
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,346 | Make it possible to read statistics about returning whistleblowers | This ticket it to track the activities to make it possible to read statistics about returning whistleblowers.
It would be in fact valuable to show statistics about:
- the amount of reports where the whistleblowers logged in back vs. not
- the average amount of time that whistleblowers logged in onto the system
- ... | open | 2023-02-09T16:38:29Z | 2023-02-09T16:38:29Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3346 | [
"C: Client",
"C: Backend",
"F: Statistics",
"T: Feature"
] | evilaliv3 | 0 |
widgetti/solara | flask | 243 | Internal Server Error by KeyError: 'load_extensions' | Thank you for this great library.
I tried to implement auth0 private site using Docker+Poetry and got an internal server error, and after looking at the code, it looks like there is no solution.
Apparently I should be able to set use_nbextensions=False when calling read_root in server.py, but I can't set it in th... | closed | 2023-08-14T13:56:35Z | 2023-08-14T14:22:31Z | https://github.com/widgetti/solara/issues/243 | [] | Sanuki-073 | 1 |
unit8co/darts | data-science | 2,531 | How to use dump or load of joblib to save or reuse fitted model | I want to use `joblib` to dump and load the fitted model, but when I used the loaded model, it reported `AttributeError: 'NoneType' object has no attribute 'set_predict_parameters'`.
Suppose that I have trained a TSMixerModel as follows,
```model_name ='tsm'
model = TSMixerModel(
**create_params(
i... | closed | 2024-09-15T07:38:34Z | 2024-10-16T08:06:11Z | https://github.com/unit8co/darts/issues/2531 | [
"question"
] | ZhangAllen98 | 4 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 417 | 请问为什么pytorch训练Faster-RCNN,出来的权重文件那么大?能不能修改只get它模型的权重? | 不知道为什么,训练出来的的权重文件有几百MB大,我训练的是faster-rcnn+mobilenetv2,按道理来说应该只有十几MB,是不是包含了其他的东西? | closed | 2021-12-06T09:00:30Z | 2021-12-06T09:23:14Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/417 | [] | nit-hmz | 2 |
skypilot-org/skypilot | data-science | 4,878 | [API server] Refine error message of version mismatch | One of our users reported the following error when trying to use a remote API server:
```
RuntimeError: SkyPilot API server is too old: v1 (client version is v3). Please restart the SkyPilot API server with: sky api stop; sky api start
```
This is only valid for local API servers and should be for remote API servers,... | open | 2025-03-05T03:46:23Z | 2025-03-05T07:31:35Z | https://github.com/skypilot-org/skypilot/issues/4878 | [
"Initial-User-Issue",
"interface/ux",
"api server"
] | aylei | 0 |
facebookresearch/fairseq | pytorch | 4,595 | How to use the past, future and self targets for text generation? | #### What is your question?
I noticed that new FairSeq models support past, future and self targets for text generation tasks. However, I have been trying to figure out a way of implementing a generator that would allow me to do it, but it seems that it is really hard to get that to work. The issue is mostly in the ... | open | 2022-07-20T21:37:49Z | 2022-07-26T11:55:06Z | https://github.com/facebookresearch/fairseq/issues/4595 | [
"question",
"needs triage"
] | AhtiAhde | 3 |
2noise/ChatTTS | python | 892 | 无法找到GPU | no GPU or NPU found, use CPU instead
如何启用GPU运行加速? | closed | 2025-02-12T09:24:35Z | 2025-02-13T15:04:57Z | https://github.com/2noise/ChatTTS/issues/892 | [] | robin12jbj | 0 |
PaddlePaddle/ERNIE | nlp | 757 | 请问下,ERNIE-Layout是否有开源计划?如果有的话什么时候开源? | 请问下,ERNIE-Layout是否有开源计划?如果有的话什么时候开源? | closed | 2021-10-20T10:20:39Z | 2021-12-28T12:30:40Z | https://github.com/PaddlePaddle/ERNIE/issues/757 | [
"wontfix"
] | cjt222 | 1 |
deeppavlov/DeepPavlov | nlp | 969 | reupload BERT model without optimizer parameters in checkpoint | Currently BERT models pretrained by DeepPavlov team contain optimizers params.
It makes impossible to use these models with `pytorch-pretrained-BERT` without changing `load_tf_weights_in_bert` function.
current workaround to this issue: https://github.com/deepmipt/DeepPavlov/issues/863#issuecomment-497928718 | closed | 2019-08-13T11:58:48Z | 2019-09-06T15:18:12Z | https://github.com/deeppavlov/DeepPavlov/issues/969 | [] | yurakuratov | 0 |
modelscope/modelscope | nlp | 420 | No module named 'fa' | ```
from modelscope.tools import run_auto_label
```
```
ModuleNotFoundError Traceback (most recent call last)
[/usr/local/lib/python3.10/dist-packages/tts_autolabel/auto_label.py](https://localhost:8080/#) in <module>
33 from tts_autolabel.speechenh.run_decode import speech_enhancem... | closed | 2023-07-27T07:18:37Z | 2023-08-15T09:56:57Z | https://github.com/modelscope/modelscope/issues/420 | [] | nijisakai | 6 |
numba/numba | numpy | 9,882 | `literal_unroll()` silently fails to unroll `range()` | Noted first when investigating #9874 and trying to do `literal_unroll(range(2))`, I note that `literal_unroll()` seems like something that should report an error if it fails to unroll. For example, the following:
```python
from numba import njit, literal_unroll
@njit
def f(x):
for i in literal_unroll(range... | open | 2024-12-30T10:03:28Z | 2025-01-14T15:51:42Z | https://github.com/numba/numba/issues/9882 | [
"bug - incorrect behavior"
] | gmarkall | 0 |
pytest-dev/pytest-cov | pytest | 618 | [docs] Switch to Furo | $sbj. is a nice theme that many use nowadays. I think it'd be nice to refresh the look and improve the Sphinx setup in general. | closed | 2023-11-24T14:17:52Z | 2024-03-18T12:38:53Z | https://github.com/pytest-dev/pytest-cov/issues/618 | [] | webknjaz | 0 |
ultralytics/ultralytics | python | 19,566 | Cleanest way to customize the model.val() method for custom validation. | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello, I plan to customise the standard validation (see photo) to my needs (... | open | 2025-03-07T09:44:22Z | 2025-03-15T03:28:25Z | https://github.com/ultralytics/ultralytics/issues/19566 | [
"question",
"OBB"
] | Petros626 | 13 |
ageitgey/face_recognition | machine-learning | 1,383 | Is it eligible to use in commercial? | Does this library or library dependencies requires permission to use in commercial?
| closed | 2021-10-24T23:31:29Z | 2021-11-09T23:29:25Z | https://github.com/ageitgey/face_recognition/issues/1383 | [] | 0x77dev | 3 |
wkentaro/labelme | deep-learning | 410 | Save after Undo results in corrupted JSON file | If I start annotation, create 2 shapes, then press ctrl+Z and save, it results in a JSON file with:
"flags": null
Such a file causes error when you opening it as flags is expected to be dict [here](https://github.com/wkentaro/labelme/blob/master/labelme/app.py#L961)
In general it is caused by the fact, that in man... | closed | 2019-05-16T09:18:15Z | 2019-05-16T12:09:54Z | https://github.com/wkentaro/labelme/issues/410 | [] | IlyaOvodov | 0 |
RobertCraigie/prisma-client-py | asyncio | 1,046 | About UnicodeEncodeError | Error Message
Error:
Traceback (most recent call last):
File "D:\Pyenv\pyenv-win-master\pyenv-win\versions\3.10.8\lib\site-packages\prisma\generator\generator.py", line 106, in run
self._on_request(request)
File "D:\Pyenv\pyenv-win-master\pyenv-win\versions\3.10.8\lib\site-packages\prisma\generator\gene... | open | 2024-11-19T14:47:16Z | 2024-11-19T15:19:28Z | https://github.com/RobertCraigie/prisma-client-py/issues/1046 | [] | wxxtaiyang | 1 |
RobertCraigie/prisma-client-py | pydantic | 396 | Table not found error with SQLite | ## Bug description
When trying to create a database entry I get the following result:
"The table `main.MenuItem` does not exist in the current database."
## How to reproduce
I'm using FastApi and Uvicorn
The script is run from routes.api.v1.endpoints.menu
### Script:
```python
@router.post("/")
async d... | closed | 2022-05-13T16:20:26Z | 2022-05-13T16:53:38Z | https://github.com/RobertCraigie/prisma-client-py/issues/396 | [
"kind/question"
] | kcrtr | 2 |
alpacahq/alpaca-trade-api-python | rest-api | 631 | [Feature Request] GTC + EXT | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
Yes, there is a problem.
We are not able to open/close positions with GTC orders on extended hours.
There are other brokers that allows you to do this.
### Describe... | closed | 2022-06-20T21:59:03Z | 2022-10-23T14:22:02Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/631 | [] | sshcli | 1 |
iterative/dvc | data-science | 9,740 | Support packaged (pkg://) configs for Hydra | Hi,
Hydra supports several ways to define config directories. The two relevant to this issue are:
1. Relative to some directory. This translates to "relative to `.dvc/config`" in DVC and is the supported mode.
2. As a Python module `pkg://some.python.module`.
Would it be possible to support the second route too... | closed | 2023-07-16T20:36:32Z | 2023-08-06T08:39:14Z | https://github.com/iterative/dvc/issues/9740 | [
"feature request",
"p2-medium",
"A: hydra"
] | exs-dmiketa | 6 |
xuebinqin/U-2-Net | computer-vision | 18 | U-2-Net for binary segmentation | Hey @NathanUA,
just to share my experience here, using the small U-2-Net architecture:
- I'm comparing the results to a baseline model (DeepLabV3, ResNet101 ~450MB) and achieved 82,... mIOU after 500 Epochs on my rather small benchmarking Dataset (license plate binary segmentation).
- The small U-2-Net model achie... | closed | 2020-05-14T13:41:24Z | 2020-07-19T15:16:57Z | https://github.com/xuebinqin/U-2-Net/issues/18 | [] | dbpprt | 3 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 755 | [FEATURE]: More info on failed/skipped applications | ### Feature summary
Add 'reason' in failed and skipped json
### Feature description
We have two JSON files that list the failed and skipped job applications where the bot either failed to apply or chose to skip for some reason. The "reason" in these files provides valuable information that can help improve our bot s... | closed | 2024-11-05T06:10:30Z | 2024-11-15T06:55:17Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/755 | [
"enhancement"
] | javad3zafar | 4 |
gradio-app/gradio | data-science | 9,872 | Custom components don't work on Lite | ### Describe the bug
Apps including custom components don't start being bound to the loading state.
Successor to #7476
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
from gradio_pdf import PDF
demo = gr.Interfac... | open | 2024-10-30T16:23:15Z | 2024-10-30T16:23:16Z | https://github.com/gradio-app/gradio/issues/9872 | [
"bug",
"gradio-lite"
] | whitphx | 0 |
TvoroG/pytest-lazy-fixture | pytest | 30 | `pytest.lazy_fixture` doesn't exist in 0.4.2 | When I downgraded it to 0.4.1, the problem is fixed.
Examples
- Broken: https://travis-ci.org/youknowone/itunes-iap/jobs/438342600
- Fixed: https://travis-ci.org/youknowone/itunes-iap/jobs/438538498
- Patch: https://github.com/youknowone/itunes-iap/commit/ef4a927db45c4f9c9e62ce9653d8a5efff906548 | open | 2018-10-08T09:53:19Z | 2019-02-13T05:50:07Z | https://github.com/TvoroG/pytest-lazy-fixture/issues/30 | [] | youknowone | 5 |
ageitgey/face_recognition | machine-learning | 1,107 | how to "face_recognition" a video | i don't know how to recognize videos,please teach me how to do | open | 2020-04-08T09:26:24Z | 2020-04-10T09:44:00Z | https://github.com/ageitgey/face_recognition/issues/1107 | [] | tim94173 | 7 |
SALib/SALib | numpy | 248 | Unexpected distribution of Morris samples with more than 4 grid levels | Hi there !
I am using SALib to run Morris sensitivity analyses, and I am facing a problem with Morris sample generation.
When using 4 grid levels, each parameter is distributed over its 4 grid levels, i.e. 0, 1/3, 2/3 and 1 when normalized. When using more grid levels, the delta value is modified accordingly but on... | closed | 2019-06-05T08:18:02Z | 2019-11-07T23:03:10Z | https://github.com/SALib/SALib/issues/248 | [
"bug"
] | mjeanner | 6 |
scikit-tda/kepler-mapper | data-visualization | 2 | 'list' object has no attribute 'fit_transform' when running "make_circles" example | ---
AttributeError Traceback (most recent call last)
<ipython-input-16-934e94845567> in <module>()
9
10 # Fit to and transform the data
---> 11 projected_data = mapper.fit_transform(data, projection=[0,1]) # X-Y axis
12
13 # Create dictionary called 'complex' with node... | closed | 2016-08-20T14:12:03Z | 2017-11-16T04:07:39Z | https://github.com/scikit-tda/kepler-mapper/issues/2 | [] | drmingle | 7 |
StackStorm/st2 | automation | 5,185 | WFL editor crashes if I click on some tasks | ## SUMMARY
The new WFL editor crashes if I click on some specific tasks. The affected actions are all part of self developed packs. It affects multiple actions belonging to multiple packs.
The same action is used two times in the workflow, one task can be edited the other one crashes the editor. -> I don't think it... | open | 2021-03-10T10:19:06Z | 2021-04-10T13:25:53Z | https://github.com/StackStorm/st2/issues/5185 | [
"bug",
"component:st2web"
] | wingiti | 3 |
CatchTheTornado/text-extract-api | api | 54 | [feat] Add `docling` support | https://github.com/DS4SD/docling?tab=readme-ov-file
- [x] Change `ocr_strategies` to `strategies` (same for strategy)
- [x] Install docling
- [x] PoC research integration - convert one format example
- [ ] Docling Strategy
- [ ] Universal Document (which will have DoclingDocument)
- [ ] ... tbd | open | 2025-01-08T10:31:55Z | 2025-01-19T11:09:48Z | https://github.com/CatchTheTornado/text-extract-api/issues/54 | [
"feature"
] | pkarw | 0 |
pytest-dev/pytest-django | pytest | 999 | How to use mysql back-end from a file for tests | Could somebody point me to how I can set mysql back-end up?
At the moment I have sqlite which simply reads from a file, I want something similar but with mysql.
```
DATABASES = {
"default": {
"ENGINE": "django.db.backends.sqlite3",
"NAME": "tests/test_db.sqlite",
},
"reader": {
... | open | 2022-03-16T15:19:08Z | 2022-03-16T16:08:27Z | https://github.com/pytest-dev/pytest-django/issues/999 | [] | manycoding | 2 |
amidaware/tacticalrmm | django | 2,071 | Easier grouping for bulk scripts | To run bulk script on all similar machines, regardless of which client or site they located in, one needs to choose them manually in bulk script each time or run script on each machine individually.
I think it would be cool to be able to run script in automation policy as it already possible for windows. Or to run s... | open | 2024-11-19T09:27:53Z | 2024-11-19T13:23:12Z | https://github.com/amidaware/tacticalrmm/issues/2071 | [] | VadymKhvoinytskyi | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 571 | ValueError: "all the input array dimensions for the concatenation axis must match exactly, but along dimension 0, the array at index 0 has size 2 and the array at index 1 has size 6" | Is there a limit on size for wav's?
Getting this error but only for a ```.wav``` input files e.g.: the same input audio in ```.mp3``` works fine.
Here is the error log:
```
Last Error Received:
Process: MDX-Net
If this error persists, please contact the developers with the error details.
Raw Error De... | open | 2023-05-23T20:30:18Z | 2023-06-16T22:54:45Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/571 | [] | pablo-01 | 1 |
ansible/awx | django | 15,552 | Private Instance Group | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | open | 2024-09-26T15:48:15Z | 2024-09-26T15:48:32Z | https://github.com/ansible/awx/issues/15552 | [
"type:enhancement",
"component:api",
"component:ui",
"component:docs",
"component:awx_collection",
"needs_triage",
"community"
] | jangel97 | 0 |
AntonOsika/gpt-engineer | python | 1,112 | Missing support for the vision capabilities in the new model gpt-4-turbo | ## Expected Behavior
When using the model gpt-4-turbo, I expect the vision capabilities to work so that I can send in image inputs using the --image_directory flag.
## Current Behavior
When using the --image_directory flag and the model gpt-4-turbo, the images in the directory are ignored and not sent to the m... | closed | 2024-04-13T21:44:07Z | 2024-04-18T09:43:08Z | https://github.com/AntonOsika/gpt-engineer/issues/1112 | [
"bug",
"triage"
] | fre-bod | 5 |
Johnserf-Seed/TikTokDownload | api | 315 | TikTokMulti报错 | Expecting value: line 1 column 1 (char 0)
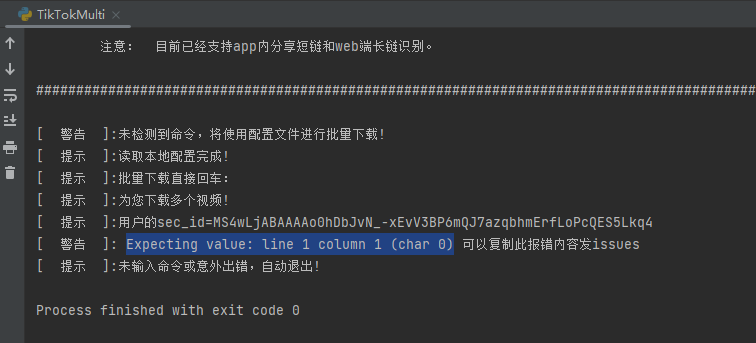
| closed | 2023-02-10T14:28:18Z | 2023-02-10T17:48:19Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/315 | [] | navyNIE | 1 |
SciTools/cartopy | matplotlib | 1,618 | Add Oblique Mercator | Will there be support for the oblique Mercator projection in Cartopy? I'd like to use it to plot some line-style geographic features that are sometimes best aligned with a rotation. Thanks!
_Originally posted by @shipengcheng1230 in https://github.com/SciTools/cartopy/issues/501#issuecomment-657857834_ | closed | 2020-07-29T19:49:20Z | 2023-03-11T08:58:27Z | https://github.com/SciTools/cartopy/issues/1618 | [
"Type: Enhancement"
] | dopplershift | 2 |
Gozargah/Marzban | api | 921 | How to find out on what day and time the traffic? | - How to find out on what day and time the traffic will be reset, there are parameters in the database such as the month. How can I make changes to the database at the time when it will be reset?
- Как узнать в какой день и время произойдет сброс трафика, есть такие параметры в базе данных как например месяц. Как я ... | closed | 2024-04-04T14:19:26Z | 2024-04-28T17:50:43Z | https://github.com/Gozargah/Marzban/issues/921 | [
"Bug"
] | whitehatqq | 8 |
allenai/allennlp | pytorch | 5,582 | Loading a HuggingFace model into AllenNLP gives different predictions | ## Checklist
<!-- To check an item on the list replace [ ] with [x]. -->
- [x] I have verified that the issue exists against the `main` branch of AllenNLP.
- [x] I have read the relevant section in the [contribution guide](https://github.com/allenai/allennlp/blob/main/CONTRIBUTING.md#bug-fixes-and-new-features) ... | closed | 2022-02-28T22:59:13Z | 2022-06-11T18:29:05Z | https://github.com/allenai/allennlp/issues/5582 | [
"bug"
] | santiagxf | 12 |
Netflix/metaflow | data-science | 1,640 | Documentation is missing information for local Kubernetes deployment | Documentation is missing information for local K8S deployment
https://docs.metaflow.org/getting-started/infrastructure
Point 5 links to AWS-K8S
We're currently evaluating Metaflow, but would like to understand on premise requirements (or possibilities).
In our case we have on premise a GPU cluster, and use ... | open | 2023-11-21T15:33:54Z | 2025-01-07T13:12:29Z | https://github.com/Netflix/metaflow/issues/1640 | [] | Felix-N | 6 |
jupyter-book/jupyter-book | jupyter | 1,836 | Issue on page /content/executable/output-insert.html | Typo "historgram" in the code block following "You can also glue visualizations, such as Matplotlib figures" | closed | 2022-09-18T12:35:43Z | 2022-09-21T04:28:59Z | https://github.com/jupyter-book/jupyter-book/issues/1836 | [] | clairedavid | 1 |
deeppavlov/DeepPavlov | nlp | 1,085 | Is there any way to build docker image for new trained NER model? | How to build a docker image for the newly trained NER model by DeepPavlov? | closed | 2019-11-27T08:21:03Z | 2020-05-06T10:18:56Z | https://github.com/deeppavlov/DeepPavlov/issues/1085 | [] | DLNSimha | 1 |
plotly/dash-core-components | dash | 919 | dcc.RangeSlider tooltip broken between 0 and 10 | The tooltip in the `dcc.RangeSlider` breaks between 0 and 10, but appears to work properly in the `dcc.Slider`.
This issue appeared in the past for the `dcc.Slider` as a result of a bug with the library that `dcc.Slider` is wrapped around: https://github.com/plotly/dash-core-components/issues/763
If this is the ... | closed | 2021-01-20T05:23:19Z | 2021-05-14T00:41:58Z | https://github.com/plotly/dash-core-components/issues/919 | [] | mtwichan | 2 |
httpie/cli | python | 732 | httpie does not allow to redirect binary data | I'm trying to do this:
```
> http https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh | bash
Please run using "bash" or "sh", but not "." or "source"\nbash: eilutė 14: return: galima grįžti (return) tik iš funkcijos ar scenarijaus
wc: /home/sirex/devel/talks/2018/cartocon/bash: Toks failas ar a... | closed | 2018-11-24T11:17:52Z | 2018-11-24T14:36:16Z | https://github.com/httpie/cli/issues/732 | [] | sirex | 1 |
proplot-dev/proplot | data-visualization | 365 | Wrong position of xlabel in Cartesian subplot mixed with Geographic subplots | ### Description
The location of xlabel is usually in the middle of subplots. But, it doesn't work for Cartesian and Geographic mixed plots.
### Steps to reproduce
```python
import proplot as pplt
fig, axs = pplt.subplots(nrows=2, ncols=2, proj=['npstere', 'npstere', None, 'npstere'])
axs[2].format(xlabel=... | open | 2022-06-05T13:50:13Z | 2023-03-29T10:02:21Z | https://github.com/proplot-dev/proplot/issues/365 | [
"enhancement"
] | zxdawn | 2 |
mars-project/mars | scikit-learn | 2,956 | Submit query condition to remote node instead of fetch to local then query | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Curently if ray fetcher gets objects with condition, it will fetch objects to local, then filter ... | closed | 2022-04-24T12:06:51Z | 2022-04-25T03:45:07Z | https://github.com/mars-project/mars/issues/2956 | [] | chaokunyang | 0 |
mwaskom/seaborn | matplotlib | 3,002 | Global matplotlib style with objects interface | Hey! thanks for the amazing 0.12 release 🚀 !
I want to use the new object interface while using a global `matplotlib` style following https://seaborn.pydata.org/generated/seaborn.objects.Plot.theme.html#seaborn.objects.Plot.theme
I have tried:
```python
import matplotlib.pyplot as plt
import seaborn as sns
... | closed | 2022-09-06T13:18:09Z | 2022-09-08T10:38:00Z | https://github.com/mwaskom/seaborn/issues/3002 | [] | juanitorduz | 2 |
piccolo-orm/piccolo | fastapi | 1,013 | Add more operators to `QueryString` | In recent releases we have been adding more SQL functions to Piccolo.
These functions return `QueryString` - the building block of queries in Piccolo.
By overriding magic methods in `QueryString` we can make a more intuitive API. For example:
```python
await Ticket.select(Round(Ticket.price) * 2)
```
In t... | closed | 2024-06-10T20:27:35Z | 2024-06-10T21:07:58Z | https://github.com/piccolo-orm/piccolo/issues/1013 | [
"enhancement"
] | dantownsend | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 802 | Discriminator loss (D_real & D_fake loss) is always between 0.001 to 1.5 | Hi,
I training a pix2pix model with my own dataset with 8000 images. The loss for G_L1 converges very fast like in 20 epochs or so. But the other losses like D_real and D_fake always remains between 0.0001 to 1.5 in almost all 64 epochs i have trained so far. Is my model is learning or not? I have attached the log... | closed | 2019-10-17T10:51:36Z | 2022-05-15T16:11:42Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/802 | [] | kalai2033 | 4 |
huggingface/diffusers | pytorch | 10,045 | Problem with importing pipelines | ### Describe the bug
When trying to import pipelines in colab i have the following error:
RuntimeError Traceback (most recent call last)
[/usr/local/lib/python3.10/dist-packages/transformers/utils/import_utils.py](https://localhost:8080/#) in _get_module(self, module_name)
1777 ... | closed | 2024-11-28T12:50:50Z | 2024-11-28T18:03:57Z | https://github.com/huggingface/diffusers/issues/10045 | [
"bug"
] | justahumanb | 0 |
streamlit/streamlit | streamlit | 10,389 | First Day of the week is still Sunday | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
As @jrieke said in the [issue](https://github... | closed | 2025-02-13T09:05:01Z | 2025-02-14T08:29:35Z | https://github.com/streamlit/streamlit/issues/10389 | [
"upstream"
] | sglbl | 2 |
chaos-genius/chaos_genius | data-visualization | 868 | Port number changes automatically on UI datasource/channel config Form | ## Describe the bug
when on Datasource add/Alert channel(Email) add form if port number field is focused and someone scrolls or presses up/down key the port number changes
## Explain the environment
- **Chaos Genius version**: 0.5.0
- **OS Version / Instance**: Debian 11
- **Deployment type**: Docker
## Curr... | open | 2022-04-01T04:07:49Z | 2022-04-01T04:08:50Z | https://github.com/chaos-genius/chaos_genius/issues/868 | [
"🐛 bug",
"🖥️ frontend"
] | rjdp | 0 |
graphql-python/gql | graphql | 225 | Phoenix transport: breaking early from async generator loop requires canceling receive_data_task | I don't know if there is a Slack channel or other forum for the gql project, so I'm posing this here as an issue. I would like to see an example of a subscription that uses one of the async transports (such as PhoenixChannelWebsocketsTransport) for the use case below. It's something that I had working with gql 2.x, aft... | closed | 2021-08-10T02:20:33Z | 2021-08-22T16:40:43Z | https://github.com/graphql-python/gql/issues/225 | [
"type: bug"
] | pzingg | 13 |
Lightning-AI/pytorch-lightning | data-science | 19,810 | Issue in Manual optimisation, during self.manual_backward call | ### Bug description
I have set automatic_optimization to False, and am using self.manual_backward to calculate and populate the gradients. The code breaks during the self.manual_backward call, raising the error "RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn". I have posted the ... | closed | 2024-04-25T10:23:19Z | 2024-10-28T14:36:26Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19810 | [
"question",
"precision: amp",
"ver: 2.0.x"
] | pranavrao-qure | 3 |
minimaxir/textgenrnn | tensorflow | 62 | Multi-GPU Support not working great | I added a Multi-GPU function that extended Keras's `multi_gpu_model()` and verified that it indeed utilizes multiple GPUs (via `nvidia-smi`). However, for smaller models, training speed is about the same, if not *worse*.
I suspect that the `CuDNNLSTM`s are so efficient that it mitigates the gains of using multiple G... | open | 2018-08-08T05:40:17Z | 2019-12-12T05:25:21Z | https://github.com/minimaxir/textgenrnn/issues/62 | [] | minimaxir | 3 |
DistrictDataLabs/yellowbrick | matplotlib | 453 | Implement Detection Error Tradeoff Curves (DET) Visualizer | A community suggestion from reddit, implement a DET curve visualizer for model comparison.
From [wikipedia](https://en.wikipedia.org/wiki/Detection_error_tradeoff):
`A detection error tradeoff (DET) graph is a graphical plot of error rates for binary classification systems, plotting the false rejection rate vs. f... | closed | 2018-05-28T14:14:00Z | 2020-06-12T05:07:19Z | https://github.com/DistrictDataLabs/yellowbrick/issues/453 | [
"type: feature",
"priority: medium",
"level: intermediate"
] | ndanielsen | 2 |
1313e/CMasher | matplotlib | 53 | Matplotlib deprecation warnings | On matplotlib 3.7 I am getting the following errors when importing and using cmasher
MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed two minor releases later.
Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap(obj)`` instead.
... | closed | 2023-08-31T13:09:19Z | 2023-12-18T07:46:29Z | https://github.com/1313e/CMasher/issues/53 | [
"feature request"
] | christopherlovell | 3 |
chezou/tabula-py | pandas | 258 | Characters out of the desired area are appearing in my tables | # Summary of your issue
Some characters are leaking from useless cells to the output dataframe
# Check list before submit
<!--- Write and check the following questionaries. -->
- [ ] Did you read [FAQ](https://tabula-py.readthedocs.io/en/latest/faq.html)? yes
- [ ] (Optional, but really helpful) Your PDF URL... | closed | 2020-08-18T20:43:54Z | 2020-08-24T13:53:51Z | https://github.com/chezou/tabula-py/issues/258 | [
"tabula-java limitation"
] | Pgovalle | 1 |
scikit-hep/awkward | numpy | 2,656 | Unflattening typetracer on axis > 0 fails | ### Version of Awkward Array
2.3.3
### Description and code to reproduce
```python3
import json
import awkward as ak
fromjson = {
"class": "RecordArray",
"fields": ["muon", "anindex"],
"contents": [
{
"class": "ListOffsetArray",
"offsets": "i64",
... | closed | 2023-08-17T18:51:51Z | 2023-08-17T19:55:44Z | https://github.com/scikit-hep/awkward/issues/2656 | [
"bug (unverified)"
] | lgray | 0 |
tartiflette/tartiflette | graphql | 92 | "official" Introspection Query doesn't work | It seems that the [official introspection Query](https://github.com/graphql/graphql-js/blob/master/src/utilities/introspectionQuery.js#L18) doesn't work. Thus, we can't use the full potential of tools which use it to provide auto-completion, like insomnia, graphiql etc...
* **Tartiflette version:** 0.3.2
* **Python... | closed | 2019-01-17T10:29:08Z | 2019-01-22T13:28:08Z | https://github.com/tartiflette/tartiflette/issues/92 | [
"bug"
] | tsunammis | 2 |
xorbitsai/xorbits | numpy | 583 | CHORE: too many warnings when running TPCH | Note that the issue tracker is NOT the place for general support. For
discussions about development, questions about usage, or any general questions,
contact us on https://discuss.xorbits.io/.
```python
/Users/codingl2k1/Work/xorbits/python/xorbits/_mars/dataframe/tseries/to_datetime.py:195: UserWarning: The arg... | closed | 2023-07-06T08:25:41Z | 2023-08-28T08:55:38Z | https://github.com/xorbitsai/xorbits/issues/583 | [
"good first issue"
] | codingl2k1 | 1 |
jupyterhub/repo2docker | jupyter | 1,324 | repo2docker.ref contains HEAD rather than the actual commit ID at the time of creation | <!-- Thank you for contributing. These HTML commments will not render in the issue, but you can delete them once you've read them if you prefer! -->
### Bug description
<!-- Use this section to clearly and concisely describe the bug. -->
When creating an image, if HEAD is used, then the `repo2docker.ref` label w... | open | 2023-12-13T17:36:18Z | 2023-12-22T16:34:05Z | https://github.com/jupyterhub/repo2docker/issues/1324 | [] | sgaist | 1 |
pydantic/pydantic-ai | pydantic | 646 | Documentation on agent control flow | I've been trying to understand the control flow for agent runs, which I think others are also trying to learn about. Here are some of the related issues for context:
https://github.com/pydantic/pydantic-ai/issues/642
https://github.com/pydantic/pydantic-ai/pull/142
https://github.com/pydantic/pydantic-ai/issues/12... | open | 2025-01-08T22:47:01Z | 2025-01-11T21:10:56Z | https://github.com/pydantic/pydantic-ai/issues/646 | [
"documentation"
] | dyllamt | 4 |
Johnserf-Seed/TikTokDownload | api | 102 | 脚本并不行,要不给你试试看? | 可以使用bat脚本实现,例如
@echo off
TikTokDownlaod -u xxx -m no
TikTokDownlaod -u xxx -m no
TikTokDownlaod -u xxx -m no
TikTokDownlaod -u xxx -m no
TikTokDownlaod -u xxx -m no
TikTokDownlaod -u xxx -m no
TikTokDownlaod -u xxx -m no
echo 下载完成
单视频保存路径选项将会更新
_Originally posted by @Johnserf-Seed in https://github.com/J... | closed | 2022-03-08T09:08:34Z | 2022-03-22T14:10:02Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/102 | [] | huangsijun17 | 3 |
dask/dask | scikit-learn | 11,420 | merge_asof Throws error when merging to single partitions | **Describe the issue**:
Encountered this issue while trying to debug other issues using a subset of the data I typically use, i.e. the data fit into a single partition. One might argue this isn't the appropriate use case for the Dask library but the error message is also confusing.
**Minimal Complete Verifiable ... | closed | 2024-10-08T15:12:20Z | 2024-10-10T16:50:25Z | https://github.com/dask/dask/issues/11420 | [
"dask-expr"
] | kylehiroyasu | 0 |
miguelgrinberg/microblog | flask | 337 | How to solve the syntax conflict between JinJia2 and CSS in chapter 21.3 ? | I met such a question that JinJia2 used in CSS inline style will cause a conflict that the default block string will be misunderstood as a css property value in visual studio code . The detail is :
```
<span id='message_count' class="badge"
style="visibility: {% if new_messages %}visible
{% ... | closed | 2023-03-02T01:40:59Z | 2023-12-03T10:54:23Z | https://github.com/miguelgrinberg/microblog/issues/337 | [
"question"
] | JTP-123 | 6 |
mouredev/Hello-Python | fastapi | 447 | 网络赌博被黑怎么办?不给出款该怎么办?平台提示账号出现异常该怎么办?注单维护系统审核该怎么办? | 被黑了不能出款找我们啊超出黑团队多年经验,如果你被黑了请联系我们帮忙把损失降到最低/微x:<>《微信:xiaolu460570》前期出不收任何费用,我们团队都是先出款/后收费。不成功不收费、
当网赢了不能提款的问题怎么办呢?
首先我们应该保持冷静,如果提现被拒绝不重复点了,切不能跟平台客服称代理人有任何争执,一旦激怒对方,极有可能账号造成冻结之类的情况,这样问题就很难处理了,此时对方的理由或者我们要表示相信,并迅速处理,在稳定住对方后希望。
第一时间联系专业出黑团队,通过藏分锁卡等手段分批出款,这样问题我们就顺利解决了,如果您目前遇到网赢钱无法提款的,请及时联系专业出黑团队为您处理↓↓↓↓↓

- 项目后续更新计划:
- 项目描述:
- 必写:这是个什么项目、能用来干什么、有什么特点或解决了什么痛点
- 可选:适用于什么场景、能够让初学者学到什么
- 描述长度(不包含示例代码): 10 - 256 个字符
- 推荐理由:令人眼前一亮的点是什么?解决了什么痛点?
- 示例代码:(可选)长度:1-20 行
... | closed | 2021-11-24T02:02:00Z | 2021-11-24T02:02:04Z | https://github.com/521xueweihan/HelloGitHub/issues/1980 | [
"恶意issue"
] | fenglong2018 | 1 |
ivy-llc/ivy | pytorch | 28,419 | Fix Frontend Failing Test: torch - math.paddle.floor | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-02-25T14:26:02Z | 2024-03-06T09:54:21Z | https://github.com/ivy-llc/ivy/issues/28419 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
graphdeco-inria/gaussian-splatting | computer-vision | 620 | Coordinate Transformation | Thank you very much for your open-source code.
I have a question to consult with you. After obtaining a mesh or point cloud using 3D Gaussian splatting, and knowing the GPS information for each frame in the video, how can I transform the relative coordinates in the three-dimensional model into absolute coordinates? Th... | open | 2024-01-17T12:18:03Z | 2024-01-17T12:18:03Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/620 | [] | oym050922021 | 0 |
gevent/gevent | asyncio | 1,163 | Make libuv the default Windows loop for 1.3? | * gevent version: 1.3
* Python version: All
* Operating System: Windows
I'd like to make the libuv backend the default on Windows for 1.3 for all supported Python implementations (currently it's the default for PyPy). This would benefit Windows users by granting access to more sockets by avoiding libev's use of th... | closed | 2018-03-30T20:16:38Z | 2018-04-14T17:52:25Z | https://github.com/gevent/gevent/issues/1163 | [
"Type: Enhancement",
"PyVer: python3",
"Platform: Windows",
"Loop: libuv"
] | jamadden | 4 |
strawberry-graphql/strawberry-django | graphql | 22 | TypeError: No type defined for 'ImageField' | Hey,
in my User model I've got this field:
```python
def user_directory_path(instance, filename):
filename, ext = os.path.splitext(filename)
return os.path.join(
f'profile_pictures/{instance.uuid}/',
f'{uuid.uuid4()}{ext}'
)
...
profile_picture = models.ImageField(
ver... | closed | 2021-04-14T08:28:37Z | 2025-03-20T15:56:59Z | https://github.com/strawberry-graphql/strawberry-django/issues/22 | [] | holtergram | 13 |
ultralytics/ultralytics | machine-learning | 19,139 | tracking using a custom dataset where objects have IDs | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I have a dataset where each of the binding boxes has a unique ID. How can I ... | open | 2025-02-08T17:57:35Z | 2025-02-09T15:40:49Z | https://github.com/ultralytics/ultralytics/issues/19139 | [
"question",
"track"
] | asghariarad | 6 |
microsoft/unilm | nlp | 977 | VALL-E ETA? | I've been eager to use VALL-E since I read about its creation, but the directory created for it is empty.
Is there an ETA on when it will be made available? | open | 2023-01-11T22:46:17Z | 2023-05-16T10:46:23Z | https://github.com/microsoft/unilm/issues/977 | [] | randolpho | 9 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 7 | [QUESTION] Colab images with scretches | I have added the `--with_scratch` option to the section
```
!python run.py --input_folder /content/photo_restoration/test_images/upload --output_folder /content/photo_restoration/upload_output --GPU 0 --with_scratch
```
in order to process images with scratches.
This is the result that I obtain:
```
Runnin... | closed | 2020-09-19T18:56:19Z | 2020-11-07T08:46:57Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/7 | [] | loretoparisi | 2 |
unionai-oss/pandera | pandas | 1,661 | Support Data synthesis strategies for polars | **Is your feature request related to a problem? Please describe.**
As stated in the docs polars lacks comprehensive data synthesis strategies
<img width="838" alt="image" src="https://github.com/user-attachments/assets/355a5151-190b-4ee8-a8e5-b11b867be97c">
**Describe the solution you'd like**
I would like to s... | open | 2024-05-29T16:57:36Z | 2024-09-13T15:53:59Z | https://github.com/unionai-oss/pandera/issues/1661 | [
"enhancement"
] | elyase | 2 |
flasgger/flasgger | api | 260 | uiversion 3 get method array says: Could not render this component, see the console. | Hi
When I specify an array using uiversion 3 on a get method. I get "Could not render this component, see the console.". Am I doing something wrong?
Below is a screenshot of what I see

| open | 2018-11-13T18:50:39Z | 2021-03-15T11:25:48Z | https://github.com/flasgger/flasgger/issues/260 | [] | wobeng | 5 |
LAION-AI/Open-Assistant | python | 3,744 | Can't open dashboard | ERROR: type should be string, got "\r\nhttps://github.com/LAION-AI/Open-Assistant/assets/29770761/254db19d-a284-41ca-8612-99103df12fac\r\n\r\n" | closed | 2024-01-06T16:14:36Z | 2024-01-06T17:25:55Z | https://github.com/LAION-AI/Open-Assistant/issues/3744 | [] | DRYN07 | 1 |
graphistry/pygraphistry | pandas | 290 | [FEA] UMAP umap_learn integration metaissue | **Is your feature request related to a problem? Please describe.**
Using umap_learn with graphistry should be more visible and easier!
See: https://github.com/graphistry/pygraphistry/blob/master/demos/demos_databases_apis/umap_learn/umap_learn.ipynb
**Describe the solution you'd like**
- [ ] umap_learn: `em... | open | 2021-12-18T18:02:08Z | 2022-09-07T14:18:16Z | https://github.com/graphistry/pygraphistry/issues/290 | [
"enhancement",
"help wanted",
"good-first-issue",
"integrations",
"umap"
] | lmeyerov | 2 |
miguelgrinberg/microblog | flask | 166 | Data not getting stored into the Database. | I've been working on a similar project like your microblog, where I created a "personal details" (an alternative registration form) table instead of a "posts table", My web App is working perfectly, but when I try to access the stored data through the shell, I'm not getting any output or error, it just returns NULL. I'... | closed | 2019-06-24T11:02:55Z | 2019-11-17T19:02:53Z | https://github.com/miguelgrinberg/microblog/issues/166 | [
"question"
] | NooriaAli | 6 |
d2l-ai/d2l-en | deep-learning | 2,605 | d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, 2 num_layers=2) | ---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[21], [line 4](vscode-notebook-cell:?execution_count=21&line=4)
[1](vscode-notebook-cell:?execution_count=21&line=1) encoder = d2l.Seq2SeqEncoder(vocab_... | open | 2024-06-17T07:45:10Z | 2024-06-17T08:29:55Z | https://github.com/d2l-ai/d2l-en/issues/2605 | [] | achaosss | 2 |
piskvorky/gensim | nlp | 2,949 | test_lda_callback.py test stalls | I've seen multiple PRs fail (red) with the same problem in log, e.g. in #2947:
https://travis-ci.org/github/RaRe-Technologies/gensim/jobs/727593115
https://travis-ci.org/github/RaRe-Technologies/gensim/jobs/727515466
<img width="1440" alt="Screen Shot 2020-09-16 at 13 49 59" src="https://user-images.githubusercont... | open | 2020-09-16T11:51:29Z | 2020-09-16T13:02:50Z | https://github.com/piskvorky/gensim/issues/2949 | [
"bug",
"testing",
"housekeeping"
] | piskvorky | 0 |
fbdesignpro/sweetviz | data-visualization | 70 | Different Scores for Uncertainty Coefficient | When showing the categorical variable's report, we have two information zones:
1. [feature_name] PROVIDES INFORMATION ON...
2. THESE FEATURES GIVE INFORMATION ON [feature_name]
This is an example from the [Kaggle Housing Price dataset](https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data):
... | closed | 2020-12-22T11:59:27Z | 2021-02-15T22:19:15Z | https://github.com/fbdesignpro/sweetviz/issues/70 | [
"question"
] | aviasd | 1 |
plotly/jupyter-dash | dash | 19 | Cannot stop server in JupyterLab using CTRL+C | I'm running the following code:
_Cell [2]_
```
app = JupyterDash(__name__)
app.layout = html.Div('Minimal')
app.run_server(mode="external", debug=False)
```
_Cel[2] Output_
```
* Running on http://127.0.0.1:8050/ (Press CTRL+C to quit)
127.0.0.1 - - [10/Jun/2020 14:17:49] "GET /_alive_a6195403-4d44-472... | open | 2020-06-10T13:31:17Z | 2022-07-31T03:21:08Z | https://github.com/plotly/jupyter-dash/issues/19 | [] | msbuckas | 5 |
PeterL1n/RobustVideoMatting | computer-vision | 155 | 推理 | 我把四个阶段训练完之后,应该拿哪个阶段的权重去推理呢,是不是stage4啊 | closed | 2022-04-03T02:46:53Z | 2022-04-09T14:02:10Z | https://github.com/PeterL1n/RobustVideoMatting/issues/155 | [] | TonFard | 1 |
holoviz/panel | plotly | 7,080 | Linking tab's "active" to a Parameter does not work as expected | [panel 1.4.4, python 3.11]
I am not quite sure this is supposed to work, but figured I'd report this. If it is not a bug I'd like to know the right way to do this.
I have a Parameterized class which holds the global states of my app. The app has two main tabs, and I would like to know which tab is active though ... | closed | 2024-08-05T21:52:23Z | 2024-08-06T08:58:12Z | https://github.com/holoviz/panel/issues/7080 | [] | samimia-swks | 1 |
deezer/spleeter | deep-learning | 415 | [Bug] IndexError: index 1 is out of bounds | Dear Sirs,
Some songs can not be spleted after I installed the new Spleeter. Pls see below:
```
Traceback (most recent call last):
File "/root/anaconda3/bin/spleeter", line 10, in <module>
sys.exit(entrypoint())
File "/root/anaconda3/lib/python3.7/site-packages/spleeter/__main__.py", line 54, in ... | closed | 2020-06-09T13:46:47Z | 2021-02-12T14:37:40Z | https://github.com/deezer/spleeter/issues/415 | [
"bug",
"invalid",
"inactive"
] | eminfan | 5 |
opengeos/leafmap | streamlit | 50 | Add GUI for loading COG | This feature allows users to load Cloud Optimized GeoTIFF without coding. | closed | 2021-06-21T00:43:32Z | 2021-06-21T01:21:40Z | https://github.com/opengeos/leafmap/issues/50 | [
"Feature Request"
] | giswqs | 1 |
BeanieODM/beanie | pydantic | 297 | QUESTION: Is events + method an atomic action, or do we need to do verbose transaction management? | Hi,
We are trying to implement an "accession number" field called ```acc``` in our Beanie Documents. Since ```acc``` is a counter that follows a specific format, we decided to make a new field instead of using MongoDB's ObjectID.
Implementation-wise, we are still deciding which approach to follow, since we are no... | closed | 2022-06-30T10:18:32Z | 2023-01-20T02:37:34Z | https://github.com/BeanieODM/beanie/issues/297 | [
"Stale"
] | edgarfelizmenio | 3 |
PablocFonseca/streamlit-aggrid | streamlit | 271 | aggrid with fastapi request | Hey !!
I also build an aggrid that works on streamlit but uses fastapi!
I don't have a pip install setup yet for it since its on my private repo but I would like to show you it and also possibly get your help with some of the features I want to add/fix.
please let me know if you would consider -- you can reac... | open | 2024-05-13T22:37:49Z | 2024-07-07T18:18:49Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/271 | [] | nafets33 | 4 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 230 | [BUG] i don't understand coding | I don't understand coding, so I use the douyin.wtf web app, when I click "video download no watermark" but that result comes out, how can I download the video? actually we can if we click "video url no watermark" but the video title uses a random title, what if I want the video title to match the title on douyin, becau... | closed | 2023-07-30T09:53:58Z | 2023-08-04T09:31:08Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/230 | [
"help wanted"
] | radenhendriawan | 1 |
vanna-ai/vanna | data-visualization | 118 | 'DataFrame' object is not callable | I have tried to connect vanna to my database using SQL Server. But when I used vn.ask() from my model, it cannot show table from DataFrame. What Should I do?
SELECT * FROM datasetSapi WHERE Ingredients LIKE '%pare%'
Couldn't run sql: 'DataFrame' object is not callable | closed | 2023-09-21T09:05:04Z | 2023-09-22T04:20:59Z | https://github.com/vanna-ai/vanna/issues/118 | [] | bryanjo28 | 1 |
Morizeyao/GPT2-Chinese | nlp | 277 | GPU9GB能跑起来吗请问 | closed | 2023-03-14T08:06:58Z | 2023-03-22T10:54:03Z | https://github.com/Morizeyao/GPT2-Chinese/issues/277 | [] | SunshineWQI | 0 | |
GibbsConsulting/django-plotly-dash | plotly | 386 | Unable to find app in conjunction with Wagtail 404 URL | I am trying to add a Dash app to a Wagtail/CoderedCMS site, but I cannot get the URL for the Dash app to be found. I followed the instructions in the documentation as well as other threads here, but I'm stuck with this. It's probably a simple issue, but I'm just not finding the solution.
Initialize site with [Codere... | closed | 2022-03-08T01:20:51Z | 2022-03-10T14:37:22Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/386 | [] | hubbs5 | 12 |
autokey/autokey | automation | 612 | Importing / running a long list of autocorrect | ## Classification: New Feature
## Notes
Thanks for making such an amazing piece of software - I use it daily and find that AutoKey really improves my efficiency.
I used to use AutoHotKey on windows back in the day. One of the things that I did was to import a very long list of autocorrect rules into the softwar... | open | 2021-09-20T14:46:03Z | 2021-09-30T20:36:18Z | https://github.com/autokey/autokey/issues/612 | [
"enhancement"
] | haydonryan | 6 |
benbusby/whoogle-search | flask | 164 | [BUG] pictures not displayed anymore | **Describe the bug**
With the latest docker version, I started to not see images (pictures) anymore since yesterday. I normally run whoogle via a reverse proxy (nginx) but the issue persists if I access it directly via the port 5000 . It is really just images - youtube preview in the main search page and in the videos... | closed | 2021-01-12T22:41:55Z | 2021-01-13T15:01:11Z | https://github.com/benbusby/whoogle-search/issues/164 | [
"bug"
] | somebody-somewhere-over-the-rainbow | 10 |
MaartenGr/BERTopic | nlp | 1,997 | Feature (Watsonx): representations using Llama-3-70b and Mixtral-8x7b | Topic representation using Llama-3-70b and/or Mixtral-8x7b via IBM Watsonx. | closed | 2024-05-19T14:28:50Z | 2024-05-21T17:41:32Z | https://github.com/MaartenGr/BERTopic/issues/1997 | [] | andreswagner | 1 |
yt-dlp/yt-dlp | python | 12,477 | [cultureunplugged] some URL types return as Unsupported | ### Checklist
- [x] I'm requesting a site-specific feature
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [x] ... | closed | 2025-02-25T19:01:01Z | 2025-02-26T18:39:51Z | https://github.com/yt-dlp/yt-dlp/issues/12477 | [
"site-bug"
] | someziggyman | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,637 | Add ROI specific loss function to generator | I would like to add an additional L1 loss function directly on the region of interest (bounding boxes) during training (Pix2pix) to try to improve clarity for object detection. Is it expected to yield better results? What are the steps that I have to follow to accomplish this? | open | 2024-03-23T12:13:01Z | 2024-03-23T12:13:29Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1637 | [] | Diogo-Valente2111 | 0 |
tflearn/tflearn | data-science | 670 | Basic example "use_hdf5.py" gets FileNotFoundError | When running "tflearn/examples/basics/use_hdf5.py", I get the error below:
```
Traceback (most recent call last):
File ".\use_hdf5_1.py", line 22, in <module>
(X, Y), (X_test, Y_test) = cifar10.load_data()
File "C:\Anaconda3\lib\site-packages\tflearn\datasets\cifar10.py", line 34, in load_data
data,... | open | 2017-03-18T13:07:10Z | 2017-03-18T13:47:31Z | https://github.com/tflearn/tflearn/issues/670 | [] | EricPerbos | 1 |
facebookresearch/fairseq | pytorch | 4,962 | Converting of unspecified list arguments fails | There is a CoLA-based RoBERTa classifier [[1][1]]. The model was trained with `pairseq` 0.10.2 (I guess). And it is impossible to load the pretrained model with the latest `pairseq` releases (e.g. 0.12.2 or 0.12.3).
```python
from fairseq.models.roberta import RobertaModel
model = RobertaModel.from_pretrained(checkp... | open | 2023-01-29T19:25:48Z | 2023-01-29T19:25:48Z | https://github.com/facebookresearch/fairseq/issues/4962 | [
"bug",
"needs triage"
] | daskol | 0 |
google/trax | numpy | 1,284 | [Question][Feature Request] Support for fine tuning | ### Description
After venturing a while with trax for novel and some predefined models I started looking into fine tuning.
As far as I've seen, I can use a pretrained model as a part of a bigger model (since models are nothing else but stacked layers) and could somehow adapt them.
But I also understand that ... | open | 2020-12-08T12:25:45Z | 2022-01-29T23:44:23Z | https://github.com/google/trax/issues/1284 | [] | Sirsirious | 8 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.