
id stringlengths 36 36 | source stringclasses 15
values | formatted_source stringclasses 13
values | text stringlengths 2 7.55M |
|---|---|---|---|
4b12e5aa-2b91-4b49-b8ca-0d2290dd7973 | trentmkelly/LessWrong-43k | LessWrong | Life, struggle, and the psychological fallout from COVID
I have a friend in the effective altruism community who is facing an unusually slippery and disheartening struggle at the moment. This person is a long-time contributor to the community, and is held up as exemplary by other community members. Due to their integr... |
0b8b07c7-1e05-42e8-9e58-5b16dd0d4d02 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Language Models can be Utility-Maximising Agents
1 minute takeaways
------------------
* It's actually pretty easy to train and run a language model to function as an agent for a specific task, rather than as a [non-agentic simulator](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators)
* The [resulting agen... |
0628bab5-d9c8-41d7-9a28-e0c54aba5b7f | trentmkelly/LessWrong-43k | LessWrong | Glide Meditations: A Statement of Intent
Have you ever experienced that feeling where you finally got an opportunity to do something you think you wanted to do, but now that you have the opportunity to do that thing, you're actually super apprehensive about it?
The first time I experienced that feeling, it was caused... |
80f768db-f728-4361-bb68-c86dfaaca0c5 | StampyAI/alignment-research-dataset/special_docs | Other | Surveying Safety-relevant AI Characteristics
Surveying Safety-relevant AI Characteristics
Jos´e Hern ´andez-Orallo
Universitat Polit `ecnica de Val `encia, Spain
Leverhulme Centre for the Future of Intelligence, UK
jorallo@dsic.upv.esFernando Mart ´ınez-Plumed
Universitat Polit `ecnica de Val `encia, Spain
fmartinez@d... |
00014e7b-ecc9-4725-8e21-20a899cf1dad | trentmkelly/LessWrong-43k | LessWrong | [AN #84] Reviewing AI alignment work in 2018-19
Find all Alignment Newsletter resources here. In particular, you can sign up, or look through this spreadsheet of all summaries that have ever been in the newsletter. I'm always happy to hear feedback; you can send it to me by replying to this email.
This is the summary... |
0c19f585-d32f-48db-9c42-15e83b141140 | trentmkelly/LessWrong-43k | LessWrong | Less Wrong views on morality?
Do you believe in an objective morality capable of being scientifically investigated (a la Sam Harris *or others*), or are you a moral nihilist/relativist? There seems to be some division on this point. I would have thought Less Wrong to be well in the former camp.
Edit: There seems t... |
192f844a-fa8a-44ca-8666-4558cba0e510 | trentmkelly/LessWrong-43k | LessWrong | Irrational Upvotes
"This premise is VERY flawed" (found here) is the sole author-supplied content of a comment. There are no supporting links or additional content, only a one-sentence quote of the "offending" premise.
Yet, it has four upvotes.
This is a statement that can be made about any premise. It is backed b... |
ec01829f-a67a-4b7a-8f52-b626bbecb990 | trentmkelly/LessWrong-43k | LessWrong | Hello, is it you I'm looking for?
Hi
Sorry if diving in with my question is a breach of your etiquette, but I have a kind of burning question I was hoping some of you guys could help me with. I've been reading the core texts and clicking around but can't quite figure out if this has been covered before.
Does anyone ... |
d6594145-7626-41de-80c2-4f4f6e47ecae | trentmkelly/LessWrong-43k | LessWrong | Optimizing Rationality T-shirts
Thanks again for all the feedback on the first set of Rationality slogan t-shirts, which Intentional Insights developed as part of our broader project of promoting rationality to a wide audience. As a reminder, the t-shirts are meant for aspiring rationalists to show their affiliation ... |
65f67d32-93fa-47a8-afcd-1715cb47284a | trentmkelly/LessWrong-43k | LessWrong | Circular Preferences Don't Lead To Getting Money Pumped
Edit: for reasons given in the comments, I don't think the question of what circular preferences actually do is well defined, so this an answer to a wrong question.
If I like Y more than X, at an exchange rate of 0.9Y for 1X, and I like Z more than Y, at an e... |
d2dad8e0-797a-4af4-b62d-3c04e6028264 | trentmkelly/LessWrong-43k | LessWrong | Launching Lightspeed Grants (Apply by July 6th)
Lightspeed Grants provides fast funding for projects that help humanity flourish among the stars. The application is minimal and grant requests of any size ($5k - $5M) are welcome. Budget is $5M for this grant round, and (probably) more in future rounds. Applications clo... |
07a9e55b-d42d-45ed-97a9-27b5ff12a113 | trentmkelly/LessWrong-43k | LessWrong | 'Preferences in AI: An Overview' [link]
Those interested in AI preferences may appreciate this recent review:
Domshlak et al., Preferences in AI: An overview |
0c861aa3-0cdc-4a9b-a418-3b55653bf165 | trentmkelly/LessWrong-43k | LessWrong | Cryptocurrency taxation in the UK
Mostly out of curiosity, I've been looking into how cryptocurrency is taxed in the UK. It's not easy to get what I consider to be a full answer, but here's my current understanding, as far as I felt like looking into it. HMRC's internal cryptoassets manual is available but I didn't fe... |
c5f9043d-9c14-43b0-9e43-b04286420e18 | trentmkelly/LessWrong-43k | LessWrong | Desiderata for Normalizers
This work originated at MIRI Summer Fellows and originally involved Pasha Kamyshev, Dan Keys, Johnathan Lee, Anna Salamon, Girish Sastry, and Zachary Vance. I was asked to look over two drafts and some notes, clean them up, and post here. Especial thanks to Zak and Pasha for drafts on which ... |
4714e97f-8eaf-4280-8b34-74c2b382f003 | StampyAI/alignment-research-dataset/blogs | Blogs | February 2017 Newsletter
| |
| --- |
|
Following up on a post outlining some of the reasons MIRI researchers and OpenAI researcher Paul Christiano are [pursuing different research directions](https://agentfoundations.org/item?id=1129), Jessica Taylor has written up the key [motivations for MIRI’s highly reliable age... |
37ce72d6-369d-4413-928b-8ea853e97fef | trentmkelly/LessWrong-43k | LessWrong | Anchor Weights for ML
In the previous post, I talked about several "anchors" that we could use to think about future ML systems, including current ML systems, humans, ideal optimizers, and complex systems.
In fact, I think we should be using all of these anchors (and any others we can think of) to reason about future... |
a7ee9bfd-b0c3-4719-8c3d-b48a66e43ab5 | trentmkelly/LessWrong-43k | LessWrong |
Against Being Against Growth
(Cross-posted from my personal website - this is mostly meant for me to link when people argue against growth at me, so it may not be as relevant here, where most people are pro-growth)
It is inconsistent to be against growth or to advocate for social systems because you think they will ... |
11c902c0-a6a0-469d-b2e0-e25958ed2396 | trentmkelly/LessWrong-43k | LessWrong | Is there a reasonable reading according to which Baric, Shi et al 2015 isn't gain-of-function research?
From the A SARS-like cluster of circulating bat coronaviruses shows potential for human emergence by Baric, Shi et al:
> Wild-type SARS-CoV (Urbani), mouse-adapted SARS-CoV (MA15) and chimeric SARS-like CoVs were c... |
8b0798e4-9eb1-424a-91d3-6f0852ea832a | trentmkelly/LessWrong-43k | LessWrong | QAPR 5: grokking is maybe not *that* big a deal?
[Thanks to support from Cavendish Labs and a Lightspeed grant, I've been able to restart the Quintin's Alignment Papers Roundup sequence.]
Introduction
Grokking refers to an observation by Power et al. (below) that models trained on simple modular arithmetic tasks wou... |
0298b0f6-d8b3-458d-b0ef-570a45045ecd | trentmkelly/LessWrong-43k | LessWrong | Yet more UFO Betting: Put Up or Shut Up
(Edit: I am not the user RatsWrongAboutUAP.)
I'm offering a new bet along similar lines to Yudkowsky's bet with the user RatsWrongAboutUAP in this thread last month. My bet has these similarities (here added explicitly after some confusion in the comments):
* I will pay out i... |
d8a2164d-ff61-49a2-a4ce-82a090f06812 | trentmkelly/LessWrong-43k | LessWrong | AISN #50: AI Action Plan Responses
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
In this newsletter, we cover AI companies’ responses to the federal government’s request for information on the development of an AI Action... |
acce1d9b-e2d6-4b57-806c-cad586533b58 | trentmkelly/LessWrong-43k | LessWrong | Split Personality Training: Revealing Latent Knowledge Through Personality-Shift Tokens
Produced as part of the ML Alignment & Theory Scholars Program - Winter 2024-25 Cohort
**Epistemic status**: I received positive feedback when I presented this idea to people at EAG, and my MATS mentor Evan Hubinger suggested I m... |
c887a123-60ba-451c-b42b-5eeb78a0903b | trentmkelly/LessWrong-43k | LessWrong | Building an civilisation scale OODA loop for the problem of AGI
You can break down our civilizations reaction to the problem of AGI into a massive decentralized OODA loop. Each part of the OODA loop is not one person but an aggregate of many people and organisations.
My current major worry is that we do not have a r... |
f4d6ceb9-f6e2-4d68-a0f7-997e13bf1eb0 | trentmkelly/LessWrong-43k | LessWrong | Do you want to do a debate on youtube? I'm looking for polite, truth-seeking participants.
I am testing a new debate format and am looking for people to debate any of the following (or make a case for other things):
* Policy decisions
* EA Cause prioritisation
* What should/will happen in Taiwan/Ukraine/Gaza
* US... |
95712c21-c227-47a9-a636-197c129ce4ae | trentmkelly/LessWrong-43k | LessWrong | Eliezer's Post Dependencies; Book Notification; Graphic Designer Wanted
I'm going to try and produce summaries of the quantum physics series today or tomorrow.
Andrew Hay has produced a neat graph of (explicit) dependencies among my Overcoming Bias posts - an automatically generated map of the "Followup to" structure... |
2e0a1d2b-8d5f-45b6-be8a-efc74c41549c | trentmkelly/LessWrong-43k | LessWrong | December 2015 Media Thread
This is the monthly thread for posting media of various types that you've found that you enjoy. Post what you're reading, listening to, watching, and your opinion of it. Post recommendations to blogs. Post whatever media you feel like discussing! To see previous recommendations, check out th... |
b226c846-9d77-4f5c-a068-d4523f379e33 | trentmkelly/LessWrong-43k | LessWrong | [Link] Faster than Light in Our Model of Physics: Some Preliminary Thoughts—Stephen Wolfram Writings
This is a link post for:
Faster than Light in Our Model of Physics: Some Preliminary Thoughts—Stephen Wolfram Writings |
0a6a8a60-6c52-400c-8e10-d94bb6adb01d | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Select Agent Specifications as Natural Abstractions
Introduction
============
The Preference Fulfillment Hypothesis (PFH) asserts that [“Humans have an innate motivation ('preference fulfillment', PF) to fulfill the preferences of those they care about"](https://www.lesswrong.com/posts/Kf6sKZudduhJmykTg/the-preferenc... |
d67b5ff3-c363-4c9b-bf8f-8df4b9299ec5 | trentmkelly/LessWrong-43k | LessWrong | Is a Purely Rational World a Technologically Advanced World?
What would our world be today if humans had started off with a purely rational intelligence?
It seems as though a dominant aspect of rationality deals with risk management. For example, an irrational person might feel that the thrill of riding a zip line f... |
7aad04d7-abed-46af-bc23-b8fb45eb9f5b | trentmkelly/LessWrong-43k | LessWrong | Utility versus Reward function: partial equivalence
A reward function is defined over past sequences of actions and observations. When the agent chooses an action, and gets an observation, they receive a reward that is a function of that observation and all previous observations and actions.
A utility function is def... |
34d4c1dd-30ca-4aee-8f38-562805c86e29 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | International cooperation vs. AI arms race
**Summary**
I think there's a decent chance that governments will be the first to build artificial general intelligence (AI). International hostility, especially an [AI arms race](http://wiki.lesswrong.com/wiki/AI_arms_race), could exacerbate risk-taking, hostile motivation... |
915950b6-0730-46da-87fe-2b099a709234 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Jade Leung and Seth Baum: The role of existing institutions in AI strategy
---
*AI is very likely to make a huge impact on our world, especially as it grows more powerful than it is today. It’s hard for us to know exactly how that impact will look, but we do know many of the actors most likely to be involved. As AI g... |
b115673e-cc6a-4396-98c0-f773156b5793 | trentmkelly/LessWrong-43k | LessWrong | The reward engineering problem
Today we usually train reinforcement learning agents to perform narrow tasks with simple goals. We may eventually want to train RL agents to behave “well” in open-ended environments where there is no simple goal.
Suppose that we are trying to train an RL agent A. In each episode, A int... |
0ab83c23-cd29-4579-b395-78f89694ef14 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Logic Programming approaches for routing fault-free and maximally-parallel Wavelength Routed Optical Networks on Chip (Application paper)
1 Introduction
---------------
Since photons move faster than electrons in the matter, and they dissipate lower power in the process,
the new technology of silicon photonics
is a... |
be044d8d-da3a-4e9b-b7db-79a804ee44d3 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | The Paradox of Expert Opinion
> *The best-informed opinions tend to be the most selection-biased ones.*
>
>
If you want to know whether string theory is true and you're not able to evaluate the technical arguments yourself, who do you go to for advice? Well, seems obvious. Ask the experts. They're likely the most i... |
8dfba8e3-34a5-4fe0-9975-340d8f3ac44f | trentmkelly/LessWrong-43k | LessWrong | aisafety.community - A living document of AI safety communities
Thanks to plex for co-authoring the post (co-authors are currently not reflected in EA Forum when crossposted from LessWrong).
The AI Safety Communities logo, by DALL-E 2
The AI safety field has been rapidly growing over the last few years, and more and... |
1209195d-73e8-4e3f-9188-d8d7869e24ac | trentmkelly/LessWrong-43k | LessWrong | Would a more deadly virus have induced greater compliance with US lockdown restrictions?
Relative to other pandemics and our initial fears, Covid has a low infection fatality rate (IFR). The IFR varies between societies depending on age and obesity distributions, such that it was more severe in the US than in India. E... |
c51cda2c-ae86-49ba-8b0b-b42036804dd0 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | QNR prospects are important for AI alignment research
***Attention conservation notice:** This discussion is intended for readers with an interest in prospects for knowledge-rich intelligent systems and potential applications of improved knowledge representations to AI capabilities and alignment. It contains no theore... |
0228a20e-142f-4103-8ff1-23c930eecc8c | trentmkelly/LessWrong-43k | LessWrong | Open thread, Dec. 05 - Dec. 11, 2016
If it's worth saying, but not worth its own post, then it goes here.
----------------------------------------
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one. (Immediately before; refresh the ... |
188767f7-f97c-4899-8e2b-fc7b2bb5b42b | trentmkelly/LessWrong-43k | LessWrong | Reflections on Premium Poker Tools: Part 4 - Smaller things that I've learned
Previous posts:
* Part 1 - My journey
* Part 2 - Deciding to call it quits
* Part 3 - What I've learned
In the previous post, I talked about what I've learned. That post focused on bigger things. But there were a lot of smaller, more mi... |
9fcdf7a0-2b0c-4066-b054-0f58c73e8611 | trentmkelly/LessWrong-43k | LessWrong | "Can't Say No" Spending
The remarkable observation that medical spending has zero net marginal effect is shocking, but not completely unprecedented.
According to Spiegel in "Too Much of a Good Thing: Choking on Aid Money in Africa", the Washington Center for Global Development calculated that it would require $3,521 ... |
8e19281a-45b5-45a9-a26a-3769650a7452 | trentmkelly/LessWrong-43k | LessWrong | My computational framework for the brain
(See comment here for some updates and corrections and retractions. —Steve, 2022)
By now I've written a bunch of blog posts on brain architecture and algorithms, not in any particular order and generally interspersed with long digressions into Artificial General Intelligence. ... |
8a34a306-1bda-4c88-9f10-d7a56ebd5b73 | trentmkelly/LessWrong-43k | LessWrong | Heroin, not window opening
It seems that heroin is a better example of the problem discussed here than window opening.
Basically, the challenge is that if the AI can make you accept a potent heroin injection, you'll agree this was a good idea - but if it doesn't, you won't. |
745b8260-c1c0-4589-a5db-c54839d63ac3 | trentmkelly/LessWrong-43k | LessWrong | Excuse me, would you like to take a survey?
Related to: Practical Rationality Questionnaire
Here among this community of prior-using, Aumann-believing rationalists, it is a bit strange that we don't have any good measure of what the community thinks about certain things.
I no longer place much credence in raw majori... |
8d327577-2f02-4295-90e8-15a23dc598a3 | trentmkelly/LessWrong-43k | LessWrong | Announcing the Inverse Scaling Prize ($250k Prize Pool)
TL;DR: We’re launching the Inverse Scaling Prize: a contest with $250k in prizes for finding zero/few-shot text tasks where larger language models show increasingly undesirable behavior (“inverse scaling”). We hypothesize that inverse scaling is often a sign of a... |
51179bab-747a-428c-9b12-3dd703de3903 | trentmkelly/LessWrong-43k | LessWrong | Open thread, Mar. 14 - Mar. 20, 2016
If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one. (Immediately before; refresh the list-of-threads page ... |
a327468f-905e-4e8b-9c54-76438857c44f | trentmkelly/LessWrong-43k | LessWrong | My current uncertainties regarding AI, alignment, and the end of the world
As I read the interview with Eliezer Yudkowsky on AI alignment problems, I had a couple of thoughts of my own. These are poorly researched, and maybe poorly formulated. I intend to think more about them, but I thought this might be a good place... |
50621007-035c-4de1-a2c6-66be013ec943 | trentmkelly/LessWrong-43k | LessWrong | What questions about the future would influence people’s actions today if they were informed by a prediction market?
I'm looking for questions that would be useful to many individuals and would influence their decisions today (not questions for those working on shaping the long term future of Earth originating life).... |
6352e9d9-72d8-4e7e-b9b5-35a006762435 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Berkeley: Implementation Intentions
Discussion article for the meetup : Berkeley: Implementation Intentions
WHEN: 05 March 2014 07:00:00PM (-0800)
WHERE: 2030 Addison, 3rd floor, Berkeley, CA
Hello all, next week's meetup will be about implementation intentions:
http://en.wikipedia.org/wiki/Implementation... |
e655c5a7-30ef-4df0-87e4-1fee04dbd225 | trentmkelly/LessWrong-43k | LessWrong | Incoherence of unbounded selfishness
Unbounded agentic selfishness isn't possible unless you can unboundedly index on and retrocausally compress "self". Otherwise future "you" is just this animal walking around, and how do you specify them in particular for good things to happen to? In practice, evil people do this by... |
0b641186-54a7-41a6-981a-3d9a5b2119d7 | trentmkelly/LessWrong-43k | LessWrong | Higher Risk of Nuclear War
With the Russian invasion of Ukraine, nuclear war is still very unlikely, but I'd guess it's the most likely it's been in my lifetime. It's worth thinking through how this impacts any disaster plans you might have:
* What would you do if you got an incoming ICBM alert? Are there supplies y... |
0bf231d7-bb2a-400e-af99-59dd6ece32d8 | trentmkelly/LessWrong-43k | LessWrong | [Fiction] It's a strange feeling, to be free
Related to: Philosophical zombies, How an algorithm feels from the inside, Fake utility function
DISCLAIMER 1: English is not my native language. Trying to compose fiction in a learned language is not an easy task: I tried to respect the style of the literary works I read ... |
292edcb0-850d-4f6d-b047-6ef7bd5ed194 | trentmkelly/LessWrong-43k | LessWrong | GiveWell and the problem of partial funding
|
e5dc5a7b-f985-4bbc-949c-069de19efef8 | StampyAI/alignment-research-dataset/special_docs | Other | Stable Agreements in Turbulent Times: A Legal Toolkit for Constrained Temporal Decision Transmission
TECHNICAL REPORT Stable Agreements in Turbulent Times: A Legal Toolkit for Constrained Temporal Decision Transmission Cullen O’Keefea J.D. Candidate, Class of 2019, Harvard Law School Research Affiliate, Center for the... |
5fc51d84-3473-4f28-b865-d968a70323f6 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "I particularly remember one scene from Bill Maher's "Religulous". I can't find the exact quote, but I will try to sum up his argument as best I remember. Christians believe that sin is caused by a talking snake. They may have billions of believers, thousands of years of tradition behind them, and a vast literature of ... |
808476b2-a22e-43b0-b92a-57d9d4de4f1b | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Why Asimov's Laws of Robotics Don't Work - Computerphile
So, should we do a video about the three laws of robotics, then?
Because it keeps coming up in the comments.
Okay, so the thing is, you won't hear serious AI researchers talking about the three laws of robotics
because they don't work. They never worked.
So I th... |
c11434f4-c611-4316-b5d8-9cfcc99d8db6 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Entropy, and Short Codes
Today's post, Entropy, and Short Codes was originally published on 23 February 2008. A summary (taken from the LW wiki):
> You use a short word for something that you won't need to describe often, or a long word for something you'll need to describe often. This can result in in... |
01604beb-adbc-4b3f-a1a3-d97f4ea74bf5 | trentmkelly/LessWrong-43k | LessWrong | Governing High-Impact AI Systems: Understanding Canada’s Proposed AI Bill. April 15, Carleton University, Ottawa
Join us this April 15th for a panel discussion, keynote address by the founder of the Montreal AI Ethics Institute, and networking mixer on the governance of AI Systems in the Canadian context, held by EA C... |
81344f13-1071-4cfb-b3d9-8f80e0f6f8bc | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | «Boundaries», Part 1: a key missing concept from utility theory
*This post has been recorded as part of the LessWrong Curated Podcast, and can be listened to on* [*Spotify*](https://open.spotify.com/episode/73rKuCaxCaAbLqNIvRVi99)*,* [*Apple Podcasts*](https://podcasts.apple.com/us/podcast/boundaries-part-1-a-key-miss... |
07f81539-cdbf-40b5-84f0-ee07976698a0 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | A very crude deception eval is already passed
I was thinking about possible evals that would tell us when we're getting to models that are capable of deception. One not-very-good idea I had was just to measure zero-shot understanding of relevant deception scenarios in a language model. I don't think this tells us very... |
d7796fe4-9154-43cb-85fa-b0b949fffe9e | StampyAI/alignment-research-dataset/arxiv | Arxiv | Shared Autonomy via Hindsight Optimization
I Introduction
---------------
Robotic teleoperation enables a user to achieve their intended goal by providing inputs into a robotic system. In direct teleoperation, user inputs are mapped directly to robot actions, putting the burden of control entirely on the user. Howe... |
abecfcc3-a188-47be-81b5-da5f499589ac | trentmkelly/LessWrong-43k | LessWrong | [link] The surprising downsides of being clever
“Happiness in intelligent people is the rarest thing I know.” ― Ernest Hemingway, The Garden of Eden see here
Did you know The surprising downsides of being clever? Is Happiness And Intelligence: Rare Combination? There are longitudinal studies which seem to imply this:... |
cc0a7fa4-32cb-4ae1-9ede-ddd859318e82 | trentmkelly/LessWrong-43k | LessWrong | Slightly against aligning with neo-luddites
To summarize,
* When considering whether to delay AI, the choice before us is not merely whether to accelerate or decelerate the technology. We can choose what type of regulations are adopted, and some options are much better than others.
* Neo-luddites do not fundamental... |
439e0d78-9d91-4235-af8e-3f1ac699ec8b | trentmkelly/LessWrong-43k | LessWrong | What will 2040 probably look like assuming no singularity?
I'm looking for a list such that for each entry on the list we can say "Yep, probably that'll happen by 2040, even conditional on no super-powerful AGI / intelligence explosion / etc." Contrarian opinions are welcome but I'm especially interested in stuff that... |
de94f240-a3c7-482b-b47a-b47aa146aeb5 | trentmkelly/LessWrong-43k | LessWrong | Luck I: Finding White Swans
Quoth the Master, great in Wisdom, to the Novice: "Ye, carry with thee all thy days a cheque folded up in your wallet. For there may be many situations in which thou shalt have need of it."
And the Novice, of high intelligence but lesser wisdom, replied, saying unto the Master: "Of what s... |
a2ef1550-ca4a-4dd8-b118-43cbf39dcc81 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Longtermists Should Work on AI - There is No "AI Neutral" Scenario
**Summary:** If you’re a longtermist (i.e you believe that most of the moral value lies in the future), and you want to prioritize impact in your career choice, **you should strongly consider either working on AI directly,** or working on things that ... |
1000820a-d31a-4e01-b214-933abc5b7ff8 | trentmkelly/LessWrong-43k | LessWrong | Should we be kind and polite to emerging AIs?
I’ve adopted the habit of engaging with chat-ish AIs / digital assistants in a polite, considerate tone (e.g. with “please” and “thank you”) as a general[1] policy.
I am doing this not because I believe such machines have feelings I might hurt or expectations of civility ... |
aa5b3640-8381-4b9e-a9a5-4ccde785511c | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Disentangling arguments for the importance of AI safety
*Note: my views have shifted significantly since writing this post. I now consider items 1, 2, 3, and 6.2 to be different facets of one core argument, which I call the "second species" argument, and which I explore in depth in [this report](https://www.alignmentf... |
0a74063f-4165-4b05-ac44-bb254fca8903 | trentmkelly/LessWrong-43k | LessWrong | Spending Update 2022
Every few years (2020, 2018, 2016, 2014) I like to look over our spending and write something up publicly. General advantages of being public here:
* This gives something I can point people to if they have questions about some aspect of how we handle money.
* Since almost everything we do eith... |
c60fbcd4-43a8-473c-8143-7c35d451c224 | trentmkelly/LessWrong-43k | LessWrong | The Hidden Status Game in Hospital Slacking
Why do highly-paid hospital workers slack off and complain so often? Most would say "because they can" or "they're just lazy" or "it's a tough job, stress release." But I suspect there's a deeper status game at play - one that may illuminate broader patterns of institutional... |
fea0c62c-40eb-4c44-9e37-ec8bf4231e3b | trentmkelly/LessWrong-43k | LessWrong | [Hebbian Natural Abstractions] Mathematical Foundations
TL;DR: We showed how Hebbian learning with weight decay could enable a) feedforward circuits (one-to-many) to extract the first principal component of a barrage of inputs and b) recurrent circuits to amplify signals which are present across multiple input streams... |
f6767882-c25f-494e-8276-23873e2ec899 | trentmkelly/LessWrong-43k | LessWrong | Against lone wolf self-improvement
LW has a problem. Openly or covertly, many posts here promote the idea that a rational person ought to be able to self-improve on their own. Some of it comes from Eliezer's refusal to attend college (and Luke dropping out of his bachelors, etc). Some of it comes from our concept of r... |
19ede9f2-6082-4773-ac84-65a5e1e4625a | trentmkelly/LessWrong-43k | LessWrong | Transformer Mech Interp: Any visualizations?
After getting to the the part of a demo (one of Neel Nanda's interp demos) where they talk about the idea of a Logit Lens, and Layer Attribution, I have a bit of trouble visualizing it as I could have for simpler concepts (e.g. residual streams, which were indeed drawn as m... |
b7c6f921-d4d8-4294-9894-fddd3dbd39d3 | trentmkelly/LessWrong-43k | LessWrong | Not a Meetup May 22 in Cambridge, MA
I enjoyed some of the conversations at the last Cambridge (MA) meetup, particularly towards the end, but I will be in California for the next couple of Cambridge meetups (though I hope to meet some of the LW community there).
I spend a lot of my time sitting and working on my lapt... |
734920fd-8ec0-462f-a77f-4438de71f41d | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [AN #172] Sorry for the long hiatus!
Listen to this newsletter on [The Alignment Newsletter Podcast](http://alignment-newsletter.libsyn.com/).
Alignment Newsletter is a publication with recent content relevant to AI alignment. Find all Alignment Newsletter [resources here](http://rohinshah.com/alignment-newsletter/)... |
af2ab1e2-b9ea-4d87-b910-21d84866afb3 | StampyAI/alignment-research-dataset/arxiv | Arxiv | A Simplified Variant of Gödel's Ontological Argument
1 Introduction
---------------
Gödel’s (GoedelNotes) ontological argument has attracted significant, albeit controversial, interest among philosophers, logicians and theologians \parencitesobel2004logic.
In this article I present a simplified variant of Gödel’s a... |
5ab57651-68cc-43f0-92bb-6b294c615458 | trentmkelly/LessWrong-43k | LessWrong | Reversed stupidity sometimes provides useful information
In his recent CATO article, Reversed Stupidity Is Not Intelligence, Eliezer writes:
> To psychoanalyze these people’s flaws, even correctly, and even if they constitute a numerical majority of the people talking about “quantum,” says nothing at all about whethe... |
72c5083b-8eb9-45c6-99c9-567ed9159440 | trentmkelly/LessWrong-43k | LessWrong | You should go to ML conferences
This is a second kind of obvious point to make, but if you are interested in AI, AI safety, or cognition in general, it is likely worth going to top ML conferences, such as NeurIPS, ICML or ICLR. In this post I cover some reasons why, and some anecdotal stories.
1. Parts of AI alignme... |
baaca486-7b4c-49a0-b8c7-fad2247e0acd | trentmkelly/LessWrong-43k | LessWrong | Are HEPA filters likely to pull COVID-19 out of the air?
Could hospitals install HEPA filters in common spaces and run them 24/7 to decrease COVID-19 spread? |
d8377109-a747-4457-9ac3-86a76d221286 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Thoughts on Robin Hanson's AI Impacts interview
There was already a LessWrong Post [here](https://www.lesswrong.com/posts/ktDKfKqukTPRiuEPM/robin-hanson-on-the-futurist-focus-on-ai). I started writing this as a comment there, but it got really long, so here we are! For convenience, [here is the link to interview trans... |
c0b6e24e-3966-4b29-95ee-0e81cdff4c34 | trentmkelly/LessWrong-43k | LessWrong | An Educational Curriculum
I'm a CS student graduating next year, my education has been pretty crap, due to personal problems, and my school curriculum being pretty bad (we never met the requisite depth in any of the courses we did, and skimmed over a lot). After graduation, I want to take a few years (I'm thinking 3 ... |
94ca7934-f746-4280-a180-6832191e3809 | trentmkelly/LessWrong-43k | LessWrong | Offering public comment in the Federal rulemaking process
This is a short linkdump of useful resources in the event you are planning to make a public comment on the AI standards. In the main these recommendations are intuitive: it helps to be an expert; identify exactly what document you are referring to; speak direct... |
673e8d27-1288-42cc-a02e-0e2902e8fbeb | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Infinite Possibility Space and the Shutdown Problem
This post is a response to the recent Astral Codex Ten post, “[CHAI, Assistance Games, And Fully-Updated Deference](https://astralcodexten.substack.com/p/chai-assistance-games-and-fully-updated)”.
A brief summary of the context, for any readers who are not subscribe... |
4da19db0-ef84-4939-a6a8-271193e02277 | trentmkelly/LessWrong-43k | LessWrong | Comments on Allan Dafoe on AI Governance
Financial status: This is independent research, now supported by a grant.
Epistemic status: Views here are almost entirely my own.
----------------------------------------
There are some think pieces that lay out a bunch of perspectives with which we might think about a thin... |
f5c98510-dc93-4fc9-b30e-1398e539cd66 | trentmkelly/LessWrong-43k | LessWrong | Open thread, Oct. 12 - Oct. 18, 2015
If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
----------------------------------------
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one. (Immediately... |
7a9b7b39-02f7-4040-ab3e-bbb7aa9d3350 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Beyond Simple Existential Risk: Survival in a Complex Interconnected World
**This is the script of a talk I gave at EAGx Rotterdam, with some citations and references linked throughout. I lay out the argument challenging the relatively narrow focus EA has in existential risk studies, and in favour of more methodologic... |
00d8d418-1a2b-437b-8a43-acf9c9ffa59f | trentmkelly/LessWrong-43k | LessWrong | Fun With The Tabula Muris (Senis)
A very cool project, sponsored by the Chan Zuckerberg Initiative, was the Tabula Muris and the Tabula Muris Senis — a single-cell gene expression “atlas” of the mouse, and then mice at various ages from 3 months (young adulthood) to 27 months (near the end of their lifespan.)
There’s... |
eb25e062-a8dc-409e-a388-a1a252697f0a | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Thoughts on "AI safety via debate"
Geoffrey Irving, Paul Christiano, and Dario Amodei of OpenAI have recently published "AI safety via debate" ([blog post](https://blog.openai.com/debate/), [paper](https://arxiv.org/abs/1805.00899)). As I read the paper I found myself wanting to give commentary on it, and LW seems lik... |
7ea7ccb6-acc6-46fe-9555-b94e4a7f73bd | trentmkelly/LessWrong-43k | LessWrong | Help Fund Lukeprog at SIAI
Singularity Institute desperately needs someone who is not me who can write cognitive-science-based material. Someone smart, energetic, able to speak to popular audiences, and with an excellent command of the science. If you’ve been reading Less Wrong for the last few months, you probably ju... |
3309e72f-a3d0-4db3-8750-82a18028a789 | trentmkelly/LessWrong-43k | LessWrong | Rationality is winning - or is it?
I feel a bit silly writing an post about connotations on a rationalist website, but I really love the quote "Rationality (is/is not) winning". I see a few different ways of interpreting it:
* "Rationality is winning" - results are more important than following a particular ritual o... |
3f4707ca-49cf-4fc6-90cb-827c6f5b1502 | trentmkelly/LessWrong-43k | LessWrong | Please vote for a title for an upcoming book
MIRI is conducting a survey to determine the best title for an upcoming book. Please consider voting on it to help us find out which title you would like best.
Click here to take survey |
f8e5f564-60ba-4b8c-a558-6bb9a84f9603 | trentmkelly/LessWrong-43k | LessWrong | A very crude deception eval is already passed
I was thinking about possible evals that would tell us when we're getting to models that are capable of deception. One not-very-good idea I had was just to measure zero-shot understanding of relevant deception scenarios in a language model. I don't think this tells us very... |
0c0f4106-dd06-4d87-bccd-6381084204cc | trentmkelly/LessWrong-43k | LessWrong | App-Based Disease Surveillance After COVID-19
With the smartphone apps for location and contact tracing being normalized for fighting coronavirus, it opens up space for using the same techniques to fight other diseases.
HIV, Syphilis, and drug resistant gonorrhea are obvious candidates because they do not have non-hu... |
1d1bf146-3062-4a64-ac00-7919fe46be70 | trentmkelly/LessWrong-43k | LessWrong | Timelines to Transformative AI: an investigation
Cross-posted on the EA Forum.
This post is part of a series by Convergence Analysis’ AI Clarity team.
Justin Bullock and Elliot Mckernon have recently motivated AI Clarity’s focus on the notion of transformative AI (TAI). In an earlier post, Corin Katzke introduced ... |
3c7b8a6d-921d-4a53-920a-752fde835bf4 | trentmkelly/LessWrong-43k | LessWrong | [Beta] Post-Read-Status on Lessestwrong
Over on Lessestwrong.com (our sometimes-staging-site), we're trying out an update to how post items display on the frontpage. Posts that you've read now appear slightly grey. The goal is to make it so you can tell when you've read a post at a glance, without making it feel like ... |
8723304a-c10f-41f6-87f0-93499bd677f1 | trentmkelly/LessWrong-43k | LessWrong | The next AI winter will be due to energy costs
Summary: We are 3 orders of magnitude from the Landauer limit (calculations per kWh). After that, progress in AI can not come from throwing more compute at known algorithms. Instead, new methods must be develloped. This may cause another AI winter, where the rate of progr... |
49c0ebf2-d483-4eff-8e24-e3e562e62661 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Berkeley: Dungeons & Discourse
Discussion article for the meetup : Berkeley: Dungeons & Discourse
WHEN: 06 March 2013 07:00:00PM (-0800)
WHERE: Berkeley, CA
This week's meetup is about Scott's philosophy RPG Dungeons and Discourse. Here is the comic strip that inspired Dungeons & Discourse:
http://dresden... |
3e5e453b-4d3d-4489-afe5-cdf41c328d81 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Did Bengio and Tegmark lose a debate about AI x-risk against LeCun and Mitchell?
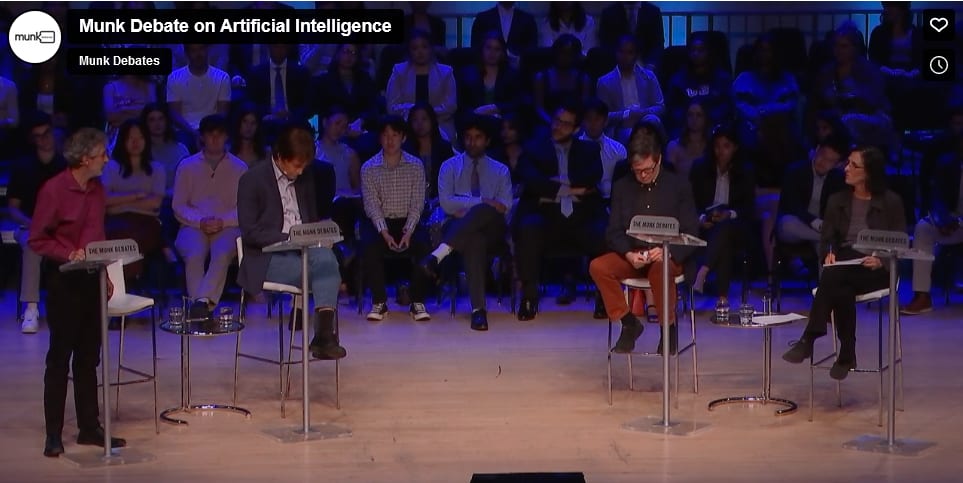On June 22nd, there was a “Munk Debate”, facilitated by the Canadian Aurea Foundation, on the question whethe... |
c5a7e762-d4e2-45ca-affb-a8c3260148b3 | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post2453
Realistic tales of doom must weave together many political, technical, and economic considerations into a single story. Such tales provide concrete projections but omit discussion of less probable paths to doom. To rectify this, here are some concrete, less realistic tales of doom; consider them fables, n... |
299638a3-5ed8-4c69-a91f-7a4ffa30cf22 | trentmkelly/LessWrong-43k | LessWrong | Where is human level on text prediction? (GPTs task)
I look at graphs like these (From the GPT-3 paper), and I wonder where human-level is:
Gwern seems to have the answer here:
> GPT-2-1.5b had a cross-entropy validation loss of ~3.3 (based on the perplexity of ~10 in Figure 4, and log2(10)=3.32). GPT-3 halved that... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.