
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
mage-ai/mage-ai | data-science | 5,221 | [BUG] Setting cache_block_output_in_memory breaking pipeline on K8s (EKS) | ### Mage version
0.9.72
### Describe the bug
All pipelines that we configure as explained in [the docs](https://docs.mage.ai/design/data-pipeline-management#cache-block-output-in-memory) to not write to the EFS filesystem but store the data in memory, are passing an empty dataframe between blocks.
We set both req... | open | 2024-06-23T16:20:34Z | 2024-06-23T16:20:34Z | https://github.com/mage-ai/mage-ai/issues/5221 | [
"bug"
] | MartinLoeper | 0 |
iperov/DeepFaceLab | machine-learning | 675 | Newest update not being able to use Full Face images... | Giving me this error when i use the aligned src that i always use, full face. This is the latest dfl with xseg and whole face. Previous versions works fine.

| closed | 2020-03-25T00:54:31Z | 2020-03-25T22:37:17Z | https://github.com/iperov/DeepFaceLab/issues/675 | [] | mpmo10 | 2 |
deeppavlov/DeepPavlov | nlp | 853 | ODQA inference speed very very slow | Running the default configuration and model on a EC2 p2.xlarge instance (60~GB Ram and Nvidia K80 GPU) and inference for simple questions take 40 seconds to 5 minutes.
Sometimes, no result even after 10 minutes.
<img width="1093" alt="MobaXterm_2019-05-27_16-36-13" src="https://user-images.githubusercontent.com... | closed | 2019-05-27T11:06:48Z | 2020-05-21T10:05:58Z | https://github.com/deeppavlov/DeepPavlov/issues/853 | [] | shubhank008 | 12 |
PaddlePaddle/PaddleHub | nlp | 2,320 | yolov3_darknet53_pedestrian 每次加载都需要下载很长时间,且推理错误 | 欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献!
在留下您的问题时,辛苦您同步提供如下信息:
- 版本、环境信息
1)PaddleHub和PaddlePaddle版本:请提供您的PaddleHub和PaddlePaddle版本号,例如PaddleHub1.4.1,PaddlePaddle1.6.2
2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本
- 复现信息:如为报错,请给出复现环境、复现步骤
-
○ →
`import paddlehub as hub
import cv2
pedestrian_detector = hub... | closed | 2024-02-27T02:21:25Z | 2024-03-17T05:39:36Z | https://github.com/PaddlePaddle/PaddleHub/issues/2320 | [] | sun-rabbit | 4 |
microsoft/qlib | machine-learning | 1,193 | How to adapt LSTM to DDG-DA | I want to adapt LSTM to DDG-DA, how can I do that?
What I have tried:
1. modify rolling_benchmark.py to fit with LSTM parameters
2. modify the bug caused by changing the dataset object to TSDatasetH.
change the file in qlib > contrib > meta > data_selection > model.py:
```
def reweight(self, data: Union[pd... | closed | 2022-07-12T11:53:33Z | 2022-10-21T15:05:41Z | https://github.com/microsoft/qlib/issues/1193 | [
"question",
"stale"
] | Xxiaoting | 2 |
taverntesting/tavern | pytest | 787 | how can i get coverage after running pytest | how can i get coverage after running
`
pytest -v test_01_init_gets.tavern.yaml --html=all.html
` | closed | 2022-06-09T10:17:46Z | 2022-06-15T09:37:31Z | https://github.com/taverntesting/tavern/issues/787 | [] | iakirago | 2 |
sqlalchemy/alembic | sqlalchemy | 1,246 | Minor typing issue for alembic.context.configure in 1.11.0 | **Describe the bug**
Signature of the `alembic.context.configure` function has changed in 1.11.0, where `compare_server_default` argument uses `Column` classes, which should be generics. This kind of definition produces type checkers warnings.
**Expected behavior**
No warnings reported by static type checkers
*... | closed | 2023-05-16T18:00:39Z | 2023-05-17T15:15:23Z | https://github.com/sqlalchemy/alembic/issues/1246 | [
"bug",
"pep 484"
] | AlexanderPodorov | 2 |
graphql-python/graphene-django | django | 840 | Validate Meta.fields and Meta.exclude on DjangoObjectType | tl;dr: DjangoObjectType ignores all unknown values in `Meta.fields`. It should compare the fields list with the available Model's fields instead.
---
I'm in the process of rewriting DRF-based backend to graphene-django, and I was surprised when my graphene-django generated schema was silently missing the fields I... | closed | 2019-12-29T11:45:02Z | 2019-12-31T13:55:46Z | https://github.com/graphql-python/graphene-django/issues/840 | [] | berekuk | 1 |
NullArray/AutoSploit | automation | 798 | Divided by zero exception68 | Error: Attempted to divide by zero.68 | closed | 2019-04-19T16:00:55Z | 2019-04-19T16:37:44Z | https://github.com/NullArray/AutoSploit/issues/798 | [] | AutosploitReporter | 0 |
seleniumbase/SeleniumBase | web-scraping | 2,216 | Setting a `user_data_dir` while using Chrome extensions | First time,I use SeleniumBase open chrome without add extensions,like editcookies, and I really add "user-data-dir",generate special folder,at the end I use driver.quit() ,second time,i just use SeleniumBase open by "user-data-dir=special folder path", I can't find the installed extensions in chrome.Did I do something... | closed | 2023-10-28T11:04:25Z | 2023-10-29T06:36:57Z | https://github.com/seleniumbase/SeleniumBase/issues/2216 | [
"question"
] | SiTu-JIanying | 1 |
scikit-learn/scikit-learn | python | 30,753 | ⚠️ CI failed on Linux_Runs.pylatest_conda_forge_mkl (last failure: Feb 03, 2025) ⚠️ | **CI failed on [Linux_Runs.pylatest_conda_forge_mkl](https://dev.azure.com/scikit-learn/scikit-learn/_build/results?buildId=73883&view=logs&j=dde5042c-7464-5d47-9507-31bdd2ee0a3a)** (Feb 03, 2025)
- Test Collection Failure | closed | 2025-02-03T02:34:16Z | 2025-02-03T16:44:29Z | https://github.com/scikit-learn/scikit-learn/issues/30753 | [] | scikit-learn-bot | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,256 | Export failure when users have configured a language that has been disabled | **Describe the bug**
'Save/Export' submission function returns error
**To Reproduce**
Steps to reproduce the behavior:
1. Recipient login
2. Go to 'Submissions'
3. Click on 'save/export' in the list of submissions
:
- Client OS:
- Server OS (for remote mode only):
- Python version:
- PyTorch/TensorFlow version:
- Is conda/virtualenv/venv used?:
- Is running in Docker?:
**Configuration**:
- Experiment config ... | open | 2022-08-01T10:26:41Z | 2022-08-04T01:49:59Z | https://github.com/microsoft/nni/issues/5038 | [] | mumu1431 | 1 |
samuelcolvin/watchfiles | asyncio | 330 | Expose `follow_links` | ### Description
Notifications for linked files seem to be deduplicated at the `notify` level, which leads to issues like https://github.com/Aider-AI/aider/issues/3315.
I believe this could be solved by exposing `notify`s `follow_links` and then setting it to `False` in the client program.
### Example Code
```Python... | open | 2025-02-27T09:06:11Z | 2025-02-27T09:06:11Z | https://github.com/samuelcolvin/watchfiles/issues/330 | [
"bug"
] | bard | 0 |
sgl-project/sglang | pytorch | 4,410 | [Bug] support gemma3 | ### Describe the bug
get this error
```
ValueError: The checkpoint you are trying to load has model type `gemma3` but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.
```
update Transformers to `transform... | closed | 2025-03-14T04:46:15Z | 2025-03-18T19:01:16Z | https://github.com/sgl-project/sglang/issues/4410 | [] | Liusuqing | 4 |
OFA-Sys/Chinese-CLIP | nlp | 20 | import cn_clip出错UnicodeDecodeError: 'gbk' codec can't decode byte 0x81 in position 1564: illegal multibyte sequence | import cn_clip.clip as clip
发生异常: UnicodeDecodeError
Traceback (most recent call last):
File "D:\develop\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "D:\develop\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "c:\Users\saizong\.vs... | closed | 2022-11-28T08:07:28Z | 2022-12-13T11:37:28Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/20 | [] | bigmarten | 13 |
huggingface/datasets | machine-learning | 6,935 | Support for pathlib.Path in datasets 2.19.0 | ### Describe the bug
After the recent update of `datasets`, Dataset.save_to_disk does not accept a pathlib.Path anymore. It was supported in 2.18.0 and previous versions. Is this intentional? Was it supported before only because of a Python dusk-typing miracle?
### Steps to reproduce the bug
```
from datasets impor... | open | 2024-05-30T12:53:36Z | 2025-01-14T11:50:22Z | https://github.com/huggingface/datasets/issues/6935 | [] | lamyiowce | 2 |
ultralytics/ultralytics | pytorch | 19,425 | KeyError: 'ratio_pad' | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
When I started training on my self-built dataset, the following error was re... | closed | 2025-02-25T16:42:35Z | 2025-02-27T06:48:48Z | https://github.com/ultralytics/ultralytics/issues/19425 | [
"question",
"detect"
] | ywWang-coder | 6 |
mlfoundations/open_clip | computer-vision | 827 | how to get hidden_state from every layers of ViT of openclip vision encoder? | if you could solve my problem, thanks a lot ! | open | 2024-02-24T07:03:10Z | 2024-04-12T19:50:25Z | https://github.com/mlfoundations/open_clip/issues/827 | [] | jzssz | 2 |
jupyter/docker-stacks | jupyter | 1,969 | [ENH] - /home/jovyan/work is confusing (documentation) | ### What docker image(s) is this feature applicable to?
scipy-notebook
### What change(s) are you proposing?
User Guide documentation suggests mounting a local directory (`$PWD`, etc.) to `/home/jovyan/work` to persist notebooks. An excellent suggestion, let's keep our data around.
But at no point in _Quick Start... | closed | 2023-08-17T13:55:59Z | 2023-08-18T17:16:50Z | https://github.com/jupyter/docker-stacks/issues/1969 | [
"type:Enhancement"
] | 4kbyte | 2 |
simple-login/app | flask | 2,188 | Wrong unsubscribe link format? | To me it looks like that the way the original unsubscribe links are encoded does not match the way simple-login would handle them.
In `app/handler/unsubscribe_encoder.py`, line 100:
`return f"{config.URL}/dashboard/unsubscribe/encoded?data={encoded}"`
In `app/dashboard/views/unsubscribe.py`, line 76:
`@dashboar... | open | 2024-08-19T06:02:53Z | 2024-12-21T18:55:35Z | https://github.com/simple-login/app/issues/2188 | [] | a-bali | 1 |
iMerica/dj-rest-auth | rest-api | 333 | RegisterView complete_signup receives HttpReuest instead of a Request | I needed to access `Request.data` inside the `AccountAdapter` and it worked until I tested it with `raw` JSON body.
By examing `perform_create()` at [RegisterView](https://github.com/iMerica/dj-rest-auth/blob/b72a55f86b2667e0fa10070485967f5e42588e3b/dj_rest_auth/registration/views.py#L76)
```
def perform_cre... | open | 2021-11-25T10:58:16Z | 2021-11-25T10:58:16Z | https://github.com/iMerica/dj-rest-auth/issues/333 | [] | 1oglop1 | 0 |
exaloop/codon | numpy | 195 | compile on mac failed when link libcodonc.dylib | Mac OS: Catalina
version: 10.15
llvm: [clang+llvm-15.0.7-x86_64-apple-darwin21.0.tar.xz](https://github.com/llvm/llvm-project/releases/download/llvmorg-15.0.7/clang+llvm-15.0.7-x86_64-apple-darwin21.0.tar.xz)
cmake version 3.24.3
codon: v0.15.5
```
[build] [ 95%] Linking CXX shared library libcodonc.dylib
[bu... | closed | 2023-02-12T05:17:33Z | 2024-11-08T18:43:29Z | https://github.com/exaloop/codon/issues/195 | [] | dipadipa | 2 |
plotly/dash | data-visualization | 2,691 | [Feature Request] Validate Arguments to components | If I break my Dash app by supplying, for example, the wrong type for `marks` when instantiating a `dcc.Slider`, the error message is not useful: "Error loading layout" is displayed in the browser, and nothing at all is logged on the back end.
What I'd hope for, and to some extent expect, is a helpful error message p... | closed | 2023-11-13T12:08:23Z | 2023-12-16T12:23:50Z | https://github.com/plotly/dash/issues/2691 | [] | zevaverbach | 7 |
scikit-learn-contrib/metric-learn | scikit-learn | 185 | [DOC] Calibration example | It would be nice to have an example in the doc which demonstrates how to calibrate the pairwise metric learners with respect to several scores as introduced in #168, as well as the use of CalibratedClassifierCV (once this is properly tested, see #173) | open | 2019-03-14T16:11:44Z | 2021-04-22T21:25:32Z | https://github.com/scikit-learn-contrib/metric-learn/issues/185 | [
"documentation"
] | bellet | 0 |
ets-labs/python-dependency-injector | flask | 335 | Unable to inject dependencies in Django Graphene project | Hi, I have tried to setup dependecy-injector in order to use in a project with Django and Graphql using [Graphene](https://graphene-python.org/). but I am get `Provide' object has no attribute 'execute_strategy`, I follow these steps [https://python-dependency-injector.ets-labs.org/examples/django.html](url) for Django... | closed | 2020-12-14T15:04:10Z | 2020-12-14T16:48:33Z | https://github.com/ets-labs/python-dependency-injector/issues/335 | [
"question"
] | juanmarin96 | 2 |
InstaPy/InstaPy | automation | 6,530 | like_by_tags not working! pls suggest if any xpath is changed | Traceback (most recent call last):
File "C:/Scarper/insta2.py", line 62, in <module>
session.like_by_tags(smart_hashtags,amount=random.randint(5, 6))
File "C:\Users\CJ\miniconda3\envs\Scarper\lib\site-packages\instapy-0.6.16-py3.7.egg\instapy\instapy.py", line 1995, in like_by_tags
self.browser, self.ma... | open | 2022-03-02T08:57:24Z | 2022-03-02T08:58:05Z | https://github.com/InstaPy/InstaPy/issues/6530 | [] | charan89 | 0 |
s3rius/FastAPI-template | graphql | 4 | Change aioschedule to aiosheduler | Currently, in schedule.py, I use the Aioschedule lib, but there is another high-performant lib called Aioscheduler.
We need to change aioschedule to the new [scheduler lib](https://pypi.org/project/aioscheduler/). | closed | 2020-11-15T12:51:38Z | 2021-08-30T01:25:07Z | https://github.com/s3rius/FastAPI-template/issues/4 | [] | s3rius | 1 |
Yorko/mlcourse.ai | seaborn | 758 | Proofread topic 7 | - Fix issues
- Fix typos
- Correct the translation where needed
- Add images where necessary | closed | 2023-10-24T07:41:55Z | 2024-08-25T08:10:28Z | https://github.com/Yorko/mlcourse.ai/issues/758 | [
"enhancement",
"articles"
] | Yorko | 2 |
pennersr/django-allauth | django | 4,070 | ModuleNotFoundError: No module named 'allauth.socialaccount.providers.linkedin' | Seems like allauth.socialaccount.providers.linkedin is not yet implemented; only linkedin_oauth2 is implemented, even though the documentation says "linkedin_oauth2" is now deprecated.
Current latest version of django-allauth: **64.1.0**
| closed | 2024-08-24T16:32:00Z | 2024-08-24T18:50:27Z | https://github.com/pennersr/django-allauth/issues/4070 | [] | takuonline | 1 |
tableau/server-client-python | rest-api | 1,520 | Retry for request in use_server_version | **Describe the bug**
We are indexing data from multiple Tableau instances as a service provider integrating with Tableau.
We observed flaky requests on some instances:
```
2024-11-01T08:42:57.565777616Z stderr F INFO 2024-11-01 08:42:57,565 server 14 140490986871680 Could not get version info from server: <clas... | open | 2024-11-01T19:57:41Z | 2025-01-03T23:54:02Z | https://github.com/tableau/server-client-python/issues/1520 | [
"Design Proposal",
"docs"
] | ad-m-ss | 2 |
donnemartin/data-science-ipython-notebooks | numpy | 33 | "Error 503 No healthy backends" | Hello,
When I try to open the hyperlinks which should direct me to the correct ipython notebook, it returns me "Error 503 No healthy backends"
"No healthy backends
Guru Mediation:
Details: cache-fra1236-FRA 1462794681 3780339426
Varnish cache server"
<img width="833" alt="capture" src="https://cloud.githubuserconte... | closed | 2016-05-09T12:19:03Z | 2016-05-10T09:55:50Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/33 | [
"question"
] | wangjiahong | 1 |
iterative/dvc | machine-learning | 10,234 | gc: keep last `n` versions of data files, while ignoring commits with only code changes | Suppose I have the following commits in my project (from newest to oldest):
```
sha | changes
------------------------------
a01 | only dvc files changed
a02 | only code files changed
a03 | only dvc files changed
a04 | both dvc and code files changed
```
Now, suppose I'd like to keep the last 2 versions of d... | closed | 2024-01-12T11:10:04Z | 2024-03-05T01:58:07Z | https://github.com/iterative/dvc/issues/10234 | [
"p3-nice-to-have",
"A: gc"
] | mkaze | 5 |
gradio-app/gradio | deep-learning | 10,813 | ERROR: Exception in ASGI application after downgrading pydantic to 2.10.6 | ### Describe the bug
There were reports of the same error in https://github.com/gradio-app/gradio/issues/10662, and the suggestion is to downgrade pydantic, but even after I downgraded pydantic, I am still seeing the same error.
I am running my code on Kaggle
and the error
```
ERROR: Exception in ASGI applicati... | open | 2025-03-15T15:27:56Z | 2025-03-17T18:26:54Z | https://github.com/gradio-app/gradio/issues/10813 | [
"bug"
] | yumengzhao92 | 1 |
nltk/nltk | nlp | 2,818 | WordNetLemmatizer in nltk.stem module | What's the parameter of WordNetLemmatizer.lemmatize() in nltk.stem module?
Turn to the document, what are the candidate value of the parameter **'pos'**?

The default value is 'Noun'. But use the function p... | closed | 2021-09-26T02:44:43Z | 2021-09-27T08:20:53Z | https://github.com/nltk/nltk/issues/2818 | [
"documentation"
] | Beliefuture | 3 |
clovaai/donut | computer-vision | 188 | key information extraction with DonUT on hand-written documents? | Hi everyone,
Has anyone tried fine-tuning DonUT for key information extraction on a corpus with documents half-digital and half-handwritten? Specifically, I am wondering if anyone has any evidence on how it performs on handwritten text, given that all the suggestions on generating a synthetic dataset with SynthDoG f... | open | 2023-05-09T14:38:18Z | 2023-05-09T18:50:13Z | https://github.com/clovaai/donut/issues/188 | [] | DiTo97 | 2 |
Esri/arcgis-python-api | jupyter | 2,231 | Setting a value with no color | I have an imagery layer, in ArcGIS Pro value of 31 is set to no colour default. But when I add to a map widget with Python API the value of 31 is having colour. How should I set it no colour. I've been looked at the docs but couldn't figure it out.
This is the layer on Living Atlas: https://www.arcgis.com/home/item.ht... | closed | 2025-03-03T00:01:48Z | 2025-03-05T19:10:14Z | https://github.com/Esri/arcgis-python-api/issues/2231 | [] | hieutrn1205 | 5 |
joke2k/django-environ | django | 113 | MySQL Socket for Host | For the host I need to use a path to a socket, but it doesn't seem to be working. Is this supported? | open | 2017-03-17T22:54:26Z | 2021-09-04T21:16:56Z | https://github.com/joke2k/django-environ/issues/113 | [
"question",
"documentation"
] | chadsaun | 1 |
kiwicom/pytest-recording | pytest | 20 | Throw an error if pytest-vcr is installed | Otherwise, it could lead to incompatibilities on the fixture level (they will be mixed) | closed | 2019-10-21T15:32:59Z | 2019-10-21T16:35:30Z | https://github.com/kiwicom/pytest-recording/issues/20 | [] | Stranger6667 | 1 |
xinntao/Real-ESRGAN | pytorch | 387 | Conda Install BasicSR | Is there a way to install basicsr on a conda environment?
I tried installing it with pip but the package doesn't show up on the conda environment so I am not able to run the model.
Thanks. | open | 2022-07-11T22:51:59Z | 2022-07-20T21:24:26Z | https://github.com/xinntao/Real-ESRGAN/issues/387 | [] | AvirupJU | 1 |
allenai/allennlp | nlp | 5,259 | Initialization of InterleavingDatasetReader from Jsonnet | **Is your feature request related to a problem? Please describe.**
It may be that it's possible to do this already, but it's unclear to me whether an `InterleavingDatasetReader` can be fully initialized from a Jsonnet config file, as it seems the `readers` parameter expects a dictionary whose values are already-constr... | closed | 2021-06-14T19:45:31Z | 2021-06-15T15:35:24Z | https://github.com/allenai/allennlp/issues/5259 | [
"Feature request"
] | wgantt | 1 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 149 | What's the ratio of each losses when training mapping T | In my case, the G_Feat_L2(lambda=60) is much larger than other loss with your script. Below is the first 1200 iters:
(epoch: 1, iters: 24, time: 1.745 lr: 0.00020) G_Feat_L2: 71.198 G_GAN: 6.186 G_GAN_Feat: 15.838 G_VGG: 11.113 D_real: 6.164 D_fake: 5.030
(epoch: 1, iters: 600, time: 0.069 lr: 0.00020) G_Feat_L2: ... | closed | 2021-04-12T05:38:06Z | 2021-04-20T02:19:02Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/149 | [] | syfbme | 2 |
oegedijk/explainerdashboard | dash | 129 | joblib.dump(explainer,explainer_path) fails with KernelExplainer | Hi Oege,
and thanks for this project. It's very helpful!
This applies to both joblib.dump and explainer.dump().
This happens only with self.shap=='kernel' Which provides the model_predict function to shap.KernelExplainer().
Here is the error:
`_pickle.PicklingError: Can't pickle <function BaseExplainer.s... | closed | 2021-07-01T10:51:33Z | 2021-07-01T13:46:16Z | https://github.com/oegedijk/explainerdashboard/issues/129 | [] | tunayokumus | 4 |
MycroftAI/mycroft-core | nlp | 2,701 | Extract existing audioservices, STT and TTS engines for new plugin system | As we are moving to a new [plugin system for audioservices, STT and TTS engines](https://github.com/MycroftAI/mycroft-core/pull/2594) we need to create a plugin for each of the services that will no longer be included by default in core.
Examples are provided in the PR #2594
We also need to explore the best ways... | closed | 2020-09-24T04:22:30Z | 2024-09-08T08:33:51Z | https://github.com/MycroftAI/mycroft-core/issues/2701 | [
"Type: Enhancement - roadmapped",
"Breaking change"
] | krisgesling | 3 |
ading2210/poe-api | graphql | 137 | timeout error | socket timeout
------------
File "/home/huyremy/.local/lib/python3.7/site-packages/poe.py", line 502, in send_message
raise RuntimeError("Response timed out.")
RuntimeError: Response timed out.
------------
Stop and restart it run well but it will be timeout error in few minutes later.
------------
P... | closed | 2023-07-01T09:07:50Z | 2023-07-04T08:54:06Z | https://github.com/ading2210/poe-api/issues/137 | [
"bug"
] | huyremy | 4 |
mljar/mljar-supervised | scikit-learn | 690 | mljar should not configure logging level | Hi Piotr,
First, I wanted to let you know you are doing a great job!
We are trying to use mljar-supervised as a library in a large application. However, when trying to get log messages we see that your code set the default log level to ERROR. For example, at exceptions.py and automl.py. Calling basicConfig the seco... | open | 2024-01-08T08:22:13Z | 2024-01-31T10:32:40Z | https://github.com/mljar/mljar-supervised/issues/690 | [
"enhancement",
"help wanted"
] | haim-cohen-moonactive | 3 |
WeblateOrg/weblate | django | 14,101 | Highlight string page number on click | ### Describe the problem
When you're translating and want to hop to a string page you remember the number of, you've got click once on the page number, and then you have to manually delete the digits and replace them with the desired number. It's a small grievance, but it can add up pretty quickly and feels unnecessar... | closed | 2025-03-04T11:54:12Z | 2025-03-19T16:07:30Z | https://github.com/WeblateOrg/weblate/issues/14101 | [
"enhancement",
"Area: UX"
] | Cwpute | 5 |
keras-team/keras | python | 20,030 | Are different "set of batches" selected at each epoch when using `steps_per_epoch` ? | This fits the model using 10 batches of 64 samples per epoch:
```py
model.fit(train_data, epochs=5, steps_per_epoch=10)
```
If the Dataset is `.batch`ed with 64 samples, but has more than 640 samples (say 2000), are all those remaining samples used at all ? | closed | 2024-07-23T11:21:43Z | 2024-07-24T17:44:07Z | https://github.com/keras-team/keras/issues/20030 | [
"type:support"
] | newresu | 3 |
koaning/scikit-lego | scikit-learn | 426 | [FEATURE] Time Series Grouped Predictor including predictions from last lag | Hi!
I am finding really useful the 'GroupedPredictor' meta estimator.
I sometimes deal with the a similar problem at work and I have my own sketchy implementation. But after finding of 'GroupedPredictor' I believe that there might be a better way to solve the problem.
I deal with supervised learning time series... | closed | 2020-12-08T10:03:31Z | 2020-12-18T09:45:40Z | https://github.com/koaning/scikit-lego/issues/426 | [
"enhancement"
] | cmougan | 2 |
marshmallow-code/flask-smorest | rest-api | 444 | UploadFile converter overrides custom converters | When adding custom converter for API spec fields the UploadFile converter resets any previous changes.
The converter should not do this. | closed | 2023-01-17T15:57:19Z | 2023-01-17T16:06:15Z | https://github.com/marshmallow-code/flask-smorest/issues/444 | [] | arthurvanduynhoven | 1 |
donnemartin/data-science-ipython-notebooks | pandas | 82 | Ipython notebook | open | 2021-03-07T14:02:35Z | 2023-03-16T10:41:21Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/82 | [
"needs-review"
] | alfa0977 | 0 | |
deepfakes/faceswap | deep-learning | 670 | train failed | 03/15/2019 22:08:06 MainProcess training_0 multithreading run DEBUG Error in thread (training_0): OOM when allocating tensor with shape[16384,1024] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc\n [[{{node training_1/Adam/mul_43}} = Mul[T=DT_FLO... | closed | 2019-03-15T14:34:28Z | 2019-03-18T17:44:52Z | https://github.com/deepfakes/faceswap/issues/670 | [] | Nostalgia1990 | 11 |
ned2/slapdash | plotly | 31 | Input('url','pathname') Not Working | Converting some existing code from another project over into slapdash, it seems like `Input('url','pathname')` cannot be used?
Am I missing something? ...Is there another way to use the url in a callback?
```
@app.callback(Output('api-connections', 'children'),
[Input('submit-settings-button', 'n_... | closed | 2020-03-05T21:30:15Z | 2020-03-06T12:45:10Z | https://github.com/ned2/slapdash/issues/31 | [] | ethanopp | 2 |
mwaskom/seaborn | matplotlib | 2,924 | next gen usage question | How can I plot all (or a subset of) the columns of a pandas dataframe, using the index as x-axis, with the new object-based interface? | closed | 2022-07-26T11:18:56Z | 2022-07-28T14:17:38Z | https://github.com/mwaskom/seaborn/issues/2924 | [
"question",
"objects-plot"
] | bdch1234 | 6 |
thunlp/OpenPrompt | nlp | 253 | How to use openprompt in an In-context learning setting? | Is there a way to use Openprompt for an in-context learning setting (i.e., adding examples to the prompt). | open | 2023-03-20T12:58:25Z | 2023-03-30T05:23:18Z | https://github.com/thunlp/OpenPrompt/issues/253 | [] | YamenAjjour | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 1,107 | gp_minimize returns lowest found point, not minimum of surrogate model | I am not sure if this is expected behavior or not, so this is a question and only potentially an actual issue:
`gp_minimize` returns the lowest seen value. However, for very noisy data, this is very unlikely to be the best estimate of the minimum.
As far as I can see, there is no option to instead have the minimum ... | open | 2022-03-02T11:02:44Z | 2023-03-10T18:51:36Z | https://github.com/scikit-optimize/scikit-optimize/issues/1107 | [] | juliusbierk | 3 |
open-mmlab/mmdetection | pytorch | 11,409 | Multi-class MOT in QDTrack | Thanks for your error report and we appreciate it a lot.
**Checklist**
1. I have searched related issues but cannot get the expected help.
2. I have read the [FAQ documentation](https://mmdetection.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
3. The bug has not been fixed in the latest v... | open | 2024-01-19T14:04:56Z | 2024-01-19T14:05:12Z | https://github.com/open-mmlab/mmdetection/issues/11409 | [] | JackWoo0831 | 0 |
httpie/cli | python | 1,599 | Request to server is very slow | ## Checklist
- [x] I've searched for similar issues.
- [x] I'm using the latest version of HTTPie.
---
## Minimal reproduction code and steps
1. Download the latest version of HTTPie (brew or pip).
2. Make a GET request to `https://repro.pacemakr.at`.
3. Wait.
## Current result
Request takes severa... | open | 2024-09-07T08:01:05Z | 2024-09-07T08:01:05Z | https://github.com/httpie/cli/issues/1599 | [
"bug",
"new"
] | gurbindersingh | 0 |
iMerica/dj-rest-auth | rest-api | 331 | How do I redirect after logout? | I'm working on a project with React and Django. I want to be redirected to the main page when I log out. Please help me ... | open | 2021-11-22T10:47:01Z | 2021-11-27T18:08:18Z | https://github.com/iMerica/dj-rest-auth/issues/331 | [] | wopa7210 | 1 |
JaidedAI/EasyOCR | deep-learning | 878 | Fine-Tuning Dataset Size | I wish to fine-tune easyocr to detect text from signs in the wild. I was wondering if there has been any research of if there are any general rules to help me estimate how many images I will need to achieve > 95% accuracy?
Thanks! | open | 2022-10-27T17:49:59Z | 2022-10-27T17:49:59Z | https://github.com/JaidedAI/EasyOCR/issues/878 | [] | jamesSmith54 | 0 |
dpgaspar/Flask-AppBuilder | rest-api | 2,188 | user_registration error | Hi,
It is my first time web development with fab.
I want to make a login page with self registration and i inspected the user_registration in examples folder. But it is not working correctly. I used a test recaptcha key, because default key didn't work. I always got registerDbModelview's error message:
Not possible... | closed | 2024-02-07T11:12:27Z | 2024-02-12T07:17:53Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2188 | [] | ayseelifvural-aras | 0 |
yzhao062/pyod | data-science | 443 | How I can use PyOD with Image and Text data along with other information present in Tabular data? | Hi,
I have data of products and for each product, I have images, descriptions (text data), and product attributes like color, size, etc. How can I use PyOD to do anomaly detection with such mix data? And also what would be right step to convert the data in right format so that I can use PyOD with such mix data to perf... | open | 2022-09-21T20:43:19Z | 2022-09-24T11:46:27Z | https://github.com/yzhao062/pyod/issues/443 | [] | karndeepsingh | 6 |
nsidnev/fastapi-realworld-example-app | fastapi | 48 | Update test running guide | I think this need some guideline to how to run unit test under the `test` dir for some beginners
It will be very helpful, so much thanks | closed | 2020-06-08T06:30:44Z | 2020-06-11T16:18:32Z | https://github.com/nsidnev/fastapi-realworld-example-app/issues/48 | [] | JasonLee-crypto | 6 |
AutoViML/AutoViz | scikit-learn | 109 | Bar Charts customization and skipping WordArt. | 
1. Could I adjust the 'Counts' displayed in the bar plots based on selected variables, or can i manually input two variables to compare in bar chart for 'depVar'? The bar generated seems lacks meaningful insights.
... | closed | 2024-04-28T06:05:29Z | 2024-04-29T18:31:26Z | https://github.com/AutoViML/AutoViz/issues/109 | [] | jackfood | 1 |
jina-ai/serve | machine-learning | 5,575 | jina实现负载均衡,是否需要自己根据需求设置executor的功能 | **Describe your proposal/problem**
<!-- A clear and concise description of what the proposal is. -->
---
<!-- Optional, but really help us locate the problem faster -->
我有一个微服务,他的参数是字符串列表,这个微服务用到gpu,我想用jina实现负载均衡,把字符串列表拆成多个固定长度的列表,然后再去调用微服务,然后再拼接结果,这个过程flow可以自动实现嘛
**Environment**
<!-- Run `jina --version-full... | closed | 2023-01-05T09:20:09Z | 2023-02-01T06:42:01Z | https://github.com/jina-ai/serve/issues/5575 | [] | fqzhao-win | 11 |
jumpserver/jumpserver | django | 14,443 | [Bug] 添加账号密钥接口,密钥参数内容需要手动加换行符(\n)且合并为一整行,才能调用成功 | ### 产品版本
3.10.1
### 版本类型
- [ ] 社区版
- [X] 企业版
- [ ] 企业试用版
### 安装方式
- [ ] 在线安装 (一键命令安装)
- [X] 离线包安装
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] 源码安装
### 环境信息
JumpServer 版本为 v3.10.15
### 🐛 缺陷描述
添加账号密钥接口,密钥参数直接复制密钥内容报错
![Uploading 336f2ac9bd40e5ae279ccaf5846ba28.png…]()
### 复现步骤
1. 调用创建账号密钥的接口
2.... | closed | 2024-11-13T07:39:28Z | 2024-11-13T07:43:42Z | https://github.com/jumpserver/jumpserver/issues/14443 | [
"🐛 Bug",
"💡 FAQ"
] | hedanhedan | 1 |
koaning/scikit-lego | scikit-learn | 551 | [FEATURE] - Grid search across model parameters AND thresholds with Thresholder() without refitting | Thanks for this great set of extensions to sklearn.
The Tresholder() model is quite close to something I've been looking for for a while.
I'm looking to include threshold optimisation as part of a *broader* parameter search.
I can perhaps best describe the desired behaviour as follows
```
for each paramete... | open | 2022-11-16T16:05:08Z | 2023-09-26T14:54:13Z | https://github.com/koaning/scikit-lego/issues/551 | [
"enhancement"
] | mcallaghan | 3 |
pydata/xarray | numpy | 10,099 | Timedelta64 data cannot be round-tripped to netCDF files without a warning | ### What is your issue?
We added a future warning about not decoding time units to timedelta64 in https://github.com/pydata/xarray/pull/9966 (cc @spencerkclark, @kmuehlbauer).
Unfortunately, this warning is raised by default when reading timedelta64 serialized data to disk. This makes it much harder to use this dtype... | open | 2025-03-05T18:20:05Z | 2025-03-06T14:32:36Z | https://github.com/pydata/xarray/issues/10099 | [] | shoyer | 3 |
marcomusy/vedo | numpy | 1,206 | Jupyter backends problems (trame, ipyvtk, k3d) | ### k3d
```python
"""Create a Volume from a numpy array"""
import numpy as np
from vedo import Volume, show, settings
settings.default_backend = "k3d"
data_matrix = np.zeros([70, 80, 90], dtype=np.uint8)
data_matrix[ 0:30, 0:30, 0:30] = 1
data_matrix[30:50, 30:60, 30:70] = 2
data_matrix[50:70, 60:80, 70:90... | closed | 2024-11-30T09:19:47Z | 2024-12-28T03:27:30Z | https://github.com/marcomusy/vedo/issues/1206 | [] | YongcaiHuang | 2 |
newpanjing/simpleui | django | 192 | 通用列表和详细信息视图 | **你希望增加什么功能?**
1.希望增加 数值的区间搜索
**留下你的联系方式,以便与你取得联系**
QQ:xxxxx
邮箱:153221318@qq.com
| closed | 2019-12-03T08:54:24Z | 2019-12-04T02:40:34Z | https://github.com/newpanjing/simpleui/issues/192 | [
"enhancement"
] | mn6538 | 0 |
aio-libs/aiomysql | sqlalchemy | 589 | aiomysql does not support TLS on Python 3.8 on Windows | Due to the Python 3.8 changing the default event loop to proactor, `start_tls` does not work, therefore you cannot connect to a server using TLS.
As per https://github.com/tornadoweb/tornado/issues/2608 and https://github.com/aio-libs/aiohttp/issues/4536, this limitation should probably be documented somewhere.
T... | open | 2021-06-04T21:53:24Z | 2022-01-22T23:09:24Z | https://github.com/aio-libs/aiomysql/issues/589 | [
"bug",
"docs"
] | huwcbjones | 0 |
widgetti/solara | jupyter | 243 | Internal Server Error by KeyError: 'load_extensions' | Thank you for this great library.
I tried to implement auth0 private site using Docker+Poetry and got an internal server error, and after looking at the code, it looks like there is no solution.
Apparently I should be able to set use_nbextensions=False when calling read_root in server.py, but I can't set it in th... | closed | 2023-08-14T13:56:35Z | 2023-08-14T14:22:31Z | https://github.com/widgetti/solara/issues/243 | [] | Sanuki-073 | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 737 | Is it possible to use a direct image comparison with realB in pix2pix | Hi, I'm trying to do something like this: to have zebras and horses in the same picture and switch each one into the other kind.
With CycleGAN you can get very good models that for instance get pictures from, ignore zebras and turn horses into zebras. And viceversa. I've managed to do that, and to have pictures wher... | open | 2019-08-20T14:31:28Z | 2019-08-20T16:59:12Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/737 | [] | thehardmenpath | 1 |
ultrafunkamsterdam/undetected-chromedriver | automation | 967 | TypeError: Can't instantiate abstract class Service with abstract method command_line_args | service = selenium.webdriver.common.service.Service(
patcher.executable_path, port, service_args, service_log_path
)
Got error for this line after update. | open | 2022-12-31T09:57:36Z | 2023-02-21T08:21:08Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/967 | [] | anovob | 2 |
gevent/gevent | asyncio | 1,901 | select.epoll support on gpio | So I was working with OPi.GPIO python library and having trouble the edge detection, I encountered No module found epoll, since edge detection uses epoll but epoll currently not supported. Is it ok to disable select? select=False in monkey patch all? | closed | 2022-08-26T22:33:31Z | 2022-08-27T11:02:12Z | https://github.com/gevent/gevent/issues/1901 | [] | pikonek | 0 |
inducer/pudb | pytest | 446 | No output displayed after pressing o | I ran a simple script with following command:
**python -m pudb test.py**
Press 'o' when stopping at Line 4, nothing but hints "Hit Enter to return:" displayed, as shown in image below:
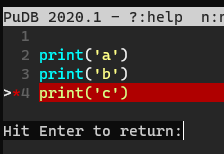
Anything wr... | closed | 2021-04-22T03:50:14Z | 2021-07-13T14:04:37Z | https://github.com/inducer/pudb/issues/446 | [] | dehiker | 5 |
hbldh/bleak | asyncio | 1,715 | leaking an uninitialized object of type CBCentralManager | Mac OS 10.11
Python 3.11
bleak 0.22.3
pyobjc 10.3.2
When calling
`await BleakScanner.discover(5.0, return_adv=True)`
I get the following error
```
/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/bleak/backends/corebluetooth/CentralManagerDelegate.py:76: UninitializedDeallocWarning: l... | open | 2025-01-22T21:53:00Z | 2025-01-23T00:06:23Z | https://github.com/hbldh/bleak/issues/1715 | [
"3rd party issue",
"Backend: Core Bluetooth"
] | paorin | 1 |
deezer/spleeter | tensorflow | 202 | [Discussion] What are the recommended CPU and memory? | What are the recommended CPU and memory?
Conventional processing music files, Example:filename-》MP3,7bm | closed | 2019-12-27T04:24:06Z | 2020-04-05T12:38:15Z | https://github.com/deezer/spleeter/issues/202 | [
"question"
] | yoorxee | 2 |
apify/crawlee-python | web-scraping | 85 | Refactor initialization of storages | ### Description
- Currently, if you want to initialize Dataset/KVS/RQ you should use `open()` constructor. And it goes like the following:
- `dataset.open()`
- `base_storage.open()`
- `dataset.__init__()`
- `base_storage.__init__()`
- In the `base_storage.open()` a specific client is selected (local - `... | closed | 2024-04-03T12:19:43Z | 2024-05-10T16:06:16Z | https://github.com/apify/crawlee-python/issues/85 | [
"t-tooling",
"debt"
] | vdusek | 11 |
pyeve/eve | flask | 1,023 | settings.py search sequence unintuitive and fragile | My first time out with Eve I ran:
from eve import Eve
app = Eve()
And got the exception:
```
Traceback (most recent call last):
File "/Users/daphtdazz/.virtualenvs/py3/lib/python3.5/site-packages/eve/flaskapp.py", line 272, in validate_domain_struct
domain = self.config['DOMAIN']
KeyError: '... | closed | 2017-05-26T15:40:07Z | 2018-05-18T17:19:54Z | https://github.com/pyeve/eve/issues/1023 | [
"enhancement",
"stale"
] | daphtdazz | 8 |
davidsandberg/facenet | computer-vision | 981 | how can i run compare.py on windows | open | 2019-02-24T19:22:52Z | 2019-04-03T22:16:27Z | https://github.com/davidsandberg/facenet/issues/981 | [] | mohammedSamirMady | 1 | |
sktime/sktime | data-science | 7,407 | [ENH] Create special case of EnsembleForecaster that consists of N copies of identical forecaster to facilitate hyperparameter tuning | Convergence of ML models such as Neural Nets is affected by the initial (random) weights. This effect is often mitigated by creating an ensemble of N instances of the ML model, where each is fitted using different initial weights. This creates a problem when trying to tune hyperparameters of the underlying ML model (e.... | closed | 2024-11-19T07:12:01Z | 2024-11-23T14:55:57Z | https://github.com/sktime/sktime/issues/7407 | [
"module:forecasting",
"enhancement"
] | ericjb | 1 |
saulpw/visidata | pandas | 1,959 | Current HEAD zsh-completion.py needs option_aliases update | **Small description**
`option_aliases` was removed in ce497f444db6d2f3fc0b8309f5ca839196c33c8b but is still referred to in the zsh completion code.
https://github.com/saulpw/visidata/blob/34808745232e798b0f25e893bb444fc9f3c034eb/dev/zsh-completion.py#L11C41-L11C41
I think the script needs a slight rejig to use... | closed | 2023-07-15T00:32:42Z | 2023-08-16T16:27:27Z | https://github.com/saulpw/visidata/issues/1959 | [
"bug",
"fixed"
] | dbaynard | 8 |
marshmallow-code/apispec | rest-api | 348 | nested load_only fields appears in response | Hi.
I'm using apispec 1.0.0b6 and I love responses swagger control with load, dump_only fields.
but when schema is nested, load_only fields appears in responses example value.
related #303 #119
Thanks | closed | 2018-12-20T11:04:28Z | 2019-03-04T09:51:03Z | https://github.com/marshmallow-code/apispec/issues/348 | [] | zeakd | 3 |
microsoft/MMdnn | tensorflow | 791 | Keras model loading broken | Platform (like ubuntu 16.04/win10): Redhat
Python version: 3.6.2
Source framework with version (like Tensorflow 1.4.1 with GPU): Keras 2.2.4
Destination framework with version (like CNTK 2.3 with GPU): Pytorch 1.2.0
Pre-trained model path (webpath or webdisk path): Can't provide (sorry)
Running scripts: ... | open | 2020-02-21T20:52:17Z | 2020-03-01T04:17:42Z | https://github.com/microsoft/MMdnn/issues/791 | [] | mortonjt | 1 |
pytest-dev/pytest-html | pytest | 395 | Fix flaky test_rerun test on Windows | [test_rerun](https://github.com/pytest-dev/pytest-html/blob/master/testing/test_pytest_html.py#L189) is flaky only for windows environments. The root cause should be identified and fixed.
I have access to a windows machine, so I'll try and take a look soon. In the meantime, please rerun pipelines if this test fails ... | open | 2020-12-01T23:52:48Z | 2020-12-13T23:04:17Z | https://github.com/pytest-dev/pytest-html/issues/395 | [
"skip-changelog",
"test",
"windows"
] | gnikonorov | 7 |
graphql-python/gql | graphql | 189 | gql 3.x.y not available as python-poetry dependency | Versions 2.x.y are available as dependencies for python-poetry, but no version 3.x.y is.
Extremely annoying for users of python-poetry, especially since docs for versions 2.x.y are apparently nowhere to be found. | closed | 2021-01-26T15:55:50Z | 2021-02-10T09:58:14Z | https://github.com/graphql-python/gql/issues/189 | [
"type: question or discussion"
] | deedf | 2 |
xlwings/xlwings | automation | 2,594 | Run-time error '13': Type mismatch (French version of Excel) | The following solved it:
```
The xlwings.conf:
I changed the attribute values “Faux” for “False”
``` | open | 2025-03-19T08:17:00Z | 2025-03-19T08:17:31Z | https://github.com/xlwings/xlwings/issues/2594 | [
"bug"
] | fzumstein | 0 |
ultralytics/yolov5 | machine-learning | 13,245 | more details about training procedure | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi,
I have a question related to the training procedure of yolov5. Specifically I was wo... | open | 2024-08-06T10:10:48Z | 2024-10-20T19:51:25Z | https://github.com/ultralytics/yolov5/issues/13245 | [
"question"
] | NGtesig | 4 |
keras-team/keras | deep-learning | 20,952 | implement of muon optimizer | [Moun optimizer](https://github.com/KellerJordan/Muon) is an optimizer proposed by OpenAI that is stronger than AdamW. And it has been verified on the [Moonlight model](https://hf-mirror.com/moonshotai/Moonlight-16B-A3B-Instruct).
Has the Keras team implemented his plan? If not yet, I can submit a relevant PR.
If I wer... | open | 2025-02-24T08:45:47Z | 2025-03-04T18:49:38Z | https://github.com/keras-team/keras/issues/20952 | [
"type:feature"
] | pass-lin | 8 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 541 | [BUG] API失效?是否与tiktok下线有关? | INFO 如果你不需要使用TikTok相关API,请忽略此消息。
INFO: Will watch for changes in these directories: ['/www/wwwroot/Douyin_TikTok_Download_API-main']
INFO: Uvicorn running on http://0.0.0.0:4335 (Press CTRL+C to quit)
INFO: Started reloader process [14167] using StatReload
ERROR 生成TikTok msToken API错误:timed out
INFO 当前网络无法正常访问TikTok服务器... | closed | 2025-01-19T07:30:02Z | 2025-01-21T04:29:23Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/541 | [
"BUG"
] | shuntan | 1 |
plotly/dash | flask | 2,979 | DatePickerRange ignoring stay_open_on_select option | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.17.1
dash-bootstrap-components 1.6.0
dash-extensions 1.0.18
dash-table 5.0.0
```
- if fro... | open | 2024-09-04T00:59:08Z | 2024-09-04T13:23:14Z | https://github.com/plotly/dash/issues/2979 | [
"bug",
"P2"
] | brett-matson | 0 |
widgetti/solara | fastapi | 615 | More detail to how Solara works without a jupyter kernel | We have a Voila workflow that we are looking to replace with regular react/api server backends so we can have a lighter weight more scaleable backend.
From this page
https://solara.dev/documentation/advanced/understanding/voila
it looks like Solara could be a good option. Can you add more detail to that documen... | open | 2024-04-22T14:22:14Z | 2024-04-23T10:38:06Z | https://github.com/widgetti/solara/issues/615 | [] | paddymul | 1 |
jupyter-incubator/sparkmagic | jupyter | 525 | Can not connect to Sparkmagic Kernel in Docker | Hi,
I am unable to connect to Spark Kernel in Docker Spawner. I am installing SparkMagic in my image and tested the functionality using ipython kernel and it works fine.
But when I am starting Spark Kernel it gives me dead kernel error.
Error Message:
```The kernel has died, and the automatic restart has fa... | closed | 2019-04-11T22:18:06Z | 2022-04-27T19:19:42Z | https://github.com/jupyter-incubator/sparkmagic/issues/525 | [] | ayushiagarwal | 0 |
xuebinqin/U-2-Net | computer-vision | 363 | How can I input video or webcam in the test.py script? | I want to get video input, how should I modify the script? | open | 2023-08-28T02:45:45Z | 2023-08-28T02:45:45Z | https://github.com/xuebinqin/U-2-Net/issues/363 | [] | Hogushake | 0 |
akfamily/akshare | data-science | 5,542 | stock_sse_deal_daily 上证交易所每日概况数据错误 | 以下涉及的是 stock_sse_deal_daily 返回的 df 中 "单日情况"列的值为"成交金额"对应的行的数据错误:
1. 官网有数据但查询失败:20060712 和 20070430,上证交易所网站可以查到数据,但是 stock_sse_deal_daily 查询这两个日期时报错。
2. 数据列错位如:20211224,对比上证交易所网站,"股票回购"列正确,其他列错位。
单日情况 股票 主板A 主板B 科创板 股票回购
成交金额 441.931463 1.320805 4342.... | closed | 2025-01-20T05:13:08Z | 2025-02-21T10:16:33Z | https://github.com/akfamily/akshare/issues/5542 | [] | LiuTaolang | 2 |
PokeAPI/pokeapi | graphql | 425 | Missing Aegislash | Aegislash is not in the pokemon database | closed | 2019-04-26T14:51:05Z | 2024-05-01T09:12:34Z | https://github.com/PokeAPI/pokeapi/issues/425 | [] | 2sodiumsandwich | 5 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.