. The representations $z$ that come out of the projection head $g(\cdot)$ have been shown to perform worse than those of the base network $f(\cdot)$ when finetuning the network for a new task. This is likely because the representations $z$ are trained to become invariant to many features like the color that can be important for downstream tasks. Thus, $g(\cdot)$ is only needed for the contrastive learning stage.
Now that the architecture is described, let's take a closer look at how we train the model. As mentioned before, we want to maximize the similarity between the representations of the two augmented versions of the same image, i.e., $z_i$ and $z_j$ in the figure above, while minimizing it to all other examples in the batch. SimCLR thereby applies the InfoNCE loss, originally proposed by [Aaron van den Oord et al.](https://arxiv.org/abs/1807.03748) for contrastive learning. In short, the InfoNCE loss compares the similarity of $z_i$ and $z_j$ to the similarity of $z_i$ to any other representation in the batch by performing a softmax over the similarity values. The loss can be formally written as:
$$
\ell_{i,j}=-\log \frac{\exp(\text{sim}(z_i,z_j)/\tau)}{\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\exp(\text{sim}(z_i,z_k)/\tau)}=-\text{sim}(z_i,z_j)/\tau+\log\left[\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\exp(\text{sim}(z_i,z_k)/\tau)\right]
$$
The function $\text{sim}$ is a similarity metric, and the hyperparameter $\tau$ is called temperature determining how peaked the distribution is. Since many similarity metrics are bounded, the temperature parameter allows us to balance the influence of many dissimilar image patches versus one similar patch. The similarity metric that is used in SimCLR is cosine similarity, as defined below:
$$
\text{sim}(z_i,z_j) = \frac{z_i^\top \cdot z_j}{||z_i||\cdot||z_j||}
$$
The maximum cosine similarity possible is $1$, while the minimum is $-1$. In general, we will see that the features of two different images will converge to a cosine similarity around zero since the minimum, $-1$, would require $z_i$ and $z_j$ to be in the exact opposite direction in all feature dimensions, which does not allow for great flexibility.
Finally, now that we have discussed all details, let's implement SimCLR below as a PyTorch Lightning module:
```
class SimCLR(pl.LightningModule):
def __init__(self, hidden_dim, lr, temperature, weight_decay, max_epochs=500):
super().__init__()
self.save_hyperparameters()
assert self.hparams.temperature > 0.0, 'The temperature must be a positive float!'
# Base model f(.)
self.convnet = torchvision.models.resnet18(pretrained=False,
num_classes=4*hidden_dim) # Output of last linear layer
# The MLP for g(.) consists of Linear->ReLU->Linear
self.convnet.fc = nn.Sequential(
self.convnet.fc, # Linear(ResNet output, 4*hidden_dim)
nn.ReLU(inplace=True),
nn.Linear(4*hidden_dim, hidden_dim)
)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer,
T_max=self.hparams.max_epochs,
eta_min=self.hparams.lr/50)
return [optimizer], [lr_scheduler]
def info_nce_loss(self, batch, mode='train'):
imgs, _ = batch
imgs = torch.cat(imgs, dim=0)
# Encode all images
feats = self.convnet(imgs)
# Calculate cosine similarity
cos_sim = F.cosine_similarity(feats[:,None,:], feats[None,:,:], dim=-1)
# Mask out cosine similarity to itself
self_mask = torch.eye(cos_sim.shape[0], dtype=torch.bool, device=cos_sim.device)
cos_sim.masked_fill_(self_mask, -9e15)
# Find positive example -> batch_size//2 away from the original example
pos_mask = self_mask.roll(shifts=cos_sim.shape[0]//2, dims=0)
# InfoNCE loss
cos_sim = cos_sim / self.hparams.temperature
nll = -cos_sim[pos_mask] + torch.logsumexp(cos_sim, dim=-1)
nll = nll.mean()
# Logging loss
self.log(mode+'_loss', nll)
# Get ranking position of positive example
comb_sim = torch.cat([cos_sim[pos_mask][:,None], # First position positive example
cos_sim.masked_fill(pos_mask, -9e15)],
dim=-1)
sim_argsort = comb_sim.argsort(dim=-1, descending=True).argmin(dim=-1)
# Logging ranking metrics
self.log(mode+'_acc_top1', (sim_argsort == 0).float().mean())
self.log(mode+'_acc_top5', (sim_argsort < 5).float().mean())
self.log(mode+'_acc_mean_pos', 1+sim_argsort.float().mean())
return nll
def training_step(self, batch, batch_idx):
return self.info_nce_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self.info_nce_loss(batch, mode='val')
```
Alternatively to performing the validation on the contrastive learning loss as well, we could also take a simple, small downstream task, and track the performance of the base network $f(\cdot)$ on that. However, in this tutorial, we will restrict ourselves to the STL10 dataset where we use the task of image classification on STL10 as our test task.
### Training
Now that we have implemented SimCLR and the data loading pipeline, we are ready to train the model. We will use the same training function setup as usual. For saving the best model checkpoint, we track the metric `val_acc_top5`, which describes how often the correct image patch is within the top-5 most similar examples in the batch. This is usually less noisy than the top-1 metric, making it a better metric to choose the best model from.
```
def train_simclr(batch_size, max_epochs=500, **kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, 'SimCLR'),
gpus=1 if str(device)=='cuda:0' else 0,
max_epochs=max_epochs,
callbacks=[ModelCheckpoint(save_weights_only=True, mode='max', monitor='val_acc_top5'),
LearningRateMonitor('epoch')],
progress_bar_refresh_rate=1)
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, 'SimCLR.ckpt')
if os.path.isfile(pretrained_filename):
print(f'Found pretrained model at {pretrained_filename}, loading...')
model = SimCLR.load_from_checkpoint(pretrained_filename) # Automatically loads the model with the saved hyperparameters
else:
train_loader = data.DataLoader(unlabeled_data, batch_size=batch_size, shuffle=True,
drop_last=True, pin_memory=True, num_workers=NUM_WORKERS)
val_loader = data.DataLoader(train_data_contrast, batch_size=batch_size, shuffle=False,
drop_last=False, pin_memory=True, num_workers=NUM_WORKERS)
pl.seed_everything(42) # To be reproducable
model = SimCLR(max_epochs=max_epochs, **kwargs)
trainer.fit(model, train_loader, val_loader)
model = SimCLR.load_from_checkpoint(trainer.checkpoint_callback.best_model_path) # Load best checkpoint after training
return model
```
A common observation in contrastive learning is that the larger the batch size, the better the models perform. A larger batch size allows us to compare each image to more negative examples, leading to overall smoother loss gradients. However, in our case, we experienced that a batch size of 256 was sufficient to get good results.
```
simclr_model = train_simclr(batch_size=256,
hidden_dim=128,
lr=5e-4,
temperature=0.07,
weight_decay=1e-4,
max_epochs=500)
```
To get an intuition of how training with contrastive learning behaves, we can take a look at the TensorBoard below:
```
%tensorboard --logdir ../saved_models/tutorial17/tensorboards/SimCLR/
```
<center width="100%"><img src="tensorboard_simclr.png" width="1200px"></center>
One thing to note is that contrastive learning benefits a lot from long training. The shown plot above is from a training that took approx. 1 day on a NVIDIA TitanRTX. Training the model for even longer might reduce its loss further, but we did not experience any gains from it for the downstream task on image classification. In general, contrastive learning can also benefit from using larger models, if sufficient unlabeled data is available.
## Logistic Regression
After we have trained our model via contrastive learning, we can deploy it on downstream tasks and see how well it performs with little data. A common setup, which also verifies whether the model has learned generalized representations, is to perform Logistic Regression on the features. In other words, we learn a single, linear layer that maps the representations to a class prediction. Since the base network $f(\cdot)$ is not changed during the training process, the model can only perform well if the representations of $h$ describe all features that might be necessary for the task. Further, we do not have to worry too much about overfitting since we have very few parameters that are trained. Hence, we might expect that the model can perform well even with very little data.
First, let's implement a simple Logistic Regression setup for which we assume that the images already have been encoded in their feature vectors. If very little data is available, it might be beneficial to dynamically encode the images during training so that we can also apply data augmentations. However, the way we implement it here is much more efficient and can be trained within a few seconds. Further, using data augmentations did not show any significant gain in this simple setup.
```
class LogisticRegression(pl.LightningModule):
def __init__(self, feature_dim, num_classes, lr, weight_decay, max_epochs=100):
super().__init__()
self.save_hyperparameters()
# Mapping from representation h to classes
self.model = nn.Linear(feature_dim, num_classes)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[int(self.hparams.max_epochs*0.6),
int(self.hparams.max_epochs*0.8)],
gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode='train'):
feats, labels = batch
preds = self.model(feats)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log(mode + '_loss', loss)
self.log(mode + '_acc', acc)
return loss
def training_step(self, batch, batch_idx):
return self._calculate_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='val')
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='test')
```
The data we use is the training and test set of STL10. The training contains 500 images per class, while the test set has 800 images per class.
```
img_transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
train_img_data = STL10(root=DATASET_PATH, split='train', download=True,
transform=img_transforms)
test_img_data = STL10(root=DATASET_PATH, split='test', download=True,
transform=img_transforms)
print("Number of training examples:", len(train_img_data))
print("Number of test examples:", len(test_img_data))
```
Next, we implement a small function to encode all images in our datasets. The output representations are then used as inputs to the Logistic Regression model.
```
@torch.no_grad()
def prepare_data_features(model, dataset):
# Prepare model
network = deepcopy(model.convnet)
network.fc = nn.Identity() # Removing projection head g(.)
network.eval()
network.to(device)
# Encode all images
data_loader = data.DataLoader(dataset, batch_size=64, num_workers=NUM_WORKERS, shuffle=False, drop_last=False)
feats, labels = [], []
for batch_imgs, batch_labels in tqdm(data_loader):
batch_imgs = batch_imgs.to(device)
batch_feats = network(batch_imgs)
feats.append(batch_feats.detach().cpu())
labels.append(batch_labels)
feats = torch.cat(feats, dim=0)
labels = torch.cat(labels, dim=0)
# Sort images by labels
labels, idxs = labels.sort()
feats = feats[idxs]
return data.TensorDataset(feats, labels)
```
Let's apply the function to both training and test set below.
```
train_feats_simclr = prepare_data_features(simclr_model, train_img_data)
test_feats_simclr = prepare_data_features(simclr_model, test_img_data)
```
Finally, we can write a training function as usual. We evaluate the model on the test set every 10 epochs to allow early stopping, but the low frequency of the validation ensures that we do not overfit too much on the test set.
```
def train_logreg(batch_size, train_feats_data, test_feats_data, model_suffix, max_epochs=100, **kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "LogisticRegression"),
gpus=1 if str(device)=="cuda:0" else 0,
max_epochs=max_epochs,
callbacks=[ModelCheckpoint(save_weights_only=True, mode='max', monitor='val_acc'),
LearningRateMonitor("epoch")],
progress_bar_refresh_rate=0,
check_val_every_n_epoch=10)
trainer.logger._default_hp_metric = None
# Data loaders
train_loader = data.DataLoader(train_feats_data, batch_size=batch_size, shuffle=True,
drop_last=False, pin_memory=True, num_workers=0)
test_loader = data.DataLoader(test_feats_data, batch_size=batch_size, shuffle=False,
drop_last=False, pin_memory=True, num_workers=0)
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"LogisticRegression_{model_suffix}.ckpt")
if os.path.isfile(pretrained_filename):
print(f"Found pretrained model at {pretrained_filename}, loading...")
model = LogisticRegression.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42) # To be reproducable
model = LogisticRegression(**kwargs)
trainer.fit(model, train_loader, test_loader)
model = LogisticRegression.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
# Test best model on train and validation set
train_result = trainer.test(model, train_loader, verbose=False)
test_result = trainer.test(model, test_loader, verbose=False)
result = {"train": train_result[0]["test_acc"], "test": test_result[0]["test_acc"]}
return model, result
```
Despite the training dataset of STL10 already only having 500 labeled images per class, we will perform experiments with even smaller datasets. Specifically, we train a Logistic Regression model for datasets with only 10, 20, 50, 100, 200, and all 500 examples per class. This gives us an intuition on how well the representations learned by contrastive learning can be transfered to a image recognition task like this classification. First, let's define a function to create the intended sub-datasets from the full training set:
```
def get_smaller_dataset(original_dataset, num_imgs_per_label):
new_dataset = data.TensorDataset(
*[t.unflatten(0, (10, -1))[:,:num_imgs_per_label].flatten(0, 1) for t in original_dataset.tensors]
)
return new_dataset
```
Next, let's run all models. Despite us training 6 models, this cell could be run within a minute or two without the pretrained models.
```
results = {}
for num_imgs_per_label in [10, 20, 50, 100, 200, 500]:
sub_train_set = get_smaller_dataset(train_feats_simclr, num_imgs_per_label)
_, small_set_results = train_logreg(batch_size=64,
train_feats_data=sub_train_set,
test_feats_data=test_feats_simclr,
model_suffix=num_imgs_per_label,
feature_dim=train_feats_simclr.tensors[0].shape[1],
num_classes=10,
lr=1e-3,
weight_decay=1e-3)
results[num_imgs_per_label] = small_set_results
```
Finally, let's plot the results.
```
dataset_sizes = sorted([k for k in results])
test_scores = [results[k]["test"] for k in dataset_sizes]
fig = plt.figure(figsize=(6,4))
plt.plot(dataset_sizes, test_scores, '--', color="#000", marker="*", markeredgecolor="#000", markerfacecolor="y", markersize=16)
plt.xscale("log")
plt.xticks(dataset_sizes, labels=dataset_sizes)
plt.title("STL10 classification over dataset size", fontsize=14)
plt.xlabel("Number of images per class")
plt.ylabel("Test accuracy")
plt.minorticks_off()
plt.show()
for k, score in zip(dataset_sizes, test_scores):
print(f'Test accuracy for {k:3d} images per label: {100*score:4.2f}%')
```
As one would expect, the classification performance improves the more data we have. However, with only 10 images per class, we can already classify more than 60% of the images correctly. This is quite impressive, considering that the images are also higher dimensional than e.g. CIFAR10. With the full dataset, we achieve an accuracy of 81%. The increase between 50 to 500 images per class might suggest a linear increase in performance with an exponentially larger dataset. However, with even more data, we could also finetune $f(\cdot)$ in the training process, allowing for the representations to adapt more to the specific classification task given.
To set the results above into perspective, we will train the base network, a ResNet-18, on the classification task from scratch.
## Baseline
As a baseline to our results above, we will train a standard ResNet-18 with random initialization on the labeled training set of STL10. The results will give us an indication of the advantages that contrastive learning on unlabeled data has compared to using only supervised training. The implementation of the model is straightforward since the ResNet architecture is provided in the torchvision library.
```
class ResNet(pl.LightningModule):
def __init__(self, num_classes, lr, weight_decay, max_epochs=100):
super().__init__()
self.save_hyperparameters()
self.model = torchvision.models.resnet18(
pretrained=False, num_classes=num_classes)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[int(self.hparams.max_epochs*0.7),
int(self.hparams.max_epochs*0.9)],
gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode='train'):
imgs, labels = batch
preds = self.model(imgs)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log(mode + '_loss', loss)
self.log(mode + '_acc', acc)
return loss
def training_step(self, batch, batch_idx):
return self._calculate_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='val')
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='test')
```
It is clear that the ResNet easily overfits on the training data since its parameter count is more than 1000 times larger than the dataset size. To make the comparison to the contrastive learning models fair, we apply data augmentations similar to the ones we used before: horizontal flip, crop-and-resize, grayscale, and gaussian blur. Color distortions as before are not used because the color distribution of an image showed to be an important feature for the classification. Hence, we observed no noticeable performance gains when adding color distortions to the set of augmentations. Similarly, we restrict the resizing operation before cropping to the max. 125% of its original resolution, instead of 1250% as done in SimCLR. This is because, for classification, the model needs to recognize the full object, while in contrastive learning, we only want to check whether two patches belong to the same image/object. Hence, the chosen augmentations below are overall weaker than in the contrastive learning case.
```
train_transforms = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(size=96, scale=(0.8, 1.0)),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9, sigma=(0.1, 0.5)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_img_aug_data = STL10(root=DATASET_PATH, split='train', download=True,
transform=train_transforms)
```
The training function for the ResNet is almost identical to the Logistic Regression setup. Note that we allow the ResNet to perform validation every 2 epochs to also check whether the model overfits strongly in the first iterations or not.
```
def train_resnet(batch_size, max_epochs=100, **kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "ResNet"),
gpus=1 if str(device)=="cuda:0" else 0,
max_epochs=max_epochs,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),
LearningRateMonitor("epoch")],
progress_bar_refresh_rate=1,
check_val_every_n_epoch=2)
trainer.logger._default_hp_metric = None
# Data loaders
train_loader = data.DataLoader(train_img_aug_data, batch_size=batch_size, shuffle=True,
drop_last=True, pin_memory=True, num_workers=NUM_WORKERS)
test_loader = data.DataLoader(test_img_data, batch_size=batch_size, shuffle=False,
drop_last=False, pin_memory=True, num_workers=NUM_WORKERS)
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "ResNet.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model at %s, loading..." % pretrained_filename)
model = ResNet.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42) # To be reproducable
model = ResNet(**kwargs)
trainer.fit(model, train_loader, test_loader)
model = ResNet.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
# Test best model on validation set
train_result = trainer.test(model, train_loader, verbose=False)
val_result = trainer.test(model, test_loader, verbose=False)
result = {"train": train_result[0]["test_acc"], "test": val_result[0]["test_acc"]}
return model, result
```
Finally, let's train the model and check its results:
```
resnet_model, resnet_result = train_resnet(batch_size=64,
num_classes=10,
lr=1e-3,
weight_decay=2e-4,
max_epochs=100)
print(f"Accuracy on training set: {100*resnet_result['train']:4.2f}%")
print(f"Accuracy on test set: {100*resnet_result['test']:4.2f}%")
```
The ResNet trained from scratch achieves 73.31% on the test set. This is almost 8% less than the contrastive learning model, and even slightly less than SimCLR achieves with 1/10 of the data. This shows that self-supervised, contrastive learning provides considerable performance gains by leveraging large amounts of unlabeled data when little labeled data is available.
## Conclusion
In this tutorial, we have discussed self-supervised contrastive learning and implemented SimCLR as an example method. We have applied it to the STL10 dataset and showed that it can learn generalizable representations that we can use to train simple classification models. With 500 images per label, it achieved an 8% higher accuracy than a similar model solely trained from supervision and performs on par with it when only using a tenth of the labeled data. Our experimental results are limited to a single dataset, but recent works such as [Ting Chen et al.](https://arxiv.org/abs/2006.10029) showed similar trends for larger datasets like ImageNet. Besides the discussed hyperparameters, the size of the model seems to be important in contrastive learning as well. If a lot of unlabeled data is available, larger models can achieve much stronger results and come close to their supervised baselines. Further, there are also approaches for combining contrastive and supervised learning, leading to performance gains beyond supervision (see [Khosla et al.](https://arxiv.org/abs/2004.11362)). Moreover, contrastive learning is not the only approach to self-supervised learning that has come up in the last two years and showed great results. Other methods include distillation-based methods like [BYOL](https://arxiv.org/abs/2006.07733) and redundancy reduction techniques like [Barlow Twins](https://arxiv.org/abs/2103.03230). There is a lot more to explore in the self-supervised domain, and more, impressive steps ahead are to be expected.
### References
[1] Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. (2020). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR. ([link](https://arxiv.org/abs/2002.05709))
[2] Chen, T., Kornblith, S., Swersky, K., Norouzi, M., and Hinton, G. (2020). Big self-supervised models are strong semi-supervised learners. NeurIPS 2021 ([link](https://arxiv.org/abs/2006.10029)).
[3] Oord, A. V. D., Li, Y., and Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748. ([link](https://arxiv.org/abs/1807.03748))
[4] Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Doersch, C., Pires, B.A., Guo, Z.D., Azar, M.G. and Piot, B. (2020). Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprint arXiv:2006.07733. ([link](https://arxiv.org/abs/2006.07733))
[5] Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C. and Krishnan, D. (2020). Supervised contrastive learning. arXiv preprint arXiv:2004.11362. ([link](https://arxiv.org/abs/2004.11362))
[6] Zbontar, J., Jing, L., Misra, I., LeCun, Y. and Deny, S. (2021). Barlow twins: Self-supervised learning via redundancy reduction. arXiv preprint arXiv:2103.03230. ([link](https://arxiv.org/abs/2103.03230))
---
[](https://github.com/phlippe/uvadlc_notebooks/) If you found this tutorial helpful, consider ⭐-ing our repository.
[](https://github.com/phlippe/uvadlc_notebooks/issues) For any questions, typos, or bugs that you found, please raise an issue on GitHub.
---
| github_jupyter |
# Fastpages Notebook Blog Post
> A tutorial of fastpages for Jupyter notebooks.
- toc: true
- badges: true
- comments: true
- categories: [jupyter]
- image: images/chart-preview.png
# About
This notebook is a demonstration of some of capabilities of [fastpages](https://github.com/fastai/fastpages) with notebooks.
With `fastpages` you can save your jupyter notebooks into the `_notebooks` folder at the root of your repository, and they will be automatically be converted to Jekyll compliant blog posts!
## Front Matter
The first cell in your Jupyter Notebook or markdown blog post contains front matter. Front matter is metadata that can turn on/off options in your Notebook. It is formatted like this:
```
# Title
> Awesome summary
- toc: true- branch: master- badges: true
- comments: true
- author: Hamel Husain & Jeremy Howard
- categories: [fastpages, jupyter]
```
- Setting `toc: true` will automatically generate a table of contents
- Setting `badges: true` will automatically include GitHub and Google Colab links to your notebook.
- Setting `comments: true` will enable commenting on your blog post, powered by [utterances](https://github.com/utterance/utterances).
More details and options for front matter can be viewed on the [front matter section](https://github.com/fastai/fastpages#front-matter-related-options) of the README.
## Markdown Shortcuts
A `#hide` comment at the top of any code cell will hide **both the input and output** of that cell in your blog post.
A `#hide_input` comment at the top of any code cell will **only hide the input** of that cell.
```
#hide_input
print('The comment #hide_input was used to hide the code that produced this.')
```
put a `#collapse-hide` flag at the top of any cell if you want to **hide** that cell by default, but give the reader the option to show it:
```
#collapse-hide
import pandas as pd
import altair as alt
```
put a `#collapse-show` flag at the top of any cell if you want to **show** that cell by default, but give the reader the option to hide it:
```
#collapse-show
cars = 'https://vega.github.io/vega-datasets/data/cars.json'
movies = 'https://vega.github.io/vega-datasets/data/movies.json'
sp500 = 'https://vega.github.io/vega-datasets/data/sp500.csv'
stocks = 'https://vega.github.io/vega-datasets/data/stocks.csv'
flights = 'https://vega.github.io/vega-datasets/data/flights-5k.json'
```
## Interactive Charts With Altair
Charts made with Altair remain interactive. Example charts taken from [this repo](https://github.com/uwdata/visualization-curriculum), specifically [this notebook](https://github.com/uwdata/visualization-curriculum/blob/master/altair_interaction.ipynb).
```
# hide
df = pd.read_json(movies) # load movies data
genres = df['Major_Genre'].unique() # get unique field values
genres = list(filter(lambda d: d is not None, genres)) # filter out None values
genres.sort() # sort alphabetically
#hide
mpaa = ['G', 'PG', 'PG-13', 'R', 'NC-17', 'Not Rated']
```
### Example 1: DropDown
```
# single-value selection over [Major_Genre, MPAA_Rating] pairs
# use specific hard-wired values as the initial selected values
selection = alt.selection_single(
name='Select',
fields=['Major_Genre', 'MPAA_Rating'],
init={'Major_Genre': 'Drama', 'MPAA_Rating': 'R'},
bind={'Major_Genre': alt.binding_select(options=genres), 'MPAA_Rating': alt.binding_radio(options=mpaa)}
)
# scatter plot, modify opacity based on selection
alt.Chart(movies).mark_circle().add_selection(
selection
).encode(
x='Rotten_Tomatoes_Rating:Q',
y='IMDB_Rating:Q',
tooltip='Title:N',
opacity=alt.condition(selection, alt.value(0.75), alt.value(0.05))
)
```
### Example 2: Tooltips
```
alt.Chart(movies).mark_circle().add_selection(
alt.selection_interval(bind='scales', encodings=['x'])
).encode(
x='Rotten_Tomatoes_Rating:Q',
y=alt.Y('IMDB_Rating:Q', axis=alt.Axis(minExtent=30)), # use min extent to stabilize axis title placement
tooltip=['Title:N', 'Release_Date:N', 'IMDB_Rating:Q', 'Rotten_Tomatoes_Rating:Q']
).properties(
width=600,
height=400
)
```
### Example 3: More Tooltips
```
# select a point for which to provide details-on-demand
label = alt.selection_single(
encodings=['x'], # limit selection to x-axis value
on='mouseover', # select on mouseover events
nearest=True, # select data point nearest the cursor
empty='none' # empty selection includes no data points
)
# define our base line chart of stock prices
base = alt.Chart().mark_line().encode(
alt.X('date:T'),
alt.Y('price:Q', scale=alt.Scale(type='log')),
alt.Color('symbol:N')
)
alt.layer(
base, # base line chart
# add a rule mark to serve as a guide line
alt.Chart().mark_rule(color='#aaa').encode(
x='date:T'
).transform_filter(label),
# add circle marks for selected time points, hide unselected points
base.mark_circle().encode(
opacity=alt.condition(label, alt.value(1), alt.value(0))
).add_selection(label),
# add white stroked text to provide a legible background for labels
base.mark_text(align='left', dx=5, dy=-5, stroke='white', strokeWidth=2).encode(
text='price:Q'
).transform_filter(label),
# add text labels for stock prices
base.mark_text(align='left', dx=5, dy=-5).encode(
text='price:Q'
).transform_filter(label),
data=stocks
).properties(
width=700,
height=400
)
```
## Data Tables
You can display tables per the usual way in your blog:
```
movies = 'https://vega.github.io/vega-datasets/data/movies.json'
df = pd.read_json(movies)
# display table with pandas
df[['Title', 'Worldwide_Gross',
'Production_Budget', 'Distributor', 'MPAA_Rating', 'IMDB_Rating', 'Rotten_Tomatoes_Rating']].head()
```
## Images
### Local Images
You can reference local images and they will be copied and rendered on your blog automatically. You can include these with the following markdown syntax:
``

### Remote Images
Remote images can be included with the following markdown syntax:
``

### Animated Gifs
Animated Gifs work, too!
`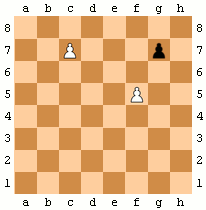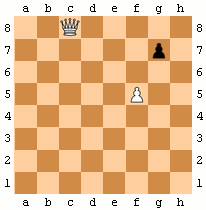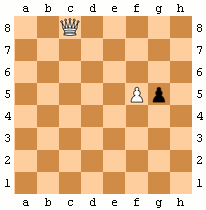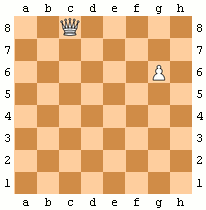`

### Captions
You can include captions with markdown images like this:
```

```

# Other Elements
## Tweetcards
Typing `> twitter: https://twitter.com/jakevdp/status/1204765621767901185?s=20` will render this:
> twitter: https://twitter.com/jakevdp/status/1204765621767901185?s=20
## Youtube Videos
Typing `> youtube: https://youtu.be/XfoYk_Z5AkI` will render this:
> youtube: https://youtu.be/XfoYk_Z5AkI
## Boxes / Callouts
Typing `> Warning: There will be no second warning!` will render this:
> Warning: There will be no second warning!
Typing `> Important: Pay attention! It's important.` will render this:
> Important: Pay attention! It's important.
Typing `> Tip: This is my tip.` will render this:
> Tip: This is my tip.
Typing `> Note: Take note of this.` will render this:
> Note: Take note of this.
Typing `> Note: A doc link to [an example website: fast.ai](https://www.fast.ai/) should also work fine.` will render in the docs:
> Note: A doc link to [an example website: fast.ai](https://www.fast.ai/) should also work fine.
## Footnotes
You can have footnotes in notebooks, however the syntax is different compared to markdown documents. [This guide provides more detail about this syntax](https://github.com/fastai/fastpages/blob/master/_fastpages_docs/NOTEBOOK_FOOTNOTES.md), which looks like this:
```
{% raw %}For example, here is a footnote {% fn 1 %}.
And another {% fn 2 %}
{{ 'This is the footnote.' | fndetail: 1 }}
{{ 'This is the other footnote. You can even have a [link](www.github.com)!' | fndetail: 2 }}{% endraw %}
```
For example, here is a footnote {% fn 1 %}.
And another {% fn 2 %}
{{ 'This is the footnote.' | fndetail: 1 }}
{{ 'This is the other footnote. You can even have a [link](www.github.com)!' | fndetail: 2 }}
| github_jupyter |
# Welcome to nbdev
> Create delightful python projects using Jupyter Notebooks
- image:images/nbdev_source.gif
`nbdev` is a library that allows you to develop a python library in [Jupyter Notebooks](https://jupyter.org/), putting all your code, tests and documentation in one place. That is: you now have a true [literate programming](https://en.wikipedia.org/wiki/Literate_programming) environment, as envisioned by Donald Knuth back in 1983!
`nbdev` makes debugging and refactor your code much easier relative to traditional programming environments. Furthermore, using nbdev promotes software engineering best practices because tests and documentation are first class citizens.
The developers use this regularly on macOS and Linux. We have not tested it on Windows and not all features may work correctly.
## Features of Nbdev
`nbdev` provides the following tools for developers:
- **Automatically generate docs** from Jupyter notebooks. These docs are searchable and automatically hyperlinked to appropriate documentation pages by introspecting keywords you surround in backticks.
- Utilities to **automate the publishing of pypi and conda packages** including version number management.
- A robust, **two-way sync between notebooks and source code**, which allow you to use your IDE for code navigation or quick edits if desired.
- **Fine-grained control on hiding/showing cells**: you can choose to hide entire cells, just the output, or just the input. Furthermore, you can embed cells in collapsible elements that are open or closed by default.
- Ability to **write tests directly in notebooks** without having to learn special APIs. These tests get executed in parallel with a single CLI command. You can even define certain groups of tests such that you don't have to always run long-running tests.
- Tools for **merge/conflict resolution** with notebooks in a **human readable format**.
- **Continuous integration (CI) comes setup for you with [GitHub Actions](https://github.com/features/actions)** out of the box, that will run tests automatically for you. Even if you are not familiar with CI or GitHub Actions, this starts working right away for you without any manual intervention.
- **Integration With GitHub Pages for docs hosting**: nbdev allows you to easily host your documentation for free, using GitHub pages.
- Create Python modules, following **best practices such as automatically defining `__all__`** ([more details](http://xion.io/post/code/python-all-wild-imports.html)) with your exported functions, classes, and variables.
- **Math equation support** with LaTeX.
- ... and much more! See the [Getting Started](https://nbdev.fast.ai/#Getting-Started) section below for more information.
## A Motivating Example
For example, lets define a class that represents a playing card, with associated docs and tests in a Jupyter Notebook:

In the above screenshot, we have code, tests and documentation in one context! `nbdev` renders this into searchable docs (which are optionally hosted for free on GitHub Pages). Below is an annotated screenshot of the generated docs for further explanation:

The above illustration is a subset of [this nbdev tutorial with a minimal example](https://nbdev.fast.ai/example.html), which uses code from [Think Python 2](https://github.com/AllenDowney/ThinkPython2) by Allen Downey.
### Explanation of annotations:
1. The heading **Card** corresponds to the first `H1` heading in a notebook with a note block _API Details_ as the summary.
2. `nbdev` automatically renders a Table of Contents for you.
3. `nbdev` automatically renders the signature of your class or function as a heading.
4. The cells where your code is defined will be hidden and replaced by standardized documentation of your function, showing its name, arguments, docstring, and link to the source code on github.
5. This part of docs is rendered automatically from the docstring.
6. The rest of the notebook is rendered as usual. You can hide entire cells, hide only cell input or hide only output by using the [flags described on this page](https://nbdev.fast.ai/export2html.html).
7. nbdev supports special block quotes that render as colored boxes in the documentation. You can read more about them [here](https://nbdev.fast.ai/export2html.html#add_jekyll_notes). In this specific example, we are using the `Note` block quote.
8. Words you surround in backticks will be automatically hyperlinked to the associated documentation where appropriate. This is a trivial case where `Card` class is defined immediately above, however this works across pages and modules. We will see another example of this in later steps.
## Installing
nbdev is on PyPI and conda so you can just run `pip install nbdev` or `conda install -c fastai nbdev`.
For an [editable install](https://stackoverflow.com/questions/35064426/when-would-the-e-editable-option-be-useful-with-pip-install), use the following:
```
git clone https://github.com/fastai/nbdev
pip install -e nbdev
```
_Note that `nbdev` must be installed into the same python environment that you use for both your Jupyter Server and your workspace._
## Getting Started
The following are helpful resources for getting started with nbdev:
- The [tutorial](https://nbdev.fast.ai/tutorial.html).
- A [minimal, end-to-end example](https://nbdev.fast.ai/example.html) of using nbdev. We suggest replicating this example after reading through the tutorial to solidify your understanding.
- The [docs](https://nbdev.fast.ai/).
- [release notes](https://github.com/fastai/nbdev/blob/master/CHANGELOG.md).
## If Someone Tells You That You Shouldn't Use Notebooks For Software Development
[Watch this video](https://youtu.be/9Q6sLbz37gk).
## Contributing
If you want to contribute to `nbdev`, be sure to review the [contributions guidelines](https://github.com/fastai/nbdev/blob/master/CONTRIBUTING.md). This project adheres to fastai`s [code of conduct](https://github.com/fastai/nbdev/blob/master/CODE-OF-CONDUCT.md). By participating, you are expected to uphold this code. In general, the fastai project strives to abide by generally accepted best practices in open-source software development.
Make sure you have the git hooks we use installed by running
```
nbdev_install_git_hooks
```
in the cloned repository folder.
## Copyright
Copyright 2019 onwards, fast.ai, Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this project's files except in compliance with the License. A copy of the License is provided in the LICENSE file in this repository.
## Appendix
### nbdev and fastai
`nbdev` has been used to build innovative software used by many developers, such as [fastai](https://docs.fast.ai/), a deep learning library which implements a [unique layered api and callback system](https://arxiv.org/abs/2002.04688), and [fastcore](https://fastcore.fast.ai/), an extension to the Python programming language. Furthermore, `nbdev` allows a very small number of developers to maintain and grow a [large ecosystem](https://github.com/fastai) of software engineering, data science, machine learning and devops tools.
Here, for instance, is how `combined_cos` is defined and documented in the `fastai` library:
<img alt="Exporting from nbdev" width="700" caption="An example of a function defined in one cell (marked with the export flag) and explained, along with a visual example, in the following cells" src="images/export_example.png" />
| github_jupyter |
```
import sys
import os
sys.path.append(os.path.join('../src/detectron2/projects/DensePose/'))
import cv2
import pickle
from src.dataset.MINDS import MINDSDataset
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
gei_ = cv2.imread("../data/MINDS-Libras_RGB-D/gei/Sinalizador02/06Bala/2-06Bala_1RGB.png", cv2.IMREAD_GRAYSCALE)/255;
plt.figure()
plt.imshow(gei_, cmap='gray')
plt.show()
with open("../data/MINDS-Libras_RGB-D/gei/Sinalizador02/06Bala/2-06Bala_1RGB.pkl", 'rb') as f:
x = pickle.load(f)
plt.figure()
plt.imshow(x, cmap='gray')
plt.show()
from sklearn.model_selection import train_test_split, KFold, RandomizedSearchCV
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA, TruncatedSVD
from skopt import BayesSearchCV
from skopt.space import Real, Categorical, Integer
from scipy.stats import uniform, loguniform
data = MINDSDataset("../data/MINDS-Libras_RGB-D/")
# pipeline class is used as estimator to enable
# search over different model types
base_pipe = Pipeline([
('reduction', TruncatedSVD()),
('model', SVC())
])
# svc_SVD_space = {
# 'reduction': Categorical([TruncatedSVD(random_state=0),]),
# 'reduction__n_components': Integer(2, 150),
# 'model': Categorical([SVC()]),
# 'model__C': Real(1e-6, 1e+6, prior='log-uniform'),
# 'model__gamma': Real(1e-6, 1e+1, prior='log-uniform'),
# 'model__degree': Integer(1,8),
# 'model__kernel': Categorical(['linear', 'poly', 'rbf']),
# }
svc_SVD = {
'reduction': [TruncatedSVD(random_state=0),],
'reduction__n_components': np.arange(60, 80, dtype=int),
# 'model': Categorical([SVC(C=0.285873, degree=5.0, gamma=0.002535, kernel='linear', )]),
'model': [SVC(),],
'model__C': loguniform(1e-6, 1e+6,),
'model__gamma': loguniform(1e-6, 1e+1),
'model__degree': np.arange(1,8, dtype=int),
'model__kernel': ['linear', 'poly', 'rbf'],
}
n_splits = 3 # for param search in bayesian optimization
cv = KFold(n_splits=n_splits, random_state=42, shuffle=True)
n_trials = 10
n_search = 512
test_size = 0.25
res_test = []
opt_SVD = dict()
dims = [(64, 48), (96, 54), (64, 36)]
for dim in dims:
print(dim)
X, y = data.load_features(
exclude={3: 'all',
4: ["Filho"],
9: 'all'
},
dim=dim,
crop_person=True,
shuffle=True,
flatten=True)
le = LabelEncoder()
y = le.fit_transform(y)
for n_trial in range(n_trials):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=n_trial)
# opt_SVD[f'trial_{n_trial}'] = BayesSearchCV(
# base_pipe,
# # (parameter space, # of evaluations)
# [(svc_SVD_space, n_search),],
# scoring='accuracy',
# cv=cv).fit(X_train, y_train)
opt_SVD[f'trial_{n_trial}'] = RandomizedSearchCV(
base_pipe,
svc_SVD,
n_iter=n_search,
scoring='accuracy',
cv=cv,
).fit(X_train, y_train)
res_trial = opt_SVD[f'trial_{n_trial}'].score(X_test, y_test)
print(f'Trial {n_trial} ACC: {res_trial}')
res_test.append(res_trial)
print(f"Mean acc: {np.mean(res_test):.5f} +/- {np.std(res_test):.5f}\n\n")
# subtracting the mean
n_trials = 10
n_search = 512random --n_eval 16 --optim rando
test_size = 0.25
res_test = []
opt_SVD = dict()
dims = [(64, 48), (96, 54), (64, 36)]
for dim in dims:
print(dim)
X, y = data.load_features(
exclude={3: 'all',
4: ["Filho"],
9: 'all'
},
dim=dim,
crop_person=True,
shuffle=True,
flatten=True)
le = LabelEncoder()
y = le.fit_transform(y)
for n_trial in range(n_trials):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=n_trial)
mean = X_train.mean(axis=0)
X_train = X_train - mean
X_test = X_test - mean
# opt_SVD[f'trial_{n_trial}'] = BayesSearchCV(
# base_pipe,
# # (parameter space, # of evaluations)
# [(svc_SVD_space, n_search),],
# scoring='accuracy',
# cv=cv).fit(X_train, y_train)
opt_SVD[f'trial_{n_trial}'] = RandomizedSearchCV(
base_pipe,
svc_SVD,
n_iter=n_search,
scoring='accuracy',
cv=cv,
).fit(X_train, y_train)
res_trial = opt_SVD[f'trial_{n_trial}'].score(X_test, y_test)
print(f'Trial {n_trial} ACC: {res_trial}')
res_test.append(res_trial)
print(f"Mean acc: {np.mean(res_test):.5f} +/- {np.std(res_test):.5f}\n\n")
# We tried running on different sizes and subtracting the mean (as in their paper).
# However, we did not notice significant improvement.
# Therefore, we keep 64x48 without subtracting the mean.
# we generate results runing `tools/main_MINDS.py`
```
| github_jupyter |
# Lecture 12: Dynamic Programming
In lecture we'll also talk about the Floyd-Warshall and Bellman-Ford algorithms. In this notebook we'll introduce the benefits of dynamic programming by considering the simple problem of computing Fibonacci numbers.
```
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import time
%matplotlib inline
```
Here is one way to compute the Fibonacci numbers:
```
def Fibonacci(n):
if n == 0 or n == 1:
return 1
return Fibonacci(n-1) + Fibonacci(n-2)
for n in range(10):
print(Fibonacci(n))
def computeSomeVals(myFn, Ns = range(10,100,10), numTrials=3):
nValues = []
tValues = []
for n in Ns:
# run myFn several times and average to get a decent idea.
runtime = 0
for t in range(numTrials):
start = time.time()
myFn(n)
end = time.time()
runtime += (end - start) * 1000 # measure in milliseconds
runtime = runtime/numTrials
nValues.append(n)
tValues.append(runtime)
return nValues, tValues
nVals = range(1,30)
nVals, tVals = computeSomeVals(Fibonacci, nVals)
plt.plot(nVals, tVals, color="blue", label="Naive Fibonacci")
plt.xlabel("n")
plt.ylabel("Time(ms)")
plt.legend()
plt.title("Computing Fibonacci Numbers")
def fasterFibonacci(n):
F = [1 for i in range(n+1)]
for i in range(2,n+1):
F[i] = F[i-1] + F[i-2]
return F[n]
for n in range(10):
print(Fibonacci(n))
nValsFast = range(1,2000,10)
nValsFast, tValsFast = computeSomeVals(fasterFibonacci, nValsFast,numTrials=50)
plt.plot(nVals, tVals, color="blue", label="Naive Fibonacci")
plt.plot(nValsFast, tValsFast, "--", color="red", label="faster Fibonacci")
plt.xlabel("n")
plt.ylabel("Time(ms)")
plt.legend()
plt.ylim([0,tValsFast[-1]])
plt.title("Computing Fibonacci Numbers")
def Fibonacci_topdown(n,F):
if F[n] != None:
return F[n]
F[n] = Fibonacci_topdown(n-1,F) + Fibonacci_topdown(n-2,F)
return F[n]
for n in range(10):
print(Fibonacci_topdown(n, [1,1] + [None for i in range(n-1)]))
nValsTD = range(1,2000,10)
nValsTD, tValsTD = computeSomeVals(fasterFibonacci, nValsTD,numTrials=50)
plt.plot(nVals, tVals, color="blue", label="Naive Fibonacci")
plt.plot(nValsFast, tValsFast, "--", color="red", label="faster Fibonacci, bottom-up")
plt.plot(nValsTD, tValsTD, ":", color="green", label="faster Fibonacci, top-down")
plt.xlabel("n")
plt.ylabel("Time(ms)")
plt.legend()
plt.ylim([0,tValsFast[-1]])
plt.title("Computing Fibonacci Numbers")
```
# Here's a puzzle:
Our code looks like it has runtime O(n). But if we go out far enough it looks like it's curving up. What's going on? (You'll see this on your HW)
```
nValsFast = list(range(1,100,10)) + list(range(100,1000,100)) + list(range(1000,10000,500)) + list(range(10000,50000,5000))
nValsFast, tValsFast = computeSomeVals(fasterFibonacci, nValsFast,numTrials=20)
plt.plot(nValsFast, tValsFast, "--", color="red", label="faster Fibonacci (bottom-up)")
plt.xlabel("n")
plt.ylabel("Time(ms)")
plt.legend()
plt.ylim([0,tValsFast[-1]])
plt.title("Computing Fibonacci Numbers")
plt.show()
def squareMat(a,b,c,d):
return ( a**2 + b*c, a*b + b*d , c*a + d*c , c*b + d**2 )
def makePower(t):
a = 0
b = 1
c = 1
d = 1
for i in range(t):
a,b,c,d = squareMat(a,b,c,d)
return a + b
for t in range(8):
print(t, fasterFibonacci(2**t), makePower(t))
fakeNVals = [x for x in range(17)]
nValsFaster, tValsFaster = computeSomeVals(makePower, fakeNVals,numTrials=50)
nValsFaster = [2**x for x in range(17)]
plt.plot(nValsFast, tValsFast, "--", color="red", label="faster Fibonacci (bottom-up)")
plt.plot(nValsFaster, tValsFaster, "-", color="blue", label="real faster Fibonacci")
plt.xlabel("n")
plt.ylabel("Time(ms)")
plt.legend()
plt.ylim([0,40])
plt.title("Computing Fibonacci Numbers")
plt.show()
```
| github_jupyter |
# Fixing the view for Detection and Tracking Example
Becuase of the wind sometime the drone moves a bit randomly. As a result, the frames will have a slight transition and rotation. This is undesriable as it will make the a transition and rotation in the detected trajectories as well. For that, we need to do some transformation on the frames to make them all to have the same view.
In the following example of the sample video all the frames should have the same position.
All the parameters for view fixing are in `configs` class, section `Fix view`.
First of all, all the required liberaries should be imported.
```
from offlinemot.utils_ import resize
from offlinemot.fix_view import FixView, BG_subtractor
from offlinemot.config import configs
import numpy as np
import os
import cv2
```
Now the sample video should be read with a video reader object from Opencv library
```
cfg = configs()
cap = cv2.VideoCapture(os.path.join(cfg.cwd,'model','sample.mp4'))
ret, bg = cap.read() # read the first frame
```
The first frame is considered the default frame in the start to compare it with the next frames in the video in order to detect the transformation needed to each frame.
In the case where we want start to the movement detection at some later frame, not the first one. We could write
```
frame_id = 1 # the frame that should we start from
cap.set(1, frame_id-1)
```
Then the first reference frame is read
```
ret,bg_rgb = cap.read()
```
Then we intilize the fix view and background substarctor objects. The latter is needed so we can see the effect of stabilizing the view.
```
Fix_obj = FixView(bg_rgb,config=cfg)
BG_s = BG_subtractor(bg,config=cfg)
ret, frame = cap.read()
```
To start fixing each frame at the start we need the forground mask. For that we run the background substarction one time before the main loop
```
fg_img= BG_s.bg_substract(frame)
```
## Main loop
Now it is time to start the fixing and background substarction loop.
The result will be shown in a new window
The video will keep running until you hit **ESC** or the video ends
```
while ret:
frame_id += 1
frame = Fix_obj.fix_view(frame,fg_img)
I_com = BG_s.bg_substract(frame)
cv2.imshow('fgmask', resize(frame,0.2))
#print(frame_id)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
```
We find that the program is slow. but we will try to run the step of filtering of small objects to evaluate the performace of the program.
```
cap = cv2.VideoCapture(os.path.join(cfg.cwd,'model','sample.mp4'))
ret, bg = cap.read() # read the first frame
BG_s = BG_subtractor(bg,config=cfg)
Fix_obj = FixView(bg_rgb,config=cfg)
ret, frame = cap.read()
fg_img= BG_s.bg_substract(frame)
frame_id = 0
while ret:
frame_id += 1
I_com = BG_s.bg_substract(frame)
# filter small objects
I_com, _ = BG_s.get_big_objects(I_com,frame)
cv2.imshow('fgmask', resize(frame,0.2))
#print(frame_id)
# save one frame for showing in the notebook
if frame_id == 30:
frame_2_save = resize(I_com).copy()
k = cv2.waitKey(30) & 0xff
if k == 27:
break
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
```
At the end we can show the background subtraction result in step 30.
```
%matplotlib inline
import matplotlib.pyplot as plt
plt.imshow(frame_2_save)
```
| github_jupyter |
# Imports
```
import torch
import torch.nn.functional as F
import torch.nn as nn
import imageio
import numpy as np
import itertools
import torch.optim as optim
import matplotlib.pyplot as plt
import os,time
from torchvision import transforms, datasets
from torch.autograd import Variable
```
# Parameters
```
lr = 0.0002
img_size = 32
batch_size = 512
num_epochs = 40
save_dir = '/home/abdullah/Documents/ai/models/Own implementation of Gan/Conditional Gan/Model results'
G_input_dim = 100
G_output_dim = 1
D_input_dim = 1
D_output_dim = 1
label_dim = 10
def to_var(x):
x = x.cuda()
return Variable(x)
def denorm(x):
out = (x+1)/2
return out.clamp(0,1)
def plot_loss(d_losses, g_losses, num_epoch, save=True ,show=False):
fig, ax = plt.subplots()
ax.set_xlim(0, num_epochs)
ax.set_ylim(0, max(np.max(g_losses), np.max(d_losses))*1.1)
plt.xlabel('Epoch {0}'.format(num_epoch + 1))
plt.ylabel('Loss values')
plt.plot(d_losses, label='Discriminator')
plt.plot(g_losses, label='Generator')
plt.legend()
# save figure
if save:
save_fn = save_dir + 'MNIST_cDCGAN_losses_epoch_{:d}'.format(num_epoch + 1) + '.png'
plt.savefig(save_fn)
if show:
plt.show()
else:
plt.close()
def plot_result(generator, noise, label, num_epoch, save=True, show=False, fig_size=(5, 5)):
generator.eval()
noise = Variable(noise.cuda())
label = Variable(label.cuda())
gen_image = generator(noise, label)
gen_image = denorm(gen_image)
generator.train()
n_rows = np.sqrt(noise.size()[0]).astype(np.int32)
n_cols = np.sqrt(noise.size()[0]).astype(np.int32)
fig, axes = plt.subplots(n_rows, n_cols, figsize=fig_size)
for ax, img in zip(axes.flatten(), gen_image):
ax.axis('off')
ax.set_adjustable('box-forced')
ax.imshow(img.cpu().data.view(img_size, img_size).numpy(), cmap='gray', aspect='equal')
plt.subplots_adjust(wspace=0, hspace=0)
title = 'Epoch {0}'.format(num_epoch+1)
fig.text(0.5, 0.04, title, ha='center')
# save figure
if save:
save_fn = save_dir + 'MNIST_cDCGAN_epoch_{:d}'.format(num_epoch+1) + '.png'
plt.savefig(save_fn)
if show:
plt.show()
else:
plt.close()
```
# Data Loading
```
transform = transforms.Compose([
transforms.Scale(img_size),
transforms.ToTensor(),
transforms.Normalize(mean = (0.5,0.5,.5), std = (.5,.5,.5))
])
mnist_data = datasets.MNIST(root="/home/abdullah/Documents/ai/models/Own implementation of Gan/Untitled Folder/DCGAN/mnist",
train=True,
transform=transform,
download=False)
data_loader = torch.utils.data.DataLoader(dataset=mnist_data,
batch_size=batch_size,
shuffle=True)
```
# Model Architecture
```
class generator(nn.Module):
def __init__(self,d=128):
super(generator,self).__init__()
self.deconv1_z = nn.ConvTranspose2d( 100 , d*2 , 4 , 1 , 0)
self.deconv1_y = nn.ConvTranspose2d( 10, d*2 , 4 , 1, 0)
self.batch_norm_1 = nn.BatchNorm2d(d*2)
self.deconv2 = nn.ConvTranspose2d(d*4 , d*2, 4, 2, 1)
self.batch_norm_2 = nn.BatchNorm2d(d*2)
self.deconv3 = nn.ConvTranspose2d(d*2 , d , 4 , 2 , 1)
self.batch_norm_3 = nn.BatchNorm2d(d)
self.deconv4 = nn.ConvTranspose2d(d , 1 , 4, 2 , 1)
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean , std)
def forward(self , input , label):
x = F.relu(self.batch_norm_1(self.deconv1_z(input)))
y = F.relu(self.batch_norm_1(self.deconv1_y(label)))
x = torch.cat([x,y],1)
x = F.relu(self.batch_norm_2(self.deconv2(x)))
x = F.relu(self.batch_norm_3(self.deconv3(x)))
x = F.tanh(self.deconv4(x))
return x
class discriminator(nn.Module):
def __init__(self, d = 128):
super( discriminator, self).__init__()
print("hello")
self.conv1_x = nn.Conv2d(1 , d//2 , 4, 2, 1)
self.conv1_y = nn.Conv2d(10 , d//2 , 4, 2, 1)
self.conv2 = nn.Conv2d( d, d*2, 4, 2, 1)
self.batch_norm_2 = nn.BatchNorm2d(d*2)
self.conv3 = nn.Conv2d( d*2, d*4, 4 , 2, 1)
self.batch_norm_3 = nn.BatchNorm2d(d*4)
self.conv4 = nn.Conv2d( d*4, 1, 4, 1, 0)
def weight_init(self, mean , std):
for m in self._modules:
normal_init(self._modules[m], mean , std)
def forward(self, input , label):
x = F.leaky_relu(self.conv1_x(input),0.2)
y = F.leaky_relu(self.conv1_y(label),0.2)
x = torch.cat([x,y],1)
x = F.leaky_relu(self.batch_norm_2(self.conv2(x)),0.2)
x = F.leaky_relu(self.batch_norm_3(self.conv3(x)),0.2)
x = F.sigmoid(self.conv4(x))
return x
def normal_init(m, mean, std):
if isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Conv2d):
m.weight.data.normal_(mean, std)
m.bias.data.zero_()
generator = generator()
discriminator = discriminator()
generator.weight_init(mean = 0 , std = 0.02)
discriminator.weight_init(mean = 0 , std = 0.02)
generator.cuda()
discriminator.cuda()
```
# Optimizations
```
opt_Gen = optim.Adam(generator.parameters(),lr = lr , betas = (.5, .999))
opt_Disc = optim.Adam(discriminator.parameters(),lr = lr , betas = (.5, .999))
criterion = torch.nn.BCELoss()
```
# Training
```
# num_test_samples = 10*10
temp_noise = torch.randn(label_dim, G_input_dim)
fixed_noise = temp_noise
fixed_c = torch.zeros(label_dim, 1)
for i in range(9):
fixed_noise = torch.cat([fixed_noise, temp_noise], 0)
temp = torch.ones(label_dim, 1) + i
fixed_c = torch.cat([fixed_c, temp], 0)
fixed_noise = fixed_noise.view(-1, G_input_dim, 1, 1)
fixed_label = torch.zeros(G_input_dim, label_dim)
fixed_label.scatter_(1, fixed_c.type(torch.LongTensor), 1)
fixed_label = fixed_label.view(-1, label_dim, 1, 1)
# label preprocess
onehot = torch.zeros(label_dim, label_dim)
onehot = onehot.scatter_(1, torch.LongTensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]).view(label_dim, 1), 1).view(label_dim, label_dim, 1, 1)
fill = torch.zeros([label_dim, label_dim, img_size, img_size])
for i in range(label_dim):
fill[i, i, :, :] = 1
D_avg_losses = []
G_avg_losses = []
for epoch in range(1, num_epochs +1):
D_losses = []
G_losses = []
epoch_start_time = time.time()
generator.train()
if epoch == 5 or epoch == 10:
opt_Gen.param_groups[0]['lr'] /=2
opt_Disc.param_groups[0]['lr'] /=2
for i, (real_images,real_labels) in enumerate(data_loader):
minibatch = real_images.size()[0]
real_images = Variable(real_images.cuda())
#labels
y_real = Variable(torch.ones(minibatch).cuda())
y_fake = Variable(torch.zeros(minibatch).cuda())
c_fill = Variable(fill[real_labels].cuda())
z_ = torch.randn(minibatch, G_input_dim).view(-1, G_input_dim, 1, 1)
z_ = Variable(z_.cuda())
## Train Discriminator
# first with real data
D_real_decision = discriminator(real_images, c_fill).squeeze()
D_real_loss = criterion(D_real_decision, y_real)
# Then with fake data
c_ = (torch.rand(minibatch, 1) * label_dim).type(torch.LongTensor).squeeze()
c_onehot_ = Variable(onehot[c_].cuda())
c_fill_ = Variable(fill[c_].cuda())
generator_image = generator(z_, c_onehot_)
D_fake_decision = discriminator(generator_image,c_fill_).squeeze()
D_fake_loss = criterion(D_fake_decision, y_fake)
# Optimization
discriminator.zero_grad()
D_loss = D_fake_loss + D_real_loss
D_loss.backward()
opt_Disc.step()
# Train Generator
generator_image = generator(z_, c_onehot_)
c_fill = Variable(fill[c_].cuda())
D_fake_decision = discriminator(generator_image,c_fill).squeeze()
G_loss = criterion(D_fake_decision, y_real)
# Optimization
generator.zero_grad()
G_loss.backward()
opt_Gen.step()
D_losses.append(D_loss.data[0])
G_losses.append(G_loss.data[0])
print('Epoch [%d/%d], Step [%d/%d], D_loss: %.4f, G_loss: %.4f'
% (epoch+1, num_epochs, i+1, len(data_loader), D_loss.data[0], G_loss.data[0]))
torch.save(generator.state_dict(), '/home/abdullah/Documents/ai/models/Own implementation of Gan/Conditional Gan/model_weights/generator_param.pkl')
torch.save(discriminator.state_dict(), '/home/abdullah/Documents/ai/models/Own implementation of Gan/Conditional Gan/model_weights/discriminator_param.pkl')
D_avg_loss = torch.mean(torch.FloatTensor(D_losses))
G_avg_loss = torch.mean(torch.FloatTensor(G_losses))
# avg loss values for plot
D_avg_losses.append(D_avg_loss)
G_avg_losses.append(G_avg_loss)
plot_loss(D_avg_losses, G_avg_losses, epoch, save=True)
# Show result for fixed noise
plot_result(generator, fixed_noise, fixed_label, epoch, save=True)
# Make gif
loss_plots = []
gen_image_plots = []
for epoch in range(2,24):
# plot for generating gif
save_fn1 = 'Model resultsMNIST_cDCGAN_losses_epoch_{:d}'.format(epoch + 1) + '.png'
loss_plots.append(imageio.imread(save_fn1))
save_fn2 = 'Model resultsMNIST_cDCGAN_epoch_{:d}'.format(epoch + 1) + '.png'
gen_image_plots.append(imageio.imread(save_fn2))
imageio.mimsave('MNIST_cDCGAN_losses_epochs_{:d}'.format(num_epochs) + '.gif', loss_plots, fps=5)
imageio.mimsave('MNIST_cDCGAN_epochs_{:d}'.format(num_epochs) + '.gif', gen_image_plots, fps=5)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/SDS-AAU/SDS-2021/blob/master/static/workshops/2021/SDS21_M2W2.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
!pip install tweet-preprocessor -qq
import pandas as pd
import preprocessor as prepro
import spacy
```
load up data
```
data_congress = pd.read_json('https://github.com/SDS-AAU/SDS-master/raw/master/M2/data/pol_tweets.gz')
data_congress
```
preprocessing
```
# prepro settings
prepro.set_options(prepro.OPT.URL, prepro.OPT.EMOJI, prepro.OPT.NUMBER, prepro.OPT.RESERVED, prepro.OPT.MENTION, prepro.OPT.SMILEY)
data_congress['text_clean'] = data_congress['text'].map(lambda t: prepro.clean(t))
data_congress['text_clean'] = data_congress['text_clean'].str.replace('#','')
```
bootstrap dictionary with spacy (add-on)
here we take a sample of 1000 tweets and create a dictionary only containinng `'NOUN', 'PROPN', 'ADJ', 'ADV'` - the assumption is that we thereby can capture "more relevant" words...we also remove stoppwords and lematize
```
nlp = spacy.load("en")
tokens = []
for tweet in nlp.pipe(data_congress.sample(5000)['text_clean']):
tweet_tok = [token.lemma_.lower() for token in tweet if token.pos_ in ['NOUN', 'PROPN', 'ADJ', 'ADV'] and not token.is_stop]
tokens.extend(tweet_tok)
# here we create this dictionary and in the next step it is used in the tokenization
bootstrap_dictionary = list(set(tokens))
```
repack preprocessing into a function
```
# now only for the cleanup. The vectorizer is removed and put into the pipeline below.
def preprocessTweets(data_tweets):
clean_text = data_tweets.map(lambda t: prepro.clean(t))
clean_text = clean_text.str.replace('#','')
return clean_text
```
vectorization and SML part
Here we also add random undersampling (using imblearn) to improve the recall on the underrerresented class "rep" (0)
For this to work we build a pipeline into which we put Tfidfvectorization, undersampline and the logistic regression. This bundles all steps together so that we don't have to exicute them all individually every time.
```
X = data_congress['text_clean']
y = data_congress['labels']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 21)
from imblearn.under_sampling import RandomUnderSampler
from imblearn.pipeline import make_pipeline as make_pipeline_imb
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
model = make_pipeline_imb(TfidfVectorizer(vocabulary=bootstrap_dictionary),
RandomUnderSampler(),
LogisticRegression())
model.fit(X_train, y_train)
model.score(X_test, y_test)
from sklearn.metrics import classification_report
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
```
apply to new data
```
data_tweets = pd.read_json('https://github.com/SDS-AAU/SDS-master/raw/master/M2/data/pres_debate_2020.gz')
data_tweets
X_new_tweets = preprocessTweets(data_tweets['tweet'])
predictions_new_tweets = model.predict_proba(X_new_tweets)
predictions_new_tweets
data_tweets['dem_probability'] = predictions_new_tweets[:,1]
for tweet in data_tweets.sort_values('dem_probability')['tweet'][:10]:
print(tweet)
print('\n')
for tweet in data_tweets.sort_values('dem_probability')['tweet'][-10:]:
print(tweet)
print('\n')
```
explainability
```
!pip -q install eli5
import eli5
eli5.show_weights(model[2], #we are pulling the model from the undersampling pipeline here (it has the index 2)
feature_names=vectorizer.get_feature_names(), target_names=['rep','dem'], top=20)
data_tweets['clean_tweet'] = preprocessTweets(data_tweets['tweet'])
eli5.show_prediction(model[2], data_tweets['clean_tweet'][5237], vec=model[0], target_names=['rep','dem'])
```
| github_jupyter |
<a href="https://colab.research.google.com/github/julianikulski/director-experience/blob/main/csr-committee/csr_committees.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Identifying CSR board committees
In this notebook, I am preprocessing the committee data from Refinitiv Eikon and identify which companies have a CSR related committee and which do not. Refinitiv has two data sources for committee information. First, they have a separate data field which lists CSR related committees on the board level AND the executive level. Because I am only interested in board level committees, I cannot use this list. Second, the director data from Refinitiv Eikon also contains information on the type of board committees a company has and which director is a part of those committees (albeit this dataset is missing the time period of committee membership, which therefore still needs to be manually gathered from DEF 14As). However, this director data only contains CSR related committees if their sole purpose is CSR. In many cases, companies have nominating and/or governance committees which also oversee sustainability and CSR at companies. Therefore, I cannot use this list alone either because there are many relevant committees missing from this dataset.
Therefore, in this notebook, I am using the information from the two sources as an indication for the manual review I will be doing of the DEF 14As for the missing biographies and the missing committee information. The final excel file which I write in this notebook contains all relevant companies and directors with the additional information on potentially relevant CSR board committees. This list was then completed by manually researching missing biographies and committee information from DEF 14A filings.
```
# connecting to Google Drive to access files
from google.colab import drive
drive.mount('/content/drive')
import numpy as np
import pandas as pd
from glob import glob
import os
import tqdm.notebook as tqdm
import re
# change settings to display full width of column content
#pd.set_option('display.max_colwidth', None)
#pd.set_option('display.max_columns', None)
```
## Read in data
```
# read in all committee data which was previously preprocessed
committee_df = pd.read_csv('/content/drive/My Drive/director-csr/all_committees.csv')
committee_df.drop(columns=['Unnamed: 0'], inplace=True)
committee_df.head()
# how many entries are in this dataframe
committee_df.shape
# read in the csr sustainability committee data field by Reuters
csr_df = pd.read_excel('/content/drive/My Drive/director-csr/committees/CSR_scores_committee.xlsx')
csr_df.head()
```
## Check whether these committees include csr committees or similiar
```
# remove brackets from committee column values and
# turn the strings in the committee column into lists
committee_df['committee'] = committee_df['committee'].apply(lambda x: x.strip('[]').replace('\'', '').replace(' ', '').split(','))
committee_df['committee']
# check what types of committees there are
unique_coms = []
for row in committee_df['committee']:
for com_type in row:
if com_type not in unique_coms:
unique_coms.append(com_type)
else:
pass
unique_coms
```
Out of these committees, the ones that are of interest to me are: environment, csr responsibility, social, and maybe human resources (although this is likely similar to the nominating committee). I will now review the csr sustainability committee data field by Reuters.
## Preprocess the csr sustainability committee data
```
# check how many companies are included
print(csr_df.shape)
# check how many variables are included per company
print((csr_df.shape[1]-2)/csr_df.shape[0])
# create a list of all ISINs that will be inserted as a row in the csr_df
all_isins_list = [item for isin in csr_df['ISIN Code'] for item in [isin]*8]
# drop the isin column
csr_df.drop(columns=['ISIN Code'], inplace=True)
# remove all empty rows
csr_df.dropna(subset=['Name'], inplace=True)
# turn the Name column which contains the years into the index
csr_df['Name'] = csr_df['Name'].astype(int)
csr_df.set_index('Name', inplace=True)
# add all ISINs to the table
csr_df.loc[0] = all_isins_list
csr_df
# drop any unnecessary columns from csr_df
cols = [col for col in csr_df.columns if any(['sustainability' in col.lower()])]
# create the new dataframe
csr_committee_df = csr_df[cols]
# change the column headers
changed_cols = [x.lower().split('-')[0].strip() for x in csr_committee_df.columns]
csr_committee_df.rename(columns=dict(zip(csr_committee_df.columns, changed_cols)), inplace=True)
# drop the year 2016 from the dataframe
csr_committee_df.drop([2016], inplace=True)
csr_committee_df
# remove any excess whitespace from values
csr_committee_df = csr_committee_df.applymap(lambda x: x.strip() if not pd.isna(x) else x)
csr_committee_df
# get the duplicate column names
duplicate_cols = list(set([x for x in list(csr_committee_df.columns) if list(csr_committee_df.columns).count(x) > 1]))
print(duplicate_cols)
# remove these duplicate columns from the dataframe
dupes_df = csr_committee_df[duplicate_cols]
csr_committee_df.drop(columns=duplicate_cols, inplace=True)
# split the dupes_df into two different dfs so that I can rename the cols
new_df = dupes_df.iloc[:, ::2]
remain_dupes_df = dupes_df.iloc[:, 1::2]
# rename the columns
new_col_names = [x+'_diff isin' for x in new_df.columns]
new_df.rename(columns=dict(zip(new_df.columns, new_col_names)), inplace=True)
# add those two dataframes back to the overall dataframe
csr_committee_df = csr_committee_df.join([new_df, remain_dupes_df])
csr_committee_df
# drop any companies that have N for all years
csr_committee_no_df = csr_committee_df.copy()
for col in csr_committee_no_df.columns:
if csr_committee_no_df[col][:-1].eq('Y').any():
csr_committee_no_df.drop(columns=[col], inplace=True)
csr_committee_yes_df = csr_committee_df.drop(columns=csr_committee_no_df.columns)
csr_committee_yes_df
# transpose the dataframe
csr_committee_yes_df = csr_committee_yes_df.T
# rename the isin column from 0 to isin
csr_committee_yes_df.rename(columns={0: 'isin'}, inplace=True)
# turn everything in dataframe into lower case
csr_committee_yes_df = csr_committee_yes_df.applymap(lambda x: x.lower() if not pd.isna(x) else x)
csr_committee_yes_df
```
## Get relevant persons from committee_df
```
# show the unique committees included in committee_df
print(unique_coms)
# select only the relevant ones
rel_comms = ['environment', 'csrresponsibility', 'social']
rel_comms
# get the relevant person who sits on a relevant committee
rel_person = []
for index, row in committee_df.iterrows():
for com_type in row['committee']:
if com_type in rel_comms:
rel_person.append(index)
else:
pass
print(len(rel_person), 'people with relevant committee memberships')
# put all relevant people in a dataframe
all_rel_persons_df = committee_df.iloc[rel_person, :]
all_rel_persons_df
# write this dataframe to an excel file
all_rel_persons_df.to_excel('/content/drive/My Drive/director-csr/committees/people_rel_comms.xlsx',
sheet_name='rel_people')
# now I also need to add a column to the csr_committee_yes_df if there is definitely
# a board committee based on the info from all_rel_persons_df
comps_with_comm = all_rel_persons_df['isin'].unique()
csr_committee_yes_df['board_committee'] = csr_committee_yes_df['isin'].apply(lambda x: 'Yes' if x in comps_with_comm else 'No')
csr_committee_yes_df
```
The categorizing whether a company has a board committee related to CSR is not perfect because it relies on director information, therefore, directors sitting on multiple boards will cause false positives. However, this will be dealt with during manual review.
```
# write this dataframe to an excel file
csr_committee_yes_df.to_excel('/content/drive/My Drive/director-csr/committees/comps_rel_comms.xlsx',
sheet_name='rel_comps')
```
## Add committee
```
# read in the biography director file
dir_bio_df = pd.read_excel('/content/drive/My Drive/director-csr/director_bios_all.xlsx')
dir_bio_df.drop(columns=['Unnamed: 0'], inplace=True)
# rename the isin_x column to just isin to prepare for merging
dir_bio_df.rename(columns={'isin_x': 'isin'}, inplace=True)
dir_bio_df.head()
# shape of the dataframe
dir_bio_df.shape
# merge both dataframes
dir_bio_comm_df = pd.merge(csr_committee_yes_df, dir_bio_df, how='right', on='isin')
dir_bio_comm_df.head()
# this function is taken from biography_matching.ipynb
def clean_names(df, bio=True):
'''
Function to clean up the director names so that they can be matched
Args: df = dataframe; containing director names
bio = bool; True if the biographies dataframe is added, False otherwise
Returns: df = dataframe
'''
# change the strings to lower case
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: x.lower())
# check if the names contain anything in parentheses and if so remove them and their content
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: re.sub(r'\([^()]*\)', '', x))
# check if the names contain a title like ms. and mr. and if so remove them
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: re.sub(r'^\w{2,3}\. ?', '', x))
# do two different things with the commas for the different dataframes
if bio:
# move the last name in the front of the comma to the back of the string and remove the comma
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: ' '.join([x.split(',')[1], x.split(',')[0]]))
else:
# create a new column that contains all the words after a comma at the end
df['qualification'] = df.iloc[:,0].apply(lambda x: x.split(',')[-1] if len(x.split(',')) > 1 else None)
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: x.split(',')[0])
# remove any initials or titles because they might be distracting when matching names
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: ' '.join([name if '.' not in name else '' for name in x.split()]))
# remove 'the' substring from names
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: re.sub(r'^the\s', '', x))
# ensure that all white space is stripped
df.iloc[:,0] = df.iloc[:,0].apply(lambda x: re.sub(' +', ' ', x).strip())
return df
# clean the names in the all_rel_persons_df
all_rel_persons_df = clean_names(all_rel_persons_df, bio=False)
all_rel_persons_df.head()
# manual sanity check
for name in dir_bio_comm_df.sort_values(by='name', ascending=True)['name']:
if 'fuller' in name:
print(name)
```
During my manual review of DEF 14A reports for biographies and committee memberships, I noticed several inconsistencies in the name files and therefore, I will be doing some name replacements
```
# merge this cleaned dataframe with the dir_bio_df
dir_bio_comm_all = pd.merge(all_rel_persons_df[['name','committee']], dir_bio_comm_df, how='right', on='name')
dir_bio_comm_all.shape
# example of the merged dataframes
dir_bio_comm_df[dir_bio_comm_df['name'] == 'george buckley']
# sort this dataframe by company name and not by director name
dir_bio_comm_all.sort_values(by='comp_name_x', ascending=True, inplace=True)
# rearrange the order of the dataframe
cols = list(dir_bio_comm_all.columns)
new_cols = ['name', 'org_name_x', 'org_name_y', 'board_committee', 'committee', 'comp_name_x', 'isin', 'biographies']
remove_cols = [col for col in cols if col not in new_cols]
new_cols.extend(remove_cols)
dir_bio_comm_all = dir_bio_comm_all[new_cols]
dir_bio_comm_all.head()
# what is the size of this final dataframe
dir_bio_comm_all.shape
# write this dataframe to an excel file
dir_bio_comm_all.to_excel('/content/drive/My Drive/director-csr/dir_bio_comm_all.xlsx',
sheet_name='dir_bio_comm')
```
## Please note the following
I had already started the manual review of the `dir_bio_comm_all` excel file when I tried some additional techniques to match directors to biographies in the `biography_matching` notebook. This additional code has now resulted in a different review list that was generated at the end of this notebook and saved as `dir_bio_comm_all.xlsx`. The manual review has been completed with the previous version of this excel list. However, it is not possible for me under the current time constraints, to revert those changes in the biography matching notebook to again generate the original excel list. Therefore, we will all have to live with this slight discrepancy in the lists generated for manual review.
**This will not change anything in relation to the overall results or calculations of this thesis.** My manually reviewed list will be compared to this newly generated excel file to ensure that no director was missed. So this can just be considered an FYI and a sorry for the inconsistency.
```
```
| github_jupyter |
### Creating multi-panel plots using `facets`.
#### Problem
You want to see more aspects of your data and it's not practcal to use the regular `aesthetics` approach for that.
#### Solution - `facets`
You can add one or more new dimentions to your plot using `faceting`.
This approach allows you to split up your data by one or more variables and plot the subsets of data together.
In this demo we will explore how various faceting functions work, as well as the built-in `sorting` and `formatting` options.
To learn more about formatting templates see: [Formatting](https://github.com/JetBrains/lets-plot-kotlin/blob/master/docs/formats.md).
```
%useLatestDescriptors
%use lets-plot
%use krangl
var data = DataFrame.readCSV("https://raw.githubusercontent.com/JetBrains/lets-plot-kotlin/master/docs/examples/data/mpg2.csv")
data.head(3)
```
### One plot
Create a scatter plot to show how `mpg` is related to a car's `engine horsepower`.
Also use the `color` aesthetic to vizualise the region where a car was designed.
```
val p = (letsPlot(data.toMap()) {x="engine horsepower"; y="miles per gallon"} +
geomPoint {color="origin of car"})
p + ggsize(800, 350)
```
### More dimentions
There are two functions for faceting:
- facetGrid()
- facetWrap()
The former creates 2-D matrix of plot panels and latter creates 1-D strip of plot panels.
We'll be using the `number of cylinders` variable as 1st fatceting variable, and sometimes the `origin of car` as a 2nd fatceting variable.
### facetGrid()
The data can be split up by one or two variables that vary on the X and/or Y direction.
#### One facet
Let's split up the data by `number of cylinders`.
```
p + facetGrid(x="number of cylinders")
```
#### Two facets
Split up the data by two faceting variables: `number of cylinders` and `origin of car`.
```
p + facetGrid(x="number of cylinders", y="origin of car")
```
#### Formatting and sorting.
Apply a formatting template to the `number of cylinders` and
sort the `origin of car` values in discending order.
To learn more about formatting templates see: [Formatting](https://github.com/JetBrains/lets-plot-kotlin/blob/master/docs/formats.md).
```
p + facetGrid(x="number of cylinders", y="origin of car", xFormat="{d} cyl", yOrder=-1)
```
### facetWrap()
The data can be split up by one or more variables.
The panels layout is flexible and controlled by `ncol`, `nrow` and `dir` options.
#### One facet
Split data by the `number of cylinders` variable and arrange tiles in two rows.
```
p + facetWrap(facets="number of cylinders", nrow=2)
```
#### Two facets
Split data by `origin of car` and `number of cylinders` and arrange tiles in 5 columns.
```
p + facetWrap(facets=listOf("origin of car", "number of cylinders"), ncol=5)
```
#### Arrange panels vertically.
Use the `dir` parameter to arrange tiles by columns, in 3 columns (the default tile arrangment is "by row").
Also, format `number of cylinders` labels and reverse the sorting direction for this facetting variable.
```
p + facetWrap(facets=listOf("origin of car", "number of cylinders"),
ncol=3,
format=listOf(null, "{} cyl"),
order=listOf(1, -1),
dir="v")
```
| github_jupyter |
# 머신 러닝 교과서 3판
# 16장 - 순환 신경망으로 순차 데이터 모델링 (2/2)
**아래 링크를 통해 이 노트북을 주피터 노트북 뷰어(nbviewer.jupyter.org)로 보거나 구글 코랩(colab.research.google.com)에서 실행할 수 있습니다.**
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://nbviewer.jupyter.org/github/rickiepark/python-machine-learning-book-3rd-edition/blob/master/ch16/ch16_part2.ipynb"><img src="https://jupyter.org/assets/main-logo.svg" width="28" />주피터 노트북 뷰어로 보기</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/rickiepark/python-machine-learning-book-3rd-edition/blob/master/ch16/ch16_part2.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />구글 코랩(Colab)에서 실행하기</a>
</td>
</table>
### 목차
- 텐서플로로 시퀀스 모델링을 위한 RNN 구현하기
- 두 번째 프로젝트: 텐서플로로 글자 단위 언어 모델 구현
- 데이터셋 전처리
- 문자 수준의 RNN 모델 만들기
- 평가 단계 - 새로운 텍스트 생성
- 트랜스포머 모델을 사용한 언어 이해
- 셀프 어텐션 메카니즘 이해하기
- 셀프 어텐션 기본 구조
- 쿼리, 키, 값 가중치를 가진 셀프 어텐션 메카니즘
- 멀티-헤드 어텐션과 트랜스포머 블록
- 요약
```
from IPython.display import Image
```
## 두 번째 프로젝트: 텐서플로로 글자 단위 언어 모델 구현
```
Image(url='https://git.io/JLdVE', width=700)
```
### 데이터셋 전처리
```
# 코랩에서 실행할 경우 다음 코드를 실행해 주세요.
!wget https://raw.githubusercontent.com/rickiepark/python-machine-learning-book-3rd-edition/master/ch16/1268-0.txt
import numpy as np
## 텍스트 읽고 전처리하기
with open('1268-0.txt', 'r', encoding='UTF8') as fp:
text=fp.read()
start_indx = text.find('THE MYSTERIOUS ISLAND')
end_indx = text.find('End of the Project Gutenberg')
print(start_indx, end_indx)
text = text[start_indx:end_indx]
char_set = set(text)
print('전체 길이:', len(text))
print('고유한 문자:', len(char_set))
Image(url='https://git.io/JLdVz', width=700)
chars_sorted = sorted(char_set)
char2int = {ch:i for i,ch in enumerate(chars_sorted)}
char_array = np.array(chars_sorted)
text_encoded = np.array(
[char2int[ch] for ch in text],
dtype=np.int32)
print('인코딩된 텍스트 크기: ', text_encoded.shape)
print(text[:15], ' == 인코딩 ==> ', text_encoded[:15])
print(text_encoded[15:21], ' == 디코딩 ==> ', ''.join(char_array[text_encoded[15:21]]))
Image(url='https://git.io/JLdVV', width=700)
import tensorflow as tf
ds_text_encoded = tf.data.Dataset.from_tensor_slices(text_encoded)
for ex in ds_text_encoded.take(5):
print('{} -> {}'.format(ex.numpy(), char_array[ex.numpy()]))
seq_length = 40
chunk_size = seq_length + 1
ds_chunks = ds_text_encoded.batch(chunk_size, drop_remainder=True)
## inspection:
for seq in ds_chunks.take(1):
input_seq = seq[:seq_length].numpy()
target = seq[seq_length].numpy()
print(input_seq, ' -> ', target)
print(repr(''.join(char_array[input_seq])),
' -> ', repr(''.join(char_array[target])))
Image(url='https://git.io/JLdVr', width=700)
## x & y를 나누기 위한 함수를 정의합니다
def split_input_target(chunk):
input_seq = chunk[:-1]
target_seq = chunk[1:]
return input_seq, target_seq
ds_sequences = ds_chunks.map(split_input_target)
## 확인:
for example in ds_sequences.take(2):
print('입력 (x):', repr(''.join(char_array[example[0].numpy()])))
print('타깃 (y):', repr(''.join(char_array[example[1].numpy()])))
print()
# 배치 크기
BATCH_SIZE = 64
BUFFER_SIZE = 10000
tf.random.set_seed(1)
ds = ds_sequences.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)# drop_remainder=True)
ds
```
### 문자 수준의 RNN 모델 만들기
```
def build_model(vocab_size, embedding_dim, rnn_units):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.LSTM(
rnn_units, return_sequences=True),
tf.keras.layers.Dense(vocab_size)
])
return model
charset_size = len(char_array)
embedding_dim = 256
rnn_units = 512
tf.random.set_seed(1)
model = build_model(
vocab_size = charset_size,
embedding_dim=embedding_dim,
rnn_units=rnn_units)
model.summary()
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True
))
model.fit(ds, epochs=20)
```
### 평가 단계 - 새로운 텍스트 생성
```
tf.random.set_seed(1)
logits = [[1.0, 1.0, 1.0]]
print('확률:', tf.math.softmax(logits).numpy()[0])
samples = tf.random.categorical(
logits=logits, num_samples=10)
tf.print(samples.numpy())
tf.random.set_seed(1)
logits = [[1.0, 1.0, 3.0]]
print('확률:', tf.math.softmax(logits).numpy()[0])
samples = tf.random.categorical(
logits=logits, num_samples=10)
tf.print(samples.numpy())
def sample(model, starting_str,
len_generated_text=500,
max_input_length=40,
scale_factor=1.0):
encoded_input = [char2int[s] for s in starting_str]
encoded_input = tf.reshape(encoded_input, (1, -1))
generated_str = starting_str
model.reset_states()
for i in range(len_generated_text):
logits = model(encoded_input)
logits = tf.squeeze(logits, 0)
scaled_logits = logits * scale_factor
new_char_indx = tf.random.categorical(
scaled_logits, num_samples=1)
new_char_indx = tf.squeeze(new_char_indx)[-1].numpy()
generated_str += str(char_array[new_char_indx])
new_char_indx = tf.expand_dims([new_char_indx], 0)
encoded_input = tf.concat(
[encoded_input, new_char_indx],
axis=1)
encoded_input = encoded_input[:, -max_input_length:]
return generated_str
tf.random.set_seed(1)
print(sample(model, starting_str='The island'))
```
* **예측 가능성 대 무작위성**
```
logits = np.array([[1.0, 1.0, 3.0]])
print('스케일 조정 전의 확률: ', tf.math.softmax(logits).numpy()[0])
print('0.5배 조정 후 확률: ', tf.math.softmax(0.5*logits).numpy()[0])
print('0.1배 조정 후 확률: ', tf.math.softmax(0.1*logits).numpy()[0])
tf.random.set_seed(1)
print(sample(model, starting_str='The island',
scale_factor=2.0))
tf.random.set_seed(1)
print(sample(model, starting_str='The island',
scale_factor=0.5))
```
# 트랜스포머 모델을 사용한 언어 이해
## 셀프 어텐션 메카니즘 이해하기
### 셀프 어텐션 기본 구조
```
Image(url='https://git.io/JLdVo', width=700)
```
### 쿼리, 키, 값 가중치를 가진 셀프 어텐션 메카니즘
## 멀티-헤드 어텐션과 트랜스포머 블록
```
Image(url='https://git.io/JLdV6', width=700)
```
| github_jupyter |
```
import xarray as xr
import numpy as np
import pandas as pd
%load_ext sql
%sql postgresql://localhost:5432/grav_29_1
%sql create extension if not exists postgis
%sql
# plotting modules
import matplotlib.pyplot as plt
%matplotlib inline
def raster_filter_range(raster0, g1, g2):
raster = raster0.copy()
raster.values = raster.values.astype(np.float32)
raster.values = gaussian_filter(raster.values,g1,mode='constant', cval=0) \
- gaussian_filter(raster.values,g2,mode='constant', cval=0)
return raster
def spectrum(raster, gammas, dgamma = 1.0):
rasters = []
for g in gammas:
print (g,". ", end = '')
_raster = raster_filter_range(raster, g-dgamma/2, g+dgamma/2)
rasters.append(_raster)
return rasters
```
## Parameters
```
# Gaussian filter sigma, km
sigmaskm = np.linspace(25,1425,29)
sigmaskm
```
## Raster from file
```
da = xr.open_dataarray('WGM2012_Bouguer_ponc_2min.grd').squeeze(drop=True)
da
# reduce dataset size
da = da.coarsen({'y':10, 'x':10}, boundary='trim').mean()
```
## Raster to Database
```
%%time
da.to_dataframe(name='z').to_csv('data.csv', header=False)
fname = !pwd
fname = fname[0] + '/data.csv'
%%time
%%sql
create extension if not exists postgis;
drop table if exists data;
create table data (lat float, lon float, z float, the_geom geography(Point, 4326));
COPY data (lat, lon, z) FROM :fname WITH DELIMITER ',';
UPDATE data SET the_geom = ST_SetSRID(ST_MakePoint(lon, lat), 4326);
CREATE INDEX data_the_geom_idx ON data USING GIST (the_geom);
ANALYZE data;
```
## Grid to Database
```
grid = da[::150,::150]
print (grid.shape[0]*grid.shape[1])
grid
grid.to_dataframe(name='z0').to_csv('grid.csv', header=False)
fname = !pwd
fname = fname[0] + '/grid.csv'
%%time
%%sql
drop table if exists grid;
create table grid (lat float, lon float, z0 float, the_geom geography(Point, 4326));
COPY grid (lat, lon, z0) FROM :fname WITH DELIMITER ',';
UPDATE grid SET the_geom = ST_SetSRID(ST_MakePoint(lon, lat), 4326);
CREATE INDEX grid_the_geom_idx ON grid USING GIST (the_geom);
ANALYZE grid;
```
## Gaussian Filtering in Database
```
%%sql
DROP FUNCTION IF EXISTS gaussian_transform(sigma float, geom geography);
CREATE OR REPLACE FUNCTION gaussian_transform(sigma float, geom geography)
RETURNS TABLE (z float, count bigint)
AS '
with weights as (
select
z,
exp(-(pow(ST_Distance($2,the_geom,false),2))/(2*pow($1,2))) as weight
from data
where ST_Buffer($2,4.*$1) && the_geom and ST_DWithin($2, the_geom, 4.*$1)
)
select
sum(z*weight)/sum(weight) as z,
count(1) as count
from weights
'
LANGUAGE SQL STABLE;
%%time
%sql drop table if exists gaussian_transform;
%sql create table gaussian_transform (sigmakm int, lat float, lon float, z0 float, z float, count bigint);
for sigmakm in sigmaskm:
print ("sigmakm", sigmakm)
%sql insert into gaussian_transform \
select :sigmakm, lat, lon, z0, t.* from grid, gaussian_transform(:sigmakm*1000, the_geom) as t;
```
## Show Gaussian Transform map
```
%sql gaussian << select * from gaussian_transform
gaussian = gaussian.DataFrame()
gaussian = gaussian.set_index(['sigmakm','lat','lon']).to_xarray()
gaussian
%%time
# discrete power spectrum
power_spectrum = gaussian.std(['lat','lon'])['z'].rename('spectrum')
fig = plt.figure(figsize=(16,6))
ax = fig.add_subplot(1, 3, 1)
ax.plot(power_spectrum.sigmakm.values, power_spectrum.values, c='blue')
ax.set_yscale('log')
ax.set_title(f'Power Spectrum (Log)\n', fontsize=22)
ax.set_ylabel('Log (Spectral density)',fontsize=18)
ax.set_xlabel('Wavelength, km', fontsize=18)
ax.set_yticks([])
ax.set_yticks([], minor=True)
ax = fig.add_subplot(1, 3, 2)
ax.plot(power_spectrum.sigmakm.values, power_spectrum.values, c='blue')
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_title(f'Power Spectrum (LogLog)\n', fontsize=22)
ax.set_ylabel('Log (Spectral density)',fontsize=18)
ax.set_xlabel('Log (Wavelength), km', fontsize=18)
ax.set_yticks([])
ax.set_yticks([], minor=True)
ax = fig.add_subplot(1, 3, 3)
# calculate fractality index
slope = np.diff(np.log10(power_spectrum))/np.diff(np.log10(power_spectrum.sigmakm))
depths = (power_spectrum.sigmakm.values[1:]+power_spectrum.sigmakm.values[:-1])/2/np.sqrt(2)
fractal = (3 - (slope/2))
ax.plot(depths, 1000*fractal, c='blue')
ax.set_title(f'Density\n', fontsize=22)
ax.set_ylabel('ρ, kg/m³',fontsize=18)
ax.set_xlabel('Depth, km', fontsize=18)
plt.suptitle('WGM2012 Bouguer Gravity Power Spectrum and Fractality Density', fontsize=28)
fig.tight_layout(rect=[0.03, 0.0, 1, 0.9])
plt.savefig('Spectral Components Analysis [WGM2012 Bouguer].jpg', dpi=150, quality=95)
plt.show()
```
| github_jupyter |
```
import tensorflow as tf
import matplotlib.pyplot as plt
import h5py
tf.get_logger().setLevel('ERROR')
!curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
```
# Import dataset
```
from google.colab import drive
import os
drive.mount('/content/GoogleDrive', force_remount=True)
path = '/content/GoogleDrive/My Drive/Vietnamese Foods'
os.chdir(path)
!ls
# Move dataset to /tmp cause reading files from Drive is very slow
!cp Dataset/vietnamese-foods-split.zip /tmp
!unzip -q /tmp/vietnamese-foods-split.zip -d /tmp
```
# Check GPU working
```
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0': raise SystemError('GPU device not found')
print('Found GPU at:', device_name)
```
# Setup path
```
TRAIN_PATH = '/tmp/Images/Train'
VALIDATE_PATH = '/tmp/Images/Validate'
TEST_PATH = '/tmp/Images/Test'
PATH = 'Models/Xception'
BASE_MODEL_BEST = os.path.join(PATH, 'base_model_best.hdf5')
BASE_MODEL_TRAINED = os.path.join(PATH, 'base_model_trained.hdf5')
BASE_MODEL_FIG = os.path.join(PATH, 'base_model_fig.jpg')
FINE_TUNE_MODEL_BEST = os.path.join(PATH, 'fine_tune_model_best.hdf5')
FINE_TUNE_MODEL_TRAINED = os.path.join(PATH, 'fine_tune_model_trained.hdf5')
FINE_TUNE_MODE_FIG = os.path.join(PATH, 'fine_tune_model_fig.jpg')
```
# Preparing data
```
IMAGE_SIZE = (300, 300)
BATCH_SIZE = 128
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_generator = ImageDataGenerator(
rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True
)
validate_generator = ImageDataGenerator(rescale=1./255)
test_generator = ImageDataGenerator(rescale=1./255)
generated_train_data = train_generator.flow_from_directory(TRAIN_PATH, target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
generated_validate_data = validate_generator.flow_from_directory(VALIDATE_PATH, target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
generated_test_data = test_generator.flow_from_directory(TEST_PATH, target_size=IMAGE_SIZE)
```
# Model implement
```
CLASSES = 30
INITIAL_EPOCHS = 15
FINE_TUNE_EPOCHS = 15
TOTAL_EPOCHS = INITIAL_EPOCHS + FINE_TUNE_EPOCHS
FINE_TUNE_AT = 116
```
## Define the model
```
from tensorflow.keras.applications.xception import Xception
from tensorflow.keras.layers import GlobalAveragePooling2D, Dense, Dropout
from tensorflow.keras.models import Model
pretrained_model = Xception(weights='imagenet', include_top=False)
last_output = pretrained_model.output
x = GlobalAveragePooling2D()(last_output)
x = Dense(512, activation='relu')(x)
x = Dropout(0.2)(x)
outputs = Dense(CLASSES, activation='softmax')(x)
model = Model(inputs=pretrained_model.input, outputs=outputs)
```
## Callbacks
```
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
base_checkpointer = ModelCheckpoint(
filepath = BASE_MODEL_BEST,
save_best_only = True,
verbose = 1
)
fine_tune_checkpointer = ModelCheckpoint(
filepath = FINE_TUNE_MODEL_BEST,
save_best_only = True,
verbose = 1,
)
# Stop if no improvement after 3 epochs
early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1)
```
## Stage 1: Transfer learning
```
for layer in pretrained_model.layers: layer.trainable = False
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(
generated_train_data,
validation_data = generated_validate_data,
validation_steps = generated_validate_data.n // BATCH_SIZE,
steps_per_epoch = generated_train_data.n // BATCH_SIZE,
callbacks = [base_checkpointer, early_stopping],
epochs = INITIAL_EPOCHS,
verbose = 1,
)
model.save(BASE_MODEL_TRAINED)
acc = history.history['accuracy']
loss = history.history['loss']
val_acc = history.history['val_accuracy']
val_loss = history.history['val_loss']
plt.figure(figsize=(20, 5))
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()), 1])
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([min(plt.ylim()), max(plt.ylim())])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.savefig(BASE_MODEL_FIG)
plt.show()
```
## Stage 2: Fine tuning
```
for layer in pretrained_model.layers[:FINE_TUNE_AT]: layer.trainable = False
for layer in pretrained_model.layers[FINE_TUNE_AT:]: layer.trainable = True
from tensorflow.keras.optimizers import SGD
model.compile(
optimizer = SGD(learning_rate=1e-4, momentum=0.9),
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
history_fine = model.fit(
generated_train_data,
validation_data = generated_validate_data,
validation_steps = generated_validate_data.n // BATCH_SIZE,
steps_per_epoch = generated_train_data.n // BATCH_SIZE,
epochs = TOTAL_EPOCHS,
initial_epoch = history.epoch[-1],
callbacks = [fine_tune_checkpointer, early_stopping],
verbose = 1,
)
model.save(FINE_TUNE_MODEL_TRAINED)
acc += history_fine.history['accuracy']
loss += history_fine.history['loss']
val_acc += history_fine.history['val_accuracy']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(20, 5))
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([min(plt.ylim()), 1])
plt.plot([INITIAL_EPOCHS - 4, INITIAL_EPOCHS - 4], plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([min(plt.ylim()), max(plt.ylim())])
plt.plot([INITIAL_EPOCHS - 4, INITIAL_EPOCHS - 4], plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.savefig(FINE_TUNE_MODE_FIG)
plt.show()
```
# Evaluation
```
loss, accuracy = model.evaluate(generated_test_data)
print('Test accuracy:', accuracy)
import gc
del model
gc.collect()
```
| github_jupyter |
# Table of Contents
<p><div class="lev1 toc-item"><a href="#Regularization" data-toc-modified-id="Regularization-1"><span class="toc-item-num">1 </span>Regularization</a></div><div class="lev2 toc-item"><a href="#1---Non-regularized-model" data-toc-modified-id="1---Non-regularized-model-11"><span class="toc-item-num">1.1 </span>1 - Non-regularized model</a></div><div class="lev2 toc-item"><a href="#2---L2-Regularization" data-toc-modified-id="2---L2-Regularization-12"><span class="toc-item-num">1.2 </span>2 - L2 Regularization</a></div><div class="lev2 toc-item"><a href="#3---Dropout" data-toc-modified-id="3---Dropout-13"><span class="toc-item-num">1.3 </span>3 - Dropout</a></div><div class="lev3 toc-item"><a href="#3.1---Forward-propagation-with-dropout" data-toc-modified-id="3.1---Forward-propagation-with-dropout-131"><span class="toc-item-num">1.3.1 </span>3.1 - Forward propagation with dropout</a></div><div class="lev3 toc-item"><a href="#3.2---Backward-propagation-with-dropout" data-toc-modified-id="3.2---Backward-propagation-with-dropout-132"><span class="toc-item-num">1.3.2 </span>3.2 - Backward propagation with dropout</a></div><div class="lev2 toc-item"><a href="#4---Conclusions" data-toc-modified-id="4---Conclusions-14"><span class="toc-item-num">1.4 </span>4 - Conclusions</a></div>
# Regularization
Welcome to the second assignment of this week. Deep Learning models have so much flexibility and capacity that **overfitting can be a serious problem**, if the training dataset is not big enough. Sure it does well on the training set, but the learned network **doesn't generalize to new examples** that it has never seen!
**You will learn to:** Use regularization in your deep learning models.
Let's first import the packages you are going to use.
```
# import packages
import numpy as np
import matplotlib.pyplot as plt
from reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec
from reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters
import sklearn
import sklearn.datasets
import scipy.io
from testCases import *
%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
```
**Problem Statement**: You have just been hired as an AI expert by the French Football Corporation. They would like you to recommend positions where France's goal keeper should kick the ball so that the French team's players can then hit it with their head.
<img src="images/field_kiank.png" style="width:600px;height:350px;">
<caption><center> <u> **Figure 1** </u>: **Football field**<br> The goal keeper kicks the ball in the air, the players of each team are fighting to hit the ball with their head </center></caption>
They give you the following 2D dataset from France's past 10 games.
```
train_X, train_Y, test_X, test_Y = load_2D_dataset()
```
Each dot corresponds to a position on the football field where a football player has hit the ball with his/her head after the French goal keeper has shot the ball from the left side of the football field.
- If the dot is blue, it means the French player managed to hit the ball with his/her head
- If the dot is red, it means the other team's player hit the ball with their head
**Your goal**: Use a deep learning model to find the positions on the field where the goalkeeper should kick the ball.
**Analysis of the dataset**: This dataset is a little noisy, but it looks like a diagonal line separating the upper left half (blue) from the lower right half (red) would work well.
You will first try a non-regularized model. Then you'll learn how to regularize it and decide which model you will choose to solve the French Football Corporation's problem.
## 1 - Non-regularized model
You will use the following neural network (already implemented for you below). This model can be used:
- in *regularization mode* -- by setting the `lambd` input to a non-zero value. We use "`lambd`" instead of "`lambda`" because "`lambda`" is a reserved keyword in Python.
- in *dropout mode* -- by setting the `keep_prob` to a value less than one
You will first try the model without any regularization. Then, you will implement:
- *L2 regularization* -- functions: "`compute_cost_with_regularization()`" and "`backward_propagation_with_regularization()`"
- *Dropout* -- functions: "`forward_propagation_with_dropout()`" and "`backward_propagation_with_dropout()`"
In each part, you will run this model with the correct inputs so that it calls the functions you've implemented. Take a look at the code below to familiarize yourself with the model.
```
def model(X, Y, learning_rate = 0.3, num_iterations = 30000, print_cost = True, lambd = 0, keep_prob = 1):
"""
Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (output size, number of examples)
learning_rate -- learning rate of the optimization
num_iterations -- number of iterations of the optimization loop
print_cost -- If True, print the cost every 10000 iterations
lambd -- regularization hyperparameter, scalar
keep_prob - probability of keeping a neuron active during drop-out, scalar.
Returns:
parameters -- parameters learned by the model. They can then be used to predict.
"""
grads = {}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 20, 3, 1]
# Initialize parameters dictionary.
parameters = initialize_parameters(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
if keep_prob == 1:
a3, cache = forward_propagation(X, parameters)
elif keep_prob < 1:
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
# Cost function
if lambd == 0:
cost = compute_cost(a3, Y)
else:
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
# Backward propagation.
assert(lambd==0 or keep_prob==1) # it is possible to use both L2 regularization and dropout,
# but this assignment will only explore one at a time
if lambd == 0 and keep_prob == 1:
grads = backward_propagation(X, Y, cache)
elif lambd != 0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 10000 iterations
if print_cost and i % 10000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
if print_cost and i % 1000 == 0:
costs.append(cost)
# plot the cost
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
```
Let's train the model without any regularization, and observe the accuracy on the train/test sets.
```
parameters = model(train_X, train_Y)
print ("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
```
The train accuracy is 94.8% while the test accuracy is 91.5%. This is the **baseline model** (you will observe the impact of regularization on this model). Run the following code to plot the decision boundary of your model.
```
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
```
The non-regularized model is obviously overfitting the training set. It is fitting the noisy points! Lets now look at two techniques to reduce overfitting.
## 2 - L2 Regularization
The standard way to avoid overfitting is called **L2 regularization**. It consists of appropriately modifying your cost function, from:
$$J = -\frac{1}{m} \sum\limits_{i = 1}^{m} \large{(}\small y^{(i)}\log\left(a^{[L](i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right) \large{)} \tag{1}$$
To:
$$J_{regularized} = \small \underbrace{-\frac{1}{m} \sum\limits_{i = 1}^{m} \large{(}\small y^{(i)}\log\left(a^{[L](i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right) \large{)} }_\text{cross-entropy cost} + \underbrace{\frac{1}{m} \frac{\lambda}{2} \sum\limits_l\sum\limits_k\sum\limits_j W_{k,j}^{[l]2} }_\text{L2 regularization cost} \tag{2}$$
Let's modify your cost and observe the consequences.
**Exercise**: Implement `compute_cost_with_regularization()` which computes the cost given by formula (2). To calculate $\sum\limits_k\sum\limits_j W_{k,j}^{[l]2}$ , use :
```python
np.sum(np.square(Wl))
```
Note that you have to do this for $W^{[1]}$, $W^{[2]}$ and $W^{[3]}$, then sum the three terms and multiply by $ \frac{1}{m} \frac{\lambda}{2} $.
```
# GRADED FUNCTION: compute_cost_with_regularization
def compute_cost_with_regularization(A3, Y, parameters, lambd):
"""
Implement the cost function with L2 regularization. See formula (2) above.
Arguments:
A3 -- post-activation, output of forward propagation, of shape (output size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
parameters -- python dictionary containing parameters of the model
Returns:
cost - value of the regularized loss function (formula (2))
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = compute_cost(A3, Y) # This gives you the cross-entropy part of the cost
### START CODE HERE ### (approx. 1 line)
L2_regularization_cost = (1. / m)*(lambd / 2) * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3)))
cost = cross_entropy_cost + L2_regularization_cost
return cost
A3, Y_assess, parameters = compute_cost_with_regularization_test_case()
print("cost = " + str(compute_cost_with_regularization(A3, Y_assess, parameters, lambd = 0.1)))
```
**Expected Output**:
<table>
<tr>
<td>
**cost**
</td>
<td>
1.78648594516
</td>
</tr>
</table>
Of course, because you changed the cost, you have to change backward propagation as well! All the gradients have to be computed with respect to this new cost.
**Exercise**: Implement the changes needed in backward propagation to take into account regularization. The changes only concern dW1, dW2 and dW3. For each, you have to add the regularization term's gradient ($\frac{d}{dW} ( \frac{1}{2}\frac{\lambda}{m} W^2) = \frac{\lambda}{m} W$).
```
# GRADED FUNCTION: backward_propagation_with_regularization
def backward_propagation_with_regularization(X, Y, cache, lambd):
"""
Implements the backward propagation of our baseline model to which we added an L2 regularization.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation()
lambd -- regularization hyperparameter, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
### START CODE HERE ### (approx. 1 line)
dW3 = 1./m * (np.dot(dZ3, A2.T) + lambd * W3)
### END CODE HERE ###
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
### START CODE HERE ### (approx. 1 line)
dW2 = 1./m * (np.dot(dZ2, A1.T) + lambd * W2 )
### END CODE HERE ###
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
### START CODE HERE ### (approx. 1 line)
dW1 = 1./m * (np.dot(dZ1, X.T) + lambd * W1 )
### END CODE HERE ###
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
X_assess, Y_assess, cache = backward_propagation_with_regularization_test_case()
grads = backward_propagation_with_regularization(X_assess, Y_assess, cache, lambd = 0.7)
print ("dW1 = "+ str(grads["dW1"]))
print ("dW2 = "+ str(grads["dW2"]))
print ("dW3 = "+ str(grads["dW3"]))
```
**Expected Output**:
<table>
<tr>
<td>
**dW1**
</td>
<td>
[[-0.25604646 0.12298827 -0.28297129]
[-0.17706303 0.34536094 -0.4410571 ]]
</td>
</tr>
<tr>
<td>
**dW2**
</td>
<td>
[[ 0.79276486 0.85133918]
[-0.0957219 -0.01720463]
[-0.13100772 -0.03750433]]
</td>
</tr>
<tr>
<td>
**dW3**
</td>
<td>
[[-1.77691347 -0.11832879 -0.09397446]]
</td>
</tr>
</table>
Let's now run the model with L2 regularization $(\lambda = 0.7)$. The `model()` function will call:
- `compute_cost_with_regularization` instead of `compute_cost`
- `backward_propagation_with_regularization` instead of `backward_propagation`
```
parameters = model(train_X, train_Y, lambd = 0.7)
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
```
Congrats, the test set accuracy increased to 93%. You have saved the French football team!
You are not overfitting the training data anymore. Let's plot the decision boundary.
```
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
```
**Observations**:
- The value of $\lambda$ is a hyperparameter that you can tune using a dev set.
- L2 regularization makes your decision boundary smoother. If $\lambda$ is too large, it is also possible to "oversmooth", resulting in a model with high bias.
**What is L2-regularization actually doing?**:
L2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights. Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values. It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes more slowly as the input changes.
<font color='blue'>
**What you should remember** -- the implications of L2-regularization on:
- The cost computation:
- A regularization term is added to the cost
- The backpropagation function:
- There are extra terms in the gradients with respect to weight matrices
- Weights end up smaller ("weight decay"):
- Weights are pushed to smaller values.
## 3 - Dropout
Finally, **dropout** is a widely used regularization technique that is specific to deep learning.
**It randomly shuts down some neurons in each iteration.** Watch these two videos to see what this means!
<!--
To understand drop-out, consider this conversation with a friend:
- Friend: "Why do you need all these neurons to train your network and classify images?".
- You: "Because each neuron contains a weight and can learn specific features/details/shape of an image. The more neurons I have, the more featurse my model learns!"
- Friend: "I see, but are you sure that your neurons are learning different features and not all the same features?"
- You: "Good point... Neurons in the same layer actually don't talk to each other. It should be definitly possible that they learn the same image features/shapes/forms/details... which would be redundant. There should be a solution."
!-->
<center>
<video width="620" height="440" src="images/dropout1_kiank.mp4" type="video/mp4" controls>
</video>
</center>
<br>
<caption><center> <u> Figure 2 </u>: Drop-out on the second hidden layer. <br> At each iteration, you shut down (= set to zero) each neuron of a layer with probability $1 - keep\_prob$ or keep it with probability $keep\_prob$ (50% here). The dropped neurons don't contribute to the training in both the forward and backward propagations of the iteration. </center></caption>
<center>
<video width="620" height="440" src="images/dropout2_kiank.mp4" type="video/mp4" controls>
</video>
</center>
<caption><center> <u> Figure 3 </u>: Drop-out on the first and third hidden layers. <br> $1^{st}$ layer: we shut down on average 40% of the neurons. $3^{rd}$ layer: we shut down on average 20% of the neurons. </center></caption>
When you shut some neurons down, you actually modify your model. The idea behind drop-out is that at each iteration, you train a different model that uses only a subset of your neurons. With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time.
### 3.1 - Forward propagation with dropout
**Exercise**: Implement the forward propagation with dropout. You are using a 3 layer neural network, and will add dropout to the first and second hidden layers. We will not apply dropout to the input layer or output layer.
**Instructions**:
You would like to shut down some neurons in the first and second layers. To do that, you are going to carry out 4 Steps:
1. In lecture, we dicussed creating a variable $d^{[1]}$ with the same shape as $a^{[1]}$ using `np.random.rand()` to randomly get numbers between 0 and 1. Here, you will use a vectorized implementation, so create a random matrix $D^{[1]} = [d^{[1](1)} d^{[1](2)} ... d^{[1](m)}] $ of the same dimension as $A^{[1]}$.
2. Set each entry of $D^{[1]}$ to be 0 with probability (`1-keep_prob`) or 1 with probability (`keep_prob`), by thresholding values in $D^{[1]}$ appropriately. Hint: to set all the entries of a matrix X to 0 (if entry is less than 0.5) or 1 (if entry is more than 0.5) you would do: `X = (X < 0.5)`. Note that 0 and 1 are respectively equivalent to False and True.
3. Set $A^{[1]}$ to $A^{[1]} * D^{[1]}$. (You are shutting down some neurons). You can think of $D^{[1]}$ as a mask, so that when it is multiplied with another matrix, it shuts down some of the values.
4. Divide $A^{[1]}$ by `keep_prob`. By doing this you are assuring that the result of the cost will still have the same expected value as without drop-out. (This technique is also called inverted dropout.)
```
# GRADED FUNCTION: forward_propagation_with_dropout
def forward_propagation_with_dropout(X, parameters, keep_prob = 0.5):
"""
Implements the forward propagation: LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
Arguments:
X -- input dataset, of shape (2, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (20, 2)
b1 -- bias vector of shape (20, 1)
W2 -- weight matrix of shape (3, 20)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1)
keep_prob - probability of keeping a neuron active during drop-out, scalar
Returns:
A3 -- last activation value, output of the forward propagation, of shape (1,1)
cache -- tuple, information stored for computing the backward propagation
"""
np.random.seed(1)
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
### START CODE HERE ### (approx. 4 lines) # Steps 1-4 below correspond to the Steps 1-4 described above.
D1 = np.random.rand(A1.shape[0], A1.shape[1]) # Step 1: initialize matrix D1 = np.random.rand(..., ...)
D1 = D1 < keep_prob # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)
A1 = np.multiply(A1, D1) # Step 3: shut down some neurons of A1
A1 /= keep_prob # Step 4: scale the value of neurons that haven't been shut down
### END CODE HERE ###
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
### START CODE HERE ### (approx. 4 lines)
D2 = np.random.rand(A2.shape[0], A2.shape[1]) # Step 1: initialize matrix D2 = np.random.rand(..., ...)
D2 = D2 < keep_prob # Step 2: convert entries of D2 to 0 or 1 (using keep_prob as the threshold)
A2 = np.multiply(A2, D2) # Step 3: shut down some neurons of A2
A2 /= keep_prob # Step 4: scale the value of neurons that haven't been shut down
### END CODE HERE ###
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
X_assess, parameters = forward_propagation_with_dropout_test_case()
A3, cache = forward_propagation_with_dropout(X_assess, parameters, keep_prob = 0.7)
print ("A3 = " + str(A3))
```
**Expected Output**:
<table>
<tr>
<td>
**A3**
</td>
<td>
[[ 0.36974721 0.00305176 0.04565099 0.49683389 0.36974721]]
</td>
</tr>
</table>
### 3.2 - Backward propagation with dropout
**Exercise**: Implement the backward propagation with dropout. As before, you are training a 3 layer network. Add dropout to the first and second hidden layers, using the masks $D^{[1]}$ and $D^{[2]}$ stored in the cache.
**Instruction**:
Backpropagation with dropout is actually quite easy. You will have to carry out 2 Steps:
1. You had previously shut down some neurons during forward propagation, by applying a mask $D^{[1]}$ to `A1`. In backpropagation, you will have to shut down the same neurons, by reapplying the same mask $D^{[1]}$ to `dA1`.
2. During forward propagation, you had divided `A1` by `keep_prob`. In backpropagation, you'll therefore have to divide `dA1` by `keep_prob` again (the calculus interpretation is that if $A^{[1]}$ is scaled by `keep_prob`, then its derivative $dA^{[1]}$ is also scaled by the same `keep_prob`).
```
# GRADED FUNCTION: backward_propagation_with_dropout
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
"""
Implements the backward propagation of our baseline model to which we added dropout.
Arguments:
X -- input dataset, of shape (2, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation_with_dropout()
keep_prob - probability of keeping a neuron active during drop-out, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1./m * np.dot(dZ3, A2.T)
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
### START CODE HERE ### (≈ 2 lines of code)
dA2 = np.multiply(dA2, D2) # Step 1: Apply mask D2 to shut down the same neurons as during the forward propagation
dA2 /= keep_prob # Step 2: Scale the value of neurons that haven't been shut down
### END CODE HERE ###
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1./m * np.dot(dZ2, A1.T)
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
### START CODE HERE ### (≈ 2 lines of code)
dA1 = np.multiply(dA1, D1) # Step 1: Apply mask D1 to shut down the same neurons as during the forward propagation
dA1 /= keep_prob # Step 2: Scale the value of neurons that haven't been shut down
### END CODE HERE ###
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1./m * np.dot(dZ1, X.T)
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
X_assess, Y_assess, cache = backward_propagation_with_dropout_test_case()
gradients = backward_propagation_with_dropout(X_assess, Y_assess, cache, keep_prob = 0.8)
print ("dA1 = " + str(gradients["dA1"]))
print ("dA2 = " + str(gradients["dA2"]))
```
**Expected Output**:
<table>
<tr>
<td>
**dA1**
</td>
<td>
[[ 0.36544439 0. -0.00188233 0. -0.17408748]
[ 0.65515713 0. -0.00337459 0. -0. ]]
</td>
</tr>
<tr>
<td>
**dA2**
</td>
<td>
[[ 0.58180856 0. -0.00299679 0. -0.27715731]
[ 0. 0.53159854 -0. 0.53159854 -0.34089673]
[ 0. 0. -0.00292733 0. -0. ]]
</td>
</tr>
</table>
Let's now run the model with dropout (`keep_prob = 0.86`). It means at every iteration you shut down each neurons of layer 1 and 2 with 24% probability. The function `model()` will now call:
- `forward_propagation_with_dropout` instead of `forward_propagation`.
- `backward_propagation_with_dropout` instead of `backward_propagation`.
```
parameters = model(train_X, train_Y, keep_prob = 0.86, learning_rate = 0.3)
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
```
Dropout works great! The test accuracy has increased again (to 95%)! Your model is not overfitting the training set and does a great job on the test set. The French football team will be forever grateful to you!
Run the code below to plot the decision boundary.
```
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
```
**Note**:
- A **common mistake** when using dropout is to use it both in training and testing. You should use dropout (randomly eliminate nodes) only in training.
- Deep learning frameworks like [tensorflow](https://www.tensorflow.org/api_docs/python/tf/nn/dropout), [PaddlePaddle](http://doc.paddlepaddle.org/release_doc/0.9.0/doc/ui/api/trainer_config_helpers/attrs.html), [keras](https://keras.io/layers/core/#dropout) or [caffe](http://caffe.berkeleyvision.org/tutorial/layers/dropout.html) come with a dropout layer implementation. Don't stress - you will soon learn some of these frameworks.
<font color='blue'>
**What you should remember about dropout:**
- Dropout is a regularization technique.
- You only use dropout during training. Don't use dropout (randomly eliminate nodes) during test time.
- Apply dropout both during forward and backward propagation.
- During training time, divide each dropout layer by keep_prob to keep the same expected value for the activations. For example, if keep_prob is 0.5, then we will on average shut down half the nodes, so the output will be scaled by 0.5 since only the remaining half are contributing to the solution. Dividing by 0.5 is equivalent to multiplying by 2. Hence, the output now has the same expected value. You can check that this works even when keep_prob is other values than 0.5.
## 4 - Conclusions
**Here are the results of our three models**:
<table>
<tr>
<td>
**model**
</td>
<td>
**train accuracy**
</td>
<td>
**test accuracy**
</td>
</tr>
<td>
3-layer NN without regularization
</td>
<td>
95%
</td>
<td>
91.5%
</td>
<tr>
<td>
3-layer NN with L2-regularization
</td>
<td>
94%
</td>
<td>
93%
</td>
</tr>
<tr>
<td>
3-layer NN with dropout
</td>
<td>
93%
</td>
<td>
95%
</td>
</tr>
</table>
Note that regularization hurts training set performance! This is because it limits the ability of the network to overfit to the training set. But since it ultimately gives better test accuracy, it is helping your system.
Congratulations for finishing this assignment! And also for revolutionizing French football. :-)
<font color='blue'>
**What we want you to remember from this notebook**:
- Regularization will help you reduce overfitting.
- Regularization will drive your weights to lower values.
- L2 regularization and Dropout are two very effective regularization techniques.
| github_jupyter |
# Паттерн Наблюдатель (Observer)
Паттерн Наблюдатель является поведенческим паттерном проектирования. Он предназначен для организации взаимодействия между классами. Он реализует взаимодействия типа один ко многим, при котором множество объектов получают информацию об изменениях основного объекта.
По данному принципу работает огромное количество приложений. Это могут быть новостные рассылки, уведомления от приложений на смартфонах, автоматическая рассылка почты, системы достижений в играх и многое другое.
Вместо решения, при котором объект наблюдатель опрашивает наблюдаемый объект о произошедших изменениях, наблюдаемый объект самостоятельно уведомляет о них наблюдателя.
В паттерне Наблюдатель в наблюдаемой системе должен быть имплементирован интерфейс наблюдаемого объекта, позволяющий "подписывать" пользователя на обновления объекта и отправлять всем подписанным пользователям уведомления об изменениях. Также должны существовать наблюдатели, реализующие интерфейс наблюдателя.
# Структура наблюдателя
<img src="https://upload.wikimedia.org/wikipedia/commons/8/8a/Observer_UML.png">
Для паттерна Observer необходимы следующие классы:
* Абстрактный наблюдаемый объект
* Абстрактный наблюдатель
* Конкретный наблюдаемый объект
* Конкретные наблюдатели
У наблюдаемого объекта должны быть реализованы методы:
* Подписать наблюдателя на обновления
* Отписать от обновления
* Уведомить всех подписчиков об изменениях
У наблюдателя должен быть реализован метод update, который будет вызван наблюдаемым объектом при обновлении.
# Использование паттерна Наблюдатель
При использовании паттерна Наблюдатель создаются наблюдатели и система. Для использования паттерна наблюдатель подписывается на обновления системы. При изменениях система оповещает об изменениях всех текущих подписчиков при помощи вызова у подписчиков метода update.
# Реализация паттерна Наблюдатеь
```
from abc import ABC, abstractmethod
class NotificationManager: # Наблюдаемая система
def __init__(self):
self.__subscribers = set() # При инициализации множество подписчиков задается пустым
def subscribe(self, subscriber):
self.__subscribers.add(subscriber) # Для того чтобы подписать пользователя, он добавляется во множество подписчиков
def unsubcribe(self, subscriber):
self.__subscribers.remove(subscriber) # Удаление подписчика из списка
def notify(self, message):
for subscriber in self.__subscribers:
subscriber.update(message) # Отправка уведомления всем подписчикам
class AbstractObserver(ABC):
@abstractmethod
def update(self, message): # Абстрактный наблюдатель задает метод update
pass
class MessageNotifier(AbstractObserver):
def __init__(self, name):
self.__name = name
def update(self, message): # Конкретная реализация метода update
print(f'{self.__name} recieved message!')
class MessagePrinter(AbstractObserver):
def __init__(self, name):
self.__name = name
def update(self, message): # Конкретная реализация метода update
print(f'{self.__name} recieved message: {message}')
notifier1 = MessageNotifier("Notifier1")
printer1 = MessagePrinter("Printer1")
printer2 = MessagePrinter("Printer2")
manager = NotificationManager()
manager.subscribe(notifier1)
manager.subscribe(printer1)
manager.subscribe(printer2)
manager.notify("Hi!")
```
| github_jupyter |
# MNIST Digit Classification - FCN
```
from __future__ import division, print_function
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
import theano
import theano.tensor as T
import os
%matplotlib inline
DATA_DIR = "../../data"
TRAIN_FILE = os.path.join(DATA_DIR, "mnist_train.csv")
TEST_FILE = os.path.join(DATA_DIR, "mnist_test.csv")
MODEL_FILE = os.path.join(DATA_DIR, "theano-mnist-fcn")
LEARNING_RATE = 0.001
REG_LAMBDA = 0.01
INPUT_SIZE = 28*28
BATCH_SIZE = 128
NUM_CLASSES = 10
NUM_EPOCHS = 10
```
## Prepare Data
```
def parse_file(filename):
xdata, ydata = [], []
fin = open(filename, "rb")
i = 0
for line in fin:
if i % 10000 == 0:
print("{:s}: {:d} lines read".format(
os.path.basename(filename), i))
cols = line.strip().split(",")
ydata.append(int(cols[0]))
xdata.append([float(x) / 255. for x in cols[1:]])
# xdata.append([float(x) for x in cols[1:]])
i += 1
fin.close()
print("{:s}: {:d} lines read".format(os.path.basename(filename), i))
X = np.array(xdata).astype("float32")
y = np.array(ydata).astype("int32")
return X, y
Xtrain, ytrain = parse_file(TRAIN_FILE)
Xtest, ytest = parse_file(TEST_FILE)
print(Xtrain.shape, ytrain.shape, Xtest.shape, ytest.shape)
```
## Define Network
```
X = T.matrix('X')
y = T.lvector('y')
W1 = theano.shared(np.random.randn(INPUT_SIZE, 128), name="W1")
b1 = theano.shared(np.zeros(128), name="b1")
W2 = theano.shared(np.random.randn(128, 64), name="W2")
b2 = theano.shared(np.zeros(64), name="b2")
W3 = theano.shared(np.random.randn(64, NUM_CLASSES), name="W3")
b3 = theano.shared(np.zeros(NUM_CLASSES), name="b3")
# FC1: 784 => 128
z1 = X.dot(W1) + b1
a1 = T.nnet.relu(z1)
# FC2: 128 => 64
z2 = a1.dot(W2) + b2
a2 = T.nnet.relu(z2)
# FC3: 64 => 10
z3 = a2.dot(W3) + b3
y_hat = T.nnet.softmax(z3)
loss_reg = (REG_LAMBDA/(2*len(Xtrain))) * (T.sum(T.sqr(W1)) +
T.sum(T.sqr(W2)) +
T.sum(T.sqr(W3)))
loss = T.nnet.categorical_crossentropy(y_hat, y).mean() + loss_reg
prediction = T.argmax(y_hat, axis=1)
forward_prop = theano.function([X], y_hat)
calculate_loss = theano.function([X, y], loss)
predict = theano.function([X], prediction)
# self-check on model
# forward_prop(np.random.randn(10, 784))
dW3 = T.grad(loss, W3)
db3 = T.grad(loss, b3)
dW2 = T.grad(loss, W2)
db2 = T.grad(loss, b2)
dW1 = T.grad(loss, W1)
db1 = T.grad(loss, b1)
gradient_step = theano.function(
[X, y],
updates=((W3, W3 - LEARNING_RATE * dW3),
(W2, W2 - LEARNING_RATE * dW2),
(W1, W1 - LEARNING_RATE * dW1),
(b3, b3 - LEARNING_RATE * db3),
(b2, b2 - LEARNING_RATE * db2),
(b1, b1 - LEARNING_RATE * db1)))
```
## Train Network
```
history = []
num_batches = len(Xtrain) // BATCH_SIZE
for epoch in range(NUM_EPOCHS):
shuffled_indices = np.random.permutation(np.arange(len(Xtrain)))
total_loss, total_acc = 0., 0.
for bid in range(num_batches - 1):
bstart = bid * BATCH_SIZE
bend = (bid + 1) * BATCH_SIZE
Xbatch = [Xtrain[i] for i in shuffled_indices[bstart:bend]]
ybatch = [ytrain[i] for i in shuffled_indices[bstart:bend]]
gradient_step(Xbatch, ybatch)
total_loss += calculate_loss(Xbatch, ybatch)
total_loss /= num_batches
# validate with 10% training data
val_indices = shuffled_indices[0:len(Xtrain)//10]
Xval = [Xtrain[i] for i in val_indices]
yval = [ytrain[i] for i in val_indices]
yval_ = predict(Xval)
total_acc = accuracy_score(yval_, yval)
history.append((total_loss, total_acc))
print("Epoch {:d}/{:d}: loss={:.4f}, accuracy: {:.4f}".format(
epoch+1, NUM_EPOCHS, total_loss, total_acc))
losses = [x[0] for x in history]
accs = [x[1] for x in history]
plt.subplot(211)
plt.title("Accuracy")
plt.plot(accs)
plt.subplot(212)
plt.title("Loss")
plt.plot(losses)
plt.tight_layout()
plt.show()
```
## Evaluate Network
```
ytest_ = predict(Xtest)
acc = accuracy_score(ytest_, ytest)
cm = confusion_matrix(ytest_, ytest)
print("accuracy: {:.3f}".format(acc))
print("confusion matrix")
print(cm)
```
| github_jupyter |
## Rember our wordcount code
you could import it here, but I repeated it to act as a reminder
```
def wordcount(userwords):
wordlist=userwords.split()
wordcount = dict()
for word in wordlist:
if word in wordcount:
wordcount[word] += 1
else:
wordcount[word] = 1
return wordcount
def a_union_b(a,b):
union = list()
keysa=a.keys()
keysb=b.keys()
for word in keysa:
if word in keysb:
# print("found :" + word)
union.append(word)
return union
def in_a_not_in_b(a, b):
a_not_b = list()
keysa=a.keys()
keysb=b.keys()
for word in keysa:
if word not in keysb:
# print("count not find :" + word)
a_not_b.append(word)
# else:
# print("found :" + word)
return a_not_b
```
## Create a couple of text files and copy and paste in the text on cats and dogs from WikiPedia
for this example create two files in the data directory (remember we've been putting code in src and data in data)
To be compleately safe that there isn't a bunch of weird characters in it run the text through the tool at: https://pteo.paranoiaworks.mobi/diacriticsremover/
* ABunchOfTextAboutCats.txt with content about cats
* ABunchOfTextAboutDogs.txt
set a couple of variables to point to these files
```
cat_filename="/Users/johnfunk/CloudStation/JupyterNotebooks/niece-python-lessons/data/ABunchOfTextAboutCats.txt" #Mac
#cat_filename="F:/CloudStation\\JupyterNotebooks\\niece-python-lessons\\data\\ABunchOfTextAboutCats.txt" #Windows
dog_filename="/Users/johnfunk/CloudStation/JupyterNotebooks/niece-python-lessons/data/ABunchOfTextAboutDogs.txt" #Mac
#dog_filename="F:/CloudStation/JupyterNotebooks/niece-python-lessons/data/ABunchOfTextAboutDogs.txt" #Windows
f = open(dog_filename,"r")
dogwords=f.read()
f.close()
f = open(cat_filename,"r")
catwords=f.read()
f.close()
dogdict=wordcount(dogwords)
catdict=wordcount(catwords)
u=a_union_b(dogdict,catdict)
u
left=in_a_not_in_b(dogdict,catdict)
left
right=in_a_not_in_b(catdict,dogdict)
right
```
## Now lets write the output out to a file
```
common_words_file="/Users/johnfunk/CloudStation/JupyterNotebooks/niece-python-lessons/data/common-words.txt" #Mac
#common_words_file="F:/CloudStation/JupyterNotebooks/niece-python-lessons/data/common-words.txt" #Windows
f = open(common_words_file,"w")
dogwords=f.write(u)
f.close()
```
## Dang - ok we've got to covert our list to a string
probably want to add a new line at the end of each one so when we write it out we get 1 word per line
```
common_words=str()
for word in u:
common_words+=word+"\n"
f = open(common_words_file,"w")
dogwords=f.write(common_words)
f.close()
```
## Coding Assignment 1:
Now based on what you've learned, write a standalone program that uses your text analytics module and two input files to output the common words between them to a file.
## Experiment Assignment - remove little words: (use Juytper notebook for this)
using what we've learned so far pull out all the little words from your cat and dog files and create a new file only containing little words. Then figure out how to use your in_a_not_in_b() function to remove all the little words. Then re-run your analysis of dogs and cats so you only see the meaningfull words without all the litte words.
## Coding Assignment 2:
using what you learned from your experiement above - write a standalone program that uses your text analytics module and two input files, plus a little-words file to output the common words between them without any little words.
| github_jupyter |
<a href="https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/master/tutorials/W2D2_LinearSystems/W2D2_Tutorial2.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Neuromatch Academy 2020, W2D2 Tutorial 2
# Markov Processes
**DRAFT: 2020-06-29**, Bing Wen Brunton
with contributions by Ellie Strandquist
#Tutorial Objectives
In this tutorial, we will look at the dynamical systems introduced in the first tutorial through a different lens.
In Tutorial 1, we studied dynamical systems as a deterministic process. For Tutorial 2, we will look at **probabilistic** dynamical systems. You may sometimes hear these systems called _stochastic_. In a probabilistic process,elements of randomness are involved. Every time you observe some probabilistic dynamical system, started from the same initial conditions, the outcome will likely be different. Put another way, dynamical systems that involve probability will incorporate random variations in their behavior.
For probabilistic dynamical systems, the differential equations express a relationship between $\dot{x}$ and $x$ at every time $t$, so that the direction of $x$ at _every_ time depends entirely on the value of $x$. Said a different way, knowledge of the value of the state variables $x$ at time t is _all_ the information needed to determine $\dot{x}$ and therefore $x$ at the next time.
This property --- that the present state entirely determines the transition to the next state --- is what defines a **Markov process** and systems obeying this property can be described as **Markovian**.
The goal of Tutorial 2 is to consider this type of Markov process in a simple example where the state transitions are probabilistic. In particular, we will:
* Understand Markov processes and history dependence.
* Explore the behavior of a two-state telegraph process and understand how its equilibrium distribution is dependent on its parameters.
# Setup
```
import numpy as np
import matplotlib.pyplot as plt
import ipywidgets as widgets
#@title Figure Settings
%matplotlib inline
fig_w, fig_h = (8, 6)
plt.rcParams.update({'figure.figsize': (fig_w, fig_h),'font.size': 16})
%config InlineBackend.figure_format = 'retina'
#@title Helper Functions
def plot_switch_simulation(t, x):
fig = plt.figure(figsize=(fig_w, fig_h))
plt.plot(t, x)
plt.title('State-switch simulation')
plt.xlabel('Time')
plt.xlim((0, 300)) # zoom in time
plt.ylabel('State of ion channel 0/1', labelpad=-60)
plt.yticks([0, 1], ['Closed (0)', 'Open (1)'])
plt.show()
return
def plot_interswitch_interval_histogram(inter_switch_intervals):
fig = plt.figure(figsize=(fig_w, fig_h))
plt.hist(inter_switch_intervals)
plt.title('Inter-switch Intervals Distribution')
plt.ylabel('Interval Count')
plt.xlabel('time')
plt.show()
def plot_state_probabilities(time, states):
fig = plt.figure(figsize=(fig_w, fig_h))
plt.plot(time, states[:,0], label='Closed to open')
plt.plot(time, states[:,1], label='Open to closed')
plt.legend()
plt.xlabel('time')
plt.ylabel('prob(open OR closed)')
```
# Part A: Telegraph Process
```
#@title Video 1
# Insert the ID of the corresponding youtube video
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="d0FHbuNf23k", width=854, height=480, fs=1)
print("Video available at https://youtu.be/" + video.id)
video
```
Let's consider a Markov process with two states, where switches between each two states are probabilistic (known as a telegraph process). To be concrete, let's say we are modeling an **ion channel in a neuron that can be in one of two states: Closed (0) or Open (1)**.
If the ion channel is Closed, it may transition to the Open state with probability $P(0 \rightarrow 1 | x = 0) = \mu_{c2o}$. Likewise, If the ion channel is Open, it transitions to Closed with probability $P(1 \rightarrow 0 | x=1) = \mu_{o2c}$.
We simulate the process of changing states as a **Poisson process**. The Poisson process is a way to model discrete events where the average time between event occurrences is known but the exact time of some event is not known. Importantly, the Poisson process dictates the following points:
1. The probability of some event occurring is _independent from all other events_.
2. The average rate of events within a given time period is constant.
3. Two events cannot occur at the same moment. Our ion channel can either be in an open or closed state, but not both simultaneously.
In the simulation below, we will use the Poisson process to model the state of our ion channel at all points $t$ within the total simulation time $T$.
As we simulate the state change process, we also track at which times thoughout the simulation the state makes a switch. We can use those times to measure the distribution of the time _intervals_ between state switches.
**Run the cell below** to show the state-change simulation process.
```
# @title State-change simulation process
# parameters
T = 5000 # total Time duration
dt = 0.001 # timestep of our simulation
# simulate state of our ion channel in time
# the two parameters that govern transitions are
# c2o: closed to open rate
# o2c: open to closed rate
def ion_channel_opening(c2o, o2c, T, dt):
# initialize variables
t = np.arange(0, T, dt)
x = np.zeros_like(t)
switch_times = []
# assume we always start in Closed state
x[0] = 0
# generate a bunch of random uniformly distributed numbers
# between zero and unity: [0, 1),
# one for each dt in our simulation.
# we will use these random numbers to model the
# closed/open transitions
myrand = np.random.random_sample(size=len(t))
# walk through time steps of the simulation
for k in range(len(t)-1):
# switching between closed/open states are
# Poisson processes
if x[k] == 0 and myrand[k] < c2o*dt: # remember to scale by dt!
x[k+1:] = 1
switch_times.append(k*dt)
elif x[k] == 1 and myrand[k] < o2c*dt:
x[k+1:] = 0
switch_times.append(k*dt)
return t, x, switch_times
c2o = 0.02
o2c = 0.1
t, x, switch_times = ion_channel_opening(c2o, o2c, T, .1)
plot_switch_simulation(t,x)
```
## Exercise 2A: Computing intervals between switches
We now have `switch_times`, which is a list consisting of times when the state switched. Using this, calculate the time intervals between each state switch and store these in a list called `inter_switch_intervals`.
We will then plot the distribution of these intervals. How would you describe the shape of the distribution?
```
##############################################################################
## TODO: Insert your code here to calculate between-state-switch intervals,
## and uncomment the last line to plot the histogram
##############################################################################
# inter_switch_intervals = ...
# plot_interswitch_interval_histogram(inter_switch_intervals)
# to_remove solution
inter_switch_intervals = np.diff(switch_times)
#plot inter-switch intervals
with plt.xkcd():
plot_interswitch_interval_histogram(inter_switch_intervals)
```
We can also generate a bar graph to visualize the distribution of the number of time-steps spent in each of the two possible system states during the simulation.
```
fig = plt.figure(figsize=(fig_w, fig_h))
states = ['Closed', 'Open']
(unique, counts) = np.unique(x, return_counts=True)
plt.bar(states, counts)
plt.ylabel('Number of time steps')
plt.xlabel('State of ion channel')
```
<!-- Though the system started initially in the Closed ($x=0$) state, over time, it settles into a equilibrium distribution where we can predict on what fraction of time it is Open as a function of the $\mu$ parameters.
Before we continue exploring these distributions further, let's first take a look at the this fraction of Open states as a cumulative mean of the state $x$: -->
Even though the state is _discrete_--the ion channel can only be either Closed or Open--we can still look at the **mean state** of the system, averaged over some window of time.
Since we've coded Closed as $x=0$ and Open as $x=1$, conveniently, the mean of $x$ over some window of time has the interpretation of **fraction of time channel is Open**.
Let's also take a look at the this fraction of Open states as a cumulative mean of the state $x$. The cumulative mean tells us the average number of state-changes that the system will have undergone after a certain amount of time.
```
fig = plt.figure(figsize=(fig_w, fig_h))
plt.plot(t, np.cumsum(x) / np.arange(1, len(t)+1))
plt.xlabel('time')
plt.ylabel('Cumulative mean of state');
```
Notice in the plot above that, although the channel started in the Closed ($x=0$) state, gradually adopted some mean value after some time. This mean value is related to the transition probabilities $\mu_{c2o}$
and $\mu_{o2c}$.
## Interactive Demo: Varying transition probability values & T
Using the interactive demo below, explore the state-switch simulation for different transition probability values of states $\mu_{c2o}$ and $\mu_{o2c}$. Also, try different values for total simulation time length *T*.
Does the general shape of the inter-switch interval distribution change or does it stay relatively the same? How does the bar graph of system states change based on these values?
```
#@title
@widgets.interact
def plot_inter_switch_intervals(c2o = (0,1, .01), o2c = (0, 1, .01), T=(1000,10000, 1000)):
t, x, switch_times = ion_channel_opening(c2o, o2c, T, .1)
inter_switch_intervals = np.diff(switch_times)
#plot inter-switch intervals
fig = plt.figure(figsize=(fig_w, fig_h))
plt.hist(inter_switch_intervals)
plt.title('Inter-switch Intervals Distribution')
plt.ylabel('Interval Count')
plt.xlabel('time')
plt.show()
plt.close()
# to_remove solution
"""
Discussion:
(1) Does the general shape of the inter-switch interval distribution
change or does it stay relatively the same?
How does the bar graph of system states change based on these values?
Answers:
(1) The shape of the distribution remains the same, but larger values of either
c2o or o2c shifts the distribution towards shorter intervals.
(2) If c2o is larger than o2c, then the channel tends to be open a larger
fraction of the time.
""";
```
# Part B: Distributional Perspective
```
#@title Video 2
# Insert the ID of the corresponding youtube video
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="B3_v8M44RfQ", width=854, height=480, fs=1)
print("Video available at https://youtu.be/" + video.id)
video
```
We can run this simulation many times and gather empirical distributions of open/closed states. Alternatively, we can formulate the exact same system probabilistically, keeping track of the probability of being in each state.
<!-- Although the system started initially in the Closed ($x=0$) state, over time, it settles into a equilibrium distribution where we can predict on what fraction of time it is Open as a function of the $\mu$ parameters. -->
(see diagram in lecture)
The same system of transitions can then be formulated using a vector of 2 elements as the state vector and a dynamics matrix $\mathbf{A}$. The result of this formulation is a *state transition matrix*:
$\left[ \begin{array}{c} C \\ O \end{array} \right]_{k+1} = \mathbf{A} \left[ \begin{array}{c} C \\ O \end{array} \right]_k = \left[ \begin{array} & 1-\mu_{\text{c2o}} & \mu_{\text{c2o}} \\ \mu_{\text{o2c}} & 1-\mu_{\text{o2c}} \end{array} \right] \left[ \begin{array}{c} C \\ O \end{array} \right]_k$.
Each transition probability shown in the matrix is as follows:
1. $1-\mu_{\text{c2o}}$, the probability that the closed state remains closed.
2. $\mu_{\text{c2o}}$, the probability that the closed state transitions to the open state.
3. $\mu_{\text{o2c}}$, the probability that the open state transitions to the closed state.
4. $1-\mu_{\text{o2c}}$, the probability that the open state remains open.
_Notice_ that this system is written as a discrete step in time, and $\mathbf{A}$ describes the transition, mapping the state from step $k$ to step $k+1$. This is different from what we did in the exercises above where $\mathbf{A}$ had described the function from the state to the time derivative of the state.
## Exercise 2B: Probability Propagation
Complete the code below to simulate the propagation of probabilities of closed/open of the ion channel through time. A variable called `x_kp1` (short for, $x$ at timestep $k$ plus 1) should be calculated per each step *k* in the loop. However, you should plot $x$.
```
# parameters
T = 500 # total Time duration
dt = 0.1 # timestep of our simulation
t = np.arange(0, T, dt)
# same parameters as above
# c2o: closed to open rate
# o2c: open to closed rate
c2o = 0.02
o2c = 0.1
A = np.array([[1 - c2o*dt, o2c*dt],
[c2o*dt, 1 - o2c*dt]])
# initial condition: start as Closed
x0 = np.array([[1, 0]])
# x will be our array to keep track of x through time
x = x0
for k in range(len(t)-1):
###################################################################
## TODO: Insert your code here to compute x_kp1 (x at k plus 1)
##
## hint: use np.dot(a, b) function to compute the dot product
## of the transition matrix A and the last state in x
###################################################################
# x_kp1 = ...
# Stack this new state onto x to keep track of x through time steps
# x = ...
# Remove the line below when you are done
pass
# Uncomment this to plot the probabilities
# plot_state_probabilities(t, x)
# to_remove solution
# parameters
T = 500 # total Time duration
dt = 0.1 # timestep of our simulation
t = np.arange(0, T, dt)
# same parameters as above
# c2o: closed to open rate
# o2c: open to closed rate
c2o = 0.02
o2c = 0.1
A = np.array([[1 - c2o*dt, o2c*dt],
[c2o*dt, 1 - o2c*dt]])
# initial condition: start as Closed
x0 = np.array([[1, 0]])
# x will be our array to keep track of x through time
x = x0
for k in range(len(t)-1):
x_kp1 = np.dot(A, x[-1,:]) # remove later
# stack this new state onto x to keep track of x through time steps
x = np.vstack((x, x_kp1))
print(x.shape, t.shape)
with plt.xkcd():
plot_state_probabilities(t,x)
```
Here, we simulated the propagation of probabilities of the ion channel's state changing through time. Using this method is useful in that we can **run the simulation once** and see **how the probabilities propagate throughout time**, rather than re-running and empirically observing the telegraph simulation over and over again.
Although the system started initially in the Closed ($x=0$) state, over time, it settles into a equilibrium distribution where we can predict on what fraction of time it is Open as a function of the $\mu$ parameters. We can say that the plot above show this _relaxation towards equilibrium_.
Re-calculating our value of the probability of $c2o$ again with this method, we see that this matches the simulation output from the telegraph process!
```
print("Probability of state c2o: %.3f"%(c2o / (c2o + o2c)))
x[-1,:]
```
# Part C: Equilibrium of the telegraph process
```
#@title Video 3
# Insert the ID of the corresponding youtube video
from IPython.display import YouTubeVideo
video = YouTubeVideo(id="EQWXZ40_C-k", width=854, height=480, fs=1)
print("Video available at https://youtu.be/" + video.id)
video
```
Since we have now modeled the propagation of probabilities by the transition matrix $\mathbf{A}$ in Part B, let's connect the behavior of the system at equilibrium with the eigendecomposition of $\mathbf{A}$.
As introduced in the lecture video, the eigenvalues of $\mathbf{A}$ tell us about the stability of the system, specifically in the directions of the corresponding eigenvectors.
```
# compute the eigendecomposition of A
lam, v = np.linalg.eig(A)
# print the 2 eigenvalues
print("Eigen values:",lam)
# print the 2 eigenvectors
eigenvector1 = v[:,0]
eigenvector2 = v[:,1]
print("Eigenvector 1:", eigenvector1)
print("Eigenvector 2:", eigenvector2)
```
## Exercise 2C: Finding a stable state
Which of these eigenvalues corresponds to the **stable** (equilibrium) solution? What is the eigenvector of this eigenvalue? How does that explain
the equilibrium solutions in simulation in Part B of this tutorial?
_hint_: our simulation is written in terms of probabilities, so they must sum to 1. Therefore, you may also want to rescale the elements of the eigenvector such that they also sum to 1. These can then be directly compared with the probabilities of the states in the simulation.
```
###################################################################
## Insert your thoughts here
###################################################################
# to_remove solution
"""
Discussion:
Which of the eigenvalues corresponds to the stable solution?
What is the eigenvector of this eigenvalue?
How does that explain the equilibrium solutions in part B?
Recommendation:
Ask the students to work in small groups (of 2 or 3) to discuss these questions.
Answers:
Whichever eigenvalue is 1 is the stable solution. There should be another
eigenvalue that is <1, which means it is decaying and goes away after the
transient period.
The eigenvector corresponding to this eigenvalue is the stable solution.
To see this, we need to normalize this eigenvector so that its 2 elements
sum to one, then we would see that the two numbers correspond to
[P(open), P(closed)] at equilibrium -- hopefully these are exactly the
equilibrium solutions observed in Part B.
""";
# whichever eigenvalue is 1, the other one makes no sense
print(eigenvector1 / eigenvector1.sum())
print(eigenvector2 / eigenvector2.sum())
```
# Summary
In this tutorial, we learned:
* The definition of a Markov process with history dependence.
* The behavior of a simple 2-state Markov proces--the telegraph process--can be simulated either as a state-change simulation or as a propagation of probability distributions.
* The relationship between the stability analysis of a dynamical system express either in continuous or discrete time.
* The equilibrium behavior of a telegraph process is predictable and can be understood using the same strategy as for deterministic systems in Tutorial 1: by taking the eigendecomposition of the A matrix.
| github_jupyter |
```
import functools
import itertools
import pickle
import string
from pathlib import Path
import cytoolz as tlz
import geopandas as gpd
import mpl_toolkits.axes_grid1 as mgrid
import numpy as np
import utils
import xarray as xr
import xskillscore as xs
from matplotlib import cm
from matplotlib import pyplot as plt
from matplotlib import tri
from scipy import interpolate
CLASSES = {
"C1": "w/o Estuary",
"C2": "Triangular Estuary",
"C3": "Trapezoidal Estuary",
}
SAVE_KWDS = {"bbox_inches": "tight", "dpi": 300, "facecolor": "w"}
LABELS = {
"S1": "Ref",
"S2_1": "R20",
"S2_2": "R30",
"S4_1": "D90",
"S4_2": "D570",
"S5_1": "S07",
"S5_2": "S31",
}
def dflow_triangulate(nx, ny, config):
triang = tri.Triangulation(nx, ny)
x = nx[triang.triangles].mean(axis=1)
y = ny[triang.triangles].mean(axis=1)
m = []
if config["class"] == 1:
m.append(np.where((x > config["x_o1"]) & (x < config["x_r1"]) & (y > config["y_o"]), 1, 0))
m.append(np.where((x > config["x_r2"]) & (x < config["x_o2"]) & (y > config["y_o"]), 1, 0))
else:
if (config["x_b3"] - config["x_b1"]) < 1e-2:
s_w, s_e = 0e0, 0e0
else:
s_w = (config["y_r"] - config["y_b"]) / (config["x_b3"] - config["x_b1"])
s_e = (config["y_r"] - config["y_b"]) / (config["x_b4"] - config["x_b2"])
m.append(np.where((x > config["x_o1"]) & (x < config["x_b1"]) & (y > config["y_o"]), 1, 0))
m.append(np.where((x > config["x_b2"]) & (x < config["x_o2"]) & (y > config["y_o"]), 1, 0))
m.append(np.where((x > config["x_b1"]) & (x < config["x_b3"]) & (y > config["y_b"]), 1, 0))
m.append(np.where((x > config["x_b4"]) & (x < config["x_b2"]) & (y > config["y_b"]), 1, 0))
m.append(np.where((x > config["x_b3"]) & (x < config["x_r1"]) & (y > config["y_b"]), 1, 0))
m.append(np.where((x > config["x_r2"]) & (x < config["x_b4"]) & (y > config["y_b"]), 1, 0))
m.append(
np.where(
(x > config["x_b1"])
& (x < config["x_b3"])
& (y > config["y_b"] + s_w * (x - config["x_b1"])),
1,
0,
)
)
m.append(
np.where(
(x > config["x_b4"])
& (x < config["x_b2"])
& (y > config["y_b"] + s_e * (x - config["x_b2"])),
1,
0,
)
)
mask = m[0]
for i in m[1:]:
mask = mask + i
mask[mask > 1] = 1
triang.set_mask(mask)
return triang
def gridded_mae_test(ref_path, case1_path, case2_path, variable, metric="mae", alpha=0.05):
wl_ref = xr.open_dataset(ref_path, chunks="auto")[variable]
config_ref = utils.read_config(ref_path.parent.joinpath("inputs.txt"))
nx = wl_ref.mesh2d_face_x.values
ny = wl_ref.mesh2d_face_y.values
triang = dflow_triangulate(nx, ny, config_ref)
wl_case1 = xr.open_dataset(case1_path, chunks="auto")[variable]
wl_case2 = xr.open_dataset(case2_path, chunks="auto")[variable]
dims = {da.time.shape[0] for da in [wl_ref, wl_case1, wl_case2]}
if len(dims) > 1:
dmin = min(list(dims))
wl_ref, wl_case1, wl_case = (
da.isel(time=slice(0, dmin)) for da in [wl_ref, wl_case1, wl_case2]
)
_, diff, hwci = xs.halfwidth_ci_test(wl_case1, wl_case2, wl_ref, metric, alpha=alpha)
score_sig = np.sign(diff) * (np.abs(diff) - hwci)
cname = ref_path.parent.name.split("_")[0]
return cname, (triang, score_sig)
def plot_dflow(ax, triang, da, vmin, vmax, cmap="coolwarm_r"):
nx = da.mesh2d_face_x.values
ny = da.mesh2d_face_y.values
wdt = interpolate.griddata((nx, ny), da.values, (triang.x, triang.y), method="linear")
norm = cm.colors.Normalize(vmax=vmax, vmin=vmin)
levels = np.linspace(vmin, vmax, 10)
cmap_lvls = cm.get_cmap(getattr(cm, cmap), len(levels) - 1)
tcf = ax.tricontourf(
triang,
wdt,
levels,
cmap=cmap_lvls,
norm=norm,
)
ax.tricontour(triang, wdt, tcf.levels, colors="k")
ax.grid(color="g", linestyle="-.", linewidth=0.3)
ax.set_axisbelow(True)
xmin, xmax = 0e3, 50e3
xticks = ax.get_xticks()
xlabels = np.linspace(xmin * 1e-3, xmax * 1e-3, len(xticks)).astype("int")
ax.set_xticks(xticks)
ax.set_xticklabels(xlabels)
yticks = np.arange(0, 1120, 120).astype("int")
ax.set_yticks(yticks * 1e3)
ax.set_yticklabels(yticks)
ax.set_ylim(0, yticks[-1] * 1e3)
ax.margins(0)
x1, x2, y1, y2 = 18.0e3, 32.0e3, 80.0e3, 330.0e3
axins = ax.inset_axes([0.58, 0.35, 0.4, 0.4])
tcf_zoom = axins.tricontourf(
triang,
wdt,
levels,
cmap=cmap_lvls,
norm=norm,
)
axins.tricontour(triang, wdt, tcf_zoom.levels, colors="k")
axins.set_xlim(x1, x2)
axins.set_ylim(y1, y2)
axins.set_xticklabels("")
axins.set_yticklabels("")
ax.indicate_inset_zoom(axins, edgecolor="k")
return tcf
def plot_mae_diff(variables, params, out_root, img_root, ci_alpha=95, cmap="coolwarm_r"):
for v, u in variables.items():
fig, ax_rows = plt.subplots(
3,
3,
figsize=(11, 11),
dpi=300,
sharey=True,
sharex=True,
gridspec_kw={"hspace": 0.05, "wspace": 0.05},
)
axs_arr = np.array(ax_rows)
alphabest = [f"({s})" for s in string.ascii_lowercase[: len(ax_rows) * len(ax_rows[0])]]
fig_label = list(tlz.partition(len(ax_rows[0]), alphabest))
for axs, (p, (s1, s2)) in zip(ax_rows, params.items()):
with open(Path(out_root, f"mae_diff_{v}_{p.lower()}.pkl"), "rb") as f:
data = pickle.load(f)
vmax = max(da.map_blocks(np.fabs).max().values for _, (_, da) in data.items())
vmin = -vmax
for ax, (_, (triang, da)) in zip(axs, data.items()):
i, j = np.argwhere(axs_arr == ax)[0]
tcf = plot_dflow(ax, triang, da, vmin, vmax, cmap=cmap)
ax.text(
0.02,
0.97,
fig_label[i][j],
size=12,
horizontalalignment="left",
verticalalignment="top",
transform=ax.transAxes,
)
axs[0].set_ylabel(f"{s2} vs. {s1}\ny (km)")
divider = mgrid.make_axes_locatable(axs[-1])
cax = divider.append_axes("right", size="3%", pad=0.1)
fig.colorbar(
tcf,
format="%.3f",
cax=cax,
label=fr"$SD$ ({u})",
)
[ax.set_title(CLASSES[c], loc="center", y=1.0) for ax, c in zip(ax_rows[0], data)]
[ax.set_xlabel("x (km)") for ax in ax_rows[-1]]
img_path = Path(img_root, f"mae_diff_{v}.tiff")
fig.savefig(img_path, **SAVE_KWDS)
plt.close("all")
root = Path("..", "data")
inp_path = Path(root, "inputs")
out_path = Path(root, "outputs")
img_path = Path(root, "figures")
sim_path = Path(Path.home(), "repos", "dev", "results")
params = {
"Discharge": ("D90", "D570"),
"Roughness": ("R20", "R30"),
"Surge": ("S07", "S31"),
}
variables = {"mesh2d_s1": "m", "mesh2d_ucmag": "m/s"}
class_list = [1, 2, 3]
stations = gpd.read_feather(Path(out_path, "gulf_east_wl_stations.feather")).set_index("id")
lat = stations.loc["8534720"].lat
for v, p in itertools.product(variables, params):
pkl_name = Path(out_path, f"mae_diff_{v}_{p.lower()}.pkl")
if not pkl_name.exists():
f_ref = functools.partial(utils.get_path, "Ref", root=sim_path)
f_s1 = functools.partial(utils.get_path, params[p][0], root=sim_path)
f_s2 = functools.partial(utils.get_path, params[p][1], root=sim_path)
data = dict(gridded_mae_test(f_ref(c), f_s1(c), f_s2(c), v) for c in class_list)
with open(pkl_name, "wb") as f:
pickle.dump(data, f)
plot_mae_diff(variables, params, out_path, img_path)
```
| github_jupyter |
# Deteksi Objek
*Deteksi objek* adalah bentuk Visi Komputer tempat model pembelajaran mesin dilatih untuk mengklasifikasikan setiap instans dari objek pada gambar, dan menunjukkan *kotak pembatas* yang menandai lokasinya. Anda dapat menganggap ini sebagai perkembangan dari *klasifikasi gambar* (di mana model menjawab pertanyaan "gambar apakah ini?") untuk membuat solusi agar kita dapat menanyakan pada model "objek apa yang ada pada gambar ini, dan di mana mereka?".

Misalnya, toko kelontong dapat menggunakan model deteksi objek untuk menerapkan sistem checkout otomatis yang memindai ban berjalan menggunakan kamera, dan dapat mengidentifikasi item tertentu tanpa perlu menempatkan masing-masing item pada ban dan memindainya satu per satu.
Layanan kognitif **Custom Vision** di Microsoft Azure memberikan solusi berbasis awan untuk membuat dan memublikasikan model deteksi objek kustom.
## Membuat sumber daya Custom Vision
Untuk menggunakan layanan Custom Vision, Anda memerlukan sumber daya Azure yang dapat Anda gunakan untuk melatih model, dan sumber daya yang dapat dipublikasikan agar dapat digunakan aplikasi. Anda dapat menggunakan sumber daya yang sama untuk masing-masing tugas ini, atau menggunakan sumber daya berbeda untuk masing-masing guna mengalokasikan biaya secara terpisah yang diberikan kedua sumber daya yang dibuat di wilayah yang sama. Sumber daya untuk salah satu (atau keduanya) tugas dapat berupa sumber daya **Cognitive Services** umum, atau sumber daya **Custom Vision** khusus. Gunakan petunjuk berikut untuk membuat sumber daya **Custom Vision** yang baru. (Atau Anda dapat menggunakan sumber daya yang ada jika memiliki satu).
1. Di tab browser baru, buka portal Azure di [https://portal.azure.com](https://portal.azure.com), dan masuk menggunakan akun Microsoft yang terkait dengan langganan Azure Anda.
2. Pilih tombol **+Buat sumber daya**, cari *custom vision*, dan buat sumber daya **Custom Vision** dengan pengaturan berikut:
- **Buat opsi**: Keduanya
- **Langganan**: *Langganan Azure Anda*
- **Grup sumber daya**: *Pilih atau buat grup sumber daya dengan nama unik*
- **Nama**: *Masukkan nama unik*
- **Lokasi pelatihan**: *Pilih wilayah yang tersedia*
- **Tingkat harga pelatihan**: F0
- **Lokasi prediksi**: *Sama dengan lokasi pelatihan*
- **Tingkat harga prediksi**: F0
>Catatan: Jika Anda sudah memiliki layanan custom vision F0 di langganan, pilih **S0** untuk yang satu ini.
3. Tunggu hingga sumber daya dibuat.
## Membuat proyek Custom Vision
Untuk melatih model deteksi objek, Anda harus membuat proyek Custom Vision berdasarkan sumber daya latihan. Untuk melakukannya, Anda akan menggunakan portal Custom Vision.
1. Di tab browser baru, buka portal Custom Vision di [https://customvision.ai](https://customvision.ai), dan masuk menggunakan akun Microsoft yang terkait dengan langganan Azure Anda.
2. Membuat proyek baru dengan pengaturan berikut:
- **Nama**: Deteksi Belanjaan
- **Deskripsi**: Deteksi objek untuk belanjaan.
- **Sumber daya**: *Sumber daya Custom Vision yang Anda buat sebelumnya*
- **Jenis Proyek**: Deteksi Objek
- **Domain**: Umum
3. Tunggu hingga proyek dibuat dan dibuka di browser.
## Menambah dan menandai gambar
Untuk melatih model deteksi objek, Anda harus mengunggah gambar yang berisi kelas yang diinginkan untuk diidentifikasi oleh model, dan menandainya untuk menunjukkan kotak pembatas bagi masing-masing instans objek.
1. Unduh dan ekstrak gambar pelatihan dari https://aka.ms/fruit-objects. Folder yang diekstrak berisi kumpulan gambar buah. **Catatan:** sebagai solusi sementara, jika Anda tidak dapat mengakses gambar pelatihan, buka https://www.github.com, lalu buka https://aka.ms/fruit-objects.
2. Di portal Custom Vision [https://customvision.ai](https://customvision.ai), pastikan Anda bekerja di proyek deteksi objek _Grocery Detection_. Kemudian pilih **Tambah gambar** dan unggah semua gambar dalam folder yang diekstrak.

3. Setelah gambar diunggah, pilih yang pertama untuk membukanya.
4. Tahan mouse di atas objek apa pun pada gambar hingga wilayah yang terdeteksi secara otomatis ditampilkan seperti gambar di bawah. Lalu pilih objek, dan jika perlu ubah ukuran wilayah di sekitarnya.

Selain itu, Anda dapat menyeret di sekitar objek untuk membuat wilayah.
5. Bila wilayah mengelilingi objek, tambah tanda baru dengan jenis objek yang sesuai (*apel*, *pisang*, atau *jeruk*) seperti ditampilkan di sini:

6. Pilih dan tandai masing-masing objek lain pada gambar, ubah ukuran wilayah dan tambah tanda baru bila perlu.

7. Gunakan tautan **>** di sebelah kanan untuk membuka gambar berikutnya, dan menandai objeknya. Lalu, terus kerjakan hingga seluruh kumpulan gambar, memberi tanda pada setiap apel, pisang, dan jeruk.
8. Saat Anda selesai menandai gambar terakhir, tutup editor **Detal Gambar** dan di halaman **Gambar Pelatihan**, di bawah **Tanda**, pilih **Ditandai** untuk melihat semua gambar yang ditandai:

## Melatih dan menguji model
Sekarang setelah menandai gambar di proyek, Anda siap untuk melatih model.
1. Di proyek Custom Vision, klik **Latih** untuk melatih model deteksi objek menggunakan gambar yang ditandai. Pilih opsi **Pelatihan Cepat**.
2. Tunggu hingga pelatihan selesai (perlu waktu kurang lebih sepuluh menit), lalu tinjau metrik performa *Presisi*, *Pendahuluan*, dan *mAP* - ketiganya mengukur akurasi prediksi model klasifikasi, dan semuanya harus tinggi.
3. Di sebelah kanan atas halaman, klik **Uji Cepat**, lalu di kotak **URL Gambar**, masukkan `https://aka.ms/apple-orange` dan lihat prediksi yang dihasilkan. Lalu, tutup jendela **Uji Cepat**.
## Memublikasikan dan mengggunakan model deteksi objek
Sekarang, Anda siap untuk memublikasikan model latihan Anda dan menggunakannya dari aplikasi klien.
1. Di bagian kiri atas halaman **Performa**, klik **🗸 Publikasikan** untuk memublikasikan model yang telah dilatih dengan pengaturan berikut:
- **Nama model**: hasil deteksi
- **Sumber Daya Prediksi**: *Sumber daya **prediksi** Custom Vision Anda*.
### (!) Cek Masuk
Apakah Anda menggunakan nama model yang sama: **hasil deteksi**?
2. Setelah memublikasikan, klik ikon *pengaturan* (⚙) di bagian kanan atas halaman **Performa** untuk melihat pengaturan proyek. Lalu, di **Umum** (di kiri), salin **ID Proyek**. Gulir ke bawah dan tempel ke sel kode di bawah langkah 5 menggantikan **YOUR_PROJECT_ID**.
> (*jika Anda menggunakan sumber daya **Cognitive Services** daripada membuat sumber daya **Custom Vision** di awal latihan ini, Anda dapat menyalin kunci dan titik akhirnya dari sisi kanan pengaturan proyek, menempelnya ke sel kode di bawah, dan menjalankannya untuk melihat hasilnya. Jika tidak, lanjutkan menyelesaikan langkah-langkah di bawah untuk mendapatkan kunci dan titik akhir untuk sumber daya prediksi Custom Vision Anda*).
3. Di bagian kiri atas halaman **Pengaturan Proyek**, klik ikon *Galeri Proyek* (👁) untuk kembali ke halaman beranda portal Custom Vision, tempat proyek Anda kini terdaftar.
4. Di halaman beranda portal Custom Vision, di bagian kanan atas, klik ikon *pengaturan* (⚙) untuk melihat pengaturan layanan Custom Vision Anda. Lalu, di **Sumber daya**, perluas sumber daya *prediksi* (<u>bukan</u> sumber daya pelatihan) dan salin nilai **Kunci** dan **Titik akhir** tersebut ke sel kode di bawah langkah 5, menggantikan **YOUR_KEY** dan **YOUR_ENDPOINT**.
### (!) Cek Masuk
Jika Anda menggunakan sumber daya **Custom Vision**, apakah Anda menggunakan sumber daya **prediksi** (<u>bukan</u> sumber daya pelatihan)?
5. Jalankan sel kode di bawah dengan mengeklik tombol Jalankan Sel <span>▷</span> (di bagian kiri atas sel) untuk mengatur variabel ID proyek, kunci dan nilai titik akhir Anda.
```
project_id = 'YOUR_PROJECT_ID' # Replace with your project ID
cv_key = 'YOUR_KEY' # Replace with your prediction resource primary key
cv_endpoint = 'YOUR_ENDPOINT' # Replace with your prediction resource endpoint
model_name = 'detect-produce' # this must match the model name you set when publishing your model iteration exactly (including case)!
print('Ready to predict using model {} in project {}'.format(model_name, project_id))
```
Sekarang Anda dapat menggunakan kunci dan titik akhir dengan klien Custom Vision untuk tersambung ke model deteksi objek Custom Vision.
Jalankan sel kode berikut, yang menggunakan model Anda untuk mendeteksi setiap item yang dihasilkan pada gambar.
> **Catatan**: Jangan terlalu khawatir dengan detail kode. Detail kode menggunakan SDK Python untuk layanan Custom Vision guna mengirim gambar ke model dan mengambil prediksi untuk objek yang terdeteksi. Masing-masing prediksi terdiri dari nama kelas (*apel*, *pisang*, atau *jeruk*) dan koordinat *kotak pembatas* yang menunjukkan tempat pada gambar objek yang diprediksi telah terdeteksi. Kemudian, kode menggunakan informasi ini untuk menggambar kotak berlabel di sekitar masing-masing objek pada gambar.
```
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
from msrest.authentication import ApiKeyCredentials
from matplotlib import pyplot as plt
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import os
%matplotlib inline
# Load a test image and get its dimensions
test_img_file = os.path.join('data', 'object-detection', 'produce.jpg')
test_img = Image.open(test_img_file)
test_img_h, test_img_w, test_img_ch = np.array(test_img).shape
# Get a prediction client for the object detection model
credentials = ApiKeyCredentials(in_headers={"Prediction-key": cv_key})
predictor = CustomVisionPredictionClient(endpoint=cv_endpoint, credentials=credentials)
print('Detecting objects in {} using model {} in project {}...'.format(test_img_file, model_name, project_id))
# Detect objects in the test image
with open(test_img_file, mode="rb") as test_data:
results = predictor.detect_image(project_id, model_name, test_data)
# Create a figure to display the results
fig = plt.figure(figsize=(8, 8))
plt.axis('off')
# Display the image with boxes around each detected object
draw = ImageDraw.Draw(test_img)
lineWidth = int(np.array(test_img).shape[1]/100)
object_colors = {
"apple": "lightgreen",
"banana": "yellow",
"orange": "orange"
}
for prediction in results.predictions:
color = 'white' # default for 'other' object tags
if (prediction.probability*100) > 50:
if prediction.tag_name in object_colors:
color = object_colors[prediction.tag_name]
left = prediction.bounding_box.left * test_img_w
top = prediction.bounding_box.top * test_img_h
height = prediction.bounding_box.height * test_img_h
width = prediction.bounding_box.width * test_img_w
points = ((left,top), (left+width,top), (left+width,top+height), (left,top+height),(left,top))
draw.line(points, fill=color, width=lineWidth)
plt.annotate(prediction.tag_name + ": {0:.2f}%".format(prediction.probability * 100),(left,top), backgroundcolor=color)
plt.imshow(test_img)
```
Lihat prediksi yang dihasilkan, yang menampilkan objek terdeteksi dan peluang untuk masing-masing prediksi.
| github_jupyter |
```
#remove cell visibility
from IPython.display import HTML
tag = HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide()
} else {
$('div.input').show()
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
Toggle cell visibility <a href="javascript:code_toggle()">here</a>.''')
display(tag)
```
## Jordan Form - Complex Eigenvalues
This example shows how the basic Jordan Form can be modified when the matrix $A$ has complex eigenvalues in order for its Jordan form $J$ to be composed by real numbers only.
When matrix $A$ has a complex eigenvalue $\lambda$, it has also its complex conjugate $\bar \lambda$ as eigenvalue. It can be shown that if the eigenvector $v$ is associated with the eigenvalue $\lambda$, then the eigenvector associated with the eigenvalue $\bar \lambda$ is the complex conjugate of $v$: $\bar v$.
This important result allows us to change the $V$ matrix (namely by substituting the columns of $v$ and $\bar v$ with their linear combinations $(v+\bar v)$ and $(v-\bar v)$) obtaining a different form of the Jordan Matrix where the complex conjugate pair of eigenvalues $\lambda$ and $\bar \lambda$ generates a Jordan element of the form:
$$
J = \begin{bmatrix}
\sigma & \omega \\
-\omega & \sigma \\
\end{bmatrix},
$$
with $\lambda = \sigma + i \omega$.
### How to use this notebook?
- Define a matrix and watch its Jordan form; experiment with both real and complex eigenvalues.
- Try to build a matrix with complex eigenvalues and multiplicity equal to 2.
- Explore the effects of changing the values of the matrix $A$ or load example matrices.
```
#Preparatory Cell
import control
import numpy
import sympy
from IPython.display import display, Markdown
import ipywidgets as widgets
import matplotlib.pyplot as plt
from sympy import Matrix
#print a matrix latex-like
def bmatrix(a):
"""Returns a LaTeX bmatrix - by Damir Arbula (ICCT project)
:a: numpy array
:returns: LaTeX bmatrix as a string
"""
if len(a.shape) > 2:
raise ValueError('bmatrix can at most display two dimensions')
lines = str(a).replace('[', '').replace(']', '').splitlines()
rv = [r'\begin{bmatrix}']
rv += [' ' + ' & '.join(l.split()) + r'\\' for l in lines]
rv += [r'\end{bmatrix}']
return '\n'.join(rv)
# Display formatted matrix:
def vmatrix(a):
if len(a.shape) > 2:
raise ValueError('bmatrix can at most display two dimensions')
lines = str(a).replace('[', '').replace(']', '').splitlines()
rv = [r'\begin{vmatrix}']
rv += [' ' + ' & '.join(l.split()) + r'\\' for l in lines]
rv += [r'\end{vmatrix}']
return '\n'.join(rv)
#create a NxM matrix widget
def createMatrixWidget(n,m):
M = widgets.GridBox(children=[widgets.FloatText(layout=widgets.Layout(width='100px', height='40px'),
value=0.0, disabled=False, label=i) for i in range(n*m)],
layout=widgets.Layout(
#width='50%',
grid_template_columns= ''.join(['100px ' for i in range(m)]),
#grid_template_rows='80px 80px 80px',
grid_row_gap='0px',
track_size='0px')
)
return M
#extract matrix from widgets and convert to numpy matrix
def getNumpyMatFromWidget(M,n,m):
#get W gridbox dims
M_ = numpy.matrix(numpy.zeros((n,m)))
for irow in range(0,n):
for icol in range(0,m):
M_[irow,icol] = M.children[irow*3+icol].value
#this is a simple derived class from FloatText used to experience with interact
class floatWidget(widgets.FloatText):
def __init__(self,**kwargs):
#self.n = n
self.value = 30.0
#self.M =
widgets.FloatText.__init__(self, **kwargs)
# def value(self):
# return 0 #self.FloatText.value
from traitlets import Unicode
from ipywidgets import register
#matrixWidget is a matrix looking widget built with a VBox of HBox(es) that returns a numPy array as value !
class matrixWidget(widgets.VBox):
def updateM(self,change):
for irow in range(0,self.n):
for icol in range(0,self.m):
self.M_[irow,icol] = self.children[irow].children[icol].value
#print(self.M_[irow,icol])
self.value = self.M_
def dummychangecallback(self,change):
pass
def __init__(self,n,m):
self.n = n
self.m = m
self.M_ = numpy.matrix(numpy.zeros((self.n,self.m)))
self.value = self.M_
widgets.VBox.__init__(self,
children = [
widgets.HBox(children =
[widgets.FloatText(value=0.0, layout=widgets.Layout(width='90px')) for i in range(m)]
)
for j in range(n)
])
#fill in widgets and tell interact to call updateM each time a children changes value
for irow in range(0,self.n):
for icol in range(0,self.m):
self.children[irow].children[icol].value = self.M_[irow,icol]
self.children[irow].children[icol].observe(self.updateM, names='value')
#value = Unicode('example@example.com', help="The email value.").tag(sync=True)
self.observe(self.updateM, names='value', type= 'All')
def setM(self, newM):
#disable callbacks, change values, and reenable
self.unobserve(self.updateM, names='value', type= 'All')
for irow in range(0,self.n):
for icol in range(0,self.m):
self.children[irow].children[icol].unobserve(self.updateM, names='value')
self.M_ = newM
self.value = self.M_
for irow in range(0,self.n):
for icol in range(0,self.m):
self.children[irow].children[icol].value = self.M_[irow,icol]
for irow in range(0,self.n):
for icol in range(0,self.m):
self.children[irow].children[icol].observe(self.updateM, names='value')
self.observe(self.updateM, names='value', type= 'All')
#self.children[irow].children[icol].observe(self.updateM, names='value')
#overlaod class for state space systems that DO NOT remove "useless" states (what "professor" of automatic control would do this?)
class sss(control.StateSpace):
def __init__(self,*args):
#call base class init constructor
control.StateSpace.__init__(self,*args)
#disable function below in base class
def _remove_useless_states(self):
pass
#define matrices
A = matrixWidget(4,4)
#this is the main callback and does all the computations and plots
def main_callback(matA,DW,sel):
#check if a specific matrix is requested or is manual
if sel=='manual definition of the system' :
pass
elif sel == 'stable system - no complex congjugate poles':
matA = numpy.zeros((4,4))
matA[0,0] = -1
matA[1,1] = -2
matA[2,2] = -3
matA[3,3] = -4
A.setM(matA)
elif sel == 'stable system - w/ complex conjugate pair':
matA = numpy.zeros((4,4))
matA[0,0] = -1
matA[0,1] = 3
matA[1,0] = -3
matA[1,1] = -1
matA[2,2] = -3
matA[3,3] = -4
A.setM(matA)
elif sel == 'unstable system - unstable real pole unstable':
matA = numpy.zeros((4,4))
matA[0,0] = 1
matA[1,1] = -2
matA[2,2] = -3
matA[3,3] = -4
A.setM(matA)
elif sel == 'unstable system - unstable complex conjugate pair ':
matA = numpy.zeros((4,4))
matA[0,0] = 1
matA[0,1] = 3
matA[1,0] = -3
matA[1,1] = 1
matA[2,2] = -3
matA[3,3] = -4
A.setM(matA)
else :
matA = numpy.zeros((4,4))
A.setM(matA)
# Work with symbolic matrix
matAs = sympy.Matrix(matA)
dictEig = matAs.eigenvals()
eigs = list(dictEig.keys())
algMult = list(dictEig.values())
# check dimension of jordan blocks
dimJblock = []
for i in range(len(eigs)):
dimJblock.append(algMult[i]-len((matAs-eigs[i]*sympy.eye(4)).nullspace())+1)
# jordan form with real numbers
matAs_P, matAs_J = matAs.jordan_form(chop=True)
zeroV = Matrix([0,0,0,0])
cols = []
for i in range(4):
RE, IM = matAs_P.col(i).as_real_imag()
if IM == zeroV:
cols.append(RE)
elif not any([matAs_P.col(i).conjugate() == matAs_P.col(j) for j in range(i+1)]):
cols.append(RE)
cols.append(IM)
matAs_P = cols[0].row_join(cols[1]).row_join(cols[2]).row_join(cols[3])
matAs_J = matAs_P.inv()*matAs*matAs_P
timeVectors = []
modeVectors = []
# compute modes simulations and prepare modestring
modestring = ''
for i in range(len(eigs)):
sim = []
if sympy.re(eigs[i]) >= 0:
# instable or integral like
time = numpy.linspace(0,10,1000)
for n in range(dimJblock[i]):
if n==0:
if sympy.im(eigs[i]) != 0 and (sympy.conjugate(eigs[i]) not in eigs[0:i]):
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time)*numpy.cos(float(sympy.im(eigs[i]))*time))
modestring = modestring + "$e^{%s t} cos(%s t + \phi)$ " % (str(float(sympy.re(eigs[i]))), str(float(sympy.im(eigs[i]))))
elif sympy.im(eigs[i]) == 0:
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time))
modestring = modestring + "$e^{%s t}$ " % (str(float(sympy.re(eigs[i]))))
else:
if sympy.im(eigs[i]) != 0 and (sympy.conjugate(eigs[i]) not in eigs[0:i]):
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time)*numpy.cos(float(sympy.im(eigs[i]))*time))
modestring = modestring + "$t^{%s}e^{%s t} cos(%s t + \phi)$ " % (str(n), str(float(sympy.re(eigs[i]))), str(float(sympy.im(eigs[i]))))
elif sympy.im(eigs[i]) == 0:
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time))
modestring = modestring + "$t^{%s}e^{%s t}$ " % (str(n), str(float(sympy.re(eigs[i]))))
else:
# stable mode
time = numpy.linspace(0,10*(1/float(sympy.Abs(eigs[i]))),1000)
for n in range(dimJblock[i]):
if n==0:
if sympy.im(eigs[i]) != 0 and (sympy.conjugate(eigs[i]) not in eigs[0:i]):
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time)*numpy.cos(float(sympy.im(eigs[i]))*time))
modestring = modestring + "$e^{%s t} cos(%s t + \phi)$ " % (str(float(sympy.re(eigs[i]))), str(float(sympy.im(eigs[i]))))
elif sympy.im(eigs[i]) == 0:
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time))
modestring = modestring + "$e^{%s t}$ " % (str(float(sympy.re(eigs[i]))))
else:
if sympy.im(eigs[i]) != 0 and (sympy.conjugate(eigs[i]) not in eigs[0:i]):
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time)*numpy.cos(float(sympy.im(eigs[i]))*time))
modestring = modestring + "$t^{%s}e^{%s t} cos(%s t + \phi)$ " % (str(n), str(float(sympy.re(eigs[i]))), str(float(sympy.im(eigs[i]))))
elif sympy.im(eigs[i]) == 0:
sim.append(time**n*numpy.exp(float(sympy.re(eigs[i]))*time))
modestring = modestring + "$t^{%s}e^{%s t}$ " % (str(n), str(float(sympy.re(eigs[i]))))
if len(sim) != 0:
timeVectors.append(time)
modeVectors.append(sim)
#print(dimJblock)
#print(len(modeVectors))
#create textual output
display(Markdown('Matrix: $%s$ has eigenvalues $%s$' % (vmatrix(matA), vmatrix(numpy.array(numpy.linalg.eig(matA)[0])))))
#for better visualization
matJlist = []
for i in range(4):
temp = []
for j in range(4):
if sympy.im(matAs_J[i,j]) != 0:
temp.append(numpy.complex(matAs_J[i,j]))
else:
temp.append(numpy.real(matAs_J[i,j]))
matJlist.append(temp)
matJ = numpy.matrix(matJlist)
display(Markdown('and the Jordan form equal to: $%s$' %str(vmatrix(matJ))))
#for better visualization
matPlist = []
for i in range(4):
temp = []
for j in range(4):
if sympy.im(matAs_P[i,j]) != 0:
temp.append(numpy.complex(matAs_P[i,j]))
else:
temp.append(numpy.real(matAs_P[i,j]))
matPlist.append(temp)
matP = numpy.matrix(matPlist)
display(Markdown('with generalized real eigenvectors $%s$.' %str(vmatrix(matP))))
display(Markdown('The modes are: %s' % modestring))
#compute total number of figures
totfig=0
for i in range(len(modeVectors)):
totfig = totfig + len(modeVectors[i])
#plot each single mode
fig = plt.figure(figsize=(20, 4))
idx = 1
for i in range(len(timeVectors)):
for j in range(len(modeVectors[i])):
sf = fig.add_subplot(1,totfig,idx)
idx = idx + 1
sf.plot(timeVectors[i],modeVectors[i][j])
sf.grid(True)
plt.xlabel(r'$t$ [s]')
plt.axvline(x=0,color='black',linewidth=0.8)
plt.axhline(y=0,color='black',linewidth=0.8)
#create dummy widget
DW = widgets.FloatText(layout=widgets.Layout(width='0px', height='0px'))
#create button widget
START = widgets.Button(
description='Test',
disabled=False,
button_style='', # 'success', 'info', 'warning', 'danger' or ''
tooltip='Test',
icon='check'
)
def on_start_button_clicked(b):
#This is a workaround to have intreactive_output call the callback:
# force the value of the dummy widget to change
if DW.value> 0 :
DW.value = -1
else:
DW.value = 1
pass
START.on_click(on_start_button_clicked)
#define type of ipout
SELECT = widgets.Dropdown(
options=['manual definition of the system', 'reset', 'stable system - no complex congjugate poles',
'stable system - w/ complex conjugate pair',
'unstable system - unstable real pole unstable',
'unstable system - unstable complex conjugate pair '],
value='manual definition of the system',
description='Examples:',
disabled=False,
)
#create a graphic structure to hold all widgets
alltogether = widgets.VBox([SELECT, widgets.Label(''), widgets.HBox([widgets.Label('$\dot{x}(t) = $',border=3), A,widgets.Label('$x(t)$',border=3), START])] )
out = widgets.interactive_output(main_callback,{'matA': A, 'DW': DW, 'sel': SELECT})
out.layout.height = '620px'
display(alltogether,out)
```
| github_jupyter |
model.cifar.vgg-cfiar.py
```
from google.colab import drive
drive.mount('/content/drive')
import torch
import torch.nn as nn
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
super(SeparableConv2d, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, padding=1)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
class Xception(nn.Module):
def __init__(self):
super(Xception, self).__init__()
self.feature = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Conv2d(64, 128, kernel_size=1, stride=2)
self.block1 = nn.Sequential(
SeparableConv2d(64, 128, kernel_size=3),
nn.ReLU(),
SeparableConv2d(128, 128, 3),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv4 = nn.Conv2d(128, 256, kernel_size=1, stride=2)
self.block2 = nn.Sequential(
nn.ReLU(),
SeparableConv2d(128, 256, kernel_size=3),
nn.BatchNorm2d(256),
nn.ReLU(),
SeparableConv2d(256, 256, 3),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv5 = nn.Conv2d(256, 728, kernel_size=1, stride=2)
self.block3 = nn.Sequential(
nn.ReLU(),
SeparableConv2d(256, 728, kernel_size=3),
nn.BatchNorm2d(728),
nn.ReLU(),
SeparableConv2d(728, 728, 3),
nn.BatchNorm2d(728),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv6 = nn.Conv2d(728, 728, kernel_size=1, stride=2)
self.block4 = nn.Sequential(
nn.ReLU(),
SeparableConv2d(728, 728, kernel_size=3),
nn.BatchNorm2d(728),
nn.ReLU(),
SeparableConv2d(728, 728, 3),
nn.BatchNorm2d(728),
nn.ReLU(),
SeparableConv2d(728, 728, 3),
nn.BatchNorm2d(728),
)
self.conv7 = nn.Conv2d(728, 1024, kernel_size=1, stride=2)
self.block5 = nn.Sequential(
nn.ReLU(),
SeparableConv2d(728, 728, kernel_size=3),
nn.BatchNorm2d(728),
nn.ReLU(),
SeparableConv2d(728, 1024, 3),
nn.BatchNorm2d(1024),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.block6 = nn.Sequential(
nn.ReLU(),
SeparableConv2d(1024, 1536, kernel_size=3),
nn.BatchNorm2d(1536),
nn.ReLU(),
SeparableConv2d(1536, 2048, 3),
nn.BatchNorm2d(2048),
nn.AvgPool2d(kernel_size=1, stride=1)
)
self.fc = nn.Linear(2048, 100)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.feature(x)
x = self.block1(x) + self.conv3(x)
x = self.block2(x) + self.conv4(x)
x = self.block3(x) + self.conv5(x)
x = self.block4(x) + self.conv6(x)
x = self.block5(x) + self.conv7(x)
x = self.block6(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def xception():
return Xception()
```
config.py
```
import easydict
def config():
cfg = easydict.EasyDict({
"arch": "xception",
"dataset": "cifar100",
"batch_size": 128,
"epochs": 200,
"learning_rate": 0.1,
"weight_decay": 0.00001,
"momentum": 0.9,
"nesterov": True,
"print_freq": 50,
"ckpt": "/content/drive/My Drive/MLVC/Baseline/checkpoint/",
"results_dir": "./results/",
"resume": False,
"evaluate": False,
"cuda": True,
"gpuids": [0],
"colab": True,
})
cfg.gpuids = list(map(int, cfg.gpuids))
model = xception()
if cfg.arch == "xception":
model = xception()
#elif cfg.arch == "resnet-cifar":
# model = resnet.resnet20()
#elif cfg.arch == "vgg-cifar-binary":
# model = vgg_bnn.vgg11()
#elif cfg.arch == "resnet-cifar-dorefa":
# model = resnet_dorefanet.resnet20()
return cfg, model
```
utility.py
```
import torch
import time
import shutil
import pathlib
from collections import OrderedDict
def load_model(model, ckpt_file, args):
if args.cuda:
checkpoint = torch.load(
ckpt_file, map_location=lambda storage, loc: storage.cuda(args.gpuids[0])
)
try:
model.load_state_dict(checkpoint["model"])
except: # noqa
model.module.load_state_dict(checkpoint["model"])
else:
checkpoint = torch.load(ckpt_file, map_location=lambda storage, loc: storage)
try:
model.load_state_dict(checkpoint["model"])
except: # noqa
# create new OrderedDict that does not contain `module.`
new_state_dict = OrderedDict()
for k, v in checkpoint["model"].items():
if k[:7] == "module.":
name = k[7:] # remove `module.`
else:
name = k[:]
new_state_dict[name] = v
model.load_state_dict(new_state_dict)
return checkpoint
def save_model(state, epoch, is_best, args):
dir_ckpt = pathlib.Path("checkpoint")
dir_path = dir_ckpt / args.dataset
dir_path.mkdir(parents=True, exist_ok=True)
model_file = dir_path / "ckpt_epoch_{}.pth".format(epoch)
torch.save(state, model_file)
if is_best:
shutil.copyfile(model_file, dir_path / "ckpt_best.pth")
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=":f"):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
return fmtstr.format(**self.__dict__)
class ProgressMeter(object):
def __init__(self, num_batches, *meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def print(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print("\t".join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = "{:" + str(num_digits) + "d}"
return "[" + fmt + "/" + fmt.format(num_batches) + "]"
def adjust_learning_rate(optimizer, epoch, lr):
"""Sets the learning rate, decayed rate of 0.1 every epoch"""
#if epoch >= 60:
# lr = 0.01
#if epoch >= 120:
# lr = 0.001
#if epoch >= 160:
# lr = 0.0001
for param_group in optimizer.param_groups:
param_group["lr"] = lr
return lr
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def print_reults(start_time, train_time, validate_time, start_epoch, epochs):
avg_train_time = train_time / (epochs - start_epoch)
avg_valid_time = validate_time / (epochs - start_epoch)
total_train_time = train_time + validate_time
print(
"====> average training time per epoch: {:,}m {:.2f}s".format(
int(avg_train_time // 60), avg_train_time % 60
)
)
print(
"====> average validation time per epoch: {:,}m {:.2f}s".format(
int(avg_valid_time // 60), avg_valid_time % 60
)
)
print(
"====> training time: {}h {}m {:.2f}s".format(
int(train_time // 3600), int((train_time % 3600) // 60), train_time % 60
)
)
print(
"====> validation time: {}h {}m {:.2f}s".format(
int(validate_time // 3600),
int((validate_time % 3600) // 60),
validate_time % 60,
)
)
print(
"====> total training time: {}h {}m {:.2f}s".format(
int(total_train_time // 3600),
int((total_train_time % 3600) // 60),
total_train_time % 60,
)
)
elapsed_time = time.time() - start_time
print(
"====> total time: {}h {}m {:.2f}s".format(
int(elapsed_time // 3600), int((elapsed_time % 3600) // 60), elapsed_time % 60
)
)
```
data_loader.py
```
import torch
import torchvision.transforms as transforms
from torchvision import datasets
def dataloader(dataset, batch_size):
train_dataset, val_dataset = load_cifar10()
if dataset == "cifar100":
train_dataset, val_dataset = load_cifar100()
# Data loader
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=batch_size, shuffle=True
)
val_loader = torch.utils.data.DataLoader(
dataset=val_dataset, batch_size=batch_size, shuffle=False
)
return train_loader, val_loader
def load_cifar10():
# CIFAR-10 dataset
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
train_dataset = datasets.CIFAR10(
root="../../data/",
train=True,
transform=transforms.Compose(
[
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor(),
normalize,
]
),
download=True,
)
val_dataset = datasets.CIFAR10(
root="../../data/",
train=False,
transform=transforms.Compose([transforms.ToTensor(), normalize]),
)
return train_dataset, val_dataset
def load_cifar100():
# CIFAR-100 dataset
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
train_dataset = datasets.CIFAR100(
root="../../data/",
train=True,
transform=transforms.Compose(
[
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor(),
normalize,
]
),
download=True,
)
val_dataset = datasets.CIFAR100(
root="../../data/",
train=False,
transform=transforms.Compose([transforms.ToTensor(), normalize]),
)
return train_dataset, val_dataset
```
main.py
```
import torch
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
import time
import pathlib
from os.path import isfile
import pandas as pd
def main():
global args, start_epoch, best_acc1
args, model = config()
print("Model: {}".format(args.arch))
if args.cuda and not torch.cuda.is_available():
raise Exception("No GPU found, please run without --cuda")
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(
model.parameters(),
lr=args.learning_rate,
weight_decay=args.weight_decay,
momentum=args.momentum,
nesterov=args.nesterov,
)
best_acc1 = 0
start_epoch = 0
if args.cuda:
torch.cuda.set_device(args.gpuids[0])
with torch.cuda.device(args.gpuids[0]):
model = model.cuda()
criterion = criterion.cuda()
model = nn.DataParallel(
model, device_ids=args.gpuids, output_device=args.gpuids[0]
)
cudnn.benchmark = True
# checkpoint file
ckpt_dir = pathlib.Path(args.ckpt)
ckpt_file = ckpt_dir / args.dataset / args.ckpt
# for resuming training
if args.resume:
retrain(ckpt_file, model, optimizer)
# Data loading
print("\n==> Load data..")
train_loader, val_loader = dataloader(args.dataset, args.batch_size)
# initiailizae
train_time, validate_time = 0.0, 0.0
avgloss_train = 0.0
acc1_train, acc5_train, acc1_valid, acc5_valid = 0.0, 0.0, 0.0, 0.0
is_best = False
# result lists
result_epoch, result_lr, result_train_avgtime, result_train_avgloss = [], [], [], []
result_train_avgtop1acc, result_train_avgtop5acc = [], []
result_val_avgtime, result_val_avgtop1acc, result_val_avgtop5acc = [], [], []
# train...
lr = args.learning_rate
curr_lr = lr
for epoch in range(start_epoch, args.epochs):
curr_lr = adjust_learning_rate(optimizer, epoch, lr)
print("\n==> Epoch: {}, lr = {}".format(epoch, optimizer.param_groups[0]["lr"]))
# train for one epoch
train_time, acc1_train, acc5_train, avgloss_train = train_epoch(
train_time,
acc1_train,
acc5_train,
avgloss_train,
train_loader,
epoch,
model,
criterion,
optimizer,
)
# evaluate on validation set
validate_time, acc1_valid, acc5_valid = validation_epoch(
validate_time, acc1_valid, acc5_valid, val_loader, model, criterion
)
# remember best Acc@1 and save checkpoint
is_best = save_model_data(
is_best, best_acc1, acc1_valid, epoch, model, optimizer, args
)
result_epoch.append(epoch)
result_lr.append(curr_lr)
result_train_avgtime.append(train_time)
result_train_avgloss.append(avgloss_train)
result_train_avgtop1acc.append(acc1_train.item())
result_train_avgtop5acc.append(acc5_train.item())
result_val_avgtop1acc.append(acc1_valid.item())
result_val_avgtop5acc.append(acc5_valid.item())
df = pd.DataFrame({
'Epoch': result_epoch,
'Learning rate': result_lr,
'Training avg loss': result_train_avgloss,
'Training avg top1 acc': result_train_avgtop1acc,
'Training avg top5 acc': result_train_avgtop5acc,
'Test avg top1 acc': result_val_avgtop1acc,
'Test avg top5 acc': result_val_avgtop5acc,
})
if args.colab:
df.to_csv('/content/drive/My Drive/MLVC/Baseline/results/{}_result.csv'.format(args.arch))
else:
df.to_csv('./results/{}_result.csv'.format(args.arch))
print_results(train_time, validate_time)
def retrain(ckpt_file, model, optimizer):
if isfile(ckpt_file):
print("\n==> Loading Checkpoint '{}'".format(args.ckpt))
checkpoint = load_model(model, ckpt_file, args)
start_epoch = checkpoint["epoch"]
optimizer.load_state_dict(checkpoint["optimizer"])
print("==> Loaded Checkpoint '{}' (epoch {})".format(args.ckpt, start_epoch))
else:
print("==> no checkpoint found '{}'".format(args.ckpt))
return
def train_epoch(
train_time, acc1_train, acc5_train, avgloss_train, train_loader, epoch, model, criterion, optimizer
):
print("===> [ Training ]")
start_time = time.time()
acc1_train, acc5_train, avgloss_train = train(
train_loader, epoch=epoch, model=model, criterion=criterion, optimizer=optimizer
)
elapsed_time = time.time() - start_time
train_time += elapsed_time
print("====> {:.2f} seconds to train this epoch\n".format(elapsed_time))
return train_time, acc1_train, acc5_train, avgloss_train
def validation_epoch(
validate_time, acc1_valid, acc5_valid, val_loader, model, criterion
):
print("===> [ Validation ]")
start_time = time.time()
acc1_valid, acc5_valid, avgloss_valid = validate(val_loader, model, criterion)
elapsed_time = time.time() - start_time
validate_time += elapsed_time
print("====> {:.2f} seconds to validate this epoch\n".format(elapsed_time))
return validate_time, acc1_valid, acc5_valid
def save_model_data(is_best, best_acc1, acc1_valid, epoch, model, optimizer, args):
is_best = acc1_valid > best_acc1
best_acc1 = max(acc1_valid, best_acc1)
state = {
"epoch": epoch + 1,
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
if (epoch + 1) % 20 == 0:
save_model(state, epoch, is_best, args)
return is_best
def train(train_loader, **kwargs):
epoch = kwargs.get("epoch")
model = kwargs.get("model")
criterion = kwargs.get("criterion")
optimizer = kwargs.get("optimizer")
batch_time = AverageMeter("Time", ":6.3f")
data_time = AverageMeter("Data", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(train_loader),
batch_time,
data_time,
losses,
top1,
top5,
prefix="Epoch: [{}]".format(epoch),
)
# switch to train mode
model.train()
end = time.time()
running_loss = 0.0
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if args.cuda:
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(acc1[0], input.size(0))
top5.update(acc5[0], input.size(0))
# compute gradient and do SGD step.
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
running_loss += loss.item()
if i % args.print_freq == 0:
progress.print(i)
end = time.time()
print(
"====> Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f}".format(top1=top1, top5=top5)
)
epoch_loss = running_loss / len(train_loader)
print("====> Epoch loss {:.3f}".format(epoch_loss))
return top1.avg, top5.avg, epoch_loss
def validate(val_loader, model, criterion):
batch_time = AverageMeter("Time", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(val_loader), batch_time, losses, top1, top5, prefix="Test: "
)
# switch to evaluate mode
model.eval()
total_loss = 0.0
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
if args.cuda:
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(acc1[0], input.size(0))
top5.update(acc5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
total_loss += loss.item()
if i % args.print_freq == 0:
progress.print(i)
end = time.time()
print(
"====> Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f}".format(
top1=top1, top5=top5
)
)
total_loss = total_loss / len(val_loader)
return top1.avg, top5.avg, loss.item()
def print_results(train_time, validate_time):
avg_train_time = train_time / (args.epochs - start_epoch)
avg_valid_time = validate_time / (args.epochs - start_epoch)
total_train_time = train_time + validate_time
print(
"====> average training time per epoch: {:,}m {:.2f}s".format(
int(avg_train_time // 60), avg_train_time % 60
)
)
print(
"====> average validation time per epoch: {:,}m {:.2f}s".format(
int(avg_valid_time // 60), avg_valid_time % 60
)
)
print(
"====> training time: {}h {}m {:.2f}s".format(
int(train_time // 3600), int((train_time % 3600) // 60), train_time % 60
)
)
print(
"====> validation time: {}h {}m {:.2f}s".format(
int(validate_time // 3600),
int((validate_time % 3600) // 60),
validate_time % 60,
)
)
print(
"====> total training time: {}h {}m {:.2f}s".format(
int(total_train_time // 3600),
int((total_train_time % 3600) // 60),
total_train_time % 60,
)
)
if __name__ == "__main__":
start_time = time.time()
main()
elapsed_time = time.time() - start_time
print(
"====> total time: {}h {}m {:.2f}s".format(
int(elapsed_time // 3600),
int((elapsed_time % 3600) // 60),
elapsed_time % 60,
)
)
```
| github_jupyter |
# CIS6930 Week 9a: Pre-trained Language Models (1) (Student version)
---
Preparation: Go to `Runtime > Change runtime type` and choose `GPU` for the hardware accelerator.
```
gpu_info = !nvidia-smi -L
gpu_info = "\n".join(gpu_info)
if gpu_info.find("failed") >= 0:
print("Not connected to a GPU")
else:
print(gpu_info)
```
## Preparation
For this notebookt, we use Hugging Face's `transformers` library.
```
!pip install transformers
import copy
from time import time
from typing import Any, Dict
import random
import numpy as np
from sklearn.metrics import accuracy_score
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, TensorDataset, DataLoader
from tqdm import tqdm
from transformers import AdamW, get_linear_schedule_with_warmup
```
## Playing with a Pre-trained Tokenizer
As discussed in the lecture, we use "pre-trained" tokenizer models for pre-trained language models. Let's take a look at the tokenizer pre-trained for `bert-base-uncased`.
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# AutoTokenizer, AutoModelForSequenceClassification are a "meta" class for
# model-specific classes such as BertTokenizer, BertForSequenceClassification
# See also Hugging Face's ModelHub
# https://huggingface.co/bert-base-uncased
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokenizer.encode("Hello, world!")
for token in tokenizer.encode("Hello, world!"):
print(tokenizer.decode(token))
tokenizer.decode(tokenizer.encode("Hello, world!"))
# "Pre-trained" vocabulary set
len(tokenizer.vocab)
# Registered special tokens
tokenizer.special_tokens_map
# What about the longest English word? :)
for tokenid in tokenizer.encode("pneumonoultramicroscopicsilicovolcanoconiosis"):
print(tokenizer.decode(tokenid))
```
Now, we see the pre-trained tokenizer does not have the OoV issue and tokenzie an input sequence into subwords.
### `transformers.Tokenizer.__call__()`
We usually use the `__call__()` method. The method returns a dictionary of `input_ids`, `token_type_ids`, and `attention_mask`, which are compatible with the interface of pre-trained language models in the `transformers` library. This function is also convenient for **padding**.
Let's take a look.
```
tokenizer("Hello, world!") # __call__() in Python
# For sequence-pair classification
tokenizer("Hello, world!", "Good morning world!")
# By providing `max_length` and `padding` arguments,
# you can make "pre-padded" token ID sequences
tokenizer(["Hello, world!", "Hello, again!"],
max_length=16, padding="max_length")
# By adding `return_tensors="pt"`, you can get PyTorch tensor objects instead of lists.
tokenizer(["Hello, world!", "Hello, again!"],
max_length=16, padding="max_length",
return_tensors="pt")
```
## Implementing Custom Dataset class
In Week 6, we created a custom dataset for the Twitter dataset (Please see [the Google Colab notebook](https://colab.research.google.com/drive/1DZN-Bo2HBnPQPm4jrQzEIchhHdN682qP?usp=sharing))
```
# https://www.kaggle.com/crowdflower/twitter-airline-sentiment
# License CC BY-NC-SA 4.0
!gdown --id 1BS_TIqm7crkBRr8p6REZrMv4Uk9_-e6W
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from torch.utils.data import Dataset, TensorDataset, DataLoader
# Loading dataset
df = pd.read_csv("Tweets.csv")
# Label encoder
le = LabelEncoder()
y = le.fit_transform(df["airline_sentiment"].values)
df["label"] = y
# Splint into 60% train, 20% valid, 20% test
train_df, test_df = train_test_split(
df, test_size=0.2, random_state=1)
train_df, valid_df = train_test_split(
train_df, test_size=0.25, random_state=1) # 0.25 x 0.8 = 0.2
print(len(train_df), len(valid_df), len(test_df))
df.columns
class TweetDataset(Dataset):
def __init__(self,
df,
tokenizer,
max_length=256):
self.df = df
input_ids = []
for text in self.df["text"].tolist():
d = tokenizer(text,
max_length=max_length,
padding="max_length",
return_tensors="pt")
for k, v in d.items():
# To remove unnecessary list
d[k] = v.squeeze(0)
input_ids.append(d)
self.df["input_ids"] = input_ids
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
return {**self.df.iloc[idx]["input_ids"],
"labels": self.df.iloc[idx]["label"]}
train_dataset = TweetDataset(train_df, tokenizer, max_length=256)
valid_dataset = TweetDataset(valid_df, tokenizer, max_length=256)
test_dataset = TweetDataset(test_df, tokenizer, max_length=256)
# Take a look at a sample batch
batch = next(iter(DataLoader(train_dataset, batch_size=4)))
batch
```
### Testing a Pre-trained Model (with a sequence classification head)
- `AutoModel`: Base model (Note that it does not have any classification heads)
- `AutoModelForSequenceClasiffication`: For single-sentence/sentnece-pair classification
- `AutoModelForTokenClassification`: For sequential tagging
- `AutoModelForQuestionAnswering`: For Question Answering
See [the official API documentation](https://huggingface.co/transformers/model_doc/auto.html) for details.
In this example, we will use `AutoModelForSequenceClassification` for a text classification problem.
```
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=3)
```
Let's take a look at how the `forward()` function is implemented for `AutoModelForSequentialClassification`, which is actually `BertModelForSequenceClassification` in this case (as we load a pre-trained BERTmodel)
https://huggingface.co/transformers/model_doc/bert.html#transformers.BertModel.forward
When `forward()` takes the optional argument `labels`, it will return the corresponding `loss` value. This is convenient and now we don't have to manually calculate the loss value.
```
output = model(**batch)
output
output.loss
```
## Training script
The following training script is based on the previous version with little modifiations:
- 1) Replaced manual loss calculation with model's output.
- 2) Added a learning rate scheduler.
Let's take a look.
```
def train(model: nn.Module,
train_dataset: Dataset,
valid_dataset: Dataset,
config: Dict[str, Any],
random_seed: int = 0):
# Random Seeds ===============
torch.manual_seed(random_seed)
random.seed(random_seed)
np.random.seed(random_seed)
# Random Seeds ===============
# GPU configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dl_train = DataLoader(train_dataset,
batch_size=config["batch_size"],
shuffle=True,
drop_last=True)
dl_valid = DataLoader(valid_dataset)
# Model, Optimzier, Loss function
model = model.to(device)
# Optimizer
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": 0.0
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0},
]
optimizer = config["optimizer_cls"](optimizer_grouped_parameters,
lr=config["lr"])
t_total = len(dl_train) * config["n_epochs"]
scheduler = config["scheduler_cls"](optimizer,
num_warmup_steps=0,
num_training_steps=t_total)
# For each epoch
eval_list = []
t0 = time()
best_val = None
best_model = None
for n in range(config["n_epochs"]):
t1 = time()
print("Epoch {}".format(n))
# Training
train_loss = 0.
train_pred_list = []
train_true_list = []
model.train() # Switch to the training mode
# For each batch
for batch in tqdm(dl_train):
optimizer.zero_grad() # Initialize gradient information
# ==================================================================
for k, v in batch.items():
batch[k] = v.to(device)
output = model(**batch)
loss = output.loss
preds = output.logits.argmax(axis=1).detach().cpu().tolist()
labels = batch["labels"].detach().cpu().tolist()
# ==================================================================
loss.backward() # Backpropagate the loss value
optimizer.step() # Update the parameters
scheduler.step() # [New] Update the scheduler step
train_loss += loss.data.item()
train_pred_list += preds
train_true_list += labels
train_loss /= len(dl_train)
train_acc = accuracy_score(train_true_list, train_pred_list)
print(" Training loss: {:.4f} Training acc: {:.4f}".format(train_loss,
train_acc))
# Validation
valid_loss = 0.
valid_pred_list = []
valid_true_list = []
model.eval() # Switch to the evaluation mode
valid_emb_list = []
valid_label_list = []
for i, batch in tqdm(enumerate(dl_valid)):
# ==================================================================
for k, v in batch.items():
batch[k] = v.to(device)
output = model(**batch)
loss = output.loss
preds = output.logits.argmax(axis=1).detach().cpu().tolist()
labels = batch["labels"].detach().cpu().tolist()
# ==================================================================
valid_loss += loss.data.item()
valid_pred_list += preds
valid_true_list += labels
valid_loss /= len(dl_valid)
valid_acc = accuracy_score(valid_true_list, valid_pred_list)
print(" Validation loss: {:.4f} Validation acc: {:.4f}".format(valid_loss,
valid_acc))
# Model selection
if best_val is None or valid_loss < best_val:
best_model = copy.deepcopy(model)
best_val = valid_loss
t2 = time()
print(" Elapsed time: {:.1f} [sec]".format(t2 - t1))
# Store train/validation loss values
eval_list.append([n, train_loss, valid_loss, train_acc, valid_acc, t2 - t1])
eval_df = pd.DataFrame(eval_list, columns=["epoch",
"train_loss", "valid_loss",
"train_acc", "valid_acc",
"time"])
eval_df.set_index("epoch")
print("Total time: {:.1f} [sec]".format(t2 - t0))
# Return the best model and trainining/validation information
return {"model": best_model,
"best_val": best_val,
"eval_df": eval_df}
```
## Let's try!
Let's run the trainin script with the following configuration. Note that it several minutes to finish one epoch.
```
config = {"optimizer_cls": optim.AdamW,
"scheduler_cls": get_linear_schedule_with_warmup,
"lr": 5e-5,
"batch_size": 8,
"n_epochs": 3}
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=3)
output = train(model, train_dataset, valid_dataset, config)
```
### Results
```
output["eval_df"]
```
| github_jupyter |
```
import pandas as pd
import numpy as np
df=pd.read_csv("./final (2).csv",index_col='Unnamed: 0')
df.head()
df
pd.set_option('display.max_columns',None)
df.drop(['WHEELS_OFF','WHEELS_ON','TAXI_IN','DEP_TIME','CRS_ARR_TIME','ARR_DELAY',
'CRS_ELAPSED_TIME','ACTUAL_ELAPSED_TIME','Wind Gust'],inplace=True,axis=1)
df.head(20)
df.CANCELLED.value_counts()
df.DIVERTED.value_counts()
total_flights_delayed=df[(df['DEP_DELAY']>0)]
df=df[(df['DEP_DELAY']>0)]
weather_delayed_flights=df[(df['WEATHER_DELAY']>0)]
```
# Ratio of weather delayed flights
```
print("Out of {} no. of flights delayed, {} no. of flights were delayed due to weather conditions".format(len(total_flights_delayed),
len(weather_delayed_flights)))
(len(weather_delayed_flights)/len(total_flights_delayed))*100
df.Condition.value_counts()
df.DEP_DELAY.value_counts()
df.info()
df.isnull().sum()
df['AIR_TIME'].fillna(df['AIR_TIME'].mean,inplace=True)
df['CARRIER_DELAY'].fillna(int(0),inplace=True)
df['WEATHER_DELAY'].fillna(int(0),inplace=True)
df['LATE_AIRCRAFT_DELAY'].fillna(int(0),inplace=True)
df.isnull().sum()
# df=df[df['DEP_DELAY','CANCELLED','DIVERTED','AIR_TIME','DISTANCE'].astype(int)]
df = df.astype({"DEP_DELAY":'int64', "CANCELLED":'int64',"DIVERTED":'int64',"DISTANCE":'int64',"CARRIER_DELAY":'int64',"WEATHER_DELAY":'int64',"LATE_AIRCRAFT_DELAY":'int64'})
df
```
# Understanding Passenger Carrier Delay Costs
The **"Total Airline Operating Cost Breakdown"** consists of:
<br>
<br>
- 44% aircraft operating expenses, which include fuel, direct maintenance,
depreciation, and crew
<br>
<br>
- 29% servicing expense:
- Aircraft servicing (7%)
- Traffic servicing (11%)
- Passenger service (11%)
<br>
<br>
- 14% reservations and sales expense
- This figure was 19.5% in 1993, but declined steadily throughout the 1990s
<br>
<br>
- 13% overhead expense
- Advertising and Publicity (2%)
- General and Administrative (6%)
- Miscellaneous expense (5%)
The **"Direct Aircraft Operating Cost per Block Minute"** for 2018:
<br>
<br>
<ul>
<li>Fuel : 27.01</li>
<li>Pilots/Flight Attendants : 23.35</li>
<li>Maintenance : 11.75</li>
<li>Aircraft Ownership : 9.28</li>
<li>Other : 2.79</li>
</ul>
<br>
<br>
<strong>Total Direct Operating Costs per Minute</strong> : 74.18
<br>
<br>
<strong>Note</strong>: costs based on DOT Form 41 data for U.S. scheduled passenger airlines
<strong>Additional Costs</strong>
<br>
<br>
Delayed aircraft are estimated to have cost the airlines several billion dollars in additional expense. Delays also drive the need for extra gates and ground personnel and impose costs on airline customers (including shippers) in the form of lost productivity, wages and goodwill.
<br>
<br>
Assuming 47 dollars per hour(1) as the average value of a passenger’s time, flight delays are estimated to have cost air travelers billions of dollars. FAA/Nextor estimated the annual costs of delays (direct cost to airlines and passengers, lost demand, and indirect costs) in 2018 to be 28 billion dollars.
<br>
<br>
(1) FAA-recommended value: https://www.faa.gov/regulations_policies/policy_guidance/benefit_cost/media/econ-value-section-1-tx-time.pdf
### Finding "Direct Aircraft Operating Cost per Block Minute" for Atlanta airport in 2018
```
df
import seaborn as sns
sns.kdeplot(x=df[df['DEP_DELAY']>0]['DEP_DELAY'])
df["DELAY_COST"]=df.DEP_DELAY*74.18
df.DELAY_COST.value_counts()
df.DELAY_COST.sum()
df_weather_delay=df[df['WEATHER_DELAY'] >0]
df_weather_delay
df_weather_delay.DELAY_COST.value_counts()
df_weather_delay.DELAY_COST.sum()
```
## The total flight delay cost in year 2018 was 335,816,717.36 dollars, out of which 60,281,635.2 dollars were lost due to weather delays
```
df.head()
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.boxenplot(y=df['DELAY_COST'])
fig,axes = plt.subplots(ncols = 2,figsize = (14,10))
sns.kdeplot(ax=axes[0],x=df['DELAY_COST'])
sns.histplot(ax=axes[1],x=df['DELAY_COST'])
df['time'] = pd.to_datetime(df['time'],format = "%Y-%m-%d %H:%M:%S")
plt.figure(figsize=(10,6))
sns.lineplot(x=df['time'].dt.month,y=df['DELAY_COST'])
```
### from the above plot we can see that the delay tends to rise in the months around June,July,August due to rain and tend to be high in december and january due to snowfall
```
conditions = df['Condition'].unique()
```
## lineplots on the basis of conditions
```
fig,axes = plt.subplots(nrows=14,ncols = 2,figsize= (30,30))
cnt= 0
for i in range(0,14):
for j in range(0,2):
sns.lineplot(ax=axes[i][j],x=df[df['Condition']==conditions[cnt]]['time'].dt.month,y=df[df['Condition']==conditions[cnt]]['DELAY_COST'],label= conditions[cnt])
cnt = cnt+1
df.to_csv("./sample(2).csv")
df.head()
df["FL_DATE"] = pd.to_datetime(df["FL_DATE"])
df["month"]=df["FL_DATE"].dt.month
df["time"]=pd.to_datetime(df["time"])
df["hour"]=df["time"].dt.hour
df
df.Condition.value_counts()
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
df["Condition"]=le.fit_transform(df["Condition"])
df["DEST"]=le.fit_transform(df["Condition"])
df
df.drop(["FL_DATE","ORIGIN","CANCELLED","DIVERTED","CARRIER_DELAY","WEATHER_DELAY","LATE_AIRCRAFT_DELAY"],axis=1,inplace=True)
df.drop(["CRS_DEP_TIME","DELAY_COST","time"],axis=1,inplace=True)
df
```
## Decision Tree
```
import pandas as pd
import numpy as np
from sklearn import model_selection
from sklearn.tree import DecisionTreeRegressor
# from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from math import sqrt
import matplotlib.pyplot as plt
target_column=["DEP_DELAY"]
predictors= list(set(list(df.columns))-set(target_column))
df[predictors] = df[predictors]/df[predictors].max()
df.describe().transpose()
X = df[predictors].values
y = df[target_column].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=40)
print(X_train.shape); print(X_test.shape)
dtree = DecisionTreeRegressor(max_depth=8, min_samples_leaf=0.13, random_state=3)
dtree.fit(X_train, y_train)
pred_train_tree= dtree.predict(X_train)
print(np.sqrt(mean_squared_error(y_train,pred_train_tree)))
print(r2_score(y_train, pred_train_tree))
pred_test_tree= dtree.predict(X_test)
print(np.sqrt(mean_squared_error(y_test,pred_test_tree)))
print(r2_score(y_test, pred_test_tree))
dtree1 = DecisionTreeRegressor(max_depth=2)
dtree2 = DecisionTreeRegressor(max_depth=5)
dtree1.fit(X_train, y_train)
dtree2.fit(X_train, y_train)
tr1 = dtree1.predict(X_train)
tr2 = dtree2.predict(X_train)
y1 = dtree1.predict(X_test)
y2 = dtree2.predict(X_test)
print(np.sqrt(mean_squared_error(y_train,tr1)))
print(r2_score(y_train, tr1))
print(np.sqrt(mean_squared_error(y_test,y1)))
print(r2_score(y_test, y1))
print(np.sqrt(mean_squared_error(y_train,tr2)))
print(r2_score(y_train, tr2))
print(np.sqrt(mean_squared_error(y_test,y2)))
print(r2_score(y_test, y2))
```
## Random Forest
```
#RF model
model_rf = RandomForestRegressor(n_estimators=500, oob_score=True, random_state=100)
model_rf.fit(X_train, y_train)
pred_train_rf= model_rf.predict(X_train)
print(np.sqrt(mean_squared_error(y_train,pred_train_rf)))
print(r2_score(y_train, pred_train_rf))
pred_test_rf = model_rf.predict(X_test)
print(np.sqrt(mean_squared_error(y_test,pred_test_rf)))
print(r2_score(y_test, pred_test_rf))
df
```
| github_jupyter |
# Target:
- Setting the basic code structure with basic transformations and data loaders
- Design model architeture of less than 8000 parameters
# Results:
- Model Parameters : 7.3k
- Best Training accuracy : 98.58
- Best Training loss : 0.01337
- Best Testing accuracy : 98.66
- Best Testing loss : 0.0464
# Analysis:
- Without batch regularization and dropout the model is not performing well
- In the initial epochs the model was underfit and with incresing epochs it showed the sighns of overfitting.
- The reason can be not adding the dropout and batchnormalization
- Future adding the batch normalization and dropout can push the performance
- The accuracy was very well with such less number of parameters and the training accuracy shows the space of future training.
**Improvment**- Improvment can be done by adding regularizations
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from tqdm.autonotebook import tqdm
from torchsummary import summary
import matplotlib.pyplot as plt # for ploting the results
import numpy as np # for mathematical work
# For training set
train = datasets.MNIST('../data', train=True, download=True, #create directory and give the path, True for training set, download if dataset is not available in local storage
transform=transforms.Compose([
transforms.ToTensor(), # Convert image to tensor
transforms.Normalize((0.1307,), (0.3081,)) # Normalize image with mean and standard deviation
]))
# For testing set
test = datasets.MNIST('../data', train=False, # create the directory for testing dataset, train is false for testing
transform=transforms.Compose([
transforms.ToTensor(), # Convert image to tensor
transforms.Normalize((0.1307,), (0.3081,)) # Normalize the data
]))
SEED = 1
# CUDA?
cuda = torch.cuda.is_available()
print("CUDA Available:", cuda)
# For reproducibility
torch.manual_seed(SEED)
if cuda:
torch.cuda.manual_seed(SEED)
# dataloader arguments - something you'll fetch these from cmdprmt
dataloader_args = dict(shuffle=True, batch_size=128, num_workers=2, pin_memory=True) if cuda else dict(shuffle=True, batch_size=64)
# train dataloader
train_loader = torch.utils.data.DataLoader(train, **dataloader_args)
# test dataloader
test_loader = torch.utils.data.DataLoader(test, **dataloader_args)
figure = plt.figure(figsize=(8,6))
dataiter = iter(train_loader)
images, labels = dataiter.next()
num_of_images = 96
for index in range(1, num_of_images + 1):
plt.subplot(8, 12, index)
plt.axis('off')
plt.imshow(images[index].numpy().squeeze(), cmap='gray_r')
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Input Block
self.convblock1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=8, kernel_size=(3, 3), padding=0, bias=False),
nn.ReLU(),
) # output_size = 26 RF: 2
# CONVOLUTION BLOCK 1
self.convblock2 = nn.Sequential(
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=(3, 3), padding=0, bias=False),
nn.ReLU(),
) # output_size = 24 RF: 5
self.pool1 = nn.MaxPool2d(2, 2) # output_size = 12 RF: 6
# TRANSITION BLOCK 1
self.trans1 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=8, kernel_size=(1, 1), padding=0, bias=False),
nn.ReLU()
) # output_size = 12 RF: 6
# CONVOLUTION BLOCK 2
self.convblock3 = nn.Sequential(
nn.Conv2d(in_channels=8, out_channels=12, kernel_size=(3, 3), padding=0, bias=False), # output_size = 10 RF: 10
nn.ReLU(),
nn.Conv2d(in_channels=12, out_channels=16, kernel_size=(3, 3), padding=0, bias=False), # output_size = 8 RF: 14
nn.ReLU(),
nn.Conv2d(in_channels=16, out_channels=20, kernel_size=(3, 3), padding=0, bias=False), # output_size = 6 RF: 18
nn.ReLU(),
)
# Global average pooling
self.gap = nn.Sequential(
nn.AvgPool2d(6) # output_size = 1 RF: 28
)
# Fully connected
self.convblock5 = nn.Sequential(
nn.Conv2d(in_channels=20, out_channels=16, kernel_size=(1, 1), padding=0, bias=False), # output_size = 1 RF: 28
nn.ReLU(),
nn.Conv2d(in_channels=16, out_channels=10, kernel_size=(1, 1), padding=0, bias=False), # output RF: 28
)
def forward(self, x):
x = self.convblock1(x)
x = self.convblock2(x)
x = self.pool1(x)
x = self.trans1(x)
x = self.convblock3(x)
x = self.gap(x)
x = self.convblock5(x)
x = x.view(-1, 10) # convert 2D to 1D
return F.log_softmax(x, dim=-1)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
print(device)
model = Net().to(device)
summary(model, input_size=(1, 28, 28))
from tqdm import tqdm
train_losses = []
test_losses = []
train_acc = []
test_acc = []
def train(model, device, train_loader, optimizer, epoch):
model.train()
pbar = tqdm(train_loader)
correct = 0
processed = 0
for batch_idx, (data, target) in enumerate(pbar):
# get samples
data, target = data.to(device), target.to(device)
# Init
optimizer.zero_grad()
# In PyTorch, we need to set the gradients to zero before starting to do backpropragation because PyTorch accumulates the gradients on subsequent backward passes.
# Because of this, when you start your training loop, ideally you should zero out the gradients so that you do the parameter update correctly.
# Predict
y_pred = model(data)
# Calculate loss
loss = F.nll_loss(y_pred, target)
train_losses.append(loss)
# Backpropagation
loss.backward()
optimizer.step()
# Update pbar-tqdm
pred = y_pred.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
processed += len(data)
pbar.set_description(desc= f'Batch_id={batch_idx} Loss={loss.item():.5f} Accuracy={100*correct/processed:0.2f}')
train_acc.append(100*correct/processed)
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test_acc.append(100. * correct / len(test_loader.dataset))
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
NUM_EPOCHS = 15
for epoch in range(1,NUM_EPOCHS+1):
print("EPOCH:", epoch)
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
fig, axs = plt.subplots(2,2,figsize=(15,10))
axs[0, 0].plot(train_losses)
axs[0, 0].set_title("Training Loss")
axs[1, 0].plot(train_acc)
axs[1, 0].set_title("Training Accuracy")
axs[0, 1].plot(test_losses)
axs[0, 1].set_title("Test Loss")
axs[1, 1].plot(test_acc)
axs[1, 1].set_title("Test Accuracy")
""
```
| github_jupyter |
# Introduction to Transmon Physics
## Contents
1. [Multi-level Quantum Systems as Qubits](#mlqsaq)
2. [Hamiltonians of Quantum Circuits](#hoqc)
3. [Quantizing the Hamiltonian](#qth)
4. [The Quantized Transmon](#tqt)
5. [Comparison of the Transmon and the Quantum Harmonic Oscillator](#cottatqho)
6. [Qubit Drive and the Rotating Wave Approximation](#qdatrwa)
## 1. Multi-level Quantum Systems as Qubits <a id='mlqsaq'></a>
Studying qubits is fundamentally about learning the physics of two-level systems. One such example of a purely two-level system is the spin of an electron (or any other spin-$1/2$ particle): it can either point up or down, and we label these states $|0\rangle$ and $|1\rangle$, respectively. Historically, the reason the $|0\rangle$ state is at the "north pole" of the Bloch sphere is that this is the lower-energy state when a magnetic field is applied in the $+\hat{z}$ direction.
Another such two-level system occurs in the first type of superconducting qubit discovered: the [Cooper Pair Box](https://arxiv.org/pdf/cond-mat/9904003v1.pdf). The reason there is no electrical resistance in superconductors is that electrons combine as Cooper pairs, which take energy to break up (and that energy is not available thermally at low temperatures), because they are effectively attracted to each other. This situation is quite counterintuitive, because electrons are both negatively-charged, they should repel each other! However, in many material systems effective interactions can be mediated by collective effects: one can think of the electrons as being attracted to the wake of other electrons in the lattice of positive charge. The Cooper Pair Box consists of a superconducting island that possesses an extra Cooper pair of charge $2e$ ($|0\rangle$) or does not ($|1\rangle$). These states can be manipulated by voltages on tunnel junctions, and is periodic with "gate" voltage control, so it is indeed a two-level system.
Qubits encoded as charge states are particularly sensitive to *charge noise*, and this is true of the Cooper Pair Box, which is why it fell out of favor with researchers. Many other quantum systems are not two-level systems, such as atoms that each feature unique spectral lines (energy transitions) that are used by astronomers to determine the composition of our universe. By effectively isolating and controlling just two levels, such as the ground and first excited state of an atom, then you could treat it as a qubit. But what about using other types of superconducting circuits as qubits? The solution to the charge noise problem of the Cooper Pair Box hedged on designing a qubit with higher-order energy levels: the [transmon](https://arxiv.org/pdf/cond-mat/0703002.pdf). (The name is derived from *transmission-line shunted plasma oscillation* qubit). By sacrificing anharmonicity (the difference between the $|0\rangle \to |1\rangle$ and $|1\rangle \to |2\rangle$ transition frequencies, see section on [Accessing Higher Energy States](/course/quantum-hardware-pulses/accessing-higher-energy-states-with-qiskit-pulse)), charge noise is suppressed while still allowing the lowest two levels to be addressed as a qubit. Now the quantum states are encoded in oscillations of Cooper Pairs across a tunnel junction between two superconducting islands, with the excited $|1\rangle$ state oscillating at a high frequency than the ground $|0\rangle$.
## 2. Hamiltonians of Quantum Circuits <a id='hoqc'></a>
The Hamiltonian is a function that equals the total energy of a system, potential and kinetic. This is true in classical mechanics, and the quantum Hamiltonian is found by promoting the variables to operators. By comparing classical Poisson brackets to quantum commutators, it is found that they do not commute, meaning they cannot be observed simultaneously, as in Heisenberg's uncertainty principle.
We'll first consider a linear $LC$ circuit, where $L$ is the inductance and $C$ is the capacitance. The Hamiltonian is the sum of the kinetic energy (represented by charge variable $Q$) and potential energy (represented by flux variable $\Phi$),
$$
\mathcal{H} = \frac{Q^2}{2C} + \frac{\Phi^2}{2L}
$$
<details>
<summary>Branch-Flux Method for Linear Circuits (click here to expand)</summary>
Hamiltonians and Lagrangians are functions involving the energies of massive objects and have a rich history in the dynamics of classical systems. They still serve as a template for "quantizing" objects, including the transmon. The method consists of writing the Lagrangian in terms of generalized coordinate: we will choose a quantity called flux that is defined by the history of voltages, classically one often chooses position in 3-dimensional space. The conjugate variable to our generalized coordinate is then calculated, and will end up being charge in our case (usually momentum in the classical case). By way of a Legendre transformation, the Hamiltonian is calculated, which represents the sum of energies of the system.
The circuit Hamiltonian can be found by considering the capacitative and inductive energies using the branch-flux method, which itself is based on classical Lagrangian mechanics. Defining the flux and charge to be time integrals of voltage and current, respectively,
$$
\Phi(t) = \int_{-\infty}^t V(t')\,dt' \quad {\rm and} \quad Q(t) = \int_{-\infty}^t I(t')\,dt'
$$
we will work with flux $\Phi$ as our generalized coordinate, where $V(t')$ and $I(t')$ are the voltage and current flowing across the transmon at time $t'$. In electric circuits, voltage functions much like potential energy and current like kinetic energy. The instantaneous energy across the transmon at time $t$ is
$$
E(t) = \int_{-\infty}^t V(t') I(t')\,dt'.
$$
The voltage and current across a capacitor (with capacitance $C$) and inductor (with inductance $L$), are related to each other by $V=L dI/dt$ and $I = C dV/dt$, respectively. In circuits, capacitors store charge and inductors store flux (current). We will work with the flux as our "coordinate" of choice. Then because inductors store flux, the potential energy is represented as
$$
U_L(t) = \int_{-\infty}^t L\frac{dI(t')}{dt'} I(t')\, dt' = \frac{1}{2} LI(t)^2 = \frac{1}{2L}\Phi^2
\quad {\rm because} \quad
\Phi(t) = \int_{-\infty}^t L \frac{dI(t')}{dt'}\,dt' = LI(t)
$$
by integration by parts. Similarly, voltage is the rate of change of flux, so it corresponds to the kinetic energy
$$
\tau_C(t) = \int_{-\infty}^t C\frac{dV(t')}{dt'} V(t')\, dt' = \frac{1}{2} CV(t)^2 = \frac{1}{2}C\dot{\Phi}^2 \quad {\rm where} \quad \dot{\Phi} = \frac{d\Phi}{dt}
$$
is the common way to denote time derivatives in Lagrangian mechanics. The Lagrangian is defined as the difference between the kinetic and potential energies and is thus
$$
\mathcal{L} = \tau_C - U_L = \frac{1}{2} C \dot{\Phi}^2 - \frac{1}{2L} \Phi^2.
$$
The dynamics are determined by the Euler-Lagrange equation
$$
0 \equiv \frac{\partial\mathcal{L}}{\partial\Phi} - \frac{d}{dt} \left(\frac{\partial\mathcal{L}}{\partial\dot{\Phi}}\right)
= \frac{\Phi}{L} + C\ddot{\Phi},
$$
which describes a harmonic oscillator in $\Phi$ with angular frequency $\omega = 1/\sqrt{LC}$ (now two dots corresponds to the second time derivative, $\ddot{\Phi} = d^2\Phi/dt^2$). However, we wish to move to the Hamiltonian framework and quantize from there. While the conjugate coordinate to flux $\Phi$ is defined by
$$
\frac{d\mathcal{L}}{d\dot{\Phi}} = C \dot{\Phi} = CV \equiv Q
$$
it is exactly the same for charge defined above due to the definition of capacitance. Now, the Hamiltonian is defined in terms of the Lagrangian as $\mathcal{H} = Q\dot{\Phi} - \mathcal{L}$, and one arrives at the equation above.
</details>
## 3. Quantizing the Hamiltonian <a id='qth'></a>
The quantum harmonic oscillator (QHO) is what we get when we quantize the Hamiltonian of an $LC$ circuit. Promote the conjugate variables to operators, $Q \to \hat{Q}$, $\Phi \to \hat{\Phi}$, so that the quantized Hamiltonian is
$$
\hat{H} = \frac{\hat{Q}^2}{2C} + \frac{\hat{\Phi}^2}{2L},
$$
where the "hats" remind us that these are quantum mechanical operators. Then make an association between the Poisson bracket of classical mechanics and the commutator of quantum mechanics via the correspondence
$$
\{A,B\} = \frac{\delta A}{\delta \Phi} \frac{\delta B}{\delta Q} - \frac{\delta B}{\delta \Phi} \frac{\delta A}{\delta Q} \Longleftrightarrow
\frac{1}{i\hbar} [\hat{A},\hat{B}] = \frac{1}{i\hbar}\left(\hat{A}\hat{B} - \hat{B}\hat{A}\right),
$$
where the $\delta$'s here represent functional derivates and the commutator reflects that the order of operations matter in quantum mechanics. Inserting our variables/operators, we arrive at
$$
\{\Phi,Q\} = \frac{\delta \Phi}{\delta \Phi}\frac{\delta Q}{\delta Q} - \frac{\delta Q}{\delta \Phi}\frac{\delta \Phi}{\delta Q} = 1-0=1 \Longrightarrow [\hat{\Phi}, \hat{Q}] = i\hbar.
$$
This implies, that just like position and momentum, charge and flux also obey a Heisenberg Uncertainty Principle ($[\hat{x},\hat{p}] = i\hbar$, as well). This means that they are not simultaneous observables, and are in fact, conjugate variables defined in the same way with the same properties. This result has been used over the history of superconducting qubits to inform design decisions and classify the types of superconducting qubits.
The above quantized Hamiltonian is usually written in a friendlier form using the reduced charge $\hat{n} = \hat{Q}/2e$ and phase $\hat{\phi} = 2\pi\hat{\Phi}/\Phi_0$, where $\Phi_0 = h/2e$ is the flux quanta, corresponding to the operators for the number of Cooper pairs and the phase across the Josephson junction, respectively. Then, the quantized Hamiltonian becomes
$$ \hat{H}_{\rm QHO}= 4E_c\hat{n}^2 + \frac{1}{2} E_L \hat{\phi}^2,$$
where $E_c = e^2/2C$ is the charging energy (the 4 in front corresponds to the fact we're dealing with Cooper pairs, not single electrons) and $E_L = (\Phi_0/2\pi)^2/L$ is the inductive energy.
<details>
<summary>Click to Expand: The Quantum Harmonic Oscillator</summary>
The Hamiltonian above represents a simple harmonic oscillator, and taking $\hat{\phi}$ as the position variable, then we can define creation and annihilation operators in terms of the zero-point fluctuations of the charge and phase,
$$ \hat{n} = i n_{\mathrm zpf}(\hat{a}^\dagger - \hat{a}) \quad \mathrm{and} \quad
\hat{\phi} = \phi_{\mathrm zpf}(\hat{a}^\dagger + \hat{a}), \qquad \mathrm{where} \quad
n_\mathrm{zpf} = \left( \frac{E_L}{32 E_c} \right)^{1/4} \quad \mathrm{and} \quad
\phi_{\mathrm{zpf}} = \left(\frac{2E_c}{E_L}\right)^{1/4}.$$
The Hamiltonian is then that of a harmonic oscillator,
$$ H_{\mathrm{QHO}} = \hbar \omega \left( \hat{a}^\dagger \hat{a} + \frac{1}{2} \right) \qquad \mathrm{with} \qquad
\omega = \sqrt{8 E_L E_c}/\hbar = 1/\sqrt{LC}.$$
Here we see that the energy spacing of the QHO corresponds to the classical resonance frequency $\omega=1/\sqrt{LC}$ of an $LC$ oscillator.
</details>
<details>
<summary>Click to Expand: The Branch-Flux Method for Transmons</summary>
While the above concerns quantizing a linear circuit, [Vool and Devoret](https://arxiv.org/abs/1610.03438) discuss the branch-flux method for quantizing circuits in general. Basically, this gives us a systematic way of enforcing Kirchhoff's Laws for circuits: the sum of the currents at a node must equal zero and the addition of voltages around any loop must also equal zero. These Kirchhoff Laws give us the equations of motion for the circuit.
There is a very special relationship between the current and flux in Josephson junctions, given by the Josephson relation
$$
I = I_0 \sin\left(2\pi \Phi/\Phi_0\right)
$$
where $I_0$ is the maximum current (critical current) that can flow through the junction while maintaining a superconducting state, and $\Phi_0 = h/2e$ is the flux quantum. Enforcing Kirchhoff's current law, the sum of the Josephson current and the current across the total capacitance $C = C_S + C_J$, where $C_S$ is the shunt capacitor and $C_J$ is the capacitance of the Josephson junction and $C_S \gg C_J$, must vanish. This gives us an equation of motion
$$
I_0 \sin\left(2\pi \Phi/\Phi_0\right) + C\ddot{\Phi} = 0.
$$
Unlike the typical situation where the equations of motions are calculated by placing the Lagrangian into the Euler-Lagrange equation as we did in the case of the QHO, here we already have the equation of motion for the variable $\Phi$. But since we want to quantize the Hamiltonian, we must convert this equation of motion to a Lagrangian and then perform a Legendre transform to find the Hamiltonian. This is achieved by "integrating" the equation of motion:
$$
0 = \frac{\partial\mathcal{L}}{\partial\Phi} - \frac{d}{dt}\left(\frac{\partial\mathcal{L}}{\partial\dot{\Phi}}\right) = I_0 \sin\left(2\pi \Phi/\Phi_0\right) + C\ddot{\Phi} \Longrightarrow
\frac{I_0 \Phi_0}{2\pi} \cos\left(2\pi \Phi/\Phi_0\right) + \frac{C\dot{\Phi}^2}{2} = \mathcal{L}
$$
Now that we have gone "backward" to find the Lagrangian, we can continue forward to find the Hamiltonian by finding the conjugate variable $Q = \partial \mathcal{L}/\partial\dot{\Phi} = C\dot{\Phi}$, which turns out to be the same as in the QHO case, and
$$
\mathcal{H} = Q\dot{\Phi} - \mathcal{L} = \frac{Q^2}{2C} - \frac{I_0 \Phi_0}{2\pi} \cos\left(2\pi \Phi/\Phi_0\right)
$$
</details>
## 4. The Quantized Transmon <a id='tqt'></a>
Making the same variable substitutions as for the QHO, we can rewrite the transmon Hamiltonian in familiar form
$$
\hat{H}_{\rm tr} = 4E_c \hat{n}^2 - E_J \cos \hat{\phi},
$$
where the Josephson energy $E_J = I_0\Phi_0/2\pi$ replaces the inductive energy from the QHO. Note that the functional form of the phase is different from the QHO due to the presence of the Josephson junction instead of a linear inductor. Often $\hat{n} \to \hat{n} - n_g$ to reflect a gate offset charge, but this is not important in the transmon regime. Now we can approach the quantization similarly to the QHO, where we define the creation and annihilation operators in terms of the zero-point fluctuations of charge and phase
$$ \hat{n} = i n_{\mathrm zpf}(\hat{c}^\dagger - \hat{c}) \quad \mathrm{and} \quad
\hat{\phi} = \phi_{\mathrm zpf}(\hat{c}^\dagger + \hat{c}), \qquad \mathrm{where} \quad
n_\mathrm{zpf} = \left( \frac{E_J}{32 E_c} \right)^{1/4} \quad \mathrm{and} \quad
\phi_{\mathrm{zpf}} = \left(\frac{2 E_c}{E_J}\right)^{1/4},
$$
where the Josephson energy $E_J$ has replaced the linear inductive energy $E_L$ of the QHO. Here we use $\hat{c} = \sum_j \sqrt{j+1} |j\rangle\langle j+1|$ to denote the transmon annihilation operator and distinguish it from the evenly-spaced energy modes of $\hat{a}$. Now, noting that $\phi \ll 1$ because in the transmon regime $E_J/E_c \gg 1$, we can take a Taylor expansion of $\cos \hat{\phi}$ to approximate the Hamiltonian
$$
H = -4E_c n_{zpf}^2 (\hat{c}^\dagger - \hat{c})^2 - E_J\left(1 - \frac{1}{2} \phi_{zpf}^2 (\hat{c}^\dagger + \hat{c})^2 + \frac{1}{24} \phi_{zpf}^4(\hat{c}^\dagger+\hat{c})^4 + \ldots \right) \\
\approx \sqrt{8 E_c E_J} \left(\hat{c}^\dagger \hat{c} + \frac{1}{2}\right) - E_J - \frac{E_c}{12}(\hat{c}^\dagger + \hat{c})^4,
$$
where it is helpful to observe $8 E_c n_{\rm zpf}^2 = E_J\phi_{zpf}^2 = \sqrt{2 E_c E_J}$. Expanding the terms of the transmon operator $\hat{c}$ and dropping the fast-rotating terms (i.e. those with an uneven number of $\hat{c}$ and $\hat{c}^\dagger$), neglecting constants that have no influence on transmon dynamics, and defining $\omega_0 = \sqrt{8 E_c E_J}$ and identifying $\delta = -E_c$ as the transmon anharmonicity, we have
$$
\hat{H}_{\rm tr} = \omega_0 \hat{c}^\dagger \hat{c} + \frac{\delta}{2}\left((\hat{c}^\dagger \hat{c})^2 + \hat{c}^\dagger \hat{c}\right)
= \left(\omega_0 + \frac{\delta}{2}\right) \hat{c}^\dagger \hat{c} + \frac{\delta}{2}(\hat{c}^\dagger \hat{c})^2
$$
which is the Hamiltonian of a Duffing oscillator. Defining $\omega \equiv \omega_0+\delta$, we see that the transmon levels have energy spacings that each differ by the anharmonicity, as $\omega_{j+1}-\omega_j = \omega + \delta j$, so that $\omega$ corresponds to "the frequency" of the transmon qubit (the transition $\omega_1-\omega_0$). From the definition of the transmon operator, $\hat{c}^\dagger \hat{c} = \sum_j j |j\rangle \langle j|$, we arrive at
$$
\hat{H}_{\rm tr} = \omega \hat{c}^\dagger \hat{c} + \frac{\delta}{2} \hat{c}^\dagger \hat{c} (\hat{c}^\dagger \hat{c} - 1)
= \sum_j \left(\left(\omega-\frac{\delta}{2}\right)j + \frac{\delta}{2} j^2\right) |j\rangle\langle j| \equiv \sum_j \omega_j |j\rangle \langle j|
$$
so that
$$
\omega_j = \left(\omega-\frac{\delta}{2}\right)j + \frac{\delta}{2} j^2
$$
are the energy levels of the transmon.
## 5. Comparison of the Transmon and the Quantum Harmonic Oscillator<a id='cottatqho'></a>
The QHO has even-spaced energy levels and the transmon does not, which is why we can use it as a qubit. Here we show the difference in energy levels by calculating them from their Hamiltonians using [`QuTiP`](http://www.qutip.org).
```
import numpy as np
import matplotlib.pyplot as plt
E_J = 20e9
w = 5e9
anharm = -300e6
N_phis = 101
phis = np.linspace(-np.pi,np.pi,N_phis)
mid_idx = int((N_phis+1)/2)
# potential energies of the QHO & transmon
U_QHO = 0.5*E_J*phis**2
U_QHO = U_QHO/w
U_transmon = (E_J-E_J*np.cos(phis))
U_transmon = U_transmon/w
# import QuTiP, construct Hamiltonians, and solve for energies
from qutip import destroy
N = 35
N_energies = 5
c = destroy(N)
H_QHO = w*c.dag()*c
E_QHO = H_QHO.eigenenergies()[0:N_energies]
H_transmon = w*c.dag()*c + (anharm/2)*(c.dag()*c)*(c.dag()*c - 1)
E_transmon = H_transmon.eigenenergies()[0:2*N_energies]
print(E_QHO[:4])
print(E_transmon[:8])
fig, axes = plt.subplots(1, 1, figsize=(6,6))
axes.plot(phis, U_transmon, '-', color='orange', linewidth=3.0)
axes.plot(phis, U_QHO, '--', color='blue', linewidth=3.0)
for eidx in range(1,N_energies):
delta_E_QHO = (E_QHO[eidx]-E_QHO[0])/w
delta_E_transmon = (E_transmon[2*eidx]-E_transmon[0])/w
QHO_lim_idx = min(np.where(U_QHO[int((N_phis+1)/2):N_phis] > delta_E_QHO)[0])
trans_lim_idx = min(np.where(U_transmon[int((N_phis+1)/2):N_phis] > delta_E_transmon)[0])
trans_label, = axes.plot([phis[mid_idx-trans_lim_idx-1], phis[mid_idx+trans_lim_idx-1]], \
[delta_E_transmon, delta_E_transmon], '-', color='orange', linewidth=3.0)
qho_label, = axes.plot([phis[mid_idx-QHO_lim_idx-1], phis[mid_idx+QHO_lim_idx-1]], \
[delta_E_QHO, delta_E_QHO], '--', color='blue', linewidth=3.0)
axes.set_xlabel('Phase $\phi$', fontsize=24)
axes.set_ylabel('Energy Levels / $\hbar\omega$', fontsize=24)
axes.set_ylim(-0.2,5)
qho_label.set_label('QHO Energies')
trans_label.set_label('Transmon Energies')
axes.legend(loc=2, fontsize=14)
```
## 6. Qubit Drive and the Rotating Wave Approximation <a id='qdatrwa'></a>
Here we will treat the transmon as a qubit for simplicity, which by definition means there are only two levels. Therefore the transmon Hamiltonian becomes
$$
\hat{H}_0 = \sum_{j=0}^1 \hbar \omega_j |j\rangle \langle j| \equiv 0 |0\rangle \langle 0| + \hbar\omega_q |1\rangle \langle 1|.
$$
Since we can add or subtract constant energy from the Hamiltonian without effecting the dynamics, we make the $|0\rangle$ and $|1\rangle$ state energies symmetric about $E=0$ by subtracting half the qubit frequency,
$$
\hat{H}_0 = - (1/2)\hbar\omega_q |0\rangle \langle 0| + (1/2)\hbar \omega_q |1\rangle \langle 1| =
-\frac{1}{2} \hbar \omega_q \sigma^z \qquad {\rm where} \qquad
\sigma^z = \begin{pmatrix}
1 & 0 \\
0 & -1 \end{pmatrix}
$$
is the Pauli-Z matrix. Now, applying an electric drive field $\vec{E}(t) = \vec{E}_0 e^{-i\omega_d t} + \vec{E}_0^* e^{i\omega_d t}$ to the transmon introduces a dipole interaction between the transmon and microwave field. The Hamiltonian is the sum of the qubit Hamiltonian $\hat{H}_0$ and drive Hamiltonian $\hat{H}_d$,
$$
\hat{H} = \hat{H}_0 + \hat{H}_d.
$$
Treating the transmon as a qubit allows us to use the Pauli raising/lowering operators $\sigma^\pm = (1/2)(\sigma^x \mp i\sigma^y)$ that have the effect $\sigma^+ |0\rangle = |1\rangle$ and $\sigma^+ |1\rangle = |0\rangle$. (Note that this definition reflects that we are using *qubit* raising/lower operators instead of those for *spin*. For the reason discussed in [Section 1](#mlqsaq), $|0\rangle \equiv |\uparrow\rangle$ and $|1\rangle \equiv |\downarrow \rangle$ so the raising and lowering operators are inverted). Now since the field will excite and de-excite the qubit, we define the dipole operator $\vec{d} = \vec{d}_0 \sigma^+ + \vec{d}_0^* \sigma^-$. The drive Hamiltonian from the dipole interaction is then
$$
\hat{H}_d = -\vec{d} \cdot \vec{E}(t) = -\left(\vec{d}_0 \sigma^+ + \vec{d}_0^* \sigma^-\right) \cdot \left(\vec{E}_0 e^{-i\omega_d t} + \vec{E}_0^* e^{i\omega_d t}\right) \\
= -\left(\vec{d}_0 \cdot \vec{E}_0 e^{-i\omega_d t} + \vec{d}_0 \cdot \vec{E}_0^* e^{i\omega_d t}\right)\sigma^+
-\left(\vec{d}_0^* \cdot \vec{E}_0 e^{-i\omega_d t} + \vec{d}_0^* \cdot \vec{E}_0^* e^{i\omega_d t}\right)\sigma^-\\
\equiv -\hbar\left(\Omega e^{-i\omega_d t} + \tilde{\Omega} e^{i\omega_d t}\right)\sigma^+
-\hbar\left(\tilde{\Omega}^* e^{-i\omega_d t} + \Omega^* e^{i\omega_d t}\right)\sigma^-
$$
where we made the substitutions $\Omega = \vec{d}_0 \cdot \vec{E}_0$ and $\tilde{\Omega} = \vec{d}_0 \cdot \vec{E}_0^*$ to describe the strength of the field and dipole. Now we transform to the interaction picture $\hat{H}_{d,I} = U\hat{H}_dU^\dagger$ (omitting terms that cancel for simplicity) with
$$
U = e^{i\hat{H}_0t/\hbar} = e^{-i\omega_q t \sigma^z/2} = I\cos(\omega_q t/2) - i\sigma^z\sin(\omega_q t/2)
$$
which can be calculated by noting that
$$
\sigma^\pm \sigma^z = (1/2) \left(\sigma^x \sigma^z \mp i \sigma^y \sigma^z\right) = (1/2)(-i\sigma^y \pm \sigma^x) = \pm\sigma^\pm = -\sigma^z \sigma^\pm.
$$
Then
$$U\sigma^\pm U^\dagger = \left(I\cos(\omega_q t/2) - i\sigma^z\sin(\omega_q t/2)\right) \sigma^\pm \left(I\cos(\omega_q t/2) + i\sigma^z\sin(\omega_q t/2)\right) \\
= \sigma^\pm \left( \cos(\omega_q t/2) \pm i\sin(\omega_q t/2)\right) \left(\cos(\omega_q t/2) \pm i\sin(\omega_q t/2) \right) \\
= \sigma^\pm \left( \cos^2(\omega_q t/2) \pm 2i\cos(\omega_q t/2)\sin(\omega_q t/2) - \sin^2(\omega_q t/2)\right) \\
= \sigma^\pm \left( \cos(\omega_q t) \pm i\sin(\omega_q t) \right) = e^{\pm i\omega_q t} \sigma^{\pm},$$
where we have used the double-angle formula from trigonometry. The transformed Hamiltonian is then
$$
\hat{H}_{d,I} = U\hat{H}_dU^\dagger = -\hbar\left(\Omega e^{-i\omega_d t} + \tilde{\Omega} e^{i\omega_d t}\right)e^{i\omega_q t} \sigma^+ -\hbar\left(\tilde{\Omega}^* e^{-i\omega_d t} + \Omega^* e^{i\omega_d t}\right)e^{-i\omega_q t} \sigma^-\\
= -\hbar\left(\Omega e^{i\Delta_q t} + \tilde{\Omega} e^{i(\omega_q+\omega_d) t}\right) \sigma^+ -\hbar\left(\tilde{\Omega}^* e^{-i(\omega_q+\omega_d) t} + \Omega^* e^{-i\Delta_q t}\right) \sigma^-
$$
Now we make the rotating-wave approximation: since $\omega_q+\omega_d$ is much larger than $\Delta_q = \omega_q-\omega_d$, the terms with the sum in the exponential oscillate much faster, so effectively average out their contribution and we therefore drop those terms from the Hamiltonian. Now the RWA interaction Hamiltonian becomes
$$
\hat{H}_{d,I}^{\rm (RWA)} =-\hbar\Omega e^{i\Delta_q t} \sigma^+ -\hbar \Omega^* e^{-i\Delta_q t} \sigma^-
$$
Moving back to the Schrödinger picture,
$$
\hat{H}_{d}^{\rm (RWA)} = U^\dagger \hat{H}_{d,I}^{\rm (RWA)} U = -\hbar\Omega e^{-i\omega_d t} \sigma^+ -\hbar\Omega^* e^{i\omega_d t} \sigma^-
$$
so that the total qubit and drive Hamiltonian is
$$
\hat{H}^{\rm (RWA)} = -\frac{1}{2} \hbar\omega_q \sigma^z -\hbar\Omega e^{-i\omega_d t} \sigma^+ -\hbar\Omega^* e^{i\omega_d t} \sigma^-.
$$
Going into the frame of the drive, using the transformation $U_d = \exp\{-i\omega_d t\sigma^z/2\}$, the Hamiltonian becomes
$$
\hat{H}_{\rm eff} = U_d \hat{H}^{\rm (RWA)} U_d^\dagger - i\hbar U_d \dot{U}_d^\dagger
$$
where $\dot{U}_d = dU_d/dt$ is the time derivative of $U_d$. Then in the drive frame under the RWA
$$
\hat{H}_{\rm eff} = -\frac{1}{2} \hbar\omega_q \sigma^z -\hbar\Omega \sigma^+ -\hbar\Omega^* \sigma^- + \frac{1}{2} \hbar\omega_d \sigma^z = -\frac{1}{2}\hbar \Delta_q \sigma^z -\hbar\Omega \sigma^+ -\hbar\Omega^* \sigma^-
$$
assuming the drive is real so that $\Omega = \Omega^*$, this simplifies to
$$
\hat{H}_{\rm eff} = -\frac{1}{2}\hbar \Delta_q \sigma^z -\hbar\Omega \sigma^x.
$$
This shows that when the drive is resonant with the qubit (i.e., $\Delta_q = 0$), the drive causes an $x$ rotation in the Bloch sphere that is generated by $\sigma^x$ with a strength of $\Omega$. We can see the effect of this on-resonant qubit drive in the [finding the frequency of a qubit with spectroscopy](/course/quantum-hardware-pulses/calibrating-qubits-using-qiskit-pulse) section. An off-resonant drive has additional $z$ rotations generated by the $\sigma^z$ contribution, and these manifest themselves as oscillations in a [Ramsey experiment](/course/quantum-hardware-pulses/calibrating-qubits-using-qiskit-pulse).
| github_jupyter |
Sebastian Raschka, 2015
# Python Machine Learning Essentials
# Chapter 2 - Training Machine Learning Algorithms for Classification
Note that the optional watermark extension is a small IPython notebook plugin that I developed to make the code reproducible. You can just skip the following line(s).
```
%load_ext watermark
%watermark -a 'Sebastian Raschka' -u -d -v -p numpy,pandas,matplotlib
# to install watermark just uncomment the following line:
#%install_ext https://raw.githubusercontent.com/rasbt/watermark/master/watermark.py
```
### Sections
- [Implementing a perceptron learning algorithm in Python](#Implementing-a-perceptron-learning-algorithm-in-Python)
- [Training a perceptron model on the Iris dataset](#Training-a-perceptron-model-on-the-Iris-dataset)
- [Adaptive linear neurons and the convergence of learning](#Adaptive-linear-neurons-and-the-convergence-of-learning)
- [Implementing an adaptive linear neuron in Python](#Implementing-an-adaptive-linear-neuron-in-Python)
<br>
<br>
## Implementing a perceptron learning algorithm in Python
[[back to top](#Sections)]
```
import numpy as np
class Perceptron(object):
"""Perceptron classifier.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
errors_ : list
Number of misclassifications in every epoch.
"""
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
"""Fit training data.
Parameters
----------
X : {array-like}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape = [n_samples]
Target values.
Returns
-------
self : object
"""
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, -1)
```
<br>
<br>
### Training a perceptron model on the Iris dataset
[[back to top](#Sections)]
#### Reading-in the Iris data
```
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
df.tail()
```
<br>
<br>
#### Plotting the Iris data
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
# select setosa and versicolor
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
# extract sepal length and petal length
X = df.iloc[0:100, [0, 2]].values
# plot data
plt.scatter(X[:50, 0], X[:50, 1],
color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1],
color='blue', marker='x', label='versicolor')
plt.xlabel('petal length [cm]')
plt.ylabel('sepal length [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./iris_1.png', dpi=300)
plt.show()
```
<br>
<br>
#### Training the perceptron model
```
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Number of misclassifications')
plt.tight_layout()
# plt.savefig('./perceptron_1.png', dpi=300)
plt.show()
```
<br>
<br>
#### A function for plotting decision regions
```
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
plot_decision_regions(X, y, classifier=ppn)
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./perceptron_2.png', dpi=300)
plt.show()
```
<br>
<br>
## Adaptive linear neurons and the convergence of learning
[[back to top](#Sections)]
### Implementing an adaptive linear neuron in Python
```
class AdalineGD(object):
"""ADAptive LInear NEuron classifier.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
errors_ : list
Number of misclassifications in every epoch.
"""
def __init__(self, eta=0.01, n_iter=50):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
""" Fit training data.
Parameters
----------
X : {array-like}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape = [n_samples]
Target values.
Returns
-------
self : object
"""
self.w_ = np.zeros(1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
output = self.net_input(X)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors**2).sum() / 2.0
self.cost_.append(cost)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, X):
"""Compute linear activation"""
return self.net_input(X)
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.activation(X) >= 0.0, 1, -1)
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
ada1 = AdalineGD(n_iter=10, eta=0.01).fit(X, y)
ax[0].plot(range(1, len(ada1.cost_) + 1), np.log10(ada1.cost_), marker='o')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('log(Sum-squared-error)')
ax[0].set_title('Adaline - Learning rate 0.01')
ada2 = AdalineGD(n_iter=10, eta=0.0001).fit(X, y)
ax[1].plot(range(1, len(ada2.cost_) + 1), ada2.cost_, marker='o')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Sum-squared-error')
ax[1].set_title('Adaline - Learning rate 0.0001')
plt.tight_layout()
# plt.savefig('./adaline_1.png', dpi=300)
plt.show()
```
<br>
<br>
#### Standardizing features and re-training adaline
```
# standardize features
X_std = np.copy(X)
X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
X_std[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
ada = AdalineGD(n_iter=15, eta=0.01)
ada.fit(X_std, y)
plot_decision_regions(X_std, y, classifier=ada)
plt.title('Adaline - Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./adaline_2.png', dpi=300)
plt.show()
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Sum-squared-error')
plt.tight_layout()
# plt.savefig('./adaline_3.png', dpi=300)
plt.show()
```
<br>
<br>
### Large scale machine learning and stochastic gradient descent
[[back to top](#Sections)]
```
from numpy.random import seed
class AdalineSGD(object):
"""ADAptive LInear NEuron classifier.
Parameters
------------
eta : float
Learning rate (between 0.0 and 1.0)
n_iter : int
Passes over the training dataset.
Attributes
-----------
w_ : 1d-array
Weights after fitting.
errors_ : list
Number of misclassifications in every epoch.
shuffle : bool (default: True)
Shuffles training data every epoch if True to prevent cycles.
random_state : int (default: None)
Set random state for shuffling and initializing the weights.
"""
def __init__(self, eta=0.01, n_iter=10, shuffle=True, random_state=None):
self.eta = eta
self.n_iter = n_iter
self.w_initialized = False
self.shuffle = shuffle
if random_state:
seed(random_state)
def fit(self, X, y):
""" Fit training data.
Parameters
----------
X : {array-like}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape = [n_samples]
Target values.
Returns
-------
self : object
"""
self._initialize_weights(X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
if self.shuffle:
X, y = self._shuffle(X, y)
cost = []
for xi, target in zip(X, y):
cost.append(self._update_weights(xi, target))
avg_cost = sum(cost)/len(y)
self.cost_.append(avg_cost)
return self
def partial_fit(self, X, y):
"""Fit training data without reinitializing the weights"""
if not self.w_initialized:
self._initialize_weights(X.shape[1])
if y.ravel().shape[0] > 1:
for xi, target in zip(X, y):
self._update_weights(xi, target)
else:
self._update_weights(X, y)
return self
def _shuffle(self, X, y):
"""Shuffle training data"""
r = np.random.permutation(len(y))
return X[r], y[r]
def _initialize_weights(self, m):
"""Initialize weights to zeros"""
self.w_ = np.zeros(1 + m)
self.w_initialized = True
def _update_weights(self, xi, target):
"""Apply Adaline learning rule to update the weights"""
output = self.net_input(xi)
error = (target - output)
self.w_[1:] += self.eta * xi.dot(error)
self.w_[0] += self.eta * error
cost = 0.5 * error**2
return cost
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, X):
"""Compute linear activation"""
return self.net_input(X)
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.activation(X) >= 0.0, 1, -1)
ada = AdalineSGD(n_iter=15, eta=0.01, random_state=1)
ada.fit(X_std, y)
plot_decision_regions(X_std, y, classifier=ada)
plt.title('Adaline - Stochastic Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
#plt.savefig('./adaline_4.png', dpi=300)
plt.show()
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Average Cost')
plt.tight_layout()
# plt.savefig('./adaline_5.png', dpi=300)
plt.show()
ada.partial_fit(X_std[0, :], y[0])
```
| github_jupyter |
# MODIS Resampling
## Subsection 1a
Continuation of "Resampling MODIS" section in the [1]ActiveFires_California.ipynb
```
import arcpy
from arcpy import env
from arcpy.sa import *
arcpy.overwriteoutput = True
# Connect to google drive directory as G: Drive in local desktop environment with arcpy installed
rootPath = "G:\My Drive\California FireTrends (2012-2020)"
env.workspace = rootPath
import arcgisscripting
gp = arcgisscripting.create()
gp.CheckOutExtension("Spatial")
gp.overwriteoutput = True
os.chdir(rootPath)
# get list of files based on directory and extension inputs
def listFiles_ByExt(rootPath, ext):
file_list = []
root = rootPath
for path, subdirs, files in os.walk(root):
for names in files:
if names.endswith(ext) and not names.startswith("._"):
file_list.append(os.path.join(path,names))
return(file_list)
# Create new folder in root path
def createFolder(rootPath, folderName):
folderPath = os.path.join(rootPath, folderName)
if not os.path.exists(folderPath):
os.makedirs(folderPath)
return folderPath + "\\"
# get all filenames for M6 Active fire shapefiles for each day in yr (created in Colab notebook)
M6_1km_path = listFiles_ByExt('Data\MODIS_Resampling\SHP', '.shp')
# from all pathnames, we extract 2020 files to perform update
recent_2020_path = [e for e in M6_1km_path if '2020' in e]
# check if all files were read
recent_2020_path.sort()
# check spatial reference is projected
arcpy.Describe(M6_1km_path[0]).spatialReference
def resampling(file_nm, attribute_ID, cell, Value):
'''
Original MODIS (M6) AF points of each unique day in year are represented as 1km raster grids,
which are then resampled to 375m and converted back to vector points.
'''
v6_name = m6.replace("SHP", "RAS")
v6_name = v6_name.replace(".shp", "_" + attribute_ID + ".tif")
resamp_v6_name = v6_name.replace("RAS", "RESAMP_RAS")
pnt_v6_name = resamp_v6_name.replace("RESAMP_RAS", "RESAMP_SHP")
pnt_v6_name = pnt_v6_name.replace(".tif", ".shp")
if os.path.exists(pnt_v6_name) == False:
if not os.path.exists(os.path.dirname(v6_name)):
os.makedirs(os.path.dirname(v6_name))
sr = arcpy.SpatialReference(3310)
arcpy.DefineProjection_management(m6, sr)
print("converting pnt to ras:")
ras = arcpy.PointToRaster_conversion(file_nm, attribute_ID, v6_name, 'MOST_FREQUENT', '', '1000') #0.009
print("resampling to 375m:", v6_name)
if not os.path.exists(os.path.dirname(resamp_v6_name)):
os.makedirs(os.path.dirname(resamp_v6_name))
resamp_ras = arcpy.Resample_management(ras, resamp_v6_name, "375", "NEAREST") #0.003378
print("converting ras to pnt:", resamp_v6_name)
if not os.path.exists(os.path.dirname(pnt_v6_name)):
os.makedirs(os.path.dirname(pnt_v6_name))
resamp_pnts = arcpy.RasterToPoint_conversion(resamp_ras, pnt_v6_name, Value)
return resamp_pnts
# reverse list to perform resampling on days that have not yet been added yet
# resample both Julian day and time so that earliest time detected can be stored
for i, m6 in enumerate(reversed(recent_2020_path)):
print(i+1, ' of ', len(recent_2020_path), ' complete')
jd_pnts = resampling(m6, "JD", "MINIMUM", 'Value')
time_pnts = resampling(m6, "Time", "MINIMUM", 'Time')
outfc = m6.replace("SHP", "RESAMP_SHP_DT")
if os.path.exists(outfc) == False:
outpth = outfc.split('\\')
outpth = '\\'.join(outpth[:-1])
if not os.path.exists(outpth):
os.makedirs(outpth)
arcpy.SpatialJoin_analysis(jd_pnts, time_pnts, outfc)
```
| github_jupyter |
# Sentiment Analysis Model - Threat Detector
## Python 401d15 - 01/22/2021
### By : Hexx King, Lee Thomas, Taylor Johnson and Ryan Pilon
## TRIGGER WARNING! Offensive language and hate speech is visible below.
```
import nltk
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
```
## Import the training data and inspect it
```
# In the `read_csv` function, we have passed a parameter for *encoding*, because our data set contains non-english words that's not supported by the default pandas `read_csv` function.
dataset = pd.read_csv('./labeled_data.csv', encoding='ISO-8859-1')
dataset.head()
# Pulling out only the columns we want in the dataset
dt_transformed = dataset[['class', 'tweet']]
dt_transformed.head()
```
# Cleaning the labeled data
```
#remove user names by pulling all the characters inbetween "@" and ":"
#removes hashtags and their text
#removes text starting with http
#removes the "RT"
import re
def remove_RT_user(text):
tweet = re.sub("@[^\s]+", "", text)
hashtag = re.sub("#[\w|\d]+", "", tweet)
remove_http = re.sub("(https?[a-zA-Z0-9]+)|(http?[a-zA-Z0-9]+)", "", hashtag)
no_rt = re.sub("RT", "", remove_http)
return no_rt
dt_transformed['tweet_wo_RT_username'] = dt_transformed['tweet'].apply(lambda x: remove_RT_user(x))
dt_transformed.head()
# removing punctuation
import string
print(string.punctuation)
def remove_punctuation(text):
no_punct=[words for words in text if words not in string.punctuation]
words_wo_punct=''.join(no_punct)
return words_wo_punct
dt_transformed['tweet_wo_RT_username_punct'] = dt_transformed['tweet_wo_RT_username'].apply(lambda x: remove_punctuation(x))
dt_transformed.head()
# Tokenization = splitting strings into words
def tokenize(text):
split = re.split("\W+", text)
return split
dt_transformed['tweet_wo_RT_username_punct_split'] = dt_transformed['tweet_wo_RT_username_punct'].apply(lambda x: tokenize(x))
dt_transformed.head()
```
# Creating the Bag of Words
```
# importing the CountVectorizer to "vectorize" sentences by creating a collection of unique words and assigning an index to each one
tweets = dt_transformed['tweet_wo_RT_username_punct_split']
# `explode()` produces the same as `tweet_list = [item for sublist in tweets for item in sublist]`
tweet_list = tweets.explode()
vectorizer = CountVectorizer(max_features=None)
# `max_features=n` builds a vocabulary that only consider the top max_features ordered by term frequency across the corpus.
vectorizer.fit_transform(tweet_list)
# fit_transform is equivalent to fit followed by transform, and returns a document-term matrix.
# A mapping of terms to feature indices.
result = vectorizer.vocabulary_
print("We have ", len(result), " words in our Bag of Words")
# transforming into feature vectors for the learning model
vectorizer.fit_transform(tweet_list).toarray()
# `fit_transform` learns a list of feature name -> indices mappings
```
## Splitting the Data into a Training Set and a Testing Set to grade the accuracy of our model
```
# Split the data into testing and training sets
tweet_text = tweets.values
y = dt_transformed['class'].values
tweet_text_train, tweet_text_test, y_train, y_test = train_test_split(tweet_text, y, test_size=0.33, random_state=0, stratify=y)
# random_state shuffles the data so that we don't accidently end up with biased data
# stratify to help keep the proportion of y values through the training and test sets
# checking the length to ensure that my samples sizes are the same
print("length of y_train:", len(y_train))
print("length of tweet_text_train:", len(tweet_text_train))
# creating the feature vectors in the training set and testing set.
tweet_text_train = [inner[0] for inner in tweet_text_train]
tweet_text_test = [inner[0] for inner in tweet_text_test]
X_train = vectorizer.transform(tweet_text_train)
X_test = vectorizer.transform(tweet_text_test)
X_train
# we have compressed the vectorized data of 6631 elements into a format that takes up less space
# LogisticRegression gives our training model a grade based off it's performance on the testing set
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print("Score : ", str(round(score * 100)) + "%")
import pickle
pickle_file = 'finalized_model.pkl'
# saving the model to a pickled file to be copied into the back-end repo
s = pickle.dumps(classifier)
with open(pickle_file, "wb") as file:
file.write(s)
vectorizer_file = 'vectorizer_pickle.pkl'
s = pickle.dumps(vectorizer)
with open(vectorizer_file, "wb") as file:
file.write(s)
# testing the pickled file
with open(pickle_file, "rb") as file:
Pickled_Classifier = pickle.load(file)
Pickled_Classifier
with open(vectorizer_file, "rb") as file:
Pickled_vectorizer = pickle.load(file)
Pickled_vectorizer
```
| github_jupyter |
```
from IPython.display import HTML
# Cell visibility - COMPLETE:
#tag = HTML('''<style>
#div.input {
# display:none;
#}
#</style>''')
#display(tag)
#Cell visibility - TOGGLE:
tag = HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide()
} else {
$('div.input').show()
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
<p style="text-align:right">
Toggle cell visibility <a href="javascript:code_toggle()">here</a>.</p>''')
display(tag)
```
## Odvajanje polinomov
Primer je namenjen seznanitvi z odvajanjem polinomov. Definirate lahko polinom prve, druge, tretje ali četrte stopnje prek izbire koeficientov polinoma. Izbrani polinom skupaj z njegovim prvim odvodom sta prikazana grafično ter zapisana v običajnem matematičnem zapisu.
<!-- This interactive example allows you to inspect and look closely at a derivation of a polynomial function.
Feel free to explore the effects of changing polynomial coefficients (up to the fourth order) - the function thus determined will be shown in the respective plot, along with its first derivation. Both the target function (set by slider widgets) and the first derivation (accordingly calculated) will be presented in mathematical notation as well. -->
```
%matplotlib inline
#%config InlineBackend.close_figures=False
from ipywidgets import interactive
from ipywidgets import widgets
from IPython.display import Latex, display, Markdown # For displaying Markdown and LaTeX code
import matplotlib.pyplot as plt
import numpy as np
import math
import sympy as sym
import matplotlib.patches as mpatches
from IPython.display import HTML, clear_output
from IPython.display import display
# Mathematical notation of a specific (user-defined) polynomial, shown as Markdown
fourth_order = "e + d * x + c * x ** 2 + b * x ** 3 + a * x ** 4"
third_order = "d + c * x + b * x ** 2 + a * x ** 3"
second_order = "c + b * x + a * x ** 2"
first_order = "b + a * x"
zero_order = "a"
tf = sym.sympify(fourth_order)
w_mark = Markdown('$%s$' %sym.latex(tf))
# General mathematical notation of a polynomial (shown in Label widget)
fourth_order_html = "$f(x)=ax^4$ + $bx^3$ + $cx^2$ + $dx$ + $e$"
third_order_html = "$f(x)=ax^3$ + $bx^2$ + $cx$ + $d$"
second_order_html = "$f(x)=ax^2$ + $bx$ + $c$"
first_order_html = "$f(x)=ax$ + $b$"
zero_order_html = "$f(x)=a$"
w_funLabel = widgets.Label(layout=widgets.Layout(width='40%', margin='0px 0px 0px 50px'),)
# Input sliders for coefficients of a polynomial
fs_a = widgets.FloatSlider(description='$a$', min=-10.0, max=10.0, step=0.5, continuous_update=False)
fs_b = widgets.FloatSlider(description='$b$',min=-10.0, max=10.0, step=0.5, continuous_update=False)
fs_c = widgets.FloatSlider(description='$c$',min=-10.0, max=10.0, step=0.5, continuous_update=False)
fs_d = widgets.FloatSlider(description='$d$',min=-10.0, max=10.0, step=0.5, continuous_update=False)
fs_e = widgets.FloatSlider(description='$e$',min=-10.0, max=10.0, step=0.5, continuous_update=False)
input_widgets = widgets.HBox([fs_a, fs_b, fs_c, fs_d, fs_e])
# Dropdown: selecting the order of a ploynomial [0-4]
# Selection will invoke showing/hiding particular slider widgets
dd_order = widgets.Dropdown(
options=['4', '3', '2', '1', '0'],
value='4',
description='Izberi stopnjo polinoma [0-4]:',
disabled=False,
style = {'description_width': 'initial'},
)
def dropdown_eventhandler(change):
fs_a.layout.visibility = 'hidden'
fs_b.layout.visibility = 'hidden'
fs_c.layout.visibility = 'hidden'
fs_d.layout.visibility = 'hidden'
fs_e.layout.visibility = 'hidden'
if (dd_order.value == '4'):
fs_a.layout.visibility = 'visible'
fs_a.description = '$a$:'
fs_b.layout.visibility = 'visible'
fs_b.description = '$b$'
fs_c.layout.visibility = 'visible'
fs_c.description = '$c$'
fs_d.layout.visibility = 'visible'
fs_d.description = '$d$'
fs_e.layout.visibility = 'visible'
fs_e.description = '$e$'
w_funLabel.value=fourth_order_html
if (dd_order.value == '3'):
fs_a.value = 0
fs_b.layout.visibility = 'visible'
fs_b.description = '$a$'
fs_c.layout.visibility = 'visible'
fs_c.description = '$b$'
fs_d.layout.visibility = 'visible'
fs_d.description = '$c$'
fs_e.layout.visibility = 'visible'
fs_e.description = '$d$'
w_funLabel.value=third_order_html
if (dd_order.value == '2'):
fs_a.value = 0
fs_b.value = 0
fs_c.layout.visibility = 'visible'
fs_c.description = '$a$'
fs_d.layout.visibility = 'visible'
fs_d.description = '$b$'
fs_e.layout.visibility = 'visible'
fs_e.description = '$c$'
w_funLabel.value=second_order_html
if (dd_order.value == '1'):
fs_a.value = 0
fs_b.value = 0
fs_c.value = 0
fs_d.layout.visibility = 'visible'
fs_d.description = '$a$'
fs_e.layout.visibility = 'visible'
fs_e.description = '$b$'
w_funLabel.value=first_order_html
if (dd_order.value == '0'):
fs_a.value = 0
fs_b.value = 0
fs_c.value = 0
fs_d.value = 0
fs_e.layout.visibility = 'visible'
fs_e.description = '$a$'
w_funLabel.value=zero_order_html
dd_order.observe(dropdown_eventhandler, names='value')
# Utility functions
x = sym.symbols('x')
def fprime(fx):
if not fx.is_zero:
return sym.diff(fx, x)
else:
return ""
def convert(base_text, ss):
if ss != "":
tf = sym.sympify(ss)
display(Markdown(base_text + '$%s$' %sym.latex(tf)))
def polynomial_function(X_quaded, X_cubed, X_squared, X, const, x):
return const + X * x + X_squared * x ** 2 + X_cubed * x ** 3 + X_quaded * x ** 4
def fun(x):
global a, b, c, d, e
return e + d * x + c * x **2 + b * x ** 3 + a * x ** 4
#Plot
red_patch = mpatches.Patch(color='red', label='$f(x)$')
blue_patch = mpatches.Patch(color='green', label='prvi odvod $f(x)$')
XLIM = 10
YLIM = 20
XTICK = 2
YTICK = 5
a = 0
b = 0
c = 0
d = 0
e = 0
def plot_function(X_quaded, X_cubed, X_squared, X, const):
global a, b, c, d, e, x
a = X_quaded
b = X_cubed
c = X_squared
d = X
e = const
fig = plt.figure(figsize=(12,6))
plt.axhline(y=0,color='k',lw=.8)
plt.axvline(x=0,color='k',lw=.8)
x_p = np.linspace(-XLIM, XLIM, num=1000)
plt.plot(x_p, polynomial_function(X_quaded, X_cubed, X_squared, X, const, x_p), 'r-')
y_p = [polynomial_function(X_quaded, X_cubed, X_squared, X, const, num) for num in x_p]
dydx = np.diff(y_p) / np.diff(x_p)
plt.plot(x_p[:-1], dydx, 'g-')
plt.grid(True)
plt.xlim(-XLIM, XLIM)
plt.ylim(-YLIM, YLIM)
plt.xlabel('$x$')
plt.ylabel('$f(x)$, odvod $f(x)$')
plt.legend(handles=[red_patch, blue_patch])
plt.show()
convert("Vhodni polinom $f(x)$: ", fun(x))
deriv = fprime(fun(x))
convert("Prvi odvod $f(x)$: ", deriv)
# Show and interact
w_funLabel.value=fourth_order_html
control_widgets = widgets.HBox()
control_widgets.children=[dd_order, w_funLabel]
display(control_widgets)
interactive(plot_function, const=fs_e, X=fs_d, X_squared=fs_c, X_cubed=fs_b, X_quaded=fs_a)
```
| github_jupyter |
```
import os, numpy as np
import pandas as pd
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
```
# Build a Keras Model
```
# shameless copy of keras example : https://github.com/keras-team/keras/blob/master/examples/mnist_cnn.py
sample = True
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
if(sample):
indices = np.random.choice(x_train.shape[0], x_train.shape[0] // 10, replace=False)
x_train = x_train[indices, : , :, :]
y_train = y_train[indices]
indices = np.random.choice(x_test.shape[0], x_test.shape[0] // 10, replace=False)
x_test = x_test[indices, : , :, :]
y_test = y_test[indices]
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
def create_model():
model = Sequential()
model.add(Conv2D(8, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
# model.add(Conv2D(4, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
return model
from keras.wrappers.scikit_learn import KerasClassifier
clf = KerasClassifier(build_fn=create_model, epochs=epochs, batch_size=batch_size, verbose=1)
clf.fit(x_train, y_train ,
batch_size=batch_size,
epochs=12,
verbose=1,
validation_data=(x_test, y_test))
print(x_test.shape)
preds = clf.predict(x_test[0,:].reshape(1, 28 , 28, 1))
print(preds)
```
# Generate SQL Code from the Model
```
import json, requests, base64, dill as pickle, sys
sys.setrecursionlimit(200000)
pickle.settings['recurse'] = False
# no luck for the web service... pickling feature of tensorflow and/or keras objects seems not to be a priority.
# there is a lot of github issues in the two projects when I search for pickle keyword!!!.
def test_ws_sql_gen(pickle_data):
WS_URL="http://localhost:1888/model"
b64_data = base64.b64encode(pickle_data).decode('utf-8')
data={"Name":"model1", "PickleData":b64_data , "SQLDialect":"postgresql"}
r = requests.post(WS_URL, json=data)
print(r.__dict__)
content = r.json()
# print(content)
lSQL = content["model"]["SQLGenrationResult"][0]["SQL"]
return lSQL;
def test_sql_gen(keras_regressor , metadata):
import sklearn2sql.PyCodeGenerator as codegen
cg1 = codegen.cAbstractCodeGenerator();
lSQL = cg1.generateCodeWithMetadata(clf, metadata, dsn = None, dialect = "postgresql");
return lSQL[0]
# commented .. see above
# pickle_data = pickle.dumps(clf)
# lSQL = test_ws_sql_gen(pickle_data)
# print(lSQL[0:2000])
lMetaData = {}
NC = x_test.shape[1] * x_test.shape[2] * x_test.shape[3]
lMetaData['features'] = ["X_" + str(x+1) for x in range(0 , NC)]
lMetaData["targets"] = ['TGT']
lMetaData['primary_key'] = 'KEY'
lMetaData['table'] = 'mnist'
lSQL = test_sql_gen(clf , lMetaData)
print(lSQL[0:50000])
```
# Execute the SQL Code
```
# save the dataset in a database table
import sqlalchemy as sa
# engine = sa.create_engine('sqlite://' , echo=False)
engine = sa.create_engine("postgresql://db:db@localhost/db?port=5432", echo=False)
conn = engine.connect()
NR = x_test.shape[0]
lTable = pd.DataFrame(x_test.reshape(NR , NC));
lTable.columns = lMetaData['features']
lTable['TGT'] = None
lTable['KEY'] = range(NR)
lTable.to_sql(lMetaData['table'] , conn, if_exists='replace', index=False)
sql_output = pd.read_sql(lSQL , conn);
sql_output = sql_output.sort_values(by='KEY').reset_index(drop=True)
conn.close()
sql_output.sample(12, random_state=1960)
```
# Keras Prediction
```
keras_output = pd.DataFrame()
keras_output_key = pd.DataFrame(list(range(x_test.shape[0])), columns=['KEY']);
keras_output_score = pd.DataFrame(columns=['Score_' + str(x) for x in range(num_classes)]);
keras_output_proba = pd.DataFrame(clf.predict_proba(x_test), columns=['Proba_' + str(x) for x in range(num_classes)])
keras_output = pd.concat([keras_output_key, keras_output_score, keras_output_proba] , axis=1)
for class_label in range(num_classes):
keras_output['LogProba_' + str(class_label)] = np.log(keras_output_proba['Proba_' + str(class_label)])
keras_output['Decision'] = clf.predict(x_test)
keras_output.sample(12, random_state=1960)
```
# Comparing the SQL and Keras Predictions
```
sql_keras_join = keras_output.join(sql_output , how='left', on='KEY', lsuffix='_keras', rsuffix='_sql')
sql_keras_join.head(12)
condition = (sql_keras_join.Decision_sql != sql_keras_join.Decision_keras)
sql_keras_join[condition]
```
| github_jupyter |
```
# EDA pkgs
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(style='darkgrid', color_codes=True)
eeg_data = pd.read_csv("EEG_data.csv")
demographic_data = pd.read_csv("demographic_info.csv")
eeg_data
demographic_data
```
### Data
These data are collected from ten students, each watching ten videos. Therefore, it can be seen as only 100 data points for these 12000+ rows. If you look at this way, then each data point consists of 120+ rows, which is sampled every 0.5 seconds (so each data point is a one minute video). Signals with higher frequency are reported as the mean value during each 0.5 second.
- EEG_data.csv: Contains the EEG data recorded from 10 students
- demographic.csv: Contains demographic information for each student
## Narrative:
We will merge the dataframe with respect to Subject ID.
- Unique identifer needs to be removed from the feature as in future this model can be generalize for any video.
## Merging DataFrame
```
demographic_data.rename(columns={"subject ID": "SubjectID"}, inplace = True)
data = demographic_data.merge(eeg_data, on='SubjectID')
data
```
### Narrative:
- We are going to remove the Unique Identifier from the data.
- We will drop "predefinedlabel" from the data as this is a function which hints the model for predictions. Our target is "userdefinedlabeln" that we need to predict if a student will be confused or not after watching a video.
```
data.info()
data.isna().sum()
```
## No missing value
# Data preparation
```
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, plot_confusion_matrix, matthews_corrcoef
def preprocess_inputs(df):
df = df.copy()
#drop unnecessary columns
df = df.drop(["SubjectID", "VideoID", "predefinedlabel"], axis=1)
#rename columns name
df.rename(columns={' age': 'Age', ' ethnicity': 'Ethnicity', ' gender': 'Gender', 'user-definedlabeln': 'Label'}, inplace=True)
#binary encoding the Gender column
df['Gender'] = df['Gender'].apply(lambda x: 1 if x == 'M' else 0)
#X and y
X = df.drop("Label", axis=1)
y = df['Label']
#split the data
X_train, X_test, y_train, y_test = train_test_split(X,y, train_size=0.7, shuffle=True, random_state=1)
return X_train, X_test, y_train, y_test
```
## Narrative:
- Need to Onehot encode "Ethnicity" column.
- Rest of the columns are well settled and numerical.
- We can scale the data if we are not using any tree-based models. Tree-based models don't require Scaled data.
- feature: all except "Label"
```
X_train, X_test, y_train, y_test = preprocess_inputs(data)
X_train
y_train
print(len(X_train))
print(len(X_test))
print(len(y_train))
print(len(y_test))
```
## Model Pipeline
```
nominal_transformer = Pipeline(steps=[
("onehot", OneHotEncoder(sparse=False))
])
preprocessor = ColumnTransformer(transformers=[
("nominal", nominal_transformer, ['Ethnicity'])
], remainder = 'passthrough')
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier())
])
clf = model.fit(X_train, y_train)
print(clf)
score = clf.score(X_test, y_test)
print("Score is: ", np.round(score*100), "%")
y_pred = clf.predict(X_test)
y_pred
matthews_corrcoef_score = matthews_corrcoef(y_test, y_pred)
print(matthews_corrcoef_score)
plot_confusion_matrix(clf, X_test, y_test, labels=clf.classes_)
clr = classification_report(y_test, y_pred, labels=clf.classes_)
print(clr)
```
## We are doing very bad. In general, this data is very challenging and complex as mentioned on the Kaggle. We will try something else for evaluation and interpretation.
# PyCaret to identify the best model.
```
!pip install pycaret
import pycaret.classification as pyc
```
# Data Preparation for PyCaret
```
def data_preparation(df):
df = df.copy()
#drop unnecessary columns
df = df.drop(["SubjectID", "VideoID", "predefinedlabel"], axis=1)
#rename columns name
df.rename(columns={' age': 'Age', ' ethnicity': 'Ethnicity', ' gender': 'Gender', 'user-definedlabeln': 'Label'}, inplace=True)
#binary encoding the Gender column
df['Gender'] = df['Gender'].apply(lambda x: 1 if x == 'M' else 0)
return df
X = data_preparation(data)
X
pyc.setup(
data = X,
target = 'Label',
train_size = 0.7,
normalize = True
)
pyc.compare_models()
```
## In Pipeline, we used RandomForestClassifier(), as it works well on the most of the classification problems but interpretation is little difficult than Logistic or Decision Tree. It is "Accuracy-Interpretation" trade-off.
Using PyCaret compare models function, we can quickly see which model is doing good. ExtraTree for example in this case.
```
best_model = pyc.create_model('et')
pyc.evaluate_model(best_model)
pyc.save_model(best_model, "eeg_confusion_model")
```
# Using Neural Net
We will do an ANN.
```
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
def data_inputs_tf(df):
#drop unnecessary columns
df = df.drop(["SubjectID", "VideoID", "predefinedlabel"], axis=1)
#rename columns name
df.rename(columns={' age': 'Age', ' ethnicity': 'Ethnicity', ' gender': 'Gender', 'user-definedlabeln': 'Label'}, inplace=True)
#binary encoding the Gender column
df['Gender'] = df['Gender'].apply(lambda x: 1 if x == 'M' else 0)
#one hot encode the "Ethnicity column"
ethnicity_dummies = pd.get_dummies(df['Ethnicity'])
df = pd.concat([df, ethnicity_dummies], axis=1)
df = df.drop('Ethnicity', axis=1)
#X and y
X = df.drop("Label", axis=1)
y = df['Label']
# Scale the data as all the columns will be in same range (mean of 0 and variance of 1)
scaler = StandardScaler()
X = scaler.fit_transform(X)
#split the data
X_train, X_test, y_train, y_test = train_test_split(X,y, train_size=0.7, shuffle=True, random_state=1)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = data_inputs_tf(data)
X_train
y_train
```
# Model architecture
```
inputs = tf.keras.Input(shape=(X_train.shape[1]))
x = tf.keras.layers.Dense(256, activation='relu')(inputs)
x = tf.keras.layers.Dense(256, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=[
'accuracy',
tf.keras.metrics.AUC(name='auc')
]
)
batch_size = 32
epochs = 50
history = model.fit(
X_train,
y_train,
validation_split=0.2,
batch_size=batch_size,
epochs=epochs,
callbacks=[
tf.keras.callbacks.ReduceLROnPlateau()
]
)
plt.figure(figsize=(16, 10))
plt.plot(range(epochs), history.history['loss'], label="Training Loss")
plt.plot(range(epochs), history.history['val_loss'], label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Loss Over Time")
plt.legend()
plt.show()
model.evaluate(X_test, y_test)
y_true = np.array(y_test)
y_pred = np.squeeze(model.predict(X_test))
y_pred = np.array(y_pred >= 0.5, dtype=np.int)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(4, 4))
sns.heatmap(cm, annot=True, fmt='g', vmin=0, cbar=False)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()
print(classification_report(y_true, y_pred))
```
| github_jupyter |
```
rootf = NAME_FOLDER_RBM-MHC ## name of the folder where RBM-MHC is saved ##
out_fold = rootf + '/data/Allele-specific_models/Allele-specific_COVID19/Results_plot/'
### Inclusions ###
import matplotlib as mpl
mpl.rcParams['font.family'] = ['Garuda']
mpl.rcParams['font.serif'] = ['Garuda-Oblique']
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
import pandas as pd
df = pd.read_csv(out_fold + 'Table_results_sars_cov_2.csv', sep = ',')
value = df['Identity to SARS'] > 70 # select identity above a certain threshold
fig, ax = plt.subplots()
fig.set_figwidth(8)
st=19
tit = plt.suptitle('SARS-CoV-2 homologs of SARS-CoV epitopes', fontsize = st+1)
sns.boxplot(x = 'Algorithm', y='Score percentile', data=df[value], fliersize=0, ax=ax, width = 0.4)
# iterate over boxes
for i,box in enumerate(ax.artists):
if i%3==0:
box.set_edgecolor('Maroon')
box.set_facecolor('white')
for j in range(6*i,6*(i+1)):
ax.lines[j].set_color('Maroon')
if i%3==1:
box.set_edgecolor('DarkGoldenRod')
box.set_facecolor('white')
# iterate over whiskers and median lines
for j in range(6*i,6*(i+1)):
ax.lines[j].set_color('DarkGoldenRod')
if i%3==2:
box.set_edgecolor('DarkGoldenRod')
box.set_facecolor('white')
# iterate over whiskers and median lines
for j in range(6*i,6*(i+1)):
ax.lines[j].set_color('DarkGoldenRod')
s1 = 6
value1=(df['Identity to SARS'] > 99.9)
sns.swarmplot(x = 'Algorithm', y='Score percentile', data=df[value & value1], linewidth = 1,
ax = ax, dodge = 'True', alpha = 0.99, palette=['Maroon', 'DarkGoldenRod','DarkGoldenRod'], s= s1)
value1=(df['Identity to SARS'] < 99.9)
sns.swarmplot(x = 'Algorithm', y='Score percentile', data=df[value & value1], linewidth = 1,
ax = ax, dodge = 'True', alpha = 0.6, edgecolor = 'k', palette=['Brown', 'GoldenRod', 'GoldenRod'], s = s1, marker = 's')
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
custom_lines =[Line2D([0], [0], marker='o', color='w', markerfacecolor='White', markersize=12, markeredgecolor='k',
markeredgewidth = 1, alpha = 0.99), Line2D([0], [0], marker='s', color='w', markerfacecolor='White',
markersize=12, markeredgecolor='k', markeredgewidth = 1, alpha = 0.65)]
lgd = ax.legend(custom_lines, ['100% Sequence identity', '70-99% Sequence identity'], loc='best', bbox_to_anchor=(1, 1) , fontsize=st)
ax.tick_params(axis = 'y', which = 'major', labelsize=st-4)
ax.tick_params(axis = 'x', which = 'major', labelsize=st)
ax.set_xlabel('', fontsize=st)
ax.set_ylabel('Score percentile', fontsize=st)
textst = '(n=22)'
ax.text(0.77, 0.03, textst, transform=ax.transAxes, fontsize=st-4, verticalalignment='bottom')
fig.subplots_adjust(right=0.5)
fig, ax = plt.subplots()
n=3
st=14
fig.set_figwidth(n)
fig.set_figheight(n)
value1=(df['Identity to SARS'] > 99.9)
value2=(df['Mut'] == 0)
sel = (df['Score percentile'][value & value1 & value2].values)
mm=int(len(sel)/2)
listr = sel[:mm]
listn = sel[mm:]
plt.scatter(listr,listn, c='gray', marker='o',edgecolor = 'k', s = 50)
value1=(df['Identity to SARS'] < 99.9)
sel = (df['Score percentile'][value & value1].values)
mm=int(len(sel)/2)
listr = sel[:mm]
listn = sel[mm:]
plt.scatter(listr,listn, c='lightgray', marker = 's', s = 46, edgecolor = 'k', alpha = 0.65)
ax.tick_params(axis = 'both', which = 'major', labelsize=st-2)
ax.set_ylabel('NetMHC score percentile', fontsize=st)
ax.set_xlabel('RBM score percentile', fontsize=st)
v0=82
v1=101
ax.set_xlim([v0,v1])
ax.set_ylim([v0,v1])
ax.plot([v0,v1], [v0,v1], ls = "--", alpha = 0.4, c = 'k')
cltms = np.loadtxt(out_fold + 'cltms_mon_YesAlpha_2020.txt')
clt = np.loadtxt(out_fold + 'clt_mon_YesAlpha_2020.txt')
cnm = np.loadtxt(out_fold + 'cnm_mon_YesAlpha_2020.txt')
namesl = ['A*01:01', 'A*02:01', 'A*03:01', 'A*11:01', 'A*24:02', 'B*40:01', 'C*04:01', 'C*07:01', 'C*07:02','C*01:02']
fig, ax = plt.subplots()
fig.set_figwidth(10)
fig.set_figheight(3)
ww2=0.14
st=14
x_post = np.array(range(10))
ax.bar(x_post, cnm, align = 'center', color = 'DarkGoldenRod', width = ww2, label = r'NetMHC $-log(K_d)$', edgecolor = 'k')
ax.bar(x_post[:6] + 0.2, clt[:6], align = 'center', color = 'Maroon', width = ww2, label = r'RBM score (BA)', edgecolor = 'k')
ax.bar(x_post + np.array(np.hstack((np.repeat(0.4,6),np.repeat(0.2,4)))), cltms, align = 'center', color = [165/255,42/255,42/255,0.7], width = ww2,
label = r'RBM score (MS)', edgecolor = 'k')
ax.set_xticks(x_post+0.2)
ax.legend(markerscale=0.09, frameon=False, loc='upper right', fontsize = st, bbox_to_anchor=(0.97, 1.03))
ax.tick_params(axis = 'both', which = 'major', labelsize=st-1)
ax.set_xticklabels(namesl, rotation = 0, fontsize = st-1.5)
ax.set_xlabel('HLA-I allele', fontsize=st)
ax.set_ylabel('Correlation to stability', fontsize=st)
```
| github_jupyter |
## Assignment 2 [Part A] Cleaning and EDA
**_Bo Cao, NUID: 001834167_**
### Dataset Description:
The dataset I picked is a collection of the U.S airline delay information on Jan. 1st, 2015. Such 9 kinds of fields included in the raw datesets:
* **AIRLINE, FLIGHT_NUMBER**
* **ORIGIN_AIRPORT, DESTINATION_AIRPORT**
* **SCHEDULED_DEPARTURE, DEPARTURE_TIME, DEPARTURE_DELAY**
* **DISTANCE**
* **SCHEDULED_ARRIVAL, ARRIVAL_TIME, ARRIVAL_DELAY**
* DIVERTED
* CANCELLED (Flight Cancelled (1 = cancelled))
* CANCELLATION_REASON (Reason for Cancellation of flight: A - Airline/Carrier; B - Weather; C - National Air System; D - Security)
* **AIR_SYSTEM_DELAY, SECURITY_DELAY, AIRLINE_DELAY, LATE_AIRCRAFT_DELAY, WEATHER_DELAY**
31 columns of data included totally for above kinds of data
data tag in **bold** will be keep in the dataset, other columns of data will be discarded
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import stats
import seaborn as sns
# Make plots larger
plt.rcParams['figure.figsize'] = (16, 10)
#read flights.csv in flights
flights = pd.read_csv('flights.csv', sep=',')
## show the data samples of first 10 lines
flights.head(n=10)
```
### Discard Columns
* **YEAR, MONTH, DAY, DAY_OF_WEEK** are discarded because all the flights wecdoing research are in the Jan. 1st, 2015.
* **TAIL_NUMBER** has no meaning to this report.
* **TAXI_OUT, WHEELS_OFF, SCHEDULED_TIME, ELAPSED_TIME, AIR_TIME, WHEELS_ON, TAXI_IN** are discarded because the time are so concreate that we do not need that kind of data.
```
flights2 = flights.drop(['YEAR','MONTH','DAY','DAY_OF_WEEK','TAIL_NUMBER','TAXI_OUT','WHEELS_OFF','SCHEDULED_TIME','ELAPSED_TIME','AIR_TIME','WHEELS_ON','TAXI_IN','CANCELLATION_REASON'],axis=1)
flights2.head(3000)
```
### Data cleaning
* Are there missing values?
** Answer: There are some missing cancel or delay values in the list because some flights are on time.**
```
flights2.isnull().sum()
flights2.info()
```
* Are there inappropraite values?
* Remove or impute any bad data.
1. **DIVERTED**: If the filght is diverted, the result of it is not meaningful because it does not have any information about delay.
2. **CANCELLED**: If the flight is cancelled, the result of it is not meaningful because it does not have any information about delay.
```
# Check how much lines of data with flight diverted
(flights2['DIVERTED']==1).sum()
## 20 lines will be discarded
# Check how much lines of data with flight cancelled
(flights2['CANCELLED']==1).sum()
## 466 lines will be discarded
# Show all the data whose flight is not diverted and not cancelled, then store them in flights_valid.
flights3 = flights2.loc[flights2['DIVERTED']==0]
flights_valid = flights3.loc[flights3['CANCELLED']==0]
flights_valid
# Show the mean of the flight ARRIVAL DELAY time (in Minutes)
flights_valid['ARRIVAL_DELAY'].mean()
```
3. [SCHEDULED_DEPARTURE], [DEPARTURE_TIME], [SCHEDULED_ARRIVAL], [ARRIVAL_TIME] should lower than 2400 (24:00), which represent the time.
** The line of which columns has a value more than 2400 will be removed.**
```
(flights_valid['SCHEDULED_DEPARTURE']>2400).sum()
(flights_valid['DEPARTURE_TIME']>2400).sum()
(flights_valid['SCHEDULED_ARRIVAL']>2400).sum()
(flights_valid['ARRIVAL_TIME']>2400).sum()
```
### Answer the following questions for the data in each column:
* How is the data distributed?
1. Data of **['DEPARTURE_DELAY']** is **Normal Distribution**, because the both extreme advance departure time and extreme late departure time have the least possibility.
2. Data of **['ARRIVAL_DELAY']** is **Normal Distribution**, because the both extreme advance arrival time and extreme late arrival time have the least possibility.
3. Data of **['SCHEDULED_DEPARTURE'], ['DEPARTURE_TIME'], ['SCHEDULED_ARRIVAL'], ['ARRIVAL_TIME']** should be **Normal Distribution**, because the time value in the middle of the day has the greatset possibility, the time value on the earliest side and latest side has the least possibility.
4. Data from **['AIR_SYSTEM_DELAY'] → ['WEATHER_DELAY']** should be **Normal Distribution**, because the value in the middle has the greatest possibility, the value on the smallest side and largest side has the least possibility.
* What are the summary statistics?
1. column **['DEPARTURE_DELAY']**
2. column **['ARRIVAL_DELAY']**
3. column **['SCHEDULED_DEPARTURE'], ['DEPARTURE_TIME'], ['SCHEDULED_ARRIVAL'], ['ARRIVAL_TIME']** have the summary statistics of familiar type.
4. column **['AIR_SYSTEM_DELAY'] → ['WEATHER_DELAY']** have the summary statistics of familiar type.
```
flights_valid.head()
flights_valid.describe()
flights_valid.info()
flights_valid.shape
# sample for the data column in Group 1
flights_valid.DEPARTURE_DELAY
# sample for the data column in Group 2
flights_valid.ARRIVAL_DELAY
# head for several representative columns of data
flights_valid[['AIRLINE','FLIGHT_NUMBER','DEPARTURE_DELAY','ARRIVAL_DELAY','AIR_SYSTEM_DELAY']].head()
```
* Are there anomalies/outliers?
Yes, there are.
## Plot each colmun as appropriate for the data type:
* Write a summary of what the plot tells you.
```
plt.show(flights_valid[['SCHEDULED_DEPARTURE','DEPARTURE_TIME','SCHEDULED_ARRIVAL','ARRIVAL_TIME']].plot(kind='box'))
```
#### What could be read from the boxplot above?
The boxplot above for Departure and Arrival time could tell me the estimate value range, maximum value, 75th percentile, 50 percentile(mean), 25 percentile, minimum value.
To the meaning of the time,
* SCHEDULE_DEPARTURE and DEPARTURE_TIME could be match with the **Normal Distribution** model because the mean of the value range is in the middle.
* SCHEDULE_ARRIVAL and ARRIVAL_TIME are somewhat like SCHEDULE_DEPARTURE and DEPARTURE_TIME with a larger mean of the value because the flight time.
```
plt.show(flights_valid[['DEPARTURE_DELAY','ARRIVAL_DELAY']].plot(kind='box'))
```
#### What could be read from the boxplot above?
* More than 50 precent of the flights departure in delay, however less than 50 percent of the flights arrive in delay.
* Some flights data are so late that they are anomalies to the boxplot.
```
plt.show(sns.lmplot(x='DEPARTURE_DELAY',y='ARRIVAL_DELAY',data=flights_valid))
```
#### What could be read from the plot above?
* There are linear realtion between DEPARTURE_DELAY and ARRIVAL_DELAY
```
flights_valid['AIR_SYSTEM_DELAY'].hist(bins=15)
flights_valid['SECURITY_DELAY'].hist(bins=15)
flights_valid['AIRLINE_DELAY'].hist(bins=15)
flights_valid['LATE_AIRCRAFT_DELAY'].hist(bins=15)
flights_valid['WEATHER_DELAY'].hist(bins=15)
flights_valid['ARRIVAL_DELAY'].hist(bins=15)
```
#### What could be read from the histogram above?
* It is obivious that the ARRIVAL_DELAY follows the model of Normal distribution. With most of the data distribute in an fixed middle, which is estimately around zero point.
```
sns.distplot(flights_valid['ARRIVAL_DELAY'])
```
## Conclusion
From the diagram above, we can get some conclusion that most flight departure at about noon and most flight arrive at afternoon and the whole time schedule are normal distribution. Most flights can arrive at destination on time and the delay flights take only a small part of the whole flights data in the day of Jan 1, 2015.
| github_jupyter |
# Explore migration scaling, parameter uplift
```
import glob
import os
import re
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import simim.data_apis
from ukpopulation.myedata import MYEData
from ukpopulation.nppdata import NPPData
from ukpopulation.snppdata import SNPPData
plt.rcParams["figure.figsize"] = (10,10)
paths = [os.path.split(p.replace('../simim/data/output\\', '')) for p in glob.glob('../simim/data/output/**/*.csv')]
paths[0]
lads = gpd.read_file('../simim/data/cache/Local_Authority_Districts_December_2016_Ultra_Generalised_Clipped_Boundaries_in_Great_Britain.shp') \
.drop(['objectid', 'lad16nmw', 'bng_e', 'bng_n', 'long', 'lat', 'st_lengths'], axis=1)
lads.head(1)
arc_lads = pd.read_csv('../simim/data/scenarios/camkox_lads.csv')
arc_lads.head(1)
def read_baseline(arc_lads):
# households
os.chdir("../simim")
simim_data = simim.data_apis.Instance({
"coverage": "GB",
"cache_dir": "./data/cache",
"output_dir": "./data/output",
"model_type": "none",
"base_projection": "ppp",
"scenario": "none",
"attractors": []
})
dfs = []
for year in range(2015, 2051):
df = simim_data.get_households(year, lads.lad16cd.unique())
dfs.append(df)
households = pd.concat(dfs, sort=False).rename(columns={"PROJECTED_YEAR_NAME": "YEAR"})
# population
lad_cds = list(arc_lads.geo_code.unique())
mye = MYEData()
years = [2015]
pop_mye = mye.aggregate(["GENDER", "C_AGE"], lad_cds, years)
npp = NPPData()
snpp = SNPPData()
snpp_years = [2030]
extra_years = [2050]
pop_snpp = snpp.aggregate(["GENDER", "C_AGE"], lad_cds, snpp_years)
pop_ex = snpp.extrapolagg(["GENDER", "C_AGE"], npp, lad_cds, extra_years)
pop = pd.concat([pop_mye, pop_snpp, pop_ex], axis=0) \
.rename(columns={'OBS_VALUE':'PEOPLE', 'PROJECTED_YEAR_NAME': 'YEAR'})
pop.PEOPLE = pop.PEOPLE.astype(int)
# merge later (after subset everything else)
os.chdir("../notebooks")
# employment, gva, dwellings
df_emp = pd.read_csv("../simim/data/arc/arc_employment__baseline.csv")
df_gva = pd.read_csv("../simim/data/arc/arc_gva__baseline.csv")
df_dwl = pd.read_csv("../simim/data/arc/arc_dwellings__baseline.csv")
# merge to single dataframe
df = df_gva \
.merge(df_emp, on=["timestep", "lad_uk_2016"], how="left") \
.merge(df_dwl, on=["timestep", "lad_uk_2016"], how="left")
baseline = df.reset_index().rename(columns={
"timestep": "YEAR",
"lad_uk_2016": "GEOGRAPHY_CODE",
"employment": "JOBS",
"gva": "GVA",
"gva_per_sector": "GVA",
"dwellings": "DWELLINGS"
})[[
"YEAR", "GEOGRAPHY_CODE", "JOBS", "GVA", "DWELLINGS"
]].merge(
households, on=["GEOGRAPHY_CODE", "YEAR"]
)
baseline["GVA"] = baseline["GVA"].round(6)
# convert from 1000s jobs to jobs
baseline["JOBS"] = (baseline["JOBS"] * 1000).round().astype(int)
baseline = baseline[
baseline.GEOGRAPHY_CODE.isin(arc_lads.geo_code)
& baseline.YEAR.isin([2015, 2030, 2050])
]
baseline = baseline \
.merge(pop, on=['GEOGRAPHY_CODE','YEAR']) \
.merge(arc_lads, left_on='GEOGRAPHY_CODE', right_on='geo_code') \
.drop(['geo_code'], axis=1) \
.rename(columns={'geo_label':'GEOGRAPHY_NAME'})
baseline['SCENARIO'] = 'baseline'
return baseline
baseline = read_baseline(arc_lads)
len(baseline.YEAR.unique()), len(baseline.GEOGRAPHY_CODE.unique()), len(baseline)
baseline.tail()
def read_output_and_scenario(arc_lads, baseline, scenario_key, output_path):
key = scenario_key
if key == "3-new-cities23":
econ_key = "1-new-cities"
elif key == "4-expansion23":
econ_key = "2-expansion"
else:
econ_key = key
df_gva = pd.read_csv("../simim/data/arc/arc_gva__{}.csv".format(econ_key))
df_emp = pd.read_csv("../simim/data/arc/arc_employment__{}.csv".format(econ_key))
df_dwl = pd.read_csv("../simim/data/arc/arc_dwellings__{}.csv".format(key))
# merge to single dataframe
scenario = df_gva \
.merge(df_emp, on=["timestep", "lad_uk_2016"], how="left") \
.merge(df_dwl, on=["timestep", "lad_uk_2016"], how="left") \
.drop("lad16nm", axis=1) \
.rename(columns={
"timestep": "YEAR",
"lad_uk_2016": "GEOGRAPHY_CODE",
"gva_per_sector": "GVA",
"employment": "JOBS",
"dwellings": "HOUSEHOLDS"})
scenario = scenario.merge(arc_lads, left_on='GEOGRAPHY_CODE', right_on='geo_code') \
.drop(['geo_code'], axis=1) \
.rename(columns={'geo_label':'GEOGRAPHY_NAME'})
scenario = scenario[
scenario.GEOGRAPHY_CODE.isin(arc_lads.geo_code)
& scenario.YEAR.isin([2015, 2030, 2050])
]
# rebase scenario households (dwelling) numbers on baseline households - this is what simim sees as input
scenario = scenario.merge(baseline[['YEAR','GEOGRAPHY_CODE','DWELLINGS','HOUSEHOLDS']], on=['YEAR','GEOGRAPHY_CODE'])
scenario.HOUSEHOLDS_x = scenario.HOUSEHOLDS_x - scenario.DWELLINGS + scenario.HOUSEHOLDS_y
scenario = scenario.drop(['HOUSEHOLDS_y'], axis=1).rename(columns={'HOUSEHOLDS_x':'HOUSEHOLDS'})
scenario.GVA = scenario.GVA.round(6)
scenario.JOBS = (scenario.JOBS * 1000).round().astype(int) # convert from 1000s jobs to jobs
scenario.HOUSEHOLDS = scenario.HOUSEHOLDS.round().astype(int)
output = pd.read_csv(os.path.join(output_path)) \
.rename(columns={'PROJECTED_YEAR_NAME': 'YEAR'})
output = scenario.merge(output, on=["YEAR", "GEOGRAPHY_CODE"], how='left') \
.drop(['PEOPLE_SNPP', 'RELATIVE_DELTA'], axis=1)
output['SCENARIO'] = scenario_key
return output
baseline['EXPERIMENT'] = 'baseline'
dfs = [baseline]
for experiment, result in paths:
if 'od_rail' not in result:
continue
path = os.path.join('../simim/data/output', experiment, result)
# regex to find scenario
m = re.search(r'scenario([^_]+)', path)
if m:
scen = m.group(1)
else:
scen = path
df = read_output_and_scenario(arc_lads, baseline, scen, path)
df.pivot(index='YEAR',columns='GEOGRAPHY_NAME', values='PEOPLE').plot(
title=experiment + ' ' + scen
)
df['EXPERIMENT'] = experiment
dfs.append(df)
dataset = pd.concat(dfs, axis=0, sort=True)
dataset.head(1)
dataset.tail(1)
dataset['PPH'] = dataset.PEOPLE / dataset.HOUSEHOLDS
dataset[dataset.PPH < 2]
summary = dataset.groupby(["YEAR",'SCENARIO', 'EXPERIMENT']).sum()
summary.PPH = summary.PEOPLE / summary.HOUSEHOLDS
summary
summary = summary.reset_index()
summary = summary.merge(
summary[summary.SCENARIO == 'baseline'][['YEAR','PPH']],
on='YEAR', how='left', suffixes=('','_BASELINE'))
summary['EXP_POP'] = summary.HOUSEHOLDS * summary.PPH_BASELINE
summary['PEOPLE_SCALE_FACTOR'] = summary.EXP_POP / summary.PEOPLE
summary
dataset = dataset.merge(
summary[['YEAR','SCENARIO', 'EXPERIMENT', 'PEOPLE_SCALE_FACTOR']],
on=['YEAR','SCENARIO','EXPERIMENT'], how='left')
dataset
dataset['SCALED_PEOPLE'] = dataset.PEOPLE * dataset.PEOPLE_SCALE_FACTOR
dataset['SCALED_PPH'] = dataset.SCALED_PEOPLE / dataset.HOUSEHOLDS
dataset
dataset[dataset.SCALED_PPH < 2]
pivot = dataset.pivot_table(index=['GEOGRAPHY_CODE','GEOGRAPHY_NAME','YEAR'], columns=['EXPERIMENT', 'SCENARIO'])
pivot
pivot.to_csv('scaled_factor_experiments.csv')
```
| github_jupyter |
**[Nuevamente, para este artículo he contado con la colaboración de [Cristián Maureira-Fredes](https://maureira.xyz/) que ha revisado todo y me ha dado una serie de correcciones y mejoras que hacen que el capítulo esté bastante mejor que el original. Cristián trabaja como ingeniero de software en el proyecto [Qt for Python](https://wiki.qt.io/Qt_for_Python) dentro de [The Qt Company](https://qt.io/)]**
Lo interesante de los GUIs es que podamos hablarle a la computadora de una forma amigable y para poder establecer esta comunicación es necesario que cuando nosotros hagamos algo la aplicación responda de alguna forma. **En este capítulo voy a dar un repaso al sistema de gestión de eventos en Qt5 que se conoce como *Signals/Slots* y que podemos ver como los conjuntos de acciones y las posibles reacciones que desencadenarán estas acciones**.
Índice:
* [Instalación de lo que vamos a necesitar](https://pybonacci.org/2019/11/12/curso-de-creacion-de-guis-con-qt5-y-python-capitulo-00-instalacion/).
* [Qt, versiones y diferencias](https://pybonacci.org/2019/11/21/curso-de-creacion-de-guis-con-qt5-y-python-capitulo-01-qt-versiones-y-bindings/).
* [Hola, Mundo](https://pybonacci.org/2019/11/26/curso-de-creacion-de-guis-con-qt5-y-python-capitulo-02-hola-mundo/).
* [Módulos en Qt](https://pybonacci.org/2019/12/02/curso-de-creacion-de-guis-con-qt5-y-python-capitulo-03-modulos-qt/).
* [Añadimos icono a la ventana principal](https://pybonacci.org/2019/12/26/curso-de-creacion-de-guis-con-qt5-y-python-capitulo-04-icono-de-la-ventana/).
* [Tipos de ventana en un GUI](https://pybonacci.org/2020/01/31/curso-de-creacion-de-guis-con-qt-capitulo-05-ventanas-principales-diferencias/).
* [Ventana inicial de carga o Splashscreen](https://pybonacci.org/2020/02/26/curso-de-creacion-de-guis-con-qt-capitulo-06-splash-screen/)
* [Menu principal. Introducción](https://pybonacci.org/2020/03/18/curso-de-creacion-de-guis-con-qt-capitulo-07-menu/).
* [Mejorando algunas cosas vistas](https://pybonacci.org/2020/03/26/curso-de-creacion-de-guis-con-qt-capitulo-08-mejorando-lo-visto/).
* [Gestión de eventos o Acción y reacción](https://pybonacci.org/2020/03/27/curso-de-creacion-de-guis-con-qt-capitulo-09-signals-y-slots/) (este capítulo).
* [Introducción a Designer](https://pybonacci.org/2020/04/14/curso-de-creacion-de-guis-con-qt-capitulo-10-introduccion-a-designer/).
* [Los Widgets vistos a través de Designer: Primera parte](https://pybonacci.org/2020/05/01/curso-de-creacion-de-guis-con-qt-capitulo-11-widgets-en-designer-i/).
* [Los Widgets vistos a través de Designer: Segunda parte](https://pybonacci.org/2020/05/02/curso-de-creacion-de-guis-con-qt-capitulo-12:-widgets-en-designer-(ii)/).
* [Los Widgets vistos a través de Designer: Tercera parte](https://pybonacci.org/2020/05/03/curso-de-creacion-de-guis-con-qt-capitulo-13-widgets-en-designer-iii/).
* [Los Widgets vistos a través de Designer: Cuarta parte](https://pybonacci.org/2020/05/04/curso-de-creacion-de-guis-con-qt-capitulo-14-widgets-en-designer-iv/).
* [Los Widgets vistos a través de Designer: Quinta parte](https://pybonacci.org/2020/05/05/curso-de-creacion-de-guis-con-qt-capitulo-15-widgets-en-designer-v/).
* [Los Widgets vistos a través de Designer: Sexta parte](https://pybonacci.org/2020/05/06/curso-de-creacion-de-guis-con-qt-capitulo-16:-widgets-en-designer-(vi)/).
* TBD… (lo actualizaré cuando tenga más claro los siguientes pasos).
**[Los materiales para este capítulo los podéis descargar de [aquí](https://github.com/kikocorreoso/pyboqt/tree/chapter09)]**
**[INSTALACIÓN] Si todavía no has pasado por el [inicio del curso, donde explico cómo poner a punto todo](https://pybonacci.org/2019/11/12/curso-de-creacion-de-guis-con-qt-capitulo-00:-instalacion/), ahora es un buen momento para hacerlo y después podrás seguir con esta nueva receta.**
Vamos a empezar a definir un poco qué es todo esto de la gestión de eventos para centrarnos y luego ya toquetearemos algo de código. Sin pretender ser muy estrictos:
* Sucede algo: pulsamos sobre algún botón del ratón, ponemos el puntero del ratón sobre algún elemento, presionamos determinada tecla, emitimos un sonido,...). Esto sería un evento que emite una señal (*Signal*) o una acción.
* Al ocurrir alguna acción, como las descritas antes, se puede desencadenar una o más reacciones (o no, como ha venido pasando principalmente hasta ahora).
En el framework Qt, todo esto se conoce como el [mecanismo de *Signals* y *Slots*](https://doc.qt.io/qt-5/signalsandslots.html) y es la forma de comunicación entre objetos en Qt:
> Se emite una señal, *signal*, cuando ocurre un evento específico. Los widgets de Qt vienen con muchas señales predefinidas. Por otro lado, un *slot* es una función o método (o clase, cualquier cosa que defina `__call__`) que se ejecutará como respuesta a una señal en particular. Al igual que con las señales, los widgets de Qt pueden tener *slots* predefinidos. Lo normal es que creemos subclases y reescribamos las señales y *slots* de los widgets para que se ajusten mejor a lo que necesitamos que hagan.
Vamos a usar un código muy simple para ver como funciona todo esto. Lo escribo y lo comento más abajo. El código está adaptado de [este ejemplo en la página de *Qt for python*](https://doc.qt.io/qtforpython/tutorials/basictutorial/clickablebutton.html):
```python
'''
Curso de creación de GUIs con Qt5 y Python
Author: Kiko Correoso
Website: pybonacci.org
Licencia: MIT
'''
import os
os.environ['QT_API'] = 'pyside2'
import sys
from qtpy.QtWidgets import QApplication, QPushButton
from qtpy.QtCore import Slot
@Slot()
def say_hello():
print("Button pulsado, ¡Hola!")
if __name__ == '__main__':
app = QApplication(sys.argv)
boton = QPushButton("Pulsa")
boton.clicked.connect(say_hello)
boton.show()
sys.exit(app.exec_())
```
El anterior ejemplo no usa una ventana principal. Solo usa un *Widget* de botón que podemos pulsar (más sobre esto en próximas entregas, ahora un *Widget* solo es una pieza de Lego). Es un ejemplo mínimo para ver como funciona el mecanismo *Signal-Slot*. Como comento, la aplicación consiste de un único botón. La parte interesante aquí es la siguiente:
-------------
```python
boton.clicked.connect(say_hello)
```
Lo que estamos haciendo es conectar un objeto a un *Slot* que se llama `say_hello` que se 'desencaderá' cuando exista una señal (*Signal*), en este caso la señal de pulsar el botón, `clicked`.
----------------
El *Slot*, en este caso, es algo muy simple que muestra en pantalla un texto (usando un simple `print`):
```python
@Slot()
def say_hello():
print("Button pulsado, ¡Hola!")
```
Si guardamos el anterior código en un fichero que se llame *main_00.py* y lo ejecutamos de la siguiente forma desde la carpeta donde has guardado el fichero:
```python
python main00.py
```
Veríamos algo que tendría esta pinta:

El ejemplo anterior es algo muy rápido para ver como funciona el mecanismo *Signal-Slot*. Un objeto emite una señal que llama a un *Slot* y este responde. Vamos a seguir viendo ejemplos sobre esto.
## *Signals* y *Slots* predefinidos
Partimos, ahora, de un código que dejamos en el [capítulo 7](https://pybonacci.org/2020/03/18/curso-de-creacion-de-guis-con-qt-capitulo-07-menu/) y mejorado con lo que vimos en el [capítulo 8](https://pybonacci.org/2020/03/26/curso-de-creacion-de-guis-con-qt-capitulo-08-mejorando-lo-visto/) (quitamos los submenús que, de momento, no los vamos a usar):
```python
'''
Curso de creación de GUIs con Qt5 y Python
Author: Kiko Correoso
Website: pybonacci.org
Licencia: MIT
'''
import os
os.environ['QT_API'] = 'pyside2'
import sys
from pathlib import Path
from qtpy.QtWidgets import QApplication, QMainWindow, QAction
from qtpy.QtGui import QIcon
import qtawesome as qta
class MiVentana(QMainWindow):
def __init__(self, parent=None):
QMainWindow.__init__(self, parent)
self._create_ui()
def _create_ui(self):
self.resize(500, 300)
self.move(0, 0)
self.setWindowTitle('Hola, QMainWindow')
ruta_icono = Path('.', 'imgs', 'pybofractal.png')
self.setWindowIcon(QIcon(str(ruta_icono)))
self.statusBar().showMessage('Ready')
self._create_menu()
def _create_menu(self):
menubar = self.menuBar()
# File menu and its QAction's
file_menu = menubar.addMenu('&File')
exit_action = QAction(qta.icon('fa5.times-circle'),
'&Exit',
self)
exit_action.setShortcut('Ctrl+Q')
exit_action.setStatusTip('Exit application')
file_menu.addAction(exit_action)
# Help menu and its QAction's
help_menu = menubar.addMenu('&Help')
about_action = QAction(qta.icon('fa5s.info-circle'),
'&Exit',
self)
about_action.setShortcut('Ctrl+I')
about_action.setStatusTip('About...')
help_menu.addAction(about_action)
if __name__ == '__main__':
app = QApplication(sys.argv)
w = MiVentana()
w.show()
sys.exit(app.exec_())
```
Lo anterior tenía esta pinta:

En la anterior aplicación, muy simple y que no hace gran cosa, ya estamos usando una serie de Widgets, `QMainWindow`, `QMenuBar`, `QStatusBar`,... Como he comentado anteriormente, todavía no me he metido a explicar en detalle lo que es un Widget. Eso vendrá más adelante. De momento, lo podemos seguir viendo como pequeñas piezas de lego que nos ayudan a construir algo. Estos Widgets ya existentes y que estamos usando pueden venir con *signals* y/o *slots* ya predefinidos aunque todavía no hemos visto nada de esto explícitamente. Ahora vamos a usar alguno para que la aplicación empiece a tener algo de funcionalidad.
Si vamos a la [documentación de, por ejemplo, `QMenuBar`](https://doc.qt.io/qtforpython/PySide2/QtWidgets/QMenuBar.html) vemos que la clase tiene muchas [funciones o métodos](https://doc.qt.io/qtforpython/PySide2/QtWidgets/QMenuBar.html#functions). Ya hemos usado alguno de estos métodos como `addMenu`. Si seguimos un poco más abajo en la documentación vemos que hay una [sección que se llama *Signals*](https://doc.qt.io/qtforpython/PySide2/QtWidgets/QMenuBar.html#signals). En esa sección se puede ver que existen dos métodos que se llaman `hovered` (estar encima) y `triggered` (desencadenado o detonado). Estos son eventos típicos que podríamos usar al pasar el puntero del ratón sobre el menú (`hovered`) o cuando pulsamos sobre el menú (`triggered`).
Por otro lado, si ahora vamos a la [documentación de `QApplication`](https://doc.qt.io/qtforpython/PySide2/QtWidgets/QApplication.html), vemos que dispone de [algunos *slots*](https://doc.qt.io/qtforpython/PySide2/QtWidgets/QApplication.html#slots) además de otras cosas. Los *slots* que tiene no nos interesan ahora pero si vamos a la sección de [funciones estáticas](https://doc.qt.io/qtforpython/PySide2/QtWidgets/QApplication.html#static-functions) vemos alguna que puede ser interesante como `closeAllWindows`.
Vamos a hacer que cuando pasemos el puntero sobre la barra de menús la aplicación se cierre. Sí, lo sé, algo muy inútil, pero es para ir viendo conceptos. En este caso, el evento será colocar el ratón sobre la barra de menús, eso disparará la señal `hovered` y queremos que cuando se dispare se cierre la aplicación.
Vamos a conectar una señal de un objeto, un `QMenuBar` en este caso, con una función de otro objeto, el método `closeAllWindows` de la instancia de `QApplication`. En este caso no es un *slot* pero nos vale como *slot* porque, como hemos comentado antes, cualquier cosa que funcione como un *callable* (función, método,...) será válido como *slot*. La conexión se hará de la siguiente forma:
```python
objeto_que_emite_la_señal.señal_emitida.connect(funcion_a_usar_como_slot)
```
Un ejemplo más real de lo anterior podría ser que la función `func` se ejecute cuando pulsemos sobre un botón (que será una instancia de un *Widget*). Cogiendo el ejemplo inicial:
```python
boton.clicked.connect(func)
```
Vamos a hacer lo que hemos comentado antes, que se cierre la aplicación cuando el puntero del ratón esté sobre la barra de menús, y así vemos un nuevo ejemplo con código real. Como siempre, pongo el código y destaco las líneas nuevas con el comentario `## NUEVA LÍNEA`:
```python
'''
Curso de creación de GUIs con Qt5 y Python
Author: Kiko Correoso
Website: pybonacci.org
Licencia: MIT
'''
import os
os.environ['QT_API'] = 'pyside2'
import sys
from pathlib import Path
from qtpy.QtWidgets import QApplication, QMainWindow, QAction
from qtpy.QtGui import QIcon
import qtawesome as qta
class MiVentana(QMainWindow):
def __init__(self, parent=None):
QMainWindow.__init__(self, parent)
self._create_ui()
instance = QApplication.instance() ## NUEVA LÍNEA
self.menuBar().hovered.connect(instance.closeAllWindows) ## NUEVA LÍNEA
def _create_ui(self):
self.resize(500, 300)
self.move(0, 0)
self.setWindowTitle('Hola, QMainWindow')
ruta_icono = Path('.', 'imgs', 'pybofractal.png')
self.setWindowIcon(QIcon(str(ruta_icono)))
self.statusBar().showMessage('Ready')
self._create_menu()
def _create_menu(self):
menubar = self.menuBar()
# File menu and its QAction's
file_menu = menubar.addMenu('&File')
exit_action = QAction(qta.icon('fa5.times-circle'),
'&Exit',
self)
exit_action.setShortcut('Ctrl+Q')
exit_action.setStatusTip('Exit application')
file_menu.addAction(exit_action)
# Help menu and its QAction's
help_menu = menubar.addMenu('&Help')
about_action = QAction(qta.icon('fa5s.info-circle'),
'&Exit',
self)
about_action.setShortcut('Ctrl+I')
about_action.setStatusTip('About...')
help_menu.addAction(about_action)
if __name__ == '__main__':
app = QApplication(sys.argv)
w = MiVentana()
w.show()
sys.exit(app.exec_())
```
Si lo anterior lo guardáis en un fichero que se llame *main01.py* y, desde la carpeta donde tenéis el fichero, lo ejecutáis desde la línea de comandos haciendo:
```
python main01.py
```
Veréis nuestra ventana que he mostrado más arriba. Si ahora pasáis el puntero del ratón sobre la barra de menús veréis que se cierra la aplicación:

Esto sería un ejemplo, muy inútil, de cómo podemos hacer que el usuario interactúe con nuestra aplicación.
Explico las líneas nuevas:
----------------
```python
instance = QApplication.instance()
self.menuBar().hovered.connect(instance.closeAllWindows)
```
* [`QApplication.instance`](https://doc.qt.io/qtforpython/PySide2/QtCore/QCoreApplication.html#PySide2.QtCore.PySide2.QtCore.QCoreApplication.instance) nos proporciona un puntero a la instancia de la aplicación.
* `self.menuBar().hovered.connect(instance.closeAllWindows)` conecta el objeto con la función estática que hemos comentado antes (`closeAllWindows`) cuando ocurre la señal `hovered` (pasar por encima).
## Creando un *slot*
Como he venido comentando, podemos usar nuestras propias funciones para que reaccionen a eventos. Ahora vamos a añadir un poco de funcionalidad para que nuestra aplicación empiece a ser un poco más útil. Pongo el código y destaco las líneas nuevas con el comentario de siempre, `## NUEVA LÍNEA`:
```python
'''
Curso de creación de GUIs con Qt5 y Python
Author: Kiko Correoso
Website: pybonacci.org
Licencia: MIT
'''
import os
os.environ['QT_API'] = 'pyside2'
import sys
from pathlib import Path
from qtpy.QtWidgets import ( ## NUEVA LÍNEA
QApplication, QMainWindow, QAction, QMessageBox ## NUEVA LÍNEA
) ## NUEVA LÍNEA
from qtpy.QtGui import QIcon
from qtpy.QtCore import Slot ## NUEVA LÍNEA
import qtawesome as qta
class MiVentana(QMainWindow):
def __init__(self, parent=None):
QMainWindow.__init__(self, parent)
self._create_ui()
def _create_ui(self):
self.resize(500, 300)
#self.move(0, 0)
self.setWindowTitle('Hola, QMainWindow')
ruta_icono = Path('.', 'imgs', 'pybofractal.png')
self.setWindowIcon(QIcon(str(ruta_icono)))
self.statusBar().showMessage('Ready')
self._create_menu()
def _create_menu(self):
menubar = self.menuBar()
# File menu and its QAction's
file_menu = menubar.addMenu('&File')
exit_action = QAction(qta.icon('fa5.times-circle'),
'&Exit',
self)
exit_action.setShortcut('Ctrl+Q')
exit_action.setStatusTip('Exit application')
exit_action.triggered.connect( ## NUEVA LÍNEA
QApplication.instance().closeAllWindows ## NUEVA LÍNEA
) ## NUEVA LÍNEA
file_menu.addAction(exit_action)
# Help menu and its QAction's
help_menu = menubar.addMenu('&Help')
about_action = QAction(qta.icon('fa5s.info-circle'), ## NUEVA LÍNEA
'&About', ## NUEVA LÍNEA
self) ## NUEVA LÍNEA
about_action.setShortcut('Ctrl+I')
about_action.setStatusTip('About...')
about_action.triggered.connect( ## NUEVA LÍNEA
self._show_about_dialog ## NUEVA LÍNEA
) ## NUEVA LÍNEA
help_menu.addAction(about_action)
@Slot()
def _show_about_dialog(self): ## NUEVA LÍNEA
msg_box = QMessageBox() ## NUEVA LÍNEA
msg_box.setIcon(QMessageBox.Information) ## NUEVA LÍNEA
msg_box.setText("Pybonacci app v -37.3") ## NUEVA LÍNEA
msg_box.setWindowTitle("Ejemplo de Slot") ## NUEVA LÍNEA
msg_box.setStandardButtons(QMessageBox.Close) ## NUEVA LÍNEA
msg_box.exec_() ## NUEVA LÍNEA
if __name__ == '__main__':
app = QApplication(sys.argv)
w = MiVentana()
w.show()
sys.exit(app.exec_())
```
Con respecto al anterior código han desaparecido algunas líneas puesto que no eran muy útiles y no forman parte de este nuevo ejemplo.
Voy a pasar a explicar un poco el código nuevo:
----------------------
```python
from qtpy.QtWidgets import (
QApplication, QMainWindow, QAction, QMessageBox
)
```
Importo `QMessageBox`. `QMessageBox` es un nuevo Widget que no voy a explicar ahora ya que se explicará en detalle más adelante. Ya sabéis, una nueva pieza de Lego, de momento.
------------------------
```python
from qtpy.QtCore import Slot ## NUEVA LÍNEA
```
Importamos `Slot` como hemos hecho con el primer ejemplo del botón.
----------------------
```python
#self.move(0, 0)
```
Esa línea, `_create_ui` la comento para que la ventana no aparezca arriba a la derecha. De momento la dejo solo comentada.
----------------------
```python
exit_action.triggered.connect(
QApplication.instance().closeAllWindows
)
```
En el método `_create_menu` hemos añadido la anterior línea a la `QAction` de salida de la aplicación. Cuando pulsemos sobre *Exit* en el menú *File* la aplicación se cerrará. Es lo mismo que hemos hecho antes cuando pasábamos el ratón sobre la barra de menús pero ahora usamos el *slot* en un lugar que tenga más sentido.
----------------------
```python
about_action = QAction(qta.icon('fa5s.info-circle'), ## NUEVA LÍNEA
'&About', ## NUEVA LÍNEA
self) ## NUEVA LÍNEA
```
También en el método `_create_menu`, simplemente cambio `&Exit` por `&About`. El anterior `&Exit` no pintaba nada ahí y ahora lo estoy corrigiendo para que tenga sentido.
----------------------
```python
about_action.triggered.connect(
self._show_about_dialog
)
```
También en el método `_create_menu` hemos añadido la anterior línea a la `QAction` de información de la aplicación. Cuando pulsemos sobre *About* en el menú *Help* la aplicación llamará al método `_show_about_dialog`.
----------------------
```python
@Slot()
def _show_about_dialog(self):
msg_box = QMessageBox()
msg_box.setIcon(QMessageBox.Information)
msg_box.setText("Pybonacci app v -37.3")
msg_box.setWindowTitle("Ejemplo de Slot")
msg_box.setStandardButtons(QMessageBox.Close)
msg_box.exec_()
```
Y, por último, añadimos un nuevo método, `_show_about_dialog` que se ejecutará cuando pulsemos sobre la opción *About* del menú *Help*. De momento no entro en detalles sobre `QMessageBox` pero veremos una ventanita con algo de información y con un único botón.
Si lo anterior lo guardáis en un fichero que se llame *main02.py* y, desde la carpeta donde tenéis el fichero, lo ejecutáis desde la línea de comandos haciendo:
```
python main02.py
```
Veréis de nuevo la ventana. Si ahora pulsáis en `Help > About` os debería salir una ventanita con un botón. Si la cerráis y luego pulsáis sobre `File > Exit` se debería cerrar la aplicación:

Bueno. Parece que nuestra aplicación, poco a poco, va siendo más útil o, al menos, hace cosas algo más interesantes.
¿Es necesario usar el decorador `Slot` en los *callables*?
La aplicación anterior funcionaría perfectamente si no usamos el decorador `Slot`. Entonces, ¿para qué usarlo? Leyendo la [documentación de PyQt5](https://www.riverbankcomputing.com/static/Docs/PyQt5/signals_slots.html#the-pyqtslot-decorator) nos dan varias razones:
* Podemos definir tipos y otras cosas (no voy a entrar en esto ahora).
* Puede ahorrar memoria.
* Puede ser más rápido.
**[INCISO]**
En PyQt5, las señales y *slots*, se definen usando `pyqtSignal` y `pyqtSlot` y se importan así:
`from PyQt5.QtCore import pyqtSignal, pyqtSlot`
En *Qt for Python* o PySide2 se definen usando `Signal` y `Slot` y se importan así:
`from PySide2.QtCore import Signal, Slot`
## Eventos
Ahora voy a hacer un pequeño inciso en la explicación del mecanismo *Signals/Slots* para hablar muy superficialmente de los eventos en Qt.
Los eventos son un mecanismo parecido a las señales y *slots* para conseguir cosas similares pero es de más bajo nivel y con fines un poco diferentes.
Las señales y *slots* son ideales cuando queremos responder a alguna acción que quiera hacer el usuario pero sin preocuparnos mucho en los detalles sobre cómo el usuario ha pedido las cosas. También podemos usar las señales y los *slots* para personalizar ligeramente algún comportamiento de algún Widget.
Por otro lado, si necesitamos que el comportamiento cambie drásticamente, normalmente cuando estamos creando nuestros propios Widgets, necesitaremos gestionar los eventos de una forma más cruda (más bajo nivel).
Por tanto, los eventos se encuentran a nivel de clase y todas las instancias de clase reaccionarán de la misma forma al evento en cuestión. Por otro lado, las señales se establecen en el objeto, instancia de clase, y cada objeto podrá tener su propia conexión entre señal y *slot*. Podéis echarle un ojo a esta [respuesta en StackOverflow](https://stackoverflow.com/a/3794944) si queréis algo más formal. Este párrafo es una traducción del primer comentario a esa respuesta que me ha parecido una buena síntesis del tema. También le podéis echar un ojo a la [documentación oficial](https://doc.qt.io/qtforpython/overviews/eventsandfilters.html).
No quiero profundizar más ahora sobre esto para no complicar más este capítulo. Supongo que lo veremos más adelante en algún capítulo futuro usando ejemplos concretos.
## Resumen
Lo que me gustaría que quedase claro es lo siguiente:
* El mecanismo de alto nivel para lidiar con eventos en Qt se conoce como el mecanismo *Signal-Slot*.
* Los eventos ocurrirán, principalmente, cuando el usuario quiera interactuar con la aplicación.
* Una señal se emite cuando sucede un evento en particular. Un evento, como hemos visto, puede ser un *click*, posar el puntero sobre algo,...
* Un *slot* puede ser cualquier *callable* Python. Funciones, métodos,... Cualquier cosa que implemente el método `__call__`.
* Un *slot* se ejecutará cuando se emite la señal a la que está conectado.
Por tanto, un evento dispara una señal, la señal puede avisar a uno o más *slots* si los hemos conectado con la señal. El *slot* o los *slots* son los que lidiaran con el evento.
Y, por hoy, creo que ya es suficiente.
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Goal" data-toc-modified-id="Goal-1"><span class="toc-item-num">1 </span>Goal</a></span></li><li><span><a href="#Var" data-toc-modified-id="Var-2"><span class="toc-item-num">2 </span>Var</a></span></li><li><span><a href="#Init" data-toc-modified-id="Init-3"><span class="toc-item-num">3 </span>Init</a></span></li><li><span><a href="#Selecting-Actinopterygii-samples" data-toc-modified-id="Selecting-Actinopterygii-samples-4"><span class="toc-item-num">4 </span>Selecting Actinopterygii samples</a></span><ul class="toc-item"><li><span><a href="#summary" data-toc-modified-id="summary-4.1"><span class="toc-item-num">4.1 </span>summary</a></span></li></ul></li><li><span><a href="#LLMGAG" data-toc-modified-id="LLMGAG-5"><span class="toc-item-num">5 </span>LLMGAG</a></span><ul class="toc-item"><li><span><a href="#Run" data-toc-modified-id="Run-5.1"><span class="toc-item-num">5.1 </span>Run</a></span></li></ul></li><li><span><a href="#Summary" data-toc-modified-id="Summary-6"><span class="toc-item-num">6 </span>Summary</a></span><ul class="toc-item"><li><span><a href="#Number-of-genes-assembled-&-clustered" data-toc-modified-id="Number-of-genes-assembled-&-clustered-6.1"><span class="toc-item-num">6.1 </span>Number of genes assembled & clustered</a></span></li><li><span><a href="#Taxonomy" data-toc-modified-id="Taxonomy-6.2"><span class="toc-item-num">6.2 </span>Taxonomy</a></span><ul class="toc-item"><li><span><a href="#Summary" data-toc-modified-id="Summary-6.2.1"><span class="toc-item-num">6.2.1 </span>Summary</a></span></li></ul></li><li><span><a href="#Annotations" data-toc-modified-id="Annotations-6.3"><span class="toc-item-num">6.3 </span>Annotations</a></span><ul class="toc-item"><li><span><a href="#COG-functional-categories" data-toc-modified-id="COG-functional-categories-6.3.1"><span class="toc-item-num">6.3.1 </span>COG functional categories</a></span><ul class="toc-item"><li><span><a href="#Grouped-by-taxonomy" data-toc-modified-id="Grouped-by-taxonomy-6.3.1.1"><span class="toc-item-num">6.3.1.1 </span>Grouped by taxonomy</a></span></li></ul></li></ul></li><li><span><a href="#humann2-db-genes" data-toc-modified-id="humann2-db-genes-6.4"><span class="toc-item-num">6.4 </span>humann2 db genes</a></span><ul class="toc-item"><li><span><a href="#Summary" data-toc-modified-id="Summary-6.4.1"><span class="toc-item-num">6.4.1 </span>Summary</a></span><ul class="toc-item"><li><span><a href="#By-Taxonomy" data-toc-modified-id="By-Taxonomy-6.4.1.1"><span class="toc-item-num">6.4.1.1 </span>By Taxonomy</a></span></li></ul></li></ul></li></ul></li><li><span><a href="#sessionInfo" data-toc-modified-id="sessionInfo-7"><span class="toc-item-num">7 </span>sessionInfo</a></span></li></ul></div>
# Goal
* Metagenome assembly of Actinopterygii samples
* assemblying genes by using `plass`
# Var
```
work_dir = '/ebio/abt3_projects/databases_no-backup/animal_gut_metagenomes/wOutVertebrata/MG_assembly_act/LLMGAG/'
samples_file = '/ebio/abt3_projects/Georg_animal_feces/data/metagenome/HiSeqRuns126-133-0138/wOutVertebrata/LLMGQC/samples_cov-gte0.3.tsv'
metadata_file = '/ebio/abt3_projects/Georg_animal_feces/data/mapping/unified_metadata_complete_190529.tsv'
pipeline_dir = '/ebio/abt3_projects/Georg_animal_feces/bin/llmgag/'
```
# Init
```
library(dplyr)
library(tidyr)
library(ggplot2)
library(data.table)
source('/ebio/abt3_projects/Georg_animal_feces/code/misc_r_functions/init.R')
```
# Selecting Actinopterygii samples
```
meta = read.delim(metadata_file, sep='\t') %>%
dplyr::select(SampleID, class, order, family, genus, scientific_name, diet, habitat)
meta %>% dfhead
samps = read.delim(samples_file, sep='\t') %>%
mutate(Sample = gsub('^XF', 'F', Sample))
samps %>% dfhead
setdiff(samps$Sample, meta$Sample)
# joining
samps = samps %>%
inner_join(meta, c('Sample'='SampleID'))
samps %>% dfhead
# all metadata
samps %>%
group_by(class) %>%
summarize(n = n()) %>%
ungroup()
samps_f = samps %>%
filter(class == 'Actinopterygii')
samps_f %>% dfhead
outF = file.path(work_dir, 'samples_act.tsv')
samps_f %>%
arrange(class, order, family, genus) %>%
write.table(outF, sep='\t', quote=FALSE, row.names=FALSE)
cat('File written:', outF, '\n')
```
## summary
```
samps_f$Total.Sequences %>% summary
```
# LLMGAG
```
F = file.path(work_dir, 'config.yaml')
cat_file(F)
```
## Run
```{bash}
(snakemake_dev) @ rick:/ebio/abt3_projects/vadinCA11/bin/llmgag
$ screen -L -S llmgag-ga-act ./snakemake_sge.sh /ebio/abt3_projects/databases_no-backup/animal_gut_metagenomes/wOutVertebrata/MG_assembly_act/LLMGAG/config.yaml cluster.json /ebio/abt3_projects/databases_no-backup/animal_gut_metagenomes/wOutVertebrata/MG_assembly_act/LLMGAG/SGE_log 27
```
# Summary
## Number of genes assembled & clustered
```
F = file.path(work_dir, 'assembly', 'plass', 'genes.faa')
cmd = glue::glue('grep -c ">" {fasta}', fasta=F)
n_raw_seqs = system(cmd, intern=TRUE)
cat('Number of assembled sequences:', n_raw_seqs, '\n')
F = file.path(work_dir, 'cluster', 'linclust', 'clusters_rep-seqs.faa')
cmd = glue::glue('grep -c ">" {fasta}', fasta=F)
n_rep_seqs = system(cmd, intern=TRUE)
cat('Number of cluster rep sequences:', n_rep_seqs, '\n')
F = file.path(work_dir, 'humann2_db', 'clusters_rep-seqs.faa.gz')
cmd = glue::glue('gunzip -c {fasta} | grep -c ">"', fasta=F)
n_h2_seqs = system(cmd, intern=TRUE)
cat('Number of humann2_db-formatted seqs:', n_h2_seqs, '\n')
```
## Taxonomy
```
# reading in taxonomy table
## WARING: slow
F = file.path(work_dir, 'taxonomy', 'clusters_rep-seqs_tax_db.tsv.gz')
cmd = glue::glue('gunzip -c {file}', file=F)
coln = c('seqID', 'taxID', 'rank', 'spp', 'lineage')
levs = c('Domain', 'Phylum', 'Class', 'Order', 'Family', 'Genus', 'Species')
tax = fread(cmd, sep='\t', header=FALSE, col.names=coln, fill=TRUE) %>%
separate(lineage, levs, sep=':')
tax %>% dfhead
# number of sequences
tax$seqID %>% unique %>% length %>% print
# which ranks found?
tax$rank %>% table %>% print
# number of classifications per seqID
tax %>%
group_by(seqID) %>%
summarize(n = n()) %>%
ungroup() %>%
.$n %>% summary
```
### Summary
```
# summarizing taxonomy
tax_s = tax %>%
filter(Domain != '',
Phylum != '') %>%
group_by(Domain, Phylum) %>%
summarize(n = seqID %>% unique %>% length) %>%
ungroup()
tax_s %>% dfhead
# plotting by phylum
p = tax_s %>%
filter(n > 10) %>%
mutate(Phylum = Phylum %>% reorder(n)) %>%
ggplot(aes(Phylum, n, fill=Domain)) +
geom_bar(stat='identity', position='dodge') +
scale_y_log10() +
labs(y = 'No. of genes') +
coord_flip() +
theme_bw() +
theme(
axis.text.y = element_text(size=7)
)
dims(5,15)
plot(p)
# top phyla
tax_s %>%
arrange(-n) %>%
head(n=30)
# summarizing taxonomy
tax_s = tax %>%
filter(Domain != '',
Phylum != '',
Class != '') %>%
group_by(Domain, Phylum, Class) %>%
summarize(n = seqID %>% unique %>% length) %>%
ungroup()
tax_s %>% dfhead
# top hits
tax_s %>%
arrange(-n) %>%
head(n=30)
```
## Annotations
```
F = file.path(work_dir, 'annotate', 'eggnog-mapper', 'clusters_rep-seqs.emapper.annotations.gz')
cmd = glue::glue('gunzip -c {file}', file=F, header=FALSE)
emap_annot = fread(cmd, sep='\t') %>%
dplyr::select(-V6)
emap_annot %>% dfhead
# adding taxonomy info
intersect(emap_annot$V1, tax$seqID) %>% length %>% print
emap_annot = emap_annot %>%
left_join(tax, c('V1'='seqID'))
emap_annot %>% dfhead
n_annot_seqs = emap_annot$V1 %>% unique %>% length
cat('Number of rep seqs with eggnog-mapper annotations:', n_annot_seqs, '\n')
```
### COG functional categories
* [wiki on categories](https://ecoliwiki.org/colipedia/index.php/Clusters_of_Orthologous_Groups_%28COGs%29)
```
# summarizing by functional group
emap_annot_s = emap_annot %>%
dplyr::select(V1, V12) %>%
separate(V12, LETTERS[1:6], sep=', ') %>%
gather(X, COG_func_cat, -V1) %>%
filter(!is.na(COG_func_cat),
COG_func_cat != '') %>%
dplyr::select(-X)
emap_annot_s %>% dfhead
# plotting summary
p = emap_annot_s %>%
ggplot(aes(COG_func_cat)) +
geom_bar() +
labs(x='COG functional category', y='No. of genes') +
theme_bw()
dims(9,3)
plot(p)
# plotting summary
p = emap_annot_s %>%
group_by(COG_func_cat) %>%
summarize(perc_abund = n() / n_annot_seqs * 100) %>%
ungroup() %>%
ggplot(aes(COG_func_cat, perc_abund)) +
geom_bar(stat='identity') +
labs(x='COG functional category', y='% of all genes') +
theme_bw()
dims(9,3)
plot(p)
```
#### Grouped by taxonomy
```
emap_annot_s = emap_annot %>%
dplyr::select(V1, V12) %>%
separate(V12, LETTERS[1:6], sep=', ') %>%
gather(X, COG_func_cat, -V1) %>%
left_join(tax, c('V1'='seqID')) %>%
filter(!is.na(COG_func_cat),
COG_func_cat != '') %>%
dplyr::select(-X)
emap_annot_s %>% dfhead
# plotting summary by domain
p = emap_annot_s %>%
ggplot(aes(COG_func_cat)) +
geom_bar() +
facet_wrap(~ Domain, scales='free_y') +
labs(x='COG functional category', y='No. of genes') +
theme_bw()
dims(9,5)
plot(p)
# plotting summary by phylum
p = emap_annot_s %>%
group_by(Phylum) %>%
mutate(n = n()) %>%
ungroup() %>%
filter(n >= 1000) %>%
mutate(Phylum = Phylum %>% reorder(-n)) %>%
ggplot(aes(COG_func_cat, fill=Domain)) +
geom_bar() +
facet_wrap(~ Phylum, scales='free_y', ncol=3) +
labs(x='COG functional category', y='No. of genes') +
theme_bw()
dims(9,14)
plot(p)
```
## humann2 db genes
```
# gene IDs
F = file.path(work_dir, 'humann2_db', 'clusters_rep-seqs_annot-index.tsv')
hm2 = fread(F, sep='\t', header=TRUE) %>%
separate(new_name, c('UniRefID', 'Gene_length', 'Taxonomy'), sep='\\|') %>%
separate(Taxonomy, c('Genus', 'Species'), sep='\\.s__') %>%
separate(Species, c('Species', 'TaxID'), sep='__taxID') %>%
mutate(Genus = gsub('^g__', '', Genus))
hm2 %>% dfhead
# adding taxonomy
intersect(hm2$original_name, tax$seqID) %>% length %>% print
hm2 = hm2 %>%
left_join(tax, c('original_name'='seqID'))
hm2 %>% dfhead
```
### Summary
```
# number of unique UniRef IDs
hm2$UniRefID %>% unique %>% length
# duplicate UniRef IDs
hm2 %>%
group_by(UniRefID) %>%
summarize(n = n()) %>%
ungroup() %>%
filter(n > 1) %>%
arrange(-n) %>%
head(n=30)
# number of genes with a taxID
hm2_f = hm2 %>%
filter(!is.na(TaxID))
hm2_f %>% nrow
```
#### By Taxonomy
```
# number of UniRefIDs
hm2_f_s = hm2_f %>%
group_by(Domain, Phylum) %>%
summarize(n = UniRefID %>% unique %>% length) %>%
ungroup()
p = hm2_f_s %>%
filter(n >= 10) %>%
mutate(Phylum = Phylum %>% reorder(n)) %>%
ggplot(aes(Phylum, n, fill=Domain)) +
geom_bar(stat='identity', position='dodge') +
scale_y_log10() +
coord_flip() +
labs(y='No. of UniRef IDs') +
theme_bw() +
theme(
axis.text.y = element_text(size=7)
)
dims(5,10)
plot(p)
```
# sessionInfo
```
sessionInfo()
```
| github_jupyter |
```
# Copyright 2021 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# E2E ML on GCP: MLOps stage 2 : experimentation: get started with Vertex Vizier
<table align="left">
<td>
<a href="https://github.com/GoogleCloudPlatform/vertex-ai-samples/tree/master/notebooks/official/automl/ml_ops_stage2/get_started_vertex_vizier.ipynb">
<img src="https://cloud.google.com/ml-engine/images/github-logo-32px.png" alt="GitHub logo">
View on GitHub
</a>
</td>
<td>
<a href="https://console.cloud.google.com/ai/platform/notebooks/deploy-notebook?download_url=https://github.com/GoogleCloudPlatform/vertex-ai-samples/tree/master/notebooks/official/automl/ml_ops_stage2/get_started_vertex_vizier.ipynb">
Open in Google Cloud Notebooks
</a>
</td>
</table>
<br/><br/><br/>
## Overview
This tutorial demonstrates how to use Vertex AI for E2E MLOps on Google Cloud in production. This tutorial covers stage 2 : experimentation: get started with Vertex Vizier.
### Dataset
The dataset used for this tutorial is the [Boston Housing Prices dataset](https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html). The version of the dataset you will use in this tutorial is built into TensorFlow. The trained model predicts the median price of a house in units of 1K USD.
### Objective
In this tutorial, you learn how to use `Vertex Vizier` for when training with `Vertex AI`.
This tutorial uses the following Google Cloud ML services:
- `Vertex Training`
- `Vertex Hyperparameter Tuning`
- `Vertex Vizier`
The steps performed include:
- Hyperparameter tuning with Random algorithm.
- Hyperparameter tuning with Vizier (Bayesian) algorithm.
### Recommendations
When doing E2E MLOps on Google Cloud, the following are best practices for when to use Vertex Vizier for hyperparameter tuning:
**Grid Search**
You have a small number of combinations of discrete values. For example, you have the following two hyperparameters and discrete values:
- batch size: \[ 16, 32, 64\]
- lr: \[ 0.001, 0.01. 0.1\]
The total number of combinations is 9 (3 x 3).
**Random Search**
You have a small number of hyperparameters, where at least one is a continuous value. For example, you have the following two hyperparameters and ranges:
- batch size: \[ 16, 32, 64\]
- lr: 0.001 .. 0.1
**Vizier Search**
You have either a:
- large number of hyperparameters and discrete values
- vast continuous search space
- multiple of objectives
## Installations
Install *one time* the packages for executing the MLOps notebooks.
```
ONCE_ONLY = False
if ONCE_ONLY:
! pip3 install -U tensorflow==2.5 $USER_FLAG
! pip3 install -U tensorflow-data-validation==1.2 $USER_FLAG
! pip3 install -U tensorflow-transform==1.2 $USER_FLAG
! pip3 install -U tensorflow-io==0.18 $USER_FLAG
! pip3 install --upgrade google-cloud-aiplatform[tensorboard] $USER_FLAG
! pip3 install --upgrade google-cloud-bigquery $USER_FLAG
! pip3 install --upgrade google-cloud-logging $USER_FLAG
! pip3 install --upgrade apache-beam[gcp] $USER_FLAG
! pip3 install --upgrade pyarrow $USER_FLAG
! pip3 install --upgrade cloudml-hypertune $USER_FLAG
```
### Restart the kernel
Once you've installed the additional packages, you need to restart the notebook kernel so it can find the packages.
```
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
```
#### Set your project ID
**If you don't know your project ID**, you may be able to get your project ID using `gcloud`.
```
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
if PROJECT_ID == "" or PROJECT_ID is None or PROJECT_ID == "[your-project-id]":
# Get your GCP project id from gcloud
shell_output = ! gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID:", PROJECT_ID)
! gcloud config set project $PROJECT_ID
```
#### Region
You can also change the `REGION` variable, which is used for operations
throughout the rest of this notebook. Below are regions supported for Vertex AI. We recommend that you choose the region closest to you.
- Americas: `us-central1`
- Europe: `europe-west4`
- Asia Pacific: `asia-east1`
You may not use a multi-regional bucket for training with Vertex AI. Not all regions provide support for all Vertex AI services.
Learn more about [Vertex AI regions](https://cloud.google.com/vertex-ai/docs/general/locations)
```
REGION = "us-central1" # @param {type: "string"}
```
#### Timestamp
If you are in a live tutorial session, you might be using a shared test account or project. To avoid name collisions between users on resources created, you create a timestamp for each instance session, and append the timestamp onto the name of resources you create in this tutorial.
```
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
```
### Create a Cloud Storage bucket
**The following steps are required, regardless of your notebook environment.**
When you initialize the Vertex SDK for Python, you specify a Cloud Storage staging bucket. The staging bucket is where all the data associated with your dataset and model resources are retained across sessions.
Set the name of your Cloud Storage bucket below. Bucket names must be globally unique across all Google Cloud projects, including those outside of your organization.
```
BUCKET_NAME = "gs://[your-bucket-name]" # @param {type:"string"}
if BUCKET_NAME == "" or BUCKET_NAME is None or BUCKET_NAME == "gs://[your-bucket-name]":
BUCKET_NAME = "gs://" + PROJECT_ID + "aip-" + TIMESTAMP
```
**Only if your bucket doesn't already exist**: Run the following cell to create your Cloud Storage bucket.
```
! gsutil mb -l $REGION $BUCKET_NAME
```
Finally, validate access to your Cloud Storage bucket by examining its contents:
```
! gsutil ls -al $BUCKET_NAME
```
### Set up variables
Next, set up some variables used throughout the tutorial.
### Import libraries and define constants
```
import google.cloud.aiplatform as aip
```
### Initialize Vertex SDK for Python
Initialize the Vertex SDK for Python for your project and corresponding bucket.
```
aip.init(project=PROJECT_ID, staging_bucket=BUCKET_NAME)
```
#### Vertex AI constants
Setup up the following constants for Vertex AI:
- `API_ENDPOINT`: The Vertex AI API service endpoint for `Dataset`, `Model`, `Job`, `Pipeline` and `Endpoint` services.
- `PARENT`: The Vertex AI location root path for `Dataset`, `Model`, `Job`, `Pipeline` and `Endpoint` resources.
```
# API service endpoint
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
# Vertex location root path for your dataset, model and endpoint resources
PARENT = "projects/" + PROJECT_ID + "/locations/" + REGION
```
#### Set hardware accelerators
You can set hardware accelerators for training.
Set the variable `TRAIN_GPU/TRAIN_NGPU` to use a container image supporting a GPU and the number of GPUs allocated to the virtual machine (VM) instance. For example, to use a GPU container image with 4 Nvidia Telsa K80 GPUs allocated to each VM, you would specify:
(aip.AcceleratorType.NVIDIA_TESLA_K80, 4)
Otherwise specify `(None, None)` to use a container image to run on a CPU.
Learn more [here](https://cloud.google.com/vertex-ai/docs/general/locations#accelerators) hardware accelerator support for your region
```
if os.getenv("IS_TESTING_TRAIN_GPU"):
TRAIN_GPU, TRAIN_NGPU = (
aip.gapic.AcceleratorType.NVIDIA_TESLA_K80,
int(os.getenv("IS_TESTING_TRAIN_GPU")),
)
else:
TRAIN_GPU, TRAIN_NGPU = (aip.gapic.AcceleratorType.NVIDIA_TESLA_K80, 1)
```
#### Set pre-built containers
Set the pre-built Docker container image for training.
- Set the variable `TF` to the TensorFlow version of the container image. For example, `2-1` would be version 2.1, and `1-15` would be version 1.15. The following list shows some of the pre-built images available:
For the latest list, see [Pre-built containers for training](https://cloud.google.com/ai-platform-unified/docs/training/pre-built-containers).
```
if os.getenv("IS_TESTING_TF"):
TF = os.getenv("IS_TESTING_TF")
else:
TF = "2.1".replace(".", "-")
if TF[0] == "2":
if TRAIN_GPU:
TRAIN_VERSION = "tf-gpu.{}".format(TF)
else:
TRAIN_VERSION = "tf-cpu.{}".format(TF)
else:
if TRAIN_GPU:
TRAIN_VERSION = "tf-gpu.{}".format(TF)
else:
TRAIN_VERSION = "tf-cpu.{}".format(TF)
TRAIN_IMAGE = "{}-docker.pkg.dev/vertex-ai/training/{}:latest".format(
REGION.split("-")[0], TRAIN_VERSION
)
print("Training:", TRAIN_IMAGE, TRAIN_GPU, TRAIN_NGPU)
```
#### Set machine type
Next, set the machine type to use for training.
- Set the variable `TRAIN_COMPUTE` to configure the compute resources for the VMs you will use for for training.
- `machine type`
- `n1-standard`: 3.75GB of memory per vCPU.
- `n1-highmem`: 6.5GB of memory per vCPU
- `n1-highcpu`: 0.9 GB of memory per vCPU
- `vCPUs`: number of \[2, 4, 8, 16, 32, 64, 96 \]
*Note: The following is not supported for training:*
- `standard`: 2 vCPUs
- `highcpu`: 2, 4 and 8 vCPUs
*Note: You may also use n2 and e2 machine types for training and deployment, but they do not support GPUs*.
```
if os.getenv("IS_TESTING_TRAIN_MACHINE"):
MACHINE_TYPE = os.getenv("IS_TESTING_TRAIN_MACHINE")
else:
MACHINE_TYPE = "n1-standard"
VCPU = "4"
TRAIN_COMPUTE = MACHINE_TYPE + "-" + VCPU
print("Train machine type", TRAIN_COMPUTE)
```
## Standalone Vertex Vizer service
The `Vizier` service can be used as a standalone service for selecting the next set of parameters for a trial.
*Note:* The service does not execute trials. You create your own trial and execution.
Learn more about [Using Vizier](https://cloud.google.com/vertex-ai/docs/vizier/using-vizier)
## Vertex Hyperparameter Tuning service
The following example demonstrates how to setup, execute and evaluate trials using the Vertex Hyperparameter Tuning service with `random` search algorithm.
Learn more about [Overview of hyperparameter tuning](https://cloud.google.com/vertex-ai/docs/training/hyperparameter-tuning-overview)
### Examine the hyperparameter tuning package
#### Package layout
Before you start the hyperparameter tuning, you will look at how a Python package is assembled for a custom hyperparameter tuning job. When unarchived, the package contains the following directory/file layout.
- PKG-INFO
- README.md
- setup.cfg
- setup.py
- trainer
- \_\_init\_\_.py
- task.py
The files `setup.cfg` and `setup.py` are the instructions for installing the package into the operating environment of the Docker image.
The file `trainer/task.py` is the Python script for executing the custom hyperparameter tuning job. *Note*, when we referred to it in the worker pool specification, we replace the directory slash with a dot (`trainer.task`) and dropped the file suffix (`.py`).
#### Package Assembly
In the following cells, you will assemble the training package.
```
# Make folder for Python hyperparameter tuning script
! rm -rf custom
! mkdir custom
# Add package information
! touch custom/README.md
setup_cfg = "[egg_info]\n\ntag_build =\n\ntag_date = 0"
! echo "$setup_cfg" > custom/setup.cfg
setup_py = "import setuptools\n\nsetuptools.setup(\n\n install_requires=[\n\n 'tensorflow==2.5.0',\n\n 'tensorflow_datasets==1.3.0',\n\n ],\n\n packages=setuptools.find_packages())"
! echo "$setup_py" > custom/setup.py
pkg_info = "Metadata-Version: 1.0\n\nName: Boston Housing tabular regression\n\nVersion: 0.0.0\n\nSummary: Demostration hyperparameter tuning script\n\nHome-page: www.google.com\n\nAuthor: Google\n\nAuthor-email: aferlitsch@google.com\n\nLicense: Public\n\nDescription: Demo\n\nPlatform: Vertex"
! echo "$pkg_info" > custom/PKG-INFO
# Make the training subfolder
! mkdir custom/trainer
! touch custom/trainer/__init__.py
```
#### Task.py contents
In the next cell, you write the contents of the hyperparameter tuning script task.py. I won't go into detail, it's just there for you to browse. In summary:
- Parse the command line arguments for the hyperparameter settings for the current trial.
- Get the directory where to save the model artifacts from the command line (`--model_dir`), and if not specified, then from the environment variable `AIP_MODEL_DIR`.
- Download and preprocess the Boston Housing dataset.
- Build a DNN model.
- The number of units per dense layer and learning rate hyperparameter values are used during the build and compile of the model.
- A definition of a callback `HPTCallback` which obtains the validation loss at the end of each epoch (`on_epoch_end()`) and reports it to the hyperparameter tuning service using `hpt.report_hyperparameter_tuning_metric()`.
- Train the model with the `fit()` method and specify a callback which will report the validation loss back to the hyperparameter tuning service.
```
%%writefile custom/trainer/task.py
# Custom Training for Boston Housing
import tensorflow_datasets as tfds
import tensorflow as tf
from tensorflow.python.client import device_lib
from hypertune import HyperTune
import numpy as np
import argparse
import os
import sys
tfds.disable_progress_bar()
parser = argparse.ArgumentParser()
parser.add_argument('--model-dir', dest='model_dir',
default=os.getenv('AIP_MODEL_DIR'), type=str, help='Model dir.')
parser.add_argument('--lr', dest='lr',
default=0.001, type=float,
help='Learning rate.')
parser.add_argument('--decay', dest='decay',
default=0.98, type=float,
help='Decay rate')
parser.add_argument('--units', dest='units',
default=64, type=int,
help='Number of units.')
parser.add_argument('--epochs', dest='epochs',
default=20, type=int,
help='Number of epochs.')
parser.add_argument('--steps', dest='steps',
default=200, type=int,
help='Number of steps per epoch.')
parser.add_argument('--param-file', dest='param_file',
default='/tmp/param.txt', type=str,
help='Output file for parameters')
parser.add_argument('--distribute', dest='distribute', type=str, default='single',
help='distributed training strategy')
args = parser.parse_args()
print('Python Version = {}'.format(sys.version))
print('TensorFlow Version = {}'.format(tf.__version__))
print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found')))
def make_dataset():
# Scaling Boston Housing data features
def scale(feature):
max = np.max(feature)
feature = (feature / max).astype(np.float)
return feature, max
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.boston_housing.load_data(
path="boston_housing.npz", test_split=0.2, seed=113
)
params = []
for _ in range(13):
x_train[_], max = scale(x_train[_])
x_test[_], _ = scale(x_test[_])
params.append(max)
# store the normalization (max) value for each feature
with tf.io.gfile.GFile(args.param_file, 'w') as f:
f.write(str(params))
return (x_train, y_train), (x_test, y_test)
# Build the Keras model
def build_and_compile_dnn_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(args.units, activation='relu', input_shape=(13,)),
tf.keras.layers.Dense(args.units, activation='relu'),
tf.keras.layers.Dense(1, activation='linear')
])
model.compile(
loss='mse',
optimizer=tf.keras.optimizers.RMSprop(learning_rate=args.lr, decay=args.decay))
return model
model = build_and_compile_dnn_model()
# Instantiate the HyperTune reporting object
hpt = HyperTune()
# Reporting callback
class HPTCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
global hpt
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='val_loss',
metric_value=logs['val_loss'],
global_step=epoch)
# Train the model
BATCH_SIZE = 16
(x_train, y_train), (x_test, y_test) = make_dataset()
model.fit(x_train, y_train, epochs=args.epochs, batch_size=BATCH_SIZE, validation_split=0.1, callbacks=[HPTCallback()])
model.save(args.model_dir)
```
#### Store hyperparameter tuning script on your Cloud Storage bucket
Next, you package the hyperparameter tuning folder into a compressed tar ball, and then store it in your Cloud Storage bucket.
```
! rm -f custom.tar custom.tar.gz
! tar cvf custom.tar custom
! gzip custom.tar
! gsutil cp custom.tar.gz $BUCKET_NAME/trainer_boston.tar.gz
```
### Prepare your machine specification
Now define the machine specification for your custom hyperparameter tuning job. This tells Vertex what type of machine instance to provision for the hyperparameter tuning.
- `machine_type`: The type of GCP instance to provision -- e.g., n1-standard-8.
- `accelerator_type`: The type, if any, of hardware accelerator. In this tutorial if you previously set the variable `TRAIN_GPU != None`, you are using a GPU; otherwise you will use a CPU.
- `accelerator_count`: The number of accelerators.
```
if TRAIN_GPU:
machine_spec = {
"machine_type": TRAIN_COMPUTE,
"accelerator_type": TRAIN_GPU,
"accelerator_count": TRAIN_NGPU,
}
else:
machine_spec = {"machine_type": TRAIN_COMPUTE, "accelerator_count": 0}
```
### Prepare your disk specification
(optional) Now define the disk specification for your custom hyperparameter tuning job. This tells Vertex what type and size of disk to provision in each machine instance for the hyperparameter tuning.
- `boot_disk_type`: Either SSD or Standard. SSD is faster, and Standard is less expensive. Defaults to SSD.
- `boot_disk_size_gb`: Size of disk in GB.
```
DISK_TYPE = "pd-ssd" # [ pd-ssd, pd-standard]
DISK_SIZE = 200 # GB
disk_spec = {"boot_disk_type": DISK_TYPE, "boot_disk_size_gb": DISK_SIZE}
```
### Define the worker pool specification
Next, you define the worker pool specification for your custom hyperparameter tuning job. The worker pool specification will consist of the following:
- `replica_count`: The number of instances to provision of this machine type.
- `machine_spec`: The hardware specification.
- `disk_spec` : (optional) The disk storage specification.
- `python_package`: The Python training package to install on the VM instance(s) and which Python module to invoke, along with command line arguments for the Python module.
Let's dive deeper now into the python package specification:
-`executor_image_spec`: This is the docker image which is configured for your custom hyperparameter tuning job.
-`package_uris`: This is a list of the locations (URIs) of your python training packages to install on the provisioned instance. The locations need to be in a Cloud Storage bucket. These can be either individual python files or a zip (archive) of an entire package. In the later case, the job service will unzip (unarchive) the contents into the docker image.
-`python_module`: The Python module (script) to invoke for running the custom hyperparameter tuning job. In this example, you will be invoking `trainer.task.py` -- note that it was not neccessary to append the `.py` suffix.
-`args`: The command line arguments to pass to the corresponding Pythom module. In this example, you will be setting:
- `"--model-dir=" + MODEL_DIR` : The Cloud Storage location where to store the model artifacts. There are two ways to tell the hyperparameter tuning script where to save the model artifacts:
- direct: You pass the Cloud Storage location as a command line argument to your training script (set variable `DIRECT = True`), or
- indirect: The service passes the Cloud Storage location as the environment variable `AIP_MODEL_DIR` to your training script (set variable `DIRECT = False`). In this case, you tell the service the model artifact location in the job specification.
- `"--epochs=" + EPOCHS`: The number of epochs for training.
- `"--steps=" + STEPS`: The number of steps (batches) per epoch.
- `"--distribute=" + TRAIN_STRATEGY"` : The hyperparameter tuning distribution strategy to use for single or distributed hyperparameter tuning.
- `"single"`: single device.
- `"mirror"`: all GPU devices on a single compute instance.
- `"multi"`: all GPU devices on all compute instances.
```
JOB_NAME = "custom_job_" + TIMESTAMP
MODEL_DIR = "{}/{}".format(BUCKET_NAME, JOB_NAME)
if not TRAIN_NGPU or TRAIN_NGPU < 2:
TRAIN_STRATEGY = "single"
else:
TRAIN_STRATEGY = "mirror"
EPOCHS = 20
STEPS = 100
DIRECT = False
if DIRECT:
CMDARGS = [
"--model-dir=" + MODEL_DIR,
"--epochs=" + str(EPOCHS),
"--steps=" + str(STEPS),
"--distribute=" + TRAIN_STRATEGY,
]
else:
CMDARGS = [
"--epochs=" + str(EPOCHS),
"--steps=" + str(STEPS),
"--distribute=" + TRAIN_STRATEGY,
]
worker_pool_spec = [
{
"replica_count": 1,
"machine_spec": machine_spec,
"disk_spec": disk_spec,
"python_package_spec": {
"executor_image_uri": TRAIN_IMAGE,
"package_uris": [BUCKET_NAME + "/trainer_boston.tar.gz"],
"python_module": "trainer.task",
"args": CMDARGS,
},
}
]
```
## Create a custom job
Use the class `CustomJob` to create a custom job, such as for hyperparameter tuning, with the following parameters:
- `display_name`: A human readable name for the custom job.
- `worker_pool_specs`: The specification for the corresponding VM instances.
```
job = aip.CustomJob(
display_name="boston_" + TIMESTAMP, worker_pool_specs=worker_pool_spec
)
```
## Create a hyperparameter tuning job
Use the class `HyperparameterTuningJob` to create a hyperparameter tuning job, with the following parameters:
- `display_name`: A human readable name for the custom job.
- `custom_job`: The worker pool spec from this custom job applies to the CustomJobs created in all the trials.
- `metrics_spec`: The metrics to optimize. The dictionary key is the metric_id, which is reported by your training job, and the dictionary value is the optimization goal of the metric('minimize' or 'maximize').
- `parameter_spec`: The parameters to optimize. The dictionary key is the metric_id, which is passed into your training job as a command line key word argument, and the dictionary value is the parameter specification of the metric.
- `search_algorithm`: The search algorithm to use: `grid`, `random` and `None`. If `None` is specified, the `Vizier` service (Bayesian) is used.
- `max_trial_count`: The maximum number of trials to perform.
```
from google.cloud.aiplatform import hyperparameter_tuning as hpt
hpt_job = aip.HyperparameterTuningJob(
display_name="boston_" + TIMESTAMP,
custom_job=job,
metric_spec={
"val_loss": "minimize",
},
parameter_spec={
"lr": hpt.DoubleParameterSpec(min=0.001, max=0.1, scale="log"),
"units": hpt.IntegerParameterSpec(min=4, max=128, scale="linear"),
},
search_algorithm="random",
max_trial_count=6,
parallel_trial_count=1,
)
```
## Run the hyperparameter tuning job
Use the `run()` method to execute the hyperparameter tuning job.
```
hpt_job.run()
```
### Display the hyperparameter tuning job trial results
After the hyperparameter tuning job has completed, the property `trials` will return the results for each trial.
```
print(hpt_job.trials)
```
### Best trial
Now look at which trial was the best:
```
best = (None, None, None, 0.0)
for trial in hpt_job.trials:
# Keep track of the best outcome
if float(trial.final_measurement.metrics[0].value) > best[3]:
try:
best = (
trial.id,
float(trial.parameters[0].value),
float(trial.parameters[1].value),
float(trial.final_measurement.metrics[0].value),
)
except:
best = (
trial.id,
float(trial.parameters[0].value),
None,
float(trial.final_measurement.metrics[0].value),
)
print(best)
```
## Get the Best Model
If you used the method of having the service tell the tuning script where to save the model artifacts (`DIRECT = False`), then the model artifacts for the best model are saved at:
MODEL_DIR/<best_trial_id>/model
```
BEST_MODEL_DIR = MODEL_DIR + "/" + best[0] + "/model"
```
### Delete the hyperparameter tuning job
The method 'delete()' will delete the hyperparameter tuning job.
```
hpt_job.delete()
```
## Vertex Hyperparameter Tuning and Vertex Vizer service combined
The following example demonstrates how to setup, execute and evaluate trials using the Vertex Hyperparameter Tuning service with `Vizier` search service.
## Create a custom job
Use the class `CustomJob` to create a custom job, such as for hyperparameter tuning, with the following parameters:
- `display_name`: A human readable name for the custom job.
- `worker_pool_specs`: The specification for the corresponding VM instances.
```
job = aip.CustomJob(
display_name="boston_" + TIMESTAMP, worker_pool_specs=worker_pool_spec
)
```
## Create a hyperparameter tuning job
Use the class `HyperparameterTuningJob` to create a hyperparameter tuning job, with the following parameters:
- `display_name`: A human readable name for the custom job.
- `custom_job`: The worker pool spec from this custom job applies to the CustomJobs created in all the trials.
- `metrics_spec`: The metrics to optimize. The dictionary key is the metric_id, which is reported by your training job, and the dictionary value is the optimization goal of the metric('minimize' or 'maximize').
- `parameter_spec`: The parameters to optimize. The dictionary key is the metric_id, which is passed into your training job as a command line key word argument, and the dictionary value is the parameter specification of the metric.
- `search_algorithm`: The search algorithm to use: `grid`, `random` and `None`. If `None` is specified, the `Vizier` service (Bayesian) is used.
- `max_trial_count`: The maximum number of trials to perform.
```
from google.cloud.aiplatform import hyperparameter_tuning as hpt
hpt_job = aip.HyperparameterTuningJob(
display_name="boston_" + TIMESTAMP,
custom_job=job,
metric_spec={
"val_loss": "minimize",
},
parameter_spec={
"lr": hpt.DoubleParameterSpec(min=0.0001, max=0.1, scale="log"),
"units": hpt.IntegerParameterSpec(min=4, max=512, scale="linear"),
},
search_algorithm=None,
max_trial_count=12,
parallel_trial_count=1,
)
```
## Run the hyperparameter tuning job
Use the `run()` method to execute the hyperparameter tuning job.
```
hpt_job.run()
```
### Display the hyperparameter tuning job trial results
After the hyperparameter tuning job has completed, the property `trials` will return the results for each trial.
```
print(hpt_job.trials)
```
### Best trial
Now look at which trial was the best:
```
best = (None, None, None, 0.0)
for trial in hpt_job.trials:
# Keep track of the best outcome
if float(trial.final_measurement.metrics[0].value) > best[3]:
try:
best = (
trial.id,
float(trial.parameters[0].value),
float(trial.parameters[1].value),
float(trial.final_measurement.metrics[0].value),
)
except:
best = (
trial.id,
float(trial.parameters[0].value),
None,
float(trial.final_measurement.metrics[0].value),
)
print(best)
```
### Delete the hyperparameter tuning job
The method 'delete()' will delete the hyperparameter tuning job.
```
hpt_job.delete()
```
## Standalone Vertex Vizer service
The `Vizier` service can be used as a standalone service for selecting the next set of parameters for a trial.
*Note:* The service does not execute trials. You create your own trial and execution.
Learn more about [Using Vizier](https://cloud.google.com/vertex-ai/docs/vizier/using-vizier)
### Create Vizier client
Create a client side connection to the Vertex Vizier service.
```
vizier_client = aip.gapic.VizierServiceClient(
client_options=dict(api_endpoint=API_ENDPOINT)
)
```
### Create a study
A study is a series of experiments, or trials, that help you optimize your hyperparameters or parameters.
In the following example, the goal is to maximize y = x^2 with x in the range of \[-10. 10\]. This example has only one parameter and uses an easily calculated function to help demonstrate how to use Vizier.
First, you will create the study using the `create_study()` method.
```
STUDY_DISPLAY_NAME = "xpow2" + TIMESTAMP
param_x = {
"parameter_id": "x",
"double_value_spec": {"min_value": -10.0, "max_value": 10.0},
}
metric_y = {"metric_id": "y", "goal": "MAXIMIZE"}
study = {
"display_name": STUDY_DISPLAY_NAME,
"study_spec": {
"algorithm": "RANDOM_SEARCH",
"parameters": [param_x],
"metrics": [metric_y],
},
}
study = vizier_client.create_study(parent=PARENT, study=study)
STUDY_NAME = study.name
print(STUDY_NAME)
```
### Get Vizier study
You can get a study using the method `get_study()`, with the following key/value pairs:
- `name`: The name of the study.
```
study = vizier_client.get_study({"name": STUDY_NAME})
print(study)
```
### Get suggested trial
Next, query the Vizier service for a suggested trial(s) using the method `suggest_trials`, with the following key/value pairs:
- `parent`: The name of the study.
- `suggestion_count`: The number of trials to suggest.
- `client_id`: blah
This call is a long running operation. The method `result()` from the response object will wait until the call has completed.
```
SUGGEST_COUNT = 1
CLIENT_ID = "1001"
response = vizier_client.suggest_trials(
{"parent": STUDY_NAME, "suggestion_count": SUGGEST_COUNT, "client_id": CLIENT_ID}
)
trials = response.result().trials
print(trials)
# Get the trial ID of the first trial
TRIAL_ID = trials[0].name
```
### Evaluate the results
After receiving your trial suggestions, evaluate each trial and record each result as a measurement.
For example, if the function you are trying to optimize is y = x^2, then you evaluate the function using the trial's suggested value of x. Using a suggested value of 0.1, the function evaluates to y = 0.1 * 0.1, which results in 0.01.
### Add a measurement
After evaluating your trial suggestion to get a measurement, add this measurement to your trial.
Use the following commands to store your measurement and send the request. In this example, replace RESULT with the measurement. If the function you are optimizing is y = x^2, and the suggested value of x is 0.1, the result is 0.01.
```
RESULT = 0.01
vizier_client.add_trial_measurement(
{
"trial_name": TRIAL_ID,
"measurement": {"metrics": [{"metric_id": "y", "value": RESULT}]},
}
)
```
### Delete the Vizier study
The method 'delete_study()' will delete the study.
```
vizier_client.delete_study({"name": STUDY_NAME})
```
# Cleaning up
To clean up all Google Cloud resources used in this project, you can [delete the Google Cloud
project](https://cloud.google.com/resource-manager/docs/creating-managing-projects#shutting_down_projects) you used for the tutorial.
Otherwise, you can delete the individual resources you created in this tutorial:
- Dataset
- Pipeline
- Model
- Endpoint
- AutoML Training Job
- Batch Job
- Custom Job
- Hyperparameter Tuning Job
- Cloud Storage Bucket
```
delete_all = True
if delete_all:
# Delete the dataset using the Vertex dataset object
try:
if "dataset" in globals():
dataset.delete()
except Exception as e:
print(e)
# Delete the model using the Vertex model object
try:
if "model" in globals():
model.delete()
except Exception as e:
print(e)
# Delete the endpoint using the Vertex endpoint object
try:
if "endpoint" in globals():
endpoint.delete()
except Exception as e:
print(e)
# Delete the AutoML or Pipeline training job
try:
if "dag" in globals():
dag.delete()
except Exception as e:
print(e)
# Delete the custom training job
try:
if "job" in globals():
job.delete()
except Exception as e:
print(e)
# Delete the batch prediction job using the Vertex batch prediction object
try:
if "batch_predict_job" in globals():
batch_predict_job.delete()
except Exception as e:
print(e)
# Delete the hyperparameter tuning job using the Vertex hyperparameter tuning object
try:
if "hpt_job" in globals():
hpt_job.delete()
except Exception as e:
print(e)
if "BUCKET_NAME" in globals():
! gsutil rm -r $BUCKET_NAME
```
| github_jupyter |
```
import numpy as np
import nltk
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import pprint
from nltk.corpus import brown
import pandas as pd
from sklearn.model_selection import train_test_split
from collections import OrderedDict, deque
```
# POS tagging
<img src="https://blog.aaronccwong.com/assets/images/bigram-hmm/pos-title.jpg" alt="topic_modeling" style="width: 620px;"/>
Prepare the texts to tag
```
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use', 'not', 'would', 'say', 'could', '_', 'be', 'know', 'good', 'go', 'get', 'do', 'done', 'try', 'many', 'some', 'nice', 'thank', 'think', 'see', 'rather', 'easy', 'easily', 'lot', 'lack', 'make', 'want', 'seem', 'run', 'need', 'even', 'right', 'line', 'even', 'also', 'may', 'take', 'come'])
nltk.download('wordnet')
with open('wiki_lingvo.txt', mode='r', encoding='utf-8') as file:
text = file.readlines()
len(text)
text[0]
#delete html tags
text = [BeautifulSoup(t, 'lxml').text for t in text]
text[4]
```
Tagging model
```
nltk.download("brown")
nltk.download('universal_tagset')
brown_tagged_sents = brown.tagged_sents(tagset="universal")
brown_tagged_sents[0]
brown_tagged_words = brown.tagged_words(tagset='universal')
brown_tagged_words = list(map(lambda x: (x[0].lower(), x[1]), brown_tagged_words))
brown_tagged_words[0]
tags = [tag for (word, tag) in brown_tagged_words]
words = [word for (word, tag) in brown_tagged_words]
tag_num = pd.Series(nltk.FreqDist(tags)).sort_values(ascending=False)
word_num = pd.Series(nltk.FreqDist(words)).sort_values(ascending=False)
brown_tagged_sents = brown.tagged_sents(tagset="universal")
my_brown_tagged_sents = []
for sent in brown_tagged_sents:
my_brown_tagged_sents.append(list(map(lambda x: (x[0].lower(),x[1]), sent)))
my_brown_tagged_sents = np.array(my_brown_tagged_sents)
train_sents, test_sents = train_test_split(my_brown_tagged_sents, test_size=0.1, shuffle=True)
```
Lets train simple HMM model
```
class HiddenMarkovModel:
def __init__(self):
pass
def fit(self, train_tokens_tags_list):
tags = [tag for sent in train_tokens_tags_list
for (word, tag) in sent]
words = [word for sent in train_tokens_tags_list
for (word, tag) in sent]
tag_num = pd.Series(nltk.FreqDist(tags)).sort_index()
word_num = pd.Series(nltk.FreqDist(words)).sort_values(ascending=False)
self.tags = tag_num.index
self.words = word_num.index
A = pd.DataFrame({'{}'.format(tag) : [0] * len(tag_num) for tag in tag_num.index}, index=tag_num.index)
B = pd.DataFrame({'{}'.format(tag) : [0] * len(word_num) for tag in tag_num.index}, index=word_num.index)
for sent in train_tokens_tags_list:
for i in range(len(sent)):
B.loc[sent[i][0], sent[i][1]] += 1
if len(sent) - 1 != i:
A.loc[sent[i][1], sent[i + 1][1]] += 1
A = A.divide(A.sum(axis=1), axis=0)
B = B / np.sum(B, axis=0)
self.A = A
self.B = B
return self
def predict(self, test_tokens_list):
predict_tags = OrderedDict({i : np.array([]) for i in range(len(test_tokens_list))})
for i_sent in range(len(test_tokens_list)):
current_sent = test_tokens_list[i_sent]
len_sent = len(current_sent)
q = np.zeros(shape=(len_sent + 1, len(self.tags)))
q[0] = 1
back_point = np.zeros(shape=(len_sent + 1, len(self.tags)))
for t in range(len_sent):
if current_sent[t] not in self.words:
current_sent[t] = 'time' #most popular word in corpus
for i_s in range(len(self.tags)):
s = self.tags[i_s]
q[t + 1][i_s] = np.max(q[t,:] *
self.A.loc[:, s] *
self.B.loc[current_sent[t], s])
back_point[t + 1][i_s] = (q[t,:] *
self.A.loc[:, s] *
self.B.loc[current_sent[t], s]).reset_index()[s].idxmax()
back_point = back_point.astype('int')
back_tag = deque()
current_tag = np.argmax(q[len_sent])
for t in range(len_sent, 0, -1):
back_tag.appendleft(self.tags[current_tag])
current_tag = back_point[t, current_tag]
predict_tags[i_sent] = np.array(back_tag)
return predict_tags
markov_model = HiddenMarkovModel()
markov_model.fit(train_sents)
from nltk import word_tokenize
word_tokenize(text[0])
#import OrderedDict
pop_word = 'time'
pred = markov_model.predict([word_tokenize(text[0])])
list(zip(word_tokenize(text[0]), pred[0]))
```
Another example
```
list(zip(word_tokenize(text[12]), markov_model.predict([word_tokenize(text[12])])[0]))
```
### Stanford model
```
from nltk.tag.stanford import StanfordPOSTagger
from nltk.tag.mapping import map_tag
jar = u'D:\ml\stanford-postagger-2018-10-16\stanford-postagger-3.9.2.jar'
model = u'D:\ml\stanford-postagger-2018-10-16\models\english-bidirectional-distsim.tagger'
stanford_tagger = StanfordPOSTagger(model, jar, encoding='utf8')
tagged_sent = stanford_tagger.tag(word_tokenize(text[0]))
list(zip(word_tokenize(text[0]), [map_tag('en-ptb', 'universal', tag) for token, tag in tagged_sent]))
```
### Stanford German model
```
german_text = 'Paul Cézanne war ein französischer Maler. Cézannes Werk wird unterschiedlichen Stilrichtungen zugeordnet: Während seine frühen Arbeiten noch von Romantik – wie die Wandbilder im Landhaus Jas de Bouffan – und Realismus geprägt sind, gelangte er durch intensive Auseinandersetzung mit impressionistischen Ausdrucksformen zu einer neuen Bildsprache, die den zerfließenden Bildeindruck impressionistischer Werke zu festigen versucht. Er gab die illusionistische Fernwirkung auf, brach die von den Vertretern der Akademischen Kunst aufgestellten Regeln und strebte eine Erneuerung klassischer Gestaltungsmethoden auf der Grundlage des impressionistischen Farbraumes und farbmodulatorischer Prinzipien an.'
jar = u'D:\ml\stanford-postagger-full-2017-06-09\stanford-postagger-3.8.0.jar'
model = u'D:\ml\stanford-postagger-full-2017-06-09\models\german-ud.tagger'
stanford_tagger = StanfordPOSTagger(model, jar, encoding='utf8')
tagged_sent = stanford_tagger.tag(word_tokenize(german_text))
list(zip(word_tokenize(german_text), [tag for token, tag in tagged_sent]))
```
| github_jupyter |
# 2. Plant Set Analysis Visualization For Time Series Reescaling
In this notebook we'll work with the visualization of the analysis performed on a plant set in order to get a sense of the best parametes conditions for our particular reescaling purpose. We'll refer to a `Plant Set` as a set of plant locations and their information. They're expected to be around a certain region.
```
from modules import plant_scaling
from modules import data_preparation
from modules import geographical_plotting
from modules import geographical_analysis
```
#### 2.1 Full Plant Set Clustered GeoDataFrames
First, we'll repeat some of the steps on `1_PlantsVisualisation.ipynb` to generate the GeoDataFrames with the spatial information on the plants distribution as well as the labels obtained from the clustering.
```
#Plant files metadata
meta_UPV, meta_DPV = data_preparation.get_plants_files_metadata( read = True, PATH = './data/Extracted/', UPV = True, DPV = True, to_csv = False)
#construction of geo_dataframes
geo_df_UPV = geographical_plotting.geographic_data(meta_UPV)
geo_df_DPV = geographical_plotting.geographic_data(meta_DPV)
#clustering
geo_df_UPV_labeled, centers_df_UPV = geographical_analysis.geographical_plant_clustering(geo_df_UPV, N_clusters = 115 )
geo_df_DPV_labeled, centers_df_DPV = geographical_analysis.geographical_plant_clustering(geo_df_DPV, N_clusters = 115 )
```
#### 2.2 Closest Cluster Centroid
We perform calculations to determine the centroid wich is closer to our coordinate point of interest.
```
index_UPV, center_long_UPV, center_lat_UPV = geographical_analysis.closest_centroid( geo_df_UPV_labeled, centers_df_UPV, coords = (-120.00, 35.00))
index_DPV, center_long_DPV, center_lat_DPV = geographical_analysis.closest_centroid( geo_df_DPV_labeled, centers_df_DPV, coords = (-120.00, 35.00))
```
#### 2.3 Cluster Group Filtering
We now filter from the full Plant Set metadata list the group with the label that is most of our interest.
That would be the group which centroid is closest to the coordinate point which we before specified.
```
cluster_group_metadata_df_UPV = geographical_analysis.cluster_group(index_UPV, geo_df_UPV_labeled)
cluster_group_metadata_df_DPV = geographical_analysis.cluster_group(index_DPV, geo_df_DPV_labeled)
```
This will get us the filtered DataFrame with the metadata that we'll actually use. the plants which belong to this subgroup, form the `Plant Set` discussed before.
From the segmentation procedure we got `cluster_group_metadata_df_UPV.shape[0]` plants filtered, which means they are relatively close to the point of interest.
```
cluster_group_metadata_df_UPV.shape
```
#### 2.4 Plant Sets Object Creation
Now we'll create two objects, each with the particular metadata on the dataframes from above. The class already has all the required functions to read the time series held in the files specified on the metadata dataframes.
```
datapath = './data/Extracted/'
UPV_plant_set = plant_scaling.Plant_set(datapath, cluster_group_metadata_df_UPV, coords = (-120.00, 35.00) )
DPV_plant_set = plant_scaling.Plant_set(datapath, cluster_group_metadata_df_DPV, coords = (-120.00, 35.00) )
```
##### Disclaimer:
Please do take into account that the less `N_clusters`that we use, the longer it will take to read the data for any object because there will be more time series to process. At the same time, the more `N_clusters` we use, the more it will take on clustering the coordinate points. Therefore, a right balance between the clustering time and the `read_data` time must be found. It is also recomended to just rund the segmentation procedure once and with the labeled dataframe, filter the plants with a particular coordinate point.
### 2.5 Plant Set Analysis
The following procedure illustrate the use of the different methods implemented on the Solar_plants_data class in order to develop some intuition on how the parameters of the plant-power-generation-timeseries-reescaling works. We'll perform it only on the UPV filtered Plant Set, but the procedure can be implemented on any Plant Set.
After the objects are created, the files on the metadata dataframes are read. We then collect on an array the total installed power of the plant and the daily registered power exactly at midday for each of the N plants which got segmented. You can specify either a dataframe or a path where a `Plant_Set_metadata.csv` file should be held. If `set_points = True` , the array of points is saved as a attribute of the object overwritting anything that would be in its place.
```
UPV_plant_set.points = UPV_plant_set.read_data(geo_data_XPV_labeled = UPV_plant_set.plants_metadata, set_points = True)
```
What the following 3 functions do is pretty self-explanatory from their name but anyway we'll get through it:
- `Plant_set.midday_distributions(create_csv=False, plot=True)` plots the distribution of points constructed from the time series specified on the metadata dataframe. It returns a dataframe.
```
UPV_plant_set.midday_distributions(create_csv=False, plot=True)
```
- `Plant_set.yearly_mean_value(self, create_csv = False, plot = False)` instead of plotting the whole miday-points distribution, takes the mean value, returns a dataframe and (if specified) plots it and creates a csv file from the data.
```
UPV_plant_set.yearly_mean_value(create_csv = False, plot = True)
```
- `Plant_set.yearly_max_value(self, create_csv = False, plot = False)` does the same as `yearly_mean_value`but instead takes the max value.
```
UPV_plant_set.yearly_max_value(create_csv = False, plot = True)
```
In order to determine how we'll reescale the signal, we use `Plant_set.fit_curve(degree = 2, data = 'max', plot = False, scale_factor = None)`, which fits a polinomial of degree `[1,2,3]` to the specified data `['max','mean','all']`. It returns polinomial's coeficients or the scaling factor if `scale_factor = True`.
```
UPV_plant_set.fit_curve(degree = 3 , data = 'max', plot = True, scale_factor = True)
```
### 2.6 Signal Reescaling
Finally we select a power time series from a random plant of the Plant Set and reescaling according to the parameters specified on `Plant_scale.scale_signal(degree, data, MW_out, write_csv = True, plot_hist = False)`. It returns the time series, and if specified, plots a histogram in order to confirm that the scalling procedure has been donde correctly.
```
UPV_plant_set.scale_signal(degree=3, data='max', MW_out=7, plot_hist=True)
```
The output file will have a name such as `Scaled_34.85_-119.85_35.0_-120.0_2006_UPV_100MW_5_Min_3deg_max_7MW.csv`, where `Scaled` means that the time series comes from a reescaling procedure, the first coordinate set `34.85_-119.85` comes from the reescaled plant location, the second coordinate set `35.0_-120.0` corrisponds to the desired location for the simulated plant, then `2006` the corresponding year climatic fluctuations, `UPV` the selected type of technology, `100MW` indicates that the reescaled plant originally was from 100MW peak power. Then the time resolution with `5_min`, then `3deg` the degree of the polinome used to extrapolate, `max` refers to the data which the polinomial was adjusted to, and finally `7MW`corrisponds to the reescaled peak power. It will be written in the `./reescaled_series/` folder
-----
| github_jupyter |
# Comparison of asymptotically chisquare-distributed test statistics
This notebook is released under the MIT license. See LICENSE.
For GoF tests, we often use a test statistic that is asymptotically $\chi^2$ distributed.
We compute the test statistic on binned data with $k$ bins with Poisson-distributed counts $n_i$ for which we have estimates of the expected counts $\nu_i$, typically obtained from a fitted model with $m$ free parameters. If the data is truely sampled from the model (the $H_0$ hypothesis), the test statistic $X$ is asymptotically distributed as $\chi^2(k - m)$.
Small p-values $P = \int_{X}^\infty \chi^2(X'; k - m) \, \text{d}X'$ can be used as evidence against the hypothesis $H_0$.
Note: the asymptotic limit is assumed to be taken while keeping the binning constant. If the binning is adaptive to the sample size so that $\nu_i$ remains constant, $X$ will *not* approach the $\chi^2(k - m)$ distribution.
There are candidates for an asymptotically $\chi^2$-distributed test statistic.
* Pearson's test statistic
$$
X_P = \sum_i \frac{(n_i - \nu_i)^2}{\nu_i}
$$
* Pearson's test statistic with $\nu_i$ replaced by bin-wise estimate $n_i$
$$
X_N = \sum_i \frac{(n_i - \nu_i)^2}{n_i}
$$
* Likelihood ratio to saturated model (see e.g. introduction of https://doi.org/10.1088/1748-0221/4/10/P10009)
$$
X_{L} = 2\sum_i \Big( n_i \ln\frac{n_i}{\nu_i} - n_i + \nu_i \Big)
$$
The statistic is equal to $-2\ln(L/L_\text{saturated})$, with $L = \prod_i P_\text{poisson}(n_i; \nu_i)$ and $L_\text{saturated} = \prod_i P_\text{poisson}(n_i; n_i)$, the likelihood for the saturated model with $\nu_i = n_i$. The saturated model has the largest possible likelihood given the data.
* Transform-based test statistic
$$
X_T = \sum_i z_i^2 \quad\text{with}\quad z_i = q_\text{norm}\bigg(\sum_{k=0}^{n_i} P_\text{poisson}(k; v_i)\bigg)
$$
where $q_\text{norm}$ is the quantile of the standard normal distribution. The double-transform converts a Poisson distributed count $k$ into a variable $z$ that has a standard normal distribution.
```
from sympy import *
n = symbols("n", integer=True, positive=True)
v = symbols("v", real=True, positive=True)
def poisson(n, v):
return v ** n * exp(-v) / factorial(n)
poisson(n, v)
X_L = simplify(- 2 * (log(poisson(n, v)) - log(poisson(n, n)))); X_L
```
Given this choice, it is fair to ask which test statistic performs best. The test statistics may approach the $\chi^2(k - m)$ distribution with different speeds.
We check this empirically with toy simulations. For each toy experiment, we use a fixed expected value $\nu_i = \mu$ and draw $k$ Poisson-distributed numbers $n_i$ from $\mu$, corresponding to $k$ bins in the toy experiment. We then compute the test statistics $X$ and its p-value, assuming it is $\chi^2(k)$ distributed ($m = 0$ here). This is repeated many times to get a histogram of p-values. The distribution is uniform if the test statistic $X$ is indeed $\chi^2(k)$ distributed. Deviations from uniformity indicate that the test statistic has not reached the asymptotic limit yet.
We then quantify the agreement of the p-value distribution with a flat distribution with the reduced $\chi^2$ value.
```
import numpy as np
import numba as nb
from scipy.stats import chi2, poisson, norm
import matplotlib.pyplot as plt
from pyik.mplext import plot_hist
# numba currently does not support scipy, so we cannot access
# scipy.stats.norm.ppf and scipy.stats.poisson.cdf in a JIT'ed
# function. As a workaround, we wrap special functions from
# scipy to implement the needed functions here.
from numba.extending import get_cython_function_address
import ctypes
def get(name, narg):
addr = get_cython_function_address("scipy.special.cython_special", name)
functype = ctypes.CFUNCTYPE(ctypes.c_double, *([ctypes.c_double] * narg))
return functype(addr)
erfinv = get("erfinv", 1)
gammaincc = get("gammaincc", 2)
@nb.vectorize('float64(float64)')
def norm_ppf(p):
return np.sqrt(2) * erfinv(2 * p - 1)
@nb.vectorize('float64(intp, float64)')
def poisson_cdf(k, m):
return gammaincc(k + 1, m)
# check implementations
m = np.linspace(0.1, 3, 20)[:,np.newaxis]
k = np.arange(10)
got = poisson_cdf(k, m)
expected = poisson.cdf(k, m)
np.testing.assert_allclose(got, expected)
p = np.linspace(0, 1, 10)
got = norm_ppf(p)
expected = norm.ppf(p)
np.testing.assert_allclose(got, expected)
@nb.njit
def xn(n, v):
r = 0.0
k = 0
for ni in n:
if ni > 0:
k += 1
r += (ni - v) ** 2 / ni
return r, k
@nb.njit
def xp(n, v):
return np.sum((n - v) ** 2 / v), len(n)
@nb.njit
def xl(n, v):
r = 0.0
for ni in n:
if ni > 0:
r += ni * np.log(ni / v) + v - ni
else:
r += v
return 2 * r, len(n)
@nb.njit
def xt(n, v):
p = poisson_cdf(n, v)
z = norm_ppf(p)
return np.sum(z ** 2), len(n)
@nb.njit(parallel=True)
def run(n, mu, nmc):
args = []
for i in range(len(n)):
for j in range(len(mu)):
for imc in range(nmc):
args.append((i, j, imc))
results = np.empty((4, len(n), len(mu), nmc, 2))
for m in nb.prange(len(args)):
i, j, imc = args[m]
ni = n[i]
mui = mu[j]
np.random.seed(imc)
x = np.random.poisson(mui, size=ni)
rp = xp(x, mui)
rn = xn(x, mui)
rl = xl(x, mui)
rt = xt(x, mui)
results[0, i, j, imc, 0] = rp[0]
results[0, i, j, imc, 1] = rp[1]
results[1, i, j, imc, 0] = rn[0]
results[1, i, j, imc, 1] = rn[1]
results[2, i, j, imc, 0] = rl[0]
results[2, i, j, imc, 1] = rl[1]
results[3, i, j, imc, 0] = rt[0]
results[3, i, j, imc, 1] = rt[1]
return results
mu = np.geomspace(1e-1, 1e3, 17)
n = 1, 3, 10, 30, 100, 1000
nmc = 10000
result = run(n, mu, nmc)
def reduced_chi2(r):
p = 1 - chi2.cdf(*np.transpose(r))
bins = 20
xe = np.linspace(0, 1, bins + 1)
n = np.histogram(p, bins=xe)[0]
v = len(p) / bins
return np.sum((n - v) ** 2 / v) / bins
matrix = np.empty((len(result), len(n), len(mu)))
for k in range(len(result)):
for i, ni in enumerate(n):
for j, mui in enumerate(mu):
matrix[k, i, j] = reduced_chi2(result[k, i, j])
def plot(r, **kwargs):
p = 1 - chi2.cdf(*np.transpose(r))
bins = 20
xe = np.linspace(0, 1, bins + 1)
n = np.histogram(p, bins=xe)[0]
plot_hist(xe, n, **kwargs)
for i, ni in enumerate(n):
for j, mui in enumerate(mu):
if j % 4 == 0: # draw only every forth value of mu
fig, ax = plt.subplots(1, 4, figsize=(15, 5))
plt.suptitle(f"k = {ni} mu = {mui:.2f}")
for k, t in enumerate("PNLT"):
plt.sca(ax[k])
plot(result[k, i, j])
plt.title(f"$X_{t}$ ($\chi^2/n_\mathrm{{dof}} = ${matrix[k, i, j]:.2g})")
```
We can by eye that $X_P$ gives the best results. Its p-value distribution converges to a uniform distribution for lower values of $\mu$ and $n$ than the other two test statistics. We summarize this by plotting the reduced $\chi^2$ for flatness as a function of $\mu$ and $n$.
```
fig, ax = plt.subplots(1, len(result), figsize=(15, 5), sharex=True, sharey=True)
for i, ni in enumerate(n):
for axi, matrixi in zip(ax, matrix):
axi.plot(mu, matrixi[i],
label=f"$k = {ni:.1f}$")
for axi, t in zip(ax, "PNLT"):
axi.set_title(f"$X_{t}$")
axi.axhline(1, ls=":", color="0.5", zorder=0)
axi.set_xlabel("$\mu$")
ax[0].set_ylabel("$\chi^2 / n_\mathrm{dof}$")
ax[1].legend()
plt.loglog();
for i, ni in enumerate(n):
plt.figure()
plt.title(f"k = {ni}")
for j, t in enumerate("PNLT"):
plt.plot(mu, matrix[j, i] / matrix[0, i],
label=f"$X_{t}$")
plt.loglog()
plt.xlabel("$\mu$")
plt.ylabel("red. $\chi^2$ ratio")
plt.legend()
```
The classic test statistics $X_P$ perform best overall, it converges to the asymptotic $\chi^2$ distribution for smaller values of $\mu$ and $k$ and is also the simplest to compute.
The statistic $X_L$ shows a curious behavior, it converges well around $k=10$, on par with $X_P$, but the convergence gets worse again for $k > 10$.
The study confirms that none of the test statistics is doing well if the expected count per bin is smaller than about 10. If the original binned data contains bins with small counts, it is recommended to compute the distribution of the test statistic via parametric bootstrapping from the fitted model instead of using the asymptotic $\chi^2$ distribution. Parametric bootstrapping in this case simplifies to drawing new samples for each data bin from a Poisson distribution whose expectation is equal to the expected count per bin predicted by the model. For many such samples one computes the test statistic to obtain a distribution. The p-value is then given by the fraction of sample values that are higher than the original value.
| github_jupyter |
```
# Install tf-transformers from github
import json
import tensorflow as tf
import time
import glob
import collections
from tf_transformers.utils.tokenization import BasicTokenizer, ROBERTA_SPECIAL_PEICE
from tf_transformers.utils import fast_sp_alignment
from tf_transformers.data.squad_utils_sp import (
read_squad_examples,
post_clean_train_squad,
example_to_features_using_fast_sp_alignment_train,
example_to_features_using_fast_sp_alignment_test,
_get_best_indexes, evaluate_v1
)
from tf_transformers.data import TFWriter, TFReader, TFProcessor
from tf_transformers.models import RobertaModel
from tf_transformers.core import optimization, SimpleTrainer
from tf_transformers.tasks import Span_Selection_Model
from transformers import RobertaTokenizer
from absl import logging
logging.set_verbosity("INFO")
from tf_transformers.pipeline.span_extraction_pipeline import Span_Extraction_Pipeline
```
### Load Tokenizer
```
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
basic_tokenizer = BasicTokenizer(do_lower_case=False)
```
### Convert train data to Features
* using Fast Sentence Piece Alignment, we convert text to features (text -> list of sub words)
```
input_file_path = '/mnt/home/PRE_MODELS/HuggingFace_models/datasets/squadv1.1/train-v1.1.json'
is_training = True
# 1. Read Examples
start_time = time.time()
train_examples = read_squad_examples(
input_file=input_file_path,
is_training=is_training,
version_2_with_negative=False
)
end_time = time.time()
print('Time taken {}'.format(end_time-start_time))
# 2.Postprocess (clean text to avoid some unwanted unicode charcaters)
train_examples_processed, failed_examples = post_clean_train_squad(train_examples, basic_tokenizer, is_training=is_training)
# 3.Convert question, context and answer to proper features (tokenized words) not word indices
feature_generator = example_to_features_using_fast_sp_alignment_train(tokenizer, train_examples_processed, max_seq_length = 384,
max_query_length=64, doc_stride=128, SPECIAL_PIECE=ROBERTA_SPECIAL_PEICE)
all_features = []
for feature in feature_generator:
all_features.append(feature)
end_time = time.time()
print("time taken {} seconds".format(end_time-start_time))
```
### Convert features to TFRecords using TFWriter
```
# Convert tokens to id and add type_ids
# input_mask etc
# This is user specific/ tokenizer specific
# Eg: Roberta has input_type_ids = 0, BERT has input_type_ids = [0, 1]
def parse_train():
result = {}
for f in all_features:
input_ids = tokenizer.convert_tokens_to_ids(f['input_ids'])
input_type_ids = tf.zeros_like(input_ids).numpy().tolist()
input_mask = tf.ones_like(input_ids).numpy().tolist()
result['input_ids'] = input_ids
result['input_type_ids'] = input_type_ids
result['input_mask'] = input_mask
result['start_position'] = f['start_position']
result['end_position'] = f['end_position']
yield result
# Lets write using TF Writer
# Use TFProcessor for smaller data
schema = {'input_ids': ("var_len", "int"),
'input_type_ids': ("var_len", "int"),
'input_mask': ("var_len", "int"),
'start_position': ("var_len", "int"),
'end_position': ("var_len", "int")}
tfrecord_train_dir = '../OFFICIAL_TFRECORDS/squad/train'
tfrecord_filename = 'squad'
tfwriter = TFWriter(schema=schema,
file_name=tfrecord_filename,
model_dir=tfrecord_train_dir,
tag='train',
overwrite=True
)
tfwriter.process(parse_fn=parse_train())
```
### Read TFRecords using TFReader
```
# Read Data
schema = json.load(open("{}/schema.json".format(tfrecord_train_dir)))
all_files = glob.glob("{}/*.tfrecord".format(tfrecord_train_dir))
tf_reader = TFReader(schema=schema,
tfrecord_files=all_files)
x_keys = ['input_ids', 'input_type_ids', 'input_mask']
y_keys = ['start_position', 'end_position']
batch_size = 16
train_dataset = tf_reader.read_record(auto_batch=True,
keys=x_keys,
batch_size=batch_size,
x_keys = x_keys,
y_keys = y_keys,
shuffle=True,
drop_remainder=True
)
```
### Load Roberta base Model
```
model_layer, model, config = RobertaModel(model_name='roberta-base', return_all_layer_token_embeddings=False)
model.load_checkpoint("/mnt/home/PRE_MODELS/LegacyAI_models/checkpoints/roberta-base/")
```
### Load Span Selection Model
```
span_selection_layer = Span_Selection_Model(model=model,
use_all_layers=False,
is_training=True)
span_selection_model = span_selection_layer.get_model()
# Delete to save up memory
del model
del model_layer
del span_selection_layer
```
### Define Loss
Loss function is simple.
* labels: 1D (batch_size) # start or end positions
* logits: 2D (batch_size x sequence_length)
```
# Cross Entropy
def span_loss(position, logits):
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits, labels=tf.squeeze(position, axis=1)))
return loss
# Start logits loss
def start_loss(y_true_dict, y_pred_dict):
start_loss = span_loss(y_true_dict['start_position'], y_pred_dict['start_logits'])
return start_loss
# End logits loss
def end_loss(y_true_dict, y_pred_dict):
end_loss = span_loss(y_true_dict['end_position'], y_pred_dict['end_logits'])
return end_loss
# (start_loss + end_loss) / 2.0
def joint_loss(y_true_dict, y_pred_dict):
sl = start_loss(y_true_dict, y_pred_dict)
el = end_loss(y_true_dict, y_pred_dict)
return (sl + el)/2.0
for (batch_inputs, batch_labels) in train_dataset.take(1):
print(batch_inputs, batch_labels)
```
### Define Optimizer
```
train_data_size = 89000
learning_rate = 2e-5
steps_per_epoch = int(train_data_size / batch_size)
EPOCHS = 3
num_train_steps = steps_per_epoch * EPOCHS
warmup_steps = int(0.1 * num_train_steps)
# creates an optimizer with learning rate schedule
optimizer_type = 'adamw'
optimizer, learning_rate_fn = optimization.create_optimizer(learning_rate,
steps_per_epoch * EPOCHS,
warmup_steps,
optimizer_type)
```
### Train Using Keras :-)
- ```compile2``` allows you to have directly use model outputs as well batch dataset outputs into the loss function, without any further complexity.
Note: For ```compile2```, loss_fn must be None, and custom_loss_fn must be active. Metrics are not supprted for time being.
```
# Keras Fit
keras_loss_fn = {'start_logits': start_loss,
'end_logits': end_loss}
span_selection_model.compile2(optimizer=tf.keras.optimizers.Adam(),
loss=None,
custom_loss=keras_loss_fn
)
history = span_selection_model.fit(train_dataset, epochs=2, steps_per_epoch=10)
```
### Train using SimpleTrainer (part of tf-transformers)
```
# Custom training
history = SimpleTrainer(model = span_selection_model,
optimizer = optimizer,
loss_fn = joint_loss,
dataset = train_dataset.repeat(EPOCHS+1), # This is important
epochs = EPOCHS,
num_train_examples = train_data_size,
batch_size = batch_size,
steps_per_call=100,
gradient_accumulation_steps=None)
```
### Save Models
You can save models as checkpoints using ```.save_checkpoint``` attribute, which is a part of all ```LegacyModels```
```
model_save_dir = '../OFFICIAL_MODELS/squad/roberta_base2'
span_selection_model.save_checkpoint(model_save_dir)
```
### Parse validation data
We use ```TFProcessor``` to create validation data, because dev data is small
```
dev_input_file_path = '/mnt/home/PRE_MODELS/HuggingFace_models/datasets/squadv1.1/dev-v1.1.json'
is_training = False
start_time = time.time()
dev_examples = read_squad_examples(
input_file=dev_input_file_path,
is_training=is_training,
version_2_with_negative=False
)
end_time = time.time()
print('Time taken {}'.format(end_time-start_time))
dev_examples_cleaned = post_clean_train_squad(dev_examples, basic_tokenizer, is_training=False)
qas_id_info, dev_features = example_to_features_using_fast_sp_alignment_test(tokenizer, dev_examples_cleaned, max_seq_length = 384,
max_query_length=64, doc_stride=128, SPECIAL_PIECE=ROBERTA_SPECIAL_PEICE)
def parse_dev():
result = {}
for f in dev_features:
input_ids = tokenizer.convert_tokens_to_ids(f['input_ids'])
input_type_ids = tf.zeros_like(input_ids).numpy().tolist()
input_mask = tf.ones_like(input_ids).numpy().tolist()
result['input_ids'] = input_ids
result['input_type_ids'] = input_type_ids
result['input_mask'] = input_mask
yield result
tf_processor = TFProcessor()
dev_dataset = tf_processor.process(parse_fn=parse_dev())
dev_dataset = tf_processor.auto_batch(dev_dataset, batch_size=32)
```
### Evaluate Exact Match
* Make Predictions
* Extract Answers
* Evaluate
### Make Batch Predictions
```
def extract_from_dict(dict_items, key):
holder = []
for item in dict_items:
holder.append(item[key])
return holder
qas_id_list = extract_from_dict(dev_features, 'qas_id')
doc_offset_list = extract_from_dict(dev_features, 'doc_offset')
# Make batch predictions
per_layer_start_logits = []
per_layer_end_logits = []
start_time = time.time()
for (batch_inputs) in dev_dataset:
model_outputs = span_selection_model(batch_inputs)
per_layer_start_logits.append(model_outputs['start_logits'])
per_layer_end_logits.append(model_outputs['end_logits'])
end_time = time.time()
print('Time taken {}'.format(end_time-start_time))
```
### Extract Answers (text) from Predictions
* Its little tricky as there will be multiple features for one example, if it is longer than max_seq_length
```
# Make batch predictions
n_best_size = 20
max_answer_length = 30
squad_dev_data = json.load(open(dev_input_file_path))['data']
predicted_results = []
# Unstack (matrxi tensor) into list arrays (list)
start_logits_unstcaked = []
end_logits_unstacked = []
for batch_start_logits in per_layer_start_logits:
start_logits_unstcaked.extend(tf.unstack(batch_start_logits))
for batch_end_logits in per_layer_end_logits:
end_logits_unstacked.extend(tf.unstack(batch_end_logits))
# Group (multiple predictions) of one example, due to big passage/context
# We need to choose the best anser of all the chunks of a examples
qas_id_logits = {}
for i in range(len(qas_id_list)):
qas_id = qas_id_list[i]
example = qas_id_info[qas_id]
feature = dev_features[i]
assert qas_id == feature['qas_id']
if qas_id not in qas_id_logits:
qas_id_logits[qas_id] = {'tok_to_orig_index': example['tok_to_orig_index'],
'aligned_words': example['aligned_words'],
'feature_length': [len(feature['input_ids'])],
'doc_offset': [doc_offset_list[i]],
'passage_start_pos': [feature['input_ids'].index(tokenizer.sep_token) + 1],
'start_logits': [start_logits_unstcaked[i]],
'end_logits': [end_logits_unstacked[i]]}
else:
qas_id_logits[qas_id]['start_logits'].append(start_logits_unstcaked[i])
qas_id_logits[qas_id]['end_logits'].append(end_logits_unstacked[i])
qas_id_logits[qas_id]['feature_length'].append(len(feature['input_ids']))
qas_id_logits[qas_id]['doc_offset'].append(doc_offset_list[i])
qas_id_logits[qas_id]['passage_start_pos'].append(feature['input_ids'].index(tokenizer.sep_token) + 1)
# Extract answer assoiate it with single (qas_id) unique identifier
qas_id_answer = {}
skipped = []
skipped_null = []
global_counter = 0
for qas_id in qas_id_logits:
current_example = qas_id_logits[qas_id]
_PrelimPrediction = collections.namedtuple( # pylint: disable=invalid-name
"PrelimPrediction",
["feature_index", "start_index", "end_index",
"start_log_prob", "end_log_prob"])
prelim_predictions = []
example_features = []
for i in range(len( current_example['start_logits'])):
f = dev_features[global_counter]
assert f['qas_id'] == qas_id
example_features.append(f)
global_counter += 1
passage_start_pos = current_example['passage_start_pos'][i]
feature_length = current_example['feature_length'][i]
start_log_prob_list = current_example['start_logits'][i].numpy().tolist()[:feature_length]
end_log_prob_list = current_example['end_logits'][i].numpy().tolist()[:feature_length]
start_indexes = _get_best_indexes(start_log_prob_list, n_best_size)
end_indexes = _get_best_indexes(end_log_prob_list, n_best_size)
for start_index in start_indexes:
for end_index in end_indexes:
# We could hypothetically create invalid predictions, e.g., predict
# that the start of the span is in the question. We throw out all
# invalid predictions.
if start_index < passage_start_pos or end_index < passage_start_pos:
continue
if end_index < start_index:
continue
length = end_index - start_index + 1
if length > max_answer_length:
continue
start_log_prob = start_log_prob_list[start_index]
end_log_prob = end_log_prob_list[end_index]
start_idx = start_index - passage_start_pos
end_idx = end_index - passage_start_pos
prelim_predictions.append(
_PrelimPrediction(
feature_index=i,
start_index=start_idx,
end_index=end_idx,
start_log_prob=start_log_prob,
end_log_prob=end_log_prob))
prelim_predictions = sorted(
prelim_predictions,
key=lambda x: (x.start_log_prob + x.end_log_prob),
reverse=True)
if prelim_predictions:
best_index = prelim_predictions[0].feature_index
aligned_words = current_example['aligned_words']
try:
tok_to_orig_index = current_example['tok_to_orig_index']
reverse_start_index_align = tok_to_orig_index[prelim_predictions[0].start_index + example_features[best_index]['doc_offset']] # aligned index
reverse_end_index_align = tok_to_orig_index[prelim_predictions[0].end_index + example_features[best_index]['doc_offset']]
predicted_words = [w for w in aligned_words[reverse_start_index_align: reverse_end_index_align + 1] if w != ROBERTA_SPECIAL_PEICE]
predicted_text = ' '.join(predicted_words)
qas_id_answer[qas_id] = predicted_text
except:
qas_id_answer[qas_id] = ""
skipped.append(qas_id)
else:
qas_id_answer[qas_id] = ""
skipped_null.append(qas_id)
eval_results = evaluate_v1(squad_dev_data, qas_id_answer)
# {'exact_match': 81.46641438032167, 'f1': 89.72853269935702}
```
### Save as Serialized version
- Now we can use ```save_as_serialize_module``` to save a model directly to saved_model
```
# Save as optimized version
span_selection_model.save_as_serialize_module("{}/saved_model".format(model_save_dir), overwrite=True)
# Load optimized version
span_selection_model_serialized = tf.saved_model.load("{}/saved_model".format(model_save_dir))
```
### TFLite Conversion
TFlite conversion requires:
- static batch size
- static sequence length
```
# Sequence_length = 384
# batch_size = 1
# Lets convert it to a TFlite model
# Load base model with specified sequence length and batch_size
model_layer, model, config = RobertaModel(model_name='roberta-base',
sequence_length=384, # Fix a sequence length for TFlite (it shouldnt be None)
batch_size=1,
use_dropout=False) # batch_size=1
# Disable dropout (important) for TFlite
span_selection_layer = Span_Selection_Model(model=model,
is_training=False)
span_selection_model = span_selection_layer.get_model()
span_selection_model.load_checkpoint(model_save_dir)
# Save to .pb format , we need it for tflite
span_selection_model.save_as_serialize_module("{}/saved_model_for_tflite".format(model_save_dir))
converter = tf.lite.TFLiteConverter.from_saved_model("{}/saved_model_for_tflite".format(model_save_dir)) # path to the SavedModel directory
converter.experimental_new_converter = True
tflite_model = converter.convert()
open("{}/converted_model.tflite".format(model_save_dir), "wb").write(tflite_model)
```
### **In production**
- We can use either ```tf.keras.Model``` or ```saved_model```. I recommend saved_model, which is much much faster and no hassle of having architecture code
```
def tokenizer_fn(features):
"""
features: dict of tokenized text
Convert them into ids
"""
result = {}
input_ids = tokenizer.convert_tokens_to_ids(features['input_ids'])
input_type_ids = tf.zeros_like(input_ids).numpy().tolist()
input_mask = tf.ones_like(input_ids).numpy().tolist()
result['input_ids'] = input_ids
result['input_type_ids'] = input_type_ids
result['input_mask'] = input_mask
return result
# Span Extraction Pipeline
pipeline = Span_Extraction_Pipeline(model = span_selection_model_serialized,
tokenizer = tokenizer,
tokenizer_fn = tokenizer_fn,
SPECIAL_PIECE = ROBERTA_SPECIAL_PEICE,
n_best_size = 20,
n_best = 5,
max_answer_length = 30,
max_seq_length = 384,
max_query_length=64,
doc_stride=20)
questions = ['What was prominent in Kerala?']
questions = ['When was Kerala formed?']
questions = ['How many districts are there in Kerala']
contexts = ['''Kerala (English: /ˈkɛrələ/; Malayalam: [ke:ɾɐɭɐm] About this soundlisten (help·info)) is a state on the southwestern Malabar Coast of India. It was formed on 1 November 1956, following the passage of the States Reorganisation Act, by combining Malayalam-speaking regions of the erstwhile states of Travancore-Cochin and Madras. Spread over 38,863 km2 (15,005 sq mi), Kerala is the twenty-first largest Indian state by area. It is bordered by Karnataka to the north and northeast, Tamil Nadu to the east and south, and the Lakshadweep Sea[14] to the west. With 33,387,677 inhabitants as per the 2011 Census, Kerala is the thirteenth-largest Indian state by population. It is divided into 14 districts with the capital being Thiruvananthapuram. Malayalam is the most widely spoken language and is also the official language of the state.[15]
The Chera Dynasty was the first prominent kingdom based in Kerala. The Ay kingdom in the deep south and the Ezhimala kingdom in the north formed the other kingdoms in the early years of the Common Era (CE). The region had been a prominent spice exporter since 3000 BCE. The region's prominence in trade was noted in the works of Pliny as well as the Periplus around 100 CE. In the 15th century, the spice trade attracted Portuguese traders to Kerala, and paved the way for European colonisation of India. At the time of Indian independence movement in the early 20th century, there were two major princely states in Kerala-Travancore State and the Kingdom of Cochin. They united to form the state of Thiru-Kochi in 1949. The Malabar region, in the northern part of Kerala, had been a part of the Madras province of British India, which later became a part of the Madras State post-independence. After the States Reorganisation Act, 1956, the modern-day state of Kerala was formed by merging the Malabar district of Madras State (excluding Gudalur taluk of Nilgiris district, Lakshadweep Islands, Topslip, the Attappadi Forest east of Anakatti), the state of Thiru-Kochi (excluding four southern taluks of Kanyakumari district, Shenkottai and Tenkasi taluks), and the taluk of Kasaragod (now Kasaragod District) in South Canara (Tulunad) which was a part of Madras State.''']
result = pipeline(questions=questions, contexts=contexts)
```
### Sanity Check TFlite
```
#### lets do a sanity check
sample_inputs = {}
input_ids = tf.random.uniform(minval=0, maxval=100, shape=(1, 384), dtype=tf.int32)
sample_inputs['input_ids'] = input_ids
sample_inputs['input_type_ids'] = tf.zeros_like(sample_inputs['input_ids'])
sample_inputs['input_mask'] = tf.ones_like(sample_inputs['input_ids'])
model_outputs = span_selection_model(sample_inputs)
# Load the TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="{}/converted_model.tflite".format(model_save_dir))
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], sample_inputs['input_ids'])
interpreter.set_tensor(input_details[1]['index'], sample_inputs['input_mask'])
interpreter.set_tensor(input_details[2]['index'], sample_inputs['input_type_ids'])
interpreter.invoke()
end_logits = interpreter.get_tensor(output_details[0]['index'])
start_logits = interpreter.get_tensor(output_details[1]['index'])
# Assertion
print("Start logits", tf.reduce_sum(model_outputs['start_logits']), tf.reduce_sum(start_logits))
print("End logits", tf.reduce_sum(model_outputs['end_logits']), tf.reduce_sum(end_logits))
# We are good :-)
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.