
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 7
112
| repo_url
stringlengths 36
141
| action
stringclasses 3
values | title
stringlengths 1
744
| labels
stringlengths 4
574
| body
stringlengths 9
211k
| index
stringclasses 10
values | text_combine
stringlengths 96
211k
| label
stringclasses 2
values | text
stringlengths 96
188k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
21,176
| 28,145,810,429
|
IssuesEvent
|
2023-04-02 13:19:47
|
MarkBind/markbind
|
https://api.github.com/repos/MarkBind/markbind
|
closed
|
Improve the init command
|
c.Enhancement p.Low a-CLI a-Process d.easy
|
Some suggestions for improving the `init` command (can be broken down to multiple PRs):
The default starter site can be enhanced to make it more useful to the user as a starting point. e.g., create a site that has all typical features (i.e., top nav, site nav, footer, search, a bunch of pages typically used such as home, contact, docs etc.) so that the user can go from there to a production website with least amount of effort.
Perhaps we can have other options?
`--minimal`: create an empty site
`--convert`: converts an existing site to a MarkBind site. This can be an 'intelligent' conversion e.g., deduce siteNav items based on page titles
`--restore`: restores the folder to the previous state (i.e., reverses the `init` command)
|
1.0
|
Improve the init command - Some suggestions for improving the `init` command (can be broken down to multiple PRs):
The default starter site can be enhanced to make it more useful to the user as a starting point. e.g., create a site that has all typical features (i.e., top nav, site nav, footer, search, a bunch of pages typically used such as home, contact, docs etc.) so that the user can go from there to a production website with least amount of effort.
Perhaps we can have other options?
`--minimal`: create an empty site
`--convert`: converts an existing site to a MarkBind site. This can be an 'intelligent' conversion e.g., deduce siteNav items based on page titles
`--restore`: restores the folder to the previous state (i.e., reverses the `init` command)
|
process
|
improve the init command some suggestions for improving the init command can be broken down to multiple prs the default starter site can be enhanced to make it more useful to the user as a starting point e g create a site that has all typical features i e top nav site nav footer search a bunch of pages typically used such as home contact docs etc so that the user can go from there to a production website with least amount of effort perhaps we can have other options minimal create an empty site convert converts an existing site to a markbind site this can be an intelligent conversion e g deduce sitenav items based on page titles restore restores the folder to the previous state i e reverses the init command
| 1
|
216
| 2,644,228,118
|
IssuesEvent
|
2015-03-12 15:52:55
|
documentcloud/documentcloud
|
https://api.github.com/repos/documentcloud/documentcloud
|
closed
|
Investigate PDFium
|
overhaul_processing
|
https://code.google.com/p/pdfium/
If it's easy enough to get running from the command-line, it could be a much, much faster and more accurate alternative to ghostscript rendering.
|
1.0
|
Investigate PDFium - https://code.google.com/p/pdfium/
If it's easy enough to get running from the command-line, it could be a much, much faster and more accurate alternative to ghostscript rendering.
|
process
|
investigate pdfium if it s easy enough to get running from the command line it could be a much much faster and more accurate alternative to ghostscript rendering
| 1
|
452,146
| 13,046,639,497
|
IssuesEvent
|
2020-07-29 09:20:11
|
metabase/metabase
|
https://api.github.com/repos/metabase/metabase
|
closed
|
Generating metrics description breaks for custom expressions
|
.Backend Administration/Metrics & Segments Priority:P1
|
On working 0.36.0:
1. Admin > Data Model > Metric
2. Create new, table Sample Dataset > Orders, view Custom Expression `Sum([Discount] * [Quantity])`, save the metric
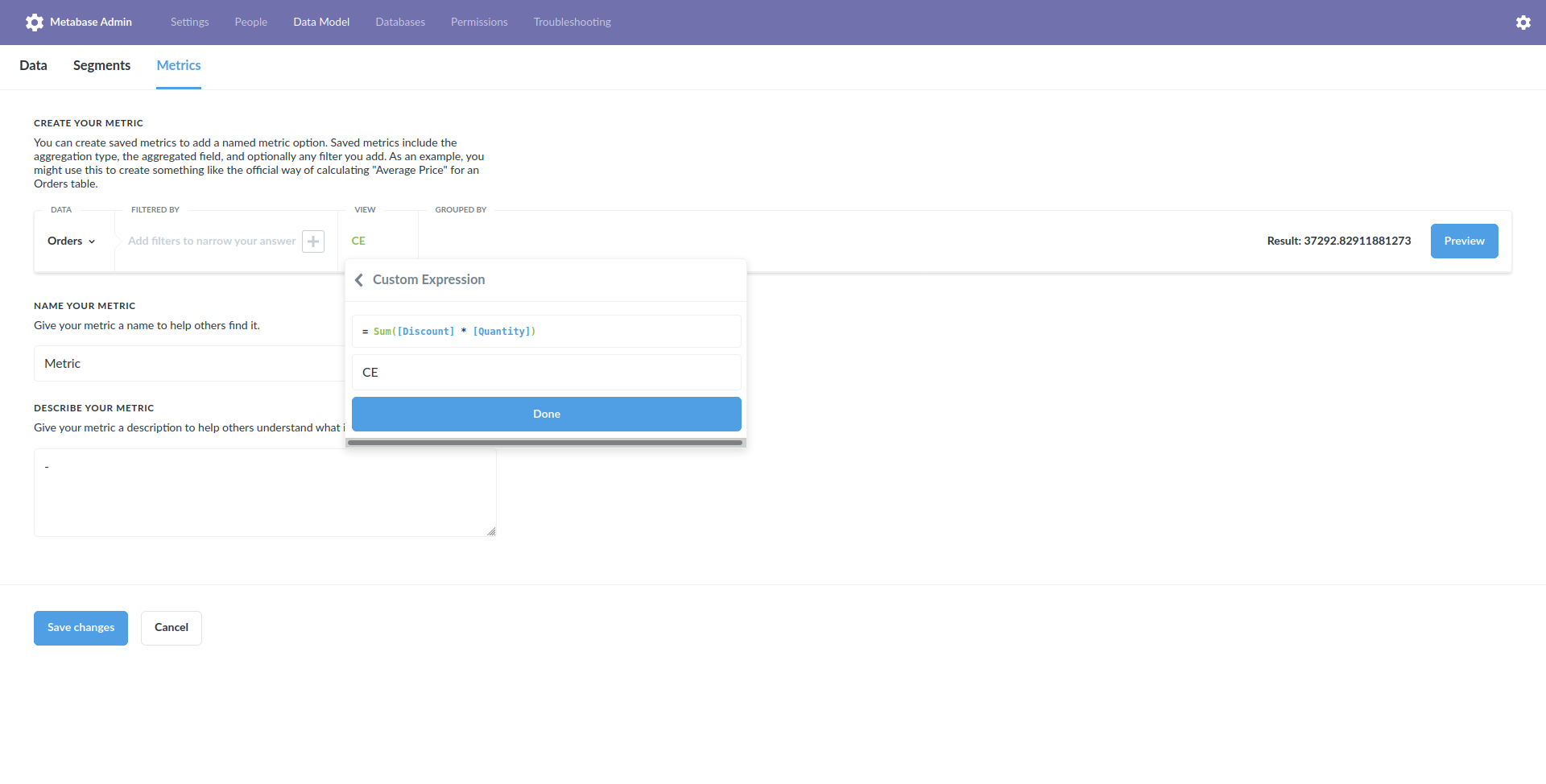
3. Refresh on Metric overview page, errors with `Unexpected input given to normalize. Expected type to be "object", found "string".`

_Originally posted by @flamber in https://github.com/metabase/metabase/issues/12982#issuecomment-664945290_
|
1.0
|
Generating metrics description breaks for custom expressions - On working 0.36.0:
1. Admin > Data Model > Metric
2. Create new, table Sample Dataset > Orders, view Custom Expression `Sum([Discount] * [Quantity])`, save the metric

3. Refresh on Metric overview page, errors with `Unexpected input given to normalize. Expected type to be "object", found "string".`

_Originally posted by @flamber in https://github.com/metabase/metabase/issues/12982#issuecomment-664945290_
|
non_process
|
generating metrics description breaks for custom expressions on working admin data model metric create new table sample dataset orders view custom expression sum save the metric refresh on metric overview page errors with unexpected input given to normalize expected type to be object found string originally posted by flamber in
| 0
|
21,507
| 29,736,738,837
|
IssuesEvent
|
2023-06-14 02:00:08
|
lizhihao6/get-daily-arxiv-noti
|
https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti
|
opened
|
New submissions for Wed, 14 Jun 23
|
event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB
|
## Keyword: events
### Generative Watermarking Against Unauthorized Subject-Driven Image Synthesis
- **Authors:** Yihan Ma, Zhengyu Zhao, Xinlei He, Zheng Li, Michael Backes, Yang Zhang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
- **Arxiv link:** https://arxiv.org/abs/2306.07754
- **Pdf link:** https://arxiv.org/pdf/2306.07754
- **Abstract**
Large text-to-image models have shown remarkable performance in synthesizing high-quality images. In particular, the subject-driven model makes it possible to personalize the image synthesis for a specific subject, e.g., a human face or an artistic style, by fine-tuning the generic text-to-image model with a few images from that subject. Nevertheless, misuse of subject-driven image synthesis may violate the authority of subject owners. For example, malicious users may use subject-driven synthesis to mimic specific artistic styles or to create fake facial images without authorization. To protect subject owners against such misuse, recent attempts have commonly relied on adversarial examples to indiscriminately disrupt subject-driven image synthesis. However, this essentially prevents any benign use of subject-driven synthesis based on protected images. In this paper, we take a different angle and aim at protection without sacrificing the utility of protected images for general synthesis purposes. Specifically, we propose GenWatermark, a novel watermark system based on jointly learning a watermark generator and a detector. In particular, to help the watermark survive the subject-driven synthesis, we incorporate the synthesis process in learning GenWatermark by fine-tuning the detector with synthesized images for a specific subject. This operation is shown to largely improve the watermark detection accuracy and also ensure the uniqueness of the watermark for each individual subject. Extensive experiments validate the effectiveness of GenWatermark, especially in practical scenarios with unknown models and text prompts (74% Acc.), as well as partial data watermarking (80% Acc. for 1/4 watermarking). We also demonstrate the robustness of GenWatermark to two potential countermeasures that substantially degrade the synthesis quality.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
### Hidden Biases of End-to-End Driving Models
- **Authors:** Bernhard Jaeger, Kashyap Chitta, Andreas Geiger
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2306.07957
- **Pdf link:** https://arxiv.org/pdf/2306.07957
- **Abstract**
End-to-end driving systems have recently made rapid progress, in particular on CARLA. Independent of their major contribution, they introduce changes to minor system components. Consequently, the source of improvements is unclear. We identify two biases that recur in nearly all state-of-the-art methods and are critical for the observed progress on CARLA: (1) lateral recovery via a strong inductive bias towards target point following, and (2) longitudinal averaging of multimodal waypoint predictions for slowing down. We investigate the drawbacks of these biases and identify principled alternatives. By incorporating our insights, we develop TF++, a simple end-to-end method that ranks first on the Longest6 and LAV benchmarks, gaining 14 driving score over the best prior work on Longest6.
## Keyword: ISP
### Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
- **Authors:** Lorenzo Baraldi, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, Andrea Pilzer, Rita Cucchiara
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
- **Arxiv link:** https://arxiv.org/abs/2306.07346
- **Pdf link:** https://arxiv.org/pdf/2306.07346
- **Abstract**
The use of self-supervised pre-training has emerged as a promising approach to enhance the performance of visual tasks such as image classification. In this context, recent approaches have employed the Masked Image Modeling paradigm, which pre-trains a backbone by reconstructing visual tokens associated with randomly masked image patches. This masking approach, however, introduces noise into the input data during pre-training, leading to discrepancies that can impair performance during the fine-tuning phase. Furthermore, input masking neglects the dependencies between corrupted patches, increasing the inconsistencies observed in downstream fine-tuning tasks. To overcome these issues, we propose a new self-supervised pre-training approach, named Masked and Permuted Vision Transformer (MaPeT), that employs autoregressive and permuted predictions to capture intra-patch dependencies. In addition, MaPeT employs auxiliary positional information to reduce the disparity between the pre-training and fine-tuning phases. In our experiments, we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers, including our proposed $k$-CLIP which directly employs discretized CLIP features. Our results demonstrate that MaPeT achieves competitive performance on ImageNet, compared to baselines and competitors under the same model setting. Source code and trained models are publicly available at: https://github.com/aimagelab/MaPeT.
### Continuous Cost Aggregation for Dual-Pixel Disparity Extraction
- **Authors:** Sagi Monin, Sagi Katz, Georgios Evangelidis
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2306.07921
- **Pdf link:** https://arxiv.org/pdf/2306.07921
- **Abstract**
Recent works have shown that depth information can be obtained from Dual-Pixel (DP) sensors. A DP arrangement provides two views in a single shot, thus resembling a stereo image pair with a tiny baseline. However, the different point spread function (PSF) per view, as well as the small disparity range, makes the use of typical stereo matching algorithms problematic. To address the above shortcomings, we propose a Continuous Cost Aggregation (CCA) scheme within a semi-global matching framework that is able to provide accurate continuous disparities from DP images. The proposed algorithm fits parabolas to matching costs and aggregates parabola coefficients along image paths. The aggregation step is performed subject to a quadratic constraint that not only enforces the disparity smoothness but also maintains the quadratic form of the total costs. This gives rise to an inherently efficient disparity propagation scheme with a pixel-wise minimization in closed-form. Furthermore, the continuous form allows for a robust multi-scale aggregation that better compensates for the varying PSF. Experiments on DP data from both DSLR and phone cameras show that the proposed scheme attains state-of-the-art performance in DP disparity estimation.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### Localization of Just Noticeable Difference for Image Compression
- **Authors:** Guangan Chen, Hanhe Lin, Oliver Wiedemann, Dietmar Saupe
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Image and Video Processing (eess.IV)
- **Arxiv link:** https://arxiv.org/abs/2306.07678
- **Pdf link:** https://arxiv.org/pdf/2306.07678
- **Abstract**
The just noticeable difference (JND) is the minimal difference between stimuli that can be detected by a person. The picture-wise just noticeable difference (PJND) for a given reference image and a compression algorithm represents the minimal level of compression that causes noticeable differences in the reconstruction. These differences can only be observed in some specific regions within the image, dubbed as JND-critical regions. Identifying these regions can improve the development of image compression algorithms. Due to the fact that visual perception varies among individuals, determining the PJND values and JND-critical regions for a target population of consumers requires subjective assessment experiments involving a sufficiently large number of observers. In this paper, we propose a novel framework for conducting such experiments using crowdsourcing. By applying this framework, we created a novel PJND dataset, KonJND++, consisting of 300 source images, compressed versions thereof under JPEG or BPG compression, and an average of 43 ratings of PJND and 129 self-reported locations of JND-critical regions for each source image. Our experiments demonstrate the effectiveness and reliability of our proposed framework, which is easy to be adapted for collecting a large-scale dataset. The source code and dataset are available at https://github.com/angchen-dev/LocJND.
## Keyword: RAW
### Instant Multi-View Head Capture through Learnable Registration
- **Authors:** Timo Bolkart, Tianye Li, Michael J. Black
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2306.07437
- **Pdf link:** https://arxiv.org/pdf/2306.07437
- **Abstract**
Existing methods for capturing datasets of 3D heads in dense semantic correspondence are slow, and commonly address the problem in two separate steps; multi-view stereo (MVS) reconstruction followed by non-rigid registration. To simplify this process, we introduce TEMPEH (Towards Estimation of 3D Meshes from Performances of Expressive Heads) to directly infer 3D heads in dense correspondence from calibrated multi-view images. Registering datasets of 3D scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans surfaces and being robust to scanning noise and outliers. Instead, we propose to jointly register a 3D head dataset while training TEMPEH. Specifically, during training we minimize a geometric loss commonly used for surface registration, effectively leveraging TEMPEH as a regularizer. Our multi-view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information. To account for partial occlusions and a large capture volume that enables head movements, we use view- and surface-aware feature fusion, and a spatial transformer-based head localization module, respectively. We use raw MVS scans as supervision during training, but, once trained, TEMPEH directly predicts 3D heads in dense correspondence without requiring scans. Predicting one head takes about 0.3 seconds with a median reconstruction error of 0.26 mm, 64% lower than the current state-of-the-art. This enables the efficient capture of large datasets containing multiple people and diverse facial motions. Code, model, and data are publicly available at https://tempeh.is.tue.mpg.de.
### AniFaceDrawing: Anime Portrait Exploration during Your Sketching
- **Authors:** Zhengyu Huang, Haoran Xie, Tsukasa Fukusato, Kazunori Miyata
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
- **Arxiv link:** https://arxiv.org/abs/2306.07476
- **Pdf link:** https://arxiv.org/pdf/2306.07476
- **Abstract**
In this paper, we focus on how artificial intelligence (AI) can be used to assist users in the creation of anime portraits, that is, converting rough sketches into anime portraits during their sketching process. The input is a sequence of incomplete freehand sketches that are gradually refined stroke by stroke, while the output is a sequence of high-quality anime portraits that correspond to the input sketches as guidance. Although recent GANs can generate high quality images, it is a challenging problem to maintain the high quality of generated images from sketches with a low degree of completion due to ill-posed problems in conditional image generation. Even with the latest sketch-to-image (S2I) technology, it is still difficult to create high-quality images from incomplete rough sketches for anime portraits since anime style tend to be more abstract than in realistic style. To address this issue, we adopt a latent space exploration of StyleGAN with a two-stage training strategy. We consider the input strokes of a freehand sketch to correspond to edge information-related attributes in the latent structural code of StyleGAN, and term the matching between strokes and these attributes stroke-level disentanglement. In the first stage, we trained an image encoder with the pre-trained StyleGAN model as a teacher encoder. In the second stage, we simulated the drawing process of the generated images without any additional data (labels) and trained the sketch encoder for incomplete progressive sketches to generate high-quality portrait images with feature alignment to the disentangled representations in the teacher encoder. We verified the proposed progressive S2I system with both qualitative and quantitative evaluations and achieved high-quality anime portraits from incomplete progressive sketches. Our user study proved its effectiveness in art creation assistance for the anime style.
### Marking anything: application of point cloud in extracting video target features
- **Authors:** Xiangchun Xu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
- **Arxiv link:** https://arxiv.org/abs/2306.07559
- **Pdf link:** https://arxiv.org/pdf/2306.07559
- **Abstract**
Extracting retrievable features from video is of great significance for structured video database construction, video copyright protection and fake video rumor refutation. Inspired by point cloud data processing, this paper proposes a method for marking anything (MA) in the video, which can extract the contour features of any target in the video and convert it into a feature vector with a length of 256 that can be retrieved. The algorithm uses YOLO-v8 algorithm, multi-object tracking algorithm and PointNet++ to extract contour of the video detection target to form spatial point cloud data. Then extract the point cloud feature vector and use it as the retrievable feature of the video detection target. In order to verify the effectiveness and robustness of contour feature, some datasets are crawled from Dou Yin and Kinetics-700 dataset as experimental data. For Dou Yin's homogenized videos, the proposed contour features achieve retrieval accuracy higher than 97% in Top1 return mode. For videos from Kinetics 700, the contour feature also showed good robustness for partial clip mode video tracing.
### Hidden Biases of End-to-End Driving Models
- **Authors:** Bernhard Jaeger, Kashyap Chitta, Andreas Geiger
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2306.07957
- **Pdf link:** https://arxiv.org/pdf/2306.07957
- **Abstract**
End-to-end driving systems have recently made rapid progress, in particular on CARLA. Independent of their major contribution, they introduce changes to minor system components. Consequently, the source of improvements is unclear. We identify two biases that recur in nearly all state-of-the-art methods and are critical for the observed progress on CARLA: (1) lateral recovery via a strong inductive bias towards target point following, and (2) longitudinal averaging of multimodal waypoint predictions for slowing down. We investigate the drawbacks of these biases and identify principled alternatives. By incorporating our insights, we develop TF++, a simple end-to-end method that ranks first on the Longest6 and LAV benchmarks, gaining 14 driving score over the best prior work on Longest6.
## Keyword: raw image
There is no result
|
2.0
|
New submissions for Wed, 14 Jun 23 - ## Keyword: events
### Generative Watermarking Against Unauthorized Subject-Driven Image Synthesis
- **Authors:** Yihan Ma, Zhengyu Zhao, Xinlei He, Zheng Li, Michael Backes, Yang Zhang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
- **Arxiv link:** https://arxiv.org/abs/2306.07754
- **Pdf link:** https://arxiv.org/pdf/2306.07754
- **Abstract**
Large text-to-image models have shown remarkable performance in synthesizing high-quality images. In particular, the subject-driven model makes it possible to personalize the image synthesis for a specific subject, e.g., a human face or an artistic style, by fine-tuning the generic text-to-image model with a few images from that subject. Nevertheless, misuse of subject-driven image synthesis may violate the authority of subject owners. For example, malicious users may use subject-driven synthesis to mimic specific artistic styles or to create fake facial images without authorization. To protect subject owners against such misuse, recent attempts have commonly relied on adversarial examples to indiscriminately disrupt subject-driven image synthesis. However, this essentially prevents any benign use of subject-driven synthesis based on protected images. In this paper, we take a different angle and aim at protection without sacrificing the utility of protected images for general synthesis purposes. Specifically, we propose GenWatermark, a novel watermark system based on jointly learning a watermark generator and a detector. In particular, to help the watermark survive the subject-driven synthesis, we incorporate the synthesis process in learning GenWatermark by fine-tuning the detector with synthesized images for a specific subject. This operation is shown to largely improve the watermark detection accuracy and also ensure the uniqueness of the watermark for each individual subject. Extensive experiments validate the effectiveness of GenWatermark, especially in practical scenarios with unknown models and text prompts (74% Acc.), as well as partial data watermarking (80% Acc. for 1/4 watermarking). We also demonstrate the robustness of GenWatermark to two potential countermeasures that substantially degrade the synthesis quality.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
### Hidden Biases of End-to-End Driving Models
- **Authors:** Bernhard Jaeger, Kashyap Chitta, Andreas Geiger
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2306.07957
- **Pdf link:** https://arxiv.org/pdf/2306.07957
- **Abstract**
End-to-end driving systems have recently made rapid progress, in particular on CARLA. Independent of their major contribution, they introduce changes to minor system components. Consequently, the source of improvements is unclear. We identify two biases that recur in nearly all state-of-the-art methods and are critical for the observed progress on CARLA: (1) lateral recovery via a strong inductive bias towards target point following, and (2) longitudinal averaging of multimodal waypoint predictions for slowing down. We investigate the drawbacks of these biases and identify principled alternatives. By incorporating our insights, we develop TF++, a simple end-to-end method that ranks first on the Longest6 and LAV benchmarks, gaining 14 driving score over the best prior work on Longest6.
## Keyword: ISP
### Learning to Mask and Permute Visual Tokens for Vision Transformer Pre-Training
- **Authors:** Lorenzo Baraldi, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, Andrea Pilzer, Rita Cucchiara
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
- **Arxiv link:** https://arxiv.org/abs/2306.07346
- **Pdf link:** https://arxiv.org/pdf/2306.07346
- **Abstract**
The use of self-supervised pre-training has emerged as a promising approach to enhance the performance of visual tasks such as image classification. In this context, recent approaches have employed the Masked Image Modeling paradigm, which pre-trains a backbone by reconstructing visual tokens associated with randomly masked image patches. This masking approach, however, introduces noise into the input data during pre-training, leading to discrepancies that can impair performance during the fine-tuning phase. Furthermore, input masking neglects the dependencies between corrupted patches, increasing the inconsistencies observed in downstream fine-tuning tasks. To overcome these issues, we propose a new self-supervised pre-training approach, named Masked and Permuted Vision Transformer (MaPeT), that employs autoregressive and permuted predictions to capture intra-patch dependencies. In addition, MaPeT employs auxiliary positional information to reduce the disparity between the pre-training and fine-tuning phases. In our experiments, we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers, including our proposed $k$-CLIP which directly employs discretized CLIP features. Our results demonstrate that MaPeT achieves competitive performance on ImageNet, compared to baselines and competitors under the same model setting. Source code and trained models are publicly available at: https://github.com/aimagelab/MaPeT.
### Continuous Cost Aggregation for Dual-Pixel Disparity Extraction
- **Authors:** Sagi Monin, Sagi Katz, Georgios Evangelidis
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2306.07921
- **Pdf link:** https://arxiv.org/pdf/2306.07921
- **Abstract**
Recent works have shown that depth information can be obtained from Dual-Pixel (DP) sensors. A DP arrangement provides two views in a single shot, thus resembling a stereo image pair with a tiny baseline. However, the different point spread function (PSF) per view, as well as the small disparity range, makes the use of typical stereo matching algorithms problematic. To address the above shortcomings, we propose a Continuous Cost Aggregation (CCA) scheme within a semi-global matching framework that is able to provide accurate continuous disparities from DP images. The proposed algorithm fits parabolas to matching costs and aggregates parabola coefficients along image paths. The aggregation step is performed subject to a quadratic constraint that not only enforces the disparity smoothness but also maintains the quadratic form of the total costs. This gives rise to an inherently efficient disparity propagation scheme with a pixel-wise minimization in closed-form. Furthermore, the continuous form allows for a robust multi-scale aggregation that better compensates for the varying PSF. Experiments on DP data from both DSLR and phone cameras show that the proposed scheme attains state-of-the-art performance in DP disparity estimation.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### Localization of Just Noticeable Difference for Image Compression
- **Authors:** Guangan Chen, Hanhe Lin, Oliver Wiedemann, Dietmar Saupe
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Image and Video Processing (eess.IV)
- **Arxiv link:** https://arxiv.org/abs/2306.07678
- **Pdf link:** https://arxiv.org/pdf/2306.07678
- **Abstract**
The just noticeable difference (JND) is the minimal difference between stimuli that can be detected by a person. The picture-wise just noticeable difference (PJND) for a given reference image and a compression algorithm represents the minimal level of compression that causes noticeable differences in the reconstruction. These differences can only be observed in some specific regions within the image, dubbed as JND-critical regions. Identifying these regions can improve the development of image compression algorithms. Due to the fact that visual perception varies among individuals, determining the PJND values and JND-critical regions for a target population of consumers requires subjective assessment experiments involving a sufficiently large number of observers. In this paper, we propose a novel framework for conducting such experiments using crowdsourcing. By applying this framework, we created a novel PJND dataset, KonJND++, consisting of 300 source images, compressed versions thereof under JPEG or BPG compression, and an average of 43 ratings of PJND and 129 self-reported locations of JND-critical regions for each source image. Our experiments demonstrate the effectiveness and reliability of our proposed framework, which is easy to be adapted for collecting a large-scale dataset. The source code and dataset are available at https://github.com/angchen-dev/LocJND.
## Keyword: RAW
### Instant Multi-View Head Capture through Learnable Registration
- **Authors:** Timo Bolkart, Tianye Li, Michael J. Black
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2306.07437
- **Pdf link:** https://arxiv.org/pdf/2306.07437
- **Abstract**
Existing methods for capturing datasets of 3D heads in dense semantic correspondence are slow, and commonly address the problem in two separate steps; multi-view stereo (MVS) reconstruction followed by non-rigid registration. To simplify this process, we introduce TEMPEH (Towards Estimation of 3D Meshes from Performances of Expressive Heads) to directly infer 3D heads in dense correspondence from calibrated multi-view images. Registering datasets of 3D scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans surfaces and being robust to scanning noise and outliers. Instead, we propose to jointly register a 3D head dataset while training TEMPEH. Specifically, during training we minimize a geometric loss commonly used for surface registration, effectively leveraging TEMPEH as a regularizer. Our multi-view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information. To account for partial occlusions and a large capture volume that enables head movements, we use view- and surface-aware feature fusion, and a spatial transformer-based head localization module, respectively. We use raw MVS scans as supervision during training, but, once trained, TEMPEH directly predicts 3D heads in dense correspondence without requiring scans. Predicting one head takes about 0.3 seconds with a median reconstruction error of 0.26 mm, 64% lower than the current state-of-the-art. This enables the efficient capture of large datasets containing multiple people and diverse facial motions. Code, model, and data are publicly available at https://tempeh.is.tue.mpg.de.
### AniFaceDrawing: Anime Portrait Exploration during Your Sketching
- **Authors:** Zhengyu Huang, Haoran Xie, Tsukasa Fukusato, Kazunori Miyata
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
- **Arxiv link:** https://arxiv.org/abs/2306.07476
- **Pdf link:** https://arxiv.org/pdf/2306.07476
- **Abstract**
In this paper, we focus on how artificial intelligence (AI) can be used to assist users in the creation of anime portraits, that is, converting rough sketches into anime portraits during their sketching process. The input is a sequence of incomplete freehand sketches that are gradually refined stroke by stroke, while the output is a sequence of high-quality anime portraits that correspond to the input sketches as guidance. Although recent GANs can generate high quality images, it is a challenging problem to maintain the high quality of generated images from sketches with a low degree of completion due to ill-posed problems in conditional image generation. Even with the latest sketch-to-image (S2I) technology, it is still difficult to create high-quality images from incomplete rough sketches for anime portraits since anime style tend to be more abstract than in realistic style. To address this issue, we adopt a latent space exploration of StyleGAN with a two-stage training strategy. We consider the input strokes of a freehand sketch to correspond to edge information-related attributes in the latent structural code of StyleGAN, and term the matching between strokes and these attributes stroke-level disentanglement. In the first stage, we trained an image encoder with the pre-trained StyleGAN model as a teacher encoder. In the second stage, we simulated the drawing process of the generated images without any additional data (labels) and trained the sketch encoder for incomplete progressive sketches to generate high-quality portrait images with feature alignment to the disentangled representations in the teacher encoder. We verified the proposed progressive S2I system with both qualitative and quantitative evaluations and achieved high-quality anime portraits from incomplete progressive sketches. Our user study proved its effectiveness in art creation assistance for the anime style.
### Marking anything: application of point cloud in extracting video target features
- **Authors:** Xiangchun Xu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
- **Arxiv link:** https://arxiv.org/abs/2306.07559
- **Pdf link:** https://arxiv.org/pdf/2306.07559
- **Abstract**
Extracting retrievable features from video is of great significance for structured video database construction, video copyright protection and fake video rumor refutation. Inspired by point cloud data processing, this paper proposes a method for marking anything (MA) in the video, which can extract the contour features of any target in the video and convert it into a feature vector with a length of 256 that can be retrieved. The algorithm uses YOLO-v8 algorithm, multi-object tracking algorithm and PointNet++ to extract contour of the video detection target to form spatial point cloud data. Then extract the point cloud feature vector and use it as the retrievable feature of the video detection target. In order to verify the effectiveness and robustness of contour feature, some datasets are crawled from Dou Yin and Kinetics-700 dataset as experimental data. For Dou Yin's homogenized videos, the proposed contour features achieve retrieval accuracy higher than 97% in Top1 return mode. For videos from Kinetics 700, the contour feature also showed good robustness for partial clip mode video tracing.
### Hidden Biases of End-to-End Driving Models
- **Authors:** Bernhard Jaeger, Kashyap Chitta, Andreas Geiger
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2306.07957
- **Pdf link:** https://arxiv.org/pdf/2306.07957
- **Abstract**
End-to-end driving systems have recently made rapid progress, in particular on CARLA. Independent of their major contribution, they introduce changes to minor system components. Consequently, the source of improvements is unclear. We identify two biases that recur in nearly all state-of-the-art methods and are critical for the observed progress on CARLA: (1) lateral recovery via a strong inductive bias towards target point following, and (2) longitudinal averaging of multimodal waypoint predictions for slowing down. We investigate the drawbacks of these biases and identify principled alternatives. By incorporating our insights, we develop TF++, a simple end-to-end method that ranks first on the Longest6 and LAV benchmarks, gaining 14 driving score over the best prior work on Longest6.
## Keyword: raw image
There is no result
|
process
|
new submissions for wed jun keyword events generative watermarking against unauthorized subject driven image synthesis authors yihan ma zhengyu zhao xinlei he zheng li michael backes yang zhang subjects computer vision and pattern recognition cs cv cryptography and security cs cr arxiv link pdf link abstract large text to image models have shown remarkable performance in synthesizing high quality images in particular the subject driven model makes it possible to personalize the image synthesis for a specific subject e g a human face or an artistic style by fine tuning the generic text to image model with a few images from that subject nevertheless misuse of subject driven image synthesis may violate the authority of subject owners for example malicious users may use subject driven synthesis to mimic specific artistic styles or to create fake facial images without authorization to protect subject owners against such misuse recent attempts have commonly relied on adversarial examples to indiscriminately disrupt subject driven image synthesis however this essentially prevents any benign use of subject driven synthesis based on protected images in this paper we take a different angle and aim at protection without sacrificing the utility of protected images for general synthesis purposes specifically we propose genwatermark a novel watermark system based on jointly learning a watermark generator and a detector in particular to help the watermark survive the subject driven synthesis we incorporate the synthesis process in learning genwatermark by fine tuning the detector with synthesized images for a specific subject this operation is shown to largely improve the watermark detection accuracy and also ensure the uniqueness of the watermark for each individual subject extensive experiments validate the effectiveness of genwatermark especially in practical scenarios with unknown models and text prompts acc as well as partial data watermarking acc for watermarking we also demonstrate the robustness of genwatermark to two potential countermeasures that substantially degrade the synthesis quality keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb hidden biases of end to end driving models authors bernhard jaeger kashyap chitta andreas geiger subjects computer vision and pattern recognition cs cv artificial intelligence cs ai machine learning cs lg robotics cs ro arxiv link pdf link abstract end to end driving systems have recently made rapid progress in particular on carla independent of their major contribution they introduce changes to minor system components consequently the source of improvements is unclear we identify two biases that recur in nearly all state of the art methods and are critical for the observed progress on carla lateral recovery via a strong inductive bias towards target point following and longitudinal averaging of multimodal waypoint predictions for slowing down we investigate the drawbacks of these biases and identify principled alternatives by incorporating our insights we develop tf a simple end to end method that ranks first on the and lav benchmarks gaining driving score over the best prior work on keyword isp learning to mask and permute visual tokens for vision transformer pre training authors lorenzo baraldi roberto amoroso marcella cornia lorenzo baraldi andrea pilzer rita cucchiara subjects computer vision and pattern recognition cs cv artificial intelligence cs ai multimedia cs mm arxiv link pdf link abstract the use of self supervised pre training has emerged as a promising approach to enhance the performance of visual tasks such as image classification in this context recent approaches have employed the masked image modeling paradigm which pre trains a backbone by reconstructing visual tokens associated with randomly masked image patches this masking approach however introduces noise into the input data during pre training leading to discrepancies that can impair performance during the fine tuning phase furthermore input masking neglects the dependencies between corrupted patches increasing the inconsistencies observed in downstream fine tuning tasks to overcome these issues we propose a new self supervised pre training approach named masked and permuted vision transformer mapet that employs autoregressive and permuted predictions to capture intra patch dependencies in addition mapet employs auxiliary positional information to reduce the disparity between the pre training and fine tuning phases in our experiments we employ a fair setting to ensure reliable and meaningful comparisons and conduct investigations on multiple visual tokenizers including our proposed k clip which directly employs discretized clip features our results demonstrate that mapet achieves competitive performance on imagenet compared to baselines and competitors under the same model setting source code and trained models are publicly available at continuous cost aggregation for dual pixel disparity extraction authors sagi monin sagi katz georgios evangelidis subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract recent works have shown that depth information can be obtained from dual pixel dp sensors a dp arrangement provides two views in a single shot thus resembling a stereo image pair with a tiny baseline however the different point spread function psf per view as well as the small disparity range makes the use of typical stereo matching algorithms problematic to address the above shortcomings we propose a continuous cost aggregation cca scheme within a semi global matching framework that is able to provide accurate continuous disparities from dp images the proposed algorithm fits parabolas to matching costs and aggregates parabola coefficients along image paths the aggregation step is performed subject to a quadratic constraint that not only enforces the disparity smoothness but also maintains the quadratic form of the total costs this gives rise to an inherently efficient disparity propagation scheme with a pixel wise minimization in closed form furthermore the continuous form allows for a robust multi scale aggregation that better compensates for the varying psf experiments on dp data from both dslr and phone cameras show that the proposed scheme attains state of the art performance in dp disparity estimation keyword image signal processing there is no result keyword image signal process there is no result keyword compression localization of just noticeable difference for image compression authors guangan chen hanhe lin oliver wiedemann dietmar saupe subjects computer vision and pattern recognition cs cv multimedia cs mm image and video processing eess iv arxiv link pdf link abstract the just noticeable difference jnd is the minimal difference between stimuli that can be detected by a person the picture wise just noticeable difference pjnd for a given reference image and a compression algorithm represents the minimal level of compression that causes noticeable differences in the reconstruction these differences can only be observed in some specific regions within the image dubbed as jnd critical regions identifying these regions can improve the development of image compression algorithms due to the fact that visual perception varies among individuals determining the pjnd values and jnd critical regions for a target population of consumers requires subjective assessment experiments involving a sufficiently large number of observers in this paper we propose a novel framework for conducting such experiments using crowdsourcing by applying this framework we created a novel pjnd dataset konjnd consisting of source images compressed versions thereof under jpeg or bpg compression and an average of ratings of pjnd and self reported locations of jnd critical regions for each source image our experiments demonstrate the effectiveness and reliability of our proposed framework which is easy to be adapted for collecting a large scale dataset the source code and dataset are available at keyword raw instant multi view head capture through learnable registration authors timo bolkart tianye li michael j black subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract existing methods for capturing datasets of heads in dense semantic correspondence are slow and commonly address the problem in two separate steps multi view stereo mvs reconstruction followed by non rigid registration to simplify this process we introduce tempeh towards estimation of meshes from performances of expressive heads to directly infer heads in dense correspondence from calibrated multi view images registering datasets of scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans surfaces and being robust to scanning noise and outliers instead we propose to jointly register a head dataset while training tempeh specifically during training we minimize a geometric loss commonly used for surface registration effectively leveraging tempeh as a regularizer our multi view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information to account for partial occlusions and a large capture volume that enables head movements we use view and surface aware feature fusion and a spatial transformer based head localization module respectively we use raw mvs scans as supervision during training but once trained tempeh directly predicts heads in dense correspondence without requiring scans predicting one head takes about seconds with a median reconstruction error of mm lower than the current state of the art this enables the efficient capture of large datasets containing multiple people and diverse facial motions code model and data are publicly available at anifacedrawing anime portrait exploration during your sketching authors zhengyu huang haoran xie tsukasa fukusato kazunori miyata subjects computer vision and pattern recognition cs cv graphics cs gr arxiv link pdf link abstract in this paper we focus on how artificial intelligence ai can be used to assist users in the creation of anime portraits that is converting rough sketches into anime portraits during their sketching process the input is a sequence of incomplete freehand sketches that are gradually refined stroke by stroke while the output is a sequence of high quality anime portraits that correspond to the input sketches as guidance although recent gans can generate high quality images it is a challenging problem to maintain the high quality of generated images from sketches with a low degree of completion due to ill posed problems in conditional image generation even with the latest sketch to image technology it is still difficult to create high quality images from incomplete rough sketches for anime portraits since anime style tend to be more abstract than in realistic style to address this issue we adopt a latent space exploration of stylegan with a two stage training strategy we consider the input strokes of a freehand sketch to correspond to edge information related attributes in the latent structural code of stylegan and term the matching between strokes and these attributes stroke level disentanglement in the first stage we trained an image encoder with the pre trained stylegan model as a teacher encoder in the second stage we simulated the drawing process of the generated images without any additional data labels and trained the sketch encoder for incomplete progressive sketches to generate high quality portrait images with feature alignment to the disentangled representations in the teacher encoder we verified the proposed progressive system with both qualitative and quantitative evaluations and achieved high quality anime portraits from incomplete progressive sketches our user study proved its effectiveness in art creation assistance for the anime style marking anything application of point cloud in extracting video target features authors xiangchun xu subjects computer vision and pattern recognition cs cv image and video processing eess iv arxiv link pdf link abstract extracting retrievable features from video is of great significance for structured video database construction video copyright protection and fake video rumor refutation inspired by point cloud data processing this paper proposes a method for marking anything ma in the video which can extract the contour features of any target in the video and convert it into a feature vector with a length of that can be retrieved the algorithm uses yolo algorithm multi object tracking algorithm and pointnet to extract contour of the video detection target to form spatial point cloud data then extract the point cloud feature vector and use it as the retrievable feature of the video detection target in order to verify the effectiveness and robustness of contour feature some datasets are crawled from dou yin and kinetics dataset as experimental data for dou yin s homogenized videos the proposed contour features achieve retrieval accuracy higher than in return mode for videos from kinetics the contour feature also showed good robustness for partial clip mode video tracing hidden biases of end to end driving models authors bernhard jaeger kashyap chitta andreas geiger subjects computer vision and pattern recognition cs cv artificial intelligence cs ai machine learning cs lg robotics cs ro arxiv link pdf link abstract end to end driving systems have recently made rapid progress in particular on carla independent of their major contribution they introduce changes to minor system components consequently the source of improvements is unclear we identify two biases that recur in nearly all state of the art methods and are critical for the observed progress on carla lateral recovery via a strong inductive bias towards target point following and longitudinal averaging of multimodal waypoint predictions for slowing down we investigate the drawbacks of these biases and identify principled alternatives by incorporating our insights we develop tf a simple end to end method that ranks first on the and lav benchmarks gaining driving score over the best prior work on keyword raw image there is no result
| 1
|
14,345
| 17,371,607,233
|
IssuesEvent
|
2021-07-30 14:41:38
|
GoogleCloudPlatform/dotnet-docs-samples
|
https://api.github.com/repos/GoogleCloudPlatform/dotnet-docs-samples
|
closed
|
Storage: HMAC tests not cleaning up after themselves. HMAC keys limit reached.
|
api: storage priority: p1 samples type: process
|
Seems like HMAC tests are not properly deleting HMAC keys and we have reached limit. All HMAC keys related tests are failing.
Sample [CI output](https://source.cloud.google.com/results/invocations/00fb02fd-8e97-40af-b459-c95f324ef2dd/targets/github%2Fdotnet-docs-samples%2Fstorage%2Fapi%2FStorage.Samples.Tests%2FTestResults/tests).
|
1.0
|
Storage: HMAC tests not cleaning up after themselves. HMAC keys limit reached. - Seems like HMAC tests are not properly deleting HMAC keys and we have reached limit. All HMAC keys related tests are failing.
Sample [CI output](https://source.cloud.google.com/results/invocations/00fb02fd-8e97-40af-b459-c95f324ef2dd/targets/github%2Fdotnet-docs-samples%2Fstorage%2Fapi%2FStorage.Samples.Tests%2FTestResults/tests).
|
process
|
storage hmac tests not cleaning up after themselves hmac keys limit reached seems like hmac tests are not properly deleting hmac keys and we have reached limit all hmac keys related tests are failing sample
| 1
|
8,547
| 11,723,543,306
|
IssuesEvent
|
2020-03-10 09:19:08
|
TOMP-WG/TOMP-API
|
https://api.github.com/repos/TOMP-WG/TOMP-API
|
closed
|
Use tags and branches for releases
|
process
|
As mentioned in the last meeting, we now have a whole bunch of files in the repository that are just there to contain old versions. By correctly tagging old commits with versions (and using branches from those commits for possible patch releases) we can keep a cleaner repository and utilise git's main features better.
Concretely, I propose that we remove the following directories and files:
components/schemas
depricated - Paths
depricated - components
tools
TOMP-API-1.1.1.yaml
TOMP-API-1.1.2.yaml
TOMP-API-1.1.yaml
TOMP-API-1.2.yaml
swagger 1.0.8.yaml
and add tags to the commits that released these versions.
This will make it very simple for someone to implement older versions (from now on, that is), as they could get any version >= 1.2 by doing `git checkout vx.x.x` and then whatever is in `TOMP-API.yaml` would be that version.
It would also make future changes to a maintained version clearer, as those would be in their own branch separate from development on the latest version.
This issue is somewhat related to #102 as both would work together to make our versioning and releases clearer to users of our API.
|
1.0
|
Use tags and branches for releases - As mentioned in the last meeting, we now have a whole bunch of files in the repository that are just there to contain old versions. By correctly tagging old commits with versions (and using branches from those commits for possible patch releases) we can keep a cleaner repository and utilise git's main features better.
Concretely, I propose that we remove the following directories and files:
components/schemas
depricated - Paths
depricated - components
tools
TOMP-API-1.1.1.yaml
TOMP-API-1.1.2.yaml
TOMP-API-1.1.yaml
TOMP-API-1.2.yaml
swagger 1.0.8.yaml
and add tags to the commits that released these versions.
This will make it very simple for someone to implement older versions (from now on, that is), as they could get any version >= 1.2 by doing `git checkout vx.x.x` and then whatever is in `TOMP-API.yaml` would be that version.
It would also make future changes to a maintained version clearer, as those would be in their own branch separate from development on the latest version.
This issue is somewhat related to #102 as both would work together to make our versioning and releases clearer to users of our API.
|
process
|
use tags and branches for releases as mentioned in the last meeting we now have a whole bunch of files in the repository that are just there to contain old versions by correctly tagging old commits with versions and using branches from those commits for possible patch releases we can keep a cleaner repository and utilise git s main features better concretely i propose that we remove the following directories and files components schemas depricated paths depricated components tools tomp api yaml tomp api yaml tomp api yaml tomp api yaml swagger yaml and add tags to the commits that released these versions this will make it very simple for someone to implement older versions from now on that is as they could get any version by doing git checkout vx x x and then whatever is in tomp api yaml would be that version it would also make future changes to a maintained version clearer as those would be in their own branch separate from development on the latest version this issue is somewhat related to as both would work together to make our versioning and releases clearer to users of our api
| 1
|
12,279
| 14,790,390,747
|
IssuesEvent
|
2021-01-12 11:58:17
|
prisma/prisma
|
https://api.github.com/repos/prisma/prisma
|
closed
|
Response of `count` queries changes when you have a middleware
|
process/candidate
|
<!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: https://pris.ly/d/bug-reports
-->
## Bug description
When you use a middleware (even an "empty" one), it changes the response of `prisma.model.count()` queries.
## How to reproduce
Here are two scripts that should produce the same output, but don't:
```
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
const main = async () => {
console.log(await prisma.user.count());
};
main()
```
Output: `20` (expected)
vs.
```
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
prisma.$use((params, next) => next(params));
const main = async () => {
console.log(await prisma.user.count());
};
main()
```
Output: `{ _all: 20 }` (unexpected)
## Expected behavior
The output of both scripts should be `20`
## Prisma information
The schema is not relevant, I can observe this with multiple schemas
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: macOS
- Database: Postgres (but the issue does not depend on this)
- Node.js version: 14.15.1
- Prisma version:
```
@prisma/cli : 2.15.0-dev.19
@prisma/client : 2.15.0-dev.19
Current platform : darwin
Query Engine : query-engine 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/query-engine-darwin)
Migration Engine : migration-engine-cli 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/migration-engine-darwin)
Introspection Engine : introspection-core 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/introspection-engine-darwin)
Format Binary : prisma-fmt 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/prisma-fmt-darwin)
Studio : 0.332.0
```
|
1.0
|
Response of `count` queries changes when you have a middleware - <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: https://pris.ly/d/bug-reports
-->
## Bug description
When you use a middleware (even an "empty" one), it changes the response of `prisma.model.count()` queries.
## How to reproduce
Here are two scripts that should produce the same output, but don't:
```
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
const main = async () => {
console.log(await prisma.user.count());
};
main()
```
Output: `20` (expected)
vs.
```
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
prisma.$use((params, next) => next(params));
const main = async () => {
console.log(await prisma.user.count());
};
main()
```
Output: `{ _all: 20 }` (unexpected)
## Expected behavior
The output of both scripts should be `20`
## Prisma information
The schema is not relevant, I can observe this with multiple schemas
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: macOS
- Database: Postgres (but the issue does not depend on this)
- Node.js version: 14.15.1
- Prisma version:
```
@prisma/cli : 2.15.0-dev.19
@prisma/client : 2.15.0-dev.19
Current platform : darwin
Query Engine : query-engine 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/query-engine-darwin)
Migration Engine : migration-engine-cli 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/migration-engine-darwin)
Introspection Engine : introspection-core 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/introspection-engine-darwin)
Format Binary : prisma-fmt 6b6ad7413a6b0c825e89eeac9adeb28830b1babb (at node_modules/@prisma/engines/prisma-fmt-darwin)
Studio : 0.332.0
```
|
process
|
response of count queries changes when you have a middleware thanks for helping us improve prisma 🙏 please follow the sections in the template and provide as much information as possible about your problem e g by setting the debug environment variable and enabling additional logging output in prisma client learn more about writing proper bug reports here bug description when you use a middleware even an empty one it changes the response of prisma model count queries how to reproduce here are two scripts that should produce the same output but don t import prismaclient from prisma client const prisma new prismaclient const main async console log await prisma user count main output expected vs import prismaclient from prisma client const prisma new prismaclient prisma use params next next params const main async console log await prisma user count main output all unexpected expected behavior the output of both scripts should be prisma information the schema is not relevant i can observe this with multiple schemas environment setup os macos database postgres but the issue does not depend on this node js version prisma version prisma cli dev prisma client dev current platform darwin query engine query engine at node modules prisma engines query engine darwin migration engine migration engine cli at node modules prisma engines migration engine darwin introspection engine introspection core at node modules prisma engines introspection engine darwin format binary prisma fmt at node modules prisma engines prisma fmt darwin studio
| 1
|
15,905
| 20,110,346,352
|
IssuesEvent
|
2022-02-07 14:33:35
|
bazelbuild/bazel
|
https://api.github.com/repos/bazelbuild/bazel
|
closed
|
bzlmod: can one extension depend on side-effect of another?
|
type: support / not a bug (process) team-ExternalDeps untriaged area-Bzlmod
|
From the error messages, it's hard to tell what's happening. I'll do my best to make this reproducible.
Today in `WORKSPACE` it's often the case that a repository rule creates a repository which the user loads from. For example in
https://github.com/aspect-build/rules_swc/releases/tag/v0.2.0
The user calls
```
load("@aspect_rules_swc//swc:repositories.bzl", "swc_register_toolchains")
swc_register_toolchains(
name = "swc",
swc_version = "v1.2.118",
)
```
which creates a `swc_cli` repository. Then the user must load from there:
```
# Fetches the npm packages needed to run @swc/cli
load("@swc_cli//:repositories.bzl", _swc_cli_deps = "npm_repositories")
_swc_cli_deps()
```
This can't happen in one starlark file because the load of `@swc_cli` is only possible after the execution of `swc_register_toolchains`.
I'm trying to convert this usage to bzlmod. I assume that a similar pattern can be done, where two different extensions are called from different starlark files:
https://github.com/aspect-build/bazel-central-registry/blob/main/modules/aspect_rules_swc/0.2.0/MODULE.bazel#L14-L18
However this is failing with only a very short error, not really enough to understand the problem:
```
ERROR: Failed to load Starlark extension '@aspect_rules_swc.0.2.0.swc.swc_cli//:repositories.bzl'.
ERROR: Analysis of target '//:transpile' failed; build aborted
```
as can be seen in context here:
https://buildkite.com/bazel/bcr-presubmit/builds/121#f117a260-ba25-4547-946d-ad69fdee183c
My best guess is that the extension call to create the `swc_cli` repository in `use_repo(npm, "swc_cli")` is not actually creating the `swc_cli` repository at this time, so the subsequent call to the second extension can't resolve the load statement?
|
1.0
|
bzlmod: can one extension depend on side-effect of another? - From the error messages, it's hard to tell what's happening. I'll do my best to make this reproducible.
Today in `WORKSPACE` it's often the case that a repository rule creates a repository which the user loads from. For example in
https://github.com/aspect-build/rules_swc/releases/tag/v0.2.0
The user calls
```
load("@aspect_rules_swc//swc:repositories.bzl", "swc_register_toolchains")
swc_register_toolchains(
name = "swc",
swc_version = "v1.2.118",
)
```
which creates a `swc_cli` repository. Then the user must load from there:
```
# Fetches the npm packages needed to run @swc/cli
load("@swc_cli//:repositories.bzl", _swc_cli_deps = "npm_repositories")
_swc_cli_deps()
```
This can't happen in one starlark file because the load of `@swc_cli` is only possible after the execution of `swc_register_toolchains`.
I'm trying to convert this usage to bzlmod. I assume that a similar pattern can be done, where two different extensions are called from different starlark files:
https://github.com/aspect-build/bazel-central-registry/blob/main/modules/aspect_rules_swc/0.2.0/MODULE.bazel#L14-L18
However this is failing with only a very short error, not really enough to understand the problem:
```
ERROR: Failed to load Starlark extension '@aspect_rules_swc.0.2.0.swc.swc_cli//:repositories.bzl'.
ERROR: Analysis of target '//:transpile' failed; build aborted
```
as can be seen in context here:
https://buildkite.com/bazel/bcr-presubmit/builds/121#f117a260-ba25-4547-946d-ad69fdee183c
My best guess is that the extension call to create the `swc_cli` repository in `use_repo(npm, "swc_cli")` is not actually creating the `swc_cli` repository at this time, so the subsequent call to the second extension can't resolve the load statement?
|
process
|
bzlmod can one extension depend on side effect of another from the error messages it s hard to tell what s happening i ll do my best to make this reproducible today in workspace it s often the case that a repository rule creates a repository which the user loads from for example in the user calls load aspect rules swc swc repositories bzl swc register toolchains swc register toolchains name swc swc version which creates a swc cli repository then the user must load from there fetches the npm packages needed to run swc cli load swc cli repositories bzl swc cli deps npm repositories swc cli deps this can t happen in one starlark file because the load of swc cli is only possible after the execution of swc register toolchains i m trying to convert this usage to bzlmod i assume that a similar pattern can be done where two different extensions are called from different starlark files however this is failing with only a very short error not really enough to understand the problem error failed to load starlark extension aspect rules swc swc swc cli repositories bzl error analysis of target transpile failed build aborted as can be seen in context here my best guess is that the extension call to create the swc cli repository in use repo npm swc cli is not actually creating the swc cli repository at this time so the subsequent call to the second extension can t resolve the load statement
| 1
|
14,812
| 18,144,021,652
|
IssuesEvent
|
2021-09-25 04:58:11
|
edmobe/android-video-magnification
|
https://api.github.com/repos/edmobe/android-video-magnification
|
closed
|
PR-0004 OpenCV no abre el vídeo, pero antes sí lo hacía
|
video-processing problem
|
Se muestra el siguiente error en consola:
```
E/cv::error(): OpenCV(4.5.3) Error: Requested object was not found (could not open directory: /data/app/com.example.videomagnification-Rg1L4AgNNhczgpK1kZy9Ow==/base.apk!/lib/arm64-v8a) in glob_rec, file /build/master_pack-android/opencv/modules/core/src/glob.cpp, line 279
```
|
1.0
|
PR-0004 OpenCV no abre el vídeo, pero antes sí lo hacía - Se muestra el siguiente error en consola:
```
E/cv::error(): OpenCV(4.5.3) Error: Requested object was not found (could not open directory: /data/app/com.example.videomagnification-Rg1L4AgNNhczgpK1kZy9Ow==/base.apk!/lib/arm64-v8a) in glob_rec, file /build/master_pack-android/opencv/modules/core/src/glob.cpp, line 279
```
|
process
|
pr opencv no abre el vídeo pero antes sí lo hacía se muestra el siguiente error en consola e cv error opencv error requested object was not found could not open directory data app com example videomagnification base apk lib in glob rec file build master pack android opencv modules core src glob cpp line
| 1
|
6,490
| 8,774,609,059
|
IssuesEvent
|
2018-12-18 20:20:45
|
wavesoftware/java-eid-exceptions
|
https://api.github.com/repos/wavesoftware/java-eid-exceptions
|
closed
|
Better, clean library structure
|
incompatibile quality
|
Actualy library consist of Eid object that holds to much responsibility. That's primary function but as well configuration and logging.
There is also issue with `tryToExecute` methods as they are in EidPreconditions. There should be other class introduced as their function isn't a precondition but execution wrapper.
|
True
|
Better, clean library structure - Actualy library consist of Eid object that holds to much responsibility. That's primary function but as well configuration and logging.
There is also issue with `tryToExecute` methods as they are in EidPreconditions. There should be other class introduced as their function isn't a precondition but execution wrapper.
|
non_process
|
better clean library structure actualy library consist of eid object that holds to much responsibility that s primary function but as well configuration and logging there is also issue with trytoexecute methods as they are in eidpreconditions there should be other class introduced as their function isn t a precondition but execution wrapper
| 0
|
8,471
| 11,642,030,609
|
IssuesEvent
|
2020-02-29 05:18:58
|
dotnet/runtime
|
https://api.github.com/repos/dotnet/runtime
|
closed
|
Test System.ServiceProcess.Tests.ServiceBaseTests.TestOnStartWithArgsThenStop failed with "System.AggregateException : One or more errors occurred. (Task timed out after 60000)\r\n".
|
area-System.ServiceProcess test-run-core untriaged
|
Test: System.ServiceProcess.Tests.ServiceBaseTests.TestOnStartWithArgsThenStop has failed.
MESSAGE:
System.AggregateException : One or more errors occurred. (Task timed out after 60000)\r\n---- System.TimeoutException : Task timed out after 60000
+++++++++++++++++++
STACK TRACE:
at System.Threading.Tasks.Task`1.GetResultCore(Boolean waitCompletionNotification) in E:\A\_work\5\s\src\mscorlib\src\System\Threading\Tasks\future.cs:line 493 at System.ServiceProcess.Tests.TestServiceProvider.GetByte() in D:\j\workspace\outerloop_net---dbe8fad8\src\System.ServiceProcess.ServiceController\tests\TestServiceProvider.cs:line 89 at System.ServiceProcess.Tests.ServiceBaseTests.TestOnStartWithArgsThenStop() in D:\j\workspace\outerloop_net---dbe8fad8\src\System.ServiceProcess.ServiceController\tests\ServiceBaseTests.cs:line 98 ----- Inner Stack Trace ----- at System.Threading.Tasks.TaskTimeoutExtensions.TimeoutAfter(Task task, Int32 millisecondsTimeout) in D:\j\workspace\outerloop_net---dbe8fad8\src\Common\tests\System\Threading\Tasks\TaskTimeoutExtensions.cs:line 26 at System.ServiceProcess.Tests.TestServiceProvider.ReadPipeAsync() in D:\j\workspace\outerloop_net---dbe8fad8\src\System.ServiceProcess.ServiceController\tests\TestServiceProvider.cs:line 85
Details: https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_netcoreapp_windows_nt_debug/389/testReport/System.ServiceProcess.Tests/ServiceBaseTests/TestOnStartWithArgsThenStop/
|
1.0
|
Test System.ServiceProcess.Tests.ServiceBaseTests.TestOnStartWithArgsThenStop failed with "System.AggregateException : One or more errors occurred. (Task timed out after 60000)\r\n". - Test: System.ServiceProcess.Tests.ServiceBaseTests.TestOnStartWithArgsThenStop has failed.
MESSAGE:
System.AggregateException : One or more errors occurred. (Task timed out after 60000)\r\n---- System.TimeoutException : Task timed out after 60000
+++++++++++++++++++
STACK TRACE:
at System.Threading.Tasks.Task`1.GetResultCore(Boolean waitCompletionNotification) in E:\A\_work\5\s\src\mscorlib\src\System\Threading\Tasks\future.cs:line 493 at System.ServiceProcess.Tests.TestServiceProvider.GetByte() in D:\j\workspace\outerloop_net---dbe8fad8\src\System.ServiceProcess.ServiceController\tests\TestServiceProvider.cs:line 89 at System.ServiceProcess.Tests.ServiceBaseTests.TestOnStartWithArgsThenStop() in D:\j\workspace\outerloop_net---dbe8fad8\src\System.ServiceProcess.ServiceController\tests\ServiceBaseTests.cs:line 98 ----- Inner Stack Trace ----- at System.Threading.Tasks.TaskTimeoutExtensions.TimeoutAfter(Task task, Int32 millisecondsTimeout) in D:\j\workspace\outerloop_net---dbe8fad8\src\Common\tests\System\Threading\Tasks\TaskTimeoutExtensions.cs:line 26 at System.ServiceProcess.Tests.TestServiceProvider.ReadPipeAsync() in D:\j\workspace\outerloop_net---dbe8fad8\src\System.ServiceProcess.ServiceController\tests\TestServiceProvider.cs:line 85
Details: https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_netcoreapp_windows_nt_debug/389/testReport/System.ServiceProcess.Tests/ServiceBaseTests/TestOnStartWithArgsThenStop/
|
process
|
test system serviceprocess tests servicebasetests testonstartwithargsthenstop failed with system aggregateexception one or more errors occurred task timed out after r n test system serviceprocess tests servicebasetests testonstartwithargsthenstop has failed message system aggregateexception one or more errors occurred task timed out after r n system timeoutexception task timed out after stack trace at system threading tasks task getresultcore boolean waitcompletionnotification in e a work s src mscorlib src system threading tasks future cs line at system serviceprocess tests testserviceprovider getbyte in d j workspace outerloop net src system serviceprocess servicecontroller tests testserviceprovider cs line at system serviceprocess tests servicebasetests testonstartwithargsthenstop in d j workspace outerloop net src system serviceprocess servicecontroller tests servicebasetests cs line inner stack trace at system threading tasks tasktimeoutextensions timeoutafter task task millisecondstimeout in d j workspace outerloop net src common tests system threading tasks tasktimeoutextensions cs line at system serviceprocess tests testserviceprovider readpipeasync in d j workspace outerloop net src system serviceprocess servicecontroller tests testserviceprovider cs line details
| 1
|
114,262
| 17,197,725,813
|
IssuesEvent
|
2021-07-16 20:16:15
|
zulip/zulip
|
https://api.github.com/repos/zulip/zulip
|
opened
|
Restrict requests with RemoteZulipServer auth to zilencer and corporate views
|
area: security
|
RemoteZulipServer auth has higher rate-limits than unauth'd requests -- but we do not restrict such requests from hitting other endpoints.
Much as we have a `allow_webhook_access=False` flag, we should also have a `allow_remoteserver_access=False` flag, and only set that on to True for endpoints which are valid for remote server access (i.e. the push bouncer endpoints).
|
True
|
Restrict requests with RemoteZulipServer auth to zilencer and corporate views - RemoteZulipServer auth has higher rate-limits than unauth'd requests -- but we do not restrict such requests from hitting other endpoints.
Much as we have a `allow_webhook_access=False` flag, we should also have a `allow_remoteserver_access=False` flag, and only set that on to True for endpoints which are valid for remote server access (i.e. the push bouncer endpoints).
|
non_process
|
restrict requests with remotezulipserver auth to zilencer and corporate views remotezulipserver auth has higher rate limits than unauth d requests but we do not restrict such requests from hitting other endpoints much as we have a allow webhook access false flag we should also have a allow remoteserver access false flag and only set that on to true for endpoints which are valid for remote server access i e the push bouncer endpoints
| 0
|
4,853
| 7,743,310,432
|
IssuesEvent
|
2018-05-29 12:27:25
|
nodejs/node
|
https://api.github.com/repos/nodejs/node
|
closed
|
Investigate test-child-process-fork-closed-channel-segfault
|
CI / flaky test child_process test windows
|
https://ci.nodejs.org/job/node-test-binary-windows/17414/COMPILED_BY=vs2017,RUNNER=win2016,RUN_SUBSET=3/console
```
not ok 51 parallel/test-child-process-fork-closed-channel-segfault
---
duration_ms: 0.259
severity: fail
exitcode: 1
stack: |-
c:\workspace\node-test-binary-windows\test\parallel\test-child-process-fork-closed-channel-segfault.js:70
throw err;
^
Error: write EMFILE
at ChildProcess.target._send (internal/child_process.js:741:20)
at ChildProcess.target.send (internal/child_process.js:625:19)
at Worker.send (internal/cluster/worker.js:40:28)
at Socket.<anonymous> (c:\workspace\node-test-binary-windows\test\parallel\test-child-process-fork-closed-channel-segfault.js:36:16)
at Object.onceWrapper (events.js:273:13)
at Socket.emit (events.js:182:13)
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1147:10)
```
Likely related:
```
not ok 52 parallel/test-child-process-fork-net
---
duration_ms: 0.354
severity: fail
exitcode: 1
stack: |-
PARENT: server listening
CHILD: server listening
CLIENT: connected
PARENT: got connection
CLIENT: connected
CHILD: got connection
CLIENT: closed
CHILD: got connection
CHILD: got connection
CLIENT: closed
CLIENT: connected
CLIENT: connected
CLIENT: closed
CLIENT: closed
PARENT: server closed
CHILD: got socket
CLIENT: got data
CLIENT: closed
testSocket, listening
events.js:167
throw er; // Unhandled 'error' event
^
Error: write EPIPE
at ChildProcess.target._send (internal/child_process.js:741:20)
at ChildProcess.target.send (internal/child_process.js:625:19)
at SocketListSend._request (internal/socket_list.js:20:16)
at SocketListSend.close (internal/socket_list.js:40:10)
at Server.close (net.js:1624:24)
at Socket.<anonymous> (c:\workspace\node-test-binary-windows\test\parallel\test-child-process-fork-net.js:179:16)
at Socket.emit (events.js:182:13)
at TCP._handle.close [as _onclose] (net.js:596:12)
Emitted 'error' event at:
at process.nextTick (internal/child_process.js:745:39)
at process._tickCallback (internal/process/next_tick.js:61:11)
```
|
1.0
|
Investigate test-child-process-fork-closed-channel-segfault - https://ci.nodejs.org/job/node-test-binary-windows/17414/COMPILED_BY=vs2017,RUNNER=win2016,RUN_SUBSET=3/console
```
not ok 51 parallel/test-child-process-fork-closed-channel-segfault
---
duration_ms: 0.259
severity: fail
exitcode: 1
stack: |-
c:\workspace\node-test-binary-windows\test\parallel\test-child-process-fork-closed-channel-segfault.js:70
throw err;
^
Error: write EMFILE
at ChildProcess.target._send (internal/child_process.js:741:20)
at ChildProcess.target.send (internal/child_process.js:625:19)
at Worker.send (internal/cluster/worker.js:40:28)
at Socket.<anonymous> (c:\workspace\node-test-binary-windows\test\parallel\test-child-process-fork-closed-channel-segfault.js:36:16)
at Object.onceWrapper (events.js:273:13)
at Socket.emit (events.js:182:13)
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1147:10)
```
Likely related:
```
not ok 52 parallel/test-child-process-fork-net
---
duration_ms: 0.354
severity: fail
exitcode: 1
stack: |-
PARENT: server listening
CHILD: server listening
CLIENT: connected
PARENT: got connection
CLIENT: connected
CHILD: got connection
CLIENT: closed
CHILD: got connection
CHILD: got connection
CLIENT: closed
CLIENT: connected
CLIENT: connected
CLIENT: closed
CLIENT: closed
PARENT: server closed
CHILD: got socket
CLIENT: got data
CLIENT: closed
testSocket, listening
events.js:167
throw er; // Unhandled 'error' event
^
Error: write EPIPE
at ChildProcess.target._send (internal/child_process.js:741:20)
at ChildProcess.target.send (internal/child_process.js:625:19)
at SocketListSend._request (internal/socket_list.js:20:16)
at SocketListSend.close (internal/socket_list.js:40:10)
at Server.close (net.js:1624:24)
at Socket.<anonymous> (c:\workspace\node-test-binary-windows\test\parallel\test-child-process-fork-net.js:179:16)
at Socket.emit (events.js:182:13)
at TCP._handle.close [as _onclose] (net.js:596:12)
Emitted 'error' event at:
at process.nextTick (internal/child_process.js:745:39)
at process._tickCallback (internal/process/next_tick.js:61:11)
```
|
process
|
investigate test child process fork closed channel segfault not ok parallel test child process fork closed channel segfault duration ms severity fail exitcode stack c workspace node test binary windows test parallel test child process fork closed channel segfault js throw err error write emfile at childprocess target send internal child process js at childprocess target send internal child process js at worker send internal cluster worker js at socket c workspace node test binary windows test parallel test child process fork closed channel segfault js at object oncewrapper events js at socket emit events js at tcpconnectwrap afterconnect net js likely related not ok parallel test child process fork net duration ms severity fail exitcode stack parent server listening child server listening client connected parent got connection client connected child got connection client closed child got connection child got connection client closed client connected client connected client closed client closed parent server closed child got socket client got data client closed testsocket listening events js throw er unhandled error event error write epipe at childprocess target send internal child process js at childprocess target send internal child process js at socketlistsend request internal socket list js at socketlistsend close internal socket list js at server close net js at socket c workspace node test binary windows test parallel test child process fork net js at socket emit events js at tcp handle close net js emitted error event at at process nexttick internal child process js at process tickcallback internal process next tick js
| 1
|
37,288
| 15,227,067,496
|
IssuesEvent
|
2021-02-18 09:43:30
|
LiskHQ/lisk-service
|
https://api.github.com/repos/LiskHQ/lisk-service
|
closed
|
Update transaction index on block arrival
|
service/core type: groomed type: improvement
|
### Description
Each block that contains transactions needs to be retrieved from Lisk Core and indexed in the transaction database.
### Motivation
- Proper event propagation is required by UI clients
### Acceptance Criteria
- A new block with transactions triggers the event
- Subscribe API is updated
|
1.0
|
Update transaction index on block arrival - ### Description
Each block that contains transactions needs to be retrieved from Lisk Core and indexed in the transaction database.
### Motivation
- Proper event propagation is required by UI clients
### Acceptance Criteria
- A new block with transactions triggers the event
- Subscribe API is updated
|
non_process
|
update transaction index on block arrival description each block that contains transactions needs to be retrieved from lisk core and indexed in the transaction database motivation proper event propagation is required by ui clients acceptance criteria a new block with transactions triggers the event subscribe api is updated
| 0
|
106,514
| 16,681,707,846
|
IssuesEvent
|
2021-06-08 01:10:28
|
yael-lindman/jenkins
|
https://api.github.com/repos/yael-lindman/jenkins
|
opened
|
CVE-2014-1904 (Medium) detected in spring-webmvc-2.5.6.SEC03.jar
|
security vulnerability
|
## CVE-2014-1904 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-webmvc-2.5.6.SEC03.jar</b></p></summary>
<p>Spring Framework: Web MVC</p>
<p>Library home page: <a href="http://www.springframework.org">http://www.springframework.org</a></p>
<p>Path to dependency file: jenkins/war/pom.xml</p>
<p>Path to vulnerable library: jenkins/war/target/jenkins/WEB-INF/lib/spring-webmvc-2.5.6.SEC03.jar,/home/wss-scanner/.m2/repository/org/springframework/spring-webmvc/2.5.6.SEC03/spring-webmvc-2.5.6.SEC03.jar,canner/.m2/repository/org/springframework/spring-webmvc/2.5.6.SEC03/spring-webmvc-2.5.6.SEC03.jar</p>
<p>
Dependency Hierarchy:
- :x: **spring-webmvc-2.5.6.SEC03.jar** (Vulnerable Library)
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Cross-site scripting (XSS) vulnerability in web/servlet/tags/form/FormTag.java in Spring MVC in Spring Framework 3.0.0 before 3.2.8 and 4.0.0 before 4.0.2 allows remote attackers to inject arbitrary web script or HTML via the requested URI in a default action.
<p>Publish Date: 2014-03-20
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2014-1904>CVE-2014-1904</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 2 Score Details (<b>4.3</b>)</summary>
<p>
Base Score Metrics not available</p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://tanzu.vmware.com/security/cve-2014-1904">https://tanzu.vmware.com/security/cve-2014-1904</a></p>
<p>Release Date: 2014-03-20</p>
<p>Fix Resolution: org.springframework:spring-webmvc:3.2.8.RELEASE,4.0.2.RELEASE</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2014-1904 (Medium) detected in spring-webmvc-2.5.6.SEC03.jar - ## CVE-2014-1904 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-webmvc-2.5.6.SEC03.jar</b></p></summary>
<p>Spring Framework: Web MVC</p>
<p>Library home page: <a href="http://www.springframework.org">http://www.springframework.org</a></p>
<p>Path to dependency file: jenkins/war/pom.xml</p>
<p>Path to vulnerable library: jenkins/war/target/jenkins/WEB-INF/lib/spring-webmvc-2.5.6.SEC03.jar,/home/wss-scanner/.m2/repository/org/springframework/spring-webmvc/2.5.6.SEC03/spring-webmvc-2.5.6.SEC03.jar,canner/.m2/repository/org/springframework/spring-webmvc/2.5.6.SEC03/spring-webmvc-2.5.6.SEC03.jar</p>
<p>
Dependency Hierarchy:
- :x: **spring-webmvc-2.5.6.SEC03.jar** (Vulnerable Library)
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Cross-site scripting (XSS) vulnerability in web/servlet/tags/form/FormTag.java in Spring MVC in Spring Framework 3.0.0 before 3.2.8 and 4.0.0 before 4.0.2 allows remote attackers to inject arbitrary web script or HTML via the requested URI in a default action.
<p>Publish Date: 2014-03-20
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2014-1904>CVE-2014-1904</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 2 Score Details (<b>4.3</b>)</summary>
<p>
Base Score Metrics not available</p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://tanzu.vmware.com/security/cve-2014-1904">https://tanzu.vmware.com/security/cve-2014-1904</a></p>
<p>Release Date: 2014-03-20</p>
<p>Fix Resolution: org.springframework:spring-webmvc:3.2.8.RELEASE,4.0.2.RELEASE</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve medium detected in spring webmvc jar cve medium severity vulnerability vulnerable library spring webmvc jar spring framework web mvc library home page a href path to dependency file jenkins war pom xml path to vulnerable library jenkins war target jenkins web inf lib spring webmvc jar home wss scanner repository org springframework spring webmvc spring webmvc jar canner repository org springframework spring webmvc spring webmvc jar dependency hierarchy x spring webmvc jar vulnerable library found in base branch master vulnerability details cross site scripting xss vulnerability in web servlet tags form formtag java in spring mvc in spring framework before and before allows remote attackers to inject arbitrary web script or html via the requested uri in a default action publish date url a href cvss score details base score metrics not available suggested fix type upgrade version origin a href release date fix resolution org springframework spring webmvc release release step up your open source security game with whitesource
| 0
|
20,895
| 27,725,913,090
|
IssuesEvent
|
2023-03-15 02:10:33
|
quark-engine/quark-engine
|
https://api.github.com/repos/quark-engine/quark-engine
|
closed
|
Can't retrieve all class_name/method_name/descriptor by Quark apkinfo find_method.
|
bug test-required work-in-progress issue-processing-state-03
|
**Describe the bug**
Cannot retrieve all in apkinfo.find_method.
**To Reproduce**
``` python
from quark.script import Method, _getQuark, findMethodInAPK
SAMPLE_PATH = "app-debug.apk"
quark = _getQuark(SAMPLE_PATH)
method = quark.apkinfo.find_method(
class_name="",
method_name="onReceive",
descriptor="(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 1 = {method}")
quark = _getQuark(SAMPLE_PATH)
method = quark.apkinfo.find_method(
class_name=".*",
method_name="onReceive",
descriptor="(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 2 = {method}")
method = quark.apkinfo.find_method(
method_name="onReceive",
descriptor="(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 3 = {method}")
method = quark.apkinfo.find_method(
"",
"onReceive",
"(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 4 = {method}")
method = quark.apkinfo.find_method(
".*",
"onReceive",
"(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 5 = {method}")
```
**Expected behavior**
I expected all returns to be the same, but here is the outcome.
``` text
lv 1 = Landroid/support/v4/media/TransportMediatorJellybeanMR2$3; onReceive (Landroid/content/Context; Landroid/content/Intent;)V
lv 2 = None
lv 3 = None
lv 4 = Landroid/support/v4/media/TransportMediatorJellybeanMR2$3; onReceive (Landroid/content/Context; Landroid/content/Intent;)V
lv 5 = None
```
**Desktop (please complete the following information):**
- OS: Windows 11
- Python: 3.8
- Sample: [InsecureBankv2](https://github.com/dineshshetty/Android-InsecureBankv2/tree/master/InsecureBankv2)
|
1.0
|
Can't retrieve all class_name/method_name/descriptor by Quark apkinfo find_method. - **Describe the bug**
Cannot retrieve all in apkinfo.find_method.
**To Reproduce**
``` python
from quark.script import Method, _getQuark, findMethodInAPK
SAMPLE_PATH = "app-debug.apk"
quark = _getQuark(SAMPLE_PATH)
method = quark.apkinfo.find_method(
class_name="",
method_name="onReceive",
descriptor="(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 1 = {method}")
quark = _getQuark(SAMPLE_PATH)
method = quark.apkinfo.find_method(
class_name=".*",
method_name="onReceive",
descriptor="(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 2 = {method}")
method = quark.apkinfo.find_method(
method_name="onReceive",
descriptor="(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 3 = {method}")
method = quark.apkinfo.find_method(
"",
"onReceive",
"(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 4 = {method}")
method = quark.apkinfo.find_method(
".*",
"onReceive",
"(Landroid/content/Context; Landroid/content/Intent;)V"
)
print(f"lv 5 = {method}")
```
**Expected behavior**
I expected all returns to be the same, but here is the outcome.
``` text
lv 1 = Landroid/support/v4/media/TransportMediatorJellybeanMR2$3; onReceive (Landroid/content/Context; Landroid/content/Intent;)V
lv 2 = None
lv 3 = None
lv 4 = Landroid/support/v4/media/TransportMediatorJellybeanMR2$3; onReceive (Landroid/content/Context; Landroid/content/Intent;)V
lv 5 = None
```
**Desktop (please complete the following information):**
- OS: Windows 11
- Python: 3.8
- Sample: [InsecureBankv2](https://github.com/dineshshetty/Android-InsecureBankv2/tree/master/InsecureBankv2)
|
process
|
can t retrieve all class name method name descriptor by quark apkinfo find method describe the bug cannot retrieve all in apkinfo find method to reproduce python from quark script import method getquark findmethodinapk sample path app debug apk quark getquark sample path method quark apkinfo find method class name method name onreceive descriptor landroid content context landroid content intent v print f lv method quark getquark sample path method quark apkinfo find method class name method name onreceive descriptor landroid content context landroid content intent v print f lv method method quark apkinfo find method method name onreceive descriptor landroid content context landroid content intent v print f lv method method quark apkinfo find method onreceive landroid content context landroid content intent v print f lv method method quark apkinfo find method onreceive landroid content context landroid content intent v print f lv method expected behavior i expected all returns to be the same but here is the outcome text lv landroid support media onreceive landroid content context landroid content intent v lv none lv none lv landroid support media onreceive landroid content context landroid content intent v lv none desktop please complete the following information os windows python sample
| 1
|
451,490
| 13,036,859,590
|
IssuesEvent
|
2020-07-28 12:57:51
|
StrangeLoopGames/EcoIssues
|
https://api.github.com/repos/StrangeLoopGames/EcoIssues
|
closed
|
[0.9.0 staging-1636] Web elections: graphs don't match
|
Category: Elections Website Category: Web Priority: High Status: Fixed
|
1. This is how graph looks in the preview for comments
See, this one has bars for actions
2. After saving we don't have this bar here no more
|
1.0
|
[0.9.0 staging-1636] Web elections: graphs don't match - 1. This is how graph looks in the preview for comments

See, this one has bars for actions
2. After saving we don't have this bar here no more

|
non_process
|
web elections graphs don t match this is how graph looks in the preview for comments see this one has bars for actions after saving we don t have this bar here no more
| 0
|
12,059
| 14,739,652,535
|
IssuesEvent
|
2021-01-07 07:39:07
|
kdjstudios/SABillingGitlab
|
https://api.github.com/repos/kdjstudios/SABillingGitlab
|
closed
|
Manual/draft invoice notifications
|
anc-process anp-2 ant-enhancement grt-reports
|
In GitLab by @kdjstudios on Sep 12, 2018, 09:02
Hello Team,
I would like to bring up a reoccurring question that continues to be asked. It is about having multiple invoices in one billing cycle and that there is no way in the GUI that notates which invoice was a manual invoice and is leading to questions being asked and is taking up unnecessary amount of support time.
My thoughts:
- We currently have a notification email when a manual draft invoice in created. This is only being sent to apperrors, it appears.
- We should add the username who created the draft be in the email and also it should go to the site's email and the user's email.
- We should add a notification email when the manual draft invoice is finalized and include the user name who did this and send to both site and user email in addition to apperrors.
- We should show or notate somehow in the gui that the invoice was manually created.
- Billing history page (Maybe add a new column "Manual Invoice" and true or false result.)
- Account Ledger (Maybe add a new column "Manual Invoice" and true or false result.)
- What other places? Reports?
|
1.0
|
Manual/draft invoice notifications - In GitLab by @kdjstudios on Sep 12, 2018, 09:02
Hello Team,
I would like to bring up a reoccurring question that continues to be asked. It is about having multiple invoices in one billing cycle and that there is no way in the GUI that notates which invoice was a manual invoice and is leading to questions being asked and is taking up unnecessary amount of support time.
My thoughts:
- We currently have a notification email when a manual draft invoice in created. This is only being sent to apperrors, it appears.
- We should add the username who created the draft be in the email and also it should go to the site's email and the user's email.
- We should add a notification email when the manual draft invoice is finalized and include the user name who did this and send to both site and user email in addition to apperrors.
- We should show or notate somehow in the gui that the invoice was manually created.
- Billing history page (Maybe add a new column "Manual Invoice" and true or false result.)
- Account Ledger (Maybe add a new column "Manual Invoice" and true or false result.)
- What other places? Reports?
|
process
|
manual draft invoice notifications in gitlab by kdjstudios on sep hello team i would like to bring up a reoccurring question that continues to be asked it is about having multiple invoices in one billing cycle and that there is no way in the gui that notates which invoice was a manual invoice and is leading to questions being asked and is taking up unnecessary amount of support time my thoughts we currently have a notification email when a manual draft invoice in created this is only being sent to apperrors it appears we should add the username who created the draft be in the email and also it should go to the site s email and the user s email we should add a notification email when the manual draft invoice is finalized and include the user name who did this and send to both site and user email in addition to apperrors we should show or notate somehow in the gui that the invoice was manually created billing history page maybe add a new column manual invoice and true or false result account ledger maybe add a new column manual invoice and true or false result what other places reports
| 1
|
14,305
| 17,290,977,259
|
IssuesEvent
|
2021-07-24 18:46:56
|
parcel-bundler/parcel
|
https://api.github.com/repos/parcel-bundler/parcel
|
closed
|
Support tilde ~ in Sass Transformer
|
:raising_hand_woman: Feature CSS Preprocessing Resolver ✨ Parcel 2
|
# 🙋 feature request
Support the `@import '~path/to/styles.scss'` syntax.
## 🤔 Expected Behavior
It should resolved from `node_modules`, it was working this way in Parcel v1.
## 😯 Current Behavior
```
Error: The @import path "~path/to/styles" is using webpack specific syntax, which isn't supported by Parcel.
To @import files from node_modules, use "path/to/styles"
```
The error message is actually incorrect. The tilde syntax is not only from Webpack, VScode also supports it: here's the demo:

## 💁 Possible Solution
Add the tilde ~ support.
## 🔦 Context
https://github.com/sweetalert2/sweetalert2-parcel-demo/blob/master/styles.scss
|
1.0
|
Support tilde ~ in Sass Transformer - # 🙋 feature request
Support the `@import '~path/to/styles.scss'` syntax.
## 🤔 Expected Behavior
It should resolved from `node_modules`, it was working this way in Parcel v1.
## 😯 Current Behavior
```
Error: The @import path "~path/to/styles" is using webpack specific syntax, which isn't supported by Parcel.
To @import files from node_modules, use "path/to/styles"
```
The error message is actually incorrect. The tilde syntax is not only from Webpack, VScode also supports it: here's the demo:

## 💁 Possible Solution
Add the tilde ~ support.
## 🔦 Context
https://github.com/sweetalert2/sweetalert2-parcel-demo/blob/master/styles.scss
|
process
|
support tilde in sass transformer 🙋 feature request support the import path to styles scss syntax 🤔 expected behavior it should resolved from node modules it was working this way in parcel 😯 current behavior error the import path path to styles is using webpack specific syntax which isn t supported by parcel to import files from node modules use path to styles the error message is actually incorrect the tilde syntax is not only from webpack vscode also supports it here s the demo 💁 possible solution add the tilde support 🔦 context
| 1
|
9,535
| 12,504,739,083
|
IssuesEvent
|
2020-06-02 09:30:43
|
zammad/zammad
|
https://api.github.com/repos/zammad/zammad
|
closed
|
Japanese encoding 7-bit iso-2022-jp is processed incorrectly
|
(probably/currently) unfixable 🤯 bug mail processing prioritized by payment third party issue verified waiting for feedback
|
<!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
Please post:
- Feature requests
- Development questions
- Technical questions
on the board -> https://community.zammad.org !
If you think you hit a bug, please continue:
- Search existing issues and the CHANGELOG.md for your issue - there might be a solution already
- Make sure to use the latest version of Zammad if possible
- Add the `log/production.log` file from your system. Attention: Make sure no confidential data is in it!
- Please write the issue in english
- Don't remove the template - otherwise we will close the issue without further comments
- Ask questions about Zammad configuration and usage at our mailinglist. See: https://zammad.org/participate
Note: We always do our best. Unfortunately, sometimes there are too many requests and we can't handle everything at once. If you want to prioritize/escalate your issue, you can do so by means of a support contract (see https://zammad.com/pricing#selfhosted).
* The upper textblock will be removed automatically when you submit your issue *
-->
### Infos:
* Used Zammad version: latest version 2.9.x
* Installation method (source, package, ..): package
* Operating system: CentOS 7.1
* Database + version: Postgres
* Elasticsearch version:
* Browser + version: All browsers
* Ticket-ID: #1042716 (1047950, 1076276)
### Expected behavior:
Normal processing of all japanese language email messages.
### Actual behavior:
While processing email messages encoded with 7-bi iso-2022-jp charset, message is decoded incorrectly.
Assuming issue with mail parser.
Other encoding/charset combinations seem to be working just fine.
### Steps to reproduce the behavior:
Send email to mailbox connected to Zammad queue in 7bit/iso-2022-jp
As already explained, combination of 7-bit encoding and iso-2022-jp charset in email message results in garbled text in corresponding ticket.
For example, below is plaintext of email:
```
--_000_SL2P216MB032969A22C6D22226A7B3613EF740SL2P216MB0329KORP_
Content-Type: text/plain; charset="iso-2022-jp"
Content-Transfer-Encoding: quoted-printable
=1B$B$3$N%"%I%l%9$X$N%a%k%^%,$r2r=3D|$7$F$/$@$5$$!#=1B(B
--_000_SL2P216MB032969A22C6D22226A7B3613EF740SL2P216MB0329KORP_
Content-Type: text/html; charset="iso-2022-jp"
Content-Transfer-Encoding: quoted-printable
<html>
<head>
<meta http-equiv=3D"Content-Type" content=3D"text/html; charset=3Diso-2022-=
jp">
<style type=3D"text/css" style=3D"display:none;"> P {margin-top:0;margin-bo=
ttom:0;} </style>
</head>
<body dir=3D"ltr">
<div style=3D"font-family: Meiryo, =1B$B%a%$%j%*=1B(B, "Hiragino Sans&=
quot;, sans-serif; font-size: 12pt; color: rgb(0, 0, 0);">
=1B$B$3$N%"%I%l%9$X$N%a%k%^%,$r2r=3D|$7$F$/$@$5$$!#=1B(B</div>
</body>
</html>
```
email client will show it as properly formatted HTML message:
```
このアドレスへのメルマガを解除してください。
```
This is how Zammad will show the ticket body:
```
$B$3$N%"%I%l%9$X$N%a%k%^%,$r2r=|$7$F$/$@$5$$!#(B
```
|
1.0
|
Japanese encoding 7-bit iso-2022-jp is processed incorrectly - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
Please post:
- Feature requests
- Development questions
- Technical questions
on the board -> https://community.zammad.org !
If you think you hit a bug, please continue:
- Search existing issues and the CHANGELOG.md for your issue - there might be a solution already
- Make sure to use the latest version of Zammad if possible
- Add the `log/production.log` file from your system. Attention: Make sure no confidential data is in it!
- Please write the issue in english
- Don't remove the template - otherwise we will close the issue without further comments
- Ask questions about Zammad configuration and usage at our mailinglist. See: https://zammad.org/participate
Note: We always do our best. Unfortunately, sometimes there are too many requests and we can't handle everything at once. If you want to prioritize/escalate your issue, you can do so by means of a support contract (see https://zammad.com/pricing#selfhosted).
* The upper textblock will be removed automatically when you submit your issue *
-->
### Infos:
* Used Zammad version: latest version 2.9.x
* Installation method (source, package, ..): package
* Operating system: CentOS 7.1
* Database + version: Postgres
* Elasticsearch version:
* Browser + version: All browsers
* Ticket-ID: #1042716 (1047950, 1076276)
### Expected behavior:
Normal processing of all japanese language email messages.
### Actual behavior:
While processing email messages encoded with 7-bi iso-2022-jp charset, message is decoded incorrectly.
Assuming issue with mail parser.
Other encoding/charset combinations seem to be working just fine.
### Steps to reproduce the behavior:
Send email to mailbox connected to Zammad queue in 7bit/iso-2022-jp
As already explained, combination of 7-bit encoding and iso-2022-jp charset in email message results in garbled text in corresponding ticket.
For example, below is plaintext of email:
```
--_000_SL2P216MB032969A22C6D22226A7B3613EF740SL2P216MB0329KORP_
Content-Type: text/plain; charset="iso-2022-jp"
Content-Transfer-Encoding: quoted-printable
=1B$B$3$N%"%I%l%9$X$N%a%k%^%,$r2r=3D|$7$F$/$@$5$$!#=1B(B
--_000_SL2P216MB032969A22C6D22226A7B3613EF740SL2P216MB0329KORP_
Content-Type: text/html; charset="iso-2022-jp"
Content-Transfer-Encoding: quoted-printable
<html>
<head>
<meta http-equiv=3D"Content-Type" content=3D"text/html; charset=3Diso-2022-=
jp">
<style type=3D"text/css" style=3D"display:none;"> P {margin-top:0;margin-bo=
ttom:0;} </style>
</head>
<body dir=3D"ltr">
<div style=3D"font-family: Meiryo, =1B$B%a%$%j%*=1B(B, "Hiragino Sans&=
quot;, sans-serif; font-size: 12pt; color: rgb(0, 0, 0);">
=1B$B$3$N%"%I%l%9$X$N%a%k%^%,$r2r=3D|$7$F$/$@$5$$!#=1B(B</div>
</body>
</html>
```
email client will show it as properly formatted HTML message:
```
このアドレスへのメルマガを解除してください。
```
This is how Zammad will show the ticket body:
```
$B$3$N%"%I%l%9$X$N%a%k%^%,$r2r=|$7$F$/$@$5$$!#(B
```
|
process
|
japanese encoding bit iso jp is processed incorrectly hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature requests development questions technical questions on the board if you think you hit a bug please continue search existing issues and the changelog md for your issue there might be a solution already make sure to use the latest version of zammad if possible add the log production log file from your system attention make sure no confidential data is in it please write the issue in english don t remove the template otherwise we will close the issue without further comments ask questions about zammad configuration and usage at our mailinglist see note we always do our best unfortunately sometimes there are too many requests and we can t handle everything at once if you want to prioritize escalate your issue you can do so by means of a support contract see the upper textblock will be removed automatically when you submit your issue infos used zammad version latest version x installation method source package package operating system centos database version postgres elasticsearch version browser version all browsers ticket id expected behavior normal processing of all japanese language email messages actual behavior while processing email messages encoded with bi iso jp charset message is decoded incorrectly assuming issue with mail parser other encoding charset combinations seem to be working just fine steps to reproduce the behavior send email to mailbox connected to zammad queue in iso jp as already explained combination of bit encoding and iso jp charset in email message results in garbled text in corresponding ticket for example below is plaintext of email content type text plain charset iso jp content transfer encoding quoted printable b n i l x n a k f b content type text html charset iso jp content transfer encoding quoted printable meta http equiv content type content text html charset jp p margin top margin bo ttom div style font family meiryo b a j b quot hiragino sans quot sans serif font size color rgb b n i l x n a k f b email client will show it as properly formatted html message このアドレスへのメルマガを解除してください。 this is how zammad will show the ticket body b n i l x n a k f b
| 1
|
12,885
| 15,278,678,966
|
IssuesEvent
|
2021-02-23 02:04:19
|
allinurl/goaccess
|
https://api.github.com/repos/allinurl/goaccess
|
closed
|
Segfault caused by extra-long line from Caddy JSON log
|
bug duplicate log-processing
|
The following line in my Caddy log appears to cause GoAccess to segfault:
```json
{"level":"error","ts":1614020651.3063405,"logger":"http.log.access.log3","msg":"handled request","request":{"remote_addr":"11.111.11.11:59694","proto":"HTTP/2.0","method":"GET","host":"exampleaaaaaaaa.com","uri":"/0","headers":{"Referer":["https://exampleaaaaaaaa.com/search?q=%3Cvideo+src%3D0+onerror%3D%26%23x77%26%23x69%26%23x6e%26%23x64%26%23x6f%26%23x77%26%23x2e%26%23x6f%26%23x6e%26%23x6c%26%23x6f%26%23x61%26%23x64%26%23x20%26%23x3d%26%23x20%26%23x28%26%23x29%26%23x20%26%23x3d%26%23x3e%26%23x20%26%23x7b%26%23x6c%26%23x65%26%23x74%26%23x20%26%23x73%26%23x74%26%23x6f%26%23x6c%26%23x65%26%23x6e%26%23x5f%26%23x75%26%23x73%26%23x65%26%23x72%26%23x20%26%23x3d%26%23x20%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x67%26%23x65%26%23x74%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x42%26%23x79%26%23x49%26%23x64%26%23x28%26%23x27%26%23x6c%26%23x6f%26%23x67%26%23x67%26%23x65%26%23x64%26%23x2d%26%23x69%26%23x6e%26%23x2d%26%23x75%26%23x73%26%23x65%26%23x72%26%23x27%26%23x29%26%23x2e%26%23x69%26%23x6e%26%23x6e%26%23x65%26%23x72%26%23x54%26%23x65%26%23x78%26%23x74%26%23x3b%26%23x6c%26%23x65%26%23x74%26%23x20%26%23x6c%26%23x61%26%23x73%26%23x74%26%23x5f%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x20%26%23x3d%26%23x20%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x67%26%23x65%26%23x74%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x73%26%23x42%26%23x79%26%23x43%26%23x6c%26%23x61%26%23x73%26%23x73%26%23x4e%26%23x61%26%23x6d%26%23x65%26%23x28%26%23x27%26%23x68%26%23x69%26%23x73%26%23x74%26%23x6f%26%23x72%26%23x79%26%23x2d%26%23x69%26%23x74%26%23x65%26%23x6d%26%23x27%26%23x29%26%23x5b%26%23x31%26%23x5d%26%23x2e%26%23x69%26%23x6e%26%23x6e%26%23x65%26%23x72%26%23x54%26%23x65%26%23x78%26%23x74%26%23x3b%26%23x6c%26%23x65%26%23x74%26%23x20%26%23x65%26%23x20%26%23x3d%26%23x20%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x63%26%23x72%26%23x65%26%23x61%26%23x74%26%23x65%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x28%26%23x27%26%23x69%26%23x6d%26%23x67%26%23x27%26%23x29%26%23x3b%26%23x65%26%23x2e%26%23x73%26%23x65%26%23x74%26%23x41%26%23x74%26%23x74%26%23x72%26%23x69%26%23x62%26%23x75%26%23x74%26%23x65%26%23x28%26%23x27%26%23x73%26%23x72%26%23x63%26%23x27%26%23x2c%26%23x20%26%23x60%26%23x68%26%23x74%26%23x74%26%23x70%26%23x3a%26%23x2f%26%23x2f%26%23x6c%26%23x6f%26%23x63%26%23x61%26%23x6c%26%23x68%26%23x6f%26%23x73%26%23x74%26%23x3a%26%23x33%26%23x31%26%23x33%26%23x33%26%23x37%26%23x2f%26%23x3f%26%23x73%26%23x74%26%23x6f%26%23x6c%26%23x65%26%23x6e%26%23x5f%26%23x75%26%23x73%26%23x65%26%23x72%26%23x3d%26%23x24%26%23x7b%26%23x73%26%23x74%26%23x6f%26%23x6c%26%23x65%26%23x6e%26%23x5f%26%23x75%26%23x73%26%23x65%26%23x72%26%23x7d%26%23x26%26%23x6c%26%23x61%26%23x73%26%23x74%26%23x5f%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x3d%26%23x24%26%23x7b%26%23x6c%26%23x61%26%23x73%26%23x74%26%23x5f%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x7d%26%23x60%26%23x29%26%23x3b%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x67%26%23x65%26%23x74%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x42%26%23x79%26%23x49%26%23x64%26%23x28%26%23x27%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x63%26%23x6f%26%23x6e%26%23x74%26%23x72%26%23x6f%26%23x6c%26%23x27%26%23x29%26%23x2e%26%23x61%26%23x70%26%23x70%26%23x65%26%23x6e%26%23x64%26%23x43%26%23x68%26%23x69%26%23x6c%26%23x64%26%23x28%26%23x65%26%23x29%26%23x3b%26%23x7d%3E%3C%2Fvideo%3E"],"Cookie":["xssdefense=3; csrfdefense=0; authuser=\"!t+lODffxjnssycOspdlRug==?gAWVFwAAAAAAAACMCGF1dGh1c2VylIwGYWJjZGVmlIaULg==\""],"Te":["trailers"],"User-Agent":["Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0"],"Accept":["video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5"],"Accept-Language":["en-US,en;q=0.5"],"Range":["bytes=0-"]},"tls":{"resumed":true,"version":772,"cipher_suite":4865,"proto":"h2","proto_mutual":true,"server_name":"exampleaaaaaaaa.com"}},"common_log":"11.111.11.11 - - [22/Feb/2021:19:04:11 +0000] \"GET /0 HTTP/2.0\" 404 729","duration":0.001380459,"size":729,"status":404,"resp_headers":{"Server":["Caddy","gunicorn/20.0.4"],"Strict-Transport-Security":["max-age=31536000; includeSubDomains; preload"],"Content-Type":["text/html; charset=UTF-8"],"Date":["Mon, 22 Feb 2021 19:04:11 GMT"],"Content-Length":["729"]}}
```
(randomized hostname and IP only)
It produces the following error:
```console
$ /usr/bin/goaccess -o ~/out.html --log-format CADDY ~/test.log
[SETTING UP STORAGE /home/hwaj/test.log] {0} @ {0/s}
==22266== GoAccess 1.4.5 crashed by Sig 11
==22266==
==22266== VALUES AT CRASH POINT
==22266==
==22266== FILE: /home/hwaj/test.log
==22266== Line number: 1
==22266== Invalid data: 1
==22266== Piping: 0
==22266==
==22266== STACK TRACE:
==22266==
==22266== 0 /usr/bin/goaccess(sigsegv_handler+0x1ae) [0x559b62eab17e]
==22266== 1 /lib/x86_64-linux-gnu/libpthread.so.0(+0x153c0) [0x7fd1a3c373c0]
==22266== 2 /usr/bin/goaccess(+0x206b6) [0x559b62eb26b6]
==22266== 3 /usr/bin/goaccess(+0x37e50) [0x559b62ec9e50]
==22266== 4 /usr/bin/goaccess(parse_json_string+0x21b) [0x559b62ece9cb]
==22266== 5 /usr/bin/goaccess(pre_process_log+0x2ba) [0x559b62eca83a]
==22266== 6 /usr/bin/goaccess(+0x39171) [0x559b62ecb171]
==22266== 7 /usr/bin/goaccess(parse_log+0xde) [0x559b62ecb78e]
==22266== 8 /usr/bin/goaccess(main+0x2ad) [0x559b62ea5cbd]
==22266== 9 /lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xf3) [0x7fd1a3a550b3]
==22266== 10 /usr/bin/goaccess(_start+0x2e) [0x559b62ea79ae]
==22266==
==22266== Please report it by opening an issue on GitHub:
==22266== https://github.com/allinurl/goaccess/issues
Segmentation fault (core dumped)
```
It appears to have something to do with the length of the message. When I remove a couple characters, the error becomes `Format Errors - Verify your log/date/time format` without a segfault.
I realize this is somewhat similar to #2018, but not completely identical.
Using Caddy v2.3.0 with default formatting, here is the Caddyfile snippet:
```
log {
output file /var/log/caddy/access.log {
roll_size 500mb
roll_keep 5
roll_keep_for 180d
}
}
```
Let me know if you need more info. Thanks.
|
1.0
|
Segfault caused by extra-long line from Caddy JSON log - The following line in my Caddy log appears to cause GoAccess to segfault:
```json
{"level":"error","ts":1614020651.3063405,"logger":"http.log.access.log3","msg":"handled request","request":{"remote_addr":"11.111.11.11:59694","proto":"HTTP/2.0","method":"GET","host":"exampleaaaaaaaa.com","uri":"/0","headers":{"Referer":["https://exampleaaaaaaaa.com/search?q=%3Cvideo+src%3D0+onerror%3D%26%23x77%26%23x69%26%23x6e%26%23x64%26%23x6f%26%23x77%26%23x2e%26%23x6f%26%23x6e%26%23x6c%26%23x6f%26%23x61%26%23x64%26%23x20%26%23x3d%26%23x20%26%23x28%26%23x29%26%23x20%26%23x3d%26%23x3e%26%23x20%26%23x7b%26%23x6c%26%23x65%26%23x74%26%23x20%26%23x73%26%23x74%26%23x6f%26%23x6c%26%23x65%26%23x6e%26%23x5f%26%23x75%26%23x73%26%23x65%26%23x72%26%23x20%26%23x3d%26%23x20%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x67%26%23x65%26%23x74%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x42%26%23x79%26%23x49%26%23x64%26%23x28%26%23x27%26%23x6c%26%23x6f%26%23x67%26%23x67%26%23x65%26%23x64%26%23x2d%26%23x69%26%23x6e%26%23x2d%26%23x75%26%23x73%26%23x65%26%23x72%26%23x27%26%23x29%26%23x2e%26%23x69%26%23x6e%26%23x6e%26%23x65%26%23x72%26%23x54%26%23x65%26%23x78%26%23x74%26%23x3b%26%23x6c%26%23x65%26%23x74%26%23x20%26%23x6c%26%23x61%26%23x73%26%23x74%26%23x5f%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x20%26%23x3d%26%23x20%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x67%26%23x65%26%23x74%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x73%26%23x42%26%23x79%26%23x43%26%23x6c%26%23x61%26%23x73%26%23x73%26%23x4e%26%23x61%26%23x6d%26%23x65%26%23x28%26%23x27%26%23x68%26%23x69%26%23x73%26%23x74%26%23x6f%26%23x72%26%23x79%26%23x2d%26%23x69%26%23x74%26%23x65%26%23x6d%26%23x27%26%23x29%26%23x5b%26%23x31%26%23x5d%26%23x2e%26%23x69%26%23x6e%26%23x6e%26%23x65%26%23x72%26%23x54%26%23x65%26%23x78%26%23x74%26%23x3b%26%23x6c%26%23x65%26%23x74%26%23x20%26%23x65%26%23x20%26%23x3d%26%23x20%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x63%26%23x72%26%23x65%26%23x61%26%23x74%26%23x65%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x28%26%23x27%26%23x69%26%23x6d%26%23x67%26%23x27%26%23x29%26%23x3b%26%23x65%26%23x2e%26%23x73%26%23x65%26%23x74%26%23x41%26%23x74%26%23x74%26%23x72%26%23x69%26%23x62%26%23x75%26%23x74%26%23x65%26%23x28%26%23x27%26%23x73%26%23x72%26%23x63%26%23x27%26%23x2c%26%23x20%26%23x60%26%23x68%26%23x74%26%23x74%26%23x70%26%23x3a%26%23x2f%26%23x2f%26%23x6c%26%23x6f%26%23x63%26%23x61%26%23x6c%26%23x68%26%23x6f%26%23x73%26%23x74%26%23x3a%26%23x33%26%23x31%26%23x33%26%23x33%26%23x37%26%23x2f%26%23x3f%26%23x73%26%23x74%26%23x6f%26%23x6c%26%23x65%26%23x6e%26%23x5f%26%23x75%26%23x73%26%23x65%26%23x72%26%23x3d%26%23x24%26%23x7b%26%23x73%26%23x74%26%23x6f%26%23x6c%26%23x65%26%23x6e%26%23x5f%26%23x75%26%23x73%26%23x65%26%23x72%26%23x7d%26%23x26%26%23x6c%26%23x61%26%23x73%26%23x74%26%23x5f%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x3d%26%23x24%26%23x7b%26%23x6c%26%23x61%26%23x73%26%23x74%26%23x5f%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x7d%26%23x60%26%23x29%26%23x3b%26%23x64%26%23x6f%26%23x63%26%23x75%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x2e%26%23x67%26%23x65%26%23x74%26%23x45%26%23x6c%26%23x65%26%23x6d%26%23x65%26%23x6e%26%23x74%26%23x42%26%23x79%26%23x49%26%23x64%26%23x28%26%23x27%26%23x73%26%23x65%26%23x61%26%23x72%26%23x63%26%23x68%26%23x63%26%23x6f%26%23x6e%26%23x74%26%23x72%26%23x6f%26%23x6c%26%23x27%26%23x29%26%23x2e%26%23x61%26%23x70%26%23x70%26%23x65%26%23x6e%26%23x64%26%23x43%26%23x68%26%23x69%26%23x6c%26%23x64%26%23x28%26%23x65%26%23x29%26%23x3b%26%23x7d%3E%3C%2Fvideo%3E"],"Cookie":["xssdefense=3; csrfdefense=0; authuser=\"!t+lODffxjnssycOspdlRug==?gAWVFwAAAAAAAACMCGF1dGh1c2VylIwGYWJjZGVmlIaULg==\""],"Te":["trailers"],"User-Agent":["Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0"],"Accept":["video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5"],"Accept-Language":["en-US,en;q=0.5"],"Range":["bytes=0-"]},"tls":{"resumed":true,"version":772,"cipher_suite":4865,"proto":"h2","proto_mutual":true,"server_name":"exampleaaaaaaaa.com"}},"common_log":"11.111.11.11 - - [22/Feb/2021:19:04:11 +0000] \"GET /0 HTTP/2.0\" 404 729","duration":0.001380459,"size":729,"status":404,"resp_headers":{"Server":["Caddy","gunicorn/20.0.4"],"Strict-Transport-Security":["max-age=31536000; includeSubDomains; preload"],"Content-Type":["text/html; charset=UTF-8"],"Date":["Mon, 22 Feb 2021 19:04:11 GMT"],"Content-Length":["729"]}}
```
(randomized hostname and IP only)
It produces the following error:
```console
$ /usr/bin/goaccess -o ~/out.html --log-format CADDY ~/test.log
[SETTING UP STORAGE /home/hwaj/test.log] {0} @ {0/s}
==22266== GoAccess 1.4.5 crashed by Sig 11
==22266==
==22266== VALUES AT CRASH POINT
==22266==
==22266== FILE: /home/hwaj/test.log
==22266== Line number: 1
==22266== Invalid data: 1
==22266== Piping: 0
==22266==
==22266== STACK TRACE:
==22266==
==22266== 0 /usr/bin/goaccess(sigsegv_handler+0x1ae) [0x559b62eab17e]
==22266== 1 /lib/x86_64-linux-gnu/libpthread.so.0(+0x153c0) [0x7fd1a3c373c0]
==22266== 2 /usr/bin/goaccess(+0x206b6) [0x559b62eb26b6]
==22266== 3 /usr/bin/goaccess(+0x37e50) [0x559b62ec9e50]
==22266== 4 /usr/bin/goaccess(parse_json_string+0x21b) [0x559b62ece9cb]
==22266== 5 /usr/bin/goaccess(pre_process_log+0x2ba) [0x559b62eca83a]
==22266== 6 /usr/bin/goaccess(+0x39171) [0x559b62ecb171]
==22266== 7 /usr/bin/goaccess(parse_log+0xde) [0x559b62ecb78e]
==22266== 8 /usr/bin/goaccess(main+0x2ad) [0x559b62ea5cbd]
==22266== 9 /lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xf3) [0x7fd1a3a550b3]
==22266== 10 /usr/bin/goaccess(_start+0x2e) [0x559b62ea79ae]
==22266==
==22266== Please report it by opening an issue on GitHub:
==22266== https://github.com/allinurl/goaccess/issues
Segmentation fault (core dumped)
```
It appears to have something to do with the length of the message. When I remove a couple characters, the error becomes `Format Errors - Verify your log/date/time format` without a segfault.
I realize this is somewhat similar to #2018, but not completely identical.
Using Caddy v2.3.0 with default formatting, here is the Caddyfile snippet:
```
log {
output file /var/log/caddy/access.log {
roll_size 500mb
roll_keep 5
roll_keep_for 180d
}
}
```
Let me know if you need more info. Thanks.
|
process
|
segfault caused by extra long line from caddy json log the following line in my caddy log appears to cause goaccess to segfault json level error ts logger http log access msg handled request request remote addr proto http method get host exampleaaaaaaaa com uri headers referer cookie te user agent accept accept language range tls resumed true version cipher suite proto proto mutual true server name exampleaaaaaaaa com common log get http duration size status resp headers server strict transport security content type date content length randomized hostname and ip only it produces the following error console usr bin goaccess o out html log format caddy test log s goaccess crashed by sig values at crash point file home hwaj test log line number invalid data piping stack trace usr bin goaccess sigsegv handler lib linux gnu libpthread so usr bin goaccess usr bin goaccess usr bin goaccess parse json string usr bin goaccess pre process log usr bin goaccess usr bin goaccess parse log usr bin goaccess main lib linux gnu libc so libc start main usr bin goaccess start please report it by opening an issue on github segmentation fault core dumped it appears to have something to do with the length of the message when i remove a couple characters the error becomes format errors verify your log date time format without a segfault i realize this is somewhat similar to but not completely identical using caddy with default formatting here is the caddyfile snippet log output file var log caddy access log roll size roll keep roll keep for let me know if you need more info thanks
| 1
|
776,683
| 27,264,557,856
|
IssuesEvent
|
2023-02-22 17:03:04
|
ascheid/itsg33-pbmm-issue-gen
|
https://api.github.com/repos/ascheid/itsg33-pbmm-issue-gen
|
opened
|
CP-2(4): Contingency Plan | Resume All Missions / Business Functions
|
Priority: P3 Suggested Assignment: IT Security Function ITSG-33 Class: Operational Control: CP-2
|
# Control Definition
CONTINGENCY PLAN | RESUME ALL MISSIONS / BUSINESS FUNCTIONS
The organization plans for the resumption of all missions and business functions within [Assignment: organization-defined time period] of contingency plan activation.
# Class
Operational
# Supplemental Guidance
Organizations may choose to carry out the contingency planning activities in this control enhancement as part of organizational business continuity planning including, for example, as part of business impact analyses. The time period for resumption of all missions/business functions may be dependent on the severity/extent of disruptions to the information system and its supporting infrastructure. Related control: PE-12.
# General Guide
Control enhancements (3) and (4) stipulate that a time period for the resumption of essential and all missions and business functions should be provided in the contingency plan.
# Suggested Assignment
IT Security Function
# Support Teams
IT Operations Group
|
1.0
|
CP-2(4): Contingency Plan | Resume All Missions / Business Functions - # Control Definition
CONTINGENCY PLAN | RESUME ALL MISSIONS / BUSINESS FUNCTIONS
The organization plans for the resumption of all missions and business functions within [Assignment: organization-defined time period] of contingency plan activation.
# Class
Operational
# Supplemental Guidance
Organizations may choose to carry out the contingency planning activities in this control enhancement as part of organizational business continuity planning including, for example, as part of business impact analyses. The time period for resumption of all missions/business functions may be dependent on the severity/extent of disruptions to the information system and its supporting infrastructure. Related control: PE-12.
# General Guide
Control enhancements (3) and (4) stipulate that a time period for the resumption of essential and all missions and business functions should be provided in the contingency plan.
# Suggested Assignment
IT Security Function
# Support Teams
IT Operations Group
|
non_process
|
cp contingency plan resume all missions business functions control definition contingency plan resume all missions business functions the organization plans for the resumption of all missions and business functions within of contingency plan activation class operational supplemental guidance organizations may choose to carry out the contingency planning activities in this control enhancement as part of organizational business continuity planning including for example as part of business impact analyses the time period for resumption of all missions business functions may be dependent on the severity extent of disruptions to the information system and its supporting infrastructure related control pe general guide control enhancements and stipulate that a time period for the resumption of essential and all missions and business functions should be provided in the contingency plan suggested assignment it security function support teams it operations group
| 0
|
116,621
| 17,380,520,577
|
IssuesEvent
|
2021-07-31 16:03:36
|
AlexRogalskiy/charts
|
https://api.github.com/repos/AlexRogalskiy/charts
|
closed
|
CVE-2020-8203 (High) detected in lodash-2.4.2.tgz - autoclosed
|
security vulnerability
|
## CVE-2020-8203 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>lodash-2.4.2.tgz</b></p></summary>
<p>A utility library delivering consistency, customization, performance, & extras.</p>
<p>Library home page: <a href="https://registry.npmjs.org/lodash/-/lodash-2.4.2.tgz">https://registry.npmjs.org/lodash/-/lodash-2.4.2.tgz</a></p>
<p>Path to dependency file: charts/package.json</p>
<p>Path to vulnerable library: charts/node_modules/dockerfile_lint/node_modules/lodash/package.json</p>
<p>
Dependency Hierarchy:
- dockerfile_lint-0.3.4.tgz (Root Library)
- :x: **lodash-2.4.2.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/AlexRogalskiy/charts/commit/8eeb0a90c1dd538ae1c6136eb70230b3c3695d4c">8eeb0a90c1dd538ae1c6136eb70230b3c3695d4c</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Prototype pollution attack when using _.zipObjectDeep in lodash before 4.17.20.
<p>Publish Date: 2020-07-15
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8203>CVE-2020-8203</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.4</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://www.npmjs.com/advisories/1523">https://www.npmjs.com/advisories/1523</a></p>
<p>Release Date: 2020-10-21</p>
<p>Fix Resolution: lodash - 4.17.19</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2020-8203 (High) detected in lodash-2.4.2.tgz - autoclosed - ## CVE-2020-8203 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>lodash-2.4.2.tgz</b></p></summary>
<p>A utility library delivering consistency, customization, performance, & extras.</p>
<p>Library home page: <a href="https://registry.npmjs.org/lodash/-/lodash-2.4.2.tgz">https://registry.npmjs.org/lodash/-/lodash-2.4.2.tgz</a></p>
<p>Path to dependency file: charts/package.json</p>
<p>Path to vulnerable library: charts/node_modules/dockerfile_lint/node_modules/lodash/package.json</p>
<p>
Dependency Hierarchy:
- dockerfile_lint-0.3.4.tgz (Root Library)
- :x: **lodash-2.4.2.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/AlexRogalskiy/charts/commit/8eeb0a90c1dd538ae1c6136eb70230b3c3695d4c">8eeb0a90c1dd538ae1c6136eb70230b3c3695d4c</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Prototype pollution attack when using _.zipObjectDeep in lodash before 4.17.20.
<p>Publish Date: 2020-07-15
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2020-8203>CVE-2020-8203</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.4</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://www.npmjs.com/advisories/1523">https://www.npmjs.com/advisories/1523</a></p>
<p>Release Date: 2020-10-21</p>
<p>Fix Resolution: lodash - 4.17.19</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve high detected in lodash tgz autoclosed cve high severity vulnerability vulnerable library lodash tgz a utility library delivering consistency customization performance extras library home page a href path to dependency file charts package json path to vulnerable library charts node modules dockerfile lint node modules lodash package json dependency hierarchy dockerfile lint tgz root library x lodash tgz vulnerable library found in head commit a href found in base branch master vulnerability details prototype pollution attack when using zipobjectdeep in lodash before publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity high privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact high availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution lodash step up your open source security game with whitesource
| 0
|
10,361
| 13,184,327,501
|
IssuesEvent
|
2020-08-12 19:11:37
|
metabase/metabase
|
https://api.github.com/repos/metabase/metabase
|
closed
|
MongoDB: Error filtering by ObjectId field with "Is empty" or "Not empty" options
|
.Backend Database/Mongo Difficulty:Easy Priority:P2 Querying/Processor Type:Bug
|
While trying to create a 'Question' filtering by a field that it's an ObjectId with the "Is empty" or "Not empty" options the result it's always the error - "invalid hexadecimal representation of an ObjectId: []"
**Steps to reproduce**
1. Choose any field that it's an ObjectId and choose "Is empty" or "Not empty" option:
<img width="571" alt="Screenshot 2019-10-14 at 19 27 44" src="https://user-images.githubusercontent.com/188404/66774381-5a214100-eeb9-11e9-9320-aade03a5be8f.png">
2. Click "Get Answer" and should get this error:
<img width="702" alt="Screenshot 2019-10-14 at 19 27 50" src="https://user-images.githubusercontent.com/188404/66774392-60afb880-eeb9-11e9-9152-187477c2bac3.png">
.
|
1.0
|
MongoDB: Error filtering by ObjectId field with "Is empty" or "Not empty" options - While trying to create a 'Question' filtering by a field that it's an ObjectId with the "Is empty" or "Not empty" options the result it's always the error - "invalid hexadecimal representation of an ObjectId: []"
**Steps to reproduce**
1. Choose any field that it's an ObjectId and choose "Is empty" or "Not empty" option:
<img width="571" alt="Screenshot 2019-10-14 at 19 27 44" src="https://user-images.githubusercontent.com/188404/66774381-5a214100-eeb9-11e9-9320-aade03a5be8f.png">
2. Click "Get Answer" and should get this error:
<img width="702" alt="Screenshot 2019-10-14 at 19 27 50" src="https://user-images.githubusercontent.com/188404/66774392-60afb880-eeb9-11e9-9152-187477c2bac3.png">
.
|
process
|
mongodb error filtering by objectid field with is empty or not empty options while trying to create a question filtering by a field that it s an objectid with the is empty or not empty options the result it s always the error invalid hexadecimal representation of an objectid steps to reproduce choose any field that it s an objectid and choose is empty or not empty option img width alt screenshot at src click get answer and should get this error img width alt screenshot at src
| 1
|
20,186
| 26,747,812,932
|
IssuesEvent
|
2023-01-30 17:11:10
|
dtcenter/MET
|
https://api.github.com/repos/dtcenter/MET
|
opened
|
Add units to ascii2nc output where possible.
|
type: enhancement priority: medium alert: NEED MORE DEFINITION alert: NEED ACCOUNT KEY alert: NEED PROJECT ASSIGNMENT requestor: METplus Team MET: PreProcessing Tools (Point)
|
## Describe the Enhancement ##
While working on #2426, I discovered that ascii2nc never writes the units string for point observations to the `obs_unit` NetCDF output variable. The pb2nc tool does write the unit strings. This issue is to enhance ascii2nc to parse and write the units of the observations to the output.
Note that this will vary considerably based on the input formats and more definition is needed.
ascii2nc should keep track of the units string for each observation type and print a warning message if that string changes during a single run.
List of input formats:
- [ ] NDBC file do define the units.
- [ ] Add details for other input file types here.
### Time Estimate ###
*Estimate the amount of work required here.*
*Issues should represent approximately 1 to 3 days of work.*
### Sub-Issues ###
Consider breaking the enhancement down into sub-issues.
None needed.
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [x] Select **component(s)**
- [x] Select **priority**
- [x] Select **requestor(s)**
### Projects and Milestone ###
- [x] Select **Repository** and/or **Organization** level **Project(s)** or add **alert: NEED PROJECT ASSIGNMENT** label
- [x] Select **Milestone** as the next official version or **Future Versions**
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [x] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdataio](https://github.com/dtcenter/METdataio/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
No impacts.
## Enhancement Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding Source**.
- [ ] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [ ] Complete the development and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **develop**.
Pull request: `feature <Issue Number> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Development** issues
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Close this issue.
|
1.0
|
Add units to ascii2nc output where possible. - ## Describe the Enhancement ##
While working on #2426, I discovered that ascii2nc never writes the units string for point observations to the `obs_unit` NetCDF output variable. The pb2nc tool does write the unit strings. This issue is to enhance ascii2nc to parse and write the units of the observations to the output.
Note that this will vary considerably based on the input formats and more definition is needed.
ascii2nc should keep track of the units string for each observation type and print a warning message if that string changes during a single run.
List of input formats:
- [ ] NDBC file do define the units.
- [ ] Add details for other input file types here.
### Time Estimate ###
*Estimate the amount of work required here.*
*Issues should represent approximately 1 to 3 days of work.*
### Sub-Issues ###
Consider breaking the enhancement down into sub-issues.
None needed.
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [x] Select **component(s)**
- [x] Select **priority**
- [x] Select **requestor(s)**
### Projects and Milestone ###
- [x] Select **Repository** and/or **Organization** level **Project(s)** or add **alert: NEED PROJECT ASSIGNMENT** label
- [x] Select **Milestone** as the next official version or **Future Versions**
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [x] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdataio](https://github.com/dtcenter/METdataio/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
No impacts.
## Enhancement Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding Source**.
- [ ] Fork this repository or create a branch of **develop**.
Branch name: `feature_<Issue Number>_<Description>`
- [ ] Complete the development and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **develop**.
Pull request: `feature <Issue Number> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Development** issues
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Close this issue.
|
process
|
add units to output where possible describe the enhancement while working on i discovered that never writes the units string for point observations to the obs unit netcdf output variable the tool does write the unit strings this issue is to enhance to parse and write the units of the observations to the output note that this will vary considerably based on the input formats and more definition is needed should keep track of the units string for each observation type and print a warning message if that string changes during a single run list of input formats ndbc file do define the units add details for other input file types here time estimate estimate the amount of work required here issues should represent approximately to days of work sub issues consider breaking the enhancement down into sub issues none needed relevant deadlines list relevant project deadlines here or state none funding source define the source of funding and account keys here or state none define the metadata assignee select engineer s or no engineer required select scientist s or no scientist required labels select component s select priority select requestor s projects and milestone select repository and or organization level project s or add alert need project assignment label select milestone as the next official version or future versions define related issue s consider the impact to the other metplus components no impacts enhancement checklist see the for details complete the issue definition above including the time estimate and funding source fork this repository or create a branch of develop branch name feature complete the development and test your changes add update log messages for easier debugging add update unit tests add update documentation push local changes to github submit a pull request to merge into develop pull request feature define the pull request metadata as permissions allow select reviewer s and development issues select repository level development cycle project for the next official release select milestone as the next official version iterate until the reviewer s accept and merge your changes delete your fork or branch close this issue
| 1
|
20,899
| 27,733,369,488
|
IssuesEvent
|
2023-03-15 09:36:10
|
Open-EO/openeo-processes
|
https://api.github.com/repos/Open-EO/openeo-processes
|
closed
|
apply_polygon: callback on pixels inside a polygon
|
new process
|
We received the following use case to support:
- the user has polygons of parcels (agriculture)
- for each parcel, a pixel-level map is expected, (a raster), so a map of the parcel (easy in openEO)
- Now it comes: the timeseries of rasters (4D cube) for a given polygon needs to be filtered on the correlation between different dates. So dates with a correlation that deviates from average correlation need to be filtered out.
So question is how we could support this?
## Proposal 1 'apply_spatiotemporal'
We already have processes like 'aggregate_spatial' and 'apply_neighbourhood'. So an 'apply_spatiotemporal' process could receive the input polygons, and simply apply a function to the timeseries of pixels within that polygon, receiving a labeled array as input? The output is then again a labeled array with updated pixel values.
In our case, the callback would probably be a UDF.
|
1.0
|
apply_polygon: callback on pixels inside a polygon - We received the following use case to support:
- the user has polygons of parcels (agriculture)
- for each parcel, a pixel-level map is expected, (a raster), so a map of the parcel (easy in openEO)
- Now it comes: the timeseries of rasters (4D cube) for a given polygon needs to be filtered on the correlation between different dates. So dates with a correlation that deviates from average correlation need to be filtered out.
So question is how we could support this?
## Proposal 1 'apply_spatiotemporal'
We already have processes like 'aggregate_spatial' and 'apply_neighbourhood'. So an 'apply_spatiotemporal' process could receive the input polygons, and simply apply a function to the timeseries of pixels within that polygon, receiving a labeled array as input? The output is then again a labeled array with updated pixel values.
In our case, the callback would probably be a UDF.
|
process
|
apply polygon callback on pixels inside a polygon we received the following use case to support the user has polygons of parcels agriculture for each parcel a pixel level map is expected a raster so a map of the parcel easy in openeo now it comes the timeseries of rasters cube for a given polygon needs to be filtered on the correlation between different dates so dates with a correlation that deviates from average correlation need to be filtered out so question is how we could support this proposal apply spatiotemporal we already have processes like aggregate spatial and apply neighbourhood so an apply spatiotemporal process could receive the input polygons and simply apply a function to the timeseries of pixels within that polygon receiving a labeled array as input the output is then again a labeled array with updated pixel values in our case the callback would probably be a udf
| 1
|
25,181
| 4,232,536,796
|
IssuesEvent
|
2016-07-05 00:31:33
|
arkayenro/arkinventory
|
https://api.github.com/repos/arkayenro/arkinventory
|
closed
|
Chauffeured Chopper in ArkInventory_Mounts Titan Panel integration
|
auto-migrated Priority-Medium Type-Defect
|
```
Downloaded from > curse
What steps will reproduce the problem?
1. Collect 35 Heirloom Items and add Chauffeured Chopper to Mounts Collection.
2. Log in with a Character that normally cannot ride any Mount (is now able to
use the Chauffeured Chopper).
3. Cannot mount the Chauffeured Chopper using the ArkInventory_Mounts Button in
TitanPanel.
The new Mount "Chauffeured Chopper" obtained from the achievement "Heirloom
Hoarder" which requires 35 Heirlooms can be used without the ability
"Apprentice Riding" and also there is no Level restriction.
Therefore any Level 1 Character is able to use it.
While using TitanPanel and the ArkInventory_Mounts button, it is not possible
to mount the Chauffeured Chopper, since it is complaining about "Skill not high
enough".
Used Version of ArkInventory is 3.05.00
```
Original issue reported on code.google.com by `dfbloods...@googlemail.com` on 26 Feb 2015 at 4:38
|
1.0
|
Chauffeured Chopper in ArkInventory_Mounts Titan Panel integration - ```
Downloaded from > curse
What steps will reproduce the problem?
1. Collect 35 Heirloom Items and add Chauffeured Chopper to Mounts Collection.
2. Log in with a Character that normally cannot ride any Mount (is now able to
use the Chauffeured Chopper).
3. Cannot mount the Chauffeured Chopper using the ArkInventory_Mounts Button in
TitanPanel.
The new Mount "Chauffeured Chopper" obtained from the achievement "Heirloom
Hoarder" which requires 35 Heirlooms can be used without the ability
"Apprentice Riding" and also there is no Level restriction.
Therefore any Level 1 Character is able to use it.
While using TitanPanel and the ArkInventory_Mounts button, it is not possible
to mount the Chauffeured Chopper, since it is complaining about "Skill not high
enough".
Used Version of ArkInventory is 3.05.00
```
Original issue reported on code.google.com by `dfbloods...@googlemail.com` on 26 Feb 2015 at 4:38
|
non_process
|
chauffeured chopper in arkinventory mounts titan panel integration downloaded from curse what steps will reproduce the problem collect heirloom items and add chauffeured chopper to mounts collection log in with a character that normally cannot ride any mount is now able to use the chauffeured chopper cannot mount the chauffeured chopper using the arkinventory mounts button in titanpanel the new mount chauffeured chopper obtained from the achievement heirloom hoarder which requires heirlooms can be used without the ability apprentice riding and also there is no level restriction therefore any level character is able to use it while using titanpanel and the arkinventory mounts button it is not possible to mount the chauffeured chopper since it is complaining about skill not high enough used version of arkinventory is original issue reported on code google com by dfbloods googlemail com on feb at
| 0
|
103,141
| 12,865,902,786
|
IssuesEvent
|
2020-07-10 01:55:40
|
lazy-suzy/lazysuzy-code
|
https://api.github.com/repos/lazy-suzy/lazysuzy-code
|
closed
|
Design Board
|
design prio: high
|
### Board Updates
See updated Board moqup here: https://app.moqups.com/5NlUwWnQDj/edit/page/ac4ab0d91
- [x] 1. Extend Board to full width of the page with equal spacing on either side
- [x] 2. Use full height of window
- [x] 3. Update icon positioning as displayed
- [x] 4. Add 'Board Title' text input bar
- [x] 5. Update Board Catalog as per moqup here: https://app.moqups.com/5NlUwWnQDj/edit/page/af086e35d
- [x] 6. No scroll bars anywhere
- [x] 7. Move publish, share and account icons to the top right of page
- [x] 8. Fix Publish button font color
- [x] 9. Fix Search Bar styling: a) Rounded Corners b) square shape for Search icon background
- [x] 10. Add more space between search bar and tabs
- [x] 11. Clicking on "+" should open Browse Tab with My Items / Add New buttons
- [x] 12. My Items / Add New button shouldn't appear in Browse tab by default
- [x] 13. Delete confirmation window not yet visible
- [x] 14. Clicking on "+" icon on top right menu should open Board Config menu
- [x] 15. Open Filters window below Search Bar & Filters icon
- [x] 16. Is Filter window set up for tabs?
- [x] 17. Fix background colors (Board area should be #ffffff and surrounding area should be #f2f4f3
- [x] 18. Extend Tabs across width of side panel
- [x] 19. Remove box around "Board Title" when user input is not active
- [x] 20. Remove space between Icons and Board here and equalize spacing between Icons:
- [x] 21. Increase icon size and spacing here and extend the grey menu bar all the way to the end of the screen:
- [x] 22. Fix call out positioning so it doesn't run over the screen
- [x] 23. Increase and equalize spacing between Icons and Middle Align (currently looks Top Aligned)
- [x] 24. Center the text within the window.
- [x] 25. If switching back to Select or Browse from Board, raise the window back to the upper height
- [x] 26. Keep Board Title to the left of Icons and reduce spacing between Board icons on Mobile
- [x] 27. Fix alignment and spacing of objects on header menu. Expand grey bar for product options to full width of screen.
- [x] 28. Move Price to the right of Name/Brand and remove spacing between Product Name and Brand (for both Desktop and Mobile)
- [x] 29. Increase width of left panel nav bar
- [x] 30. **Select** panel looks nothing like the moqup.
- All category buttons should be the same size
- Category labels should not be on the same line as the category icon
- Filter window is appearing for some reason in the Select panel (see screenshot)
- Increase padding between category buttons on the same row
- [x] 31. **Browse** panel is missing Category title
- [x] 32. Product modal window should not move with scroll bar
- [x] 33. Update product modal window to match moqup. Position of _add_ and _like_ buttons should not move around.
- [x] 34. Mobile screenshot. Fix.
- [x] 35. Board tab
- Update title as per moqup
- Add more space between header and content
- Add more padding on left of item list in the panel
- [x] 36. Board title - Add input box around Board title on mouse hover
- [x] 37. Text icons
- Set equal spacing between icons
- Missing color for font color
- Conform label call-out spacing to match that for the image icons
- Case toggle icon looks smaller than others
- [x] 38. Update mobile menu as per moqup here: https://app.moqups.com/5NlUwWnQDj/edit/page/a3b3b1f58
Use > and < arrow to scroll between text menu options in a single row
- [x] 39. Make the _Board Name_ box on hover be transparent with border in #d6d6d6 and make sure the box does not touch the design board (see screenshot below)
- [x] 40. Fix styling for menu scroll arrow as per moqup to be white background, no border and #999999 color for arrow (see moqup here: https://app.moqups.com/5NlUwWnQDj/view/page/a5069bd4b)
- [x] 41. What is the grey box for next to the font size? Can we remove? Also scrolling for the menu bar should be one item at a time rather than the full row.
- [x] 42. Switch the top menu to scrolling menu on desktop if running out of space due to window resize rather than dropping in to multiple lines
- [x] 43. Update Select tab per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/aa0980e6c
- add header title (fixed)
- [x] 44. Update Browse tab per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/ac4ab0d91
- add back button next to Header title (return user to Select tab on click)
- add pre-defined filters (Sale, New, Best Sellers) - use _Click_ action to toggle between Selected and Unselected style
- Use "<" for Back button
- [x] 45. Add UI for price filter
- Change price label color and the price bar color to # b76e79
- [x] 46. Update open window icon in product modal window as per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/ac4ab0d91
- [x] 47. Add option to remove Favorites
- Nothing happens when I click on heart icon?
- [x] 48. Update text input per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/afb79b70c
- Increase font size and line spacing
- [x] 49. Update My Items page as per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/a1ace1e1d
- Add background to 'My Items' and 'All Uploads' options on mouse hover as per moqup
- Add instruction call-out as per screenshot below
- [x] 50. Update Screen Two and Three here: https://app.moqups.com/5NlUwWnQDj/edit/page/a954c051d
Screen Three:
- Increase spacing between rows
- Left align "Keep private" check box
- [x] 51. Clicking on 'Add via URL' button should directly open to the below window
- [x] 52. Fix scroll bar issue in content bar
- [x] 53. Reduce spacing here
- [x] 54. On Favorites page:
- remove heart icon from images
- add product detail bar at bottom of content menu
- show heart colored in for products on here in detail bar
[UPDATE]: clicking on any item here is not opening up the product detail window at the bottom
- [x] 55. Only product listing section should scroll in content menu
[UPDATE]:
- How do I test this on desktop view? Why is the page only pulling 15 products and not more?
Mobile view comments (see screenshot):
- Product detail window is not appearing properly
- Scroll-bar should appear in product window section only
- Add more spacing between the filters and product listing section
- Overall, look at how neat the layout appears in the second screenshot below vs. ours looks very raw as if we just cobbled bunch of elements together
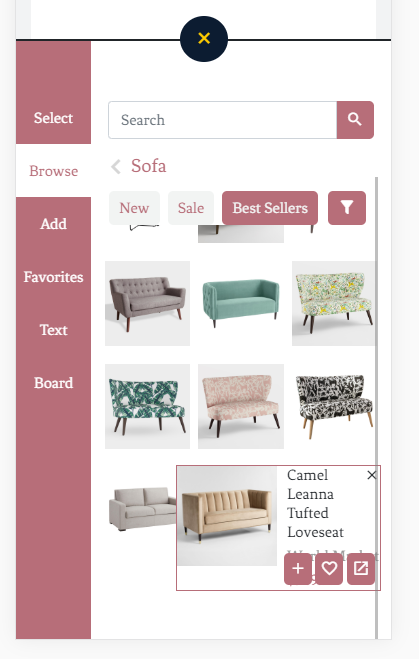
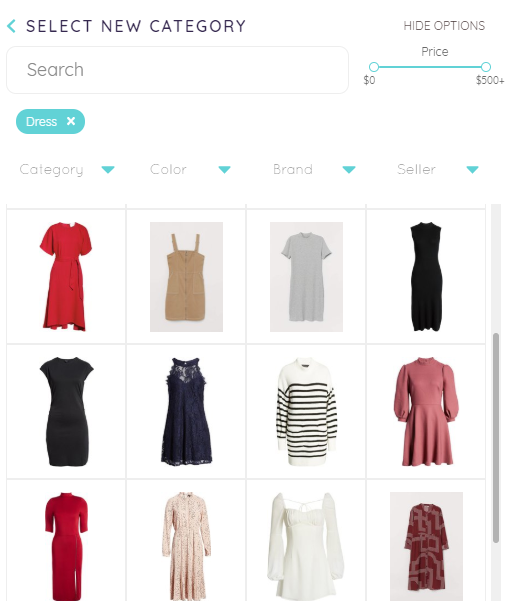
- [x] 56. Change call out for gear icon from "New Board" to "Edit Board settings"
- [x] 57. Header of content section for _Browse_ tab should match the Category selected. Currently is hard coded to "Sofa" no matter what Category is chosen.
**Add Image Menu**
- [x] 1. Position Upload Image / Add Image by URL buttons in middle of window
- [x] 2. Position Image URL input in middle of window
- [x] 3. Fix text in "Must be .png or .jpg"
- [x] 4. Remove curves at endpoints of input line
- [ ] 5. Remove input text on mouse click
- [x] 6. Move instruction text closer to input line
- [x] 7. Make image URL a required field
- [x] 8. Space out Title / Price / Tags input lines across the window
- [x] 9. Use large x for window close with thinner lines and fix color
- [x] 10. Add more space between Buttons and Step counter
- [x] 11. Close window on Add Button click
- [x] 12. Window appears cut-off on mobile. Is it being opened as modal window on mobile as well?

----------------------------
- [x] 1. Create Board Configuration menu
(M) https://app.moqups.com/5NlUwWnQDj/edit/page/a14bef619
For Desktop, create same menu in a pop-up window
- [x] 2. Clicking on **"+" Button** in Browse window should take user to the following screen:
(D) https://app.moqups.com/5NlUwWnQDj/edit/page/a2fa4a11f
(M) https://app.moqups.com/5NlUwWnQDj/edit/page/a5e429983
Clicking on **"Add New" Button** in the above screens should then take user to the add product menu
- [x] 3. Add Catalog Panel
(D) https://app.moqups.com/5NlUwWnQDj/edit/page/aa482ba12
(M) https://app.moqups.com/5NlUwWnQDj/edit/page/a5e429983
- [x] 4. Product Panel is missing Delete Button and Forward / Backward buttons
- [x] 5. Add Delete Confirmation pop-up when clicking on Delete Button in Canvas Panel
Confirmation window: https://app.moqups.com/5NlUwWnQDj/edit/page/a304f8c44
- [x] 6. Desktop: Move Canvas Panel to upper right corner of panel as per moqup and space out icons further
|
1.0
|
Design Board - ### Board Updates
See updated Board moqup here: https://app.moqups.com/5NlUwWnQDj/edit/page/ac4ab0d91
- [x] 1. Extend Board to full width of the page with equal spacing on either side
- [x] 2. Use full height of window
- [x] 3. Update icon positioning as displayed
- [x] 4. Add 'Board Title' text input bar
- [x] 5. Update Board Catalog as per moqup here: https://app.moqups.com/5NlUwWnQDj/edit/page/af086e35d
- [x] 6. No scroll bars anywhere
- [x] 7. Move publish, share and account icons to the top right of page
- [x] 8. Fix Publish button font color
- [x] 9. Fix Search Bar styling: a) Rounded Corners b) square shape for Search icon background
- [x] 10. Add more space between search bar and tabs
- [x] 11. Clicking on "+" should open Browse Tab with My Items / Add New buttons
- [x] 12. My Items / Add New button shouldn't appear in Browse tab by default
- [x] 13. Delete confirmation window not yet visible
- [x] 14. Clicking on "+" icon on top right menu should open Board Config menu
- [x] 15. Open Filters window below Search Bar & Filters icon
- [x] 16. Is Filter window set up for tabs?
- [x] 17. Fix background colors (Board area should be #ffffff and surrounding area should be #f2f4f3
- [x] 18. Extend Tabs across width of side panel
- [x] 19. Remove box around "Board Title" when user input is not active
- [x] 20. Remove space between Icons and Board here and equalize spacing between Icons:
- [x] 21. Increase icon size and spacing here and extend the grey menu bar all the way to the end of the screen:
- [x] 22. Fix call out positioning so it doesn't run over the screen
- [x] 23. Increase and equalize spacing between Icons and Middle Align (currently looks Top Aligned)
- [x] 24. Center the text within the window.
- [x] 25. If switching back to Select or Browse from Board, raise the window back to the upper height
- [x] 26. Keep Board Title to the left of Icons and reduce spacing between Board icons on Mobile
- [x] 27. Fix alignment and spacing of objects on header menu. Expand grey bar for product options to full width of screen.
- [x] 28. Move Price to the right of Name/Brand and remove spacing between Product Name and Brand (for both Desktop and Mobile)
- [x] 29. Increase width of left panel nav bar
- [x] 30. **Select** panel looks nothing like the moqup.
- All category buttons should be the same size
- Category labels should not be on the same line as the category icon
- Filter window is appearing for some reason in the Select panel (see screenshot)
- Increase padding between category buttons on the same row
- [x] 31. **Browse** panel is missing Category title
- [x] 32. Product modal window should not move with scroll bar
- [x] 33. Update product modal window to match moqup. Position of _add_ and _like_ buttons should not move around.
- [x] 34. Mobile screenshot. Fix.
- [x] 35. Board tab
- Update title as per moqup
- Add more space between header and content
- Add more padding on left of item list in the panel
- [x] 36. Board title - Add input box around Board title on mouse hover
- [x] 37. Text icons
- Set equal spacing between icons
- Missing color for font color
- Conform label call-out spacing to match that for the image icons
- Case toggle icon looks smaller than others
- [x] 38. Update mobile menu as per moqup here: https://app.moqups.com/5NlUwWnQDj/edit/page/a3b3b1f58
Use > and < arrow to scroll between text menu options in a single row
- [x] 39. Make the _Board Name_ box on hover be transparent with border in #d6d6d6 and make sure the box does not touch the design board (see screenshot below)
- [x] 40. Fix styling for menu scroll arrow as per moqup to be white background, no border and #999999 color for arrow (see moqup here: https://app.moqups.com/5NlUwWnQDj/view/page/a5069bd4b)
- [x] 41. What is the grey box for next to the font size? Can we remove? Also scrolling for the menu bar should be one item at a time rather than the full row.
- [x] 42. Switch the top menu to scrolling menu on desktop if running out of space due to window resize rather than dropping in to multiple lines
- [x] 43. Update Select tab per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/aa0980e6c
- add header title (fixed)
- [x] 44. Update Browse tab per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/ac4ab0d91
- add back button next to Header title (return user to Select tab on click)
- add pre-defined filters (Sale, New, Best Sellers) - use _Click_ action to toggle between Selected and Unselected style
- Use "<" for Back button
- [x] 45. Add UI for price filter
- Change price label color and the price bar color to # b76e79
- [x] 46. Update open window icon in product modal window as per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/ac4ab0d91
- [x] 47. Add option to remove Favorites
- Nothing happens when I click on heart icon?
- [x] 48. Update text input per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/afb79b70c
- Increase font size and line spacing
- [x] 49. Update My Items page as per moqup: https://app.moqups.com/5NlUwWnQDj/edit/page/a1ace1e1d
- Add background to 'My Items' and 'All Uploads' options on mouse hover as per moqup
- Add instruction call-out as per screenshot below
- [x] 50. Update Screen Two and Three here: https://app.moqups.com/5NlUwWnQDj/edit/page/a954c051d
Screen Three:
- Increase spacing between rows
- Left align "Keep private" check box
- [x] 51. Clicking on 'Add via URL' button should directly open to the below window
- [x] 52. Fix scroll bar issue in content bar
- [x] 53. Reduce spacing here

- [x] 54. On Favorites page:
- remove heart icon from images
- add product detail bar at bottom of content menu
- show heart colored in for products on here in detail bar
[UPDATE]: clicking on any item here is not opening up the product detail window at the bottom
- [x] 55. Only product listing section should scroll in content menu
[UPDATE]:
- How do I test this on desktop view? Why is the page only pulling 15 products and not more?
Mobile view comments (see screenshot):
- Product detail window is not appearing properly
- Scroll-bar should appear in product window section only
- Add more spacing between the filters and product listing section
- Overall, look at how neat the layout appears in the second screenshot below vs. ours looks very raw as if we just cobbled bunch of elements together


- [x] 56. Change call out for gear icon from "New Board" to "Edit Board settings"
- [x] 57. Header of content section for _Browse_ tab should match the Category selected. Currently is hard coded to "Sofa" no matter what Category is chosen.
**Add Image Menu**
- [x] 1. Position Upload Image / Add Image by URL buttons in middle of window
- [x] 2. Position Image URL input in middle of window
- [x] 3. Fix text in "Must be .png or .jpg"
- [x] 4. Remove curves at endpoints of input line
- [ ] 5. Remove input text on mouse click
- [x] 6. Move instruction text closer to input line
- [x] 7. Make image URL a required field
- [x] 8. Space out Title / Price / Tags input lines across the window
- [x] 9. Use large x for window close with thinner lines and fix color
- [x] 10. Add more space between Buttons and Step counter
- [x] 11. Close window on Add Button click
- [x] 12. Window appears cut-off on mobile. Is it being opened as modal window on mobile as well?

----------------------------
- [x] 1. Create Board Configuration menu
(M) https://app.moqups.com/5NlUwWnQDj/edit/page/a14bef619
For Desktop, create same menu in a pop-up window
- [x] 2. Clicking on **"+" Button** in Browse window should take user to the following screen:
(D) https://app.moqups.com/5NlUwWnQDj/edit/page/a2fa4a11f
(M) https://app.moqups.com/5NlUwWnQDj/edit/page/a5e429983
Clicking on **"Add New" Button** in the above screens should then take user to the add product menu
- [x] 3. Add Catalog Panel
(D) https://app.moqups.com/5NlUwWnQDj/edit/page/aa482ba12
(M) https://app.moqups.com/5NlUwWnQDj/edit/page/a5e429983
- [x] 4. Product Panel is missing Delete Button and Forward / Backward buttons
- [x] 5. Add Delete Confirmation pop-up when clicking on Delete Button in Canvas Panel
Confirmation window: https://app.moqups.com/5NlUwWnQDj/edit/page/a304f8c44
- [x] 6. Desktop: Move Canvas Panel to upper right corner of panel as per moqup and space out icons further
|
non_process
|
design board board updates see updated board moqup here extend board to full width of the page with equal spacing on either side use full height of window update icon positioning as displayed add board title text input bar update board catalog as per moqup here no scroll bars anywhere move publish share and account icons to the top right of page fix publish button font color fix search bar styling a rounded corners b square shape for search icon background add more space between search bar and tabs clicking on should open browse tab with my items add new buttons my items add new button shouldn t appear in browse tab by default delete confirmation window not yet visible clicking on icon on top right menu should open board config menu open filters window below search bar filters icon is filter window set up for tabs fix background colors board area should be ffffff and surrounding area should be extend tabs across width of side panel remove box around board title when user input is not active remove space between icons and board here and equalize spacing between icons increase icon size and spacing here and extend the grey menu bar all the way to the end of the screen fix call out positioning so it doesn t run over the screen increase and equalize spacing between icons and middle align currently looks top aligned center the text within the window if switching back to select or browse from board raise the window back to the upper height keep board title to the left of icons and reduce spacing between board icons on mobile fix alignment and spacing of objects on header menu expand grey bar for product options to full width of screen move price to the right of name brand and remove spacing between product name and brand for both desktop and mobile increase width of left panel nav bar select panel looks nothing like the moqup all category buttons should be the same size category labels should not be on the same line as the category icon filter window is appearing for some reason in the select panel see screenshot increase padding between category buttons on the same row browse panel is missing category title product modal window should not move with scroll bar update product modal window to match moqup position of add and like buttons should not move around mobile screenshot fix board tab update title as per moqup add more space between header and content add more padding on left of item list in the panel board title add input box around board title on mouse hover text icons set equal spacing between icons missing color for font color conform label call out spacing to match that for the image icons case toggle icon looks smaller than others update mobile menu as per moqup here use and arrow to scroll between text menu options in a single row make the board name box on hover be transparent with border in and make sure the box does not touch the design board see screenshot below fix styling for menu scroll arrow as per moqup to be white background no border and color for arrow see moqup here what is the grey box for next to the font size can we remove also scrolling for the menu bar should be one item at a time rather than the full row switch the top menu to scrolling menu on desktop if running out of space due to window resize rather than dropping in to multiple lines update select tab per moqup add header title fixed update browse tab per moqup add back button next to header title return user to select tab on click add pre defined filters sale new best sellers use click action to toggle between selected and unselected style use for back button add ui for price filter change price label color and the price bar color to update open window icon in product modal window as per moqup add option to remove favorites nothing happens when i click on heart icon update text input per moqup increase font size and line spacing update my items page as per moqup add background to my items and all uploads options on mouse hover as per moqup add instruction call out as per screenshot below update screen two and three here screen three increase spacing between rows left align keep private check box clicking on add via url button should directly open to the below window fix scroll bar issue in content bar reduce spacing here on favorites page remove heart icon from images add product detail bar at bottom of content menu show heart colored in for products on here in detail bar clicking on any item here is not opening up the product detail window at the bottom only product listing section should scroll in content menu how do i test this on desktop view why is the page only pulling products and not more mobile view comments see screenshot product detail window is not appearing properly scroll bar should appear in product window section only add more spacing between the filters and product listing section overall look at how neat the layout appears in the second screenshot below vs ours looks very raw as if we just cobbled bunch of elements together change call out for gear icon from new board to edit board settings header of content section for browse tab should match the category selected currently is hard coded to sofa no matter what category is chosen add image menu position upload image add image by url buttons in middle of window position image url input in middle of window fix text in must be png or jpg remove curves at endpoints of input line remove input text on mouse click move instruction text closer to input line make image url a required field space out title price tags input lines across the window use large x for window close with thinner lines and fix color add more space between buttons and step counter close window on add button click window appears cut off on mobile is it being opened as modal window on mobile as well create board configuration menu m for desktop create same menu in a pop up window clicking on button in browse window should take user to the following screen d m clicking on add new button in the above screens should then take user to the add product menu add catalog panel d m product panel is missing delete button and forward backward buttons add delete confirmation pop up when clicking on delete button in canvas panel confirmation window desktop move canvas panel to upper right corner of panel as per moqup and space out icons further
| 0
|
8,898
| 11,992,641,058
|
IssuesEvent
|
2020-04-08 10:28:26
|
digitalmethodsinitiative/4cat
|
https://api.github.com/repos/digitalmethodsinitiative/4cat
|
opened
|
Provide insight into the content of word lists
|
(mostly) front-end enhancement processors
|
A couple of processors use lexicons for filtering, etc. Some of these are sourced from elsewhere and easy to look up but some were compiled by OILab or are more obscure. With 4CAT's goal of transparence in mind, it should be possible (and straightforward) to view the content of these word lists in the 4CAT interface.
|
1.0
|
Provide insight into the content of word lists - A couple of processors use lexicons for filtering, etc. Some of these are sourced from elsewhere and easy to look up but some were compiled by OILab or are more obscure. With 4CAT's goal of transparence in mind, it should be possible (and straightforward) to view the content of these word lists in the 4CAT interface.
|
process
|
provide insight into the content of word lists a couple of processors use lexicons for filtering etc some of these are sourced from elsewhere and easy to look up but some were compiled by oilab or are more obscure with s goal of transparence in mind it should be possible and straightforward to view the content of these word lists in the interface
| 1
|
286,697
| 21,605,237,167
|
IssuesEvent
|
2022-05-04 01:23:49
|
kubernetes/kubernetes
|
https://api.github.com/repos/kubernetes/kubernetes
|
closed
|
kubectl create help implies a list of service accounts can be references in a clusterrolebinding
|
kind/documentation sig/cli triage/accepted
|
### What happened?
I'm not sure whether this is the documentation being unclear, or a bug with kubectl itself but I suspect the former.
Given this help page
```bash
$ kubectl create clusterrolebinding --help
Create a cluster role binding for a particular cluster role.
# Omitted for brevity
--serviceaccount=[]: Service accounts to bind to the clusterrole, in the format <namespace>:<name>
```
I expected to be able to use
```bash
$ kubectl create clusterrolebinding pipelineSAs --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
```
Instead I got the following error
```bash
$ kubectl create clusterrolebinding pipelinesas --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
error: exactly one NAME is required, got 2
See 'kubectl create clusterrolebinding -h' for help and examples
```
### What did you expect to happen?
To get the same output as defining the flag twice
aka
```bash
$ kubectl create clusterrolebinding pipelinesas --clusterrole=view --serviceaccount=ns1:pipeline --serviceaccount=ns2:pipeline
clusterrolebinding.rbac.authorization.k8s.io/pipelinesas created
```
and
```bash
$ kubectl create clusterrolebinding pipelineSAs --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
clusterrolebinding.rbac.authorization.k8s.io/pipelinesas created
```
should give the same output, or the help page shouldn't list `[]` as the parameter type for --serviceaccount
### How can we reproduce it (as minimally and precisely as possible)?
```bash
kubectl create ns ns1
kubectl create ns ns2
kubectl --namespace ns1 create sa pipeline
kubectl --namespace ns2 create sa pipeline
kubectl create clusterrolebinding pipelineSAs --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
```
### Anything else we need to know?
_No response_
### Kubernetes version
<details>
```console
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:41:01Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:34:54Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
```
</details>
### Cloud provider
<details>
N/A
</details>
### OS version
<details>
```console
# On Linux:
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.3 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.3 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal
$ uname -a
Linux controlplane 5.4.0-88-generic #99-Ubuntu SMP Thu Sep 23 17:29:00 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
# On Windows:
N/A
```
</details>
### Install tools
<details>
```console
$ kubectl -n kube-system get cm kubeadm-config -oyaml
apiVersion: v1
data:
ClusterConfiguration: |
apiServer:
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.23.1
networking:
dnsDomain: cluster.local
podSubnet: 192.168.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
kind: ConfigMap
metadata:
name: kubeadm-config
namespace: kube-system
```
</details>
### Container runtime (CRI) and version (if applicable)
<details>
architecture: amd64
bootID: 09b2e311-c6dc-40bb-9485-64c98f77cf66
containerRuntimeVersion: containerd://1.5.5
kernelVersion: 5.4.0-88-generic
kubeProxyVersion: v1.23.1
kubeletVersion: v1.23.1
</details>
### Related plugins (CNI, CSI, ...) and versions (if applicable)
<details>
</details>
|
1.0
|
kubectl create help implies a list of service accounts can be references in a clusterrolebinding - ### What happened?
I'm not sure whether this is the documentation being unclear, or a bug with kubectl itself but I suspect the former.
Given this help page
```bash
$ kubectl create clusterrolebinding --help
Create a cluster role binding for a particular cluster role.
# Omitted for brevity
--serviceaccount=[]: Service accounts to bind to the clusterrole, in the format <namespace>:<name>
```
I expected to be able to use
```bash
$ kubectl create clusterrolebinding pipelineSAs --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
```
Instead I got the following error
```bash
$ kubectl create clusterrolebinding pipelinesas --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
error: exactly one NAME is required, got 2
See 'kubectl create clusterrolebinding -h' for help and examples
```
### What did you expect to happen?
To get the same output as defining the flag twice
aka
```bash
$ kubectl create clusterrolebinding pipelinesas --clusterrole=view --serviceaccount=ns1:pipeline --serviceaccount=ns2:pipeline
clusterrolebinding.rbac.authorization.k8s.io/pipelinesas created
```
and
```bash
$ kubectl create clusterrolebinding pipelineSAs --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
clusterrolebinding.rbac.authorization.k8s.io/pipelinesas created
```
should give the same output, or the help page shouldn't list `[]` as the parameter type for --serviceaccount
### How can we reproduce it (as minimally and precisely as possible)?
```bash
kubectl create ns ns1
kubectl create ns ns2
kubectl --namespace ns1 create sa pipeline
kubectl --namespace ns2 create sa pipeline
kubectl create clusterrolebinding pipelineSAs --clusterrole=view --serviceaccount=["ns1:pipeline", "ns2:pipeline"]
```
### Anything else we need to know?
_No response_
### Kubernetes version
<details>
```console
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:41:01Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:34:54Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
```
</details>
### Cloud provider
<details>
N/A
</details>
### OS version
<details>
```console
# On Linux:
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.3 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.3 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal
$ uname -a
Linux controlplane 5.4.0-88-generic #99-Ubuntu SMP Thu Sep 23 17:29:00 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
# On Windows:
N/A
```
</details>
### Install tools
<details>
```console
$ kubectl -n kube-system get cm kubeadm-config -oyaml
apiVersion: v1
data:
ClusterConfiguration: |
apiServer:
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.23.1
networking:
dnsDomain: cluster.local
podSubnet: 192.168.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
kind: ConfigMap
metadata:
name: kubeadm-config
namespace: kube-system
```
</details>
### Container runtime (CRI) and version (if applicable)
<details>
architecture: amd64
bootID: 09b2e311-c6dc-40bb-9485-64c98f77cf66
containerRuntimeVersion: containerd://1.5.5
kernelVersion: 5.4.0-88-generic
kubeProxyVersion: v1.23.1
kubeletVersion: v1.23.1
</details>
### Related plugins (CNI, CSI, ...) and versions (if applicable)
<details>
</details>
|
non_process
|
kubectl create help implies a list of service accounts can be references in a clusterrolebinding what happened i m not sure whether this is the documentation being unclear or a bug with kubectl itself but i suspect the former given this help page bash kubectl create clusterrolebinding help create a cluster role binding for a particular cluster role omitted for brevity serviceaccount service accounts to bind to the clusterrole in the format i expected to be able to use bash kubectl create clusterrolebinding pipelinesas clusterrole view serviceaccount instead i got the following error bash kubectl create clusterrolebinding pipelinesas clusterrole view serviceaccount error exactly one name is required got see kubectl create clusterrolebinding h for help and examples what did you expect to happen to get the same output as defining the flag twice aka bash kubectl create clusterrolebinding pipelinesas clusterrole view serviceaccount pipeline serviceaccount pipeline clusterrolebinding rbac authorization io pipelinesas created and bash kubectl create clusterrolebinding pipelinesas clusterrole view serviceaccount clusterrolebinding rbac authorization io pipelinesas created should give the same output or the help page shouldn t list as the parameter type for serviceaccount how can we reproduce it as minimally and precisely as possible bash kubectl create ns kubectl create ns kubectl namespace create sa pipeline kubectl namespace create sa pipeline kubectl create clusterrolebinding pipelinesas clusterrole view serviceaccount anything else we need to know no response kubernetes version console client version version info major minor gitversion gitcommit gittreestate clean builddate goversion compiler gc platform linux server version version info major minor gitversion gitcommit gittreestate clean builddate goversion compiler gc platform linux cloud provider n a os version console on linux cat etc os release name ubuntu version lts focal fossa id ubuntu id like debian pretty name ubuntu lts version id home url support url bug report url privacy policy url version codename focal ubuntu codename focal uname a linux controlplane generic ubuntu smp thu sep utc gnu linux on windows n a install tools console kubectl n kube system get cm kubeadm config oyaml apiversion data clusterconfiguration apiserver extraargs authorization mode node rbac timeoutforcontrolplane apiversion kubeadm io certificatesdir etc kubernetes pki clustername kubernetes controllermanager dns etcd local datadir var lib etcd imagerepository gcr io kind clusterconfiguration kubernetesversion networking dnsdomain cluster local podsubnet servicesubnet scheduler kind configmap metadata name kubeadm config namespace kube system container runtime cri and version if applicable architecture bootid containerruntimeversion containerd kernelversion generic kubeproxyversion kubeletversion related plugins cni csi and versions if applicable
| 0
|
2,696
| 5,541,381,284
|
IssuesEvent
|
2017-03-22 12:43:15
|
tc39/proposal-regexp-unicode-property-escapes
|
https://api.github.com/repos/tc39/proposal-regexp-unicode-property-escapes
|
closed
|
Advance to stage 3
|
process
|
Criteria taken from [the TC39 process document](https://tc39.github.io/process-document/) minus those from previous stages:
> - [x] Complete spec text
https://github.com/mathiasbynens/es-regexp-unicode-property-escapes/blob/master/spec.html
https://mathiasbynens.github.io/es-regexp-unicode-property-escapes/
> - [ ] Designated reviewers have signed off on the current spec text
- [ ] Bradley Farias (@bmeck): https://github.com/mathiasbynens/es-regexp-unicode-property-escapes/issues/3#issuecomment-257887725
- [ ] Waldemar Horwat (@waldemarhorwat): https://github.com/tc39/proposal-regexp-unicode-property-escapes/issues/3#issuecomment-262101570
- [ ] Allen Wirfs-Brock (@allenwb): https://github.com/mathiasbynens/es-regexp-unicode-property-escapes/issues/created_by/allenwb
> - [ ] The ECMAScript editor has signed off on the current spec text
TODO
|
1.0
|
Advance to stage 3 - Criteria taken from [the TC39 process document](https://tc39.github.io/process-document/) minus those from previous stages:
> - [x] Complete spec text
https://github.com/mathiasbynens/es-regexp-unicode-property-escapes/blob/master/spec.html
https://mathiasbynens.github.io/es-regexp-unicode-property-escapes/
> - [ ] Designated reviewers have signed off on the current spec text
- [ ] Bradley Farias (@bmeck): https://github.com/mathiasbynens/es-regexp-unicode-property-escapes/issues/3#issuecomment-257887725
- [ ] Waldemar Horwat (@waldemarhorwat): https://github.com/tc39/proposal-regexp-unicode-property-escapes/issues/3#issuecomment-262101570
- [ ] Allen Wirfs-Brock (@allenwb): https://github.com/mathiasbynens/es-regexp-unicode-property-escapes/issues/created_by/allenwb
> - [ ] The ECMAScript editor has signed off on the current spec text
TODO
|
process
|
advance to stage criteria taken from minus those from previous stages complete spec text designated reviewers have signed off on the current spec text bradley farias bmeck waldemar horwat waldemarhorwat allen wirfs brock allenwb the ecmascript editor has signed off on the current spec text todo
| 1
|
117,571
| 17,500,480,587
|
IssuesEvent
|
2021-08-10 08:50:26
|
jimmypw/adcs
|
https://api.github.com/repos/jimmypw/adcs
|
reopened
|
Allow Kerberos Authentication
|
enhancement security
|
NTLM authentication method is not secure anymore, Microsoft disables it by a security update. Is there any chance the application can support Kerberos instead of NTLM?
https://msrc.microsoft.com/update-guide/vulnerability/ADV210003
|
True
|
Allow Kerberos Authentication - NTLM authentication method is not secure anymore, Microsoft disables it by a security update. Is there any chance the application can support Kerberos instead of NTLM?
https://msrc.microsoft.com/update-guide/vulnerability/ADV210003
|
non_process
|
allow kerberos authentication ntlm authentication method is not secure anymore microsoft disables it by a security update is there any chance the application can support kerberos instead of ntlm
| 0
|
27,317
| 13,223,713,500
|
IssuesEvent
|
2020-08-17 17:44:29
|
yalelibrary/YUL-DC
|
https://api.github.com/repos/yalelibrary/YUL-DC
|
closed
|
Remove hard-coded Honeybadger keys from Camerata
|
performance team
|
Best practice is not to have Honeybadger keys committed, remove from https://github.com/yalelibrary/yul-dc-camerata/blob/ae2af74995cbd1fece3675a3cfb9dd5749ca8398/docker-compose.ecs.yml#L35
QUESTION: Remove from history? Or change keys?
**ACCEPTANCE**
- [x] Remove any honeybadger API keys directly specified in `yul-dc-camerata` (see #354)
Once the above step is complete,
- [x] Reset the API keys to new values that have never been checked into GitHub - e.g. https://app.honeybadger.io/projects/72587/tokens
- [x] Save the new keys to the Parameter Store
- [x] Redeploy to current clusters (probably yul-test & yul-demo) to activate new keys
|
True
|
Remove hard-coded Honeybadger keys from Camerata - Best practice is not to have Honeybadger keys committed, remove from https://github.com/yalelibrary/yul-dc-camerata/blob/ae2af74995cbd1fece3675a3cfb9dd5749ca8398/docker-compose.ecs.yml#L35
QUESTION: Remove from history? Or change keys?
**ACCEPTANCE**
- [x] Remove any honeybadger API keys directly specified in `yul-dc-camerata` (see #354)
Once the above step is complete,
- [x] Reset the API keys to new values that have never been checked into GitHub - e.g. https://app.honeybadger.io/projects/72587/tokens
- [x] Save the new keys to the Parameter Store
- [x] Redeploy to current clusters (probably yul-test & yul-demo) to activate new keys
|
non_process
|
remove hard coded honeybadger keys from camerata best practice is not to have honeybadger keys committed remove from question remove from history or change keys acceptance remove any honeybadger api keys directly specified in yul dc camerata see once the above step is complete reset the api keys to new values that have never been checked into github e g save the new keys to the parameter store redeploy to current clusters probably yul test yul demo to activate new keys
| 0
|
234,992
| 7,733,610,746
|
IssuesEvent
|
2018-05-26 13:59:34
|
hassio-addons/addon-appdaemon3
|
https://api.github.com/repos/hassio-addons/addon-appdaemon3
|
closed
|
Addon seems to overwrite the ha_key when it restarts
|
Accepted Closed: Done Priority: High Type: Bug Type: Enhancement
|
# Problem/Motivation
The addon seems to overwrite the ha_key when it restarts. I tried to replace it with:
`ha_key: !secret home_assistant_key`
But it is replaced by the actual key whenever the plugin starts.
I don’t really understand the consequences of this, I’m just trying to clean up my repo before publishing it on GitHub (I have some custom widgets to share).
This behavior only occurs when the internal hassio URL is used, as recommended by the add-on manual.
## Expected behavior
The manual set `ha_key: !secret home_assistant_key` to be persistent between add-on restarts
## Actual behavior
The value gets replaced by the API token.
## Steps to reproduce
See above
## Proposed changes
Don't change the `ha_key` in case it is being fetched from the secrets file.
## Ref
https://community.home-assistant.io/t/community-hass-io-add-on-appdaemon/41261/113?u=frenck
home-assistant/appdaemon#280
|
1.0
|
Addon seems to overwrite the ha_key when it restarts - # Problem/Motivation
The addon seems to overwrite the ha_key when it restarts. I tried to replace it with:
`ha_key: !secret home_assistant_key`
But it is replaced by the actual key whenever the plugin starts.
I don’t really understand the consequences of this, I’m just trying to clean up my repo before publishing it on GitHub (I have some custom widgets to share).
This behavior only occurs when the internal hassio URL is used, as recommended by the add-on manual.
## Expected behavior
The manual set `ha_key: !secret home_assistant_key` to be persistent between add-on restarts
## Actual behavior
The value gets replaced by the API token.
## Steps to reproduce
See above
## Proposed changes
Don't change the `ha_key` in case it is being fetched from the secrets file.
## Ref
https://community.home-assistant.io/t/community-hass-io-add-on-appdaemon/41261/113?u=frenck
home-assistant/appdaemon#280
|
non_process
|
addon seems to overwrite the ha key when it restarts problem motivation the addon seems to overwrite the ha key when it restarts i tried to replace it with ha key secret home assistant key but it is replaced by the actual key whenever the plugin starts i don’t really understand the consequences of this i’m just trying to clean up my repo before publishing it on github i have some custom widgets to share this behavior only occurs when the internal hassio url is used as recommended by the add on manual expected behavior the manual set ha key secret home assistant key to be persistent between add on restarts actual behavior the value gets replaced by the api token steps to reproduce see above proposed changes don t change the ha key in case it is being fetched from the secrets file ref home assistant appdaemon
| 0
|
17,302
| 23,119,491,422
|
IssuesEvent
|
2022-07-27 19:52:24
|
dotnet/fabricbot-config
|
https://api.github.com/repos/dotnet/fabricbot-config
|
closed
|
Onboard roslyn-analyzers repo for area pod boards
|
process
|
We need to start generating fabricbot config for the dotnet/roslyn-analyzers repository for integrating issues/PRs from that repository into the area pod boards.
|
1.0
|
Onboard roslyn-analyzers repo for area pod boards - We need to start generating fabricbot config for the dotnet/roslyn-analyzers repository for integrating issues/PRs from that repository into the area pod boards.
|
process
|
onboard roslyn analyzers repo for area pod boards we need to start generating fabricbot config for the dotnet roslyn analyzers repository for integrating issues prs from that repository into the area pod boards
| 1
|
130,947
| 18,162,488,070
|
IssuesEvent
|
2021-09-27 11:14:53
|
XusinboyBekchanov/VisualFBEditor
|
https://api.github.com/repos/XusinboyBekchanov/VisualFBEditor
|
closed
|
In linux, TabPages and RadioButtons
|
Bug Designer
|
1. RadioButtons are not shown well in designer on TabPages
2. i get these errors at compiling
21:49:29: Compilation: "/home/user/Bin/FreeBASIC-1.08.1-ubuntu-20.04-x86_64/bin/fbc" -b "Untitled.bas" -exx -i "/home/user/Bin/VisualFBEditor/./MyFbFramework" -i "/home/user/Bin/FreeBASIC-1.08.1-ubuntu-20.04-x86_64/include/freebasic" -p "/home/user/Bin/FreeBASIC-1.08.1-ubuntu-20.04-x86_64/lib/freebasic/linux-x86_64" 2> "/home/user/Bin/VisualFBEditor/Temp/Compile.log"
ld: Untitled.o: in function `FORM1::FORM1()':
Untitled.c:(.text+0x59f9b): undefined reference to `MY::SYS::FORMS::TABPAGE::TABINDEX__set__(long)'
ld: Untitled.c:(.text+0x5a008): undefined reference to `MY::SYS::FORMS::TABPAGE::TABINDEX__set__(long)'
21:49:49: Do not build file.
[Untitled.bas.zip](https://github.com/XusinboyBekchanov/VisualFBEditor/files/7150135/Untitled.bas.zip)
|
1.0
|
In linux, TabPages and RadioButtons - 1. RadioButtons are not shown well in designer on TabPages
2. i get these errors at compiling
21:49:29: Compilation: "/home/user/Bin/FreeBASIC-1.08.1-ubuntu-20.04-x86_64/bin/fbc" -b "Untitled.bas" -exx -i "/home/user/Bin/VisualFBEditor/./MyFbFramework" -i "/home/user/Bin/FreeBASIC-1.08.1-ubuntu-20.04-x86_64/include/freebasic" -p "/home/user/Bin/FreeBASIC-1.08.1-ubuntu-20.04-x86_64/lib/freebasic/linux-x86_64" 2> "/home/user/Bin/VisualFBEditor/Temp/Compile.log"
ld: Untitled.o: in function `FORM1::FORM1()':
Untitled.c:(.text+0x59f9b): undefined reference to `MY::SYS::FORMS::TABPAGE::TABINDEX__set__(long)'
ld: Untitled.c:(.text+0x5a008): undefined reference to `MY::SYS::FORMS::TABPAGE::TABINDEX__set__(long)'
21:49:49: Do not build file.
[Untitled.bas.zip](https://github.com/XusinboyBekchanov/VisualFBEditor/files/7150135/Untitled.bas.zip)
|
non_process
|
in linux tabpages and radiobuttons radiobuttons are not shown well in designer on tabpages i get these errors at compiling compilation home user bin freebasic ubuntu bin fbc b untitled bas exx i home user bin visualfbeditor myfbframework i home user bin freebasic ubuntu include freebasic p home user bin freebasic ubuntu lib freebasic linux home user bin visualfbeditor temp compile log ld untitled o in function untitled c text undefined reference to my sys forms tabpage tabindex set long ld untitled c text undefined reference to my sys forms tabpage tabindex set long do not build file
| 0
|
421,687
| 28,353,411,905
|
IssuesEvent
|
2023-04-12 05:08:16
|
neu-cs4530/spring-23-team-514
|
https://api.github.com/repos/neu-cs4530/spring-23-team-514
|
closed
|
Review code and documentation for front end features.
|
documentation size:S test
|
Make sure that all changes from original starter-code frontend portion are documented and tested.
|
1.0
|
Review code and documentation for front end features. - Make sure that all changes from original starter-code frontend portion are documented and tested.
|
non_process
|
review code and documentation for front end features make sure that all changes from original starter code frontend portion are documented and tested
| 0
|
306,716
| 26,492,178,366
|
IssuesEvent
|
2023-01-18 00:10:57
|
unifyai/ivy
|
https://api.github.com/repos/unifyai/ivy
|
closed
|
Fix linalg.test_torch_svdvals
|
PyTorch Frontend Sub Task Failing Test
|
| | |
|---|---|
|tensorflow|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-failure-red></a>
|torch|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-success-success></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-success-success></a>
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-success-success></a>
<details>
<summary>FAILED ivy_tests/test_ivy/test_frontends/test_torch/test_linalg.py::test_torch_svdvals[cpu-ivy.functional.backends.tensorflow-False-False]</summary>
2023-01-16T19:46:05.0076522Z E AssertionError: [1.6278013e+01 8.7431078e+00 6.8812180e+00 7.9080409e-01 1.3175042e-03] != [1.6278006e+01 8.7431087e+00 6.8812184e+00 7.9080427e-01 1.3162501e-03]
2023-01-16T19:46:05.0076944Z E Falsifying example: test_torch_svdvals(
2023-01-16T19:46:05.0077338Z E dtype_and_x=(['float32'],
2023-01-16T19:46:05.0078416Z E array([[1.7750025e+00, 2.6702881e-05, 1.0000000e+00, 1.0000000e+00,
2023-01-16T19:46:05.0078676Z E 1.0000000e+00],
2023-01-16T19:46:05.0079008Z E [1.5000000e+00, 9.5367432e-06, 1.0000000e+00, 1.1000004e+00,
2023-01-16T19:46:05.0079293Z E 1.9103289e-05],
2023-01-16T19:46:05.0079623Z E [3.5021975e+00, 2.2888184e-05, 9.0000000e+00, 7.0000000e+00,
2023-01-16T19:46:05.0079865Z E 1.0000000e+00],
2023-01-16T19:46:05.0080202Z E [8.1250000e-01, 8.1250000e+00, 1.0000000e+00, 8.5009842e+00,
2023-01-16T19:46:05.0080445Z E 1.0000000e+00],
2023-01-16T19:46:05.0080693Z E [8.7522087e+00, 1.0000000e+00, 1.0000000e+00, 3.8693943e+00,
2023-01-16T19:46:05.0080948Z E 1.0000000e+00]], dtype=float32)),
2023-01-16T19:46:05.0081196Z E with_out=False,
2023-01-16T19:46:05.0081569Z E native_array=[False],
2023-01-16T19:46:05.0081801Z E as_variable=[False],
2023-01-16T19:46:05.0082039Z E num_positional_args=0,
2023-01-16T19:46:05.0082444Z E fn_tree='ivy.functional.frontends.torch.linalg.svdvals',
2023-01-16T19:46:05.0082795Z E on_device='cpu',
2023-01-16T19:46:05.0083052Z E frontend='torch',
2023-01-16T19:46:05.0083256Z E )
2023-01-16T19:46:05.0083421Z E
2023-01-16T19:46:05.0084500Z E You can reproduce this example by temporarily adding @reproduce_failure('6.55.0', b'AXicY2BmYGBoAGJGzrRkIHXgPwMIMDPAASNOZgOCeRDCZMKigHXmDJC5f8CCIAUNUoyMjAc4GRG2IZnLiWCyoxp2AMJkBZlgAGayoNlmALYB3ZEgUWZO3B5qkAeZylmNrgAA2+YPJw==') as a decorator on your test case
</details>
|
1.0
|
Fix linalg.test_torch_svdvals - | | |
|---|---|
|tensorflow|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-failure-red></a>
|torch|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-success-success></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-success-success></a>
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/3933422957/jobs/6727107438" rel="noopener noreferrer" target="_blank"><img src=https://img.shields.io/badge/-success-success></a>
<details>
<summary>FAILED ivy_tests/test_ivy/test_frontends/test_torch/test_linalg.py::test_torch_svdvals[cpu-ivy.functional.backends.tensorflow-False-False]</summary>
2023-01-16T19:46:05.0076522Z E AssertionError: [1.6278013e+01 8.7431078e+00 6.8812180e+00 7.9080409e-01 1.3175042e-03] != [1.6278006e+01 8.7431087e+00 6.8812184e+00 7.9080427e-01 1.3162501e-03]
2023-01-16T19:46:05.0076944Z E Falsifying example: test_torch_svdvals(
2023-01-16T19:46:05.0077338Z E dtype_and_x=(['float32'],
2023-01-16T19:46:05.0078416Z E array([[1.7750025e+00, 2.6702881e-05, 1.0000000e+00, 1.0000000e+00,
2023-01-16T19:46:05.0078676Z E 1.0000000e+00],
2023-01-16T19:46:05.0079008Z E [1.5000000e+00, 9.5367432e-06, 1.0000000e+00, 1.1000004e+00,
2023-01-16T19:46:05.0079293Z E 1.9103289e-05],
2023-01-16T19:46:05.0079623Z E [3.5021975e+00, 2.2888184e-05, 9.0000000e+00, 7.0000000e+00,
2023-01-16T19:46:05.0079865Z E 1.0000000e+00],
2023-01-16T19:46:05.0080202Z E [8.1250000e-01, 8.1250000e+00, 1.0000000e+00, 8.5009842e+00,
2023-01-16T19:46:05.0080445Z E 1.0000000e+00],
2023-01-16T19:46:05.0080693Z E [8.7522087e+00, 1.0000000e+00, 1.0000000e+00, 3.8693943e+00,
2023-01-16T19:46:05.0080948Z E 1.0000000e+00]], dtype=float32)),
2023-01-16T19:46:05.0081196Z E with_out=False,
2023-01-16T19:46:05.0081569Z E native_array=[False],
2023-01-16T19:46:05.0081801Z E as_variable=[False],
2023-01-16T19:46:05.0082039Z E num_positional_args=0,
2023-01-16T19:46:05.0082444Z E fn_tree='ivy.functional.frontends.torch.linalg.svdvals',
2023-01-16T19:46:05.0082795Z E on_device='cpu',
2023-01-16T19:46:05.0083052Z E frontend='torch',
2023-01-16T19:46:05.0083256Z E )
2023-01-16T19:46:05.0083421Z E
2023-01-16T19:46:05.0084500Z E You can reproduce this example by temporarily adding @reproduce_failure('6.55.0', b'AXicY2BmYGBoAGJGzrRkIHXgPwMIMDPAASNOZgOCeRDCZMKigHXmDJC5f8CCIAUNUoyMjAc4GRG2IZnLiWCyoxp2AMJkBZlgAGayoNlmALYB3ZEgUWZO3B5qkAeZylmNrgAA2+YPJw==') as a decorator on your test case
</details>
|
non_process
|
fix linalg test torch svdvals tensorflow img src torch img src numpy img src jax img src failed ivy tests test ivy test frontends test torch test linalg py test torch svdvals e assertionerror e falsifying example test torch svdvals e dtype and x e array e e e e e e e e e dtype e with out false e native array e as variable e num positional args e fn tree ivy functional frontends torch linalg svdvals e on device cpu e frontend torch e e e you can reproduce this example by temporarily adding reproduce failure b ypjw as a decorator on your test case
| 0
|
10,884
| 13,654,065,049
|
IssuesEvent
|
2020-09-27 15:40:10
|
timberio/vector
|
https://api.github.com/repos/timberio/vector
|
closed
|
New `slice` remap function
|
domain: mapping domain: processing transform: remap type: feature
|
The `slice` remap function slices arrays and strings.
## Example
### Strings
#### Remaining
Given the following event:
```
{
"message": "Supercalifragilisticexpialidocious"
}
```
```
.message = slice(.message, -7)
```
Would result in
```
{
"message": "docious"
}
```
#### Exact
Given the following event:
```
{
"message": "supercalifragilisticexpialidocious"
}
```
```
.message = slice(.message, 5, 9)
```
Would result in:
```
{
"message": "cali"
}
```
### Arrays
The same as above but with an array.
|
1.0
|
New `slice` remap function - The `slice` remap function slices arrays and strings.
## Example
### Strings
#### Remaining
Given the following event:
```
{
"message": "Supercalifragilisticexpialidocious"
}
```
```
.message = slice(.message, -7)
```
Would result in
```
{
"message": "docious"
}
```
#### Exact
Given the following event:
```
{
"message": "supercalifragilisticexpialidocious"
}
```
```
.message = slice(.message, 5, 9)
```
Would result in:
```
{
"message": "cali"
}
```
### Arrays
The same as above but with an array.
|
process
|
new slice remap function the slice remap function slices arrays and strings example strings remaining given the following event message supercalifragilisticexpialidocious message slice message would result in message docious exact given the following event message supercalifragilisticexpialidocious message slice message would result in message cali arrays the same as above but with an array
| 1
|
15,063
| 18,764,623,648
|
IssuesEvent
|
2021-11-05 21:16:50
|
ORNL-AMO/AMO-Tools-Suite
|
https://api.github.com/repos/ORNL-AMO/AMO-Tools-Suite
|
closed
|
Fixes to HeatWaterUsingFlue
|
Needs Verification Process Heating
|
Issue overview
--------------
C++ not matching algorithm

1 - add switch to line 25
enthalpySteam =
if condSteam == Saturated -->
`SteamProperties(prSteam, SteamProperties::ThermodynamicQuantity::QUALITY, 1).calculate().specificEnthalpy`
else -->
`SteamProperties(prSteam, SteamProperties::ThermodynamicQuantity::TEMPERATURE, tempSteam).calculate().specificEnthalpy`
2. remove line 24 and tempSteamSat from return (not needed)
|
1.0
|
Fixes to HeatWaterUsingFlue - Issue overview
--------------
C++ not matching algorithm

1 - add switch to line 25
enthalpySteam =
if condSteam == Saturated -->
`SteamProperties(prSteam, SteamProperties::ThermodynamicQuantity::QUALITY, 1).calculate().specificEnthalpy`
else -->
`SteamProperties(prSteam, SteamProperties::ThermodynamicQuantity::TEMPERATURE, tempSteam).calculate().specificEnthalpy`
2. remove line 24 and tempSteamSat from return (not needed)
|
process
|
fixes to heatwaterusingflue issue overview c not matching algorithm add switch to line enthalpysteam if condsteam saturated steamproperties prsteam steamproperties thermodynamicquantity quality calculate specificenthalpy else steamproperties prsteam steamproperties thermodynamicquantity temperature tempsteam calculate specificenthalpy remove line and tempsteamsat from return not needed
| 1
|
15,374
| 19,557,711,351
|
IssuesEvent
|
2022-01-03 12:05:22
|
ooi-data/RS01SBPS-PC01A-06-VADCPA101-streamed-vadcp_velocity_beam
|
https://api.github.com/repos/ooi-data/RS01SBPS-PC01A-06-VADCPA101-streamed-vadcp_velocity_beam
|
opened
|
🛑 Processing failed: GroupNotFoundError
|
process
|
## Overview
`GroupNotFoundError` found in `processing_task` task during run ended on 2022-01-03T12:05:22.100600.
## Details
Flow name: `RS01SBPS-PC01A-06-VADCPA101-streamed-vadcp_velocity_beam`
Task name: `processing_task`
Error type: `GroupNotFoundError`
Error message: group not found at path ''
<details>
<summary>Traceback</summary>
```
Traceback (most recent call last):
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/pipeline.py", line 165, in processing
final_path = finalize_data_stream(
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/__init__.py", line 64, in finalize_data_stream
final_group = zarr.open_group(final_store, mode='r+')
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/hierarchy.py", line 1168, in open_group
raise GroupNotFoundError(path)
zarr.errors.GroupNotFoundError: group not found at path ''
```
</details>
|
1.0
|
🛑 Processing failed: GroupNotFoundError - ## Overview
`GroupNotFoundError` found in `processing_task` task during run ended on 2022-01-03T12:05:22.100600.
## Details
Flow name: `RS01SBPS-PC01A-06-VADCPA101-streamed-vadcp_velocity_beam`
Task name: `processing_task`
Error type: `GroupNotFoundError`
Error message: group not found at path ''
<details>
<summary>Traceback</summary>
```
Traceback (most recent call last):
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/pipeline.py", line 165, in processing
final_path = finalize_data_stream(
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/ooi_harvester/processor/__init__.py", line 64, in finalize_data_stream
final_group = zarr.open_group(final_store, mode='r+')
File "/srv/conda/envs/notebook/lib/python3.9/site-packages/zarr/hierarchy.py", line 1168, in open_group
raise GroupNotFoundError(path)
zarr.errors.GroupNotFoundError: group not found at path ''
```
</details>
|
process
|
🛑 processing failed groupnotfounderror overview groupnotfounderror found in processing task task during run ended on details flow name streamed vadcp velocity beam task name processing task error type groupnotfounderror error message group not found at path traceback traceback most recent call last file srv conda envs notebook lib site packages ooi harvester processor pipeline py line in processing final path finalize data stream file srv conda envs notebook lib site packages ooi harvester processor init py line in finalize data stream final group zarr open group final store mode r file srv conda envs notebook lib site packages zarr hierarchy py line in open group raise groupnotfounderror path zarr errors groupnotfounderror group not found at path
| 1
|
6,102
| 13,731,658,728
|
IssuesEvent
|
2020-10-05 01:53:34
|
k9mail/k-9
|
https://api.github.com/repos/k9mail/k-9
|
closed
|
Separate folder name from remote folder ID
|
architecture enhancement
|
I've been looking into various folder related issues recently and I've come to the conclusion we need to introduce the concept of remote folder ID.
This will help in the following circumstances:
1. For #630 we will be able to use the folder name as the actual name (i.e. Computing.K9 will become K9.
2. For #1342 we will be able to uniquely identify folders as to which namespace they are under
3. For #606 we will then be able to support EWS which mostly uses a 'unique ID' to reference folders rather than name.
This will impact the following areas of code:
### Database Structure
The folders table will have a new column, `remoteID`
Existing folders will have their current folderName copied to the remoteID column during migration.
### Stores
All access to folders will be via the ID, not the name. Hence the folder cache will map from ID to `Folder<?>`
When the folder list is refreshed (`getPersonalNamespaces()` [which is by the way a terribly IMAP specific name]) we can update the name of existing folders.
|
1.0
|
Separate folder name from remote folder ID - I've been looking into various folder related issues recently and I've come to the conclusion we need to introduce the concept of remote folder ID.
This will help in the following circumstances:
1. For #630 we will be able to use the folder name as the actual name (i.e. Computing.K9 will become K9.
2. For #1342 we will be able to uniquely identify folders as to which namespace they are under
3. For #606 we will then be able to support EWS which mostly uses a 'unique ID' to reference folders rather than name.
This will impact the following areas of code:
### Database Structure
The folders table will have a new column, `remoteID`
Existing folders will have their current folderName copied to the remoteID column during migration.
### Stores
All access to folders will be via the ID, not the name. Hence the folder cache will map from ID to `Folder<?>`
When the folder list is refreshed (`getPersonalNamespaces()` [which is by the way a terribly IMAP specific name]) we can update the name of existing folders.
|
non_process
|
separate folder name from remote folder id i ve been looking into various folder related issues recently and i ve come to the conclusion we need to introduce the concept of remote folder id this will help in the following circumstances for we will be able to use the folder name as the actual name i e computing will become for we will be able to uniquely identify folders as to which namespace they are under for we will then be able to support ews which mostly uses a unique id to reference folders rather than name this will impact the following areas of code database structure the folders table will have a new column remoteid existing folders will have their current foldername copied to the remoteid column during migration stores all access to folders will be via the id not the name hence the folder cache will map from id to folder when the folder list is refreshed getpersonalnamespaces we can update the name of existing folders
| 0
|
7,338
| 10,473,660,107
|
IssuesEvent
|
2019-09-23 13:05:26
|
aiidateam/aiida-core
|
https://api.github.com/repos/aiidateam/aiida-core
|
opened
|
Exception raised in `WorkChain.out` will cause it to be stuck in `Running`
|
priority/important topic/processes topic/workflows type/bug
|
This appears when trying to output an unstored data node in a workchain step for example. The exception will appear in the daemon log, but the process will never properly transition to the excepted state.
|
1.0
|
Exception raised in `WorkChain.out` will cause it to be stuck in `Running` - This appears when trying to output an unstored data node in a workchain step for example. The exception will appear in the daemon log, but the process will never properly transition to the excepted state.
|
process
|
exception raised in workchain out will cause it to be stuck in running this appears when trying to output an unstored data node in a workchain step for example the exception will appear in the daemon log but the process will never properly transition to the excepted state
| 1
|
159,809
| 12,491,132,096
|
IssuesEvent
|
2020-06-01 02:57:06
|
ufcg-lsd/saps-engine
|
https://api.github.com/repos/ufcg-lsd/saps-engine
|
closed
|
Perform endtoend testing with real algorithms
|
test
|
The entire environment was created to perform the endtoend test described in [endtoend doc](https://github.com/ufcg-lsd/saps-engine/blob/develop/docs/end-to-end-test.md#end-to-end-test-using-real-algorithms), but the current deployment of test does not have workers with sufficient capacity to result in successful processing. It must be done after allocating workers with the minimum settings of 16GB ram and 2 vcpus with 50GB host size.
|
1.0
|
Perform endtoend testing with real algorithms - The entire environment was created to perform the endtoend test described in [endtoend doc](https://github.com/ufcg-lsd/saps-engine/blob/develop/docs/end-to-end-test.md#end-to-end-test-using-real-algorithms), but the current deployment of test does not have workers with sufficient capacity to result in successful processing. It must be done after allocating workers with the minimum settings of 16GB ram and 2 vcpus with 50GB host size.
|
non_process
|
perform endtoend testing with real algorithms the entire environment was created to perform the endtoend test described in but the current deployment of test does not have workers with sufficient capacity to result in successful processing it must be done after allocating workers with the minimum settings of ram and vcpus with host size
| 0
|
533,072
| 15,576,375,664
|
IssuesEvent
|
2021-03-17 12:17:58
|
huridocs/uwazi
|
https://api.github.com/repos/huridocs/uwazi
|
closed
|
Add vertical size hidden overflow to all properties in cards
|
Priority: Medium UX/UI
|
Some users are accidentally getting these kind of results:
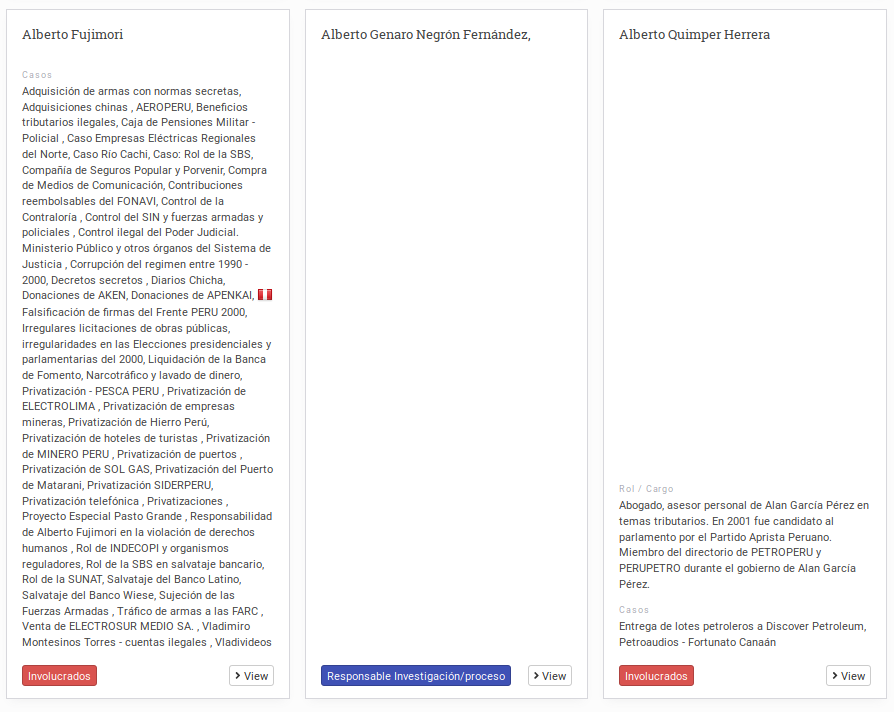
|
1.0
|
Add vertical size hidden overflow to all properties in cards - Some users are accidentally getting these kind of results:

|
non_process
|
add vertical size hidden overflow to all properties in cards some users are accidentally getting these kind of results
| 0
|
13,586
| 16,137,468,305
|
IssuesEvent
|
2021-04-29 13:35:46
|
prisma/prisma
|
https://api.github.com/repos/prisma/prisma
|
closed
|
[Bug] Prisma-fmt sqlserver NVarChar(m) causes thread 'main' panicked at 'called `Result::unwrap()`
|
bug/2-confirmed kind/bug process/candidate topic: cli-format topic: sql server
|
<!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: https://pris.ly/d/bug-reports
-->
## Bug description
This is especially annoying when using the vscode extension, since apparently whatever part is causing this is also being run for highlighting, since it throws the panic while trying to type `NVarChar(max)` while you only have `(m)` and `(ma)` typed in the parentheses.
## How to reproduce
Steps to reproduce the behavior:
1. Create a model with a column database type of `NVarChar()`
2. Enter any partial string of the keyword `max`
3. Run `prisma format`
## Expected behavior
Produce non-panic errors (hopefully resulting in the syntax marking as invalid through things like the vscode extension)
## Prisma information
```prisma
model Config {
key String @id
value String? @db.NVarChar(m)
}
```
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: Ubuntu (WSL)
- Database: SQL Server
- Node.js version: v14.16.1
- Prisma version:
<!--[Run `prisma -v` to see your Prisma version and paste it between the ´´´]-->
```
prisma : 2.21.2
@prisma/client : 2.21.2
Current platform : debian-openssl-1.1.x
Query Engine : query-engine e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/query-engine-debian-openssl-1.1.x)
Migration Engine : migration-engine-cli e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/migration-engine-debian-openssl-1.1.x)
Introspection Engine : introspection-core e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/introspection-engine-debian-openssl-1.1.x)
Format Binary : prisma-fmt e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/prisma-fmt-debian-openssl-1.1.x)
Default Engines Hash : e421996c87d5f3c8f7eeadd502d4ad402c89464d
Studio : 0.371.0
Preview Features : microsoftSqlServer
```
<details>
<summary>Backtrace</summary>
```
Error: Error: Command failed with exit code 101: /home/jhemphill/data-model/node_modules/@prisma/engines/prisma-fmt-debian-openssl-1.1.x format -i /home/jhemphill/data-model/prisma/schema.prisma
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: ParseIntError { kind: InvalidDigit }', libs/datamodel/connectors/sql-datamodel-connector/src/mssql_datamodel_connector.rs:391:57
stack backtrace:
0: rust_begin_unwind
at /rustc/2fd73fabe469357a12c2c974c140f67e7cdd76d0/library/std/src/panicking.rs:493:5
1: core::panicking::panic_fmt
at /rustc/2fd73fabe469357a12c2c974c140f67e7cdd76d0/library/core/src/panicking.rs:92:14
2: core::option::expect_none_failed
at /rustc/2fd73fabe469357a12c2c974c140f67e7cdd76d0/library/core/src/option.rs:1300:5
3: sql_datamodel_connector::mssql_datamodel_connector::parse_mssql_type_parameter
4: <sql_datamodel_connector::mssql_datamodel_connector::MsSqlDatamodelConnector as datamodel_connector::Connector>::parse_native_type
5: datamodel::transform::ast_to_dml::lift::LiftAstToDml::lift_field_type
6: datamodel::transform::ast_to_dml::validation_pipeline::ValidationPipeline::validate
7: datamodel::parse_datamodel_internal
8: datamodel::ast::reformat::reformatter::Reformatter::new
9: prisma_fmt::format::run
10: prisma_fmt::main
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
at makeError (/home/jhemphill/data-model/node_modules/prisma/build/index.js:2564:15)
at handlePromise (/home/jhemphill/data-model/node_modules/prisma/build/index.js:3232:31)
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:93:5)
at async Object.formatSchema2 (/home/jhemphill/data-model/node_modules/prisma/build/index.js:14792:16)
at async _Format.parse (/home/jhemphill/data-model/node_modules/prisma/build/index.js:140770:18)
at async main (/home/jhemphill/data-model/node_modules/prisma/build/index.js:141299:18)
```
</details>
|
1.0
|
[Bug] Prisma-fmt sqlserver NVarChar(m) causes thread 'main' panicked at 'called `Result::unwrap()` - <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: https://pris.ly/d/bug-reports
-->
## Bug description
This is especially annoying when using the vscode extension, since apparently whatever part is causing this is also being run for highlighting, since it throws the panic while trying to type `NVarChar(max)` while you only have `(m)` and `(ma)` typed in the parentheses.
## How to reproduce
Steps to reproduce the behavior:
1. Create a model with a column database type of `NVarChar()`
2. Enter any partial string of the keyword `max`
3. Run `prisma format`
## Expected behavior
Produce non-panic errors (hopefully resulting in the syntax marking as invalid through things like the vscode extension)
## Prisma information
```prisma
model Config {
key String @id
value String? @db.NVarChar(m)
}
```
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: Ubuntu (WSL)
- Database: SQL Server
- Node.js version: v14.16.1
- Prisma version:
<!--[Run `prisma -v` to see your Prisma version and paste it between the ´´´]-->
```
prisma : 2.21.2
@prisma/client : 2.21.2
Current platform : debian-openssl-1.1.x
Query Engine : query-engine e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/query-engine-debian-openssl-1.1.x)
Migration Engine : migration-engine-cli e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/migration-engine-debian-openssl-1.1.x)
Introspection Engine : introspection-core e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/introspection-engine-debian-openssl-1.1.x)
Format Binary : prisma-fmt e421996c87d5f3c8f7eeadd502d4ad402c89464d (at ../../.config/nvm/versions/node/v14.16.1/lib/node_modules/prisma/node_modules/@prisma/engines/prisma-fmt-debian-openssl-1.1.x)
Default Engines Hash : e421996c87d5f3c8f7eeadd502d4ad402c89464d
Studio : 0.371.0
Preview Features : microsoftSqlServer
```
<details>
<summary>Backtrace</summary>
```
Error: Error: Command failed with exit code 101: /home/jhemphill/data-model/node_modules/@prisma/engines/prisma-fmt-debian-openssl-1.1.x format -i /home/jhemphill/data-model/prisma/schema.prisma
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: ParseIntError { kind: InvalidDigit }', libs/datamodel/connectors/sql-datamodel-connector/src/mssql_datamodel_connector.rs:391:57
stack backtrace:
0: rust_begin_unwind
at /rustc/2fd73fabe469357a12c2c974c140f67e7cdd76d0/library/std/src/panicking.rs:493:5
1: core::panicking::panic_fmt
at /rustc/2fd73fabe469357a12c2c974c140f67e7cdd76d0/library/core/src/panicking.rs:92:14
2: core::option::expect_none_failed
at /rustc/2fd73fabe469357a12c2c974c140f67e7cdd76d0/library/core/src/option.rs:1300:5
3: sql_datamodel_connector::mssql_datamodel_connector::parse_mssql_type_parameter
4: <sql_datamodel_connector::mssql_datamodel_connector::MsSqlDatamodelConnector as datamodel_connector::Connector>::parse_native_type
5: datamodel::transform::ast_to_dml::lift::LiftAstToDml::lift_field_type
6: datamodel::transform::ast_to_dml::validation_pipeline::ValidationPipeline::validate
7: datamodel::parse_datamodel_internal
8: datamodel::ast::reformat::reformatter::Reformatter::new
9: prisma_fmt::format::run
10: prisma_fmt::main
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
at makeError (/home/jhemphill/data-model/node_modules/prisma/build/index.js:2564:15)
at handlePromise (/home/jhemphill/data-model/node_modules/prisma/build/index.js:3232:31)
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:93:5)
at async Object.formatSchema2 (/home/jhemphill/data-model/node_modules/prisma/build/index.js:14792:16)
at async _Format.parse (/home/jhemphill/data-model/node_modules/prisma/build/index.js:140770:18)
at async main (/home/jhemphill/data-model/node_modules/prisma/build/index.js:141299:18)
```
</details>
|
process
|
prisma fmt sqlserver nvarchar m causes thread main panicked at called result unwrap thanks for helping us improve prisma 🙏 please follow the sections in the template and provide as much information as possible about your problem e g by setting the debug environment variable and enabling additional logging output in prisma client learn more about writing proper bug reports here bug description this is especially annoying when using the vscode extension since apparently whatever part is causing this is also being run for highlighting since it throws the panic while trying to type nvarchar max while you only have m and ma typed in the parentheses how to reproduce steps to reproduce the behavior create a model with a column database type of nvarchar enter any partial string of the keyword max run prisma format expected behavior produce non panic errors hopefully resulting in the syntax marking as invalid through things like the vscode extension prisma information prisma model config key string id value string db nvarchar m environment setup os ubuntu wsl database sql server node js version prisma version prisma prisma client current platform debian openssl x query engine query engine at config nvm versions node lib node modules prisma node modules prisma engines query engine debian openssl x migration engine migration engine cli at config nvm versions node lib node modules prisma node modules prisma engines migration engine debian openssl x introspection engine introspection core at config nvm versions node lib node modules prisma node modules prisma engines introspection engine debian openssl x format binary prisma fmt at config nvm versions node lib node modules prisma node modules prisma engines prisma fmt debian openssl x default engines hash studio preview features microsoftsqlserver backtrace error error command failed with exit code home jhemphill data model node modules prisma engines prisma fmt debian openssl x format i home jhemphill data model prisma schema prisma thread main panicked at called result unwrap on an err value parseinterror kind invaliddigit libs datamodel connectors sql datamodel connector src mssql datamodel connector rs stack backtrace rust begin unwind at rustc library std src panicking rs core panicking panic fmt at rustc library core src panicking rs core option expect none failed at rustc library core src option rs sql datamodel connector mssql datamodel connector parse mssql type parameter parse native type datamodel transform ast to dml lift liftasttodml lift field type datamodel transform ast to dml validation pipeline validationpipeline validate datamodel parse datamodel internal datamodel ast reformat reformatter reformatter new prisma fmt format run prisma fmt main note some details are omitted run with rust backtrace full for a verbose backtrace at makeerror home jhemphill data model node modules prisma build index js at handlepromise home jhemphill data model node modules prisma build index js at runmicrotasks at processticksandrejections internal process task queues js at async object home jhemphill data model node modules prisma build index js at async format parse home jhemphill data model node modules prisma build index js at async main home jhemphill data model node modules prisma build index js
| 1
|
11,290
| 3,197,635,201
|
IssuesEvent
|
2015-10-01 06:58:24
|
uProxy/uproxy
|
https://api.github.com/repos/uProxy/uproxy
|
closed
|
Move freedom mocking out of remote-connection.spec.ts into more obvious file
|
C:Testing
|
Right now a number of the tests for uProxy core all use the global storage object, which in unit tests is mocked to use our freedom_mocks.MockStorage class. However the glue to sets freedom['storage'] to freedom_mocks.MockStorage is in remote-connection.spec.ts, despite it being depended on by all our other unit tests in the core. This is not an obvious place for it, rather we should move it to some new file that is included in all our tests. We have a similar situation for MockLoggingController and now MockMetrics
|
1.0
|
Move freedom mocking out of remote-connection.spec.ts into more obvious file - Right now a number of the tests for uProxy core all use the global storage object, which in unit tests is mocked to use our freedom_mocks.MockStorage class. However the glue to sets freedom['storage'] to freedom_mocks.MockStorage is in remote-connection.spec.ts, despite it being depended on by all our other unit tests in the core. This is not an obvious place for it, rather we should move it to some new file that is included in all our tests. We have a similar situation for MockLoggingController and now MockMetrics
|
non_process
|
move freedom mocking out of remote connection spec ts into more obvious file right now a number of the tests for uproxy core all use the global storage object which in unit tests is mocked to use our freedom mocks mockstorage class however the glue to sets freedom to freedom mocks mockstorage is in remote connection spec ts despite it being depended on by all our other unit tests in the core this is not an obvious place for it rather we should move it to some new file that is included in all our tests we have a similar situation for mockloggingcontroller and now mockmetrics
| 0
|
1,665
| 3,077,598,159
|
IssuesEvent
|
2015-08-21 02:03:44
|
DerekRies/entito
|
https://api.github.com/repos/DerekRies/entito
|
opened
|
Implement Performance Tests
|
performance
|
Repo needs some performance tests before any of performance tests are implemented.
|
True
|
Implement Performance Tests - Repo needs some performance tests before any of performance tests are implemented.
|
non_process
|
implement performance tests repo needs some performance tests before any of performance tests are implemented
| 0
|
20,531
| 27,190,058,187
|
IssuesEvent
|
2023-02-19 17:40:05
|
apache/arrow-ballista
|
https://api.github.com/repos/apache/arrow-ballista
|
closed
|
Ballista 0.10.0 Release (Nov 2022)
|
enhancement development-process
|
**Is your feature request related to a problem or challenge? Please describe what you are trying to do.**
I plan on cutting the release candidate on November 18th. It would be nice to get as many of these features in as possible, but none should block the release.
- [ ] Features & Bug Fixes
- [ ] See https://github.com/apache/arrow-ballista/milestone/1
- [ ] Release Process
- [ ] Prepare the release candidate
- [ ] Publish the release once the vote passes
- [ ] Blog post
**Describe the solution you'd like**
:point_up:
**Describe alternatives you've considered**
None
**Additional context**
None
|
1.0
|
Ballista 0.10.0 Release (Nov 2022) - **Is your feature request related to a problem or challenge? Please describe what you are trying to do.**
I plan on cutting the release candidate on November 18th. It would be nice to get as many of these features in as possible, but none should block the release.
- [ ] Features & Bug Fixes
- [ ] See https://github.com/apache/arrow-ballista/milestone/1
- [ ] Release Process
- [ ] Prepare the release candidate
- [ ] Publish the release once the vote passes
- [ ] Blog post
**Describe the solution you'd like**
:point_up:
**Describe alternatives you've considered**
None
**Additional context**
None
|
process
|
ballista release nov is your feature request related to a problem or challenge please describe what you are trying to do i plan on cutting the release candidate on november it would be nice to get as many of these features in as possible but none should block the release features bug fixes see release process prepare the release candidate publish the release once the vote passes blog post describe the solution you d like point up describe alternatives you ve considered none additional context none
| 1
|
575,828
| 17,063,638,469
|
IssuesEvent
|
2021-07-07 02:52:13
|
Team-uMigrate/umigrate
|
https://api.github.com/repos/Team-uMigrate/umigrate
|
closed
|
App: Create UsersList component
|
easy high priority
|
We need to create a reusable component that renders a list of users passed in as props. Follow the designs on figma and use the right components (usually material-ui/react-native-paper).
|
1.0
|
App: Create UsersList component - We need to create a reusable component that renders a list of users passed in as props. Follow the designs on figma and use the right components (usually material-ui/react-native-paper).
|
non_process
|
app create userslist component we need to create a reusable component that renders a list of users passed in as props follow the designs on figma and use the right components usually material ui react native paper
| 0
|
5,820
| 8,653,434,467
|
IssuesEvent
|
2018-11-27 10:49:39
|
OpenSourcePolitics/decidim
|
https://api.github.com/repos/OpenSourcePolitics/decidim
|
closed
|
Survey already answered when it shouldn't
|
Non-blocking bug component: surveys space: processes
|
**Describe the bug**
To be complete, when the survey is published even though there are no questions, as a user who answered the original survey, I am told i have already answered the survey. When questions are added, I see the survey as expected.
To link with => #327
**To Reproduce**
Steps to reproduce the behavior:
As a user who answered the original survey
1. Go to 'https://steamroll.osp.cat/processes/test-copie-composant/f/76/'
2. See error
<img width="1270" alt="screen shot 2018-10-30 at 10 19 27" src="https://user-images.githubusercontent.com/32680605/47708628-c403f480-dc2e-11e8-85a9-1040714a2f48.png">
**Expected behavior**
As a user, when I go to the published and copied survey, I shouldn't see a message telling me I have already answered the survey. I should see no message.
|
1.0
|
Survey already answered when it shouldn't - **Describe the bug**
To be complete, when the survey is published even though there are no questions, as a user who answered the original survey, I am told i have already answered the survey. When questions are added, I see the survey as expected.
To link with => #327
**To Reproduce**
Steps to reproduce the behavior:
As a user who answered the original survey
1. Go to 'https://steamroll.osp.cat/processes/test-copie-composant/f/76/'
2. See error
<img width="1270" alt="screen shot 2018-10-30 at 10 19 27" src="https://user-images.githubusercontent.com/32680605/47708628-c403f480-dc2e-11e8-85a9-1040714a2f48.png">
**Expected behavior**
As a user, when I go to the published and copied survey, I shouldn't see a message telling me I have already answered the survey. I should see no message.
|
process
|
survey already answered when it shouldn t describe the bug to be complete when the survey is published even though there are no questions as a user who answered the original survey i am told i have already answered the survey when questions are added i see the survey as expected to link with to reproduce steps to reproduce the behavior as a user who answered the original survey go to see error img width alt screen shot at src expected behavior as a user when i go to the published and copied survey i shouldn t see a message telling me i have already answered the survey i should see no message
| 1
|
5,763
| 8,599,881,841
|
IssuesEvent
|
2018-11-16 04:37:46
|
gfrebello/qs-trip-planning-procedure
|
https://api.github.com/repos/gfrebello/qs-trip-planning-procedure
|
opened
|
Improve design of the trip summary page
|
Priority:Medium Process:Implement Requirement
|
The purpose of the trip summary page is to show information of all the reserved flights, hotels, and other items of interest. As such, its functionality is quite simple. But the design is still lackluster and should be improved.
|
1.0
|
Improve design of the trip summary page - The purpose of the trip summary page is to show information of all the reserved flights, hotels, and other items of interest. As such, its functionality is quite simple. But the design is still lackluster and should be improved.
|
process
|
improve design of the trip summary page the purpose of the trip summary page is to show information of all the reserved flights hotels and other items of interest as such its functionality is quite simple but the design is still lackluster and should be improved
| 1
|
18,366
| 24,495,256,128
|
IssuesEvent
|
2022-10-10 08:06:25
|
bazelbuild/bazel
|
https://api.github.com/repos/bazelbuild/bazel
|
closed
|
[Mirror] zstd-jni v1.5.2-3
|
P2 type: process team-OSS mirror request
|
### Please list the URLs of the archives you'd like to mirror:
Please help mirror `zstd-jni v1.5.2-3` to help with https://github.com/bazelbuild/bazel/pull/16394
URL: https://github.com/luben/zstd-jni/archive/refs/tags/v1.5.2-3.zip
|
1.0
|
[Mirror] zstd-jni v1.5.2-3 - ### Please list the URLs of the archives you'd like to mirror:
Please help mirror `zstd-jni v1.5.2-3` to help with https://github.com/bazelbuild/bazel/pull/16394
URL: https://github.com/luben/zstd-jni/archive/refs/tags/v1.5.2-3.zip
|
process
|
zstd jni please list the urls of the archives you d like to mirror please help mirror zstd jni to help with url
| 1
|
20,081
| 26,576,539,947
|
IssuesEvent
|
2023-01-21 22:15:27
|
opensearch-project/data-prepper
|
https://api.github.com/repos/opensearch-project/data-prepper
|
opened
|
Allow configuring values in otel_trace_raw
|
enhancement plugin - processor
|
**Is your feature request related to a problem? Please describe.**
The `otel_trace_raw` processor has some hard-coded values. Make these configurable.
**Describe the solution you'd like**
Add two new configurations:
```
otel_trace_raw:
trace_id_ttl: 10s
max_trace_id_cache_size: 1000000
```
|
1.0
|
Allow configuring values in otel_trace_raw - **Is your feature request related to a problem? Please describe.**
The `otel_trace_raw` processor has some hard-coded values. Make these configurable.
**Describe the solution you'd like**
Add two new configurations:
```
otel_trace_raw:
trace_id_ttl: 10s
max_trace_id_cache_size: 1000000
```
|
process
|
allow configuring values in otel trace raw is your feature request related to a problem please describe the otel trace raw processor has some hard coded values make these configurable describe the solution you d like add two new configurations otel trace raw trace id ttl max trace id cache size
| 1
|
18,682
| 24,594,637,573
|
IssuesEvent
|
2022-10-14 07:12:42
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[FHIR] Questionnaire resource > JSON > Duplicate branching logic data is getting mapped into the JSON file for text choice
|
Bug P1 Response datastore Process: Fixed Process: Tested QA Process: Tested dev
|
**AR:** Questionnaire resource > JSON > Duplicate branching logic data is getting mapped into the JSON file for text choice
**ER:** Questionnaire resource > JSON > Duplicate branching logic data should not mapped into the JSON file for text choice
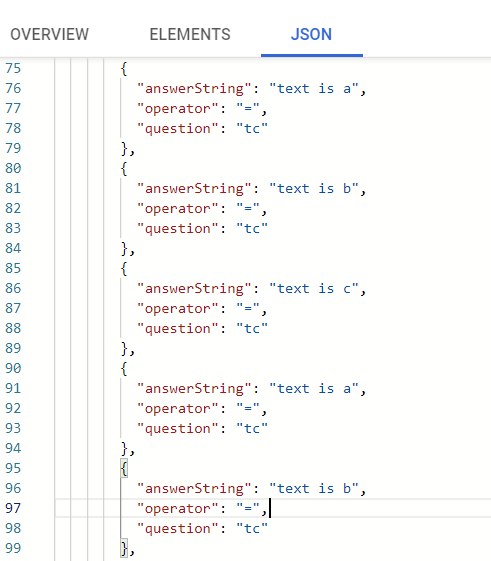
|
3.0
|
[FHIR] Questionnaire resource > JSON > Duplicate branching logic data is getting mapped into the JSON file for text choice - **AR:** Questionnaire resource > JSON > Duplicate branching logic data is getting mapped into the JSON file for text choice
**ER:** Questionnaire resource > JSON > Duplicate branching logic data should not mapped into the JSON file for text choice

|
process
|
questionnaire resource json duplicate branching logic data is getting mapped into the json file for text choice ar questionnaire resource json duplicate branching logic data is getting mapped into the json file for text choice er questionnaire resource json duplicate branching logic data should not mapped into the json file for text choice
| 1
|
10,710
| 13,507,260,534
|
IssuesEvent
|
2020-09-14 05:31:24
|
jnickg/dungen-core
|
https://api.github.com/repos/jnickg/dungen-core
|
closed
|
Separate Heroku dyno for test deploys
|
process
|
Create a second Heroku app and flesh out `heroku.yml` and `Dockerfile` so that we can manually test deploys before opening PRs
|
1.0
|
Separate Heroku dyno for test deploys - Create a second Heroku app and flesh out `heroku.yml` and `Dockerfile` so that we can manually test deploys before opening PRs
|
process
|
separate heroku dyno for test deploys create a second heroku app and flesh out heroku yml and dockerfile so that we can manually test deploys before opening prs
| 1
|
409,446
| 27,738,967,824
|
IssuesEvent
|
2023-03-15 13:10:47
|
appsmithorg/appsmith-docs
|
https://api.github.com/repos/appsmithorg/appsmith-docs
|
closed
|
[Docs]: Rehaul: Github OAuth
|
Documentation Doc Rehaul High User Education Pod
|
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Documentation Link
https://docs.appsmith.com/getting-started/setup/instance-configuration/authentication/github-login
### Discord/slack/intercom Link
_No response_
### Describe the problem and improvement.
Rehaul the Github OAuth page
|
1.0
|
[Docs]: Rehaul: Github OAuth - ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Documentation Link
https://docs.appsmith.com/getting-started/setup/instance-configuration/authentication/github-login
### Discord/slack/intercom Link
_No response_
### Describe the problem and improvement.
Rehaul the Github OAuth page
|
non_process
|
rehaul github oauth is there an existing issue for this i have searched the existing issues documentation link discord slack intercom link no response describe the problem and improvement rehaul the github oauth page
| 0
|
2,837
| 5,795,382,389
|
IssuesEvent
|
2017-05-02 16:57:24
|
pelias/api
|
https://api.github.com/repos/pelias/api
|
closed
|
low confidence score
|
bug low priority processed
|
hey @dianashk when I was looking at another issue I noticed the result in https://github.com/pelias/pelias/issues/141#issuecomment-146583343 has a pretty low confidence score for a very good linguistic match.
any idea what's going on here?
|
1.0
|
low confidence score - hey @dianashk when I was looking at another issue I noticed the result in https://github.com/pelias/pelias/issues/141#issuecomment-146583343 has a pretty low confidence score for a very good linguistic match.
any idea what's going on here?
|
process
|
low confidence score hey dianashk when i was looking at another issue i noticed the result in has a pretty low confidence score for a very good linguistic match any idea what s going on here
| 1
|
14,275
| 17,241,715,043
|
IssuesEvent
|
2021-07-21 00:08:06
|
googleapis/repo-automation-bots
|
https://api.github.com/repos/googleapis/repo-automation-bots
|
closed
|
Upgrade to Probot 12
|
package: gcf-utils priority: p2 type: bug type: process
|
We use `Probot.receive` for handling Cron and Pub/Sub requests as well as Github Webhooks.
However, Probot started to use `@octokit/webhooks` V9 and introduced corresponding changes.
The `WebhookEvent` is changed from:
```
import { WebhookEvent } from "@octokit/webhooks";
```
to:
```
import { EmitterWebhookEvent as WebhookEvent } from "@octokit/webhooks";
```
As a result, our payload doesn't match the method signature any more.
We need to figure it out how to upgrade to Probot 12.
|
1.0
|
Upgrade to Probot 12 - We use `Probot.receive` for handling Cron and Pub/Sub requests as well as Github Webhooks.
However, Probot started to use `@octokit/webhooks` V9 and introduced corresponding changes.
The `WebhookEvent` is changed from:
```
import { WebhookEvent } from "@octokit/webhooks";
```
to:
```
import { EmitterWebhookEvent as WebhookEvent } from "@octokit/webhooks";
```
As a result, our payload doesn't match the method signature any more.
We need to figure it out how to upgrade to Probot 12.
|
process
|
upgrade to probot we use probot receive for handling cron and pub sub requests as well as github webhooks however probot started to use octokit webhooks and introduced corresponding changes the webhookevent is changed from import webhookevent from octokit webhooks to import emitterwebhookevent as webhookevent from octokit webhooks as a result our payload doesn t match the method signature any more we need to figure it out how to upgrade to probot
| 1
|
111,472
| 9,532,690,158
|
IssuesEvent
|
2019-04-29 19:15:46
|
yarnpkg/website
|
https://api.github.com/repos/yarnpkg/website
|
closed
|
yarn-version #80 failed
|
failure test
|
Build 'yarn-version' is failing!
Last 50 lines of build output:
```
Started by remote host 209.141.56.29 with note: Automated release of Yarn 1.16.0
Building remotely on build05 (9.6 linuxbrew Debian Debian-9.6 amd64-Debian linux nodejs amd64-Debian-9.6 amd64) in workspace /var/lib/jenkins/worker/workspace/yarn-version
No credentials specified
> git rev-parse --is-inside-work-tree # timeout=10
Fetching changes from the remote Git repository
> git config remote.origin.url git@github.com:yarnpkg/website.git # timeout=10
Fetching upstream changes from git@github.com:yarnpkg/website.git
> git --version # timeout=10
> git fetch --tags --progress git@github.com:yarnpkg/website.git +refs/heads/*:refs/remotes/origin/* # timeout=10
> git rev-parse origin/master^{commit} # timeout=10
Checking out Revision e4a64335e19cd1047f3c99e1b18f1d93d2097205 (origin/master)
> git config core.sparsecheckout # timeout=10
> git checkout -f e4a64335e19cd1047f3c99e1b18f1d93d2097205 # timeout=10
> git branch -a -v --no-abbrev # timeout=10
> git branch -D master # timeout=10
> git checkout -b master e4a64335e19cd1047f3c99e1b18f1d93d2097205 # timeout=10
Commit message: "Automated upgrade to Yarn 1.16.0"
> git rev-list --no-walk f6b4e11191a2ec6f64d13981421b9e3dad446cc5 # timeout=10
[yarn-version] $ /bin/sh -xe /tmp/jenkins6616345851965410602.sh
+ ./scripts/set-version.sh
+ '[' -z 1.16.0 -o -z true ']'
++ dirname ./scripts/set-version.sh
+ configFile=./scripts/../_config.yml
+ '[' true = true ']'
+ sed -i -e 's/latest_rc_version:.\+/latest_rc_version: 1.16.0/' ./scripts/../_config.yml
+ sed -i -e 's/show_rc:.\+/show_rc: true/' ./scripts/../_config.yml
+ git commit -m Automated upgrade to Yarn 1.16.0 _config.yml
On branch master
nothing to commit, working tree clean
Build step 'Execute shell' marked build as failure
No credentials specified
Pushing HEAD to branch master at repo origin
> git --version # timeout=10
> git push git@github.com:yarnpkg/website.git HEAD:master # timeout=10
```
Changes since last successful build:
- [Daniel15's Build Bot] e4a64335e19cd1047f3c99e1b18f1d93d2097205 - Automated upgrade to Yarn 1.16.0
[View full output](https://build.dan.cx/job/yarn-version/80/)
cc @Daniel15
|
1.0
|
yarn-version #80 failed - Build 'yarn-version' is failing!
Last 50 lines of build output:
```
Started by remote host 209.141.56.29 with note: Automated release of Yarn 1.16.0
Building remotely on build05 (9.6 linuxbrew Debian Debian-9.6 amd64-Debian linux nodejs amd64-Debian-9.6 amd64) in workspace /var/lib/jenkins/worker/workspace/yarn-version
No credentials specified
> git rev-parse --is-inside-work-tree # timeout=10
Fetching changes from the remote Git repository
> git config remote.origin.url git@github.com:yarnpkg/website.git # timeout=10
Fetching upstream changes from git@github.com:yarnpkg/website.git
> git --version # timeout=10
> git fetch --tags --progress git@github.com:yarnpkg/website.git +refs/heads/*:refs/remotes/origin/* # timeout=10
> git rev-parse origin/master^{commit} # timeout=10
Checking out Revision e4a64335e19cd1047f3c99e1b18f1d93d2097205 (origin/master)
> git config core.sparsecheckout # timeout=10
> git checkout -f e4a64335e19cd1047f3c99e1b18f1d93d2097205 # timeout=10
> git branch -a -v --no-abbrev # timeout=10
> git branch -D master # timeout=10
> git checkout -b master e4a64335e19cd1047f3c99e1b18f1d93d2097205 # timeout=10
Commit message: "Automated upgrade to Yarn 1.16.0"
> git rev-list --no-walk f6b4e11191a2ec6f64d13981421b9e3dad446cc5 # timeout=10
[yarn-version] $ /bin/sh -xe /tmp/jenkins6616345851965410602.sh
+ ./scripts/set-version.sh
+ '[' -z 1.16.0 -o -z true ']'
++ dirname ./scripts/set-version.sh
+ configFile=./scripts/../_config.yml
+ '[' true = true ']'
+ sed -i -e 's/latest_rc_version:.\+/latest_rc_version: 1.16.0/' ./scripts/../_config.yml
+ sed -i -e 's/show_rc:.\+/show_rc: true/' ./scripts/../_config.yml
+ git commit -m Automated upgrade to Yarn 1.16.0 _config.yml
On branch master
nothing to commit, working tree clean
Build step 'Execute shell' marked build as failure
No credentials specified
Pushing HEAD to branch master at repo origin
> git --version # timeout=10
> git push git@github.com:yarnpkg/website.git HEAD:master # timeout=10
```
Changes since last successful build:
- [Daniel15's Build Bot] e4a64335e19cd1047f3c99e1b18f1d93d2097205 - Automated upgrade to Yarn 1.16.0
[View full output](https://build.dan.cx/job/yarn-version/80/)
cc @Daniel15
|
non_process
|
yarn version failed build yarn version is failing last lines of build output started by remote host with note automated release of yarn building remotely on linuxbrew debian debian debian linux nodejs debian in workspace var lib jenkins worker workspace yarn version no credentials specified git rev parse is inside work tree timeout fetching changes from the remote git repository git config remote origin url git github com yarnpkg website git timeout fetching upstream changes from git github com yarnpkg website git git version timeout git fetch tags progress git github com yarnpkg website git refs heads refs remotes origin timeout git rev parse origin master commit timeout checking out revision origin master git config core sparsecheckout timeout git checkout f timeout git branch a v no abbrev timeout git branch d master timeout git checkout b master timeout commit message automated upgrade to yarn git rev list no walk timeout bin sh xe tmp sh scripts set version sh dirname scripts set version sh configfile scripts config yml sed i e s latest rc version latest rc version scripts config yml sed i e s show rc show rc true scripts config yml git commit m automated upgrade to yarn config yml on branch master nothing to commit working tree clean build step execute shell marked build as failure no credentials specified pushing head to branch master at repo origin git version timeout git push git github com yarnpkg website git head master timeout changes since last successful build automated upgrade to yarn cc
| 0
|
13,193
| 15,614,048,968
|
IssuesEvent
|
2021-03-19 17:14:50
|
MicrosoftDocs/azure-devops-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-devops-docs
|
closed
|
How are tags used for deployment filtering?
|
Pri2 devops-cicd-process/tech devops/prod doc-enhancement
|
I can't find any info about this on this page or the YAML schema page. How are multiple tags interpreted when filtering for a deployment? If I specify my deployment environment with tags `tag1` and `tag2`, will it target all VMs that have *EITHER* of `tag1` or `tag2`, or will it only target machines that have both tags applied?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 91d0d31f-81ee-c024-db7e-daddbf525f71
* Version Independent ID: 330f1649-386c-d0aa-5f96-b8343a1480d3
* Content: [Environment - Virtual machine resource - Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/process/environments-virtual-machines?view=azure-devops)
* Content Source: [docs/pipelines/process/environments-virtual-machines.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/master/docs/pipelines/process/environments-virtual-machines.md)
* Product: **devops**
* Technology: **devops-cicd-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
1.0
|
How are tags used for deployment filtering? - I can't find any info about this on this page or the YAML schema page. How are multiple tags interpreted when filtering for a deployment? If I specify my deployment environment with tags `tag1` and `tag2`, will it target all VMs that have *EITHER* of `tag1` or `tag2`, or will it only target machines that have both tags applied?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 91d0d31f-81ee-c024-db7e-daddbf525f71
* Version Independent ID: 330f1649-386c-d0aa-5f96-b8343a1480d3
* Content: [Environment - Virtual machine resource - Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/process/environments-virtual-machines?view=azure-devops)
* Content Source: [docs/pipelines/process/environments-virtual-machines.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/master/docs/pipelines/process/environments-virtual-machines.md)
* Product: **devops**
* Technology: **devops-cicd-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
process
|
how are tags used for deployment filtering i can t find any info about this on this page or the yaml schema page how are multiple tags interpreted when filtering for a deployment if i specify my deployment environment with tags and will it target all vms that have either of or or will it only target machines that have both tags applied document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id content content source product devops technology devops cicd process github login juliakm microsoft alias jukullam
| 1
|
17,806
| 23,729,429,103
|
IssuesEvent
|
2022-08-30 23:27:50
|
w3c/payment-method-id
|
https://api.github.com/repos/w3c/payment-method-id
|
closed
|
Prepare for Proposed Recommendation
|
Process aid
|
The working group:
- [x] must show adequate implementation experience except where an exception is approved by the Director,
- [ ] must show that the document has received wide review,
- [ ] must show that all issues raised during the Candidate Recommendation review period other than by Advisory Committee representatives acting in their formal AC representative role have been formally addressed,
- [ ] must identify any substantive issues raised since the close of the Candidate Recommendation review period by parties other than Advisory Committee representatives acting in their formal AC representative role,
- [x] may have removed features identified in the Candidate Recommendation document as "at risk" without republishing the specification as a Candidate Recommendation.
|
1.0
|
Prepare for Proposed Recommendation - The working group:
- [x] must show adequate implementation experience except where an exception is approved by the Director,
- [ ] must show that the document has received wide review,
- [ ] must show that all issues raised during the Candidate Recommendation review period other than by Advisory Committee representatives acting in their formal AC representative role have been formally addressed,
- [ ] must identify any substantive issues raised since the close of the Candidate Recommendation review period by parties other than Advisory Committee representatives acting in their formal AC representative role,
- [x] may have removed features identified in the Candidate Recommendation document as "at risk" without republishing the specification as a Candidate Recommendation.
|
process
|
prepare for proposed recommendation the working group must show adequate implementation experience except where an exception is approved by the director must show that the document has received wide review must show that all issues raised during the candidate recommendation review period other than by advisory committee representatives acting in their formal ac representative role have been formally addressed must identify any substantive issues raised since the close of the candidate recommendation review period by parties other than advisory committee representatives acting in their formal ac representative role may have removed features identified in the candidate recommendation document as at risk without republishing the specification as a candidate recommendation
| 1
|
18,715
| 24,604,762,815
|
IssuesEvent
|
2022-10-14 15:15:26
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[Big query] Views are not getting created for the tables under the datasets
|
Bug Blocker P0 Response datastore Process: Tested dev Process: Reopened
|
AR: Views are not getting created for the tables under the datasets
ER: Views should get created for the tables in Big query for each datasets
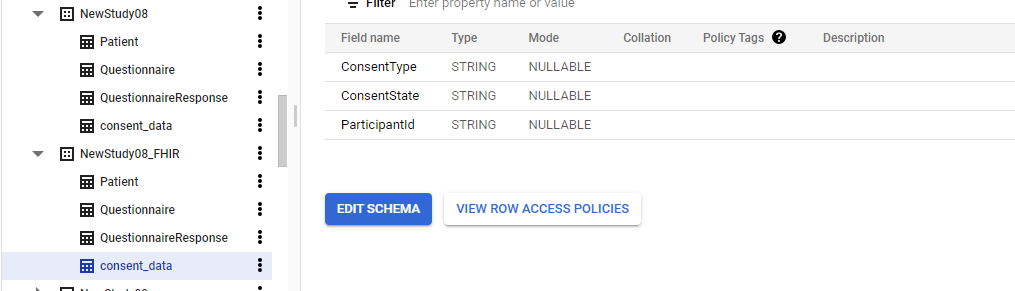
|
2.0
|
[Big query] Views are not getting created for the tables under the datasets - AR: Views are not getting created for the tables under the datasets
ER: Views should get created for the tables in Big query for each datasets

|
process
|
views are not getting created for the tables under the datasets ar views are not getting created for the tables under the datasets er views should get created for the tables in big query for each datasets
| 1
|
559,326
| 16,555,930,172
|
IssuesEvent
|
2021-05-28 13:57:09
|
kaiwalyakoparkar/Find-Me-Resource
|
https://api.github.com/repos/kaiwalyakoparkar/Find-Me-Resource
|
closed
|
[Bug] Get the current actions working
|
Priority: High Review Required bug want fix
|
Current actions don't seem to work. Troubleshoot the problem and fix it
|
1.0
|
[Bug] Get the current actions working - Current actions don't seem to work. Troubleshoot the problem and fix it
|
non_process
|
get the current actions working current actions don t seem to work troubleshoot the problem and fix it
| 0
|
14,626
| 17,767,537,732
|
IssuesEvent
|
2021-08-30 09:27:23
|
KI-Vorlesung/kitest
|
https://api.github.com/repos/KI-Vorlesung/kitest
|
closed
|
Pandoc-Lecture: CSS und Shortcodes ergänzen
|
WEB PRE-PROCESSING
|
- [x] CSS und Shortcodes ergänzen: BSP-Button, Quellen-Angaben, ~~Formatierung Tabellen~~, … (aus Pandoc-Lecture)
- [x] Shortcodes durch Pandoc-Divs ersetzen: Pre-Processing-Step mit Pandoc macht daraus Shortcodes für Hugo (war #10)
Pandoc-Lecture:
- [x] native Divs:
- `::: notes`, `::: slides` => einfaches Herausfiltern: `prepareSlides.lua` und `prepareHandout.lua` (Pandoc-Lecture)
- `::: cbox` => Div mit Klasse `cbox`
- `::: center` => Div mit Klasse `.center`
- `::: columns` => **???**
- `::: showme` => Shortcode `expand`
- [x] native Spans:
- `[]{.notes}`, `[]{.slides}` => einfaches Herausfiltern: `prepareSlides.lua` und `prepareHandout.lua` (Pandoc-Lecture)
- `[]{.bsp}` => Shortcode `button` mit Link auf Code im Repo (oder Herausfiltern??? i.d.R. nur auf den Folien benötigt?!)
- `[]{.origin}` => Div mit Klasse `.origin`
- `[]{.alert}` => Div mit Klasse `.alert`
|
1.0
|
Pandoc-Lecture: CSS und Shortcodes ergänzen - - [x] CSS und Shortcodes ergänzen: BSP-Button, Quellen-Angaben, ~~Formatierung Tabellen~~, … (aus Pandoc-Lecture)
- [x] Shortcodes durch Pandoc-Divs ersetzen: Pre-Processing-Step mit Pandoc macht daraus Shortcodes für Hugo (war #10)
Pandoc-Lecture:
- [x] native Divs:
- `::: notes`, `::: slides` => einfaches Herausfiltern: `prepareSlides.lua` und `prepareHandout.lua` (Pandoc-Lecture)
- `::: cbox` => Div mit Klasse `cbox`
- `::: center` => Div mit Klasse `.center`
- `::: columns` => **???**
- `::: showme` => Shortcode `expand`
- [x] native Spans:
- `[]{.notes}`, `[]{.slides}` => einfaches Herausfiltern: `prepareSlides.lua` und `prepareHandout.lua` (Pandoc-Lecture)
- `[]{.bsp}` => Shortcode `button` mit Link auf Code im Repo (oder Herausfiltern??? i.d.R. nur auf den Folien benötigt?!)
- `[]{.origin}` => Div mit Klasse `.origin`
- `[]{.alert}` => Div mit Klasse `.alert`
|
process
|
pandoc lecture css und shortcodes ergänzen css und shortcodes ergänzen bsp button quellen angaben formatierung tabellen … aus pandoc lecture shortcodes durch pandoc divs ersetzen pre processing step mit pandoc macht daraus shortcodes für hugo war pandoc lecture native divs notes slides einfaches herausfiltern prepareslides lua und preparehandout lua pandoc lecture cbox div mit klasse cbox center div mit klasse center columns showme shortcode expand native spans notes slides einfaches herausfiltern prepareslides lua und preparehandout lua pandoc lecture bsp shortcode button mit link auf code im repo oder herausfiltern i d r nur auf den folien benötigt origin div mit klasse origin alert div mit klasse alert
| 1
|
24,459
| 12,301,028,373
|
IssuesEvent
|
2020-05-11 14:49:58
|
IBM/FHIR
|
https://api.github.com/repos/IBM/FHIR
|
opened
|
bulkimport is much slower when updating existing resources than importing new resources
|
performance
|
We found at least 20-25% import rate drop when re-import the already imported resource files for most of the resource types, and we found the rate drop could reach more than 90% for the observation resource type.
|
True
|
bulkimport is much slower when updating existing resources than importing new resources - We found at least 20-25% import rate drop when re-import the already imported resource files for most of the resource types, and we found the rate drop could reach more than 90% for the observation resource type.
|
non_process
|
bulkimport is much slower when updating existing resources than importing new resources we found at least import rate drop when re import the already imported resource files for most of the resource types and we found the rate drop could reach more than for the observation resource type
| 0
|
9,851
| 12,838,834,291
|
IssuesEvent
|
2020-07-07 18:11:36
|
GetTerminus/terminus-oss
|
https://api.github.com/repos/GetTerminus/terminus-oss
|
closed
|
Move ESLint config into monorepo
|
Goal: Process Improvement Type: chore
|
- [ ] Publish to existing NPM package
- [ ] Move any applicable issues
|
1.0
|
Move ESLint config into monorepo - - [ ] Publish to existing NPM package
- [ ] Move any applicable issues
|
process
|
move eslint config into monorepo publish to existing npm package move any applicable issues
| 1
|
690,798
| 23,672,805,174
|
IssuesEvent
|
2022-08-27 16:21:59
|
OpenTabletDriver/OpenTabletDriver
|
https://api.github.com/repos/OpenTabletDriver/OpenTabletDriver
|
opened
|
Tablet and monitor area can no longer separately use Lock to usable area/Keep inside maximum bounds
|
priority:low desktop
|
## Description
In 0.6.0 the monitor area and tablet area could use `Lock to usable area` separately due to there being one option for each area. This is no longer possible in 0.7.0's `Keep inside maximum bounds` due to the options being merged.
## System Information:
<!-- Please fill out this information -->
| Name | Value |
| ---------------- | ----- |
| Operating System | Win10
| Software Version | [82b9c1f](https://github.com/OpenTabletDriver/OpenTabletDriver/commit/82b9c1f2131a4312cab456a3bc73b5d39a2113fb)
|
1.0
|
Tablet and monitor area can no longer separately use Lock to usable area/Keep inside maximum bounds - ## Description
In 0.6.0 the monitor area and tablet area could use `Lock to usable area` separately due to there being one option for each area. This is no longer possible in 0.7.0's `Keep inside maximum bounds` due to the options being merged.
## System Information:
<!-- Please fill out this information -->
| Name | Value |
| ---------------- | ----- |
| Operating System | Win10
| Software Version | [82b9c1f](https://github.com/OpenTabletDriver/OpenTabletDriver/commit/82b9c1f2131a4312cab456a3bc73b5d39a2113fb)
|
non_process
|
tablet and monitor area can no longer separately use lock to usable area keep inside maximum bounds description in the monitor area and tablet area could use lock to usable area separately due to there being one option for each area this is no longer possible in s keep inside maximum bounds due to the options being merged system information name value operating system software version
| 0
|
72,056
| 7,276,630,889
|
IssuesEvent
|
2018-02-21 16:54:22
|
pvlib/pvlib-python
|
https://api.github.com/repos/pvlib/pvlib-python
|
closed
|
avoid and/or silence common warnings
|
bug testing
|
A handful of pvlib functions often cause spit out runtime warnings for things like dividing by 0 or comparing the size of a nan value to a float. We should avoid or silence the warnings that we know are ok. They also make the test output a pain to read.
Here's a possibly incomplete list:
- [x] irradiance.perez divide by 0
- [x] irradiance.perez comparison with nan
- [x] clearsky.simplified_solis comparison with nan
- [x] pvsystem.sapm divide by 0 in log
- [x] pvsystem.ashraeiam comparison with nan
- [x] pvsystem.physicaliam comparison with nan
- [x] pvsystem.adrinverter comparison with nan
- [x] pvsystem.v_from_i overflow
~I have some code ready for addressing the warnings in the perez model implementation. I'll post it soon.~
Checked items are addressed in #429.
|
1.0
|
avoid and/or silence common warnings - A handful of pvlib functions often cause spit out runtime warnings for things like dividing by 0 or comparing the size of a nan value to a float. We should avoid or silence the warnings that we know are ok. They also make the test output a pain to read.
Here's a possibly incomplete list:
- [x] irradiance.perez divide by 0
- [x] irradiance.perez comparison with nan
- [x] clearsky.simplified_solis comparison with nan
- [x] pvsystem.sapm divide by 0 in log
- [x] pvsystem.ashraeiam comparison with nan
- [x] pvsystem.physicaliam comparison with nan
- [x] pvsystem.adrinverter comparison with nan
- [x] pvsystem.v_from_i overflow
~I have some code ready for addressing the warnings in the perez model implementation. I'll post it soon.~
Checked items are addressed in #429.
|
non_process
|
avoid and or silence common warnings a handful of pvlib functions often cause spit out runtime warnings for things like dividing by or comparing the size of a nan value to a float we should avoid or silence the warnings that we know are ok they also make the test output a pain to read here s a possibly incomplete list irradiance perez divide by irradiance perez comparison with nan clearsky simplified solis comparison with nan pvsystem sapm divide by in log pvsystem ashraeiam comparison with nan pvsystem physicaliam comparison with nan pvsystem adrinverter comparison with nan pvsystem v from i overflow i have some code ready for addressing the warnings in the perez model implementation i ll post it soon checked items are addressed in
| 0
|
20,637
| 27,316,804,191
|
IssuesEvent
|
2023-02-24 16:18:56
|
MicrosoftDocs/azure-devops-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-devops-docs
|
closed
|
Please document if and how the build name can be set within a yaml template
|
doc-bug Pri1 azure-devops-pipelines/svc azure-devops-pipelines-process/subsvc
|
Confusion over if this is possible has been discussed previously on [StackOverflow](https://stackoverflow.com/questions/59684253/how-to-set-build-name-build-buildnumber-in-an-azure-devops-build-pipeline-temp) without a clear resolution (no selected answer) and 13k views. There is still no clarification in the template documentation.
Can it be done? And if so, how?
USE CASE
To minimize (accidental) variation in build naming, as well as to have a central way to update naming conventions, we would like to define the build name in some of our templates, but on usage with an extends this causes the error `Unexpected value 'name'`. Below is an example of the top of the template file. Since we are including stages in the template, and name is a property of stages it seems logical for this to work.
```
parameters:
- name: 'NugetVersion'
type: string
default: 6.3.1
stages:
- stage: secure_buildstage
pool:
name: default
name: '$(Build.DefinitionName)_$(Year:yyyy).$(Month).$(DayOfMonth)$(Rev:.rr)'
variables:
```
---
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.com ➟ GitHub issue linking.*
* ID: 6724abea-bbdc-bf66-ed5e-3214fa6c3e66
* Version Independent ID: 4f8dab21-3f0e-da32-cc0e-1d85c13c0065
* Content: [Templates - Azure Pipelines](https://learn.microsoft.com/en-us/azure/devops/pipelines/process/templates?view=azure-devops)
* Content Source: [docs/pipelines/process/templates.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/main/docs/pipelines/process/templates.md)
* Service: **azure-devops-pipelines**
* Sub-service: **azure-devops-pipelines-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
1.0
|
Please document if and how the build name can be set within a yaml template - Confusion over if this is possible has been discussed previously on [StackOverflow](https://stackoverflow.com/questions/59684253/how-to-set-build-name-build-buildnumber-in-an-azure-devops-build-pipeline-temp) without a clear resolution (no selected answer) and 13k views. There is still no clarification in the template documentation.
Can it be done? And if so, how?
USE CASE
To minimize (accidental) variation in build naming, as well as to have a central way to update naming conventions, we would like to define the build name in some of our templates, but on usage with an extends this causes the error `Unexpected value 'name'`. Below is an example of the top of the template file. Since we are including stages in the template, and name is a property of stages it seems logical for this to work.
```
parameters:
- name: 'NugetVersion'
type: string
default: 6.3.1
stages:
- stage: secure_buildstage
pool:
name: default
name: '$(Build.DefinitionName)_$(Year:yyyy).$(Month).$(DayOfMonth)$(Rev:.rr)'
variables:
```
---
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.com ➟ GitHub issue linking.*
* ID: 6724abea-bbdc-bf66-ed5e-3214fa6c3e66
* Version Independent ID: 4f8dab21-3f0e-da32-cc0e-1d85c13c0065
* Content: [Templates - Azure Pipelines](https://learn.microsoft.com/en-us/azure/devops/pipelines/process/templates?view=azure-devops)
* Content Source: [docs/pipelines/process/templates.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/main/docs/pipelines/process/templates.md)
* Service: **azure-devops-pipelines**
* Sub-service: **azure-devops-pipelines-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
process
|
please document if and how the build name can be set within a yaml template confusion over if this is possible has been discussed previously on without a clear resolution no selected answer and views there is still no clarification in the template documentation can it be done and if so how use case to minimize accidental variation in build naming as well as to have a central way to update naming conventions we would like to define the build name in some of our templates but on usage with an extends this causes the error unexpected value name below is an example of the top of the template file since we are including stages in the template and name is a property of stages it seems logical for this to work parameters name nugetversion type string default stages stage secure buildstage pool name default name build definitionname year yyyy month dayofmonth rev rr variables document details ⚠ do not edit this section it is required for learn microsoft com ➟ github issue linking id bbdc version independent id content content source service azure devops pipelines sub service azure devops pipelines process github login juliakm microsoft alias jukullam
| 1
|
3,056
| 2,652,996,788
|
IssuesEvent
|
2015-03-16 20:31:17
|
Semantic-Org/Semantic-UI
|
https://api.github.com/repos/Semantic-Org/Semantic-UI
|
closed
|
Columns Example from Documentation renders differently.
|
Needs Test Case
|
From the Divider Documentation, i've assembled a snippet looking like so:
```haml
%body
.ui.page.grid
.ui.two.column.middle.aligned.relaxed.fitted.stackable.grid
.column
.ui.form.segment
%h4.ui.dividing.header Column 1
.ui.vertical.divider
Or
.center.aligned.column
.ui.form.segment
%h4.ui.dividing.header Column 2
```
Here is the CSS for this test:
```scss
//= require 'semantic-ui/dist/semantic'
//= require_self
html, body {
margin: 0;
padding: 0;
}
```
Most importantly, it doesn't place the columns horizontally:

And on small screens, it renders with a larger gutter on the right than on the left: 
Is that a known bug, or is there something i'm doing incorrectly here?
|
1.0
|
Columns Example from Documentation renders differently. - From the Divider Documentation, i've assembled a snippet looking like so:
```haml
%body
.ui.page.grid
.ui.two.column.middle.aligned.relaxed.fitted.stackable.grid
.column
.ui.form.segment
%h4.ui.dividing.header Column 1
.ui.vertical.divider
Or
.center.aligned.column
.ui.form.segment
%h4.ui.dividing.header Column 2
```
Here is the CSS for this test:
```scss
//= require 'semantic-ui/dist/semantic'
//= require_self
html, body {
margin: 0;
padding: 0;
}
```
Most importantly, it doesn't place the columns horizontally:

And on small screens, it renders with a larger gutter on the right than on the left: 
Is that a known bug, or is there something i'm doing incorrectly here?
|
non_process
|
columns example from documentation renders differently from the divider documentation i ve assembled a snippet looking like so haml body ui page grid ui two column middle aligned relaxed fitted stackable grid column ui form segment ui dividing header column ui vertical divider or center aligned column ui form segment ui dividing header column here is the css for this test scss require semantic ui dist semantic require self html body margin padding most importantly it doesn t place the columns horizontally and on small screens it renders with a larger gutter on the right than on the left is that a known bug or is there something i m doing incorrectly here
| 0
|
14,685
| 17,798,486,986
|
IssuesEvent
|
2021-09-01 03:08:30
|
lynnandtonic/nestflix.fun
|
https://api.github.com/repos/lynnandtonic/nestflix.fun
|
closed
|
Add Serve & Protect
|
suggested title in process
|
**Title**
Serve & Protect
**Type**
Tv show
**Show in which it appears**
Brooklyn Nine-Nine
**Is the parent film/show streaming anywhere?**
In my country it's on Netflix, I know it's on Peacock in the United States.
**About when in the parent film/show does it appear?**
S04E14 "Serve & Protect"
**Actual footage of the film/show can be seen?**
Yes
|
1.0
|
Add Serve & Protect - **Title**
Serve & Protect
**Type**
Tv show
**Show in which it appears**
Brooklyn Nine-Nine
**Is the parent film/show streaming anywhere?**
In my country it's on Netflix, I know it's on Peacock in the United States.
**About when in the parent film/show does it appear?**
S04E14 "Serve & Protect"
**Actual footage of the film/show can be seen?**
Yes
|
process
|
add serve protect title serve protect type tv show show in which it appears brooklyn nine nine is the parent film show streaming anywhere in my country it s on netflix i know it s on peacock in the united states about when in the parent film show does it appear serve protect actual footage of the film show can be seen yes
| 1
|
2,204
| 5,047,269,512
|
IssuesEvent
|
2016-12-20 08:48:54
|
hbz/lobid-resources
|
https://api.github.com/repos/hbz/lobid-resources
|
reopened
|
Problems with label for corporate body as contributor and subfield "e"
|
bug processing
|
Reported by @fsteeg in https://github.com/hbz/nwbib/pull/355#issuecomment-264499102:
> the two contributors have the same label. This seems to be an error in the Lobid data 2.0 conversion. Compare `200` and `204` in http://lobid.org/hbz01/HT019093814 and `contributor` in http://lobid.org/resources/HT019093814.
[Source](http://lobid.org/hbz01/HT019093814) snippet:
```xml
<datafield tag="200" ind1="b" ind2="1">
<subfield code="k">Kultur Ruhr GmbH</subfield>
<subfield code="9">(DE-588)7741856-6</subfield>
</datafield>
<datafield tag="204" ind1="b" ind2="1">
<subfield code="e">Ruhrtriennale</subfield>
<subfield code="9">(DE-588)5555595-0</subfield>
</datafield>
```
Usually, there are no problems with labels of double contributors, see e.g. http://lobid.org/resources/HT006947678. The problem here obviously is the label being recorded in subfield `e`. I guess we should probably just pull subfield `e` into the label field as we do with subfield `k`.
|
1.0
|
Problems with label for corporate body as contributor and subfield "e" - Reported by @fsteeg in https://github.com/hbz/nwbib/pull/355#issuecomment-264499102:
> the two contributors have the same label. This seems to be an error in the Lobid data 2.0 conversion. Compare `200` and `204` in http://lobid.org/hbz01/HT019093814 and `contributor` in http://lobid.org/resources/HT019093814.
[Source](http://lobid.org/hbz01/HT019093814) snippet:
```xml
<datafield tag="200" ind1="b" ind2="1">
<subfield code="k">Kultur Ruhr GmbH</subfield>
<subfield code="9">(DE-588)7741856-6</subfield>
</datafield>
<datafield tag="204" ind1="b" ind2="1">
<subfield code="e">Ruhrtriennale</subfield>
<subfield code="9">(DE-588)5555595-0</subfield>
</datafield>
```
Usually, there are no problems with labels of double contributors, see e.g. http://lobid.org/resources/HT006947678. The problem here obviously is the label being recorded in subfield `e`. I guess we should probably just pull subfield `e` into the label field as we do with subfield `k`.
|
process
|
problems with label for corporate body as contributor and subfield e reported by fsteeg in the two contributors have the same label this seems to be an error in the lobid data conversion compare and in and contributor in snippet xml kultur ruhr gmbh de ruhrtriennale de usually there are no problems with labels of double contributors see e g the problem here obviously is the label being recorded in subfield e i guess we should probably just pull subfield e into the label field as we do with subfield k
| 1
|
84,669
| 16,533,774,063
|
IssuesEvent
|
2021-05-27 09:21:31
|
google/web-stories-wp
|
https://api.github.com/repos/google/web-stories-wp
|
opened
|
Add a sniff / lint to remove unused use statements
|
PHP Pod: WP & Infra Type: Code Quality Type: Enhancement
|
<!-- NOTE: For help requests, support questions, or general feedback, please use the WordPress.org forums instead: https://wordpress.org/support/plugin/web-stories/ -->
## Feature Description
Add a lint to detect and remove unused use statements in PHP codebase. See [UnusedUseStatementSniff](https://github.com/klausi/coder/blob/8.x-2.x/coder_sniffer/Drupal/Sniffs/Classes/UnusedUseStatementSniff.php) for inspiration.
## Alternatives Considered
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
## Additional Context
<!-- Add any other context or screenshots about the feature request. -->
---
_Do not alter or remove anything below. The following sections will be managed by moderators only._
## Acceptance Criteria
<!-- One or more bullet points for acceptance criteria. -->
## Implementation Brief
<!-- One or more bullet points for how to technically implement the feature. -->
|
1.0
|
Add a sniff / lint to remove unused use statements - <!-- NOTE: For help requests, support questions, or general feedback, please use the WordPress.org forums instead: https://wordpress.org/support/plugin/web-stories/ -->
## Feature Description
Add a lint to detect and remove unused use statements in PHP codebase. See [UnusedUseStatementSniff](https://github.com/klausi/coder/blob/8.x-2.x/coder_sniffer/Drupal/Sniffs/Classes/UnusedUseStatementSniff.php) for inspiration.
## Alternatives Considered
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
## Additional Context
<!-- Add any other context or screenshots about the feature request. -->
---
_Do not alter or remove anything below. The following sections will be managed by moderators only._
## Acceptance Criteria
<!-- One or more bullet points for acceptance criteria. -->
## Implementation Brief
<!-- One or more bullet points for how to technically implement the feature. -->
|
non_process
|
add a sniff lint to remove unused use statements feature description add a lint to detect and remove unused use statements in php codebase see for inspiration alternatives considered additional context do not alter or remove anything below the following sections will be managed by moderators only acceptance criteria implementation brief
| 0
|
327,532
| 28,069,156,318
|
IssuesEvent
|
2023-03-29 17:41:38
|
SPW-DIG/metawal-core-geonetwork
|
https://api.github.com/repos/SPW-DIG/metawal-core-geonetwork
|
closed
|
Batch editing - xpath - modifier un attribut
|
module.Editeur Env test - OK Env valid - OK Env prod - OK
|
Impossible de modifier un attribut ?
`Cannot set Xml on an attribute. Xpath:'/mdb:MD_Metadata/mdb:metadataScope/mdb:MD_MetadataScope/mdb:resourceScope/mcc:MD_ScopeCode/@codeListValue' value: '<gn_replace>application</gn_replace>'`
|
1.0
|
Batch editing - xpath - modifier un attribut - Impossible de modifier un attribut ?
`Cannot set Xml on an attribute. Xpath:'/mdb:MD_Metadata/mdb:metadataScope/mdb:MD_MetadataScope/mdb:resourceScope/mcc:MD_ScopeCode/@codeListValue' value: '<gn_replace>application</gn_replace>'`
|
non_process
|
batch editing xpath modifier un attribut impossible de modifier un attribut cannot set xml on an attribute xpath mdb md metadata mdb metadatascope mdb md metadatascope mdb resourcescope mcc md scopecode codelistvalue value application
| 0
|
74,702
| 9,105,512,039
|
IssuesEvent
|
2019-02-20 21:00:19
|
adobe/spectrum-css
|
https://api.github.com/repos/adobe/spectrum-css
|
opened
|
Breadcrumbs (design update & new variant)
|
Spectrum Design Team design change
|
### Overview
Implement design updates to Breadcrumb component. Updates include:
- Additional Variant ("Compact")
- Renaming of "Title" variant to "Multiline"
- Hierarchy truncation (into a dropdown)
- Additional state for Drag-and-Drop
Redlines & DNA tokens are in staging, Documentation in progress.
#### Screenshots (if applicable)

|
2.0
|
Breadcrumbs (design update & new variant) - ### Overview
Implement design updates to Breadcrumb component. Updates include:
- Additional Variant ("Compact")
- Renaming of "Title" variant to "Multiline"
- Hierarchy truncation (into a dropdown)
- Additional state for Drag-and-Drop
Redlines & DNA tokens are in staging, Documentation in progress.
#### Screenshots (if applicable)



|
non_process
|
breadcrumbs design update new variant overview implement design updates to breadcrumb component updates include additional variant compact renaming of title variant to multiline hierarchy truncation into a dropdown additional state for drag and drop redlines dna tokens are in staging documentation in progress screenshots if applicable
| 0
|
10,630
| 13,440,916,786
|
IssuesEvent
|
2020-09-08 02:30:17
|
google/go-jsonnet
|
https://api.github.com/repos/google/go-jsonnet
|
closed
|
Releases lack jsonnetfmt cmd
|
formatter process
|
The archives provided (`.tar.gz` & `.zip`) as GitHub releases lack the `jsonnetfmt` command under `./cmd`.
```bash
can't load package: package ./cmd/jsonnetfmt: cannot find package "." in:
/private/tmp/go-jsonnet-20200413-91992-2xpfjb/go-jsonnet-0.15.0/src/github.com/google/go-jsonnet/cmd/jsonnetfmt
```
|
1.0
|
Releases lack jsonnetfmt cmd - The archives provided (`.tar.gz` & `.zip`) as GitHub releases lack the `jsonnetfmt` command under `./cmd`.
```bash
can't load package: package ./cmd/jsonnetfmt: cannot find package "." in:
/private/tmp/go-jsonnet-20200413-91992-2xpfjb/go-jsonnet-0.15.0/src/github.com/google/go-jsonnet/cmd/jsonnetfmt
```
|
process
|
releases lack jsonnetfmt cmd the archives provided tar gz zip as github releases lack the jsonnetfmt command under cmd bash can t load package package cmd jsonnetfmt cannot find package in private tmp go jsonnet go jsonnet src github com google go jsonnet cmd jsonnetfmt
| 1
|
3,358
| 6,487,658,714
|
IssuesEvent
|
2017-08-20 10:05:26
|
Great-Hill-Corporation/quickBlocks
|
https://api.github.com/repos/Great-Hill-Corporation/quickBlocks
|
closed
|
blockScrape --check --deep
|
apps-blockScrape status-inprocess type-enhancement
|
This command should write a report at the end and keeps stats such as XX items were marked as empty, but had transactions. YY items were marked as full but had zero transactions.
And the --deep check should report some things such as that the mismatch between the quickBlocks block and the node's block.
|
1.0
|
blockScrape --check --deep - This command should write a report at the end and keeps stats such as XX items were marked as empty, but had transactions. YY items were marked as full but had zero transactions.
And the --deep check should report some things such as that the mismatch between the quickBlocks block and the node's block.
|
process
|
blockscrape check deep this command should write a report at the end and keeps stats such as xx items were marked as empty but had transactions yy items were marked as full but had zero transactions and the deep check should report some things such as that the mismatch between the quickblocks block and the node s block
| 1
|
11,670
| 14,530,654,953
|
IssuesEvent
|
2020-12-14 19:35:07
|
akamai/terraform-provider-akamai
|
https://api.github.com/repos/akamai/terraform-provider-akamai
|
closed
|
Activation is executed, even without changes
|
Fix in process PR Review/Upcoming Release
|
### Terraform Version
Terraform v0.12.24
+ provider.akamai v0.5.0
+ provider.aws v2.58.0
+ provider.template v2.1.2
### Affected Resource(s)
resource "akamai_property_activation" "tf-activate-staging" {
property = akamai_property.tf-property-xxxx-yyy-nl.id
network = "STAGING"
activate = true
contact = ["qwe@rty.uio"]
}
### Expected Behavior
When the terraform apply is executed and akamai_property.tf-property-xxxx-yyy-nl.id is not changed (no version update in akamai), the activation should not be started
### Actual Behavior
The activation is started on an already activated propertyversion and the execution fails:
Error: API Error: 422 422 Unprocessable Entity Version 2 of property `prp_123456` has already been activated. More Info https://problems.luna.akamaiapis.net/papi/v0/activation/already-activated
on main.tf line 36, in resource "akamai_property_activation" "tf-activate-staging":
36: resource "akamai_property_activation" "tf-activate-staging" {
|
1.0
|
Activation is executed, even without changes - ### Terraform Version
Terraform v0.12.24
+ provider.akamai v0.5.0
+ provider.aws v2.58.0
+ provider.template v2.1.2
### Affected Resource(s)
resource "akamai_property_activation" "tf-activate-staging" {
property = akamai_property.tf-property-xxxx-yyy-nl.id
network = "STAGING"
activate = true
contact = ["qwe@rty.uio"]
}
### Expected Behavior
When the terraform apply is executed and akamai_property.tf-property-xxxx-yyy-nl.id is not changed (no version update in akamai), the activation should not be started
### Actual Behavior
The activation is started on an already activated propertyversion and the execution fails:
Error: API Error: 422 422 Unprocessable Entity Version 2 of property `prp_123456` has already been activated. More Info https://problems.luna.akamaiapis.net/papi/v0/activation/already-activated
on main.tf line 36, in resource "akamai_property_activation" "tf-activate-staging":
36: resource "akamai_property_activation" "tf-activate-staging" {
|
process
|
activation is executed even without changes terraform version terraform provider akamai provider aws provider template affected resource s resource akamai property activation tf activate staging property akamai property tf property xxxx yyy nl id network staging activate true contact expected behavior when the terraform apply is executed and akamai property tf property xxxx yyy nl id is not changed no version update in akamai the activation should not be started actual behavior the activation is started on an already activated propertyversion and the execution fails error api error unprocessable entity version of property prp has already been activated more info on main tf line in resource akamai property activation tf activate staging resource akamai property activation tf activate staging
| 1
|
17,652
| 10,098,145,767
|
IssuesEvent
|
2019-07-28 12:48:06
|
Shuunen/bergerac-roads
|
https://api.github.com/repos/Shuunen/bergerac-roads
|
closed
|
CVE-2017-16026 Medium Severity Vulnerability detected by WhiteSource
|
security vulnerability
|
## CVE-2017-16026 - Medium Severity Vulnerability
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>request-2.64.0.tgz</b></p></summary>
<p>Simplified HTTP request client.</p>
<p>path: /bergerac-roads/node_modules/cypress/dist/Cypress/resources/app/packages/server/node_modules/node-webkit-updater/node_modules/request/package.json</p>
<p>
<p>Library home page: <a href=http://registry.npmjs.org/request/-/request-2.64.0.tgz>http://registry.npmjs.org/request/-/request-2.64.0.tgz</a></p>
Dependency Hierarchy:
- :x: **request-2.64.0.tgz** (Vulnerable Library)
</p>
</details>
<p></p>
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Request is an http client. If a request is made using ```multipart```, and the body type is a ```number```, then the specified number of non-zero memory is passed in the body. This affects Request >=2.2.6 <2.47.0 || >2.51.0 <=2.67.0.
<p>Publish Date: 2018-06-04
<p>URL: <a href=https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-16026>CVE-2017-16026</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.9</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: None
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nodesecurity.io/advisories/309">https://nodesecurity.io/advisories/309</a></p>
<p>Release Date: 2017-04-14</p>
<p>Fix Resolution: Update to version 2.68.0 or later</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2017-16026 Medium Severity Vulnerability detected by WhiteSource - ## CVE-2017-16026 - Medium Severity Vulnerability
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>request-2.64.0.tgz</b></p></summary>
<p>Simplified HTTP request client.</p>
<p>path: /bergerac-roads/node_modules/cypress/dist/Cypress/resources/app/packages/server/node_modules/node-webkit-updater/node_modules/request/package.json</p>
<p>
<p>Library home page: <a href=http://registry.npmjs.org/request/-/request-2.64.0.tgz>http://registry.npmjs.org/request/-/request-2.64.0.tgz</a></p>
Dependency Hierarchy:
- :x: **request-2.64.0.tgz** (Vulnerable Library)
</p>
</details>
<p></p>
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Request is an http client. If a request is made using ```multipart```, and the body type is a ```number```, then the specified number of non-zero memory is passed in the body. This affects Request >=2.2.6 <2.47.0 || >2.51.0 <=2.67.0.
<p>Publish Date: 2018-06-04
<p>URL: <a href=https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-16026>CVE-2017-16026</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.9</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: High
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: None
- Availability Impact: None
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://www.whitesourcesoftware.com/wp-content/uploads/2018/10/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nodesecurity.io/advisories/309">https://nodesecurity.io/advisories/309</a></p>
<p>Release Date: 2017-04-14</p>
<p>Fix Resolution: Update to version 2.68.0 or later</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve medium severity vulnerability detected by whitesource cve medium severity vulnerability vulnerable library request tgz simplified http request client path bergerac roads node modules cypress dist cypress resources app packages server node modules node webkit updater node modules request package json library home page a href dependency hierarchy x request tgz vulnerable library vulnerability details request is an http client if a request is made using multipart and the body type is a number then the specified number of non zero memory is passed in the body this affects request publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity high privileges required none user interaction none scope unchanged impact metrics confidentiality impact high integrity impact none availability impact none for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution update to version or later step up your open source security game with whitesource
| 0
|
59,761
| 12,014,412,756
|
IssuesEvent
|
2020-04-10 11:22:51
|
fac19/week6-BGJK
|
https://api.github.com/repos/fac19/week6-BGJK
|
closed
|
user.js & 401 template
|
P3 code review
|
401() template should be declared in the templates as you are creating multiple instances of it and importing the template.js but aren't using that declaration in user.js, submitPost & submitGet
|
1.0
|
user.js & 401 template - 401() template should be declared in the templates as you are creating multiple instances of it and importing the template.js but aren't using that declaration in user.js, submitPost & submitGet
|
non_process
|
user js template template should be declared in the templates as you are creating multiple instances of it and importing the template js but aren t using that declaration in user js submitpost submitget
| 0
|
112,010
| 9,550,644,308
|
IssuesEvent
|
2019-05-02 12:42:14
|
material-components/material-components-ios
|
https://api.github.com/repos/material-components/material-components-ios
|
opened
|
[BottomNavigation] Unit tests not logging string comparison failures
|
[BottomNavigation] [testing] skill:Refactoring type:Internal cleanup
|
Several unit tests are comparing strings but not logging the values when it fails. This has made debugging challenging in #7288.
|
1.0
|
[BottomNavigation] Unit tests not logging string comparison failures - Several unit tests are comparing strings but not logging the values when it fails. This has made debugging challenging in #7288.
|
non_process
|
unit tests not logging string comparison failures several unit tests are comparing strings but not logging the values when it fails this has made debugging challenging in
| 0
|
157,783
| 13,722,468,768
|
IssuesEvent
|
2020-10-03 03:49:55
|
TheIOFoundation/ProjectLockdown
|
https://api.github.com/repos/TheIOFoundation/ProjectLockdown
|
opened
|
Transition Wiki from v1.0 to v2.0
|
Documentation
|
@TheIOFoundation/tiof-pld-team-documentation
**Problem**
**Objectives**
- Update all links in v1.0 repo to point to v2.0
- Update text in Repo landing page to reflect that all development is to be diverted towards v2.0
**Extra information**
**Pending**
**Related Issues**
|
1.0
|
Transition Wiki from v1.0 to v2.0 - @TheIOFoundation/tiof-pld-team-documentation
**Problem**
**Objectives**
- Update all links in v1.0 repo to point to v2.0
- Update text in Repo landing page to reflect that all development is to be diverted towards v2.0
**Extra information**
**Pending**
**Related Issues**
|
non_process
|
transition wiki from to theiofoundation tiof pld team documentation problem objectives update all links in repo to point to update text in repo landing page to reflect that all development is to be diverted towards extra information pending related issues
| 0
|
6,801
| 9,940,723,900
|
IssuesEvent
|
2019-07-03 09:48:17
|
aiidateam/aiida_core
|
https://api.github.com/repos/aiidateam/aiida_core
|
opened
|
Missing data migration for change in sealed key from `_sealed` to `sealed`
|
priority/critical-blocking topic/database-migrations topic/engine topic/processes type/bug
|
This means that for older processes that still have the `_sealed` attribute, the `ProcessNode.is_sealed` will return `False`, which is problematic
|
1.0
|
Missing data migration for change in sealed key from `_sealed` to `sealed` - This means that for older processes that still have the `_sealed` attribute, the `ProcessNode.is_sealed` will return `False`, which is problematic
|
process
|
missing data migration for change in sealed key from sealed to sealed this means that for older processes that still have the sealed attribute the processnode is sealed will return false which is problematic
| 1
|
135,625
| 30,325,352,321
|
IssuesEvent
|
2023-07-10 23:15:59
|
Traaanaelle/anaelle.dev
|
https://api.github.com/repos/Traaanaelle/anaelle.dev
|
opened
|
Fix issues detected by Google PageSpeed Insights
|
Project Organization and Code Quality
|
[Google PageSpeed Insights](https://pagespeed.web.dev/analysis/https-anaelle-dev/3zamro47pz) detected some problems concerning "best practices" on mobile, and SEO, that we should fix.
There are also problems on other pages, like [recette.html](https://pagespeed.web.dev/analysis/https-anaelle-dev-recette-html/m2vmpjo2nn) that need to be checked too.
|
1.0
|
Fix issues detected by Google PageSpeed Insights - [Google PageSpeed Insights](https://pagespeed.web.dev/analysis/https-anaelle-dev/3zamro47pz) detected some problems concerning "best practices" on mobile, and SEO, that we should fix.
There are also problems on other pages, like [recette.html](https://pagespeed.web.dev/analysis/https-anaelle-dev-recette-html/m2vmpjo2nn) that need to be checked too.
|
non_process
|
fix issues detected by google pagespeed insights detected some problems concerning best practices on mobile and seo that we should fix there are also problems on other pages like that need to be checked too
| 0
|
18,029
| 24,037,135,144
|
IssuesEvent
|
2022-09-15 20:18:54
|
magland/spikesortingview
|
https://api.github.com/repos/magland/spikesortingview
|
closed
|
Focus time interval
|
in process
|
In TimeScrollView, allow user to select a time interval for focus. This is part of #111.
<!-- Edit the body of your new issue then click the ✓ "Create Issue" button in the top right of the editor. The first line will be the issue title. Assignees and Labels follow after a blank line. Leave an empty line before beginning the body of the issue. -->
|
1.0
|
Focus time interval - In TimeScrollView, allow user to select a time interval for focus. This is part of #111.
<!-- Edit the body of your new issue then click the ✓ "Create Issue" button in the top right of the editor. The first line will be the issue title. Assignees and Labels follow after a blank line. Leave an empty line before beginning the body of the issue. -->
|
process
|
focus time interval in timescrollview allow user to select a time interval for focus this is part of
| 1
|
22,003
| 30,505,167,707
|
IssuesEvent
|
2023-07-18 16:20:27
|
NCAR/kcor-pipeline
|
https://api.github.com/repos/NCAR/kcor-pipeline
|
opened
|
Simulate CME detection for selected dates with expanded time range in .csv file in report
|
process
|
1) Please change the CME alert code so that it reports 'tracking data' in the .csv file that was taken up to 30 minutes BEFORE the start of the CME ( CME Tstart < 30 minutes )
If you can do #1 then Please rerun these 3 CMEs so we get more data points in the .csv file that comes with the CME report:
- [ ] 20210507
- [ ] 20220613
- [ ] 20221031
IF you CAN't do #1 please just rerun 20210507. Thanks very much!
|
1.0
|
Simulate CME detection for selected dates with expanded time range in .csv file in report - 1) Please change the CME alert code so that it reports 'tracking data' in the .csv file that was taken up to 30 minutes BEFORE the start of the CME ( CME Tstart < 30 minutes )
If you can do #1 then Please rerun these 3 CMEs so we get more data points in the .csv file that comes with the CME report:
- [ ] 20210507
- [ ] 20220613
- [ ] 20221031
IF you CAN't do #1 please just rerun 20210507. Thanks very much!
|
process
|
simulate cme detection for selected dates with expanded time range in csv file in report please change the cme alert code so that it reports tracking data in the csv file that was taken up to minutes before the start of the cme cme tstart minutes if you can do then please rerun these cmes so we get more data points in the csv file that comes with the cme report if you can t do please just rerun thanks very much
| 1
|
224,964
| 7,474,065,289
|
IssuesEvent
|
2018-04-03 17:10:43
|
mozilla/addons-frontend
|
https://api.github.com/repos/mozilla/addons-frontend
|
closed
|
expand add-on description by default on desktop
|
component: ux priority: p3 size: S triaged type: papercut
|
Please expand, at least on desktop, the add-on description by default. I don't see any good reason to hide the most important part of the add-on page by default and it's annoying to have to click on every add-on page the "read more" link to read the description.
|
1.0
|
expand add-on description by default on desktop - Please expand, at least on desktop, the add-on description by default. I don't see any good reason to hide the most important part of the add-on page by default and it's annoying to have to click on every add-on page the "read more" link to read the description.
|
non_process
|
expand add on description by default on desktop please expand at least on desktop the add on description by default i don t see any good reason to hide the most important part of the add on page by default and it s annoying to have to click on every add on page the read more link to read the description
| 0
|
227,896
| 7,543,959,539
|
IssuesEvent
|
2018-04-17 16:57:24
|
GingerWalnut/SQ5.0Public
|
https://api.github.com/repos/GingerWalnut/SQ5.0Public
|
closed
|
Canora exiting issue
|
Priority High Ships Bug
|
I was flying out of Canora and I managed to get into space, but when I moved, I was teleported back to the 3rd quartile of the planet. When I flew back out, I was in the same place in space as before, and so on until I tried flying a couple thousand blocks East on Canora, then managed to successfully fly way from Canora. I had no error messages, seems like the planet TP boxes are a bit strangely configured.
|
1.0
|
Canora exiting issue - I was flying out of Canora and I managed to get into space, but when I moved, I was teleported back to the 3rd quartile of the planet. When I flew back out, I was in the same place in space as before, and so on until I tried flying a couple thousand blocks East on Canora, then managed to successfully fly way from Canora. I had no error messages, seems like the planet TP boxes are a bit strangely configured.
|
non_process
|
canora exiting issue i was flying out of canora and i managed to get into space but when i moved i was teleported back to the quartile of the planet when i flew back out i was in the same place in space as before and so on until i tried flying a couple thousand blocks east on canora then managed to successfully fly way from canora i had no error messages seems like the planet tp boxes are a bit strangely configured
| 0
|
16,834
| 22,066,889,149
|
IssuesEvent
|
2022-05-31 04:59:53
|
hashgraph/hedera-json-rpc-relay
|
https://api.github.com/repos/hashgraph/hedera-json-rpc-relay
|
opened
|
Release v0.1.0
|
enhancement P1 process
|
### Problem
With the completion of v0.1.0 a release needs to be deployed representing a stable version
### Solution
For now follow a manual release process
- [ ] Create a `release/0.1` branch off of main Ensure github test actions run
- [ ] Tag as `v0.1.0-rc1`
- [ ] git tag
- [ ] Deploy docker image version
- [ ] Integration Testing
- [ ] Manual testing against Integration
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
- [ ] Previewnet Testing
- [ ] Manual testing
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
- [ ] Testnet Testing
- [ ] Manual testing
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
- [ ] Tag as `v0.1.0`
- [ ] git tag
- [ ] Deploy docker image version
- [ ] Write up release notes and changelist
- Let bake
- [ ] Mainnet Testing
- [ ] Manual testing
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
Any bugs or missed features found should see a new ticket opened, addressed in main and cherry-picked to release/0.1 with a new rc version tagged and docker image deployed
### Alternatives
Automate process
|
1.0
|
Release v0.1.0 - ### Problem
With the completion of v0.1.0 a release needs to be deployed representing a stable version
### Solution
For now follow a manual release process
- [ ] Create a `release/0.1` branch off of main Ensure github test actions run
- [ ] Tag as `v0.1.0-rc1`
- [ ] git tag
- [ ] Deploy docker image version
- [ ] Integration Testing
- [ ] Manual testing against Integration
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
- [ ] Previewnet Testing
- [ ] Manual testing
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
- [ ] Testnet Testing
- [ ] Manual testing
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
- [ ] Tag as `v0.1.0`
- [ ] git tag
- [ ] Deploy docker image version
- [ ] Write up release notes and changelist
- Let bake
- [ ] Mainnet Testing
- [ ] Manual testing
- [ ] Run acceptance tests (if yet available)
- [ ] Run performance tests (if yet applicable)
Any bugs or missed features found should see a new ticket opened, addressed in main and cherry-picked to release/0.1 with a new rc version tagged and docker image deployed
### Alternatives
Automate process
|
process
|
release problem with the completion of a release needs to be deployed representing a stable version solution for now follow a manual release process create a release branch off of main ensure github test actions run tag as git tag deploy docker image version integration testing manual testing against integration run acceptance tests if yet available run performance tests if yet applicable previewnet testing manual testing run acceptance tests if yet available run performance tests if yet applicable testnet testing manual testing run acceptance tests if yet available run performance tests if yet applicable tag as git tag deploy docker image version write up release notes and changelist let bake mainnet testing manual testing run acceptance tests if yet available run performance tests if yet applicable any bugs or missed features found should see a new ticket opened addressed in main and cherry picked to release with a new rc version tagged and docker image deployed alternatives automate process
| 1
|
12,931
| 15,298,821,548
|
IssuesEvent
|
2021-02-24 10:11:07
|
scikit-learn/scikit-learn
|
https://api.github.com/repos/scikit-learn/scikit-learn
|
opened
|
Weighted variance computation for sparse data is not numerically stable
|
Bug Moderate module:linear_model module:preprocessing
|
This issue was discovered when adding tests for #19527 (currently marked XFAIL).
Here is minimal reproduction case using the underlying private API:
https://gist.github.com/ogrisel/bd2cf3350fff5bbd5a0899fa6baf3267
The results are the following (macOS / arm64 / Python 3.9.1 / Cython 0.29.21 / clang 11.0.1):
```
## dtype=float64
_incremental_mean_and_var [0.]
csr_mean_variance_axis0 [-2.292436e-12]
incr_mean_variance_axis0 csr [-2.292436e-12]
csc_mean_variance_axis0 [-2.292436e-12]
incr_mean_variance_axis0 csc [-2.292436e-12]
## dtype=float32
_incremental_mean_and_var [1.38710347e-12]
csr_mean_variance_axis0 [0.00246148]
incr_mean_variance_axis0 csr [0.00246148]
csc_mean_variance_axis0 [0.00246148]
incr_mean_variance_axis0 csc [0.00246148]
```
So the `sklearn.utils.extmath._incremental_mean_and_var` function for dense numpy arrays is numerically stable, both in float32 (~1e-12 is much below `np.finfo(np.float32).eps`) and float64, but the sparse counterparts, either incremental are not are all wrong in the same way.
So the gist above should be adapted to write a new series of new tests for these Cython functions and the fix will probably involve adapting the algorithm implemented in `sklearn.utils.extmath._incremental_mean_and_var` to the sparse case.
|
1.0
|
Weighted variance computation for sparse data is not numerically stable - This issue was discovered when adding tests for #19527 (currently marked XFAIL).
Here is minimal reproduction case using the underlying private API:
https://gist.github.com/ogrisel/bd2cf3350fff5bbd5a0899fa6baf3267
The results are the following (macOS / arm64 / Python 3.9.1 / Cython 0.29.21 / clang 11.0.1):
```
## dtype=float64
_incremental_mean_and_var [0.]
csr_mean_variance_axis0 [-2.292436e-12]
incr_mean_variance_axis0 csr [-2.292436e-12]
csc_mean_variance_axis0 [-2.292436e-12]
incr_mean_variance_axis0 csc [-2.292436e-12]
## dtype=float32
_incremental_mean_and_var [1.38710347e-12]
csr_mean_variance_axis0 [0.00246148]
incr_mean_variance_axis0 csr [0.00246148]
csc_mean_variance_axis0 [0.00246148]
incr_mean_variance_axis0 csc [0.00246148]
```
So the `sklearn.utils.extmath._incremental_mean_and_var` function for dense numpy arrays is numerically stable, both in float32 (~1e-12 is much below `np.finfo(np.float32).eps`) and float64, but the sparse counterparts, either incremental are not are all wrong in the same way.
So the gist above should be adapted to write a new series of new tests for these Cython functions and the fix will probably involve adapting the algorithm implemented in `sklearn.utils.extmath._incremental_mean_and_var` to the sparse case.
|
process
|
weighted variance computation for sparse data is not numerically stable this issue was discovered when adding tests for currently marked xfail here is minimal reproduction case using the underlying private api the results are the following macos python cython clang dtype incremental mean and var csr mean variance incr mean variance csr csc mean variance incr mean variance csc dtype incremental mean and var csr mean variance incr mean variance csr csc mean variance incr mean variance csc so the sklearn utils extmath incremental mean and var function for dense numpy arrays is numerically stable both in is much below np finfo np eps and but the sparse counterparts either incremental are not are all wrong in the same way so the gist above should be adapted to write a new series of new tests for these cython functions and the fix will probably involve adapting the algorithm implemented in sklearn utils extmath incremental mean and var to the sparse case
| 1
|
3,818
| 6,800,694,276
|
IssuesEvent
|
2017-11-02 14:44:14
|
w3c/w3process
|
https://api.github.com/repos/w3c/w3process
|
reopened
|
Clarify the voting process
|
AC-review Process2018Candidate
|
The last line in Section 7.3 (about votes) says
'In the case of Advisory Board and TAG elections, "one vote" means "one vote per available seat".'
I think this line is a holdover from previous voting procedures. We now use STV. A literal interpretation of this line is that (e.g.) in an AB election with 4 open seats, each AC rep would have 4 votes: i.e. 4 opportunities to use STV. This is absurd.
I recommend dropping this line.
|
1.0
|
Clarify the voting process - The last line in Section 7.3 (about votes) says
'In the case of Advisory Board and TAG elections, "one vote" means "one vote per available seat".'
I think this line is a holdover from previous voting procedures. We now use STV. A literal interpretation of this line is that (e.g.) in an AB election with 4 open seats, each AC rep would have 4 votes: i.e. 4 opportunities to use STV. This is absurd.
I recommend dropping this line.
|
process
|
clarify the voting process the last line in section about votes says in the case of advisory board and tag elections one vote means one vote per available seat i think this line is a holdover from previous voting procedures we now use stv a literal interpretation of this line is that e g in an ab election with open seats each ac rep would have votes i e opportunities to use stv this is absurd i recommend dropping this line
| 1
|
163
| 2,492,177,443
|
IssuesEvent
|
2015-01-04 15:01:49
|
NewSpring/Norma
|
https://api.github.com/repos/NewSpring/Norma
|
closed
|
Core - reinstall / update removes files
|
bug priority:high
|
On update Norma asks for your name, even though it was entered during the initial install
|
1.0
|
Core - reinstall / update removes files - On update Norma asks for your name, even though it was entered during the initial install
|
non_process
|
core reinstall update removes files on update norma asks for your name even though it was entered during the initial install
| 0
|
2,617
| 5,394,414,035
|
IssuesEvent
|
2017-02-27 03:06:23
|
mitchellh/packer
|
https://api.github.com/repos/mitchellh/packer
|
closed
|
Cannot use vSphere post processor even on an older version
|
need-more-info post-processor/vsphere question
|
For some reason when ever I run the vSphere post processor it refuses to work. I have followed several guidelines on how to do this but have had no success.
I get an error from the OVFtool stating that the "locator does not refer to an object" despite the path being 100% correct in my opinion. I can get the path to work using the OVFtool directly but packers seems to be including a random "ha-datacenter" inside the string following vi:\.
Anyone else had this issue or know a fix???
|
1.0
|
Cannot use vSphere post processor even on an older version - For some reason when ever I run the vSphere post processor it refuses to work. I have followed several guidelines on how to do this but have had no success.
I get an error from the OVFtool stating that the "locator does not refer to an object" despite the path being 100% correct in my opinion. I can get the path to work using the OVFtool directly but packers seems to be including a random "ha-datacenter" inside the string following vi:\.
Anyone else had this issue or know a fix???
|
process
|
cannot use vsphere post processor even on an older version for some reason when ever i run the vsphere post processor it refuses to work i have followed several guidelines on how to do this but have had no success i get an error from the ovftool stating that the locator does not refer to an object despite the path being correct in my opinion i can get the path to work using the ovftool directly but packers seems to be including a random ha datacenter inside the string following vi anyone else had this issue or know a fix
| 1
|
11,091
| 13,935,065,127
|
IssuesEvent
|
2020-10-22 10:57:00
|
nodejs/node
|
https://api.github.com/repos/nodejs/node
|
closed
|
worker: file creation races with process.umask()
|
fs process worker
|
This code is unsafe when worker threads are active:
https://github.com/nodejs/node/blob/40b559a376ae1db031132a86a76834decf6f0c2d/src/node_process_methods.cc#L248-L249
The `umask(0)` call temporarily changes the process-wide umask and races with fs operations from other threads.
Test case:
```js
'use strict';
const { Worker, isMainThread } = require('worker_threads');
const { statSync, writeFileSync, unlinkSync } = require('fs');
function pummel() {
for (let i = 0; i < 1e4; i++) process.umask();
setImmediate(pummel);
}
if (isMainThread) {
process.umask(0o22);
new Worker(__filename);
pummel();
} else {
const file = 'x.txt';
for (;;) {
writeFileSync(file, 'ok', { mode: 0o666 });
const s = statSync(file);
s.mode &= 0o777;
if (0o644 !== s.mode) throw 'unexpected mode: ' + s.mode.toString(8);
unlinkSync(file);
}
}
```
Fails within a few iterations with `unexpected mode: 666`
`process.umask()` (no arg) is allowed in workers so this test case works both ways.
This bug is potentially a security issue.
|
1.0
|
worker: file creation races with process.umask() - This code is unsafe when worker threads are active:
https://github.com/nodejs/node/blob/40b559a376ae1db031132a86a76834decf6f0c2d/src/node_process_methods.cc#L248-L249
The `umask(0)` call temporarily changes the process-wide umask and races with fs operations from other threads.
Test case:
```js
'use strict';
const { Worker, isMainThread } = require('worker_threads');
const { statSync, writeFileSync, unlinkSync } = require('fs');
function pummel() {
for (let i = 0; i < 1e4; i++) process.umask();
setImmediate(pummel);
}
if (isMainThread) {
process.umask(0o22);
new Worker(__filename);
pummel();
} else {
const file = 'x.txt';
for (;;) {
writeFileSync(file, 'ok', { mode: 0o666 });
const s = statSync(file);
s.mode &= 0o777;
if (0o644 !== s.mode) throw 'unexpected mode: ' + s.mode.toString(8);
unlinkSync(file);
}
}
```
Fails within a few iterations with `unexpected mode: 666`
`process.umask()` (no arg) is allowed in workers so this test case works both ways.
This bug is potentially a security issue.
|
process
|
worker file creation races with process umask this code is unsafe when worker threads are active the umask call temporarily changes the process wide umask and races with fs operations from other threads test case js use strict const worker ismainthread require worker threads const statsync writefilesync unlinksync require fs function pummel for let i i i process umask setimmediate pummel if ismainthread process umask new worker filename pummel else const file x txt for writefilesync file ok mode const s statsync file s mode if s mode throw unexpected mode s mode tostring unlinksync file fails within a few iterations with unexpected mode process umask no arg is allowed in workers so this test case works both ways this bug is potentially a security issue
| 1
|
22,057
| 30,574,596,042
|
IssuesEvent
|
2023-07-21 03:28:19
|
h4sh5/pypi-auto-scanner
|
https://api.github.com/repos/h4sh5/pypi-auto-scanner
|
opened
|
bcpandas 2.4.2 has 2 GuardDog issues
|
guarddog exec-base64 silent-process-execution
|
https://pypi.org/project/bcpandas
https://inspector.pypi.io/project/bcpandas
```{
"dependency": "bcpandas",
"version": "2.4.2",
"result": {
"issues": 2,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "bcpandas-2.4.2/bcpandas/__init__.py:18",
"code": " run([\"bcp\", \"-v\"], stdout=DEVNULL, stderr=DEVNULL, stdin=DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
],
"exec-base64": [
{
"location": "bcpandas-2.4.2/bcpandas/utils.py:254",
"code": " proc = Popen(\n cmd,\n stdout=PIPE,\n stderr=STDOUT,\n encoding=\"utf-8\",\n errors=\"utf-8\",\n shell=with_shell,\n )",
"message": "This package contains a call to the `eval` function with a `base64` encoded string as argument.\nThis is a common method used to hide a malicious payload in a module as static analysis will not decode the\nstring.\n"
}
]
},
"path": "/tmp/tmprgnw7t_e/bcpandas"
}
}```
|
1.0
|
bcpandas 2.4.2 has 2 GuardDog issues - https://pypi.org/project/bcpandas
https://inspector.pypi.io/project/bcpandas
```{
"dependency": "bcpandas",
"version": "2.4.2",
"result": {
"issues": 2,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "bcpandas-2.4.2/bcpandas/__init__.py:18",
"code": " run([\"bcp\", \"-v\"], stdout=DEVNULL, stderr=DEVNULL, stdin=DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
],
"exec-base64": [
{
"location": "bcpandas-2.4.2/bcpandas/utils.py:254",
"code": " proc = Popen(\n cmd,\n stdout=PIPE,\n stderr=STDOUT,\n encoding=\"utf-8\",\n errors=\"utf-8\",\n shell=with_shell,\n )",
"message": "This package contains a call to the `eval` function with a `base64` encoded string as argument.\nThis is a common method used to hide a malicious payload in a module as static analysis will not decode the\nstring.\n"
}
]
},
"path": "/tmp/tmprgnw7t_e/bcpandas"
}
}```
|
process
|
bcpandas has guarddog issues dependency bcpandas version result issues errors results silent process execution location bcpandas bcpandas init py code run stdout devnull stderr devnull stdin devnull message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null exec location bcpandas bcpandas utils py code proc popen n cmd n stdout pipe n stderr stdout n encoding utf n errors utf n shell with shell n message this package contains a call to the eval function with a encoded string as argument nthis is a common method used to hide a malicious payload in a module as static analysis will not decode the nstring n path tmp e bcpandas
| 1
|
37,084
| 2,814,731,275
|
IssuesEvent
|
2015-05-18 21:41:25
|
GoogleCloudPlatform/kubernetes
|
https://api.github.com/repos/GoogleCloudPlatform/kubernetes
|
closed
|
Recurring error in kubelet log when cadvisor is not functional
|
priority/P2 team/node
|
The kubelet log fills up quickly with:
```
2755 kubelet.go:683] failed to record system OOMs - cAdvisor is unsupported in this build
```
|
1.0
|
Recurring error in kubelet log when cadvisor is not functional - The kubelet log fills up quickly with:
```
2755 kubelet.go:683] failed to record system OOMs - cAdvisor is unsupported in this build
```
|
non_process
|
recurring error in kubelet log when cadvisor is not functional the kubelet log fills up quickly with kubelet go failed to record system ooms cadvisor is unsupported in this build
| 0
|
4,682
| 7,299,572,205
|
IssuesEvent
|
2018-02-26 20:34:29
|
LLK/scratch-vm
|
https://api.github.com/repos/LLK/scratch-vm
|
closed
|
Errors when no sprites are in loaded Scratch 2.0 project
|
bug compatibility
|
> Uncaught TypeError: Cannot read property 'blocks' of undefined
Presumably, I've made an assumption somewhere that there would be a stage and a first sprite. However this is not always the case: https://llk.github.io/scratch-vm/#125571490
The project functions fine as far as execution, but the blocks loading fails; must be something about setting the editing target.
|
True
|
Errors when no sprites are in loaded Scratch 2.0 project - > Uncaught TypeError: Cannot read property 'blocks' of undefined
Presumably, I've made an assumption somewhere that there would be a stage and a first sprite. However this is not always the case: https://llk.github.io/scratch-vm/#125571490
The project functions fine as far as execution, but the blocks loading fails; must be something about setting the editing target.
|
non_process
|
errors when no sprites are in loaded scratch project uncaught typeerror cannot read property blocks of undefined presumably i ve made an assumption somewhere that there would be a stage and a first sprite however this is not always the case the project functions fine as far as execution but the blocks loading fails must be something about setting the editing target
| 0
|
12,577
| 14,989,797,781
|
IssuesEvent
|
2021-01-29 04:46:40
|
eddieantonio/predictive-text-studio
|
https://api.github.com/repos/eddieantonio/predictive-text-studio
|
closed
|
Import wordlist from TSV
|
data-backing data-processing good first issue worker
|
Allow import using the TSV format given on this page: https://help.keyman.com/developer/current-version/reference/file-types/tsv
Although users are encouraged to use something they're familiar with, such Google Sheets of Microsoft Excel, they should be able to use this option as well!
|
1.0
|
Import wordlist from TSV - Allow import using the TSV format given on this page: https://help.keyman.com/developer/current-version/reference/file-types/tsv
Although users are encouraged to use something they're familiar with, such Google Sheets of Microsoft Excel, they should be able to use this option as well!
|
process
|
import wordlist from tsv allow import using the tsv format given on this page although users are encouraged to use something they re familiar with such google sheets of microsoft excel they should be able to use this option as well
| 1
|
150,892
| 19,634,158,179
|
IssuesEvent
|
2022-01-08 01:40:51
|
andygonzalez2010/store
|
https://api.github.com/repos/andygonzalez2010/store
|
opened
|
CVE-2021-42392 (High) detected in h2-1.4.199.jar
|
security vulnerability
|
## CVE-2021-42392 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>h2-1.4.199.jar</b></p></summary>
<p>H2 Database Engine</p>
<p>Library home page: <a href="http://www.h2database.com">http://www.h2database.com</a></p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /canner/.m2/repository/com/h2database/h2/1.4.199/h2-1.4.199.jar</p>
<p>
Dependency Hierarchy:
- :x: **h2-1.4.199.jar** (Vulnerable Library)
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
H2 Console in versions since 1.1.100 (2008-10-14) to 2.0.204 (2021-12-21) inclusive allows loading of custom classes from remote servers through JNDI.
<p>Publish Date: 2021-10-15
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-42392>CVE-2021-42392</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.1</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/h2database/h2database/security/advisories/GHSA-h376-j262-vhq6">https://github.com/h2database/h2database/security/advisories/GHSA-h376-j262-vhq6</a></p>
<p>Release Date: 2021-10-15</p>
<p>Fix Resolution: com.h2database:h2:2.0.206</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2021-42392 (High) detected in h2-1.4.199.jar - ## CVE-2021-42392 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>h2-1.4.199.jar</b></p></summary>
<p>H2 Database Engine</p>
<p>Library home page: <a href="http://www.h2database.com">http://www.h2database.com</a></p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /canner/.m2/repository/com/h2database/h2/1.4.199/h2-1.4.199.jar</p>
<p>
Dependency Hierarchy:
- :x: **h2-1.4.199.jar** (Vulnerable Library)
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
H2 Console in versions since 1.1.100 (2008-10-14) to 2.0.204 (2021-12-21) inclusive allows loading of custom classes from remote servers through JNDI.
<p>Publish Date: 2021-10-15
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-42392>CVE-2021-42392</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.1</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/h2database/h2database/security/advisories/GHSA-h376-j262-vhq6">https://github.com/h2database/h2database/security/advisories/GHSA-h376-j262-vhq6</a></p>
<p>Release Date: 2021-10-15</p>
<p>Fix Resolution: com.h2database:h2:2.0.206</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve high detected in jar cve high severity vulnerability vulnerable library jar database engine library home page a href path to dependency file pom xml path to vulnerable library canner repository com jar dependency hierarchy x jar vulnerable library found in base branch master vulnerability details console in versions since to inclusive allows loading of custom classes from remote servers through jndi publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact high availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution com step up your open source security game with whitesource
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.