
code stringlengths 38 801k | repo_path stringlengths 6 263 |
|---|---|
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # Protein expression (MDAnderson RPPA)
#
# The goal of this notebook is to introduce you to the Protein expression BigQuery table.
#
# This table contains all available TCGA Level-3 protein expression data produced by MD Anderson's RPPA pipeline, as of July 2016. The most recent archives (*eg* ``mdanderson.org_COAD.MDA_RPPA_Core.Level_3.2.0.0``) for each of the 32 tumor types was downloaded from the DCC, and data extracted from all files matching the pattern ``%_RPPA_Core.protein_expression%.txt``. Each of these “protein expression” files has two columns: the ``Composite Element REF`` and the ``Protein Expression``. In addition, each mage-tab archive contains an ``antibody_annotation`` file which is parsed in order to obtain the correct mapping between antibody name, protein name, and gene symbol. During the ETL process, portions of the protein name and the antibody name were extracted into additional columns in the table, including ``Phospho``, ``antibodySource`` and ``validationStatus``.
#
# In order to work with BigQuery, you need to import the python bigquery module (`gcp.bigquery`) and you need to know the name(s) of the table(s) you are going to be working with:
import gcp.bigquery as bq
rppa_BQtable = bq.Table('isb-cgc:tcga_201607_beta.Protein_RPPA_data')
# From now on, we will refer to this table using this variable ($rppa_BQtable), but we could just as well explicitly give the table name each time.
#
# Let's start by taking a look at the table schema:
# %bigquery schema --table $rppa_BQtable
# Let's count up the number of unique patients, samples and aliquots mentioned in this table. We will do this by defining a very simple parameterized query. (Note that when using a variable for the table name in the FROM clause, you should not also use the square brackets that you usually would if you were specifying the table name as a string.)
# + magic_args="--module count_unique" language="sql"
#
# DEFINE QUERY q1
# SELECT COUNT (DISTINCT $f, 25000) AS n
# FROM $t
# -
fieldList = ['ParticipantBarcode', 'SampleBarcode', 'AliquotBarcode']
for aField in fieldList:
field = rppa_BQtable.schema[aField]
rdf = bq.Query(count_unique.q1,t=rppa_BQtable,f=field).results().to_dataframe()
print " There are %6d unique values in the field %s. " % ( rdf.iloc[0]['n'], aField)
# + active=""
# We can do the same thing to look at how many unique gene symbols and proteins exist in the table:
# -
fieldList = ['Gene_Name', 'Protein_Name', 'Protein_Basename']
for aField in fieldList:
field = rppa_BQtable.schema[aField]
rdf = bq.Query(count_unique.q1,t=rppa_BQtable,f=field).results().to_dataframe()
print " There are %6d unique values in the field %s. " % ( rdf.iloc[0]['n'], aField)
# Based on the counts, we can see that there are several genes for which multiple proteins are assayed, and that overall this dataset is quite small compared to most of the other datasets. Let's look at which genes have multiple proteins assayed:
# + language="sql"
#
# SELECT
# Gene_Name,
# COUNT(*) AS n
# FROM (
# SELECT
# Gene_Name,
# Protein_Name,
# FROM
# $rppa_BQtable
# GROUP BY
# Gene_Name,
# Protein_Name )
# GROUP BY
# Gene_Name
# HAVING
# ( n > 1 )
# ORDER BY
# n DESC
# -
# Let's look further in the the EIF4EBP1 gene which has the most different proteins being measured:
# + language="sql"
#
# SELECT
# Gene_Name,
# Protein_Name,
# Phospho,
# antibodySource,
# validationStatus
# FROM
# $rppa_BQtable
# WHERE
# ( Gene_Name="EIF4EBP1" )
# GROUP BY
# Gene_Name,
# Protein_Name,
# Phospho,
# antibodySource,
# validationStatus
# ORDER BY
# Gene_Name,
# Protein_Name,
# Phospho,
# antibodySource,
# validationStatus
# -
# Some antibodies are non-specific and bind to protein products from multiple genes in a gene family. One example of this is the AKT1, AKT2, AKT3 gene family. This non-specificity is indicated in the antibody-annotation file by a list of gene symbols, but in this table, we duplicate the entries (as well as the data values) on multiple rows:
# + language="sql"
#
# SELECT
# Gene_Name,
# Protein_Name,
# Phospho,
# antibodySource,
# validationStatus
# FROM
# $rppa_BQtable
# WHERE
# ( Gene_Name CONTAINS "AKT" )
# GROUP BY
# Gene_Name,
# Protein_Name,
# Phospho,
# antibodySource,
# validationStatus
# ORDER BY
# Gene_Name,
# Protein_Name,
# Phospho,
# antibodySource,
# validationStatus
# + language="sql"
#
# SELECT
# SampleBarcode,
# Study,
# Gene_Name,
# Protein_Name,
# Protein_Expression
# FROM
# $rppa_BQtable
# WHERE
# ( Protein_Name="Akt" )
# ORDER BY
# SampleBarcode,
# Gene_Name
# LIMIT
# 9
# -
| notebooks/Protein expression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
from sklearn.model_selection import train_test_split
import config
import random
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.neural_network import MLPClassifier
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
from matplotlib import pyplot
from keras.callbacks import History
import h5py
# +
def read_files():
tfidf_df = pd.read_csv(config.datasets_dir + config.tfidf_file_name)
#print(list(tfidf_df.columns)[:30])
clean_df = pd.read_csv(config.datasets_dir + config.clean_csv_name)
df = tfidf_df
df['ASSET_CLASS'] = clean_df['ASSET_CLASS']
return df
# -
def trainTestSplit(df,n):
random.seed(123)
df1 = df['ASSET_CLASS'].value_counts().rename_axis('Assets').reset_index(name = 'counts')
df_new = df1[df1['counts']>=n] # Train Test split 75% - train
assets = list(df_new['Assets'])
dffiltered = df[df['ASSET_CLASS'].isin(assets)]
dffiltered['ASSET_CLASS_CODES'] = pd.Categorical(dffiltered['ASSET_CLASS'])
dffiltered['ASSET_CLASS_CODES'] = dffiltered['ASSET_CLASS_CODES'].cat.codes
x = dffiltered.drop(columns = ['ASSET_CLASS','ASSET_CLASS_CODES','important_words'])
xcols = list(x.columns)
y = dffiltered['ASSET_CLASS_CODES']
X_train, X_test, Y_train, Y_test = train_test_split(x,y, test_size = 0.20, stratify = y)
print(' Number of Assets ' + str(len(set(list(dffiltered['ASSET_CLASS'])))))
#dict_codes = pd.Series(df.ASSET_CLASS.values, index = df.ASSET_CLASS_CODES).to_dict()
return X_train, X_test, Y_train, Y_test
def scores(y_pred, Y_test):
print('Hiiii')
print('Accuracy: '+str(accuracy_score(y_pred, Y_test)))
print('Precision Macro: '+ str(precision_score(y_pred, Y_test,average = 'macro')))
print('Recall Macro: '+str(recall_score(y_pred, Y_test, average = 'macro')))
print('F1 Score Macro: '+str(f1_score(y_pred, Y_test, average = 'macro')))
print('\n')
# +
def MLP(X_train, X_test, Y_train, Y_test):
print(X_train.shape)
print(X_train.shape[1])
model = Sequential()
model.add(Dense(1000, input_dim = X_train.shape[1],activation = 'softmax'))
model.add(Dense(750, activation = 'softmax'))
model.add(Dense(500, activation = 'softmax'))
model.add(Dense(204, activation = 'softmax'))
# compile keras
model.compile(loss='sparse_categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.summary()
# Early stopping
#es = EarlyStopping(monitor = 'val_loss', mode=1, verbose=3.1)
#es = EarlyStopping(monitor='val_loss', mode='min', verbose=1)
# Fit the keras
history = History()
#mc = ModelCheckpoint(config.mlp_model_data1, monitor='val_loss', verbose=1, save_best_only=True)
#callbacks_list = [checkpoint]
history = model.fit(X_train, Y_train, epochs = 10, batch_size = 32, validation_split = 0.1,verbose = 1,callbacks=[history])
# Model Evaluation
_, train_acc = model.evaluate(X_train, Y_train, verbose =2)
_, test_acc = model.evaluate(X_test, Y_test, verbose=2)
# predicted classes
y_pred = model.predict_classes(X_test)
scores(y_pred, Y_test)
print('Train Accuracy '+str(train_acc))
print('Test Accuracy '+str(test_acc))
pyplot.plot(history.history['loss'], label = 'train')
pyplot.plot(history.history['val_loss'], label = 'Validation')
pyplot.xlabel('Epochs')
pyplot.ylabel('Loss')
pyplot.legend()
pyplot.show()
# save the best Model
# save best Model
# -
def main():
df = read_files()
n = 100
X_train, X_test, Y_train, Y_test = trainTestSplit(df,n)
print(X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
MLP(X_train, X_test, Y_train, Y_test)
#print(len(Y_train.unique()))
main()
x = [1,2,3,4,5]
y = x[2:]
y
| DeepLearning/MLPdata1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Watson Assistant Dialog Flow Analysis
# <img src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/flow-vis.png" width="70%">
#
# ## Introduction
#
# This notebook demonstrates the use of visual analytics tools that help you measure and understand user journeys within the dialog logic of your Watson Assistant system, discover where user abandonments take place, and reason about possible sources of issues. The visual interface can also help to better understand how users interact with different elements of the dialog flow, and gain more confidence in making changes to it. The source of information is your Watson Assistant skill definitions and conversation logs.
#
# As described in <a href="https://github.com/watson-developer-cloud/assistant-improve-recommendations-notebook/raw/master/notebook/IBM%20Watson%20Assistant%20Continuous%20Improvement%20Best%20Practices.pdf" target="_blank" rel="noopener noreferrer">Watson Assistant Continuous Improvement Best Practices</a>, you can use this notebook to measure and understand in detail the behavior of users in areas that are not performing well, e.g. having low **Task Completion Rates**.
#
#
# >**Task Completion Rate** - is the percentage of user journeys within key tasks/flows of your virtual assistant that reach a successful resolution. This metric is one of the metrics you can use to measure the **Effectiveness** of your assistant.
#
#
# ### Prerequisites
# This notebook assumes some familiarity with the Watson Assistant dialog programming model, such as skills (formerly workspaces), and dialog nodes. Some familiarity with Python is recommended. This notebook runs on Python 3.5.
#
# ## Table of contents
# 1. [Installation and setup](#setup)<br>
#
# 2. [Load Assistant Skills and Logs](#load)<br>
# 2.1 [Load option one: from a Watson Assistant instance](#load_api)<br>
# 2.2 [Load option two: from JSON files](#load_file)<br>
# 2.3 [Load option three: from IBM Cloud Object Storage (using Watson Studio)](#load_cos_studio)<br>
# 2.4 [Load option four: from custom location](#load_custom)<br>
#
# 3. [Extract and transform](#extract_transform)<br>
#
# 4. [Visualizing user journeys and abandonments](#dialog_flow)<br>
# 4.1 [Visualize dialog flow (turn-based)](#flow_turn_based)<br>
# 4.1.1. [Visualize flows in all conversations](#flows_all_conversations)<br>
# 4.1.2. [Visualize flows in subset of conversations](#flow_subset_conversations)<br>
# 4.1.3. [Analyzing reverse flows](#flow_reverse)<br>
# 4.1.4. [Analyzing trends in flows](#flow_trend)<br>
# 4.2 [Visualize dialog flow (milestone-based)](#flow_milestone_based)<br>
# 4.3 [Select conversations at point of abandonment](#flow_selection)<br>
#
# 5. [Analyzing abandoned conversations](#analyze_abandonment)<br>
# 5.1 [Explore conversation transcripts for qualitative analysis](#transcript_vis)<br>
# 5.2 [Identify key words and phrases at point of abandonment](#keywords_analysis)<br>
# 5.2.1 [Summarize frequent keywords and phrases](#keywords_analysis_summarize)<br>
#
# 6. [Measuring high level tasks of the Assistant](#tasks)<br>
#
# 7. [Advanced Topics](#advanced_topics)<br>
# 7.1 [Locating important dialog nodes in your assistant](#search)<br>
# 7.1.1 [Searching programatically](#search_programatically)<br>
# 7.1.2 [Interactive Search and Exploration](#search_visually)<br>
# 7.2 [Filtering](#filtering)<br>
# 7.3 [Advanced keyword analysis: Comparing abandoned vs. Successful conversations](#keywords_analysis_compare)<br>
#
# 8. [Summary and next steps](#summary)<br>
# <a id="setup"></a>
# ## 1. Configuration and Setup
#
# In this section, we install and import relevant python modules.
# <a id="install"></a>
# #### Install required Python libraries
# Note, on Watson Studio the pip magic command `%pip` is not supported from within the notebook. Use !pip instead.
# #!pip install --user conversation_analytics_toolkit
# %pip install --user conversation_analytics_toolkit
import nltk
nltk.download('words')
nltk.download('punkt')
nltk.download('stopwords')
# <a id="import"></a>
# #### 1. Import required modules
# +
import conversation_analytics_toolkit
from conversation_analytics_toolkit import wa_assistant_skills
from conversation_analytics_toolkit import transformation
from conversation_analytics_toolkit import filtering2 as filtering
from conversation_analytics_toolkit import analysis
from conversation_analytics_toolkit import visualization
from conversation_analytics_toolkit import selection as vis_selection
from conversation_analytics_toolkit import wa_adaptor
from conversation_analytics_toolkit import transcript
from conversation_analytics_toolkit import flows
from conversation_analytics_toolkit import keyword_analysis
from conversation_analytics_toolkit import sentiment_analysis
import json
import pandas as pd
from pandas.io.json import json_normalize
from IPython.core.display import display, HTML
# -
# <a id="configure"></a>
# #### 2. Configure the notebook
# set pandas to show more rows and columns
import pandas as pd
#pd.set_option('display.max_rows', 200)
pd.set_option('display.max_colwidth', -1)
# <a id="load"></a>
# ## 2. Load Assistant Skills and Logs
# <img style="float:right;margin-left: 10px" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/load.png" width="40%">
# The analytics in this notebook are based on two main artifacts:
#
# 1. **Assistant logs** - logs generated from the communication with Watson Assistant via the /message API;
# 2. **Assistant skill(s)** - the skills that comprise the virtual assistant (aka ["workspace"](https://cloud.ibm.com/apidocs/assistant#get-information-about-a-workspace)).
# <br><br>
#
# These artifacts can be loaded from multiple sources, such as directly from Watson Assistant [log](https://cloud.ibm.com/apidocs/assistant#list-log-events-in-a-workspace) or [message](https://cloud.ibm.com/apidocs/assistant#get-response-to-user-input) APIs, or from other locations such as local/remote file system, Cloud Object Storage, or a Database.
#
# **Note**: below are a set of options to load workspace(s) and log data from different sources into the notebook. Use only **one** of these methods, and then skip to [section 2.2](#organize_skills)
# <a id="load_api"></a>
# ## 2.1 Load option one: from a Watson Assistant instance
# #### 2.1.1 Add Watson Assistant configuration
#
# This notebook uses the Watson Assistant v1 API to access your skill definition and your logs. Provide your Watson Assistant credentials and the workspace id that you want to fetch data from.
#
# You can access the values you need for this configuration from the Watson Assistant user interface. Go to the Skills page and select View API Details from the menu of a skill tile.
#
# - The string to set in the call to `IAMAuthenticator` is your API Key under Service Credentials
# - The string to set for version is a date in the format version=YYYY-MM-DD. The version date string determines which version of the Watson Assistant V1 API will be called. For more information about version, see [Versioning](https://cloud.ibm.com/apidocs/assistant/assistant-v1#versioning).
# - The string to pass into `service.set_service_url` is the portion of the Legacy v1 Workspace URL that ends with `/api`. For example, `https://gateway.watsonplatform.net/assistant/api`. This value will be different depending on the location of your service instance. Do not pass in the entire Workspace URL.
#
# For Section 2.1.2, the value of `workspace_id` can be found on the same View API Details page. The value of the Skill ID can be used for the workspace_id variable. If you are using versioning in Watson Assistant, this ID represents the Development version of your skill definition.
#
# For more information about authentication and finding credentials in the Watson Assistant UI, please see [Watson Assistant v1 API](https://cloud.ibm.com/apidocs/assistant/assistant-v1) in the offering documentation.
# +
import ibm_watson
from ibm_watson import AssistantV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
authenticator = IAMAuthenticator("<YOUR APIKEY>")
service = AssistantV1(version='2019-02-28',authenticator = authenticator)
service.set_service_url("<YOUR SERVICE URL>")
# -
# #### 2.1.2 Fetch and load a workspace
# Fetch the workspace for the workspace id given in `workspace_id` variable.
# +
#select a workspace by specific id
workspace_id = ''
# or fetch one via the APIs
# workspaces=service.list_workspaces().get_result()
# workspace_id = service['workspaces'][0]['workspace_id']
#fetch the workspace
workspace=service.get_workspace(
workspace_id=workspace_id,
export=True
).get_result()
# set query parameters
limit_number_of_records=5000
# example of time range query
query_filter = "response_timestamp>=2019-10-30,response_timestamp<2019-10-31"
#query_filter = None
# Fetch the logs for the workspace
df_logs = wa_adaptor.read_logs(service, workspace_id, limit_number_of_records, query_filter)
# -
# <a id="load_file"></a>
# ## 2.2 Load option two: from JSON files
# +
import requests
# this example uses Watson Assistant data sample on github
# pull sample workspace from watson developer cloud
response = requests.get("https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/data/banking-sample/wa-workspace.json").text
workspace = json.loads(response)
# NOTE: the workspace_id is typically available inside the workspace object.
# If you've used the `export skill` feature in Watson Assistant UI, you can find the skill id
# by clicking the `skill`-->`View API details` and copying the value of skill_id
workspace_id = workspace["workspace_id"]
#workpace_id = ''
# pull logs sample from watson develop cloud
response = requests.get("https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/data/banking-sample//wa-logs.json").text
df_logs = pd.DataFrame.from_records(json.loads(response))
print("loaded {} log records".format(str(len(df_logs))))
# -
# <a id="load_cos_studio"></a>
# ## 2.3 Load option three: from IBM Cloud Object Storage (using Watson Studio)
# +
# @hidden_cell
# The project token is an authorization token that is used by Watson Studio to access project resources.
# For more details on project tokens, refer to https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/token.html
from project_lib import Project
project = Project(project_id='<replace by Watson Studio project id>', project_access_token='<replace by Watson Studio access token')
workspace_file = "wa-workspace.json"
log_files = "wa-logs.json"
workspace = json.loads(project.get_file(workspace_file))
df_logs = pd.DataFrame.from_records(json.loads(project.get_file(log_files)))
# -
# <a id="load_custom"></a>
# ## 2.4 Load option four: from custom location
# +
# Depending on your production environment, your logs and workspace files might be stored in different locations.
# such as NoSQL databases, Cloud Object Storage files, etc.
# use custom code here, and make sure you load the workspace as a python dictionary, and the df_logs as a pandas DataFrame.
#workspace =
#df_logs =
# -
# <a id="extract_transform"></a>
# ## 3 Extract and Transform
# <img src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/extract-transform.png" width="50%">
# During this step, relevant information is extracted from the assistant logs, and combined with information from the assistant skills to create single ("canonical") dataframe for the analyses in this notebook.
#
# **Note**: If your logs are in a custom format or you wish to extract additional fields, you may need to customize the extraction process. You can learn more about this topic <a href="https://github.com/watson-developer-cloud/assistant-dialog-flow-analysis/blob/master/FAQ.md#what-is-the-format-of-the-canonical-data-model" target="_blank">here</a>.
# <a id="organize_skills"></a>
# #### Step 1: Prepare skills
#
# Create the **WA_Assistant_Skills** class, to organize relevant workspace objects for the analysis. The **Extract and Transform** phase will use this class to match the workspace_id column in your logs, and fetch additional relevant information from the skill.
#
# Call the `add_skill()` function to add relevant workspaces for the analysis. You can add multiple workspaces that correspond to different versions of a skill, or multiple skills of a **multi-skill** assistant (e.g. if you have your own custom code that routes messages to different dialog skills and want to analyze the collection of skills together)
#if you have more than one skill, you can add multiple skill definitions
skill_id = workspace_id
assistant_skills = wa_assistant_skills.WA_Assistant_Skills()
assistant_skills.add_skill(skill_id, workspace)
#validate the number of workspace_ids
print("workspace_ids in skills: " + pd.DataFrame(assistant_skills.list_skills())["skill_id"].unique())
print("workspace_ids in logs: "+ df_logs.workspace_id.unique())
# #### Step 2: Extract and Transform
# Call the `to_canonical_WA_v2()` function to perform the extract and transform steps
#
# If your assistant is **multi-skill**, set `skill_id_field="workspace_id"` to link information in the logs, with the corresponding workspace object based on the value of the `workspace_id` attribute in the logs.
df_logs_canonical = transformation.to_canonical_WA_v2(df_logs, assistant_skills, skill_id_field=None, include_nodes_visited_str_types=True, include_context=True)
#df_logs_canonical = transformation.to_canonical_WA_v2(df_logs, assistant_skills, skill_id_field="workspace_id", include_nodes_visited_str_types=True, include_context=False)
# the rest of the notebook runs on the df_logs_to_analyze object.
df_logs_to_analyze = df_logs_canonical.copy(deep=False)
df_logs_to_analyze.head(2)
# <a id="dialog_flow"></a>
# ## 4. Visualizing user journeys and abandonments
#
# The dialog flow visualization is an interactive tool for investigating user journeys, visits and abandonments within the steps of the dialog system.
#
# The visualization aggregates the temporal sequences of steps from Watson Assistant logs. The interaction allows to explore the distribution of visits across dialog steps and where abandonment takes place, and select the conversations that visit a certain step for further exploration and analysis.
#
# You can use the visualization to:
# * **understand end-to-end journeys** with the complete log dataset
# * **understand sub-journeys of interest** by using filters
# * **understand which flows end at a certain point** by using reverse flow aggregation
# * **undersatnd how flows are trending** by using merging the flows of two consecutive time periods
#
# This notebook demonstrates how to construct the visualization at two levels of abstraction
# * **turn-based** - for measuring and discovering how conversations progress across every turn in the conversation.
# * **milestone-based** - for measuring how conversations progress between key points of interest ("milestones") within the conversation
#
# <img style="float: right;margin: 13px;" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/turn-flow.png" width="40%">
# <a id="flow_turn_based"></a>
# ## 4.1 Visualize dialog flow (turn-based)
# Use the `draw_flowchart` function to create a flow-based visualization on the canonical dataset. By default, the visualization will present the progression of conversations on a turn-by-turn basis, aggregated and sorted by visit sequence frequencies. You can control many of the default, by modifying the `config` object.
#
# The following mouse interactions are supported:
# * **click** on a node to expand/collapse its children
# * **drag** to pan
# * **scroll** to zoom in/out
#
# When you hover or click on a node the following information is displayed:
# * **visits:** the number of conversations that progressed along a specific path of conversation steps.
# * **drop offs:** the number of conversations that ended at this conversation step
#
# The examples below demonstrate how to create a turn-based flow analysis: (1) for all conversations in the dataset; and (2) for a subset of conversations that were escalated (denoted by visiting the node **Transfer to Live Agent**)
# <a id="flows_all_conversations"></a>
# ### 4.1.1. Visualize flows in all conversations
# Visualizing all conversations on a turn-by-turn basis can help you to discover all existing conversation flows in your assistant
title = "All Conversations"
turn_based_path_flows = analysis.aggregate_flows(df_logs_to_analyze, mode="turn-based", on_column="turn_label", max_depth=400, trim_reroutes=False)
# increase the width of the Jupyter output cell
display(HTML("<style>.container { width:95% !important; }</style>"))
config = {
'commonRootPathName': title, # label for the first root node
'height': 800, # control the visualization height. Default 600
'nodeWidth': 250,
'maxChildrenInNode': 6, # control the number of immediate children to show (and collapse rest into *others* node). Default 5
'linkWidth' : 400, # control the width between pathflow layers. Default 360 'sortByAttribute': 'flowRatio' # control the sorting of the chart. (Options: flowRatio, dropped_offRatio, flows, dropped_off, rerouted)
'sortByAttribute': 'flowRatio',
'title': title,
'mode': "turn-based"
}
jsondata = json.loads(turn_based_path_flows.to_json(orient='records'))
visualization.draw_flowchart(config, jsondata, python_selection_var="selection")
# <a id="flow_subset_conversations"></a>
# ### 4.1.2. Visualize flows in subset of conversations
# Sometime you might want to explore a subset of conversations that meet a certain criteria, or look at the conversations only from a specific point onwards. The example below shows how to filter conversations that pass through two specific dialog nodes.
#
# For more details about using filters, please refer to [section 7.2](#filtering)
#
# filter the conversations that include escalation
title2="Banking Card Escalated"
filters = filtering.ChainFilter(df_logs_to_analyze).setDescription(title2)
# node with condition on the #Banking-Card_Selection (node_1_1510880732839) and visit the node "Transfer To Live Agent" (node_25_1516679473977)
filters.by_dialog_node_id('node_1_1510880732839')\
.by_dialog_node_id('node_25_1516679473977')
filters.printConversationFilters()
# get a reference to the dataframe. Note: you can get access to intermediate dataframes by calling getDataFrame(index)
filtered_df = filters.getDataFrame()
turn_based_path_flows = analysis.aggregate_flows(filtered_df, mode="turn-based", on_column="turn_label", max_depth=400, trim_reroutes=False)
config = {
'commonRootPathName': title2, 'title': title2,
'height': 800, 'nodeWidth': 250, 'maxChildrenInNode': 6, 'linkWidth' : 400, 'sortByAttribute': 'flowRatio',
'mode': "turn-based"
}
jsondata = json.loads(turn_based_path_flows.to_json(orient='records'))
visualization.draw_flowchart(config, jsondata, python_selection_var="selection")
# <a id="flow_reverse"></a>
# ### 4.1.3. Analyzing reverse flows
# Sometime you might want to understand which flows lead to a certain outcome which is represented by some node of interest, e.g. escalation to a live human agent. This can be achieved by passing `reverse=True` to the `aggregate_flow` function
# +
# filter only conversations that include Confirming Live Agent Transfer. In addition, remove true nodes, which simplifies the journey
#removeing the true node, helps to make the visualization simpler
cf = filtering.ChainFilter(df_logs_canonical).setDescription("Escalated conversations")\
.by_turn_label("Confirming Live Agent Transfer")\
.remove_turn_by_label("true")\
.printConversationFilters()
escalated_df = cf.getDataFrame()
#addiginal remove duplicates consecutive states will also make the visualization simpler
escalated_simplified_df = analysis.simplify_consecutive_duplicates(escalated_df, on_column="turn_label")
# -
#note reverse=True in the aggregation step
escalated_similified_reversed_df = analysis.aggregate_flows(escalated_simplified_df, mode="turn-based",\
on_column="turn_label", max_depth=30, trim_reroutes=False, reverse=True)
title3 = 'Escalation Flows (reversed)'
config = {
'commonRootPathName': title3, 'title': title3,
'height': 800, 'nodeWidth': 250, 'maxChildrenInNode': 6, 'linkWidth' : 400, 'sortByAttribute': 'flowRatio',
'mode': "turn-based"
}
jsondata = json.loads(escalated_similified_reversed_df.to_json(orient='records'))
visualization.draw_flowchart(config, jsondata, python_selection_var="selection")
# <a id="flow_trend"></a>
# ### 4.1.4. Analyzing trends in flows
# Occasionally you may want to observe how the flows change across time periods, for example, after you have improved the training of an intent, or the dialog steps, and want to observe the improvement.
#
# To achieve this, you should aggregate each time period separately and use the `merge_compare_flows` function. This will create a union of the unique flows and the visualization will show you how the flow changes between the two periods.
# +
# we will simiulate this on the previous chart (reverse escalated flows) by comparing the first and second 1000 logs
prev_period_df = escalated_simplified_df[0:1000]
curr_period_df = escalated_simplified_df[1001:2000]
prev_flows = analysis.aggregate_flows(prev_period_df, mode="turn-based", on_column="turn_label", max_depth=30, trim_reroutes=False, reverse=True)
curr_flows = analysis.aggregate_flows(curr_period_df, mode="turn-based", on_column="turn_label", max_depth=30, trim_reroutes=False, reverse=True)
df_logs_compare_periods = analysis.merge_compare_flows(curr_flows, prev_flows)
# -
title3 = 'Trending flows (curr vs. prev)'
config = {
'commonRootPathName': title3, 'title': title3,
'height': 800, 'nodeWidth': 250, 'maxChildrenInNode': 6, 'linkWidth' : 400, 'sortByAttribute': 'flowRatio',
'mode': "turn-based"
}
jsondata = json.loads(df_logs_compare_periods.to_json(orient='records'))
visualization.draw_flowchart(config, jsondata, python_selection_var="selection")
# <a id="flow_milestone_based"></a>
# ## 4.2 Visualize dialog flow (milestone-based)
# Use the milestone-based dialog visualization to measure the flow of visits and abandonment between key points of interest (aka "milestones") in your assistant.
#
# The milestone-based visualization requires two extra steps:
# 1. definition of the milestones names, and mapping of which dialog nodes map to each milestone.
# 2. processing of the log data to find and filter log rows that are part of a milestone.
#
# Use the `mode="milestone-based"` to configure the flow aggregation and visualization steps. The visualization uses a special **Other** node to model conversations that are flowing to other parts of the dialog which were not defined to be of interest in the milestone definitions.
#
# In this notebook we demonstrate how to produce a milestone dialog flow key points of interest that are part of the **Schedule Appointment** task of the assistant.
#
# <img src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/milestone-flow.png" width="80%">
# #### 1. Define milestones
# +
#define the milestones and corresponding node ids for the `Schedule Appointment` task
milestone_analysis = analysis.MilestoneFlowGraph(assistant_skills.get_skill_by_id(skill_id))
milestone_analysis.add_milestones(["Appointment scheduling start", "Schedule time", "Enter zip code", "Branch selection",
"Enter purpose of appointment", "Scheduling completion"])
milestone_analysis.add_node_to_milestone("node_21_1513047983871", "Appointment scheduling start")
milestone_analysis.add_node_to_milestone("handler_28_1513048122602", "Schedule time")
milestone_analysis.add_node_to_milestone("handler_31_1513048234102", "Enter zip code")
milestone_analysis.add_node_to_milestone("node_3_1517200453933", "Branch selection")
milestone_analysis.add_node_to_milestone("node_41_1513049128006", "Enter purpose of appointment")
milestone_analysis.add_node_to_milestone("node_43_1513049260736", "Scheduling completion")
# -
# #### 2. Derive a new dataset, using enrichment & filtering
#enrich with milestone information - will add a column called 'milestone'
milestone_analysis.enrich_milestones(df_logs_to_analyze)
#remove all log records without a milestone
df_milestones = df_logs_to_analyze[pd.isna(df_logs_to_analyze["milestone"]) == False]
#optionally, remove consecutive milestones for a more simplified flow visualization representation
df_milestones = analysis.simplify_flow_consecutive_milestones(df_milestones)
# #### 3. Aggregate and visualize
# compute the aggregate flows of milestones
computed_flows= analysis.aggregate_flows(df_milestones, mode="milestone-based", on_column="milestone", max_depth=30, trim_reroutes=False)
config = {
'commonRootPathName': 'All Conversations', # label for the first root node
'height': 800, # control the visualization height. Default 600
'maxChildrenInNode': 6, # control the number of immediate children to show (and collapse the rest into *other* node). Default 5
# 'linkWidth' : 400, # control the width between pathflow layers. Default 360 '
'sortByAttribute': 'flowRatio', # control the sorting of the chart. (Options: flowRatio, dropped_offRatio, flows, dropped_off, rerouted)
'title': "Abandoned Conversations in Appointment Schedule Flow",
'showVisitRatio' : 'fromTotal', # default: 'fromTotal'. 'fromPrevious' will compute percentages from previous step,
'mode': 'milestone-based'
}
jsondata = json.loads(computed_flows.to_json(orient='records'))
visualization.draw_flowchart(config, jsondata, python_selection_var="milestone_selection")
# **Note**: The rest of this notebook will demonstrate selection and analysis on selections made in the milestone-based dialog flow (designated by setting the python_selection_var variable to `milestone_selection`. To select and analyze conversations from the turn-based dialog flow, set the variable to `selection` instead).
# <a id="flow_selection"></a>
# ## 4.3 Select conversations at the point of abandonment
# <img style="float: right;margin:15px;" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/abandonment.png" width="40%">
# Selecting nodes in the visualization enables you to explore and analyze abandoned conversations with a common conversation path. You can use the visualization to identify large volumes of conversations that users abandon at unexpected locations during the conversation.
#
#
# **Note:**
# > Selecting a node in the visualization will also copy the selection from the visualization into the variable designated by `python_selection_var`, thus making the selection available to other cells of this notebook.
#
# Before you run the next cell, you will interact with the milestone dialog visualization above to select a portion of the dialog to analyze. First, interact with the milestone dialog visualization to observe visit frequencies and abandonments within the milestones of `Schedule Appointment`. Click on nodes to drill down and expand the next step in sequence. Navigate along this path: `Appointment scheduling start`-->`Schedule time`-->`Enter zip code`-->`Branch selection` to observe a relative high proportion of abandonments that occur in the middle of the flow. Select the `Branch selection` node. Note the large volume and ratio of abandoned conversations. Now run the following cell to process conversations that were abandoned at your point of selection.
#the selection variable contains details about the selected node, and conversations that were abandoned at that point
print("Selected Path: ",milestone_selection["path"])
#fetch the dropped off conversations from the selection
dropped_off_conversations = vis_selection.to_dataframe(milestone_selection)["dropped_off"]
print("The selection contains {} records, with a reference back to the converstion logs".format(str(len(dropped_off_conversations))))
dropped_off_conversations.head()
# <a id="analyze_abandonment"></a>
# ## 5. Analyzing abandoned conversations
# After selecting a large group of abandoned conversations and their corresponding log records, you can apply additional analyses to better understand why these conversations were lost.
#
# Some possible reasons could be:
# * The assistant didn't anticipate or understand the user utterance. This means the dialog skill is not trained to “cover” the user utterance. Coverage is an important measure of how well your assistant is performing. See the [Watson Assistant Continuous Improvement Best Practices](https://github.com/watson-developer-cloud/assistant-improve-recommendations-notebook/raw/master/notebook/IBM%20Watson%20Assistant%20Continuous%20Improvement%20Best%20Practices.pdf) for details on how to measure and improve coverage
# * The options presented to the user were not relevant
# * The conversation didn't progress in the right direction
# * The assistant’s response wasn't accurate or relevant
#
# This section of the notebook demonstrates two visual components that can help you investigate the user utterances in the abandoned conversations:
# * The transcript visualization can show you every user utterance and assistant response until the point of abandonment.
# * The key words and phrases analysis can help find frequent terms in abandoned conversations.
# <a id="transcript_vis"></a>
# ## 5.1 Explore conversation transcripts for qualitative analysis
# <img style="float: right;margin:13px;" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/transcript-vis.png" width="50%">
# The transcript visualization shows the full sequence of conversation steps in the selected group of conversations. You can view the user utterances as well as observe the assistant response and the dialog nodes that were triggered to produce those responses.
#
# Try to navigate to the 3rd conversation (conversation_id == `0Aw68rNq6kSGxaDurGG1NSf3c9LtLK3kurWm`) using the toggle buttons, and scroll down to view the user's last utterance before abandoning the conversation (where user utterance is `wrong map`). In this conversation, the assistant response in the previous step wasn't satisfactory and when the user communicated that to the assistant, the assistant didn't understand his utterance. This may indicate that some modification to the dialog logic might be needed to better respond in this situation, as well as the service itself might need to be fixed.
#
# You might want to check if this situation occurs in other conversations too. A complementary approach is to try to find frequent terms in user utterances and see how prevalent this is across all abandoned conversations (see [next section](#keywords_analysis) for details).
# #### Optionally enrich with sentiment information
# Adding sentiment will allow you to observe negative utterances more quickly in the transcripts. You can generate other type of analysis insights, by enriching the `insights_tag` column
df_logs_to_analyze = sentiment_analysis.add_sentiment_columns(df_logs_to_analyze)
#create insights, and highlights annotation for the transcript visualization
NEGATIVE_SENTIMENT_THRESHOLD=-0.15
df_logs_to_analyze["insights_tags"] = df_logs_to_analyze.apply(lambda x: ["Negative Sentiment"] if x.sentiment < NEGATIVE_SENTIMENT_THRESHOLD else [], axis=1)
df_logs_to_analyze["highlight"] = df_logs_to_analyze.apply(lambda x: True if x.sentiment < NEGATIVE_SENTIMENT_THRESHOLD else False, axis=1)
# fetch the conversation records
dropped_off_conversations = vis_selection.fetch_logs_by_selection(df_logs_to_analyze, dropped_off_conversations)
# visualize using the transcript visualization
dfc = transcript.to_transcript(dropped_off_conversations)
config = {'debugger': True}
visualization.draw_transcript(config, dfc)
# <a id="keywords_analysis"></a>
# ## 5.2 Identify key words and phrases at point of abandonment
#
# <img style="float: right;" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/keywords.png" width="30%">
# The keywords and phrases analysis allows you to check if the phrase `wrong map` is prevalent in many of the abandoned conversations, or what are the most common words or phrases overall.
#
# The analysis performs some basic linguistic processing from a group of utterances, such as removal of stop words, or extraction of the base form of words, and then computes their frequencies. Frequencies for words that appear together in sequence (bi-grams, tri-grams) are also computed.
#
#
# Finally, the visualization displays the most frequent words and phrases.
# #### Gather utterances from abandoned conversations
# gather user utterances from the dropped off conversations - last utterances and all utterances
last_utterances_abandoned=vis_selection.get_last_utterances_from_selection(milestone_selection, df_logs_to_analyze)
all_utterances_abandoned=vis_selection.get_all_utterances_from_selection(milestone_selection, df_logs_to_analyze)
# <a id="keywords_analysis_summarize"></a>
# ## 5.2.1 Summarize frequent keywords and phrases
# Analyze the last user utterances prior to abandonment to potentially identify common issues at that point.
# analyze the last user input before abandonment
num_unigrams=10
num_bigrams=15
custom_stop_words=["would","pm","ok","yes","no","thank","thanks","hi","i","you"]
data = keyword_analysis.get_frequent_words_bigrams(last_utterances_abandoned, num_unigrams,num_bigrams,custom_stop_words)
config = {'flattened': True, 'width' : 800, 'height' : 500}
visualization.draw_wordpackchart(config, data)
# **Note**: in the visual above, the term `wrong map` appears quite often. Other relevant keywords and phrases such as `error`, `map error`, `wrong location`, `wrong branches` are also observed.
# <a id="tasks"></a>
# ## 6. Measuring high level tasks of the Assistant
# <img style="float:right;margin-left: 10px" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/flow-def.png" width="60%">
# In some scenarios you might want to first measure the effectiveness of your assistant at key areas within the skill, before drilling into specific flows. Measuring the volume and effectiveness of specific key areas, can help you detect trends around your release dates, as well as prioritize your improvement efforts.
#
# A conversation can be view and measured as being composed of one or more logical tasks (aka "high level flows"). This section of the notebook demonstrates measuring **transactional tasks** (aka **"flows"**) by defining their corresponding starting (parent) and successful ending dialog nodes.
#
# You can define and measure a task by providing a mapping to dialog nodes that correspond to the start and successful end of a task.
# #### 1. Define tasks
# <a id="define_tasks"></a>
#
# You can use the programmatic and interactive search options as showed in [section 7.1](#search) to locate and copy corresponding dialog node ids, and use them in the flows definition as shown below.
#
#
# The example below shows how to define the **Credit card payment** and **Schedule appointments** tasks. In this example, the starting point was mapped to the node that has a condition on the corresponding intent, and the completion nodes to the nodes that generate the confirmation response.
#
# **Note:**
# >Parent and completion nodes can be defined using one or more nodes. Defining multiple parent nodes is useful if a single logical flow is implemented across different branches of the dialog tree. Defining multiple completion nodes can be relevant if you have more than one location in the dialog that can determine successful ending of the flow.
# a flow is defined by a name, one or more "starting/parent_nodes" and one or more "success/completion nodes".
# All the nodes which are descendants to the parent nodes are considered to be part of the flow
# A flow is considered successful if reaches the completion node
flow_defs_initial = {
'flows': [{
'name': 'Credit card payment',
'parent_nodes': ['node_3_1511326054650'], #condition on #Banking-Billing_Payment_Enquiry || #Banking-Billing_Making_Payments
'completion_nodes': ['node_8_1512531332315'] # Display of confirmation "Thank you for your payment..."
},
{
'name': 'Schedule appointment',
'parent_nodes': ['node_21_1513047983871'], #condition on '#Business_Information-Make_Appointment'
'completion_nodes': ['node_43_1513049260736'] #Display Appointment Confirmation
}]
}
#create a list of all the nodes that map to a flow including descendant nodes
flow_defs = flows.enrich_flows_by_workspace(flow_defs_initial, workspace)
# #### 2. Measure task volume and completion rates
# <a id="measure_tasks"></a>
# Using the task's flow definition and enrichment of the logs, we can now measure the visits in each flow, and the completion percentages.
#
# The **Abandoned** state refers to conversation that terminated in the middle of the flow. **Rerouted** refers to conversation that left the scope of the flow and didn't return. **Completed** refers to conversations that successfully reached the completion point.
#enrich the logs dataframe with additional columns ["flow", "flow_state"] that represent the state of the flow
df_logs_to_analyze = flows.enrich_canonical_by_flows(df_logs_to_analyze, flow_defs)
flow_outcome_summary = flows.count_flows(df_logs_to_analyze, flow_defs)
print(flow_outcome_summary)
flows.plot_flow_outcomes(flow_outcome_summary)
# **Note**: as shown in above figure, the **Schedule Appointment** task has a relatively large volume of conversations with poor **effectiveness** (as 65% of conversations are abandoned). As a next step you might want to drill down to understand in more detail where exactly in the dialog logic the conversations were abandoned and why.
#
# <a id="advanced_topics"></a>
# ## 7. Advanced Topics
# <a id="search"></a>
# ## 7.1 Locating important dialog nodes in your assistant
#
# In order to measure the performance of specific tasks, or understand user journeys between specific points of the dialog, you will need to be able to reference dialog nodes by their unique `node_id`. This section demonstrates how to find the `node_id` of nodes of interest in your dialog using two complementary techniques: a programmatic API, and an interactive visual component.
# <a id="search_programatically"></a>
# ## 7.1.2 Searching programmatically
#
# The `WA_Assistant_Skills` class provides utility functions for searching dialog nodes in your assistant or in a specific skill.
#
# The `re_search_in_dialog_nodes()` supports a case-insensitive, regular expression-based search. You can search for strings that appears in the node's title, condition, or id.
#
# Sample usage of the API:
# * `re_search_in_dialog_nodes(search_term)` - search in all fields, in all skills
# * `re_search_in_dialog_nodes(search_term, keys=['condition'], in_skill=skill_id)` - search only in condition fields of nodes in specific skill
#
# Examples of search terms:
# * `"card"` - search for a word
# * `"@CC_Types"` - search for an entity
# * `"#General_Conversation-VA_State"` - search for an intent
# * `'#.*banking.*card'` - search for intent that includes banking and card
# example of searching for all occurences of the word 'Card'
search_term='Card'
results = assistant_skills.re_search_in_dialog_nodes(search_term)
results.head(5)
# <img style="float: right;margin: 35px;" src="https://raw.githubusercontent.com/watson-developer-cloud/assistant-dialog-flow-analysis/master/notebooks/images/search.png" width="40%">
#
# <a id="search_visually"></a>
# ## 7.1.3 Interactive search and exploration
#
# You can use the `draw_wa_dialog_chart()` to visualize the dialog nodes of a specific skill in the same tree layout as in Watson Assistant Dialog Editor. You can interact with the visualization to navigate to, or search for, a particular node, from which you can copy its `node_id`
workspace = assistant_skills.get_skill_by_id(skill_id)
data = {
'workspace': workspace
}
config = {}
visualization.draw_wa_dialog_chart(config, data)
# <a id="filtering"></a>
# ## 7.2 Filtering
# You can use a built-in filter to narrow down your log records and focus on specific conversations or journey steps. There are two types of filters
# 1. **selection** - filters that select a subset of conversations based on some criteria. Example of selection filters: `by_dialog_node_id`, `by_dialog_not_node_id`, `by_turn_label`, `by_date_range`, `by_dialog_node_str`, `by_column_values`
# 2. **selection and trimming** - filters that select a subset of conversations and in addition remove some of the conversation steps before a specific point of interest. This allows you to focus on how conversation journeys progress from that point on. Example of these filters: `trim_from_node_id`, `trim_from_turn_label`
# 3. **removing turns** - filters that remove some of the conversation steps based on some criteria. This allows you to simplify journeys, by removing steps that don't add value to your exploration, e.g. true nodes. Example of selection filters: `remove_turn_by_label`.
# 4. **simplification of journeys** - remove duplicate consecutive turns. This allows you to see a more simplified verstion of the journeys when the same turn is repeated several times in the journey. Note, this filter is not part of the ChainFilter module and can be invoked by calling the `analysis.simplify_consecutive_duplicates` function.
#
# You can create a chain of filters to work in sequence to narrow down the log records for specific exploration activities.
#
# Below is an example of a chained filter that finds conversations that pass through the 'Collect Appointment Data' node during Jan 2020
# +
import datetime
import pytz
filters = filtering.ChainFilter(df_logs_to_analyze).setDescription("Filter: collect Appointment Data during Jan 2020")
filters.by_dialog_node_id('node_22_1513048049461') # corresponding to 'Collect Appointment Data' node.
# You can use the search utilities described earlier in the notebook to find this node
# You can also use cf.by_turn_label('Collect Appointment Data') to filter on information in the turn label
start_date = datetime.datetime(2020, 1, 1, 0, 0, 0, 0, pytz.UTC)
end_date = datetime.datetime(2020, 1, 31, 0, 0, 0, 0, pytz.UTC)
filters.by_date_range(start_date,end_date)
filters.printConversationFilters()
# get a reference to the dataframe. Note: you can get access to itermediate dataframes by calling getDataFrame(index)
filtered_df = filters.getDataFrame()
print("number of unique conversations in filtered dataframe: {}".format(len(filtered_df["conversation_id"].unique())))
# -
# <a id="keywords_analysis_compare"></a>
# ## 7.3 Advanced keyword analysis: Comparing abandoned vs. successful conversations
# Sometimes looking at the last utterances of the abandoned conversations is not enough to find the **root cause** of a problem. A more advanced approach is to look also at the conversations that successfully completed the flow, and compare which keywords and phrases, are statistically associated more with the abandoned group, not only for the last utterance before the drop off point, but in general at all the utterances of the conversation.
# #### Gather utterances from all conversations that completed the journey on the same flow
#get the logs of conversations that continue to successful completion
scheduling_completed_filter = filtering.ChainFilter(df_logs_to_analyze).setDescription("Appointement Scheduling flow - Completed")
scheduling_completed_filter.by_dialog_node_id('node_21_1513047983871') # started the Appointment Scheduling flow
scheduling_completed_filter.by_dialog_node_id('node_3_1517200453933') # passed through the "Branch selection" node
scheduling_completed_filter.by_dialog_node_id('node_43_1513049260736') # reached the completion node of Scheduling Appointment flow
scheduling_completed_filter.printConversationFilters()
#get the user utterances
scheduling_completed_df = scheduling_completed_filter.getDataFrame()
all_utterances_completed=scheduling_completed_df[scheduling_completed_df.request_text!=""].request_text.tolist()
print("Gathered {} utterances from {} successful journeys".format(str(len(all_utterances_completed)),
str(len(scheduling_completed_df["conversation_id"].unique()))))
# #### Outcome analysis: all utterances prior to abandonment vs completed
# Which keywords/phrases are statistically more associated with the **all utterances** in abandoned conversations than with completed ones
num_keywords=25
custom_stop_words=["would","pm","ok","yes","no","thank","thanks","hi","i","you"]
data = keyword_analysis.get_data_for_comparison_visual(all_utterances_abandoned, all_utterances_completed, num_keywords,custom_stop_words)
config = {'debugger': True, 'flattened': True, 'width' : 800, 'height' : 600}
visualization.draw_wordpackchart(config, data)
# **Note**: as shown above when doing an outcome-driven analysis **only** terms that are statistically associated with the dropped off conversations are highlighted, for example `next`, `day`, and `day tomorrow`
# <a id="summary"></a>
# ## 8. Summary and next steps
# The analysis presented in this notebook can help you measure the effectiveness of specific tasks/flows within the dialog flows of your assistant skills. The visual components can be used to find large groups of conversations with potentially common issues to improve. The flow analysis can help you discover existing journeys, and focus on specific journey points where many conversations are lost. The transcript and visual keywords/phrases analysis helps you explore those conversations to a greater depth and detect potential issues.
#
#
# We suggest the following possible next steps:
# - **Identify candidate areas to focus your improvement efforts**
# - Use the filtering and the flow visualization capabilities to focus on low performing flows, and identify high volume of problematic areas (e.g. abandonments)
# - **Perform initial assessment of potential issues**
# - Use the transcript visualization and text analysis components to identify a list of potential issues to further narrow down groups of common conversations that require a common solution
# - missing intent or entities
# - existing intent, candidate for more training
# - out of scope, candidate for more training
# - dialog logic (sequence of steps, context, changes to condition, list and order of options,. etc)
# - bot response was not relevant
# - backend/webhook related
# - **Export candidate utterances for expanding the coverage of your intents**
# - Export candidate utterances from selected conversations
# - Upload the utterances as a CSV to Watson Assistant using the [Intent Recommendations](https://cloud.ibm.com/docs/services/assistant?topic=assistant-intent-recommendations#intent-recommendations-log-files-add) feature
# - **Perform detailed analysis to identify the changes needed to the dialog logic**
# - Export a selected group of conversations that require detailed analysis
# - Perform an assessment of the conversations using the provided spreadsheet template
# - Import the assessment spreadsheet to the [Effectiveness Notebook](https://github.com/watson-developer-cloud/assistant-improve-recommendations-notebook/blob/master/notebook/Effectiveness%20Notebook.ipynb) to identify the most commonly occurring problems and prioritize a list of improvement actions
# - **Measure change in user journeys after deploying to production**
# - Gain more confidence in making changes, by tracking changes to the flow metrics and user journeys in the dialog flow before and after deploying to production
# - Load data of similar time range from before and after deployment of a new release. Create a separate flow analysis for each time period, and observe expected changes to user journeys that were updated from the last release, and that no negative side-effects impact otherwise stable flows.
#
# For more information, please check <a href="https://github.com/watson-developer-cloud/assistant-improve-recommendations-notebook/raw/master/notebook/IBM%20Watson%20Assistant%20Continuous%20Improvement%20Best%20Practices.pdf" target="_blank" rel="noopener noreferrer">Watson Assistant Continuous Improvement Best Practices</a>.
#
# #### Here are a few useful exports you can use to support above activities
# +
#to export all user utterances in the dropoff point of flow visualization selection
dropped_off_conversations[dropped_off_conversations["request_text"] != ""].to_csv('abandoned-user-utterances.csv', columns=["request_text"], index=False, header=False)
#to export all user utterances in the dropoff point of flow visualization selection
dropped_off_conversations.to_csv('abandoned-conversation-ids.csv', columns=["conversation_id"], index=False,header=False)
#to export all columns of the canonical model for abandoned conversations
dropped_off_conversations.to_csv('abandoned-logs.csv', index=False,)
#to export specific conversation, e.g. 00KjvlWcGozRTcSYTrlGqj4JYtYH5gjbvw3j
conversation_id_to_export = '00KjvlWcGozRTcSYTrlGqj4JYtYH5gjbvw3j'
df_logs_to_analyze[df_logs_to_analyze["conversation_id"] == conversation_id_to_export].to_csv(conversation_id_to_export + ".csv", index=False)
#to export user utterances for intent training with Watson Recommends
from conversation_analytics_toolkit import export
sentences = dropped_off_conversations[dropped_off_conversations["request_text"] != ""].reset_index()
sentences = sentences[["request_text"]]
sentences.columns = ['example']
filtered_sentences = export.filter_sentences(sentences, min_complexity = 3, max_complexity = 20)
df_sentences = pd.DataFrame(data={"training_examples": filtered_sentences})
df_sentences.to_csv("./utterances-for-Watson-Intent-Recommendations.csv", sep=',',index=False, header=False)
# -
# ### <a id="authors"></a>Authors
#
# **<NAME>** is a Research Staff Member at IBM Research AI organization, where he develops algorithms and tools for discovering insights in complex data. His research interests include data mining, information visualization, natural language processing, and cloud computing. Avi has published more than 30 papers and patents.
#
# **<NAME>**, Ph.D. in Statistics, is a Data Scientist in IBM Research - Haifa. His research agenda includes text analytics, machine learning, forecasting and operations research. Sergey has broad experience in data analysis, model development and implementation. His research has been published at top operations research and statistical journals.
# ### <a id="acknowledgement"></a> Acknowledgement
#
# The authors would like to thank the following members of IBM Watson, Research and Services for their contributions and feedback of the underlying technology and notebook: <NAME>, <NAME>, <NAME>, <NAME>, <NAME>, <NAME>, and <NAME>.
# Copyright © 2020 IBM. This notebook and its source code are released under the terms of the MIT License.
| notebooks/Dialog Flow Analysis Notebook.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="mLcmGG387N5t" colab_type="text"
#
# # Motivations
#
# 
#
# 
#
# - Deep Reinforcment learning is responsible for the 2 biggest AI victories most recently (The Deep Q Network, AlphaGo, OpenAI Five)
# - Deep Q started the surge of interest in Deep RL
# - Deep Q was so impressive that Google bought DeepMind for half a billion US dollars to leverage it for their products
# - Deep Q exceled because of 3 (at the time) state-of-the art techniques; replay memory, large-scale distributed training, and distributional modeling methods
# - The time and attention it took Google researchers to develop these techniques made them realize they needed a framework that fit some key pain points
#
# ### Wait, Siraj. What's replay memory?
# - To perform experience replay, an agent will store it's experiences t=(s,a,r,st+1)
# - So instead of running Q-learning on state/action pairs as they occur during simulation or actual experience, the system stores the data discovered for [state, action, reward, next_state] - typically in a large table.
# Note this does not store associated values - this is the raw data to feed into action-value calculations later.
# - The learning phase is then logically separate from gaining experience, and based on taking random samples from this table.
# - You still want to interleave the two processes - acting and learning - because improving the policy will lead to different behaviour that should explore actions closer to optimal ones, and you want to learn from those.
#
# ### Can we learn Deep reinforcement learning now lol?
# - Neural networks are the agent that learns to map state-action pairs to rewards.
# - Thats all for now. We need to continue with pure RL before deep RL
#
# # Paint Points include
#
# - Existing reinforcement learning frameworks are not flexible. It takes time to make changes, and this kind of research requires rapid experimentation
# - Code reproducability is abysmal in RL research. Lets be real. This needs to be fixed.
# - TL;DR - Needs moar Flexibility, Stabilitiy, Reproducability
#
# # Framework Features
#
# ## Agents
#
# ### DQN
#
# 
#
# ### C51
# - Basically it is a good old Deep-Q network. But instead of approximating expected future reward values it generates the whole distributions over possible outcomes.
# -They’ve done it by replacing the output of DQN with probabilities over categorical variables representing different reward values ranges.
#
# ### Rainbow
# -Six extensions to the DQN algorithm
#
# 
#
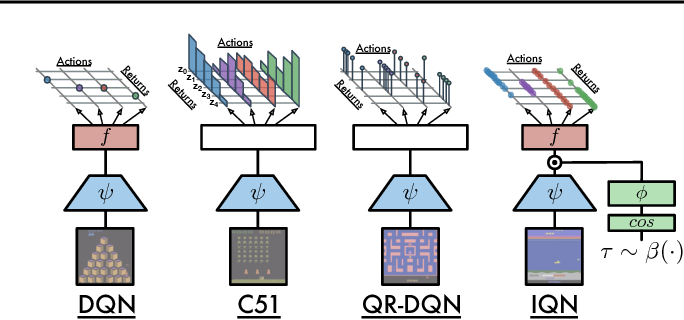
# ### Implicit Quantile (Very New)
#
# 
#
# - Approximates the full quantile function for the state-action return distribution
#
# ## Atari (Environment, wraps OpenAI's gym)
#
# - 60 Atari Environments at https://gym.openai.com/envs/#atari
#
# ## Common (logging, checkpointing)
#
# - Dopamine will save an experiment checkpoint every iteration: one training and one evaluation phase
# - Checkpoint 1: Experiment statistics (number of iterations performed, learning curves, etc.)
# - Checkpoint 2: Agent variables, including the tensorflow graph.
# - Checkpoint 3: Replay buffer data. Atari 2600 replay buffers have a large memory footprint, this prevents that
# -It also records the agent's performance, both during training and (if enabled) during an optional evaluation phase.
#
# ## Replay Memory (several neatly wrapped functions)
#
# - Circular Replay
# - Prioritized Replay
# - Sum Tree
#
# ## Tests
#
# - Self explanatory
#
# # Markov Decision Processes
#
# 
#
# 
#
# # Policies
#
# 
#
# - A policy describes a way of acting.
# - It is a function that takes in a state and an action and returns the probability of taking that action in that state.
# -Our goal in reinforcement learning is to learn an optimal policy
# - An optimal policy is a policy which tells us how to act to maximize return in every state.
#
# # Value Functions
#
# 
#
# - To learn the optimal policy, we make use of value functions.
# - There are two types of value functions that are used in reinforcement learning:
# - 2 types: the state value function, denoted V(s), and the action value function, denoted Q(s, a).
# - The state value function describes the value of a state when following a policy. It is the expected return when starting from state s acting according to our policy
#
# 
#
# - The action value function tells us the value of taking an action in some state when following a certain policy. It is the expected return given the state and action
#
# 
#
# # The Bellman Equations
#
# - There are 4 Bellman Equations, lets discuss just 2
# - Theres a Bellman Equation for the state value function and one for the action value function
# - The Bellman equations let us express values of states as values of other states.
# -This means that if we know the value of s_{t+1}, we can very easily calculate the value of s_t.
# - This opens a lot of doors for iterative approaches for calculating the value for each state
# - Since if we know the value of the next state, we can know the value of the current state.
# - The Bellman Equation characterizes the optimal values, dynamic programming (+ other methods) help compute them
#
# 
# + id="WRNPgSEHt02V" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 510} outputId="10517953-494a-4cde-b9d1-d105f8cd299a"
# @title Install necessary packages.
#dopamine for RL
# !pip install --upgrade --no-cache-dir dopamine-rl
# dopamine dependencies
# !pip install cmake
#Arcade Learning Environment
# !pip install atari_py
# + id="Atm0qogwttgW" colab_type="code" colab={}
# @title Necessary imports and globals.
#matrix math
import numpy as np
#load files
import os
#DQN for baselines
from dopamine.agents.dqn import dqn_agent
#high level agent-environment excecution engine
from dopamine.atari import run_experiment
#visualization + data downloading
from dopamine.colab import utils as colab_utils
#warnings
from absl import flags
#where to store training logs
BASE_PATH = '/tmp/colab_dope_run' # @param
#which arcade environment?
GAME = 'Asterix' # @param
# + id="FDbx7hFduBJ9" colab_type="code" colab={}
# @title Create a new agent from scratch.
#define where to store log data
LOG_PATH = os.path.join(BASE_PATH, 'basic_agent', GAME)
class BasicAgent(object):
"""This agent randomly selects an action and sticks to it. It will change
actions with probability switch_prob."""
def __init__(self, sess, num_actions, switch_prob=0.1):
#tensorflow session
self._sess = sess
#how many possible actions can it take?
self._num_actions = num_actions
# probability of switching actions in the next timestep?
self._switch_prob = switch_prob
#initialize the action to take (randomly)
self._last_action = np.random.randint(num_actions)
#not debugging
self.eval_mode = False
#How select an action?
#we define our policy here
def _choose_action(self):
if np.random.random() <= self._switch_prob:
self._last_action = np.random.randint(self._num_actions)
return self._last_action
#when it checkpoints during training, anything we should do?
def bundle_and_checkpoint(self, unused_checkpoint_dir, unused_iteration):
pass
#loading from checkpoint
def unbundle(self, unused_checkpoint_dir, unused_checkpoint_version,
unused_data):
pass
#first action to take
def begin_episode(self, unused_observation):
return self._choose_action()
#cleanup
def end_episode(self, unused_reward):
pass
#we can update our policy here
#using the reward and observation
#dynamic programming, Q learning, monte carlo methods, etc.
def step(self, reward, observation):
return self._choose_action()
def create_basic_agent(sess, environment):
"""The Runner class will expect a function of this type to create an agent."""
return BasicAgent(sess, num_actions=environment.action_space.n,
switch_prob=0.2)
# Create the runner class with this agent. We use very small numbers of steps
# to terminate quickly, as this is mostly meant for demonstrating how one can
# use the framework. We also explicitly terminate after 110 iterations (instead
# of the standard 200) to demonstrate the plotting of partial runs.
basic_runner = run_experiment.Runner(LOG_PATH,
create_basic_agent,
game_name=GAME,
num_iterations=200,
training_steps=10,
evaluation_steps=10,
max_steps_per_episode=100)
# + id="EYACjtrtuEgt" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 13668} outputId="f416de1e-d7a8-4883-b565-def9f40dde25"
# @title Train Basic Agent.
print('Will train basic agent, please be patient, may be a while...')
basic_runner.run_experiment()
print('Done training!')
# + id="gzwHF0k0vetd" colab_type="code" colab={}
# @title Load baseline data
# !gsutil -q -m cp -R gs://download-dopamine-rl/preprocessed-benchmarks/* /content/
experimental_data = colab_utils.load_baselines('/content')
# + id="Njtxlx3auIXW" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="fec4129c-263f-4f35-8424-8d0aa3b04708"
# @title Load the training logs.
basic_data = colab_utils.read_experiment(log_path=LOG_PATH, verbose=True)
basic_data['agent'] = 'BasicAgent'
basic_data['run_number'] = 1
experimental_data[GAME] = experimental_data[GAME].merge(basic_data,
how='outer')
# + id="G556kKh1uKWN" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 512} outputId="4c838e06-3e2b-47b7-9b69-dc33275c11c4"
# @title Plot training results.
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(16,8))
sns.tsplot(data=experimental_data[GAME], time='iteration', unit='run_number',
condition='agent', value='train_episode_returns', ax=ax)
plt.title(GAME)
plt.show()
| Google_Dopamine_(LIVE).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: pytorch
# language: python
# name: pytorch
# ---
# # Creating a Neural-Network from scratch
# > A tutorial to code a neural network from scratch in python using numpy.
#
# - toc: false
# - badges: true
# - comments: true
# - categories: [machinelearning, deeplearning, python3.x, numpy]
# - image: images/backprop.jpeg
# I will assume that you all know what a artificial neural network is and have a little bit of knowledge about `forward and backward propagation`. Just having a simple idea is enough.
#
# > Tip: If you do not know what the above terms are or would like to brush up on the topics, I would suggest going through this amazing [youtube playlist](https://www.youtube.com/watch?v=aircAruvnKk&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi) by [3Blue1Brown](https://www.3blue1brown.com/).
# > youtube: https://www.youtube.com/watch?v=aircAruvnKk&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
# ## Setting up Imports:
import numpy as np
import gzip
import pickle
import pandas as pd
import matplotlib.pyplot as plt
#hide_input
import warnings
np.random.seed(123)
# %matplotlib inline
warnings.filterwarnings("ignore")
# ## Preparing the data
# For this blog post, we'll use one of the most famous datasets in computer vision, [MNIST](https://en.wikipedia.org/wiki/MNIST_database). MNIST contains images of handwritten digits, collected by the National Institute of Standards and Technology and collated into a machine learning dataset by <NAME> and his colleagues. Lecun used MNIST in 1998 in [Lenet-5](http://yann.lecun.com/exdb/lenet/), the first computer system to demonstrate practically useful recognition of handwritten digit sequences. This was one of the most important breakthroughs in the history of AI.
# Run the code given below to download the `MNIST` dataset.
# ```shell
# wget -P path http://deeplearning.net/data/mnist/mnist.pkl.gz
# ```
#
# > Note: the above code snippet will download the dataset to `{path}` so be sure to set the `{path}` to the desired location of your choice.
# +
def get_data(path):
"""
Fn to unzip the MNIST data and return
the data as numpy arrays
"""
with gzip.open(path, 'rb') as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
return map(np.array, (x_train,y_train,x_valid,y_valid))
# Grab the MNIST dataset
x_train,y_train,x_valid,y_valid = get_data(path= "../../Datasets/mnist.pkl.gz")
tots,feats = x_train.shape
print("Shape of x_train:",x_train.shape)
print("Total number of examples:", tots)
print("Number of pixel values per image:", feats)
# -
# ## Preparing our `train` & `validation` datasets
# To make our life a bit easier we are going to take only the examples that contain a 1 or 0.
# +
zero_mask = [y_train==0] # grab all the index values where 0 is present
one_mask = [y_train==1] # grad all the index valus where 1 is present
# grab all the 1's and 0's and make training set
x_train = np.vstack((x_train[zero_mask], x_train[one_mask]))
y_train = np.reshape(y_train, (-1,1))
y_train = np.squeeze(np.vstack((y_train[zero_mask], y_train[one_mask]))).reshape(-1,1)
x_train.shape, y_train.shape
# -
# **Our training set now has 10610 examples**
# +
zero_mask = [y_valid==0] # grab all the index values where 0 is present
one_mask = [y_valid==1] # grad all the index valus where 1 is present
# grab all the 1's and 0's and make training set
x_valid = np.vstack((x_valid[zero_mask], x_valid[one_mask]))
y_valid = np.reshape(y_valid, (-1,1))
y_valid = np.squeeze(np.vstack((y_valid[zero_mask], y_valid[one_mask]))).reshape(-1,1)
x_valid.shape, y_valid.shape
# -
# **Our validation set now has 2055 examples**
# **Why do we need different training and validation sets ?**
#
# Since, this topic requires a different post on it's own I won't be covering it here. But you can get the idea from this above video:
#
# > youtube: https://youtu.be/1waHlpKiNyY?t=243
# Let's view some example images from our dataset:
#collapse
plt.imshow(x_train[50].reshape(28,28), cmap="gray");
#collapse
plt.imshow(x_train[5000].reshape(28,28), cmap="gray");
# ## Basic Model Architecture
# For this task we are going to use a very basic model architecture this 2 linear layers and a output layer with 1 unit.
#hide_input
import graphviz
def gv(s): return graphviz.Source('digraph G{ rankdir="LR"' + s + '; }')
# ## Let's take a deep dive into what this network means:
# Let's take at look at all the individual components of this network:
# - **Linear:**
# The linear layer computes the following :
# ```
# out = matmul(input,W1) + B1
# ```
#
# - **ReLU:**
# The relu computes the following:
# ```
# out = max(0, input)
# ```
# - **Sigmoid:**
# The sigmoid computes the following:
# ```
# out = 1/(1 + e.pow(input))
# ```
#
# - **Loss:**
# For the loss we are going to use the CrossEntropy Loss which is defined by the follwoing equation:
# $$loss= -\frac{1}{m} \sum\limits_{i = 1}^{m} (y^{(i)}\log\left(yhat^{(i)}\right) + (1-y^{(i)})\log\left(1-yhat^{(i)}\right)) $$
# **Now that we have our model architecture, let's create the different parts needed to assemble the model:**
# - linear layer
# - relu activation
# - sigmoid activation
# - loss
# **Let's first try to make some sense of what is happening in the backward and forward pass of our model:**
# **On paper our forward pass would look something like this:**
#
# > Note: `@` in python is the `matrix-multiplication operator`.
#
# ```python
# inputs = x_train # original inputs
# targets = y_train # original targets
#
# # forward pass for the 1st linear layer
# z1 = inputs @ w2 + b2
# a1 = relu(z1)
# # forward pass for the 2nd linear layer
# z2 = a1 @ w2 + b2
# a2 = relu(z2)
# # forward pass for the output linear layer
# z3 = a2 @ w3 + b3
# pred = a3 = sigmoid(z3) # these are our model predictions
# # calculate loss between original targets & model predictions
# loss = loss_fn(a3, targets)
# ```
# > Note: This is not actual code it's just psuedo-code for understanding.
# **Forward pass :**
#hide_input
gv('''
X->linear1->relu1->linear2->relu2->linear3->sigmoid->prediction
W1->linear1
B1->linear1
W2->linear2
B2->linear2
W3->linear3
B3->linear3
''')
#hide_input
gv('''
prediction->loss_fn
target->loss_fn
loss_fn-> loss
''')
# **Consequently our backward pass would look something like this :**
#
# (Let us assume that the `grad(inp, out)` computes the gradients of `inp` wrt `out`)
#
# ```python
# # gradient of loss wrt to the output of the last activation layer: (a3)
# # (or the predictions of model)
# da3 = grad(loss, a3)
#
# # gradient of loss wrt to the output of the current linear layer: (z3)
# dz3 = grad(loss, z3) = grad(loss, a3) * grad(a3, z3)
# # gradient of loss wrt to w3
# dw3 = grad(loss, w3) = grad(loss, z3) * grad(z3, w3) = dz3 * grad(z3, w3)
# # gradient of loss wrt to b3
# db3 = grad(loss, b3) = grad(loss, z3) * grad(z3, b3) = dz3 * grad(z3, b3)
# # gradient of loss wrt to the input of the current linear layer: (a2)
# da2 = grad(loss, a2) = grad(loss, a3) = grad(a2, )
#
# # gradient of loss wrt to the output of the current linear layer: (z2)
# dz2 = grad(loss, z2) = grad(loss, a2) * grad(a2, z2)
# # gradient of loss wrt to w2
# dw2 = grad(loss, w2) = grad(loss, z2) * grad(z2, w2) = dz2 * grad(z2, w2)
# # gradient of loss wrt to b2
# db2 = grad(loss, b2) = grad(loss, z2) * grad(z2, b2) = dz2 * grad(z2, b2)
# # gradient of loss wrt to the input of the current linear layer: (a1)
# da1 = grad(loss, a1) = grad(loss, z2) * grad(z2, a1) = dz2 * grad(z2, a1)
#
# # gradient of loss wrt to the output of the current linear layer: (z1)
# dz1 = grad(loss, z1) = grad(loss, a1) * grad(a1, z1) = da1 * grad(a1, z1)
# # gradient of loss wrt to w1
# dw1 = grad(loss, w1) = grad(loss, z1) * grad(z1, w1) = dz1 * grad(z1, w1)
# # gradient of loss wrt to b1
# db1 = grad(loss, b1) = grad(loss, z1) * grad(z1, 1) = dz1 * grad(z1, b1)
# # In this layer the inputs are out training examples which we cannot change so
# # we do not need to commpute more gradients
#
# # Update parameters :
# # since we now have all the required gradients we can now perform the update step
# w1 -= learning_rate * dw1
# b1 -= learning_rate * db1
#
# w2 -= learning_rate * dw2
# b2 -= learning_rate * db2
# ```
# > Note: This is not actual code it's just psuedo-code for understanding.
# **Backward pass:**
#hide_input
gv('''
Loss -> sigmoid->linear3
linear3->W3
linear3->B3
linear3->relu2->linear2
linear2->W2
linear2->B2
linear2->relu1->linear1
linear1->W1
linear1->B1
''')
# ### The `Linear` Layer
# Below code creates a `Linear class` which represents a `Linear` layer in our neural-network. The `forward function` of the class implements the of the `layer's forward propagation` & the `backward function` implements the `layers's backward propagation`. Let's go to detail into what the code means:
#
# - **Forward:**
# This part is quite straight-forward it computes the dot-product between the **`input`** and the **`weights`** & adds the **`bias`** term to get **`z`**. It also stores all the intermidiate values generated to use in the backward pass.
#
#
# - **Backward:**
# * The backward method of the class **`Linear`** takes in the argument **`grads`**.
# * **`grads`** is the gradient of the loss wrt to the output of the current linear layer ie., **`dz`** if we were to follow the nomenclature of our pseudo-code.
# * To succesfully compute the backward pass for our linear layer we need the following:
# - **`grad(z, w)`**
# - **`grad(z, b)`**
# - **`grad(z, a_prev)`**
#
#
# > Note: `z`, `w`, `b`, `a_prev` are the outputs, weights, bias and input-activations of the Linear layer respectively.
class Linear:
def __init__(self, w, b):
self.w = w
self.b = b
def forward(self, inp):
"""
Implement the linear part of a layer's forward propagation.
Args:
inp : activations from previous layer (or input data)
Returns:
z : the input of the activation function, also called pre-activation parameter
"""
self.inp = inp
self.z = inp @ self.w + self.b
return self.z
def backward(self, grads):
"""
Implement the linear portion of backward propagation for a single layer.
Args:
grads : Gradient of the cost with respect to the linear output.
or the accumulated gradients from the prev layers.
This is used for the chain rule to compute the gradients.
Returns:
da : Gradient of cost wrt to the activation of the previous layer or the input of the
current layer.
dw : Gradient of the cost with respect to W
db : Gradient of the cost with respect to b
"""
m = self.inp.shape[1]
# gradient of loss wrt to the weights
dw = 1/m * (self.inp.T @ grads)
# gradient of the loss wrt to the bias
db = 1/m * np.sum(grads, axis=0, keepdims=True)
# gradient of the loss wrt to the input of the linear layer
# this is used to continue the chain rule
da_prev = grads @ self.w.T
return (da_prev, dw, db)
# ### The `ReLU` Layer
# - **Forward**:
# The mathematical formula for ReLU is $A = RELU(Z) = max(0, Z)$
# - **Backward**:
# During the backward pass the relu accepts the gradients of the `loss wrt to the activation` i.e, `da` then computes
# the gradients of the `loss wrt to the input-of-relu(z)` i.e, `dz`.
class RelU:
def forward(self, inp):
"""
Implement the RELU function.
Args:
inp : Output of the linear layer, of any shape
Returns:
a : Post-activation parameter, of the same shape as Z
"""
self.inp = inp
self.output = np.maximum(0, self.inp)
return self.output
def backward(self, grads):
"""
Implement the backward propagation for a single RELU unit.
Ars:
grads : gradients of the loss wrt to the activation output
Returns:
dz : Gradient of the loss with respect to the input of the activation
"""
dz = np.array(grads, copy=True)
dz[self.inp <= 0] = 0
return dz
# ### The `sigmoid` Layer
# The sigmoid layer functions in exactly the same way as the `ReLU` layer . The only difference is the forward pass output calculation.
#
#
# In the `sigmoid layer`: $\sigma(Z) = \frac{1}{ 1 + e^{-(W A + b)}}$
class Sigmoid:
def forward(self, inp):
"""
Implements the sigmoid activation in numpy
Args:
inp: numpy array of any shape
Returns:
a : output of sigmoid(z), same shape as inp
"""
self.inp = inp
self.out = 1/(1+np.exp(-self.inp))
return self.out
def backward(self, grads):
"""
Implement the backward propagation for a single sigmoid unit.
Args:
grads : gradients of the loss wrt to the activation output
Returns:
dz : Gradient of the loss with respect to the input of the activation
"""
s = 1/(1+np.exp(-self.inp))
dz = grads * s * (1-s)
return dz
# ## `Loss` function :
# For this task we are going to use the [CrossEntropy Loss](https://en.wikipedia.org/wiki/Cross_entropy)
#
# The `forward` pass of the CrossEntropy Loss is computed as follows:
# $$loss= -\frac{1}{m} \sum\limits_{i = 1}^{m} (y^{(i)}\log\left(yhat^{(i)}\right) + (1-y^{(i)})\log\left(1-yhat^{(i)}\right)) $$
class CELoss():
def forward(self, pred, target):
"""
Implement the CrossEntropy loss function.
Args:
pred : predicted labels from the neural network
target : true "label" labels
Returns:
loss : cross-entropy loss
"""
self.yhat = pred
self.y = target
m = self.y.shape[0]
# commpute loss
term1 = (np.multiply(self.y, np.log(self.yhat)))
term2 = (np.multiply((1-self.y),(np.log(1-self.yhat))))
loss = -1/m * np.sum(term1+term2)
self.output = loss
return np.squeeze(self.output) # convert array to a single value number
def backward(self):
"""
Computes the gradinets of the loss_fn wrt to the predicted labels
Returns:
da : derivative of loss_fn wrt to the predicted labels
"""
# derivative of loss_fn with respect to a [predicted labels]
da = - (np.divide(self.y, self.yhat) - np.divide(1 - self.y, 1 - self.yhat))
return da
# ## Model:
#
# **Let's go over the architecture that we are going to use for our neural netwok:**
#
# - Our model is going to have 2 hidden layers and a output layer.
# - The 2 `hidden layers` `(linear layers)` are going to have `16 units` each followed by a `ReLU` activation layer and the `output layer` `(linear layer)` is going to have `1 unit` followed by a `Sigmoid` unit.
# - The output layer is going to predict the `probability` of wether the given input is either a `0` or a `1`. If the predicted probability is `> 0.5 we` will assumse that the `predicted output` is `1` else `0`.
# Let's assemble the layers required to construct out model:
# **These are our inputs and targets:**
# +
#collapse
print("Shape of Inputs:", x_train.shape)
print("Shape of Targets:", y_train.shape)
fig = plt.figure(figsize=(12,5))
for i in range(10):
n = np.random.randint(len(x_train))
val = x_train[n]
ax = plt.subplot(2, 5, i+1)
plt.imshow(val.reshape(28,28), cmap="binary")
plt.title(f"Target value: {y_train[n].squeeze()}")
plt.axis("off")
# -
# **Initialize model parameters:**
# +
#hide_output
nh1 = 16 # no. of units in the first hidden layer
nh2 = 16 # no. of units in the 2nd hidden layer
nh3 = 1 # no. of units in the output layer
w1 = np.random.randn(x_train.shape[1], nh1) * 0.01
b1 = np.zeros((1, nh1))
w2 = np.random.randn(nh1, nh2) * 0.01
b2 = np.zeros((1, nh2))
w3 = np.random.randn(nh2, nh3)
b3 = np.zeros((1, nh3))
w1.shape, b1.shape, w2.shape, b2.shape, w3.shape, b3.shape
# -
# **Instaniating the layers needed to construct our model:**
# +
lin1 = Linear(w1,b1) # 1 hidden layer
relu1 = RelU()
lin2 = Linear(w2,b2) # 2nd hidden layer
relu2 = RelU()
lin3 = Linear(w3,b3) # output layer
sigmoid = Sigmoid()
loss_fn = CELoss() # loss_fn
# -
# ### Forward pass:
# +
# forward pass
z1 = lin1.forward(x_train)
a1 = relu1.forward(z1)
z2 = lin2.forward(a1)
a2 = relu2.forward(z2)
z3 = lin3.forward(a2)
pred = a3 = sigmoid.forward(z3)
# calculate loss
loss = loss_fn.forward(pred, y_train)
print("Loss:", loss) # print out the loss
# -
# ### Backward pass:
# +
# backward pass
da3 = loss_fn.backward() # gradient of loss wrt to final output
dz3 = sigmoid.backward(da3)
da2, dw3, db3 = lin3.backward(dz3)
dz2 = relu2.backward(da2)
da1, dw2, db2 = lin2.backward(dz2)
dz1 = relu1.backward(da1)
_, dw1, db1 = lin1.backward(da1)
# check if the parameters and the gradients are of same shape
# so that we can preform the update state
assert lin1.w.shape == dw1.shape
assert lin2.w.shape == dw2.shape
assert lin3.w.shape == dw3.shape
assert lin1.b.shape == db1.shape
assert lin2.b.shape == db2.shape
assert lin3.b.shape == db3.shape
# -
# ### Update parameters:
# +
# set learning rate
learning_rate = 0.0002
# update parameters
lin1.w -= learning_rate * dw1
lin2.w -= learning_rate * dw2
lin3.w -= learning_rate * dw3
lin1.b -= learning_rate * db1
lin2.b -= learning_rate * db2
lin3.b -= learning_rate * db3
# -
# So, this is how our training our model is going to look we first calculate the `loss` of the model during the `forward pass` , then we calculate the gradients of the `loss` wrt to the `parameters` of the model. After which these `gradients` are used to `update the model parameters`. We continue this workflow for a certain number of `iterations` or until our `loss` reaches the desired value.
#
# Let's code up a class which will make this steps easir to achieve.
# ### Putting it all together:
# - **Initializing parameters:**
# +
#hide_output
# Instantiate parameters
nh1 = 16 # no. of units in the first hidden layer
nh2 = 16 # no. of units in the 2nd hidden layer
nh3 = 1 # no. of units in the output layer
w1 = np.random.randn(x_train.shape[1], nh1) * 0.01
b1 = np.zeros((1, nh1))
w2 = np.random.randn(nh1, nh2) * 0.01
b2 = np.zeros((1, nh2))
w3 = np.random.randn(nh2, nh3)
b3 = np.zeros((1, nh3))
w1.shape, b1.shape, w2.shape, b2.shape, w3.shape, b3.shape
# -
# For our convenice, we will create a `Model` class .
#
# This `Model` class will store all the parameters for our neural-network.
# The `forward` method will compute the `forward pass` of the network to generate the `loss` (and or `predictions`) of the model. The `backward` method will compute the `backward pass` of the network to get the gradinets of the `loss` wrt to the `parameters` of the model. Finally the `update` method will update the parameters of the model.
class Model:
def __init__(self, learning_rate):
"""
A simple neural network model
The `forward` method computes the forward propagation step of the model
The `backward` method computes the backward step propagation of the model
The `update_step` method updates the parameters of the model
"""
self.lin1 = Linear(w1,b1) # 1st linear layer
self.relu1 = RelU() # 1st activation layer
self.lin2 = Linear(w2,b2) # 2nd linear layer
self.relu2 = RelU() # 2nd activation layer
self.lin3 = Linear(w3,b3) # 3rd linear layer
self.sigmoid = Sigmoid() # 3rd activation layer
self.loss_fn = CELoss() # loss_fn
# learning_rate to update model parameters
self.lr = learning_rate
# stores the loss at each iteration
self.losses = []
def forward(self, inp, calc_loss=True, targ=None):
"""
Computs the forward step for out model Additionally
it also returns the loss [Optional] and the predictions
of the model.
Args:
inp : the training set.
calc_loss : wether to calculate loss of the model if False only predictions
are calculated.
targ : the original targets to the training set.
Note: to calculate the `loss` the `targ` must be given
Returns:
pred : outputs of the 3rd activation layer.
loss : [Optional] loss the model , if the `targ` is given.
"""
out = self.relu1.forward(self.lin1.forward(inp))
out = self.relu2.forward(self.lin2.forward(out))
pred = self.sigmoid.forward(self.lin3.forward(out))
if calc_loss:
assert targ is not None, "to calculate loss targets must be given"
loss = self.loss_fn.forward(pred, targ)
# appending the loss of the current iteration
self.losses.append(loss)
return loss, pred
else:
return pred
def _assert_shapes(self):
"""
Checks the shape of the parameters and the gradients of the model
"""
assert lin1.w.shape == dw1.shape
assert lin2.w.shape == dw2.shape
assert lin3.w.shape == dw3.shape
assert lin1.b.shape == db1.shape
assert lin2.b.shape == db2.shape
assert lin3.b.shape == db3.shape
def backward(self):
"""
Computes the backward step
and return the gradients of the parameters with the loss
"""
da3 = self.loss_fn.backward()
dz3 = self.sigmoid.backward(da3)
da2, dw3, db3 = self.lin3.backward(dz3)
dz2 = self.relu2.backward(da2)
da1, dw2, db2 = self.lin2.backward(dz2)
dz1 = self.relu1.backward(da1)
_, dw1, db1 = self.lin1.backward(dz1)
self._assert_shapes()
self.dws = [dw1, dw2, dw3]
self.dbs = [db1, db2, db3]
def update(self):
"""
Performs the update step
"""
self.lin1.w -= self.lr * self.dws[0]
self.lin2.w -= self.lr * self.dws[1]
self.lin3.w -= self.lr * self.dws[2]
self.lin1.b -= self.lr * self.dbs[0]
self.lin2.b -= self.lr * self.dbs[1]
self.lin3.b -= self.lr * self.dbs[2]
# +
nn = Model(learning_rate=0.0005)
epochs = 60 # no. of iterations to train
for n in range(epochs):
loss, _ = nn.forward(x_train, calc_loss=True, targ=y_train)
nn.backward()
nn.update()
print(f"Loss after interation {n} is {loss:.4f}")
# -
#collapse
plt.plot(nn.losses, color="teal")
plt.title("Loss per Iteration")
plt.xlabel("Iteration")
plt.ylabel("Loss");
# ## Computing accuracy of our model
# **Let's check our model performance by computing the `accuracy` on the `validation` dataset**
def comp_accuracy(preds, targs):
"""
Fn that computes the accuracy between the predicted values and the targets
"""
m = len(targs)
p = np.zeros_like(preds)
# convert probas to 0/1 predictions
for i in range(len(preds)):
if preds[i] > 0.5:
p[i] = 1
else:
p[i] = 0
print("Accuracy: " + str(np.sum((p == targs)/m)))
# computing accuracy on the train set:
preds = nn.forward(x_train, calc_loss=False) # generate predictions from our model
# compute accuracy
comp_accuracy(preds, y_train)
# computing accuracy on the validation set:
preds = nn.forward(x_valid, calc_loss=False) # generate predictions from our model
# compute accuracy
comp_accuracy(preds, y_valid)
# > Note: our model achieved a `accuracy` of **`0.99`** on both the `train` and the `validation` set !
# ## Generating predictions from the model
# +
#collapse
test_inp = x_valid[0] # one example from the validation set
plt.title("Input: ")
plt.imshow(test_inp.reshape(28,28), cmap="binary")
plt.show()
pred = nn.forward(test_inp, calc_loss=False)
predicted_val = int(pred > 0.5)
print(f"Predicted output: {predicted_val}")
# +
#collapse
test_inp = x_valid[2000] # one example from the validation set
plt.title("Input: ")
plt.imshow(test_inp.reshape(28,28), cmap="binary")
plt.show()
pred = nn.forward(test_inp, calc_loss=False)
predicted_val = int(pred > 0.5)
print(f"Predicted output: {predicted_val}")
# -
# ## Summary:
# - We were able to create a model that can identify classify handwritten digits as either 1's or 0's
# - We successfully computed the `forward` and `backward` progation of a `neural network` from scratch.
# **Thanks for reading !**
| _notebooks/2020-09-22-nn-from-scratch.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Looping using while
_test = ["AUD","IDR","JPY","USD","GBP"]
i = 0
while i < len(_test) :
print(_items[i])
i+=1
# +
# Looping for
_vars = {
"username" : "reshaffa",
"email" : "<EMAIL>",
"access" : "superadmin"
}
for x,y in _vars.items() :
print(y)
# -
# Looping in dictionaries
_users = {
"user1" : {
"userId" : 1,
"name" : "<NAME>"
},
"user2" : {
"userId" : 2,
"name" : "<NAME>"
},
"user3" : {
"userId" : 3,
"name" : "<NAME>"
}
}
print(_users)
| #01 Python Fundamental/#12_looping_statement.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.7.4 32-bit
# name: python374jvsc74a57bd0b39ab04170b6c60b52a31d4a7ab4d204539d261a537423dd50ae2a4297d5cc93
# ---
# # "Problem 1: Multiples of 3 and 5"
# > Utilitize the basic properties of multiples and sums.
#
# - permalink: p1
# - toc: true
# - badges: true
# - comments: true
# - categories: [solution]
# ## 🔒 [Problem](https://projecteuler.net/problem=1)
#
# If we list all the natural numbers below 10 that are multiples of 3 or 5, we get 3, 5, 6 and 9. The sum of these multiples is 23.
#
# Find the sum of all the multiples of 3 or 5 below 1000.
#
# ### 🔐 Key Idea
# using mathematical concepts to reduce the iteration number
# ## 🔑 Solution
#
# ### 🧭 Initial idea
#
# $O(1)$ complexity.
#
# Using the mathematical concept of sum of multiples exists as a pair in a range.
#
# For example, for the sum of multiples of 2 not exceeding 8, there would be 5 pairs with equal sum: (2, 8), (4, 6). These pairs sum to 2 + 8, which is the minimum and the maximum multiple. Numbers with odd number of multiples, we can just add `(min + max) // 2` to the sum.
# +
# Target number used to limit iteration
k = 999
f = [3, 5, 15] # factors
n = [k//3, k//5, k//15] # number of multiples
max = [k - k%3, k - k%5, k - k%15] # biggest multiples for each factor
sum = [] # sum of each factors
for i in range(3):
minmax = f[i] + max[i]
s = (n[i] // 2) * minmax
if n[i] % 2 is 1:
s += minmax // 2
sum.append(s)
print(str(sum[0] + sum[1] - sum[2]))
# -
# > WARNING: Since it's defined in the problem as *'below 1000'*, it shouldn't contain 1000.
#
# <br/>
#
# > TIP: Consider the range with operands such as `<`, `>`, etc.
#
# <br/>
#
# > NOTE: Clarify the *range* of the problem before diving into it.
# ### 🔨 Bruteforce method
#
# $O(n)$ complexity.
# +
s = 0
for i in range(1000):
if i % 3 is 0 or i % 5 is 0:
s += i
print(s)
# -
# ### 🔁 Function method (from overview)
#
# $O(1)$ complexity.
#
# > TIP: Use functons or external blocks for complicated for loops or loops with small iteration count.
# +
k = 999
def get_multiple_sum(f):
n = k // f
max = k - k % f
sum = (f + max) * (n // 2)
if n % 2 is 1:
sum += (f + max) // 2
return sum
print(str(get_multiple_sum(3) + get_multiple_sum(5) - get_multiple_sum(15)))
| _notebooks/2021-06-10-p1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # WeatherPy
# ----
#
# #### Note
# * Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.
# +
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import time
from scipy.stats import linregress
# Import API key
from api_keys import weather_api_key
# Incorporated citipy to determine city based on latitude and longitude
from citipy import citipy
# Output File (CSV)
output_data_file = "output_data/cities.csv"
# Range of latitudes and longitudes
lat_range = (-90, 90)
lng_range = (-180, 180)
# -
units = "metric"
url = "http://api.openweathermap.org/data/2.5/weather?"
# weather_api_key = "58d8fb8ea04b85df327bf2aea1d25a06"
##query_cityName = "q={city name},{country code}"
##query_zip = "zip={" + zip_code + "},{" + country_code + "}"
query_url = f"{url}appid={weather_api_key}&units={units}&q="
output = requests.get(query_url+"london").json()
output
output["clouds"]["all"]
# ## Generate Cities List
# +
# List for holding lat_lngs and cities
lat_lngs = []
cities = []
# Create a set of random lat and lng combinations
lats = np.random.uniform(low=-90.000, high=90.000, size=1500)
lngs = np.random.uniform(low=-180.000, high=180.000, size=1500)
lat_lngs = zip(lats, lngs)
# Identify nearest city for each lat, lng combination
for lat_lng in lat_lngs:
city = citipy.nearest_city(lat_lng[0], lat_lng[1]).city_name
# If the city is unique, then add it to a our cities list
if city not in cities:
cities.append(city)
# Print the city count to confirm sufficient count
len(cities)
## for city in cities[:20]:
## print(city)
# -
# ### Perform API Calls
# * Perform a weather check on each city using a series of successive API calls.
# * Include a print log of each city as it'sbeing processed (with the city number and city name).
#
weather_data=[]
counter=0
for city in cities[:50]:
## print(city)
json = requests.get(query_url + city).json()
counter=counter+1
try:
tempmax=json["main"]['temp_max']
humidity=json["main"]["humidity"]
speed=json['wind']["speed"]
cloudiness=json["clouds"]["all"]
lat=json["coord"]["lat"]
country=json['sys']["country"]
date=json['dt']
lon=json["coord"]["lon"]
data.append([city,cloudiness,country,date,humidity,lat,lon,tempmax,speed])
## data.append([city,temp,temp1,temp2,temp3,temp6,temp4,temp5,temp7])
print(f"counter {counter} |^| {city}")
time.sleep(.1)
except:
print("city not found")
# +
# weather_data = []
# counter = 0
# for city in cities[:10]:
# result = requests.get(query_url + city).json()
# counter = counter + 1
# try:
# cloudiness = result["clouds"]["all"]
# country = result["sys"]["country"]
# date = result["dt"]
# humidity = result["main"]["humidity"]
# lat = result["coord"]["lat"]
# lng = result["coord"]["lon"]
# maxTemp = result["main"]["temp_max"]
# windSpeed = result["wind"]["speed"]
# weather_data.append([city, cloudiness, country, date, humidity, lat, lng, maxTemp, windSpeed])
# time.sleep(.2)
# except:
# print("City not found")
# -
# ### Convert Raw Data to DataFrame
# * Export the city data into a .csv.
# * Display the DataFrame
# ### Plotting the Data
# * Use proper labeling of the plots using plot titles (including date of analysis) and axes labels.
# * Save the plotted figures as .pngs.
# #### Latitude vs. Temperature Plot
# #### Latitude vs. Humidity Plot
# #### Latitude vs. Cloudiness Plot
# #### Latitude vs. Wind Speed Plot
# ## Linear Regression
# OPTIONAL: Create a function to create Linear Regression plots
# Create Northern and Southern Hemisphere DataFrames
# #### Northern Hemisphere - Max Temp vs. Latitude Linear Regression
# #### Southern Hemisphere - Max Temp vs. Latitude Linear Regression
# #### Northern Hemisphere - Humidity (%) vs. Latitude Linear Regression
# #### Southern Hemisphere - Humidity (%) vs. Latitude Linear Regression
# #### Northern Hemisphere - Cloudiness (%) vs. Latitude Linear Regression
# #### Southern Hemisphere - Cloudiness (%) vs. Latitude Linear Regression
# #### Northern Hemisphere - Wind Speed (mph) vs. Latitude Linear Regression
# #### Southern Hemisphere - Wind Speed (mph) vs. Latitude Linear Regression
| starter_code/WeatherPy.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.8 64-bit (''base'': conda)'
# language: python
# name: python3
# ---
# +
import pickle
import numpy as np
import random
import pandas as pd
import datetime
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
# + pycharm={"name": "#%%\n"}
from sklearn.model_selection import GroupShuffleSplit, GridSearchCV
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# + pycharm={"name": "#%%\n"}
def get_data(col: str):
with open('data.pickle', 'rb') as f:
data = pickle.load(f)
data = [d for d in data if d.bezier_features is not None]
groups = [d.user_id for d in data]
X = [getattr(d, col) for d in data]
y = [d.label for d in data]
return X, y, groups
def split(X, y, groups):
gss = GroupShuffleSplit(n_splits=1, train_size=0.7, random_state=SEED)
train_idx, test_idx = next(gss.split(X, y, groups))
trainX = [X[i] for i in train_idx]
trainY = [y[i] for i in train_idx]
testX = [X[i] for i in test_idx]
testY = [y[i] for i in test_idx]
return trainX, testX, trainY, testY
# -
# # Baseline
# +
now = datetime.datetime.now()
X, y, groups = get_data('data')
X = [x[:, 0:-1] for x in X]
max_len = max([arr.shape[0] for arr in X])
X = [np.pad(arr, ((0, max_len - arr.shape[0]), (0, 0)), 'constant', constant_values=0) for arr in X]
X = [np.concatenate(x) for x in X]
X = np.asarray(X)
print(X.shape)
trainX, testX, trainY, testY = split(X, y, groups)
clf = RandomForestClassifier(n_estimators=60, min_samples_split=4, random_state=SEED)
clf.fit(trainX, trainY)
print("Train accuracy:", accuracy_score(trainY, clf.predict(trainX)))
print("Test accuracy:", accuracy_score(testY, clf.predict(testX)))
print('Time taken: ' + str((datetime.datetime.now() - now).microseconds/1000000))
# -
# # Bezier
#
# +
now = datetime.datetime.now()
X, y, groups = get_data('bezier_features')
X = [x[:, 0:-1] for x in X]
X = [x[~np.isnan(x).any(axis=1)] for x in X]
max_len = max([arr.shape[0] for arr in X])
X = [np.pad(arr, ((0, max_len - arr.shape[0]), (0, 0)), 'constant', constant_values=0) for arr in X]
X = [np.concatenate(x) for x in X]
X = np.asarray(X)
print(X.shape)
trainX, testX, trainY, testY = split(X, y, groups)
clf = RandomForestClassifier(n_estimators=60, min_samples_split=4, random_state=SEED)
clf.fit(trainX, trainY)
print("Train accuracy:", accuracy_score(trainY, clf.predict(trainX)))
print("Test accuracy:", accuracy_score(testY, clf.predict(testX)))
print('Time taken: ' + str((datetime.datetime.now() - now).microseconds/1000000))
# +
gs = GridSearchCV(RandomForestClassifier(), {
'n_estimators': [10, 100, 250, 500],
'criterion': ['gini', 'entropy'],
'max_depth': [None, 5, 10, 25],
'min_samples_split': [0.1, 0.3, 0.7, 1.0],
'max_features': ['sqrt', 'log2']
})
gs.fit(trainX, trainY)
print("Train accuracy:", accuracy_score(trainY, gs.predict(trainX)))
print("Test accuracy:", accuracy_score(testY, gs.predict(testX)))
# -
# ## Late fusion
# +
X, y, groups = get_data('bezier_features')
X = [x[~np.isnan(x).any(axis=1)] for x in X]
trainX, testX, trainY, testY = split(X, y, groups)
fusion = []
results = []
for col_id in range(X[0].shape[1]):
trainX_ = [ x[:, col_id].astype('float64') for x in trainX ]
testX_ = [ x[:, col_id].astype('float64') for x in testX ]
max_len = max(max([arr.shape[0] for arr in trainX_]), max([arr.shape[0] for arr in testX_]))
trainX_ = [np.pad(arr, (0, max_len-arr.shape[0])) for arr in trainX_]
testX_ = [np.pad(arr, (0, max_len-arr.shape[0])) for arr in testX_]
clf = RandomForestClassifier(n_estimators=40, min_samples_split=4, random_state=SEED)
clf.fit(trainX_, trainY)
results.append({
'train_accuracy': np.round(accuracy_score(trainY, clf.predict(trainX_)), 2),
'test_accuracy': np.round(accuracy_score(testY, clf.predict(testX_)), 2)
})
fusion.append(clf.predict_proba(testX_))
fusion_preds = np.argmax(np.mean(np.asarray(fusion), axis=0), axis=1)
print(pd.DataFrame(results))
print('\nTotal test accuracy:', np.round(accuracy_score(testY, fusion_preds), 2))
# + [markdown] pycharm={"name": "#%% md\n"}
# ## Per feature
# + pycharm={"name": "#%%\n"}
X, y, groups = get_data('bezier_features')
classes, _, _ = get_data('type_')
X = [x[~np.isnan(x).any(axis=1)] for x in X]
results = []
for i in np.unique(classes):
row_idx = np.where(classes==i)[0]
X_ = [X[i] for i in row_idx]
y_ = [y[i] for i in row_idx]
groups_ = [groups[i] for i in row_idx]
max_len = max([arr.shape[0] for arr in X_])
X_ = [np.pad(arr, ((0, max_len - arr.shape[0]), (0, 0)), 'constant', constant_values=0) for arr in X_]
X_ = [np.concatenate(x) for x in X_]
X_ = np.asarray(X_)
trainX, testX, trainY, testY = split(X_, y_, groups_)
clf = RandomForestClassifier(n_estimators=60, min_samples_split=4, random_state=SEED)
clf.fit(trainX, trainY)
results.append({
'shape': X_.shape,
'train_accuracy': np.round(accuracy_score(trainY, clf.predict(trainX)), 2),
'test_accuracy': np.round(accuracy_score(testY, clf.predict(testX)), 2)
})
print(pd.DataFrame(results))
| model.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + colab={"base_uri": "https://localhost:8080/"} gradient={} id="54j16swJY1dW" outputId="872bfbec-1238-47be-9d67-532b1d8e9574"
import io
import os
import re
import time
import unicodedata
from itertools import chain
import matplotlib.pyplot as plt
import math
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers.experimental import preprocessing
from deepcomedy.models.transformer import *
from deepcomedy.preprocessing import *
from deepcomedy.utils import *
from deepcomedy.metrics import *
import tqdm
from nlgpoetry.hyphenation import *
# %load_ext autoreload
# %autoreload 2
# + [markdown] gradient={"editing": false} id="8RuMqNB4ujuT" tags=[]
# ## 1. Data preprocessing
# + gradient={} id="jH7n29oxB0z4"
raw_text = open("./data/divina_textonly.txt", "rb").read().decode(encoding="utf-8")
raw_syll_text = (
open("./data/divina_syll_textonly.txt", "rb").read().decode(encoding="utf-8")
)
syll_text = preprocess_text(raw_syll_text, end_of_tercet='')
text = preprocess_text(raw_text, end_of_tercet='')
# + [markdown] id="9ASHyaMBC84V"
# Split preprocessed text into verses
# + gradient={} id="-IF6sE6FC_4J"
sep = "<EOV>"
input_tercets = [x.lstrip() + sep for x in text.split(sep)][:-1]
target_tercets = [x.lstrip() + sep for x in syll_text.split(sep)][:-1]
# + [markdown] id="cdUmYhUKDEuj"
# Encode with input and target tokenizers
# + gradient={} id="-mob1kOzDD4z"
input_tokenizer = tf.keras.preprocessing.text.Tokenizer(
char_level=False, filters="", lower=False
)
input_tokenizer.fit_on_texts(input_tercets)
target_tokenizer = tf.keras.preprocessing.text.Tokenizer(
char_level=False, filters="", lower=False
)
target_tokenizer.fit_on_texts(target_tercets)
enc_input_tercets = input_tokenizer.texts_to_sequences(input_tercets)
enc_target_tercets = target_tokenizer.texts_to_sequences(target_tercets)
input_vocab_size = len(input_tokenizer.word_index) + 1
target_vocab_size = len(target_tokenizer.word_index) + 1
# -
# Get windows of three and four verses on the whole dataset.
# + gradient={} id="xDKv92yAL_t8"
input_text = [] # All windows of three verses (not-syll)
target_text = [] # All windows of four verses (syll)
target_text_tercet = [] # All windows of three verses (syll)
for line in range(len(enc_input_tercets) - 2):
input_text.append(list(chain(*enc_input_tercets[line : line + 3])))
target_text_tercet.append(list(chain(*enc_target_tercets[line : line + 3])))
target_text.append(list(chain(*enc_target_tercets[line : line + 4])))
# + [markdown] id="CY44HP5lKz2-"
# Pad sequences
# + gradient={} id="Pq34y57yK3wd"
padded_input_text = tf.keras.preprocessing.sequence.pad_sequences(
input_text, padding="post"
)
padded_target_text = tf.keras.preprocessing.sequence.pad_sequences(
target_text, padding="post"
)
padded_target_text_tercet = tf.keras.preprocessing.sequence.pad_sequences(
target_text_tercet, padding="post"
)
# + id="KEg3jSHBqx3A"
input_train, input_val, target_train, target_val, target_tercet_train, target_tercet_val = train_test_split(padded_input_text, padded_target_text, padded_target_text_tercet)
# -
# ## 2. Load model
#
# If needed, load the model changing the the parameters accordingly.
# + id="pGbmUKt3hzy5"
config = {
"num_layers" : 4,
"d_model" : 256,
"num_heads" : 4,
"dff" : 512,
}
transformer = load_transformer_model(config, input_vocab_size, target_vocab_size, target_tokenizer, './models/char2char-50-4-4-512.h5')
# + [markdown] id="8LSUOYgsPFvn"
# ## 3. Hyperparameter sweep
#
# We use weights and biases to perform hyperparameter optimization.
# + gradient={} id="JAcuJAgrPOV4" outputId="c6a1335e-c016-45e8-934f-12dd47402344"
sweep_config = {
"name": "char2char-sweep-2",
"method": "grid",
"metric": {"name": "loss", "goal": "minimize"},
"parameters": {
"batch_size": {"value": 32},
"epochs": {"value": 50},
"num_layers": {"values": [4, 8, 12]},
"num_heads": {"values": [4, 8]},
"d_model": {"value": 256},
"dff": {"value": 512},
},
}
sweep_id = wandb.sweep(sweep_config, project='deepcomedy', entity='deepcomedy')
# + colab={"referenced_widgets": [""]} gradient={} id="_ivK7q12PTF8" jupyter={"outputs_hidden": true} outputId="456f33cf-6d2e-4b20-d5d2-b6cae0ff7186" tags=[]
start_symbol = target_tokenizer.word_index["<GO>"]
stop_symbol = target_tokenizer.word_index["<EOV>"]
# Input for generation
encoder_input = [input_text[0]]
decoder_input = [target_text_tercet[0]]
def sweep():
with wandb.init() as run:
config = wandb.config
dataset = make_dataset(input_train, target_train, batch_size=config["batch_size"])
validation_dataset = make_dataset(input_val, target_val, batch_size=config["batch_size"])
model, trainer = make_transformer_model(config, input_vocab_size, target_vocab_size, checkpoint_save_path=None)
trainer.train(dataset, config["epochs"], log_wandb=True, validation_dataset=validation_dataset, validation_every=5)
# Generate
result = generate(model, encoder_input, decoder_input, input_tokenizer, target_tokenizer, 30, start_symbol, stop_symbol)
html_result = re.sub(r'\n', '<br>', result)
wandb.log({"generated": wandb.Html("<pre>" + html_result + "</pre>", inject=False)})
path = './models/char2char-' + str(config['epochs']) + '-' + str(config['num_layers']) + '-' + str(config['num_heads']) + '-' + str(config['dff']) + '.h5'
model.save_weights(path)
wandb.save(path)
# Generation metrics
# avg_syll, hend_ratio, plagiarism, correctness, incorrectness, rhymeness = generation_metrics(result)
avg_syll, hend_ratio, rhymeness, plagiarism, correctness, incorrectness = generation_metrics(result)
wandb.log({
'avg_syll': avg_syll,
'hend_ratio': hend_ratio,
'plagiarism': plagiarism,
'correctness': correctness,
'incorrectness': incorrectness,
'rhymeness': rhymeness,
})
wandb.agent(sweep_id, function=sweep)
# + [markdown] id="4PLTOETK4_m6"
# ## 4. Training
# + gradient={} id="6v2e1bIcLRZi"
dataset = make_dataset(input_train, target_train)
val_dataset = make_dataset(input_val, target_val)
# + gradient={} id="miEcmOVmL0Rt"
config = {
"num_layers" : 4,
"d_model" : 256,
"num_heads" : 4,
"dff" : 512,
}
transformer, transformer_trainer = make_transformer_model(config, input_vocab_size, target_vocab_size, checkpoint_save_path= None)
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} gradient={} id="QaR03YUNL_uF" outputId="7302ba4b-4e25-48b1-d942-2b9efaa12468"
wandb.init()
transformer_trainer.train(dataset, 30, validation_dataset=val_dataset, validation_every=1, log_wandb=True)
# -
# Save model.
save_transformer_model(transformer, 'models/c2c-gen-input_train.h5')
# + [markdown] id="OWt3LC2Zl7UN"
# ## 5. Generation
# + gradient={} id="MLJSJJCVnaKL"
def generate(transformer, input_sequence, target_sequence, input_tokenizer, target_tokenizer, steps, start_symbol, stop_symbol):
result = strip_tokens(target_tokenizer.sequences_to_texts(target_sequence)[0])
encoder_input = input_sequence
decoder_input = target_sequence
for _ in tqdm.tqdm(range(steps)):
encoder_input = tf.convert_to_tensor(encoder_input)
decoder_input = tf.convert_to_tensor(decoder_input)
output = evaluate(transformer, encoder_input, decoder_input, stop_symbol, choose_next_token=choose_topk)
# Detokenize output
generated_text = target_tokenizer.sequences_to_texts(output.numpy())[0]
# Remove structural tokens (<EOV>, <GO>, <SEP>)
generated_text = strip_tokens(generated_text)
# Split into verses
generated_verses = generated_text.split('\n')
# Append last generated verse to result
result = '\n'.join([result, generated_verses[-1]])
# Create input for next step by taking last three verses
next_input = '\n'.join(generated_verses[-3:])
next_input = preprocess_text(next_input, end_of_tercet='')
decoder_input = target_tokenizer.texts_to_sequences([next_input])
# The encoder input should not have syllable separators
encoder_input = remove_syll_token(next_input)
encoder_input = input_tokenizer.texts_to_sequences([encoder_input])
return result
# + gradient={} id="v5ZwOIEml7UP"
start_symbol = target_tokenizer.word_index["<GO>"]
stop_symbol = target_tokenizer.word_index["<EOV>"]
encoder_input = [input_text[0]]
decoder_input = [target_text_tercet[0]]
result = generate(transformer, encoder_input, decoder_input, input_tokenizer, target_tokenizer, 30, start_symbol, stop_symbol)
# + colab={"base_uri": "https://localhost:8080/"} id="Zjxf7FV1hzy_" outputId="06f959e4-f9fe-4f11-d22b-06a5c9eeea3d"
print(result)
# + [markdown] id="jpptrYaFhzzG"
# ### Generation metrics
#
# The following function computes all generation metrics
# + id="ZiRgjaIuhzzH"
original_text = preprocess_text(raw_text, end_of_verse='\n', end_of_tercet='', start_of_verse='', word_level=True)
original_text = re.sub(r' <SEP> ', ' ', original_text)
original_text
# Get the set of real words from the Divine Comedy to evaluate word correctness
# TODO create function to obtain word-level vocabulary from divine comedy
word_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='\n-:,?“‘)—»«!”(";.’ ', lower=False)
word_tokenizer.fit_on_texts([raw_text])
real_words = set(word_tokenizer.word_index.keys())
def generation_metrics(result):
result_verses = result.split("\n")
avg_syll = average_syllables(result_verses)
hend_ratio = correct_hendecasyllables_ratio(result_verses)
result_verses = re.sub(r'\|', '', result)
result_verses = remove_punctuation(result_verses)
plagiarism = ngrams_plagiarism(result_verses, original_text)
gen_tokenizer = tfds.deprecated.text.Tokenizer()
gen_words = gen_tokenizer.tokenize(result_verses)
correctness, _ = correct_words_ratio(gen_words, real_words, return_errors=True)
incorrectness_score = incorrectness(set(gen_words), real_words)
result_verses = result_verses.split('\n')
rhyme_ratio = chained_rhymes_ratio(result_verses)
return avg_syll, hend_ratio, rhyme_ratio, plagiarism, correctness, incorrectness_score
# + colab={"base_uri": "https://localhost:8080/"} gradient={} id="rbN7xd5ZX5_4" outputId="b491f64e-832b-448a-9e4a-f9411728bd81"
avg_syll, hend_ratio, rhyme_ratio, plagiarism, correctness, incorrectness_score = generation_metrics(result)
# + colab={"base_uri": "https://localhost:8080/"} id="zBIvhyErhzzA" outputId="c08cdc7d-509c-4759-cc5a-d78afb07929f"
print("average syllables per verse: {}\nhendecasyllables ratio: {}\nrhyme_ratio: {}\nngrams plagiarism: {}\ncorrectness: {}\nincorrectness_score: {}\n"\
.format(avg_syll, hend_ratio, rhyme_ratio, plagiarism, correctness, incorrectness_score))
# + [markdown] id="XJ8V3_ZIX5_4" tags=[]
# ### Hendecasyllabicness
# + gradient={} id="_imHUafkX5_4"
result_verses = stripped_result.split("\n")
# + gradient={} id="jJlY06MKX5_5"
avg_syll = average_syllables(result_verses)
# + gradient={} id="mF5pJaZjX5_5"
hend_ratio = correct_hendecasyllables_ratio(result_verses)
# + id="xlSQQF2ghzzB" outputId="356b33b1-7a36-4f7e-d864-283dc0c5faf4"
print('Average number of syllables per verse: {}'.format(avg_syll))
print('Ratio of hendecasyllables to total number of verses: {}'.format(hend_ratio))
# + [markdown] id="KoPaDVXkqAGI"
# ### Ngrams plagiarism
# + gradient={} id="QIAsEzakqN5Q"
original_text = preprocess_text(raw_text, end_of_verse='\n', end_of_tercet='', start_of_verse='', word_level=True)
original_text = re.sub(r' <SEP> ', ' ', original_text)
# + id="V7sLJ6QfOtT3"
result_verses = re.sub(r'\|', '', strip_result)
result_verses = remove_punctuation(result_verses)
# + gradient={} id="zXFylUGNqQlu"
plagiarism = ngrams_plagiarism(result_verses, original_text)
# + id="PXrisZtlhzzC" outputId="a1a8cb99-ab68-448b-cd29-c4416e1e5629"
print('Plagiarism: {}'.format(plagiarism))
# + [markdown] id="DGLKbtWoqSoM"
# ### Word correctness
# + id="vwQ5dYpSQbm4"
word_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='\n-:,?“‘)—»«!”(";.’ ', lower=False)
word_tokenizer.fit_on_texts([raw_text])
real_words = set(word_tokenizer.word_index.keys())
# + id="3NaV3qHEQIUB"
gen_tokenizer = tfds.deprecated.text.Tokenizer()
gen_words = gen_tokenizer.tokenize(result_verses)
# + id="LYVbfmW4QPEh"
correctness, errors = correct_words_ratio(gen_words, real_words, return_errors=True)
incorrectness_score = incorrectness(set(gen_words), real_words)
# + id="rIPPZsUChzzE" outputId="ae9e384d-77cd-45df-92de-14742a5a6d2b"
print('Correct words: {:.2f}%'.format(correctness * 100))
# + [markdown] id="KNuLU980hzzE"
# The incorrectness score also considers "how wrong" a word is, by computing the edit distance between an incorrect word and the nearest correct word in the vocabulary.
# + id="rpb2ltTMhzzE" outputId="d383b5d4-10a0-46bf-bb91-5a722e936339"
print('Incorrectness score: {}'.format(incorrectness_score))
# + [markdown] id="1XgsYN5RQw-a"
# ### Rhymeness
# + id="jmBpfTiUQzYZ"
result_verses = result_verses.split('\n')
rhyme_ratio = chained_rhymes_ratio(result_verses)
# + id="XzLN5F0FhzzG" outputId="82945ad7-2116-4b7c-9046-95bfedf53f6d"
print('Correct rhymes ratio: {}'.format(rhyme_ratio))
# + [markdown] id="U46tRTY3l7UP"
# ## 6. Syllabification
#
# ### 6.1 Experiment on the first verses of the Divine Comedy
#
# Let's see how the algorithm performs on the first verses of the Divine Comedy.
# + id="8rQ1rQF3BXn0"
sep = "<EOV>"
input_verses = [x.lstrip() + sep for x in text.split(sep)][:-1]
target_verses = [x.lstrip() + sep for x in syll_text.split(sep)][:-1]
enc_input_verses = input_tokenizer.texts_to_sequences(input_verses)
# + id="0dTkjE0ScUb-"
correct_syll_text = list(map(lambda x: strip_tokens(x), target_verses))
# + id="lkgdEsvgISLL"
padded_input_verses = tf.keras.preprocessing.sequence.pad_sequences(
enc_input_verses, padding="post"
)
# + id="tU_H01fBB-B1"
N=9
start_symbol = target_tokenizer.word_index["<GO>"]
stop_symbol = target_tokenizer.word_index["<EOV>"]
encoder_input = tf.convert_to_tensor(padded_input_verses[:N])
decoder_input = tf.repeat([[start_symbol]], repeats=encoder_input.shape[0], axis=0)
output = evaluate(transformer, encoder_input, decoder_input, stop_symbol, stopping_condition=stop_after_stop_symbol)
# Only take output before the first end of verse
stripped_output_N = list(map(lambda x: x.split('<EOV>')[0], target_tokenizer.sequences_to_texts(output.numpy())))
stripped_output_N = list(map(strip_tokens, stripped_output_N))
# + colab={"base_uri": "https://localhost:8080/"} id="_Psa6_G4CwjG" outputId="4176097e-ab5f-40ab-937c-2f4a66713032"
stripped_output_N
# + colab={"base_uri": "https://localhost:8080/"} id="IkxidoMSa4bp" outputId="4fe6291c-e4c1-43e3-d530-d794dbed0402"
exact_matches, similarities = zip(*validate_syllabification(stripped_output_N, correct_syll_text))
accuracy = sum(exact_matches) / len(exact_matches)
avg_similarities = np.mean(similarities)
print('Syllabification exact matches: {:.2f}%'.format(accuracy * 100))
print('Average similarity: {:.2f}'.format(avg_similarities))
# + [markdown] id="CdOJKFLmkoZo"
# ### 6.2 Syllabification of the validation set
# Validation of the syllabification on input_val
# + id="P8n0ecocsQpQ"
n_verses = len(input_val)
# Obtain tercets from input and target "windows"
syll_input = input_val[:n_verses:3]
syll_input_text = strip_tokens(' '.join(input_tokenizer.sequences_to_texts(syll_input)))
syll_input_text = preprocess_text(syll_input_text, end_of_tercet='')
correct_syll = target_tercet_val[:n_verses:3]
correct_syll_text = strip_tokens(' '.join(target_tokenizer.sequences_to_texts(correct_syll)))
correct_syll_text = correct_syll_text.split('\n')
# + id="aSupVRhfwZlo"
sep = "<EOV>"
input_verses_val = [x.lstrip() + sep for x in syll_input_text.split(sep)][:-1]
enc_input_verses_val = input_tokenizer.texts_to_sequences(input_verses_val)
padded_input_verses_val = tf.keras.preprocessing.sequence.pad_sequences(
enc_input_verses_val, padding="post"
)
# -
# The evaluate function can handle many syllabification tasks in parallel, generating each output sentence simultaneously until all outputs contain at least one \<EOV\> token. This is faster than handling one sentence at a time, however we found that giving the whole test set in parallel results in GPU out-of-memory, so we came up with this solution that seems to be a good trade-off between parallelism and memory consumption.
#
# What we do is split the test set in batches of 100 verses, and call `evaluate` on one batch at a time passing the appropriate stopping condition.
#
# As an empirical proof, try using a `window_size` of 1: you will see that the ETA will grow to several hours, while the whole process only took about 20 minutes in this experiment.
# + colab={"base_uri": "https://localhost:8080/"} id="LUE-5tb10r_2" outputId="aaea1554-920f-41b2-d787-c18c025cb00b"
start_symbol = target_tokenizer.word_index["<GO>"]
stop_symbol = target_tokenizer.word_index["<EOV>"]
window_size = 100
result = []
for i in tqdm.tqdm(range(math.ceil(len(input_val) / window_size))):
window = padded_input_verses_val[i*window_size:min((i + 1)*window_size, len(padded_input_verses_val))]
encoder_input = tf.convert_to_tensor(window)
decoder_input = tf.repeat([[start_symbol]], repeats=encoder_input.shape[0], axis=0)
output = evaluate(transformer, encoder_input, decoder_input, stop_symbol, stopping_condition=stop_after_stop_symbol)
# Only take output before the first end of verse
stripped_output = list(map(lambda x: x.split('<EOV>')[0], target_tokenizer.sequences_to_texts(output.numpy())))
stripped_output = list(map(strip_tokens, stripped_output))
result += stripped_output
# + colab={"base_uri": "https://localhost:8080/"} id="lPws9NSRkLHK" outputId="53e030e6-df10-487c-e31c-4271a55576cd"
exact_matches, similarities = zip(*validate_syllabification(result, correct_syll_text))
accuracy = sum(exact_matches) / len(exact_matches)
avg_similarities = np.mean(similarities)
print('Syllabification exact matches: {:.2f}%'.format(accuracy * 100))
print('Average similarity: {:.2f}'.format(avg_similarities))
# + id="S_q7o3oukb4-"
result = np.array(result)
correct_syll_text = np.array(correct_syll_text)
error_mask = ~np.array(exact_matches)
errors_output = result[error_mask]
errors_correct = correct_syll_text[error_mask]
# + colab={"base_uri": "https://localhost:8080/"} id="mU3fAdHUK2H1" jupyter={"outputs_hidden": true} outputId="7e63bf54-9a70-46b7-d86a-de8140b52c1a" tags=[]
errors_output
# + colab={"base_uri": "https://localhost:8080/"} id="hsRo4zcDK4hJ" jupyter={"outputs_hidden": true} outputId="1606bf7f-dd33-4c03-e6e8-00a1ea80b657" tags=[]
errors_correct
# + [markdown] id="CF-1it9jwtFn"
# ### 6.3 Syllabificatio of the Orlando Furioso
# We performed the syllabification of the whole *Orlando Furioso* by Ludovico Ariosto and compared the results with the `hyphenation` algorithm from Neural Poetry.
# + id="rMBeTqg3StCX"
def is_not_number(string):
try:
int(string)
return False
except:
return True
def is_not_chapter(string):
return not re.match(r'CANTO .*', string)
# + id="fWnsqKS0SywM"
raw_text_ariosto = open("./data/orlando.txt", "rb").read().decode(encoding="utf-8")
raw_text_ariosto = raw_text_ariosto.split('\n')[44:53579]
raw_text_ariosto = list(map(lambda x: x.strip(), raw_text_ariosto))
raw_text_ariosto = list(filter(is_not_empty, raw_text_ariosto))
raw_text_ariosto = list(filter(is_not_number, raw_text_ariosto))
raw_text_ariosto = list(filter(is_not_chapter, raw_text_ariosto))
# + id="wnknbsl-SD9g" tags=[]
sep = "<EOV>"
raw_text_ariosto_joined = "\n".join(raw_text_ariosto)
text_ariosto = preprocess_text(raw_text_ariosto_joined, end_of_tercet='')
text_ariosto = re.sub("'", '’', text_ariosto)
ariosto_verses = [x.lstrip() + sep for x in text_ariosto.split(sep)][:-1]
enc_ariosto_verses = input_tokenizer.texts_to_sequences(ariosto_verses)
# + id="6RK7SAoe5STY"
padded_enc_ariosto_verses = tf.keras.preprocessing.sequence.pad_sequences(
enc_ariosto_verses, padding="post"
)
# + [markdown] id="qGjBv75whzzO"
# Actually produce the syllabification, the whole process requires a few hours. So we provide the results in the outputs folder. If you want to see the results just skip this cell and run the following ones.
# + colab={"base_uri": "https://localhost:8080/"} id="iWS1uEL3hzzP" outputId="6203eb95-d14d-4ea5-aedd-0b49ea2c17b7"
start_symbol = target_tokenizer.word_index["<GO>"]
stop_symbol = target_tokenizer.word_index["<EOV>"]
window_size = 100
result = []
for i in tqdm.tqdm(range(math.ceil(len(ariosto_verses) / window_size))):
window = padded_enc_ariosto_verses[i*window_size:min((i + 1)*window_size, len(padded_enc_ariosto_verses))]
encoder_input = tf.convert_to_tensor(window)
decoder_input = tf.repeat([[start_symbol]], repeats=encoder_input.shape[0], axis=0)
output = evaluate(transformer, encoder_input, decoder_input, stop_symbol, stopping_condition=stop_after_stop_symbol)
# Only take output before the first end of verse
stripped_output = list(map(lambda x: x.split('<EOV>')[0], target_tokenizer.sequences_to_texts(output.numpy())))
stripped_output = list(map(strip_tokens, stripped_output))
result += stripped_output
# -
result = []
with open('outputs/orlando_syll.txt') as file:
for line in file:
result.append(line)
# + colab={"base_uri": "https://localhost:8080/"} id="pb9_hftvUSiV" jupyter={"outputs_hidden": true} outputId="d7d16286-ad78-4696-f4d8-12e24969ac89" tags=[]
result
# + [markdown] id="ljz37pjChzzQ"
# Obtain alternative syllabification for the Orlando furioso (from Neural Poetry)
# + id="2N2NunZ3hzzQ"
ariosto_alt_syll = list(map(hyphenation, raw_text_ariosto))
ariosto_alt_syll = list(map(lambda x: '|' + '|'.join(x), ariosto_alt_syll))
# + colab={"base_uri": "https://localhost:8080/"} id="CS72M0HmhzzQ" jupyter={"outputs_hidden": true} outputId="d0034b26-da89-4114-a4cc-cc250c2a6d44" tags=[]
ariosto_alt_syll
# -
# Substitute quotes with the ones used in the Divine Comedy.
# + id="QzaIZTxPTepq"
result = list(map(lambda x: re.sub('’', "'", x), result))
# + colab={"base_uri": "https://localhost:8080/"} id="4q3uF-1bhzzR" outputId="9d9e71cf-d45d-4e92-c2d0-521d67c4356d"
exact_matches, similarities = zip(*validate_syllabification(result, ariosto_alt_syll[:100]))
accuracy = sum(exact_matches) / len(exact_matches)
avg_similarities = np.mean(similarities)
print('Syllabification exact matches: {:.2f}%'.format(accuracy * 100))
print('Average similarity: {:.2f}'.format(avg_similarities))
# + [markdown] id="F2Uv-zMNC9k0"
# ### 6.4 Syllabification of other poetry
# We show once again that the model is able to handle text in metric forms other than the hendecasyllable.
# + id="9zvjycGwD8JF"
arbitrary_verses = """
Sempre caro mi fu quest’ermo colle,
e questa siepe, che da tanta parte
dell’ultimo orizzonte il guardo esclude.
Ma sedendo e mirando, interminati
spazi di là da quella, e sovrumani
silenzi, e profondissima quïete
io nel pensier mi fingo; ove per poco
il cor non si spaura. E come il vento
odo stormir tra queste piante, io quello
infinito silenzio a questa voce
vo comparando: e mi sovvien l’eterno,
e le morte stagioni, e la presente
e viva, e il suon di lei. Così tra questa
immensità s’annega il pensier mio:
e il naufragar m’è dolce in questo mare.
"""
arbitrary_verses = preprocess_text(arbitrary_verses, end_of_tercet='')
arbitrary_verses = [verse.strip() + ' <EOV>' for verse in arbitrary_verses.split('<EOV>')][:-1]
# + id="nHaQFMJ_D_xo"
encoded_verses = input_tokenizer.texts_to_sequences(arbitrary_verses)
padded_verses = tf.keras.preprocessing.sequence.pad_sequences(
encoded_verses, padding="post"
)
# + id="SorvaCsMEAl4"
encoder_input = tf.convert_to_tensor(padded_verses)
decoder_input = tf.repeat([[start_symbol]], repeats=encoder_input.shape[0], axis=0)
output = evaluate(transformer, encoder_input, decoder_input, stop_symbol, stopping_condition=stop_after_stop_symbol)
# + id="Y1vlZrCwEE3C"
# Only take output before the first end of verse
stripped_output = list(map(lambda x: x.split('<EOV>')[0], target_tokenizer.sequences_to_texts(output.numpy())))
stripped_output = list(map(strip_tokens, stripped_output))
# + colab={"base_uri": "https://localhost:8080/"} id="Q-AGSZDvEGjj" outputId="41ee2fb9-5d77-4685-f1dc-45b944506b50" tags=[]
print('\n'.join(stripped_output))
# + id="9zvjycGwD8JF"
arbitrary_verses = """
È una canzone senza titolo
Tanto pe’ cantà
Pe’ fa quarche cosa
Non è gnente de straordinario
È robba der paese nostro
Che se po’ cantà pure senza voce
Basta ’a salute
Quanno c'è 'a salute c'è tutto
Basta ’a salute e un par de scarpe nove
Poi girà tutto er monno
E m’a accompagno da me
Pe’ fa la vita meno amara
Me so’ comprato 'sta chitara
E quanno er sole scenne e more
Me sento ’n core cantatore
La voce e’ poca ma ’ntonata
Nun serve a fa ’na serenata
Ma solamente a fa 'n maniera
De famme ’n sogno a prima sera
Tanto pe’ cantà
Perché me sento un friccico ner core
Tanto pe’ sognà
Perché ner petto me ce naschi ’n fiore
Fiore de lillà
Che m'ariporti verso er primo amore
Che sospirava le canzoni mie
E m’aritontoniva de bucie
Canzoni belle e appassionate
Che Roma mia m’aricordate
Cantate solo pe’ dispetto
Ma co’ ’na smania dentro ar petto
Io nun ve canto a voce piena
Ma tutta l’anima è serena
E quanno er cielo se scolora
De me nessuna se ’nnamora
Tanto pe’ cantà
Perché me sento un friccico ner core
Tanto pe’ sognà
Perché ner petto me ce naschi un fiore
Fiore de lillà
Che m’ariporti verso er primo amore
Che sospirava le canzoni mie
E m’aritontoniva de bucie
"""
arbitrary_verses = preprocess_text(arbitrary_verses, end_of_tercet='')
arbitrary_verses = [verse.strip() + ' <EOV>' for verse in arbitrary_verses.split('<EOV>')][:-1]
# + id="nHaQFMJ_D_xo"
encoded_verses = input_tokenizer.texts_to_sequences(arbitrary_verses)
padded_verses = tf.keras.preprocessing.sequence.pad_sequences(
encoded_verses, padding="post"
)
# + id="SorvaCsMEAl4"
encoder_input = tf.convert_to_tensor(padded_verses)
decoder_input = tf.repeat([[start_symbol]], repeats=encoder_input.shape[0], axis=0)
output = evaluate(transformer, encoder_input, decoder_input, stop_symbol, stopping_condition=stop_after_stop_symbol)
# + id="Y1vlZrCwEE3C"
# Only take output before the first end of verse
stripped_output = list(map(lambda x: x.split('<EOV>')[0], target_tokenizer.sequences_to_texts(output.numpy())))
stripped_output = list(map(strip_tokens, stripped_output))
# + colab={"base_uri": "https://localhost:8080/"} id="Q-AGSZDvEGjj" outputId="41ee2fb9-5d77-4685-f1dc-45b944506b50" tags=[]
print('\n'.join(stripped_output))
| Char2Char generation and syllabification.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + pycharm={"name": "#%%\n"}
import pandas as pd
# + pycharm={"name": "#%%\n"}
df = pd.read_excel("ML Data/Color.xlsx")
df
# + pycharm={"name": "#%%\n"}
# Pandas
pd.get_dummies(df.Color)
pd.get_dummies(df["Color"])
# + pycharm={"name": "#%%\n"}
df = pd.read_excel("ML Data/Color2.xlsx")
df
# + pycharm={"name": "#%%\n"}
pd.get_dummies(df.Color)
# + pycharm={"name": "#%%\n"}
dummies = pd.get_dummies(df.Color)
dummies
# + pycharm={"name": "#%%\n"}
df = pd.concat([df, dummies], axis="columns")
df
# + pycharm={"name": "#%%\n"}
| ML/Week5-2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
from IPython.display import display, clear_output
dp = pd.read_pickle('../00_Data/dblp.pickle')
ss = pd.read_pickle('../00_Data/semantic_scholar.pickle')
# +
data = {}
for i,paper in dp.iterrows():
authors = paper['author'].split(',')
for author in authors:
author = author.strip()
if author not in data:
data[author] = {
'collaborators': set(),
'num_papers': 0,
'years': set()
}
data[author]['collaborators'].update(set(authors) - set([author]))
data[author]['num_papers'] += 1
data[author]['years'].add(paper['year'])
if i % 50000 == 0:
clear_output(wait=True)
print(i)
# +
authors = []
for author in data:
authors.append({
'author': author,
'num_unique_collaborators': len(data[author]['collaborators']),
'num_papers': data[author]['num_papers'],
'first_year': min(data[author]['years']),
'last_year': max(data[author]['years']),
'work_age': int(max(data[author]['years'])) - int(min(data[author]['years']))
})
authors = pd.DataFrame.from_dict(authors)
# -
authors.describe()
authors.to_pickle('../00_Data/authors.pickle')
| 03_Analysis/ExploreAuthors.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Welcome to qso_toolbox
# ## This library of python modules serves to consolidate a multitude of useful routines for quasar selection and observations.
#
# ***
# # <font color=red>Disclaimer: This code is in development and will change on small time scales (weeks)!!!</font>
#
# ***
#
# ## The qso_toolbox consists of the following python modules:
# #### catalog_tools.py
# A collection of python routines to download a variety of catalog data, especially image cutouts
#
# #### image_tools.py
# This module largely focuses on the display, manipulation and forced photometry calculation of image data.
#
# #### photometry_tools.py
# This module focuses on the work with photometric data (magnitudes, fluxes), their conversion (e.g. between different magnitude systems) and manipulation (e.g. dereddening).
#
# #### utils.py
# A collection of routines to serve the other modules
#
# ## Multiprocessing:
# A range of functions in the associated python modules have been prepared to be run with the python multiprocessing package. The function keyword "n_jobs" specifies in how many processes will be spawned. We specifically use the multiprocessing.starmap() function.
# For more information on the multiprocessing package, please follow this link:
# https://docs.python.org/3/library/multiprocessing.html#module-multiprocessing
# ## Before getting started - Things to know!
# - The functionality of the qso toolbox is based on a range of other python libraries. Especially knowledge of astropy, pandas, and numpy is of great importance in this context.
# - The code uses a unique combination of target position + survey/data release + band (+ fov) to save and read image cutouts. Once cutouts are downloaded and are requested to be accessed by either the forced photometry or plotting routines, it will look for these unique image names. An example of such a name is J224028.85-010649.87_unwise-neo3_w1_fov100.fits
#
# ## The jupyter notebook examples
# We highly recommend to get started with the examples given in the associated jupyter notebooks.
| examples/GettingStarted.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import pathlib
# For loading geotiff data
import rasterio
# For performing geospatial analysis
import pylandstats as pls
# Import modules
import numpy as np
import matplotlib.pyplot as plt
import os
from rasterio.plot import show
from rasterio.plot import show_hist
from rasterio.mask import mask
from shapely.geometry import box
import geopandas as gpd
from fiona.crs import from_epsg
import pycrs
CEDA_DIR = pathlib.Path("/") / "neodc"
LANDCOVER_DIR = CEDA_DIR / "esacci" / "land_cover" / "data" / "land_cover_maps" / "v2.0.7"
# Load sample data file:
landcover_2015_path = LANDCOVER_DIR / "ESACCI-LC-L4-LCCS-Map-300m-P1Y-2015-v2.0.7.tif"
data = rasterio.open(landcover_2015_path)
print(data.bounds)
print(data.shape)
# +
#Show tif
#show((data)) #full dataset too large to plot
# -
# Clipping box
minx, miny = -2, 51
maxx, maxy = 1, 53
bbox = box(minx, miny, maxx, maxy)
# Give box a crs
geo = gpd.GeoDataFrame({'geometry': bbox}, index=[0], crs="EPSG:4326")
# Make sure box crs and data crs match
geo = geo.to_crs(crs=data.crs)
def getFeatures(gdf):
"""Function to parse features from GeoDataFrame in such a manner that rasterio wants them"""
import json
return [json.loads(gdf.to_json())['features'][0]['geometry']] #returns geojson representation of geodataframe
# Co-ordinates of polygon (box)
coords = getFeatures(geo)
# Mask(crop)
out_img, out_transform = mask(dataset=data, shapes=coords, crop=True) #rasterio mask
# Meta data for new file
out_meta = data.meta.copy()
print(out_meta)
epsg_code = int(data.crs.data['init'][5:]) #putting crs into output data
# Update meta-data
out_meta.update({"driver": "GTiff",
"height": out_img.shape[1],
"width": out_img.shape[2],
"transform": out_transform,
"crs": pycrs.parse.from_epsg_code(epsg_code).to_proj4()})
# Write output file
out_tif = r"/gws/nopw/j04/ai4er/users/kmgreen/data/landcover_esacci_2015_cropped1.tif"
with rasterio.open(out_tif, "w+", **out_meta) as dest:
dest.write(out_img)
# Quick image of new file
clipped = rasterio.open(out_tif)
show((clipped)) #shows East England
#Load output in pylandstats
ls=pls.Landscape(out_tif)
ls.plot_landscape(legend=True)
#Calculate patch metrics using pylandstats
patch_metrics_df = ls.compute_patch_metrics_df()
patch_metrics_df.head()
#Calculate class metrics using pylandstats
class_metrics_df = ls.compute_class_metrics_df()
class_metrics_df
| notebooks/exploratory/1.0_kmg_landscape-metrics-example.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # Introductory applied machine learning (INFR10069)
# # Lab 4: Clustering, PCA, and Evaluation
# In this lab we consider unsupervised learning in the form of clustering methods and principal component analysis (PCA), as well as more thorough performance evaluation of classifiers.
#
# All the datasets that you will need for this lab are located at the `./datasets` directory which is adjacent to this file.
# Import packages
from __future__ import division, print_function # Imports from __future__ since we're running Python 2
import os
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
from sklearn.decomposition import PCA
# %matplotlib inline
# ## Part 1: Clustering the landsat dataset
# We first consider clustering of the Landsat data. For information about the Landsat data you can read [this description](http://www.inf.ed.ac.uk/teaching/courses/dme/html/landsat.html). Since there are 6 classes in the data, it would be interesting to try clustering with k=6 centres...
# ### ========== Question 1.1 ==========
# 1. With pandas, read the csv dataset located at './datasets/landsat.csv'
# 1. Split the data into the features `X` (pandas dataframe), and the labels `y` (easier to make it a numpy array)
# 1. Give it a once over
# * Get a feel for the size
# * Check it looks ok
# * Understand what the features are
# * Plot the class distribution
# Your code goes here
data_path = os.path.join(os.getcwd(), 'datasets', 'landsat.csv')
landsat = pd.read_csv(data_path, delimiter = ',')
landsat.info
X = landsat.drop('class', axis=1)
y = landsat['class'].values
print('Number of instances: {}, number of attributes: {}'.format(X.shape[0], X.shape[1]))
print(landsat.describe())
# Notice that class is categorical (not numeric) and count
labeldict = {1:'red soil', 2:'cotton crop', 3:'grey soil',
4:'damp grey soil', 5:'soil with vegetation stubble',
6:'mixture class (all types present)',
7:'very damp grey soil'}
fig, ax = plt.subplots()
landsat['class'].astype('category').value_counts().plot(kind='bar', ax=ax)
ax.get_xticklabels()
labels = [int(ticklabel.get_text()) for ticklabel in ax.get_xticklabels()]
ax.set_xticklabels([labeldict[l] for l in labels])
plt.xlabel('Classes')
plt.ylabel('Count')
plt.title('Class distribution')
plt.show()
# ### ========== Question 1.2 ==========
# *Tip - don't get stuck on this, move on after 10 mins or so (it's not critical)*
#
# Plot a few datapoints. You'll need to understand and reshape the datapoints to do this. *Hint: try reading the [detailed description](http://www.inf.ed.ac.uk/teaching/courses/dme/html/satdoc.txt), it'll take you 2 minutes...`plt.imshow()` or `sns.heatmap()` (with an `ax.invert_yaxis()`) may also be handy ;)*
# +
# Your code goes here
def get_images(row, bands=None):
# Get each of the 4 3x3 images contained in the row
# Pixels are labeled 1 to 9 from topleft to bottom right
# They are measured at 4 spectral bands
#
# row - a numpy array
if bands is None:
img = [[]] * 4
for ii in range(4):
img[ii] = row[[4*p + ii for p in range(9)]].values.reshape((3,3)).astype(int)
elif isinstance(bands, int):
img = row[[4*p + bands for p in range(9)]].values.reshape((3,3)).astype(int)
elif isinstance(bands, list):
img = [[]] * len(bands)
for ii, band in enumerate(bands):
img[ii] = row[[4*p + band for p in range(9)]].values.reshape((3,3)).astype(int)
return img
for ii in range(4):
fig, ax = plt.subplots(1,4)
plt.suptitle('Row {}'.format(ii), fontsize=16)
for jj, img in enumerate(get_images(landsat.iloc[ii,:])):
ax[jj] = sns.heatmap(img, annot=True, fmt="d", ax=ax[jj], vmin=0, vmax=255,
cbar=False, square=True, cmap=plt.cm.gray)
ax[jj].invert_yaxis()
ax[jj].set_title('Band {}'.format(jj))
plt.tight_layout()
plt.subplots_adjust(top=1.4)
# -
# ### ========== Question 1.3 ==========
# Read [this demonstration of k-means clustering assumptions](http://scikit-learn.org/0.17/auto_examples/cluster/plot_kmeans_assumptions.html#sphx-glr-auto-examples-cluster-plot-kmeans-assumptions-py) from the sklearn documentation. Get a feel for how to create and fit a k-means object and what the different arguments do.
#
# Initialise a [k-means clustering](http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans) object with 6 clusters, and one other parameter that ensures you can reproduce your results (other arguments kept as default). Call the object `kmeans`. Use the `fit()` method to fit to the training data (`X` - the features of `landsat` created above)
#
# **Be careful to fit `X` - only the features - not the class labels!**
# Your code goes here
# It's really important that you set a random_state such that you can
# reproduce your results
kmeans = KMeans(n_clusters=6, random_state=1337)
kmeans.fit(X)
# ### ========== Question 1.4 ==========
# So, how well did that work? Are the classes well separated and form 6 nice clusters? The sklearn documentation gives a great introduction to k-means [here](http://scikit-learn.org/stable/modules/clustering.html#k-means). It describes what the algorithm is trying to minimise - the squared difference between datapoints and their closest cluster centre - a.k.a. the **inertia**. Lower inertia implies a better fit.
#
# Since we have the true class labels in this case, we can use another metric: the [adjusted rand index](http://scikit-learn.org/stable/modules/clustering.html#clustering-performance-evaluation). Understand what it is and roughly how it is calculated (try the [mathematical formulation on sklearn](http://scikit-learn.org/stable/modules/clustering.html#mathematical-formulation) or [on wikipedia](https://en.wikipedia.org/wiki/Rand_index)).
#
# Print the `inertia` and the `adjusted_rand_score` of the kmeans object. The inertia is contained within the `kmeans` object you just fitted as a property. You need to use `y` and the cluster labels (another property of the `kmeans` object you just made), and are welcome to use the sklearn metrics function [adjusted_rand_score](http://scikit-learn.org/0.17/modules/generated/sklearn.metrics.adjusted_rand_score.html).
# Your code goes here
kmeans.inertia_, adjusted_rand_score(y, kmeans.labels_)
# ### ========== Question 1.5 ==========
# Let's have a look at the counts of the labels within each cluster. If the clustering has worked well, and the labels are inticative of genuine difference in the data, we should expect each cluster to have one dominant label.
#
# Use `sns.countplot` on `kmeans.labels_` with a hue of `y` to get a plot that counts the number of instances within each cluster, and breaks them down by the class labels.
#
# Below the plot, comment on:
# 1. How successful the clustering has been at separating data with different labels
# 1. Focussing on clusters, which are the best?
# 1. Focussing on labels, which are well identified by the clustering?
# 1. Which labels are the hardest to determine by the data point cluster assignment?
#
# **Extension**: create a vector `y_labels` from `y` which has the names for the classes for a more interpretable plot with respect to the data
# +
# Your code goes here
# -
# *Your answer goes here*
# ## Part 2: Dimensionality reduction
# The landsat data is 36 dimensional, so we cannot visualise it, with respect to class, on a nice two dimensional plot. Additionally, as dimensionality increases, euclidean distance [becomes less meaningful](https://en.wikipedia.org/wiki/Curse_of_dimensionality#Distance_functions)...
#
# Perhaps if we found a lower dimensional subspace the data lies upon, we could more easily distinguish the datapoints...
# ### ========== Question 2.1 ==========
# Have a look at the [PCA example](http://scikit-learn.org/0.17/auto_examples/decomposition/plot_pca_iris.html) in the sklearn documentation. For more information about PCA and decomposition in general check out the sklearn [user guide on decomposition](http://scikit-learn.org/stable/modules/decomposition.html#pca).
#
# We are going to project the data down to 2 dimensions and visualise it using PCA.
#
# 1. Create `pca`, an instance of an [sklearn PCA object](http://scikit-learn.org/0.17/modules/generated/sklearn.decomposition.PCA.html#sklearn.decomposition.PCA), setting n_components to 2.
# 1. Create `X_2d` by using the pca method `fit_transform()` and supplying the features `X` to fit and transform to 2d.
# +
# Your code goes here
# -
# ### ========== Question 2.2 ==========
# Let's visualise the data! Use a scatterplot and colour the datapoints by their class. You'll find [this example](http://scikit-learn.org/stable/auto_examples/decomposition/plot_pca_vs_lda.html) very helpful to stea-I mean, adapt.
#
# Below the plot, comment on whether the data looks more or less seperable now. Do the data look like they will be confused by a k-means clustering in the same way now?
#
# **Extension**: Unless the data is somehow magically perfectly seperable, you may want to try and describe the space a little better than a scatterplot (bacause points are plotted on top of one another). Try and make a plot that clarifies the location of the classes. We're actually interested in where the **density** is.
# +
# Your code goes here
# -
# *Your answer goes here*
# ### ========== Question 2.3 ==========
# Let's find out whether it's easier to model the transformed data. Fit k-means to the transformed data and report the inertia and the adjusted rand index. Below, comment on whether it is better or worse.
# +
# Your code goes here
# -
# *Your answer goes here*
# ### ========== Question 2.4 ==========
# The blobs in the 2 dimensional plot do look quite gaussian...try another classifier on the 2d data and see if it can perform better. What about using 3 principal component?
#
# Maybe there are subclasses within each class? Maybe increasing the number of clusters will increase your `adjusted_rand_score`.
#
# Use the adjusted rand score for fair comparison. Why do you think it works better or worse? Discuss with your colleagues and lab tutors why you think you got better/worse/the same results.
# +
# Your code goes here
# -
# # Credits
# Lab prepared by <NAME> and <NAME>, November 2008; revised <NAME> Nov 2009; revised <NAME> Nov 2011; revised <NAME> Oct 2013; revised and converted python by <NAME> and <NAME> Oct 2016
| 08_Lab_4_Clustering_PCA_and_Evaluation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import collections as cl
t = int(input())
for _ in range(t):
input()
words = str(input()).split()
input()
elements = str(input()).split()
elm = []
for word in words:
y = cl.Counter(word)
x = cl.Counter(elements)
x.subtract(y)
if x.most_common()[:-2:-1][0][1] >= 0:
elm += [word]
if len(elm) == 0:
print(-1)
else:
elm = [i for i in set(elm)]
elm.sort()
print(' '.join(elm))
# +
import itertools as it
n,k = 7,23
elms = [10, 2, 3, 4, 5, 7, 8]
out = []
def iterunique(iterable):
tmp = set()
for i in iterable:
if not i in tmp:
yield i
tmp.add(i)
for i in it.combinations(elms, 4):
if sum(i) == k:
out.append(sorted(i))
out.sort()
print(''.join([' '.join(map(str,i))+'$' for i in iterunique([tuple(i) for i in out])]))
# +
def twoseq(iterable):
it = iter(iterable)
try:
while True:
x = [next(it)]
y = [next(it)]
yield x + y
except BaseException:
pass
def setseq(iterable):
for i in iterable:
x, y = i
yield { i for i in range(x, y+1)}
elms = [1, 3, 2, 4, 6, 8, 9, 10]
# elms = [6, 8, 1, 9, 2, 4, 4, 7]
elms = sorted([i for i in twoseq(elms)])
prev = None
seq = []
has = False
# print(elms)
for i in setseq(elms):
# print(i)
if prev is None:
prev = i
has = False
elif len(prev & i) > 0:
# print("yes")
prev |= i
# print(prev)
has = True
else:
seq += [sorted([i for i in prev])]
prev = i
has = False
seq += [sorted([i for i in prev])]
elms = []
for i in seq:
elms += [[i[0],i[-1]]]
elms.sort()
def flatten(it):
for i in it:
yield str(i[0])
yield str(i[1])
print(' '.join(flatten(elms)))
# -
import itertools as it
import math
data = "00100101"
indexes = [k for k, i in enumerate(data) if i == '1']
def revseq(start,end):
while start >= end:
yield start
start -= 1
n = len(indexes)
r = 2
val = 1
for i in revseq(n,n-r + 1):
val *= i
print(val//2)
# # codechef
# praveen, arjun
# +
import collections as cl
import itertools as it
n, q = 11, 6
edges = [(1,2), (2, 3), (2, 4),(4, 5),(4, 6),(2, 8),(2, 7),(7, 9),(7, 10),(11, 10)]
query = [(5, 10),(1, 9),(6, 10),(3 ,7),(2, 9),(9, 2)]
# n, q = 20, 4
# edges = [(1, 2),(2, 3),(2 ,4),(4 ,6),(5, 6),(6, 20),(8, 20),(7, 20),(4, 9),(9, 10),(10, 19),(17, 19),(18, 19),(10, 11),(11, 12),(11, 13),(13, 14),(13, 15),(15, 16)]
# query = [(4, 10),(1, 16),(17, 18),(11, 11)]
tree = cl.defaultdict(set)
for i, j in edges:
tree[i].add(j)
tree[j].add(i)
weights = cl.defaultdict(int)
print(tree)
for i in range(1, n + 1):
if len(tree[i])> 2:
weights[i] = 2
else:
if len(tree[i]) == 2:
t1, t2 = tree[i]
if len(tree[t1]) > 2 and len(tree[t2]) > 2:
weights[i] = 2
else:
weights[i] = 1
else:
weights[i] = 1
print(weights)
def bfs(graph, src, dst, visited = set(), path = []):
visited.add(src)
if src == dst:
return path + [src]
else:
for i in graph[src]:
if not i in visited:
res = bfs(graph, i, dst, visited, path + [src])
if res != None:
return res
def twiter(it):
it = iter(it)
c = next(it)
p = None
for i in it:
p = c
c = i
yield (p,c)
for i, j in query:
tmp = bfs(tree, i, j, set(), [])
tmp = [(i,weights[i]) for i in tmp]
print(tmp)
count = 0
l = len(tmp)
for k in range(l):
for m in range(k+1,l):
if tmp[k][1] > tmp[m][1]:
count +=1
print(count)
# -
s = "12:05:45AM"
dom = s[-2:]
h, m, s = [int(i) for i in s[:-2].split(':')]
if dom == 'PM' and h != 12:
h += 12
elif dom == 'AM' and h == 12:
h = 0
print("{:02}:{:02}:{:02}".format(h, m, s))
# # Vasya
# from collections import defaultdict
arr = [4, 8, 2, 6]
n = 4
n = int(input())
arr = list(map(int,input().strip().split()))
arr.sort()
m = 0
i = 1
counts = [1]
while i < n:
count = 1
for j in range(i):
if arr[i] % arr[j] == 0:
count = max(counts[j] + 1,count)
m = max(m, count)
counts += [count]
i += 1
if m <= 1:
m =-1
print(m)
# +
# -
# # Floyd warshall with path generator addon
# +
from collections import defaultdict
import math
math.inf = float('Inf') #avoid crashing with python2
# initialize weighted graph
dist = [
[0, 1, 2, math.inf],
[math.inf, math.inf, math.inf, 1],
[math.inf, math.inf, 0, 2],
[2, math.inf, math.inf, 0],
]
#data structure to store distance vector
path = defaultdict(defaultdict)
v = 4 #number of vertices
#floyd warshall
for i in range(v):
for j in range(v):
for k in range(v):
# addon code to generate path
# else it is just dist[j][k] = min(dist[j][k], dist[j][i] + dist[i][k])
val = dist[j][i] + dist[i][k]
if dist[j][k] > val:
path[j][k] = i
dist[j][k] = val
else:
try:
path[j][k]
except:
if dist[j][k] != math.inf:
path[j][k] = k
#end addon
# get shortest path's total weight
def getWeight(g_dist, src, dst):
'''
type g_dist : 2d Integer weight list
type src : Integer
type dst : Integer
'''
return g_dist[src][dst]
def getPath(g, src, dst):
'''
path generator
type g : defaultdict(defaultdict)
type src : Integer
type dst : Integer
'''
# pythonic checking of no path since it is a default dict with two level
# It should throw error
try:
g[src][dst]
except:
return
# starting node
yield src
# all other
while src != dst:
src = g[src][dst]
yield src
pass
# result
print(list(getPath(path, 1, 0)))
print(getWeight(dist, 1,0))
# -
# # Kruskal's algorithm
# +
from collections import namedtuple
Edge = namedtuple('Edge', 'x y w')
edges = [Edge(x,y,w) for x,y,w in [(1,2,1),(1,3,2),(2,4,1),(3,4,4)]]
print(edges)
# later
# -
primes = [2, 3, 5, 7]
for i in range(10,10000):
for j in [2, 3, 5, 7]:
if i % j == 0:
break
else:
primes += [i]
print(primes)
# +
a = 'aabxbxbaa'
etr = 0
eor = 0
print(a)
for i in range(1,len(a)):
ee = '::'
oe = '::'
print('start',a[i], end=' ')
if etr >= 0:
ee = a[etr]
if eor >= 0:
oe = a[eor]
e = a[i]
if e == ee:
print('either',ee,i + 1 - etr , end='')
elif e == oe:
print('or',oe, i + 1 - eor , end='')
eor -= 1
else:
print('neither',ee, 'nor',oe)
eor, etr = i-1, i
print()
# +
import PIL.Image as im
import numpy as np
pic = im.open('test.jpg')
width, height = pic.width, pic.height
pic = pic.convert('L')
array = np.array(pic)
array = array.flatten()
import random
#generating random seed password
seed = random.randint(100,1000000)
#random sequence generator
def random_seq(length, seed):
tmp = set()
random.seed(seed)
while len(tmp) != length:
r = random.randint(0, length -1)
if not r in tmp:
tmp.add(r)
yield r
def encode(data_bin, seq):
crypt = [0 for i in data_bin]
for i, loc in enumerate(seq):
crypt[loc] = data_bin[i]
return crypt
def getNum(binary):
out = 0
for i in binary:
out = (out << 1)|(i == '1')
return out
# print("encoded : ", getNum(encoded))
def decode(crypt_bin, seq):
data = [0 for i in crypt_bin]
for i, loc in enumerate(seq):
data[i] = crypt_bin[loc]
return data
def encode_array(array, seed, bits):
crypt = []
seq = list(random_seq(bits, seed))
for i, e in enumerate(array):
data_bin = "{:08}".format(int(bin(e)[2:]))
data_len = len(data_bin)
encoded = encode(data_bin, seq)
crypt += [getNum(encoded)]
return crypt
crypt = encode_array(array, seed, 8)
# -
import matplotlib.pyplot as plt
img = np.reshape(crypt, (width, height))
plt.imshow(img)
plt.show()
# +
def decode_array(array, seed, bits):
crypt = []
seq = list(random_seq(bits, seed))
for i, e in enumerate(array):
data_bin = "{:08}".format(int(bin(e)[2:]))
data_len = len(data_bin)
encoded = decode(data_bin, seq)
crypt += [getNum(encoded)]
return crypt
uncrypt = decode_array(crypt, seed, 8)
# -
img_recovered = np.reshape(uncrypt, (width, height))
plt.imshow(img_recovered)
plt.show()
plt.imshow(pic)
plt.show()
uncrypt
second = encode(uncrypt, list(random_seq(len(uncrypt), seed)))
sim = np.reshape(second, (width, height))
plt.imshow(sim)
plt.show()
second_decode = decode(second,list(random_seq(len(uncrypt), seed )) )
sim2 = np.reshape(second_decode, (width, height))
plt.imshow(sim2)
plt.show()
| Solved problems.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # QR Factorisation
#
# We will look at two different ways for computing the QR factorisation of a matrix. To goal is to start from a matrix $A$ and write it as the product of an orthogonal matrix $Q$ and an upper-triangular matrix $R$.
# +
import numpy as np
from numpy.linalg import norm
A = np.array([[1,2,3],[4,5,6],[7,8,10]])
b = np.array([1,2,3])
n = 3
# -
# Numpy has a built-in function for doing this. Let's use it to check what the answer should be:
A=np.array([[1,9,4],[0,4,3],[5,4,4]])
(Q,R) = np.linalg.qr(A)
(Q,R)
# ## Gram-Schmidt orthogonalization
#
# The first approach will be to transform the vectors in the columns of $A$ to a set of orthogonal vectores using the Gram-Schmidt approach. The basic idea of Gram-Schmidt is to build up an orthonormal set of vectors by projecting out non-orthogonal pieces. The following image illustrates this.
# 
# Let's now implement this with our test matrix $A$.
# First, we construct three vectors $a_1$, $a_2$ and $a_3$ from the columns of $A$.
(a1, a2, a3) = np.transpose(A)
a1
# Now, our first orthonormal vector is just $a_1$ normalised to have length 1:
u1 = a1
e1 = u1 / norm(u1)
# To construct our second orthonormal vector, let's start with $a_2$, project out the part along the $a_1$ direction and normalise the result:
u2 = a2 - (e1@a2)*e1
e2 = u2/norm(u2)
# Let's also project this piece out from $a_3$ now (this is not essential, but helps improve the numerical stability of the algorithm)
u3 = a3 - (e1@a3)*e1
u3
# To construct our third orthonormal vector, let's project out the part along the previous two directions and normalise the result:
u3 = u3 - (e2@a3)*e2
e3 = u3 / norm(u3)
[e1,e2,e3]
u3
# Now we have our three orthogonal vectors, we can put them into the columns of Q
Q = np.transpose([e1, e2, e3])
Q
# To get $R$, we note that $A = Q R$ means that $Q^T A = Q^T Q R = R$ since $Q$ is an orthogonal matrix. Let's use this to compute $R$:
R = np.transpose(Q)@A
np.transpose(Q)
Q@R
# As expected, $R$ is (almost) an upper-triangular matrix. It is only __almost__ upper triangular because floating point arithmetic is not exact.
# ## Using Householder reflections
#
# The Gram-Schmidt process can be a very effective way to orthogonalise a set of vectors, but it does run into problems with numerical stability. This can happen, for example, in the case where we are starting with vectors that are nearly linearly dependent. Then we would be subtracting two large vectors to produce one small one, and we know that this is a recipe for disaster with floating point arithmetic.
#
# One way around this problem is to use a different approach to orthogonalization. A very popular method uses the idea of Householder reflections. These take a vector $x$ and reflect it about a plane defined by another vector $v$:
# 
# This is clearly equivalent to multiplying $x$ by the __Householder reflection matrix__
# $$ H = I - 2 \frac{v v^T}{||v||^2}$$
# Note that $H$ is a *symmetric, orthogonal matrix*.
#
# Now, if we choose $v$ appropriately then we can use it to zero out below the pivot in each column, thus producing $R$. In particular, if
# $$v = a - ||a|| e_k$$ then $H a = |a| e_k$ so if $e_k$ is a unit vector in the $k$-th direction this does exactly what we want to the column $a$.
#
# Let's now implement this in practice.
# First, we work on the first column of $A$.
-np.sign(a3[0])
np.outer(v1,v1)
H1
u1 = a1 - (-np.sign(a1[0]))*norm(a1)*np.array([1,0,0])
v1 = u1/norm(u1)
H1 = np.identity(3) - 2*np.outer(v1,v1)
A1 = H1@A
np.outer(v2,v2)
# and the second column
a2 = A1[1:,1]
u2 = a2 - (-np.sign(a2[0]))*norm(a2)*np.array([1,0])
v2 = u2/norm(u2)
H2 = np.identity(3)
H2[1:,1:] -= 2*np.outer(v2,v2)
H2
A2 = H2@A1
A2
u3
# and finally the third column
a3 = A2[2:,2]
u3 = a3 - (-np.sign(a3[0]))*norm(a3)*np.array([1])
v3 = u3/norm(u3)
H3 = np.identity(3)
H3[2:,2:] -= 2*np.outer(v3,v3)
H3
A3 = H3@A2
A3
# We now have transformed to exactly $R$.
Q
# And we can easily construct $Q$ from the Householder matrices
Q=np.transpose(H3@H2@H1)
Q@R
Q@R
| Matrix Factorisation/QR-Solution.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:py35]
# language: python
# name: conda-env-py35-py
# ---
# +
import http.client
import urllib.parse
import time
import json
# Request headers
headers = {
'Ocp-Apim-Subscription-Key': '<KEY>',
'Content-Type': 'application/json'
}
# Request parameters
params = json.dumps()
def query_graph(query):
params = json.dumps(query)
request_url = "/academic/v1.0/graph/search?mode=lambda"
conn = http.client.HTTPSConnection('westus.api.cognitive.microsoft.com')
# Wait for response, this can take a while...
response_code = None
while response_code == 503 or response_code is None:
if response_code is not None:
print("Got",response_code,"...")
time.sleep(600)
# Try again, make the POST request
conn.request("POST", request_url, params, headers)
response = conn.getresponse()
response_code = response.code
assert response_code == 200, response.read()
data = response.read().decode('utf-8')
conn.close()
return json.loads(data)
#
query = {
"path": "/author/PaperIDs/paper",
"author": {
"type": "Author",
"select": [ "DisplayAuthorName","Name","Aliases"],
"match": { "Name": "<NAME>" }
},
"paper": {
"type": "Paper",
"select": [ "NormalizedTitle", "FieldOfStudyIDs" ]#,
#"return": { "NormalizedTitle": "checking cache coherence protocols with tla" }
}
}
results = query_graph(query)
print(json.dumps(results["Results"][0],indent=4))
# -
type(data)
| notebooks/jaklinger/microsoft_academic_knowledge/academic_graph_search.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Your First Quantum Game
# If you've already read some of this textbook, you should know at least a few quantum gates. If you are wondering what to do with that knowledge, perhaps making a game can be the answer. Making simple games can be a fun way to try out new programming knowledge.
#
# If we are going to make a game, we'll need a game engine. Here we'll introduce a simple game engine that can run here in the Jupyter notebooks of this textbook. With this we'll make make a very simple game based on single qubit gates.
#
# First, we import the game engine.
from qiskit_textbook.games.qiskit_game_engine import QiskitGameEngine
# ## A few simple examples
#
# A minimal example of using this game engine is to simply set all the pixels to a certan colour.
# +
# function called when setting up
def start(engine):
# just move on to the first frame
next_frame(engine)
# this is the function that does everything
def next_frame (engine):
# set all pixels to green
for x in range(engine.L):
for y in range(engine.L):
engine.screen.pixel[x,y].set_color('green')
# run the game for an 8x8 screen
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# Now let's set one specific pixel to a different colour.
# +
# function called when setting up
def start(engine):
# set a parameter to keep track of the player pixel
engine.X = 1
engine.Y = 2
# then move on to the first frame
next_frame(engine)
# this is the function that does everything
def next_frame (engine):
# set all pixels to green
for x in range(engine.L):
for y in range(engine.L):
engine.screen.pixel[x,y].set_color('green')
# draw the player pixel
engine.screen.pixel[engine.X,engine.Y].set_color('red')
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# We'll move this around using the arrow buttons.
# +
# this is the function that does everything
def next_frame (engine):
# change player position
if engine.controller['up'].value:
engine.Y -= 1
if engine.controller['down'].value:
engine.Y += 1
if engine.controller['right'].value:
engine.X += 1
if engine.controller['left'].value:
engine.X -= 1
# set all pixels to green
for x in range(engine.L):
for y in range(engine.L):
engine.screen.pixel[x,y].set_color('green')
# draw the player pixel
engine.screen.pixel[engine.X,engine.Y].set_color('red')
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# Walking off the edge of the screen results in an error. We can fix this.
# +
# this is the function that does everything
def next_frame (engine):
# change player position
if engine.controller['up'].value:
engine.Y -= 1
if engine.controller['down'].value:
engine.Y += 1
if engine.controller['right'].value:
engine.X += 1
if engine.controller['left'].value:
engine.X -= 1
# set all pixels to green
for x in range(engine.L):
for y in range(engine.L):
engine.screen.pixel[x,y].set_color('green')
# draw the player pixel
Xs = engine.X%engine.L
Ys = engine.Y%engine.L
engine.screen.pixel[Xs,Ys].set_color('red')
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# Here the `engine.X` and `engine.Y` coordinates are still allowed to go beyond the screen, but the pixel is displayed such that it wraps back round. We can interpret this as the pixel moving on to another screen.
#
# Now let's move towards giving our pixel a more exciting world to explore. We'll use a function to decide what colour each point should be. We'll start by not changing very much.
# +
import numpy as np
def get_color(X,Y):
return 'green'
# this is the function that does everything
def next_frame (engine):
# change player position
if engine.controller['up'].value:
engine.Y -= 1
if engine.controller['down'].value:
engine.Y += 1
if engine.controller['right'].value:
engine.X += 1
if engine.controller['left'].value:
engine.X -= 1
# set all pixels to green
for x in range(engine.L):
for y in range(engine.L):
# get the 'world' coordinates X,Y from the onscreen coordinates x,y
X = np.floor(engine.X/engine.L)*engine.L+x
Y = np.floor(engine.Y/engine.L)*engine.L+y
# set it to whatever colour it should be
engine.screen.pixel[x,y].set_color(get_color(X,Y))
# draw the player pixel
Xs = engine.X%engine.L
Ys = engine.Y%engine.L
engine.screen.pixel[Xs,Ys].set_color('red')
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# Now let's change `get_color` to create a beach.
# +
def get_color(X,Y):
if X<12:
color = 'green'
else:
color = 'orange'
return color
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# We'll now put a single qubit circuit inside this terrain generator, so that we can experiment with single qubit gates by making terrain. For that we'll need some Qiskit tools.
from qiskit import QuantumCircuit
from qiskit.quantum_info import Statevector
# First, let's see what the results from a circuit look like. Here's an example with just a `ry` gate for a given angle of rotation.
# +
theta = np.pi/2
qc = QuantumCircuit(1)
qc.ry(theta,0)
state = Statevector.from_instruction(qc)
probs = state.probabilities_dict()
print(probs)
# -
# Here the angle $\pi/2$ means that the result of a measurement at the end of this circuit would be equally likely to give `0` or `1`. For other angles we can get a bias towards one or the other. This is exactly the kind of behaviour we would expect from these gates, as explained in Chapter 1.
# Let's use the probability of the output '1' as a height, and set the colour accordingly.
# +
def get_color(X,Y):
# set an angle for ry based on the coordinate
theta = X*(np.pi/16)
# create and simulate the circuit
qc = QuantumCircuit(1)
qc.ry(theta,0)
state = Statevector.from_instruction(qc)
probs = state.probabilities_dict()
# get the prob of '1'
if '1' in probs:
height = probs['1']
else:
height = 0
# set colour accordingly
if height<0.1: # sea/river
color = 'blue'
elif height<0.3: # beach
color = 'orange'
elif height<0.9: # grass
color = 'green'
else: # mountain
color = 'grey'
return color
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# By adding more complex rotations, and thinking about how these gates combine, we can build on this to create more complex terrain.
# +
import random
seed = [random.random() for _ in range(4)]
def get_color(X,Y):
qc = QuantumCircuit(1)
theta1 = (seed[0]*X+seed[1]*Y)*np.pi/16
theta2 = (seed[2]*X-seed[3]*Y)*np.pi/16
qc.ry(theta1,0)
qc.rx(theta2,0)
state = Statevector.from_instruction(qc)
probs = state.probabilities_dict()
try:
height = probs['1']
except:
height = 0
# set colour accordingly
if height<0.1: # sea/river
color = 'blue'
elif height<0.3: # beach
color = 'orange'
elif height<0.9: # grass
color = 'green'
else: # mountain
color = 'grey'
return color
# run the game
engine = QiskitGameEngine(start,next_frame,L=8)
# -
# Now experiment by making your own circuits to generate more interesting terrain, and use it to explore what simple quantum gates can do. Or perhaps make a completely new game of your own!
# ## How to use the game engine
#
# To make full use of the game engine, you'll need all the details of how it works. It gives us the ability to make games for a low-pixel screen (8x8 by default), controlled by a D-pad and five buttons. Note that the screen will only update when a button is pressed.
#
# The game engine is all based around the `QiskitGameEngine` object. You can call this whatever you like. In the following we will call it `engine`.
#
# ### The screen
#
# The pixels can be addressed in the functions using `engine.screen`. The pixel at position (x,y) is addressed as `engine.screen.pixel[x,y]`. It has three methods:
#
# * `set_color(color)` - The argument `color` is a string: either `'grey'`, `'green'`, `'blue'`, `'orange'` or `'red'`.
# * `set_brightness(bright)` - The argument `bright` is a Boolean value: `False` for dim and `True` for bright.
# * `set_text(text)` - The argument is text to be displayed.
#
# Note that most pixels won't contain more than a few characters. A larger piece of text can be written on the long pixel at the bottom of the screen, which is accessed with `engine.screen.pixel['text']`.
#
# ### The controller
#
# The controller is accessed using `engine.controller`. Its buttons are addressed using the keys `'down'`, `'up'`, `'left'`, `'right'`, `'A'`, `'B'`, `'X'`, `'Y'` and `'next'`. Each is a Jupyter widget button object. Pressing any of these buttons will cause the `next_frame` function to run. Use the `value` attribute of each button to determine whether the button has been pressed (`True`) or not (`False`).
#
#
# ### The game loop
#
# Games are made by defining two functions, `start` and `next_frame`. The `start` function runs when the game begins, and `next_frame` runs every time a button is pressed to move the game along. Both should have a single argument: the class `engine`. All parameters required for the game should be defined as attributes to the `engine` class.
#
#
# ### Putting it all together
#
# The game is started by initiating the `QiskitGameEngine` object with the `start` and `next_frame` functions. You can also choose a size other than the default 8x8 grid using the keyword argument `L`.
#
# ```
# QiskitGameEngine(start,next_frame,L=8)
# ```
#
# Note that the grid size can be accessed in the `start` and `next_frame` functions as `engine.L`. You can also choose a size other than the default 8x8 grid using the kwarg `L`.
| notebooks/ch-demos/first-quantum-game.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # HyperLearning AI - Introduction to Python
# An introductory course to the Python 3 programming language, with a curriculum aligned to the Certified Associate in Python Programming (PCAP) examination syllabus (PCAP-31-02).<br/>
# https://knowledgebase.hyperlearning.ai/courses/introduction-to-python
#
#
# ## 06. Functions and Modules Part 1
# https://knowledgebase.hyperlearning.ai/en/courses/introduction-to-python/modules/6/functions-and-modules-part-1
#
# In this module we will formally introduce functions, generator functions and lambda functions in Python, starting with formal definitions before exploring their structures and core components, including:
#
# * **Functions** - bespoke functions, parameters, arguments, default parameters, name scope, and important keywords such as return, None and global
# * **Generator Functions** - bespoke generators, lazy evaluation and lazy iterators, generator termination and generator expressions
# * **Lambda Functions** - functional programming, anonymous functions, and lambda functions within filter, map, reduce, sorted and reversed functions
# ### 1. Functions
# A simple example of a user-defined function
def product(number_1, number_2):
return number_1 * number_2
# Call the user-defined function
a = 12
b = 20
c = product(a, b)
print(c)
# #### 1.1. Defining Functions
# Define a function to test whether a given number is a prime number or not
def is_prime(num):
""" Test whether a given number is a prime number or not.
Tests whether a given number is a prime number or not,
by first testing whether it is 0, 1, negative or not a
whole number. If neither of these conditions are met,
then the function proceeds to test whether the given
number can be divided by the numbers from 2 to the
floor division of the given number by 2 without a
remainder. If not, then the given number is indeed a
prime number.
Args:
num (int): The number to test
Returns:
True if the number is a prime number,
False otherwise.
"""
if num <= 1 or num % 1 > 0:
return False
for i in range(2, num//2):
if num % i == 0:
return False
return True
# #### 1.2. Calling Functions
# Call the is_prime() function on a given integer
a = 8
print(f'Is the number {a} a prime number? {is_prime(a)}')
b = 13
print(f'Is the number {b} a prime number? {is_prime(b)}')
c = 277
print(f'Is the number {c} a prime number? {is_prime(c)}')
d = -23
print(f'Is the number {d} a prime number? {is_prime(d)}')
e = 7.181
print(f'Is the number {e} a prime number? {is_prime(e)}')
f = 0
print(f'Is the number {f} a prime number? {is_prime(f)}')
# Call a function with an incorrect number of positional arguments
print(is_prime())
# #### 1.3. Arbitrary Arguments
# Define a function to expect an arbitrary number of arguments
def product(*nums):
x = 1
for num in nums:
x *= num
return x
# +
# Call this function with a tuple of arguments
print(product(2, 10, 5))
my_numbers = (9, 11, 2)
print(f'\nThe product of the numbers {my_numbers} is {product(*my_numbers)}')
# -
# #### 1.4. Unpacking Argument Lists
# Define a function expecting separate positional arguments
def findPrimesBetween(start_num, end_num):
return [num for num in range(start_num, end_num) if is_prime(num)]
# Call this function using argument unpacking
args = [1, 100]
print(findPrimesBetween(*args))
# #### 1.5. Keyword Arguments
# Call a function using keyword arguments
print(findPrimesBetween(start_num = 100, end_num = 200))
# #### 1.6. Arbitrary Keyword Arguments
# Define a function to expect an arbitrary number of keyword arguments
def concatenate_words(**words):
return ' '.join(words.values())
# Call this function with a dictionary of arguments
print(concatenate_words(word_1="Wonderful", word_2="World", word_3="of", word_4="Python"))
# #### 1.7. Default Parameter Values
# Define a function with default parameter values
def findPrimesBetween(start_num = 2, end_num = 100):
return [num for num in range(start_num, end_num) if is_prime(num)]
# Call this function without sending selected arguments
print(findPrimesBetween())
print(findPrimesBetween(end_num = 50))
print(findPrimesBetween(start_num = 25))
print(findPrimesBetween(start_num = 1000, end_num = 1250))
print(findPrimesBetween(100, 200))
# #### 1.8. Passing Mixed Arguments
# Define a function with parameters of mixed types
def calculate_bmi(fname, lname, /, dob, *, weight_kg, height_m):
bmi = round((weight_kg / (height_m * height_m)), 2)
print(f'{fname} {lname} (DOB: {dob}) has a BMI of: {bmi}')
# Call this function with mixed arguments
calculate_bmi("Barack", "Obama", height_m = 1.85, weight_kg = 81.6, dob = '04/08/1961')
# #### 1.9. Pass Statement
# Try to define a function without a body
def my_empty_function():
# Define an empty function using the pass keyword
def my_empty_function():
pass
# #### 1.10. None Keyword and Returning None
# +
# Define a function that does not return a value
def my_logging_function(message):
print(message)
# Call this function and examine the type that it returns
log = my_logging_function("01/09/2020 00:01 - Audit Log 1")
print(type(log))
# -
# #### 1.11. Function Recursion
# Calculate the Nth element in Fibonacci sequence using function recursion
def fibonacci_sequence(n):
if n <= 1:
return n
else:
return(fibonacci_sequence(n-1) + fibonacci_sequence(n-2))
# +
# Calculate the Nth element in the Fibonacci sequence
print(fibonacci_sequence(10))
# Print the first N elements in the Fibonacci sequence
for num in range(0, 10):
print(fibonacci_sequence(num), end = ' ')
# -
# #### 1.12. Name Scope and Global Keyword
# Define a function that contains variables with local scope
def calculate_bmi(weight_kg, height_m):
weight_lb = weight_kg * 2.205
height_inches = height_m * 39.37
bmi = round((weight_lb / (height_inches * height_inches)) * 703, 2)
return bmi
# Try to access a variable with local scope
print(weight_lb)
# +
# Define the kg to lb ratio
kg_lb = 2.205
# Define the metres to inches ratio
m_inches = 39.37
# Define a function that uses variables created outside of the function
def calculate_bmi(weight_kg, height_m):
weight_lb = weight_kg * kg_lb
height_inches = height_m * m_inches
bmi = round((weight_lb / (height_inches * height_inches)) * 703, 2)
return bmi
# Call this function
print(calculate_bmi(weight_kg = 81.6, height_m = 1.85))
# +
# Define variables with global scope
x = 1
y = 2
# Define a simple function
def sum():
x = 10
y = 20
return x + y
# Print the value of x
print(sum())
print(x)
# +
# Define variables with global scope
x = 1
y = 2
# Define a simple function
def sum():
global x
x = 10
y = 20
return x + y
# Print the value of x
print(sum())
print(x)
# +
# Define a function that creates new variables with global scope
def product():
global alpha, beta
alpha = 1000
beta = 1_000_000
return alpha * beta
# Print the value of alpha and beta
print(product())
print(alpha)
print(beta)
# -
# ### 2. Generator Functions
# #### 2.1. Defining Generator Functions
# Define a generator function to generate an infinite sequence
def infinite_sequence_generator():
counter = 0
while True:
yield counter
counter += 1
# Call this generator function and lazily evaluate the next element in the iterable object
infinite_generator = infinite_sequence_generator()
print(next(infinite_generator))
print(next(infinite_generator))
print(next(infinite_generator))
print(next(infinite_generator))
print(next(infinite_generator))
# #### 2.2. Generator Termination
# Define a generator function to lazily return an ordered sequence of letters given a starting letter and an ending letter
def letter_sequence_generator(start, stop, step=1):
for ord_unicode_int in range(ord(start.lower()), ord(stop.lower()), step):
yield chr(ord_unicode_int)
# Call this generator function until there are no further elements in the sequence to be evaluated
alphabet = letter_sequence_generator("a", "e")
print(next(alphabet))
print(next(alphabet))
print(next(alphabet))
print(next(alphabet))
# Attempt to call the next() function again on the terminated generator function
print(next(alphabet))
# #### 2.3. Generators and For Loops
# Use a for loop to iterate over the iterable object returned by our letter sequence generator function
alphabet = letter_sequence_generator("a", "z")
for letter in alphabet:
print(letter)
# #### 2.4. Generator Expressions
# Use a generator expression to create a lazily evaluated iterable object
first_million_numbers = (num for num in range(1, 1_000_000))
print(next(first_million_numbers))
print(next(first_million_numbers))
print(next(first_million_numbers))
# #### 2.5. Generator Objects as Lists
# +
# Create a lazily evaluated generator object
alphabet = letter_sequence_generator("a", "z")
# Convert the generator object into a list
alphabet_list = list(alphabet)
print(alphabet_list)
# -
# ### 3. Lambda Functions
# #### 3.1. Defining Lambda Functions
# +
# Create a simple lambda function to square a given number
square = lambda n: n * n
# Call this lambda function
print(square(8))
# +
# Create a simple lambda function with three arguments
product = lambda x, y, z: x * y * z
# Call this lambda function
print(product(3, 10, 5))
# -
# #### 3.2. Using Lambda Functions
# +
# Create a list of numbers
my_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Use the imperative paradigm to filter the list of integers, keeping only the even numbers
def filter_evens_imperative(number_list):
even_number_list = []
for number in number_list:
if number % 2 == 0:
even_number_list.append(number)
return even_number_list
# Filter the list of numbers, keeping only the even numbers
even_numbers = filter_evens_imperative(my_numbers)
print(even_numbers)
# -
# Use a functional approach to filter the same list of integers
even_numbers = list(filter(lambda num: num % 2 == 0, my_numbers))
print(even_numbers)
# #### 3.2.1. User Defined Functions
# +
# Create a Python function containing a lambda anonymous function
def multiply(multiplier):
return lambda x: x * multiplier
# Instantiate a function that always doubles a given number
doubler = multiply(2)
# Call this function with the value 10
print(doubler(10))
# Instantiate a function that always quadruples a given number
quadrupler = multiply(4)
# Call this function with the value 100
print(quadrupler(100))
# -
# #### 3.2.2. Filter Function
# +
# Create a list of numbers
my_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Create a function that will test whether a given number is even or not
def test_even(num):
if num % 2 == 0:
return True
return False
# Apply this function to the list of numbers using the filter() function
my_even_numbers = list(filter(test_even, my_numbers))
print(my_even_numbers)
# -
# Use a lambda function within filter() to perform the same task
my_even_numbers = list(filter(lambda num: num % 2 == 0, my_numbers))
print(my_even_numbers)
# #### 3.2.3. Map Function
# +
# Create a function that will square a given number but only if that number is odd
def square_odd_number(num):
if num % 2 == 0:
return num
return num * num
# Apply this function to the list of numbers using the map() function
my_squared_odd_numbers = list(map(square_odd_number, my_numbers))
print(my_squared_odd_numbers)
# -
# Use a lambda function within map() to perform the same task
my_squared_odd_numbers = list(map(lambda num: num if num % 2 == 0 else num * num, my_numbers))
print(my_squared_odd_numbers)
# #### 3.2.4. Reduce Function
# +
from functools import reduce
# Create a function that will calculate the product of two given numbers
def product(a, b):
return a * b
# Apply this function to the list of numbers using the reduce() function
my_product_of_numbers = reduce(product, my_numbers)
print(my_product_of_numbers)
# Apply this function to the list of numbers using the reduce() function and an initializer value of 2
my_product_of_numbers = reduce(product, my_numbers, 2)
print(my_product_of_numbers)
# Apply this function to the list of numbers using the reduce() function and an initializer value of 10
my_product_of_numbers = reduce(product, my_numbers, 10)
print(my_product_of_numbers)
# -
# Use a lambda function within reduce() to perform the same task
my_product_of_numbers = reduce(lambda a, b: a * b, my_numbers)
print(my_product_of_numbers)
# #### 3.2.5. Sorted Function
# +
# Create a list of unordered numbers
my_unordered_numbers = [2, 100, 99, 3, 7, 8, 13, 48, 88, 38]
# Sort the list of numbers
sorted_numbers = sorted(my_unordered_numbers)
print(sorted_numbers)
# Sort the list of numbers in descending order
sorted_numbers_desc = sorted(my_unordered_numbers, reverse=True)
print(sorted_numbers_desc)
# +
# Create a list of tuples modelling a football league (team name, total points, total goals scored, total goals conceded)
completed_football_league = [
('Manchester United', 75, 64, 35),
('<NAME>', 56, 48, 44),
('Arsenal', 90, 73, 26),
('Newcastle United', 56, 52, 40),
('Liverpool', 60, 55, 37),
('Chelsea', 79, 67, 30)
]
# Create a function to create a compound sorting key
def sorting_key(item):
total_points = item[1]
goal_difference = item[2] - item[3]
return (total_points, goal_difference)
# Use this sorting function with the sorted() function to sort the football league by multiple keys i.e. total points and goal difference
sorted_football_league = sorted(completed_football_league, key=sorting_key, reverse=True)
print(sorted_football_league)
# -
# Use a lambda function within sorted() as the key function to perform the same task
sorted_football_league = sorted(completed_football_league, key=lambda item: (item[1], item[2] - item[3]), reverse=True)
print(sorted_football_league)
# #### 3.2.6. Reversed Function
# +
# Use the reversed() function to return a reversed iterable object
my_reversed_numbers = list(reversed(my_numbers))
print(my_reversed_numbers)
# Reverse a range of numbers
my_range = range(11, 21)
my_reversed_range = list(reversed(my_range))
print(my_reversed_range)
# Reverse the characters in a string
my_string = 'abracadabra'
my_reversed_string = list(reversed(my_string))
print(my_reversed_string)
# -
# #### 3.2.7. Sort Method
# +
import copy
# Create a deepcopy of the previous list of tuples representing a football league
completed_football_league_deep_copy_1 = copy.deepcopy(completed_football_league)
# Sort the previous list of tuples representing a football league using the list sort() method
completed_football_league_deep_copy_1.sort(reverse=True, key=sorting_key)
print(completed_football_league_deep_copy_1)
# -
# Use a lambda function within the list sort() method as the key function to perform the same task
completed_football_league_deep_copy_2 = copy.deepcopy(completed_football_league)
completed_football_league_deep_copy_2.sort(reverse=True, key=lambda item: (item[1], item[2] - item[3]))
print(completed_football_league_deep_copy_2)
| 06. Functions and Modules Part 1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
# Be sure to restart the notebook kernel if you make changes to the helper.py
# Re-running this cell does not re-load the module otherwise
from helper import *
# We use matplotlib for plotting. You can basically get any plot layout/style
# etc you want with this module. I'm setting it up for basics here, meaning
# that I want it to parse LaTeX and use the LaTeX font family for all text.
# !! If you don't have a LaTeX distribution installed, this notebook may
# throw errors when it tries to create the plots. If that happens,
# either install a LaTeX distribution or remove/comment the
# matplotlib.rcParams.update(...) line.
# In both cases, restart the kernel of this notebook afterwards.
import matplotlib
import matplotlib.pyplot as plt
# %matplotlib inline
rcparams = {
"pgf.texsystem": "pdflatex", # change this if using xetex or lautex
"text.usetex": True, # use LaTeX to write all text
"font.family": "lmodern",
"font.serif": [], # blank entries should cause plots to inherit fonts from the document
"font.sans-serif": [],
"font.monospace": [],
"font.size": 12,
"legend.fontsize": 12,
"xtick.labelsize": 12,
"ytick.labelsize": 12,
"pgf.preamble": [
r"\usepackage[utf8x]{inputenc}", # use utf8 fonts becasue your computer can handle it :)
r"\usepackage[T1]{fontenc}", # plots will be generated using this preamble
]
}
matplotlib.rcParams.update(rcparams)
# -
# # Load the title dataset
re_parse = False
if re_parse:
all_titles = load_and_parse_all_titles('alltitles.txt')
# Save to a file, so we can load it much faster than having
# to re-parse the raw data.
np.save("alltitles.npy", all_titles)
else:
# Load the titles from the file.
# The atleast_2d is a hack for correctly loading the dictionary...
all_titles = np.atleast_2d(np.load("alltitles.npy"))[0][0]
# Check the available years
all_years = sorted(list(all_titles.keys()))
print("Available years: ", all_years )
# # Number of papers per year/month
# +
fig, ax = plt.subplots(dpi=600)
fig.set_size_inches(3.54,3.54)
numpapers = []
for k in all_years:
numpapers.append( len(get_titles_for_years(all_titles, [k])) )
ax.plot( np.arange(len(numpapers)), numpapers, '-o', markersize=3 )
ax.annotate("%d"%numpapers[0], xy=(0, numpapers[0]), xytext=(0, numpapers[0]+2000),
arrowprops=dict(arrowstyle="->"))
ax.set_xticks( list(range(len(all_titles.keys()))[::2]) + [26] )
ax.set_xticklabels( list(all_titles.keys())[::2] + [2018], rotation=75 )
ax.set_yticklabels( [0, '0', '2.5k', '5k', '7.5k', '10k', '12.5k', '15k', '17.5k'])
ax.grid()
#--------------------------------------------------------------------------
# Add an inset
#--------------------------------------------------------------------------
ax2 = fig.add_axes([0.6, 0.25, 0.25, 0.25])
numpapers = []
for k in all_years[-4:]:
num_per_month = [len(all_titles[k][m]) for m in all_titles[k].keys()]
ax2.plot( list(all_titles[k].keys()), num_per_month/np.sum(num_per_month), label="%d"%k )
ax2.legend(fancybox=True, ncol=2, prop={'size':3})
ax2.set_xticks( range(13) )
ax2.set_xticklabels( ["", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"], rotation=75, fontsize=5 )
ax2.set_yticklabels( [0, '6%', '8%', '10%'])
ax2.yaxis.grid(True)
#fig.savefig("numpapers.png", bbox_inches='tight', transparent=False)
# -
# ## Phrase detection
titles = get_titles_for_years(all_titles, all_years)
ngram_titles, bigrams, ngrams = get_ngrams(titles)
# ## Sort ngrams by certainty
# +
sortedbis = sorted( [(bigrams[b][0], bigrams[b][1], b) for b in bigrams.keys()] )[::-1]
sortedns = sorted( [(ngrams[b][0], ngrams[b][1], b) for b in ngrams.keys()] )[::-1]
print("Top bigrams by certainty:")
for i in range(20):
print("{0:2}: {1:50} \t({2}) ".format(i+1, str(sortedbis[i][2])[2:-1], "%.2f"%sortedbis[i][0]))
print("\n")
print("Top 3- and 4-grams by certainty:")
for i in range(20):
print("{0:2}: {1:50} \t({2}) ".format(i+1, str(sortedns[i][2])[2:-1], "%.2f"%sortedns[i][0]))
# -
# ## Sorted by frequency
# +
sortedbis = sorted( [(bigrams[b][1], bigrams[b][0], b) for b in bigrams.keys()] )[::-1]
sortedns = sorted( [(ngrams[b][1], ngrams[b][0], b) for b in ngrams.keys()] )[::-1]
print("Top bigrams by total count:")
for i in range(20):
print("{0:2}: {1:50} \t({2}) ".format(i+1, str(sortedbis[i][2])[2:-1], "%.2f"%sortedbis[i][0]))
print(sortedbis[12])
print("\n")
print("Top 3- and 4-grams by total count:")
for i in range(20):
print("{0:2}: {1:50} \t({2}) ".format(i+1, str(sortedns[i][2])[2:-1], "%.2f"%sortedns[i][0]))
# -
# # Track bigrams over the years
# +
# Track bigrams over time
bigrams_per_year = {}
ngrams_per_year = {}
# For every year..
years = np.arange(2000,2018)
for y,year in enumerate(years):
# .. get the bigrams
titles_per_year = get_titles_for_years([year])
_, bigrams, ngrams = get_ngrams(titles_per_year)
# .. and count each of them them
for b in bigrams.keys():
if b not in bigrams_per_year:
bigrams_per_year[b] = np.zeros_like(years)
bigrams_per_year[b][y] = bigrams[b][1]
# .. and count each of them them
for b in ngrams.keys():
if b not in ngrams_per_year:
ngrams_per_year[b] = np.zeros_like(years)
ngrams_per_year[b][y] = ngrams[b][1]
# +
print(bigrams_per_year[b'machine learning'][:])
print(bigrams_per_year[b'phase transition'][:])
print(years)
# -4:-1 is [2014 - 2016]
print(np.diff(bigrams_per_year[b'machine learning'][-9:-1]))
print(np.mean( np.diff(bigrams_per_year[b'machine learning'][-3:-1])) )
# -4:-1 is [2014 - 2016]
# -8:-1 is [2010 - 2016]
idx = [-3,-1]
bigram_change_over_the_years = {}
for b in bigrams_per_year.keys():
bigram_change_over_the_years[b] = np.mean( np.diff(bigrams_per_year[b][idx[0]:] ) )
#trigram_change_over_the_years = {}
#for b in trigrams_per_year.keys():
# trigram_change_over_the_years[b] = np.mean( np.diff(trigrams_per_year[b][idx[0]:] ) )
# -
changelist = [(bigram_change_over_the_years[b],b) for b in bigram_change_over_the_years.keys()]
print(sorted(changelist)[::-1][:20])
print("\n")
#changelist = [(trigram_change_over_the_years[b],b) for b in trigram_change_over_the_years.keys()]
#print(sorted(changelist)[::-1][:20])
# # Abstracts
# Parse abstract into sentences
def parse_abstract(file):
# Buffer for storing the file
abstr = open(file, "r").read()
# Clean up abstract
words = re.split(' |-|\\|/|.', abstr.lower())
words = [ singularize(stripchars(w, '\\/$(){}.<>,;:_"|\'\n `?!#%')) for w in words if w != ' ' ]
return words
| PhraseAnalysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# %matplotlib inline
a = sns.load_dataset('tips')
a.head()
sns.boxplot(x=a['size'])
sns.boxplot(x=a['total_bill'])
sns.boxplot(x='sex',y='total_bill',data=a)
sns.boxplot(x='day',y='total_bill',data=a)
sns.boxplot(x='day',y='total_bill',data=a,hue='sex')
sns.boxplot(x='day',y='total_bill',data=a,hue='smoker',palette='husl')
sns.boxplot(x='day',y='total_bill',data=a,hue='time')
sns.boxplot(x='day',y='total_bill',data=a,hue='time', order=['Fri','Sat','Thur','Sun'])
sns.boxplot(x='total_bill',y='day',data=a, orient='horizontal')
sns.boxplot(x='day',y='total_bill',data=a,palette='husl')
sns.swarmplot(x='day',y='total_bill',data=a)
sns.boxplot(x='day',y='total_bill',data=a,palette='husl')
sns.swarmplot(x='day',y='total_bill',data=a,color='black')
| 04. Box Plot.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# +
# 自定义层
# 构造一个没有任何参数的自定义层
import torch
import torch.nn.functional as F
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()
layer = CenteredLayer()
layer(torch.FloatTensor([1, 2, 3, 4, 5]))
# +
# 将层作为组件合并到构建更复杂的模型中
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
Y = net(torch.rand(4, 8))
Y.mean()
# +
# 带参数的层
class MyLinear(nn.Module):
def __init__(self, in_units, units): # 两个参数:输入维度、输出维度
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)
linear = MyLinear(5, 3)
linear.weight
# -
# 使用自定义层直接执行正向传播计算
linear(torch.rand(2, 5))
# 使用自定义层构建模型
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
net(torch.rand(2, 64))
| artificial-intelligence/d2l-pytorch/notes/18_build_layer.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# #!pip install selenium
# #!pip install webdriver_manager
# -
# Dependencies
from selenium import webdriver
from bs4 import BeautifulSoup as bs
import time
from webdriver_manager.chrome import ChromeDriverManager
# +
# Set up Splinter
driver = webdriver.Chrome(ChromeDriverManager().install())
# Visit url
url = "https://mars.nasa.gov/news/?page=0&per_page=40&order=publish_date+desc%2Ccreated_at+desc&search=&category=19%2C165%2C184%2C204&blank_scope=Latest"
driver.get(url)
html= driver.page_source
soup = bs(html, 'html.parser')
# +
news_title = soup.find('div', class_="content_title").text
news_p = soup.find('div', class_="article_teaser_body").text
print(f"Title {news_title}, Body {news_p}")
# -
driver.close()
| .ipynb_checkpoints/mission_to_mars-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + deletable=true editable=true
from os import path
fname = path.expanduser('~/Desktop/Exercise Files/Ch04/04_02/track.csv')
# + deletable=true editable=true
print('c:\path\to\nowhere.csv')
# + deletable=true editable=true
print(r'c:\path\to\nowhere.csv')
# + deletable=true editable=true
# !ls -lh "$fname"
# + deletable=true editable=true
path.getsize(fname)
# + deletable=true editable=true
path.getsize(fname) / (1<<10)
# + deletable=true editable=true
# !head "$fname"
# + deletable=true editable=true
with open(fname) as fp:
for lnum, line in enumerate(fp):
if lnum > 10:
break
print(line[:-1])
# + deletable=true editable=true
# !wc -l "$fname"
# + deletable=true editable=true
with open(fname) as fp:
print(sum(1 for line in fp))
# + deletable=true editable=true
import pandas as pd
# + deletable=true editable=true
df = pd.read_csv(fname)
# + deletable=true editable=true
len(df)
# + deletable=true editable=true
df.columns
# + deletable=true editable=true
df.info()
# + deletable=true editable=true
df.head()
# + deletable=true editable=true
df.dtypes
# + deletable=true editable=true
df = pd.read_csv(fname, parse_dates=['time'])
# + deletable=true editable=true
df.dtypes
# + deletable=true editable=true
df['lat']
# + deletable=true editable=true
df.lat
# + deletable=true editable=true
df[['lat', 'lng']]
# + deletable=true editable=true
df['lat'][0]
# + deletable=true editable=true
df.loc[0]
# + deletable=true editable=true
df.loc[2:7]
# + deletable=true editable=true
df[['lat', 'lng']][2:7]
# + deletable=true editable=true
df.index
# + deletable=true editable=true
import numpy as np
df1 = pd.DataFrame(np.arange(10).reshape((5,2)), columns=['x', 'y'], index=['a', 'b', 'c', 'd', 'e'])
df1
# + deletable=true editable=true
df1.loc['a']
# + deletable=true editable=true
df1.loc['b': 'd']
# + deletable=true editable=true
df.index
# + deletable=true editable=true
df.index = df['time']
df.index
# + deletable=true editable=true
df.loc['2015-08-20 04:18:54']
# + deletable=true editable=true
df.loc['2015-08-20 03:48']
# + deletable=true editable=true
import pytz
# + deletable=true editable=true
ts = df.index[0]
# + deletable=true editable=true
ts.tz_localize(pytz.UTC)
# + deletable=true editable=true
ts.tz_localize(pytz.UTC).tz_convert(pytz.timezone('Asia/Jerusalem'))
# + deletable=true editable=true
df.index = df.index.tz_localize(pytz.UTC).tz_convert(pytz.timezone('Asia/Jerusalem'))
df.index[:10]
# -
| Ch04/04_04/04_04.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import matplotlib.pyplot as plt
# %matplotlib inline
import numpy as np
import math
from math import pi, factorial
from pprint import pprint
from numpy import absolute, vdot
from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister, execute, Aer, transpile
from qiskit.tools.visualization import circuit_drawer, plot_circuit_layout, plot_histogram
from qiskit.test.mock import FakeVigo, FakeAthens
from qiskit.quantum_info import state_fidelity, DensityMatrix, Statevector, Operator
from qiskit import BasicAer
from qiskit.extensions import Initialize
from qiskit.providers.aer import QasmSimulator
from qiskit.providers.aer.extensions import snapshot_density_matrix
from qiskit.tools.jupyter import *
from qiskit.circuit.library import Permutation
from qiskit.transpiler import PassManager, CouplingMap, Layout
from qiskit.transpiler.passes import BasicSwap, LayoutTransformation, RemoveFinalMeasurements
backend = BasicAer.get_backend('unitary_simulator')
# +
fake_machine = FakeAthens()
n = 4
#print(fake_machine.properties().to_dict()['gates'])
# A coupling map of fake Athens
#coupling = [[0, 1], [1, 0], [1, 2], [2, 1], [2, 3], [3, 2], [3, 4], [4, 3]]
#coupling_map = CouplingMap(couplinglist=coupling)
# +
desired_vector = np.random.rand(2**n)+1j*np.random.rand(2**n)
desired_vector = desired_vector/np.linalg.norm(desired_vector)
print(desired_vector)
print(np.linalg.norm(desired_vector))
# +
init = Initialize(desired_vector)
init_circ = init.gates_to_uncompute().inverse()
init_circ.draw('mpl')
qr = QuantumRegister(n)
cr = ClassicalRegister(n)
qc = QuantumCircuit(qr, cr)
qc.initialize(desired_vector, qr)
qc.barrier()
qc.measure(qr, cr)
init_circ = qc
init_circ.draw('mpl')
# +
backend = BasicAer.get_backend('statevector_simulator')
job = execute(init_circ, backend)
init_state = job.result().get_statevector(init_circ)
print(state_fidelity(desired_vector,init_state))
# +
circs = []
depths = []
n_iter = 10
for _ in range(n_iter):
new_circ = transpile(init_circ,fake_machine,optimization_level=3)
circs.append(new_circ)
depths.append(new_circ.depth())
#init_circ.draw('mpl')
#plt.figure(figsize=(8, 6))
#plt.hist(depths, bins=list(range(min(depths),max(depths)+2)), align='left', color='#AC557C')
#plt.xlabel('Depth', fontsize=14)
#plt.ylabel('Counts', fontsize=14);
# -
best_init_circ = circs[np.argmin(depths)]
best_init_circ.draw('mpl')
plot_circuit_layout(best_init_circ,fake_machine)
# +
#machine_simulator = Aer.get_backend('qasm_simulator')
#best_init_circ.save_density_matrix()
#init_circ.save_density_matrix()
#for i in range(n_iter):
# circs[i].remove_final_measurements()
# circs[i].save_density_matrix()
# +
machine_simulator = Aer.get_backend('qasm_simulator')
#best_init_circ.snapshot_density_matrix('final')
#best_init_circ.save_density_matrix()
fidelities = []
n_shots = n_iter
pad_vectors = []
for i in range(n_iter):
qubit_pattern = list(circs[i]._layout.get_virtual_bits().values()) # How virtual bits map to physical bits
n_phys = len(qubit_pattern) # n of physical bits
perm = [0,1,2,3,4]
if (n < 3) :
for j in range(n_phys):
perm[qubit_pattern[j]] = j
else:
for op, qubits, clbits in circs[i].data:
if op.name == 'measure':
perm[qubits[0].index] = clbits[0].index
circs[i].remove_final_measurements()
circs[i].snapshot_density_matrix('final')
#circs[i].save_density_matrix()
qubit_pattern = perm
aug_desired_vector = desired_vector
for k in range(n_phys-n):
aug_desired_vector = np.kron([1,0],aug_desired_vector) #Kronecker product
perm_circ = Permutation(n_phys, qubit_pattern) # Creating a circuit for qubit mapping
perm_unitary = Operator(perm_circ) # Matrix for the said circuit
perm_aug_desired_vector = perm_unitary.data @ aug_desired_vector
pad_vectors.append(perm_aug_desired_vector)
#from itertools import permutations
#p = list(permutations(range(5), 5))
#for i in range(n_iter):
# for j in range(factorial(5)):
# perm_circ = Permutation(n_phys, p[j])
# perm_unitary = Operator(perm_circ)
# perm_aug_desired_vector = perm_unitary.data @ aug_desired_vector
# fid = state_fidelity(perm_aug_desired_vector,execute(circs[i], machine_simulator, shots=1).result().data()['density_matrix'])
# #fid = state_fidelity(perm_aug_desired_vector,execute(circs[i], backend).result().get_statevector(circs[i]))
# if (1-fid < 0.01):
# print()
# print("circuit " + str(i))
# print(p[j])
# print(qubit_pattern)
# print(fid)
from qiskit.providers.aer.noise import NoiseModel
noise_model = NoiseModel.from_backend(fake_machine)
coupling_map = fake_machine.configuration().coupling_map
basis_gates = noise_model.basis_gates
#print(perm_aug_desired_vector)
#print("RESULT")
#job = execute(best_init_circ,backend,shots=1).result()
#print(job)
for i in range(n_shots):
result = execute(circs[i], machine_simulator,
coupling_map=coupling_map,
basis_gates=basis_gates,
noise_model=noise_model,
shots=1).result()
# job = execute(circs[i],backend)
#print(result)
# noisy_dens_matr = DensityMatrix(result.data()['snapshots']['density_matrix']['final'][0]['value'],n_phys*(2,))
noisy_dens_matr = result.data()['snapshots']['density_matrix']['final'][0]['value']
# noisy_dens_matr = DensityMatrix(result.data()['density_matrix'],n_phys*(2,))
# noisy_dens_matr = result.data()['density_matrix']
# noisy_dens_matr = job.result().get_statevector(circs[i])
#print(noisy_dens_matr)
fid = state_fidelity(pad_vectors[i],noisy_dens_matr)
print("---")
print(fid)
for _ in range(10):
result = execute(circs[i], machine_simulator,
coupling_map=coupling_map,
basis_gates=basis_gates,
noise_model=noise_model,
shots=1).result()
noisy_dens_matr = result.data()['snapshots']['density_matrix']['final'][0]['value']
fid2 = state_fidelity(pad_vectors[i],noisy_dens_matr)
print(fid2)
print("---")
fidelities.append(fid)
#print(fid)
#print(noisy_dens_matr)
mean_fidelity = sum(fidelities)/len(fidelities)
print("mean fidelity: " + str(mean_fidelity))
plt.figure(figsize=(8, 6))
plt.hist(fidelities, bins=list(np.arange(0,1.2,0.01)), align='left', color='#AC557C')
plt.xlabel('Fidelity', fontsize=14)
plt.ylabel('Counts', fontsize=14);
# +
machine_simulator = QasmSimulator.from_backend(fake_machine)
#meas = ClassicalRegister(n)
#best_init_circ.add_register(meas)
best_init_circ.measure(list(range(n)), list(range(n)))
result_noise = execute(best_init_circ, machine_simulator).result()
counts_noise = result_noise.get_counts(best_init_circ)
plot_histogram(counts_noise, title="Counts for initialized state with device noise model")
# -
print(best_init_circ._layout.get_virtual_bits().values())
best_init_circ.draw('mpl')
fake_machine
pattern = list(best_init_circ._layout.get_virtual_bits().values())
print(pattern)
# +
augmented_desired_vector = desired_vector
for k in range(2):
augmented_desired_vector = np.kron(augmented_desired_vector,[1,0])
permutation_circ = Permutation(5,[2,1,0,3,4])
permutation_unitary = Operator(permutation_circ)
perm_vector = permutation_unitary.data @ augmented_desired_vector
print(perm_vector)
# -
permutation_unitary.data
augmented_desired_vector
print(augmented_desired_vector)
print(permutation_unitary.data @ augmented_desired_vector)
backend = BasicAer.get_backend('statevector_simulator')
for circ in circs:
job = execute(circ, backend)
init_state = job.result().get_statevector(circ)
print(absolute(vdot(desired_vector, init_state))**2)
print(state_fidelity(desired_vector,init_state))
print(list(circ._layout.get_virtual_bits().values()))
# #
| qiskit_transpiler/transpiled_initialization_circuits.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Perspective Transform
# ## Import all the necessary libraries
# +
import cv2
import numpy as np
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
# %matplotlib inline
#import sys
#np.set_printoptions(threshold=sys.maxsize)
# -
# ## Read and display an image
img = mpimg.imread("img/speed_sign.jpg")
fig = plt.figure(figsize=(10, 5))
plt.imshow(img)
# ## Cordinates of the 4 corners of the original and desired image
#
# - First entry: top-left
# - Second entry: top-right
# - Third entry: bottom-right
# - Fourth entry: bottom-left
# +
height, width = img.shape[:2]
# Cordinates of the 4 corners of the original image
source_points = np.float32([[200,60], [450,150], [520, 500], [170,470] ])
# Cordinates of the 4 corners of the desired output
destination_points = np.float32([[0,0], [width,0], [width,height], [0,height]])
# -
# ## Perform Perspective Transform
# +
# Use the two sets of four points to compute
# the Perspective Transformation matrix, M
M = cv2.getPerspectiveTransform(source_points, destination_points)
warped = cv2.warpPerspective(img, M, (width, height))
plt.imshow(warped)
| Computer Vision/basics/perspective_transform.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Home
# In this interactive notebook we will go through a series of processing steps specific to spinal cord MRI analysis. We will be using the [Spinal Cord Toolbox (SCT)](https://github.com/neuropoly/spinalcordtoolbox), lead by Prof. <NAME> and the [NeuroPoly](https://www.neuro.polymtl.ca) lab at Polytechnique de Montréal. The main goal is to demonstrate an end-to-end template-based analysis pipeline, where we start of with the raw NIFTI data and end up with quantitative metrics. Here, the metric will be magnetization transfer saturation (MTsat) extracted in specific white matter tracts.
# ## Acknowledgements
#
# The development of this notebook was supported by the <a href="http://conp.ca" target="_blank">Canadian Open Neuroscience Platform (CONP)</a> initiative, the <a href="https://www.rbiq-qbin.qc.ca/" target="_blank">Quebec Bio-Imaging Network (QBIN)</a>, and the <a href="https://www.icm-mhi.org/en/foundation" target="_blank">Montreal Heart Institute Foundation</a>.
#
#
| content/introduction.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] _cell_guid="c6e42e34-db68-49ef-8070-a69f5c7337b3" _uuid="da038af3ad452113ee3fb4017e3eedab48e9f86a"
# # Implementing Advanced Regression Techniques for Prediction:
#
# There are several factors that impact the overall price of the house, some of those factors are more **tangible** as the quality of the house or the overall size (area) of the house and other factors are more **intrinsic** such as the performance of the economy. Coming with an accurate model that predicts with such precision the actual value is an arduous task since there are both internal and external factors that will affect the price of a single house. Nevertheless, what we can do is **detect** those features that carry a heavier weight on the overall output (Price of the house). <br><br>
#
# Before the housing crisis that occurred during the years of (2007-2008), most people believed that the prices of houses tended to go up throughout the years and that people that invested into properties were certain that they will get a return. This was not the case since banks were basically approving loans to people that were not able to afford to pay a house, there were even financial institutions who were approving loans to ordinary individuals at a variable interest rate (meaning rate will change depending on the current market rate) and when the crisis occurred lots of those ordinary individuals were not able to afford to pay back their mortgages. Of course, there were other reasons that caused the financial crisis in the first place such as the introduction of complex financial instruments (*derivatives are still not widely understood*), hedging financial instruments (credit default swaps), and the deregulation of the financial industry as a whole. While we can argue about the factors that caused the financial crisis, the main objective of this post is to determine what possible features could have a real impact on the overall value of a house. We will try to answer questions such as to what extent did the recession impacted the value house prices? What materials were most commonly used with houses that had a high price range? (Rooftop, walls etc.) Which neighborhoods were the most exclusive? <br><br>
#
# I believe that in order to perform an extensive analysis of this data we should explore our data, by this I mean getting a sense of what is the **story behind the data**. Most of the time I tend to reject the idea of just building a model that have a good accuracy score for predicting values instead, I analyze my data carefully (determining distributions, missing values, visualizations) in order to have a better understanding of what is going on. ONly after my extensive analysis I proceed to developing the predictive model, in this case we will use **regression models.** The downside of this to many of you who will see this post, is that it will be somewhat long, so if you think you should **skip** all the sections and start from the regression model step, please feel free to do so! I will create an outline so it will help you find the section you wish to start with. <br><br>
#
# **I'd rather have a full house at a medium price than a half-full at a high price. - <NAME>**
# ***
# + [markdown] _cell_guid="c6cbbd64-bc2c-48a8-b297-5a4e2e5429bd" _uuid="e40e74e83039e7eeca270b412107999f7176c1b2"
# ## Goal of this Project:
# ***
# ### Achieving our goal is split into two phases: <br>
# 1) **Exploratory Data Analysis (EVA)**: In this phase our main aim is to have a better understanding of the features involved in our data. It might be possible that some are left behind but I will be focusing on the features that have the highest correlation towards SalePrice. <br><br>
#
# 2) **Advanced Regression**: We will implement Regression model to predict a possible SalePrice (label) of the house.
# + [markdown] _cell_guid="a60e022f-aaa3-4b3f-b031-574d3c3ef7e0" _uuid="fca3556b83c3c5348d8bff3b436475baeda0b26c"
# ## Outline:
# ***
# I. **Understanding our Data**<br>
# a) [Splitting into Different Categories](#splitting)<br>
# b) [Gathering Basic Insight](#insight) <br><br>
#
# II. **Economic Activity**<br><br>
# III. [Outside Surroundings](#outside)<br>
# a) [Type of Zoning](#zoning)<br>
# b) [Neighborhoods](#neighborhoods) <br><br>
#
# IV. **Areas of the House** <br>
# a) [The Impact of Space towards Price](#space)<br><br>
#
# V. **Building Characteristics**<br>
# a) [Correlations with SalePrice](#correlation)<br>
# b) [What garages tell about House Prices?](#garage)<br><br>
#
# VI. **Miscellaneous and Utilities**<br>
# a) [What determines the quality of the house?](#quality)<br>
# b) [Intersting insights](#interesting)<br>
# c) [Which Material Combination increased the Price of Houses?](#material)<br><br>
#
# VII. [Quality of Neighborhoods](#quality_neighborhoods)<br><br>
#
# VIII. **The Purpose of using Log Transformations** <br>
# a)[Log Transformations](#log_transformations)<br>
# b) [Skewedness and Kurtosis](#skew_kurt)<br>
# c) [Outliers Analysis](#analysis_outliers)<br>
# d) [Bivariate Analysis](#bivariate) <br><br>
#
# IX. **Feature Engineering** <br>
# a) [Dealing with Missing Values](#missing_values)<br>
# b) [Transforming Values](#transforming_values)<br>
# c) [Combining Attributes](#combining_atributes) <br>
# d) [Dealing with numerical and categorical values](#num_cat_val) <br><br>
#
# X. **Scaling** <br>
# a) [Categorical Encoding Class](#categorical_class)<br>
# b) [Combine Attribute Class](#combining)<br>
# c) [Pipelines](#combining)<br><br>
#
# XI. **Predictive Models** <br>
# a) [Residual Plot](#residual_plot) <br>
# b) [RandomForests Regressor](#random_forest) <br>
# c) [GradientBoosting Regressor](#gradient_boosting)<br>
# d) [Stacking Regressor](#stacking_regressor)
# + [markdown] _cell_guid="344b4951-2329-456f-ade4-7a95c69a9ddf" _uuid="d9d95d01af4628543de7a82b03b85c0f5fa6d59d"
# ### References:
# 1) <a href="https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard">Stacked Regressions : Top 4% on LeaderBoard</a> by Serigne.
# - Good if you are looking for stacking models and to gather an in-depth analysis for feature engineering. <br><br>
#
# 2) <a href="https://www.kaggle.com/vhrique/simple-house-price-prediction-stacking"> Simple House Price Prediction Stacking </a> by <NAME>.
# - Gave me an idea of which algorithms to implement in my ensemble methods. <br>
# - Also Victor is really open to answer any doubts with regards to this project. <br><br>
#
# 3) <a href="https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python"> Comprehensive data exploration with Python </a> by <NAME>.
# - Help me understand more in depth the different linear regularization methods and its parameters. <br><br>
#
# 4) <b> Hands on Machine Learning with Scikit-Learn & TensorFlow by <NAME> (O'Reilly). CopyRight 2017 <NAME> </b><br>
# - Good reference for understanding how Pipelines work. <br>
# - Good for understanding ensemble methods such as RandomForests and GradientBoosting. <br>
# - This book is a must have for people starting in the area of machine learning.<br><br>
#
#
# 5) <a href="https://www.analyticsvidhya.com/blog/2017/06/a-comprehensive-guide-for-linear-ridge-and-lasso-regression/"> A comprehensive beginners guide for Linear, Ridge and Lasso Regression </a> by <NAME> at Analytics Vidhya.
# - Helped me implement a residual plot.. <br>
# - Better understanding of Ridge, Lasso and ElasticNet (Good for Beginners).
# + _cell_guid="6334b548-5cc8-4428-9547-7cd5df81910b" _uuid="52eb856d0e92b16802a39483b459f360376352ea"
# Data and plotting imports
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
# Statistical Libraries
from scipy.stats import skew
from scipy.stats.stats import pearsonr
from scipy import stats
# Plotly imports
from plotly import tools
import plotly.plotly as py
import plotly.figure_factory as ff
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
# Maintain the Ids for submission
train_id = train['Id']
test_id = test['Id']
# + _cell_guid="8046b415-b485-417b-9c79-a62c072bb9e4" _uuid="9fbdf22ef21b4e098b6e0bdcb4aeaa60b64e7d71"
train['SalePrice'].describe()
# + _cell_guid="16ac8751-f327-4724-8d0c-268014c910db" _uuid="c8149e8753105daed717a7caa3620bdb5f169204"
# It seems we have nulls so we will use the imputer strategy later on.
Missing = pd.concat([train.isnull().sum(), test.isnull().sum()], axis=1, keys=['train', 'test'])
Missing[Missing.sum(axis=1) > 0]
# + _cell_guid="afa92edd-1801-4cc1-ad98-c94f3dd32f07" _uuid="b0ed34b9319a2ae0426927cd655225bed0dc79e8"
# We have several columns that contains null values we should replace them with the median or mean those null values.
train.info()
# + _cell_guid="587c4a32-99bf-4878-83c9-8e69476b9117" _uuid="aa9275261e010f1d8270d4958e112413fb99f64f"
train.describe()
# + _cell_guid="934b7836-e0af-4d75-b35c-da60f3eabce4" _uuid="0934facc068a4dc79afa328c2bf9aecff9122c80"
corr = train.corr()
plt.figure(figsize=(14,8))
plt.title('Overall Correlation of House Prices', fontsize=18)
sns.heatmap(corr,annot=False,cmap='RdYlBu',linewidths=0.2,annot_kws={'size':20})
plt.show()
# + [markdown] _cell_guid="87c42fd0-adc5-46e0-9951-8323346751c3" _uuid="3f9dcd8fa94d75cfc21e05d15ca4b2aa37231787"
# # Splitting the Variables into Different Categories:
# <a id="splitting"></a>
# ## Data Analysis:
# For data analysis purposes I am going to separate the different features into different categories in order to segment our analysis. These are the steps we are going to take in our analysis: Nevertheless, I will split the categories so you can analyse thoroughly the different categories.<br>
# 1) Separate into different categories in order to make our analysis easier. <br>
# 2) All of our categories will contain sales price in order to see if there is a significant pattern.<br>
# 3) After that we will create our linear regression model in order to make accurate predictions as to what will the price of the houses will be.<br><br>
# 4) For all the categories we have id, salesprice, MoSold, YearSold, SaleType and SaleCondition.
#
# **Note:** At least for me, it is extremely important to make a data analysis of our data, in order to have a grasp of what the data is telling us, what might move salesprice higher or lower. Instead of just running a model and just predict prices, we must make a thorough analysis of our data. Also, using these different categories is completely optional in case you want to make a more in-depth analysis of the different features.
# + _cell_guid="a36e8f64-73cb-4741-afc7-b39734a25d07" _uuid="b3e3427ce88e2a0b6c6cd97288c6a4f4a4af0d73"
# Create the categories
outsidesurr_df = train[['Id', 'MSZoning', 'LotFrontage', 'LotArea', 'Neighborhood', 'Condition1', 'Condition2', 'PavedDrive',
'Street', 'Alley', 'LandContour', 'LandSlope', 'LotConfig', 'MoSold', 'YrSold', 'SaleType', 'LotShape',
'SaleCondition', 'SalePrice']]
building_df = train[['Id', 'MSSubClass', 'BldgType', 'HouseStyle', 'YearBuilt', 'YearRemodAdd', 'RoofStyle',
'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea', 'Foundation', 'Functional',
'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'MoSold', 'YrSold', 'SaleType',
'SaleCondition', 'SalePrice']]
utilities_df = train[['Id', 'Utilities', 'Heating', 'CentralAir', 'Electrical', 'Fireplaces', 'PoolArea', 'MiscVal', 'MoSold',
'YrSold', 'SaleType', 'SaleCondition', 'SalePrice']]
ratings_df = train[['Id', 'OverallQual', 'OverallCond', 'ExterQual', 'ExterCond', 'BsmtQual', 'BsmtCond', 'BsmtExposure',
'BsmtFinType1', 'BsmtFinType2', 'HeatingQC', 'KitchenQual', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature',
'GarageCond', 'GarageQual', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition', 'SalePrice']]
rooms_df = train[['Id', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BsmtFinSF1', 'BsmtFinSF2',
'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF','TotRmsAbvGrd',
'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'MoSold', 'YrSold', 'SaleType',
'SaleCondition', 'SalePrice']]
# Set Id as index of the dataframe.
outsidesurr_df = outsidesurr_df.set_index('Id')
building_df = building_df.set_index('Id')
utilities_df = utilities_df.set_index('Id')
ratings_df = ratings_df.set_index('Id')
rooms_df = rooms_df.set_index('Id')
# Move SalePrice to the first column (Our Label)
sp0 = outsidesurr_df['SalePrice']
outsidesurr_df.drop(labels=['SalePrice'], axis=1, inplace=True)
outsidesurr_df.insert(0, 'SalePrice', sp0)
sp1 = building_df['SalePrice']
building_df.drop(labels=['SalePrice'], axis=1, inplace=True)
building_df.insert(0, 'SalePrice', sp1)
sp2 = utilities_df['SalePrice']
utilities_df.drop(labels=['SalePrice'], axis=1, inplace=True)
utilities_df.insert(0, 'SalePrice', sp2)
sp3 = ratings_df['SalePrice']
ratings_df.drop(labels=['SalePrice'], axis=1, inplace=True)
ratings_df.insert(0, 'SalePrice', sp3)
sp4 = rooms_df['SalePrice']
rooms_df.drop(labels=['SalePrice'], axis=1, inplace=True)
rooms_df.insert(0, 'SalePrice', sp4)
# + [markdown] _cell_guid="cb7328fa-02c2-4dd5-80df-1f10afb1cef7" _uuid="353cae140157401b318eb47e18a130d587ee3d94"
# # Gathering a Basic Insight of our Data:
# <a id="insight"></a>
# <br><br>
# <img src="http://blog.algoscale.com/wp-content/uploads/2017/06/algoscale_data_analytics4.jpg">
# <br><br>
#
# ## Summary:
# <ul>
# <li> The distribution of <b> house prices </b> is right skewed.</li>
# <li> There is a <b>drop</b> in the number of houses sold during the year of 2010. </li>
# </ul>
# + _cell_guid="929a8de8-77c6-4c7c-8cb7-a7db6238e811" _uuid="39728320ed58ca2f49844ba8e80b5a54b67385b1"
import seaborn as sns
sns.set_style('white')
f, axes = plt.subplots(ncols=4, figsize=(16,4))
# Lot Area: In Square Feet
sns.distplot(train['LotArea'], kde=False, color="#DF3A01", ax=axes[0]).set_title("Distribution of LotArea")
axes[0].set_ylabel("Square Ft")
axes[0].set_xlabel("Amount of Houses")
# MoSold: Year of the Month sold
sns.distplot(train['MoSold'], kde=False, color="#045FB4", ax=axes[1]).set_title("Monthly Sales Distribution")
axes[1].set_ylabel("Amount of Houses Sold")
axes[1].set_xlabel("Month of the Year")
# House Value
sns.distplot(train['SalePrice'], kde=False, color="#088A4B", ax=axes[2]).set_title("Monthly Sales Distribution")
axes[2].set_ylabel("Number of Houses ")
axes[2].set_xlabel("Price of the House")
# YrSold: Year the house was sold.
sns.distplot(train['YrSold'], kde=False, color="#FE2E64", ax=axes[3]).set_title("Year Sold")
axes[3].set_ylabel("Number of Houses ")
axes[3].set_xlabel("Year Sold")
plt.show()
# + [markdown] _cell_guid="5a042a5a-03c0-413b-b425-084a96224d7c" _uuid="2469263ed508422b7fb60f269466d97689aece5f"
# ## Right-Skewed Distribution Summary:
# In a right skew or positive skew the mean is most of the times to the right of the median. There is a higher frequency of occurence to the left of the distribution plot leading to more exceptions (outliers to the right). Nevertheless, there is a way to transform this histogram into a normal distributions by using <b>log transformations</b> which will be discussed further below.
# + _cell_guid="a224da7c-297b-44e7-acd3-c010dd1dc7b9" _uuid="11ce898b3dd301033abcaa4016c1869cf3311133"
# Maybe we can try this with plotly.
plt.figure(figsize=(12,8))
sns.distplot(train['SalePrice'], color='r')
plt.title('Distribution of Sales Price', fontsize=18)
plt.show()
# + [markdown] _cell_guid="9f3a7f33-aa4c-4dc7-b555-edf16a0b8d7f" _uuid="59bfd3406c4a3b4d63ccdf2c479875e06a17738e"
# <h1 align="center"> Economic Activity: </h1>
# <a id="economy"></a>
# <img src="http://vietsea.net/upload/news/2016/12/1/11220161528342876747224.jpg">
# We will visualize how the housing market in **Ames, IOWA** performed during the years 2006 - 2010 and how bad it was hit by the economic recession during the years of 2007-2008.
#
# ## Level of Supply and Demand (Summary):
# <ul>
# <li><b>June</b> and <b>July</b> were the montnths in which most houses were sold. </li>
# <li> The <b> median house price </b> was at its peak in 2007 (167k) and it was at its lowest point during the year of 2010 (155k) a difference of 12k. This might be a consequence of the economic recession. </li>
# <li> Less houses were <b>sold</b> and <b>built</b> during the year of 2010 compared to the other years. </li>
# </ul>
#
#
# + _cell_guid="f0c2f981-a1c1-4746-aaeb-c5fc02cc708d" _uuid="714d805655f7502236957271829f8b8a12292d75"
# People tend to move during the summer
sns.set(style="whitegrid")
plt.figure(figsize=(12,8))
sns.countplot(y="MoSold", hue="YrSold", data=train)
plt.show()
# + _cell_guid="46963c46-6273-4901-86d3-1529346d0077" _uuid="5af8386dfba37785d7ccc216e746946869102f5f"
plt.figure(figsize=(12,8))
sns.boxplot(x='YrSold', y='SalePrice', data=train)
plt.xlabel('Year Sold', fontsize=14)
plt.ylabel('Price sold', fontsize=14)
plt.title('Houses Sold per Year', fontsize=16)
# + _cell_guid="b227db2a-a4cd-4676-b081-2f7226dc192d" _uuid="c0ef7749d7cdfcff10c63f29da080865b43657e5"
plt.figure(figsize=(14,8))
plt.style.use('seaborn-white')
sns.stripplot(x='YrSold', y='YearBuilt', data=train, jitter=True, palette="Set2", linewidth=1)
plt.title('Economic Activity Analysis', fontsize=18)
plt.xlabel('Year the house was sold', fontsize=14)
plt.ylabel('Year the house was built', rotation=90, fontsize=14)
plt.show()
# + [markdown] _cell_guid="533edecf-edc6-4924-ba58-ea1fe2da134c" _uuid="ff30e79d2d3b7f298810868e33a3feb8860e0ae7"
# <h1 align="center"> Outside Surroundings of the House: </h1>
# <a id="outside"></a>
# <img src="https://upload.wikimedia.org/wikipedia/commons/b/bc/Lot_map.PNG">
# ## Features from Outside:
# In this section we will create an in-depth analysis of how the outside surroundings affect the price. Which variables have the highest weight on price. You can use the **train** dataframe or the **outsidesurr_df** to simplify the amount of features and have a closer look as to how they behave towards **"SalePrice"**. For the correlation matrix I will be using outsidesurr_df so you can have a better look as to which variables from the **outside surroundings category** impact the most on the price of a house. <br><br>
#
# ## Summary:
# <ul>
# <li> The <b>mean price</b> of the house of is 180,921, this will explain why the data is right skewed. </li>
# <li> <b>Standard deviation</b> is pretty high at 79442.50 meaning the data deviates a lot from the mean (many outliers) </li>
# <li> <b>LotArea</b> and <b>LotFrontage</b> had the highest correlation with the price of a house from the <b> outside surroundings category </b>. </li>
# <li> Most of the houses that were sold were from a <b> Residential Low Density Zone </b>.</li>
# <li> The most exclusive Neighborhoods are <b>Crawfor</b>, <b>Sawyer</b> and <b>SawyerW</b></li>
# </ul>
# + _cell_guid="f7c9dd44-8e33-48cb-bdd1-e78cce5c9fc4" _uuid="4ca45fc9200da92a9be10ad22414290d5f4993d2"
outsidesurr_df.describe()
# + _cell_guid="dc78058e-1319-4a8f-bf30-33bbdfda41e6" _uuid="394c7fd3f4a8fa8a60428646b1fe21aad711dd62"
outsidesurr_df.columns
# + _cell_guid="97318a13-5bfd-4739-98cf-2d82b8c799d2" _uuid="ebf2d6a85c6db6d72ac2581d90d16e63959fcf64"
# Lot Area and Lot Frontage influenced hugely on the price.
# However, YrSold does not have that much of a negative correlation with SalePrice as we previously thought.
# Meaning the state of IOWA was not affected as other states.
plt.style.use('seaborn-white')
corr = outsidesurr_df.corr()
sns.heatmap(corr,annot=True,cmap='YlOrRd',linewidths=0.2,annot_kws={'size':20})
fig=plt.gcf()
fig.set_size_inches(14,10)
plt.title("Outside Surroundings Correlation", fontsize=18)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()
# + [markdown] _cell_guid="0bc1aced-4ffd-4577-9905-5cf5bd09d977" _uuid="31b77f81bec040f84c78f58e030cc76899cb8b61"
# ## Type of Zoning:
# <a id="zoning"></a>
# + _cell_guid="4a975f1f-f149-47e7-a53a-c28142a3a55d" _uuid="0dfa70ef8fcffec3667efc23d6e2453bd54e77fc"
# We already know which neighborhoods were the most sold but which neighborhoods gave the most revenue.
# This might indicate higher demand toward certain neighborhoods.
plt.style.use('seaborn-white')
zoning_value = train.groupby(by=['MSZoning'], as_index=False)['SalePrice'].sum()
zoning = zoning_value['MSZoning'].values.tolist()
# Let's create a pie chart.
labels = ['C: Commercial', 'FV: Floating Village Res.', 'RH: Res. High Density', 'RL: Res. Low Density',
'RM: Res. Medium Density']
total_sales = zoning_value['SalePrice'].values.tolist()
explode = (0, 0, 0, 0.1, 0)
fig, ax1 = plt.subplots(figsize=(12,8))
texts = ax1.pie(total_sales, explode=explode, autopct='%.1f%%', shadow=True, startangle=90, pctdistance=0.8,
radius=0.5)
ax1.axis('equal')
plt.title('Sales Groupby Zones', fontsize=16)
plt.tight_layout()
plt.legend(labels, loc='best')
plt.show()
# + _cell_guid="dbf77538-b46e-40e2-9d27-be3430a36011" _uuid="9d0ffe29bd3632de5def232d7d2bbb9a54fb3f87"
plt.style.use('seaborn-white')
SalesbyZone = train.groupby(['YrSold','MSZoning']).SalePrice.count()
SalesbyZone.unstack().plot(kind='bar',stacked=True, colormap= 'gnuplot',
grid=False, figsize=(12,8))
plt.title('Building Sales (2006 - 2010) by Zoning', fontsize=18)
plt.ylabel('Sale Price', fontsize=14)
plt.xlabel('Sales per Year', fontsize=14)
plt.show()
# + [markdown] _cell_guid="9c6d8890-959e-458b-9222-6473c688df08" _uuid="537f161c5034c1cd2563a5cce1b7e49f5a06732d"
# ## Neighborhoods:
# <a id="neighborhoods">
#
# + _cell_guid="e5ccbdbf-83db-497f-8756-641941c3c993" _uuid="47f5b705ca6f121ec93fa6810872f453a0530e07"
fig, ax = plt.subplots(figsize=(12,8))
sns.countplot(x="Neighborhood", data=train, palette="Set2")
ax.set_title("Types of Neighborhoods", fontsize=20)
ax.set_xlabel("Neighborhoods", fontsize=16)
ax.set_ylabel("Number of Houses Sold", fontsize=16)
ax.set_xticklabels(labels=train['Neighborhood'] ,rotation=90)
plt.show()
# + _cell_guid="0bd519e3-4721-4ed6-a527-eb6b4f96f044" _uuid="a442cf4b99c5f7f1c8486fa456a2d169b818cab7"
# Sawyer and SawyerW tend to be the most expensive neighberhoods. Nevertheless, what makes them the most expensive
# Is it the LotArea or LotFrontage? Let's find out!
fig, ax = plt.subplots(figsize=(12,8))
ax = sns.boxplot(x="Neighborhood", y="SalePrice", data=train)
ax.set_title("Range Value of the Neighborhoods", fontsize=18)
ax.set_ylabel('Price Sold', fontsize=16)
ax.set_xlabel('Neighborhood', fontsize=16)
ax.set_xticklabels(labels=train['Neighborhood'] , rotation=90)
plt.show()
# + [markdown] _cell_guid="efee15fa-3279-498a-b7bc-04cff114a0e5" _uuid="c08df6b6b3b5254783b9b5963180c956741474f2"
# <h1 align="center">The Impact of Space towards Price:</h1>
# <a id="space"></a>
# <img src="http://www.archiii.com/wp-content/uploads/2013/06/Office-Orchard-House-Interior-Design-by-Arch11-Architecture-Interior.jpg" width=700 height=300>
# <br><br>
#
# ## The Influence of Space:
# How much influence does space have towards the price of the house. Intuitively, we might think the bigger the house the higher the price but let's take a look in order to see ifit actually has a positive correlation towards **SalePrice**.
#
# ## Summary:
# <ul>
# <li><b>GrlivingArea:</b> The living area square feet is positively correlated with the price of the house.</li>
# <li> <b> GarageArea:</b> Apparently, the space of the garage is an important factor that contributes to the price of the house. </li>
# <li> <b>TotalBsmft:</b> The square feet of the basement contributes positively to the value of the house. </li>
# <li> <b>LotArea and LotFrontage:</b> I would say from all the area features these are the two that influencess the less on the price of the house. </li>
# </ul>
# + _cell_guid="6a9e50e5-1e60-4f41-8f1e-fe961571783d" _uuid="638e509c053e79e245ad882b80caa95fb933f9ab"
sns.jointplot(x='GrLivArea',y='SalePrice',data=train,
kind='hex', cmap= 'CMRmap', size=8, color='#F84403')
plt.show()
# + _cell_guid="d9a5165a-46ff-467c-89cc-6cd5174388d3" _uuid="c68bec4b5dd3c1a943131fe9711baa344952377b"
sns.jointplot(x='GarageArea',y='SalePrice',data=train,
kind='hex', cmap= 'CMRmap', size=8, color='#F84403')
plt.show()
# + _cell_guid="69e4df30-1df1-4ec4-9b71-fa3a5fc0515a" _uuid="e87aa194c7f7924f731627100d73d65e447010ba"
sns.jointplot(x='TotalBsmtSF',y='SalePrice',data=train,
kind='hex', cmap= 'CMRmap', size=8, color='#F84403')
plt.show()
# + _cell_guid="9c0d3aae-e696-451a-9a37-d5b0ca8047c8" _uuid="c90cb862e4df74442a5335e499d57741db1b2e93"
plt.figure(figsize=(16,6))
plt.subplot(121)
ax = sns.regplot(x="LotFrontage", y="SalePrice", data=train)
ax.set_title("Lot Frontage vs Sale Price", fontsize=16)
plt.subplot(122)
ax1 = sns.regplot(x="LotArea", y="SalePrice", data=train, color='#FE642E')
ax1.set_title("Lot Area vs Sale Price", fontsize=16)
plt.show()
# + [markdown] _cell_guid="701c1242-355c-4925-9859-374e42436acf" _uuid="9f50d96e0d77b542baf964446dfad80ddf2be141"
# <h1 align="center"> Building Characteristics: </h1>
# <a id="building_characteristics"></a>
#
# + _cell_guid="884be202-6221-450e-911d-c75ca4f031be" _uuid="f8505ef47f686c96e7855dcc0f19b8335a4e4673"
building_df.head()
# + [markdown] _cell_guid="d0b1e39b-77f2-4a38-b01c-84862a7766bd" _uuid="01d295f03bbe9da6f938308f9c58aaed560f3704"
# # High Correlated Variables with SalePrice:
# <a id="correlation"></a>
# 1) YearBuilt - The Date the building was built. <br>
# 2) YearRemodAdd - The last time there wasa building remodeling. <br>
# 3) MasVnArea - Masonry veneer area in square feet. <br>
# 4) GarageYrBlt - Year garage was built. <br>
# 5) GarageCars - Size of garage in car capacity. <br>
# 6) GarageArea - Size of garage in square feet. <br>
# + _cell_guid="3defcb33-0d60-4b23-9eaa-f9e8eecd3a88" _uuid="2856658f3342eb3bad9fe43dba93358e4a13e814"
corr = building_df.corr()
g = sns.heatmap(corr,annot=True,cmap='coolwarm',linewidths=0.2,annot_kws={'size':20})
g.set_xticklabels(g.get_xticklabels(), rotation = 90, fontsize = 8)
fig=plt.gcf()
fig.set_size_inches(14,10)
plt.title("Building Characteristics Correlation", fontsize=18)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()
# + _cell_guid="052ca14a-6ed3-44ea-ad00-db9d594eb917" _uuid="8e99f096023a26d68555e409513917a36174fa5f"
# To understand better our data I will create a category column for SalePrice.
train['Price_Range'] = np.nan
lst = [train]
# Create a categorical variable for SalePrice
# I am doing this for further visualizations.
for column in lst:
column.loc[column['SalePrice'] < 150000, 'Price_Range'] = 'Low'
column.loc[(column['SalePrice'] >= 150000) & (column['SalePrice'] <= 300000), 'Price_Range'] = 'Medium'
column.loc[column['SalePrice'] > 300000, 'Price_Range'] = 'High'
train.head()
# + [markdown] _cell_guid="0b67cfcd-5746-47b2-8d7b-1330d393197b" _uuid="9965be480715f52dce4417e786fac897f7acb344"
# ## What Garages tells us about each Price Category:
# <a id="garage"></a>
# <img src="https://www.incimages.com/uploaded_files/image/970x450/garage-office-970_24019.jpg">
# + _cell_guid="a0fc4608-5222-43da-ad23-542070bfcb8f" _uuid="e20e37f793b815982c16d30b0ad3870b768ac702"
import matplotlib.pyplot as plt
palette = ["#9b59b6", "#BDBDBD", "#FF8000"]
sns.lmplot('GarageYrBlt', 'GarageArea', data=train, hue='Price_Range', fit_reg=False, size=7, palette=palette,
markers=["o", "s", "^"])
plt.title('Garage by Price Range', fontsize=18)
plt.annotate('High Price \nCategory Garages \n are not that old', xy=(1997, 1100), xytext=(1950, 1200),
arrowprops=dict(facecolor='black', shrink=0.05))
plt.show()
# + [markdown] _cell_guid="9268369a-6983-42a4-879a-3bb61536f080" _uuid="a2256ef96288b72b3fff13bf7b837049f3e33fcf"
# # Miscellaneous and Utilities:
# <a id="utilities"></a>
# + _cell_guid="22135021-afd1-43cf-8e49-3a0ff2ee9445" _uuid="402978c2f5d0f0870cee57efdb761ed1cf08333f"
plt.style.use('seaborn-white')
types_foundations = train.groupby(['Price_Range', 'PavedDrive']).size()
types_foundations.unstack().plot(kind='bar', stacked=True, colormap='Set1', figsize=(13,11), grid=False)
plt.ylabel('Number of Streets', fontsize=16)
plt.xlabel('Price Category', fontsize=16)
plt.xticks(rotation=45, fontsize=12)
plt.title('Condition of the Street by Price Category', fontsize=18)
plt.show()
# + _cell_guid="1e357ce6-b3e7-4bc0-9ecb-3aa41547056c" _uuid="6f9356a63e567869b3906a95843b64d2e375ff8d"
# We can see that CentralAir impacts until some extent the price of the house.
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(14,10))
plt.suptitle('Relationship between Saleprice \n and Categorical Utilities', fontsize=18)
sns.pointplot(x='CentralAir', y='SalePrice', hue='Price_Range', data=train, ax=ax1)
sns.pointplot(x='Heating', y='SalePrice', hue='Price_Range', data=train, ax=ax2)
sns.pointplot(x='Fireplaces', y='SalePrice', hue='Price_Range', data=train, ax=ax3)
sns.pointplot(x='Electrical', y='SalePrice', hue='Price_Range', data=train, ax=ax4)
plt.legend(loc='best')
plt.show()
# + _cell_guid="c37bd2e9-2bb4-446f-955a-4a61f3bb1780" _uuid="1707964c255934f901679a49dbd976b3e139a86d"
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
fig, ax = plt.subplots(figsize=(14,8))
palette = ["#9b59b6", "#3498db", "#95a5a6", "#e74c3c", "#34495e", "#2ecc71", "#FF8000", "#AEB404", "#FE2EF7", "#64FE2E"]
sns.swarmplot(x="OverallQual", y="SalePrice", data=train, ax=ax, palette=palette, linewidth=1)
plt.title('Correlation between OverallQual and SalePrice', fontsize=18)
plt.ylabel('Sale Price', fontsize=14)
plt.show()
# + [markdown] _cell_guid="99ecf603-34fa-4ee7-bece-6edf56579494" _uuid="ecc231824aab0e21301e8bc959a468af1a629670"
# <h1 align="center"> What determines the quality of the House? </h1>
# <a id="quality"></a>
#
# Remember quality is the most important factor that contributes to the SalePrice of the house. <br>
# **Correlations with OverallQual:**<br>
# 1) YearBuilt <br>
# 2) TotalBsmtSF <br>
# 3) GrLivArea <br>
# 4) FullBath <br>
# 5) GarageYrBuilt <br>
# 6) GarageCars <br>
# 7) GarageArea <br><br>
# + [markdown] _cell_guid="3977df8c-b6b6-47f0-9ef7-6a85e2cf050f" _uuid="893fb4f0caa60512f0352c4be17f80fa45b56c37"
# <img src="http://tibmadesignbuild.com/images/female-hands-framing-custom-kitchen-design.jpg">
#
# ## Interesting insights:
# <a id="interesting"></a>
# 1) **Overall Condition**: of the house or building, meaning that further remodelations are likely to happen in the future, either for reselling or to accumulate value in their real-estate.. <br>
# 2) **Overall Quality**: The quality of the house is one of the factors that mostly impacts SalePrice. It seems that the overall material that is used for construction and the finish of the house has a great impact on SalePrice. <br>
# 3) **Year Remodelation**: Houses in the **high** price range remodelled their houses sooner. The sooner the remodelation the higher the value of the house. <br>
#
# + _cell_guid="9daf8cd0-7110-49ce-bd1f-f0c73029a4ff" _uuid="063e832325c06356c26cef82b91c39dd46168821"
with sns.plotting_context("notebook",font_scale=2.8):
g = sns.pairplot(train, vars=["OverallCond", "OverallQual", "YearRemodAdd", "SalePrice"],
hue="Price_Range", palette="Dark2", size=6)
g.set(xticklabels=[]);
plt.show()
# + [markdown] _cell_guid="425e24c3-233b-46ec-9d31-563af06fcdbe" _uuid="eeb007ed26b1f2c17ed8ee09558b8eaec51f496f"
# ## Which Material Combination increased the Price of Houses?
# <a id="material"></a>
# <ul>
# <li> <b>Roof Material</b>: <b>Hip</b> and <b>Gable</b> was the most expensive since people who bought <b>high value</b> houses tended to buy this material bor he rooftop.</li>
# <li> <b>House Material</b>: Houses made up of <b>stone</b> tend to influence positively the price of the house. (Except in 2007 for <b>High Price House Values. </b>) </li>
# </ul>
#
# + _cell_guid="fe77e25e-6b6c-4fc6-8d14-ce54db24da75" _uuid="5b8103aa4d84a3ce2f9a080bfa831febc05499d7"
# What type of material is considered to have a positive effect on the quality of the house?
# Let's start with the roof material
with sns.plotting_context("notebook",font_scale=1):
g = sns.factorplot(x="SalePrice", y="RoofStyle", hue="Price_Range",
col="YrSold", data=train, kind="box", size=5, aspect=.75, sharex=False, col_wrap=3, orient="h",
palette='Set1');
for ax in g.axes.flatten():
for tick in ax.get_xticklabels():
tick.set(rotation=20)
plt.show()
# + [markdown] _cell_guid="60fb58c9-239e-4257-ae12-47262b828887" _uuid="479286941f3eab9bcbf90bbb3ae4d0f232a9995b"
# **Note:** Interestingly, the Masonry Veneer type of stone became popular after 2007 for the houses that belong to the **high** Price Range category. I wonder why? <br>
# **For some reason during the year of 2007, the Saleprice of houses within the high range made of stone dropped drastically!
#
#
# + _cell_guid="bbd9b8c2-1222-4e0c-9a45-e62755e96949" _uuid="f019b248b45203a2224184aae072af3b47803203"
with sns.plotting_context("notebook",font_scale=1):
g = sns.factorplot(x="MasVnrType", y="SalePrice", hue="Price_Range",
col="YrSold", data=train, kind="bar", size=5, aspect=.75, sharex=False, col_wrap=3,
palette="YlOrRd");
plt.show()
# + [markdown] _cell_guid="2050ed7f-6aed-421b-b499-1770485cb16b" _uuid="256571deaec5bc97d1d23c978f2f261264ac36cc"
# <h1 align="center"> Quality of Neighborhoods </h1>
# <a id="quality_neighborhoods"></a>
# <img src="http://www.unitedwaydenver.org/sites/default/files/UN_neighborhood.jpg">
#
# ## Which Neighborhoods had the best Quality houses?
# <a id="which_neighborhoods"></a>
# + _cell_guid="243f1646-3239-49e2-a349-89d1aabe7e1c" _uuid="e4428cd36f331f349367bc68b567e6d75c8df279"
plt.style.use('seaborn-white')
types_foundations = train.groupby(['Neighborhood', 'OverallQual']).size()
types_foundations.unstack().plot(kind='bar', stacked=True, colormap='RdYlBu', figsize=(13,11), grid=False)
plt.ylabel('Overall Price of the House', fontsize=16)
plt.xlabel('Neighborhood', fontsize=16)
plt.xticks(rotation=90, fontsize=12)
plt.title('Overall Quality of the Neighborhoods', fontsize=18)
plt.show()
# + _cell_guid="c6348bed-ac97-4f2d-b657-ba871cc0a5a1" _uuid="77ee87f2455fb63fee906495fb587a83d94d7f27"
# Which houses neighborhoods remodeled the most.
# price_categories = ['Low', 'Medium', 'High']
# remod = train['YearRemodAdd'].groupby(train['Price_Range']).mean()
fig, ax = plt.subplots(ncols=2, figsize=(16,4))
plt.subplot(121)
sns.pointplot(x="Price_Range", y="YearRemodAdd", data=train, order=["Low", "Medium", "High"], color="#0099ff")
plt.title("Average Remodeling by Price Category", fontsize=16)
plt.xlabel('Price Category', fontsize=14)
plt.ylabel('Average Remodeling Year', fontsize=14)
plt.xticks(rotation=90, fontsize=12)
plt.subplot(122)
sns.pointplot(x="Neighborhood", y="YearRemodAdd", data=train, color="#ff9933")
plt.title("Average Remodeling by Neighborhood", fontsize=16)
plt.xlabel('Neighborhood', fontsize=14)
plt.ylabel('')
plt.xticks(rotation=90, fontsize=12)
plt.show()
# + [markdown] _cell_guid="703dfdce-e604-4275-9039-57146e2e64ff" _uuid="e0e81b8ebd73bdf455e83672c096b978c4f3787e"
# ## The Purpose of Log Transformations:
# <a id="log_transformations"></a>
# The main reason why we use log transformation is to reduce **skewness** in our data. However, there are other reasons why we log transform our data: <br>
# <ul>
# <li> Easier to interpret patterns of our data. </li>
# <li> For possible statistical analysis that require the data to be normalized.</li>
# </ul>
# + _cell_guid="d6474adb-2d0f-4c73-9e7c-e5732d1313b7" _uuid="d90bbab56a752e09980326132adea02a15fc039e"
numeric_features = train.dtypes[train.dtypes != "object"].index
# Top 5 most skewed features
skewed_features = train[numeric_features].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'Skew' :skewed_features})
skewness.head(5)
# + _cell_guid="c7d5ce49-5ae8-41d1-ba23-2a291f269ae0" _uuid="097a16f9376ae1e8d6457be75541a1cc12d88bb6"
from scipy.stats import norm
# norm = a normal continous variable.
log_style = np.log(train['SalePrice']) # log of salesprice
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(14,10))
plt.suptitle('Probability Plots', fontsize=18)
ax1 = sns.distplot(train['SalePrice'], color="#FA5858", ax=ax1, fit=norm)
ax1.set_title("Distribution of Sales Price with Positive Skewness", fontsize=14)
ax2 = sns.distplot(log_style, color="#58FA82",ax=ax2, fit=norm)
ax2.set_title("Normal Distibution with Log Transformations", fontsize=14)
ax3 = stats.probplot(train['SalePrice'], plot=ax3)
ax4 = stats.probplot(log_style, plot=ax4)
plt.show()
# + [markdown] _cell_guid="db8bec52-2ec2-4913-975d-aef616ec0c23" _uuid="9b45a50d5ff22e844ee9a29e2879e6b3b5049779"
# ## Skewedness and Kurtosis:
# <a id="skew_kurt"></a>
# **Skewedness**: <br>
# <ul>
# <li> A skewness of <b>zero</b> or near zero indicates a <b>symmetric distribution</b>.</li>
# <li> A <b>negative value</b> for the skewness indicate a <b>left skewness</b> (tail to the left) </li>
# <li> A <b>positive value</b> for te skewness indicate a <b> right skewness </b> (tail to the right) </li>
# <ul>
# + [markdown] _cell_guid="5168901c-4159-4313-b873-32e786ccab30" _uuid="7fa11c3fd2a19e49d21c904a2eb2ff3d40380f96"
# **Kurtosis**:
# <ul>
# <li><b>Kourtosis</b> is a measure of how extreme observations are in a dataset.</li>
# <li> The <b> greater the kurtosis coefficient </b>, the more peaked the distribution around the mean is. </li>
# <li><b>Greater coefficient</b> also means fatter tails, which means there is an increase in tail risk (extreme results) </li>
# </ul>
#
# **Reference**:
# Investopedia: https://www.investopedia.com/terms/m/mesokurtic.asp
#
# + _cell_guid="cfb28d73-e55e-4072-bbbf-11c2ffed6f33" _uuid="dab54e7b727ec161090fbc9acf09f488617a2ce2"
print('Skewness for Normal D.: %f'% train['SalePrice'].skew())
print('Skewness for Log D.: %f'% log_style.skew())
print('Kurtosis for Normal D.: %f' % train['SalePrice'].kurt())
print('Kurtosis for Log D.: %f' % log_style.kurt())
# + [markdown] _cell_guid="116d031b-68fa-4669-9f77-281d82124481" _uuid="244f8b117bf70048d742d7984d6669831e7e2065"
# # Outliers Analysis:
# <a id="analysis_outliers"></a>
# **Analysis**:
# <ul>
# <li> The year of <b>2007</b> had the highest outliers (peak of the housing market before collapse). </li>
# <li> The highest outliers are located in the <b> High category </b> of the Price_Range column.</li>
# </ul>
# + _cell_guid="0c380a21-0b6d-4cc0-b671-2d7cc7b89127" _uuid="6d933503dd4bcfa447f51c3208e2ffb0e3078dfb"
# Most outliers are in the high price category nevertheless, in the year of 2007 saleprice of two houses look extremely high!
fig = plt.figure(figsize=(12,8))
ax = sns.boxplot(x="YrSold", y="SalePrice", hue='Price_Range', data=train)
plt.title('Detecting outliers', fontsize=16)
plt.xlabel('Year the House was Sold', fontsize=14)
plt.ylabel('Price of the house', fontsize=14)
plt.show()
# + _cell_guid="15323cfc-e797-4070-b5be-bb54a683305c" _uuid="9dd053a3f05c23caae8380d97a670870050a3d53"
corr = train.corr()
corr['SalePrice'].sort_values(ascending=False)[:11]
# + [markdown] _cell_guid="cb8cca18-6d66-4bb6-b760-aee9093bcdeb" _uuid="80cdd7b126e798e520e27bdab4adf7e36f6f2b17"
# ## Bivariate Analysis (Detecting outliers through visualizations):
# <a id="bivariate"></a>
# **There are some outliers in some of this columns but there might be a reason behind this, it is possible that these outliers in which the area is high but the price of the house is not that high, might be due to the reason that these houses are located in agricultural zones.**
# + _cell_guid="3e93ad4a-2355-4172-949a-5c6d68cbc129" _uuid="34659c061e00804cb5304bf593c29a0918d57d75"
fig, ((ax1, ax2), (ax3, ax4))= plt.subplots(nrows=2, ncols=2, figsize=(14,8))
var1 = 'GrLivArea'
data = pd.concat([train['SalePrice'], train[var1]], axis=1)
sns.regplot(x=var1, y='SalePrice', data=data, fit_reg=True, ax=ax1)
var2 = 'GarageArea'
data = pd.concat([train['SalePrice'], train[var2]], axis=1)
sns.regplot(x=var2, y='SalePrice', data=data, fit_reg=True, ax=ax2, marker='s')
var3 = 'TotalBsmtSF'
data = pd.concat([train['SalePrice'], train[var3]], axis=1)
sns.regplot(x=var3, y='SalePrice', data=data, fit_reg=True, ax=ax3, marker='^')
var4 = '1stFlrSF'
data = pd.concat([train['SalePrice'], train[var4]], axis=1)
sns.regplot(x=var4, y='SalePrice', data=data, fit_reg=True, ax=ax4, marker='+')
plt.show()
# + [markdown] _cell_guid="c77243c8-8d0b-452d-be15-56dd37f9cf47" _uuid="f095b123ce7fe0d209f40b8804a88c401a8a295b"
# <h1 align="center"> Feature Engineering </h1>
# <a id="feature_engineering"></a>
# ## Dealing with Missing Values:
# <a id="missing_values"></a>
# + _cell_guid="dbefe68d-d72d-4869-9b11-59c1308179f7" _uuid="54125a784ec558d277a295195bfdba4885e84315"
y_train = train['SalePrice'].values
# We will concatenate but we will split further on.
rtrain = train.shape[0]
ntest = test.shape[0]
train.drop(['SalePrice', 'Price_Range', 'Id'], axis=1, inplace=True)
test.drop('Id', axis=1, inplace=True)
# + _cell_guid="de1cf174-9e35-4b1b-8144-5069b3186530" _uuid="d9689d00483ea635f4c612657cd117b70c724aa9"
complete_data = pd.concat([train, test])
complete_data.shape
# + _cell_guid="fe78d1fd-772e-4f10-b870-9ce0888bf10a" _uuid="61a51a6158c6cea5352d6a61eb0b3efec26bd99e"
total_nas = complete_data.isnull().sum().sort_values(ascending=False)
percent_missing = (complete_data.isnull().sum()/complete_data.isnull().count()).sort_values(ascending=False)
missing = pd.concat([total_nas, percent_missing], axis=1, keys=['Total_M', 'Percentage'])
# missing.head(9) # We have 19 columns with NAs
# + [markdown] _cell_guid="aee2f1be-4344-4d90-93ca-0d9027e0463c" _uuid="824e23e3ada2cbaf4a581faaf76fafec1e518f97"
# ## Transforming Missing Values:
# <a id="transforming_values"></a>
#
# + _cell_guid="c8d656e0-4fd0-4457-bb7e-b8ebd00b5725" _uuid="7352ea7dd1818c761c2a5c2fd99f78862671c464"
complete_data["PoolQC"] = complete_data["PoolQC"].fillna("None")
complete_data["MiscFeature"] = complete_data["MiscFeature"].fillna("None")
complete_data["Alley"] = complete_data["Alley"].fillna("None")
complete_data["Fence"] = complete_data["Fence"].fillna("None")
complete_data["FireplaceQu"] = complete_data["FireplaceQu"].fillna("None")
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
complete_data[col] = complete_data[col].fillna('None')
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
complete_data[col] = complete_data[col].fillna('None')
complete_data['MSZoning'] = complete_data['MSZoning'].fillna(complete_data['MSZoning'].mode()[0])
complete_data["MasVnrType"] = complete_data["MasVnrType"].fillna("None")
complete_data["Functional"] = complete_data["Functional"].fillna("Typ")
complete_data['Electrical'] = complete_data['Electrical'].fillna(complete_data['Electrical'].mode()[0])
complete_data['KitchenQual'] = complete_data['KitchenQual'].fillna(complete_data['KitchenQual'].mode()[0])
complete_data['Exterior1st'] = complete_data['Exterior1st'].fillna(complete_data['Exterior1st'].mode()[0])
complete_data['Exterior2nd'] = complete_data['Exterior2nd'].fillna(complete_data['Exterior2nd'].mode()[0])
complete_data['SaleType'] = complete_data['SaleType'].fillna(complete_data['SaleType'].mode()[0])
complete_data['MSSubClass'] = complete_data['MSSubClass'].fillna("None")
# + _cell_guid="869c05dc-5d4d-4fca-b229-50e7efb5afe2" _uuid="936c1e801685756352b217bac27e635a82302360"
# Group by neighborhood and fill in missing value by the median LotFrontage of all the neighborhood
complete_data["LotFrontage"] = complete_data.groupby("Neighborhood")["LotFrontage"].transform(
lambda x: x.fillna(x.median()))
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
complete_data[col] = complete_data[col].fillna(0)
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
complete_data[col] = complete_data[col].fillna(0)
complete_data["MasVnrArea"] = complete_data["MasVnrArea"].fillna(0)
# + _cell_guid="e32b904b-71b1-4f1d-b8fb-dda88d05ead9" _uuid="9c77e4ca6e65f45ec2a0e6e055d55f8f7c232a9a"
# Drop
complete_data = complete_data.drop(['Utilities'], axis=1)
# + [markdown] _cell_guid="b901c4f7-2e13-474e-93cd-09ef04ed719b" _uuid="1cfa443cee4496ba76c9d5086a69b9d3d204b9ab"
# ## Combining Attributes
# <a id="combining_atributes"></a>
# + _cell_guid="afa290bf-5ed7-40ef-982c-97b78a9b33a9" _uuid="bc53f619d77a6b06479e10ee2f05ff236a2cc20d"
# Adding total sqfootage feature
complete_data['TotalSF'] = complete_data['TotalBsmtSF'] + complete_data['1stFlrSF'] + complete_data['2ndFlrSF']
# + [markdown] _cell_guid="437298f3-4212-4b68-ac7d-7af4ba1bd0e9" _uuid="cf323e92e0b9bdb90a47462a9d9dc4083dc62c38"
# ## Dealing with Numerical and Categorical Values:
# <a id="num_cat_val"></a>
# + [markdown] _cell_guid="12198e5a-e3a0-4f58-b15d-5490406ec6ae" _uuid="d86480c2937af244aa10f10d845de9156c2dc5b2"
# ## Transforming our Data:
# <ul>
# <li> Separate the <b> features </b> and <b> labels </b> from the training dataset. </li>
# <li> Separate <b> numeric </b> and <b> categorical </b> variables for the purpose of running them in separate pipelines and scaling them with their respective scalers. </li>
#
# </ul>
# + _cell_guid="1b8ed912-6e85-4c98-a57c-cf25b6264919" _uuid="d3c56bc3c0b804d0b2013b139340d60662babfc5"
complete_data.head()
# + _cell_guid="a1304790-d245-4d84-8e9d-c668ab8c4d73" _uuid="65c485814e967f638ab70483a9d9660116f6dfcb"
# splitting categorical variables with numerical variables for encoding.
categorical = complete_data.select_dtypes(['object'])
numerical = complete_data.select_dtypes(exclude=['object'])
print(categorical.shape)
print(numerical.shape)
# + [markdown] _cell_guid="146dfde7-e796-4d82-a319-ed7ea75adee8" _uuid="e18d1b3dff5983a4b3b80aeb22a9c24964832394"
# ## Categorical Encoding Class:
# <a id="categorical_class"></a>
# This is a way to encode our features in a way that it avoids the assumption that two nearby values are more similar than two distant values. This is the reason we should avoid using LabelEncoder to scale features (inputs) in our dataset and in addition the word **LabelEncoder** is used for scaling labels (outputs). This could be used more often in **binary classification problems** were no *association* exists between the outputs.
# + _cell_guid="84ec7a4e-6bf8-42bc-85f5-ee2e26f336f9" _uuid="68fddce5f01fdeef1aa01a9a052a81cbc2453cba"
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils import check_array
from sklearn.preprocessing import LabelEncoder
from scipy import sparse
class CategoricalEncoder(BaseEstimator, TransformerMixin):
"""Encode categorical features as a numeric array.
The input to this transformer should be a matrix of integers or strings,
denoting the values taken on by categorical (discrete) features.
The features can be encoded using a one-hot aka one-of-K scheme
(``encoding='onehot'``, the default) or converted to ordinal integers
(``encoding='ordinal'``).
This encoding is needed for feeding categorical data to many scikit-learn
estimators, notably linear models and SVMs with the standard kernels.
Read more in the :ref:`User Guide <preprocessing_categorical_features>`.
Parameters
----------
encoding : str, 'onehot', 'onehot-dense' or 'ordinal'
The type of encoding to use (default is 'onehot'):
- 'onehot': encode the features using a one-hot aka one-of-K scheme
(or also called 'dummy' encoding). This creates a binary column for
each category and returns a sparse matrix.
- 'onehot-dense': the same as 'onehot' but returns a dense array
instead of a sparse matrix.
- 'ordinal': encode the features as ordinal integers. This results in
a single column of integers (0 to n_categories - 1) per feature.
categories : 'auto' or a list of lists/arrays of values.
Categories (unique values) per feature:
- 'auto' : Determine categories automatically from the training data.
- list : ``categories[i]`` holds the categories expected in the ith
column. The passed categories are sorted before encoding the data
(used categories can be found in the ``categories_`` attribute).
dtype : number type, default np.float64
Desired dtype of output.
handle_unknown : 'error' (default) or 'ignore'
Whether to raise an error or ignore if a unknown categorical feature is
present during transform (default is to raise). When this is parameter
is set to 'ignore' and an unknown category is encountered during
transform, the resulting one-hot encoded columns for this feature
will be all zeros.
Ignoring unknown categories is not supported for
``encoding='ordinal'``.
Attributes
----------
categories_ : list of arrays
The categories of each feature determined during fitting. When
categories were specified manually, this holds the sorted categories
(in order corresponding with output of `transform`).
Examples
--------
Given a dataset with three features and two samples, we let the encoder
find the maximum value per feature and transform the data to a binary
one-hot encoding.
>>> from sklearn.preprocessing import CategoricalEncoder
>>> enc = CategoricalEncoder(handle_unknown='ignore')
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
... # doctest: +ELLIPSIS
CategoricalEncoder(categories='auto', dtype=<... 'numpy.float64'>,
encoding='onehot', handle_unknown='ignore')
>>> enc.transform([[0, 1, 1], [1, 0, 4]]).toarray()
array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.],
[ 0., 1., 1., 0., 0., 0., 0., 0., 0.]])
See also
--------
sklearn.preprocessing.OneHotEncoder : performs a one-hot encoding of
integer ordinal features. The ``OneHotEncoder assumes`` that input
features take on values in the range ``[0, max(feature)]`` instead of
using the unique values.
sklearn.feature_extraction.DictVectorizer : performs a one-hot encoding of
dictionary items (also handles string-valued features).
sklearn.feature_extraction.FeatureHasher : performs an approximate one-hot
encoding of dictionary items or strings.
"""
def __init__(self, encoding='onehot', categories='auto', dtype=np.float64,
handle_unknown='error'):
self.encoding = encoding
self.categories = categories
self.dtype = dtype
self.handle_unknown = handle_unknown
def fit(self, X, y=None):
"""Fit the CategoricalEncoder to X.
Parameters
----------
X : array-like, shape [n_samples, n_feature]
The data to determine the categories of each feature.
Returns
-------
self
"""
if self.encoding not in ['onehot', 'onehot-dense', 'ordinal']:
template = ("encoding should be either 'onehot', 'onehot-dense' "
"or 'ordinal', got %s")
raise ValueError(template % self.handle_unknown)
if self.handle_unknown not in ['error', 'ignore']:
template = ("handle_unknown should be either 'error' or "
"'ignore', got %s")
raise ValueError(template % self.handle_unknown)
if self.encoding == 'ordinal' and self.handle_unknown == 'ignore':
raise ValueError("handle_unknown='ignore' is not supported for"
" encoding='ordinal'")
X = check_array(X, dtype=np.object, accept_sparse='csc', copy=True)
n_samples, n_features = X.shape
self._label_encoders_ = [LabelEncoder() for _ in range(n_features)]
for i in range(n_features):
le = self._label_encoders_[i]
Xi = X[:, i]
if self.categories == 'auto':
le.fit(Xi)
else:
valid_mask = np.in1d(Xi, self.categories[i])
if not np.all(valid_mask):
if self.handle_unknown == 'error':
diff = np.unique(Xi[~valid_mask])
msg = ("Found unknown categories {0} in column {1}"
" during fit".format(diff, i))
raise ValueError(msg)
le.classes_ = np.array(np.sort(self.categories[i]))
self.categories_ = [le.classes_ for le in self._label_encoders_]
return self
def transform(self, X):
"""Transform X using one-hot encoding.
Parameters
----------
X : array-like, shape [n_samples, n_features]
The data to encode.
Returns
-------
X_out : sparse matrix or a 2-d array
Transformed input.
"""
X = check_array(X, accept_sparse='csc', dtype=np.object, copy=True)
n_samples, n_features = X.shape
X_int = np.zeros_like(X, dtype=np.int)
X_mask = np.ones_like(X, dtype=np.bool)
for i in range(n_features):
valid_mask = np.in1d(X[:, i], self.categories_[i])
if not np.all(valid_mask):
if self.handle_unknown == 'error':
diff = np.unique(X[~valid_mask, i])
msg = ("Found unknown categories {0} in column {1}"
" during transform".format(diff, i))
raise ValueError(msg)
else:
# Set the problematic rows to an acceptable value and
# continue `The rows are marked `X_mask` and will be
# removed later.
X_mask[:, i] = valid_mask
X[:, i][~valid_mask] = self.categories_[i][0]
X_int[:, i] = self._label_encoders_[i].transform(X[:, i])
if self.encoding == 'ordinal':
return X_int.astype(self.dtype, copy=False)
mask = X_mask.ravel()
n_values = [cats.shape[0] for cats in self.categories_]
n_values = np.array([0] + n_values)
indices = np.cumsum(n_values)
column_indices = (X_int + indices[:-1]).ravel()[mask]
row_indices = np.repeat(np.arange(n_samples, dtype=np.int32),
n_features)[mask]
data = np.ones(n_samples * n_features)[mask]
out = sparse.csc_matrix((data, (row_indices, column_indices)),
shape=(n_samples, indices[-1]),
dtype=self.dtype).tocsr()
if self.encoding == 'onehot-dense':
return out.toarray()
else:
return out
# + [markdown] _cell_guid="50b4a15f-b21f-4dab-b522-f8f05997060f" _uuid="08fac02446cb084512e1c0a25baf68cc42bb975d"
# ## Combine Attribute Class:
# <a id="combining"></a>
# This class will help us to include the total area variable into our pipeline for further scaling.
# + _cell_guid="efe1afb9-76d8-4a7c-adf7-9aeec3d21c1e" _uuid="e2e00985162f30c8b87c493cea532ca17101e78f"
from sklearn.base import BaseEstimator, TransformerMixin
# class combination attribute.
# First we need to know the index possition of the other cloumns that make the attribute.
numerical.columns.get_loc("TotalBsmtSF") # Index Number 37
numerical.columns.get_loc("1stFlrSF") # Index NUmber 42
numerical.columns.get_loc("2ndFlrSF") # Index NUmber 43
ix_total, ix_first, ix_second = 9, 10, 11
# complete_data['TotalSF'] = complete_data['TotalBsmtSF'] + complete_data['1stFlrSF'] + complete_data['2ndFlrSF']
class CombineAttributes(BaseEstimator, TransformerMixin):
def __init__(self, total_area=True): # No args or kargs
self.total_area = total_area
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
total_sf = X[:,ix_total] + X[:,ix_first] + X[:,ix_second]
if self.total_area:
return np.c_[X, total_sf]
else:
return np.c_[X]
attr_adder = CombineAttributes(total_area=True)
extra_attribs = attr_adder.transform(complete_data.values)
# + _cell_guid="c81d0992-e5a8-447a-9bc5-12d88ffae1bd" _uuid="0e544587a7019e447023edbc660bf7dcc5f1265d"
# Scikit-Learn does not handle dataframes in pipeline so we will create our own class.
# Reference: Hands-On Machine Learning
from sklearn.base import BaseEstimator, TransformerMixin
# Create a class to select numerical or cateogrical columns.
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit (self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
# + [markdown] _cell_guid="9f9375b0-ee58-4f08-b94c-b9bd7594e3ac" _uuid="ebe88610a875c14db02370c5c735090d120c4dbc"
# ## Pipelines:
# <a id="pipelines"></a>
#
# Create our numerical and cateogircal pipelines to scale our features.
# + _cell_guid="3bd281a4-6358-411a-be67-78a5078f108a" _uuid="5a850ab511119c69d06855e6505ae5c1ea42c40a"
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
lst_numerical = list(numerical)
numeric_pipeline = Pipeline([
('selector', DataFrameSelector(lst_numerical)),
('extra attributes', CombineAttributes()),
('std_scaler', StandardScaler()),
])
categorical_pipeline = Pipeline([
('selector', DataFrameSelector(['MSZoning', 'Street', 'LotShape', 'LandContour', 'LotConfig', 'LandSlope',
'Neighborhood', 'Condition1', 'Condition2','BldgType', 'HouseStyle', 'RoofStyle',
'RoofMatl', 'Exterior1st', 'Exterior2nd','ExterQual','ExterCond', 'Foundation',
'Heating','HeatingQC', 'CentralAir', 'Electrical', 'KitchenQual', 'Functional',
'PavedDrive', 'SaleType', 'SaleCondition'])),
('encoder', CategoricalEncoder(encoding="onehot-dense")),
])
# + _cell_guid="9a9f7bd5-41a8-4033-8325-52575e8dd96e" _uuid="92a6c79bb863ddb3f6ffaa3bc0438ec2b68c9080"
# Combine our pipelines!
from sklearn.pipeline import FeatureUnion
main_pipeline = FeatureUnion(transformer_list=[
('num_pipeline', numeric_pipeline),
('cat_pipeline', categorical_pipeline)
])
data_prepared = main_pipeline.fit_transform(complete_data)
data_prepared
# + _cell_guid="e9abd64d-8f4f-44d0-adcc-7e4411d8edf8" _uuid="7c0cd7c49c578e7b04e941998a6354206ccb2fbd"
features = data_prepared
labels = np.log1p(y_train) # Scaling the Saleprice column.
train_scaled = features[:rtrain]
test_scaled = features[rtrain:]
# + [markdown] _cell_guid="46b9e444-95d7-47ba-8daa-fae5716490fd" _uuid="84beb256996094d60de193f6d310ed40d5693dc8"
# <h1 align="center"> Implementing Predictive Models </h1>
#
# <img src="http://precisionanalytica.com/blog/wp-content/uploads/2014/09/Predictive-Modeling.jpg">
#
# ## Residual Plot:
# <a id="residual_plot"></a>
# <ul>
# <li><b>Residual plots</b> will give us more or less the actual prediction errors our models are making. In this example, I will use <b>yellowbrick library</b> (statistical visualizations for machine learning) and a simple linear regression model. In our <b>legends</b> of the residual plot it says training and test data but in this scenario instead of the test set it is the <b>validation set</b> we are using. [If there is a possibility to change the name of the legend to validation I will make the update whenever possible.</li>
# <li> Create a validation set within the training set to actually predict values. (Remember the test set does not have the training price, and also when testing data it should be done during the last instance of the project.) </li>
#
# </ul>
# + _cell_guid="74353242-ae2e-4c3c-966f-5994d112c13e" _uuid="62fe6aec0e3f66b7a03a640c290c224f670bc3db"
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
from sklearn.linear_model import Ridge
from yellowbrick.regressor import PredictionError, ResidualsPlot
# + _cell_guid="bc745f6c-89f1-460a-ae9a-6c89b7ff413b" _uuid="b34089f383b5c9ca58274d7dc09f9f2ff0eba4dd"
# This is data that comes from the training test.
X_train, X_val, y_train, y_val = train_test_split(train_scaled, labels, test_size=0.25, random_state=42)
# + _cell_guid="4018e6c1-a791-4c76-b5e1-d2889e4abe05" _uuid="49cd7cb88a92f4516a965e391b742daac6d20c59"
# Our validation set tends to perform better. Less Residuals.
ridge = Ridge()
visualizer = ResidualsPlot(ridge, train_color='#045FB4', test_color='r', line_color='#424242')
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_val, y_val)
g = visualizer.poof(outpath="residual_plot")
# + _cell_guid="9c508d75-3986-40f8-bc89-e4fa9fe67d81" _uuid="19f080d2d25613bd2dcf308dcf8e13d5888dd564"
#Validation function
n_folds = 5
def rmsle_cv(model, features, labels):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(features) # Shuffle the data.
rmse= np.sqrt(-cross_val_score(model, features, labels, scoring="neg_mean_squared_error", cv = kf))
return(rmse.mean())
# + _cell_guid="32daeebd-c98a-4ced-b776-3019055d29dd" _uuid="1c81226155771c0ddcd5c5c46c36f200876c1a5d"
rid_reg = Ridge()
rid_reg.fit(X_train, y_train)
y_pred = rid_reg.predict(X_val)
rmsle_cv(rid_reg, X_val, y_val)
# + _cell_guid="0685c1e5-acda-4e5c-9718-ac9d652d7180" _uuid="79923eb111f9cc3de3692ea3fde16ee3c67d3082"
# + [markdown] _cell_guid="8709f187-2d9f-4c9b-9a43-25eb0537a931" _uuid="2acc40d953a273b297704e0cf016c756a9bfb2cc"
# ### RandomForestRegressor:
# <a id="random_forest"></a>
# <img src="https://techblog.expedia.com/wp-content/uploads/2017/06/BoostedTreeExample.jpg">
# **RandomForestRegressor** gives us more randomness, insead of searching through impurity the best feature, RandomForest picks features in a randomly manner to reduce variance at the expense of a higher bias. Nevertheless, this helps us find what the trend is. After all the trees have predicted the outcome for a specific instance, the average from all the DecisionTree models is taken and that will be the prediction for a specific instance.
# + _cell_guid="aa14ba95-a92c-433e-8c61-08503c191067" _uuid="2342501a592756832501c67df533fac252f37ad5"
from sklearn.model_selection import GridSearchCV
params = {'n_estimators': list(range(50, 200, 25)), 'max_features': ['auto', 'sqrt', 'log2'],
'min_samples_leaf': list(range(50, 200, 50))}
grid_search_cv = GridSearchCV(RandomForestRegressor(random_state=42), params, n_jobs=-1)
grid_search_cv.fit(X_train, y_train)
# + _cell_guid="dd56337b-bc0e-4da1-b187-a13c36283336" _uuid="504eceaf309d72747ee32c42a283573b33f7b177"
grid_search_cv.best_estimator_
# + _cell_guid="b974254e-aa49-4a94-8bd5-43cbaf871379" _uuid="17eb2e3749e012037ac1067028b00d7319299778"
# Show best parameters.
grid_search_cv.best_params_
# + _cell_guid="3a150e67-6cb2-4b8c-a493-2a53b3acb982" _uuid="e0cd3b6ee6ff37827567fe0dfc30fb76ae7ac1cc"
# You can check the results with this functionof grid search.
# RandomSearchCV takes just a sample not all possible combinations like GridSearchCV.
# Mean test score is equivalent to 0.2677
grid_search_cv.cv_results_
df_results = pd.DataFrame(grid_search_cv.cv_results_)
df_results.sort_values(by='mean_test_score', ascending=True).head(2)
# + _cell_guid="0a070ecf-121f-47da-bf54-27347b392919" _uuid="7645089595ee6389e25ffa12640787b15d79d95d"
rand_model = grid_search_cv.best_estimator_
rand_model.fit(X_train, y_train)
# + _cell_guid="df44ca07-5be7-4d3d-b6e9-d295d0431887" _uuid="1ad4024ee2ec9ab425ef33dd81c1fd6643d61b98"
# Final root mean squared error.
y_pred = rand_model.predict(X_val)
rand_mse = mean_squared_error(y_val, y_pred)
rand_rmse = np.sqrt(rand_mse)
rand_rmse
# + _cell_guid="c0510209-f600-4a8b-b862-f2cc6caa4cba" _uuid="0bbd759fc6e4efd7c38cb8fcde1b45a02a2255fc"
# It was overfitting a bit.
score = rmsle_cv(rand_model, X_val, y_val)
print("Random Forest score: {:.4f}\n".format(score))
# + _cell_guid="5f2ef30c-73e0-4ea8-9a2c-4cd39bd22f50" _uuid="10679dbe71cea057537db892bbd1960ca0800414"
# Display scores next to attribute names.
# Reference Hands-On Machine Learning with Scikit Learn and Tensorflow
attributes = X_train
rand_results = rand_model.feature_importances_
cat_encoder = categorical_pipeline.named_steps["encoder"]
cat_features = list(cat_encoder.categories_[0])
total_features = lst_numerical + cat_features
feature_importance = sorted(zip(rand_results, total_features), reverse=True)
feature_arr = np.array(feature_importance)
# Top 10 features.
feature_scores = feature_arr[:,0][:10].astype(float)
feature_names = feature_arr[:,1][:10].astype(str)
d = {'feature_names': feature_names, 'feature_scores': feature_scores}
result_df = pd.DataFrame(data=d)
fig, ax = plt.subplots(figsize=(12,8))
ax = sns.barplot(x='feature_names', y='feature_scores', data=result_df, palette="coolwarm")
plt.title('RandomForestRegressor Feature Importances', fontsize=16)
plt.xlabel('Names of the Features', fontsize=14)
plt.ylabel('Feature Scores', fontsize=14)
# + [markdown] _cell_guid="87328362-909a-4b95-a95e-07b0a5dbdb44" _uuid="943d5724022bd996b299751188830f250c9efe64"
# ## GradientBoostingRegressor:
# <img src="https://image.slidesharecdn.com/slides-140224130205-phpapp02/95/gradient-boosted-regression-trees-in-scikitlearn-21-638.jpg?cb=1393247097">
# <a id="gradient_boosting"></a>
# The Gradient Boosting Regressor class trains the models over the residuals (prediction errors) leading to smaller variances and higher accuracy.
# + _cell_guid="54559c0c-c141-46b1-a558-922186c3f779" _uuid="c3930ca569d68634af09da729ed909317e4513f2"
params = {'learning_rate': [0.05], 'loss': ['huber'], 'max_depth': [2], 'max_features': ['log2'], 'min_samples_leaf': [14],
'min_samples_split': [10], 'n_estimators': [3000]}
grad_boost = GradientBoostingRegressor(learning_rate=0.05, loss='huber', max_depth=2,
max_features='log2', min_samples_leaf=14, min_samples_split=10, n_estimators=3000,
random_state=42)
grad_boost.fit(X_train, y_train)
# + _cell_guid="14b81859-359f-4b48-b2b5-7a7ba8bde659" _uuid="fd64206cdc8d6b20b120c6379ebdd65d7e70ac4f"
y_pred = grad_boost.predict(X_val)
gboost_mse = mean_squared_error(y_val, y_pred)
gboost_rmse = np.sqrt(gboost_mse)
gboost_rmse
# + _cell_guid="825db809-4808-4e15-aea0-b2d548587888" _uuid="4437ab39cbb96a0fb3c80afc5bcf9d35120de0e8"
# Gradient Boosting was considerable better than RandomForest Regressor.
# scale salesprice.
# y_val = np.log(y_val)
score = rmsle_cv(grad_boost, X_val, y_val)
print("Gradient Boosting score: {:.4f}\n".format(score))
# + [markdown] _cell_guid="667b290b-1689-4e41-bb3e-d9af847d91eb" _uuid="aaa84ed41b0fb5b5ae5b15c592d2a8f01eab3e9e"
# ## StackingRegressor:
# <img src="https://rasbt.github.io/mlxtend/user_guide/regressor/StackingRegressor_files/stackingregression_overview.png">
# <a id="stacking_regressor"></a>
# In stacking regressor we combine different models and use the predicted values in the training set to mae further predictions. In case you want to go deeper into parameter <b>"tuning"</b> I left you the code above the different models so you can perform your own GridSearchCV and find even more efficient parameters! <br>
# <ul>
# <li> ElasticNet </li>
# <li> DecisionTreeRegressor </li>
# <li> MLPRegressor (Later I will include it after learning more about neural networks) </li>
# <li> SVR </li>
# </ul>
# + _cell_guid="44f09db7-2ce5-4583-b11f-ff3f249af36a" _uuid="a2f7f301d208d42685ed3572e5ed4c1c7b5206c4"
# Define the models
from sklearn.linear_model import ElasticNet
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import Lasso, Ridge
# Parameters for Ridge
# params = {"alpha": [0.5, 1, 10, 30, 50, 75, 125, 150, 225, 250, 500]}
# grid_ridge = GridSearchCV(Ridge(random_state=42), params)
# grid_ridge.fit(X_train, y_train)
# Parameters for DecisionTreeRegressor
# params = {"criterion": ["mse", "friedman_mse"], "max_depth": [None, 2, 3], "min_samples_split": [2,3,4]}
# grid_tree_reg = GridSearchCV(DecisionTreeRegressor(), params)
# grid_tree_reg.fit(X_train, y_train)
# Parameters for SVR
# params = {"kernel": ["rbf", "linear", "poly"], "C": [0.3, 0.5, 0.7, 0.7, 1], "degree": [2,3]}
# grid_svr = GridSearchCV(SVR(), params)
# grid_svr.fit(X_train, y_train)
# Tune Parameters for elasticnet
# params = {"alpha": [0.5, 1, 5, 10, 15, 30], "l1_ratio": [0.3, 0.5, 0.7, 0.9, 1], "max_iter": [3000, 5000]}
# grid_elanet = GridSearchCV(ElasticNet(random_state=42), params)
# Predictive Models
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.9, max_iter=3000)
svr = SVR(C=1, kernel='linear')
tree_reg = DecisionTreeRegressor(criterion='friedman_mse', max_depth=None, min_samples_split=3)
ridge_reg = Ridge(alpha=10)
# grid_elanet.fit(X_train, y_train)
# + _cell_guid="f2bf6304-1b8a-42eb-9324-c685ee899856" _uuid="56cf784717e9d9b88b72caa5633cd38831ec44ed"
from mlxtend.regressor import StackingRegressor
from sklearn.linear_model import LinearRegression
# Try tomorrow with svr_rbf = SVR(kernel='rbf')
# Check this website!
# Consider adding two more models if the score does not improve.
lin_reg = LinearRegression()
ensemble_model = StackingRegressor(regressors=[elastic_net, svr, rand_model, grad_boost], meta_regressor=SVR(kernel="rbf"))
ensemble_model.fit(X_train, y_train)
score = rmsle_cv(ensemble_model, X_val, y_val)
print("Stacking Regressor score: {:.4f}\n".format(score))
# + _cell_guid="aa21ead6-7f60-4c4e-8b21-d4401438b82d" _uuid="f4b50203905a8482f8a7db6fb8913988dc9f619e"
# We go for the stacking regressor model
# although sometimes gradientboosting might show to have a better performance.
final_pred = ensemble_model.predict(test_scaled)
# + _cell_guid="5ae686ad-8145-495b-a1e3-5f5e5702da27" _uuid="657e682198b46b7830cf08d0df5f03ec89e1d3e7"
# # Dataframe
final = pd.DataFrame()
# Id and Predictions
final['Id'] = test_id
final['SalePrice'] = np.expm1(final_pred)
# CSV file
final.to_csv('submission.csv', index=False) # Create Submission File
print('The File has been Submitted!')
# + [markdown] _cell_guid="9f22442e-2a8b-4607-b02d-3f74b36b3cc6" _uuid="c776995fa0739a42269e102e4a1e5da47ce58a25"
# ## Keras and TensorFlow:
# Although the accuracy of our neural network is still not as accurate as our ensemble and boosting model, I wanted to share two main aspects of tensorflow.
# <ul>
# <li> Implementing a Neural Network with a real life <b>regression scenario</b>. </li>
# <li>Show the structure of Neural Networks through <b>tensorboard</b> (we will do this with ipython display.) </li>
# </ul>
# <br><br>
#
# (Reference: Hands On Machine Learning and TensorFlow by <NAME>)
# + _cell_guid="6bafb4ca-d2b6-44c3-8a3c-793fa8db5dd0" _uuid="b152e7a15904b66f363e08a9421e3b2250138deb"
# import tensorflow as tf
# import keras
# from keras import backend as K
# from keras.models import Sequential
# from keras.layers import Activation
# from keras.layers.core import Dense
# from keras.optimizers import Adam
# from keras.initializers import VarianceScaling
# # Reset the graph looks crazy
# def reset_graph(seed=42):
# tf.reset_default_graph()
# tf.set_random_seed(seed)
# np.random.seed(seed)
# reset_graph()
# m, n = X_train.shape
# # Look at the preprocess data of the video and see the reshape part and apply it to X_train!
# # he_init = keras.initializers.VarianceScaling(scale=1.0, mode="fan_in", distribution='normal', seed=None)
# # Create a model (Add layers)
# model = Sequential([
# Dense(n, input_shape=(n,), kernel_initializer='random_uniform', activation='relu'), # Start with the inputs
# Dense(50, input_shape=(1,), kernel_initializer='random_uniform', activation='relu'), # Number of Layers
# Dense(1, kernel_initializer='random_uniform')
# ])
# model.summary()
# + [markdown] _cell_guid="dc46da56-8217-4fee-8091-55c36083c2f0" _uuid="d585b2b5e43728a0704e02136279d0ed8946536d"
# ## Conclusion:
# I got a 0.13 score approximately, in the future I aim to fix some issues with regards to the tuning of hyperparameters and implement other concepts of feature engineering that will help algorithms make a more concise prediction. Nevertheless, this project helped me understand more complex models that could be implemented in practical situations. Hope you enjoyed our in-depth analysis of this project and the predictive models used to come with close to accurate predictions. Open to constructive criticisms!
| 8 HOUSE PRICES/predicting-house-prices-regression-techniques.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %matplotlib inline
# # Isochrone fitting using gaia-isochrones
#
# In this demo, we'll fit the Gaia data for a TESS target.
# The stack is:
#
# * [MIST](http://waps.cfa.harvard.edu/MIST/) stellar evolution and atmospheric grids,
# * [isochrones.py](https://github.com/timothydmorton/isochrones) to compute the model, and
# * [dynesty](https://dynesty.readthedocs.io) to do the parameter estimation.
#
# But first, let's set up the plotting to look a little nicer:
import matplotlib.pyplot as plt
plt.style.use("default")
plt.rcParams["savefig.dpi"] = 100
plt.rcParams["figure.dpi"] = 100
plt.rcParams["font.size"] = 16
plt.rcParams["font.family"] = "sans-serif"
plt.rcParams["font.sans-serif"] = ["Liberation Sans"]
plt.rcParams["mathtext.fontset"] = "custom"
# Then, all of our imports:
# +
import gaia_isochrones
import numpy as np
import astropy.units as u
from astropy.coordinates import SkyCoord
# -
# In this demo, we'll fit the stellar properties for HD 21749, one of the TESS targets that [was found to host a system of transiting planets](https://ui.adsabs.harvard.edu/abs/2019ApJ...875L...7D/abstract).
# In practice, it would be easier to use the shortcuts in `gaia_isochrones.tess` to do this fit, but for completeness, we'll start from scratch here.
#
# We extract the coordinates and TESS magnitude of the target from the paper and then query the Gaia catalog at those coordinates:
# +
ra = "03:27:00.045"
dec = "-63:30:00.60"
coord = SkyCoord(ra, dec, unit=(u.hourangle, u.deg), obstime="J2015.5")
tess_mag = 6.95
gaia_data = gaia_isochrones.get_gaia_data(coord, approx_mag=tess_mag)
print(gaia_data)
# -
# Then, we fit these data using dynesty to sample.
# If we provide an `output_dir` argument then the results are saved to disk.
model, sampler = gaia_isochrones.fit_gaia_data(gaia_data, output_dir="hd21749", clobber=True)
# This function returns both the isochrones model and the dynesty `NestedSampler` object so we can do everything that we might want to do with those.
#
# For example, we can make the corner plots that isochrones knows how to make:
model.corner_observed();
model.corner_physical();
# Finally, let's summarize these results.
# The raw samples are saved in the isochrones model as a pandas `DataFrame` called `_derived_samples`:
# +
samples = model._derived_samples
for k in ["mass", "radius", "age", "Teff", "logg", "feh", "distance", "AV"]:
x = samples[k]
if k == "age":
# "age" is actually "log10(age)"
x = 10 ** (x - 9)
k = "age [Gyr]"
print("{0} = {1:.3f} ± {2:.3f}".format(k, np.mean(x), np.std(x)))
# -
| demo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Explore The Data: What Data Are We Using?
#
# Using the Titanic dataset from [this](https://www.kaggle.com/c/titanic/overview) Kaggle competition.
#
# This dataset contains information about 891 people who were on board the ship when departed on April 15th, 1912. As noted in the description on Kaggle's website, some people aboard the ship were more likely to survive the wreck than others. There were not enough lifeboats for everybody so women, children, and the upper-class were prioritized. Using the information about these 891 passengers, the challenge is to build a model to predict which people would survive based on the following fields:
#
# - **Name** (str) - Name of the passenger
# - **Pclass** (int) - Ticket class (1st, 2nd, or 3rd)
# - **Sex** (str) - Gender of the passenger
# - **Age** (float) - Age in years
# - **SibSp** (int) - Number of siblings and spouses aboard
# - **Parch** (int) - Number of parents and children aboard
# - **Ticket** (str) - Ticket number
# - **Fare** (float) - Passenger fare
# - **Cabin** (str) - Cabin number
# - **Embarked** (str) - Port of embarkation (C = Cherbourg, Q = Queenstown, S = Southampton)
# ### Read In Data
# +
# Read in the data from the data folder
import pandas as pd
titanic = pd.read_csv('../../../data/titanic.csv')
titanic.head()
# -
# Check the number of rows and columns in the data
titanic.shape
# Check the type of data stored in each column
titanic.dtypes
# See the distribution of our target variable
titanic['Survived'].value_counts()
| ml_feature/03_Explore_Data/03_01/End/03_01.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Data Augmentation
#
# ### Let's look at our untouched dataset
# +
# Plot images
from keras.datasets import mnist
from matplotlib import pyplot
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# create a grid of 3x3 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_train[i], cmap=pyplot.get_cmap('gray'))
# show the plot
pyplot.show()
# -
# ### Random Rotations
# - As per Keras documentation random is 50%
# +
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K
# Load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Reshape our data to be in the forma [samples, width, height, color_depth]
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# Change datatype to float32
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Create our image generator
# Define random rotation parameter to be 60 degrees
train_datagen = ImageDataGenerator(rotation_range=60)
# fit parameters from data
train_datagen.fit(x_train)
# configure batch size and retrieve one batch of images
for x_batch, y_batch in train_datagen.flow(x_train, y_train, batch_size=9):
# create a grid of 3x3 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))# show the plot
pyplot.show()
break
# -
# ### <NAME> and zooming
# +
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K
# Load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Reshape our data to be in the forma [samples, width, height, color_depth]
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# Change datatype to float32
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Create our image generator
# Define shearing and zooming parameters to be 0.5 each
train_datagen = ImageDataGenerator(shear_range=0.5,
zoom_range=0.5)
# fit parameters from data
train_datagen.fit(x_train)
# configure batch size and retrieve one batch of images
for x_batch, y_batch in train_datagen.flow(x_train, y_train, batch_size=9):
# create a grid of 3x3 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))# show the plot
pyplot.show()
break
# -
# ### Horizontal and Vertical Flips
# +
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K
# Load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Reshape our data to be in the forma [samples, width, height, color_depth]
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# Change datatype to float32
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# define data preparation
train_datagen = ImageDataGenerator(vertical_flip=True,
horizontal_flip=True)
# fit parameters from data
train_datagen.fit(x_train)
# configure batch size and retrieve one batch of images
for x_batch, y_batch in train_datagen.flow(x_train, y_train, batch_size=9):
# create a grid of 3x3 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))# show the plot
pyplot.show()
break
# -
# ### Random Shifts
# +
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K
# Load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Reshape our data to be in the forma [samples, width, height, color_depth]
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# Change datatype to float32
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# define data preparation
train_datagen = ImageDataGenerator(width_shift_range=0.3,
height_shift_range=0.3)
# fit parameters from data
train_datagen.fit(x_train)
# configure batch size and retrieve one batch of images
for x_batch, y_batch in train_datagen.flow(x_train, y_train, batch_size=9):
# create a grid of 3x3 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))# show the plot
pyplot.show()
break
# -
# ### Applying all at once
# +
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K
# Load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Reshape our data to be in the forma [samples, width, height, color_depth]
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# Change datatype to float32
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# define data preparation
train_datagen = ImageDataGenerator(
rotation_range=45,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# fit parameters from data
train_datagen.fit(x_train)
# configure batch size and retrieve one batch of images
for x_batch, y_batch in train_datagen.flow(x_train, y_train, batch_size=9):
# create a grid of 3x3 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))# show the plot
pyplot.show()
break
# -
# ### Read more about it at the official Keras Documentation
# https://keras.io/preprocessing/image/
# ### Test Augmentation on a single image
# - Outputs to ./preview diretory
# +
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('dog.jpeg')
x = img_to_array(img) # creating a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # converting to a Numpy array with shape (1, 3, 150, 150)
i = 0
for batch in datagen.flow(x, save_to_dir='output', save_prefix='dog', save_format='jpeg'):
i += 1
if i > 35:
break
# -
| Data Augmentation Demos.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="pYl-PPaVY1fO" colab_type="code" colab={}
# #!pip install datadotworld
# #!pip install datadotworld[pandas]
# + id="VOY9WKa8a4oS" colab_type="code" colab={}
# #!dw configure
# + id="qX791yrWXUE5" colab_type="code" colab={}
from google.colab import drive
import pandas as pd
import numpy as np
import datadotworld as dw
# + id="4vPh0gKhbUvw" colab_type="code" colab={}
#drive.mount ("/content/drive")
# + id="GzdzRFDzblz2" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="446624eb-04f4-4156-f4c7-50ba13cafaf6" executionInfo={"status": "ok", "timestamp": 1581511644136, "user_tz": -60, "elapsed": 566, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
# cd "drive/My Drive/Colab Notebooks/matrix"
# + id="Kn0woTVFb4-_" colab_type="code" colab={}
# !echo 'data' > .gitignore
# + id="FGEVDweecLo-" colab_type="code" colab={}
# !git add .gitignore
# + id="1SImwX9CdN3U" colab_type="code" colab={}
data = dw.load_dataset('datafiniti/mens-shoe-prices')
# + id="w0KMZu10eYjM" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 122} outputId="a78c40a1-d0d9-40d4-ce00-32a79646f33e" executionInfo={"status": "ok", "timestamp": 1581512340316, "user_tz": -60, "elapsed": 1887, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/<KEY>DN=s64", "userId": "15273861130524040784"}}
df = data.dataframes['7004_1']
df.shape
# + id="6bP9NO_gedEC" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 479} outputId="ae1495b2-f301-4ec9-938f-87b97342c25d" executionInfo={"status": "ok", "timestamp": 1581512381458, "user_tz": -60, "elapsed": 450, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df.sample(5)
# + id="Xz2Xj2oLe9HB" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 221} outputId="7abe21ab-8dc2-44bc-8d22-7259b7fd976e" executionInfo={"status": "ok", "timestamp": 1581512430874, "user_tz": -60, "elapsed": 467, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df.columns
# + id="A189FPTJfJLY" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 102} outputId="cc3fbafe-f575-4cad-c940-f3657bfc201f" executionInfo={"status": "ok", "timestamp": 1581512483259, "user_tz": -60, "elapsed": 514, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df.prices_currency.unique()
# + id="UC2tYvIMfV9g" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 255} outputId="ec8e345c-7f31-48a2-c1e5-8814f49e681c" executionInfo={"status": "ok", "timestamp": 1581512877183, "user_tz": -60, "elapsed": 557, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df.prices_currency.value_counts()
# + id="3ncThWiZflVQ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="4a97a2b1-911c-4126-a385-91240be6d425" executionInfo={"status": "ok", "timestamp": 1581512837974, "user_tz": -60, "elapsed": 575, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df_usd = df[ df.prices_currency == 'USD'].copy()
df_usd.shape
# + id="ficmHcGigsh3" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 282} outputId="ec1a9bc3-97d8-4284-cc94-e1470a9098ea" executionInfo={"status": "ok", "timestamp": 1581513784246, "user_tz": -60, "elapsed": 832, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df_usd['prices_amountmin'] = df_usd.prices_amountmin.astype(np.float)
df_usd['prices_amountmin'].hist()
# + id="4iNy_0CMhOTV" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="67d33eff-d515-4040-bfa8-7cb499adaf1a" executionInfo={"status": "ok", "timestamp": 1581514032682, "user_tz": -60, "elapsed": 548, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
filter_max = np.percentile( df_usd['prices_amountmin'], 99 )
filter_max
# + id="nnMmaAv-ky0o" colab_type="code" colab={}
df_usd_filter = df_usd[ df_usd['prices_amountmin'] < filter_max ]
# + id="RAsWW3TslpX1" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 282} outputId="d9b34dfa-1c92-44ec-ebcc-0c91ff6ea58d" executionInfo={"status": "ok", "timestamp": 1581514373755, "user_tz": -60, "elapsed": 963, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
df_usd_filter.prices_amountmin.hist(bins=100)
# + id="6h19FzMql8Us" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="3ab7192e-d4e0-4cb7-f82d-3239c3390d45" executionInfo={"status": "ok", "timestamp": 1581514446050, "user_tz": -60, "elapsed": 4482, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
# ls
# + id="Puk9t2Gzm0Li" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="ec86803f-a47d-48b0-aafa-c579989a20e3" executionInfo={"status": "ok", "timestamp": 1581514470704, "user_tz": -60, "elapsed": 4435, "user": {"displayName": "ZupaGrzybowa", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDJBheFQvfQGwvLId5HrYzTz61IcAewxeKNEtDN=s64", "userId": "15273861130524040784"}}
# ls matrix_one/day3.ipynb
# + id="gZmMQcLpm6OB" colab_type="code" colab={}
| matrix_one/day3.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import random
import numpy as np
import sys
sys.path.append('../')
from gaussian_mixture_em import GaussianMixtureEM
# +
from sklearn.datasets import load_iris
data = load_iris()
data.keys()
data['data'].shape, data['target'].shape
# -
n_class = len(np.unique(data['target']))
n_class
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(data['data'])
model = GaussianMixtureEM(n_class, max_iter=300)
model.fit(X, data['target'])
pred = model.predict(X)
print(model.pi)
# +
import matplotlib
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
matplotlib.rcParams['figure.figsize'] = (21, 4)
ax = 0
ay = 2
mu = model.mu
cov = model.cov
rnk = model.rnk
for k in range(n_class):
plt.subplot(1, n_class, k+1)
plt.scatter(X[:, ax], X[:, ay], c=rnk[:, k])
plt.scatter(mu[:, ax], mu[:, ay], c='b', marker='x', s=100)
plt.scatter(mu[k, ax], mu[k, ay], c='r', marker='x', s=100)
rv = multivariate_normal(mu[k, [ax, ay]], cov[k, [ax, ay], [ax, ay]])
x, y = np.mgrid[-3:3:.01, -3:3:.01]
pos = np.empty(x.shape + (2,))
pos[:, :, 0] = x; pos[:, :, 1] = y
plt.contour(x, y, rv.pdf(pos))
# -
| samples/gaussian_mixture.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] colab_type="text"
# # Sequence to sequence learning for performing number addition
#
# **Author:** [Smerity](https://twitter.com/Smerity) and others<br>
# **Date created:** 2015/08/17<br>
# **Last modified:** 2020/04/17<br>
# **Description:** A model that learns to add strings of numbers, e.g. "535+61" -> "596".
# + [markdown] colab_type="text"
# ## Introduction
#
# In this example, we train a model to learn to add two numbers, provided as strings.
#
# **Example:**
#
# - Input: "535+61"
# - Output: "596"
#
# Input may optionally be reversed, which was shown to increase performance in many tasks
# in: [Learning to Execute](http://arxiv.org/abs/1410.4615) and
# [Sequence to Sequence Learning with Neural Networks](
#
# http://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf)
#
# Theoretically, sequence order inversion introduces shorter term dependencies between
# source and target for this problem.
#
# **Results:**
#
# For two digits (reversed):
#
# # + One layer LSTM (128 HN), 5k training examples = 99% train/test accuracy in 55 epochs
#
# Three digits (reversed):
#
# # + One layer LSTM (128 HN), 50k training examples = 99% train/test accuracy in 100 epochs
#
# Four digits (reversed):
#
# # + One layer LSTM (128 HN), 400k training examples = 99% train/test accuracy in 20 epochs
#
# Five digits (reversed):
#
# # + One layer LSTM (128 HN), 550k training examples = 99% train/test accuracy in 30 epochs
#
# + [markdown] colab_type="text"
# ## Setup
#
# + colab_type="code"
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# Parameters for the model and dataset.
TRAINING_SIZE = 50000
DIGITS = 3
REVERSE = True
# Maximum length of input is 'int + int' (e.g., '345+678'). Maximum length of
# int is DIGITS.
MAXLEN = DIGITS + 1 + DIGITS
# + [markdown] colab_type="text"
# ## Generate the data
#
# + colab_type="code"
class CharacterTable:
"""Given a set of characters:
+ Encode them to a one-hot integer representation
+ Decode the one-hot or integer representation to their character output
+ Decode a vector of probabilities to their character output
"""
def __init__(self, chars):
"""Initialize character table.
# Arguments
chars: Characters that can appear in the input.
"""
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, C, num_rows):
"""One-hot encode given string C.
# Arguments
C: string, to be encoded.
num_rows: Number of rows in the returned one-hot encoding. This is
used to keep the # of rows for each data the same.
"""
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(C):
x[i, self.char_indices[c]] = 1
return x
def decode(self, x, calc_argmax=True):
"""Decode the given vector or 2D array to their character output.
# Arguments
x: A vector or a 2D array of probabilities or one-hot representations;
or a vector of character indices (used with `calc_argmax=False`).
calc_argmax: Whether to find the character index with maximum
probability, defaults to `True`.
"""
if calc_argmax:
x = x.argmax(axis=-1)
return "".join(self.indices_char[x] for x in x)
# All the numbers, plus sign and space for padding.
chars = "0123456789+ "
ctable = CharacterTable(chars)
questions = []
expected = []
seen = set()
print("Generating data...")
while len(questions) < TRAINING_SIZE:
f = lambda: int(
"".join(
np.random.choice(list("0123456789"))
for i in range(np.random.randint(1, DIGITS + 1))
)
)
a, b = f(), f()
# Skip any addition questions we've already seen
# Also skip any such that x+Y == Y+x (hence the sorting).
key = tuple(sorted((a, b)))
if key in seen:
continue
seen.add(key)
# Pad the data with spaces such that it is always MAXLEN.
q = "{}+{}".format(a, b)
query = q + " " * (MAXLEN - len(q))
ans = str(a + b)
# Answers can be of maximum size DIGITS + 1.
ans += " " * (DIGITS + 1 - len(ans))
if REVERSE:
# Reverse the query, e.g., '12+345 ' becomes ' 543+21'. (Note the
# space used for padding.)
query = query[::-1]
questions.append(query)
expected.append(ans)
print("Total questions:", len(questions))
# + [markdown] colab_type="text"
# ## Vectorize the data
#
# + colab_type="code"
print("Vectorization...")
x = np.zeros((len(questions), MAXLEN, len(chars)), dtype=np.bool)
y = np.zeros((len(questions), DIGITS + 1, len(chars)), dtype=np.bool)
for i, sentence in enumerate(questions):
x[i] = ctable.encode(sentence, MAXLEN)
for i, sentence in enumerate(expected):
y[i] = ctable.encode(sentence, DIGITS + 1)
# Shuffle (x, y) in unison as the later parts of x will almost all be larger
# digits.
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
# Explicitly set apart 10% for validation data that we never train over.
split_at = len(x) - len(x) // 10
(x_train, x_val) = x[:split_at], x[split_at:]
(y_train, y_val) = y[:split_at], y[split_at:]
print("Training Data:")
print(x_train.shape)
print(y_train.shape)
print("Validation Data:")
print(x_val.shape)
print(y_val.shape)
# + [markdown] colab_type="text"
# ## Build the model
#
# + colab_type="code"
print("Build model...")
num_layers = 1 # Try to add more LSTM layers!
model = keras.Sequential()
# "Encode" the input sequence using a LSTM, producing an output of size 128.
# Note: In a situation where your input sequences have a variable length,
# use input_shape=(None, num_feature).
model.add(layers.LSTM(128, input_shape=(MAXLEN, len(chars))))
# As the decoder RNN's input, repeatedly provide with the last output of
# RNN for each time step. Repeat 'DIGITS + 1' times as that's the maximum
# length of output, e.g., when DIGITS=3, max output is 999+999=1998.
model.add(layers.RepeatVector(DIGITS + 1))
# The decoder RNN could be multiple layers stacked or a single layer.
for _ in range(num_layers):
# By setting return_sequences to True, return not only the last output but
# all the outputs so far in the form of (num_samples, timesteps,
# output_dim). This is necessary as TimeDistributed in the below expects
# the first dimension to be the timesteps.
model.add(layers.LSTM(128, return_sequences=True))
# Apply a dense layer to the every temporal slice of an input. For each of step
# of the output sequence, decide which character should be chosen.
model.add(layers.Dense(len(chars), activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
# + [markdown] colab_type="text"
# ## Train the model
#
# + colab_type="code"
epochs = 30
batch_size = 32
# Train the model each generation and show predictions against the validation
# dataset.
for epoch in range(1, epochs):
print()
print("Iteration", epoch)
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=1,
validation_data=(x_val, y_val),
)
# Select 10 samples from the validation set at random so we can visualize
# errors.
for i in range(10):
ind = np.random.randint(0, len(x_val))
rowx, rowy = x_val[np.array([ind])], y_val[np.array([ind])]
preds = np.argmax(model.predict(rowx), axis=-1)
q = ctable.decode(rowx[0])
correct = ctable.decode(rowy[0])
guess = ctable.decode(preds[0], calc_argmax=False)
print("Q", q[::-1] if REVERSE else q, end=" ")
print("T", correct, end=" ")
if correct == guess:
print("☑ " + guess)
else:
print("☒ " + guess)
# + [markdown] colab_type="text"
# You'll get to 99+% validation accuracy after ~30 epochs.
#
| examples/nlp/ipynb/addition_rnn.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 0.6.1
# language: julia
# name: julia-0.6
# ---
using RDatasets
irisdf=dataset("datasets","iris")
sample(irisdf[:SepalLength],5)
wv=Weights([1., 2., 3.], 6.)
length(wv)
isempty(wv)
values(wv)
sum(wv)
eltypes(irisdf)
# # Histgram
using RDatasets
using StatsBase
using Distributions
using Gadfly
sleep = dataset("lme4","sleepstudy")
plot(x=sleep[:Reaction],Geom.histogram(bincount=30),color=sleep[:Days])
| dataScience/stats/stats.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.6.13 64-bit (''pytorch'': conda)'
# name: python3
# ---
# # 3.1 线性回归
# +
import torch
from time import time
print(torch.__version__)
# -
a = torch.ones(1000)
b = torch.ones(1000)
# 将这两个向量按元素逐一做标量加法:
start = time()
c = torch.zeros(1000)
for i in range(1000):
c[i] = a[i] + b[i]
print(time() - start)
# 将这两个向量直接做矢量加法:
start = time()
d = a + b
print(time() - start)
# **结果很明显,后者比前者更省时。因此,我们应该尽可能采用矢量计算,以提升计算效率。**
# 广播机制例子🌰:
a = torch.ones(3)
b = 10
print(a + b)
| code/chapter03_DL-basics/3.1_linear-regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# This notebook was prepared by [<NAME>](https://github.com/donnemartin). Source and license info is on [GitHub](https://github.com/donnemartin/interactive-coding-challenges).
# # Solution Notebook
# ## Problem: Implement foo(val), which returns val
#
# * [Constraints](#Constraints)
# * [Test Cases](#Test-Cases)
# * [Algorithm](#Algorithm)
# * [Code](#Code)
# * [Unit Test](#Unit-Test)
# ## Constraints
#
# * Does foo do anything else?
# * No
# ## Test Cases
#
# * foo(val) -> val
# ## Algorithm
#
# Return the input, val
#
# Complexity:
# * Time: O(1)
# * Space: O(1)
# ## Code
def foo(val):
return val
# ## Unit Test
# +
# %%writefile test_foo.py
from nose.tools import assert_equal
class TestFoo(object):
def test_foo(self):
assert_equal(foo(None), None)
assert_equal(foo(0), 0)
assert_equal(foo('bar'), 'bar')
print('Success: test_foo')
def main():
test = TestFoo()
test.test_foo()
if __name__ == '__main__':
main()
# -
# %run -i test_foo.py
| graphs_trees/templates/foo_solution.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python
# language: python
# name: conda-env-python-py
# ---
# <a href="https://cognitiveclass.ai"><img src = "https://ibm.box.com/shared/static/ugcqz6ohbvff804xp84y4kqnvvk3bq1g.png" width = 300, align = "center"></a>
#
# <h1 align=center><font size = 5>Lab: Analyzing a real world data-set with SQL and Python</font></h1>
# # Introduction
#
# This notebook shows how to store a dataset into a database using and analyze data using SQL and Python. In this lab you will:
# 1. Understand a dataset of selected socioeconomic indicators in Chicago
# 1. Learn how to store data in an Db2 database on IBM Cloud instance
# 1. Solve example problems to practice your SQL skills
# ## Selected Socioeconomic Indicators in Chicago
#
# The city of Chicago released a dataset of socioeconomic data to the Chicago City Portal.
# This dataset contains a selection of six socioeconomic indicators of public health significance and a “hardship index,” for each Chicago community area, for the years 2008 – 2012.
#
# Scores on the hardship index can range from 1 to 100, with a higher index number representing a greater level of hardship.
#
# A detailed description of the dataset can be found on [the city of Chicago's website](
# https://data.cityofchicago.org/Health-Human-Services/Census-Data-Selected-socioeconomic-indicators-in-C/kn9c-c2s2), but to summarize, the dataset has the following variables:
#
# * **Community Area Number** (`ca`): Used to uniquely identify each row of the dataset
#
# * **Community Area Name** (`community_area_name`): The name of the region in the city of Chicago
#
# * **Percent of Housing Crowded** (`percent_of_housing_crowded`): Percent of occupied housing units with more than one person per room
#
# * **Percent Households Below Poverty** (`percent_households_below_poverty`): Percent of households living below the federal poverty line
#
# * **Percent Aged 16+ Unemployed** (`percent_aged_16_unemployed`): Percent of persons over the age of 16 years that are unemployed
#
# * **Percent Aged 25+ without High School Diploma** (`percent_aged_25_without_high_school_diploma`): Percent of persons over the age of 25 years without a high school education
#
# * **Percent Aged Under** 18 or Over 64:Percent of population under 18 or over 64 years of age (`percent_aged_under_18_or_over_64`): (ie. dependents)
#
# * **Per Capita Income** (`per_capita_income_`): Community Area per capita income is estimated as the sum of tract-level aggragate incomes divided by the total population
#
# * **Hardship Index** (`hardship_index`): Score that incorporates each of the six selected socioeconomic indicators
#
# In this Lab, we'll take a look at the variables in the socioeconomic indicators dataset and do some basic analysis with Python.
#
# ### Connect to the database
# Let us first load the SQL extension and establish a connection with the database
# %load_ext sql
# Remember the connection string is of the format:
# # %sql ibm_db_sa://my-username:my-password@my-hostname:my-port/my-db-name
# Enter the connection string for your Db2 on Cloud database instance below
# i.e. copy after db2:// from the URI string in Service Credentials of your Db2 instance. Remove the double quotes at the end.
# %sql ibm_db_sa://jqk40022:5jbhgkfgr9-4ptf3@dash<EMAIL>.<EMAIL>mix.net:50000/BLUDB
# ### Store the dataset in a Table
# ##### In many cases the dataset to be analyzed is available as a .CSV (comma separated values) file, perhaps on the internet. To analyze the data using SQL, it first needs to be stored in the database.
#
# ##### We will first read the dataset source .CSV from the internet into pandas dataframe
#
# ##### Then we need to create a table in our Db2 database to store the dataset. The PERSIST command in SQL "magic" simplifies the process of table creation and writing the data from a `pandas` dataframe into the table
import pandas
chicago_socioeconomic_data = pandas.read_csv('https://data.cityofchicago.org/resource/jcxq-k9xf.csv')
# %sql PERSIST chicago_socioeconomic_data
# ##### You can verify that the table creation was successful by making a basic query like:
# %sql SELECT * FROM chicago_socioeconomic_data limit 5;
# ## Problems
#
# ### Problem 1
#
# ##### How many rows are in the dataset?
# %sql SELECT COUNT(*) FROM Chicago_socioeconomic_data;
# Double-click __here__ for the solution.
#
# <!-- Hint:
#
# # %sql SELECT COUNT(*) FROM chicago_socioeconomic_data;
#
# Correct answer: 78
#
# -->
# ### Problem 2
#
# ##### How many community areas in Chicago have a hardship index greater than 50.0?
# %sql SELECT COUNT(*) FROM Chicago_socioeconomic_data WHERE hardship_index > 50.0;
# Double-click __here__ for the solution.
#
# <!-- Hint:
#
# # %sql SELECT COUNT(*) FROM chicago_socioeconomic_data WHERE hardship_index > 50.0;
# Correct answer: 38
# -->
#
# ### Problem 3
#
# ##### What is the maximum value of hardship index in this dataset?
# %sql SELECT MAX(hardship_index) FROM Chicago_socioeconomic_data;
# Double-click __here__ for the solution.
#
# <!-- Hint:
#
# # %sql SELECT MAX(hardship_index) FROM chicago_socioeconomic_data;
#
# Correct answer: 98.0
# -->
#
# ### Problem 4
#
# ##### Which community area which has the highest hardship index?
#
# %sql select community_area_name from chicago_socioeconomic_data where hardship_index = (select max (hardship_index) from chicago_socioeconomic_data)
# Double-click __here__ for the solution.
#
# <!-- Hint:
#
# ## We can use the result of the last query to as an input to this query:
# # %sql SELECT community_area_name FROM chicago_socioeconomic_data where hardship_index=98.0
#
# ## or another option:
# # %sql SELECT community_area_name FROM chicago_socioeconomic_data ORDER BY hardship_index DESC NULLS LAST FETCH FIRST ROW ONLY;
#
# ## or you can use a sub-query to determine the max hardship index:
# # %sql select community_area_name from chicago_socioeconomic_data where hardship_index = ( select max(hardship_index) from chicago_socioeconomic_data )
#
# Correct answer: 'Riverdale'
# -->
# ### Problem 5
#
# ##### Which Chicago community areas have per-capita incomes greater than $60,000?
# %sql SELECT community_area_name FROM chicago_socioeconomic_data WHERE per_capita_income_ > 60000;
# Double-click __here__ for the solution.
#
# <!-- Hint:
#
# # %sql SELECT community_area_name FROM chicago_socioeconomic_data WHERE per_capita_income_ > 60000;
#
# Correct answer:Lake View,Lincoln Park, Near North Side, Loop
# -->
#
# ### Problem 6
#
# ##### Create a scatter plot using the variables `per_capita_income_` and `hardship_index`. Explain the correlation between the two variables.
import matplotlib.pyplot as plt
# %matplotlib inline
import seaborn as sns
# %sql SELECT per_capita_income_, hardship_index FROM chicago_socioeconomic_data;
plot = sns.jointplot(x='per_capita_income_',y='hardship_index', data=income_vs_hardship.DataFrame())
# Double-click __here__ for the solution.
#
# <!-- Hint:
# # if the import command gives ModuleNotFoundError: No module named 'seaborn'
# # then uncomment the following line i.e. delete the # to install the seaborn package
# # # !pip install seaborn
# import matplotlib.pyplot as plt
# # %matplotlib inline
# import seaborn as sns
#
# # income_vs_hardship = %sql SELECT per_capita_income_, hardship_index FROM chicago_socioeconomic_data;
# plot = sns.jointplot(x='per_capita_income_',y='hardship_index', data=income_vs_hardship.DataFrame())
#
# Correct answer:You can see that as Per Capita Income rises as the Hardship Index decreases. We see that the points on the scatter plot are somewhat closer to a straight line in the negative direction, so we have a negative correlation between the two variables.
# -->
#
# ### Conclusion
#
# ##### Now that you know how to do basic exploratory data analysis using SQL and python visualization tools, you can further explore this dataset to see how the variable `per_capita_income_` is related to `percent_households_below_poverty` and `percent_aged_16_unemployed`. Try to create interesting visualizations!
# ## Summary
#
# ##### In this lab you learned how to store a real world data set from the internet in a database (Db2 on IBM Cloud), gain insights into data using SQL queries. You also visualized a portion of the data in the database to see what story it tells.
# Copyright © 2018 [cognitiveclass.ai](cognitiveclass.ai?utm_source=bducopyrightlink&utm_medium=dswb&utm_campaign=bdu). This notebook and its source code are released under the terms of the [MIT License](https://bigdatauniversity.com/mit-license/).
#
| Curso-SQL/DB0201EN-Week3-1-4-Analyzing-v5-py.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# # Klasifikasi menggunakan KNN
#
# Notebook ini merupakan bagian dari buku **Machine Learning menggunakan Python** oleh **<NAME>**. Notebook ini berisi contoh kode untuk **BAB V - K-NEAREST NEIGHBOR**
# ## Data Understanding
# +
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, matthews_corrcoef, ConfusionMatrixDisplay
# -
# Membaca data dari file CSV
df = pd.read_csv(r'../datasets/iris.csv')
# Menampilkan sampel 5 data teratas
df.head()
# Menampilkan banyaknya data per spesies
df.groupby('class').size()
# Menampilkan statistik deskriptif dari data
df.describe()
# Membuat pairplot (diagram pencar dan distribusi data) antar variabel
sns.pairplot(df, hue='class')
# ## Data Preparation
# Memisahkan features dan label
X = df.iloc[:, :-1].values
y = df.iloc[:, 4].values
# +
# Membagi data latih dan uji
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, shuffle=True, stratify=y, random_state=42)
print("Banyaknya data latih: ", len(X_train))
print("Banyaknya data uji: ", len(X_test))
# +
# Melakukan label encoding
lb = LabelEncoder()
lb.fit(y_train)
y_train = lb.transform(y_train)
y_test = lb.transform(y_test)
class_mapping = dict(zip(lb.classes_, lb.transform(lb.classes_)))
print("Pemetaan kelas:", class_mapping)
# +
# Normalisasi data
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# +
# Menentukan nilai k dari invers akurasi
error = []
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(1 - accuracy_score(y_test, pred_i))
plt.plot(range(1, 40), error, marker='o')
plt.xlabel('Nilai K')
plt.ylabel('Invers akurasi')
# -
# ## Modelling
# Membuat model dengan data latih dan k = 9
classifier = KNeighborsClassifier(n_neighbors=9)
classifier.fit(X_train, y_train)
# ## Evaluation
# + tags=[]
# Melakukan prediksi dengan data uji dan menampilkan statistik klasifikasi
y_pred = classifier.predict(X_test)
print(classification_report(y_test, y_pred, target_names=lb.classes_))
print("MCC:", matthews_corrcoef(y_test, y_pred))
# + tags=[]
# Menampilkan confusion matrix
ConfusionMatrixDisplay.from_predictions(y_test, y_pred, display_labels=lb.classes_)
# +
# Prediksi data baru
pred_input = [[3.0, 1.2, 2.4, 1.1]] # input data
pred_input = scaler.transform(pred_input) # normalisasi data
probabilities = classifier.predict_proba(pred_input) # hitung probabilitas
predicted = classifier.predict(pred_input) # prediksi kelas
print("Probabilitas:", probabilities)
print("Hasil klasifikasi:", lb.inverse_transform(predicted))
# -
| jupyter/classification_knn.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Pandas Profiling: NASA Meteorites example
# Source of data: https://data.nasa.gov/Space-Science/Meteorite-Landings/gh4g-9sfh
# ### Import libraries
# +
from pathlib import Path
import requests
import numpy as np
import pandas as pd
import pandas_profiling
from pandas_profiling.utils.cache import cache_file
# -
# ### Load and prepare example dataset
# We add some fake variables for illustrating pandas-profiling capabilities
# +
file_name = cache_file(
"meteorites.csv",
"https://data.nasa.gov/api/views/gh4g-9sfh/rows.csv?accessType=DOWNLOAD",
)
df = pd.read_csv(file_name)
# Note: Pandas does not support dates before 1880, so we ignore these for this analysis
df['year'] = pd.to_datetime(df['year'], errors='coerce')
# Example: Constant variable
df['source'] = "NASA"
# Example: Boolean variable
df['boolean'] = np.random.choice([True, False], df.shape[0])
# Example: Mixed with base types
df['mixed'] = np.random.choice([1, "A"], df.shape[0])
# Example: Highly correlated variables
df['reclat_city'] = df['reclat'] + np.random.normal(scale=5,size=(len(df)))
# Example: Duplicate observations
duplicates_to_add = pd.DataFrame(df.iloc[0:10])
duplicates_to_add[u'name'] = duplicates_to_add[u'name'] + " copy"
df = df.append(duplicates_to_add, ignore_index=True)
# -
# ### Inline report without saving object
report = df.profile_report(sort='None', html={'style':{'full_width': True}}, progress_bar=False)
report
# ### Save report to file
profile_report = df.profile_report(html={'style': {'full_width': True}})
profile_report.to_file("/tmp/example.html")
# ### More analysis (Unicode) and Print existing ProfileReport object inline
profile_report = df.profile_report(explorative=True, html={'style': {'full_width': True}})
profile_report
# ### Notebook Widgets
profile_report.to_widgets()
| examples/meteorites/meteorites.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# %pylab inline
# +
#Graph comp kaiser model z=0
e0z=zeros(40)
e2z=zeros(40)
e4z=zeros(40)
for i in range(1,126):
f = loadtxt('/home/arocher/Stage/hearin/hearin_z0.695/xil_hearin15_threshold2_z_0.695_'+str(i)+'.dat')
e0z += f[:,1]
e2z += f[:,2]
e4z += f[:,3]
e0z /= 126
e2z /= 126
e4z /= 126
r2z = f[:,0]
mul=loadtxt("code_GSRSD/hearin/multipole_Pk_hearin.dat")
f055=loadtxt("code_GSRSD/hearin/multipole_kaiser_hearin.dat")
clpt=loadtxt("code_GSRSD/hearin/multipole_CLPT_hearin_b0.dat")
reid=loadtxt("code_GSRSD/hearin/xi_s_hearin_reid.txt")
figure(figsize=(10,10))
#semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,1]),color='red')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,1]),':', color='red')
#semilogx(mul[:,0],mul[:,0]*mul[:,0]*(mul[:,1]),'--',color='red',label='$\\xi_0$')
semilogx(reid[:,0],reid[:,0]*reid[:,0]*(reid[:,1]*0.7806),'-.',color='red')
#semilogx(r2z,r2z*r2z*e0z,color='k')
semilogx(reid[:,0],reid[:,0]*reid[:,0]*abs(reid[:,2]*0.7806),'-.',color='blue')
#semilogx(f055[:,0],f055[:,0]*f055[:,0]*abs(f055[:,2]),color='blue')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*abs(clpt[:,2]),':',color='blue')
#semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,2]),'--',color='blue',label='$\\xi_2$')
#semilogx(r2z,r2z*r2z*abs(e2z),color='k')
#semilogx(reid[:,0],reid[:,0]*reid[:,0]*(reid[:,3]),'-.',color='green')
#semilogx(mul[:,0],mul[:,0]*mul[:,0]*(mul[:,3]),'--',color='green',label='$\\xi_4$')
#semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,3]),':', color='green')
#semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,3]),color='green')
xlabel('$s$ Mpc/h',size=20)
ylabel('$s^2|\\xi_l|\ (Mpc/h)^2$', size=25)
ylim(0,150)
xlim(10,120)
xticks(fontsize=15)
yticks(fontsize=15)
gca().add_artist(legend(['Kaiser','GS+Clpt','GS linear','Code Reid+White','Simu'], loc='upper right',fontsize=15))
legend(fontsize=15)
title("Multipole comparison Kaiser-Model at z=0", size =20)
#savefig('code_GSRSD/comp_all_simu_hearin.png')
# +
mul=loadtxt("code_GSRSD/multipole_Pk_hearin_riemann.dat")
f055=loadtxt("code_GSRSD/hearin/Xim_hearin.dat")
clpt=loadtxt("code_GSRSD/hearin/Xim_kaiser_hearin.dat")
e0=zeros(40)
e2=zeros(40)
e4=zeros(40)
for i in range(1,126):
filename ='/home/arocher/Stage/hearin/hearin15/corr_hearin15_standard_0.695_'+str(i)+'.dat'
f = np.loadtxt(filename)
e0 += f[:,1]
e2 += f[:,2]
e4 += f[:,3]
e0 /= 126
e2 /= 126
e4 /= 126
r2 = f[:,0]
figure(figsize=(10,10))
#semilogx(r2,r2*r2*e0,color='k')
#semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,1]),color='red')
#semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,1]),':', color='red')
semilogx(mul[:,0],mul[:,1]-1,'--',color='red',label='$\\xi_0$')
#semilogx(reid[:,0],reid[:,0]*reid[:,0]*(reid[:,1]),'-.',color='red')
# -
f, (ax1, ax2, ax3) = plt.subplots(3, sharex=True, sharey=True)
ax1.plot(x, y)
ax1.set_title('Sharing both axes')
ax2.scatter(x, y)
ax3.scatter(x, 2 * y ** 2 - 1, color='r')
# Fine-tune figure; make subplots close to each other and hide x ticks for
# all but bottom plot.
f.subplots_adjust(hspace=0)
plt.setp([a.get_xticklabels() for a in f.axes[:-1]], visible=False)
# +
#Graph comp kaiser model z=0.55 avec une normalisation a sigma=0.58
mul55=loadtxt("/home/arocher/Stage/gaussian_stream_model/code_GSRSD/multipole_EBOSS.dat")
#mul55=loadtxt("code_GSRSD/data_simu/multipole_kaiser_simu.dat")
f55=loadtxt("/home/arocher/Stage/gaussian_stream_model/code_GSRSD/multipole_kaiser_EBOSS.dat")
figure(figsize=(10,10))
semilogx(f55[:,0],f55[:,0]*f55[:,0]*abs(f55[:,1]),color='red')
semilogx(mul55[:,0],mul55[:,0]*mul55[:,0]*abs(mul55[:,1]),'--',color='red',label='$\\xi_0$')
semilogx(f55[:,0],f55[:,0]*f55[:,0]*abs(f55[:,2]),color='blue')
semilogx(mul55[:,0],mul55[:,0]*mul55[:,0]*abs(mul55[:,2]),'--',color='blue',label='$\\xi_2$')
#semilogx(f55[:,0],f55[:,0]*f55[:,0]*(f55[:,3]),color='green')
#semilogx(mul55[:,0],mul55[:,0]*mul55[:,0]*abs(mul55[:,3]),'--',color='green',label='$\\xi_4$')
xlabel('$s$ Mpc/h',size=20)
ylabel('$s^2|\\xi_l|\ (Mpc/h)^2$', size=25)
ylim(0,100)
xlim(10,120)
xticks(fontsize=15)
yticks(fontsize=15)
gca().add_artist(legend(['Kaiser','Model CLPT White'], loc='lower left',fontsize=15))
legend(fontsize=15)
title("Multipole comparison Kaiser-CLPT papier z=0.55", size =20)
#savefig('code_GSRSD/comp_kaiser_CLPT_papier.png')
# -
mul55=loadtxt("code_GSRSD/multipole_Pk_hearin.dat")
#a=loadtxt("code_GSRSD/multipole_kaiser_simu.dat")
figure(figsize=(10,10))
#semilogx(mul55[:,0],mul55[:,0]*mul55[:,0]*abs(mul55[:,1])/pi,'--',color='red',label='$\\xi_0$')
semilogx(mul55[:,0],mul55[:,0]*mul55[:,0]*abs(mul55[:,2]),'--',color='blue',label='$\\xi_2$')
#semilogx(mul55[:,0],mul55[:,0]*mul55[:,0]*abs(mul55[:,3]),'--',color='green',label='$\\xi_4$')
#semilogx(a[:,0],a[:,0]*a[:,0]*abs(a[:,1]))
#semilogx(a[:,0],a[:,0]*a[:,0]*abs(a[:,2]))
#semilogx(a[:,0],a[:,0]*a[:,0]*abs(a[:,3]))
xlim(0,130)
ylim(0,100)
# +
#Graph comp kaiser model z=0
mul=loadtxt("code_GSRSD/data_z0/multipole_kaiser_z0.dat")
f055=loadtxt("code_GSRSD/data_z0/multipole_Pk_z0.dat")
clpt=loadtxt("code_GSRSD/data_z0/multipole_CLPT_z0.dat")
figure(figsize=(10,10))
semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,1]),color='red')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,1]),':', color='red')
semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,1]),'--',color='red',label='$\\xi_0$')
semilogx(f055[:,0],f055[:,0]*f055[:,0]*abs(f055[:,2]),color='blue')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*abs(clpt[:,2]),':',color='blue')
semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,2]),'--',color='blue',label='$\\xi_2$')
semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,3]),color='green')
semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,3]),'--',color='green',label='$\\xi_4$')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,3]),':', color='green')
xlabel('$s$ Mpc/h',size=20)
ylabel('$s^2|\\xi_l|\ (Mpc/h)^2$', size=25)
ylim(0,100)
xlim(10,130)
xticks(fontsize=15)
yticks(fontsize=15)
gca().add_artist(legend(['Model GS','Kaiser'], loc='upper left',fontsize=15))
legend(fontsize=15)
title("Multipole comparison Kaiser-Model at z=0", size =20)
#savefig('code_GSRSD/data_z0/comp_kaiser_model_z0.png')
# -
def compute_simu():
#calcul les points de simu s=2.5 a 157.5
xi0_simu=zeros(32)
xi2_simu=zeros(32)
for i in range(0,1000):
f =loadtxt('/home/arocher/Stage/Simu/2PCF_EBOSSCMASS/2PCF_EZmock_eBOSS_LRGpCMASS_SGC_v5_z0.6z1.0_'+(str(i+1).zfill(4))+'.dat')
xi0_simu += f[:,1][range(0,32)]
xi2_simu += f[:,2][range(0,32)]
xi0_simu /= 1000
xi2_simu /= 1000
return xi0_simu,xi2_simu
# +
#Graph comp kaiser model z=0
simu_ebo = compute_simu()[0]
kaiser=loadtxt("/home/arocher/Stage/gaussian_stream_model/code_GSRSD/multipole_kaiser_EBOSS.dat")
clpt_ebo=loadtxt("/home/arocher/Stage/gaussian_stream_model/code_GSRSD/multipole_EBOSS.dat")
xi0_sim = simu_ebo/kaiser[:,1]
xi0_clpt= clpt_ebo[:,1]/kaiser[:,1]
r = kaiser[:,0]
y_sim = (xi0_sim+100)
y_clpt = (xi0_clpt+100)
figure(figsize=(10,10))
semilogx(r,y_sim,color='red')
semilogx(r,y_clpt,'--',color='red',label='$\\xi_0$')
xlabel('$s$ Mpc/h',size=20)
ylabel('$s^2|\\xi_l|\ (Mpc/h)^2$', size=25)
ylim(100,103)
xlim(10,130)
xticks(fontsize=15)
yticks(fontsize=15)
legend(fontsize=15)
title("Multipole comparison Kaiser-Model at z=0", size =20)
#savefig('code_GSRSD/data_z0/comp_kaiser_model_z0.png')
# +
#Graph comp kaiser model z=0
mul=loadtxt("/home/arocher/Stage/Simu/mesure_sylvain/xi_l_M12.5+_rspace.dat")
f055=loadtxt("code_GSRSD/data_z0/multipole_CLPT_z0_Reid.dat")
clpt=loadtxt("code_GSRSD/data_z0/multipole_CLPT_z0.dat")
figure(figsize=(10,10))
semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,1]),color='red')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,1]),':', color='red')
semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,1]),'--',color='red',label='$\\xi_0$')
semilogx(f055[:,0],f055[:,0]*f055[:,0]*abs(f055[:,2]),color='blue')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*abs(clpt[:,2]),':',color='blue')
semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,2]),'--',color='blue',label='$\\xi_2$')
semilogx(f055[:,0],f055[:,0]*f055[:,0]*(f055[:,3]),color='green')
semilogx(mul[:,0],mul[:,0]*mul[:,0]*abs(mul[:,3]),'--',color='green',label='$\\xi_4$')
semilogx(clpt[:,0],clpt[:,0]*clpt[:,0]*(clpt[:,3]),':', color='green')
xlabel('$s$ Mpc/h',size=20)
ylabel('$s^2|\\xi_l|\ (Mpc/h)^2$', size=25)
ylim(0,100)
xlim(10,130)
xticks(fontsize=15)
yticks(fontsize=15)
gca().add_artist(legend(['Model GS','Kaiser'], loc='upper left',fontsize=15))
legend(fontsize=15)
title("Multipole comparison Kaiser-Model at z=0", size =20)
# -
| code python/plot_xi_1D.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # Figure 1(i): 3D State Plots with Profiles
# This notebook reproduces figure with the 3D plots of the different states which occurred during hysteresis, along with the profiles diplayed below the 3D plots.
#
# The 3D plots were created using Paraview (http://www.paraview.org/). The VTK files are located in the directory, `data/hysteresis/3d_from_paraview/vtk/`
#
# The 3D plots were all created from the simulations of a nanocylinder with thickness, $t=55$nm, apart from the last figure, (h), which was taken from the simulation of a $t=35$nm thick nanocylinder (as this state did not occur in the $t=55$ nanocylinder).
# %matplotlib inline
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from matplotlib._png import read_png
# +
# Create the figure containing the 3D images.
fig = plt.figure(figsize=(16,8))
gs = gridspec.GridSpec(2, 5, width_ratios=[7,7,7,7,1], hspace=0.1, wspace=0.1)
ax0 = plt.subplot(gs[0,0])
ax1 = plt.subplot(gs[0,1])
ax2 = plt.subplot(gs[0,2])
ax3 = plt.subplot(gs[0,3])
ax4 = plt.subplot(gs[1,0])
ax5 = plt.subplot(gs[1,1])
ax6 = plt.subplot(gs[1,2])
ax7 = plt.subplot(gs[1,3])
ax8 = plt.subplot(gs[0:2, 4])
# Note that 'states' is a list of index values associated with the hysteresis loop simulation.
# They define which step number from the hysteresis simulation where these 3D plots were taken
# from. There were 801 steps in the hysteresis loop in total. Thus the first 3D plot, (a)
# was the relaxed state from the 155th step of the hysteresis.
states = [155, 175, 184, 210, 215, 225, 304, 217]
labels = ['(a)', '(b)', '(c)', '(d)', '(e)', '(f)', '(g)', '(h)']
for i, state in enumerate(states):
if state == 217:
imageFileName = '../data/figure_1/3d_data/images/'\
'sim_hysteresis_FeGe_nanodisk_d150_h35_{}.png'.format(state)
else:
imageFileName = '../data/figure_1/3d_data/images/'\
'sim_hysteresis_FeGe_nanodisk_d150_h55_{}.png'.format(state)
imRead = read_png(imageFileName)
ax = eval('ax{}'.format(i))
ax.imshow(imRead)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
ax.set_frame_on(False)
ax.text(0, 1, labels[i], fontsize=20)
cmap = mpl.cm.RdBu_r
norm = mpl.colors.Normalize(vmin=-1, vmax=1)
cb = mpl.colorbar.ColorbarBase(ax8, cmap=cmap, norm=norm, orientation='vertical')
cb.set_label(r'$\mathrm{m}_{\mathrm{z}}$', fontsize=30)
cb.set_ticks([-1, 0, 1])
cb.ax.tick_params(labelsize=24)
plt.savefig('pdfs/figure-1ii-3d-states.pdf')
fig.show()
# -
# create a numpy array of the x-coordinates where the magnetisation was probed.
# The cylinders in the simulations had a diameter of 150nm with the mid-point
# at x,y=0.
x_coords = np.linspace(-75, 75, 100)
# +
# set up the figure
fig = plt.figure(figsize=(16, 4.5))
gs = gridspec.GridSpec(2, 4, height_ratios=[1,1], hspace=0.3, wspace=0.15)
ax0 = plt.subplot(gs[0, 0])
ax1 = plt.subplot(gs[0, 1])
ax2 = plt.subplot(gs[0, 2])
ax3 = plt.subplot(gs[0, 3])
ax4 = plt.subplot(gs[1, 0])
ax5 = plt.subplot(gs[1, 1])
ax6 = plt.subplot(gs[1, 2])
ax7 = plt.subplot(gs[1, 3])
# Note that 'states' is a list of index values associated with the hysteresis loop simulation.
# They define which step number from the hysteresis simulation where these 3D plots were taken
# from. There were 801 steps in the hysteresis loop in total. Thus the first 3D plot, (a)
# was the relaxed state from the 155th step of the hysteresis.
states = [155, 175, 184, 210, 215, 225, 304, 217]
labels = ['(a)', '(b)', '(c)', '(d)', '(e)', '(f)', '(g)', '(h)']
for i, state in enumerate(states):
if state == 217:
mz = np.load('../data/figure_1/magnetisation_profiles/'\
'hysteresis_probe_d150_h35_mz{}.npy'.format(state))
else:
mz = np.load('../data/figure_1/magnetisation_profiles/'\
'hysteresis_probe_d150_h55_mz{}.npy'.format(state))
ax = eval('ax{}'.format(i))
ax.plot(x_coords, mz)
ax.axes.set_ylim([-1, 1.02])
ax.axes.set_yticks([-1, 0, 1])
ax.axes.set_yticks([0, 1], minor=True)
ax.axes.set_xlim([-75, 76])
ax.axes.set_xticks([-75, 0, 75])
ax.axes.set_xticks([0, 75], minor=True)
ax.axes.set_xticklabels(['-d/2', 0, 'd/2'])
ax.axes.grid(b=True, which='minor', color='grey', linestyle='--')
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax0.set_ylabel(r'm$_z$(x)')
ax4.set_ylabel(r'm$_z$(x)')
plt.savefig('pdfs/figure-1ii-profiles.pdf')
fig.show()
# -
| notebooks/figure-1ii-3D-states-with-profiles.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
numbers = [1,2,3,4,5,6,7,8]
numbers[2:len(numbers)]
numbers[5:]
range_numbers = list(range(0,90))
print(range_numbers)
show_title = 'game of thrones'
print(show_title[2:])
| pythoncourse/Slicing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Covariance Matrix
# ## Install libraries
import sys
# !{sys.executable} -m pip install -r requirements.txt
# ## Imports
import numpy as np
import quiz_tests
# ## Hints
#
# ### covariance matrix
# If we have $m$ stock series, the covariance matrix is an $m \times m$ matrix containing the covariance between each pair of stocks. We can use [numpy.cov](https://docs.scipy.org/doc/numpy/reference/generated/numpy.cov.html) to get the covariance. We give it a 2D array in which each row is a stock series, and each column is an observation at the same period of time.
#
# The covariance matrix $\mathbf{P} =
# \begin{bmatrix}
# \sigma^2_{1,1} & ... & \sigma^2_{1,m} \\
# ... & ... & ...\\
# \sigma_{m,1} & ... & \sigma^2_{m,m} \\
# \end{bmatrix}$
# ## Quiz
# +
import numpy as np
def covariance_matrix(returns):
"""
Create a function that takes the return series of a set of stocks
and calculates the covariance matrix.
Parameters
----------
returns : numpy.ndarray
2D array containing stock return series in each row.
Returns
-------
x : np.ndarray
A numpy ndarray containing the covariance matrix
"""
#covariance matrix of returns
cov = np.cov(returns)
return cov
quiz_tests.test_covariance_matrix(covariance_matrix)
# +
"""Test with a 3 simulated stock return series"""
days_per_year = 252
years = 3
total_days = days_per_year * years
return_market = np.random.normal(loc=0.05, scale=0.3, size=days_per_year)
return_1 = np.random.uniform(low=-0.000001, high=.000001, size=days_per_year) + return_market
return_2 = np.random.uniform(low=-0.000001, high=.000001, size=days_per_year) + return_market
return_3 = np.random.uniform(low=-0.000001, high=.000001, size=days_per_year) + return_market
returns = np.array([return_1, return_2, return_3])
"""try out your function"""
cov = covariance_matrix(returns)
print(f"The covariance matrix is \n{cov}")
# -
# If you're stuck, you can also check out the solution [here](m3l4_covariance_solution.ipynb)
| portfolio_risk_and_return/m3l4_covariance.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: nn
# language: python
# name: nn
# ---
# +
# %load_ext autoreload
# %autoreload 2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import timm
from PIL import Image
import albumentations as A
import cv2
import os
from pytorch_models_imp.datasets.penn_funn import PennFudanDataset, center_to_corners_format
from torch.utils.data import DataLoader
from pytorch_models_imp.detr import DETR, PositionEncoder, HungarianMatcher, DetrLoss
# -
sizes = (224, 224)
transforms = A.Compose([
# A.RandomCrop(width=450, height=450),
A.Resize(sizes[0], sizes[1]),
A.HorizontalFlip(p=0.5),
], bbox_params=A.BboxParams(format='pascal_voc', label_fields=['class_labels']))
root = 'data/PennFudanPed'
imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))[:40]
masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))[:40]
dataset = PennFudanDataset('data/PennFudanPed', imgs, masks, transforms)
# +
im, target = dataset[0]
plt.figure(figsize=(8, 8))
display = im.numpy().transpose(1, 2, 0).copy()
h, w, c = display.shape
for bbox in target['bboxes']:
bbox = center_to_corners_format(bbox) * np.array([w, h, w, h])
bbox = list(map(int, bbox))
cv2.rectangle(display, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color=(0, 255, 0))
plt.imshow(display)
# -
BATCH_SIZE = 4
train_loader = DataLoader(dataset, batch_size=BATCH_SIZE, collate_fn=dataset.collate_fn)
imgs, targets = next(iter(train_loader))
# ### Position encoding
# +
HIDDEN_DIM = 256
pos_encoder = PositionEncoder(max_hw=70, hidden_dim=HIDDEN_DIM)
# -
h, w = sizes[0] // 16, sizes[1] // 32
pos_example = torch.randn(BATCH_SIZE, HIDDEN_DIM, h, w)
pos_out = pos_encoder(pos_example)
assert pos_out.shape == (1, HIDDEN_DIM, h, w)
# ### Minimal detr
num_classes = 2
num_queries = 10
n_head = 4
num_encoder_layers = 3
num_decoder_layers = 3
dropout = 0.0
detr = DETR(num_classes, num_queries, HIDDEN_DIM, n_head, num_encoder_layers, num_decoder_layers, dropout)
preds = detr(imgs)
preds['logits'].shape
preds['bboxes'].shape
# ### Match prediction via hungarian matches
matcher = HungarianMatcher()
matched_indexes = matcher(preds, targets)
matched_indexes
# ### Hungarian based loss
losses_types = ["labels", "boxes"]
detr_loss = DetrLoss(matcher, num_classes, 1, losses_types)
losses = detr_loss(preds, targets)
indices = detr_loss._get_src_permutation_idx(matched_indexes)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, matched_indexes)])
target_classes_o
src_logits = preds['logits']
src_logits.shape
target_classes = torch.full(
src_logits.shape[:2], num_classes, dtype=torch.int64, device=src_logits.device
)
target_classes[indices] = target_classes_o
target_classes
targets
matched_indexes
loss_ce = nn.functional.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
src_logits.transpose(1, 2).shape
target_classes.shape
target_classes
losses
full_loss = sum(losses.values())
# ### Load model
checkpoint = "model_outputs/detection_transforer/transformer_model"
model = torch.load(checkpoint)
model.eval();
output = model(imgs)
logits = output['logits']
bboxes = output['bboxes']
bboxes.shape
import torchmetrics
from torchmetrics.detection import MAP
probas = output['logits'].softmax(-1)[:, :, :-1]
keep_values, keep_indexes = probas.max(-1)
keep_indexes
mask = keep_values > 0.001
mask.shape
# +
imgs, targets = next(iter(train_loader))
preds = []
for i in range(len(imgs)):
b, h, w, c = imgs.shape
obj_prob = probas[i]
obj_bboxes = bboxes[i]
keep_values = obj_prob.max(-1).values > 0.002
obj_prob_keep = obj_prob[keep_values]
obj_bboxes = center_to_corners_format(obj_bboxes[keep_values]) * torch.as_tensor([w, h, w, h])
pred_dict = {"boxes": obj_bboxes.detach(), "scores": obj_prob_keep.detach().flatten(), "labels": torch.as_tensor([1] * len(obj_prob_keep))}
preds.append(pred_dict)
# -
for objs in targets:
objs["boxes"] = objs.pop("bboxes")
objs['boxes'] = center_to_corners_format(objs['boxes']) * torch.as_tensor([w, h, w, h])
# objs['labels'] = torch.as_tensor([0] * len(objs['labels']))
# +
# preds = [
# dict(
# # The boxes keyword should contain an [N,4] tensor,
# # where N is the number of detected boxes with boxes of the format
# # [xmin, ymin, xmax, ymax] in absolute image coordinates
# boxes=torch.Tensor([[258.0, 41.0, 606.0, 285.0]]),
# # The scores keyword should contain an [N,] tensor where
# # each element is confidence score between 0 and 1
# scores=torch.Tensor([0.536]),
# # The labels keyword should contain an [N,] tensor
# # with integers of the predicted classes
# labels=torch.IntTensor([0]),
# )
# ]
# # Target should be a list of elements, where each element is a dict
# # containing 2 keys: boxes and labels. Each keyword should be formatted
# # similar to the preds argument. The number of elements in preds and
# # target need to match
# target = [
# dict(
# boxes=torch.Tensor([[214.0, 41.0, 562.0, 285.0]]),
# labels=torch.IntTensor([0]),
# )
# ]
# -
preds[0]['scores'].flatten().shape
targets[:1]
metric = MAP()
metric.update(preds[:1], targets[:1])
metric.compute()
| detr.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # GP Classifier
from functools import partial
import matplotlib.pyplot as plt
import numpy as np
from typing import *
# ## Inputs
#
# Input to Algorithm 3.1
#
# ### Train Data
# +
num_samples = 20
dim = 2
X = np.random.uniform(low=-2, high=2, size=(num_samples,dim))
# random classes in {-1, +1}
# y = np.random.randint(low=0, high=2, size=(num_samples,)) * 2 - 1
# some dependence between X and y
y = np.logical_or(X[:, 0] > .5, X[:, 1] > 1).astype(np.int32) * 2 - 1
# -
X, y
plt.scatter(*X.T, c=y)
X_test = np.mgrid[-3:3.01:.5, -3:3.01:.5].reshape(2,-1).T
# np.linspace(start=-3, stop=3, num=100)
X_test
# ### Kernel "Squared-Exponential Covariance Function"
#
# ~~Eq. (2.16) from the book~~ Eq. 2.31 from the book (and for multi-dimensional see [here](https://stats.stackexchange.com/a/362537/249793)).
# +
def se_y_onedim(x_p: float, x_q: float, l: float, sigma_f: float) -> float:
return sigma_f ** 2 * np.exp(-((x_p - x_q) ** 2) / (2.0 * l ** 2))
def se_y(x_p: np.ndarray, x_q: np.ndarray, l: float, sigma_f: float) -> float:
return sigma_f ** 2 * np.exp(-.5 * np.sum(((x_p - x_q) / l) ** 2))
def se(x_p: np.ndarray, x_q: np.ndarray, l: float, sigma_f: float) -> float:
f = partial(se_y, l=l, sigma_f=sigma_f)
return np.array(
[
[f(x_p[i], x_q[j]) for j in range(x_q.shape[0])]
for i in range(x_p.shape[0])
]
)
# -
# Kernel was determined with a comprehensive hyperparameter search comprising the configurations
#
# ```
# # kernel = partial(se, l=2, sigma_f=1)
# # kernel = partial(se, l=.01, sigma_f=0.01)
# # kernel = partial(se, l=2, sigma_f=.01)
# # kernel = partial(se, l=0.01, sigma_f=1)
# ```
kernel = partial(se, l=1, sigma_f=1)
# ### Covariance matrix
#
# See also [page 105 here](https://www.microsoft.com/en-us/research/uploads/prod/2006/01/Bishop-Pattern-Recognition-and-Machine-Learning-2006.pdf).
# +
noise_scale = 0
# K in the book; input to Algorithm 3.1
kXX = kernel(X, X) # sigma_bb
# K* in the book
kxX = kernel(X_test, X) # sigma_ab and sigma_ba
kxx = kernel(X_test, X_test) # sigma_aa
m_pre = np.linalg.inv(kXX + noise_scale**2 * np.eye(X.shape[0]))
mpost = kxX @ m_pre @ y
vpost = kxx - kxX @ m_pre @ kxX.T
spost = np.random.multivariate_normal(mpost.flatten(), vpost, size=10).T
# -
mpost.shape
plt.imshow(kXX)
plt.colorbar()
plt.show()
# ### Likelihood function
#
# $p(\boldsymbol{y}\mid\boldsymbol{f})$
#
# (Equation 3.5; using logit sigmoid function here)
# $\log p(y_i\mid f_i) = \log\sigma(y_i\times f_i) = -\log(1 + \exp(-y_i f_i))$
#
# $p(y\mid f)=\sigma(f_iy_i)$
#
# $\nabla\sigma(z)=\sigma(z)\times(1-\sigma(z))$
# $\nabla\nabla\sigma(z)=\sigma(z)\times(1-\sigma(z))\times(1-\sigma(z))+\sigma(z)\times-\sigma(z)\times(1-\sigma(z))$ substitute $\pi=\sigma(z)$
#
# (Equation 3.15)
# $\nabla\nabla\sigma(z)=\pi\times(1-\pi)\times(1-\pi)+\pi\times-\pi\times(1-\pi)=\pi\times(1-\pi)$
#
# Second derivative $\nabla\nabla\log p(y_i\mid f_i) = -\pi_i\times(1-\pi_i)$ with $\pi_i=p(y_i=1\mid f_i)$
# $p(y\mid f)=\Pi_i(p(y_i\mid f_i))=\Pi_i(\sigma(y_i\times f_i))$
#
# $\log$ for sum
# +
def sigmoid(x: np.ndarray) -> np.ndarray:
return 1 / (1 + np.exp(-x))
# for logistic regression we'd have the following
# but we don't have weights here
# def f_fn(x: np.ndarray, w: np.ndarray) -> np.ndarray:
# return sigmoid(np.dot(x, w))
# -
def log_likelihood(f: np.ndarray, y: np.ndarray):
return np.sum(list(sigmoid(f_i * y_i) for f_i, y_i in zip(f, y)))
log_likelihood(np.array([-2, 10, -4]), np.array([-1, 1, -1]))
# ---
#
# At this point all inputs to Algorithm 3.1 are available. Below are some loose notes.
sigma = np.eye(dim)
mean = np.zeros(dim)
sigma, mean
w = np.random.multivariate_normal(mean=mean, cov=sigma)
w
X
# **General note:**
#
# * $Ax = b$ --> $O(n^2 + n)$ (?) but numerically stable
# * $x = A^{-1}b$ --> $O(n^3)$ numerically instable
# _On line 7 in Algorithm 3.1:_
#
# Instead of solving $Ax=b$ we run $L:=\operatorname{cholesky}(A)$ and solve for $LL^Tx=b$
#
# ---
#
# $L\underbrace{\left(L^Tx\right)}_z=b$
#
# $L$ is a lower-triangular matrix.
#
# $z:=L^Tx$
#
# Solve $Lz=b$, once we got $z$ we solve $L^Tx=z$.
# Example
#
# ```
# A = [[1, 2], [3, 4]]
# LL^T := A
#
# A[1][1] = L[1][1]*L[1][1] + L[1][1]*L[1][2] + ...
# # gives n^2 equations (one for each entry in the L matrix)
# ```
# ### Prediction
from scipy.linalg import cho_solve, cho_factor
G = kXX + noise_scale ** 2 * np.eye(X.shape[0])
# with Cholesky
L = cho_factor(G)
A = cho_solve(L, kxX.T).T
# +
# alternative (w/o Cholesky)
# kxX.shape = [num_test X_test.shape[0], num_train X.shape[0]]
# AG = kxX
# G^TA^T = kxX^t
# cholesky(G^T) = L^TL
# L^T @ (L @ A^T) = kxX^T
# L^T @ z = kxX^T (solve this first) # corresponds to 'A = cho_solve(L, kxX.T).T'
# L @ A&^T = z
A = kxX @ np.linalg.inv(G)
# +
# mpost = mean_function(X_test) + A @ (Y - mean_function(X))
# vpost = kernel(X_test, X_test) - A @ kxX.T
# mpost = mx + A @ (Y - mX)
# vpost = kxx - A @ kxX.T
# -
# We want to maximize $p(f\mid X, y)$ (from Eq. 3.9). It is proportional to
#
# $$\displaystyle p(y\mid f)p(f\mid X)\,.$$
#
#
# We can take the log of the function we want to maximize:
#
# $\max_f\quad\ln \underbrace{p(y\mid f)}_{\text{likelihood}}+\ln \underbrace{p(f\mid X)}_\text{prior}$
#
# The **likelihood** factorizes: $\Pi_i p(y_i\mid f_i)=\Pi_i \sigma(y_i f_i)$; $f$ are the _parameters_ (here function values) over which we optimize.
#
# The log of the likelihood is a sum: $\ln\Pi_i \sigma(y_i f_i)=\sum_i \ln\sigma(y_i f_i)$. This is a concrete function, the derivative and second derivative are known (see Eq. 3.15), so we can optimize it.
#
# The **prior** $p(f\mid X)$ is a normal distribution with mean 0 and variance $K$ (`kXX`) (see Eq. 3.12 on the right-hand side).
# ## Algorithm 3.1 / Equation 3.9
arr = np.ndarray
sqrt_elem = np.vectorize(np.sqrt)
sigmoid_elem = np.vectorize(sigmoid)
def algorithm_31(K: arr, y: arr, log_likelihood_fn: Callable[[arr, arr], arr], eps: float) -> Tuple[arr, arr]:
n = y.shape[0]
f = np.zeros_like(y)
converged = False
prev_obj = 0
while not converged:
W = -np.diag([-sigmoid(f_i * y_i) * (1 - sigmoid(f_i * y_i)) for f_i, y_i in zip(f, y)]) # line 4
G = np.eye(n) + sqrt_elem(W) @ K @ sqrt_elem(W) # line 5 a
L, lower = cho_factor(G, lower=True) # line 5 b
b = W @ f + (y + 1) / 2 - sigmoid_elem(f * y) # line 6; Eq. 3.15
# A\b --> Ax = b --> cho_solve(cho_factor(A), b)
# line 7
z2 = cho_solve((L, lower), sqrt_elem(W) @ K @ b)
z1 = cho_solve((L.T, lower), z2)
a = b - sqrt_elem(W) @ z1
f = K @ a # line 8
obj = -.5 * a.T @ f + log_likelihood_fn(f, y) # line 9 (right)
print(obj)
converged = abs(obj - prev_obj) < eps # line 9 (left)
prev_obj = obj
# log likelihood = p(y | X, theta) aka. quality of the fit
approx_log_marginal_likelihood = obj - np.trace(np.log(L)) # line 10
f_hat = f # mpost
return f_hat, approx_log_marginal_likelihood
out = algorithm_31(K=kXX, y=y, log_likelihood_fn=log_likelihood, eps=.001)
f_hat, approx_log_marginal_likelihood = out
f_hat, approx_log_marginal_likelihood
# $\hat{f}$ has greater values where $y=1$
list(zip(f_hat, y))
list(zip((round(sigmoid(f_i) * 2 - 1, 4) for f_i in f_hat), y))
# ## Algorithm 3.2 / Equation 3.10
from scipy import integrate
from scipy.stats import norm
def algorithm_32(
f_hat: arr, X: arr, y: arr, k: Callable, log_likelihood_fn: Callable[[arr, arr], arr], x_test: arr
) -> arr:
"""
Algorithm 3.2: Predictions for binary Laplace GPC.
f_hat: mode (from Algorithm 3.1)
X: inputs
y: +-1 targets
k: covariance function (kernel)
log_likelihood_fn: log likelihood function
x_test: test input
"""
n = y.shape[0]
K = kernel(X, X)
W = -np.diag([-sigmoid(f_i * y_i) * (1 - sigmoid(f_i * y_i)) for f_i, y_i in zip(f_hat, y)]) # line 2
G = np.eye(n) + sqrt_elem(W) @ K @ sqrt_elem(W) # line 3 a
L, lower = cho_factor(G, lower=True) # line 3 b
f_bar_star = kernel(x_test, X) @ ((y + 1) / 2 - sigmoid_elem(f_hat * y)) # line 4; Eq. 3.15
v = cho_solve((L, lower), sqrt_elem(W) @ kernel(x_test, X).T) # line 5
V_f_star = kernel(x_test, x_test) - v.T @ v # line 6
def integral_fn(z: arr, f_bar_star_i: arr, V_f_star_ii: arr):
return sigmoid(z) * norm(f_bar_star_i, V_f_star_ii).pdf(z)
pi_bar_star = np.array([
integrate.quad(
func=partial(integral_fn, f_bar_star_i=f_bar_star_i, V_f_star_ii=V_f_star_ii),
a=-10, b=10)[0]
for f_bar_star_i, V_f_star_ii in zip(f_bar_star, np.diagonal(V_f_star))
]) # line 7 (heavy computation!)
return pi_bar_star # line 8
pi_bar_star = algorithm_32(f_hat=f_hat, X=X, y=y, k=kernel, log_likelihood_fn=log_likelihood, x_test=X_test)
pi_bar_star[:10]
# +
import matplotlib.tri as tri
import matplotlib.pyplot as plt
plt.tricontour(*X_test.T, pi_bar_star, 15, linewidths=0.5, colors='k')
plt.tricontourf(*X_test.T, pi_bar_star, 15, alpha=.7)
plt.scatter(*X.T, c=y, s=100, edgecolors='black');
# -
# Test points are are in the grid (dots) `X_test`, train points are the `+`es, `X`.
plt.scatter(*X_test.T, c=pi_bar_star, s=20)
plt.scatter(*X.T, c=y, marker='+', s=200);
| gaussian-processes/classifier.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
from __future__ import print_function
import datetime
from functools import reduce
import os
import pandas as pd
import numpy as np
# %matplotlib nbagg
import matplotlib.pyplot as plt
# -
# Data collected from a spark query at CERN, in pandas pickle format
# CRAB jobs only have data after Oct. 2017
ws = pd.read_pickle("data/working_set_day.pkl.gz")
# spark returns lists, we want to use sets
ws['working_set_blocks'] = ws.apply(lambda x: set(x.working_set_blocks), 'columns')
ws['working_set'] = ws.apply(lambda x: set(x.working_set), 'columns')
# +
# DBS BLOCKS table schema:
# BLOCK_ID NOT NULL NUMBER(38)
# BLOCK_NAME NOT NULL VARCHAR2(500)
# DATASET_ID NOT NULL NUMBER(38)
# OPEN_FOR_WRITING NOT NULL NUMBER(38)
# ORIGIN_SITE_NAME NOT NULL VARCHAR2(100)
# BLOCK_SIZE NUMBER(38)
# FILE_COUNT NUMBER(38)
# CREATION_DATE NUMBER(38)
# CREATE_BY VARCHAR2(500)
# LAST_MODIFICATION_DATE NUMBER(38)
# LAST_MODIFIED_BY VARCHAR2(500)
if not os.path.exists('data/block_size.npy'):
blocksize = pd.read_csv("data/dbs_blocks.csv", dtype='i8', usecols=(0,5), names=['block_id', 'block_size'])
np.save('data/block_size.npy', blocksize.values)
blocksize = blocksize.values
else:
blocksize = np.load('data/block_size.npy')
# We'll be accessing randomly, make a dictionary
blocksize = {v[0]:v[1] for v in blocksize}
# -
# join the data tier definitions
datatiers = pd.read_csv('data/dbs_datatiers.csv').set_index('id')
ws['data_tier'] = datatiers.loc[ws.d_data_tier_id].data_tier.values
date_index = np.arange(np.min(ws.day.values//86400), np.max(ws.day.values//86400)+1)
date_index_ts = np.array(list(datetime.date.fromtimestamp(day*86400) for day in date_index))
ws_filtered = ws[(ws.crab_job==True) & (ws.data_tier.str.contains('MINIAOD'))]
ws_filtered.head()
ws_filtered[(ws_filtered.day==1505779200)]
ws_filtered[(ws_filtered.day==1505779200)].working_set_blocks
# +
blocks_day = []
for i, day in enumerate(date_index):
today = (ws_filtered.day==day*86400)
blocks_day.append(reduce(lambda a,b: a.union(b), ws_filtered[today].working_set_blocks, set()))
print("Done assembling blocklists")
# -
block_dict = {}
i=0
for el in blocks_day:
i=i+1
if len(el)>0:
block_dict[i] = el
block_dict.keys()
block_dict
len(block_dict[481]-block_dict[480])
len(block_dict[481].intersection(block_dict[480]))
len(block_dict[481].intersection(block_dict[480]).intersection(block_dict[482]))
b=block_dict[450]
i=450
print("%i, %i"%(i-450,len(b)))
for i in range(451,500):
b=b.intersection(block_dict[i])
print("%i, %i"%(i-450,len(b)))
| Archive/working_set_reuse.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Linear Regression (OLS)
#
# ### Key Equation: $Ax =b ~~ \text{for} ~~ n \times p+1 $
#
#
# Linear regression - Ordinary Least Square (OLS) is the most basic form of supervised learning. In this we have a target variable (y) and we want to establish a linear relationship with a set of features (x<sub>1</sub>, x<sub>2</sub>, x<sub>3</sub>, ...)
#
# Lets take a simple example to illustrate this problem:
#
# We have price ('000 INR) and mileage (kmpl) for 7 hatchback cars as below
#
# ```
# price = [199 , 248 , 302 , 363 , 418 , 462 , 523 ]
# kmpl = [23.9, 22.7, 21.1, 20.5, 19.8, 20.4, 18.6]
# ```
#
# We want to predict the target variable `price`, given the input variable `kmpl`
import numpy as np
# +
import matplotlib.pyplot as plt
# %matplotlib inline
plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = (10, 6)
import ipywidgets as widgets
from ipywidgets import interact, interactive
# -
price = np.array([199, 248, 302, 363, 418, 462, 523])
kmpl = np.array([23.9, 22.7, 21.1, 20.5, 19.8, 20.4, 18.6])
plt.scatter(kmpl, price, s = 150)
plt.xlabel('kmpl')
plt.ylabel('price')
# ## Thinking Linear Algebra Way
#
# The basic problem in linear regression is solving - `n` linear equation, with `p` unknowns, where `p < n`
#
# So a linear relationship can be written as:
#
# $$ price = \beta_{0} + \beta_{1} kmpl $$
#
# We have added an intercept to the equation, so that the line does not need to pass through zero
#
# So we are trying to solve these n = 7 equations with, p = 2
#
# $$ 199 = \beta_{0} + \beta_{1} 23.9 ~~~~ \text{(eq 1)} $$
# $$ 248 = \beta_{0} + \beta_{1} 22.7 ~~~~ \text{(eq 2)} $$
# $$ 302 = \beta_{0} + \beta_{1} 21.1 ~~~~ \text{(eq 3)} $$
# $$ 363 = \beta_{0} + \beta_{1} 20.5 ~~~~ \text{(eq 4)} $$
# $$ 418 = \beta_{0} + \beta_{1} 19.8 ~~~~ \text{(eq 5)} $$
# $$ 462 = \beta_{0} + \beta_{1} 20.4 ~~~~ \text{(eq 6)} $$
# $$ 523 = \beta_{0} + \beta_{1} 18.6 ~~~~ \text{(eq 7)} $$
#
# So the key to remember here is that we are solving for $\beta_{0}$ and $ \beta_{1} $
#
# Now if we plot these lines, it is clear that there will not be a one point of intersection that we can get like we get if we had only 2 equations.
# +
b0 = np.arange(-500,4000, 100)
for i in range(7):
b1 = (price[i] - b0)/kmpl[i]
plt.plot(b0, b1, linewidth = 1)
plt.text(b0[-10], b1[-10], 'eq %s'% (i + 1), fontsize = 8 )
plt.axhline(0, color='grey', linewidth=2)
plt.axvline(0, color='grey', linewidth=2)
plt.xlabel('beta0')
plt.ylabel('beta1')
plt.ylim(-150,50)
# -
# Now we don't have an exact solution. But can see the $\beta_{0} $ is around [1500,1700] and $ \beta_{1} $ is around [-50,-70]. So one possible line is
#
# $$ price = 1600 - 60 * kmpl $$
#
# But we can clearly see that this is probably not the best possible line!!
beta_0_list = widgets.IntSlider(min=1500, max=1700, step=10, value=1600)
beta_1_list = widgets.IntSlider(min=-70, max=-50, step=2, value=-60)
beta_0 = 1600
beta_1 = -60
def plot_line(beta_0, beta_1):
plt.scatter(kmpl, price, s = 150)
plt.xlabel('kmpl')
plt.ylabel('price')
y = beta_0 + beta_1 * kmpl
plt.plot(kmpl, y, '-')
# Lets change the value of beta_0 and beta_1 and see if can find the right answer
interactive(plot_line, beta_0 = beta_0_list, beta_1 = beta_1_list )
# ## Adding Error Term
#
# The linear relationship hence needs to be modeled through a error variable $\epsilon_{i}$ — an unobserved random variable that adds noise to the linear relationship between the target variable and input variable.
#
# If we have `p` input variables then,
#
# $$ y_{i} = \beta_{0} + \sum_{i=1}^p \beta_{i} x_{i} + \epsilon_{i} $$
#
# We can add the $x_{0} = 1 $ in the equation:
#
# $$ y_{i} = \sum_{i=0}^p \beta_{i} x_{i} + \epsilon_{i} $$
#
# $$ y_{i} = x_{i}^T \beta_{i} + \epsilon_{i} $$
#
#
#
plt.scatter(kmpl, price, s = 150)
plt.xlabel('kmpl')
plt.ylabel('price')
y = 1600 - 60 * kmpl
yerrL = y - price
yerrB = y - y
plt.errorbar(kmpl,y, fmt = 'o', yerr= [yerrL, yerrB], c= 'r')
plt.plot(kmpl, y,linewidth = 2)
# ## Represent Matrix Way
#
# If we write this in matrix form
#
# $$ y = X\beta + \epsilon $$
#
# $$ \text{where} ~~~~ X = \begin{bmatrix} - x_{1}^T- \\ - x_{2}^T- \\ ... \\ - x_{n}^T- \end{bmatrix} ~~ \text{,} ~~ y = \begin{bmatrix} y_{1} \\ y_{2} \\ ... \\ y_{n} \end{bmatrix} ~~ \text{and} ~~ \epsilon = \begin{bmatrix} \epsilon_{1} \\ \epsilon_{2} \\ ... \\ \epsilon_{n} \end{bmatrix} $$
#
# For our specific example, the matrix looks like:
#
# $$ \begin{bmatrix}199 \\ 248 \\ 302 \\ 363 \\ 418 \\ 462 \\ 523 \end{bmatrix} = \begin{bmatrix} 1 & 23.9 \\ 1 & 22.7 \\ 1 & 21.1 \\ 1 & 20.5 \\ 1 & 19.8 \\ 1 & 20.4 \\ 1 & 18.6 \end{bmatrix} \begin{bmatrix}
# \beta_{0} \\ \beta_{1} \end{bmatrix} + \begin{bmatrix} \epsilon_{1} \\ \epsilon_{2} \\ \epsilon_{3} \\ \epsilon_{4} \\ \epsilon_{5} \\ \epsilon_{6} \\ \epsilon_{7} \end{bmatrix} $$
#
#
# ## Minimize Error - Ordinary Least Square
#
#
# The error we will aim to minimize is the squared error:
#
# $$ E(\beta)= \frac {1}{n} \sum _{i=1}^{n}(\epsilon_{i})^2 $$
#
# This is why this technique is called **Ordinary Least Square** (OLS) regression
#
# $$ E(\beta)= \frac {1}{n} \sum _{i=1}^{n}(y_{i}-x_{i}^{T}\beta)^{2} $$
#
# which in matrix way is equal to:
#
# $$ E(\beta)= \frac {1}{n} (y-X\beta)^{T}(y-X\beta) $$
#
# $$ E(\beta)= \frac {1}{n} ((y^{T} - \beta^{T}X^{T})(y-X\beta)) $$
#
# $$ E(\beta)= \frac {1}{n} (y^{T}y - \beta^{T}X^{T}y - y^{T}X\beta - \beta^{T}X^{T}X\beta) $$
#
# Now, $ y^{T}X\beta = {\beta^{T}X^{T}y}^T $ and is a scalar matrix of $1 x 1$, which means it is equal to its transpose and hence $ y^{T}X\beta = \beta^{T}X^{T}y $
#
# $$ E(\beta)= \frac {1}{n} (y^{T}y - 2\beta^{T}X^{T}y + \beta^{T}X^{T}X\beta) $$
#
#
# To get the minimum for this error function, we need to differentiate by $\beta^T$
#
# $$ \nabla E(\beta) = 0 $$
#
# $$ \nabla E(\beta) ={\frac {dE(\beta)}{d\beta^T}} = {\frac {d}{d\beta^T}}{\bigg (}{ \frac {1}{n} ||y - X\beta||}^2{\bigg )} = 0 $$
#
# $$ {\frac {d}{d\beta^T}}{\bigg (}{ y^{T}y - 2\beta^{T}X^{T}y + \beta^{T}X^{T}X\beta}{\bigg )} = 0 $$
#
# $$ - 2 X^Ty + 2X^{T}X\beta = 0 $$
#
# $$ X^T X\beta = X^T y $$
#
# So the solution to OLS:
#
# $$ \beta = X^†y ~~ \text{where} ~~ X^† = (X^T X)^{−1} X^T $$
#
# $$X^† ~~ \text{is the pseudo inverse of} ~~ X $$
#
#
#
#
# ## Calculate Pseudo Inverse
#
# $$ X^† = (X^T X)^{−1} X^T $$
#
# $X^† $ is the pseudo inverse of $ X $ has good properties
#
# $$ X^† = \left( \begin{matrix} ~ \\
# \begin{bmatrix} ~ \\ p + 1 \times n \\ ~ \end{bmatrix}
# \begin{bmatrix} ~ \\ n \times p + 1 \\ ~ \end{bmatrix}
# \\ ~
# \end{matrix}
# \right)^{-1}
# \begin{bmatrix} ~ \\ (p + 1 \times n) \\ ~ \end{bmatrix}$$
#
# $$ X^† = \left( \begin{matrix} ~ \\
# \begin{bmatrix} ~ \\ p + 1 \times p + 1 \\ ~ \end{bmatrix}
# \\ ~
# \end{matrix}
# \right)^{-1}
# \begin{bmatrix} ~ \\ (p + 1 \times n) \\ ~ \end{bmatrix}$$
#
#
# $$ X^† = \begin{bmatrix} ~ \\ (p + 1 \times n) \\ ~ \end{bmatrix}$$
#
#
# $$ X^†_{p + 1 \times n} = {(X^T_{p + 1 \times n} ~ X_{n \times p+1})}^{-1} ~ X^T_{p + 1 \times n}$$
#
#
n = 7
x0 = np.ones(n)
x0
x1 = kmpl
x1
# Create the X matrix
X = np.c_[x0, x1]
X = np.asmatrix(X)
X
# Create the y matrix
y = np.asmatrix(price.reshape(-1,1))
y
y.shape
X_T = np.transpose(X)
X_T
X_T * X
X_pseudo = np.linalg.inv(X_T * X) * X_T
X_pseudo
beta = X_pseudo * y
beta
# ## OLS Solution
#
# Hence we now know that the best-fit line is $\beta_0 = 1662 $ and $\beta_1 = -62$
#
# $$ price = 1662 - 62 * kmpl $$
#
#
beta_0 = 1662
beta_1 = -62
plt.scatter(kmpl, price, s = 150)
plt.xlabel('kmpl')
plt.ylabel('price')
y = beta_0 + beta_1 * kmpl
plt.plot(kmpl, y, '-')
# ## Exercise 1
#
# We had price ('000 INR), mileage (kmpl) and now we have one more input variable - horsepower (bhp) for the 7 cars
#
# ```
# price = [199 , 248 , 302 , 363 , 418 , 462 , 523 ]
# kmpl = [23.9, 22.7, 21.1, 20.5, 19.8, 20.4, 18.6]
# bhp = [38 , 47 , 55 , 67 , 68 , 83 , 82 ]
# ```
# We want to predict the value of `price`, given the variable `kmpl` and `bhp`
bhp = np.array([38, 47, 55, 67, 68, 83, 82])
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.scatter(bhp, kmpl, price, c='r', marker='o', s = 200)
ax.view_init(azim=30)
# So a linear relationship can be written as:
#
# $$ price = \beta_{0} + \beta_{1} kmpl + \beta_{2} bhp $$
#
# We have added an intercept to the equation, so that the plane does not need to pass through zero
#
# So we are trying to solve these n = 7 equations with, p = 3
#
# $$ 199 = \beta_{0} + \beta_{1} 23.9 + \beta_{2} 38 + \epsilon_{1} ~~~~ \text{(eq 1)} $$
# $$ 248 = \beta_{0} + \beta_{1} 22.7 + \beta_{2} 47 + \epsilon_{2} ~~~~ \text{(eq 2)} $$
# $$ 302 = \beta_{0} + \beta_{1} 21.1 + \beta_{2} 55 + \epsilon_{3} ~~~~ \text{(eq 3)} $$
# $$ 363 = \beta_{0} + \beta_{1} 20.5 + \beta_{2} 67 + \epsilon_{4} ~~~~ \text{(eq 4)} $$
# $$ 418 = \beta_{0} + \beta_{1} 19.8 + \beta_{2} 68 + \epsilon_{5} ~~~~ \text{(eq 5)} $$
# $$ 462 = \beta_{0} + \beta_{1} 20.4 + \beta_{2} 83 + \epsilon_{6} ~~~~ \text{(eq 6)} $$
# $$ 523 = \beta_{0} + \beta_{1} 18.6 + \beta_{2} 82 + \epsilon_{7} ~~~~ \text{(eq 7)} $$
#
# or in matrix form - we can write it as
#
# $$ \begin{bmatrix}199 \\ 248 \\ 302 \\ 363 \\ 418 \\ 462 \\ 523 \end{bmatrix} = \begin{bmatrix} 1 & 23.9 & 38 \\ 1 & 22.7 & 47 \\ 1 & 21.1 & 55 \\ 1 & 20.5 & 67 \\ 1 & 19.8 & 68 \\ 1 & 20.4 & 83 \\ 1 & 18.6 & 82 \end{bmatrix} \begin{bmatrix}\beta_{0} \\ \beta_{1} \\ \beta_{2}\end{bmatrix} + \begin{bmatrix} \epsilon_{1} \\ \epsilon_{2} \\ \epsilon_{3} \\ \epsilon_{4} \\ \epsilon_{5} \\ \epsilon_{6} \\ \epsilon_{7} \end{bmatrix}$$
#
#
# Develop the $X$ matrix for this problem?
# +
n = 7
x0 = np.ones(n)
x1 = np.array([23.9, 22.7, 21.1, 20.5, 19.8, 20.4, 18.6])
x2 = np.array([38, 47, 55, 67, 68, 83, 82])
X = np.c_[x0, x1, x2]
X = np.asmatrix(X)
X
# -
# Develop the $y$ matrix for this problem?
# Create the y matrix
price2 = np.array([199, 248, 302, 363, 418, 462, 523])
y = np.asmatrix(price2.reshape(-1,1))
y
y.shape
# Calculate the pseudo inverse of $X$.
X_T = np.transpose(X)
X_T
X_T * X
X_pseudo = np.linalg.inv(X_T * X) * X_T
X_pseudo
# Find the $\beta$ for the best-fit plane.
beta = X_pseudo * y
beta
# Plot the `price`, `kmpl` and `bhp` and the best-fit plane.
# +
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.scatter(bhp, kmpl, price, c='r', marker='o', s = 200)
xrange = np.arange(min(bhp), max(bhp), 1)
yrange = np.arange(min(kmpl), max(kmpl), 1)
x, y = np.meshgrid(xrange, yrange)
z = 524 - 22 * y + 4 * x
ax.plot_surface(x, y, z, color ='blue', alpha = 0.5)
ax.view_init(azim=60)
# -
# ## Using a package: sklearn
#
# Run the Ordinary Least Square using the package sklearn
import pandas as pd
df = pd.read_csv("data/cars_sample.csv")
from sklearn import linear_model
y = df.price
X = df[['kmpl', 'bhp']]
model_sklearn = linear_model.LinearRegression()
model_sklearn.fit(X, y)
model_sklearn.coef_
model_sklearn.intercept_
model_sklearn_norm = linear_model.LinearRegression(normalize = True)
model_sklearn_norm.fit(X, y)
model_sklearn_norm.coef_
model_sklearn_norm.intercept_
# ## Non Linear Transformation
#
# What happens when we do Non-Linear transforms to the features?
#
# What if we want to predict $price$ based on $kmpl$, $bhp$, $kmpl^2$ and $bhp / kmpl$
#
# The think to remember is that non-linear transforms of the features does not impact the Linear Regression. Because the linear relationship is really about $\beta $ and not the features.
#
# We can be write this as:
#
# $$ price = \beta_{0} + \beta_{1} kmpl + \beta_{2} bhp + \beta_{3} kmpl^2 + \beta_{4} bhp/kmpl $$
df['kmpl2'] = np.power(df.kmpl,2)
plt.scatter(df.kmpl2, df.price, s = 150)
plt.xlabel('kmpl2')
plt.ylabel('price')
df['bhp_kmpl'] = np.divide(df.bhp, df.kmpl)
plt.scatter(df.bhp_kmpl, df.price, s = 150)
plt.xlabel('bhp/kmpl')
plt.ylabel('price')
df
# ## Exercise 2
#
# Run a linear regeression:
# $$ price = \beta_{0} + \beta_{1} kmpl + \beta_{2} bhp + \beta_{3} kmpl^2 + \beta_{4} bhp/kmpl $$
#
# Using Pseudo-Inverse Matrix:
# +
n = 7
x0 = np.ones(n)
x1 = np.array([23.9, 22.7, 21.1, 20.5, 19.8, 20.4, 18.6])
x2 = np.array([38, 47, 55, 67, 68, 83, 82])
x3 = x1**2
x4 = x2 / x1
X = np.c_[x0, x1, x2, x3, x4]
X = np.asmatrix(X)
X
# -
# Create the y matrix
y = np.asmatrix(price.reshape(-1,1))
y
y.shape
X_T = np.transpose(X)
X_T
X_T * X
X_pseudo = np.linalg.inv(X_T * X) * X_T
X_pseudo
beta = X_pseudo * y
beta
# ## Using sklearn package:
# Run the Ordinary Least Square using the package sklearn
df
y = df.price
X = df[['kmpl', 'bhp','kmpl2', 'bhp_kmpl']]
model_sklearn = linear_model.LinearRegression()
model_sklearn.fit(X, y)
model_sklearn.coef_
model_sklearn.intercept_
model_sklearn_norm = linear_model.LinearRegression(normalize = True)
model_sklearn_norm.fit(X, y)
model_sklearn_norm.coef_
model_sklearn_norm.intercept_
| Data Science and Machine Learning/Machine-Learning-In-Python-THOROUGH/MACHINE_LEARNING/HACKERMATH_FOR_ML/Module_1b_linear_regression_ols.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:oaigym]
# language: python
# name: conda-env-oaigym-py
# ---
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
# +
# for benchmarks
# on 18000 frame episodes, average of 10 episodes
soloRandomScores = {
'Alien-v0': 164.0,'Asteroids-v0': 815.0,'Atlantis-v0': 21100.0,'BankHeist-v0': 17.0,
'BattleZone-v0': 3300.0,'Bowling-v0': 20.2,'Boxing-v0': 2.4,'Centipede-v0': 2229.7,
'ChopperCommand-v0': 660.0,'DoubleDunk-v0': -19.2,'FishingDerby-v0': -92.2,
'Freeway-v0': 0.0,'Frostbite-v0': 53.0,'Gravitar-v0': 310.0,'Hero-v0': 1217.5,
'IceHockey-v0': -10.9,'Jamesbond-v0': 25.0,'Kangaroo-v0': 60.0,'Krull-v0': 1479.8,
'KungFuMaster-v0': 760.0,'MsPacman-v0': 246.0,'PrivateEye-v0': 40.0,
'RoadRunner-v0': 20.0, 'Skiing-v0': -16270.7, 'Tennis-v0': -24.0,'TimePilot-v0': 3190.0,
'UpNDown-v0': 422.0,'Venture-v0': 0.0,'WizardOfWor-v0': 750.0,'Zaxxon-v0': 0.0}
soloTpgScores = {
'Alien-v0': 3382.7,'Asteroids-v0': 3050.7,'Atlantis-v0': 89653,'BankHeist-v0': 1051,
'BattleZone-v0': 47233.4,'Bowling-v0': 223.7,'Boxing-v0': 76.5,'Centipede-v0': 34731.7,
'ChopperCommand-v0': 7070,'DoubleDunk-v0': 2,'FishingDerby-v0': 49,
'Freeway-v0': 28.9,'Frostbite-v0': 8144.4,'Gravitar-v0': 786.7,'Hero-v0': 16545.4,
'IceHockey-v0': 10,'Jamesbond-v0': 3120,'Kangaroo-v0': 14780,'Krull-v0': 12850.4,
'KungFuMaster-v0': 43353.4,'MsPacman-v0': 5156,'PrivateEye-v0': 15028.3,
'RoadRunner-v0': 17410, 'Skiing-v0': 0, 'Tennis-v0': 1,'TimePilot-v0': 13540,
'RoadRunner-v0': 17410,'Tennis-v0': 0,'TimePilot-v0': 13540,
'UpNDown-v0': 34416,'Venture-v0': 576.7,'WizardOfWor-v0': 5196.7,'Zaxxon-v0': 6233.4}
# +
df = pd.read_csv('15-shrink-novir.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==300]
df.head()
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(4,19):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1)
plt.title('Multi-Task Scores of 15 Envs. w/o Virulence')
plt.xlabel('TPG Agent')
#plt.ylabel('Score')
plt.show()
# +
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(4,19):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(df.iloc[i,j]) + ' : ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
for scores in agentsScores:
print(sum([score[1] for score in scores])/len(scores))
# +
df = pd.read_csv('15-shrink-vir.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==300]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(4,19):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1)
plt.title('Multi-Task Scores of 15 Envs. w/ Virulence')
plt.xlabel('TPG Agent')
plt.ylabel('Score')
plt.show()
# +
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(4,19):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(df.iloc[i,j]) + ' : ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
for scores in agentsScores:
print(sum([score[1] for score in scores])/len(scores))
# +
dfv = pd.read_csv('15-shrink-vir.txt')
dfv = dfv[dfv.tpgGen==120]
df = pd.read_csv('15-shrink-novir.txt')
df = df[df.tpgGen==120]
distVir = []
distNovir = []
for i in range(len(dfv)):
for j in range(4,19):
distVir.append((dfv.iloc[i,j] - soloRandomScores[dfv.columns[j][5:]]) /
(soloTpgScores[dfv.columns[j][5:]] - soloRandomScores[dfv.columns[j][5:]]))
distNovir.append((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]]))
print(stats.ks_2samp(distVir, distNovir))
# +
df = pd.read_csv('8-all-at-once.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==150]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(3,11):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1.1)
plt.title('MT Scores of 8 Envs (Max AAO)')
plt.xlabel('TPG Agent')
plt.ylabel('Score')
plt.show()
# -
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(3,11):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
# +
df = pd.read_csv('8-all-at-once-window-2.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==150]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(3,11):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.boxplot(scoreDists)
plt.ylim(-1,1)
plt.title('Multi-Task Scores per TPG Agent')
plt.xlabel('TPG Agent')
plt.ylabel('Normalized Score')
plt.show()
# -
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(3,11):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
# +
df = pd.read_csv('8-all-at-once-window-4.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==150]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(3,11):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1.1)
plt.title('MT Scores of 8 Envs (4 AAO)')
plt.xlabel('TPG Agent')
#plt.ylabel('Score')
plt.show()
# -
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(3,11):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
# +
df = pd.read_csv('8-all-at-once-window-4-2.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==150]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(3,11):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1.1)
plt.title('MT Scores of 8 Envs (4 AAO)')
plt.xlabel('TPG Agent')
#plt.ylabel('Score')
plt.show()
# +
df = pd.read_csv('8-merge.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==100]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(3,11):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1)
plt.title('MT Scores of 8 Envs (Max Merge)')
plt.xlabel('TPG Agent')
plt.ylabel('Score')
plt.show()
# -
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(3,11):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
# +
df = pd.read_csv('8-merge-window-4.txt')
# scores distributions normalized to random and solo tpg
df = df[df.tpgGen==100]
scoreDists = []
for i in range(len(df)):
scoreDists.append([])
for j in range(3,11):
scoreDists[i].append(
((df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] -
soloRandomScores[df.columns[j][5:]])).tolist())
plt.figure(figsize=(4,4))
plt.boxplot(scoreDists)
plt.ylim(-1,1)
plt.title('MT Scores of 8 Envs (4 Merge)')
plt.xlabel('TPG Agent')
plt.show()
# -
agentsScores = []
for i in range(len(df)):
print('Agent #' + str(i+1) + ':')
agentsScores.append([])
for j in range(3,11):
agentsScores[-1].append((str(df.columns[j][5:]),
(df.iloc[i,j] - soloRandomScores[df.columns[j][5:]]) /
(soloTpgScores[df.columns[j][5:]] - soloRandomScores[df.columns[j][5:]])))
print(agentsScores[-1][-1][0] + ': ' + str(agentsScores[-1][-1][1]))
print('\nSorted:')
agentsScores[-1].sort(key=lambda x: x[1], reverse=True)
for score in agentsScores[-1]:
print(score[0] + ': ' + str(score[1]))
print('\n')
# +
df1 = pd.read_csv('8-all-at-once.txt')
df1 = df1[df1.tpgGen==150]
df2 = pd.read_csv('8-all-at-once-window-4.txt')
df2 = df2[df2.tpgGen==150]
df3 = pd.read_csv('8-merge.txt')
df3 = df3[df3.tpgGen==100]
df4 = pd.read_csv('8-merge-window-4.txt')
df4 = df4[df4.tpgGen==150]
dist1 = []
dist2 = []
dist3 = []
dist4 = []
for i in range(len(dfv)):
for j in range(3,11):
dist1.append((df1.iloc[i,j] - soloRandomScores[df1.columns[j][5:]]) /
(soloTpgScores[df1.columns[j][5:]] - soloRandomScores[df1.columns[j][5:]]))
dist2.append((df2.iloc[i,j] - soloRandomScores[df1.columns[j][5:]]) /
(soloTpgScores[df1.columns[j][5:]] - soloRandomScores[df1.columns[j][5:]]))
dist3.append((df3.iloc[i,j] - soloRandomScores[df1.columns[j][5:]]) /
(soloTpgScores[df1.columns[j][5:]] - soloRandomScores[df1.columns[j][5:]]))
dist4.append((df4.iloc[i,j] - soloRandomScores[df1.columns[j][5:]]) /
(soloTpgScores[df1.columns[j][5:]] - soloRandomScores[df1.columns[j][5:]]))
print('aao max vs aao 4')
print(stats.ks_2samp(dist1, dist2))
print()
print('aao max vs merge max')
print(stats.ks_2samp(dist1, dist3))
print()
print('aao max vs merge 4')
print(stats.ks_2samp(dist1, dist4))
print()
print('aao 4 vs merge max')
print(stats.ks_2samp(dist2, dist3))
print()
print('aao 4 vs merge 4')
print(stats.ks_2samp(dist2, dist4))
print()
print('merge max vs merge 4')
print(stats.ks_2samp(dist3, dist4))
# -
df.head()
| champion-scores/champion-scores.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # A simple DNN model built in Keras.
#
# In this notebook, we will use the ML datasets we read in with our Keras pipeline earlier and build our Keras DNN to predict the fare amount for NYC taxi cab rides.
#
# ### Learning objectives
# 1. Review how to read in CSV file data using tf.data
# 2. Specify input, hidden, and output layers in the DNN architecture
# 3. Review and visualize the final DNN shape
# 4. Train the model locally and visualize the loss curves
# 5. Deploy and predict with the model using Cloud AI Platform
#
# Each learning objective will correspond to a __#TODO__ in the [student lab notebook](../labs/keras_dnn.ipynb) -- try to complete that notebook first before reviewing this solution notebook.
# + language="bash"
# export PROJECT=$(gcloud config list project --format "value(core.project)")
# echo "Your current GCP Project Name is: "$PROJECT
# +
import os, json, math
import numpy as np
import shutil
import tensorflow as tf
print("TensorFlow version: ",tf.version.VERSION)
PROJECT = "your-gcp-project-here" # REPLACE WITH YOUR PROJECT NAME
REGION = "us-central1" # REPLACE WITH YOUR BUCKET REGION e.g. us-central1
# Do not change these
os.environ["PROJECT"] = PROJECT
os.environ["REGION"] = REGION
os.environ["BUCKET"] = PROJECT # DEFAULT BUCKET WILL BE PROJECT ID
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # SET TF ERROR LOG VERBOSITY
if PROJECT == "your-gcp-project-here":
print("Don't forget to update your PROJECT name! Currently:", PROJECT)
# + language="bash"
# ## Create GCS bucket if it doesn't exist already...
# exists=$(gsutil ls -d | grep -w gs://${PROJECT}/)
#
# if [ -n "$exists" ]; then
# echo -e "Bucket exists, let's not re-create it. \n\nHere are your buckets:"
# gsutil ls
#
# else
# echo "Creating a new GCS bucket."
# gsutil mb -l ${REGION} gs://${PROJECT}
# echo "\nHere are your current buckets:"
# gsutil ls
# fi
# -
# ## Locating the CSV files
#
# We will start with the CSV files that we wrote out in the [first notebook](../01_explore/taxifare.iypnb) of this sequence. Just so you don't have to run the notebook, we saved a copy in ../data
# !ls -l ../data/*.csv
# ## Use tf.data to read the CSV files
#
# We wrote these cells in the [third notebook](../03_tfdata/solution/input_pipeline.ipynb) of this sequence where we created a data pipeline with Keras.
#
# First let's define our columns of data, which column we're predicting for, and the default values.
CSV_COLUMNS = ['fare_amount', 'pickup_datetime',
'pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude',
'passenger_count', 'key']
LABEL_COLUMN = 'fare_amount'
DEFAULTS = [[0.0],['na'],[0.0],[0.0],[0.0],[0.0],[0.0],['na']]
# Next, let's define our features we want to use and our label(s) and then load in the dataset for training.
# +
def features_and_labels(row_data):
for unwanted_col in ['pickup_datetime', 'key']:
row_data.pop(unwanted_col)
label = row_data.pop(LABEL_COLUMN)
return row_data, label # features, label
# load the training data
def load_dataset(pattern, batch_size=1, mode=tf.estimator.ModeKeys.EVAL):
dataset = (tf.data.experimental.make_csv_dataset(pattern, batch_size, CSV_COLUMNS, DEFAULTS)
.map(features_and_labels) # features, label
)
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(1000).repeat()
dataset = dataset.prefetch(1) # take advantage of multi-threading; 1=AUTOTUNE
return dataset
# -
# ## Build a DNN with Keras
#
# Now let's build the Deep Neural Network (DNN) model in Keras and specify the input and hidden layers. We will print out the DNN architecture and then visualize it later on.
# +
## Build a simple Keras DNN using its Functional API
def rmse(y_true, y_pred):
return tf.sqrt(tf.reduce_mean(tf.square(y_pred - y_true)))
def build_dnn_model():
INPUT_COLS = ['pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude',
'passenger_count']
# input layer
inputs = {
colname : tf.keras.layers.Input(name=colname, shape=(), dtype='float32')
for colname in INPUT_COLS
}
feature_columns = {
colname : tf.feature_column.numeric_column(colname)
for colname in INPUT_COLS
}
# the constructor for DenseFeatures takes a list of numeric columns
# The Functional API in Keras requires that you specify: LayerConstructor()(inputs)
dnn_inputs = tf.keras.layers.DenseFeatures(feature_columns.values())(inputs)
# two hidden layers of [32, 8] just in like the BQML DNN
h1 = tf.keras.layers.Dense(32, activation='relu', name='h1')(dnn_inputs)
h2 = tf.keras.layers.Dense(8, activation='relu', name='h2')(h1)
# final output is a linear activation because this is regression
output = tf.keras.layers.Dense(1, activation='linear', name='fare')(h2)
model = tf.keras.models.Model(inputs, output)
model.compile(optimizer='adam', loss='mse', metrics=[rmse, 'mse'])
return model
print("Here is our DNN architecture so far:\n")
model = build_dnn_model()
print(model.summary())
# -
# ### Visualize the DNN
#
# We can visualize the DNN using the Keras [plot_model](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/utils/plot_model) utility.
tf.keras.utils.plot_model(model, 'dnn_model.png', show_shapes=False, rankdir='LR')
# ## Train the model
#
# To train the model, simply call [model.fit()](https://keras.io/models/model/#fit).
#
# Note that we should really use many more NUM_TRAIN_EXAMPLES (i.e. a larger dataset). We shouldn't make assumptions about the quality of the model based on training/evaluating it on a small sample of the full data.
# +
TRAIN_BATCH_SIZE = 32
NUM_TRAIN_EXAMPLES = 10000 * 5 # training dataset repeats, so it will wrap around
NUM_EVALS = 5 # how many times to evaluate
NUM_EVAL_EXAMPLES = 10000 # enough to get a reasonable sample, but not so much that it slows down
trainds = load_dataset('../../data/taxi-train*', TRAIN_BATCH_SIZE, tf.estimator.ModeKeys.TRAIN)
evalds = load_dataset('../../data/taxi-valid*', 1000, tf.estimator.ModeKeys.EVAL).take(NUM_EVAL_EXAMPLES//1000)
steps_per_epoch = NUM_TRAIN_EXAMPLES // (TRAIN_BATCH_SIZE * NUM_EVALS)
history = model.fit(trainds,
validation_data=evalds,
epochs=NUM_EVALS,
steps_per_epoch=steps_per_epoch)
# -
# ### Visualize the model loss curve
#
# Next, we will use matplotlib to draw the model's loss curves for training and validation.
# +
# plot
import matplotlib.pyplot as plt
nrows = 1
ncols = 2
fig = plt.figure(figsize=(10, 5))
for idx, key in enumerate(['loss', 'rmse']):
ax = fig.add_subplot(nrows, ncols, idx+1)
plt.plot(history.history[key])
plt.plot(history.history['val_{}'.format(key)])
plt.title('model {}'.format(key))
plt.ylabel(key)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left');
# -
# ## Predict with the model locally
#
# To predict with Keras, you simply call [model.predict()](https://keras.io/models/model/#predict) and pass in the cab ride you want to predict the fare amount for.
model.predict({
'pickup_longitude': tf.convert_to_tensor([-73.982683]),
'pickup_latitude': tf.convert_to_tensor([40.742104]),
'dropoff_longitude': tf.convert_to_tensor([-73.983766]),
'dropoff_latitude': tf.convert_to_tensor([40.755174]),
'passenger_count': tf.convert_to_tensor([3.0]),
}, steps=1)
# Of course, this is not realistic, because we can't expect client code to have a model object in memory. We'll have to export our model to a file, and expect client code to instantiate the model from that exported file.
# ## Export the model for serving
#
# Let's export the model to a TensorFlow SavedModel format. Once we have a model in this format, we have lots of ways to "serve" the model, from a web application, from JavaScript, from mobile applications, etc.
import shutil, os, datetime
OUTPUT_DIR = './export/savedmodel'
shutil.rmtree(OUTPUT_DIR, ignore_errors=True)
EXPORT_PATH = os.path.join(OUTPUT_DIR, datetime.datetime.now().strftime('%Y%m%d%H%M%S'))
tf.saved_model.save(model, EXPORT_PATH) # with default serving function
# !saved_model_cli show --tag_set serve --signature_def serving_default --dir {EXPORT_PATH}
# !find {EXPORT_PATH}
os.environ['EXPORT_PATH'] = EXPORT_PATH
# ## Deploy the model to AI Platform
#
# Next, we will use the `gcloud ai-platform` command to create a new version for our __taxifare__ model and give it the version name of __dnn__.
#
# Deploying the model will take 5 - 10 minutes.
# + language="bash"
# PROJECT=${PROJECT}
# BUCKET=${BUCKET}
# REGION=${REGION}
# MODEL_NAME=taxifare
# VERSION_NAME=dnn
#
# if [[ $(gcloud ai-platform models list --format='value(name)' | grep $MODEL_NAME) ]]; then
# echo "The model named $MODEL_NAME already exists."
# else
# # create model
# echo "Creating $MODEL_NAME model now."
# gcloud ai-platform models create --regions=$REGION $MODEL_NAME
# fi
#
# if [[ $(gcloud ai-platform versions list --model $MODEL_NAME --format='value(name)' | grep $VERSION_NAME) ]]; then
# echo "Deleting already the existing model $MODEL_NAME:$VERSION_NAME ... "
# gcloud ai-platform versions delete --model=$MODEL_NAME $VERSION_NAME
# echo "Please run this cell again if you don't see a Creating message ... "
# sleep 2
# fi
#
# # create model
# echo "Creating $MODEL_NAME:$VERSION_NAME"
# gcloud ai-platform versions create --model=$MODEL_NAME $VERSION_NAME --async \
# --framework=tensorflow --python-version=3.5 --runtime-version=1.14 \
# --origin=$EXPORT_PATH --staging-bucket=gs://$BUCKET
# -
# Monitor the model creation at [GCP Console > AI Platform](https://console.cloud.google.com/mlengine/models/taxifare/) and once the model version `dnn` is created, proceed to the next cell.
#
# ### Predict with model using `gcloud ai-platform predict`
#
# To predict with the model, we first need to create some data that the model hasn't seen before. Let's predict for a new taxi cab ride for you and two friends going from [from Kips Bay and heading to Midtown Manhattan](https://www.google.com/maps/dir/40.742104,-73.982683/'40.755174,-73.983766'/@40.7487493,-73.9892016,16z/data=!3m1!4b1!4m6!4m5!1m0!1m3!2m2!1d-73.983766!2d40.755174) for a total distance of 1.3 miles. How much would that cost?
# %%writefile input.json
{"pickup_longitude": -73.982683, "pickup_latitude": 40.742104,"dropoff_longitude": -73.983766,"dropoff_latitude": 40.755174,"passenger_count": 3.0}
# !gcloud ai-platform predict --model taxifare --json-instances input.json --version dnn
# In the [next notebook](../05_feateng), we will improve this model through feature engineering.
# Copyright 2019 Google Inc.
# Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| quests/serverlessml/04_keras/solution/keras_dnn.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.6.3
# language: julia
# name: julia-1.6
# ---
using SPECTrecon: imrotate1, imrotate1_adj
using SPECTrecon: imrotate2, imrotate2_adj
using MIRTjim: jim
using ImageTransformations: imrotate, Linear
using Plots: savefig
# +
"""
`imrotate1` visualization
"""
T = Float32
N = 100
img = zeros(T, N, N)
img[30:50, 20:60] .= 1
θ = 3*π/16
my = imrotate1(img, θ)
julia = imrotate(img, -θ, axes(img), method = Linear(), fill = 0)
diff1 = my - julia
my_adj = imrotate1_adj(img, θ)
julia_adj = imrotate(img, θ, axes(img), method = Linear(), fill = 0)
diff1_adj = my_adj - julia_adj
jim(jim(my, "my"), jim(julia, "julia"), jim(diff1, "diff1"),
jim(my_adj, "my_adj"), jim(julia_adj, "julia_adj"), jim(diff1_adj, "diff1_adj"))
# savefig()
# +
"""
`imrotate2` visualization
"""
T = Float32
N = 100
img = zeros(T, N, N)
img[30:50, 20:60] .= 1
θ = 3*π/16
my = imrotate2(img, θ)
julia = imrotate(img, -θ, axes(img), method = Linear(), fill = 0)
diff2 = my - julia
my_adj = imrotate2_adj(img, θ)
julia_adj = imrotate(img, θ, axes(img), method = Linear(), fill = 0)
diff2_adj = my_adj - julia_adj
jim(jim(my, "my"), jim(julia, "julia"), jim(diff2, "diff1"),
jim(my_adj, "my_adj"), jim(julia_adj, "julia_adj"), jim(diff2_adj, "diff1_adj"))
# savefig()
# -
| visualization/rotatez.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.5.1
# language: julia
# name: julia-1.5
# ---
using AvailablePotentialEnergyFramework, Statistics, JLD
using PyPlot, PyCall
tkr = pyimport("matplotlib.ticker")# import FormatStrFormatter
data_dir = "/global/cscratch1/sd/aramreye/for_postprocessing/CompositeOutputs_50d_9hpa/"
file_list_nomask = ["f5e-4_2km_1000km_control_nomask.jld"
"f5e-4_2km_1000km_homoRad_homoSfc_nomask.jld"
"f5e-4_2km_1000km_homoRad_nomask.jld"
"f5e-4_2km_1000km_homoSfc_nomask.jld"]
file_list_withmask = ["f5e-4_2km_1000km_control_withmask.jld"
"f5e-4_2km_1000km_homoRad_homoSfc_withmask.jld"
"f5e-4_2km_1000km_homoRad_withmask.jld"
"f5e-4_2km_1000km_homoSfc_withmask.jld"]
control_withmask_composite = load(string(data_dir,"f5e-4_2km_1000km_control_withmask.jld"))
control_nomask_composite = load(string(data_dir,"f5e-4_2km_1000km_control_nomask.jld"))
homoSfc_withmask_composite = load(string(data_dir,"f5e-4_2km_1000km_homoSfc_withmask.jld"))
homoSfc_nomask_composite = load(string(data_dir,"f5e-4_2km_1000km_homoSfc_nomask.jld"))
homoRad_withmask_composite = load(string(data_dir,"f5e-4_2km_1000km_homoRad_withmask.jld"))
homoRad_nomask_composite = load(string(data_dir,"f5e-4_2km_1000km_homoRad_nomask.jld"))
homoAll_withmask_composite = load(string(data_dir,"f5e-4_2km_1000km_homoRad_homoSfc_withmask.jld"))
homoAll_nomask_composite = load(string(data_dir,"f5e-4_2km_1000km_homoRad_homoSfc_nomask.jld"))
PyPlot.matplotlib.rc("font", family="sans-serif",size=8)
radiusbins = 1000:2000:512000;
length(radiusbins)
# +
function get_tangential_and_radial_speed(composite)
tangential = similar(composite["V"])
radial = similar(composite["V"]);
for index in CartesianIndices(tangential)
center = (256,256)
index_of_point = (index[1],index[2])
tangential[index],radial[index] = AvailablePotentialEnergyFramework.velocity_cartesian_to_polar(composite["U"][index],composite["V"][index],index_of_point,center)
end
return tangential,radial
end
function get_azimuthal_average(array :: Array{T,3},radiusbins) where T
azimuthalaverage = zeros(eltype(array),length(radiusbins) - 1,size(array,3));
for rindex in 1:(length(radiusbins) - 1)
azimuthalaverage[rindex,:] .= AvailablePotentialEnergyFramework.averageallindistance((radiusbins[rindex],radiusbins[rindex+1]),array,(256,256),2000.0)
end
return azimuthalaverage
end
function get_azimuthal_average(array :: Array{T,2},radiusbins) where T
azimuthalaverage = zeros(eltype(array),length(radiusbins) - 1);
for rindex in 1:(length(radiusbins) - 1)
azimuthalaverage[rindex] = AvailablePotentialEnergyFramework.averageallindistance((radiusbins[rindex],radiusbins[rindex+1]),array,(256,256),2000.0)
end
return azimuthalaverage
end
# +
fig, ax = plt.subplots(1,4,figsize=(12,4),sharex=true,sharey=true)
p1 = ax[1].contourf(permutedims(control_nomask_composite["V"][:,256,1:50]))
cb1 = fig.colorbar(p1, ax = ax[1],format=tkr.FormatStrFormatter("% d"))
p2 = ax[2].contourf(permutedims(control_nomask_composite["U"][256,:,1:50]))
cb2 = fig.colorbar(p2
, ax = ax[2],format=tkr.FormatStrFormatter("% d"))
# -
tangential_control_nomask, radial_control_nomask = get_azimuthal_average(get_tangential_and_radial_speed(control_nomask_composite)[1],radiusbins),get_azimuthal_average(get_tangential_and_radial_speed(control_nomask_composite)[2],radiusbins)
# +
dia_heating_control_nomask = 86400/g*get_azimuthal_average(control_nomask_composite["convec_heating_anomaly"].*mean(control_nomask_composite["TABS"],dims=(1,2)),radiusbins)
dia_heating_homoRad_nomask = 86400/g*get_azimuthal_average(homoRad_nomask_composite["convec_heating_anomaly"].*mean(homoRad_nomask_composite["TABS"],dims=(1,2)),radiusbins)
dia_heating_homoSfc_nomask = 86400/g*get_azimuthal_average(homoSfc_nomask_composite["convec_heating_anomaly"].*mean(homoSfc_nomask_composite["TABS"],dims=(1,2)),radiusbins)
dia_heating_homoAll_nomask = 86400/g*get_azimuthal_average(homoAll_nomask_composite["convec_heating_anomaly"].*mean(homoAll_nomask_composite["TABS"],dims=(1,2)),radiusbins)
tpert_control_nomask = get_azimuthal_average(control_nomask_composite["TABS"] .- mean(control_nomask_composite["TABS"],dims=(1,2)),radiusbins)
tpert_homoRad_nomask = get_azimuthal_average(homoRad_nomask_composite["TABS"] .- mean(homoRad_nomask_composite["TABS"],dims=(1,2)),radiusbins)
tpert_homoSfc_nomask = get_azimuthal_average(homoSfc_nomask_composite["TABS"] .- mean(homoSfc_nomask_composite["TABS"],dims=(1,2)),radiusbins)
tpert_homoAll_nomask = get_azimuthal_average(homoAll_nomask_composite["TABS"] .- mean(homoAll_nomask_composite["TABS"],dims=(1,2)),radiusbins)
surfu_control_nomask = hypot.(control_nomask_composite["USFC"],control_nomask_composite["VSFC"])
surfu_homoRad_nomask = hypot.(homoRad_nomask_composite["USFC"],homoRad_nomask_composite["VSFC"])
surfu_homoSfc_nomask = hypot.(homoSfc_nomask_composite["USFC"],homoSfc_nomask_composite["VSFC"])
surfu_homoAll_nomask = hypot.(homoAll_nomask_composite["USFC"],homoAll_nomask_composite["VSFC"])
averagespeed_control_nomask = get_azimuthal_average(surfu_control_nomask,radiusbins)
averagespeed_homoRad_nomask = get_azimuthal_average(surfu_homoRad_nomask,radiusbins)
averagespeed_homoSfc_nomask = get_azimuthal_average(surfu_homoSfc_nomask,radiusbins)
averagespeed_homoAll_nomask = get_azimuthal_average(surfu_homoAll_nomask,radiusbins)
surfpres_control_nomask = control_nomask_composite["PSFC"]
surfpres_homoRad_nomask = homoRad_nomask_composite["PSFC"]
surfpres_homoSfc_nomask = homoSfc_nomask_composite["PSFC"]
surfpres_homoAll_nomask = homoAll_nomask_composite["PSFC"]
averagepres_control_nomask = get_azimuthal_average(surfpres_control_nomask,radiusbins)
averagepres_homoRad_nomask = get_azimuthal_average(surfpres_homoRad_nomask,radiusbins)
averagepres_homoSfc_nomask = get_azimuthal_average(surfpres_homoSfc_nomask,radiusbins)
averagepres_homoAll_nomask = get_azimuthal_average(surfpres_homoAll_nomask,radiusbins)
tangential_control_nomask, radial_control_nomask = get_azimuthal_average(get_tangential_and_radial_speed(control_nomask_composite)[1],radiusbins),get_azimuthal_average(get_tangential_and_radial_speed(control_nomask_composite)[2],radiusbins)
tangential_homoRad_nomask, radial_homoRad_nomask = get_azimuthal_average(get_tangential_and_radial_speed(homoRad_nomask_composite)[1],radiusbins),get_azimuthal_average(get_tangential_and_radial_speed(homoRad_nomask_composite)[2],radiusbins)
tangential_homoSfc_nomask, radial_homoSfc_nomask = get_azimuthal_average(get_tangential_and_radial_speed(homoSfc_nomask_composite)[1],radiusbins),get_azimuthal_average(get_tangential_and_radial_speed(homoSfc_nomask_composite)[2],radiusbins)
tangential_homoAll_nomask, radial_homoAll_nomask = get_azimuthal_average(get_tangential_and_radial_speed(homoAll_nomask_composite)[1],radiusbins),get_azimuthal_average(get_tangential_and_radial_speed(homoAll_nomask_composite)[2],radiusbins)
# -
z_grd = [50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 950 1000 1050 1178.57142857143 1385.71428571429 1671.42857142857 2035.71428571429 2478.57142857143 3000 3600 4200 4800 5400 6000 6600 7200 7800 8400 9000 9600 10200 10800 11400 12000 12600 13200 13800 14400 15000 15600 16200 16800 17400 18000 18600 19200 19800 20400 21000 21600 22200 22800 23400 24000 24600 25200 25800 26400 27000 27600 28200 28800 29400 30000 30600 31200 31800 32400 33000 33600 34200 34800];
x = 1e-3collect(range(0,step=2000,length=255))
y = x
z_iter = 1:56;
x_iter = 1:100
size(tangentia_control)
# +
#cmap = "PiYG"
#cmap = "PuOr_r"
cmap = "RdBu_r"
#cmap = "viridis"
labelfontsize = 6
clabfmt = "%d"
ccolor = "k"
levels_tpert = range(-maximum(abs.(tpert_control_nomask[x_iter,z_iter])),length=15,stop=maximum(abs.(tpert_control_nomask[x_iter,z_iter])))#[[1:5;8:15]]
levels_tangential = range(-42.0,length=80,stop=42)
levels_heating = range(-90,length=180,stop=90)
fig, ax = plt.subplots(2,4,figsize=(12,4.8),sharex=true,sharey=true)
p2 = ax[2,1].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_control_nomask[x_iter,z_iter]),cmap=cmap,vmin=-90,vmax=90)
p3 = ax[1,1].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_control_nomask[x_iter,z_iter]),cmap=cmap,levels=levels_tangential)
p31 = ax[1,1].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_control_nomask[x_iter,z_iter]),levels=levels_tpert,colors=ccolor,linewidth=1)
ax[1,1].axhline(y=15.6, color="r", linestyle="-")
ax[2,1].axhline(y=15.6, color="r", linestyle="-")
cb2 = fig.colorbar(p2, ax = ax[2,1],format=tkr.FormatStrFormatter("% d"))
cb3 = fig.colorbar(p3, ax = ax[1,1],format=tkr.FormatStrFormatter("% d"))
contlab3 = ax[1,1].clabel(p31, inline=1, fontsize=labelfontsize,fmt=clabfmt)
###################################
p5 = ax[2,2].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_homoRad_nomask[x_iter,z_iter]),cmap=cmap,vmin=-90,vmax=90)
p6 = ax[1,2].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_homoRad_nomask[x_iter,z_iter]),cmap=cmap,levels_tangential)
p61 = ax[1,2].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_homoRad_nomask[x_iter,z_iter]),levels=levels_tpert,colors=ccolor,linewidth=1)
contlab6 = ax[1,2].clabel(p61, inline=1, fontsize=labelfontsize,fmt=clabfmt)
ax[1,2].axhline(y=16.6, color="r", linestyle="-")
ax[2,2].axhline(y=16.6, color="r", linestyle="-")
cb5 = fig.colorbar(p5, ax = ax[2,2],format=tkr.FormatStrFormatter("% d"))
cb6 = fig.colorbar(p6, ax = ax[1,2],format=tkr.FormatStrFormatter("% d"))
###################################
p7 = ax[2,3].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_homoSfc_nomask[x_iter,z_iter]),cmap=cmap,vmin=-90,vmax=90)
p8 = ax[1,3].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_homoSfc_nomask[x_iter,z_iter]),cmap=cmap,levels_tangential)
p81 = ax[1,3].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_homoSfc_nomask[x_iter,z_iter]),levels=levels_tpert,colors=ccolor,linewidth=1)
contlab6 = ax[1,3].clabel(p61, inline=1, fontsize=labelfontsize,fmt=clabfmt)
ax[1,3].axhline(y=15.0, color="r", linestyle="-")
ax[2,3].axhline(y=15.0, color="r", linestyle="-")
cb7 = fig.colorbar(p7, ax = ax[2,3],format=tkr.FormatStrFormatter("% d"))
cb8 = fig.colorbar(p8, ax = ax[1,3],format=tkr.FormatStrFormatter("% d"))
####################################
p9 = ax[2,4].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_homoAll_nomask[x_iter,z_iter]),cmap=cmap,vmin=-90,vmax=90)
p10 = ax[1,4].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_homoAll_nomask[x_iter,z_iter]),cmap=cmap,levels_tangential)
p101 = ax[1,4].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_homoAll_nomask[x_iter,z_iter]),levels=levels_tpert,colors=ccolor,linewidth=1)
contlab7 = ax[1,4].clabel(p101, inline=1, fontsize=1.3labelfontsize,fmt=clabfmt)
ax[1,4].axhline(y=14, color="r", linestyle="-")
ax[2,4].axhline(y=14, color="r", linestyle="-")
cb9 = fig.colorbar(p9, ax = ax[2,4],format=tkr.FormatStrFormatter("% d"))
cb10 = fig.colorbar(p10, ax = ax[1,4],format=tkr.FormatStrFormatter("% d"))
ax[2,1].text(-0.3, 1.04, string("Convec heating (K/day)"), transform=ax[2,1].transAxes, size=6)
ax[1,1].text(-0.3, 1.04, string("Tangential wind speed (m/s) and contours temperature perturbation (K)"), transform=ax[1,1].transAxes, size=6)
ax[1,1].annotate("a", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,2].annotate("b", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,3].annotate("c", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,1].annotate("d", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,2].annotate("e", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,3].annotate("f", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,1].set_ylabel("Z (km)")
ax[2,1].set_ylabel("Z (km)")
#ax[3,1].set_ylabel("Z (km)")
ax[2,1].set_xlabel("X (km)")
ax[2,2].set_xlabel("X (km)")
ax[2,3].set_xlabel("X (km)")
ax[1,1].set_title("Control",y=1.08)
ax[1,2].set_title("HomoRad",y=1.08)
ax[1,3].set_title("HomoSfc",y=1.08)
ax[1,4].set_title("HomoAll",y=1.08)
#fig.suptitle("Treshold $treshold hPa")
plt.tight_layout
# +
#cmap = "PiYG"
#cmap = "PuOr_r"
cmap = "RdBu_r"
#cmap = "viridis"
labelfontsize = 6
clabfmt = "%d"
ccolor = "k"
levels_tpert = range(-maximum(abs.(tpert_control_nomask[x_iter,z_iter])),length=15,stop=maximum(abs.(tpert_control_nomask[x_iter,z_iter])))#[[1:5;8:15]]
levels_tangential = range(-10.0,length=11,stop=10)
fig, ax = plt.subplots(2,4,figsize=(12,4.8),sharex=true,sharey=true)
p2 = ax[2,1].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_control_nomask[x_iter,z_iter]),cmap=cmap)
p3 = ax[1,1].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_control_nomask[x_iter,z_iter]),cmap=cmap)
p31 = ax[1,1].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_control_nomask[x_iter,z_iter]),colors=ccolor,linewidth=1)
ax[1,1].axhline(y=17, color="r", linestyle="-")
ax[2,1].axhline(y=17, color="r", linestyle="-")
cb2 = fig.colorbar(p2, ax = ax[2,1])
cb3 = fig.colorbar(p3, ax = ax[1,1])
contlab3 = ax[1,1].clabel(p31, inline=1, fontsize=labelfontsize)
###################################
p5 = ax[2,2].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_homoRad_nomask[x_iter,z_iter]),cmap=cmap)
p6 = ax[1,2].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_homoRad_nomask[x_iter,z_iter]),cmap=cmap)
p61 = ax[1,2].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_homoRad_nomask[x_iter,z_iter]),colors=ccolor,linewidth=1)
contlab6 = ax[1,2].clabel(p61, inline=1, fontsize=labelfontsize)
ax[1,2].axhline(y=16.6, color="r", linestyle="-")
ax[2,2].axhline(y=16.6, color="r", linestyle="-")
cb5 = fig.colorbar(p5, ax = ax[2,2])
cb6 = fig.colorbar(p6, ax = ax[1,2])
###################################
p7 = ax[2,3].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_homoSfc_nomask[x_iter,z_iter]),cmap=cmap)
p8 = ax[1,3].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_homoSfc_nomask[x_iter,z_iter]),cmap=cmap)
p81 = ax[1,3].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_homoSfc_nomask[x_iter,z_iter]),colors=ccolor,linewidth=1)
contlab6 = ax[1,3].clabel(p61, inline=1, fontsize=labelfontsize)
ax[1,3].axhline(y=16.6, color="r", linestyle="-")
ax[2,3].axhline(y=16.6, color="r", linestyle="-")
cb7 = fig.colorbar(p7, ax = ax[2,3])
cb8 = fig.colorbar(p8, ax = ax[1,3])
####################################
p9 = ax[2,4].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(dia_heating_homoAll_nomask[x_iter,z_iter]),cmap=cmap)
p10 = ax[1,4].contourf(x[x_iter],1e-3*z_grd[z_iter],permutedims(tangential_homoAll_nomask[x_iter,z_iter]),cmap=cmap)
p101 = ax[1,4].contour(x[x_iter],1e-3*z_grd[z_iter],permutedims(tpert_homoAll_nomask[x_iter,z_iter]),colors=ccolor,linewidth=1)
contlab7 = ax[1,4].clabel(p101, inline=1, fontsize=1.3labelfontsize)
ax[1,4].axhline(y=15, color="r", linestyle="-")
ax[2,4].axhline(y=15, color="r", linestyle="-")
cb9 = fig.colorbar(p9, ax = ax[2,4])
cb10 = fig.colorbar(p10, ax = ax[1,4])
ax[2,1].text(-0.3, 1.04, string("Convec heating (K/day)"), transform=ax[2,1].transAxes, size=6)
ax[1,1].text(-0.3, 1.04, string("Tangential wind speed (m/s) and contours temperature perturbation (K)"), transform=ax[1,1].transAxes, size=6)
ax[1,1].annotate("a", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,2].annotate("b", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,3].annotate("c", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,1].annotate("d", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,2].annotate("e", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,3].annotate("f", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,1].set_ylabel("Z (km)")
ax[2,1].set_ylabel("Z (km)")
#ax[3,1].set_ylabel("Z (km)")
ax[2,1].set_xlabel("X (km)")
ax[2,2].set_xlabel("X (km)")
ax[2,3].set_xlabel("X (km)")
ax[1,1].set_title("Control",y=1.08)
ax[1,2].set_title("HomoRad",y=1.08)
ax[1,3].set_title("HomoSfc",y=1.08)
ax[1,4].set_title("HomoAll",y=1.08)
#fig.suptitle("Treshold $treshold hPa")
plt.tight_layout
# -
fig, ax = plt.subplots(2,4,sharex=true,sharey=true,figsize=(12,4.8))
x_domain = 1e-3collect(range(0,step=2000,length=512))
p1 = ax[1,1].contourf(x_domain,x_domain,surfu_control_nomask,levels=range(0,length=9,stop=26))
cb1 = fig.colorbar(p1, ax = ax[1,1],format=tkr.FormatStrFormatter("% d"))
p2 = ax[2,1].contourf(x_domain,x_domain,surfpres_control_nomask,levels=range(944,length=10,stop=1008))
cb2 = fig.colorbar(p2, ax = ax[2,1],format=tkr.FormatStrFormatter("% d"))
#cb2[:ax][:set_title]("This is a title")
#p3 = ax[3,1][:contourf](x,x,pw_control[:,:,end])
#cb3 = fig[:colorbar](p3, ax = ax[3,1])
############################
p4 = ax[1,2].contourf(x_domain,x_domain,surfu_homoSfc_nomask,levels=range(0,length=9,stop=26))
cb4 = fig.colorbar(p4, ax = ax[1,2],format=tkr.FormatStrFormatter("% d"))
p5 = ax[2,2].contourf(x_domain,x_domain,surfpres_homoSfc_nomask,levels=range(944,length=10,stop=1008))
cb5 = fig.colorbar(p5, ax = ax[2,2],format=tkr.FormatStrFormatter("% d"))
#p6 = ax[3,2][:contourf](x,x,pw_homoRad[:,:,end])
#cb6 = fig[:colorbar](p6, ax = ax[3,2])
############
p4 = ax[1,3].contourf(x_domain,x_domain,surfu_homoRad_nomask,levels=range(0,length=9,stop=26))
cb4 = fig.colorbar(p4, ax = ax[1,3],format=tkr.FormatStrFormatter("% d"))
p5 = ax[2,3].contourf(x_domain,x_domain,surfpres_homoRad_nomask,levels=range(944,length=10,stop=1008))
cb5 = fig.colorbar(p5, ax = ax[2,3],format=tkr.FormatStrFormatter("% d"))
#p6 = ax[3,2][:contourf](x,x,pw_homoRad[:,:,end])
#cb6 = fig[:colorbar](p6, ax = ax[3,2])
############
p6 = ax[1,4].contourf(x_domain,x_domain,surfu_homoAll_nomask,levels=range(0,length=9,stop=26))
cb6 = fig.colorbar(p6, ax = ax[1,4],format=tkr.FormatStrFormatter("% d"))
p7 = ax[2,4].contourf(x_domain,x_domain,surfpres_homoAll_nomask,levels=range(944,length=10,stop=1008))
cb7 = fig.colorbar(p7, ax = ax[2,4],format=tkr.FormatStrFormatter("% 4d"))
#p9 = ax[3,3][:contourf](x,x,pw_homoRad_homoSfc[:,:,end])
#cb9 = fig[:colorbar](p9, ax = ax[3,3])
ax[1,1].text(-0.3, 1.05, string("Surf speed (m/s)"), transform=ax[1,1].transAxes,
size=6)
ax[2,1].text(-0.3, 1.05, string("Surface pressure (hPa)"), transform=ax[2,1].transAxes,
size=6)
ax[1,1].annotate("a", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,2].annotate("b", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[1,3].annotate("c", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,1].annotate("d", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,2].annotate("e", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2,3].annotate("f", xy=(0.1, 0.9), xycoords="axes fraction",backgroundcolor="white")
#ax[3,1][:text](-0.2, 1.03, "Precip water (kg/m^2)", transform=ax[3,1][:transAxes],
# size=10)
ax[1,1].set_ylabel("Y (km)")
ax[2,1].set_ylabel("Y (km)")
ax[2,1].set_xlabel("X (km)")
ax[2,2].set_xlabel("X (km)")
ax[2,3].set_xlabel("X (km)")
ax[1,1].set_title("Control")
ax[1,2].set_title("HomoSfc")
ax[1,3].set_title("HomoRad")
ax[1,4].set_title("HomoAll")
# +
fig, ax = plt.subplots(2,1,sharex=true,figsize=(3.74,4.5))
p1 = ax[1].plot(1e-3x,averagespeed_control_nomask,label="Control")
p2 = ax[1].plot(1e-3x,averagespeed_homoSfc_nomask,label="HomoSfc")
p3 = ax[1].plot(1e-3x,averagespeed_homoRad_nomask,label="HomoRad")
p4 = ax[1].plot(1e-3x,averagespeed_homoAll_nomask,label="HomoAll")
ax[1].set_ylabel(string("Speed (m/s)"))
#######################
p1 = ax[2].plot(1e-3x,averagepres_control_nomask,label="Control")
p2 = ax[2].plot(1e-3x,averagepres_homoSfc_nomask,label="HomoSfc")
p3 = ax[2].plot(1e-3x,averagepres_homoRad_nomask,label="HomoRad")
p4 = ax[2].plot(1e-3x,averagepres_homoAll_nomask,label="HomoAll")
ax[2].set_ylabel(string("P (hPa)"))
# #######################
ax[2].set_xlabel(string("Distance from center (Km)"))
ax[1].yaxis.set_label_coords(-0.1,0.5)
ax[2].yaxis.set_label_coords(-0.1,0.5)
ax[1].annotate("a", xy=(0.9, 0.9), xycoords="axes fraction",backgroundcolor="white")
ax[2].annotate("b", xy=(0.9, 0.9), xycoords="axes fraction",backgroundcolor="white")
plt.tight_layout
ax[1].legend(loc = (-0.0, 1), ncol=4 ,frameon=false,fontsize=6)
lw = 1.8
[ln.set_linewidth(lw) for i in 1:length(ax) for ln in ax[i].lines]
ax[1].grid(b=true,which="major",color="xkcd:gray", linestyle="--",alpha=0.2)
ax[2].grid(b=true,which="major",color="xkcd:gray", linestyle="--",alpha=0.2)
# -
| plots_notebooks/Composites_Plots_nomask.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (PyTorch 1.8 Python 3.6 CPU Optimized)
# language: python
# name: python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:ap-northeast-2:806072073708:image/1.8.1-cpu-py36
# ---
# **Jupyter Kernel**:
#
# * If you are in SageMaker Notebook instance, please make sure you are using **conda_pytorch_latest_p36** kernel
# * If you are on SageMaker Studio, please make sure you are using **SageMaker JumpStart PyTorch 1.0** kernel
#
# **Run All**:
#
# * If you are in SageMaker notebook instance, you can go to *Cell tab -> Run All*
# * If you are in SageMaker Studio, you can go to *Run tab -> Run All Cells*
#
# **Note**: To *Run All* successfully, make sure you have executed the entire demo notebook `0_demo.ipynb` first.
#
# ## Resume Training
#
# In this notebook, we retrain our pretrained detector for a few more epochs and compare its results. The same process can be applied when finetuning on another dataset. For the purpose of this notebook, we use the same **NEU-DET** dataset.
#
# ## Finetuning
#
# Finetuning is one way to do Transfer Learning. Finetuning a Deep Learning model on one particular task, involves using the learned weights from a particular dataset to enhance the performace of the model on usually another dataset. In a sense, finetuning can be done over the same dataset used in the intial training but perhaps with different hyperparameters.
#
# +
import json
import sagemaker
from sagemaker.s3 import S3Downloader
sagemaker_session = sagemaker.Session()
sagemaker_config = json.load(open("../stack_outputs.json"))
role = sagemaker_config["IamRole"]
solution_bucket = sagemaker_config["SolutionS3Bucket"]
region = sagemaker_config["AWSRegion"]
solution_name = sagemaker_config["SolutionName"]
bucket = sagemaker_config["S3Bucket"]
# -
# First, we download our **NEU-DET** dataset from our public S3 bucket
original_bucket = f"s3://{solution_bucket}-{region}/{solution_name}"
original_pretained_checkpoint = f"{original_bucket}/pretrained"
original_sources = f"{original_bucket}/build/lib/source_dir.tar.gz"
# Note that for easiler data processing, we have already executed `prepare_data` once in our `0_demo.ipynb` and have already uploaded the prepared data to our S3 bucket
# DATA_PATH = !echo $PWD/neu_det
DATA_PATH = DATA_PATH.n
# After data preparation, we need to setup some paths that will be used throughtout the notebook
# + tags=[]
prefix = "neu-det"
neu_det_s3 = f"s3://{bucket}/{prefix}"
sources = f"{neu_det_s3}/code/"
train_output = f"{neu_det_s3}/output/"
neu_det_prepared_s3 = f"{neu_det_s3}/data/"
s3_checkpoint = f"{neu_det_s3}/checkpoint/"
sm_local_checkpoint_dir = "/opt/ml/checkpoints/"
s3_pretrained = f"{neu_det_s3}/pretrained/"
# -
# ## Visualization
#
# Let examine some datasets that we will use later by providing an `ID`
# +
import copy
import numpy as np
import torch
from PIL import Image
from torch.utils.data import DataLoader
try:
import sagemaker_defect_detection
except ImportError:
import sys
from pathlib import Path
ROOT = Path("../src").resolve()
sys.path.insert(0, str(ROOT))
from sagemaker_defect_detection import NEUDET, get_preprocess
SPLIT = "test"
ID = 30
assert 0 <= ID <= 300
dataset = NEUDET(DATA_PATH, split=SPLIT, preprocess=get_preprocess())
images, targets, _ = dataset[ID]
original_image = copy.deepcopy(images)
original_boxes = targets["boxes"].numpy().copy()
original_labels = targets["labels"].numpy().copy()
print(f"first images size: {original_image.shape}")
print(f"target bounding boxes: \n {original_boxes}")
print(f"target labels: {original_labels}")
# -
# And we can now visualize it using the provided utilities as follows
# +
from sagemaker_defect_detection.utils.visualize import unnormalize_to_hwc, visualize
original_image_unnorm = unnormalize_to_hwc(original_image)
visualize(
original_image_unnorm,
[original_boxes],
[original_labels],
colors=[(255, 0, 0)],
titles=["original", "ground truth"],
)
# -
# Here we resume from a provided pretrained checkpoint `epoch=294-loss=0.654-main_score=0.349.ckpt` that we have copied into our `s3_pretrained`. This takes about **10 minutes** to complete
# + tags=["outputPrepend"]
# %%time
import logging
from os import path as osp
from sagemaker.pytorch import PyTorch
NUM_CLASSES = 7 # 6 classes + 1 for background
# Note: resnet34 was used in the pretrained model and it has to match the pretrained model backbone
# if need resnet50, need to train from scratch
BACKBONE = "resnet34"
assert BACKBONE in [
"resnet34",
"resnet50",
], "either resnet34 or resnet50. Make sure to be consistent with model_fn in detector.py"
EPOCHS = 5
LEARNING_RATE = 1e-4
SEED = 123
hyperparameters = {
"backbone": BACKBONE, # the backbone resnet model for feature extraction
"num-classes": NUM_CLASSES, # number of classes + background
"epochs": EPOCHS, # number of epochs to finetune
"learning-rate": LEARNING_RATE, # learning rate for optimizer
"seed": SEED, # random number generator seed
}
assert not isinstance(sagemaker_session, sagemaker.LocalSession), "local session as share memory cannot be altered"
finetuned_model = PyTorch(
entry_point="detector.py",
source_dir=osp.join(sources, "source_dir.tar.gz"),
role=role,
train_instance_count=1,
train_instance_type="ml.g4dn.2xlarge",
hyperparameters=hyperparameters,
py_version="py3",
framework_version="1.5",
sagemaker_session=sagemaker_session,
output_path=train_output,
checkpoint_s3_uri=s3_checkpoint,
checkpoint_local_path=sm_local_checkpoint_dir,
# container_log_level=logging.DEBUG,
)
finetuned_model.fit(
{
"training": neu_det_prepared_s3,
"pretrained_checkpoint": osp.join(s3_pretrained, "epoch=294-loss=0.654-main_score=0.349.ckpt"),
}
)
# -
# Then, we deploy our new model which takes about **10 minutes** to complete
# %%time
finetuned_detector = finetuned_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge",
endpoint_name=sagemaker_config["SolutionPrefix"] + "-finetuned-endpoint",
)
# ## Inference
#
# We change the input depending on whether we are providing a list of images or a single image. Also the model requires a four dimensional array / tensor (with the first dimension as batch)
input = list(img.numpy() for img in images) if isinstance(images, list) else images.unsqueeze(0).numpy()
# Now the input is ready and we can get some results
# %%time
finetuned_predictions = finetuned_detector.predict(input)
# Here we want to compare the results of the new model and the pretrained model that we already deployed in `0_demo.ipynb` visually by calling our endpoint from SageMaker runtime using `boto3`
# +
import boto3
import botocore
config = botocore.config.Config(read_timeout=200)
runtime = boto3.client("runtime.sagemaker", config=config)
payload = json.dumps(input.tolist() if isinstance(input, np.ndarray) else input)
response = runtime.invoke_endpoint(
EndpointName=sagemaker_config["SolutionPrefix"] + "-demo-endpoint", ContentType="application/json", Body=payload
)
demo_predictions = json.loads(response["Body"].read().decode())
# -
# Here comes the slight changes in inference
visualize(
original_image_unnorm,
[original_boxes, demo_predictions[0]["boxes"], finetuned_predictions[0]["boxes"]],
[original_labels, demo_predictions[0]["labels"], finetuned_predictions[0]["labels"]],
colors=[(255, 0, 0), (0, 0, 255), (127, 0, 127)],
titles=["original", "ground truth", "pretrained", "finetuned"],
dpi=250,
)
# ## Optional: Delete the endpoint and model
#
# When you are done with the endpoint, you should clean it up.
#
# All of the training jobs, models and endpoints we created can be viewed through the SageMaker console of your AWS account.
#
finetuned_detector.delete_model()
finetuned_detector.delete_endpoint()
# ### [Click here to continue](./2_detection_from_scratch.ipynb)
| 1_retrain_from_checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <h1>**Data Bootcamp Final Project**</h1>
# <h2>**Success rate of movies: released date and production cost**</h2>
# **Name: <NAME>**
# **Net ID: jn1402**
# **N#: N10448338**
# ***Description of the project: This project is figuring out the correlation
# between the amount of revenue a movie creates and the month it was released in,
# and the correlation betwen the amount of revenue a movie creates and the production cost.
# For the size of the data, movies released from 1995-2016 are in the dataset.***
# The data used in this project is imported from 'the-numbers.com.' This site has the data of all movies with the information of their ['title','release_date','production cost', 'domestic gross', 'worldwide gross']. We will look at domestic gross and worldwide gross separately to avoid bias.
# Also, the site can create different report with certain standards. EX)Movie released within year(1995-2016), production cost(0-1 mil USD), and releaded month(January).
# With these inbuilt functions, we create the online table, import the table through read_html, play around with them to get more useful data, and then do the analysis/visulaization.
# The reason that we import so many separate tables is for two reasons.
# 1. If we import the whole dataset table, the table size is too large, that jupyter notebook lacks for minutes, and becomes time-inefficient.
# 2. The ready-filtered tables have the same sizes (100 movies in each table). So, as we have the same size of data size for each table, there would be less bias.
# +
import pandas as pd
import sys
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
# -
# Below is importing the different tables (according to month).
new_table_1 = pd.read_html("http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/1/1/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc")
new_table_2 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/2/2/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_3 = pd.read_html("http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/3/3/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc")
new_table_4 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/4/4/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_5 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/5/5/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_6 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/6/6/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_7 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/7/7/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_8 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/8/8/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_9 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/9/9/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_10 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/10/10/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_11 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/11/11/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
new_table_12 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/None/1995/2016/12/12/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
#Creating list with all the dataframes
all_of_nt = [new_table_1[0], new_table_2[0], new_table_3[0],new_table_4[0], new_table_5[0],new_table_6[0],new_table_7[0],new_table_8[0],new_table_9[0],new_table_10[0],new_table_11[0],new_table_12[0]]
#Stripping unused parts of the table
for nt in all_of_nt:
nt['DomesticBox Office'] = nt['DomesticBox Office'].str.strip('$')
nt['DomesticBox Office'] = nt['DomesticBox Office'].str.replace(',','')
nt['DomesticBox Office'] = nt['DomesticBox Office'].astype(int)
nt['InternationalBox Office'] = nt['InternationalBox Office'].str.strip('$')
nt['InternationalBox Office'] = nt['InternationalBox Office'].str.replace(',','')
nt['InternationalBox Office'] = nt['InternationalBox Office'].astype(int)
nt['WorldwideBox Office'] = nt['WorldwideBox Office'].str.strip('$')
nt['WorldwideBox Office'] = nt['WorldwideBox Office'].str.replace(',','')
nt['WorldwideBox Office'] = nt['WorldwideBox Office'].astype(int)
# +
avg_dom_rev = []
for nt2 in all_of_nt:
avg_dom_rev.append(nt2['DomesticBox Office'].mean())
dom_rev = pd.DataFrame(avg_dom_rev)
dom_rev = dom_rev.transpose()
dom_rev.columns = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
dom_rev.rename(index={0: 'Domestic Revenue'})
# -
row = dom_rev.iloc[0]
row.plot(kind = 'bar',figsize = (10,5), title = 'Domestic BoxOffice Revenue by month (in 100 million USD)')
# +
avg_int_rev = []
for nt3 in all_of_nt:
avg_int_rev.append(nt3['InternationalBox Office'].mean())
int_rev = pd.DataFrame(avg_int_rev)
int_rev = int_rev.transpose()
int_rev.columns = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
int_rev.rows = ['International Revenue']
int_rev.rename(index={0: 'International BoxOffice Revenue'})
# -
row = int_rev.iloc[0]
row.plot(kind = 'bar',figsize = (10,5), title = 'International BoxOffice Revenue by month (in 100 million USD)')
# +
avg_ww_rev = []
for nt4 in all_of_nt:
avg_ww_rev.append(nt4['WorldwideBox Office'].mean())
ww_rev = pd.DataFrame(avg_ww_rev)
ww_rev = ww_rev.transpose()
ww_rev.columns = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
ww_rev.rows = ['Worldwide Revenue']
ww_rev.rename(index={0: 'Worldwide BoxOffice Revenue'})
# -
row = int_rev.iloc[0]
row.plot(kind = 'bar',figsize = (10,5), title = 'Worldw BoxOffice Revenue by month (in 100 million USD)')
# Now we import the different tables filtered by the different production costs. [0-1,1-10,11-50,51-120,120-] (mil USD)
# They are divided into 5 different categories.
# +
prod_table_1 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/None/1/1995/2016/None/None/None/None?show-release-date=On&show-domestic-box-office=On&show-international-box-office=On&show-worldwide-box-office=On&view-order-by=domestic-box-office&view-order-direction=desc')
prod_table_2 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/1/10/1995/2016/None/None/None/None?show-release-date=On&view-order-by=domestic-box-office&view-order-direction=desc&show-domestic-box-office=On&show-international-box-office=On')
prod_table_3 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/10/50/1995/2016/None/None/None/None?show-release-date=On&view-order-by=domestic-box-office&view-order-direction=desc&show-domestic-box-office=On&show-international-box-office=On')
prod_table_4 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/50/120/1995/2016/None/None/None/None?show-release-date=On&view-order-by=domestic-box-office&view-order-direction=desc&show-domestic-box-office=On&show-international-box-office=On')
prod_table_5 = pd.read_html('http://www.the-numbers.com/movies/report/All/All/All/All/All/All/All/All/All/120/None/1995/2016/None/None/None/None?show-release-date=On&view-order-by=domestic-box-office&view-order-direction=desc&show-domestic-box-office=On&show-international-box-office=On')
# -
#Making list with all the dataframes.
prod = [prod_table_1[0], prod_table_2[0], prod_table_3[0], prod_table_4[0], prod_table_5[0]]
for tab in prod:
tab['DomesticBox Office'] = tab['DomesticBox Office'].str.strip('$')
tab['DomesticBox Office'] = tab['DomesticBox Office'].str.replace(',','')
tab['DomesticBox Office'] = tab['DomesticBox Office'].astype(int)
tab['InternationalBox Office'] = tab['InternationalBox Office'].str.strip('$')
tab['InternationalBox Office'] = tab['InternationalBox Office'].str.replace(',','')
tab['InternationalBox Office'] = tab['InternationalBox Office'].astype(int)
# +
#Making the right format of dataframe.
avg_dom_rev2 = []
for tab2 in prod:
avg_dom_rev2.append(tab2['DomesticBox Office'].mean())
dom_rev2 = pd.DataFrame(avg_dom_rev2)
dom_rev2 = dom_rev2.transpose()
dom_rev2.columns = ['0-1', '1-10', '11-50', '51-120','120-']
dom_rev2.rename(index={0: 'Domestic Revenue'})
# -
row = dom_rev2.iloc[0]
row.plot(kind = 'bar',figsize = (12,5), title = 'Domestic BoxOffice Revenue by production cost (x axis in 1 mil USD, y axis in 100 million USD)')
# +
#Making the right form of dataframe.
avg_int_rev2 = []
for tab3 in prod:
avg_int_rev2.append(tab3['InternationalBox Office'].mean())
int_rev2 = pd.DataFrame(avg_int_rev2)
int_rev2 = int_rev2.transpose()
int_rev2.columns = ['0-1', '1-10', '11-50', '51-120','120-']
int_rev2.rename(index={0: 'International Revenue'})
# -
row = int_rev2.iloc[0]
row.plot(kind = 'bar',figsize = (12,5), title = 'International BoxOffice Revenue by production cost (x axis in 1 mil USD, y axis in 100 million USD)')
# # Short Concluding Remarks
# **Correlation between released month and BoxOffice revenue**
# For Domestic BoxOffice: May and December had the most revenue followed by June, July and November.
# For International BoxOffice: May had the most revenue, outstanding over any other month.
# For Worldwide BoxOffice: May was the best month to release a movie. July was second, followed by November. January and September, generally the beginning of the semester turned out to be the worst time to release a movie.
# **Correlation between production cost and BoxOffice Revenue**
# For Domestic BoxOffice: There was a decrease from the first index to the second index. A big jump from the second to third index. And then, there is a gradual growth. But if we look at the actual index, the revenue doesn’t increase as substantially as the production costs increase.
# For International BoxOffice: There is a slight increase from first index to second index. And compared to Domestic BoxOffice, the increase of revenue over the last three indexes are larger.
# # Thank you!
| UG_F16/Jaehurn-Nam-Movies.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # EEG/MEG signal preprocessing
# ### ANSWERS TO THE EXERCISES
#
# #### Max Planck School of Cognition, Methods in Cognitive Neuroscience
#
#
# ##### Contact: <NAME> @ MPI CBS, Leipzig, Germany, <EMAIL>
# **Note**: It is clear that you cannot run this notebook. It only includes the answers. You should copy the answers to the main notebook.
# --------------
# --------------
# **EXERCISE 1**: Looking at `raw_orig.info`, could you explain the rationale of why the low-pass frequency is at 1000 Hz?
#
# Hint: Read about nyquist rate.
#
# **ANSWER:** Based on the nyquist theorem, "the highest frequency which can be represented accurately is one half of the sampling rate"[<a href="https://www.sciencedirect.com/topics/engineering/nyquist-theorem#:~:text=Nyquist's%20theorem%20states%20that%20a,higher%20than%20this%20is%20necessary."> REF </a>]. Check sources like <a href='https://en.wikipedia.org/wiki/Nyquist_rate'>Wikipedia: Nyquist Rate</a>, or search Youtube for tutorials.
# ---
# **EXERCISE 2:**
#
# * How long is the duration of the recording?
# * Hint: You can either use the `times` attribute of `raw_orig` or use the number of samples and sampling rate to compute the duration of the recording.
#
# * How many channels does the recording have?
#
# **ANSWER:** (in the cell below)
# TO BE COMPLETED BY STUDENTS # -------------------
# ANSWER TO EXERCISE 2
duration_1 = raw_orig.times[-1] # take the last element of times attribute of raw_orig
duration_2 = data_orig.shape[1]/raw_orig.info['sfreq'] # number of samples is equal to sampling rate multiplied by the duration in seconds.
# Now you have the sampling rate and the number of samples, compute the duration.
number_of_channels = raw_orig.info['nchan'] # You have this value in info attribute of raw class
#---------------------------------------------------
# ---
# **EXERCISE 3:** Complete the code below.
#
# Hint: you can go back to section 1, where we introduced the events and computed `event_mat` of the raw class.
# TO BE COMPLETED BY STUDENTS ------------------
# ANSWER TO EXERCISE 3
annot_onset = events_mat[:, 0]
annot_description = events_mat[:, -1]
# ---------------------------------------------
# ---
# **EXERCISE 4**: complete the code below.
# TO BE COMPLETED BY STUDENTS ------------------
# ANSWER TO EXERCISE 4
ec_array = np.zeros(annot_description.shape) # build an array of zeros with the same size as annot_description
# ---------------------------------------------
# ---
# **EXERCISE 6**: Determine another good alpha source. Plot the PSD.
#
# **ANSWER:** component 9:In the PSD you see the clear alpha peak (around 10 Hz) and beta peak (around 20Hz).
# TO BE COMPLETED BY STUDENTS ------------------
# ANSWER TO EXERCISE 6
cmp_alpha = 9
ax = hf.plot_psd(src[cmp_alpha, :], fs=raw.info['sfreq'], f_max=45)
plt.title('PSD of component ' + srt(cmp_alpha) + ' as an alpha source signal')
# ---------------------------------------------
# ---
# **EXERCISE 8:** You can see three channels which are flying! They are noisy with muscle artifact. Using the interactive window of `plot_psd`, determine these three channels. Look at the figure of 10-20 EEG system. Where are they located? Can you determine the ICA component corresponding to this noise source? Plot its PSD and add it to the bad ICA components list.
# **ANSWER:**
# TO BE COMPLETED BY STUDENTS ------------------
# ANSWER TO EXERCISE 8
ica.exclude += [2, 7]
# ---------------------------------------------
| EEG_tutorial_exercise_solutions.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="6"
# +
from torchvision.models import resnet50
from flopco import FlopCo
device = 'cuda'
# +
model = resnet50()
model.to(device)
stats = FlopCo(model, img_size=(1, 3, 224, 224), device=device)
# -
stats.__dict__.keys()
stats.total_macs, stats.relative_flops
| flopco_keras/examples/model_stats.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
L1= [10,20,30,40,50]
L2 = [1,2,3,4,5]
L3 = L1+L2
print(L3)
import numpy as np
array1= np.array([10,20,30,40,50])
array2 = np.arange(5)
array1
array2
array3 = array1+array2
array3
sum(array1,array2)
array4 = np.array([1,2,3,4])
array4+array1
# we cannot add arrays with different dimensions, to add arrays the dimensions of both arrays have to be same
print(array4.shape)
print(array1.shape)
array = np.linspace(1,10,5)
array
array*2
array**2
# ##### hstack and vstack
array1 = np.array([1,2,3,4])
array2 = np.array([5,6,7,8])
np.hstack((array1,array2))
np.vstack((array1,array2))
np.arange(12)
array1= np.arange(12).reshape(3,4) ##3x4 matrix i.e., 3 rows and 4 columns
array1
array2= np.arange(20).reshape(5,4)
array2
array3= np.arange(12).reshape(4,3) ## 4x3 matrix i.e,. 4 rows and 3 columns
array3
np.vstack((array1,array2))
np.vstack((array1,array3)) ### This will show an error as the dimensions of the column are not the same
np.arange(12).reshape(2,6)
np.arange(12).reshape(6,2)
# ##### Index of the 100th Element
#
# Consider an (11,12) shape array.
#
# What is the index (x,y) of the 100th element?
#
# Note: For counting the elements, go row-wise. For example, in the array:
#
#
# [[1, 5, 9],
# [3, 0, 2]]
# the 5th element would be '0'.
array100 = np.arange(1,133).reshape(11,12)
array100
# ### Answer: 100 is present in 8th row and 3rd column. So (8,3). Note that indexing starts from 0 for both rows and coloumns
# #### Reshaping an Array
# Suppose you have an array 'p':
# [[1, 5],
# [3, 7],
# [4, 9]]
#
# What will be the output of the following code? np.reshape(p, -1)
# Answer: 1-D Array
p = np.array([[1, 5], [3, 7], [4, 9]])
np.reshape(p,-1)
help(np.reshape)
# ##### Reshaping an Array
#
# Consider the array provided below:
#
# [[1, 2, 3, 4, 5]
# [6, 7, 8, 9, 10]
# [11, 12, 13, 14, 15]
# [16, 17, 18, 19, 20]]
#
# Now, you are expected to generate the following array out of it:
#
# [[1, 3]
# [5, 7]
# [9, 11]
# [13, 15]
# [17, 19]]
#
# Which code will give you the correct output?
#
# #### Answer
# Step 1: Subset the array and apply the condition
#
# Step 2: reshape the array into a 5x2 matrix
a = np.array([[1, 2, 3, 4, 5],[6, 7, 8, 9, 10],[11, 12, 13, 14, 15],[16, 17, 18, 19, 20]])
a
a[a%2!=0].reshape(5,2)
# Reshaping an array
# Suppose you have an array 'p'
#
# [[1, 5],
# [3, 7],
# [4, 9]]
#
# What will be the output of the following code?
#
# np.reshape(p, (1, -1))
#
p = np.array([[1, 5], [3, 7], [4, 9]])
p.shape
p.ndim
p1 = np.reshape(p,(1,-1))
p1
p1.ndim
# ##### Stacking arrays
#
# Description
# Merge the three arrays provided to you to form a one 4x4 array.
#
# [Hint: Check the function np.transpose() in the 'Manipulating Arrays' notebook provided.]
#
#
#
# Input:
#
# #### Array 1: 3*3
#
# [[7, 13, 14]
#
# [18, 10, 17]
#
# [11, 12, 19]]
#
#
#
# ##### Array 2: 1-D array
#
# [16, 6, 1]
#
#
#
# #### Array 3: 1*4 array
#
# [[5, 8, 4, 3]]
#
#
#
# ##### Output:
#
# [[7 13 14 5]
#
# [18 10 17 8]
#
# [11 12 19 4]
#
# [16 6 1 3]]
array1 = np.array([[7, 13, 14],[18, 10, 17],[11, 12, 19]])
array2 = np.array([16, 6, 1])
array3= np.array([[5, 8, 4, 3]])
array1.shape
array2.shape
array3.shape
new_array = np.vstack((array1,array2))
new_array
new_array.shape
temp_array = np.transpose(new_array)
temp_array
temp_array.shape
final_array = np.vstack((temp_array,array3))
final_array
output = np.transpose(final_array)
output
# ##### Numpy inbuilt functions
# ###### Raise all the elements in the output array to the power of 3
import numpy as np
np.power(output,3)
np.arange(9).reshape(3,3)
x = np.array([-1,1,-2,3,-5,7, -10])
np.absolute(x)
| Practise notebook on Mathematical Operations on Arrays - 1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ---
#
# _You are currently looking at **version 1.2** of this notebook. To download notebooks and datafiles, as well as get help on Jupyter notebooks in the Coursera platform, visit the [Jupyter Notebook FAQ](https://www.coursera.org/learn/python-machine-learning/resources/bANLa) course resource._
#
# ---
# # Assignment 3 - Evaluation
#
# In this assignment you will train several models and evaluate how effectively they predict instances of fraud using data based on [this dataset from Kaggle](https://www.kaggle.com/dalpozz/creditcardfraud).
#
# Each row in `fraud_data.csv` corresponds to a credit card transaction. Features include confidential variables `V1` through `V28` as well as `Amount` which is the amount of the transaction.
#
# The target is stored in the `class` column, where a value of 1 corresponds to an instance of fraud and 0 corresponds to an instance of not fraud.
import numpy as np
import pandas as pd
# ### Question 1
# Import the data from `fraud_data.csv`. What percentage of the observations in the dataset are instances of fraud?
#
# *This function should return a float between 0 and 1.*
# +
def answer_one():
# Your code here
df = pd.read_csv('fraud_data.csv')
return df['Class'].value_counts()[1]/len(df['Class']) # Return your answer
answer_one()
# +
# Use X_train, X_test, y_train, y_test for all of the following questions
from sklearn.model_selection import train_test_split
df = pd.read_csv('readonly/fraud_data.csv')
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# -
# ### Question 2
#
# Using `X_train`, `X_test`, `y_train`, and `y_test` (as defined above), train a dummy classifier that classifies everything as the majority class of the training data. What is the accuracy of this classifier? What is the recall?
#
# *This function should a return a tuple with two floats, i.e. `(accuracy score, recall score)`.*
# +
def answer_two():
from sklearn.dummy import DummyClassifier
from sklearn.metrics import recall_score
# Your code here
dummy_majority = DummyClassifier(strategy = 'most_frequent').fit(X_train, y_train)
y_dummy_predictions = dummy_majority.predict(X_test)
return (dummy_majority.score(X_test, y_test), recall_score(y_test, y_dummy_predictions)) # Return your answer
answer_two()
# -
# ### Question 3
#
# Using X_train, X_test, y_train, y_test (as defined above), train a SVC classifer using the default parameters. What is the accuracy, recall, and precision of this classifier?
#
# *This function should a return a tuple with three floats, i.e. `(accuracy score, recall score, precision score)`.*
# +
def answer_three():
from sklearn.metrics import recall_score, precision_score, accuracy_score
from sklearn.svm import SVC
# Your code here
svm = SVC(kernel='rbf', C=1).fit(X_train, y_train)
svm_predicted = svm.predict(X_test)
return (accuracy_score(y_test,svm_predicted), recall_score(y_test,svm_predicted), precision_score(y_test,svm_predicted)) # Return your answer
answer_three()
# -
# ### Question 4
#
# Using the SVC classifier with parameters `{'C': 1e9, 'gamma': 1e-07}`, what is the confusion matrix when using a threshold of -220 on the decision function. Use X_test and y_test.
#
# *This function should return a confusion matrix, a 2x2 numpy array with 4 integers.*
# +
def answer_four():
from sklearn.metrics import confusion_matrix
from sklearn.svm import SVC
# Your code here
svm = SVC(kernel='rbf', C = 1e9, gamma = 1e-07).fit(X_train, y_train)
y_scores_svm = svm.decision_function(X_test)
y_scores_svm = np.where(y_scores_svm > -220, 1, 0)
return confusion_matrix(y_test, y_scores_svm) # Return your answer
answer_four()
# -
# ### Question 5
#
# Train a logisitic regression classifier with default parameters using X_train and y_train.
#
# For the logisitic regression classifier, create a precision recall curve and a roc curve using y_test and the probability estimates for X_test (probability it is fraud).
#
# Looking at the precision recall curve, what is the recall when the precision is `0.75`?
#
# Looking at the roc curve, what is the true positive rate when the false positive rate is `0.16`?
#
# *This function should return a tuple with two floats, i.e. `(recall, true positive rate)`.*
# +
def answer_five():
# Your code here
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import roc_curve, auc
from sklearn.linear_model import LogisticRegression
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('seaborn')
# %matplotlib notebook
y_scores_lr = LogisticRegression().fit(X_train, y_train).decision_function(X_test)
precision, recall, thresholds = precision_recall_curve(y_test, y_scores_lr)
closest_zero = np.argmin(np.abs(thresholds))
closest_zero_p = precision[closest_zero]
closest_zero_r = recall[closest_zero]
plt.figure()
plt.xlim([0.0, 1.01])
plt.ylim([0.0, 1.01])
plt.plot(precision, recall, label='Precision-Recall Curve')
plt.plot(closest_zero_p, closest_zero_r, 'o', markersize = 12, fillstyle = 'none', c='r', mew=3)
plt.xlabel('Precision', fontsize=16)
plt.ylabel('Recall', fontsize=16)
plt.axes().set_aspect('equal')
plt.show()
fpr_lr, tpr_lr, _ = roc_curve(y_test, y_scores_lr)
roc_auc_lr = auc(fpr_lr, tpr_lr)
plt.figure()
plt.xlim([-0.01, 1.00])
plt.ylim([-0.01, 1.01])
plt.plot(fpr_lr, tpr_lr, lw=3, label='LogRegr ROC curve (area = {:0.2f})'.format(roc_auc_lr))
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.title('ROC curve (1-of-10 digits classifier)', fontsize=16)
plt.legend(loc='lower right', fontsize=13)
plt.plot([0, 1], [0, 1], color='navy', lw=3, linestyle='--')
plt.axes().set_aspect('equal')
plt.show()
prc = list(zip(np.around(precision, decimals=3), np.around(recall, decimals=3)))
rocc= list(zip(np.around(fpr_lr, decimals=3), np.around(tpr_lr, decimals=3)))
recall =[item for item in prc if item[0] == 0.75][0][1]
tpr = [item for item in rocc if item[0] >= 0.16 and item[0] <= 0.17][0][1]
return (recall, tpr)# Return your answer
answer_five()
# -
# ### Question 6
#
# Perform a grid search over the parameters listed below for a Logisitic Regression classifier, using recall for scoring and the default 3-fold cross validation.
#
# `'penalty': ['l1', 'l2']`
#
# `'C':[0.01, 0.1, 1, 10, 100]`
#
# From `.cv_results_`, create an array of the mean test scores of each parameter combination. i.e.
#
# | | `l1` | `l2` |
# |:----: |---- |---- |
# | **`0.01`** | ? | ? |
# | **`0.1`** | ? | ? |
# | **`1`** | ? | ? |
# | **`10`** | ? | ? |
# | **`100`** | ? | ? |
#
# <br>
#
# *This function should return a 5 by 2 numpy array with 10 floats.*
#
# *Note: do not return a DataFrame, just the values denoted by '?' above in a numpy array. You might need to reshape your raw result to meet the format we are looking for.*
# +
def answer_six():
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
# Your code here
lrc = LogisticRegression()
grid_values = {'penalty': ['l1', 'l2'], 'C':[0.01, 0.1, 1, 10, 100]}
grid_lrc = GridSearchCV(lrc, param_grid = grid_values, cv=3, scoring = 'recall')
best_lrc = grid_lrc.fit(X_train,y_train)
penalty_list = best_lrc.cv_results_['mean_test_score']
l1l2_list = []
for i in list(range(0,10,2)):
l1l2_list.append([penalty_list[i], penalty_list[i+1]])
l1l2_list = np.array(l1l2_list)
return l1l2_list # Return your answer
answer_six()
# +
# Use the following function to help visualize results from the grid search
def GridSearch_Heatmap(scores):
# %matplotlib notebook
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure()
sns.heatmap(scores.reshape(5,2), xticklabels=['l1','l2'], yticklabels=[0.01, 0.1, 1, 10, 100])
plt.yticks(rotation=0);
GridSearch_Heatmap(answer_six())
# -
| Course3_Applied_Machine_Learning_in_Python/Assignment+3.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/trista-paul/DS-Unit-1-Sprint-2-Data-Wrangling/blob/master/DS_Unit_1_Sprint_Challenge_2_Data_Wrangling.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="4yMHi_PX9hEz" colab_type="text"
# # Data Science Unit 1 Sprint Challenge 2
#
# ## Data Wrangling
#
# In this Sprint Challenge you will use data from [Gapminder](https://www.gapminder.org/about-gapminder/), a Swedish non-profit co-founded by <NAME>. "Gapminder produces free teaching resources making the world understandable based on reliable statistics."
# - [Cell phones (total), by country and year](https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/ddf--datapoints--cell_phones_total--by--geo--time.csv)
# - [Population (total), by country and year](https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/ddf--datapoints--population_total--by--geo--time.csv)
# - [Geo country codes](https://github.com/open-numbers/ddf--gapminder--systema_globalis/blob/master/ddf--entities--geo--country.csv)
#
# These two links have everything you need to successfully complete the Sprint Challenge!
# - [Pandas documentation: Working with Text Data](https://pandas.pydata.org/pandas-docs/stable/text.html]) (one question)
# - [Pandas Cheat Sheet](https://github.com/pandas-dev/pandas/blob/master/doc/cheatsheet/Pandas_Cheat_Sheet.pdf) (everything else)
# + [markdown] id="wWEU2GemX68A" colab_type="text"
# ## Part 0. Load data
#
# You don't need to add or change anything here. Just run this cell and it loads the data for you, into three dataframes.
# + id="bxKtSi5sRQOl" colab_type="code" colab={}
import pandas as pd
cell_phones = pd.read_csv('https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/ddf--datapoints--cell_phones_total--by--geo--time.csv')
population = pd.read_csv('https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/ddf--datapoints--population_total--by--geo--time.csv')
geo_country_codes = (pd.read_csv('https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/ddf--entities--geo--country.csv')
.rename(columns={'country': 'geo', 'name': 'country'}))
# + [markdown] id="AZmVTeCsX9RC" colab_type="text"
# ## Part 1. Join data
# + [markdown] id="GLzX58u4SfEy" colab_type="text"
# First, join the `cell_phones` and `population` dataframes (with an inner join on `geo` and `time`).
#
# The resulting dataframe's shape should be: (8590, 4)
# + id="GVV7Hnj4SXBa" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="0ace953e-5d4d-4eab-9803-07585a1273b2"
cellandpop = cell_phones.merge(population, on=['geo', 'time'], how='inner')
cellandpop.shape
# + [markdown] id="xsXpDbwwW241" colab_type="text"
# Then, select the `geo` and `country` columns from the `geo_country_codes` dataframe, and join with your population and cell phone data.
#
# The resulting dataframe's shape should be: (8590, 5)
# + id="Q2LaZta_W2CE" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="232785c5-e5bb-45d5-a426-7868fe2efcf3"
df = cellandpop.merge(geo_country_codes[['geo', 'country']], how='inner')
df.shape
# + [markdown] id="oK96Uj7vYjFX" colab_type="text"
# ## Part 2. Make features
# + [markdown] id="AD2fBNrOYzCG" colab_type="text"
# Calculate the number of cell phones per person, and add this column onto your dataframe.
#
# (You've calculated correctly if you get 1.220 cell phones per person in the United States in 2017.)
# + id="gBQRnCXZvGil" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 118} outputId="8bac287f-392b-4fa4-89ec-f41bd1f5b7f1"
df.dtypes
# + id="2KR1Q-ZMv30T" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 299} outputId="9158d002-692b-41c4-a3ea-206766bb4c6d"
df['cell_per_person'] = df.cell_phones_total/df.population_total
df[df.country == 'United States'].tail()
# + [markdown] id="S3QFdsnRZMH6" colab_type="text"
# Modify the `geo` column to make the geo codes uppercase instead of lowercase.
# + id="93ADij8_YkOq" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 195} outputId="ca1dd862-8e23-46e7-fbf2-ee1d5c961788"
df.geo = df.geo.str.upper()
df.head()
# + [markdown] id="hlPDAFCfaF6C" colab_type="text"
# ## Part 3. Process data
# + [markdown] id="k-pudNWve2SQ" colab_type="text"
# Use the describe function, to describe your dataframe's numeric columns, and then its non-numeric columns.
#
# (You'll see the time period ranges from 1960 to 2017, and there are 195 unique countries represented.)
# + id="g26yemKre2Cu" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 304} outputId="c880d0b4-f77d-481f-9ae7-29be6a93bfc0"
import numpy as np
df.describe()
# + id="JKKcVnKzzAXW" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 166} outputId="40bf27f9-01b7-4243-a0c2-530b6295bbc4"
df.describe(exclude = np.number)
# + [markdown] id="zALg-RrYaLcI" colab_type="text"
# In 2017, what were the top 5 countries with the most cell phones total?
#
# Your list of countries should have these totals:
#
# | country | cell phones total |
# |:-------:|:-----------------:|
# | ? | 1,474,097,000 |
# | ? | 1,168,902,277 |
# | ? | 458,923,202 |
# | ? | 395,881,000 |
# | ? | 236,488,548 |
#
#
# + id="JdlWvezHaZxD" colab_type="code" colab={}
# This optional code formats float numbers with comma separators
pd.options.display.float_format = '{:,}'.format
# + id="1QCbmKMp9j6r" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 225} outputId="6b2fd582-26e1-48ff-9228-c6fa8f7121cb"
year = df[df['time'] == 2017]
first = year[['country', 'cell_phones_total']].groupby('country').first()
sort = first.sort_values('cell_phones_total', ascending = False)
sort.head(5)
# + [markdown] id="03V3Wln_h0dj" colab_type="text"
# 2017 was the first year that China had more cell phones than people.
#
# What was the first year that the USA had more cell phones than people?
# + id="KONQkQZ3haNC" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 114} outputId="3c1603e9-29a0-419a-9ce3-71dff8659891"
usa = df[df['country']=='United States']
threshold = usa[usa['cell_phones_total']>usa['population_total']]
sort = threshold.sort_values('time', ascending=True)
sort.head(1)
# + [markdown] id="ZopQ_lL9EUCT" colab_type="text"
# 2014 was the first year the total number of cell phones in the USA surpassed the population.
# + [markdown] id="6J7iwMnTg8KZ" colab_type="text"
# ## Part 4. Reshape data
# + [markdown] id="LP9InazRkUxG" colab_type="text"
# Create a pivot table:
# - Columns: Years 2007—2017
# - Rows: China, India, United States, Indonesia, Brazil (order doesn't matter)
# - Values: Cell Phones Total
#
# The table's shape should be: (5, 11)
# + id="JD7mXXjLj4Ue" colab_type="code" colab={}
years = df[(df['time']>=2007) & (df['time']<=2017)]
years = years.set_index('country')
countrylist = ['China', 'India', 'United States', 'Indonesia', 'Brazil']
countries = years.loc[countrylist]
# + id="ZkE0MV7RGDHw" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 262} outputId="ff7419e4-a21f-495c-899e-6b6e352e6d1a"
pivot = countries.pivot_table(index='country', columns='time', values='cell_phones_total')
pivot
# + id="olaGpM1JOlAH" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="800ac777-55ce-4bf0-b302-190829448d02"
pivot.shape
# + [markdown] id="CNKTu2DCnAo6" colab_type="text"
# #### OPTIONAL BONUS QUESTION!
#
# Sort these 5 countries, by biggest increase in cell phones from 2007 to 2017.
#
# Which country had 935,282,277 more cell phones in 2017 versus 2007?
# + id="O4Aecv1fmQlj" colab_type="code" colab={}
# + [markdown] id="7iHkMsa3Rorh" colab_type="text"
# If you have the time and curiosity, what other questions can you ask and answer with this data?
| DS_Unit_1_Sprint_Challenge_2_Data_Wrangling.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import os
os.chdir("20")
files = os.listdir()
print (files)
acc_dict = {
'bi' : {
'et':{},
'rf':{},
},
'tri' : {
'et':{},
'rf':{},
},
'multi' : {
'et':{},
'rf':{},
}
}
# +
def populate(filename,key,algo):
df = pd.read_csv(filename)
all_subjects = ['[2]','[3]','[4]','[5]','[6]','[7]','[8]','[9]','[10]','[11]','[13]','[14]','[15]','[16]','[17]']
for sub in all_subjects:
all_sub = df[df['subjects_in_test'] == sub]
# print(all_sub.shape)
# break
mean = all_sub['acc'].mean()
std = all_sub['acc'].std()
if mean >= .99:
print(sub,mean,key,algo)
elif mean <= .80:
print (sub,mean,key,algo)
val = "{} {} {}".format(round(mean,3),u"\u00B1",round(std,3))
acc_dict[key][algo][sub.replace('[','').replace(']','')] = val
# print ("\n")
# break
# -
for filename in files:
if '2' in filename:
if 'et' in filename:
populate(filename,'bi','et')
else:
populate(filename,'bi','rf')
if '3' in filename:
if 'et' in filename:
populate(filename,'tri','et')
else:
populate(filename,'tri','rf')
if '4' in filename:
if 'et' in filename:
populate(filename,'multi','et')
else:
populate(filename,'multi','rf')
acc_dict
bi = pd.DataFrame(acc_dict['bi'])
tri = pd.DataFrame(acc_dict['tri'])
multi = pd.DataFrame(acc_dict['multi'])
frames = [bi.T, tri.T, multi.T]
concated = pd.concat(frames)
concated
concated['Affective State'] = ['Bi','Bi','Tri','Tri','Multi','Multi']
concated['Classifiers'] = ['ET','RF','ET','RF','ET','RF']
cols = ['Affective State', 'Classifiers','2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '13', '14', '15', '16', '17']
# cols = cols[-1:] + cols[:-1]
concated = concated[cols]
concated
concated.to_csv("acc.csv")
concated.to_latex()
| User Independence Analysis/Random Forest (Code + Result Analysis + Log)/others/UI/Untitled.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Alice creates a qubit
from cqc.pythonLib import *
#
# Interface for Alice.
#
alice = CQCConnection("Alice")
#
# Helper function to see how many qubits Alice has in her quantum register.
#
def num_qubits():
reg = alice.active_qubits
n = len(reg)
print("Alice has {} qubit(s).".format(n))
#
# Helper function to clean up Alice's quantum register.
#
def cleanup_qubits():
reg = alice.active_qubits
n = len(reg)
for i in range(n):
q = reg[0]
m = q.measure() # removes q from reg; we are not interested in m
print("Measured and discarded qubit {}".format(i+1))
print("Alice's register is empty.")
#
# Alice creates a |0> qubit.
#
q = qubit(alice) # creates |0> by default
#
# Let's see how many qubits Alice has in her quantum register.
#
num_qubits()
#
# Alice measures q. What result do you expect?
#
m = q.measure()
print("Measurement returned {}".format(m))
#
# In SimulaQron, measurement discards the qubit, and removes it from the quantum register.
# Due to measurement, the qubit's state collapses, so it's considered "used up" by SimulaQron.
#
num_qubits()
#
# Let now Alice create a |1> qubit!
#
q = qubit(alice) # creates |0> by default
q.X() # the Pauli X gate: X|0>=|1>
#
# Alice measures q. What result do you expect?
#
m = q.measure()
print("Measurement returned {}".format(m))
#
# Again, the qubit is gone, due to measurement.
#
num_qubits()
# # Alice applies Hadamard gate
# - Reminder:
# > $H|0\rangle=|+\rangle=\frac{1}{\sqrt{2}}|0\rangle+\frac{1}{\sqrt{2}}|1\rangle$
# >
# > $H|1\rangle=|-\rangle=\frac{1}{\sqrt{2}}|0\rangle-\frac{1}{\sqrt{2}}|1\rangle$
# +
#
# Let now Alice create a |+> qubit!
#
q = qubit(alice) # creates |0> by default
q.H() # the Hadamard gate: H|0>=|+>
#
# I'd like to see the amplitudes to be sure... CAN I HAVE A LOOK?
#
# NO WAY, SimulaQron doesn't let you cheat! You HAVE TO MEASURE if you want any information out of a qubit!
#
# +
#
# Alice measures q. This will return randomly 0 or 1, with 50% chance each.
# (Because in q, both |0> and |1> have absolute amplitude squared equal to 1/2.)
#
m = q.measure()
print("Measurement returned {}".format(m))
#
# In theory, this is a so-called True Random Number Generator (TRNG).
# (A quantum random number generator typically creates and measures |+> qubits under the hood.)
#
# -
# # Exercise: create and measure a $|-\rangle$ qubit
# - Solution: double-click here.
# <font color="white">
# # prepare |-> in variable q
# q = qubit(alice) # |0>
# q.X() # changes q to |1>, as X|0>=|1>
# q.H() # changes q to |->, as H|1>=|->
# # measure q in variable m (again, it's 50-50% chance to get 0 or 1, can you explain why?)
# m = q.measure()
# </font>
# +
#
# Write your code below.
#
# prepare |-> in variable q
YOUR CODE COMES HERE
# measure q in variable m (again, it's 50-50% chance to get 0 or 1, can you explain why?)
YOUR CODE COMES HERE
print("Measurement returned {}".format(m))
#
# It's a typical mistake to accidentally prepare the |+> state instead of |->.
# Check the "official" solution above to make sure you really prepared the |-> state.
#
# Bonus question: what is X|+>?
# Hint: what's the amplitude vector of X|+>?
#
# +
#
# To prove that it's really 50-50% chance, place your previous code below.
# Here we create and measure 100 times the |-> qubit.
#
N = 100
count = 0
for i in range(0, N):
PLACE YOUR CODE TO CREATE AND MEASURE |-> FROM ABOVE HERE
USE INDENTATION OF 4 SPACES INSIDE THE FOR LOOP, LIKE THIS VERY LINE, OTHERWISE PYTHON COMPLAINS
print(m, end=' ')
count += m
print("\n\nNumber of 0s: {}\nNumber of 1s: {}".format(N-count, count))
# -
#
# But wait a moment! Didn't I say MAX. 20 QUBITS in the register? We've just created 100! How comes?
#
# Sure, we did, but each qubit was measured immediately after creation. So at no point in time were there more than 1 qubit in Alice's register.
#
# Let's see what Alice has now in her register.
#
num_qubits()
# # Alice encodes a bit as qubit and sends it to Bob
# - Encoding a bit in the **Standard way**:
# > $0\leftrightarrow|0\rangle$
# >
# > $1\leftrightarrow|1\rangle$
#
#
# - Encoding a bit in the **Hadamard way**:
# > $0\leftrightarrow|+\rangle$
# >
# > $1\leftrightarrow|-\rangle$
# +
#
# Alice sends 1 to Bob, encoded in the Hadamard way.
#
q = qubit(alice) # |0>
q.X() # |1>
q.H() # |-> (this corresponds to 1 in the Hadamard way of encoding)
num_qubits()
print("Sending qubit to Bob...")
alice.sendQubit(q, "Bob") # qubit is gone, it's with Bob now
num_qubits()
# -
# # Continue with Bob now
# Click to open [Bob's notebook](Bob.ipynb).
| notebooks/Alice.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Implementing HMM for POS Tagging
#
# In this notebook we will implement a Hidden Markov Model for Parts-of-Speech Tagging.
#
# Associating each word in a sentence with a proper POS (part of speech) is known as POS tagging or POS annotation. POS tags are also known as word classes, morphological classes, or lexical tags. The tag in case of is a POS tag, and signifies whether the word is a noun, adjective, verb, and so on.
#
# 
# +
import nltk
import numpy as np
from tqdm import tqdm
# +
# Inorder to get the notebooks running in current directory
import os, sys, inspect
currentdir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
sys.path.insert(0, parentdir)
import hmm
# -
# We will be making use of the Treebank corpora with the Universal Tagset.
#
# The Treebank corpora provide a syntactic parse for each sentence. The NLTK data package includes a 10% sample of the Penn Treebank (in treebank), as well as the Sinica Treebank (in sinica_treebank).
#
# Not all corpora employ the same set of tags. Initially we want to avoid the complications of these tagsets, so we use a built-in mapping to the "Universal Tagset".
# +
# Download the treebank corpus from nltk
nltk.download('treebank')
# Download the universal tagset from nltk
nltk.download('universal_tagset')
# -
# Reading the Treebank tagged sentences
nltk_data = list(nltk.corpus.treebank.tagged_sents(tagset='universal'))
# # A Look At Our Data
#
# Let's take a look at the data we have
#
# We have a total of *100,676* words tagged.
#
# This includes a total of *12* unique tags with *12,408* unique words.
# Sample Output
for (word, tag) in nltk_data[0]:
print(f"Word: {word} | Tag: {tag}")
tagged_words = [tags for sent in nltk_data for tags in sent]
print(f"Size of tagged words: {len(tagged_words)}")
print(f"Example: {tagged_words[0]}")
tags = list({tag for (word, tag) in tagged_words})
print(f"Tags: {tags} | Number of tags: {len(tags)}")
words = list({word for (word, tag) in tagged_words})
print(f"First 15 Words: {words[:15]} | Number of words: {len(words)}")
# # Computing Transition and Emission Matrices
#
# Once we have our data ready, we will need to create our transition and emission matrices.
#
# Inorder to do this, we need to understand how we calculate these probability matrices.
#
# ## For Transition Matrices
#
# - For a given source_tag and destination_tag do:
# - Get total counts of source_tag in corpus (all_tags)
# - Loop through all_tags and do:
# - Get all counts of instances where at timestep i, the source_tag had dest_tag at timestep i + 1
# - Get probability for dest_tag given source_tag as *P(destintation tag | source tag) = Count of destination tag to source tag / Count of source tag*
#
# ## For Emission Matrices
#
# - For a given word and tag do:
# - Get a list of (word, tag) from each pair of tagged words such that the iterating tag matches the given tag.
# - From this stored tags that was created from the given tag, create a list of words for which the iterating word matches the given word
# - Using the counts of the word given a tag and the total occurances of a tag, we compute the conditional probability *P(word | tag) = Count of word and tag / Count of given tag*
def compute_transition_matrix(tags, tagged_words):
all_tags = [tag for (_, tag) in tagged_words]
def compute_counts(dest_tag, source_tag):
count_source = len([t for t in all_tags if t == source_tag])
count_dest_source = 0
for i in range(len(all_tags) - 1):
if all_tags[i] == source_tag and all_tags[i + 1] == dest_tag:
count_dest_source += 1
return count_dest_source, count_source
trans_matrix = np.zeros((len(tags), len(tags)))
for i, source_tag in enumerate(tags):
for j, dest_tag in enumerate(tags):
count_dest_source, count_source = compute_counts(dest_tag, source_tag)
trans_matrix[i, j] = count_dest_source / count_source
return trans_matrix
# +
# transition_matrix = compute_transition_matrix(tags, tagged_words)
# -
# Computing Emission Probability
def compute_emission_matrix(words, tags, tagged_words):
def compute_counts(given_word, given_tag):
tags = [word_tag for word_tag in tagged_words if word_tag[1] == given_tag]
word_given_tag = [word for (word, _) in tags if word == given_word]
return len(word_given_tag), len(tags)
emi_matrix = np.zeros((len(tags), len(words)))
for i, tag in enumerate(tags):
for j, word in enumerate(tqdm(words, desc=f"Current Tag - {tag}")):
count_word_given_tag, count_tag = compute_counts(word, tag)
emi_matrix[i, j] = count_word_given_tag / count_tag
return emi_matrix
# +
# emission_matrix = compute_emission_matrix(words, tags, tagged_words)
# -
def save_matrices(observable_states, emission_matrix, hidden_states, transition_matrix, save_dir="state"):
try:
os.mkdir(save_dir)
except FileExistsError:
raise FileExistsError(
"Directory already exists! Please provide a different output directory!"
)
np.save(save_dir + '/observable_states', observable_states)
np.save(save_dir + '/emission_matrix', emission_matrix)
np.save(save_dir + '/hidden_states', hidden_states)
np.save(save_dir + '/transition_matrix', transition_matrix)
# +
# save_matrices(words, emission_matrix, tags, transition_matrix)
# -
def load_matrices(save_dir):
observable_states = np.load(save_dir + '/observable_states.npy')
emission_matrix = np.load(save_dir + '/emission_matrix.npy')
hidden_states = np.load(save_dir + '/hidden_states.npy')
transition_matrix = np.load(save_dir + '/transition_matrix.npy')
return observable_states.tolist(), emission_matrix, hidden_states.tolist(), transition_matrix
observable_states, emission_matrix, hidden_states, transition_matrix = load_matrices('./state')
# Let us take a look at some of the observed and hidden states
observable_states[:15], hidden_states
# We will need to write a function that tokenizes the input sentence with the index specified by our saved words list.
def tokenize(input_sent, words):
lookup = {word: i for i, word in enumerate(words)}
tokenized = []
input_sent = input_sent.split(' ')
for word in input_sent:
idx = lookup[word]
tokenized.append(idx)
return tokenized
# # Run The Markov Model
#
# Let us now run our Hidden Markov Model with the observered and hidden states with our transition and emission matrices.
model = hmm.HiddenMarkovModel(
observable_states, hidden_states, transition_matrix, emission_matrix
)
model.print_model_info()
input_sent = '<NAME> , 61 years old , will join the board as a nonexecutive director Nov. 29 .'
input_tokens = tokenize(input_sent, observable_states)
print(input_tokens)
# # Forward Algorithm
alpha, a_probs = model.forward(input_tokens)
hmm.print_forward_result(alpha, a_probs)
# # Backward Algorithm
#
# Let us verify the output of the Forward Algorithm by running the Backward Algorithm.
beta, b_probs = model.backward(input_tokens)
hmm.print_backward_result(beta, b_probs)
# # Viterbi Algorithm
#
# This algorithm will give us the POS for each token or word. This is useful to generate POS Tagger for different sentences.
path, delta, phi = model.viterbi(input_tokens)
hmm.print_viterbi_result(input_tokens, observable_states, hidden_states, path, delta, phi)
| notebooks/POS-HMM.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# **Вопросы для повторения:**
#
# * что такое calling convention?
# * что такое RVO / NRVO / copy elision простыми словами?
# * Какие рекомендации по возвращению объекта из функции?
#
# <details>
# <summary>Ответ</summary>
# <p>
#
# ```c++
# предпочтительнее конструировать объект в return, чтобы отработал copy elision, компилятор его гарантирует
#
# House build() {
# ...
# return House(...);
# }
# если без именованного объекта не обойтись, желательно заиспользовать NRVO (и молиться на добрую волю компилятора)
#
# House build(bool stone) {
# House house;
# if (stone) {
# ... // setup stone house
# } else {
# ... // setup another house
# }
# return house;
# }
# ```
#
# </p>
# </details>
#
# * как будем передавать параметры и возвращать значение?
# * функция считает кол-во символов `char c` в `std::string s`
# * функция возвращает длину радиус-вектора точки:
#
# ```c++
# struct Point
# {
# double x;
# double y;
# double z;
# };
# ```
#
# * функция возвращает длину радиус-вектора взвешенной точки:
#
# ```c++
# struct WeightedPoint
# {
# double x;
# double y;
# double z;
# double w;
# };
# ```
| 2020/sem1/lecture10_algo_lambdas/repetition.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] pycharm={"name": "#%% md\n"}
# # Pivot tables
# + pycharm={"name": "#%%\n"}
import numpy as np
import pandas as pd
import matplotlib as plt
# + pycharm={"name": "#%%\n"}
df = pd.read_csv('DATA/Sales_Funnel_CRM.csv')
df
# + pycharm={"name": "#%%\n"}
# help(pd.pivot)
# + pycharm={"name": "#%%\n"}
licenses = df[['Company', 'Product', 'Licenses']]
licenses
# + pycharm={"name": "#%%\n"}
pd.pivot(data=licenses, index='Company', columns='Product', values='Licenses')
# + pycharm={"name": "#%%\n"}
df
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index='Company', aggfunc='sum')
# + pycharm={"name": "#%%\n"}
df.groupby('Company').sum()
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index='Company', aggfunc='sum', values=['Licenses', 'Sale Price'])
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index=['Account Manager', 'Contact'], values=['Sale Price'], aggfunc='sum')
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index=['Account Manager', 'Contact'], values=['Sale Price'], columns=['Product'], aggfunc='sum')
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index=['Account Manager', 'Contact'], values=['Sale Price'], columns=['Product'], aggfunc='sum', fill_value=0)
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index=['Account Manager', 'Contact'], values=['Sale Price'], columns=['Product'], aggfunc=[np.sum, np.mean], fill_value=0)
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index=['Account Manager', 'Contact', 'Product'], values=['Sale Price'], aggfunc=[np.sum, np.mean], fill_value=0)
# + pycharm={"name": "#%%\n"}
pd.pivot_table(df, index=['Account Manager', 'Contact', 'Product'], values=['Sale Price'], aggfunc=[np.sum, np.mean], fill_value=0, margins=True)
# + pycharm={"name": "#%%\n"}
| 011_pandas_pivot_tables.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # B99 and NBC Show Scraper
#
# In this notebook, I'll be scraping Wikipedia info on "Brooklyn Nine Nine".
#Imports
from bs4 import BeautifulSoup as bs
import requests
import pandas
#Get content
r = requests.get("https://en.wikipedia.org/wiki/Brooklyn_Nine-Nine")
soup = bs(r.content)
content = soup.prettify()
# ### Finding Relevant Info from HTML Tags
info_box = soup.find(class_='infobox vevent')
info_rows = info_box.find_all('tr')
def get_content_value(row_data):
if row.find("li") is not None:
return [li.get_text(" ", strip = True).replace("\xa0", ' ') for li in row.find_all('li')]
else:
return row.find('td').get_text(" ", strip = True).replace("\xa0", ' ')
# +
show_info={}
X = info_box.find_all('tr')
for index, row in enumerate(X):
if index==0:
show_info['Title']=row.find('th').get_text()
elif index == 1:
continue
else:
x = row.find('th')
y = row.find('td')
if x is not None and y is not None:
key = row.find('th').get_text()
value = get_content_value(row.find('td'))
show_info[key] = value
for key in show_info:
print (f"{key}:{show_info[key]}")
# -
# Done!
#
#
| Brooklyn Nine Nine Scraper.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.5 64-bit (''spectral'': conda)'
# name: python3
# ---
# # Example of spectral contrasting
#
# This example demonstrates how to use the contrasting module for finding the frequency bands that provide maximal separation between two timeseries arrays.
#
# #### To open this notebook in collab, right-click the link below and open in a new tab:
# [](https://colab.research.google.com/github/theonlyid/spectral/blob/release/1.1/docs/notebooks/python/example_contrast.ipynb)
#
# +
# Run this cell if running notebook from Google Colab
if 'google.colab' in str(get_ipython()):
print('Running on CoLab')
# clone repo from github
# !git clone -b release/1.1 --depth 1 https://github.com/theonlyid/spectral.git
# install the package
# %cd spectral
# !python setup.py install
# %cd ..
# -
# import depencies
import numpy as np
from spectral.contrast import decimate, contrast, filter
from spectral.data_handling import *
# +
# The dataset is composed of two objects: a timeseries and params
# The 'simulate()' method simulates timeseries data
# We'll generate two timeseries' and contrast them
ts1 = DataArray.simulate_recording(fs=1000, nchannels=10, ntrials=5, seed=10)
ts2 = DataArray.simulate_recording(fs=1000, nchannels=10, ntrials=5, seed=30)
ts = np.append(ts1, ts2, axis=-1)
print(f"shape of ts array={np.shape(ts)}")
# +
# DataArray stores the timeseries array along with its sampling frequency
da = DataArray(ts, fs=1000)
# TsParams stores the params for time-frequency analysis
params = TsParams(nperseg=64, noverlap=48)
# A dataset object is a combination of DataArray and TsParams
# This ensures that they are locked together to enable correct processing
ds = Dataset(da, params)
# We're going to decimate our data by a factor of 10
ds.data_array.data = decimate(ds.data_array.data, 10)
ds.data_array.fs = ds.data_array.fs//10
# y stores binary labels of the trials to contrast
y = np.ones((ds.data_array.data.shape[-1]))
y[5:] = 0
# Contrast then returns an SNR matrix with combinations of band_start and band_stop
# This will inform timseries filtering that enables maximal separability between signals
snr, f = contrast(ds, y, fs=100, nperseg=64, noverlap=48)
# -
# Plot the SNR matrix to visualize results
import matplotlib.pyplot as plt
plt.pcolormesh(f, f, np.log(snr));
plt.xlabel('Band stop (Hz)');
plt.ylabel('Band start (Hz)');
plt.grid();
plt.colorbar();
# Find the frequency range where SNR is highest
idx = np.where(snr==max(snr.ravel()))
start_band, stop_band = np.squeeze(f[idx[0]]), np.squeeze(f[idx[1]])
print(f"optimal band for separating the signals is {start_band:.1f} - {stop_band:.1f} Hz")
# +
# filter the signal within that range
# first check if band ranges aren't extremums
start_band = 0.1 if start_band == 0 else start_band
stop_band = 49.9 if stop_band ==50 else stop_band
filtered_signal = filter(data=ds.data_array.data, low_pass=start_band, high_pass=stop_band, fs=100)
# generate t for plotting
t = np.arange(start=0, stop=filtered_signal.shape[1]/100, step=1/100)
plt.plot(t, filtered_signal[0,:,1]);
plt.plot(t, filtered_signal[0,:,-1]);
plt.xlabel('time (s)')
plt.ylabel('amplitude')
| docs/notebooks/python/example_contrast.ipynb |
// ---
// jupyter:
// jupytext:
// text_representation:
// extension: .js
// format_name: light
// format_version: '1.5'
// jupytext_version: 1.14.4
// kernelspec:
// display_name: Javascript (Node.js)
// language: javascript
// name: javascript
// ---
// # Maps
//
// The flip side to `Set` in JavaScript is `Map`. Maps are objects that hold key/value pairs, and act the same way that other iterables do in JavaScript. When you iterate over a `Map` object, the iterator does so in insertion order.
var a = [[1, "a"], [2, "b"], [3, "c"]]
var m = new Map(a);
console.log(m);
// Much like with `Set`, `Map` does not offer a `length` property, but instead depends on `size`
console.log(m.length);
console.log(m.size);
// ## You can check for entries in a similar manner as `Set`
var b = m.has(1);
console.log(b);
// ## And managing maps also works the similarly
//
// The biggest difference is that instead of `add()` with maps, we have `set()`, which takes two parameters: a key and a value.
// +
m.set(4,"d");
m.delete(1);
console.log(m);
// -
m.clear();
console.log(m);
var m1 = new Map(a);
console.log(m1);
// ## And, of course, you can `get()` items as well
var v = m1.get(3);
console.log(v);
// ## What about iterating?
//
// Iterating works the same way as it did with the `Set` object. You can use `values()`, `entries()`, and `forEach()`. But remember that `entries()` and the callback function for `forEach()` used key/value pairs. This makes way more sense with maps than sets.
var iter = m1.entries();
for(var e of iter) {
console.log(e);
}
// ## Now about `keys()` and `values()`
//
// With `Set` the `values()` method provided the entries in a set, while the `keys()` method did the same thing. This is because the `Set` specification wanted to remain closely aligned with `Map`. With maps, `keys()` will actually return the keys.
var k = m1.keys();
console.log(k);
| Notebooks/Maps.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
import sys
sys.path.append(r'../../HelperFunctions')
import DataHelper as dh
import AugHelper as ah
import ModelConfigHelper as mch
path_info = dh.getFileDirectory()
path_info
dh.showFileCount(pathInfo=path_info)
df = dh.getDataFrame(pathInfo=path_info)
df.info()
df.dtypes
df
from PIL import Image
img = Image.open(df.iloc[5,0])
img
dictlabels=dh.getLabelDicts(df=df)
dictlabels
df = dh.dfPreProcess(df=df)
df.info()
df.dtypes
df
from sklearn.model_selection import train_test_split
X_train,X_val = train_test_split(df,test_size=0.2)
augDict = ah.getAugmentation(augmentRequired=False,angle=90)
augDict
imgTransform = ah.getImageTransform(200)
imgTransform
X_train = ah.augmentDataFrame(df=X_train,augDict=augDict)
X_train
X_train['augmentation'].unique()
X_val
X_val['augmentation'].unique()
train_ds = ah.KroniaDataset(data=X_train,transforms=imgTransform)
val_ds = ah.KroniaDataset(data=X_train,transforms=imgTransform)
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
train_dl = DataLoader(dataset=train_ds,batch_size=32,shuffle=True)
val_dl = DataLoader(dataset=val_ds,batch_size=32,shuffle=True)
from SoilTypeModel import SoilTypeModel
torch.manual_seed(42)
model = SoilTypeModel()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
train_loss,val_loss = mch.trainModel(model=model,train_dl=train_dl,val_dl=val_dl,criterion=criterion,optim=optimizer,train_samples=len(X_train),batch_size=32,soft_max=False,epochs=20)
mch.visualiziseTrainResults(train_losses=train_loss,test_losses=val_loss)
# +
# mch.saveModel(model=model,filename="SoilTypeClassifier")
| Soil/SoilType/SoilTypeClassifier.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# #[Work work, money money][repeatyoutube]
# Combine job board and BLS data to find trends in job / industry growth in Chicago and elsewhere.
#
# ##Data:
# - BLS: http://www.bls.gov/help/hlpforma.htm,
# + Occupational Employment Statistics http://download.bls.gov/pub/time.series/oe/
# + National Compensation Survey http://download.bls.gov/pub/time.series/nc/
# - Census:
# + county shapefiles https://www.census.gov/geo/maps-data/data/tiger-cart-boundary.html
# + or, better, Mike Bostock's [US-atlas project] [usatlas] (census shapefiles ⇒ GeoJSON)
# - [JobsAggregator][ja]: (results from all 5 of [Indeed][indeed], [SimplyHired][simply], [CareerBuilder][cb], [Monster][monster], and [CareerJet][cj]):
#
# ##Technology:
# - Apache Spark on an Amazon EC2 (Elastic Cloud 2) cluster; instructions below
# - input data stored in Amazon S3 buckets, output written to HDFS permanent storage
# - Images rendered in D3 via a private [Lightning][lightning] server
#
# [bls_api]: http://www.bls.gov/developers/api_python.htm
# [cb]: http://developer.careerbuilder.com/
# [cj]: http://www.careerjet.com/partners/
# [indeed]: http://www.indeed.com/publisher
# [ja]: http://www.jobsaggregator.com/US/
# [lightning]: http://lightning-viz.org/documentation/
# [monster]: http://partner.monster.com/developers
# [repeatyoutube]: http://listenonrepeat.com/watch/?v=SvpsoEOJ0_E
# [simply]: https://simply-partner.com/partners-signup
# [usatlas]: https://github.com/mbostock/us-atlas
# ##Steps to launch Spark AWS EC2 cluster
# Here is how to do your own:
#
# 0. Get an [Amazon Web Services account] [aws_main]
# 1. Get the [newest version of Spark, pre-built for Hadoop 2.4] [spark_source]. It has to be
# pre-built so that the pyspark client will have the proper jars
#
# curl -O http://www.apache.org/dyn/closer.cgi/spark/spark-1.3.0/spark-1.3.0-bin-hadoop2.4.tgz
# tar -xzvf spark-1.3.0-bin-hadoop2.4.tgz
#
#
# 2. Launch it on Amazon EC2 using a script in the ec2 directory in the source [instructions] [ec2_quickstart]
#
# cd spark-1.3.0-bin-hadoop2.4
# export SPARK_HOME=`pwd`
# $SPARK_HOME/ec2/spark-ec2 --slaves 2 \
# --key-pair <Amazon_Keypair_Name> \
# --identity-file <path/to/Amazon_Keypair.pem> \
# --copy-aws-credentials \
# --zone us-east-1b --instance-type=m1.medium \
# launch spark_cluster
#
# 3. At the end of the startup run, it will show a URL we can use to connect, or else
# navigate to the EC2 dashboard through the [Amazon Web Service Console] [aws_console]
# to find out what the IP address is for the master node. The Spark dashboard is on
# port 8080 by default: `<ip address>:8080` <br/>
# Mine is here: http://ec2-54-166-72-95.compute-1.amazonaws.com:8080/
#
#
# [aws_main]: http://aws.amazon.com/
# [spark_source]: https://spark.apache.org/downloads.html
# [ec2_quickstart]: http://spark.apache.org/docs/latest/ec2-scripts.html
# [aws_console]: https://console.aws.amazon.com
# ##Steps to launch IPython notebook connecting to AWS EC2 cluster
#
# A handful of blogs describe how to set up IPython + Spark; they're helpful but outdated:
#
# 1. [Presentation of two distinct ways to do it][cloudera]
# 2. [Too much information][fperez]
# 3. [Two separate ways presented as if they were one][ramheiser]
#
# IPython options are built into pyspark. Follow option 3 above to create a password-protected IPython notebook configuration file, but instead of setting `c.NotebookApp.ip = *` like it says, use the Master's designated address. (e.g. `'ec2-54-166-72-95.compute-1.amazonaws.com'`).
#
# ###Configuration for Python 2.7
# PySpark prefers Python 2.7 but Python 2.6 is the default Python for an Amazon EC2 instance. The below are a set of scripts to install Python 2.7 and some dependencies I need (`requests`, `pymongo` and `lxml`). All of the others are PySpark dependencies.
#
# SSH in to the master node and execute:
#
# xargs -L1 -a commands.txt ./go.sh
#
#
# ####with `commands.txt` containing:
#
# yes | yum install python27-devel
# unlink /etc/alternatives/python
# ln -s /usr/bin/python2.7 /etc/alternatives/python
#
# wget https://bootstrap.pypa.io/ez_setup.py
# python ez_setup.py
# easy_install pip
# rm ez_setup.py
# rm setuptools-16.0.zip
#
# easy_install Cython
# yes | yum install freetype-devel
# yes | yum install libpng-devel
# pip install numpy scipy
# pip install matplotlib
#
# yes | yum install libxml2-devel
# yes | yum install libxslt-devel
# pip install requests lxml pymongo
# pip install ipython[notebook]
#
#
# ####and `go.sh` containing:
#
# # #!/usr/bin/env bash
#
# echo '------------------------------------------------'
# echo $@; $@
#
# while read worker
# do
# ssh ${worker} "echo 'machine ${worker}'; $@"
# done < /root/spark/conf/slaves
#
#
#
#
# ###Back to launching an IPython notebook
# 1. Add a Custom TCP rule to the `spark_cluster-master` Amazon EC2 security group to allow the port for the IPython notebook (8888 by default; Cloudera says to watch for potential port assignment collisions but 8888 worked fine.)
# a. Navigate to the [EC2 console][ec2_console]
# b. Click on the master instance, and then on the security group assigned to that instance
# c. It will open another user interface. Click on **Actions** → **Edit inbound rules** and add a custom TCP rule with protocol **TCP**, port range **8888**, and source **Anywhere**
#
# 2. Set environment variables for `<spark-home>/bin/pyspark` to use to launch a properly configured IPython notebook, ready to use pyspark. As of Spark 1.2:
#
# export PYSPARK_DRIVER_PYTHON=ipython
# export PYSPARK_DRIVER_PYTHON_OPTS='notebook --profile=pyspark'
#
#
#
# 3. Launch pyspark. Specifically designate the master node or else `pyspark` will run as a local standalone spark instance:
#
# /root/spark/bin/pyspark --master spark://ec2-54-166-72-95.compute-1.amazonaws.com:7077
#
#
# And to ensure persistence after logging out, the above was wrapped in `nohup <command> &`
#
# [ec2_console]: https://console.aws.amazon.com/ec2/v2
# [spark_submit]: https://spark.apache.org/docs/1.2.0/submitting-applications.html
# [aws_console]: https://console.aws.amazon.com
# [fperez]: http://nbviewer.ipython.org/gist/fperez/6384491/00-Setup-IPython-PySpark.ipynb
# [cloudera]: http://blog.cloudera.com/blog/2014/08/how-to-use-ipython-notebook-with-apache-spark/
# [ramheiser]: http://ramhiser.com/2015/02/01/configuring-ipython-notebook-support-for-pyspark/
###
# There is now a 'SparkContext' instance available as the named variable 'sc'
# and there is a HiveContext instance (for SQL-like queries) available as 'sqlCtx'
#
## Check that this simple code runs without error:
sc.parallelize([1,2,3,4,5]).take(2)
###
# Inspect the SparkContext [sc] or the HiveContext [sqlCtx]
#help(sc)
help(sqlCtx)
# ##De Pie :: (parallel calculation)
#
# ${SPARK_HOME}/spark/examples/src/main/python/pi.py
#
# <img src="http://www.mixingbowlgal.com/wp-content/uploads/2013/06/IMG_3999.jpg" style="width:250px;"></img>
#
# +
from random import random
from operator import add
def monte_carlo(_):
"""4 * area (1 quadrant of a unit circle) pi"""
x = random()
y = random()
return 4.0 if pow(x, 2) + pow(y, 2) < 1 else 0
N = 1000
parts = 2
sc.parallelize(xrange(N), parts).map(monte_carlo).reduce(add) / N
# -
# ##The data
# We will merge a job postings dataset and the BLS Occupations and Earnings data together, using location, occupation, and possibly industry category.
#
#
# ###Amazon S3 buckets
#
# Information on connecting to S3 from Spark is at the bottom of the
# [Spark docs on EC2 scripts] [ec2-scripts], and copied here:
#
#
# > You can specify a path in S3 as input through a URI of the form `s3n://<bucket>/path`. To provide AWS credentials for S3 access, launch the Spark cluster with the option `--copy-aws-credentials`. Full instructions on S3 access using the Hadoop input libraries can be found on the [Hadoop S3 page] [hadoop-s3].
# >
# > In addition to using a single input file, you can also use a directory of files as input by simply giving the path to the directory.
#
# Separate files listing the BLS categories were loaded to an [Amazon S3 bucket][s3buckets]: `tts-wwmm/areas.txt`, `tts-wwmm/industry.txt`, `tts-wwmm/occupations.txt`. All are two-column files with no headers, and a tab separating the variable code and the variable label.
#
#
# ###The JobsAggregator data
#
# JobsAggregator aggregates from Indeed, SimplyHired, CareerBuilder, Monster, and CareerJet, showing the most recent job posts on each site.
#
# The function `scrape` in the file `jobs_aggregator_scraper.py` iteratively scrapes the site, and returns a generator that yields current job listings (as a dictionary) for a given state and occupation.
#
# ###The BLS data
#
# The data are actually *not* best pulled via the [BLS API][blsapi]. It has only the most recent year's statistics; the rest are archived at http://www.bls.gov/oes/tables.htm.
#
# The contents of the archive files were loaded to a MongoDB database. There was manual work to handle different column names and file formats for the different years. Data are available by occupation at the state and national level, and at more aggregated levels for municipal areas. Below is an example of one observation. The `ANNUAL` and `OVERALL` entries are lists of dictionaries with one entry per year, possibly with data from as far back as 2000.
#
# ```
# { "AREA": "3800003",
# "AREA_NAME": "East Central North Dakota",
# "ST": "ND",
# "OCC_CODE": "39-1012",
# "OCC_TITLE": "Slot key persons",
# "ANNUAL": [
# {
# "YEAR": 2009,
# "pct90": 34530,
# "pct75": 32730,
# "pct50": 30170,
# "pct25": 27610,
# "pct10": 19250
# }
# ],
# "OVERALL": [
# {
# "YEAR": 2009,
# "JOBS_1000": 0.923,
# "TOT_EMP": 40,
# "A_MEAN": 29100,
# "MEAN_PRSE": 5.6,
# "H_MEAN": 13.99,
# "EMP_PRSE": 30.2
# }
# ]
# }
# ```
#
# [blsapi]: http://www.bls.gov/developers/api_sample_code.htm
# [ec2-scripts]: https://spark.apache.org/docs/1.2.0/ec2-scripts.html
# [hadoop-s3]: http://wiki.apache.org/hadoop/AmazonS3
# [s3buckets]: http://docs.aws.amazon.com/AmazonS3/latest/dev/UsingBucket.html
# ##Load the lookup tables from Amazon S3
# +
### ------------------------------------------------- AMAZON ----- ###
# ⇒ These files identify columns that will be common to the job
# board data and the BLS datasets.
#
# To use S3 buckets add `--copy-aws-credentials` to the ec2 launch command.
#
# Create a Resilient Distributed Dataset with the
# list of occupations in the BLS dataset:
# https://s3.amazonaws.com/tts-wwmm/occupations.txt
from pyspark.sql import Row
# Load the occupations lookups and convert each line to a Row.
lines = sc.textFile('s3n://tts-wwmm/occupations.txt')
Occupation = Row('OCC_CODE', 'OCC_TITLE')
occ = lines.map(lambda l: Occupation( *l.split('\t') ))
# Do the same for the areas lookups.
lines = sc.textFile('s3n://tts-wwmm/areas.txt')
Area = Row('AREA', 'AREA_NAME')
area = lines.map(lambda l: Area( *l.split('\t') ))
area_df = sqlCtx.createDataFrame(area)
area_df.registerTempTable('area')
# Just to show how sqlCtx.sql works
states = sqlCtx.sql("SELECT AREA_NAME, AREA FROM area WHERE AREA RLIKE '^S.*'")
print states.take(2)
# Same as above, but result is another Resilient Distributed Dataset
states = area.filter(lambda a: a.AREA.startswith('S'))
# Create every combination of occupation, state
occ_by_states = occ.cartesian(states)
# Broadcast makes a static copy of the variable available to all nodes
#broadcast_state_names = sc.broadcast(broadcast_state_names)
#
#print broadcast_state_names.take(2)
# -
# ##Scrape JobsAggregator
# +
### ----------------------------------------- JOBS_AGGREGATOR ----- ###
#
# Make `jobs_aggregator_scraper.py` available on all nodes
# and iteratively get the top 5 jobs from each poster in each state for
# each occupation via JobsAggregator.com
sc.addPyFile('s3n://tts-wwmm/jobsaggregator_scraper.py')
def scrape_occupation(occ_state):
from jobsaggregator_scraper import scrape
occ_row, state_entry = occ_state
return [Row(**job)
for job in scrape(state=state_entry[1], occupation=occ_row.OCC_TITLE)]
jobs = occ_by_states.flatMap(scrape_occupation).distinct()
jobs_df = sqlCtx.inferSchema(jobs)
jobs_df.registerTempTable('jobs')
# -
jobs_df.toJSON().saveAsTextFile('wwmm/jobsaggregator_json')
jobs.saveAsTextFile('wwmm/jobsaggregator_df')
jobs.take(2)
# ##Load OES Data
# +
### -------------------------------------------- BLS OES DATA ----- ###
#
# The OES data were loaded to a mongolabs database. Read the URI
# (which has a user name and password) from an environment variable
# and create a connection. The pymongo API is very simple.
#
# Datasets are stored one entry per Occupation ID (OCC_ID)
# per area (00-0000)
from pymongo import MongoClient
MONGO_URI = os.getenv('MONGO_URI')
client = MongoClient(MONGO_URI) # connection
oe = client.oe # database
# Confirm we can get data from each collection
oo = oe['nat'].find(filter={'OCC_CODE':'00-0000'},
projection={'_id':False,
'OCC_CODE':True, 'OCC_TITLE':True,
'ANNUAL':{'$slice':-5}, 'OVERALL':{'$slice':-2}})
for o in oo:
print o
# +
# Which OCC contains software-type people?
occ_df = sqlCtx.createDataFrame(occ)
occ_df.registerTempTable('occ')
computer_jobs = sqlCtx.sql((
"SELECT OCC_CODE, OCC_TITLE "
"FROM occ "
"WHERE OCC_TITLE RLIKE 'omputer'"
)).collect()
# -
for row in computer_jobs:
print "{OCC_CODE}: {OCC_TITLE}".format(**row.asDict())
# +
# Want Chicago's area code
chicago = sqlCtx.sql((
"SELECT AREA, AREA_NAME "
"FROM area "
"WHERE AREA_NAME RLIKE 'icago' or AREA_NAME RLIKE 'llinois'"
)).collect()
print "\n".join("{}: {}".format(c.AREA, c.AREA_NAME) for c in chicago)
# +
# Now get the data:
## -------------------------------------- National
desired_data = {'_id':False,
'ANNUAL':{'$slice':-5}, 'OVERALL':{'$slice':-2}}
nat = oe['nat'].find(filter={'OCC_CODE':'15-1131'},
projection=desired_data)
nat = [n for n in nat]
len(nat)
# +
## -------------------------------------- State
il = oe['st'].find(filter={'OCC_CODE':'15-1131',
'AREA':'17'},
projection=desired_data)
il = [i for i in il]
len(il)
# -
## -------------------------------------- Municipal Areas
## The lookup for chicago didn't work...
## ... so I am looking through all of the municipal areas...
chi = oe['ma'].find(filter={'OCC_CODE':'15-1131'},
projection=desired_data)
chi = [c for c in chi if 'IL' in c['AREA_NAME']]
len(chi)
# +
# Get the mean
import tablib
nat_annual = tablib.Dataset()
nat_annual.dict = nat[0]['ANNUAL']
il_annual = tablib.Dataset()
il_annual.dict = il[0]['ANNUAL']
chi_annual = tablib.Dataset()
chi_annual.dict = chi[1]['ANNUAL']
# -
# ##Lightning-viz plots for inline D3.js in IPython
#
# http://lightning-viz.org/
#
# +
from lightning import Lightning
lgn = Lightning(host="https://tts-lightning.herokuapp.com",
ipython=True,
auth=("<EMAIL>", "password"))
# -
# Median salaries
lgn.line(series=[nat_annual['pct50'], il_annual['pct50'], chi_annual['pct50']],
index=nat_annual['YEAR'],
color=[[0,0,0],[255,0,0],[0,155,0]],
size=[5,2,2],
xaxis="Year",
yaxis="Median annual salary")
# +
# How about regionally?
all_states = oe['st'].find(filter={'OCC_CODE':'15-1131'},
projection={'$_id': False,
'OVERALL':{'$slice':-2}})
all_states = [a for a in all_states]
len(all_states)
# -
state_abbrs = [a['ST'] for a in all_states]
mean_salaries = [a['OVERALL'][0]['A_MEAN'] for a in all_states]
num_employed = [a['OVERALL'][0]['TOT_EMP'] for a in all_states]
# Mean salaries
print "max average salary:", max(mean_salaries)
print "Illinois:", mean_salaries[state_abbrs.index('IL')]
lgn.map(regions=state_abbrs, values=mean_salaries)
# Employees
print "Most programmers:", max(num_employed)
print "Illinois:", num_employed[state_abbrs.index('IL')]
lgn.map(regions=state_abbrs, values=num_employed)
salaries = tablib.Dataset(*zip(state_abbrs, mean_salaries),
headers=('State', 'Salary'))
employees= tablib.Dataset(*zip(state_abbrs, num_employed),
headers=('State', 'Employees'))
salaries = salaries.sort("Salary", reverse=True)
print "\n".join("{s[0]}: {s[1]:0,.0f}".format(s=s) for s in salaries[:5])
employees = employees.sort("Employees", reverse=True)
print "\n".join("{e[0]}: {e[1]:0,.0f}".format(e=e) for e in employees[:5])
| WorkWorkMoneyMoney.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
skngb = GaussianNB()
dataframe = pd.read_csv('Fertilizer Prediction.csv')
dataframe.head()
drop = dataframe[dataframe.columns[6:8]]
df = dataframe.drop(drop, axis=1)
soil = list(np.unique(df['Soil Type']))
soil
crop = list(np.unique(df['Crop Type']))
crop
df['Soil Type'].replace(['Black', 'Clayey', 'Loamy', 'Red', 'Sandy'], [1,2,3,4,5], inplace=True)
df['Crop Type'].replace(['Barley',
'Cotton',
'Ground Nuts',
'Maize',
'Millets',
'Oil seeds',
'Paddy',
'Pulses',
'Sugarcane',
'Tobacco',
'Wheat'], [1,2,3,4,5,6,7,8,9,10,11], inplace=True)
df.head()
X = df[df.columns[:6]]
#
y = df['Fertilizer Name']
sample = np.array([29, 58, 57, 1, 9, 12])
sample = sample.reshape(1, -1)
skngb.fit(X, y)
print(skngb)
skngb.predict(sample)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
X_train.shape
X_test.shape
skngb.fit(X_train, y_train)
predict = skngb.predict(X_test)
from sklearn.metrics import accuracy_score
score = accuracy_score(y_test, predict)
score
print(metrics.classification_report(y_test, predict))
print(metrics.confusion_matrix(y_test, predict))
| NB_Fertilizer_Accuracy.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.6.10 64-bit (''PythonData'': conda)'
# language: python
# name: python361064bitpythondataconda29aaf85289304b3d90fb2f723b3eead0
# ---
import pandas as pd
df = pd.read_csv('Resources/cities.csv')
df.head()
html = df.to_html()
print(html)
| .ipynb_checkpoints/convert-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Grouping your data
#
# + activity=false run_control={"read_only": false}
import warnings
warnings.simplefilter('ignore', FutureWarning)
import matplotlib
matplotlib.rcParams['axes.grid'] = True # show gridlines by default
# %matplotlib inline
import pandas as pd
# +
if pd.__version__.startswith('0.23'):
# this solves an incompatibility between pandas 0.23 and datareader 0.6
# taken from https://stackoverflow.com/questions/50394873/
core.common.is_list_like = api.types.is_list_like
from pandas_datareader.wb import download
# -
# ?download
YEAR = 2013
GDP_INDICATOR = 'NY.GDP.MKTP.CD'
gdp = download(indicator=GDP_INDICATOR, country=['GB','CN'],
start=YEAR-5, end=YEAR)
gdp = gdp.reset_index()
gdp
gdp.groupby('country')['NY.GDP.MKTP.CD'].aggregate(sum)
gdp.groupby('year')['NY.GDP.MKTP.CD'].aggregate(sum)
LOCATION='comtrade_milk_uk_monthly_14.csv'
# +
# LOCATION = 'http://comtrade.un.org/api/get?max=5000&type=C&freq=M&px=HS&ps=2014&r=826&p=all&rg=1%2C2&cc=0401%2C0402&fmt=csv'
# + activity=false run_control={"read_only": false}
milk = pd.read_csv(LOCATION, dtype={'Commodity Code':str, 'Reporter Code':str})
milk.head(3)
# + activity=false run_control={"read_only": false}
COLUMNS = ['Year', 'Period','Trade Flow','Reporter', 'Partner', 'Commodity','Commodity Code','Trade Value (US$)']
milk = milk[COLUMNS]
# + activity=false run_control={"read_only": false}
milk_world = milk[milk['Partner'] == 'World']
milk_countries = milk[milk['Partner'] != 'World']
# + activity=false run_control={"read_only": false}
milk_countries.to_csv('countrymilk.csv', index=False)
# + activity=false run_control={"read_only": false}
load_test = pd.read_csv('countrymilk.csv', dtype={'Commodity Code':str, 'Reporter Code':str})
load_test.head(2)
# + activity=false run_control={"read_only": false}
milk_imports = milk[milk['Trade Flow'] == 'Imports']
milk_countries_imports = milk_countries[milk_countries['Trade Flow'] == 'Imports']
milk_world_imports=milk_world[milk_world['Trade Flow'] == 'Imports']
# + activity=false run_control={"read_only": false}
milkImportsInJanuary2014 = milk_countries_imports[milk_countries_imports['Period'] == 201401]
milkImportsInJanuary2014.sort_values('Trade Value (US$)',ascending=False).head(10)
# -
# # Make sure you run all the cell above!
# ## Grouping data
#
# On many occasions, a dataframe may be organised as groups of rows where the group membership is identified based on cell values within one or more 'key' columns. **Grouping** refers to the process whereby rows associated with a particular group are collated so that you can work with just those rows as distinct subsets of the whole dataset.
#
# The number of groups the dataframe will be split into is based on the number of unique values identified within a single key column, or the number of unique combinations of values for two or more key columns.
#
# The `groupby()` method runs down each row in a data frame, splitting the rows into separate groups based on the unique values associated with the key column or columns.
#
# The following is an example of the steps and code needed to split a dataframe.
# ### Grouping the data
# Split the data into two different subsets of data (imports and exports), by grouping on trade flow.
# + activity=false run_control={"read_only": false}
groups = milk_countries.groupby('Trade Flow')
# -
# Inspect the first few rows associated with a particular group:
# + activity=false run_control={"read_only": false}
groups.get_group('Imports').head()
# -
# As well as grouping on a single term, you can create groups based on multiple columns by passing in several column names as a list. For example, generate groups based on commodity code *and* trade flow, and then preview the keys used to define the groups.
# + activity=false run_control={"read_only": false}
GROUPING_COMMFLOW = ['Commodity Code','Trade Flow']
groups = milk_countries.groupby(GROUPING_COMMFLOW)
groups.groups.keys()
# -
# Retrieve a group based on multiple group levels by passing in a tuple that specifies a value for each index column. For example, if a grouping is based on the `'Partner'` and `'Trade Flow'` columns, the argument of `get_group` has to be a partner/flow pair, like `('France', 'Import')` to get all rows associated with imports from France.
# + activity=false run_control={"read_only": false}
GROUPING_PARTNERFLOW = ['Partner','Trade Flow']
groups = milk_countries.groupby(GROUPING_PARTNERFLOW)
GROUP_PARTNERFLOW= ('France','Imports')
groups.get_group( GROUP_PARTNERFLOW )
# -
# To find the leading partner for a particular commodity, group by commodity, get the desired group, and then sort the result.
# + activity=false run_control={"read_only": false}
groups = milk_countries.groupby(['Commodity Code'])
groups.get_group('0402').sort_values("Trade Value (US$)", ascending=False).head()
# -
# ### Task
#
# Using your own data set from Exercise 1, try to group the data in a variety of ways, finding the most significant trade partner in each case:
#
# - by commodity, or commodity code
# - by trade flow, commodity and year.
| Ajiboye Azeezat WT-21-011/2-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# IMPORT:
# +
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import matplotlib.pyplot as plt
import seaborn as sns
# -
# Loading Datasets
train_df = pd.read_csv('datasets/kaggle/application_train.csv')
test_df = pd.read_csv('datasets/kaggle/application_test.csv')
# # Preprocessing
# +
le = LabelEncoder()
le_count = 0
for col in train_df:
if train_df[col].dtype == 'object':
if len(list(train_df[col].unique())) <= 2:
le.fit(train_df[col])
train_df[col] = le.transform(train_df[col])
test_df[col] = le.transform(test_df[col])
le_count += 1
train_df = pd.get_dummies(train_df)
test_df = pd.get_dummies(test_df)
# +
labels = train_df['TARGET']
train_df, test_df = train_df.align(test_df, join = 'inner', axis = 1)
train_df['TARGET'] = labels
# +
train_df['DAYS_EMPLOYED_ANOM'] = train_df["DAYS_EMPLOYED"] == 365243
train_df['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
train_df['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram')
plt.xlabel('Days Employment')
# -
test_df['DAYS_EMPLOYED_ANOM'] = test_df["DAYS_EMPLOYED"] == 365243
test_df['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
correlations = train_df.corr()['TARGET'].sort_values()
print(correlations.head(20))
print(correlations.tail(20))
# +
from sklearn.preprocessing import MinMaxScaler
from sklearn.impute import SimpleImputer
if 'TARGET' in train_df:
train = train_df.drop(columns = ['TARGET'])
else:
train = train_df.copy()
features = list(train.columns)
test = test_df.copy()
imputer = SimpleImputer(strategy = 'median')
scaler = MinMaxScaler(feature_range = (0, 1))
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(test_df)
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)
# +
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(C = 0.0001)
log_reg.fit(train, labels)
# -
log_reg_pred = log_reg.predict_proba(test)[:, 1]
# +
submit = test_df[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
submit.head()
# -
submit.to_csv('log_reg_baseline.csv', index = False)
| notebooks/Draft/sakib/Test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import cv2
import numpy as np
import os
from random import shuffle
from tqdm import tqdm
TRAIN_DIR = './dog-cat-data/train'
TEST_DIR = './dog-cat-data/test'
IMG_SIZE = 50
LR = 1e-3
# -
def label_img(img):
word_label = img.split('.')[-3]
if word_label == 'cat':
return [1,0]
elif word_label == 'dog':
return [0,1]
def create_train_data():
training_data = []
for img in tqdm(os.listdir(TRAIN_DIR)):
label = label_img(img)
path = os.path.join(TRAIN_DIR,img)
img = cv2.imread(path,cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (IMG_SIZE,IMG_SIZE))
training_data.append([np.array(img),np.array(label)])
shuffle(training_data)
np.save('./npy/train-data-dog-cat.npy', training_data)
return training_data
# train_data = create_train_data()
train_data = np.load('./npy/train-data-dog-cat.npy')
import keras
import matplotlib.pyplot as plt
import numpy
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Activation
from keras.utils import to_categorical
from keras.optimizers import SGD
from keras.layers import SimpleRNN
from keras import initializers
from keras.optimizers import RMSprop
from keras.models import load_model
from keras import regularizers
def get_model():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(IMG_SIZE, IMG_SIZE, 1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(2, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
print(model.summary())
return model
# +
train = train_data[:-500]
validate = train_data[-500:]
X = np.array([i[0] for i in train]).reshape(-1,IMG_SIZE,IMG_SIZE,1)
Y = [i[1] for i in train]
Y = np.array(Y)
validate_x = np.array([i[0] for i in validate]).reshape(-1,IMG_SIZE,IMG_SIZE,1)
validate_y = [i[1] for i in validate]
validate_y = np.array(validate_y)
# +
# # X[0][0]
# Y
# -
cnn = get_model()
history = cnn.fit(X, Y, epochs=5, verbose = 1, validation_data=(validate_x, validate_y))
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
# plt.savefig("cnn_accuracy_table_epoch500_wrong_pros.jpg")
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
# plt.savefig("cnn_loss_table_epoch500_wrong_pros.jpg")
plt.show()
cnn.save("dog-cat-cnn.h5")
def predict(filename, model):
path = os.path.join(TEST_DIR, filename)
img = cv2.imread(path,cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (IMG_SIZE,IMG_SIZE))
img = np.array(img)
data = img.reshape(-1, IMG_SIZE,IMG_SIZE,1)
out = model.predict(data)
if np.argmax(out) == 1:
str_label='Dog'
else:
str_label='Cat'
return str_label
m = load_model("cnn_epoch500.h5")
print(predict('517.jpg', m))
# +
import os
ctr_cat = 0
ctr_dog = 0
# for i in range(1, len(os.listdir(TEST_DIR))):
for i in range(1, 100):
o = predict(str(i) + '.jpg', m)
# print(o)
if o == 'Cat':
ctr_cat += 1
else:
ctr_dog += 1
print("ctr_cat, ctr_dog", ctr_cat, ctr_dog)
# -
| src/main/Notebooks/DogCat.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda root]
# language: python
# name: conda-root-py
# ---
# In this notebook, we mainly utilize extreme gradient boost to improve the prediction model originially proposed in TLE 2016 November machine learning tuotrial. Extreme gradient boost can be viewed as an enhanced version of gradient boost by using a more regularized model formalization to control over-fitting, and XGB usually performs better. Applications of XGB can be found in many Kaggle competitions. Some recommended tutorrials can be found
# Our work will be orginized in the follwing order:
#
# •Background
#
# •Exploratory Data Analysis
#
# •Data Prepration and Model Selection
#
# •Final Results
# # Background
# The dataset we will use comes from a class excercise from The University of Kansas on Neural Networks and Fuzzy Systems. This exercise is based on a consortium project to use machine learning techniques to create a reservoir model of the largest gas fields in North America, the Hugoton and Panoma Fields. For more info on the origin of the data, see Bohling and Dubois (2003) and Dubois et al. (2007).
#
# The dataset we will use is log data from nine wells that have been labeled with a facies type based on oberservation of core. We will use this log data to train a classifier to predict facies types.
#
# This data is from the Council Grove gas reservoir in Southwest Kansas. The Panoma Council Grove Field is predominantly a carbonate gas reservoir encompassing 2700 square miles in Southwestern Kansas. This dataset is from nine wells (with 4149 examples), consisting of a set of seven predictor variables and a rock facies (class) for each example vector and validation (test) data (830 examples from two wells) having the same seven predictor variables in the feature vector. Facies are based on examination of cores from nine wells taken vertically at half-foot intervals. Predictor variables include five from wireline log measurements and two geologic constraining variables that are derived from geologic knowledge. These are essentially continuous variables sampled at a half-foot sample rate.
#
# The seven predictor variables are:
# •Five wire line log curves include gamma ray (GR), resistivity logging (ILD_log10), photoelectric effect (PE), neutron-density porosity difference and average neutron-density porosity (DeltaPHI and PHIND). Note, some wells do not have PE.
# •Two geologic constraining variables: nonmarine-marine indicator (NM_M) and relative position (RELPOS)
#
# The nine discrete facies (classes of rocks) are:
#
# 1.Nonmarine sandstone
#
# 2.Nonmarine coarse siltstone
#
# 3.Nonmarine fine siltstone
#
# 4.Marine siltstone and shale
#
# 5.Mudstone (limestone)
#
# 6.Wackestone (limestone)
#
# 7.Dolomite
#
# 8.Packstone-grainstone (limestone)
#
# 9.Phylloid-algal bafflestone (limestone)
#
# These facies aren't discrete, and gradually blend into one another. Some have neighboring facies that are rather close. Mislabeling within these neighboring facies can be expected to occur. The following table lists the facies, their abbreviated labels and their approximate neighbors.
#
#
# Facies/ Label/ Adjacent Facies
#
# 1 SS 2
#
# 2 CSiS 1,3
#
# 3 FSiS 2
#
# 4 SiSh 5
#
# 5 MS 4,6
#
# 6 WS 5,7
#
# 7 D 6,8
#
# 8 PS 6,7,9
#
# 9 BS 7,8
#
# # Exprolatory Data Analysis
# After the background intorduction, we start to import the pandas library for some basic data analysis and manipulation. The matplotblib and seaborn are imported for data vislization.
# +
# %matplotlib inline
import pandas as pd
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
import matplotlib.colors as colors
import xgboost as xgb
import numpy as np
from sklearn.metrics import confusion_matrix, f1_score, accuracy_score, roc_auc_score
from classification_utilities import display_cm, display_adj_cm
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_svmlight_files
from sklearn.model_selection import StratifiedKFold, cross_val_score, LeavePGroupsOut
from sklearn.datasets import make_classification
from xgboost.sklearn import XGBClassifier
from scipy.sparse import vstack
#use a fixed seed for reproducibility
seed = 123
np.random.seed(seed)
# -
filename = './facies_vectors.csv'
training_data = pd.read_csv(filename)
training_data.head(10)
# Set columns 'Well Name' and 'Formation' to be category
training_data['Well Name'] = training_data['Well Name'].astype('category')
training_data['Formation'] = training_data['Formation'].astype('category')
training_data.info()
training_data.describe()
# Check distribution of classes in whole dataset
# +
plt.figure(figsize=(5,5))
facies_colors = ['#F4D03F', '#F5B041','#DC7633','#6E2C00','#1B4F72',
'#2E86C1', '#AED6F1', '#A569BD', '#196F3D']
facies_labels = ['SS', 'CSiS', 'FSiS', 'SiSh', 'MS','WS', 'D','PS', 'BS']
facies_counts = training_data['Facies'].value_counts().sort_index()
facies_counts.index = facies_labels
facies_counts.plot(kind='bar',color=facies_colors,title='Distribution of Training Data by Facies')
# -
# Check distribution of classes in each well
wells = training_data['Well Name'].unique()
plt.figure(figsize=(15,9))
for index, w in enumerate(wells):
ax = plt.subplot(2,5,index+1)
facies_counts = pd.Series(np.zeros(9), index=range(1,10))
facies_counts = facies_counts.add(training_data[training_data['Well Name']==w]['Facies'].value_counts().sort_index())
#facies_counts.replace(np.nan,0)
facies_counts.index = facies_labels
facies_counts.plot(kind='bar',color=facies_colors,title=w)
ax.set_ylim(0,160)
# We can see that classes are very imbalanced in each well
plt.figure(figsize=(5,5))
sns.heatmap(training_data.corr(), vmax=1.0, square=True)
# # Data Preparation and Model Selection
# Now we are ready to test the XGB approach, and will use confusion matrix and f1_score, which were imported, as metric for classification, as well as GridSearchCV, which is an excellent tool for parameter optimization.
X_train = training_data.drop(['Facies', 'Well Name','Formation','Depth'], axis = 1 )
Y_train = training_data['Facies' ] - 1
dtrain = xgb.DMatrix(X_train, Y_train)
features = ['GR','ILD_log10','DeltaPHI','PHIND','PE','NM_M','RELPOS']
# The accuracy function and accuracy_adjacent function are defined in the following to quatify the prediction correctness.
# +
def accuracy(conf):
total_correct = 0.
nb_classes = conf.shape[0]
for i in np.arange(0,nb_classes):
total_correct += conf[i][i]
acc = total_correct/sum(sum(conf))
return acc
adjacent_facies = np.array([[1], [0,2], [1], [4], [3,5], [4,6,7], [5,7], [5,6,8], [6,7]])
def accuracy_adjacent(conf, adjacent_facies):
nb_classes = conf.shape[0]
total_correct = 0.
for i in np.arange(0,nb_classes):
total_correct += conf[i][i]
for j in adjacent_facies[i]:
total_correct += conf[i][j]
return total_correct / sum(sum(conf))
# -
# Before processing further, we define a functin which will help us create XGBoost models and perform cross-validation.
skf = StratifiedKFold(n_splits=5)
cv = skf.split(X_train, Y_train)
def modelfit(alg, Xtrain, Ytrain, useTrainCV=True, cv_fold=skf):
#Fit the algorithm on the data
alg.fit(Xtrain, Ytrain,eval_metric='merror')
#Predict training set:
dtrain_prediction = alg.predict(Xtrain)
#dtrain_predprob = alg.predict_proba(Xtrain)[:,1]
#Pring model report
print ("\nModel Report")
print ("Accuracy : %.4g" % accuracy_score(Ytrain,dtrain_prediction))
print ("F1 score (Train) : %f" % f1_score(Ytrain,dtrain_prediction,average='micro'))
#Perform cross-validation:
if useTrainCV:
cv_score = cross_val_score(alg, Xtrain, Ytrain, cv=cv_fold, scoring='f1_micro')
print ("CV Score : Mean - %.7g | Std - %.7g | Min - %.7g | Max - %.7g" %
(np.mean(cv_score), np.std(cv_score), np.min(cv_score), np.max(cv_score)))
#Pring Feature Importance
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar',title='Feature Importances')
plt.ylabel('Feature Importance Score')
# # General Approach for Parameter Tuning
# We are going to preform the steps as follows:
#
# 1.Choose a relatively high learning rate, e.g., 0.1. Usually somewhere between 0.05 and 0.3 should work for different problems.
#
# 2.Determine the optimum number of tress for this learning rate.XGBoost has a very usefull function called as "cv" which performs cross-validation at each boosting iteration and thus returns the optimum number of tress required.
#
# 3.Tune tree-based parameters(max_depth, min_child_weight, gamma, subsample, colsample_bytree) for decided learning rate and number of trees.
#
# 4.Tune regularization parameters(lambda, alpha) for xgboost which can help reduce model complexity and enhance performance.
#
# 5.Lower the learning rate and decide the optimal parameters.
# # Step 1:Fix learning rate and number of estimators for tuning tree-based parameters
# In order to decide on boosting parameters, we need to set some initial values of other parameters. Lets take the following values:
#
# 1.max_depth = 5
#
# 2.min_child_weight = 1
#
# 3.gamma = 0
#
# 4.subsample, colsample_bytree = 0.8 : This is a commonly used used start value.
#
# 5.scale_pos_weight = 1
#
# Please note that all the above are just initial estimates and will be tuned later. Lets take the default learning rate of 0.1 here and check the optimum number of trees using cv function of xgboost. The function defined above will do it for us.
xgb1= XGBClassifier(
learning_rate=0.05,
objective = 'multi:softmax',
nthread = 4,
seed = seed
)
xgb1
modelfit(xgb1, X_train, Y_train)
# # Step 2: Tune max_depth and min_child_weight
# +
param_test1={
'n_estimators':range(20, 100, 10)
}
gs1 = GridSearchCV(xgb1,param_grid=param_test1,
scoring='accuracy', n_jobs=4,iid=False, cv=skf)
gs1.fit(X_train, Y_train)
gs1.grid_scores_, gs1.best_params_,gs1.best_score_
# -
gs1.best_estimator_
# +
param_test2={
'max_depth':range(5,16,2),
'min_child_weight':range(1,15,2)
}
gs2 = GridSearchCV(gs1.best_estimator_,param_grid=param_test2,
scoring='accuracy', n_jobs=4,iid=False, cv=skf)
gs2.fit(X_train, Y_train)
gs2.grid_scores_, gs2.best_params_,gs2.best_score_
# -
gs2.best_estimator_
modelfit(gs2.best_estimator_, X_train, Y_train)
# # Step 3: Tune gamma
# +
param_test3={
'gamma':[0,.05,.1,.15,.2,.3,.4],
'subsample':[0.6,.7,.75,.8,.85,.9],
'colsample_bytree':[i/10.0 for i in range(4,10)]
}
gs3 = GridSearchCV(gs2.best_estimator_,param_grid=param_test3,
scoring='accuracy', n_jobs=4,iid=False, cv=skf)
gs3.fit(X_train, Y_train)
gs3.grid_scores_, gs3.best_params_,gs3.best_score_
# -
gs3.best_estimator_
modelfit(gs3.best_estimator_,X_train,Y_train)
# # Step 5: Tuning Regularization Parameters
# +
param_test4={
'reg_alpha':[0, 1e-5, 1e-2, 0.1, 0.2],
'reg_lambda':[0, .25,.5,.75,.1]
}
gs4 = GridSearchCV(gs3.best_estimator_,param_grid=param_test4,
scoring='accuracy', n_jobs=4,iid=False, cv=skf)
gs4.fit(X_train, Y_train)
gs4.grid_scores_, gs4.best_params_,gs4.best_score_
# -
modelfit(gs4.best_estimator_,X_train, Y_train)
gs4.best_estimator_
# +
param_test5={
'reg_alpha':[.15,0.2,.25,.3,.4],
}
gs5 = GridSearchCV(gs4.best_estimator_,param_grid=param_test5,
scoring='accuracy', n_jobs=4,iid=False, cv=skf)
gs5.fit(X_train, Y_train)
gs5.grid_scores_, gs5.best_params_,gs5.best_score_
# -
modelfit(gs5.best_estimator_, X_train, Y_train)
gs5.best_estimator_
# # Step 6: Reducing Learning Rate
xgb4 = XGBClassifier(
learning_rate = 0.025,
n_estimators=120,
max_depth=7,
min_child_weight=7,
gamma = 0.05,
subsample=0.6,
colsample_bytree=0.8,
reg_alpha=0.2,
reg_lambda =0.75,
objective='multi:softmax',
nthread =4,
seed = seed,
)
modelfit(xgb4,X_train, Y_train)
xgb5 = XGBClassifier(
learning_rate = 0.00625,
n_estimators=480,
max_depth=7,
min_child_weight=7,
gamma = 0.05,
subsample=0.6,
colsample_bytree=0.8,
reg_alpha=0.2,
reg_lambda =0.75,
objective='multi:softmax',
nthread =4,
seed = seed,
)
modelfit(xgb5,X_train, Y_train)
# Next we use our tuned final model to do cross validation on the training data set. One of the wells will be used as test data and the rest will be the training data. Each iteration, a different well is chosen.
# +
# Load data
filename = './facies_vectors.csv'
data = pd.read_csv(filename)
# Change to category data type
data['Well Name'] = data['Well Name'].astype('category')
data['Formation'] = data['Formation'].astype('category')
X_train = data.drop(['Facies', 'Formation','Depth'], axis = 1 )
X_train_nowell = X_train.drop(['Well Name'], axis=1)
Y_train = data['Facies' ] - 1
# Final recommended model based on the extensive parameters search
model_final = gs5.best_estimator_
model_final.fit( X_train_nowell , Y_train , eval_metric = 'merror' )
# +
# Leave one well out for cross validation
well_names = data['Well Name'].unique()
f1=[]
for i in range(len(well_names)):
# Split data for training and testing
train_X = X_train[X_train['Well Name'] != well_names[i] ]
train_Y = Y_train[X_train['Well Name'] != well_names[i] ]
test_X = X_train[X_train['Well Name'] == well_names[i] ]
test_Y = Y_train[X_train['Well Name'] == well_names[i] ]
train_X = train_X.drop(['Well Name'], axis = 1 )
test_X = test_X.drop(['Well Name'], axis = 1 )
# Train the model based on training data
# Predict on the test set
predictions = model_final.predict(test_X)
# Print report
print ("\n------------------------------------------------------")
print ("Validation on the leaving out well " + well_names[i])
conf = confusion_matrix( test_Y, predictions, labels = np.arange(9) )
print ("\nModel Report")
print ("-Accuracy: %.6f" % ( accuracy(conf) ))
print ("-Adjacent Accuracy: %.6f" % ( accuracy_adjacent(conf, adjacent_facies) ))
print ("-F1 Score: %.6f" % ( f1_score ( test_Y , predictions , labels = np.arange(9), average = 'weighted' ) ))
f1.append(f1_score ( test_Y , predictions , labels = np.arange(9), average = 'weighted' ))
facies_labels = ['SS', 'CSiS', 'FSiS', 'SiSh', 'MS',
'WS', 'D','PS', 'BS']
print ("\nConfusion Matrix Results")
from classification_utilities import display_cm, display_adj_cm
display_cm(conf, facies_labels,display_metrics=True, hide_zeros=True)
print ("\n------------------------------------------------------")
print ("Final Results")
print ("-Average F1 Score: %6f" % (sum(f1)/(1.0*len(f1))))
# -
# Use final model to predict the given test data set
# Load test data
test_data = pd.read_csv('validation_data_nofacies.csv')
test_data['Well Name'] = test_data['Well Name'].astype('category')
X_test = test_data.drop(['Formation', 'Well Name', 'Depth'], axis=1)
# Predict facies of unclassified data
Y_predicted = model_final.predict(X_test)
test_data['Facies'] = Y_predicted + 1
# Store the prediction
test_data.to_csv('Prediction4.csv')
test_data[test_data['Well Name']=='STUART'].head()
test_data[test_data['Well Name']=='CRAWFORD'].head()
def make_facies_log_plot(logs, facies_colors):
#make sure logs are sorted by depth
logs = logs.sort_values(by='Depth')
cmap_facies = colors.ListedColormap(
facies_colors[0:len(facies_colors)], 'indexed')
ztop=logs.Depth.min(); zbot=logs.Depth.max()
cluster=np.repeat(np.expand_dims(logs['Facies'].values,1), 100, 1)
f, ax = plt.subplots(nrows=1, ncols=6, figsize=(8, 12))
ax[0].plot(logs.GR, logs.Depth, '-g')
ax[1].plot(logs.ILD_log10, logs.Depth, '-')
ax[2].plot(logs.DeltaPHI, logs.Depth, '-', color='0.5')
ax[3].plot(logs.PHIND, logs.Depth, '-', color='r')
ax[4].plot(logs.PE, logs.Depth, '-', color='black')
im=ax[5].imshow(cluster, interpolation='none', aspect='auto',
cmap=cmap_facies,vmin=1,vmax=9)
divider = make_axes_locatable(ax[5])
cax = divider.append_axes("right", size="20%", pad=0.05)
cbar=plt.colorbar(im, cax=cax)
cbar.set_label((17*' ').join([' SS ', 'CSiS', 'FSiS',
'SiSh', ' MS ', ' WS ', ' D ',
' PS ', ' BS ']))
cbar.set_ticks(range(0,1)); cbar.set_ticklabels('')
for i in range(len(ax)-1):
ax[i].set_ylim(ztop,zbot)
ax[i].invert_yaxis()
ax[i].grid()
ax[i].locator_params(axis='x', nbins=3)
ax[0].set_xlabel("GR")
ax[0].set_xlim(logs.GR.min(),logs.GR.max())
ax[1].set_xlabel("ILD_log10")
ax[1].set_xlim(logs.ILD_log10.min(),logs.ILD_log10.max())
ax[2].set_xlabel("DeltaPHI")
ax[2].set_xlim(logs.DeltaPHI.min(),logs.DeltaPHI.max())
ax[3].set_xlabel("PHIND")
ax[3].set_xlim(logs.PHIND.min(),logs.PHIND.max())
ax[4].set_xlabel("PE")
ax[4].set_xlim(logs.PE.min(),logs.PE.max())
ax[5].set_xlabel('Facies')
ax[1].set_yticklabels([]); ax[2].set_yticklabels([]); ax[3].set_yticklabels([])
ax[4].set_yticklabels([]); ax[5].set_yticklabels([])
ax[5].set_xticklabels([])
f.suptitle('Well: %s'%logs.iloc[0]['Well Name'], fontsize=14,y=0.94)
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.colors as colors
from mpl_toolkits.axes_grid1 import make_axes_locatable
make_facies_log_plot(
test_data[test_data['Well Name'] == 'STUART'],
facies_colors)
| HouMath/Face_classification_HouMath_XGB_04.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <b>Encontre o vetor $v$ colinear ao vetor $\vec {u} = (-4, 2, 6)$, tal que $<v,w> = - 12$, sendo $w = (-1, 4, 2)$.</b>
# <b>O vetor $\vec {v}$ será o vetor $\vec u$ multiplicando por $\lambda$</b>
# $\vec v = \vec{u} \cdot \lambda = (-4\cdot \lambda,2 \cdot \lambda, 6 \cdot \lambda)$
# $\vec v = (-4\lambda, 2\lambda, 6\lambda)$
# <b>Encontrando o valor de $\lambda$ pelo produto escalar $<v,w>$</b>
# $<(-4\lambda, 2\lambda, 6\lambda),(-1,4,2)> = -12$
# $4\lambda + 8\lambda + 12\lambda = -12$
# $24\lambda = -12$
# $\lambda = \frac{-12}{24}$
# $\lambda = -\frac{1}{2}$
# <b>Agora com o valor de $\lambda$ e possível achar os valores de $\vec{v}$</b>
# $\vec{v} = (-4(-\frac{1}{2}), 2(-\frac{1}{2}), 6(-\frac{1}{2}))$
# $\vec{v} = (2, -1, -3)$
| Lista de retas/04.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="3oF_DFbvlUyw" colab={"base_uri": "https://localhost:8080/", "height": 309} outputId="e9d55d08-e20b-4b9d-9acc-b2a571eb7962"
from google.colab import drive
drive.mount("/content/gdrive/")
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sbn
import scipy.stats as st
filepath = "/content/gdrive/My Drive/DATA/Automobiles-Processed.csv"
data = pd.read_csv(filepath)
data.head(20)
data.columns
data.drop(["Unnamed: 0", "Unnamed: 0.1"], axis = 1, inplace = True)
data.columns
data.head(20)
data.to_csv("/content/gdrive/My Drive/DATA/Automobiles-Processed.csv")
datapath = 'https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DA0101EN-SkillsNetwork/labs/Data%20files/automobileEDA.csv'
df1 = pd.read_csv(datapath)
df1.head()
# + [markdown] id="SHqFa-q2pbrs"
# <h1>Exploratory Data Analysis</h1>
# <p>Exploratory Data Analysis or EDA is an approach to analyze data in order to summarize the main characteristics of the data, gain better understanding of the data set, uncover relationships between different variables, and extract important variables for the problem we are tring to solve
# + colab={"base_uri": "https://localhost:8080/", "height": 141} id="mMBLjM83pzmv" outputId="8b0326f2-7b2c-43ad-80d8-7209d000ea49"
data.describe() #Distribution of the variables
data["Drive-Wheels"].value_counts()
data.columns
data["Drive-Wheels"].value_counts()
#to_frame() casts to dataframe
drive_wheels_count = data["Drive-Wheels"].value_counts().to_frame()
drive_wheels_count
drive_wheels_count.rename(columns = {"Drive-Wheels": "Value-Counts"}, inplace = True)
drive_wheels_count
sbn.boxplot(x = "Drive-Wheels", y = "Price", data = data)
#Scatterplot
xaxis = data["Engine-Size"]
yaxis = data["Price"]
plt.scatter(xaxis, yaxis)
plt.xlabel("Engine-Size")
plt.ylabel("Price")
plt.title("Correlation between Engine Size and Price")
# + [markdown] id="MmLPbHIXhaiD"
# <h1>Grouping Data</h1>
#
# <p>The Python method dataframe.GroupBy() is applied to categorical variables. It groups data by the categories in that variable. We can group by a single variable or multiple variables.
# + colab={"base_uri": "https://localhost:8080/", "height": 449} id="9IPv9EKmturM" outputId="b6ba988d-6a61-4837-e95d-cf488f48ad78"
data.columns
dummy_df = data[["Drive-Wheels", "Body-Style", "Price"]]
dummy_df
df_grouping = dummy_df.groupby(["Drive-Wheels", "Body-Style"], as_index=False).mean()
df_grouping
# + colab={"base_uri": "https://localhost:8080/", "height": 269} id="oFeKPzd51fcn" outputId="55a8b053-3d48-46f1-8e37-a1c62afbd399"
#Pivot table has one variable displayed along the column and another along the row.
#data_pivot = df_grouping.pivot(index = "Drive-Wheels", columns = "Body-Style")
data_pivot = df_grouping.pivot(index="Body-Style", columns="Drive-Wheels")
data_pivot
#Heatmap Plot
plt.pcolor(data_pivot, cmap = "RdBu") #Red-Blue color scheme
plt.colorbar()
plt.show()
# + [markdown] id="ej7Ko6E57ywP"
# <h1>Correlation</h1>
# <p>Correlation is a statistical metric for measuring to what extent different variables are interdependent on each other. In other words, over time, if one variable changes, how does this affect the other variable?</p>
#
# <p>Correlation = A measure of the extent of interdependence between variables</p>
# <p>Causation = The relationship between cause and effect between two variables</p>
#
# <p>Determining correlation is much simpler than determining causation as causation may require independent experimentation.</p>
#
# + colab={"base_uri": "https://localhost:8080/", "height": 296} id="Lf0EnKXm8RGA" outputId="e508d2d3-6fc0-4cea-db6e-b90c089423cb"
#Correlation between 'Engine-Size' and 'Price'
sbn.regplot(x = "Engine-Size", y = "Price", data = data)
plt.ylim(0,)
data.columns
#Correlation between "Highway-LtrsPerKM" and "Price"
sbn.regplot(x="Highway-LtrsPerKM", y = "Price", data = data)
plt.ylim(0,)
#Weak Correlation
#Correlation between "Peak-RPM" and "Price"
sbn.regplot(x = "Peak-RPM", y= "Price", data = data)
plt.ylim(0,)
# + [markdown] id="DlKRGXB2MamA"
# <h1>Pearson Correlation</h1>
# <p>Pearson Correlation measures the linear dependence between two variables X and Y. The resulting coefficient is a value between -1 and 1, where:</p>
# <ul><li>1: Total positive linear correlation</li>
# <li>0: No linear correlation. The two variables likely do not affect one another.</li>
# <li>-1: Total negative linear correlation</li>
# </ul>
# <p>Pearson Correlation is the default method of the function corr()</p>
#
# + colab={"base_uri": "https://localhost:8080/", "height": 887} id="N1HpxcKtMXUL" outputId="fc51f63f-d205-43d4-e883-ccb8bd23f490"
#Pearson Correlation
pearson_coef, p_value = st.pearsonr(data["Horsepower"], data["Price"])
print("Pearson Coefficient: ", pearson_coef)
print("P-Value: ", p_value)
data.corr()
# + [markdown] id="PCae7c4vPep1"
# <h1>Analysis of Variance (ANOVA)</h1>
# <p>Analysis of Variance (ANOVA) is a statistical test that can be used to find the correlation between different groups of a categorical variable. The ANOVA test returns two values, the F-Test and the P-Value. The F-Test score is the variation between sample group means divided the variation within sample group.</p>
# + colab={"base_uri": "https://localhost:8080/", "height": 416} id="XeBJyP5BLqRq" outputId="d381500b-57a1-4efb-9a8e-6ce132d2dc65"
#Creating a bar chart
data.columns
dummy_df2 = data[["Make", "Price"]]
data.dtypes
grouped_df = dummy_df2.groupby(["Make"], as_index=False).mean()
grouped_df
sbn.barplot("Make", "Price", data = grouped_df, order = grouped_df.sort_values("Price").Make)
#plt.tight_layout()
plt.xticks(rotation = 90)
plt.xlabel("Car Make")
plt.ylabel("Price")
plt.title("Price according to the make")
plt.savefig("/content/gdrive/My Drive/DATA/PriceAccordingToCarMake.jpg", dpi = 800)
#ANOVA test
df_anova = data[["Make", "Price"]]
grouped_anova = df_anova.groupby(["Make"])
anova_results = st.f_oneway(grouped_anova.get_group("honda")["Price"], grouped_anova.get_group("jaguar")["Price"])
anova_results
# + [markdown] id="LW3dNPPMoOuk"
# <h1>Chi-Squared Tests</h1>
#
# + colab={"base_uri": "https://localhost:8080/"} id="-tIQ4LXuoR31" outputId="a17c4887-02c8-4fa5-c004-c78a2d49e9bb"
#Cross-Tabulation
cross_tab = pd.crosstab(data["Body-Style"], data["Drive-Wheels"])
st.chi2_contingency(cross_tab, correction=True)
#cross_tab1 = pd.crosstab(df1["fuel-type"], df1["aspiration"])
#st.chi2_contingency(crosstab1, correction=True)
# + [markdown] id="Gdd6rbTqF1Qo"
# <h1>Lab</h1>
# + colab={"base_uri": "https://localhost:8080/", "height": 312} id="A4zJrCP1F6A7" outputId="4fcea28c-69b1-48a5-e565-14e5e7f12a81"
print(data.dtypes["Peak-RPM"])
data.corr()
dummy_df3 = data[["Bore", "Stroke", "Compression-Ratio", "Horsepower"]]
dummy_df3.corr()
sbn.regplot(x = "Engine-Size", y = "Price", data = data)
plt.xlabel("Engine-Size")
plt.ylabel("Price")
plt.title("Engine Size vs Price")
plt.ylim(0,)
#Correlation between "Engine-Size" and "Price"
data[["Engine-Size", "Price"]].corr()
sbn.regplot(x = "Highway-LtrsPerKM", y = "Price", data = data)
plt.xlabel("Highway-MPG")
plt.ylabel("Price")
plt.title("Highway-LtrsPerKM vs Price")
plt.ylim(0,)
data.columns
#Correlation between "Highway-LtrsPerKM" and "Price"
data[["Highway-LtrsPerKM", "Price"]].corr()
#Weak Linear Relationship
sbn.regplot(x = "Peak-RPM", y = "Price", data = data)
plt.xlabel("Peak-RPM")
plt.ylabel("Price")
plt.title("Peak-RPM vs Price")
plt.ylim(0,)
#Correlation between "Peak-RPM" and "Price"
data[["Peak-RPM", "Price"]].corr()
#Correlation between "Stroke" and "Price"
data[["Stroke", "Price"]].corr()
sbn.regplot(x = "Stroke", y = "Price", data = data)
plt.xlabel("Stroke")
plt.ylabel("Price")
plt.title("Stroke vs Price")
plt.ylim(0,)
# + colab={"base_uri": "https://localhost:8080/", "height": 296} id="_cH5so1bMtLi" outputId="843c87a7-280c-4702-e248-f1ee6b5b81b7"
#Categorical Variables
#Boxplots are a good way to visualize categorical variables
sbn.boxplot(x = "Body-Style", y = "Price", data = data)
sbn.boxplot(x = "Engine-Location", y = "Price", data = data)
sbn.boxplot(x = "Drive-Wheels", y = "Price", data = data)
# + colab={"base_uri": "https://localhost:8080/"} id="wATnRYD5OY7x" outputId="8956ac64-2345-4cd9-efc5-7c328fa91a44"
#Descriptive Statistical Analysis
data.describe()
data.describe(include=["object"])
df1["drive-wheels"].value_counts()
drive_wheels_df = df1["drive-wheels"].value_counts().to_frame()
drive_wheels_df
drive_wheels_df.rename(columns = {"drive-wheels":"Value Counts"}, inplace = True)
drive_wheels_df
drive_wheels_count.index.name = "Drive-Wheels"
drive_wheels_count
drive_wheels_df.index.name = "Drive-Wheels"
drive_wheels_df
#"Engine-Location"
#The error here was the double brackets
data["Engine-Location"].value_counts()
engine_loc_df = data["Engine-Location"].value_counts().to_frame()
engine_loc_df
engine_loc_df.rename(columns = {"Engine-Location":"Value-Counts"}, inplace = True)
engine_loc_df
engine_loc_df.index.name = "Engine-Location"
engine_loc_df
data.columns
data.head(20)
data.describe()
# + colab={"base_uri": "https://localhost:8080/", "height": 203} id="0bfiiaItxrox" outputId="51fa6c89-35c2-4c20-a01f-0b23d7540dcc"
#Grouping
data["Drive-Wheels"].unique()
test_df = data[["Drive-Wheels", "Body-Style", "Price"]]
test_df = test_df.groupby(["Drive-Wheels"], as_index=False).mean()
test_df
test_df2 = data[["Drive-Wheels", "Body-Style", "Price"]]
test_df2 = test_df2.groupby(["Drive-Wheels", "Body-Style"], as_index = False).mean()
test_df2
#Pivot Table
pivot_table1 = test_df2.pivot(index = "Drive-Wheels", columns = "Body-Style")
pivot_table1
pivot_table1 = pivot_table1.fillna(0) #Fill missing values with 0
pivot_table1
#Average price of each car based on body style
test_df3 = data[["Body-Style", "Price"]]
test_df3 = test_df3.groupby(["Body-Style"], as_index = False).mean()
test_df3
# + colab={"base_uri": "https://localhost:8080/", "height": 563} id="KiyAsC1A0g3z" outputId="e7777e00-0b3e-45db-f040-9cbe5aad5c8c"
#Using heatmap to visualize the relationship between "Body-Style" and "Price"
plt.pcolor(pivot_table1, cmap = "RdBu")
plt.colorbar()
plt.show()
# #???
#Styling the heatmap
fig, ax = plt.subplots()
im = ax.pcolor(pivot_table1, cmap = "RdBu")
#Label names
row_labels = pivot_table1.columns.levels[1] #"Body-Style"
column_labels = pivot_table1.index #"Drive-Wheels"
#Move ticks and labels to the center
ax.set_xticks(np.arange(pivot_table1.shape[1])+0.5, minor = False)
ax.set_yticks(np.arange(pivot_table1.shape[0])+0.5, minor = False)
#Insert labels
ax.set_xticklabels(row_labels, minor = False)
ax.set_yticklabels(column_labels, minor = False)
plt.xticks(rotation = 90)
fig.colorbar(im)
plt.show()
# + colab={"base_uri": "https://localhost:8080/", "height": 172} id="NFciVdpo4Fbw" outputId="0bd369e0-3a7d-450b-b2e6-90859ed9a378"
#Correlation and Causation
data.columns
data.describe()
data.describe(include = ['object'])
# + [markdown] id="FYiwNBxHRXN-"
# <h1>P-Value</h1>
# <p>P-Value is the probability value that the correlation between two variables is statistically significant. Normally, a significance level of 0.05 is chosen, which means that there is a 95% confidence that the correlation between two variables is significant. By convention,</p>
# <ul><li>P-Value < 0.001 - Strong evidence that the correlation is significant</li>
# <li>P-Value < 0.05 - Moderate evidence that the correlation is significant</li>
# <li>P-Value < 0.1 - Weak evidence that the correlation is significant</li>
# <li>P-Value > 0.1 - No evidence that the correlation is significant</li></ul>
# + colab={"base_uri": "https://localhost:8080/"} id="umi7AxR7CI4A" outputId="111242d5-0db9-4e7d-fd3b-63844d43480b"
#"Wheel-Base" vs "Price"
data["Wheel-Base"].head(20)
data["Wheel-Base"].dtypes
data["Price"].dtypes
pearson_coef, p_value = st.pearsonr(data["Wheel-Base"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant but linear relationship is weak
#"Horsepower" vs "Price"
data["Horsepower"].head(20)
pearson_coef, p_value = st.pearsonr(data["Horsepower"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant and linear relationship is strong
#"Length" vs "Price"
data["Length"].head(20)
pearson_coef, p_value = st.pearsonr(data["Length"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Moderately significant but linear relationship is moderate
#"Width" vs "Price"
data["Width"].head(20)
pearson_coef, p_value = st.pearsonr(data["Width"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant and linear relationship is strong
#"Curb-Weight" vs "Price"
data["Curb-Weight"].head(20)
data["Curb-Weight"].dtypes
pearson_coef, p_value = st.pearsonr(data["Curb-Weight"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant and linear relationship is strong
#"Engine-Size" vs "Price"
data["Engine-Size"].head(20)
data["Engine-Size"].dtypes
print("The data type of Engine-Size is: ", data["Engine-Size"].dtypes)
pearson_coef, p_value = st.pearsonr(data["Engine-Size"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant and linear relationship is ~very~ strong
#"Bore" vs "Price"
data["Bore"].head(20)
data["Bore"].dtypes
pearson_coef, p_value = st.pearsonr(data["Bore"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant but linear relationship is moderately strong
#"City-LtrsPerKM" vs "Price"
data["City-LtrsPerKM"].head(20)
data["City-LtrsPerKM"].dtypes
pearson_coef, p_value = st.pearsonr(data["City-LtrsPerKM"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant and linear relationship is strong
#"Highway-LtrsPerKM" vs "Price"
data["Highway-LtrsPerKM"].head(20)
data["Highway-LtrsPerKM"].dtypes
pearson_coef, p_value = st.pearsonr(data["Highway-LtrsPerKM"], data["Price"])
print("The Pearson Correlation coefficient is: ", pearson_coef, "with a P-Value of: ", p_value) #Statistically significant and linear relationship is strong
# + [markdown] id="kS3qMXGyY65v"
# <h1>ANOVA</h1>
# <p>The Analysis of Variance (ANOVA) is a statistical method used to test whether there are significant differences between the means of two or more groups. ANOVA returns two parameters,
# <ul><li><b>F-Test Score: </b>ANOVA assumes the means of all groups are same, calculates how much the actual means deviate from the assumption, and reports it as the F-Test score. A larger score means there is a large difference between the means.<li>
# <li><b>P-Value: </b>P-Value tells how statistically significant our calculated score is.</li>
# </ul>
# + colab={"base_uri": "https://localhost:8080/"} id="3ixe7X_3a2xN" outputId="c465e679-0e84-467e-8297-5023b52d9503"
#"Drive-Wheels" vs "Price"
testdf1 = data[["Drive-Wheels", "Price"]]
testdf1 = testdf1.groupby(["Drive-Wheels"])
testdf1.head(20)
testdf2 = data[["Drive-Wheels", "Body-Style", "Price"]]
testdf2
testdf1.get_group("4wd")["Price"]
f_value, p_value = st.f_oneway(testdf1.get_group("fwd")["Price"], testdf1.get_group("rwd")["Price"], testdf1.get_group("4wd")["Price"])
print("ANOVA results= ", f_value, "with a P-Value of: ", p_value)
#STRONG correlation and statistically significant
#Separately, fwd and rwd
f_value, p_value = st.f_oneway(testdf1.get_group("fwd")["Price"], testdf1.get_group("rwd")["Price"]) #STRONG correlation and statistically significant
print("ANOVA results: ", f_value, "with a P-Value of: ", p_value)
#Separately, fwd and 4wd
f_value, p_value = st.f_oneway(testdf1.get_group("fwd")["Price"], testdf1.get_group("4wd")["Price"]) #NO correlation and not statistically significant
print("ANOVA ressults: ", f_value, "with a P-Value of: ", p_value)
#Separately, rwd and 4wd
f_value, p_value = st.f_oneway(testdf1.get_group("rwd")["Price"], testdf1.get_group("4wd")["Price"]) #WEAK correlation and weakly statistically significant
print("ANOVA test results: ", f_value, "with a P-Value of: ", p_value)
| Notebooks/EDA.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
dia = int(input("Qual o dia da semana? "))
if dia == 6 or dia == 7:
print("Hoje é dia de descanso!")
else:
print("Você precisa trabalhar!")
| Python/exercicios_DSA/exercicios/ex011.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import sys, os, time
from pathlib import Path
import pandas as pd
import numpy as np
df = pd.read_parquet('../data/MAG_20191122_PaperReferences_subset_parquet/')
len(df)
x = np.concatenate((df.PaperId.values, df.PaperReferenceId.values), axis=0)
x.shape
x = np.unique(x)
x.shape
df_ids = pd.DataFrame(x, columns=['node_name'])
df_ids['node_id'] = range(1, len(df_ids)+1)
id_map = df_ids.set_index('node_name')['node_id']
df['citing_id'] = df.PaperId.map(id_map)
df['cited_id'] = df.PaperReferenceId.map(id_map)
df
df_ids['node_name'] = df_ids['node_name'].astype(str)
outfpath = Path('../data/test_out_pajek.net')
outf = outfpath.open('w')
quotechar = '"'
df_ids['node_name'] = quotechar + df_ids['node_name'] + quotechar
outf.write('*Vertices {}\n'.format(len(df_ids)))
import csv
df_ids[['node_id', 'node_name']].to_csv(outf, index=False, sep=' ', header=False, quoting=csv.QUOTE_NONE)
outf.write('*Arcs {}\n'.format(len(df)))
outf.flush()
df[['citing_id', 'cited_id']].to_csv(outf, index=False, sep=' ', header=False)
outf.close()
outf.close()
| notebooks/plan_pandas_save_pajek.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# %matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from GetData import WISE_LC
# -
import matplotlib
matplotlib.rcParams.update({'font.size':18})
matplotlib.rcParams.update({'font.family':'serif'})
# +
# download the data and generate some WISE plots.
# this is based on a wrapper script I was using previously...
df1, df2, df3, df4 = WISE_LC('V1309Sco', returndata=True)
# there's a bad datapoint (ra,dec is off) in df1 (NEOWISE)
df1 = df1.drop(np.where((df1['w1mpro'] < 8))[0])
# +
vvv_file = 'data/wdb_query_54573_eso.csv'
vvv = pd.read_csv(vvv_file, skiprows=2, comment='#')
print(vvv.columns)
plt.scatter(vvv['MJD Obs'], vvv['ABMAGLIM'], marker='o', alpha=0.5)
plt.gca().invert_yaxis()
plt.xlabel('MJD')
plt.ylabel('$K_S$ (Mag)')
#--> the original data is blended, not reliable apparently
# +
# Ferreira et al. did more careful photometry... which they don't publish.
# Might be able to get from them, but for now I've digitized their figure
vvv = pd.read_csv('data/VVV_digitized.csv', names=('MJD', 'Ks'))
plt.scatter(vvv['MJD'], vvv['Ks'])
plt.gca().invert_yaxis()
plt.xlabel('MJD')
plt.ylabel('$K_S$ (Mag)')
# plt.savefig('fig1.pdf', dpi=300, bbox_inches='tight', pad_inches=0.25)
# +
jd = np.array([2455437, 2457282], dtype='float')
J = np.array([13.849, 15.080], dtype='float')
Ks = np.array([12.449, 14.659], dtype='float')
dist=2100. # pc
# +
plt.figure(figsize=(8,5))
W1 = np.concatenate((df1['w1mpro'],df2['w1mpro'],df3['w1mpro']))
W2 = np.concatenate((df1['w2mpro'],df2['w2mpro'],df3['w2mpro']))
MJD = np.concatenate((df1['mjd'],df2['mjd'],df3['mjd']))
plt.scatter(MJD, W1,c='C0', label='WISE W1', alpha=0.5)
plt.scatter(MJD, W2,c='C1', label='WISE W2', alpha=0.5)
plt.scatter(vvv['MJD'], vvv['Ks'], c='k', s=10, label='VVV Ks')
plt.scatter(jd-2400000.5, Ks, c='C2', s=100, alpha=0.7)
plt.legend(fontsize=14)
plt.gca().invert_yaxis()
plt.xlabel('MJD')
plt.ylabel('Mag')
plt.title('V1309 Sco', fontsize=18)
# +
plt.scatter(W1-W2, W1 - 5*np.log10(dist) + 5, c=MJD, cmap=plt.cm.Spectral_r)
plt.gca().invert_yaxis()
plt.xlabel('$W1-W2$')
plt.ylabel('$M_{W1}$')
# +
# are we seeing blending take over? Has V1309 Sco actually disappeared from WISE?
RA = np.concatenate((df1['ra'],df2['ra'],df3['ra']))
DEC = np.concatenate((df1['dec'],df2['dec'],df3['dec']))
plt.scatter((RA-np.nanmedian(RA))*60*60,
(DEC-np.nanmedian(DEC))*60*60,
c=MJD, cmap=plt.cm.Spectral_r)
# +
from astropy.timeseries import LombScargle
LS_W1 = LombScargle(MJD, W2)
periods = np.logspace(-2,1, 10000)
power = LS_W1.power(1/periods)
plt.plot(periods,power)
plt.xscale('log')
# there's no robust short period I can see in the WISE data...
# -
| explore.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] colab_type="text" id="vN99YjPTDena"
# # Random Forest Regression
#
# > A tutorial on How to use Random Forest Regression.
#
# - toc: true
# - badges: true
# - comments: true
# - categories: [jupyter, Regression]
# -
# ## 0. Data Preprocessing
# + [markdown] colab_type="text" id="ZIx_naXnDyHd"
# ### 0.1 Importing the libraries
# + colab={} colab_type="code" id="FjnmdyPLD2tS"
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# + [markdown] colab_type="text" id="6c8YExmOD5x5"
# ### 0.2 Importing the dataset
# + colab={} colab_type="code" id="nQOdXhjXD_AE"
housing = pd.read_csv("housing.csv")
housing
# -
# ### 0.3 Check if any null value
housing.isna().sum()
housing['total_bedrooms'].median()
housing['total_bedrooms'].fillna(housing['total_bedrooms'].median(),inplace=True) #with pandas fillna
housing.isna().sum()
housing.info()
# ### 0.4 Split into X & y
X = housing.drop("median_house_value",axis=1)
X
y = housing["median_house_value"]
y
# ### 0.5 Convert categorical data into numbers
# +
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
categorical_features = ["ocean_proximity"]
one_hot = OneHotEncoder()
transformer = ColumnTransformer([("one_hot",
one_hot,
categorical_features)],
remainder="passthrough")
transformed_X = transformer.fit_transform(X)
# -
pd.DataFrame(transformed_X)
# ### 0.6 Split the data into test and train
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(transformed_X, y, test_size = 0.25, random_state = 2509)
# + [markdown] colab_type="text" id="Le8SEL-YEOLb"
# ## 1. Training the Random Forest Regression model on the training set
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" id="2eZ4xxbKEcBk" outputId="41074f6d-44c7-4a04-fd49-14bda9fb2885"
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(x_train, y_train)
# -
# ### 1.2 Score
model.score(x_test, y_test)
# + [markdown] colab_type="text" id="diyJFZHhFFeK"
# ## 2. Predicting a new result on test set
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" id="Blmp6Hn7FJW6" outputId="f01610bc-b077-4df0-cae4-ea37c8b0037f"
y_preds = model.predict(x_test)
# -
df = pd.DataFrame(data={"actual values": y_test,
"predicted values": y_preds})
df["differences"] = df["predicted values"] - df["actual values"]
df
# ## 3. Save a model
# +
import pickle
# Save an extisting model to file
pickle.dump(model, open("random_forest_model.pkl", "wb"))
| _notebooks/2020-10-27-Random_forest_regression.ipynb |
# ---
# jupyter:
# jupytext:
# split_at_heading: true
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
#|hide
#|skip
! [ -e /content ] && pip install -Uqq fastai # upgrade fastai on colab
# +
#|default_exp callback.tracker
# -
#|export
from __future__ import annotations
from fastai.basics import *
from fastai.callback.progress import *
from fastai.callback.fp16 import MixedPrecision
#|hide
from nbdev.showdoc import *
from fastai.test_utils import *
# # Tracking callbacks
#
# > Callbacks that make decisions depending how a monitored metric/loss behaves
# ## TerminateOnNaNCallback -
#|export
class TerminateOnNaNCallback(Callback):
"A `Callback` that terminates training if loss is NaN."
order=-9
def after_batch(self):
"Test if `last_loss` is NaN and interrupts training."
if torch.isinf(self.loss) or torch.isnan(self.loss): raise CancelFitException
learn = synth_learner()
learn.fit(10, lr=100, cbs=TerminateOnNaNCallback())
assert len(learn.recorder.losses) < 10 * len(learn.dls.train)
for l in learn.recorder.losses:
assert not torch.isinf(l) and not torch.isnan(l)
# ## TrackerCallback -
#|export
class TrackerCallback(Callback):
"A `Callback` that keeps track of the best value in `monitor`."
order,remove_on_fetch,_only_train_loop = 60,True,True
def __init__(self, monitor='valid_loss', comp=None, min_delta=0., reset_on_fit=True):
if comp is None: comp = np.less if 'loss' in monitor or 'error' in monitor else np.greater
if comp == np.less: min_delta *= -1
self.monitor,self.comp,self.min_delta,self.reset_on_fit,self.best= monitor,comp,min_delta,reset_on_fit,None
def before_fit(self):
"Prepare the monitored value"
self.run = not hasattr(self, "lr_finder") and not hasattr(self, "gather_preds")
if self.reset_on_fit or self.best is None: self.best = float('inf') if self.comp == np.less else -float('inf')
assert self.monitor in self.recorder.metric_names[1:]
self.idx = list(self.recorder.metric_names[1:]).index(self.monitor)
def after_epoch(self):
"Compare the last value to the best up to now"
val = self.recorder.values[-1][self.idx]
if self.comp(val - self.min_delta, self.best): self.best,self.new_best = val,True
else: self.new_best = False
def after_fit(self): self.run=True
# When implementing a `Callback` that has behavior that depends on the best value of a metric or loss, subclass this `Callback` and use its `best` (for best value so far) and `new_best` (there was a new best value this epoch) attributes. If you want to maintain `best` over subsequent calls to `fit` (e.g., `Learner.fit_one_cycle`), set `reset_on_fit` = True.
#
# `comp` is the comparison operator used to determine if a value is best than another (defaults to `np.less` if 'loss' is in the name passed in `monitor`, `np.greater` otherwise) and `min_delta` is an optional float that requires a new value to go over the current best (depending on `comp`) by at least that amount.
# +
#|hide
class FakeRecords(Callback):
order=51
def __init__(self, monitor, values): self.monitor,self.values = monitor,values
def before_fit(self): self.idx = list(self.recorder.metric_names[1:]).index(self.monitor)
def after_epoch(self): self.recorder.values[-1][self.idx] = self.values[self.epoch]
class TestTracker(Callback):
order=61
def before_fit(self): self.bests,self.news = [],[]
def after_epoch(self):
self.bests.append(self.tracker.best)
self.news.append(self.tracker.new_best)
# +
#|hide
learn = synth_learner(n_trn=2, cbs=TestTracker())
cbs=[TrackerCallback(monitor='valid_loss'), FakeRecords('valid_loss', [0.2,0.1])]
with learn.no_logging(): learn.fit(2, cbs=cbs)
test_eq(learn.test_tracker.bests, [0.2, 0.1])
test_eq(learn.test_tracker.news, [True,True])
#With a min_delta
cbs=[TrackerCallback(monitor='valid_loss', min_delta=0.15), FakeRecords('valid_loss', [0.2,0.1])]
with learn.no_logging(): learn.fit(2, cbs=cbs)
test_eq(learn.test_tracker.bests, [0.2, 0.2])
test_eq(learn.test_tracker.news, [True,False])
# +
#|hide
#By default metrics have to be bigger at each epoch.
def tst_metric(out,targ): return F.mse_loss(out,targ)
learn = synth_learner(n_trn=2, cbs=TestTracker(), metrics=tst_metric)
cbs=[TrackerCallback(monitor='tst_metric'), FakeRecords('tst_metric', [0.2,0.1])]
with learn.no_logging(): learn.fit(2, cbs=cbs)
test_eq(learn.test_tracker.bests, [0.2, 0.2])
test_eq(learn.test_tracker.news, [True,False])
#This can be overwritten by passing `comp=np.less`.
learn = synth_learner(n_trn=2, cbs=TestTracker(), metrics=tst_metric)
cbs=[TrackerCallback(monitor='tst_metric', comp=np.less), FakeRecords('tst_metric', [0.2,0.1])]
with learn.no_logging(): learn.fit(2, cbs=cbs)
test_eq(learn.test_tracker.bests, [0.2, 0.1])
test_eq(learn.test_tracker.news, [True,True])
# -
#|hide
#Setting reset_on_fit=True will maintain the "best" value over subsequent calls to fit
learn = synth_learner(n_val=2, cbs=TrackerCallback(monitor='tst_metric', reset_on_fit=False), metrics=tst_metric)
tracker_cb = learn.cbs.filter(lambda cb: isinstance(cb, TrackerCallback))[0]
with learn.no_logging(): learn.fit(1)
first_best = tracker_cb.best
with learn.no_logging(): learn.fit(1)
test_eq(tracker_cb.best, first_best)
#|hide
#A tracker callback is not run during an lr_find
from fastai.callback.schedule import *
learn = synth_learner(n_trn=2, cbs=TrackerCallback(monitor='tst_metric'), metrics=tst_metric)
learn.lr_find(num_it=15, show_plot=False)
assert not hasattr(learn, 'new_best')
# ## EarlyStoppingCallback -
#|export
class EarlyStoppingCallback(TrackerCallback):
"A `TrackerCallback` that terminates training when monitored quantity stops improving."
order=TrackerCallback.order+3
def __init__(self, monitor='valid_loss', comp=None, min_delta=0., patience=1, reset_on_fit=True):
super().__init__(monitor=monitor, comp=comp, min_delta=min_delta, reset_on_fit=reset_on_fit)
self.patience = patience
def before_fit(self): self.wait = 0; super().before_fit()
def after_epoch(self):
"Compare the value monitored to its best score and maybe stop training."
super().after_epoch()
if self.new_best: self.wait = 0
else:
self.wait += 1
if self.wait >= self.patience:
print(f'No improvement since epoch {self.epoch-self.wait}: early stopping')
raise CancelFitException()
# `comp` is the comparison operator used to determine if a value is best than another (defaults to `np.less` if 'loss' is in the name passed in `monitor`, `np.greater` otherwise) and `min_delta` is an optional float that requires a new value to go over the current best (depending on `comp`) by at least that amount. `patience` is the number of epochs you're willing to wait without improvement.
learn = synth_learner(n_trn=2, metrics=F.mse_loss)
learn.fit(n_epoch=200, lr=1e-7, cbs=EarlyStoppingCallback(monitor='mse_loss', min_delta=0.1, patience=2))
learn.validate()
learn = synth_learner(n_trn=2)
learn.fit(n_epoch=200, lr=1e-7, cbs=EarlyStoppingCallback(monitor='valid_loss', min_delta=0.1, patience=2))
#|hide
test_eq(len(learn.recorder.values), 3)
# ## SaveModelCallback -
#|export
class SaveModelCallback(TrackerCallback):
"A `TrackerCallback` that saves the model's best during training and loads it at the end."
order = TrackerCallback.order+1
def __init__(self, monitor='valid_loss', comp=None, min_delta=0., fname='model', every_epoch=False, at_end=False,
with_opt=False, reset_on_fit=True):
super().__init__(monitor=monitor, comp=comp, min_delta=min_delta, reset_on_fit=reset_on_fit)
assert not (every_epoch and at_end), "every_epoch and at_end cannot both be set to True"
# keep track of file path for loggers
self.last_saved_path = None
store_attr('fname,every_epoch,at_end,with_opt')
def _save(self, name): self.last_saved_path = self.learn.save(name, with_opt=self.with_opt)
def after_epoch(self):
"Compare the value monitored to its best score and save if best."
if self.every_epoch:
if (self.epoch%self.every_epoch) == 0: self._save(f'{self.fname}_{self.epoch}')
else: #every improvement
super().after_epoch()
if self.new_best:
print(f'Better model found at epoch {self.epoch} with {self.monitor} value: {self.best}.')
self._save(f'{self.fname}')
def after_fit(self, **kwargs):
"Load the best model."
if self.at_end: self._save(f'{self.fname}')
elif not self.every_epoch: self.learn.load(f'{self.fname}', with_opt=self.with_opt)
# `comp` is the comparison operator used to determine if a value is best than another (defaults to `np.less` if 'loss' is in the name passed in `monitor`, `np.greater` otherwise) and `min_delta` is an optional float that requires a new value to go over the current best (depending on `comp`) by at least that amount. Model will be saved in `learn.path/learn.model_dir/name.pth`, maybe `every_epoch` if `True`, every nth epoch if an integer is passed to `every_epoch` or at each improvement of the monitored quantity.
learn = synth_learner(n_trn=2, path=Path.cwd()/'tmp')
learn.fit(n_epoch=2, cbs=SaveModelCallback())
assert (Path.cwd()/'tmp/models/model.pth').exists()
learn = synth_learner(n_trn=2, path=Path.cwd()/'tmp')
learn.fit(n_epoch=2, cbs=SaveModelCallback(fname='end',at_end=True))
assert (Path.cwd()/'tmp/models/end.pth').exists()
learn.fit(n_epoch=2, cbs=SaveModelCallback(every_epoch=True))
for i in range(2): assert (Path.cwd()/f'tmp/models/model_{i}.pth').exists()
shutil.rmtree(Path.cwd()/'tmp')
learn.fit(n_epoch=4, cbs=SaveModelCallback(every_epoch=2))
for i in range(4):
if not i%2: assert (Path.cwd()/f'tmp/models/model_{i}.pth').exists()
else: assert not (Path.cwd()/f'tmp/models/model_{i}.pth').exists()
shutil.rmtree(Path.cwd()/'tmp')
# ## ReduceLROnPlateau
#|export
class ReduceLROnPlateau(TrackerCallback):
"A `TrackerCallback` that reduces learning rate when a metric has stopped improving."
order=TrackerCallback.order+2
def __init__(self, monitor='valid_loss', comp=None, min_delta=0., patience=1, factor=10., min_lr=0, reset_on_fit=True):
super().__init__(monitor=monitor, comp=comp, min_delta=min_delta, reset_on_fit=reset_on_fit)
self.patience,self.factor,self.min_lr = patience,factor,min_lr
def before_fit(self): self.wait = 0; super().before_fit()
def after_epoch(self):
"Compare the value monitored to its best score and reduce LR by `factor` if no improvement."
super().after_epoch()
if self.new_best: self.wait = 0
else:
self.wait += 1
if self.wait >= self.patience:
old_lr = self.opt.hypers[-1]['lr']
for h in self.opt.hypers: h['lr'] = max(h['lr'] / self.factor, self.min_lr)
self.wait = 0
if self.opt.hypers[-1]["lr"] < old_lr:
print(f'Epoch {self.epoch}: reducing lr to {self.opt.hypers[-1]["lr"]}')
learn = synth_learner(n_trn=2)
learn.fit(n_epoch=4, lr=1e-7, cbs=ReduceLROnPlateau(monitor='valid_loss', min_delta=0.1, patience=2))
#|hide
test_eq(learn.opt.hypers[-1]['lr'], 1e-8)
learn = synth_learner(n_trn=2)
learn.fit(n_epoch=6, lr=5e-8, cbs=ReduceLROnPlateau(monitor='valid_loss', min_delta=0.1, patience=2, min_lr=1e-8))
#|hide
test_eq(learn.opt.hypers[-1]['lr'], 1e-8)
# Each of these three derived `TrackerCallback`s (`SaveModelCallback`, `ReduceLROnPlateu`, and `EarlyStoppingCallback`) all have an adjusted order so they can each run with each other without interference. That order is as follows:
#
# > Note: in parenthesis is the actual `Callback` order number
#
# 1. `TrackerCallback` (60)
# 2. `SaveModelCallback` (61)
# 3. `ReduceLrOnPlateu` (62)
# 4. `EarlyStoppingCallback` (63)
# ## Export -
#|hide
from nbdev.export import notebook2script
notebook2script()
| nbs/17_callback.tracker.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Merge Sort
# © 2021, <NAME>
# +
import sys
def merge_sort(A):
split(A, 0, len(A)-1)
def split(A, first, last):
if first < last:
middle = (first + last)//2
split(A, first, middle)
split(A, middle+1, last)
merge(A, first, middle, last)
def merge(A, first, middle, last):
L = A[first:middle+1]
R = A[middle+1:last+1]
L.append(sys.maxsize)
R.append(sys.maxsize)
l = r = 0
for a in range (first, last+1):
if L[l] <= R[r]:
A[a] = L[l]
l += 1
else:
A[a] = R[r]
r += 1
# -
# ### Test Function
# Set a result flag. The j loop is used to perform 1000 test iterations. The next two lines create and shuffle list A of 100 integers. Then A is passed to our sorting function. The sorted result is compared to a sort using Python's sorted function. After 1000 iterations of the test, the result is printed.
# +
import random
def test(func):
result = 'Success'
for j in range(1000):
A = [k for k in range(100)]
random.shuffle(A)
func(A)
if A != sorted(A):
result = 'Failed'
print(result)
test(merge_sort)
# -
| Sorting Algorithms/Merge Sort.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
import matplotlib.pyplot as plt
# +
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:, 2:]
y = iris.target
# -
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()
# +
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=2, criterion="entropy")
dt_clf.fit(X, y)
# -
# #### 什么是决策树?
# - 非参数学习算法
# - 可以解决分类问题
# - 天然可以解决多分类问题
# - 也可以解决回归问题
# - 非常好的可解释性
# #### 问题:每个节点在那个维度做划分?
# #### 问题:某个维度在那个值上做划分?
| data-science/scikit-learn/10/01-What-is-Decision-Tree.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from scipy.optimize import minimize
from scipy.optimize import Bounds
import pandas as pd
import numpy as np
import os
import json
data_dir = '../data'
nutrition_profile_df = pd.DataFrame(index=['RDI', 'UL', 'target_fac', 'target_mask'], data={
"Calories (kcal)": [2000, 2200, 1.0, True],
"Carbohydrates (g)": [279, 300, 1.0, True],
"Protein (g)": [104, 300, 1.0, True],
"Total Fat (g)": [57, 70, 1.0, True],
"Saturated Fat (g)": [0, 0, 1.0, False],
"Monounsaturated Fat (g)": [0, 0, 1.0, False],
"Polyunsaturated Fat (g)": [0, 0, 1.0, False],
"Omega-3 Fatty Acids (g)": [8.5, np.NaN, 1.2, True],
"Omega-6 Fatty Acids (g)": [12, np.NaN, 1.2, True],
"Total Fiber (g)": [38, np.NaN, 1.2, True],
"Soluble Fiber (g)": [3, np.NaN, 1.2, True],
"Insoluble Fiber (g)": [30, np.NaN, 1.2, True],
"Cholesterol (mg)": [0, np.NaN, 1.0, False],
"Vitamin A (IU)": [3000, 10000, 1.2, True],
"Vitamin B6 (mg)": [1.3, 100, 1.2, True],
"Vitamin B12 (ug)": [2.4, np.NaN, 1.2, True],
"Vitamin C (mg)": [90, 2000, 1.2, True],
"Vitamin D (IU)": [600, 4000, 1.2, True],
"Vitamin E (IU)": [20, 1000, 1.2, True],
"Vitamin K (ug)": [120, np.NaN, 1.2, True],
"Thiamin (mg)": [1.2, np.NaN, 1.2, True],
"Riboflavin (mg)": [1.3, np.NaN, 1.2, True],
"Niacin (mg)": [16, 41, 1.2, True],
"Folate (ug)": [400, 1000, 1.2, True],
"Pantothenic Acid (mg)": [5, np.NaN, 1.2, True],
"Biotin (ug)": [30, np.NaN, 1.2, True],
"Choline (mg)": [550, 3500, 1.2, True],
"Calcium (g)": [1, 2.5, 1.2, True],
"Chloride (g)": [2.3, np.NaN, 1.2, True],
"Chromium (ug)": [35, np.NaN, 1.0, True],
"Copper (mg)": [0.9, 10, 1.0, True],
"Iodine (ug)": [150, 1100, 1.2, True],
"Iron (mg)": [8, 45, 1.2, True],
"Magnesium (mg)": [420, np.NaN, 1.2, True],
"Manganese (mg)": [2.3, 11, 1.0, True],
"Molybdenum (ug)": [45, 2000, 1.2, True],
"Phosphorus (g)": [0.7, 4, 1.2, True],
"Potassium (g)": [4.7, np.NaN, 1.2, True],
"Selenium (ug)": [55, 400, 1.2, True],
"Sodium (g)": [1.5, 2.3, 1.2, True],
"Sulfur (g)": [0.8, 2, 1.2, True],
"Zinc (mg)": [11, 40, 1.2, True]
})
#nutrition_profile_df = nutrition_profile_df.loc[4] = np.zeros(nutrition_profile_df.shape[1]).reshape(1,42), index=['target']))
#np.zeros(nutrition_profile_df.shape[1]).reshape(1,42)
#nutrition_profile_df.shape
#pd.DataFrame(np.zeros(nutrition_profile_df.shape[1]), index=['target'])
#nutrition_profile_df.loc['target'] = nutrition_profile_df.loc['RDI'] * nutrition_profile_df.loc['target_fac']
#nutrition_profile_df.append(pd.Series(np.zeros(nutrition_profile_df.shape[1]).reshape(1,42)))
nutrition_profile_df.append(pd.DataFrame(np.zeros(nutrition_profile_df.shape[1]).reshape(1,42), columns=nutrition_profile_df.columns, index=['target']))
#nutrition_profile_df.head(5)
nutrition_profile_df.loc['target'] = nutrition_profile_df.loc['RDI'] * nutrition_profile_df.loc['target_fac']
nutrition_profile_df.head(5)
# +
field_map = {
'Name': 8,
'Container Size (g)': 12,
'Cost ($)': 16,
'Source': 18,
'Link': 20,
'Calories (kcal)': 32,
'Carbohydrates (g)': 35,
"Protein (g)": 38,
"Total Fat (g)": 41,
"Saturated Fat (g)": 44,
"Monounsaturated Fat (g)": 47,
"Polyunsaturated Fat (g)": 50,
"Omega-3 Fatty Acids (g)": 53,
"Omega-6 Fatty Acids (g)": 56,
"Total Fiber (g)": 59,
"Soluble Fiber (g)": 62,
"Insoluble Fiber (g)": 65,
"Cholesterol (mg)": 68,
"Vitamin A (IU)": 116,
"Vitamin B6 (mg)": 119,
"Vitamin B12 (ug)": 122,
"Vitamin C (mg)": 125,
"Vitamin D (IU)": 128,
"Vitamin E (IU)": 131,
"Vitamin K (ug)": 134,
"Thiamin (mg)": 137,
"Riboflavin (mg)": 140,
"Niacin (mg)": 143,
"Folate (ug)": 146,
"Pantothenic Acid (mg)": 149,
"Biotin (ug)": 152,
"Choline (mg)": 155,
"Calcium (g)": 71,
"Chloride (g)": 74,
"Chromium (ug)": 77,
"Copper (mg)": 80,
"Iodine (ug)": 83,
"Iron (mg)": 86,
"Magnesium (mg)": 89,
"Manganese (mg)": 92,
"Molybdenum (ug)": 95,
"Phosphorus (g)": 98,
"Potassium (g)": 101,
"Selenium (ug)": 104,
"Sodium (g)": 107,
"Sulfur (g)": 110,
"Zinc (mg)": 113
}
ingredients = {}
for file in os.listdir(f'{data_dir}/raw'):
if not file.endswith('.txt'):
continue
#print(f"name of file: {file}")
lines = open(f'{data_dir}/raw/{file}', 'r').readlines()
name = lines[8].strip()
ingred = {}
for k, v in field_map.items():
if k.endswith(')'):
ingred[k] = float(lines[v].strip())
else:
ingred[k] = lines[v].strip()
ingredients[name] = ingred
open(f'{data_dir}/interim/ingredients.json', 'w').write(json.dumps(ingredients, indent=4))
#print(str(ingredients))
# +
ingredient_labels=list(ingredients[list(ingredients.keys())[0]].keys())[5:]
ingredient_names=list(ingredients.keys())
data = {}
for label in ingredient_labels:
data[label]=[]
for name in ingredient_names:
for label in ingredient_labels:
data[label].append(ingredients[name][label])
ingredients_df = pd.DataFrame(index=ingredient_names, data=data)
ingredients_df.to_json(open(f'{data_dir}/interim/ingredients_df.json','w'))
ingredients_df.head(5)
# -
def objective(recipe):
# recipe: contains the proportion of each ingredient measured in fractions of 100g
# Find the total amount of all nutrients for the given recipe
total = np.zeros(len(ingredients_df.values[0]))
for i, amount in [ (i, np.transpose(recipe)[i]) for i in range(len(recipe))]:
print(str(total))
ingredient = ingredients_df.values[i]
scaled = ingredient * amount
total = total + scaled
# Find the difference between the total and the target
# Calculate the sum of the differences
#rec = np.array(np.ones(42))
objective(rec)
#np.transpose(rec)[1]
a = ingredients_df.values[0]
np.absolute(a * -1)
np.zeros(2)
| notebooks/Solver-orig.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="WP1koyfTkNDA" colab_type="code" outputId="5fbe2731-8405-47a2-9fc8-ab95a7bbe86c" executionInfo={"status": "ok", "timestamp": 1580408108794, "user_tz": -60, "elapsed": 5049, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDKbKLxJt0onqLfwKPEIvwzHNMlzqJ7JFd26iHN9Q=s64", "userId": "04700668765937042741"}} colab={"base_uri": "https://localhost:8080/", "height": 360}
# !pip install gplpy
# + id="1EA2R58bSukp" colab_type="code" outputId="51c5567a-b9b9-4a8d-b04c-c4ab2e2c2e0f" executionInfo={"status": "error", "timestamp": 1580408876412, "user_tz": -60, "elapsed": 648221, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mDKbKLxJt0onqLfwKPEIvwzHNMlzqJ7JFd26iHN9Q=s64", "userId": "04700668765937042741"}} colab={"base_uri": "https://localhost:8080/", "height": 922}
""" TODO """
import sys
import os
from gplpy.gggp.grammar import CFG, ProbabilisticModel
from gplpy.evo.evolution import Experiment, Setup, Problem, Evolution_EDA, Evolution_WX
from gplpy.evo.log import DBLogger
from gplpy.gggp.derivation import Derivation, WX, OnePointMutation
from gplpy.gggp.metaderivation import MetaDerivation, EDA
from bson.objectid import ObjectId
import tensorflow
gp_setups = {}
# SETUP EXAMPLES ###########################################################
WX_setup = Setup(name='WX', evolution=Evolution_WX, max_recursions = 250, probabilistic_model=ProbabilisticModel.uniform, crossover=WX, selection_rate=2, mutation=OnePointMutation, mutation_rate=0.05, immigration_rate=.15)
EDA_setup = Setup(name='EDA', evolution=Evolution_EDA, max_recursions = 250, crossover=EDA, selection_rate=0.5, exploration_rate=0., model_update_rate=.5, offspring_rate=1, immigration_rate=.15)
EDX_setup = Setup(name='EDX', evolution=Evolution_EDA, max_recursions = 250, crossover=EDA, selection_rate=0.5, exploration_rate=0.001, model_update_rate=.5, offspring_rate=.25, immigration_rate=.15)
class DFFNN(Problem):
epochs = 2
batch_size = 128
@staticmethod
def fitness(individual, args):
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
topology = list(map(len, str(individual.derivation).replace(' ','').split("0")))
input_size, num_classes, X_train, X_test, y_train, y_test = args
model = Sequential()
# First layer and hidden layer
model.add(Dense(topology.pop(0), activation='relu', input_dim=input_size))
# Hidden layers
for layer_size in topology:
model.add(Dense(layer_size, activation='relu'))
# Output layer
model.add(Dense(1 if num_classes==2 else num_classes, activation='sigmoid' if num_classes==2 else 'softmax'))
# Setup optimizer
model.compile(loss='binary_crossentropy'if num_classes==2 else 'categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(X_train, y_train,
epochs=DFFNN.epochs,
batch_size=DFFNN.batch_size,
verbose=0,
validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, verbose=0)
#print('Test loss:', score[0])
#print('Test accuracy:', score[1])
individual._fitness = score[0]
individual.learning_iterations = len(history.epoch)
individual.mature.set()
if __name__ == "__main__":
sys.setrecursionlimit(10000)
os.chdir('/content/')
if not os.path.exists('experiments'):
os.mkdir('experiments')
## IS
study = "DFFNN"
study_id = None
#study_id = ObjectId("590b99f0d140a535c9dfbe12")
# Grammar initialization
grammar_file = study.replace(' ', '_') + '.gr'
gr = CFG(grammar_file)
# logger initialization
# Set to True to log into mongodb
logger = False
if logger:
logger = DBLogger(server='cluster0-21cbd.gcp.mongodb.net', user='gplpy_logger', password='<PASSWORD>', cluster=True)
if study_id:
logger.resume_study(study_id=study_id, grammar=grammar_file[5:])
else:
logger.new_study(study=study, grammar=grammar_file[5:])
logger.createDeleteStudyRoutine()
# Setup problem
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.utils import to_categorical
exp_name = "Cancer"
X, y = datasets.load_breast_cancer(return_X_y=True)
num_classes = len(set(y))
input_size = X.shape[1]
if num_classes > 2:
y = to_categorical(y, num_classes)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
y_train = y_train.reshape(y_train.size, 1)
y_test = y_test.reshape(y_test.size, 1)
args = (input_size, num_classes, X_train, X_test, y_train, y_test)
# Run
samples = 1
ids =Experiment(study=study, experiment=exp_name, grammar=gr, problem=DFFNN, fitness_args=args,
setups=[EDX_setup, EDA_setup, WX_setup], logger=logger, samples=samples).run()
if logger and logger.server is 'localhost':
logger.plot_experiments_evolution()
logger.plot_range_study()
logger.report_statistics()
# + id="cpisZ1o8eFHa" colab_type="code" colab={}
| dffnn_demo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # UDF Testing in the Notebook
#
# This notebook shows how to write and test BigQuery Javascript UDFs (user-defined functions) within a notebook.
#
# Before using this tutorial you should go through the [UDFs in BigQuery](notebooks/datalab/tutorials/BigQuery/UDFs%20in%20BigQuery.ipynb) tutorial which discusses how to use UDFs in notebooks without external code.
#
# You can read more about UDFs [here](https://cloud.google.com/bigquery/user-defined-functions).
#
#
# ## Scenario
#
# This notebook uses the same scenario as before, looking at some anonymized logs that originated in Google AppEngine.
# ## Creating and Testing the UDF
#
# UDFs are Javascript functions that take a row object and emitter function as input; they perform some computation and then call the emitter function to output a result row object. We will first write and test our UDF as Javascript. We can use a %%javascript cell for this. We will write the code of the UDF (and its helper function `getParameters`), then define some test data, and finally call the UDF with the test data after creating a mock version of the emitter function. Note that in a %%javascript cell you can access the output area element with the name `element`; our mock emitter will use that to produce output we can see in the notebook.
#
# There is no state shared between %%javascript cells so we have to do this all in a single cell.
# + language="javascript"
#
# /**
# * A helper function to split a set of URL query parameters into an object
# * as key/value properties.
# */
# function getParameters(path) {
# var re = /[?&]([^=]*)=([^&]*)/g;
# var result = {};
# var match;
# while ((match = re.exec(path)) != null) {
# result[match[1]] = decodeURIComponent(match[2]);
# }
# return result;
# }
#
# /**
# * Our UDF function, which takes a row r and emitter function emitFn.
# * We assume each row r has the five columns from our input (timestamp,
# * method, latency, status and path). We will parse path from the input
# * and add its constituent parts, then call the emitter.
# *
# * Note: we re-use r for the output as we are keeping its fields but we
# * could have created a new object if that was more appropriate.
# */
# var udf = function(r, emitFn) {
# var q = getParameters(r.path);
# var split = r.path.indexOf('?');
# r.event = r.path.substr(5, split - 5);
# r.project = q.project;
# r.instance = q.instance;
# r.user = q.user;
# r.page = q.page;
# r.path = q.path;
# r.version = q.version;
# r.release = q.release;
# emitFn(r);
# }
#
# // Now we want to test the UDF. We can try calling it using a sample line from our table.
# // Note that the variable 'element' is available to us to create output in the notebook,
# // so our test emitter will use that to display the fields.
# // Also note that the Date function in Javascript uses 0-based months so October is 9 (wat!)
#
# var test_row = {
# latency: 0.00311,
# method: 'POST',
# path: '/log/page?project=14&instance=81&user=16&page=master&path=63&version=0.1.1&release=alpha',
# status: 204,
# timestamp: new Date(2015, 9, 27, 2, 41, 20, 430256)
# };
#
# function emitter(r) {
# for (var p in r) {
# element.append(p + '=' + r[p] + '<br>');
# }
# }
#
# udf(test_row, emitter);
#
# -
# Looks like we are good to go!
#
# ## Next Steps
#
# If you have code that you use regularly in your UDFs you can factor that out and put it in Google Cloud Storage then import it; this is covered in the tutorial [UDFs using Code in Cloud Storage](notebooks/datalab/tutorials/BigQuery/UDFs%20using%20Code%20in%20Cloud%20Storage.ipynb).
| docs/tutorials/BigQuery/UDF Testing in the Notebook.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Dependencies
# + _kg_hide-input=true
import os, warnings, shutil, re
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from transformers import AutoTokenizer
from sklearn.utils import shuffle
from sklearn.model_selection import StratifiedKFold
SEED = 0
warnings.filterwarnings("ignore")
pd.set_option('max_colwidth', 160)
# + _kg_hide-input=true
# Preprocess data
def clean_text(text):
text = str(text)
text = re.sub(r'[0-9"]', '', text) # number
text = re.sub(r'#[\S]+\b', '', text) # hash
text = re.sub(r'@[\S]+\b', '', text) # mention
text = re.sub(r'https?\S+', '', text) # link
text = re.sub(r'\s+', ' ', text) # multiple white spaces
# text = re.sub(r'\W+', ' ', text) # non-alphanumeric
return text.strip()\
# Preprocess inputs
CLS = 0
PAD = 1
SEP = 2
def preprocess_roberta(text, tokenizer, max_seq_len):
encoded = tokenizer.encode_plus(text, return_token_type_ids=False)
# Truncate
input_ids = encoded['input_ids'][:max_seq_len]
attention_mask = encoded['attention_mask'][:max_seq_len]
# Update input_ids
input_ids[0] = CLS
input_ids[-1] = SEP
# Pad
input_ids = input_ids + [PAD] * (max_seq_len - len(input_ids))
attention_mask = attention_mask + [0] * (max_seq_len - len(attention_mask))
x = [np.asarray(input_ids, dtype=np.int32),
np.asarray(attention_mask, dtype=np.int8)]
return x
def preprocess_roberta_tail(text, tokenizer, max_seq_len):
encoded = tokenizer.encode_plus(text, return_token_type_ids=False)
# Truncate
input_ids = encoded['input_ids'][-max_seq_len:]
attention_mask = encoded['attention_mask'][-max_seq_len:]
# Update input_ids
input_ids[0] = CLS
input_ids[-1] = SEP
# Pad
input_ids = input_ids + [PAD] * (max_seq_len - len(input_ids))
attention_mask = attention_mask + [0] * (max_seq_len - len(attention_mask))
x = [np.asarray(input_ids, dtype=np.int32),
np.asarray(attention_mask, dtype=np.int8)]
# if len(encoded['input_ids']) > max_seq_len:
# return x
# else:
# return None
return x
def preprocess_roberta_tail_test(text, tokenizer, max_seq_len):
encoded = tokenizer.encode_plus(text, return_token_type_ids=False)
# Truncate
input_ids = encoded['input_ids'][-max_seq_len:]
attention_mask = encoded['attention_mask'][-max_seq_len:]
# Update input_ids
input_ids[0] = CLS
input_ids[-1] = SEP
# Pad
input_ids = input_ids + [PAD] * (max_seq_len - len(input_ids))
attention_mask = attention_mask + [0] * (max_seq_len - len(attention_mask))
x = [np.asarray(input_ids, dtype=np.int32),
np.asarray(attention_mask, dtype=np.int8)]
return x
def get_data(df, text_col, tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta):
x_input_ids = []
x_attention_masks = []
y_data = []
y_data_int = []
for row in df.itertuples():
x = preprocess_fn(getattr(row, text_col), tokenizer, MAX_LEN)
if x is not None:
x_input_ids.append(x[0])
x_attention_masks.append(x[1])
y_data.append(getattr(row, 'toxic'))
y_data_int.append(getattr(row, 'toxic_int'))
x_data = [np.asarray(x_input_ids, dtype=np.int32),
np.asarray(x_attention_masks, dtype=np.int8)]
y_data = [np.asarray(y_data, dtype=np.float32),
np.asarray(y_data_int, dtype=np.int8)]
return x_data, y_data
def get_data_test(df, text_col, tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta):
x_input_ids = []
x_attention_masks = []
for row in df.itertuples():
x = preprocess_fn(getattr(row, text_col), tokenizer, MAX_LEN)
x_input_ids.append(x[0])
x_attention_masks.append(x[1])
x_data = [np.asarray(x_input_ids, dtype=np.int32),
np.asarray(x_attention_masks, dtype=np.int8)]
return x_data
# -
# # Parameters
MAX_LEN = 192
tokenizer_path = 'jplu/tf-xlm-roberta-large'
sample_rate = 4
# # Load data
# + _kg_hide-input=true
train1 = pd.read_csv("/kaggle/input/jigsaw-multilingual-toxic-comment-classification/jigsaw-toxic-comment-train.csv")
train2 = pd.read_csv("/kaggle/input/jigsaw-multilingual-toxic-comment-classification/jigsaw-unintended-bias-train.csv")
valid_df = pd.read_csv("/kaggle/input/jigsaw-multilingual-toxic-comment-classification/validation.csv", usecols=['comment_text', 'toxic', 'lang'])
test_df = pd.read_csv("/kaggle/input/jigsaw-multilingual-toxic-comment-classification/test.csv", usecols=['content'])
n_neg_samp_df1 = len(train1.query('toxic > .5')) * sample_rate
n_neg_samp_df2 = len(train2.query('toxic > .5')) * sample_rate
train_df = pd.concat([train1[['comment_text', 'toxic']].query('toxic > .5'),
train1[['comment_text', 'toxic']].query('toxic <= .5').sample(n=n_neg_samp_df1, random_state=SEED),
train2[['comment_text', 'toxic']].query('toxic > .5'),
train2[['comment_text', 'toxic']].query('toxic <= .5').sample(n=n_neg_samp_df2, random_state=SEED)
])
print(f'Dataframe 1 samples: toxic|non-toxic | {n_neg_samp_df1 // sample_rate}|{n_neg_samp_df1}')
print(f'Dataframe 2 samples: toxic|non-toxic | {n_neg_samp_df2 // sample_rate}|{n_neg_samp_df2}')
print('Train samples %d' % len(train_df))
display(train_df.head())
display(train_df.describe())
print('Validation samples %d' % len(valid_df))
display(valid_df.head())
display(valid_df.describe())
print('Test samples %d' % len(test_df))
display(test_df.head())
display(test_df.describe())
# -
# # Tokenizer
# + _kg_hide-output=true
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, lowercase=False)
# -
# ## Preprocess
# +
# Train
train_df['comment_text'] = train_df.apply(lambda x: clean_text(x['comment_text']), axis=1)
train_df['length'] = train_df['comment_text'].apply(lambda x : len(x))
train_df['word_count'] = train_df['comment_text'].apply(lambda x : len(x.split(' ')))
train_df['token_count'] = train_df['comment_text'].apply(lambda x : len(tokenizer.encode(x)))
train_df['toxic_int'] = train_df['toxic'].round().astype(int)
# Validation
valid_df['comment_text'] = valid_df.apply(lambda x: clean_text(x['comment_text']), axis=1)
valid_df['length'] = valid_df['comment_text'].apply(lambda x : len(x))
valid_df['word_count'] = valid_df['comment_text'].apply(lambda x : len(x.split(' ')))
valid_df['token_count'] = valid_df['comment_text'].apply(lambda x : len(tokenizer.encode(x)))
valid_df['toxic_int'] = valid_df['toxic'].round().astype(int)
# Test
test_df['content'] = test_df.apply(lambda x: clean_text(x['content']), axis=1)
test_df['length'] = test_df['content'].apply(lambda x : len(x))
test_df['word_count'] = test_df['content'].apply(lambda x : len(x.split(' ')))
test_df['token_count'] = test_df['content'].apply(lambda x : len(tokenizer.encode(x)))
print('Train samples %d' % len(train_df))
display(train_df.head())
display(train_df.describe())
print('Validation samples %d' % len(valid_df))
display(valid_df.head())
display(valid_df.describe())
print('Test samples %d' % len(test_df))
display(test_df.head())
display(test_df.describe())
# -
# ## Filter
# +
# train_df = train_df[train_df['word_count'] <= 250]
# train_df = train_df[train_df['token_count'] <= 1000]
train_df = shuffle(train_df, random_state=SEED).reset_index(drop=True)
print('Train samples %d' % len(train_df))
display(train_df.head())
display(train_df.describe())
# -
# # Data generation sanity check
# + _kg_hide-input=true
for idx in range(5):
print('\nRow %d' % idx)
max_seq_len = 32
comment_text = train_df['comment_text'].loc[idx]
x_train, y_train = get_data(train_df[idx:idx+1], 'comment_text', tokenizer, max_seq_len, preprocess_fn=preprocess_roberta)
print('label : "%.4f"' % y_train[0])
print('label int : "%d"' % y_train[1])
print('comment_text : "%s"' % comment_text)
print('input_ids : "%s"' % x_train[0][0])
print('attention_mask: "%s"' % x_train[1][0])
x_train, _ = get_data(train_df[idx:idx+1], 'comment_text', tokenizer, max_seq_len, preprocess_fn=preprocess_roberta_tail)
if len(x_train[0]) > 0:
print('-------------------- TAIL --------------------')
print('input_ids : "%s"' % x_train[0][0])
print('attention_mask: "%s"' % x_train[1][0])
assert len(x_train[0][0]) == len(x_train[1][0]) == max_seq_len
# -
# # 5-Fold split
# + _kg_hide-input=true
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=SEED)
for fold_n, (train_idx, val_idx) in enumerate(folds.split(train_df, train_df['toxic_int'])):
print('Fold: %s, Train size: %s, Validation size %s' % (fold_n+1, len(train_idx), len(val_idx)))
train_df[('fold_%s' % str(fold_n+1))] = 0
train_df[('fold_%s' % str(fold_n+1))].loc[train_idx] = 'train'
train_df[('fold_%s' % str(fold_n+1))].loc[val_idx] = 'validation'
# -
# # Label distribution
# + _kg_hide-input=true
for fold_n in range(folds.n_splits):
fold_n += 1
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 6))
fig.suptitle('Fold %s' % fold_n, fontsize=22)
sns.countplot(x="toxic_int", data=train_df[train_df[('fold_%s' % fold_n)] == 'train'], palette="GnBu_d", ax=ax1).set_title('Train')
sns.countplot(x="toxic_int", data=train_df[train_df[('fold_%s' % fold_n)] == 'validation'], palette="GnBu_d", ax=ax2).set_title('Validation')
sns.despine()
plt.show()
# + _kg_hide-input=true
for fold_n in range(folds.n_splits):
fold_n += 1
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 6))
fig.suptitle('Fold %s' % fold_n, fontsize=22)
sns.distplot(train_df[train_df[('fold_%s' % fold_n)] == 'train']['toxic'], ax=ax1).set_title('Train')
sns.distplot(train_df[train_df[('fold_%s' % fold_n)] == 'validation']['toxic'], ax=ax2).set_title('Validation')
sns.despine()
plt.show()
# -
# # Output 5-fold set
# + _kg_hide-input=true
train_df.to_csv('5-fold.csv', index=False)
display(train_df.head())
for fold_n in range(folds.n_splits):
if fold_n < 1:
fold_n += 1
base_path = 'fold_%d/' % fold_n
# Create dir
os.makedirs(base_path)
x_train, y_train = get_data(train_df[train_df[('fold_%s' % fold_n)] == 'train'], 'comment_text',
tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta)
x_valid, y_valid = get_data(train_df[train_df[('fold_%s' % fold_n)] == 'validation'], 'comment_text',
tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta)
y_train_float, y_train_int = y_train
y_valid_float, y_valid_int = y_valid
x_train, y_train_float, y_train_int = np.asarray(x_train), np.asarray(y_train_float), np.asarray(y_train_int)
x_valid, y_valid_float, y_valid_int = np.asarray(x_valid), np.asarray(y_valid_float), np.asarray(y_valid_int)
np.save(base_path + 'x_train', x_train)
np.save(base_path + 'y_train', y_train_float)
np.save(base_path + 'y_train_int', y_train_int)
np.save(base_path + 'x_valid', x_valid)
np.save(base_path + 'y_valid', y_valid_float)
np.save(base_path + 'y_valid_int', y_valid_int)
print('\nFOLD: %d' % (fold_n))
print('x_train shape:', x_train.shape)
print('y_train_float shape:', y_train_float.shape)
print('y_train_int shape:', y_train_int.shape)
print('x_valid shape:', x_valid.shape)
print('y_valid_float shape:', y_valid_float.shape)
print('y_valid_int shape:', y_valid_int.shape)
#################### ENCODE TAIL ONLY ####################
x_train, y_train = get_data(train_df[train_df[('fold_%s' % fold_n)] == 'train'], 'comment_text',
tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta_tail)
x_valid, y_valid = get_data(train_df[train_df[('fold_%s' % fold_n)] == 'validation'], 'comment_text',
tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta_tail)
y_train_float, y_train_int = y_train
y_valid_float, y_valid_int = y_valid
x_train, y_train_float, y_train_int = np.asarray(x_train), np.asarray(y_train_float), np.asarray(y_train_int)
x_valid, y_valid_float, y_valid_int = np.asarray(x_valid), np.asarray(y_valid_float), np.asarray(y_valid_int)
np.save(base_path + 'x_train_tail', x_train)
np.save(base_path + 'y_train_tail', y_train_float)
np.save(base_path + 'y_train_int_tail', y_train_int)
np.save(base_path + 'x_valid_tail', x_valid)
np.save(base_path + 'y_valid_tail', y_valid_float)
np.save(base_path + 'y_valid_int_tail', y_valid_int)
print('\nFOLD: %d [TAIL]' % (fold_n))
print('x_train shape:', x_train.shape)
print('y_train_float shape:', y_train_float.shape)
print('y_train_int shape:', y_train_int.shape)
print('x_valid shape:', x_valid.shape)
print('y_valid_float shape:', y_valid_float.shape)
print('y_valid_int shape:', y_valid_int.shape)
# Compress logs dir
# !tar -czf fold_1.tar.gz fold_1
# # !tar -czf fold_2.tar.gz fold_2
# # !tar -czf fold_3.tar.gz fold_3
# # !tar -czf fold_4.tar.gz fold_4
# # !tar -czf fold_5.tar.gz fold_5
# Delete logs dir
shutil.rmtree('fold_1')
# shutil.rmtree('fold_2')
# shutil.rmtree('fold_3')
# shutil.rmtree('fold_4')
# shutil.rmtree('fold_5')
# -
# # Validation set
# + _kg_hide-input=true
display(valid_df.head())
display(valid_df.describe())
x_valid, y_valid = get_data(valid_df, 'comment_text', tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta)
y_valid_float, y_valid_int = y_valid
x_valid, y_valid_float, y_valid_int = np.asarray(x_valid), np.asarray(y_valid_float), np.asarray(y_valid_int)
np.save('x_valid', x_valid)
np.save('y_valid', y_valid_float)
np.save('y_valid_int', y_valid_int)
print('x_valid shape:', x_valid.shape)
print('y_valid_float shape:', y_valid_float.shape)
print('y_valid_int shape:', y_valid_int.shape)
#################### ENCODE TAIL ONLY ####################
x_valid, y_valid = get_data(valid_df, 'comment_text', tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta_tail)
y_valid_float, y_valid_int = y_valid
x_valid, y_valid_float, y_valid_int = np.asarray(x_valid), np.asarray(y_valid_float), np.asarray(y_valid_int)
np.save('x_valid_tail', x_valid)
np.save('y_valid_tail', y_valid_float)
np.save('y_valid_int_tail', y_valid_int)
print('x_valid shape:', x_valid.shape)
print('y_valid_float shape:', y_valid_float.shape)
print('y_valid_int shape:', y_valid_int.shape)
# -
# # Test set
# + _kg_hide-input=true
display(test_df.head())
display(test_df.describe())
x_test = get_data_test(test_df, 'content', tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta)
x_test = np.asarray(x_test)
np.save('x_test', x_test)
print('x_test shape:', x_test.shape)
#################### ENCODE TAIL ONLY ####################
x_test = get_data_test(test_df, 'content', tokenizer, MAX_LEN, preprocess_fn=preprocess_roberta_tail_test)
x_test = np.asarray(x_test)
np.save('x_test_tail', x_test)
print('[TAIL] x_test shape:', x_test.shape)
# -
# # Test set EDA
# ## Word count distribution
# + _kg_hide-input=true
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(20, 8.7), sharex=True)
sns.distplot(train_df['word_count'], ax=ax1).set_title("Train")
sns.distplot(test_df['word_count'], ax=ax2).set_title("Test")
sns.despine()
plt.show()
# -
# ## Token count distribution
# + _kg_hide-input=true
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(20, 8.7), sharex=True)
sns.distplot(train_df['token_count'], ax=ax1).set_title("Train")
sns.distplot(test_df['token_count'], ax=ax2).set_title("Test")
sns.despine()
plt.show()
| Datasets/jigsaw-data-split-roberta-192-ratio-4-clean-polish.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# +
import matplotlib.pyplot as plt
import numpy as np
from rich.progress import track
# %load_ext lab_black
# %load_ext watermark
# -
# # Gibbs Sampler Example 1
#
# Adapted from [Codes for Unit 5: norcaugibbs.m](https://www2.isye.gatech.edu/isye6420/supporting.html).
#
# Associated lecture video: Unit 5 Lesson 11
# +
rng = np.random.default_rng(1)
obs = 100000
burn = 1000
# params
x = 2
sigma2 = 1
tau2 = 1
mu = 0
# inits
theta = 0
lam = 1
thetas = np.zeros(obs)
lambdas = np.zeros(obs)
# pre-generate randoms where possible
randn = rng.standard_normal(obs)
for i in track(range(obs)):
d = tau2 + lam * sigma2
theta = (tau2 / d * x + lam * sigma2 / d * mu) + np.sqrt(tau2 * sigma2 / d) * randn[
i
]
lam = rng.exponential(1 / ((tau2 + (theta - mu) ** 2) / (2 * tau2)))
thetas[i] = theta
lambdas[i] = lam
thetas = thetas[burn:]
lambdas = lambdas[burn:]
print(f"{np.mean(thetas)=}")
print(f"{np.var(thetas)=}")
print(f"{np.mean(lambdas)=}")
print(f"{np.var(lambdas)=}")
plt.hist(thetas, 40)
plt.xlabel("theta")
plt.show()
plt.hist(lambdas, 40)
plt.xlabel("lambda")
plt.show()
# -
# %watermark --iversions -v
| unit5/Unit5-GibbsSampler.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/vincentdavis/Hacking_Riddler_FiveThirtyEight/blob/master/Can_You_Escape_The_Enemy_Submarines%3F.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="kxRYW8cYG9zV" colab_type="text"
# OCT. 11, 2019, AT 8:00 AM
#
# ## [DRAFT] Can You Escape The Enemy Submarines?
#
# ### Riddler Express
#
# This week’s Riddler Express was related to me by <NAME>, who heard it from <NAME>, who heard it from … well, let’s just say this puzzle has been circulating for a while and is ready for prime time!
#
# An auditorium with 200 seats, numbered from 1 to 200, is filled to capacity. A speaker, who happens to be a mathematician, steps up to the podium overlooking the audience and pauses for a moment. “You know,” she says, “I’m thinking of a rather large whole number. Every seat number in this auditorium evenly divides my number, except for two of them — and those two seats happen to be next to each other.”
#
# As you’d expect, adjacent seats in the auditorium have consecutive numbers. Which two numbers was the speaker referring to?
# + [markdown] id="k7plb4kaHIXR" colab_type="text"
# #### First attempt:
# My first thought is that I know how to get a large number that is divisidble by all the seat numbers. Multiply all the car seat numbers. 1-200. Then possibly removing 199 and 200 with luck 1-198 multiplied is not divisible by 199 and 200. Lets try that.
# + id="rMsX7OzdHJyv" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="a4fc0ac8-151a-40ed-a802-c6ba5a89d42c"
# really wishing I had puthon 3.8 for the product fuction.
d = 1
for n in range(1,199):
d *= n
if 0 not in {d%199, d%200}:
print('I win')
else:
print(f'I loose: {d%199}, {d%200}')
# + [markdown] id="7642YOGZHWYm" colab_type="text"
# #### Second attempt:
# That didn't work I could try a few other guesses but lets just try every pair. I dont think this will work out either.
# + id="ngMwPK2gHSzU" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 34} outputId="91f833f7-ccef-4d7e-93f6-ddf3c3b870b8"
winner = False
for a in range(1,200):
d = 1
for n in range(1,201):
if d not in {a, a+1}:
d *= n
if 0 not in {d%a, d%(a+1)}:
print(f'I win. seats are: ({a}, {a+1})')
winner = True
if not winner:
print('I loose')
# + [markdown] id="N4xbEAbRHTPh" colab_type="text"
# #### Third attempt:
# That is what I figured. I know what I need is a pair of agacent numbers coprime with this large number and not with all the other 198 seats.
# I am trying to stick to my brute force ethose and not delve to much into therory. I looked a a prperty of modulo multiplication (A * B) mod C = (A mod C * B mod C) mod C. I dont see an obviouse way to use this.
# I am sticking with my guess that 199 and 200 are the two numbers. This is probably worng because its an easy guess. Lets modify the primes up to 199.
# + id="spnyuL1_Hgvj" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 105} outputId="59ada33f-7ca2-40f6-c59a-98df5bf1dbbe"
# lets define a checker.
def checker(d):
'''
Check if there is an (a, a+1) that is co prime to d and that all other numbers
divide d evenly
'''
solution_count = 0
solutions = set()
for a in range(1,200):
if 0 != d%a and 0 != d%(a+1):
solutions.add((a, a+1))
solution_count += 1
return (solution_count, solutions)
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199]
# First lets make a large number form all the primes less then 200.
d = 1
for p in primes:
d *= p
p, pc = checker(d)
print(f'From primes: Possible solution count: {p}\n Possible solutions: {pc}')
# I have 24 number pairs that are co prime to the large number.
for c in range(1, 200):
if 0 == d%c and not 0 == d%(c+1) and 0 != d%(c-1): # remove the isolated numbers
d *= c
p, pc = checker(d)
print(f'From primes and more: Possible solution count: {p}\n Possible solutions: {pc}')
# for c in range(1, 200):
# if 0 == d%c and not 0 == d%(c+1) and 0 != d%(c-1): # remove the isolated numbers
# d *= c
# winner = True
# loosers = set()
# for s in range(1,198):
# if 0 != d%s:
# winner = False
# print(f"Looser: {s}")
# loosers.add(s)
# for l in loosers:
# if 0 not in {d*l%198, d*l%199}:
# d *= l
# for s in range(1,199):
# if 0 != d%s:
# winner = False
# print(f"Looser2: {s}")
# if 0 not in {d%198, d%199}:
# print('I win')
# else:
# print(f'I loose: {d%198}, {d%199}')
# + [markdown] id="NyJCQ_-0AuD8" colab_type="text"
# #### Fourth attempt:
# In that last attempt I got down to 6 possibilities. Then I got to thinking maybe I should start with a very large prime and multiply it by the other numbers. If this works it would make me think there is more then one solution whihc I am guessing there is not.
# Looking for a large prime, [List of the first 50 million primes](https://primes.utm.edu/lists/small/millions/)
# the fifteith million appers to be 982,451,653
# + id="poFsqmDHBz_2" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 51} outputId="9c68387d-706f-414c-e63a-25275eb6521d"
large_p = 982451653
d = 1 * p
count = 200
for c in range(1, 200):
d *= c
p, pc = checker(d)
if p < count and p!= 1: # this in not eaxtly right, there cant be 200 because it is only pairs
count = p
if p == 1:
print(f'Solution found: {d}\nThe solution is: {pc}')
break
# + id="mLb7HXPI_abs" colab_type="code" colab={}
# + id="BmNKp_4iL8LB" colab_type="code" colab={}
| Can_You_Escape_The_Enemy_Submarines?.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: cmip6-processing
# language: python
# name: cmip6-processing
# ---
# # Preprocessing of CMIP models
# This notebook should demonstrate how to use `pyremo` and the underlying [pyintorg](https://git.gerics.de/python/pyintorg) package to easily preprocess global model data from CMIP models that comply to CF conventions. The workflow is basically the same as before but is reimplmented in python for better integration into the workflow and for more flexibility of in and ouput data. This notebook basically show how to use the [remap](https://pyremo.readthedocs.io/en/latest/generated/pyremo.preproc.remap.html#pyremo.preproc.remap) API that understands CF conventions. The API takes and returns xarray datasets which has several advantages. For example, it will automatically vectorize computations along levels and time axes so we don't have to care about different calendars any more. Additionally, we can conserve important meta data from the input model and keep it in the forcing data, and consequently, in the REMO model ouput. Another critical advantage is the lazy computation which will allow dask to easiy parallelize the computation along the time axis and levels.
# ## Accessing CMIP input data
# For this notebook, we take CMIP6 `MPI-ESM1-2-HR` model data directly from the DKRZ filesystem. However, the input is quite flexible and could come also from any other source the xarray accepts as input.
# %load_ext autoreload
# %autoreload 2
#from dask_jobqueue import SLURMCluster
import pyremo as pr
import xarray as xr
from dask.distributed import Client, progress
import dask
dask.config.set(**{'array.slicing.split_large_chunks': False})
# We will create a dask client here to make efficient use of the DKRZ node resources. In this example, we run the noteook on a `shared` node at DKRZ.
client = Client()
client
# Now, we collect all input files from the filesystem. For the example, we just take ten years. We combine the input files into a dataset dictionary that complies to CF conventions in the variable names. For preprocessing of the (dynamic) variables, we require from the input model at least:
# * `ta`: the amospheric temperature
# * `ps`: surface pressure
# * `ua`, `va`: the wind components
# * `orog`: the global models orography
# * `sftlf`: the land seamask of the global model
#
# The data should have, at least, a 6 hourly resolution although the preprocessing workflow is independent from the temporal resolution.
# +
from glob import glob
ta_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/6hrLev/ta/gn/v20190710/ta_6hrLev_MPI-ESM1-2-HR_historical_r1i1p1f1_gn_197901010600-198001010000.nc"
ps_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/6hrLev/ps/gn/v20190710/ps_6hrLev_MPI-ESM1-2-HR_historical_r1i1p1f1_gn_197501010600-198001010000.nc"
hus_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/6hrLev/hus/gn/v20190710/hus_6hrLev_MPI-ESM1-2-HR_historical_r1i1p1f1_gn_197901010600-198001010000.nc"
ua_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/6hrLev/ua/gn/v20190815/ua_6hrLev_MPI-ESM1-2-HR_historical_r1i1p1f1_gn_197901010600-198001010000.nc"
va_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/6hrLev/va/gn/v20190815/va_6hrLev_MPI-ESM1-2-HR_historical_r1i1p1f1_gn_197901010600-198001010000.nc"
orog_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/fx/orog/gn/v20190710/orog_fx_MPI-ESM1-2-HR_historical_r1i1p1f1_gn.nc"
sftlf_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/fx/sftlf/gn/v20190710/sftlf_fx_MPI-ESM1-2-HR_historical_r1i1p1f1_gn.nc"
#tos_file = "/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/Oday/tos/gn/v20190710/tos_Oday_MPI-ESM1-2-HR_historical_r1i1p1f1_gn_19750101-19791231.nc"
tos_files = glob("/pool/data/CMIP6/data/CMIP/MPI-M/MPI-ESM1-2-HR/historical/r1i1p1f1/Oday/tos/gn/v20190710/*")
tos_files.sort()
datasets = {'ta': ta_file,
'ps': ps_file,
'hus': hus_file,
'ua': ua_file,
'va': va_file,
'orog': orog_file,
'sftlf': sftlf_file
}
# -
# Now, we define a slightly optimized access function that works well at the DKRZ filesystem. Since we have a quite large input dataset, we want to access it lazily.
def open_mfdataset(files, use_cftime=True, parallel=True, data_vars='minimal', chunks={'time':1},
coords='minimal', compat='override', drop=None, **kwargs):
"""optimized function for opening CMIP6 6hrLev 3d datasets
based on https://github.com/pydata/xarray/issues/1385#issuecomment-561920115
"""
def drop_all_coords(ds):
#ds = ds.drop(drop)
return ds.reset_coords(drop=True)
ds = xr.open_mfdataset(files, parallel=parallel, decode_times=False, combine='by_coords',
preprocess=drop_all_coords, decode_cf=False, chunks=chunks,
data_vars=data_vars, coords='minimal', compat='override', use_cftime=use_cftime, **kwargs)
return xr.decode_cf(ds, use_cftime=use_cftime)
# The dataset for the SST is optional. In this example, we use the SST also from `MPI-ESM1-2-HR`. The SST for CMIP usually has a daily resolution and also probably a different grid.
#ref_ds = open_mfdataset(ta_file)
tos_ds = open_mfdataset(tos_files)
# ## Creating the global dataset
# With the input data at hand, we can now create a global dataset that contains all neccessary input data for the dynamic preprocessing. We use the [gfile](https://pyremo.readthedocs.io/en/latest/generated/pyremo.preproc.gfile.html#pyremo.preproc.gfile) function here that will automatically check the input data and convert units if neccessary. If the SST dataset is given, it will also resample and regrid the SST to the atmospheric grid and a 6 hourly temporal resolution. In this example, we will only preprocess one month (`1979-01`).
gfile = pr.preproc.gfile(datasets, tos=tos_ds.tos, time_range = slice("1979-01-01T06:00:00", "1979-02-01T00:00:00"))
# The `gfile` dataset is comprable to the gfiles that were explictly created in the old preprocessing workflow. But here we don't have to store this dataset on disk but simply create it directly from the CMIP input lazily. However, we could also still read in the gfile dataset from older gfiles on the filesystem that were created in a different way. The preprocessing workflow does not depend on where the data comes from, it only depends on the gfile dataset having the right conventions concerning units and variable names. In addition, the gfile function also adds vertical coordinates and static variables, e.g., `orog` and `sftlf` to the dataset. Let's have a look:
gfile
# ## Target grid information
# Now, we need to collect some information about the target grid. Here, we choose the `EUR-11` grid directly from pyremo:
domain_info = pr.domain_info('EUR-11')
domain_info
# The preprocessing also needs the orography (`FIB`) and land sea mask (`BLA`) for the REMO target grid. We take those from the surface library that can be accessed from a surface library dataset.
surflib = pr.data.surflib('EUR-11', crop=False)
surflib
# For the vertical interpolation, we have to give the vertical coordinates table containing the hybrid sigma coefficients for the target grid (`ak` and `bk`).
vc = pr.vc.tables['vc_27lev']
vc
# ## Creating the forcing dataset
# With the `gfile` dataset and the target grid information, we can now create the forcing dataset. We can use the [remap](https://pyremo.readthedocs.io/en/latest/generated/pyremo.preproc.remap.html#pyremo.preproc.remap) function here that basically assembles the same workflow as the former Fortran source code. The function basically does all the horizontal and vertical interpolations as well as pressure corrections including height corrections etc... Please note, that the efficiency of the computation might depend on how we access the input data and, of course, on the length of the time axis in the gfile dataset. For a long time axis, the computation should be done lazily!
ads = pr.preproc.remap(gfile, domain_info, vc, surflib)
ads
# The forcing dataset seems to look fine! Please note, that also all global attributes from the input gfile dataset are copied to the forcing dataset. To check, we will explicitly look at the first timestep.
ads_ = ads.isel(time=0).compute()
#progress(ads_)
ads_.PS.plot()
# Note, that the whole `ads` forcing dataset has not been computed explicitly yet but only lazily. If we would trigger the whole computation, we might get in trouble to hold it in the memory. However, since we want a single file for each timestep on the disk anyway, we can start the computation only at this point, when we want to write it to disk. To organize the output, pyremo provides the [to_netcdf](https://pyremo.readthedocs.io/en/latest/generated/pyremo.preproc.to_netcdf.html) function that simply creates one NetCDF file per timestep and uses a REMO compliant naming convention. To start the computation and file writing, you can simply call
# %time output = pr.preproc.to_netcdf(ads, path='/scratch/g/g300046/xa')
# +
#pr.preproc.to_tar(output, os.path.join(path, 'test.tar'), mode="w")
| notebooks/preprocessing-cf.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Implement a linked list with append, prepend, find, insert, delete, length
class Node:
"""
An object for storing a single node in a linked list
Attributes:
data: Data stored in node
next_node: Reference to next node in linked list
"""
def __init__(self, data, next_node = None):
self.data = data
self.next_node = next_node
def is_empty(self):
return self.data == None
def __repr__(self):
return f"<Node data: {self.data}>"
class LinkedList:
"""
Singly Linked List
Linear data structure that stores values in nodes.
The list maintains a reference to the first node, also called head.
Each node points to the next node in the list
Attributes:
head: The head node of the list
"""
def __init__(self, head = None):
self.head = head
self.tail = None
def __repr__(self):
"""
Return a string representation of the list.
Takes O(n) time.
"""
nodes = []
current = self.head
while current:
if current is self.head:
nodes.append(f"[Head: {current.data}]")
elif current.next_node is None:
nodes.append(f"[Tail: {current.data}]")
else:
nodes.append(f"[{current.data}]")
current = current.next_node
return '-> '.join(nodes)
def is_empty(self):
"""
Determines if the linked list is empty
Takes O(1) time
"""
return self.head == None
def size(self):
"""
Returns the number of nodes in a Linked list.
Takes O(n) time
"""
current = self.head
count = 0
while current:
count += 1
current = current.next_node
return count
def append(self, new_data):
"""
Adds new node to containing data to the tail of the list
This method can also be optimized to work in O(1) by keeping an extra pointer to the tail of linked list
Takes O(n) time
"""
node = Node(new_data)
current = self.head
if self.head:
while current.next_node:
current = current.next_node
current.next_node = node
else:
self.head = node
def prepend(self, new_data):
"""
Adds new Node containing data to head of the list
Also called prepend
Takes O(1) time
"""
node = Node(new_data)
current = self.head
node.next_node = self.head
self.head = node
def search(self, key):
"""
Determine if an key exist.
Takes O(n) time
Attributes:
key: The element being searched
"""
node = Node(key)
if self.head:
current = self.head
while current:
if current.data == node.data:
return current.data
current = current.next_node
return None
def insert(self, new_data, pos):
"""
Inserts a new Node containing data at pos position
Insertion takes O(1) time but finding node at insertion point takes
O(n) time.
Takes overall O(n) time.
"""
if pos == None or pos == 0:
self.prepend(new_data)
# elif self.size() < pos:
# return None
else:
node = Node(new_data)
current = self.head
cnt = 1
while current.next_node:
if cnt == pos:
node.next_node = current.next_node
current.next_node = node
current = current.next_node
cnt += 1
def remove(self, key):
"""
Removes Node containing data that matches the key
Returns the node or `None` if key doesn't exist
Takes O(n) time
"""
current = self.head
previous = None
found = False
while current and not found:
if current.data == key and current is self.head:
self.head = current.next_node
found = True
elif current.data == key:
previous.next_node = current.next_node
found = True
else:
previous = current
current = current.next_node
return False
# +
import unittest
class TestLink(unittest.TestCase):
def setUp(self):
self.n1 = Node(19)
self.ll = LinkedList(self.n1)
self.ll2 = LinkedList(self.n1)
self.ll3 = LinkedList(self.n1)
def test_node_is_empty(self):
self.assertEqual(self.n1.is_empty(), False)
def test_linked_list_is_empty(self):
self.assertEqual(self.ll.is_empty(), False)
def test_linked_list_size(self):
self.assertEqual(self.ll.size(), 1)
def test_linked_list_append(self):
self.assertEqual(self.ll.size(), 1)
self.ll.append(20)
self.assertEqual(self.ll2.size(), 2)
self.ll.append('a')
self.ll.append('bc')
self.assertEqual(self.ll.size(), 4)
def test_linked_list_prepend(self):
self.assertEqual(self.ll2.size(), 1)
self.ll2.prepend(21)
self.assertEqual(self.ll2.size(), 2)
self.assertEqual(self.ll2.head.data, 21)
self.ll2.prepend('a')
self.ll2.prepend('bc')
self.assertEqual(self.ll2.size(), 4)
self.assertEqual(self.ll2.head.data, 'bc')
def test_linked_list_search(self):
self.ll2.prepend(21)
self.assertEqual(self.ll2.search(21), 21)
self.ll2.append('a')
self.ll2.append('bc')
self.assertEqual(self.ll2.search(""), None)
self.assertEqual(self.ll2.search(None), None)
self.assertEqual(self.ll2.search(19), 19)
def test_linked_list_insert(self):
self.ll3.append(40)
self.ll3.insert(42, 1)
self.ll3.insert('a',0)
self.assertEqual(self.ll3.size(), 4)
self.assertEqual(self.ll3.search(40), 40)
self.assertEqual(self.ll3.search('a'), 'a')
def test_linked_list_remove(self):
self.ll3.append(40)
self.ll3.insert(42, 1)
self.ll3.insert('a',0)
self.assertEqual(self.ll3.remove(90), False)
self.ll3.remove(42)
self.assertEqual(self.ll3.search(42), None)
self.assertEqual(self.ll3.search('a'), 'a')
def test_linked_list_remove_index(self):
self.ll3.append(40)
self.ll3.insert(42, 1)
self.ll3.insert('a',0)
self.assertEqual(self.ll3.remove(90), False)
self.ll3.remove(42)
self.assertEqual(self.ll3.search(42), None)
self.assertEqual(self.ll3.search('a'), 'a')
# -
unittest.main(argv=[''], verbosity=2, exit=False)
| Linkedlist/sll.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from socket import socket
import threading
# +
# Server Program
skt = socket()
# Initialiing blank IP, so that next time automatic dynamic IP of the server is Initialized!
serverip = ""
serverport = 1234
skt.bind((serverip, serverport))
skt.listen()
def program(session, details):
print(details)
session.send("I am server!")
data = session.recv(515)
print(data)
while True:
session, details = skt.accept()
t1 = threading.Thread(target = program, args = (session, details))
t1.start()
# -
| Parallel-Chat.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Advanced Classical Machine Learning:
#
# <div class="youtube-wrapper">
# <iframe src="https://www.youtube.com/embed/lpPij21jnZ4" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
# </div>
#
#
# This is the second session of the classical machine learning (ML) introduction presented by Amira. She presents a brief of history of ML, then introduces simple ML methods, i.e., linear regression based models. Amira introduces neural networks, starting with simple perceptron and then illustrating Feed Forward Neural Networks (FFNNs). In the final section, Amira introduces Supper Vector Machines (SVM) concepts for classification type tasks. Amira introduces a very high level overview of Quantum Machine Learning, with the quadrants showing both classical and quantum machine learning in terms of Data Processing device as one axis and the Data generating system as the remaining axis.
#
# ### Suggested links
#
# - Download the lecturer's notes [here](/content/summer-school/2021/resources/lecture-notes/Lecture4.2.pdf)
#
# <!-- ::: q-block.reminder -->
#
# ### FAQ
#
# <details>
# <summary>How are linear models related to the standard statistical methods of least squares for regression analysis?</summary>
# They are the same
# </details>
#
# <details>
# <summary>Are the activation functions in each layer the same or different?</summary>
# - "It can be differnt" - <NAME>
# - "Usually last activation function is different rest all are kept same." - Edwin
# </details>
#
# <details>
# <summary>Just confirming...The more data there is the easier the higher accuracy the model has? How to combat lack of available data especialy when create a CNN network?</summary>
# One way to combat is replicating present data and augment that data. Maybe vertical flip, horizontal flip, crop, blur, etc.
# </details>
#
# <details>
# <summary>Do linear models in general get more/less accurate when taking more features into account?</summary>
# If you'll take more more features, it'll result in overfitting. If less, then you'll have biased output.
# </details>
#
# <details>
# <summary>On the regression model, does theta include the magnitude of the intercept?</summary>
# Yes, it's $\theta_0$
# </details>
#
# <details>
# <summary>During the lecture it was stated that one can easily add or out a bias, how does this work? Could you please explain?</summary>
# - A1: For example, think about on a linear model, you can change the value of the intercept to move the boundary within the plane.
#
# - A2: The main function of a bias is to provide every node with a trainable constant value (in addition to the normal inputs that the node receives). You can achieve that with a single bias node with connections to N nodes, or with N bias nodes each with a single connection; the result should be the same
# </details>
#
# <details>
# <summary>Is it correct to think of neural networks (NN) as models that can be used for non-linear fitting, in general? Would it an overkill to use NNs for datasets with linear dependencies?</summary>
# NN requires lots of data and computationally expensive. If its a linear model, we can get away with less computationally expensive ML methods.
# </details>
#
# <details>
# <summary>Is there a rule of thumb in the selection of the weights and thus the number of neurons?</summary>
# Actually in practice, number of neurons in each layer is 2^x. Number of layers is your call. Weights are automatically selected for you during backpropagation (optimization). You just initialize weight vector with random numbers. Thats it.
# </details>
#
# <details>
# <summary>Does noise affect all these models?</summary>
# Yes it does. It won't if your model is generalized aptly (which hasn't been achieved yet as still in one way or the other, models are affected by some kind of a noise)
# </details>
#
# <details>
# <summary>Can we use a circular or elliptical function instead of a feature map for data that is not separable linearly?</summary>
# Yes. feature mapping is easier.
# </details>
#
# <details>
# <summary>Can we use a circular or elliptical function instead of a feature map for data that is not separable linearly?</summary>
# Yes. feature mapping is easier.
# </details>
#
# ### Live Q&A
#
# <details>
# <summary>What are the different ways to map the data in higher dimensions?</summary>
# Answer was provided at timestamp 2m 29s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>Could you please explain again what a kernel is?</summary>
# Answer was provided at timestamp 4m 48s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>How do we decide the Bias ? and does it remain same throughout training?</summary>
# Answer was provided at timestamp 9m 30s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>Someone in the previous video wanted a bit more clarification on why the dual formulation is useful</summary>
# Answer was provided at timestamp 10m 40s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>What if, after applying the feature map, data is still not linearly separable?</summary>
# Answer was provided at timestamp 13m 4s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>Why do we not have a different activation function for each parameter set ?</summary>
# Answer was provided at timestamp 14m 46s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>How can we choose a good activation function for a FFNN ?</summary>
# Answer was provided at timestamp 17m 21s in the Lecture 4.2 Live Q&A session
# </details>
#
# <details>
# <summary>How do we incorporate the optimization of the distance between the linear model and nearest points in each class into the SVM ?</summary>
# Answer was provided at timestamp 20m 5s in the Lecture 4.2 Live Q&A session
# </details>
#
# <!-- ::: -->
#
# ### Suggested links
#
# - Read <NAME> (1973) on [Artificial Intelligence: A General Survey (Lighthill Report)](https://en.wikipedia.org/wiki/Lighthill_report)
# - Read <NAME> Thesis (1970) on [<NAME>](https://people.idsia.ch//~juergen/linnainmaa1970thesis.pdf)
# - Watch MIT Opencourseware on [Learning: Support Vector Machines](https://www.youtube.com/watch?v=_PwhiWxHK8o&t=1123s)
# - Read Stanford University Statistics 315a Modern Applied Statistics course material on [Glossary for terminology used in Machine Learning versus Statistics](http://statweb.stanford.edu/~tibs/stat315a/glossary.pdf)
# - Read <NAME> on [Support Vector Machine: Complete Theory](https://towardsdatascience.com/understanding-support-vector-machine-part-1-lagrange-multipliers-5c24a52ffc5e)
# - Read <NAME> on [Support Vector Machine: Kernel Trick; Mercer’s Theorem](https://towardsdatascience.com/understanding-support-vector-machine-part-2-kernel-trick-mercers-theorem-e1e6848c6c4d)
# - Read Support Vector Machines (SVM) Tutorial on [Note: above link was posted as useful link for visual representation](https://web.mit.edu/zoya/www/SVM.pdf)
# - Watch <NAME> on [Improving and automating quantum computers with machine learning](https://youtu.be/G_UMvI2bASg)
# - Read Qiskit on [Feature Maps](https://qiskit.org/documentation/apidoc/qiskit.aqua.components.feature_maps.html)
# - Read Google on [Machine Learning Crash Course with TensorFlow APIs](https://developers.google.com/machine-learning/crash-course)
# - Read [Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition](https://learning.oreilly.com/library/view/hands-on-machine-learning/9781492032632/)
# - Read [Deep Learning Specialization](https://www.coursera.org/learn/neural-networks-deep-learning/home/welcome)
# - Read [Google ML Crash Course](https://developers.google.com/machine-learning/crash-course/ml-intro)
# - Watch [MIT Introduction to Deep Learning](https://www.youtube.com/playlist?list=PLUl4u3cNGP63gFHB6xb-kVBiQHYe_4hSi)
# - Read [TensorFlow Tutorials](https://www.tensorflow.org/tutorials)
# - Read [Stanford ML Course](https://www.coursera.org/learn/machine-learning)
# - Watch [3Blue1Brown series on Neural Nets (Gradient descent, how neural networks learn | Chapter 2, Deep learning)](https://www.youtube.com/watch?v=IHZwWFHWa-w)
# - Read [Tinker With a Neural Network Right Here in Your Browser.](https://playground.tensorflow.org)
# - Read [Comparison of activation functions](https://en.wikipedia.org/wiki/Activation_function#Comparison_of_activation_functions)
# - Read [Detailed responses in Stackoverflow on “What is the role of the bias in neural networks?“](https://stackoverflow.com/questions/2480650/what-is-the-role-of-the-bias-in-neural-networks)
# - Read [Pattern Recognition and Machine Learning (by <NAME>)](https://www.microsoft.com/en-us/research/people/cmbishop/prml-book/)
# - Watch [StatQuest with <NAME>](https://www.youtube.com/c/joshstarmer)
# - Read [Deep Learning related introductory content by <NAME>](https://www.jonkrohn.com/)
#
#
# ### Suggested Reading
# - _Deep Learning_ by <NAME> et al.
# - _Neural Network Youtube Series_ by 3blue1brown
#
| notebooks/summer-school/2021/lec4.2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Dialog skill analysis for Watson Assistant
#
# ## Introduction
# Dialog Skill Analysis for Watson Assistant (WA) is intended for use by chatbot designers, developers and data scientists who would like to experiment with and improve their existing dialog skill design.
#
# This notebook assumes familiarity with the Watson Assistant product as well as concepts involved in dialog skill design such as intent, entities, and utterances.
#
# ### Environment
# - Python version 3.6 or above is required.
# - Install dependencies with `pip install -r requirements.txt` and refer to `requirements.txt`
#
# Install all the required packages and filter out any warnings.
from IPython.display import Markdown, display, HTML
import warnings
warnings.filterwarnings('ignore')
# +
# Standard python libraries
import sys, os
import json
import importlib
from collections import Counter
# External python libraries
import pandas as pd
import numpy as np
import nltk
nltk.download('stopwords')
nltk.download('punkt')
import ibm_watson
# Internal python libraries
from assistant_dialog_skill_analysis.utils import skills_util
from assistant_dialog_skill_analysis.highlighting import highlighter
from assistant_dialog_skill_analysis.data_analysis import summary_generator
from assistant_dialog_skill_analysis.data_analysis import divergence_analyzer
from assistant_dialog_skill_analysis.data_analysis import similarity_analyzer
from assistant_dialog_skill_analysis.term_analysis import chi2_analyzer
from assistant_dialog_skill_analysis.term_analysis import keyword_analyzer
from assistant_dialog_skill_analysis.term_analysis import entity_analyzer
from assistant_dialog_skill_analysis.confidence_analysis import confidence_analyzer
from assistant_dialog_skill_analysis.inferencing import inferencer
from assistant_dialog_skill_analysis.experimentation import data_manipulator
# -
# ## Table of contents
#
# 1. [Part 1: Prepare the training data](#part1)<br>
# 2. [Part 2: Prepare the test data](#part2)<br>
# 3. [Part 3: Perform advanced analysis](#part3)<br>
# 4. [Part 4: Summary](#part4)<br>
# <a id='part1'></a>
# # Part 1: Prepare the training data
# 1.1 [Set up access to the training data](#part1)<br>
# 1.2 [Process Dialog Skill Training Data](#part1.2)<br>
# 1.3 [Analyze data distribution](#part1.3)<br>
# 1.4 [Perform a correlation analysis](#part1.4)<br>
# 1.5 [Visualize terms using a heat map](#part1.5)<br>
# 1.6 [Ambiguity in the training data](#part1.6)<br>
# <a id='setup'></a>
# ## 1.1 Set up access to the training data
#
# Provide access credentials for an existing dialog skill that you would like to analyze. For this you need your API Key and Workspace ID values.
# +
importlib.reload(skills_util)
# Change Assistant API version if needed
# Find Latest --> https://cloud.ibm.com/docs/services/assistant?topic=assistant-release-notes
API_VERSION = '2019-02-28'
# Change URL based on IBM Cloud datacenter you use
URL = "https://gateway.watsonplatform.net/assistant/api" # Dallas (Default US South)
#URL = "https://gateway-s.watsonplatform.net/assistant/api" # Dallas Staging
#URL = "https://gateway-wdc.watsonplatform.net/assistant/api" # Washington, DC
#URL = "https://gateway-fra.watsonplatform.net/assistant/api" # Frankfurt
#URL = "https://gateway-syd.watsonplatform.net/assistant/api" # Sydney
#URL = "https://gateway-tok.watsonplatform.net/assistant/api" # Tokyo
#URL = "https://gateway-lon.watsonplatform.net/assistant/api" # London
# For ICP(IBM Cloud Private), you can disable SSL verification by changing this to True
DISABLE_SSL_VERTIFICATION = False
# By default we only need the IAM API Key & the Workspace ID
# If you run the notebook regularly you can uncomment the two lines below
# & comment out the line after it
#iam_apikey = '###'
#workspace_id = '###'
#Prompt user for credentials
iam_apikey, workspace_id = skills_util.input_credentials()
conversation = skills_util.retrieve_conversation(iam_apikey=iam_apikey,
url=URL,
api_version=API_VERSION)
#If you do not have IAM based API Keys
#but have access to a Username, Password & Workspace ID
#You can comment out the two lines above & uncomment the lines below to authenticate
# username = 'apikey'
# password = '###'
# workspace_id = '###'
# conversation = skills_util.retrieve_conversation(username=username,
# password=password,
# url=URL,
# api_version=API_VERSION)
conversation.set_disable_ssl_verification(DISABLE_SSL_VERTIFICATION)
workspace = skills_util.retrieve_workspace(workspace_id=workspace_id,
conversation=conversation)
# +
# Extract user workspace
workspace_data, workspace_vocabulary = skills_util.extract_workspace_data(workspace)
entity_dict = conversation.list_entities(workspace_id).get_result()
entities_list = [item['entity'] for item in entity_dict['entities']]
# Create workspace data frame
workspace_pd = pd.DataFrame(workspace_data)
display(Markdown("### Sample of Utterances & Intents"))
display(HTML(workspace_pd.sample(n = len(workspace_pd) if len(workspace_pd)<10 else 10)
.to_html(index=False)))
if entities_list:
display(Markdown("### Sample of Entities"))
display(HTML(pd.DataFrame({"Entity":entities_list})
.sample(n = len(entities_list) if len(entities_list)<10 else 10)
.to_html(index=False)))
# -
# <a id='part1.2'></a>
# ## 1.2 Process the dialog skill training data
#
# Generate summary statistics related to the given skill and workspace.
importlib.reload(summary_generator)
summary_generator.generate_summary_statistics(workspace_data, entities_list)
# <a id='part1.3'></a>
# ## 1.3 Analyze the data distribution
#
# - [Analyze class imbalance](#imbalance)
# - [List the distribution of user examples by intent](#distribution)
# - [Actions for class imbalance](#actionimbalance)
# ### Analyze class imbalance<a id='imbalance'></a>
#
# Analyze whether the data set contains class imbalance by checking whether the largest intent contains less than double the number of user examples contained in the smallest intent. If there is an imbalance it does not necessarily indicate an issue; but you should review the [actions](#actionimbalance) section below.
importlib.reload(summary_generator)
class_imb_flag = summary_generator.class_imbalance_analysis(workspace_pd)
# ### List the distribution of user examples by intent<a id='distribution'></a>
# Display the distribution of intents versus the number of examples per intent (sorted by the number of examples per intent) below. Ideally you should not have large variations in terms of number of user examples for various intents.
importlib.reload(summary_generator)
summary_generator.scatter_plot_intent_dist(workspace_pd)
importlib.reload(summary_generator)
summary_generator.show_user_examples_per_intent(workspace_data)
# ### Actions for class imbalance<a id='actionimbalance'></a>
#
# Class imbalance will not always lead to lower accuracy, which means that all intents (classes) do not need to have the same number of examples.
#
# Given a hypothetical chatbot related to banking:<br>
#
# - For intents like `updateBankAccount` and `addNewAccountHolder` where the semantics difference between them is subtler, the number of examples per intent needs to be somewhat balanced otherwise the classifier might favor the intent with the higher number of examples.
# - For intents like `greetings` that are semantically distinct from other intents like `updateBankAccount`, it may be acceptable for it to have fewer examples per intent and still be easy for the intent detector to classify.
#
#
#
# If the intent classification accuracy is lower than expected during testing, you should re-examine the distribution analysis.
#
# With regard to sorted distribution of examples per intent, if the sorted number of user examples varies a lot across different intents, it can be a potential source of bias for intent detection. Large imbalances in general should be avoided. This can potentially lead to lower accuracy. If your graph displays this characteristic, this could be a source of error.
#
# For further guidance on adding more examples to help balance out your distribution, refer to
# <a href="https://cloud.ibm.com/docs/services/assistant?topic=assistant-intent-recommendations#intent-recommendations-get-example-recommendations" target="_blank" rel="noopener no referrer">Intent Example Recommendation</a>.
# <a id='part1.4'></a>
# ## 1.4 Perform correlation analysis
#
# - [Retrieve the most correlated unigrams and bigrams for each intent](#retrieve)
# - [Actions for anomalous correlations](#anomalous)
# ### Retrieve the most correlated unigrams and bigrams for each intent<a id='retrieve'></a>
#
# Perform a chi square significance test using count features to determine the terms that are most correlated with each intent in the data set.
#
# A `unigram` is a single word, while a `bigram` is two consecutive words from within the training data. For example, if you have a sentence like `Thank you for your service`, each of the words in the sentence are considered unigrams while terms like `Thank you`, `your service` are considered bigrams.
#
# Terms such as `hi`, `hello` correlated with a `greeting` intent are reasonable. But terms such as `table`, `chair` correlated with the `greeting` intent are anomalous. A scan of the most correlated unigrams & bigrams for each intent can help you spot potential anomalies within your training data.
#
# **Note**: We ignore the following common words (\"stop words\") from consideration `an, a, in, on, be, or, of, a, and, can, is, to, the, i`
importlib.reload(chi2_analyzer)
unigram_intent_dict, bigram_intent_dict = chi2_analyzer.get_chi2_analysis(workspace_pd)
# ### Actions for anomalous correlations<a id='anomalous'></a>
#
# If you identify unusual or anomalous correlated terms such as: numbers, names and so on, which should not be correlated with an intent, consider the following:
#
# - **Case 1** : If you see names appearing amongst correlated unigrams or bigrams, add more variation of names so no specific names will be correlated
# - **Case 2** : If you see specific numbers like 1234 amongst correlated unigrams or bigrams and these are not helpful to the use case, remove or mask these numbers from the examples
# - **Case 3** : If you see terms which should never be correlated to that specific intent, consider adding or removing terms/examples so that domain specific terms are correlated with the correct intent
# <a id='part1.5'></a>
# ## 1.5 Visualize terms using a heat map
#
# - [Display term analysis for a custom intent list](#customintent)
# - [Actions for anomalous terms in the heat map](#heatmap)
#
# A heat map of terms is a method to visualize terms or words that frequently occur within each intent. Rows are the terms, and columns are the intents.
#
# The code below displays the top 30 intents with the highest number of user examples in the analysis. This number can be changed if needed.
# +
importlib.reload(keyword_analyzer)
INTENTS_TO_DISPLAY = 30 # Total number of intents for display
MAX_TERMS_DISPLAY = 30 # Total number of terms to display
intent_list = []
keyword_analyzer.seaborn_heatmap(workspace_pd, INTENTS_TO_DISPLAY, MAX_TERMS_DISPLAY, intent_list)
# -
# ### Display term analysis for a custom intent list<a id='customintent'></a>
#
# If you wish to see term analysis for specific intents, feel free to add those intents to the intent list. This generates a custom term heatmap. The code below displays the top 20 terms, but this can be changed if needed.
# +
importlib.reload(keyword_analyzer)
# intent_list = ['intent1','intent2','intent3']
intent_list = []
MAX_TERMS_DISPLAY = 20 # Total number of terms to display
if intent_list:
keyword_analyzer.seaborn_heatmap(workspace_pd, INTENTS_TO_DISPLAY, MAX_TERMS_DISPLAY, intent_list)
# -
# ### Actions for anomalous terms in the heat map<a id='heatmap'></a>
#
# If you notice any terms or words which should not be frequently present within an intent, consider modifying examples in that intent.
# <a id='part1.6'></a>
# ## 1.6 Ambiguity in the training data
#
# - [Uncover ambiguous utterances across intents](#uncover)
# - [Actions for ambiguity in the training data](#ambiguityaction)
#
# Run the code blocks below to uncover possibly ambiguous terms based on feature correlation.
#
# Based on the chi-square analysis above, generate intent pairs which have overlapping correlated unigrams and bigrams.
# This allows you to get a glimpse of which unigrams or bigrams might cause potential confusion with intent detection:
# #### A. Top intent pairs with overlapping correlated unigrams
importlib.reload(chi2_analyzer)
ambiguous_unigram_df = chi2_analyzer.get_confusing_key_terms(unigram_intent_dict)
# #### B. Top intent pairs with overlapping correlated bigrams
importlib.reload(chi2_analyzer)
ambiguous_bigram_df = chi2_analyzer.get_confusing_key_terms(bigram_intent_dict)
# #### C. Overlap checker for specific intents
# Add specific intent or intent pairs for which you would like to see overlap
importlib.reload(chi2_analyzer)
intent1 = 'Goodbye'
intent2 = ''
chi2_analyzer.chi2_overlap_check(ambiguous_unigram_df,ambiguous_bigram_df,intent1,intent2)
# ### Uncover ambiguous utterances across intents<a id='uncover'></a>
# The following analysis shows user examples that are similar but fall under different intents.
importlib.reload(similarity_analyzer)
similar_utterance_diff_intent_pd = similarity_analyzer.ambiguous_examples_analysis(workspace_pd)
# ### Actions for ambiguity in the training data<a id='ambiguityaction'></a>
#
# **Ambiguous intent pairs**
# If you see terms which are correlated with more than 1 intent, review if this seems anomalous based on the use case for that intent. If it seems reasonable, it is probably not an issue.
#
# **Ambiguous utterances across intents**
# - **Duplicate utterances**: For duplicate or almost identical utterances, remove those that seem unnecessary.
# - **Similar utterances**: For similar utterances, review the use case for those intents and make sure that they are not accidental additions caused by human error when the training data was created.
#
# For more information about entity, refer to the <a href="https://cloud.ibm.com/docs/services/assistant/services/assistant?topic=assistant-entities" target="_blank" rel="noopener no referrer">Entity Documentation</a>.
#
# For more in-depth analysis related to possible conflicts in your training data across intents, try the conflict detection feature in Watson Assistant. Refer to <br> <a href="https://cloud.ibm.com/docs/services/assistant?topic=assistant-intents#intents-resolve-conflicts" target="_blank" rel="noopener no referrer">Conflict Resolution Documentation</a>.
# <a id='part2'></a>
# # Part 2: Prepare the test data
#
# Analyze your existing Watson Assistant Dialog Skill with the help of a test set.
#
# 2.1. [Obtain test data from Cloud Object Storage](#cos)<br>
# 2.2. [Evaluate the test data](#evaluate) <br>
# 2.3. [Analyze the test data](#testanalysis) <br>
# ## 2.1 Obtain test data from Cloud Object Storage<a id='cos'></a>
#
# Upload a test set in tsv format. Each line in the file should have only `User_Input<tab>Intent`
#
# For example:
# ```
# hello how are you<tab>Greeting
# I would like to talk to a human<tab>AgentHandoff
# ```
# +
importlib.reload(skills_util)
#Separator: Use '\t' for tab separated data, ',' for comma separated data
separator = '\t'
test_set_path = 'test_set.tsv'
test_df = skills_util.process_test_set(test_set_path, separator)
display(Markdown("### Random Test Sample"))
display(HTML(test_df.sample(n=10).to_html(index=False)))
display(HTML(test_df.sample(n=10).to_html(index=False)))
# -
# ## 2.2 Evaluate the test data<a id='evaluate'></a>
# These steps can take time if you have a large test set.
#
# **<font color=red>Note</font>**: You will be charged for calls made from this notebook based on your Watson Assistant plan. The user_id will be the same for all message calls.
# Maximum of 5 threads for faster inference
THREAD_NUM = 5
full_results = inferencer.inference(conversation,
workspace_id,
test_df,
max_retries=10,
max_thread=THREAD_NUM,
verbose=False)
# <a id='part2.1'></a>
# ## 2.3 Analyze the test data<a id='testanalysis'></a>
#
# - [Display an overview of the test data](#overview)
# - [Compare the test data and the training data](#compare)
# - [Determine the overall accuracy on the test set](#accuracy)
# - [Analyze the errors](#errors)
# ### Display an overview of the test data<a id='overview'></a>
importlib.reload(summary_generator)
summary_generator.generate_summary_statistics(test_df)
summary_generator.show_user_examples_per_intent(test_df)
# ### Compare the test data and the training data<a id='compare'></a>
#
# Ideally the test and training data distributions should be similar. The following metrics can help identify gaps between the test set and the training set:
#
# **1.** The distribution of user examples per intent for the test data should be comparable to the training data
# **2.** The average length of user examples for test and training data should be comparable to the training data <br>
# **3.** The vocabulary and phrasing of utterances in the test data should be comparable to the training data
#
# If your test data comprises of examples labelled from your logs, and the training data comprises of examples created by human subject matter experts, there may be discrepancies between what the virtual assistant designers thought the end users would type and the way they actually type in production. Thus, if you find discrepancies in this section, consider changing your design to resemble the way in which end users use your system more closely.
#
# **<font color=red>Note</font>**: You will be charged for calls made from this notebook based on your WA plan. The user_id will be the same for all message calls.
importlib.reload(divergence_analyzer)
divergence_analyzer.analyze_train_test_diff(workspace_pd, test_df, full_results)
# ### Determine the overall accuracy on the test set<a id='accuracy'></a>
importlib.reload(inferencer)
results = full_results[['correct_intent', 'top_confidence','top_intent','utterance']]
accuracy = inferencer.calculate_accuracy(results)
display(Markdown("### Accuracy on Test Data: {} %".format(accuracy)))
# ### Analyze the errors<a id='errors'></a>
#
# This section gives you an overview of the errors made by the intent classifier on the test set.
#
# **Note**: `System Out of Domain` labels are assigned to user examples which get classified with confidence scores less than 0.2 as Watson Assistant considers them to be irrelevant.
# +
importlib.reload(inferencer)
wrongs_df = inferencer.calculate_mistakes(results)
display(Markdown("### Intent Detection Mistakes"))
display(Markdown("Number of Test Errors: {}".format(len(wrongs_df))))
with pd.option_context('max_colwidth', 250):
if not wrongs_df.empty:
display(wrongs_df)
# -
# <a id='part3'></a>
# # Part 3: Perform advanced analysis
#
# 3.1 [Perform analysis using confidence thresholds](#part3.1)<br>
# 3.2 [Analysis interpretation @ confidence level T](#levelT)<br>
# 3.3 [Highlighting term importance](#part3.2)<br>
# 3.4 [Analyzing abnormal confidence levels](#part3.3)<br>
# 3.5 [Perform an analysis using correlated entities per intent](#part3.4)<br>
# <a id='part3.1'></a>
# ## 3.1 Perform analysis using confidence thresholds
#
# This analysis illustrates how a confidence threshold is used to determine which data considered irrelevant or out of domain can be used for analysis.
importlib.reload(confidence_analyzer)
analysis_df= confidence_analyzer.analysis(results,None)
# ## 3.2 Analysis interpretation @ confidence level T <a id='levelT'></a>
#
# If a certain confidence threshold T is selected, then:
# - The on-topic accuracy for test examples which cross the threshold is ***TOA***
# - The percentage of total test examples which returns confidences higher than the threshold is measured as ***Bot Coverage %***
# - If out of domain examples exist, falsely accept out of domain examples as on topic examples at a rate measured by ***FAR*** (False Acceptance Rate)
analysis_df.index = np.arange(1, len(analysis_df)+1)
display(analysis_df)
# ### Select the threshold value
#
# By selecting a higher threshold, you can potentially bias your systems so that they are more accurate in terms of determining whether an utterance is on topic or out of domain. The default confidence threshold for Watson Assistance is 0.2.
#
# **Effect on accuracy**: When you select a higher threshold T, this can result in higher accuracy (TOA) because only examples with confidences greater than the threshold T are included.
#
# **Effect on bot coverage %**: However, when you select a higher threshold T, this can also result in the virtual assistant responding to less examples.
#
# **Deflection to human agent**: In the scenarios where the virtual assistant is setup to hand off to a human agent when it is less confident, having a higher threshold T can:
#
# - Improve end user experience when interacting with a virtual assistant, as it continues interaction only when its highly confident
# - Result in higher costs to the customer as this can result in more deflections to the human agents
#
# Thus, there is a trade-off and you need to decide on a threshold value on a per customer basis.
# ### Examine the threshold selection on individual intents
# This section allows the examination of thresholds on specific intents.
#
# - Use `INTENT_LIST = []` to get analysis which averages across all intents
# - Use `INTENT_LIST = ['intent1', 'intent2']` to examine specific intents and threshold analysis on these intents
# - Use `INTENT_LIST = ['ALL_INTENTS']` to examine all intents and threshold analysis for each
# - Use `INTENT_LIST = [MOST_FREQUENT_INTENT]` to get analysis on the intent with the most test examples (DEFAULT)
#
# **False Acceptance Rate (FAR) for specific intents**
# When we calculate FAR across all intents (as in previous section) we calculate fraction of out of domain examples falsely considered on topic. When we calculate FAR for specific intents, we calculate the fraction of examples which were falsely predicted to be that specific intent.
# +
importlib.reload(confidence_analyzer)
# Calculate intent with most test examples
for label in list(test_df['intent'].value_counts().index):
if label != skills_util.OFFTOPIC_LABEL:
MOST_FREQUENT_INTENT = label
break
# Specify intents of interest for analysis
INTENT_LIST = [MOST_FREQUENT_INTENT]
analysis_df_list = confidence_analyzer.analysis(results, INTENT_LIST)
# -
# <a id='part3.2'></a>
# ## 3.3 Highlight term importance
#
# This intent can be ground-truth or an incorrectly predicted intent. It provides term level insights about which terms the classifier thought were important in relation to that specific intent.
#
# Even if the system predicts an intent correctly, the terms which the intent classifier thought were important may not be as expected by human insight. Human insight might suggest that the intent classifier is focusing on the wrong terms.
#
# The score of each term in the following highlighted images can be viewed as importance factor of that term for that specific intent. The larger the score, the more important the term.
# You can get the highlighted images for either wrongly-predicted utterances or utterances where the classifier returned a low confidence.
#
# **<font color=red>Note</font>**: You will be charged for calls made from this notebook based on your WA plan. The user_id will be the same for all message calls.
# +
importlib.reload(highlighter)
# Pick an example from section 1 which was misclassified
# Add the example and correct intent for the example
utterance = "Where is the closest agent?" # input example
intent = "General_Connect_to_Agent" # input an intent in your workspace which you are interested in.
inference_results = inferencer.inference(conversation=conversation,
workspace_id=workspace_id,
test_data=pd.DataFrame({'utterance':[utterance],
'intent':[intent]}),
max_retries = 10,
max_thread = 1,
verbose = False)
highlighter.get_highlights_in_batch_multi_thread(conversation,
workspace_id,
inference_results,
None,
1,
1)
# -
# In the section below you analyze your test results and produce highlighting for the top 25 problematic utterances which were either mistakes or had confidences below the threshold that was set.
#
# **<font color=red>Note</font>**: You will be charged for calls made from this notebook based on your WA plan. The user_id will be the same for all message calls.
# +
importlib.reload(highlighter)
# The output folder for generated images
# Note modify this if you want the generated images to be stored in a different directory
highlighting_output_folder = './highlighting_images/'
if not os.path.exists(highlighting_output_folder):
os.mkdir(highlighting_output_folder)
# The threshold the prediction needs to achieve below which
# it will be considered as `out of domain` or `offtopic` utterances.
threshold = 0.2
# Maximum number of test set examples whose highlighting analysis will be conducted
K=25
highlighter.get_highlights_in_batch_multi_thread(conversation,
workspace_id,full_results,
highlighting_output_folder,
threshold,
K)
# -
# <a id='part3.3'></a>
# ## 3.4 Analyze abnormal confidence levels
# Every test utterance is classified as a specific intent with a specific confidence by the Watson Assistant intent classifier. It is expected that model would be confident when it correctly predicts examples and not highly confident when it incorrectly predicts examples.
#
# But this is not always true. This can be because there are anomalies in the design. Examples that are predicted correctly with low confidence and the examples that are predicted incorrectly with high confidence are cases which need to be reviewed.
importlib.reload(confidence_analyzer)
correct_thresh, wrong_thresh = 0.3, 0.7
correct_with_low_conf_list, incorrect_with_high_conf_list = confidence_analyzer.abnormal_conf(
full_results, correct_thresh, wrong_thresh)
if len(correct_with_low_conf_list) > 0:
display(Markdown("#### Examples correctedly predicted with low confidence"))
with pd.option_context('max_colwidth', 250):
display(HTML(correct_with_low_conf_list.to_html(index=False)))
if len(incorrect_with_high_conf_list) > 0:
display(Markdown("#### Examples incorrectedly predicted with high confidence"))
with pd.option_context('max_colwidth', 250):
display(HTML(incorrect_with_high_conf_list.to_html(index=False)))
# ### Actions to take when you have examples of abnormal confidence
#
# If there are examples which are incorrectly classified with high confidence for specific intents, it may indicate an issue in the design of those specific intents because the user examples provided for that intent may be overlapping with the design of other intents.
#
# If intent A seems to always get misclassified as intent B with high confidence or gets correctly predicted with low confidence, consider using intent conflict detection. For more information, refer to the <a href="https://cloud.ibm.com/docs/services/assistant?topic=assistant-intents#intents-resolve-conflicts" target="_blank" rel="noopener no referrer">Conflict Resolution Documentation</a>.
#
# Also consider whether those two intents need to be two separate intents or whether they need to be merged. If they can't be merged, then consider adding more user examples which distinguish intent A specifically from intent B.
# <a id='part3.4'></a>
# ## 3.5 Perform an analysis using correlated entities per intent
#
# Perform a chi square significance test for entities such as we or you for unigrams and bigrams in the previous section. For each utterance in the training data, this analysis will call the message API for entity detection on each utterance and find the most correlated entities for each intent.
#
# **<font color=red>Note</font>**: You will be charged for calls made from this notebook based on your Watson Assistant plan. The user_id will be the same for all message calls.
importlib.reload(entity_analyzer)
importlib.reload(inferencer)
if entities_list:
THREAD_NUM = 5# we allow a maximum of 5 threads for faster inference
train_full_results = inferencer.inference(conversation,
workspace_id,
workspace_pd,
max_retries=10,
max_thread=THREAD_NUM,
verbose=False)
entity_label_correlation_df = entity_analyzer.entity_label_correlation_analysis(
train_full_results, entities_list)
with pd.option_context('display.max_colwidth', 200):
entity_label_correlation_df.index = np.arange(1, len(entity_label_correlation_df) + 1)
display(entity_label_correlation_df)
else:
display(Markdown("### Target workspace has no entities."))
# <a id='part4'></a>
# ## Part 4: Summary
# Congratulations! You have successfully completed the dialog skill analysis training. <br>
# This notebook is designed to improve our dialog skill analysis in an iterative fashion. Use it to tackle one aspect of your dialog skill at a time and start over for another aspect later for continuous improvement.
# ## Glossary
#
# **True Positives (TP):** True Positive measures the number of correctly predicted positive values meaning that predicted class is the same as the actual class which is the target intent.
#
# **True Negatives (TN):** True Negative measures the number of correctly predicted negative values meaning that the predicted class is the same as the actual class which is not the target intent.
#
# **False Positives (FP):** False Positive measures the number of incorrectly predicted positive values meaning that the predicted class is the target intent but the actual class is not the target intent.
#
# **False Negatives (FN):** False Negatives measures the number of incorrectly predicted negative values meaning that the predicted class is not the target intent but the actual class is the target intent.
#
# **Accuracy:** Accuracy measures the ratio of corrected predicted user examples out of all user examples.
# Accuracy = (TP + TN) / (TP + TN + FP + FN)
#
# **Precision:** Precision measures the ratio of correctly predicted positive observations out of total predicted positive observations.
# Precision = TP / (TP + FP)
#
# **Recall:** Recall measures the ratio of correctly predicted positive observations out of all observations of the target intent.
# Recall = TP / (TP + FN)
#
# **F1 Score:** F1 Score is the harmonic average of Precision and Recall.
# F1 = 2 \* (Precision \* Recall)/ (Precision + Recall)
#
# For more information related to Watson Assistant, refer to the <a href="https://cloud.ibm.com/docs/services/assistant" target="_blank" rel="noopener no referrer">Watson Assistant Documentation</a>.
# ### Authors
#
# **<NAME>** is a data scientist at IBM Watson who delivers new machine learning algorithms into IBM Watson's market leading conversational AI service. He works with clients to help improve their conversational AI agents and helps them tackle complex challenges at scale with tools like Dialog Skill Analysis. His work primarily focuses on natural language technology with interests in defending adversarial attacks in text, PII redaction and Auto-AI for text. He is also a believer in open-source and has been contributing to open-source projects like the IBM Auto-AI framework - Lale.
#
# **<NAME>** is an engineering lead at IBM Watson who believes in building unique AI-powered experiences which augment human capabilities. He currently works on AI innovation & research for IBM's award-winning conversational computing platform, the IBM Watson Assistant. His primary areas of interest include machine learning problems related to conversational AI, natural language understanding, semantic search & transfer learning.
#
# **<NAME>**, PhD, is a research scientist at IBM Watson who works on prototyping and productizing various algorithmic features for the IBM Watson Assistant. His research interests include a broad spectrum of problems related to conversational AI such as low-resource intent classification, out-of-domain detection, multi-user chat channels, passage-level semantic matching and entity detection. His work has been published at various top tier NLP conferences.
#
# **<NAME>**, PhD, is a research scientist at IBM Watson focusing on problems related to language understanding, question answering, deep learning and representation learning for various NLP tasks. He has been awarded by IBM for his contributions to several internal machine learning competitions which have included researchers from across the globe. Novel machine learning solutions designed by him have helped solve critical question answering and human-computer dialog problems for various IBM Watson products.
# <hr>
# Copyright © IBM Corp. 2019. This notebook and its source code are released under the terms of the Apache License, Version 2.0.
# <div style="background:#F5F7FA; height:110px; padding: 2em; font-size:14px;">
# <span style="font-size:18px;color:#152935;">Love this notebook? </span>
# <span style="font-size:15px;color:#152935;float:right;margin-right:40px;">Don't have an account yet?</span><br>
# <span style="color:#5A6872;">Share it with your colleagues and help them discover the power of Watson Studio!</span>
# <span style="border: 1px solid #3d70b2;padding:8px;float:right;margin-right:40px; color:#3d70b2;"><a href="https://ibm.co/wsnotebooks" target="_blank" style="color: #3d70b2;text-decoration: none;">Sign Up</a></span><br>
# </div>
| skill_analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:tensorflow]
# language: python
# name: conda-env-tensorflow-py
# ---
import os
import pandas as pd
import numpy as np
from stackregression import stack_regression_step1, stack_regression_step2, print_prediction_report
from utils import encode_numeric_zscore_list, encode_numeric_zscore_all, to_xy
from sklearn import preprocessing
from sklearn.cross_validation import train_test_split
from scipy.sparse import csr_matrix
from xgboost import XGBRegressor
from random import randint
import xgboost as xgb
#Read Input CSV file
path = "./data/self"
inputFilePath = os.path.join(path, "TestRegression.csv")
#df = pd.read_csv(inputFilePath, compression="zip", header=0, na_values=['NULL'])
df = pd.read_csv(inputFilePath, header=0, na_values=['NULL'])
x,y = to_xy(df, "Label")
x_train, x_valid, y_train, y_valid = train_test_split(x,y, test_size=0.20, random_state=43)
xgtrain = xgb.DMatrix(x_train, label=y_train)
xgvalid = xgb.DMatrix(x_valid, label=y_valid)
# +
#best params on 11/1 for 85% train data: {'subsample': 1.0, 'n_estimators': 174.0, 'eta': 0.1,
#'colsample_bytree': 0.4, 'gamma': 0.2, 'min_child_weight': 1.0, 'max_depth': 3}
RANDOM_STATE = randint(1,429496)
params = {
'min_child_weight': 1,
'eta': 0.1,
'colsample_bytree': 0.5,
'max_depth': 12,
'subsample': 0.8,
'alpha': 1,
'gamma': 1,
'silent': 1,
'verbose_eval': False,
'seed': RANDOM_STATE,
'eval_metric': 'mae',
'objective': 'reg:linear',
}
watchlist = [(xgtrain, 'train'), (xgvalid, 'eval')]
model = xgb.train(params, xgtrain, 100000, watchlist, early_stopping_rounds=300, verbose_eval=100)
# -
predictions = model.predict(xgvalid)
predictions
from utils import chart_regression
chart_regression(predictions, y_valid)
| TestRegression.ipynb |
# +
# Illustrate expoentnially-weighted moving average
# Based on
# http://people.duke.edu/~ccc14/sta-663-2019/notebook/S09G_Gradient_Descent_Optimization.html#Smoothing-with-exponentially-weighted-averages
# http://people.duke.edu/~ccc14/sta-663-2018/notebooks/S09G_Gradient_Descent_Optimization.html
import numpy as np
import matplotlib.pyplot as plt
from probml_utils import savefig
def ema(y, beta):
"""Exponentially weighted average."""
n = len(y)
zs = np.zeros(n)
z = 0
for i in range(n):
z = beta * z + (1 - beta) * y[i]
zs[i] = z
return zs
def ema_debiased(y, beta):
"""Exponentially weighted average with hias correction."""
n = len(y)
zs = np.zeros(n)
z = 0
for i in range(n):
z = beta * z + (1 - beta) * y[i]
zc = z / (1 - beta ** (i + 1))
zs[i] = zc
return zs
np.random.seed(0)
n = 50
x = np.arange(n) * np.pi
y = np.cos(x) * np.exp(x / 100) - 10 * np.exp(-0.01 * x)
betas = [0.9, 0.99]
for i, beta in enumerate(betas):
plt.figure()
plt.plot(x, y, "o-")
plt.plot(x, ema(y, beta), c="red", label="EMA")
plt.plot(x, ema_debiased(y, beta), c="orange", label="EMA with bias correction")
plt.title("beta = {:0.2f}".format(beta))
plt.legend()
name = "EMA{}.pdf".format(i)
savefig(name)
plt.show()
| notebooks/book1/04/ema_demo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/Serbeld/Tensorflow/blob/master/DenseNet_Drone.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="88RcMmZcQMM5" colab_type="text"
# # Convolutional Neural Network
#
# Build a CNN using Tensorflow and Keras to classify Towers. The Inspection_320x240 dataset consists in 22000 colour images, divided in 2 classes. There are 15399 training images, 3001 validation images and 3000 test images.
#
#
# - Author: <NAME>
# - Date: 2020-03-25
#
#
# + [markdown] id="RcdPSzhNin_C" colab_type="text"
# ## Setup
#
# + [markdown] id="WR44KFuNikmS" colab_type="text"
# Install and import TensorFlow and dependencies:
#
# + id="Stg_iSxrnXSl" colab_type="code" outputId="a67e6793-1c0c-42a9-efe2-2b0af394c7f4" colab={"base_uri": "https://localhost:8080/", "height": 176}
# !pip install h5py
import h5py
from google.colab import drive,files
drive.mount('/content/drive/')
import sys
sys.path.append('/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code')
# + id="jYnPCpUxfH4U" colab_type="code" colab={}
hdf5_path = '/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code/Inspection_320x240.hdf5'
dataset = h5py.File(hdf5_path, "r")
# + id="7H3fNBSyDf32" colab_type="code" colab={}
# #!pip install tensorflow==1.3
# + [markdown] id="JAIR7BqhQ9fO" colab_type="text"
# ## Exploratory Data Analysis
# + id="yYOfbPJISNDC" colab_type="code" colab={}
# Parameters
batch_size = 10
num_classes = 2
num_epochs = 10
lrate = 2e-5
# + colab_type="code" id="Nx8ze1tqSKc0" colab={}
import tensorflow as tf
import numpy as np
import os
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import backend as k
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense,Dropout,Flatten,Input,AveragePooling2D
from tensorflow.keras.callbacks import TensorBoard, ModelCheckpoint
from tensorflow.keras.optimizers import SGD,Adam
from tensorflow.keras.applications import densenet
import matplotlib.pylab as plt
# Size
filas,columnas = 240,320
img_shape = (filas, columnas, 3)
#train
train_img = dataset["train_img"]
xt = np.array(train_img)
yt = np.array(dataset["train_labels"])
#test
xtest = np.array(dataset["test_img"])
ytest = np.array(dataset["test_labels"])
#Validation
xval = np.array(dataset["val_img"])
yval = np.array(dataset["val_labels"])
#Categorical values or OneHot
yt = to_categorical(yt,num_classes)
ytest = to_categorical(ytest,num_classes)
yval = to_categorical(yval,num_classes)
# + id="AZa4Q6VQiXRJ" colab_type="code" outputId="09b73dae-eb6e-4eea-9d19-2deb6030d4a4" colab={"base_uri": "https://localhost:8080/", "height": 356}
#Labels Classes OneHot
#Nothing: 0 [1 0]
#Inspecting: 1 [0 1]
print("Labels Classes OneHot")
print("Nothing 0 [1. 0.]")
print("Inspecting 1 [0. 1.]")
#Image
num_de_imagen = 10020
print()
print("Output: "+ str(yt[num_de_imagen]))
imagen = train_img[num_de_imagen]
plt.imshow(imagen)
plt.show()
# + [markdown] id="GHLuQBiYSlve" colab_type="text"
# As we can see, the images in the dataset have a dimension of 240x320x3
# + id="xB7s22VCSm-_" colab_type="code" outputId="4404fedb-17da-446d-d255-562f0b7db9d7" colab={"base_uri": "https://localhost:8080/", "height": 121}
#Get the shape of x_train
print('x_train shape: ', xt.shape)
#Get the shape of y_train
print('y_train shape: ', yt.shape)
#Get the shape of x_validation
print('x_validation shape:', xval.shape)
#Get the shape of y_validation
print('y_validation shape:', yval.shape)
#Get the shape of x_test
print('x_test shape: ', xtest.shape)
#Get the shape of y_test
print('y_test shape: ', ytest.shape)
# + [markdown] id="Yc-08L8rS6-q" colab_type="text"
# ## Model Setup
# + id="UkIL0XW9Wy5e" colab_type="code" outputId="294f8d4e-6774-4461-bc49-15464d8cf5ad" colab={"base_uri": "https://localhost:8080/", "height": 399}
from tensorflow.keras.callbacks import ModelCheckpoint
#Inputs
inputs = Input(shape=img_shape, name='images')
#Nasnet Model
output = densenet.DenseNet121(include_top=False,weights=None,
input_shape=img_shape,
classes = num_classes)(inputs)
#AveragePooling2D
output = AveragePooling2D(pool_size=(2, 2), strides=None,
padding='valid',name='AvgPooling')(output)
#Flattened
output = Flatten(name='Flatten')(output)
#Dropout
output = Dropout(0.2,name='Dropout')(output)
#ReLU layer
output = Dense(10, activation = 'relu',name='ReLU')(output)
#Dense layer
output = Dense(num_classes, activation='softmax',name='softmax')(output)
#Checkpoint_path
# Create checkpoint callback
model_checkpoint = ModelCheckpoint(filepath="/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code/densenet",
monitor='val_loss', save_best_only=True)
#Model
modelo = Model(inputs=inputs, outputs=output)
ADAM = Adam(lr=lrate)
modelo.compile(loss='categorical_crossentropy',optimizer=ADAM,
metrics=['categorical_accuracy'])
#Summary
modelo.summary()
# + [markdown] id="tAmvL--aa598" colab_type="text"
# ## Traning
# + id="Q2tPte4-a7sq" colab_type="code" outputId="112ae86f-3d61-4d14-abc6-93c27cda59dd" colab={"base_uri": "https://localhost:8080/", "height": 506}
#Training Model
stad = modelo.fit({'images': xt}, {'softmax': yt}, batch_size=batch_size,
epochs=num_epochs, validation_data=(xval, yval),shuffle=True, callbacks = [model_checkpoint])
# + [markdown] id="sLKvuiqej3Sa" colab_type="text"
# The primary use case is to automatically save checkpoints *during* and at *the end* of training. This way you can use a trained model without having to retrain it, or pick-up training where you left of—in case the training process was interrupted.
#
# #### Checkpoint callback usage
#
# Train the model and pass it the `ModelCheckpoint` callback:
# + id="ORNZEtqHjMD_" colab_type="code" colab={}
from tensorflow.keras.models import load_model
#Load the best model trained
modelo = load_model("/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code/densenet")
# + id="qxZkUY2y3QoC" colab_type="code" outputId="a13715f1-7e2e-4813-c79c-d1ca568f4709" colab={"base_uri": "https://localhost:8080/", "height": 121}
from sklearn.metrics import confusion_matrix
#Evaluate the model
puntuacion = modelo.evaluate(xtest,ytest,verbose=0)
print("Loss: " + str(round(puntuacion[0],4)) + " Accuracy: " + str(round(puntuacion[1],4)))
predIdxs = modelo.predict(xtest)
predIdxs = np.argmax(predIdxs, axis=1) # argmax for the predicted probability
#print(classification_report(ytest.argmax(axis=1), predIdxs,target_names=lb.classes_))
cm = confusion_matrix(ytest.argmax(axis=1), predIdxs)
total = sum(sum(cm))
acc = (cm[0, 0] + cm[1, 1]) / total
sensitivity = cm[0, 0] / (cm[0, 0] + cm[0, 1])
specificity = cm[1, 1] / (cm[1, 0] + cm[1, 1])
# show the confusion matrix, accuracy, sensitivity, and specificity
print(cm)
print("acc: {:.4f}".format(acc))
print("sensitivity: {:.4f}".format(sensitivity))
print("specificity: {:.4f}".format(specificity))
# + [markdown] id="ptJg8mbaKsuO" colab_type="text"
# ##Predictions
# + id="hJcrS7lXKr4T" colab_type="code" outputId="d0ea4c69-0f34-4cd3-e137-2a31c9b5d508" colab={"base_uri": "https://localhost:8080/", "height": 373}
plt.figure(3)
Num_image = 1000
inputoimage = xt[Num_image]
print(inputoimage.shape)
x = inputoimage.reshape((-1, 240, 320, 3))
imagen = xt[Num_image]
plt.imshow(imagen)
plt.show()
print("Labels Classes OneHot")
print("Nothing 0 [1. 0.]")
print("Inspecting 1 [0. 1.]")
ynew = modelo.predict(x)
print()
print("Predictions: "+ str(np.round(ynew,2)))
# + id="UTIqzuwT2HJw" colab_type="code" outputId="3a81907d-daf0-490f-87f6-ef23274fab5e" colab={"base_uri": "https://localhost:8080/", "height": 307}
plt.figure(0)
plt.plot(stad.history['categorical_accuracy'],'r',linewidth=4)
plt.plot(stad.history['val_categorical_accuracy'],'g',linewidth=4)
plt.xlabel("Num of Epochs",fontsize = 'xx-large')
plt.ylabel("Accuracy",fontsize = 'xx-large')
plt.title("Training Accuracy vs Validation Accuracy",fontsize = 'xx-large')
plt.grid(color='b', ls = '-.', lw = 0.2)
plt.legend(['train','validation'],fontsize = 'x-large')
plt.savefig("/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code/densenet/categorical_accuracy.png", bbox_inches = 'tight')
plt.show()
# + id="eYqvJsBlawWT" colab_type="code" outputId="fc70682f-1143-4fb8-cdd4-7094bb6d3d4b" colab={"base_uri": "https://localhost:8080/", "height": 307}
plt.figure(2)
plt.plot(stad.history['loss'],'r',linewidth=4)
plt.plot(stad.history['val_loss'],'g',linewidth=4)
plt.xlabel("Num of Epochs",fontsize = 'xx-large')
plt.ylabel("Loss",fontsize = 'xx-large')
plt.title("Training Loss vs Validation Loss",fontsize = 'xx-large')
plt.grid(color='b', ls = '-.', lw = 0.2)
plt.legend(['train','validation'],fontsize = 'x-large')
plt.savefig("/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code/densenet/Loss.png", bbox_inches = 'tight')
plt.show()
# + id="sN65DmAT5yWb" colab_type="code" outputId="a7c1112d-5033-48be-d15a-ed906e02c7cd" colab={"base_uri": "https://localhost:8080/", "height": 337}
plt.rcParams["figure.figsize"] = (10,5)
## explain
plt.style.use("ggplot")
plt.figure(1)
plt.plot(stad.history['loss'], label="train_loss")
plt.plot(stad.history['val_loss'], label="val_loss")
plt.plot(stad.history['categorical_accuracy'], label="train_acc")
plt.plot(stad.history['val_categorical_accuracy'], label="val_acc")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig("/content/drive/My Drive/Serbeld_Drone/DATASET/Dataset_320x240_and_Code/densenet/Tesis.png")
plt.show()
| Drone/DenseNet_Drone.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Image Patches
#
# In this module, we will explore the topology of different collections of image patches capturing line segments, which, as we will show using persistent homology and projective coordinates, concentrate on the projective plane $RP^2$. Each image patch is a square $d \times d$ region of pixels. Each pixel can be thought of as a dimension, so each patch lives in $\mathbb{R}^{d \times d}$, and a collection of patches can be thought of as a Euclidean point cloud in $\mathbb{R}^{d \times d}$
#
# First, we perform all of the necessary library imports.
# +
import numpy as np
# %matplotlib notebook
import matplotlib.pyplot as plt
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
from ripser import ripser
from persim import plot_diagrams as plot_dgms
from dreimac import ProjectiveCoords, get_stereo_proj_codim1
import warnings
warnings.filterwarnings('ignore')
import numpy as np
from matplotlib import pyplot as plt
# %matplotlib notebook
from skimage.io import imread,imshow,imsave
from numpy.fft import fft,ifft,fft2,ifft2,fftshift,ifftshift
def fourier2(im):
return fftshift(fft2(im))
def ifourier2(f):
return ifft2(ifftshift(f)).real
def fourier(s):
return fftshift(fft(s))
def ifourier(f):
return ifft(ifftshift(f)).real
def ampl(f):
return np.sqrt(f.real**2 + f.imag**2)
def phase(f):
return np.arctan2(f.imag, f.real)
# -
# We now define a few functions which will help us to sample patches from an image and to plot a collection of patches
# +
def getPatches(I, dim):
"""
Given an image I, return all of the dim x dim patches in I
:param I: An M x N image
:param d: The dimension of the square patches
:returns P: An (M-d+1)x(N-d+1)x(d^2) array of all patches
"""
#http://stackoverflow.com/questions/13682604/slicing-a-numpy-image-array-into-blocks
shape = np.array(I.shape*2)
strides = np.array(I.strides*2)
W = np.asarray(dim)
shape[I.ndim:] = W
shape[:I.ndim] -= W - 1
if np.any(shape < 1):
raise ValueError('Window size %i is too large for image'%dim)
P = np.lib.stride_tricks.as_strided(I, shape=shape, strides=strides)
P = np.reshape(P, [P.shape[0]*P.shape[1], dim*dim])
return P
def imscatter(X, P, dim, zoom=1):
"""
Plot patches in specified locations in R2
Parameters
----------
X : ndarray (N, 2)
The positions of each patch in R2
P : ndarray (N, dim*dim)
An array of all of the patches
dim : int
The dimension of each patch
"""
#https://stackoverflow.com/questions/22566284/matplotlib-how-to-plot-images-instead-of-points
ax = plt.gca()
for i in range(P.shape[0]):
patch = np.reshape(P[i, :], (dim, dim))
x, y = X[i, :]
im = OffsetImage(patch, zoom=zoom, cmap = 'gray')
ab = AnnotationBbox(im, (x, y), xycoords='data', frameon=False)
ax.add_artist(ab)
ax.update_datalim(X)
ax.autoscale()
ax.set_xticks([])
ax.set_yticks([])
def plotPatches(P, zoom = 1):
"""
Plot patches in a best fitting rectangular grid
"""
N = P.shape[0]
d = int(np.sqrt(P.shape[1]))
dgrid = int(np.ceil(np.sqrt(N)))
ex = np.arange(dgrid)
x, y = np.meshgrid(ex, ex)
X = np.zeros((N, 2))
X[:, 0] = x.flatten()[0:N]
X[:, 1] = y.flatten()[0:N]
imscatter(X, P, d, zoom)
def fft_img(img, r = 3):
#Output is a 2D complex array. 1st channel real and 2nd imaginary
#For fft in opencv input image needs to be converted to float32
dft = cv2.dft(np.float32(img), flags=cv2.DFT_COMPLEX_OUTPUT)
#Rearranges a Fourier transform X by shifting the zero-frequency
#component to the center of the array.
#Otherwise it starts at the tope left corenr of the image (array)
dft_shift = np.fft.fftshift(dft)
##Magnitude of the function is 20.log(abs(f))
#For values that are 0 we may end up with indeterminate values for log.
#So we can add 1 to the array to avoid seeing a warning.
magnitude_spectrum = 20 * np.log(cv2.magnitude(dft_shift[:, :, 0], dft_shift[:, :, 1])) +1
# Circular HPF mask, center circle is 0, remaining all ones
#Can be used for edge detection because low frequencies at center are blocked
#and only high frequencies are allowed. Edges are high frequency components.
#Amplifies noise.
rows, cols = img.shape
crow, ccol = int(rows / 2), int(cols / 2)
mask = np.ones((rows, cols, 2), np.uint8)
center = [crow, ccol]
x, y = np.ogrid[:rows, :cols]
mask_area = (x - center[0]) ** 2 + (y - center[1]) ** 2 >= r*r
mask[mask_area] = 0
# print(np.count_nonzero(mask))
# apply mask and inverse DFT
fshift = dft_shift * mask
fshift_mask_mag = 2000 * np.log(cv2.magnitude(fshift[:, :, 0], fshift[:, :, 1])+1)
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1])
return img_back, fshift_mask_mag
# -
# Finally, we add a furthest points subsampling function which will help us to subsample image patches when displaying them
# +
# def getCSM(X, Y):
# """
# Return the Euclidean cross-similarity matrix between the M points
# in the Mxd matrix X and the N points in the Nxd matrix Y.
# :param X: An Mxd matrix holding the coordinates of M points
# :param Y: An Nxd matrix holding the coordinates of N points
# :return D: An MxN Euclidean cross-similarity matrix
# """
# C = np.sum(X**2, 1)[:, None] + np.sum(Y**2, 1)[None, :] - 2*X.dot(Y.T)
# C[C < 0] = 0
# return np.sqrt(C)
# def getGreedyPerm(X, M, Verbose = False):
# """
# Purpose: Naive O(NM) algorithm to do the greedy permutation
# :param X: Nxd array of Euclidean points
# :param M: Number of points in returned permutation
# :returns: (permutation (N-length array of indices), \
# lambdas (N-length array of insertion radii))
# """
# #By default, takes the first point in the list to be the
# #first point in the permutation, but could be random
# perm = np.zeros(M, dtype=np.int64)
# lambdas = np.zeros(M)
# ds = getCSM(X[0, :][None, :], X).flatten()
# for i in range(1, M):
# idx = np.argmax(ds)
# perm[i] = idx
# lambdas[i] = ds[idx]
# ds = np.minimum(ds, getCSM(X[idx, :][None, :], X).flatten())
# if Verbose:
# interval = int(0.05*M)
# if i%interval == 0:
# print("Greedy perm %i%s done..."%(int(100.0*i/float(M)), "%"))
# Y = X[perm, :]
# return {'Y':Y, 'perm':perm, 'lambdas':lambdas}
# -
P.shape
# ## Oriented Line Segments
#
# We now examine the collection of patches which hold oriented, slightly blurry line segments that are varying distances from the center of the patch. First, let's start by setting up the patches. Below, the "dim" variable sets the patch resolution, and the "sigma" variable sets the blurriness (a larger sigma means blurrier line segments).
# +
def getLinePatches(dim, NAngles, NFreq):
"""
Sample a set of line segments, as witnessed by square patches
Parameters
----------
dim: int
Patches will be dim x dim
NAngles: int
Number of angles to sweep between 0 and pi
NOffsets: int
Number of offsets to sweep from the origin to the edge of the patch
sigma: float
The blur parameter. Higher sigma is more blur
"""
N = NAngles*NFreq
P = np.zeros((N, dim*dim))
thetas = np.linspace(0, 2*np.pi, NAngles+1)[0:NAngles]
# ps = np.linspace(-0.5*np.sqrt(2), 0.5*np.sqrt(2), NFreq)
idx = 0
[Y, X] = np.meshgrid(np.linspace(0, 2*np.pi, dim), np.linspace(0, np.pi, dim))
wavelengths = np.linspace(2, 1, NFreq)
for i in range(NAngles):
for j in range(NFreq):
patch = (np.sin(2*np.pi*(X*np.cos(thetas[i]) + Y*np.sin(thetas[i])) / wavelengths[j])+1)/2
P[idx, :] = patch.flatten()
idx += 1
return P
P = getLinePatches(dim=10, NAngles = 10**2, NFreq = 1)
print(np.max(P))
print(np.min(P))
plt.figure(figsize=(8, 8))
plotPatches(P, zoom=2)
ax = plt.gca()
ax.set_facecolor((0.7, 0.7, 0.7))
plt.show()
# -
# Now let's compute persistence diagrams for this collection of patches. This time, we will compute with both $\mathbb{Z}/2$ coefficients and $\mathbb{Z}/3$ coefficients up to H2.
dgmsz2 = ripser(P, coeff=2, maxdim=2,thresh=20)['dgms']
dgmsz3 = ripser(P, coeff=3, maxdim=2,thresh=20)['dgms']
plt.figure(figsize=(8, 4))
plt.subplot(121)
plot_dgms(dgmsz2)
plt.title("$\mathbb{Z}/2$")
plt.subplot(122)
plot_dgms(dgmsz3)
plt.title("$\mathbb{Z}/3$")
plt.show()
# Notice how there is one higher persistence dot both for H1 and H2, which both go away when switching to $\mathbb{Z} / 3\mathbb{Z}$. This is the signature of the projective plane! To verify this, we will now look at these patches using "projective coordinates" (finding a map to $RP^2$).
#
| ImageAnalysis/02_ImagePatchesHomology.ipynb |