
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pywinauto/pywinauto | automation | 1,122 | Couldnt get my way around for more than 5 hours | ## Expected Behavior
Sometimes the script prints the value of `dlg.print_control_identifiers()`,but the pywinauto is stubborn. I use the same windows title every time but anytime I get the error `MatchError: Could not find 'Miracle 9.0 (Rel 6.0) - Standard Copy (Single User) ' in 'dict_keys([])'` | open | 2021-10-01T10:29:42Z | 2022-02-20T12:11:47Z | https://github.com/pywinauto/pywinauto/issues/1122 | [
"bug",
"duplicate"
] | meet1919 | 2 |
ultralytics/yolov5 | deep-learning | 12,424 | Multigpu and multinode performance | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I'm training Yolov5 on custom dataset and HPC machine, having 4 GPU per node. I'm... | closed | 2023-11-24T13:06:21Z | 2024-01-09T00:21:50Z | https://github.com/ultralytics/yolov5/issues/12424 | [
"question",
"Stale"
] | unrue | 10 |
sherlock-project/sherlock | python | 2,375 | Instagram results not showing in Sherlock | ### Installation method
Other (indicate below)
### Package version
Sherlock v0.15.0
### Description
When using Sherlock to check for the existence of an Instagram profile by providing a valid username, the expected result should be that the tool returns whether the profile exists or not.
When performing this ac... | closed | 2024-11-30T10:18:47Z | 2025-02-17T05:16:31Z | https://github.com/sherlock-project/sherlock/issues/2375 | [
"bug"
] | ZuhairZeiter | 6 |
horovod/horovod | tensorflow | 3,497 | NotFoundError: Local Variable does not exist with backward_passes_per_step > 1 | **Environment:**
1. Framework: tensorflow.keras
2. Framework version: 2.5.0
3. Horovod version: 0.22.0
4. MPI version:
5. CUDA version: 11.0
6. NCCL version:
7. Python version: 3.8
8. Spark / PySpark version:
9. Ray version:
10. OS and version:
11. GCC version:
12. CMake version:
**Checklist:**
1. Did... | open | 2022-03-28T09:21:57Z | 2022-04-26T21:55:39Z | https://github.com/horovod/horovod/issues/3497 | [
"bug"
] | lenroed | 1 |
ipython/ipython | jupyter | 14,232 | IPython.display.IFrame running on remote JupyterLab references localhost on client machine | <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories.
If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org.
If you are unsure, it's ok to post here, though, there are few ... | closed | 2023-10-31T15:12:21Z | 2024-09-30T07:34:41Z | https://github.com/ipython/ipython/issues/14232 | [] | jcaxle | 2 |
raphaelvallat/pingouin | pandas | 47 | Add support for Aligned Rank Transformed data Anova | Good morning,
I had to work on non-normal and heteroscedastic variables but had to compute interactions between those variables. Unfortunately, no methods in your package allow to do so.
I found ART beeing quite straight forward and easy to use. I think it could be very valuable to include ART inside your library. ... | closed | 2019-07-02T10:19:24Z | 2019-09-28T19:05:08Z | https://github.com/raphaelvallat/pingouin/issues/47 | [
"feature request :construction:"
] | clementpoiret | 3 |
taverntesting/tavern | pytest | 364 | Would like to be able to define a variable in a stage to use in various places in that stage | In this stage:
- name: -007C PUT update organization incomplete payload
request:
url: "{host}/v2/institutions/{institution_data.id}/organizations/{organization_data.id}/"
method: PUT
json:
branded: !bool "true"
organization_type: !int 8
... | open | 2019-05-30T20:19:21Z | 2019-08-30T14:51:37Z | https://github.com/taverntesting/tavern/issues/364 | [
"Type: Enhancement",
"Priority: Low"
] | pmneve | 3 |
wkentaro/labelme | deep-learning | 533 | How to add point for my annotated polygons? | Hi,thanks for your great work.But i met some problem recently.I have annotated some datas for sementic works before, and i want to add some points for per polygon in images i annotated,but i don't want to delete the annotated polygons to annotate again,I just want to add one or two point for the annotated polygon.But i... | closed | 2019-12-31T08:07:31Z | 2021-04-13T11:20:28Z | https://github.com/wkentaro/labelme/issues/533 | [] | chegnyanjun | 4 |
faif/python-patterns | python | 384 | what's the difference betwen builder.py and abstruct_factory.py | closed | 2022-01-02T09:51:57Z | 2022-01-03T08:24:29Z | https://github.com/faif/python-patterns/issues/384 | [
"question"
] | SeekPoint | 2 | |
hzwer/ECCV2022-RIFE | computer-vision | 233 | no module named moviepy | 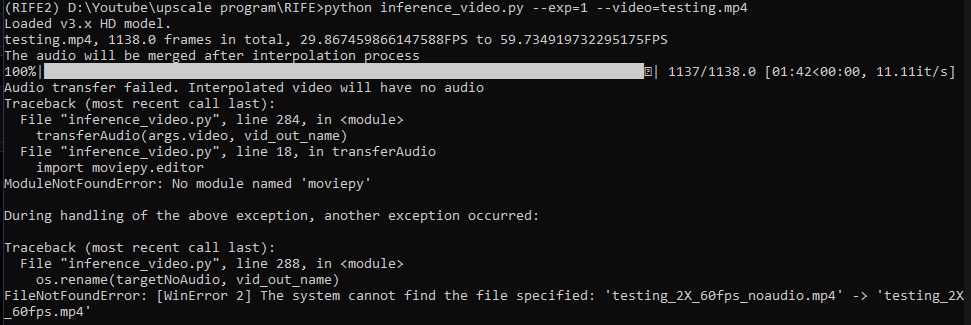
can anyone help? | closed | 2022-01-23T09:14:05Z | 2022-01-23T09:28:48Z | https://github.com/hzwer/ECCV2022-RIFE/issues/233 | [] | danieltan007 | 1 |
coqui-ai/TTS | deep-learning | 3,627 | Please update to be able to use with Python 3.12 | RuntimeError: TTS requires python >= 3.9 and < 3.12 but your Python version is 3.12.0 (tags/v3.12.0:0fb18b0, Oct 2 2023, 13:03:39) [MSC v.1935 64 bit (AMD64)]
This happens even with trying to install using
pip3 install --ignore-requires-python TTS
| closed | 2024-03-11T02:42:57Z | 2024-10-07T00:36:54Z | https://github.com/coqui-ai/TTS/issues/3627 | [
"wontfix",
"feature request"
] | Aphexus | 7 |
tflearn/tflearn | data-science | 963 | how to use pretrained word2vec in tflearn for text classification | Hi Guys,
I found tflearn is a good tool for deep learning.
I am just wondering if i can load pretrained word2vec model (like google word2vec, i.e. https://code.google.com/archive/p/word2vec/). And how to use that to initialise embedding layer in tflearn.
Thank You,
Biswajit | open | 2017-11-21T05:43:28Z | 2017-11-21T05:48:13Z | https://github.com/tflearn/tflearn/issues/963 | [] | Biswajit2902 | 0 |
ydataai/ydata-profiling | jupyter | 795 | Profile contains incorrect types and rejected columns | **Description:**
Profile contains incorrect types and rejected columns.
**Reproduction:**
```python
import datetime
import pandas
import pandas_profiling
df = pandas.DataFrame({
"time": [datetime.datetime(2021, 5, 11)] * 4,
"symbol": ["AAPL", "AMZN", "GOOG", "TSLA"],
"price": [125.91, 3223... | closed | 2021-05-19T15:06:14Z | 2021-06-30T10:16:26Z | https://github.com/ydataai/ydata-profiling/issues/795 | [] | ashwin153 | 1 |
pallets/quart | asyncio | 145 | Not working with PyLTI even after 'import quart.flask_patch' | I'm trying to make an app using Quart together with [PyLTI](https://pypi.org/project/PyLTI/).
PyLTI is originally for Flask, so I'm using `import quart.flask_patch`.
However, the following error happens when I run the app with `python main.py`.
Could you please give me some advice?
I'm not sure where I should ask... | closed | 2022-04-13T15:10:17Z | 2022-10-03T00:26:21Z | https://github.com/pallets/quart/issues/145 | [] | yuttie | 2 |
nerfstudio-project/nerfstudio | computer-vision | 3,611 | Throw an error on non-zero k4, k5 or k6 | Hi @jb-ye @devernay, why is there a problem when k4 is not equal to 0? #3355 #3381 When reading the camera distortion coefficients such as [this](https://github.com/nerfstudio-project/nerfstudio/blob/73fe54dda0b743616854fc839889d955522e0e68/nerfstudio/process_data/colmap_utils.py#L262C2-L278C42), k4 is correctly assi... | open | 2025-03-12T12:24:12Z | 2025-03-15T04:07:31Z | https://github.com/nerfstudio-project/nerfstudio/issues/3611 | [] | Yubel426 | 3 |
pyeve/eve | flask | 1,222 | Demo fails | QuickStart:
root@xtgl-app-009:/root/a#cat run.py
from eve import Eve
app = Eve()
app.run()
root@xtgl-app-009:/root/a#cat settings.py
DOMAIN = {'people': {}}
root@xtgl-app-009:/root/a#
--------------------------------------------------------------------------------------
Then I run the demo:
root@xtgl-app-00... | closed | 2019-01-23T09:17:26Z | 2019-03-28T15:13:26Z | https://github.com/pyeve/eve/issues/1222 | [] | SuperHighMan | 1 |
awesto/django-shop | django | 727 | Add tag for version 0.12.1 | Apparently, the git tag for version 0.12.1 was forgotten. Please add it (as documented [here](/awesto/django-shop/blob/master/shop/__init__.py#L6-L18)). | closed | 2018-04-29T07:07:02Z | 2018-04-30T00:37:34Z | https://github.com/awesto/django-shop/issues/727 | [] | r4co0n | 1 |
python-gitlab/python-gitlab | api | 2,738 | ldap_group_links.list() not usable | ## Description of the problem, including code/CLI snippet
The current implementation of the list() method for the ldap_group_links api is not usable. The cli throws an exceptions and the api returns unusable data, because an id is missing.
$ gitlab group-ldap-group-link list --group-id xxxxxx
[<GroupLDAPGroupLink ... | open | 2023-12-04T20:19:26Z | 2024-01-21T19:10:49Z | https://github.com/python-gitlab/python-gitlab/issues/2738 | [
"bug"
] | zapp42 | 5 |
skfolio/skfolio | scikit-learn | 6 | [BUG] Python Version Request: Reduce python >= 3.9 | Thanks for the great-looking package!
I have hopefully a small request. Currently you have:
https://github.com/skfolio/skfolio/blob/a1e79d3cf732467dcd078cd414b466b889a2b1c5/pyproject.toml#L16
Is it possible to change this to `3.9` to reduce the restrictiveness?
Sklearn doesn't actually specify a python ver... | closed | 2024-01-12T14:39:31Z | 2024-01-16T20:51:33Z | https://github.com/skfolio/skfolio/issues/6 | [
"bug"
] | mdancho84 | 3 |
mwouts/itables | jupyter | 199 | Pandas Style fail to render in Colab | Pandas Style objects fail to render in Google Colab.
This is because the HTML representation of the style object generated by `to_html` is
```
<table id="T_4b0528c8-6c7e-4821-bad4-20c3dbda01a8" class="dataframe">
```
while `itables` expect it to be only equal to
```
<table id="T_4b0528c8-6c7e-4821-bad4-20c3db... | closed | 2023-10-01T13:54:02Z | 2023-10-01T22:33:52Z | https://github.com/mwouts/itables/issues/199 | [] | mwouts | 0 |
tflearn/tflearn | data-science | 1,001 | no pip3 package | The installation of the stable release, as described in the docs, does not work when using pip3:
$ pip3 install tflearn
Collecting tflearn
Could not find a version that satisfies the requirement tflearn (from versions: )
No matching distribution found for tflearn | open | 2018-01-19T23:19:30Z | 2018-01-30T21:59:19Z | https://github.com/tflearn/tflearn/issues/1001 | [] | Eezzeldin | 1 |
jazzband/django-oauth-toolkit | django | 711 | authorization_code should use pkce to verify public clients | According to RFC [https://tools.ietf.org/html/rfc7636#section-4](https://tools.ietf.org/html/rfc7636#section-4) For public clients with `authorization_code` grant PKCE's `code_verifier` must be used to authenticate client. Currently authentication for public client is dropped altogether.
**Current behaviour:**
Cl... | closed | 2019-04-25T07:34:41Z | 2019-05-29T19:20:23Z | https://github.com/jazzband/django-oauth-toolkit/issues/711 | [] | Abhishek8394 | 3 |
ageitgey/face_recognition | python | 1,351 | is it possible to get accuracy/confidence level when predicting face? | i want to get accuracy/confidence level of the prediction result, is it possible??
i'm using [https://github.com/ageitgey/face_recognition/blob/master/examples/facerec_ipcamera_knn.py](this example) | open | 2021-08-04T11:03:44Z | 2021-09-03T20:12:43Z | https://github.com/ageitgey/face_recognition/issues/1351 | [] | moinologics | 1 |
StackStorm/st2 | automation | 6,021 | action_service.list_values no limit or offset support? | ## SUMMARY
action_service.list_values not working properly?
### STACKSTORM VERSION
3.7.0
##### OS, environment, install method
OS install on RHEL
## Steps to reproduce the problem
As per the contrib/runners/python_runner/python_runner/python_action_wrapper.py the action service allows for listing o... | open | 2023-09-06T13:26:59Z | 2023-09-06T13:27:45Z | https://github.com/StackStorm/st2/issues/6021 | [] | fdrab | 0 |
jpadilla/django-rest-framework-jwt | django | 394 | Help configuring JWT_PRIVATE_KEY/JWT_PUBLIC_KEY | I'm utilising `django-rest-framework-jwt` for an REST API authentication and i'd like to have the same web token authorize access to another http service (couchdb).
For creating a JWT enabled reverse proxy i'm looking at jwtproxy (https://github.com/coreos/jwtproxy) which 8afaik) can use a preshared RSA key, so i'm ... | closed | 2017-10-31T20:35:54Z | 2018-03-02T11:46:17Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/394 | [] | zemanel | 3 |
httpie/cli | python | 571 | Should build official Docker image and add usage instructions | I created this: https://github.com/teracyhq/docker-files/tree/master/httpie-jwt-auth
and I'd like to do the same for official Docker image of httpie (instead of under teracy/ umbrella)
Let's discuss here for anyone interested and I could lead the effort.
related: https://github.com/jakubroztocil/httpie/pull/23... | open | 2017-03-23T18:23:12Z | 2021-05-29T06:08:03Z | https://github.com/httpie/cli/issues/571 | [
"packaging"
] | hoatle | 2 |
axnsan12/drf-yasg | rest-api | 473 | DeprecationWarning on Python 3.7/3.8 and breakage on master/3.10 due to coreapi dependency | Originally posted at https://github.com/encode/django-rest-framework/issues/6991
Relates to #389
___________
Python 3.8 releases today but this warning is still triggered from `djangorestframework` 3.10.3 and `drf-yasg` 1.17.0 :
https://github.com/tomchristie/itypes/issues/11
This makes causes users who r... | closed | 2019-10-16T12:43:42Z | 2020-09-17T12:36:20Z | https://github.com/axnsan12/drf-yasg/issues/473 | [] | johnthagen | 5 |
eriklindernoren/ML-From-Scratch | data-science | 23 | MatplotlibWrapper is an undefined name | MatplotlibWrapper is an undefined name in gaussian_mixture_model.py and k_means.py. Undefined names can raise [NameError](https://docs.python.org/3/library/exceptions.html#NameError) at runtime.
flake8 testing of https://github.com/eriklindernoren/ML-From-Scratch on Python 2.7.13
$ flake8 . --count --select=E901... | closed | 2017-09-14T09:19:28Z | 2017-09-18T14:31:12Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/23 | [] | cclauss | 1 |
piskvorky/gensim | machine-learning | 3,025 | Custom Keyword inclusion | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2021-01-12T07:33:17Z | 2021-01-12T10:28:36Z | https://github.com/piskvorky/gensim/issues/3025 | [] | Vignesh9395 | 1 |
encode/databases | asyncio | 208 | aiopg engine raises ResourceWarning in transactions | Step to reproduce:
Python 3.7.7
```python3
import asyncio
from databases import Database
url = "postgresql+aiopg://localhost:5432"
async def generate_series(db, *args):
async with db.connection() as conn:
async for row in conn.iterate( # implicitly starts transaction
f"se... | open | 2020-05-20T10:55:25Z | 2021-03-16T16:59:38Z | https://github.com/encode/databases/issues/208 | [] | nkoshell | 3 |
sktime/sktime | scikit-learn | 7,587 | [ENH] Forecast reconciliation with Machine Learning | One of the new approaches to forecast reconciliation is using ML regressors that leverage the base forecasts as inputs to predict forecasts of the bottom levels (similar to stacking models). The reconciled forecast is then the aggregation of such predicted values. For more information, refer to [1] and [2]
**Describ... | open | 2024-12-30T13:29:11Z | 2024-12-30T13:29:11Z | https://github.com/sktime/sktime/issues/7587 | [
"enhancement"
] | felipeangelimvieira | 0 |
mwaskom/seaborn | data-visualization | 3,546 | Interest in seaborn.objects API contributions? | I've seen a few contributions floating around for the seaborn.objects API (e.g., #3320). Sounds like there's a reluctance to move too fast while the API is settling, but I happen to have a very good student looking to do some work, and I'd _love_ to see the objects API have better integration with modelling tools (espe... | closed | 2023-11-03T17:46:20Z | 2023-11-06T15:17:11Z | https://github.com/mwaskom/seaborn/issues/3546 | [] | nickeubank | 2 |
yinkaisheng/Python-UIAutomation-for-Windows | automation | 1 | Adding ProcessId property to Control class | Hi !
I tried to add ProcessId property
``` python
class Control():
@property
def ProcessId(self):
'''Return process id'''
return ClientObject.dll.GetProcessId(self.Element)
```
and when I call the property I got this error message
```
Traceback (most recent call last):
File "<stdin>", line 1... | closed | 2015-12-28T21:27:05Z | 2015-12-29T07:00:48Z | https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/1 | [] | thu2004 | 1 |
jschneier/django-storages | django | 1,207 | Make django-storages compatible with the new Django's settings `STORAGES` | In Django 4.2 the new settings ``STORAGES`` has been added.
https://github.com/django/django/commit/1ec3f0961fedbe01f174b78ef2805a9d4f3844b1
The ``DEFAULT_FILE_STORAGE`` and ``STATICFILES_STORAGE`` settings are deprecated in Django 4.2 and will be removed Django 5.1.
https://github.com/django/django/commit/32940d3... | closed | 2023-01-12T11:05:07Z | 2023-04-05T12:23:46Z | https://github.com/jschneier/django-storages/issues/1207 | [
"Help Wanted 💕"
] | pauloxnet | 3 |
dynaconf/dynaconf | flask | 1,252 | [RFC] Combining settings from different applications / packages | **Is your feature request related to a problem? Please describe.**
I am currently working on setting up an inheritance-based package and applications. In this model, I would have a base package (core) which has an abstract class with a defined dynaconf settings and config file. For example, the core class (which is pac... | closed | 2025-02-13T21:19:00Z | 2025-02-17T23:05:41Z | https://github.com/dynaconf/dynaconf/issues/1252 | [
"Not a Bug",
"RFC"
] | omri-cavnue | 2 |
pytest-dev/pytest-html | pytest | 815 | Crashes with KeyError: 'retried' when test is retried with pytest-retry | It looks like the html reporter does not handle tests with the outcome `retried`.
It's quite easy to reproduce:
1. Create a failing test with the mark `@pytest.mark.flaky(retries=3, delay=1)`
2. Run the test and wait for it to fail so that it is retried
3. Pytest crashes with:
```
File "/__w/xi/xi/tests/venv/l... | open | 2024-05-30T13:51:00Z | 2024-12-02T10:40:36Z | https://github.com/pytest-dev/pytest-html/issues/815 | [] | angelos-p | 3 |
seleniumbase/SeleniumBase | web-scraping | 2,635 | UC Mode not working on window server 2022 | Last week, my code worked fine but after updating my code couldn't bypass the cloudflare bot. For information, I use Windows Server 2022.
This is my code:
```
def you_message(text: str, out_type: str = 'json', timeout: int = 20):
"""Function to send a message and get results from YouChat.com
Args:
... | closed | 2024-03-24T17:45:54Z | 2024-03-24T18:14:44Z | https://github.com/seleniumbase/SeleniumBase/issues/2635 | [
"invalid usage",
"UC Mode / CDP Mode"
] | zing75blog | 1 |
jupyter/nbgrader | jupyter | 969 | Add link to the Jupyter in Education map in third-party resources | Here is the link: https://elc.github.io/jupyter-map/ | closed | 2018-05-19T13:10:49Z | 2018-10-07T11:14:54Z | https://github.com/jupyter/nbgrader/issues/969 | [
"documentation",
"good first issue"
] | jhamrick | 2 |
plotly/dash-component-boilerplate | dash | 150 | Import errors | Im trying to create a component and when i tried to run the usage.py file im getting an import error:
I have recently received similar errors when trying to run some dash apps and it seems to be from an old version of dash, I would have thought running this inside of this repo it would have an updated version of dash ... | closed | 2023-01-13T01:10:10Z | 2023-05-31T13:38:11Z | https://github.com/plotly/dash-component-boilerplate/issues/150 | [] | Tedmcm | 1 |
e2b-dev/code-interpreter | jupyter | 7 | CodeInterpreter.reconnect() not working as expected | I ran into this issue and am extremely confused, is this a problem on my end or through the library

| closed | 2024-04-08T20:00:36Z | 2024-04-08T20:25:11Z | https://github.com/e2b-dev/code-interpreter/issues/7 | [] | im-calvin | 2 |
gee-community/geemap | streamlit | 623 | Not getting same interactive map as showing tutorial video | I am getting as given via code
Map = geemap.Map()
Map
we did not get inspector and other tools on map thats why facing problem in adding layers
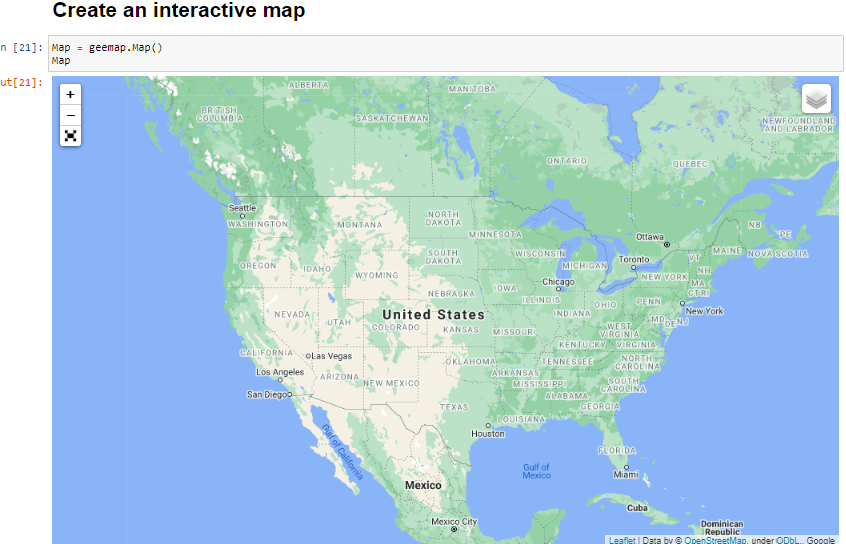
video tutorial show as given
 to a `requests.post` call. Since urllib3 2.x this causes the body of the request to be truncated. It seems that the Content-Length is calculated based on the length of the string and the string itself is handed over to the call as a... | closed | 2023-12-13T14:09:36Z | 2024-12-13T00:06:48Z | https://github.com/psf/requests/issues/6601 | [] | secorvo-jen | 1 |
amidaware/tacticalrmm | django | 1,898 | At the top of the devices list, it would be great to have number of items | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear an... | closed | 2024-06-21T09:47:47Z | 2024-06-21T15:29:05Z | https://github.com/amidaware/tacticalrmm/issues/1898 | [] | JCbarreau | 0 |
microsoft/nni | pytorch | 5,790 | Error in model speedup when using a single logit output layer | **Describe the issue**:
**Environment**:
- NNI version: 3.0
- Training service (local|remote|pai|aml|etc): local
- Client OS: Ubuntu 18.04.4 LTS
- Server OS (for remote mode only):
- Python version: 3.9
- PyTorch/TensorFlow version: 1.12.0
- Is conda/virtualenv/venv used?: conda
- Is running in Docker?:... | open | 2024-05-30T10:10:29Z | 2024-05-30T10:10:29Z | https://github.com/microsoft/nni/issues/5790 | [] | rishabh-WIAI | 0 |
recommenders-team/recommenders | machine-learning | 1,718 | [ASK] How can I save SASRec model for re-training and prediction? | I have tried to save trained SASRec model.
pickle, tf.saved_model.save, model.save(), and surprise.dump are not working.
While saving, I got warning saying 'Found untraced functions',
and while loading, 'AttributeError: 'SASREC' object has no attribute 'seq_max_len''.
Plz someone let me know how to save and... | open | 2022-05-13T18:23:23Z | 2023-08-30T14:03:13Z | https://github.com/recommenders-team/recommenders/issues/1718 | [
"help wanted"
] | beomso0 | 2 |
praw-dev/praw | api | 1,090 | Submission stream returning duplicates | If you stream submissions from r/all, the stream returns duplicate copies of items. See this example code: https://github.com/Watchful1/Sketchpad/blob/master/streamTester.py
Streaming 5000 submissions resulted in 3508 duplicates, many 5 or 6 times each.
Increasing the size of the seen_attributes BoundedSet in str... | closed | 2019-06-26T04:03:13Z | 2019-07-01T15:41:35Z | https://github.com/praw-dev/praw/issues/1090 | [] | Watchful1 | 2 |
tableau/server-client-python | rest-api | 1,102 | [Type 1] Support `vizWidth` and `vizHeight` parameters of Query View PDF endpoint | ## Description
Currently these are not exposed anywhere. The `PDFRequestOptions` object is shared between the "Query View PDF" and the "Download Workbook PDF" endpoint however the workbook variant does not e.g. support filters and the query view variant has the visWidth/visHeight parameters. These are not exposed an... | open | 2022-09-08T16:56:05Z | 2023-03-23T19:14:41Z | https://github.com/tableau/server-client-python/issues/1102 | [
"enhancement"
] | septatrix | 0 |
marcomusy/vedo | numpy | 505 | addSlider2D: TypeError: DestroyTimer argument 1: an integer is required (got type NoneType) | Hi @marcomusy,
Here is another error that I could not figure out by myself. I am still trying to play with the same data as I used in Issue #504, and this time I am playing with the slider.
Here is the code I used:
```Python
#!/usr/bin/env python3
import numpy as np
from vedo import TetMesh, show, screensho... | closed | 2021-11-02T22:29:11Z | 2022-01-11T13:49:42Z | https://github.com/marcomusy/vedo/issues/505 | [] | XushanLu | 2 |
gradio-app/gradio | data-science | 10,373 | Is there any possible way to specify the editable of columns or rows | Hello buddy,
I'm using the Dataframe component in gradio to represent a csv file, in some scenario, some columns or some rows are editable and others are read-only. Is there anyway for me to do that? I just want to do it in the front end not the back end.
Thanks.
| closed | 2025-01-16T06:26:25Z | 2025-01-17T16:38:04Z | https://github.com/gradio-app/gradio/issues/10373 | [
"pending clarification"
] | Yb2S3Man | 3 |
google-research/bert | tensorflow | 468 | Can I use Low-level TF APIs to fine-tuning bert for my task? Do I have to use Estimators? | I am not clear about the optimizer in `optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, False)`. | closed | 2019-03-01T03:00:37Z | 2019-03-01T09:58:38Z | https://github.com/google-research/bert/issues/468 | [] | yumath | 1 |
flairNLP/flair | pytorch | 3,416 | [Question]: Pre-Tagging information in Sequence-Tagging? | ### Question
My specific use case:
I'm trying to solve an event-extraction task which I model as a sequence-tagging problem. So this event-tagger should be able to identify the event trigger, actors and objects in a given span. Now, I've got pretty reliable NER-tags which I would like as a additional information for ... | open | 2024-03-04T09:01:29Z | 2024-04-04T22:07:50Z | https://github.com/flairNLP/flair/issues/3416 | [
"question"
] | raykyn | 4 |
mwaskom/seaborn | data-science | 3,593 | Discrpancy in seaborn.objects.Dodge groupby order | Hi, I would like to report a strange behavior in the `Move` object `Dodge`.
Seaborn version: 0.13.0
Matplotlib version: 3.8.2
Everything start because I wanted to play around with the `objects` namespace.
As dataset I use the penguins dataset, I drop both the nan and all the values that I do not consider outlie... | open | 2023-12-14T15:38:57Z | 2023-12-19T12:05:22Z | https://github.com/mwaskom/seaborn/issues/3593 | [] | tiamilani | 6 |
pytest-dev/pytest-xdist | pytest | 187 | different tests collected between workers in Python 3.5 | I'm trying to run my tests via xdist in python 3.5 and it fails saying different tests were collected between gw0 and gw1. It works fine in python 2.7. This is the same issue as #149 but that issue does not explain the solution. | closed | 2017-07-14T14:46:13Z | 2017-08-07T19:44:49Z | https://github.com/pytest-dev/pytest-xdist/issues/187 | [
"question"
] | havok2063 | 4 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,397 | uc wont find element | this is my code:
```
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_condi... | open | 2023-07-15T22:40:42Z | 2023-07-17T21:26:36Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1397 | [] | x3n1al | 2 |
dropbox/PyHive | sqlalchemy | 220 | create hive table and get 'timestamp is not supported' | **I have used HiveDate and HiveTimestamp but still get the error:**
TExecuteStatementResp(status=TStatus(statusCode=3, infoMessages=['*org.apache.hive.service.cli.HiveSQLException:Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
**My code is:**
`... | open | 2018-07-03T12:41:06Z | 2018-07-03T12:41:06Z | https://github.com/dropbox/PyHive/issues/220 | [] | glorialove323 | 0 |
sigmavirus24/github3.py | rest-api | 1,187 | Can we expose the `timeout` parameter to `Repository.create_tree()` to create large tree objects? | Currently, when trying to create a tree with large data there is a timeout error:
```python3
import github3
gh = github3.login(token=<token>)
repo = gh.repository(<org>, <repo>)
...
# Make big tree_data and tree_sha here.
...
tree = repo.create_tree(tree_data, tree_sha)
```
> github3.exceptions.Connecti... | open | 2024-07-25T19:59:51Z | 2024-07-25T19:59:51Z | https://github.com/sigmavirus24/github3.py/issues/1187 | [] | rduve | 0 |
benbusby/whoogle-search | flask | 124 | [FEATURE] Password protected search engine | Hi,
I think would be a good option to add a password protection to use the search engineer. I would like to use Whoogle in a VPS and only allow to use Whoogle to the people that knows the password.
Thanks
| closed | 2020-09-11T12:41:23Z | 2023-10-24T11:57:22Z | https://github.com/benbusby/whoogle-search/issues/124 | [
"enhancement"
] | joan-carles | 4 |
noirbizarre/flask-restplus | api | 541 | Can it declare more than one model? | I declare 2 models like this
```
fields = api.model('MyModel', {
'id_siswa': fields.String(),
'nama_siswa': fields.String(),
'kelas': fields.String(),
'hasil': fields.List(fields.Integer),
'id_penilai': fields.String(),
'nama_penilai':fields.String(),
})
indicators = api.model('Mode... | closed | 2018-10-18T09:53:19Z | 2018-10-19T03:24:49Z | https://github.com/noirbizarre/flask-restplus/issues/541 | [] | kafey | 2 |
jupyter-incubator/sparkmagic | jupyter | 397 | Update the environment variables of the SparkSubmit process (yarn spark client spawned by Livy Server) | I need to update the environment variables of the SparkSubmit process (i need to add PYSPARK_PYTHON to support using a conda environment).
However, i can't figure out how to do this (apart from updating the global $SPARK_HOME/conf/spark-env.sh). Can I do this through configuration or does it need a PR (which I would... | closed | 2017-08-08T18:37:28Z | 2019-07-03T13:36:31Z | https://github.com/jupyter-incubator/sparkmagic/issues/397 | [] | jimdowling | 5 |
piskvorky/gensim | data-science | 3,268 | Can't suppress lifecycle events | #### Problem description
I'm trying to use gensim inside another tool that is using `logging` module and want to suppress logging messages from gensim.
`gensim.models.word2vec.logger.level = logging.ERROR` removes the training progress but the lifecycle messages still appear.
According to https://radimrehurek.com/... | closed | 2021-11-16T12:50:38Z | 2021-11-17T12:22:16Z | https://github.com/piskvorky/gensim/issues/3268 | [] | ZJaume | 2 |
pytorch/vision | machine-learning | 8,071 | How to tell if Faster RCNN Detection model is overfitting | I'm confused as to how I can tell if the Faster RCNN Detection model I'm training is overfitting or not given that the validation loss is not computed in the `evaluate` function seen [here](https://github.com/pytorch/vision/blob/main/references/detection/engine.py#L75C1-L115C26) and below.
Any help would be greatly ... | open | 2023-10-27T00:03:39Z | 2024-01-16T14:49:37Z | https://github.com/pytorch/vision/issues/8071 | [] | 1andDone | 2 |
django-import-export/django-import-export | django | 1,764 | The error message for invalid column names is misleading | **Describe the bug**
The error message for invalid column names is misleading. It also breaks the interface because `FieldError` is raised and thrown from the process, ignoring the `raise_error` flag.
**To Reproduce**
- See test in PR
**Versions (please complete the following information):**
- Django... | closed | 2024-02-29T20:22:30Z | 2024-03-13T10:15:26Z | https://github.com/django-import-export/django-import-export/issues/1764 | [
"bug",
"v4"
] | matthewhegarty | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 690 | Model overfitting, smooth triplet margin loss | Hi there!
Thank you for the awesome library!
I'm currently working on training a model using the CARS196 dataset with the following parameters:
```python
distance = distances.CosineSimilarity()
reducer = reducers.ThresholdReducer(low=0)
loss_func = losses.TripletMarginLoss(margin=0.2, distance=distance, red... | open | 2024-03-23T05:11:37Z | 2024-04-01T14:19:16Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/690 | [] | taaresh7 | 2 |
axnsan12/drf-yasg | django | 358 | Best practice for documenting permissions | Hi,
AFAIU there are two general use-cases for schema generation - schema for user, in which case I should use `get_schema_view(public=False,)` and second use-case - schema as API documentation, in which case I should use `get_schema_view(public=True,)`.
Probably permissions documentation is not important in first c... | closed | 2019-05-01T17:19:50Z | 2022-11-22T16:38:05Z | https://github.com/axnsan12/drf-yasg/issues/358 | [] | K0Te | 6 |
aio-libs/aiopg | sqlalchemy | 471 | Is there a way to wrap all transactions in test to rollback them at the end of a test? | I use aiopg.sa.create_engine and I'm looking for a way to wrap all transactions in my tests to rollback them at the end of each test to remove all data.
Is it possible? | closed | 2018-05-03T14:51:38Z | 2018-05-04T11:58:57Z | https://github.com/aio-libs/aiopg/issues/471 | [] | GregEremeev | 3 |
SYSTRAN/faster-whisper | deep-learning | 474 | adding initial_prompt is changing the segment duration | For the same audio without inital_prompt, the segments are smaller and more accurate
[0.00s -> 6.20s] text ...
[6.30s -> 10.80s] text ...
[11.30s -> 13.80s] text ...
[13.90s -> 18.60s] text ...
[20.60s -> 23.80s] text ...
[27.88s -> 30.88s] text ...
[31.48s -> 36.98s] text ...
[37.08s -> 39.08s] text ...
[39.9... | closed | 2023-09-14T08:45:05Z | 2024-11-14T13:59:44Z | https://github.com/SYSTRAN/faster-whisper/issues/474 | [] | abdulnim | 3 |
python-visualization/folium | data-visualization | 1,581 | Dynamization in Folium | **Describe the solution you'd like**
I would like to update marker data live based on actual data. Same goes for the data in the marker pop-up. I would also like to draw circles and maybe add or remove markers based on live data.
**Describe alternatives you've considered**
Writing in JavaScript with Leaflet.js its... | closed | 2022-04-07T18:14:23Z | 2023-01-11T16:55:09Z | https://github.com/python-visualization/folium/issues/1581 | [] | Theagainmen | 15 |
QingdaoU/OnlineJudge | django | 426 | system error 的原因 | 您好,謝謝您提供這麼好的平台服務。
已經建立好平台,不過在測試交卷後會出現 system error,
訪使用者帳號登入交卷也會出現 system error,
應該說只有這個結果,想請問原因為何?及該如何處置謝謝您。
<img width="210" alt="image" src="https://user-images.githubusercontent.com/75984915/185625350-cb3d2cfa-1c13-4636-9227-dc79ee0fbc77.png">
| open | 2022-08-19T13:10:18Z | 2024-10-07T07:14:06Z | https://github.com/QingdaoU/OnlineJudge/issues/426 | [] | r07341010 | 1 |
plotly/dash | jupyter | 2,969 | Remove all JavaScript warnings from our libraries | See https://github.com/plotly/dash-core/issues/284 for details. (GitHub won't let me transfer the issue to this repository.) | open | 2024-08-28T15:50:29Z | 2024-08-28T15:50:30Z | https://github.com/plotly/dash/issues/2969 | [
"bug",
"P2"
] | gvwilson | 0 |
tensorflow/tensor2tensor | deep-learning | 1,490 | Hyper parameter tuning for local execution | ### Description
I know t2t has a hyperparameter tuning functin, but it's only for ML Engine.
I implented hyperparameter tuning with Optuna for t2t v1.10.0.
https://github.com/Drunkar/tensor2tensor-optuna
 by changing only this line to u... | closed | 2022-03-14T15:51:30Z | 2024-03-24T09:14:05Z | https://github.com/recommenders-team/recommenders/issues/1673 | [
"help wanted"
] | leemengtw | 7 |
serengil/deepface | machine-learning | 1,395 | [FEATURE]: <There are multiple people in a picture> | ### Description
If we have an ID card information, can the individuals in picture 2 be compared one by one?
### Additional Info
_No response_ | closed | 2024-12-05T09:04:42Z | 2024-12-05T09:09:18Z | https://github.com/serengil/deepface/issues/1395 | [
"enhancement",
"question"
] | jhluaa | 2 |
schemathesis/schemathesis | graphql | 1,889 | [BUG] hypothesis-max-examples is ignored when using docker run | ### Checklist
- [x ] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [ x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [ x] I am using the latest version of Schemathesi... | closed | 2023-11-15T09:13:43Z | 2023-12-06T17:36:15Z | https://github.com/schemathesis/schemathesis/issues/1889 | [
"Type: Bug",
"Status: Needs Triage"
] | dbire | 5 |
scikit-learn/scikit-learn | python | 30,540 | Failure generating a pdf of the documentations using make latexpdf | ### Describe the bug
Hi sklearn team and fans,
I am trying to generate a pdf of the documentations to be able to read/use sklearn documentations offline. On multiple systems ranging from Macos (ARM or AMD processors) to Ubuntu, I am facing this issue and I am unable to troubleshoot it further:
```
Configuration... | closed | 2024-12-25T19:16:30Z | 2024-12-28T19:12:55Z | https://github.com/scikit-learn/scikit-learn/issues/30540 | [
"Bug",
"Needs Triage"
] | hassanshallal | 6 |
fastapi/sqlmodel | pydantic | 534 | [Querying] negating `Model.boolean` in `where()` | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2023-01-21T22:50:44Z | 2023-01-22T15:07:49Z | https://github.com/fastapi/sqlmodel/issues/534 | [
"question"
] | Pk13055 | 2 |
OpenBB-finance/OpenBB | machine-learning | 6,694 | [IMPROVE] Can't complete openbb.build() when using Spark due to failure in renaming temporary cache file | When installing the `multpl` openbb extension and building the Python interface as recommended by the [docs](https://docs.openbb.co/platform/installation#post-installation), I encounter an error when executing the build command as the temporary cache file cannot be renamed and subsequently I encounter an error pulling ... | closed | 2024-09-25T03:49:10Z | 2024-09-26T18:07:29Z | https://github.com/OpenBB-finance/OpenBB/issues/6694 | [] | eram576 | 4 |
waditu/tushare | pandas | 1,038 | 资产负债表固定资产数据错误与重复 |
ts_code ann_date f_ann_date end_date total_cur_assets fix_assets total_cur_liab total_liab
600038.SH 20190426 20190426 20190331 1.997876e+10 0.000000e+00 1.440746e+10 1.515330e+10
600038.SH 20190426 20190426 20190331 1.997876e+10 0.000000e+00 1.440746e+10 1.515330e+10
600... | closed | 2019-05-11T01:22:03Z | 2019-05-11T04:23:21Z | https://github.com/waditu/tushare/issues/1038 | [] | KaimingOuyang | 1 |
yzhao062/pyod | data-science | 240 | HBOS negative scores | Hello,
I have been reading the paper Histogram-Base Outlier Score and testing a little bit with the implementation of this python module. By looking at the paper we can see that the minimum score that we can have is 0 by the normalization and logarithm in the formula but when I try it with the PyOD module I get some... | open | 2020-10-22T08:48:44Z | 2023-06-21T23:40:50Z | https://github.com/yzhao062/pyod/issues/240 | [] | nacheteam | 2 |
mwaskom/seaborn | pandas | 3,457 | Deprecation warnings when seaborn is used with Pandas 2.1.0 | Pandas 2.1.0 has [deprecated](https://pandas.pydata.org/docs/whatsnew/v2.1.0.html#other-deprecations) a number of functions, and this results in `FutureWarning`s when Seaborn is used.
For example:
```py
import seaborn as sns
tips = sns.load_dataset("tips")
sns.relplot(data=tips, x="total_bill", y="tip")
sns... | closed | 2023-08-31T14:44:49Z | 2023-08-31T14:58:26Z | https://github.com/mwaskom/seaborn/issues/3457 | [] | wch | 1 |
airtai/faststream | asyncio | 1,507 | feature: concurrent Redis consuming | **Describe the bug**
It seems tasks don't run in parallel
**How to reproduce**
Include source code:
```python
import asyncio
from faststream import FastStream
from faststream.redis import RedisBroker
from pydantic import BaseModel
redis_dsn = 'xxxx'
rb = RedisBroker(redis_dsn)
class User(BaseModel... | open | 2024-06-07T04:16:37Z | 2024-11-08T10:41:08Z | https://github.com/airtai/faststream/issues/1507 | [
"enhancement",
"good first issue",
"Redis"
] | ryanrain2016 | 14 |
nltk/nltk | nlp | 2,717 | FreqDist Relative Frequencies (Corpus Linguistics) | `FreqDist` is a very useful tool for corpus linguists trying to generate frequency tables. However, in many cases, relative frequencies (i.e., normalized frequencies) are desired in these cases.
There are two common ways of doing this: Either the frequency of an item is divided by the total number of items (e.g., w... | closed | 2021-05-25T13:09:59Z | 2021-06-02T12:48:17Z | https://github.com/nltk/nltk/issues/2717 | [] | IngoKl | 3 |
GibbsConsulting/django-plotly-dash | plotly | 303 | Remove multiple return value check for clientside_callbacks | As reported in #301 there is a check to prevent use of multiple server-side callback values as this is not handled at present.
However, the check appears to also prevent the use of client-side callbacks with multiple return values, and should be relaxed to not prevent this use case.
| closed | 2021-01-15T16:52:54Z | 2021-01-24T03:35:28Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/303 | [
"bug"
] | GibbsConsulting | 1 |
RobertCraigie/prisma-client-py | pydantic | 962 | Error: spawn prisma-client-py ENOENT} | I've been using Prisma in node.js & I'm loving it.
Right now I have a Fastapi backend that I want to use Prisma with, yet I'm facing this issue whenever I run "Prisma db push" :
`prisma db push
Environment variables loaded from .env
Prisma schema loaded from schema.prisma
Datasource "db": PostgreSQL database "... | open | 2024-05-13T16:37:28Z | 2024-11-27T03:21:48Z | https://github.com/RobertCraigie/prisma-client-py/issues/962 | [] | AideFlood | 3 |
horovod/horovod | machine-learning | 3,655 | Collective ops: support for GatherOP for model parallel use cases. | **Is your feature request related to a problem? Please describe.**
In model parallel use cases where each rank trains a part of model, after training, for constructing and saving the full model, usually on rank 0, it needs to gather the weights from other ranks.
**Describe the solution you'd like**
An ideal soluti... | closed | 2022-08-15T18:11:08Z | 2022-08-23T23:23:52Z | https://github.com/horovod/horovod/issues/3655 | [
"enhancement"
] | MrAta | 1 |
AirtestProject/Airtest | automation | 848 | iOS真机的两个问题。1.横屏ui定位不准,2.iOS弹窗点击不到,点击到的层级为下方appUI层,请问有解决办法吗 | (请尽量按照下面提示内容填写,有助于我们快速定位和解决问题,感谢配合。否则直接关闭。)
**(重要!问题分类)**
* 测试开发环境AirtestIDE使用问题 -> https://github.com/AirtestProject/AirtestIDE/issues
* 控件识别、树状结构、poco库报错 -> https://github.com/AirtestProject/Poco/issues
* 图像识别、设备控制相关问题 -> 按下面的步骤
**描述问题bug**
(简洁清晰得概括一下遇到的问题是什么。或者是报错的traceback信息。)
1.横屏ui定位不准,2.iOS弹窗点击不到,点击到... | closed | 2021-01-04T04:09:53Z | 2021-02-21T08:54:59Z | https://github.com/AirtestProject/Airtest/issues/848 | [] | wslyyy | 1 |
deepspeedai/DeepSpeed | machine-learning | 7,136 | [BUG]When I use deepspeed ZeRO3 to train the vision-language-action model ,it met error of loading weights | **Describe the bug**
I want train vision-language-action model openvla with ZeRO3 and it cant load weight
Loading checkpoint shards: 100%|██████████| 3/3 [00:26<00:00, 7.72s/it]
Loading checkpoint shards: 100%|██████████| 3/3 [00:26<00:00, 8.99s/it]
[rank0]: Traceback (most recent call last):
[rank0]: File "/fs1/p... | open | 2025-03-14T02:33:21Z | 2025-03-14T02:35:57Z | https://github.com/deepspeedai/DeepSpeed/issues/7136 | [
"bug",
"training"
] | hahans | 0 |
InstaPy/InstaPy | automation | 6,815 | selenium.common.exceptions.WebDriverException: Message: Failed to decode response from marionette | selenium.common.exceptions.WebDriverException: Message: Failed to decode response from marionette

| open | 2024-07-01T14:15:45Z | 2024-07-01T14:15:45Z | https://github.com/InstaPy/InstaPy/issues/6815 | [] | DavidFFerreira | 0 |
matplotlib/matplotlib | data-visualization | 29,653 | [ENH]: Make fill_between 'step' argument consistent with plot | ### Problem
When I use fill_between, I typically want a plotted line as well. A nice way of doing this on several axes is to use a dict of keyword arguments, e.g.
kw = dict(color: 'red', ls='--', lw=1)
ax.plot(..., **kw)
ax.fill_between(..., **kw)
One thing that can't be set this way is the `drawstyle`, ... | open | 2025-02-21T11:25:49Z | 2025-02-24T11:15:35Z | https://github.com/matplotlib/matplotlib/issues/29653 | [
"New feature",
"API: consistency"
] | MichaelClerx | 1 |
plotly/dash-table | dash | 569 | Filter does not support empty strings | Running the following code will fail with an AST error
```
import dash
from dash_table import DataTable
app = dash.Dash(__name__)
app.layout = DataTable(
id='table',
columns=[{
'name': x,
'id': x,
'selectable': True
} for x in ['a', 'b', 'c']],
data=[{
... | closed | 2019-09-05T15:01:40Z | 2019-09-05T16:46:13Z | https://github.com/plotly/dash-table/issues/569 | [
"dash-type-bug",
"size: 0.5"
] | Marc-Andre-Rivet | 1 |
tensorflow/tensor2tensor | deep-learning | 1,031 | Trouble with ASR example in Windows OS | ### Description
For some reasons, I'm trying to run the tensor2tensor in Windows OS,
and I have trouble in executing the example described in https://github.com/tensorflow/tensor2tensor/blob/master/docs/tutorials/asr_with_transformer.md
Running the ASR with transformer example in cmd.exe by
`python t2t_trainer.... | open | 2018-08-30T11:29:35Z | 2018-08-30T11:29:35Z | https://github.com/tensorflow/tensor2tensor/issues/1031 | [] | Minuk101 | 0 |
ivy-llc/ivy | tensorflow | 28,089 | Fix Frontend Failing Test: paddle - tensor.paddle.Tensor.rsqrt_ | To-do List: https://github.com/unifyai/ivy/issues/27500 | closed | 2024-01-27T15:32:33Z | 2024-01-30T17:58:05Z | https://github.com/ivy-llc/ivy/issues/28089 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
harry0703/MoneyPrinterTurbo | automation | 341 | 可以针对0基础更有好些 | 这个开源项目很棒。感谢作者的付出。
今天尝试了一下。对于我这种0基础的,那些api就让我头疼。不知道作者能否出个详细部署教程(api部分怎么用)。谢谢。
另外:微信群超过200人了 | closed | 2024-05-08T23:12:39Z | 2024-05-10T00:48:50Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/341 | [] | stella741 | 1 |
fastapi/sqlmodel | sqlalchemy | 156 | How can I change the string column type to Unicode? | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | closed | 2021-11-16T01:27:20Z | 2023-10-29T08:13:23Z | https://github.com/fastapi/sqlmodel/issues/156 | [
"question"
] | phi-friday | 5 |
PeterL1n/RobustVideoMatting | computer-vision | 257 | Possible to use from within Nuke, as with BackgroundMatting? | Is this project yet possible to use from within Nuke, as with BackgroundMatting?
I came here from https://community.foundry.com/cattery where I found Background Matting.
| open | 2023-11-06T12:52:29Z | 2024-02-05T19:53:45Z | https://github.com/PeterL1n/RobustVideoMatting/issues/257 | [] | haakonstorm | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.