
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
miguelgrinberg/Flask-Migrate | flask | 242 | Tutorial sections 4.5+ - No Changes in Schema detected (Solution?) | Hi
For the command line examples in Section 4.5 - 4.9 to work. Namely the "flask db migrate -m "users table" and subsequent upgrades.
You need the import statements seen in the Shell Context example for Ex 4.10.
As stated in other issues / posts the Model and the DB aren't imported to be seen by the Flask db m... | closed | 2018-12-24T19:30:01Z | 2019-04-07T09:55:51Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/242 | [
"question"
] | JeanNiBee | 2 |
jina-ai/serve | machine-learning | 5,272 | Align on OpenTelemetry service names and cloud semantic attributes. | The current tracers are using the default runtime name or module name to create spans. These are currently very generic and don't differentiate between different flows. Without unique service names and other cloud deployment attributes ([k8s](https://opentelemetry.io/docs/reference/specification/resource/semantic_conve... | closed | 2022-10-11T15:07:15Z | 2022-11-21T12:38:55Z | https://github.com/jina-ai/serve/issues/5272 | [] | girishc13 | 1 |
holoviz/panel | matplotlib | 6,927 | panel.serve() implicitly and unconditionally captures SIGINT under the hood | ### ALL software version info
panel 1.4.4 (currently latest). Others are irrelevant, I believe, but still:
- python 3.9
- bokeh 3.4.1
- OS Windows 11
- browser FireFox (definitely irrelevant)
### Description of expected behavior and the observed behavior
#### Observed:
`panel.serve(..., threaded=False)` de... | open | 2024-06-17T13:26:21Z | 2024-06-17T13:45:18Z | https://github.com/holoviz/panel/issues/6927 | [] | mcskatkat | 0 |
inducer/pudb | pytest | 257 | Failure on Windows 10 | `pip install` reports success:
```
C:\Users\bruce\Documents\Git\on-java>pip install pudb
Collecting pudb
Downloading pudb-2017.1.2.tar.gz (53kB)
100% |████████████████████████████████| 61kB 72kB/s
Collecting urwid>=1.1.1 (from pudb)
Downloading urwid-1.3.1.tar.gz (588kB)
100% |████████████████████... | closed | 2017-06-06T16:44:20Z | 2017-06-06T21:20:14Z | https://github.com/inducer/pudb/issues/257 | [] | BruceEckel | 10 |
alteryx/featuretools | data-science | 2,287 | Move all Natural Language primitives that don't require an external library into core Featuretools | - As a user of Featuretools core, I want to apply NL primitives without install nlp-primitives.
- We need to move all the primitives that don't require an external library into Featuretools core:
- https://github.com/alteryx/nlp_primitives | closed | 2022-09-12T18:00:12Z | 2022-10-20T16:25:16Z | https://github.com/alteryx/featuretools/issues/2287 | [] | gsheni | 0 |
PokeAPI/pokeapi | graphql | 373 | Availability of named resources (for current hosting) | This issue is to consolidate updates for the current outage of named resources (eg. /pokemon/bulbasaur) into one place.
See also #374 for work on getting named resources working when we move to Netlify. | closed | 2018-09-22T22:10:54Z | 2018-09-22T23:55:51Z | https://github.com/PokeAPI/pokeapi/issues/373 | [] | tdmalone | 14 |
slackapi/python-slack-sdk | asyncio | 959 | RTMClient v2 - OSError: [Errno 9] Bad file descriptor | RTMClientv2 regularly disconnects. (26 times in a 24 hour period).
### Reproducible in:
#### The Slack SDK version
slack-sdk==3.3.1
#### Python runtime version
Python 3.8.7
#### OS info
Linux 5.4.97-gentoo #1 SMP
#### Steps to reproduce:
Run the RTMClientv2 for extended periods of time.
##... | closed | 2021-02-17T00:46:52Z | 2021-02-19T08:42:31Z | https://github.com/slackapi/python-slack-sdk/issues/959 | [
"rtm-client",
"Version: 3x"
] | nzlosh | 4 |
PaddlePaddle/models | computer-vision | 4,833 | 已解决 | closed | 2020-09-03T03:12:17Z | 2020-09-03T07:32:16Z | https://github.com/PaddlePaddle/models/issues/4833 | [] | kyuer | 0 | |
d2l-ai/d2l-en | deep-learning | 2,097 | d2l makes os.environ["CUDA_VISIBLE_DEVICES"] = "1" invalid | when i try to import d2l into my project, I found if os.environ["CUDA_VISIBLE_DEVICES"] is set after the d2l, then it will be valid.
<img width="443" alt="image" src="https://user-images.githubusercontent.com/38461329/162663129-7294395b-f58a-4de4-8eed-4dde85bd2229.png">
before run this program

حالا وقتی ادمین سودو از طریق ربات اقدام به سایت یوزر میکنه؛ `admin_id` در جدول `users` مقدارش null هست:
... | closed | 2024-06-23T21:17:27Z | 2024-07-03T06:34:55Z | https://github.com/Gozargah/Marzban/issues/1059 | [
"Bug"
] | amotlagh | 1 |
blb-ventures/strawberry-django-plus | graphql | 249 | hard dependency on django.contrib.auth | The line in utils/typing.py:
UserType: TypeAlias = Union[AbstractUser, AnonymousUser]
requires the inclusion of "django.contrib.auth" in INSTALLED_APPS
it would be better to use the
AbstractBaseUser of django/contrib/auth/base_user.py as it doesn't require the inclusion and is even the base of AbstractUser... | closed | 2023-06-19T09:05:20Z | 2023-06-24T12:25:58Z | https://github.com/blb-ventures/strawberry-django-plus/issues/249 | [] | devkral | 1 |
KrishnaswamyLab/PHATE | data-visualization | 124 | Install issue, probably sklearn -> scikit-learn versions | We are having errors installing phate, and I think it tracks back to here, and to updates in scikit-learn. I posted details in the graphtools repo: https://github.com/KrishnaswamyLab/graphtools/issues/64.
I believe scikit-learn 1.2.0 breaks graphtools /PHATE. Have you seen this issue? Thanks in advance. | closed | 2022-12-27T15:29:49Z | 2023-01-03T07:14:53Z | https://github.com/KrishnaswamyLab/PHATE/issues/124 | [
"bug"
] | bbimber | 4 |
onnx/onnx | pytorch | 6,572 | It should be dim instead of a | https://github.com/onnx/onnx/blob/96a0ca4374d2198944ff882bd273e64222b59cb9/onnx/reference/ops/op_center_crop_pad.py#L24 | open | 2024-12-04T08:03:06Z | 2024-12-04T08:03:06Z | https://github.com/onnx/onnx/issues/6572 | [] | aksenventwo | 0 |
postmanlabs/httpbin | api | 661 | URL prefix? | Hey there,
My company has been using httpbin copiously and while we think it's fantastic, one consistent problem we've been having is trying to set httpbin behind a url path prefix (e.g. no httpbin.mydomain.com but mydomain.com/httpbin). We've scoured the documentation and it does not seem like this is possible alth... | open | 2021-11-30T18:24:13Z | 2023-08-29T00:05:59Z | https://github.com/postmanlabs/httpbin/issues/661 | [] | juandiegopalomino | 1 |
mckinsey/vizro | pydantic | 798 | Add default styling for waterfall chart to chart template | Context: https://github.com/mckinsey/vizro/pull/786 | open | 2024-10-08T09:50:55Z | 2024-10-08T13:35:27Z | https://github.com/mckinsey/vizro/issues/798 | [] | huong-li-nguyen | 3 |
ansible/ansible | python | 84,743 | PowerShell module doesn't accept type list in spec | ### Summary
When I try to run a custom module whose spec has a list type, it errors with
`"Exception calling "Create" with "2" argument(s): Unable to cast object of type 'System.String' to type 'System.Collections.IList'.`
# min viable:
```powershell
#AnsibleRequires -CSharpUtil Ansible.Basic
$spec = @{
optio... | closed | 2025-02-24T16:12:51Z | 2025-03-10T13:00:03Z | https://github.com/ansible/ansible/issues/84743 | [
"bug",
"affects_2.18"
] | michaeldcanady | 5 |
python-gino/gino | sqlalchemy | 692 | Continually Getting TypeError: 'GinoExecutor' object is not callable | * GINO version: 1.0.0
* Python version: 3.7
* asyncpg version: 0.20.1
* aiocontextvars version: Not installed
* PostgreSQL version: 12.1
### Description
Attempting to make a simple query but am unable to.
### What I Did
While running:
```
domain = await Domain.get(Domain.domain == 'http://domain.c... | closed | 2020-06-03T08:46:19Z | 2020-06-03T15:06:26Z | https://github.com/python-gino/gino/issues/692 | [] | austincollinpena | 4 |
ultralytics/ultralytics | pytorch | 19,708 | Assertion Error | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hellooo,
I have done a fine-tunning like this with my images with a differe... | closed | 2025-03-14T23:15:49Z | 2025-03-15T22:13:59Z | https://github.com/ultralytics/ultralytics/issues/19708 | [
"question",
"segment",
"exports"
] | davidpacios | 5 |
vanna-ai/vanna | data-visualization | 408 | Add No-SQL Database Support | Description: This feature request proposes adding support for No-SQL databases to the vanna project. No-SQL databases are a type of database that is not based on the relational model. They are a good option for storing data that does not fit well into a relational schema, such as JSON data.
Benefits:
- Increased fl... | open | 2024-05-04T16:33:26Z | 2025-03-20T06:33:58Z | https://github.com/vanna-ai/vanna/issues/408 | [] | shrijayan | 4 |
deeppavlov/DeepPavlov | nlp | 1,239 | Provide an extensive example of API usage in go-bot | The go-bot is able ([example](https://github.com/deepmipt/DeepPavlov/blob/master/examples/gobot_extended_tutorial.ipynb)) to query an API to get the data. It allows to perform the dialog relying onto some explicit knowledge.
In the provided example the bot queries the database to perform some read operations. Operat... | closed | 2020-06-04T13:50:55Z | 2022-04-06T10:17:34Z | https://github.com/deeppavlov/DeepPavlov/issues/1239 | [
"Documentation",
"code",
"easy"
] | oserikov | 1 |
mithi/hexapod-robot-simulator | plotly | 33 | ❗Some unstable poses are marked as stable | ❗ Some unstable poses are not marked as unstable
<img width="1253" alt="Screen Shot 2020-04-18 at 10 19 55 PM" src="https://user-images.githubusercontent.com/1670421/79640224-f9a1f200-81c2-11ea-9ee0-c18d8d655417.png">
| closed | 2020-04-11T10:26:25Z | 2020-04-23T15:22:07Z | https://github.com/mithi/hexapod-robot-simulator/issues/33 | [
"bug",
"help wanted",
"PRIORITY"
] | mithi | 1 |
Johnserf-Seed/TikTokDownload | api | 719 | [BUG] Error Downloading TikTok Posts Due to msToken API Error | ## 错误的详细描述
在使用 `f2 tk` 命令尝试下载抖音帖子时,我经常遇到错误。相同的设置过程用于下载抖音(Douyin)时正常工作。
## 系统平台
<details>
<summary>点击展开</summary>
- **操作系统**: Windows 11
- **Python 版本**: Python 3.11.1
- **F2 版本**: 0.0.1.5
- **浏览器**: Firefox
- **网络环境**: 美国,无代理
</details>
## 错误复现步骤
<details>
<summary>点击展开</summary>
1. 在 `douyin\Li... | closed | 2024-05-25T13:39:14Z | 2024-07-03T00:11:59Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/719 | [
"故障(bug)",
"已确认(confirmed)"
] | iDataist | 4 |
521xueweihan/HelloGitHub | python | 2,844 | 【开源自荐】ReactPress — 基于React的博客&CMS内容管理系统 | ## 推荐项目
- 项目地址:<https://github.com/fecommunity/reactpress>
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:JS
<!--请用 20 个左右的字描述它是做什么的,类似文章标题让人一目了然 -->
- 项目标题:基于React的博客&CMS内容管理系统
<!--这是个什么项目、能用来干什么、有什么特点或解决了什么痛点,适用于什么场景、能够让初学者学到什么。长度 32-256 字符-->
- 项目... | open | 2024-11-11T14:40:52Z | 2024-11-11T14:40:52Z | https://github.com/521xueweihan/HelloGitHub/issues/2844 | [] | fecommunity | 0 |
odoo/odoo | python | 202,218 | [18.0] hr_holidays: on leave refusal, first_approver_id and second_approver_id are wrongly updated | ### Odoo Version
- [ ] 16.0
- [ ] 17.0
- [x] 18.0
- [ ] Other (specify)
### Steps to Reproduce
Given a leave having 'both' as validate_type (leave 'By Employee's Approver and Time Off Officer').
When the employee's first approver approves the leave, and the second approver refuses the leave
Then the leave first_appr... | open | 2025-03-18T05:20:46Z | 2025-03-18T05:20:46Z | https://github.com/odoo/odoo/issues/202218 | [] | dsauvage | 0 |
learning-at-home/hivemind | asyncio | 320 | [Minor] make "could not connect" errors in example more pronounced | In examples/albert, if a peer cannot connect to others, it will print something like:
```
[...][WARN][dht.node.create:234] DHTNode bootstrap failed: none of the initial_peers responded to a ping.
```
Which is nice, but no one will ever see this warning among 100+ lines of other logs (training config, module warni... | closed | 2021-07-15T13:10:20Z | 2021-08-20T15:08:42Z | https://github.com/learning-at-home/hivemind/issues/320 | [
"enhancement"
] | justheuristic | 0 |
jupyterlab/jupyter-ai | jupyter | 871 | Jupyter AI plugin schema is never loaded; contains unused cell toolbar and menus | I was trying to add a shortcut for https://github.com/jupyterlab/jupyter-ai/issues/799 and noticed that there is `schema/plugin.json` which contains a cell toolbar button and menu actions:
https://github.com/jupyterlab/jupyter-ai/blob/5183bc9281d81a953b0f360e76b03dc15f3d8987/packages/jupyter-ai/schema/plugin.json#L7... | closed | 2024-07-05T09:24:31Z | 2024-07-08T15:51:15Z | https://github.com/jupyterlab/jupyter-ai/issues/871 | [
"bug"
] | krassowski | 1 |
facebookresearch/fairseq | pytorch | 5,538 | Has anyone got the MMPT example to work? | ## 🐛 Bug
I am running into so many dependency errors when trying to use VideoCLIP model. If anyone has gotten it to work please share your details on which package versions you have installed, etc.
By the way, I'm trying to get the model to compare if a video and text match and get a score from that.
I am cur... | open | 2024-09-05T18:08:36Z | 2024-10-13T07:51:31Z | https://github.com/facebookresearch/fairseq/issues/5538 | [
"bug",
"needs triage"
] | qingy1337 | 1 |
jeffknupp/sandman2 | sqlalchemy | 112 | does sandman2 query data support “>” "<" | ### Environment
MySQL 8.0
sandman2 1.2.1
pymysql 0.9.3
Postman 7.2.2
Operating system: win7 x64
### Description of issue
**step1 create table and insert data**
create database paspce ,create table t_areainfo , insert data to table.
like this
"create database if not exists pspace;
create table if not exis... | closed | 2019-07-11T06:35:48Z | 2019-07-22T07:33:35Z | https://github.com/jeffknupp/sandman2/issues/112 | [] | abcweizhuo | 1 |
graphdeco-inria/gaussian-splatting | computer-vision | 1,151 | Why not camera's intrinsic parameters(cx,cy) adjusted with image resolution ? | Why, when the image resolution is adjusted by factors of 2, 4, or 8 and the image size is reduced, are the camera's intrinsic parameters not adjusted, especially the values of the intrinsic parameters cx and cy?
| open | 2025-02-03T16:43:58Z | 2025-03-04T08:34:51Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/1151 | [] | scott198510 | 1 |
strawberry-graphql/strawberry | fastapi | 3,349 | When i use run with python3, ImportError occured | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
ImportError : cannot import name 'GraphQLError' from... | closed | 2024-01-19T02:17:47Z | 2025-03-20T15:56:34Z | https://github.com/strawberry-graphql/strawberry/issues/3349 | [] | evan-hwang | 6 |
mckinsey/vizro | data-visualization | 991 | Allow horizontally-aligned radio items | ### Which package?
vizro
### What's the problem this feature will solve?
[dbc.RadioItems](https://dash-bootstrap-components.opensource.faculty.ai/docs/components/input/) on which `vm.RadioItems` is based allows horizontally-aligned radio items through the `inline` option.
### Describe the solution you'd like
Allow... | closed | 2025-02-04T16:39:06Z | 2025-03-24T20:03:57Z | https://github.com/mckinsey/vizro/issues/991 | [
"Feature Request :nerd_face:"
] | gtauzin | 11 |
pydata/xarray | numpy | 9,877 | infer_freq() doesn't recognize monthly output if the time dimension is the middle of each month | ### What happened?
CESM used to write the time dimension of its output files at the end of the averaging period, so for monthly output the following would hold:
* January averages would have a time dimension of midnight on February 1
* February averages would have a time dimension of midnight on March 1
* etc
... | open | 2024-12-11T22:31:47Z | 2024-12-11T22:31:47Z | https://github.com/pydata/xarray/issues/9877 | [
"bug",
"needs triage"
] | mnlevy1981 | 0 |
joeyespo/grip | flask | 121 | Perhaps it would be nice to have WYSIWYG possibility | I'd like to see if it would be nice to edit in the localhost and then have it push back to the readme file once done.
Not sure if it is possible and not sure if it would be an improvement, but just thought to throw it out there.
| closed | 2015-05-23T08:50:57Z | 2015-05-23T16:30:46Z | https://github.com/joeyespo/grip/issues/121 | [
"out-of-scope"
] | kootenpv | 1 |
wkentaro/labelme | deep-learning | 1,495 | Raster and ghost appear when adjusting brightness and contrast labelme v5.5 | ### Provide environment information
python 3.8.19
### What OS are you using?
Windows 10
### Describe the Bug
When I adjust the brightness and contrast, the raster and ghost will appear. The contrast will change, but it will be obscured by the raster and overlap, and going back to the default values will ... | open | 2024-09-19T02:20:25Z | 2024-09-19T02:27:36Z | https://github.com/wkentaro/labelme/issues/1495 | [
"issue::bug"
] | Downsiren | 1 |
AirtestProject/Airtest | automation | 493 | 关于opencv-contrib-python版本问题,"There is no SIFT module in your OpenCV environment!" | (请尽量按照下面提示内容填写,有助于我们快速定位和解决问题,感谢配合。否则直接关闭。)
**(重要!问题分类)**
* 测试开发环境AirtestIDE使用问题 -> https://github.com/AirtestProject/AirtestIDE/issues
* 控件识别、树状结构、poco库报错 -> https://github.com/AirtestProject/Poco/issues
* 图像识别、设备控制相关问题 -> 按下面的步骤
**描述问题bug**
(简洁清晰得概括一下遇到的问题是什么。或者是报错的traceback信息。)
Linux执行airtest脚本报"There ... | open | 2019-08-12T13:41:51Z | 2019-08-13T01:43:04Z | https://github.com/AirtestProject/Airtest/issues/493 | [] | SHUJIAN01 | 1 |
babysor/MockingBird | deep-learning | 234 | 请问训练到25k的时候注意力线还是没有出来,并且文件多出了一个出来这个是正常的吗? | 请问训练到25k的时候注意力线还是没有出来,并且文件多出了一个出来这个是正常的吗?
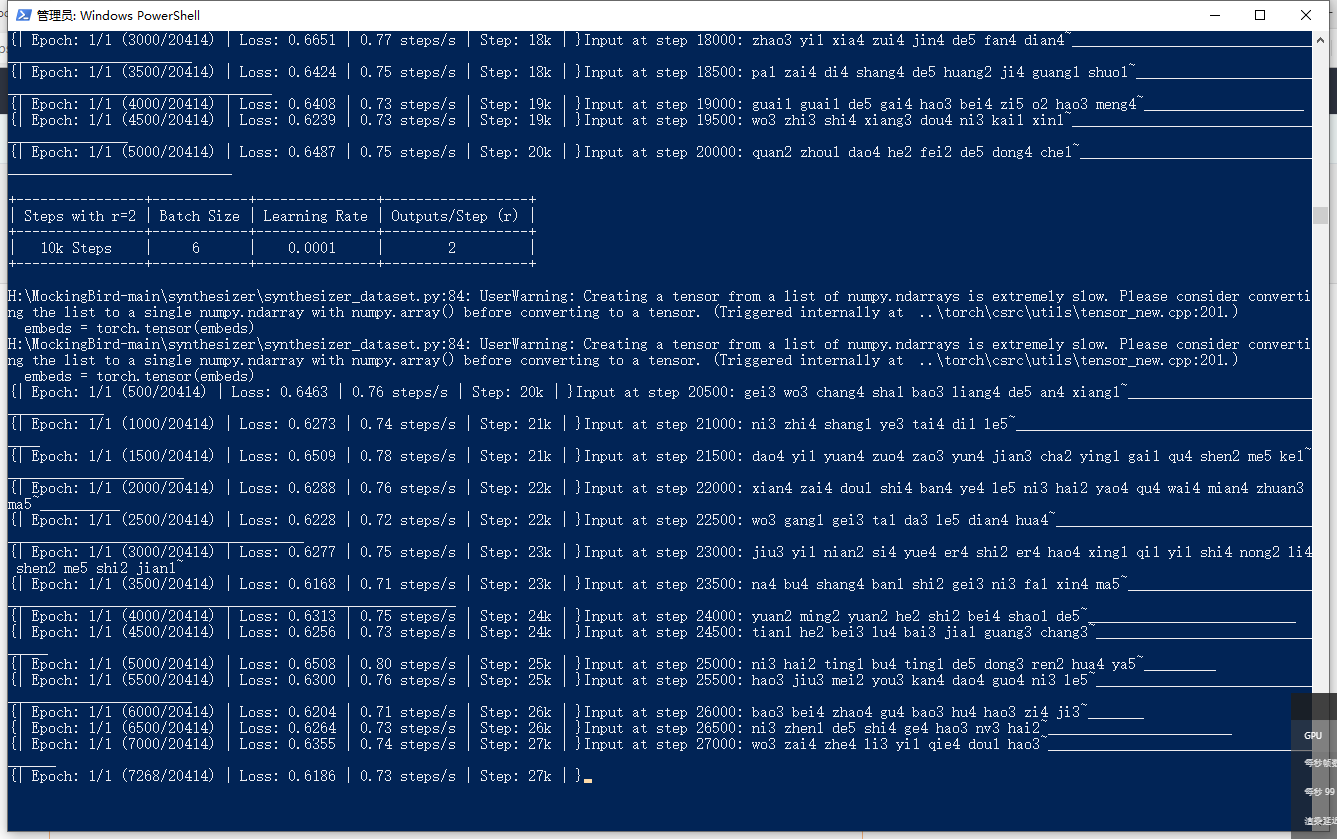

![attention_s... | open | 2021-11-25T08:53:44Z | 2022-05-27T13:22:16Z | https://github.com/babysor/MockingBird/issues/234 | [] | yemaohaker | 13 |
ultralytics/ultralytics | computer-vision | 18,920 | Validation of YOLO pretrained COCO on custom Dataset - Zero metrics | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello, I want to test the Yolo model pre-trained on YOLO on my custom datase... | open | 2025-01-27T15:58:13Z | 2025-01-31T14:07:29Z | https://github.com/ultralytics/ultralytics/issues/18920 | [
"question",
"detect"
] | adriengoleb | 37 |
streamlit/streamlit | python | 10,112 | pills and segmented_control with customized image display for options | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
The `pills` and `segmented_control` components are fantastic. However, I currently miss 1 functionalit... | closed | 2025-01-04T16:09:34Z | 2025-01-10T15:26:58Z | https://github.com/streamlit/streamlit/issues/10112 | [
"type:enhancement",
"feature:st.segmented_control",
"feature:st.pills"
] | nycjersey | 2 |
streamlit/streamlit | streamlit | 10,115 | Input widget does not take input from password manager | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
When my password manager (Dashlane version 6.... | open | 2025-01-06T14:24:31Z | 2025-03-09T08:25:35Z | https://github.com/streamlit/streamlit/issues/10115 | [
"type:bug",
"status:confirmed",
"priority:P3",
"feature:st.text_input"
] | sandervdhimst | 4 |
TencentARC/GFPGAN | pytorch | 499 | gfpgan | billing problem
| open | 2024-01-29T06:48:54Z | 2024-02-29T04:42:55Z | https://github.com/TencentARC/GFPGAN/issues/499 | [] | assassin1382 | 6 |
ultralytics/yolov5 | deep-learning | 13,042 | how to find why mAP suddenly increased | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I trained YOLOv5s for 500 epochs, and around the 385th to 387th epochs, there was a sudde... | closed | 2024-05-28T02:09:34Z | 2024-10-20T19:46:43Z | https://github.com/ultralytics/yolov5/issues/13042 | [
"question"
] | MiNaMisan | 6 |
aimhubio/aim | tensorflow | 2,645 | Remove soft lock from UI | ## 🚀 Feature
When running in aim remote server mode it's difficult for users to clear failed runs / soft locks.
From the UI they see a generic error. Remote server side in logs shows:
```
Error while trying to delete run '1901419848fb433ab111647c'. Cannot delete Run '1901419848fb433ab111647c'. Run is locked.... | open | 2023-04-11T12:45:24Z | 2023-12-29T14:28:13Z | https://github.com/aimhubio/aim/issues/2645 | [
"type / enhancement",
"area / Web-UI"
] | dcarrion87 | 5 |
dolevf/graphql-cop | graphql | 27 | How can I use graphql-cop as package in the test suite | Hi,
I would like to know if graphql-cop can be imported as a package
Aswathy | closed | 2023-08-30T09:00:15Z | 2023-10-31T05:12:31Z | https://github.com/dolevf/graphql-cop/issues/27 | [
"question"
] | abnair24 | 2 |
mljar/mljar-supervised | scikit-learn | 100 | Add `explain` and `performance` modes | There should be `explain` mode in the AutoML which will produce explanations.
There should be `performance` mode for max accuracy of models from AutoML. | closed | 2020-06-02T10:57:12Z | 2020-07-08T09:38:35Z | https://github.com/mljar/mljar-supervised/issues/100 | [
"enhancement"
] | pplonski | 1 |
allenai/allennlp | pytorch | 5,033 | Publish info about each model implementation in models repo | From our discussion on Slack.
This could be markdown docs, ideally automatically generated. Could also publish to our API docs.
Kind of related to #4720 | open | 2021-03-02T18:12:27Z | 2021-03-02T18:12:27Z | https://github.com/allenai/allennlp/issues/5033 | [] | epwalsh | 0 |
Esri/arcgis-python-api | jupyter | 1,750 | Doc - remove reference to "PlacesAPI (beta)" | In the "Find Places" guide, we have a reference to the Places API beta. This feature is no longer in beta so we can remove reference to it in the guide. We can simply refer to it as "Places service".
https://developers.arcgis.com/python/guide/find-places/
,
chatbot=chatbot,
textbox=message_box,
theme="soft",
cache_examples=True,
)
```
This cau... | closed | 2024-11-27T22:27:08Z | 2024-11-29T16:59:12Z | https://github.com/gradio-app/gradio/issues/10057 | [
"bug",
"needs repro"
] | csanadpoda | 2 |
lepture/authlib | django | 251 | Django OAuth2/OIDC server example | This Issue is not related to any problems regarding authlib but it want just to get some useful information and also purpose some Documentation and example enhanchements. Is there a working example as an example django project, to get a fully featured and working authlib AS/Provider?
- I found some django client/rel... | open | 2020-07-12T14:27:26Z | 2025-02-21T10:23:08Z | https://github.com/lepture/authlib/issues/251 | [
"feature request",
"server",
"in future"
] | peppelinux | 2 |
encode/httpx | asyncio | 3,029 | Auth type makes problem in `dbt-duckdb` > `fsspec` > `webdav4` > `httpx` | ```python
# _types.py
AuthTypes = Union[
Mapping[str, Any], # added
Tuple[Union[str, bytes], Union[str, bytes]],
Callable[["Request"], "Request"],
"Auth",
]
# _client.py
def _build_auth(self, auth: typing.Optional[AuthTypes]) -> typing.Optional[Auth]:
if auth is None:
... | closed | 2023-12-31T16:14:09Z | 2023-12-31T16:55:43Z | https://github.com/encode/httpx/issues/3029 | [] | ZergRocks | 0 |
jacobgil/pytorch-grad-cam | computer-vision | 224 | GradCAM results doesn't seem valid with resenet50 | `
import cv2
import torch
import numpy as np
from pytorch_grad_cam import GradCAM
from pytorch_grad_cam.utils.image import show_cam_on_image, preprocess_image
from torchvision.models import resnet50
from torchvision import transforms
import matplotlib.pyplot as plt
rgb_img = cv2.imread("/home/zeeshan/Downloa... | closed | 2022-04-05T11:29:51Z | 2022-04-06T01:53:38Z | https://github.com/jacobgil/pytorch-grad-cam/issues/224 | [] | zeahmd | 2 |
ydataai/ydata-profiling | pandas | 723 | Negative exponents appear positive | **Describe the bug**
Negative exponents do not appear in a profiling report
**To Reproduce**
```python
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
data = { 'some_numbers' : (0.0001, 0.00001, 0.00000001, 0.002, 0.0002, 0.00003) * 100}
df = pd.DataFrame(data)
profile... | closed | 2021-03-05T15:36:26Z | 2021-03-25T23:29:32Z | https://github.com/ydataai/ydata-profiling/issues/723 | [
"bug 🐛"
] | rdpapworth | 1 |
apache/airflow | automation | 47,891 | clean duplications of Xcom backend docs from core | ### Body
Most of the text in [Object Storage XCom Backend](https://airflow.apache.org/docs/apache-airflow/2.10.5/core-concepts/xcoms.html#object-storage-xcom-backend) is duplicated with [Object Storage XCom Backend (common-io provider)](https://airflow.apache.org/docs/apache-airflow-providers-common-io/1.5.1/xcom_back... | closed | 2025-03-18T06:45:18Z | 2025-03-20T09:10:51Z | https://github.com/apache/airflow/issues/47891 | [
"good first issue",
"kind:documentation",
"provider:common-io"
] | eladkal | 1 |
wkentaro/labelme | computer-vision | 879 | How to convert a dataset to cityscape format using labelme | closed | 2021-07-01T02:12:35Z | 2022-06-25T04:42:29Z | https://github.com/wkentaro/labelme/issues/879 | [] | dreamlychina | 0 | |
dask/dask | numpy | 11,087 | test_division_or_partition in test_sql is failing for pandas 3 | The test is broken, the memory usage doesn't work as expected | open | 2024-04-30T10:15:15Z | 2024-04-30T10:15:15Z | https://github.com/dask/dask/issues/11087 | [
"dataframe"
] | phofl | 0 |
tensorflow/tensor2tensor | machine-learning | 1,867 | The checkpoint is always not found when i use decoder command | ### Description
The checkpoint is always not found in T2T-decoder. After deleting checkpoint, can run T2T-decoder,Which model is used at this time?and why?
### Environment information
OS: <your answer here>
$ pip freeze | grep tensor
mesh-tensorflow==0.1.17
tensor2tensor==1.15.7
tensorboard==2.3.0
tenso... | open | 2020-11-04T16:33:40Z | 2020-11-04T16:33:40Z | https://github.com/tensorflow/tensor2tensor/issues/1867 | [] | Nanamumuhan | 0 |
InstaPy/InstaPy | automation | 6,472 | like_by_tags or like_by_feed dosen't work anymore | Hi!
From one day to the next, the script no longer worked. No matter whether I used the method:
session.like_by_tags
or
session.like_by_feed
the script logs in, opens the feed and then crashes with the error. I don't know if this is the correct error message. I am new to python. If you want me to look for the err... | open | 2022-01-25T15:57:11Z | 2022-03-28T14:38:20Z | https://github.com/InstaPy/InstaPy/issues/6472 | [] | T1000MG | 10 |
httpie/cli | api | 964 | Support header values read from file ? | httpie allows to get url params and form data from file, by using @ syntax
There are sometimes complicated headers, for example tokens.
It seems this is not yet possible for headers.
Can this feature be added for headers as well?
Probably with a syntax like:
```
':@'
```
like:
```
Referer:http://h... | closed | 2020-09-10T12:42:57Z | 2021-12-23T19:06:35Z | https://github.com/httpie/cli/issues/964 | [] | coldcoff | 3 |
modin-project/modin | data-science | 7,453 | MODIN creates new partition if we add new column to dataframe | ```
import logging
logger = logging.getLogger(__name__)
def log_partitions(input_df):
partitions = input_df._query_compiler._modin_frame._partitions
# Iterate through the partition matrix
logger.info(f"Row partitions: {len(partitions)}")
row_index = 0
for partition_row in partitions:
print(f... | open | 2025-03-04T07:42:04Z | 2025-03-06T21:15:26Z | https://github.com/modin-project/modin/issues/7453 | [
"question ❓"
] | Sumukhagc | 1 |
xonsh/xonsh | data-science | 5,768 | Remove unexpectedly sourcing foreign shell run control files | We need to remove unwanted sourcing of RC files for other shells.
### How to repeat
```xsh
echo 'echo 1' >> ~/.bashrc
xonsh --no-rc --no-env
# 1
# @
```
### Discussed in https://github.com/xonsh/xonsh/discussions/5764
<details>
<div type='discussions-op-text'>
<sup>Originally posted by **JeffMelt... | closed | 2025-01-03T14:47:02Z | 2025-01-10T13:53:35Z | https://github.com/xonsh/xonsh/issues/5768 | [
"source-foreign",
"xonshrc",
"startup",
"v1"
] | anki-code | 3 |
unionai-oss/pandera | pandas | 967 | Request: A date-time type that is timezone aware, or any timezone. | **Is your feature request related to a problem? Please describe.**
We have the need to accept timestamps that require having a timezone (any timezone, not a specific one).
I believe Pandera requires you to provide the specific timezone at the moment.
**Describe the solution you'd like**
A new dtype for "datet... | open | 2022-10-18T04:12:45Z | 2023-02-03T16:05:17Z | https://github.com/unionai-oss/pandera/issues/967 | [
"enhancement"
] | blais | 8 |
biolab/orange3 | data-visualization | 6,675 | File widget: add option to skip a range of rows not holding headers or data | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
Many datasets that are available online as open data have rows that are not column headers or ac... | closed | 2023-12-13T14:28:02Z | 2024-01-05T10:38:14Z | https://github.com/biolab/orange3/issues/6675 | [] | wvdvegte | 5 |
pydata/xarray | numpy | 9,880 | ⚠️ Nightly upstream-dev CI failed ⚠️ | [Workflow Run URL](https://github.com/pydata/xarray/actions/runs/12307067834)
<details><summary>Python 3.12 Test Summary</summary>
```
xarray/tests/test_backends.py::TestInstrumentedZarrStore::test_append: TypeError: Group.create_array() got an unexpected keyword argument 'exists_ok'
xarray/tests/test_backends.py::Tes... | closed | 2024-12-13T00:34:41Z | 2024-12-13T15:59:56Z | https://github.com/pydata/xarray/issues/9880 | [
"CI"
] | github-actions[bot] | 2 |
plotly/dash-table | plotly | 150 | A final pass on the default styles | Once the styling and sizing tests are fixed, I'll take another pass through the default styles | closed | 2018-10-22T17:13:26Z | 2019-07-02T14:01:53Z | https://github.com/plotly/dash-table/issues/150 | [] | chriddyp | 7 |
ultralytics/ultralytics | python | 18,885 | train yolo with random weighted sampler | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I have many data sources, Now I can write all data paths in data.yaml file a... | open | 2025-01-25T18:40:01Z | 2025-01-26T16:52:01Z | https://github.com/ultralytics/ultralytics/issues/18885 | [
"enhancement",
"question"
] | Dreahim | 7 |
microsoft/qlib | deep-learning | 1,888 | How to create a new Stock Pool (Market) | ## ❓ Questions and Help
How can I create a new Stock Pool (Market) in Qlib and define a specific set of stocks? For example, how can I classify certain stocks under a category similar to CSI 300?"
I have checked the documentation, but it seems that there is no relevant information. If there is, could you please provide... | open | 2025-02-15T16:39:58Z | 2025-03-11T08:02:27Z | https://github.com/microsoft/qlib/issues/1888 | [
"question"
] | Len1925 | 1 |
RobertCraigie/prisma-client-py | asyncio | 744 | Can't run prisma migrate on mysql8: Unknown authentication plugin `sha256_password'. | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | open | 2023-04-18T23:32:33Z | 2023-04-22T13:10:00Z | https://github.com/RobertCraigie/prisma-client-py/issues/744 | [
"bug/0-needs-info",
"kind/bug"
] | travisneilturner | 1 |
litestar-org/litestar | pydantic | 4,031 | Docs: new middleware docs | ### Summary
something seems off here: https://docs.litestar.dev/2/usage/middleware/creating-middleware.html

| open | 2025-02-26T17:34:24Z | 2025-02-26T17:34:47Z | https://github.com/litestar-org/litestar/issues/4031 | [
"Documentation :books:"
] | euri10 | 0 |
chiphuyen/stanford-tensorflow-tutorials | tensorflow | 59 | I need help with "data.py" file | Hello, like the title i need some help with "data.py" file
When i run the original "data.py" file that clone from here it go error like below
```
Traceback (most recent call last):
File "/Users/NGUYENQUANGHUY/PycharmProjects/stanford-tensorflow-tutorials/assignments/chatbot/data.py", line 255, in <module>
... | open | 2017-09-02T03:14:03Z | 2020-09-20T14:05:21Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/59 | [] | Huygin2394 | 8 |
coqui-ai/TTS | deep-learning | 4,097 | [Bug] OS Error | ### Describe the bug
C:\Users\Emire\Desktop\Kılıç>pip install TTS --user
Collecting TTS
Using cached TTS-0.22.0-cp311-cp311-win_amd64.whl
Requirement already satisfied: numpy>=1.24.3 in c:\users\emire\appdata\local\packages\pythonsoftwarefoundation.python.3.11_qbz5n2kfra8p0\localcache\local-packages\python311\s... | closed | 2024-12-26T20:01:33Z | 2025-02-07T06:03:12Z | https://github.com/coqui-ai/TTS/issues/4097 | [
"bug",
"wontfix"
] | JustLmr | 3 |
mars-project/mars | pandas | 2,972 | [Proposal] a lineage reconstruction based failover for mars | # Background
Large-scale distributed computing systems may fail due to various reasons, including network problems, machine failures, and process restarts. Network failures can cause nodes and workers to fail to send and receive data; machine failures and process restarts can cause data loss and tasks to be re-execute... | open | 2022-04-26T15:12:45Z | 2022-05-20T03:36:23Z | https://github.com/mars-project/mars/issues/2972 | [] | chaokunyang | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,601 | Question about Cyclegan's FCN SCORE source code | Excuse me, can you provide the source code of Cyclegan's FCN Score? I want to evaluate the results I do, thank you very much | closed | 2023-09-30T10:20:22Z | 2023-10-20T02:12:06Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1601 | [] | HuXiaokai12138 | 0 |
moshi4/pyCirclize | data-visualization | 83 | Unable to auto adjust annotation | AttributeError: module 'pycirclize.config' has no attribute 'ann_adjust'
config.ann_adjust.enable = True
pycirclize.__version__=1.8.0
| closed | 2025-02-14T09:10:01Z | 2025-02-14T09:40:29Z | https://github.com/moshi4/pyCirclize/issues/83 | [
"question"
] | jishnu-lab | 1 |
tox-dev/tox | automation | 2,633 | Undocumented user level config file [tox4] | In FAQ for tox 4 I discovered a note about "user level config-file", but I can't find any details, such as default file location, structure of the config and its behavior. | closed | 2022-12-08T08:15:15Z | 2023-06-17T01:12:09Z | https://github.com/tox-dev/tox/issues/2633 | [
"area:documentation",
"help:wanted"
] | ziima | 5 |
LibrePhotos/librephotos | django | 763 | Implement viewing videos | **Describe the enhancement you'd like**
As a user, I want to be able to watch my videos.
**Describe why this will benefit the LibrePhotos**
Use react-native-vlc-media-player as this should be very stable and reliable.
| open | 2023-02-27T17:09:16Z | 2023-12-11T14:56:50Z | https://github.com/LibrePhotos/librephotos/issues/763 | [
"enhancement",
"good first issue",
"mobile"
] | derneuere | 2 |
dunossauro/fastapi-do-zero | pydantic | 240 | Texto inconforme com código na aula 7 sobre a função `get_current_user` | Na aula 7, quando entramos na seção [Protegendo os Endpoints](https://fastapidozero.dunossauro.com/06/#protegendo-os-endpoints) a função `get_current_user` é definida de forma **síncrona**:
```python
# ...
def get_current_user(
session: Session = Depends(get_session),
token: str = Depends(oauth2_scheme),... | closed | 2024-09-16T21:09:31Z | 2024-10-02T22:03:24Z | https://github.com/dunossauro/fastapi-do-zero/issues/240 | [] | RWallan | 0 |
huggingface/text-generation-inference | nlp | 2,363 | Build Intel CPU optimized image automatically | Hello, we are looking for the best way for deploying TGI on Xeons.
I understand that container images tagged with `x.y.z-intel` are the XPU builds, while `Dockerfile_intel` defines both XPU and CPU paths, XPU being the default. I have successfully ran manual builds for CPU and those works great.
By using the def... | open | 2024-08-06T12:47:59Z | 2024-08-08T14:47:11Z | https://github.com/huggingface/text-generation-inference/issues/2363 | [] | Feelas | 1 |
kymatio/kymatio | numpy | 501 | ENH more 1D tests for np/tf frontend/backend | closed | 2020-01-24T03:40:08Z | 2022-05-31T00:49:07Z | https://github.com/kymatio/kymatio/issues/501 | [] | edouardoyallon | 2 | |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,209 | error on requirments.txt MacOS | trying to install on MacOS. When I enter "pip install -r requirements.txt" it goes through a bunch of stuff but then errors out with what is pasted below. Anyone have any ideas?
MacOS 12.3.1, Mac Studio M1
Error output:
` …
Processing numpy/random/mtrand.pyx
Processing numpy/random/_generat... | open | 2023-05-04T14:39:23Z | 2023-09-28T14:15:57Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1209 | [] | dlogneb | 4 |
ultrafunkamsterdam/undetected-chromedriver | automation | 787 | TypeError: expected str, bytes or os.PathLike object, not NoneType | I am trying to run undetected chromedriver with the get started code but keep getting this error:
```
[Process Process-1:
Traceback (most recent call last):
File "C:\Users\DC\AppData\Local\Programs\Python\Python39\lib\multiprocessing\process.py", line 315, in _bootstrap
self.run()
File "C:\Users\DC\AppDat... | open | 2022-08-19T11:21:47Z | 2022-12-03T10:45:21Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/787 | [] | saif-byte | 4 |
d2l-ai/d2l-en | data-science | 1,837 | Minor typo in Figure 9.1.1: `function` misspelled as `fuction` | In [Fig. 9.1.1](https://github.com/d2l-ai/d2l-en/blob/master/img/gru-1.svg) as well as some other diagrams in [9.1. GRU](https://d2l.ai/chapter_recurrent-modern/gru.html), `activation function` is misspelled as `activation fuction`.
` I noticed that the autogeneration does not pick up the keyword argument `match`.
I already checked, the constraint is interpreted correctly and only during rendering in:
https://github.com/sqlalchemy/alembic/blob/dbdec2661b8a01132ea3f7a027f85fed2eaf5e54/alem... | closed | 2023-08-24T14:08:56Z | 2023-08-31T18:27:04Z | https://github.com/sqlalchemy/alembic/issues/1302 | [
"bug",
"autogenerate - rendering",
"PRs (with tests!) welcome"
] | asibkamalsada | 3 |
Zeyi-Lin/HivisionIDPhotos | machine-learning | 10 | 在docker中部署以后网页404 not found。 | 您好,我在docker中编译并完成部署以后,点击打开对应的网站,显示404not found,请问是什么原因导致的呢?
| closed | 2024-03-27T06:42:02Z | 2024-09-23T01:39:26Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/10 | [] | hxj0316 | 1 |
SALib/SALib | numpy | 256 | Unable to install v1.3.7 on Python 2.7 | Install of SALib-1.3.7 fails on Python 2.7. Based on a related discussion, I believe this would solve the issue, but not familiar enough with the library to ensure compatibility:
https://github.com/pbrod/numdifftools/issues/37#issuecomment-395794866
```log
Collecting salib
Using cached https://files.pythonhos... | closed | 2019-07-25T10:06:46Z | 2019-08-18T14:29:58Z | https://github.com/SALib/SALib/issues/256 | [] | dxdc | 4 |
litestar-org/litestar | pydantic | 3,899 | Bug: create_static_files_router with S3FS crashes due to unsupported fs info key (`mtime`) | ### Description
When using S3FS in a static router, [ASGIFileResponse](https://github.com/litestar-org/litestar/blob/f31ef97d6cb725bf9898f55abbb5150b36823f27/litestar/response/file.py#L220) uses the `mtime` attribute on fs_info which is not consistently available across fssspec implementations (See: https://github.c... | closed | 2024-12-12T22:45:54Z | 2025-03-20T15:55:03Z | https://github.com/litestar-org/litestar/issues/3899 | [
"Bug :bug:"
] | thomastu | 3 |
sanic-org/sanic | asyncio | 2,554 | Support overwriting a route of blueprint from copy | **Feture Description**
I want to overwrite the implement of route partially when they belong to different version blueprint, and it raises sanic_routing.exceptions.RouteExists.
**Sample Code**
```python
from sanic import Blueprint
from sanic.response import json
from sanic import Sanic
app = Sanic('test')
b... | closed | 2022-09-28T09:23:42Z | 2023-07-07T11:56:44Z | https://github.com/sanic-org/sanic/issues/2554 | [
"idea discussion",
"feature request"
] | Tpinion | 5 |
gee-community/geemap | jupyter | 1,062 | geemap.ee_export_image problem. | Hi! Thanks for the great package and awsome work. I have a problem with ee_export_image that I will explain it below.
### Environment Information
- geemap version: 0.11.0
- Python version: 3.9.8
- Operating System: Windows 10 x64
### Description
I want to download a decadal mvc for NDSI (1-10, 11-20, a... | closed | 2022-05-18T08:30:43Z | 2022-05-19T14:21:26Z | https://github.com/gee-community/geemap/issues/1062 | [
"bug"
] | georgeboldeanu | 12 |
ultralytics/ultralytics | python | 19,466 | Pausing and Resuming Model Training in YOLO | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi everyone,
Thank you for all the amazing work you do! I know Glenn Jocher ... | closed | 2025-02-27T19:19:15Z | 2025-02-28T14:54:15Z | https://github.com/ultralytics/ultralytics/issues/19466 | [
"question"
] | AISoltani | 4 |
flasgger/flasgger | api | 327 | Feature request: support `pydantic` schema | Recently I just found [fastapi](https://github.com/tiangolo/fastapi) has very nice OpenAPI support with the help of [pydantic](https://github.com/samuelcolvin/pydantic)(Python 3.6+). So people can declare schema with Python types, which is very convenient.
Would like to know if this library will support pydantic in ... | closed | 2019-08-16T08:21:29Z | 2022-02-17T11:22:26Z | https://github.com/flasgger/flasgger/issues/327 | [] | kemingy | 2 |
hbldh/bleak | asyncio | 731 | BleakClient accessing attribute that does not exist | * bleak version: 0.14.0
* Python version: 3.10.1
* Operating System: Windows 10
I'm trying to debug some windows connection issues. I noticed that if I supply `BleakClient` with a device like this:
```python
import os
os.environ["BLEAK_LOGGING"] = "1"
import asyncio
from bleak import BleakClient, BleakS... | closed | 2022-01-11T17:21:48Z | 2022-01-12T21:12:50Z | https://github.com/hbldh/bleak/issues/731 | [
"Backend: WinRT"
] | rhyst | 1 |
pytorch/vision | machine-learning | 8,034 | Need to update Efficientnet weight | As reported @ar0ck in https://github.com/pytorch/vision/issues/7744#issuecomment-1754154799 the efficientnet weight still have the wrong hash. | closed | 2023-10-10T08:36:25Z | 2023-10-11T10:13:55Z | https://github.com/pytorch/vision/issues/8034 | [
"bug",
"module: models"
] | NicolasHug | 0 |
Guovin/iptv-api | api | 431 | 链接后面的$1920x1080不要 | 链接后面的$1920x1080、$LR•IPV4『线路28』|1920x1080不要添加上去,有些播放器不支持,导致不能播放。 | closed | 2024-10-22T03:13:08Z | 2024-10-25T09:10:32Z | https://github.com/Guovin/iptv-api/issues/431 | [
"enhancement"
] | wuyihuai | 3 |
litestar-org/litestar | pydantic | 3,058 | Bug: Response examples are not generated even with `generate_examples=True` | ### Description
It's unclear how to enable/disable the example the example generation for responses.
Is it by default on or not? `Parameter` defaults to `generate_examples=True` but no examples appear by default.
Yet in a larger app I do get examples, but I don't seem to understand how to reproduce the same on... | closed | 2024-02-01T15:18:28Z | 2025-03-20T15:54:23Z | https://github.com/litestar-org/litestar/issues/3058 | [
"Bug :bug:"
] | tuukkamustonen | 5 |
keras-team/keras | machine-learning | 20,285 | Possible typo in the "Transfer learning & fine-tuning" guide | I'm not sure if this is issue. For now it is an observation.
Reading the guide about [Transfer learning & fine-tuning](https://github.com/keras-team/keras/blob/master/guides/transfer_learning.py) I had some trouble to understand the following statement: https://github.com/keras-team/keras/blob/38db71acb207fb1dda380a... | closed | 2024-09-24T23:02:56Z | 2024-09-30T04:21:12Z | https://github.com/keras-team/keras/issues/20285 | [
"type:support"
] | miticollo | 6 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 504 | setting db on the fly | Wanted to ask if there is something in the library to let me change the database connection to point to a different db on the fly? The thing I'm trying to do is from a POST request I use the credentials to connect to the database. | closed | 2017-06-09T21:41:27Z | 2020-12-05T20:55:49Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/504 | [] | mtung2017 | 6 |
zappa/Zappa | flask | 436 | [Migrated] Pass Additional Arguments to Zappa Manage | Originally from: https://github.com/Miserlou/Zappa/issues/1136 by [lifeignite](https://github.com/lifeignite)
if some column or data can be changed or deleted while migrating, django warns like below.
> Any objects related to these content types by a foreign key will also
> be deleted. Are you sure you want to de... | closed | 2021-02-20T08:32:54Z | 2024-04-13T16:17:49Z | https://github.com/zappa/Zappa/issues/436 | [
"enhancement",
"help wanted",
"hacktoberfest",
"no-activity",
"auto-closed"
] | jneves | 2 |
wemake-services/django-test-migrations | pytest | 109 | Add more DB configuration checks | In #91 we are introducing new Django check that validate `system timeout` settings on following database:
+ `postgresql` -`statement_timeout`
+ `mysql` - `max_execution_time`
The idea behind this group of checks is to help developers configure databases according to best practices.
If you have any ideas of such... | open | 2020-07-24T13:14:17Z | 2020-07-25T07:25:17Z | https://github.com/wemake-services/django-test-migrations/issues/109 | [] | skarzi | 0 |
RafaelMiquelino/dash-flask-login | dash | 5 | current_user.is_authenticated returns false in deployment | Hello,
Thanks for making this repository.
I have been using it with success on a localhost, but as soon as I deploy it, on a hosted server, the user authentication stops behaving. As the user logs in, it registers that the user is authenticated, but within less than a 1s the bool current_user.is_authenticated is... | closed | 2020-06-04T07:39:04Z | 2020-06-09T09:23:49Z | https://github.com/RafaelMiquelino/dash-flask-login/issues/5 | [] | max454545 | 12 |
piskvorky/gensim | machine-learning | 3,165 | Streaming instead of online LDA | The current implementation of LDA in gensim is not actually well suited for streaming.
Here is an interesting [publication:](http://proceedings.mlr.press/v37/theis15.pdf)
Theis, Lucas, and Matt Hoffman. "A trust-region method for stochastic variational inference with applications to streaming data." International C... | open | 2021-06-06T14:04:15Z | 2021-06-06T14:07:33Z | https://github.com/piskvorky/gensim/issues/3165 | [] | jonaschn | 0 |
ageitgey/face_recognition | python | 1,348 | One column per each feature | Can I use this method for storage? How to achieve
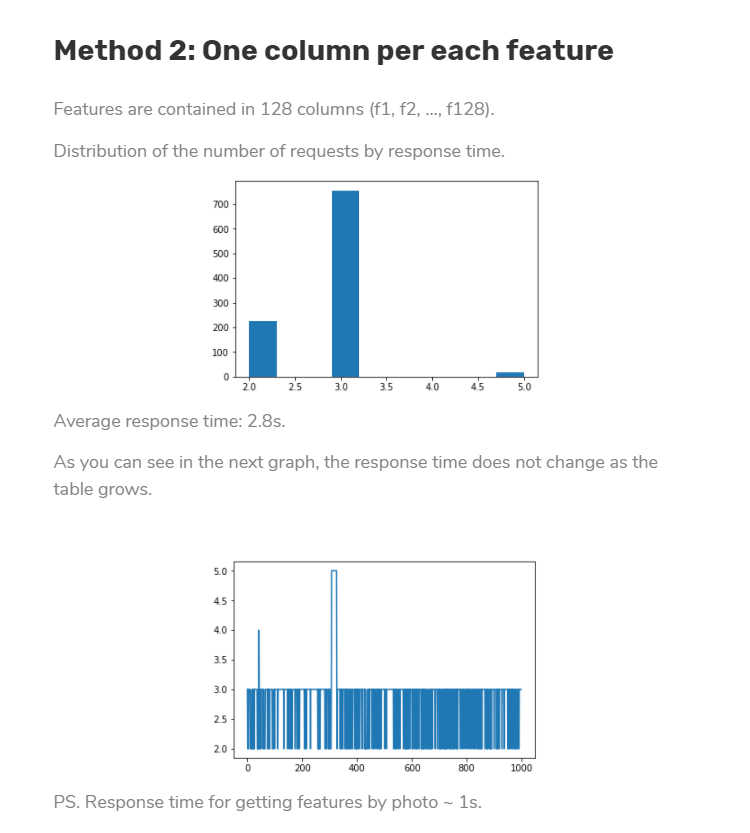
[Original link](https://ardas-it.com/comparing-3-ways-to-store-faces-when-developing-facial-recognition-search) | open | 2021-07-21T07:40:55Z | 2021-07-21T07:40:55Z | https://github.com/ageitgey/face_recognition/issues/1348 | [] | Flour-MO | 0 |
akfamily/akshare | data-science | 5,689 | AKShare 接口问题报告 | stock_zh_a_hist报错 | akshare 版本 1.16.3
df = ak.stock_zh_a_hist("300114", period='daily', start_date="20200101", end_date="20250218", adjust='qfq')
site-packages\akshare\stock_feature\stock_hist_em.py:1049, in stock_zh_a_hist(symbol, period, start_date, end_date, adjust, timeout)
1041 period_dict = {"daily": "101", "weekly": "... | closed | 2025-02-18T06:37:42Z | 2025-02-18T08:46:03Z | https://github.com/akfamily/akshare/issues/5689 | [
"bug"
] | caihua | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.