
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
cc-by-4.0 | ['question generation'] | false | Overview - **Language model:** [t5-base](https://huggingface.co/t5-base) - **Language:** en - **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (grocery) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation) - **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992) | b12da68ad99fba82e0d40c3aa67e3e96 |
cc-by-4.0 | ['question generation'] | false | model prediction questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "research-backup/t5-base-subjqa-vanilla-grocery-qg") output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.") ``` | 5a088c55039229153ff84575340306d6 |
cc-by-4.0 | ['question generation'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/t5-base-subjqa-vanilla-grocery-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.grocery.json) | | Score | Type | Dataset | |:-----------|--------:|:--------|:-----------------------------------------------------------------| | BERTScore | 78.84 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_1 | 3.05 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_2 | 0.88 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_3 | 0 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_4 | 0 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | METEOR | 2.08 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | MoverScore | 51.78 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | ROUGE_L | 1.33 | grocery | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | d11e95811d58f8e2d744a1175599a4bc |
cc-by-4.0 | ['question generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_subjqa - dataset_name: grocery - input_types: ['paragraph_answer'] - output_types: ['question'] - prefix_types: ['qg'] - model: t5-base - max_length: 512 - max_length_output: 32 - epoch: 3 - batch: 16 - lr: 1e-05 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 8 - label_smoothing: 0.15 The full configuration can be found at [fine-tuning config file](https://huggingface.co/research-backup/t5-base-subjqa-vanilla-grocery-qg/raw/main/trainer_config.json). | edcdf40da565d529c9b1d402ec939b5c |
mit | ['generated_from_trainer'] | false | xlm-roberta-base-finetuned-panx-en This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset. It achieves the following results on the evaluation set: - Loss: 0.3848 - F1: 0.6994 | 24518c5f0103f6363ac5d57d1f7e291b |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | 1.0435 | 1.0 | 74 | 0.5169 | 0.5532 | | 0.4719 | 2.0 | 148 | 0.4224 | 0.6630 | | 0.3424 | 3.0 | 222 | 0.3848 | 0.6994 | | 1262cb93109680b573f601c427a39da0 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | <iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe> <br/><br/> | 9ca30a8d77ba04b2649353e0e98ee26a |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | Neural SI-SNR Estimator The Neural SI-SNR Estimator predicts the scale-invariant signal-to-noise ratio (SI-SNR) from the separated signals and the original mixture. The performance estimation is blind (i.e., no targets signals are needed). This model allows a performance estimation on real mixtures, where the targets are not available. This repository provides the SI-SNR estimator model introduced for the REAL-M dataset. The REAL-M dataset can downloaded from [this link](https://sourceseparationresearch.com/static/REAL-M-v0.1.0.tar.gz). The paper for the REAL-M dataset can be found on [this arxiv link](https://arxiv.org/pdf/2110.10812.pdf). | Release | Test-Set (WHAMR!) average l1 error | |:---:|:---:| | 18-10-21 | 1.7 dB | | 69c6be659ade63ef47cb49beea9f8301 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | Install SpeechBrain First of all, currently you need to install SpeechBrain from the source: 1. Clone SpeechBrain: ```bash git clone https://github.com/speechbrain/speechbrain/ ``` 2. Install it: ``` cd speechbrain pip install -r requirements.txt pip install -e . ``` Please notice that we encourage you to read our tutorials and learn more about [SpeechBrain](https://speechbrain.github.io). | 88fe9ef7ae16108dff2aaa0a8e541701 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | Minimal example for SI-SNR estimation ```python from speechbrain.pretrained import SepformerSeparation as separator from speechbrain.pretrained.interfaces import fetch from speechbrain.pretrained.interfaces import SNREstimator as snrest import torchaudio | 71cd382bfc0d7a4b73b7d4c930370079 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | 2- Separate the mixture with a pretrained model (sepformer-whamr in this case) model = separator.from_hparams(source="speechbrain/sepformer-whamr", savedir='pretrained_models/sepformer-whamr') est_sources = model.separate_file(path='test_mixture.wav') | 7517d4ea3181ca0c70822d205491de81 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | 3- Estimate the performance snr_est_model = snrest.from_hparams(source="speechbrain/REAL-M-sisnr-estimator",savedir='pretrained_models/REAL-M-sisnr-estimator') mix, fs = torchaudio.load('test_mixture.wav') snrhat = snr_est_model.estimate_batch(mix, est_sources) print(snrhat) | d3db0537405c717aaaf8db61e633056e |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | Training The model was trained with SpeechBrain (fc2eabb7). To train it from scratch follows these steps: 1. Clone SpeechBrain: ```bash git clone https://github.com/speechbrain/speechbrain/ ``` 2. Install it: ``` cd speechbrain pip install -r requirements.txt pip install -e . ``` 3. Run Training: ``` cd recipes/REAL-M/sisnr-estimation python train.py hparams/pool_sisnrestimator.yaml --data_folder /yourLibri2Mixpath --base_folder_dm /yourLibriSpeechpath --rir_path /yourpathforwhamrRIRs --dynamic_mixing True --use_whamr_train True --whamr_data_folder /yourpath/whamr --base_folder_dm_whamr /yourpath/wsj0-processed/si_tr_s ``` You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1NGncbjvLeGfbUqmVi6ej-NH9YQn5vBmI). | ca4c9f04f652444aac4cf4e50ac99d48 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | Referencing SpeechBrain ```bibtex @misc{speechbrain, title={{SpeechBrain}: A General-Purpose Speech Toolkit}, author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio}, year={2021}, eprint={2106.04624}, archivePrefix={arXiv}, primaryClass={eess.AS}, note={arXiv:2106.04624} } ``` | ea2ddc5a498fa0351716c0bfc6e46065 |
apache-2.0 | ['audio-source-separation', 'Source Separation', 'Speech Separation', 'WHAM!', 'REAL-M', 'SepFormer', 'Transformer', 'pytorch', 'speechbrain'] | false | Referencing REAL-M ```bibtex @misc{subakan2021realm, title={REAL-M: Towards Speech Separation on Real Mixtures}, author={Cem Subakan and Mirco Ravanelli and Samuele Cornell and François Grondin}, year={2021}, eprint={2110.10812}, archivePrefix={arXiv}, primaryClass={eess.AS} } ``` ``` | b8db6cdffba8de041192635731d581e4 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-xlsr-53-espeak-cv-ft-evn2-ntsema-colab This model is a fine-tuned version of [facebook/wav2vec2-xlsr-53-espeak-cv-ft](https://huggingface.co/facebook/wav2vec2-xlsr-53-espeak-cv-ft) on the audiofolder dataset. It achieves the following results on the evaluation set: - Loss: 2.0299 - Wer: 0.9867 | e9e753b45ad7f1cac16cbe340113296c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 4.2753 | 6.15 | 400 | 1.6106 | 0.99 | | 0.8472 | 12.3 | 800 | 1.6731 | 0.99 | | 0.4462 | 18.46 | 1200 | 1.8516 | 0.99 | | 0.2556 | 24.61 | 1600 | 2.0299 | 0.9867 | | b93c76b542cd1f5dba1eb35af780e718 |
mit | ['generated_from_keras_callback'] | false | Sultannn/bert-base-ft-pos-xtreme This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.1518 - Validation Loss: 0.2837 - Epoch: 3 | 05f9f99d34d77f305a5a5d8cd0951af3 |
mit | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 3e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 1008, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 500, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01} - training_precision: mixed_float16 | ba91154fd31b457f77d3bbe45683ba00 |
mit | ['generated_from_keras_callback'] | false | Training results | Train Loss | Validation Loss | Epoch | |:----------:|:---------------:|:-----:| | 0.9615 | 0.3139 | 0 | | 0.3181 | 0.2758 | 1 | | 0.2173 | 0.2774 | 2 | | 0.1518 | 0.2837 | 3 | | aaf955cb6ed2bc8a1d71e279099ec024 |
mit | [] | false | Maurice-Quentin- de-la-Tour-style on Stable Diffusion This is the `<maurice>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:     | 56f636a1f1272ddc9d051b44658052cd |
apache-2.0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'model_for_talk', 'mozilla-foundation/common_voice_8_0', 'mt', 'robust-speech-event'] | false | wav2vec2-large-xls-r-300m-maltese This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MT dataset. It achieves the following results on the evaluation set: - Loss: 0.2994 - Wer: 0.2781 | 52c0c6b9d07da39414d58e6c78174360 |
apache-2.0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'model_for_talk', 'mozilla-foundation/common_voice_8_0', 'mt', 'robust-speech-event'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 7e-05 - train_batch_size: 32 - eval_batch_size: 16 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1800 - num_epochs: 100.0 - mixed_precision_training: Native AMP | 16113f677d76671b7132eeb7bcc9d659 |
apache-2.0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'model_for_talk', 'mozilla-foundation/common_voice_8_0', 'mt', 'robust-speech-event'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 3.0174 | 9.01 | 1000 | 3.0552 | 1.0 | | 1.0446 | 18.02 | 2000 | 0.6708 | 0.7577 | | 0.7995 | 27.03 | 3000 | 0.4202 | 0.4770 | | 0.6978 | 36.04 | 4000 | 0.3054 | 0.3494 | | 0.6189 | 45.05 | 5000 | 0.2878 | 0.3154 | | 0.5667 | 54.05 | 6000 | 0.3114 | 0.3286 | | 0.5173 | 63.06 | 7000 | 0.3085 | 0.3021 | | 0.4682 | 72.07 | 8000 | 0.3058 | 0.2969 | | 0.451 | 81.08 | 9000 | 0.3146 | 0.2907 | | 0.4213 | 90.09 | 10000 | 0.3030 | 0.2881 | | 0.4005 | 99.1 | 11000 | 0.3001 | 0.2789 | | a784e0a6753b31314ed84ecdfb52edda |
apache-2.0 | ['generated_from_trainer'] | false | mt5-small-finetuned-amazon-en-es This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 3.0283 - Rouge1: 17.6736 - Rouge2: 8.5399 - Rougel: 17.4107 - Rougelsum: 17.3637 | f362e00a66900cf5efd20c097c4b45ed |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | |:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:| | 3.7032 | 1.0 | 1209 | 3.1958 | 16.1227 | 7.4852 | 15.2662 | 15.3552 | | 3.6502 | 2.0 | 2418 | 3.1103 | 17.2284 | 8.1626 | 16.757 | 16.6583 | | 3.4365 | 3.0 | 3627 | 3.0698 | 17.2326 | 8.7096 | 17.0961 | 16.9705 | | 3.312 | 4.0 | 4836 | 3.0324 | 16.9472 | 8.1386 | 16.6025 | 16.6126 | | 3.2343 | 5.0 | 6045 | 3.0385 | 17.8752 | 8.0578 | 17.4985 | 17.5298 | | 3.1661 | 6.0 | 7254 | 3.0334 | 17.8822 | 8.5243 | 17.5825 | 17.5242 | | 3.1305 | 7.0 | 8463 | 3.0289 | 17.8187 | 8.124 | 17.4815 | 17.4688 | | 3.1039 | 8.0 | 9672 | 3.0283 | 17.6736 | 8.5399 | 17.4107 | 17.3637 | | 3264c33457c30b617e29d1c3430c9acf |
apache-2.0 | ['generated_from_trainer'] | false | M6_MLM_cross This model is a fine-tuned version of [S2312dal/M6_MLM](https://huggingface.co/S2312dal/M6_MLM) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.0197 - Pearson: 0.9680 - Spearmanr: 0.9098 | 61224bb6d1a65ad9df6500ad27b43470 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 16 - eval_batch_size: 16 - seed: 25 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 8.0 - num_epochs: 3 - mixed_precision_training: Native AMP | 347e00c5d244ac60a6a4532174c81022 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | |:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:| | 0.0723 | 1.0 | 131 | 0.0646 | 0.8674 | 0.8449 | | 0.0433 | 2.0 | 262 | 0.0322 | 0.9475 | 0.9020 | | 0.0015 | 3.0 | 393 | 0.0197 | 0.9680 | 0.9098 | | 73bb67106b5ceedbe91ff54e3affd6b5 |
creativeml-openrail-m | [] | false | Shinobu Kochou (Demon Slayer) [Download .safetensors](https://huggingface.co/Apel/LoRa/tree/main/Characters/Demon%20Slayer%3A%20Kimetsu%20no%20Yaiba/Shinobu%20Kochou) Relevant full-character prompt: ``` masterpiece, best quality, ultra-detailed, illustration, 1girl, solo, kochou shinobu, multicolored hair, no bangs, hair intakes, purple eyes, forehead, wisteria, black shirt, black pants, haori, butterfly, standing waist-deep in the crystal clear water of a tranquil pond, peaceful expression, surrounded by lush green foliage and wildflowers, falling petals, falling leaves, large breasts, cowboy shot, buttons, belt, light smile, ```  | 6d5172d7881dc213f5e700471c56dfe4 |
mit | ['generated_from_trainer'] | false | amazing_shannon This model was trained from scratch on the tomekkorbak/detoxify-pile-chunk3-0-50000, the tomekkorbak/detoxify-pile-chunk3-50000-100000, the tomekkorbak/detoxify-pile-chunk3-100000-150000, the tomekkorbak/detoxify-pile-chunk3-150000-200000, the tomekkorbak/detoxify-pile-chunk3-200000-250000, the tomekkorbak/detoxify-pile-chunk3-250000-300000, the tomekkorbak/detoxify-pile-chunk3-300000-350000, the tomekkorbak/detoxify-pile-chunk3-350000-400000, the tomekkorbak/detoxify-pile-chunk3-400000-450000, the tomekkorbak/detoxify-pile-chunk3-450000-500000, the tomekkorbak/detoxify-pile-chunk3-500000-550000, the tomekkorbak/detoxify-pile-chunk3-550000-600000, the tomekkorbak/detoxify-pile-chunk3-600000-650000, the tomekkorbak/detoxify-pile-chunk3-650000-700000, the tomekkorbak/detoxify-pile-chunk3-700000-750000, the tomekkorbak/detoxify-pile-chunk3-750000-800000, the tomekkorbak/detoxify-pile-chunk3-800000-850000, the tomekkorbak/detoxify-pile-chunk3-850000-900000, the tomekkorbak/detoxify-pile-chunk3-900000-950000, the tomekkorbak/detoxify-pile-chunk3-950000-1000000, the tomekkorbak/detoxify-pile-chunk3-1000000-1050000, the tomekkorbak/detoxify-pile-chunk3-1050000-1100000, the tomekkorbak/detoxify-pile-chunk3-1100000-1150000, the tomekkorbak/detoxify-pile-chunk3-1150000-1200000, the tomekkorbak/detoxify-pile-chunk3-1200000-1250000, the tomekkorbak/detoxify-pile-chunk3-1250000-1300000, the tomekkorbak/detoxify-pile-chunk3-1300000-1350000, the tomekkorbak/detoxify-pile-chunk3-1350000-1400000, the tomekkorbak/detoxify-pile-chunk3-1400000-1450000, the tomekkorbak/detoxify-pile-chunk3-1450000-1500000, the tomekkorbak/detoxify-pile-chunk3-1500000-1550000, the tomekkorbak/detoxify-pile-chunk3-1550000-1600000, the tomekkorbak/detoxify-pile-chunk3-1600000-1650000, the tomekkorbak/detoxify-pile-chunk3-1650000-1700000, the tomekkorbak/detoxify-pile-chunk3-1700000-1750000, the tomekkorbak/detoxify-pile-chunk3-1750000-1800000, the tomekkorbak/detoxify-pile-chunk3-1800000-1850000, the tomekkorbak/detoxify-pile-chunk3-1850000-1900000 and the tomekkorbak/detoxify-pile-chunk3-1900000-1950000 datasets. | 5532be2656f4be376ab3c67f908f37a5 |
mit | ['generated_from_trainer'] | false | Full config {'dataset': {'datasets': ['tomekkorbak/detoxify-pile-chunk3-0-50000', 'tomekkorbak/detoxify-pile-chunk3-50000-100000', 'tomekkorbak/detoxify-pile-chunk3-100000-150000', 'tomekkorbak/detoxify-pile-chunk3-150000-200000', 'tomekkorbak/detoxify-pile-chunk3-200000-250000', 'tomekkorbak/detoxify-pile-chunk3-250000-300000', 'tomekkorbak/detoxify-pile-chunk3-300000-350000', 'tomekkorbak/detoxify-pile-chunk3-350000-400000', 'tomekkorbak/detoxify-pile-chunk3-400000-450000', 'tomekkorbak/detoxify-pile-chunk3-450000-500000', 'tomekkorbak/detoxify-pile-chunk3-500000-550000', 'tomekkorbak/detoxify-pile-chunk3-550000-600000', 'tomekkorbak/detoxify-pile-chunk3-600000-650000', 'tomekkorbak/detoxify-pile-chunk3-650000-700000', 'tomekkorbak/detoxify-pile-chunk3-700000-750000', 'tomekkorbak/detoxify-pile-chunk3-750000-800000', 'tomekkorbak/detoxify-pile-chunk3-800000-850000', 'tomekkorbak/detoxify-pile-chunk3-850000-900000', 'tomekkorbak/detoxify-pile-chunk3-900000-950000', 'tomekkorbak/detoxify-pile-chunk3-950000-1000000', 'tomekkorbak/detoxify-pile-chunk3-1000000-1050000', 'tomekkorbak/detoxify-pile-chunk3-1050000-1100000', 'tomekkorbak/detoxify-pile-chunk3-1100000-1150000', 'tomekkorbak/detoxify-pile-chunk3-1150000-1200000', 'tomekkorbak/detoxify-pile-chunk3-1200000-1250000', 'tomekkorbak/detoxify-pile-chunk3-1250000-1300000', 'tomekkorbak/detoxify-pile-chunk3-1300000-1350000', 'tomekkorbak/detoxify-pile-chunk3-1350000-1400000', 'tomekkorbak/detoxify-pile-chunk3-1400000-1450000', 'tomekkorbak/detoxify-pile-chunk3-1450000-1500000', 'tomekkorbak/detoxify-pile-chunk3-1500000-1550000', 'tomekkorbak/detoxify-pile-chunk3-1550000-1600000', 'tomekkorbak/detoxify-pile-chunk3-1600000-1650000', 'tomekkorbak/detoxify-pile-chunk3-1650000-1700000', 'tomekkorbak/detoxify-pile-chunk3-1700000-1750000', 'tomekkorbak/detoxify-pile-chunk3-1750000-1800000', 'tomekkorbak/detoxify-pile-chunk3-1800000-1850000', 'tomekkorbak/detoxify-pile-chunk3-1850000-1900000', 'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'], 'filter_threshold': 0.00078, 'is_split_by_sentences': True}, 'generation': {'force_call_on': [25354], 'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}], 'scenario_configs': [{'generate_kwargs': {'do_sample': True, 'max_length': 128, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'unconditional', 'num_samples': 2048}, {'generate_kwargs': {'do_sample': True, 'max_length': 128, 'min_length': 10, 'temperature': 0.7, 'top_k': 0, 'top_p': 0.9}, 'name': 'challenging_rtp', 'num_samples': 2048, 'prompts_path': 'resources/challenging_rtp.jsonl'}], 'scorer_config': {'device': 'cuda:0'}}, 'kl_gpt3_callback': {'force_call_on': [25354], 'max_tokens': 64, 'num_samples': 4096}, 'model': {'from_scratch': True, 'gpt2_config_kwargs': {'reorder_and_upcast_attn': True, 'scale_attn_by': True}, 'path_or_name': 'gpt2'}, 'objective': {'name': 'MLE'}, 'tokenizer': {'path_or_name': 'gpt2'}, 'training': {'dataloader_num_workers': 0, 'effective_batch_size': 64, 'evaluation_strategy': 'no', 'fp16': True, 'hub_model_id': 'amazing_shannon', 'hub_strategy': 'all_checkpoints', 'learning_rate': 0.0005, 'logging_first_step': True, 'logging_steps': 1, 'num_tokens': 3300000000, 'output_dir': 'training_output104340', 'per_device_train_batch_size': 16, 'push_to_hub': True, 'remove_unused_columns': False, 'save_steps': 25354, 'save_strategy': 'steps', 'seed': 42, 'warmup_ratio': 0.01, 'weight_decay': 0.1}} | 5e3fd9187e062b66623fc39931a56d57 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 4 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 8 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 100 | 78d2af376a1611638767486121b6e6b9 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-demo-M02-2 This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset. It achieves the following results on the evaluation set: - Loss: 2.2709 - Wer: 1.0860 | b48d7fd76956e4c3478b5ae1affeb0f9 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 23.4917 | 0.91 | 500 | 3.2945 | 1.0 | | 3.4102 | 1.81 | 1000 | 3.1814 | 1.0 | | 2.9438 | 2.72 | 1500 | 2.7858 | 1.0 | | 2.6698 | 3.62 | 2000 | 2.4745 | 1.0035 | | 1.9542 | 4.53 | 2500 | 1.8675 | 1.3745 | | 1.2737 | 5.43 | 3000 | 1.6459 | 1.3703 | | 0.9748 | 6.34 | 3500 | 1.8406 | 1.3037 | | 0.7696 | 7.25 | 4000 | 1.5086 | 1.2476 | | 0.6396 | 8.15 | 4500 | 1.8280 | 1.2476 | | 0.558 | 9.06 | 5000 | 1.7680 | 1.2247 | | 0.4865 | 9.96 | 5500 | 1.8210 | 1.2309 | | 0.4244 | 10.87 | 6000 | 1.7910 | 1.1775 | | 0.3898 | 11.78 | 6500 | 1.8021 | 1.1831 | | 0.3456 | 12.68 | 7000 | 1.7746 | 1.1456 | | 0.3349 | 13.59 | 7500 | 1.8969 | 1.1519 | | 0.3233 | 14.49 | 8000 | 1.7402 | 1.1234 | | 0.3046 | 15.4 | 8500 | 1.8585 | 1.1429 | | 0.2622 | 16.3 | 9000 | 1.6687 | 1.0950 | | 0.2593 | 17.21 | 9500 | 1.8192 | 1.1144 | | 0.2541 | 18.12 | 10000 | 1.8665 | 1.1110 | | 0.2098 | 19.02 | 10500 | 1.9996 | 1.1186 | | 0.2192 | 19.93 | 11000 | 2.0346 | 1.1040 | | 0.1934 | 20.83 | 11500 | 2.1924 | 1.1012 | | 0.2034 | 21.74 | 12000 | 1.8060 | 1.0929 | | 0.1857 | 22.64 | 12500 | 2.0334 | 1.0798 | | 0.1819 | 23.55 | 13000 | 2.1223 | 1.1040 | | 0.1621 | 24.46 | 13500 | 2.1795 | 1.0957 | | 0.1548 | 25.36 | 14000 | 2.1545 | 1.1089 | | 0.1512 | 26.27 | 14500 | 2.2707 | 1.1186 | | 0.1472 | 27.17 | 15000 | 2.1698 | 1.0888 | | 0.1296 | 28.08 | 15500 | 2.2496 | 1.0867 | | 0.1312 | 28.99 | 16000 | 2.2969 | 1.0881 | | 0.1331 | 29.89 | 16500 | 2.2709 | 1.0860 | | a4c7df405e8df7fcc9797631b5441c6a |
mit | ['keyphrase-generation'] | false | 🔑 Keyphrase Generation Model: KeyBART-inspec Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳. Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text. | 08de9f09c1321869e59d24d627a38e98 |
mit | ['keyphrase-generation'] | false | 📓 Model Description This model uses [KeyBART](https://huggingface.co/bloomberg/KeyBART) as its base model and fine-tunes it on the [Inspec dataset](https://huggingface.co/datasets/midas/inspec). KeyBART focuses on learning a better representation of keyphrases in a generative setting. It produces the keyphrases associated with the input document from a corrupted input. The input is changed by token masking, keyphrase masking and keyphrase replacement. This model can already be used without any fine-tuning, but can be fine-tuned if needed. You can find more information about the architecture in this [paper](https://arxiv.org/abs/2112.08547). Kulkarni, Mayank, Debanjan Mahata, Ravneet Arora, and Rajarshi Bhowmik. "Learning Rich Representation of Keyphrases from Text." arXiv preprint arXiv:2112.08547 (2021). | 55b364e16f67fae2e01b13a21a710673 |
mit | ['keyphrase-generation'] | false | 🛑 Limitations * This keyphrase generation model is very domain-specific and will perform very well on abstracts of scientific papers. It's not recommended to use this model for other domains, but you are free to test it out. * Only works for English documents. | 1c1166497b451b88fb83996a2ea5f16b |
mit | ['keyphrase-generation'] | false | Model parameters from transformers import ( Text2TextGenerationPipeline, AutoModelForSeq2SeqLM, AutoTokenizer, ) class KeyphraseGenerationPipeline(Text2TextGenerationPipeline): def __init__(self, model, keyphrase_sep_token=";", *args, **kwargs): super().__init__( model=AutoModelForSeq2SeqLM.from_pretrained(model), tokenizer=AutoTokenizer.from_pretrained(model), *args, **kwargs ) self.keyphrase_sep_token = keyphrase_sep_token def postprocess(self, model_outputs): results = super().postprocess( model_outputs=model_outputs ) return [[keyphrase.strip() for keyphrase in result.get("generated_text").split(self.keyphrase_sep_token) if keyphrase != ""] for result in results] ``` ```python | 42ade8cea6f103c4c6f2ebdb53675e45 |
mit | ['keyphrase-generation'] | false | Inference text = """ Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time. Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text. """.replace("\n", " ") keyphrases = generator(text) print(keyphrases) ``` ``` | a11f602e312c174e56f4ae852f4faa79 |
mit | ['keyphrase-generation'] | false | 📚 Training Dataset [Inspec](https://huggingface.co/datasets/midas/inspec) is a keyphrase extraction/generation dataset consisting of 2000 English scientific papers from the scientific domains of Computers and Control and Information Technology published between 1998 to 2002. The keyphrases are annotated by professional indexers or editors. You can find more information in the [paper](https://dl.acm.org/doi/10.3115/1119355.1119383). | 606b66aa93b872c4fb5f830494f9e7a2 |
mit | ['keyphrase-generation'] | false | Preprocessing The documents in the dataset are already preprocessed into list of words with the corresponding keyphrases. The only thing that must be done is tokenization and joining all keyphrases into one string with a certain seperator of choice( ```;``` ). ```python from datasets import load_dataset from transformers import AutoTokenizer | ad678c72e44f16fe6fa78f54e248e136 |
mit | ['keyphrase-generation'] | false | Dataset parameters dataset_full_name = "midas/inspec" dataset_subset = "raw" dataset_document_column = "document" keyphrase_sep_token = ";" def preprocess_keyphrases(text_ids, kp_list): kp_order_list = [] kp_set = set(kp_list) text = tokenizer.decode( text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True ) text = text.lower() for kp in kp_set: kp = kp.strip() kp_index = text.find(kp.lower()) kp_order_list.append((kp_index, kp)) kp_order_list.sort() present_kp, absent_kp = [], [] for kp_index, kp in kp_order_list: if kp_index < 0: absent_kp.append(kp) else: present_kp.append(kp) return present_kp, absent_kp def preprocess_fuction(samples): processed_samples = {"input_ids": [], "attention_mask": [], "labels": []} for i, sample in enumerate(samples[dataset_document_column]): input_text = " ".join(sample) inputs = tokenizer( input_text, padding="max_length", truncation=True, ) present_kp, absent_kp = preprocess_keyphrases( text_ids=inputs["input_ids"], kp_list=samples["extractive_keyphrases"][i] + samples["abstractive_keyphrases"][i], ) keyphrases = present_kp keyphrases += absent_kp target_text = f" {keyphrase_sep_token} ".join(keyphrases) with tokenizer.as_target_tokenizer(): targets = tokenizer( target_text, max_length=40, padding="max_length", truncation=True ) targets["input_ids"] = [ (t if t != tokenizer.pad_token_id else -100) for t in targets["input_ids"] ] for key in inputs.keys(): processed_samples[key].append(inputs[key]) processed_samples["labels"].append(targets["input_ids"]) return processed_samples | 8a9c1e952ef5707b8fb7bd72b1b5d39d |
mit | ['keyphrase-generation'] | false | Postprocessing For the post-processing, you will need to split the string based on the keyphrase separator. ```python def extract_keyphrases(examples): return [example.split(keyphrase_sep_token) for example in examples] ``` | 9325ac1e73f2fafd6b9f509b9bb385d5 |
mit | ['keyphrase-generation'] | false | 📝 Evaluation results Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases. In keyphrase generation you also look at F1@O where O stands for the number of ground truth keyphrases. The model achieves the following results on the Inspec test set: | a7217baf2e217dd478ee84600ce3122e |
mit | ['keyphrase-generation'] | false | Extractive Keyphrases | Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O | |:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:| | Inspec Test Set | 0.40 | 0.37 | 0.35 | 0.20 | 0.37 | 0.24 | 0.42 | 0.37 | 0.36 | 0.33 | 0.33 | 0.33 | | 62b1d5eedd824ae648690ad4a8a36c37 |
mit | ['keyphrase-generation'] | false | Abstractive Keyphrases | Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O | |:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:| | Inspec Test Set | 0.07 | 0.12 | 0.08 | 0.03 | 0.12 | 0.05 | 0.08 | 0.12 | 0.08 | 0.08 | 0.12 | 0.08 | | f14624769913a0d0b5c66b14cbd6f070 |
creativeml-openrail-m | [] | false | --- license: creativeml-openrail-m --- This is a low-quality bocchi-the-rock (ぼっち・ざ・ろっく!) character model. Similar to my [yama-no-susume model](https://huggingface.co/alea31415/yama-no-susume), this model is capable of generating **multi-character scenes** beyond images of a single character. Of course, the result is still hit-or-miss, but I with some chance you can get the entire Kessoku Band right in one shot, and otherwise, you can always rely on inpainting. Here are two examples: With inpainting  Without inpainting  | 28ce893d788cba22505f42c41bca4fbd |
creativeml-openrail-m | [] | false | Characters The model knows 12 characters from bocchi the rock. The ressemblance with a character can be improved by a better description of their appearance (for example by adding long wavy hair to ShimizuEliza).   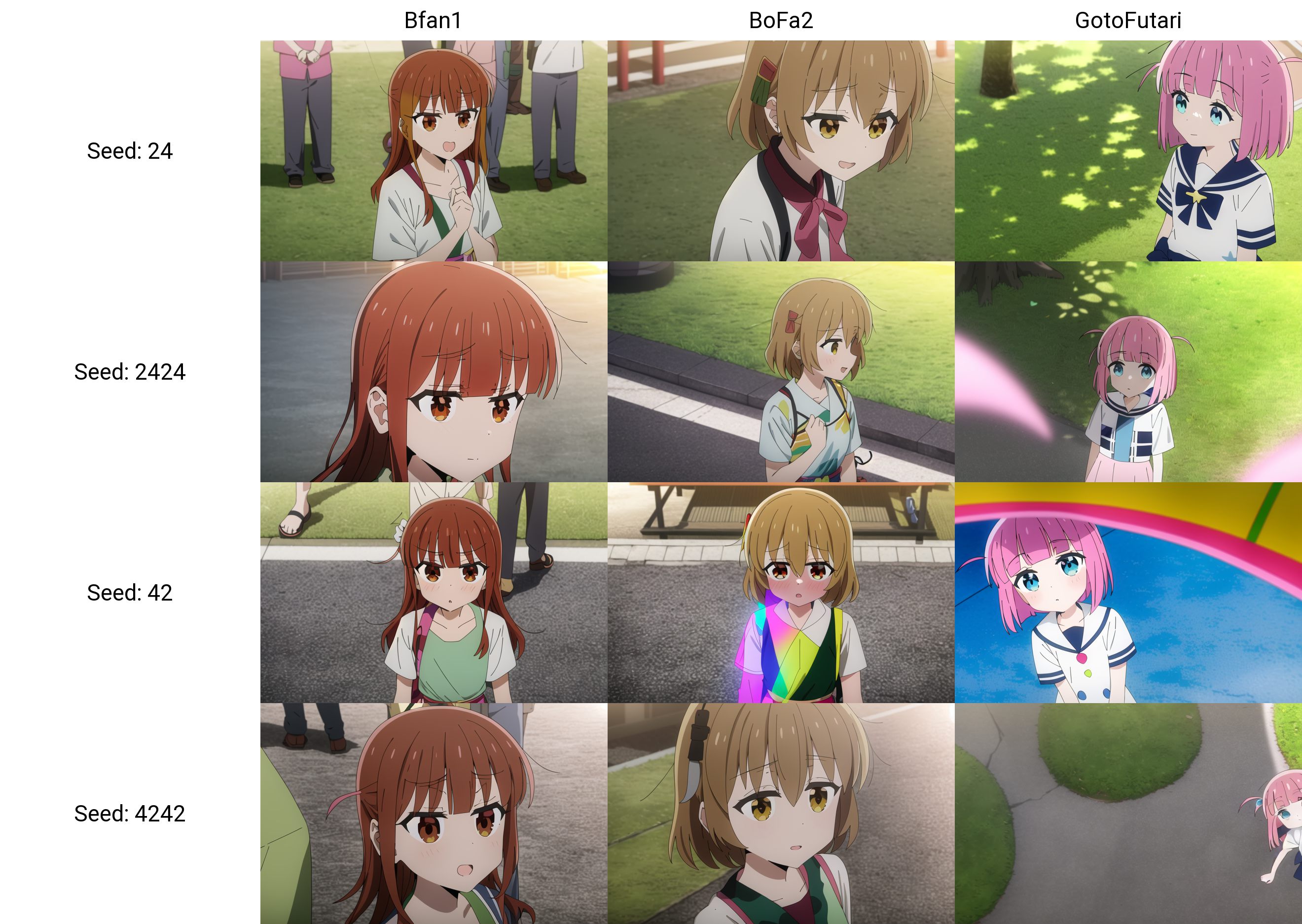 | 29d071fe9bdab91b85abc14918c7483e |
creativeml-openrail-m | [] | false | Dataset description The dataset contains around 27K images with the following composition - 7024 anime screenshots - 1630 fan arts - 18519 customized regularization images The model is trained with a specific weighting scheme to balance between different concepts. For example, the above three categories have weights respectively 0.3, 0.25, and 0.45. Each category is itself split into many sub-categories in a hierarchical way. For more details on the data preparation process please refer to https://github.com/cyber-meow/anime_screenshot_pipeline | 929378ed4898bc8ab6f755f370ffff7c |
creativeml-openrail-m | [] | false | Trainer The model is trained using [EveryDream1](https://github.com/victorchall/EveryDream-trainer) as EveryDream seems to be the only trainer out there that supports sample weighting (through the use of `multiply.txt`). Note that for future training it makes sense to migrate to [EveryDream2](https://github.com/victorchall/EveryDream2trainer). | 82236f9ad5c9385179a2e08614ad3fae |
creativeml-openrail-m | [] | false | Hyperparameter specification The model is trained for 50000 steps, at batch size 4, lr 1e-6, resolution 512, and conditional dropping rate of 10%. Note that as a consequence of the weighting scheme which translates into a number of different multiply for each image, the count of repeat and epoch has a quite different meaning here. For example, depending on the weighting, I have around 300K images (some images are used multiple times) in an epoch, and therefore I did not even finish an entire epoch with the 50000 steps at batch size 4. | 2656391690f2b3744a3c0c30e448e715 |
creativeml-openrail-m | [] | false | Failures - For the first 24000 steps I use the trigger words `Bfan1` and `Bfan2` for the two fans of Bocchi. However, these two words are too similar and the model fails to different characters for these. Therefore I changed Bfan2 to Bofa2 at step 24000. This seemed to solve the problem. - Character blending is always an issue. - When prompting the four characters of Kessoku Band we often get side shots. I think this is because of some overfitting to a particular image. | 1363c977b893137363d97012171d6a29 |
creativeml-openrail-m | [] | false | More Example Generations With inpainting    Without inpainting         Some failure cases     | 41aa0d3eb7323be01c2878ce9c685924 |
mit | ['audio', 'automatic-speech-recognition', 'endpoints-template'] | false | OpenAI [Whisper](https://github.com/openai/whisper) Inference Endpoint example > Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification. For more information about the model, license and limitations check the original repository at [openai/whisper](https://github.com/openai/whisper). --- This repository implements a custom `handler` task for `automatic-speech-recognition` for 🤗 Inference Endpoints using OpenAIs new Whisper model. The code for the customized pipeline is in the [pipeline.py](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/handler.py). There is also a [notebook](https://huggingface.co/philschmid/openai-whisper-endpoint/blob/main/create_handler.ipynb) included, on how to create the `handler.py` | a5e33dbefdf178d424f314540340479c |
mit | ['audio', 'automatic-speech-recognition', 'endpoints-template'] | false | run request curl --request POST \ --url https://{ENDPOINT}/ \ --header 'Content-Type: audio/x-flac' \ --header 'Authorization: Bearer {HF_TOKEN}' \ --data-binary '@sample1.flac' ``` **Python** ```python import json from typing import List import requests as r import base64 import mimetypes ENDPOINT_URL="" HF_TOKEN="" def predict(path_to_audio:str=None): | e3c6a9c3902183f6c2891b92ca40ca86 |
mit | ['audio', 'automatic-speech-recognition', 'endpoints-template'] | false | get mimetype content_type= mimetypes.guess_type(path_to_audio)[0] headers= { "Authorization": f"Bearer {HF_TOKEN}", "Content-Type": content_type } response = r.post(ENDPOINT_URL, headers=headers, data=b) return response.json() prediction = predict(path_to_audio="sample1.flac") prediction ``` expected output ```json {"text": " going along slushy country roads and speaking to damp audiences in draughty school rooms day after day for a fortnight. He'll have to put in an appearance at some place of worship on Sunday morning, and he can come to us immediately afterwards."} ``` | 2f25a81efb44b99f8cc0f0b874dd7462 |
apache-2.0 | ['image-classification', 'vision', 'generated_from_trainer'] | false | vit-base-beans This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset. It achieves the following results on the evaluation set: - Loss: 0.0866 - Accuracy: 0.9850 | 71341e66cd072b7af7363804ce957503 |
apache-2.0 | ['image-classification', 'vision', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.2501 | 1.0 | 130 | 0.2281 | 0.9624 | | 0.2895 | 2.0 | 260 | 0.1138 | 0.9925 | | 0.1549 | 3.0 | 390 | 0.1065 | 0.9774 | | 0.0952 | 4.0 | 520 | 0.0866 | 0.9850 | | 0.1511 | 5.0 | 650 | 0.0875 | 0.9774 | | ff17cdefa5d7a1bbc29007ea091b0693 |
mit | [] | false | durer style on Stable Diffusion This is the `<drr-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:    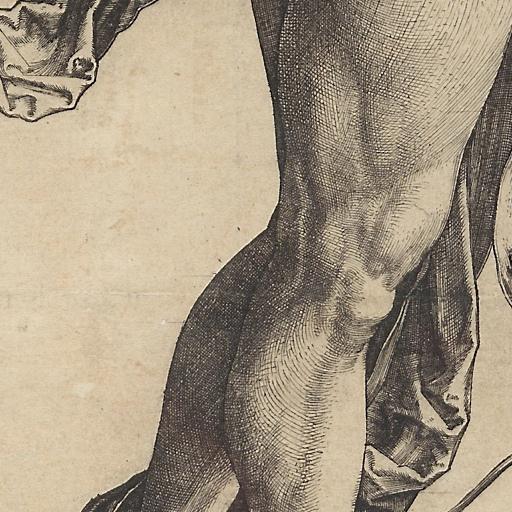  | 67bff1c47e60ab3078a00b7543b0e047 |
apache-2.0 | ['generated_from_trainer'] | false | distilbart-cnn-12-6-finetuned-1.3.0 This model is a fine-tuned version of [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.7396 - Rouge1: 50.4996 - Rouge2: 23.7554 - Rougel: 35.3613 - Rougelsum: 45.8275 | 37c21dbbe22f9840c29f0c99c6698486 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 4 - eval_batch_size: 4 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 2 | 29f056c0c76348bbffa1ab4b89fa0319 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:| | 2.0871 | 1.0 | 982 | 1.8224 | 49.5261 | 23.1091 | 34.3266 | 44.7491 | | 1.5334 | 2.0 | 1964 | 1.7396 | 50.4996 | 23.7554 | 35.3613 | 45.8275 | | 03bced2659e8eeb7c406309eaf9128b6 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-cola This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset. It achieves the following results on the evaluation set: - Loss: 0.7663 - Matthews Correlation: 0.5396 | 10f30c5711bdb9896a4e2ecd2409f668 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | |:-------------:|:-----:|:----:|:---------------:|:--------------------:| | 0.5281 | 1.0 | 535 | 0.5268 | 0.4071 | | 0.3503 | 2.0 | 1070 | 0.5074 | 0.5126 | | 0.2399 | 3.0 | 1605 | 0.6440 | 0.4977 | | 0.1807 | 4.0 | 2140 | 0.7663 | 0.5396 | | 0.1299 | 5.0 | 2675 | 0.8786 | 0.5192 | | 7c63f616008f74d2908cc8d77ac0afe1 |
apache-2.0 | ['vision', 'image-classification'] | false | Big Transfer (BiT) The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby. BiT is a simple recipe for scaling up pre-training of [ResNet](resnet)-like architectures (specifically, ResNetv2). The method results in significant improvements for transfer learning. Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team. | 28920049db71a18c09ce5a40105d489d |
apache-2.0 | ['vision', 'image-classification'] | false | Model description The abstract from the paper is the following: *Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.* | f54cc89eb50b471584acc4d01843387e |
apache-2.0 | ['vision', 'image-classification'] | false | Intended uses & limitations You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=bit) to look for fine-tuned versions on a task that interests you. | 3d97185831171c30cfdbcb023f669743 |
apache-2.0 | ['vision', 'image-classification'] | false | How to use Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes: ```python from transformers import BitImageProcessor, BitForImageClassification import torch from datasets import load_dataset dataset = load_dataset("huggingface/cats-image") image = dataset["test"]["image"][0] feature_extractor = BitImageProcessor.from_pretrained("google/bit-50") model = BitForImageClassification.from_pretrained("google/bit-50") inputs = feature_extractor(image, return_tensors="pt") with torch.no_grad(): logits = model(**inputs).logits | a781d2b31a78d3ef127e2fc9fbdd28e6 |
apache-2.0 | ['vision', 'image-classification'] | false | model predicts one of the 1000 ImageNet classes predicted_label = logits.argmax(-1).item() print(model.config.id2label[predicted_label >>> tabby, tabby cat ``` For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/bit). | f6a2506c857e3a9e24e18cf1abf1f15f |
apache-2.0 | ['vision', 'image-classification'] | false | BibTeX entry and citation info ```bibtex @misc{https://doi.org/10.48550/arxiv.1912.11370, doi = {10.48550/ARXIV.1912.11370}, url = {https://arxiv.org/abs/1912.11370}, author = {Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Puigcerver, Joan and Yung, Jessica and Gelly, Sylvain and Houlsby, Neil}, keywords = {Computer Vision and Pattern Recognition (cs.CV), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Big Transfer (BiT): General Visual Representation Learning}, publisher = {arXiv}, year = {2019}, copyright = {arXiv.org perpetual, non-exclusive license} } ``` | 10ccbad68b6f5ba76669d1b4331130d0 |
mit | ['text-generation', 'novel-generation', 'fiction', 'gpt-neo-x', 'pytorch'] | false | Usage ``` from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast model_name = 'FrostAura/gpt-neox-20b-fiction-novel-generation' model = GPTNeoXForCausalLM.from_pretrained(model_name) tokenizer = GPTNeoXTokenizerFast.from_pretrained(model_name) prompt = 'GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI.' input_ids = tokenizer(prompt, return_tensors="pt").input_ids gen_tokens = model.generate( input_ids, do_sample=True, temperature=0.9, max_length=100, ) gen_text = tokenizer.batch_decode(gen_tokens)[0] print(f'Result: {gen_text}') ``` | aba573f0b856a2bd1a6e963d97825c51 |
mit | ['text-generation', 'novel-generation', 'fiction', 'gpt-neo-x', 'pytorch'] | false | Support If you enjoy FrostAura open-source content and would like to support us in continuous delivery, please consider a donation via a platform of your choice. | Supported Platforms | Link | | ------------------- | ---- | | PayPal | [Donate via Paypal](https://www.paypal.com/donate/?hosted_button_id=SVEXJC9HFBJ72) | For any queries, contact dean.martin@frostaura.net. | b1aa6ef16cde2a87d2d06e12e5b9f6e4 |
apache-2.0 | ['automatic-speech-recognition', 'ja'] | false | exp_w2v2t_ja_xlsr-53_s781 Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 3bb02eb1ac0a14e1ae2681ef46318ab8 |
cc0-1.0 | [] | false | You want more than a digital style - you want to feel brush strokes and see the built-up paint of an oil painting. You love physical objects and want your AI-generated art to fool you that you're looking at a photograph of something analog, hanging on a wall somewhere. This is the embedding for you. Download the the 'classipeint.pt' file and trigger it in your prompt "art by classipeint" or "painted by classipeint" or simply "by classipeint" <strong>Interested in generating your own embeddings? <a href="https://docs.google.com/document/d/1JvlM0phnok4pghVBAMsMq_-Z18_ip_GXvHYE0mITdFE/edit?usp=sharing" target="_blank">My Google doc walkthrough might help</a></strong> It is reasonably flexible - I find I can prompt for fantasy elements, classic scenes, modern architecture ... it does sometimes take a little finessing but except for bad anatomy, I am using surprisingly few negative prompts. You can rename the file and use that filename as the prompt. Just be sure your filename is unique and not something that may be an existing token that Stable Diffusion is trained on.         | 37036a048d161626dae863742759eb4e |
apache-2.0 | ['generated_from_trainer'] | false | my_awesome_billsum_model This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset. It achieves the following results on the evaluation set: - Loss: 2.4612 - Rouge1: 0.1424 - Rouge2: 0.0506 - Rougel: 0.1186 - Rougelsum: 0.1185 - Gen Len: 19.0 | 4a731c66ca5d043bfa9a09f4b8bb337e |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:| | No log | 1.0 | 62 | 2.7438 | 0.1291 | 0.0351 | 0.1081 | 0.1083 | 19.0 | | No log | 2.0 | 124 | 2.5394 | 0.1366 | 0.0457 | 0.1129 | 0.1128 | 19.0 | | No log | 3.0 | 186 | 2.4761 | 0.1405 | 0.0482 | 0.1166 | 0.1166 | 19.0 | | No log | 4.0 | 248 | 2.4612 | 0.1424 | 0.0506 | 0.1186 | 0.1185 | 19.0 | | 48fbcf9d8c98fdcfff81af3faa82b4bb |
apache-2.0 | ['translation'] | false | lit-spa * source group: Lithuanian * target group: Spanish * OPUS readme: [lit-spa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/lit-spa/README.md) * model: transformer-align * source language(s): lit * target language(s): spa * model: transformer-align * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.zip) * test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.test.txt) * test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.eval.txt) | 3c655a0190074e60990a2b251807db23 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: lit-spa - source_languages: lit - target_languages: spa - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/lit-spa/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['lt', 'es'] - src_constituents: {'lit'} - tgt_constituents: {'spa'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/lit-spa/opus-2020-06-17.test.txt - src_alpha3: lit - tgt_alpha3: spa - short_pair: lt-es - chrF2_score: 0.68 - bleu: 50.5 - brevity_penalty: 0.963 - ref_len: 2738.0 - src_name: Lithuanian - tgt_name: Spanish - train_date: 2020-06-17 - src_alpha2: lt - tgt_alpha2: es - prefer_old: False - long_pair: lit-spa - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | 46925c0acbeb3870b3f949706c5d23b3 |
apache-2.0 | ['generated_from_trainer'] | false | opus-mt-es-en-finetuned-es-to-en This model is a fine-tuned version of [Helsinki-NLP/opus-mt-es-en](https://huggingface.co/Helsinki-NLP/opus-mt-es-en) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.5851 - Bleu: 71.1382 - Gen Len: 10.3225 | 2165257ad51531f7ff7bfdb0c968ab52 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:| | No log | 1.0 | 112 | 0.5693 | 71.7823 | 10.3676 | | No log | 2.0 | 224 | 0.5744 | 69.5504 | 10.6739 | | No log | 3.0 | 336 | 0.5784 | 71.6553 | 10.3117 | | No log | 4.0 | 448 | 0.5826 | 71.0576 | 10.3261 | | 0.2666 | 5.0 | 560 | 0.5851 | 71.1382 | 10.3225 | | e30f3bc5e8bbc68347bc250e9dfe3eef |
mit | ['generated_from_trainer'] | false | bert-base-historic-english-cased-squad-en This model is a fine-tuned version of [dbmdz/bert-base-historic-english-cased](https://huggingface.co/dbmdz/bert-base-historic-english-cased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.7739 | cf92911b3d4bd6c0b8356412944e801e |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.2943 | 1.0 | 4686 | 1.9503 | | 2.0811 | 2.0 | 9372 | 1.7739 | | c71c4edee055bc4aa49246e11dd47862 |
cc-by-4.0 | ['question-answering, multi-step-reasoning, multi-hop-reasoning'] | false | digit_tokenization.py from https://github.com/stonybrooknlp/teabreac model_name = "StonyBrookNLP/teabreac-preasm-large-iirc-gold" tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) | f75102f7c748429a912544e44a1500cc |
apache-2.0 | ['generated_from_trainer'] | false | distilbert_sa_GLUE_Experiment_mnli_96 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE MNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.9288 - Accuracy: 0.5545 | 22d308ee42f0c45c8db10384f2a46484 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:-----:|:---------------:|:--------:| | 1.0498 | 1.0 | 1534 | 0.9988 | 0.5084 | | 0.9757 | 2.0 | 3068 | 0.9532 | 0.5303 | | 0.9458 | 3.0 | 4602 | 0.9435 | 0.5377 | | 0.9272 | 4.0 | 6136 | 0.9306 | 0.5456 | | 0.9122 | 5.0 | 7670 | 0.9305 | 0.5474 | | 0.8992 | 6.0 | 9204 | 0.9294 | 0.5489 | | 0.8867 | 7.0 | 10738 | 0.9260 | 0.5522 | | 0.8752 | 8.0 | 12272 | 0.9319 | 0.5559 | | 0.8645 | 9.0 | 13806 | 0.9336 | 0.5604 | | 0.8545 | 10.0 | 15340 | 0.9200 | 0.5629 | | 0.8443 | 11.0 | 16874 | 0.9200 | 0.5664 | | 0.8338 | 12.0 | 18408 | 0.9298 | 0.5672 | | 0.8252 | 13.0 | 19942 | 0.9383 | 0.5647 | | 0.8168 | 14.0 | 21476 | 0.9428 | 0.5691 | | 0.8084 | 15.0 | 23010 | 0.9325 | 0.5730 | | 1c516d466f124e097ac48d66126e9a34 |
apache-2.0 | ['translation'] | false | opus-mt-en-INSULAR_CELTIC * source languages: en * target languages: ga,cy,br,gd,kw,gv * OPUS readme: [en-ga+cy+br+gd+kw+gv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-ga+cy+br+gd+kw+gv/README.md) * dataset: opus+techiaith+bt * model: transformer-align * pre-processing: normalization + SentencePiece * a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID) * download original weights: [opus+techiaith+bt-2020-04-24.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-ga+cy+br+gd+kw+gv/opus+techiaith+bt-2020-04-24.zip) * test set translations: [opus+techiaith+bt-2020-04-24.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-ga+cy+br+gd+kw+gv/opus+techiaith+bt-2020-04-24.test.txt) * test set scores: [opus+techiaith+bt-2020-04-24.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-ga+cy+br+gd+kw+gv/opus+techiaith+bt-2020-04-24.eval.txt) | 805ce6ccf9eb0c88a4db3a5bf6afc522 |
apache-2.0 | ['generated_from_trainer'] | false | finetuning-sentiment-model-3000-samples This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 0.3275 - Accuracy: 0.8767 - F1: 0.8779 | 6c7e43c1f6e039338ac737ca831a0ecd |
mit | ['generated_from_trainer'] | false | roberta-large_cls_CR This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.3325 - Accuracy: 0.9043 | 2c6e19f89706eb089b4062b011f25082 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 213 | 0.4001 | 0.875 | | No log | 2.0 | 426 | 0.4547 | 0.8324 | | 0.499 | 3.0 | 639 | 0.3161 | 0.8963 | | 0.499 | 4.0 | 852 | 0.3219 | 0.9069 | | 0.2904 | 5.0 | 1065 | 0.3325 | 0.9043 | | 03545d0424975fc49b49cbe8b1821986 |
cc-by-4.0 | ['question generation'] | false | Model Card of `lmqg/t5-large-subjqa-electronics-qg` This model is fine-tuned version of [lmqg/t5-large-squad](https://huggingface.co/lmqg/t5-large-squad) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: electronics) via [`lmqg`](https://github.com/asahi417/lm-question-generation). | 526f02ac84134be79ec28dc3dcf0c02a |
cc-by-4.0 | ['question generation'] | false | Overview - **Language model:** [lmqg/t5-large-squad](https://huggingface.co/lmqg/t5-large-squad) - **Language:** en - **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (electronics) - **Online Demo:** [https://autoqg.net/](https://autoqg.net/) - **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation) - **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992) | 3f9b17176f8bb1eceab4b3e5071c6a3c |
cc-by-4.0 | ['question generation'] | false | model prediction questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner") ``` - With `transformers` ```python from transformers import pipeline pipe = pipeline("text2text-generation", "lmqg/t5-large-subjqa-electronics-qg") output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.") ``` | f209d9876ad0005cd10fb4b4178b683c |
cc-by-4.0 | ['question generation'] | false | Evaluation - ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/t5-large-subjqa-electronics-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.electronics.json) | | Score | Type | Dataset | |:-----------|--------:|:------------|:-----------------------------------------------------------------| | BERTScore | 94.27 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_1 | 29.72 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_2 | 21.47 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_3 | 10.86 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | Bleu_4 | 4.57 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | METEOR | 27.56 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | MoverScore | 68.8 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | ROUGE_L | 30.55 | electronics | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | | 119956fcdbc9b6a37a5d0ff72295433f |
cc-by-4.0 | ['question generation'] | false | Training hyperparameters The following hyperparameters were used during fine-tuning: - dataset_path: lmqg/qg_subjqa - dataset_name: electronics - input_types: ['paragraph_answer'] - output_types: ['question'] - prefix_types: ['qg'] - model: lmqg/t5-large-squad - max_length: 512 - max_length_output: 32 - epoch: 3 - batch: 16 - lr: 0.0001 - fp16: False - random_seed: 1 - gradient_accumulation_steps: 8 - label_smoothing: 0.0 The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/t5-large-subjqa-electronics-qg/raw/main/trainer_config.json). | 38246bb69309869c14689b54c488ffbe |
apache-2.0 | ['generated_from_trainer'] | false | NLP-CIC-WFU_Clinical_Cases_NER_Paragraph_Tokenized_mBERT_cased_fine_tuned This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.0537 - Precision: 0.8585 - Recall: 0.7101 - F1: 0.7773 - Accuracy: 0.9893 | 3bbec1b325202ef8ea24c8dc814fa71e |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | 0.0693 | 1.0 | 514 | 0.0416 | 0.9485 | 0.6492 | 0.7708 | 0.9884 | | 0.0367 | 2.0 | 1028 | 0.0396 | 0.9391 | 0.6710 | 0.7827 | 0.9892 | | 0.0283 | 3.0 | 1542 | 0.0385 | 0.9388 | 0.6889 | 0.7947 | 0.9899 | | 0.0222 | 4.0 | 2056 | 0.0422 | 0.9456 | 0.6790 | 0.7904 | 0.9898 | | 0.0182 | 5.0 | 2570 | 0.0457 | 0.9349 | 0.6925 | 0.7956 | 0.9901 | | 0.013 | 6.0 | 3084 | 0.0484 | 0.8947 | 0.7062 | 0.7894 | 0.9899 | | 0.0084 | 7.0 | 3598 | 0.0537 | 0.8585 | 0.7101 | 0.7773 | 0.9893 | | 2ceb97fae73bdf8fca1a596a599e87b9 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-imdb This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - eval_loss: 2.8413 - eval_runtime: 304.6965 - eval_samples_per_second: 3.282 - eval_steps_per_second: 0.053 - epoch: 0.01 - step: 2 | 5775a3acb6682456104eb0ec21972fdb |
mit | ['BERT', 'Text Classification', 'relation'] | false | Arabic Relation Extraction Model - [Github repo](https://github.com/edchengg/GigaBERT) - Relation Extraction model based on [GigaBERTv4](https://huggingface.co/lanwuwei/GigaBERT-v4-Arabic-and-English). - Model detail: mark two entities in the sentence with special markers (e.g., ```XXXX <PER> entity1 </PER> XXXXXXX <ORG> entity2 </ORG> XXXXX```). Then we use the BERT [CLS] representation to make a prediction. - ACE2005 Training data: Arabic - [Relation tags](https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/arabic-relations-guidelines-v6.5.pdf) including: Physical, Part-whole, Personal-Social, ORG-Affiliation, Agent-Artifact, Gen-Affiliation | fc4535170bee9df977cf9b386fd56a04 |
mit | ['BERT', 'Text Classification', 'relation'] | false | How to use Workflow of a relation extraction model: 1. Input --> NER model --> Entities 2. Input sentence + Entity 1 + Entity 2 --> Relation Classification Model --> Relation Type ```python >>> from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer, AuotoModelForSequenceClassification >>> ner_model = AutoModelForTokenClassification.from_pretrained("ychenNLP/arabic-ner-ace") >>> ner_tokenizer = AutoTokenizer.from_pretrained("ychenNLP/arabic-ner-ace") >>> ner_pip = pipeline("ner", model=ner_model, tokenizer=ner_tokenizer, grouped_entities=True) >>> re_model = AutoModelForSequenceClassification.from_pretrained("ychenNLP/arabic-relation-extraction") >>> re_tokenizer = AutoTokenizer.from_pretrained("ychenNLP/arabic-relation-extraction") >>> re_pip = pipeline("text-classification", model=re_model, tokenizer=re_tokenizer) def process_ner_output(entity_mention, inputs): re_input = [] for idx1 in range(len(entity_mention) - 1): for idx2 in range(idx1 + 1, len(entity_mention)): ent_1 = entity_mention[idx1] ent_2 = entity_mention[idx2] ent_1_type = ent_1['entity_group'] ent_2_type = ent_2['entity_group'] ent_1_s = ent_1['start'] ent_1_e = ent_1['end'] ent_2_s = ent_2['start'] ent_2_e = ent_2['end'] new_re_input = "" for c_idx, c in enumerate(inputs): if c_idx == ent_1_s: new_re_input += "<{}>".format(ent_1_type) elif c_idx == ent_1_e: new_re_input += "</{}>".format(ent_1_type) elif c_idx == ent_2_s: new_re_input += "<{}>".format(ent_2_type) elif c_idx == ent_2_e: new_re_input += "</{}>".format(ent_2_type) new_re_input += c re_input.append({"re_input": new_re_input, "arg1": ent_1, "arg2": ent_2, "input": inputs}) return re_input def post_process_re_output(re_output, text_input, ner_output): final_output = [] for idx, out in enumerate(re_output): if out["label"] != 'O': tmp = re_input[idx] tmp['relation_type'] = out tmp.pop('re_input', None) final_output.append(tmp) template = {"input": text_input, "entity": ner_output, "relation": final_output} return template text_input = """ويتزامن ذلك مع اجتماع بايدن مع قادة الدول الأعضاء في الناتو في قمة موسعة في العاصمة الإسبانية، مدريد.""" ner_output = ner_pip(text_input) | 7381944d141e804262fb011869acd300 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.