
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
sktime/sktime | scikit-learn | 7,557 | [BUG] 1st generation reducer - inconsistent use of parameters in global vs local case | The sliding window transform in the 1st generation reducer interfaced via `make_reduce` seems to be problematic, as some parameters are only used in the global or the local case, whereas one would expect them to be used in both.
Specifically, as the refactor https://github.com/sktime/sktime/pull/7556 shows:
* `fh... | open | 2024-12-21T17:55:45Z | 2024-12-21T17:56:13Z | https://github.com/sktime/sktime/issues/7557 | [
"bug",
"module:forecasting"
] | fkiraly | 0 |
pydantic/pydantic-settings | pydantic | 171 | Field fails to be initialized/validated when explicitly passing `env=` | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
When explicitly passing the value of the environment variable to use to initialize a field, such field is not initialized with the given env var. This results in an error like this `Field required [type=missing, input_value={}, input_type=... | closed | 2023-09-26T20:55:19Z | 2023-10-02T16:24:05Z | https://github.com/pydantic/pydantic-settings/issues/171 | [
"unconfirmed"
] | gvso | 2 |
streamlit/streamlit | data-visualization | 10,880 | `st.dataframe` displays wrong indizes for pivoted dataframe | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Under some conditions streamlit will display ... | open | 2025-03-23T15:50:44Z | 2025-03-24T13:49:35Z | https://github.com/streamlit/streamlit/issues/10880 | [
"type:bug",
"feature:st.dataframe",
"status:confirmed",
"priority:P3",
"feature:st.data_editor"
] | punsii2 | 2 |
aminalaee/sqladmin | sqlalchemy | 700 | Add messages support | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
I would like to display feedback to users after a form submission, not just error messages. This would allow for warnings and success messages.
### Describe the solution ... | open | 2024-01-19T23:25:17Z | 2024-05-15T20:07:55Z | https://github.com/aminalaee/sqladmin/issues/700 | [] | jonocodes | 11 |
dunossauro/fastapi-do-zero | pydantic | 55 | Criar uma lista de contribuição! | Adicionar ao README do mkdocs uma lista de agradecimento a todas as pessoas que revisaram e editaram material nas páginas! | closed | 2023-11-30T04:57:23Z | 2023-12-01T00:21:13Z | https://github.com/dunossauro/fastapi-do-zero/issues/55 | [
"Site"
] | dunossauro | 0 |
FlareSolverr/FlareSolverr | api | 1,403 | Browser doesn't load testing page | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I hav... | closed | 2024-10-28T10:21:51Z | 2024-11-24T18:30:36Z | https://github.com/FlareSolverr/FlareSolverr/issues/1403 | [] | MAKMED1337 | 13 |
collerek/ormar | pydantic | 541 | 'str' object has no attribute 'toordinal' | **Describe the bug**
Hi!
After the latest update (0.10.24), it looks like querying for dates, using strings, is no longer working.
- My field is of type `ormar.Date(nullable=True)`.
- Calling `await MyModel.objects.get(field=value)` fails when the value is `'2022-01-20'`
- Calling `await MyModel.objects.get(... | open | 2022-01-20T13:38:50Z | 2022-01-24T09:44:58Z | https://github.com/collerek/ormar/issues/541 | [
"bug"
] | sondrelg | 5 |
ShishirPatil/gorilla | api | 934 | [bug] Hosted Gorilla: <Issue> | Exception: Error communicating with OpenAI: HTTPConnectionPool(host='zanino.millennium.berkeley.edu', port=8000): Max retries exceeded with url: /v1/chat/completions (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7c39c8555a10>: Failed to establish a new connection: [Errno 111] Connection ... | open | 2025-03-12T05:01:02Z | 2025-03-12T05:01:02Z | https://github.com/ShishirPatil/gorilla/issues/934 | [
"hosted-gorilla"
] | tolgakurtuluss | 0 |
biolab/orange3 | pandas | 6,461 | Data Sets doesn't remember non-English selection | According to @BlazZupan, if one chooses a Slovenian dataset (in English version of Orange?) and saves the workflow, this data set is not selected after reloading the workflow.
I suspect the problem occurs because the language combo is not a setting and is always reset to English for English Orange (and to Slovenian ... | closed | 2023-06-02T12:50:51Z | 2023-06-16T08:02:49Z | https://github.com/biolab/orange3/issues/6461 | [
"bug"
] | janezd | 0 |
microsoft/nni | tensorflow | 5,253 | AssertionError: Could not found shapes for layer body.conv1" for QAT_quantizer() | **Describe the issue**:
I am using QAT_quantizer() and my quantize config is :
Config_list = [{
'quant_tyes': ['input'],
'quant_bits': {'input': 8},
'op_types': ['Conv2d']
}]
I call the quantizer by "quantizer = QAT_quantizer (net, config_list, optimizer)" without passing "dummy_input". But I encounter such... | closed | 2022-11-30T23:24:28Z | 2023-05-08T07:47:29Z | https://github.com/microsoft/nni/issues/5253 | [] | ToniButland1998 | 3 |
Avaiga/taipy | data-visualization | 1,979 | [DOCS] Fix Markdown in README.md | ### Issue Description
In README.md, the following 'Getting Started' link is not rendered correctly as there is a typo in the markdown.
### Screenshots or Examples (if applicable)

### Proposed Solution (optional)
... | closed | 2024-10-09T06:53:20Z | 2024-10-09T14:07:22Z | https://github.com/Avaiga/taipy/issues/1979 | [
"📈 Improvement",
"📄 Documentation",
"🟨 Priority: Medium"
] | Sriparno08 | 9 |
AirtestProject/Airtest | automation | 896 | windows窗口无法切换到子窗口 | **windows窗口无法切换到子窗口**
```
通过 airtest 连接到主窗口,主窗口通过操作打开一个子窗口,但是我没法用 airtest 的 api 去切换到子窗口,需要自己写自定义的方法才行,如下是我自己实现的切换到子窗口后截图判断位置的代码,相当于 exists 方法切换到子窗口去操作。
```
```
from airtest.core.win.win import Windows
dev = device()
child_win = dev._app.window(title="xx", class_name="xx")
handle = child_win.wrapper_object()... | open | 2021-04-22T07:08:27Z | 2021-04-27T08:37:57Z | https://github.com/AirtestProject/Airtest/issues/896 | [
"enhancement"
] | hfdzlsw | 0 |
MaartenGr/BERTopic | nlp | 1,277 | OSError: libcudart.so: cannot open shared object file: No such file or directory | Having already done:
```
!pip install cugraph-cu11 cudf-cu11 cuml-cu11 --extra-index-url=https://pypi.nvidia.com
!pip uninstall cupy-cuda115 -y
!pip uninstall cupy-cuda11x -y
!pip install cupy-cuda11x -f https://pip.cupy.dev/aarch64
```
When trying to:
`from cuml.cluster import HDBSCAN
`
I get:
`OSError:... | closed | 2023-05-19T10:02:18Z | 2023-05-19T13:38:43Z | https://github.com/MaartenGr/BERTopic/issues/1277 | [] | noahberhe | 2 |
opengeos/leafmap | streamlit | 119 | style_callback param for add_geojson() not working? | ### Environment Information
- leafmap version: 0.5.0
- Python version: 3.9
- Operating System: Linux/macOS
### Description
I want to use the `style_callback` parameter for `map.add_geojson()`, but the chosen style which sets only the color seems not to be respected. I think the style dicts are the same... | closed | 2021-10-03T09:19:18Z | 2024-09-22T07:42:05Z | https://github.com/opengeos/leafmap/issues/119 | [
"bug"
] | deeplook | 11 |
deezer/spleeter | deep-learning | 593 | [Errno 11001] getaddrinfo failed | I have a problem when I execute this command :
python -m spleeter separate -o output/ audio_example.mp3
the error I get is the following:
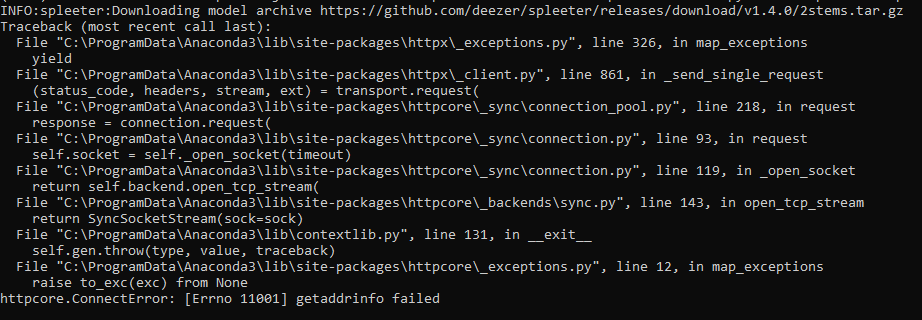
I would like to point out that:
1 - I'm on windows that'... | closed | 2021-03-05T15:31:55Z | 2021-05-18T17:03:56Z | https://github.com/deezer/spleeter/issues/593 | [
"bug",
"invalid"
] | hadji-yousra | 1 |
ageitgey/face_recognition | python | 1,288 | Append new entries to pickle file (KNNClassifier object) | * face_recognition version: v1.22
* Python version: 3.6
* Operating System: Mac
### Description
I am trying to add new encodings and names to saved pickle file (KNNClassifier object) - but unable to append.
### What I Did
```
# Save the trained KNN classifier
if os.path.getsize(model_sav... | closed | 2021-02-24T06:39:40Z | 2021-03-07T15:05:37Z | https://github.com/ageitgey/face_recognition/issues/1288 | [] | rathishkumar | 3 |
pydantic/pydantic-ai | pydantic | 559 | You can't use sync call and async streaming in the same application | If you use the async streaming text feature together with a sync call in the same application this leads to an exception regarding the event loop.
Python 3.12.8
pydantic-ai-slim[vertexai, openai]==0.0.15
Steps to reproduce:
```
import asyncio
from pydantic_ai import Agent
from pydantic_ai.models.vertexai... | closed | 2024-12-28T12:05:41Z | 2025-01-11T14:02:40Z | https://github.com/pydantic/pydantic-ai/issues/559 | [
"question",
"Stale"
] | alenowak | 7 |
deepinsight/insightface | pytorch | 1,985 | Could you tell me how to use this framework for face detection and alignment of my own dataset? | open | 2022-04-25T03:28:13Z | 2022-04-25T03:28:13Z | https://github.com/deepinsight/insightface/issues/1985 | [] | leonardzzy | 0 | |
zappa/Zappa | django | 973 | SQLite 3.8.3 or later is required (found 3.7.17). | I keep getting the error when I call zappa deploy dev. The zappa tail provides this output:
SQLite 3.8.3 or later is required (found 3.7.17).
SQLite 3.8.3 or later is required (found 3.7.17).
Traceback (most recent call last):
File "/var/task/handler.py", line 609, in lambda_handler
return LambdaHandler.lamb... | closed | 2021-04-29T20:12:03Z | 2022-07-16T04:56:14Z | https://github.com/zappa/Zappa/issues/973 | [] | viktor-idenfy | 4 |
Textualize/rich | python | 2,859 | [BUG] COLORTERM in combination with FORCE_COLOR does not work anymore | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2023-03-06T10:12:41Z | 2023-04-14T06:37:40Z | https://github.com/Textualize/rich/issues/2859 | [
"Needs triage"
] | ThunderKey | 3 |
aleju/imgaug | machine-learning | 391 | bgr image preprocess problem | I use cv2 read the image, but after use the function of `imgaug` preprocess the image. I think the image auto become to `rgb` channel. How to use `imgaug` preprocess the `bgr` image? | closed | 2019-08-22T07:41:48Z | 2019-08-23T05:55:41Z | https://github.com/aleju/imgaug/issues/391 | [] | as754770178 | 4 |
tox-dev/tox | automation | 2,430 | Tox can't handle path that contains dash (" - ") in it | ### Tox.ini
```
[tox]
minversion = 3.8.0
envlist = python3.8, python3.9, flake8, mypy
isolated_build = true
[testenv]
setenv =
PYTHONPATH = {toxinidir}
deps =
-r {toxinidir}{/}requirements_dev.txt
commands =
pytest pytest --basetemp={envtmpdir} --cov-report term-missing`
```
### Steps
R... | closed | 2022-06-01T13:38:14Z | 2023-01-19T11:50:02Z | https://github.com/tox-dev/tox/issues/2430 | [
"bug:normal",
"needs:more-info"
] | MdFahimulIslam | 3 |
polarsource/polar | fastapi | 5,088 | License Key Read resource is missing Created At field | Looks like the License Key Read resource is missing a Created At field.
We should expose it as we usually do with our resources. | open | 2025-02-24T13:32:38Z | 2025-02-28T10:09:46Z | https://github.com/polarsource/polar/issues/5088 | [
"bug",
"contributor friendly",
"python"
] | emilwidlund | 1 |
huggingface/transformers | machine-learning | 36,058 | TypeError: BartModel.forward() got an unexpected keyword argument 'labels' | ### System Info
```
TypeError Traceback (most recent call last)
[<ipython-input-37-3435b262f1ae>](https://localhost:8080/#) in <cell line: 0>()
----> 1 trainer.train()
5 frames
[/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _call_imp... | closed | 2025-02-06T05:41:36Z | 2025-02-07T09:05:38Z | https://github.com/huggingface/transformers/issues/36058 | [
"bug"
] | mwnthainarzary | 2 |
xuebinqin/U-2-Net | computer-vision | 362 | 对u2netp模型进行qat量化 | 使用pytorch的量化工具fx对u2netp进行qat量化,首先加载了训练好的fp32模型,然后按照流程对u2netp模型进行qat,loss随着epoch迭代越来越大,miou越来越小,qat后的模型完全错误。 | open | 2023-08-10T06:13:08Z | 2023-08-10T06:13:08Z | https://github.com/xuebinqin/U-2-Net/issues/362 | [] | ZHIZIHUABU | 0 |
jupyter/nbgrader | jupyter | 1,304 | adding students requires both web gui and jupyter_config.py | <!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
### Operating system
ubunt... | open | 2020-01-21T07:45:45Z | 2020-01-21T07:45:45Z | https://github.com/jupyter/nbgrader/issues/1304 | [] | Lapin-Blanc | 0 |
scikit-image/scikit-image | computer-vision | 6,871 | New canny implementation silently fails with integer images. | ### Description:
The new `skimage.feature.canny` implementation silently fails if given an integer image. This worked on `scikit-image<=0.19`, and no longer works with `scikit-image=0.20`. The documentation says that any dtype should work:
```
image : 2D array
Grayscale input image to detect edges on;... | closed | 2023-04-05T19:13:19Z | 2023-09-17T11:41:52Z | https://github.com/scikit-image/scikit-image/issues/6871 | [
":bug: Bug"
] | erykoff | 27 |
sqlalchemy/alembic | sqlalchemy | 661 | MySQL dialect types generating spurious revisions in 1.4 | Auto-generating a revision in 1.3.3 does not pick up any changes, however after upgrading to 1.4, every MySQL dialect type column generates a revision such as this one:
```
op.alter_column('comp_details', 'market_type_id',
existing_type=mysql.INTEGER(display_width=10, unsigned=True),
... | closed | 2020-02-21T13:34:10Z | 2020-02-27T20:50:51Z | https://github.com/sqlalchemy/alembic/issues/661 | [
"bug",
"autogenerate - detection",
"mysql"
] | peterschutt | 10 |
dunossauro/fastapi-do-zero | sqlalchemy | 291 | Erro ao rodar o alembic upgrade head no exercicio da aula 9 | Ao realizar o exercício da aula 9 de adicionar as colunas created_at e updated_at na tabela todos, quando rodo o comando alembic upgrade head, recebo o seguinte erro:
sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) Cannot add a column with non-constant default
[SQL: ALTER TABLE todos ADD COLUMN created_at ... | closed | 2025-02-03T13:17:58Z | 2025-02-03T18:06:40Z | https://github.com/dunossauro/fastapi-do-zero/issues/291 | [] | leoneville | 2 |
strawberry-graphql/strawberry | asyncio | 2,791 | DataLoader load_many should set or provide an option to return exceptions | <!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Feature Request Type
- [ ] Core functionality
- [x] Alteration (enhancement/optimization) of existing feature(s)... | open | 2023-05-30T08:01:56Z | 2025-03-20T15:56:11Z | https://github.com/strawberry-graphql/strawberry/issues/2791 | [] | jthorniley | 0 |
flasgger/flasgger | rest-api | 545 | Flasgger does not load when hostname has a path | I have a Flask application and I've integrated [Flasgger](https://github.com/flasgger/flasgger) for documentation. When I run my app locally, I can access swagger at http://127.0.0.1:8000/swagger/index.html. But when it's deployed to our dev environment, the hostname is https://services.company.com/my-flask-app. And wh... | open | 2022-08-05T07:40:30Z | 2022-08-05T07:40:30Z | https://github.com/flasgger/flasgger/issues/545 | [] | catalinapopa-uipath | 0 |
yt-dlp/yt-dlp | python | 11,907 | No video formats found with youtube:player_client=all and live-from-start in livestreams | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting that yt-dlp is broken on a **supported** site
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update ... | closed | 2024-12-25T22:03:02Z | 2024-12-26T01:19:18Z | https://github.com/yt-dlp/yt-dlp/issues/11907 | [
"site-bug",
"site:youtube"
] | ThePhoenix576 | 2 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,056 | Create Generated Column in MariaDB cannot specify null | ### Discussed in https://github.com/sqlalchemy/sqlalchemy/discussions/10055
<div type='discussions-op-text'>
<sup>Originally posted by **iamrinshibuya** July 3, 2023</sup>
Hello, when using [Computed Columns](https://docs.sqlalchemy.org/en/20/core/defaults.html#computed-columns-generated-always-as), the followi... | closed | 2023-07-03T19:29:03Z | 2023-10-20T04:51:21Z | https://github.com/sqlalchemy/sqlalchemy/issues/10056 | [
"bug",
"sql",
"PRs (with tests!) welcome",
"mariadb"
] | CaselIT | 16 |
microsoft/nni | machine-learning | 5,412 | Support for unified lightning package | **Describe the issue**:
It seems that nni does not support lightning with the new unified package name `lightning` instead of `pytorch_lightning`. When using nni with the new unified package it breaks. Unfortunately I don't know the pythonian way to fix this as there are still two seperate package versions out there... | open | 2023-02-28T12:31:02Z | 2023-03-01T02:39:20Z | https://github.com/microsoft/nni/issues/5412 | [] | funnym0nk3y | 1 |
tflearn/tflearn | tensorflow | 1,181 | tflearn | WARNING:tensorflow:From /home/ubuntu/anaconda3/envs/zzy_data/lib/python3.7/site-packages/tensorflow/python/compat/v2_compat.py:101: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not su... | open | 2024-03-25T01:02:29Z | 2024-03-25T01:04:05Z | https://github.com/tflearn/tflearn/issues/1181 | [] | WillingDil | 1 |
flasgger/flasgger | rest-api | 134 | HTTPS is not supported in the current flasgger version | it seems that there is an issue regarding the HTTPS for swagger ui that was solved in more advanced version
https://github.com/swagger-api/swagger-ui/issues/3166
so currently flasgger also does not support the HTTPS api requests .
| closed | 2017-07-18T06:33:01Z | 2018-07-31T07:53:07Z | https://github.com/flasgger/flasgger/issues/134 | [
"bug"
] | ghost | 12 |
CorentinJ/Real-Time-Voice-Cloning | python | 436 | Error in preprocessing data for synthesizer | While running `synthesizer_preprocess_audio.py`, I'm getting the following error:
```
Arguments:
datasets_root: /home/amin/voice_cloning/Datasets
out_dir: /home/amin/voice_cloning/Datasets/SV2TTS/synthesizer
n_processes: None
skip_existing: True
hparams:
Using ... | closed | 2020-07-22T06:52:38Z | 2020-07-22T07:35:15Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/436 | [] | amintavakol | 0 |
ets-labs/python-dependency-injector | flask | 665 | Allow Closing to detect dependent resources passed as kwargs | Hi,
I have the same issue of this user:
https://github.com/ets-labs/python-dependency-injector/issues/633#issuecomment-1361813043
Can you fix it? | open | 2023-02-06T08:37:43Z | 2023-02-06T09:03:47Z | https://github.com/ets-labs/python-dependency-injector/issues/665 | [] | mauros191 | 0 |
ipython/ipython | data-science | 14,368 | gtk/GTKAgg matplotlib backend is not available | Using the latest IPython (8.22.2) and Matplotlib (3.8.3) the list of available IPython backends is
```python
In [1]: %matplotlib --list
Available matplotlib backends: ['tk', 'gtk', 'gtk3', 'gtk4', 'wx', 'qt4', 'qt5', 'qt6', 'qt', 'osx', 'nbagg', 'webagg', 'notebook', 'agg', 'svg', 'pdf', 'ps', 'inline', 'ipympl', 'w... | closed | 2024-03-11T14:14:38Z | 2024-05-14T09:24:17Z | https://github.com/ipython/ipython/issues/14368 | [] | ianthomas23 | 1 |
vitalik/django-ninja | pydantic | 1,158 | Exceptions log level | **Is your feature request related to a problem? Please describe.**
_Feature to change log level of exceptions and/or remove the logging._
By default in operation.py any raised exception during endpoint handling inside context manager activates this part of the code regardless of what kind of exception it is.
![imag... | closed | 2024-05-09T11:52:05Z | 2024-05-09T11:56:05Z | https://github.com/vitalik/django-ninja/issues/1158 | [] | mrisedev | 1 |
sgl-project/sglang | pytorch | 4,404 | [Bug] When starting with dp, forward_batch.global_num_tokens_gpu is None. | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [ ] 2. The bug has not been fixed in the latest version.
- [ ] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | open | 2025-03-14T01:04:33Z | 2025-03-20T02:35:51Z | https://github.com/sgl-project/sglang/issues/4404 | [] | zzk2021 | 3 |
jpadilla/django-rest-framework-jwt | django | 292 | auth0 and rest framework jwt | Please restframwork-jwt assume that you have already registered user.
in my case, I want to authenticate user via auith0 and then create them in my django app.
how could i do this?
Thanks | closed | 2016-12-22T08:26:26Z | 2017-03-04T16:38:50Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/292 | [] | saius | 1 |
dpgaspar/Flask-AppBuilder | rest-api | 2,195 | Support Personal Access Tokens in addition to AUTH_TYPE | Hi, is it possible to support access token in addition to oauth/oidc authentication.
so that other applications can communicate with the API of the FAB application.
I am dealing this issue when I want to use datahub to ingest metadata from Superset that is built with FAB and the only way for now is when superset ... | open | 2024-02-10T19:44:17Z | 2024-02-20T09:58:38Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2195 | [] | shohamyamin | 1 |
recommenders-team/recommenders | deep-learning | 1,980 | [BUG] Set scipy version back to use the latest one | ### Description
This issue is a backlog to revert the temporary workaround #1971 | closed | 2023-08-29T03:39:45Z | 2024-04-30T04:58:10Z | https://github.com/recommenders-team/recommenders/issues/1980 | [
"bug"
] | loomlike | 2 |
sdl60660/letterboxd_recommendations | web-scraping | 18 | Failed on "Getting User's Movie" stage: redis_get_user_data_job_status failed | Can't seem to scrape my profile's movie on any device or network. Seems to be logging "redis_get_user_data_job_status" as failed. | closed | 2023-11-30T05:11:41Z | 2024-02-02T22:37:54Z | https://github.com/sdl60660/letterboxd_recommendations/issues/18 | [] | TomasCarlson | 2 |
iMerica/dj-rest-auth | rest-api | 319 | Sending verification email to false email produces 500 Internal server error | Currently when a user registers im sending a verification email using a Custom Account Adapter:
```
class CustomAccountAdapter(DefaultAccountAdapter):
def get_email_confirmation_url(self, request, confirmation):
return f"{secret.FRONT_URL}/verify-email?key={confirmation.key}"
def send_mail(self... | open | 2021-10-19T01:40:38Z | 2021-10-19T01:40:38Z | https://github.com/iMerica/dj-rest-auth/issues/319 | [] | adrenaline681 | 0 |
OWASP/Nettacker | automation | 250 | CSV result export feature | Currently Nettacker is only capable of producing results in JSON,TXT and HTML format A new feature to produce results in CSV format is needed
Command line option -o :
`-o results.csv
` | closed | 2020-04-26T23:38:24Z | 2020-05-16T23:53:06Z | https://github.com/OWASP/Nettacker/issues/250 | [
"ask for feature"
] | securestep9 | 1 |
kizniche/Mycodo | automation | 1,058 | Generic Analog pH/EC Actions broken on AJAX-enabled interface | ### Describe the problem/bug
AJAX-enabled interface doesn't allow Actions to be executed. Clicking on the "Calibrate Slot" buttons don't appear to do anything.
### Versions:
- Mycodo Version: 8.11.0 + master branch commit [8d46745](https://github.com/kizniche/Mycodo/commit/8d46745b8439abad903f49eb9da0e27756e8... | closed | 2021-07-18T21:36:01Z | 2021-08-30T02:43:41Z | https://github.com/kizniche/Mycodo/issues/1058 | [
"bug",
"Fixed and Committed"
] | dookaloosy | 1 |
huggingface/diffusers | deep-learning | 10,518 | Some wrong in "diffusers/examples/research_projects/sd3_lora_colab /train_dreambooth_lora_sd3_miniature.py" | ### Describe the bug
https://github.com/huggingface/diffusers/blob/89e4d6219805975bd7d253a267e1951badc9f1c0/examples/research_projects/sd3_lora_colab/train_dreambooth_lora_sd3_miniature.py#L768
<img width="791" alt="截屏2025-01-10 15 09 29" src="https://github.com/user-attachments/assets/4d470d53-56c8-4a4a-be22-9308f... | closed | 2025-01-10T07:10:11Z | 2025-01-13T13:47:29Z | https://github.com/huggingface/diffusers/issues/10518 | [
"bug"
] | CuddleSabe | 0 |
tfranzel/drf-spectacular | rest-api | 778 | How to annotate a serializer field with different request/response schemas? | I have this custom serializer field that is used in a number of serializers:
```python
class NestedPrimaryKeyRelatedField(serializers.PrimaryKeyRelatedField):
def __init__(self, serializer, **kwargs):
"""
On read display a complete nested representation of the object(s)
On write only... | closed | 2022-07-27T00:03:38Z | 2022-07-27T16:08:22Z | https://github.com/tfranzel/drf-spectacular/issues/778 | [] | jerivas | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 868 | Is this model implemented identity mapping loss? | I want to translate painting to photo. | closed | 2019-12-05T14:37:04Z | 2019-12-05T14:49:55Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/868 | [] | Yukkuri5 | 0 |
lukas-blecher/LaTeX-OCR | pytorch | 410 | ValidationError: 1 validation error for InitSchema | I have a problem with importing LatexOCR
`from pix2tex.cli import LatexOCR`
throws me next error:
```
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[1], line 2
1 from PIL import Image
---->... | closed | 2025-01-10T11:01:50Z | 2025-01-13T09:24:28Z | https://github.com/lukas-blecher/LaTeX-OCR/issues/410 | [] | Qwedon | 2 |
chaos-genius/chaos_genius | data-visualization | 671 | Search bug in the KPI screen | closed | 2022-02-09T05:36:58Z | 2022-02-16T18:11:32Z | https://github.com/chaos-genius/chaos_genius/issues/671 | [
"🖥️ frontend"
] | Santhoshkumar1023 | 1 | |
aleju/imgaug | deep-learning | 28 | Getting black image! | First of all thank you very much for this.
When I try to run your example code with these two images, I always get a black image!

.
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software pro... | open | 2024-06-26T09:27:46Z | 2024-07-24T17:34:05Z | https://github.com/ansible/awx/issues/15302 | [
"type:enhancement",
"help wanted",
"community"
] | valkiriaaquatica | 3 |
FactoryBoy/factory_boy | sqlalchemy | 961 | `FuzzyAttribute` actually should be named as `FuzzyFunction` | #### The problem
There is `LazyFunction` (takes callable, without args) and `LazzyAttribute` (takes callable with one argument - self). But only one fuzzy class - `FuzzyAttribute`, which actually takes the same as `LazyFunction`.
#### Proposed solution
I would like to see `FuzzyAttribute` that takes callable and a... | open | 2022-07-10T19:07:01Z | 2022-12-22T14:30:52Z | https://github.com/FactoryBoy/factory_boy/issues/961 | [
"Feature"
] | PerchunPak | 5 |
noirbizarre/flask-restplus | flask | 387 | Requested response fields | In my API, responses contain many fields. In order to download as small responses as possible, I use `X-Fields` header to filter out fields I don't need. How can I get a list of requested response fields in `Resource` method functions so that I can optimize my database queries too? | open | 2018-01-25T11:42:09Z | 2018-01-25T11:42:09Z | https://github.com/noirbizarre/flask-restplus/issues/387 | [] | lubo | 0 |
httpie/cli | python | 722 | --ssl — TLS 1.3 & Python 3.7 compatibility | Now that TLS1.3 is out **[1]** it would be great to add that to the list of supported ssl parameters.
` [--ssl {ssl2.3,tls1,tls1.1,tls1.2}] [--cert CERT]`
**[1]** https://tools.ietf.org/html/rfc8446
| open | 2018-10-17T10:04:07Z | 2023-12-19T19:12:50Z | https://github.com/httpie/cli/issues/722 | [] | jaimejim | 4 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,613 | Training the model on custom dataset | HI team it's a wonderful work you've. It's appreciable.
However I am trying to fine tune the model on my custom dataset which has noise(check boxes) in them and need the output as data without checkboxes. I trained the model using the necessary requirements of the CycleGAN but still when I test the the images with che... | open | 2023-11-09T10:16:26Z | 2023-11-09T10:16:26Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1613 | [] | AGRocky | 0 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 948 | Missing synthesizer pretrained.pt | I already tried these files
https://drive.google.com/drive/folders/1aPYBbabQGNFHp6DegcKhfwNyLTXcKg5f?usp=sharing from Francisco
https://drive.google.com/drive/folders/1lb-LlS8Sx9RqcGzuV6GxvKHk-PC9TqQx?usp=sharing from Alex
https://drive.google.com/file/d/1n1sPXvT34yXFLT47QZA6FIRGrwMeSsZc/view from RobbeW
I still... | closed | 2021-12-12T18:57:52Z | 2021-12-28T16:57:09Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/948 | [] | AsterTheWanderer | 2 |
coqui-ai/TTS | python | 3,187 | AttributeError: 'TTS' object has no attribute 'is_multi_speaker'[Bug] | ### Describe the bug
pip list | grep TTS
TTS 0.20.2
### To Reproduce
pip list | grep TTS
TTS 0.20.2
### Expected behavior
_No response_
### Logs
_No response_
### Environment
``... | closed | 2023-11-10T04:47:43Z | 2023-12-21T10:01:51Z | https://github.com/coqui-ai/TTS/issues/3187 | [
"bug"
] | lucasjinreal | 9 |
huggingface/datasets | numpy | 7,448 | `datasets.disable_caching` doesn't work | When I use `Dataset.from_generator(my_gen)` to load my dataset, it simply skips my changes to the generator function.
I tried `datasets.disable_caching`, but it doesn't work! | open | 2025-03-13T06:40:12Z | 2025-03-22T04:37:07Z | https://github.com/huggingface/datasets/issues/7448 | [] | UCC-team | 2 |
flairNLP/flair | pytorch | 3,313 | [Question]: How the StackedEmbeddings function actually works? | ### Question
How the StackedEmbeddings function actually works?
Is it concatinating the two word embeddings, i.e. using torch.cat([emb1, emb2]).
I want to concatinate BytePairEmbeddings with TransformerWordEmbeddings, so i'm doing like this:
bert_emb = TransformerWordEmbeddings(
model='xlm-roberta-base',
... | open | 2023-09-08T02:18:21Z | 2023-09-18T08:13:31Z | https://github.com/flairNLP/flair/issues/3313 | [
"question"
] | ijazul-haq | 3 |
plotly/dash-table | dash | 957 | please I need a feature that dragging to selecting range on datatable | please I need a feature that dragging to selecting range on datatable
it is available in Streamlit...!!!! | open | 2024-05-30T16:08:18Z | 2024-05-30T16:08:18Z | https://github.com/plotly/dash-table/issues/957 | [] | nicobockko | 0 |
tensorly/tensorly | numpy | 580 | [doc] Adding proper documentation for proximal operators | #### Issue
We have several cool proximal operators inside the submodule `tenalg/proximal.py`, which are not documented.
#### Fix
It would be simple and useful, in my opinion, to have a small text in the documentation about it.
I should be able to tackle this in the near future.
| open | 2024-10-31T07:58:04Z | 2024-10-31T08:09:14Z | https://github.com/tensorly/tensorly/issues/580 | [
"documentation",
"easy issue"
] | cohenjer | 0 |
onnx/onnx | deep-learning | 6,426 | [Feature request] Deno webgpu support | ### System information
_No response_
### What is the problem that this feature solves?
Support to running onnx models in webgpu using deno
### Alternatives considered
_No response_
### Describe the feature
Deno has support to webgpu since v1.39
### Will this influence the current api (Y/N)?
_No response_
### ... | closed | 2024-10-04T03:14:35Z | 2024-10-04T03:17:59Z | https://github.com/onnx/onnx/issues/6426 | [
"topic: enhancement"
] | jlucaso1 | 0 |
seleniumbase/SeleniumBase | pytest | 3,053 | Need updated UC examples | The example code for using SB with UC given here seem to no longer work:
https://github.com/seleniumbase/SeleniumBase/blob/af3d9545473e55b2a25cdbab8be0b1ed5e1f6afa/examples/raw_uc_mode.py
Here's my code running the example on Python 3.12 on Ubuntu 24.04 LTS
```python
import os
import sys
import time
imp... | closed | 2024-08-24T07:02:52Z | 2024-08-24T21:03:32Z | https://github.com/seleniumbase/SeleniumBase/issues/3053 | [
"invalid usage",
"UC Mode / CDP Mode"
] | krypterro | 5 |
piskvorky/gensim | data-science | 2,951 | calculation of downsampling .sample_int after vocab-updates looks wrong | The updating of `.sample_int` after a `build_vocab(..., update=True)` looks wrong at:
https://github.com/RaRe-Technologies/gensim/blob/3.8.3/gensim/models/word2vec.py#L1534-L1544
In particular, by only consulting the `raw_vocab` (which in this case is only the new vocab-survey), in many cases it may be failing to... | open | 2020-09-16T19:04:43Z | 2020-09-16T19:05:04Z | https://github.com/piskvorky/gensim/issues/2951 | [] | gojomo | 0 |
httpie/cli | api | 639 | Print request headers regardless of connection error | If `-v` is set in the command line arguments HTTPie prints the request along with the response.
The request is however not printed if a connection error happened, eg. the connection was closed by server before receiving a response.
I think it would be helpful to see the request printed in such case for debugging ... | closed | 2017-12-07T13:21:34Z | 2019-09-03T15:22:37Z | https://github.com/httpie/cli/issues/639 | [
"enhancement",
"planned"
] | maciej | 4 |
huggingface/datasets | pytorch | 7,441 | `drop_last_batch` does not drop the last batch using IterableDataset + interleave_datasets + multi_worker | ### Describe the bug
See the script below
`drop_last_batch=True` is defined using map() for each dataset.
The last batch for each dataset is expected to be dropped, id 21-25.
The code behaves as expected when num_workers=0 or 1.
When using num_workers>1, 'a-11', 'b-11', 'a-12', 'b-12' are gone and instead 21 and 22 a... | open | 2025-03-08T10:28:44Z | 2025-03-09T21:27:33Z | https://github.com/huggingface/datasets/issues/7441 | [] | memray | 2 |
tiangolo/uvicorn-gunicorn-fastapi-docker | pydantic | 152 | How to embed a fairseq model in a uvicorn-gunicorn-fastapi-docker | Hi,
I'm trying to embed a fairseq (https://fairseq.readthedocs.io/en/latest/) model into a uvicorn-gunicorn-fastapi-docker based service. My problem is that fairseq is adding a lot of elements to argparse.ArgumentParser before gunicorn starts and that the latter tries to parse them:
```
semparsing_tool-semanticparsi... | closed | 2022-02-08T11:54:17Z | 2022-02-09T18:23:05Z | https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker/issues/152 | [] | kleag | 1 |
mckinsey/vizro | pydantic | 964 | Is it possible to restrict Dash AG Grid editing to admins only? | ### Question
I would like to know if it’s possible to create a feature where only users with admin credentials can access and edit the Dash AG Grid. The goal is to display the grid with view-only permissions for non-admin users, while allowing admins to modify the grid’s content.
Could you provide guidance on how to ... | closed | 2025-01-23T07:29:09Z | 2025-01-27T07:24:30Z | https://github.com/mckinsey/vizro/issues/964 | [
"Needs triage :mag:",
"General Question :question:"
] | BalaNagendraReddy | 2 |
davidsandberg/facenet | tensorflow | 614 | How to pretrain model when setting --pretrained_model | Error:
```
Data loss: not an sstable (bad magic number)
```
I used pretrained model by repository and first-echo-model from scratch training, both failed with the same error. | closed | 2018-01-16T12:14:09Z | 2019-06-18T11:59:44Z | https://github.com/davidsandberg/facenet/issues/614 | [] | xiaoxinyi | 2 |
proplot-dev/proplot | data-visualization | 169 | Pass rc.cmap and rc.cycle arguments through respective constructor functions | ### Description
Since `cycle` supports cmaps, the input of cmap name in the configuration should be supported.
### Steps to reproduce
```python
import proplot as plot
import numpy as np
fig, axs = plot.subplots()
state = np.random.RandomState(51423)
data = (20 * state.rand(10, 21) - 10).cumsum(axis=0)
... | closed | 2020-05-16T12:11:52Z | 2021-08-18T19:36:42Z | https://github.com/proplot-dev/proplot/issues/169 | [
"duplicate"
] | zxdawn | 2 |
joke2k/django-environ | django | 123 | Expose .env variables as a dictionary | Use case:
I try to use my project on a AWS Beanstalk instance. For this to run, I have to set environment variables. If django-environ would expose the .env variables in a structure that can be looped, I could script this and it would save me some time (and allow to automate).
Pointer to https://github.com/pedrobur... | open | 2017-05-05T08:06:26Z | 2021-09-04T20:26:36Z | https://github.com/joke2k/django-environ/issues/123 | [
"enhancement"
] | philippeluickx | 0 |
nltk/nltk | nlp | 2,456 | grammar.CFG.is_chomsky_normal_form returns True even if start symbol is produced by some production | In a Chomsky normal form grammar, the start symbol must not occur on the right side of a production by definition. However, the current implementation does not check for this. As a result, NLTK indicates that the grammar `S -> S S` is in normal form, even though it does not comply with the definition.
```
>>> import ... | closed | 2019-11-03T07:27:13Z | 2021-11-17T08:34:08Z | https://github.com/nltk/nltk/issues/2456 | [
"resolved"
] | jacobdweightman | 2 |
nvbn/thefuck | python | 1,453 | Python 3.11 and 3.12 complains about `imp` which cannot be installed in those environments. | FYI: Python 3.11 and 3.12 on latest Ubuntu, `thefuck` screams `imp` is missing... there seem to be not viable workaround except custom `imp` build. Ehhh... | open | 2024-07-03T02:45:22Z | 2024-08-12T00:35:55Z | https://github.com/nvbn/thefuck/issues/1453 | [] | krstp | 5 |
keras-team/keras | python | 20,172 | Is there a keras 3 equivalent to serialization.DisableSharedObjectScope()? | I am trying to add support for keras 3 to TensorFlow Federated and I need to check whether there was shared embeddings between layers when cloning a model and if that is the case to raise an error. Here is the code in question:
https://github.com/google-parfait/tensorflow-federated/blob/523c129676236f7060fafb95b2a8fe... | closed | 2024-08-27T09:14:41Z | 2024-10-21T11:43:41Z | https://github.com/keras-team/keras/issues/20172 | [
"type:support"
] | markomitos | 5 |
vitalik/django-ninja | rest-api | 487 | Personalize and securize Redoc Page | Hello!
I'm trying to customize the Swagger/REDOC documenter a bit.
Is there a way to change the favicon displayed in the REDOC/Swagger documenter, without doing a complete override of templates/ninja/swagger.html|redoc.html ?
Swagger, in conjunction with the rest_famework package, can be configured to not allow ... | closed | 2022-06-28T10:29:41Z | 2022-06-30T08:59:56Z | https://github.com/vitalik/django-ninja/issues/487 | [] | JFeldaca | 3 |
fastapiutils/fastapi-utils | fastapi | 261 | [QUESTION] There's a way to add a custom decorator to a class-based view? | I'm trying to do something like the following:
```python
@cbv(users_router)
@ResponseHandler.class_decorator
class Users:
controller = UserController()
@users_router.post("/users", status_code=201)
async def create_user(self, user_data: Dict, response: Response) -> Dict:
return self.c... | open | 2022-10-18T04:42:07Z | 2022-10-18T04:43:53Z | https://github.com/fastapiutils/fastapi-utils/issues/261 | [
"question"
] | JesusFragoso | 1 |
chaoss/augur | data-visualization | 2,292 | Explore incorporatating softcite/softcite_kb data into Augur for Academic Metrics | **Is your feature request related to a problem? If so, please describe the problem:**
Working in the context of the @chaoss project, we are developing metrics for Academic open source contexts. These include alt metrics related to software, as well as more conventional metrics related to academic publications.
htt... | open | 2023-04-05T20:04:27Z | 2023-06-04T17:38:58Z | https://github.com/chaoss/augur/issues/2292 | [
"good first issue",
"first-timers-only"
] | sgoggins | 1 |
dynaconf/dynaconf | django | 348 | Add mount point option for vault | **Is your feature request related to a problem? Please describe.**
We are using this library for configuration and are currently moving our secrets to vault. However, there is no option to set the `mount_point`. This means it ends up using the default from the `hvac` client (`secret`).
**Describe the solution you'... | closed | 2020-05-29T15:04:49Z | 2020-05-29T17:11:37Z | https://github.com/dynaconf/dynaconf/issues/348 | [
"Not a Bug",
"RFC"
] | sfunkhouser | 0 |
piskvorky/gensim | data-science | 3,232 | Negative exponent with value -1 (minus one) raises error when loading Doc2Vec model | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2021-09-13T16:12:11Z | 2021-10-28T01:18:52Z | https://github.com/piskvorky/gensim/issues/3232 | [
"bug",
"difficulty easy",
"good first issue",
"impact HIGH",
"reach LOW"
] | edg-stg | 3 |
LibreTranslate/LibreTranslate | api | 202 | Frontend is bugged | I try to go and enter some text here:
https://libretranslate.com/#
As I type it it tries to translate each time, and then within a couple seconds I reach a translation timeout limit.
There should be some kind of cool off period between typing where it waits a bit before it tries a translation. | closed | 2022-01-31T09:58:38Z | 2022-01-31T15:50:30Z | https://github.com/LibreTranslate/LibreTranslate/issues/202 | [] | mayeaux | 6 |
zappa/Zappa | django | 596 | [Migrated] Fix the naming of event rule target id | Originally from: https://github.com/Miserlou/Zappa/issues/1546 by [jaykay](https://github.com/jaykay)
<!--
Before you submit this PR, please make sure that you meet these criteria:
* Did you read the [contributing guide](https://github.com/Miserlou/Zappa/#contributing)?
* If this is a non-trivial commit, did ... | closed | 2021-02-20T12:26:22Z | 2022-08-18T12:56:39Z | https://github.com/zappa/Zappa/issues/596 | [] | jneves | 1 |
docarray/docarray | fastapi | 1,099 | Investigate if we can depend on `jaxtyping` for tensor type hints | @johannes what is the conclusion here ? | open | 2023-02-08T08:24:07Z | 2023-02-08T10:33:09Z | https://github.com/docarray/docarray/issues/1099 | [] | JohannesMessner | 4 |
plotly/dash | data-visualization | 2,423 | Add loading attribute to html.Img component | **Is your feature request related to a problem? Please describe.**
I'm trying to lazy load images using the in built browser functionality, but I can't because that's not exposed in the html.Img component.
**Describe the solution you'd like**
I'd like the loading attribute to be added to the html.Img built in comp... | open | 2023-02-13T12:15:58Z | 2024-08-13T19:26:45Z | https://github.com/plotly/dash/issues/2423 | [
"feature",
"P3"
] | LiamLombard | 1 |
seleniumbase/SeleniumBase | web-scraping | 2,728 | Exporting recorded script to json | Hi, I am using **seleniumbase** to record actions on my browser. It works fine and generates a script having all the steps followed during the recording. I want to export all the actions and the subsequent element id/URL/texts into a json file. How can I do that?
I am using **sbase mkrec new_test_1.py --url=imdb.com*... | closed | 2024-04-29T12:27:36Z | 2024-05-03T14:45:38Z | https://github.com/seleniumbase/SeleniumBase/issues/2728 | [
"question"
] | Ashish3080 | 3 |
httpie/http-prompt | api | 160 | Support for custom methods (or WebDAV methods) | I think WebDAV is not the only http extension out there, maybe it makes sense to just consider the first word (if it is not reserved word) a method? | open | 2019-09-18T12:51:45Z | 2019-09-18T12:51:45Z | https://github.com/httpie/http-prompt/issues/160 | [] | trollfred | 0 |
encode/httpx | asyncio | 2,892 | Constrain which encodings are supported by `response.text`. | - [x] Initially raised as discussion #2881
---
Currently when accessing `response.text` any installed codec may be loaded, depending on the `Content-Type` header of the response. This is problematic partly because not all codecs are text codecs. It also feels too open, as custom codecs might be installed with arb... | open | 2023-10-13T12:44:03Z | 2023-10-13T12:46:04Z | https://github.com/encode/httpx/issues/2892 | [
"enhancement"
] | tomchristie | 0 |
deepfakes/faceswap | deep-learning | 677 | Dockerfile.gpu use the latest tensorflow version | The Dockerfile.gpu use `FROM tensorflow/tensorflow:latest-py3`
The latest version of tensorflow is 2.0 alpha.(You may check this )[docker hub](https://hub.docker.com/r/tensorflow/tensorflow/tags?page=1)
It will cause compatibility problems。
So ,I think we should use the specified tensorflow version。
We may use `FRO... | closed | 2019-03-21T09:09:09Z | 2019-03-21T09:39:06Z | https://github.com/deepfakes/faceswap/issues/677 | [] | lynnfi | 1 |
OpenInterpreter/open-interpreter | python | 1,320 | one-line installer does not set up openinterpreter | ### Describe the bug
both: on a windows 11 system with python 3.12, and on a linux system with python3 3.10,
running the one-line installation script leaves me with:
`openinterpreter: command not found` or its windows equivalent
The same occurs with installing via pip
I tried adding /usr/local/bin to PATH as... | open | 2024-06-23T17:05:56Z | 2024-07-10T13:55:17Z | https://github.com/OpenInterpreter/open-interpreter/issues/1320 | [] | MisterE123 | 3 |
tensorflow/tensor2tensor | machine-learning | 1,663 | cannot import name 'loas2' | ### Description
I am trying to run `rl/trainer_model_based.py`.
I run the example command in the file and got the error at line 24 of `env/client_env.py`.
`from grpc import loas2`
I tried several version of grpc in case of library change, but not succeed.
### Environment information
```
OS: ubuntu 16.... | closed | 2019-08-16T15:17:30Z | 2019-08-26T18:39:01Z | https://github.com/tensorflow/tensor2tensor/issues/1663 | [] | KyunghyunLee | 4 |
AntonOsika/gpt-engineer | python | 133 | ValueError: too many values to unpack (expected 1) | Anyone can help with this one? | closed | 2023-06-18T00:51:08Z | 2023-06-18T07:38:29Z | https://github.com/AntonOsika/gpt-engineer/issues/133 | [] | Suketug | 6 |
huggingface/datasets | tensorflow | 6,824 | Winogrande does not seem to be compatible with datasets version of 1.18.0 | ### Describe the bug
I get the following error when simply running `load_dataset('winogrande','winogrande_xl')`.
I do not have such an issue in the 1.17.0 version.
```Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/dist-packages/datasets/load.py", line... | closed | 2024-04-18T16:11:04Z | 2024-04-19T09:53:15Z | https://github.com/huggingface/datasets/issues/6824 | [] | spliew | 2 |
zappa/Zappa | django | 527 | [Migrated] An error occurred (IllegalLocationConstraintException) during zappa deploy | Originally from: https://github.com/Miserlou/Zappa/issues/1398 by [mcmonster](https://github.com/mcmonster)
See https://github.com/Miserlou/Zappa/issues/569
I also experienced this issue when attempting to deploy following the out-of-the-box README commands. Zappa's deploy procedure is obfuscating the cause of th... | closed | 2021-02-20T09:43:57Z | 2023-08-17T01:08:28Z | https://github.com/zappa/Zappa/issues/527 | [
"bug",
"aws"
] | jneves | 1 |
falconry/falcon | api | 1,743 | Why the examples need to modify, or it can run | closed | 2020-07-21T09:34:51Z | 2020-07-21T09:35:22Z | https://github.com/falconry/falcon/issues/1743 | [] | mansonami | 1 | |
absent1706/sqlalchemy-mixins | sqlalchemy | 71 | Using existing database | I already have a database, I am using SQLAlchemy to interact with it. I have currently mapped database tables to SQLAlchemy objects as mentioned below.
`Base = automap_base()`
`Material = Base.classes.app1_material`
`Customer = Base.classes.app1_customer`
Can you share how to extend `sqlalchemy-mixi... | open | 2021-04-27T04:56:50Z | 2021-04-27T17:04:04Z | https://github.com/absent1706/sqlalchemy-mixins/issues/71 | [] | mswastik | 1 |
jonaswinkler/paperless-ng | django | 1,717 | [Other] Each User own Documents | <!--
=> Discussions, Feedback and other suggestions belong in the "Discussion" section and not on the issue tracker.
=> If you would like to submit a feature request please submit one under https://github.com/jonaswinkler/paperless-ng/discussions/categories/feature-requests
=> If you encounter issues while ins... | closed | 2022-07-14T13:26:37Z | 2023-01-14T12:56:27Z | https://github.com/jonaswinkler/paperless-ng/issues/1717 | [] | Nollknolle | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.