
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Разработка HTML5-игр в Intel XDK. Часть 4. Система координат и перемещение объектов

[Часть 1](https://habrahabr.ru/company/intel/blog/281380/) » [Часть 2](https://habrahabr.ru/company/intel/blog/281453/) » [Часть 3](https://habrahabr.ru/company/intel/blog/281523/) » [Часть 4](https://habrahabr.ru/company/intel/blog/281607/) » [Часть 5](https://habrahabr.ru/company/intel/blog/281639/) » [Часть 6](https://habrahabr.ru/company/intel/blog/281873/) » [Часть 7](https://habrahabr.ru/company/intel/blog/281981/) // Конец )

Сегодня разберёмся с системой координат, которая применяется в Cocos2d-JS и поговорим о том, как перемещать игровые объекты на экране.
[](https://habrahabr.ru/company/intel/blog/281607/)
Система координат
-----------------
В Cocos2d-JS положение объектов в игровом пространстве определяется посредством системы координат. Каждый узел в движке имеет координаты x и y, определяющие его позицию. Здесь используется правая [прямоугольная система координат](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D1%8F%D0%BC%D0%BE%D1%83%D0%B3%D0%BE%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%BA%D0%BE%D0%BE%D1%80%D0%B4%D0%B8%D0%BD%D0%B0%D1%82), точно такая же, которую изучают на занятиях по математике.
*Система координат*
Размер видимой области
----------------------
Максимальные координаты по осям x и y определяются размерами видимой области. Cocos2d-JS предоставляет объект, который называется «view», или «вид», который занимается поддержкой различных разрешений и размеров экрана.
Вот строка кода из main.js, которая задаёт размер видимой области.
```
cc.view.setDesignResolutionSize(480, 800, cc.ResolutionPolicy.SHOW_ALL);
```
Первый аргумент вызываемого метода – это ширина, второй – высота. В нашем случае собственное разрешение видимой области составляет 480x800. Третий аргумент задаёт правила изменения размера игрового пространства, когда программа запускается на устройстве, экран которого имеет разрешение и соотношение сторон, которые отличаются от заданных параметров.
Движок предоставляет пять способов решения проблемы несоответствия характеристик экрана параметрам, заданным в программе. Их описания можно найти в файле main.js, выше той строки кода, которую мы только что рассмотрели. Мы будем пользоваться значением по умолчанию, SHOW\_ALL. При таком подходе соотношение сторон видимой области сохранится на любом дисплее, при этом незанятые изображением участки экрана будут закрашены чёрным цветом – по бокам игрового поля появятся чёрные полосы.
Пространство координат
----------------------
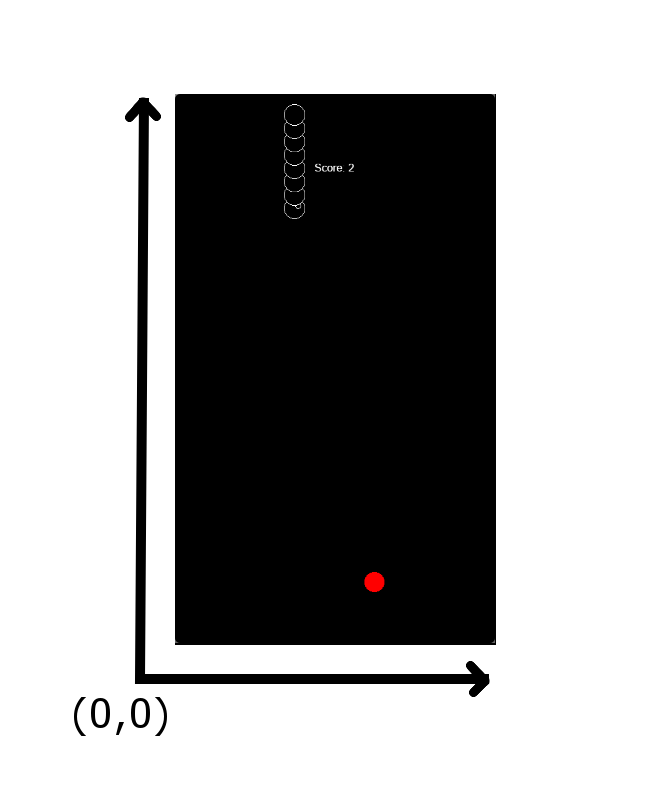
У каждого узла есть собственное внутреннее пространство координат. И окно, и каждый из узлов, имеют систему координат, начало которой находится в нижнем левом углу прямоугольника, ограничивающего объект.
*Начало координат окна и игрового объекта*
Задавая позицию узла, мы задаём его место в пространстве координат объекта-родителя. Например, задавая позицию для красной точки (угощения для змеи), изображённой на рисунке выше, вы заставляете её перемещаться в пределах координатной системы слоя (оси, нарисованные чёрными линиями), а не в пределах собственного пространства координат (оси жёлтого цвета).
Вытаскиваем змею из угла
------------------------
Теперь, когда мы разобрались с системой координат, мы можем вытащить голову змеи из угла и поместить её в более приличное место. А именно, в нашем варианте игры Snake всё будет начинаться в центре экрана.
Обновите код слоя SnakeLayer так, как показано ниже. Новый код надо добавить ниже комментария «Добавьте код ниже».
```
var SnakeLayer = cc.Layer.extend({
snakeHead: null
ctor: function () {
// Добавьте код ниже
/* Получим размер окна */
var winSize = cc.view.getDesignResolutionSize();
/* Вызовем конструктор суперкласса */
this._super();
/* Создадим голову змеи */
this.snakeHead = new SnakePart(asset.SnakeHead_png);
// Добавьте код ниже
/* Установим координаты для головы змеи */
this.snakeHead.x = winSize.width / 2;
this.snakeHead.y = winSize.height / 2;
/* Добавим объект в качестве потомка слоя */
this.addChild(this.snakeHead);
},
});
```
Переменная winSize – это объект, который содержит размеры окна – его ширину и высоту. Используя эти данные, мы назначаем голове змеи позицию, координата x которой равна половине ширины окна, а координата y – половине высоты.
Теперь запустим то, что получилось, в эмуляторе.

*Голова змеи переместилась к центру экрана*
Научим змею двигаться.
Перемещение объектов
--------------------
После того, как с системой координат мы разобрались, очевидно то, что для перемещения узла по экрану, нужно изменить его координаты x и y. Займёмся этим.
Для того, чтобы змея смогла двигаться, добавьте в код слоя SnakeLayer следующий метод.
```
moveSnake: function(dir) {
/* Набор значений, задающих направление перемещения */
var up = 1, down = -1, left = -2, right = 2,
step = 20;
/* Перенесём переменную snakeHead в локальную область видимости */
var snakeHead = this.snakeHead;
/* Сопоставление направлений и реализующего перемещения кода */
var dirMap = {};
dirMap[up] = function() {snakeHead.move(snakeHead.x, snakeHead.y + step);};
dirMap[down] = function() {snakeHead.move(snakeHead.x, snakeHead.y - step);};
dirMap[left] = function() {snakeHead.move(snakeHead.x - step, snakeHead.y);};
dirMap[right] = function() {snakeHead.move(snakeHead.x + step, snakeHead.y);};
/* Перемещаем голову в заданном направлении */
if (dirMap[dir] !== undefined) {
dirMap[dir]();
}
},
```
Этот метод занимается тем, что перемещает голову змеи с постоянным, жёстко заданным, шагом (переменная step) всякий раз, когда его вызывают. В качестве шага мы выбрали 20, так как это значение нацело делит и ширину, и высоту игрового экрана. Для указания направления перемещения мы пользуемся числами, которые задают нужные изменения координат объектов. Теперь этот метод надо как-то вызвать.
Игровой цикл
------------
В игровом движке имеется бесконечный цикл, который решает следующие задачи: обработка событий ввода без блокирования программы, исполнение игровой логики, вывод графики. Каждый проход цикла называется «тактом» или «тиком» (tick). Его можно сравнить с регулярно срабатывающим таймером.
Если описать структуру игрового цикла в псевдокоде, то получится следующее:
```
while (true) {
processInput();
runGameLogic();
renderGame();
}
```
Когда движок занимается исполнением игровой логики, он проходит по списку игровых объектов, выполняет код и обновляет их состояние. Например, если в игре есть персонаж, который падает с неба, игре нужно будет обновлять его позицию каждый такт, основываясь на заданном алгоритме. Добавим слой SnakeLayer в список обновления Cocos2d-JS.
Добавьте в код SnakeLayer метод update и вызовите метод scheduleUpdate в методе ctor. Остальной код в листинге приведен для того, чтобы помочь сориентироваться.
```
var SnakeLayer = cc.Layer.extend({
snakeHead: null,
ctor: function () {
...
/* Запланируем обновления */
this.scheduleUpdate();
},
moveSnake: function(dir) {
...
},
update: function() {
/* Число, соответствующее направлению */
var up = 1;
this.moveSnake(up);
},
});
```
Теперь, всякий раз, после создания объекта, метод update будет вызываться в каждом такте игрового цикла. Если запустить сейчас проект в эмуляторе, голова змеи, как ракета, вылетит за верхнюю границу экрана.
Ограничение скорости перемещения
--------------------------------
Змейка сейчас мгновенно улетает с экрана, хотя каждый вызов метода moveSnake перемещает её лишь на один шаг. Это происходит потому, что игровой цикл исполняется очень быстро. В отличие от той примитивной схемы подобного цикла, которую мы приводили выше, настоящий игровой цикл отслеживает время между тактами. Мы можем использовать этот факт для того, чтобы метод обновления позиции объекта работал с нужной скоростью. Вот, как это сделать.
1. Добавьте два новых члена класса – это interval и counter.
```
var SnakeLayer = cc.Layer.extend({
snakeHead: null,
// Добавьте код ниже
interval: 0.25, /* 1/4 секунды */
counter: this.interval,
ctor: function () {...},
moveSnake: function(dir) {...},
update: function(dt) {...},
});
```
2. Замените код метода update на приведенный ниже.
```
update: function(dt) {
/* Число, соответствующее направлению */
var up = 1;
/* Перемещаем объект только если истёк заданный срок */
if (this.counter < this.interval) {
this.counter += dt;
} else {
this.counter = 0;
this.moveSnake(up);
}
},
```
У метода update теперь есть аргумент «dt» (delta time, изменение времени). Это – время в секундах после последнего кадра. Данный аргумент передаёт этому методу игровой цикл. Мы создали два новых члена класса: interval и counter. Interval (интервал) задаёт число секунд, которое должно пройти между вызовами update(). Counter (счётчик) нужен для подсчёта числа секунд, прошедших с момента предыдущего перемещения объекта. При этом в счётчике накапливаются данные, поступающие из игрового цикла, доступные в аргументе метода dt.
Теперь, если запустить игру в эмуляторе, змея будет двигаться куда медленнее.
Выводы
------
Подведём итоги сегодняшнего занятия:
* Cocos2d-JS использует правую систему координат.
* Имеется такое понятие, как собственный размер видимой области.
* Узлы позиционируются в координатном пространстве объектов-родителей
* Игровой движок имеет бесконечный цикл, который обновляет логику игры.
* Один проход игрового цикла называют «**тактом» или «тиком» (tick)**.
Теперь вы умеете следующее:
* Располагать игровые объекты в нужной позиции экрана.
* Перемещать объекты по экрану.
В следующий раз увеличим длину змейки и сделаем её движения боле осмысленными.

[Часть 1](https://habrahabr.ru/company/intel/blog/281380/) » [Часть 2](https://habrahabr.ru/company/intel/blog/281453/) » [Часть 3](https://habrahabr.ru/company/intel/blog/281523/) » [Часть 4](https://habrahabr.ru/company/intel/blog/281607/) » [Часть 5](https://habrahabr.ru/company/intel/blog/281639/) » [Часть 6](https://habrahabr.ru/company/intel/blog/281873/) » [Часть 7](https://habrahabr.ru/company/intel/blog/281981/) // Конец )
 | https://habr.com/ru/post/281607/ | null | ru | null |
# О, эти планы запросов
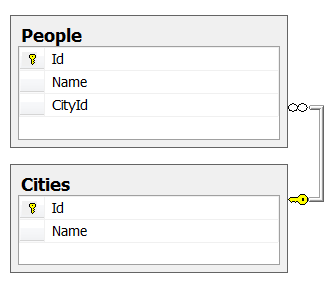
История стара как мир. Две таблицы:
* Cities – 100 уникальных городов.
* People – 10 млн. людей. У некоторых людей город может быть не указан.
Распределение людей по городам – равномерное.
Индексы на поля Cites.Id, Cites.Name, People .CityId – в наличии.
Нужно выбрать первых 100 записей People, отсортированных по Cites.
Засучив рукава, бодро пишем:
`select top 100 p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name`
При этом мы получим что-то вроде:
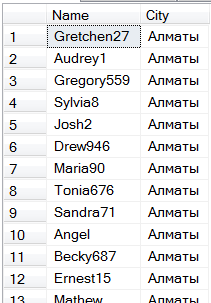
За… 6 секунд. (MS SQL 2008 R2, i5 / 4Gb)
Но как же так! Откуда 6 секунд?! Мы ведь знаем, что в первых 100 записях будет исключительно Алматы! Ведь записей – 10 миллионов, и значит на город приходится по 100 тыс. Даже если это и не так, мы ведь можем выбрать первый город в списке, и проверить, наберется ли у него хотя бы 100 жителей.
Почему SQL сервер, обладая статистикой, не делает так:
`select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]`
Данный запрос возвращает примерно 100 тыс. записей менее чем за секунду! Убедились, что есть искомые 100 записей и отдали их очень-очень быстро.
Однако MSSQL делает все по плану. А план у него, «чистый термояд» (с).
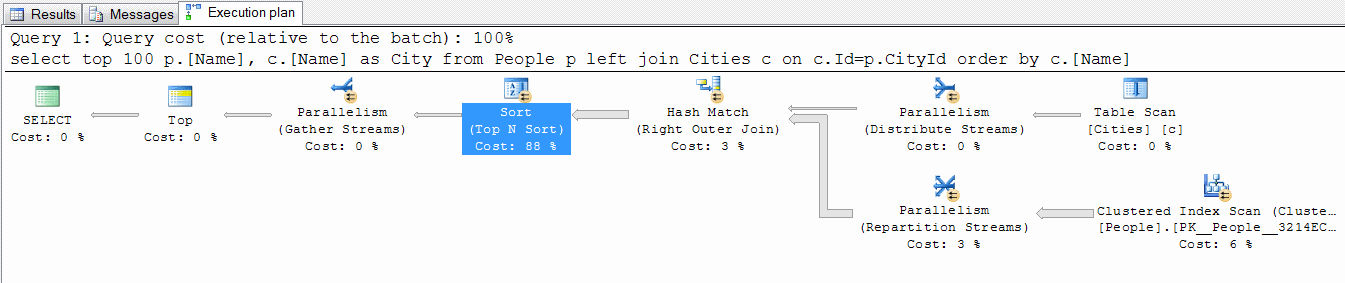
**Вопрос к знатокам:
каким образом необходимо исправить SQL запрос или сделать какие-то действия над сервером, чтобы получить по первому запросу результат в 10 раз быстрее?**
P.S.
`CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
[CityId] uniqueidentifier
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO`
P.P.S
Откуда растут ноги:
Задача вполне реальная. Есть таблица с основной сущностью, от нее по принципу «звезда» отходит множество измерений. Пользователю нужно ее отобразить в гриде, предоставив сортировку по полям.
Начиная с некоторого размера основной таблицы сортировка сводится к тому, что выбирается окно с одинаковыми (крайними) значениями, (вроде «Алматы») но при этом система начинает жутко тормозить.
Хочется иметь ОДИН параметризированный запрос, который будет эффективно работать как с малым размером таблицы People так и с большим.
P.P.P.S
Интересно, что если бы City были бы NotNull и использовался InnerJoin то запрос выполняется мгновенно.
Интересно, что ДАЖЕ ЕСЛИ поле City было бы NotNull но использовался LeftJoin – то запрос тормозит.
В комментах идея: Сперва выбрать все InnerJoin а потом Union по Null значениям. Завтра проверю эту и остальные безумные идеи )
P.P.P.P.S Попробовал. Сработало!
WITH Help AS
(
select top 100 p.Name, c.Name as City from People p
INNER join Cities c on c.Id=p.CityId
order by c.Name ASC
UNION
select top 100 p.Name, NULL as City from People p
WHERE p.CityId IS NULL
)
SELECT TOP 100 \* FROM help
Дает 150 миллисекунд при тех же условиях! Спасибо [holem](http://holem.habrahabr.ru/). | https://habr.com/ru/post/98622/ | null | ru | null |
# Введение в Spring Boot Actuator
Салют, хабровчане! Уже через неделю стартуют занятия в новой группе курса [«Разработчик на Spring Framework»](https://otus.pw/Acap/). В связи с этим делимся с вами полезным материалом в котором рассказано о том, что такое Spring Actuator и чем он может быть полезен.

1. Что такое Spring Actuator?
2. Как добавить Spring Actuator в проект Maven или Gradle?
3. Создание проекта Spring Boot с зависимостью Spring Actuator.
4. Мониторинг приложений с Spring Actuator Endpoints.
**Что такое Spring Actuator?**
После того как вы разработали приложение и развернули его в продакшене, очень важно следить за его работоспособностью. Особенно это актуально для критически важных приложений, таких как банковские системы, в которых отказ приложений напрямую влияет на бизнес.
Традиционно, до Spring Actuator, нам нужно было писать код для проверки работоспособности приложения, но с Spring Actuator нам не нужно писать код. Spring Actuator предоставляет несколько готовых конечных точек (endpoint), которые могут быть полезны для мониторинга приложения.
**Как добавить Spring Actuator в проект Maven или Gradle?**
***Maven***
```
org.springframework.boot
spring-boot-starter-actuator
```
***Gradle***
```
dependencies {
compile("org.springframework.boot:spring-boot-starter-actuator")
}
```
**Создание проекта Spring Boot с Spring Actuator**
Давайте продолжим и создадим с помощью [Spring Initializer](https://start.spring.io) проект Spring Boot с зависимостями Spring Actuator, Web и DevTools.
Обратите внимание, что на момент написания этой статьи версия Spring Boot была 2.1.0.
Импортируйте проект в Eclipse или любую другую IDE и запустите `SpringActuatorApplication.java`.
В консоли вы увидите следующее:
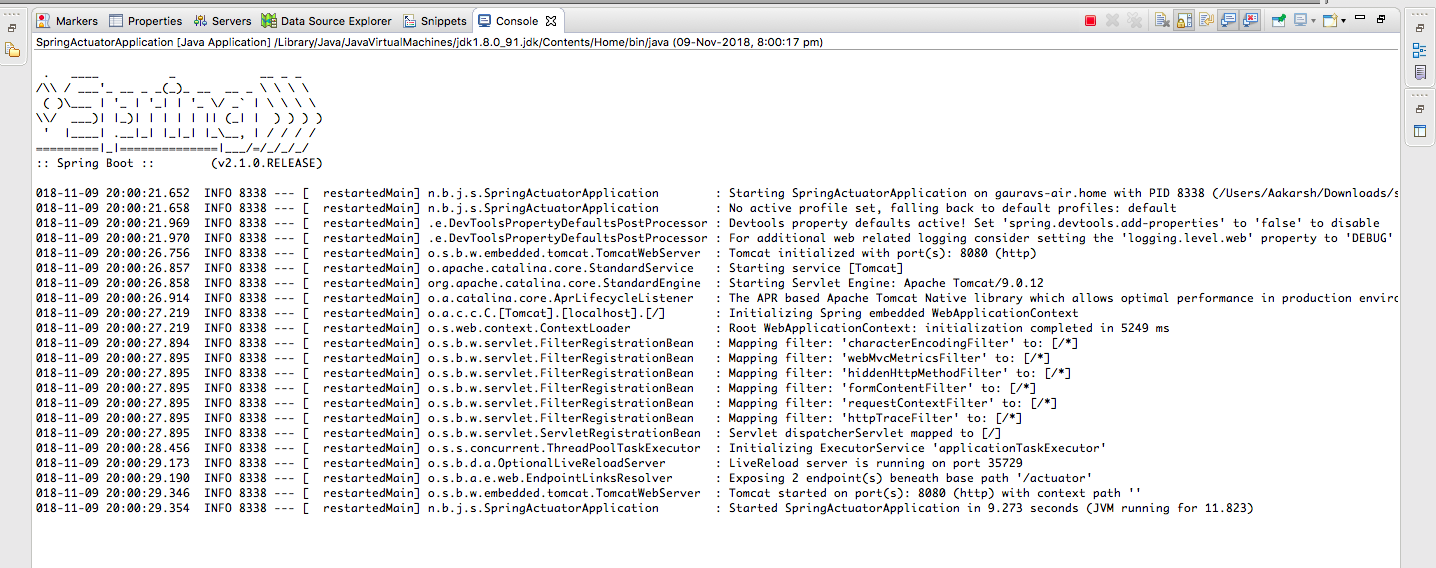
Видно, что встроенный Tomcat запущен на порту 8080, а `SpringActuatorApplication` запущен в Tomcat. Также вы можете увидеть, что конечные точки actuator’а доступны по адресу `/actuator.`
```
018-11-09 20:00:29.346 INFO 8338 --- [ restartedMain] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2018-11-09 20:00:29.354 INFO 8338 --- [ restartedMain] n.b.j.s.SpringActuatorApplication : Started SpringActuatorApplication in 9.273 seconds (JVM running for 11.823)
2018-11-09 20:00:29.190 INFO 8338 --- [ restartedMain] o.s.b.a.e.web.EndpointLinksResolver : Exposing 2 endpoint(s) beneath base path '/actuator'.
```
**Мониторинг приложений с Spring Actuator Endpoints**
Как мы уже говорили выше, Spring Actuator предоставляет несколько готовых конечных точек (endpoints), которые мы можем использовать для мониторинга работоспособности приложения.
| ID | Описание |
| --- | --- |
| auditevents | Предоставляет информацию о событиях
аудита для текущего приложения. |
| beans | Отображает полный список всех
Spring-бинов в приложении. |
| caches | Информация о кэше. |
| conditions | Показывает условия (Condition), которые
были вычислены для классов конфигурации
и автоконфигурации, и причины, по
которым они соответствовали или не
соответствовали. |
| configprops | Отображает список всех
@ConfigurationProperties |
| env | Отображает свойства из
ConfigurableEnvironment. |
| flyway | Показывает миграции баз данных
Flyway, которые были применены. |
| health | Показывает сведения о работоспособности
приложения. |
| httptrace | Отображает информацию трассировки
HTTP (по умолчанию последние 100 HTTP
запросов-ответов). |
| info | Отображает дополнительную информацию
о приложении. |
| integrationgraph | Граф Spring Integration. |
| loggers | Отображает и позволяет
изменить конфигурацию логгеров в
приложении. |
| liquibase | Показывает примененные миграции
базы данных Liquibase. |
| metrics | Показывает информацию о метриках
для текущего приложения. |
| mappings | Отображает список всех путей
@RequestMapping. |
| scheduledtasks | Отображает запланированные задачи
(scheduled tasks). |
| sessions | Позволяет извлекать и удалять
пользовательские сессии из хранилищ,
поддерживаемых Spring Session. Недоступно
при использовании Spring Session для реактивных
веб-приложений. |
| shutdown | Позволяет приложению корректно
завершить работу. |
| threaddump | Отображает информацию о потоках. |
**Включение конечных точек**
По умолчанию включены все конечные точки, кроме `shutdown`. Чтобы включить конечную точку, используйте следующее свойство в файле `application.properties`.
```
management.endpoint.`<`id`>`.enabled
```
> *Примечание переводчика: по умолчанию доступ ко всем конечным точкам есть только через JMX, доступа через HTTP ко всем конечным точкам нет (см. ниже).*
*Пример:*
Чтобы включить конечную точку `shutdown`, нам нужно сделать следующую запись в файле `application.properties`:
```
management.endpoint.shutdown.enabled=true
```
Мы можем отключить все конечные точки, а затем включать только те, которые нам нужны. При следующей конфигурации все конечные точки, кроме `info`, будут отключены.
```
management.endpoints.enabled-by-default=false
management.endpoint.info.enabled=true
```
**Доступ к конечным точкам через HTTP**
Давайте перейдем по URL-адресу [localhost](http://localhost):8080/actuator и посмотрим на доступные конечные точки.
Примечание: я использую [Postman](https://www.getpostman.com/) для тестирования, поскольку он показывает JSON в хорошо структурированном формате. Вы можете использовать любой другой инструмент или просто браузер.

Как вы уже заметили, здесь показаны только конечные точки `health` и `info`. Потому что это единственные конечные точки, которые по умолчанию доступны через http. Доступ через http к другим конечным точкам закрыт по умолчанию из соображений безопасности, поскольку они могут содержать конфиденциальную информацию и, следовательно, могут быть скомпрометированы.
***Доступ к конкретным конечным точкам***
Если мы хотим предоставить доступ через web (http) к другим конечным точкам то, нам нужно сделать следующие записи в файле `application.properties`.
```
management.endpoints.web.exposure.include=<список конечных точек через запятую>
```
*Пример*:
```
management.endpoints.web.exposure.include= health,info,env
```
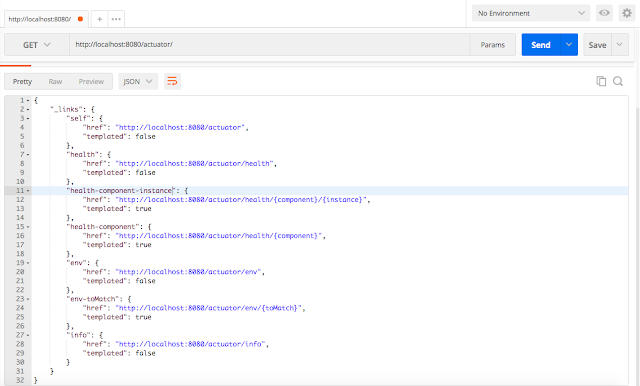
Теперь, после добавления в `application.properties` указанной выше записи, давайте снова перейдем по <http://localhost:8080/actuator>
Как мы видим на скриншоте ниже, конечная точка `env` также включена.
***Доступ ко всем конечным точкам***
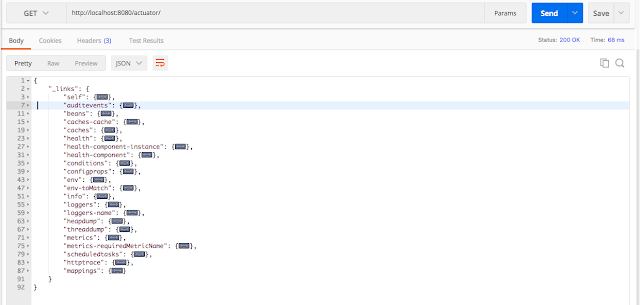
Если мы хотим включить все конечные точки, мы можем использовать знак `*`, как показано ниже.
```
management.endpoints.web.exposure.include=*
```
***Доступ ко всем конечным точкам, кроме некоторых***
Две записи ниже активируют все конечные точки, но отключают конечную точку env.
```
management.endpoints.web.exposure.include=*
management.endpoints.web.exposure.exclude=env
```
***Отключение всех конечных точек HTTP***
Если вы не хотите предоставлять конечные точки через HTTP, это можно сделать, настроив в файле `application.properties` следующее:
```
management.server.port=-1
```
или так:
```
management.endpoints.web.exposure.exclude=*
```
***Настройка URL для доступа к конечным точкам***
По умолчанию все конечные точки доступны по URL `/actuator` по адресам вида `/actuator/{id}`. Однако можно изменить базовый путь `/actuator`, используя следующее свойство в `application.properties`.
```
management.endpoints.web.base-path
```
Например, если вы хотите сделать базовый URL-адрес как `/monitor` вместо `/actuator` это можно сделать следующим образом:
```
management.endpoints.web.base-path=/monitor
```
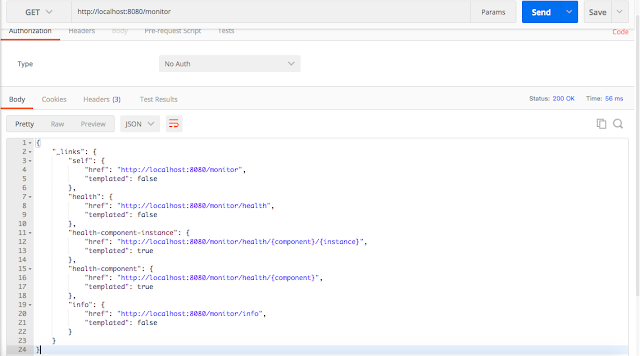
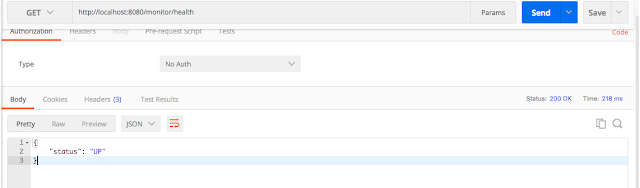
При этом все конечные точки будут доступны как `/monitor/{id}` вместо `/actuator/{id}`
**Конечные точки Spring Boot Actuator**
Давайте обсудим некоторые из наиболее важных конечных точек.
***/health***
Конечная точка `health` даёт общий статус приложения: запущено и работает или нет. Это очень важно для мониторинга состояния приложения, когда оно находится в продакшене. Эта конечная точка может быть интегрирована с приложениями мониторинга и будет очень полезна для определения работоспособности приложений в реальном времени.
Объем информации, предоставляемой конечной точкой `health`, зависит от свойства `management.endpoint.health.show-details` в файле `application.properties`.
Если `management.endpoint.health.show-details=never`, то никакая дополнительная информация не отображается. В этом случае вы увидите только следующее (это поведение по умолчанию).

Если `management.endpoint.health.show-details=always`, то дополнительная информация показывается всем пользователям. Как мы видим в ответе ниже, у нас появилась информация о дисковом пространстве (diskSpace). Если ваше приложение подключено к базе данных, то у вас также будет отображаться информация о состоянии базы данных.
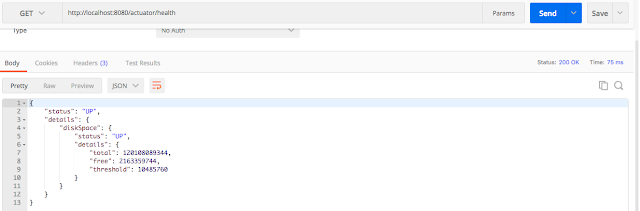
Если `management.endpoint.health.show-details=when-authorized`, то дополнительная информация будет показана только авторизованным пользователям. Авторизацию можно настроить с помощью свойства `management.endpoint.health.roles`.
***Преднастроенные индикаторы***
Spring Boot Actuator имеет множество автоматически настроенных “индикаторов здоровья” (HeathIndicators)для проверки работоспособности различных частей приложения. Например, `DiskspaceHealthIndicator` предоставляет информацию о дисковом пространстве. Если вы используете MongoDB, то `MongoHealthIndicator` проверит работоспособность БД Mongo (запущен сервер или нет) и отобразит соответствующую информацию. По умолчанию окончательный статус приложения определяет `HealthAggregator`, который просто сортирует список статусов, предоставленных каждым `HealthIndicator`. Первый статус в отсортированном списке используется как окончательный статус приложения.
***Отключение всех преднастроенных индикаторов***
Описанные выше “индикаторы здоровья” включены по умолчанию, однако, их можно отключить с помощью следующего свойства:
```
management.health.defaults.enabled=false
```
***Отключение отдельного индикатора***
В качестве альтернативы можно отключить отдельный `HealthIndicator`, как показано ниже, например, для отключения проверки дискового пространства:
```
management.health.diskspace.enabled=false
```
Примечание: идентификатором любого `HealthIndicator` будет имя бина без суффикса `HealthIndicator`.
*Например*:
```
DiskSpaceHealthIndicator diskspace
MongoHealthIndicator mongo
CassandraHealthIndicator cassandra
DataSourceHealthIndicator datasource
```
и так далее…
***Написание своих индикаторов (HealthIndicator)***
Наряду со встроенными `HealthIndicator`, предоставляемыми Spring Boot Actuator, мы можем создавать собственные индикаторы состояния. Для этого вам нужно создать класс, который реализует интерфейс `HealthIndicator`, реализовать его метод `health()` и вернуть `Health` в качестве ответа с соответствующей информацией, как показано ниже:
```
import org.springframework.boot.actuate.health.Health;
import org.springframework.boot.actuate.health.HealthIndicator;
import org.springframework.stereotype.Component;
@Component
public class CustomHealthIndicator implements HealthIndicator {
@Override
public Health health() {
int errorCode = 0;
// In the above line,I am simple assigning zero,but you can call Health check related code like below commented line and that method can return the appropriate code.
// int errorCode = performHealthCheck();
if (errorCode != 0) {
return Health.down().withDetail("Error Code", errorCode).build();
}
return Health.up().build();
}
}
```
Давайте снова перейдем на конечную точку health и посмотрим, отражается ли наш индикатор или нет.
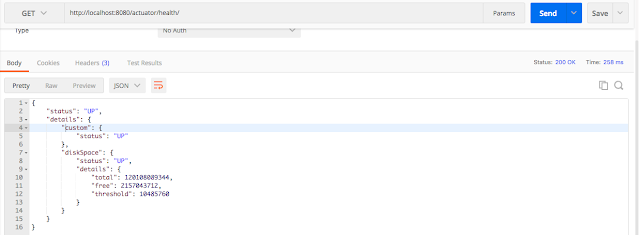
Мы видим наш индикатор.
***Статус отдельного компонента***
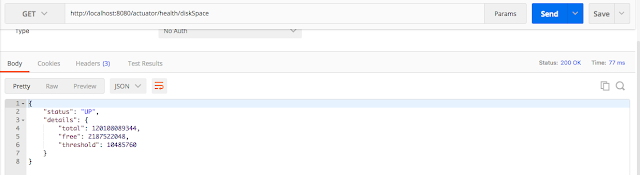
Можно также проверить состояние отдельного компонента. В приведенном выше примере мы видели написанный нами индикатор и diskSpace.
Если мы хотим видеть только состояние диска, мы можем использовать следующее URL:
<http://localhost:8080/actuator/health/diskSpace>
***/info***
Конечная точка `info` предоставляет общую информацию о приложении, которую она получает из файлов, таких как `build-info.properties` или `git.properties`, или из свойств, указанных в `application.properties`.
Так как в нашем проекте такого файла нет, то ответ будет пустой, как показано ниже:
Spring Boot Actuator отображает информацию о сборке, если присутствует файл `META-INF/build-info.properties`. Этот файл с информацией о проекте создается время сборки целью `build-info`. Здесь также можно добавить произвольное количество дополнительных свойств.
Давайте добавим в `pom.xm`l цель `build-info` для плагина `spring-boot-maven-plugin`.
```
org.springframework.boot
spring-boot-maven-plugin
2.1.0.RELEASE
build-info
UTF-8
UTF-8
${maven.compiler.source}
${maven.compiler.target}
```
Теперь давайте снова посмотрим на конечную точку `info` и увидим информацию о сборке, как показано ниже:
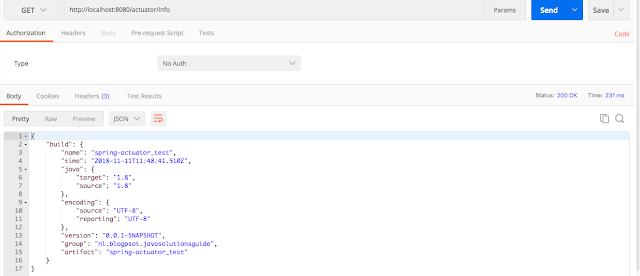
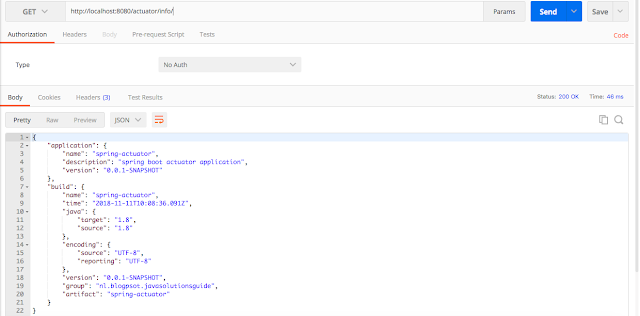
Кроме того, мы можем добавить информацию о приложении с ключом `info` в `application.properties`, как показано ниже, и она будет отображаться в конечной точке `/info`.
```
info.application.name=spring-actuator
info.application.description=spring boot actuator application
info.application.version=0.0.1-SNAPSHOT
```
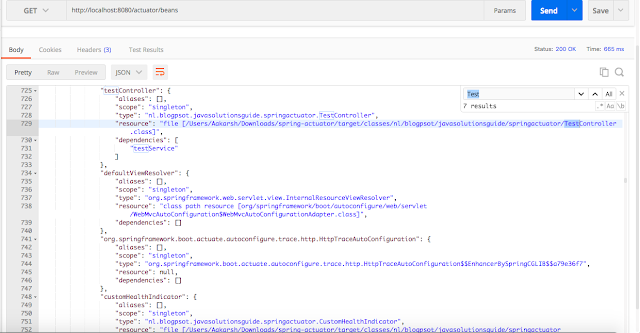
***/beans***
Конечная точка `beans` показывает все бины, определенные в Spring-контейнере со следующей информацией о каждом бине:
```
aliases : названия всех псевдонимов
scope : область видимости
type : полное имя бина
resource : ресурс (класс), в котором определён бин
dependencies : имена зависимых бинов
```
Например, я создал RestController с именем `TestController` и заинжектил компонент с именем `TestService`
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {
@Autowired
private TestService testService;
@GetMapping("/messages")
public String getMessage() {
return "Hello";
}
}
import org.springframework.context.annotation.Configuration;
@Configuration
public class TestService {
}
```
Вы можете увидеть, как это показывается для testController, на скриншоте ниже.
***/configprops***
Конечная точка `configProps` показывает все бины, аннотированные `@ConfigurationProperties`.
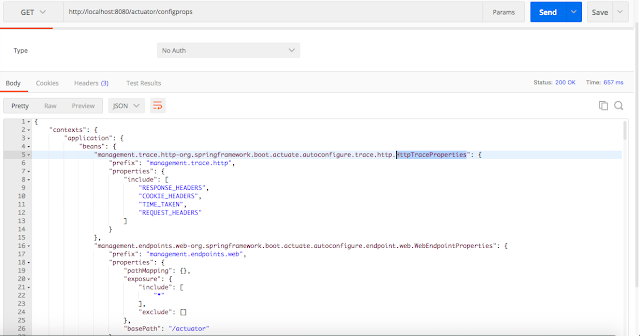
На приведенном выше скриншоте мы видим два бина, которые определены в самом Spring Framework и снабжены аннотацией `@ConfigurationProperties` и, следовательно, отображаются в этой конечной точке.
На скриншоте ниже показан исходный код `HttpTraceProperties`, аннотированный `@ConfigurationProperties`.
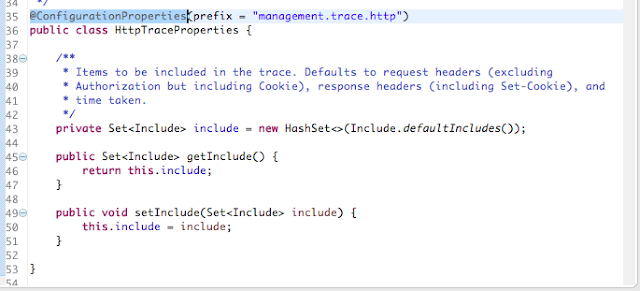
***/env***
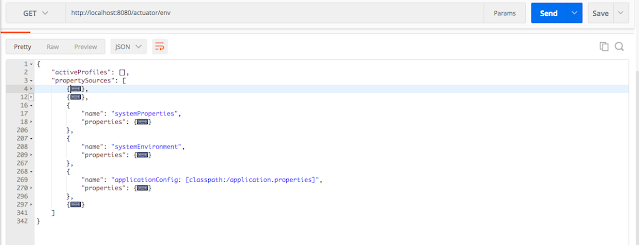
Конечная точка `env` предоставляет всю информацию, относящуюся к окружению, в следующем порядке:
| Свойства системы | зависит от JVM (не зависит от платформы) |
| --- | --- |
| Системное окружение или переменные
окружения | зависит от операционной
системы (зависит от платформы) |
| Настройки уровня приложения | определены в
application.properties |
***/heapdump***
Конечная точка heapdump делает дамп кучи приложения. Эта конечная точка возвращает двоичные данные в формате HPROF. Поскольку обычно возвращается много данных, вы должны их сохранить и проанализировать.
***/loggers***
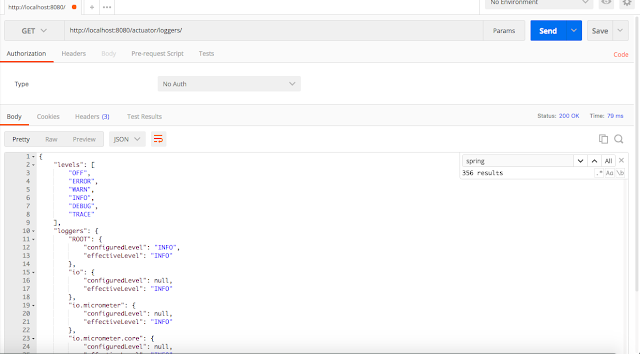
Конечная точка `loggers` предоставляет логгеры приложения с информацией об их настроенном уровне логирования (configuredLevel) и эффективном уровне (effectiveLevel). Если для логера и его родителя настроенный уровень не указан (null), то эффективным уровнем будет уровень корневого логера.
Свойство `level` указывает, какие уровни логирования поддерживаются фреймворком логирования.
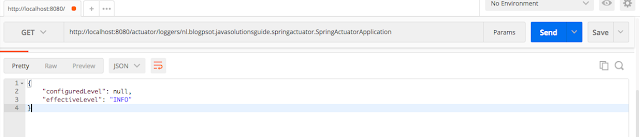
Чтобы получить информацию для конкретного логера, передайте имя (ид) логера в URL-адресе после конечной точки `/loggers`, как показано ниже:
<http://localhost:8080/actuator/loggers/nl.blogpsot.javasolutionsguide.springactuator.SpringActuatorApplication>
***/metrics***
Конечная точка `metrics` показывает все метрики, которые вы можете отслеживать для вашего приложения.
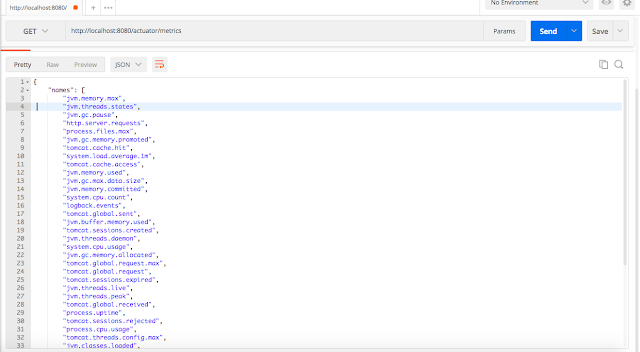
***Проверка индивидуальной метрики***
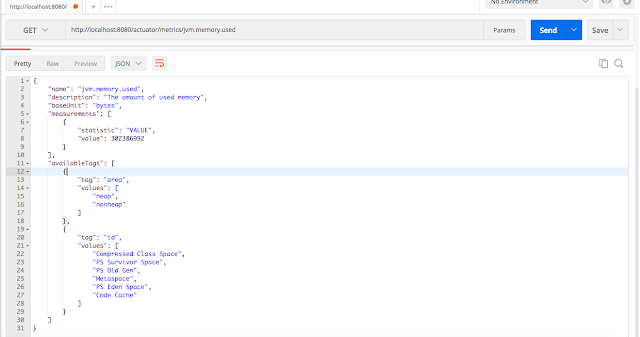
Вы можете смотреть отдельную метрику, передав её в URL-адресе после `/metrics`, как показано ниже:
<http://localhost:8080/actuator/metrics/jvm.memory.used>
**Ссылки**
[docs.spring.io/spring-boot/docs/current/reference/html/production-ready-endpoints.html](https://docs.spring.io/spring-boot/docs/current/reference/html/production-ready-endpoints.html)
[docs.spring.io/spring-boot/docs/current/actuator-api/html](https://docs.spring.io/spring-boot/docs/current/actuator-api/html/)
По устоявшейся традиции ждем ваши комментарии и приглашаем всех на [день открытых дверей](https://otus.pw/9xe7/), который пройдет 23 мая. | https://habr.com/ru/post/452624/ | null | ru | null |
# Mikrotik + IPSec + Cisco. Часть 2. Тоннель на «сером» IP
*В продолжение к [посту](http://habrahabr.ru/post/151951/).*
В прошлый раз я рассматривал соединение, когда со стороны циски и микрота были реальные IP'ы.
Здесь рассмотрю пример «серого реальника», т.е серый IP, который провайдер маскирует у себя под внешний с безусловной переадресацией (binat).
#### Техническая задача: организовать ipip-тоннель между офисами, с шифрованием ipsec, при помощи Mikrotik RB450G и Cisco 2821.
##### Ньюансы
на циске внешний IP, а на микротике серый, который маскируется провайдером под внешний, с безусловной переадресацией (обращения к этому внешнику из интернета редиректятся на интерфейсный, серый «IP»).
Схема:

##### Исходные данные
* Cisco 2821 (OS v12.4)
* 2. Mikrotik RB450G
* 3. Реальные внешние IP на обоих устройствах
* 4. Адрес циски: 77.77.77.226. Подсеть со стороны циски: 10.192.0.0/22
* 5. Адрес микротика: 99.99.99.2. Подсеть со стороны микротика: 192.168.100.0/24
* 6. Серый адрес микротика на внешнем интерфейсе: 172.16.99.2.
##### Предыстория
При подключении нового филиала обнаружил, что провайдер (единственный местный) вместо внешнего IP выдал мне «серый».
На моё законное возмущение, что по договору нам должны дать внешний адрес — провайдер ответил, что внешний для нас сделан средствами nat'а, и все обращения из интернета на этот внешник редиректятся на наш «серый» ip, и по другому они ничего сделать не могут.
На этом наш разговор окончился, и я стал настраивать тоннель. Тоннель не завёлся :)
Ситуация неоднозначная. С одной стороны вроде и внешник, который на деле выглядит «серым», но и NAT-T использовать смысла нет
Около часа я мучал микротик с циской, в результате получилась странная, но работоспособная конструкция (кстати попробовал её повторить на racoon под freebsd — не взлетело).
###### Что получилось в итоге
На циске создал тунель, в котором указал серый ip микротика в destination.
Все настройки (консольные и аналогичные графические) привожу ниже.
#### Cisco:
```
! Политика авторизации - хеш мд5 и шифрование 3des по парольному ключу (pre-share)
crypto isakmp policy 20
encr 3des
hash md5
authentication pre-share
! group2 означает, что в микротике надо установить dh-group=modp1024
group 2
! Сам ключ
crypto isakmp key MyPassWord address 99.99.99.2 no-xauth
crypto isakmp keepalive 30
! Трансформ. Внимание! Используется transport, а не tunnel режим
crypto ipsec transform-set transform-2 esp-3des esp-md5-hmac
mode transport
crypto dynamic-map dynmap 10
set transform-set transform-2
reverse-route
crypto map vpnmap client configuration address respond
crypto map vpnmap 5 ipsec-isakmp dynamic dynmap
crypto map vpnmap 10 ipsec-isakmp
! криптомапа микротика
crypto map vpnmap 95 ipsec-isakmp
description polyanka
! ip микротика
set peer 99.99.99.2
set security-association lifetime seconds 86400
set transform-set transform-2
! pfs group2 означает, что в микротике надо установить dh-group=modp1024
set pfs group2
! access-лист, разрешающий соединение
match address 136
! Сам тоннель
interface Tunnel95
description tunnel_NewMikrotik
ip unnumbered GigabitEthernet0/1
! Цискин адрес
tunnel source 77.77.77.226
! Адрес микрота.
! ВНИМАНИЕ - АДРЕС СЕРЫЙ. Если указывать белый - соединение не устанавливается...
! Точнее устанавливается, но работать отказывается и рвёт связь.
tunnel destination 172.16.99.2
tunnel mode ipip
interface GigabitEthernet0/1
description Internet
ip address 77.77.77.226 255.255.255.224
no ip redirects
no ip unreachables
no ip proxy-arp
ip wccp web-cache redirect out
ip virtual-reassembly
ip route-cache policy
no ip mroute-cache
duplex auto
speed auto
no mop enabled
! ВКЛЮЧАЕМ ШИФРОВАНИЕ НА ИНТЕРФЕЙСЕ
crypto map vpnmap
! Роутинг сети, находящейся за микротиком
ip route 192.168.100.0 255.255.255.0 Tunnel95
! Разрешение на соединение тоннеля
access-list 136 permit ip host 77.77.77.226 host 99.99.99.2
access-list 136 permit ip host 77.77.77.226 host 172.16.99.2
```
#### Микротик:
```
/interface ipip
add comment="Office tunnel" disabled=no dscp=0 local-address=172.16.99.2 \
mtu=1260 name=Cisco-VPN remote-address=77.77.77.226
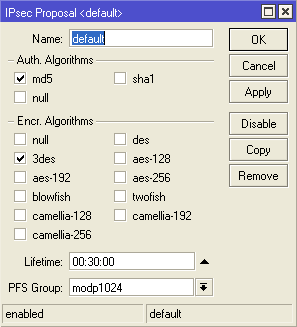
/ip ipsec proposal
set [ find default=yes ] auth-algorithms=md5 disabled=no enc-algorithms=3des \
lifetime=30m name=default pfs-group=modp1024
/ip ipsec peer
add address=77.77.77.226/32 auth-method=pre-shared-key dh-group=modp1024 \
disabled=no dpd-interval=2m dpd-maximum-failures=5 enc-algorithm=3des \
exchange-mode=main generate-policy=yes hash-algorithm=md5 lifebytes=0 \
lifetime=1d my-id-user-fqdn="" nat-traversal=no port=500 proposal-check=\
obey secret=MyPassWord send-initial-contact=yes
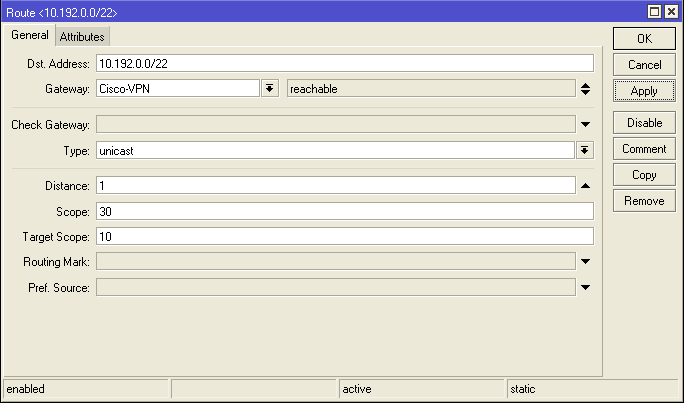
/ip route
add disabled=no distance=1 dst-address=10.192.0.0/22 gateway=Cisco-VPN scope=30 \
target-scope=10
/ip firewall filter
add action=accept chain=input comment="default configuration" disabled=no
add action=accept chain=output disabled=no
```
Этот же конфиг, глазами WinBox:
1. **Интерфейсы-IP Tunnel**. Добавить:

2. В разделе **IP-IPSec-Proposals** в дефолтном правиле **ОБЯЗАТЕЛЬНО** сменить SHA1 на MD5, т.к в рассматриваемом примере используется MD5.
3. **IP-IPSec-Peers**. Добавить:

4. **IP-Routes**. Добавить:
Надеюсь, материал был полезен. | https://habr.com/ru/post/154829/ | null | ru | null |
# Как мы оптимизировали i-запросы, а нашли неточности в документации Django
**В современных веб-приложениях большинство запросов к базе данных пишется не на сыром SQL, а с использованием объектно-реляционного отображения (ORM). Оно автоматически генерирует SQL-запросы по привычному объектно-ориентированному коду. Однако эти запросы не всегда оптимальны, и с ростом нагрузки на веб-приложение встает вопрос их оптимизации. Как раз в ходе такой оптимизации наша команда обнаружила, что документация Django с нами не совсем честна.**
Меня зовут Альбина Альмухаметова, я python разработчица в Технократии. О вводящей в заблуждение документации Django я [рассказывала](https://www.youtube.com/watch?v=kq-1PzEE4IQ&ab_channel=%D0%92%D0%B8%D0%B4%D0%B5%D0%BE%D1%81%D0%BA%D0%BE%D0%BD%D1%84%D0%B5%D1%80%D0%B5%D0%BD%D1%86%D0%B8%D0%B9IT-People) на Pycon в этом году. Этот текст — адаптация моего выступления для тех, кто слишком занят, чтобы смотреть видео. В качестве бонуса я добавила пару примеров, которых нет видео-докладе, но которые любезно предложили наши зрители. Так что, если вы смотрели доклад, смело листайте к заголовку “Заметки с доклада” и изучайте новые сравнения индексов.
Но если вам интересно посмотреть, как я выступала на Pycon, то вот запись:
Также перед стартом хочу послать благодарность Павлу Гаркину, который первый из нашей команды обнаружил описанные ниже особенности и предложил способ их решения. Теперь поехали.
Содержание:
1. [Проблема](#1)
2. [Подсчет исходных данных](http://2)
3. [Попытка №1 - db\_index=True](#3)
4. [Попытка №2 – свой индекс](#4)
5. [Попытка №3 — Trigram](#5)
6. [Как пользоваться?](#6)
7. [Итоговая модель с индексами](#7)
8. [Django 3.2](#8)
9. [Бонус. Заметки после доклада](#9)
Проблема
--------
Функция поиска на сайте — привычно и удобно, но лишь до тех пор, пока поиск быстрый. В нашем случае проблемы возникли в поисковой строке Django-админки. Если вы хоть раз пытались поменять запросы, которые делает Django для отображения страниц админки, вы знаете, что это очень больно.
Ситуацию получили следующую:
* пользователи долго ждут загрузки страницы и не могут с нее уйти (ответ получить надо, а альтернатив нет)
* разработчики не могут переписать запрос, чтобы его ускорить
Чтобы все спасти, решили вешать индексы на таблицы. **И тут началось самое интересное.**
Важное замечание: в докладе речь идет про Django 2.2 в связке с PostgreSQL. За время составления доклада и написания статьи вышла Django 3.2 со значительными улучшениями, которые играют роль в контексте данного доклада. В конце мы разберем, что же такого поменялось и как будет выглядеть код в обновленной версии.
### Подсчет исходных данных
*Note: Для упрощения кода и соблюдения NDA в качестве примера используем поиск по полю name, что в целом не меняет сущности проблемы.*
Код модели:
```
class Person(models.Model):
name = models.CharField(max_length=100)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
```
В интересующих нас запросах участвовали следующие lookup’ы:
* \_\_exact
* \_\_iexact
* \_\_contains
* \_\_icontains
Первое, что мы сделали, — перевели запросы из ORM в сырой SQL и посмотрели, как и сколько они выполняются. Для статьи в качестве примера в таблицу добавили 1 000 000 записей и запустили запрос несколько раз.
\_\_exact повел себя ожидаемым образом и дал результаты на картинке ниже:
```
>>> str(Person.objects.filter(name__exact='test').query)
SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE "names_person"."name" = test
```
А вот \_\_iexact удивил. Дело в том, что в документации Django [явно указано](https://docs.djangoproject.com/en/3.1/ref/models/querysets/#iexact), что будет генерироваться следующий SQL запрос:
```
>>> qs.filter(first_name__iexact='олег')
SELECT ... WHERE first_name ILIKE '%олег%';
```
Однако реальность в случае с PostgreSQL оказалась иной:
```
>>> str(Person.objects.filter(name__iexact='test').query)
SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE UPPER("names_person"."name"::text) = UPPER(test)
```
Аналогичная магия произошла с \_\_contains и \_\_icontains: \_\_contains ведет себя нормально и выдает ожидаемые результаты:
```
>>> str(Person.objects.filter(name__contains='test').query)
SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE "names_person"."name"::text LIKE %test%
```
А \_\_icontains тоже использует UPPER, вместо обещанного ILIKE
```
>>> str(Person.objects.filter(name__icontains='test').query)
SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE UPPER("names_person"."name"::text) LIKE UPPER(%test%)
```
Итого:
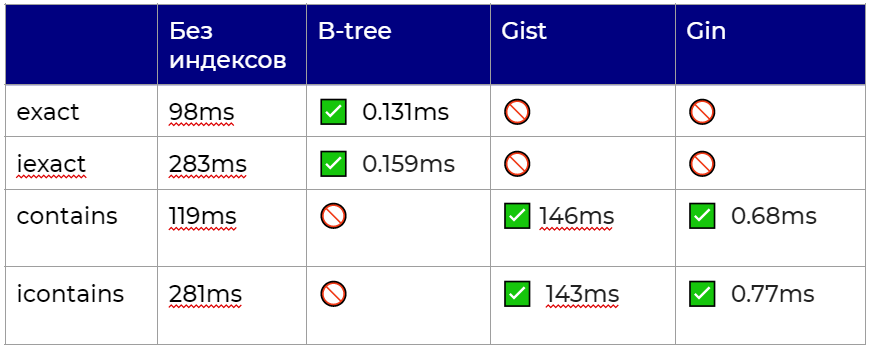
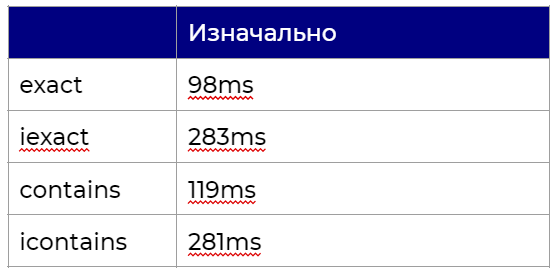### Попытка №1 - db\_index=True
Можно было бы занять этим делом ~~специально обученных людей~~ DBA: попросить покопаться в производительности, построить индексы вручную под конкретные задачи, но:
* придется помнить, что в базе есть индексы, которые не зафиксированы в коде
* мы программисты, нам надо все автоматизировать
Поэтому решили вешать индексы через Django. В первую итерацию постаили db\_index=True на нашу колонку.
Спойлер
```
class Person(models.Model):
name = models.CharField(max_length=100, db_index=True)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
```
После этого снова сделали замеры и получили следующее:
Из всех наших запросов индекс использовал только оператор \_\_exact. Это становится очевидно, если заглянуть в код миграции, которую генерирует Django:
```
BEGIN;
--
-- Alter field name on person
--
CREATE INDEX "names_person_name_f55af680" ON "names_person" ("name");
CREATE INDEX "names_person_name_f55af680_like" ON "names_person" ("name" varchar_pattern_ops);
COMMIT;
```
Здесь используется B-Tree индекс (т.к. по умолчанию в PostgreSQl берется именно он), а по документации этот индекс будет использоваться только в операторах сравнения
> B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators:
>
> **< , <= , = , >= , >**
>
> <...>
>
> The optimizer can also use a B-tree index for queries involving the pattern matching operators LIKE and ~ if the pattern is a constant and is anchored to the beginning of the string — for example, **col LIKE 'foo%' or col ~ '^foo'**, but not col LIKE '%bar'.
>
> [*via PostgresPro*](https://www.google.com/url?q=https://postgrespro.com/docs/postgresql/9.6/indexes-types&sa=D&source=docs&ust=1640600914728405&usg=AOvVaw3hMvEsHtfuMtSvvgMXdiX8)
>
>
Здесь стоит также отдельно остановиться на ключевом слове “varchar\_pattern\_ops”, поскольку оно нам еще понадобится. Это так называемый op\_class или operator class. Он определяет особые правила использования индекса. В данном случае, например, при использовании нестандартной С-локали и сравнении строк по паттерну (LIKE и ~) будет происходить посимвольное сравнение, а не принятое в локали. Подробнее можно почитать тут: <https://www.postgresql.org/docs/9.5/indexes-opclass.html>
### Попытка №2 – свой индекс
Во второй итерации, осознав, что \_\_iexact в целом тоже можно покрыть B-tree индексом, если повесить его на выражение UPPER(“name”), мы пошли искать, как это провернуть средствами Django. Ответ оказался прозаичным — никак. В документации есть описание класса Index, сокращенной версией которого является атрибут db\_index, но все, что о нем известно, это [описание](https://docs.djangoproject.com/en/2.2/ref/models/indexes/#index-options) 5 ключевых атрибутов.
Недолго подумав, мы полезли на github (спасибо открытым исходникам), нашли там класс Index и в нем метод create\_sql, который судя по названию должен генерировать SQL-выражение самого индекса. Подробно о пути до конечной цели мы рассказываем в докладе, здесь оставим краткую выдержку:
1. Пишем наследника от Index, переопределяем в нем create\_sql и ставим точку дебага в этом месте. Дальше запускаем выполнение миграции и смотрим, что получается.
```
class UpperIndex(Index):
def create_sql(self, model, schema_editor, using='', **kwargs):
statement = super().create_sql(
model, schema_editor, using, **kwargs
)
return statement
class Person(models.Model):
name = models.CharField(max_length=100, db_index=True)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
class Meta:
indexes = [
UpperIndex(fields=['name'],
name='name_upper_index')
]
```
2. В возвращаемом statement находим шаблон SQL-выражения и словарь parts, ключ columns которого подставится в этот шаблон как название колонки.
3. Находим [исходники](https://github.com/django/django/blob/stable/2.2.x/django/db/backends/ddl_references.py#L76) Columns на github и смотрим, как генерируется название колонки (метод \_\_str\_\_)
```
def __str__(self):
def col_str(column, idx):
try:
return self.quote_name(column) + self.col_suffixes[idx]
except IndexError:
return self.quote_name(column)
return ', '.join(col_str(column, idx) for idx, column in enumerate(self.columns))
```
4. Понимаем, что название оборачивается в метод self.quote\_name и переопределяем его на свой — главное не напутать: метод quote\_name — это метод column, соответственно, переопределять его надо у statement.parts[‘columns’]
```
class UpperIndex(Index):
def create_sql(self, model, schema_editor, using='', **kwargs):
statement = super().create_sql(
model, schema_editor, using, **kwargs
)
quote_name = statement.parts['columns'].quote_name
def upper_quoted(column):
return 'UPPER({0})'.format(quote_name(column))
statement.parts['columns'].quote_name = upper_quoted
return statement
```
После этого запрос с \_\_iexact начинает использовать индекс и показывать прирост по скорости
### Попытка №3 — Trigram
Разобравшись с \_\_exact и \_\_iexact, остался вопрос, что делать с запросами на \_\_contains и \_\_icontains, потому что они используют LIKE, а с ним B-tree индекс не поможет. Покопавшись в документации PostgreSQL и возможных вариантов индекса, стало понятно, что ни один из индексов из коробки нам не поможет. Но многие индексы работают через те самые op\_classes, о которых мы говорили выше, и нашлось расширение Trigram, которое предоставляет классы для GiST и Gin индексов специально под LIKE и ILIKE операторы.
Мы попробовали оба индекса и получили следующее:
* на проде GiST показал значительный прирост, а на синтетических данных (тот самый 1 000 000 из начала статьи) прироста в скорости нет
* Gin показал прирост в производительности и на проде, и на синтетике, что в целом и понятно — он заточен под работу с текстом
Результаты замеров:
*Gist \_\_contains*
*Gist \_\_icontains*
*Gin \_\_contains*
*Gin \_\_icontains*
Итоговая таблица у нас получаются следующая (галочку мы ставим за использование индекса):
Как пользоваться?
-----------------
Для \_\_contains добавляем GinIndex к нашей модели и указываем gin\_trgm\_op
```
from django.contrib.postgres.indexes import GinIndex
class Person(models.Model):
name = models.CharField(max_length=100, db_index=True)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
class Meta:
indexes = [
GinIndex(fields=['name'], name='name_gin_index',
opclasses=['gin_trgm_ops'])
]
```
Для \_\_icontains берем наш самописный класс, меняем родителя на GinIndex и подключаем, не забыв указать gin\_trgm\_op
```
class UpperGistIndex(GinIndex):
def create_sql(self, model, schema_editor, using='', **kwargs):
statement = super().create_sql(
model, schema_editor, using, **kwargs
)
quote_name = statement.parts['columns'].quote_name
def upper_quoted(column):
return 'UPPER({0})'.format(quote_name(column))
statement.parts['columns'].quote_name = upper_quoted
return statement
```
**Важно** т.к. Trigram — это расширение для PostgreSQL, по умолчанию оно выключено и его надо включить. Для этого ДО того, как в миграциях появятся индексы c **'gin\_trgm\_ops'** нужно вызвать класс TrigramExtension(). Например, это можно сделать в миграции, которая сгенерируется при добавлении индексов
```
from django.contrib.postgres.operations import TrigramExtension
class Migration(migrations.Migration):
dependencies = [
('users', '0001__initial'),
]
operations = [
TrigramExtension(),
# тут добавление ваших индексов
]
```
### Итоговая модель с индексами
```
class UpperIndex(Index):
def create_sql(self, model, schema_editor, using='', **kwargs):
statement = super().create_sql(
model, schema_editor, using, **kwargs
)
quote_name = statement.parts['columns'].quote_name
def upper_quoted(column):
return 'UPPER({0})'.format(quote_name(column))
statement.parts['columns'].quote_name = upper_quoted
return statement
class UpperGinIndex(GinIndex):
def create_sql(self, model, schema_editor, using='', **kwargs):
statement = super().create_sql(
model, schema_editor, using, **kwargs
)
quote_name = statement.parts['columns'].quote_name
def upper_quoted(column):
return 'UPPER({0})'.format(quote_name(column))
statement.parts['columns'].quote_name = upper_quoted
return statement
class Person(models.Model):
name = models.CharField(max_length=100, db_index=True)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
class Meta:
indexes = [
UpperIndex(fields=['name'],
name='name_upper_index'),
GinIndex(fields=['name'], name='name_gin_index',
opclasses=['gin_trgm_ops']),
UpperGinIndex(fields=['name'], name='name_gin_upper_index',
opclasses=['gin_trgm_ops']),
]
```
### Django 3.2
Если вы уже обновились, для вас приятные новости: в 3.2 ввели синтаксис expressions в индексах, и больше не нужно писать свои классы, модель будет выглядеть вот так:
```
class Person(models.Model):
name = models.CharField(max_length=100, db_index=True)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
class Meta:
indexes = [
Index(Upper('name'), name='name_upper_index'),
GinIndex(fields=['name'], name='name_gin_index',
opclasses=['gin_trgm_ops']),
GinIndex(OpClass(Upper('name'), name='gin_trgm_ops'),
name='name_upper_gin_index'),
]
```
### Заметки после доклада
После доклада нам подкинули идею проверить еще Hash и Rum индексы.
#### Hash
Hash индекс будет работать только с “=”, поэтому повесим его в нашу колонку вместо B-Tree и посчитаем за сколько отработает запрос
Подсказка о том, как это подключитьHash не входит в стандартную поставку Django индексов и как и Gist и Gin находится в пакете для postgres, поэтому код модели будет выглядеть как-то так
```
from django.contrib.postgres.indexes import HashIndex
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=100)
address = models.CharField(max_length=100)
status = models.CharField(max_length=100)
class Meta:
indexes = [
HashIndex(fields=['name'], name='name_hash_index'),
UpperIndex(fields=['name'], name='name_upper_hash_index')
]
```
*\_\_exact*
*\_\_iexact*
#### Rum
А вот с Rum индексом все немного сложнее:
1. Rum поставляется только в PostgresPro Enterprise, а мы используем базовую версию.
2. Намеков на Rum в документации Django не найдено, а значит весь код по подключению extension и настройке индексов придется писать вручную. В принципе не проблема, но не очень приятно
3. И самое важное: Rum заточен под сложные поисковые запросы и, хоть он и предполагается как улучшение Gin, с оператором LIKE Rum-индекс не работает, а значит наши запросы придется переписывать.
Подведем итоги:

---
Также подписывайтесь на наш телеграм-канал [«Голос Технократии»](https://t.me/technokratos). Каждое утро мы публикуем новостной дайджест из мира ИТ, а по вечерам делимся интересными и полезными мастридами. | https://habr.com/ru/post/598107/ | null | ru | null |
# Защита и взлом Xbox 360 (Часть 3)

В 2011 году, через 6 лет после выпуска игровой приставки Xbox 360, исследователями был обнаружен занимательный факт — если на вывод RESET центрального процессора на очень короткое время подать сигнал «0», процессор не сбросит своё состояние (как должно быть), но вместо этого изменит своё поведение! На основе этой «особенности» был разработан [Reset Glitch Hack (RGH)](https://github.com/gligli/tools/tree/master/reset_glitch_hack), с помощью которого удалось полностью скомпрометировать защиту Xbox 360, запустить неподписанный код, тем самым открыв путь к взлому самой системы и победе над «невзламываемыми» приводами [DG-16D5S](https://habr.com/ru/post/495662/).
Давайте же рассмотрим в деталях, как работал RGH, как разработчики пытались залатать дыру и как эти заплатки смогли обойти!
Что вообще за глич атака?
-------------------------
Процессор — штука довольно глупая, что бы ни говорили маркетологи. Весь высокоуровневый код, написанный программистами, сводится к исполнению простых команд — арифметика с числами, перемещение данных, условные и безусловные прыжки. Предполагается, что процессор всегда исполняет эти команды без ошибок, а результат соответствует документации.
Действительно, компилируя код
```
i = i + 2;
```
вы полагаетесь на то, что значение переменной i увеличится ровно на 2, даже не представляя себе, как может быть иначе.
Глич-атаки нарушают эту уверенность — их цель направлена на то, чтобы процессор «сглючил» и повёл себя не так, как надо. Способов «глюкнуть» процессор несколько, например:
* Просадить напряжение питания ЦПУ
* Дать лишний импульс в опорную частоту ЦПУ
* «Посветить» на проц радиацией
Есть специальные устройства для проведения подобных атак — например, ChipWhisperer предлагает широкий ассортимент атак по частоте и питанию:

В случае же с Xbox 360, «глюк» происходит в результате воздействия на линию RESET. Процессор начинает процедуру сброса, но из-за очень краткой длительности сигнала, не успевает её завершить и продолжает работать как ни в чём ни бывало. Но именно на этот краткий миг, пока сигнал RESET активен, его поведение изменяется!
Глючим процессор
----------------
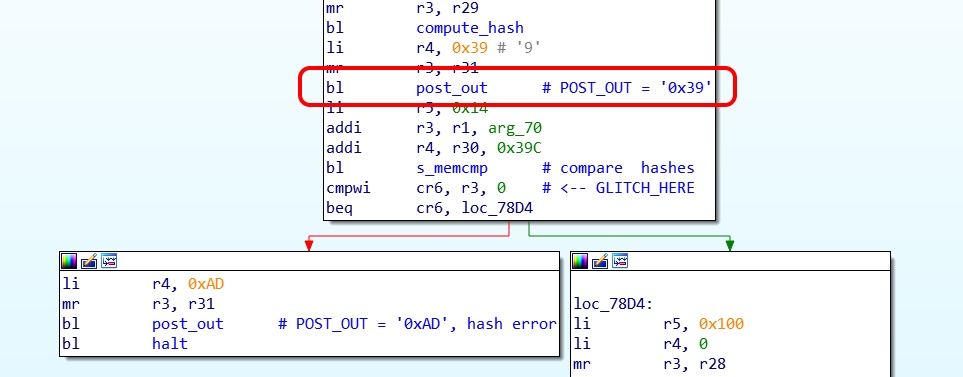
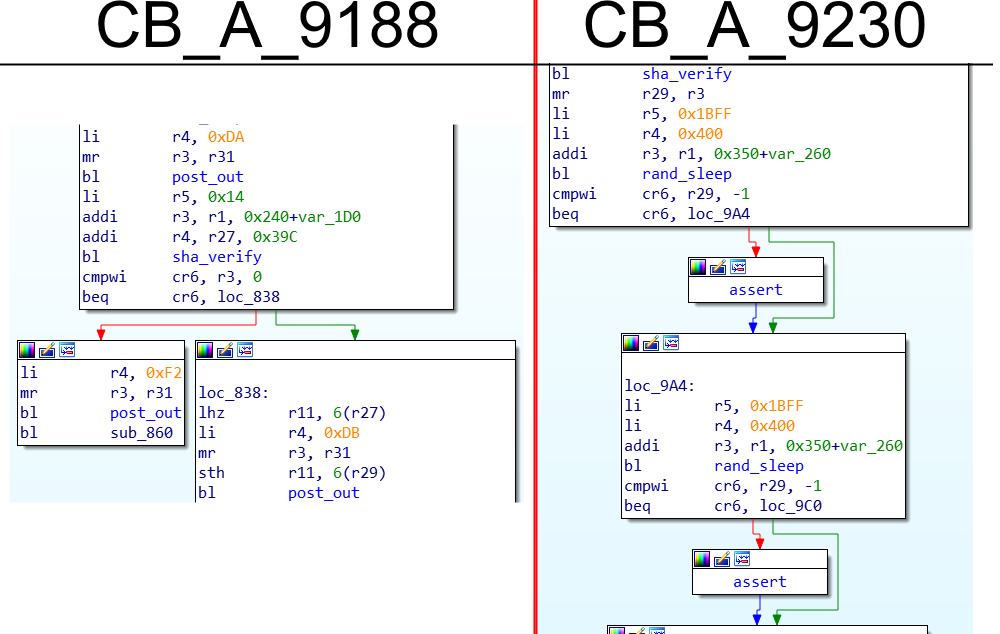
Защита Xbox 360 держится на том, что загрузчики проверяют друг друга по цепочке. В конечном итоге, проверка на каждом этапе сводится к вызову функции сравнения хеш-суммы с «образцом». Тут-то и применили глич-атаку, заставив процессор проигнорировать несовпадение. Импульс на линию RESET сразу после вызова процедуры **memcmp** заставляет процессор «пойти» по другой ветке и продолжить загрузку, даже если хеш-сумма неверна:
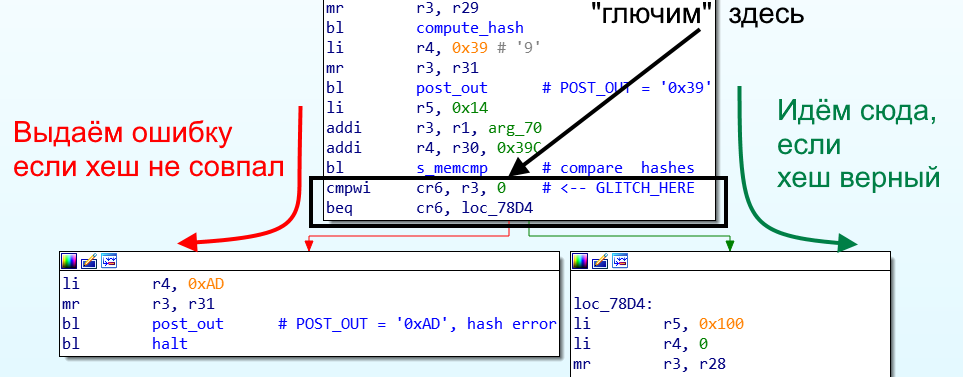
*UPDATE: дальнейшее исследование показало, что глич происходит несколько раньше, чем указано на картинке, а именно в арифметических операциях, например, addi r3, r4, 5. Если ещё точнее, то обнуляется регистр источника, в примере это r4*
Наилучшее место для атаки нашлось в загрузчике второго этапа, «CB». Более поздние этапы атаковать сложнее (да и легко пофиксят), а на первом этапе загрузки («1BL», ROM) из-за несколько иного построения программного кода атака не удалась.
Звучит просто, но на деле при попытке осуществить атаку, обнаружилось множество нюансов.
Для начала, чтобы успешно провести глич-атаку, необходимо очень точно определить момент времени, когда следует подавать RESET импульс. Если ошибиться хотя бы на микросекунду, послать слишком короткий или длинный импульс, атака не срабатывает.
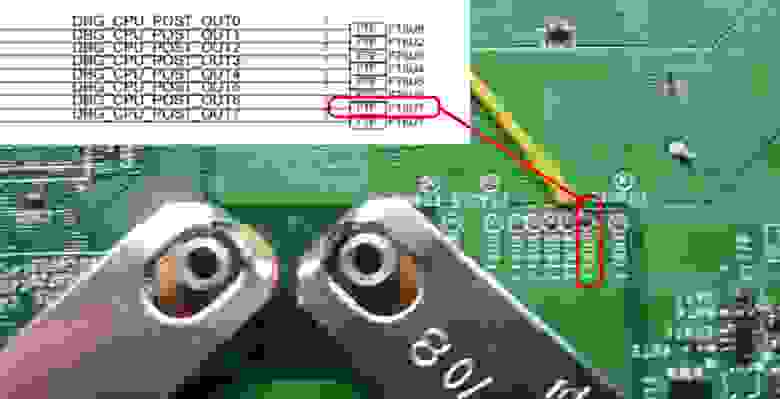
К счастью, в Xbox 360 каждый этап загрузки сопровождается изменением значения на отладочной шине [POST\_OUT](https://github.com/Free60Project/wiki/blob/master/POST.md). Более того, отладочный вывод настолько часто расставлен, что новое значение POST задаётся сразу перед сравнением хеш-суммы:
Настолько близкое расположение отладочного вывода от места атаки оказалось крайне удобным триггером. POST\_OUT является параллельной шиной и выводится на 8 тестовых площадок на печатной плате, каждая из которых отвечает за один из битов значения. Удалось даже упростить схему подключения, используя только один бит и считая количество изменений его состояния с момента загрузки системы:
Также выяснилось, что из-за высокой частоты работы процессора, почти невозможно попасть в нужный момент по точности и длительности. Время воздействия должно быть очень мало, порядка времени исполнения одной инструкции процессором. Но чем медленнее работает процессор, тем больший временной промежуток нас устраивает. Поэтому берём и замедляем процессор!
На обычном ПК частота CPU определяется как произведение внешней, «опорной» частоты и множителя:

Так и в Xbox 360, к процессору подходят внешние линии опорной частоты, а внутри эта частота умножается с помощью [PLL](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D1%8F_%D0%B0%D0%B2%D1%82%D0%BE%D0%BF%D0%BE%D0%B4%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B0_%D1%87%D0%B0%D1%81%D1%82%D0%BE%D1%82%D1%8B). И на старых, «толстых» ревизиях приставки механизм PLL можно было отключить, замедлив процессор аж в 128 раз:

На «Slim» версиях трюк с PLL провернуть нельзя (линия не разведена на плате), и раз на множитель в «Slim» мы повлиять не можем, то уменьшим «опорную» частоту!
*UPDATE: благодаря утечке схем на слим платы, PLL линия была успешно обнаружена, благодаря чему появились методы RGH 1.2 Slim и RGH3*
Она генерируется чипом HANA, и его можно конфигурировать по шине I2C:

К сожалению, сильно снизить не получилось, «на малых оборотах» итоговая частота процессора начинала сильно «плавать», что снижало шансы на успех. Самым стабильным вариантом оказалось замедление в 3.17 раз. Не 128 раз, но хоть что-то.
Всё? Нет, не всё. Далеко не факт, что атака сработает с первого раза (особенно на Slim). А при неудачном запуске, приставка перезагружается и пробует запуститься снова. На запуск даётся всего 5 попыток, после чего приставка останавливается и начинает моргать «красным кольцом смерти». Поэтому патчим ещё и прошивку южного моста (SMC), чтобы не страдала фигнёй и перезагружала приставку до посинения:
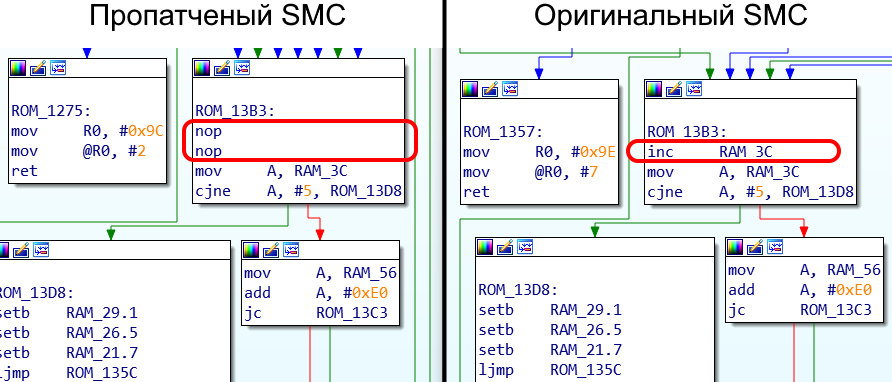
Итак, получаем алгоритм:
1. патчим SMC
2. замедляем проц (через PLL или I2C)
3. ждём триггера POST
4. ждём N микросекунд
5. шлём импульс на RESET
6. ускоряем проц обратно
Для большей точности подсчётов, частоту берём с того же HANA (48 МГц):

И получаем вот такую конструкцию на базе недорогого CPLD Xilinx XC2C64A:

Не забудем пошаманить с длиной и расположением проводка на RESET (обратите внимание на «катушку» снизу фото) и вперёд, надеяться, что запуск получится в течение минуты.
Но это только с аппаратной стороны. Как же нам пропатчить загрузчик и запихнуть свой код?
Патчим загрузчики
-----------------
Как я уже упоминал, атакуется загрузчик второго уровня, «CB». Этот загрузчик шифруется фиксированным ключом, одинаковым для всех приставок, но как раз «CB» модифицировать нельзя, его мы только атакуем. А вот следующий за ним уже зашифрован ключом CPU, уникальным для каждой приставки. И чтобы его модифицировать, нужно знать этот ключ…
Или нет?
В старых «толстых» ревизиях Xbox 360 в загрузчике «CB» поддерживался так называемый «Zero-Pairing» режим, использующийся на этапе производства приставки. В заголовке каждого загрузчика по смещению 0x10 находится случайный набор данных «Pairing Data», используемый как часть ключа при расшифровывании. И если этот набор данных состоял целиком из нулей («Zero-Pairing»), то ключ процессора игнорировался и вместо него использовался фиксированный, нулевой ключ!
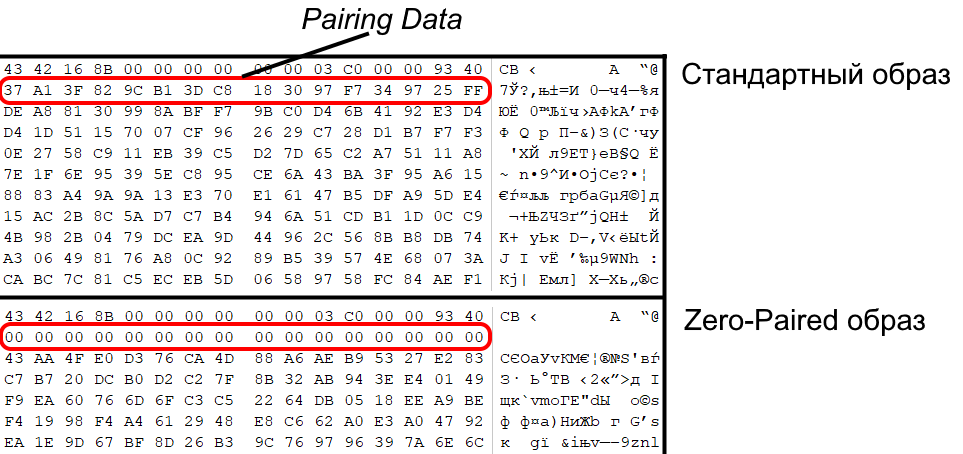
С помощью этого трюка можно было собрать образ с оригинальным «CB», зашифровать нулевым ключом следующий загрузчик, «CD» (уже со своим кодом) и запустить его с помощью RGH!
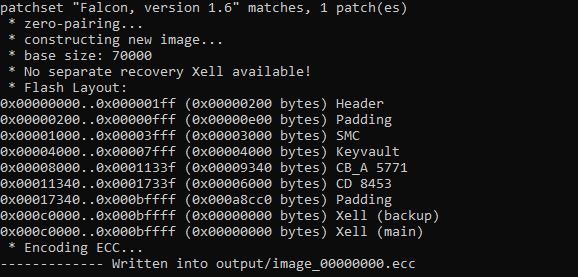
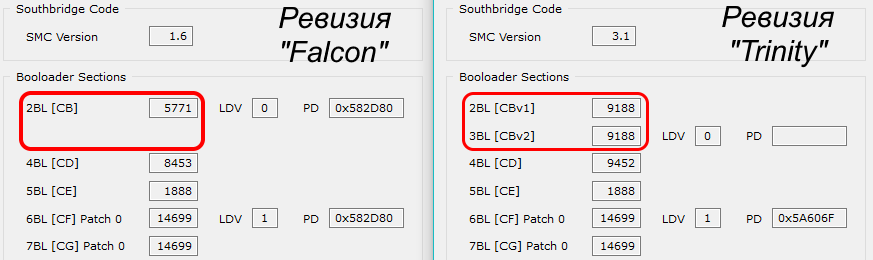
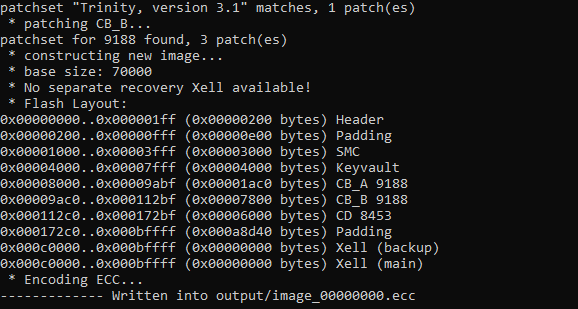
В приставках «Slim» и этот трюк завернули, убрав «Zero-Pairing» режим и поделив «CB» на две части. Здесь «CB» делился на очень простой и небольшой «CB\_A» и шифрованный ключом процессора «CB\_B»:
Но шифрование алгоритмом RC4 (а именно этим алгоритмом зашифрован «CB\_B»), имеет одну особенность. В процессе шифрования на основе ключа генерируется псевдослучайный поток данных, который бинарно «складывается» (операция 'исключающее или', 'xor') с исходными данными. При расшифровывании, соответственно, происходит то же самое, сложение с этим же псевдослучайным потоком возвращает данные в исходное значение:

Но операция бинарного сложения коммутативна и ассоциативна, что означает, что мы можем модифицировать зашифрованные данные, не зная ключа, просто за**xor**'ив зашифрованный код с нужным нам патчем!

В итоге, мы можем зашифровать «CB\_A», пропатчить зашифрованный «CB\_B» (чтобы он не выполнял расшифровку вообще) и положить в открытом виде «CD» со своим кодом!
Короче, если собрать воедино, то запуск выглядит как-то так:
(XeLL — загрузчик хоумбрю, линукса, а ещё он ключи CPU показывает)
Microsoft наносит ответный удар
-------------------------------
Конечно, Microsoft постарались всё залатать.
В новом системном обновлении все старые приставки перевели на «раздельную» загрузку с «CB\_A» и «CB\_B», тем самым окончательно закрыв «Zero-Paired» режим. На «Slim» загрузчики тоже подверглись обновлению. Новые загрузчики серьёзно доработали для защиты от RGH, наибольший упор при этом был сделан на защиту «CB\_A»:
* Полностью убрали отладочный вывод в POST
* Проверку хеш-суммы переделали и продублировали для надёжности
* По всему коду расставили sleep() на случайное время (зависящее от ключа CPU!!)
* Добавили проверку фьюза CBLDV для возможности отзыва «CB\_A»
Список нововведений не оставляет ни одного шанса для RGH. Но обратим внимание на последний пункт списка — до этого в «CB\_A» не было проверки фьюзов! Фатальный недостаток. Более того, как мы помним, в расшифровке «CB\_A» ключ процессора не участвует. А это значит, что уязвимый к RGH загрузчик «CB\_A» можно запустить на любой приставке, и запретить это нельзя.
А вот чтобы что-то запустить с помощью этого уязвимого «CB\_A», нужно несколько извернуться. Если мы не знаем ключа CPU, всё, что нам остаётся — патчить существующий «CB\_B». Но что, если вместо модификации единичных участков, мы заXOR’им весь загрузчик целиком? И за счёт этого «запишем» старый загрузчик, который мы уже умеем патчить, на место нового? Так и поступили:
1. Шифруем уязвимый «CB\_A» точно так же, как в исходном образе
2. XOR’им наш «CB\_B» с новым, получая «разницу»
3. Накладываем её на шифрованный «CB\_B»!
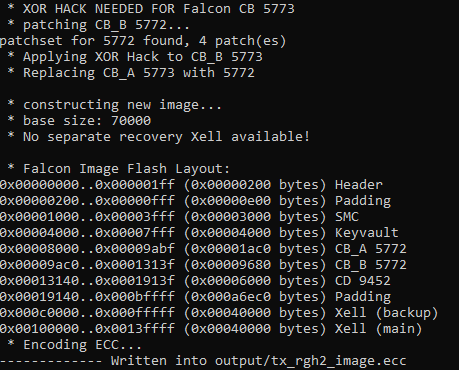
Всё, мы снова, не зная ключа, успешно подменили шифрованное содержимое, ещё и уязвимый загрузчик засунули. Приставки взламываются, Microsoft удивляются.
Разработчики напряглись, и в очередном системном обновлении … чуть изменили метод шифрования «CB\_B», теперь ключ шифрования стал зависеть ещё и от версии «CB\_A»:

Теперь при попытке за**xor**’ить и подсунуть данные уязвимому «CB\_A» старой версии, загрузчик расшифровывал мусор из-за различий в ключах. А новый загрузчик взломать нельзя, он хорошо защищён от глич атак. Пока что победа за Microsoft!
Проблем подкинула Corona
------------------------
Тем временем, на рынок вышла новая ревизия Xbox 360 — Corona, и принесла она моддерам проблем:

Маловато чипов на плате, не находите? Всё верно, чип HANA «спрятали» в южный мост. Больше неоткуда брать частоту 48 MHz для мод-чипа, прежние команды замедления по I2C не срабатывают. Да что уж там, NAND-флеш на 16 MB, все эти годы служившую в качестве системного хранилища Xbox 360, вероломно заменили на 4 GB чип с интерфейсом eMMC! (правда, только в более дешёвой версии приставки, но всё же):

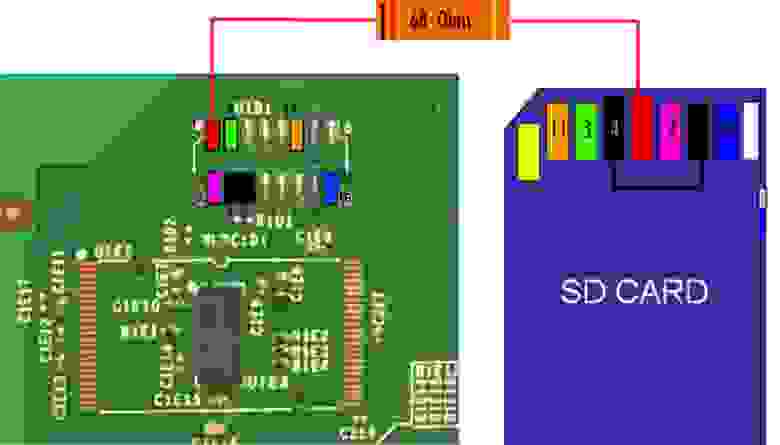
Но ничего, со всем справились. Придумали как читать/писать флеш-память через картридер:
Нашли новые I2C команды замедления, внешний 48 MHz кварцевый генератор заменил HANA:

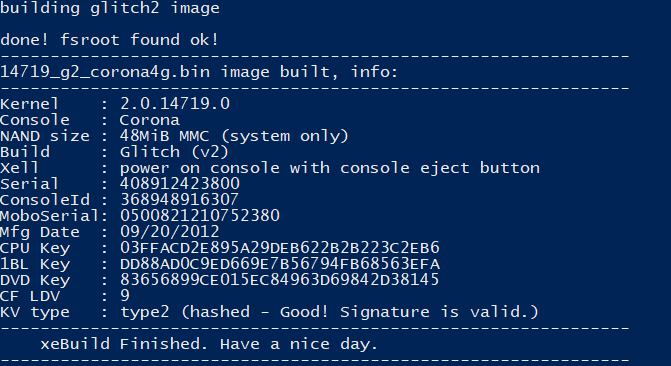
Доделали скрипты для сборки, добавили поддержку 4 GB NAND…
Но Microsoft продолжали вставлять палки в колёса. Например, на новых платах пропали некоторые резисторы, без которых мод-чип переставал работать:

Правда, исправлялось это установкой перемычек паяльником:

Серьёзнее дела пошли, когда с платы пропали дорожки POST\_OUT:

Но и здесь Microsoft не повезло, нужные для RGH «шары» CPU находились на крайнем ряду:
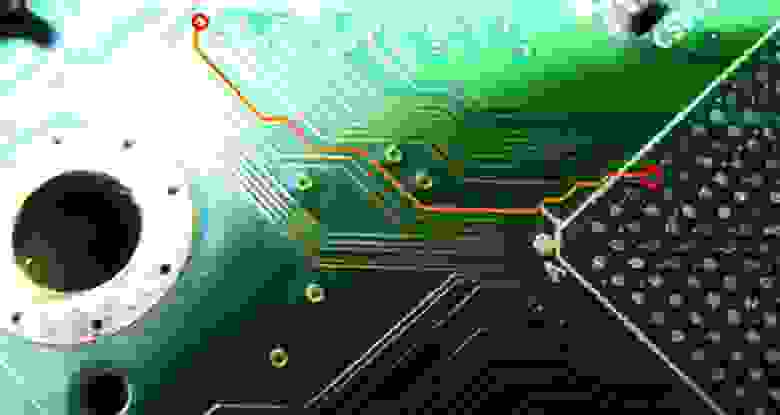
И, естественно, к ним смогли подключиться. Сначала самые рукастые, чуть подсверлив край процессора и подпаявшись проводком прямо к шарику:


А затем китайцы выпустили рамки с подпружиненной иглой, точно упирающейся в шарик, и проблема решилась для всех остальных:

Последний рубеж
---------------
После того, как одолели «корону», осталась одна проблема — новые версии системы так и не поддавались взлому. Чтобы запустить RGH, нужно знать ключ CPU, а чтобы узнать ключ CPU, нужно хотя бы раз запустить RGH. Проблема курицы и яйца, в общем.
И тут возникла мысль — а давайте не только проверку подлинности «глюкнем», но и расшифровку пропустим! Если получится, то нам не нужно знать ключа, положим «CB\_B» в открытом виде, да и всё. Именно эта идея легла в основу Double Glitch Hack (DGX):

Этот чип «глючил» проц дважды, первым импульсом пропускался этап расшифровки загрузчика, а уже второй импульс пропускал проверку подлинности. Работало куда менее стабильно, благо требовался хотя бы один успешный запуск — дальше получаем ключ CPU и действуем по-старинке.
Актуален DGX был недолго, спустя 3 месяца китайцы вбросили релиз «DGX R.I.P» с образами, которые запускались на любых приставках, работали со стандартным RGH и, естественно, запускались куда стабильнее:
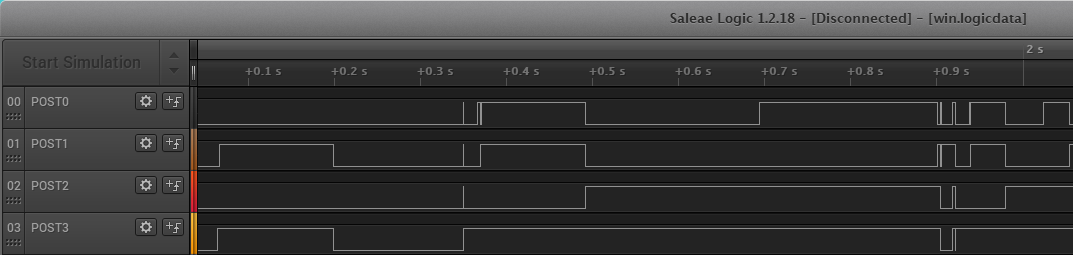
Эти образы содержали специальную версию загрузчика «CB\_A», используемую на производстве Xbox 360 и, по сути, являющуюся полным аналогом старого доброго «Zero-Pairing» режима. Вместо ключа процессора, этот «CB\_A\_mfg» расшифровывал «CB\_B» фиксированным нулевым ключом:

И вот здесь Microsoft всё. В этом «сервисном» варианте «CB\_A» тоже не было проверки фьюз и забанить его было невозможно. Достаточно было записать образ согласно ревизии Xbox 360, припаять чип — и всё работало.
Winchester!
-----------
Полностью пофиксили RGH только в новой ревизии приставки под кодовым именем Winchester. Впервые процессоры CPU и GPU совместили в одном кристалле, плату максимально упростили:

Дорожки POST\_OUT не просто убрали. Даже если подпаяться на площадки под процессором:


И даже, если запаять процессор на специальную версию платы для разработчиков, XDK, где эти дорожки всё ещё есть:

На POST\_OUT виден только один импульс при запуске приставки. Шина заблокирована:
Более того, она блокируется только на этапе производства. Если взять «чистый» процессор с фабрики, где ещё не успели прожечь фьюзы — на нём POST\_OUT работает!
Но вот RGH на нём уже не срабатывает. Как бы вы ни пытались подать RESET импульс, процессор корректно выполняет сброс, или же игнорирует ваш сигнал из-за слишком малой длительности. По-видимому, в процессор добавили специальный логический модуль, фильтрующий линию RESET и тем самым окончательно исправили аппаратную ошибку.
Post Scriptum
-------------
Выходит, последнюю ревизию Xbox 360 взломать невозможно?
И да, и нет. На данный момент известен только один способ запустить модифицированную систему на ревизии Winchester.
В наборе ПО для разработчиков (XDK) есть различные приватные ключи для подписи скомпилированного кода. И так вышло, что среди них затесался ключ подписи «shadowboot», загрузчика третьего уровня для XDK систем. И с его помощью можно собрать легитимный подписанный образ с модифицированной прошивкой. Вот только работать на обычных, «магазинных» приставках он не будет. Нужен процессор с XDK версии приставки, либо «чистый» CPU с непрожжёными фьюзами (можно было встретить на Aliexpress):
И только тогда у вас будет возможность лицезреть в «сведениях о системе» кастомной оболочки такую вот надпись:

А на этом всё! Как обычно, готов ответить на ваши вопросы в комментариях :)
[Защита и взлом Xbox 360, Часть 1](https://habr.com/ru/post/491634/)
[Защита и взлом Xbox 360, Часть 2](https://habr.com/ru/post/495662/)
[Защита и взлом Xbox 360, Часть 3](https://habr.com/ru/post/500246/) | https://habr.com/ru/post/500246/ | null | ru | null |
# Иконочные шрифты для мобильных устройств
Уже достаточно долгое время мы ведем поддержку двух мобильных версий Поиска Mail.Ru. Этим постом хотелось бы раскрыть немного технической информации о графических интерфейсах.
Первая из версий ориентирована на простые телефоны, которые медленно, но верно покидают современный рынок мобильных устройств, но еще не полностью забыты. К этой категории мы относим телефоны без полноценной операционной системы, браузеры в которых устарели, не понимают полноценного JavaScript-кода и не могут в силу своих ограничений поддержать быстро развивающиеся интернет-технологии. Для этой группы пришлось применять проверенный старый способ — .png- и .gif-графику.
Вторая версия, которую мы поддерживаем и развиваем, предназначена для смартфонов. О ней сегодня и пойдет речь.
##### Часть 1: Подключение иконочных шрифтов
Современные смартфоны обладают рядом особенностей, о которых нельзя забывать и к которым приходится подстраиваться. Одна из них — появление экранов с увеличенной плотностью пикселей (в частности, Retina-экранов), возможность увеличения страницы и, как следствие этого, размытие обычных картинок. Из-за этого возникла потребность в использовании масштабируемой графики, которая бы выглядела четко как в масштабе 1:1, так и после многократного увеличения. Выходом из этой ситуации стало использование иконочных шрифтов. На картинке ниже представлено два варианта: на верхнем показана картинка .png, увеличенная в 2 раза, а снизу — результат применения шрифта с иконками с тем же увеличением.

Суть процесса заключается в том, что в шрифтовом файле буквы заменяются на графические иконки — по сути, создается уникальный шрифт. В нашем случае, к примеру, значок “@” заменен на лупу, английская буква “I” (от Internet) — на иконку земного шара, буква “P” (от pictures) — на иконку изображений, и так далее. При замене желательно придерживаться относительной схожести графики и символов-букв, чтобы в случае, если по каким-то причинам шрифт не подгрузился, пользователь все равно смог ориентироваться на сайте.
Подгрузка нестандартного шрифта происходит так же, как и для PC, с помощью CSS-конструкции @font-face. Единственным отличием и большим плюсом является то, что при работе со смартфонами не нужно заботиться о поддержке различных форматов шрифтов (.eot, .woff, .ttf, .svg), как это необходимо делать для PC из-за разнообразия браузеров.
Для телефонов на основе операционных систем iOS, Android, bada и BlackBerry достаточно подгружать один формат .ttf. Его прекрасно понимают не только встроенные браузеры, но и такие, как мобильный Firefox, Сhrome и Opera Mobile.
В файле стилей подгрузка выглядит следующим образом:
```
@font-face {
font-family: 'goMailIco';
src: url("/font/goMailIco.ttf");
font-weight: normal;
font-style: normal;
}
```
И все же, несмотря на то, что современные смартфоны обладают характеристиками, порой сравнимыми с персональными компьютерами, есть среди них и те, к которым требуется особый подход. В борьбе за улучшение качества отображения сайта пришлось выделить группу смартфонов, которой отдаются картинки. В эту группу вошли устройства на таких ОС, как Windows Phone 7 и Android версии ниже 2.2, а также браузер Opera Mini, открытый в телефоне с любой ОС. Это разделение мы произвели после экспериментов с тестовыми устройствами.
На серверной стороне каждое устройство, с которого заходят на сайт go.mail.ru, определяется по user agent и другим параметрам. Дальше эти данные передаются в шаблонизатор — на проекте Поиск Mail.Ru используется [Jinja](http://jinja.pocoo.org). Запись по определению необходимости отдавать пользователю шрифт или картинку выглядит так:
```
{% set switchFont = (detector.os in ('iphone os', 'blackberry', 'bada') or
detector.os == 'android' and detector.osver >= 2.2) and
(not detector.is_opera_mini) %}
```
Переменная switchFont является true, если на устройство установлена операционная система iOS, BlackBerry, bada или Android версии выше или равной 2.2, а переменная is\_opera\_mini равна false. Далее в зависимости от значения switchFont в шаблонах выводится одно из двух.
Ниже показан кусок кода в шаблоне на примере логотипа:
```
{% if switchFont %}
[поиск@mail.ru](#)
{% else %}
{% endif %}
```
Стили для него выглядят так:
```
.logo__img {
background: url(data:image/png) 0 0 no-repeat;
background-size: 100% auto;
width: 165px;
height: 25px;
}
.logo__ttf {
font-family: 'goMailIco';
color: #fff;
font-size: 24px;
}
.logo__ttf_color {
color: #ffb81d;
}
```
Если шаблонизатор решил использовать вариант со шрифтом, к каждой букве, имеющей класс .logo\_\_ttf, применяется нестандартный шрифт ‘goMailIco’, в котором стандартная буква m заменена на букву из фирменного шрифта mail.ru. Остается только подобрать правильный размер с помощью font-size, задать цвет, тени и при желании использовать все возможности CSS3.
В случае, когда мы берем картинку, ситуация практически стандартная, не считая того, что мы загружаем изображение в два раза больше необходимого. Например, чтобы показать картинку 200х300 пикселей на экране с увеличенной плотностью пикселей, необходимо загрузить картинку размером 400х600 пикселей и затем уменьшить, используя CSS-атрибуты, html-параметры, или, как в нашем случае, изображение в качестве фона с необходимыми размерами контейнера, фон в котором ужимается в два раза с помощью стиля “background-size: 100% auto;”.
При таком варианте возможна загрузка избыточно больших изображений для смартфонов со стандартным разрешением экрана (device-pixel-ratio: 1), которые не приспособлены для увеличения. Это компенсируется кодированием фонового изображения в формат base-64, что позволяет выиграть разницу в размере файла и избавиться от необходимости хранить и поддерживать изображения в двух форматах — 1 к 1 и 2 к 1. Плюс еще в том, что этот способ существенно минимизирует количество http-запросов к серверу, что увеличивает общую скорость загрузки.
##### Часть 2: Разработка шрифта
Обсудив технические детали подключения шрифта с иконками, расскажем, как разрабатывается подобный шрифт. Если у вас уже есть иконки или другая графика в векторном формате, то половина работы сделана; в противном случае имеющиеся растровые иконки придется заново отрисовать в векторном редакторе. Можно расположить весь набор графики слоями в одном документе, но для сборки в шрифт лучше экспортировать каждый символ в отдельные файлы, формат которых сможет импортировать имеющийся редактор шрифтов.

Предпочтительно работать с большими размерами обьектов, от 500 до 1000 пикселей. При этом стоит избегать излишней детализации, ведь иконка может быть растеризована на экране размером 16-32 пикселя. Используйте одноцветные формы, без обводок и каких-либо эффектов; цвет и другие эффекты, например, тень, могут быть применены к иконке уже при верстке страницы. При необходимости использовать в иконке несколько цветов придется разбить ее на элементы, каждый из которых сделайте отдельным символом шрифта, которые затем будут наложены друг на друга и соответственно окрашены.

Существует несколько программ-редакторов, например [Font Creator](http://www.high-logic.com/font-editor/fontcreator.html) (для Windows), [Glyphs](http://glyphsapp.com) (для Mac) или [Inkscape](http://inkscape.org) (для Windows, Mac, Linux) — в нем можно сразу редактировать векторную графику и создать шрифт в svg-формате.
Для итогового результата не так важно, создаете ли вы новый шрифт или заменяете символы готового; но, добавляя символ в пустой шрифт, придется вручную искать и назначать соответствующий символу индекс для разных операционных систем, затем настраивать различные метрики. Проще взять за основу готовый шрифт с лицензией, допускающей его изменение — например, с сайта [font.cc](http://font.cc). Импортируем подготовленную векторную графику, заменяя выбранные буквы, и следим за соответствием размеров, отступов, выравниваем по базовой линии.

Если вы разбили иконку на разноцветные элементы, то лучше сохранить их позицию и размеры относительно друг друга при дальнейшем наложении. На этом этапе наверняка придется протестировать и, возможно, уточнить положение и размеры иконки.

Если ваш редактор сохраняет шрифт только в формат, отличный от .ttf, можно воспользоваться online-сервисами для конвертации, например, [Fontsquirrel](http://www.fontsquirrel.com/tools/webfont-generator). Подобные сервисы также позволяют уменьшить размер файла, удалив неиспользуемые символы, но лучше это сделать на этапе разработки в редакторе.
Вот и все. Если вы нашли какое-то альтернативное решение для экранов со сверхвысоким разрешением — делитесь.
Ознакомиться с мобильной версией проекта Поиск можно зайдя по ссылке [go.mail.ru](http://go.mail.ru/) с мобильного устройства.
*Дария Скакун, разработчик мобильных версий проекта Поиск
Алексей Лиходзиевский, руководитель мобильного направления проекта Поиск* | https://habr.com/ru/post/173881/ | null | ru | null |
# Собеседование для фронтенд-разработчика на JavaScript: самые лучшие вопросы
Недавно мне довелось побывать на [встрече](https://www.meetup.com/Free-Code-Camp-SF/) участников проекта [FreeCodeCamp](https://www.freecodecamp.com/) в Сан-Франциско. Если кто не знает, Free Code Camp — это сообщество, нацеленное на изучение JavaScript и веб-программирования. Там один человек, который готовился к собеседованиям на позицию фронтенд-разработчика, попросил меня подсказать, какие вопросы по JavaScript стоит проработать. Я немного погуглил, но не смог найти подходящего списка вопросов, на который я бы мог дать ссылку и сказать: «Разбери эти вопросы и работа твоя». [Некоторые](https://github.com/h5bp/Front-end-Developer-Interview-Questions) [списки](https://github.com/khan4019/front-end-Interview-Questions) [были](https://github.com/kennymkchan/interview-questions-in-javascript) [близки](https://medium.freecodecamp.com/3-questions-to-watch-out-for-in-a-javascript-interview-725012834ccb) к тому, что мне хотелось найти, [некоторые](https://medium.com/javascript-scene/10-interview-questions-every-javascript-developer-should-know-6fa6bdf5ad95) [выглядели](https://www.toptal.com/javascript/interview-questions) очень уж [простыми](https://www.codementor.io/nihantanu/21-essential-javascript-tech-interview-practice-questions-answers-du107p62z), но все они были либо неполными, либо содержали вопросы, которые вряд ли кто станет задавать на реальном собеседовании.
[](https://habrahabr.ru/company/ruvds/blog/334538/)
В итоге я решил составить собственный список. В него входят и те вопросы, которые задавали мне, когда я искал работу, и те, которые задавал я, когда искал сотрудников на позиции фронтенд-разработчиков. Обратите внимание на то, что некоторые компании (вроде Google) уделяют особое внимание таким вещам, как проектирование эффективных алгоритмов. Поэтому, если вы хотите в подобной компании работать, в дополнение к приведённым тут вопросам, порешайте задачки с соревнований [CodeJam](https://code.google.com/codejam/past-contests).
Я буду добавлять и редактировать ответы на эти вопросы [здесь](https://github.com/bcherny/frontend-interview-questions). Если у вас возникнет желание что-нибудь дополнить или улучшить — буду рад вашим пулл-реквестам.
Вопросы разбиты на несколько разделов:
* Теория.
* Программирование.
* Отладка.
* Проектирование систем.
Итак, вот мои вопросы.
Теория
------
Интервьюируемый должен обладать чётким пониманием концепций, которые затрагивают вопросы из этого раздела, должен уметь всё это объяснить. Программирование тут не требуется.
1. Что такое нотация «О-большое» и как ей пользоваться?
2. Что такое DOM?
3. Что такое цикл событий?
4. Что такое замыкание?
5. Как работает прототипное наследование и чем оно отличается от классической модели наследования? (По моему мнению, это не особенно полезный вопрос, но многим нравится его задавать.)
6. Как работает ключевое слово `this`?
7. Что такое всплытие событий и как работает этот механизм? (Мне этот вопрос тоже не нравится, но его часто задают на собеседованиях.)
8. Опишите несколько способов обмена данными между клиентом и сервером. Расскажите, не вдаваясь в подробности, о том, как работают несколько сетевых протоколов (IP, TCP, HTTP/S/2, UDP, RTC, DNS, и так далее).
9. Что такое REST и почему эта технология популярна?
10. Мой сайт тормозит. Расскажите о шагах по его диагностированию и исправлению. Опишите популярные подходы к оптимизации, и расскажите о том, когда их следует использовать.
11. Какими фреймворками вы пользовались? Каковы их сильные и слабые стороны? Почему программисты пользуются фреймворками? Проблемы какого рода решают фреймворки?
Программирование
----------------
Ответы на эти вопросы предполагают реализацию функций на JavaScript. За каждым вопросом следуют тесты, которые должно успешно проходить решение.
### ▍Простые задания
1. Реализуйте функцию `isPrime()`, которая возвращает `true` или `false`, указывая, является ли переданное ей число простым.
```
isPrime(0) // false
isPrime(1) // false
isPrime(17) // true
isPrime(10000000000000) // false
```
2. Реализуйте функцию `factorial()`, которая возвращает факториал переданного ей числа.
```
factorial(0) // 1
factorial(1) // 1
factorial(6) // 720
```
3. Реализуйте функцию `fib()`, возвращающую n-ное [число Фибоначчи](https://en.wikipedia.org/wiki/Fibonacci_number).
```
fib(0) // 0
fib(1) // 1
fib(10) // 55
fib(20) // 6765
```
4. Реализуйте функцию `isSorted()`, которая возвращает `true` или `false` в зависимости о того, отсортирован ли переданный ей числовой массив.
```
isSorted([]) // true
isSorted([-Infinity, -5, 0, 3, 9]) // true
isSorted([3, 9, -3, 10]) // false
```
5. Создайте собственную реализацию функции [`filter()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/Filter).
```
filter([1, 2, 3, 4], n => n < 3) // [1, 2]
```
6. Создайте собственную реализацию функции [`reduce()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/Reduce).
```
reduce([1, 2, 3, 4], (a, b) => a + b, 0) // 10
```
7. Реализуйте функцию `reverse()`, которая обращает порядок следования символов переданной ей строки. Не пользуйтесь встроенной функцией [`reverse()`](https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Global_Objects/Array/reverse).
```
reverse('') // ''
reverse('abcdef') // 'fedcba'
```
8. Создайте собственную реализацию функции [`indexOf()`](https://developer.mozilla.org/nl/docs/Web/JavaScript/Reference/Global_Objects/Array/indexOf) для массивов.
```
indexOf([1, 2, 3], 1) // 0
indexOf([1, 2, 3], 4) // -1
```
9. Реализуйте функцию `isPalindrome()`, которая возвращает `true` или `false` в зависимости от того, является ли переданная ей строка палиндромом (функция нечувствительна к регистру и к наличию в строке пробелов).
```
isPalindrome('') // true
isPalindrome('abcdcba') // true
isPalindrome('abcd') // false
isPalindrome('A man a plan a canal Panama') // true
```
10. Реализуйте функцию `missing()`, которая принимает неотсортированный массив уникальных чисел (то есть, числа в нём не повторяются) от 1 до некоего числа *n*, и возвращает число, отсутствующее в последовательности. Там может быть либо одно отсутствующее число, либо их может не быть вовсе.
Способны ли вы добиться того, чтобы функция решала задачу за время *O(N)*? Подсказка: есть одна хорошая формула, которой вы можете воспользоваться.
```
missing([]) // undefined
missing([1, 4, 3]) // 2
missing([2, 3, 4]) // 1
missing([5, 1, 4, 2]) // 3
missing([1, 2, 3, 4]) // undefined
```
11. Реализуйте функцию i`sBalanced()` которая принимает строку и возвращает `true` или `false`, указывая на то, сбалансированы ли фигурные скобки, находящиеся в строке.
```
isBalanced('}{') // false
isBalanced('{{}') // false
isBalanced('{}{}') // true
isBalanced('foo { bar { baz } boo }') // true
isBalanced('foo { bar { baz }') // false
isBalanced('foo { bar } }') // false
```
### ▍Задания средней сложности
1. Реализуйте функцию `fib2()`. Она похожа на функцию `fib()` из предыдущей группы заданий, но поддерживает числа вплоть до 50. Подсказка: используйте мемоизацию.
```
fib2(0) // 0
fib2(1) // 1
fib2(10) // 55
fib2(50) // 12586269025
```
2. Реализуйте функцию `isBalanced2()`. Она похожа на функцию `isBalanced()` из предыдущей группы заданий, но поддерживает три типа скобок: фигурные `{}`, квадратные `[]`, и круглые `()`. При передаче функции строки, в которой имеются неправильные скобочные последовательности, функция должна возвращать `false`.
```
isBalanced2('(foo { bar (baz) [boo] })') // true
isBalanced2('foo { bar { baz }') // false
isBalanced2('foo { (bar [baz] } )') // false
```
3. Реализуйте функцию `uniq()`, которая принимает массив чисел и возвращает уникальные числа, найденные в нём. Может ли функция решить эту задачу за время *O(N)*?
```
uniq([]) // []
uniq([1, 4, 2, 2, 3, 4, 8]) // [1, 4, 2, 3, 8]
```
4. Реализуйте функцию `intersection()`, которая принимает два массива и возвращает их пересечение. Можете ли вы добиться того, чтобы функция решала эту задачу за время *O(M+N)*, где *M* и *N* — длины массивов?
```
intersection([1, 5, 4, 2], [8, 91, 4, 1, 3]) // [4, 1]
intersection([1, 5, 4, 2], [7, 12]) // []
```
5. Создайте реализацию функции [`sort()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/sort), которая сортирует числовой массив за время *O(N×log(N))*.
```
sort([]) // []
sort([-4, 1, Infinity, 3, 3, 0]) // [-4, 0, 1, 3, 3, Infinity]
```
6. Реализуйте функцию `includes()`, которая возвращает `true` или `false` в зависимости от того, встречается ли переданное ей число в переданном ей отсортированном массиве. Может ли функция решить эту задачу за время *O(log(N))*?
```
includes([1, 3, 8, 10], 8) // true
includes([1, 3, 8, 8, 15], 15) // true
includes([1, 3, 8, 10, 15], 9) // false
```
7. Реализуйте функцию `assignDeep()`, которая похожа на [`Object.assign()`](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Object/assign), но выполняет глубокое объединение объектов. Для того, чтобы не усложнять задачу, можно исходить из допущения, что объекты могут содержать только числа и другие объекты (в них не может быть массивов, строк, и так далее).
```
assignDeep({ a: 1 }, {}) // { a: 1 }
assignDeep({ a: 1 }, { a: 2 }) // { a: 2 }
assignDeep({ a: 1 }, { a: { b: 2 } }) // { a: { b: 2 } }
assignDeep({ a: { b: { c: 1 }}}, { a: { b: { d: 2 }}, e: 3 })
// { a: { b: { c: 1, d: 2 }}, e: 3 }
```
8. Реализуйте функцию `reduceAsync()`, которая похожа на функцию [`reduce()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/Reduce) из группы простых заданий, но работает с функциями, возвращающими promise-объекты, каждый из которых должен быть разрешён до перехода к следующему.
```
let a = () => Promise.resolve('a')
let b = () => Promise.resolve('b')
let c = () => new Promise(resolve => setTimeout(() => resolve('c'), 100))
await reduceAsync([a, b, c], (acc, value) => [...acc, value], [])
// ['a', 'b', 'c']
await reduceAsync([a, c, b], (acc, value) => [...acc, value], ['d'])
// ['d', 'a', 'c', 'b']
```
9. Реализуйте функцию `seq()`, пользуясь тем же подходом, что и при работе над функцией `reduceAsync()`. Эта функция должна принимать массив функций, которые возвращают promise-объекты, и разрешать их один за другим.
```
let a = () => Promise.resolve('a')
let b = () => Promise.resolve('b')
let c = () => Promise.resolve('c')
await seq([a, b, c]) // ['a', 'b', 'c']
await seq([a, c, b]) // ['a', 'c', 'b']
```
### ▍Сложные задания
Некоторые задания из этой группы связаны с созданием структур данных. Не нужно запоминать все тонкости их функционирования, достаточно понимания их устройство, при этом сведения о предоставляемом ими интерфейсе можно найти в интернете. Далее, нужно знать, для чего эти структуры данных используются, каковы их ограничения в сравнении с другими структурами данных.
1. Реализуйте функцию `permute()`, которая возвращает массив строк, содержащий все пермутации заданной строки.
```
permute('') // []
permute('abc') // ['abc', 'acb', 'bac', 'bca', 'cab', 'cba']
```
2. Создайте самостоятельную реализацию функции [`debounce()`](https://lodash.com/docs/4.17.4#debounce).
```
let a = () => console.log('foo')
let b = debounce(a, 100)
b()
b()
b() // только этот вызов должен вызывать a()
```
3. Реализуйте класс [`LinkedList`](https://en.wikipedia.org/wiki/Linked_list), не используя встроенные массивы JavaScript ( `[]` ). Ваш `LinkedList` должен поддерживать лишь 2 метода: `add()` и `has()`.
```
class LinkedList {...}
let list = new LinkedList(1, 2, 3)
list.add(4) // undefined
list.add(5) // undefined
list.has(1) // true
list.has(4) // true
list.has(6) // false
```
4. Реализуйте класс [`HashMap`](https://en.wikipedia.org/wiki/Hash_table), не используя встроенные объекты JavaScript ( `{}` ) или функцию `map()`. Вам дана функция `hash()`, которая принимает строку и возвращает некое число. Эти числа, в основном, уникальны, но возможна и ситуация, когда двум разным строкам соответствуют одинаковые числа.
```
function hash (string) {
return string
.split('')
.reduce((a, b) => ((a << 5) + a) + b.charCodeAt(0), 5381)
}
```
Ваша реализация `HashMap` должна поддерживать лишь 2 метода: `get()` и `set()`.
```
let map = new HashMap
map.set('abc', 123) // undefined
map.set('foo', 'bar') // undefined
map.set('foo', 'baz') // undefined
map.get('abc') // 123
map.get('foo') // 'baz'
map.get('def') // undefined
```
5. Реализуйте класс `BinarySearchTree`. Он должен поддерживать 4 метода: `add()`, `has()`, `remove()`, и `size()`.
```
let tree = new BinarySearchTree
tree.add(1, 2, 3, 4)
tree.add(5)
tree.has(2) // true
tree.has(5) // true
tree.remove(3) // undefined
tree.size() // 4
```
6. Реализуйте класс `BinaryTree`, который поддерживает поиск в ширину, а также функции симметричного, прямого и обратного поиска в глубину.
```
let tree = new BinaryTree
let fn = value => console.log(value)
tree.add(1, 2, 3, 4)
tree.bfs(fn) // undefined
tree.inorder(fn) // undefined
tree.preorder(fn) // undefined
tree.postorder(fn) // undefined
```
Отладка
-------
При ответе на следующие вопросы сначала постарайтесь понять, почему представленный код не работает. Объясните причину ошибки. Затем предложите пару вариантов исправления проблемы и перепишите код, реализуя один из предложенных вариантов. В итоге программа должна работать правильно.
1. Необходимо, чтобы этот код выводил в лог `hey amy`, но он выводит `hey arnold`. Почему?
```
function greet(person) {
if (person == { name: 'amy' }) {
return 'hey amy'
} else {
return 'hey arnold'
}
}
greet({ name: 'amy' })
```
2. Необходимо, чтобы этот код выводил в лог числа `0, 1, 2, 3` в указанном порядке, но он этого не делает (Однажды вы столкнётесь с этой ошибкой. Некоторые люди любят задавать этот вопрос на собеседованиях).
```
for (var i = 0; i < 4; i++) {
setTimeout(() => console.log(i), 0)
}
```
3. Необходимо, чтобы этот код выводил в лог `doggo`, но он выводит лишь `undefined`.
```
let dog = {
name: 'doggo',
sayName() {
console.log(this.name)
}
}
let sayName = dog.sayName
sayName()
```
4. Попытка вызова метода `bark()` объекта `Dog` вызывает ошибку. Почему?
```
function Dog(name) {
this.name = name
}
Dog.bark = function() {
console.log(this.name + ' says woof')
}
let fido = new Dog('fido')
fido.bark()
```
5. Почему функция `isBig()` возвращает именно такой результат?
```
function isBig(thing) {
if (thing == 0 || thing == 1 || thing == 2) {
return false
}
return true
}
isBig(1) // false
isBig([2]) // false
isBig([3]) // true
```
Проектирование систем
---------------------
Если вы не уверены, что знаете, что такое «проектирование систем», сначала почитайте [это](https://github.com/donnemartin/system-design-primer).
1. Расскажите о реализации виджета автозавершения вводимого пользователем текста. Данные для автозавершения загружаются с сервера. Рассмотрите клиентскую и серверную части системы.
* Как бы вы спроектировали клиентскую часть системы, которая поддерживает следующие возможности:
+ Получение данных с применением серверного API.
+ Вывод результатов в виде дерева, когда у элементов могут быть родительские и дочерние элементы, то есть, подсказки автозаполнения — это не обычный плоский список.
+ Поддержка, помимо обычных текстовых фрагментов, элементов разных типов: флажков, радиокнопок, иконок.
* Как выглядит API компонента?
* Как выглядит серверное API?
* Какие соображения, касающиеся производительности, нужно учитывать для того, чтобы виджет работал в режиме реального времени, выводя подсказки по мере ввода данных пользователем? Есть ли здесь какие-нибудь пограничные случаи (например, когда пользователь вводит текст быстро при медленном сетевом соединении)?
* Как бы вы спроектировали сетевую подсистему и серверную часть высокопроизводительного решения такого рода? Как организовали бы взаимодействие клиента и сервера? Как данные хранятся на сервере? Как всё это масштабируется для поддержки больших объёмов данных и большого количества клиентов?
2. Расскажите о реализации сервиса, подобного Twitter, описав клиентскую и серверную части (этот вопрос бессовестно украден у моего друга [Майкла Ву](https://github.com/blaisebaileyfinnegan)).
* Как твиты загружаются с сервера и выводятся в пользовательском интерфейсе?
* Как, при обновлении твитов, обновляется лента? Как клиентская часть приложения узнаёт о появлении новых твитов?
* Как выполняется поиск по твитам? Как организован поиск по автору? Расскажите о том, как спроектирована база данных, серверная часть приложения и API.
Итоги
-----
Надеемся, эти вопросы пригодятся и тем, кто собирается на собеседования, и тем, кто их проводит. А если вы не относитесь ни к тем, ни к другим, полагаем, вопросы помогут вам поддерживать себя в хорошей программистской форме.
Вот, кстати, ещё несколько мест, куда можно заглянуть, если вам хочется попрактиковаться: [The Algorithm Design Manual](https://smile.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693), задачи с соревнований [CodeJam](https://code.google.com/codejam/past-contests), репозиторий [keon/algorithms](https://github.com/keon/algorithms). А вот — несколько ресурсов, которые будут полезны JS-разработчикам: [JavaScript Allonge](https://leanpub.com/javascriptallongesix/read), [You Don’t Know JS](https://github.com/getify/You-Dont-Know-JS), [Effective JavaScript](https://smile.amazon.com/Effective-JavaScript-Specific-Software-Development/dp/0321812182).
Уважаемые читатели! Если у вас есть на примете вопросы, которые, по вашему мнению, стоит добавить в этот список (или если вы обнаружите ошибку) — расскажите нам и [напишите](mailto:boris@performancejs.com) автору этого материала. | https://habr.com/ru/post/334538/ | null | ru | null |
# Установка центра сертификации на предприятии. Часть 2
Мы продолжаем нашу серию статей о центре сертификации на предприятии. Сегодня поговорим о построении диаграммы открытого ключа, планировании имен центра сертификации, планировании списков отзыва сертификатов и еще нескольких моментах. Присоединяйтесь!

> [*Первая часть серии*](https://habrahabr.ru/company/microsoft/blog/348944/)
>
>
>
> [*Третья часть серии*](https://habrahabr.ru/company/microsoft/blog/349202/)
Введение
--------
#### Словарь терминов
В этой части серии использованы следующие сокращения и аббревиатуры:
* **PKI** (*Public Key Infrastructure*) — инфраструктура открытого ключа, набор средств (технических, материальных, людских и т. д.), распределённых служб и компонентов, в совокупности используемых для поддержки криптозадач на основе закрытого и открытого ключей. Поскольку аббревиатура ИОК не является распространённой, здесь и далее будет использоваться более знакомая англоязычная аббревиатура PKI.
* **X.509** — стандарт ITU-T для инфраструктуры открытого ключа и инфраструктуры управления привилегиями.
* **ЦС** (*Центр Сертификации*) — служба выпускающая цифровые сертификаты. Сертификат — это электронный документ, подтверждающий принадлежность открытого ключа владельцу.
* **CRL** (*Certificate Revocation List*) — список отзыва сертификатов. Подписанный электронный документ, публикуемый ЦС и содержащий список отозванных сертификатов, действие которых прекращено по внешним причинам. Для каждого отозванного сертификата указывается его серийный номер, дата и время отзыва, а также причина отзыва (необязательно). Приложения могут использовать CRL для подтверждения того, что предъявленный сертификат является действительным и не отозван издателем… Приложения могут использовать CRL для подтверждения, что предъявленный сертификат является действительным и не отозван издателем.
* **SSL** (*Secure Sockets Layer*) или **TLS** (*Transport Layer Security*) — технология обеспечивающая безопасность передачи данных между клиентом и сервером поверх открытых сетей.
* **HTTPS** (*HTTP/Secure*) — защищённый HTTP, является частным случаем использования SSL.
* **Internet PKI** — набор стандартов, соглашений, процедур и практик, которые обеспечивают единый (унифицированный) механизм защиты передачи данных на основе стандарта X.509 по открытым каналам передачи данных.
* **CPS** (*Certificate Practice Statement*) — документ, описывающий процедуры управления инфраструктурой открытого ключа и цифровыми сертификатами.
Общие вопросы планирования
--------------------------
Для успешного внедрения любого технического решения необходимо тщательное планирование. Внедрение PKI не является исключением. Более того, если в определённых случаях ошибки изначального планирования могут быть исправлены относительно быстро и легко, то в PKI это однозначно не так. Как я уже отмечал, службы PKI рассчитаны на работу на протяжении многих лет с минимальными (или некритичными) изменениями в ходе работы.
Например, срок действия сертификатов CA составляет порядка 10-20 лет. Одна из причин такого долгого срока жизни в том, что перевыпуск этих сертификатов является несколько трудоёмкой операцией и могут потребовать изменений на большом количестве клиентов. Усугубляется это тем, что изменения потребуются и на клиентах, к которым вы можете не иметь доступа. Другой момент заключается в том, что при внесении некоторых изменений в архитектуру PKI вам потребуется поддерживать текущую конфигурацию на всё время жизни уже изданных сертификатов. Иными словами, для новых сертификатов будет действовать новая конфигурация, но параллельно с ней необходимо будет поддерживать и предыдущую конфигурацию, чтобы уже изданные сертификаты могли корректно работать. Это тоже добавляет сложности в поддержке PKI в работоспособном состоянии.
Учитывая указанные моменты, к планированию PKI следует подходить самым серьёзным образом. И только тогда PKI будет успешно выполнять свои функции в обеспечении цифровой безопасности в течении продолжительного срока.
Многоступенчатый процесс планирования опирается на логическую диаграмму выбранной модели. На каждой ступени элементы диаграммы разворачиваются (детализуется) и для него формализуются связи, задачи и требования. При необходимости детализация продолжается до тех пор, когда будет получена полностью формализованная система. В этой статье демонстрируется пример такого подхода к планированию.
Построение диаграммы PKI
------------------------
Как я уже говорил, всё начинается с логической диаграммы выбранной модели. Логическая диаграмма отображает все компоненты PKI и она должна быть переложена на физическую топологию. В случае применения двухуровневой модели PKI такая диаграмма может иметь следующий вид:
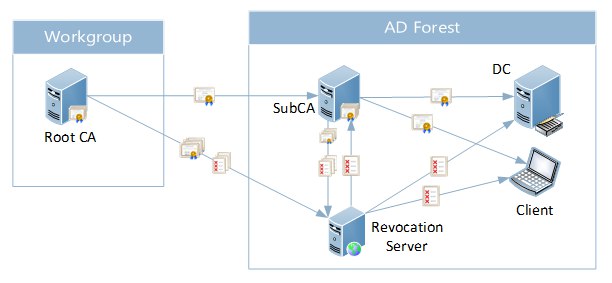
На диаграмме представлены следующие компоненты и их логические связи:
* **Корневой ЦС** — выдаёт сертификат только подчинённому ЦС и публикует свой сертификат и списки отзыва на сервер отзыва (Revocation Server);
* **Подчинённый (промежуточный) ЦС** — выдаёт сертификаты конечным потребителям и публикует свой сертификат и списки отзыва на сервер отзыва. При этом сам скачивает список отзыва корневого ЦС с сервера отзыва;
* **Сервер отзыва** — является хранилищем сертификатов ЦС и их списков отзыва, которые может скачать любой клиент;
* **Клиентские подключения** — получают свои сертификаты у подчинённого ЦС и скачивают списки отзыва с сервера отзыва.
Физическая топология будет несколько отличаться и иметь следующий вид:
В физической топологии в явном виде выделено, что сервер отзыва доступен для всех клиентов, как внутри, так и снаружи сети, благодаря чему клиенты могут проверять сертификаты в любом месте.
Планирование имён ЦС
--------------------
Имя ЦС – это имя, которое будет отображено в поле `Subject` конкретного ЦС. Не путать с именем хоста, на котором работает служба сертификатов. Полное имя ЦС будет состоять из двух компонентов, самого имени (атрибут CN или Common Name) и опционального суффикса в формате X.500. По умолчанию ADCS назначает имя в следующем формате:
Для Standalone CA: <`ComputerName`>-`CA`
Для Enterprise CA: <`DomainShortName`>-<`ComputerName`>-`CA,` <`X500DomainSuffix`>
Хорошо это или плохо? Технически, вы можете выбрать любое имя, функционально оно ни на что влиять не будет. Есть мнение, что имя вашего ЦС является в некотором роде визитной карточкой вашей PKI, отражая ваше отношение к деталям, которые не имеют непосредственного отношения к функциональности, но обеспечивают достаточный уровень информативности и открытости. Поэтому при выборе полного имени сертификата следует руководствоваться несколькими рекомендациями:
* Имя должно отражать название организации (можно и сокращённое) и роль конкретного ЦС в иерархии (атрибут CN, Common Name);
* Суффикс должен отражать название отдела или подразделения, которое отвечает за его управление в атрибуте OU (Organizational Unit);
* Дублировать полное название организации (атрибут O, Organization);
* Юридическое место дислокации ЦС. Для этого достаточно использовать атрибуты L (Locality) и C (Country). Как правило, это название города и страны, где юридически зарегистрирована организация. Если необходимо, можно указать штат/область посредством атрибута S (State).
Предположим, что вы подбираете имя для корневого ЦС компании Contoso Pharmaceuticals Ltd., которая находите в городе Рига, Латвия и управление обеспечивается отделом информационных технологий. В этом случае имя ЦС может иметь следующий вид:
```
CN=Contoso Pharm Root Certification Authority, OU=Division Of IT (DoIT), O=Contoso Pharmaceuticals Ltd., L=Riga, C=LV
```
Следует помнить, что атрибут Country поддерживает только двухбуквенный индекс страны. Например, LV, GB, RU, US и т.д. В качестве дополнительных примеров, можете обратиться к сертификатам ЦС коммерческих провайдеров, как VeriSign/Symantec, DigiCert и т.д. Для подчинённого ЦС это имя будет похожим, за исключением того, что слово Root в имени будет заменено на Subordinate или Issuing. В случае трёхуровневой иерархии, где явно выделяется ЦС политик, слово Root будет заменено на Policy. Как я выше отмечал, в вашей компании могут применяться другие правила, и вы можете их внедрить в имена ЦС, на функциональность это влиять не будет. При этом следует избегать:
* Чрезмерно длинных имён в атрибуте CN (не более 50 символов). При длине атрибута CN свыше 51 символа, оно будет укорочено с пристыковкой хэша отброшенного фрагмента имени в конец имени. Это называется процессом «санитизации» имени, который описан в [§3.1.1.4.1.1](https://msdn.microsoft.com/en-us/library/cc249826.aspx) протокола [[MS-WCCE](https://msdn.microsoft.com/en-us/library/cc249879.aspx)]. Т.е. может случиться так, что при слишком длинном имени слово оборвётся на середине и будет иметь неприглядный вид.
* Использовать буквы, которые не входят в состав латинского алфавита, т.е. никакой криллицы или диактрических букв (например, ā, ž, Ü, ẞ). ADCS поддерживает только однобайтовые кодировки для атрибута CN и для ограниченного набора символов. Неподдерживаемые символы будут преобразованы в другую кодировку и станут нечитаемыми. Полный список запрещённых символов представлен в [§3.1.1.4.1.1.2](https://msdn.microsoft.com/en-us/library/cc249743.aspx) протокола [[MS-WCCE](https://msdn.microsoft.com/en-us/library/cc249879.aspx)]. Здесь работает принцип «лучшее – враг хорошему», поэтому имена должны быть достаточно лаконичными и информативными.
Планирование списков отзыва (CRL)
---------------------------------
В соответствии с логической диаграммой, каждый ЦС будет публиковать свой список отзыва. Списки отзыва у нас будут характеризоваться двумя основными категориями:
1. Точки публикации и распространения списков отзыва;
2. Состав и срок действия списков отзыва.
#### Точки публикации и распространения списков отзыва
Для публикации списков отзыва используются два типа точек распространения CRL: точка публикации (куда физический файл будет записываться) и точка распространения (получения) файла.
Первый тип точек указывает локальный или сетевой путь (в формате UNC) куда будет записываться файл. Второй тип точек будет регистрироваться в издаваемых сертификатах с указанием пути, по которому клиенты могут скачать список отзыва. Эти пути публикуются в расширении сертификата CRL Distribution Points. Эти пути в общем случае не будут совпадать (кроме протокола LDAP, где пути публикации и распространения совпадают). При определении точек публикации следует руководствоваться следующими правилами:
* Для корневого ЦС указывается строго локальный путь, поскольку этот сервер будет изолирован от сети. Копирование файла на сервер распространения (IIS) будет производиться вручную. Это не проблема, поскольку периодичность публикации списков отзыва для корневого ЦС будет измеряться месяцами (об этом см. далее).
* Для издающих ЦС указывается сетевой путь. Я рекомендую создать общую папку в DFS, которую можно легко определить как виртуальную директорию в IIS. В этом случае процесс публикации физического файла в точку распространения будет полностью автоматизирован.
* Протокол LDAP не должен использоваться для публикации и распространения списков отзыва.
Более детально о планировании расширений CRL Distribution Points и Authority Information Access и практиками вы можете ознакомиться в статье моего блога: [Designing CRL Distribution Points and Authority Information Access locations](https://www.sysadmins.lv/blog-en/designing-crl-distribution-points-and-authority-information-access-locations.aspx).
#### Состав списков отзыва
Перед планированием состава и срока действия списков отзыва необходимо понять назначение списков отзыва и оптимальные параметры в зависимости от условий их эксплуатации. Как известно, каждый ЦС периодически публикует списки отзывов, которые включают списки всех отозванных конкретным ЦС сертификатов. Причём каждый список включает все отозванные сертификаты за всё время жизни ЦС. При сроке жизни ЦС, например, в 10 лет этот список может вырасти до внушительных размеров (порядка нескольких мегабайт).
Даже при наличии высокоскоростных подключений трафик списков отзыва будет существенным по размеру, т.к. все потребители сертификатов нуждаются в актуальной версии списка отзыва.
Для уменьшения трафика списков отзыва предусматривают публикацию двух типов CRL: базовый (Base CRL) и дифференциальные (Delta CRL). Базовый список включает полный список отзыва. Дифференциальный список включает в себя только список отозванных сертификатов, которые были отозваны с момента последней публикации базового CRL. Это позволяет вам публиковать базовый список реже и на более длительный срок, а для ускорения времени реакции клиентов на отозванные сертификаты в промежутке выпускать несколько короткоживущих дифференциальных CRL.
Подбор параметров зависит от несколько факторов. Например, планируемый объём издаваемых сертификатов и планируемый объём отзыва. Рассмотрим типовые сценарии.
**Корневой ЦС**
Корневой ЦС выписывает сертификаты только промежуточным ЦС, количество которых обычно в пределах десятка. Срок действия промежуточных ЦС сопоставим со сроком жизни сертификата корневого ЦС. Также предполагается, что риск отзыва нижестоящих ЦС весьма низкий, поскольку они управляются обученным персоналом и в отношении них обеспечиваются надлежащие меры безопасности. Поэтому можно утверждать, что объём списка отзыва может включать в себя лишь небольшое количество отозванных сертификатов и, соответственно, файл CRL будет гарантированно маленьким по размеру.
*Справка: как посчитать планируемый размер файла CRL исходя из объёмов отзыва? Типичный пустой CRL занимает примерно 600-800 байт. Каждая запись об отозванном сертификате занимает 88 байт. Исходя из этих значений можно высчитать размер CRL в зависимости от количества отозванных сертификатов.*
Отсюда следует, что на протяжении всей жизни корневого ЦС список отзыва будет в пределах 1кб и смысла в дифференциальном CRL нет.
**Издающий ЦС**
Для издающего ЦС картина меняется. Объём издаваемых сертификатов уже высок, он может составлять тысячи и миллионы штук. Потребителями являются пользователи и устройства, которые обладают высоким риском отзыва, поскольку они не находятся под постоянным контролем квалифицированного персонала, и невозможно обеспечить надлежащие меры. Как следствие, список отзыва может достигать серьёзных размеров. Например, если заложить 10% риск отзыва, то на миллион изданных сертификатов приходится порядка 100к отозванных. 100к записей по 88 байт будет составлять немногим меньше 10мб. Очень часто обновлять файл на 10мб не очень практично, целесообразней его публиковать реже, а в интервале между публикациями основного CRL распространять несколько облегчённых дифференциальных Delta CRL. Т.е. если для корневого ЦС достаточно только базового списка отзыва, то для ЦС, выпускающих сертификаты конечным потребителям, следует применять и дельты.
#### Планирование сроков действия CRL
Это всё было о составе списков отзыва для каждого ЦС. Теперь следует определить сроки:
* На какой срок следует публиковать список отзыва?
* Как долго информация в нём может считаться достоверной и достаточно актуальной?
Здесь тоже можно применить подход в зависимости от условий эксплуатации. Риск отзыва промежуточного ЦС весьма низкий, следовательно, нет смысла слишком часто публиковать пустой CRL. В современной практике применяются следующие типовые значения по сроку действия CRL для ЦС, которые выписывают сертификаты только другим ЦС: 3, 6 или 12 месяцев. Здесь следует отталкиваться от степени риска и административных расходов на обслуживание списков отзыва. Если нет никаких особых условий, то я рекомендую выбирать что-то среднее, порядка 6 месяцев.
Для подчиненных ЦС схема такая же. Поскольку риск отзыва клиентских сертификатов высокий, то можно предположить и высокую частоту отзыва. Следовательно, таким ЦС следует выполнять публикацию списков отзыва гораздо чаще, а для экономии трафика комбинировать базовые и дифференциальные CRL. По умолчанию Microsoft CA публикует списки отзыва со следующей периодичностью: базовый CRL раз в неделю, дельты – ежедневно. В этой ситуации клиенты будут оповещены о последних отозванных сертификатах в пределах суток.
Можно понять желание администраторов уменьшить это время (в идеале – мгновенно), чтобы клиенты не признавали отозванный сертификат действительным. Однако, уменьшение одного риска приводит к увеличению другого риска. Представьте, что по какой-то причине отказал сервер ЦС в момент, когда предыдущий CRL близок к истечению срока действия, а новый CRL невозможно опубликовать. Тогда начнутся проблемы с проверкой отзыва сертификатов и их остановке, пока сервер ЦС не будет восстановлен в работе. Этот момент необходимо обязательно учитывать при настройке сроков действия списков отзыва.
Microsoft CA по умолчанию уже закладывает некоторый резерв по времени на непредвиденные случаи и когда распространение списков отзыва по всем точкам публикации занимает некоторое время (например, вызваны латентностью репликации). Этот резерв в английской терминологии называется CRL overlap. Идея защитного механизма заключается в том, что ЦС генерирует и публикует списки отзыва до истечения действия предыдущего опубликованного списка.
Это достигается использованием двух полей в списке отзыва: Next CRL Publish и Next Update. Поле Next CRL Publish указывает на время, когда ЦС опубликует обновлённый список отзыва (автоматически). Next Update указывает на время, когда срок действия текущего списка истечёт. Поле Next Update будет всегда выставлен на несколько позднее время, чем Next CRL Publish. Другими словами, ЦС опубликует обновлённый список отзыва до истечения срока предыдущего. Алгоритм вычисления автоматических значений для этих полей нетривиален и описан в следующей статье: [How ThisUpdate, NextUpdate and NextCRLPublish are calculated (v2)](https://www.sysadmins.lv/blog-en/how-thisupdate-nextupdate-and-nextcrlpublish-are-calculated-v2.aspx). Если значения по умолчанию вас не устраивают по тем или иным причинам, их можно отредактировать. Необходимо учитывать, что запас по времени имеет нижние и верхние границы. Например, верхняя граница не может превышать срока действия самого CRL. Так, если срок действия CRL составляет 1 день, то запас может составлять максимум 1 день, и тогда ЦС будет публиковать списки отзыва ежедневно, но срок действия будет составлять 2 дня. Тем самым достигается запас времени на восстановление ЦС в случае непредвиденных обстоятельств.
*На практике я достаточно часто наблюдал желание администраторов закрутить настройки сроков действия CRL до минимального предела с таким обоснованием: «пользователь уволился и не должен иметь возможность аутентифицироваться с отозванным сертификатом». Мотивация понятна, но решение задачи через списки отзыва не совсем правильно. В случае, если пользователю необходимо прекратить доступ к корпоративным системам, необходимо отключить учётную запись пользователя или компьютера.*
При планировании сроков действия CRL и периодичности следует руководствоваться следующими рекомендациями:
* Все ЦС, которые выдают сертификаты только другим ЦС (не конечным потребителям), должны публиковать CRL сроком действия от 3-х до 12 месяцев с запасом в один месяц.
* Все ЦС, которые выдают сертификаты конечным потребителям (пользователям и устройствам), должны публиковать базовые CRL не реже одного раза в неделю и дифференциальные списки не реже 3-х дней (желательно, ежедневно). Запас по времени не следует корректировать (используйте тот, который будет автоматически высчитан внутренней логикой ЦС).
#### Online Certificate Status Protocol
В рамках данного цикла статей я не буду использовать OCSP серверы для дополнительного метода распространения информации об отозванных сертификатах. При желании вы можете обратиться к исчерпывающей статье на сайте TechNet: [Online Responder Installation, Configuration, and Troubleshooting Guide](https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/cc770413(v=ws.10)). Как показывает практика, в большинстве случаев установка и поддержка OCSP не оправдывает себя по ряду причин.
Основная задача OCSP: разгрузка трафика скачивания CRL. Как известно, CRL содержит список всех отозванных сертификатов за всё время жизни ЦС, и в какой-то момент при интенсивном отзыве сертификатов его размер может достичь внушительных размеров (несколько мегабайт). Выше уже отмечалось, что 100к отозванных сертификатов составит порядка 9МБ в CRL файле. В то время как проверка отзыва любого сертификата при использовании OCSP будет занимать фиксированный размер ~2.5КБ. Есть ощутимая разница. На практике же, зачастую интенсивность отзыва гораздо ниже. Если говорить о корневых ЦС или ЦС политик, у них отзыв будет штучный, и размер их списка отзыва едва ли превысит 1КБ.
Следует отметить, что OCSP может быть эффективным в ситуации, когда есть один проверяемый сертификат и много клиентов, которые его хотят проверить. Это типичный сценарий сертификата SSL/TLS. В этом случае каждый клиент вместо скачивания условного 9МБ списка отзыва потратит 2.5КБ трафика OCSP. Но в обратной ситуации (один сервер проверяет множество клиентских сертификатов) OCSP может вызвать значительную нагрузку на сеть. К этому можно отнести типичные сценарии корпоративных сетей: аутентификация клиентов при помощи сертификатов, такие как аутентификация EAP-TLS в беспроводных сетях и VPN, аутентификация Kerberos на контроллерах домена. Предположим, сотрудники пришли на работу и используют сертификаты для аутентификации в сети (смарт-карты, сертификаты на мобильных устройствах) и контроллер домена, Серверы RADIUS вынуждены проверять каждый клиентский сертификат. Для проверки только 1К сертификатов будет затрачено 2.5МБ трафика. В этой ситуации пользы от OCSP никакой, даже наоборот.
Этот аспект учтен в логике продуктов Microsoft. Если за определённый промежуток времени клиент Crypto API проверяет 50 (это значение можно настроить) сертификатов от одного издателя при помощи OCSP, тогда на этом работа с OCSP заканчивается, и клиент скачивает и кэширует CRL для этого издателя. Более подробно с этим поведением можно ознакомиться в разделе [Optimizing the Revocation Experience](https://technet.microsoft.com/en-us/library/ee619783(v=ws.10).aspx) документа [Certificate Revocation Checking in Windows Vista and Windows Server 2008](https://technet.microsoft.com/en-us/library/ee619730(v=ws.10).aspx).
Планирование политик выдачи сертификатов
----------------------------------------
Политики выдачи сертификатов являются одним из самых сложных для понимания аспектов в работе сертификатов и зачастую полностью игнорируется администраторами при планировании и развёртывании PKI на предприятии. Однако понимание и умение управлять политиками выдачи даёт нам более гибкую систему, дополнительный уровень контроля и, в конце концов, как метод описания и документирования PKI.
#### Определение политик
Для начала необходимо ввести определение политик выдачи сертификатов. Любой процесс выдачи/получения сертификата по сути является контрактом между получателем сертификата и издающим ЦС. Этот контракт определяет множество аспектов, таких как порядок выдачи, использования и зоны ответственности.
В каждой компании могут существовать различные методы проверки заявок и выдачи сертификатов. Рассмотрим несколько типовых случаев:
* Сертификаты для подписи электронной почты могут выдаваться автоматически с минимальной проверкой заявителя (только на основании успешной аутентификации пользователя в Active Directory). Никаких дополнительных действий для выпуска этих сертификатов не проводится.
* Сертификаты для цифровой подписи документов могут выдаваться только после согласования с непосредственным руководителем и предоставления письменной заявки со всеми необходимыми подписями.
* Сертификаты для смарт-карт могут выдаваться только при личном присутствии работника наряду с инструктажем по правилам использования карт, подписанием соответствующих регулирующих документов.
* Все пользователи могут получить сертификат аутентификации для доступа к беспроводной сети с мобильных устройств, но доступ к критическим системам будет разрешён, если аутентификация была выполнена только с помощью смарт-карт.
Все эти сценарии имеют чётко выраженное различие в порядке выдачи сертификатов. В одном случае достаточно зарегистрироваться в системе, и можно сразу получить сертификат. В другом случае нужно пройти процедуру согласования заявки, в третьем — необходимо личное присутствие заявителя и т.д. Также, политика определяет правила использования полученного сертификата, процедуры обновления или аннулирования сертификата и действия в нестандартных ситуациях (например, при утере или краже сертификата с ключами).
Вот эти различия в процедурах и являются политиками выдачи, и эти политики должны регистрироваться в сертификатах. Конечные приложения могут использовать политики выдачи для определения доступа к ресурсу. Наиболее известными примерами таких приложений являются **Network Policy Server (NPS)** и **Active Directory Dynamic Access Control**. Например, все сотрудники компании могут подключаться при помощи сертификатов к общей беспроводной сети компании. Но могут быть беспроводные сети, доступ к которым будет разрешён только при использовании сертификатов на смарт-картах.
В NPS можно настроить правило, что будет приниматься не просто сертификат входа, а тот, который был выдан в соответствии с политикой выдачи сертификатов для смарт-карт. Поскольку эта информация отражена в сертификате, NPS может различить два похожих сертификата (оба для аутентификации пользователя) по политикам выдачи. Если сертификат не содержит свидетельств, что он был выдан в соответствии с указанной политикой выдачи, то доступ к сети не будет разрешён. Похожий принцип заложен и в Active Directory Dynamic Access Control, где можно указать критерии для различных уровней доступа.
#### Описание политик
Политики выдачи просто характеризуют в общих чертах набор процедур и процессов, выполняемых при выдаче тех или иных сертификатов. Следует понимать, что в программном коде никак не проверяется, соблюдались эти процедуры на самом деле или нет. Если на уровне кода невозможно проверить их выполнение, то зачем они? На этот вопрос есть два ответа.
Первый заключается в том, что ряд ИТ-процессов невозможно отследить на программном уровне. Они проверяются на соответствие принятым правилам аудитом, который проводится людьми. Чаще всего в качестве аудиторов выступают сторонние организации, имеющие компетенцию в рассматриваемых вопросах. Это касается и политик выдачи сертификатов. В частности, при создании доверия (на уровне PKI и сертификатов) между организациями, они предоставляют документы, описывающие процессы и заказывают сторонний аудит для проверки того, что эти процессы соблюдаются.
Второй ответ вытекает из первого: описание политик выдачи сертификатов в конечном итоге станет документацией на всю PKI и будет иметь своё фирменное название – **Certificate Practice Statement** или CPS (к сожалению, не нашёл подходящего термина на русском языке, поэтому буду использовать англоязычную аббревиатуру). Для унификации описания политик выдачи существует рекомендованный (но не обязательный) шаблон, [описанный в RFC 3647](https://tools.ietf.org/html/rfc3647). По сути, этот документ является фреймворком по написанию политик и освещает всевозможные аспекты работы PKI. Совершенно не обязательно описывать все имеющиеся разделы в документе. Можно документировать только то, что применимо к вашей ситуации, или добавлять что-то своё.
В общем случае CPS будет состоять из двух частей:
1. Описание иерархий PKI, общих для всех процедур и положений, которые будут общими для всех конкретных политик выдачи.
2. Описание положения специфичные для конкретной политики выдачи. В зависимости от размерности PKI, её особенностей, на каждую политику может составляться отдельный CPS, но чаще всего это сводится к составлению единого документа, который будет описывать всё.
#### Программирование политик
В процессе составления CPS будет определена одна или несколько уникальных политик выдачи (как минимум одна будет обязательно). Каждая политика выдачи должна иметь уникальный идентификатор и указатель на CPS (гиперссылка или текстовая строка).
Идентификаторы политик должны быть представлены в формате ITU-T и ISO. В своё время я написал небольшую вводную статью про объектные идентификаторы: [Что в OID'е тебе моём?](https://www.sysadmins.lv/blog-ru/chto-v-oide-tebe-moem.aspx) В ней есть информация о том, как получить в IANA (Internet Assigned Numbers Authority) свою ветку идентификаторов. Получив свою ветку, вы внутри неё выделяете подмножество идентификаторов для политик выдачи, например: 1.3.6.1.4.1.x.1, где x – уникальный идентификатор компании, зарегистрированный в IANA. И в нём вы регистрируете конкретные политики выдачи:
* 1.3.6.1.4.1.x.1.1
* 1.3.6.1.4.1.x.1.2
* 1.3.6.1.4.1.x.1.3
* 1.3.6.1.4.1.x.1.4
* ...
Далее вы назначаете конкретные политики выдачи для ЦС, которые будут их поддерживать. Например, у вас может быть несколько издающих ЦС, каждый из которых будет поддерживать только определённые политики. Список поддерживаемых политик будет содержаться в расширении Certificate Policies сертификата ЦС, а также в сертификатах конечных потребителей.
Например, на картинке показан сертификат DigiCert, выданный в соответствии с политикой выдачи под идентификатором 2.16.840.1.114412.2.1 (в данном случае это **Extended Validation**) и 2.23.140.1.1 (указывает, что ЦС выпускает сертификаты согласно правилами CAB/Forum) и с ссылкой на CPS. По этой ссылке можно скачать самую последнюю версию их CPS и ознакомиться с условиями получения и использования сертификатов.
Когда все политики определены, им присвоены идентификаторы и определены указатели, эта информация помещается в конфигурационный файл установки ЦС, чтобы эти сведения попали в сертификат. Для включения информации о политиках выдачи конечных сертификатов следует настроить шаблоны сертификатов и для каждого шаблона указать конкретные политики выдачи. Причём, если какая-то политика включена в конечный сертификат, её идентификатор должен быть представлен как в самом конечном сертификате, так и во всех промежуточных сертификатах цепочки (кроме корневого ЦС). Более подробно об этом можно прочесть в статьях моего блога: [Certificate Policies extension – all you should know (part 1)](https://www.sysadmins.lv/blog-en/certificate-policies-extension-all-you-should-know-part-1.aspx) и [Certificate Policies extension – all you should know (part 2)](https://www.sysadmins.lv/blog-en/certificate-policies-extension-all-you-should-know-part-2.aspx). Эти статьи освещают общие вопросы, связанные с политиками выдачи, правилами их проверки в цепочках сертификатов и способы их включения в сертификаты на платформе Windows.
Здесь есть один тонкий момент: сертификат ЦС выдаётся на довольно большой срок (10 лет и более) и при добавлении или удалении политик выдачи на конкретном ЦС необходимо перевыпускать сертификат самого ЦС, что усложняет процесс управления ЦС и увеличивает административные расходы. Не существует способа описать группу политик одним идентификатором (например, идентификатором компании), поскольку маски не поддерживаются. В [RFC 5280 §4.2.1.4](https://tools.ietf.org/html/rfc5280#section-4.2.1.4) предусмотрен глобальный идентификатор (global wildcard) anyPolicy = 2.5.29.32.0, который покрывает любые политики выдачи.
Технически, можно использовать один этот идентификатор в сертификате ЦС, тогда этот ЦС может выдавать сертификаты по любым политикам. Его использование не рекомендовано, т.к. при аудите невозможно определить, по каким конкретно политикам происходит выдача сертификатов на конкретном ЦС и, если будет проводиться внешний аудит, вполне возможно, что к идентификатору anyPolicy могут быть претензии, что повлечет необходимость указывать политики в явном виде. Но это очень сильно зависит от местных условий, поэтому на раннем этапе можно использовать и этот идентификатор в сертификате ЦС и уже указывать конкретные политики выдачи в конечных сертификатах. В рамках данных статей я буду использовать anyPolicy в сертификате издающего ЦС.
Планирование аппаратных требований
----------------------------------
Службы сертификатов AD CS в целом нетребовательны к аппаратным ресурсам (на фоне других серверных служб). Основная нагрузка ложится на центральный процессор для выполнения криптографических операций (хэширование, шифрование и подпись). Кроме того, есть определённая нагрузка на диски для работы базы данных сертификатов (AD CS использует JET Database Engine). Это в теории.
На практике аппаратных ресурсов даже бюджетных линеек серверов будет более чем достаточно для функционирования служб сертификатов, поскольку реальные потребности весьма малы на фоне требований ОС к аппаратным ресурсам. В эпоху Windows Server 2003 была написана статья [Evaluating CA Capacity, Performance, and Scalability](http://web.archive.org/web/20090904082231/http:/technet.microsoft.com/en-us/library/cc778985(WS.10).aspx) (ссылка на архивную копию, т.к. оригинал удалён с сайта TechNet), освещающую общие моменты, которые нужно учитывать при планировании аппаратных ресурсов. Статья несколько устарела (например, лимит количества выдаваемых сертификатов в разрезе БД значительно увеличен), но общие характеристики мало изменились.
В 2010 году, Windows PKI Team провела тесты производительности с использованием более современного оборудования (образца 2007 года) под управлением Windows Server 2008. С результатами можно ознакомиться в их блоге: [Windows CA Performance Numbers](https://blogs.technet.microsoft.com/pki/2010/01/11/windows-ca-performance-numbers/). Данные в этих статьях, говорят о том, что сервер AD CS на аппаратном сервере выпуска 2007 года позволяет выпускать порядка 150 сертификатов в секунду. Реальная же потребность в скорости выдачи сертификатов на порядки ниже. Поэтому для ЦС общего назначения советую ориентироваться на рекомендуемые аппаратные требования к самой ОС. Это касается как корневого, так и издающих ЦС. Поэтому перечислю здесь требования для Windows Server 2016 ([Windows Server 2016 System Requirements](https://docs.microsoft.com/en-us/windows-server/get-started/system-requirements)):
* CPU — dual-core 1.4 GHz;
* Память — 1GB RAM;
* Диск — 48 GB для системного диска и не менее 48 GB для локальных резервных копий. Системный раздел желательно разместить на дисках с RAID1.
* Дисплей — SVGA (800\*600);
* Сеть — стандартный сетевой интерфейс.
Здесь следует отметить, что в конфигурации для корневого ЦС будет отсутствовать (или должен быть отключен) сетевой интерфейс (поскольку он не будет подключен к сети) и присутствовать хотя бы один интерфейс для съёмных носителей.
Итоговая конфигурация
---------------------
По итогам планирования весьма полезно логически сгруппировать и наглядно представить основные компоненты (и их значения), которые потребуется сконфигурировать в процессе развёртывания. Можно использовать различные форматы, например, таблицы. Данные из этих таблиц будут использоваться в конфигурационных файлах и скриптах.
#### Корневой ЦС
Для установки и создания корневого ЦС вам потребуется определить и сконфигурировать параметры сертификата и сервера ЦС в соответствии с представленными в следующей таблице значениями.
| Название параметра | Значение параметра |
| --- | --- |
| **Сервер ЦС** |
| Класс ЦС | Standalone CA |
| Тип ЦС | Root CA |
| Срок действия издаваемых сертификатов | 15 лет |
| Публикация в AD (контейнеры) | Certification Authorities
AIA |
| Точки публикации CRT | 1) По-умолчанию
2) C:\CertData\contoso-rca.crt
3) IIS:\InetPub\PKIdata\contoso-rca.crt\* |
| Точки распространения CRT | 1) URL=http://cdp.contoso.com/pki/contoso-rca.crt |
| Точки публикации CRL | 1) По-умолчанию
2) C:\CertData\contoso-rca.crt
3) IIS:\InetPub\PKIdata\contoso-rca.crt\* |
| Точки распространения CRL | 1) URL=http://cdp.contoso.com/pki/contoso-rca.crt |
| **Сертификат** |
| Имя сертификата | Contoso Lab Root Certification authority |
| Дополнительный суффикс | OU=Division Of IT, O=Contoso Pharmaceuticals, C=US |
| Провайдер ключа | RSA#Microsoft Software Key Storage Provider |
| Длина ключа | 4096 бит |
| Алгоритм подписи | SHA256 |
| Срок действия | 15 лет |
| Состав CRL | Base CRL |
| **Base CRL** |
| Тип | Base CRL |
| Срок действия | 6 месяцев |
| Расширение срока действия | 1 месяц |
| Алгоритм подписи | SHA256 |
| Публикация в AD | Нет |
\* — копируется на сервер IIS вручную.
#### Издающий ЦС
Аналогичная таблица составляется и для издающего ЦС.
| Название параметра | Значение параметра |
| --- | --- |
| **Сервер ЦС** |
| Класс ЦС | Enterprise CA |
| Тип ЦС | Subordinate CA |
| Срок действия издаваемых сертификатов | Максимально: 5 лет (остальное контролируется шаблонами сертификатов) |
| Автоматическая загрузка шаблонов | Нет |
| Публикация в AD (контейнеры) | AIA
NTAuthCertificates |
| Состав CRL | Base CRL
Delta CRL |
| Точки публикации CRT | 1) По-умолчанию
2) \\IIS\PKI\contoso-pica.crt |
| Точки распространения CRT | 1) URL=http://cdp.contoso.com/pki/contoso-pica.crt |
| Точки публикации CRL | 1) По-умолчанию
2) \\IIS\PKI\contoso-pica.crl |
| Точки распространения CRL | 1) URL=http://cdp.contoso.com/pki/contoso-pica.crl |
| **Сертификат** |
| Имя сертификата | Contoso Lab Issuing Certification authority |
| Дополнительный суффикс | OU=Division Of IT, O=Contoso Pharmaceuticals, C=US |
| Провайдер ключа | RSA#Microsoft Software Key Storage Provider |
| Длина ключа | 4096 бит |
| Алгоритм подписи | SHA256 |
| Срок действия | 15 лет (определяется вышестоящим ЦС) |
| Политики выдачи | 1) Имя: All Issuance Policies
OID=2.5.29.32.0
URL=http://cdp.contoso.com/pki/contoso-cps.html |
| Basic Constraints | isCA=True (тип сертификата — сертификат ЦС)
PathLength=0 (запрещается создание других промежуточных ЦС под текущим ЦС). |
| **Base CRL** |
| Тип | Base CRL |
| Срок действия | 1 неделя |
| Расширение срока действия | По умолчанию |
| Алгоритм подписи | SHA256 |
| Публикация в AD | Нет |
| **Delta CRL** |
| Тип | Delta CRL |
| Срок действия | 1 день |
| Расширение срока действия | По-умолчанию |
| Алгоритм подписи | SHA256 |
| Публикация в AD | Нет |
#### Сервер IIS
| Название параметра | Значение параметра |
| --- | --- |
| **Сервер ЦС** |
| Веб-сайт | cdp |
| Заголовок хоста | cdp.contoso.com |
| Виртуальные директории | PKI=C:\InetPub\wwwroot\PKIdata |
| Double Escaping | Включен |
Как я отмечал, эти таблицы будут использоваться для составления конфигурационных файлов и скриптов. После установки их можно использовать для проверки того, что все фактические значения конфигурации соответствуют запланированным.
Об авторе
---------
**Вадим Поданс** — специалист в области автоматизации PowerShell и Public Key Infrastructure, Microsoft MVP: Cloud and Datacenter Management с 2009 года и автор модуля PowerShell PKI. На протяжении 9 лет в своём блоге освещает различные вопросы эксплуатации и автоматизации PKI на предприятии. Статьи Вадима о PKI и PowerShell можно найти на его [сайте](https://www.sysadmins.lv). | https://habr.com/ru/post/348956/ | null | ru | null |
# Яндекс для разработчика
Как всем известно, у Яндекса и Гугла есть сервисы со схожей функциональностью. И я считаю, что это очень хорошо: конкуренция заставляет двигаться вперёд обоих конкурентов, а это выливается во много приятных бонусов для простых пользователей. (Если не вспоминать про такие сомнительные случаи, как покупка Яндексом Смилинка)
Но мне кажется, у руководства или разработчиков Яндекса довольно странное отношение к сторонним разработчиками. Я приведу только два примера, с которыми столкнулся, и надеюсь, что, возможно, благодаря этому посту ситуация изменится в лучшую сторону.
#### Поиск на сайте
Однажды мне потребовалось установить поиск на сайт. Оказалось, что Google не очень хорошо индексирует наш сайт, и я захотел поставить форму Яндекса. Когда я увидел код, то испугался.
``> <style type="text/css">div.b-yandexbox \* { font-size: 12px !important; margin: 0 !important; } div.b-yandexbox a img { border: 0 !important; } div.b-yandexbox input, div.b-yandexbox label { vertical-align: middle; } div.b-yandexbox table { font-size: 12px; width: 100%; border-collapse: collapse; border: 0; background: #96a8c8; } div.b-yandexbox table td { padding: 7px 0 6px 0; white-space: nowrap; vertical-align: middle; } div.b-yandexbox .b-yandexbox-image { padding: 6px 6px 0 6px; } div.b-yandexbox .b-yandexbox-search { width: 100%; padding: 0 6px; } div.b-yandexbox .b-yandexbox-search table { margin: 0; padding: 0; background: none; } div.b-yandexbox .b-yandexbox-search .b-yandexbox-txt { width: 100%; padding-right: 6px; } div.b-yandexbox .b-yandexbox-text { position: relative; width: 100%; } div.b-yandexbox .b-yandexbox-text input { float: left; width: 100%; padding-right: 0; border: 1px solid #7f9db9; } div.b-yandexbox .b-yandexbox-search .b-yandexbox-submit { padding: 0; } div.b-yandexbox .b-hint-input { position: absolute; z-index: 100; left: 0; display: none; width: 30px; height: 11px; margin: 0.16em 0.2em !important; cursor: text; line-height: 0; background: url(http://site.yandex.ru/i/ysearch\_small.png) no-repeat; } div.b-yandexbox .button-search { width: 19px; height: 15px; outline: none; cursor: pointer; border: none; background: url(http://site.yandex.ru/i/search.png) no-repeat; }style>--[if lte IE 8]><style type="text/css">\*:first-child+html div.b-yandexbox .b-hint-input { position: absolute; margin-top: 4px !important; } \* html div.b-yandexbox .b-hint-input { position: relative; bottom: -0.5em; left: 0.3em; float: left; display: block; margin: 0 0 -1em !important; }style>[endif]--><script type="text/javascript">/\*\*/</font>(<font color="#0000ff">function</font>(Lego){ <font color="#0000ff">if</font> (!Lego) Lego = window.Lego = {}; Lego.clean = <font color="#0000ff">function</font>(a) { <font color="#0000ff">var</font> p = a.previousSibling; <font color="#0000ff">if</font> (p) { a.onblur = <font color="#0000ff">function</font>() { <font color="#0000ff">if</font> (!a.value) { p.style.top = <font color="#A31515">""</font>; } }; p.style.top = <font color="#A31515">"-9999px"</font>; } }; Lego.cleanIfNotEmpty = <font color="#0000ff">function</font>(id) { <font color="#0000ff">var</font> e = <font color="#0000ff">document</font>.getElementById(id); e.previousSibling.style.display = <font color="#A31515">"block"</font>; <font color="#0000ff">var</font> f = <font color="#0000ff">function</font>() { <font color="#0000ff">if</font> (e.value) { Lego.clean(e); } }; setInterval(f, 100); }; })(window.Lego);<font color="#008000">/\*\*/script>
>
> class="b-yandexbox">"get" action="http://dev.xxxx.ru/search">
>
> | |
> | --- |
> | class |
>
> ="b-yandexbox-search">
>
> | |
> | --- |
> | class |
>
> ="b-yandexbox-txt">class="b-yandexbox-text">for="yandexbox-text" class="b-hint-input" onfocus="Lego.clean(this)" title="Яндекс">"text" id="yandexbox-text" onfocus="Lego.clean(this)"/>`` | https://habr.com/ru/post/69380/ | null | ru | null |
# Реализация Model-View-Presenter в Qt
Проектируя архитектуру одного проекта, остановился на паттерне MVP — подкупила возможность легко менять ui, а также простота покрытия тестами. Все примеры реализации MVP, что я нашёл в сети, были на C#. При реализации на Qt возникла пара неочевидных моментов, решение которых было успешно найдено. Собранная информация ниже.
#### История MVP
Как следует из [1] и [2], шаблон проектирования MVP является модификацией MVC, примененной впервые в компании IBM в 90-х годах прошлого века при работе над объектно-ориентированной операционной системой Taligent. Позднее MVP подробно описал Майк Потел.
Чтобы увидеть, в чём же отличие MVP от MVC, можно посмотреть соответствующие параграфы [3]: [MVC](http://www.rsdn.ru/article/patterns/ModelViewPresenter.xml#ENB), [MVP](http://www.rsdn.ru/article/patterns/ModelViewPresenter.xml#E6AAE)
#### Реализация MVP в Qt
В общем и целом, MVP уже и так применяется в Qt в неявном виде, как это показано в [4]:
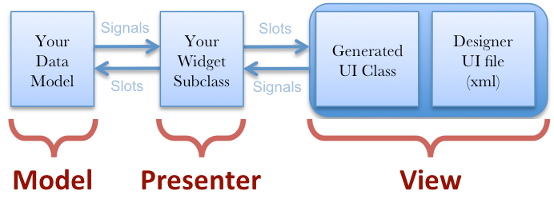
Но такая реализация MVP имеет ряд недостатков:
* невозможно создать несколько представлений для одного представителя (Presenter)
* невозможно использовать паттерн *Inversion of Control*, описанный в [3] ([тут](http://www.rsdn.ru/article/patterns/ModelViewPresenter.xml#EGGAC)), т.к. в данной схеме View генерируется автоматически и не может быть унаследовано от интерфейса
Полная реализация MVP будет выглядеть так:
Отсюда диаграмма классов:
Рассмотрим каждый класс:
* **IView** — интерфейсный класс, определяющий методы и сигналы, которые должен реализовывать конкретный View (см. *Inversion of Control* в [3])
* **Ui::View** — класс, сгенерированный по .ui файлу Qt-дизайнера
* **View** — конкретное представление, наследуемое от QWidget (или его потомка) и от IView. Содержит логику GUI, т.е. поведение объектов (например, их анимацию)
* **Model** — модель данных предметной области (Domain Model); содержит переменные, флаги, модели таблиц и т.д.
* **Presenter** — представитель; реализует взаимодействие между моделью и представлением. Также через него происходит взаимодействие с внешним миром, т.е. с основным приложением, с сервером (например, через слой служб приложения) и т.д.
На этапе «рисования квадратиков» всё понятно. Проблемы у меня возникли при попытке реализации.
1. При написании IView необходимо объявлять сигналы. Но для этого IView должен быть унаследован от QObject. Далее при попытке наследовать View одновременно от QWidget и IView возникала ошибка. Оказалось, что класс не может быть унаследован одновременно от двух QObject-объектов (не помогло даже виртуальное наследование). Как обойти эту проблему показано в [5]: [ссылка](http://doc.trolltech.com/qq/qq15-academic.html#multipleinheritance). Таким образом, IView не наследуется от QObject и просто объявляет сигналы как полностью виртуальные (абстрактные) методы в секции public. Это вполне логично, т.к. сигнал — это тоже функция, по вызову которой происходит оповещение наблюдателей через их слоты (см. паттерн Observer).
2. Еще одна проблема возникла при привязке сигналов IView в классе Presenter. Дело в том, что Presenter содержит ссылку на IView (конкретный View добавляется в Presenter на этапе выполнения, но хранится как IView — используется полиморфизм). Но для соединения сигналов и слотов используется статический метод `QObject::connect()`, принимающий в качестве объектов только наследников от QObject, а IView не является таковым. Но мы то знаем, что любой наш View будет им являться. Так что проблема решается динамическим приведением типов, как это показано в [6]:
`QObject \*view_obj = dynamic\_cast<QObject\*>(m_view); // где m\_view - IView
QObject::connect(view_obj, SIGNAL(okActionTriggered()),
this, SLOT(processOkAction()));`
Также стоит заметить, что при реализации IView нужен только заголовочный (.h) файл. Если для IView создан .cpp файл — его необходимо удалить, иначе могут возникнуть проблемы при компиляции.
В принципе, этой информации достаточно, чтобы самостоятельно реализовать MVP в Qt, но я приведу простой пример (только реализация MVP, без рассмотрения взаимодействия в контексте реального приложения).
#### Простой пример использования MVP в Qt
В архиве 3 примера, это одно и то же приложение, но с дополнениями в каждом примере.
1. Реализация MVP
2. Добавлена возможность создавать несколько представлений
3. Полная синхронизация между представлениями при изменении данных
Весь код комментирован в Doxygen-стиле, т.е. вы легко можете сгенерировать документацию с помощью Doxywizard.
Скачать примеры можно [тут](http://dl.dropbox.com/u/14612485/examples.tar.gz)
#### Out of scope
Вот список интересных вопросов по теме, которые не вошли в статью:
* тестирование модулей полученной системы
* реализация View в виде библиотек (с помощью QtPlugin) в контексте MVP
* реализация View с помощью QtDeclarative (QML) в контексте MVP
* передача представлений в Presenter посредством фабрики классов (таким образом можно легко менять стили)
В комментариях приветствуется любая информация по этим вопросам.
#### Источники
1. <http://www.rsdn.ru/article/patterns/generic-mvc2.xml>
2. <http://en.wikipedia.org/wiki/Model-view-presenter>
3. <http://www.rsdn.ru/article/patterns/ModelViewPresenter.xml>
4. <http://thesmithfam.org/blog/2009/09/27/model-view-presenter-and-qt/>
5. <http://doc.trolltech.com/qq/qq15-academic.html>
6. <http://developer.qt.nokia.com/forums/viewthread/284> | https://habr.com/ru/post/107698/ | null | ru | null |
# Создаем игру на SFML
Приветствую всех игроделов и им сочуствующих. В этой статье я хочу рассказать о таком фреймворке, как SFML, и попытаться написать на нем простейшую игру (в нашем случае это будет клон легендарного Pong).
v
#### Скачивание и установка
Скачать фреймворк можно с [официального сайта](http://sfml-dev.org/download.php). На данный момент для скачивания доступны две версии — 1.6 и 2.0. Я использовал версию 2.0 для Visual C++ 2010. Вы же можете выбрать необходимый для вашей ОС и компилятора вариант SFML.
Так как целью статьи не является обсуждение особенности подключения библиотек в разных IDE, то руководство по установке можно прочитать на [оф. сайте](http://sfml-dev.org/tutorials/). Я же постараюсь вести рассказ не привязываясь к какой-либо ОС и компилятору.
#### Создаем основу
Из библиотек нам будут нужны только *sfml-graphics, sfml-window, sfml-system* (можно подключить *sfml-main* для кроссплатформенности функции main). Начинаем создавать скелет будущей игры.
```
#include
int main()
{
// Создаем главное окно приложения
sf::RenderWindow window(sf::VideoMode(800, 600), "Pong");
// Главный цикл приложения
while(window.isOpen())
{
// Обрабатываем события в цикле
sf::Event event;
while(window.pollEvent(event))
{
// Кроме обычного способа наше окно будет закрываться по нажатию на Escape
if(event.type == sf::Event::Closed ||
(event.type == sf::Event::KeyPressed && event.key.code == sf::Keyboard::Escape))
window.close();
}
// Очистка
window.clear();
// Тут будут вызываться функции обновления и отрисовки объектов
// Отрисовка
window.display();
}
return 0;
}
```
Итак, что же мы тут сделали? В первой строке был подключен заголовочный файл *Graphics.hpp*, и далее мы создали функцию *main()* и окно размером 800X600 c заголовком «Pong».
SFML предлагает удобные средства для работы с событиями. Именно их мы используем для создания цикла работы приложения и обработки событий окна. C помощью цикла мы реализуем закрытие окна по нажатию Escape. Вообще, *sf::Event* предоставляет возможность работы не только с клавиатурой, но и, например, с мышью. Кроме этого можно работать с некоторыми системными событиями, и не переписывать код под каждую новую платформу. Так что, если вы захотите использовать в игре джойстик, то вам не придется переписывать половину кода — достаточно будет добавить пару строк в цикл обработки.
Далее мы очищаем окно и отрисовываем содержимое буфера. Всё, каркас игры готов, можно компилировать и проверить работу. Перед вами должно появиться черное окно.
#### Ракетка
В Pong существует всего два вида объектов — ракетка и мяч. Мячом мы займемся в следующей статье, а класс ракетки создадим сейчас. Но для начала нам нужно добавить в *main()* несколько строк.
```
// Создаем переменную таймера (нужен для плавной анимации)
sf::Clock clock;
float time;
// Включаем вертикальную синхронизацию (для плавной анимации)
window.setVerticalSyncEnabled(true);
/* Ставим эти строки после window.clear(). Здесь мы сохраняем прошедшее время в миллисекундах и перезапускаем таймер */
time = clock.getElapsedTime().asMilliseconds();
clock.restart();
```
Теперь начнем создавать класс **Paddle**. Я привел здесь только основные методы, всё остальное вы сможете увидеть в исходниках (ссылка на скачивание в конце статьи).
```
class Paddle {
sf::RenderWindow* window; // Указатель на окно, нужен для отрисовки
sf::RectangleShape rectangle; // Собственно, сама ракетка
int y; // Координата y ракетки (x мы задаем в коде)
int player; // Номер игрока (1 или 2)
int score; // Переменная для хранения счета
public:
// Конструктор
Paddle(sf::RenderWindow* window, int player) {
this->score = 0;
this->y = 300;
this->player = player;
this->window = window;
// Устанавливаем размер для ракетки с помощью Vector2f
this->rectangle.setSize(sf::Vector2f(10, 100));
// Для удобства перенесем основную точку из левого верхнего угла в центр
this->rectangle.setOrigin(5, 50);
// И устанавливаем ракетки в начальные позиции
if(this->player == 1) {
this->rectangle.setPosition(25, this->y);
}
else {
this->rectangle.setPosition(775, this->y);
}
}
// Метод для отрисовки ракетки
void draw() {
this->window->draw(this->rectangle);
}
/* Обработка нажатия клавиш и перемещение ракеток
Первый игрок управляет стрелками, второй -- клавишами W и S */
void update(float time) {
if(this->player == 1) {
if(sf::Keyboard::isKeyPressed(sf::Keyboard::Up)) {
// Изменяем положение ракетки в зависимости от времени таймера
this->y -= time * 0.3;
this->setY(this->y); // setY - сеттер для переменной Y
}
else if(sf::Keyboard::isKeyPressed(sf::Keyboard::Down)) {
this->y += time * 0.3;
this->setY(this->y);
}
}
else {
if(sf::Keyboard::isKeyPressed(sf::Keyboard::W)) {
this->setY(this->y - time * 0.3);
}
else if(sf::Keyboard::isKeyPressed(sf::Keyboard::S)) {
this->setY(this->y + time * 0.3);
}
}
}
```
Ракеткой нам послужит прямоугольник размером 10X100. Размер мы задаем с помощью класса *Vector2f* — это вполне обычный вектор, в будущем он пригодится нам для задания направления движения мяча.
Кроме системы событий в SFML есть еще один способ для обработки устройств ввода. Именно его мы используем для управления ракетками с клавиатуры. Также можно перенести управление игрока на мышь — для этого, соответственно, будет использоваться *sf::Mouse* (или *sf::Joystick*).
В исходном коде рекомендую обратить внимание на метод *setY* — он проверяет координаты ракетки и не дает ей выйти за пределы поля.
Теперь можно создать пару объектов *Paddle* и вызвать методы *draw* и *update* после очистки окна. Если вы откомпилируете исходный код, то увидите две ракетки на противоположных сторонах окна, первая управляется с помощью курсорных клавиш «вверх», «вниз», вторая — клавишами W и S.
#### Заключение
Пока на этом мы остановимся, а в следующей статье я расскажу, как создать класс мяча и систему очков.
[Исходники](https://dl.dropbox.com/u/36198187/Pong_Source.zip). | https://habr.com/ru/post/149071/ | null | ru | null |
# Результаты конкурса на самый глючный код C++
После продолжительного обсуждения [объявлены победители](http://tgceec.tumblr.com/post/74534916370/results-of-the-grand-c-error-explosion-competition) конкурса Grand C++ Error Explosion Competition. Награды должны были объявить в двух номинациях. Участники первой соревновались по максимальному количеству ошибок на минимальный объём кода. Вторая номинация — творческая, там важно не количество и размер, а качество и красота глюков.
В итоге, абсолютным победителем назван программист Эд Хэнвей (Ed Hanway), приславший такую программу.
```
#include ".//.//.//.//jeh.cpp"
#include "jeh.cpp"
`
```
Программа Хэнвея вызывала в шесть раз больше сообщений об ошибках, чем программа ближайшего конкурента в этой номинации.
Победителем по количеству ошибок в категории *Plain* стал программист Крис Хопман с двойным *include*.
```
#include "set>.cpp"
#include "set>.cpp"
```
В категории «Чистые руки» было запрещено использование препроцессора и здесь победил Марк Алдораси с такой программой.
```
templateclass
C{Ca;Cb;};Cc;
```
В категории «Лучшая обманка» (Best Cheat) победителем назван уже упоминавшийся Крис Хопман. Жюри особенно отметило «использование Perl, единственного языка, менее понятного, чем шаблоны C++».
```
/usr/include; perl -e "@c=\"x\"x(2**16); while(1) {print @c}" 1>&2
```
Номинация «Самый неожиданный код».
```
templateclass L{Loperator->()};Li=i->
```
В номинации «самый правдоподобный код» победила работа Виктора Зверовича. По мнению жюри, подобная программа способна лишить желания жить любого, кто пытается в ней разобраться.
```
#include
#include
templatevoid f(T,U u){std::vector>v;auto i=end(v);find(i,i,u);find(i,i,&u);U\*p,\*\*q,r(),s(U);find(i,i,&p);find(i,i,&q);find(i,i,r);find(i,i,&r);find(i,i,s);find(i,i,&s);}templatevoid f(T t){f(t,0);f(t,0l);f(t,0u);f(t,0ul);f(t,0ll);f(t,.0);f(t,.0l);f(t,.0f);f(t,' ');f(t,L' ');f(t,u' ');f(t,U' ');f(t,"");f(t,L"");}int main(){f(0);f(0l);f(0u);f(0ul);f(0ll);f(.0);f(.0l);f(.0f);f(' ');f(L' ');f(u' ');f(U' ');f("");f(L"");f(u"");f(U"");}
```
Наконец, приз в номинации «Чистейшие руки» присуждён Джону Регеру с отличным использованием рекурсии.
```
struct x struct zv
``` | https://habr.com/ru/post/210500/ | null | ru | null |
# Повышение качества отбора персонала на основе данных
На протяжении последних нескольких лет я управляю разработкой и мне регулярно приходится набирать новых сотрудников.
Глядя на то, как с этим обстоят дела в среднем по IT-отрасли, осмелюсь дать достаточно негативную оценку: на мой взгляд, собеседования полны субъективности и случайности, а среднее качество отбора получается весьма посредственным — работодатели жалуются на [неадекватность](https://habrahabr.ru/company/regionsoft/blog/339284/) запросов кандидатов, вакансии могут оставаться незакрытыми месяцами, а принятые в штат сотрудники часто не оправдывают ожиданий.
Предположу, что причиной является тот факт, что мало кто из технарей, проводящих собеседования, имеет образование в сфере управления персоналом (естественно), либо хотя бы что-то читали об этом. А рекрутеры, в свою очередь, слабо смыслят в анализе данных. В итоге, пара этих компетенций редко соединяется в одном человеке и нанимающие просто повторяют [внешние признаки](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%80%D0%B3%D0%BE-%D0%BA%D1%83%D0%BB%D1%8C%D1%82) понравившихся им самим собеседований, не понимая, какой цели они служили исходно и какую информацию были задуманы извлечь. В итоге, с каждой такой копипастой, качество принятия решений падает.
Учитывая мою техническую специализацию, я попытался повысить качество отбора и попутно снизить затраты времени, требуемые для этого, разработав процесс, опирающийся на объективные данные, и внедрив его для найма разработчиков в свой отдел. В итоге, процесс продемонстрировал эффективность, широко распространился по компаниям, в которых я работал, и применяется сейчас для найма специалистов самого разного профиля.
Пару лет назад я уже рассказывал о нëм на [HR Unconference](http://www.globalhru.com/). Но записи выступления нет, а знакомые, которые не могут найти себе людей в отдел, всë чаще интересуются деталями, так что я решил, наконец, подробно всë расписать, а заодно и опубликовать свой первый пост на Хабре, поделившись своими наработками с широким кругом читателей.
Вот ключевые свойства данного процесса:
* он лучше всего подходит для вакансий, на которые новые сотрудники нанимаются регулярно, так как требует потратить некоторое время на наладку, которое однако очень быстро окупается при регулярном найме, превращая принятие решения по каждому кандидату из творческого процесса в рутину, занимающую несколько минут на кандидата и обеспечивающую при этом более высокое качество решений;
* вместе с этим, повышается и процент принятия офферов кандидатами, так как, во-первых, сам процесс отбора производит на них положительное впечатление, а во-вторых, при использовании данного процесса появляется возможность опередить всех конкурентов и выставить оффер человеку буквально в тот же день, когда он откликнулся на вакансию.
Итак, начнëм с типичного процесса и будем его улучшать. Обычно дело обстоит так:
* вакансия, перегруженная «обязательными требованиями»;
* первый этап — скрининг по резюме;
* затем, возможно, беседа с «эйчаром» для первичного отсева;
* после чего, длительное техническое интервью без чëткого плана с обсуждением опыта работы, углублением в произвольные детали и «задачками на сообразительность», по итогам которого принимается окончательное решение.
Иногда используются и совсем экстравагантные приëмы, такие как длительный разговор на свободную тему, применение интуиции в попытках разглядеть скрытые таланты и даже анализ плейлиста вконтакте (всë это — реальные случаи).
Шаг 1. Просейте вакансию
========================
Сперва приступим к улучшению текста вакансии.
В описании вакансии присутствует с десяток «обязательных требований», при этом в итоге нанимается кандидат, удовлетворяющий только половине из них. Знакомая ситуация? Можно ли в этом случае считать, что требования действительно были настолько обязательными?
По моему опыту, чаще всего это происходит из-за завышенных ожиданий нанимающего (что, кстати, приводит ещë и к тому, что не удаëтся никого отобрать за несколько месяцев собеседований), а также из-за того, что в «обязательные требования» попадают его личные хотелки («я не смогу работать с человеком, который не знаком с bash, даже если это тестировщик»; «если разработчик не сталкивался с git, значит он никогда серьëзно не работал и я не буду его рассматривать»; ...). Отчасти такие требования возникают из-за того, что личное собеседование занимает много времени и отнимает много сил, поэтому приходится искать какие-то эвристики, чтобы отсеять побольше сомнительных кандидатов на этапе просмотра резюме.
Итак, что требуется для улучшения процесса.
На данном шаге отделите *действительно* обязательное от желательного. Подумайте, а готовы ли вы в крайнем случае взять человека, который не будет уметь вот этого и этого из вашего списка обязательных требований? Если да, то перенесите такие требования в желательные. Не бойтесь, что на личное собеседование попадëт слишком много недостойных кандидатов — от этого мы защитимся на следующем шаге. Сейчас важно понимать, что обязательно, а что — нет. Лучше бойтесь того, что из-за небольших несоответствий будут отсеяны действительно достойные соискатели.
Приведëнный ниже простой чеклист поможет вам отделить обязательное от желательного:
1. **Есть ли необходимость в том, чтобы *все* сотрудники обладали данным навыком?** Например, часть задач по системе связаны с доработкой внутренней админки, которая использует Vue.js. Если только половина сотрудников отдела разработки будет знать Vue.js, достаточно ли будет их ресурсов, чтобы решать все задачи такого плана?
2. **Может ли человек быстро обучиться этому навыку?** К примеру, если работа в вашем отделе построена по git flow, совершенно не обязательно требовать этого навыка от кандидатов — любой человек легко разберëтся в git flow за пару первых рабочих дней, даже если никогда раньше не работал с git.
Вообще, следует обратить внимание на следующую мысль: любому айтишнику в любом случае придëтся чему-то учиться. Даже если вы волшебным образом найдëте человека, профиль которого на 100% соответствует текущим требованиям, через пару месяцев ситуация изменится и наверняка появится новое требование, которому уже не все будут соответствовать. В проекте могут появиться новые библиотеки, которые потребуется изучить; вы внедрите новые технологии, методологии и во всëм этом сотрудникам придëтся разбираться. Поэтому значительно важнее, чтобы человек показывал хорошую кривую обучения, нежели имел высокое значение обученности на данный момент.
Итак, после описанных манипуляций, в списке обязательных требований должно остаться не более 3-5 пунктов. Это те навыки, которыми обязаны обладать все сотрудники и которые при этом невозможно приобрести относительно быстро. Вот пример того, что могло бы получиться для вакансии разработчика:
* уверенное знание основного языка программирования, используемого в проекте (действительно, у вас не будет времени ждать, когда сотрудник получше освоит Java);
* уверенное знание ключевой техники, используемой на проекте, освоение которой невозможно за короткое время (к примеру, многопоточное программирование);
* высокая скорость разработки ([поговаривают](https://softwareengineering.stackexchange.com/questions/179616/a-good-programmer-can-be-as-10x-times-more-productive-than-a-mediocre-one), что скорость реализации задач у разных сотрудников может отличаться в 10 раз, и я полагаю, что этот показатель вряд ли сильно меняется со временем у отдельно взятого человека);
* высокая обучаемость (как я писал выше, хорошую кривую обучения я считаю важнейшим показателем);
* сочетаемость по личным качествам с текущими сотрудниками (даже при прочих плюсах я считаю, что не стоит брать человека, который не впишется в коллектив).
Теперь ваша задача — это проверить.
Шаг 2. Разработайте объективный механизм проверки обязательных требований
=========================================================================
Человек не может быть объективным и непредвзятым в вопросе оценки кандидатов, так как подвержен множеству [когнитивных искажений](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%BA%D0%BE%D0%B3%D0%BD%D0%B8%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D1%85_%D0%B8%D1%81%D0%BA%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9).
**Вот лишь некоторые из них.*** [иррациональное усиление](https://en.wikipedia.org/wiki/Escalation_of_commitment) — чем больше усилий было вложено в оценку кандидата, тем больше желание его взять, чтобы эти усилия не пропали даром;
* [эффект первого впечатления](https://ru.wikipedia.org/wiki/%D0%AD%D1%84%D1%84%D0%B5%D0%BA%D1%82_%D0%BF%D0%B5%D1%80%D0%B2%D0%BE%D0%B3%D0%BE_%D0%B2%D0%BF%D0%B5%D1%87%D0%B0%D1%82%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F) — независимо от длительности собеседования, в большинстве случаев окончательное решение подсознательно принимается уже в первые 15 минут разговора;
* [групповое мышление](http://www.psychologos.ru/articles/view/ogrupplenie-myshleniya) — хотя кажется, что оценка кандидата группой собеседующих должна быть более объективной, нежели принятие решения одним человеком, на самом деле в группах из 3-5 человек наиболее часто проявляется конформизм по отношению ко мнению авторитета, самоцензура мнения, отличного от мнения большинства и пониженная самокритичность авторитета в случае, когда его поддерживает группа. Сочетание этих факторов в конечном счëте приводит к тому, что принятые группой решения реже оказываются качественными;
* [эффект сверхуверенности](https://ru.wikipedia.org/wiki/%D0%AD%D1%84%D1%84%D0%B5%D0%BA%D1%82_%D1%81%D0%B2%D0%B5%D1%80%D1%85%D1%83%D0%B2%D0%B5%D1%80%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8) — переоценка любым человеком собственной экспертизы в умении отличать хороших кандидатов от плохих;
* [склонность к подтверждению своей точки зрения](https://ru.wikipedia.org/wiki/%D0%A1%D0%BA%D0%BB%D0%BE%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%BA_%D0%BF%D0%BE%D0%B4%D1%82%D0%B2%D0%B5%D1%80%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8E_%D1%81%D0%B2%D0%BE%D0%B5%D0%B9_%D1%82%D0%BE%D1%87%D0%BA%D0%B8_%D0%B7%D1%80%D0%B5%D0%BD%D0%B8%D1%8F) — склонность выдëргивать из поступающей от кандидата информации ту, что подтверждает сложившееся о нëм впечатление и игнорировать ту, что идëт с ним вразрез;
* [эффект знакомства с объектом](https://ru.wikipedia.org/wiki/%D0%AD%D1%84%D1%84%D0%B5%D0%BA%D1%82_%D0%B7%D0%BD%D0%B0%D0%BA%D0%BE%D0%BC%D1%81%D1%82%D0%B2%D0%B0_%D1%81_%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BE%D0%BC) — склонность всë более сопереживать кандидату по мере увеличения продолжительности знакомства;
* [гало-эффект](https://ru.wikipedia.org/wiki/%D0%93%D0%B0%D0%BB%D0%BE-%D1%8D%D1%84%D1%84%D0%B5%D0%BA%D1%82) — впечатление, что у людей с более привлекательной внешностью более выдающиеся умственные способности;
* в состоянии голода (до обеда) люди гораздо более склонны к критике;
* люди боятся изменять и стремятся защищать своë мнение, если оно было публично озвучено.
Список можно продолжать и дальше…
В связи с этим, я стараюсь исключить человеческий фактор и объективизировать процесс отбора настолько, насколько это возможно. Дополнительным положительным эффектом является то, что процесс становится воспроизводимым любым человеком и фактор личности собеседующего перестаëт оказывать влияние на результат кандидата.
Компания [TripleByte](https://triplebyte.com/), специализирующаяся на отборе кандидатов, вывела 10 тезисов о том, как должна производиться работа с кандидатами и назвала их [собственным манифестом](https://triplebyte.com/manifesto). Мой опыт подтверждает их тезисы на 100%.
**Поэтому ниже приведу в переводе на русский язык наиболее релевантные нашей теме.*** **процесс найма должен быть стандартизован.** Написание программ на доске и алгоритмические вопросы не могут качественно предсказать того, насколько эффективно данный человек будет писать реальный код. Такой технический процесс найма вредит как превосходным кандидатам, которые не могут хорошо справиться с такими заданиями, так и компаниям, которые хотели бы нанять хороших программистов;
* **решения о найме должны быть объективными.** Решения о найме должны приниматься с использованием четкой системы подсчета очков, а не интуитивно. Люди хорошо собирают информацию, но слишком предвзяты. Мы бессознательно пытаемся наклеивать ярлыки. Это наносит ущерб кандидатам, которые не соответствуют нашим ожиданиям;
* **процесс найма должен быть сосредоточен на выявлении сильных сторон, а не недостатков.** У всех есть недостатки. Но роль играют прежде всего достоинства, отличающие кандидата от остальных, и то, насколько быстро они могут учиться новым вещам;
* **кандидаты должны знать, чего ожидать на собеседовании.** Все кандидаты должны иметь равную возможность подготовиться заранее. Комфортное для кандидата интервью, скорее всего, приведет к лучшему принятию решения о найме;
* **кандидаты заслуживают обратной связи.** Кандидатам следует давать ясные, правдивые отзывы о том, как они справились с заданиями на собеседовании и где находятся их зоны роста.
* **диплом ничего не значит.** Здесь должен быть какой-то текст об этом, но на сайте компании в этом месте по ошибке приведëн абзац из другого пункта. Я полагаю, они хотели написать о том, что по бумажке нельзя однозначно судить о профессионализме кандидата;
* **процесс найма должен непрерывно измеряться и улучшаться.** Процесс найма следует рассматривать как программный продукт, постоянно улучшающийся со временем на основе данных и обратной связи. Необходимо больше экспериментировать и выяснить, что действительно работает.
Я выявил несколько способов оценки кандидатов, дающих возможность объективно их сравнивать по формальным критериям и так, чтобы результаты этого сравнения высоко коррелировали с реальным уровнем кандидата.
### 1. Тест с вариантами ответа
Составить хороший тест с вариантами ответа непросто. Чтобы не позволить читерам получить наивысшие оценки, тест должен удовлетворять следующим критериям:
* ответы должно быть нельзя нагуглить (по крайней мере, за отведëнное время) — для этого хороший вопрос должен требовать не фактическое знание, а некоторую манипуляцию в голове, основанную на глубоком понимании темы, чтобы дойти до правильного ответа;
* если вопрос содержит блок кода, его должно быть невозможно запустить, чтобы узнать правильный ответ;
* вопрос не должен быть слишком простым (в этом случае ответ на него не даст никакой информации);
* вопрос не должен быть слишком сложным (если процент правильных ответов близок к `1 / количество_вариантов`, то мы отсеим неудачников, а не тех, кто хуже знает тему);
* не должно проверяться знание наизусть того, что можно легко нагуглить во время работы — наличие этих знаний в голове ничего не показывает; правильный ответ должен показывать понимание, а не знание;
* не должно проверяться то, что не будет использоваться кандидатом в работе у нас («общая эрудиция», навороченные структуры данных и алгоритмы, умение моделировать физические процессы, ...) — вопросы должны составляться только по обязательным требованиям;
* хорошим количеством вариантов ответа будет от 4 до 7 — при 3 и меньше вариантах ответа слишком велика вероятность угадать, в то время как при более чем 7 вариантах ответа велика вероятность [не удержать](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B0%D1%82%D0%BA%D0%BE%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D1%8C) все варианты в голове и запутаться.
Со временем у меня выработались несколько техник, которые помогают написать хорошие вопросы:
* несколько тезисов (переформулированные, чтобы не гуглились один в один), один из них ложный (либо один из них верный) — необходимо его назвать;
* найдите ошибку в коде/конфигурации (ряд спорных моментов, один из которых — это ошибка, а остальные — относительно редкие кейсы);
* код/запрос/… и варианты ответа, что он делает. Чтобы нельзя было проверить запуском, код может принимать на вход несколько аргументов и не работать без них; требовать иную «обвязку», без которой он не запустится или не будет работать корректно;
* код/запрос/…, в котором пропущена строка и варианты кода для вставки. Подставьте правильный вариант, чтобы код решал указанную в задании задачу.
[PluralSight](https://www.pluralsight.com/) (бывший Smarterer) предлагает адаптивные тесты с вариантами ответа по множеству тематик — каждый следующий вопрос подбирается по сложности с учëтом предыдущих ответов. В конце концов, можно прорешать несколько раз тесты на интересующую вас тематику и вдохновиться понравившимися вопросами на создание собственных похожих.
Хорошие примеры вопросов также можно встретить на [TripleByte](https://triplebyte.com/users/start), причëм тексты вопросов содержат примеры кода на совершенно различных языках программирования, однако ответить на все вопросы можно и без знания этих языков. Таким образом, они проверяют не только сообразительность, но и мотивацию кандидата — часть людей сдаëтся, увидев название незнакомого им языка, даже не попытавшись прочитать код. По моему опыту, люди отвечают либо на 90 и более процентов таких вопросов, либо на 50 и менее — промежуточных результатов практически не встречается.
**Вот пример хорошего на мой взгляд вопроса.**
> Выберите, какой вариант строки следует вставить в приведëнный код:
>
>
> ```
> // возвращает индекс наименьшего элемента в массиве
> function minIndex(array) {
> minIndex = -1;
> minValue = 0;
> for (i = 0; i < array.length; ++i) {
> if (array[i] < minValue || minIndex == -1) {
> minIndex = i;
> // ПРОПУЩЕННАЯ СТРОКА
> }
> }
> return minIndex;
> }
> ```
>
>
> 1. return minIndex;
> 2. return minValue;
> 3. minValue = array[i];
> 4. i = minValue;
>
Ответить на данный вопрос несложно даже не зная языка JavaScript. Данный вопрос хорош ещë тем, что набрать и запустить этот код недостаточно для того, чтобы узнать ответ — требуется ещë подставить входные данные, которые позволят однозначно классифицировать результат, а также перебрать каждый из вариантов ответа. Едва ли это проще, чем подумать головой и логически додуматься до правильного ответа.
Блоки кода я, конечно, даю скриншотами, чтобы затруднить их запуск.
Для проведения тестирования, я использую платформу [TypeForm](https://www.typeform.com/). Помимо прочего, платформа умеет подсчитывать общее время, затраченное на тест, что является немаловажным фактором. Форму можно брендировать в ваши корпоративные цвета. Также мне нравится платформа [SurveyGizmo](https://www.surveygizmo.com/), раньше я использовал еë.
Следует иметь в виду, что основная задача данного этапа — отсеять существенную часть недостойных кандидатов (и тем самым охватить больше входящих лидов), по возможности оставив всех достойных. То есть, не так страшны false positives, как false negatives. Поэтому требования к прохождению теста я стараюсь держать немного заниженными (выявляем достоинства, а не недостатки).
Исключите скрининг по резюме и направляйте на тест всех! Это не требует никаких усилий от компании, а кандидату хороший тест также доставляет удовольствие. Я часто встречал хороших кандидатов с плохим резюме и наоборот, и убедился в том, что умение красиво описывать свой опыт — это отдельный навык, который обычно слабо коррелирует с рабочими качествами кандидата, поэтому не стоит попадаться на крючок и делать какие-то выводы по резюме.
### 2. Практическое задание
Многие компании предлагают на собеседованиях задачки типа «сколько люков в нашем городе» или «как определить фальшивую монету за N взвешиваний», а потом удивляются, что кандидаты, отлично ответившие на эти вопросы (то есть, очевидно, много в своей жизни ходившие по собеседованиям и знающие такие задачки наизусть) потом работают плохо. Google, который долгое время славился использованием подобных задач на своих собеседованиях, в конечном счëте [признал](https://habrahabr.ru/post/184008/), что они не работают.
Я придерживаюсь следующей позиции: чтобы понять, насколько человек будет хорошо работать, надо на собеседовании… заставить его поработать!
Для этого отлично подходит тестовое задание, максимально имитирующее обычную рабочую деятельность. Я разрабатываю такие задания для каждой позиции. Ниже приведëн пример для позиции разработчика.
**Вот такую вводную я отправляю кандидатам заранее, чтобы они были готовы к тому, что их ожидает.**
> На следующем собеседовании (длительностью 1.5 часа) вы должны будете решать несложные задачи. Задачи связаны в единую канву — при решении каждой следующей задачи, будет удобно отталкиваться от кода, написанного при решении предыдущих.
>
>
>
> К моменту начала этого этапа, я прошу вас подготовить на своëм компьютере окружение, в котором вам будет удобно писать код и запускать его.
**А вот такую вводную я отправляю им непосредственно перед началом собеседования.**
> Сегодняшнее собеседование продлится не более чем полтора часа, в течение которых вы будете решать задачи, одну за одной.
>
>
>
> Перед началом вам необходимо убедиться, что на компьютере установлено и удобно настроено ваше любимое средство разработки (IDE), есть возможность писать и запускать код на языке программирования <...>.
>
>
>
> Оцениваться будет:
>
>
>
> 1. Количество задач, которые вы успеете решить за отведëнное время.
>
> 2. Количество попыток, которое вам потребуется для решения каждой из задач.
>
>
>
> Данный этап собеседования построен так, чтобы максимально имитировать обычный рабочий процесс. Этому способствуют следующие его особенности:
>
>
>
> 1. Качество кода оцениваться не будет, однако каждая следующая задача является некоторым развитием либо усложнением предыдущей. Таким образом, код выгодно писать так, чтобы вам удалось его переиспользовать. Как и в обычном рабочем процессе, вы не знаете заранее, какие участки кода придëтся развивать в будущем.
>
>
>
> 2. Как и на работе, можно без ограничения пользоваться любой информацией из интернета.
>
>
>
> 3. Перед «релизом» (то есть перед тем, как сгенерировать ответ по каждой из задач), вам необходимо самостоятельно убедиться, что ваш код работает, потому что в реальной работе никто не обнаружит ошибку за вас.
>
>
>
> 4. Пишите сконцентрировано, но без спешки. По опыту, излишняя спешка по сравнению с вашим обычном рабочим темпом вам скорее помешает, чем поможет.
>
>
>
> Желаю удачи!
Разработчикам далее выдаëтся последовательность заданий. Это не олимпиадные задачи, хоть и внешне всë похоже! Это задачи, в наилучшей степени отражающие то, что придëтся делать кандидату на рабочем месте. Например, для кандидатов на должность, которая предполагала подключение на потоке различных рекламных сетей по API, мы выбрали API, с которым точно [никто не работал](http://swapi.co/) (чтобы уравнять исходные позиции кандидатов) и наделали заданий, связанных с этим API, которые проверяют:
* внимательность кандидата;
* умение парсить сложные ответы;
* умение разбираться в плохо написанных спецификациях;
* умение обнаружить, что API не всегда работает корректно и применить workaround;
* умение искать дополнительную информацию в интернете;
* умение оперировать комплексными структурами данных.
В общем, всë то, с чем реально придëтся столкнуться при работе с различными API. Всë это нам удалось найти в приведëнном выше по ссылке API.
Неплохой отправной точкой для тех, у кого пока нет идей, может стать сайт [CryproPals.com](http://cryptopals.com/), где собраны несложные задачи на тему криптографии, решение которых не требует никаких специальных знаний, в том числе и по криптографии.
Для админов мы готовили виртуалку, на которой требуется разобраться в проблемах и исправить конфигурацию, чтобы достичь целевых показателей по нагрузке. Залогом успеха для кандидата в этом случае является сочетание базового знания основных технологий, умения находить информацию в интернете, анализировать логи и эффективно использовать bash. Похожие задачи предлагает Яндекс в рамках олимпиад [Яндекс.Root](https://academy.yandex.ru/events/system_administration/root-2015/).
Тестировщикам давали страничку и просили найти как можно больше проблем. При этом, проблемы могут быть самого разного плана: и баги при вводе граничных значений, и уязвимости, и ухудшение отзывчивости при заполнении системы большим количеством данных, и ошибки в js-консоли, и проблемы с юзабилити. Всë зависит лишь от того, какие компетенции мы ищем в кандидате.
С аккаунт-менеджерами было немного сложнее, но нашли способ сформировать практическое задание и для них: мы давали синтетические кейсы возражений клиентов и просили менеджера написать ответы, а затем отмечали по пунктам, какие из важных установок были применены при ответах (например, если в вопросе отмечалось, что общение происходит со старым клиентом, генерирующим компании существенную часть оборота, было важно, чтобы менеджер пытался найти win-win решение даже несмотря на то, что клиент настаивает на варианте, невыгодном для себя, но выгодном для компании в краткосрочной перспективе).
Важным положительным свойством такого задания является то, что кандидата не требуется контролировать, ведь для решения задачи ему разрешено использовать любые доступные ему средства, равно как и в обычном рабочем процессе.
### 3. Личное собеседование
Личное собеседование является наиболее затратным по времени и самым субъективным, поэтому на нëм я стараюсь проверять только то, что невозможно проверить на более ранних этапах. Обычно, дело остаëтся за малым:
* удостовериться в личной совместимости кандидата с действующими сотрудниками;
* убедиться в том, что за кандидата тесты не проходил старший брат.
Последнее проверяется дополнительными вопросами по пройденным тестам: почему вы ответили именно так; а как изменится ответ, если поменяется вот эта вводная; почему в практическом задании вы реализовали такую-то вещь именно таким образом.
Конечно, такие истории случаются не часто (вроде бы, мне такие случаи так ни разу и не попадались), да и в любом случае всë быстро станет очевидно на испытательном сроке, но зачем до этого доводить. В конце концов, иногда и рекрутерам за взятых кандидатов надо платить, так что лучше по возможности выявить читеров сразу.
Кстати, именно в начале личного собеседования я, к удивлению кандидатов, впервые открываю их резюме.
### 4. Другие варианты
Вы можете пробовать и иные варианты объективного тестирования качеств кандидата, описанными выше способами мир не ограничен. Я какое-то время использовал тестовое задание, однако затем решил, что этот этап является избыточным и отказался от него. Помните, что главная мысль заключается не в том, что вот есть тест и есть практическое задание — используйте их. А в том, что вам следует на первом шаге понять, что же вам действительно требуется от кандидата, а затем найти самый простой объективный способ это проверить.
Шаг 3. Тюнингуйте
=================
Не следует принимать на веру, что данный механизм сразу заработает. Так и не будет. Я использую методику «постепенного ввода» этого процесса.
На первом этапе я прошу пройти тест людей, уровень которых я хорошо знаю и результат которых я могу предсказать. Обычно это действующие и бывшие коллеги и друзья, уровень профессионализма которых мне отлично понятен. Я даю им протестировать каждый этап и смотрю, насколько предсказуемым оказался для меня их результат. Можно также попробовать дать, например, админское задание разработчикам и убедиться, что их результат будет ниже проходного, в то время как профессиональные админы получают проходной результат. В идеале, мы должны сделать отборочные этапы такими, чтобы достаточно сильные люди проходили их почти в 100% случаев, а слабые не проходили как можно чаще.
Если удаëтся добиться устойчивой корреляции, я перехожу ко второму этапу — боевой проверке. Первые 5-10 кандидатов довожу до личного собеседования независимо от их результатов на отборочных этапах, а на личном собеседовании прошу каждого присутствующего независимо от других дать свою оценку кандидату по каждому из проверенных тестами критериев. При этом присутствующие коллеги не знают результата кандидата на тестах, а также оценок друг друга (чтобы минимизировать влияние группового мышления). Если кандидаты, плохо прошедшие отборочные этапы, будут один за другим заваливать и личное собеседование, то можно прекращать их звать.
Если же корреляция между отборочными этапами и результатом личного собеседования низкая, то попытайтесь локализовать проблемы и исправить их.
В тесте с вариантами ответа следует сделать следующее:
* найдите вопросы, на которые отвечают все. Исключите их или сделайте сложнее, иначе они не будут нести никакой информации;
* найдите вопросы, на которые отвечают примерно на уровне случайного попадания в вариант ответа. Исключите их или упростите. Вопрос даëт больше всего информации, если на него отвечает примерно 50-60% кандидатов;
* посмотрите, не палятся ли правильные ответы по какому-то простому критерию. Например, сколько баллов получит в вашем тесте человек, если всегда будет выбирать самые длинные ответы? Скорее всего, если вы об этом раньше не задумывались, то большинство правильных ответов у вас окажутся самыми длинными;
* посчитайте корреляцию каждого отдельно взятого вопроса с итоговым впечатлением от кандидата и с результатом прохождения им других этапов (функция подсчëта корреляции доступна из коробки в любых электронных таблицах). Вопросы, имеющие близкую к нулю или отрицательную корреляцию следует удалить или улучшить — скорее всего, в них есть какая-то проблема и они проверяют не то, что нужно;
* если сильный человек неправильно ответил на вопрос — уточните на личном собеседовании, почему он выбрал именно этот вариант. Может быть, вы чего-то не учли, вопрос составлен с ошибкой, содержит двусмысленность или просто ничего не проверяет;
* вместо всех удалëнных вопросов придумайте новые, чтобы примерно сохранить их количество.
В практическом задании постарайтесь устранить случайные факторы. Например, бывают такие сложности, столкновение с которыми не говорит о кандидате ничего плохого, но оказывает сильное отрицательное влияние на результат. Например, в задании с API таким фактором стало то, что авторы API предлагали библиотеку для работы с ним, которая на деле не работала. Те, кто пытались ей воспользоваться, теряли много времени и в итоге заканчивали с плохим результатом. Мы сделали в задании подсказку, что не нужно использовать эту библиотеку. Ведь попытка ей воспользоваться априори не является неправильным действием, а значит не должна негативно влиять на результат.
Не всегда тесты оказываются хорошими с первого раза, но почти всегда *одной итерации* улучшений хватает, чтобы тест и практическое задание начали работать идеально.
Шаг 4. Делегируйте
==================
Когда система налажена, всë взаимодействие на этапе теста с вариантами ответа можно делегировать абсолютно любому сотруднику организации — например, менеджеру по персоналу или офис-менеджеру. Второй этап также может проводить любой человек, однако на практике проводит человек в той же должности, на которую ищется новый сотрудник, чтобы ответить на вопросы кандидата о компании и таким образом немного замотивировать его на прохождение второго этапа. Общение с кандидатом отнимает на данном этапе 5-10 минут времени.
Делегируя, следите за тем, чтобы объективность отбора не снизилась — заставляйте в обязательном порядке фиксировать формальные результаты по каждому взятому в работу кандидату.
Итог
====
Когда система налажена, мне удаëтся по итогам личного собеседования брать более половины попавших на него людей. Все набранные таким образом кандидаты прошли испытательный срок и я могу назвать их прекрасными, эффективными сотрудниками.
Как только появляется потребность расширить штат, эффективный поиск очередного нового сотрудника при уже готовой вышеописанной системе становится очень простым и быстрым: главное это организовать входящий поток кандидатов, а выбрать из этого потока наилучший вариант становится очень простой задачей, которая решается в кратчайшие сроки и без мук выбора.
Итак, повторю основные шаги:
1. критически посмотрите на список обязательных требований и постарайтесь оставить лишь несколько главных;
2. продумайте, каким образом можно объективно проверить соответствие кандидатов этим требованиям — хорошо работают тесты с вариантами ответа и практическое задание, максимально приближенное к реальной работе; на личном же собеседовании лучше проверять только то, что не получается проверить на других этапах;
3. убедитесь, что построенная система работает как надо и действительно позволяет отделить хороших кандидатов от плохих;
4. смело делегируйте отборочные этапы коллегам, чтобы высвободить себе время на более стратегические дела. | https://habr.com/ru/post/341220/ | null | ru | null |
# MySQL и SQLite — регулярные выражения в предикате
Регулярные выражения могут оказать Вам неоценимую услугу при их разумном применении в SQL-запросах.
Они могут избавить Вас от необходимости перебирать в курсорных циклах, или (о ужас!) в циклах базового языка приложения солидные куски таблиц. Правда иногда услуга может оказаться «медвежьей».
Примеры и особености применения этой техники
Для примера — имеем безнес-логику приложения, в которой на первом этапе пользователь может создавать произвольную запись в базе, а на втором этапе — использовать данную произвольную запись в качестве внешнего ключа.
Задача вполне предсказуема — требуется соблюдать уникальность записи.
Могу предложить к рассмотрению вот такое решение *(да, оно не универсально, потому что я дополняю произвольную запись пользователя, тем самым формально ее изменяя. С другой стороны, цитируя Кларксона: "-Да, я тиран! Хотите демократии — езжайте в Ирак!")*:
DDL таблицы
> `CREATE TABLE `human\_link` (
>
> `translit\_link` varchar(255) NOT NULL DEFAULT 'main',
>
> `owner` int NOT NULL,
>
> PRIMARY KEY (`translit\_link`)
>
> ) ENGINE=MyISAM DEFAULT CHARSET=utf8
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Где обсуждаемая произвольная запись есть поле `translit\_link`, которую для соблюдения уникальности мы дополняем цифрой (1) или, если цифра уже есть — увеличиваем цифру на +1.
Узнать, если ли подобная запись, можно запросом
> `SELECT `translit\_link` FROM `foo`.`human\_link`
>
> WHERE `translit\_link` REGEXP CONCAT('^',?,'[[:digit:]]\*$') ORDER BY `translit\_link` DESC LIMIT 1;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Собственно, остается только разобраться, что к нам вернулось и сделать с возвратом то, что велит нам логика сохранения уникальности поля (более приближеный к жизни пример этой техники, с использованием perl и хранимой процедуры — в [читайте](http://www.fotov.net/2009/06/chetkaya-nechetkaya-logika/#more-866) моем блоге).
Но это все была только присказка.
Сказка вот в чем — EXPLAIN **MySql** про этот запрос скажет `Using where; Using index`, а вот при использовании **SQLite** из комлпекта DBD::SQLite —
> **REGEXP function**
>
> Note that regexp matching will not use SQLite indices, but will iterate over all rows, so it could be quite costly in terms of performance.
>
>
Кроме того и в MySQL не все так гладко — в книге *«High performance MySQL: optimization, backups, replication, and load balancing» By Jeremy D. Zawodny, Derek J. Balling* есть строка том, что выражение типа WHERE last\_name RLIKE "(son|ith)$" будет нереально медленно по объяснимым причинам, а вот выражение типа WHERE rev\_last\_name RLIKE "^(thi|nos)" окажется медленне двух union по WHERE rev\_last\_name like «thi%» и «nos%», потому что что *«MySQL оптимизатор никогда не пытается оптимизировать основаный на регулярном выражении запрос»*.
Из чего делаем вывод, что не все йогурты одинаково полезны.
PS. Буду весьма признателен за подсказку как обстоят дела в PostgreSQL, Oracle и в стане MS. :)
PPS. Я в курсе существования **ON DUPLICATE KEY UPDATE** — процедура ведет себя некорректно при использовании составного уникального индекса (multiple unique indexes). Т.е. ИМХО теоретически она вообще небезопасна для бизнес-логики, т.к. накладывает неявные ограничения на создаваемые индексы. | https://habr.com/ru/post/67294/ | null | ru | null |
# Динамическая инструментация — не просто, а тривиально*: пишем yet another инструментацию для American Fuzzy Lop
*(\*) На самом деле, не совсем.*
Наверное, многие слышали про Valgrind — отладчик, который может сказать, где в вашей нативной программе утечка памяти, где ветвление зависит от неинициализированной переменной и многое другое (а ведь кроме memcheck, у него есть и другие режимы работы). Внутри себя эта чудо-программа перемалывает нативный код в некий промежуточный байткод, инструментирует его и генерирует новый машинный код — уже с run-time проверками. Но есть проблема: Valgrind не умеет работать под Windows. Когда мне это понадобилось, поиски привели меня к аналогичной утилите под названием [DrMemory](http://www.drmemory.org/), также с ней в комплекте был аналог `strace`. Но речь не столько о них, сколько о библиотеке динамической инструментации, на базе которой они построены, [DynamoRIO](http://dynamorio.org/). В какой-то момент я заинтересовался этой библиотекой с точки зрения написания собственной инструментации, начал искать документацию, набрёл на [большое количество примеров](http://dynamorio.org/docs/API_samples.html) и был поражён тем, что простенькую, но законченную инструментацию вроде [подсчёта инструкций вызова](https://github.com/DynamoRIO/dynamorio/blob/master/api/samples/countcalls.c) можно написать буквально в 237 строк сишного кода, 32 из которых — лицензия, а 8 — описание. Нет, это, конечно не "пишем убийцу Valgrind в 30 строк кода на JavaScript", но сильно проще, чем то, что можно представить для подобной задачи.
В качестве примера давайте напишем уже четвёртую реализацию инструментации для фаззера American Fuzzy Lop, о котором недавно [уже писали на Хабре](https://habrahabr.ru/post/328652/).
Что такое AFL
=============
[AFL](http://lcamtuf.coredump.cx/afl/) — это инструмент для поиска багов и уязвимостей на основе guided fuzzing, собранный из железобетонных ~~костылей~~ эвристик, реализованных максимально тривиальным и эффективным способом. Вот так смотришь на инструмент, способный, наблюдая за поведением libjpeg, синтезировать валидные джипеги, и поражаешься, что всё это сделано на основе не такой уж и заумной механики. Вкратце, для полноценной работы AFL целевой бинарник должен быть инструментирован таким образом, чтобы в процессе выполнения собирать *рёберное покрытие*: представим себе каждый базовый блок (**basic block**, что-то вроде последовательности инструкций от метки и до ближайшей инструкции перехода) в качестве вершины графа. Рёбра — это возможные пути передачи управления между ББ. Соответственно, AFL интересует то, какие переходы и в каком примерно количестве происходили между базовыми блоками программы.
Основной способ инструментации в AFL — статическая на этапе компиляции с помощью обёрток `afl-gcc` / `afl-g++` или их аналогов для `clang`. Что забавно, `afl-gcc` подменяет вызываемую команду `as` на обёртку, переписывающую ассемблерный листинг, сгенерированный компилятором. Есть и более продвинутый вариант, называемый `llvm mode`, который честно встраивается в процесс компиляции (производимой с помощью LLVM, естественно) и, теоретически, должен поэтому давать большую производительность генерируемого кода. Наконец, для фаззинга уже скомпилированных бинарников есть `qemu mode` — патч к QEMU в режиме эмуляции одного процесса, добавляющий необходимую инструментацию (изначально этот режим работы QEMU предназначался, чтобы запускать отдельные процессы, собранные для другой архитектуры, используя хостовое ядро).
Что такое DynamoRIO
===================
[DynamoRIO](http://www.dynamorio.org/) — это система динамической инструментации (то есть она инструментирует уже скомпилированные бинарники прямо во время выполнения), работающая на Windows, Linux и Android на архитектурах x86 и x86\_64, а также ARM (поддержка AArch64 есть в release candidate версии 7.0). В отличие от QEMU, она предназначена не для исполнения программ "близко к тексту" на чужой архитектуре, а для лёгкого создания собственных инструментаций, модифицирующих поведение программы на родной архитектуре. При этом ставится цель по возможности не портить оптимизированный код. К сожалению, я так и не нашёл способ, при котором *клиенты* (так называются пользовательские библиотеки инструментации) могли бы не знать о целевом наборе инструкций (кроме каких-то тривиальных случаев, где достаточно кроссплатформенных обёрток для базовых инструкций), поскольку **не происходит** конверсии "машинный код -> байткод — [инструментация] -> новый байткод -> инструментированный машинный код". Вместо этого на каждый транслируемый базовый блок происходит передача клиенту списка декодированных инструкций, который он может изменять и дополнять с помощью удобных функций и макросов. То есть в машинных кодах программировать не нужно, но набор инструкций x86 (или другой платформы) знать, скорее всего, придётся.
**В качестве небольшого бонуса:** полез я посмотреть, что ещё есть интересного в их аккаунте на Гитхабе, и набрёл на занятный репозиторий: [DRK](https://github.com/DynamoRIO/drk). Репозиторий, похоже, заброшен и несколько потерял актуальность, но описание впечатляет:
> DRK is DynamoRIO as a loadable Linux Kernel module. When DRK is loaded, all kernel-mode execution (system calls, interrupt & exception handlers, kernel threads, etc.) happens under the purview of DynamoRIO whereas user-mode execution is untouched — the inverse of normal DynamoRIO, which instruments a user-mode process and doesn't touch kernel-mode execution.
Тестовая программа
==================
Для начала посмотрим, на что в принципе способен AFL. Нет, мы не будем брать уязвимую версию какой-нибудь библиотеки и ждать часы или сутки. Для теста напишем максимально тупую программу, которая разыменовывает нулевой указатель, если на stdin подать ей строку, начинающуюся с букв `NULL`. Это, конечно, не синтез джипега из ниоткуда, но зато и ждать почти не нужно.
Итак, скачаем AFL [отсюда](http://lcamtuf.coredump.cx/afl/releases/afl-latest.tgz) и соберём его. Как вы уже, наверное, догадались, собирать будем под GNU/Linux. Впрочем, другие Unix-like системы и Юниксы вроде Mac OS X тоже должны работать. Возьмём небольшую программку:
```
#include
#include
volatile int \*ptr = NULL;
const char cmd[] = "NULL";
int main(int argc, char \*argv[]) {
char buf[16];
fgets(buf, sizeof buf, stdin);
if (strncmp(buf, cmd, 4)) {
return 0;
}
\*ptr = 1;
return 0;
}
```
Скомпилируем её и запустим фаззинг:
```
$ export AFL_PATH=~/tmp/build/afl-2.42b/
$ # Запустим стандартную обёртку, которая статически добавит инструментацию
$ $AFL_PATH/afl-gcc example-bug-libc.c -o example-bug-libc
$ # Создадим какой-нибудь пример входного файла (можно несколько)
$ mkdir input
$ echo test > input/1
$ # Запустим фаззер
$ $AFL_PATH/afl-fuzz -i input -o output -- ./example-bug-libc
```
И что же мы видим:

Как-то оно не работает… Обратите внимание на строчку last new path: AFL ругается, что по прошествии 91 тысячи запусков он так и не нашёл новый путь. На самом деле это вполне логично: напомню, мы использовали статическую инструментацию на этапе вызова ассемблера. Основное же сравнение делает функция из libc, которая не инструментирована, и поэтому не получится посчитать количество совпавших символов. Так я думал, пока не решил это проверить, но оказалось, что наш бинарник не импортирует функцию `strncmp`. Судя по выводу `objdump -d`, компилятор просто сгенерировал на месте `strncmp` инструкцию с префиксом вместо цикла, куда можно было бы впихнуть инструментацию.
**Инструментированная функция main со strncmp**
```
00000000000007f0 <.plt.got>:
7f0: ff 25 82 17 20 00 jmpq *0x201782(%rip) # 201f78
7f6: 66 90 xchg %ax,%ax
7f8: ff 25 8a 17 20 00 jmpq \*0x20178a(%rip) # 201f88 <\_exit@GLIBC\_2.2.5>
7fe: 66 90 xchg %ax,%ax
800: ff 25 8a 17 20 00 jmpq \*0x20178a(%rip) # 201f90
806: 66 90 xchg %ax,%ax
808: ff 25 8a 17 20 00 jmpq \*0x20178a(%rip) # 201f98 <\_\_stack\_chk\_fail@GLIBC\_2.4>
80e: 66 90 xchg %ax,%ax
810: ff 25 8a 17 20 00 jmpq \*0x20178a(%rip) # 201fa0
816: 66 90 xchg %ax,%ax
818: ff 25 8a 17 20 00 jmpq \*0x20178a(%rip) # 201fa8
81e: 66 90 xchg %ax,%ax
820: ff 25 92 17 20 00 jmpq \*0x201792(%rip) # 201fb8
826: 66 90 xchg %ax,%ax
828: ff 25 9a 17 20 00 jmpq \*0x20179a(%rip) # 201fc8
82e: 66 90 xchg %ax,%ax
830: ff 25 a2 17 20 00 jmpq \*0x2017a2(%rip) # 201fd8
836: 66 90 xchg %ax,%ax
838: ff 25 a2 17 20 00 jmpq \*0x2017a2(%rip) # 201fe0
83e: 66 90 xchg %ax,%ax
840: ff 25 aa 17 20 00 jmpq \*0x2017aa(%rip) # 201ff0 <\_\_cxa\_finalize@GLIBC\_2.2.5>
846: 66 90 xchg %ax,%ax
848: ff 25 aa 17 20 00 jmpq \*0x2017aa(%rip) # 201ff8
84e: 66 90 xchg %ax,%ax
...
0000000000000850 :
850: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
857: ff
858: 48 89 14 24 mov %rdx,(%rsp)
85c: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
861: 48 89 44 24 10 mov %rax,0x10(%rsp)
866: 48 c7 c1 04 6a 00 00 mov $0x6a04,%rcx
86d: e8 9e 02 00 00 callq b10 <\_\_afl\_maybe\_log>
872: 48 8b 44 24 10 mov 0x10(%rsp),%rax
877: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
87c: 48 8b 14 24 mov (%rsp),%rdx
880: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
887: 00
888: 53 push %rbx
889: be 10 00 00 00 mov $0x10,%esi
88e: 48 83 ec 20 sub $0x20,%rsp
892: 48 8b 15 77 17 20 00 mov 0x201777(%rip),%rdx # 202010
899: 48 89 e7 mov %rsp,%rdi
89c: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
8a3: 00 00
8a5: 48 89 44 24 18 mov %rax,0x18(%rsp)
8aa: 31 c0 xor %eax,%eax
8ac: e8 6f ff ff ff callq 820 <.plt.got+0x30>
8b1: 48 8d 3d dc 06 00 00 lea 0x6dc(%rip),%rdi # f94
8b8: b9 04 00 00 00 mov $0x4,%ecx
8bd: 48 89 e6 mov %rsp,%rsi
8c0: f3 a6 repz cmpsb %es:(%rdi),%ds:(%rsi)
8c2: 75 45 jne 909
8c4: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
8cb: ff
8cc: 48 89 14 24 mov %rdx,(%rsp)
8d0: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
8d5: 48 89 44 24 10 mov %rax,0x10(%rsp)
8da: 48 c7 c1 2d 5b 00 00 mov $0x5b2d,%rcx
8e1: e8 2a 02 00 00 callq b10 <\_\_afl\_maybe\_log>
8e6: 48 8b 44 24 10 mov 0x10(%rsp),%rax
8eb: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
8f0: 48 8b 14 24 mov (%rsp),%rdx
8f4: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
8fb: 00
8fc: 48 8b 05 1d 17 20 00 mov 0x20171d(%rip),%rax # 202020
903: c7 00 01 00 00 00 movl $0x1,(%rax)
909: 0f 1f 00 nopl (%rax)
90c: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
913: ff
914: 48 89 14 24 mov %rdx,(%rsp)
918: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
91d: 48 89 44 24 10 mov %rax,0x10(%rsp)
922: 48 c7 c1 8f 33 00 00 mov $0x338f,%rcx
929: e8 e2 01 00 00 callq b10 <\_\_afl\_maybe\_log>
92e: 48 8b 44 24 10 mov 0x10(%rsp),%rax
933: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
938: 48 8b 14 24 mov (%rsp),%rdx
93c: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
943: 00
944: 31 c0 xor %eax,%eax
946: 48 8b 54 24 18 mov 0x18(%rsp),%rdx
94b: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx
952: 00 00
954: 75 40 jne 996
956: 66 90 xchg %ax,%ax
958: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
95f: ff
960: 48 89 14 24 mov %rdx,(%rsp)
964: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
969: 48 89 44 24 10 mov %rax,0x10(%rsp)
96e: 48 c7 c1 0a 7d 00 00 mov $0x7d0a,%rcx
975: e8 96 01 00 00 callq b10 <\_\_afl\_maybe\_log>
97a: 48 8b 44 24 10 mov 0x10(%rsp),%rax
97f: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
984: 48 8b 14 24 mov (%rsp),%rdx
988: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
98f: 00
990: 48 83 c4 20 add $0x20,%rsp
994: 5b pop %rbx
995: c3 retq
996: 66 90 xchg %ax,%ax
998: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp
99f: ff
9a0: 48 89 14 24 mov %rdx,(%rsp)
9a4: 48 89 4c 24 08 mov %rcx,0x8(%rsp)
9a9: 48 89 44 24 10 mov %rax,0x10(%rsp)
9ae: 48 c7 c1 a8 dc 00 00 mov $0xdca8,%rcx
9b5: e8 56 01 00 00 callq b10 <\_\_afl\_maybe\_log>
9ba: 48 8b 44 24 10 mov 0x10(%rsp),%rax
9bf: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx
9c4: 48 8b 14 24 mov (%rsp),%rdx
9c8: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp
9cf: 00
9d0: e8 33 fe ff ff callq 808 <.plt.got+0x18>
9d5: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
9dc: 00 00 00
9df: 90 nop
```
**То же, но без инструментации**
```
0000000000000630 <.plt.got>:
630: ff 25 82 09 20 00 jmpq *0x200982(%rip) # 200fb8
636: 66 90 xchg %ax,%ax
638: ff 25 8a 09 20 00 jmpq \*0x20098a(%rip) # 200fc8 <\_\_stack\_chk\_fail@GLIBC\_2.4>
63e: 66 90 xchg %ax,%ax
640: ff 25 92 09 20 00 jmpq \*0x200992(%rip) # 200fd8
646: 66 90 xchg %ax,%ax
648: ff 25 aa 09 20 00 jmpq \*0x2009aa(%rip) # 200ff8 <\_\_cxa\_finalize@GLIBC\_2.2.5>
64e: 66 90 xchg %ax,%ax
...
0000000000000780 :
780: 55 push %rbp
781: 48 89 e5 mov %rsp,%rbp
784: 48 83 ec 30 sub $0x30,%rsp
788: 89 7d dc mov %edi,-0x24(%rbp)
78b: 48 89 75 d0 mov %rsi,-0x30(%rbp)
78f: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
796: 00 00
798: 48 89 45 f8 mov %rax,-0x8(%rbp)
79c: 31 c0 xor %eax,%eax
79e: 48 8b 15 6b 08 20 00 mov 0x20086b(%rip),%rdx # 201010
7a5: 48 8d 45 e0 lea -0x20(%rbp),%rax
7a9: be 10 00 00 00 mov $0x10,%esi
7ae: 48 89 c7 mov %rax,%rdi
7b1: e8 8a fe ff ff callq 640 <.plt.got+0x10>
7b6: 48 8d 45 e0 lea -0x20(%rbp),%rax
7ba: ba 04 00 00 00 mov $0x4,%edx
7bf: 48 8d 35 ce 00 00 00 lea 0xce(%rip),%rsi # 894
7c6: 48 89 c7 mov %rax,%rdi
7c9: e8 62 fe ff ff callq 630 <.plt.got>
7ce: 85 c0 test %eax,%eax
7d0: 74 07 je 7d9
7d2: b8 00 00 00 00 mov $0x0,%eax
7d7: eb 12 jmp 7eb
7d9: 48 8b 05 40 08 20 00 mov 0x200840(%rip),%rax # 201020
7e0: c7 00 01 00 00 00 movl $0x1,(%rax)
7e6: b8 00 00 00 00 mov $0x0,%eax
7eb: 48 8b 4d f8 mov -0x8(%rbp),%rcx
7ef: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx
7f6: 00 00
7f8: 74 05 je 7ff
7fa: e8 39 fe ff ff callq 638 <.plt.got+0x8>
7ff: c9 leaveq
800: c3 retq
801: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
808: 00 00 00
80b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
```
Что интересно, похоже, AFL сам включил оптимизацию, потому что в неинструментированном коде честно вызывается `strncmp`. Что же до разбухшей PLT в коде, собранном `afl-gcc`, то, судя по всему, мы видим функции, вызываемые forkserver-ом — его мы тоже напишем, но обо всём по порядку. Хорошо, сделаем вид, что этого не видели, и попробуем наивным образом переписать наш пример без библиотечных функций:
```
#include
volatile int \*ptr = NULL;
const char cmd[] = "NULL";
int main(int argc, char \*argv[]) {
char buf[16];
fgets(buf, sizeof buf, stdin);
for (int i = 0; i < sizeof cmd - 1; ++i) {
if (buf[i] != cmd[i])
return 0;
}
\*ptr = 1;
return 0;
}
```
Компилируем, запускаем и… тадам!

Пишем свой forkserver
=====================
Как я уже говорил, AFL предполагает наличие инструментации, собирающей информацию о переходах между базовыми блоками исследуемой программы. Но есть и ещё одна оптимизация, добавляемая `afl-gcc`: [forkserver](https://lcamtuf.blogspot.ru/2014/10/fuzzing-binaries-without-execve.html). Смысл её в том, чтобы не перезапускать программу с помощью связки `fork`-`execve`, каждый раз выполняя динамическую линковку и т. д., а один раз внутри процесса фаззера сделать `fork`, потом `execve` в инструментированную программу. Как же мы будем перезапускать исследуемую программу? Смысл в том, что тестировать мы будем не этот запущенный процесс. Вместо этого в нём запускается код, который в бесконечном цикле ждёт команды от фаззера, делает `fork`, ждёт завершения дочернего процесса и отзванивается о результате. А вот отпочковавшийся процесс уже реально обрабатывает входные данные и собирает информацию о рёберном покрытии. В случае `afl-gcc`, если я правильно понимаю его логику, forkserver запускается при первом обращении к инструментированному коду. В случае же `llvm mode` также поддерживается режим *deferred forkserver* — таким образом можно пропустить не только динамическую линковку, но и стандартную для исследуемого процесса инициализацию, что потенциально может ускорить весь процесс на порядки, но нужно учитывать некоторые нюансы:
* выполнение процесса до запуска forkserver никак не должно зависеть от входных данных
* порождаемые процессы не должны делить общее состояние, например, указатель текущей позиции для открытого на момент запуска forkserver-а файлового дескриптора
* вызов `fork` создаёт копию процесса, но в этой копии будет только тот поток, который и сделал вызов `fork`
* ...
Также в llvm mode поддерживается *persistent mode*, в котором несколько тестовых примеров подряд выполняются внутри одного отпочкованного процесса. Наверное, это ещё больше снижает накладные расходы, но при этом есть опасность, что результат выполнения программы на очередном тестовом примере будет зависеть не только от текущего примера, но и от истории запусков. Кстати, уже после начала написания статьи я наткнулся на информацию о том, что [порт AFL на Windows](https://github.com/ivanfratric/winafl) тоже использует DynamoRIO для инструментации, и он как раз использует persistent mode. Ну а что ему ещё остаётся без поддержки `fork`?
Итак, нужно написать свой forkserver на DynamoRIO, но для начала нужно понять требуемый протокол его взаимодействия с процессом фаззера. Что-то можно почерпнуть по указанной выше ссылке на блог автора AFL, но проще найти в каталоге фаззера файл `llvm_mode/afl-llvm-rt.o.c`. В нём есть много интересного, но для начала посмотрим на функцию `__afl_start_forkserver` — там всё подробно описывается, даже с комментариями. Persistent mode нас не интересует, в остальном всё довольно понятно: нам дано два файловых дескриптора с известными номерами — из одного читаем, в другой пишем. Нам нужно:
1. Цитата из исходника: *Phone home and tell the parent that we're OK*. Записываем любые 4 байта.
2. Читаем 4 байта. Поскольку похоже, что в нашем случае (без persistent mode) мы имеем инвариант `child_stopped == 0`, то что именно мы прочитали, значения не имеет.
3. Отпочковываем дочерний процесс и закрываем в нём файловые дескрипторы для связи с фаззером.
4. Пишем 4 байта с PID дочернего процесса в файловый дескриптор и ожидаем его (процесса) завершения.
5. Дождавшись, пишем ещё 4 байта с кодом возврата и переходим к пункту 2.
И вот мы, собственно, подошли к написанию своего *клиента*. Тут нужно сделать лирическое отступление о том, что хотя примеры из документации и занимают всего пару сотен строчек, но документацию почитать всё-таки стоит. Начать можно, например, [отсюда](http://dynamorio.org/docs/using.html), где, в частности, написано о том, чего делать не стоит. Например, перефразировав известного литературного персонажа, можно сказать, что "клиент инструментации — это очень уж странный предмет: вроде он есть, но его как бы нет", что в документации именуется [client transparency](http://dynamorio.org/docs/transparency.html): в частности, нужно пользоваться своими копиями системных библиотек (в чём поможет private loader), либо пользоваться API DynamoRIO (выделение памяти, разбор опций командной строки и многое другое). Также важная информация есть в документации на функции API: например, в описании функции [dr\_register\_bb\_event](http://dynamorio.org/docs/dr__events_8h.html#a13e10779d8f91465a0b7aefdf4d87d16) указан краткий список из 11 пунктов, чему должна удовлетворять получившаяся последовательность инструкций после инструментации.
Для управления сборкой клиентов для DynamoRIO рекомендуется использовать CMake — им мы и воспользуемся. О том, как это сделать, можно прочитать в [документации](http://dynamorio.org/docs/using.html#sec_build), мы же перейдём к более интересным вопросам. Например, для того, чтобы сделать deferred forkserver, нам нужно как-то пометить место его запуска в исследуемой программе, а потом найти эту пометку в DynamoRIO (впрочем, вроде бы ничто не мешает сделать forkserver просто в виде вызова обычной функции внутри исследуемой программы, но ведь так же не интересно, правда?), К счастью, подобная функциональность встроена в DynamoRIO и называется [аннотациями](http://dynamorio.org/docs/using.html#sec_annotations). Разработчик клиента должен собрать специальную статическую библиотеку, которую нужно прилинковать к исследуемой программе, и в требуемом месте вызвать функцию из этой библиотеки, последовательность инструкций в которой не делает ничего интересного при обычном исполнении, но при запуске под DynamoRIO распознаётся им и заменяется на определённую константу или вызов функции.
Не буду повторять [официальный учебник](http://dynamorio.org/docs/API_tutorial_annotation1.html), скажу лишь, что предлагается скопировать заголовочный файл из поставки DynamoRIO, переделать в нём "вызов" двух макросов под название и сигнатуру нашей аннотации (этот файл нужно будет подключить в тестируемую программу), а также создать сишный исходник с ещё одним вызовом макроса, который сгенерирует реализацию заглушки для аннотации (из него будет собрана статическая библиотека, которую нужно прилинковать к тестируемой программе).
По поводу реализации forkserver-а всё тоже довольно прямолинейно, за исключением того, что, вероятно, не очень правильно вызывать `fork` из нашей копии `libc`: например, автор AFL в указанной выше статье про особенности реализации forkserver говорил о том, что `libc` кеширует PID. В случае же вызова `fork` из копии `libc` исследуемого приложения и оно будет знать про произошедший вызов `fork`, и DynamoRIO это, хочется верить, тоже заметит. Поэтому пришлось написать что-то вроде
```
module_data_t *module = dr_lookup_module_by_name("libc.so.6");
EXIT_IF_FAILED(module != NULL, "Cannot lookup libc.\n", 1)
fork_fun_t fork_ptr = (fork_fun_t)dr_get_proc_address(module->handle, "fork");
EXIT_IF_FAILED(fork_ptr != NULL, "Cannot get fork function from libc.\n", 1)
dr_free_module_data(module);
```
Поэтому, чтобы поддержать традиционный режим запуска forkserver-а при старте программы, нужно убедиться, что к этому моменту уже доступна libc.
Когда я попытался это протестировать, я столкнулся со странным поведением: тестируемая программа запускалась, а forkserver — нет. Я добавил в `dr_client_main` печать на консоль — её тоже не появилось. Переключился на сборочный каталог чернового варианта кода. Хм… работает. Сравнил вывод `nm -D` на рабочей и нерабочей библиотеке инструментации: и там, и там есть функция `dr_client_main`. Сравнил ещё раз — действительно есть… Указал для drrun опции `-verbose -debug`. В общем, после некого количества экспериментов выяснилось, что дело было не в библиотеке клиента, и даже не в тестовой программе. Просто для чернового сборочного каталога QtCreator создал путь `.../build-afl-dr-Desktop_3fb6e5-Выпуск`, а для "рабочего" — `.../build-afl-dr-Desktop-По умолчанию`. Ну вы поняли, во втором *был пробел*. Нет, я понимаю, что некоторые программы не работают, когда в пути есть пробелы, но втихаря выкинуть библиотеку инструментации, это, конечно, креативненько… *(Да, я отправил [баг-репорт](https://github.com/DynamoRIO/dynamorio/issues/2538).)*
Тестируем:
```
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
Running forkserver...
Cannot connect to fuzzer.
1
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug 198<&0 199>/dev/null
Running forkserver...
xxxx
1
Incorrect spawn command from fuzzer.
```
Ну, более-менее работает. Проверим, как отнесётся к нему AFL. Для этого запустим его в dumb mode (не собирать рёберное покрытие), но попросим его всё-таки использовать forkserver:
```
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -- ./example-bug
... что-то там про Fork server handshake failed -- правильно, инструментации нет ...
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
... что-то там про Timeout while initializing fork server (adjusting -t may help)
$ # изучаем логи strace-а и...
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -m 2048 -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
... всё работает, если дать больше памяти (опция -m)
```

Впрочем, скорость не ахти. Но речь пока о работе на качественном уровне.
И тут обнаружилась проблема: хотя с тестовой программой такой forkserver работает нормально, некоторые программы с ним просто рушатся по SIGSEGV. После некого времени, потраченного на отладку, ответа так и не появилось, однако оказалось, что в качестве обходного пути можно вызывать `fork` из копии `libc`, принадлежащей клиенту, а не приложению. Ну что же, это повод познакомиться с extension под названием `droption`. Чтобы его использовать, нужно всего лишь объявить статическую переменную типа `dr_option_t`, в параметрах указав имя опции, описание и значение по умолчанию, а в начале `dr_client_main` вызвать `droption_parser_t::parse_argv(...)` (да, клиент теперь у нас получается на C++). Внезапно оказалось, что документация на сайте относится к версии 7.0 RC1, а в 6.2.0-2 документация на это расширение отсутствует, и стандартным способом через CMake именно `droption` почему-то не подключается. Но само расширение есть. Впрочем, нам нужен лишь путь к заголовочным файлам, поэтому просто подключим другое расширение с тем же путём, например, `drutil`.
В итоге получились следующие реализации:
**afl-annotations.h**
```
// Based on dr_annotations.h from DynamoRIO sources
#ifndef _AFL_DR_ANNOTATIONS_H_
#define _AFL_DR_ANNOTATIONS_H_ 1
#include "annotations/dr_annotations_asm.h"
/* To simplify project configuration, this pragma excludes the file from GCC warnings. */
#ifdef __GNUC__
# pragma GCC system_header
#endif
#define RUN_FORKSERVER() \
DR_ANNOTATION(run_forkserver)
#ifdef __cplusplus
extern "C" {
#endif
DR_DECLARE_ANNOTATION(void, run_forkserver, ());
#ifdef __cplusplus
}
#endif
#endif
```
**afl-annotations.c**
```
#include "afl-annotations.h"
DR_DEFINE_ANNOTATION(void, run_forkserver, (), );
```
**afl-dr.c**
```
#include
#include
#include
#include
#include
#include "afl-annotations.h"
static const int FROM\_FUZZER\_FD = 198;
static const int TO\_FUZZER\_FD = 199;
typedef int (\*fork\_fun\_t)();
#define EXIT\_IF\_FAILED(isOk, msg, code) \
if (!(isOk)) { \
dr\_fprintf(STDERR, (msg)); \
dr\_exit\_process((code)); \
}
static droption\_t opt\_private\_fork(DROPTION\_SCOPE\_CLIENT, "private-fork", false,
"Use fork function from the private libc",
"Use fork function from the private libc");
static void parse\_options(int argc, const char \*argv[]) {
std::string parse\_err;
if (!droption\_parser\_t::parse\_argv(DROPTION\_SCOPE\_CLIENT, argc, argv, &parse\_err, NULL)) {
dr\_fprintf(STDERR, "Incorrect client options: %s\n", parse\_err.c\_str());
dr\_exit\_process(1);
}
}
static void start\_forkserver() {
// For references, see https://lcamtuf.blogspot.ru/2014/10/fuzzing-binaries-without-execve.html
// and \_\_afl\_start\_forkserver in llvm\_mode/afl-llvm-rt.o.c from AFL sources
static bool forkserver\_is\_running = false;
uint32\_t unused\_four\_bytes = 0;
uint32\_t was\_killed;
if (!forkserver\_is\_running) {
dr\_printf("Running forkserver...\n");
forkserver\_is\_running = true;
} else {
dr\_printf("Warning: Attempt to re-run forkserver ignored.\n");
return;
}
if (write(TO\_FUZZER\_FD, &unused\_four\_bytes, 4) != 4) {
dr\_printf("Cannot connect to fuzzer.\n");
return;
}
fork\_fun\_t fork\_ptr;
// Lookup the fork function from target application, so both DynamoRIO
// and application's copy of libc know about fork
// Currently causes crashes sometimes, in that case use the private libc's fork.
if (!opt\_private\_fork.get\_value()) {
module\_data\_t \*module = dr\_lookup\_module\_by\_name("libc.so.6");
EXIT\_IF\_FAILED(module != NULL, "Cannot lookup libc.\n", 1)
fork\_ptr = (fork\_fun\_t)dr\_get\_proc\_address(module->handle, "fork");
EXIT\_IF\_FAILED(fork\_ptr != NULL, "Cannot get fork function from libc.\n", 1)
dr\_free\_module\_data(module);
} else {
fork\_ptr = fork;
}
while (true) {
EXIT\_IF\_FAILED(read(FROM\_FUZZER\_FD, &was\_killed, 4) == 4, "Incorrect spawn command from fuzzer.\n", 1)
int child\_pid = fork\_ptr();
EXIT\_IF\_FAILED(child\_pid >= 0, "Cannot fork.\n", 1)
if (child\_pid == 0) {
close(TO\_FUZZER\_FD);
close(FROM\_FUZZER\_FD);
return;
} else {
int status;
EXIT\_IF\_FAILED(write(TO\_FUZZER\_FD, &child\_pid, 4) == 4, "Cannot write child PID.\n", 1)
EXIT\_IF\_FAILED(waitpid(child\_pid, &status, 0) >= 0, "Wait for child failed.\n", 1)
EXIT\_IF\_FAILED(write(TO\_FUZZER\_FD, &status, 4) == 4, "Cannot write child exit status.\n", 1)
}
}
}
DR\_EXPORT void dr\_client\_main(client\_id\_t id, int argc, const char \*argv[]) {
parse\_options(argc, argv);
EXIT\_IF\_FAILED(
dr\_annotation\_register\_call("run\_forkserver", (void \*)start\_forkserver, false, 0, DR\_ANNOTATION\_CALL\_TYPE\_FASTCALL),
"Cannot register forkserver annotation.\n", 1);
}
```
Собираем рёберное покрытие
==========================
И вот, наконец, настало время приступить к полноценному перекорёживанию машинного кода. Как и в прошлый раз, не будем изобретать велосипед, а посмотрим в исходниках AFL, как делается существующая инструментация. А именно, изменения вносимые `afl-gcc` описаны в `afl-as.c`, а сам вписываемый ассемблерный код находится в виде строковых литералов в `afl-as.h`. Подробности работы AFL и, в частности, используемая инструментация, описаны в официальном документе [technical details](http://lcamtuf.coredump.cx/afl/technical_details.txt). По сути, в места ветвления программы вписывается код эквивалентный
```
cur_location = ;
shared\_mem[cur\_location ^ prev\_location]++;
prev\_location = cur\_location >> 1;
```
(псевдокод нагло позаимствован из документации AFL). Каждая локация помечается случайным идентификатором, а ребру в графе переходов соответствует байт в карте с номером, состоящим из поксоренных идентификаторов текущей и предыдущей локации, причём один из идентификаторов сдвигается на 1 — это позволяет сделать рёбра *ориентированными*. Для взаимодействия с процессом фаззера программе через переменную окружения передаётся ссылка на 64-килобайтную карту в shared memory, пример работы с которой можно посмотреть всё в том же файле `llvm_mode/afl-llvm-rt.o.c`.
О том, как это всё реализовать с помощью DynamoRIO, есть ещё один [официальный учебник](http://dynamorio.org/docs/API_tutorial_bbdynsize1.html). Суть в том, что при наступлении некоторых событий (таких как трансляция очередного базового блока или, например, запуск / остановка потока) DynamoRIO вызывает зарегистрированные обработчики. Поскольку мы хотим дописывать машинный код в каждый базовый блок, то нам потребуется зарегистрировать свой обработчик с помощью функции `dr_register_bb_event`. Также, последуем совету из туториала, и вместо атомарных операций инкремента будем использовать thread-local карты, а по завершении потока всё суммировать, поэтому нам также понадобится подписаться на создание и завершение потоков и создать мьютекс для синхронизации обращения к глобальной карте. Наконец, по-хорошему, мьютекс надо бы удалить в конце работы, поэтому подпишемся ещё и на завершение работы программы:
```
// Внутри dr_client_main:
lock = dr_mutex_create();
dr_register_thread_init_event(event_thread_init);
dr_register_thread_exit_event(event_thread_exit);
dr_register_bb_event(event_basic_block);
dr_register_exit_event(event_exit);
```
Обработчики создания и удаления потоков довольно бесхитростны:
```
typedef struct {
uint64_t scratch;
uint8_t map[MAP_SIZE];
} thread_data;
static void event_thread_init(void *drcontext) {
void *data = dr_thread_alloc(drcontext, sizeof(thread_data));
memset(data, 0, sizeof(thread_data));
dr_set_tls_field(drcontext, data);
}
static void event_thread_exit(void *drcontext) {
thread_data *data = (thread_data *) dr_get_tls_field(drcontext);
dr_mutex_lock(lock);
for (int i = 0; i < MAP_SIZE; ++i) {
shmem[i] += data->map[i];
}
dr_mutex_unlock(lock);
dr_thread_free(drcontext, data, sizeof(thread_data));
}
```
… а удаление мьютекса я даже приводить не буду. Из интересного в этом коде стоит обратить внимание, во-первых, на то, что DynamoRIO имеет собственные функции и для выделения памяти, и для примитивов синхронизации, причём есть вариант аллокатора с thread-specific memory pool. Во-вторых, здесь мы видим создание глобальных-на-уровне-потока структур `thread_data`, чей адрес мы заносим в tls field.
И вот, мы подошли к сути происходящего: функции `event_basic_block(void *drcontext, void *tag, instrlist_t *bb, bool for_trace, bool translating)`, которая и занимается переписыванием машинного кода. Как я и обещал, нам не придётся ворочать шестнадцатиричные коды инструкций и высчитывать байты — инструкции придут к нам уже в декодированном виде в параметре `instrlist_t *bb`. Есть даже несколько макросов для кроссплатформенной (в плане архитектуры процессора) генерации наиболее типичных инструкций, но, увы, нам всё же придётся разбираться с ассемблером amd64 aka x86\_64. Читать документацию по используемым функциям DynamoRIO вообще полезно, а в случае с [`dr_register_bb_event`](http://dynamorio.org/docs/dr__events_8h.html#a13e10779d8f91465a0b7aefdf4d87d16) это полезно вдвойне. Например, вот что понимается под basic block:
> DR constructs dynamic basic blocks, which are distinct from a compiler's classic basic blocks. DR does not know all entry points ahead of time, and will end up duplicating the tail of a basic block if a later entry point is discovered that targets the middle of a block created earlier, or if a later entry point targets straight-line code that falls through into code already present in a block.
Также, там имеется список ограничений на результирующий машинный код, который может получаться после инструментации — при написании своих клиентов обязательно почитайте!
Для работы нашей инструментации нам понадобится два регистра. Также мы будем выполнять арифметические операции, целую одну штуку, поэтому нужно сохранить флаги вроде признака переполнения:
```
static dr_emit_flags_t event_basic_block(void *drcontext, void *tag, instrlist_t *bb,
bool for_trace, bool translating) {
instr_t *where = instrlist_first(bb);
reg_id_t tls_reg = DR_REG_XDI, offset_reg = DR_REG_XDX;
dr_save_arith_flags(drcontext, bb, where, SPILL_SLOT_1);
dr_save_reg(drcontext, bb, where, tls_reg, SPILL_SLOT_2);
dr_save_reg(drcontext, bb, where, offset_reg, SPILL_SLOT_3);
dr_insert_read_tls_field(drcontext, bb, where, tls_reg);
// здесь будет дописываться инструментация
dr_restore_reg(drcontext, bb, where, offset_reg, SPILL_SLOT_3);
dr_restore_reg(drcontext, bb, where, tls_reg, SPILL_SLOT_2);
dr_restore_arith_flags(drcontext, bb, where, SPILL_SLOT_1);
return DR_EMIT_DEFAULT;
}
```
В `tls_reg` тут же положим адрес нашей структуры с вр**е**менной картой для текущего потока. Также в приведённом выше псевдокоде из документации фигурирует COMPILE\_TIME\_RANDOM. Проблема с использованием случайных идентификаторов в том, что наш `event_basic_block` может вызываться несколько раз: обратите внимание на аргументы `for_trace` и `translating`. Дело в том, что, кроме трансляции отдельных блоков, наиболее часто встречающиеся цепочки блоков DynamoRIO собирает в *трейсы*. Перед тем, как добавить блок в трейс, ещё раз вызываются зарегистрированные обработчики трансляции базового блока, но уже с `for_trace = true`, в которых можно сгенерировать специальную инструментацию для помещения блока в трейс. Также иногда возникает необходимость понять, какому реальному адресу кода соответствует кешированный, на котором произошло некое событие, тогда наш обработчик вызывается с `translating = true` — тут уже, конечно, нужно повторить ровно те же преобразования, как с `translating = false`. Впрочем, можно вернуть из обработчика `DR_EMIT_STORE_TRANSLATIONS` вместо `DR_EMIT_DEFAULT`, и адреса будут запомнены за нас, но на это потребуются дополнительные ресурсы. Даже, если бы никаких повторных вызовов не предполагалось бы by design, всё равно пришлось бы хитро координировать наши случайные метки с учётом того, что часть будет создана уже после форка процесса. Поэтому просто будем давать идентификатор как функцию от адреса кода, где лежит basic block.
```
void *app_pc = dr_fragment_app_pc(tag);
uint32_t cur_location = ((uint32_t)(uintptr_t)app_pc * (uint32_t)33533) & 0xFFFF;
```
Если уже после форка будут загружены дополнительные динамические библиотеки, то ASLR испортит нам планы, но будем считать это редким случаем. Кстати, "если припрёт", рандомизацию можно временно отключить для всей системы с помощью `sysctl -w kernel.randomize_va_space=0`.
Наконец, сам сбор рёберного покрытия. Нам нужно добавить четыре инструкции. Для этого в API имеются удобные функции и макросы для создания инструкций, операндов разных видов и т. д.:
```
instrlist_meta_preinsert(bb, where,
XINST_CREATE_load(drcontext,
opnd_create_reg(offset_reg),
OPND_CREATE_MEM64(tls_reg, offsetof(thread_data, scratch))));
instrlist_meta_preinsert(bb, where,
INSTR_CREATE_xor(drcontext,
opnd_create_reg(offset_reg),
OPND_CREATE_INT32(cur_location)));
instrlist_meta_preinsert(bb, where,
XINST_CREATE_store(drcontext,
OPND_CREATE_MEM32(tls_reg, offsetof(thread_data, scratch)),
OPND_CREATE_INT32(cur_location >> 1)));
instrlist_meta_preinsert(bb, where,
INSTR_CREATE_inc(drcontext,
opnd_create_base_disp(tls_reg, offset_reg, 1, offsetof(thread_data, map), OPSZ_1)));
```
Кстати, если вы ошибётесь с инструкциями, то вместо подробного сообщения о том, что ай-ай-ай такие операнды задавать этой инструкции, вы получите просто Segmentation fault. Например, заменим в первой инстукции `XINST_CREATE_load` на `XINST_CREATE_store` и запустим:
```
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so --private-fork -- ./example-bug
Cannot get SHM id from environment.
Creating dummy map.
Running forkserver...
Cannot connect to fuzzer.
^C
$ # Поменяли load на store
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so --private-fork -- ./example-bug
Cannot get SHM id from environment.
Creating dummy map.
```
Что делать? Можно по одной комментировать инструкции, пока не перестанет падать. Можно задать опции командной строки вроде `-debug -loglevel 1 -logdir /tmp/dynamorio/` и тогда вместо невразумительного падения на консоль будет написано о невозможности закодировать инструкцию, а в логе будет что-то вроде:
```
ERROR: Could not find encoding for: mov (%rdi)[8byte] -> %rdx
SYSLOG_ERROR: Application /path/to/example-bug (5192) DynamoRIO usage error : instr_encode error: no encoding found (see log)
SYSLOG_ERROR: Usage error: instr_encode error: no encoding found (see log) (/dynamorio_package/core/arch/x86/encode.c, line 2417)
```
Пожалуй, оба способа имеют право на жизнь: второй позволяет понять **что** не понравилось, а первый — **где оно происходит**.
Что же, инструментация готова, можно запускать:
```
$ $AFL_PATH/afl-fuzz -i input -o output -m 2048 -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
afl-fuzz 2.42b by
[+] You have 4 CPU cores and 1 runnable tasks (utilization: 25%).
[+] Try parallel jobs - see docs/parallel\_fuzzing.txt.
[\*] Checking CPU core loadout...
[+] Found a free CPU core, binding to #0.
[\*] Checking core\_pattern...
[\*] Checking CPU scaling governor...
[\*] Setting up output directories...
[+] Output directory exists but deemed OK to reuse.
[\*] Deleting old session data...
[+] Output dir cleanup successful.
[\*] Scanning 'input'...
[+] No auto-generated dictionary tokens to reuse.
[\*] Creating hard links for all input files...
[\*] Validating target binary...
[-] Looks like the target binary is not instrumented! The fuzzer depends on
compile-time instrumentation to isolate interesting test cases while
mutating the input data. For more information, and for tips on how to
instrument binaries, please see docs/README.
When source code is not available, you may be able to leverage QEMU
mode support. Consult the README for tips on how to enable this.
(It is also possible to use afl-fuzz as a traditional, "dumb" fuzzer.
For that, you can use the -n option - but expect much worse results.)
[-] PROGRAM ABORT : No instrumentation detected
Location : check\_binary(), afl-fuzz.c:6894
```
Но… У нас же есть инструментация… Неужели она не работает? На самом деле ситуация ещё смешнее: если посмотреть на лог `strace` для этой команды, то мы увидим, что `drrun` даже не запускался. И что же это за телепатия, как `afl-fuzz` видит отсутствие инструментации, даже не запуская программу? Помните, я говорил о том, что AFL — это подборка железобетонных эвристик? Так вот, идём куда послали, ну, в смысле, в `afl-fuzz.c:6894`, и видим:
```
f_data = mmap(0, f_len, PROT_READ, MAP_PRIVATE, fd, 0);
// ...
if (!qemu_mode && !dumb_mode &&
!memmem(f_data, f_len, SHM_ENV_VAR, strlen(SHM_ENV_VAR) + 1)) {
// ...
FATAL("No instrumentation detected");
}
```
Да-да, именно так: AFL ищет в бинарнике строчку `__AFL_SHM_ID` — имя переменной окружения, через которую инструментированная программа получает идентификатор общей памяти. Теперь-то всё ясно, ~~`echo -ne "__AFL_SHM_ID\0" >> /path/to/drrun`~~ впрочем, нет, не повторяйте моих ошибок: если посмотреть в исходнике чуть выше, то окажется, что можно просто задать переменную окружения `AFL_SKIP_BIN_CHECK` и отключить проверку:
```
$ # Опция -d заставляет пропустить детерминированные шаги фаззинга
$ AFL_SKIP_BIN_CHECK=1 $AFL_PATH/afl-fuzz -i input -o output -m 2048 -d -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug
```

Ура, AFL признал нашу инструментацию, но что это, Бэрримор, `total paths: 12`, а раньше было только 4-5. Точно сказать сложно, но подозреваю, что это ~~овся~~libc. Ведь теперь инструментации подвергается не только наш код из `example-bug`, но и всё, что исполняется в процессе (ну, кроме DynamoRIO, конечно). Да и скорость не ахти… Поэтому самое время начать делать
Оптимизации
===========
… и первой будет выбор, какие модули процесса мы хотим инструментировать. Точнее, пока просто будем ограничивать инструментацию главным модулем программы, и сделаем опцию "сделать как раньше". Для этого я заведу глобальную переменную типа `module_data_t *`, в `dr_client_main` проинициализирую её информацией о главном модуле программы, а в `event_basic_block` буду сразу прерывать обработку, если код "не наш":
```
module_data_t *main_module;
// В dr_client_main:
main_module = dr_get_main_module();
// В event_basic_block:
if (!opt_instrument_everything.get_value() && !dr_module_contains_addr(main_module, pc)) {
return DR_EMIT_DEFAULT;
}
```
Для тестового примера это увеличило скорость фаззинга до 80 запусков в секунду (приблизительно в 2 раза), а в `output/queue` строка `test` за пару минут уже превратилась в `NU` — медленно, но как будто бы работает.
Далее, у DynamoRIO есть опция `-thread_private`, при указании которой он будет использовать отдельные кеши кода для каждого потока. В этом случае значение из tls field фактически становится константой, поэтому, хотя выкинуть использование регистра у меня не получилось, но инициализировать его можно immediate-константой:
```
if (dr_using_all_private_caches()) {
instrlist_meta_preinsert(bb, where,
INSTR_CREATE_mov_imm(drcontext,
opnd_create_reg(tls_reg),
OPND_CREATE_INTPTR(dr_get_tls_field(drcontext))));
} else {
dr_insert_read_tls_field(drcontext, bb, where, tls_reg);
}
```
Запускаем с опцией `-thread_private` (но эта опция должна идти до `-c libafl-dr.so`, поскольку она принадлежит самому DynamoRIO, а не нашему клиенту), и получаем приблизительно на 5 запусков в секунду больше. Впрочем, даже если написать `if (0 && dr_using_all_private_caches())`, то результат идентичный — видимо, DynamoRIO просто эффективнее работает в таком режиме. :)
В принципе, мы можем указать ещё одну опцию командной строки: `-disable_traces` — она отключает создание трейсов, что, вероятно, негативно скажется на производительности долго живущих программ, но, как сказано в документации, может благотворно сказаться на скорости больших короткоживущих приложений. Попробуем… и получаем ещё плюс 10-15 запусков в секунду. Но, повторюсь, с этой опцией нужно экспериментировать, возможно, даже, уже после появления в очереди интересных test case-ов.
Напоследок скажу, что ещё чуть улучшить производительность можно, если "прогреть" тестируемую программу перед запуском forkserver-а: добавим в `example-bug.c` код
```
ungetc('1', stdin);
char ch;
fscanf(stdin, "%c", &ch);
RUN_FORKSERVER();
```
… и получим ещё плюс 15 запусков в секунду. Впрочем, сложно с ходу сказать, в чём конкретно дело: возможно, за счёт этого кода какая-то затратная инициализация в libc произошла *до* запуска forkserver, а возможно, просто был транслирован какой-то ощутимый кусок кода.
За сим разрешите откланяться. В этом небольшом проекте ещё есть над чем подумать:
* можно не тратиться на инструментацию безусловных переходов, как это и сделано в `afl-as`
* можно попытаться научиться пересоздавать запущенные потоки после форка (такой функциональности в текущих реализациях, вроде бы, нет)
* можно по аналогии с патчем для QEMU отправлять в сторону forkserver информацию о транслированных адресах, чтобы он их также транслировал у себя и последующие его потомки уже не тратили на это время (но, видимо, в лучшем случае придётся допиливать DynamoRIO. *Хотя, надо отдать должное гитхабовским телепатам: не успел я отправить feature request, полез смотреть существующие issues, а они это уже две недели назад [закоммитили](https://github.com/DynamoRIO/dynamorio/pull/2505)...*)
… но это уже совсем другая история. И помните, *все врут*: не стоит на вопрос "А правда ли эту функцию API / ассемблерную инструкцию можно так использовать?" отвечать, "Да, конечно, я так вон в той статье видел!" — сложно сказать, сколько разнокалиберных неожиданностей ещё предстоит вычистить из этого небольшого кода. Впрочем, надеюсь, вы убедились, что написание несложной, но полезной динамической инструментации — задача намного более выполнимая, чем кажется на первый взгляд.
Ссылки:
* [Этот проект на Github](https://github.com/atrosinenko/afl-dr).
* [WinAFL](https://github.com/ivanfratric/winafl) — ещё одна реализация подобного на DynamoRIO (для Windows).
* Ещё размышления и эксперименты по поводу неофициальных реализаций инструментации: [раз](https://www.reddit.com/r/netsec/comments/30dux0/american_fuzzy_lop_dyninst_afl_fuzzing_blackbox/), [два](https://groups.google.com/forum/#!topic/afl-users/ccWhGps_dZY).
* [Dynamic Binary Instrumentation в ИБ](https://habrahabr.ru/company/dsec/blog/142575/) — статья 2012 года про другую систему динамической инструментации, PIN
**UPD:** [Реализовал](https://github.com/atrosinenko/afl-dr/commit/6c7598547c10b840facfdf7eff3437f5433a606c) трансляцию в родительском процессе базовых блоков, исполненных в дочерних процессах (как это сделано в `qemu_mode`). Пришлось использовать API слегка не по назначению, но скорость на примитивной тестовой программе из статьи поднялась раз в 5. Вот теперь, пожалуй, пора оптимизировать генерируемую инструментацию. | https://habr.com/ru/post/332076/ | null | ru | null |
# Memoization
Dynamic programming is applied to solve optimization problems. In optimization, we try to find out the maximum or minimum solution of something. It will find out the optimal solution to any problem if that solution exists. If the solution does not exist, dynamic programming is not able to get the optimal solution.
Optimization problems are the ones that require either lowest or highest possible results. We attempt to discover all the possible solutions in dynamic programming and then choose the best optimal solution. Dynamic programming problems are solved by utilizing the recursive formulas though we will not use a recursion of programming the procedures are recursive. Dynamic programming pursues the rule of optimality.
A dynamic programming working involves around following significant steps:
* Dividing the complex problem into more straightforward subproblems.
* And then find the optimal solution to these subproblems.
* Then store the results of the subproblems.
* Then reuse these subproblems so that the same subproblem cannot be calculated more than once.
* Finally, it calculates the result of a complex problem.
The process of storing the results of intermediate or subproblems is called ***memoization***.
If we have a complex problem and solve that part of the problem, we need to get to the final problem. We realize we need to use that part again. Are we going to solve that part again?. We are just going to look back at the answer and see what you got. We will not walk through all the steps of solving it again. That's just a waste of time. Cannot imagine anyone doing that, so now when we program which is possible our aim is to do the same thing. Now that's where the ***memoization*** comes in.
Memoization is top-down, depth-first optimization, a technique that stores previously computed results so that it does not need to be re-computed. It is an optimization procedure used in several programming languages to lessen unwanted, expensive function calls. It is performed by caching the return value of a function centered on its inputs. Its purpose is to speed up the operations. It can be automatically done or manually handcrafted.
Memoization is a technique for storing values written by a function to avoid redo computation that is performed already previously. This technique is beneficial when we have a regularly called function and when its analysis is expensive. So in real life, the concept of memorization becomes extremely important when you're working on developing software for custom asset tracking and live tracking. Because in those cases, we will be calling a function repeatedly, and computation cost is expensive.
This technique can trade space for time. It utilizes additional memory to save computation time. Occasionally, it can transform a slow function into a quick one. Memoization is a cache. When you call the memoization function, it does all sorts of work. If we are calling a similar function several times with the same arguments, then memoization is helpful. However, if we are always doing different arguments, caching will not support them at all.
**Working**
Memoization works through breaking down a complex problem into several subproblems. Then, the memoized algorithm checks if the result of the subproblem stored in the table could be an array, a hash, or a map. If it is available in the table, it's just going to take that data from the table. However, if the table does not contain the result, the memorized algorithm should enter the data value into the table.
**Recursion and Memoization**
Fibonacci sequence is the xth term equivalent to the xth minus one term plus the xth minus two-term. Suppose a sequence of 1,1,2,3,5,8,14,23. So to put it simply, 8 in the sequence is the sixth term would be equivalent to the fifth term, which would be five plus the fourth term, which would be the three, so 5 plus 3 equals 8. On moving to the eighth term, that is equivalent to the seventh term plus the sixth term, which equals 23.
Now we will define a function 'fib' and give it one parameter, 'x'. Now we will start off using a base case. A base case will give back a constant value. So, the base case will be x is less than or equivalent to 2.We need to return a value of 1.If it is not less than or equal to 2, we will return the Fibonacci sequence of x minus one plus the Fibonacci sequence of x minus 2.
```
function fib(x){
if(x<=2){
return 1;
} else {
return fib(x-1) + fib(x-2)
}
}
```
Now we try to call the Fibonacci sequence of 4 and use-value of x equal to 4. As the four is not smaller than or equal to 2. So control will return the condition. We look for Fibonacci of 3 plus the Fibonacci of 2. Now for the Fibonacci of 3, we call this function again. As three is not less than or equal to 2, we will move down to the following condition. Now we have Fibonacci of 2 plus Fibonacci of 1, and that applies to the base case, so it will be 1 plus 1, which will be 2. Now that is just the three parts. That's only done the first call on the 4. Now we move to Fibonacci of 2 because four minus 2 is just a 2. That applies to the base case, so that will be 1. We have already calculated this value which is 2 and 2 plus 1 equal to 3.
```
console.log(fib(4))
```
We will get output very smoothly for a smaller number. But for the more significant number, the program takes forever. It is a problem with recursion on a fundamental level. We are constantly recalculating answers. That's why running time is slow for a more significant number. And every time we have to do an addition that uses up the processor, it takes a lot longer to calculate the answers. It is highly inefficient. So we will write a recursion statement that is a lot more efficient and takes constant time rather than exponential time. So we will write down statements with 'num' equal to empty curly braces. Now we will make a new function fib1 with parameter 'x'. Then we will start with the base case as done previously. We are going to take if n is smaller than or equal to 2. We are going to return a value of 1. Now we don't need to recalculate the answer if we have already calculated it. So we need to check if we have previously computed that answer.
```
var nums = { }
function fib1(x){
if(x <= 2){
return 1
}
if(x in nums){
return nums[x]
}else{
num = fib1 ( x-1 ) + fib1(x-2)
nums[x] =num
return num;
}
}
```
**Fibonacci Series**
Following is a simple function that calculates the sum of the Fibonacci series. In this example, we have a function called Fibonacci, which takes a number as its only argument, and inside the function, we have only two conditions. The first one being if the number is less than or equal to zero, then we write zero. And if the number is similar to one, then we have written one. As a recursive function, it calls itself repeatedly, so we call the Fibonacci function by passing num minus one and num minus two as its two parameters into our Fibonacci function. And since we want to print the sum of the Fibonacci series. We are adding it and returning the value as well. So we will get five as an output on running the following code.
```
function fibonacci(num){
if (num <= 0){
return 0;
}
if (num == 1){
return 1;
}
return fibonacci(num -1) + fibonacci(num -2)
}
fibonacci(5)
```
Output: 5
**Example**
Let's take an example of a Fibonacci series to understand memoization. In this series, we will calculate the following number by adding the last two numbers. If the number is negative, we will take one function, 'fib', and pass the value of x because we find the xth digit of the Fibonacci series. So it would print an error message in case of a negative number. On the other hand, if the value of 'x' is equal to zero, it will return zero. And if the value of 'x' is similar to one, it will return one returned.
Suppose we pass n equal to 5 in Fibonacci expression. Now the first three conditions in the above code will not satisfy this. So now control will go to sum condition. At this condition, fib(5) will divide into two parts that are fib(4) and fib(3). We will continue to divide these subproblems until we get fib(0) and fib(1). Then it will be a return sum. The Fibonacci function will be called 15 times.
When we use a recursive function, time complexity will increase x, and the count value will increase exponentially. Because whenever we call the same subproblem, a recursive tree of that subproblem is generated. We can use these repeated values one time only by just storing them using the concept of memoization. In addition, we can store intermediate results and then use those results. In this way, we do not need to compute subproblems again and again.
Now, we will take an array to store values. We keep the name of the array as "memo". This array contains five indexes from 0 to 5. The array initializes with -1, which shows null.
Before the execution of the count function, it will check that if the value of n exists in the array, it will return the memo value; otherwise, we will call the following function. If we call fib(1), this value is null in the memo. So, we will call a function and return at one the condition where x is equal to 1.And we will write one at index 1 in the memo. For fib(0), initially, we write null values at zero indexes in the memo. So after calling the function, we will store 0 at index zero in the memo. For fib(2), x is equal to 2. So, it will store one value at index 2 in the memo. For fib(3), we have to calculate fib(1), but we already have a value of 1 at fib(1). So, we do not call fib(1) function, and we take the value of fib(1). Now fib(3) will store two. Now for fib(4), we will store 3. For fib(5), we need to call fib(3) and fib(4). But fib(3) already has some value in the memo. So we don't need to call fib(3). So five will be stored at fib(5). During this whole memoization process, we have avoided the repeated function calls. This memoization technique is also known as the top-down approach because we start from the top and divide the problem into different subproblems.
**Big-O-Notation**
The big-o-notation O(n) value for the Fibonacci sequence without memoization is O(2^n). While the O(n) value for a Fibonacci sequence with memoization is O(n), We can see below the graph of the algorithm complexity, which is the group of input N values. The yellow line represents without memoization. The green line shows memoization with a linear line. The linear line will significantly influence how fast the program can run as the input grows. So for minimal inputs, it's OK with all memorization you probably don't have to write all that, but if it gets enormous, you should consider using it applicable.
**Graph**
**Drawbacks and Limitations**
Memoization has the following drawbacks and limitations:
* It does sacrifice space for speed. It means we have to store all the values somewhere. Those computer results for computation have to be stored somewhere, just like if we solve the problem.
* It is used for primarily pure functions where we expect the same input to return the same output. For example, suppose we are getting a function where you pass in parameters with the same input, but it's giving different results. We probably cannot use memoization for that. Because when we loop up the table, it does not make any sense. It could be a different value. So it has to be the same value. | https://habr.com/ru/post/559524/ | null | en | null |
# Использование дополнительных инструкций CPU в одной из задач на PHP для ускорения производительности
При построении крупных PHP-проектов многие сталкивались с нехваткой производительности, даже на мощных серверах. Даже небольшой участок кода может ощутимо повлиять на весь ресурс в целом: в плане прибыли, и в плане затрат на поддержку и обслуживание данного ресурса. Расскажу Вам мой опыт о нестандартном подходе решения одной задачи.
На протяжении года, мы постоянно добавляли новый функционал: писали больше кода, создавали больше модулей, модули из модулей, больше таблиц с миллионами записями, которые участвовали в перекрестной выборке. Проект рос с большой скоростью. Состав разработчиков не раз менялся, а это хоть и несущественно, но, все же, отрицательно сказывалось на проекте, что также добавляло лишних проблем. В общем, достаточно большой проект, как это бывает у крупных компаний.
Уже когда все написано, работает, и продолжает дальше разрабатываться, и ни времени, ни бюджета переделывать что-либо – дабы улучшить производительность – нет, а двигаться нужно только вперед, причем как можно быстрее, я получаю очередное задание. Сначала я посмотрел на него как на обычный тикет: вся личная информация пользователя: фамилия, адрес, телефон, идентификационный код – должна храниться в базе в зашифрованном виде, и быть доступна только при запросе с ключами для расшифровки. Так как это мой первый серьезный опыт, связанный с шифрованием данных, я начал искать в гугле возможные пути решения задачи средствами PHP, и, естественно, наткнулся на всем известную библиотеку mcrypt. Не нужно особо много времени, чтобы разобраться, как с ней работать. Библиотека работала – на форумах можно найти много примеров, комментариев, обсуждений. Она показалась мне идеальным вариантом для решения моей задачи, особенно учитывая, что времени было совсем немного.
В итоге, я использовал код, который находится прямо на странице описания функции mcrypt\_encrypt:
<http://us2.php.net/manual/en/function.mcrypt-encrypt.php>
`php <br/
$iv_size = mcrypt_get_iv_size(MCRYPT_RIJNDAEL_256, MCRYPT_MODE_ECB);
$iv = mcrypt_create_iv($iv_size, MCRYPT_RAND);
$key = "This is a very secret key";
$text = "Meet me at 11 o'clock behind the monument.";
echo strlen($text) . "\n";
$crypttext = mcrypt_encrypt(MCRYPT_RIJNDAEL_256, $key, $text, MCRYPT_MODE_ECB, $iv);
echo strlen($crypttext) . "\n";
?>`
Все работает хорошо, за исключением одного маленького НО: 5-ый параметр $iv (он же – IV — вектор инициализации) в функции mcrypt\_encrypt не к месту — так как он вообще не используется в режиме шифрования ECB ([Electronic codebook](http://en.wikipedia.org/wiki/Block_cipher_modes_of_operation#Electronic_codebook_.28ECB.29)). И меня вообще удивляет, почему данный пример присутствует в документации — это сбивает с толку.
Наш Engineer Lead провел code review, и сделал два аргументированных замечания:
1. IV не используется в режиме ECB (о чем я писал выше) — это что касается безопасности, к производительности дела не имеет.
2. mcrypt является слишком тяжелым и медленным, чтобы позволить вызывать его на каждом page load, лучше найти куски кода, где действительно нужны эти данные и расшифровывать их только в тех случаях.
Первое – не проблема, погуглив дальше, сразу же натыкаешься на режим CBC ([Cipher-block chaining](http://en.wikipedia.org/wiki/Block_cipher_modes_of_operation#Cipher-block_chaining_.28CBC.29)). Но вот что делать со вторым – это ведь нужно перерыть все модули, ведь фамилии пользователей используются почти на каждой странице сайта. Это слишком много, подумал я, учитывая сроки, риски – ведь все еще должно будет пройти QA.
Одним вечером, обсуждая ежедневные проблемы, связанные с работой, попивая пиво с другом, который далек от PHP и «этих» проблем, но очень опытен в низкоуровневом программировании и С++ – это оказалось не только приятным времяпрепровождением, но к тому же очень полезным для работы.
Раскрыл он мне одну тайну (на самом деле только для меня это было тайной, а вот для мира С++ программистов, конечно же это очевидность): если использовать определённые инструкции процессора, то можно поднять в 10-ки раз производительность вычислительных задач, в том числе и задач, связанных с шифрованием данных. Новые процессоры intel уже поддерживают инструкции для ускорения шифрования и расшифровывания данных — [Advanced Encryption Standard (AES) Instruction Set](http://en.wikipedia.org/wiki/AES_instruction_set). И к счастью, как оказалось, наш проект работает на серверах с процессорами Intel Xeon E5645, которые уже имеют в наличии эти инструкции ([AES New Instructions](http://ark.intel.com/products/48768/Intel-Xeon-Processor-E5645-%2812M-Cache-2_40-GHz-5_86-GTs-Intel-QPI%29)).
###### Но как все это использовать в PHP?
Мы напишем свой PHP модуль, который будет принимать значение из PHP и шифровать/расшифровывать, используя возможности процессора. После нескольких бессонных ночей, сравнения результатов производительности и вообще – концепции, что должен делать модуль, где и как хранить вектор с данными (ведь он необходим для расшифровки) – получилось нижеследующее.
PHP модуль, состоящий из двух частей:
1. Botan (<http://botan.randombit.net/>) открытая библиотека, написанная на С++, которая реализует множество алгоритмов шифрования, в том числе AES256, который нам нужен, и при этом имеет возможность использовать AES-NI.
2. libaecrypt – уже наша часть – служит переходником C++ интерфейса библиотеки Botan в C интерфейс (функции, а не классы), который можно вызвать из главного С файла модуля.
В модуле мы реализовали три функции:
1. Генератор случайных ключей — возвращает случайные данные длиной в N байт, которые можно использовать как ключ или вектор.
2. Шифрование
3. Расшифровка
Шифрование/расшифровка – использует в качестве параметров:
* ключ данных – 32 байта, который должен быть создан один раз и храниться скрыто
* ключ вектора – 32 байта, который тоже должен быть создан один раз и храниться скрыто
* IV – 16 байт, который создается «генератором случайных ключей»
Алгоритм выглядит примерно так: генерируется случайный IV, потом шифруются данные, используя ключ данных и IV; шифруется вектор с помощью ключа вектора. Зашифрованный вектор добавляется к зашифрованным данным с разделителем # и сохраняется в базе, расшифровка идет в обратном порядке.
###### Основная особенность Botan:
Я не думаю, что выкладывать листинги кода в статье разумно, потому что их много, поэтому расскажу о инициализации модуля, что и есть самый сок.
В комплекте с библиотекой Ботан, идет вспомогательный инструмент, который позволяет определить процессор и его инструкции (botan/cpuid.h). Для ускорения шифрования/расшифровки проверяется, есть ли у процессора AES-NI; если нет – то есть ли SSSE3.
`int Init()
{
// Инициализируем Ботана
pInitObj = new Botan::LibraryInitializer();
// Узнаем какой процессор
CPUID::initialize();
// Узнаем есть ли у процессора поддержка инструкций
if(CPUID::has_aes_ni())
global_state().algorithm_factory().set_preferred_provider("AES-256", "aes_isa");
else if(CPUID::has_ssse3())
global_state().algorithm_factory().set_preferred_provider("AES-256", "simd");
else
global_state().algorithm_factory().set_preferred_provider("AES-256", "core");
return 1;
}`
В результате, инструмент для тестирование нагрузок от Apache – ab (Apache Benchmark), показал разницу между нашим модулем и реализацией такого же алгоритма с использованием mcrypt: приблизительно 600 requests/second против 1400 requests/second – в пользу нашего модуля.
###### Вывод:
OpenSSL, который так же поставляется с PHP, начиная с версии 1.0.1, выпущенной 14 марта 2012 года (после всех наших мучений), уже тоже умеет использовать инструкции AES-NI (и SSSE3), и в производительности схожий алгоритм, написаный на PHP c OpenSSL, уступает нашему модулю всего-то в 200 requests per second ([Software supporting AES instruction set](http://en.wikipedia.org/wiki/AES_instruction_set), OpenSSL from version 1.0.1 есть в списке).
Лично я, в будущем, буду использовать OpenSSL, вместо MCrypt. Помимо того, что mcrypt медленнее, он в качестве вектора инициализации требует ключ в 32 байта! — что не совсем стандартно, так как OpenSSL, Botan, и как я понимаю, многие другие библиотеки реализующие криптование в режиме AES256-CBC принимают ключ для IV размером в 16 байт. Если использовать mcrypt, то уже только им можно будет расшифровать данные.
— **UPD1:** Насчет примеров кода и ссылки на мой модуль: проблема заключается в том, что я подписал контракт, который не позволяет мне выкладывать публично исходный код проекта, т.к. это может повлиять на безопасность (речь идет о 100-ни тысяч пользователей США). Но я постараюсь сегодня выложить измененный вариант модуля для просмотра, чтобы не нарушать условия контракта.
**UPD2:** Я был удивлен резкому негативу и минусу в карму, поэтому хочу сказать: я хотел поделиться опытом, рассказать, что если вы работаете на PHP и имеете дело с шифрованием, то mcrypt не самый лучший выбор, поскольку эта библиотека имеет проблемы с производительностью. В комплекте php, так же поставляется OpenSSL, который с версии 1.0.1 (как я уже писал выше), использует инструкции процессора, работает намного быстрее и на отлично выполняет криптование данных. После выхода новой версии OpenSSL, наш самописный модуль уже не имеет значения, но это, к сожалению, было до его выхода, и опять же отмечу, что у нас было слишком мало времени.
**UPD3:** Еще раз прошу заметить, что 25k Page Views и проблемы с производительностью нашего проекта — не главный смысл, пожалуйста, акцентируйте внимание на главный вывод из моего опыта: использование AES-NI (инструкции процессора для ускорения производительности) и OpenSSL vs. MCrypt. Спасибо всем, кто прокомментировал и высказал свое мнение, я как можно скорее постараюсь переписать статью, дабы уделить больше внимание AES-NI, OpenSSL vs. MCrypt и как написать модуль для PHP. | https://habr.com/ru/post/142823/ | null | ru | null |
# Объекты в JavaScript и создание JS-компонента. Часть 1
> Эта статья — первая часть туториала об ООП в JavaScript и о создании простого JS-компонента.
Об объектах и JavaScript
------------------------
Думайте об объекте, как о совокупности каких-то вещей. Например, представьте, что у вас есть велосипед. Этот велосипед является *объектом*, и он имеет совокупность каких-то признаков / частей / etc, называющихся *свойствами объекта*. Примером такого свойства может служить модель велосипеда, год его производства, его детали. Детали также могут иметь собственный набор свойств.
JavaScript является объекто-ориентированным языком. Поэтому всё в JavaScript является объектом и имеет свой набор свойств, к которым мы можем получить доступ. Более формальное объяснение с MDN:
> JavaScript основан на простой объектно-ориентированной парадигме. Объект является коллекцией свойств, а свойство — это ассоциация между именем и значением. Значение свойства может быть функцией, и в таком случае функция будет называться методом. В дополнение к стандартным объектам, уже определённым в браузере, вы можете создавать собственные объекты.
Создание собственных объектов является весьма полезной возможностью. В JavaScript мы можем получить доступ к свойствам объекта через *dot notation*. Но прежде чем разбираться с доступом к свойствам, давайте разберёмся с созданием и инициализацией объектов.
Создание объекта
----------------
Наверняка вы уже создавали или использовали объекты, сами того не зная, так как всё в JavaScript является объектом. Небольшая заметка с MDN:
> Все примитивные типы, кроме `null` и `undefined` рассматриваются в качестве объектов. Им могут быть присвоены какие-то свойства, и они имеют все характеристики объектов.
В JavaScript существует огромное количество стандартных объектов, однако в этой статье я не буду их рассматривать. С этого момента и на протяжении всей статьи мы будем создавать очень простой JavaScript-компонент под названием «SimpleAlert». Ввиду этого давайте создадим наш собственный объект.
```
var simpleAlert = new Object();
// От переводчика: на самом деле, объект можно создать ещё проще.
var simpleAlert = {};
```
Вот и всё! Просто, не так ли? Однако, всё это не имеет смысла до тех пор, пока мы не добавим объекту какие-либо свойства. Мы можем сделать это, используя *dot notation*:
```
// создание нового объекта
var simpleAlert = new Object();
// добавление некоторых свойств
simpleAlert.sa_default = "Hello World!";
simpleAlert.sa_error = "Error...";
simpleAlert.sa_success = "Success!";
// вывод объекта в консоли
console.log(simpleAlert);
```
В консоли видно, что наш объект имеет 3 свойства. Поскольку мы задали эти свойства выше, мы можем получить доступ к ним в любом месте нашего скрипта. Например, если бы мы захотели послать в консоль пользователя уведомление об ошибке, мы могли бы сделать следующее:
```
// вывод сообщения об ошибке
alert(simpleAlert.sa_error);
```
Это всего лишь один из способов создания объекта и доступа к его свойствам.
### Создание объекта с инициализаторами
Другой способ создания объекта — с помощью так называемых *object initializer*, инициализаторов объекта. Определение на MDN:
> … вы можете создавать объекты с помощью инициализатора объекта. Использование инициализатора иногда называют созданием объекта с помощью **literal notation**. Название **object initializer** также соответствует терминологии, используемой в C++.
Создание нашего «SimpleAlert» таким способом будет весьма простым:
```
// создание нового объекта
var simpleAlert = {
sa_default : "Hello World!",
sa_error : "Error...",
sa_success : "Success!"
}
// вывод объекта в консоль
console.log(simpleAlert);
```
Свойства объекта также могут быть функциями. Например:
```
// создание нового объекта
var simpleAlert = {
sa_default : "Hello World!",
sa_error : "Error...",
sa_success : "Success!",
sa_fallback : function(){
console.log("Fallback");
}
}
// запуск fallback'a
simpleAlert.sa_fallback();
```
Код выше выведет в консоль строку «Fallback». Как уже упоминалось выше, когда свойство объекта является функцией, оно также может называться *методом*.
### Использование конструктора
Другой способ создания объекта в JavaScript — использование *функции-конструктора*. И снова цитата с MDN:
> Определите объект, написав конструктор. Хорошей практикой считается именование функции с большой буквы. Создайте экземпляр объекта, используюя ключевое слово `new`.
Вы можете прочитать больше об этом способе [здесь](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Working_with_Objects#Using_a_constructor_function). Создание нашего объекта с помощью конструктора:
```
// конструктор
function SimpleAlert( sa_default, sa_error, sa_success ) {
this.sa_default = sa_default;
this.sa_error = sa_error;
this.sa_success = sa_success;
}
// создание нового объекта
var my_alert = new SimpleAlert( "Hello World!", "Error...", "Success!" );
```
Если мы выведем объект в консоли, то мы получим тот же результат, что и в предыдущих случаях.
```
console.log(my_alert); // выведет объект
console.log(my_alert.sa_error); // выведет "Error..."
```
Изящность этого способа заключается в том, что с его помощью можно создавать несколько экземпляров объекта с разным набором свойств. Свойствами также могут быть объекты и функции.
### Ещё подробнее об объектах
На самом деле, об объектах можно рассказать гораздо больше, чем я рассказал выше. Однако методы, упомянутые мной, весьма полезны, и в дальнейшем мы будем их использовать их для создания нашего компонента. Я настойчиво рекомендую прочитать материал с MDN [Working with objects](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Working_with_Objects) для того чтобы полностью разобраться с объектами. Также стоит взглянуть на [документацию по объектам](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object), чтобы иметь представление о том, какие методы и свойства для работы с ними существуют.
Создаём части нашего компонента
-------------------------------
Мы собираемся создать компонент под названием «SimpleAlert», который выводит сообщение на экран пользователя, когда тот нажимает на кнопку. От того, какая кнопка будет нажата, зависит сообщение, которое будет выведено. Разметка для кнопок:
```
Show Default Message
Show Success Message
Show Error Message
```
Что касается самого компонента — его код мы обернем в анонимную функцию и сделаем её доступной в глобальной области видимости. Для начала это будет выглядеть как-то так:
```
;(function( window ) {
'use strict';
})( window );
```
Несколько замечаний по поводу кода:
* Я использую `strict mode`. Вы можете прочитать о нём [здесь](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions_and_function_scope/Strict_mode).
* Мы передаём `window` в нашу анонимную функцию, благодаря чему мы впоследствии сможем добавить SimpleAlert в глобальную область видимости.
Давайте напишем немного кода нашего компонента. Для начала нам нужно создать функцию `SimpleAlert`. Также нам нужно её в глобальную область видимости.
```
;(function( window ) {
'use strict';
/**
* SimpleAlert function
*/
function SimpleAlert( message ) {
this.message = message;
}
// большинство кода будет здесь...
/**
* Добавление SimpleAlert в глобальную область видимости
*/
window.SimpleAlert = SimpleAlert;
})( window );
```
Если мы создадим экземпляр объекта SimpleAlert, то пока что ничего не произойдет.
```
(function() {
/**
* Отобразить стандартное уведомление
*/
var default_btn = document.getElementById( "default" );
default_btn.addEventListener( "click", function() {
var default_alert = new SimpleAlert("Hello World!");
} );
})();
```
Прежде чем продолжить, вам следует ознакомиться с `Object.prototype`. MDN:
> Все объекты в JavaScript являются потомками `Object`; все объекты наследуют свойства и методы от `Object.prototype`, хотя они могут быть переопределены. Исключение — объект с `null`-прототипом, например `Object.create(null)`).
[Подробнее](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/prototype). Мы будем использовать этот подход в создании нашего компонента. Давайте добавим функцию `init`, и вызовем её сразу после создания объекта. Эта функция будет отправлять в консоль сообщение.
```
;(function( window ) {
'use strict';
/**
* SimpleAlert function
*/
function SimpleAlert( message ) {
this.message = message;
this._init();
}
/**
* Initialise the message
*/
SimpleAlert.prototype._init = function() {
console.log(this.message);
}
/**
* Add SimpleAlert to global namespace
*/
window.SimpleAlert = SimpleAlert;
})( window );
```
Теперь созданный экземпляр объекта будет выводить в консоль сообщение *«Hello, world!»*. Это прогресс! Теперь давайте сделаем так, чтобы сообщение выводилось на экран пользователя, а не в консоль.
```
;(function( window ) {
'use strict';
/**
* SimpleAlert function
*/
function SimpleAlert( message ) {
this.message = message;
this._init();
}
/**
* Initialise the message
*/
SimpleAlert.prototype._init = function() {
this.component = document.getElementById("component");
this.box = document.createElement("div");
this.box.className = "simple-alert";
this.box.innerHTML = this.message;
this.component.appendChild( this.box );
}
/**
* Add SimpleAlert to global namespace
*/
window.SimpleAlert = SimpleAlert;
})( window );
```
Давайте по пунктам рассмотрим работу нашего кода.
1. Мы создаём переменную `message` внутри конструктора и делаем её доступной внутри анонимной фунции с помощью `this.message = message`.
2. Далее мы вызываем нашу функцию `_init` через `this._init()`. Каждый раз когда мы создаем новый экземпляр объекта, эти два шага автоматически выполняются.
3. Внутри `_init()` мы объявляем нужные переменные с помощью ключевого слова `this`. Затем получаем доступ к элементу `#component`, и в него помещаем `div`, содержащий в себе сообщение.
Весьма аккуратно, правда?
Весь код
--------
Ниже представлен весь написанный код, включая немного CSS для более приятного внешнего вида. Для начала разметка:
```
Show Default Message
Show Success Message
Show Error Message
```
Такая же, какая была выше. Теперь немного CSS:
```
.simple-alert {
padding: 20px;
border: solid 1px #ebebeb;
}
```
Отредактируйте его так, как вам захочется! И, наконец, JS-код. В него я также добавил обработчики событий, чтобы при нажатии на кнопку сообщение корректно отображалось.
```
// COMPONENT
//
// The building blocks for our SimpleAlert component.
////////////////////////////////////////////////////////////
;(function( window ) {
'use strict';
/**
* SimpleAlert function
*/
function SimpleAlert( message ) {
this.message = message;
this._init();
}
/**
* Инициализация компонента
*/
SimpleAlert.prototype._init = function() {
this.component = document.getElementById("component");
this.box = document.createElement("div");
this.box.className = "simple-alert";
this.box.innerHTML = this.message;
this.component.appendChild( this.box );
this._initUIActions;
}
SimpleAlert.prototype._initUIActions = function() {
}
/**
* Добавляем SimpleAlert в глобальную область видимости
*/
window.SimpleAlert = SimpleAlert;
})( window );
// EVENTS
//
// Код для создания новых экземпляров объекта
// в зависимости от нажатой кнопки.
////////////////////////////////////////////////////////////
;(function() {
/**
* Show default
*/
var default_btn = document.getElementById( "default" );
default_btn.addEventListener( "click", function() {
var default_alert = new SimpleAlert("Hello World!");
} );
/**
* Show success
*/
var default_btn = document.getElementById( "success" );
default_btn.addEventListener( "click", function() {
var default_alert = new SimpleAlert("Success!!");
} );
/**
* Show error
*/
var default_btn = document.getElementById( "error" );
default_btn.addEventListener( "click", function() {
var default_alert = new SimpleAlert("Error...");
} );
})();
```
Подведём итог
-------------
В этой статье мы рассмотрели создание простого JavaScript-компонента с помощью объектов. Этот компонент прост, но его код даёт нам фундаментальные знания для создания многократно используемых и расширяемых компонентов. На досуге подумайте, как можно реализовать кнопку «закрыть оповещение» (подсказка — нажатие кнопки должно запустить метод `hide()`).
В следующей части мы немного усовершенствуем SimpleAlert, а также узнаем, как устанавливать параметры по умолчанию и как передавать собственные наборы параметров. Вот когда вся красота программирования будет видна в действии!
Я надеюсь, что вам понравилась эта статья. Ждите вторую часть. Спасибо за чтение! | https://habr.com/ru/post/240375/ | null | ru | null |
# Разработка быстрых мобильных приложений на Android. Часть вторая
В [Edison](http://www.edsd.ru/) мы часто сталкиваемся с оптимизацией мобильных приложений и хотим поделиться материалом, который считаем крайне полезным, если вы решаете одну из двух задач: а) хотите чтобы приложение меньше тормозило; б) хотите сделать красивый, мягкий и гладкий интерфейс для массового пользователя.
Предлагаем вашему вниманию первую часть перевода статьи Udi Cohen, которую мы использовали как пособие для обучения молодых коллег оптимизации под Android.
(Читать [первую часть](http://habrahabr.ru/company/edison/blog/271761/))

#### **Общие советы по работе с памятью**
Вот несколько простых рекомендаций, которые я использую при написании кода.
* **Перечисления** уже являются предметом горячих споров о производительности. Вот [видео](https://youtu.be/Hzs6OBcvNQE), в котором обсуждается размер памяти, который тратят перечисления, и [обсуждение](https://plus.google.com/+JakeWharton/posts/bTtjuFia5wm) данного видео и некоторой информации, потенциально вводящей в заблуждение. Используют ли перечисления больше памяти, чем обычные константы? Определенно. Плохо ли это? Не обязательно. Если вы пишете библиотеку и нуждаетесь в сильной типобезопасности, она могла бы оправдать их использование по сравнению с другими решениями, такими как [@IntDef](https://developer.android.com/reference/android/support/annotation/IntDef.html). Если у вас просто есть куча констант, которые могут быть сгруппированы вместе, использование перечислений будет не очень мудрым решением. Как обычно, есть компромисс, который нужно учесть при принятии решения.
* **Обёртка** — это автоматическое конвертирование примитивных типов к их объектному представлению (например, int -> Integer). Каждый примитивный тип «оборачивается» в объектное представление, создается новый объект (шокирует, я знаю). Если у нас есть много таких объектов, вызов сборщика мусора будет выполняться чаще. Легко не заметить количество оборачиваний, потому что это делается автоматически для нас при назначении примитивному типу объекта. В качестве решения, постарайтесь использовать соответствующие типы. Если вы используете примитивные типы в своем приложении, постарайтесь избежать их обёртки без реальной на то необходимости. Вы можете использовать инструменты профилирования памяти, чтобы найти объекты, представляющие примитивные типы. Вы также можете использовать Traceview и искать Integer.valueOf(), Long.valueOf() и пр.
* **HashMap vs ArrayMap / Sparse\*Array** — также, как и в случае с обёртками, использование HashMap требует использование объектов в качестве ключей. Если мы используем примитивный тип int в своем приложении, он автоматически оборачивается в Integer при взаимодействии с HashMap, в этом случае мы могли бы использовать SparseIntArray. В случае, когда мы по-прежнему используем объекты в качестве ключей, мы можем использовать ArrayMap. Оба варианта требуют меньший объем памяти, чем HashMap, но они [работают по-другому](https://www.youtube.com/watch?v=ORgucLTtTDI), что делает их более эффективными в потреблении памяти ценой уменьшения скорости. Обе альтернативы имеют меньший отпечаток памяти, чем HashMap, но время, требуемое для извлечения элемента или выделения памяти, немного выше, чем у HashMap. Если у вас нет более 1000 элементов, различия во времени выполнения не существенны, что делает жизнеспособными эти два вариантом.
* **Осознание контекста** — как вы видели ранее, относительно легко создать утечки памяти. Вы, возможно, не будете удивлены, узнав, что активити являются наиболее частой причиной утечек памяти в Android(!). Их утечки также очень дорого стоят, так как они содержат все представления иерархии их UI, которые сами по себе могут занять много места. Убедитесь в том, что понимаете, что происходит в активити. Если ссылка на объект в кэше и этот объект живет дольше, чем ваша активити, без очистки этой ссылки вы получите утечку памяти.
* **Избегайте использование нестатических внутренних классов**. При создании нестатического внутреннего класса и его экземпляра вы создаете неявную ссылку на ваш внешний класс. Если экземпляр внутреннего класса необходим на более длительный период времени, чем внешний класс, внешний класс будет продолжать находиться в памяти, даже если он больше не нужен. Например, создается нестатический класса, который наследует AsyncTask внутри класса Activity, затем происходит переход к новой асинхронной задаче и, пока она длится, завершение работы активити. Пока длится эта асинхронная задача, она будет сохранять активити живой. Решение простое — не делайте этого, объявите внутренний статический класс, если это необходимо.
#### **Профилирование GPU**
Новым добавлением в Android Studio 1.4 является профилирование GPU рендеринга.
Под окном Android перейдите на вкладку GPU, и вы увидите график, показывающий время, которое потребовалось, чтобы сделать каждый кадр на экране:
[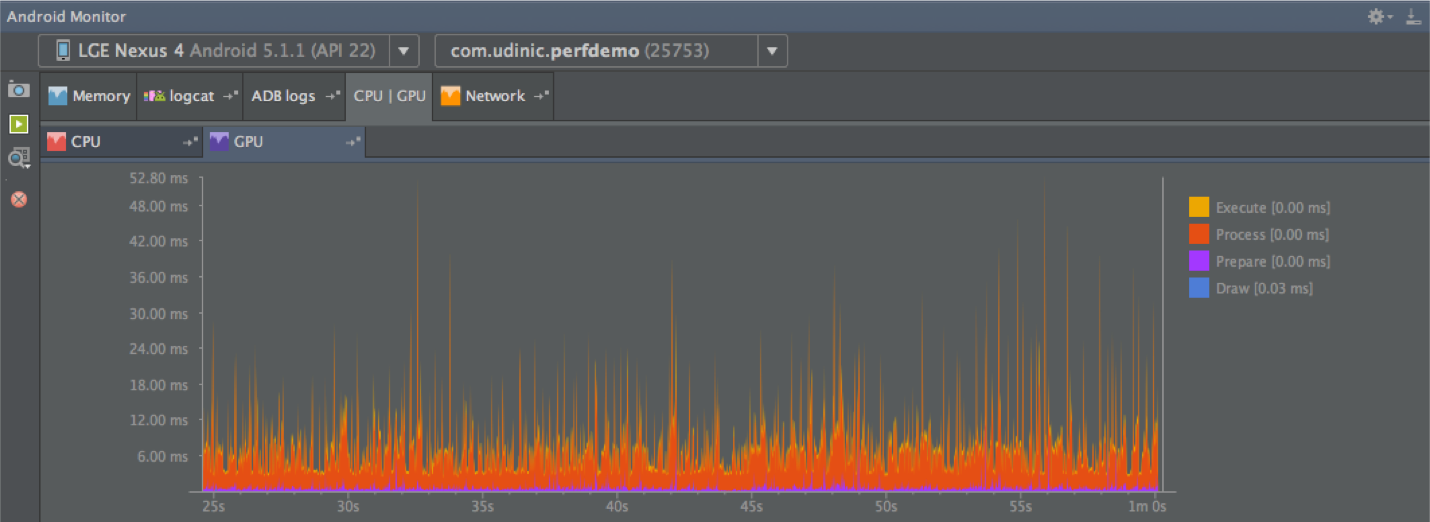](https://habrastorage.org/getpro/habr/post_images/eed/aaf/ec3/eedaafec3e549d1d967c001abeb07596.png)
Каждая панель на графике представляет собой один отрисованный кадр, а цвет представляет различные этапы процесса.
* **Draw** (синий) — представляет метод View#onDraw(). Эта часть строит/обновляет объекты DisplayList, которые затем будут конвертированы в OpenGL команды, понятные для GPU. Высокие показатели могут быть из-за сложных используемых представлений, требующих больше времени для построения их списка отображения, либо много представлений стали недействительными в короткий промежуток времени.
* **Prepare** (фиолетовый) — в Lollipop был добавлен ещё один поток, чтобы помочь отрисовывать UI быстрее. Он называется RenderThread. Он отвечает за преобразование списков отображения в OpenGL команды и отправку их графическому процессору. Как только это происходит, поток UI может переходить к обработке следующего кадра. Время, затраченное потоком UI, чтобы передать все необходимые ресурсы RenderThread, отражается на данном этапе. Если у нас длинные/тяжелые списки отображения, этот шаг может занять больше времени.
* **Process** (красный) — выполнение списков отображения для создания OpenGL команд. Этот шаг может занять больше времени, если списки длинные или сложные, потому что необходимо перерисовать множество элементов. Представление может быть перерисовано, так как стало недействительным или было открыто после передвижения скрывающего его представления.
* **Execute** (жёлтый) — отправка команд OpenGL на GPU. Этот этап может длиться долго, так как CPU отправляет буфер с командами на GPU, ожидая получить обратно чистый буфер для следующего кадра. Количество буферов ограничено, и если GPU слишком занят, процессор будет ждать, пока освободится первый. Поэтому если мы видим высокие значения на этом шаге, это может означать, что GPU был занят отрисовкой нашего интерфейса, который может быть слишком сложным, чтобы быть отрисованным за более короткое время.
В Marshmallow было добавлено больше цветов для отображения большего количества шагов, таких как Measure/Layout, Input Handing и другие:
EDIT 09/29/2015: John Reck, фреймворк инженер из Google, [добавил](https://plus.google.com/+AlexLockwood/posts/Yj23fFY7Eon) следующую информацию про некоторые из этих цветов:
> «Точное определение слова «анимация» — это всё, что зарегистрировано с Choreographer как CALLBACK\_ANIMATION. Это включает в себя Choreographer#postFrameCallback и View#postOnAnimation, которые используются view.animate(), ObjectAnimator, Transitions и другие… И да, это то же самое, что и отмечается меткой «анимация» в systrace.
>
>
>
> «Misc» это задержка между временной меткой vsync и текущей временной меткой, когда он был получен. Если вы уже видели логи из Choreographer «Missed vsync by blabla ms skipping blabla frames», сейчас это будет представлено как “misc”. Существует различие между INTENDED\_VSYNC и VSYNC в framestats dump (https://developer.android.com/preview/testing/performance.html#timing-info).»
Но перед тем как начать использовать эту возможность, нам необходимо включить режим GPU рендеринга в меню разработчика:
This will allow the tool to use ADB commands to get all the information it needs, and so are we (!), using:
```
adb shell dumpsys gfxinfo
```
можем получить информацию и построить график самостоятельно. Команда выведет полезную информацию, такую как число элементов в иерархии, размер всех списков отображения и прочее. В Marshmallow мы получим больше информации.
Если у нас есть автоматизированное тестирование UI нашего приложения, мы можем сделать сборку, запускающую эту команду после определенных действий (прокрутка списка, тяжелая анимация и др.) и увидеть, есть ли изменения в значениях, таких как «Janky Frames», с течением времени. Это может помочь определить упадок производительности после нескольких изменений в коде, позволяя нам устранить проблему, пока приложение не вышло на рынок. Мы можем получить еще более точную информацию, когда используем ключевое слово «framestats», как это показано [здесь](https://developer.android.com/preview/testing/performance.html).
Но это не единственный способ увидеть такой график!
Как видно в меню разработчика «Profile GPU Rendering», есть также вариант “On screen as bars”. Его выбор покажет график для каждого окна на вашем экране вместе с зеленой линией, указывающей на порог 16 мс.
[](https://habrastorage.org/getpro/habr/post_images/665/46f/8ef/66546f8ef1549720f6fbaa169dfe8d3f.png)
На примере справа мы можем видеть, что некоторые фреймы пересекают зеленую линию, что означает, что они требуют более 16мс для отрисовки. Поскольку синий цвет, кажется, доминирует, мы понимаем, что было много представлений для отрисовки, или они были сложными. В этом случае, я прокручиваю ленту, которая поддерживает различные типы представления. Некоторые элементы становятся недействительными, а некоторые — более сложными по сравнению с другими. Возможно, причина, по которой некоторые кадры пересекли эту черту, в том, что попался сложный для отображения элемент.
#### **Hierarchy Viewer**
Я обожаю этот инструмент, и мне очень жаль, что многие его не используют!
Используя Hierarchy Viewer, мы можем получить статистику производительности, увидеть полную иерархию представления на экране и иметь доступ ко всем свойствам элемента. Вы также можете сделать дамп всех данных темы, увидеть все параметры, используемые для каждого атрибута стиля, но это возможно только если Hierarchy Viewer запущен standalone, не из Android Monitor. Я использую этот инструмент, когда создаю макеты приложения и хочу оптимизировать их.
[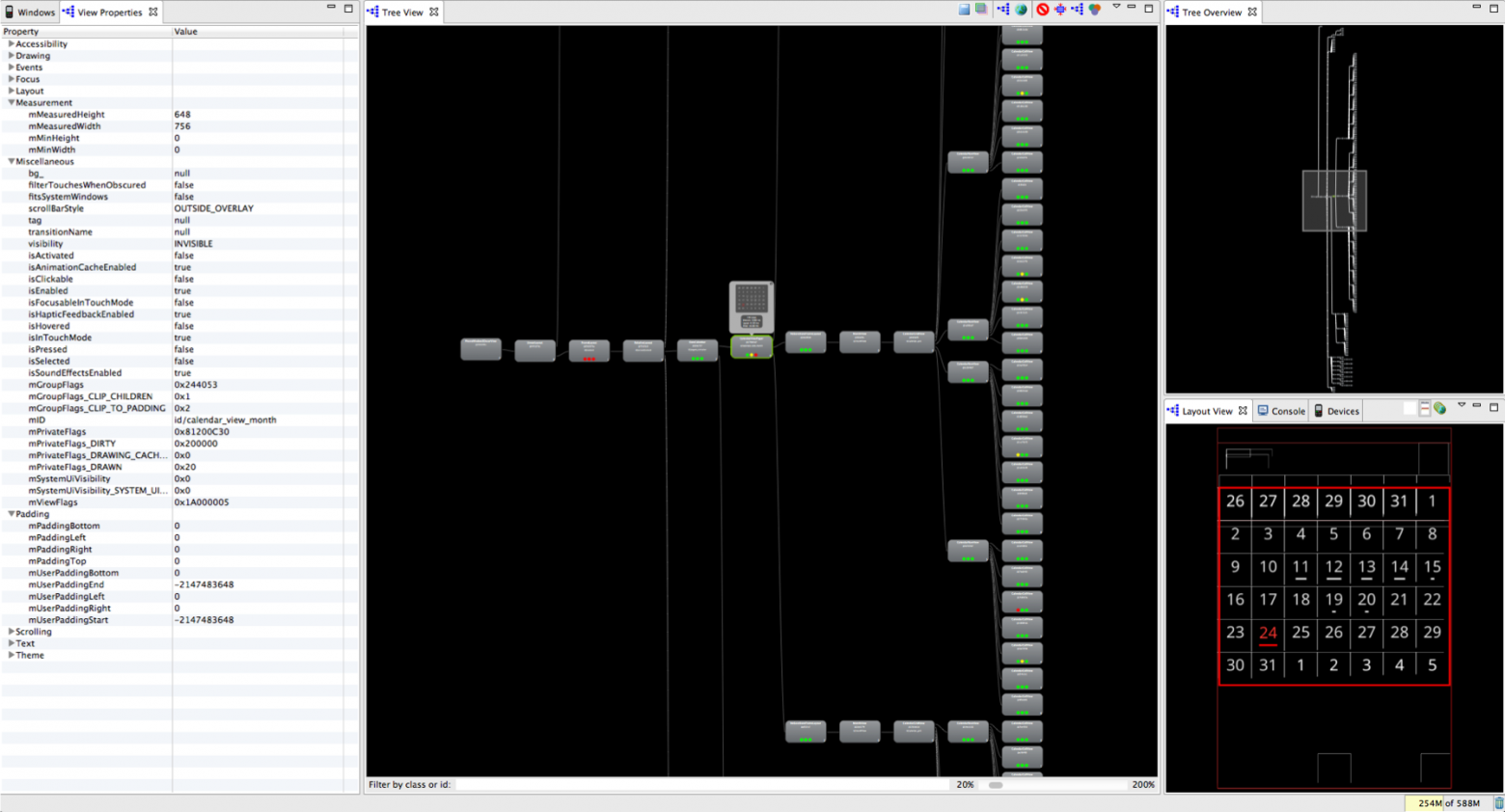](https://habrastorage.org/getpro/habr/post_images/0b2/4bf/caf/0b24bfcaf1d3ca92b047ac00f6a82aaa.png)
По центру мы можем видеть дерево, отражающее иерархию представления. Иерархия представления может быть широкой, но если она слишком глубокая (~10 уровней), это может нам дорого стоить. Каждый раз, когда происходит измерения представления в View#onMeasure(), или когда размещаются его потомки в View#onLayout(), эти команды распространяются на потомков этих представлений, делая то же самое. Некоторые макеты будут делать каждый шаг дважды, например, RelativeLayout и некоторые LinearLayout конфигурации, и если они вложены — число проходов увеличивается в геометрической прогрессии.
В нижнем правом углу мы можем видеть «план» нашего макета, отмечая, где каждое представление располагается. Мы можем выбрать представление здесь, или на дереве и увидеть слева все свойства. При проектировании макета я иногда не уверен, почему определенное представление заканчивается там, где оно заканчивается. Используя этот инструмент, я могу отследить на дереве, выбрать его и увидеть, где он находится в окне предварительного просмотра. Я могу сделать интересные анимации, глядя на итоговые измерения представлений на экране, и использовать эту информацию, чтобы точно размещать элементы вокруг. Я могу найти потерянные представления, которые были перекрыты другими представлениями непреднамеренно.
[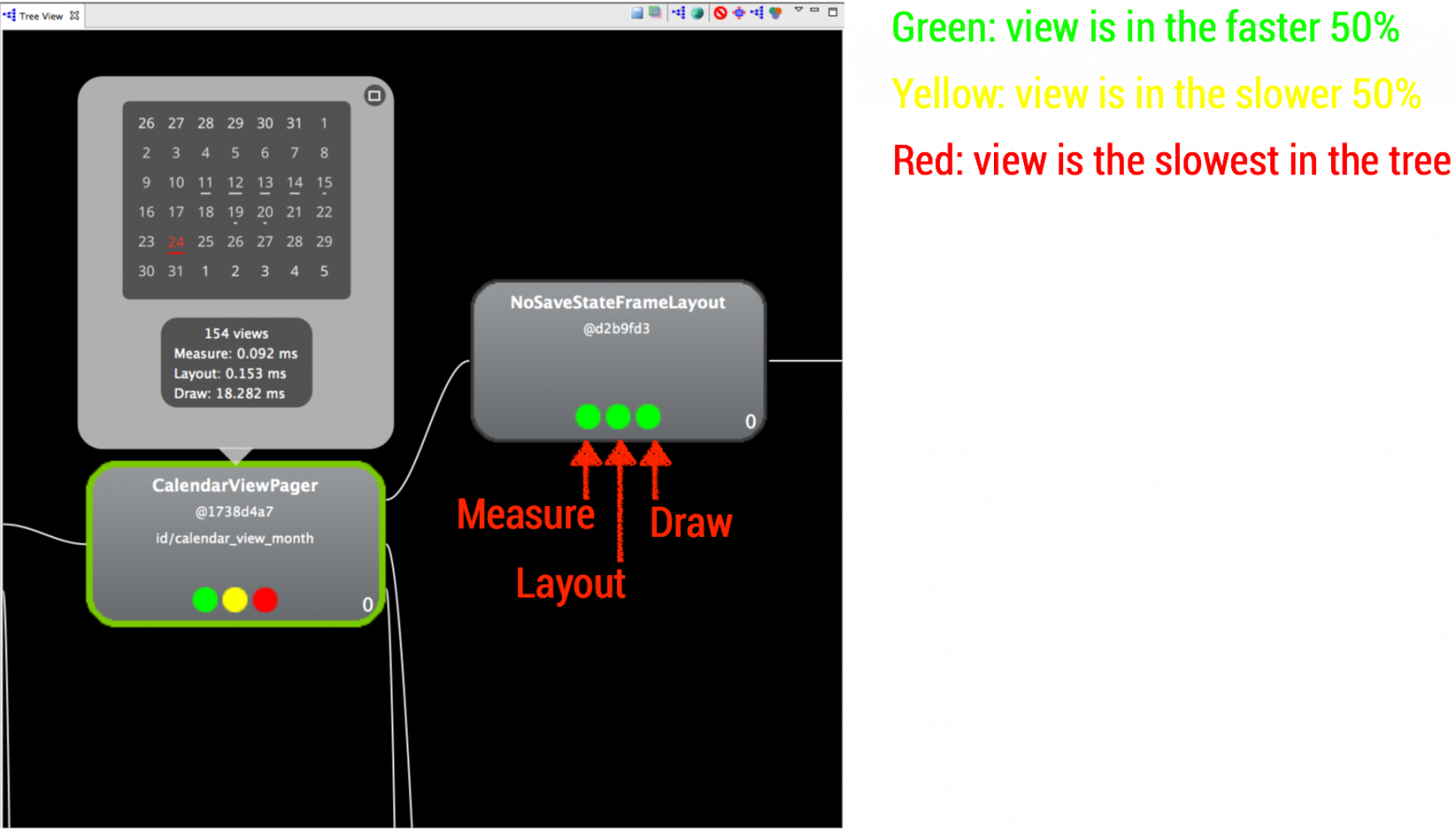](https://habrastorage.org/getpro/habr/post_images/35f/630/c3a/35f630c3af834ace323cf28b87459fe5.png)
Для каждого представления у нас есть время, которое потребовалось для измерения/создания макета/отрисовки его и всех его потомков. Цвета отражают, как эти представления выполняются в сравнении с другими представлениями в дереве, это отличный способ найти слабое звено. Поскольку мы также видим предпросмотр представления, мы можем пройти по дереву и следовать инструкциям, создающим их, находя лишние шаги, которые мы могли бы удалить. Одна из таких вещей, которая влияет на производительность, называется Overdraw.
#### **Overdraw**
Как видно в разделе профилирования GPU — фаза Execute, представленная желтым цветом на графике, может занять больше времени, чтобы завершиться, если GPU должен отрисовать много элементов, увеличивая время, требуемое для отрисовки каждого кадра. Overdraw происходит когда мы рисуем что-то поверх чего-то другого, например желтую кнопку на красном фоне. GPU требуется нарисовать, во-первых, красный фон и затем желтую кнопку поверх него, что делает неизбежным overdraw. Если у нас слишком много слоев overdraw, это может стать причиной, по которой GPU работает интенсивнее и не успевает в 16 мс.
[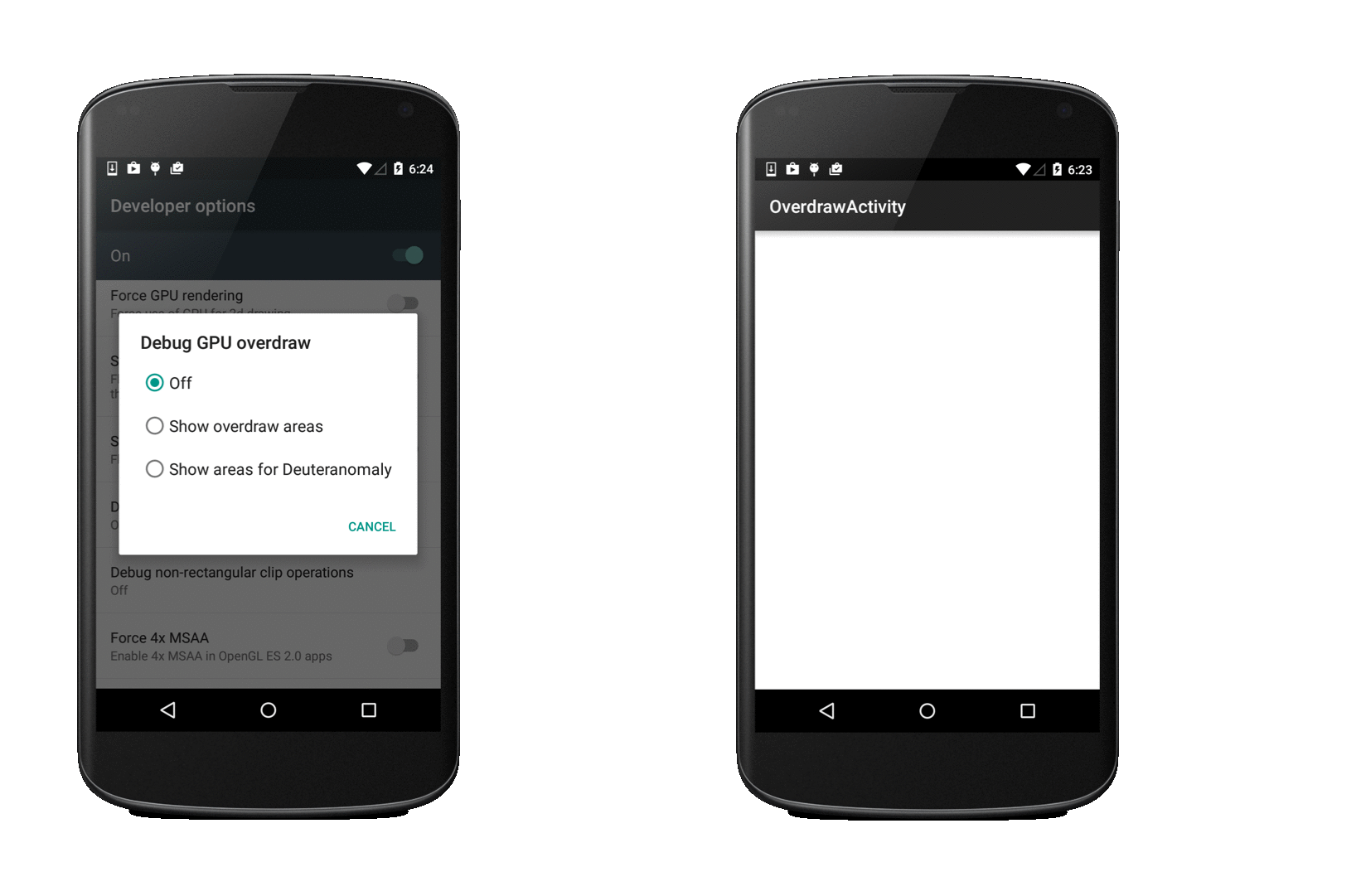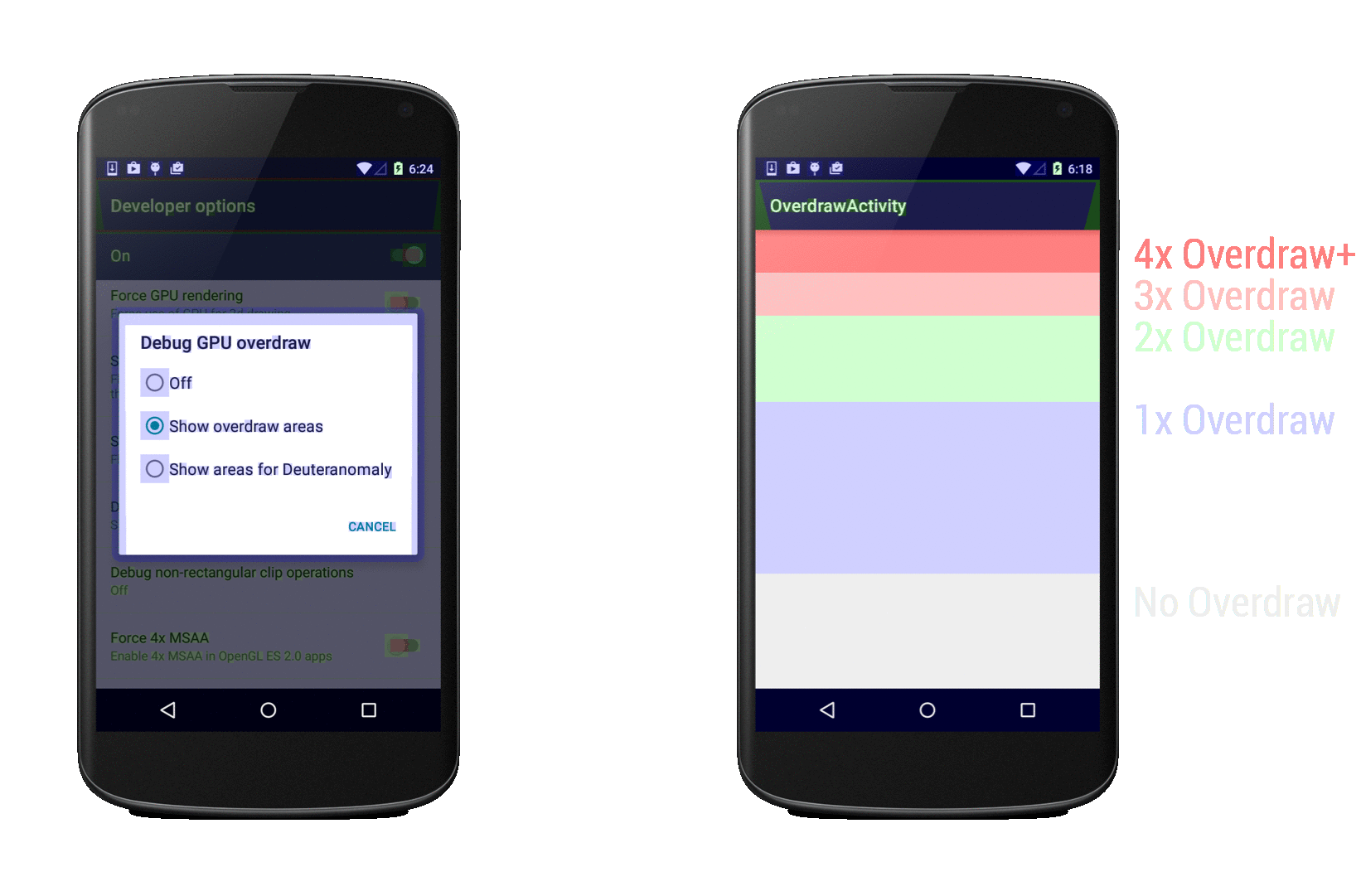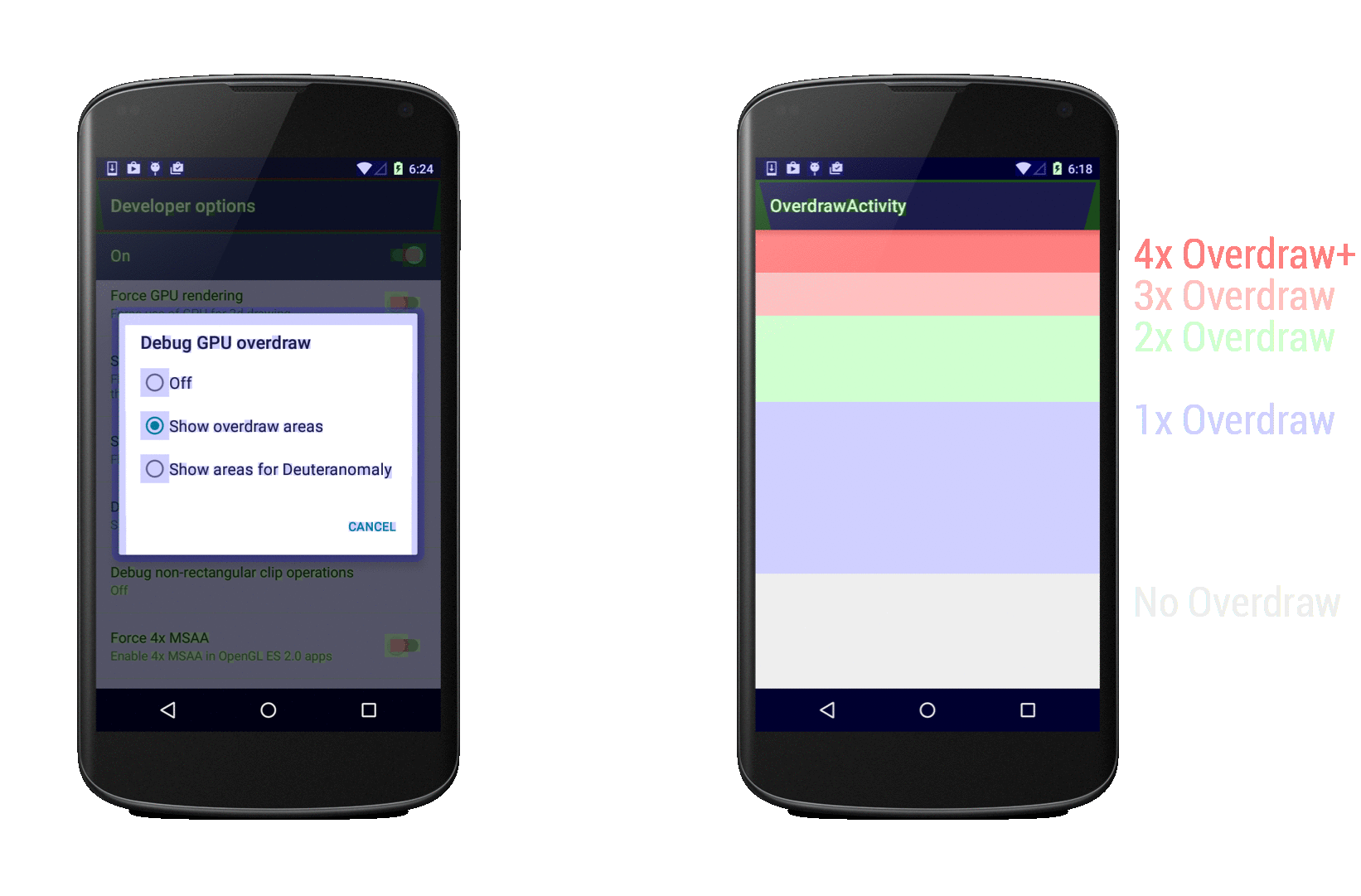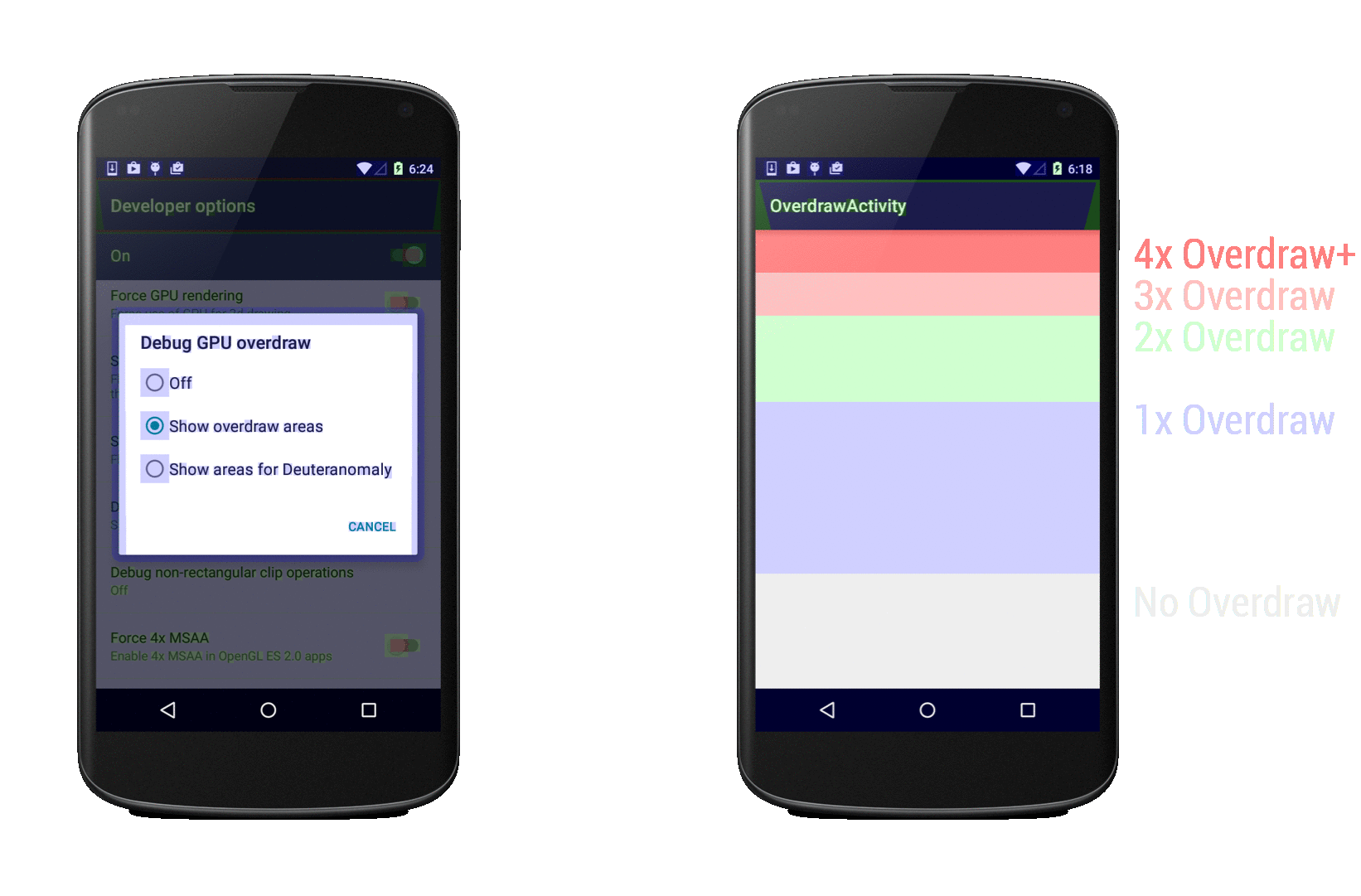](https://habrastorage.org/getpro/habr/post_images/ec4/829/96d/ec482996dca6f9697e79d55e085663de.gif)
Используя настройку «Debug GPU Overdraw» в меню разработчика, все overdraw будут подкрашены, чтобы продемонстрировать степень overdraw в данной области. Если overdraw имеет степень 1x/2x, это нормально, даже небольшие красные области это тоже неплохо, но если мы имеем слишком много красных элементов на экране, вероятно у нас есть проблема. Давайте посмотрим на несколько примеров:
[](https://habrastorage.org/getpro/habr/post_images/130/550/1e5/1305501e5cc7be899e43da3550042975.png)
На примере слева присутствует список, окрашенный зеленым, обычно это нормально, но здесь есть overdraw наверху, который делает экран красным, и это уже становится проблемой. На примере справа весь список светло-красный. В обоих примерах есть непрозрачный список с 2x/3x степенью overdraw. Эти может случиться, если есть фоновый цвет на весь экран в окне, которое перекрывает ваш активити или фрагмент, а также на представлении списка и представлении каждого его элемента.
Заметьте: тема по умолчанию задает фоновый цвет для всего вашего окна. Если у вас есть активити с непрозрачным макетом, который перекрывает весь экран, вы можете убрать задний фон для этого окна, чтобы убрать один слой overdraw. Это может быть сделано в теме или в коде путем вызова getWindow().setBackgroundDrawable(null) в onCreate().
Используя Hierarchy Viewer, вы можете экспортировать все ваши слои иерархии в PSD файл, чтобы открыть его в Photoshop. В результате исследования различных слоев будут раскрыты все overdraw в макете. Используйте эту информацию, чтобы убрать избыточные overdraws, и не соглашайтесь на зеленый, стремитесь к голубому!
#### **Альфа**
Использование прозрачности может повлиять на производительность, и для того, чтобы понять — почему, давайте посмотрим, что происходит при установке параметра альфа в представлении. Рассмотрим следующую структуру:
[](https://habrastorage.org/getpro/habr/post_images/5c6/6b8/807/5c66b8807ef509f1289c80823227a9f7.png)
Мы видим макет, который содержит 3 ImageView, которые перекрывают друг друга. В прямой реализации, устанавливая альфа с помощью setAlpha(), будет вызвана команда, чтобы распространиться на всех представления потомков, ImageView в данном случае. Затем эти ImageView будут нарисованы с параметром alpha в буфере кадра. Результат:
[](https://habrastorage.org/getpro/habr/post_images/c67/957/d0f/c67957d0fe61dafcd6ebeb8d530ddd54.png)
Это не то, что мы хотим видеть.
Поскольку каждый ImageView был отрисован со значением альфа, все перекрывающиеся изображения сольются. К счастью, у ОС есть решение такой проблемы. Макет будет скопирован в отдельный off-screen буфер, альфа будет применяться в этом буфере в целом и результат будет скопирован в буфер кадра. Результат:
[](https://habrastorage.org/getpro/habr/post_images/afd/0bf/c64/afd0bfc6437b1a02afb4f9299901b392.png)
Но… мы заплатим за это свою цену.
Дополнительная отрисовка представления в off-screen буфере до того, как это будет сделано в буфере кадра, добавляет еще один незаметный overdraw слой. ОС не знает, когда именно использовать этот или прямой подход раньше, так что по умолчанию всегда использует один комплексный. Но есть еще способы, позволяющие установить альфа и избежать сложностей с добавлением off-screen буфера:
* **TextViews** — используйте setTextColor() вместо setAlpha(). Использование канала альфа для текста приведет к тому, текст будет перерисован.
* **ImageView** — используйте setImageAlpha() вместо setAlpha(). Те же причины, что и для TextView.
* **Пользовательские представления** — если наше пользовательское представление не поддерживает перекрытия, это комплексное решение не имеет для нас значение. Нет способа, которым наши представления-потомки будут соединены вместе, как это показано на примере выше. Переопределив метод hasOverlappingRendering() таким образом, чтобы он возвращал false, мы сигнализирует ОС взять непосредственно путь к нашему представлению. Также есть вариант вручную обрабатывать то, что происходит при установке альфа путем переопределения метода onSetAlpha() так, чтобы он возвращал true.
#### **Аппаратное ускорение**
Когда аппаратное ускорение было включено в Honeycomb, мы получили новую модель отрисовки для отображения нашего приложения на экране. Это включает структуру DisplayList, которая записывает команды отрисовки представления для более быстрого получения изображения. Но есть еще другая интересная особенность, о которой разработчики обычно забывают — уровни представления.
Используя их, мы можем отрисовывать представление в off-screen буфере (как мы видели ранее, когда использовали альфа-канал) и манипулировать с ним как мы пожелаем. Это отлично подходит для анимации, поскольку мы можем анимировать сложные представления быстрее. Без уровней анимация представлений стала бы недоступной после изменения свойств анимации (таких как x-координата, масштаб, альфа-значение и др.). Для сложных представлений эта неспособность распространяется на представления потомков, и они в свою очередь будут перерисовывать себя, что является дорогостоящей операцией. Используя уровни представления, опираясь на аппаратные средства, текстура для нашего представления создается в графическом процессоре. Существует несколько операций, которые мы можем применить к текстуре, без необходимости её замены, такие как изменение положения по осям x/y, вращение, альфа и другие. Всё это означает, что мы можем анимировать сложные представления на нашем экране без их замены в процессе анимации! Это делает анимацию более гладкой. Вот пример кода, демонстрирующий, как это можно сделать:
```
// Using the Object animator
view.setLayerType(View.LAYER_TYPE_HARDWARE, null);
ObjectAnimator objectAnimator = ObjectAnimator.ofFloat(view, View.TRANSLATION_X, 20f);
objectAnimator.addListener(new AnimatorListenerAdapter() {
@Override
public void onAnimationEnd(Animator animation) {
view.setLayerType(View.LAYER_TYPE_NONE, null);
}
});
objectAnimator.start();
// Using the Property animator
view.animate().translationX(20f).withLayer().start();
```
Просто, верно?
Да, но есть несколько моментов, о которых нужно помнить при использовании аппаратного уровня.
* **Делайте очистку** после работы вашего представления — аппаратный уровень использует место на ограниченном пространстве памяти на вашем GPU. Попробуйте использовать его только в случаях, когда он нужны, например, в анимации, и делайте очистку после. В примере выше с ObjectAnimator я использовал метод withLayers(), который автоматически создает слой в начале и удаляет его, когда анимация заканчивается.
* Если вы **изменяете ваше представление** после использования аппаратного уровня, это приведет к его непригодности и придется вновь воспроизводить представление на off-screen буфере. Это произойдет, когда изменится свойство, не оптимизированное для аппаратного уровня (на данный момент оптимизированы: поворот, масштабирование, передвижения по осям x/y, альфа). Например, если вы анимируете представление, используя аппаратный уровень, и двигаете представление по экрану, пока обновляется цвет фона, это приведет к постоянным обновлениям на аппаратном уровне. Это требует дополнительных расходов, которые могут сделать его использование неоправданным.
Для второго случая есть способ визуализировать это обновление. Используя настройки разработчика, мы можем активировать “Show hardware layers updates”.
После этого представление будет подсвечивается зеленым цветом при обновления на аппаратном уровне. Я использовал это некоторое время назад, когда у меня был ViewPager, который не пролистывал страницы с тем сглаживанием, которое я ожидал. После того, как я включил эту опцию, я вернулся назад и пролистал ViewPager, и вот что я увидел:
[](https://habrastorage.org/getpro/habr/post_images/054/16c/cd5/05416ccd594f1600dc7e9f7c41345d2e.gif)
Обе страницы были зелеными на протяжении всей прокрутки!
Это означает, что для оптимизации страниц использовался аппаратный уровень, и страницы приходили в негодность, когда мы пролистывали ViewPager. Я обновил страницы и пролистал их, используя параллакс-эффект на заднем фоне и постепенно оживил элементы на странице. Что я не сделал, так это не создал аппаратный слой для страниц ViewPager. После изучения кода ViewPager я обнаружил, что когда пользователь начинает пролистывание, на аппаратном уровне создаются обе страницы и удаляются после того, как пролистывание заканчивается.
В то время как имеет смысл использовать аппаратные уровни для пролистывания страниц, в моем случае это не подошло. Обычно страницы не изменяются, когда мы пролистываем ViewPager, и поскольку они могут быть достаточно сложными, аппаратный уровень помогают делать отрисовку гораздо быстрее. В приложении, над которым я работал, это было не так, и я убрал этот аппаратный слой, используя небольшой [хак, который я написал сам.](http://blog.udinic.com/2013/09/16/viewpager-and-hardware-acceleration)
Аппаратный слой — не серебряная пуля. Важно понимать, как он работает, и использовать должным образом, иначе вы можете столкнуться с большой проблемой.
#### **Сделай сам**
При подготовке для всех этих примеров, показанных здесь, я написал множество кода для симуляции этих ситуаций. Вы можете найти их на [репозитории Github](https://github.com/Udinic/PerformanceDemo), а также на [Google Play](https://play.google.com/store/apps/details?id=com.udinic.perfdemo). Я разделил сценарии для различных активити, и старался задокументировать их насколько возможно, чтобы помочь понять, с какого рода проблемами вы можете столкнуться, используя активити. Прочтите документацию по активити, откройте инструменты и поиграйте с приложением.
#### **Больше информации**
По мере развития ОС Android развиваются и способы, с помощью которых вы можете оптимизировать ваши приложения. Новые инструменты вводятся в Android SDK, добавляются и новые функции в ОС (например, аппаратные уровни). Очень важно осваивать новое и изучать компромиссы, прежде чем решить что-то изменить.
Есть замечательный плейлист на YouTube, который называется [Android Performance Patterns](https://www.youtube.com/playlist?list=PLOU2XLYxmsIKEOXh5TwZEv89aofHzNCiu), с множеством коротких видео от Google, объясняющими различные вещи, связанные с производительностью. Вы можете найти сравнения между различными структурами данных (HashMap vs ArrayMap), оптимизацию Bitmap и даже про оптимизацию сетевых запросов. Я очень рекомендуют посмотреть всех их.
Вступите в [Android Performance Patterns Google+ community](https://plus.google.com/communities/116342551728637785407) и обсуждайте производительность с другими участниками, включая сотрудников Google, чтобы поделиться идеями, статьями и вопросами.
#### **Другие интересные ссылки**
* Изучите, как работает [Graphics Architecture in Android](http://source.android.com/devices/graphics/architecture.html). Там есть все, что вам надо знать про отрисовку вашего UI в Android, объясняются различные системные компоненты, такие как SurfaceFlinger, и как они все друг с другом взаимодействуют.
* [Talk from Google IO 2012](https://www.youtube.com/watch?v=Q8m9sHdyXnE) показывает как работает модель отрисовки и как/почему мы получаем мусор, когда наше UI отрисовывается.
* Android Performance Workshop talk из Devoxx 2013 демонстрирует некоторые оптимизации, которые были сделаны в Android 4.4 в модели отрисовки, и представляет различные инструменты для оптимизации производительности (Systrace, Overdraw и др.).
* Замечательный пост о [Профилактической оптимизации](https://medium.com/google-developers/the-truth-about-preventative-optimizations-ccebadfd3eb5), и чем она отличаются от Преждевременной оптимизации. Многие разработчики не оптимизируют свой код, потому что они думают, что это изменение незначительно. Одна мысль, которую вы должны запомнить, это то, что все это в сумме становится [большой проблемой](https://plus.google.com/105051985738280261832/posts/YDykw2hstUu). Если у вас есть возможность оптимизировать только небольшую часть кода, это может показаться незначительным, не исключаю.
* [Управление памятью в Android](https://www.youtube.com/watch?v=_CruQY55HOk) — старое видео с Google IO 2011, которое всё еще актуально. Оно демонстрирует, как Android управляет памятью наших приложений, и как использовать инструменты, такие как Eclipse MAT, чтобы выявить проблемы.
* [Тематическое исследование](http://www.curious-creature.com/docs/android-performance-case-study-1.html), сделанное инженером Google Romain Guy, для оптимизации популярного twitter-клиента. В этом исследовании Romain показывает, как он нашел проблемы производительности в приложении и что он рекомендует сделать, чтобы исправить их. [Вот следующий пост](http://www.curious-creature.com/2015/03/25/android-performance-case-study-follow-up/), демонстрирующий другие проблемы, после того как оно было переработано.
Я надеюсь, у вас теперь есть достаточно информации, и больше уверенности, чтобы начать оптимизацию приложений уже сегодня!
Начните трассировку, или включите некоторые другие доступные опции разработчика, и просто начните с них. Предлагаю поделиться вашими мыслями в комментариях. | https://habr.com/ru/post/271811/ | null | ru | null |
# Я твой WAF payload шатал
Пару недель назад команда Vulners опубликовала сравнение нескольких популярных WAF. Поймав себя на мысли - "а как оценивать качество его работы?", я решил разобрать подробнее тему security-тестов и критериев оценки Web Application Firewall. Статья пригодится, в первую очередь, тем, кому интересна тема веб-безопасности, ровно как и счастливым обладателям WAF.
### Критерии оценки
Сравнивая различные решения, мы привыкли ориентироваться на показатели скорости и стабильности работы, удобства настройки, управления, обновления и масштабирования. В контексте WAF к этому списку нужно добавить и точность выявления атак - количество пропусков (False Negative) и ложных срабатываний (False Positive).
### Зоопарк из UTF-8
Чтобы понять, сколько тонкостей существует при анализе запросов, рассмотрим в качестве примера особенность работы с UTF-8. Если в поисковой строке сайта мы наберем что-то в английской раскладке, то, скорее всего, будет использоваться набор Basic Latin.
UTF-8: Basic LatinПри этом запрос, который будет передаваться в веб-приложение, выглядит следующим образом: `GET /?s=test`
Ищем "test", фиксируем выводТеперь попробуем использовать набор символов из Halfwidth and Fullwidth Forms (ищем тот же test, только с другим набором символов).
UTF-8: Halfwidth and Fullwidth FormsВыглядит так, будто мы использовали пробел между символами, но на самом деле - нет.
Используем другой набор символов и получаем тот же результат в поисковой выдачеЗапрос (в URLencode): `GET /?s=%EF%BD%94%EF%BD%85%EF%BD%93%EF%BD%94`
При этом оба запроса (с разными наборами символов) приведут к выводу одного и того же результата - объекта, содержащего вхождение "test".
Меняем "test" на "tes1", чтобы убедиться в корректности работы поиска - ничего не выводитсяСперва мы подумали, что само веб-приложение (проверяли на WordPress, но отработает и на других) производит нормализацию данных до Basic Latin, но в итоге выяснили, что данные передаются без нормализации напрямую в БД. Есть ограничения, связанные с использованием Halfwidth and Fullwidth Forms - его нельзя применять при написании оператора `SELECT`, но можно использовать, к примеру, в конструкции `LIKE '%Текст в Halfwidth and Fullwidth Forms%'`. Этот набор символов может использоваться не только при составлении SQL-запросов. Есть примеры его применения при поиске XSS и т.д.
Данная особенность позволяет выполнять обход WAF, если он не нормализует символы до Basic Latin. Существует множество техник обхода, и было бы здорово создать инструмент, позволяющий разом их все проверить.
WAF Bypass: инструментарий
--------------------------
На github можно найти множество решений, позволяющих тестировать WAF, есть даже специальные аккаунты, производящие сбор такого инструментария, например [waflib](https://github.com/waflib).
Помимо основного Unit-теста, который используем для тестирования Nemesida WAF перед каждым релизом (тест на каждую версию ОС занимает примерно 30 часов), мы разработали собственный [waf-bypass](https://github.com/nemesida-waf/waf-bypass), позволяющий оценить точность выявления атак. Но всегда интересно и полезно проверить работу продукта с использованием сторонних решений, поэтому в качестве второго (а в рамках этой статьи - основного) инструмента я выбрал [Go Test WAF](https://github.com/wallarm/gotestwaf), размещенный в git-репозитории пользователя wallarm.
Для использования [waf-bypass](https://github.com/nemesida-waf/waf-bypass), написанного на Python3, необходимо клонировать проект, установить зависимости и запустить скрипт:
```
git clone https://github.com/nemesida-waf/waf_bypass.git /opt/waf-bypass/
python3 -m pip install -r /opt/waf-bypass/requirements.txt
python3 /opt/waf-bypass/main.py --host='example.com'
```
Если следовать документации, [Go Test WAF](https://github.com/wallarm/gotestwaf) можно запускать из докер-контейнера, что я и сделал:
```
docker build . --force-rm -t gotestwaf
docker run gotestwaf --url='http://example.com'
```
Если проводить сравнение инструментов исходя из их использования, то Go Test WAF работает быстрее (за счет многопоточности) и содержит небольшой набор для проверки False Positive. Учтем это в следующих релизах waf-bypass.
Вижу цель, иду к ней!
---------------------
Тестировать буду 2 версии: [Nemesida WAF](https://waf.pentestit.ru) (полноценную с машинным обучением) и Nemesida WAF Free (бесплатную, но только с сигнатурным анализом).
Когда увидел результаты тестов WAFВ обзоре [Vulners](https://blog.vulners.com/2021/01/21/payload-detection-waf-challenge/) в финальной таблице максимальным результатом WAF, полученным путем тестирования Go Test WAF, являлось значение 83.06%, при этом ModSecurity набрал 49.82%. Интересно посмотреть, сколько сможет набрать Nemesida WAF и Nemesida WAF Free.
### Nemesida WAF Free bypass
Напомню, анализ в Nemesida WAF Free производится только сигнатурным методом, при этом эта версия имеет качественно написанную и автоматически обновляемую базу сигнатур (ознакомиться с которой можно по [ссылке](https://rlinfo.nemesida-security.com/)), а также **Личный кабинет** (также устанавливается локально) - веб-интерфейс для визуализации событий. Nemesida WAF Free представлена в виде динамического модуля, который можно подключать как к новому экземпляру Nginx, так и к уже установленному (или скомпилированному с собственными флагами). Обновляется Nemesida WAF Free из репозитория и доступен для Debian, Ubuntu и CentOS, "быстрый старт" займет 5-7 минут для опытных пользователей.
Часть содержимого первой страницы Личного кабинета Nemesida WAF FreeЗапускаем Go Test WAF, смотрим результаты.
Nemesida WAF Free: GoTestWAF45.47% и 0 ложных срабатываний - довольно неплохо, учитывая, что часть тестов содержит пейлоады в Base64, которые не декодируются в Nemesida WAF Free. Теперь ловким движением руки и не меняя настроек Nemesida WAF Free, проверим его с помощью waf-bypass:
Nemesida WAF Free: waf-bypass325 пропусков и 1054 заблокированных пейлоадов. Пытаемся запомнить результаты и двигаемся дальше.
### Nemesida WAF bypass
Помимо функционала нормализации данных, Nemesida WAF позволяет производить декодирование запросов в различных кодировках, в том числе и в Base64, поэтому было особенно интересно, какой скор он сможет набрать. Начнем с waf-bypass, запускаем, смотрим результаты:
Nemesida WAF: waf-bypass4 пропуска, остальные запросы заблокированы. Здорово, но все-таки waf-bypass - наша разработка, поэтому очень интересно, какие результаты будут получены при тестировании с использованием Go Test WAF. Запускаем Go Test WAF, смотрим результаты:
Nemesida WAF: gotestwafПроверка заняла немного больше времени, но и показатели в 2 раза лучше - 94.45%, и на 11.39% выше, чем наилучший результат в обзоре Vulners. Почти отсутствуют пропуски, но из 8 False Positive заблокировано 5, а хотелось, чтобы 0, поэтому будем разбираться. Сперва посмотрим содержимое всех [8](https://github.com/wallarm/gotestwaf/blob/master/testcases/false-pos/texts.yml) FP-запросов:
```
- union was a great select
- 'h2
```
Из них ошибочно заблокированные:
```
- f971e9ace6=union was a great select
- 24d85a0990=D'or 1st parfume
- 48105a7f77=john+or@var.es
- 18196a6191=DEAR FINN,--I think it would do; copy should reach us second post
- e7e5421304=The Senora found herself a heroine; more than that, she became aware
```
Чтобы понять, почему запросы были заблокированы, нужно понимать, как работает модуль машинного обучения в Nemesida WAF - построение моделей происходит за счет использования 2-х наборов обучающих выборок - базы атак и базы условно чистого трафика. Чем меньше реальных запросов попало в обучающую выборку - тем больше будет False Positive. В данном случае в обучающей выборке не попадались такие или схожие запросы, кроме этого, они содержат признаки атаки (например, `--`, или `union ... select`, или `'or`), поэтому были заблокированы. Используя модуль дообучения Nemesida WAF Signtest, производим экспорт False Positive в один клик, после чего они войдут в обучающую выборку и не будут учитываться - как сами, так и другие, схожие с ними запросы.
Запускаем тест заново:
")Nemesida WAF: gotestwaf (с FP в обучающей выборке)Несмотря на то, что содержимое запросов имеет динамический контент `24d85a0990` в `24d85a0990=D'or 1st parfume`, ложные срабатывания отсутствуют, при этом количество пропусков не изменилось. Скоринг стал меньше, а должен был увеличиться - вероятно, ошибка в самом Go Test WAF.
Чтобы разобраться в пропусках, я настроил журналирование Nginx таким образом, чтобы фиксировать содержимое запросов, не получивших код ответа 403:
Расширенное журналирование NginxЕсли вы хотите проверить, какие запросы не были заблокированы - активируйте расширенное журналирование в Nginx:
1. В секцию `http {}` добавив:
***logformat extended '$msec $requesttime $timeiso8601 $timelocal $requestid $status $remoteaddr $scheme $host $request $httphost $httpcookie $httpuseragent $contentlength $contenttype $httporigin $requestbody\n';***
и
`map $status $loggable { 403 0; default 1; }`
2. В секцию `server {}` файла виртуального хоста (например, /etc/nginx/conf.d/1.conf) добавив:
`access_log /var/log/nginx/extended_access.log extended if=$loggable;`
После перезапуска Nginx в /var/log/nginx/extended\_access.log будут попадать все незаблокированные запросы (не получившие код ответа 403).
Фактически пропусков было всего 3, и об их критичности судите сами:
`GET /AEAEAFAEAEAFetcAFpasswd`
`GET / QUIT /`
`GET /foo_bar=foo bar=foo[barfoo[bar`
Визуализация атак: графики, поиск, отчеты
-----------------------------------------
Вне зависимости от того, используется ли Nemesida WAF или Nemesida WAF Free, к любому из них можно подключить Личный кабинет - веб-интерфейс, позволяющий визуализировать работу модулей:
Личный кабинет: графики и диаграммыЛичный кабинет: графики и диаграммыЛичный кабинет: графики и диаграммыNemesida WAF: информация об атакахВ Личном кабинете есть и другие разделы - информация по атакам методом перебора и SMS-флуде, статистика работы сканера уязвимостей и т.д. Также можно выгрузить общий отчет в формате PDF или CSV. Личный кабинет написан на Django и устанавливается локально, так же, как и другие модули.
#### Демонстрационный стенд:
[demo.lk.nemesida-security.com](https://demo.lk.nemesida-security.com/) (demo@pentestit.ru / pentestit)
И пока на версусе решают, кто из них круче...
---------------------------------------------
Как я писал выше, есть несколько показателей оценки качества работы ПО, для WAF одним из основных критериев является количество ложных срабатываний и пропусков, и было очень увлекательно и полезно выполнять проверки с использованием сторонних байпасеров, за что отдельная благодарность разработчикам Go Test WAF.
Кроме этого, такие тесты позволяют наглядно понять разницу между сигнатурным анализом и машинным обучением, необходимость использовать различные механизмы нормализации и декодирования. Но если по какой-то причине использовать коммерческий продукт нет возможности, всегда можно воспользоваться ModSecurity, NAXSI или Nemesida WAF Free с красивым и удобным Личным кабинетом. Nemesida WAF Free доступен в виде установочных дистрибутивов для Debian/Ubuntu/CentOS, в виде Virtual Appliance для KVM/VirtualBox/VMWare и [образа](https://waf.pentestit.ru/manuals/6387) для Docker-контейнера. Больше информации можно найти [здесь](https://waf.pentestit.ru/about/2511).
Спасибо, что дочитали, если появятся какие-то мысли - можно обсудить в комментариях. | https://habr.com/ru/post/540188/ | null | ru | null |
# Мой extend и стиль наследования классов
В данном посте хочу рассказать как предпочитаю реализовывать наследование в объемном JavaScript приложении.
Допустим для проекта необходимо множество родственных и не очень классов.
Если мы попытаемся каждый тип поведения описать в отдельном классе, то классов может стать очень много. И у финальных классов может быть с десяток предков. В таком случае обычного JavaScript наследования через prototype может оказаться не достаточно. Например мне понадобилась возможность из метода вызывать аналогичный метод класса-предка. И захотелось создавать и наследовать некоторые статические свойства и методы класса. Такую функциональность можно добавить, вызывая для каждого класса ниже изложенную ф-ию extend:
Функция extend
--------------
```
cSO = {}; // Просто для отдельного пространства имен.
cSO.extend = function(child, parent, other) {
if(parent) {
var F = function() {};
F.prototype = parent.prototype;
child.prototype = new F();
child.prototype.constructor = child;
child.prototype.proto = function() {
return parent.prototype;
}
// Пока все стандартно.
} else {
child.prototype.proto = function() {
return;
}
}
/*
* У классов есть параметр stat, предназначенный для статических ф-ий и данных.
* Он доступен через _class.stat или из объекта(экземпляра) класса через this.stat.
* Потомки могут обращаться к статическому методу предка, для этого их нужно
* объявлять так: _class.stat.prototype.myStaticMethod = function() {...habracut
* Можно запретить наследовать метод, объявляя его без prototype.
* Все данные в stat доступны наследникам, если не перекрываются другими данными.
* Для удаления переменной из stat - используем _class.stat.deleteStatVal("name");
*/
child.statConstructor = function() {};
if(parent && ("statConstructor" in parent) && parent.statConstructor && typeof (parent.statConstructor) === "function") {
var S = function() {};
S.prototype = parent.statConstructor.prototype;
child.statConstructor.prototype = new S();
child.statConstructor.prototype.constructor = child.statConstructor;
child.statConstructor.prototype.proto = function() {
return parent.statConstructor.prototype;
}
child.statConstructor.prototype.protoStat = function() {
return parent.stat;
}
} else {
child.statConstructor.prototype.proto = function() {
return;
}
child.statConstructor.prototype.protoStat = function() {
return;
}
}
var oldChildStat = child.stat; // если в stat что-то уже добавляли...
child.stat = new child.statConstructor();
if(oldChildStat) { // не забываем перенести старые методы и свойства.
for(var k in oldChildStat) {
child.stat[k] = oldChildStat[k];
}
}
child.stat.prototype = child.statConstructor.prototype;
if(oldChildStat && oldChildStat.prototype) {
// не забываем перенести старые методы и свойства для прототипа.
for(var k in oldChildStat.prototype) {
child.stat.prototype[k] = oldChildStat.prototype[k];
}
}
child.prototype.stat = child.stat;
if(other) {
// Выполняем условленные действия по дополнительным параметрам.
if(other.statConstruct) {
child.stat.prototype.construct = other.statConstruct;
}
}
child.stat._class = child; // чтобы ссылаться на класс из статических методов.
child.stat.deleteStatVal = function(name) {
// Удаляет переменную так, чтобы после ссылаться на переменную предка.
if( name in child.stat) {
try {
delete child.stat[name];
} catch(e) {
}
if(parent) {
child.stat[name] = child.stat.protoStat()[name];
}
}
}
child.prototype.protoFunc = child.statConstructor.prototype.protoFunc = function(callerFuncName, args, applyFuncName) {
/*
* Позволяет вызвать функцию более ранней версии в иерархии прототипов (Правильное имя
* вызывающей ф-ии - необходимо передать в первом параметре). Если установленна
* переменная applyFuncName - вместо callerFuncName будет вызываться другая ф-ия но из
* прототипа на один уровень старше, чем прототип обладающий вызывающей ф-ией.
*/
if(!args) {
args = [];
}
if(applyFuncName) {
// Пока не стал заморачиваться, решил отложить на лучшие времена.
} else {
applyFuncName = callerFuncName;
}
var tProto = this;
var ok = false;
do {
if(ok && arguments.callee.caller !== tProto[applyFuncName]) {
if(( applyFuncName in tProto) && ( typeof (tProto[applyFuncName]) === "function")) {
return tProto[applyFuncName].apply(this, args);
}
} else if(arguments.callee.caller === tProto[callerFuncName]) {
ok = true;
}
} while(("proto" in tProto) && (tProto = tProto.proto()))
return;
}
if(child.stat.construct) {
// Вызывается при создании класса или создании потомка без stat.construct
child.stat.construct();
}
}
```
### Небольшая проверка как работает, и какие результаты выдает ф-ия extend()
Создаем 3 класса, каждый — наследник предидущего.
```
cSO.class001 = function() {
}
cSO.extend(cSO.class001, 0, {"statConstruct":function(sc1) {
console.log("statConstruct001");
}}); // выведет statConstruct001
cSO.class001.prototype.construct = function(c1) {
console.log('c1');
this.protoFunc("construct", arguments);
}
cSO.class001.stat.prototype.st = function(s1) {
console.log('st1');
this.protoFunc("st");
}
cSO.class001.stat.dat = ["hello1"];
cSO.class002 = function() {
}
cSO.extend(cSO.class002, cSO.class001, {"statConstruct":function(sc2) {
console.log("statConstruct002");
this.protoFunc("construct", arguments);
}}); // выведет statConstruct002 statConstruct001
cSO.class002.prototype.construct = function(c2) {
console.log('c2');
this.protoFunc("construct", arguments);
}
cSO.class002.stat.st = function(s2) {
console.log('st2');
this.protoFunc("st");
}
cSO.class003 = function() {
}
cSO.extend(cSO.class003, cSO.class002); // выведет statConstruct002 statConstruct001
cSO.class003.prototype.construct = function(c3) {
console.log('c3');
this.protoFunc("construct", arguments);
}
cSO.class003.stat.prototype.st = function(s3) {
console.log('st3');
this.protoFunc("st");
}
cSO.class003.stat.dat = ["hello3"];
```
А теперь узнаем, в каком порядке выполняются их действия.
```
var obj001 = new cSO.class001();
var obj002 = new cSO.class002();
var obj003 = new cSO.class003();
obj001.construct(); // c1
obj002.construct(); // c2 c1
obj003.construct(); // c3 c2 c1
cSO.class001.stat.st(); // st1
cSO.class002.stat.st(); // st2 st1
cSO.class003.stat.st(); // st3 st1 // потому что объявили cSO.class002.stat.st без prototype
console.log(obj003.stat.dat); // ["hello3"]
obj002.stat.dat = ["world"];
console.log(obj002.stat.dat); // ["world"]
cSO.class002.stat.deleteStatVal("dat");
console.log(obj002.stat.dat); // ["hello1"]
console.log(obj001.stat.dat); // ["hello1"]
```
Еще несколько штрихов, которые мне показались важными
-----------------------------------------------------
В результате ежедневной практики, у меня примерно такая структура объектов:
```
_class={
construct:function(){}, // Вызываем при создании каждого объекта-наследника.
destruct:function(){}, // Вызываем при удалении любого объекта-наследника.
// и т.д.
stat:{
create:function(){}, // Вызывается при создании класса или потомка класса.
collection:[], // В некоторых классах удобно журналировать все созданные экземпляры.
clearAll:function(){} // Иногда удобно иметь возможность удалить всю коллекцию.
// и т.д.
}
}
```
Сейчас объясню почему именно так.
Для создания класса необходимо вызывать конструктор, тот конструктор, что вызывается при new Foo() — не вызывается при создании объектов-потомков данного класса.
Вот например:
```
var id = 0;
var Foo = function() {
this.id = id++;
console.log("Вы создали объект, имеющий метод boom");
}
foo.prototype.boom = function() {}
var Bar = function() {
}
Bar.prototype = new Foo();
var fooOb = new Foo(); // Вы создали объект, имеющий метод boom
var barOb = new Bar();
var barOb2 = new Bar();
console.log(fooOb.id); // 1
console.log(barOb.id); // 0
console.log(barOb2.id); // 0
```
А мне хочется, чтобы все объекты, наследники класса Foo имели уникальный id и предупреждали пользователя, что умеют взрываться.
Для реализации этого — я создаю специальный метод cnstruct (constructor — уже занято), и выполняю его при создании каждого объекта. Чтобы не забыть его выполнять, отказываюсь от создания объектов через new Foo() и создаю объекты через статический метод Foo.stat.create().
Далее представлена укороченная версия реально используемого класса, как пример того, какими получаются классы.
Реальный пример
---------------
Данный класс необходимо рассматривать как один из многих в цепочке прототипов от базового класса к финальному (скорее в обратную сторону).
```
(function() {
var _class = cSO.LocalStorageSyncDataType = function () {
/*
* Вообще класс описывает поведение объектов, которые
* сохраняются и загружаются с жесткого диска клиента.
* Но это только часть реализации, остальное вырезал.
*/
}
cSO.extend(_class, cSO.ServerSyncDataType, {"statConstruct": function() {
this.protoFunc("construct", arguments); // Если конструктор объявлен, но в нем не вызывается protoFunc - цепочка предидущих конструкторов обрывается.
if("addToClassesForSnapshot" in this) { // Условие не удовлетворяется для cSO.LocalStorageSyncDataType, который по идее абстрактен, а только для его потомков.
this.addToClassesForSnapshot(this._class); // Все потомки по умолчанию будут регистрироваться.
}
}});
var _class_stat = _class.stat; // Такими присвоениями - позволяем минимизатору (компилятору) уменьшать размер скриптов на 15%-25% ежели без присвоений. Обычно устанавливаю подсветку этих слов как констант.
var _class_stat_prototype = _class_stat.prototype;
var _class_prototype = _class.prototype;
var cfs = _class_stat.classesForSnapshot = [];
_class_stat.create = function(args) {
// Метод написан просто для примера, такой метод д.б. в финальных классах.
this.addedToLocalStorage = false;
if(args.addedToLocalStorage) {
this.addedToLocalStorage = true;
}
this.protoFunc("construct", arguments);
}
_class_prototype.construct = function(args) {
/*
* Конструктор достраивает созданный объект, но автоматически не вызывается.
* Он добавляет достоинства концепции фабрики объектов в данный стиль.
*/
this.addedToLocalStorage = false;
if(args.addedToLocalStorage) {
this.addedToLocalStorage = true;
}
this.protoFunc("construct", arguments);
}
_class_prototype.setLoaded = function(val) {
this.protoFunc("setLoaded", arguments);
// знаю, что здесь будет код, но пока не знаю какой именно.
}
_class_stat.addToClassesForSnapshot = function(clas) {
clas = clas || this._class;
for(var i = 0; i < cfs.length; i++) {
if(cfs[i] === clas) return;
}
cfs.push(clas);
}
_class_stat.createAllSnapshots = function() {
for(var i = 0; i < cfs.length; i++) {
cfs[i].stat.createSnapshot();
}
}
_class_stat_prototype.createSnapshot = function() {
var co = this.collection;
var str = "";
for(var i in co) {
if(co[i]) {
if(!str) {
str = "[";
} else {
str += ",";
}
str += co[i].getJSON();
}
}
if(str) str += "]";
this.snapshot = str;
}
_class_stat.saveAllSnapshotsOnLocalStorage = function() {
for(var i = 0; i < cfs.length; i++) {
cfs[i].stat.saveSnapshotOnLocalStorage();
}
}
_class_stat_prototype.saveSnapshotOnLocalStorage = function() {
if(this.snapshot) {
cSO.localStorage.setItem(this.tableName, this.snapshot);
}
}
_class_stat.setAllBySnapshotsFromLocalStorage = function() {
for(var i = 0; i < cfs.length; i++) {
cfs[i].stat.setBySnapshotFromLocalStorage();
}
}
_class_stat_prototype.setBySnapshotFromLocalStorage = function() {
var arr = $.parseJSON(cSO.localStorage.getItem(this.tableName));
for(var i = 0; i < arr.length; i++) {
if(arr[i]) {
this.createOrGet({"cells":arr[i], "addedToLocalStorage":true});
}
}
}
})();
```
Добавлю, что такой подход стоит использовать именно для классов объектов, а для «одиноких» объектов (например cSO.localStorage) стоит использовать традиционную фабрику объектов.
P.S. Понимаю, что большинство концепций программирования и скорость исполнения при таком подходе сильно страдают.
Так же понимаю, что такой стиль не нов, и наверняка существуют другие, более подходящие (спасибо если укажете их).
P.S. Не ругайтесь сильно на код, моя проблема еще и в том, что я практически ни разу не показывал своего кода другим.
[В личном блоге](http://rogallic-projects.blogspot.com/2012/02/extend.html) | https://habr.com/ru/post/138913/ | null | ru | null |
# Сервер Prometheus и TLS

[Prometheus](https://prometheus.io/) теперь поддерживает TLS и базовую аутентификацию для HTTP эндпоинтов.
Скрейпинг таргетов через HTTPS вместо HTTP поддерживается уже давно. Метрики можно собирать с поддержкой HTTPS, аутентификации по клиентским сертификатам и базовой аутентификации.
В прошлом году [Node Exporter](https://github.com/prometheus/node_exporter) стал первым официальным экспортером, который нативно предоставляет метрики по HTTPS. Все подробности в [предыдущем посте](https://inuits.eu/blog/prometheus-tls/). На этой неделе (*прим. переводчика: статья вышла 6 января 2021 года*) мы встречаем Prometheus [2.24.0](https://github.com/prometheus/prometheus/releases/tag/v2.24.0). В последнее время Prometheus радует нас крутыми новшествами — это и TLS, и backfilling (обратное заполнение, тоже в версии 2.24) и даже переход на современный пользовательский интерфейс на React.
В этом посте мы расскажем о TLS и базовой аутентификации.
[Здесь](https://prometheus.io/docs/operating/security/) можно узнать больше о модели безопасности Prometheus и о том, как пожаловаться на уязвимости.
Если вы обнаружили в Prometheus, официальном экспортере или библиотеке какую-нибудь критическую уязвимость, не рассказывайте об этом публично, а сообщите нам, чтобы мы все исправили.
### API для администрирования и управления жизненным циклом
По умолчанию Prometheus предоставляет эндпоинты API только для запроса данных. При необходимости можно включить еще эндпоинты для управления жизненным циклом (перезагрузка конфигурации, выход) и для администрирования (удаление метрик, создание снапшотов).
При этом нужно будет защитить порт Prometheus, например, с помощью аутентификации.
### Защита доступа к Prometheus
Раньше между клиентами и сервером Prometheus для защиты обычно ставили обратный прокси:

С такой конфигурацией можно не только управлять доступом и шифрованием, но и автоматизировать создание сертификатов, использовать троттлинг, дополнительные средства контроля, изменения имен (mangling) и так далее. За задачи балансировщиков нагрузки и обратных прокси Prometheus не отвечает, так что продолжайте использовать обратный прокси, если вам нужны эти расширенные функции.
Если ваш сценарий попроще или нужно защитить трафик между обратным прокси и Prometheus, теперь у вас есть встроенные средства для защиты входящего HTTP-трафика.

### Как настроить TLS
Посмотрим, как это работает на практике, на примере Prometheus на Linux.
#### Настройка рабочего каталога
Мы будем работать в отдельном каталоге:
```
$ mkdir ~/prometheus_tls_example
$ cd ~/prometheus_tls_example
```
#### Создание TLS-сертификатов
Для начала создадим самоподписанный TLS-сертификат.
```
$ cd ~/prometheus_tls_example
$ openssl req -new -newkey rsa:2048 -days 365 -nodes -x509 -keyout prometheus.key -out prometheus.crt -subj "/C=BE/ST=Antwerp/L=Brasschaat/O=Inuits/CN=localhost" -addext "subjectAltName = DNS:localhost"
```
Здесь localhost — это имя хоста для сервера Prometheus.
Создается два файла: prometheus.crt и prometheus.key.
#### Веб-конфигурация Prometheus
Скачиваем Prometheus [v2.24.0](https://github.com/prometheus/prometheus/releases/tag/v2.24.0), распаковываем, переносим сертификаты, которые создали выше:
```
$ cd ~/prometheus_tls_example
$ wget https://github.com/prometheus/prometheus/releases/download/v2.24.0/prometheus-2.24.0.linux-amd64.tar.gz
$ tar xvf prometheus-2.24.0.linux-amd64.tar.gz
$ cp prometheus.crt prometheus.key prometheus-2.24.0.linux-amd64
$ cd prometheus-2.24.0.linux-amd64
```
Сейчас нужно создать новый файл конфигурации. Мы не будем настраивать TLS и аутентификацию в основном файле конфигурации prometheus.yml. Это позволит нам перечитывать отдельный файл конфигурации при каждом запросе, чтобы на лету подхватывать новые учетки и сертификаты.
Создадим файл web.yml с конфигурацией TLS:
```
tls_server_config:
cert_file: prometheus.crt
key_file: prometheus.key
```
Запускаем сервер Prometheus, указывая --web.config.file в командной строке:
```
$ ./prometheus --web.config.file=web.yml
[...]
enabled and it cannot be disabled on the fly." http2=true
level=info ts=2021-01-05T13:27:53.677Z caller=tls_config.go:223 component=web
msg="TLS is enabled." http2=true
```
Если мы видим это сообщение, сервер Prometheus запущен с поддержкой TLS.
*Примечание:* Все параметры TLS можно менять динамически, но если уж мы включили TLS, то без перезапуска Prometheus его не отключишь.
Подробности об этом дополнительном файле конфигурации смотрите в [документации](https://prometheus.io/docs/prometheus/latest/configuration/https/).
#### Проверка конфигурации TLS вручную
В curl проверим конфигурацию TLS. В новом терминале запустим пару команд для теста:
```
$ cd ~/prometheus_tls_example
$ curl localhost:9090/metrics
Client sent an HTTP request to an HTTPS server.
$ curl --cacert prometheus.crt https://localhost:9090/metrics
[...]
```
Вместо --cacert prometheus.crt можно передать -k, чтобы пропустить проверку
сертификата в curl.
#### Конфигурация скрейпа
Настроить TLS выборочно не получится — если он включен, он распространяется на все эндпоинты. Это значит, что собственные метрики Prometheus тоже будет извлекать через TLS, поэтому настроим использование HTTPS.
Изменим задание prometheus в файле prometheus.yml:
```
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scheme: https
tls_config:
ca_file: prometheus.crt
static_configs:
- targets: ['localhost:9090']
```
Для tls\_config и scheme установим https. Полный список [параметров клиента tls\_config см. в конфигурации Prometheus](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#tls_config).
Перечитаем конфигурацию Prometheus:
```
$ killall -HUP prometheus
```
Откроем <https://localhost:9090/targets> локально в браузере и увидим <https://localhost:9090/metrics> в списке таргетов.
Таргет имеет статус UP? Ура! Мы настроили TLS для сервера Prometheus и теперь собираем метрики с шифрованием.
### Как настроить базовую аутентификацию
Давайте пойдем еще дальше и затребуем имя пользователя и пароль. TLS здесь не обязателен, но крайне рекомендуется (настраивать его мы уже умеем).
#### Веб-конфигурация
Для начала создадим хэш паролей (с помощью bcrypt). Для этого используем команду htpasswd (пакет apache2-utils или httpd-tools есть в дистрибутиве; если это не продакшен, можно найти [генераторы bcrypt онлайн](https://bcrypt-generator.com/)).
```
$ htpasswd -nBC 10 "" | tr -d ':\n'
New password:
Re-type new password:
$2y$10$EYxs8IOG46m9CtpB/XlPxO1ei7E4BjAen0SUv6di7mD4keR/8JO6m
```
Для примера возьмем пароль inuitsdemo.
Добавим пользователя в файл веб-конфигурации Prometheus web.yml:
```
tls_server_config:
cert_file: prometheus.crt
key_file: prometheus.key
basic_auth_users:
prometheus: $2y$10$EYxs8IOG46m9CtpB/XlPxO1ei7E4BjAen0SUv6di7mD4keR/8JO6m
```
*Примечание:* В этом файле prometheus — это имя пользователя.
Если Prometheus еще запущен, введите пароль для доступа к веб-интерфейсу по адресу [https://127.0.0.1:9090](https://127.0.0.1:9090/), иначе на странице [targets](https://localhost:9090/targets) для таргета будет отображаться ошибка 401 Unauthorized.

#### Конфигурация Prometheus
Внесём изменения в prometheus.yml, чтобы скрейпинг шёл с использованием логина и пароля.
```
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scheme: https
basic_auth:
username: prometheus
password: inuitsdemo
tls_config:
ca_file: prometheus.crt
static_configs:
- targets: ['localhost:9090']
```
Перезагрузим конфигурацию Prometheus сигналом SIGHUP:
```
$ killall -HUP prometheus
```
Если все работает, Prometheus снова откроет страницу [targets](https://localhost:9090/targets).

### Promtool
У Prometheus есть свой инструмент командной строки — promtool, которым теперь можно проверять и файлы веб-конфигурации:
```
$ ./promtool check web-config web.yml
web.yml SUCCESS
```
Используйте любой инструмент автоматизации для удобного обновления файлов web.yml.
### Grafana
Grafana поддерживает все необходимые функции для подключения к серверу Prometheus. Можно указать CA (наш prometheus.crt) или пропустить проверку сертификатов.
### Заключение
Это только общий обзор. В продакшене нужно будет использовать подходящий CA и продумать еще много деталей. Можно настроить клиентские сертификаты, но из соображений безопасности эта функция считается экспериментальной. Со временем поддерживаемая версия TLS может меняться, а с ней и поведение функций.
В следующие несколько месяцев мы планируем развернуть эту поддержку HTTPS по всем официальным экспортерам Prometheus и другим проектам, например, Alertmanager, Pushgateway.
Мы за безопасный мониторинг.
***От редакции:*** *Подробнее о работе с Prometheus можно узнать на курсе Слёрма [«Мониторинг и логирование инфраструктуры в Kubernetes»](https://slurm.io/monitoring?utm_source=habr&utm_medium=post&utm_campaign=monitoring&utm_content=post_15-01-2021&utm_term=averina). Сейчас курс находится в разработке и его можно купить по цене предзаказа.*
**Полезные ссылки**
[Prometheus 2.24.0](https://github.com/prometheus/prometheus/releases/tag/v2.24.0)
[Модель безопасности Prometheus](https://prometheus.io/docs/operating/security/)
[Документация по конфигурации TLS-сервера](https://prometheus.io/docs/prometheus/latest/configuration/https/) (для Prometheus)
[Документация по конфигурации TLS-клиента](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#tls_config) (для сервера Prometheus) | https://habr.com/ru/post/537504/ | null | ru | null |
# Astra Linux «Орел» Common Edition: есть ли жизнь после Windows
*Мы получили развернутый обзор от одного из пользователей нашей ОС, которым хотели бы с вами поделиться.*
Astra Linux — дериватив Debian, который был создан в рамках российской инициативы перехода на СПО. Существует несколько версий Astra Linux, одна из которых предназначена для общего, повседневного использования — Astra Linux «Орел» Common Edition. Российская операционка для всех — это по определению интересно, и я хочу рассказать об «Орле» с позиции человека, который ежедневно пользуется тремя операционными системами (Windows 10, Mac OS High Sierra и Fedora) и при этом последние 13 лет был верен Ubuntu. Опираясь на этот опыт, я рассмотрю систему с точки зрения установки, интерфейсов, ПО, базовых возможностей для разработчиков и удобства с разных ракурсов. Как покажет себя Astra Linux в сравнении с более распространенными системами? И сможет ли она заменить Windows дома?

Ставим Astra Linux
------------------
Установщик Astra Linux имеет большое сходство с установщиком Debian. Пожалуй, первый даже проще, так как большинство параметров фиксировано по умолчанию. Начинается все с общего лицензионного соглашения на фоне не слишком многоэтажной застройки. Возможно, даже в Орле.
Важный пункт в установке — это выбор софта, который идет по умолчанию с системой. Доступные опции покрывают стандартные офисные и рабочие потребности (для «неразработчиков»).
Также последним окном идет дополнительный набор настроек: блокировка интерпретаторов, консоли, трассировки, установки бита исполнения и т. д. Если эти слова вам ничего не говорят, лучше нигде галочки не проставлять. К тому же все это при необходимости можно настроить потом.

Система ставилась внутри виртуальной среды при скромных ресурсах (относительно современных систем). Нареканий по скорости и производительности не возникало. Конфигурация, на которой проходило тестирование, описана ниже.

Процедура установки обычная: монтируем [iso-образ](https://dl.astralinux.ru/astra/stable/orel/iso/orel-2.12.13-06.05.2019_12.39.iso), инсталлируем через стандартный процесс установки системы и выжигаем GRUB загрузчик.

Система при загрузке нетребовательна к ресурсам — порядка 250-300 МБ RAM при запуске для десктопного режима.
Альтернативные варианты запуска: режим планшета и телефона
----------------------------------------------------------
При входе в систему можно выбрать один из нескольких вариантов запуска: безопасный, десктоп, мобильный или планшетный.
Для работы на сенсорных устройствах можно включить экранную клавиатуру.
Посмотрим, что интересного в разных режимах. Десктопный — это обычный режим, где система похожа на Windows.
Планшетный режим подойдет для крупных сенсорных экранов. Помимо очевидных внешних отличий, которые можно увидеть на скриншоте ниже, здесь есть другие особенности интерфейса. Курсор в планшетном режиме невидим, кнопка закрытия приложений вынесена на панель задач. Полноэкранные приложения работают несколько иначе, файлы в файл-менеджере также выбираются по-другому.
Стоит упомянуть и мобильный режим — здесь все примерно так же, как в Android. Используется графическая среда Fly. В сенсорных режимах работает длительное касание, по которому можно вызвать контекстное меню. Мобильный режим потребляет несколько больше ресурсов по сравнению с десктопным и планшетным.

Наличие разных режимов работы — это удобно. Например, если вы используете планшет с подключаемой клавиатурой и, соответственно, сенсорные и несенсорные сценарии использования.
Обновление системы
------------------
Перед тем как начать пользоваться системой, ее нужно обновить. В основном [репозитории](http://dl.astralinux.ru/) Astra Linux 14 тысяч пакетов ([стабильная](https://mirrors.edge.kernel.org/astra/stable/), [тестовая](https://mirrors.edge.kernel.org/astra/testing/) и [экспериментальная](https://mirrors.edge.kernel.org/astra/current/) ветка). Экспериментальная ветка в скором времени получит нестабильные обновления, поэтому будем тестировать ветку testing. Меняем репозиторий на testing.
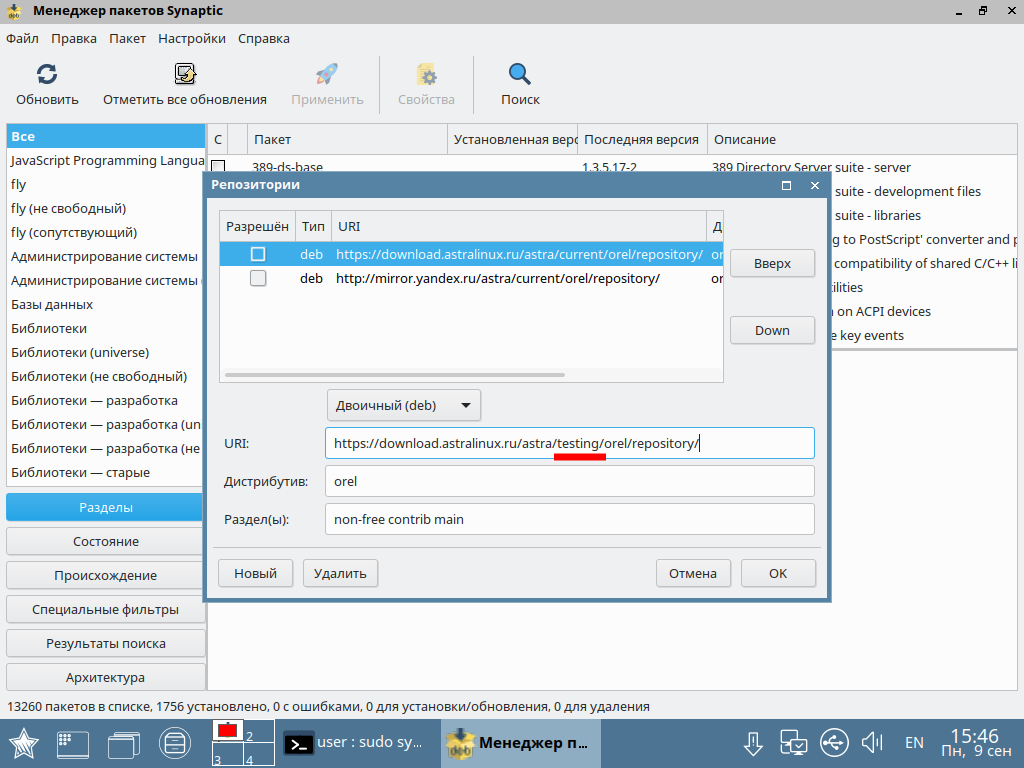
Запускаем обновление репозитория и обновляем систему. Для этого жмем кнопку «Обновить» сверху слева, потом «Отметить все обновления», затем «Применить». Перезагружаемся.
Пользовательская политика
-------------------------
Новые пользователи создаются в системе через утилиту управления политикой безопасности.
По умолчанию предусмотрена функция удаленного входа (Панель управления — Система — Вход в систему).
Помимо обычной отдельной и удаленной сессии, можно запустить вложенную сессию (Пуск — Завершение работы — Сессия).
С первыми двумя все понятно. А вложенная сессия — это сессия, которая запускается в окне текущей сессии.

Сессии, кстати, можно завершать через отложенное время: не дожидаться окончания длительных операций, а просто настроить автоматическое выключение.

Интерфейс и стандартное ПО Astra Linux
--------------------------------------
Astra Linux Common Edition напоминает Debian, каким он был несколько лет назад. Заметно, что внешне Astra Linux Common Edition пытается приблизиться к Windows.

Навигация и работа с файловой системой ближе к Windows, чем к Linux. С образом системы прилагается стандартный набор ПО: офисное, работа с сетью, графика, музыка, видео. Системные настройки также сгруппированы в основном меню. По умолчанию доступно четыре экрана.
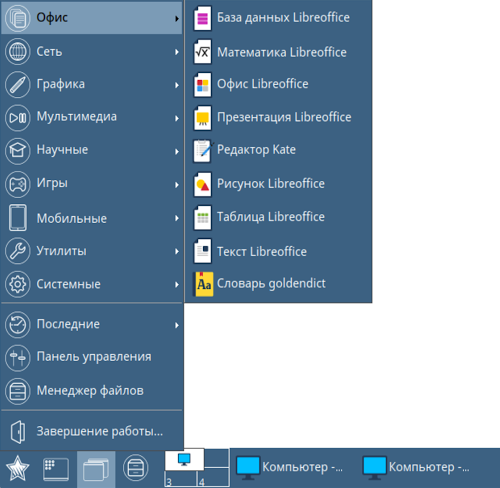
*Как видно, в качестве офисного пакета в системе установлен LibreOffice*
Панель управления схожа с Windows/Mac/etc и группирует основные настройки в одном месте.
Файл-менеджер имеет двухпанельный интерфейс и способен монтировать архивы как папки.

Файл-менеджер умеет вычислять контрольные суммы, в том числе по [ГОСТ Р 34.11-2012](https://habr.com/ru/post/210684/).

В качестве стандартного браузера установлен Mozilla Firefox. Выглядит довольно аскетично, но при этом вполне адекватно. Для примера я открыл и полистал свежий Хабр. Страницы рендерятся, система не падает и не виснет.

Следующий тест — редактирование графики. Скачали картинку с заголовка статьи Хабра, попросили систему открыть ее в GIMP. Тут тоже ничего необычного.

И вот легким движением руки дописываем тест на КПДВ одной из статей. В принципе, здесь отличий от стандартных Linux-систем нет.

Попробуем выйти за пределы простых сценариев и поставить стандартные пакеты через apt-get.
После апдейта индексов:
```
sudo apt-get update
```
Для теста установили python3-pip, zsh и прошли установку oh-my-zsh (с доп зависимостью git). Система отработала в штатном режиме.
Как видим, система хорошо показывает себя в рамках стандартных повседневных сценариев обычного пользователя. Если вы ожидаете увидеть здесь привычные для Debian/Ubuntu программы, то их придется ставить дополнительно, ручками (например, если вам нужны пакеты наподобие ack-grep — они ставятся через curl/sh). Можно добавить репозитории в sources.list и пользоваться привычным apt-get.
Собственные утилиты Astra Linux
-------------------------------
Описанные выше инструменты — это всего лишь часть того, что доступно пользователям Astra Linux. Помимо этого, разработчики создали порядка ста дополнительных утилит, которые можно поставить через тот же репозиторий, который использовали для обновления системы.

Чтобы найти утилиты, достаточно провести поиск по слову «fly» — у всех нужных утилит такой префикс.

Рассказать обо всех приложениях в рамках одного обзора сложновато, так что мы выберем несколько полезных с точки зрения простого пользователя. Погодное приложение отображает прогноз в выбранных городах России, оно оптимизировано под российский регион.
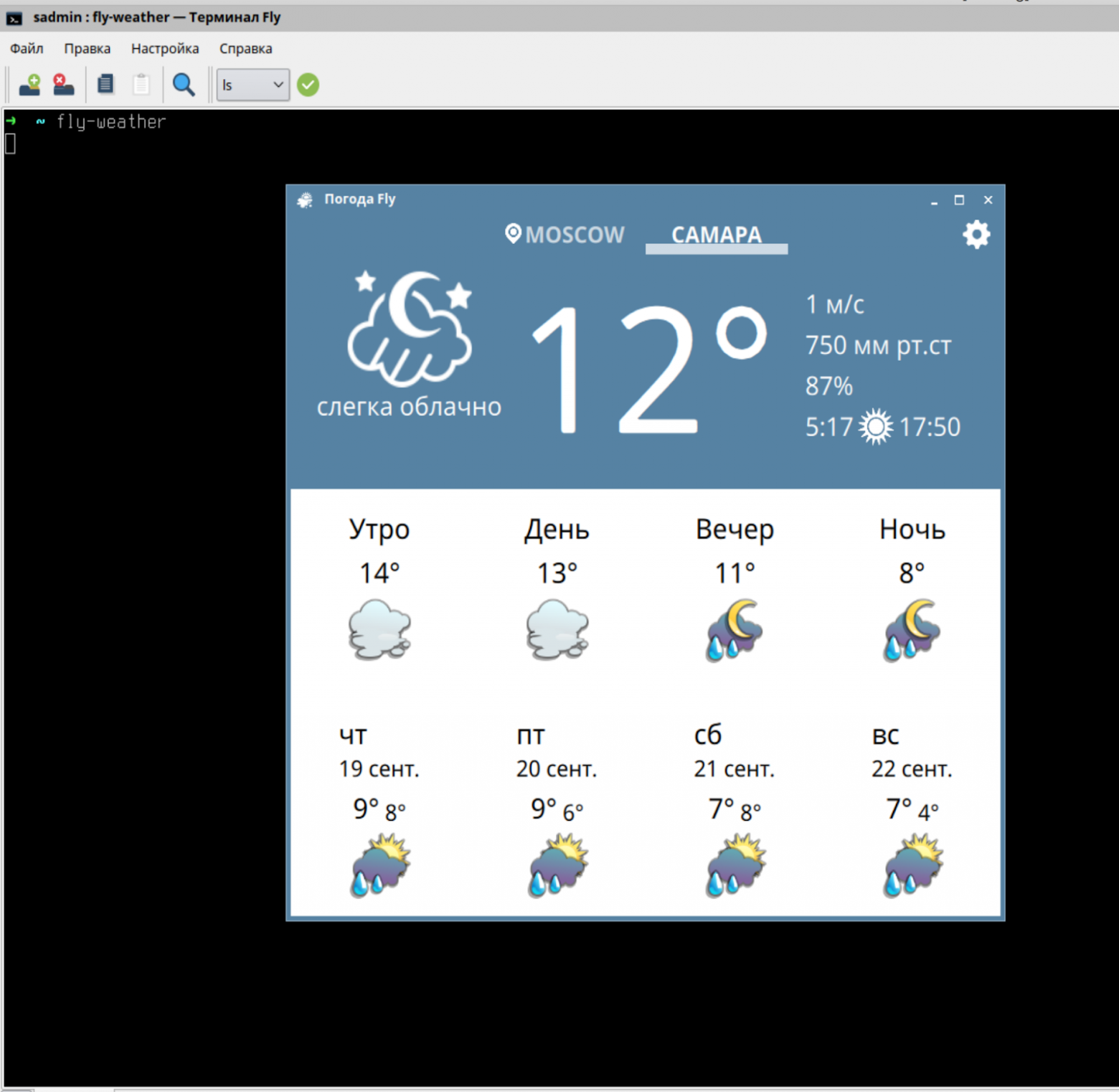
Также имеется простая графическая утилита с несколькими фильтрами и настройками для поиска по файлам.

Есть собственная утилита контроля заряда батареи и различные режимы, переход к которым настраивается через таймер — выключение монитора, сон, гибернация.

Выбор исполняемых файлов для команд тоже обернули в графическую оболочку. К примеру, можно указать, какой именно «vi» выберет система при запуске команды.
Отдельной админской утилитой можно настроить, какие приложения стартанут при запуске системы.

Присутствует также мониторинг GPS/ГЛОНАСС, скорее полезный в телефоне/планшете (в которых обычно и присутствует соответствующий модуль).

Имеется и своя несложная PDF-читалка, для тестов запущена на книге Free Culture от Lawrence Lessig.

Обо всех утилитах Fly можно почитать в [виртуальном туре](https://tour.astralinux.ru/) по Astra Linux, в разделе «Помощь» на виртуальном рабочем столе.
Контраст с основными системами
------------------------------
С точки зрения интерфейса и логики элементов управления система скорее напоминает классический Windows XP, а временами — отдельные элементы Mac OS.
С точки зрения утилит, консоли и «железячной» части система похожа на классический Debian, что довольно неплохо и привычно тем же пользователям Ubuntu и Minted, хотя самым продвинутым будет не хватать привычного спектра пакетов из всех репозиториев.
Если накладывать свой опыт на портрет потенциальных пользователей, в отношении новой системы у меня создаются положительные ожидания. Основываясь на своем опыте работы с Windows/Mac, обычные пользователи смогут без проблем освоиться в Astra Linux Common Edition. А более продвинутые юзеры Linux с помощью стандартных unix-утилит настроят все, как им удобно.
Текущая версия Astra Linux основана на Debian 9.4, также в ней доступно свежее ядро из Debian 10 (4.19).
Конечно, существуют более новые версии Ubuntu, но есть один маленький, но значимый нюанс — они не LTS (Long Term Support). LTS-версии Ubuntu идут вровень с Astra Linux по версиям пакетов. Я взял данные по Astra Linux (сертифицированной Astra Linux Special Edition, чтобы было легче отследить даты выпуска версий ОС) из W[ikipedia](https://ru.wikipedia.org/wiki/Astra_Linux), сравнил со сроками выхода LTS-версий Ubuntu, и вот что получилось:
| | |
| --- | --- |
| LTS релиз Ubuntu | Релиз Astra Linux Special Edition |
| Дата | Версия | Дата | Версия |
| 17.04.2014 | 14.04 LTS | 19.12.2014 | 1.4 |
| 21.04.2016 | 16.04 LTS | 08.04.2016 | 1.5 |
| 26.04.2018 | 18.04 LTS | 26.09.2018 | 1.6 |
Вердикт
-------
Основные преимущества Astra Linux «Орел» Common Edition:
* Не падает, не зависает, критичных глюков не замечено.
* Удачно мимикрирует под интерфейсы Windows NT/XP.
* Простота и удобство установки.
* Низкие требования по ресурсам.
* Предустановлено основное ПО: офисный пакет LibreOffice, графический редактор GIMP и т. д.
* Большой набор дополнительных утилит.
* Версии пакетов старее, чем у последних версий Ubuntu.
* Свой репозиторий меньше, чем у Ubuntu и Debian.
Вывод: последние, не LTS-версии Ubuntu для домашнего пользователя подойдут больше, чем Astra.
Вместе с тем, для домашних пользователей сидеть на LTS-дистрибутиве, может, и не актуально, а для организаций — вполне нормальный вариант. Поэтому выбор разработчиков Astra Linux, нацеленных на корпоративный сегмент, понятен и логичен.
Что касается недостатков, то они, скорее, справедливы для тех, кто привык работать с Linux, так как внешне Astra Linux «Орел» гораздо ближе к Windows, чем к Linux.
Astra Linux «Орел» Common Edition выглядит как неплохая замена офисной версии Windows в рамках программы перехода на свободное программное обеспечение госорганов, а для домашнего использования она может показаться несколько консервативной.
*От компании Astra Linux: мы постоянно общаемся с пользователями нашей операционной системы. Нам регулярно пишут о своих впечатлениях — не только те, кто недавно перешел на нашу ОС, но и пользователи, которые давно пользуются нашим ПО. Если у вас есть инсайты, которыми вы готовы поделиться и описать свои пользовательские впечатления от Астры — пишите в комментариях и в наших социальных сетя* | https://habr.com/ru/post/470808/ | null | ru | null |
# Вышел Bootstrap 5: оцениваем 7 главных нововведений

Пройдя через несколько альфа- и бета-версий, наконец-то появился Bootstrap 5, на что у разработчиков ушло несколько месяцев. Новая версия претерпела серьезные изменения, включая отказ от поддержки Internet Explorer (IE) и зависимости jQuery. От IE было решено отказаться, потому что браузер занимает всего 3% рынка и его доля продолжает снижаться.
Что такое Bootstrap? Это самый популярный в мире CSS-фреймворк с открытым исходным кодом, который разработан командой Twitter. В v5 внесено сразу несколько критически важных изменений, давайте посмотрим, что там и как.
### 1. Отказ от jQuery
Больше Bootstrap не поддерживает библиотеку jQuery. Вместо этого команда разработчиков улучшила поддержку библиотеки JavaScript.
В целом, зависимость от jQuery не была в Bootstrap чем-то плохим. Наоборот, появление jQuery радикально изменило способ использования JavaScript. Это упростило написание задач на JavaScript, которые в противном случае требовали бы много строк кода.
Несмотря на эти преимущества, команда решила завершить поддержку. Причина: снижение размера исходных файлов и уменьшение времени загрузки страницы, что делает Bootstrap более перспективным инструментом.
Исходный файл уменьшился на 85 КБ, что очень важно, ведь Google считает фактор времени загрузки страницы для мобильных и веб-сайтов критическим.
При необходимости jQuery все равно можно использовать. Все плагины JavaScript при этом остаются доступными.
### 2. Настраиваемые свойства CSS
От Internet Explorer отказались, а значит, теперь разработчики могут использовать настраиваемые свойства CSS, как хотят и когда хотят. Проблема IE была в том, что он не поддерживает кастомные CSS.
Соответственно, CSS custom properties делают CSS более гибким и программируемым. Для того, чтобы предотвратить появление конфликтов со сторонними CSS, используется префикс -bs.
Всего доступно два типа переменных: корневые и компонентные. Что касается первого класса, то доступ к ним можно получить везде, где загружен Bootstrap CSS. Эти переменные находятся в файле root.scss и являются частью скомпилированных файлов dist. Что касается второго класса, то эти переменные локальны в отдельных компонентах. Они помогают избежать случайного наследования стилей в таких компонентах, как вложенные таблицы.
### 3. Улучшенная система сеток (Grid)
Поскольку при переходе с 3 на 4 версию возникли некоторые проблемы, v5 сохраняет большую часть системы сеток, а не обновляет ее полностью. Вот некоторые изменения:
* Вместо gutter ввели новые классы g\* для указания отступов между ячейками.
* Также были включены классы вертикального интервала.
* У столбцов больше нет дефолтного значения position: relative.
### 4. Улучшенная документация
Разработчики добавили больше информации о фреймворке, в особенности о его настройке. У пятой версии улучшенный внешний вид и усовершенствованная настройка. Вероятно, по сайту, где используется Bootstrap 5, не так легко будет определить, что он применяет эту технологию.
Разработчики добавили больше гибкости в настройку тем, чтобы сайты не были похожими друг на друга. Тему четвертой версии доработали, добавили контент и фрагменты кода для разработки поверх Sass (популярный препроцессор CSS). Пример стартового npm-проекта можно [найти на Github](https://www.makeuseof.com/what-is-github-an-introduction/).
Расширена и цветовая палитра, пользоваться которой теперь проще. Проделана дополнительная работа по улучшению цветового контраста.
### 5. Управление формой
Разработчики улучшили элементы управления формой, input groups и прочие компоненты.
В предыдущей версии настраиваемые элементы управления формой использовались в качестве дополнения к дефолтным инструментам браузера. В v5 это отдельная группа элементов управления, включая переключатели, флажки и т.п. Сделано это для того, чтобы придать им одинаковый вид и поведение в разных браузерах.
У новых элементов нет более ненужной разметки, разработчики воспользовались стандартными и логическими функциями.
### 6. Добавление API-утилит
Здесь разработчики Bootstrap не оригинальны, библиотеки утилит ранее добавили, например, создатели CSS-библиотеки Tailwind CSS.
Команда Bootstrap добавила возможность использования утилит еще в 4 версии, там это было организовано с использованием глобальных классов $ enable- \*. В новой версии разработчики решили перейти на API, новый язык и синтаксис в Sass. Все это дает возможность создавать собственные утилиты, сохраняя при этом возможность удалять и или изменять дефолтные.
Для улучшения организации процесса работы некоторые утилиты из версии 4 переместили в раздел Helpers.
### 7. Новая библиотека иконок
Еще одно приятное нововведение — добавление открытой библиотеки иконок, в которой содержится более 1300 элементов. Поскольку библиотека открыта, пользователи могут модифицировать иконки по своему вкусу.
Поскольку это изображения SVG, их можно быстро масштабировать и модифицировать, а также стилизовать с помощью CSS.
Установить иконки можно при помощи npm:
`$ npm i bootstrap-icons`
### Кое-что еще
Кроме указанных нововведений, команда представила еще несколько:
* Новый логотип. Иронизируя над этим достижением, сами разработчики поместили новинку на первое место в списке.
* Новый компонент offcanvas. Он поставляется с настраиваемым фоном, body scroll и размещением. Компоненты offcanvas можно разместить с разных сторон от viewport. Настраиваются параметры посредством атрибутов данных или API JavaScript.
* .accordion, основанный на .card, заменили реализацией .accordion без .card. Новинка все же использует плагин Collapse JavaScript, но с кастомными HTML и CSS.
Ну а загрузить Bootstrap 5 можно с [официальной странички фреймворка](https://getbootstrap.com/).
[](https://slc.tl/KeoPY) | https://habr.com/ru/post/555930/ | null | ru | null |
# Динамические мат. функции в C++
Здравствуйте, Хабраюзеры.
Недавно я прочитал здесь [статью](http://habrahabr.ru/post/66021/) об анонимных функциях в С++, и тут же у меня в голове возникла мысль: нужно срочно написать класс для работы с функциями, которые нам знакомы из математики. А именно, принимающими вещественный аргумент и возвращающими вещественное же значение. Нужно дать возможность обращаться с такими объектами максимально просто, не задумываясь о реализации.
И вот, как я это реализовал.
##### Проблема.
Все эти лямбда-выражения ведут себя порой довольно странно, по крайней мере для меня. Связано это, вероятно, с тем, что я не могу до конца понять, как устроен механизм создания этих выражений. Создавать большие функции я буду на основе уже имеющихся примитивными действиями, т.е. что-то вроде f(x) = a(x) + b(x). А это значит, что все лямбды, созданные даже лишь как промежуточные звенья в построении функций, должны сохраняться для обращения к ним. Сейчас попробую объяснить попонятнее.
Скажем, мы хотим, чтобы некая процедура принимала пару функций A и B и возвращала новое выражение, например, 5A + B. Наша процедура создаст лямбду 5A, затем создаст 5A + B, используя 5А и В. Полученное процедура вернет и завершится, в этот момент лямбда 5А пропадет из области видимости, и возвращенное выражение попросту не будет работать.
##### Решение.
Я решил создать одну глобальную коллекцию всех лямбд, все строящиеся выражения хранятся в ней, а в объектах будут присутствовать лишь указатели на элементы коллекции. Поясню кодом:
```
#include
#include
#include
typedef std::tr1::function realfunc; // y = f(x) as in maths
class func\_t
{
protected:
static std::list all\_functions; //коллекция всех функций
realfunc \*f; //указатель на элемент коллекции
public:
func\_t();
func\_t(const double);
func\_t(const realfunc&);
func\_t(const func\_t&);
~func\_t() {};
friend func\_t operator+ (const func\_t&, const func\_t&);
friend func\_t operator- (const func\_t&, const func\_t&);
friend func\_t operator\* (const func\_t&, const func\_t&);
friend func\_t operator/ (const func\_t&, const func\_t&);
friend func\_t operator^ (const func\_t&, const func\_t&);
func\_t operator() (const func\_t&);
double operator() (const double);
};
```
Для начала **конструкторы**.
Конструктор по умолчанию (без параметров) будет создавать функцию, возвращающую аргумент. Это будет точка отправления. f(x) = x.
Остальные понятны: второй создает функцию-константу — f(x) = c, третий превращает лямбду нужного типа в объект моего класса, последний — просто конструктор копирования.
Реализация конструкторов, по ней сразу будет видно, как устроены все методы класса:
```
func_t::func_t()
{
f = &(*all_functions.begin());
}
func_t::func_t(const double c)
{
func_t::all_functions.push_back(
[=](double x)->double {return c;}
);
this->f = &all_functions.back();
}
func_t::func_t(const realfunc &realf)
{
func_t::all_functions.push_back(realf);
this->f = &all_functions.back();
}
func_t::func_t(const func_t &source)
{
this->f = source.f;
}
```
Как видите, я создаю лямбду, толкаю ее в конец коллекции и возвращаю объект с указателем на нее.
Хочу сразу пояснить первый же конструктор. Как я уже говорил, создание «аргумента», т.е. функции f(x)=x является началом почти любой работы с моим классом, поэтому я решил особо выделить эту функцию и положил в первую же ячейку коллекции это выражение. И тогда при вызове конструктора по умолчанию объект всегда получает указатель на первый элемент коллекции.
Ах да, чуть не забыл, все конструкторы могут быть использованы для неявного преобразования, что и создает основное удобство использования.
Далее, **операторы**. С ними всё просто. Покажу три из них: первый реализует сложение, второй композицию функций, третий оценку.
```
func_t operator+ (const func_t &arg, const func_t &arg2)
{
realfunc realf = [&](double x)->double {
return (*arg.f)(x) + (*arg2.f)(x);
};
return func_t(realf);
}
func_t func_t::operator() (const func_t &arg)
{
realfunc realf = [&](double x)->double {
return (*f)((*arg.f)(x));
};
return func_t(realf);
}
double func_t::operator() (const double x)
{
return (*f)(x);
}
```
Всё просто, правда? В первых двух опять создается нужная лямбда, а потом посылается в конструктор объекта. В третьем методе вообще халява =)
Поясню, что я везде использую передачу окружения по ссылкам (это [&] перед лямбдой) для доступа к аргументам метода.
В принципе, это всё. Теперь пара технических деталей. Я не очень силень в инициализации статических полей, поэтому пришлось вспоминать ужасно громозкие и некрасивые способы, которые я когда-то где-то подсмотрел.
```
protected:
static class func_t_static_init_class
{ public: func_t_static_init_class(); };
static func_t_static_init_class func_t_static_init_obj;
...
//Static:
std::list func\_t::all\_functions = std::list();
func\_t::func\_t\_static\_init\_class func\_t::func\_t\_static\_init\_obj = func\_t::func\_t\_static\_init\_class();
func\_t::func\_t\_static\_init\_class::func\_t\_static\_init\_class()
{
func\_t::all\_functions.push\_back(
[](double x)->double {return x;}
);
}
```
Ну вы поняли, создаю список и пихаю в него первый элемент, о котором уже упомянал.
Прошу прощения за этот ужас, только учусь программировать.
##### Бонусы.
В принципе, вот и всё. Осталась пара вещей, которые я делал уже чисто для интереса (хотя, собственно, как и всё).
Во-первых, перегрузим парочку функций из cmath.
```
friend func_t sin(const func_t&);
friend func_t cos(const func_t&);
friend func_t tan(const func_t&);
friend func_t abs(const func_t&);
...
func_t sin(const func_t& arg)
{
realfunc realf = [&](double x)->double {
return sin((*arg.f)(x));
};
return func_t(realf);
}
```
Во-вторых, куда ж без производных и первообразных =)
```
static double delta_x;
func_t operator~ ();
func_t operator| (const double);
...
double func_t::delta_x = 0.01;
func_t func_t::operator~ ()
{
realfunc realf = [&](double x)->double {
return ((*f)(x + delta_x / 2) - (*f)(x - delta_x / 2)) / delta_x;
};
return func_t(realf);
}
func_t func_t::operator| (double first_lim)
{
realfunc realf = [=](double x)->double {
double l_first_lim = first_lim; //will move with this copy of first_lim
double area = 0;
bool reverse = x < first_lim; //first_lim > second_lim?
if (reverse) {
l_first_lim = x;
x = first_lim;
}
double l_delta_x = delta_x; //step
while (l_first_lim < x) { //move along the whole span
if ((l_first_lim += l_delta_x) > x) //stepped too far?
l_delta_x += x - l_first_lim; //the last l_delta_x may be shorter
/* integral summ, the point is chosen between
the point for f(x) is chosen between l_first_lim and l_first_lim + l_delta_x */
area += l_delta_x * (*f)(l_first_lim + l_delta_x / 2);
}
return area * (reverse?-1:1);
};
return func_t(realf);
}
```
Не буду вдаваться в объяснение данного кода, он скучный и является абсолютно наивной реализацией производной в точке и интеграла с переменным верхним пределом (в обоих случаях вместо предела используется фиксированная дельта).
##### Заключение.
Ну вот, собственно, и всё. Надеюсь, что было интересно. Не знаю, имеет ли что-то такое хоть какой-то смысл, но я попрактиковался в классах, всяких & и \*, а для меня это главное =) Спасибо за внимание.
##### Упс! Еще кое-что.
Ну да, как это использовать.
Например вот так:
```
func_t f1 = cos(5 * func_t() + 8);
```
это создаст, как видно, функцию
f1(x) = cos(5x + 8)
или вот так:
```
funt_t x = func_t();
func_t f = x + f1(x / ~f1);
```
это f(x) = x + f1(x / f1`(x)) *кэп мимо проходил*
или в конце концов так:
```
realfunc g = [](double->double) {
...
//что вашей душе угодно, хоть сокеты создавайте
...
}
func_t f3 = g;
```
##### Заключение номер 2.
Ну теперь точно всё. Еще раз спасибо за внимание!
Если что, полный и недоделанный код [тут](https://www.dropbox.com/sh/8dm9w1msj9ymcqb/zp5Lc_wLJc/func_t). | https://habr.com/ru/post/149450/ | null | ru | null |
# Минимальная реализация Lua на Rust
После того, как вы освоите это руководство, в вашем распоряжении окажется минимальная реализация Lua (парсер, компилятор, виртуальная машина), написанная на Rust с чистого листа. Этот проект получил название Lust, его код можно найти на [GitHub](https://github.com/eatonphil/lust).
[](https://habr.com/ru/company/ruvds/blog/649973/)
С его помощью, кроме прочих, можно запустить такую программу:
```
function fib(n)
if n < 2 then
return n;
end
local n1 = fib(n-1);
local n2 = fib(n-2);
return n1 + n2;
end
print(fib(30));
```
Это — мой второй Rust-проект. А выдумыванием набора инструкций я занимаюсь лишь в третий раз. Поэтому прошу не принимать мой стиль программирования за истину в последней инстанции. Полагаю, этот материал может быть интересен тем, кто, как и я, смотрел другие руководства по парсингу команд в Rust и счёл их неоправданно сложными. Надеюсь, моя статья окажется проще тех руководств.
Начало работы
-------------
Команда `cargo init` создаст шаблонный пакет Cargo, который послужит отправной точкой нашего проекта. В коде файла `src/main.rs` мы принимаем имя файла из параметров командной строки и выполняем лексический анализ находящегося в нём текста программы, выделяя токены. Далее — выполняем грамматический анализ токенов и формируем древовидную структуру. После этого компилируем полученное дерево в линейный набор инструкций виртуальной машины. А в итоге мы интерпретируем инструкции виртуальной машины.
```
mod eval;
mod lex;
mod parse;
use std::env;
use std::fs;
fn main() {
let args: Vec = env::args().collect();
let contents = fs::read\_to\_string(&args[1]).expect("Could not read file");
let raw: Vec = contents.chars().collect();
let tokens = match lex::lex(&raw) {
Ok(tokens) => tokens,
Err(msg) => panic!("{}", msg),
};
let ast = match parse::parse(&raw, tokens) {
Ok(ast) => ast,
Err(msg) => panic!("{}", msg),
};
let pgrm = eval::compile(&raw, ast);
eval::eval(pgrm);
}
```
Как видите, пока всё очень просто. Реализуем теперь лексический анализатор.
Лексический анализ
------------------
В ходе лексического анализа убирают пробельные символы (они, за исключением тех, что разделяют имена и ключевые слова, Lua безразличны) и разбивают все символы исходного кода на минимальные имеющие смысл фрагменты, вроде запятых, чисел, идентификаторов, ключевых слов и прочих подобных элементов.
Для того чтобы у нас была бы возможность выдавать осмысленные сообщения об ошибках, мы храним сведения о том, с чем именно в файле мы работаем, пользуясь структурой `Location`, реализующей `increment` и `debug`. Следующий код будет в файле `src/lex.rs`.
```
#[derive(Copy, Clone, Debug)]
pub struct Location {
col: i32,
line: i32,
index: usize,
}
```
Функция `increment` отвечает за обновление номеров строк и столбцов, а так же — за текущее значение индекса, по которому осуществляется работа с содержимым файла.
```
impl Location {
fn increment(&self, newline: bool) -> Location {
if newline {
Location {
index: self.index + 1,
col: 0,
line: self.line + 1,
}
} else {
Location {
index: self.index + 1,
col: self.col + 1,
line: self.line,
}
}
}
```
Функция `debug` выдаёт информацию о текущей строке с указателем на её текущий столбец и с сообщением.
```
pub fn debug>(&self, raw: &[char], msg: S) -> String {
let mut line = 0;
let mut line\_str = String::new();
// Поиск конкретной строки в первоначальном исходном коде
for c in raw {
if \*c == '\n' {
line += 1;
// Выполняем поиск интересующей нас строки
if !line\_str.is\_empty() {
break;
}
continue;
}
if self.line == line {
line\_str.push\_str(&c.to\_string());
}
}
let space = " ".repeat(self.col as usize);
format!("{}\n\n{}\n{}^ Near here", msg.into(), line\_str, space)
}
}
```
Наименьший отдельный элемент, который оказывается в нашем распоряжении после лексического анализа кода — это токен. Он может быть ключевым словом, идентификатором, оператором или синтаксической конструкцией. (В этой реализации Lua мы сознательно опускаем множество реальных синтаксических конструкций Lua наподобие строк.)
```
#[derive(Debug, PartialEq, Eq, Clone)]
pub enum TokenKind {
Identifier,
Syntax,
Keyword,
Number,
Operator,
}
#[derive(Debug, Clone)]
pub struct Token {
pub value: String,
pub kind: TokenKind,
pub loc: Location,
}
```
Функция верхнего уровня `lex` будет перебирать элементы файла и вызывать вспомогательные функции лексического анализа для токенов разных видов. После успешного завершения работы она возвратит массив, содержащий все найденные токены. В процессе лексического анализа она будет «поглощать пробельные символы».
```
pub fn lex(s: &[char]) -> Result, String> {
let mut loc = Location {
col: 0,
index: 0,
line: 0,
};
let size = s.len();
let mut tokens: Vec = vec![];
let lexers = [
lex\_keyword,
lex\_identifier,
lex\_number,
lex\_syntax,
lex\_operator,
];
'outer: while loc.index < size {
loc = eat\_whitespace(s, loc);
if loc.index == size {
break;
}
for lexer in lexers {
let res = lexer(s, loc);
if let Some((t, next\_loc)) = res {
loc = next\_loc;
tokens.push(t);
continue 'outer;
}
}
return Err(loc.debug(s, "Unrecognized character while lexing:"));
}
Ok(tokens)
}
```
### ▍Пробельные символы
Поглощение пробельных символов — это всего лишь увеличение значения переменной, хранящей позицию в файле при нахождении пробела, символа табуляции, символа перехода на новую строку и прочих подобных.
```
fn eat_whitespace(raw: &[char], initial_loc: Location) -> Location {
let mut c = raw[initial_loc.index];
let mut next_loc = initial_loc;
while [' ', '\n', '\r', '\t'].contains(&c) {
next_loc = next_loc.increment(c == '\n');
if next_loc.index == raw.len() {
break;
}
c = raw[next_loc.index];
}
next_loc
}
```
### ▍Числа
Лексический анализатор чисел проходится по исходному коду начиная с определённой позиции и до того места, где заканчивается последовательность десятичных цифр (в этой реализации Lua поддерживаются лишь целые числа).
```
fn lex_number(raw: &[char], initial_loc: Location) -> Option<(Token, Location)> {
let mut ident = String::new();
let mut next_loc = initial_loc;
let mut c = raw[initial_loc.index];
while c.is_digit(10) {
ident.push_str(&c.to_string());
next_loc = next_loc.increment(false);
c = raw[next_loc.index];
}
```
Если цифр в строке нет — значит — это не число.
```
if !ident.is_empty() {
Some((
Token {
value: ident,
loc: initial_loc,
kind: TokenKind::Number,
},
next_loc,
))
} else {
None
}
}
```
### ▍Идентификаторы
Идентификатор — это произвольный набор алфавитных символов, цифр и знаков подчёркивания.
```
fn lex_identifier(raw: &Vec, initial\_loc: Location) -> Option<(Token, Location)> {
let mut ident = String::new();
let mut next\_loc = initial\_loc;
let mut c = raw[initial\_loc.index];
while c.is\_alphanumeric() || c == '\_' {
ident.push\_str(&c.to\_string());
next\_loc = next\_loc.increment(false);
c = raw[next\_loc.index];
}
```
Но идентификатор не может начинаться с цифры.
```
// Первый символ не должен быть цифрой
if ident.len() > 0 && !ident.chars().next().unwrap().is_digit(10) {
Some((
Token {
value: ident,
loc: initial_loc,
kind: TokenKind::Identifier,
},
next_loc,
))
} else {
None
}
}
```
### ▍Ключевые слова
Ключевые слова состоят из алфавитных символов, что роднит их с идентификаторами, но программист не может использовать их в качестве имён переменных.
```
fn lex_keyword(raw: &[char], initial_loc: Location) -> Option<(Token, Location)> {
let syntax = ["function", "end", "if", "then", "local", "return"];
let mut next_loc = initial_loc;
let mut value = String::new();
'outer: for possible_syntax in syntax {
let mut c = raw[initial_loc.index];
next_loc = initial_loc;
while c.is_alphanumeric() || c == '_' {
value.push_str(&c.to_string());
next_loc = next_loc.increment(false);
c = raw[next_loc.index];
let n = next_loc.index - initial_loc.index;
if value != possible_syntax[..n] {
value = String::new();
continue 'outer;
}
}
// Неполное совпадение
if value.len() < possible_syntax.len() {
value = String::new();
continue;
}
// Если мы добрались до этого места - значит — совпадение найдено и можно выполнить ранний выход из функции.
// Нам не нужно совпадение с более длинной последовательностью символов.
break;
}
if value.is_empty() {
return None;
}
```
Помимо выполнения сравнений фрагментов кода со списком строк, нам нужно ещё убедиться в том, что перед нами — полное совпадение с нужным словом. Например, `function1` — это не ключевое слово. Это — допустимый идентификатор. И хотя `function 1` — это правильная последовательность токенов (ключевое слово `function` и число `1`), она не относится к допустимым грамматическим конструкциям Lua.
```
// Если следующий символ будет частью допустимого идентификатора, тогда
// это - не ключевое слово.
if next_loc.index < raw.len() - 1 {
let next_c = raw[next_loc.index];
if next_c.is_alphanumeric() || next_c == '_' {
return None;
}
}
Some((
Token {
value: value,
loc: initial_loc,
kind: TokenKind::Keyword,
},
next_loc,
))
}
```
### ▍Синтаксические конструкции
Синтаксические конструкции (в этом контексте) — это просто фрагменты кода, не являющиеся операторами. Это нечто вроде запятых, скобок и так далее.
```
fn lex_syntax(raw: &[char], initial_loc: Location) -> Option<(Token, Location)> {
let syntax = [";", "=", "(", ")", ","];
for possible_syntax in syntax {
let c = raw[initial_loc.index];
let next_loc = initial_loc.increment(false);
// TODO: это не будет работать с многосимвольными синтаксическими конструкциями вроде >= или ==
if possible_syntax == c.to_string() {
return Some((
Token {
value: possible_syntax.to_string(),
loc: initial_loc,
kind: TokenKind::Syntax,
},
next_loc,
));
}
}
None
}
```
### ▍Операторы
Операторы — это нечто вроде плюса, минуса и знака «меньше». Операторы — это синтаксические конструкции, но выделение их в отдельную группу токенов пригодится нам в дальнейшей работе.
```
fn lex_operator(raw: &[char], initial_loc: Location) -> Option<(Token, Location)> {
let operators = ["+", "-", "<"];
for possible_syntax in operators {
let c = raw[initial_loc.index];
let next_loc = initial_loc.increment(false);
// TODO: это не будет работать с многосимвольными синтаксическими конструкциями вроде >= или ==
if possible_syntax == c.to_string() {
return Some((
Token {
value: possible_syntax.to_string(),
loc: initial_loc,
kind: TokenKind::Operator,
},
next_loc,
));
}
}
None
}
```
На этом мы завершили создание системы лексического анализа!
Грамматический анализ
---------------------
В ходе парсинга выполняется поиск грамматических (древовидных) паттернов в плоском списке токенов. То, что получается, называется синтаксическим деревом или абстрактным синтаксическим деревом (AST, Abstract Syntax Tree).
Тут нам предстоит решить одну скучную задачу, которая заключается в определении дерева. В общем случае (и, конкретно, в этом проекте), синтаксическое дерево — это список инструкций. Инструкция может быть объявлением функции или выражением. Она может быть представлена инструкцией `if` или `return`. Это может быть объявление локальной переменной.
Следующий код размещён в файле `src/parse.rs`.
```
#[derive(Debug)]
pub enum Statement {
Expression(Expression),
If(If),
FunctionDeclaration(FunctionDeclaration),
Return(Return),
Local(Local),
}
pub type Ast = Vec;
```
В остальном определение дерева не содержит практически ничего особенного.
```
#[derive(Debug)]
pub enum Literal {
Identifier(Token),
Number(Token),
}
#[derive(Debug)]
pub struct FunctionCall {
pub name: Token,
pub arguments: Vec,
}
#[derive(Debug)]
pub struct BinaryOperation {
pub operator: Token,
pub left: Box,
pub right: Box,
}
#[derive(Debug)]
pub enum Expression {
FunctionCall(FunctionCall),
BinaryOperation(BinaryOperation),
Literal(Literal),
}
#[derive(Debug)]
pub struct FunctionDeclaration {
pub name: Token,
pub parameters: Vec,
pub body: Vec,
}
#[derive(Debug)]
pub struct If {
pub test: Expression,
pub body: Vec,
}
#[derive(Debug)]
pub struct Local {
pub name: Token,
pub expression: Expression,
}
#[derive(Debug)]
pub struct Return {
pub expression: Expression,
}
```
Работа над AST завершена!
### ▍Вспомогательные механизмы
Теперь, прежде чем мы перейдём к самому интересному, нам надо определить несколько вспомогательных функций для проверки токенов разного вида.
```
fn expect_keyword(tokens: &[Token], index: usize, value: &str) -> bool {
if index >= tokens.len() {
return false;
}
let t = tokens[index].clone();
t.kind == TokenKind::Keyword && t.value == value
}
fn expect_syntax(tokens: &[Token], index: usize, value: &str) -> bool {
if index >= tokens.len() {
return false;
}
let t = tokens[index].clone();
t.kind == TokenKind::Syntax && t.value == value
}
fn expect_identifier(tokens: &[Token], index: usize) -> bool {
if index >= tokens.len() {
return false;
}
let t = tokens[index].clone();
t.kind == TokenKind::Identifier
}
```
А теперь пришло время интересных дел. Займёмся работой с деревьями!
### ▍Парсинг верхнего уровня
Функция `parse` верхнего уровня и её основная вспомогательная функция, `parse_statement`, очень похожи на функцию `lex` верхнего уровня. При анализе инструкции из файла выполняется проверка того, является ли она объявлением функции, инструкцией `if` или `return`, объявлением локальной переменной или инструкцией-выражением.
```
fn parse_statement(raw: &[char], tokens: &[Token], index: usize) -> Option<(Statement, usize)> {
let parsers = [
parse_if,
parse_expression_statement,
parse_return,
parse_function,
parse_local,
];
for parser in parsers {
let res = parser(raw, tokens, index);
if res.is_some() {
return res;
}
}
None
}
pub fn parse(raw: &[char], tokens: Vec) -> Result {
let mut ast = vec![];
let mut index = 0;
let ntokens = tokens.len();
while index < ntokens {
let res = parse\_statement(raw, &tokens, index);
if let Some((stmt, next\_index)) = res {
index = next\_index;
ast.push(stmt);
continue;
}
return Err(tokens[index].loc.debug(raw, "Invalid token while parsing:"));
}
Ok(ast)
}
```
### ▍Инструкции-выражения
Инструкция-выражение — это всего лишь обёртка для системы типов Rust. Она оборачивает выражение в инструкцию, осуществляет вызов функции `parse_expression` (которую мы скоро определим), в её конце ожидается наличие точки с запятой.
```
fn parse_expression_statement(
raw: &[char],
tokens: &[Token],
index: usize,
) -> Option<(Statement, usize)> {
let mut next_index = index;
let res = parse_expression(raw, tokens, next_index)?;
let (expr, next_next_index) = res;
next_index = next_next_index;
if !expect_syntax(tokens, next_index, ";") {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected semicolon after expression:")
);
return None;
}
next_index += 1; // Пропустить точку с запятой
Some((Statement::Expression(expr), next_index))
}
```
### ▍Выражения
Выражения в этой минимальной реализации Lua могут быть представлены лишь отдельными вызовами функций, литералами (числами, идентификаторами) или операциями с двумя операндами. Для того чтобы ничего не усложнять, тут операции с двумя операндами нельзя комбинировать. То есть, вместо конструкции вроде `1 + 2 + 3` надо воспользоваться конструкцией `local tmp1 = 1 + 2;` `local tmp2 = tmp1 + 3;` и так далее.
```
fn parse_expression(raw: &[char], tokens: &[Token], index: usize) -> Option<(Expression, usize)> {
if index >= tokens.len() {
return None;
}
let t = tokens[index].clone();
let left = match t.kind {
TokenKind::Number => Expression::Literal(Literal::Number(t)),
TokenKind::Identifier => Expression::Literal(Literal::Identifier(t)),
_ => {
return None;
}
};
```
Если за первым литералом идёт открытая скобка — значит — мы попытаемся распарсить вызов функции.
```
let mut next_index = index + 1;
if expect_syntax(tokens, next_index, "(") {
next_index += 1; // Пропустить открытую скобку
// Вызов функции
let mut arguments: Vec = vec![];
```
Для каждого из аргументов, переданных функции, нужно рекурсивно вызывать `parse_expression`.
```
while !expect_syntax(tokens, next_index, ")") {
if arguments.is_empty() {
if !expect_syntax(tokens, next_index, ",") {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected comma between function call arguments:")
);
return None;
}
next_index += 1; // Пропустить запятую
}
let res = parse_expression(raw, tokens, next_index);
if let Some((arg, next_next_index)) = res {
next_index = next_next_index;
arguments.push(arg);
} else {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid expression in function call arguments:")
);
return None;
}
}
next_index += 1; // Пропустить открытую скобку
return Some((
Expression::FunctionCall(FunctionCall {
name: tokens[index].clone(),
arguments,
}),
next_index,
));
}
```
Если же открывающей скобки нет, значит нам надо будет распарсить либо литеральное выражение, либо операцию с двумя операндами. Если следующий токен представлен оператором, значит — перед нами операция с двумя операндами.
```
// Это может быть литеральное выражение
if next_index >= tokens.len() || tokens[next_index].clone().kind != TokenKind::Operator {
return Some((left, next_index));
}
// В противном случае это операция с двумя операндами
let op = tokens[next_index].clone();
next_index += 1; // Пропустить операнд
if next_index >= tokens.len() {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid right hand side binary operand:")
);
return None;
}
let rtoken = tokens[next_index].clone();
```
Именно тут мы можем (но не будем) рекурсивно вызывать `parse_expression`. Прямо сейчас мне не хочется связываться с приоритетом операций, поэтому тут мы просто требуем, чтобы правой частью выражения был бы другой литерал.
```
let right = match rtoken.kind {
TokenKind::Number => Expression::Literal(Literal::Number(rtoken)),
TokenKind::Identifier => Expression::Literal(Literal::Identifier(rtoken)),
_ => {
println!(
"{}",
rtoken
.loc
.debug(raw, "Expected valid right hand side binary operand:")
);
return None;
}
};
next_index += 1; // Пропустить операнд из правой части выражения
Some((
Expression::BinaryOperation(BinaryOperation {
left: Box::new(left),
right: Box::new(right),
operator: op,
}),
next_index,
))
}
```
На этом парсинг выражений завершён!
### ▍Объявления функций
Объявление функции начинается с ключевого слова `function`, за которым следует токен идентификатора.
```
fn parse_function(raw: &[char], tokens: &[Token], index: usize) -> Option<(Statement, usize)> {
if !expect_keyword(tokens, index, "function") {
return None;
}
let mut next_index = index + 1;
if !expect_identifier(tokens, next_index) {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid identifier for function name:")
);
return None;
}
let name = tokens[next_index].clone();
```
После имени функции расположен список аргументов, который может быть пустым, или список идентификаторов, разделённых запятыми.
```
next_index += 1; // Пропустить имя
if !expect_syntax(tokens, next_index, "(") {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected open parenthesis in function declaration:")
);
return None;
}
next_index += 1; // Пропустить открывающую скобку
let mut parameters: Vec = vec![];
while !expect\_syntax(tokens, next\_index, ")") {
if !parameters.is\_empty() {
if !expect\_syntax(tokens, next\_index, ",") {
println!("{}", tokens[next\_index].loc.debug(raw, "Expected comma or close parenthesis after parameter in function declaration:"));
return None;
}
next\_index += 1; // Пропустить запятую
}
parameters.push(tokens[next\_index].clone());
next\_index += 1; // Пропустить параметр
}
next\_index += 1; // Пропустить закрывающую скобку
```
Далее — мы выполняем парсинг всех инструкций в теле функции, занимаясь этим до тех пор, пока не найдём ключевое слово `end`.
```
let mut statements: Vec = vec![];
while !expect\_keyword(tokens, next\_index, "end") {
let res = parse\_statement(raw, tokens, next\_index);
if let Some((stmt, next\_next\_index)) = res {
next\_index = next\_next\_index;
statements.push(stmt);
} else {
println!(
"{}",
tokens[next\_index]
.loc
.debug(raw, "Expected valid statement in function declaration:")
);
return None;
}
}
next\_index += 1; // Пропустить end
Some((
Statement::FunctionDeclaration(FunctionDeclaration {
name,
parameters,
body: statements,
}),
next\_index,
))
}
```
Теперь мы завершили половину работ по созданию парсера.
### ▍Инструкции return
Выявление инструкции `return` заключается в нахождении ключевого слова `return`, выражения и точки с запятой.
```
fn parse_return(raw: &[char], tokens: &[Token], index: usize) -> Option<(Statement, usize)> {
if !expect_keyword(tokens, index, "return") {
return None;
}
let mut next_index = index + 1; // Пропустить return
let res = parse_expression(raw, tokens, next_index);
if res.is_none() {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid expression in return statement:")
);
return None;
}
let (expr, next_next_index) = res.unwrap();
next_index = next_next_index;
if !expect_syntax(tokens, next_index, ";") {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected semicolon in return statement:")
);
return None;
}
next_index += 1; // Пропустить точку с запятой
Some((Statement::Return(Return { expression: expr }), next_index))
}
```
### ▍Объявления локальных переменных
Объявления локальных переменных начинаются с ключевого слова `local`. Потом идёт имя переменной, затем — знак равенства, выражение и точка с запятой.
```
fn parse_local(raw: &[char], tokens: &[Token], index: usize) -> Option<(Statement, usize)> {
if !expect_keyword(tokens, index, "local") {
return None;
}
let mut next_index = index + 1; // Пропустить local
if !expect_identifier(tokens, next_index) {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid identifier for local name:")
);
return None;
}
let name = tokens[next_index].clone();
next_index += 1; // Пропустить имя
if !expect_syntax(tokens, next_index, "=") {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected = syntax after local name:")
);
return None;
}
next_index += 1; // Пропустить =
let res = parse_expression(raw, tokens, next_index);
if res.is_none() {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid expression in local declaration:")
);
return None;
}
let (expr, next_next_index) = res.unwrap();
next_index = next_next_index;
if !expect_syntax(tokens, next_index, ";") {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected semicolon in return statement:")
);
return None;
}
next_index += 1; // Пропустить точку с запятой
Some((
Statement::Local(Local {
name,
expression: expr,
}),
next_index,
))
}
```
### ▍Инструкции if
В этой реализации Lua конструкция `elseif` не поддерживается. Поэтому парсинг инструкции `if` заключается в простой проверке того, чтобы после ключевого слова `if` шла бы проверка некоего условия. Затем выполняется проверка на наличие ключевого слова `else`, а потом обрабатывается тело инструкции `if` (список выражений). В конце обрабатывается ключевое слово `end`.
```
fn parse_if(raw: &[char], tokens: &[Token], index: usize) -> Option<(Statement, usize)> {
if !expect_keyword(tokens, index, "if") {
return None;
}
let mut next_index = index + 1; // Пропустить if
let res = parse_expression(raw, tokens, next_index);
if res.is_none() {
println!(
"{}",
tokens[next_index]
.loc
.debug(raw, "Expected valid expression for if test:")
);
return None;
}
let (test, next_next_index) = res.unwrap();
next_index = next_next_index;
if !expect_keyword(tokens, next_index, "then") {
return None;
}
next_index += 1; // Пропустить then
let mut statements: Vec = vec![];
while !expect\_keyword(tokens, next\_index, "end") {
let res = parse\_statement(raw, tokens, next\_index);
if let Some((stmt, next\_next\_index)) = res {
next\_index = next\_next\_index;
statements.push(stmt);
} else {
println!(
"{}",
tokens[next\_index]
.loc
.debug(raw, "Expected valid statement in if body:")
);
return None;
}
}
next\_index += 1; // Пропустить end
Some((
Statement::If(If {
test,
body: statements,
}),
next\_index,
))
}
```
Работа над системой парсинга на этом окончена.
Компиляция кода для самодельной виртуальной машины
--------------------------------------------------
Наша виртуальная машина полностью основана на стеке, за исключением того, что тут используется указатель стека и счётчик команд.
Принятое здесь соглашение о вызовах заключается в том, что вызывающая сторона помещает в стек аргументы, а затем — указатель кадра и счётчик команд. После этого в стек помещают количество аргументов (для целей очистки памяти). Далее — осуществляется изменение счётчика команд и указателя кадра. После этого вызывающая сторона выделяет место в стеке для аргументов и объявлений локальных переменных, сделанных в функции.
Для упрощения применения механизмов адресации объявление функции, как только осуществляется переход к нему, копирует аргументы из места, предшествующего указателю кадра в место, находящееся перед ним (знаю, что выглядит это довольно-таки глупо).
Виртуальная машина поддерживает операции сложения и вычитания, операцию «меньше, чем», а так же — безусловный переход, переход при ненулевом значении, возврат, вызов. Она будет поддерживать немного больше специфических инструкций по работе с памятью для загрузки литералов и идентификаторов, а так же — для управления аргументами.
Я поясню неочевидные вещи по мере реализации соответствующих инструкций.
```
use crate::parse::*;
use std::collections::HashMap;
#[derive(Debug)]
enum Instruction {
DupPlusFP(i32),
MoveMinusFP(usize, i32),
MovePlusFP(usize),
Store(i32),
Return,
JumpIfNotZero(String),
Jump(String),
Call(String, usize),
Add,
Subtract,
LessThan,
}
```
Результатом компиляции будет экземпляр `Program`. Он будет содержать символьную информацию и инструкции, которые планируется выполнить.
```
#[derive(Debug)]
struct Symbol {
location: i32,
narguments: usize,
nlocals: usize,
}
#[derive(Debug)]
pub struct Program {
syms: HashMap,
instructions: Vec,
}
```
В компиляции нет ничего особенного. Она, как и парсинг, заключается в вызове вспомогательной функции `compile_statement` для каждой инструкции из AST.
```
pub fn compile(raw: &[char], ast: Ast) -> Program {
let mut locals: HashMap = HashMap::new();
let mut pgrm = Program {
syms: HashMap::new(),
instructions: Vec::new(),
};
for stmt in ast {
compile\_statement(&mut pgrm, raw, &mut locals, stmt);
}
pgrm
}
```
Функция `compile_statement`, кроме того, прибегает к дополнительным вспомогательным функциям для обработки инструкций разных видов.
```
fn compile_statement(
pgrm: &mut Program,
raw: &Vec,
locals: &mut HashMap,
stmt: Statement,
) {
match stmt {
Statement::FunctionDeclaration(fd) => compile\_declaration(pgrm, raw, locals, fd),
Statement::Return(r) => compile\_return(pgrm, raw, locals, r),
Statement::If(if\_) => compile\_if(pgrm, raw, locals, if\_),
Statement::Local(loc) => compile\_local(pgrm, raw, locals, loc),
Statement::Expression(e) => compile\_expression(pgrm, raw, locals, e),
}
}
```
### ▍Объявления функций
Для начала разберёмся с самым сложным — с объявлениями функций. Их окружают защитные механизмы, работающие без каких-либо условий, поэтому мы можем начинать их выполнение с нулевой инструкции верхнего уровня. Мы можем сделать так, чтобы вычислялись бы только инструкции, не являющиеся объявлениями функций.
```
fn compile_declaration(
pgrm: &mut Program,
raw: &[char],
_: &mut HashMap,
fd: FunctionDeclaration,
) {
// Перейти к концу функции для защиты конструкций верхнего уровня
let done\_label = format!("function\_done\_{}", pgrm.instructions.len());
pgrm.instructions
.push(Instruction::Jump(done\_label.clone()));
```
Далее — мы реализуем ещё одно ограничение/упрощение, заключающееся в том, что локальные переменные доступны только в области видимости текущей функции.
При обработке параметров мы копируем каждый из них в стек, размещая перед указателем кадра. Это позволяет обойти ограничения системы адресации нашей виртуальной машины.
```
let mut new_locals = HashMap::::new();
let function\_index = pgrm.instructions.len() as i32;
let narguments = fd.parameters.len();
for (i, param) in fd.parameters.iter().enumerate() {
pgrm.instructions.push(Instruction::MoveMinusFP(
i,
narguments as i32 - (i as i32 + 1),
));
new\_locals.insert(param.value.clone(), i as i32);
}
```
После этого компилируем тело функции.
```
for stmt in fd.body {
compile_statement(pgrm, raw, &mut new_locals, stmt);
}
```
Теперь, когда тело функции скомпилировано, нам известно общее количество локальных переменных. Это позволяет нам правильно заполнить таблицу символов. Значение поля `location` уже задано, так как это — то место, где находится инструкция, расположенная в самом начале функции.
```
pgrm.syms.insert(
fd.name.value,
Symbol {
location: function_index as i32,
narguments,
nlocals: new_locals.keys().len(),
},
);
```
И мы, наконец, добавляем символ, связанный с меткой, указывающей на завершение функции. Это, опять же, позволяет пропустить объявление функции при вычислении значений инструкций от 0 до N.
```
pgrm.syms.insert(
done_label,
Symbol {
location: pgrm.instructions.len() as i32,
narguments: 0,
nlocals: 0,
},
);
}
```
Как видите, не так уж всё и сложно. А то, что нам осталось сделать, будет ещё проще.
### ▍Объявления локальных переменных
Мы компилируем выражения для объявлений локальных переменных, после чего локальные имена сохраняются в таблице локальных имён, увязанной с текущим количеством локальных объявлений (включая аргументы). Это позволяет компилятору свести поиск токена `identifier` к использованию смещения относительно указателя кадра.
```
fn compile_local(
pgrm: &mut Program,
raw: &[char],
locals: &mut HashMap,
local: Local,
) {
let index = locals.keys().len();
locals.insert(local.name.value, index as i32);
compile\_expression(pgrm, raw, locals, local.expression);
pgrm.instructions.push(Instruction::MovePlusFP(index));
}
```
И обратите внимание на то, что паттерн обработки инструкции заключается в вычислении выражения и в копировании того, что получилось, обратно, с использованием относительной позиции в стеке.
### ▍Литералы
Числовые литералы используют инструкцию `store` для помещения чисел в стек. Литералы-идентификаторы копируются из своих позиций, вычисляемых относительно указателя кадра, в верхнюю часть стека.
```
fn compile_literal(
pgrm: &mut Program,
_: &[char],
locals: &mut HashMap,
lit: Literal,
) {
match lit {
Literal::Number(i) => {
let n = i.value.parse::().unwrap();
pgrm.instructions.push(Instruction::Store(n));
}
Literal::Identifier(ident) => {
pgrm.instructions
.push(Instruction::DupPlusFP(locals[&ident.value]));
}
}
}
```
### ▍Вызовы функций
Тут всё очень просто: компилируем все аргументы и выполняем инструкцию вызова.
```
fn compile_function_call(
pgrm: &mut Program,
raw: &Vec,
locals: &mut HashMap,
fc: FunctionCall,
) {
let len = fc.arguments.len();
for arg in fc.arguments {
compile\_expression(pgrm, raw, locals, arg);
}
pgrm.instructions
.push(Instruction::Call(fc.name.value, len));
}
```
### ▍Операции с двумя операндами
Операции с двумя операндами компилируются так: сначала — их левая часть, потом — правая, а после этого, на основании используемого в них оператора, выполняется соответствующая инструкция. Все операторы являются встроенными. Они работают с двумя верхними элементами стека.
```
fn compile_binary_operation(
pgrm: &mut Program,
raw: &[char],
locals: &mut HashMap,
bop: BinaryOperation,
) {
compile\_expression(pgrm, raw, locals, \*bop.left);
compile\_expression(pgrm, raw, locals, \*bop.right);
match bop.operator.value.as\_str() {
"+" => {
pgrm.instructions.push(Instruction::Add);
}
"-" => {
pgrm.instructions.push(Instruction::Subtract);
}
"<" => {
pgrm.instructions.push(Instruction::LessThan);
}
\_ => panic!(
"{}",
bop.operator
.loc
.debug(raw, "Unable to compile binary operation:")
),
}
}
```
### ▍Выражения
При компиляции выражений соответствующие задачи перенаправляются вспомогательным функциям компиляции. Выбор функции зависит от типа выражения. Эти функции мы уже написали.
```
fn compile_expression(
pgrm: &mut Program,
raw: &[char],
locals: &mut HashMap,
exp: Expression,
) {
match exp {
Expression::BinaryOperation(bop) => {
compile\_binary\_operation(pgrm, raw, locals, bop);
}
Expression::FunctionCall(fc) => {
compile\_function\_call(pgrm, raw, locals, fc);
}
Expression::Literal(lit) => {
compile\_literal(pgrm, raw, locals, lit);
}
}
}
```
### ▍Инструкции if
Для начала мы компилируем условие, а затем, если получен ненулевой результат, переходим к инструкциям, идущим после `if`.
```
fn compile_if(pgrm: &mut Program, raw: &[char], locals: &mut HashMap, if\_: If) {
compile\_expression(pgrm, raw, locals, if\_.test);
let done\_label = format!("if\_else\_{}", pgrm.instructions.len());
pgrm.instructions
.push(Instruction::JumpIfNotZero(done\_label.clone()));
```
Потом компилируем тело `if`.
```
for stmt in if_.body {
compile_statement(pgrm, raw, locals, stmt);
}
```
И наконец — обеспечиваем размещение символа `done` в правильном месте после `if`.
```
pgrm.syms.insert(
done_label,
Symbol {
location: pgrm.instructions.len() as i32 - 1,
nlocals: 0,
narguments: 0,
},
);
}
```
### ▍Инструкции return
Последний тип инструкций, который нам осталось обработать, представлен инструкцией `return`. При обработке таких инструкций мы просто компилируем возвращаемое выражение и выполняем инструкцию `return`.
```
fn compile_return(
pgrm: &mut Program,
raw: &[char],
locals: &mut HashMap,
ret: Return,
) {
compile\_expression(pgrm, raw, locals, ret.expression);
pgrm.instructions.push(Instruction::Return);
}
```
Компилятор готов! А теперь — решим самую хитрую задачу. Работа над фрагментом кода, который я опишу ниже, заняла у меня несколько часов, наполненных вознёй с отладчиком и доработкой кода.
Виртуальная машина
------------------
Итак, нам на руку то, что тут имеется всего два регистра, счётчик команд и указатель кадра. Имеется тут и стек данных. Указатель кадра указывает на место в стеке данных, которое функции могут использовать как начальную позицию хранения своих локальных сущностей.
Выполнение инструкций начинается с нулевой инструкции и продолжается до последней инструкции.
```
pub fn eval(pgrm: Program) {
let mut pc: i32 = 0;
let mut fp: i32 = 0;
let mut data: Vec = vec![];
while pc < pgrm.instructions.len() as i32 {
match &pgrm.instructions[pc as usize] {
```
Каждая инструкция ответственна за инкрементирование счётчика команд или за организацию перехода.
### ▍Сложение, вычитание, операция «меньше, чем»
Проще всего реализовать выполнение математических операторов. Мы просто вытаскиваем то, что нужно, из стека данных, выполняем операцию и сохраняем результат.
```
Instruction::Add => {
let right = data.pop().unwrap();
let left = data.pop().unwrap();
data.push(left + right);
pc += 1;
}
Instruction::Subtract => {
let right = data.pop().unwrap();
let left = data.pop().unwrap();
data.push(left - right);
pc += 1;
}
Instruction::LessThan => {
let right = data.pop().unwrap();
let left = data.pop().unwrap();
data.push(if left < right { 1 } else { 0 });
pc += 1;
}
```
Инструкция `store` тоже никаких сложностей не вызывает. Она просто помещает числовой литерал в стек.
```
Instruction::Store(n) => {
data.push(*n);
pc += 1;
}
```
### ▍Различные переходы
Реализовать переходы тоже несложно. Надо просто взять сведения о месте, куда надо перейти, и соответстветствующим образом изменить счётчик команд. Если же речь идёт об условном переходе — сначала надо проверить условие.
```
Instruction::JumpIfNotZero(label) => {
let top = data.pop().unwrap();
if top == 0 {
pc = pgrm.syms[label].location;
}
pc += 1;
}
Instruction::Jump(label) => {
pc = pgrm.syms[label].location;
}
```
### ▍Загрузка данных из переменных
Инструкция `MovePlusFP` копирует значение из стека (смещение по отношению к указателю кадра) в верхнюю часть стека. Это делается для организации обращений к аргументам и к локальным переменным.
```
Instruction::MovePlusFP(i) => {
let val = data.pop().unwrap();
let index = fp as usize + *i;
// Рассчитано на локальные переменные верхнего уровня
while index >= data.len() {
data.push(0);
}
data[index] = val;
pc += 1;
}
```
### ▍Хранение локальных переменных
Инструкция `DupPlusFP` используется функцией `compile_locals` для сохранения локальных переменных в стеке после компиляции. Позиция их хранения вычисляется относительно указателя кадра.
```
Instruction::DupPlusFP(i) => {
data.push(data[(fp + i) as usize]);
pc += 1;
}
```
### ▍Дублирование аргументов
Инструкция `MoveMinusFP` — это, так сказать, «хак», нужный для обхода ограничений адресации нашей минималистичной виртуальной машины. Она копирует аргументы из места, находящегося за указателем кадра, в место, находящееся перед ним.
```
Instruction::MoveMinusFP(local_offset, fp_offset) => {
data[fp as usize + local_offset] = data[(fp - (fp_offset + 4)) as usize];
pc += 1;
}
```
Нам осталось разобраться лишь с двумя инструкциями: `call` и `return`.
### ▍Инструкция call
Инструкция `call` по-особенному обрабатывает встроенные функции (единственная такая функция — `print`).
```
Instruction::Call(label, narguments) => {
// Обработка встроенных функций
if label == "print" {
for _ in 0..*narguments {
print!("{}", data.pop().unwrap());
print!(" ");
}
println!();
pc += 1;
continue;
}
```
В противном случае она помещает в стек текущий указатель кадра, счётчик команд, и, наконец — количество аргументов (не локальных переменных). Она, таким образом, обеспечивает их сохранность. После этого `call` задаёт новые значения счётчику команд и указателю кадра, а потом, после нового указателя кадра, выделяет место для локальных переменных и аргументов.
```
data.push(fp);
data.push(pc + 1);
data.push(pgrm.syms[label].narguments as i32);
pc = pgrm.syms[label].location;
fp = data.len() as i32;
// Выделить место для всех аргументов и локальных переменных
let mut nlocals = pgrm.syms[label].nlocals;
while nlocals > 0 {
data.push(0);
nlocals -= 1;
}
}
```
### ▍Инструкции return
Инструкция `return` берёт возвращаемое значение из стека. Потом она извлекает оттуда все локальные переменные и аргументы. Далее — она восстанавливает счётчик команд и указатель кадра, а так же — берёт из стека аргументы, находящиеся перед указателем кадра. В итоге она помещает возвращаемое значение обратно в стек.
```
Instruction::Return => {
let ret = data.pop().unwrap();
// Очистить локальный стек
while fp < data.len() as i32 {
data.pop();
}
// Восстановить счётчик команд и указатель стека
let mut narguments = data.pop().unwrap();
pc = data.pop().unwrap();
fp = data.pop().unwrap();
// Очистить аргументы
while narguments > 0 {
data.pop();
narguments -= 1;
}
// Добавить в стек возвращаемое значение
data.push(ret);
}
```
Конечно, эта реализация виртуальной машины будет гораздо эффективнее, если вместо того, чтобы, в буквальном смысле, помещать значения в стек и извлекать их из него, мы бы просто инкрементировали или декрементировали указатель стека.
Вот и всё! Мы завершили работу над простейшими парсером, компилятором и виртуальной машиной, которые рассчитаны на обработку конструкций, являющихся подмножеством Lua. Странноватая система у нас получилась? Да. Простая? Пожалуй, что так. Рабочая? Такое ощущение, что вполне рабочая!
Итоги
-----
Итак, написав менее чем 1200 строк Rust-кода, мы создали нечто такое, что умеет выполнять вполне приличные программы, написанные на Lua. Попробуем запустить следующую программу в нашей системе и в Lua 5.4.3 (это — не LuaJIT). Что у нас получится?
```
$ cargo build --release
$ cat test/fib.lua
function fib(n)
if n < 2 then
return n;
end
local n1 = fib(n-1);
local n2 = fib(n-2);
return n1 + n2;
end
print(fib(30));
$ time ./target/release/lust test/fib.lua
832040
./target/release/lust test/fib.lua 0.29s user 0.00s system 99% cpu 0.293 total
$ time lua test/fib.lua
832040
lua test/fib.lua 0.06s user 0.00s system 99% cpu 0.063 total
```
Оказалось, что наша реализация Lua медленнее стандартной. А значит — пришло время заняться профилированием программы и, возможно, доработкой фрагментов кода, о неэффективности которых мы говорили выше.
Занимались ли вы созданием собственных парсеров, компиляторов или виртуальных машин?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=minimalnaya_realizaciya_lua_na_rust) | https://habr.com/ru/post/649973/ | null | ru | null |
# Тактика Red Team: продвинутые методы мониторинга процессов в наступательных операциях
***И снова здравствуйте. В преддверии старта курса [«Пентест. Практика тестирования на проникновение»](https://otus.pw/4Fhq/) перевели для вас еще один интересный материал.***

---
В этой статье мы собираемся разобраться в возможностях широко известных утилит мониторинга процессов и продемонстрировать, как использовать технологию, лежащую в основе этих инструментов, для наступательных операций Red Team.
Хорошее техническое понимание системы, на которое мы опираемся, является ключевым критерием принятия решений о том, каким будет следующий шаг операции. Сбор и анализ данных о запущенных процессах в скомпрометированных системах дает нам огромное количество информации и помогает понять, как устроена IT-инфраструктура целевой организации. Помимо этого, периодически запрашиваемые данные о процессах помогают нам реагировать на изменения в окружающей среде и получать сигналы-триггеры о начале расследования.
Чтобы иметь возможность собирать детализированные данные о процессах в скомпрометированных конечных точках, мы создали набор инструментов, который собрал воедино мощь продвинутых процессных утилит и фреймворков С2 (таких как Cobalt Strike).
Инструменты (и их исходный код) можно [найти здесь](https://github.com/outflanknl/Ps-Tools).
### Внутренние системные утилиты Windows
Для начала мы разберемся, какие утилиты можно использовать для сбора информации о процессах компьютера на Windows. Затем мы узнаем, каким образом эти утилиты собирают информацию, чтобы впоследствии использовать их в инструментарии Red Team.
Операционная система Windows оснащена множеством готовых утилит для администрирования системы. Несмотря на то, что большинство предоставленных инструментов подходят для целей базового системного администрирования, некоторые из них не обладают необходимыми функциями для расширенного поиска неисправностей и мониторинга. Например, диспетчер задач Windows дает нам базовую информацию обо всех процессах, запущенных в системе, но что делать, если нам требуется более подробная информация, такая, как дескрипторы объектов, сетевые подключения или же модули, загруженные в рамках определенного процесса?
Для сбора подобной информации имеется более продвинутый инструмент. Например, системные утилиты пакета [Sysinternals](https://docs.microsoft.com/en-us/sysinternals/). Как участник Red Team с большим опытом в сетевом и системном администрировании, я всегда был большим поклонником Sysinternals.
При устранении неполадок в медленно работающей серверной системе или зараженном клиентском компьютере, я чаще всего начинал устранение неполадок с помощью таких инструментов, как Process Explorer или Procmon.
С точки зрения цифровой криминалистики эти инструменты также представляются очень полезными для проведения базового динамического анализа образцов вредоносных программ и поиска артефактов в зараженных системах. Так почему же эти инструменты так популярны среди системных администраторов, а также специалистов по безопасности? Давайте разберемся в этом, углубившись в некоторую информацию о процессе, которую мы можем получить с помощью инструмента Process Explorer.
### Использование Process Explorer
Первое, что мы видим при запуске [Process Explorer](https://docs.microsoft.com/en-us/sysinternals/downloads/process-explorer) – это список/дерево всех запущенных процессов системы. Это дает нам информацию об именах процессов, их идентификаторах, контексте пользователя и уровне целостности информации о процессе и версии. Дополнительную информацию также можно отразить, настроив столбцы соответствующим образом.

Если мы задействуем нижнюю панель, то сможем просмотреть все модули, загруженные определенным процессом, или переключиться на просмотр дескрипторов, чтобы ознакомиться со всеми именованными объектами-дескрипторами, которые используются процессом:
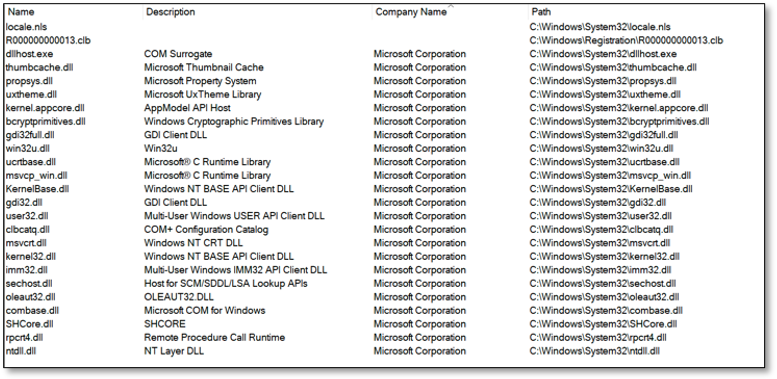
Просмотр модулей может быть полезен при поиске вредоносных библиотек, загружаемых в процессе или же для Red Team – это активный продукт безопасности (например, EDR), который внедрил модуль подключения по API в режиме пользователя.

Переключение на просмотр дескрипторов позволяет ознакомиться с типом и именем всех именованных объектов, используемых в процессе. Это может быть полезно, чтобы узнать, какие файлы и разделы реестра открыты, какие именованные каналы используются для межпроцессного взаимодействия.
Если вы щелкнете дважды на имя процесса, то появится окно с более подробной информацией. Давайте рассмотрим некоторые вкладки, чтобы узнать о дополнительных свойствах объекта:

Вкладка *Image* показывает информацию о бинарном пути, рабочем каталоге и параметрах командной строки. Помимо этого, в ней видна информация о пользовательском контексте, родительском процессе, типе образа (x86 или x64) и многое другое.
Вкладка *Threads* содержит информацию о запущенных потоках в процессе. При выборе потока и последующем нажатии на него, кнопка stack отразит стек вызовов для данного конкретного потока. Для просмотра потоков/вызовов, запущенных в режиме ядра, Process Explorer использует драйвер ядра, который устанавливается при работе в режиме повышенных полномочий.
С точки зрения DFIR, информация о потоках полезна для обнаружения инъекций в память, например, при угрозе безфайловых вирусов. Таким образом, потоки, не подкрепленные файлами на диске, могут сигнализировать о подозрительном поведении. Чтобы получить больше информации о потоках и памяти, я настоятельно рекомендую обратить внимание на инструмент [Process Hacker](https://processhacker.sourceforge.io/).

Еще одна интересная вкладка в Process Explorer — это вкладка TCP/IP. На ней вы увидите все сетевые подключения, связанные с этим процессом. С точки зрения атаки это может быть полезно для понимания, когда соединение осуществляется из скомпрометированной системы. Входящий сеанс удаленного взаимодействия PowerShell или RDP-сессия может служить сигналом к тому, что расследование уже начато.
### Использование рассмотренных методов для нападения
Теперь, когда мы узнали немного интересного о процессах, и об информации, которую мы можем о них собрать с помощью Process Explorer, вы можете задаться вопросом, как получить доступ к этой информации из наших любимых фреймворков C2. Конечно, мы могли бы воспользоваться PowerShell, поскольку это дало бы нам возможность использовать мощный скриптовый язык и Windows API. Однако сегодня PowerShell находится под неустанным надзором службы безопасности, поэтому мы стараемся избегать этого метода.
В [Cobalt Strike](https://www.cobaltstrike.com/) мы можем использовать команду ps в контексте биконов. Эта команда отображает основную информацию о процессе исходя из всех процессов, запущенных в системе. В сочетании со скриптом `[@r3dQu1nn ProcessColor](https://github.com/harleyQu1nn/AggressorScripts/blob/master/ProcessColor.cna)`, этот способ, вероятно, окажется наилучшим для получения данных о процессе.
Выходные данные команды *ps* полезны для быстрой сортировки запущенных процессов, но они не содержат подробной информации, которая помогла бы лучше разобраться в системе. Чтобы собрать более детализированную информацию, мы создали собственные утилиты для получения информации о процессах. С их помощью мы можем собрать и обогатить информацию, полученную из скомпрометированных систем.
### Инструменты Ps
Непросто реплицировать функциональные возможности и информацию, предоставляемую таким инструментом как Process Explorer. Для начала нам нужно выяснить как эти инструменты работают под капотом (и в пользовательском режиме), затем нам нужно понять, как лучше отражать эту информацию в консоли, а не в графическом интерфейсе.
После анализа исходного кода стало понятно, что многие низкоуровневые средства предоставления системной информации в значительной степени основываются на нативном API *[NtQuerySystemInformation](https://docs.microsoft.com/en-us/windows/win32/api/winternl/nf-winternl-ntquerysysteminformation)*. Несмотря на то, что API и связанные с ним структуры не полностью задокументированы, этот API позволяет собирать большое количество информации о системе Windows. Таким образом, используя *NtQuerySystemInformation* в качестве отправной точки для сбора информации о процессах, запущенных в системе, мы будем использовать [PEB](https://docs.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb) отдельных процессов для сбора детализированной информации о каждом из них. С помощью API *[NtQueryInformationProcess](https://docs.microsoft.com/en-us/windows/win32/api/winternl/nf-winternl-ntqueryinformationprocess)* мы сможем прочитать структуру `PROCESS_BASIC_INFORMATION`, используя дескриптор процесса, и найти `PebBaseAddress`. Затем мы используем `NtReadVirtualMemory` API для чтения структуры `RTL_USER_PROCESS_PARAMETERS`, которая позволит нам узнать параметры `ImagePathName` и `CommandLine` процесса.
Используя эти API в качестве фундамента нашего кода, мы написали следующие инструменты для получения информации о процессах:
* *Psx*: показывает подробный список всех процессов, запущенных в системе.
* *Psk*: показывает информацию о ядре, включая загруженные драйверы.
* *Psc*: показывает подробный список всех процессов с установленными TCP-соединениями.
* *Psm*: показывает подробную информацию о модуле из конкретного идентификатора процесса (загруженные модули или сетевые подключения, например).
* *Psh*: показывает подробную информацию о дескрипторе определенного идентификатора процесса (например, дескрипторы объектов, сетевые подключения).
* *Psw*: показывает названия окон процессов для которых окна активны.
Все эти инструменты написаны на С как рефлективные DLL и могут быть рефлективно внедрены в порожденный процесс с помощью С2 фреймворка, такого как Cobalt Strike (или любого другого фреймворка, который поддерживает рефлективные DLL-инъекции). Для Cobalt Strike мы добавили скрипт-агрессор, который можно использовать для загрузки инструментов с помощью менеджера скриптов Cobalt Strike.
Давайте рассмотрим каждый конкретный инструмент, запущенный в Cobalt Strike, чтобы продемонстрировать функциональность и показать какую информацию можно собрать с его помощью:
#### Psx
Этот инструмент показывает подробный список всех процессов, запущенных в системе. Выходные данные можно сравнить с информацией на главном экране Process Explorer. Psx выводит имя процесса, его id, родительский PID, время создания и информацию, связанную с бинарными файлами процесса (архитектуру, название компании, версии и т.д.). Как вы видите, он также отображает кое-какую интересную информацию активного ядра системы, например, базовый адрес ядра, который полезен при эксплуатации ядра (например, для вычисления смещений ROP-гаджетов). Всю эту информацию можно собрать из обычного пользовательского контекста (без повышения прав).
Если у нас достаточно разрешений, чтобы открыть дескриптор процесса, можно прочитать дополнительную информацию, такую как контекст пользователя и уровень целостности его токена. Перечисление PEB и связанных структур позволяет получить информацию о пути образа и параметры командной строки:
Как вы могли заметить, мы читаем и выводим информацию о версии из бинарных образов процесса, например, название компании и описание. Зная название компании, можно легко перечислить все активные продукты безопасности в системе. С помощью этого инструмента мы сравниваем названия компаний всех активных процессов со списком известных поставщиков продуктов безопасности и выводим результаты:

#### Psk
Этот инструмент отражает информацию о работающем ядре, включая все загруженные модули драйверов. Как и инструмент Psx, он также предоставляет сводку обо всех загруженных модулях ядра от известных продуктов безопасности.

#### Psc
Этот инструмент использует те же методы для вывода информации об активных процессах, что и *Psx*, за исключением того, что он отображает только процессы с активным сетевым соединением (IPv4, IPv6 TCP, RDP, ICA):
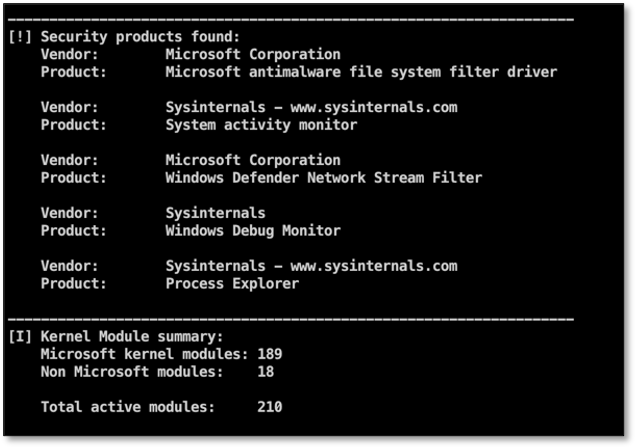
### Psm
Этот инструмент можно использовать для получения подробных сведений о конкретном процессе. Он будет отображать список всех модулей (DLL), используемых процессом и сетевым соединением:

### Psh
То же самое, что и *Psm*, но вместо загруженных модулей, показывает список дескрипторов процесса:
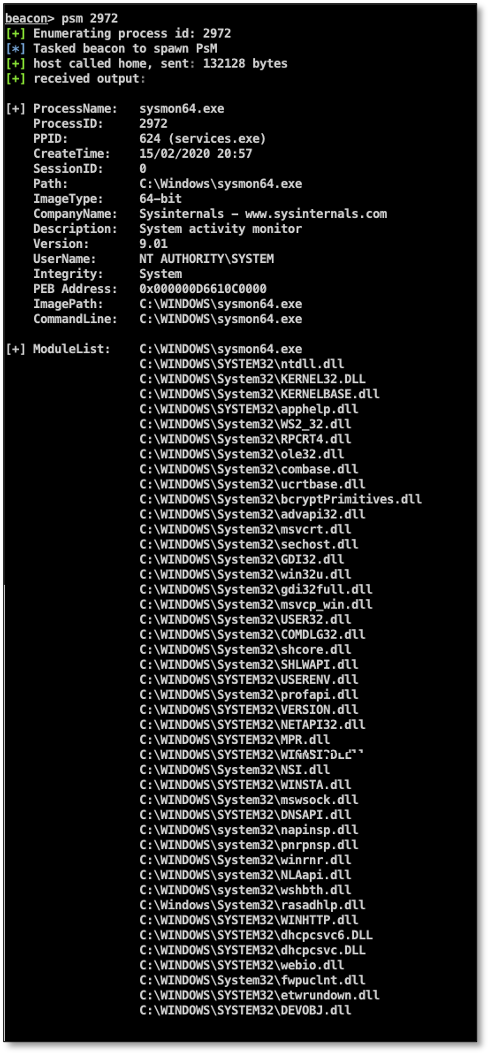
### Psw
Последний, но не менее важный инструмент *Psw*. Этот инструмент покажет список процессов с активными дескрипторами окон, тех, которые открыты на рабочем столе пользователя, включая заголовки окон. Это полезно для определения того, какие графические интерфейсы приложений открываются пользователем без необходимости создавать скриншоты рабочего стола:
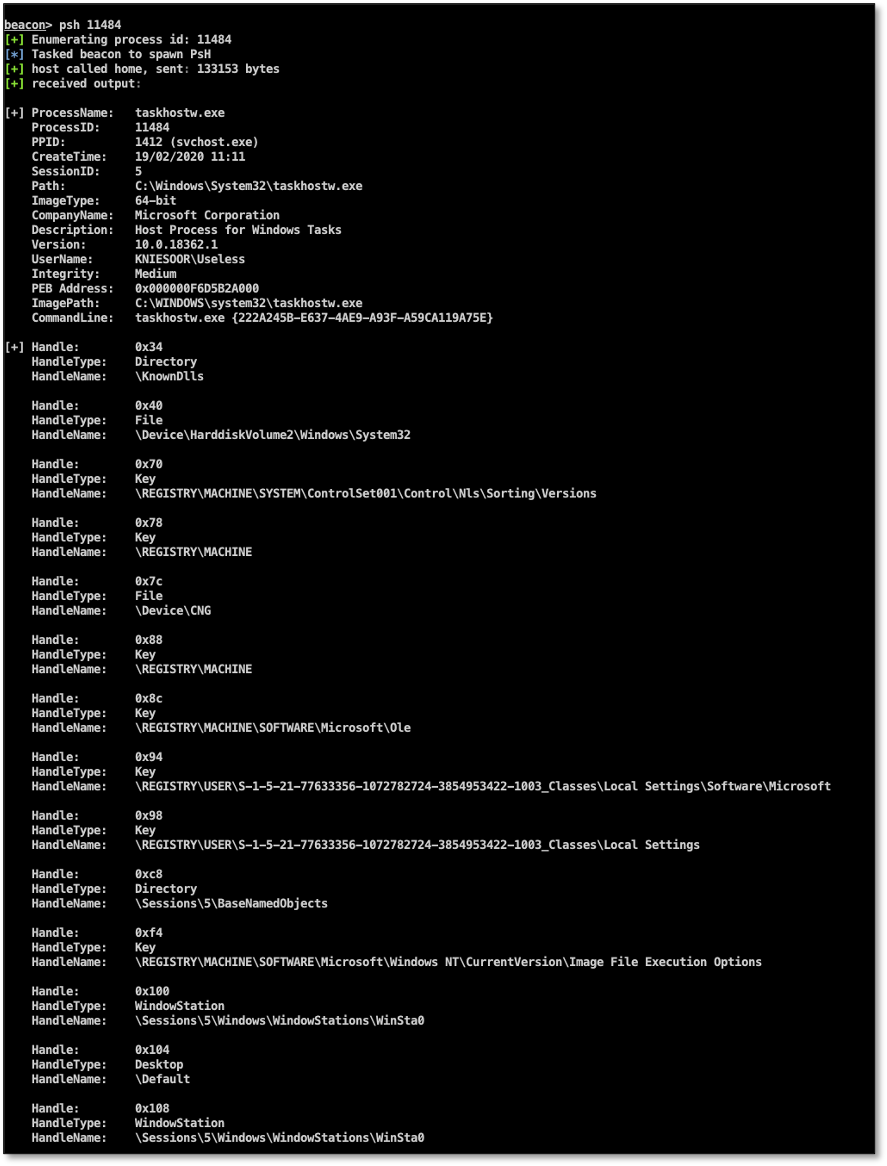
### Варианты использования
Вы можете задаться вопросом: «И как же это все поможет нам в операциях по наступлению?» После получения доступа к скомпрометированному активу мы обычно используем эту информацию для следующих целей:
* Обнаружить инструменты безопасности на скомпрометированном активе. Не только по информации о процессе, но и по загруженным модулям.
* Обнаружение пользовательских hook-engine’ов.
* Поиск возможностей для маневров (с помощью сетевых сеансов) и эскалации привилегий.
После первой компрометации вы можете периодически запрашивать подобную информацию о процессах и приступить к созданию триггеров. Например, мы автоматически вводим эту информацию в [RedELK](https://github.com/outflanknl/RedELK). Затем можно создать оповещения о подозрительных изменениях в информации о процессе, таких как:
* Запуск инструмента проверки безопасности или установка нового продукта end-point security.
* Входящие сетевые подключения из отдела обеспечения безопасности через RDP – сессию или удаленный PowerShell.
* Открытие дескриптора другим процессом на одном из наших вредоносных артефактов (например, файл, используемый для сохранения присутствия).
### Заключение
В этой статье мы показали, как такие инструменты, как Sysinternals Process Explorer, можно использовать для получения подробной информации о процессах, запущенных в системе, и как эта информация может помочь администраторам и специалистам по безопасности устранять неполадки и проверять систему на наличие проблем с безопасностью или производительностью.
Эта же информация также актуальна и полезна для Red Team, которые имеют доступ к скомпрометированным системам во время работы. Она помогает лучше понять систему и IT-инфраструктуру вашей цели, а периодический опрос такой системы позволяет Red Team реагировать на возможные изменения среды (например, триггер расследования).
Мы реплицировали некоторые функциональные возможности, предоставляемые такими инструментами, как Process Explorer, поэтому мы можем использовать ту же информацию в наступательных операциях. Для этого были созданы несколько инструментов мониторинга процессов, которые могут быть использованы в рамках фреймворка С2, например Cobalt Strike. Мы показали, как пользоваться этими инструментами и какую информацию с помощью них можно собрать.
Эти инструменты доступны на нашей [GitHub-странице](https://github.com/outflanknl/Ps-Tools) и готовы к использованию в составе Cobalt Strike.
---
[Узнать подробнее о курсе.](https://otus.pw/4Fhq/)
--- | https://habr.com/ru/post/498544/ | null | ru | null |
# CLion 2019.1: ClangFormat, подсветка кода через Clangd, memory view, начальная поддержка микроконтроллеров
Привет, Хабр!
У команды CLion множество отличных новостей — питерская часть команды вместе с другими коллегами успешно перебралась в новый офис, к нам присоединились новые классные разработчики, а главное, мы буквально на днях выпустили первое большое обновление в этом году, **CLion 2019.1**!
Работа в новой версии шла сразу по нескольким фронтам:
* **Усовершенствования поддержки языка C++**: подсветка кода через Clangd, улучшения рефакторингов Extract и Rename, новая проверка на то, что функцию-член класса можно объявить статической.
* **Больше возможностей в настройках стиля написания кода**: интеграция с ClangFormat, поддержка стилей именования переменных в C/C++, поддержка разных стилей для header guards.
* **Новые возможности и улучшения отладчика**: просмотр состояния памяти — Memory View — для указателей, просмотр дизассемблированного кода в случае LLDB, ускорение работы пошаговой отладки.
* **CLion для микроконтроллеров**, первые шаги.
* Возможность создавать Build Targets и конфигурации для запуска/отладки в CLion, которые никак не связаны с проектной моделью.
* Работа с другими языками программирования в строковых литералах в С/С++.
* Новые визуальные темы и другие платформенные возможности.

Подробнее об этих и других нововведениях читайте ниже. А чтобы попробовать новые возможности и улучшения, скачайте бесплатную 30-дневную версию CLion [с нашего сайта](https://www.jetbrains.com/clion/download/).
Поддержка языка C++
-------------------
### Clangd
Как вы уже знаете, в CLion два инструмента для поддержки языка C++ — один полностью свой, а второй основан на Clangd. Они работают совместно, дополняя друг друга и обмениваясь необходимой информацией. При этом, если производительность и критерий функциональной полноты позволяют, мы сейчас стараемся перенести умные средства по работе с кодом на C++ в CLion на инструмент на базе Clangd. Речь пока не идет про рефакторинги кода, но вот подсветка кода в 2019.1 сделана уже на базе Clangd. Это существенно улучшило “отзывчивость” редактора.
Еще несколько релизов назад мы перевели CLion на инструмент на базе Clangd при показе ошибок в редакторе. Теперь текст ошибок показывается более детально. Это пригодится, например, при отладке ошибок, связанных с перегрузкой функций:
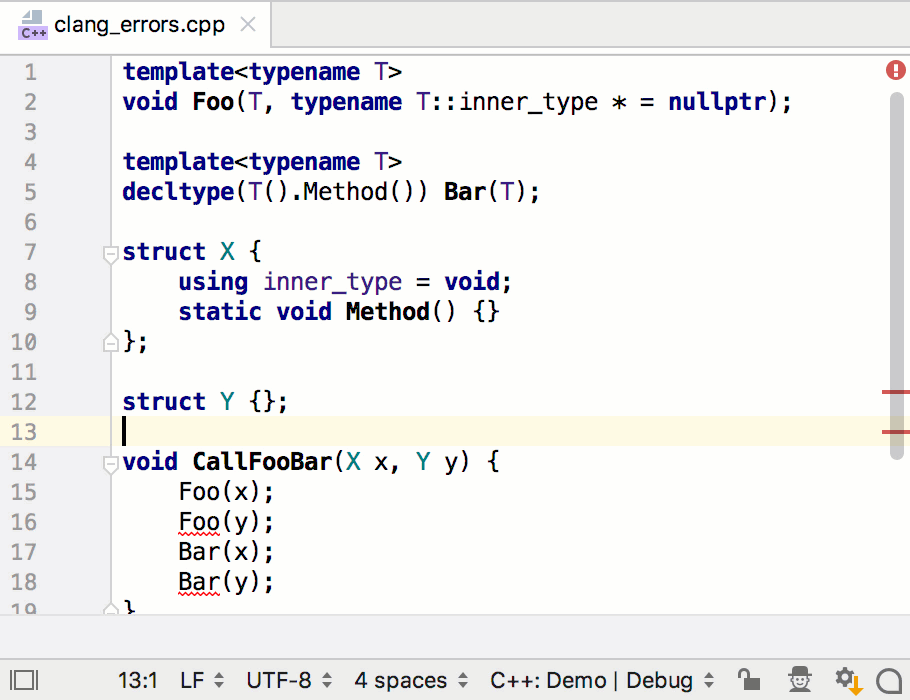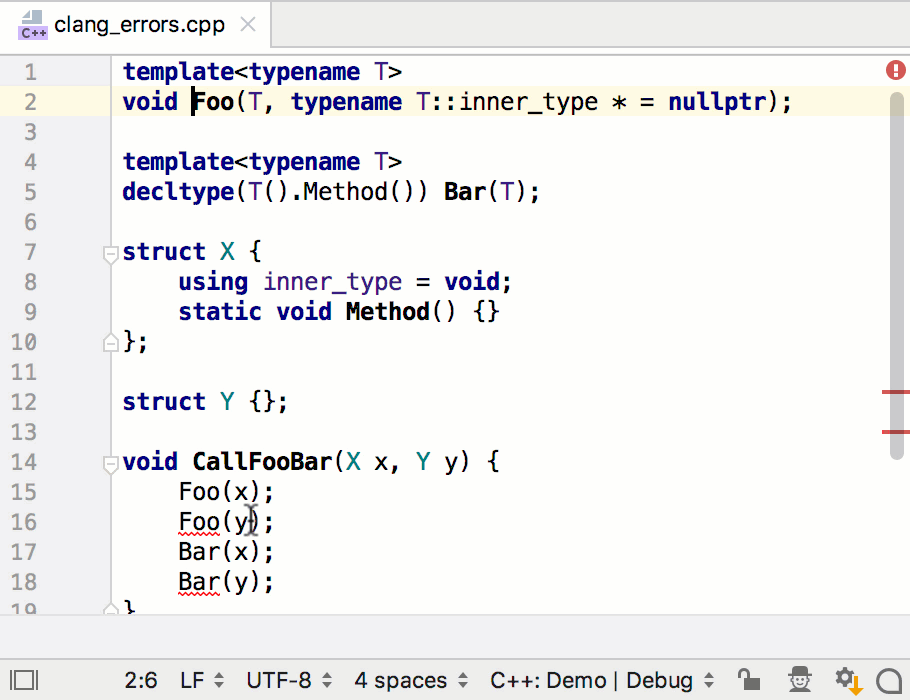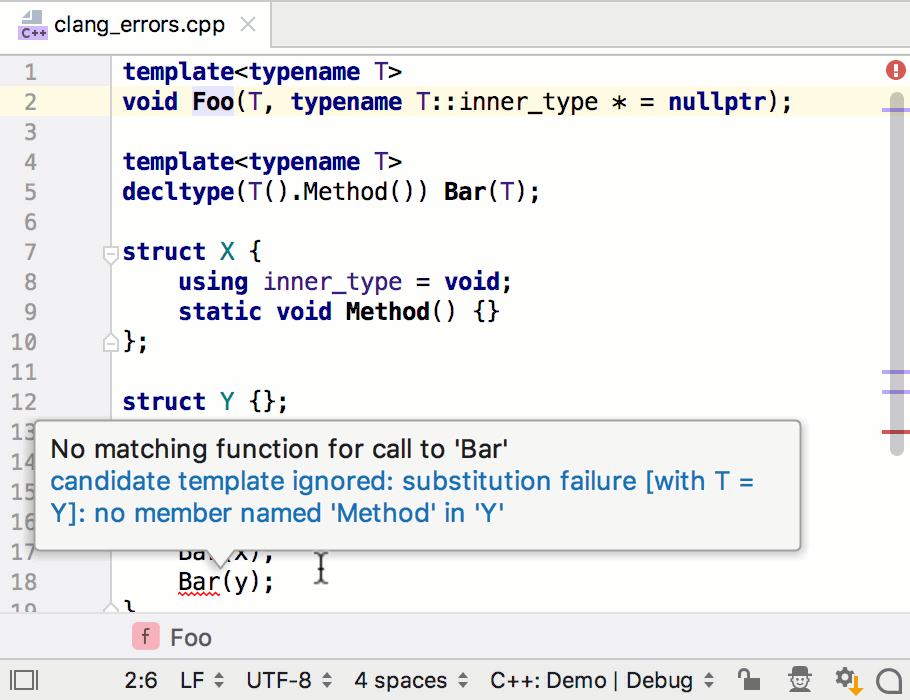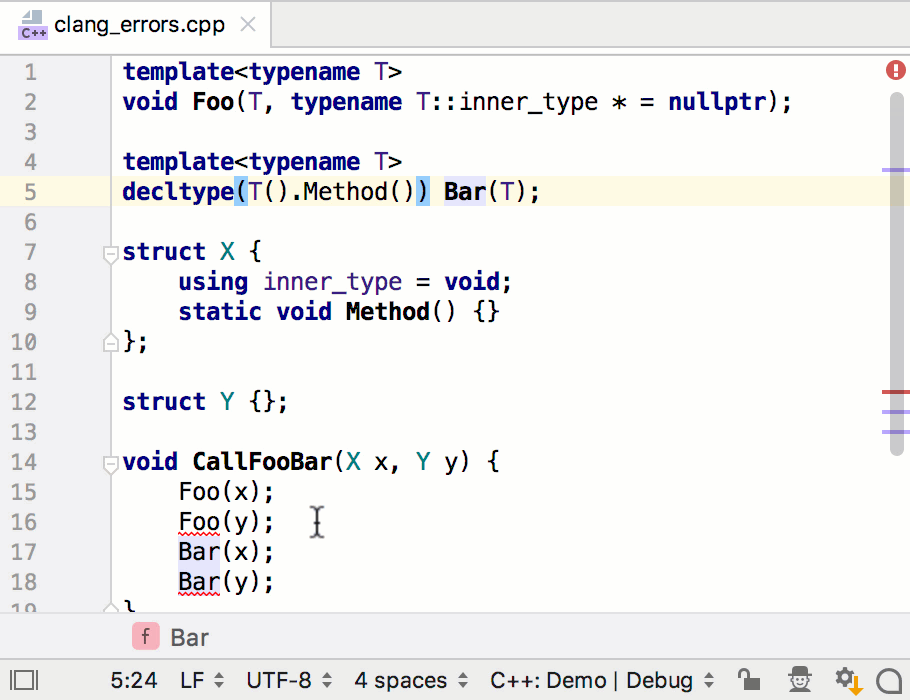
К этому добавилась возможность вычисления позиции возможного исправления (quick-fix) тоже через Clangd. Само же исправление предоставляется непосредственно собственным инструментом CLion.
Еще одно интересное направление нашей работы — это написание новых проверок на инструменте парсинга кода на Clangd. Начиная с CLion 2019.1, новая проверка для кода на C++ подскажет, когда функцию-член класса можно объявить статической:
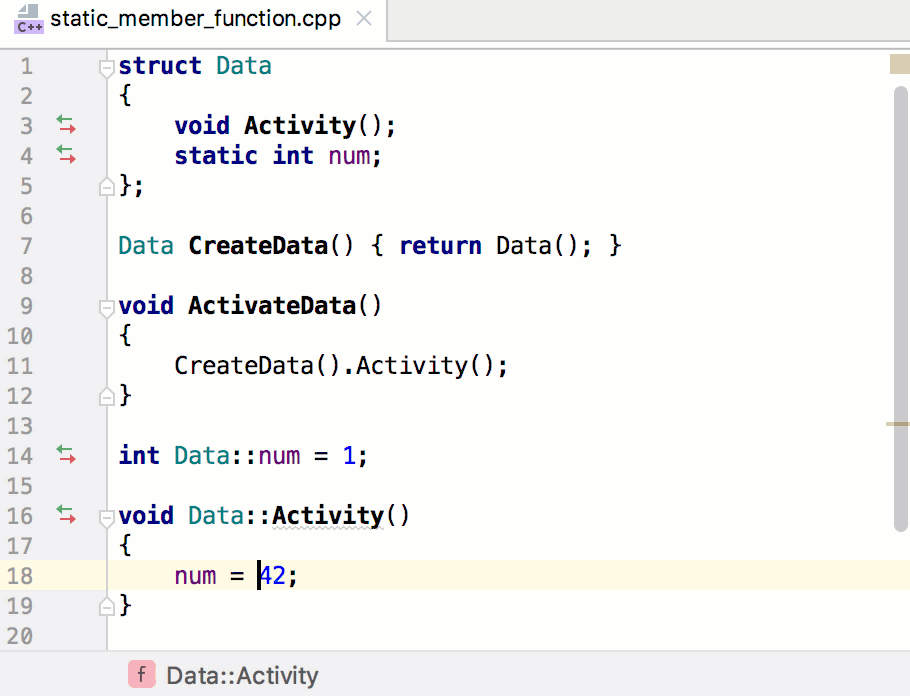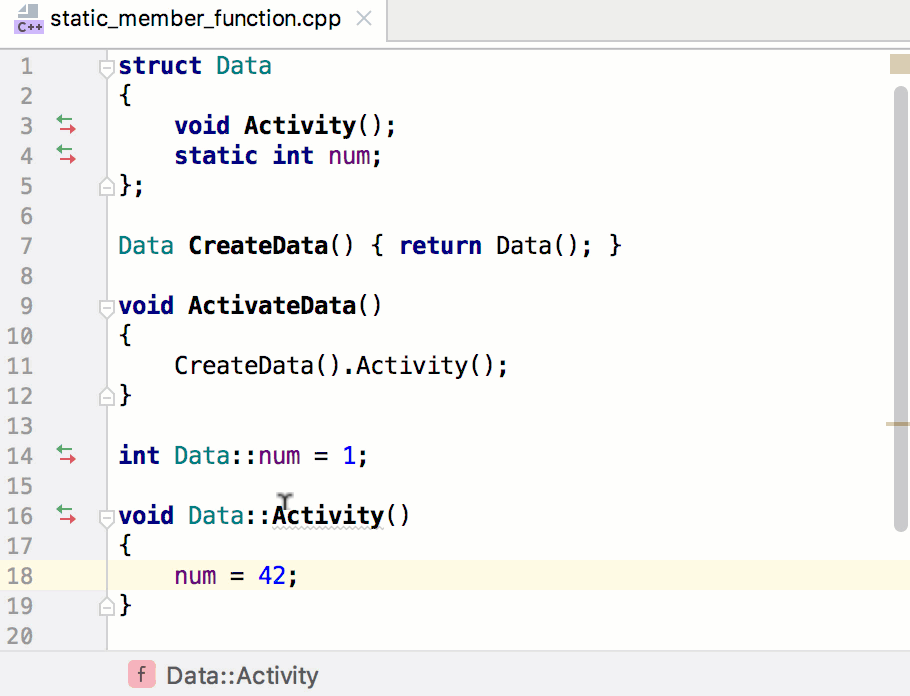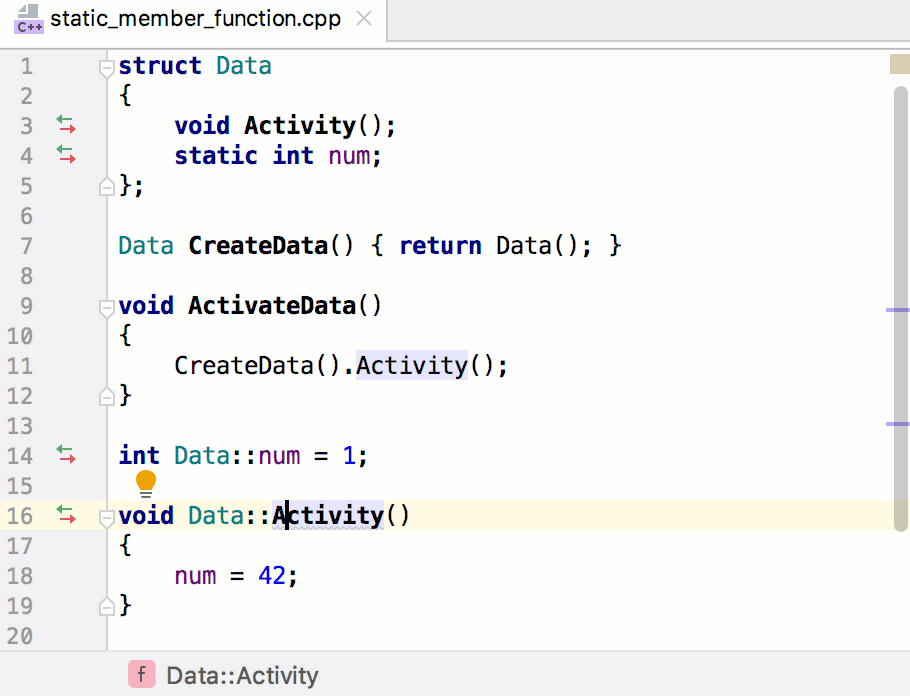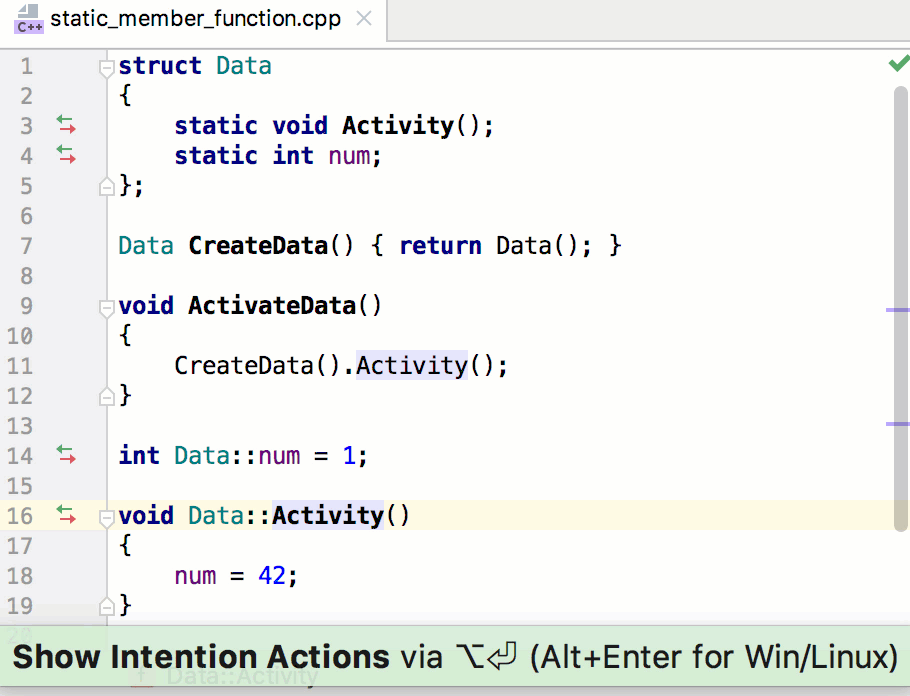
Кстати, управление настройками этого альтернативного инструмента на Clangd можно найти в Settings/Preferences | Languages & Frameworks | C/C++ | Clangd.
### Собственный инструмент парсинга кода
Производительность редактора является одной из наших самых приоритетных целей. Помимо множества небольших улучшений, в этом релизе стоит отметить существенное улучшение начального времени индексирования проекта. Оно случается не всегда, но в случаях, когда для своих проектов вы используете одни и те же библиотеки: тогда CLion может это автоматически заметить и переиспользовать символы для этих библиотек для нового открытого проекта, который их использует. Когда речь идет об STL или Boost, улучшения становятся очень заметными!
В наших планах на этот год повышение аккуратности и точности наших рефакторингов для C++. Мы начали с двух самых базовых — Rename и Extract. Для Extract мы поправили множество случаев, когда результат рефакторинга оказывался некорректным из-за неправильно учтенных квалификаторов пространства имен (например, `std::`), специализаций шаблонов и переопределенных имен типов (type aliases).
Применительно к Rename мы обратили внимание на случай, когда происходит переименование класса или структуры, совпадающей с именем файла, в котором они находятся. Раньше мы всегда переименовывали и файл тоже, а теперь CLion спрашивает вас о предпочтительном исходе во время рефакторинга. Можете переименовать, а можете оставить старое имя файла. В обратную сторону тоже работает — переименование файла не приводит к безусловному переименованию класса. (Где-то здесь должны быть крики из зала: “Наконец-то!”.)
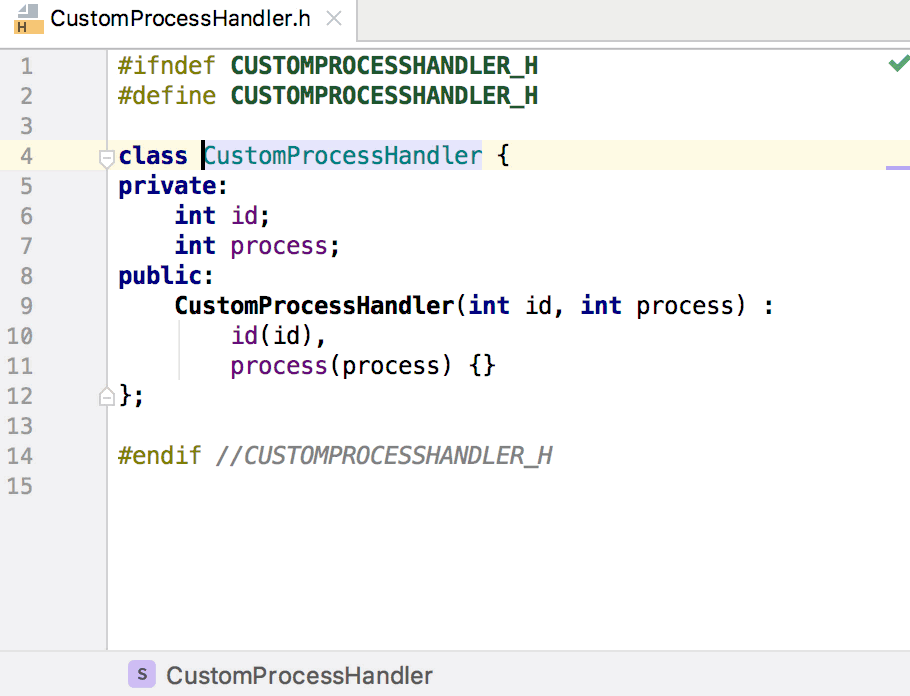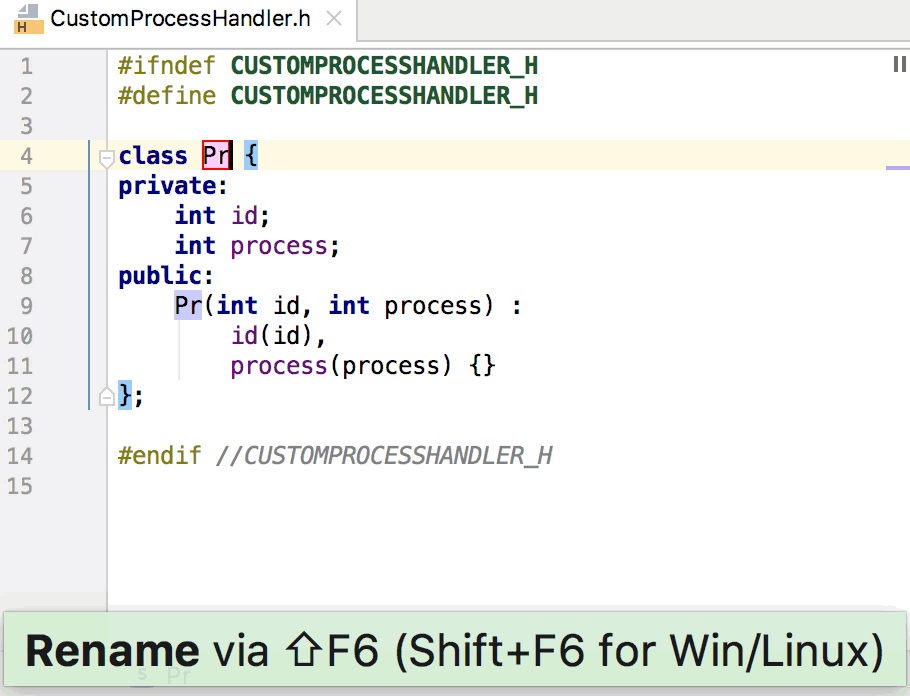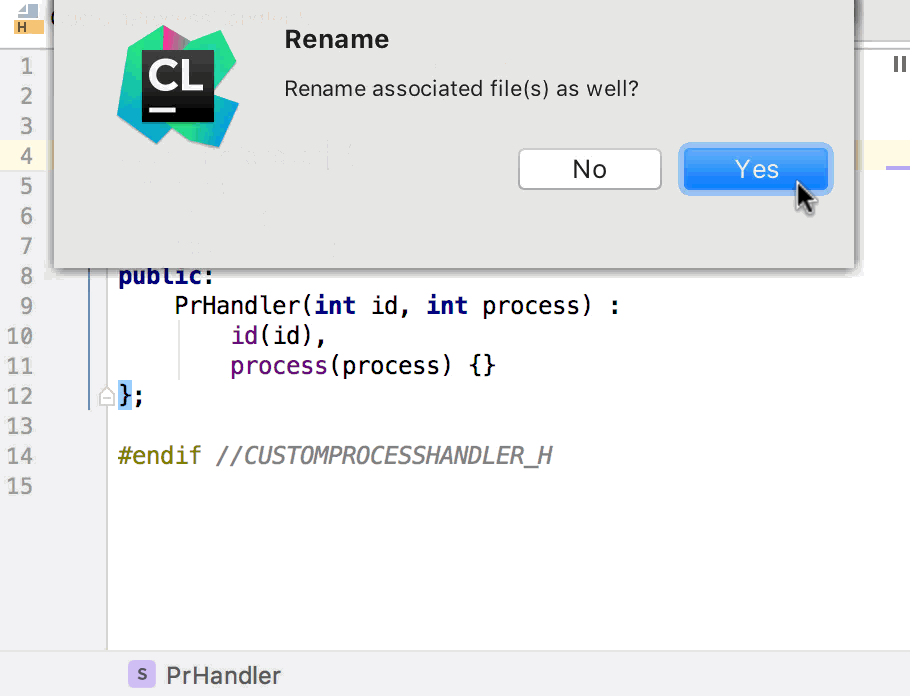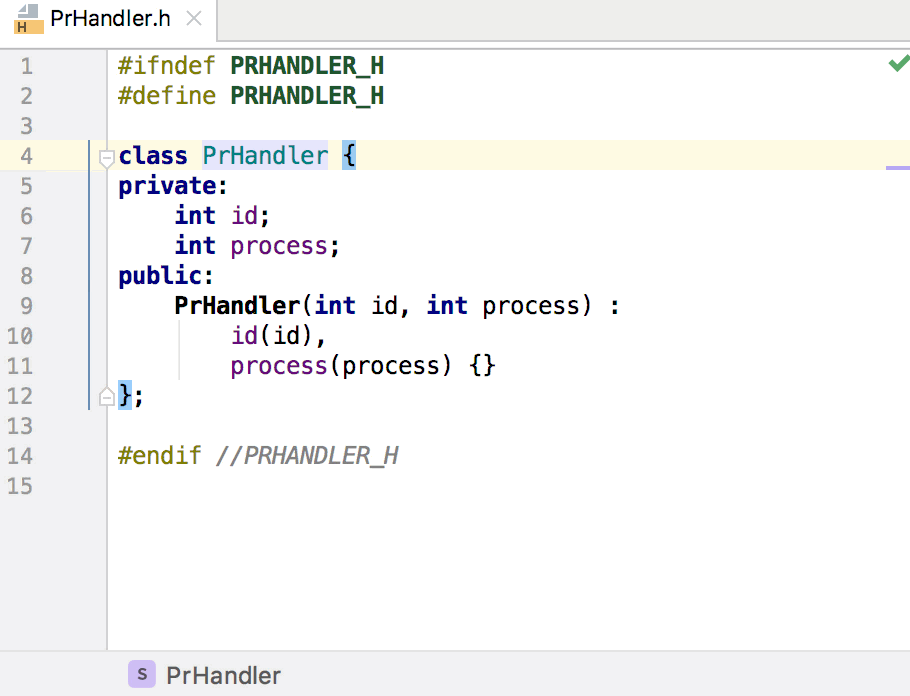
И, кстати, чуть ниже я расскажу о возможности задавать стили header guards. Так вот, если использованный в файле header guard следует заданному шаблону стиля и при этом в его имени есть имя переименованного файла, то CLion обновит и header guard!
Стили кодирования
-----------------
В версии 2019.1 мы добавили возможность переключиться на ClangFormat для форматирования кода в CLion. Это включает в себя не только само действие форматирования (`Ctrl+Alt+L` на Windows/Linux, `⌥⌘L` на macOS) или автоформатирование при печати кода, но и форматирование перед коммитом (pre-commit hook), при генерации кода средствами CLion, при рефакторингах и при применении исправлений (quick-fixes). В общем, в любом месте, где IDE форматирует код, будет вызываться ClangFormat.
Переключиться на ClangFormat можно глобально — в настройках Settings/Preferences | Editor | Code Style. А можно только для конкретного проекта. Причем, если в проекте будет обнаружен конфигурационный файл *.clang-format*, CLion предложит переключиться на ClangFormat именно с использованием этого конфигурационного файла:
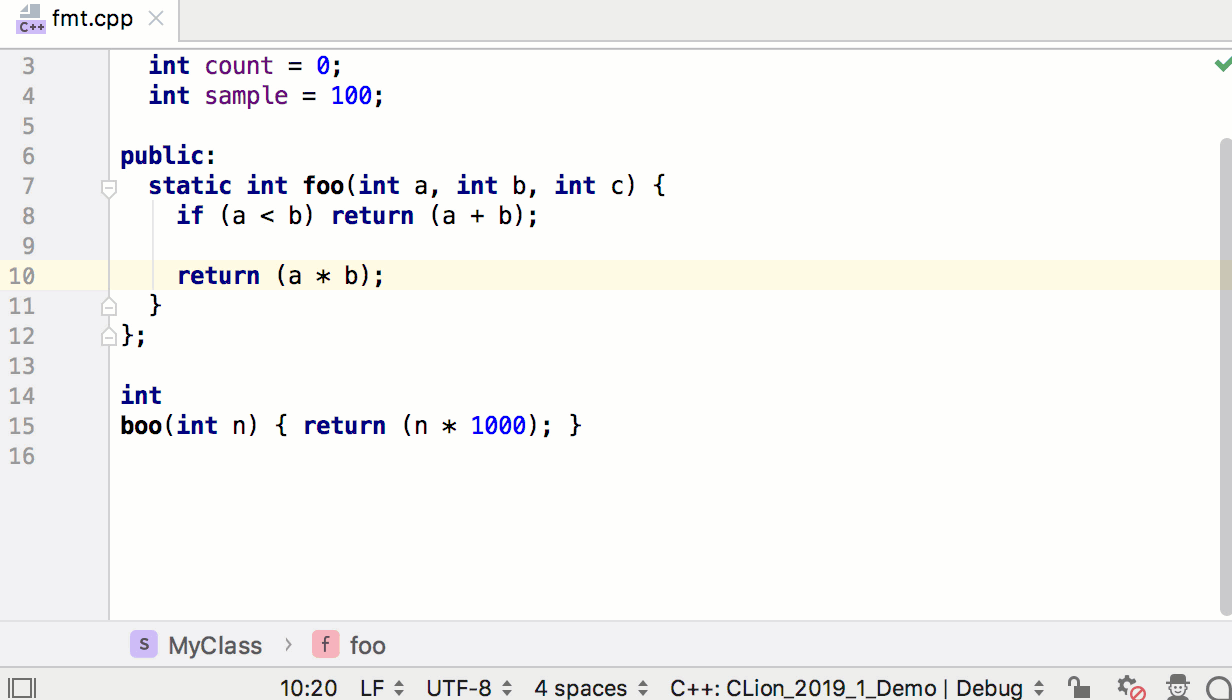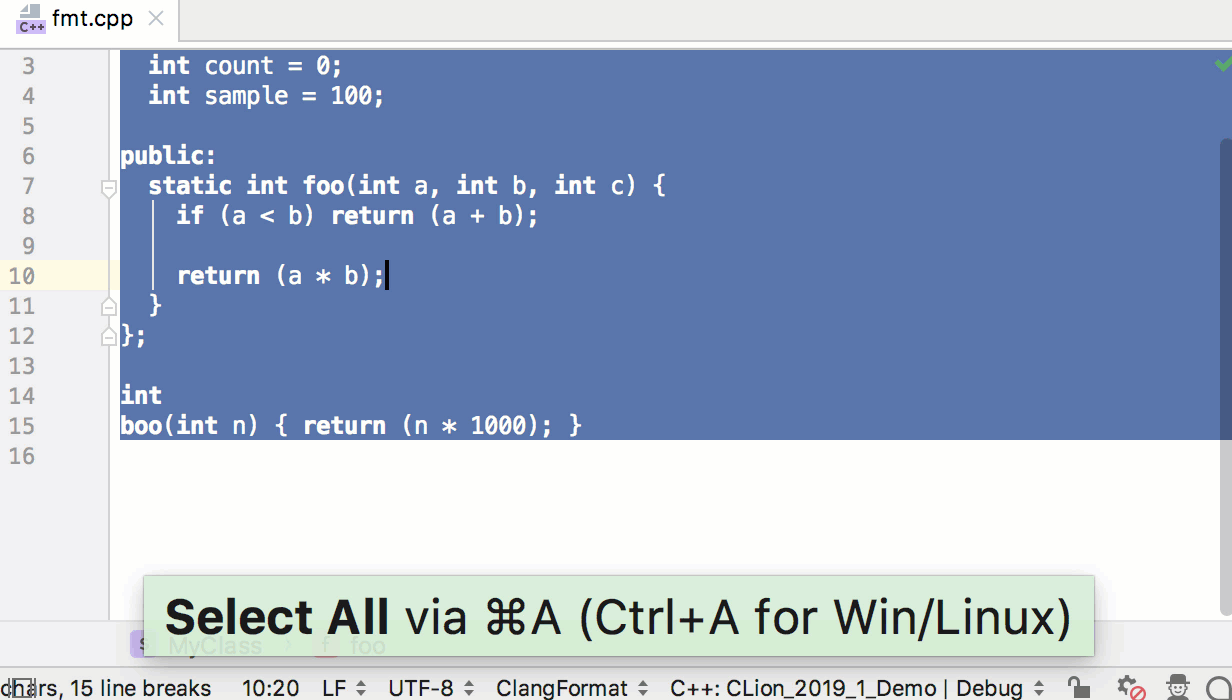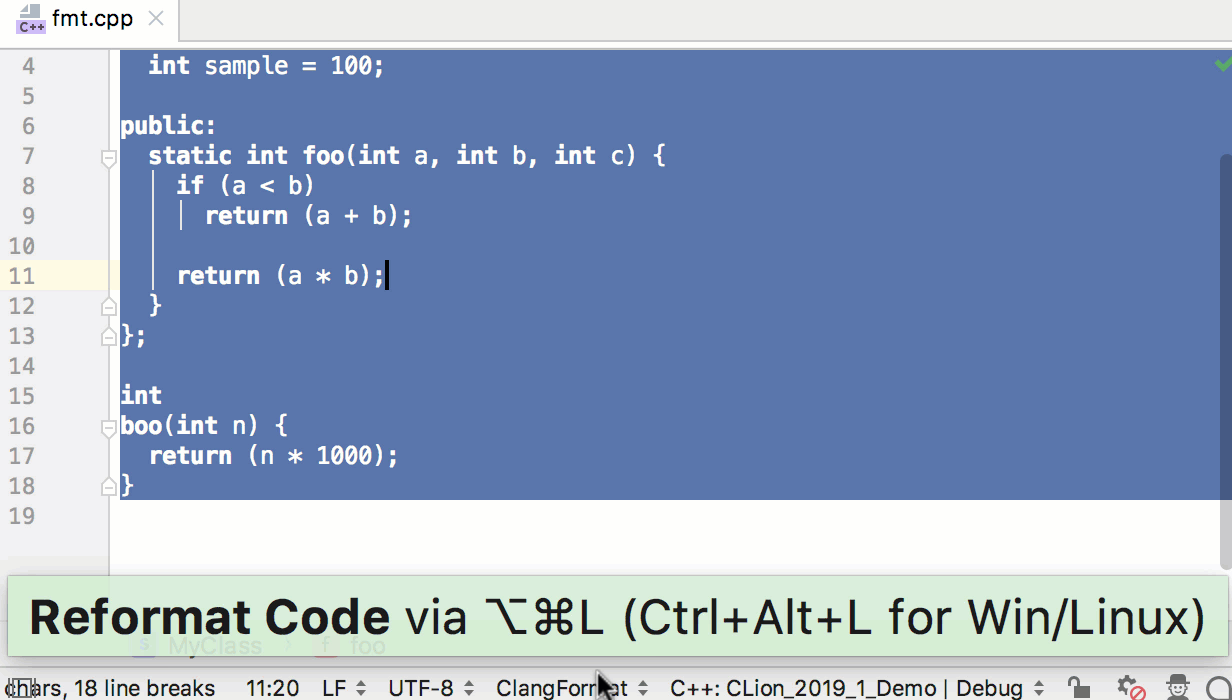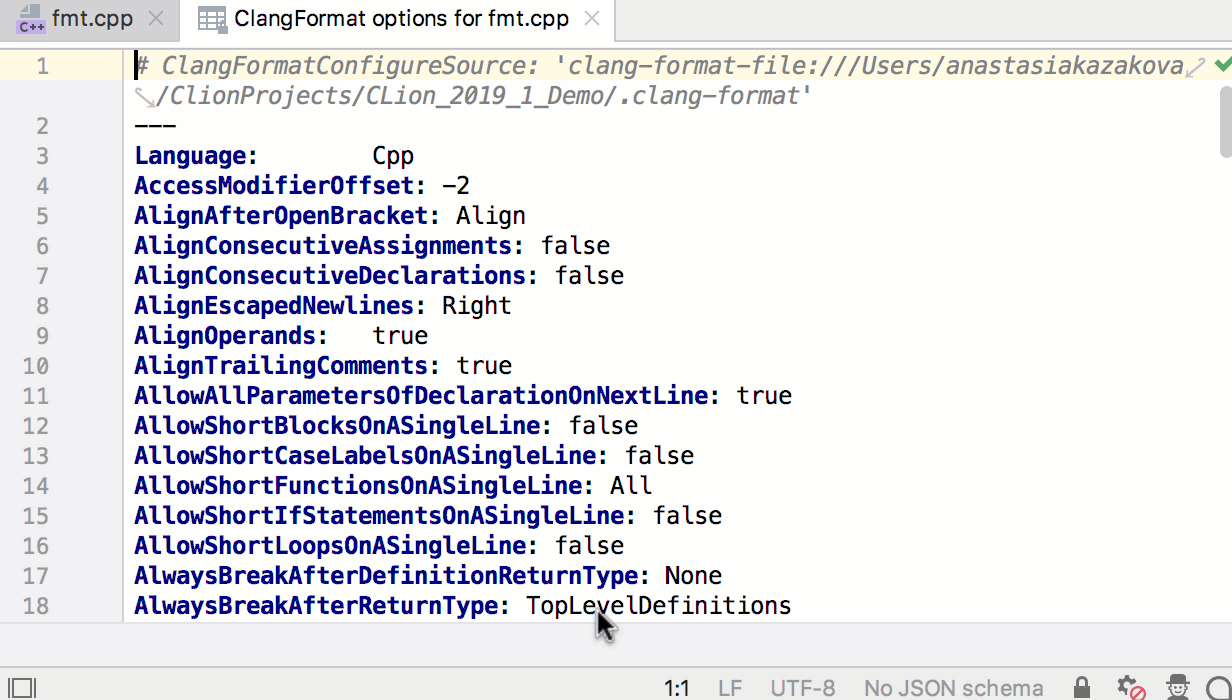
Чуть больше деталей можно найти [в нашем блоге](https://blog.jetbrains.com/clion/2019/01/clion-opens-2019-1-eap-clangformat-disasm-lldb-injected-languages/#clangformat_support) (на английском).
Именование переменных, типов и других символов в коде — сложный, порою даже философский вопрос. Но в мире программирования (для улучшения читаемости кода) давно придумали стили именования. Есть стиль LLVM, есть Qt, есть Google. Поэтому в настройках CLion Settings/Preferences | Editor | Code Style | C/C++ теперь появилась новая вкладка — Naming Convention, в которой можно выбрать один из предопределенных стилей или настроить свой, задав стиль именования для различных типов символов (макросов, глобальных функций, членов класса, параметров, локальных переменных и пр.). Выбранная конвенция будет использоваться во всех действиях IDE — кодогенерации, рефакторинга, автоматических исправлениях и т. д. Кроме того, если хочется еще более точно следить за выполнением правил именования, можно включить новую проверку Inconsistent Naming, которая покажет имена, не соответствующие правилам, и предложит вариант переименования:

В этой же вкладке можно найти настройки стиля header guards, которые я упоминала выше:
Кстати, если вы предпочитаете использовать `#pragma`, то просто поправьте шаблон новых заголовочных файлов в Settings/Preferences | Editor | File and Code Templates.
Отладчик
--------
### Просмотр памяти Memory View
У нас наконец дошли руки до просмотра памяти в отладчике. В текущей версии можно посмотреть память по указателю: достаточно встать на любой указать в панели Variables во время отладки и запросить Memory View (`Ctrl+Enter` на Windows/Linux, `⌘Enter` на macOS). А если вкладка memory view открыта при пошаговой отладке, то в ней можно видеть подсвеченные изменения в памяти:
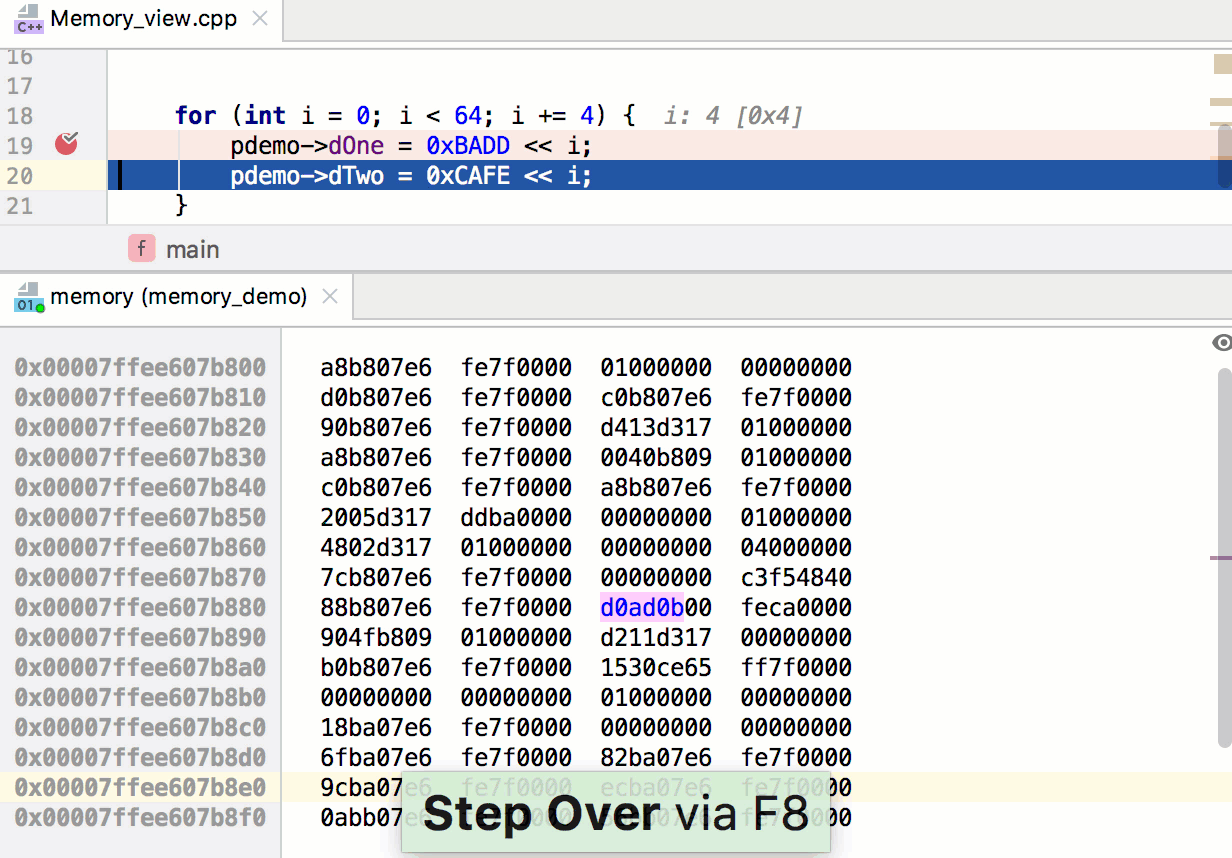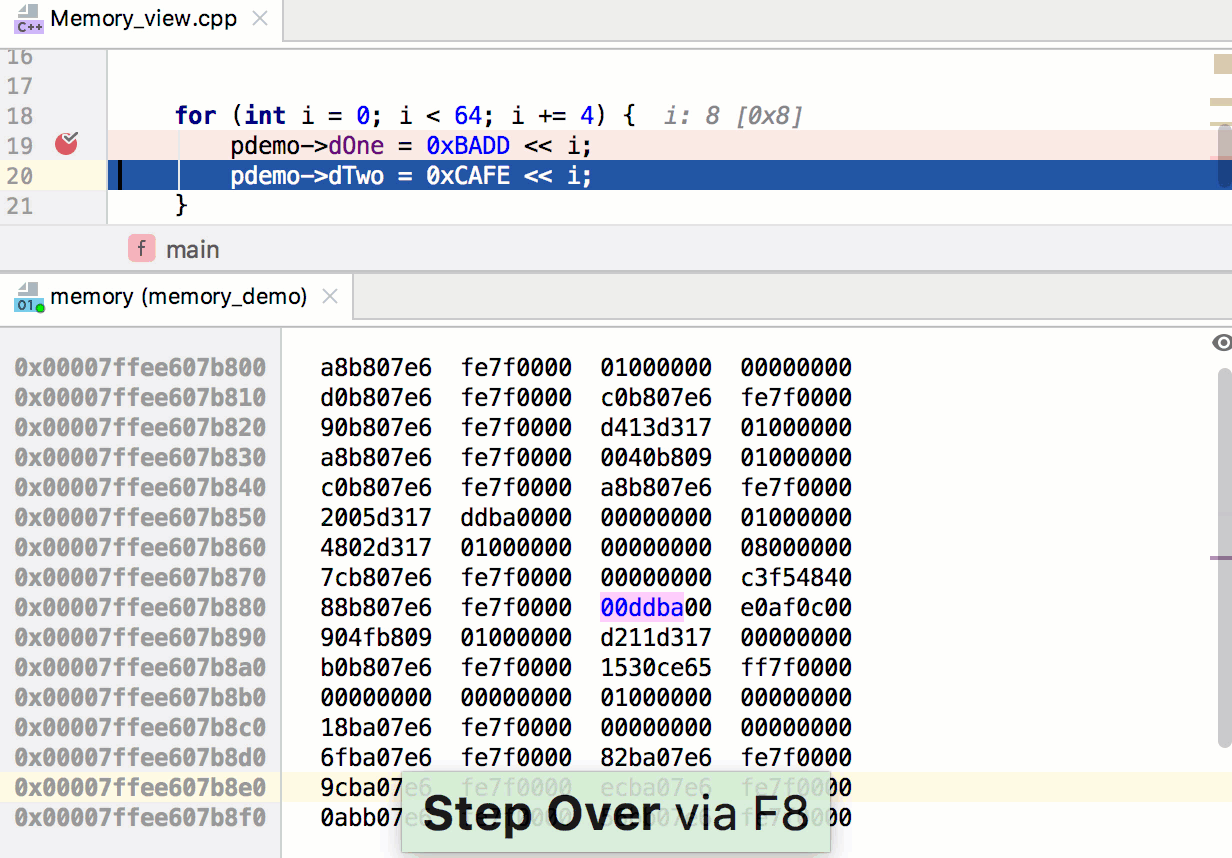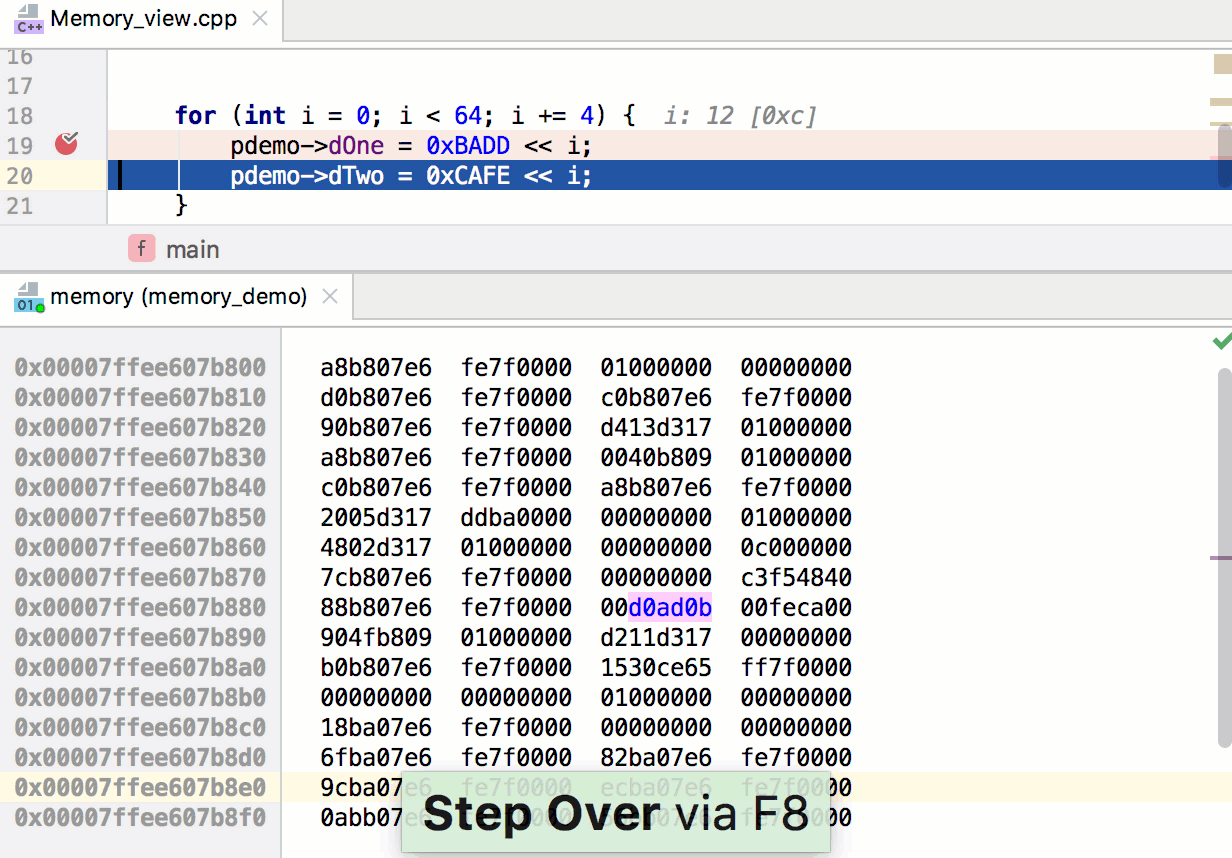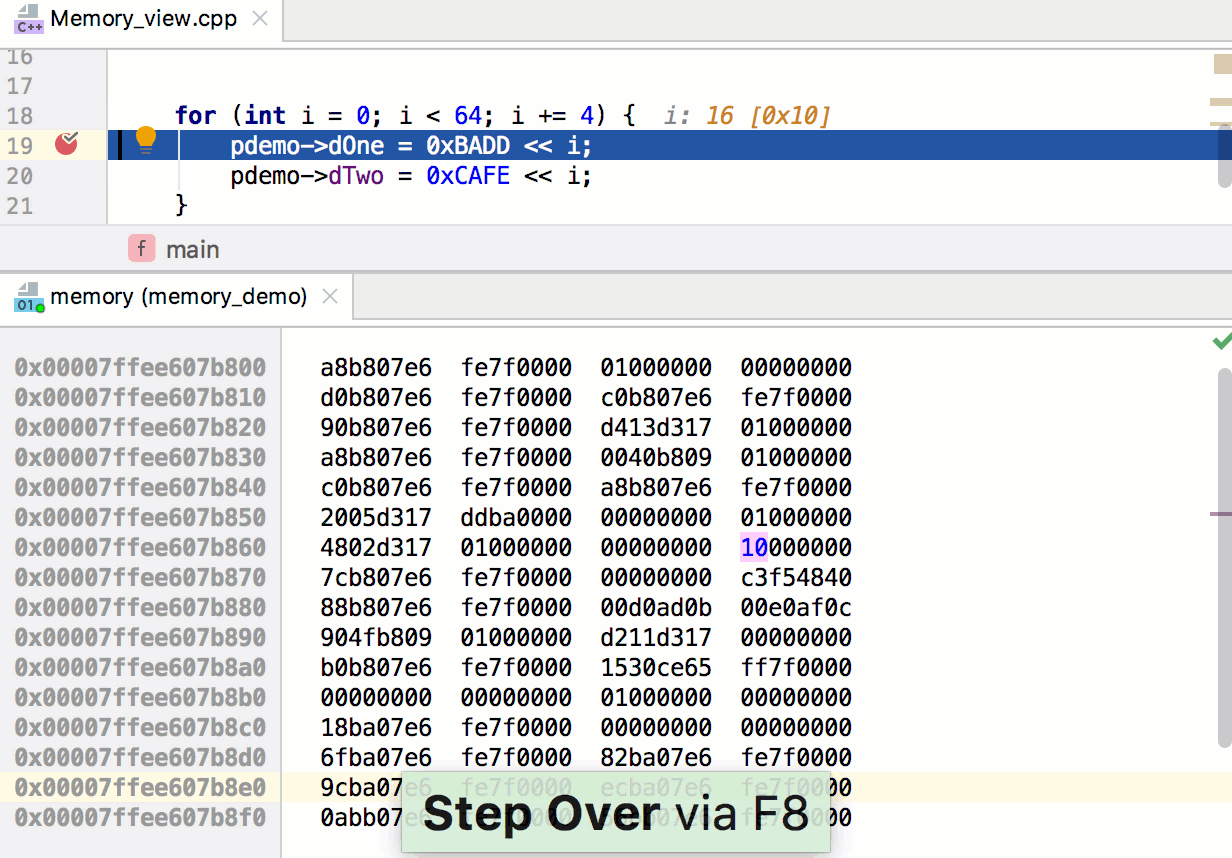
На следующий релиз уже запланированы изменения в UI/UX, но сначала хотелось бы собрать отзывы от пользователей. Так что пишите!
### Дизассемблирование в случае LLDB
Ассемблерный код теперь разбит по функциям и, главное, показывается не только в случае GDB, но и для LLDB!
Стоит, правда, отметить, что ассемблерный код показывается до сих пор только в тех случаях, когда нет исходных кодов функции. Так называемый режим [disassemble on demand](https://youtrack.jetbrains.com/issue/CPP-9091) пока не поддержан.
### Производительность пошаговой отладки
Иногда пошаговая отладка затягивается из-за длительного вычисления переменных на каждом шаге. Но ведь порою эти вычисления никому не нужны — хочется как можно быстрее пройти какую-то область кода по шагам, изредка просматривая значения пары переменных! Теперь в CLion появилась возможность отключить пересчет переменных при пошаговой отладке — *Mute Variables* в контекстном меню отладчика делает ровно это. А когда понадобится вычислить и отобразить значения, на переменной можно нажать *Load*:
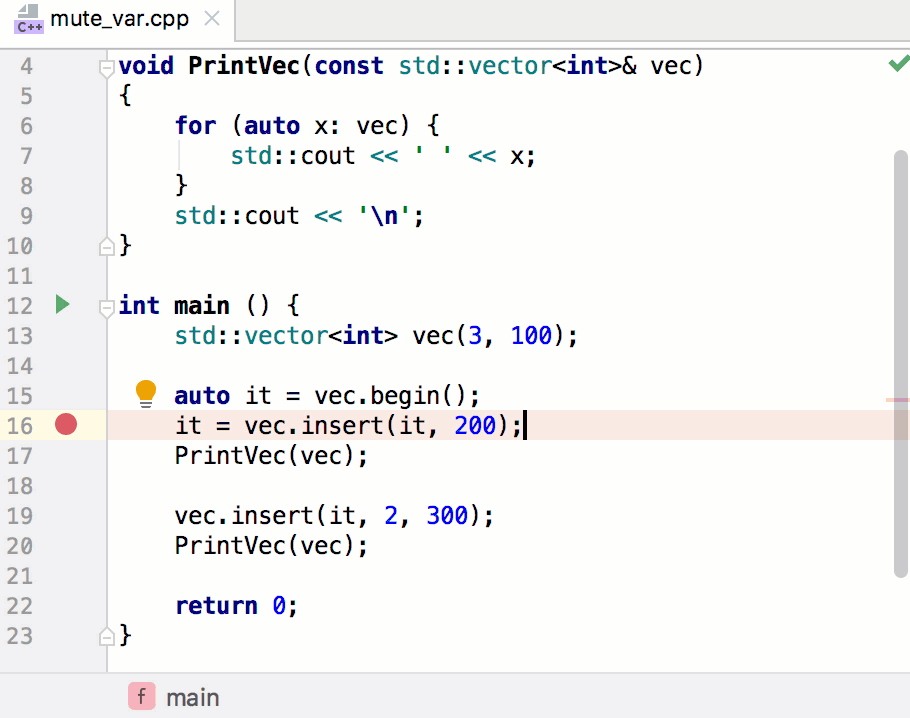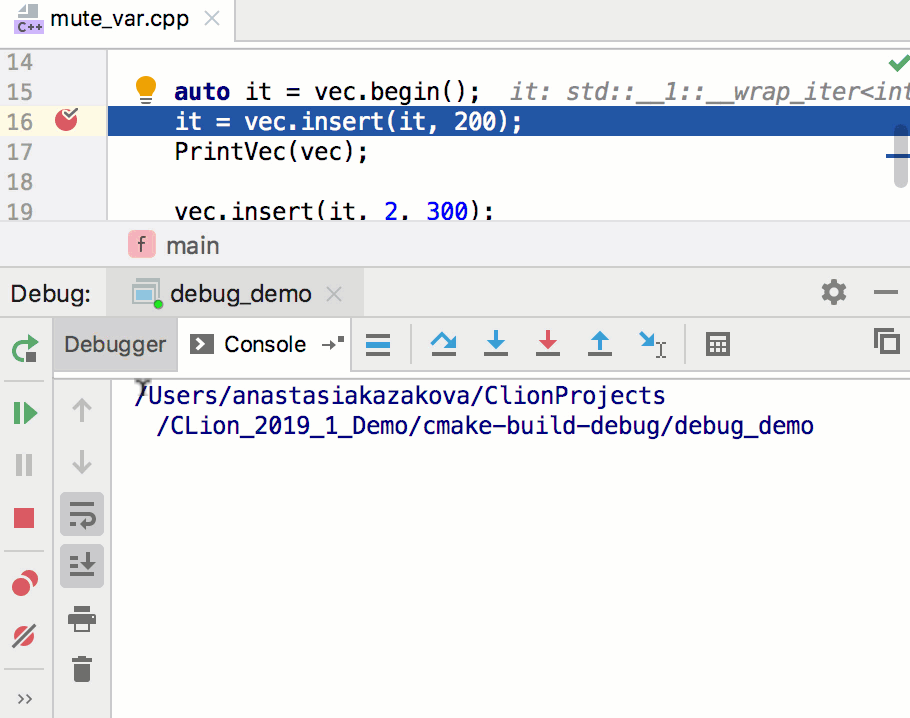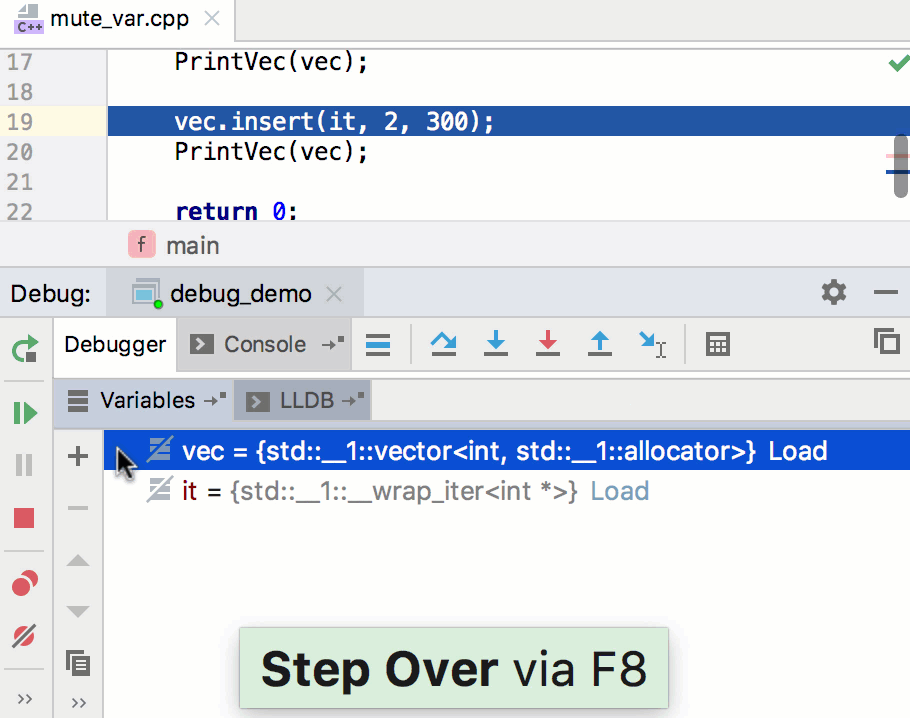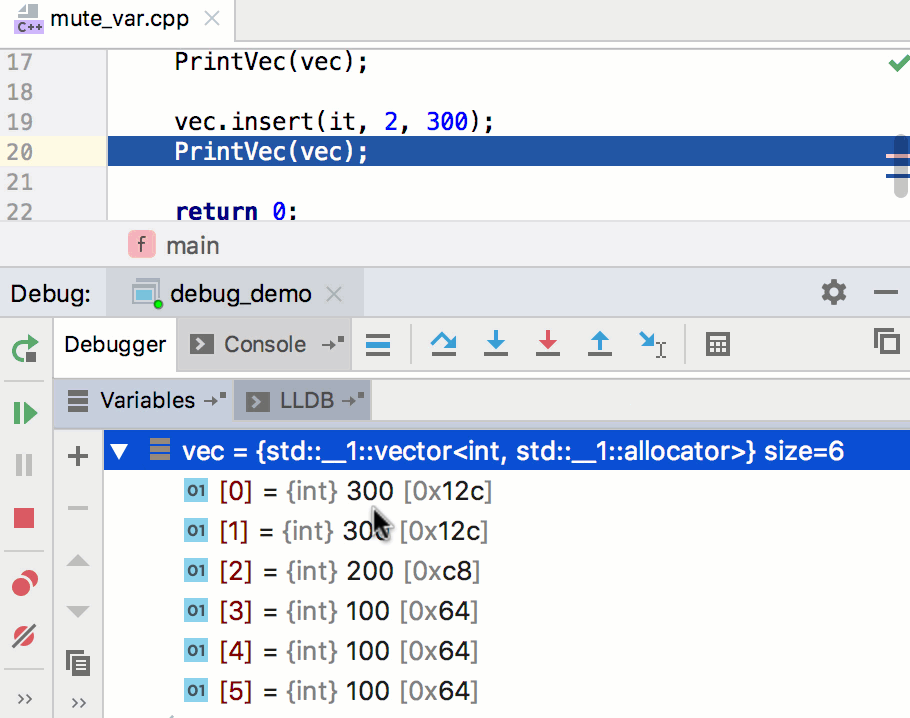
CLion для микроконтроллеров
---------------------------
Илья Моторный ([elmot](https://habr.com/ru/users/elmot/)) уже писал [здесь на Хабре](https://habr.com/ru/post/345670/) про свой плагин для интеграции CLion с STM32CubeMX и поддержкой отладчика OpenOCD. В конце прошлого года Илья присоединился к нашей команде и уже успел существенно обновить плагин и перенести его внутрь CLion.
Довольно большой и детальный блог пост по обновленному плагину можно найти в [нашем блоге](https://blog.jetbrains.com/clion/2019/02/clion-2019-1-eap-clion-for-embedded-development-part-iii/). Здесь же я опишу самое главное, что теперь можно сделать:
* В диалоге New Project можно создать проект STM32CubeMX (*.ioc*).
* Прямо из CLion запустить для проекта STM32CubeMX, чтобы обновить настройки микроконтроллера и сгенерировать код для проекта.
* CLion при этом сам сгенерирует корректный CMake-файл для работы с этим проектом.
* CLion предложит выбор конфигурационного файла для железа (board config).
* Для отладки с помощью OpenOCD нужно создать конфигурацию специального типа “OpenOCD Download and Run”. Для проекта STM32CubeMX CLion создаст такую сам. Указав все настройки, можно отлаживаться на микроконтроллере прямо из CLion!
У Ильи много грандиозных планов, поэтому нам очень важны ваши отзывы. Так что, если вам интересна разработка под встроенные системы в CLion, ждем вас в комментариях!
Проектно-независимые таргеты и конфигурации
-------------------------------------------
Некоторое время назад список поддерживаемых проектных моделей в CLion был расширен Gradle C++ и compilation database. С последним были проблемы, связанные с тем, что формат не включает информацию о сборке всего проекта, поэтому ни сборка, ни запуск, ни отладка проекта в случае compilation database не были возможны. Да и просто в случае известной CLion проектной модели, иногда хочется иметь таргет, который просто собирается какой-то командой в терминале.
Теперь для таких случаев есть Custom Targets (Settings/Preferences | Build, Execution, Deployment | Custom Build Targets) и Custom Run/Debug Configurations (Run | Edit Configurations…). В случае таргета надо задать параметры внешних инструментов (external tools), которые будут использоваться при сборке и очистке проекта:
А в случае проектно-независимой конфигурации для запуска и отладки надо указать таргет, исполняемый файл и желаемые аргументы для запуска:
Injected Language
-----------------
Встречаются ли в вашем коде строковые литералы, внутри которых запрос SQL, HTML код или регулярное выражение? Если да, то наверняка вам бы хотелось хотя бы подсветить код внутри литерала в соответствии с его происхождением. Теперь это возможно! Временно включить в строковом литерале другой язык можно простым нажатием `Alt+Enter` и выбором опции “Inject language or reference”. Теперь выбираем нужный нам язык и в еще недавно обычном строковом литерале появляется подсветка выбранного языка, а также все специальные действия. Самый яркий пример — регулярные выражения и возможность проверки строки на соответствие им прямо в IDE:
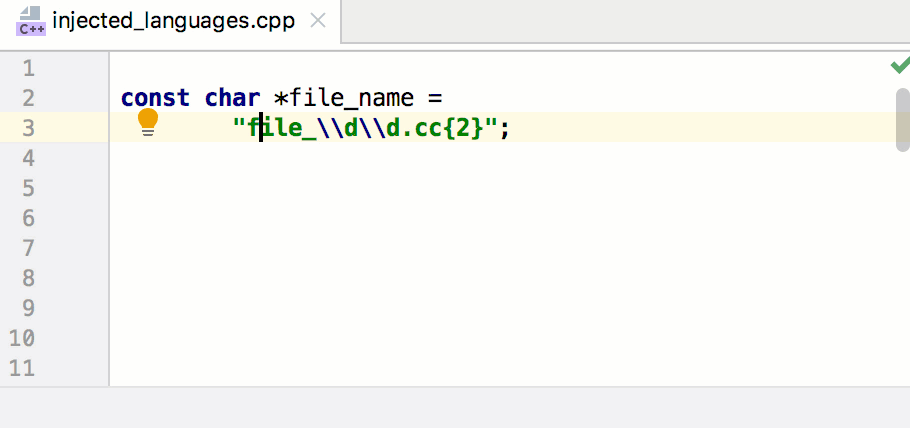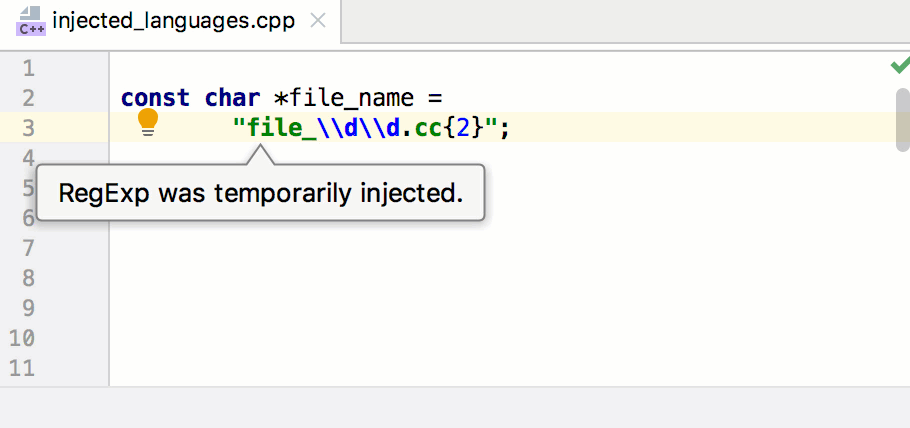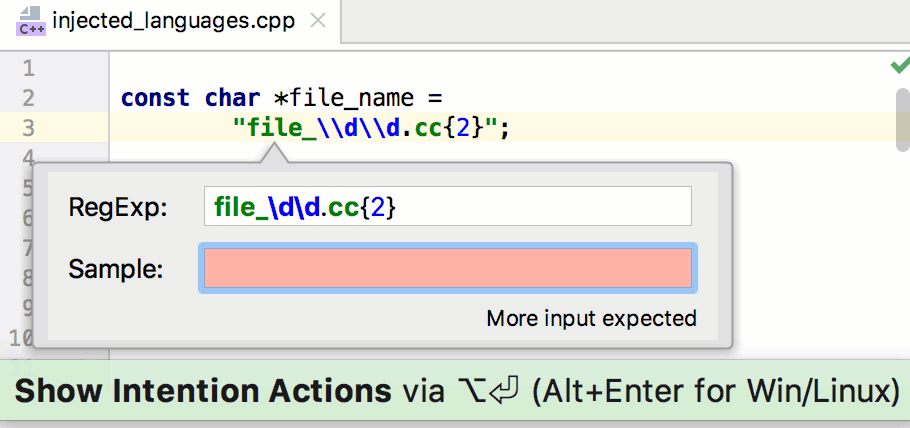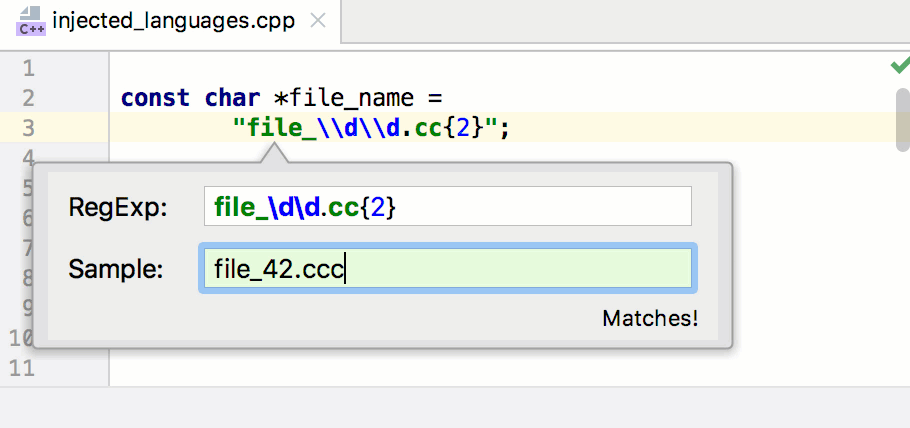
И многое другое
---------------
Продукты в компании JetBrains как правило создаются не одной небольшой командой, а командой всей соответствующей платформы. Поэтому в CLion попадают возможности из IntelliJ IDEA, WebStorm, AppCode, DataGrip, PyCharm и пр. В этом релизе из таких улучшений стоит отметить:
* Просмотр всех мест в коде проекта, где разработчик производил какие-то изменения или просто читал код, — Recent Locations Popup (`Shift+Ctrl+E` на Win/Lin, `⇧⌘E` на macOS).
* Создание новых тем для интерфейса IDE, в дополнение к стандартным светлой, темной (Darcula) и контрастной (High-Contrast). Примеры таких тем-плагинов и пошаговый туториал можно найти в [нашей документации](http://www.jetbrains.org/intellij/sdk/docs/reference_guide/ui_themes/themes_intro.html).
* Кстати, о плагинах. Если вы пишете на Rust, то наверняка знаете, что есть плагин IntelliJ Rust. В CLion его версия включает поддержку Cargo и отладчик. А с новым релизом в плагине появились инструменты профилирования кода на Линуксе и macOS, возможность автодополнения еще не импортированных символов, а также другие улучшения.
На этом пока все. Спасибо, если дочитали до конца!
Демо
----
Ну, и традиционный ролик о новых возможностях CLion 2019.1 (на английском):
Вопросы, пожелания, баг-репорты и просто мысли высказывайте в комментариях! Мы будем рады ответить.
*Ваша команда JetBrains CLion*
*The Drive to Develop* | https://habr.com/ru/post/445646/ | null | ru | null |
# PHP Дайджест № 222 (7 – 21 февраля 2022)
[](https://habr.com/ru/post/652753/)
Подборка свежих новостей, инструментов, видео и материалов из мира PHP.
Приятного чтения!
> Этот дайджест подготовлен совместно с [Insolita](https://twitter.com/DonnaInsolita). Если понравился выпуск, плюсаните пост, пожалуйста.
>
>
⚡️️ Новости
-----------
* **[PHP 7.4.28](https://www.php.net/ChangeLog-7.php#7.4.28), [PHP 8.0.16](https://www.php.net/ChangeLog-8#8.0.16), [PHP 8.1.3](https://www.php.net/ChangeLog-8#8.1.3)**
Обновления актуальных веток PHP с фиксом уязвимости в `php_filter_float()`, а в 8.0 и 8.1 еще с пачкой других фиксов.
Для PHP 7.3 обновления [уже не выходят](https://www.php.net/supported-versions.php), даже если обнаружены проблемы безопасности. И хотя данной уязвимости PHP 7.3 не подвержена, тем не менее если вы все еще используете эту версию, то лучше запланировать обновление в ближайшее время.
* **[Ubuntu 22.04 LTS выйдет с PHP 8.1](https://linuxconfig.org/ubuntu-22-04-features-and-release-date)**
Очередной релиз популярного Linux дистрибутива выйдет 21 апреля с предустановленным PHP версии 8.1.
В связи с этим [предлагается](https://github.com/symfony/symfony/pull/45377) поднять минимальную версию PHP в следующем релизе Symfony 6.1. А для Drupal 10 это [уже сделали](https://www.drupal.org/node/3264830).
* **[PhpStorm 2022.1 EAP](https://blog.jetbrains.com/phpstorm/2022/02/phpstorm-2022-1-eap-3/)**
Продолжается программа раннего доступа первого мажорного релиза IDE в этом году. Сделали поддержку многострочных и вложенных аннотаций array shape! Можно использовать как в виде `PHPDoc`, так и в виде атрибута `#[ArrayShape]`.
* **[[RFC] Redacting parameters in back traces](https://wiki.php.net/rfc/redact_parameters_in_back_traces)**
На голосовании предложение добавить аттрибут `#[SensitiveParameter]` для предотвращения отображения конфиденциальныx данных в отладочных логах.
**Скрытый текст**
```
function test(
$foo,
#[\SensitiveParameter] $bar,
$baz
) {
throw new \Exception('Error');
}
test('foo', 'bar', 'baz');
// В результате в отладочной строке значение секретной переменной должно быть заменено на какое-то абстрактное значение:
/*
Fatal error: Uncaught Exception: Error in test.php:8
Stack trace:
#0 test.php(11): test('foo', Object(SensitiveParameterValue), 'baz')
#1 {main}
thrown in test.php on line 8
*/
```
* **[[RFC] Undefined Variable Error Promotion](https://wiki.php.net/rfc/undefined_variable_error_promotion)**
Автор ранее [предложил](https://externals.io/message/116918) в PHP 9 перевести многие оставшиеся предупреждения (`WARNING`) в полноценные исключения. Такое уже раньше [делали в PHP 8.0](https://wiki.php.net/rfc/engine_warnings).
Ну а начать решил с использования необъявленных переменных. Сейчас в этом случае бросается `Warning` и используется значение `null`.
**Скрытый текст**
```
// PHP < 8.2
if ($user->admin) {
$restricted = false;
}
if ($restricted) { // Сейчас тут просто WARNING, а будет Exception
die('You do not have permission to be here');
}
// Чтоб исправить, нужно добавить инициализацию переменной
// PHP >= 8.2
$restricted = true; // <-- Вот тут
if ($user->admin) {
$restricted = false;
}
if ($restricted) {
die('You do not have permission to be here');
}
```
* **[[RFC] Random Extension 4.0](https://wiki.php.net/rfc/rng_extension)**
Сейчас функции типа `rand()` или `mt_rand()` будут генерировать одну и ту же последовательность для одинакового посевного (seed) значения, заданного с помощью `srand()`. Но из-за использования глобального состояния невозможно создать несколько генераторов с разными посевными значениями и использовать их одновременно.
Автор предлагает добавить объектный API для работы с генераторами псевдослучайных последовательностей, чтоб решить проблему глобального состояния.
**Скрытый текст**
```
// Сейчас вот так
mt_srand(1234, MT_RAND_PHP);
foobar();
$result = str_shuffle('foobar');
mt_srand(1234, MT_RAND_MT19937);
foobar();
$next = mt_rand();
// Предлагается вот так
$randomizer = new Random\Randomizer(new Random\Engine\MersenneTwister(1234, MT_RAND_PHP));
foobar();
$result = $randomizer->shuffleString('foobar');
$randommizer = new Random\Randomizer(new Random\Engine\MersenneTwister(1234, MT_RAND_MT19937));
foobar();
$next = $randomizer->getInt();
```
* **[[RFC] Allow null and false as stand-alone types](https://wiki.php.net/rfc/null-false-standalone-types)**
Предлагается добавить возможность использовать `null` и `false` в декларациях типов.
Во-первых, это недостающие куски для полноты системы типов в PHP — есть `mixed`, добавили `never`, объединения и пересечения, не хватает [юнит-типа](https://en.wikipedia.org/wiki/Unit_type).
Во-вторых, такие типы позволят покрыть некоторые граничные случаи и улучшить статический анализ.
🛠 Инструменты
-------------
* [cebe/php-openapi](https://github.com/cebe/php-openapi) — Преобразовывает OpenAPI-спецификации из yaml/json файлов в PHP-объекты.
* [spatie/github-actions-watcher](https://github.com/spatie/github-actions-watcher) — Консольный инструмент для просмотра состояния всех GitHub Actions в
реальном времени.
* [nette/php-generator](https://github.com/nette/php-generator) — Генератор PHP-кода теперь с поддержкой PHP 8.1.
* [sherifabdlnaby/kubephp](https://github.com/sherifabdlnaby/kubephp) — Продакшн шаблон для развертывания приложения в Docker и Kubernetes. Совместим с Laravel 5+ и Symfony 4+.
* [jaem3l/unfuck](https://github.com/jaem3l/unfuck) — Инструмент налету удаляет все `final`, `private` и определения типов в коде из vendor. Потому что сколько можно терпеть эти издевательства! Под капотом использует обертку над стримом, поэтому на проде лучше не запускать :-)
Появился в ответ на твит про функцию `invade()` и пакет [spatie/invade](https://github.com/spatie/invade):
Symfony
--------
* Книга [«Symfony: The Fast Track» Symfony](https://symfony.com/book) теперь доступна в варианте для Symfony 6.0.
* [Доступна сертификация по Twig 3](https://certification.symfony.com/exams/twig.html) — 60 минут и 45 вопросов.
* [How to Build and Distribute Beautiful Command-Line Applications with PHP and Composer](https://levelup.gitconnected.com/how-to-build-and-distribute-beautiful-command-line-applications-with-php-and-composer-50b6420245f2)
* [Decoupling frontend and backend development — The easy way!](https://mrtnschndlr.medium.com/decoupling-frontend-and-backend-development-the-easy-way-5b93a6513e0d)
* [How does Symfony decide what content type to return in a response?](https://akashicseer.com/web-development/how-does-symfony-decide-what-content-type-to-return-in-a-response/)
Laravel
--------
* **[Вышел Laravel 9](https://laravel.com/docs/master/releases#laravel-9)**
Есть отличные обзоры:
+ 🇷🇺📺 [Релиз Laravel 9: обзор новых функций](https://www.youtube.com/watch?v=EMecJtEgttg) — Коротко в видео на русском от CutCode.
+  [9 интересных новшеств в Laravel 9](https://habr.com/ru/company/reksoft/blog/651553/) — В тексте на Хабре.
+ 📺 [What's New in Laravel 9](https://www.youtube.com/watch?v=MnSzUX7kU-E) — В 12 минут от Mohamed Said (Laravel Core).
+ 📺 [Laracasts: What's New in Laravel 9](https://laracasts.com/series/whats-new-in-laravel-9) — Подробный разбор от [Jeffrey Way](https://twitter.com/jeffrey_way) в 11 эпизодах. Или можно посмотреть одним роликом [на YouTube (45 минут)](https://www.youtube.com/watch?v=GwunZ5sH2P8).
От себя еще добавлю, что теперь коллекции [illuminate/collections](https://github.com/illuminate/collections) покрыты дженериками и дополнение кода для них [работает в PhpStorm](https://laravel.com/docs/master/releases#improved-collections-ide-support).
* 📺 [Laracon Online Winter '22](https://www.youtube.com/watch?v=0Rq-yHAwYjQ)
Тейлор рассказывал [про Laravel 9 и про Nova 4](https://www.youtube.com/watch?v=0Rq-yHAwYjQ&t=21680s#:~:text=05%3A04%3A46). Из хайпового был доклад от Marcel Pociot про [Web3 на Laravel](https://www.youtube.com/watch?v=0Rq-yHAwYjQ&t=14048s).
Краткий 🇷🇺📺 [обзор Laracon online winter 2022](https://www.youtube.com/watch?v=wS7fYSiPb5E) подготовили камрады из CutCode.
* [hmones/laravel-digest](https://github.com/hmones/laravel-digest) — С помощью пакета можно отправлять письма пользователям в виде настраиваемых дайджестов.
* [ellgreen/laravel-loadfile](https://github.com/ellgreen/laravel-loadfile) — Небольшой инструмент для использования MySQL [LOAD DATA](https://dev.mysql.com/doc/refman/8.0/en/load-data.html) для быстрой вставки строк из файла в таблицу.
* [worksome/envy](https://github.com/worksome/envy) — Команда `artisan` для синхронизации настроек окружения и поддержания `.env.example` в актуальном состоянии. [Пост](https://downing.tech/posts/keeping-your-envexample-file-updated) в поддержку.
* 🇷🇺 [Как найти самые медленные запросы в Laravel приложении](https://laravel.demiart.ru/how-to-find-the-slowest-queries/)
Yii
----
* [Yii 2.0.45](https://www.yiiframework.com/news/443/yii-2-0-45) — Добавлена поддержка PHP 8.1
* Вышел [Yii Runner](https://github.com/yiisoft/yii-runner) для Yii3 и адаптеры для консольного приложения ([Yii Console Runner](https://github.com/yiisoft/yii-runner-console)), HTTP-приложения ([Yii HTTP Runner](https://github.com/yiisoft/yii-runner-http)) и приложения на базе RoadRunner ([Yii RoadRunner Runner](https://github.com/yiisoft/yii-runner-roadrunner)). Раннеры позволяют упростить процесс настройки приложения, скрывая детали инициализации.
* 🇷🇺 [Как помочь с релизом Yii 3](https://telegra.ph/Kak-pomoch-s-relizom-Yii3-02-14) — Статья Виктора Бабанова из core-команды Yii3 подробно рассказывает как помочь фреймворку кодом, даже если вы никогда раньше этого не делали.
> Спасибо [Сергею Предводителеву](https://github.com/vjik) за подготовку блока про Yii!
📝 Статьи
--------
* Frank de Jonge: [О разных типах событий в событийных (event-driven) системах](https://blog.frankdejonge.nl/the-different-types-of-events-in-event-driven-systems/)
* Damien Seguy: [All the Dynamic Syntaxes in PHP](https://www.exakat.io/en/all-the-dynamic-syntaxes-in-php/) — Список всех динамических возможностей PHP. Хороший вариант для вопросов на собеседованиях?
* Brent Roose: [Service locator: an anti-pattern](https://stitcher.io/blog/service-locator-anti-pattern)
* 🇷🇺 Пых: [fromName для enum](https://t.me/phpyh/284) — Про методы `fromName` и `tryFromName` для получения перечисления любого типа по его имени (`$name`).
📣 Сообщество
------------
* 💵🇷🇺 [Курс по принципам SOLID на примере Laravel от CutCode](https://solid.cutcode.ru/) — Ребятки сделали классную фишку и обещают донатить 10% от продаж курса в [Фонд PHP](https://opencollective.com/phpfoundation).
В тему также пара постов про SOLID от сообщества: 🇷🇺 [Вывернутый SOLID](https://leonidchernenko.ru/solid-inside-out/), 🇷🇺 [SRP или DRY?](https://otis22.github.io/srp/dry/2022/02/14/SRP-or-DRY.html)
* [Shopware получили $100 млн инвестиций от PayPal и Carlyle](https://techcrunch.com/2022/02/08/shopware-an-e-commerce-platform-that-powers-100k-brands-raises-its-first-outside-funding-100m-from-paypal-and-carlyle/)
Открытая е-commerce платформа на базе Symfony поднимает хорошие деньги, пока кто-то говорит, что PHP мертв. Ранее в 2020 [$130 млн получили Spryker](https://techcrunch.com/2020/12/17/spryker-raises-130m-at-a-500m-valuation-to-provide-b2bs-with-agile-e-commerce-tools/) — другая e-com платформа на PHP.
Обе компании, кстати, поддерживают [фонд PHP](https://opencollective.com/phpfoundation).
* 🇷🇺📺 [Чем запомнился 2021 год русскоязычному PHP-сообществу — в 3000+ ответах](https://www.youtube.com/watch?v=Nx39a7n9KIQ) — Стрим, посвящённый итогам года с Александром Макаровым, Валентином Удальцовым и Кириллом Несмеяновым.
*  [Что смотрели и читали по PHP в 2021: список от сообщества](https://habr.com/ru/company/skyeng/blog/648669/)
* Brent Roose высказался о шаблонизаторах и аргументирует в пользу Blade:
В ответ, конечно, [указали](https://twitter.com/dabernathy89/status/1494325995855179776) на преимущества Twig. Но вот Patrick Allaert, релиз-менеджер PHP 8.1, поделился своим весьма интересным подходом:
Его вьюшки — это не просто файлы, а классы в которых HTML он выводит непосредственно в методе `__invoke()`. Кто-нибудь использует подобный подход?
* Tim Glabisch предложил интересную идею для обновления легаси-проектов: инструмент, который в рантайме отслеживает типы переменных и потом позволяет их проставить уже в коде. Что думаете?
*
---
> Подписывайтесь на Telegram-канал **[PHP Digest](https://t.me/phpdigest)**.
>
>
> Этот дайджест подготовлен совместно с [Insolita](https://twitter.com/DonnaInsolita). Если вам понравился выпуск, подпишитесь на Юлию [в твиттере](https://twitter.com/DonnaInsolita) и поставьте плюс в пост, пожалуйста.
>
>
Заметили ошибку или опечатку? Сообщите в [личку хабра](https://habrahabr.ru/conversations/pronskiy/) или [телеграм](https://t.me/pronskiy).
Прислать ссылку можно [через форму](https://bit.ly/php-digest-add-link) или просто напишите мне в [телеграм](https://t.me/pronskiy).
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 221](https://habr.com/ru/post/650145/) | https://habr.com/ru/post/652753/ | null | ru | null |
# Времена меняются, или смена часовых поясов сразу в пяти регионах РФ
Если вы ещё не в курсе, то сообщаю вам, что сокращение числа часовых поясов на территории России вот-вот начнётся. В пяти регионах присоединение к соседнему часовому поясу уже запланировано на ближайшее воскресенье, 28 марта. До этого события осталось меньше недели!
Телевизор я не смотрю, возможно, там этот вопрос подробно обсуждается уже давно, но лично для меня эта информация в начале этой недели стала новостью.
До недавнего времени я был уверен, что идея с сокращением числа часовых поясов в России до 5 штук — это просто чьё-то неудачное предложение или очередной бредовый законопроект, который обязательно будет отвергнут и далее обсуждений не пройдёт. Однако, оказывается, все решения на этот счёт «у них там наверху» уже приняты и соответствующие постановления Правительства уже подписаны (В.Путиным) и опубликованы.
Постановление по Кемеровской области было подписано ещё осенью 2009 года, а постановления по Самарской области, Удмуртии, Камчатке и Чукотке были подписаны буквально на днях.
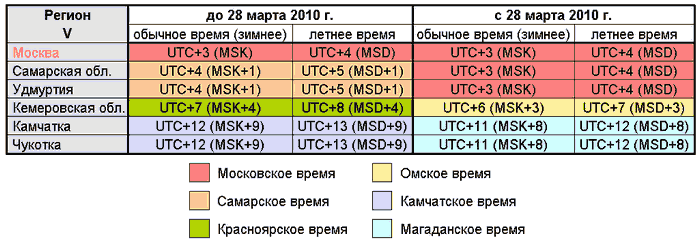
Далее рассмотрим когда и как именно будет происходить этот переход, кого это коснётся, чего от этого ждать и как к этому готовиться с точки зрения администрирования IT-инфраструктуры.
#### \* Ссылки на текст постановлений:
1. [Постановление Правительства Российской Федерации от 14 сентября 2009 г. N 740 г. Москва «О применении на территории Кемеровской области времени пятого часового пояса»](http://www.rg.ru/2009/09/24/kemerovo-dok.html)
2. [Постановление Правительства Российской Федерации от 17 марта 2010 г. N 166 г. Москва «О применении на территории Удмуртской Республики времени второго часового пояса»](http://www.rg.ru/2010/03/22/udmuria-shasy-dok.html)
3. [Постановление Правительства Российской Федерации от 19 марта 2010 г. N 170 г. Москва «О применении на территории Самарской области времени второго часового пояса»](http://www.rg.ru/2010/03/22/samara-chasy-dok.html)
4. [Постановление Правительства Российской Федерации от 19 марта 2010 г. N 171 г. Москва «О применении на территории Камчатского края и Чукотского автономного округа времени десятого часового пояса»](http://www.rg.ru/2010/03/22/poyas-kamshatka-dok.html)
#### \* Где и когда?
Изменения часового пояса коснутся сразу пяти субъектов РФ:
1. Самарская область.
2. Удмуртская Республика.
3. Кемеровская область.
4. Камчатский край.
5. Чукотский автономный округ.
Чтобы эта смена часвого пояса прошла максимально мягко и беспроблемно, её решили совместить с моментом перехода на летнее время. Т.е. если во всех остальных регионах России 28 марта 2010 года (в воскресенье) в 02:00 по местному времени стрелки часов переведут на час вперёд (на 03:00 по метному времени), то в указанных пяти регионах в 2010 году часы переводиться на летнее время не будут, таким образом в 02:00 по метному времени эти регионы автоматически без перевода часов перейдут в летнее время соседнего часового пояса. Ну а дальнейшие переводы часов в этих регионах будут осуществляться в соответствии с тем часовым поясом, в который они перейдут.
После этого перехода 28 марта 2010 года в России перестанут существовать два часовых пояса: [Самарское время](http://ru.wikipedia.org/wiki/Самарское_время) и [Камчатское время](http://ru.wikipedia.org/wiki/Камчатское_время).
Теперь нам больше не услышать привычное многим с детства: «В Москве 15 часов, в Петропавловске-Камчатском полночь», полночь на камчатке теперь будет в 16:00 по Москве.
Но это всё лирика. В действительности я сейчас хотел обсудить здесь не саму эту новость и не целесообразность таких изменений в целом. Я хотел рассмотреть в первую очередь то, как это изменение часовых поясов коснётся IT-инфраструктуры, т.е. к чему готовиться айтишникам и в первую очередь системным администраторам предприятий в свете грядущих событий.
Например, у нашей организации есть филиалы в четырёх из этих пяти регионов (кроме Чукотки), соответственно IT-инфраструктура присутствует во всех наших филиалах. Если у вашей компании тоже есть IT-инфраструктура в этих регионах, которую вы администрируете, то вам тоже стоит заранее озаботиться этим вопросом.
#### \* Что произойдёт со временем?
Для начала нужно чётко осознать, что при этой смене часовых поясов, так же как и при переходе на летнее/зимнее время, меняется только представление локального времени, а именно сдвиг локального времени относительно универсального UTC. Само же абсолютное универсальное время (UTC) для данных регионов и их IT-инфраструктуры не меняется и не прыгает, оно продолжает идти всё так же равномерно и непрерывно, без разрывов и скачков.
Поэтому паниковать тут точно не стоит, глобальных проблем и временных скачков этот переход никому не создаст.
На многих unix-серверах, которые живут по UTC и локальное время вообще ни для чего не используют, эта смена часовых поясов вообще пройдёт незамеченной.
Однако, если в каких-то приложениях, сервисах и интерфейсах есть привязка к часовому поясу и используется локальное время, то здесь для корректировки потребуются системные изменения. Например, нужно сделать, чтобы системные часы на десктопах всех пользователей показывали им правильное локальное время. Если какое-то приложение пишет логи в локальном времени, то здесь опять же нужно корректное отображение локального времени. Ну и все прочие интерфейсы, использующие локальное время должны его правильно отобразить.
Свои заморочки из-за этой смены часовых поясов могут быть и у разработчиков. Например, в правилах обработчика на каком-то форуме/блоге может быть прописано: «если в профиле пользователя указано расположение [Самарская область] или [Удмуртская республика], то отображать все сообщения для него в его локальном времени UTC+4 (летом UTC+5)» и так для каждого региона. В этом случае шаблон правил обработчика локального времени с 28 марта придётся корректировать.
Можно придумать и другие случаи, когда в приложениях и иных проектах может быть привязка к локальному времени.
Ещё раз советую всем внимательно взглянуть на свою IT-инфраструктуру и свои проекты, нет ли там завязки на часовые пояса или локальное время упомянутых пяти регионов. И если есть, то стоит уже принимать какие-то решения и тестировать изменения, если они потребуются.
#### \* Какие изменения в системе потребуются?
Все приложения/сервисы, которые работают с локальным временем в рамках локальной ОС, обычно завязаны именно на системное локальное время. Поэтому для десктопного/серверного парка (в частности Windows-машин) нужно будет скорректировать их локальное время.
Само значение времени, разумеется, трогать на машинах не нужно (время же не меняется в глобальном смысле). Нужно на всех машинах соответствующего региона изменить только часовой пояс (TimeZone), и тут есть два варианта:
**Вариант 1.**
Оставить на всех машинах прежний установленный часовой пояс, но в параметрах самого выбранного часового пояса изменить его относительный сдвиг относительно UTC. Т.е., например, для Камчатского времени вместо UTC+12 (летом: UTC+13) указать сдвиг UTC+11 (летом: UTC+12), как у Магаданского времени.
Отредактировать параметры системных тайм-зон в Windows можно с помощью утилиты [TZedit.exe](http://support.microsoft.com/kb/914387) или напрямую внесением изменений в системный реестр, в раздел HKEY\_LOCAL\_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Time Zones\…
**Вариант 2.**
Не изменять системные параметры часовых поясов, а просто выбрать в качестве текущего часового пояса часовой пояс соседнего региона (того, к чьему часовому поясу присоединились).
Оба варианта рабочие, но идеологически верно будет не создавать дублирующийся часовой пояс с такими же параметрами, как у соседнего, а просто выбрать уже существующий соседний часовой пояс (т.е. Вариант 2). Тем более и в формулировке постановлений Правительства указано, что регион переходит в соседний часовой пояс, а не изменяет параметры своего часового пояса.
#### \* Как выбрать другой часовой пояс в Windows?
Выбирать текущую тайм-зону в Windows можно, конечно, и вручную через окно редактирования системных Даты/Времени, по двойному клику на системных часиках в трее. Но нам нужно это дело автоматизировать, т.к. эти изменения придётся сделать на десятках Windows-серверов и сотнях рабочих станций. Как вариант для смены таймзоны можно будет воспользоваться такими командами:
Установка московского часового пояса (для Самары и Ижевска):
`control.exe timedate.cpl,,/z Russian Standard Time`
Установка омского/новосибирского часового пояса (для Кемерово):
`control.exe timedate.cpl,,/z N. Central Asia Standard Time`
Установка магаданского часового пояса (для Камчатки и Чукотки):
`control.exe timedate.cpl,,/z Central Pacific Standard Time`
P.S. Для большей точности можно в этой командной конструкции перед control.exe и перед timedate.cpl дописать путь %SystemRoot%\system32\, но не обязательно, т.к. этот путь по умолчанию входит в системную переменную среды %PATH%.
**UPD:**
Важная особенность: для того, чтобы в Windows можно было переключать часовой пояс, нужно быть администратором системы (ну или запускать от Local System). Если пользователь не администратор, но ему в политиках безопасности системы (secpol.msc \ Local Policies \ User Rights Assignment) дано право Change the system time («Изменение системного времени»), то даже в этом случае он не может выбирать часовой пояс. Т.е. дату и время он с этими правами изменить может, а вот всего лишь выбрать другой часовой пояс уже не может. Никак не может, ни через команды, ни через GUI, причём система в этом случае даже не ругается на отсутствие доступа, а просто молча игнорирет попытки смены часового пояса и всё. Вот такая она Винда нелогичная.
Также не забываем, что по умолчанию в Windows для Магаданского часового пояса не включен переход на летнее время. Поэтому в Чукотке и Камчатке кроме переключения часового пояса на Магаданский ещё придётся вносить изменения в сам системный магаданский пояс, чтобы добавить в него переход на летнее время и обратно. Поэтому в скрипт для Камчатки/Чукотки кроме указанной выше конструкции добавляем правку в реестре Магаданской таймзоны.
Наш скрипт **Kamch-TZ-change.cmd**:
`@echo off
echo Add Daylight time to Magadan Time Zone ...
regedit.exe /s %~dp0Magadan\_daylight.reg
echo OK
echo.
echo Change current Time Zone to Magadan Time Zone (Moscow +8) ...
control.exe timedate.cpl,,/z Central Pacific Standard Time
echo OK`
И рядом с файлом Kamch-TZ-change.cmd кладём файл **Magadan\_daylight.reg**:
`Windows Registry Editor Version 5.00
[HKEY\_LOCAL\_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Time Zones\Central Pacific Standard Time]
"TZI"=hex:6c,fd,ff,ff,00,00,00,00,c4,ff,ff,ff,00,00,0a,00,00,00,05,00,03,00,00,\
00,00,00,00,00,00,00,03,00,00,00,05,00,02,00,00,00,00,00,00,00`
(не забываем про обязательную пустую строку в конце reg-файла)
Поскольку у нас развёрнута инфраструктура AD, то для рабочих станций эту команду можно поместить в cmd/bat-скрипт, а потом установить этот скрипт в качестве startup/shutdown-скриптов в групповой политике. Групповую политику активировать ближе к концу рабочего дня 26 марта (пятница).
Для серверов startup/shutdown-скрипты не подойдут, т.к. серверы на выходные не выключаются, поэтому на серверах эту команду придётся запускать удалённо, например, через [psexec](http://technet.microsoft.com/en-us/sysinternals/bb896649.aspx) по заранее составленному текстовому списку Windows-серверов.
Думаю, в оставшиеся пару дней потестируем на нескольких рабочих станциях и серверах, а в ближайшую пятницу назначим групповую политику с этой командой в скрипте на все рабочие станции. По крайней мере у меня на этот счёт планы именно такие.
А что по этому поводу думаете вы, коллеги? | https://habr.com/ru/post/88713/ | null | ru | null |
# Готовим плагин для qutIM на дому
Cегодня мы будем заниматься приготовлением плагина для qutIM'а, но не для того, который совсем недавно зарелизился, а для будущего, активная разработка которого сейчас идёт.
Для начала хотел бы сказать немного общих слов:
1. В sdk03 мы постарались учесть все «ошибки бурной молодости»
2. Оно полностью несовместимо со старым skd02
3. Скорее всего, больше таких резких переходов в API между версиями не будет
И именно поэтому я рекомендую всем, кто ещё ни разу не писал плагины для Кутима, ориентироваться на sdk03
Хочу отметить немаловажный факт, что сейчас разработка ведется с использованием Qt 4.6, она предоставляет огромные дополнительные возможности, от которых просто грех отказываться.
Если вы горите желанием реализовать что-то интересное, но не знаете куда направить свою энергию, то эта статья для вас!
Ещё летом мы пришли к выводу, что текущая реализация плагинной системы завела программу в тупик:
Стало очень тяжело наращивать функционал, программа давно перестала быть легковесной и на слабых машинах, при загрузке длинного контакт листа, тормозила. На исправление багов уходило много времени.
Поэтому началась разработка libqutim, в которой мы постарались учесть все промахи старой плагинной системы, и сделать разработку Кутима максимально простой и приятной.
**> Структура нового qutIM'а:**
* Микроядро — в нём находится реализация менеджера модулей. Оно отвечает за загрузку и корректную работу всех частей qutIM'а. В нем имеется возможность выбора, какие модули грузить, а какие нет. Плюс в нем заложена возможность отслеживание зависимостей, что может быть незаменимо для модулей, которые в своей работе опираются на другие компоненты. Кроме того, активные модули можно переключать прямо в runtime'е, что, к примеру, активно используется в configbackend'ах
* libqutim — в этой библиотеке хранятся интерфейсы всех модулей, а также набор наиболее полезных и часто используемых функций
* corelayers — тот набор модулей, который компилируется непосредственно с приложением, при желании его можно легко менять, о чем будет сказано ниже
* plugins — традиционные разделяемые библиотеки, которые на данный момент проще всего помещать в папку plugins рядом с исполняемым файлом, лучше всего подходит для протоколов
Первым делом необходимо установить библиотеку Qt4.6, для Windows и Macos X они есть на [официальном сайте](http://qt.nokia.com/developer/qt-4.6-preview "Nokia").
Пользователи Убунты могут воспользоваться репозиторием kubuntu-experimental, добавить её можно командой:
$add-apt-repository ppa:kubuntu-experimental
Гентушникам достаточно размаскировать соответствующие ebuild'ы. Для остальных не составит труда найти нужные пакеты или собрать их самостоятельно.
Исходный код забираем отсюда:
[www.qutim.org/svn/qutim/branches/sdk03](http://www.qutim.org/svn/qutim/branches/sdk03/)
После как обычно командуем в терминале
`$ mkdir build && cd build && cmake ..`
В результате cmake создаст вам Makefile, если окажется, что не все зависимости для сборки удовлетворены, то доустановите недостающие пакеты.
Прошу обратить внимание на строчки типа
`+ layer KINETICPOPUPS added to build
+ layer XSETTINGSDIALOG added to build
+ layer ADIUMCHAT added to build`
На сегодняшний день в cmake скрипте реализовано автоопределение используемых слоев. Вам достаточно положить исходные коды вашего плагина в scr/corelayers/имя\_слоя, чтобы он был распознан системой. Это открывает огромные перспективы для создания собственных сборок, и упрощает разработку.
В данной статье я буду описывать, как реализовать диалог настроек:
Создаем в каталоге src/corelayers подкаталог simplesettingsdialog.
Создаем класс settingslayerimpl и наследуем его от класса SettingsLayer из libqutim'а, как показано ниже:
**settingslayeriml.h**
> `#include "libqutim/settingslayer.h"
>
>
>
> class SettingsDialog;
>
> using namespace qutim\_sdk\_0\_3;
>
>
>
> class SettingsLayerImpl : public SettingsLayer
>
> {
>
> Q\_OBJECT
>
> public:
>
> SettingsLayerImpl();
>
> virtual ~SettingsLayerImpl();
>
> virtual void close();
>
> virtual void show ( const SettingsItemList& settings );
>
> private:
>
> QPointer m\_dialog;
>
> };
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**settingslayeriml.cpp**
Внимание: если вы вкомпиливаете модуль прямо в бинарный файл, то подключать заголовочные файлы нужно так, как показано в примере. Если вы выносите его в плагин, то нужно заменить на
Работа слоя очень проста: по запросу show передается список настроек, которые необходимо вывести
**settingslayeriml.cpp**
> `#include "settingslayerimpl.h"
>
> #include "settingsdialog.h"
>
> #include "modulemanagerimpl.h"
>
> #include
>
> static Core::CoreModuleHelper settings\_layer\_static( //регистрируем наш модуль, теперь он станет видимым для менеджера модулей
>
> QT\_TRANSLATE\_NOOP("Plugin", "Simple Settings dialog"), //описание, макрос QT\_TRANSLATE\_NOOP позволяет делать его переводимым на разные языки
>
> QT\_TRANSLATE\_NOOP("Plugin", "SDK03 example")
>
> );
>
>
>
> void SettingsLayerImpl::show (const SettingsItemList& settings )
>
> {
>
> if (m\_dialog.isNull())
>
> m\_dialog = new SettingsDialog(settings); //создаем диалог, которому передаем наш список настроек
>
> m\_dialog->show();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В реализации диалога настроек тоже нет ничего хитрого, важно лишь помнить, что SettingsItem генерирует виджет настроек лишь по запросу, чтобы минимизировать затраты памяти.
Далее создаем сам диалог:
**settingsdialog.cpp**
> `#include "settingsdialog.h"
>
> #include "ui\_settingsdialog.h"
>
> #include
>
> SettingsDialog::SettingsDialog ( const qutim\_sdk\_0\_3::SettingsItemList& settings)
>
> : ui (new Ui::SettingsDialog)
>
> {
>
> m\_setting\_list = settings;
>
> ui->setupUi(this);
>
>
>
> foreach (SettingsItem \*settings\_item, m\_setting\_list) //заполняем список настроек самым бесхистростным образом без деления на категории
>
> {
>
> QListWidgetItem \*list\_item = new QListWidgetItem (settings\_item->icon(),
>
> settings\_item->text(),
>
> ui->listWidget
>
> );
>
> }
>
> connect(ui->listWidget,SIGNAL(currentRowChanged(int)),SLOT(currentRowChanged(int)));//навигация по списку настроек
>
> ui->listWidget->setCurrentRow(0);
>
> }
>
>
>
> void SettingsDialog::currentRowChanged ( int index)
>
> {
>
> SettingsWidget \*widget = m\_setting\_list.at(index)->widget();//генерируем виджет или даем указатель на него, если он существует
>
> if (widget == 0)
>
> return;
>
> if (ui->stackedWidget->indexOf(widget) == -1) //если виджет не добавлен в стек, то добавляем его
>
> {
>
> widget->load();
>
> ui->stackedWidget->addWidget(widget);
>
> }
>
> ui->stackedWidget->setCurrentWidget(widget);//просим показать текущий виджет
>
> }
>
>
>
> SettingsDialog::~SettingsDialog()
>
> {
>
> delete ui;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
После добавления файлов не забудьте опять выполнить команду:
`$ cmake ..`
Если в выводе появилась строчка, которая приведена ниже, то вы сделали всё правильно.
`+ layer SIMPLESETTINGSDIALOG added to build`
Теперь нужно добавить куда-нибудь вызов функции Settings:showWidget(), я обычно её добавляю в конструктор одного из слоев.
Когда все соберется, можно запускать приложение. В конечном итоге появится вот такое симпатичное окошко.

Надеюсь, вы убедились, что писать плагины теперь весьма просто. Как можно заметить, настроек пока не густо, поэтому дерзайте, заполняйте пробелы, а лучшие плагины попадут в ядро!
Я надеюсь, что это не последняя статья о разработке нового Кутима, в дальнейшем я планирую рассказать о работе движка настроек, о том, насколько удобен формат json для их хранения, и о многом другом.
Благодарю всех за внимание, [Исходный код можно скачать здесь](http://sauron.me/sources/sdk03/simplesettingsdialog.zip) | https://habr.com/ru/post/74025/ | null | ru | null |
# Генетическое программирование («Yet Another Велосипед» Edition)

Давайте на время отвлечемся от очередного "языка-убийцы C++", ошеломляющих синтетических тестов производительности какой-нибудь NoSQL-ой СУБД, хайпа вокруг нового JS-фреймворка, и окунемся в мир "программирования ради программирования".
Предисловие
-----------
Март начинался для меня с чтения статей про то, что Хабр уже [не](https://habrahabr.ru/post/278325/) [торт](https://habrahabr.ru/post/278353/). Судя по отклику, тема была вскрыта наболевшая. С другой стороны, мне удалось кое-что для себя вынести из этого: ~~"вы и есть Сопротивление"~~, если вы это читаете — вы и есть Хабр. И сделать его интереснее (или хотя бы разнообразнее, отойти от наметившейся тенденции на агрегацию рекламных постов, околоализарщины и корпоративных блогов) можно только силами рядовых пользователей. У меня как раз имелся на тот момент небольшой проект, хоть и требующий серьезной доработки, о котором мне захотелось рассказать. И я решил — за месяц (*наивный!*) напишу статью. Как мы видим, сейчас уже ~~середина~~ ~~конец апреля~~ ~~начало мая~~ май в самом разгаре, винить в этом можно как мою лень, так и нерегулярность свободного времени. Но всё же, статья увидела свет! Что интересно, пока я трудился над статьей, уже успели выйти две похожие: [Что такое грамматическая эволюция + легкая реализация](https://habrahabr.ru/post/281404/), [Символьная регрессия и еще один подход](https://habrahabr.ru/post/281334/). Не будь я таким слоупоком, можно было вписаться и объявить месяц генетических алгоритмов :)
Да, я осознаю в полной мере, что на дворе 2016 год, а я пишу такой длиннопост. Ещё и рисунки выполнены ~~в стиле "курица лапой"~~ пером на планшете, с шрифтами ~~**Comics Sans** для гиков~~ **xkcd**.
Введение
--------
Некоторое время назад на ГТ появилась интересная [статья](https://geektimes.ru/post/266308/), с, что характерно, **ещё более** интересными комментариями (а какие там были словесные баталии об естественном отборе!). Возникла мысль, что если применить принципы естественного отбора в программировании (если быть точнее, то в [метапрограммировании](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%B0%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5))? Как вы можете догадаться, эта мысль в итоге и привела меня к переоткрытию давно существовашей концепции *генетических алгоритмов*. Бегло изучив матчасть, я с энтузиазмом ринулся экспериментировать.
Но давайте обо всём по порядку.
Ликбез
------
Практически все принципы, лежащие в основе генетических алгоритмов, почерпнуты из природного *естественного отбора* — популяции через смену поколений адаптируются к условиям окружающей среды, наиболее приспособленные из них становятся доминирующими.
Как с помощью генетических алгоритмов решать задачи? Вы удивитесь, как всё просто работает в нулевом приближении:
Теперь **WE NEED TO GO DEEPER**. Первое приближение:
Значит, у нас есть задача\проблема, мы хотим найти её решение. У нас есть какое-нибудь базовое, плохенькое, *наивное* решение, результаты которого нас, скорей всего, не удовлетворяют. Мы возьмём алгоритм этого решения и немного изменим его. Натурально случайным образом, без аналитики, без вникания в суть проблемы. Новое решение стало выдавать результат хоть на капельку лучше? Если нет — отбрасываем, повторяем заново. Если да — **ура**! Удовлетворяет ли результат нового решения нас полностью? Если да — мы молодцы, решили задачу с заданной точностью. Если нет — берем полученное решение, и проводим над ним те же операции.
Вот такое краткое и бесхитростное описание идеи в первом приближении. Впрочем, думаю, пытливые умы оно не удовлетворит.
Для начала, как мы модифицируем решения?
Наше решение состоит из набора дискретных блоков — характеристик, или, если позволите, генов. Меняя набор, мы меняем решение, улучшая, или ухудшая получаемый результат. Я изобразил генотип как цепочку генов, но на практике это будет древовидная структура (не исключающая, впрочем, и возможности содержать цепочку в одном из своих узлов).
Теперь давайте рассмотрим основной цикл подробнее:
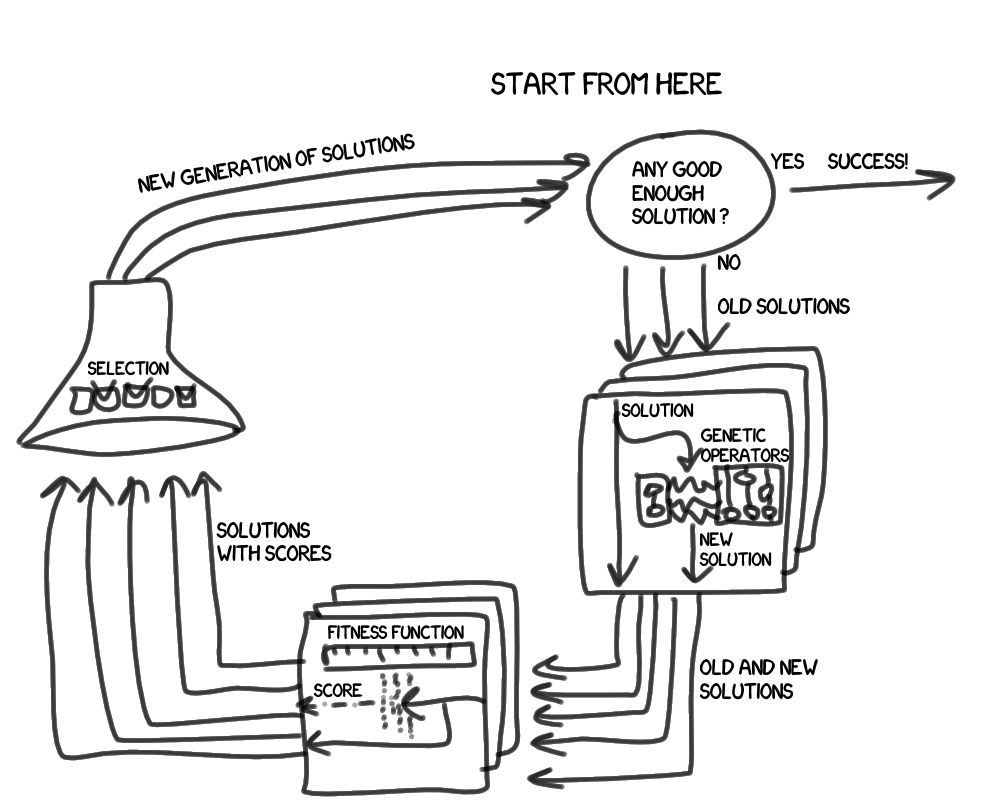
Что стало различимо во втором приближении? Во-первых, мы оперируем не одним, а группой решений, которую назовем *поколение*. Во-вторых, появились новые сущности:
* **Генетические операции** (да-да, извечная путаница с переводом, английское "**operator**" суть наше "**операция**") нужны чтобы получить новое решение на базе предыдущих. Обычно это *скрещивание* (случайное совмещение двух различающихся решений) и *мутация* (случайное изменение одного решения).
* **Функция приспособленности** (мне больше понравилось *фитнесс-функция*) нужна для оценки степени нашей удовлетворенности результатом решения.**Кому на ум пришло TDD?**В самом деле, ~~когда~~ если мы научимся легко писать тесты которые отвечают **не только** на вопрос, завалил ли наш код тест или нет, **но и** дают измеримую оценку, насколько он близко он подо*шел к успеху*, мы станем на шаг ближе к самопишущимся программам. Не удивлюсь, если такие попытки уже были.
* **Селекция** описывает принципы отбора решений в следующее поколение.
### Недостатки
Как бы многообещающе всё ни звучало, у обсуждаемого подхода к решению задач полно ~~фатальных~~ фундаментальных недостатков. Практикуясь, я споткнулся, наверное, обо все известные подводные камни. Самый главный, на мой взгляд, из них: плохая масштабируемость. Скорость роста затрат на вычисления в среднем превышает скорость роста входных данных (как в наивных алгоритмах сортировки). Об остальных недостатках я расскажу попутно далее.
---
Практика
--------
### Выбор языка
Был выбран **Ruby**. Этот язык заполнил в моих делах нишу, каковую традиционно занимал Питон, и он настолько меня очаровал, что я непременно решил познакомиться с ним поближе. А тут такая возможность! Люблю убивать **N** (где **N** > 1) зайцев за раз. Не исключаю, что мой код может местами вызывать улыбки, если не фейспалмы у олдовых рубистов (нет, извините, но именно [рУбистов](https://translate.google.ru/#en/ru/ruby), остальные варианты — троллинг).
### Генотип
Первой мыслью было то, что раз в языке есть **eval**, то генотип решения может без каких-либо ухищрений строиться из произвольных символов (выступающих в роли генов), и на выходе мы будем иметь скрипт, интерпретируемый самим **Ruby**. Второй мыслью было то, что на эволюцию решений с такими высокими степенями свободы может уйти реально **много** лет. Так что я даже не шевельнул пальцем в этом направлении, и думаю, не прогадал. Можно попробовать данный подход лет этак через 30, если сохранится закон Мура.
Эволюция в итоге была заключена в достаточно жесткие рамки. Генами решения являются высокоорганизованные **токены** с возможностью вложенности (построения древовидной структуры).
В первом эксперименте, где мы будем говорить о решениях как математических выражениях, токены это константы, переменные, и бинарные операции (не знаю, насколько легитимен термин, в контексте проекта "бинарная операция" значит действие над на двумя операндами, например сложение).
Кстати, я решил частично оставить совместимость с **eval**, поэтому если запросить строковое представление токена (через стандартный **to\_s**), то можно получить вполне удобоваримую строку для интерпретации. Например:
```
f = Formula::AdditionOperator.new(Formula::Variable.new(:x), Formula::IntConstant.new(5))
f.to_s # "(x+5)"
```
Да и нагляднее так.
### Генетические операции
В качестве основного и единственного способа изменения генотипа решений я выбрал *мутацию*. Главным образом потому, что она проще формализуется. Не исключаю, что размножение скрещиванием могло бы быть эффективнее (а если судить на примере живой природы, то, похоже, так и есть), однако в её формализации кроется много подводных камней, и, скорей всего, накладываются определенные ограничения на саму структуру генотипа. В общем, я пошёл простым путем.
В разделах статьи, посвященных описанию конечных экспериментов, подробно расписаны правила мутации решений. Но есть и общие особенности, о которых хочется рассказать:
* Иногда (на самом деле часто) бывает, что лишь за один шаг мутации невозможно добиться улучшения результатов, хотя мутация идет, в целом, в верном направлении. Поэтому в фазе применения генетических операций решениям позволено мутировать неограниченное количество раз за ход. Вероятность выглядит так:
— 50% — одна мутация
— 25% — две мутации
— 12.5% — три мутации
— и т.д.
* Бывает, за несколько шагов мутант может стать идентичным родителю, или разные родители получают одинаковых мутантов; такие случаи пресекаются. Более того, я вообще решил поддерживать строгую уникальность решений в рамках одного поколения.
* Иногда мутации порождают совершенно неработоспособные решения. С этим бороться аналитически крайне сложно, обычно, проблема вскрывается только в момент их оценки фитнесс-функцией. Я позволяю таким решениям быть. Всё равно бОльшая часть со временем исчезнет в результате селекций.
### Фитнесс-функция
С её реализацией никаких проблем нет, но есть один *нюанс*: сложность фитнесс-функции растет практически наравне с ростом сложности решаемой задачи. Чтобы она была способна выполнять свою работу в разумные сроки, я постарался реализовать её настолько просто, насколько возможно.
Напомню, что генерируемые решения возвращают определенный результат на основе определенного набора входных данных. Так вот, подразумевается, что мы знаем, какой идеальный(*эталонный*) результат нужно получить на определенный набор входных данных. Результаты являются исчислимыми, а значит, мы способны выдать количественную оценку качества определенного решения, проведя сравнение возвращенного результата с *эталонным*.
Помимо этого, каждое решение обладает косвенными характеристиками, из которых я выделил, по моему мнению, основную — ресурсоемкость. В некоторых задачах ресурсоемкость решения бывает зависима от набора входных данных, а в других — нет.
Итого, фитнесс-функция:
* вычисляет насколько результаты решения отличаются от эталонных
* определяет, насколько ресурсоемко решение
**О ресурсоемкости**В ранних прототипах я пробовал замерять затраченное на прохождение испытаний процессорное время, но даже при длительных (десятки миллисекунд) прогонах наблюдался разброс в ±10% времени на одно и то же решение, вносимый операционной системой, с периодическими выбросами +в 100-200%.
Так что в первом эксперименте ресурсоемкость вычисляется суммарной сложностью генотипа, а во втором подсчётом реально выполненных инструкций кода
### Селекция
Каждое поколение содержит не более чем **N** решений. После применения генетических операторов, у нас максимум **2N** решений, притом в следующее поколение пройдет, опять же, не больше **N** из них.
По какому принципу формируется следующее поколение решений? Мы на этапе, когда каждое из решений уже получило оценку фитнесс-функции. Оценки, разумеется, можно сравнивать друг с другом. Таким образом, мы можем отсортировать текущее поколение решений. Дальше видится логичным просто взять **X** лучших решений, и сформировать из них следующее поколение. *Однако*, я решил не останавливаться на этом, и включать в новое поколение также **Y** случайных решений из оставшихся.
Например, если **X = Y**, то чтобы решению пройти в следующее поколение, ему нужно оказаться среди 25% лучших, либо выкинуть 3 на трёхгранном кубике (если бы такой существовал). Достаточно гуманные условия, не так ли?
Так вот, включение случайно выживших в следующее поколение нужно для сохранения видового многообразия. Дело в том что подолгу держащиеся среди лучших похожие друг на друга решения выдавливают остальные, и чем дальше, тем быстрее процесс, а ведь зачастую бывает что доминирующая ветвь оказывается тупиковой.
Параметры **X** и **Y**, разумеется, являются настраиваемыми. Я прогонял тесты, как со случайными выжившими, так и без них, и доказал справедливость их добавления в алгоритм: в отдельных случаях (при поиске решений повышенной сложности), удавалось достичь более хороших результатов с их использованием (притом суммарная затрачиваемая на поиск решений мощность оставалась постоянной, например, **X1** = 250, **Y1** = 750 против **X2** = 1000, **Y2**=0).
### Условия победы
Тут кроется загвоздка: как понять, что пора заканчивать? Допустим, решение удовлетворяет нас по точности результатов, но как быть с трудоемкостью? Вдруг алгоритм сейчас поработает и выдаст решение по раскраске графов за **O(n)**? Утрирую конечно, но критерий остановки работы необходимо формализовать. В моей реализации выполнение алгоритма заканчивается, когда **Top 1** решение не меняется определённое количество поколений (сокращенно **R** — rounds). Отсутствие ротации значит, что, во-первых, не нашлось альтернативного решения, которое бы смогло превзойти лучшее текущее решение; во-вторых, лучшее текущее решение не смогло породить улучшенную мутацию себя в течение заданного времени. Количество поколений, через которое наступает победа лучшего решения, обычно большое число — чтобы действительно убедиться в том, что эволюция не способна продвинуться дальше, требуется смена нескольких сотен (число варьируется в зависимости от сложности самой задачи) поколений.
К сожалению, несмотря на многочисленные предосторожности, случаи когда эволюция заходит в тупик всё же бывают. Это известная проблема генетических алгоритмов, когда основная популяция решений сосредотачивается на *локальном оптимуме*, игнорируя, в итоге, искомый *глобальный оптимум*. На это можно ответить игрой с параметрами: уменьшением квоты для победителей, увеличением квоты для случайных, и увеличением времени доминирования для победы, параллелизацией независимых друг от друга поколений. Но всё это требует мощностей\времени.
### Конкретная реализация
Как принято, всё выложено [на гитхабе](https://github.com/augur/NaturalSelectionProgramming) (правда, пока без доков).
Теперь о том, что мы увидим в конкретно моей ~~велосипеде~~ реализации:
1. Вводится понятие эталона (Model). Относимся к нему, как к чёрному ящику, с помощью которого, на основе набора входных данных (Input), можно получить *эталонный результат*(Model Result).
2. *Дело* (Case) попросту содержит набор входных данных и эталонный результат.
3. Собираем набор дел (Case group) на основании совокупности входных данных (Input group).
4. Вызов (или *испытание*) (Challenge) это комплекс действий по прохождению сформированного ранее *набора дел*. На плечах *испытания* также работа по оценке результатов прохождения, и сравнению оценок.
5. У нас появляется *претендент* (Challenger), имеющий определенное решение (Solution). Претендент произносит сакраментальное "**вызов принят!**", и узнает свою степень пригодности (Score).
6. В итоге у нас выстраивается цепочка композиции — *решение*(Solution — предоставляет решение определенного вида задач) -> *претендент*(Challenger — проходит *испытания*) -> *штамм*(Strain — участвуют в *естественном отборе* и *эволюции*(см.ниже))
7. Имеется *естественный отбор* (Natural Selection), который включает в себя *испытание*, и фильтрует поступающую к нему группу штаммов по заданным правилам.
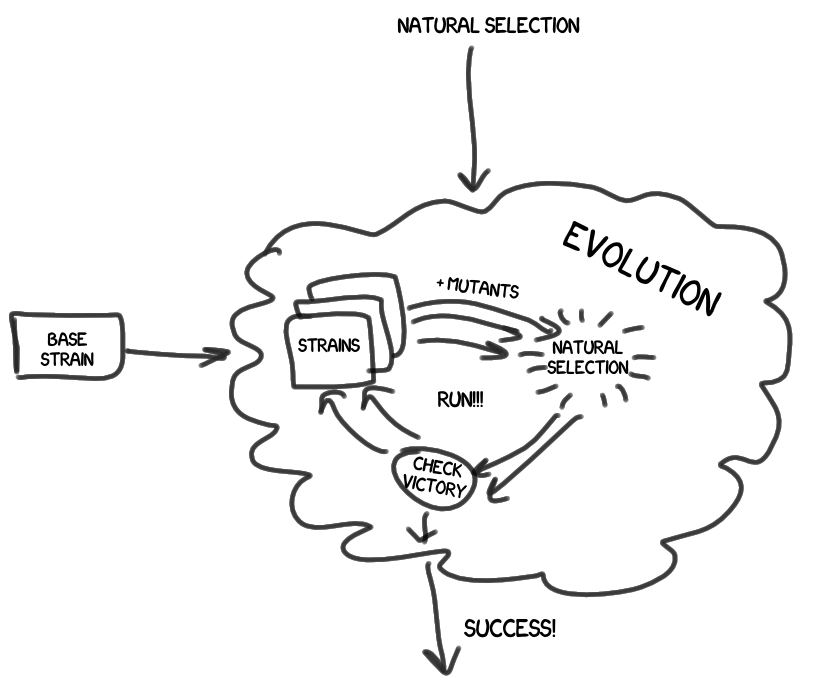
8. На верхнем уровне располагается *эволюция* (Evolution), которая, включая в себя *естественный отбор*, управляет всем жизненными циклом штаммов.
9. Результатом работы *эволюции* является штамм-победитель, которого мы чествуем как героя, а затем внимательно изучаем его, в том числе и его родословную. И делаем выводы.
Такова в общих чертах моя реализация генетического алгоритма. За счёт абстрактных классов (в **Ruby**, ага >\_<), удалось написать в целом независимый от конкретной области задач код.
В последующих экспериментах дописывались нужные **Input, Model, Solution, Score** (что, конечно, немало).
Эксперимент Первый: Формулы
---------------------------
Вообще, вернее было назвать **Эксперимент Первый: Арифметические выражения**, но когда я выбирал имя для базового класса выражений, то, недолго думая, остановился на `Formula`, и дальше в статье я буду называть арифметические выражения *формулами*. В эксперименте мы вводим *формулы-эталоны* (та самая **Model**), содержащие одну или несколько переменных величин. Например:
> x2 — 8\*x + 2.5
У нас есть набор значений переменных (**Input Group**, ага), например:
* x = 0;
* x = 1;
* x = 2;
* ....
* x = 255;
Решения (**Solutions**), которые мы будем сравнивать с *эталонами*, представляют из себя такие же формулы, но создаваемые случайно — последовательно мутирующие из базовой формулы (обычно это просто `x`). Оценкой (**Score**) качества решения является среднее отклонение результата от результата *эталона*, плюс ресурсоемкость решения (суммарный вес операций и аргументов формулы).
### Мутация формул
Как было упомянуто ранее, **токенами** формул являются константы, переменные, и бинарные операции.
Как происходит мутация формул? Она затрагивает один из **токенов**, содержащихся в формуле, и может пойти тремя путями:
1. **grow** — рост, усложнение
2. **shrink** — уменьшение, упрощение
3. **shift** — видоизменение с условным сохранением сложности
Вот таблица происходящего с разными типами формул при разных видах мутации:
| Формула → Мутация ↓ | Константа | Переменная | Бинарная операция |
| --- | --- | --- | --- |
| **grow** | становится переменной, или включается в новую случайную бинарную операцию (со случайным вторым операндом) | в новую случайную бинарную операцию (со случайным вторым операндом) | включается в новую случайную бинарную операцию (со случайным вторым операндом) |
| **shrink** | невозможно уменьшить, так что применяем к ней операцию **shift** | становится константой | вместо операции остается лишь один из операндов |
| **shift** | изменяет свое значение на случайную величину, может поменять тип (Float<->Int) | становится другой случайной переменной (если это допустимо в данном контексте) | либо операнды меняются местами, либо меняется вид операции, либо происходит попытка *сокращения* операции |
**Примечание 1** *Сокращение формул* это попытка заранее произвести операции над константами, где это возможно. Например из "`(3+2)`" получить "`5`", а из "`8/(x/2)`" получить "`(16/x)`". Задача неожиданно оказалась настолько нетривиальна, что вынудила меня писать [прототип решения](https://github.com/augur/NaturalSelectionProgramming/blob/master/formula/formula_cut_prototype.rb) с исчерпывающим [юнит-тестом](https://github.com/augur/NaturalSelectionProgramming/blob/master/autotests/tc_formula_cut_prototype.rb), и то, я не добился настоящего рекурсивного решения, достающего константы для сокращения с любой глубины. Разбираться в этом было увлекательно, но в какой-то момент мне пришлось остановить себя и ограничиться достигнутым решением, так как я слишком отклонился от основных задач. В большинстве ситуаций, сокращение и так полноценно работает.
**Примечание 2** У мутации бинарных операций есть особенность, в силу того, что операции имеют вложенные в себя другие *формулы*-операнды. Мутировать и операцию, и операнды — слишком большое изменение для одного шага. Так что случайным образом определяется, какое событие произойдёт: с вероятностью 20% мутирует сама бинарная операция, с вероятностью 40% мутирует первый операнд, и с оставшейся 40% вероятностью, мутирует второй операнд. Не могу сказать, что соотношение 20-40-40 идеально, возможно следовало бы ввести корреляцию вероятности мутации операции в зависимости от их *весов* (фактически, глубины вложенности), но пока что работает так.
### Результаты
Теперь ради чего, собственно, всё затевалось:
Первый эталон — простой полином:
> x2 — 8\*x + 2.5
**X** принимает значения от 0 до 255, с шагом 1
**R** = 64, **X** = 128, **Y** = 128
Прогоны выполняются по три раза, здесь отражен лучший результат из трёх. (Обычно все три раза выдают идентичные результаты, но изредка бывает, что мутации заходят в тупик и не могут достичь даже заданной точности)
Результаты поразили меня в самое сердце :) За 230 (включая те **R** раз, когда **Top 1** не менялся) поколений было выведено такое решение:
> (-13.500+((x-4)2))
>
> **Полная родословная**Как вы помните, между один поколением допускается и более одной мутации.
>
>
> ```
> x
> (x-0)
> ((x-0)-0.050)
> (0.050-(x-0))
> (0.050-(x-1))
> (x-1)
> (x-1.000)
> ((x-1.000)--0.010)
> ((x-1.000)-0)
> ((x-1.000)-(1*0.005))
> ((x-1.000)/(1*0.005))
> ((x-1.020)/(1*0.005))
> ((x-1.020)/(0.005*1))
> ((x**1.020)/(0.005*1))
> ((x**1)/(0.005*1))
> ((x**1)/(0.005*(0.005+1)))
> ((x**1)/(0.005*(0.005+1.000)))
> (x**2)
> ((x--0.079)**2)
> ((x-0)**2.000)
> (((x-0)**2.000)/1)
> (((x-0)**2)/1)
> ((((x-0)**2)-0)/1)
> (((x-0)**2)-0)
> (((x-0)**2)-0.000)
> (((x-(0--1))**2)-0.000)
> (((x-(0--2))**2)-0.000)
> (((x-(0--2))**2)+0.000)
> (((x-((0--2)--1))**2)+0.000)
> (((x-((0--2)--1))**2)+-0.015)
> (((x-((0--2)--1))**2)+0)
> ((-0.057+0)+((x-((0--2)--1))**2.000))
> ((-0.057+0)+((x-3)**2.000))
> (((-0.057+0)**-1)+((x-3)**2.000))
> (((-0.057+0)**-1)+((x-4)**2.000))
> (((-0.057+0)**-1.000)+((x-4)**2.000))
> (((-0.057+0.000)**-1.000)+((x-4)**2.000))
> (((x-4)**2.000)+((-0.057+0.000)**-1.000))
> (((x-4)**2)+((-0.057+0.000)**-1.000))
> (((x-4)**2)+((-0.057+0.000)**-0.919))
> ((((x-4)**2)+((-0.057+0.000)**-0.919))+-0.048)
> ((((-0.057+0.000)**-0.919)+((x-4)**2))+-0.048)
> ((((-0.057+0.000)**-0.919)+((x-4)**2))+-0.037)
> (((-0.057**-0.919)+((x-4)**2))+-0.037)
> (-0.037+((-0.057**-0.919)+((x-4)**2)))
> (-13.524+((x-4)**2))
> (-13.500+((x-4)**2))
> ```
>
>
>
То есть после того как результаты вычислений окончательно стали совпадать с эталонными, он погнался за ресурсоемкостью, и провел преобразования, и в итоге формула на основе естественного отбора выигрывает по компактности!
Любопытно то, что такой результат я получил, фактически, по ошибке. При первых прогонах был запрещены виды мутации, при которых добавлялась бы еще одна переменная **x**. Как ни странно, так сработало даже лучше, чем при полноценной мутации. Вот результаты, когда баг был пофиксен:
* **R** = 250, **X** = 250, **Y** = 750, Точность = 0.001, (*вес* результата 49)
> (2.500+((x-8)\*x))
>
>
* **R** = 250, **X** = 1000, **Y** = 0, Точность = 0.001, (*вес* результата 60)
> (((x-1)\*(-7+x))-4.500)
>
>
В данном случае, вариант с квотой для случайных один раз споткнулся, но всё же смог выдать более оптимальный результат, чем второй вариант, который каждый из прогонов проходил ровно и однообразно. Здесь для каждого приближения результата к оптимуму хватает, в основном, одного шага мутации. В следующем случае всё окажется не так просто!
---
Второй эталон — натуральный логарифм:
> ln(1 + x)
**x** принимает значения от 0 до 25.5, с шагом 0.1
Наши решения лишены возможности использовать логарифмы напрямую, но данный эталон раскладывается в ряд Тейлора:
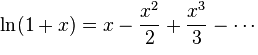
Вот и посмотрим, сможет ли решение воспроизвести такой ряд с заданной точностью.
Поначалу, пробовал прогоны с точностью до 0.001, но после нескольких суток упорной работы алгоритма решения достигли точности только около 0.0016, а размер выражений стремился к тысяче символов, и я решил снизить планку точности до 0.01. Результаты таковы:
* **R** = 250, **X** = 250, **Y** = 750, Точность = 0.01, (*вес* результата 149)
> ((((-1.776-x)/19.717)+(((x\*x)-0.318)\*\*0.238))-(0.066/(x+0.136)))
>
>
* **R** = 250, **X** = 1000, **Y** = 0, Точность = 0.01, (*вес* результата 174)
> (((-0.025\*x)+(((x\*x)\*\*0.106)\*\*2))/(1+(0.849/((x\*x)+1))))
>
>
Как видите, в случае включения случайных выживших для данного эталона найдено менее ресурсоемкое решение, с сохранением заданной точности. Не то, чтобы это сильно походило на ряд Тейлора, но оно считает верно :)
---
Третий эталон — синус, задаваемый в радианах:
> sin(x)
**x** принимает значения от 0 до 6.28, с шагом 0.02
Опять же, эталон раскладывается в ряд Тейлора:
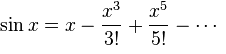
В данном случае, учитывая что при любом **x** результат принимает значение от -1 до 1, точность определения в 0.01 была более серьёзным испытанием, но алгоритм справился.
* **R** = 250, **X** = 250, **Y** = 750, Точность = 0.01, (*вес* результата 233)
> ((((-0.092\*\*x)/2.395)+(((-1.179\*\*((((x-1)\*0.070)+-0.016)\*4.149))-(0.253\*\*x))+0.184))\*\*(0.944-(x/-87)))
>
>
* **R** = 250, **X** = 1000, **Y** = 0, Точность = 0.01, (*вес* результата 564)
> (((x+x)\*((x\*-0.082)\*\*(x+x)))+(((x+x)\*\*(0.073\*\*x))\*((((1-(-0.133\*x))\*(-1-x))\*((x/-1)\*(-0.090\*\*(x--0.184))))+(((((-1.120+(x\*((x+1)\*-0.016)))\*\*(-0.046/((0.045+x)\*\*-1.928)))+(-0.164-(0.172\*\*x)))\*1.357)\*\*0.881))))
>
>
Опять же, ввиду повышенной сложности эталона, лучшего результата добилась версия алгоритма с пулом случайным решений.
---
Четвертый эталон — выражение с четырьмя (совпадение? не думаю) переменными:
> 2\*v + 3\*x — 4\*y + 5\*z — 6
>
>
Каждая из переменных принимает значения от 0 до 3 c шагом 1, всего 256 комбинаций.
* **R** = 250, **X** = 250, **Y** = 750, Точность = 0.01, (*вес* результата 254)
> ((y\*0.155)+(-2.166+(((((z\*4)-(((y-(x+(y/-0.931)))\*2)+-0.105))+((v+(v-2))+-0.947))+x)+(z+-1))))
>
>
* **R** = 250, **X** = 1000, **Y** = 0, Точность = 0.01, (*вес* результата 237)
> ((-3+(v+z))+(((v+((x-y)+((((z+z)-(((0.028-z)-x)+(y+y)))-y)+z)))+x)+-2.963))
>
>
Вопреки моим ожиданиям, трудоемкость по сравнению с первым эталоном подскочила очень серьезно. Вроде бы эталон не сложный, можно спокойно шаг за шагом наращивать решение, приближая результат к нужному. Однако точность в 0.001 была так и не осилена! Тут я и начал подозревать, что проблемы с масштабированием задач у нашего подхода серьезные.
### Итоги
В целом, я остался скорее *не* доволен полученными результатами, особенно, по эталонам 2 и 3. Понадобились тысячи поколений, чтобы вывести в итоге громоздкие формулы. Я вижу три варианта, почему это случается:
1. Несовершенный механизм сокращения — например, не хватает более дальновидного раскрытия скобок\выноса за скобки. Из-за этого формулы не привести в удобный вид.
2. Слишком спонтанная мутация, причем, чем больше формула, тем меньше вероятность правильного дальнейшего развития. Я подумывал о создании "исчерпывающего" (exhaustive) механизма мутации, когда формируется группа условно всех возможных мутантов на базе оригинала, и над ней производится пред-селекция. Дойдут ли руки проверить догадку, улучшит ли это алгоритм, пока неизвестно.
3. Принципиальная непрактичность такого метода для нахождения решений сложных задач. Быть может, данный подход не так уж далеко ушел от попыток написать "Войну и мир" силами армии [обезьян с пишущими машинками](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%BE_%D0%B1%D0%B5%D1%81%D0%BA%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D1%85_%D0%BE%D0%B1%D0%B5%D0%B7%D1%8C%D1%8F%D0%BD%D0%B0%D1%85). Быть может, сложность, необходимость аналитического подхода, это природное и неотъемлемое свойство таких задач.**Курьёз**Вспомнил, как лет десять назад интересовался сжатием данных, пробовал силы в написании своего решения. Сокрушался, что никак не удается сжимать рандомные паттерны, пока меня не просветили :) Может, и здесь так?
Дальнейшие эксперименты
-----------------------
Здесь должен был идти рассказ про более амбициозный эксперимент, целью которого является автоматическая генерация алгоритма сортировки массива.
Был создан минимально допустимый [набор выражений](https://github.com/augur/NaturalSelectionProgramming/blob/master/sorting/expression.rb), состоящий из примитивов и управляющих структур (следований, циклов, ветвлений) позволяющий [реализовать](https://github.com/augur/NaturalSelectionProgramming/blob/master/sorting/sorting_algs_probe.rb) наивные сортировки (как минимум, "пузырьковую" и "выбором"), а также простейшая [виртуальная машина](https://github.com/augur/NaturalSelectionProgramming/blob/master/sorting/sorting_vm.rb), предназначенная исключительно для сортировки массивов.
Но рассказа здесь нет — эксперимент еще не проведен. Реализация мутирования еще далека от завершения. Плюс, итоги первого эксперимента заставили меня сильно усомниться в шансах на успех с сортировками: если в первом случае хоть как-то присутствует возможность линейного наращивания решения с планомерными приближением к эталонному результату, то в случае с сортировками, алгоритмы с единственным неверным шагом коверкают результат до неузнаваемости.
Как в таких условиях адекватно оценить, насколько хорошо претендент прошел испытание? У меня нет ответа. Как выбрать из двух претендентов, если они одинаково *не* отсортировали массив, но за разное количество выполненных команд? Выбрав простой, мы можем скатиться к доминированию претендентов типа
```
nil
```
Выбор более сложного контринтуитивен — зачем эволюции намеренное усложнение при одинаковой эффективности? Так что с селекцией тоже проблемы.
Возможно, к тому моменту, как будет дописана основная часть кода, я поменяю цели на более простые — например, на алгоритм нахождения индекса максимального элемента массива. Надеюсь, так у генетического алгоритма будет хоть какое-то ощутимое преимущество перед брутфорсным построением решения с перебором всех доступных комбинаций.
Если будет о каком успехе докладывать, будет и вторая часть статьи.
Закончим на этой задумчиво неопределенной ноте. Большое спасибо за уделенное время! | https://habr.com/ru/post/279813/ | null | ru | null |
# Прокачиваем работу с событиями в Angular
Давным-давно я написал [статью о работе с EventManager в Angular](https://habr.com/ru/company/tinkoff/blog/429692/). В ней я рассказал, как можно сохранить привычный нам синтаксис подписок на события, при этом избежав лишних запусков проверки изменений на частых и чувствительных событиях.
Однако описанный мною метод громоздкий и сложный для восприятия. Пришло время переписать фильтрацию на декораторы.

Краткий повтор
--------------
Для тех, кто не читал и не хочет читать прошлую статью, краткое изложение проблемы:
1. Angular позволяет декларативно подписываться на события в шаблоне (`(eventName)`) и через декораторы (`@HostListener(‘eventName’)`).
2. При стратегии проверки изменений `OnPush` Angular запустит проверку, если произошло событие, на которое мы таким образом подписались.
3. События вроде `scroll`, `mousemove`, `drag` срабатывают очень часто. На практике реагировать нужно только на некоторые из них (например, когда пользователь прокрутил контейнер до конца — загружаем новые элементы).
4. Обработкой событий в Angular занимается `EventManager` с помощью предоставленных ему `EventManagerPlugin`ов.
5. Если мы научим Angular игнорировать ненужные нам события, то избежим лишних проверок изменений.
В прошлой статье я предлагал механизм фильтрации событий с возможностью при подписке отменить действие браузера по умолчанию или остановить всплытие события. В этот раз мы доведем данный подход до рабочего кода. Его можно подключать к проекту и использовать с минимумом дополнительных телодвижений.
Плагины
-------
Для настройки обработки будем использовать модификаторы имени события аналогично встроенным в Angular псевдособытиям нажатия клавиш (`keydown.ctrl.enter` и тому подобные).
Вспомним, как работает `EventManager`. В момент создания он собирает имеющиеся плагины. В Angular заложено несколько стандартных плагинов, а добавить свои можно благодаря внедрению зависимостей через `EVENT_MANAGER_PLUGINS` мультитокен. При подписке на событие он находит подходящий плагин, спрашивая все по очереди, поддерживают ли они событие с таким именем. Затем он вызывает метод `addEventListener` подходящего плагина, передавая в него имя события, элемент, на котором мы его слушаем, и обработчик, который нужно вызвать. Назад плагин возвращает метод для удаления подписки.
Начнем с `preventDefault` и `stopPropagation`. Создадим пару плагинов, которые, получив на вход имя события и обработчик, выполнят свою задачу и передадут обработку дальше:
```
@Injectable()
export class StopEventPlugin {
supports(event: string): boolean {
return event.split('.').includes('stop');
}
addEventListener(
element: HTMLElement,
event: string,
handler: Function
): Function {
const wrapped = (event: Event) => {
event.stopPropagation();
handler(event);
};
return this.manager.addEventListener(
element,
event
.split('.')
.filter(v => v !== 'stop')
.join('.'),
wrapped,
);
}
}
```
Задачу пропуска событий решить несколько сложнее. По сути, она состоит из трех составляющих:
1. Вывод обработчика из зоны видимости Angular, чтобы проверка не запускалась.
2. Отмена вызова обработчика при невыполнении условия.
3. Вызов обработчика и запуск проверки изменений при выполнении условия.
С первым пунктом отлично справится плагин, так как у него есть доступ к `NgZone` и запустить обработчик вне зоны очень просто:
```
@Injectable()
export class SilentEventPlugin {
supports(event: string): boolean {
return event.split('.').includes('silent');
}
addEventListener(
element: HTMLElement,
event: string,
handler: Function
): Function {
return this.manager.getZone().runOutsideAngular(() =>
this.manager.addEventListener(
element,
event
.split('.')
.filter(v => v !== 'silent')
.join('.'),
handler,
),
);
}
}
```
Для второго и третьего пунктов используем декоратор, фильтрующий вызов метода.
Декоратор
---------
Создадим фабрику, которая будет получать на вход функцию-фильтр. Мы сможем выполнять ее в контексте инстанса нашего компонента/директивы, так что у нас будет доступ к `this`.
Однако часто нужно изучить само событие, чтобы понять, нужно ли на него реагировать. Самый простой способ получить доступ к нему для нас — вызывать функцию-фильтр с теми же аргументами, что и метод, на который мы вешаем декоратор. Тогда останется только передавать `$event` в обработчик события в шаблоне или `@HostListener`. Код декоратора с использованием фильтра будет выглядеть следующим образом:
```
export function shouldCall(
predicate: Predicate
): MethodDecorator {
return (\_target, \_key, desc: PropertyDescriptor) => {
const {value} = desc;
desc.value = function(this: T, ...args: any[]) {
if (predicate.apply(this, args)) {
value.apply(this, args);
}
};
};
}
```
Так мы избежим лишних вызовов. Но если фильтр даст зеленый свет и обработчик выполнится — нужно как-то сообщить Angular, что необходимо запустить проверку изменений.
Когда выйдет Angular 10 и Ivy стабилизируется и станет доступным для библиотек, будет достаточно вызывать `markDirty(this)`. Но пока этого не случилось, нам нужно как-то добраться до `NgZone`. Для этого запилим временный хак. Как мы помним, доступ к зоне есть у плагинов. Напишем специальный плагин, который пришлет `NgZone` к нам, а декоратор ее перехватит:
```
@Injectable()
export class ZoneEventPlugin {
supports(event: string): boolean {
return event.split('.').includes('init');
}
addEventListener(
_element: HTMLElement,
_event: string,
handler: Function
): Function {
const zone = this.manager.getZone();
const subscription = zone.onStable.subscribe(() => {
subscription.unsubscribe();
handler(zone);
});
return () => {};
}
}
```
Единственная задача этого плагина — слушать подписку на событие с модификатором `.init` и передавать в обработчик зону, как только она стабилизируется (иными словами, когда компонент соберется). Наш декоратор будет использоваться вместе с `@HostListener(‘prop.init’, [‘$event’])` и будет ловить зону:
```
export function shouldCall(
predicate: Predicate
): MethodDecorator {
return (\_, key, desc: PropertyDescriptor) => {
const {value} = desc;
desc.value = function() {
const zone = arguments[0] as NgZone;
Object.defineProperty(this, key, {
value(this: T, ...args: any[]) {
if (predicate.apply(this, args)) {
zone.run(() => {
value.apply(this, args);
});
}
},
});
};
};
}
```
Конечно, это хак. Но можно утешиться тем, что это временное решение и оно работает. Остается дождаться дивного нового мира Ivy.
Использование
-------------
Демо из прошлой статьи, переработанное на новый подход, можно изучить тут:
<https://stackblitz.com/edit/angular-event-filter-decorator>
Помните, что для АОТ компиляции функции, которые передаются в фабрики декораторов, выносятся в отдельные экспортируемые сущности. В качестве простейшего примера сделаем компонент, который показывает список и подгружает новые элементы, когда он полностью прокручен вниз. В шаблоне будет `async` пайп на `Observable` из элементов:
```
{{item}}
```
В коде компонента добавим сервис, имитирующий запросы на сервер за новыми элементами и подписку на событие скролла с фильтрацией:
```
export function scrolledToBottom(
{scrollTop, scrollHeight, clientHeight}: HTMLElement
): boolean {
return scrollTop >= scrollHeight - clientHeight - 20;
}
@Component({
selector: 'awesome-component',
templateUrl: './awesome-component.component.html',
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class AwesomeComponent {
constructor(@Inject(Service) readonly service: Service) {}
@HostListener('scroll.silent', ['$event.currentTarget'])
@HostListener('init.onScroll', ['$event'])
@shouldCall(scrolledToBottom)
onScroll() {
this.service.loadMore();
}
}
```
Вот и все. Посмотреть работу в действии можно тут:
<https://stackblitz.com/edit/angular-event-filters-scroll>
Обратите внимание на консоль, в которой выводится сообщение на каждый цикл проверки изменений. Весь этот код будет работать и с произвольными `CustomEvent`ами, которые создаются и диспатчатся руками. Синтаксис при этом никак не изменится.
Описанное решение вынесено в крошечную (1 КБ gzip) open-source-библиотеку под названием **`@tinkoff/ng-event-filters`**. К релизу Angular 10 выпустим версию 2.0.0, в которой перейдем на `markDirty(this)`, а текущий код работает даже с Angular 4.
[Исходный код](https://github.com/TinkoffCreditSystems/ng-event-filters)
[npm-пакет](https://npmjs.com/package/@tinkoff/ng-event-filters)
> У вас тоже есть что-то, что вы мечтали выложить в open source, но вас отпугивают сопутствующие хлопоты? Попробуйте [Angular Open-source Library Starter](https://github.com/TinkoffCreditSystems/angular-open-source-starter), который мы сделали для своих проектов. В нем уже настроен CI, проверки при коммитах, линтеры, генерация CHANGELOG, покрытие тестами и все в таком духе. | https://habr.com/ru/post/492766/ | null | ru | null |
# Создаем процессорный модуль под Ghidra на примере байткода v8
В прошлом году наша команда столкнулась с необходимостью анализа байткода V8. Тогда еще не существовало готовых инструментов, позволявших восстановить такой код и обеспечить удобную навигацию по нему. Было принято решение попробовать написать процессорный модуль под фреймворк Ghidra. Благодаря особенностям используемого языка описания инструкций на выходе мы получили не только читаемый набор инструкций, но и C-подобный декомпилятор. Эта статья — продолжение серии материалов ([1](https://habr.com/ru/company/pt/blog/551540/), [2](https://habr.com/ru/company/pt/blog/514292/)) о нашем плагине для Ghidra.
Между написанием процессорного модуля и статьи прошло несколько месяцев. За это время спецификация SLEIGH не изменилась, и описанный модуль работает на версиях 9.1.2–9.2.2, которые были выпущены за последние полгода.
Сейчас на [ghidr](https://ghidra.re/courses/languages/html/sleigh.html)[a.re](https://ghidra.re/courses/languages/html/sleigh_context.html) и в приложенной к Ghidra документации есть достаточно хорошее описание возможностей языка — эти материалы стоит почитать перед написанием своих модулей. Отличными примерами могут быть уже готовые процессорные модули разработчиков фреймворка, особенно если вы знаете описываемую в них архитектуру.
В документации можно прочесть, что процессорные модули для Ghidra пишутся на языке SLEIGH, который произошел от языка SLED (Specification Language for Encoding and Decoding) и разрабатывался целенаправленно под Ghidra. Он транслирует машинный код в p-code (промежуточный язык, используемый Ghidra для построения декомпилированного кода). Как у языка, предназначенного для описания инструкций процессора, у него достаточно много ограничений, которые, однако, можно купировать за счет механизма внедрения p-code в java-коде.
Исходный код созданного процессорного модуля представлен на [github](https://github.com/PositiveTechnologies/ghidra_nodejs). В этой статье будут рассматриваться принципы и ключевые понятия, которые использовались при разработке процессорного модуля на чистом SLEIGH на примере некоторых инструкций. Работа с пулом констант, инъекции p-code, анализатор и загрузчик будут или были рассмотрены в других статьях. Также про анализаторы и загрузчики можно почитать в книге *The Ghidra Book: The Definitive Guide*.
С чего начать
-------------
Для работы понадобится установленная среда разработки Eclipse, в которую нужно добавить плагины, поставляемые с Ghidra: [GhidraDev](https://initrd.net/stuff/ghidra/GhidraBuild/EclipsePlugins/GhidraDev/GhidraDevPlugin/GhidraDev_README.html) и [GhidraSleighEditor](https://initrd.net/stuff/ghidra/GhidraBuild/EclipsePlugins/GhidraSleighEditor/ghidra.xtext.sleigh/GhidraSleighEditor_README.html). Далее создается Ghidra Module Project с именем v8\_bytecode. Созданный проект содержит шаблоны важных для процессорного модуля файлов, которые мы будем модифицировать под свои нужды.
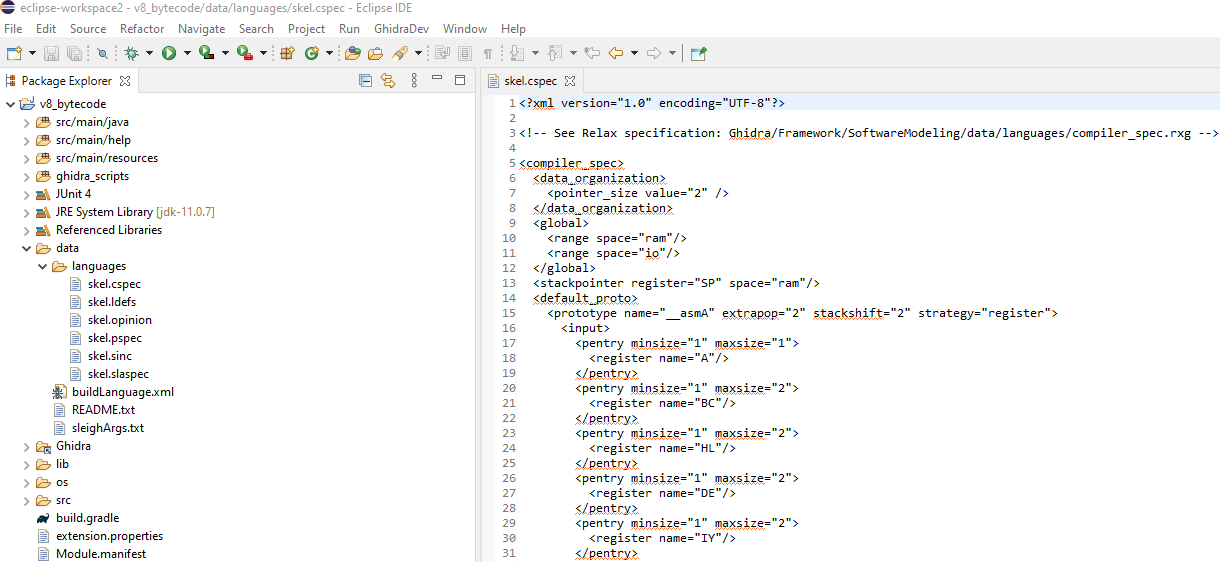Чтобы получить общее представление о файлах, с которыми предстоит работать, обратимся к официальной документации либо вышедшей недавно книге Криса Игла и Кары Нанс *The Ghidra Book: The Definitive Guide*. Вот описание этих файлов.
* \*.сspec — спецификация компилятора.
* \*.ldefs — определение языка. Содержит отображаемые в интерфейсе параметры процессорного модуля. Также содержит ссылки на файлы \*.sla, спецификацию процессора и спецификации компилятора.
* \*.pspec — спецификация процессора.
* \*.opinion — конфигурации для загрузчика; поскольку мы будем описывать только один вид файлов, файл opinion можно оставить пустым: он не пригодится.
* \*.slaspec, \*.sinc — файлы, описывающие регистры и инструкции процессора на языке SLEIGH.
Также после первого запуска вашего проекта появится файл с расширением .sla, он генерируется на основании slaspec-файла.
Перед тем как приступить к разработке процессорного модуля, необходимо разобраться с тем, какие есть регистры, как происходит работа с ними, со стеком и т. п. для описываемого процессора или интерпретатора.
О регистрах V8
--------------
Jsc-файл, который нас интересовал, был собран c использованием среды выполнения JavaScript Node.Js 8.16.0 через bytenode (этот модуль либо будет в поставке Node.Js, либо нужно будет доставить его через npm). По сути, bytenode использует документированный функционал Node.js для создания скомпилированного файла. Вот исходный код функции, компилирующей jsc файлы из js:
Node.js можно скачать как в собранном виде, так и в виде исходников. При детальном изучении исходных файлов и примеров инструкций становится ясно, как кодируются регистры в байткоде (для понимания расчета индекса будут полезны файлы bytecode-register.cc, bytecode-register.h). Примеры инструкций v8 с расчетами индексов регистров в соответствии с Node.js:
Если вам показалось, что регистры aX кодируются разными байтами в зависимости от количества аргументов функции, то вы все поняли правильно. Более наглядная схема ниже.
Тут Х — количество аргументов текущей функции без учета передаваемого , aX — регистры, содержащие аргументы функции, а rN — регистры, используемые как локальные переменные. Регистры могут кодироваться 1-байтовыми значениями для обычных инструкций, 2-байтовыми для инструкций с пометкой Wide- и 4-байтовыми для инструкций с пометкой ExtraWide-. Пример кодировки Wide-инструкции с пояснениями:
Более подробно о Node.js и v8 можно почитать в [статье Сергея Федонина](https://habr.com/ru/company/pt/blog/551540/).
Стоит заметить, что SLEIGH не совсем подходит для описания подобных интерпретируемых байткодов, поэтому у написанного процессорного модуля есть некоторые ограничения. Например, определена работа не более чем с 124 регистрами rN и 125 регистрами aX. Была попытка решить эту проблему через стековую модель взаимодействия с регистрами, так как она больше соответствовала концепции. Однако в этом случае дизассемблированный байткод тяжелее читался:
Также без введения дополнительных псевдоинструкций, регистров или областей памяти не представляется возможным высчитывать название регистра аргумента в соответствии с Node.js из-за отсутствия информации о количестве аргументов. В связи с этим нами было принято решение проставлять номера в названии регистров аргументов функций (X в aX) в обратном порядке. Это не мешает разбору кода, что было для нас важным критерием, однако может смущать при сравнении результатов вывода инструкций файла в разных инструментах.
После изучения того, что нужно описывать, можно приступить к формированию необходимых файлов для процессорного модуля.
CSPEC
-----
Немного текстовой информации о тегах, используемых в cspec-файлах, можно найти в исходниках фреймворка на [github](https://github.com/NationalSecurityAgency/ghidra/blob/master/Ghidra/Features/Decompiler/src/main/doc/cspec.xml). В описании назначения файла говорится:
> *Спецификация компилятора является необходимой частью модуля языка Ghidra для поддержки разборки и анализа конкретного процессора. Его цель — закодировать информацию о целевом двоичном файле, специфичном для компилятора, сгенерировавшего этот двоичный файл. В Ghidra спецификация SLEIGH позволяет декодировать машинные инструкции для конкретного процессора, например Intel x86, но эти инструкции могут продуцировать более одного компилятора. Для конкретного целевого двоичного файла понимание деталей о конкретном компиляторе, используемом для его сборки, важно для процесса разбора кода. Спецификация компилятора удовлетворяет эту потребность, позволяя формально описывать такие концепции, как соглашения о передаче параметров и механизмы стека.*
>
>
Также становится понятно, что теги используются для следующих целей:
* Compiler Specific P-code Interpretation;
* Compiler Datatype Organization (у нас использовался );
* Compiler Scoping and Memory Access (у нас использовался );
* Compiler Special Purpose Registers (у нас использовался );
* Parameter Passing (у нас использовался ).
Изучая структуру шаблона, описанные теги в документации и примеры подобных файлов, можно попробовать сформировать файл под свои нужды.
Теги и достаточно типовые; разберем тег в , частично описывающий соглашение о вызове функций. Для него определим: , , .
Как говорилось выше, аргументы в функцию передаются через регистры aX. В модуле регистры должны быть определены как непрерывная последовательность байтов по смещению в некотором пространстве. Как правило, в таких случаях используется специально придуманное для этого пространство register. Однако теоретически не запрещено использовать любое другое. В случае наличия большого количества регистров, выполняющих примерно одни функции, проще всего не прописывать каждый отдельно, а просто указать смещение в пространстве регистров, по которому они будут определены. Поэтому в спецификации компилятора помечаем область памяти в пространстве регистров (`space="register"`) в теге для регистров, через которые происходит передача аргументов в функции, по смещению 0x14000 (0x14000 не несет в себе сакрального смысла, это просто смещение, по которому в \*.slaspec далее будут определены регистры aX).
По умолчанию результат вызова функций сохраняется в аккумулятор (acc), что нужно прописать в теге . Для альтернативных вариантов регистров, в которые происходит сохранение возвращаемых функциями значений, можно определить логику при описании инструкций. Отметим в теге , что вызовы функций на регистр, хранящий указатель на стек, не влияют.
Для работы с частью регистров наиболее удобным будет вариант определения их как изменяемых глобально, поэтому в теге определяем диапазон регистров в пространстве register по смещению 0x2000.
LDEFS
-----
Перейдем к определению языка — это файл с расширением .ldefs. Он требует немного информации для оформления: порядок байт (у нас le), названия ключевых файлов (\*.sla, \*.pspec,\*.cspec), id и название байткода, которое будет отображаться в списке поддерживаемых процессорных модулей при импорте файла в Ghidra. Если когда-то понадобится добавить процессорный модуль для файла, скомпилированного версией Node.js, существенно отличающейся от текущей, то имеет смысл описать его тут же через создание еще одного тега , как это сделано для описания семейств процессоров в \*.ldefs модулей, поставляемых в рамках Ghidra.
Практическое применение информации, не касающейся определения файлов, будет видно при попытке импорта файла.
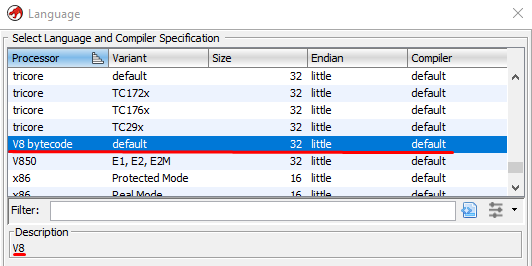PSPEC
-----
Сложнее в плане документации дела обстоят со спецификацией процессора (файл с расширением .pspec). В данном случае можно обратиться к готовым решениям в рамках самого фреймворка или к файлу [processor\_spec.rxg](https://github.com/NationalSecurityAgency/ghidra/blob/master/Ghidra/Framework/SoftwareModeling/data/languages/processor_spec.rxg) (вариант с полноценным разбором исходных кодов Ghidra мы не рассматривали). Чего-то более подробного на момент написания модуля не было. Вероятно, со временем разработчики опубликуют официальную документацию.
В текущем проекте на данный момент от спецификации процессора может понадобиться только программный счетчик, оставим этот тег из стандартного шаблона свежесозданного проекта (на самом деле можно оставить пустым).
SLASPEC
-------
Теперь можно приступить к непосредственному описанию инструкций на SLEIGH в файле с расширением .slaspec.
### Базовые определения и макросы препроцессора
Сначала при его описании необходимо указать порядок байтов. Также можно определить выравнивание и константы, которые могут понадобиться в процессе описания, через макросы препроцессора.
Адресные пространства, которые понадобятся для описания байткода (у нас создаются пространства с именами register и ram), определяются через **define space**, а регистры — через **define** register. Значение **offset** в определении регистров не принципиально, главное, чтобы они находились по разным смещениям. Занимаемое регистрами количество байтов определяется параметром **size**. Стоит помнить, что определенная тут информация должна соответствовать обращениям к аналогичным абстракциям и величинам в рамках \*.cspec и анализатора, если вы ссылаетесь на эти регистры.
### Описание инструкций
В документации (<https://ghidra.re/courses/languages/html/sleigh_constructors.html>) можно прочитать, что определение инструкций происходит через таблицы, которые состоят из одного и более конструкторов и имеют связанные с ними идентификаторы символов семейства. Таблицы в SLEIGH по сути позволяют создавать то, что называется символами семейства, в статье мы не будем углубляться в определения символов, для этих целей проще прочитать «[Знакомство с символами](https://ghidra.re/courses/languages/html/sleigh_symbols.html)». Однако, возможно, концепция станет чуть более понятна после изучения этой статьи. Конструкторы состоят из 5 частей.
1. Table Header (заголовок таблицы)
2. Display Section (секция отображения)
3. Bit Pattern Sections (секция битового шаблона)
4. Disassembly Actions Section (секция действий при дизассемблировании инструкций)
5. Semantics Actions Section (семантическая секция)
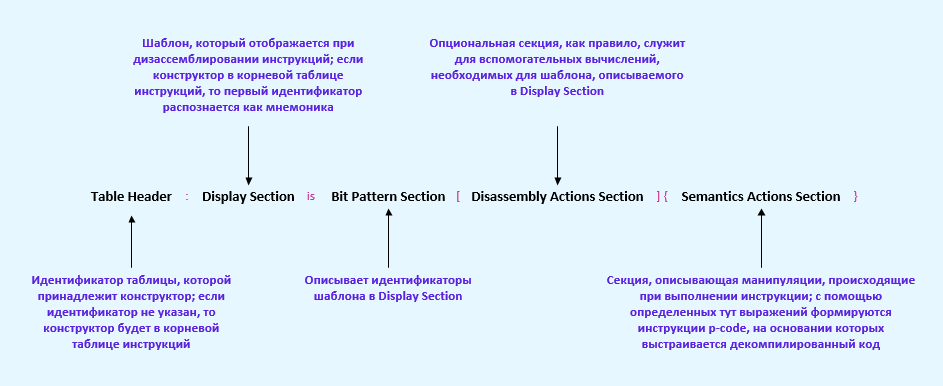Пока что звучит страшно, опишем основной смысл.
1. В Table Header либо помечается идентификатор, который можно использовать в других конструкторах, либо ничего нет (тогда это непосредственно описание инструкции).
2. Display Section — шаблон, показывающий как выводить инструкцию в листинг Ghidra.
3. Bit Pattern Section — перечень каких-либо идентификаторов, которые «забирают» реальные биты программы под инструкцию и выводятcя в листинг по шаблону секции отображения (иногда с использованием следующей секции).
4. Disassembly Actions Section дополняет секцию битового шаблона какими-то вычислениями, если ее в чистом виде недостаточно.
5. Semantics Actions Section описывает, что делает эта инструкция по смыслу, чтобы показать это в декомпиляторе.
Изначально существует корневая таблица инструкций (за ней закреплен идентификатор instruction), все описанные конструкторы с пустым заголовком таблицы становятся ее частью, а первый идентификатор этих конструкторов в секции отображения распознается как мнемоника инструкций.
Для конструкторов, имеющих идентификатор в заголовке таблицы, создается новая таблица с соответствующим именем. Если она уже существовала, конструктор становится частью той же таблицы, этот случай будет рассмотрен в разделе про диапазоны регистров. При использовании идентификатора этой таблицы в другой таблице он становится ее дополнительной частью. То есть создание таблиц, чьи идентификаторы нигде не используются (они никак не будут связаны с корневой таблицей инструкций), не имеет практического смысла.
Несколько документированных особенностей секции отображения, которые понадобятся дальше:
* ^ — разделяет идентификаторы и/или символы в секции, между которыми не должно быть пробелов;
* “” — используются, чтобы вставлять жестко закодированные строки, которые не будут считаться идентификатором;
* пробельные символы обрезаются в начале и конце секции, а их последовательности сжимаются в один пробел;
* некоторые знаки пунктуации и спецсимволы вставляются в шаблон (неиспользуемые для каких-то определенных функций, в отличие от, например #, которые применяются для комментариев).
### Токены и их поля
Для описания конструкторов инструкций необходимо определить битовые поля. Через них осуществляется привязка битов программы к определенным абстракциям языка, в который будет происходить трансляция. Такими абстракциями могут быть мнемоники, операнды и т. п. Определение полей происходит в рамках задания токенов, синтаксис их определения выглядит так:
Размер токена tokenMaxSize должен быть кратен 8. Это может быть неудобно, если операнды или какие-то нюансы для инструкции кодируются меньшим количеством бит. С другой стороны, это компенсируется возможностью создавать поля разных размеров, кодирующих позиционно любые биты в пределах размеров, задаваемых токеном. Для таких полей должны соблюдаться условия: start- и endBitNumX находятся в диапазоне от 0 до tokenMaxSize-1 включительно и startBitNumX <= endBitNumX.
Для разбираемого байткода v8 не было необходимости создавать поля, отличные по размеру от токена. Но, если бы такие поля были и использовались совместно, они бы объединялись через логические операторы [«&» или «|»](https://ghidra.re/courses/languages/html/sleigh_constructors.html).
Обратите внимание: даже если вы используете поле или комбинацию полей в секции битового шаблона, не покрывающие своими битовыми масками полный размер токена, к которому они принадлежат, по факту из байтов программы под операнд все равно будет «забираться» количество бит, определяемое размером токена.
Теперь опишем простейшую инструкцию байткода, не имеющую операндов. Определим поле, которое будет описывать опкод инструкции. Как видно выше в разделе про v8, код инструкции описывается одним байтом (есть также Wide- и ExtraWide- инструкции, но они здесь не будут рассматриваться, по сути они просто используют операнды больших размеров и дополнительный байт под опкод инструкции). Таким образом получаем:
Теперь, используя поле op для идентификации первого и единственного опкода, определяющего инструкции **Illegal** и **Nop**, пишем для них конструкторы:
Байт «0xa7» в листинге Ghidra отобразит как инструкцию **Illegal**, не имеющую операндов. Для этой инструкции в примере использовалось ключевое слово unimpl. Это неимплементированная команда, дальнейшая декомпиляция будет прервана, что удобно для отслеживания нереализованных семантических описаний. Для **Nop** оставлена пустая семантическая секция, то есть команда не повлияет на отображение в декомпиляторе, что и должна делать эта инструкция. На самом деле **Nop** не присутствует как инструкция в Node.js нашей версии, мы ввели ее искусственно для реализации функционала **SwitchOnSmiNoFeedback**, но об этом будет рассказано в [статье Владимира Кононовича](https://habr.com/ru/company/pt/blog/514292/).
### Описываем операнды и семантику
Усложним концепцию: опишем конструктор для операций **LdaSmi**, в рамках которой происходит загрузка целого числа в аккумулятор (acc в определении пространства регистров), и **AddSmi**, которая по сути представляет собой сложение значения в аккумуляторе c целым числом.
Для текущих и будущих нужд определим чуть больше полей на манер операндов в bytecodes.h Node.js, создадим их в новом токене с именем operand, поскольку у этих полей будет другое назначение. Создание нескольких полей с одинаковыми битовыми масками может быть обусловлено как удобством восприятия, так и использованием нескольких полей одного токена в рамках одной инструкции (см. пример с **AddSmi**).
С точки зрения листинга хочется видеть что-то наподобие **LdaSmi [-0х2]**. Поэтому определяем в секции отображения мнемонику, а в шаблон прописываем имена полей, которые должны подставляться из секции disassembly action или битового шаблона (квадратные скобки тут не обязательны, это просто оформление).
Для инструкции **AddSmi** в секции битового шаблона, помимо поля op, устанавливающего ограничение на опкод, через «;» появляются поля из токена operand. Они будут подставлены в секцию отображения в качестве операндов. Маппинг на реальные биты происходит в том порядке, в котором поля указаны в секции битового шаблона. В семантической секции, используя [документированные операции](https://ghidra.re/courses/languages/html/sleigh_ref.html), реализуем логику инструкций (то, что делал бы интерпретатор, выполняя эти инструкции).
Через «;» могут также, например, идти регистры, контекстные переменные (о них поговорим позже), комбинации полей одного токена или полей с контекстными переменными.
Вот так выглядит окно листинга с описанными инструкциями со включенным полем PCode в меню «изменение полей» листинга Ghidra. Окно декомпилятора пока что не будет показательным из-за оптимизации кода, поэтому на данном этапе стоит ориентироваться только на промежуточный p-code.
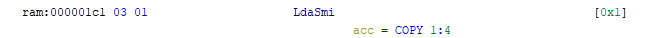В байткоде v8 инструкции, чьи мнемоники начинаются с lda, и так подразумевают загрузку значения в аккумулятор. Но при желании явно видеть регистр acc в инструкциях байткода можно определить его для отображения в конструкторе. В данном случае неважно, на какой позиции в секции битового шаблона находится acc, так как он не является полем и не занимает биты инструкции, но вписать его необходимо.
Инструкции возврата значения из функции реализуются с помощью ключевого слова return, и, как уже упоминалось ранее, чаще всего возвращение значения при вызове функции происходит через аккумулятор:
### Выводим регистры по битовым маскам
В инструкциях, которые мы описывали выше, не используются регистры в качестве операндов. Теперь же реализуем конструктор инструкции **Mul**, в рамках которой происходит умножение аккумулятора на значение, сохраненное в регистре.
В разделе «Базовые определения и макросы препроцессора» регистры уже были объявлены, но для того, чтобы нужные регистры выбирались в зависимости от представленных в байткоде бит, необходимо «привязать» их список к соответствующим битовым маскам. Поле kReg имеет размер 8 бит. Через конструкцию attach variables последовательно определяем каким битовым маскам от 0b до 11111111b вышеприведенные регистры будут соответствовать в рамках последующего использования полей из заданного списка (в нашем случае только kReg) в конструкторах. Например, в этом описании видно, что операнд, закодированный как 0xfb (11111011b), интерпретируется при описании его через kReg как регистр r0.
Теперь, когда за переменной kReg закреплены регистры, ее можно использовать в конструкторах:
Усложним конструкцию для соответствия конструктора более высокоуровневым описаниям инструкций из interpreter-generator.cc исходников Node.js. Вынесем поле kReg в отдельный конструктор, идентификатор таблицы которого в Table Header назовем src. В его семантической секции появляется новое ключевое слово — **export**. Если не вдаваться в детали построения p-code, то по смыслу **export** определяет значение, которое должно быть «подставлено» в семантическую секцию конструктора вместо src. Вывод в Ghidra не изменится.
Примеры аналогичных с точки зрения описания инструкций, которые понадобятся позже для тестирования модуля на реальном файле:
### Переходы по адресам с goto
В байткоде встречаются операции условного и безусловного перехода по смещению относительно текущего адреса. Для перехода по адресу или метке в SLEIGH используется ключевое слово goto. Примечательно для определения то, что в секции битового шаблона используется поле kUImm, однако оно не используется в чистом виде. В секцию отображения выводится просчитанное в disassembly action секции значение через идентификатор rel. Величина [**inst\_start**](https://ghidra.re/courses/languages/html/sleigh_symbols.html)предопределена для SLEIGH и содержит адрес текущей инструкции.
Компиляция SLEIGH проходит. Правда, в таком варианте (листинг ниже), судя по выводу, не получается создать варноду (это объекты, которыми манипулирует p-code инструкция), содержащую привязку к конкретному пространству.
Воспользуемся рекомендуемым разработчиками способом и «вынесем» часть определения через создание дополнительного конструктора с идентификатором dest. Конструкция \*[ram]:4 rel не обозначает, что мы берем 4 байта по адресу rel. По факту экспортируется адрес rel в пространстве ram. Оператор «\*» в SLEIGH обозначает разыменование, но в данном конкретном случае относится к нюансу создания варнод (подробнее в [Dynamic References](https://ghidra.re/courses/languages/html/sleigh_constructors.html#sleigh_star_operator)).
Указание пространства [ram] может быть опущено (пример в комментарии), так как при определении мы указали его пространством по умолчанию. Как видно в инструкциях p-code, смещение было помечено как принадлежащее ram.
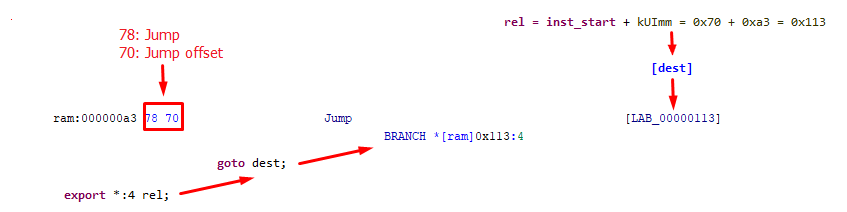Чуть сложнее выглядит инструкция **JumpIfFalse** из-за использования условной конструкции. В SLEIGH она используется вместе с ключевым словом goto. Для большего соответствия концепциям js величина **False** ранее была определена как регистр, и можно заметить, что в pspec диапазон пространства регистров, к которому она привязана, помечен как глобальный. Благодаря этому в псевдокоде она отображается в соответствии с именованием регистра, а не численным значением.
В рассмотренных примерах переход осуществляется по рассчитываемому относительно **inst\_start** адресу. Рассмотрим инструкцию **TestGreaterThan**, в которой происходит переход с помощью **goto** к метке ( в примере ниже) и **inst\_next.** Переход к метке в принципе должен быть интуитивно понятным: если условие истинно, то далее должны выполняться инструкции, следующие за местом ее расположения. Метка действительна в только в пределах ее семантической секции.
Конструкция **goto** **inst\_next** фактически завершает обработку текущей инструкции и передает управление на следующую. Стоит обратить внимание, что для выполнения знакового сравнения используется «s>», см. [документацию](https://ghidra.re/courses/languages/html/sleigh_ref.html).
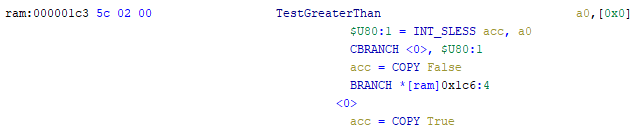### Несколько регистровых операндов
В предыдущих инструкциях использовалось не более одного регистра в качестве операнда. Так что сначала поговорим об использовании большего количества регистров для этих целей.
Описание однотипных операндов через конструкторы, имеющие разные идентификаторы таблиц (см. конструкторы в примере ниже), может иметь практическое применение для использования в рамках одного конструктора корневой таблицы. Такой вариант применим не только с точки зрения соответствия описанию инструкций v8, но и для преодоления возможных ошибок. Например, 4 операнда инструкции **CallProperty2** являются регистрами, идентично задаваемыми с точки зрения битовой маски. Попытка определить конструктор как :**CallProperty2** **kReg,** **kReg,** **kReg, kReg,** **[kIdx]** вызовет ошибку в компиляторе Sleigh при попытке открыть файл с помощью процессорного модуля. Поэтому в нашем модуле использовались конструкторы для создания чего-то наподобие алиасов:
Стоит отметить, конечно, что решить эту проблему также можно было без определения новых конструкторов. Например, определив и прописав поля callable, receiver, arg1 и arg2 в рамках какого-либо токена с последующей их привязкой через attach к списку регистров:
Каждое из этих полей работало бы аналогично kReg в предыдущих примерах. Какой именно способ использовать — вопрос эстетики.
### Вызовы функций
В инструкции **CallProperty2** также примечательно то, что она в семантической секции использует конструкцию **call** *[callable]*;, которую мы не использовали до этого. В v8 аргументы функции хранятся в регистрах aX (как мы и пометили в cspec). Однако, с точки зрения байткода, помещения туда аргументов непосредственно перед вызовом функции не происходит (случаи, когда это происходит, можно посмотреть в sinc-файле, например для x86). Интерпретатор делает это самостоятельно, ведь у него есть вся необходимая информация. Но ее нет у Ghidra, поэтому в семантической секции мы пропишем помещение аргументов в регистры вручную. Однако нам необходимо будет восстановить значения задействованных регистров после вызова, так как в вызывающей функции эти регистры тоже могут хранить какие-то значения, необходимые для потока выполнения. Можно сохранить их через локальные переменные:
Можно также применять вариант с сохранением аргументов в памяти (в данном случае на стеке: sp не используется инструкциями, потому не повлияет на отображение в декомпиляторе) при использовании макросов на примере **CallUndefinedReceiver1**:
При написании подобных модулей вместе с загрузчиком и анализатором стоит следить, чтобы порядок передаваемых аргументов совпадал с порядком аргументов функции, определяемых при их создании в java-коде. Также стоит отметить, что для нашей ситуации было полезно сохранять не больше аргументов функции, чем их количество в вызывающей функции, но это сложно реализовать на SLEIGH. Вариант решения проблемы можно будет прочитать в статье Вячеслава Москвина про внедрение p-code инструкций.
### Определяемые пользователем операции
Чтобы не терять при декомпиляции инструкции, в которых не планируется или нет возможности описывать семантический раздел, можно использовать определяемые пользователем операции. Стоит отметить, что в ситуации с acc не требуется явно указывать размер, поскольку размер регистра определен явно, а использовать его не полностью тут не нужно. Однако при передаче в подобные пользовательские операции, например, числовых констант придется явно указывать размер передаваемого значения (как в примере с CallVariadicCallOther в разделе «О диапазонах регистров» далее по тексту). Пользовательские операции определяются как **define** **pcodeop** *OperationName* и используются в семантическом разделе конструкторов в формате, напоминающем вызов функции во многих языках программирования.
Эти операции могут использоваться для внедрения p-code-инструкций в анализаторе: вызовы добавляются через тег `callotherfixup` в cspec-файл и прописывается логика в анализаторе.
Без переопределения в java-коде пользовательские операции в декомпиляторе выглядят так же, как они определены в семантическом разделе:
### Тестируем модуль
Уже на этом этапе можно попробовать проверить работу процессорного модуля на практике. Скомпилируем через bytenode jsc-файл из небольшого примера на js:
Попробуем запустить написанный на основании статьи проект и импортировать полученный [jsc-файл](https://github.com/PositiveTechnologies/ghidra_nodejs/blob/main/samples/article_data/v8_test.jsc) в Ghidra. Если что-то описано неправильно, Ghidra выдаст ошибку, а в логах eclipse будет локализирован номер строки, вызвавшей ошибку. При исправлении кода не нужно перестраивать проект: sleigh перекомпилируется при следующей попытке открыть файл.
На всякий случай [тут](https://github.com/PositiveTechnologies/ghidra_nodejs/tree/main/samples/article_data/languages) прикладываем архив с файлами, которые должны были получиться. Также можно посмотреть полную версию написанного инструмента в репозитории проекта.
Поскольку мы описывали только инструкции, файл не будет проанализирован и разобран по функциям. Код находится по смещению 0х1с0. Нажмем D для преобразования байтов в инструкции по этому смещению и F, чтобы создать функцию. Вот так она будет выглядеть:
Более понятным становится вывод при использовании других средств (помимо SLEIGH), доступных разработчикам модулей. Например, при добавлении работы с пулом констант (для обращения к нему в SLEIGH зарезервировано ключевое слово cpool) появится возможность разрезолвить числовой идентификатор в команде LdaGlobal. Вот так в последней версии нашего проекта выглядит функция (для сравнения):
Разумеется, было бы приятнее видеть большее соответствие исходному коду, написанному на JavaScript, однако этого нельзя добиться, описывая инструкции только в файлах .slaspec (и .sinc). Чуть больший простор для воображения откроет статья, в которой будет описан механизм внедрения операций p-code, позволяющий при полном доступе ко всем ресурсам приложения манипулировать инструкциями, из которых собирается дерево p-code. Как раз на основании созданного дерева p-code результат декомпиляции выстраивается и отображается в интерфейсе.
### О диапазонах регистров
В байткоде v8 для ряда инструкций реализована работа с диапазонами, парами и/или тройками регистров. С точки зрения кодирования диапазонов присутствует байткод первого регистра и количество используемых в диапазоне регистров. Для пар и троек указывается только начальный регистр, так как интерпретатору заранее известно, сколько регистров надо использовать для данной инструкции.
На основании описания понятно, что достаточно простым решением было бы отобразить при разборе инструкций первый регистр и их количество, то есть примерно так: ForInPrepare r9, r10!3. Чуть большим компромиссом в пользу читаемости было бы выводить первый и последний регистры диапазона, но, забегая вперед, можно сказать, что с точки зрения реализации уже это потребовало бы использования таблиц, состоящих из нескольких конструкторов.
#### Таблицы, содержащие несколько конструкторов
В рамках проекта для удобства восприятия было решено отображать в листинге весь список передаваемых регистров. Для секции отображения нет готового шаблона для выведения диапазонов регистров. Можно руководствоваться принципами, аналогичными использованным для процессорного модуля ARM: распечатыванием переменных через цепочку конструкторов (только сам принцип, реализация нам не подойдет из-за разности архитектур).
Тут наглядно видно тот самый случай, когда таблица с неким идентификатором состоит из нескольких конструкторов. По сути, это несколько конструкторов с одинаковыми идентификаторами в секции заголовка таблицы с разными условиями в секции битового шаблона. Выбираться при работе с идентификатором в других конструкторах будет наиболее подходящий по условию вариант. Например, если описан конструктор с неким условием и без условий, то при истинности условия будет выбран первый вариант, хотя второй формально ему не противоречит, поскольку не накладывает вообще никаких условий.
Как можно предположить, глядя на побайтовое описание инструкции **CallProperty** выше, для «раскрытия» диапазона необходимо распечатать регистры, отталкиваясь от первого вхождения, ориентируясь на известный первый регистр диапазона и количество элементов в нем. С точки зрения секции отображения, диапазон создается из двух конструкторов: rangeSrc и rangeDst. rangeSrc — своего рода инициализация, где мы сохраняем входные данные, rangeDst будет «распечатывать» регистры на основании полученной информации. И как раз для rangeDst понадобится создавать таблицы, содержащие несколько конструкторов: как минимум для отображения диапазонов на регистрах aX и rX отдельно.
Для реализации условий необходимо учесть ряд ограничений. Проверять значения в секции битового шаблона рекомендуется только через «=», а уточнять тут значение напрямую регистра нельзя, как и присваивать ему значения в секции disassembly action. Это лишает нас возможности использовать какой-то временный регистр. Стартовый регистр и длина диапазона могут быть любыми, а реализоваться, как уже упоминалось, диапазон может как на регистрах aX, так и на rX, а также быть нулевой длины. Уже на этом этапе понятно: если мы не хотим создавать гигантское количество определений на все случаи жизни, было бы неплохо иметь некие счетчики, чтобы выяснить, сколько регистров выводить и с какой позиции.
#### Контекстные переменные
Для решения задачи подходят контекстные переменные. Их определение похоже на определение полей токенов. Но поля в данном случае используют не реальные биты программы, а биты указанного регистра (contextreg ниже).
При записи через поля, определенные в регистре поверх одинаковых битовых диапазонов, значения будут перезатираться (в некоторых случаях не пройдет компиляция), поскольку это биты одного и того же регистра. У нас контекстные переменные *counter* и *offStart* используют разные битовые диапазоны в пределах регистра, так как по смыслу это разные значения.
Важно отметить, что контекстные переменные должны объявляться до конструкторов.
[В документации](https://ghidra.re/courses/languages/html/sleigh_context.html) поясняется, что контекстные переменные, как правило, используются в секции битовых шаблонов для проверки наличия какого-то контекста и изменяются в секции disassembly action. Так что в конструкторе с идентификатором таблицы rangeSrc, которую мы будем использовать для отображения диапазонов, в disassembly action секции сохраняем код первого регистра диапазона в контекстную переменную offStart, а их количество — в counter. В секции отображения обозначаем начало диапазона открывающейся скобкой «{».
Также стоит отметить, что в v8 не используется регистр **range\_size**: он введен искусственно для хранения размера диапазона, чтобы было удобнее работать с этим значением в рамках семантической секции конструктора инструкции. Именно rangeSrc поставляет стартовый регистр и размер диапазона для семантической секции инструкции.
 В рамках таблицы с идентификатором rangeDst описано 5 конструкторов для следующих случаев.
* Код стартового регистра диапазона соответствует a0 и счетчик counter равен 0 (пустой диапазон).
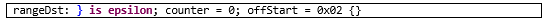* Код стартового регистра диапазона соответствует r0 и счетчик counter равен 0 (пустой диапазон).
* Код регистра диапазона в offStartсовпадает с a0, в disassembly action секции счетчик counter уменьшается, код регистра в offStart увеличивается, переход к конструктору rangedst1.
* Код регистра диапазона в offStartсовпадает с r0, в disassembly action секции счетчик counter и код регистра в offStart уменьшаются, переход к конструктору rangedst1.
* Код стартового регистра диапазона пока не найден, переход к конструктору rangedst1(для этого случая в конструкторе нет никаких условий, как упоминалось выше, он будет браться, когда остальные конструкторы не подошли).
В третьем и четвертом случаях происходит вывод регистра в отображение. Последующие конструкторы rangeDstN, где N — натуральное число, состоят из тех же вариантов, только для регистров aN/rN.
Стоит обратить внимание на секцию битового шаблона. При описании конструктора rangeSrc в рамках секции битового шаблона задействованы оба байта, идентифицирующих диапазон, то есть в рамках определения rangeDst нет потребности считывать какие-то биты байткода, так как они не будут относиться к описываемой конструкции. Для подобных ситуаций можно использовать предопределенный символ **epsilon**, соответствующий пустому битовому шаблону.
В примере ниже описаны только rangeDst, rangeDst1, rangeDst2, чтобы не загромождать статью. Для получения представления о виде подобных таблиц этого достаточно, полную версию можно посмотреть в исходниках проекта на [github](https://github.com/PositiveTechnologies/ghidra_nodejs). По сути, при работе с rangeDst будет проходиться цепочка конструкторов по возрастанию индекса Х в rangeDstX, пока не встретится стартовый регистр, а затем — цепочка конструкторов, соответствующая по длине размеру выводимого диапазона.
Конструкторы с закрывающими фигурными скобками выглядят похожими, можно попробовать их объединить. Вспоминаем про использование логических операторов «&» и «|».
Конструктор для **CallProperty** в готовом проекте выглядит так:
Вот что получается в листинге:
Возможно, сейчас сбивает с толку, что в семантической секции используется пользовательская операция CallVariadicCallOther. В проекте на [github](https://github.com/PositiveTechnologies/ghidra_nodejs) она была переопределена в java-коде инструкциями p-code. Использование инъекции p-code вместо реализации через операцию call было обусловлено желанием видеть список передаваемых аргументов в декомпиляторе (согласно исходникам Node.js, первый регистр диапазона является приемником, а остальные — передаваемыми аргументами). Используя только slaspec, добиться этого было бы, мягко говоря, тяжело:
Если есть желание попробовать повторить реализацию диапазонов самостоятельно, можно описать семантику как:
Затем по аналогии можно доопределить конструкторы rangeDstХ (понадобится до r7 включительно) и уже тогда попробовать посмотреть, как выглядит скомпилированный код console.log(1,2,3,4,5,6). Можно собрать его самостоятельно через bytenode или забрать готовый [тут](https://github.com/PositiveTechnologies/ghidra_nodejs/blob/main/samples/article_data/for_ranges/v8_rangeTest.jsc). Функция будет находиться по смещению 0x167, а сама инструкция — на 0x18b.
В итоге инструкции, подразумевающие вызовы даже с постоянным количеством аргументов, были реализованы аналогичным образом для решения проблем, возникающих при декомпиляции, так как часто возникала путаница при подсчете количества аргументов из-за нюанса с инициализацией регистров аХ (она проявляется при запуске автоанализа, иногда встречается до сих пор и решается, как и при работе с другими архитектурами, путем изменения прототипа функции в декомпиляторе).
Стоит отметить, что в нашем проекте мы вынесли все конструкторы rangeDst в отдельный файл, чтобы не загромождать файл с описанием инструкций (как и расширенные инструкции, работающие операндами размером 2 и 4 байта):
Итог
----
Разработанный процессорный модуль удовлетворяет требованиям, которые мы к нему предъявляли: инструмент дает возможность просматривать инструкции байткода для заданных функций файла, который необходимо было разбирать в рамках проекта. В качестве бонуса мы получили декомпилятор, пусть не идеальный, но позволяющий быстрее ориентироваться в логике приложения. Однако, как и при работе со многими процессорными модулями, в данном случае лучше сверяться непосредственно с инструкциями, а не слепо ему верить. Можно также отметить, что при наличии времени и желания улучшить инструмент стоит реализовать хранение типов, продумать концепцию импортов и устранить проблему с обратным порядком аргументов функций. Надеемся, это руководство упростит ваше погружение в написание процессорных модулей на языке SLEIGH.
Также хочется сказать большое спасибо за исследование Node.js и разработку модуля Вячеславу Москвину, Владимиру Кононовичу, Сергею Федонину.
Полезные ссылки:
1. <https://ghidra.re/courses/languages/html/sleigh.html> — документация на SLEIGH.
2. <https://github.com/NationalSecurityAgency/ghidra/tree/master/Ghidra/Framework/SoftwareModeling/data/languages> — полезные файлы с описаниями \*.cspec, \*.pspec, \*.opinion, \*.ldefs.
3. <https://spinsel.dev/2020/06/17/ghidra-brainfuck-processor-1.html> —хорошая статья о реализации модуля для brainfuck в Ghidra.
4. <https://github.com/PositiveTechnologies/ghidra_nodejs> — репозиторий с полной версией процессорного модуля для Ghidra с загрузчиком и анализатором. | https://habr.com/ru/post/554036/ | null | ru | null |
# О чем должен помнить веб-разработчик, чтобы сделать всё по SEO-феншую
Сегодня очень сложно оставаться монопрофильным специалистом. И часто, делая новый сайт или внося различные правки, можно позаботиться заранее об основных вещах, которые помогут сразу сделать всё чисто и красиво не только с точки зрения программирования, но и с точки зрения SEO.

Так о чём же надо помнить, чтобы делать работу качественно, и SEO-специалисты были довольны вашей работой?
Подтягиваем общие знания
------------------------
В первую очередь, пожалуй, следует подтянуть собственные знания по SEO (а может, и контекстной рекламе). Такие вещи в сфере интернет-маркетинга никогда не помешают, а вам дадут преимущество — делать всё осознанно, а не просто “как в ТЗ написано”. Кроме того, полезно и для самопроверки. Это — общая канва, на которую наслаиваются остальные пункты.
Закрываем ссылки от индексации
------------------------------

Если вы работаете с SEO-аудитами, наверняка вы знаете что такое внешние ссылки, циклические ссылки и висячие узлы.
В общем случае: внешние ссылки — это те, которые ведут на другие сайты и получается уводят ваших посетителей в другое место; циклические ссылки — ведут на самих себя (тоже плохо); висячие узлы — например, ссылки на скачивание документов, которые никуда не ведут на другие страницы. Всем таким ссылкам мы добавляем атрибут ‘rel=”nofollow”’, которые даст поисковым роботам понять, что по этой ссылке идти не надо и учитывать её не стоит. Таким образом мы сохраняем вес страницы. Внешним ссылкам лучше вообще добавить target=”\_blank” — так ваш сайт останется открытым у пользователя, и шанс на его возвращение будет больше.
Частый пример циклических ссылок — это меню, логотип, хлебные крошки. В этих типовых элементах частенько прячутся ссылки на текущую страницу, и важно помнить о том, чтобы сразу их закрыть от индексации (спрятать от роботов).
Наиболее типичные внешние ссылки — ссылка на разработчика сайта в подвале, ссылки на соцсети, источники новостей, клиенты компании, телефоны, почты и т д.
Склеиваем зеркала
-----------------

Говоря об уменьшении дублей, нельзя не вспомнить о склейке зеркал. Это значит, что ваши страницы должны быть доступны только по 1 адресу. В то время как ваши могут быть доступны по:
* [www.site.ru](http://www.site.ru)
* [www.site.ru](https://www.site.ru)
* [site.ru](http://site.ru)
* [site.ru](https://site.ru)
* [site.ru](http://site.ru/)
* и т д
То есть существует три основных вида зеркал: по протоколу (http / https), по наличию слеша в конце страниц и по наличию заветных трёх букв “www”.
При использовании редиректов — важно помнить, что для склейки он должен быть по умолчанию **301** (постоянный редирект), а не 302 (временный редирект).
Если у вас работают сортировки \ фильтры \ постраничная навигация через GET-параметры, как правило, это тоже создает дубль для поисковой системы. Поэтому на такие страницы лучше хотя бы вешать склейку. Для этого в добавляется специальная ссылка . Такая ссылка говорит роботу, что эта страница — не основная, а основная находится по адресу в атрибуте href. Это позволит избавиться как правило от многих дублей ваших страниц.
Устанавливаем правильные мета-теги и микроразметку
--------------------------------------------------

Не менее важны при разработке мета-теги страниц. Свойства title и description должны быть заполнены как минимум у основных страниц (главная, о компании, контакты, каталог, услуги), лучше — заранее позаботиться о правилах формирования мета-тегов у добавляемых впоследствии категорий, товаров или новостей. В качестве title можно брать название, а в качестве description — добавлять к названию общую информацию в стиле .
В идеальном мире можно сразу внедрить микроразметку. Ну хотя бы Open Graph. Чем дальше, тем чаще встречается этот пункт в различных аудитах на внедрение, делается обычно быстро и просто, но может дать приличный value в плане отображения сайта и его привлекательности для клиентов. Про микроразметку можно почитать [тут](https://www.seonews.ru/analytics/mikrorazmetka-ot-teorii-k-praktike/).
Также создаем стандартный robots.txt. Обычно на просторах интернета можно найти такой для CMS, которую вы используете — для всех он разный. Во многих CMS есть автоматический генератор, либо плагины, которые возьмут этот пункт на себя.
Оптимизируем скорость загрузки сайта
------------------------------------

Одним из основных факторов привлекательности сайта для пользователя является скорость его загрузки. Это и понятно — ждать по 2 минуты загрузки страницы было нормально в 2000-х, но сегодня скорость потребления информации в разы выше, как и потребности пользователя. Если тебе приходится больше 5 секунд смотреть на прелоадер, это начинает раздражать. Часто в вопросе скорости загрузки SEO-специалисты ориентируются на инструмент [Google PageSpeed Insights](https://developers.google.com/speed/pagespeed/insights/).
Основное, на что делается упор в этом аудите — оптимизация изображений. Сейчас просто неприлично заливать огромные картинки, никаких их не обрабатывая и не сжимая. Если ваша картинка весит 2-3 мегабайта, обычно это говорит о том, что ваша страница будет грузиться намного дольше, чем могла бы, и вы не заботитесь о своём продукте. Этот пункт сразу отберет у вашей страницы порядка 40 очков (если всё совсем плохо) в том же PageSpeed Insights.
Также сервис предлагает перенести Javasciptы вниз страницы, т.к. их загрузка препятствует загрузке отображаемого контента, а также использовать сжатие файлов и кеш браузера. Для этого используются модули сервера, к которым обращаются через директиву .htaccess. Можно заранее подготовить себе правила, которые достаточно универсальны, со сроком кеширования и сжатия, чтобы вставлять их потом на проект.
Выглядит это примерно так:
```
ExpiresActive on
ExpiresDefault "access plus 6 hour"
ExpiresByType image/jpeg "access plus 7 day"
ExpiresByType image/gif "access plus 7 day"
ExpiresByType image/png "access plus 7 day"
ExpiresByType image/x-icon "access plus 7 day"
ExpiresByType text/css "access plus 6 hour"
ExpiresByType application/javascript "access plus 6 hour"
ExpiresByType application/x-javascript "access plus 6 hour"
ExpiresByType application/x-shockwave-flash "access plus 6 hour"
SetOutputFilter DEFLATE
```
К вопросу кеширования и сжатия также можно отнести минимальное подключение сторонних файлов. Если сайт, с которого мы их подключаем, перестанет работать, мы можем этого вовремя не заметить. Кроме того, внешний ресурс мы не минифицируем, не сжимаем и не кешируем (на то он и внешний). Именно поэтому хорошей практикой будет загрузка шрифтов и подключение скриптов (вроде jquery) с нашего сервера.
Создаем страницу для 404 ошибки
-------------------------------
Все несуществующие страницы должны отдавать код ответа 404. Многие о ней забывают, но на этой страницы рекомендуется иметь общие элементы навигации (шапка \ меню), чтобы пользователь мог с нее перейти на интересующую страницу, и несколько ссылок — обычно на главную и на предыдущую страницу. Важно, чтобы пользователь понимал, что попал на несуществующую страницу, но его при этом не сбивало и вовсе покинуть ваш сайт.
Не забываем про адаптивную / мобильную версию
---------------------------------------------

С каждым днем все больше информации ищется через мобильные устройства. Поэтому если вы вносите правки, влияющие на внешний вид сайта в десктопе, надо не полениться и проверить, что от этого не поедет ничего и в адаптиве. Если мобильной версии нет, то хорошим тоном будет хотя бы привести все в нераздражающий резиновый вид, чтобы сайт не приходилось постоянно крутить вправо\влево при просмотре с телефона. Кроме того, наличие мобильной версии повышает ваши позиции в поисковой выдаче.
Закрываем от индексации среду разработки
----------------------------------------

Если вы разрабатываете новый сайт или работаете на поддомене, необходимо закрыть его для индексации, чтобы не попасть под аффилирование (несколько одинаковых сайтов, из которых система определит основной, и только у него все будет нормально). Обычно это делается через специальный файл robots.txt, в котором вся информация закрывается от всех роботов.
В этом пункте самое важное — не забыть удалить этот файл впоследствии, иначе поисковый робот о вашем новом сайте точно не узнает, а клиент будет наверняка очень недоволен.
Вишенка на торте (страницы пагинации)
-------------------------------------

Для желающих особо выделиться и перфекционистов — прорабатываем страницы постраничной пагинации. Список действий при этом достаточно простой:
1. Склеиваем тегом canonical страницы с основной ().
2. Добавляем в специальные мета-теги, которые скажут роботу, где находятся предыдущая и следующая страницы. Для этого используем (на всех страницах, кроме последней), и (на всех страницах, кроме первой). При этом если мы находимся на второй странице, к первой не должно добавляться параметров пагинации.
3. На всех страницах, кроме первой, добавляем подписи “ — страница N” к тегам , , (где N — номер страницы). Это поможет нам избежать еще целой серии дублирования контента.
==========================================================================================
Комментируем правильно
----------------------
Часто клиент решает убрать какой-либо баннер или просто блок, который пока не может наполнить. Но через полгода, а то и год “чудесным образом” о нем вспоминает и просит вернуть. Каким образом вы его достанете — это уже ваша проблема. Поэтому если надо скрыть какие то вещи, которые впоследствии могут оказаться опять нужными, лучше их закомментировать или сделать копию файла. Причем комментарий не должен быть вида , т.е. обычным html. Такой комментарий будет выводиться в коде страницы, его увидит поисковик и вполне возможно посчитает мусорным кодом. Кроме того, это увеличивает объем загружаемого html-кода. Поэтому лучше обернуть этот комментарий например в комментарий php. И не забывайте подписать, к чему он относится! Ибо не факт, что через год вы сами будете об этом помнить.
Итоговый чек-лист
-----------------

Итого. Можем составить примерный чек-лист для себя любимого:
* Закрываем циклические ссылки (меню, логотип, хлебные крошки), внешние ссылки (соцсети, источники, клиенты, телефоны, почты) и висячие узлы (документы для скачивания)
* Склеиваем зеркала (www, http, /), а также страницы с GET-параметрами (фильтры, сортировка)
* Проверяем, что все редиректы на сайте являются 301
* Устанавливаем правила для мета-тегов
* Микроразмечаем в максиразмерах
* Оптимизируем скорость загрузки сайта (сжатие ресурсов, кеш браузера, оптимизация изображений, минифицированные версии скриптов и стилей, скрипты внизу страницы)
* Не забываем проверять мобильную версию
* Закрываем от индексации среду разработки
* Оптимизируем страницы постраничной пагинации под поисковые системы
* Комментируем код не в html-формате, а в php либо бэкапим отдельно
* Не забываем создать страницу с ошибкой 404
Это, пожалуй, основные моменты, которые следует держать в уме при разработке \ оптимизации сайта, чтобы познать дзен поискового продвижения (ну, насколько это можно сделать разработчику). | https://habr.com/ru/post/417503/ | null | ru | null |
# Стартап WigWag создаёт среду для программирования умного дома на JavaScript
Сегодня разные производители предлагают десятки разных (и часто несовместимых между собой) систем, устройств, приложений и интерфейсов для превращения обычного дома или квартиры в «умный» — интеллектуальные дверные замки и лампочки с управлением по WiFi, розетки, датчики и выключатели с аккаунтом в Твиттере, интернет-холодильники кондиционеры. [Стартап WigWag](http://www.wigwag.com/), который уже собрал на Кикстартере почти в четыре раза больше денег, чем планировал, подошел к вопросу создания умного дома более системно. Они предлагают не просто набор сенсоров и актуаторов, но и целую инфраструктуру, совместимую со множеством уже существующих интеллектуальных электроприборов, и, что ещё важнее — открытую для модификаций и дружелюбную как к простым пользователям, так и к программистам и хакерам.
WigWag позволяет создавать «правила», подобные [рецептам IFTTT](https://ifttt.com/wtf), которые могут на основе информации с датчиков или из интернета управлять любыми устройствами. Это могут быть датчики и актуаторы WigWag, интернет-сервисы, Raspberry Pi, Arduino, Belkin WeMo, Philips Hue, и любые другие, поддерживающие протоколы IP, RS-232, 6loWPAN, Bluetooth и Zigbee. Причем создавать правила можно не только через графический интерфейс, но и на JavaScript, с помощью среды выполнения DeviceJS, которую разработчики WigWag позиционируют как способ писать приложения для умного дома точно так же, как пишутся приложения для Web.
Разработчики обещают опубликовать все чертежи и спецификации устройств, исходники и API DeviceJS на Гитхабе. «Железная» часть WigWag состоит из трёх компонентов. Первый из них — универсальный мультисенсор-актуатор, имеющий датчики температуры, влажности, звука, вибрации, движения, света, механический контактный датчик, и несколько каналов связи с окружающим миром, служащих как для получения сигналов извне, так и для управления другими устройствами — реле, инфракрасный излучатель, цифровой и аналоговый входы-выходы для присоединения внешних датчиков, светодиод и зумммер для подачи сигналов. Для питания служат четыре батарейки AA или разъём microUSB. Второй компонент — светодиодная лента с контроллером, имеющим собственные датчики уровня освещённости и движения. Третий — базовая станция, которая подключается к интернету и поддерживает беспроводную связь с остальными компонентами и другими совместимыми устройствами.
Вот примерный список того, что может WigWag:
Облачные сервисы WigWag позволяют управлять устройствами из любой точки планеты через веб-интерфейс. При этом на локальном уровне система может работать без доступа к интернету — базовая станция будет выполнять все заданные правила для присоединённых к ней устройств без помощи облака.
[Среда DeviceJS](http://devicejs.org/) будет построена на базе Node.js и V8. API DeviceJS будет построен по образу и подобию привычных большинству веб-программистов библиотек, таких как JQuery или d3.js. Вот так может выглядеть вызов API для включения красного света на кухне:
```
dev$.byLocation("kitchen").setColor("red");
```
А вот включение света в коридоре при срабатывании детектора движения:
```
dev$.byDeviceAlias('hallway-sensor').trigger('motion', function() {
dev$.byLocation('hallway').setOn();
});
```
Кроме готовых компонентов, WigWag предлагает платы для самостоятельного создания совместимых устройств на базе Arduino и Raspberry Pi. | https://habr.com/ru/post/187316/ | null | ru | null |
# Функциональный Rust: Готовим говядину

Попался мне на глаза Brainfuck-оподобный язык [Cow](https://ru.wikipedia.org/wiki/Brainfuck#.D0.AF.D0.B7.D1.8B.D0.BA.D0.B8_.D0.BD.D0.B0_.D0.BE.D1.81.D0.BD.D0.BE.D0.B2.D0.B5_Brainfuck). И решил я написать для него интерпретатор на новомодном [Rust](https://www.rust-lang.org/). А так как Rust — мультипарадигменный язык, то стиль написания программы будет функциональный. Чтобы узнать что получилось — прошу под кат.
Повествование постараюсь вести в виде туториала, вопросы в комментариях, ценные замечания о недостаточной функциональности — туда же: будем исправлять! А пока что поехали.
Предварительное проектирование
------------------------------
Состояние виртуальной ~~коровы~~ машины будем хранить в неизменяемой переменной `state`. Все изменения будут производится с помощью функций, имеющих такую семантику:
```
fn change(previousState: CowVM) -> CowVM // newState
```
Похоже на **Elm**, **Redux**, может ещё на что-то, чего я и сам не знаю. Не правда ли?
На самом деле, именно то, что с самого начала очень хорошо видно, как хранить данные, делает эту задачу пригодной для функционального подхода.
Действительно, что такое виртуальная машина Cow?
* Массив команд — самый обычный целочисленный массив;
* Память — второй такой же самый простой целочисленный массив;
* Текущая ячейка команды — индекс ячейки в массиве команд;
* Текущая ячейка памяти — индекс ячейки в массиве памяти;
* Регистр — почти обычное целое число. Почему почти? Узнаем дальше!
* ???
* **PROFIT**
Уже в самом начале работы над задачей я точно уверен, что все данные на любом этапе работы программы будут храниться именно так. Не появится дополнительных *fields* или *views*, заказчик не подкинет парочку модификаций бизнес-логики… Мечта программиста!
Как будем сохранять иммутабельность?
------------------------------------
На самом деле сохранять иммутабельность можно только одним способом — каждый раз, когда надо что-то изменить в состоянии нашей программы — создаём заново **абсолютно** новое состояние, сохраняем его а старое выкидываем на свалку под названием *out of the scope*. В этом нам помогут следующие волшебные фичи языка **Rust**:
* Трейт **Copy**. Если вы пришли из ООП, то структуры с определённым на них **Copy** трейтом как бы не **reference type** а **value type**.
Играть можно [тут](https://is.gd/kCDewy), но если кратко — присваивание не забирает переменную, а копирует её.
* Волшебный [**struct update syntax**](https://doc.rust-lang.org/book/structs.html#update-syntax). Эта штука внезапно копирует поля из старой структуры в новую.
**ВАЖНО:** К сожалению, оно совершенно не **копирует** параметры, на которых не определён трейт **Copy** (в нашем случае это **Vec**). Он их просто переносит. И это очень важно, потому что можно попасться на всякие [вот такие](https://is.gd/2ghhxP) ошибки. **НО** только не в нащем случае! Ведь нам плевать на старую структуру — что там из неё перенесено нам не важно — мы никогда её не будем использовать. Вот это халява!!
Модель
------
Модель, она же структура, будет в нашей программе одна — как раз таки виртуальная машина языка **COW**:
```
#[derive(Debug, Default, Clone)]
pub struct CowVM {
pub program: Vec,
pub memory: Vec,
pub program\_position: usize,
pub memory\_position: usize,
pub register: Option
}
```
Добавим к нашей структуре немного вкусняшек — Debug, Default, Clone. Что это и зачем — можно прочитать в [моей предыдущей статье](https://habrahabr.ru/post/277461/).
Редьюсер
--------
Тут в общем то тоже нету ничего сложного. Следуя семантическому дзену, определённому на этапе предварительного проектирования, клепаем на каждый опкод языка свою отдельную команду, принимающую виртуальную машину и создающую новую, уже изменённую, которую в дальнеёшем и возвращающую.
Для примера рассмотрим функию для очень важного опкода **mOo** — команда смещает назад на один указатель на ячейку памяти:
```
pub fn do_mOo(state: CowVM) ->CowVM {
CowVM{
memory_position: state.memory_position-1,
program_position: state.program_position+1,
..state
}
}
```
Вся функция делает только две вещи — смещает указатель на ячейку памяти на 1 назад — и указатель на ячейку команд на 1 вперёд. Заметим, что не все функции смещают указатель на ячейку программ вперёд, поэтому было принято решение не выделять этот функционал в отдельную функцию. Место это занимает немного — пол строчки, и вызов функции занимал бы приблизительно такое же место, так что в общем-то всё равно…
Ну да ладно, перейдём к более интересным вещам. Помните, я говорил что регистр наш не совсем обычный? То-то и оно — лучший (и пожалуй единственный адекватный) способ хранить **nullable** значение в **Rust** — тип [**Option**](https://doc.rust-lang.org/std/option/). Способ, кстати, прямиком из пекла функционального программирования. Что это такое [углубляться пожалуй не будем](https://en.wikipedia.org/wiki/Option_type), заметим лишь, что такой подход навязывается самим языком во-первых, а во вторых координально отличается от всех этих ваших языков, в которых есть **nil**, **null** и иже с ними. Такие языки обычно называются классическими ООП языками: **Java**, **C#**, **Python**, **Ruby**, **Go**… Продолжать в общем-то смысла нету. Просто привыкайте к такому положению вещей.
Вернёмся к нашим баранам. Так как регистр может быть пустой, а может быть не пустой, приходиться работать с ним как с **Option**. А вот и исходный код нашего редьюсера:
```
pub fn do_MMM(state: CowVM) -> CowVM {
match state.register {
Some(value) => {
let mut memory = state.memory;
memory[state.memory_position] = value;
CowVM{
register: None,
program_position: state.program_position+1,
memory: memory,
..state
}
},
None => {
CowVM{
register: Some(state.memory[state.memory_position]),
program_position: state.program_position+1,
..state
}
},
}
}
```
Видите эти 4 закрывающие скобочки вконце? Выглядят страшно. Не зря всётаки многие функциональные языки не пользуются скобками. Бррр…
Заметим по дороге не очень элегантный способ поменять значение в памяти нашей виртуальной машины. Ничего лучшего не придумывается, может вы подскажете в комментариях?
Для честности отметим, что в "чисто функциональных" языках нету массивов. Там есть списки или словари. Замена элемента в списке занимает **O(N)**, в словаре — **O(logN)**, а тут по крайней мере **O(1)**. И это радует. Да и память вида:
```
{"0": 0, "1": 4, .... "255": 0}
```
меня пробирает до дрожи. Так что пусть будет так, как будет.
Остальные команды делаем по аналогии — можно в исходнике на них посмотреть.
Основной цикл работы программы
------------------------------
Тут всё просто:
* Читаем му-му-му исходник,
* Создаём новую виртуальную машину с пустой памятью и заполненным массивом команд,
* Выполняем последовательно все команды пока работа программы не закончится.
Так как у нас *функциональный* подход — делать всё нужно без циклов: рекурсивно. Так и поступим.
Определим основную рекурсивную функцию — **execute**:
```
fn execute(state: CowVM) -> CowVM {
new_state = match state.program[state.program_position] {
0 => commands::do_moo(state),
1 => commands::do_mOo(state),
2 => commands::do_moO(state),
3 => commands::do_mOO(state),
4 => commands::do_Moo(state),
5 => commands::do_MOo(state),
6 => commands::do_MoO(state),
7 => commands::do_MOO(state),
8 => commands::do_OOO(state),
9 => commands::do_MMM(state),
10 => commands::do_OOM(state),
11 => commands::do_oom(state),
_ => state,
}
execute(new_state)
}
```
Логика простая — смотрим новую команду, выполняем её и повторяем сначала. И так до победного конца.
Вот и всё. Интерпретатор языка **COW** — готов!
**Настоящий** основной цикл работы программы
--------------------------------------------
Вы спросите меня — **"Это что, шутка такая?"** Такой же вопрос задал я сам себе, когда оказалось, что в "мультипарадигменном" (ха-ха!) языке **Rust** нету **Tail Call Optimization**. (Что это — читать [здесь](http://stackoverflow.com/questions/310974/what-is-tail-call-optimization).)
Без этой занимательной вещицы вы очень быстро узнаете на себе, почему сайт **stackoverflow** [назван именно так](https://is.gd/zaouNL).
Что же, придётся переделывать в цикл.
Для этого выкинем рекурсию из функции **execute**:
```
fn execute(state: CowVM) -> CowVM {
match state.program[state.program_position] {
0 => commands::do_moo(state),
1 => commands::do_mOo(state),
2 => commands::do_moO(state),
3 => commands::do_mOO(state),
4 => commands::do_Moo(state),
5 => commands::do_MOo(state),
6 => commands::do_MoO(state),
7 => commands::do_MOO(state),
8 => commands::do_OOO(state),
9 => commands::do_MMM(state),
10 => commands::do_OOM(state),
11 => commands::do_oom(state),
_ => state,
}
}
```
А цикл будем запускать прямо в функции **main**:
```
fn main() {
let mut state = init_vm();
loop {
if state.program_position == state.program.len() {
break;
}
state = execute(state);
}
}
```
Вы чуствуете всю боль мирового функционального программирования? Мало того, что этот язык заставил нас забыть о красоте родных рекурсий, так ещё и заставил сделать мутабельную переменную!!!
А и на самом деле — к сожалению написать так не получится
```
fn main() {
let state = init_vm();
loop {
if state.program_position == state.program.len() {
break;
}
let state = execute(state);
}
}
```
из-за причин, которые скрыты в сумраке… На самом деле из-за того что созданные внутри `loop` переменные исчезают при выходе из области видимости (на следующей строчке в этом случае).
Чтение му-му-му исходников
--------------------------
А вот в работе с **IO** в **Rust** нету ничего функционального. Совсем. Так что эта часть выходит за рамки этой статьи и может быть найдена в исходниках этого интерпретатора.
Вывод
-----
По субьективным ощущениям, язык **Rust** успел *заржаветь* не состарившись. И ООП в нём какое-то не ООП, и ФП — не совсем ФП. Зато — "мультипарадигменность". Хотя, может на стыке этих парадигм получится нечто **ВАУ**! Остаётся на это надеятся — и писть на **Rust**.
Впрочем, очевидные плюсы в функциональном подходе есть. Написав целую программу удалось:
* Не вступить ни разу в коридоры ООП и не создать ни одного класса.
* Ни разу не поиметь проблем с отдалживанием, переназначением, указаним и бог ещё знает что там есть у **Rust** при работе с переменными. Да мы вообще не делали никаких ссылок, изменяемых переменных (ну почти), я почти забыл что такое `borrow` и `ownership`. Скажу честно, писать не думая о том, что у тебя может не скомпилироваться из-за всего этого — сущее наслаждение.
* Нам удалось ещё и ни разу не вступить в **lifetime** параметры — вот уж действительно сумеречная сторона всего **Rust**. Скажу честно — меня пугают `(x: &'a mut i32)` и я очень рад, что мог избежать всего этого.
* Мы не реализовали ни одного трейта. Так себе достижение, но внезапно оказывается что в ФП трейты не так уж и нужны/важны.
* Все эти функции по сути своей — чистые, и их очень легко тестировать (возможно об этом будет следующая статья, хотя отличие тестирования в ООП и ФП давно известны и легко гуглятся и так).
Послесловие
-----------
Спасибо всем, кто дочитал. Приглашаю вас в комментарии к статье, там мы сможем обсудить различные парадигмы программирования в **Rust**. Замечания, предложения — всё туда же.
[Ссылка на исходник](https://github.com/Virviil/cow.rs)
Благодарности
-------------
Огромное спасибо [@minizinger](https://github.com/minizinger) за разработку особо сложных для меня (потому что самых не*функциональных*) мест в программе, вдохновение и поддержку. | https://habr.com/ru/post/283450/ | null | ru | null |
# Немного интересных данных, вытянутых из автодополнения «Моего круга»

Да, всё верно. Среди пользователей «Моего круга» Microsoft Office более популярен чем Golang или Kotlin. Подробности того, как я это узнал и ссылки под катом.
Однажды мне стало интересно получить список ключевых, по мнению «Моего круга» навыков. Не, ну мало ли. Вдруг важно уметь не только писать на ~~смузискрипте~~ тайпскрипте, а ещё и жонглировать хорьками. Решение я выбрал прямое и простое.
Посмотрим, куда же стучится при вводе навыка автодополнение чтобы получить варианты:
`https://moikrug.ru/suggest/skills?term=java&_=1518063342596`
term, очевидно, содержит начало фразы, \_ содержит метку времени в секундах.
А что нам шлёт сервер в ответ?
А вот это уже интересно. Число пользователей и популярность. Судя по поиску, число пользователей более-менее соответствует истине. Популярность не бывает меньше числа пользователей и отличается от него максимум на пару процентов. Предполагаю что этот параметр указывает количество случаев, когда пользователь указывал этот навык, не учитывая по прошествии времени менял его на другой.
После перебора с подстановкой сочетаний двух букв в term получилось 1094 уникальных навыка со значениями популярности. Я слегка посыпал этот список ванилью чтобы получить сортировку и фильтрацию. Наслаждайтесь.
[Репозиторий](https://github.com/e-h-h/mkskills/)
Некоторое время можно будет поcмотреть тут: [81.171.12.58](http://81.171.12.58)
Фильтр регистронезависим, разделитель параметров пробел или |, например выражение «java lang» найдёт все навыки содержащие java или lang. Пустой фильтр выдаст все доступные навыки. Фильтры можно задавать в адресе через хэш, например [81.171.12.58/#java|scala](http://81.171.12.58/#java%7Cscala)
Обратите внимание, что данные эти не стоит рассматривать как точные. Во-первых, люди склонны завышать свои навыки. Во-вторых, на «Моём круге» можно найти такие экзерсисы как [многопоточный плотник](https://moikrug.ru/aleksandr-zaharyants) и [штукатур-кондитер](https://moikrug.ru/resumes?q=%D1%88%D1%82%D1%83%D0%BA%D0%B0%D1%82%D1%83%D1%80¤cy=rur).
Если поискать, то окажется что значимый процент пользователей от информационных технологий далеки и выбор навыков из предложенных вариантов дал не самый лучший результат. Предполагаю что плотник имел в виду, что имеет делать несколько дел сразу, а отнюдь не многопоточную резьбу по дереву. С другой стороны, штукатур-кондитер сильно похож на фейк от юных фанатов Евгения Вагановича и таких фейков тоже немало.
Однако мне кажется что данные отражают достаточно приближенную к реальности картину. Пользуясь ими с умом можно составить представление о том, чем живёт российская сфера ИТ. | https://habr.com/ru/post/348582/ | null | ru | null |
# Популяризация JSON-RPC (часть 2)
Продолжим строить подобие JSON-RPC сервера, начатого в [части 1](https://habr.com/ru/post/709362/) и анализировать его плюсы и минусы. В прошлой статье был описан механизм отделения бизнес логики бэкенда от транспортного протокола (HTTP) через шаблон проектирования "Front Controller", роль которого исполняет в нашем случае JsonRpcController.
### API gateway
Бэкенд API до передачи запроса в код, отвечающий за бизнес логику, обычно предоставляет частичный функционал API шлюза (API gateway) - он может делать аутентификацию, авторизацию, роутинг, валидацию данных, логгирование, кэширование, обеспечивать меры безопасности и другое.
Часть указанных сервисов работает на уровне транспортного протокола (здесь HTTP), другие от него не зависят.
Оба случая можно реализовать в виде фильтров/интерсепторов. Например, аутентификация происходит при перехвате запроса внутри фреймворка (у большинства есть свои методы для создания подобных фильтров) до передачи его контроллеру, а авторизация - уже после отработки JsonRpcController. Добавить свой функционал фильтров перед передачей запроса в код бизнес логики полезно, потому что могут понадобиться и другие сервисы - например, дополнительная валидация параметров, защита от SQL инъекций, кэширование, логгирование, шифрование и прочее. Фильтры, которые могут потребоваться на уровне HTTP - управление CORS политикой, защита от CSRF, throttler, определение ботов/спайдеров.
Разделение кода на бэкенде на часть, работающую с транспортным протоколом, и чисто бизнес логику позволяет достаточно безболезненно не только поменять фреймворк, но и перейти при необходимости с HTTP на, скажем, Websockets или gRPC. При этом нужно будет переделать только то, что связано с HTTP - фильтр аутентификации, например. А код бизнес логики, включая фильтры авторизации и кэширования, останутся как есть. В случае с обычным фреймворком и реализации бэкенд API как RESTful работы будет намного больше.
### Authentication & Authorization
Аутентификация (как проверка пользователя) и авторизация (как проверка разрешения конкретного пользователя на доступ к конкретному ресурсу) в случае с JSON-RPC полностью разделяются. Аутентификация обычно жестко привязана к протоколу передачи данных - для JWT, например, рефреш токен должен храниться в http-only куках, токены могут передаваться в HTTP заголовках и прочее. Авторизация же зависит от установленных правил доступа и определяется идентификатором текущего пользователя, вызываемым методом и его параметрами. Грубо говоря, по этим параметрам идет просто валидация. Аутентификация происходит до передачи запроса JsonRpcController контроллеру, авторизация - после его отработки, но до передачи выполнения программы коду бизнес логики. Аутентификация реализуется частично средствами бэкенд фреймворка, авторизация к фреймворку не привязана.
Встает вопрос, каким образом передать расшифрованную информацию об аутентифицированном пользователе дальше в бизнес логику? Варианта видится два - либо добавить параметр в тело JSON-RPC запроса внутри JsonRpcController, что сделает его формат несколько выбивающимся из спецификации, либо через контекст фреймворка. Выбор конкретной реализации особо ни на что не влияет.
### File upload/download
Пожалуй, единственное, для чего кажется что требуются стандартные средства HTTP протокола - загрузка и скачивание файлов. Можно это реализовать отдельными эндпойнтами на бэкенде и специальным контроллером, можно отдельным фильтром перед JsonRpcController, но, на самом, деле любые файлы можно вполне несложно передавать как данные внутри JSON-RPC params используя средства JavaScript на фронте. Недавно стояла задача сгенерировать на бэке несколько отчетов в CSV формате, зазиповать и передать клиенту для скачивания, - так передать текстом всё на фронт, там сформировать архив и дать на сохранение оказалось проще и короче по коду.
Бинарные данные пакуем в base64. Если не нужно постоянно гонять туда-сюда десятки мегабайт файлов, то решение вполне эффективное. Не забываем настроить на вебсервере компрессию потока JSON-RPC данных.
### Batch
Отправка запросов в пакете (batch) кажется довольно экзотичной задачей, но только поначалу. Представим себе страницу с товарами. Для её отображения используется метод `products:list`. У любого товара менеджер может поменять цену - соответственно, `product:update`. Можно сделать универсальный доступ к CRUD ресурсам с помощью resources:list и resources:update и в параметрах уже передаем product как имя ресурса, и цену как параметр апдейта (в данном примере это не существенно, можно так не делать, но к примеру).
При изменении цены возможны сбои - из-за сети, из-за нарушения внутренних бизнес ограничений, проблем с БД. Соответственно, после вызова update нужно удостовериться, что цена изменилась - получить подтверждение в каком-то виде. Для определенных ресурсов нужно такое подтверждение, для других - нет. Значит нужно ввести параметр в запрос, который говорит, получать ли в виде ответа новое значение из БД или нет (это ведь дополнительный запрос в БД, дополнительная ненужная нагрузка). Кроме того, при добавлении в update функционала read теряется идеология CRUD и унижается буковка S в термине SOLID.
Также теперь на фронте нам нужно добавить код, который проапдейтит конкретный продукт по пришедшему ответу. Код компонента легко может увеличиться раза в два.
Самый простой способ избежать всех этих усложнений - послать два запроса: сперва чистый update, а потом list; Но это два последовательных сетевых запроса, клиентский UX страдает.
И тут приходит JSON-RPC batch. Посылаем два запроса в одном пакете - [resources:update, resources:list]. На сервере они обрабатываются последовательно, и мы получаем на фронте актуальные данные. Ресурсы по-прежнему CRUD, всё хорошо.
Теперь представим, что на определенных ресурсах у нас есть кэширование. Бэкенд фреймворки часто прозрачно позволяют использовать Memcashed, Redis или простой файловый кэш для ускорения на порядок-другой доступа к данным по сравнению с БД. Если мы обновили данные, нам нужно обновить/очистить и кэш этого ресурса. И тут всего лишь нужно добавить третью команду: [resources:update, cache:clear, resources:list]. Возможны возражения, что таким образом бизнес логика частично переносится на клиент, но код реально становится проще, красивей и лаконичней. И не будем забывать, что с чистым REST CRUD **вся** логика на клиенте.
### Обработка ошибок
Ответ на JSON-RPC запрос приходит с сервера либо в виде result, либо error. Вместо мучений с HTTP кодами ошибок и квази-ошибок 3хх-5хх транспортного протокола, можно определить свои коды ошибок уровня приложения и спокойно работать с ними, оставив сову и глобус в покое. Это намного удобней и намного естественней.
### Кэширование
В современных SPA приложениях, использующих backend API, кэширование ресурсов может происходить:
1. На клиенте с помощью Service Worker.
2. На сервере, используя Redis и прочие соответствующие сервисы.
Оба эти варианта дают **управляемое** кэширование, когда разработчик точно знает где и какие у него данные, в отличие от неуправляемого браузерного HTTP кэширования, которое может быть, а может не быть. Полагаться на него нельзя, поэтому, в 99% случаях оно просто не нужно, а часто и приносит только проблемы. За 30 лет веб достаточно сильно развился, чтобы заменить HTTP кэширование на что-то более удобное и надежное, если сайт не простой "Hello world".
### Developer eXpirience
Наверное, самый неприятный для разработчика момент работы с JSON-RPC - это отладка запросов в браузерных DevTools. Вкладка Network показывает только запросы к `/rpc` эндпойнту, и приходится лезть в секцию payload и смотреть детали запроса. Теряется визуальное восприятие потока выполнения программы, тратятся время и нервы.
Есть варианты решения этого через расширение браузера, которое будет показывать в списке сетевых соединений дополнительную информацию. Но можно поступить намного проще. При отправке запроса преобразуем его, добавив в конец URI название вызываемого метода JSON-RPC или что-то еще подходящее по смыслу. А на бэке просто редиректим все запросы по `/rpc/(.+)` на `/rpc`. Это можно сделать на уровне вебсервера (Apache или Nginx), либо сам фреймворк бэкенда может предоставлять такой функционал, как и в случае с CI:
`$routes->post('rpc/(.+)', 'JsonRpcController::index');`
Можно задавать данный URI опционально явно при вызове ( здесь {uri: 'updateSetting'} ):
Код Batch запроса примера выше
```
async updateSetting(keyName: string, keyValue: string | number) {
const resp = await http.jsonRpc(
[
{
method: 'utils.resources:updateByKey',
params: {
resource: 'settings',
key: 'name',
value: keyName,
data: { value: keyValue },
},
},
{
method: 'utils.resourceCache:clear',
params: {
name: 'settings',
},
},
{
method: 'utils.resources:getByKey',
params: {
resource: 'settings',
key: 'name',
value: keyName,
},
id: 'resource',
},
],
{ uri: 'updateSetting' }
);
return resp.find((resp: JsonRpcResponseMessage) => {
return resp.id === 'resource';
}).result?.data[0].value;
}
```
В данном примере используется id для определения нужного ответа, потому что ответы для batch приходят тоже как массив. Для единичных запросов id особо не нужен, а для batch - вполне.
Когда uri явно не указан, используется алгоритм его построения через вызываемый метод. Для batch запросов названия методов соединяются с разделителем.
В итоге в DevTools Network получаем всю нужную информацию.
```
/rpc/productCategories:list
/rpc/batch[utils.products:update+utils.products:list]
/rpc/sendEmail
```
На бэкенде в логах вебсервера информация также будет в удобоваримом виде.
В prod env эту штуку можно отключить и использовать только `/rpc` эндпойнт.
### Документирование
Для документирования JSON-RPC API существует спецификация [OpenRPC](https://open-rpc.org/). Но из-за того, что точка входа бэкенд API является по сути точкой входа в некий блок кода на каком-то языке и не зависит от HTTP, документировать можно чем угодно. Например, javadoc-ом для бэка на java. Бэкендер просто пишет код бизнес логики, а JSON-RPC работает именно как RPC (remote procedure call), позволяя фронту прозрачно вызывать функцию на бэке не заботясь о транспортных посредниках.
Также у OpenRPC есть небольшая экосистема в виде генераторов, расширения для VS Сode и прочий инструментарий.
### Минусы JSON-RPC
Неизвестны. Может кто напишет в комментариях.
### Заключение
С моей точки зрения внедрение JSON-RPC в проект является очень полезным улучшением его архитектуры, позволяя отвязать бизнес логику бэкенда от транспортного протокола, внося ясность и чистоту как в код, так и во интерфейс между фронтенд и бэкенд разработчиками, облегчая развитие и поддержку приложения. Код как asset приобретет бо́льшую ценность. | https://habr.com/ru/post/710652/ | null | ru | null |
# Управляем сервоприводами из OpenWRT без Arduino
#### Краткий пост о том как можно избежать лишних элементов в системе с сервоприводами и использовать железо по максимуму
#### Предыстория
Я весьма давно и плотно болен Linux, OpenWRT, сетевыми и беспроводными технологиями, безопасностью, а теперь еще и стал потихоньку заражаться роботостроением и умными домами. Все это очень круто, особенно когда есть столько готовых шаблонов, свободного и открытого исходного кода, а временами можно совсем перейти на сторону зла и быстренько накидать логику в Scratch.
Но потом просыпается интерес уже не просто поморгать светодиодами, вау-эффект проходит и необходимо решать прикладные задачи. Вроде и тут следовало бы восхититься обилием готового, но дьявол как всегда в деталях. Одно дело — управлять логикой **`ЕСТЬ/НЕТ`**, это позволяет легко включать или отключать свет, можно даже датчик качества воздуха (MQ-135) подцепить и включать вытяжку при необходимости. Все это круто, но на дворе 21 век, космические корабли бороздят большой театр и душа просит чего-то по-круче. Взор мой пал на управление сервоприводами. Почему бы и нет? Тема весьма широкая, ведь они присутствуют во многих механизмах, от роботов до простых открывалок-закрывалок. Плюсом так же является и то что в летательных аппаратах двигатели управляются аналогично и это расширяет диапазон использования просто в разы.
Заинтересовавшихся приглашаю под кат
Те кто уже давно знаком с темой и хочет перейти сразу к сути — смело проматывайте до раздела "**Пошаговая инструкция**".
#### Начнем с начала
Чтобы суть этой заметки была понятна всем, стоит сперва обратить внимание на составляющие сервопривода.
Электродвигатель, редуктор, потенциометр и контроллер. Все гениальное просто, не правда ли?
Для управления сервоприводом используется широтно-импульсная модуляция или ШИМ. Ничего сложного, это просто сигнал в виде импульсов прямоугольной формы. основными параметрами является ширина импульса и ширина «паузы». «Пауза», а лучше называть ее правильно — период, задает частоту сигнала. Скажем, если у нас ширина периода равна 100 мс, то частота будет равна 10 Гц. Посчитать очень просто: переводим миллисекунды в секунды и делим единицу на это число. Соответственно, 100мс = 0,1с и если 1 разделить на 0,1 то получим 10. Можете проверить на калькуляторе.
Ширина импульса задает угол поворота сервопривода, а в случае с моторами летательного аппарата задает скорость и направление вращения.
Схематично это выглядит примерно так:

А на осциллографе вот так:

Теперь поговорим о том как сервопривод воспринимает такой сигнал. И уже тихонько подкрадывается дьявол с деталями.
Дело в том что контроллер может быть цифровой или аналоговый.
Если совсем по-простому, то разница в том что аналоговый контроллер подает или не подает напряжение только в момент импульса. Выставив интервал импульса 40, 120 или, скажем, 240 мс можно заметить как сервопривод начнет «дергаться» при работе. Все потому что внутри стоит микросхема и частота работы всего сервопривода равна частоте внешнего сигнала. Стандартные 20 мс это 50 Гц, 40 мс это 25 Гц, и по аналогии. Соответственно, 50 или 25 раз в секунду на двигатель подается (или не подается) напряжение. Снизив частоту можно существенно уменьшить крутящий момент и добиться более медленной работы механизма, правда ценой уже описанного «дергания».
Цифровые контроллеры, как правило, представляют из себя небольшой микропроцессор с обвязкой. Ключевое отличие от аналоговой микросхемы в том что внутренняя частота работы постоянна. Вы можете сколько угодно снижать частоту управляющего сигнала, это будет влиять только на время реакции, но крутящий момент будет постоянным. Хотя, выдавая изменение положения через длинные промежутки и небольшими порциями, можно добиться медленной скорости вращения. Тут уже зависит от конкретного сервопривода и его параметров.
#### Как генерировать сигнал?
Для этого обычно применяют какой-нибудь микроконтроллер, особенную любовь питают к платформе Arduino. Там все просто. Используется готовая библиотека, скармливаем нужной функции параметры сигнала и получаем на заданном GPIO нужной ширины импульсы.
Но что делать если нет возможности использовать микроконтроллер, сопряженный с основным устройством, а мощности самого контроллера для решения задач, ну, никак не хватает? Остается искать альтернативные варианты. И таких есть у меня!
Как уже стало понятным из заголовка, будет использоваться операционная система OpenWrt. Которая по сути своей является полноценным дистрибутивом на ядре Linux. А это дает широкие возможности и гибкость настройки. OpenWrt и ее производные активно используются в различных системах «умный дом», но об этом в другой статье. Как же генерировать ШИМ (или на буржуйском PWM) сигнал? Оказывается, не многим сложнее чем на Arduino. Для этого необходимо задействовать все те же GPIO, а вместо библиотеки модуль ядра под названием PWM-GPIO-Custom. Последняя стабильная версия OpenWrt где он работает — 12.09, но чтобы это понять я потратил около недели, пытаясь заставить работать на текущем Trunk. Не знаю по какой причине, но в официальном репозитории пакета с этим модулем нет и придется собирать его самостоятельно, но это не так сложно. Ниже я напишу как.
#### Пошаговая инструкция
Итак, для начала нам необходимо загрузить сборочный инструментарий OpenWrt. Хотя, если совсем честно, то начать нужно с уcтановки Linux, но я надеюсь что многие из вас этот пункт уже выполнили.
Итак, вы создали папку для инструментария, перешли в нее
Выполнить загрузку исходников можно командой
`git clone git://git.openwrt.org/12.09/openwrt.git`
У вас же присутствует терминал в нижней части окна, правда?
Жаль, это очень удобно.
После загрузки нужно перейти в папку openwrt и скачать пакеты командой
`git clone git://git.openwrt.org/12.09/packages.git`
Теперь у нас есть все исходные коды пакетов. Хотя постойте… А как же pwm-gpio-custom? Его нет.
Не отчаивайтесь, [вот он](https://drive.google.com/file/d/0B9RaaZBRecRYNkQyRGlSeDV2Slk/edit?usp=sharing)
Нужно просто распаковать содержимое в **openwrt/package** и все будет хорошо.
Теперь перейдем непосредственно к сборке.
Находясь в папке openwrt необходимо выполнить `make -j n kernel_menuconfig`
Вместо n нужно подставить число ваших ядер + 1.
Откроется синее меню. Выбираем пункт Device Drivers.
Находим PWM Support:

Активируем пункт PWM emulation using GPIO. Выбирать пробелом. Нужно чтобы везде стояли звездочки, это важно:

После этого нужно немного переконфигурировать ядро. Ищем соответствующий пункт:

Ставим звездочку на пункте High Resolution Timer Support, выставляем значение Timer frequency на 1000HZ, а в параметре Premption Model выбираем Low-Latency Desktop:

Необходимо наверняка знать аппаратную платформу своего роутера. Но еще важнее указать ее в конфигурации. У меня это Atheros ar71xx:


Необходимая настройка ядра завершена. Теперь как только вы нажмете финальный Exit система спросит вас о том стоит ли сохранять изменения, на что нужно ответить утвердительно.
Теперь нужно таким же способом сконфигурировать сборку самой ОС командой `make -j n menuconfig`
Затем в меню Kernel Modules:
Выбрать Other modules:
И поставить звездочку на пункте kmod-pwm-gpio-custom:

Все, можно приступить к сборке. Все та же команда `make -j n`
Остается откинуться на спинку кресла и что-нибудь посмотреть, можно попить чаю/кофе, процесс сборки не быстрый.
Как только сборка закончится, можно переходить в папку **bin**. В ней будет папка с вашей платформой и образы. Прошиться можно в полном соответствии со стандартной инструкцией. Как только завершится процесс прошивки, можно смело заходить через telnet. Необходимо будет еще дополнительно закачать пакет **kmod-pwm-gpio-custom** на само устройство. Это можно сделать через SCP, либо через wget, или же установить openssh-sftp-server и воспользоваться FileZilla.
Загружать сам пакет лучше в директорию /tmp, так как ПЗУ не резиновая, а данная директория физически располагается в оперативной памяти, которой обычно от 32 до 64 Mb. После закачки пакет необходимо установить командой `opkg install /tmp/kmod-pwm-gpio-custom_xxx.ipk.` Можно сильно не заморачиваться с названием пакета, автодополнение по TAB прекрасно работает.
#### Генерация ШИМ сигнала
После установки пакета можно переходить к непосредственному управлению GPIO и генерации ШИМ сигнала.
Для этого необходимо активировать модуль ядра. Сделать это можно командой `insmod pwm-gpio-custom bus0=0,23 bus1=1,20`
Это просто пример того как оно может быть. busX задает номер шины, которой можно управлять через символьное устройство под этим самым номером в `/sys/сlass/pwm` У нас их появится два: **gpio\_pwm.0:0** и **gpio\_pwm.1:0**. Манипулировать параметрами ШИМ можно просто записывая соответствующие переменные в файлы. Да, чуть не забыл, все значения задаются в наносекундах. Поехали:
`echo 10000000 > /sys/class/pwm/gpio_pwm.0\:0/period_ns` Задает период. В данном случае это 100 Гц.
`echo 8500000 > /sys/class/pwm/gpio_pwm.0\:0/duty_ns` Задает скважность.
Да, некоторые выводы инвертированы по умолчанию и необходимо задать время «пустоты» внутри периода. Если же значением High для GPIO явдяется 1, то нужно задать `echo 1500000 > /sys/class/pwm/gpio_pwm.0\:0/duty_ns` Будет указываться время самого импульса.
Проверить можно опытным путем. Возможно я найду или кто-то подскажет способ сделать это более красиво =)
Теперь осталось только активировать подачу сигнала.
`echo 1 > /sys/class/pwm/gpio_pwm.0\:0/run` И мы получаем на осциллографе что-то вроде этого
Если подключить к выводу PWM кабель сервопривода — он встанет ровно в центральное положение. Разумеется, питание тоже нужно подключить.
#### Заключение
Таким способом можно добиться генерации сигнала на частоте 200 Гц, а это означает что время реакции для одного привода снизится до 5 мс. Для открывания-закрывания замка, может, и не критично, а вот для летательных аппаратов будет весьма актуально. Надеюсь что я обзаведусь в ближайшее время мотором и контроллером, либо добрый читатель из города Екатеринбург согласится одолжить мне такой для экспериментов и появится вторая статья.
Спасибо что дочитали до конца. На закуску позвольте представить вам немного видео.
Демонатрация работы. Два канала, настроенные на крайнее правое и крайнее левое положение.
Видеодемонстрация ШИМ сигнала.
#### P.S.
Хочу выразить огромную благодарность автору модуля **Claudio Mignanti**, который ответил по почте и разъяснил необходимые вопросы.
Схема сервопривода и управляющих сигналов были взяты на [wiki.amperka.ru](http://wiki.amperka.ru/робототехника:сервоприводы).
Если у вас есть какие-то дополнения или пожелания — пишите в комментариях.
UPD: [a5b](https://habrahabr.ru/users/a5b/) интересуется что за устройство было использовано. Ну, это никакой не секрет. Плата — китайский аналог EL-M150. Процессор внутри — Atheros AR9331.
Он используется очень широко в таких распространенных роутерах как mr3020 или wr703n.
Выглядит плата следующим образом.
 | https://habr.com/ru/post/235207/ | null | ru | null |
# Обратные вызовы и исключения С++
### Введение
Как известно, многие С-библиотеки используют обратные вызовы для обеспечения какого-либо функционала. Так поступает, например, библиотека expat для реализации SAX модели. Обратный вызов или callback используется для возможности выполнить пользовательский код на стороне библиотеки. Пока такой код не несет побочных эффектов — все нормально, но как только на арене появляется С++, все, как всегда, становится нетривиальным.
Итак, код С++ может генерировать исключения, к которым не подготовлен код на С. Ведь функция обратного вызова, выполняется в контексте библиотеки. И если выход из такой функции будет выполнен по генерации исключения, то оно пойдет дальше, разрушая стек.
Очевидное решение, именно то, которое я встречал чаще всего, когда только начал заниматься этим вопросом, состоит в полном отказе от исключений в таких callback`ах. Но это, вестимо, не наш случай.
### Случай
Я не зря привел в пример expat. Проблема исключений встала именно при использовании этой библиотеки. Задача состояла в следующем:
* Есть некий код, который раньше использовал библиотеку xml, написанную на С++ и этот код активно применял исключения;
* Есть необходимость заменить библиотеку xml на другую без переписывания остального кода.
Я принялся за разработку обертки над expat, которая точь-в-точь повторяла интерфейс прежней библиотеки. Именно в процессе решения этой задачи родилась данная идея.
### Идея
Нужно каким-то образом отложить выброс исключения до тех пор, пока выполнение не вернется в С++ код. Единственный способ — где-то сохранить исключение и выбросить его заново в безопасном месте. Но здесь есть ряд сложностей, связанных с реализацией.
### Реализация
#### Класс exception\_storage
Для начала нужно реализовать хранилище для брошенных исключений, выглядеть оно будет вот так просто:
> `class exception\_storage
>
> {
>
> public:
>
> inline ~exception\_storage() {}
>
> inline exception\_storage() {}
>
>
>
> void rethrow() const;
>
>
>
> inline void store(clone\_base const & exc);
>
> inline bool thrown() const;
>
> private:
>
> std::auto\_ptr<const clone\_base> storedExc\_;
>
> };`
Класс clone\_base — это boost::exception\_detail::clone\_base очень хорошо подходит для нашей цели.
Реализация тоже не сложна:
> `inline
>
> void exception\_storage::store(clone\_base const & exc)
>
> {
>
> storedExc\_.reset(exc.clone());
>
> }
>
> inline
>
> bool exception\_storage::thrown() const
>
> {
>
> return storedExc\_.get() != 0;
>
> }
>
> inline
>
> void exception\_storage::rethrow()
>
> {
>
> class exception\_releaser
>
> {
>
> public:
>
> inline
>
> exception\_releaser(std::auto\_ptr<const clone\_base> & excRef)
>
> : excRef\_(excRef)
>
> {}
>
> inline
>
> ~exception\_releaser()
>
> {
>
> excRef\_.reset();
>
> }
>
> private:
>
> std::auto\_ptr<const clone\_base> & excRef\_;
>
> };
>
>
>
> if(thrown())
>
> {
>
> volatile exception\_releaser dummy(storedExc\_);
>
> storedExc\_->rethrow();
>
> }
>
> }`
Три метода, store — служит для сохранения текущего исключения с помощью clone\_base::clone, rethrow генерирует заново последнее исключение, если оно случалось, thrown — сигнализирует было ли исключение вообще. Функция clone\_base::clone — чисто виртуальная, а возможность использовать ее для любых исключений дает boost::enable\_current\_exception, которая убивает сразу двух зайцев: позволяет непосредственным исключениям вообще не знать о том, что его должны клонировать и сохранить информацию о типе за абстрактным интерфейсом clone\_base.
Отдельно хочу поговорит о реализации метода rethrow. В нем вызывается виртуальная функция rethrow (и именно эта функция имеет понятие о том, что именно за исключение мы генерируем). Класс exception\_releaser осуществляет очистку памяти сохраненного исключения, при его выбросе. Исключение при генерации копируется, следовательно объект на который указывает storedExc\_ становится ненужным. Кроме того это позволило мне сэкономить на булевском флаге для обозначения необходимости генерации.
#### Фильтр исключений
Самая хитрая штука во всей этой системе, на мой взгляд, это фильтр исключений. В его реализации нам очень поможет замечательная библиотека boost::mpl. Рассмотрим его подробнее.
Очевидно, чтобы записать исключение в хранилище, нужно сначала его поймать. Фильтр призван решить именно эту задачу. Возьмем гипотетический callback:
> `void callback(void \*userData, char const \*libText);`
Как сделать, чтобы исключения не вылетали за пределы этой функции?
Первое решение — перехватывать все. Но здесь мы натыкаемся на досадное ограничение языка. Нельзя переносимым способом получить в блоке catch(...) информацию о типе исключения. Тут-то мне и пришла мысль, что мы можем сделать это фичей. Дать возможность пользователю библиотеки задавать какие исключения нужно ловить в этих callback`ах.
Начал я с того, что реализовал расширяемый в compile-time фильтр исключений. Выглядит он так:
> `template <typename List, size\_t i = boost::mpl::size<List>::value - 1>
>
> class exception\_filter
>
> {
>
> typedef typename boost::mpl::at\_c::type exception\_type;
>
> public:
>
> static inline void try\_(exception\_storage & storage)
>
> {
>
> try
>
> {
>
> exception\_filter::try\_(storage);
>
> }
>
> catch(exception\_type const & e)
>
> {
>
> storage.store(boost::enable\_current\_exception(e));
>
> }
>
> }
>
> };
>
> template <typename List>
>
> class exception\_filter
>
> {
>
> typedef typename boost::mpl::at\_c::type exception\_type;
>
> public:
>
> static inline void try\_(exception\_storage & storage)
>
> {
>
> try
>
> {
>
> throw;
>
> }
>
> catch(exception\_type const & e)
>
> {
>
> storage.store(boost::enable\_current\_exception(e));
>
> }
>
> }
>
> };`
Это рекурсивно инстанцирующийся шаблон, который использует boost::mpl::vector в качестве параметра List. В векторе можно будет задать типы исключений, которые необходимо ловить. Шаблон при инстанцировании разворачивается в примерно такое (псевдокод):
> `try
>
> {
>
> try
>
> {
>
> try
>
> {
>
> throw;
>
> }
>
> catch(exception\_type\_1)
>
> {
>
> }
>
> }
>
> catch(exception\_type\_2)
>
> {
>
> }
>
> }
>
> catch(exception\_type\_N)
>
> {
>
> }`
Где N — это количество типов в mpl::vector.
Если исключение фильтру известно, то оно сохраняется в exception\_storage с помощью boost::enable\_current\_exception. Управляет шаблоном функция smart\_filter. Она, в дополнение, ловит все остальные исключения, которые не были заданы в списке типов.
> `template List>
>
> inline void smart\_filter(exception\_storage & storage)
>
> {
>
> try
>
> {
>
> exception\_filter::try\_(storage);
>
> }
>
> catch(...)
>
> {
>
> storage.store(boost::enable\_current\_exception(std::runtime\_error("unexpected")));
>
> }
>
> }`
### Итог
Теперь настало время объединить это в классе-обертке над С-библиотекой. Я покажу его схематично, для демонстрации идеи:
> `template <typename List>
>
> class MyLib
>
> {
>
> public:
>
> MyLib()
>
> {
>
> pureCLibRegisterCallback(&MyLib::callback);
>
> pureCLibSetUserData(this);
>
> }
>
> virtual void doIt()
>
> {
>
> pureCLibDoIt();
>
> storage\_.rethrow();
>
> }
>
> protected:
>
> virtual void callback(char const \*) = 0;
>
> private:
>
> static void callback(void \* userData, char const \* libText)
>
> {
>
> if(MyLib \* this\_ = static\_cast\*>(userData))
>
> {
>
> try
>
> {
>
> this\_->callback(libText);
>
> }
>
> catch(...)
>
> {
>
> smart\_filter(this\_->storage\_);
>
> }
>
> }
>
> }
>
> exception\_storage storage\_;
>
> };`
Вот собственно и все. Теперь я приведу небольшой пример использования.
> `struct MyClass
>
> : public MyLib <
>
> boost::mpl::vector
>
> <
>
> std::runtime\_error,
>
> std::logic\_error,
>
> std::exception
>
> >
>
> >
>
> {
>
> private:
>
> void callback(char const \* text)
>
> {
>
> throw std::runtime\_error(text);
>
> }
>
> };
>
> int main()
>
> {
>
> MyClass my;
>
>
>
> try
>
> {
>
> my.doIt();
>
> }
>
> catch(std::exception const & e)
>
> {
>
> std::cout << e.what() << std::endl;
>
> }
>
> return 0;
>
> }`
Данная реализация предназначена для однопоточного окружения. | https://habr.com/ru/post/100623/ | null | ru | null |
# Вариант простой backup-системы на Python, Bash и Git
Недавно появилось некоторое чувство дискомфорта когда я приступаю к работе. Чувство было не то чтобы сильным, но сосредоточиться мешало. Думал, лень. Оказалось, что все чуть сложнее :) Ноуту, за которым я работаю, уже почти 3 года; стоит на нем Mac OS X 10.6.1, но яблок на нем нигде не нарисовано, и система периодического резервного копирования на нем отсутствует как класс. В общем, не было ощущения стабильности и надежности, так что я занялся этим вопросом вплотную. Собственно, далее я опишу результат, который мое подсознание удовлетворил :) Может быть, кому-то что-нибудь будет полезно.
### Задача
#### Что бекапим
* Каталоги с разнообразными исходниками. Некоторые проекты являются Git-репозиториями, соответственно, хочется сохранить репозиторий, а не просто последнюю версию исходников. NB: выполнять make clean или аналоги в конце дня я как-то не привык, так что добавляем требование, что бинарники не копируются.
* Каталоги с конфигами и параметрами.
* Каталоги с TeX-исходниками. На самом деле, можно было бы добавить к первому пункту.
У меня, конечно, временами и фотографии появляются, которые хотелось бы сохранить, и прочие бинарники, но вопроса их резервного копирования мы касаться не будем, потому что надежного места, куда можно скриптами запихнуть больше 10 Гб у меня нет, да и чаще чем раз в месяц они не изменяются обычно.
#### Куда бекапим
* Собственно, файлохранилища. Был выбран бесплатный аккаунт на [Dropbox](http://www.getdropbox.com), ибо копировать командой cp – просто и удобно.
* Почта на Gmail. Все равно 7 гигов не используются, да и в надежности пока не было поводов сомневаться.
Возможно, в ближайшем будущем этот список расширится, а пока, как мне кажется, этого более-менее достаточно.
#### Какие фичи
* **Простота.** Основная фича :) Не нужно сложных и больших программ, я сам в состоянии решить какие файлы откуда мне нужно копировать. Проще быть уверенным в корректности работы небольшой программы.
* **История изменений.** Первая фича, которую хочется – это история изменений, чтобы не ругаться на тему «чем же этот файл мне мешал!»
* **Сжатие.** Git, конечно, жмет, но т.к. хранить бекапы все равно удобнее в одном файле, так что пускай его дожмет кто-нибудь еще.
* **Шифрование** Я не сомневаюсь в честности и секъюрности провайдеров интернета и провайдеров хранилищ. Тем не менее, не хочу, чтобы то, что я делаю, передавалось и лежало непонятно где в открытом виде.
### Решение
Гугл по моим запросам ничего путного и удовлетворяющего моим запросам не выдал, поэтому пришлось писать самому. Заодно потрогал что есть Python, давно искал подходящий повод.
#### Копирование
Вариант «копировать все» не проходит из-за нехватки места. К тому же, как-то кажется глупым держать кучу резервных копий ненужных файлов (объектников, логов сборки и т.п.). В итоге, так сказать, техзадание получилось следующим:
* Список каталогов и файлов для копирования хранится в отдельном файле.
* Для каждого каталога можно указать маски файлов, которые из него нужно копировать. Если маска не указана, копировать все.
* Сохраняется исходная структура каталогов.
* Скрипт копирует (и только копирует) файлы в указанную папку.
* Если в целевой папке файл уже существует, копировать только в случае, если время модификации исходного файла больше.
Скрипт копирования написан на Python и занимает чуть меньше 200 строк (с учетом отступов, комментариев и т.п.). Дополнительно использует один нагугленный модуль для преобразования абсолютных путей в относительные и наоборот.
Использование:
```
sn-backup.py <файл со списком> <базовый каталог> <каталог для резервного копирования>
```
Ограничения:
1. Строгий формат файла со списком. Формат строки:
```
<путь относительно базового каталога>[\t<маски через запятую>]
```
Более одного знака табуляции не допускается. Маски идут через запятую без пробелов.
2. Практически не реализована защита от дурака.
Пример списка (с базовым каталогом ~):
```
.emacs
Documents/Programming *.c,*.h,*.cpp,*.pro,*.py,.git
Scripts
```
Исходники (наверное, удобнее когда на файлохостинге лежат, чем когда те самые 200 строк засоряют текст):
**[sn-backup.py](http://dl.dropbox.com/u/233593/sn-backup.py)** ([посмотреть на dumpz.org](http://dumpz.org/14127/))
**[relpath.py](http://dl.dropbox.com/u/233593/relpath.py)** ([посмотреть на dumpz.org](http://dumpz.org/14128/))
relpath.py был взят [отсюда](http://code.activestate.com/recipes/208993/), из первого коммента, и чуть подправлен.
#### Сжатие и шифрование
Сжатие и шифрование требуют по одной строчке, так что как-то странно было бы их писать на Python. Чем сжимать – дело вкуса. Я предпочитаю 7-zip. Командная строка тут, соответственно, будет простой (имя архива – backup.7z, имя папки – .backup):
```
7za a -mx7 backup.7z .backup
```
Для шифрования выбрал openssl, так как, в теории, почти везде есть и работает из коробки, без необходимости генерации чего бы то ни было. Команда выглядит так:
```
openssl enc -aes-256-cbc -salt -in backup.7z -out backup.aes256cbc -pass file:
```
Соответственно, имя исходного файла backup.7z, имя выходного файла backup.aes256cbc (на случай, если вдруг забуду как зовется алгоритм шифрования). Пароль хранится в файле и может иметь произвольную длину. Лучше, все же, не менее 32 символов.
#### Отправка
Отправку, из-за потенциального разнообразия способов, сначала хотелось сделать тоже через очень настраиваемый Python-скрипт, но потом я решил, что копировать на небольшое число хостов гораздо проще вручную, а копировать на большое число хостов попахивает паранойей. Поэтому отправка реализована в sh-скрипте. Команда копирования на Dropbox при установленном клиенте интереса не представляет, так что рассмотрим только команду отправки на почту (она хоть чуть реже встречается):
```
uuencode <путь к зашифрованному архиву> $(basename <путь к зашифрованному архиву>) | mail -s "[BACKUP] $(date)" <адрес>
```
Внимание: чтобы эта команда работала, необходимо настроить на локальной машине SMTP-сервер. У меня провайдер его предоставляет Команда прикрепляет зашифрованный архив к сообщению с темой «[BACKUP] <текущая дата и время>» и отправляет сообщение на <адрес>. У меня эта команда лежит в скрипте sn-upload.sh, который в качестве единственного аргумента принимает имя файла зашифрованного архива.
#### Все вместе
Все вместе собирается скриптом backup.sh, который выглядит примерно так:
`# ~/.backup - каталог, в который и происходит резервное копирование.
# Предварительно в нем должен быть инициализирован .git-репозиторий.
cd ~/.backup
# Список удобно держать там же.
~/Scripts/sn-backup.py ./list ~ .
# Скопировали, теперь коммитим в git.
git add .
git commit -m "Backup at $(date)"
# Возвращаемся назад и архивируем.
cd ..
7za a -mx7 backup.7z .backup > /dev/null
# Шифруем.
openssl enc -aes-256-cbc -salt -in backup.7z -out backup.aes256cbc -pass file:///${SECRET_PATH}/.password
# Отправляем.
~/Scripts/sn-upload.sh ./backup.aes256cbc
# ???
rm backup.7z
# PROFIT!`
### Направления для дальнейшего развития
На досуге, возможно, сделаю такие доработки:
1. Перевести все bash-скрипты на Python.
2. Возможно, переключиться на pylzma и встроенную криптографию Python (для кроссплатформенности).
3. Сделать формат файла-списка помягче и поприличнее.
### Заключение
Я не исключаю возможности, что я изобрел велосипед. Но я потратил на это не так много времени, и получил немного опыта. Хочу отметить, что прежде всего в, кхм, дизайн этой системы закладывалась простота. Я знаю какие файлы и откуда мне надо скопировать. Я знаю что с ними потом делать. Мне нужен скрипт только для того, чтобы все это делалось на автомате. На мой взгляд, свои задачи он выполняет полностью.
Благодарю за внимание! | https://habr.com/ru/post/74532/ | null | ru | null |
# Люди и интерфейсы. Рассказ незрячего тестировщика о том, как сервисы Яндекса становятся доступнее

Привет, меня зовут Анатолий Попко. Последние 15 лет (или около того) я работаю над тем, чтобы технологии становились доступнее для пользователей с различными ограничениями. Участвовал и продолжаю участвовать в работе разных групп и организаций, которые объясняют разработчикам технологий реальные потребности людей, пишут гайды, стандарты и так далее.
Уже много лет я сотрудничаю с Яндексом, а с прошлого года мы вместе строим единые процессы улучшения доступности в сервисах. Это бесконечный путь, всегда можно сделать лучше — текущее состояние продуктов Яндекса тоже не отражает идеальную картину. Я бы хотел рассказать об этой работе и поделиться примерами, которые можно брать и реализовывать где угодно. Поговорим о мифах, о моей работе тестировщиком цифровой доступности, да и в целом о восприятии окружающего мира.
Как смотрят мультфильмы
-----------------------
Однажды, ещё задолго до того, как я начал сотрудничать с Яндексом, мы с коллегами организовывали [показ мультфильма «Шрек»](https://yandex.ru/video/preview/18158695189242879) для незрячих ребят из школы-интерната. Наверное вы слышали, что на таких показах мультфильмы сопровождают тифлокомментариями — закадровыми описаниями того, что происходит на экране. Комментарии звучат в промежутках между диалогами и описывают действия, предметы и даже внешность героев. Но нам такого описания показалось недостаточно — захотелось действительно показать юным зрителям главного героя, этого забавного великана со странными ушами. Ведь у многих незрячих детей ничего со словом «Шрек» не ассоциировалось.
Я подумал — дать пощупать его, что ли? И мы позвали ростовых кукол. Живые и настоящие, Шрек с Ослом подверглись, скажем так, тщательному тактильному изучению и произвели фурор. Мы (будучи организаторами) расщупали Шрека раньше, поэтому за детьми просто наблюдали, радуясь их ажиотажу.
А я в этот момент обратил внимание на воспитательницу, которая приехала вместе с ребятами. Обратил внимание потому, что она всхлипнула, стоя рядом со мной. Спросил, что случилось. Оказалось, она воспринимала ситуацию совсем не так, как я, и жалела детей. Хотя в этот момент ребята изучали окружающий мир. Не привычным для воспитателя способом (глазами), а ощупывая Шрека.
Незрячие люди смотрят руками — и это нормально. Показывая Шрека, мы делаем окружающую среду доступнее. Адаптируя интерфейсы цифровых сервисов, мы возвращаем людям независимость. Я совершенно уверен, что любой пользователь может и должен иметь возможность самостоятельно выбрать способ взаимодействия с окружающим миром и цифровым контентом, то есть самостоятельно решить, использовать ли голосового ассистента, заказывать ли по телефону или тыкать пальцами в экран планшета. Если интерфейс доступен, то любой человек может хоть и своим собственным уникальным способом, но без посторонней помощи им пользоваться.
А теперь давайте поговорим о том, что такое цифровая доступность и как с ней «борются» в Яндексе. :)
Доступность — это для всех
--------------------------
Доступный цифровой контент означает воспринимаемый, управляемый, понятный и надёжный. Доступность — это возможность людям с инвалидностью получить такую же информацию, что и людям без инвалидности, обеспечить такое же взаимодействие, высказываться и быть понятыми также эффективно, использовать те же цифровые сервисы с тем же уровнем безопасности, независимости и простоты.
Когда мы говорим о цифровой доступности, первыми на ум приходят именно незрячие пользователи, потому что:
* Полное отсутствие зрения — очень понятное и однозначное ограничение. Оно не вызывает вопросов о квалификации пользователя, не зависит от внешних факторов (освещённости), а главное, его никак нельзя преодолеть (хоть надевай очки, хоть нет).
* Программы экранного доступа (англ. screen reader), которыми пользуются незрячие люди — наглядный инструмент для тестирования на доступность: бесплатный, не такой сложный, как айтрекеры, и не зависящий от индивидуальных ограничений, как, например, система Стивена Хокинга.
Однако повышая доступность для незрячих пользователей, можно решить ряд проблем, актуальных для людей с другими ограничениями, например тех, кто не может использовать мышку. И хотя в этой статье я говорю в основном про незрячих, круг людей, заинтересованных в доступности сервисов, очень широк.
Но давайте сначала поймём, как незрячий человек пользуется графическими интерфейсами.
Во-первых, он совершенно точно ими пользуется или хотя бы пытается. Он так же, как и все, ездит на такси, покупает еду и разные вещи, ходит на выставки и концерты, узнаёт погоду, читает новости в интернете.
Во-вторых, делает он всё это с помощью программы экранного доступа, которая технические характеристики элементов интерфейса переводит в понятный человеку текст. Программа либо озвучивает получившийся текст с помощью синтезатора речи, либо выводит его на брайлевский дисплей.
Программа экранного доступа зачитывает не только названия элементов интерфейса, но и другую информацию, которая лежит в коде. Например, если на экране есть текст «Купить» и это кнопка, незрячий пользователь услышит: «Купить, кнопка».
Как пользователь управляет цифровым контентом? Если он работает за компьютером, программа экранного доступа создаст виртуальный курсор, которым можно управлять при помощи клавиатуры, а если использует смартфон или планшет, она адаптирует под него жесты. Всё просто: человек взаимодействует с графическим интерфейсом через ещё один интерфейс.
Теперь давайте для примера возьмём элемент интерфейса, который открывает меню настроек и часто выглядит как шестерёнка. Как понять, что этот элемент доступен? Всё просто — с ним могут взаимодействовать разные пользователи:
1. Незрячий пользователь устанавливает на шестерёнку курсор программы экранного доступа и слышит: «Настройки, кнопка» или читает «Настройки КНП» на брайлевском дисплее.
2. Пользователь клавиатуры может переместить системный фокус на шестерёнку и убедиться, что фокус установлен именно на ней, увидев рамку (синюю обводку).
3. Пользователь с нарушениями мелкой моторики также может без труда открыть настройки, так как шестерёнка занимает достаточно места на экране и по ней легко попасть пальцем.
4. Слабовидящий пользователь замечает её, потому что есть необходимый уровень контраста.
5. А условно здоровый пользователь (без каких-либо ограничений жизнедеятельности, которые мешают воспринимать цифровой контент и управлять им) видит всё ту же шестерёнку и также успешно заходит в настройки.
**Программы экранного доступа**
Программы экранного доступа есть для всех популярных операционных систем:
* Windows: NVDA, JAWS, Narrator;
* Linux: Orca;
* macOS и iOS: VoiceOver;
* Android: TalkBack.
### Как сделать интерфейс доступным для незрячих
Жизнь была бы прекрасной и простой, если бы программе экранного доступа передавалась вся требуемая информация. Проблемы возникают, если в коде отсутствует необходимая техническая информация — не указаны типы, названия, состояния или другие значимые характеристики элементов интерфейса.
Например, если у шестерёнки нет подписи, то программа экранного доступа, попав на неё, произнесёт «кнопка» и всё. Пользоваться такой кнопкой приходится на собственный страх и риск: ведь непонятно, зачем она здесь и надо ли её нажимать.
Если у элемента есть название, но отсутствует роль (или тип), то приходится догадываться, а можно ли вообще сюда нажать или это просто текст. В самых проблемных случаях может отсутствовать и подпись, и тип. В таких случаях использование цифрового сервиса без визуального контроля становится похожим на сказку: «Нажми то, не знаю что».
### Уровни погружения в проблему
Чтобы понять, что такое доступный цифровой контент, стоит заглянуть в стандарты доступности. В России это [ГОСТ-Р 52872-2019](https://protect.gost.ru/document.aspx?control=7&id=233736), основанный на созданном W3C руководстве по обеспечению доступности веб-контента ([WCAG 2.1](https://www.w3.org/TR/WCAG21)).
Чтобы сделать доступными конкретные элементы интерфейса, нужно следовать техническим спецификациям: HTML, CSS, [WAI-ARIA](https://www.w3.org/WAI/standards-guidelines/aria) (описывает цифровой контент для программы экранного доступа).
Есть такой феномен — случайной доступности. Приложение может быть доступным не потому, что разработчик специально об этом думал. А потому, что он использовал те инструменты, которые ему предоставляет операционная система. Например, на ранних стадиях развития iOS и macOS разработчики активно использовали системные компоненты, доступность которых обеспечила Apple. Приложения, по слухам, были внешне похожи, но отличались большей доступностью. Затем разработчики стали создавать собственные компоненты, зачастую пренебрегая требованиями доступности.
> Начать повышать доступность интерфейса можно с того, что проанализировать клавиатурную навигацию и разметку элементов интерфейса.
Для интерактивных элементов важно, чтобы программа экранного доступа понимала, какие у элемента:
* Тип или роль («кнопка»).
* Название («настройки»).
* Состояние. Например, у флажка (check box) это: «отмечен» и «не отмечен».
* Значение. Пример — уровень громкости.
Для неинтерактивных элементов важны корректно размеченные заголовки, которые не только передают структуру контента, но и обеспечивают навигацию. Любая программа экранного доступа понимает команду: «Перейти к следующему заголовку». Проблемы появляются, когда разработчики отказываются от разметки текста тегами , или, наоборот, используют заголовочные теги для его визуального оформления.
Чтобы проверить интерфейс на доступность, тестировщикам нужно будет использовать специализированный софт. Я обычно советую тестировать в таком порядке:
1. Начать с клавиатуры. Если вы разрабатываете веб-приложение или сайт, попробуйте пройти базовые кейсы без мыши. Клавиатурный доступ отлично работает и без программы экранного доступа.
2. Использовать инструменты автоматизированного выявления дефектов доступности (например, [Lighthouse](https://developers.google.com/web/tools/lighthouse), [AXE](https://www.deque.com/axe), [Wave](https://wave.webaim.org)). Они помогают найти до 40 процентов всех проблем и существенно облегчают последующее ручное тестирование.
3. Провести ручное тестирование с профессиональным пользователем программы экранного доступа. Историю про ручное тестирование я расскажу чуть позже.
Чтобы доступность не страдала
-----------------------------
### История 1. Применяйте стандарты
Невероятно, но факт: вообще все кнопки, во всех приложениях, на слух — совершенно одинаковые. Программа экранного доступа не произносит «круглая красная кнопка с тенью», поскольку внешний вид кнопки на суть не влияет. Важно, что это кнопка и что с её помощью можно делать.
Если в процессе разработки опираться на системные компоненты, многие проблемы доступности решаются сами собой. В спецификации HTML для кнопки предусмотрен тег .
Если всё-таки нужно использовать , то как минимум потребуются следующие атрибуты:
1. Роль кнопки .
2. Состояние «нажата» и «не нажата» , если кнопка — переключатель.
3. Клавиатурный фокус ([иначе она не примет фокус](https://www.smashingmagazine.com/2022/11/guide-keyboard-accessibility-html-css-part1)).
4. Обработчик событий клавиатуры `keyDown` (чтобы кнопку можно было нажать при помощи пробела или клавиши `Enter`).
5. Состояние «недоступна» `[aria-disabled]`, если применимо, иначе кнопка будет нажиматься даже тогда, когда не должна.
#### HTML
```
toggle
```
#### CSS
```
[aria-disabled] {
pointer-events: none;
opacity: 0.5;
}
```
#### JavaScript
```
wrapper.addEventListener("keydown", e => {
if (e.key === " " || e.key === "Enter" || e.key === "Spacebar") {
toggleBtn(e.target);
}
});
```
#### Поэтому
Поэтому, если мне задают вопрос, как сделать доступной кнопку, обёрнутую в , я сначала спрашиваю, нет ли возможности использовать . Иначе драматично возрастает количество аспектов, которые разработчику нужно контролировать, а главное, в реальных проектах вся эта красота рискует сломаться при каждом обновлении.
### История 2. Применяйте стандарты и тестируйте
Когда мы работали над доступностью Яндекс Карт, я обнаружил, что реклама при обновлении блока автоматически озвучивалась программой экранного доступа. Происходило это внезапно и не зависело от того, где в этот момент находился клавиатурный фокус и что делал пользователь.
Но ведь коллеги честно следовали стандартам:
— Контент на странице обновляется, так?
— Так.
— Мы должны показывать это обновление всем пользователям, так?
— Так.
— С помощью [live-region](https://developer.mozilla.org/en-US/docs/Web/Accessibility/ARIA/ARIA_Live_Regions) мы передаём эти сведения программе экранного доступа. В чём же тут проблема?
Дело в том, что есть разница между визуальным и аудиальным восприятием. Приведу аналогию. На экране вашего компьютера скорее всего есть часы. Время — это важная информация? Разумеется. Если вы не убрали часы, значит поглядываете на них периодически. Тогда давайте эту важную информацию сообщать. Незрячему пользователю время будет проговаривать синтезатор речи, а зрячему мы эти часы будем просто показывать. Раз в минуту, всего на несколько секунд, но очень красочно и на весь экран.
Почему обязательно на весь экран? Если вы зрячий пользователь, вы очень часто пользуетесь периферийным зрением. И можете позволить себе выбор: переводить ли взгляд на рекламные блоки и отвлекаться на них или продолжить смотреть, куда смотрели. Незрячий пользователь фокусирует всё своё внимание на речевом выводе — и только на нём. Всё, что попадает в речевой вывод, сразу (одномоментно) занимает весь экран.
#### Поэтому
Поэтому важно не только следовать стандартам, но и руководствоваться пользовательским опытом. В данном случае реклама, автоматически попадая в речевой вывод, воздействовала на незрячего пользователя гораздо агрессивнее, чем на зрячих посетителей сайта. Повышая доступность, мы пытаемся выровнять ситуацию — обеспечить и зрячему, и незрячему пользователю возможность получать рекламную информацию тогда, когда он попадает на рекламный блок — взглядом или курсором программы экранного доступа.
### История 3. Что бывает, если не применять стандарты и не тестировать
Никому не нравится, когда приложение перестает вести себя предсказуемо и начинает жить своей жизнью. Но если цифровой контент недоступен, то незрячий пользователь просто не сможет отследить самопроизвольные изменения. Так случилось и со мной однажды.
Несколько лет назад, когда я ещё не сотрудничал с Яндексом, я заказал такси, чтобы доехать до работы. Обычно я пользовался iOS-приложением, но тут под рукой оказался Android — решил поэкспериментировать. Указал адрес подачи и пункт назначения, а потом (для большей надёжности) решил не искать кнопку «Заказать» внизу экрана, а последовательно до неё дойти, смахивая одним пальцем вправо.
Такси приехало. Социального проекта «Помощь рядом» тогда ещё не было, поэтому я немало удивился, когда ко мне подошёл мужчина, поздоровался и представился водителем. Затем он так же вежливо спросил, открыть ли мне дверь и предложил подержать трость, пока я буду садиться. Вы знаете, салон дорогого автомобиля имеет свой особый запах. То ли дорогой кожаной обивки, то ли просто финансового благополучия. В общем, я, на всякий случай, переспросил адрес — всё правильно. В тот же день добродушный замдиректора похлопал меня по плечу и поделился, что он пока не может позволить себе ездить на работу на «Майбахе», но за меня очень рад. Я залез в приложение и… тоже порадовался, что вместо привычного эконома ехал бизнес-классом.
Позже, тестируя Яндекс Go, я выяснил, что при последовательном перемещении фокуса по элементам экран прокручивался, а при прокрутке открывалась карточка произвольного тарифа. В нижней части карточки тоже была кнопка «Заказать». Тариф поменялся, визуально это было заметно, а программе экранного доступа эта информация не передавалась.
#### Поэтому
Поэтому нужно помнить, что проблемы доступности могут быть совершенно не очевидны. Если не применять стандарты и не тестировать, то тогда обнаруживать их придётся пользователям. Что касается Яндекс Go на Android, то эту и другие проблемы исправили в процессе масштабной адаптации интерфейса Такси в 2021 году.
### История 4. Сосредоточьтесь на стандартах и спецификациях
Освоить программу экранного доступа — первое что приходит в голову разработчику, когда он задумывается о тестировании на доступность. Но путь это, прямо скажем, не вполне тривиальный.
Современный скринридер — сложный программный продукт, который опирается на сотню-полторы клавиатурных сочетаний и использует совершенно неочевидные решения (тот же виртуальный курсор для навигации по странице). Невизуальное использование современных цифровых интерфейсов требует времени и сил, которые трудно представить условно здоровому пользователю. Например, для того, чтобы незрячий пользователь компьютера средней квалификации освоил гугл-календарь, нужно 4—6 часов обучения (желательно под руководством незрячего преподавателя).
Другая беда: у неискушённого в вопросах доступности разработчика может сложиться впечатление, что для тестирования на доступность не нужно уметь эффективно пользоваться «говорилкой», достаточно нескольких базовых команд.
Представьте, разработчик включает программу экранного доступа и начинает перемещаться по элементам интерфейса с помощью клавиш `Tab` и `Shift+Tab`. В процессе он понимает, что какая-то надпись, хотя и размечена правильно, как заголовок, программой экранного доступа не озвучивается. Тогда разработчик решает, что проблема в текстовом элементе и помещает важную надпись в какой-нибудь подходящий интерактивный элемент. А дальше у нас может состояться примерно такой диалог.
— А что это за элемент?
— Это кнопка, но ты её не нажимай, она нужна, чтобы программа экранного доступа тебе этот важный текст озвучила.
Так делать не нужно. Потому что клавиатурный фокус должны принимать только интерактивные элементы (ссылки, кнопки, поля), и если это кнопка, то она должна нажиматься и как-то реагировать на нажатие. Секрет в том, что у программы экранного доступа есть тот самый виртуальный фокус, который и используется для навигации по веб-странице и доступа к неинтерактивному контенту (заголовкам, спискам, таблицам, абзацам текста). Если нужно перемещаться по интерактивным элементам (например, чтобы заполнить форму), можно использовать клавиатурный фокус, то есть `Tab` и `Shift+Tab`. А если требуется прочитать текст, то для этого используется виртуальный курсор. Это основы просмотра веб-страниц при помощи программы экранного доступа для настольных операционных систем.
А ещё при повышении доступности важно держать в голове некоторые различия в том, как цифровой контент обрабатывается программами экранного доступа на разных платформах. Например, на macOS есть VoiceOver. Нажимаешь `Command`+`F5` и компьютер говорит с тобой псевдо-человеческим голосом. Представим, что разработчик разобрался с ARIA-атрибутами, подобрал нужное их сочетание: теперь `live-region` озвучивается, как положено. Но при тестировании выяснилось, что NVDA на Windows воспроизводит совсем не то же самое, что VoiceOver на macOS. А подавляющее большинство незрячих пользователей, естественно, работает на Windows.
#### Поэтому
Поэтому я советую разработчикам погружаться в стандарты, спецификации и лучшие практики, а не в особенности вспомогательных технологий. Как правило достаточно краткого руководства, например, [Desktop screenreader survival guide](https://dequeuniversity.com/screenreaders/survival-guide) от Deque University.
Конечно, вам всё равно придётся тестировать сервис вручную, но гораздо продуктивнее делать это с помощью незрячих тестировщиков или хотя-бы квалифицированных пользователей программ экранного доступа. Хотя организация тестирования — это тема отдельной статьи.
### История 5. Не упрощайте интерфейс, а делайте его доступным
Чуть больше полугода назад на Хабре вышла статья о том, [как мы учимся адаптировать Яндекс Go для незрячих пользователей](https://habr.com/ru/company/yandex/blog/660663). Один из читателей спросил, не проще ли сделать отдельный интерфейс. Мне этот вопрос задают довольно часто.
Главная ошибка, которую может совершить разработчик, только начинающий думать о доступности — это попытаться решить, нужна ли та или иная функциональность пользователям с инвалидностью и различными ограничениями жизнедеятельности.
Повышение доступности не предполагает кардинальных изменений интерфейса (уменьшения количества компонентов на странице, изменения структуры или пользовательской логики). Повышение доступности решает принципиально другую задачу: как дать человеку возможность использовать именно этот интерфейс?
Всевозможные «специальные версии для незрячих» — это неистовое зло, которое никак не удаётся искоренить. Если интерфейс сложен и неудобен — это проблема эргономики. А смысл повышения доступности в том, чтобы в результате любой пользователь смог сам убедиться: «хм, а интерфейс-то сложен и неудобен» — и написать об этом в техподдержку или отказаться от него в пользу более удобных решений. Поэтому, например, если бы мы предложили незрячим пользователям заказывать такси не в Яндекс Go, а через Алису или колл-центр, мы бы не сделали лучше, мы бы забрали возможность выбрать тот способ заказа такси, который для них удобен и привычен.
Ещё есть такой миф — незрячим нужно, чтобы дизайн был попроще. На самом деле не сложный дизайн непонятен, а недоступный дизайн непонятен. Простота и доступность — две принципиально разных характеристики интерфейса. Интерфейс может быть простой и доступный или сложный и доступный. В обоих случаях у незрячего человека есть все шансы стать полноценным пользователем цифрового сервиса. Если же интерфейс не соответствует требованиям доступности, то сложный он или простой — совершенно неважно. У цифрового сервиса с недоступным интерфейсом незрячих пользователей не бывает.
Если же вернуться к сложным интерфейсам, то для меня огромная страница вообще никакая не проблема. Дело в том, что я не знаю, много там контента или мало, пока по всему контенту не пройду. Когда зрячий пользователь открывает веб-страницу Яндекс Лавки, он сразу получает массу информации, а когда незрячий пользователь открывает ту же самую страницу, то он слышит: «Яндекс Лавка заголовок первого уровня». Потому что в Лавке правильно размечены заголовки первого уровня — ровно по одному на страницу. Это уже очень большое дело!
Ещё иногда спрашивают — а если сделать так, чтобы вместо бездушного металлического голоса скринридера всё озвучивала Алиса? Однажды мне предложили протестировать Алису, там был такой сексуальный женский голос. Вообще классная идея конечно, но работать невозможно. Разные настроения бывают у каждого человека, вы сами скорее всего не захотели бы слушать такой голос по 12 часов, каждый день.
Столь разные требования к голосовому ассистенту и синтезатору речи программы экранного доступа могут удивить стороннего наблюдателя, поскольку оказывается, что очевидные для одних людей преимущества (яркое интонирование, красивый тембр, сходство с человеческой речью) либо являются глубоко второстепенными, либо вообще становятся препятствием, а не преимуществом для других.
#### Поэтому
Поэтому я предлагаю подумать не о том, чтобы сделать другой сервис, а о том, где мы создаём проблемы для тех, кто пользуется вспомогательными технологиями. Например, когда программа экранного доступа не находит и, следовательно, не сообщает пользователю какую-то значимую информацию. А не сообщает она значимую информацию потому, что контент не соответствует требованиям доступности.
Как работа над доступностью устроена в Яндексе
----------------------------------------------
Работа над доступностью сервисов в Яндексе началась не вчера. Главная страница, страница результатов поисковой выдачи (SERP), Погода отличались довольно высокой степенью доступности. Яндекс Диск на Windows и мобильных платформах всегда был очень популярен среди незрячих пользователей. Лёгкая версия Яндекс Почты, Метро и Электрички также были в значительной степени доступны. Отдельные задачи по доступности решала команда Яндекс Браузера. Были и адаптации и [техническая экспертиза](https://habr.com/ru/company/yandex/blog/515460).
Проблема была в том, что цифровая доступность оставалась делом энтузиастов: не было регулярных активностей, выделенных ресурсов, обмена опытом. Работа стала более системной летом прошлого года: появился человек, ответственный за инклюзию в Яндексе и команда, куда пригласили в том числе и меня. Мы [начали с Яндекс Такси](https://yandex.ru/company/services_news/2021/2021-11-12). Потом придумали рейтинг доступности и пошли в другие сервисы.
### Рейтинг доступности
Рейтинг доступности — это большая исследовательская и просветительская работа, которую команда инклюзии начала в прошлом году (с 16 сервисов) и продолжила в этом (уже 21 сервис).
Рейтинг помогает:
1. Понимать, каков текущий уровень доступности сервисов Яндекса.
2. Повышать приоритет инклюзии и цифровой доступности.
3. Мотивировать отдельные сервисы и компанию в целом.
Рейтинг формируется по итогам аудита, который проводит команда инклюзии.
В процессе аудита мы:
1. Формируем список сервисов и платформ присутствия. В 2022 году в список попал 21 сервис на разных окружениях.
2. Описываем целевой сценарий и целевые действия. Если коротко, сценарий — это ответ на вопрос, зачем нужен этот сервис (например, работать с электронной почтой). Целевые действия — это конкретные задачи пользователя (просмотреть список писем, написать сообщение, изменить настройки). Обычно, проводя аудит нового сервиса, мы запрашиваем пользовательские сценарии у команды сервиса.
3. Исследуем то, насколько полно и корректно интерфейс сервиса представляется программой экранного доступа. В работе участвует зрячий исследователь и незрячий эксперт (я).
4. Готовим отчёт с итогами аудита, то есть с очень подробным описанием проблем доступности.
После аудита мы предлагаем сервисам, которые впервые попали в рейтинг доступности, поучаствовать в открытом тестировании. Открытое тестирование — это встреча с командой сервиса, на которой мы обсуждаем результаты аудита и показываем, как незрячий пользователь выполняет целевые действия с помощью программы экранного доступа. Это зрелище не для слабонервных, особенно если сервис недоступен, но оно позволяет всей команде погрузиться в тему и перевести проблемы доступности в очень конкретную практическую плоскость.
Тут надо сказать, что на аудите наша работа над доступностью сервиса не заканчивается. Например, команда сервиса приняла решение адаптировать конкретную функциональность. Ребята приходят ко мне на тестирование. Мы вместе с тестировщиком проходим по сценариям и смотрим на проблемы доступности. Тестировщик фиксирует их, разработчики сервиса — уточняют, а затем мы вместе их обсуждаем. После этого команда планирует доработку и начинает исправлять интерфейс.
По итогам аудита команда инклюзии оценивает уровень доступности в баллах и решает, в какую лигу попадает тот или иной сервис.
### Лиги доступности
Всего у нас 4 лиги. В первую лигу попадают сервисы, базовые сценарии которых доступны незрячим пользователям. Это не значит, что у них вообще нет проблем доступности, важно, что пользователи программ экранного доступа, как и все остальные пользователи вообще, могут пройти базовые сценарии.
Например, в первой лиге сейчас 10 сервисов. Среди них приложение Яндекс, Браузер, Почта и Лавка. У Поискового приложения и Браузера адаптированы базовые сценарии, а Почта и Лавка адаптировали интерфейс целиком, то есть весь их интерфейс покрыт доступностью. Яндекс Почта на iOS по уровню доступности сейчас сопоставима с почтовым клиентом от Apple.
Наша новая главная страница изначально разрабатывалась с учётом требований доступности, и она сразу стала доступной. Браузер, мобильное приложение Поиска буквально полгода назад были вообще недоступны. Ребята за это время сделали огромный рывок, сейчас незрячие пользователи не просто могут работать в приложениях, ими удобно пользоваться.
### При чём тут Шрек?
Работа над доступностью требует сил, времени и денег. Это определённые обязательства, которые взяли на себя команды разных сервисов. По итогам рейтинга доступности 2022 мы поблагодарили 202 коллег, которые вывели свои сервисы в первую лигу. Это люди, которые радикально меняют цифровую среду в России, делая её доступной для пользователей с различными ограничениями.
В каком-то смысле доступный интерфейс — это осознанный и осмысленный интерфейс. В нём правильно использованы элементы, разметка и клавиатурный фокус. Когда ты много внимания уделяешь интерфейсу, он становится лучше, окружающая среда — доступнее, а людям возвращается независимость. Впрочем, кажется, это я уже говорил… :) | https://habr.com/ru/post/700596/ | null | ru | null |
# Из опыта использования SObjectizer: акторы в виде конечных автоматов – это плохо или хорошо?
[Познакомив читателей с фреймворком SObjectizer](https://habrahabr.ru/post/304386/), его возможностями и особенностями, можно перейти к рассказу о некоторых уроках, которые нам довелось усвоить за более чем четырнадцать лет использования SObjectizer-а в разработке C++ного софта. Сегодня поговорим о том, когда агенты в виде конечных автоматов не являются хорошим выбором, а когда являются. О том, что возможность создания большого количества агентов – это не столько решение, сколько сама по себе проблема. И о том, как первое соотносится со вторым...
Итак, в трех предыдущих статьях ([раз](https://habrahabr.ru/post/306858/), [два](https://habrahabr.ru/post/307306/) и [три](https://habrahabr.ru/post/308084/)) мы наблюдали за тем, как агент email\_analyzer развивался от очень простого до более-менее сложного класса. Думаю, что у многих, кто посмотрел [на финальный вариант email\_analyzer-а](https://bitbucket.org/sobjectizerteam/habrhabr_article_2/src/f79ca804983bf4cf52e573ae5180ac5a01de122f/dev/v7/main.cpp?at=default&fileviewer=file-view-default#main.cpp-61), возник вопрос: «Но ведь это же очень сложно, неужели нельзя было проще?»
Получилось так сложно потому, что агенты представляются в виде конечных автоматов. Для того чтобы обработать входящее сообщение, должен быть описан отдельный метод – обработчик события. Для того чтобы у агента мог запуститься новый обработчик события, текущий обработчик должен завершиться. Поэтому, чтобы отослать запрос и получить ответ агент должен завершить свой текущий обработчик, чтобы дать диспетчеру возможность вызвать соответствующий обработчик при поступлении ответа. Т.е. вместо:
```
void some_agent::some_event() {
...
// Отсылаем запрос.
send< request >(receiver, reply_to, params…);
// И сразу же ждем результ.
auto resp = wait_reply< response >(reply_to);
... // Обрабатываем ответ.
}
```
Приходится писать вот так:
```
void some_agent::some_event() {
...
// Чтобы получить результат нужно на него подписаться.
so_subscribe(reply_to).event(&some_agent::on_response);
// Отсылаем запрос.
send< request >(receiver, reply_to, params...);
// Больше оставаться в some_event нет смысла.
// Нужно вернуть управление диспетчеру дабы он смог вызвать
// нас потом, когда придет ответ.
}
void some_agent::on_response(const response & resp) {
... // Обрабатываем ответ.
}
```
Отсюда и такой объем, и такая сложность у получившегося агента email\_analyzer.
Возможно, и в таком подходе найдутся какие-то ухищрения, которые бы сократили объем писанины на 20-30%, но принципиально ситуация не изменится.
Вот что может существенно повлиять на понятность и компактность, так это уход от событийной модели на базе коллбэков в сторону линейного кода с синхронными операциями. Что-то вроде:
```
void email_analyzer(context_t ctx, string email_file, mbox_t reply_to) {
try {
// Выполняем запрос синхронно.
auto raw_content = request_value< load_email_succeed, load_email_request >(
ctx.environment().create_mbox( "io_agent" ),
1500ms, // Ждать результата не более 1.5s
email_file ).content_;
auto parsed_data = parse_email( raw_content );
// Запускаем агентов-checker-ов, которые будут отсылать результаты
// в отдельный message chain, специально созданный для этих целей.
auto check_results = create_mchain( ctx.environment() );
introduce_child_coop( ctx,
disp::thread_pool::create_disp_binder( "checkers",
disp::thread_pool::bind_params_t{} ),
[&]( coop_t & coop ) {
coop.make_agent< email_headers_checker >(
check_results, parsed_data->headers() );
coop.make_agent< email_body_checker >(
check_results, parsed_data->body() );
coop.make_agent< email_attach_checker >(
check_results, parsed_data->attachments() );
} );
// Т.к. все обработчики результатов будут очень похожи, то вынесем
// их логику в отдельную локальную функцию.
auto check_handler = [&]( const auto & result ) {
if( check_status::safe != result.status )
throw runtime_error( "check failed: " + result );
} );
// Ждем результатов не более 0.75s и прерываем ожидание, если
// хотя бы один результат оказался неудачным.
auto r = receive( from( check_results ).total_time( 750ms ),
[&]( const email_headers_check_result & msg ) { check_handler( msg ); },
[&]( const email_body_check_result & msg ) { check_handler( msg ); },
[&]( const email_attach_check_result & msg ) { check_handler( msg ); } );
// Если собраны не все ответы, значит истекло время ожидания.
if( 3 != r.handled() )
throw runtime_error( "check timedout" );
// Ну а раз уж добрались сюда, значит проверка прошла успешно.
send< check_result >( reply_to, email_file, check_status::safe );
}
catch( const exception & ) {
send< check_result >( reply_to, email_file, check_status::check_failure );
}
}
```
Вот в таком случае получился бы более компактный и понятный код, который был бы похож на решение этой задачи в таких языках, как Erlang или Go.
Наш опыт говорит о том, что в ситуациях, когда агент выполняет какой-то линейный набор операций вида «отослал запрос, тут же стал ждать единственный ответ», его реализация в виде конечного автомата будет невыгодной с точки зрения объема и сложности кода. Вместо простого ожидания ответа и непосредственного продолжения работы после его получения, агенту нужно завершать свой текущий обработчик события, а все остальные действия приходится выносить в другой обработчик. Если агент в течении своей жизни выполняет N последовательно идущих асинхронных операций, то у этого агента, скорее всего будет (N+1) обработчик. Что не есть хорошо, т.к. разработка и сопровождение такого агента будет отнимать много сил и времени.
Совсем другая ситуация будет в случае, если в каждый момент, когда агент чего-то ждет, к нему может прийти несколько разных сообщений, и на каждое из них агент должен будет среагировать. Например, агент может ждать результата текущей операции, и в этот момент к агенту могут прийти запросы с проверкой статуса операции и с требованием выполнить новую операцию. В этом случае на каждом ожидании агента придется расписывать реакцию на все ожидаемые типы сообщений и это также довольно быстро может превратить код агента в объемную и плохо понимаемую лапшу.
Поскольку SObjectizer на данный момент поддерживает агентов только в виде конечных автоматов, то нужно тщательно оценить, насколько хорошо логика прикладных агентов ложится на конечные автоматы. Если не очень хорошо, то SObjectizer может быть не лучшим выбором и имеет смысл посмотреть на решения, которые используют сопрограммы. Например, [boost.fiber](https://github.com/boostorg/fiber) или [Synca](https://github.com/gridem/Synca) (о последнем были интересные статьи на Хабре: [№1](https://habrahabr.ru/post/201826/) и [№2](https://habrahabr.ru/company/yandex/blog/240525/)).
Так что три предыдущие статьи в минисерии «SObjectizer: от простого к сложному», с одной стороны, показывают возможности SObjectizer-а, но, с другой стороны, позволяют увидеть, куда можно зайти, есть подойти к решению задачи не с той стороны. Например, если начать использовать агентов в виде конечных автоматов там, где имело бы смысл использовать агентов в виде сопрограмм.
Но если для многих случаев сопрограммы выгоднее чем конечные автоматы, то почему SObjectizer не поддерживает агентов в виде сопрограммы? Тому есть несколько серьезных причин, как технических, так и организационных. Вероятно, если бы сопрограммы были частью языка C++, агенты-сопрограммы в SObjectizer уже были бы. Но т.к. сопрограммы в C++ сейчас доступны лишь посредством сторонних библиотек и тема это не самая простая, то мы не спешим с добавлением этой функциональности в SObjectizer. Тем более, что у этой проблемы есть совсем другая сторона. Но чтобы поговорить об этом, нужно зайти издалека...
Давным давно, когда заработала первая версия SObjectizer-а, мы сами совершили ту же ошибку, что и многие новички, впервые получившие в руки инструмент на базе модели акторов: если есть возможность создавать агентов на каждый чих, значит нужно создавать. Выполнение любой задачки должно быть представлено в виде агента. Даже если эта задачка состоит в получении всего одного запроса и отсылки всего одного ответа. В общем, опьянение от новых возможностей из-за чего внезапно начинаешь придерживаться мнения, что «в мире нет ничего кроме агентов».
Вылилось это в несколько негативных последствий.
Во-первых, код приложений оказывался объемнее и сложнее, чем того хотелось бы. Ведь асинхронные сообщения подвержены потерям и там, где можно было бы написать один синхронный вызов, возникали навороты вокруг посылки сообщения-запроса, обработки сообщения-ответа, отсчета тайм-аута для диагностирования потери запроса или ответа. При анализе кода оказывалось, что где-то в половине случаев взаимодействие на сообщениях оправданы, т.к. там осуществлялась передача данных между разными рабочими потоками. А в оставшихся местах можно было слить кучу мелких агентов в один большой и выполнять все операции у него внутри через обычные синхронные вызовы функций.
Во-вторых, оказалось, что за поведением построенного на агентах приложения гораздо сложнее следить и еще сложнее его предсказывать. Хорошей аналогией будет наблюдение за полетом большой стаи птиц: хотя правила поведения отдельной особи просты и понятны, предсказать поведение всей стаи практически невозможно. Так и в приложении, в котором одновременно живут десятки тысяч агентов: каждый из них работает вполне понятным образом, но совокупный эффект от их совместной работы может быть непредсказуем.
Что еще плохо, так это увеличение объема информации, которая нужна для понимания происходящего в приложении. Возьмем наш пример с email\_analyzer-ами. Один-единственный агент analyzer\_manager может поставлять такие сведения, как общее количество ожидающих своей очереди запросов, общее количество живых агентов email\_analyzer, минимальное, максимальное и среднее время ожидания запроса в очереди (аналогично и по временам обработки запросов). Поэтому контроль за деятельностью analyzer\_manager не представляет из себя проблемы. А вот сбор, агрегация и обработка сведений от отдельных email\_analyzer-ов – это уже сложнее. Причем, тем сложнее, чем больше этих агентов и чем короче их время жизни.
Так что, чем меньше агентов живет в приложении, тем проще за ними следить, тем проще понимать, что и как происходит, тем проще предсказывать поведение приложения в тех или иных условиях.
В-третьих, непредсказуемости, которые возникают время от времени в приложениях с десятками тысяч агентов внутри, могут приводить приложение в частично или полностью неработающее состояние.
Характерный случай: в приложении под сотню тысяч агентов. Они все с помощью периодических сообщений контролируют тайм-ауты своих операций. И вот в один прекрасный момент наступают тайм-ауты сразу для, скажем, 20 тысяч агентов. Соответствующим образом на рабочих нитях распухают очереди сообщений для обработки. Эти очереди начинают разгребаться, каждый агент получает свое сообщение и обрабатывает его. Но пока эти 20 тысяч сообщений обрабатываются, проходит слишком много времени и от таймера прилетает еще 20 тысяч. Это в довесок к той части старых сообщений, которые все еще стоят в очередях. Понятное дело, что все обработаться не успевает и прилетает еще 20 тысяч сообщений. И т.д. Приложение вроде как честно пытается работать, но постепенно деградирует до полной неработоспособности.
В результате хождения по этим граблям в самом начале использования SObjectizer в своих проектах мы пришли к выводу, что возможность создать миллион агентов – это в большей степени маркетинговый булшит, нежели востребованная в нашей практике[\*](#our_practice_note) штука. И что подход, который стал известен под названием [SEDA-way](https://en.wikipedia.org/wiki/Staged_event-driven_architecture), позволяет строить приложения, которые намного проще контролировать и которые ведут себя намного предсказуемее.
Суть использования SEDA-подхода в купе с моделью акторов в том, что вместо создания акторов, выполняющих целую цепочку последовательно идущих операций, лучше создать по одному актору на каждую операцию и выстроить их в конвейер. Для нашего примера с email-анализаторами, вместо того, чтобы делать агентов email\_analyzer, последовательно выполняющих загрузку содержимого email-а, парсинг и анализ этого содержимого, мы могли бы сделать несколько stage-агентов. Один stage-агент контролировал бы очередь запросов. Следующий stage-агент обслуживал бы операции загрузки файлов с email-ами. Следующий stage-агент выполнял бы парсинг загруженного содержимого. Следующий – анализ. И т.д., и т.п.
Принципиальный момент в том, что в показанных ранее реализациях email\_analyzer сам инициирует все операции, но только для одного конкретного email-а. А в SEDA-подходе у нас было бы по одному агенту на каждую операцию, но каждый агент мог бы делать ее сразу для нескольких email-ов. Кстати говоря, следы этого SEDA-подхода видны даже в наших примерах в виде IO-агента, который есть ни что иное, как stage-агент из SEDA.
И вот, когда мы стали активно использовать идеи из SEDA, то выяснилось, что stage-агенты вполне удобно реализуются в виде конечных автоматов, т.к. им в каждый конкретный момент времени приходится ожидать разных входящих воздействий и реагировать на них в зависимости от своего состояния. Тут, на наш взгляд, конечные автоматы в долгосрочной перспективе оказываются удобнее, чем сопрограммы.
Кстати говоря, можно отметить еще один момент, на который часто обращают внимание те, кто впервые знакомится с SObjectizer-ом: многословность агентов. Действительно, как правило, агент в SObjectizer – это отдельный C++ класс, у которого, как минимум, будет конструктор, будут какие-то поля, которые должны быть проинициализированы в конструкторе, будет переопределен метод so\_define\_agent(), будет несколько обработчиков событий в виде отдельных методов… Понятное дело, что для простых случаев все это приводит к изрядному синтаксическому оверхеду (с). Например, в Just::Thread Pro простой актор-логгер может выглядеть так:
```
ofstream log_file("...");
actor logger_actor( [&log_file] {
for(;;) {
actor::receive().match([&](std::string s) {
log\_file << s << endl;
} );
}
} );
```
Тогда как в SObjectizer, если пользоваться традиционным подходом к написанию агентов, потребуется сделать что-то вроде:
```
class logger_actor : public agent_t {
public :
logger_actor( context_t ctx, ostream & stream ) : agent_t{ctx}, stream_{stream} {}
virtual void so_define_agent() override {
so_subscribe_self().event( &logger_actor::on_message );
}
private :
ostream & stream_;
void on_message( const std::string & s ) {
stream_ << s << endl;
}
};
...
ofstream log_file("...");
env.introduce_coop( [&log_file]( coop_t & coop ) {
coop.make_agent< logger_actor >( log_file );
} );
```
Очевидно, что в SObjectizer писанины больше. Однако, парадокс в том, что если придерживаться SEDA-подхода, когда агентов не очень много, но они могут обрабатывать разные типы сообщений, код агентов довольно быстро распухает. Отчасти из-за самой логики работы агентов (как правило, более сложной), отчасти из-за того, что агенты наполняются дополнительными вещами, вроде логгирования и мониторинга. И тут-то и оказывается, что когда основной прикладной код агента имеет объем в несколько сотен строк, а то и больше, то размер синтаксического оверхеда со стороны SObjectizer-а совершенно незначителен. Более того, чем больше и сложнее агент, тем выгоднее оказывается его представление в виде отдельного C++ класса. На игрушечных примерах этого не видно, но в «боевом» коде ощущается довольно сильно (вот, скажем, [маленький пример](http://eao197.blogspot.com.by/2016/05/progc14-sobjectizer.html) не самого сложного реального агента).
Таким образом, на основании своего практического опыта мы пришли к выводу, что если должным образом сочетать модель акторов и SEDA-подход, то представление агентов в виде конечных автоматов – это вполне нормальное решение. Конечно, где-то такое решение будет проигрывать сопрограммам по выразительности. Но в целом, агенты в виде конечных автоматов работают более чем хорошо и особых проблем не создают. За исключением, разве что, сравнения различных подходов к реализации модели акторов [на микропримерчиках](http://eao197.blogspot.com/2016/08/progcflame-codesize-battle-justthread.html).
В завершении статьи хочется обратиться к читателям. У нас в планах есть еще одна статья, в которой мы хотим затронуть такую важную проблему механизма взаимодействия на основе асинхронных сообщений, как перегрузка агентов. И, заодно, показать, как SObjectizer реагирует на ошибки в агентах. Но интересно было бы узнать мнение аудитории: что вам понравилось, что не понравилось, о чем хотелось бы узнать больше. Это сильно поможет нам как в подготовке очередной статьи, так и в развитии самого SObjectizer-а.
---
**\***Подчеркнем, что речь идет о нашем опыте. Очевидно, что другие команды, решающие с помощью модели акторов другие задачи, могут с успехом использовать большое количество акторов в своих приложениях. И имееть на этот счет прямо противоположное мнение. | https://habr.com/ru/post/308486/ | null | ru | null |
# Я создал приложение, которое делает изучение алгоритмов и структур данных гораздо интереснее
*Интерфейс CS-Playground-React*
[Я программист-самоучка](https://medium.freecodecamp.org/the-freecodecamp-alumni-network-a-homegrown-mentorship-network-for-fcc-alumni-529e4531c34f). Это значит, что я постоянно имею дело с [синдромом самозванца](https://medium.freecodecamp.org/i-built-an-app-that-makes-learning-algorithms-and-data-structures-way-more-fun-46fbb8afacaf). Для меня не редкость чувствовать, что я неполноценный, и я в невыгодном положении для понимания сложных концепций информатики.
Я никогда не разбирался в математике. И я всегда привязывал сильные математические навыки к своей естественной способности преуспеть в программировании. Я чувствую, что мне приходится больше работать, чем другим (у которых есть врожденные навыки к математике), чтобы изучать одни и те же понятия. С этой идеей, глубоко укоренившейся в моем мозгу, я был уверен, что никогда не смогу научиться чему-либо, например, обходить деревья двоичного поиска, и как мысленно анализировать рекурсивные кошмары, такие как сортировка слиянием.
Зайдите на [CS-Playground-React](http://cs-playground-react.surge.sh/), простую браузерную JavaScript-песочницу для изучения и практикования алгоритмов и структур данных.
Это приложение не требует регистрации и автоматически сохраняет ваши достижения, предлагает решения когда вы застряли, и имеет [кучу ссылок на полезные статьи, туториалы, и другие ресурсы](https://github.com/no-stack-dub-sack/cs-playground-react/blob/master/RESOURCES.md), чтобы помочь сделать ваше обучение не очень болезненным, как было у меня.
---
*Перевод выполнен при поддержке компании [EDISON Software](https://www.edsd.ru/), которая профессионально занимается разработкой [сервисов видеонаблюдения](https://www.edsd.ru/oblachnyj-servis-videonablyudeniya-zodiak), [приложения для виртуального сотового оператора](https://www.edsd.ru/mobilnye-prilozheniya-virtualnogo-sotovogo-operatora) и [разработкой программ на C и C++ (IPTV-плеер)](https://www.edsd.ru/razrabotka-programm-na-c).*
---
Позвольте мне сразу признать, что это приложение не является новаторским. (Я знаю, что вы так думали!) Существует множество приложений, которые учат подобным навыкам и дают вам возможность писать и запускать код прямо в вашем браузере.
CS Playground React — минималистичный инструмент для изучения специфического набора тем. Создание этого приложения это всего лишь мой способ выучить то что я хочу с интересом. Если оно окажется ценным ресурсом для еще одного человека на этом пути, тем лучше.
Приложение все еще развивается, и есть много места для размышления, когда дело касается предмета и потенциальных возможностей. Поэтому, если вы знаете крутую задачу или структуру данных, которые я не рассматривал, или заметили то, что можете улучшить, не стесняйтесь [открывать проблему](https://github.com/no-stack-dub-sack/cs-playground-react/issues/new) или отправлять pull request.
Если вы просто хотите посмотреть приложение, не читайте дальше — оно живет [здесь](http://cs-playground-react.surge.sh/) (также доступно через https, будет регистрировать сервис-воркер для автономного кэширования).
Если вас интересует код, не листайте дальше — [он тут](https://github.com/no-stack-dub-sack/cs-playground-react).
Далее будут — скучные вещи о том, почему и как.
### Почему я создал это
Мои мотивы для создания этого приложения были простыми: я хотел учиться, и я хотел сделать обучение более легким и интересным. Более важно — почему я хотел получить эти конкретные навыки.
За последние 18 месяцев или около того я могу с уверенностью сказать, что я научился писать код. Хотя я все еще не решаюсь назвать себя программистом. И это не потому, что я не пишу код для жизни (а я не пишу), а из-за явления [синдрома самозванца](https://en.wikipedia.org/wiki/Impostor_syndrome), о котором я упоминал ранее. Я конечно знаю как делать вещи. Но до недавнего времени я очень мало знал о настоящей информатике.
Изучив основы информатики, я надеялся не только чувствовать себя увереннее в том, чтобы думать о себе, как о программисте, но и о том, чтобы помочь другим увидеть меня таким же образом.
Программисты-самоучки — это таблетка, которую в последние годы технологическая индустрия стала легче глотать. Особенно в таких местах, как Силиконовая долина, где кодинг буткемпы возникли на каждом углу улицы.
Тем не менее, по-прежнему существует серьезное препятствие для большинства программистов, надеющихся войти в отрасль без формального образования в области информатики.
Поэтому, чтобы помочь уменьшить разницу между бакалавром гуманитарных и бакалавром технических наук, я решил учить себя некоторым из понятий, которые могут изучить студенты первого или второго курса направления информатики. Я думал, что это будет дополнять некоторые из моих практических навыков разработки и помогать другим воспринимать меня более серьезно как программиста.
Я использовал набор тем, которые, как известно, являются общими для программирования в качестве базы, которую я хотел бы охватить.
Сортировка пузырьком, сортировка выбором, сортировка вставками, сортировка слиянием, быстрая сортировка, сортировка кучей, стеки, очереди, связные списки, хэш таблицы и деревья двоичного поиска…
Я был очень напуган этим набором задач и довольно долго откладывал их.
Не желая принять поражение, я, наконец, начал копаться. Поиск учебников, чтение каждой статьи, которую я мог найти, изо дня в день.
Со временем некоторые из концепций начали проясняться. Но было несколько проблем:
1. **Мне стало скучно**. Мне нравится решение задач, но давайте посмотрим правде в глаза, решение `reverseLevelOrder` обхода двоичного дерева поиска намного менее интересно, чем решение реальной задачи для вашего последнего приложения.
2. **Это заняло много времени**. Я работаю полный рабочий день (НЕ пишу код весь день), и мое свободное время для кодинга чрезвычайно ценно. Я знал, что буду тратить на это месяцы, и я стал беспокоиться о том, что потеряю связь с моими более существующими навыками.
Весь этот материал по информатике хорош, чтобы иметь его на вооружении, но давайте посмотрим правде в глаза, чаще всего мы, веб-разработчики, нанимаемся, чтобы создавать. И существует не слишком много практических применений для большинства этих концепций в повседневной веб-разработке.
Для меня изучение этих концепций было предметом гордости, и я не собирался сдаваться. Но, по-прежнему приоритетно для меня было иметь опыт в веб-разработке.
Поэтому я решил объединить две идеи. Идея состояла в том, чтобы создать простое приложение, которое помогло бы мне достичь моих целей и сохранить мои основные навыки.
Для меня лучший способ узнать что-то (особенно что-то сложное) — это связать его с чем-то, что вы любите. По мере того как я создавал это приложение, и, выполнял задания, я также разрабатывал для него контент.
Теперь изучение алгоритмов и структур данных было необходимой частью моего последнего проекта. Потому что в чем смысл создания приложения для подготовки к собеседованию, если вы не собираетесь заполнять его задачами!
Каждые несколько дней я изучал новый алгоритм или структуру данных. Как только я чуть было не сдался, я собрал учебные ресурсы и добавил их в приложение. Теперь я мог практиковать их снова и снова в супер простой рабочей области, которую я создал. Насколько это круто!?
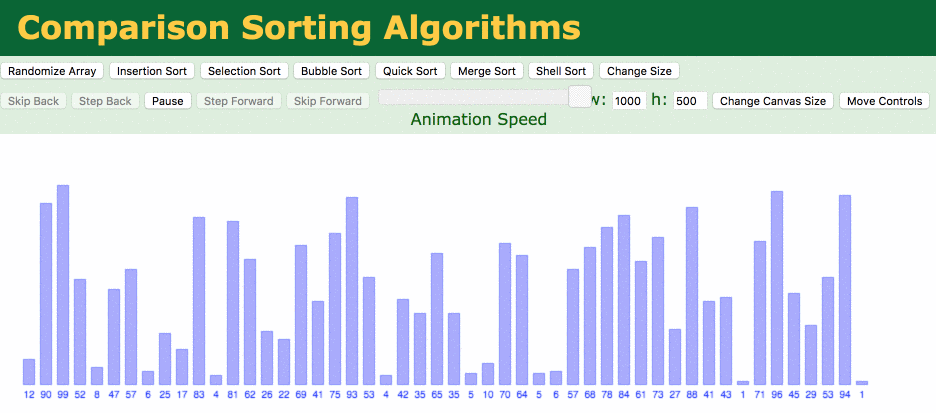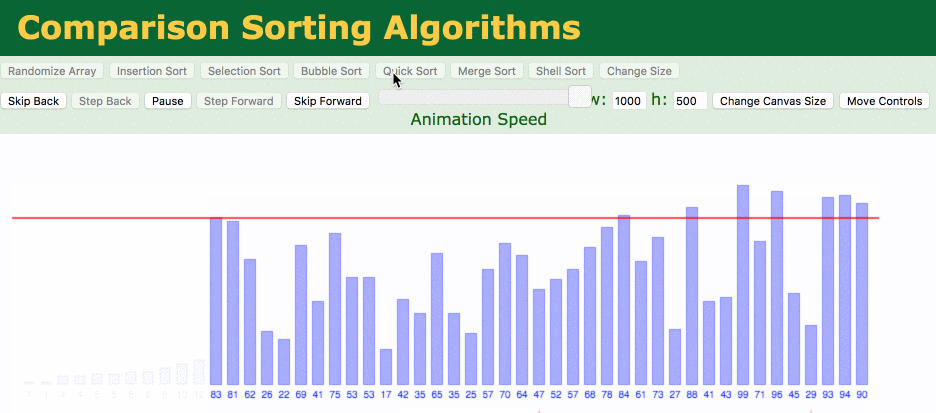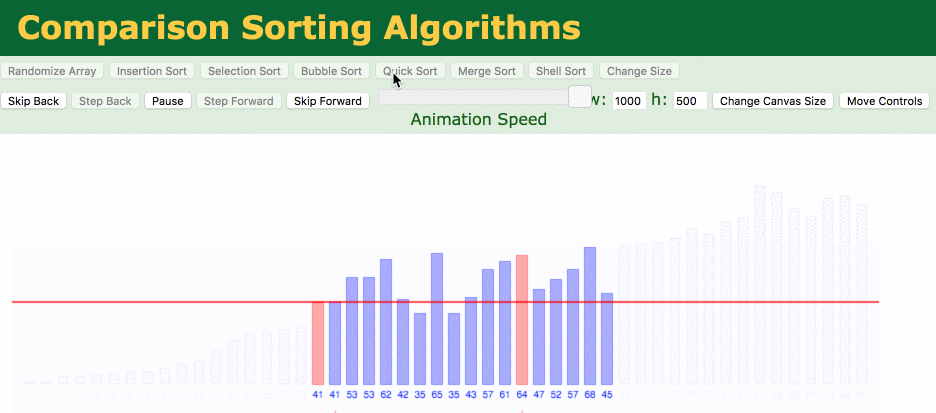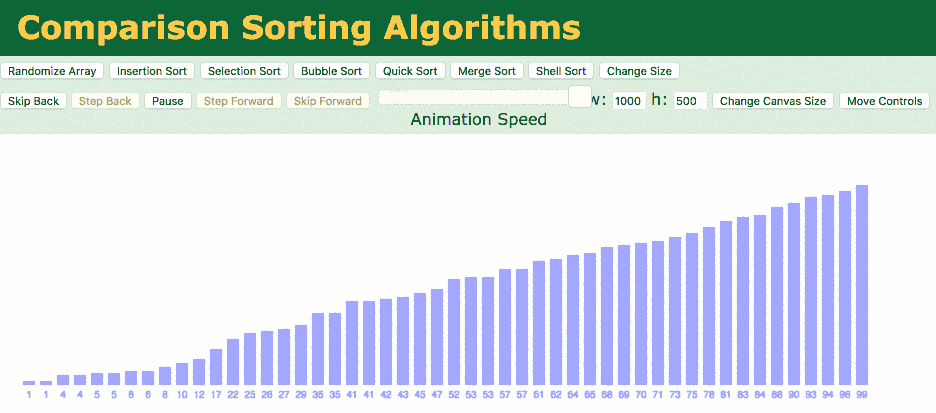
*Действительно классный сайт, который я нашел, который визуализирует, как работают алгоритмы сортировки и структуры данных. Это быстрая сортировка выполняет свое дело в массиве из 100 элементов. Здесь вы можете найти полный [список визуализаций](https://www.cs.usfca.edu/~galles/visualization/Algorithms.html). Спасибо USF, это потрясающе!*
Главное, я взялся за то, что откладывал надолго, и нашел способ сделать это интересным. И, конечно же, у меня был большой прорыв в достижении моих целей из-за этого.
Я создал это приложение для себя, но я хотел поделиться им со всеми вами по какой-то причине. Если даже еще один человек найдет для себя пользу в CS-Playground-React, я почувствую, что сделал свою работу(или, по крайней мере, часть ее), чтобы отдать это сообществу.
Есть очень много программистов, которые свободно делятся своими знаниями и опытом и просят либо мало либо ничего взамен. Без такого открытого сообщества вряд ли можно было бы научиться самостоятельно программировать.
Десять лет назад было гораздо меньше вариантов, когда речь заходила о самостоятельном обучении. Поэтому я благодарен каждый день за то, что живу в эпоху информации, где так много знаний, которые так легко доступны.
Это сделало путешествие возможным для меня, и я надеюсь, что кто-то еще там наткнется на эту статью и обнаружит, что их собственное путешествие стало немного легче.
### Стек технологий и фишки
В случае, если вам интересно, я создал это приложение с помощью React & React-Redux (хотя [первой версией](https://github.com/no-stack-dub-sack/algos-and-data-structures) был ванильный JS, CSS и HTML). Оно также использует [CodeMirror](https://codemirror.net/) и [React-Codemirror2](https://github.com/scniro/react-codemirror2) для встраивания редактора в браузер (ПРИМЕЧАНИЕ: исходный React-CodeMirror больше не поддерживается и не очень хорошо работает с более новыми версиями React).
### Фиктивная консоль
Небольшая фишка позволяет мне запускать действие redux каждый раз, когда пользователь вызывает console.log в своем коде. Таким образом, я могу поймать журнал сообщений и, в свою очередь, выводить консоль в браузере, чтобы показать результат выполнения кода — я думаю это классно! Вы можете использовать clearConsole() в любое время, когда хотите очистить сообщения фиктивной консоли.
```
import { store } from './index';
export const hijackConsole = () => {
const OG_LOG = console.log;
console.log = function(...args) {
// map over arguments and convert
// objects in to readable strings
const messages = [...args].map(msg => {
return typeof msg !== 'string'
? JSON.stringify(msg)
: msg;
}).join(' ');
store.dispatch({
type: CONSOLE_LOG,
messages
});
// retain original functionality
OG_LOG.apply(console, [...args]);
};
};
```
*Переопределение console.log для поимки и сохранения записанного кода*
### Сохраняемый код
Я хотел сделать это приложение супер простым в использовании. Поэтому вместо того, чтобы внедрять базу данных и запрашивать у пользователей вход в систему, я выбрал более простой подход для сохранения прогресса. Redux управляет состоянием приложения во время каждого сеанса, и я использую `localStorage` для сохранения кода в сеансах. Приложение извлекает это сохраненное состояние при следующем посещении и регидратирует с ним хранилище Redux. Таким образом, вы можете вернуться на место, где вы остановились.
Если по какой-то причине вы хотите удалить все ваши достижения, вы можете использовать `resetState()` в любое время в редакторе. Если вы не хотите сохранять свой код, оставьте комментарий // `DO NOT SAVE` перед прохождением. Это предотвратит сохранение какого-либо кода не только для этого файла.
```
import { store } from './fileWhereStoreLives';
// add this code in your app's entry point file to
// set localStorage when navigating away from app
window.onbeforeunload = function(e) {
const state = store.getState();
localStorage.setItem(
'local-storage-key',
JSON.stringify(state.stateYouWantToPersist)
);
};
```
```
import { importedState } from './fileWhereStateLives';
// define your reducer's initial state:
const initialState = {
...importedState;
};
// define default state for each subsequent visit.
// if localStorage with this key exists, assign it
// to this variable, otherwise, use initialState.
const defaultState = JSON.parse(
localStorage.getItem('local-storage-key')
) || initialState;
// set defaultState of reducer to result of above operation
const reducer = (state = defaultState, action) => {
switch (action.type) {
case 'DO_SOMETHING_COOL':
return {
...state,
...action.newState
};
default:
return state;
}
}
export default reducer;
```
С другой стороны есть пакет, который делает это за вас, называемый Redux-Persist (о чем я узнал постфактум). Но для простого использования, если вы можете сделать что-то с несколькими строками кода, или установить пакет NPM, чтобы сделать то же самое? Я выберу первое в любом случае. Скорее всего, вы сохраняете сотни строк кода и целый набор новых зависимостей. Это вечный компромисс, и вы должны решить, когда хорошо оптимизированное решение лучше, чем ваш упрощенный способ.
### Изменение размеров панели
Последний трюк, который у меня был в рукаве, делать рабочее пространство гибким и простым в использовании. Я хотел дать пользователям возможность изменять размер как редактора, так и консоли, поэтому я использовал небольшой скрипт, который я нашел — [`simpleDrag.js`](https://github.com/lingtalfi/simpledrag), `React refs` и волшебство flexbox, чтобы сделать это возможным.
**Читать еще**
[Учим CSS Grid за 5 минут](https://habrahabr.ru/company/edison/blog/343614/) | https://habr.com/ru/post/343706/ | null | ru | null |
# Монтируем видео на облачном сервере в AWS
Мой рабочий компьютер - Macbook Air 2020 (Intel), и его вполне хватает для написания кода и прочих задач. Однако, когда потребовалось смонтировать небольшой видеоролик, выяснилось что мощи моего ноута катастрофически не хватает, и я стал искать варианты.
### Что я пытался сделать
Я не занимаюсь профессиональным монтажом видео, и впервые уткнулся в эту тему пытаясь сделать вот такой небольшой демонстрационный ролик для [Teamplify](https://teamplify.com/) (с озвучкой помог Мэтт, наш учитель английского):
На первый взгляд, тут ничего сложного - это же просто трехминутный скринкаст с озвучкой и парой незатейливых эффектов. Однако, видимо по неопытности, я встретил на этом пути какое-то неожиданное количество подводных граблей. После нескольких неудачных попыток, я пришел к трем важным выводам:
1. Обязательно нужен сценарий, и его важно написать заранее, продумав дословно все что будет говориться и делаться в кадре;
2. Записать это единым куском практически невозможно - то замешкаешься где-то, то ошибешься, то интернет подтупит;
3. Нельзя просто так взять и записать качественный звук в домашних условиях.
В итоге, конечный результат я собирал в After Effects из множества отдельных коротких видео, скриншотов, и аудио-фрагментов, которые подгонялись по таймингу, и на них накладывались эффекты с переходами:
Фоновую музычку изначально добавлять не планировал, но оказалось что она прекрасно маскирует не совсем качественную запись с микрофона, так что добавил.
Монтаж видео требует ресурсов
-----------------------------
Мои попытки работать с видео на Macbook Air были похожи на мучение. Оказалось, что After Effects любит побольше памяти, и моих 16ГБ явно не хватало. Ноутбучный проц и слабая видюха также не улучшали картину. Превью в After Effects работало с сильными лагами. Финальный рендер трехминутного ролика занимал 3 часа (!!).
Если бы у меня был настольный игровой комп с видюхой и кучей памяти, наверное, приключения на этом бы и закончились, но у меня такого не было, а идея вложить в него пару тысяч долларов (да и вообще иметь такую бандуру дома) мне не нравилась.
Что нам может предложить AWS?
-----------------------------
Мне он предложил примерно следующее:
* Регион eu-north-1 (Стокгольм), пинг до меня ~30мс (я живу в Вильнюсе), до Москвы чуть побольше, но тоже неплохо - около 40мс;
* Сервер g4dn.2xlarge - 8 ядер, 32ГБ, Nvidia Tesla T4, 225 GB NVMe SSD;
* Образ [винды с дровами от Nvidia](https://aws.amazon.com/marketplace/search/results?page=1&filters=VendorId%2CAmi::OperatingSystem&VendorId=e6a5002c-6dd0-4d1e-8196-0a1d1857229b&Ami::OperatingSystem=Win2016%2CWin2019&searchTerms=tesla+driver);
* Цену в $1.166 в час. И это кстати еще одна причина выбрать Стокгольм, ибо во Франкфурте на ~12% дороже.
Разумеется, можно взять и побольше, и поменьше. На момент написания статьи [цены](https://aws.amazon.com/ec2/pricing/on-demand/) в Стокгольме такие (инстансы с Nvidia Tesla T4, на винде):
Подготовка к работе
-------------------
Для коннекта к серверу я использовал [Microsoft Remote Desktop](https://www.microsoft.com/en-us/p/microsoft-remote-desktop/9wzdncrfj3ps). Сначала я думал, что мне потребуются какие-то специальные клиенты, рассчитанные на стриминг видео, но оказалось что и обычный Remote Desktop неплохо справляется, никаких особенных лагов я не замечал.
Остается решить вопрос с диском и доставкой исходников на него. Тут амазона предлагает нам два варианта - EBS и Instance Store. Отличаются они следующим:
* **EBS** - подключаемый сетевой диск, по надежности примерно как RAID 1. Такой диск в вашем сервере обязательно будет как основной, по умолчанию он небольшого размера (достаточного чтобы влезла операционка), но вы можете при желании его расширить. Данные на EBS сохраняются и после выключения сервера. Платите вы за такой диск постоянно, даже если сервер выключен, в размере $0.0836 за ГБ в месяц (в версии gp3, burstable IOPS). У EBS есть [разные варианты по производительности](https://aws.amazon.com/ebs/pricing/). Можно купить гарантированную производительность, но тогда она может влететь в копеечку, или же можно остаться на “стандартном” gp3, который основан на модели burstable IOPS. Когда диск простаивает, у вас накапливаются кредиты на IO, а когда он активно используется - они расходуются. Подробнее можно почитать в [доках](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volume-types.html).
* **Instance store** - так называемый “эфемерный” диск, который может идти в комплекте к некоторым типам инстансов. В частности, к g4dn.2xlarge прилагается 225 GB NVMe SSD. Он быстрый, производительность ничем не ограничена, однако данные на нем полностью пропадают при выключении сервера (при перезагрузке - остаются).
Поскольку монтаж видео активно использует и диск тоже, использование Instance store выглядело для меня более привлекательным. По умолчанию он не монтируется как диск в Windows, поэтому нужно сделать небольшую настройку чтобы он [автоматически подключался при запуске](https://serverfault.com/questions/814515/on-ec2-windows-server-2016-automatically-mount-instance-storage-when-restarting).
Когда диск готов, нужно как-то доставить на него исходники. Я использую для этого pCloud (аналог Dropbox), который установлен и на моем ноуте, и на облачном сервере. При старте сервера на нем запускается небольшой батничек, который инициализирует расшаренную папку pCloud (для исходников и результатов) и заодно создает папку для кеша After Effects:
```
mkdir Z:\"Teamplify Videos"
mkdir Z:\"AE Cache"
```
После этого стартует pCloud, который синхронизирует папку “Teamplify Videos” с исходниками. Отрендеренный результат я пишу в ту же папку, и таким образом он попадает обратно на мой компьютер.
Как возможную альтернативу Dropbox / pCloud можно еще рассмотреть что-то вроде [ownCloud с хранилищем на S3](https://doc.owncloud.com/server/admin_manual/enterprise/external_storage/s3_swift_as_primary_object_store_configuration.html). Если исходники будут выкачиваться из S3 в том же AWS регионе, что и ваш сервер, то это должно быть очень быстро, что может иметь значение при большом размере исходников.
Ну и заключительный штрих в настройке - я добавил CloudWatch alarm, который автоматически выключает сервер после пары часов неактивности, чтобы не забыть его случайно включенным и не тратить деньги.
И как это все работает?
-----------------------
Да вроде неплохо. Превью в After Effects нормальное, без лагов. Поскольку пинг до сервера хороший, работа на нем почти не отличается от работы с настольным компьютером. Рендер того ролика, который у меня на ноуте выполнялся три часа, на g4dn.2xlarge делается за 13-17 минут. День работы на таком сервере обходится в несколько долларов.
Из побочных плюсов - я сохраняю мобильность с ноутом, и могу работать с видео откуда угодно, лишь бы были нормальные интернеты.
---
P.S. После опубликования этой статьи [@Stas911](/users/stas911) подкинул идею попробовать [NICE DCV](https://aws.amazon.com/hpc/dcv/) вместо Remote Desktop для подключения к серверу (для EC2 - бесплатно), и я попробовал. Работает :) Запускайте сервер на базе [NICE DCV AMI](https://aws.amazon.com/marketplace/seller-profile?id=74eff437-1315-4130-8b04-27da3fa01de1) (версия для g4), не забудьте добавить [роль инстансу](https://docs.aws.amazon.com/dcv/latest/adminguide/setting-up-license.html#setting-up-license-ec2) чтобы оно перестало ругаться на лицензию, и установите [EC2Launch v2](https://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/ec2launch-v2.html) чтобы инстанс видел собственную мета-дату.
EC2Launch вам также понадобится чтобы подключить Instance store как диск в винде. Для этого натыкайте в нем мышкой галочку "Initialize" в разделе Volumes и перезагрузите сервер:
 | https://habr.com/ru/post/555414/ | null | ru | null |
# PHP 7.0.0
Несколько часов назад Anatol Belski, релиз менеджер PHP, [тегнул стабильный релиз](https://github.com/php/php-src/releases/tag/php-7.0.0) PHP 7.0.0. Это значит, что сегодня-завтра мы увидим официальный анонс на php.net. Наконец, можно будет пользоваться новыми прекрасными возможностями: строгой типизацией, оператором `??`, анонимными классами, безопасным рандомом и многим другим. Как приличный бонус все перешедшие получат значительный прирост производительности.
В официальной англоязычной документации уже доступен раздел с описанием всех новых возможностей и инструкциями по миграции старых проектов: <https://secure.php.net/manual/en/migration70.php>. Также почитать о семёрке можно и на хабре:
* [Чего ждать, когда ждешь ребенка: PHP 7, часть 1](http://habrahabr.ru/post/257237/)
* [Чего ждать, когда ждешь ребенка: PHP 7, часть 2](http://habrahabr.ru/post/258139/)
* [Сравнение скорости исполнения кода Drupal для PHP 5.3-5.6 и 7.0. «Битва оптимизаторов кода» apc vs xcache vs opcache](http://habrahabr.ru/post/264775/)
* [Мой опыт миграции на PHP 7](http://habrahabr.ru/post/271181/)
**Апдейт**: [а вот и официальный анонс](https://secure.php.net/archive/2015.php#id2015-12-03-1). | https://habr.com/ru/post/272099/ | null | ru | null |
# Reactive Spring ABAC Security: безопасность уровня Enterprise
В продолжение предыдущей статьи [Передовые технологии на службе СЭД](https://habr.com/ru/post/572952/) рассмотрим современные подходы к обеспечению корпоративной безопасности и ожидаемые системные риски.
### Аннотация
Что такое безопасность уровня Enterprise? Встречается огромное разнообразие схем конфигурации безопасности инфраструктуры. Например: валидация и кэширование токена только в сервисе Gateway с прямой отправкой логина и списка ролей сервисам или ретрансляция токена с Gateway в сервисы для активации функций Spring Security через распаковку токена в логин и роли с проверкой только подписи токена и т.д. и т.п.
На самом деле, любую существующую схему безопасности можно отнести к Enterprise. Базовая конфигурация Spring Security, предоставляемая по умолчанию, не выдерживает ни высоких ни средних нагрузок. Данный фактор стал одним из главных причин разнообразия подходов к безопасности, возникших в поиске оптимального способа поддержки высоких нагрузок в рамках существующей инфраструктуры и технологий.
В статье рассматриваются основные аспекты конфигурирования корпоративной безопасности с поддержкой высоких нагрузок в реактивном стеке технологий. Подробно описана модель безопасности *attribute-based access control* (ABAC), которая применяет совокупность абстрактных правил к определённому типу действий, с учётом роли при необходимости.
Перечисляются видимые риски более высокого уровня с обзором их снижения или обхода. А также, некоторый поучительный исторический экскурс с акцентом на до сих пор возможные риски безопасности.
### Введение
Начнём с рассмотрения основополагающей на данный момент модели безопасности ABAC в сравнении с классической моделью *role-based access control* (RBAC).
Классическая модель безопасности RBAC предлагает грубый подход, не позволяющий описать политику безопасности многоуровневой филиальной системы.
RBAC оперирует ролями и группами ролей. Каждая роль напрямую привязана к действию, что приводит к созданию большого количества ролей (роль менеджера головной организации, роль менеджера филиала, роль менеджера подразделения филиала – разные сущности в силу функциональных различий).
Большое множество ролей не позволяют эффективно выстроить политики безопасности, группирующие типичные действия из-за неочевидности их разграничения. Модель RBAC стала архаичной не смотря на сегодняшнее присутствие в большинстве информационных систем.
Основное преимущество модели безопасности ABAC в возможности описания политики безопасности через совокупность правил, основанных на атрибутах участвующих в действиях пользователя. Такой подход позволяет детализировать политики безопасности до необходимого уровня.
Целевое направление применения ABAC – описание политик безопасности филиальной системы с полным контролем доступа до любого уровня вложенности и сложности описания правил. Все правила ABAC описываются в виде SpEL-выражений и в отличии от RBAC хранятся в базе данных, где соответственно легко поддаются анализу и модификации.
Можно отметить интересный факт связанный с переходом информационной безопасности от модели RBAC к ABAC – на первом этапе каждая политика будет содержать одно правило.
Предлагаемые в статье технологии и подходы в полной мере реализуют концепцию ABAC с поддержкой высоких нагрузок за счёт применения каскадного кэширования с гарантией консистентности.
В итоге, реализована библиотека [Reactive Spring ABAC Security](https://github.com/SevenParadigms/reactive-spring-abac-security) с открытым исходным кодом на GitHub, обладающая рядом свойств: как гибкость в настройках, мощь в широких возможностях и скорость в работе. Библиотека опубликована в Maven Central:
```
io.github.sevenparadigms
reactive-spring-abac-security
1.0.4
```
Исходного кода получилось немало, поэтому, выделим в статье только часть касательно ABAC и особенно важных моментов. Примечательно, что реализация ABAC крайне проста при столь гибком функционале.
Через настройки библиотеки можно выбрать любую гомоморфную исходной схему конфигурации безопасности из коробки, а также генерировать или валидировать токен – в совокупности, такая гибкость и излишняя функциональность становится особенно удобной при разработке прототипа проекта на начальной стадии с целью точной оценки итоговых сроков реализации или участия в тендере, продемонстрировав готовый прототип с основным функционалом, в то время, как у конкурентов ничего нет.
Совсем необязательно поднимать дополнительный корпоративный SSO-сервер аутентификации типа Keycloak для задач такого рода, когда скорость реализации и простота развёртывания выходят на передний план – для таких задач достаточно фрилансера, без отрыва внутренних ресурсов от основных задач.
Предлагаемая библиотека на клиентской стороне активирует Spring Security с моделью безопасности ABAC, при этом, кэшируя данные по токену, обратившись к сервису авторизации только раз. Пометка отозванности токена в кэше происходит через событие Spring Event, инициацию которого оставляем за логикой инфраструктуры при завершении сессии пользователя.
### Основные аспекты реализации
Рассмотрим основные моменты при настройке конфигурации безопасности Spring Security:
```
@Bean
fun securityWebFilterChain(
http: ServerHttpSecurity,
authenticationWebFilter: AuthenticationWebFilter,
abacRulePermissionService: AbacRulePermissionService,
expressionHandler: DefaultMethodSecurityExpressionHandler
): SecurityWebFilterChain {
expressionHandler.setPermissionEvaluator(abacRulePermissionService)
http.csrf().disable()
.headers().frameOptions().disable()
.cache().disable()
.and()
.exceptionHandling().authenticationEntryPoint(unauthorizedEntryPoint())
.and()
.authorizeExchange()
.pathMatchers(HttpMethod.OPTIONS)
.permitAll()
.and()
.requestCache().requestCache(NoOpServerRequestCache.getInstance())
.and()
.authorizeExchange()
.matchers(EndpointRequest.toAnyEndpoint())
.hasAuthority(Constants.ROLE_ADMIN)
.and()
.authorizeExchange()
.pathMatchers(*Constants.whitelist).permitAll()
.anyExchange().authenticated()
.and()
.securityContextRepository(NoOpServerSecurityContextRepository.getInstance())
.addFilterAt(authenticationWebFilter, SecurityWebFiltersOrder.AUTHORIZATION)
.httpBasic().disable()
.formLogin().disable()
.logout().disable()
return super.tryAddTokenIntrospector(http).build()
}
```
Строка expressionHandler.setPermissionEvaluator(abacRulePermissionService) включает функционал ABAC. Все правила ABAC представляют собой компилируемые и кэшируемые SpEL-выражения, предоставляя полную свободу в предикатах. Подробное описание подключения ABAC в разделе настройки безопасности на стороне клиентского сервиса через файл конфигурации application.yml
По умолчанию, при первом запросе клиента, Spring создаёт web-сессию для кэширования сессионных переменных и результата запросов, а также сбора различных данных при взаимодействии с клиентом в рамках сессии. Данный подход устарел – сессии занимают значительный объем памяти и вся логика вокруг сессий не имеет перспектив, не говоря уже о проблемах утечки в реактивном стеке.
На много проще и увереннее поддерживать жизнь сессии в рамках одной реактивной цепочки инструкций запрос-ответа, после чего, сессия благополучно закроется вместе с сессионным потоком. Кто-то возразит и скажет, что кэширование сессий экономит до тысячи инструкций на её создание, но тут дело в совокупности факторов: неоднозначность данной устаревшей оптимизации пришедшей с наследством из синхронного стека, высокой эффективности современных процессоров, когда тысяча инструкций выполняются менее чем за 1 мс и риске утечки памяти реактивного стека.
Следующей строкой отключаем поддержку сессий: securityContextRepository(NoOpServerSecurityContextRepository.getInstance())
В Webflux была проблема [#7157](https://github.com/spring-projects/spring-security/issues/7157) связанная с автоматическим кэшированием в сессиях, поэтому также отключаем сессионное кэширование строкой: requestCache().requestCache(NoOpServerRequestCache.getInstance()), чтобы Webflux оперировал только кэшем уровня бизнес-логики и только в контексте потока исполняемого запроса.
По умолчанию, Spring Security не кэширует токен из-за постоянной необходимости проверки токена на отозванность в сервисе авторизации. Но допустим, если взять с десяток сервисов с разной степенью нагруженностью в зависимости от решаемых бизнес-задач, разнесённых в десятки подов, то сервису авторизации понадобится больше сотни подов из-за чрезмерной нагрузки, т.к. один внешний запрос может каскадно индуцировать подзапросы на все сервисы и создавая таким образом подобие DDoS-атаки на сервис авторизации.
Возможность кэширования токенов предусмотрена в библиотеке Spring OAuth2 через расширение OpaqueToken и кэширующий интроспектор NimbusOpaqueToken, который единожды валидирует токен в сервисе авторизации. Заменим интроспектор на свою реализацию, т.к. в нашей библиотеке не используются автоконфиги Spring OAuth2, не смотря на заимствование функционала, и включим в конфигурацию строкой: http.oauth2ResourceServer().opaqueToken().introspector(super.tokenIntrospector())
Появилась прямая необходимость в регистрации бина билдера WebClient сразу по нескольким причинам:
```
@Bean
fun webClientBuilder(): WebClient.Builder = WebClient.builder()
.clientConnector(
ReactorClientHttpConnector(
HttpClient.create(
ConnectionProvider.builder("fixed")
.maxConnections(500)
.maxIdleTime(Duration.ofSeconds(30))
.maxLifeTime(Duration.ofSeconds(60))
.pendingAcquireTimeout(Duration.ofSeconds(60))
.evictInBackground(Duration.ofSeconds(120)).build()
).keepAlive(false)
)
)
.exchangeStrategies(ExchangeStrategies.builder()
.codecs { c: ClientCodecConfigurer ->
c.customCodecs().register(Jackson2JsonDecoder(JsonUtils.getMapper()))
c.customCodecs().register(Jackson2JsonEncoder(JsonUtils.getMapper()))
}
.build())
.filter { clientRequest: ClientRequest, next: ExchangeFunction ->
Mono.deferContextual { ctx: ContextView ->
val requestHeaders = ctx.get(ServerWebExchange::class.java).request.headers.toSingleValueMap()
val request =
ClientRequest.from(clientRequest).headers { headers -> headers.setAll(requestHeaders) }.build()
next.exchange(request)
}
}
.codecs { it.defaultCodecs().apply { maxInMemorySize(16 * 1024 * 1024) } }
```
чтобы поправить маленький таймаут соединения, решить проблему ограничения пула в 16 соединений, зарегистрировать настроенный ObjectMapper, включить ретрансляцию заголовков и увеличить размер буфера обмена – работа с WebClient с дефолтными настройками со временем может привести к ряду ошибок, например 'Connection reset by peer'.
Также решилась проблема Netty с постоянным ростом незакрытых соединений при высокой нагрузке:
```
@Bean
fun nettyWebServerFactoryCustomizer() = WebServerFactoryCustomizer {
it.addServerCustomizers(
NettyServerCustomizer { server: HttpServer ->
server.doOnConnection { connection: Connection ->
connection.addHandler(
object : IdleStateHandler(0, 0, 0) {
override fun channelIdle(ctx: ChannelHandlerContext, evt: IdleStateEvent) {
ctx.fireExceptionCaught(
if (evt.state() == IdleStateEvent.WRITER\_IDLE\_STATE\_EVENT.state())
WriteTimeoutException.INSTANCE
else
ReadTimeoutException.INSTANCE
)
ctx.write(CloseWebSocketFrame())
ctx.close()
}
}
)
}
}
)
}
```
Для удобства доступа к контексту безопасности помимо реактивного ExchangeHolder, был добавлен синхронный ExchangeContext, т.к. часто контекст безопасности запрашивается в статических методах вне реактивной цепочки:
```
object ExchangeHolder {
fun getHeaders(): Mono> {
return Mono.deferContextual { ctx: ContextView ->
Mono.just(
ctx.get(ServerWebExchange::class.java).request.headers as MultiValueMap
)
}
}
fun getResponse(): Mono {
return Mono.deferContextual { ctx: ContextView ->
Mono.just(ctx.get(ServerWebExchange::class.java).attributes[RESPONSE] as ServerHttpResponse)
}
}
fun getUser(): Mono {
return Mono.deferContextual { ctx: ContextView ->
ctx.get(ServerWebExchange::class.java).getPrincipal()
.cast(UsernamePasswordAuthenticationToken::class.java)
.map { it.principal }
.cast(User::class.java)
}
}
}
```
Также для удобства библиотека отключает CORS и CSRF в связи с настройкой данной защиты на уровне HaProxy или Gateway перед сервисом:
```
override fun addCorsMappings(corsRegistry: CorsRegistry) {
corsRegistry.addMapping("/**")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedOriginPatterns("*")
.allowedHeaders("*")
.maxAge(3600)
}
```
В библиотеку включено активно разрабатываемый проект [jjwt](https://github.com/jwtk/jjwt), обладающий наибольшими возможностями при работе с JWT-токенами. Также используется проект [r2dbc-dsl](https://github.com/SevenParadigms/r2dbc-dsl) для инициализации репозитория через url к базе данных:
```
@Bean
fun abacRuleRepository(@Value("\${spring.security.abac.url}") url: String) =
R2dbcUtils.getRepository(url, AbacRuleRepository::class.java)
```
Предлагаемое R2DBC Spring Data конфигурирование соединений к нескольким базам данных чересчур громоздко для инициализации всего одного репозитория. В ближайшем будущем будет произведена интеграция r2dbc-dsl со Spring Security на уровне контекста безопасности с привязкой на заднем фоне всех SQL-запросов к идентификаторам userId и tenantId для автоматической фиксации в базе данных вне бизнес-логики.
Процесс бизнес-логирования действий пользователя порой **занимает до 50%** от всей нагрузки на базу данных и решение этой задачи критично для любого проекта. Обычно она решается через создание виртуального потокового репликатора PostgreSQL с сохранением собранных данных через команду *Copy* или можно воспользоваться библиотекой [PgBulkInsertPublic](https://github.com/PgBulkInsert/PgBulkInsert) – такой подход к бизнес-логированию полностью разгружает БД.
### Настройка безопасности клиента
Рассмотрим файл конфигурации application.yml из демонстрационного проекта [webflux-dsl-abac-example](https://github.com/SevenParadigms/webflux-dsl-abac-example):
```
spring:
r2dbc:
url: r2dbc:postgresql://postgres:postgres@localhost/dsl_abac?schema=public
pool:
maxSize: 20
main:
allow-bean-definition-overriding: true
security:
abac.url: r2dbc:postgresql://postgres:postgres@localhost/abac_rules?schema=public
iteration: 512
length: 720
secret: eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJ1c2VyIiwiYXV0aCI6IlJPTEVfVVNFUiIsImV4cCI6MTYzMDYxMDI5NX0.m0XU2NvGaAtzptgLfmptj3Fk7S1e1NrBTYTqBAjHoPI8lbRB7z3J52FiLRw-PUZPjQusDt19RszrUQDsZoVXeQ
expiration: 1800
X-User-Id: true
skip-token-validation: true
cache-token: true
```
Как видим, есть основное соединение с базой данных, а есть отдельная база данных *abac\_rules*, в которой аккумулируются правила со всех сервисов, что удобно в управлении безопасностью и появляется возможность переиспользования правил.
С точки зрения атаки, когда вся безопасность сервисов вынесена в БД – возникает новая цель в виде таблицы с правилами. Сервисы могут читать свои правила из общей таблицы за счёт применения безопасности со стороны PostgreSQL *защиты на уровне строк*, когда пользователь БД может видеть только свои записи. Если пароли сервиса скомпрометированы, то атакующий может увидеть правила безопасности сервиса и запланировать стратегию атаки для получения конфиденциальной информации.
При описании правил ABAC лучше всего учитывать принципы наименьших привилегий и тогда маловероятно, что будет достигнут хоть какой-либо успех атакующим, но попытки необычных запросов легко зафиксировать и отразить в журнале логов для оповещения уполномоченной группы.
Необязательные переменные iteration и length используются для генерации секретного ключа и соли системного пароля пользователя. Необязательная переменная secret используется как часть секрета для генерации пароля пользователя и токена. Переменная expiration имеет значение времени жизни токена в секундах.
Переменные iteration, length, secret являются критическими для безопасности и в общем, рекомендуется хранить все значения переменных окружения на сервере секретов типа HashiCorp Vault.
X-User-Id при значении true активирует Spring Security, когда ожидается в заголовке X-User-Id значение id пользователя, а в X-Roles массив ролей. Имя пользователя в Spring Security указывается как пустая строка, если отсутствует заголовок X-Login.
Такая беззащитная конфигурация значительно ускоряет работу с ролевой моделью, но явно открывает сервис атакующему из локальной сети. Для защиты такой конфигурации обычно включают межсервисную авторизацию между sidecar в Istio и строгую сетевую политику ограничения межсервисных доступов.
Необязательная переменная skip-token-validation при значении true активирует Spring Security, извлекая из токена имя пользователя и роли, где присутствует единственная проверка на время жизни токена. Такая же беззащитная конфигурация как и предыдущая, но позволяет передать сервису работу по распаковке токена вместо Gateway. Защищается с помощью Istio.
Необязательная переменная cache-token при значении true активирует Spring Security с полной валидацией токена и кэшированием данных токена. В случае, если в конфигурации не прописан путь до сервиса авторизации *spring.security.introspection.uri*, тогда ожидается, что токен каким-то образом уже лежит в текущем CacheManager – это удобно при кустомном способе авторизации пользователя, а иначе CacheManager используется для кластерного кэширования. Вместо пути до сервиса авторизации можно указать в переменной *spring.security.public* сохраненный в Base64 публичный ключ токена для проверки подписи.
Это основная конфигурация безопасности с валидацией токена, кэшированием и возможностью отзыва, не требует Istio. За счёт кэширования получаем максимально возможную пропускную способность от реактивного стека. При использовании публичного ключа заметно увеличивается нагрузка на процессор. Все представленные конфигурации можно комбинировать.
### Практическое применение ABAC
Скрипт создания таблицы с правилами:
```
CREATE TABLE abac_rule
(
id uuid DEFAULT uuid_generate_v1mc() NOT NULL PRIMARY KEY,
name text,
domain_type text,
target text,
condition text
);
insert into abac_rule(name, domain_type, target, condition)
values('Test Rule', 'Dsl', 'action == ''findAll'' and subject.roles.contains(''ROLE_ADMIN'')', 'domainObject.sort == ''id:desc'''),
('IP Rule', 'Dsl', 'action == ''findAll'' and environment.ip == ''192.168.2.207''', 'domainObject.sort == ''id:desc'''),
('Query jtree not null Rule', 'Dsl', 'action == ''findAll'' and subject.roles.contains(''ROLE_ADMIN'')', 'domainObject.query == ''!@jtree'' and domainObject.fields ==''id'' and domainObject.sort == ''id:desc'''),
('Query equals jsonb field Rule', 'Dsl', 'action == ''findAll'' and subject.roles.contains(''ROLE_ADMIN'')', 'domainObject.query == ''jtree.name==Acme doc'' and domainObject.sort == ''id:desc'''),
('Query equals jsonb field in Rule', 'Dsl', 'action == ''findAll'' and subject.roles.contains(''ROLE_ADMIN'')', 'domainObject.query == ''jtree.name^^Acme doc'' and domainObject.sort == ''id:desc''');
```
Применение правила в аннотации над методом:
```
@PreAuthorize("hasPermission(#dsl, 'findAll')")
fun findAll(@PathVariable jfolderId: UUID, dsl: Dsl)
= objectService.findAll(jfolderId, dsl)
```
Как уже ранее указывалось, выражения ABAC в виде SpEL компилируется и кэшируются. Если взглянуть на код, то логика очень простая:
```
@Component
class ExpressionParserCache : ExpressionParser {
private val cache: MutableMap = ConcurrentHashMap(720)
private val parser: ExpressionParser = SpelExpressionParser()
@Throws(ParseException::class)
override fun parseExpression(expressionString: String): Expression {
return cache.computeIfAbsent(expressionString) {
parser.parseExpression(it)
}
}
@Throws(ParseException::class)
override fun parseExpression(expressionString: String,
context: ParserContext): Expression {
throw UnsupportedOperationException("not supported")
}
}
```
Затем перегружается стандартный метод безопасности *hasPermission*:
```
@Service
class AbacRulePermissionService(
private val abacRuleRepository: AbacRuleRepository,
private val expressionParserCache: ExpressionParserCache,
private val exchangeContext: ExchangeContext
) : DenyAllPermissionEvaluator() {
override fun hasPermission(authentication: Authentication,
domainObject: Any, action: Any): Boolean {
debug("Secure user %s action '%s' on object %s", authentication.name, action, domainObject)
val user = authentication.principal as User
return checkIn(
AbacSubject(user.username, user.authorities.map { it.authority }.toSet()),
domainObject,
action as String
)
}
private fun checkIn(subject: AbacSubject, domainObject: Any, action: String): Boolean {
var result = false
runBlocking {
val context = AbacControlContext(
subject, domainObject, action,
AbacEnvironment(ip = exchangeContext.getRemoteIp(subject.username))
)
result = abacRuleRepository.findAllByDomainType(domainObject.javaClass.simpleName)
.filter { abacRule: AbacRule ->
expressionParserCache.parseExpression(abacRule.target).getValue(
context,
Boolean::class.java
)!!
}
.any { abacRule: AbacRule ->
expressionParserCache.parseExpression(abacRule.condition)
.getValue(context, Boolean::class.java)!!
}
.awaitFirst()
}
return result
}
}
```
Сначала формируется контекст в виде модели AbacControlContext, содержащий поля: subject с логином и ролями пользователя, domainObject – входящий объект, action – наименование правила и AbacEnvironment с текущей датой и ip клиента.
Как видно из кода, при поиске всех правил по атрибуту domain (имя класса из domainObject)*,* сначала фильтруем по SpEL выражению из атрибута target и если найдены правила, то по ним в атрибуте condition прогоняем итоговое SpEL выражение.
Для включения в проекте Spring Security вместе с моделью безопасности ABAC достаточно добавить аннотацию [@EnableAbacSecurity](/users/enableabacsecurity) в класс Application.
Более подробно применение ABAC можно посмотреть в исходном коде тестов демонстрационного проекта [webflux-dsl-abac-example](https://github.com/SevenParadigms/webflux-dsl-abac-example).
В тестовом окружении демо-проекта в качестве используемой базы данных поднимается контейнер *postgres-rum* – что невероятно удобно и практично:
```
private fun createContainer(): KContainer =
KContainer(DockerImageName.parse("jordemort/postgres-rum:latest")
.asCompatibleSubstituteFor("postgres"))
.withDatabaseName("test-db")
.withUsername("postgres")
.withPassword("postgres")
.withCreateContainerCmdModifier { cmd ->
cmd.withHostConfig(
HostConfig().withPortBindings(
PortBinding(
Ports.Binding.bindPort(5432), ExposedPort(5432)
)
)
)
}
.withReuse(true)
.withCopyFileToContainer(
MountableFile.forClasspathResource("init.sql"),
"/docker-entrypoint-initdb.d/"
)
```
Пример теста из демо-проекта, проверяющий потоковую изолированность извлечения контекста безопасности из реактивной цепочки:
```
@Test
fun `test Holder race condition by two users`() {
val flux = Flux.range(1, 100)
.parallel(10)
.runOn(Schedulers.boundedElastic())
.flatMap { rangeCount ->
val testIp: String
if (rangeCount % 2 == 0) {
testIp = nonCorrectIp + rangeCount
webClient.get()
.uri("dsl-abac/context")
.header(HttpHeaders.AUTHORIZATION, Constants.BEARER + adminToken)
.header(Constants.AUTHORIZE_IP, testIp)
.exchangeToMono { it.bodyToMono(List::class.java) }
.zipWith(Mono.just(testIp))
} else {
testIp = correctIp + rangeCount
webClient.get()
.uri("dsl-abac/context")
.header(HttpHeaders.AUTHORIZATION, Constants.BEARER + userToken)
.header(Constants.AUTHORIZE_IP, testIp)
.exchangeToMono { it.bodyToMono(List::class.java) }
.zipWith(Mono.just(testIp))
}
}
StepVerifier.create(flux)
.expectNextCount(98)
.expectNextMatches { it.t2 == it.t1[1] }
.expectNextMatches { it.t2 == it.t1[1] }
.thenCancel()
.verify()
}
```
Еще один интересный пример использования данной библиотеки – [проект реактивной Spring Cloud Gateway](https://github.com/SevenParadigms/spring-cloud-websocket-gateway), который публикует реактивный вебсокет для конвертации запросов из вебсокета в http-запросы к сервисам и обратно. Чтобы подключиться к вебсокету необходимо передать jwt-токен, который валидируется только по времени, публичному ключу, а статус отозванности обновляется через событие kafka, т.е. максимальное ускорение.
Логика запуска реактивного вебсокета с ожиданием авторизации в Spring Security занимает всего несколько строк:
```
@Component
@WebsocketEntryPoint("/wsf")
class WebsocketFactory : WebSocketHandler {
override fun handle(session: WebSocketSession): Mono {
return session.handshakeInfo.principal
.cast(UsernamePasswordAuthenticationToken::class.java)
.flatMap { authenticationToken: UsernamePasswordAuthenticationToken ->
val input = session.receive().map { obj: WebSocketMessage -> obj.payloadAsText }
.map { it.parseJson(MessageWrapper::class.java) }
.doOnNext { handling(it, authenticationToken) }.then()
val output =
session.send(Flux.create {
clients[authenticationToken.name] = WebsocketSessionChain(session, it)
})
Mono.zip(input, output).then().doFinally { signal: SignalType ->
clients.remove(authenticationToken.name)
info("WebSocket revoke connection with signal[${signal.name}] and user[${authenticationToken.name}]")
}
}
}
```
Фронт отправляет и принимает запросы в обвёртке:
```
data class MessageWrapper(
val type: HttpMethod = HttpMethod.GET,
val baseUrl: String = StringUtils.EMPTY,
val uri: String = StringUtils.EMPTY,
val body: JsonNode = JsonUtils.objectNode()
)
```
при ответе body заменяется ответом с сервиса как JSON: *message.copy(body = it)*, а uri служит идентификатором запроса в обработчике вебсокета на фронте.
Функция преобразования запросов вебсокета в RESTful и обратно:
```
fun handling(message: MessageWrapper, authenticationToken: UsernamePasswordAuthenticationToken) {
clients[authenticationToken.name].access = LocalDateTime.now()
val webClient = Beans.of(WebClient.Builder::class.java).baseUrl(message.baseUrl).build()
when (message.type) {
HttpMethod.GET -> webClient.get().uri(message.uri).retrieve()
HttpMethod.POST -> webClient.post().uri(message.uri).body(BodyInserters.fromValue(message.body)).retrieve()
HttpMethod.PUT -> webClient.put().uri(message.uri).body(BodyInserters.fromValue(message.body)).retrieve()
HttpMethod.DELETE -> webClient.delete().uri(message.uri).retrieve()
}.bodyToMono(JsonNode::class.java).subscribe {
info("Request[${message.baseUrl}${message.uri}] by user[${authenticationToken.name}] accepted")
clients[authenticationToken.name].sendMessage(message.copy(body = it))
}
}
```
### Нагрузочное тестирование
Тестирование проводилась на обычной рабочей станции со средними характеристиками и с дефолтными настройками r2dbc (без увеличенных таймаутов и пула соединений). При тестировании демо-проект с библиотекой ABAC стабильно выдерживает 100 одновременных запросов контекста безопасности через REST каждые 20 мс.
При уменьшении периода вызова и увеличении одновременных запросов возникали ошибки в R2DBC Spring Data – обычного размера пула в 20 соединений не хватило, т.к. некоторые запросы падали по таймауту из-за нехватки доступных соединений. Главная причина такого поведения – полное отсутствие кэша 1-го уровня в реактивном Spring Data.
Срочным образом, в библиотеку [r2dbc-dsl](https://github.com/SevenParadigms/r2dbc-dsl) был добавлен кэш 1-го уровня, причём его можно использовать и как кэш 2-го уровня без in-memory базы данных, т.к. достаточно подписаться на изменения нужных таблиц через application.yml
Кэш 1-го уровня – это технический кэш, используемый в рамках одного действия, после чего, кэш должен очистится. В то время, как кэш 2-го уровня живёт значительно дольше и обеспечивает именно бизнес-логику. По умолчанию, кэш 1-го уровня в библиотеке [r2dbc-dsl](https://github.com/SevenParadigms/r2dbc-dsl) живёт 500 мс, что достаточно для логики одного действия и быстрее, чем пользователь успеет выполнить следующее действие. Кэш 1-го уровня часто используется как кэш глобального уровня, что значительно упрощает и сокращает исходный код.
Кэш 1-го уровня повышает стабильность и производительность, но только в случае правильной реализации. К примеру, проблемой кэша 1-го уровня в Hibernate является её вечная жизнь и невозможность принудительного обновления или отключения, что приводит к ограничениям и логическим ошибкам бизнес-логики. Hibernate по умолчанию хранит в кэше 1-го уровня свыше миллиона записей, но даже исправив размер кэша в одну запись – проблем это не решает.
После подключения кэша 1-го уровня, выдерживаемая нагрузка составила более 10 тыс. запросов в секунду, что быстрее синхронной Spring Security примерно в 15 раз. Производительность реактивного стека явно ограничивается процессорным временем и шириной канала связи.
Наиболее прогрессивной in-memory базой данных на мой взгляд является Hazelcast из-за поддержки старта как Embedded вместе с сервисом и поддержки кластера Kubernetes между подами одного сервиса. К сожалению, последняя версия насквозь пронизана уязвимостями с количеством более 10 штук. Поэтому, создал [безопасную обвёртку вокруг Hazelcast](https://github.com/SevenParadigms/kubernetes-embedded-hazelcast), работающая в Kubernetes как межподовый кластер сервиса без внешнего доступа. Данная библиотека активирует в Spring Security кэш 2-го уровня с единым хранилищем для всех подов одного сервиса.
### Системные риски безопасности
Терминология вокруг системного риска сводится к превентивному взлому, от которого практически невозможно защитится. При этом, охватывается масштаб страны целиком. Вся политика безопасности сервисов должна учитывать возможность атаки с локального хоста и компрометации всех паролей.
Microsoft, согласно статьям тех лет, и на самом деле, точно не известно правда это или вымысел – до 2013 года встраивала в свои ОС дыры и сообщала о выявленных спецслужбам США. Диванные эксперты считают, что в настоящее время взаимодействие всех корпораций со спецслужбами происходит на коммерческой основе для формирования баланса между репутационным имиджем и уровнем технологичности ведения разведки.
В новостях 2013-2014 годов иногда проскакивало, что были взломаны правительственные сервера Китая используя маршрутизаторы Cisco. Последователи теории заговора предполагают, что маршрутизаторы подменили во время таможенного досмотра на территории США, но всё это лишь слухи.
Возможно, в результате данного инцидента и скорее всего с текущего 2022 года – правительственные учреждения, подрядчиковые организации и финансовые институты Китая начнут работать с маршрутизаторами, серверами и операционными системами только отечественного производства.
Есть и оборотная сторона, согласно материалам Bloomberg, от которых вскоре отказались – с 2013 по 2015 года в Китае было произведено десятки тысяч серверов Supermicro с дополнительным чипом 2х3 мм, которые в массовом порядке поставлены сотням компаний по всей планете. Из них 7000 серверов были установлены в Apple. Также сервера доставили подрядчику Министерства обороны США Elemental, который устанавливал их в бортовые сети боевых кораблей ВМФ, центры управления беспилотников ЦРУ, центры обработки данных Министерства обороны, NASA, обе палаты Конгресса, подразделение внутренней безопасности Госдепа, а также в Amazon.
Легенды с просторов Интернета гласят, что в результате этой атаки, все представляющие интерес сервера Supermicro с выходом в Интернет были взломаны и на десятки анонимных серверов выгружены гигабайты информации. Микрокод встроенного чипа регулярно с разным периодом времени пытался установить соединение с рядом действующих DNS-серверов в Интернете, имитируя dns-запрос и как только соединение устанавливалось, сразу загружалась подпрограмма сканирования и идентификации.
Опять же по тем же отозванным материалам Bloomberg, в 2015 году новое подразделение Amazon Web Services (AWS), созданное для нужд ЦРУ, наняла стороннюю компанию для проверки безопасности серверов, поставляемые Elemental, где обнаружили чип вне оригинальной конструкции плат Supermicro. Apple в том же году демонтировал 7000 серверов Supermicro и разорвал контракт на поставку еще 30 тыс. серверов Supermicro.
Затем в сентябре 2015 года, КНР и США пришли к договоренности о правовой поддержке защиты интеллектуальной собственности и увеличении поставок сетевого оборудования из США в Китай. Если эта история на самом деле имело место, то она весьма и весьма поучительна – не шутите ни с каким из централов.
В России же налажен выпуск отечественных маршрутизаторов на процессоре «Байкал-Т1», но по ним пока нет эксплуатационной экспертизы и соответственно компании не готовы к переходу. Также пока нет отечественной серверной ОС и все на свой страх и риск продолжают использовать Windows Server от Miscrosoft и AWS от Amazon, не смотря на высокие корпоративные стандарты онных.
В случае начала театра военных действий, чего конечно ни кто в здравом уме не пожелает, и в силу «чуждости» повсеместно используемых технологий, вполне логично ожидать атаки и попытки уничтожения баз данных крупных государственных и частных организаций страны для нарушения работы экономики.
И обратно, если прилегающая страна, нарушая принципы добрососедства стала размещать у себя системы ПРО-ПВО и авиационные системы противника, то во время боевых действий вероятность «утечки» данных к противнику будет высокой, сколько не из-за желания соседей их передать, а из-за возможного наличия дополнительного чипа.
Поэтому, в силу стратегии национальной безопасности, с первых же секунд начала боевых действий, чисто гипотетически, должна начаться операция по принуждению к миру обведённого вокруг пальца противником соседствующей страны, когда уничтожаются всё вооружение и военная инфраструктура.
К слову, Россия производит модульную военную технику, отчасти чтобы исключить возможность использования дополнительного чипа, чтобы заказчики могли устанавливать свои модули в самые чувствительные места самолёта, корабля, танка или средств ПВО.
Основным способом защиты от системных угроз является внедрение искусственного интеллекта в маршрутизаторы, в средства мониторинга сетей, в кластер Kubernetes, в Spring Security для автоматической блокировки необычной активности. А в случае централизованного управления – блокировка в остальных случаях будет мгновенной по базовым признакам без анализа поведения.
### Резюме
Расширение модели безопасности до ABAC не несёт дополнительных затрат, т.к. RBAC естественным образом интегрируется, после чего, информационная безопасность предприятия становится управляемой. Библиотека активно используется и дорабатывается, отчего данная статья будет потихоньку дополнятся. Стоит подключить Z Garbage Collector для хорошего улучшения производительности приложений реактивного стека.
Наиболее эффективная защита от любых типов атак - это централизованный искусственный интеллект уровня государства, который разом защитит все организации. На глобальном уровне все атаки будут видны как на ладони, т.к. визуализируются частые повторы одних и тех же логических шаблонов, как бы их не перетасовывали и не видоизменяли структуру пакетов.
Очень вдохновляет возможность запуска в тестах любого докера – это открывает новую эпоху в тестировании и позволяет значительно усилить тестовое окружение за счёт предустановки дополнительного ПО, что значительно увеличит стабильность всех проектов в целом.
Усиление информационной безопасности Китая привело к значительному ускорению развития отечественных технологий. Было бы естественным рассмотреть существующие стандарты информационной безопасности Китая, что сэкономит немало времени в корректировке обобщённых итоговых целей.
Самый быстрый способ, на мой взгляд, соответствовать общемировым трендам в информационной безопасности – перенести часть производственных мощностей процессоров и системных плат из Китая в Россию для целенаправленного замещения оборудования в госсекторе и смежных областях совместной продукцией. Это так же и самый быстрый способ подойти к производству процессоров техпроцесса от 10-нм и меньше.
Интересная идея, с целью ускорения развития России, построить совместные научно-технические кластера с Китаем и Индией, как с ближайшими союзниками, для выстраивания многополярного технического сотрудничества в охвате сотен стран, в частности, стран Африканского региона и Ближнего Востока. Что приведёт к быстрому техническому развитию стран-участниц союза до мирового уровня из-за эволюционного принципа удешевления применения новых технологий с каждым этапом их развития. Конечной целью союза могло бы стать формирование единого рынка высоких технологий во всех областях экономик стран участниц.
Финансовым институтам России, также с целью ускорения, выгодно наладить партнёрские отношения с IT-гигантами Alibaba и Xiaomi для обоюдного обогащения компетенциями и совместного развития opensource-проектов. Ведь все opensource-проекты мирового уровня, уже признанные в своих областях стандартами де-факто, сосредоточены в Кремниевой долине.
Opensource-проекты часто вытесняют с рынка другие продукты через формирование достаточной критической массы комьюнити вокруг своих технологий. Наличие большого количества экспертов по всему миру и делает продукт стандартом де-факто. В итоге это привело к аккумуляции лучших специалистов планеты в одной стране, т.к. массовая потребность приводит к удовлетворению спроса через дополнительную капитализацию.
Бизнес-модель вокруг opensource-проектов сложная, содержащая множество нюансов и стратегий, требующая немало вложений, но этой модели придерживаются все IT-гиганты Кремниевой долины, т.к. она возникла эволюционно, когда самой выгодной стратегией оказалась "игра в долгую".
Основной стратегией opensource-проектов является высокоуровневая консультация разработчика при доработке продукта сторонними компаниями, когда сходу решаются возникающие проблемы в кодировании. А одной из самых изощренных стратегий является продвижение проекта как платформы для других opensource-проектов более прикладного характера.
Россия обладает лучшими технологиями во многих сферах. Но если сравнивать степень вовлечённости молодых людей в стартапы, то для примера, в Китае созданы более 150 компаний-единорогов с оценочной стоимостью более $1 млрд. и при этом, половина из них выросла до единорога за счёт иностранных инвестиций менее чем за 5 лет. Данный феномен связан с массовым инвестированием государства в стартапы при их создании сразу в акционерный капитал, иначе говоря, инвестирование непосредственно в молодых людей.
Но надо также отметить сильнейшую сторону России как державы. Ведь настоящая мощь всех исторических империй и особенно Российской – в разнообразии способа выражения силы: через культуру, благородство, историческое наследие, взаимное уважение, равенства и поддержки общих интересов, бескорыстия в добрых отношениях, искренней заинтересованности в сильном союзнике и конечно в стремлении к новым знаниям и вершинам. | https://habr.com/ru/post/645923/ | null | ru | null |
# Легкий способ изменить фон ячеек в группированном UITableView
При использовании `UITableView` в iOS приложениях достаточно часто возникает необходимость изменить его внешний вид. Как минимум – поменять цвет фона ячеек и цвет разделителей. И в общем это не проблема для `UITableView` в виде списка, но немного нетривиально для группированного `UITableView`.
Проблема состоит в том что поменяв `backgroundColor` ячейки в группированном `UITableView` результат будет отличаться от ожидаемого. Решение состоит в том чтоб изменить `backgroundView` ячейки. Довольно часто с этой целью используются заранее отрисованые картинки и соответственно `UIImageView`. Но этот способ довольно неудобен если нужно всего лишь поменять цвет фона и границ ячейки.
Так что я создал подкласс `UIView` для повторного использования в качестве фона ячеек. Благодаря использованию `UIBezierPath` его реализация тривиальна, вот практически весь код:
```
- (void)drawRect:(CGRect)rect
{
CGRect bounds = CGRectInset(self.bounds,
0.5 / [UIScreen mainScreen].scale,
0.5 / [UIScreen mainScreen].scale);
UIBezierPath *path;
if (position == CellPositionSingle) {
path = [UIBezierPath bezierPathWithRoundedRect:bounds cornerRadius:kCornerRadius];
} else if (position == CellPositionTop) {
bounds.size.height += 1;
path = [UIBezierPath bezierPathWithRoundedRect:bounds
byRoundingCorners:UIRectCornerTopLeft | UIRectCornerTopRight
cornerRadii:CGSizeMake(kCornerRadius, kCornerRadius)];
} else if (position == CellPositionBottom) {
path = [UIBezierPath bezierPathWithRoundedRect:bounds
byRoundingCorners:UIRectCornerBottomLeft | UIRectCornerBottomRight
cornerRadii:CGSizeMake(kCornerRadius, kCornerRadius)];
} else {
bounds.size.height += 1;
path = [UIBezierPath bezierPathWithRect:bounds];
}
[self.fillColor setFill];
[self.borderColor setStroke];
[path fill];
[path stroke];
}
```
Использовать этот код просто, что-то вроде этого:
```
- (void)tableView:(UITableView *)tableView willDisplayCell:(UITableViewCell *)cell forRowAtIndexPath:(NSIndexPath *)indexPath
{
CellBackgroundView *backgroundView = [CellBackgroundView new];
cell.backgroundView = backgroundView;
backgroundView.backgroundColor = [UIColor clearColor];
backgroundView.borderColor = self.tableView.separatorColor;
backgroundView.fillColor = [UIColor colorWithRed:1.0 green:1.0 blue:0.9 alpha:1.0];
int rowsInSection = [self tableView:tableView numberOfRowsInSection:indexPath.section];
if (rowsInSection == 1) {
backgroundView.position = CellPositionSingle;
} else {
if (indexPath.row == 0) {
backgroundView.position = CellPositionTop;
} else if (indexPath.row == rowsInSection - 1) {
backgroundView.position = CellPositionBottom;
} else {
backgroundView.position = CellPositionMiddle;
}
}
}
```
Результат выглядит как-то так:
Кстати такой интересный момент – используя `[UIColor colorWithPatternImage:]` при задании цвета фона, можно использовать текстуры и градиенты в качестве фона ячейки.
Полный код доступен тут [gist.github.com/4062103](https://gist.github.com/4062103) | https://habr.com/ru/post/158533/ | null | ru | null |
# Анализ тональности текстов с помощью сверточных нейронных сетей
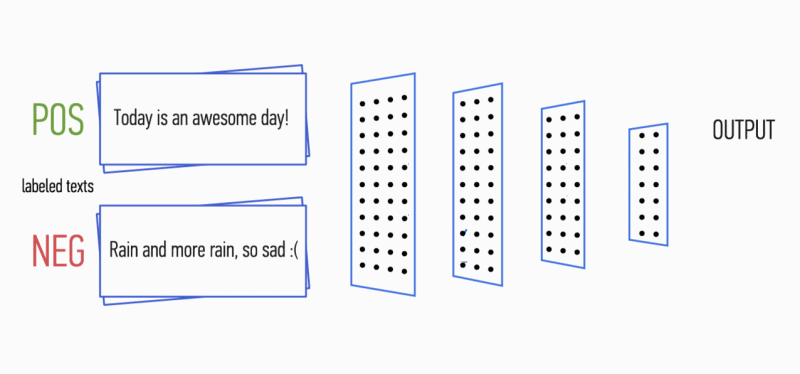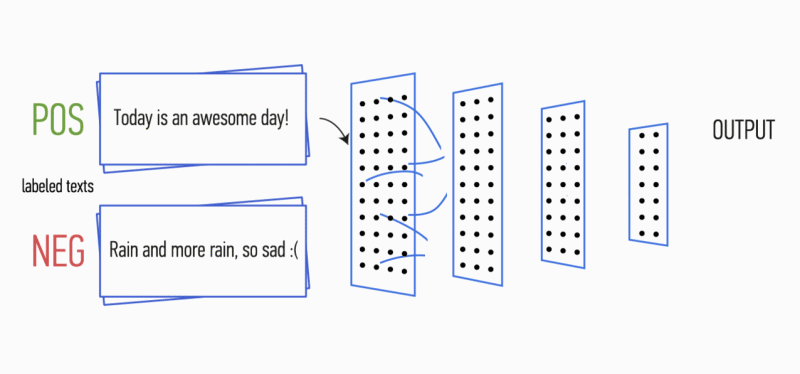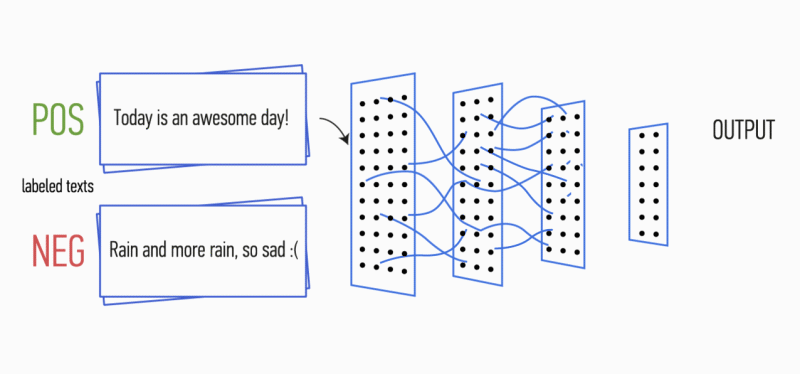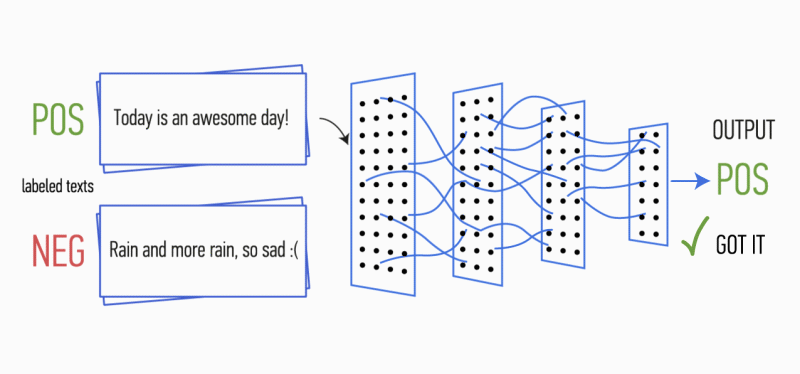
Представьте, что у вас есть абзац текста. Можно ли понять, какую эмоцию несет этот текст: радость, грусть, гнев? Можно. Упростим себе задачу и будем классифицировать эмоцию как позитивную или как негативную, без уточнений. Есть много способов решать такую задачу, и один из них — **свёрточные нейронные сети** (Convolutional Neural Networks). CNN изначально были разработаны для обработки изображений, однако они успешно справляются с решением задач в сфере автоматической обработки текстов. Я познакомлю вас с бинарным анализом тональности русскоязычных текстов с помощью свёрточной нейронной сети, для которой векторные представления слов были сформированы на основе обученной **Word2Vec** модели.
Статья носит обзорный характер, я сделал акцент на практическую составляющую. И сразу хочу предупредить, что принимаемые на каждом этапе решения могут быть неоптимальными. Перед прочтением рекомендую ознакомиться с [вводной статьей](https://habr.com/company/ods/blog/353060/) по использованию CNN в задачах обработки естественных языков, а также прочитать [материал](https://habr.com/company/ods/blog/329410/) про методы векторного представление слов.
Архитектура
-----------
Рассматриваемая архитектура CNN основана на подходах [1] и [2]. Подход [1], в котором используется ансамбль сверточных и рекуррентных сетей, на крупнейшем ежегодном соревновании по компьютерной лингвистике SemEval-2017 занял первые места [3] в пяти номинациях в задаче по анализу тональности [Task 4](http://alt.qcri.org/semeval2017/task4/).
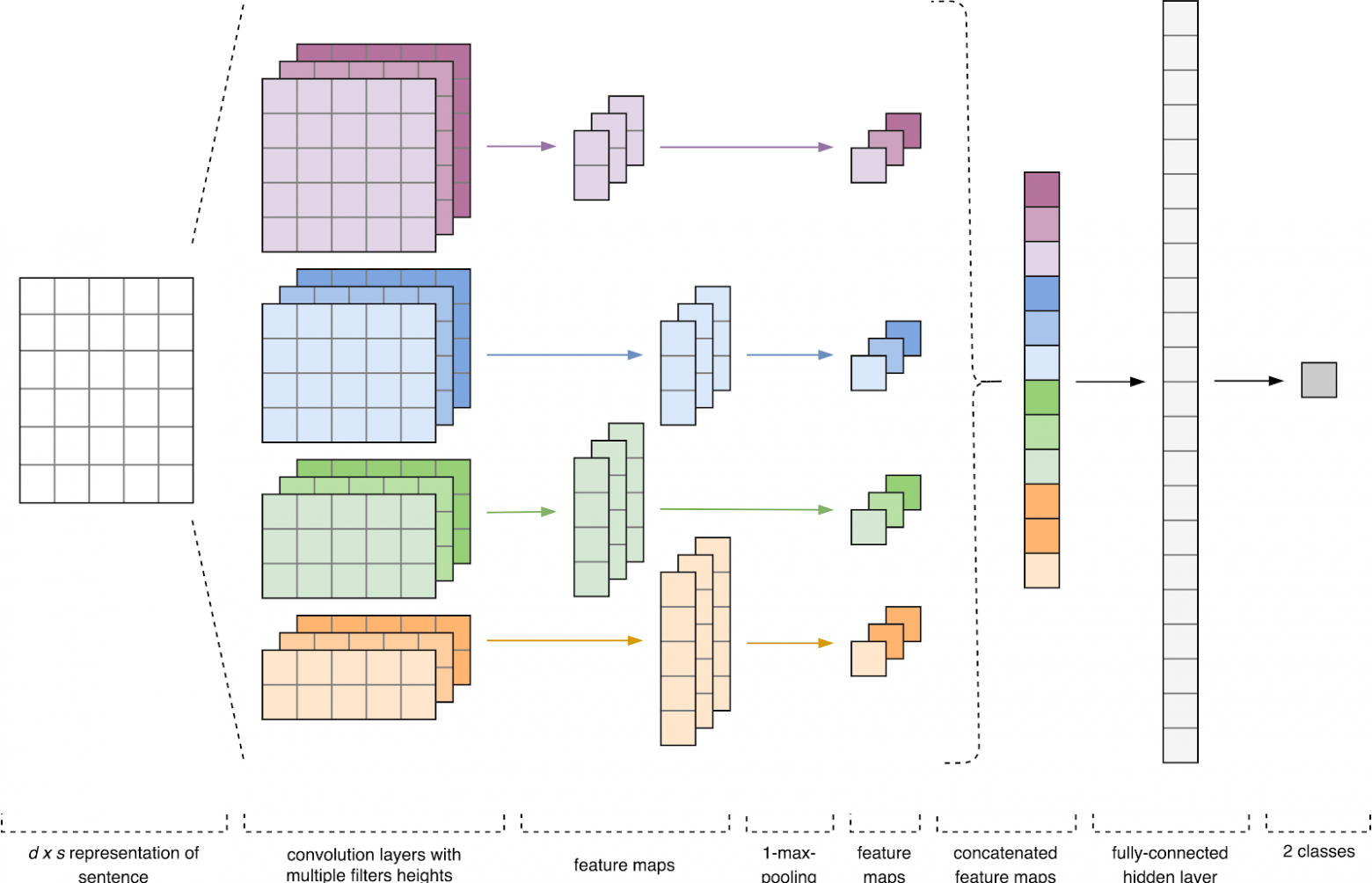
*Рисунок 1. Архитектура CNN [2].*
Входными данными CNN (рис. 1) является матрица с фиксированной высотой *n*, где каждая строка представляет собой векторное отображение токена в признаковое пространство размерности *k*. Для формирования признакового пространства часто используют инструменты дистрибутивной семантики, такие как Word2Vec, Glove, FastText и т.д.
На первом этапе входная матрица обрабатывается слоями свертки. Как правило, фильтры имеют фиксированную ширину, равную размерности признакового пространства, а для подбора размеров у фильтров настраивается только один параметр — высота *h*. Получается, что *h* — это высота смежных строк, рассматриваемых фильтром совместно. Соответственно, размерность выходной матрицы признаков для каждого фильтра варьируется в зависимости от высоты этого фильтра *h* и высоты исходной матрицы *n*.
Далее карта признаков, полученная на выходе каждого фильтра, обрабатывается слоем субдискретизации с определенной функцией уплотнения (на изображении — 1-max pooling), т.е. уменьшает размерность сформированной карты признаков. Таким образом извлекается наиболее важная информация для каждой свертки независимо от её положения в тексте. Другими словами, для используемого векторного отображения комбинация слоев свёртки и слоев субдискретизации позволяет извлекать из текста наиболее значимые *n*-граммы.
После этого карты признаков, рассчитанные на выходе каждого слоя субдискретизации, объединяются в один общий вектор признаков. Он подаётся на вход скрытому полносвязному слою, а потом поступает на выходной слой нейронной сети, где и рассчитываются итоговые метки классов.
Данные для обучения
-------------------
Для обучения я выбрал [корпус коротких текстов Юлии Рубцовой](http://study.mokoron.com/), сформированный на основе русскоязычных сообщений из Twitter [4]. Он содержит 114 991 положительных, 111 923 отрицательных твитов, а также базу неразмеченных твитов объемом 17 639 674 сообщений.
```
import pandas as pd
import numpy as np
# Считываем данные
n = ['id', 'date', 'name', 'text', 'typr', 'rep', 'rtw', 'faw', 'stcount', 'foll', 'frien', 'listcount']
data_positive = pd.read_csv('data/positive.csv', sep=';', error_bad_lines=False, names=n, usecols=['text'])
data_negative = pd.read_csv('data/negative.csv', sep=';', error_bad_lines=False, names=n, usecols=['text'])
# Формируем сбалансированный датасет
sample_size = min(data_positive.shape[0], data_negative.shape[0])
raw_data = np.concatenate((data_positive['text'].values[:sample_size],
data_negative['text'].values[:sample_size]), axis=0)
labels = [1] * sample_size + [0] * sample_size
```
Перед началом обучения тексты прошли процедуру предварительной обработки:
* приведение к нижнему регистру;
* замена «ё» на «е»;
* замена ссылок на токен «URL»;
* замена упоминания пользователя на токен «USER»;
* удаление знаков пунктуации.
```
import re
def preprocess_text(text):
text = text.lower().replace("ё", "е")
text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text)
text = re.sub('@[^\s]+', 'USER', text)
text = re.sub('[^a-zA-Zа-яА-Я1-9]+', ' ', text)
text = re.sub(' +', ' ', text)
return text.strip()
data = [preprocess_text(t) for t in raw_data]
```
Далее я разбил набор данных на обучающую и тестовую выборку в соотношении 4:1.
```
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
```
Векторное отображение слов
--------------------------
Входными данными сверточной нейронной сети является матрица с фиксированной высотой *n*, где каждая строка представляет собой векторное отображение слова в признаковое пространство размерности *k*. Для формирования embedding-слоя нейронной сети я использовал утилиту дистрибутивной семантики Word2Vec [5], предназначенную для отображения семантического значения слов в векторное пространство. Word2Vec находит взаимосвязи между словами согласно предположению, что в похожих контекстах встречаются семантически близкие слова. Подробнее о Word2Vec можно прочитать в [оригинальной статье](https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf), а также [тут](https://habr.com/company/ods/blog/329410/) и [тут](https://habr.com/post/249215/). Поскольку твитам характерна авторская пунктуация и эмотиконы, определение границ предложений становится достаточно трудоемкой задачей. В этой работе я допустил, что каждый твит содержит лишь одно предложение.
База неразмеченных твитов хранится в SQL-формате и содержит более 17,5 млн. записей. Для удобства работы я конвертировал её в SQLite с помощью [этого](https://github.com/dumblob/mysql2sqlite) скрипта.
```
import sqlite3
# Открываем SQLite базу данных
conn = sqlite3.connect('mysqlite3.db')
c = conn.cursor()
with open('data/tweets.txt', 'w', encoding='utf-8') as f:
# Считываем тексты твитов
for row in c.execute('SELECT ttext FROM sentiment'):
if row[0]:
tweet = preprocess(row[0])
# Записываем предобработанные твиты в файл
print(tweet, file=f)
```
Далее с помощью библиотеки Gensim обучил Word2Vec-модель со следующими параметрами:
* *size = 200* — размерность признакового пространства;
* *window = 5* — количество слов из контекста, которое анализирует алгоритм;
* *min\_count = 3* — слово должно встречаться минимум три раза, чтобы модель его учитывала.
```
import logging
import multiprocessing
import gensim
from gensim.models import Word2Vec
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# Считываем файл с предобработанными твитами
data = gensim.models.word2vec.LineSentence('data/tweets.txt')
# Обучаем модель
model = Word2Vec(data, size=200, window=5, min_count=3, workers=multiprocessing.cpu_count())
model.save("models/w2v/model.w2v")
```
*Рисунок 2. Визуализация кластеров похожих слов с использование t-SNE.*
Для более детального понимания работы Word2Vec на рис. 2 представлена визуализация нескольких кластеров похожих слов из обученной модели, отображенных в двухмерное пространство с помощью [алгоритма визуализации t-SNE](https://habr.com/post/267041/).
Векторное отображение текстов
-----------------------------

*Рис 3. Распределение длины текстов.*
На следующем этапе каждый текст был отображен в массив идентификаторов токенов. Я выбрал размерность вектора текста *s=26*, поскольку при данном значении полностью покрываются 99,71% всех текстов в сформированном корпусе (рис. 3). Если при анализе количество слов в твите превышало высоту матрицы, оставшиеся слова отбрасывались и не учитывались в классификации. Итоговая размерность матрицы предложения составила *s×d=26×200*.
```
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# Высота матрицы (максимальное количество слов в твите)
SENTENCE_LENGTH = 26
# Размер словаря
NUM = 100000
def get_sequences(tokenizer, x):
sequences = tokenizer.texts_to_sequences(x)
return pad_sequences(sequences, maxlen=SENTENCE_LENGTH)
# Cоздаем и обучаем токенизатор
tokenizer = Tokenizer(num_words=NUM)
tokenizer.fit_on_texts(x_train)
# Отображаем каждый текст в массив идентификаторов токенов
x_train_seq = get_sequences(tokenizer, x_train)
x_test_seq = get_sequences(tokenizer, x_test)
```
Свёрточная нейронная сеть
-------------------------
Для построения нейронной сети я использовал библиотеку Keras, которая выступает высокоуровневой надстройкой над TensorFlow, CNTK и Theano. У Keras есть отличная документация, а также блог, который освещает многие задачи машинного обучения, к примеру, [инициализацию embedding-слоя](https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html). В нашем случае embedding-слой был инициирован весами, полученными при обучении Word2Vec. Чтобы минимизировать изменения в embedding-слое, я заморозил его на первом этапе обучения.
```
from keras.layers import Input
from keras.layers.embeddings import Embedding
tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32')
tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH,
weights=[embedding_matrix], trainable=False)(tweet_input)
```
В разработанной архитектуре использованы фильтры с высотой *h=(2, 3, 4, 5)*, которые предназначены для параллельной обработки биграмм, триграмм, 4-грамм и 5-грамм соответственно. Добавил в нейронную сеть по 10 свёрточных слоев для каждой высоты фильтра, функция активации — ReLU. С рекомендациями по поиску оптимальной высоты и количества фильтров можно ознакомиться в работе [2].
После обработки слоями свертки, карты признаков поступали на слои субдискретизации, где к ним применялась операция 1-max-pooling, тем самым извлекая наиболее значимые n-граммы из текста. На следующем этапе происходило объединение в общий вектор признаков (слой объединения), который подавался в скрытый полносвязный слой с 30 нейронами. На последнем этапе итоговая карта признаков подавалась на выходной слой нейронной сети с сигмоидальной функцией активации.
Поскольку нейронные сети склонны к переобучению, после embedding-слоя и перед скрытым полносвязным слоем я добавил dropout-регуляризацию c вероятностью выброса вершины p=0.2.
```
from keras import optimizers
from keras.layers import Dense, concatenate, Activation, Dropout
from keras.models import Model
from keras.layers.convolutional import Conv1D
from keras.layers.pooling import GlobalMaxPooling1D
branches = []
# Добавляем dropout-регуляризацию
x = Dropout(0.2)(tweet_encoder)
for size, filters_count in [(2, 10), (3, 10), (4, 10), (5, 10)]:
for i in range(filters_count):
# Добавляем слой свертки
branch = Conv1D(filters=1, kernel_size=size, padding='valid', activation='relu')(x)
# Добавляем слой субдискретизации
branch = GlobalMaxPooling1D()(branch)
branches.append(branch)
# Конкатенируем карты признаков
x = concatenate(branches, axis=1)
# Добавляем dropout-регуляризацию
x = Dropout(0.2)(x)
x = Dense(30, activation='relu')(x)
x = Dense(1)(x)
output = Activation('sigmoid')(x)
model = Model(inputs=[tweet_input], outputs=[output])
```
Итоговую модель сконфигурировал с функцией оптимизации Adam (Adaptive Moment Estimation) и бинарной кросс-энтропией в качестве функции ошибок. Качество работы классификатора оценивал в критериях макро-усредненных точности, полноты и f-меры.
```
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1])
model.summary()
```
На первом этапе обучения заморозил embedding-слой, все остальные слои обучались в течение 10 эпох:
* Размер группы примеров, используемых для обучения: 32.
* Размер валидационной выборки: 25%.
```
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1)
history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
```
**Логи**`Train on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636`
Затем выбрал модель с наивысшими показателями F-меры на валидационном наборе данных, т.е. модель, полученную на восьмой эпохе обучения (F1=0.7791). У модели разморозил embedding-слой, после чего запустил еще пять эпох обучения.
```
from keras import optimizers
# Загружаем веса модели
model.load_weights('models/cnn/cnn-frozen-embeddings-09-0.77.hdf5')
# Делаем embedding слой способным к обучению
model.layers[1].trainable = True
# Уменьшаем learning rate
adam = optimizers.Adam(lr=0.0001)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=[precision, recall, f1])
model.summary()
checkpoint = ModelCheckpoint("models/cnn/cnn-trainable-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1)
history_trainable = model.fit(x_train_seq, y_train, batch_size=32, epochs=5, validation_split=0.25, callbacks = [checkpoint])
```
**Логи**`Train on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703`
Наивысший показатель *F1=76.80%* на валидационной выборке был достигнут на третьей эпохе обучения. Качество работы обученной модели на тестовых данных составило *F1=78.1%*.
Таблица 1. Качество анализа тональности на тестовых данных.
| | | | | |
| --- | --- | --- | --- | --- |
| Метка класса | Точность | Полнота | F1 | Количество объектов |
| Negative | 0.78194 | 0.78243 | 0.78218 | 22457 |
| Positive | 0.78089 | 0.78040 | 0.78064 | 22313 |
| avg / total | 0.78142 | 0.78142 | 0.78142 | 44770 |
Результат
---------
В качестве baseline-решения я [обучил](https://towardsdatascience.com/sentiment-analysis-of-tweets-using-multinomial-naive-bayes-1009ed24276b) наивный байесовский классификатор с мультиномиальной моделью распределения, результаты сравнения представлены в табл. 2.
Таблица 2. Сравнение качества анализа тональности.
| | | | |
| --- | --- | --- | --- |
| Классификатор | Precision | Recall | F1 |
| MNB | 0.7577 | 0.7564 | 0.7560 |
| CNN | **0.78142** | **0.78142** | **0.78142** |
Как видите, качество классификации CNN превысило MNB на несколько процентов. Значения метрик можно увеличить еще больше, если поработать над оптимизацией гиперпараметров и архитектуры сети. К примеру, можно изменить количество эпох обучения, проверить эффективность использования различных векторных представлений слов и их комбинаций, подобрать количество фильтров и их высоту, реализовать более эффективную предобработку текстов (исправление опечаток, нормализация, стемминг), настроить количество скрытых полносвязных слоев и нейронов в них.
Исходный код [доступен на Github](https://github.com/sismetanin/sentiment-analysis-of-tweets-in-russian), обученные модели CNN и Word2Vec можно скачать [здесь](https://yadi.sk/d/Xohf3dTuVTakDA).
Источники
---------
1. Cliche M. BB\_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). — 2017. — С. 573-580.
2. Zhang Y., Wallace B. A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification //arXiv preprint arXiv:1510.03820. — 2015.
3. Rosenthal S., Farra N., Nakov P. SemEval-2017 task 4: Sentiment Analysis in Twitter //Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). — 2017. — С. 502-518.
4. Ю. В. Рубцова. Построение корпуса текстов для настройки тонового классификатора // Программные продукты и системы, 2015, №1(109), —С.72-78.
5. Mikolov T. et al. Distributed Representations of Words and Phrases and Their Compositionality //Advances in Neural Information Processing Systems. — 2013. — С. 3111-3119. | https://habr.com/ru/post/417767/ | null | ru | null |
# 3D-индикатор крена и тангажа для HUD на Three.js
Браузерные игры с трехмерной графикой создаются достаточно давно. Существуют и симуляторы различных транспортных средств, где игроку необходимо контролировать пространственное положение управляемого объекта.

В статье «[Индикатор искусственного горизонта на HTML5 canvas](https://habr.com/ru/post/530334/)» представлен код индикатора с объемным макетом управляемого объекта на основе [изобретения](https://patents.s3.yandex.net/RU2331848C2_20080820.pdf) Пленцова А. П. и Законовой Н. А. В реальной технике такая индикация распространения не получила, но в компьютерных играх она вполне может быть использована.
К числу достоинств идеи индикатора с объемным макетом следует отнести эффектность. На этот раз необычный формат визуализации искусственного горизонта будет адаптирован для систем [дополненной реальности](https://habr.com/ru/post/419437/).
**HUD vs HDD**
Дизайн индикатора, копирующий вид лицевой части электромеханического прибора, подходит для вывода на простом экране или *head down display (HDD)*. *HDD* обладают недостатком обычных приборных панелей: взгляд оператора фиксируется или на инструментальной информации, или на внешнем мире, с заметными переходами между этими двумя режимами восприятия.
Сегодня даже в автомобилях широко используется индикация на лобовом стекле ([head up display](https://en.wikipedia.org/wiki/Head-up_display) или *HUD* – дословно «экран поднятой головы»), позволяющая минимизировать затраты времени и усилий оператора на переключение внимания.
Формату индикации на лобовом стекле посвящено большое количество исследований. Примеры современных публикаций:
* [Эргономические рекомендации для пользовательского интерфейса HUD в полуавтоматическом управлении;](https://www.mdpi.com/2079-9292/9/4/611/htm)
* [Методология проектирования графических интерфейсов автомобильных HUD;](https://www.researchgate.net/publication/330548481_Methodology_for_the_design_of_automotive_HUD_graphical_interfaces)
* [HUD для пилотов и водителей;](https://www.longdom.org/open-access/headup-display-for-pilots-and-drivers-2165-7556.1000e120.pdf)
* [Воспринимаемая важность информационных элементов автомобильных HUD: исследование с опытными пользователями;](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8341494)
Особенности оформления HUD
==========================
Дополнение наблюдаемой реальности инструментальной информацией заметно отличается от обычной индикации значений параметров. Специфика задачи отражается на визуальном оформлении *HUD*. В наиболее сложных и ответственных системах ([например](https://www.youtube.com/watch?v=QWh4-05LTdA), на рабочем месте пилота авиалайнера), как правило, используют монохромную зеленую индикацию в «контурном» исполнении.
Минимализм дизайна *HUD* – ответ на комплекс противоречивых требований к системе. Например, контурные элементы способны иметь достаточный для считывания оператором угловой размер, не перекрывая при этом обзор внешнего пространства.
Требования к решению
====================
Определим ключевые положения задания на разработку класса индикатора искусственного горизонта:
1. Конструктор класса должен иметь следующие аргументы:
* размер лицевой части индикатора;
* предельное отображаемое значение крена;
* предельное отображаемое значение тангажа.
2. Предельные отображаемые значения каждого угла определяются одним значением, которое не должно превышаться абсолютной величиной отображаемого значения. Предельные значения не могут превышать величину 90 градусов.
3. Шкала тангажа должна иметь семь числовых отметок значений угла в градусах. Масштаб шкалы должен быть оптимизирован при инстанцировании объекта, интервал отображаемых значений должен быть минимальным при соблюдении следующих условий:
* верхняя и нижняя отметки кратны 30;
* максимальное значение угла тангажа, переданное конструктору, не выходит за пределы шкалы, в том числе при умножении на -1.
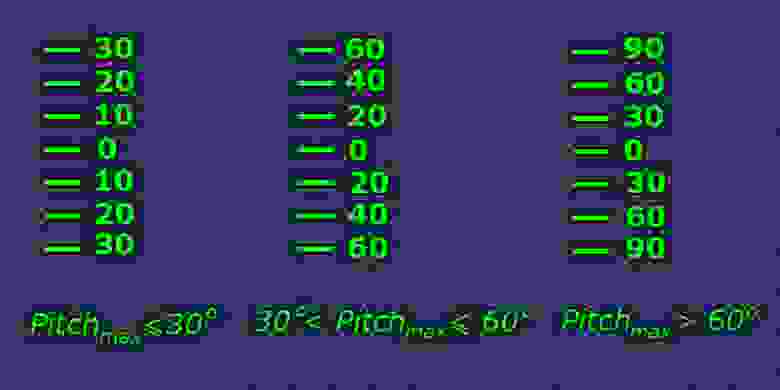
4. Шкала крена должна иметь отметки с шагом 30 градусов по всей окружности циферблата, независимо от максимального значения угла крена, переданного конструктору. Метки шкалы крена должны отображаться с учетом положения макета по тангажу, то есть циферблат должен поворачиваться в плоскости симметрии рабочего места на угол тангажа вокруг оси, проходящей через центр циферблата.
5. Макет транспортного средства должен быть выполнен в виде плоской фигуры, имеющей форму стрелки. Отношение длины макета к его ширине должно обеспечивать рациональное использование площади экрана. Например, если шкала тангажа ограничена значением 90 градусов, то длина макета должна соответствовать примерно половине его ширины. При ограничении шкалы значением 30 градусов существенная доля высоты экрана перестает использоваться, что показано в правой части схемы.

Для правильного масштабирования шкалы с меньшим интервалом необходимо изменить пропорции макета.

6. В классе должна присутствовать функция обновления, принимающая текущие значения углов крена и тангажа.
7. Индикация должна иметь зеленый цвет и контурный вид. Количество элементов индикатора должно быть по возможности минимальным, необходимо обеспечить сохранение обзора фоновой анимации.
Результат
=========
Оценить получившийся индикатор в интерактивном режиме можно на [github pages](https://yeryomin1.github.io/HUD-artificial-horizon/).
Объект в этом примере движется всегда строго в направлении своей продольной оси. Имеется возможность задавать значения скорости движения, углов крена и тангажа. Движение осуществляется только в вертикальной плоскости, поскольку значение угла курса постоянно.
Код индикатора
==============
Код индикации искусственного горизонта представлен ниже. В классе *Attitude* используется библиотека *three.js*.
**Код класса Attitude**
```
class Attitude {
constructor(camera, scene, radius, maxPitch, maxRoll) {
//тангаж:
//устанавливаем кратный 30 с запасом в большую сторону предел значений угла:
if (maxPitch > 90) maxPitch = 90;
this.maxPitch = maxPitch;
maxPitch /= 30;
maxPitch = Math.ceil(maxPitch) * 30;
//крен:
if (maxRoll > 90) maxRoll = 90;
this.maxRoll = maxRoll;
//определяем длину силуэта:
let skeletonLength = radius / Math.sin(maxPitch * Math.PI / 180);
//строим контурный силуэт:
let geometry = new THREE.Geometry();
geometry.vertices.push(new THREE.Vector3(0, 0, -skeletonLength / 4));
geometry.vertices.push(new THREE.Vector3(-radius, 0, 0));
geometry.vertices.push(new THREE.Vector3(0, 0, -skeletonLength));
geometry.vertices.push(new THREE.Vector3(radius, 0, 0));
geometry.vertices.push(new THREE.Vector3(0, 0, -skeletonLength / 4)); // замыкаем контур
//контурный материал:
let material = new THREE.LineBasicMaterial({ color: 0x00ff00, linewidth: 1 });
//создаем линию контура:
this.skeleton = new THREE.Line(geometry, material);
scene.add(this.skeleton);
//создаем шкалу тангажа:
let pitchScaleStep = maxPitch / 3;
let textLabelsPos = [];//позиции текстовых меток шкалы
for (let i = 0; i < 7; i++) {
let lineGeometry = new THREE.Geometry();
//левый и правый края линии метки:
let leftPoint = new THREE.Vector3(-radius / 10,
skeletonLength * Math.sin((maxPitch - pitchScaleStep * i) * Math.PI / 180),
-skeletonLength * Math.cos((maxPitch - pitchScaleStep * i) * Math.PI / 180));
let rightPoint = new THREE.Vector3();
rightPoint.copy(leftPoint);
rightPoint.x += (radius / 5);
//линия метки:
lineGeometry.vertices.push(leftPoint);
lineGeometry.vertices.push(rightPoint);
let line = new THREE.Line(lineGeometry, material);
scene.add(line);
//позиция текстовой метки
let textPos = new THREE.Vector3();
textPos.copy(leftPoint);
textLabelsPos.push(textPos);
}
//создаем шкалу крена:
let rollScaleStep = 30;
this.rollLines = [];
for (let i = 0; i < 12; i++) {
if (i != 3 && i != 9) {//не ставим верхнюю и нижнюю метки
let lineGeometry = new THREE.Geometry();
//края линии метки:
lineGeometry.vertices.push(new THREE.Vector3(-Math.cos(
i * rollScaleStep * Math.PI / 180) * radius * 1.1,
Math.sin(i * rollScaleStep * Math.PI / 180) * radius * 1.1,
0));
lineGeometry.vertices.push(new THREE.Vector3(-Math.cos(
i * rollScaleStep * Math.PI / 180) * radius * 0.9,
Math.sin(i * rollScaleStep * Math.PI / 180) * radius * 0.9,
0));
this.rollLines.push(new THREE.Line(lineGeometry, material));
scene.add(this.rollLines[this.rollLines.length - 1]);
}
}
//текстовые метки:
for (let i = 0; i < 7; i++) {
let labelText = document.createElement('div');
labelText.style.position = 'absolute';
labelText.style.width = 100;
labelText.style.height = 100;
labelText.style.color = "Lime";
labelText.style.fontSize = window.innerHeight / 35 + "px";
labelText.innerHTML = Math.abs(maxPitch - pitchScaleStep * i);
let position3D = textLabelsPos[i];
let position2D = to2D(position3D);
labelText.style.top = (position2D.y) * 100 / window.innerHeight - 2 + '%';
labelText.style.left = (position2D.x) * 100 / window.innerWidth - 4 + '%';
document.body.appendChild(labelText);
}
function to2D(pos) {
let vector = pos.project(camera);
vector.x = window.innerWidth * (vector.x + 1) / 2;
vector.y = -window.innerHeight * (vector.y - 1) / 2;
return vector;
}
}
update(roll, pitch) {
//проверка выхода за ограничение:
if (pitch > this.maxPitch) pitch = this.maxPitch;
if (pitch < -this.maxPitch) pitch = -this.maxPitch;
if (roll > this.maxRoll) roll = this.maxRoll;
if (roll < -this.maxRoll) roll = -this.maxRoll;
//установка силуэта в положение, соответствующее текущим значениям крена и тангажа
this.skeleton.rotation.z = -roll * Math.PI / 180;
this.skeleton.rotation.x = pitch * Math.PI / 180;
//перемещаем только отметки крена:
let marksNum = this.rollLines.length;
for (let i = 0; i < marksNum; i++)
this.rollLines[i].rotation.x = pitch * Math.PI / 180;
}
}
```
**Разбор кода**
Индикатор размещен таким образом, что центр циферблата шкалы крена совпадает с началом мировой системы координат. При отсутствии тангажа и крена макет лежит в плоскости *XOZ*, его продольная ось совпадает с осью *OZ*, нос макета направлен в сторону отрицательных значений *z*.
Плоскостью симметрии рабочего места оператора будем считать плоскость *YOZ*. Взгляд оператора направлен в сторону отрицательных значений *z*.
Основную часть кода класса *Attitude* составляет его конструктор. Здесь определены геометрические свойства и дизайн всех элементов индикатора. Помимо параметров, указанных в требованиях, конструктору передаются камера и сцена.
```
constructor(camera, scene, radius, maxPitch, maxRoll){
```
Первая понадобится для проекции трехмерного положения текстовых отметок на экран (функция *to2D()*), а вторая – для добавления к ней всех видимых компонентов индикатора через метод *add()*.
Установка пределов шкал выполняется довольно просто. Для шкалы тангажа дополнительно устанавливаются границы по условиям п. 3 требований.
```
if (maxPitch > 90) maxPitch = 90;
this.maxPitch = maxPitch;
maxPitch /= 30;
maxPitch = Math.ceil(maxPitch) * 30;
```
Шкала тангажа может иметь предел 30, 60 или 90 градусов. Для рационального использования пространства экрана пропорции макета-стрелки должны выбираться в соответствии с этими значениями.
```
let skeletonLength = radius / Math.sin(maxPitch * Math.PI / 180);
```
Если параметр radius однозначно определяет ширину макета, то длина *skeletonLength* зависит от *maxPitch*: чем выше максимальное значение тангажа, тем короче макет. Таким образом, пропорции самого индикатора не зависят от *maxPitch*.
Строго говоря, для перспективной камеры пропорции индикатора сохраняются лишь на бесконечном удалении. Тем не менее, и в реальных условиях различия достаточно малы.
Контур макета строится по четырем точкам, начиная с ближней к оператору вершины на продольной оси макета.
```
let geometry = new THREE.Geometry();
geometry.vertices.push(new THREE.Vector3(0, 0, -skeletonLength / 4));
geometry.vertices.push(new THREE.Vector3(-radius, 0, 0));
geometry.vertices.push(new THREE.Vector3(0, 0, -skeletonLength));
geometry.vertices.push(new THREE.Vector3(radius, 0, 0));
geometry.vertices.push(new THREE.Vector3(0, 0, -skeletonLength / 4));
let material = new THREE.LineBasicMaterial({ color: 0x00ff00, linewidth: 1 });
this.skeleton = new THREE.Line(geometry, material);
scene.add(this.skeleton);
```
Обход силуэта осуществляется по часовой стрелке, если смотреть на него сверху. Повторение в коде первой точки замыкает контур фигуры.
Аналогичные средства *three.js* используются для создания линий отметок шкал. Шкалы тангажа и крена имеют следующие различия:
1. Шкала тангажа неподвижна, положение ее элементов не меняется при вызове метода *update()*, а все метки шкалы крена, кроме двух нулевых, вращаются по тангажу. Различие обусловлено природой самих углов. Вращение по тангажу осуществляется вокруг поперечной оси нормальной земной системы координат, а вращение по крену – вокруг продольной оси связанной системы координат.
2. Отметки шкалы тангажа расположены горизонтально, перпендикулярно плоскости шкалы (плоскости симметрии рабочего места оператора), а отметки шкалы крена находятся в ее плоскости и имеют радиальное направление.
Метод *update()* после проверки значений тангажа и крена на соответствие установленным ограничениям осуществляет поворот всех подвижных компонентов:
* макет поворачивается на углы крена и тангажа;
* шкала крена поворачивается на угол тангажа.
Текстовые подписи числовых значений шкалы тангажа выполняются посредством создания тегов *html*. Использование *3D* шрифтов в этом случае лишено практического смысла.
Недостатки индикатора
=====================
Беглого знакомства с интерактивной демонстрацией достаточно, чтобы заметить сложности в считывании показаний при больших абсолютных значениях углов:
* начало снижения качества индикации крена соответствует значениям угла тангажа 75-80 градусов, при которых шкала крена становится заметно сжатой;
* начало снижения качества индикации малых значений угла тангажа соответствует значениям угла крена 70-75 градусов, при которых силуэт макета теряет стреловидность;
* индикация перевернутого положения объекта в представленном решении исключена в принципе.
Стоит отметить, что индикации искусственного горизонта, идеально работающей в любых пространственных положениях транспортного средства, не существует. Представленное решение можно считать пригодным для использования на маневрах умеренной интенсивности. | https://habr.com/ru/post/534046/ | null | ru | null |
# Современная отладка JavaScript
В связи с достаточно широким выбором неплохих отладчиков, JavaScript-программисты могут получить достаточно много пользы, изучая то как их можно использовать. Их пользовательские интерфейсы становятся все более совершенными, более стандартизированными между собой и более легкими в использовании, что делает их полезными как для экспертов так и новичков в отладке JS. В этой статье мы обсудим передовые методы отладки для диагностики и анализа ошибок, используя типичное веб-приложение.
В настоящее время средства отладки доступны для всех основных браузеров.
* [Firefox](http://www.mozilla.com/firefox/) имеет хорошо известное расширение [Firebug](http://getfirebug.com/)
* [IE8](http://www.microsoft.com/windows/products/winfamily/ie/ie8/default.mspx) выпускается со встроенными Developer Tools
* [Опера](http://www.opera.com/) 9.5+ поддердивает отладчик [Dragonfly](http://www.opera.com/products/dragonfly/)
* У [Safari](http://www.apple.com/safari/) есть JS-отладчик [Drosera](http://webkit.org/blog/61/introducing-drosera/) и DOM-вьювер [WebInspector](http://webkit.org/blog/41/introducing-the-web-inspector/). В более свежих версиях отладчик интегрирован в WebInspector.
На данный момент Firebug и Dragonfly наиболее стабильны. Утилиты IE8 иногда игнорируют контрольные точки, а во время написания этой статьи WebInspector имеет некоторые проблемы совмстимости с последними билдами Webkit.
Изучите несколько средств отладки — вы никогда не знаете, в котором браузере возникнет следующая ошибка. Так как отладчики примерно сопоставимы в функциональных возможностях, между ними легко переключиться, как только вы разберетесь как использовать хотя бы один.
### Технология отладки.
Натыкаясь на определенную проблему, обычно вы будете проходить следующие этапы
1. Найти соответствующий код на панели просмотра кода отладчика
2. Установить контрольную точку или точки в том месте, которое вам кажется потенциально проблемным
3. Запустить скрипт еще раз, перезагрузив страницу или нажать кнопку, если речь идет об обработчике события.
4. Ждать, пока отладчик остановит выполнение и сделает возможным пошаговое выполнение кода.
5. Исследовать значения переменных. Например, искать переменные, которые почему то неопределенны(undefined), хотя должны содержать значение, или возвращают «ложь», хотя вы ожидаете, что они возвратят «истину».
6. В случае необходимости, использовать командную строку, для вычисления кода или изменения значений переменных
7. Найти проблему изучив часть кода её вызвашую и устранить её.
Чтобы создать контрольную точку, вы можете также добавлять в ваш код специальную инструкцию отладчика:
> `function frmSubmit(event){
>
> event = event || window.event;
>
> debugger;
>
> var form = this;
>
> }`
### Требования
Большинство отладчиков требуют, чтобы код был хорошо отформатирован. Скрипты, написанные «в одну строку», мешают определять ошибки в построчных отладчиках. Обфусцированный код черезвычайно сложен для отладки, особенно упакованный. Много библиотек JavaScript позволяют вам выбирать между упакованными/обфусцированными и нормально отформатированными версиями, разумеется отлаживать скрипты нужно с последними.
### Демонстрация отладки
Давайте начнем с маленького, специально «забаженного» примера, чтобы научится находить и исправлять ошибки. Наш пример — [страница авторизации](http://www.alistapart.com/d/advanceddebuggingwithjavascript/debugmeapp-ETM.htm).
Представьте себе, что вы работаете над этим невероятным новым веб-приложением, и ваши тестеры попросили вас исправить следующие ошибки:
1. “Loading…” сообщение строки состояния не исчезает, когда приложение закончило загружаться.
2. Язык по умолчанию — норвежский, даже в английских версиях IE и Firefox.
3. Где то в коде образовалась глобальная переменная prop (зло — прим. пер.).
4. В DOM-вьювере все элементы почему то имеют атрибут «clone».
### Запуск отладчиков
* В Firefox вы должны убедится, что у вам установлено расширение Firebug. Выберите “Инструменты > Firebug > Open Firebug”.
* В Опере 9.5+, выберите “Инструменты > Дополнительно > Средства разработки.”
* В бете IE, выберите “Сервис > Панели > Панели обозревателя > IE Developer Toolbar.”
* В Safari или WebKit, сначала включите меню отладки (1), затем выберите “Разработать > Показать веб-инспектор”
Пришло время запускать отладчики. Так как некоторые инструкции требуют изменения кода, вам лучше сохранить тестовую страницу и загрузить ее браузером с диска.
### Ошибка № 1: Сообщение “Загрузка …”
Если вы посмотрите на отлаживаемое приложение, то сначала вы увидите то, что изображено на рисунке 1.


*рис. 1: начальный вид нашего JavaScript-приложения в Dragonfly и Firebug, соответственно.*
Когда вы смотрите на исходный текст в отладчике, обратите внимание на функцию clearLoadingMessage() в самом начале кода. Это неплохое место для контрольной точки.
Как её поставить:
1. Щелкните мышью в левом поле на номере строки, чтобы установить контрольную точку на первой строке **внутри** функции clearLoadingMessage().
2. Перезагрузите страницу.
Обратите внимание: контрольная точка должна быть установлена на строке с кодом, который выполнится, когда функция будет запущена. Строка, которая содержит clearLoadingMessage(){ не подходит, так как является лишь определением функции. Если вы установите контрольную точку здесь, отладчик на ней не остановится, вместо этого контрольную точку надо устанавливать внутри функции.
Когда страница будет перезагружена, выполнение скрипта будет остановлено и вы увидите то, что показано на рисунке два.


*рис. 2: отладчики остановились в контрольной точке внутри clearLoadingMessage.*
Давайте взглянем на код функции. Как нетрудно заметить, в ней обновляются два DOM элемента, а в строке 31 упоминается слово statusbar. Похоже, что getElements( 'p', {'class':'statusbar'} )[0].innerHTML ищет элемент statusbar в дереве DOM. Как бы нам быстро проверить своё предположение?
Вставьте эту инструкцию в командную строку, чтобы проверить. На рисунке три показаны три скриншота (Dragonfly, Firebug и IE8) после чтения innerHTML или outerHTML элемента, возвращенного командой, которую вы исследуете.
Чтобы проверить сделайте следующее:
1. Найдите командную строку:
\* В Firebug, переключитесь в закладку “Console”.
\* В Dragonfly, просмотрите пониже панели кода JavaScript.
\* В IE8, найдите закладку справа «Console».
2. Вставьте getElements( 'p', {'class':'statusbar'} )[0].innerHTML в командную строку.
3. Нажмите Enter.



*рис. 3: вывод результата команды в Dragonfly, Firebug, и IE8, соответственно.*
Командная строка — очень полезный инструмент, который позволяет вам быстро проверять маленькие куски кода. Интеграция консоли Firebug очень полезна — если Ваша команда выводит объект, вы получаете очень интеллектуальное представление. Например, если это объект DOM — вы увидите размеченный результат.
Можно использовать консоль, чтобы провести более глубокое исследование. Строка JavaScript, которую мы изучаем, делает следующие три вещи:
1. Получает ссылку на элемент statusbar.
2. Находит firstChild, другими словами, первый узел в этом параграфе.
3. Устанавливает свойство innerText.
Давайте попробуем запустить в консоли, что-то большее, чем предыдущая команда. Например вы можете попробовать узнать, какое текущее значение у свойства innerText, перед тем как ему присваивается новое значние. Чтобы узнать это, вы можете напечатать всю команду до знака "=" в командную строку:
> `getElements( 'p', {'class':'statusbar'} )[0].firstChild.innerText`
Сюрприз, на выходе… ничего. Таким образом выражение getElements ('p', {'класс:'statusbar' '}) [0].firstChild указывает на какой то объекст в DOM, который не содержит никакого текста, или не имеет свойства innerText.
Тогда, следующий вопрос: что на самом деле является первым дочерним элементом у параграфа? Давайте зададим этот вопрос коммандной строке. (См. четвертый рисунок).

*рис. 4: командная строка отладчика СтDragonfly, вывод [объект Text].*
Вывод отладчика Dragonfly’s — [объект Text] показывает, что это — текстовый узел DOM. Таким образом мы нашли причину первой проблемы. У текстового узла нет свойства innerText, следовательно, установка значения для p.firstChild.innerText ничего не делает. Эта ошибка легко может быть исправлена, если заменить innerText на nodeValue, который является свойством, определенным стандартом W3C для текстовых узлов.
Теперь, после того как мы разобрались с первой ошибкой:
1. Нажмите [F5] или кнопку Run, чтобы закончить скрипт.
2. Не забудьте сбросить поставленную контрольную точку, кликнув по номеру строки еще раз.
### Ошибка два: проблема определения языка.
Вы, возможно, обратили внимание на переменную lang;/\*language\*/ в начале скрипта. Можно предпложить, что код устанавливающий значение этой переменной и вызывает проблему. Можно попробовать найти этот код используя встроенную в отладчики функцию поиска. В Dragonfly поиск находтится прямо над просмотрщиком кода, в Firebug — в правом верхнем углу (см. рисунок 5)
Чтобы найти место, где вероятно происходит проблема локализации сделайте следующее:
1. Напечатайте lang = в поле поиска.
2. Установите контрольную точку на строке, где переменной lang задается значение.
3. Перезагрузите страницу.
У WebInspector тоже есть очень удобная функция поиска. Она позволяет искать что угодно одновременно и в разметке страницы, и в CSS, и в коде JavaScript. Результаты показывюется на отдельной панели, где вы можете дважды кликнуть по ним, чтобы перейти в нужное место, как показано на скриншоте.


*рис. 5: поиск в Dragonfly и в WebInspector.*
Для того, чтобы проверить, что делает эта функция:
1. Нажмите кнопку «step into» для входа внутрь функции getLanguage.
2. Жмите ее еще и еще, пошагово выполняя код
3. В окне просмотра переменных смотрите как меняются их значния.
Войдя в функцию вы увидите попытку прочитать язык из строки юзер-агента браузера, путем анализа navigator.userAgent.
> `var str1 = navigator.userAgent.match( /\((.\*)\)/ )[1];
>
> var ar1 = str1.split(/\s\*;\s\*/), lang;
>
> for (var i = 0; i < ar1.length; i++){
>
> if (ar1[i].match(/^(.{2})$/)){
>
> lang = ar1[i];
>
> }
>
> }`
В процессе пошагового прохождения кода, вы можете использовать окно просмотра локальных переменных. На рисунке 6 показано как это выглядит в Firebug и IE8 DT, массив ar1 мы развернули, чтобы видеть его элементы.

*рис. 6: Панель просмотра локальных переменных фукции getLanguage в Firebug IE8’s*
Выражение ar1[i].match(/^(.{2})$/) просто ищет строку, состоящую их двух символов, типа «no», «en». Однако как видно на скриншоте у Firefox информация о языке представлена в виде «nn-NO» (2). IE же и вовсе не помещает в юзер-агента информации о языке.
Таким образом мы нашли вторую ошибку: определение языка производилось путем поиска двухбуквенного кода в строке юзерагента, но Firefox имеет пятисимвольное обозначение языка, а IE не имеет его вовсе. Такой код должен быть переписан и заменен на определение языка либо на стороне сервера с помощью HTTP заголовка Accept-Language, либо получением его из navigator.language (navigator.userLanguage для IE). Вот пример того, какой может быть такая функция
> `function getLanguage() {
>
> var lang;
>
>
>
> if (navigator.language) {
>
> lang = navigator.language;
>
> } else if (navigator.userLanguage) {
>
> lang = navigator.userLanguage;
>
> }
>
>
>
> if (lang && lang.length > 2) {
>
> lang = lang.substring(0, 2);
>
> }
>
>
>
> return lang;
>
> }`
### Ошибка три: таинственная переменная «prop»

*рис. 7: В панели просмотра переменных Firebug и Dragonfly видна глобальная переменная prop*
На рисунке 7 хорошо видно переменную «prop». В хорошо написанных приложениях количество глобальных переменных должно быть минимально, поскольку они могут стать причиной проблем, когда, например две части приложения захотят использовать одну и ту же переменную. Предположим, что завтра другая команда добавит новые возможности в наше приложение и тоже объявит переменную «prop». Мы получим две разные части кода приложения, использующие одно имя для разных вещей. Такая ситуация часто приводит к конфликтам и ошибкам. Можно попробовать найти эту переменную и объявить ее локальной. Для этого можно воспользоваться поиском, как мы делали это в предыдущем случае, но есть и более умный способ…
У отладчиков для многих других языков программирования есть понятие «наблюдателя»(watch), который переходит в режим отладки, когда изменяется заданная переменная. Ни Firebug, ни Dragonfly не поддерживают «наблюдателей» в настоящее время, но мы можем легко эмулировать похожее поведение, добавив следующую строку в начало исследуемого кода:
> `\_\_defineSetter\_\_('prop', function() { debugger; });`
Сделайте следующее:
1. Добавьте отладочный код в начало самого первого скрипта.
2. Перезагрузите страницу.
3. Отметьте, как прерывается выполнение скрипта.
В IE8 DT имеется закладка «Watch», однако прерывания в момент изменения переменной не происходит. Так что этот пример работает только в Firefox, Opera и Safari.
Когда вы перезагрузите страницу, выполнение кода немедленно остановится там где будет определена переменная «prop». Фактически остановка произодет в том месте, где вы добаили вышеупомянутую строку. Один клик по кнопке «step out» перекинет вас в место установки переменной.
> `for (prop in attributes) {
>
> if (el.getAttribute(prop) != attributes[prop]) includeThisElement = false;`
Нетрудно заметить цикл for в котором объявляется переменная prop без ключевого слова var, т.е. глобальная. Исправить это несложно, просто допишем var и исправим ошибку.
### Ошибка четыре: атрибут «clone», которого быть не должно
Четвертая ошибка очевидно была обнаружена продвинутым тестировщиком, использующим DOM инспектор, так как ее существование никак не проявляется в пользовательском интерфейсе приложения. Если и мы откроем DOM инспектор (в Firebug это закладка «HTML», в Dragonfly она называется «DOM»), то увидим что многие элементы имеют атрибут clone, которого быть не должно.

*рис. 8: Dragonfly’s DOM инспектор показывает проблемный код.*
Так как это никак не отражается на пользователях приложения, можно не считать этот баг серьезным, однако не стоит забывать, что он может существенно сказаться на производительности, поскольку скрипт устанавливает атрибут на сотнях и тысячах элементов.
Самый быстрый способ найти эту проблему состоит в том, чтобы установить контрольную точку, которая срабатывает тогда, когда атрибут с названием clone будет установлен для какого-нибудь HTML элемента. Могут ли отладчики сделать это?
JavaScript — очень гибкий язык, и одна из его сильных сторон (или слабых, в зависимости от вашей точки зрения) — это то, что вы можете заменить базовые функции языка своими собственными. Добавьте этот кусок кода на страницу, он переопределит системный метод setAttribute, вызывая остановку кода в момент установки свойства «clone»:
> `var funcSetAttr = Element.prototype.setAttribute; /\* сохраняем ссылку на системный метод \*/
>
> Element.prototype.setAttribute = function(name, value) {
>
> if (name == 'clone') {
>
> debugger; /\* останавливаем скрипт \*/
>
> }
>
> funcSetAttr.call(this,name,value); /\* вызываем ранее сохраненный системный метод, чтобы нормальные свойства устанавливались корректно \*/
>
> };`
Итак, делаем следующее:
1. Добавьте приведенный код в начало первого скрипта на странице.
2. Перезагрузите страницу.
После перезагрузки, скрипт начинает обрабатывать DOM-дерево, но сразу же останавливается, как только произойдет установка «плохого» атрибута. (Обратите внимание, что в текущих версиях Firefox, реализация setAttribute различна для разных элементов. Код, приведенный выше работает всегда как надо только в Опере; чтобы получить тот же самый эффект в Firefox, вы можете заменить слово Element на HTMLFormElement, чтобы переопределить более специфический метод HTMLFormElement.prototype.setAttribute).
Когда выполнение остановится в контрольной точке, вы захотите узнать где же произошел вызов setAttribute(), то есть вам нужно вернуться на уровень выше в цепочке вызовов функций и посмотреть что происходит там. Для этого вы можете использовать стек вызовов.
*рис. 9: Стек вызовов в Dragonfly и IE8.*
На рисунке 10 показан стек в Firebug. В строке "*setAttribute " рядом с именем файла самой левой является текущая взванная функция.

*рис. 10: Стек вызовов в Firebug. Самая последняя вызванная функция слева.*
Кликая по именам функций в стеке вы можете определить каким образом вы оказались в данной точке. Очень важно попробовать это самому, чтобы понять как это работает. Учтите, что когда вы перемещаетесь по стеку, содержимое панели локальных переменных также обновляется, показывая их состояние в момент выполнения выбранной вами функции.
Как использовать стек вызовов, чтобы найти проблемную функцию:
1. Нажмите на имя функции в стеке, которую вы хотите видеть.
2. Обратите внимние, что локальные переменные обновляются на значения которые они имеют в выбраном контексте.
3. Помните, что, если вы используете кнопки пошагового исполнения то они будут перемещать вас с места точки остановки, даже если вы находитесь в другой части стека.
Выбор makeElement перенесет нас в другую часть кода:
> `for (var prop in attributes) {
>
> el.setAttribute(prop, attributes[prop]);
>
> }`
где вы увидите вызов setAttribute. Панель локальных переменных показывает, что значение переменной «prop» действительно «clone». Переменная prop определена в цикле for...in. Это говорит нам о том, что так называется одно из свойств объекта «attributes». Данный объект передается в функцию вторым параметром. Если вы подниметесь по стеку еще на один уровень выше, то увидите следующий код:
> `var form = makeElement(‘form’, **{ action:’/login’, method:’post’, name:’loginform’ }**, document.body);`
Второй параметр метода подсвечен жирным — у этого объекта нет свойства clone. Так откуда же оно взялось?
Давайте еще раз вернемся в функцию makeElement и внимательно посмотрим на переменную attribute и её свойство «clone». Вы можете кликнуть по значению-функции этого свойства для перехода к месту, где оно назначается, оно будет подсвечено голубым цветом

*рис. 11: Firebug показывает нам, где было определено свойство clone.*
Вот мы и нашли причину четвертой ошибки: метод clone добавляется всем объектам с помощью Object.prototype. Такой подход считается плохой практикой, потому что в циклах for...in объектов будут видны все свойства заданные вами через Object.prototype. Это может приводить к очень трудно уловимым ошибкам.
Чтобы исправить эту ошибку, можно переместить метод clone из прототипа объекта непосредственно в сам объект, после чего заменить все вызовы obj.clone() на Object.clone(obj), как показано в примере:
> `// ПЛОХО, так делать не стоит
>
> Object.prototype.clone = function() {
>
> var obj = {};
>
> for (var prop in this) {
>
> obj[prop] = this[prop];
>
> }
>
> return obj;
>
> }
>
> // Код. демонстрирующий использование метода clone():
>
> var myObj1 = { 'id': '1' };
>
> var myObj2 = myObj1.clone();`
Сделайте лучше так:
> `Object.clone = function(originalObject) {
>
> var obj = {};
>
> for (var prop in originalObject) {
>
> obj[prop] = originalObject[prop];
>
> }
>
> return obj;
>
> }
>
> // Код. демонстрирующий использование метода clone():
>
> var myObj1 = { 'id': '1' };
>
> var myObj2 = Object.clone(myObj1);
>
> \* All source code was highlighted with Source Code Highlighter.`
Если у вас возникли проблемы в понимании или использовании каких-то частей данной статьи, не волнуйтесь! Овладение основами сделает вас более профессиональным разработчиком и в конечном счете вы разработаете свой набор методик для использования.
###### Примечания
*1 Для того, чтобы включить меню отладки/разработки в Safari, нужно зайти в «Правка -> Настройки -> Дополнительно» и поставить галку «Включить меню „Разработка“», после чего в меню браузера появится пункт «Разработать» (небанальное название :) ).
2 Для русского языка это не совсем актуально и код сработает, т.к. в FF код выглядит как «ru». Но это только потому, что русский язык один, а норвежских два. Не считая прочих недостатков, если ваш код будет использоваться с другими языками, так делать не стоит** | https://habr.com/ru/post/51354/ | null | ru | null |
# IR интерфейс, Raspberry и LIRC
Моя задача сейчас — научиться отправлять команды кондиционерам и другим устройствам в доме. Исходно эти устройства имеют только IR remote control. Для решения этой задачи у меня есть Raspberry Pi и IR transceiver shield. В статье можно найти конфиги, команды, советы и немного теории. Из софта будут LIRC (Linux Infrared Remote Control) и Python.
[LIRC](http://www.lirc.org/) я нашел с помощью Гугла. В процессе исследования выяснил, что LIRC работает как с передатчиками, так и с приемниками IR сигналов, может декодировать принятый сигнал и выполнять какие-то действия в связи с этим. Сейчас прием сигналов мне не нужен, но в будущем может оказаться полезным. Если будете возиться с LIRC сами, прочтение [LIRC Configuration Guide](http://www.lirc.org/html/configuration-guide.html) крайне рекомендуется.
### Конфигурация
```
apt-get update
apt-get install lirc
```
```
# /etc/modules (добавить в конец)
lirc_dev
lirc_rpi gpio_in_pin=18 gpio_out_pin=17
```
```
# /etc/lirc/hardware.conf (по умолчанию файла нет, надо создать)
LIRCD_ARGS="--uinput --listen"
LOAD_MODULES=true
DRIVER="default"
DEVICE="/dev/lirc0"
MODULES="lirc_rpi"
```
```
# /boot/config.txt (в конце уже есть заготовка секции про lirc, исходно пустая)
dtoverlay=lirc-rpi,gpio_in_pin=18,gpio_out_pin=17
```
```
# /etc/lirc/lirc_options.conf (найти и заменить эти параметры)
driver = default
device = /dev/lirc0
```
```
reboot
sudo /etc/init.d/lircd status
```
### Запись
Сначала необходимо создать конфигурационный файл с последовательностями данных для всех необходимых команд. Я дальше называю этот файл `lircd.conf`, но на самом для каждого устройства создается свой файл `my_device_name.lircd.conf` в каталоге `/etc/lirc/lircd.conf.d`.
Формат файла описан [здесь](http://www.lirc.org/html/lircd.conf.html). Если есть пульт, то можно записать передаваенмые им сигналы в файл с помощью утилиты [irrecord](http://www.lirc.org/html/irrecord.html).
```
/etc/init.d/lircd stop
irrecord -d /dev/lirc0 ~/my_device.lircd.conf
mv ~/my_device.lircd.conf /etc/lirc/lircd.conf.d/
```
`irrecord` анализирует последовательности и пытается определить протокол и временные параметры. В некоторых случаях `irrecord` терпит неудачу в анализе, поэтому есть возможность сохранить последовательность как она была принята, в "сыром" (raw) виде, для этого есть ключ `--force`.
Но даже с `--force` `irrecord` пытается что-то анализировать, и тоже может потерпеть неудачу. Тогда можно записать последовательности с помощью `mode2` и создать файл самостоятельно.
`mode2` печатает последовательно длительности наличия и отсутствия сигнала, из которых и складываются передаваемые данные. Длительность измеряется в микросекундах (1e-6 секунды). В raw формате в lircd.conf указыватся эти же длительности, начиная с 'pulse' (ведущий 'space' не нужен). Сответственно, всегда должно быть нечетное количество чисел (начинается и заканчивается наличием сигнала — 'pulse').
Для автоматизации я сделал скрипт для записи, который спрашивает имя команды, запускает `mode2` на 5 секунд, запоминает и в конце печатает результат в формате, готовом для lircd.conf (см. под спойлером).
**Скрипт**
```
#!/usr/bin/env python3
import io
import sys
import os
r = """begin remote
name DEVICE_NAME_CHANGE_ME
flags RAW_CODES
eps 30
aeps 100
gap 19037
begin raw_codes
"""
while True:
print()
print("enter the command name, or just press Enter to finish")
a = sys.stdin.readline().rstrip("\n\r")
if not a:
break
first_space = True
n = 0
r += " name " + a + "\n"
for line in os.popen('timeout 5s mode2 -d /dev/lirc0 2> /dev/null').read().split('\n'):
words = line.split()
if len(words) < 2:
continue
if words[0] != 'space' and words[0] != 'pulse':
continue
if first_space and words[0] == 'space':
first_space = False
continue
if n % 4 == 0:
r += "\n "
r += words[1] + " "
n = n+1
if n > 5:
print ("got", n, "values, looks good")
else:
print ("no signal, something went wrong")
r += "\n\n"
r += """ end raw_codes
end remote
"""
print()
print(r)
print()
```
Созданный файл можно еще раз попытаться "распознать" с помощью `irrecord --analyse`. Не всегда это проходит удачно, не спешите выбрасывать старый файл. Моя статистика такая: пульт от телевизора LG был понят с легкостью, все кондиционеры и пылесос потребовали ручного создания, пылесос был потом обработан `--analyse`.
Просто как пример: [вот так выглядит файл для моего пылесоса](https://gist.github.com/tseglevskiy/6d9bf05b57ec7cf351b91466fba19390).
#### Стандартные имена команд
LIRC по своему прямому назначению должен принятый и распознанный IR сигнал превратить в событие *Linux input*. Поэтому по умолчанию от нас требуют, чтобы имена команд в lircd.conf были из стандартного списка. Можно посмотреть список допустимых имен:
```
irrecord --list-namespace
```
Кондиционеры под этот шаблон не попадают. Требование к именам можно выключить, добавив при записи параметр:
```
irrecord --disable-namespace ....
```
### Отладка
Проверить приемник помогает утилита `mode2`, которая печатает все видимые сигналы.
```
/etc/init.d/lircd stop
mode2 -d /dev/lirc0
```
Проверить передачу проще всего, если есть другой приемник и запущенная на нем `mode2`. В особо безнадежных случаях можно менять значение на выходе GPIO и проверять тестером или осцилографом, куда доходит сигнал. Команда `gpio` входит в состав пакета [wiringpi](http://wiringpi.com/the-gpio-utility/).
```
while sleep 1; do
gpio -g toggle 17
done
```
Посмотреть на логи можно с помощью `journalctl`, в частности это позволяет увидеть ошибки в файле конфигурации:
```
journalctl -b 0 /usr/sbin/lircd
```
### Отправка команд
Для передачи записанных команд есть утилита `irsend`. Она же может показать список известных устройств, и список известных команд для каждого устройства. Обратите внимание на "пустые аргументы" в примере ниже, они там нужны.
`irsend` — это клиент для `lircd`, поэтому если что-то пошло не так, заглядывайте в логи (см. выше).
```
# список устройств
irsend LIST "" ""
# список команд для устройства LG_TV
irsend LIST LG_TV ""
# отправить команду ON
irsend SEND_ONCE LG_TV ON
```
Теоретически, есть еще одна возможность — отправлять команды в *lircd* через его сокет. Не разбирался.
### Вызов из Python
Почти все библиотеки являются всего лишь обвесом над `irsend`. Единственная найденная мной библиотека, которая компилирует клиента для API через сокет, не работает на Raspberry (нужна другая версия lircd). Поэтому смысла в них мало, команду вызвать я могу сам:
```
import subprocess
subprocess.call(["irsend", "send_once", "BEDROOM_AC", "OFF"])
```
### Hardware

Я использую готовую плату, их много на [Amazon](https://www.amazon.com/IR-Remote-Control-Transceiver-Raspberry/dp/B0713SK7RJ) и [AliExpress](https://www.aliexpress.com/wholesale?catId=0&SearchText=raspberry+infrared+transmitter+shield). Гуглить можно как "Raspberry infrared sheild". Она использует GPIO 17 на выход, и GPIO 18 на вход, что видно из конфигов выше.
На плате есть место для второго (дополнительного) светодиода D2, который по умолчанию не установлен. При использовании двух светодиодов, они подключаются **последовательно**. Поэтому при отсутствии светодиода D2 нужно замкнуть перемычку SJ1. С удивлением обнаружил, что на всех моих платах перемычка исходно была разомкнута. Пришлось доработать паяльником.
**Фотография крупнее для желающих поразглядывать**
### Итоги
Работает: сигнал передается, устройства его видят и правильно на него реагируют.
Многое зависит от положения диода-излучателя, он должен быть точно направлен на приемник. Один неподвижный передатчик не может управлять всеми устройствами в комнате. Клонировать решение на базе Raspberry Pi для каждого гаджета дорого, нужно или доработать излучатель для "покрытия большей площади", или найти более дешевую платформу.
LIRC исходно создавался для преобразования IR сигналов в стандарнтные линуксовые события устройств ввода. Поэтому для него ествественно, что одна кнопка — один код. Для некоторых устройств (болшинства Air conditioner) это не так: при нажатии на любую кнопку пульт передает пакет данных, содержащий полное состояние устройства (включено, режим работы, температура, режимы работы вентилятора, время, таймер и т.д.). Возможности собирать многокомпонентный пакет на основе нескольких параметров в LIRC нет, поэтому как быстрый инструмент "из коробки" он помогает, но дальше придется искать что-то еще. Хотя для большинства случаев записанных данных с привычными настройками вентилятора и без экзотических режимов вполне достаточно. | https://habr.com/ru/post/461195/ | null | ru | null |
# Разработчики приложений не заботятся о безопастности пользователей, что приводит к утечке данных (с примерами java-кода)
Копаясь в своем android телефоне я заметил, что в каталоге /storage/sdcard есть директории и файлы — приложений, которые я давно удалил, поэтому я спросил на toster.ru [Может ли одно приложение на Android читать временные файлы другого приложения?](https://toster.ru/q/288937)
Что же это за временные файлы и почему на них следует обратить внимание? Это ваши фотографии, записи телефонных разговоров, базы данных ваших ежедневников.
В андроид есть общая директория /storage/sdcard. Туда пишут временные файлы все приложения, а когда приложение удаляешь, данные от него там остаются, если разработчик не позаботился о том чтобы их удалить.
Поэтому эти вопросы я задал на toster.ru:
1) By design система не удаляет эти временные файлы из этой директории?
2) Android не знает какие файлы какому приложению принадлежат?
3) Может ли одно приложение прочесть данные другого приложения из этой директории?
Пользователь [NeiroNx](https://habrahabr.ru/users/neironx/) написал:
> /data достаточно четко разделен по правам — не обладая root правами приложения не видят даже какие файлы там есть.
Я отвечаю [NeiroNx](https://habrahabr.ru/users/neironx/): Погодите, вот я только что скачал файловый менеджер из google.play и читаю временные файлы из директории популярного мессенджера, а там фотографии, которые мне прислали лежат в незашифрованном виде, устройство у меня не рутованое.
Пользователь [dobergroup](https://habrahabr.ru/users/dobergroup/) написал:
> По какому пути находятся эти файлы? Если они в произвольной директории на разделе, который в fat32, то к ним нельзя применить разделяемый доступ. Поэтому, надо уточнять, что именно Вы понимаете под «временными файлами»
Я отвечаю [dobergroup](https://habrahabr.ru/users/dobergroup/): По пути /storage/sdcard, не следует путать с /storage/extSdCard, здесь «временные файлы» всех установленных приложений на моем устройстве: мессенджеров, sip телефонии с незашифрованными записями телефонных разговоров, браузеров с историей просмота страниц, плееров с их плейлистами, соц сетей, ежедневников, с личными записями неотложных дел.
**Под временными файлами я понимаю одно, а разработчики приложений видимо другое, если разработчики мессенджера whatsapp с аудиторией [33 000 000](https://play.google.com/store/apps/details?id=com.whatsapp) там хранят незашифрованные фотографии и зашифрованную переписку. Whatsapp — это только пример, практически все популярные приложения хранят Ваши личные данные в /storage/sdcard/%appName% и к этой директории имеет доступ любое другое приложение.**
Например, этот мессенджер хранит фотографии которые Вам прислали в директории, к которой имеют доступ все приложения Вашего устройства, если у них есть разрешение на работу с хранилищем:

\* фотографии из бесплатного фотохостинга под лицензией [Creative Commons CC0](https://creativecommons.org/publicdomain/zero/1.0/deed.en). [1](https://pixabay.com/en/arno-river-florence-italy-1066307/), [2](https://pixabay.com/en/salad-lunch-food-healthy-meal-933268/), [3](https://pixabay.com/en/girl-teenager-young-beautiful-teen-375114/), [4](https://pixabay.com/en/guitar-country-girl-music-1139397/).
А вот популярный клиент sip хранит там же настройки Вашего sip аккаунта:

#### Временные файлы может прочесть любое другое приложение?
То есть кто-то может разместить в google.play игру «2048 — играй по сети с друзьями» и таскать фотографии полуобнаженных девушек с вашего телефона?
Я решил это проверить и написал небольшую программу на java для android. Она отсылает структуру каталога /storage/sdcard на email.
Исходный код. Он отправляет структуру каталога /storage/sdcard на email:
```
package android.com.testapp;
import android.content.Intent;
import android.os.Environment;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
import android.widget.Toast;
import java.io.File;
import java.util.Date;
public class MainActivity extends AppCompatActivity {
Button emailButton;
EditText email;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
email = (EditText) findViewById(R.id.email);
emailButton = (Button) findViewById(R.id.emailButton);
emailButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
getFileStrucure();
}
});
}
protected void getFileStrucure(){
Filewalker fw = new Filewalker();
fw.walk(new File(Environment.getExternalStorageDirectory().getAbsolutePath()));
}
private class Filewalker {
private int count = 0;
private String sked = "";
public void walk(File root) {
count++;
File[] list = root.listFiles();
for (File f : list) {
if (f.isDirectory()) {
sked += "time: " + new Date(f.lastModified()) + ", dir: " + f.getAbsoluteFile() + "\n";
walk(f);
}
else {
sked += "time: " + new Date(f.lastModified()) + ", size: " + f.length() + ", " + f.getAbsoluteFile() + "\n";
}
}
count--;
if (count == 0) {
sendMail(sked);
}
}
}
protected void sendMail(String sked) {
Intent i = new Intent(Intent.ACTION_SEND);
i.setType("message/rfc822");
i.putExtra(Intent.EXTRA_EMAIL, new String[]{email.getText().toString()});
i.putExtra(Intent.EXTRA_SUBJECT, "android storage structure");
i.putExtra(Intent.EXTRA_TEXT, sked);
try {
startActivity(Intent.createChooser(i, "Send mail..."));
} catch (android.content.ActivityNotFoundException ex) {
Toast.makeText(getApplicationContext(), "There are no email clients installed.", Toast.LENGTH_SHORT).show();
}
}
}
```

Вы вводите email, приложение отсылает структуру каталога /storage/sdcard, как Вы понимаете это можно делать и не спрашивая email и отправлять, не только структуру каталога, но и сами файлы. Врядли в google.play так чщательно проверяют приложения, которые там находятся. К сожалению, это очень хороший инструмент для мактетологов, они всегда хотят знать как можно больше о своих пользователях, неговоря уже о том, что таким образом можно получить личные данные.
А вот какое письмо приходит Вам с содержанием /storage/sdcard, там будут все файлы и каталоги приложений, установленных на Вашем устройстве:

**\* Здесь нет каталогов и файлов приложений из google.play, которые есть на Вашем мобильном устройстве, которое Вы используете каждый день — это директория sdcard эмулятора android.**
Ссылка на [репозиторий github](https://github.com/irveorg/android_storade_reader), для ознакомительных целей.
Посмотрите свою директорию /storage/sdcard с помощью любого файлового менеджера для android, также, по-моему, она доступна при подключении устройства к PC как /phone, если Вы пользуетесь мессенджерами, соц сетями, планировщиком задач, посмотрите, что теоретически может увидеть любой разработчик android, который напишет в манифесте android.permission.READ\_EXTERNAL\_STORAGE.
**Смысл статьи в том, что множество разработчиков приложений: соц. сетй, мессенджеров, клиентов sip телефонии, ежедневников, не заботятся о безопастности своих пользователей.** | https://habr.com/ru/post/277047/ | null | ru | null |
# Расширение Google Chrome для экспорта контактов Facebook
Несмотря на [давление со стороны Google](http://habrahabr.ru/blogs/social_networks/107614/) и даже [критику от Тима Бернерса-Ли](http://habrahabr.ru/blogs/sw/108687/), компания Facebook упорно отказывается предоставить своим пользователям функцию экспорта социального графа, то есть информации обо всех френдах в сети. Она получает заслуженные упрёки в том, что захватывает юзеров в «информационную ловушку», из которой они не могут выбраться.
Но если очень нужно, то выход всё-таки найдётся. Некий неизвестный разработчик [dimator](http://code.google.com/u/@UBlXQ1NRARNNWQV%2B/) выпустил расширение для Google Chrome [Facebook Doesn’t Own My Friends](http://code.google.com/p/fb-exporter/) ([исходный код](http://fb-exporter.googlecode.com/svn/trunk/)), позволяющее легко экспортировать список друзей из Facebook в CSV-файл или напрямую в список контактов Gmail (там создаётся новая группа “Imported from Facebook”).
Разработчик подчёркивает, что он не имеет отношения к Facebook или Google, а созданное им расширение не противоречит соглашению пользователя Facebook. Фактически, расширение всего лишь автоматизирует ту работу, которую пользователь может сделать вручную, копируя имена и почтовые адреса друзей методом копипаста.
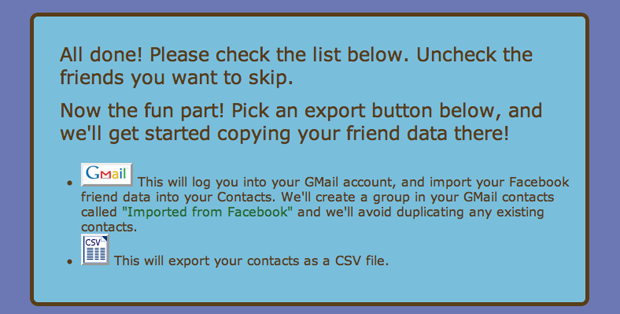
Особого внимания заслуживают строки 101-103 в background.html для fb-exporter.crx.
`if (request.pissOffZuckerberg) {
chrome.tabs.sendRequest(fb_tab, {pissOffZuckerberg: 1});
}`
P.S. После того, как информация о расширении [была опубликована](http://techcrunch.com/2010/11/25/google-facebook-disconnect/) на TechCrunch девять часов назад, появились сообщения, что скрипт перестал работать. Судя по всему, Facebook смог каким-то образом заблокировать его. | https://habr.com/ru/post/108862/ | null | ru | null |
# Настраиваем интернет шлюз с прозрачным обходом блокировок (а рекламу таки будем блокировать)

У вас есть старенький (или не очень) компьютер с двумя сетевыми картами? Вам надоела реклама и лишние телодвижения для обхода блокировок? Вы не хотите с этим мириться? Тогда добро пожаловать под кат.
Цель
----
Настроить интернет шлюз таким образом, чтобы клиенты внутри локальной сети без дополнительных настроек работали с интернетом без ограничений. К заблокированным сайтам доступ будет осуществляться через тор, к остальным через обычное интернет соединение. К .onion ресурсам доступ из любого браузера как к обычным сайтам. В качестве бонуса, настроим блокировку рекламных доменов и доступ к условно заблокированным сайтам через тор (имеются в виду сайты, которые ограничивают функциональность для пользователей из РФ). Мой интернет провайдер ~~чтоб тебе икнулось~~ осуществляет перехват DNS запросов и подмену адресов (т.е. при резольвинге запрещенных сайтов возвращает адрес своей заглушки), поэтому все DNS запросы я отправляю в тор.
**Предупреждение**Все что описано ниже помогает обойти блокировки, но НЕ ОБЕСПЕЧИВАЕТ анонимности. От слова совсем.
Идеи и способы реализации взял [отсюда](https://www.alexeykopytko.com/2016/tor-transparent-proxy/) и [отсюда](https://advanxer.com/blog/2015/05/adblocking-using-bind-dns-server/). Авторам этих статей большое спасибо.
Итак поехали
------------
Предполагается, что на начальном этапе у вас уже есть установленная ОС (в моем случае Ubuntu server 16.04) на компьютере с двумя сетевыми интерфейсами. Один из которых (у меня это ppp0) смотрит в сторону провайдера, а второй (у меня это enp7s0) в локалку. Внутренний IP шлюза 192.168.1.2. Локальная сеть 192.168.1.0/24.
Как подойти к этому этапу в данной статье не рассматривается, так как информации в сети более чем достаточно. Скажу только, что pppoe подключение к провайдеру удобно настраивать утилитой pppoeconf.
### Подготовительный этап
Если вы, как и я, используете н{е|оу}тбук, то возможно вам захочется, чтобы он не засыпал при закрытии крышки.
```
sudo nano /etc/systemd/logind.conf
```
```
HandleLidSwitch=ignore
```
Разрешаем форвардинг в ядре. Я за одно отключил IPv6.
```
sudo nano /etc/sysctl.conf
```
```
net.ipv4.ip_forward=1
# IPv6 disabled
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
```
Применим изменения без перезагрузки.
```
sudo sysctl -p
```
Настройка DHCP
--------------
Мы хотим, чтобы клиенты настраивались автоматически, поэтому без DHCP сервера не обойтись.
```
$ sudo apt install isc-dhcp-server
$ sudo nano /etc/dhcp/dhcpd.conf
```
Приводим файл примерно к такому виду.
```
default-lease-time 600;
max-lease-time 7200;
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.100 192.168.1.200;
option routers 192.168.1.2;
option domain-name-servers 192.168.1.2, 8.8.8.8;
option broadcast-address 192.168.1.255;
}
```
**Пояснение****subnet 192.168.1.0 netmask 255.255.255.0** — определяет сеть и маску,
**range 192.168.1.100 192.168.1.200;** — диапазон адресов, который будет выдаваться сервером,
**option routers 192.168.1.2;** — адрес шлюза
**option domain-name-servers 192.168.1.2, 8.8.8.8;** — адреса DN серверов
**option broadcast-address 192.168.1.255;** — широковещательный адрес.
Перезапустим сервер
```
sudo /etc/init.d/isc-dhcp-server restart
```
Настройка TOR
-------------
Устанавливаем и открываем настройки.
```
$ sudo apt install tor
$ sudo nano /etc/tor/torrc
```
Добавляем строки
```
#Определяем подсеть в которую тор будет разрешать имена onion
#такой диапазон достаточно жирный. Можно смело сокращать.
VirtualAddrNetworkIPv4 10.0.0.0/8
#Включаем DNS от луковицы
AutomapHostsOnResolve 1
#Определяем порты прозрачного прокси и DNS
TransPort 0.0.0.0:9040
DNSPort 0.0.0.0:5353
#Не пользуемся выходными узлами из этих стран
ExcludeExitNodes {RU}, {UA}, {BY}
```
Настройка DNS
-------------
Если вам не нужна блокировка рекламы, то данный пункт можно не выполнять. Если вы хотите просто пользоваться DNS от тора, добавьте в файл **/etc/tor/torrc** строку **DNSPort 0.0.0.0:53** и всё.
Но я буду резать рекламу, а значит устанавливаем и открываем настройки
```
$ sudo apt install bind9
$ sudo nano /etc/bind/named.conf.options
```
Приводим файл к следующему виду
```
options {
directory "/var/cache/bind";
forwarders {
127.0.0.1 port 5353;
};
listen-on {
192.168.1.2;
127.0.0.1;
};
dnssec-validation auto;
auth-nxdomain no;
listen-on-v6 { none; };
};
```
Если ваш провайдер не химичит с DNS запросами, можете направить трафик на другие днс серверы. Например на сервера гугла:
```
forwarders {
8.8.8.8;
8.8.4.4;
};
```
Теоретически должно работать по шустрее, чем через тор.
К дальнейшей настройке DNS вернемся чуть позже. Пока этого достаточно. А сейчас перезапустим службу.
```
sudo /etc/init.d/bind9 restart
```
Настройка iptables
------------------
Вся магия будет твориться именно здесь.
**Суть идеи**1. Формируем список IP адресов на которые мы хотим ходить через тор.
2. Заворачиваем запросы к этим адресам на прозрачный прокси тора.
3. Заворачиваем DNS запросы к ресурсам .onion на DNS тора
4. Тор при резольвинге имен из зоны .onion возвращает IP адрес из подсети 10.0.0.0/8 (которую мы указали при настройке ТОР). Разумеется, эта зона не маршрутизируется в интернете и нам нужно завернуть обращения на эту подсеть на прозрачный прокси тора.
**Лирическое отступление**Изначально я полагал, что можно обойтись без перенаправления DNS запросов к .onion в iptables. Что можно настроить bind таким образом, чтобы он перенаправлял запросы на тор DNS и возвращал адреса из 10-й зоны. У меня не получилось так настроить.
```
forwarders {
127.0.0.1 port 5353;
};
```
Не приводит к желаемому результату, так же как выделение отдельной зоны ".onion" с forwarders на 127.0.0.1 port 5353.
Если кто-нибудь знает почему так происходит и как это исправить, напишите в комментариях.
Полагаю, что iptables уже установлен. Устанавливаем ipset. С помощью этой утилиты мы сможем управлять списком заблокированных адресов и заворачивать пакеты в прозрачный прокси тора.
```
sudo apt install ipset
```
Далее последовательно из под рута выполняем команды по настройке iptables. Разумеется вам нужно заменить имена интерфейсов и адреса на свои. Я поместил эти команды в /etc/rc.local **перед exit 0** и они выполняются каждый раз после загрузки.
**Предлагаю и вам поступить аналогично.**
```
#Создаем ipset для списка блокировок
ipset -exist create blacklist hash:ip
#Редирект запросов DNS на TOR для доменов onion. Средствами bind9 такой редирект настроить не удалось
iptables -t nat -A PREROUTING -p udp --dport 53 -m string --hex-string "|056f6e696f6e00|" --algo bm -j REDIRECT --to-port 5353
iptables -t nat -A OUTPUT -p udp --dport 53 -m string --hex-string "|056f6e696f6e00|" --algo bm -j REDIRECT --to-port 5353
#Редирект на ТОР IP адресов из списка блокировок
iptables -t nat -A PREROUTING -p tcp -m set --match-set blacklist dst -j REDIRECT --to-port 9040
iptables -t nat -A OUTPUT -p tcp -m set --match-set blacklist dst -j REDIRECT --to-port 9040
#Редирект на тор для ресурсов разрезольвенных тором в локалку 10.0.0.0/8
#обычно это .onion
iptables -t nat -A PREROUTING -p tcp -d 10.0.0.0/8 -j REDIRECT --to-port 9040
iptables -t nat -A OUTPUT -p tcp -d 10.0.0.0/8 -j REDIRECT --to-port 9040
###########################################
#Все что ниже относится к настройке самого шлюза, а не к обходу
#блокировок
###########################################
#Включаем NAT
iptables -t nat -A POSTROUTING -o ppp0 -j MASQUERADE
# Рзрешаем пинги
iptables -A INPUT -p icmp --icmp-type echo-reply -j ACCEPT
iptables -A INPUT -p icmp --icmp-type destination-unreachable -j ACCEPT
iptables -A INPUT -p icmp --icmp-type time-exceeded -j ACCEPT
iptables -A INPUT -p icmp --icmp-type echo-request -j ACCEPT
# Отбрасываем неопознанные пакеты
iptables -A INPUT -m state --state INVALID -j DROP
iptables -A FORWARD -m state --state INVALID -j DROP
# Отбрасываем нулевые пакеты
iptables -A INPUT -p tcp --tcp-flags ALL NONE -j DROP
# Закрываемся от syn-flood атак
iptables -A INPUT -p tcp ! --syn -m state --state NEW -j DROP
iptables -A OUTPUT -p tcp ! --syn -m state --state NEW -j DROP
#Разрешаем входящие из локалки и локальной петли, и все уже установленные соединения
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -i enp7s0 -j ACCEPT
iptables -A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
#Остальные входящие запрещаем
iptables -P INPUT DROP
#Разрешаем форвардинг изнутри локалки.
iptables -A FORWARD -i enp7s0 -j ACCEPT
iptables -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
#Остальной форвардинг запрещаем
iptables -P FORWARD DROP
```
После перезагрузки мы должны получить шлюз, который:
* Выдает IP адреса и настройки сети клиентам.
* Раздает интернет.
* Резольвит имена через тор DNS.
* Резольвит имена .onion и позволяет посещать эти ресурсы через обычный браузер.
* Закрывает нас от входящих подключений.
Обхода блокировок пока нет, так как несмотря на то, что мы создали blacklist и настроили маршрутизацию, сам blacklist пока пустой. Настало время это исправить.
Заполняем blacklist
-------------------
Создаем каталог в котором будет лежать скрипт.
```
# mkdir -p /var/local/blacklist
```
Создаем скрипт
```
# nano /var/local/blacklist/blacklist-update.sh
```
**со следующим содержимым**
```
#! /bin/bash
#Переходим в каталог скрипта
cd $(dirname $0)
#Скачиваем с github репозиторий со списком заблокированных ресурсов
git pull -q || git clone https://github.com/zapret-info/z-i.git .
#Обрабатываем dump.csv так чтобы получился файл blacklist.txt с IP адресами заблокированных ресурсов
cat dump.csv | cut -f1 -d\; | grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' | sort | uniq > blacklist.txt
#Обрабатываем файл my-blacklist c именами доменов, которые не под блокировкой
#но на которые мы хотим ходить через тор. Дополняем blacklist.txt
dig +short -f my-blacklist >> blacklist.txt
#Очищаем ipset
ipset flush blacklist
#Запиcываем новые данные
cat blacklist.txt | xargs -n1 ipset add blacklist
```
Делаем скрипт исполняемым
```
# chmod +x /var/local/blacklist/blacklist-update.sh
```
создаем файл my-blacklist, который в дальнейшем будем наполнять вручную теми ресурсами, на которые хотим ходить через тор.
```
# echo lostfilm.tv > /var/local/blacklist/my-blacklist
```
Выполняем скрипт
```
# /var/local/blacklist/blacklist-update.sh
```
Скрипт работает долго, ~~будь пациентом~~ be patient. Теперь ~~должна открываться флибуста~~ должны работать заблокированные сайты. Добавляем в конец файла /etc/rc.local, но **перед exit 0**
```
#Ждем минуту чтобы тор полностью загрузился, подключился,
#заработал тор DNS
sleep 60
#Заполняем список запрещенных сайтов. Длительная операция.
/var/local/blacklist/blacklist-update.sh
```
Настраиваем фильтр рекламы
--------------------------
**Суть идеи**1. Устанавливаем и запускаем микро HTTP сервер, который слушает 80 порт и на любой запрос возвращает картинку png с одним прозрачным пикселем.
2. Получаем список рекламных доменов.
3. Настраиваем bind как авторитативный сервер для них.
4. Заворачиваем все запросы на рекламные домены на наш HTTP сервер с чудесной картинкой.
Приступим. Займемся севером. Создаем файл
```
# nano /usr/local/bin/pixelserv
```
**с содержимым**
```
#! /usr/bin/perl -Tw
use IO::Socket::INET;
$crlf="\015\012";
$pixel=pack("C*",qw(71 73 70 56 57 97 1 0 1 0 128 0 0 255 255 255 0 0 0 33 249 4 1 0 0 0 0 44 0 0 0 0 1 0 1 0 0 2 2 68 1 0 59));
$sock = new IO::Socket::INET ( LocalHost => '0.0.0.0',
LocalPort => '80',
Proto => 'tcp',
Listen => 30,
Reuse => 1);
if (!defined($sock)) {
print "error : cannot bind : $! exit\n";
exit(1);
}
while ($new_sock = $sock->accept()) {
while (<$new_sock>) {
chop;chop;
# print "$_\n";
if ($_ eq '') { last; }
}
print $new_sock "HTTP/1.1 200 OK$crlf";
print $new_sock "Content-type: image/gif$crlf";
print $new_sock "Accept-ranges: bytes$crlf";
print $new_sock "Content-length: 43$crlf$crlf";
print $new_sock $pixel;
shutdown($new_sock,2);
undef($new_sock);
}
close($sock);
exit(0);
```
делаем его исполняемым
```
# chmod +x /usr/local/bin/pixelserv
```
Создаем файл инициализации сервера
```
# nano /etc/init.d/pixelserv
```
**с содержимым**
```
#! /bin/sh
# /etc/init.d/pixelserv
#
# Carry out specific functions when asked to by the system
case "$1" in
start)
echo "Starting pixelserv "
/usr/local/bin/pixelserv &
;;
stop)
echo "Stopping script pixelserv"
killall pixelserv
;;
*)
echo "Usage: /etc/init.d/pixelserv {start|stop}"
exit 1
;;
esac
exit 0
```
Делаем его исполняемым, регистрируем сервис, запускаем http сервер
```
# chmod +x /etc/init.d/pixelserv
# update-rc.d pixelserv defaults
# /etc/init.d/pixelserv start
```
Теперь создаем скрипт обновления рекламных доменов
```
# nano var/local/blacklist/ad-update.sh
```
с содержимым
```
#! /bin/bash
cd /etc/bind/
curl "http://pgl.yoyo.org/adservers/serverlist.php?hostformat=bindconfig&showintro=0&mimetype=plaintext" | sed 's/null.zone.file/\/etc\/bind\/db.adzone/g' > named.ad.conf
rndc reload
```
Делаем его исполняемым
```
# chmod +x /var/local/blacklist/ad-update.sh
```
и выполняем
```
# /var/local/blacklist/ad-update.sh
```
Создаем файл зоны
```
# nano /etc/bind/db.adzone
```
со следующим содержимымсервис
```
$TTL 86400 ; one day
@ IN SOA ads.example.com. hostmaster.example.com. (
2014090102
28800
7200
864000
86400 )
NS my.dns.server.org
A 192.168.1.2
@ IN A 192.168.1.2
* IN A 192.168.1.2
```
Добавляем в файл
```
# nano /etc/bind/named.conf
```
строку
```
include "/etc/bind/named.ad.conf";
```
Применяем изменения
```
rndc reload
```
Настраиваем обновление списка доменов при загрузке. Для этого открываем файл /etc/rc.local и добавляем после sleep 60
```
/var/local/blacklist/ad-update.sh
```
Последние штрихи
----------------
Для периодического обновления списков, создадим файл
```
# nano /etc/cron.daily/blacklist-update
```
Со следующим содержимым
```
#!/bin/bash
#Загружаем свежий список рекламных доменов для фильтрации
/var/local/blacklist/ad-update.sh
#Заполняем список запрещенных сайтов. Длительная операция.
/var/local/blacklist/blacklist-update.sh
```
Делаем его исполняемым
```
# chmod +x /etc/cron.daily/blacklist-update
```
.
Замечание для пользователей десктопных версий Ubuntu
----------------------------------------------------
Несмотря на то, что целью было создать шлюз, который не требует настроек клиентов, в моем случае получилось не совсем так. В качестве рабочей операционной системы я использую десктопную Ubuntu 16.04. Для настройки сети в ней используется утилита NetworkManager, которая по умолчанию настроена таким образом, что адрес DN сервера берется не с DHCP сервера, а устанавливается как 127.0.1.1:53. На этом порту висит dnsmasq и только по ему известным правилам резольвит имена. В обычной жизни это никак не мешает, а в нашем случае делает совершенно неработоспособной зону .onion
Чтобы это исправить нужно в файле /etc/NetworkManager/NetworkManager.conf закоментировать строку
```
dns=dnsmasq
```
вот так
```
#dns=dnsmasq
```
После перезагрузки все работает.
Заключение ~~лишь бы не под стражу~~
------------------------------------
Клиенты на андроид работают нормально без дополнительных настроек.
Windows не проверял, так как не использую, но думаю, проблем возникнуть не должно.
Ограничения для firefox и iOs описаны [здесь](https://www.alexeykopytko.com/2016/tor-transparent-proxy/#firefox-onion)
Прошу прощения за сумбурное изложение. Дополнения, исправления, замечания приветствуются.
Спасибо за внимание.
**Дополнение от 03.09.2017**По просьбам трудящихся выложил [свои настройки](https://github.com/fabrikant/TransparentTorProxy.git) на github.
Настройки даны как справочная информация. Из коробки они вам не подойдут с вероятностью близкой к 100%. Требуется подгонка под себя. | https://habr.com/ru/post/336966/ | null | ru | null |
# Короткая заметка: 2 zabbix сервера один клиент
В качестве системы мониторинга [у нас](http://centos-admin.ru) используется zabbix. Недавно один из клиентов обратился с просьбой/вопросом может ли подключить сервера еще и к его zabbix серверу.
Чтение документации подсказало, что очевидного решения нету и один клиент может принимать запросы только от одного сервера. Но нет ничего невозможного. Немного поразмыслив и понаблюдав за работой zabbix агента было принято решение запускать 2 агента на одном хосте, с использованием одних и тех же бинарников и разными конфигурационными файлами.
Осталось только сделать второй набор конфигурационных файлов. Второй экземпляр zabbix агента настроить на нужный сервер и настроить его на другой порт, немного подправить скрипт автозапуска и запустить второй zabbix агент.
В скрипт автозапуска было добавлено:
**init.d/zabbix-agent**
```
conf_c=/etc/zabbix_client/zabbix_zgentd.conf
lockfile_c=/var/lock/subsys/zabbix-agent_c
....................................................................
start()
{
echo -n $"Starting Zabbix agent: "
daemon $exec -c $conf
rv=$?
echo
[ $rv -eq 0 ] && touch $lockfile
return $rv
echo -n $"Starting client Zabbix agent : "
daemon $exec -c $conf_c
rv=$?
echo
[ $rv -eq 0 ] && touch $lockfile_c
return $rv
}
```
В такой конфигурации все работает прекрасно.
P.S.: Изначально был вариант иметь два отдельных init скрипта, но выяснилось, что для stop там прописано killall и это приводило к остановки обоих агентов. В случае рестарта, получалось, что останавливались оба агента, а запускался только один.
###### Автор: [Magvai69](http://habrahabr.ru/users/magvai69/)
**UPD**
Ошибочка вышла.
Правильно делать через
Server=192.168.0.1,192.168.0.2
ServerActive=192.168.0.1,192.168.0.2
Спасибо! ) | https://habr.com/ru/post/259519/ | null | ru | null |
# Функции высших порядков и монады для PHP`шников
Среди PHP программ преобладает процедурный или в последних версиях частично объектно-ориентированный стиль программирования. Но можно писать и иначе, в связи с чем хочется рассказать о функциональном стиле, благо кое-какие инструменты для этого имеются и в PHP.
Поэтому мы рассмотрим реализацию парсера JSON в виде простейших функций и функций их комбинирующих в более сложные, постепенно дойдя до полноценного парсера JSON формата. Вот пример кода, который мы получим:
```
$jNumber = _do(function() {
$number = yield literal('-')->orElse( literal('+') )->orElse( just('') );
$number .= yield takeOf('[0-9]')->onlyIf( notEmpty() );
if ( yield literal('.')->orElse( just(false) ) ) {
$number .= '.'. yield takeOf('[0-9]');
}
return +$number;
});
```
*Кроме собственно функционального подхода можно обратить внимание на использование классов для создания DSL-подобного синтаксиса и на использование генераторов для упрощения синтаксиса комбинаторов.*
**UPDATE** само-собой парсинг JSON уже давно решенная задача и конечно готовая и протестированная функция на C будет работать лучше. Статья использует эту задачу как пример для объяснения функционального подхода. Так же не пропагандируется использование именно такого кода в продакшене, каждый может почерпнуть себе какие-то идеи, которые могут упростить код и жизнь.
Полный код находится на [github](https://github.com/atamurius/phpM).
Функциональный стиль
--------------------
Как программист справляется с огромной сложностью программ? Он берет простые блоки и строит из них более сложные, из которых строятся еще более сложные блоки и в конце-концов программа. По крайней мере так было после появляния первых языков с подпрограммами.
В основе процедурного стиля лежит описание процедур, которые вызывают другие процедуры вместе меняющие какие-то общие данные. Объекто-ориентированный стиль добавляет возможность описывать структуры данных, составленные из других структур данных. Функциональный же стиль использует композицию (соединение) функций.
Чем же отличается композиция функций от композиции процедур и объектов? Основа функционального подхода — чистота функций, это значит, что результат работы функций зависит только от входных параметров. Если функции чисты, то гораздо проще предсказать результат их композиции и даже создать готовые функции для преобразования других функций.
Именно функции принимающие и/или возвращающие в качестве результата другие функции называются функциями высшего порядка и представляют тему этой статьи.
Какую задачу будем решать?
--------------------------
Для примера возьмем задачу, которую не очень просто решить целиком и посмотрим как функциональный подход поможет нам эту задачу упростить.
Для примера попробуем сделать парсер формата JSON, который из строки JSON получит соответствующий PHP объект: число, строку, список или ассоциированный список (со всеми возможными вложенными значениями конечно).
### Что такое парсер?
Начнем с самых простых элементов: мы пишем парсер, что же это такое? Парсер это функция, которая берет строку и в случае успеха возвращает пару значений: результат разбора и остаток строки (если разбираемое значение занимало не всю строку) или пустой набор, если разобрать строку не удалось:
```
Parser: string => [x,string] | []
```
Например если у нас есть функция-парсер `number` то мы могли бы написать такие тесты:
```
assert(number('123;') === [123,';']);
assert(number('none') === []);
```
**DISCLAMER**: PHP имеет не слишком удобный синтаксис для работы с функциями, поэтому для более простого и понятного кода мы будем использовать класс, который является ни чем иным, как просто оберткой вокруг функции парсера и нужен для указания типов и для использования удобного синтаксиса цепочных вызовов, о чем подробнее поговорим дальше.
```
class Parser {
const FAILED = [];
private $parse;
function __construct(callable $parse) {
$this->parse = $parse;
}
function __invoke(string $s): array {
return ($this->parse)($s);
}
}
```
Но будем помнить, что `Parser` это не более чем функция `string => array`.
Для удобства так же введем функцию `parser`, которую будем использовать вместо вызова конструктора `new Parser` для краткости:
```
function parser($f, $scope = null) {
return new Parser($f->bindTo($scope));
}
```
Простейшие парсеры
------------------
Итак, мы разобрались что такое парсеры, но ни одного так и не написали, давайте это исправим. Вот пример парсера, который всегда возвращает `1`, независимо от исходной строки:
```
$alwaysOne = parser(function($s) {
return [1, $s];
});
assert($alwaysOne('123') === [1, '123']);
```
Полезность этой функции не очевидна, давайте сделаем ее более общей и объявим функцию, которая позволит создавать подобный парсер для любого значения:
```
function just($x): Parser {
return parser(function($s) use ($x) {
return [ $x, $s ];
});
}
```
Пока все просто, но все еще не очень полезно, ведь мы хотим парсить строку, а не возвращать всегда одно и то же. Давайте сделаем парсер, который возвращает первые несколько символов входной строки:
```
function take(int $n): Parser {
return parser(function($s) use ($n) {
return strlen($s) < $n ? Parser::FAILED : [ substr($s, 0, $n), substr($s, $n) ];
});
}
test(take(2), 'abc', ['ab','c']);
test(take(4), 'abc', Parser::FAILED);
```
Уже лучше, первый наш парсер, который действительно разбирает строку! Напомню: мы описываем простейшие кирпичики из который сможем собрать более сложный парсер. Поэтому для полноты картины нам нехватает только парсера, который ничего не парсит вообще.
```
function none(): Parser {
return parser(function($s) {
return Parser::FAILED;
});
}
```
Он нам еще пригодится.
Вот и все парсеры, которые нам нужны. Этого достаточно, чтобы разобрать JSON. Не верите? Осталось придумать способ собирать эти кирпичики в более сложные блоки.
Собираем кирпичики вместе
-------------------------
Поскольку мы решили заняться функциональным программированием, то для комбинирования функций парсеров в более сложные парсеры логично использовать функции!
Например если у нас есть парсеры `first` и `second` и мы хотим применить к строке любой из них мы можем определить комбинатор парсеров — функцию, создающую новый парсер на основе существующих:
```
function oneOf(Parser $first, Parser $second): Parser {
return parser(function($s) use ($first,$second) {
$result = $first($s);
if ($result === Parser::FAILED) {
$result = $second($s);
}
return $result;
});
}
test(oneOf(none(),just(1)), '123', [1,'123']);
```
Но, как уже упоминалось выше, такой синтаксис может быстро стать нечитаемым (например `oneOf($a,oneOf($b,oneOf($c,$d)))`), поэтому мы перепишем эту (и все следующие) функции как методы класса `Parser`:
```
function orElse(Parser $alternative): Parser {
return parser(function($s) use ($alternative) {
$result = $this($s);
if ($result === Parser::FAILED) {
$result = $alternative($s);
}
return $result;
}, $this); // <- вот зачем в функции parser был bindTo: чтобы использовать $this в функции
}
test(none()->orElse(just(1)), '123', [1,'123']);
```
Так уже лучше, можно писать `$a->orElse($b)->orElse($c)->orElse($d)` вместо того, что было выше.
И еще одна, не такая простая, но зато гораздо более мощная функция:
```
function flatMap(callable $f): Parser {
return parser(function($s) use ($f) {
$result = $this($s);
if ($result != Parser::FAILED) {
list ($x, $rest) = $result;
$next = $f($x);
$result = $next($rest);
}
return $result;
}, $this);
}
```
Давайте разберемся с ней подробнее. Она принимает функцию `f: x => Parser`, которая принимает результат парсинга нашего существующего парсера и возвращает на его основе новый парсер, который продолжает разбор строки с того места, где остановился наш предыдущий парсер.
Например:
```
test(take(1), '1234', ['1','234']);
test(take(2), '234', ['23', '4']);
test(
take(1)->flatMap(function($x) { # x -- результат парсинга take(1)
return take(2)->flatMap(function($y) use ($x) { # y -- результат парсинга take(2)
return just("$x~$y"); # -- финальный результат
});
}),
'1234',
['1~23','4']
);
```
Таким образом мы скомбинировали `take(1)`, `take(2)` и `just("$x~$y")` и получили довольно сложный парсер, который сначала парсит один символ, за ним еще два и возвращает их в виде `$x~$y`.
Основная особенность проделанной работы состоит в том, что мы описываем, что делать с результатами парсинга, но сама разбираемая строка тут не участвует, у нас нет возможности ошибиться и тем, какую часть строки куда передавать. А дальше мы увидим как сделать синтаксис таких комбинаций более простым и читабельным.
Эта функция позволит нам описать несколько других полезных комбинаторов:
```
function onlyIf(callable $predicate): Parser {
return $this->flatMap(function($x) use ($predicate) {
return $predicate($x) ? just($x) : none();
});
}
```
Этот комбинатор позволяет уточнить действие парсера и проверить его результат на соответствие какому-то критерию. Например с его помощью мы постром очень полезный парсер:
```
function literal(string $value): Parser {
return take(strlen($value))->onlyIf(function($actual) use ($value) {
return $actual === $value;
});
}
test(literal('test'), 'test1', ['test','1']);
test(literal('test'), 'some1', []);
```
DO нотация
----------
Мы уже описали простейшие парсеры `take`, `just` и `none`, способы их комбинации (`orElse`,`flatMap`,`onlyIf`) и даже описали с их помощью парсер литералов `literal`.
Теперь мы приступим к построению более сложных парсеров, но перед этим хотелось бы сделать способ их описания более простым: комбинирующая функция `flatMap` позволяет нам многое, но выглядит это не очень.
В связи с этим подсмотрим как решают эту проблему другие языки. Так в языках Haskell и Scala есть весьма удобный синтаксис для работы с подобными вещами (они даже имеют свое название — монады), называется он (в Haskell) DO-нотация.
Что по-сути делает `flatMap`? Он позволяет описать что делать с результатом парсинга не совершая собственно парсинга. Т.е. процедура как-бы приостанавливается до момента получения промежуточного результата. Для реализации подобного эффекта можно использовать новый для PHP синтаксис — генераторы.
### Генераторы
Давайте сделаем небольшое отступление и рассмотрим что такое генераторы. В PHP 5.5.0 и выше появилась возможность описать функцию:
```
function generator() {
yield 1;
yield 2;
yield 3;
}
foreach (generator() as $i) print $i; # -> 123
```
Что более интересно для нас, данные можно не только получать из генератора, но и передавать в него через `yield`, и даже с 7 версии получить результат генератора через `getReturn`:
```
function suspendable() {
$first = yield "first";
$second = yield "second";
return $first.$second;
}
$gen = suspendable();
while ($gen->valid()) {
$current = $gen->current();
print $current.',';
$gen->send($current.'!');
}
print $gen->getReturn();
# -> first,second,first!second!
```
Это можно использовать, чтобы спрятать вызовы `flatMap` от программиста.
### `flatMap` используя комбинаторы
```
function _do(Closure $gen, $scope = null) {
$step = function ($body) use (&$step) {
if (! $body->valid()) {
$result = $body->getReturn();
return is_null($result) ? none() : just($result);
} else {
return $body->current()->flatMap(
function($x) use (&$step, $body) {
$body->send($x);
return $step($body);
});
}
};
$gen = $gen->bindTo($scope);
return parser(function($text) use ($step,$gen) {
return $step($gen())($text);
});
}
```
Эта функция берет каждый `yield` в генераторе (который содержит парсер, результат которого мы хотим получить) и комбинирует его с оставшимся фрагментом кода (в виде рекурсивной функции `step`) через `flatMap`.
То же самое без рекурсии и функции `flatMap` можно было бы записать так:
```
function _do(Closure $gen, $scope = null) {
$gen = $gen->bindTo($scope); # ради использования $this в функции
return parser(function($text) use ($gen) {
$body = gen();
while ($body->valid()) {
$next = $body->current();
$result = $next($text);
if ($result === Parser::FAILED) {
return Parser::FAILED;
}
list($x,$text) = $result;
$body->send($x);
}
return $body->getReturn();
});
}
```
Но первая запись более интересна тем, что она не привязана особо к парсерам, от них там только функции `flatMap`, `just` и `none` (да и то, можно было бы переписать `just` чтобы обрабатывать null особым образом и обойтись без `none`).
Объекты, которые можно комбинировать с помощью двух методов `flatMap` и `just` называют монады (это немного упрощенное определение) и этот же код можно использовать, чтобы писать комбинаторы для промисов (Promise), опциональных значений (Maybe,Option) и многих других.
Но ради чего же мы писали эту не самую простую функцию? Для того, чтобы дальнейшее использование `flatMap` было гораздо легче. Сравним один и тот же код с чистым `flatMap`:
```
test(
take(1)->flatMap(function($x) {
return take(2)->flatMap(function($y) use ($x) {
return just("$x~$y");
});
}),
'1234',
['1~23','4']
);
```
и тот же самый код, но написанный через `_do`:
```
test(
_do(function() {
$x = yield take(1);
$y = yield take(2);
return "$x~$y";
}),
'1234',
['1~23','4']
);
```
Результирующий парсер делает то же самое тем же способом, но читать и писать такой код гораздо проще!
Строим более сложные парсеры и комбинаторы
------------------------------------------
Теперь, используя эту нотацию мы можем написать еще несколько полезных парсеров:
```
function takeWhile(callable $predicate): Parser {
return _do(function() use ($predicate) {
$c = yield take(1)->onlyIf($predicate)->orElse(just(''));
if ($c !== '') {
$rest = yield takeWhile($predicate);
return $c.$rest;
} else {
return '';
}
});
}
function takeOf(string $pattern): Parser {
return takeWhile(function($c) use ($pattern) {
return preg_match("/^$pattern$/", $c);
});
}
test(takeOf('[0-9]'), '123abc', ['123','abc' ]);
test(takeOf('[a-z]'), '123abc', [ '','123abc']);
```
И полезные методы класса `Parser` для повторяющихся элементов:
```
function repeated(): Parser {
$atLeastOne = _do(function() {
$first = yield $this;
$rest = yield $this->repeated();
return array_merge([$first],$rest);
},$this);
return $atLeastOne->orElse(just([]));
}
function separatedBy(Parser $separator): Parser {
$self = $this;
$atLeastOne = _do(function() use ($separator) {
$first = yield $this;
$rest = yield $this->prefixedWith($separator)->repeated();
return array_merge([$first], $rest);
},$this);
return $atLeastOne->orElse(just([]));
}
```
JSON
----
Каждый из написанных нами парсеров и комбинаторов в отдельности просты (ну может кроме `flatMap` и `_do`, но их всего два и они очень универсальны), но используя их теперь нам не составит труда написать парсер JSON.
### `jNumber = ('-'|'+'|'') [0-9]+ (.[0-9]+)?`
```
$jNumber = _do(function() {
$number = yield literal('-')->orElse(literal('+'))->orElse(just(''));
$number .= yield takeOf('[0-9]');
if (yield literal('.')->orElse(just(false))) {
$number .= '.'. yield takeOf('[0-9]');
}
if ($number !== '')
return +$number;
});
```
Код вполне самодокументирующийся, читать и искать в нем ошибки довольно просто.
### `jBool = true | false`
```
$jBool = literal('true')->orElse(literal('false'))->flatMap(function($value) {
return just($value === 'true');
});
```
### `jString = '"' [^"]* '"'`
```
$jString = _do(function() {
yield literal('"');
$value = yield takeOf('[^"]');
yield literal('"');
return $value;
});
```
### `jList = '[' (jValue (, jValue)*)? ']'`
```
$jList = _do(function() use (&$jValue) {
yield literal('[');
$items = yield $jValue->separatedBy(literal(','));
yield literal(']');
return $items;
});
```
### `jObject = '{' (pair (, pair)*)? '}'`
```
$jObject = _do(function() use (&$jValue) {
yield literal('{');
$result = [];
$pair = _do(function() use (&$jValue,&$result) {
$key = yield takeOf('\\w');
yield literal(':');
$value = yield $jValue;
$result[$key] = $value;
return true;
});
yield $pair->separatedBy(literal(','));
yield literal('}');
return $result;
});
```
### `jValue = jNull | jBool | jNumber | jString | jList | jObject`
```
$jValue = $jNull->orElse($jBool)->orElse($jNumber)->orElse($jString)->orElse($jList)->orElse($jObject);
```
Вот и готов парсер JSON `jValue`! Причем выглядит не так уж непонятно, как казалось вначале. Есть некоторые замечания к производительности, но они решаются заменой способа разделения строки (например вместо `string => [x, string]` можно использовать `[string,index] => [x,string,index]` и избежать многократного разбиения строки). Причем для изменения такого рода достаточно переписать `just`, `take` и `flatMap`, весь остальной код, построенный на их основе останется без изменений!
Заключение
----------
Моей целью было конечно не написание очередного парсера JSON, а демонстрация того, как написание маленьких простых (и функционально чистых) функций, а так же простых способов их комбинирования позволяет строить сложные функции простым способом.
А в простом и понятном коде и ошибок меньше. Не бойтесь функционального подхода. | https://habr.com/ru/post/309962/ | null | ru | null |
# Автоматическое обновление расширений Firefox
*Предлагаю вашему вниманию перевод статьи [Automatic Firefox Extension Updates](https://www.borngeek.com/firefox/automatic-firefox-extension-updates/).
Статья старенькая, но вся информация актуальна и по сей день.*
Разработчики расширений Firefox конечно знают, что при распространении расширений через [официальный store](https://addons.mozilla.org/) вы бесплатно получаете возможность автоматически обновлять свои расширения. Но что делать, если мы хотим сами хостить свое расширение на своем сайте? Как нам самим реализовать поддержку автоматических обновлений?
### Подписывание расширений
Начиная с третьей версии Firefox все обновления расширений должны предоставляться по надежным каналам. Раз уж мы решили самостоятельно хостить свое расширение, у нас есть два варианта, чтобы выполнить это требование:
* Предоставлять обновления по защищенному (https) соединению
* Подписывать расширение электронной подписью
Первый вариант мы рассматривать не будем — в большинстве случаев это требует дополнительных затрат (надо купить SSL сертификат и иметь статичный IP (*сам не понял, к чему это, но из песни слов не выкинешь [прим. перев.]*)) Цифровая подпись напротив — бесплатна, легка в использовании и быстро реализуема. Ну давайте уже научимся ею пользоваться!
### Создаем пару приватный/публичный ключ
Первый шаг в подписывании нашего расширения заключается в создании пары приватного/публичного ключа. Mozilla предоставляет утилиту [McCoy](https://developer.mozilla.org/en-US/docs/McCoy) для этих целей. Не самая простая утилита в мире, так что ниже расписано как её готовить:
* идем на сайт [McCoy](https://developer.mozilla.org/en-US/docs/McCoy) и качаем подходящий пакет (есть версии для Windows, Linux и Mac OS X)
* распаковываем пакет в удобную нам директорию
* запускаем приложение. При первом запуске оно предложит создать master password для защиты ключей. Создание такого пароля крайне настойчиво рекомендуется! При каждом последующем запуске McCoy он будет спрашивать этот пароль.
* Приложение запущено, выбираем в меню Keys » Create New Key. Введите вменяемое имя своему ключу и нажмите Ok. Имейте в виду, даже если вы хотите хостить несколько расширений на своем сайте — вам достаточно будет одного ключа.
Ну что же, ключи созданы, теперь необходимо обновить манифест расширения.
### Обновляем install.rdf
Предполагается, что вы знакомы с install.rdf, так что не будем тратить время на описание его структуры (если нет — вам [сюда](https://www.borngeek.com/firefox/toolbar-tutorial/chapter-2/)). Для примера я использую install.rdf из [Toolbar Tutorial](https://www.borngeek.com/firefox/toolbar-tutorial/). Вот его исходный вариант:
```
xml version="1.0"?
tuttoolbar@borngeek.com
Tutorial Toolbar
2
1.0
{ec8030f7-c20a-464f-9b0e-13a3a9e97384}
4.0
30.\*
Jonah Bishop
An example toolbar extension.
https://www.borngeek.com/firefox/
```
Нам надо добавить два элемента в этот манифест: `em:updateURL` и `em:updateKey`. Элемент `em:updateURL` указывает на URL по которому лежит манифест **обновления** (update.rdf). Выглядит вот так:
```
http://www.example.com/update.rdf
```
Имейте в виду — вы не сможете разместить расширение в официальном store, если ваш манифест содержит этот элемент.
Следующий у нас `em:updateKey`. Он просто содержит в себе публичный ключ. Чтобы получить его, откройте McCoy, сделайте правый клик на ключе, который вы создали ранее и выберите **Copy Public Key** в контекстном меню. После поместите ключ между открывающим и закрывающим тегами:
```
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDW8qxAeURIMLnHjb
KrjR/uqnRsiomahNArMh3KqRLDDmRGCoO21fyHyh5kdgiEL+2Q+sNP
z+j5maIG4qePXp7BVp90QMqiGLvl+z4baDOqcNvErN0l8scd8EegXc
G7Ofa5Gc5oEU/gItIVR4k9AICyW2pJhe51UPa3UKXDS0v3TwIDAQAB
```
Абракадабра. К счастью, Firefox достаточно умен и позволяет использовать пробелы в `em:updateKey` элементе, что позволяет сделать install.rdf более читаемым (как показано выше, это уже отформатированный вариант). По умолчанию из McCoy копируется одна длинная строка.
После добавления этих двух элементов install.rdf начинает выглядет так:
```
xml version="1.0"?
tuttoolbar@borngeek.com
Tutorial Toolbar
2
1.0
{ec8030f7-c20a-464f-9b0e-13a3a9e97384}
4.0
30.\*
Jonah Bishop
An example toolbar extension.
https://www.borngeek.com/firefox/
http://www.example.com/update.rdf
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDW8qxAeURIMLnHjb
KrjR/uqnRsiomahNArMh3KqRLDDmRGCoO21fyHyh5kdgiEL+2Q+sNP
z+j5maIG4qePXp7BVp90QMqiGLvl+z4baDOqcNvErN0l8scd8EegXc
G7Ofa5Gc5oEU/gItIVR4k9AICyW2pJhe51UPa3UKXDS0v3TwIDAQAB
```
Мы завершили обновление манифеста нашего расширения! Обратите внимание — этот шаг необходимо сделать всего один раз. То есть при каждом следующем обновлении эти действия повторять не придется (если только вы не измените URL update.rdf или не поменяете ключ). Все, на этом этапе уже можно паковать расширение для дальнейшей дистрибуции (раздавать пользователям).
### Создаем update.rdf
Раз уж мы завершили с самим расширением, самое время создать манифест обновления. Этот файл (update.rdf) будет жить у нас на сервере и, собственно, именно он определяет, что увидит пользователь при проверке наличия обновлений. Давайте начнем с того, что взглянем сразу на конечный вариант файла, который мы собираемся создать:
```
xml version="1.0"?
1.0.2
{ec8030f7-c20a-464f-9b0e-13a3a9e97384}
4.0
30.\*
http://www.example.com/downloads/tuttoolbar\_1\_0\_2.xpi
sha256:c22ad513c1243959a6d8e6b3cfad18a2a9141306f0165da6b05b008b2042e502
```
Давайте пробежимся построчно и обсудим, что тут происходит. Во первых, мы имеем стандартный XML заголовок с последующим r:RDF элементом, который и говорит нам о том, что перед нами RDF (Resource Description Framework) файл. Нас в основном интересует элемент r:Description. Вы должны иметь по одному элементу на каждое расширение, которое описываете в update.rdf.
(*Да, да, в одном update.rdf можно описывать обновления множества расширений, [Extension Versioning, Update and Compatibility](https://developer.mozilla.org/en/docs/Extension_Versioning,_Update_and_Compatibility#Update_RDF_Format) [прим. перевод.]*)
Далее, первое, что мы должны прописать — это аттрибут `about`. Часть `urn:mozilla:extension` обязательна, далее следует GUID вашего расширения. В нашем случае GUID такой: tuttoolbar@borngeek.com. Имейте в виду — если у вас не email-style GUID ( а что то вроде d4373b50-43b3-11de-8a39-0800200c9a66), то его надо заключить в фигурные скобки: `{d4373b50-43b3-11de-8a39-0800200c9a66}`.
После нескольких дочерних элементов (`updates`, `r:Seq`, `r:li`, и еще одного `r:Description`) остановимся на элементе `version`. Это версия вашего расширения, в нашем случае `1.0.2`.
Далее у нас идет информация о приложении, для которого предназначено наше расширение (Firefox). У нас есть `targetApplication` элемент, заключенный в `r:Description` и содержащий крайне важный `id` элемент. Значение этого элемента — GUID Firefox-а.
(*Сразу видно, басурмане писали. Коротко — у каждого target есть свой GUID — у Firefox-а, у Thunderbird- а, у Firefox for Android, у всех разные. Идем вот [сюда](https://addons.mozilla.org/en-US/firefox/pages/appversions/), выбираем приложение, под которым работает наше расширение и копируем его GUID. [Тут](https://developer.mozilla.org/en/docs/Updating_an_extension_to_support_multiple_Mozilla_applications) можно взглянуть на пример update.rdf для нескольких targets [прим. перевод.]*)
Далее следуют знакомые нам `minVersion` и `maxVersion` элементы, которые соответственно определяют минимальную и максимальную версии Firefox-а *(или иного target-а)*, на работу в которых рассчитано расширение. Очень важно, чтобы эти значения совпадали с указанными в install.rdf.
Следующим у нас идет `updateLink` элемент. В нем указывается URL самого расширения (т.е. xpi файла). Убедитесь в том, что URL указывает на соответствующий файл, особенно если вы поддерживаете и даете скачать более старые версии расширения.
Ну и в конце нас ждет `updateHash` элемент. Этот элемент содержит sha1, sha256, sha384, или sha512 хэш нашего расширения (то есть xpi файла). Я предпочитаю sha256, поскольку были проблемы с обратной совместимостью для sha384 и sha512 (см. [bug 383390](https://bugzilla.mozilla.org/show_bug.cgi?id=383390) (*пофиксено все уже давно*). Если вы на Линуксе — у вас уже есть все необходимое для генерации sha. Пользователи Windows могут скачать соответствующую утилиту (я использую sha256sum), например, тут: [Cygwin](http://www.cygwin.com/). Для того, чтобы получить хэш, наберите что-то вроде этого в терминале:
```
sha256sum tuttoolbar_1_0_2.xpi
```
Вывод будет выглядеть примерно так:
```
c22ad513c1243959a6d8e6b3cfad18a2a9141306f0165da6b05b008b2042e502 *tuttoolbar.xpi
```
Шестнадцатеричная строка (все что до пробела) — это то, что вам надо положить в `updateHash` с указанием типа шифрования. Выглядеть это должно примерно так:
```
sha256:c22ad513c1243959a6d8e6b3cfad18a2a9141306f0165da6b05b008b2042e502
```
Собственно все! **Сохраните его как девелоперскую версию!** Я лично использую название update.rdf.dev. Почему надо держать отдельную версию для девелопмента? Потому что когда вы подпишите этот манифест (*а мы ведь рассматриваем вариант с подписью [прим. перев.]*) его содержимое станет немного малочитаемым и малопригодным для дальнейшего редактирования. Так что лучше держать отдельно девелоперскую версию, а когда надо — подписывать её копию.
### Подписываем манифест
Для того, чтобы подписать манифест, последовательно выполните следующие несложные действия:
* скопируйте девелоперскую версию манифеста и назовите её update.rdf. Именно этот файл мы и будем подписывать
* запустите McCoy если он еще не запущен
* выделите в нем ключ, которым вы собираетесь подписать и выберите в меню Update » Sign Update Manifest
* в открывшемся меню выберите update.rdf, который мы только что создали, и жмите Open
**Будет выглядеть так, будто ничего не происходит, но это не так!** Есть у меня такая претензия к McCoy — он ничего не говорит по завершении работы. Но если вы откроете манифест, то можете заметить, что он немного изменился. Собственно на этом работа над расширением завершается — пришло время загружать файлы на сервер.
### Хостим update.rdf
Перед тем, как залить файлы, мы должны убедиться в том, что наш сервер готов хостить rdf и xpi файлы. На Apache мы можем сделать это через правила .htaccess (не знаю как это работает в IIS или TomCat, имейте в виду — это инструкция только для Apache). Я обычно кладу эти правила в .htaccess корня сайта — на тот случай, если мне захочется поперемещать xpi и rdf. Правила простые:
```
AddType application/x-xpinstall .xpi
AddType text/xml .rdf
```
(*сейчас-то уже модно nginx, под него делаем так:
```
types {
application/x-xpinstall xpi;
text/xml xml, rdf;
}
```
и кладем это либо в общий `/etc/nginx/mime.types`, либо в конфиг нашего сервера. [прим. перевод.]*)
Это необходимо для правильной отдачи файлов сервером. **Это очень важный момент!** В противном случае ваше расширение не будет установлено, также не будут работать обновления. Также имейте в виду: если вы используете какую-либо CMS (типа WordPress), то лучше на всякий случай эти правила разместить в корне сайта.
После того, как все прописано, можно залить наш xpi и update.rdf по соответствующим адресам. Update.rdf должен лежать там, куда указывает install.rdf расширения (тег `em:updateURL` файла install.rdf расширения). Само расширение (.xpi) должно лежать там, куда указывает update.rdf (тег `updateLink`). Постарайтесь не запутаться.
На этом все! Хоть процедура слегка запутанна на первый раз — все достаточно просто.
Чистого кода! | https://habr.com/ru/post/279063/ | null | ru | null |
# Обновление Windows 8.1 с Enterprise до Pro, или как удалить драйвер Sentinel Runtime Drivers
Доброго времени суток, %username%.
При обновлении с Windows 8.1 Enterprise до Pro версии ([ссылка](http://habrahabr.ru/post/192986/)) у меня возникла проблема: необходимо было удалить Sentinel Runtime Driver.
#### Решение:
Для этого нам надо будет скачать данный [файл](http://sentinelcustomer.safenet-inc.com/DownloadNotice.aspx?dID=8589947873)
Далее запустить командную строку от имени администратора и ввести следующее:
`cd ПУТЬ_ДО_ПАПКИ_СО_СКАЧАННЫМ_ФАЙЛОМ`
Например:
`cd C:\Users\***\Downloads\Sentinel_LDK_Run-time_cmd_line\Sentinel_LDK_Run-time_cmd_line`
Далее введите
`haspdinst.exe -purge`
У вас вылезет окно с прогресс-баром. Дождитесь завершения и можете возвращаться в окно установки Windows 8.1
На этом всё. Удачного обновления! | https://habr.com/ru/post/194876/ | null | ru | null |
# Использование IoC контейнеров. За и Против
В свете выхода новой версии Enterprise Library, одной из важнейших частей которой является IoC-контейнер Unity, лично я ожидаю всплеск интереса к теме IoC(Inversion of Control) контейнеров, которые, по сути, являются реализацией достаточно известного паттерна Service Locator.
В этом топике я хотел бы подискутировать на тему «правильного» использования таких контейнеров, а также предостеречь новичков от применения его «везде и всюду». Ну и просто интересующимся возможностями «новых технологий» тоже должно быть любопытно.
#### Предыстория проблемы
Обычно к знакомству с IoC-контейнерами подталкивает осознание необходимости следования [принципам проектирования классов (SOLID)](http://en.wikipedia.org/wiki/Solid_(object-oriented_design)), а именно, последний принцип, который говорит о том, что каждый класс должен зависеть не от конкретных объектов, а от абстракций(интерфейсов), и совсем замечательно, когда все эти зависимости объявляются в конструкторе.
То есть код вида:
> `class TextManager {
>
> public TextManager(ITextReader reader, ITextWriter writer) {
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
это хорошо, а код вида:
> `class TextManager {
>
> public TextManager(TextFromFileReader reader) {
>
> }
>
>
>
> public property DatabaseWriter Writer {
>
> set {
>
> \_writer = value;
>
> }
>
> }
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
это плохо.
При этом, если приложение/библиотека у вас большая, ITextWriter используется во многих классах, а какой именно Writer будет использоваться определяется на входе в библиотеку (допустим, у нас есть Writer'ы в БД и файл с общим интерфейсом), то логично возникает желание как-то связать ITextWriter с DatabaseWriter'ом где-то в одном месте.
До SOLID-ов считалось вполне нормальным объявить внутри библиотеки в статическом классе переменную типа ITextWriter и хранить конкретный используемый на текущий момент Writer там. Но когда начинаешь задумываться о нормальной архитектуре… :) минусы статичных классов становятся очевидными — совершенно непрозрачно от чего именно каждый класс зависит, что ему нужно для работы, а что нет, и страшно даже представить, что «потянется» вместе с этим классом, если вдруг необходимо будет его перенести в другой проект или хотя бы другую библиотеку.
#### IoC-контейнер
Что же предлагается нам для решения проблемы? Решение давно придумано в виде IoC-контейнеров: мы «связываем» интерфейсы с конкретными классами, как только получаем необходимую информацию:
> `var container = new UnityContainer();
>
> container.RegisterInstance(new DatabaseWriter());
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и имеем удобный способ создания объектов:
> `container.Resolve();
>
> \* This source code was highlighted with Source Code Highlighter.`
И если на примере одной зависимости, преимущество контейнеров неочевидно, то если представить, что конструкторы требуют 2-3 интерфейса, и таких классов у нас хотя бы 5-10, то о применении контейнеров покажется многим настоящим спасением.
#### Когда контейнер — хорошо..
Собственно, Unity и создавался для активного применения в сложных составных приложениях, с множеством реализаций идентичных интерфейсов и нелинейной логикой взаимозависимостей между реализациями. Говоря проще, если у нас на всю библиотеку не один-единственный интерфейс IWriter с двумя реализациями DbWriter и TextWriter, а еще, к примеру, IReader и ITextProcessor, для каждого из которых тоже существует 3-4 реализации, и TextWriter работает только с CsvReader'ом и ExcelReader'ом, а какой именно из ридеров надо использовать, зависит от конкретного типа текущего TextProcessor'а, ну и от фазы луны заодно.
Очень сложно привести конкретные примеры кода, применение Unity в котором было бы, с моей точки зрения, обоснованно, и не загромоздить текст тонной ненужного кода. Но описанный «пример» создает некое подобие такой сложной и комплексной задачи :)
#### А когда — не очень
Применение конструкций типа *container.Resolve();* кажется очень удобным, и поначалу так и тянет использовать его почаще, и инстанциировать классы таким образом везде, где это только возможно. Всё это влечет к пробрасыванию контейнера «по всей глубине» библиотеки/приложения, и организации доступа к IUnityContainer'у либо через конструкторы классов, либо, возвращаясь к прошлому, через статичные классы.
> `class TextManager {
>
> public TextManager(IUnityContainer container) {
>
> \_writer = container.Resolve();
>
> \_reader = container.Resolve();
>
> }
>
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
Это и является крайностью использования UnityContainer'а. Потому что:
* наличие в конструкторе «непонятного» IUnityContainer скрывает пути его использования внутри класса, и постороннему человеку при повторном использовании вашего класса будет неясно, какие именно объекты/интерфейсы требуются классу для работы;
* это усложняет Unit-тестирование, опять же потому, что непонятно, какие интерфейсы и операции замещать;
* и, наконец, это прямое нарушение принципа [Interface Segregation](http://en.wikipedia.org/wiki/Interface_segregation_principle), говорящего об использовании интерфейсов без «лишних» методов (методов, не используемых в классе).
#### ...Profit!
Подытоживая, мне кажется, что использование IoC-контейнеров идеально именно в ситуациях со сложными переплетениями взаимозависимостей между конкретными реализациями, и только на самых верхних уровнях библиотеки/приложения.
То есть сразу после точки входа в библиотеку следует регистрировать в Юнити реализации интерфейсов, и как можно раньше резолвить необходимые нам типы. Таким образом мы пользуемся всей мощью Юнити по упрощению процесса генерации сложнозависимых объектов, и в то же время следуем принципам хорошего дизайна и сводим к минимуму использование весьма абстрактного «контейнера» в нашем приложении, тем самым упрощая его тестирование.
P.S. Поскольку сам в данной теме далеко не гуру, в комментариях буду рад услышать о собственных ошибках, а также о других возможных применениях IoC-контейнеров. | https://habr.com/ru/post/91650/ | null | ru | null |
# Получение видео из Tik Tok без водяного знака
Добрый день, всем любителям habr. В этой статье я хочу поделиться с Вами как можно получить видео с Tik Tok без водяного знака, с помощью такого языка как PHP.
В настоящее время Tik Tok набирает популярность и было бы не прилично не написать про него маленькую статейку, и так, меньше слов, больше дела.
Создадим класс под названием TikTok, он будет содержать три метода и одно свойство.
**Методы:**
* cUrl (curl запрос)
* redirectUrl (получить ссылку после redirect)
* getUrl (получить ссылку на видео)
**Свойства:**
* public $url;
Создадим конструктор для передачи url адреса.
```
public function __construct (string $url) {
$this->url = $url;
}
```
**Метод cUrl.** Отправляем запрос на сервер и получаем ответ.
```
private function cUrl (string $url) :? string {
$user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/79.0.3945.130 Safari/537.36';
$curl = curl_init($url);
curl_setopt_array($curl, [
CURLOPT_URL => $url,
CURLOPT_RETURNTRANSFER => TRUE,
CURLOPT_FOLLOWLOCATION => TRUE,
CURLOPT_USERAGENT => $user_agent,
CURLOPT_CONNECTTIMEOUT => 5,
CURLOPT_TIMEOUT => 10,
]);
$response = curl_exec($curl);
if ($response === FALSE) {
curl_close($curl);
return NULL;
}
$httpCode = (int)curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($httpCode !== 200)
return NULL;
return $response;
}
```
**Метод redirectUrl**
```
private function redirectUrl (string $url) :? string {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$headers = get_headers($url, 1);
return $headers['Location'] ?? NULL;
}
```
**Метод getUrl.**
```
public function getUrl () :? string {
// Получаем код страницы.
$responseHtml = $this->cUrl($this->url);
// Находим ссылку на видео.
if (!preg_match('/contentUrl\\":\\"(.*?)\\",\\"embedUrl/ui', $responseHtml, $mInterUrl))
throw new \Exception('Ссылка не найдена!');
// Отправляем запрос и в ответе получаем видео в виде bytecode
if (!$respByteVideo = $this->cUrl($mInterUrl[1]))
throw new \Exception('Запрос не обработался!');
// Чтобы регулярное выражение начало искать, нужно перевести в формат utf-8.
$strByteVideo = mb_convert_encoding($respByteVideo, 'UTF-8', 'auto');
// Ищем специальный id видео, чтобы на его основе построить запрос.
if (!preg_match('/vid:(.*?)%/sui', $strByteVideo, $mVideoId))
throw new \Exception('id video не было найдено!');
// Уберём лишние символы.
$url = str_replace("\0", '', $mVideoId[1]);
// Строим ссылку для получения видео без водяного знака.
$url = "https://api.tiktokv.com/aweme/v1/playwm/?video_id=$url";
// Так как эта redirect на другую ссылку к видео, то пытаемся получить конечную ссылку после redirect
return $this->redirectUrl($url);
}
```
Создадим объект на основе класса, передадим в него ссылку.
```
$TikTok = new TikTok('https://www.tiktok.com/@sonyakisa8/video/6828487583694163205?lang=ru');
echo $TikTok->getUrl();
```
Все готово.
Примеры:
* [Видео с водяным знаком](https://www.tiktok.com/@sonyakisa8/video/6828487583694163205?lang=ru)
* [Видео без водяного знака](http://v16m.tiktokcdn.com/aa5d505fe6144f6121a6b725bdf56116/5f0f3b17/video/tos/useast2a/tos-useast2a-ve-0068c003/fd36f79670e9429d9a6ef0f8915778d9/?a=1180&br=2384&bt=1192&cr=0&cs=0&dr=0&ds=6&er=&l=202007151121220101152270600805E257&lr=tiktok&mime_type=video_mp4&qs=0&rc=ajZobHRmeWZ0dTMzNjczM0ApO2g6NTU2Z2RpN2hmaGYzOWdmMjA0a2BjZi5fLS01MTZzczZfYDNiNDRiLl5hMTAzX146Yw%3D%3D&vl=&vr=)
**Весь код целиком**
```
class TikTok {
/**
* @var string
*/
public $url;
public function __construct (string $url) {
$this->url = $url;
}
/**
* @return null|string
* @throws Exception
*/
public function getUrl () :? string {
// Получаем код страницы
$responseHtml = $this->cUrl($this->url);
// Находим ссылку на видео
if (!preg_match('/contentUrl\\":\\"(.*?)\\",\\"embedUrl/ui', $responseHtml, $mInterUrl))
throw new \Exception('Ссылка не найдена!');
// Отправляем запрос и в ответе получаем видео ввиде bytecode
if (!$respByteVideo = $this->cUrl($mInterUrl[1]))
throw new \Exception('Запрос не обработался!');
// Чтобы регулярное выражение начало искать, нужно перевести в формат utf-8
$strByteVideo = mb_convert_encoding($respByteVideo, 'UTF-8', 'auto');
// Ищем специальный id видео, чтобы на его основе построить запрос
if (!preg_match('/vid:(.*?)%/sui', $strByteVideo, $mVideoId))
throw new \Exception('id video не было найдено!');
// Уберём лишние символы
$url = str_replace("\0", '', $mVideoId[1]);
// Строим ссылку на получения видео без водяного знака
$url = "https://api.tiktokv.com/aweme/v1/playwm/?video_id=$url";
// Так как эта redirect на другую ссылку к видео, то пытаемся получить ее после redirect
return $this->redirectUrl($url);
}
/**
* Получение url адреса после redirect
*
* @param string $url
* @return null|string
*/
private function redirectUrl (string $url) :? string {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$headers = get_headers($url, 1);
return $headers['Location'] ?? NULL;
}
/**
* @param string $url
* @return null|string
*/
private function cUrl (string $url) :? string {
$user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36';
$curl = curl_init($url);
curl_setopt_array($curl, [
CURLOPT_URL => $url,
CURLOPT_RETURNTRANSFER => TRUE,
CURLOPT_FOLLOWLOCATION => TRUE,
CURLOPT_USERAGENT => $user_agent,
CURLOPT_CONNECTTIMEOUT => 5,
CURLOPT_TIMEOUT => 10,
]);
$response = curl_exec($curl);
if ($response === FALSE) {
curl_close($curl);
return NULL;
}
$httpCode = (int)curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($httpCode !== 200)
return NULL;
return $response;
}
}
``` | https://habr.com/ru/post/511796/ | null | ru | null |
# GraphQL на Rust
В этой статье я покажу как создать GraphQL сервер, используя Rust и его экосистему; будут приведены примеры реализации наиболее часто встречающихся задач при разработке GraphQL API. В итоге API трёх микросервисов будут объединены в единую точку доступа с помощью Apollo Server и [Apollo Federation](https://www.apollographql.com/docs/federation/). Это позволит клиентам запрашивать данные одновременно из нескольких источников без необходимости знать какие данные приходят из какого сервиса.
Введение
--------
### Обзор
С точки зрения функциональности описываемый проект довольно похож на представленный в моей [предыдущей статье](https://romankudryashov.com/blog/2020/02/how-to-graphql/), но в этот раз с использованием стэка Rust. Архитектурно проект выглядит так:
Каждый компонент архитектуры освещает несколько вопросов, которые могут возникнуть при реализации GraphQL API. Доменная модель включает данные о планетах Солнечной системы и их спутниках. Проект имеет многомодульную структуру (или монорепозиторий) и состоит из следующих модулей:
* [planets-service](https://github.com/rkudryashov/graphql-rust-demo/tree/master/planets-service) (Rust)
* [satellites-service](https://github.com/rkudryashov/graphql-rust-demo/tree/master/satellites-service) (Rust)
* [auth-service](https://github.com/rkudryashov/graphql-rust-demo/tree/master/auth-service) (Rust)
* [apollo-server](https://github.com/rkudryashov/graphql-rust-demo/tree/master/apollo-server) (JS)
Существуют две основных библиотеки для разработки GraphQL сервера на Rust: [Juniper](https://github.com/graphql-rust/juniper) и [Async-graphql](https://github.com/async-graphql/async-graphql), но только последняя поддерживает Apollo Federation, поэтому она была выбрана для реализации проекта (есть также открытый [запрос](https://github.com/graphql-rust/juniper/issues/376) на реализацию поддержки Federation в Juniper). Обе библиотеки предлагают [code-first](https://blog.logrocket.com/code-first-vs-schema-first-development-graphql/) подход.
Помимо этого использованы PostgreSQL — для реализации слоя данных, [JWT](https://jwt.io/) — для аутентификации и Kafka — для асинхронного обмена сообщениями.
### Стэк технологий
В следующей таблице показан стэк основных технологий, использованных в проекте:
| Тип | Название | Сайт | GitHub |
| --- | --- | --- | --- |
| Язык программирования | Rust | [link](https://www.rust-lang.org) | [link](https://github.com/rust-lang/rust) |
| GraphQL библиотека | Async-graphql | [link](https://async-graphql.github.io/async-graphql/en/index.html) | [link](https://github.com/async-graphql/async-graphql) |
| Единая GraphQL точка доступа | Apollo Server | [link](https://www.apollographql.com/docs/apollo-server/) | [link](https://github.com/apollographql/apollo-server) |
| Web фреймворк | actix-web | [link](https://actix.rs) | [link](https://github.com/actix/actix-web) |
| База даных | PostgreSQL | [link](https://www.postgresql.org) | [link](https://github.com/postgres/postgres) |
| Брокер сообщений | Apache Kafka | [link](https://kafka.apache.org/) | [link](https://github.com/apache/kafka) |
| Оркестрация контейнеров | Docker Compose | [link](https://docs.docker.com/compose/) | [link](https://github.com/docker/compose) |
Также некоторые использованные Rust библиотеки:
| Тип | Название | Сайт | GitHub |
| --- | --- | --- | --- |
| ORM | Diesel | [link](https://diesel.rs/) | [link](https://github.com/diesel-rs/diesel) |
| Kafka клиент | rust-rdkafka | [link](https://crates.io/crates/rdkafka) | [link](https://github.com/fede1024/rust-rdkafka) |
| Хэширование паролей | argonautica | [link](https://crates.io/crates/argonautica) | [link](https://github.com/bcmyers/argonautica) |
| JWT библиотека | jsonwebtoken | [link](https://crates.io/crates/jsonwebtoken) | [link](https://github.com/Keats/jsonwebtoken) |
| Библиотека для тестирования | Testcontainers-rs | [link](https://crates.io/crates/testcontainers) | [link](https://github.com/testcontainers/testcontainers-rs) |
### Необходимое ПО
Чтобы запустить проект локально, вам нужен только Docker Compose. В противном случае вам может понадобиться следующее:
* [Rust](https://www.rust-lang.org/tools/install)
* [Diesel CLI](https://diesel.rs/guides/getting-started/) (для установки выполните `cargo install diesel_cli --no-default-features --features postgres`)
* [LLVM](https://releases.llvm.org/download.html) (это нужно для работы крэйта `argonautica`)
* [CMake](https://cmake.org/install/) (это нужно для работы крэйта `rust-rdkafka`)
* [PostgreSQL](https://www.postgresql.org/download/)
* [Apache Kafka](https://kafka.apache.org/quickstart)
* [npm](https://www.npmjs.com/get-npm)
Реализация
----------
В `Cargo.toml` в корне проекта указаны три приложения и одна библиотека:
*Root* [*Cargo.toml*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/Cargo.toml)
```
[workspace]
members = [
"auth-service",
"planets-service",
"satellites-service",
"common-utils",
]
```
Начнём с `planets-service`.
### Зависимости
`Cargo.toml` выглядит так:
[*Cargo.toml*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/Cargo.toml)
```
[package]
name = "planets-service"
version = "0.1.0"
edition = "2018"
[dependencies]
common-utils = { path = "../common-utils" }
async-graphql = "2.4.3"
async-graphql-actix-web = "2.4.3"
actix-web = "3.3.2"
actix-rt = "1.1.1"
actix-web-actors = "3.0.0"
futures = "0.3.8"
async-trait = "0.1.42"
bigdecimal = { version = "0.1.2", features = ["serde"] }
serde = { version = "1.0.118", features = ["derive"] }
serde_json = "1.0.60"
diesel = { version = "1.4.5", features = ["postgres", "r2d2", "numeric"] }
diesel_migrations = "1.4.0"
dotenv = "0.15.0"
strum = "0.20.0"
strum_macros = "0.20.1"
rdkafka = { version = "0.24.0", features = ["cmake-build"] }
async-stream = "0.3.0"
lazy_static = "1.4.0"
[dev-dependencies]
jsonpath_lib = "0.2.6"
testcontainers = "0.9.1"
```
`async-graphql` — это GraphQL библиотека, `actix-web` — web фреймворк, а `async-graphql-actix-web` обеспечивает интеграцию между ними.
### Ключевые функции
Начнём с `main.rs`:
[*main.rs*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/main.rs)
```
#[actix_rt::main]
async fn main() -> std::io::Result<()> {
dotenv().ok();
let pool = create_connection_pool();
run_migrations(&pool);
let schema = create_schema_with_context(pool);
HttpServer::new(move || App::new()
.configure(configure_service)
.data(schema.clone())
)
.bind("0.0.0.0:8001")?
.run()
.await
}
```
Здесь окружение и HTTP сервер конфигурируются с помощью функций, определённых в `lib.rs`:
[*lib.rs*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/lib.rs)
```
pub fn configure_service(cfg: &mut web::ServiceConfig) {
cfg
.service(web::resource("/")
.route(web::post().to(index))
.route(web::get().guard(guard::Header("upgrade", "websocket")).to(index_ws))
.route(web::get().to(index_playground))
);
}
async fn index(schema: web::Data, http\_req: HttpRequest, req: Request) -> Response {
let mut query = req.into\_inner();
let maybe\_role = common\_utils::get\_role(http\_req);
if let Some(role) = maybe\_role {
query = query.data(role);
}
schema.execute(query).await.into()
}
async fn index\_ws(schema: web::Data, req: HttpRequest, payload: web::Payload) -> Result {
WSSubscription::start(Schema::clone(&\*schema), &req, payload)
}
async fn index\_playground() -> HttpResponse {
HttpResponse::Ok()
.content\_type("text/html; charset=utf-8")
.body(playground\_source(GraphQLPlaygroundConfig::new("/").subscription\_endpoint("/")))
}
pub fn create\_schema\_with\_context(pool: PgPool) -> Schema {
let arc\_pool = Arc::new(pool);
let cloned\_pool = Arc::clone(&arc\_pool);
let details\_batch\_loader = Loader::new(DetailsBatchLoader {
pool: cloned\_pool
}).with\_max\_batch\_size(10);
let kafka\_consumer\_counter = Mutex::new(0);
Schema::build(Query, Mutation, Subscription)
.data(arc\_pool)
.data(details\_batch\_loader)
.data(kafka::create\_producer())
.data(kafka\_consumer\_counter)
.finish()
}
```
Эти функции делают следующее:
* `index` — обрабатывает GraphQL [запросы (query) и мутации](https://graphql.org/learn/queries/)
* `index_ws` — обрабатывает GraphQL [подписки](https://www.apollographql.com/docs/react/data/subscriptions/)
* `index_playground` — предоставляет Playground GraphQL IDE
* `create_schema_with_context` — создаёт GraphQL схему с глобальным контекстом доступным в рантайме, например, пул соединений с БД
### Определение GraphQL запроса и типа
Рассмотрим как определить запрос:
[*Определение запроса*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[Object]
impl Query {
async fn get_planets(&self, ctx: &Context<'_>) -> Vec {
repository::get\_all(&get\_conn\_from\_ctx(ctx)).expect("Can't get planets")
.iter()
.map(|p| { Planet::from(p) })
.collect()
}
async fn get\_planet(&self, ctx: &Context<'\_>, id: ID) -> Option {
find\_planet\_by\_id\_internal(ctx, id)
}
#[graphql(entity)]
async fn find\_planet\_by\_id(&self, ctx: &Context<'\_>, id: ID) -> Option {
find\_planet\_by\_id\_internal(ctx, id)
}
}
fn find\_planet\_by\_id\_internal(ctx: &Context<'\_>, id: ID) -> Option {
let id = id.to\_string().parse::().expect("Can't get id from String");
repository::get(id, &get\_conn\_from\_ctx(ctx)).ok()
.map(|p| { Planet::from(&p) })
}
```
Эти запросы получают данные из БД используя слой репозитория. Полученные сущности конвертируются в GraphQL DTO (это позволяет соблюсти принцип единственной ответственности для каждой структуры). Запросы `get_planets` и `get_planet` могут быть выполнены из любой GraphQL IDE например так:
*Пример использования запроса*
```
{
getPlanets {
name
type
}
}
```
Структура `Planet` определена так:
[*Определение GraphQL типа*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[derive(Serialize, Deserialize)]
struct Planet {
id: ID,
name: String,
planet_type: PlanetType,
}
#[Object]
impl Planet {
async fn id(&self) -> &ID {
&self.id
}
async fn name(&self) -> &String {
&self.name
}
/// From an astronomical point of view
#[graphql(name = "type")]
async fn planet_type(&self) -> &PlanetType {
&self.planet_type
}
#[graphql(deprecation = "Now it is not in doubt. Do not use this field")]
async fn is_rotating_around_sun(&self) -> bool {
true
}
async fn details(&self, ctx: &Context<'_>) -> Details {
let loader = ctx.data::>().expect("Can't get loader");
let planet\_id = self.id.to\_string().parse::().expect("Can't convert id");
loader.load(planet\_id).await
}
}
```
В `impl` определяется резолвер для каждого поля. Также для некоторых полей определены описание (в виде Rust комментария) и deprecation reason. Это будет отображено в GraphQL IDE.
### Проблема N+1
В случае *наивной* реализации функции `Planet.details` выше возникла бы проблема N+1, то есть, при выполнении такого запроса:
*Пример возможного ресурсоёмкого GraphQL запроса*
```
{
getPlanets {
name
details {
meanRadius
}
}
}
```
для поля `details` каждой из планет был бы сделан отдельный SQL запрос, т. к. `Details` — отдельная от `Planet` сущность и хранится в собственной таблице.
Но с помощью [DataLoader](https://github.com/graphql/dataloader), реализованного в Async-graphql, резолвер `details` может быть определён так:
[*Определение резолвера*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
async fn details(&self, ctx: &Context<'_>) -> Result {
let data\_loader = ctx.data::>().expect("Can't get data loader");
let planet\_id = self.id.to\_string().parse::().expect("Can't convert id");
let details = data\_loader.load\_one(planet\_id).await?;
details.ok\_or\_else(|| "Not found".into())
}
```
`data_loader` — это объект в контектсе приложения, определённый так:
[*Определение DataLoader'а*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/lib.rs)
```
let details_data_loader = DataLoader::new(DetailsLoader {
pool: cloned_pool
}).max_batch_size(10);
```
`DetailsLoader` реализован следующим образом:
[*DetailsLoader definition*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
pub struct DetailsLoader {
pub pool: Arc
}
#[async\_trait::async\_trait]
impl Loader for DetailsLoader {
type Value = Details;
type Error = Error;
async fn load(&self, keys: &[i32]) -> Result, Self::Error> {
let conn = self.pool.get().expect("Can't get DB connection");
let details = repository::get\_details(keys, &conn).expect("Can't get planets' details");
Ok(details.iter()
.map(|details\_entity| (details\_entity.planet\_id, Details::from(details\_entity)))
.collect::>())
}
}
```
Такой подход позволяет предотвратить проблему N+1, т. к. каждый вызов `DetailsLoader.load` выполняет только один SQL запрос, возвращающий пачку `DetailsEntity`.
### Определение интерфейса
GraphQL интерфейс и его реализации могут быть определены следующим образом:
[*Определение GraphQL интерфейса*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[derive(Interface, Clone)]
#[graphql(
field(name = "mean_radius", type = "&CustomBigDecimal"),
field(name = "mass", type = "&CustomBigInt"),
)]
pub enum Details {
InhabitedPlanetDetails(InhabitedPlanetDetails),
UninhabitedPlanetDetails(UninhabitedPlanetDetails),
}
#[derive(SimpleObject, Clone)]
pub struct InhabitedPlanetDetails {
mean_radius: CustomBigDecimal,
mass: CustomBigInt,
/// In billions
population: CustomBigDecimal,
}
#[derive(SimpleObject, Clone)]
pub struct UninhabitedPlanetDetails {
mean_radius: CustomBigDecimal,
mass: CustomBigInt,
}
```
Здесь вы также можете видеть, что если в структуре нет ни одного поля со "сложным" резолвером, то она может быть реализована с использованием атрибута `SimpleObject`.
### Определение кастомного скалярного типа
Кастомные скаляры позволяют определить как представлять и как парсить значения определённого типа. Проект содержит два примера определения кастомных скаляров; оба являются обёртками для числовых структур (т. к. невозможно определить внешний трейт на внешней структуре из-за [*orphan rule*](https://doc.rust-lang.org/book/ch10-02-traits.html#implementing-a-trait-on-a-type)). Эти обёртки определены так:
[*Кастомный скаляр: обёртка для BigInt*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[derive(Clone)]
pub struct CustomBigInt(BigDecimal);
#[Scalar(name = "BigInt")]
impl ScalarType for CustomBigInt {
fn parse(value: Value) -> InputValueResult {
match value {
Value::String(s) => {
let parsed\_value = BigDecimal::from\_str(&s)?;
Ok(CustomBigInt(parsed\_value))
}
\_ => Err(InputValueError::expected\_type(value)),
}
}
fn to\_value(&self) -> Value {
Value::String(format!("{:e}", &self))
}
}
impl LowerExp for CustomBigInt {
fn fmt(&self, f: &mut Formatter<'\_>) -> fmt::Result {
let val = &self.0.to\_f64().expect("Can't convert BigDecimal");
LowerExp::fmt(val, f)
}
}
```
[*Кастомный скаляр: обёртка для BigDecimal*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[derive(Clone)]
pub struct CustomBigDecimal(BigDecimal);
#[Scalar(name = "BigDecimal")]
impl ScalarType for CustomBigDecimal {
fn parse(value: Value) -> InputValueResult {
match value {
Value::String(s) => {
let parsed\_value = BigDecimal::from\_str(&s)?;
Ok(CustomBigDecimal(parsed\_value))
}
\_ => Err(InputValueError::expected\_type(value)),
}
}
fn to\_value(&self) -> Value {
Value::String(self.0.to\_string())
}
}
```
В первом примере также показано, как представить гигантское число в виде экспоненциальной записи.
### Определение мутации
Мутация может быть определена следующим образом:
[*Определение мутации*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
pub struct Mutation;
#[Object]
impl Mutation {
#[graphql(guard(RoleGuard(role = "Role::Admin")))]
async fn create_planet(&self, ctx: &Context<'_>, planet: PlanetInput) -> Result {
let new\_planet = NewPlanetEntity {
name: planet.name,
planet\_type: planet.planet\_type.to\_string(),
};
let details = planet.details;
let new\_planet\_details = NewDetailsEntity {
mean\_radius: details.mean\_radius.0,
mass: BigDecimal::from\_str(&details.mass.0.to\_string()).expect("Can't get BigDecimal from string"),
population: details.population.map(|wrapper| { wrapper.0 }),
planet\_id: 0,
};
let created\_planet\_entity = repository::create(new\_planet, new\_planet\_details, &get\_conn\_from\_ctx(ctx))?;
let producer = ctx.data::().expect("Can't get Kafka producer");
let message = serde\_json::to\_string(&Planet::from(&created\_planet\_entity)).expect("Can't serialize a planet");
kafka::send\_message(producer, message).await;
Ok(Planet::from(&created\_planet\_entity))
}
}
```
Чтобы использовать объект как входной параметр мутации, надо определить структуру следующим образом:
[*Определение input type*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[derive(InputObject)]
struct PlanetInput {
name: String,
#[graphql(name = "type")]
planet_type: PlanetType,
details: DetailsInput,
}
```
Мутация защищена `RoleGuard`'ом, который гарантирует что только пользователи с ролью `Admin` могут выполнить её. Таким образом, для выполнения, например, следующей мутации:
*Пример использования мутации*
```
mutation {
createPlanet(
planet: {
name: "test_planet"
type: TERRESTRIAL_PLANET
details: { meanRadius: "10.5", mass: "8.8e24", population: "0.5" }
}
) {
id
}
}
```
вам нужно указать заголовок `Authorization` с JWT, полученным из `auth-service` (это будет описано далее).
### Определение подписки
В определении мутации выше вы могли видеть что при добавлении новой планеты отправляется сообщение:
[*Отправка сообщения в Kafka*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
let producer = ctx.data::().expect("Can't get Kafka producer");
let message = serde\_json::to\_string(&Planet::from(&created\_planet\_entity)).expect("Can't serialize a planet");
kafka::send\_message(producer, message).await;
```
Клиент API может быть уведомлен об этом событии с помощью подписки, слушающей Kafka consumer:
[*Определение подписки*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
pub struct Subscription;
#[Subscription]
impl Subscription {
async fn latest_planet<'ctx>(&self, ctx: &'ctx Context<'_>) -> impl Stream + 'ctx {
let kafka\_consumer\_counter = ctx.data::>().expect("Can't get Kafka consumer counter");
let consumer\_group\_id = kafka::get\_kafka\_consumer\_group\_id(kafka\_consumer\_counter);
let consumer = kafka::create\_consumer(consumer\_group\_id);
async\_stream::stream! {
let mut stream = consumer.start();
while let Some(value) = stream.next().await {
yield match value {
Ok(message) => {
let payload = message.payload().expect("Kafka message should contain payload");
let message = String::from\_utf8\_lossy(payload).to\_string();
serde\_json::from\_str(&message).expect("Can't deserialize a planet")
}
Err(e) => panic!("Error while Kafka message processing: {}", e)
};
}
}
}
}
```
Подписка может быть использована так же, как запросы и мутации:
*Пример использования подписки*
```
subscription {
latestPlanet {
id
name
type
details {
meanRadius
}
}
}
```
Подписки должны отправляться на `ws://localhost:8001`.
### Интеграционные тесты
Тесты запросов и мутаций можно написать так:
[*Тест запроса*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/tests/query_tests.rs)
```
#[actix_rt::test]
async fn test_get_planets() {
let docker = Cli::default();
let (_pg_container, pool) = common::setup(&docker);
let mut service = test::init_service(App::new()
.configure(configure_service)
.data(create_schema_with_context(pool))
).await;
let query = "
{
getPlanets {
id
name
type
details {
meanRadius
mass
... on InhabitedPlanetDetails {
population
}
}
}
}
".to_string();
let request_body = GraphQLCustomRequest {
query,
variables: Map::new(),
};
let request = test::TestRequest::post().uri("/").set_json(&request_body).to_request();
let response: GraphQLCustomResponse = test::read_response_json(&mut service, request).await;
fn get_planet_as_json(all_planets: &serde_json::Value, index: i32) -> &serde_json::Value {
jsonpath::select(all_planets, &format!("$.getPlanets[{}]", index)).expect("Can't get planet by JSON path")[0]
}
let mercury_json = get_planet_as_json(&response.data, 0);
common::check_planet(mercury_json, 1, "Mercury", "TERRESTRIAL_PLANET", "2439.7");
let earth_json = get_planet_as_json(&response.data, 2);
common::check_planet(earth_json, 3, "Earth", "TERRESTRIAL_PLANET", "6371.0");
let neptune_json = get_planet_as_json(&response.data, 7);
common::check_planet(neptune_json, 8, "Neptune", "ICE_GIANT", "24622.0");
}
```
Если часть запроса может быть переиспользована в другом запросе, вы можете использовать [фрагменты](https://graphql.org/learn/queries/#fragments):
[*Тест запроса с использованием фрагмента*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/tests/query_tests.rs)
```
const PLANET_FRAGMENT: &str = "
fragment planetFragment on Planet {
id
name
type
details {
meanRadius
mass
... on InhabitedPlanetDetails {
population
}
}
}
";
#[actix_rt::test]
async fn test_get_planet_by_id() {
...
let query = "
{
getPlanet(id: 3) {
... planetFragment
}
}
".to_string() + PLANET_FRAGMENT;
let request_body = GraphQLCustomRequest {
query,
variables: Map::new(),
};
...
}
```
Чтобы использовать [переменные](https://graphql.org/learn/queries/#variables), запишите тест так:
[*Тест запроса с использованием фрагмента и переменной*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/tests/query_tests.rs)
```
#[actix_rt::test]
async fn test_get_planet_by_id_with_variable() {
...
let query = "
query testPlanetById($planetId: String!) {
getPlanet(id: $planetId) {
... planetFragment
}
}".to_string() + PLANET_FRAGMENT;
let jupiter_id = 5;
let mut variables = Map::new();
variables.insert("planetId".to_string(), jupiter_id.into());
let request_body = GraphQLCustomRequest {
query,
variables,
};
...
}
```
В этом проекте используется библиотека `Testcontainers-rs`, что позволяет подготовить тестовое окружение, то есть, создать временную БД PostgreSQL.
### Клиент к GraphQL API
Вы можете использовать код из предыдущего раздела для создания клиента к внешнему GraphQL API. Также для этого существуют специальные библиотеки, например, [graphql-client](https://github.com/graphql-rust/graphql-client), но я их не использовал.
### Безопасность API
Существуют различные угрозы безопасности GraphQL API (см. [список](https://leapgraph.com/graphql-api-security)); рассмотрим некоторые из них.
#### Ограничения глубины и сложности запроса
Если бы структура `Satellite` содержала поле `planet`, был бы возможен такой запрос:
*Пример тяжёлого запроса*
```
{
getPlanet(id: "1") {
satellites {
planet {
satellites {
planet {
satellites {
... # more deep nesting!
}
}
}
}
}
}
}
```
Сделать такой запрос невалидным можно так:
[*Пример ограничения глубины и сложности запроса*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/lib.rs)
```
pub fn create_schema_with_context(pool: PgPool) -> Schema {
...
Schema::build(Query, Mutation, Subscription)
.limit\_depth(3)
.limit\_complexity(15)
...
}
```
Стоит отметить, что при указании ограничений выше может перестать отображаться документация сервиса в GraphQL IDE. Это происходит потому, что IDE пытается выполнить introspection query, который имеет заметные глубину и сложность.
#### Аутентификация
Эта функциональность реализована в `auth-service` с использованием крэйтов `argonautica` и `jsonwebtoken`. Первый отвечает за хэширование паролей пользователей с использованием алгоритма [Argon2](https://en.wikipedia.org/wiki/Argon2). Аутентификация и авторизация показаны исключительно в демонстрационных целях; пожалуйста, изучите вопрос более тщательно перед использованием в продакшене.
Рассмотрим как реализован вход в систему:
[*Реализация входа в систему*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/auth-service/src/graphql.rs)
```
pub struct Mutation;
#[Object]
impl Mutation {
async fn sign_in(&self, ctx: &Context<'_>, input: SignInInput) -> Result {
let maybe\_user = repository::get\_user(&input.username, &get\_conn\_from\_ctx(ctx)).ok();
if let Some(user) = maybe\_user {
if let Ok(matching) = verify\_password(&user.hash, &input.password) {
if matching {
let role = AuthRole::from\_str(user.role.as\_str()).expect("Can't convert &str to AuthRole");
return Ok(common\_utils::create\_token(user.username, role));
}
}
}
Err(Error::new("Can't authenticate a user"))
}
}
#[derive(InputObject)]
struct SignInInput {
username: String,
password: String,
}
```
Посмотреть реализацию функции `verify_password` можно в [модуле](https://github.com/rkudryashov/graphql-rust-demo/blob/master/auth-service/src/utils.rs) `utils`, `create_token` в [модуле](https://github.com/rkudryashov/graphql-rust-demo/blob/master/common-utils/src/lib.rs) `common_utils`. Как вы могли бы ожидать, функция `sign_in` возвращает JWT, который в дальнейшем может быть использован для авторизации в других сервисах.
Для получения JWT выполните следующую мутацию:
*Получение JWT*
```
mutation {
signIn(input: { username: "john_doe", password: "password" })
}
```
Используйте параметры *john\_doe/password*. Включение полученного JWT в последующие запросы позволит получить доступ к защищённым ресурсам (см. следующий раздел).
#### Авторизация
Чтобы запросить защищённые данные, добавьте заголовок в HTTP запрос в формате `Authorization: Bearer $JWT`. Функция `index` извлечёт роль пользователя из HTTP запроса и добавит её в параметры GraphQL запроса/мутации:
[*Получение роли*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/lib.rs)
```
async fn index(schema: web::Data, http\_req: HttpRequest, req: Request) -> Response {
let mut query = req.into\_inner();
let maybe\_role = common\_utils::get\_role(http\_req);
if let Some(role) = maybe\_role {
query = query.data(role);
}
schema.execute(query).await.into()
}
```
К ранее показанной мутации `create_planet` применён следующий атрибут:
[*Использование гарда*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
#[graphql(guard(RoleGuard(role = "Role::Admin")))]
```
Сам гард реализован так:
[*Реализация гарда*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs)
```
struct RoleGuard {
role: Role,
}
#[async_trait::async_trait]
impl Guard for RoleGuard {
async fn check(&self, ctx: &Context<'_>) -> Result<()> {
if ctx.data_opt::() == Some(&self.role) {
Ok(())
} else {
Err("Forbidden".into())
}
}
}
```
Таким образом, если вы не укажете токен, сервер ответит сообщением "Forbidden".
### Определение перечисления
GraphQL перечисление может быть определено так:
[*Определение перечисления*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/satellites-service/src/graphql.rs)
```
#[derive(SimpleObject)]
struct Satellite {
...
life_exists: LifeExists,
}
#[derive(Copy, Clone, Eq, PartialEq, Debug, Enum, EnumString)]
#[strum(serialize_all = "SCREAMING_SNAKE_CASE")]
pub enum LifeExists {
Yes,
OpenQuestion,
NoData,
}
```
### Работа с датами
Async-graphql поддерживает типы даты/времени из библиотеки `chrono`, поэтому вы можете определить такие поля как обычно:
[*Определение поля с датой*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/satellites-service/src/graphql.rs)
```
#[derive(SimpleObject)]
struct Satellite {
...
first_spacecraft_landing_date: Option,
}
```
### Поддержка Apollo Federation
Одна из целей `satellites-service` — продемонстрировать как распределённая GraphQL [*сущность*](https://www.apollographql.com/docs/federation/entities/) (`Planet`) может резолвиться в двух (или более) сервисах и затем запрашиваться через Apollo Server.
Тип `Planet` был ранее определён в `planets-service` так:
[*Определение типа*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs) `Planet` в `planets-service`
```
#[derive(Serialize, Deserialize)]
struct Planet {
id: ID,
name: String,
planet_type: PlanetType,
}
```
Также в `planets-service` тип `Planet` является сущностью:
[*Определение сущности*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/planets-service/src/graphql.rs) `Planet`
```
#[Object]
impl Query {
#[graphql(entity)]
async fn find_planet_by_id(&self, ctx: &Context<'_>, id: ID) -> Option {
find\_planet\_by\_id\_internal(ctx, id)
}
}
```
`satellites-service` расширяет сущность `Planet` путём добавления поля `satellites`:
[*Расширение типа*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/satellites-service/src/graphql.rs) `Planet` в `satellites-service`
```
struct Planet {
id: ID
}
#[Object(extends)]
impl Planet {
#[graphql(external)]
async fn id(&self) -> &ID {
&self.id
}
async fn satellites(&self, ctx: &Context<'_>) -> Vec {
let id = self.id.to\_string().parse::().expect("Can't get id from String");
repository::get\_by\_planet\_id(id, &get\_conn\_from\_ctx(ctx)).expect("Can't get satellites of planet")
.iter()
.map(|e| { Satellite::from(e) })
.collect()
}
}
```
Также вам нужно реализовать функцию поиска для расширяемого типа. В примере ниже функция просто создаёт новый инстанс `Planet`:
[*Функция поиска для типа*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/satellites-service/src/graphql.rs) `Planet`
```
#[Object]
impl Query {
#[graphql(entity)]
async fn get_planet_by_id(&self, id: ID) -> Planet {
Planet { id }
}
}
```
Async-graphql генерирует два дополнительных запроса (`_service` and `_entities`), которые будут использованы Apollo Server'ом. Эти запросы — внутренние, то есть они не будут отображены в API Apollo Server'а. Конечно, сервис с поддержкой Apollo Federation по-прежнему может работать автономно.
### Apollo Server
Apollo Server и Apollo Federation позволяют достичь две основные цели:
* создать единую точку доступа к нескольким GraphQL API
* создать единый граф данных из распределённых сущностей
Таким образом, даже если вы не используете распределённые сущности, для frontend разработчиков удобнее использовать одну точку доступа, чем несколько.
Существует и другой способ создания единой GraphQL схемы, [schema stitching](https://www.graphql-tools.com/docs/schema-stitching/), но пока что я его не использовал.
Модуль включает следующий исходный код:
[*Мета-информация и зависимости*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/apollo-server/package.json)
```
{
"name": "api-gateway",
"main": "gateway.js",
"scripts": {
"start-gateway": "nodemon gateway.js"
},
"devDependencies": {
"concurrently": "5.3.0",
"nodemon": "2.0.6"
},
"dependencies": {
"@apollo/gateway": "0.21.3",
"apollo-server": "2.19.0",
"graphql": "15.4.0"
}
}
```
[*Определение Apollo Server*](https://github.com/rkudryashov/graphql-rust-demo/blob/master/apollo-server/gateway.js)
```
const {ApolloServer} = require("apollo-server");
const {ApolloGateway, RemoteGraphQLDataSource} = require("@apollo/gateway");
class AuthenticatedDataSource extends RemoteGraphQLDataSource {
willSendRequest({request, context}) {
if (context.authHeaderValue) {
request.http.headers.set('Authorization', context.authHeaderValue);
}
}
}
let node_env = process.env.NODE_ENV;
function get_service_url(service_name, port) {
let host;
switch (node_env) {
case 'docker':
host = service_name;
break;
case 'local': {
host = 'localhost';
break
}
}
return "http://" + host + ":" + port;
}
const gateway = new ApolloGateway({
serviceList: [
{name: "planets-service", url: get_service_url("planets-service", 8001)},
{name: "satellites-service", url: get_service_url("satellites-service", 8002)},
{name: "auth-service", url: get_service_url("auth-service", 8003)},
],
buildService({name, url}) {
return new AuthenticatedDataSource({url});
},
});
const server = new ApolloServer({
gateway, subscriptions: false, context: ({req}) => ({
authHeaderValue: req.headers.authorization
})
});
server.listen({host: "0.0.0.0", port: 4000}).then(({url}) => {
console.log(`? Server ready at ${url}`);
});
```
Если код выше может быть упрощён, не стесняйтесь поправить.
Авторизация в `apollo-service` работает так же, как было показано ранее для Rust сервисов (вам надо указать заголовок `Authorization` и его значение).
Приложение, написанное на любом языке или фреймворке, может быть добавлено в качестве нижележащего сервиса под Apollo Server, если оно реализует [спецификацию Federation](https://www.apollographql.com/docs/federation/federation-spec/); список библиотек, добавляющих поддержку этой спецификации доступен в [документации](https://www.apollographql.com/docs/federation/other-servers/).
При реализации модуля я столкнулся со следующими ограничениями:
* Apollo Gateway [не поддерживает](https://github.com/apollographql/apollo-server/issues/3357) подписки (но они по-прежнему работают в standalone Rust сервисе)
* сервису, пытающемуся расширить GraphQL интерфейс [требуется информация о его конкретных имплементациях](https://github.com/apollographql/apollo-server/issues/2849)
### Взаимодействие с БД
Уровень хранения реализован с помощью PostgreSQL and Diesel. Если вы не используете Docker при локальном запуске, то нужно выполнить `diesel setup`, находясь в директории каждого из сервисов. Это создаст пустую БД, к которой далее будут применены миграции, создающие таблицы и инициализирующие данные.
### Запуск проекта и тестирование API
Как было отмечено ранее, проект можно запустить двумя способами:
* с использованием Docker Compose ([docker-compose.yml](https://github.com/rkudryashov/graphql-rust-demo/blob/master/docker-compose.yml))
Здесь, в свою очередь, также возможны два варианта:
+ режим разработки (используя локально собранные образы)
`docker-compose up --build`
+ production mode (используя релизные образы)
`docker-compose -f docker-compose.yml up`
* без Docker
Запустите каждый Rust сервис с помощью `cargo run`, потом запустите Apollo Server:
+ `cd` в папку `apollo-server`
+ определите переменную среды `NODE_ENV`, например, `set NODE_ENV=local` (для Windows)
+ `npm install`
+ `npm run start-gateway`
Успешный запуск `apollo-server` должен выглядеть так:
*Лог запуска Apollo Server*
```
[nodemon] 2.0.6
[nodemon] to restart at any time, enter `rs`
[nodemon] watching path(s): *.*
[nodemon] watching extensions: js,mjs,json
[nodemon] starting `node gateway.js`
Server ready at http://0.0.0.0:4000/
```
Вы можете перейти на `http://localhost:4000` в браузере и использовать встроенную Playground IDE:
Здесь возможно выполнять запросы, мутации и подписки, определённые в нижележащих сервисах. Кроме того, каждый из этих сервисов имеет собственную Playground IDE.
### Тест подписки
Чтобы убедиться в том, что подписка работает, откройте две вкладки любой GraphQL IDE; в первой подпишитесь таким образом:
*Пример подписки*
```
subscription {
latestPlanet {
name
type
}
}
```
Во второй укажите заголовок `Authorization` как было описано ранее и выполните мутацию:
*Пример мутации*
```
mutation {
createPlanet(
planet: {
name: "Pluto"
type: DWARF_PLANET
details: { meanRadius: "1188", mass: "1.303e22" }
}
) {
id
}
}
```
Подписанный клиент будет уведомлен о событии:
### CI/CD
CI/CD сконфигурирован с помощью GitHub Actions ([workflow](https://github.com/rkudryashov/graphql-rust-demo/blob/master/.github/workflows/workflow.yml)), который запускает тесты приложений, собирает их Docker образы и разворачивает их на Google Cloud Platform.
Вы можете посмотреть на описанные API [здесь](http://demo.romankudryashov.com).
**Замечание:** На "продакшн" среде пароль отличается от указанного ранее, чтобы предотвратить изменение данных.
Заключение
----------
В этой статье я рассмотрел как решать наиболее частые вопросы, которые могут возникнуть при разработке GraphQL API на Rust. Также было показано как объединить API Rust GraphQL микросервисов для получения единого GraphQL интерфейса; в подобной архитектуре сущность может быть распределена среди нескольких микросервисов. Это достигается за счёт использования Apollo Server, Apollo Federation и библиотеки Async-graphql. Исходный код рассмотренного проекта доступен на [GitHub](https://github.com/rkudryashov/graphql-rust-demo). Не стесняйтесь написать мне, если найдёте ошибки в статье или исходном коде. Благодарю за внимание!
Полезные ссылки
---------------
* [graphql.org](https://graphql.org/)
* [spec.graphql.org](https://spec.graphql.org/)
* [graphql.org/learn/best-practices](https://graphql.org/learn/best-practices/)
* [howtographql.com](https://www.howtographql.com/)
* [Async-graphql](https://github.com/async-graphql/async-graphql)
* [Async-graphql book](https://async-graphql.github.io/async-graphql/en/index.html)
* [Awesome GraphQL](https://github.com/chentsulin/awesome-graphql)
* [Public GraphQL APIs](https://github.com/APIs-guru/graphql-apis)
* [Apollo Federation demo](https://github.com/apollographql/federation-demo) | https://habr.com/ru/post/546208/ | null | ru | null |
# 5 популярных JavaScript-хаков
Существует несколько JavaScript-хаков, которыми постоянно пользуются опытные программисты. Они не совсем очевидны, особенно для новичков. Эти хаки используют возможности языка, имеющие некоторые побочные эффекты. В этой статье я объясню, как работают 5 таких распространённых хаков.
Использование оператора `!!` для конвертации в логическое значение
------------------------------------------------------------------
Всё в JavaScript может быть интерпретировано как *истинное* или *ложное*. Это означает, что если вы поместите объект в условный оператор `if`, то он выполнит либо `true`-ветку кода (когда объект имеет значение `true`), либо выполнит `false`-ветку (соответственно, когда объект имеет значение `false`).
*0, false, "", null, undefined, NaN* — это ложные значения. Все остальные значения возвращают `true`. Иногда вам может потребоваться конвертировать переменную в логическое значение. Это можно сделать с помощью оператора `!!`:
```
var something = 'variable';
!!something // returns true
```
С другой стороны, вместо `if (x == "test")` можно просто написать `if (x)`. Если же `x` будет пустой переменной, то просто выполнится код из блока `else`.
Конвертация строки в число с помощью оператора +
------------------------------------------------
В JavaScript `+` — это унарный оператор, который возвращает числовое представление операнда или `NaN`, если операнд не имеет такового. Например, с помощью этого оператора можно проверить, является ли переменная `x` числом (такой код можно увидеть в библиотеке [underscore](http://underscorejs.org)): `x === +x`.
Такой способ не очевиден. Скорее всего, вы бы применили методы `parseFloat` и `parseInt`.
Определение значения по умолчанию с оператором ||
-------------------------------------------------
В JavaScript `||` является примером выполнения **короткого замыкания**. Этот оператор сперва анализирует выражение слева от него, и, если оно ложно, анализирует выражение справа. В любом случае, он возвращает первое истинное выражение. Рассмотрим следующий пример:
```
function setAge(age) {
this.age = age || 10
}
setAge();
```
В этом примере мы вызываем функцию `setAge()` без аргументов, таким образом `age || 10` вернет 10 (`!!age == false`). Такой способ весьма хорош для того, чтобы задавать значения переменных по умолчанию. На самом деле, такой подход эквивалентен следующему примеру:
```
var x;
if (age) {
this.age = age;
} else {
this.age = 10;
}
```
Первый пример с оператором `||` более лаконичен, поэтому именно такой способ используется во всем мире.
Лично я часто использую этот способ. Мне нравится его лаконичность и простота. Однако стоит заметить, что с таким способом вам не удастся задать переменной значение 0, так как 0 является ложным выражением. Поэтому я советую при необходимости использовать такой способ:
```
this.age = (typeof age !== "undefined") ? age : 10;
```
Использование void 0 вместо undefined
-------------------------------------
Ключевое слово `void` принимает один аргумент и всегда возвращает `undefined`. Почему просто не использовать `undefined`? Потому что в некоторых браузерах `undefined` — это просто переменная, которая может быть переопределена. Поэтому `void 0` даёт нам больше уверенности в том, что ничего не будет случайно сломано. Хотя вы можете найти этот хак в исходниках многих библиотек, я бы не рекомендовал использовать его регулярно, так как все ES5-совместимые браузеры не позволяют перезаписывать значение `undefined`.
Инкапсуляция с помощью паттерна (function() {...})()
----------------------------------------------------
В ES5 есть только 2 типа областей видимости: глобальная область видимости и область видимости функции. Всё, что вы пишите, принадлежит к глобальной области, которая доступна из любого места кода. Она включает в себя объявление переменных и функций. Однако, что если вы захотите инкапсулировать большинство кода, а в глобальной области видимости оставить только интерфейс? Тогда вам следует использовать анонимную функцию. Рассмотрим следующий пример:
```
(function() {
function div(a, b) {
return a / b;
}
function divBy5(x) {
return div(x, 5);
}
window.divBy5 = divBy5;
})()
div // => undefined
divBy5(10); // => 2
```
Из всех перечисленных в статье хаков этот хак является самым безвредным; вы можете и должны использовать его в своих проектах, чтобы предотвратить взаимодействие внутренней логики с глобальной областью видимости.
В заключение я хотел бы напомнить вам, что любой написанный вами код должен быть прост и понятен для других программистов. И любые стандартные конструкции, предоставляемые языком, следует использовать в первую очередь.
Некоторые из хаков, рассмотренных в статье, могут быть решены элегантнее с помощью ES6 (следующая версия JavaScript). Например, в ES6 вместо `age = age || 10` можно написать следующее:
```
function(age = 10) {
// ...
}
```
Другой пример — паттерн `(function() {...})()`, который вы уже вряд ли станете использовать после того, как [модули ES6](http://eviltrout.com/2014/05/03/getting-started-with-es6.html) станут поддерживаться современными браузерами.
Дополнительные материалы
------------------------
Если вы хотите погрузиться в тему JS-хаков ещё глубже, вам могут пригодиться следующие ресурсы:
* [Byte Saving Techniques](https://github.com/jed/140bytes/wiki/Byte-saving-techniques)
* [JavaScript Idiosyncrasies (kinda)](https://github.com/miguelmota/javascript-idiosyncrasies)
* [JavaScript language advanced Tips & Tricks](https://code.google.com/p/jslibs/wiki/JavascriptTips)
Оригинал статьи: [JavaScript hacks explained](http://blog.mdnbar.com/javascript-common-tricks)
Автор статьи: Yanis T | https://habr.com/ru/post/240357/ | null | ru | null |
# Безопасность REST API от А до ПИ
Введение
--------
Умение реализовать грамотное REST API — полезный навык в наше время, т.к. все больше сервисов предоставляют свои возможности с помощью API. Но разработка REST API не ограничивается реализацией HTTP запросов в определенном стиле и формированием ответов в соответствии со спецификацией. Задача обеспечения безопасности REST API не так очевидна, как, например, обеспечение безопасности баз данных, но ее необходимость не менее важна.
В настоящее время многие онлайн системы с помощью API передают приватные данные пользователей, такие как медицинские или финансовые. Текущая же ситуация с безопасностью в веб-приложениях весьма печальна: [по данным Comnews](https://www.comnews.ru/content/207166/2020-05-19/2020-w21/veb-prilozheniya-pod-udarom) порядка 70% содержат критические уязвимости. Поэтому всем, кто участвует в проектировании, реализации и тестировании онлайн систем, важно иметь общую картину по существующим угрозам и способам обеспечения безопасности как всей системы, так и используемого REST API.
В статье я попытался обобщить информацию о существующих уязвимостях REST API, чтобы у читателей сложилась общая картина. На схемах представлена современная архитектура клиент-сервер и обобщенный REST API запрос с потенциальными угрозами безопасности. Далее я подробнее расскажу об этих угрозах, и как технически реализовать защиту от них.
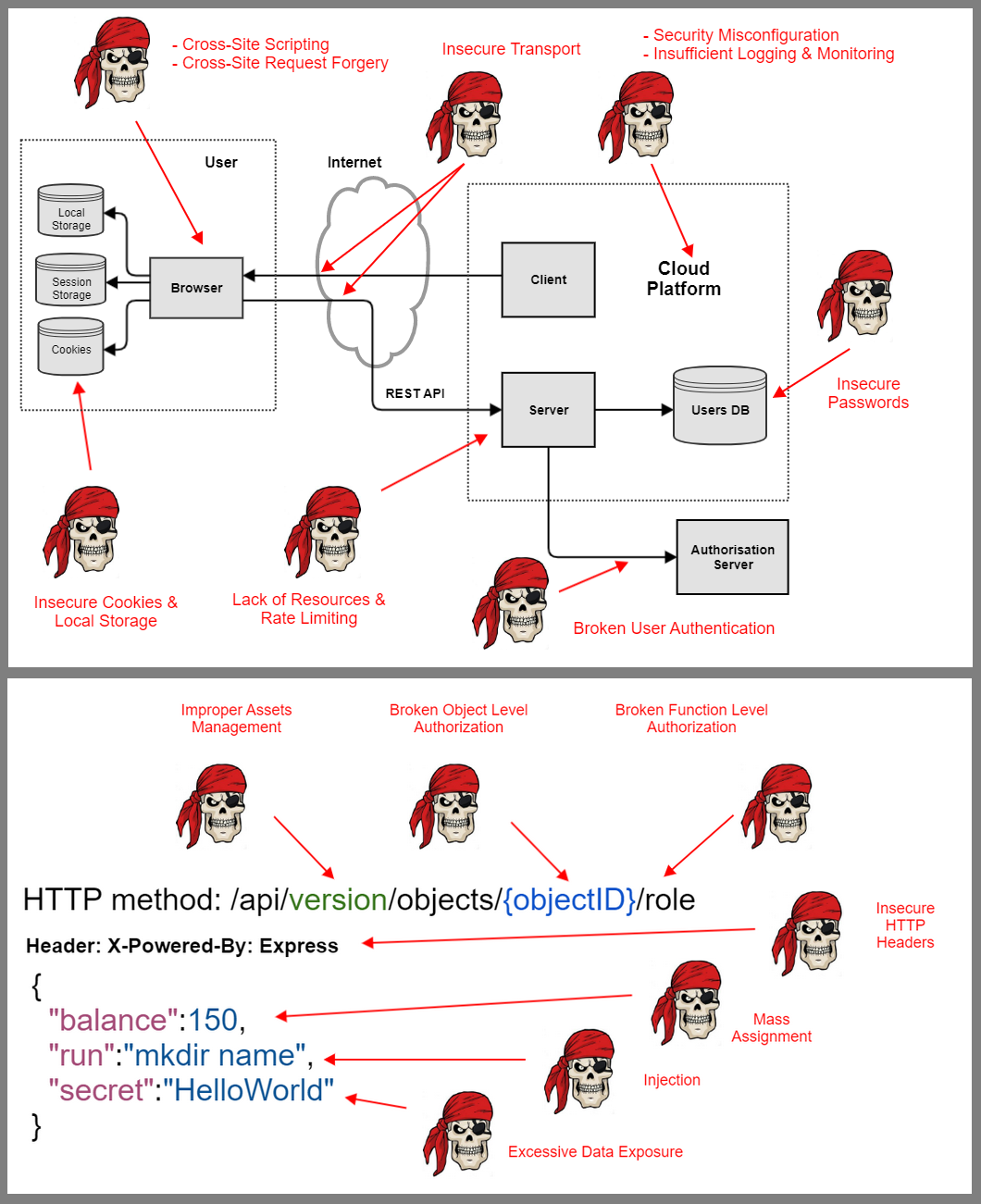
Стандарты безопасности
----------------------
Начнем со стандартов. Существует несколько стандартов, которые помогут нам сформулировать список требований к безопасности API:
[OWASP](https://owasp.org/) (Open Web Application Security Project) известна своими списками рисков в разных программных технологиях. Нам интересен список [«10 наиболее опасных уязвимостей при разработке API»](https://owasp.org/www-project-api-security/):
* API1:2019 Broken Object Level Authorization (Недостатки контроля доступа к объектам). Другое название этого риска: Insecure Direct Object References (Небезопасные прямые ссылки на объекты)
* API2:2019 Broken User Authentication (Недостатки аутентификации пользователей)
* API3:2019 Excessive Data Exposure (Разглашение конфиденциальных данных)
* API4:2019 Lack of Resources & Rate Limiting (Отсутствие проверок и ограничений)
* API5:2019 Broken Function Level Authorization (Недостатки контроля доступа на функциональном уровне)
* API6:2019 Mass Assignment (Небезопасная десериализация)
* API7:2019 Security Misconfiguration (Некорректная настройка параметров безопасности)
* API8:2019 Injection (Внедрение)
* API9:2019 Improper Assets Management (Недостатки управления API)
* API10:2019 Insufficient Logging & Monitoring (Недостатки журналирования и мониторинга)
Добавлю пункты, которые [не вошли в Top10](https://owasp.org/www-community/vulnerabilities/), но относятся к нашей теме:
* [Insecure Transport](https://owasp.org/www-community/vulnerabilities/Insecure_Transport) (Небезопасный транспортный уровень)
* [Insecure Passwords](https://owasp.org/www-community/vulnerabilities/Password_Plaintext_Storage) (Небезопасные пароли)
* [Using Components with Known Vulnerabilities](https://owasp.org/www-project-top-ten/OWASP_Top_Ten_2017/Top_10-2017_A9-Using_Components_with_Known_Vulnerabilities) (Использование компонент с известными уязвимостями)
А также уязвимости из списка другой организации Common Weakness Enumeration (CWE): [CWE Top 25 Most Dangerous Software Errors](https://cwe.mitre.org/top25/archive/2019/2019_cwe_top25.html):
* CWE-79 Cross-site Scripting (XSS) (Межсайтовое выполнение сценариев)
* CWE-352 Cross-Site Request Forgery (CSRF) (Межсайтовая подмена запросов)
И несколько пунктов из других найденных списков:
* Insecure Cookies and Local Storage (Небезопасные Cookies и Local Storage)
* Insecure HTTP Headers (Небезопасные HTTP заголовки)
* Improper Cross-origin resource sharing (Неправильное использование CORS)
* Clickjacking (Подмена кликов)
В результате получился список, который, на мой взгляд, достаточно полно отражает современные проблемы безопасности API. Для проверки того, что список получился общим и применимым для всех технологий я использовал рекомендации по безопасности API, найденные на просторах Интернета (ссылки приведены в конце статьи). Далее рассмотрим все перечисленные пункты.
API2:2019 — Broken User Authentication (Недостатки аутентификации пользователей)
--------------------------------------------------------------------------------
Тема аутентификации пользователей идет на втором месте в списке OWASP, но я ее поставил на первое, т.к. с этого все начинается. Современные стандарты аутентификации и авторизации я уже рассматривал в своей статье про [OAuth 2.0, OpenID Connect, WebAuthn](https://habr.com/ru/post/491116/). Здесь кратко опишу основные схемы безопасности и рассмотрим более подробно наиболее надежную на данный момент схему, основанную на токенах.
### API key
API Key — это строка символов, которую передает клиент в запросах к серверу. Для успешной аутентификации строка должна совпадать у клиента и у сервера. Данная схема обеспечивает защиту от несанкционированного использования API и позволяет осуществлять, например, проверку лимитов использования API.
### Basic Authentication
В Basic Authentication используется аутентификация по двум строкам, например логину/паролю.
Для передачи информации используется HTTP заголовок 'Authorization' с ключевым словом Basic далее пробел и base64 закодированная строка username:password. Например:
```
Authorization: "Basic dXNlcm5hbWU6cGFzc3dvcmQ="
```
### Cookie-Based Authentication
Cookie-Based Authentication использует механизм передачи Cookies в HTTP запросах. В ответ на запрос клиента сервер посылает заголовок Set-Cookie, который содержит имя и значение cookie, а также дополнительные атрибуты: expires, domain, path, secure, httponly. Пример отправки cookie:
```
Authorization: Set-Cookie: JSESSIONID=123456789; Path=/; HttpOnly
```
После этого клиент автоматически будет посылать заголовок Cookie при каждом запросе:
```
Cookie: JSESSIONID=123456789
```
Для реализации этого механизма необходимо на сервере организовать хранение и проверку сессий пользователей. Подробнее использование Cookies рассмотрено в разделе «Insecure Cookies and Local Storage»
### Token-Based Authentication
Также называют Bearer Authentication.
Token-Based Authentication использует подписанный сервером токен (bearer token), который клиент передает на сервер в заголовке Authorization HTTP с ключевым словом Bearer или в теле запроса. Например:
```
Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IjI4Y
```
При получении токена сервер должен проверять его на валидность — что пользователь существует, время использования не прошло и т.д. Token-Based Authentication может использоваться как часть OAuth 2.0 или OpenID Connect протоколов, так и сервер сам может сформировать токен.
При любом способе аутентификации для безопасного использования должен использоваться протокол, который обеспечивает шифрование данных, HTTP заголовков и URL, например HTTPS.
### Алгоритм Token-Based Authentication
Разберем подробнее последнюю из описанных схем. На схеме представлен упрощенный алгоритм Token-Based Authentication на примере реализации возможности «Зайти с помощью Google аккаунта»

1. Пользователь заходит на сайт и нажимает кнопку «Зайти с помощью Google аккаунта»
2. Сервер посылает запрос на Google.
3. Google показывает пользователю свою форму логина.
4. Пользователь вводит логин/пароль.
5. Google проверяет логин/пароль и отправляет на наш сервер приложений access token и refresh token.
6. Для аутентификации сервер расшифровывает token или получает информацию о пользователе по Google API.
7. Далее сервер находит пользователя в своей базе, сообщает об успешной аутентификации и сохраняет токены в локальном хранилище пользователя для реализации возможности «Запомнить меня на этом устройстве». В каком конкретно: Local Storage, Session Storage или Cookies, решается в зависимости от требований бизнеса и безопасности. OWASP склоняется к Cookies с реализацией дополнительных механизмов безопасности: [JSON Web Token Cheat Sheet](https://github.com/OWASP/CheatSheetSeries/blob/master/cheatsheets/JSON_Web_Token_Cheat_Sheet_for_Java.md#token-sidejacking). Нужно ли генерировать дополнительный «session token», где его хранить и как использовать — также должно определяться бизнесом, для которого реализуется система.
8. После этого при каждом запросе к серверу клиент будет передавать access token в запросе, а наш сервер проверять его на валидность в Google и только после этого передавать запрошенные данные.
9. При окончании срока действия access токена сервер использует refresh токен для получения нового.
**Какие плюсы Token-Based Authentication для сервера приложений:**
1. Не надо хранить пароли в базе данных на сервере, таким образом сразу избавляемся от уязвимости Insecure Passwords.
2. В некоторых случаях можно вообще избавиться от базы данных на сервере и получать всю необходимую информацию из Google или других систем.
3. Нет проблем с безопасностью, характерных для остальных методов:
* При компрометации логина/пароля доступ к данным получается сразу и длится пока пользователь сам не заметит факт взлома, у токенов же есть время жизни, которое может быть небольшим.
* Токен автоматически не уйдет на сторонний сайт, как Cookie.
* Cookie-Based Authentication подвержена атаке Cross-Site Request Forgeries (CSRF) и, соответственно, необходимо использовать дополнительные механизмы защиты.
* Можно не хранить сессию пользователя на сервере, а токен проверять каждый раз в Google.
**Минус видится один:**
В случае перехвата токена, злоумышленник может какое-то время выдавать себя за владельца токена. Поэтому для передачи токена надо обязательно использовать HTTPS.
API1:2019 Broken Object Level Authorization (Недостатки контроля доступа к объектам)
------------------------------------------------------------------------------------
Другое название этого риска: Insecure Direct Object References (Небезопасные прямые ссылки на объекты). Это самая распространенная проблема с API в настоящее время. Для иллюстрации приведу API, которое в дальнейшем использую еще для нескольких примеров уязвимостей.
Получить одного пользователя с userID:
```
GET /users/{userID}
```
Получить всех пользователей (может только администратор):
```
GET /users
```
Удалить пользователя c userID: DELETE /users/{userID}
```
DELETE /users/1
```
Итак, если вызывается команда удаления пользователя:
```
DELETE /users/1
```
То необходима проверка, что эту команду может вызвать только сам пользователь 1 или администратор, а не, например, пользователь 2 от своего имени, просто изменив значение ID в вызове команды. Чтобы избежать подобных проблем нужно:
* Проверять права доступа к объектам при каждом запросе.
* Проверять, что залогиненный пользователь имеет доступ только к разрешенным объектам.
* ID объектов должны быть сложными для подбора, например в виде UUID, а не простая последовательность 1, 2, 3.
OWASP рекомендует ([Access Control Cheat Sheet](https://cheatsheetseries.owasp.org/cheatsheets/Access_Control_Cheat_Sheet.html)) следующие модели обеспечения контроля доступа:
* Role-Based Access Control (RBAC)
* Discretionary Access Control (DAC)
* Mandatory Access Control (MAC)
* Permission Based Access Control
API5:2019 Broken Function Level Authorization (Недостатки контроля доступа на функциональном уровне)
----------------------------------------------------------------------------------------------------
Должна быть разработана четкая система разграничения доступа между ролями пользователей API. Например, есть роль: обычные пользователи и роль: администраторы. Команду по просмотру всех пользователей может вызвать только администратор:
```
GET /users/all
```
При каждом вызове команды необходима проверка прав доступа, чтобы обычный пользователь не мог вызвать команду, только изменив формат.
API3:2019 Excessive Data Exposure (Разглашение конфиденциальных данных)
-----------------------------------------------------------------------
На самом деле пункт называется — предоставление излишних данных, но при этом как раз и может происходить разглашение конфиденциальных или персональных данных. Как такое получается? На запрос клиента сервер, как правило, формирует запрос к базе данных, которая возвращает запись или список записей. Эти данные зачастую сериализируются в JSON без проверок и отправляется клиенту с предположением, что клиент сам отфильтрует нужные данные. Но проблема в том, что запрос может отправить не только клиент, а может сформировать злоумышленник напрямую к серверу и получить конфиденциальные данные. Например, безобидный запрос данных по пользователю с ID 1:
```
GET /users/1
```
может вернуть не только имя / возраст, но и ответ на секретный вопрос, который пользователь задал во время регистрации:
```
{"userName":"Alex","age":25,"secretAnswer":"HelloWorld"}
```
Это и называется излишняя передача данных. Проблема усугубляется тем, что лишних данных может быть еще и просто много по объёму. При больших нагрузках это приведет к сетевым проблемам. Соответственно, при разработке API нельзя полагаться на фильтрацию данных в клиенте — все данные должны фильтроваться на сервере.
API6:2019 Mass Assignment (Небезопасная десериализация)
-------------------------------------------------------
В данном случае ситуация обратная предыдущему пункту Excessive Data Exposure — лишние данные передаются на сервер с целью несанкционированной замены значений. Как это понимать? Предположим у нас есть пользователь-хакер с ID 1 со следующими данными:
```
{"userName":"Alex","age":25,"balance":"150"}
```
Некоторые поля записей пользователь может легитимно менять сам, например, свой возраст. А поля, такие как balance должны устанавливать внешние системы.
Но наш сервер подвержен атаке Mass Assignment и без проверок источника записывает все пришедшие данные. Наш пользователь-хакер может отправить на сервер запрос на изменение возраста, в который добавляет дополнительный атрибут balance:
```
POST /users/1
```
```
{"userName":"Alex","age":26,"balance":"1000000"}
```
После этого баланс увеличится без внесения реальных денег. Чтобы предотвратить данную атаку необходимо:
* Не допускать автоматическую десериализацию пришедших данных.
* Ограничить список атрибутов, которые может менять пользователь.
API4:2019 Lack of Resources & Rate Limiting (Отсутствие проверок и ограничений)
-------------------------------------------------------------------------------
Необходимо защитить сервер от атак по подбору пароля (brute force attack). Для этого нужно реализовать следующие ограничения:
* Ограничить число неудачных попыток авторизации одного пользователя. Как вариант использовать reCapture или аналогичный механизм.
* Блокировать IP, если число неудачных попыток с него превысило определенное значение по всем пользователям.
Для JS существуют средства, позволяющие делать такие проверки автоматически (например, [Rate limiter](https://www.npmjs.com/package/ratelimiter)) и сразу посылать ответ «429 Too Many Requests», не нагружая сервер.
Необходимо защитить сервер и от отказа в обслуживании (DoS-атаки)
* Ограничить число запросов от одного пользователя или по одному ресурсу в течении определенного времени.
* Также атаки по отказу в обслуживании могут основываться на передаче заведомо больших значений.
Например, сервер ожидает в параметре size число записей:
```
/api/users?page=1&size=100
```
Если на сервере отсутствует проверка size на максимальное значение, то передача в параметре злоумышленником, например, 1 000 000 может привести к исчерпанию памяти на сервере и отказу в обслуживании. Поэтому нужно проверять на сервере все значения параметров на допустимые, даже если на нашем клиенте есть такие проверки. Ведь никто не помешает вызвать API напрямую.
API7:2019 Security Misconfiguration (Некорректная настройка параметров безопасности)
------------------------------------------------------------------------------------
Следующие действия могут привести к проблемам с безопасностью, соответственно, их надо избегать:
* Используются дефолтные настройки приложений, которые могут быть небезопасны.
* Используются открытые хранилища данных.
* В OpenSourсe попала закрытая информация, например, конфигурация системы или параметры доступа.
* Неправильно используются регулярные выражения, что позволяет провести атаку ReDoS ([Regular expression Denial of Service](https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service_-_ReDoS))
* Неправильно сконфигурированы HTTP заголовки (данная тема рассмотрена далее в разделе «Insecure HTTP Headers»).
* Аутентификационные данные (логин/пароль, токен, apiKey) посылаются в URL. Это небезопасно, т.к. параметры из URL могут оставаться в логах веб серверов.
* Отсутствует или неправильно используется политика Cross-Origin Resource Sharing (CORS) (данная политика рассмотрена далее в одноимённом разделе).
* Не используется HTTPS (использование HTTPS рассмотрено в разделе «Insecure Transport»).
* При эксплуатации промышленной системы используются настройки, предназначенные для разработки и отладки.
* Сообщения об ошибках содержат чувствительную информацию, например, трейсы стека.
Также необходимо уделять внимание конфигурации облачных сервисов:
* Для пользователей устанавливать только необходимые права доступа.
* Открывать только необходимые сетевые порты.
* Устанавливать безопасные версии патчей OS и приложений (подробно рекомендации рассмотрены в разделе «Using Components with Known Vulnerabilities»).
API8:2019 Injection (Внедрение)
-------------------------------
Внедрение — это выполнение программного кода, не предусмотренного системой. Разделяют внедрения:
* SQL команд
* Команд OS
Атака будет успешна, если сервер выполняет полученные команды без проверки. Чем-то напоминает «небезопасную десериализацию», только используются не дополнительные атрибуты, а SQL код или команды OS. В результате SQL инъекции можно получить несанкционированный доступ к данным. С помощью инъекции команд OS можно получить доступ к серверу или вывести его из строя. Например, в строке ввода пользователь ввел имя каталога «name» и на сервер посылается команда:
```
GET /run
```
```
{"mkdir":"name"}
```
Если сервер выполняет команды без проверки, то злоумышленник может послать следующую команду с большой вероятностью вывода сервера из строя:
```
GET /run
```
```
{"mkdir":"name && format C:/"}
```
Для предотвращения подобных атак:
* Нельзя подавать введенные данные напрямую в команды.
* Если без этого никак, то необходимо делать все возможные проверки, очистку, фильтрацию и валидацию данных.
API9:2019 Improper Assets Management (Недостатки управления API)
----------------------------------------------------------------
API может иметь несколько точек входа (endpoints) с разными версиями и функциональными назначениями. Например:
```
http://localhost:5000/myAPI/v1
```
```
http://localhost:5000/myAPI/v2
```
```
http://localhost:5000/myTestAPI/v1
```
Необходимо обеспечить учет и контроль версий API:
* Нужно вести список имеющихся API, их версий, назначение (production, test, development) и кто имеет к ним доступ (public, internal, partners).
* Необходимо управлять жизненным циклом API и своевременно запускать новые версии, снимать с поддержки старые.
* В открытом доступ выставлять только актуальные версии API.
* Не оставлять в открытом доступе endpoints, предназначенные для отладки.
Если не обеспечить подобный контроль, то возможно использование API в непредусмотренных целях. Например, злоумышленник обнаружит рабочий endpoint с версией API, которая имела уязвимости в безопасности, но была оставлена на время перехода на новую безопасную версию, но так и осталась в эксплуатации.
API10:2019 Insufficient Logging & Monitoring (Недостатки журналирования и мониторинга)
--------------------------------------------------------------------------------------
Чтобы выявить атаку или подозрительное поведение пользователей, систему надо мониторить, а события логировать с достаточным уровнем подробности:
* Логировать все неудачные попытки аутентификации, отказы в доступе, ошибки валидации входных данных.
* Обеспечить целостность логов, чтобы предотвратить возможность их подделки.
* Мониторить надо не только приложения и вызовы API, но и инфраструктуру, сетевую активность, загрузку OS.
* Необходимо обеспечить не только мониторинг, но и оперативное оповещение о нарушениях штатной работы системы.
* Общие советы по мониторингу можно посмотреть в статье [Monitoring Done Right](https://medium.com/hackernoon/node-js-monitoring-done-right-70418ecbbff9)
Insecure Transport (Небезопасный транспортный уровень)
------------------------------------------------------
Если не шифровать трафик между клиентом и сервером, то все HTTP данные и заголовки будут передаваться в открытом виде. Чтобы предотвратить утечку данных, надо использовать протокол HTTPS (Hyper Text Transfer Protocol Secure) или реализовывать шифрование самостоятельно. Для использования HTTPS нужен SSL-сертификат. Сайты в интернете должны получать такие сертификаты в доверительных центрах выдачи сертификатов CA (Certificate Authority). Но для целей шифрования данных между нашим клиентом и сервером можно поступить проще:
* Самостоятельно сгенерировать, так называемый, self-signed сертификат.
* На сервере настроить использование HTTPS протокола.
* С клиента формировать запросы, начинающиеся с https.
Браузер, конечно, будет ругаться, что сертификат сервера подписан не известно кем, но мы-то можем сами себе доверять).
Обеспечить поддержку HTTPS можно также средствами Apache, Nginx или других веб-серверов.
Insecure Passwords (Небезопасные пароли)
----------------------------------------
С этой темой все просто:
* Пароли пользователей должны быть достаточно сложными и длинными. В настоящее время не существует единых требований к паролям, все определяется бизнесом.
* На сервере нельзя хранить пароли пользователей в открытом виде.
* На сервере храним только хеши паролей, вычисленные надежным алгоритмом, например, [Argon2](https://en.wikipedia.org/wiki/Argon2).
Insecure Cookies and Local Storage (Небезопасные Cookies и данные в Local Storage)
----------------------------------------------------------------------------------
Cookies должны использоваться безопасно:
* Нельзя использовать дефолтные имена.
* При создании Cookies следует устанавливать следующие опции:
```
secure - браузер будет отправлять cookies только по HTTPS протоколу.
httpOnly - браузер будет отправлять cookies только по HTTP или HTTPS и не отправлять при запросах из JavaScript, что предотвратит атаки Cross-site Scripting (XSS).
domain - определяет domain cookie.
path - определяет path cookie.
expires - определяет дату устаревания cookies.
SameSite - браузер будет отправлять cookies только тому сайту, который их установил.
```
* Европейские сайты [должны явно спрашивать](https://www.privacypolicies.com/blog/eu-cookies-directive/) разрешение у пользователя о применении Cookies. Так как, например, если в Cookies записать последовательность действий пользователя на сайте, то это уже считается персональной информацией.
Общие правила безопасности для Cookies и Local Storage:
* Нельзя хранить важную информацию с сервера, т.к. она доступна пользователю.
* Нельзя хранить персональную информацию пользователя, т.к. она может стать доступна другим пользователям компьютера.
* Соответственно, можно хранить только зашифрованные данные или служебную информацию.
Using Components with Known Vulnerabilities (Использование компонент с известными уязвимостями)
-----------------------------------------------------------------------------------------------
Компоненты, такие как библиотеки и framework-и выполняются с теми же привилегиями, что и приложение. Поэтому если среди используемых библиотек окажется небезопасный компонент, то это может привести к захвату или выводу из строя сервера. Для проверки безопасности компонент используются специальные приложения, например, для JavaScript можно использовать [Retire](https://www.npmjs.com/package/retire).
CWE-79 Cross-site Scripting (XSS) (Межсайтовое выполнение скриптов)
-------------------------------------------------------------------
Межсайтовое выполнение скриптов считается самой опасной web-атакой. Суть ее в том, что вредоносный скрипт может быть внедрен в нашу страницу, а результат выполнения может привести к утечке конфиденциальных данных или к повреждению сервера. Чтобы защититься от атаки в запрос надо включить HTTP заголовок, который включает Cross-site scripting (XSS) фильтр:
```
X-XSS-Protection : 1; mode=block
```
или
```
Content-Security-Policy: script-src 'self'
```
CWE-352 Cross-Site Request Forgery (CSRF) (Межсайтовая подмена запросов)
------------------------------------------------------------------------
Для понимания сути атаки приведу пример: предположим, есть финансовая организация с онлайн кабинетом. В Cookies запоминается пользователь, чтобы при входе ему не надо было каждый раз вводить свой логин/пароль. Пользователь случайно заходит на сайт злоумышленника, который отправляет в финансовую организацию транзакцию на перевод денег, в которую браузер автоматически помещает данные из запомненных Cookies.
Финансовый сайт успешно проверяет валидность Cookies и выполняет несанкционированную транзакцию. Для защиты от атак CSRF надо:
* На сервере реализовать механизм «CSRF токенов». Это такой механизм, когда для каждой сессии пользователя генерируется новый токен и сервер проверяет его валидность при любых запросах с клиента.
* На сервере проверять заголовки Origin и Referer, в которых содержится адрес источника запроса. Но эти заголовки могут отсутствовать.
* Также можно всегда требовать от пользователя подтверждать критические действия вводом пароля или вторым фактором аутентификации, но возможность таких мер зависит от бизнеса.
* При создании Cookies выставлять параметр SameSite, но этот механизм поддерживают не все браузеры.
Cross-origin resource sharing (CORS) (Кросс-доменное использование ресурсов)
----------------------------------------------------------------------------
CORS — это механизм безопасности, который позволяет серверу задать правила доступа к его API. Например, если на сервере установить заголовок:
```
Access-Control-Allow-Origin: *
```
то это позволит использовать API без ограничения. Если это не публичное API, то для безопасности надо явно устанавливать Origin-ы, с которых разрешен доступ к API, например:
```
Access-Control-Allow-Origin: https://example.com:8080
```
Также можно ограничивать HTTP методы, которые могут быть использованы для доступа к API:
```
Access-Control-Allow-Methods: GET, POST, DELETE, PUT
```
И задать список заголовков, которые сервер может принимать:
```
Access-Control-Allow-Headers: Origin, Content-Type, Authorization
```
Insecure HTTP Headers (Безопасность HTTP заголовков)
----------------------------------------------------
HTTP протокол включает в себя большое число заголовков, которые можно использовать в HTTP запросах/ответах. Для того, чтобы определить наиболее важные заголовки с точки зрения обеспечения безопасности, я использовал несколько списков:
* [OWASP Secure Headers Project](https://owasp.org/www-project-secure-headers/)
* Рекомендации Express: [Production Best Practices](https://expressjs.com/en/advanced/best-practice-security.html)
Далее рассмотрим основные заголовки:
### X-Powered-By
Этот заголовок автоматически вставляется некоторыми серверами, что дает понять злоумышленнику, с каким сервером он имеет дело, например:
```
X-Powered-By: Express
```
Отсутствие этого заголовка, конечно, никого не остановит, но сразу давать такую подсказку не стоит. Поэтому передачу этого заголовка надо запретить.
### HTTP Strict Transport Security (HSTS)
Strict-Transport-Security заголовок запрещает браузеру обращаться к ресурсам по HTTP протоколу, только HTTPS:
```
Strict-Transport-Security: max-age=31536000
```
max-age=31536000 — это год в секундах. Рекомендуется выcтавлять этот заголовок, т.к. он предотвратит атаки, связанные с принуждением браузера перейти на HTTP протокол и начать передавать информацию (например cookies) в открытом виде, которую может перехватить злоумышленник. Запрос к серверу по HTTP и атака возможна только при первом обращении к серверу, при последующих браузер запомнит настройку Strict-Transport-Security и будет обращаться только по HTTPS.
### X-Frame-Options (защита от Clickjacking)
Позволяет защититься от атаки Clickjacking. Так называется технология, когда злоумышленник помещает кнопку или поле ввода в прозрачный фрейм и пользователь думает, что он нажимает нужную кнопку или безопасно вводит данные, а на самом деле идет перенаправление на другой ресурс, полезный атакующему, например, на сайт с навязчивой рекламой. Для защиты от Clickjacking сервер должен посылать запрет использовать страницу во фрейме вообще:
```
X-Frame-Options: deny
```
или разрешить использование только в нашем домене:
```
X-Frame-Options: sameorigin
```
А лучше для предотвращения атаки Clickjacking использовать более современный механизм и установить правильную политику безопасности **Content-Security-Policy**
### Content-Security-Policy
Позволяет защититься от атаки Cross-site scripting и других кросс-сайтовых инъекций, в том числе Clickjacking. Требует вдумчивого конфигурирования, т.к. параметров много. Но надо хотя бы поставить дефолтную политику, что предотвратит возможность атаки Cross-site Scripting:
```
Content-Security-Policy: default-src 'self'
```
Подробно значения заголовка Content-Security-Policy разбираются, например, [по ссылке](https://content-security-policy.com/).
### X-Content-Type-Options
Установка данного заголовка запрещает браузеру самому интерпретировать тип присланных файлов и принуждает использовать только тот, что был прислан в заголовке Content-Type. Без этого возможна ситуация, когда, например, посылается безобидный на вид txt файл, внутри которого вредоносный скрипт и браузер его выполняет как скрипт, а не как текстовой файл. Поэтому устанавливаем:
```
X-Content-Type-Options: nosniff
```
### Cache-Control
Cache-Control позволяет управлять кешом на стороне клиента, рекомендуется запретить кеширование, чтобы в кеше случайно не оставались приватные данные:
```
Cache-Control: no-store
```
Заключение
----------
В статье мы рассмотрели угрозы, которые подстерегают API при его эксплуатации и способы борьбы с ними. В заключении приведу несколько общих выводов:
* Нужно держать круговую оборону и защищаться со всех сторон. Как ни банально звучит, но безопасность системы определяется самым слабым звеном. И если мы забыли защитить даже незначительную часть, последствия могут быть весьма печальными.
* Разработчик API должен не только уметь программировать, но и разбираться в безопасности систем и приложений. Или в команде должен быть сотрудник, отвечающий за безопасность.
* Нужно следить за актуальным положением дел с безопасностью, т.к. даже относительно свежая информация может быстро устареть, и система окажется неработоспособной или беззащитной перед атаками.
Ссылки на использованные списки:
--------------------------------
* [API Security Top 10](https://owasp.org/www-project-api-security)
* [Top 25 Most Dangerous Software Errors](https://cwe.mitre.org/top25/archive/2019/2019_cwe_top25.html)
* [Рекомендации RedHat: API security](https://www.redhat.com/en/topics/security/api-security)
* [Рекомендации Express: Production Best Practices](https://expressjs.com/en/advanced/best-practice-security.html)
* [Рекомендации Node.js: Security Checklist](https://blog.risingstack.com/node-js-security-checklist)
***Желаю всем легкодоступных, но безопасных API! )***
**It's only the beginning!** | https://habr.com/ru/post/503284/ | null | ru | null |
# Go, практика асинхронного взаимодействия
Немножко про каналы, про выполнение в основном процессе, про то как вынести блокирующие операции в отдельную *горутину*.
* Каналы и пустое значение
* Односторонние каналы
* Выполнение в основном треде ОС
* Вынос блокирующих операций
#### Каналы и пустое значение
Каналы — это инструмент для асинхронной разработки. Но зачастую не важно что переслать по каналу — важен лишь факт пересылки. Порой встречается
> done := make(chan bool)
>
> /// [...]
>
> done <- true
Размер *bool* зависит от платформы, да, обычно, это не тот случай, когда следует беспокоиться о размере. Но всё же существует способ ничего не отправлять, а если точнее — то отправлять ничего (если быть ещё точнее, то речь о пустой структуре).
> done := make(chan struct{})
>
> // [...]
>
> done <- struct{}{}
Вот собственно и всё.
#### Односторонние каналы
Есть ещё один момент, который хотелось бы явно осветить. Пример:
> func main() {
>
> done := make(chan struct{})
>
> go func() {
>
> // stuff
>
> done <- struct{}{} // перед завершением сообщаем об этом
>
> }()
>
> <- done // ожидание завершения горутины
>
> }
Всё просто — *done* в *горутине* нужен только для записи. В принципе, в *горутине* его можно и прочитать (получить значение из канала *done*). Во избежании неприятностей, если код путаный, выручают параметры. Параметры функции, что передаётся *горутине*. Теперь так
> func main() {
>
> done := make(chan struct{})
>
> go func(done chan<- struct{}) {
>
> // stuff
>
> done <- struct{}{} // перед завершением сообщаем об этом
>
> } (done)
>
> <- done // ожидание завершения горутины
>
> }
Теперь, при передаче канала так, он будет преобразован в канал только для записи. Но вот внизу, канал по прежнему останется двунаправленным. В принципе, канал можно преобразовать в односторонний и не передавая его аргументом:
> done := make(chan struct{})
>
> writingChan := (chan<- struct{})(done) // первые скобки не важны
>
> readingChan := (<-chan struct{})(done) // первые скобки обязательны
При частой необходимости, можно сделать функцию, которая будет всем этим заниматься. [Вот пример на play.golang.org](http://play.golang.org/p/8rV_VZgYBI). Всё это позволяет отловить некоторые ошибки на этапе компиляции.
#### Выполнение в основном треде ОС
Например такие библиотеки как — OpenGL, libSDL, Cocoa — используют локальные для процесса структуры данных (thread local storage). Это значит, что они должны выполняться в основном треде ОС (main OS thread), иначе — ошибка. Функция [`runtime.LockOSThread()`](http://godoc.org/runtime#LockOSThread) позволяет приморозить текущую *горутину* к текущему треду (thread) ОС. Если вызвать её при инициализации (в функции `init`), то это и будет основной тред ОС (main OS thread). При этом другие *горутины* спокойно могут выполняться в параллельных тредах ОС.
Для того, чтобы вынести вычисления в отдельный тред (в данном случае речь о горутине, не факт что она будет в отдельном треде ОС) достаточно просто пересылать функции в основной. Вот и всё.
**Простыня**На [play.golang.org](http://play.golang.org/p/D7ee5xXBC1)
> package main
>
>
>
> import (
>
> "fmt"
>
> "runtime"
>
> )
>
>
>
> func init() {
>
> runtime.LockOSThread() // примораживаем текущую горутину к текущему треду
>
> }
>
>
>
> func main() {
>
> /\*
>
> коммуникации
>
> \*/
>
> done := make(chan struct{}) // <- остановка и выход
>
> stuff := make(chan func()) // <- отправка функций в основной тред
>
>
>
> /\*
>
> создадим второй тред (в данном случае - вторую горутину, но это не важно)
>
> и начнём отправлять "работу" в первый
>
> \*/
>
> go func(done chan<- struct{}, stuff chan<- func()) { // параллельная работа
>
> stuff <- func() { // первый пошёл
>
> fmt.Println("1")
>
> }
>
> stuff <- func() { // второй пошёл
>
> fmt.Println("2")
>
> }
>
> stuff <- func() { // третий пошёл
>
> fmt.Println("3")
>
> }
>
> done <- struct{}{}
>
> }(done, stuff)
>
> Loop:
>
> for {
>
> select {
>
> case do := <-stuff: // получение "работы"
>
> do() // и выполнение
>
> case <-done:
>
> break Loop
>
> }
>
> }
>
> }
#### Вынос блокирующих операций
Куда чаще встречаются блокирующие *IO*-операции, но они побеждаются аналогично.
**Простыня**На [play.golang.org](http://play.golang.org/p/Lq51wdlus2)
> package main
>
>
>
> import "os"
>
>
>
> func main() {
>
> /\*
>
> коммуникации
>
> \*/
>
> stop := make(chan struct{}) // нужен для остановки "пишущей" горутины
>
> done := make(chan struct{}) // ожидание её завершения
>
> write := make(chan []byte) // данные для записи
>
>
>
> /\*
>
> параллельный поток для IO-операций
>
> \*/
>
> go func(write <-chan []byte, stop <-chan struct{}, done chan<- struct{}) {
>
> Loop:
>
> for {
>
> select {
>
> case msg := <-write: // получения сообщения для записи
>
> os.Stdout.Write(msg) // асинхронная запись
>
> case <-stop:
>
> break Loop
>
> }
>
> }
>
> done <- struct{}{}
>
> }(write, stop, done)
>
> write <- []byte("Hello ") // отправка сообщений
>
> write <- []byte("World!\n") // на запись
>
> stop <- struct{}{} // остановка
>
> <-done // ожидание завершения
>
> }
Если несколько *горутин* будут отправлять свои сообщения к одной «пишущей», то они всё равно будут блокироваться. В этом случае выручит канал с буфером. Учитывая, что *slice* — это референсный тип, по каналу будет пересылаться только указатель.
---
#### Референс
1. [Разъяснение LockOSThread](https://github.com/golang/go/wiki/LockOSThread) (*англ.*)
2. [Пустые структуры на blog.golang.org](https://blog.golang.org/pipelines#TOC_6.) (*англ.*)
3. [Ещё про пустые структуры](http://dave.cheney.net/2014/03/25/the-empty-struct) (*англ.*) | https://habr.com/ru/post/267785/ | null | ru | null |
# Откуда идут «функциональные» корни Python
Я никогда не полагал, что Python попадет под влияние функциональных языков, независимо от того что люди говорят или думают. Я знаком с императивными языками, такими как C и Algol68 и хотя я сделал функции объектами «первого класса», я не рассматривал Python как язык функционального программирования. Однако, было ясно, что пользователи хотят больше от списков и функций.
Операции над списками применялись к каждому элементу списка и создавали новый список. Например:
```
def square(x):
return x*x
vals = [1, 2, 3, 4]
newvals = []
for v in vals:
newvals.append(square(v))
```
На функциональных языках, таких как Lisp и Scheme, операции, такие как эта были разработаны как встроенные функции языка. Таким образом пользователи, знакомые с такими языками, реализовывали аналогичную функциональность в Python. Например:
```
def map(f, s):
result = []
for x in s:
result.append(f(x))
return result
def square(x):
return x*x
vals = [1, 2, 3, 4]
newvals = map(square,vals)
```
Тонкость вышеупомянутого кода в том, что многим людям не нравился факт, что функция применяется к элементам списка как набор отдельных функций. Языки, такие как Lisp позволили функциям определяться «налету» при маппинге. Например, в Scheme Вы можете создавать анонимные функции и выполнить маппинг в единственном выражении, используя лямбду, как ниже:
```
(map (lambda (x) (* x x)) '(1 2 3 4))
```
Хотя в Python функции были объектами «первого класса», у него не было никакого подобного механизма для того, чтобы создавать анонимные функции.
В конце 1993, пользователи метались вокруг различных идей, чтобы создать анонимные функции. Например, Марк Луц написал код функции, которая создает функции, используя exec:
```
def genfunc(args, expr):
exec('def f(' + args + '): return ' + expr)
return eval('f')
# Sample usage
vals = [1, 2, 3, 4]
newvals = map(genfunc('x', 'x*x'), vals)
```
Тим Петерс написал решениерешения, которое упростило синтаксис, разрешая пользователям следующее:
```
vals = [1, 2, 3, 4]
newvals = map(func('x: x*x'), vals)
```
Стало ясно, что действительно появилось необходимость в такой функциональности. Одновременно, это казалось заманчиво — определить анонимные функции как строки кода, которые программист должен вручную обработать через exec. Таким образом, в январе 1994, map(), filter(), и reduce() функции были добавлены к стандартной библиотеке. Кроме того, был представлен оператор лямбды для того, чтобы создавать анонимные функции (как выражения) в более прямом синтаксисе. Например:
```
vals = [1, 2, 3, 4]
newvals = map(lambda x:x*x, vals)
```
Эти дополнения были существенными на ранней стадии разработки. К сожалению, я не помню автора, и логи SVN не записали его. Если это Ваша заслуга, оставьте комментарий!
Мне никогда не нравилось использовать терминологию «лямбды», но из-за отсутствия лучшей и очевидной альтернативы, она была принята в Python. В конце концов это был выбор теперь анонимного автора, и в то время большие изменения требовали намного меньшего количества обсуждений чем в настоящее время.
Лямбда была предназначена действительно только, чтобы быть синтаксическим сахаром для определения анонимных функций. Однако, у такого выбора терминологии было много непреднамеренных последствий. Например, пользователи, знакомые с функциональными языками, ожидали, что семантика лямбды будет соответствовать онной из других языков. В результате они нашли, что реализации Python очень недоставало расширенного функционала. Например, проблема с лямбдой состоит в том, что предоставленное выражение не могло обратиться к переменным в окружающем контексте. Например, если бы у Вас этот код, map() прервется, потому что функция лямбды работала бы с неопределенной ссылкой на переменную 'a'.
```
def spam(s):
a = 4
r = map(lambda x: a*x, s)
```
Существовали обходные решения этой проблемы, но они заключались в использовании «аргументов по умолчанию» и передачу скрытых параметров в лямбда-выражение. Например:
```
def spam(s):
a = 4
r = map(lambda x, a=a: a*x, s)
```
«Корректное» решение этой проблемы для внутренних функций было в том, чтобы неявно перенести ссылки на все локальные переменные в контекст функции. Данный подход известен как «замыкание» и является важным аспектом функциональных языков. Однако, эта возможность не была представлена в Python до выпуска версии 2.2.
Любопытно, что map, filter, и reduce функции, которые первоначально смотивировали введение лямбды, и других функциональных возможностей были в большой степени заменены на “list comprehensions” и генераторы. Фактически, функция reduce была удалена из списка встроенных функций в Python 3.0.
Даже при том, что я не задумывал Python как функциональный язык, введение замыканий было полезно в разработке многих других возможностей языка. Например, определенные аспекты классов нового стиля, декораторов, и других современных возможностей используют замыкания.
Наконец, даже при том, что много возможностей функционального программирования были введены за эти годы, Python все еще испытывает недостаток в определенном функционале из «настоящих» функциональных языков. Например, Python не выполняет определенные виды оптимизации (например, хвостовая рекурсия). Динамический характер Python сделал невозможным ввести оптимизации времени компиляции, известные в функциональных языкых как Haskell или ML. | https://habr.com/ru/post/111756/ | null | ru | null |
# Обработка изображений ReactJS — NodeJS
Доброго времени суток.
Разбор полетов провожу на **Reactjs** (сторона клиента) и **Nodejs** (сторона сервера).
Недавно в моем маленьком проекте встал вопрос, как легко и просто можно обмениваться изображениями по типу клиент — сервер.
Сегодня мы научимся отправлять бинарные данные (конкретно изображения ) со стороны клиента и обрабатывать их на сервере. Добро пожаловать в под кат.
Если ваше web-приложение — это соц.сеть или мессенджер или что-то подобное, то вам непременно придется работать с бинарными данными, в большинстве случаев — это обработка изображений. Об этом и пойдет речь.
Чтобы иметь общее представление, я буду толковать последовательно.
#### Ознакомимся со следующим
1. [Двоичная система счисления](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%81%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F) и десятичная система счисления
2. [Кодовая страница](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B4%D0%BE%D0%B2%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0): [ASCII](https://ru.wikipedia.org/wiki/ASCII), [Unicode](https://ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4)
3. [Бит](https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%82) и [байт](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B9%D1%82)
4. [Формат hex](https://ru.wikipedia.org/wiki/%D0%A8%D0%B5%D1%81%D1%82%D0%BD%D0%B0%D0%B4%D1%86%D0%B0%D1%82%D0%B5%D1%80%D0%B8%D1%87%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%81%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F)
5. [Двоичный файл](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D1%8B%D0%B9_%D1%84%D0%B0%D0%B9%D0%BB)
6. [Буффер и потоки nodejs](https://habr.com/ru/company/ruvds/blog/348970/)
7. [ArrayBuffer и Uint8Array](https://learn.javascript.ru/arraybuffer-binary-arrays)
8. [FileReader](https://developer.mozilla.org/en-US/docs/Web/API/FileReader/FileReader)
### Двоичная система счисления и десятичная система счисления.
Это число, которое записывается с помощью двух символов: единиц и нулей.
Простым языком — это 2 (основание) в степени n (количество разрядов), например число 10001 имеет 5 разрядов:
4 разряд = 1; 2^4 = 16;
3 разряд = 0;
2 разряд = 0;
1 разряд = 0;
0 разряд = 1; 2^0 = 1;
1-true — производим расчет;
0-false — не производим расчет;
В итоге получаем 16 + 1 = 17;
Обратной операцией компьютер представляет данные в двоичном виде.
```
const num = 17; // десятичное число
const binNum = num.toString(2); // преобразование в двоичный вид
const initNum = parseInt(binNum, 2); // обратная операция
```
Десятичная система счисления — это число, которое записывается с помощью 10 символов, от 0 — 9. Мы используем их повседневно.
Дело в том, что компьютер живет своим представлением информации. Если мы пишем на родном языке или считаем в десятичной системе счисления, то для компьютера все это двоичное представление. Вы спросите: “Что значит двоичное представление?”. Как говорила моя учительница английского, “как слышится, так и пишется”. Компьютер представляет файлы, содержащие текст или иное, или какие-либо вычисления в двоичную систему счисления — это и есть двоичное представление. Языком машины число «17» является — 10001.
### Кодовая страница: ASCII, Unicode
Возникает вопрос. Понятно с числами, но как же текст? Как машина будет преобразовывать текст в двоичный вид? Все просто. Для этого существуют кодировки типа ASCII или Unicode. Это простая таблица ( [кодовая страница](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B4%D0%BE%D0%B2%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0) ), где имеется сопоставление нашему символу число, например символ “S” — это число 53 по таблице ASCII, далее компьютер представит число 53 в двоичном виде — 110101.
Что касаемо Unicode — это мощный стандарт, включающий в себя кодировку UTF-8, которая имеет большой спрос в web-пространстве и unix подобных системах. Принцип работы общий.
### Бит и байт
Бит — это единица измерения информации компьютером. А мы уже знаем как компьютер представляет информацию. Да! Вы правы. Один бит равен 1 или 0. Для компьютера 1 или 0 — это что-то вроде транзистора, true или false. Теперь понять что такое байт совсем не трудно — это 8 битов, его еще называют октет ( типа состоит из 8 ).
### Формат hex
Переходим к “hex” формату. Мы говорили о двоичной системе счисления, десятичной системе, помимо прочего существует и шестнадцатиричная система счисления, верстальщики поймут о чем я. Это число, которое записывается с помощью 16 символов, от 0 — 9 и от a-f. Навивается вопрос: “Зачем так все усложнять?”. Так как единицей памяти является 8-битный байт, все же значение его удобнее записывать двумя шестнадцатиричными цифрами. Также в стандарте Юникода номер символа принято записывать в шестнадцатиричном виде, используя не менее 4 цифр.
Данный формат работает следующим образом: в случае с 8 битным байтом, он делит 8 битов по полам, то есть 10101011 — 1010 | 1011, после преобразует каждую часть соответственно. 1010 — a, 1011 — b;
```
const num = 196; // десятичное число
const hexNum = num.toString(16); // преобразование в hex вид
const initNum = parseInt(hexNum, 16); // преобразование в десятичный вид - обратная операция
```
### Двоичный файл
Переходим к следующему пункту, его еще называют бинарным файлом — это массив байтов. Почему двоичный? Байты состоят из битов, то есть символов двоичной системы счисления, отсюда и название двоичный. Под категорию двоичный файл подходят абсолютно все файлы, то есть файлы содержащие текст, изображения — все это двоичные файлы, отсюда двоичные данные, отсюда бинарные данные.
Нередко бинарные данные выводятся символами кодовой страницы ASCII, а также в формате hex, в частности изображения. Приведу пример. У нас есть следующее изображение:
**Смотреть вложение**
Его частичная визуализация представляется в виде [hex-agent-smith](https://hexed.it#base64:agent_smith_matrix_revolution.jpg;/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAIBAQEBAQIBAQECAgICAgQDAgICAgUEBAMEBgUGBgYFBgYGBwkIBgcJBwYGCAsICQoKCgoKBggLDAsKDAkKCgr/2wBDAQICAgICAgUDAwUKBwYHCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgr/wgARCAHgAoADASIAAhEBAxEB/8QAHQAAAgMBAQEBAQAAAAAAAAAABQYDBAcIAgEACf/EABoBAAIDAQEAAAAAAAAAAAAAAAECAAMEBQb/2gAMAwEAAhADEAAAAeYjJ0hh5vkW7DXVVX9DGyLMDjESPJTFCiR6OVCQMxCJ2oj74liel9+otUp8vhVYqGNo9ehaFGWfQ/zGbPNSGKX804ICLrnWkoIUt1ysBuOJjMZ+9TiYCYK+IJY4IxcBbwPpyfU30CfXNMtGKtDUSWWioSkAbDVCem5/onLK+odRerE5EtbNlvZxrVK3SuT8QpXyScEvhV+FBhYIOv2KUIFvSXwRcIh2cgeSjmrKe0Kp+wy3BxRAsTxXrCKuQT5GPDCFISCjfpE+69muxuWqhsIveJ/UIuner2WLda5S0k9dHkDVcvD5kWjcq3KbIactQn5PDcBuwevjLaqlxYn5rWTMBRBeUmsEzQZgeGVFnXVWEcaisPqsTqiA8mKrj7fPmSWX0iw6VWvtCiz1j0aCNdY0LYs26v4k9FBpKvRFifR8FlXCOfdP5J0c+QlzwTqYpvHusykK/wC8RWkJdrpFp2RW4gS4KTlJPTuw0FAOhDWg/iYMmIHI0Z4atiCbFCkX2ix+V7NEi7WljJlNr5gCjUnrFoIpInYBPWH6yXLCC8Sf5UtBfF+mWqcFWvUAfZwWUEj8+oWU8Js1FX2ZCXY5NSaFVQRZF1hIqQe/wX3NStk2s0J4udH2xYb22jjLDcpZFKEyyGuNZfVQEFyGt4tRvSkZrwx4JKpoG4dV78QzxX3Gp2U8OquiHOjixKvZrdjJerR/QCc/qERdck52KgmVUYhCUcVysIpENfue3JFfQBCQRpMDT/PeBrVMjVaV6F+kZajl8mRFRtxhDRtppdjhzq1bazDvlV0=)
**Смотреть вложение**
Правая часть символов является символами таблицы ASCII, левая же часть как раз и есть hex формат, преобразованный от двоичного кода.
### ArrayBuffer и Uint8Array
**ArrayBuffer** — объект для работы с бинарными данными на javascript. Фиксирует длину памяти для работы с бинарником. Например: **new ArrayBuffer(256)** — создаст массивоподобный объект размером в 256 байт, не больше — не меньше. На каждый байт приходится конкретная информация. **ArrayBuffer** не является массивом и методы массива к нему не применимы. Вы зададите вопрос, как же его использовать? Объект **Uint8Array** дает представление **ArrayBuffer** в беззнаковое 8-битное число, то есть от 0 — 255.
### FileReader
**FileReader**? Это конструктор по созданию следующего:
#### Что дальше?
Теперь рассмотрим [прекрасный пример](https://gitlab.com/ImaGadzhiev/filereader.git), демонстрирующий обработку изображения:
1. Модуль ReactJS
```
import React, {useState, useRef, useCallback} from 'react';
import axios from 'axios';
export const UPLOAD_AVATAR = 'http://localhost:8080/api/upload_avatar';
function App() {
// определим изменяемый ref для объекта FileReader
const fileRef = useRef(null);
const [ loading, setLoading ] = useState(false);
const handleSubmit = useCallback( event => {
event.preventDefault();
const fetchData = async (uint8Array) => {
try {
const response = await axios({
method: 'post',
url: UPLOAD_AVATAR,
data: [...uint8Array] // не отправляем в JSON, размер изображения увеличится
});
setLoading(false);
console.log(response);
} catch (e) {
console.error(e.message, 'function handleSubmit')
}
};
if(!fileRef.current) return void null;
const reader = new FileReader();
reader.onloadend = () => {
const uint8Array = new Uint8Array(reader.result);
setLoading(true);
fetchData(uint8Array);
};
// рекомендованный метод
reader.readAsArrayBuffer(fileRef.current[0]);
// метод reader.readAsBinaryString(fileRef.current[0])
// согласно MDN,
// уже был однажды удален из File API specification,
// но после его вернули
// в использование, но все же рекомендуют
// использовать readAsArrayBuffer
// https://developer.mozilla.org/en-US/docs/Web/API/FileReader/readAsBinaryString
}, []);
const nodeDom = (
fileRef.current = e.target.files}
accept="image/\*"
type="file"
id="button-file"
/>
{loading ? 'Сохраняю...' : 'Сохранить'}
);
return nodeDom
}
export default App;
```
2. Модуль ExpressJS
```
const express = require("express");
const cors = require("cors");
const crypto = require('crypto');
const fs = require('fs');
const PORT = 8080;
const app = express();
app.use(express.static("public"));
app.use(express.json({ limit: "50mb" }));
app.use(cors());
app.post("/api/upload_avatar", (req, res) => {
console.log(req.body);
const randomString = crypto.randomBytes(5).toString('hex');
const stream = fs.createWriteStream(`./public/images/${randomString}.png`);
stream.on('finish', function () {
console.log('file has been written');
res.end('file has been written');
});
stream.write(Buffer.from(req.body), 'utf-8');
stream.end();
});
app.listen(PORT, () => console.log(`Server running at ${PORT}`));
```
#### Итог:
* Для чего нужны кодировки
* Общее представление бинарных данных
* Рекомендуемый способ отправки байтов
* Объект буфера
* Объект FileReader
* Простая реализация на хуках | https://habr.com/ru/post/491548/ | null | ru | null |
# Pilot: многофункциональный JavaScript роутер
С каждым днем сайты становятся все сложнее и динамичнее. Уже недостаточно просто «оживить» интерфейс — все чаще требуется создать полноценное одностраничное приложение. Ярким примером такого приложения является любая web-почта (например, [Mail.Ru](https://e.mail.ru/)), где переходы по ссылкам приводят не к перезагрузке страницы, а только к смене представления. А это значит, что задача получения данных и их отображения в зависимости от маршрута, которая всегда была прерогативой сервера, ложится на клиент. Обычно эту проблему решают с помощью простенького роутера, на основе регулярных выражений, и дальше не развивают, в то время как на back-end этой теме уделяют гораздо больше внимания. В этой статье я постараюсь восполнить этот пробел.
Что такое роутинг?
------------------
Это, наверное, самая недооцененная часть JavaScript-приложения :]
На сервере роутинг — это процесс определения маршрута внутри приложения в зависимости от запроса. Проще говоря, это поиск контроллера по запрошенному URL и выполнение соответствующих действий.
Рассмотрим следующую задачу: нужно создать одностраничное приложение «Галерея», которое будет состоять из трех экранов:
* Главная — выбор направления в живописи
* Просмотр галереи — вывод картин с постраничной навигацией и возможностью изменять количество элементов на странице
* Детальный просмотр выбранного произведения
Схематично приложение будет выглядеть следующим образом:
```
...
...
...
```
Каждому экрану будет соответствовать свой URL, и роутер, их описывающий, может выглядеть, например, так:
```
var Router = {
routes: {
"/": "indexPage",
"/gallery/:tag/": "galleryPage",
"/gallery/:tag/:perPage/": "galleryPage",
"/gallery/:tag/:perPage/page/:page/": "galleryPage",
"/artwork/:id/": "artworkPage",
}
};
```
В объекте `routes` непосредственно задаются маршруты: ключ — шаблон пути, а значение — название функции-контроллера.
Далее нужно преобразовать ключи объекта `Router.routes` в регулярные выражения. Для этого определим метод `Router.init`:
```
var Router = {
routes: { /* ... */ },
init: function (){
this._routes = [];
for( var route in this.routes ){
var methodName = this.routes[route];
this._routes.push({
pattern: new RegExp('^'+route.replace(/:\w+/, '(\\w+)')+'$'),
callback: this[methodName]
});
}
}
};
```
Осталось описать метод навигации, который будет осуществлять поиск маршрута и вызов контроллера:
```
var Router = {
routes: { /* … */ },
init: function (){ /* … */ },
nav: function (path){
var i = this._routes.length;
while( i-- ){
var args = path.match(this._routes[i].pattern);
if( args ){
this._routes[i].callback.apply(this, args.slice(1));
}
}
}
};
```
Когда всё готово, инициализируем роутер и выставляем начальную точку навигации. Важно не забыть перехватить событие `click` со всех ссылок и перенаправить на маршрутизатор.
```
Router.init();
Router.nav("/");
// Перехватывает клики
$("body").on("click", "a", function (evt){
Router.nav(evt.currentTarget.href);
evt.preventDefault();
});
```
Как видите, ничего сложного; думаю, многим знаком подобный подход. Обычно все отличия в реализациях сводятся к формату записи маршрута и его трансформации в регулярное выражение.
Вернемся к нашему примеру. Единственное, что в нем отсутствует — это реализация функций, отвечающих за обработку маршрута. Обычно в них идет сбор данных и отрисовка, например, так:
```
var Router = {
routes: { /*...*/ },
init: function (){ /*...*/ },
nav: function (url){ /*...*/ },
indexPage: function (){
ManagerView.set("index");
},
galleryPage: function (tag, perPage, page){
var query = {
tag: tag,
page: page,
perPage: perPage
};
api.find(query, function (items){
ManagerView.set("gallery", items);
});
},
artworkPage: function (id){
api.findById(id, function (item){
ManagerView.set("artwork", item);
});
}
};
```
На первый взгляд, выглядит неплохо, но есть и подводные камни. Получение данных происходит асинхронно, и при быстром перемещении между маршрутами можно получить совсем не то, что ожидалось. Например, рассмотрим такую ситуацию: пользователь кликнул на ссылку второй страницы галереи, но в процессе загрузки заинтересовался произведением с первой страницы и решил посмотреть его подробно. В итоге ушло два запроса. Отработать они могут в произвольном порядке, и пользователь вместо картины получит вторую страницу галереи.
Эту проблему можно решить разными способами; каждый выбирает свой путь. Например, можно вызвать `abort` для предыдущего запроса, или перенести логику в `ManagerView.set`.
Что же делает `ManagerView`? Метод `set(name, data)` принимает два параметра: название «экрана» и «данные» для его построения. В нашем случае задача сильно упрощена, и метод `set` отображает нужный элемент по id. Он использует название вида как постфикс `«app-»+name`, а данные — для построения html. Также `ManagerView` должен запоминать название предыдущего экрана и определять, когда начался/изменился/закончился маршрут, чтобы корректно манипулировать внешним видом.
Вот мы и создали одностраничное приложение, со своим `Router` и `ManagerView`, но пройдет время, и нужно будет добавить новый функционал. Например, раздел «Статьи», где будут описания «работ» и ссылки на них. При переходе на просмотр «работы» нужно построить ссылку «Назад к статье» или «Назад в галерею», в зависимости от того, откуда пришел пользователь. Но как это сделать? Ни `ManagerView`, ни `Router` не обладают подобными данными.
Также остался ещё один важный момент — это ссылки. Постраничная навигация, ссылки на разделы и т.п., как их «строить»? «Зашить» прямо в код? Создать функцию, которая будет возвращать URL по мнемонике и параметрам? Первый вариант совсем плохой, второй лучше, но не идеален. С моей точки зрения, наилучший вариант — это возможность задать `id` маршрута и метод, который позволяет получать URL по ID и параметрам. Это хорошо тем, что маршрут и правило для формирования URL есть одно и то же, к тому же этот вариант не приводит к дублированию логики получения URL.
Как видите, такой роутер не решает поставленных задач, поэтому, чтобы не выдумывать велосипед, я отправился в поисковик, сформировав список требований к идеальному (в моём понимании) маршрутизатору:
* максимально гибкий синтаксис описания маршрута (например, как у Express)
* работа именно с запросом, а не только отдельными параметрами (как в примере)
* события «начала», «изменения»и «конца» маршрута (/gallery/cubism/ -> /gallery/cubism/12/page/2 -> /artwork/123/)
* возможность назначения нескольких обработчиков на один маршрут
* возможность назначения ID маршрутам и осуществления навигации по ним
* иной способ взаимодействия `data ←→ view` (по возможности)
Как вы уже догадались, я не нашел то, чего хотел, хотя попадались очень достойные решения, такие как:
* [Crossroads.js](http://millermedeiros.github.com/crossroads.js/) — очень мощная работа с маршрутами
* [Path.js](https://github.com/mtrpcic/pathjs) — есть реализация событий «начала» и «конца» маршрута, 1KB (Closure compiler + gzipped)
* [Router.js](http://haithembelhaj.github.com/RouterJs/) — простой и функциональный, всего 443 байта (Closure compiler + gzipped)
Pilot
-----
А теперь пришло время сделать всё то же самое, но используя Pilot. Он состоит из трех частей:
1. **Pilot** — сам маршрутизатор
2. **Pilot.Route** — контроллер маршрута
3. **Pilot.View** — расширенный контроллер маршрута, наследует Pilot.Route
Определим контроллеры, отвечающие за маршруты. HTML-структура приложения остается той же, что и в примере в первой части статьи.
```
// Объект, где будут храниться контроллеры
var pages = {};
// Контроллер для главной страницы
pages.index = Pilot.View.extend({
el: "#app-index"
});
// Просмотр галереи
pages.gallery = Pilot.View.extend({
el: "#app-gallery",
template: function (data/**Object*/){
/* шаблонизация на основе this.getData() */
return html;
},
loadData: function (req/**Object*/){
// app.find — возвращает $.Deferred();
return app.find(req.params, this.bound(function (items){
this.setData(items);
}));
},
onRoute: function (evt/**$.Event*/, req/**Object*/){
// Метод вызывается при routerstart и routeend
this.render();
}
});
// Просмотр произведения
pages.artwork = Pilot.View.extend({
el: "#app-artwork",
template: function (data/**Object*/){
/* шаблонизация на основе this.getData() */
return html;
},
loadData: function (req/**Object*/){
return api.findById(req.params.id, this.bound(function (data){
this.setData(data);
}));
},
onRoute: function (evt/**$.Event*/, req/**Object*/){
this.render();
}
});
```
Переключение между маршрутами влечет за собой смену экранов, поэтому в примере я использую Pilot.View. Помимо работы с DOM-элементами, экземпляр его класса изначально подписан на события routestart и routeend. При помощи этих событий Pilot.View контролирует отображение связанного с ним DOM-элемента, выставляя ему `display: none` или убирая его. Сам узел назначается через свойство `el`.
Существует три типа событий: routestart, routechange и routeend. Их вызывает роутер на котроллер(ы). Схематично это выглядит так:
Есть три маршрута и их контроллеры:
```
"/" -- pages.index
"/gallery/:page?" -- pages.gallery
"/artwork/:id/" -- pages.artwork
```
Каждому маршруту может соответствовать несколько URL. Если новый URL соответствует текущему маршруту, то роутер генерит событие routechage. Если маршрут изменился, то его контроллер получает событие routeend, а контроллер нового — событие routestart.
```
"/" -- pages.index.routestart
"/gallery/" -- pages.index.routeend, pages.gallery.routestart
"/gallery/2/" -- pages.gallery.routechange
"/gallery/3/" -- pages.gallery.routechange
"/artwork/123/" -- pages.artwork.routestart, pages.gallery.routeend
```
Помимо изменения видимости контейнера (`this.el`), как правило, нужно обновлять его содержимое. Для этого у Pilot.View есть следующие методы, которые нужно переопределить в зависимости от задачи:
**template(data)** — метод шаблонизации, внутри которого формируется HTML. В примере используются данные, полученные в loadData.
**loadData(req)** — пожалуй, самый важный метод контроллера. Вызывается каждый раз, когда изменяется URL, в качестве параметра получает объект запроса. У него есть особенность: если вернуть $.Deferred, роутер не перейдет на этот URL, пока данные не будут собраны.
**req — запрос**
```
{
url: "http://domain.ru/gallery/cubism/20/page/3",
path: "/gallery/cubism/20/page/123",
search: "",
query: {},
params: { tag: "cubism", perPage: 20, page: 123 },
referrer: "http://domain.ru/gallery/cubism/20/page/2"
}
```
**onRoute(evt, req)** — вспомогательное событие. Вызывается после routestart или routechange. В примере используется для обновления содержимого контейнера с помощью вызова метода render.
**render()** — метод для обновления HTML контейнера (`this.el`). Вызывает this.template(this.getData()).
Теперь осталось собрать приложение. Для этого нам понадобится роутер:
```
var GuideRouter = Pilot.extend({
init: function (){
// Задаем маршруты и их контроллеры:
this
.route("index", "/", pages.index)
.route("gallery", "/gallery/:tag/:prePage?(/page/:page/)?", pages.gallery)
.route("artwork", "/artwork/:id/", pages.artwork)
;
}
});
var Guide = new GuideRouter({
// Указываем элемент, внутри которого перехватываем клики на ссылках
el: "#app",
// Используем HistoryAPI
useHistory: true
});
// Запускаем роутер
Guide.start();
```
Первым делом мы создаем роутер и в методе `init` определяем маршруты. Маршрут задается методом `route`. Он принимает три аргумента: id маршрута, паттерн и контролер.
Синтаксис маршрута, лукавить не буду, позаимствован у Express. Он подошел по всем пунктам, и тем, кто уже работал с [Express](http://expressjs.com), будет проще. Единственное — добавил группы; они позволяют гибче настраивать паттерн маршрута и помогают при навигации по id.
Рассмотрим маршрут, отвечающий за галерею:
```
// Выражение в скобках и есть группа
this.route("gallery", "/gallery/:tag/:prePage?(/page/:page/)?", …)
// Скобки позволяют выделить часть паттерна, связанного с переменной `page`.
// Если она не задана, то весь блок не учитывается.
Guide.getUrl("gallery", { tag: "cubism" }); // "/gallery/cubism/";
Guide.getUrl("gallery", { tag: "cubism", page: 2 }); // "/gallery/cubism/page/2/";
Guide.getUrl("gallery", { tag: "cubism", page: 2, perPage: 20 }); // "/gallery/cubism/20/page/2/";
```
Получилось очень удобно: маршрут и URL есть одно и то же. Это позволяет избежать явных URL в коде и необходимости создавать дополнительные методы для формировал URL. Для навигации на нужный маршрут, используется Guide.go(id, params).
Последним действием создается инстанс GuideRouter с опциями перехвата ссылок и использования History API. По умолчанию Pilot работает с location.hash, но есть возможность использовать history.pushState. Для этого нужно установить Pilot.pushState = true. Но, если браузер не поддерживает location.hash или history.pushState, то для полноценной поддержки History API нужно использовать полифил, либо любую другую подходящую библиотеку. При реализации придется переопределить два метода — Pilot.getLocation() и Pilot.setLocation(req).
Вот в целом и всё. Остальные возможности можно узнать из документации.
Жду ваших вопросов, issue и любой другой отдачи :]
###### Полезные ссылки
— [Пример](http://rubaxa.github.com/Pilot/#app) ([app.js](http://rubaxa.github.com/Pilot/example/app.js))
— [Документация](http://rubaxa.github.com/Pilot/)
— [Исходники](https://github.com/RubaXa/Pilot)
— [jquery.leaks.js](https://gist.github.com/RubaXa/5057568) (утилита для мониторинга [jQuery.cache](http://ibnrubaxa.blogspot.ru/2013/03/jquery-memory-leaks.html)) | https://habr.com/ru/post/172333/ | null | ru | null |
# Еще один загрузчик скриптов для JavaScript
При разработке одного сайта мне понадобился загрузчик скриптов, так как хотелось что бы загрузка вызывалась из js кода. Из готовых решений нашел [requirejs](http://requirejs.org) и [yepnope](http://yepnopejs.com). Requirejs — модульный, что к моим требованиям не подходило. Yepnope — асинхронный, это означает, что код в каждом файле мне пришлось бы обертывать в callback функции. Ничего не оставалось, кроме как написать что-нибудь самому. И вот что у меня получилось: wakeloader — безмодульный синхронный загрузчик скриптов для JavaScript. В этой статье я расскажу про него.
Инициализация
-------------
В html код нужно добавить следующее:
```
```
Параметры
---------
В wakeloader несколько параметров загрузки, вот их перечень:
```
string main-file путь к файлу с главным кодом (main.js)
string main имя функции, вызываемой после загрузки страницы
string update при изменении, кеш очереди скриптов будет обновлен
bool quick если true, то функция main будет вызвана по событию DOMContentLoaded, false - onload
bool cached кешировать ли очередь скриптов
object alias алиасы путей
array queue очередь скриптов для загрузки
```
Параметры можно задавать двумя способами:
### 1. С помощью создания объекта с параметрами
```
wakeloader = {
mainFile : "/app/main",
main : "main",
update : "04.04.2013",
quick : true,
cached : true,
alias : { "http://code.jquery.com/" : "jquery/" },
queue : ["/app/widget","jquery/jquery-2.0.2.min",{ "http://some.serv.er/lib/" : ["sugar","backbone"] }]
};
```
### 2. Через атрибуты тега script
```
["/app/widget","jquery/jquery-2.0.2.min",{ "http://some.serv.er/lib/" : ["sugar","backbone"] }]
```
Очередь можно задать и через атрибут `data-queue`.
Функции
-------
Wakeloader имеет всего две функции: это `require` и `updateQueue`.
`require` загружает указанные вами скрипты, доступна в глобальном пространстве имен.
```
require('jquery/jquery-1.10.1.min','/app/lastfm-api');
```
После вызова функции `updateQueue`, при первом обновлении страницы, кеш очереди будет обновлен. Функция доступна только из объекта `wakeloader`.
Как это работает
----------------
Работает это все достаточно просто: достигнуть синхронность функции `require` можно было только одним способом — загрузка скриптов через XMLHttpRequest и помещение кода внутрь тегов ```. Если скрипт лежит на другом сервере, то указывайте его в очереди тега загрузчика.
Не спешите писать гневные комментарии: да, так будет неудобно инспектировать код в браузере, и по скорости это будет работать медленно.

Что бы не было таких проблем, необходимо параметру cached` задать значение `true`, и тогда при обновлении страницы все скрипты будут загружены уже браузером.
[](https://habrastorage.org/getpro/habr/post_images/b2b/5cc/6d8/b2b5cc6d8932bd28b17270db30a178c5.png)
Дело в том что при включенном кешировании функция `require` еще и записывает очередь скриптов в `localStorage`, благодаря этому все последующие загрузки будут проходить очень быстро.

Мне было интересно сравнить мой загрузчик с requirejs, для этого я обернул код скриптов в модули.
[](https://habrastorage.org/getpro/habr/post_images/1ef/af5/8ef/1efaf58ef77bf7cfaaea17834e2c5f38.png)
На всех скриншотах видно колличтесво файлов и их размеры(они не минимизированы). В среднем получилось, что при данном наборе файлов скорость загрузки wakeloader c включенным кешированием - 700ms, скорость requirejs - 800ms.
**UPD:** так же проверил на скорость requirejs, когда все скрипты прописаны в shim:
[](https://habrastorage.org/getpro/habr/post_images/1e5/a7e/42e/1e5a7e42ef64c51733472ccb027f7b02.png)
Еще медленней чем модульная загрузка.
[Исходники на GitHub.](https://github.com/TrigenSoftware/wakeloader) [Демо.](http://wakeloader.trigen.pro/)
P.S.: Скоро напишу php-cli скрипт для склеивания файлов, ссылка на него будет в описании wakeloader'a на github'e.`` | https://habr.com/ru/post/182292/ | null | ru | null |
# А на прошлом месте работы было по-другому
Все мы проходили (или пройдем) этап, когда все-таки серьезно решили устроиться в IT, готовились какое-то время, читали информацию, мечтали об успехе, и вот наконец устроились в первую компанию. Маловероятно, что получится испытать те же эмоции еще раз, ведь это момент, когда ты получаешь свои первые деньги за то, что прошлые условные полгода делал бесплатно. В этот самый момент кто-то может предпочесть стабильность, и останется в этой компании на достаточно длительное время.
Это третья статья из цикла возможных ошибок, которые могут допустить разработчики в начале своей карьеры. Из этого следует, что сейчас я буду рассуждать о том, почему такое решение может обернуться проблемой в будущем.
Прошлые статьи* [Ожидание / реальность работы разработчика](https://habr.com/ru/sandbox/153134/)
* [Почему ты не учишь английский язык](https://habr.com/ru/post/552276/)
Примерный план будущих статей:
* О выгорании на ранних этапах
* О важности изучения языка, но не фреймворка
* Когда ты перестаешь быть *junior* разработчиком
Если вам интересна какая-то из этих будущих тем больше, чем остальные, пишите в комментариях, постараюсь выпустить как можно раньше.
---
> **Disclaimer**: эта статья не является абсолютным правилом, и ваш опыт может отличаться.
>
>
Давайте для начала определим исходные условия для появления проблемы, которую я опишу чуть ниже.
1. Это ваше **первое** местое работы
2. Вы работаете там достаточно продолжительное время (1 - 1,5 года +)
3. Вы работаете с одним и тем же лидом/ментором
4. Вы работаете на одном и том же проекте с одинаковым стеком
Если говорить грубо, вы устроились на работу, и у вас в целом особо ничего не поменялось за то время, пока вы тут работаете. Проблема возникает в тот момент, когда вы решите сменить место работы.
В чем же суть проблемы, спросите вы? Первая работа и опытный ментор имеют крайне сильное влияние на человека. У вас нет времени оценивать каждое требование, нет каких-либо особых предпочтений, вы полностью доверяете старшему разработчику и это нормально. В какой-то момент вы так привыкаете к каким-то правилам (или отсутствию правил), что весь процесс работы над задачей проходит автоматически.
Если вы сейчас думаете, что я буду говорить о том, что первый ментор может быть не таким уж опытным и передать неправильные знания, то вы ошибаетесь. Хотя такой вариант тоже возможен, но чаще всего это редкий случай.
Но если мы принимаем как факт, что все-таки первый лид был достаточно опытным, то где же кроется проблема? И ответ на этот вопрос - в гибкости. Возможно сейчас кто-то со мной поспорит, но нет плохой архитектуры и плохих правил как таковых. Есть не рекомендуемые конструкции, но это не делает их плохими. Опытный человек понимает, где это не принесет больших проблем, а где стоит все-таки потратить больше времени и продумать удобную, расширяемую архитектуру.
Но есть гораздо более важный момент, вы работаете в команде, а самая лучшая команда - это та, которая пишет как один человек. В таком случае задача может легко перейти другому разработчику, а когда тебе поступает новая, ты можешь легко разобраться, что происходит в участке кода, который писал не ты. Также в каждой команде принят стандартный workflow для задачи, включающий в себя даже такие этапы, как именование веток или названия коммитов.
И workflow хорош именно тем, что он гибкий. Он изменяется под нужды текущей команды, проекта, релизов, постановки задач. То есть нет такого единого стандартного решения, есть база, которая видоизменяется со временем.
Если вы еще не поняли, как выражается эта проблема, то более конкретно - в непринятии новых правил, требований, стека. На автомате человек делает как раньше, не понимая потом, почему его задачу не принимают и просят переделать. Ему может показаться, что к нему придираются и просят изменить что-то малозначительное, хотя если смотреть шире - то можно увидеть, что это может быть давно принятым правилом, и команде так удобнее.
Смена работы - это часто стресс. Особенно в IT, где от команды к команде может измениться все. Когда ты долго работаешь на одном месте и уходишь в другое, то довольно тяжело принять что твое понятие *хорошо*, здесь может быть вообще *не хорошо*. Или наоборот, то что ты считал плохим решением, здесь используется повсеместно. Самое главное - понять на этом этапе, что такое возникает не потому что в другой команде делают неправильно, а что они приняли такой вариант, потому что им было удобно с этим работать в данный момент времени.
> В дальнейшем будут приводиться примеры, они взяты из личного опыта. Примеры необходимы для иллюстрации, как это происходит на практике с объяснением почему в данном проекте и команде было принято так, или почему вот так не сделали. Ни в коем случае они не сделаны, для того чтобы показать, что люди чего-то не понимали или были не правы.
>
>
Пример из жизни о правиле, которое не понятно сразуНа одной из моих работ руководитель откатывал все задачи с формами, где нельзя было заполнить ее только с помощью клавиатуры. И казалось бы, ну это же мелочь, и статистика показывает, что обычные пользователи активно пользуются мышкой и редко нажимают `tab` и `enter` (а уж про сочетание `shift + tab` мало кто даже из IT знает). Но в той компании руководитель активно участвовал в тестировании, и для ускорения его прохождения он строго требовал, чтобы такая возможность была, так как тогда он может закончить приемку задачи в разы быстрее, что улучшает эффективность команды в целом.
Пример о хорошей практике разработчика, которая не была принятаОдин из моих разработчиков довольно тесно работал с *husky*, и он предлагал ввести его в проект. И это действительно хороший инструмент, но было принято решение отдать предпочтение *ci/cd*, так как в команде есть правило о маленьких, атомарных коммитах, и частенько возникала ситуация, когда коммитили частично, и остальные файлы могли быть еще на стадии доработки.
Да, *husky* можно было бы настроить на изменения в коммите, или перевести на команду `push`, но то ли я не доразобралась, то ли что, но на `push` оно в результате все равно отправлялось несмотря на то, что проверки проваливались.
Другой момент - практика показала, что гораздо удобнее для команды, когда это происходит на стороннем сервисе и ты не прерываешь свою мысль над задачей в середине, потому что не можешь что-то закоммитить или запушить.
То есть в результате, контроль качества кода проводился, просто другим способом, который более привычен для большей части команды. Но разработчику все равно было некомфортно, потому что для него это было не то решение, к которому он привык.
Иногда проблема возникает из-за незнания по какой причине было принято определенное правило или использовалась какая-то библиотека в силу неопытности. Неосознанно, чтобы уменьшить "незнакомость" проекта и вернуться во что-то привычное, человек может начать продвигать технологии, которые использовались на прошлом месте работы. Иногда эти предложения могут быть серьезными усложнениями, не дающими в перспективе значительных улучшений в качестве и простоте кода.
Пример из жизни на эту темуДано: есть проект на *Vue*, который был написан бэкендщиком без знания клиентской архитектуры, и который в кратчайшие сроки нужно было привести в более менее работающий вид. Разработчик из команды предлагает ввести *RxJS* в проект (до этого он долго работал с *Angular*, это было кстати его первое место работы).
Немного почитав я вижу, что *RxJS* использует паттерн *Observable*, который уже реализован во *Vue*, и большинство потребностей в виде подписки на изменение переменной / реактивности и т.д. там уже реализованы из коробки. Предполагаю, что это очень классный инструмент, который можно круто применить. Но человек предложил его именно по причине, что он привык с ним работать. В данной ситуации не было особой пользы в его применении.
В том же проекте, часть файлов он написал на *TypeScript* (большая часть была на *JS*). Мне очень нравится *TS*, но по опыту я знаю что 2-я версия *Vue* не очень хорошо с ним работает, и местами это вызывает трудности. В результате больше времени тратится на то, как правильно этот тип прокинуть, а то и вовсе просто пишется `any`. Также нужно учитывать момент, что перевод проекта на *TS* - это увеличение сроков, и в данном случае это было нецелесообразное решение. Причина по которой он начал это делать довольно проста, привычка и мысль, что так правильно, а по-другому плохо, значит нужно переделать.
До этого я приводила примеры и описывала ситуации, которые возникают с людьми, которые работали с опытными менторами. Но все-таки стоит затронуть ситуацию с низкими стандартами кода, которая иногда встречается в тех же веб-студиях. Если в прошлых примерах разговор чаще шел о хороших практиках, которые просто не подходят под текущую ситуацию и стиль команды, то с людьми из следующих примеров чаще обратная проблема. Им наоборот кажется, что все правила - это усложнения и зачем заморачиваться, если и так все работает.
Бывает, что они могут отнестись с негативом к изменениям их кода в пользу более удобной архитектуры, которая рассчитана на дальнейшие изменения. Также может быть негатив к линтерам и форматтерам, если они с ним не работали, их могут раздражать эти "ошибки", которые они не считают ошибками, а своим стилем. Но как я уже объясняла выше, важно, чтобы команда писала как один человек, поэтому их задачи будут продолжать откатываться, чтобы привести все к единому стандарту.
Пример о непринятии замечаний в силу неопытностиЯ какое-то время работала в веб-студии, а потом попала в компанию с более строгими стандартами. Тогда по началу у меня часто возникали споры с дизайнером, потому что он очень внимательно проверял задачи, обращал внимание на то, посередине ли элемент, какой размер шрифта, как выглядит адаптив на каждом пикселе, какие ховеры у элементов, как выглядит при нажатии, и не остается ли ховер на мобильных устройствах.
Для меня это было абсолютно ново, и мне казалось что он отправляет на доработку просто из-за мелочей, которые не особо важны. По сути он научил меня тогда, как делать правильно, как улучшить *UI/UX* для обычного рядового пользователя, и почему важны такие мелочи. Конечно потом я поняла, что была не права, но также поняла для себя, что это сильно зависит от проекта и его задачи.
Проекты, к которым ты должен возвращаться (то есть рассчитанные на удержание клиента) должны быть как флагман в мире телефонов, то есть ты просто им пользуешься и все работает так, как ты ожидаешь и как ты хочешь. Тогда к нему возвращаться приятнее, и не хочется разбираться в другом продукте, который менее отзывчивый.
Пример о непринятии новой архитектурыВ практике встретилась довольно интересная задача о многосоставных опросах. Руководитель проекта хотел видеть опросы, которые перемешивались бы с кастомными страничками, и чтобы еще были а/б тесты. Так как сроки были довольно ужатые было принято решение захардкодить 2-х составной опрос, то есть он мог работать только при определенных условиях и рассчитан был на конкретные компоненты между опросами и конкретную очередность.
Но также при работе с задачей уже было понимание, что на данный момент это очень не гибко, руководитель хотел больше возможностей, так как на эти опросы была высокая ставка. Для этого я спроектировала архитектуру, включая возможности а/б тестирования, показа компонентов, возможности нескольких шагов и самое главное, гибкую. Я учла возможность добавлять и реализовывать другие параметры, которые возможно нам понадобятся в будущем.
Разработчик подошел к этому негативно, так как по его мнению это было лишнее усложнение системы. Для текущей задачи она действительно работала, но для того, чтобы по максимуму реализовать желания руководителя, было необходимо более серьезно подойти к вопросу архитектуры.
Кстати именно из-за этого в вакансиях на разработчиков может присутствовать строчка “*от n лет* ***коммерческой*** *разработки*”, не всегда у команды есть время ждать, пока новый сотрудник привыкнет к высоким стандартам, и более простым решением становится нанять того, кто на практике уже к этому привык.
Немного о фрилансе
------------------
Если человек долго работает в фрилансе, у него также могут возникнуть проблемы, когда он начинает работать в команде. Кстати по той же причине, что и у людей, еще не менявших до этого работу. Иногда у людей во фрилансе нет понимания, что при работе в команде ты не один показываешь результат, а вся команда, и оценивают ее в целом, а не кого-то отдельного. Соответственно, гораздо более приоритетен результат и продуктивность всех в общем, а не конкретно взятого сотрудника.
По секретуФрилансерам может прийти отказ после собеседования в продуктовую компанию именно по причине того, что собеседующий может засомневаться в том, что человек привыкнет к работе в команде и присутствию лида, который устанавливает определенные правила и контролирует их выполнение.
Заключение
----------
Проблему я описала, а решение нет. Если вы впринципе не хотите столкнуться с этой проблемой, то это абсолютно нормально сменить несколько мест работы ~~(только не через 3 месяца, пожалуйста)~~, даже при условии, что на текущей вас все устраивает. В начале карьеры вы максимально гибки, и вам будет легче адаптироваться, в дальнейшем в этом уже нет необходимости, так как приходит понимание, почему важно придерживаться определенных правил и где стоит гнуть свою линию, а где важнее командная продуктивность.
Если же вы уже довольно длительное время в одном месте, и сейчас задумались о том, чтобы сменить работу, то настройте себя на максимальную гибкость, и попробуйте поработать в другом стиле, даже если для вас это будет непривычно. Старайтесь замечать хорошие вещи в новом подходе и не зацикливайтесь на старом. Получайте максимальный опыт от людей и пробуйте разные варианты, в этом же прелесть работы разработчиком, что жизнь всегда подкидывает что-то новое.
Если же вы недавно сменили и столкнулись с непринятием и негативом из-за новых правил, то постарайтесь оценить объективно, не является ли это стремлением к тому, чтобы вернуться в старые знакомые края, и действительно ли то, что вы считаете правильным, будет являться правильным для всей команды? Если вы считаете, что да, то постарайтесь аргументированно доказать свою точку зрения с практическими примерами, но также учтите сроки и пользу таких изменений и являются ли эти 2 метрики соразмерными.
> Вообще в этой статье я также хотела поговорить о навыке релиза продуктов, но текста уже достаточно много, так что я поговорю об этом в следующий раз.
>
> | https://habr.com/ru/post/553886/ | null | ru | null |
# Ubiquity: just another map plug-in

На Хабре уже [была статья](http://habrahabr.ru/blogs/firefox/38203/) про чудесный плагин для Firefox — [Ubiquity](https://addons.mozilla.org/uk/firefox/addon/9527). Очень экспериментальный плагин. Советую как минимум посмотреть на него.
Так вот, мне он очень понравился и я написал своё расширение — поиск адреса на картах [mapia.ua](http://mapia.ua). О чём и написал статейку.
Превью
------
Что же примечательного в этом Ubiquity?
* Во-первых этот плагин суть сборище веб-сервисов в одной *командной строке* (!): *Google [Calculator, Mail, Maps, Translate, ...], Twitter, delicious, Wiki, Digg, tinyurl, Yahoo, Flickr* и много чего ещё. Список участников постоянно пополняется. И дело тут даже не в количестве и качестве предоставляемых веб-сервисов. Дело в удобстве использования самого Ubiquity: теперь необязательно обвешивать бедный Firefox сотней чудесных тулбаров и плагинов, всё — в одном месте. И это действительно удобно.
* [](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BA%D0%B8%D0%BD,_%D0%94%D0%B6%D0%B5%D1%84)[](http://ru.wikipedia.org/wiki/%D0%90%D0%B7%D0%B0_%D0%A0%D0%B0%D1%81%D0%BA%D0%B8%D0%BD)Во-вторых, разрабатывает его не кто-то там, а сам [Аза Раскин](http://ru.wikipedia.org/wiki/%D0%90%D0%B7%D0%B0_%D0%A0%D0%B0%D1%81%D0%BA%D0%B8%D0%BD), сын великого (не побоюсь этого слова) эксперта в юзабилити [Джефа Раскина](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BA%D0%B8%D0%BD,_%D0%94%D0%B6%D0%B5%D1%84) (земля ему пухом), автора великолепной книги [«The Human Interface»](http://en.wikipedia.org/wiki/The_Humane_Interface), которую просто обязан прочесть каждый, кто имеет дело с юзер-интерфейсом. Аза Раскин сейчас — ведущий спец по юзабилити в Mozilla Labs. Респект ему и уважуха :-)
Вот [ознакомительное видео](http://vimeo.com/1561578) от автора плагина.
Всё действо происходит в **командной строке**, прямо в браузере. Достаточно нажать Ctrl+Space. Как говорится, всем любителям POSIX посвящается. Но всё настолько просто и ясно, что и мартышка освоит: команды вводить полностью не надо (suggestions), параметров раз-два и обчёлся. По умолчанию первым аргументом в команду передаётся то, что выделено мышкой на странице. Собственно в этом огромный плюс, скажем, при переводе статей с немецкого (по нажатию Enter, кстати, выделенный кусок текста переведётся прямо на странице). Или чтоб скинуть текст другу на мыло. Вообщем, Аза потрудился на славу.
Велосипед
---------
Чтобы создать свой чудо-сервис, нам понадобится, собственно, Firefox с установленным [Ubiquity](https://addons.mozilla.org/uk/firefox/addon/9527). Есть? Приступим.
### Карты, карты, как мне вас не хватает

В Ubiquity уже есть предустановленные карты Google Maps. Но я, как житель славного города Киева, привык пользоваться другими — <http://mapia.ua> Да и в качестве примера — сойдёт :-)
Да, специально для тех, кто не любит многабукаф — [вот ссылка на уже готовый плагин](http://kott.ho.ua/master/mapia_ubiquity.html).
### Чтобы начать редактировать, нажмите «Редактировать». Спасибо, Кэп!
Итак, нажимаем *Ctrl+Space*, набираем help, переходим на страничку настроек Ubiquity, находим и нажимаем «Hack Ubiquity». Мы в редакторе. Если не очень удобно кодить в *textarea*, то можно подключить любой внешний редактор и работать в нём (я предпочитаю *notepad++*, к примеру).
### Первые шаги
> `CmdUtils.CreateCommand({
>
> names: ["mapia", "mpi"],
>
> icon: "http://mapia.ua/favicon.ico",
>
> description: \_("Kiev map powered by mapia.ua"),
>
> author: {name: "Kottenator", email: "kottenator@gmail.com"},
>
> license: "MIT"
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Тут всё очень просто:
* names, icon, description, author, license — очевидно :-)
* `_(...)` — метод для i18n
И мы уже можем запустить и посмотреть нашу команду:
Ctrl+Space -> type «mapia» or «mpi» -> увидим такое:

Прямо гордость берёт за содеянное! :) Но продолжим:
> `CmdUtils.CreateCommand({
>
> names: ["mapia", "mpi"],
>
> icon: "http://mapia.ua/favicon.ico",
>
> description: \_("Kiev map powered by mapia.ua"),
>
> author: {name: "Kottenator", email: "kottenator@gmail.com"},
>
> license: "MIT",
>
>
>
> arguments: [
>
> {role: 'object', nountype: noun\_arb\_text, label: \_('address')}
>
> ],
>
>
>
> preview: function preview(pblock, args) {
>
> var msg = "You'd just typed \"${text}\"";
>
> pblock.innerHTML = \_(msg, { text: args.object.text });
>
> },
>
>
>
> execute: function execute(args) {
>
> var msg = "You choose address: \"${text}\"";
>
> displayMessage(\_(msg, { text: args.object.text }));
>
> }
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Что же мы наделали?
* `arguments: [arg1, arg2, ...]` — описание аргументов нашей команды (спасибо, Кэп!).
К примеру, `{role: 'object', nountype: noun_arb_text, label: _('address')}`:
`role: 'object'` означает, что это первый аргумент, ожидаемый сразу же после имени команды; `nountype` означает что-то вроде типа этой переменной; `label` — то, что мы увидим в описании команды (н-р «mpi *(address)*»). Подробнее об аргументах команд можно почитать [тут](https://wiki.mozilla.org/Labs/Ubiquity/Ubiquity_0.5_Author_Tutorial#Commands_with_Arguments)
* > `preview: function preview(pblock, args) {
>
> var msg = "You'd just typed \"${text}\"";
>
> pblock.innerHTML = \_(msg, { text: args.object.text });
>
> }`
Это метод для отображения превью в окошке Ubiquity. `pblock` — контейнер превьюхи, `args` — текущие аргументы комманды; `args.object.text` — тот самый аргумент с `role: 'object'`.
Как видим, метод `_(...)` умеет делать не только i18n, но и подставляет параметры в шаблон.
* > `execute: function execute(args) {
>
> var msg = "You choose address: \"${text}\"";
>
> displayMessage(\_(msg, { text: args.object.text }));
>
> }`
А этот метод вызывается, когда мы нажмём Enter.
`displayMessage(...)` выводит небольшое slide-up уведомление.
Сохранили, поигрались, красота:

Собственно, а где же карты? Начнём с [Mapia Static API](http://mapia.ua/api_static_docs.html) — это просто картинка участка карты. Продолжим наш код:
> `arguments: [
>
> {role: 'object', nountype: noun\_arb\_text, label: \_('address')},
>
> {role: 'goal', nountype: noun\_arb\_text, label: \_('zoom')},
>
> {role: 'source', nountype: noun\_arb\_text, label: \_('map size')}
>
> ],
>
>
>
> previewDelay: 800,
>
>
>
> getStaticURL: function(address, zoom, size) {
>
> var mapUrl = "http://mapia.ua/static?";
>
>
>
> address = address || '';
>
> zoom = parseInt(zoom, 10) || 15;
>
> zoom = Math.min(18, Math.max(zoom, 6));
>
> size = size || '400x300';
>
>
>
> var params = {
>
> address: address,
>
> zoom: zoom,
>
> size: size
>
> };
>
>
>
> return mapUrl + jQuery.param(params);
>
> },
>
>
>
> preview: function preview(pblock, args) {
>
> var img = '';
>
> var url = this.getStaticURL(args.object.text, args.goal.text, args.source.text);
>
> pblock.innerHTML = \_(img, { url: url });
>
> },
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
* Во-первых, мы добавили ещё 2 аргумента:
> `{role: 'goal', nountype: noun\_arb\_text, label: \_('zoom')},
>
> {role: 'source', nountype: noun\_arb\_text, label: \_('map size')}
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Первый будет отвечать за zoom карты, второй — за размер рисунка.
`role: 'goal'` будет ожидать, что мы напишем что-то вроде *«mapia Адресс to 16»*. Вот это «to 16» будет означать, что `args.goal.text == '16'` и это будет наш zoom. Возможные значения — от 6 до 18.
Аналогично *«mapia Адресс from 300x200»* будет означать, что `args.source.text == '300x200'` и это будет размер рисунка.
* Метод `getStaticURL(address, zoom, size)` возвращает строку адреса нашей карты.
* Метод `preview(...)` теперь делает что-то дельное :) — показывает карту
* `previewDelay: 800` — чтобы не убивать сервера mapia.ua сумасшедшей нагрузкой (по запросу на каждое нажатие клавиши), введём задержку перед запросом в 800 миллисекунд
Вот результат:

Отлично, на этом можно было бы и закончить, но я лично хотел создать действительно удобную штуку. Статический рисунок — маловато для моих потребностей. И вот что я сделал…
### Вторые шаги
Собственно, предисловие. Mapia не предоставляет открытого веб-сервиса для поиска по адресу улицы. Но ведь это работает на их сайте! И я подумал — ведь нет ничего преступного в том, что я воспользуюсь их поиском через XSS? В конце концов это не уязвимость, и вреда я не наношу, ничего не ворую, а лишь создаю дополнительную рекламу [этим ребятам](http://mapia.ua) ;-)
Добавим такой метод:
> `loadDetails: function(pblock, args, page\_num) {
>
> var baseUrl = "http://mapia.ua/search";
>
> var params = {city: "%u041A%u0438%u0435%u0432", "search[query]": args.object.text};
>
> var self = this;
>
>
>
> jQuery.ajax({
>
> type: "GET",
>
> url: baseUrl,
>
> data: params,
>
> dataType:'html',
>
> error: function() { },
>
> success: function(html) {
>
> $('#content', pblock).html(html);
>
> }
>
> });
>
> },
>
>
>
> preview: function preview(pblock, args) {
>
> var img = '';
>
> var url = this.getStaticURL(args.object.text, args.goal.text, args.source.text);
>
> pblock.innerHTML = \_(img, { url: url });
>
>
>
> this.loadDetails(pblock, args);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как видим, Ubiquity поддерживает jQuery. Это чудесно!
И вот тот самый поиск по mapia — «[mapia.ua/search?city=Киев&search](http://mapia.ua/search?city=Киев&search)[query]=Введённый адресс»
Что делает метод `loadDetails(...)`? Он просто подгружает в наше превью результаты поиска. Думаю, что код ясен и объяснению не подлежит.

Перед нами результаты поиска. Но почему-то мы не можем никуда перейти. Ссылки не работают, всё плохо. На самом деле это нормально :) Как я сказал выше, этот механизм предназначен вовсе не для нас, а лишь для самого сайта mapia.ua. Но Ubiquity позволяет делать крос-доменные запросы, что мы и сделали.
Поэтому придётся поработать напильником (RegExp pre-fix + jQuery post-fix):
> `mapiaURL: "http://mapia.ua/#popup\_class=${cat}&popup\_id=${sid}",
>
>
>
> clearSearchResultsCode: function(html) {
>
> html = html.replace(/((?:.|\s)\*?)<\/div>/i, '### $1
>
> ')
>
> .replace(/.\*?<\/p>/i, '(результаты поиска предоставлены сайтом mapia.ua)
>
> ')
>
> .replace(/(]\*>/gi, '$1>')
>
> .replace(/[')
>
> .replace(/]+onclick="\$\('street\_\d+\_buildings'\).\*?<\/a>/i, '')
>
> .replace(/[')
>
> .replace(/[')
>
> .replace(/[')
>
> .replace(/[')
>
> .replace(/(/i, '$1')
>
> .replace(/(/i, '$1') /\* not a duplicate \*/
>
> .replace(/href="\/search?[^"]\*pages\_feature=(\d+)[^"]\*"/gi, 'page\_num="$1"')
>
> .replace(/]\*onclick="load\_content(?:.|\s)\*?<\/p>/i, '')
>
> .replace(/](\/center\/city\/(\d+)[^>]*>/gi, '<a href=)](\/center\/station\/(\d+)[^>]*>/gi, '<a href=)](\/center\/feature\/(\d+)[^>]*>/gi, '<a href=)](\/center\/address\/(\d+)[^>]*>/gi, '<a href=)](\/center\/street\/(\d+)[^>]*>/i, '<a href=)` | https://habr.com/ru/post/74514/ | null | ru | null |
# Классификация разработчиков по рангам боевых искусств
Как называют разработчиков
==========================
В своём блоге я взаимозаменяемо использую термины «программист», «кодер», «разработчик» и «инженер», чтобы избежать тавтологии. Тем не менее я считаю, что между этими словами и другими аналогичными есть некоторые различия.
В этой статье обсудим набор типичных существительных для обозначения человека, который пишет код. Я дам свою интерпретацию, как эти термины соотносятся с уровнем мастерства.
Толкование значений
-------------------
Представленные здесь определения не являются официальными. Я не знаю каких-то формальных определений или принятого стандарта. Тем не менее, у многих людей есть твёрдое мнение по этому вопросу. Мое понимание каждого термина основано на 30 годах опыта в индустрии программного обеспечения, но я абсолютно готов к тому, что другие не согласятся с моей интерпретацией.
Не хочу спорить или убеждать людей с иным мнением. Вообще, вряд ли тут можно говорить о правильном или неправильном мнении. Тем не менее, если вы ещё не сформировали позицию по данному вопросу, надеюсь, что это руководство внесёт некоторую ясность.
Трёхсторонний подход
--------------------
Для ясности каждый термин получит три характеристики:
### 1. Уровень мастерства
Описание уровня квалификации для этого термина, в моей интерпретации.
### 2. Параллель с рангами боевых искусств
Аналогия с рангами боевых искусств. В частности, сравним технический уровень навыков с цветами поясов у мастеров боевых искусств.
### 3. Пример кода
Пример того, как человек этого уровня должен подойти к простой программистской задаче. Определение тут тривиальное и не задумывалось как реалистичный пример. Цель — сравнить и обсудить уровень квалификации. Простотой пример подобран так, чтобы подойти специалисту любого уровня. Вот какую проблему мы рассмотрим:
> Вычислить сумму целых чисел
Пожалуйста, подыграйте мне и представьте эту задачу как промежуточную для гораздо более сложной. В нашей вымышленной Вселенной задача требует серьёзных размышлений и имеет много потенциальных решений и подходов. Представьте, что это центральный модуль системы, которую нужно масштабировать.
Я буду использовать Ruby для тривиальных примеров реализации. Код достаточно прост: он понятен, даже если вы не знаете Ruby.
### 3. Список
Обсуждаемые существительные:
* Новичок
* Кодер
* (Хакер)
* Программист
* Исследователь (computer scientist)
* Разработчик программного обеспечения
* Инженер программного обеспечения
* Архитектор программного обеспечения
Итак, начнём.
Пояса боевых искусств
=====================

Когда я жил в Италии в юности — около 20 килограммов назад — то несколько лет практиковал дзюдо и кунг-фу. Тогда я узнал, что во многих боевых искусствах уровню мастерства соответствует цвет пояса. Обычно цвет изменяется от белого к чёрному, где уровень опыта соответствует темноте пояса.
Новичок носит белый пояс, потому что у него нет опыта. Белый цвет означает «новый и чистый». По мере тренировки пояс темнеет, демонстрируя прогресс. Цвет олицетворяет грязь, накопленную с тяжёлой работой и потом. Мастер боевых искусств с многолетним опытом в конечном итоге достигает чёрного пояса, который означает высокий уровень знаний и навыков.
Традиционно пояса были только чёрные или белые. В последние десятилетия появилось больше цветов. Сегодня в разных школах боевых искусств используются разные цвета. Схема зависит от стиля, школы и страны.
Почему мы говорим о боевых искусствах?
--------------------------------------
Цвета поясов используются, чтобы провести параллель между навыками создания программного обеспечения и навыками мастера боевых искусств. Для этого возьмём цветовую схему, обычно используемую в Европе: белый, жёлтый, оранжевый, зелёный, синий, коричневый и чёрный.
В следующей таблице показаны уровни разработчика, о которых я говорил. Для каждого показан цвет пояса и должность, которую обычно дают специалисту этого уровня:
| Уровень профессионала | Уровень боевых искусств (цвет пояса) | Пример должности |
| --- | --- | --- |
| Новичок | Белый | |
| Хакер | Уличный боец (без пояса) | |
| Кодер | Жёлтый | Джуниор-разработчик (Jr.Dev) |
| Программист | Оранжевый | Разработчик ПО |
| Исследователь (Computer Scientist) | Зелёный | Разработчик ПО (Software Developer) |
| Разработчик ПО | Синий | Старший разработчик ПО (Sr. Software Dev) |
| Инженер-программист (Software Engineer) | Коричневый | Ведущий разработчик (Principal Dev) |
| Архитектор ПО (Software Architect) | Чёрный | Архитектор ПО |
Уровень инженерных навыков связан с техническими способностями и навыками командной работы. Название должности — пример, как человека на этом уровне называют в отрасли (это сильно зависит от компании и региона).
Новичок: белый пояс
-------------------

С чего-то нужно начинать, и обычно это уровень «вообще нет опыта». Новичок в разработке программного обеспечения — это тот, кто только что познакомился с программированием и находится на ранних этапах обучения. Новички ещё не могут уверенно программировать и не понимают простых программ, не сверившись с книгами, учебниками или не спросив совета у опытного товарища.
Новички способны писать рабочий код, но часто не понимают деталей, почему этот код работает. Они тратят много времени на поиск фрагментов кода на StackOverflow или подобных сайтах и совмещение этих фрагментов, пока что-нибудь не заработает.
### Мощные инструменты — это не то, что надёжные навыки
Чтобы ещё больше всё запутать, многие «современные» языки и фреймворки позволяют кому угодно генерировать структуру и некоторые реализации сложных программ без понимания, что происходит за кулисами. Например, запуск простого приложения Ruby on Rails и приём HTTP-запросов можно организовать с помощью нескольких команд из командной строки.
Вот как это делается под \*nix:
`$ gem install rails
…
$ rails new website
…
$ cd website
$ bin/rails server
...`
Готово! Этого достаточно, чтобы сервер отвечал на HTTP-запросы от браузера. Если сравнить с боевыми искусствами, то это как появиться на татами в доспехах и с оружием. Броня позволит вам чуть дольше прожить, а с оружием можно выиграть схватку. Но такая победа не делает вас квалифицированным мастером боевых искусств. Эти инструменты просто позволяют сделать что-то сложное без традиционного обучения и усилий.
Не поймите меня неправильно. Инструменты вроде Ruby on Rails позволяют быстро выполнить работу, и они великолепны. На самом деле я считаю фантастикой возможность сократить время на написание начального стандартного кода. Это отличное начало проекта, но здесь достаточно лишь белого пояса.
Настоящая схватка начинается там, где учебник заканчивается, где инструменты не могут автоматически сгенерировать нужное вам приложение. Чтобы двигаться дальше, нужно стать кодером.
### Пример
Если новичок захочет написать программу, которая суммирует набор чисел с помощью Ruby, то может загуглить вопрос и найти [такую страницу](https://stackoverflow.com/questions/1538789/how-to-sum-array-of-numbers-in-ruby). Это первый результат в выдаче Google на момент написания этой статьи. На странице StackOverflow самый заплюсованный ответ с 524 голосами:
```
array.inject(0){|sum,x| sum + x }
```
Конечно, это работает. Вот пример:
```
$ irb
2.4.2 :001 > array=[1,2,3]
=> [1, 2, 3]
2.4.2 :002 > array.inject (0){|sum, x| sum + x }
=> 6
```
Это может работать у новичка, но он не понимает особенностей этого кода. Насколько он читаем? Насколько быстро выполняется по сравнению с другими вариантами? Легко ли его поддерживать? Почему он работает? Что именно произойдёт при выполнении этой строки? Сколько используется процессорного времени? Определены ли переменные *sum* и *x* после выполнения этой строки?
Начинающий разработчик на Ruby не знает ответов на большинство из этих вопросов.
Кодер: жёлтый пояс
------------------

Кодер может без посторонней помощи собрать много строк компьютерного кода для решения простых проблем. Результат будет не очень красивым, но кодер понимает, почему программа работает, и он успешно выполняет задание.
### Первый необходимый шаг
Я назвал свой блог CoderHood, потому что каждый, кто зарабатывает на жизнь программированием, в какой-то момент достиг уровня кодера. Слово Coderhood отражает жизнь разработчика в мире технологий, начиная с первого жёлтого пояса.
Основное различие между новичком и кодером в том, что кодер способен писать код и понимать его. Они может не понимать в деталях, что происходит за кулисами, но он знает, почему написал именно такой код.
В отрасли кодеру обычно присваивают должность вроде «младшего разработчика» (jr. developer) или стажёра (developer in training).
### Пример
Я думаю, что «Ruby-кодер» сможет придумать большинство нижеперечисленных методов вычисления суммы массива целых чисел и понять разницу между ними:
```
$ irb
2.4.2 :001 > array=[1,2,3]
=> [1,2,3]
2.4.2 :002 > array.inject (0){|sum, x| sum + x }
=> 6
2.4.2 :003 > sum=0;array.each { |x| sum+= x }
=> 6
2.4.2 :004 > array. sum
=> 6
2.4.2 :005 > array.inject(0, :+)
=> 6
2.4.2 :006 > array.reduce(0, :+)
=> 6
2.4.2 :007 > eval array.join '+'
=> 6
```
Если вам интересно, некоторые из этих методов ужасны, но они работают.
Хакер: джинсы без пояса
-----------------------

Я включил в список «хакера», потому что меня попросили об этом. Но он не слишком хорошо подходит для нашей дискуссии.
### Не главный навык
Я не считаю, что «хакерство» является необходимым навыком на пути развития разработчика программного обеспечения. Такой опыт полезен, чтобы научиться тестировать и защищать программные приложения и системы, но я не вижу здесь описания общего «уровня навыков». Я бы классифицировал это как некую область дейстельности, а не уровень технического мастерства. На самом деле уровень квалификации хакера может быть любой. Некоторые из них удивительны, а другие [не очень](https://www.youtube.com/watch?v=oJagxe-Gvpw).
Поскольку хакерство не является необходимым шагом в развитии разработчика, по моей аналогии, у хакера нет традиционного пояса. Они больше похожи на уличных бойцов, носящих джинсы.
Некоторые из них злые головорезы, другие пытаются выжить, третьи — хорошие ребята, которые защищают остальных, но большинство где-то посередине.
### Много видов «хакеров»
Есть много типов хакеров. Некоторые умеют программировать, другие нет. Значение слова зависит от контекста и от того, кто его использует. Некоторые общие определения:
1. Компьютерный эксперт, который придерживается субкультуры технологий и программирования.
2. Человек, который может поставить под угрозу компьютерную безопасность из вредоносных (black-hat) или исследовательских (white-hat) целей.
3. Разработчик, который выполняет работу самым быстрым и грязным способом.
4. Человек, который изучает, экспериментирует или исследует телекоммуникационные системы, оборудование и системы, подключенные к телефонным сетям. Таких хакеров также называют фрикерами (phreaker).
5. Квалифицированный инженер, работающий очень близко к железу, чтобы получить лучший контроль над системой ради хорошего дела (т.е. чтобы выжать больше производительности из оборудования) или для вредоносных целей (т.е. чтобы использовать дыры в безопасности и найти способ обойти защиту операционной системы).
### Некоторые примеры
#### Тип 3
Хакер типа 3 может выбрать такой вариант суммирования массива целых чисел:
> $ irb
>
> 2.4.2 :001 > 'echo «1 2 3» / bc'.to\_i
>
> => 6
Способ работает, по крайней мере, на некоторых системах, но это… «полный хак». Так делают неквалифицированные хакеры, умеющие программировать. Они решают вопросы сомнительными способами, обычно выполняя нечитаемые команды командной строки, пока каким-то образом не получат желаемый результат.
#### Тип 5
Хакеры типа 5 работают на очень низком уровне. Такие навыки нелегко приобрести и они могут быть очень ценными, если вы пытаетесь настроить защиту программного обеспечения или создать чрезвычайно высокопроизводительные приложения. Я никогда не был «хакером», но я программировал на низком уровне (C и ассемблер) и по-прежнему в глубине души считаю себя специалистом по низкоуровневому программированию.
Хакеры 5-го типа могут быть фантастическими уличными бойцами, с безумными навыками, которые утрут нос многим профессиональным программистам на некоторых специализированных задачах. Такие «хакеры» могли бы суммировать массив целых чисел с помощью ассемблера [примерно так](http://www.ee.nmt.edu/~rison/ee308_spr02/supp/020201.pdf).
Программист: оранжевый пояс
---------------------------

Программист может писать функционирующие приложения, понимает основные алгоритмы и знает основы информатики. Он может заставить программу работать, даже если она будет не очень масштабируемой и поддерживаемой в долгосрочной перспективе. Как правило, программист хорошо работает в одиночку. Не факт, что он будет хорошим командным игроком.
Большинство разработчиков останавливаются на этом уровне, особенно если не планируют изучать теорию информатики. Программисты могут написать приличный код и работать в индустрии программного обеспечения на этом уровне в течение всей карьеры.
С точки зрения должности, программистов часто именуют «разработчиками программного обеспечения» (Software Developer) или «инженерами-программистами» (Software Engineer).
В простом примере суммы массива целых чисел программист может написать код таким образом:
```
#!/usr/bin/env ruby
if ARGV.size==0
puts "Usage: "
puts " sum [список целых чисел, разделённых пробелами]"
else
puts ARGV.sum{|x| x.to_i}
end
```
Этот код реализует полезную команду командной строки для суммирования списка чисел. Если вызвать её без параметров, она отображает полезное сообщение об использовании. В противном случае печатает стандартную выдачу. Вот пример использования:
`$./sum
Usage:
sum [список целых чисел, разделённых пробелами]
$ sum 1 2 3
6`
Это «комплексное решение», самодокументируемое и несколько абстрактное, поскольку программу можно вызвать из командной строки.
Исследователь: зелёный пояс
---------------------------

Исследователь (computer scientist) изучал информатику или в школе, или на работе. Он имеет хорошее понимание таких понятий:
* Основание Base-N (N = 2, 10, 16)
* Бинарные операции
* Булева логика
* Алгоритмическая сложность и нотация big-O
* Структуры данных (массивы, связанные списки, B-деревья, красно-чёрные деревья, очереди, стеки, хэш-таблицы, кучи, наборы, графы)
* Алгоритмы сортировки и когда их использовать
+ Базовое понимание NP-полноты
* Основные многопоточные алгоритмы
* Управление памятью и сборка мусора (только то, что ваш язык программирования сам заботится об управлении памятью, не значит, что можно пропустить эту тему)
* Указатели (нужно хотя бы понять концепцию, даже если вы не кодируете на C) и разницу между передачей параметров по значению или ссылке.
* Концепции ООП (интерфейсы, наследование, конструкторы, деструкторы, классы, объекты, абстракции, инкапсуляция, полиморфизм и т.д…)
* Объектно-ориентированный дизайн и шаблоны
* Рекурсия
* Некоторые основные понятия о динамическом программировании, жадных алгоритмах и амортизационном анализе, алгоритмах сравнения строк и аппроксимации
У исследователя степень по Computer Science или он много лет работал разработчиком, изучая прикладную информатику на работе. Как вы знаете, [я не считаю, что для успешной карьеры разработчика необходима степень CS](https://www.coderhood.com/5-cs-degree-myth-busting-software-engineering-fact/).
Один только статус «компьютерного учёного» не делает вас отличным программистом. Здесь как будто нарушается аналогия с цветами поясов. Но это не так. Подумайте с такой стороны: даже в мире боевых искусств есть специализации. Некоторые зелёные пояса лучше других делают некоторые вещи. Прогрессия нелинейная. Цвет пояса часто представляет собой уровень опыта и количество труда, затраченного на овладение боевым искусством, а не обязательный уровень мастерства в каждом аспекте.
Учёный, вероятно, напишет такой же код для суммы чисел, как и программист. Разница в том, что учёный может сразу сказать, что сложность этого алгоритма O(n) времени. Как уже упоминалось, это элементарный пример, но вы уловили мысль.
Разработчик программного обеспечения: синий пояс
------------------------------------------------

Разработчик программного обеспечения способен осилить более крупные и сложные проекты. По сравнению с программистом и исследователем он:
* Пишет более чистый, структурированный, поддерживаемый, документированный и читаемый код.
* Допускает меньше ошибок.
* Работает быстрее.
* Лучше работает в команде и понимает ценность процессов разработки.
* Лучше находит и оптимизирует узкие места кода и программных систем.
* Имеет больше опыта.
### Пример
В простом примере суммы целых чисел разработчик программного обеспечения может решить проблему путём создания службы, предоставляющей Web API. Интерфейс принимает набор целых чисел и возвращает сумму.
Я полагаю, что приложение будет хорошо документировано и поддерживать настройки, сопровождаться тестами, иметь правильную структуру кода и легко обслуживаться другими разработчиками.
На Ruby основное приложение с использованием Sinatra может выглядеть примерно так:
```
require 'sinatra'
require "sinatra/config_file"
# Load the server configuration from config.yml:
config_file 'config.yml'
#
# EndPoints:
#
# /sum/n1 n2 n3 n4 ...
# Return:
# {result: [sum of n1,n2,n3,n4,...]}
#
# Example:
# $ curl http://localhost:8080/sum/1 2 3 4
# {"result":"10"}
#
get '/sum/:numbers' do |numbers|
{result: numbers.split(" ").collect{ |x| x.to_i}.sum}.to_json
end
```
Хороший разработчик программного обеспечения хорошо осведомлён о многих ограничениях этого решения по сравнению с другими. Например, оно ограничено суммой набора чисел, которая помещается в URI; здесь нет явной проверки на ошибки, строки должны начинаться с числа и т. д.
Инженер-программист: коричневый пояс
------------------------------------

Разница между разработчиком (software developer) и инженером-программистом (software engineer) тонкая; я это полностью признаю. Эти термины обычно используются как синонимы. Тем не менее, я предполагают, что инженер-программист — специалист, имеющий знания в области информатики и большой опыт в качестве разработчика программного обеспечения. Основные отличия:
* Возможность создания более масштабируемых систем.
* Долговечность. Они работают дольше и с меньшим количеством проблем.
* Меньше ошибок и лучшее качество кода.
* Умение выступать в роли технического руководителя проекта и команды.
* Отличные навыки сотрудничества и общения.
* Достаточное знание архитектуры программного обеспечения для выполнения работы.
В компаниях у таких разработчиков могут быть должности «старший разработчик» (senior developer) или «ведущий разработчик» (principal developer).
### Пример
Инженер-программист может написать приложение как разработчик, создав службу и предоставив API, чтобы взять набор целых чисел. Но я считаю, что решение инженера будет включать в себя некоторые улучшения:
* Кэширование результатов.
* Абстрагирование концепции от суммы к любому математическому выражению в запросе.
* Ведение журнала, аутентификация, отслеживание хуков и т. д.
### Пример становится глупым
Как видите, слишком простой пример на этом этапе становится немного глупым. Он сводится к обсуждению, как улучшить и так избыточное решение тривиальной проблемы.
Например, управление кэшем с результатами простых операций над небольшим набором чисел, скорее всего, тяжелее и медленнее, чем простые вычисления. Кэш имел бы смысл в случае огромного массива чисел для передачи в API, но тогда список не поместится в URI запроса.
Вы можете переместить список чисел в тело запроса, но тогда он больше не будет RESTFUL API, и запрос больше не будет кэшироваться. В этот момент возникнет соблазн изменить запрос на POST, но так он никогда не станет кэшируемым. В любом случае, обсуждение может продолжаться и продолжаться.
### Критическая часть
Видите, что происходит? По мере совершенствования навыков разработчика и усложнения проектов происходит забавная вещь. Проблемы всё больше отдаляются от «основного кода». Вместо этого они всё больше уходят на обработку контекста, в котором работает основной код.
В результате высококвалифицированные разработчики тратят большую часть времени на совершенствование таких аспектов системы, как масштабируемость, производительность, проверка ошибок, надёжность, сопровождаемость, абстракция, переносимость, обработка граничных условий и т. д.
Кроме того, они узнают, как работать более эффективно или улучшить взаимодействие с другими разработчиками и как подойти к работе, чтобы минимизировать риски и т. д. Разработка программного обеспечения уходит от кодирования в сторону инженерных систем и решения проблем.
Архитектор программного обеспечения: чёрный пояс
------------------------------------------------

Все разработчики и инженеры должны быть в состоянии проектировать части систем и продуктов, которые собираются построить. «Архитектор программного обеспечения» выводит этот навык на более высокий уровень и делает выбор при проектировании высокоуровневых взаимодействий более крупных программных систем, разработанных другими инженерами.
### Пример
В нашем примере, среди прочего, архитектор может нарисовать такую диаграмму, чтобы направить разработку сервиса для суммирования целых чисел:
Чтобы эффективно решать такие задачи, архитектору программного обеспечения требуются годы опыта работы на всех уровнях. Этот практический опыт входит в мышечную память. Он позволяет архитектору принимать правильные решения высокого уровня, не зацикливаясь на деталях.
Тем не менее, я не верю в чистых архитекторов, то есть инженеров, которые полный рабочий день принимают решения на высоком уровне. Думаю, что надёжный архитектор должен спускаться на уровень отдельных деталей и выходить оттуда, когда это необходимо. Он готов регулярно и эффективно погружаться в код.
В боевых искусствах чёрный пояс — учитель и наставник. Думаю, что обучение и наставничество также являются задачами архитектора программного обеспечения. Преподавание, о котором я говорю, не прямое (лекции), но больше делается на примере, показывая путь и направляя людей к принятию своих решений.
Выводы
======
Серьёзные бойцы изучают боевое искусство всю жизнь; серьёзные разработчики программного обеспечения делают то же самое. Надеюсь, вы нашли полезным это обсуждение. Хочу надеяться, что оно обеспечит контекст некоторым плохо определённым терминам, а в идеале поможет объяснить, как более точно их использовать. | https://habr.com/ru/post/418467/ | null | ru | null |
# Ускоряем процесс сборки с maven
Наверное многие из Вас работают с Maven. Если так, то полагаю каждый из Вас ежедневно собирает свой проект по несколько раз, особенно если Вы сейчас в активной фазе разработки и изменения затрагивают много модулей. В определенный момент времени проект становится довольно большим и билд с каждым днем начинает выполнятся все дольше и дольше… И вот приходит время, когда пора что-то с этим делать.
###### Мигрируйте с Maven 2 на Maven 3
Вы еще используете maven2? Странно. Одна только миграция на 3-ю версию может значительно ускорить процесс сборки. В моем проекте переход на Maven 3 дал прирост в скорости сборки на 10%. Вероятней всего за счет каких-то фиксов и оптимизаций, что были сделаны в новой версии (так как заявляют разработчики количество кода было существенно уменьшено и сильно отрефакторено). Миграция займет у Вас несколько минут и в большинстве случаев будет безболезненной. Хотя есть шанс, что некоторые конфигурационные файлы все же придется подправить.
###### Используем ядра и дополнительные потоки
В Maven 3 есть замечательная опция:
```
mvn -T 4 clean intall
mvn -T 2C clean install
```
В первом случае мы явно указываем, что хотим запустить процесс сборки на 4 потока. Во втором случае мы указываем, что на каждое ядро должно быть выделено по 2 потока для процесса сборки. Это одна из новых фич нового мавена — Parallel Builds. Эта фича анализирует граф зависимостей Вашего проекта
и распихивает модули по разным потокам, сборка которых может быть выполнена параллельно.
Для моего текущего проекта скорость сборки со вторым параметром (-T 2C) ускорилась на 20%. Правда тут есть один минус. Количество ресурсов, что будет потребляться для билда может значительно вырасти. В моем случае это +30% к потребляемой памяти.
Хочу сразу обратить внимание — если связанность модулей в Вашем проекте очень низкая — то
скорость сборки этой опцией можно увеличить на порядок.
Это, кстати, повод задуматься об Вашей архитектуре проекта. Ведь если билд занимает довольно много времени, то небольшой рефакторинг поможет уменьшить эту цифру. Хотя, конечно, это все очень индивидуально.
Вообще разработчики заявляют, что прирост в скорости сборки может быть 20-50%.
###### Разделяй и властвуй
Сейчас я скажу банальность, но — если у Вас цельный проект, лучше разбить его на логические модули. Разбиение не должно становится самоцелью. Но чем больше разбиение и меньше зависимости тем быстрее происходит процесс сборки. Распределение тестов по модулям тоже увеличит производительность, да и в принципе это удобно.
###### mvnsh
Maven Shell — по сути, просто активная командная строка maven. Вся фишка в том, что она висит постоянно в памяти, следовательно при каждом новом билде нету необходимости запускать по новой JVM. В дополнение кешируются все конфигурационные файлы и все плагины уже предварительно загружены. Подробней прочитать можно [тут](http://ericmiles.wordpress.com/2010/03/23/intro-to-maven-shell/) и [тут](http://ericmiles.wordpress.com/2010/03/26/maven-shell-features/).
###### Плагины
Убедитесь, что Вы не используете лишние плагины и не используете дополнительные там, где можно обойтись без них. Мавен — это целая эко-система, поэтому важно понимать, что каждый элемент этой системы влияет на производительность в целом.
Стоит также упомянуть, что во время билда с параметром "-T" Вы можете обнаружить подобное в логе выполнения:
```
[WARNING] *****************************************************************
[WARNING] * Your build is requesting parallel execution, but project *
[WARNING] * contains the following plugin(s) that are not marked as *
[WARNING] * @threadSafe to support parallel building. *
[WARNING] * While this /may/ work fine, please look for plugin updates *
[WARNING] * and/or request plugins be made thread-safe. *
[WARNING] * If reporting an issue, report it against the plugin in *
[WARNING] * question, not against maven-core *
[WARNING] *****************************************************************
[WARNING] The following plugins are not marked @threadSafe in eridanus-supervoid-module:
[WARNING] org.codehaus.mojo:jboss-maven-plugin:1.5.0
```
Поэтому, собственно, желательно использовать последние версии плагинов, потому что они с большой вероятностью могут быть уже thread-safe. Как Вы понимаете — если плагин не thread-safe, то все его задачи, не могут быть распределены между потоками при опции "-T".
Буду благодарен за любую дополнительную информацию, которая поможет ускорить сборку. | https://habr.com/ru/post/141393/ | null | ru | null |
# Создание следов на снегу в Unreal Engine 4

Если вы играете в современные AAA-игры, то могли заметить тенденцию использования покрытых снегом ландшафтов. Например, они есть в *Horizon Zero Dawn*, *Rise of the Tomb Raider* и *God of War*. Во всех этих играх у снега есть важная особенность: на нём можно оставлять следы!
Благодаря такому взаимодействию с окружением усиливается погружение игрока в игру. Оно делает окружение более реалистичным, и будем честными — это просто интересно. Зачем тратить долгие часы на создание любопытных механик, если можно просто позволить игроку упасть на землю и делать снежных ангелов?
В этом туториале вы научитесь следующему:
* Создавать следы с помощью захвата сцены для маскировки объектов, близких к земле
* Использовать маску с материалом ландшафта, чтобы создавать деформируемый снег
* Для оптимизации отображать следы на снегу только рядом с игроком
> *Примечание:* подразумевается, что вам уже знакомы основы работы с Unreal Engine. Если вы новичок, то изучите нашу серию туториалов [Unreal Engine для начинающих](https://habr.com/post/344394/).
Приступаем к работе
-------------------
Скачайте [материалы](https://koenig-media.raywenderlich.com/uploads/2018/06/SnowDeformation.zip) для этого туториала. Распакуйте их, перейдите в *SnowDeformationStarter* и откройте *SnowDeformation.uproject*. В этом туториале мы будем создавать следы с помощью персонажа и нескольких ящиков.

Прежде чем мы начнём, вам нужно знать, что способ из этого туториала будет сохранять следы только в заданной области, а не во всём мире, потому что скорость зависит от разрешения целевого рендера.
Например, если мы хотим хранить следы для большой области, то придётся увеличивать разрешение. Но это также увеличивает влияние захвата сцены на скорость игры и объём памяти под целевой рендер. Для оптимизации необходимо ограничить область действия и разрешение.
Разобравшись с этим, давайте узнаем, что нужно для реализации следов на снегу.
Реализация следов на снегу
--------------------------
Первое, что нужно для создания следов — это *целевой рендер*. Целевой рендер (render target) будет маской в градациях серого, в которой белый цвет обозначает наличие следа, а чёрный — его отсутствие. Затем мы можем спроецировать целевой рендер на землю и использовать его для смешивания текстур и смещения вершин.
Второе, что нам потребуется — это способ маскирования только влияющих на снег объектов. Это можно реализовать, сначала рендеря объекты в *Custom Depth*. Затем можно использовать *захват сцены (scene capture)* с *материалом постобработки (post process material)* для маскировки всех объектов, отрендеренных в Custom Depth. Потом можно вывести маску в целевой рендер.
> *Примечание:* захват сцены (scene capture) — это, по сути, камера с возможностью вывода целевого рендера.
Самая важная часть захвата сцены — это *место* его расположения. Ниже показан пример целевого рендера, захваченного из *вида сверху*. Здесь маскируются персонаж от третьего лица и ящики.

На первый взгляд захват с видом сверху нам подходит. Формы выглядят соответствующим мешам, поэтому проблем быть не должно, правда?
Не совсем. Проблема захвата из вида сверху заключается в том, что он не захватывает ничего под самой широкой точкой. Вот пример:
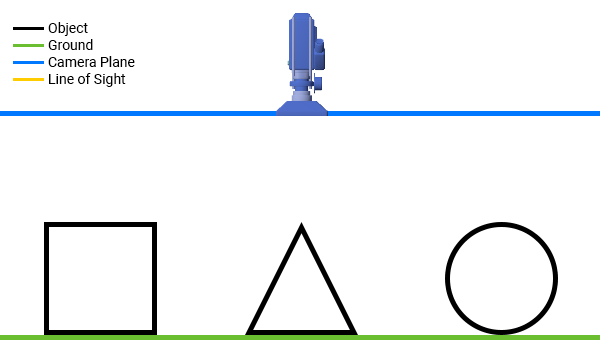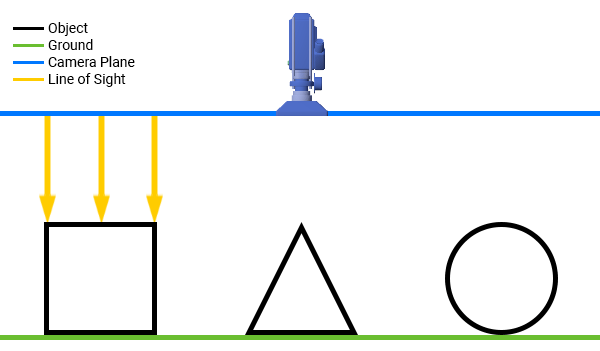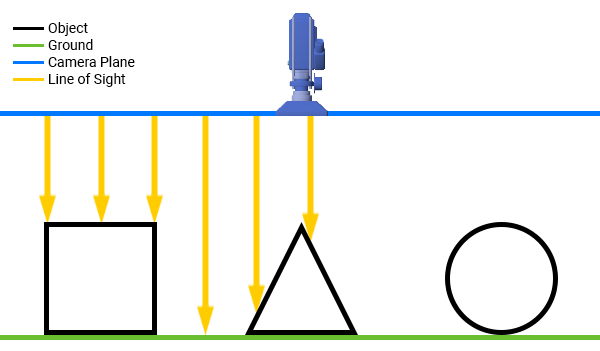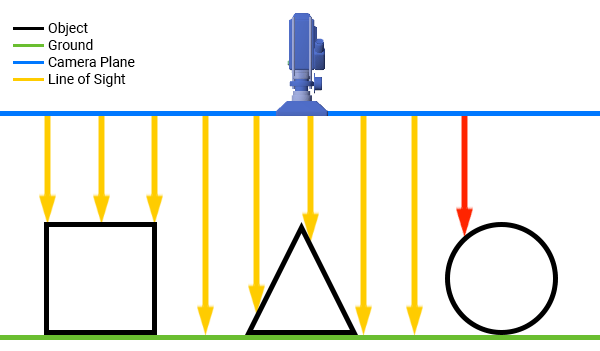
представьте, что жёлтые стрелки проходят весь путь до земли. В случае куба и конуса остриё стрелки всегда будет оставаться внутри объекта. Однако в случае сферы остриё при приближении к земле выходит из неё. Но по мнению камеры остриё всегда находится внутри сферы. Вот как будет выглядеть сфера для камеры:
Поэтому маска сферы будет больше, чем должна, даже если область контакта с землёй мала.
Кроме того, эта проблема дополняется тем, что нам сложно определить, касается ли объект земли.
Справиться с обеими этими проблемами можно с помощью захвата *снизу*.
### Захват снизу
Захват снизу выглядит следующим образом:
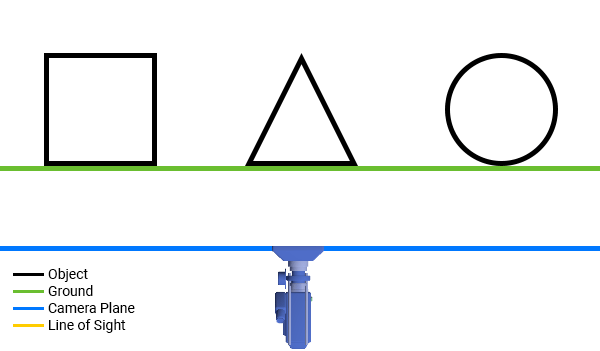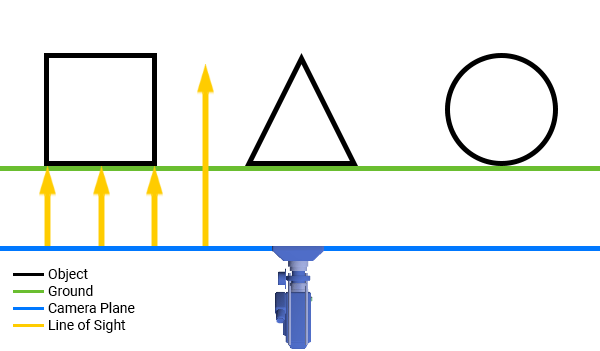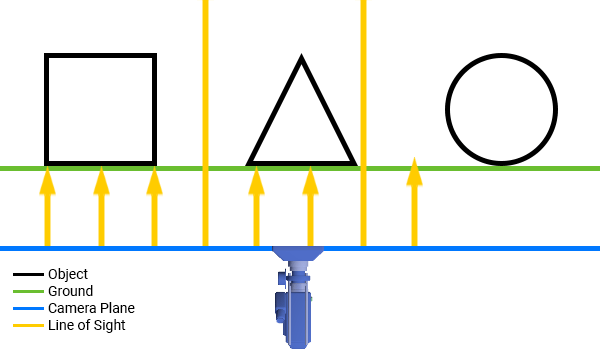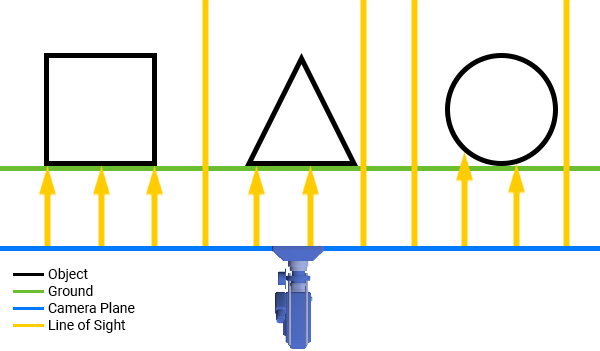
Как видите, камера теперь захватывает нижнюю сторону, то есть ту, которая касается земли. Это устраняет проблему «самой широкой области», появляющуюся при захвате сверху.
Чтобы определить, касается ли объект земли, можно для выполнения проверки глубины использовать материал постобработки. Он проверяет, больше ли глубина объекта глубины земли *и* ниже ли она заданного смещения. Если оба условия соблюдаются, то мы можем замаскировать этот пиксель.
Ниже представлен пример внутри движка с зоной захвата в 20 единицах над землёй. Заметьте, что маска появляется только когда объект проходит через определённую точку. Также заметьте, что маска становиться белее при приближении объекта к земле.

Для начала создадим материал постобработки для выполнения проверки глубины.
Создание материала проверки глубины
-----------------------------------
Для выполнения проверки глубины нужно использовать два буфера глубины — один для земли, другой для влияющих на снег объектов. Так как захват сцены видит только землю, *Scene Depth* будет выводить глубину для земли. Чтобы получить глубину для объектов, мы просто будем рендерить их *Custom Depth*.
> *Примечание:* для экономии времени я уже отрендерил персонажа и ящики в Custom Depth. Если вы хотите добавить другие влияющие на снег объекты, то необходимо включить для них *Render CustomDepth Pass*.
Во-первых, нужно вычислить расстояние каждого пикселя до земли. Откройте *Materials\PP\_DepthCheck* и создайте следующее:
Далее необходимо создать зону захвата. Для этого добавьте выделенные ноды:
Теперь если пиксель находится в пределах *25* единиц от земли, то он появится в маске. Яркость маскирования зависит от того, насколько пиксель близок к земле. Нажмите на *Apply* и вернитесь в основной редактор.
Далее нужно создать захват сцены.
Создание захвата сцены
----------------------
Сначала нам необходим целевой рендер, в который можно записывать захват сцены. Перейдите в папку *RenderTargets* и создайте новый *Render Target* под названием *RT\_Capture*.
Теперь давайте создадим захват сцены. В этом туториале мы добавим захват сцены в блюпринт, потому что позже нам понадобится для него скрипт. Откройте *Blueprints\BP\_Capture* и добавьте *Scene Capture Component 2D*. Назовите его *SceneCapture*.
Сначала нам нужно задать поворот захвата, чтобы он смотрел на землю. Перейдите в панель Details и задайте *Rotation* значения *(0, 90, 90)*.
Дальше идёт тип проецирования. Поскольку маска — это 2D-представление сцены, нам нужно избавиться от перспективного искажения. Для этого зададим для *Projection\Projection Type* значение *Orthographic*.
Далее нам нужно сообщить захвату сцены, в какой целевой рендер выполнять запись. Для этого выберем для *Scene Capture\Texture Target* значение *RT\_Capture*.
Наконец, нам нужно использовать материал проверки глубины. Добавим к *Rendering Features\Post Process Materials* *PP\_DepthCheck*. Чтобы постобработка работала, нам нужно также изменить *Scene Capture\Capture Source* на *Final Color (LDR) in RGB*.
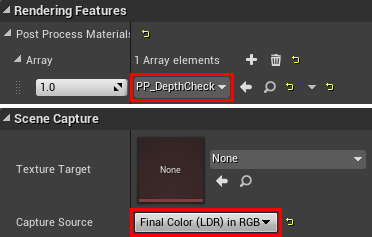
Теперь, когда захват сцены настроен, нам нужно указать размер области захвата.
### Задание размера области захвата
Так как для целевого рендера лучше использовать низкие разрешения, нам нужно пользоваться пространством эффективно. То есть мы должны выбрать, какую область будет покрывать один пиксель. Например, если разрешения области захвата и целевого рендера одинаковы, то мы получаем соотношение 1:1. Каждый пиксель будет покрывать область 1×1 (в единицах измерения мира).
Для следов на снегу соотношение 1:1 не требуется, потому что такая детализация нам скорее всего не понадобится. Я рекомендую использовать бОльшие соотношения, потому что это позволит вам увеличить размер области захвата при низком разрешении. Но не делайте соотношение слишком большим, иначе начнут теряться детали. В этом туториале мы будем использовать соотношение 8:1, то есть размер каждого пикселя будет 8×8 единиц измерения мира.
Можно изменить размер области захвата, меняя свойство *Scene Capture\Ortho Width*. Например, если вы хотите выполнять захват области 1024×1024, то задайте значение 1024. Так как мы используем соотношение 8:1, задайте значение *2048* (разрешение целевого рендера по умолчанию равно 256×256).
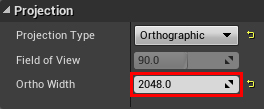
Это значит, что захват сцены будет захватывать область *2048×2048*. Это приблизительно 20×20 метров.
Материалу земли тоже необходим доступ к размеру захвата для правильного проецирования целевого рендера. Проще всего это сделать, сохраняя размер захвата в *Material Parameter Collection*. По сути, это коллекция переменных, к которой может получить доступ *любой* материал.
### Сохранение размера захвата
Вернитесь в основной редактор и перейдите в папку *Materials*. Создайте *Material Parameter Collection*, которая будет находиться в *Materials & Textures*. Переименуйте её в *MPC\_Capture* и откройте.
Затем создайте новый *Scalar Parameter* и назовите его *CaptureSize*. Не беспокойтесь о задании его значения — мы займёмся этим в блюпринтах.
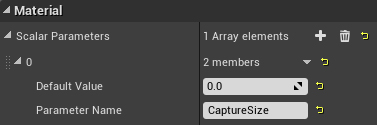
Вернитесь к *BP\_Capture* и добавьте к *Event BeginPlay* выделенные ноды. Выберите для *Collection* значение *MPC\_Capture*, а для *Parameter Name* значение *CaptureSize*.
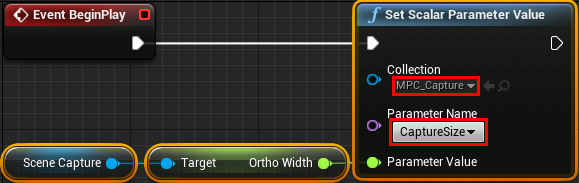
Теперь любой материал может получать значение *Ortho Width*, считывая его из параметра *CaptureSize*. Пока с захватом сцены мы закончили. Нажмите на *Compile* и вернитесь в основной редактор. Следующий шаг — проецирование целевого рендера на землю и использование его для деформации ландшафта.
Деформация ландшафта
--------------------
Откройте *M\_Landscape* и перейдите в панель Details. Затем задайте следующие свойства:
* Для *Two Sided* выберите значение *enabled*. Так как захват сцены будет «смотреть» снизу, он будет видеть только обратные грани земли. По умолчанию движок не рендерит обратные грани мешей. Это значит, что он не будет сохранять глубину земли в буфер глубин. Чтобы исправить это, нам нужно сказать движку рендерить обе стороны меша.
* Для *D3D11 Tessellation* выберите значение *Flat Tessellation* (также можно использовать PN Triangles). Тесселляция разобьёт треугольники меша на более мелкие. По сути это увеличивает разрешение меша и позволяет нам получать более тонкие детали при смещении вершин. Без этого плотность вершин будет слишком мала для создания правдоподобных следов.
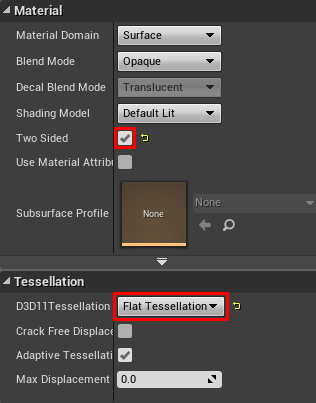
После включения тесселляции включатся *World Displacement* и *Tessellation Multiplier*.
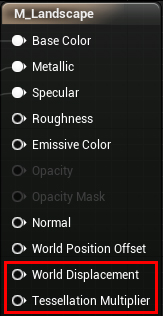
*Tessellation Multipler* управляет величиной тесселляции. В этом туториале мы не будет подключать этот нод, то есть используем значение по умолчанию (*1*).
*World Displacement* получает векторное значение, описывающее, в каком направлении и насколько перемещать вершину. Чтобы вычислить значение для этого контакта, нам нужно сначала спроецировать целевой рендер на землю.
### Проецирование целевого рендера
Для проецирования целевого рендера необходимо вычислить его UV-координаты. Для этого нужно создать следующую схему:

Что здесь происходит:
1. Сначала нам нужно получить позицию по XY текущей вершины. Так как мы выполняем захват снизу, координата X перевёрнута, поэтому необходимо перевернуть её обратно (если бы мы выполняли захват сверху, нам бы это не понадобилось).
2. В этой части выполняются две задачи. Во-первых, она центрирует целевой рендер таким образом, чтобы его середина находилась в координатах *(0, 0)* мирового пространства. Затем она преобразует координаты из мирового пространства в UV-пространство.
Далее создадим выделенные ноды и соединим предыдущие расчёты так, как показано ниже. Для текстуры *Texture Sample* выберите значение *RT\_Capture*.
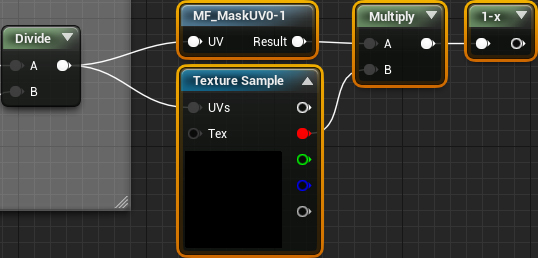
Это спроецирует целевой рендер на землю. Однако все вершины за пределами области захвата будут сэмплировать грани целевого рендера. На самом деле это проблема, потому что целевой рендер должен использоваться только для вершин внутри области захвата. Вот, как это выглядит в игре:

Чтобы исправить это, нам нужно замаскировать все UV, находящиеся за пределами интервала от 0 до 1 (то есть области захвата). Для этого я создал функцию *MF\_MaskUV0-1*. Она возвращает *0*, если переданная UV находится за пределами интервала от 0 до 1 и возвращает *1*, если в его пределах. Умножая результат на целевой рендер, мы выполняем маскирование.
Теперь, когда мы спроецировали целевой рендер, можно использовать его для смешивания цветов и смещения вершин.
### Использование целевого рендера
Давайте начнём со смешения цветов. Для этого мы просто соединим *1-x* с *Lerp*:
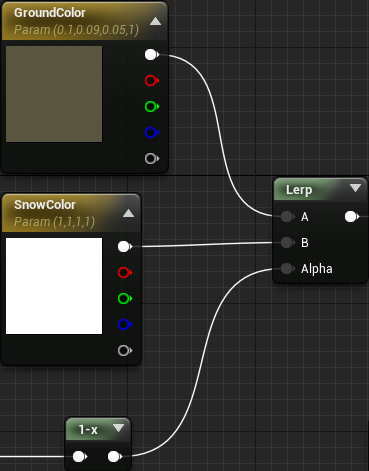
> *Примечание:* если вы не понимаете, почему я использую *1-x*, объясню — это нужно для инвертирования целевого рендера, чтобы вычисления стали чуть проще.
Теперь, когда у нас есть след, цвет земли становится коричневым. Если цвета нет, он остаётся белым.
Следующий шаг — смещение вершин. Для этого добавим выделенные ноды и соединим всё следующим образом:
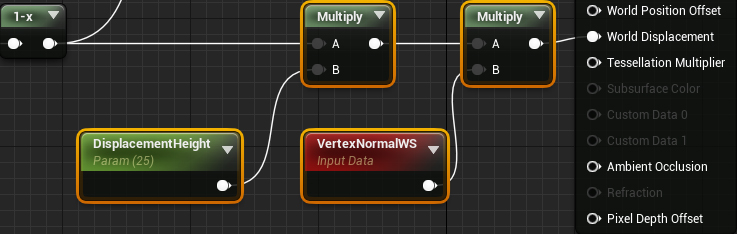
Это приведёт к тому, что все снежные области переместятся вверх на *25* единиц. Области без снега имеют нулевое смещение, благодаря чему будет создаваться след.
> *Примечание:* можно менять *DisplacementHeight* для повышения или уменьшения уровня снега. Также заметьте, что DisplacementHeight — это то же значение, что и смещение захвата. Когда они имеют одинаковое значение, это даёт нам точную деформацию. Но существуют случаи, когда требуется менять их по отдельности, поэтому я оставил их отдельными параметрами.
Нажмите на *Apply* и вернитесь в основной редактор. Создайте на уровне экземпляр *BP\_Capture* и задайте ему координаты *(0, 0, -2000)*, чтобы разместить его под землёй. Нажмите на *Play* и побродите вокруг с помощью клавиш *W*, *A*, *S* и *D*, чтобы деформировать снег.

Деформация работает, но следов не остаётся! Так получилось, потому что захват перезаписывает целевой рендер каждый раз при выполнении захвата. Нам нужен какой-то способ, чтобы сделать следы *постоянными*.
Создание постоянных следов
--------------------------
Для создания постоянства нам необходим ещё один целевой рендер (*постоянный буфер*), в котором будет сохраняться всё содержимое захвата перед перезаписью. Затем мы будем добавлять постоянный буфер к захвату (после его перезаписи). Мы получим цикл, в котором каждый целевой рендер выполняет запись в другой. Вот так мы создадим постоянство следов.
Во-первых, нам нужно создать постоянный буфер.
### Создание постоянного буфера
Перейдите в папку *RenderTargets* и создайте новый *Render Target* под названием *RT\_Persistent*. В этом туториале нам не придётся менять параметры текстур, но в собственном проекте вам необходимо будет убедиться, что оба целевых рендера используют одинаковое разрешение.
Далее нам необходим материал, который будет копировать захват в постоянный буфер. Откройте *Materials\M\_DrawToPersistent* и добавьте нод *Texture Sample*. Выберите ему текстуру *RT\_Capture* и соедините его следующим образом:
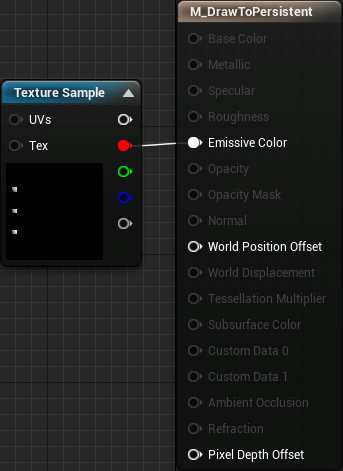
Теперь нам необходимо использовать материал отрисовки (draw material). Нажмите на *Apply*, а затем откройте *BP\_Capture*. Сначала создадим динамический экземпляр материала (позже нам нужно будет передавать в него значения). Добавьте к *Event BeginPlay* выделенные узлы:
[](https://koenig-media.raywenderlich.com/uploads/2018/06/unreal-engine-snow-20.jpg)
Ноды *Clear Render Target 2D* очищают перед использованием каждый целевой рендер.
Затем откройте функцию *DrawToPersistent* и добавьте выделенные ноды:
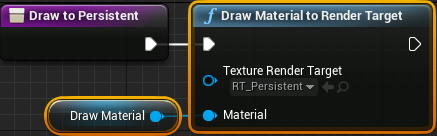
Далее нам нужно сделать так, чтобы отрисовка в постоянный буфер выполнялась в каждом кадре, потому что захват происходит в каждом кадре. Для этого добавим *DrawToPersistent* к *Event Tick*.
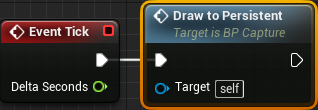
Наконец, нам нужно добавить постоянный буфер обратно в целевой рендер захвата.
### Запись обратно в захват
Нажмите на *Compile* и откройте *PP\_DepthCheck*. Затем добавьте выделенные ноды. Для *Texture Sample* задайте значение *RT\_Persistent*:
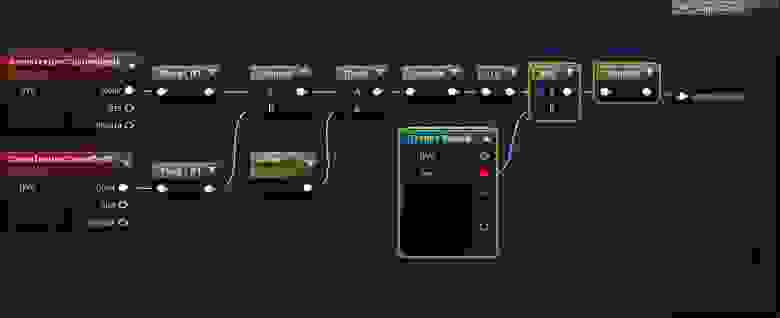
Теперь, когда целевые рендеры выполняют запись друг в друга, мы получим сохраняющиеся следы. Нажмите на *Apply*, а затем закройте материал. Нажмите на *Play* и начинайте оставлять следы!

Результат выглядит отлично, но получившаяся схема работает только для одной области карты. Если выйти за пределы области захвата, то следы перестанут появляться.

Можно решить эту проблему, перемещая область захвата *вместе* с игроком. Это означает, что следы всегда будут появляться вокруг области, в которой находится игрок.
*Примечание:* так как захват перемещается, вся информация за пределами области захвата убирается. Это значит, что если вернуться в область, где уже были следы, то они уже пропадут. В следующем туториале я расскажу, как создать частично сохраняющиеся следы.
Перемещение захвата
-------------------
Можно решить, что достаточно просто привязать позицию захвата по XY к позиции игрока по XY. Но если так сделать, то целевой рендер начнёт размываться. Так происходит потому, что мы двигаем целевой рендер с шагом, который меньше пикселя. Когда такое случается, новая позиция пикселя оказывается *между* пикселями. В результате один пиксель интерполируются несколько пикселей. Вот как это выглядит:

Чтобы устранить эту проблему, нам нужно двигать захват дискретными шагами. Мы вычислим *размер пикселя в мире*, а затем переместим захват на шаги, равные этому размеру. Тогда каждый пиксель никогда не окажется между другими, поэтому размытие не будет появляться.
Для начала давайте создадим параметр, в котором будет храниться местоположение захвата. Он понадобится материалу земли для выполнения вычислений проецирования. Откройте *MPC\_Capture* и добавьте *Vector Parameter* под названием *CaptureLocation*.
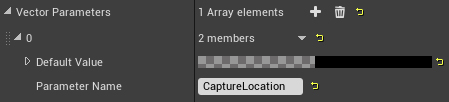
Далее необходимо обновить материал земли, чтобы использовать новый параметр. Закройте *MPC\_Capture* и откройте *M\_Landscape*. Измените первую часть вычислений проецирования следующим образом:
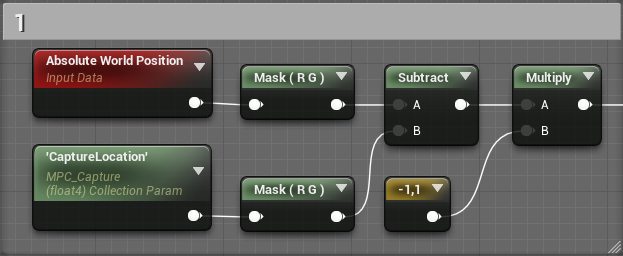
Теперь целевой рендер всегда будет проецироваться на местоположение захвата. Нажмите на *Apply* и закройте материал.
Далее мы сделаем так, чтобы захват перемещался с дискретным шагом.
### Перемещение захвата с дискретным шагом
Для вычисления размера пикселя в мире можно использовать следующее уравнение:
```
(1 / RenderTargetResolution) * CaptureSize
```
Для вычисления новой позиции мы используем показанное ниже уравнение для каждого компонента позиции (в нашем случае — для координат X и Y).
```
(floor(Position / PixelWorldSize) + 0.5) * PixelWorldSize
```
Теперь используем их в блюпринте захвата. Чтобы сэкономить время, я создал для второго уравнения макрос *SnapToPixelWorldSize*. Откройте *BP\_Capture*, а затем откройте функцию *MoveCapture*. Далее создайте следующую схему:

Она будет вычислять новое местоположение, а затем сохранять разницу между новым и текущим местоположением в *MoveOffset*. Если вы используете разрешение, отличающееся от 256×256, то измените выделенное значение.
Далее добавим выделенные ноды:
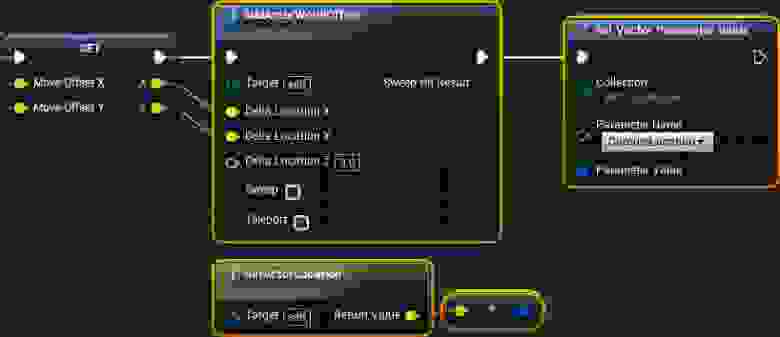
Эта схема будет перемещать захват с вычисленным смещением. Затем она будет сохранять новое местоположение захвата в *MPC\_Capture*, чтобы его мог использовать материал земли.
Наконец, нам нужно выполнять в каждом кадре обновление позиции. Закройте функцию и добавьте в *Event Tick* перед *DrawToPersistent* *MoveCapture*.
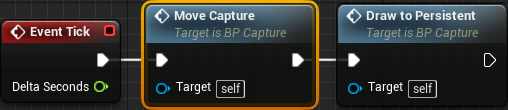
Перемещение захвата — это только половина решения. Также нам нужно перемещать постоянный буфер. В противном случае захват и постоянный буфер рассинхронизируются и будут создавать странные результаты.

### Перемещение постоянного буфера
Для сдвига постоянного буфера нам нужно передавать вычисленное смещение перемещения. Откройте *M\_DrawToPersistent* и добавьте выделенные ноды:
Благодаря этому постоянный буфер будет сдвигаться на величину переданного смещения. Как и в материале земли, нам необходимо переворачивать координату X и выполнять маскировку. Нажмите на *Apply* и закройте материал.
Затем необходимо передать смещение. Откройте *BP\_Capture*, а затем откройте функцию *DrawToPersistent*. Далее добавьте выделенные ноды:
Так мы преобразуем *MoveOffset* в UV-пространство, а затем передаём его в материал отрисовки.
Нажмите на *Compile*, а затем закройте блюпринт. Нажмите на *Play* и побегайте всласть! Как бы далеко вы ни убежали, вокруг вас всегда будут оставаться следы.

Куда двигаться дальше?
----------------------
Готовый проект можно скачать отсюда.
Не обязательно использовать созданные в этом туториале следы только для снега. Можно применять их даже для таких вещей, как примятая трава (в следующем туториале я покажу, как создать расширенную версию системы).
Если вы хотите ещё поработать с ландшафтами и целевыми рендерами, то рекомендую посмотреть видео Криса Мёрфи [Building High-End Gameplay Effects with Blueprint](https://www.youtube.com/watch?v=67z5u8ZcEcw). Из этого туториала вы научитесь создавать огромный лазер, сжигающий землю и траву! | https://habr.com/ru/post/416703/ | null | ru | null |
# Работа с PGPool + ORM Yii2
Сегодня будет небольшой «хак» для ORM Yii2, если вы используете PGPool.
Да, это опять некие костыли (как и в первой моей статье), но мне кажется, что эти (учитывая победное шествие PostgreSQL) могут и пригодится даже большему числу людей.
Все кто работают с PGPool в режиме Master-Slave рано или поздно столкнутся с задачей, когда делать селекты надо непременно из мастера. Благо разработчики о нас позаботились и дали такую возможность. Кто видел схему работы PGPool меня поймут: пишем перед селектом нехитрую строчку /\*NO LOAD BALANCE\*/ и наш запрос PGpool отправит в мастер базу.
Проблемы начинаются тогда, когда нам нужно использовать ORM.
На примере Yii2 мы пока решили это так:
Переопределяем класс ActiveQuery и, главное, его метод createCommand()
```
class ActiveQuery extends \yii\db\ActiveQuery {
private $_noLoadBalance = false;
/**
* Не отправлять запрос на балансировщик, а прямо в мастер
*
* @return $this
*/
public function noBalance() {
$this->_noLoadBalance = true;
return $this;
}
/**
* @inheritdoc
*/
public function createCommand($db = null)
{
/* @var $modelClass ActiveRecord */
$modelClass = $this->modelClass;
if ($db === null) {
$db = $modelClass::getDb();
}
if ($this->sql === null) {
list ($sql, $params) = $db->getQueryBuilder()->build($this);
} else {
$sql = $this->sql;
$params = $this->params;
}
$comment = '';
if (true === $this->_noLoadBalance) {
$comment = '/*NO LOAD BALANCE*/';
}
return $db->createCommand($comment . $sql, $params);
}
}
```
А используем мы это так:
```
$user = User::find()->where([
User::ATTR_ID => $userid,
])
->noBalance()
->one();
```
И, очень хочется, чтобы разработчики Yii все-таки как-то это сделали «внутри» из коробки. | https://habr.com/ru/post/307248/ | null | ru | null |
# Философия ActiveRecord
Сегодня в нашей заметке мы рассмотрим паттерн под названием ActiveRecord, который представляет из себя средство работы с базой данных. Сразу же попрошу профессионалов сильно такого рода заметки не критиковать. Написаны они лишь для того, чтобы заитересовать, дать стимул читать такие книженции как Agile Web Development with Ruby on Rails.
ActiveRecord правильнее даже будет назвать реализацией технологии ORM:
*«ORM (англ. Object-relational mapping) — технология программирования, которая связывает базы данных с концепциями объектно-ориентированных языков программирования, создавая «виртуальную объектную базу данных»*
ActiveRecord в Ruby on Rails очень меня порадовал, когда впервые с ним познакомился. Его реализации можно найти в разных веб фреймворках, как RoR, CakePHP, Castle и так далее. Идея его состоит в том, что каждая **таблица** базы данных превращается в **класс**, каждая **строка** таблицы в **объект** этого класса. ActiveRecord обеспечивает методы работы с данными каждого столбца таблицы.
Скажем, пусть у нас будет таблица с данными Хабра-населения **users**, тогда добавить запись о новом комраде, желающем пополнить эти стройные ряды можно будет таким образом:
`x = User.new
x.name = "Роман Иванов"
x.login = "ivanov"
x.email = "no@reply.com"
x.homepage = "ivanov-thebest.com -- просто лучший и все здесь"
x.save`
Эти магические операции создадут и отправят в базу следующий запрос:
`INSERT INTO users (name, login, email, homepage) VALUES
\ ('Роман Иванов', 'ivanov', 'no@reply.com', 'ivanov-thebest.com -- просто лучший и все здесь');`
С не меньшим успехом можно искать и выбирать записи из базы таким образом:
`#найдем всех пользователей
f = User.find(:all)
#найдем пользователя с логином ivanov
search_str = "ivanov"
f = User.find(:first, :conditions => ["login = ?", search_str])`
Такой прием автоматически защитит нас от SQL-инъекции (это будет сделано Рельсам за нас в варианте приведенном выше), а также сгенерирует следующий запрос:
`SELECT * FROM users WHERE login = 'ivanov'`
Благодаря Рельсам и их заботливым разработчикам приведенное выше можно сделать еще проще:
`f = User.find_by_login("ivanov")`
Вот, в самом кратком кратце все, снасти расставлены :) А кто заинтересовался советую начать со странички РельсоВики посвященной [ActiveRecord](http://wiki.rubyonrails.org/rails/pages/ActiveRecord), а дальше (если сразу хочется поперед батька в пекло) открыть [Active Record Reference Documentation](http://ar.rubyonrails.org/). Ленивым предлагаю продолжать читать этот блог, еще чего-нибудь обязательно расскажем, благо про ActiveRecord рассказов непочатый край. Смелым — не ждать продолжения, а пробовать-пробовать-пробовать. | https://habr.com/ru/post/11525/ | null | ru | null |
# Эмуляция носителя FAT32 на stm32f4
Недавно возникла данная задача — эмуляция носителя FAT32 на stm32f4.
Её необычность заключается в том, что среди обвязки микроконтроллера вовсе может не быть накопителя.
В моём случае накопитель был, но правила работы с ним не позволяли разместить файловую систему. В ТЗ, тем не менее, присутствовало требование организовать Mass Storage интерфейс для доступа к данным.
Результатом работы явился модуль, который я озаглавил «emfat», состоящий из одноимённого .h и .c файла.
Модуль независим от платформы. В прилагаемом примере он работает на плате stm32f4discovery.
Функция модуля — отдавать куски файловой системы, которые запросит usb-host, подставляя пользовательские данные, если тот пытается считать некоторый файл.
#### Кому может быть полезным
В первую очередь — полезно в любом техническом решении, где устройство предлагает Mass Storage интерфейс в режиме «только чтение». Эмуляция FAT32 «на лету» в этом случае позволит хранить данные как Вам угодно, без необходимости поддерживать ФС.
Во вторую очередь — полезно эстетам. Тому кто не имеет физический накопитель, но хочет видеть своё устройство в виде диска в заветном «Мой компьютер». В корне диска при этом могут находиться инструкция, драйверы, файл с описанием версии устройства, и пр.
В этом случае, нужно заметить, вместо эмуляции носителя, можно отдавать хосту части «вкомпиленного» слепка преподготовленной ФС. Однако в этом случае, вероятнее всего, расход памяти МК будет существенно выше, а гибкость решения — нулевая.
#### Итак, как это работает.
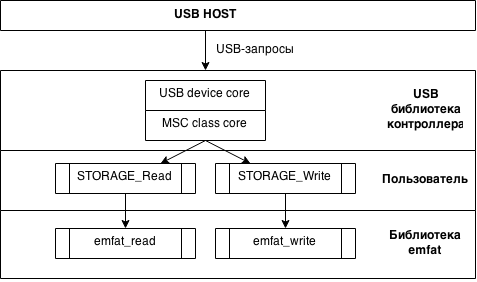
При попытке пользователя прочитать или записать файл, соответствующий вызов транслируется в usb-запросы, которые передаются нашему устройству. Суть запросов проста — записать или считать сектор на конечном носителе.
При этом, надо отметить, винда (или другая ОС) ведёт себя как хозяйка в плане организации хранения на носителе. Только она знает какой сектор хочет считать или записать. А захочет — и вовсе дефрагментирует нас, устроив хаотичное «жанглирование» секторами… Таким образом, функция типового USB MSC контроллера — безропотно вылить на носитель порцию в 512 байт со сдвигом, или считать порцию.
Теперь вернёмся к функции эмуляции.
Сразу предупрежу, мы не эмулируем запись на носитель. Наш «носитель» только для чтения.
Это связано с повышенной сложностью контроля за формированием файловой таблицы.
Тем не менее, в API модуля присутствует функция-пустышка emfat\_write. Возможно, в будущем будет найдено решение для корректной эмуляции записи.
Задача модуля при запросе на чтение — «отдать» валидные данные. В этом и состоит его основная работа. В зависимости от запрашиваемого сектора, этими данными могут являться:
* Запись MBR;
* Загрузочный сектор;
* Один из секторов файловой таблицы FAT1 или FAT2;
* Сектор описания директории;
* Сектор данных, относящийся к файлу.
Надо отметить, что на ускорение принятия решения «какие данные отдать» был сделан акцент. Поэтому накладные расходы были минимизированы.
Из-за того что мы отказались от обслуживания записи на накопитель, мы вольны организовать структуру хранения, как нам захочется:

Всё совершенно стандартно, кроме нескольких деталей:
* Данные не фрагментированы;
* Отсутствуют некоторые ненужные области FAT;
* Свободных кластеров нет (размер носителя «подогнан» под размер данных);
* Размер FAT-таблиц также «подогнан» под размер данных.
Естественно, нужно понимать, что данная структура мнимая. В реальности она не содержится в оперативной памяти, а формируется соответствующим образом, в зависимости от номера читаемого сектора.
#### API модуля
API составлен всего из трёх функций:
```
bool emfat_init(emfat_t *emfat, const char *label, emfat_entry_t *entries);
void emfat_read(emfat_t *emfat, uint8_t *data, uint32_t sector, int num_sectors);
void emfat_write(emfat_t *emfat, const uint8_t *data, uint32_t sector, int num_sectors);
```
Из них главная функция — emfat\_init.
Её пользователь вызывает один раз — при подключении нашего usb-устройства или на старте контроллера.
Параметры функции — экземпляр файловой системы (emfat), метка раздела (label) и таблица элементов ФС (entries).
Таблица задаётся как массив структур emfat\_entry\_t следующим образом:
```
static emfat_entry_t entries[] =
{
// name dir lvl offset size max_size user read write
{ "", true, 0, 0, 0, 0, 0, NULL, NULL }, // root
{ "autorun.inf", false, 1, 0, AUTORUN_SIZE, AUTORUN_SIZE, 0, autorun_read_proc, NULL }, // autorun.inf
{ "icon.ico", false, 1, 0, ICON_SIZE, ICON_SIZE, 0, icon_read_proc, NULL }, // icon.ico
{ "drivers", true, 1, 0, 0, 0, 0, NULL, NULL }, // drivers/
{ "readme.txt", false, 2, 0, README_SIZE, README_SIZE, 0, readme_read_proc, NULL }, // drivers/readme.txt
{ NULL }
};
```
Следующие поля присутствуют в таблице:
name: отображаемое имя элемента;
dir: является ли элемент каталогом (иначе — файл);
lvl: уровень вложенности элемента (нужен функции emfat\_init чтобы понять, отнести элемент к текущему каталогу, или к каталогам выше);
offset: добавочное смещение при вызове пользовательской callback-функции чтения файла;
size: размер файла;
user: данное значение передаётся «как есть» пользовательской callback-функции чтения файла;
read: указатель на пользовательскую callback-функцию чтения файла.
Callback функция имеет следующий прототип:
```
void readcb(uint8_t *dest, int size, uint32_t offset, size_t userdata);
```
В неё передаётся адрес «куда» читать файл (параметр dest), размер читаемых данных (size), смещение (offset) и userdata.
Также в таблице присутствует поле max\_size и write. Значение max\_size всегда должно быть равным значению size, а значение write должно быть NULL.
Остальные две функции — emfat\_write и emfat\_read.
Первая, как говорилось раньше, пустышка, которую, однако, мы вызываем, если от ОС приходит запрос на запись сектора.
Вторая — функция, которую мы должны вызывать при чтении сектора. Она заполняет данные по передаваемому ей адресу (data) в зависимости от запрашиваемого сектора (sector).
При чтении сектора данных, относящегося к файлу, модуль emfat транслирует номер сектора в индекс читаемого файла и смещение, после чего вызывает пользовательскую callback-функцию чтения. Пользователь, соответственно, отдаёт «кусок» конкретного файла. Откуда он берётся библиотеке не интересно. Так, например, в проекте заказчика, файлы настроек я отдавал из внутренней flash памяти, другие файлы — из ОЗУ и spi-flash.
#### Код примера
```
#include "usbd_msc_core.h"
#include "usbd_usr.h"
#include "usbd_desc.h"
#include "usb_conf.h"
#include "emfat.h"
#define AUTORUN_SIZE 50
#define README_SIZE 21
#define ICON_SIZE 1758
const char *autorun_file =
"[autorun]\r\n"
"label=emfat test drive\r\n"
"ICON=icon.ico\r\n";
const char *readme_file =
"This is readme file\r\n";
const char icon_file[ICON_SIZE] =
{
0x00,0x00,0x01,0x00,0x01,0x00,0x18, ...
};
USB_OTG_CORE_HANDLE USB_OTG_dev;
// Экземпляр виртуальной ФС
emfat_t emfat;
// callback функции чтения файлов
void autorun_read_proc(uint8_t *dest, int size, uint32_t offset, size_t userdata);
void icon_read_proc(uint8_t *dest, int size, uint32_t offset, size_t userdata);
void readme_read_proc(uint8_t *dest, int size, uint32_t offset, size_t userdata);
// Элементы ФС
static emfat_entry_t entries[] =
{
// name dir lvl offset size max_size user read write
{ "", true, 0, 0, 0, 0, 0, NULL, NULL }, // root
{ "autorun.inf", false, 1, 0, AUTORUN_SIZE, AUTORUN_SIZE, 0, autorun_read_proc, NULL }, // autorun.inf
{ "icon.ico", false, 1, 0, ICON_SIZE, ICON_SIZE, 0, icon_read_proc, NULL }, // icon.ico
{ "drivers", true, 1, 0, 0, 0, 0, NULL, NULL }, // drivers/
{ "readme.txt", false, 2, 0, README_SIZE, README_SIZE, 0, readme_read_proc, NULL }, // drivers/readme.txt
{ NULL }
};
// callback функция чтения файла "autorun.inf"
void autorun_read_proc(uint8_t *dest, int size, uint32_t offset, size_t userdata)
{
int len = 0;
if (offset > AUTORUN_SIZE) return;
if (offset + size > AUTORUN_SIZE)
len = AUTORUN_SIZE - offset; else
len = size;
memcpy(dest, &autorun_file[offset], len);
}
// callback функция чтения файла "icon.ico"
void icon_read_proc(uint8_t *dest, int size, uint32_t offset, size_t userdata)
{
int len = 0;
if (offset > ICON_SIZE) return;
if (offset + size > ICON_SIZE)
len = ICON_SIZE - offset; else
len = size;
memcpy(dest, &icon_file[offset], len);
}
// callback функция чтения файла "readme.txt"
void readme_read_proc(uint8_t *dest, int size, uint32_t offset, size_t userdata)
{
int len = 0;
if (offset > README_SIZE) return;
if (offset + size > README_SIZE)
len = README_SIZE - offset; else
len = size;
memcpy(dest, &readme_file[offset], len);
}
// Три предыдущие функции можно объединить в одну, но оставлено именно так - для наглядности
// Точка входа
int main(void)
{
emfat_init(&emfat, "emfat", entries);
#ifdef USE_USB_OTG_HS
USBD_Init(&USB_OTG_dev, USB_OTG_HS_CORE_ID, &USR_desc, &USBD_MSC_cb, &USR_cb);
#else
USBD_Init(&USB_OTG_dev, USB_OTG_FS_CORE_ID, &USR_desc, &USBD_MSC_cb, &USR_cb);
#endif
while (true)
{
}
}
```
Также ключевая часть модуля StorageMode.c (обработка событий USB MSC):
```
int8_t STORAGE_Read(
uint8_t lun, // logical unit number
uint8_t *buf, // Pointer to the buffer to save data
uint32_t blk_addr, // address of 1st block to be read
uint16_t blk_len) // nmber of blocks to be read
{
emfat_read(&emfat, buf, blk_addr, blk_len);
return 0;
}
int8_t STORAGE_Write(uint8_t lun,
uint8_t *buf,
uint32_t blk_addr,
uint16_t blk_len)
{
emfat_write(&emfat, buf, blk_addr, blk_len);
return 0;
}
```
#### Выводы
Для использования в своём проекте Mass Storage не обязательно иметь накопитель с организованной на нём ФС. Можно воспользоваться эмулятором ФС.
Библиотека реализовывает только базовые функции и имеет ряд ограничений:
* Нет поддержки длинных имён (только 8.3);
* Имя должно быть на латинице строчного регистра.
Несмотря на ограничения, лично мне в проектах имеющегося функционала хватает, но, в зависимости от востребованности, в будущем допускаю выпуск обновлённой версии.
[Репозиторий проекта](https://github.com/fetisov/emfat)
[Ссылка на архив проекта](https://cloud.mail.ru/public/3402e372b391/emfat.zip) | https://habr.com/ru/post/247673/ | null | ru | null |
# Поддержка окончена: Что делать? Кто и что может помочь?
Кажется, что об этом знают уже все: 14 июля этого года официально прекращена поддержка Windows Server 2003/R2. А дискуссия о том, что нужно делать и стоит ли вообще что-то предпринимать, продолжается. Я же предлагаю взглянуть на сложившуюся ситуацию со стратегической точки зрения. Во-первых, разобраться, как это может повлиять на бизнес-процессы компании, и взглянуть на ситуацию с юридической (а также технической и экономической) точки зрения. Во-вторых, понять, для чего нужны консультанты по миграции со старой ОС на последние версии, в чём от них польза. И, наконец, облегчить жизнь многим компаниям, рассказав о практическом опыте миграции веб- сайтов, основанных на технологии IIS с помощью утилиты Web Deployment Tool.

**Окончание поддержки Windows Server 2003/R2. Лирика
==================================================**
Что же значит для бизнеса «окончание поддержки WS2003/R2»? C первого взгляда, вероятно, может показаться, что это приведёт к:
1. Дополнительным расходам на лицензии и, возможно, новое оборудование (мы же их уже покупали 12 лет назад. Опять?!?!).
2. Проблемам с контролирующими органами (особенно для компаний, которые хранят персональные данные (а какие компании их не хранят?), так как WS2003/R2 более не получает обновлений безопасности, а это значит невыполнение требований по обеспечению сохранности персональных данных.
3. Несоответствию различным стандартам: как локальным, так и отраслевым, а это может ограничить возможность участия компании в ряде тендеров, привести к штрафным санкциям и пр.
Исходя из вышесказанного, может сложиться впечатление, что окончание поддержки WS2003/R2 — это негативное событие, ведущее к издержкам, проблемам и «снова это ИТ вместо того, чтобы помогать в кризис, просит денег». Ведь дополнительные проблемы, риски и затраты в сложный экономический период никому не нужны. К тому же, многие компании только сокращают бюджеты на ИТ и требуют от ИТ-отделов не только сокращения расходов, но повышения эффективности. Как же в таких условиях [проводить миграцию](http://icl-services.com/services/migratsiya/) и проводить ли её вообще? Может быть лучше всё оставить как есть «до лучших времён»?
Давайте разберёмся во всём по порядку. Разложим стандартную ситуацию в типовом ИТ-отделе на цели, требования и ограничения.
**Цели:**
1. Сокращение расходов на ИТ
2. Повышение эффективности
**Требования:**
1. Соответствие ожиданиям бизнеса
2. Решение и поддержка бизнес-задач со стороны ИТ
**Ограничения:**
1. Сокращённый ИТ-бюджет
2. Окончание поддержки WS2003/R2
Как мы видим, последний пункт — это лишь одна часть общей картины. И она дает отличную возможность пересмотреть всю ИТ-стратегию. Заново осмыслить ИТ-инфраструктуру компании. Посмотреть на неё под разными углами и понять, как её оптимизировать и адаптировать к новой реальности. А имеющиеся у вас проекты по модернизации, которые постоянно откладывались из-за различных технических, финансовых и прочих ограничений? Пришло время пересмотреть их и оценить заново!
Определимся, что есть в вашей инфраструктуре. Для этого в первую очередь получим ответы на такие вопросы, как:
* Сколько есть серверов? Какие ОС установлены на них?
* Какую нагрузку они испытывают и какими характеристиками/мощностями обладают?
* Есть ли у вас ОС Windows Server 2003/R2? Какие роли, сервисы и приложения на неё возложены?
* Какие из этих приложений используются? Кто их использует?
* Можно ли переместить роли, сервисы и приложения на другие сервера с последней ОС?
Помощь в получении этой информации может оказать приложение по планированию инфраструктуры [Microsoft Assessment and Planning Toolkit](http://habrahabr.ru/company/icl_services/blog/258935/). Результатом его работы будет отчёт с анализом имеющейся инфраструктуры и техническими рекомендациями по её оптимизации или переносу в облако MS Azure.
После того, как ответы на вопросы будут найдены, и проведен анализ существующей инфраструктуры, может оказаться, что:
1. У вас нет серверов с WS2003/R2.
2. У вас достаточно ресурсов, чтобы просто передать роли/службы/приложения с Windows Server 2003/R2 на другие, имеющиеся в наличии сервера с последней версией ОС и вывести их с поддержки.
3. Вы не используете максимально эффективно имеющиеся ресурсы, и есть возможность высвободить часть лицензий/оборудования.
4. То самое уникальное приложение для бухгалтерии нещадно устарело и имеет современный аналог, и уже не обязательно для него поддерживать 2003 сервер (обычно, современные приложения позволяют работать более эффективно, включают в себя новые функции и т.д.)
После того, как вы поняли, что имеете сейчас, и как это используется, пришла пора сверить своё видение дальнейшего развития ИТ с бизнесом, понять, что нужно бизнесу от ИТ:
* Каковы стратегические цели бизнеса?
* Какие у него планы на обозримую перспективу и какие ожидания от ИТ? Возможно, это повышение мобильности сотрудников? Или открытие новых филиалов по всему миру?
Оценив цели бизнеса, вы сможете выбрать максимально эффективный способ их достижения. Ведь обновляя инфраструктуру с видением перспективы, вы делаете большой задел для гибкости, масштабируемости и эффективности её дальнейшего использования. Пожалуй, здесь пришла пора вспомнить **про консультантов по миграции**. Для чего компании, и ИТ отделу в частности, может понадобиться внешний консультант по миграции? Ведь в ИТ-отделе есть классные специалисты, которые могут всё сделать сами.
Ниже в списке перечислены этапы миграции. Их длительность зависит от конкретной инфраструктуры и квалификации персонала, который будет их выполнять:
1. Анализ существующей инфраструктуры
2. Разработка плана миграции
3. Выбор оптимального решения
4. Внедрение решения (собственно, миграция)
5. Анализ и тестирование результата миграции
Теперь попробуйте оценить:
* есть ли в ИТ-отделе специалисты, способные выделить этому проекту требуемое время и обладают ли они достаточной квалификацией и опытом?
* как это скажется на текущей поддержке сервисов?
* если выполнять проект миграции без отрыва от производства, какие сроки в итоге получатся и с какой эффективностью?
* насколько качественно и продуманно будет проведена миграция и как это скажется на стабильности сервисов?
Если у вас:
* небольшие объёмы работы (менее 15 серверов);
* имеются свободные и достаточно квалифицированные ресурсы или мигрируемые сервисы/приложения не критичны,
**то оптимальным решением будет выполнить проект по миграции своими силами.**
Однако, если у вас:
* достаточно большая инфраструктура (более 15 серверов);
* есть бизнес-критичные сервисы/приложения;
* из-за ограничения «Сокращённый ИТ-бюджет» сотрудники ИТ-отдела загружены и не могут выделить нужное время для реализации проекта без вреда для оказываемых сервисов,
**то рекомендуется выбрать компанию-консультанта по миграции, которая может либо выполнить все работы по миграции, либо реализует их часть.** Например, проведет оценку существующей инфраструктуры и даст рекомендации по её модернизации, а внедрение полученных предложений вы реализуете своими силами.
Плюсы ИТ-аутсорсера в том, что это компания с высококвалифицированным профессионалом, который имеет за плечами не один законченный проект и прекрасно осведомлён о возможных «подводных камнях» и вероятных сложностях в процессе. Он поможет вам в формировании и реализации вашей ИТ-стратегии, синхронизированной со стратегией бизнеса.

Например, порекомендует внимательнее присмотреться к облачным решениям:
1. если в стратегической цели бизнеса есть пункт о повышении мобильности сотрудников, а у вас при этом есть 2003 сервер, на котором развернут MS Exchange, то может пригодиться облачное решение Office 365, вместо миграции на другой сервер.
2. если бизнес планирует открывать филиалы по всему миру, то здесь внимание уделим MS Azure.
3. возможно, также пришла пора присмотреться к гибридным облакам и рассмотреть возможность передачи ряда некритичных сервисов в публичное облако, а бизнес-критичные развернуть в частном облаке внутри организации?
*На картинке ниже можно увидеть различные варианты предоставления облачных сервисов. Доводы «За» миграцию в публичное облако:
* Нет необходимости обслуживать и сопровождать сервера
* Есть возможность выбора подходящего варианта получения ресурсов и их объемов (IaaS, PaaS или SaaS)
* Высокая отказоустойчивость.*
*Если какие-либо приложения или сервисы нельзя передавать на хостинг в публичное облако, то можно построить гибридное облако на базе Windows Server 2012 R2 & System Center 2012 R2 & Windows Azure. Доводы «За» гибридное облако:*
** Вы определяете и размещаете в своём частном облаке приложения и службы, которые не должны быть в публичном.
* У вас есть возможность использовать как ресурсы своего облака, так и MS Azure, что позволяет гибко управлять доступностью приложений или сервисов и количеством необходимых мощностей.*

**Наш опыт миграции сайтов с IIS 6.0
==================================**
Имея немалый практический опыт миграции сайтов с IIS 6.0 на последние версии, я хочу поделиться руководством по такой миграции с помощью Web Deployment Tool.
**Перед началом миграции убедитесь, что:**
1. У вас есть бэкап.
2. Если сайт использует SQL базу, убедитесь, что она была заранее мигрирована на новый сервер.
3. У вас есть все необходимые логины и пароли.
4. Все порты необходимые для работы сайтов открыты на новом сервере.
**Что можно мигрировать с помощью Web Deployment Tool?**
* 1 или 1000 веб сайтов, включая их конфигурации, контент и сертификаты.
* Приложение.
* Весь сервер (все веб-сайты, пулы приложений, ключи регистра, контент и прочее).
* Пользовательский манифест, состоящий из сайтов, пула приложений, ключей регистра, контента и пр.
Для миграции у вас должен быть установлен .NET Framework 2.0 SP1 или выше и Web Deployment Tool. (Как установить web deployment tool можно посмотреть [здесь](http://www.iis.net/learn/install/installing-publishing-technologies/installing-and-configuring-web-deploy) (eng) или [здесь](http://habrahabr.ru/post/192150/) (рус)).
**Шаг 1. Проверьте зависимости сайта и найдите скрипты или установленные компоненты, которые он использует.**
1. Проверить зависимости веб сайта можно с помощью следующей команды
```
msdeploy -verb:getDependencies -source:metakey=lm/w3svc/1
```
1 – это ID сайта
2. Посмотрите вывод зависимостей и определите, какие компоненты использует сайт. Например, если сайт использует авторизацию windows, вывод команды будет следующим:
```
/.
```
3. Если сайт наследует какие-либо скрипты, то их не будет в выводе списка зависимостей, наследуемые скрипты нужно будет проверить вручную.
Подробное описание анализа вывода команды getDependencies можно посмотреть [здесь](http://technet.microsoft.com/en-us/library/dd569091(WS.10).aspx).
**Шаг 2. Настройка целевого сервера**
Согласно полученного в 1-м шаге списка зависимостей, установите необходимые компоненты. Например, если в вашем списке зависимостей есть компоненты:
* ASP.NET
* Windows Authentication
* Anonymous Authentication
Следовательно, на основе этого списка зависимостей вам необходимо будет установить соответствующие компоненты и модули.
**Шаг 3. Миграция сайта с использованием архива**
1. Всегда делайте бэкап сервера, на который планируете миграцию. Даже в случае тестирования. Это позволит вам быстро вернуть сервер в исходное состояние
```
%windir%\system32\inetsrv\appcmd add backup “PreWebDeploy”
```
2. Чтобы создать файл с архивом сайта, на исходном сервере выполните команду:
```
msdeploy -verb:sync -source:metakey=lm/w3svc/1 -dest:package=c:\Site1.zip > WebDeployPackage.log
```
1 – это ID сайта
3. Скопируйте полученный архив на целевой сервер.
4. Для проверки, что произойдёт при запуске синхронизации, на целевом сервере выполните команду
```
msdeploy -verb:sync -source:package=c:\Site1.zip -dest:metakey=lm/w3svc/1 -whatif > WebDeploySync.log
```
1 – это ID сайта
5. После проверки результатов выполнения команды, выполните её без ключа –whatif (разумеется, если вывод предыдущей команды был без ошибок)
```
msdeploy -verb:sync -source:package=c:\Site1.zip -dest:metakey=lm/w3svc/1 > WebDeploySync.log
```
1 – это ID сайта
**Миграция сайта с использованием web deployment agent service**
Если вы хотите использовать синхронизацию сайтов в режиме реального времени, то можно воспользоваться Web Deployment Agent Service.
1. Установите Web Deployment Agent Service на исходный или целевой сервер, или на оба для максимальной гибкости возможных сценариев синхронизации (агент может как принимать синхронизируемые данные от источника, так и отправлять их)
2. Запустите сервис
```
net start msdepsvc
```
3. Запустите следующую команду, чтобы начать синхронизацию (отправку данных) с локального источника на удалённый сервер (Server1 замените именем своего сервера). Сначала рекомендуется запускать команду с флагом –whatif, а после проверки результатов её выполнения – без неё.
```
msdeploy -verb:sync -source:metakey=lm/w3svc/1 -dest:metakey=lm/w3svc/1,computername=Server1 -whatif > msdeploysync.log
```
1 – это ID сайта
4. Следующая команда запускает синхронизацию в режиме «приёма» данных с удалённого сервера
```
msdeploy -verb:sync -source:metakey=lm/w3svc/1,computername=Server1 -dest:metakey=lm/w3svc/1 -whatif > msdeploysync.log
```
1 – это ID сайта
На этом процесс миграции закончен, остаётся проверить работу сайта на целевом сервере. В случае проблем для поиска их решения можно воспользоваться [Troubleshooting Web Deploy](http://www.iis.net/learn/publish/troubleshooting-web-deploy/troubleshooting-web-deploy).
Важно помнить, что прогресс – это постоянное движение. Использование устаревших технологий очень часто означает ограничения в возможностях или отставание от прогресса, которое рано или поздно придётся навёрстывать, а чем больше отставание, тем больше усилий придётся приложить для его сокращения, не говоря уже о том, чтобы догнать лидеров.
Автор [aleksjoke](http://habrahabr.ru/users/aleksjoke/) | https://habr.com/ru/post/266637/ | null | ru | null |
# В Firefox отключат возможность устанавливать расширения без подписи
### В 41 версии обязательность подписи будет отключаемой, а в 42 эту опцию уберут совсем
Mozilla [вводит](https://wiki.mozilla.org/Addons/Extension_Signing) обязательное получение подписи для расширений браузера Firefox. Подпись можно будет получить на сайте [addons.mozilla.org](http://addons.mozilla.org/) (AMO). Все расширения должны иметь цифровую подпись вне зависимости от ресурса, где они находятся. Расширения можно будет продолжать устанавливать из сторонних источников, нужна будет лишь подпись.
Решение будет вводиться поэтапно. Следующая версия Firefox (40) начнёт предупреждать об отсутствии подписи у расширений, но не будет как-то ограничивать действия пользователя. В 41 версии по умолчанию можно будет установить только расширения с подписью. Опцию можно будет отключить изменением параметра `xpinstall.signatures.required` в окне `about:config`. В бета и релизной версиях Firefox 42 отключить обязательность подписи расширений будет невозможно.
В ночных сборках и в версии для разработчиков возможность отключить обязательность подписи останется. Также Mozilla указывает, что будут созданы специальные версии браузера только с английским интерфейсом без брэндирования и имени Firefox с возможностью отключения обязательности подписи. Подпись будет требоваться только расширениям [второго типа](https://developer.mozilla.org/en-US/Add-ons/Install_Manifests#type). Цифровая подпись не требуется для словарей, тем оформления и плагинов. Новинка коснётся только браузера Firefox. Руководители проектов Thunderbird, Seamonkey, Palemoon и т. д. примут решение самостоятельно. Но в Mozilla говорят, что о подобных намерениях им ничего неизвестно.
Если разработчик загрузил своё расширение на AMO, то от не не потребуется никаких специальных действий — Mozilla подпишет расширение самостоятельно. Новые версии будут получать подпись после прохождения проверки. Создателям отсутствующих в каталоге AMO расширений придётся регистрироваться на AMO и выгружать файл, выбрав опцию, которая отключит публикацию расширения. После прохождения автоматической проверки файл будет выслан разработчику в подписанном виде. При отрицательном решении автоматической системы можно будет запросить ручную проверку, которая займёт менее двух суток.
Mozilla заявляет, что этот процесс не означает цензуру, а лишь направлен на соблюдение уже существующих [правил](https://developer.mozilla.org/en-US/Add-ons/Add-on_guidelines). Возможность подписи дополнений для Firefox [появилась](https://blog.mozilla.org/addons/2015/02/10/extension-signing-safer-experience/) в начале года. В Google Chrome с 2014 года расширения можно устанавливать только из магазина Chrome Web Store.
[Фотография самки малой панды Кинта в зоопарке Ногеяма](https://www.flickr.com/photos/dakiny/8973352950/), CC-BY 2.0. | https://habr.com/ru/post/382805/ | null | ru | null |
# Другой IncludeJS
Только не смейтесь. Наверное это самая лучшая вводная фраза — так как ну на самом деле, «Как? Ещё один сборщик скриптов?». Да, в посте пойдёт речь о ещё одной «личной наработке ». Постараюсь не просто вбросить ещё одну либу, а поразмышлять над тем, чем же это решение могло бы быть лучше миллиона других. Возможно у меня не получится донести до вас, все как есть, но я попытаюсь, а вы не судите строго. Это будет вторая статья в серии о компонентах и MVP. Если интересно можете ознакомиться с [первой](http://habrahabr.ru/post/149509/).
### Проблема компонент
Часто компоненты/виджэты помимо скриптов состоят из других ресурсов — html разметки, стилей, картинок, компонентов. И вот, хотелось бы получить сборщик этих самых ресурсoв. Во время разработки указываете путь к директории с компонентами/библиотеками, подключаете нужное, а во время сборки html склеится в один, стили и *javascript* тоже, картинки скопируются в наше приложение — «Кушать подано». Прошу не пинать больно, такие «конструкторы» уже наверняка существуют, но подходящего я не нашёл — и к тому же, моей целью было не создать конкурирующий продукт, а сделать нужную мне вещь для себя.
[Здесь(github)](http://tenbits.github.com/IncludeJS/) эту вещь можно скачать/глянуть на апи. Того, кому эта тема показалась интересной, и кто готов уделить 10 минут на эту неумелую писанину, приглашаю под кат.
### Немного истории, или что такое правильный велосипед
Если честно, мне немного неловко называть вещи «правильными» или писать «как надо что-то делать» — ведь это все субъективно, поэтому так к этому и относитесь.
Когда перед нами стоит задача, мы оцениваем какие инструменты у нас есть для её решения, а каких нету. Также думаем, что могло бы ускорить процесс. И вот если мы решили немножко, совсем чуть-чуть, подправить существующий инструментарий — всё, первый шаг в сотню миль к велосипеду сделан. Должно быть решено ещё много подобных задач, где по кирпичику будем выстраивать функционал. Не всё переживёт поставленные задачи, где-то мы плюнем и возьмём готовые библиотеки. А где-то просто отпадёт нужда в этих самых «чуть-чуть доделать», и тогда подобно воде, которой некуда течь, превратится в болото. Но болото, это не плохо, а напротив — оно даёт жизнь миллионам видам.
Но если инструментарий пережил, это множественное «чуть-чуть доделывание», то в результате, мы получим «Вещь», где мы узнаем каждую запятую или наоборот, будущий Я удивится и посмеётся над Я настоящим. Где уже с лёгкостью добавляем, изменяем, правим функционал. Где ощущается ветер свободы, когда эта «Вещь» делает, то *что* ты хочешь, и так, *как* ты этого хочешь. Прошу прощение за это лирическое отступление.
### А сама история — банальна
* Надоело писать весь скрипт в одном файле? — Разбиваем на несколько.
* Файлов стало больше и надоело все подключать в index.html? — Немного динамики: создаём *и вставлаем в *dom**
Скрипты требуют стили и *ajax*? Вот тэг *link* с атрибутом *href* и *xmlhttprequest* с *onreadystatechange*
Скриптам надо знать, когда *вложенные/рекурсивные* ресурсы загружены? Сейчас используется дерево ресурсов и eval. За eval не ругайтесь, так как первое, он упрощает нам обработку зависимостей, и таким образом нам не надо нигде больше указывать *(в никаких package.json файлах)*, что это за модуль и что он требует. А также не надо строить конструкций вида *«define»*. И второе, цель ведь у нас будет — собрать приложение, вот там-то этот eval уже будет отсутствовать *(кроме ленивых скриптов, см. ниже)*. Хотя должен отметить, что даже если и не собирать приложение, то в этом eval-e нет ничего криминального, так как используется по назначению, одинаково быстр как и подключение скрипта через тэг и не является проблемой безопасности *(если злой человек смог дойти до возможности использовать этот eval, то собственно он ему уже даже и не нужен)*.
Нужен ленивый скрипт, который будет доступен сразу по требованию *(без никаких IDeferred)*? Схема простая: XMLHTTRequest → \_\_defineGetter\_\_ → eval. Из примера:
`include.lazy({'ui.notification':'path'})`, и как только мы вызовем `ui.notification./**eval происходит сейчас, далее вызываем функцию*/show('Hello World');` Обращу внимание, на то, что модуль должен быть с учётом того, как и что возвращает функция eval.
Нужна удобная обработка путей и маршрутизация? `"utils.js"` — путь относительный к родительскому. `"/utils.js"` — путь относительный к приложению. `.js({ dom: "zepto" })` — перед этим зарегистрируем наш маршрут `dom`: `.cfg({dom: "/scripts/dom/{name}.js"})`.
простой и неправильный пример диалогового окна, но не это главное — главное, что бы вы увидели, как просто подключается отдельный ресурс, с картинками, стилями и html разметкой. Здесь же немножко показал MaskJS в действии, а в следующей статье к ним подключится библиотека компонент, и это совсем будет торт. Хотя это снова же субъективное мнение, возможно все это ерунда, но она помогает приятно разрабатывать html5 приложения. Если знаете похожие инструменты, поделитесь ими. Также хочу предупредить, что пока это все очень сырое, но я буду продолжать над этим всем работать — приносит море удовольствия. Если бы такая штука была полезна кому-то, тогда было бы больше мотивации. Но если нет, и того хватит, что есть ;)
Удачи. | https://habr.com/ru/post/150370/ | null | ru | null |
# Кэши для «чайников»
Кэш глазами «чайника»:
Кэш – это комплексная система. Соответственно, под разными углами результат может лежать как в действительной, так и в мнимой области. Очень важно понимать разницу между тем, что мы ждем и тем, что есть на самом деле.
Давайте прокрутим полный оборот ситуаций.
Tl;dr: добавляя в архитектуру кэш важно явно осознавать, что кэш может быть средством **дестабилизации** системы под нагрузкой. Смотрите конец статьи.
Представим, что у нас есть доступ к базе данных, возвращающей курсы валют. Мы спрашиваем [rates.example.com/?currency1=XXX¤cy2=XXX](http://rates.example.com/?currency1=XXX¤cy2=XXX) и в ответ получаем plain text значение курса. Каждые 1000 запросов к базе данных для нас, допустим, стоят 1 евроцент.
Итак, теперь мы хотим показывать на нашем сайте курс доллара к евро. Для этого нам нужно получить курс, поэтому на нашем сайте мы создаём API-обёртку для удобного использования:
Например, так:
```
php // побудем немного ближе к народу :)
function get_current_rate($currency1, $currency2) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
return $rate;
} else {
return (float) $rate;
}
}
```
И в шаблонах в нужном месте вставляем что-нибудь вроде:
```
{{ get_current_rate("USD","EUR")|format(".2f") }} USD/EUR
```
(ну или даже `=sprintf(".2f", get_current_rate("USD","EUR"))?`, но это прошлый век).
Наивная имплементация делает самое простое, что можно придумать: на каждый запрос от пользователя спрашивает удалённую систему и использует ответ напрямую. Это означает, что теперь каждые 1000 просмотров пользователями нашей страницы стоят для нас на копейку больше. Казалось бы – гроши. Но вот проект растёт, у нас уже 1000 постоянных пользователей, которые каждый день заходят на сайт и просматривают по 20 страниц, а это уже 6 евро в месяц, что превращает сайт из [бесплатного](https://cloud.google.com/appengine/docs/quotas#Instances) во вполне уже сопоставимый с платой за самые дешевые выделенные виртуальные серверы.
**Вот тут на сцену выходит его величество Кэш**
Зачем нам спрашивать курс для каждого пользователя на каждое обновление страницы, если для людей эта информация, в общем-то, не нужна так часто? Давайте просто ограничим частоту обновления до, например, раз в 5 секунд. Пользователи, переходя со страницы на страницу, всё равно будут видеть новое число, а мы платить будем в 1000 раз меньше.
Сказано – сделано! Добавляем несколько строчек:
```
php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
// ссылка на https://cloud.google.com/appengine/docs/php/memcache/
$memcache = new Memcache;
$memcache-addServer("localhost", 11211);
$rate = $memcache->get($cache_key);
if ($rate) {
return $rate;
} else {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
return $rate;
} else {
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
}
}
```
Это самый главный аспект кэша: **хранение последнего результата**.
И вуаля! Сайт снова становится для нас почти бесплатным… До конца месяца, когда мы обнаруживаем от внешней системы счет на 4 евро. Конечно, не 6, но мы ожидали намного большей экономии!
К счастью, внешняя система позволяет посмотреть начисления, где мы видим всплески по 100 и более запросов каждые ровные 5 секунд в течение пиковой посещаемости.
Так мы познакомились со вторым важным аспектом кэша: **дедупликацией запросов**. Дело в том, что как только значение устарело, между проверкой наличия результата в кэше и сохранением нового значения, все пришедшие запросы фактически выполняют запрос к внешней системе одновременно.
В случае с memcache это можно реализовать, например, так:
```
php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
$memcache = new Memcache();
$memcache-addServer("localhost", 11211);
while (true) {
$rate = $memcache->get($cache_key);
if ($rate == "?") {
sleep(0.05);
} else if ($rate) {
return $rate;
} else {
// Создаём запись, только один сможет это сделать, остальные уйдут спать
if ($memcache->add($cache_key, "?", 0, 5)) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
return $rate;
} else {
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
}
}
}
}
```
И вот, наконец, потребление сравнялось с ожидаемым — 1 запрос в 5 секунд, расходы сократились до 2 евро в месяц.
Почему 2? Было 6 без кэширования для тысячи человек, мы же всё закэшировали, а сократилось всего в 3 раза? Да, стоило просчитать пораньше… 1 раз в 5 секунд = 12 в минуту = 72 в час = 576 за рабочий день = 17 тысяч в месяц, а ещё не все ходят по расписанию, есть странные личности заглядывающие поздней ночью… Вот и получается, в пике вместо сотни обращений одно, а в тихое время — по-прежнему запрос почти на каждое обращение проходит. Но всё равно, даже в худшем случае счёт должен быть 31×86400÷5 = 5.36 евро.
Так мы познакомились с еще одной гранью: кэш **помогает**, но **не устраняет** нагрузку.
Впрочем, в нашем случае люди приходят в проект и уходят и в какой-то момент начинают жаловаться на тормоза: страницы замирают на несколько секунд. А еще бывает под утро сайт не отвечает вообще… Просмотр [консоли сайта](https://console.cloud.google.com/appengine?serviceId=default&duration=P4D) показывает, что иногда днём запускаются дополнительные инстансы. В это же время скорость выполнения запросов падает до 5-15 секунд на запрос — из-за чего это и происходит.
*Упражнение для читателя: посмотреть внимательно предыдущий код и найти причину.*
Да-да-да. Конечно же, это в ветке `if ($rate === FALSE)`. Если внешний сервис вернул ошибку, мы не освободили блокировку… В том смысле, что "?" так и остался записан, и все ждут когда он устареет. Что ж, это легко исправить:
```
if ($rate === FALSE) {
$memcache->delete($cache_key);
return $rate;
} else {
```
Кстати, это грабли отнюдь не только кэша, это общий аспект распределённых блокировок: важно освобождать блокировки и иметь таймауты, во избежание дедлоков. Если бы мы добавляли "?" вообще без времени жизни, всё б замирало при первой же ошибке связи с внешней системой. К сожалению, memcache не предоставляет хороших способов для создания распределённых блокировок, использование полноценной БД с блокировками на уровне строк лучше, но это было просто лирическое отступление, необходимое просто потому, что на эти грабли наступили.
Итак, мы исправили проблему, вот только ничего не изменилось: всё равно изредка начинались тормоза. Что примечательно, они совпадали по времени с информационным бюллетенем от внешней системы о технических работах…
Ну-ка ну-ка… Давайте сделаем краткую передышку и пересчитаем, что мы насобирали уже сейчас, что должен уметь кэш:
1. помнить последний известный результат;
2. дедуплицировать запросы, когда результат еще или уже не известен;
3. обеспечивать корректную разблокировку в случае ошибки.
Заметили? Кэш должен обеспечивать пункты 1-2 и для случая ошибки! Изначально это кажется очевидным: мало ли что случилось, отвалился один запрос, следующий обновит. Вот только что произойдёт, если и следующий тоже вернет ошибку? И следующий? Вот у нас пришло 10 запросов, первый захватил блокировку, попробовал получить результат, отвалился, вышел. Следующий проверяет – так, блокировки нет, значения нет, идём за результатом. Обломался, вышел. И так для каждого. Ну глупость же! По хорошему 10 пришло, один попробовал — все отвалились. А уже следующий пусть попробует заново!
Отсюда: кэш обязан уметь какое-то время **хранить отрицательный результат**. Наше наивное исходное предположение по сути подразумевает хранение отрицательного результата 0 секунд (но передачу этого самого отрицания всем, кто уже ждёт его). К сожалению, в случае с Memcache реализация нулевого времени ожидания весьма проблематична (*оставлю как домашнее задание въедливому читателю*; cовет: используйте механизм [CAS](http://php.net/manual/en/memcached.cas.php); и да, в AppEngine можно использовать и Memcache и Memcached).
Мы же просто добавим сохранение отрицательного значения с 1 секундой жизни:
```
php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
$memcache = new Memcache();
$memcache-addServer("localhost", 11211);
while (true) {
$flags = FALSE;
$rate = $memcache->get($cache_key, $flags);
if ($rate == "?") {
sleep(0.05);
} else if ($flags !== FALSE) {
// Если ключа нет, тип не меняется, иначе будет число,
// и мы вернём любое значение из кэша, даже false.
return $rate;
} else {
if ($memcache->add($cache_key, "?", 0, 5)) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
// Здесь мы можем задать отдельный срок жизни отрицательного значения
$memcache->set($cache_key, $rate, 0, 1);
return $rate;
} else {
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
}
}
}
}
```
Казалось бы, *ну теперь-то* уже всё, и можно успокоиться? Как бы не так. Пока мы росли, наш любимый внешний сервис тоже рос, и в какой-то момент начал иногда тормозить и отвечать аж по секунде… И что примечательно – вместе с ним начал тормозить и наш сайт! Причем снова для всех! Но почему? Мы же всё кэшируем, в случае ошибок запоминаем ошибку и тем самым отпускаем всех ожидающих сразу, разве нет?
…А вот и нет. Внимательно посмотрим на код еще раз: запрос ко внешней системе будет исполняться столько, сколько позволит `file_get_contents()`. На время исполнения запроса все остальные ждут, поэтому каждый раз, когда кэш устаревает, все потоки ждут исполнения главного, и получат новые данные только, когда они поступят.
Что ж, мы можем вместо ожидания, добавить ветку `else{}` у условия вокруг `memcache->add`… Правда, стоит, наверное, вернуть последнее известное значение, да? Ведь мы кэшируем ровно затем, что мы согласны получить устаревшие сведения, если нет свежих; итак, еще одно требование к кэшу: **пусть подтормаживает не более одного запроса**.
Сказано – сделано:
```
php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
$memcache = new Memcache();
$memcache-addServer("localhost", 11211);
while (true) {
$flags = FALSE;
$rate = $memcache->get($cache_key, $flags);
if ($rate == "?") {
sleep(0.05);
} else if ($flags !== FALSE) {
return $rate;
} else {
if ($memcache->add($cache_key, "?", 0, 5)) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
// Мы не меняем последнее успешное значение, пусть смотрят на
// устарелые сведения. При желании, поведение можно изменить.
$memcache->set($cache_key, $rate, 0, 1);
return $rate;
} else {
// Ставим срок жизни бесконечным для _stale_ ключа, но можем и задать
// какой-нибудь большой: например, минуту, тем самым ограничив
// срок жизни устаревших сведений.
$memcache->set("_stale_".$cache_key, (float) $rate);
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
} else {
// Если нет актуальных данных, и не мы их обновляем —
// вернём значение из копии данных, для которых не указан срок жизни.
// Если и их нет, то вернём false, что соответствует обычному поведению.
return $memcache->get("_stale_".$cache_key);
}
}
}
}
```
Итак, мы снова победили: даже если тормозит внешний сервис, подтормаживает не более одной страницы… То есть как бы среднее время ответа сократилось, но пользователи всё равно немного недовольны.
*Примечание:* обычный PHP по умолчанию пишет сессии в файлы, блокируя параллельные запросы. Чтобы избежать этого поведения, можно передать в session\_start параметр read\_and\_close либо принудительно закрывать через session\_close сессию после совершения всех необходимых изменений, иначе тормозить будет не одна страница, а один пользователь: так как скрипт, обновляющий значение, будет блокировать открытие сессии другим запросом от того же пользователя. При исполнении на AppEngine по умолчанию включено [хранение сессий в memcache](https://cloud.google.com/appengine/docs/php/runtime#PHP_Sessions), то есть без блокировок, поэтому будет проблема не так заметна.
Так вот, пользователи всё равно недовольны (ох уж эти пользователи!). Те, кто проводят времени больше всех на сайте, всё равно замечают эти короткие зависания. И их нисколько не радует осознание факта того, что так случается редко, и им просто не везёт. Придётся *для данного случая* сделать требование еще более жестким: **никакие запросы не должны ждать ответа**.
Что же мы можем сделать в такой постановке вопроса? Мы можем:
1. Попытаться исполнить трюки «[исполнение после ответа](http://stackoverflow.com/questions/138374/close-a-connection-early)», то есть если мы должны обновить значение – регистрируем хендлер, который это сделает после исполнения всего остального скрипта. Вот только это сильно зависит от приложения и окружения исполнения; самый надёжный способ — использование `[fastcgi\_finish\_request](http://php.net/fastcgi_finish_request)()`, требующий настройку сервера через php-fpm (соответственно, недоступен для AppEngine).
2. Сделать обновление в отдельном потоке (то есть выполнить `[pcntl\_fork()](http://php.net/pcntl_fork)` или запустить скрипт через `[system()](http://php.net/system)` или ещё как-то) – опять же, может сработать для своего сервера, иногда даже работает на некоторых shared-хостингах, где не сильно озаботились безопасностью, но, разумеется, не сработает на сервисах с параноидальной безопасностью, то есть AppEngine не подходит.
3. Иметь постоянно работающий фоновый процесс для обновления кэша: процесс должен с заданной периодичностью проверять, не устаревает ли значение в кэше, и если срок жизни подходит к концу, а значение требовалось за время жизни кэша – обновляет его. Мы обсудим этот момент чуть позднее, когда устанем уже от нашего бедного сайта с курсом валюты и перейдём к более весёлым материям.
По сути поддержание данных во всегда горячем состоянии – задача чуть более сложная, чем просто несколько строчек PHP-кода, поэтому для нашего простого случая нам придётся смириться с тем, что *какой-то* запрос будет регулярно «задумываться» (важно: не случайный, а какой-то; то есть не *random*, а *arbitrary*). Применимость этого подхода **всегда** важно примерять к задаче!
Итак, наш поставщик данных растёт, но не все его клиенты читают хабр, а потому они не используют правильного кэширования (если используют его вообще) и в какой-то момент начинают выдавать огромное количество запросов, из-за чего сервису становится плохо, и эпизодически он начинает отвечать не просто медленно, а *очень медленно*. До десятков секунд и более. Пользователи, конечно, быстро обнаружили, что можно нажать F5 или иначе перезагрузить страницу, и она появляется моментально – вот только страница снова начала упираться в бесплатные пределы, так как постоянно начали висеть процессы, просто ожидающие внешний ответ, но потребляющие наши ресурсы.
В числе прочих побочных эффектов участились случаи показа устаревшего курса. [Мда… в общем, представьте, что мы сейчас говорим не про наш случай, а про что-нибудь более сложное, где устаревание видно невооруженным глазом :) на самом деле, даже в простом случае обязательно найдётся пользователь, который заметит такие совершенно неочевидные косяки].
Смотрите, что получается:
1. Пришел запрос 1, данных в кэше нет, так что добавили маркер '?' на 5 секунд и пошли за курсом.
2. Спустя 1 секунду пришел запрос номер 2, увидел маркер '?', вернул данные из stale записи.
3. Спустя 3 секунды пришел запрос номер 3, увидел маркер '?', вернул stale.
4. Спустя 1 секунду маркер '?' устарел, несмотря на то, что запрос 1 всё еще ждет ответа.
5. Спустя еще 2 секунды пришел запрос номер 4, маркера нет, добавляет новый маркер и отправляется за курсом.
6. …
7. Запрос 1 получил ответ, сохранил результат.
8. Пришел запрос X, получил актуальный ответ из кэша 1-го вопроса (а когда пришел тот ответ? На момент запроса, или момент ответа? –, этого никто не знает…).
9. Запрос номер 4 получил ответ, сохранил результат – причем снова непонятно, был ли этот ответ более новый или более старый...
Разумеется, тут мы должны задать нужный нам таймаут через `[ini\_set("default\_socket\_timeout")](http://php.net/default_socket_timeout)` или воспользоваться `[stream\_context\_create](http://php.net/stream_context_create)`… Так мы приходим к еще одному важному аспекту: **кэш должен учитывать время получения значений**. Общего решения для поведения нет, но, как правило, время кэширования должно быть больше чем время вычисления. В случае если время вычисления превышает время жизни кэша, **кэш неприменим**. Это уже не кэш, а *предвычисления*, которые следует хранить в надежном хранилище.
Итак, давайте подведём промежуточный итог. В бытовом понимании кэш:
1. заменяет большинство запросов на получение уже известного ответа;
2. ограничивает число запросов к получению дорогих данных;
3. делает время запросов невидимыми для пользователя.
В реальности же:
1. заменяет *некоторые* запросы из окна жизни кэша на запомненные значения (кэш может потеряться в любой момент, например, из-за нехватки памяти либо экстравагантных запросов);
2. *пытается* ограничить число запросов (но без специальной имплементации ограничения частоты исходящих запросов, реально можно обеспечить только характеристики типа «максимум 1 исходящий запрос в один момент времени»);
3. время исполнения запроса видимо только *некоторым* пользователям (причем распределены «счастливчики» отнюдь не равномерно).
Кэш предполагает «эфемерность» хранящихся данных, в связи с чем системы кэширования вольны обращаться со временем жизни вообще и с самим фактом запроса на сохранение данных:
* кэш может быть потерян в любой момент времени. Даже наши маркеры блокировки исполнения '?' могут быть потеряны, если параллельно еще 10 тысяч пользователей гуляет по сайту, все сохраняя что-то (зачастую время последнего обращения на сайт) в сессию, которая лежит на том же кэш-сервере; после того как маркер потерян («кэш отравлен»), следующий запрос опять начнёт процедуру обновления значения в кэше;
* чем быстрее исполняется запрос в удалённой системе, тем меньше запросов будет дедуплицировано в случае отравления кэша.
Таким образом, просто применяя кэш, мы зачастую закладываем мину отложенного действия, которая обязательно взорвется — но не сейчас, а в будущем, когда решение обойдётся значительно дороже. Рассчитывая производительность системы, важно считать без учета сокращения времени исполнения от кэширования положительных ответов, иначе мы улучшаем поведение системы *в спокойное время* (когда сache hit ratio максимален), а не во время пиковой нагрузки / перегруженности зависимостей (когда обычно и случается отравления кэша).
Рассмотрим простейший случай:
* Мы смотрим на систему в спокойном состоянии, и видим среднее время исполнения 0.05 сек.
* Вывод: 1 процесс может обслужить 20 запросов в секунду, значит, для 100 запросов в секунду достаточно 5 процессов.
* Вот только если время обновления запроса возрастает до 2 секунд, то получается:
* 1 процесс занят обновлением (в течение 2 секунд);
* в течение этих 2 секунд у нас доступно только 4 процесса = 80 запросов в секунду.
И вот под большой нагрузкой наш кэш отравлен, и запросы кэшируются не на 5 секунд, а на 1 секунду только, а это означает, что у нас постоянно заняты 2 запроса (один исполняет первый запрос, второй начинает обновлять кэш через секунду, пока первый еще работает), и остаточная ёмкость для обслуживания сокращается до 60 запросов в секунду. То есть эффективная ёмкость от (исходя из среднего) 6000 запросов в минуту резко проседает до ~3600. Что означает, что если отравление наступило на 5000 запросах в минуту, до тех пор, пока нагрузка не упадёт с 5000 до 3000 система нестабильна. То есть любой (даже пиковый!) всплеск трафика потенциально может вызвать длительную нестабильность системы.
Особенно прекрасно это смотрится, когда после новостной рассылки с какими-либо новыми функциями практически одновременно приходит волна пользователей. Эдакий маркетологический хабраэффект на регулярной основе.
Всё это не означает, что кэш нельзя или вредно использовать! О том, как правильно применять кэш для улучшения стабильности системы и как восстанавливаться от вышеупомянутой петли гистерезиса, мы поговорим в следующей статье, не переключайтесь. | https://habr.com/ru/post/316344/ | null | ru | null |
# Применение языка Python в инженерной практике. Часть 1 — обзор модуля Pint
Единицы измерения физических величин в программах на языке Python
-----------------------------------------------------------------
### Введение
Язык Python (правильно это читается "Пайтон", но в русскоязычном сообществе так же прижилось и прочтение "Питон", мне оно тоже больше по душе ;) в последнее время получил очень большую популярность в среде непрограммистов по двум причинам:
* лёгкий синтаксис, очень близкий к естественным языкам и математическому мышлению;
* огромное количество различных библиотек (модулей), написанных как на самом питоне, так и на более быстрых "профессиональных" языках С/С++ и Фортран.
Хотя для изучения основ Питона есть очень много хорошей литературы, в том числе и на русском языке, вопросы использования многих модулей описаны недостаточно. Особенно тяжело здесь русскоязычным инженерам. Этой статьёй я хочу начать цикл туториалов, в которых я поделюсь своим опытом использования языка Питон в практической инженерной деятельности. В настоящем туториале речь пойдёт о модуле *Pint*, который сильно упрощает манипулирование физическими величинами.
Настоящие туториалы нельзя рассматривать как основы языка Питон. Предполагается, что читатель с ними знаком, а так же знаком с модулями *Math, CMath, Numpy, Scipy, Pandas.* Язык Питон и перечисленные модули хорошо описаны в литературе и Интернете.
### Для начала немного теории, что бы освежить мозг
В инженерных расчётах очень большое значение имеет приведение, преобразование и отображение единиц измерения. Результат любых инженерных измерений и расчётов не имеет никакого смысла, если не указаны две его основные характеристики: **единица измерения** и **точность**. О точности я напишу следующий туториал, а сейчас поговорим об единицах измерения.
Напомню основные определения:
**Физической величиной** называется физическое свойство материального объекта, процесса, физического явления, охарактеризованное количественно.
**Значение физической величины** выражается одним или несколькими числами, характеризующими эту физическую величину, с указанием единицы измерения.
**Размером физической величины** являются значения чисел, фигурирующих в значении физической величины.
**Единицей измерения физической величины** является величина фиксированного размера, которой присвоено числовое значение, равное единице. Применяется для количественного выражения однородных с ней физических величин.
**Размерность физической величины** — выражение, показывающее связь этой величины с основными величинами данной системы физических величин; записывается в виде произведения степеней сомножителей, соответствующих основным величинам, в котором численные коэффициенты опущены.
**Системой единиц физических величин** называют совокупность основных и производных единиц, основанную на некоторой системе величин. Широкое распространение получило всего лишь некоторое количество систем единиц. В большинстве случаев во многих странах пользуются метрической системой.
**Измерить физическую величину** – значит сравнить ее с другой такой же физической величиной, принятой за единицу. Например, длину предмета сравнивают с единицей длины, массу тела – с единицей веса и т.д. Но если один исследователь измерит длину в саженях, а другой в футах, им будет трудно сравнить эти две величины. Поэтому все физические величины во всем мире принято измерять в одних и тех же единицах. В 1963 году была принята Международная система единиц СИ (System international - SI). Для каждой физической величины в системе единиц должна быть предусмотрена соответствующая единица измерения. Эталоном единицы измерения является ее физическая реализация. Эталоном длины является метр – расстояние между двумя штрихами, нанесенными на стержне особой формы, изготовленном из сплава платины и иридия. Эталоном времени служит продолжительность какого-либо правильно повторяющегося процесса, в качестве которого выбрано движение Земли вокруг Солнца: один оборот Земля совершает за год. Но за единицу времени принимают не год, а секунду. Единицы измерения, для которых существуют физические эталоны, называют **основными единицами**
**Производными единицами измерения физических величин** называют такие единицы, для которых нет физических эталонов и которые определяются через соотношения основных единиц. Например, за единицу скорости принимают скорость такого равномерного прямолинейного движения, при котором тело за 1 с совершает перемещение в 1 м - поэтому единица скорости обозначается . Единицей площади является площадь квадрата, длина каждой стороны которого равна 1 м - поэтому единица площади называется "квадратный метр" и обозначается .
**Приставки** используются для того, что бы сделать запись значения физической величины более компактным. Например, . приставки бывают *десятичные* и *двоичные*. Десятичные приставки представляют собой множители . Двоичные приставки представляют собой множители .
#### Основные единицы системы СИ
| Величина | Наименование | Обозначение |
| --- | --- | --- |
| Длина | метр | m |
| Масса | килограмм | kg |
| Время | секунда | s |
| Сила электрического тока | ампер | A |
| Термодинамическая температура | кельвин | K |
| Сила света | канделла | cd |
| Количество веществ | моль | mol |
| Плоский угол | радиан | rad |
| Телесный угол | стерадиан | sr |
#### Производные единицы системы СИ
| Величина | Наименование | Обозначение | Выражение через основные единицы | Выражение через производные единицы |
| --- | --- | --- | --- | --- |
| Частота | герц | Hz | 1\s | - |
| Сила | ньютон | N | kg \cdot m / s^2 | - |
| Давление | паскаль | Pa | kg / m \cdot s^2 | N / m^2 |
| Энергия, работа, количество теплоты | джоуль | J | kg \cdot m^2 /s^2 | N \cdot m |
| Мощность, поток энергии | ватт | W | kg \cdot m^2/s^3 | J / s |
| Количество электричества, заряд | кулон | С | A \cdot s | - |
| Электрическое напряжение, потенциал | вольт | V | kg \cdot m^2 / A \cdot s^3 | W / A |
| Электрическая ёмкость | фарада | F | A^2 \cdot s^3 / kg \cdot m^2 | C / V |
| Электрическое сопротивление | ом | Ω | {kg \cdot m^2} / {A^2 \cdot s^3} | {V} / {A} |
| Электропроводность | сименс | S | {A^2 \cdot s^3} / {kg \cdot m^2} | {A} / {V} или{1} / {Ω} |
| Поток магнитной индукции | вебер | Wb | {kg \cdot m^2} / {A \cdot s^2} | V \cdot s |
| Магнитная индукция | тесла | Т | {kg} . {A \cdot s^2} | {Wb} / {m^2} |
| Индуктивность | генри | H | {kg \cdot m^2} / {A^2 \cdot s^2} | {Wb} / {A} |
| Световой поток | люмен | Im | cd \cdot sr | - |
| Освещённость | люкс | Ix | m^2 \cdot cd \cdot sr | - |
### Физические и технические константы
Для удобства и наглядности работы, в том числе для перевода несистемных единиц в системные, кроме приставок и обозначения физических единиц, в модуле Pint определены некоторые физические константы:
| Наименование | Значение | Обозначение |
| --- | --- | --- |
| \pi | 3.1415926535 | pi |
| Экспонента | 2.718281884 | e |
| Скорость света | 299792458 \; {m} / {s} | c speed\_of\_light |
| Гравитационная постоянная | 9.806650 \; {m} / {s^2} | g\_0 graviti |
| Вакуумная проницаемость | 4 \cdot \pi \cdot 1e^{-7}\; {N}/{A^2} | mu\_0 magnetic\_constant |
| Диэлектрическая проницаемость | {1} / {\mu_0 \cdot c^2} | electric\_constant |
| Вакуумный импеданс | \mu_0 \cdot c | Z\_0 impedance\_of\_free\_space characteristic\_impedance\_of\_vacuum |
| Постоянная Планка | 6.62606957e^{-34} J\cdot s | h |
| Постоянная Дирака | {h} / {2\pi} | hbar |
| Гравитационная константа Ньютона | 6.67384 \cdot 10^{-11} \; {m^3} / {kg^{-1} \cdot s^{-2}} | newtonian\_constant\_of\_gravitation |
| Молярная газовая постоянная | 8.3144621 \; {J} / {mol^{-1} \cdot K^{-1}} | R |
| Число Авогадро | 6.02214129 \cdot 10^{23} mol^{-1} | N\_A |
| Постоянная Больцмана | 1.3806488 \cdot 10^{-23} \; {J} / {K^{-1}} | k |
| Постоянная Вина | 5.8789254 \cdot 10^{10} \; {Hz} / {K^{-1}} | wien\_frequency\_displacement\_law\_constant |
| Постоянная Ридберга | 10973731.568539 \; m^{-1} | rydberg\_constant |
| Масса электрона | 9.10938291\cdot 10^{-31} kg | m\_e electron\_mass |
| Масса нейтрона | 1.674927351 \cdot 10^{-27} kg | m\_n neutron\_mass |
| Масса протона | 1.672621777 \cdot 10^{-27} kg | m\_p proton\_mass |
#### Несистемные единицы
Модуль Pint содержит единицы не только системы СИ, но и других известных систем единиц, что позволяет применять его для перевода значений физических величин из одной системы единиц в другую. В модуле определено очень много разных единиц, поэтому не будем раздувать туториал ещё одной таблицей, вместо этого ниже будет показано, как получить названия нужных единиц средствами самого питона.
#### Десятичные приставки
| Множитель | Название | Обозначение |
| --- | --- | --- |
| 10^{-24} | иокто | y |
| 10^{-21} | зепто | z |
| 10^{-18} | aттo | a |
| 10^{-15} | фемто | f |
| 10^{-12} | пико | p |
| 10^{-9} | нано | n |
| 10^{-6} | микро | μ |
| 10^{-3} | милли | m |
| 10^{-2} | санти | c |
| 10^{-1} | деци | d |
| 10^1 | дека | deka |
| 10^2 | гекта | h |
| $10^3 | кило | k |
| 10^6 | мега | M |
| 10^9 | гига | G |
| $10^{12} | тера | T |
| $10^{15} | пента | P |
| $10^{18} | экса | E |
| $10^{21} | зетта | Z |
| $10^{24} | иотта | Y |
#### Двоичные приставки
| Множитель | Название | Обозначение |
| --- | --- | --- |
| 2^{10} | киби | Ki |
| 2^{20} | меби | Mi |
| 2^{30} | гиби | Gi |
| 2^{40} | теби | Ti |
| 2^{50} | пеби | Pi |
| 2^{60} | эксби | Ei |
| 2^{70} | зеби | Zi |
| 2^{80} | иоби | Yi |
#### Дополнительные приставки
Кроме стандартных приставок системы СИ, в модуле *Pint* определены три дополнительные приставки:
| Множитель | Обозначение |
| --- | --- |
| 0.1 | demi |
| 0.5 | semi |
| 1.5 | sesqui |
### Установка и начало использования модуля Pint
Установка модуля производится стандартным для Python образом:
`c:\>pip install pint`
Если вы используете менеджер *Anaconda*, то команда установки будет такой:
`c:\>conda install pint --channels conda-forge`
Для использования модуля его надо импортировать в вашу программу. Рекомендуется это делать следующими командами:
```
>>>from pint import UnitRegistry
>>>ureg = UnitRegistry()
```
Вторая строка инициализирует объект класса `UnitRegistry`, который хранит определения единиц измерения, их связи и обрабатывает преобразования между единицами (разумеется, имя объекта может быть произвольным, совсем не обязательно `ureg`; можно даже определить несколько таких объектов, хотя я не могу представить, для чего это может быть нужно). При этом объект `ureg` заполняется списком единиц и префиксов по умолчанию, полный список которых можно посмотреть в файле *default\_en.txt*, который находится в папке, в которую установлена библиотека. Узнать расположение этой паки можно командой:
`c:\>pip show pint`
> Name: Pint
> Version: 0.19.2
> Summary: Physical quantities module
> Home-page: <https://github.com/hgrecco/pint>
> Author: Hernan E. Grecco
> Author-email: [hernan.grecco@gmail.com](mailto:hernan.grecco@gmail.com)
> License: BSD
> **Location: c:\users\andre\anaconda3\lib\site-packages**
> Requires:
> Required-by:
>
>
Другой способ увидеть, какие несистемные единицы уже определены в модуле. Для этого надо вызвать метод `get_compatible_units()` объекта класса `UnitRegistry`, передав ему величину интересующих единиц (в даном примере мы получаем возможные единицы измерения энергии):
```
>>>ureg.get_compatible_units('[energy]')
frozenset({,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
})
```
### Проверка того, определена ли единица измерения
Для того, что бы проверить, определена ли необходимая единица измерения, можно воспользоваться следующими командами Питона:
```
>>> 'MHz' in ureg
True
>>> 'gigatrees' in ureg
False
```
### Дополнение списка единиц
Если требуемой единицы измерения в файле *default\_en.txt* нет, её можно добавить тремя способами:
1. Дописать определение единицы в конец файла *default\_en.txt*.
2. Создать свой собственный файл определения единиц, например, *mydef.txt*.
3. Добавить описание единицы программно.
#### Формат файла описания
Независимо от того, дописывается ли единица в файл *default\_en.txt* или создаётся новый файл описания единиц, структура описания каждой единицы следующая:
```
hour = 60 * minute = h = hr
minute = 60 * second = min
```
Это довольно просто, не так ли? Мы говорим, что минута равна 60 секундам и также известна как "мин".
1. Первое слово – это всегда каноническое имя.
2. После знака равенства следует определение единицы, основанное на других, ранее определённых единицах.
3. После следующего знака равенства, опционально, указывается символ единицы измерения.
4. Наконец, опять же опционально, приводится список псевдонимов единицы измерения, разделенных знаками равенства. Если надо указать только псевдонимы без символа единицы, символ единицы должен быть заменён на символ "\_":
`millennium = 1e3 * year = _ = millennia`
Эта команда определяет единицу "millennium", равную 1000 годам ("year", определена в файле *default\_en.txt*) без символа единицы измерения. Так же определён псевдоним "millennia", который может использоваться в программе вместо обозначения "millennium".
Порядок определения единиц измерения не имеет значения, Pint разрешит зависимости, чтобы определить их в правильном порядке. Важно только, что бы все единицы, использованные справа от первого знака равенства, были определены в доступных файлах определения единиц. Если надо добавить единицу, которую нельзя выразить через другие определённые единицы, её следует выражать через эталонные физические размерности:
`second = [time] = s = sec`
* *time* - это физическая величина
* *second* - единица измерения времени (секунда)
Новые физические величины так же можно определять через другие физические величины:
`[density] = [mass] / [volume]`
Обратите внимание, что первичные физические величины не нужно объявлять.
Кроме основных единиц измерения, в файле описания определяются их кратные десятичные префиксы, они обозначаются конечным тире:
`yocto- = 10.0**-24 = y-`
Наконец, можно добавить псевдонимы к уже существующему определению единицы:
`@alias meter = metro = metr`
Кроме того, файл описания может содержать необрабатываемый библиотекой Pint комментарии, начинающиеся с символа "#" (как в синтаксисе Питона)
#### Создание собственного файла описания
Если вы добавляете новые описания в файл *default\_en.txt*, то они могут пропасть при обновлении версии библиотеки - при этом будет установлен новый **стандартный** файл *default\_en.txt* без добавленных вами определений. Что бы этого избежать, лучше собственные определения поместить в отдельный текстовой файл с произвольным именем, например, *mydef.txt* и загружать его в своих программах после импорта библиотеки и создания объекта класса `UnitRegistry()` с помощью команды:
```
>>>ureg.load_definitions('/your_path/mydef.txt')
```
При этом ваши определения **добавятся** к стандартным. Если же вы ходите получить **только свои** определения и не загружать стандартные (например, если вы переопределяете стандартную единицу измерения), то передайте свой файл конструктору объекта:
```
>>>ureg = UnitRegistry('/your_path/mydef.txt')`
```
#### Добавление определения единицы измерения непосредственно в программе
Вы можете легко добавлять единицы измерения, измерения или псевдонимы в реестр программным путем. Давайте добавим `dog_year` (иногда пишется как `dy`), эквивалентный 52 (человеческим) дням:
```
>>>from pint import UnitRegistry
>>>ureg = UnitRegistry()
>>>Q_ = ureg.Quantity
>>>#Здесь мы добавляем новую единицу
>>>ureg.define('dog_year = 52 * day = dy')
>>>#Далее создаём количественную переменную и переводим её в новые единицы
>>>lassie_lifespan = Q_(10, 'year')
>>>print(lassie_lifespan.to('dog_years'))
```
В результате получим: `70.24038461538461 dog_year`. Обратите внимание, что мы использовали имя `dog_years` хотя мы не определили форму множественного числа как псевдоним. Модуль *Pint* заботится об этом, поэтому вам не нужно этого делать. Формы множественного числа, которые не просто строятся путем добавления суффикса "s" к форме единственного числа, должны быть явно указаны как псевдонимы (см., например, millennia)
Вот, что тут любопытно: если вместо формы множественного числа
```
>>>print(lassie_lifespan.to('dog_years'))
```
написать в единственном числе:
```
>>>print(lassie_lifespan.to('dog_year'))
```
результат будет тот же самый. Зачем это сделано? Не знаю... Вероятно, что бы следовать принципам Питона в стремлении к максимальному приближению к естественному языку.
Вы также можете добавить префиксы программным путем:
```
>>>ureg.define('myprefix- = 30 = my-')
```
где число указывает на коэффициент умножения.
То же самое для псевдонимов и производных размеров:
```
>>>ureg.define('@alias meter = metro = metr')
>>>ureg.define('[hypervolume] = [length] ** 4')
```
Некоторые единицы содержат константы. Они могут быть определены с помощью ведущего подчеркивания:
```
>>>ureg.define('_100km = 100 * kilometer')
>>>ureg.define('mpg = 1 * mile / gallon')
>>>fuel_ec_europe = 5 * ureg.L / ureg._100km
>>>fuel_ec_us = (1 / fuel_ec_europe).to(ureg.mpg)
```
**ПРЕДУПРЕЖДЕНИЕ**
Единицы измерения, префиксы и псевдонимы, добавленные программным путем, забываются при завершении работы программы.
### Присоединение единиц измерения к числам и переменным и вычисления с ними
Пожалуй, это самое главное назначение модуля *Pint*. Он позволяет присоединять единицы измерения к операндам вычислений и автоматически получать единицу результата. Для присоединения единиц измерения к операнду математической операции, надо всего лишь умножить операнд на объект `ureg`:
```
>>>10 * ureg.kg + 20 * ureg.kg
30
```
В данном примере мы сложили 10 килограммов и 20 килограммов и получили 30 килограммов. Т.е. Питон сработал чисто математически - он вынес `ureg.kg` за скобки и сложил 10 + 20. Но модуль Pint позволяет правильно прибавлять и граммы к килограммам:
```
>>>10 * ureg.kg + 300 * ureg.g
10.3
```
Если присвоить единицу измерения переменной, то она изменит свой тип на объект класса `Quantity()`:
```
>>>distance = 24.0 # пока без единицы измерения
>>>type(distance)
float
>>>distance = distance * ureg.km # теперь distance равно 24 километра
>>>type(distance)
pint.quantity.build_quantity_class..Quantity
```
Теперь обычная математика с переменной `distance` невозможна:
```
>>>distance + 3
DimensionalityError: Cannot convert from 'kilometer' to 'dimensionless'
```
Так же нельзя и прибавить несовместимую единицу:
```
>>>distance + 3 * ureg.g
DimensionalityError: Cannot convert from 'kilometer' ([length]) to 'gram' ([mass])
```
Разумно - сложение расстояния и массы не имеет физического смысла. А вот умножать, делить и возводить в степени переменные с разными единицами можно:
```
>>>distance = 24.0 * ureg.km # расстояние 24 км
>>>time = 3.0 * ureg.hour + 30.0 * ureg.minute # время 3 часа 30 минут
>>>speed = distance / time # скорость это действительно пройденное расстояние, делённое на затраченное время
>>>print(speed)
7.199999999999999 kilometer / hour # поэтому иы и получили километры в час
>>>acceleration = distance / time ** 2
>>>print(acceleration)
2.1599999999999997 kilometer / hour ** 2
```
Мы можем посмотреть, какую размерность у нас имеют результаты вычислений:
```
>>>print(speed.dimensionality)
[length] / [time]
>>>print(acceleration.dimensionality)
[length] / [time] ** 2
```
При вычислении ускорения получилось вроде и правильно, но как то непривычно видеть . Можно преобразовать к более каноничным :
```
>>>print(acceleration.to('m/s**2'))
0.00016666666666666663 meter / second ** 2
```
В последнем примере интересно не только простота преобразования единиц измерения (метод `to()` объектов класса `Quantity()`), но и новый способ представления единиц измерения - в виде строки. Этот способ работает не только при преобразовании величин, но и во всех других случаях применения модуля *Pint*. Например:
```
>>>distance = 24.0 * ureg('km')
>>>print(distance)
24.0 kilometer
```
Вообще оба способа представления единиц измерения взаимозаменяемы во всех случаях и могут как угодно комбинироваться в одном выражении. Например, видоизменим команду преобразования единицы:
```
>>>print(distance.to(ureg.m))
24000.0 meter
```
Объекты `Quantity()` также хорошо работают с массивами *NumPy* (соответственно, переменными с присоединенными единицами измерения можно использовать все функции математических модулей *Numpy* и *Scipy*) и таблицами *Pandas*
### Выделение значения и единицы измерения
Как было выше сказано, после присоединения к переменной единицы измерения, переменная превращается в объект класса `Quantity()` и дальнейшая математика с ней возможна только с другими объектами класса `Quantity()` (величинами или переменными, имеющими совместимые единицы измерения). Строго говоря, это не совсем так. При необходимости из переменной (объекта) класса `Quantity()` можно выделить её значение в обычную переменную типа `int` или `float`. Это возможно благодаря тому, что у всех объектов класса `Quantity()` есть два свойства: `magnetude` и `units` - содержащие. соответственно, значение и единицу измерения:
```
>>>type(distance)
pint.quantity.build_quantity_class..Quantity
>>>d = distance.magnitude
>>>type(d)
float
>>>print(distance.magnetude)
24.0
>>>print(distance.units)
kilometer
```
### Упрощение единиц измерения
Иногда величина величины будет очень большой или очень маленькой. Метод `to_compact()` может корректировать единицы измерения, чтобы сделать количество более удобочитаемым для человека:
```
>>>wavelength = 1550 * ureg.nm # длина волны 1550 нанометров
>>>frequency = (ureg.speed_of_light / wavelength).to('Hz') # разделим скорость света на длину волны и приведём результат к герцам
>>>print(frequency)
193414489032258.03 hertz
>>>print(frequency.to_compact())
193.41448903225802 terahertz
```
193 терагерца воспринимается человеком более естественно и понятно, чем 193414489032258 герц
Существуют также методы `to_base_units()` и `ito_base_units()`, которые автоматически преобразуют несистемные единицы в эталонные единицы СИ правильной размерности:
```
>>>height = 5.0 * ureg.foot + 9.0 * ureg.inch
>>>print(height)
5.75 foot
>>>print(height.to_base_units())
1.7525999999999997 meter
>>>print(height)
5.75 foot
>>>height.ito_base_units()
>>>print(height)
1.7525999999999997 meter
```
Из примера видно, что разница между этими методами в том. что метод `to_base_units()` возвращет результат преобразования, а метод `ito_base_units()` изменяет саму переменную.
Модуль *Pint* может автоматически приводить результаты вычислений к эталонным единицам СИ. Для этого при создании объекта класса `UnitRegistry` надо передать конструктору параметр `autoconvert_offset_to_baseunit = True`.
Существуют также методы `to_reduced_units()` и `ito_reduced_units()`, которые выполняют упрощенное уменьшение размеров, объединяя единицы измерения с одинаковой размерностью и не затрагивая остальные единицы измерения:
```
>>>density = 1.4 * ureg.gram / ureg.cm ** 3
>>>volume = 10 * ureg.cc
>>>mass = density * volume
>>>print(mass)
14.0 cubic_centimeter * gram / centimeter ** 3
>>>print(mass.to_reduced_units())
>>>print(mass)
14.0 cubic_centimeter * gram / centimeter ** 3
>>>mass.ito_reduced_units()
>>>print(mass)
14.0 gram
```
Конечно, измерять массу в кубических сантиметрах и граммах неправильно. Учитывая, что , метод сокращает эти единицы и остаются правильные граммы.
Модуль *Pint* может автоматически сокращать единицы и упрощать результат. Для этого при создании объекта класса `UnitRegistry` надо передать конструктору параметр `auto_reduce_dimensions = True`.
### Синтаксический анализ строк
Как уже было показано выше, ещиницы измерения объекту `ureg` можно передавать в виде строк. При этом содержимое строки может быть в достаточной степени произвольным. Всё дело в том. что модуль *Pint* содержит в себе мощный синтаксический анализатор строковых выражений. И его возможности не ограничиваются одним присоединением и преобразованием единиц измерения. Числа также анализируются, поэтому вы можете использовать выражение:
```
>>>ureg('2.54 * centimeter')
2.54
```
Можно так же использовать конструктор объекта класса `Quantity`:
```
>>>Q_ = ureg.Quantity
>>>Q_('2.54 * centimeter')
2.54
```
Более того, знак "\*" можно опускать:
```
>>>Q_('2.54cm')
2.54
```
Это позволяет вам написать простой конвертер единиц измерения:
```
>>>user_input = '2.54 * centimeter to inch'
>>>src, dst = user_input.split(' to ')
>>>Q_(src).to(dst)
1.0
```
Строки, содержащие значения, могут быть проанализированы более глубоко с помощью метода `parse_pattern()`. В качестве шаблона используется строка, подобная формату, с определенными в ней единицами измерения:
```
>>>input_string = '10 feet 10 inches'
>>>pattern = '{feet} feet {inch} inches'
>>>ureg.parse_pattern(input_string, pattern)
[10.0 , 10.0 ]
```
Чтобы выполнить поиск нескольких совпадений, установите параметр `many = True`. Следующий пример демонстрирует, как анализатор может находить совпадения среди символов-заполнителей:
```
>>>input_string = '10 feet - 20 feet ! 30 feet.'
>>>pattern = '{feet} feet'
>>>ureg.parse_pattern(input_string, pattern, many=True)
[[10.0 ], [20.0 ], [30.0 ]]
```
Обратите внимание, что фигурные скобки (`{}`) преобразуются синтаксическим анализатором в шаблон сопоставления с плавающей точкой.
Эта функция полезна для таких задач, как массовое извлечение единиц измерения из тысяч однородных строк или даже очень больших текстов, в которых единицы измерения разбросаны без определенного шаблона.
### Форматирование строк
Физические величины можно легко распечатать несколькими способами.
**Стандартный код форматирования строки**
```
>>>accel = 1.3 * ureg['meter/second**2']
>>>print('The str is {!s}'.format(accel))
print('The str is {!s}'.format(accel))
```
**Стандартный код форматирования представления**
```
>>>print('The repr is {!r}'.format(accel))
print('The repr is {!r}'.format(accel))
```
**Доступ к полезным атрибутам**
```
>>>print('The magnitude is {0.magnitude} with units {0.units}'.format(accel))
The magnitude is 1.3 with units meter / second ** 2
```
Модуль *Pint* также поддерживает форматирование с плавающей запятой для массивов *Numpy*:
```
>>>import numpy as np
>>>accel = np.array([-1.1, 1e-6, 1.2505, 1.3]) * ureg['meter/second**2']
>>>print('The array is {:.2f}'.format(accel))
The array is [-1.10 0.00 1.25 1.30] meter / second ** 2
>>>print('The array is {:+.2E~P}'.format(accel))
The array is [-1.10E+00 +1.00E-06 +1.25E+00 +1.30E+00] m/s²
```
Модуль *Pint* поддерживает f-строки Питона:
```
>>>accel = 1.3 * ureg['meter/second**2']
>>>print(f'The str is {accel}')
he str is 1.3 meter / second ** 2
>>>print(f'The str is {accel:.3e}')
The str is 1.300e+00 meter / second ** 2
>>>print(f'The str is {accel:~}')
The str is 1.3 m / s ** 2
>>>print(f'The str is {accel:~.3e}')
The str is 1.300e+00 m / s ** 2
```
Так же можно выводить строки в форматах HTML и LaTeX:
```
>>>accel = 1.3 * ureg['meter/second**2']
>>>print('The pretty representation is {:P}'.format(accel))
The pretty representation is 1.3 meter/second²
>>>print('The HTML representation is {:H}'.format(accel))
The HTML representation is 1.3 meter/second2
>>>print('The LaTeX representation is {:L}'.format(accel))
The LaTeX representation is 1.3\ \frac{\mathrm{meter}}{\mathrm{second}^{2}}
```
Если вы хотите использовать сокращенные названия единиц измерения, добавьте перед спецификацией префикс ~.
Спецификации форматирования (L, H и P) можно использовать с синтаксисом форматирования строк с плавающей точкой. Например, научная нотация:
```
>>>print('Scientific notation: {:.3e~L}'.format(accel))
Scientific notation: 1.300\\times 10^{0}\\ \\frac{\\mathrm{m}}{\\mathrm{s}^{2}}
```
Кроме того, вы можете указать спецификацию формата по умолчанию:
```
>>>ureg.default_format = 'P'
>>>print('The acceleration is {}'.format(accel))
The acceleration is 1.3 meter/second²
``` | https://habr.com/ru/post/682306/ | null | ru | null |
# Numl – Альтернативный язык разметки и стилизации для веб
Всем привет! Меня зовут Андрей, я профессионально разрабатываю веб-интерфейсы уже больше 11 лет и последний год развиваю проект Numl, который можно назвать языком разметки и стилизации для веб. В этой статье я расскажу, как в попытке перебороть ряд особенностей CSS и упростить вёрстку веб-проектов получился целый язык, который не только удовлетворил все наши потребности в стилизации, но также позволил уменьшить кол-во JS-кода и улучшить доступность.

Для начала, коротко про Numl и чем он может быть интересен разработчикам.
Numl это язык разметки, который объединяет в себе функции **CSS-фреймворка**, **JS-фреймворка** без композиции и **Дизайн-системы**, и предоставляет набор готовых элементов, каждый из которых имеет обширный набор свойств для кастомизации. Язык основывается на нативном браузерном API **Custom Elements** из спецификации Web Components, и совместим с популярными JS-фреймворками, такими как **Vue**, **Svelte**, **Angular** и **React**. Отличительной (и я бы даже сказал "уникальной") чертой Numl является то, что все стили для интерфейса он **генерирует в runtime**, что позволяет выжать максимум из CSS и добиться огромной гибкости в стилизации и кастомизации элементов. **Эта статья — ответ на вопрос, как так получилось и почему такой подход заслуживает право на жизнь.**
На прошлой неделе, 4-го июля, проекту исполнился ровно год и он уже давно прошёл стадию **proof of concept**. На нём написан крупный проект **Sellerscale** и браузерное расширение от **Sellerscale**. Также с помощью Numl создано еще несколько сайтов, включая собственный лэндинг и Storybook. **Полный набор ссылок будет в конце.**
*Дашборд Sellerscale. Стэк: VueJS, Numl*
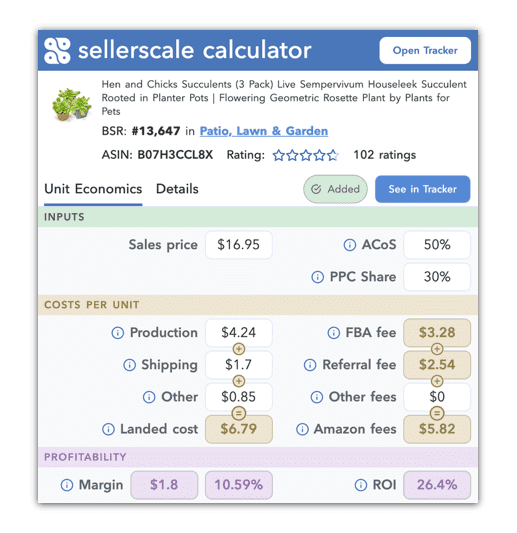
*Расширение Sellerscale. Стэк: Svelte, Numl*
Numl сам по себе может быть интересен всем, кто знаком с основами HTML/CSS и хочет создавать качественные, доступные и красивые веб-интерфейсы, без глубокого погружения в тонкости CSS и ARIA. Однако данная статья выходит за рамки базовых знаний и больше подойдёт для людей, которые разбираются в различных CSS методологиях, много верстают, пишут свои инструменты для стилизации или же интересуются необычными инструментами из мира фронтенд-разработки. Используете **Utility-First CSS**? Тогда вам определённо стоит дочитать до конца.
Для тех, кому просто хочется узнать про Numl, я предлагаю посетить сайт [numl.design](https://numl.design), полистать [Storybook](https://numl.design/storybook) с кучей примеров, почитать статью про [базовый синтаксис в гайде](https://numl.design/guide/getting-started) и **попробовать Numl прямо в браузере** с помощью [REPL](https://numl.design/repl).
В поисках идеальной методологии вёрстки
---------------------------------------
Программировать я начал примерно 22 года назад, и уже тогда, используя Turbo Pascal, создавал различные оконные интерфейсы с кнопочками, окнами, инпутами и прочим. Двумя годами позднее, изучив веб-платформу я принялся за разработку сайтов и с тех пор моё хобби стало плавно превращаться в профессию. Многие веб-разработчики овладев HTML/CSS, погружаются в JS-экосистему и постепенно перестают верстать. Но мне всегда хотелось создавать качественные интерфейсы, а это невозможно без вёрстки как активного навыка. Поэтому, если было время, я старался верстать проекты самостоятельно, применять новые методологии, новые CSS-свойства, новые хаки.
В основном я использовал методологию, очень похожую на БЭМ, только без Modifier Value (впрочем почти все его так и используют). Это не было идеальным, но позволяло верстать качественно и с относительно большой скоростью, так как стили имели чёткую структуру. Можно было располагать куски кода в нужном месте, не сильно задумываясь.
Спустя много лет, пришло понимание, что независимо от методологии, **у CSS есть ряд особенностей, которые очень сложно упростить или скрыть за абстракцию**. Далее я попробую их перечислить. Хочу сразу отметить, что я питаю огромное уважение к разработчикам веб-стандартов, ценю их огромный труд, и не пытаюсь его обесценить. Веб-стандарты в первую очередь дают нам больше возможностей для решения наших задач, но это не означает, что эти стандарты обязаны быть идеальными для каждого отдельно взятого разработчика, проекта, компании или отдельной задачи. Поэтому это не список "проблем CSS", а список его особенностей в контексте создания больших и сложных интерфейсов:
* **CSS является достаточно низкоуровневым языком.** Да, там есть такие крутые высокоуровневые спецификации как Grid, но бОльшая часть языка это примитивы и часто одна задача требует использования нескольких из них одновременно. Например для того, чтобы спозиционировать элемент над другим элементом по середине (тот же тултип), надо использовать одновременно `position`, `top/right/bottom/left` и `transform`, плюс обязательно надо добавить немного JS, чтобы тултип не убежал за экран.
* **В CSS много свойств**, которые одновременно могут использоваться для решения разных задач. Например, `box-shadow` (внутренняя/внешняя тень или красивый бордер), `transform` (смещение и масштабирование) и т.п. Это может быть также неудобно, как одна JS-функция, которая решает несколько задач.
* **Специфичность селекторов и приоритизация стилей** с помощью порядка в коде до сих пор **создают проблемы**, особенно для новичков. Про `!important` я промолчу.
* **Привязка свойств к состояниям элемента** может быть очень простой, но непредсказуемой. Приоритет стилей для `.cls:hover` и `.cls:focus` зависит от порядка и в более сложных случаях от специфичности. Чтобы добавить стиль в состояние, мы должен убедиться, что он не конфликтует со стилями из другого состояния. Но можно писать предсказуемый CSS (`.cls:hover:not(:focus)` и т.п.), но мы получим очень комплексный синтаксис, в котором легко запутаться, и который потребует огромного рефакторинга в случае добавления нового состояния. В реальных проектах мы обычно сталкиваемся со смешанным подходом, который старается минимизировать кол-во кода, что дополнительно усложняет его поддержку.
* Из предыдущего пункта также следует, что **переопределения набора стилизованных состояний у элемента становится экспоненциально сложной задачей**. А это значит, что наследование стилей с помощью добавления класса (`.btn.fancy-btn`) в общем случае не работает, даже если мы используем "предсказуемый подход". Мы не можем создать и применить универсальный класс, который бы, к примеру, сказал "убери/замени все стили связанные с состоянием **hover** для этого элемента". Достаточно банальная задача дизайна "замена набора состояний", (например для оптимизации под touch-устройства) не имеет универсального и простого решения через CSS.
* **CSS Media Queries имеют чрезмерно мощный и запутанный** (`@media not all and (hover: none)`) **синтаксис** для тех задач, для которых мы их используем.
* Интерфейс создаётся с помощью CSS+HTML, которые в браузере превращаются в **сложную связку CCSOM+DOM с кучей правил**. Это даёт огромную гибкость, которую мы так любим, но также создаёт простор для ошибок и появления багов, усложняя создание и поддержку кода.
* В отличие от JS, **контролировать качество CSS-кода очень сложно**. Его крайне тяжело статически анализировать. А в runtime получение хоть какой-то информации о стилях элемента требует вызова `getComputedStyle()`, что влияет на производительность.
* **CSS огромен и постоянно развивается**. Поддерживать проект в актуальном состоянии может быть очень дорого, потому что внедрение отдельных новшеств требует радикального переписывания кода.
Причём **создание обёрток посредством препроцессоров может даже усложнять ситуацию**, добавляя в и без того сложную абстракцию дополнительное измерение. А бывает и так, что попытка что-то упростить начинает сильно нас ограничивать. Например, фиксированные breakpoints для адаптивности почти в каждом первом CSS-фреймворке.
Я считаю, что в хорошем инструменте простые задачи должны решаться просто, а сложные — пропорционально сложнее. И CSS прекрасно вписывается в эту концепцию, пока мы создаём относительно простые сайты с небольшим кол-вом требований, но по мере усложнения задач и объёмов проектов, поддержка CSS становится **несоизмеримо** более затратной.
Всё это привело меня к идее, что нужно искать новые подходы к стилизации.
Начнём с малого...
------------------
Разумеется, я не надеялся побороть все описанные выше особенности CSS, но мне хотелось разобраться хотя бы с некоторыми из них. Начиная один новый крупный проект, я решил поставить эксперимент и **не использовать CSS вне компонентов**. Это позволило бы минимизировать технический долг в будущем и мне было интересно посмотреть куда меня это приведёт, ведь подобный подход не сильно популярен, а значит в этом направлении возможно мало копали.
Самой первой проблемой стала раскладка страниц. Да, разумеется, можно создать компоненты `MyGrid` или `MyFlex` с соответствующим `display` свойством, что я и сделал, но для задания item-свойств (`basis/width/height`) нужно было что-то придумать и я решил эту проблему создав **Базовый элемент** (далее просто **БЭ**) от которого все остальные компоненты должны были наследоваться. Таким образом **каждый** компонент получил свойства `basis`, `width`, `height` и другие, что позволило корректировать их размеры и создавать адекватную раскладку.
Также с самого начала были добавлены свойства `size` и `text`, которые относились к тексту. `size` использовался для выставления `font-size/line-heigh`, а текст накладывал различные модификаторы текста (атомарный css в чистом виде), чтобы можно было легко делать текст жирным, выставлять выравнивание и т.п.
Всё это работало на обычных inline-стилях. На данном этапе проекта, адаптивность под мобильные не требовалась и я решил, что такой подход имеет место быть, учитывая, что он позволял нам очень быстро итерироваться по различным версиям дизайна, не жертвуя качеством и не создавая технический долг.
После трех месяцев оказалось, что данный подход не только улучшает качество кодовой базы и ускоряет разработку, но и **улучшает DX** (Developer Experience). Больше не требовалось переключение между контекстами разметка/стили для вёрстки страниц и составных компонентов.
Кол-во свойств **БЭ** росло, всё больше помогая быстро решать локальные задачи вёрстки. Но появились и первые проблемы.
Всю сложную кастомизацию элементов приходилось уносить в свойства и некоторые компоненты сильно от этого пухли. Качество кода самих компонентов существенно снижалось. Чем больше элементов имел внутри себя компонент, тем больше проблем вызывала его кастомизация. Чтобы это исправить, я решил по максимуму отказаться от компонентов в пользу обычных элементов. Вот типичный элемент изнутри:
```
```
*Ура, первый кусочек кода!*
Т.е. никакой композиции других элементов внутри нет. Композицией мы занимаемся на верхнем уровне. Пример для наглядности:
```
Button
Popup content
```
Мы объявили кнопку с попапом внутри, создав сложный интерактивный компонент. Теперь мы можем достаточно гибко кастомизировать всё что находится и внутри самой кнопки, и внутри попапа без дополнительных свойств. Там где гибкости не требуется мы можем завернуть это всё в отдельный компонент `MyDropdown`, чтобы не писать лишний код. Спустя месяц мне настолько понравилось использовать этот подход, что я просто выкинул большую часть компонентов, заменив их элементами.
В этот момент стало очевидно, что подход очень удобен и надо думать, как его развивать, чтобы добавить адаптивность, контекстные стили, стили для состояний, более удобную работу с цветом (у нас в проекте было много раскрашенных элементов). Примерно в это время я давал мастер-класс по гридам и для упрощения демок создал простенький веб-компонент `my-grid`, который брал атрибуты и мапил их на стили. Я был поражен насколько хорошо мой подход вписался в концепцию [Custom Elements](https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_custom_elements). Ведь, в них по умолчанию нет никакой композиции! Следующие несколько дней я потратил на миграцию элементов нашего проекта на Custom Elements, а сами элементы вынес в отдельный **Open Source проект NUDE Elements**, название которого позже было сокращено до Numl. Все элементы получили префикс `nu-`.
> Справка: **NUDE** – это название JS-фреймворка, на котором основан Numl и который был специально для него написан.
Миграция прошла на удивление легко. И началась активная работа над Numl параллельно основному проекту. В первую очередь нужно было избавиться от inline-стилей. Это сильно ограничивало возможности CSS и потребляло лишнюю мощность на маппингах. Таким образом был создан механизм генерации CSS в рантайме. Если упрощенно, то работало это следующим образом: Элемент `nu-grid` получал в атрибут `columns` значение `1fr 1fr`. Генератор анализирует это, вызывает функцию `columnsAttr('1fr 1fr')`, которая выглядит следующим образом:
```
export function columnsAttr(val) {
return {
'grid-template-columns': val,
};
}
```
Дальше генератор берёт результат и создаёт на его основе CSS:
```
nu-grid[columns="1fr 1fr"] {
grid-template-columns: 1fr 1fr;
}
```
… и вставляет это всё в | https://habr.com/ru/post/510026/ | null | ru | null |
# Удобная расшифровка для быстрой обработки аудиозаписей
### Описание
Преобразование аудио в текст широко применяется, например для создания субтитров к видео, протоколов собраний и расшифровки интервью. С сервисом ML Kit процесс становится гораздо проще: он очень точно преобразует аудиозаписи в текст с корректной пунктуацией.
### Подготовка к разработке
Настройте репозиторий Maven Huawei и интегрируйте SDK для расшифровки аудиозаписей. Подробное описание процесса можно найти [здесь](https://developer.huawei.com/consumer/en/doc/development/HMSCore-Guides-V5/audio-sdk-0000001050038090-V5).
### Указание прав в файле AndroidManifest.xml
Откройте файл **AndroidManifest.xml** в папке **main**. Добавьте разрешения на подключение к сети, доступ к статусу сети и чтению данных хранилища до **. Обратите внимание, что запрашивать нужно динамические разрешения. В противном случае будет ошибка **Permission Denied**.**
```
```
### Процесс разработки
#### Создание и инициализация движка расшифровки аудиозаписей
Переопределите метод **onCreate** в классе **MainActivity** для создания движка расшифровки аудиозаписей.
```
private MLRemoteAftEngine mAnalyzer;
mAnalyzer = MLRemoteAftEngine.getInstance();
mAnalyzer.init(getApplicationContext());
mAnalyzer.setAftListener(mAsrListener);
```
Используйте **MLRemoteAftSetting** для настройки движка. Сейчас сервис поддерживает стандартный вариант китайского языка и английский, поэтому для параметра **mLanguage** есть только опции **zh** и **en**.
```
MLRemoteAftSetting setting = new MLRemoteAftSetting.Factory()
.setLanguageCode(mLanguage)
.enablePunctuation(true)
.enableWordTimeOffset(true)
.enableSentenceTimeOffset(true)
.create();
```
Параметр **enablePunctuation** указывает, нужно ли автоматически проставлять пунктуацию в полученном тексте. Значение по умолчанию — **false**.
Если установить для этого параметра значение **true**, в полученном тексте будет автоматически проставлена пунктуация, а если **false** — пунктуации не будет.
Параметр **enableWordTimeOffset** указывает, нужно ли добавлять временную метку к каждому сегменту аудиозаписи. Значение по умолчанию — **false**. Настраивайте этот параметр, только если длительность записи меньше минуты.
Если значение параметра — **true**, временные метки будут возвращены с расшифровкой. Эти параметры применяются при расшифровке коротких аудиозаписей длительностью не более минуты. Если значение параметра — **false**, будет возвращена только расшифровка аудиозаписи.
Параметр **enableSentenceTimeOffset** указывает, нужно ли добавлять временную метку к каждому предложению в аудиозаписи. Значение по умолчанию — **false**.
Если значение параметра — **true**, временные метки будут возвращены с расшифровкой. Если значение параметра — **false**, будет возвращена только расшифровка аудиозаписи.
#### Создание обратного вызова слушателя для обработки результата расшифровки
```
private MLRemoteAftListener mAsrListener = new MLRemoteAftListener()
```
После инициализации слушателя вызовите **startTask** в слушателе **AftListener** для начала расшифровки.
```
@Override
public void onInitComplete(String taskId, Object ext) {
Log.i(TAG, "MLRemoteAftListener onInitComplete" + taskId);
mAnalyzer.startTask(taskId);
}
```
Переопределите методы **onUploadProgress**, **onEvent** и **onResult** в слушателе **MLRemoteAftListener**.
```
@Override
public void onUploadProgress(String taskId, double progress, Object ext) {
Log.i(TAG, " MLRemoteAftListener onUploadProgress is " + taskId + " " + progress);
}
@Override
public void onEvent(String taskId, int eventId, Object ext) {
Log.e(TAG, "MLAsrCallBack onEvent" + eventId);
if (MLAftEvents.UPLOADED_EVENT == eventId) { // The file is uploaded successfully.
showConvertingDialog();
startQueryResult(); // Obtain the transcription result.
}
}
@Override
public void onResult(String taskId, MLRemoteAftResult result, Object ext) {
Log.i(TAG, "onResult get " + taskId);
if (result != null) {
Log.i(TAG, "onResult isComplete " + result.isComplete());
if (!result.isComplete()) {
return;
}
if (null != mTimerTask) {
mTimerTask.cancel();
}
if (result.getText() != null) {
Log.e(TAG, result.getText());
dismissTransferringDialog();
showCovertResult(result.getText());
}
List segmentList = result.getSegments();
if (segmentList != null && segmentList.size() != 0) {
for (MLRemoteAftResult.Segment segment : segmentList) {
Log.e(TAG, "MLAsrCallBack segment text is : " + segment.getText() + ", startTime is : " + segment.getStartTime() + ". endTime is : " + segment.getEndTime());
}
}
List words = result.getWords();
if (words != null && words.size() != 0) {
for (MLRemoteAftResult.Segment word : words) {
Log.e(TAG, "MLAsrCallBack word text is : " + word.getText() + ", startTime is : " + word.getStartTime() + ". endTime is : " + word.getEndTime());
}
}
List sentences = result.getSentences();
if (sentences != null && sentences.size() != 0) {
for (MLRemoteAftResult.Segment sentence : sentences) {
Log.e(TAG, "MLAsrCallBack sentence text is : " + sentence.getText() + ", startTime is : " + sentence.getStartTime() + ". endTime is : " + sentence.getEndTime());
}
}
}
}
```
#### Обработка результата расшифровки в режиме опроса
После выполнения расшифровки вызовите **getLongAftResult** для получения результата. Обрабатывайте полученный результат раз в 10 секунд.
```
private void startQueryResult() {
Timer mTimer = new Timer();
mTimerTask = new TimerTask() {
@Override
public void run() {
getResult();
}
};
mTimer.schedule(mTimerTask, 5000, 10000); // Process the obtained long speech transcription result every 10 seconds.
}
private void getResult() {
Log.e(TAG, "getResult");
mAnalyzer.setAftListener(mAsrListener);
mAnalyzer.getLongAftResult(mLongTaskId);
}
```
#### Работа функции в приложении
Создайте и запустите приложение со встроенной функцией расшифровки аудиозаписей. Затем выберите аудиофайл на устройстве и преобразуйте аудио в текст. | https://habr.com/ru/post/655761/ | null | ru | null |
# Грузите апельсины бочках. Релизы в Golang проектах
Данная статья является продолжением инструментальной темы, затронутой в [прошлой публикации](https://habrahabr.ru/post/346254/). Сегодня мы постараемся разобраться со сборкой релизов Golang приложений в виде единого исполняемого файла, включающего ресурсные зависимости, и вопросом оптимизации размера итоговой сборки. Также рассмотрим процесс построения рабочего окружения отвечающего следующим требованиям:
1. Переносимость. Окружение должно быть легко воспроизводимо на различных машинах.
2. Изолированность. Окружение не должно влиять на версии установленных библиотек и программ на машине разработчика.
3. Гибкость. Окружение должно позволять собирать релизы для различных версий Golang и Linux (разные версии дистрибутивов и glibc).
4. Повторяемость. Не должно быть магии и тайных знаний, то есть все шаги сборки проекта и зависимостей должны быть описаны кодом.
Введение
--------
Golang предлагает путь статической сборки приложений. Это вполне удобно и подходит для многих случаев. При разработке утилит с web-интерфейсом или же полноценных web-сервисов неизбежно появляются зависимости от:
* файлов конфигурации
* шаблонов, стилей, скриптов и картинок для пользовательского интерфейса
* чувствительной информации, например ключей для SSL, если ваш сервис работает напрямую с https
* и многого другого
Неплохо было бы иметь возможность упаковки необходимых ресурсов статически в исполняемый файл таким образом, чтобы итоговый релиз представлял из себя следующий набор:
* файл конфигурации сервиса
* исполняемый файл релиза
* файл конфигурации сервиса для systemd или его аналога.
Данный подход позволяет решить сразу несколько вопросов:
* упростить доставку кода конечным потребителям.
* обеспечить контроль за ресурсами
* обеспечить безопасность (невозможность изменения третьими лицами)
Схожий подход применяют, например, авторы популярных открытых проектов, таких как mailhog, consul, vault.
Рабочее окружение
-----------------
Если вы одновременно ведете несколько проектов с разными версиями компиляторов и зависимостей, то наверняка уже нашли способ изоляции рабочих окружений разных проектов в рамках одной машины разработчика.
Поскольку в моей практике повсеместно используются гибридные системы, состоящие из компонент, написанных на различных языках и включенных в поставку одновременно, то дополнительно возникает вопрос гибкости и быстроты переключения между ними.
В прошлой статье можно найти объяснение базовых идей при проектировании рабочего окружения для Erlang проекта. На схожих принципах построена песочница и для Golang проектов.
Исходный код демонстрационного приложения и окружения для разработки Golang проектов можно найти по адресу <https://github.com/Vonmo/relgo>
**Замечание:** Код проверен на debian-like дистрибутивах. Для успешной работы с данной статьей на вашей машине должен быть установлен [docker](https://docs.docker.com/engine/installation/linux/docker-ce/ubuntu/), [docker-compose](https://docs.docker.com/compose/install/) и GNU Make. Установка docker не занимает много времени, необходимо лишь помнить, что ваш пользователь должен быть добавлен в группу docker.
В make предопределены следующие цели:
* **build\_imgs**. Отвечает за сборку базовых контейнеров для запуска контейнеров рабочей среды.
* **up**. Создает или обновляет контейнеры песочницы и после этого запускает их.
* **down**. Останавливает и удаляет контейнеры песочницы.
* **test**. Запускает тесты
* **rel**. Готовит итоговый релиз приложения.
* **run**. Запускает приложение в песочнице
* **deps**. Получает и обновляет зависимости
* **new\_migration**. Создает миграцию базы данных
* **migrate**. Применяет миграции
* **format\_code**. Форматирует исходный код с помощью gofmt
Демонстрационное приложение
---------------------------
Разрабатывать будем атомарный счетчик (atomic counter). Для демонстрации усложним приложение путем ввода зависимости от базы данных. В данном случае значения счетчиков будут храниться в postgresql.
Определим требования:
1. Функциональность.
Приложение должно выполнять следующие функции:
* increment
* decrement
* reset
* value
2. Целевая система: ubuntu 16.04 LTS
3. Простейшее HTTP API
4. Использование Golang >= 1.9
5. Наличие начального интерфейс мониторинга внутренних процессов приложения
### Архитектура
Архитектура приложения базируется на идее изоляции логически законченных единиц в отдельных пакетах. В приложении присутствуют следующие слои:
* core – ядро системы, предоставляет базовые функции: конфигурация, логирование, метрики; обеспечивает корректный запуск и остановку сервисов.
* config – отвечает за парсинг конфигурации
* models – реализует интерфейс общения с базой данных.
* migrations – миграции для схемы базы данных.
* log – добавляет уровни логирования в стандартный log.
* metrics – реализует простейшие метрики приложения.
* services – пакет включающий в себя все сервисы системы.
Слои и разделение приложения на сервисы позволяют легко добавлять новый функционал в систему и, помимо этого, гибко конфигурировать релиз в распределенной среде.
### Ядро
Основной целью ядра является создание корректного окружения с базовыми функциями для всех подключаемых к нему сервисов. В демонстрационном приложении реализованы функции ядра:
* Конфигурация
* Логгер
* Метрики
* Реестр сервисов
### Конфигурация узла
Для простейших утилит можно использовать переменные командной строки и механизм флагов. Для более сложных программ оправдано введение конфигурационного файла.
Мне импонирует формат yaml, поэтому в данном примере используется именно он, но заменить парсер можно простой доработкой в config.go функции Parse/1 и самих атрибутов, отвечающих за парсинг в декларации структуры конфига.
Вся конфигурация разбита на секции, группирующие логически связанные параметры:
* Node – группа параметров, определяющих название узла и его положение в кластере (имя ноды, датацентр, полка)
* Runtime – позволяет настроить runtime go, например степень параллелизации.
* Dirs – задает список директорий, которые автоматически создаст ядро. При этом обращаться к ним в коде довольно просто, пример получения пути к папке с данными – System.Config.Dirs.Data
* Log – определяет параметры логгера. Мы можем писать логи в stdout либо в файл, при этом гибко настроить количество событий через уровни логирования.
* Metrics – предоставляет параметры метрик приложений. Файл метрик позволяет получить представление о происходящих внутри приложения процессах, например если каких-то событий стало слишком много, или слишком мало. Также метрики полезны при тестировании, поскольку позволяют отправить запрос в систему и увидеть, как изменились счетчики в процессе обработке запроса.
* DataSources – содержит параметры подключения к внешним источникам данных, таким, например, как базы данных.
* Services – позволяет определить специфичный набор опций для каждого сервиса .
### Сервисы
Для корректной инициализации сервиса необходимо выполнить ряд условий:
1. Реализовать описание структуры сервиса, унаследовав стандартный интерфейс описания:
Пример для нашего сервиса:
```
type ACounter struct {
core.Service
http *http.Server
}
```
2. Определить `init()` функцию, в которой создается и запускается экземпляр сервиса:
```
func init() {
go (&ACounter{
Service: core.NewService(Acounter),
}).start()
}
```
3. Реализовать логику запуска и остановки сервиса
```
func (srv *ACounter) start() {
waitCore()
srv.Ready = true
srv.ShutdownFun = func(reason string) {
log.Debug("acounter: soft shutdown")
...
}
core.Register(&srv.Service)
...
}
```
Для регистрации сервисов используется стандартный вызов `init()`. Поскольку мы не можем гарантировать порядок вызова `init()` в модулях, то ядро предоставляет механизмы дожидания:
* `core.WaitCore()` – вызов ждет завершения полной инициализации ядра: настройка метрик, логгера, подключение к базе данных и других внутренних процессов
* `core.WaitService(srv string)` – позволяет дождаться завершения инициализации другого сервиса. Данный механизм позволяет определить порядок запуска связанных сервисов.
В случае получения от операционной системы сигнала остановки, ядро сообщает об этом всем сервисам путем вызова их `srv.ShutdownFun`.
### Управление зависимостями
В базовый образ включен Dep. Данная утилита позволяет произвести vendor locking и в настоящее время является стандартом. Для внесения зависимости в проекте импортируем ее в любом файле проекта и запускаем предопределенную цель:
* `$ make deps`
Все новые зависимости будут помещены в vendor директории. Также хочется заметить, что Dep автоматически удаляет неиспользуемые зависимости.
### Логгер
Существует масса библиотек для логирования на go. Например, glog от google кастомизируем, имеет уровни и прекрасно справляется с задачей. Но мне не хотелось дополнительной зависимости в проекте, да и многие библиотеки не подходили по той или иной причине.
В качестве решения пришлось расширить стандартный log, чтобы он соответствовал следующим требованиям:
1. Реализовывал исходное API log.
Вызовы log.\* должны работать.
2. Позволял легко перейти на него в уже существующих проектах.
`imprt “log”` заменяется на `import "github.com/Vonmo/relgo/log"`
3. Выводил микросекундные метки времени.
4. Показывал имя файла и строку, в которой произошел вызов функции логирования.
5. Имел типизацию сообщений: Debug, Info, Error, Panic, Fatal и настройку уровня логирования.
### Миграции
Поскольку в нашем проекте есть зависимость от базы данных и в postgresql есть схема данных, то хорошей практикой является применение миграций. Подходы к миграциям различны, можно писать их в рамках языка проекта, реализуя функции миграции и отката, а можно использовать дополнительные утилиты.
Выбор инструмента зависит от предпочтения разработчика и окружения проекта. Если вы работаете на нескольких языках одновременно и хотели бы единообразия в миграциях, можно использовать внешнюю утилиту. Для себя я выбрал [sql-migrate](https://github.com/rubenv/sql-migrate). Данная утилита генерирует plain text, в который необходимо поместить sql миграции и отката.
### Тестирование
В мире go предлагают тестировать http api без запуска сервера, путем прямого вызова обработчиков (см. <https://golang.org/pkg/net/http/httptest/>). Однако хочется отойти от юнит тестов и провести полное тестирование интерфейса чтобы приблизиться к интеграционному тестированию.
В примере можно найти реализацию тестирования полноценного ядра и всех определенных сервисов в тестовом окружении.
**Замечание:** Наверняка я недостаточно хорошо искал, но есть ли на Golang фреймворк для тестирования, который по функциональности близок к Common Test из Erlang?
Размер итогового файла
----------------------
Возникает вопрос: почему сборки Golang такие большие? Например если мы соберем простой `main(){ fmt.Println("done.") }` то получим примерно 1.9 Мб, из которых runtime golang занимает около 1 Мб (данные актуальны для go 1.9.2 amd64).
С реальными проектами дела обстоят еще интереснее:
* consul-Linux-x86\_64 – 42.8 Мб
* vault-Linux-x86\_64 – 75.5 Мб
* mailhog-Linux-x86\_64 – 11.2 Мб
Поскольку в релиз идет стабильный код, можно отключить DWARF debuggin information и общую отладочную информацию, задав -w и -s ключи в качестве опций сборки. Данная мера позволит сократить размер примерно на 30%.
Дальнейшим шагом является применение упаковщиков исполняемых файлов. Одним из популярных упаковщиков является upx. После применения упаковщика итоговый размер сборки сократился с начальных 1.9 Мб до 423 кб, таким образом мы сократили размер исходного файла почти на 78%. С этим уже можно жить.
Итоги
-----
Нам удалось создать среду, в которой можно легко разрабатывать приложения. Так же, как и с рабочим окружением для Erlang, данная среда позволяет получать повторяющийся результат вне зависимости от машины, на которой ведется разработка, избавиться от конфликтов библиотек и версий инструментов, упростить дальнейший CI и – самое главное – выявить проблемы на ранних этапах разработки, так как с помощью docker можно воспроизвести довольно сложные окружения.
Уважаемые читатели, благодарю вас за уделенное время и проявленный к теме интерес. | https://habr.com/ru/post/347094/ | null | ru | null |
# Вычисляем потенциальных «злых» ботов и блокируем их по IP

Доброго дня! В статье расскажу как можно пользователям обычного хостинга отловить IP адреса генерирующие излишнюю нагрузку на сайт и затем блокировать их при помощи средств хостинга, будет «чуть-чуть» php кода, несколько скриншотов.
**Вводные данные:**
1. Сайт созданный на CMS WordPress
2. Хостинг Бегет (это не реклама, но скрины админки будут именно этого хостинг провайдера)
3. WordPress сайт запущен где то в начале 2000 и имеет большое количество статей и материалов
4. Версия PHP 7.2
5. WP имеет последнюю версию
6. С некоторых пор сайт начал генерировать высокую нагрузку на MySQL по данным хостинга. Каждый день это значение превышало 120% от нормы на учётную запись
7. По данным Яндекс. Метрика сайт посещает 100-200 человек в сутки
**В первую очередь было сделано:**
1. Очищены таблицы БД от накопившегося мусора
2. Отключены не нужные плагины, убраны участки устаревшего кода
*При этом обращаю внимание, пробовались варианты кеширования(плагины кеширования), проводились наблюдения — но нагрузка в 120% от одного сайта была неизменна и могла только расти.*
**То как выглядела примерная нагрузка по базам данных хостинга**

*В топе находится сайт о котором идёт речь, чуть ниже другие сайты которые имеют ту же cms и примерно такую же посещаемость, но создают меньше нагрузки.*
**Анализ**
* Было предпринято много попыток с вариантами кеширования данных, проводились наблюдения в течении нескольких недель (благо хостинг за это время мне ни разу не написал что я такой плохой и меня отключат)
* Был анализ и поиск медленных запросов, затем была немного изменена структура БД и тип таблиц
* Для анализа в первую очередь использовался встроенный AWStats (он кстати помог вычислить самый злой IP адрес по объему трафика
* Метрика — метрика даёт информацию только о людях, а не о ботах
* Были попытки использовать плагины для WP, которые умеют фильтровать и блокировать посетителей даже по стране нахождения и по различным комбинациям
* Совсем радикальный способ оказался закрыть сайт на сутки с пометкой «Мы на техническом обслуживании» — это было так же сделано при помощи знаменитого плагина. В этом случае нагрузка ожидаем упала, но не до 0-левых значений, так как идеология WP базируется на хуках и плагины начинают свою активность при наступлении какого — либо «хука», а до наступления «хука» могут быть уже сделаны запросы к БД
**Идея**
1. Вычислить IP адреса которые делают много запросов за короткий промежуток времени.
2. Зафиксировать количество обращений к сайту
3. На основе количества обращений блокировать доступ к сайту
4. Блокировать при помощи записи «Deny from» в файле .htaccess
5. Другие варианты, вроде iptables и правил для Nginx не рассматривая, ибо пишу про хостинг
Появилась идея, значит надо реализовывать, как без этого…
* Создаём таблицы для накопления данных
```
CREATE TABLE `wp_visiters_bot` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`ip` VARCHAR(300) NULL DEFAULT NULL,
`browser` VARCHAR(500) NULL DEFAULT NULL,
`cnt` INT(11) NULL DEFAULT NULL,
`request` TEXT NULL,
`input` TEXT NULL,
`data_update` DATETIME NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE INDEX `ip` (`ip`)
)
COMMENT='Кандидаты для блокировки'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=1;
```
```
CREATE TABLE `wp_visiters_bot_blocked` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`ip` VARCHAR(300) NOT NULL,
`data_update` DATETIME NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE INDEX `ip` (`ip`)
)
COMMENT='Список уже заблокированных'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=59;
```
```
CREATE TABLE `wp_visiters_bot_history` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`ip` VARCHAR(300) NULL DEFAULT NULL,
`browser` VARCHAR(500) NULL DEFAULT NULL,
`cnt` INT(11) NULL DEFAULT NULL,
`data_update` DATETIME NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`data_add` DATETIME NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE INDEX `ip` (`ip`)
)
COMMENT='История всех запросов для дебага'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=1;
```
* Создадим файл в который поместим код. Код будет запись в таблицы кандидатов на блокировку и вести историю для дебага.
**Код файла, для записи IP адресов**
```
php
if (!defined('ABSPATH')) {
return;
}
global $wpdb;
/**
* Вернёт конкретный IP адрес посетителя
* @return boolean
*/
function coderun_get_user_ip() {
$client_ip = '';
$address_headers = array(
'HTTP_CLIENT_IP',
'HTTP_X_FORWARDED_FOR',
'HTTP_X_FORWARDED',
'HTTP_X_CLUSTER_CLIENT_IP',
'HTTP_FORWARDED_FOR',
'HTTP_FORWARDED',
'REMOTE_ADDR',
);
foreach ($address_headers as $header) {
if (array_key_exists($header, $_SERVER)) {
$address_chain = explode(',', $_SERVER[$header]);
$client_ip = trim($address_chain[0]);
break;
}
}
if (!$client_ip) {
return '';
}
if ('0.0.0.0' === $client_ip || '::' === $client_ip || $client_ip == 'unknown') {
return '';
}
return $client_ip;
}
$ip = esc_sql(coderun_get_user_ip()); // IP адрес посетителя
if (empty($ip)) {// Нет IP, ну и идите лесом...
header('Content-type: application/json;');
die('Big big bolt....');
}
$browser = esc_sql($_SERVER['HTTP_USER_AGENT']); //Данные для анализа браузера
$request = esc_sql(wp_json_encode($_REQUEST)); //Последний запрос который был к сайту
$input = esc_sql(file_get_contents('php://input')); //Тело запроса, если было
$cnt = 1;
//Запрос в основную таблицу с временными кондидатами на блокировку
$query = <<<EOT
INSERT INTO wp_visiters_bot (`ip`,`browser`,`cnt`,`request`,`input`)
VALUES ('{$ip}','{$browser}','{$cnt}','{$request}','$input')
ON DUPLICATE KEY UPDATE cnt=cnt+1,request=VALUES(request),input=VALUES(input),browser=VALUES(browser)
EOT;
//Запрос для истории
$query2 = <<<EOT
INSERT INTO wp_visiters_bot_history (`ip`,`browser`,`cnt`)
VALUES ('{$ip}','{$browser}','{$cnt}')
ON DUPLICATE KEY UPDATE cnt=cnt+1,browser=VALUES(browser)
EOT;
$wpdb-query($query);
$wpdb->query($query2);
```
Суть кода в том что бы получить IP адрес посетителя и записать его в таблицу. Если ip уже есть в таблице, будет произведено увеличение поля cnt (количество запросов к сайту)
* Теперь страшное… Сейчас меня сожгут за мои действиия :)
Что бы записывать каждое обращение сайту, подключаем код файла в главный файл WordPress — wp-load.php. Да именно изменяем файл ядра и именно после того как уже существует глобальная переменная $wpdb
Итак, теперь мы можем видеть как часто тот или иной IP адрес отмечается у нас в таблице и с кружкой кофе заглядываем туда раз в 5-ь минут для понимания картины

Дальше просто, скопировали «вредный» IP, открыли файл .htaccess и добавили в конец файла
```
Order allow,deny
Allow from all
# start_auto_deny_list
Deny from 94.242.55.248
# end_auto_deny_list
```
Всё, теперь 94.242.55.248 — не имеет доступа к сайту и не генерирует нагрузку на БД
Но каждый раз так руками копировать не очень праведное занятие, да и к тому же код задумывался как автономный
Добавим файл, который будет исполняться по CRON каждые 30 минут:
**Код файла модифицирующий .htaccess**
```
php
/**
* Файл автоматического задания блокировок по IP адресу
* Должен запрашиваться через CRON
*/
if (empty($_REQUEST['key'])) {
die('Hello');
}
require('wp-load.php');
global $wpdb;
$limit_cnt = 70; //Лимит запросов по которым отбирать
$deny_table = $wpdb-get_results("SELECT * FROM wp_visiters_bot WHERE cnt>{$limit_cnt}");
$new_blocked = [];
$exclude_ip = [
'87.236.16.70'//адрес хостинга
];
foreach ($deny_table as $result) {
if (in_array($result->ip, $exclude_ip)) {
continue;
}
$wpdb->insert('wp_visiters_bot_blocked', ['ip' => $result->ip], ['%s']);
}
$deny_table_blocked = $wpdb->get_results("SELECT * FROM wp_visiters_bot_blocked");
foreach ($deny_table_blocked as $blocked) {
$new_blocked[] = $blocked->ip;
}
//Очистка таблицы
$wpdb->query("DELETE FROM wp_visiters_bot");
//echo '
```
';print_r($new_blocked);echo '
```
';
$file = '.htaccess';
$start_searche_tag = 'start_auto_deny_list';
$end_searche_tag = 'end_auto_deny_list';
$handle = @fopen($file, "r");
if ($handle) {
$replace_string = '';//Тест для вставки в файл .htaccess
$target_content = false; //Флаг нужного нам участка кода
while (($buffer = fgets($handle, 4096)) !== false) {
if (stripos($buffer, 'start_auto_deny_list') !== false) {
$target_content = true;
continue;
}
if (stripos($buffer, 'end_auto_deny_list') !== false) {
$target_content = false;
continue;
}
if ($target_content) {
$replace_string .= $buffer;
}
}
if (!feof($handle)) {
echo "Ошибка: fgets() неожиданно потерпел неудачу\n";
}
fclose($handle);
}
//Текущий файл .htaccess
$content = file_get_contents($file);
$content = str_replace($replace_string, '', $content);
//Очищаем все блокировки в файле .htaccess
file_put_contents($file, $content);
//Запись новых блокировок
$str = "# {$start_searche_tag}" . PHP_EOL;
foreach ($new_blocked as $key => $value) {
$str .= "Deny from {$value}" . PHP_EOL;
}
file_put_contents($file, str_replace("# {$start_searche_tag}", $str, file_get_contents($file)));
```
Код файла достаточно прост и примитивен и главная его идея в том что бы взять кандидатов на блокировку и вписать правила блокирвоки в файл .htaccess между комментариями
# start\_auto\_deny\_list и # end\_auto\_deny\_list
Теперь «вредные» ip блокируются сами собой, а файл .htaccess выглядит примерно так:
```
# BEGIN WordPress
RewriteEngine On
RewriteBase /
RewriteRule ^index\.php$ - [L]
RewriteCond %{REQUEST\_FILENAME} !-f
RewriteCond %{REQUEST\_FILENAME} !-d
RewriteRule . /index.php [L]
# END WordPress
Order allow,deny
Allow from all
# start_auto_deny_list
Deny from 94.242.55.248
Deny from 207.46.13.122
Deny from 66.249.64.164
Deny from 54.209.162.70
Deny from 40.77.167.86
Deny from 54.146.43.69
Deny from 207.46.13.168
....... ниже другие адреса
# end_auto_deny_list
```
В итоге после начала действия такого кода можно увидеть результат в хостинг панели:

*PS: Материал авторский, хоть его часть я и публиковал на своём сайте но на Habre получилась более расширенная версия.* | https://habr.com/ru/post/473030/ | null | ru | null |
# Инсталляция Bitrix Web Environment в облаке МегаФон
Мало кто знает, что Мегафон с недавнего времени вышел на рынок хостинга и предлагает такую услугу, как виртуальный сервер. На днях занимался развертыванием среды окружения Битрикс в их облаке, и обнаружил несколько интересных моментов. Кому интересно, дальше читаем под катом.

Итак, создаем виртуальный сервер и выбираем необходимые нам параметры. Далее ждем 20-30 минут, пока система оркестрации создаст виртуальную машину по указанным параметрам.
#### Подключение к серверу и смена пароля
После того, как машина создана, подключаемся к нашему серверу по SSH. В первую очередь необходимо сменить пароль пользователя root, так как он по умолчанию одинаковый для всех виртуальных машин – Qwerty123456. Автор этого пароля явно в [тренде последних событий](http://xakep.ru/news/yandex-mail-passwords/):
```
# passwd root
```
#### Увеличение размера диска в виртуальной машине
Дальше начинается самое интересное. Если выполнить команду df, то можно увидеть, что из заказанных 20 Gb, реально доступно только около 3,5 Gb. И в чем же подвох, спросите вы?
```
# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root
2.6G 1.7G 767M 70% /
tmpfs 495M 0 495M 0% /dev/shm
/dev/sda1 485M 37M 423M 8% /boot
```
А дело в том, что все остальное пространство выдается нам неразмеченным. Соответственно, нам необходимо ручками расширить раздел на все оставшееся доступное пространство. Для начала, с помощью команды fdisk с параметром L определяем устройство, на котором находится выделенное дисковое пространство. В нашем случае это диск /dev/sda (для 32 битной системы это будет /dev/hda).
```
#fdisk –l
Disk /dev/sda: 21.5 GB, 21474836480 bytes
…
Device Boot Start End Blocks Id System
/dev/sda1 * 1 64 512000 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 64 914 6827008 8e Linux LVM
Partition 2 does not end on cylinder boundary.
…
```
Создаем новый раздел с файловой системой LVM (8e) (подробнее про LVM [тут](https://ru.wikipedia.org/wiki/LVM)), который займет имеющееся нераспределенное дисковое пространство устройства /dev/sda. По результатам выполнения предыдущей команды мы увидели, что на диске уже есть два раздела, поэтому создаваемый раздел будет третьим по счету.
```
# fdisk /dev/sda
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 3
First cylinder (914-2610, default 914):
Using default value 914
Last cylinder, +cylinders or +size{K,M,G} (914-2610, default 2610):
Using default value 2610
```
Меняем тип файловой системы на LVM
```
Command (m for help): t
Partition number (1-4): 3
Hex code (type L to list codes): 8e
Changed system type of partition 3 to 8e (Linux LVM)
```
Записываем таблицу разделов на диск:
```
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
```
Перезагружаем сервер
```
#reboot
```
Далее запускаем утилиту lvm и преобразуем раздел /dev/sda3 в физический том, чтобы LVM мог использовать его:
```
# lvm
lvm> pvcreate /dev/sda3
Physical volume "/dev/sda3" successfully created
```
Смотрим, какие существуют группы томов и логические разделы
```
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
lv_root VolGroup -wi-ao--- 2.60g
lv_swap VolGroup -wi-ao--- 3.91g
```
Добавляем новый физический том в группу томов:
```
lvm> vgextend VolGroup /dev/sda3
Volume group "VolGroup" successfully extended
```
Увеличиваем размер логического тома lv\_root на все доступное свободное дисковое пространство в группе:
```
lvm> lvextend -l +100%FREE /dev/VolGroup/lv_root
Extending logical volume lv_root to 15.59 GiB
Logical volume lv_root successfully resized
```
Теперь логическому тому выделено все доступное дисковое пространство, но, если выполнить команду df, то мы увидим, что операционная система все еще не может его использовать. Нам нужно изменить еще размер смонтированной корневой файловой системы:
```
# resize2fs -p /dev/mapper/VolGroup-lv_root
resize2fs 1.41.12 (17-May-2010)
Filesystem at /dev/mapper/VolGroup-lv_root is mounted on /; on-line resizing required
old desc_blocks = 1, new_desc_blocks = 1
Performing an on-line resize of /dev/mapper/VolGroup-lv_root to 4087808 (4k) blocks.
The filesystem on /dev/mapper/VolGroup-lv_root is now 4087808 blocks long.
```
Проверяем размер дискового пространства файловой системы, теперь все, как надо:
```
# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root 16G 1.7G 13G 12% /
tmpfs 495M 0 495M 0% /dev/shm
/dev/sda1 485M 37M 423M 8% /boot
```
#### Установка окружения Bitrix
Установить apache, nginx, mysql, php и сконфигурировать их в соответствии с рекомендациями Битрикс можно за считанные минуты с помощью скрипта из официального репозитория. При инсталляции выбираем 4 поколение среды окружения Bitrix
```
# cd /
# wget http://repos.1c-bitrix.ru/yum/bitrix-env.sh
# chmod +x bitrix-env.sh
# ./bitrix-env.sh
```
После установки среды окружения заходим в меню, устанавливаем пароль пользователя bitrix, при необходимости добавляем домены.
```
# cd /root
# sh menu.sh
```
Теперь машина готова, можно открывать порты.
```
iptables -I INPUT -p tcp --dport 25 -j ACCEPT
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
iptables -I INPUT -p tcp --dport 443 -j ACCEPT
iptables -I INPUT -p tcp --dport 5222 -j ACCEPT
iptables -I INPUT -p tcp --dport 5223 -j ACCEPT
iptables -I INPUT -p tcp --dport 8890 -j ACCEPT
iptables -I INPUT -p tcp --dport 8891 -j ACCEPT
iptables -I INPUT -p tcp --dport 8893 -j ACCEPT
iptables -I INPUT -p tcp --dport 8894 -j ACCEPT
service iptables save
/etc/init.d/iptables restart
```
25 — smtp сервер, 80 — http, 443 — https, 5222 — bitrix xmpp сервер, 5223 — bitrix xmpp сервер по ssl, 8890 — ntlm авторизация, 8891 — ntlm авторизация по ssl, 8893 — http сервер мгновенных сообщений, 8894 — https сервер мгновенных сообщений
На этом настройка сервера завершена, приятной вам работы. | https://habr.com/ru/post/236469/ | null | ru | null |
# iPhone. Проигрывание аудио в фоновом режиме
Надеюсь что кому-то поможет это небольшое руководство по написанию iPhone-клиента для интернет-радио. Недавно мне понадобилось написать такое. В самообразовательных целях. Постараюсь охватить тему как можно шире в будущем, но сейчас хотелось бы сосредоточится на конкретном моменте, который вызвал у меня затруднения не далее чем сегодня, а именно на проигрывании радио в фоновом режиме.
Для этого нам потребуются пара нехитрых манипуляций.
Во-первых, нужно сообщить нашему приложению, о том, что оно должно проигрывать музыку даже после нажатия на «HOME»
Делается это в файле Info.plist проекта:
Выбираем файл в Project Navigator
Щёлкаем правой кнопкой мыши по свободному месту и выбираем «Add row»
В поле «Key» введём «Required background modes»,
это создаст нам массив, в качестве значения для первого элемента мы добавим «App plays audio».

Всё, наша программа знает что в фоновом режиме она не должна засыпать полностью, а должна продолжать играть музыку.
Другой, быстрый способ сделать тоже самое это открыть Info.plist обычным редактором(по сути это просто XML-файл) и дописать
```
UIBackgroundModes
audio
```
Теперь инициализируем наш плеер.
Вообще в iOS SDK есть несколько различных классов для работы со звуком. Я сначала использовал [AVQueuePlayer](http://developer.apple.com/library/ios/documentation/AVFoundation/Reference/AVQueuePlayer_Class/Reference/Reference.html), потом решил отдать предпочтение [AVPlayer](http://developer.apple.com/library/ios/#documentation/AVFoundation/Reference/AVPlayer_Class/Reference/Reference.html) как самому, на мой взгляд, гибкому.
В любом случае [AVFoundation](http://developer.apple.com/library/ios/#DOCUMENTATION/AVFoundation/Reference/AVFoundationFramework/_index.html#//apple_ref/doc/uid/TP40008072) вам в помощь, для работы с аудио.
```
- (void)viewDidLoad {
[super viewDidLoad];
// Convert the file path to a URL.
NSString *urlAddress = @"http://www.example.com/stream";
//Create a URL object.
NSURL *urlStream = [NSURL URLWithString:urlAddress];
AVPlayer *player = [[AVPlayer alloc] initWithURL:urlStream];
//Starts playback
[player play];
}
```
А теперь создаём сессию:
```
// очень важная строчка, она должна быть ПОСЛЕ инициализации плеера.
[[AVAudioSession sharedInstance] setCategory:AVAudioSessionCategoryPlayback error:nil];
```
Вот в принципе и всё, плеер умеет и будет работать в фоновом режиме. Вы можете свернуть программу нажатием на «Home» и музыка не прекратится.
**И самый важный момент: воспроизведение фонового аудио почему-то не работает в симуляторе, поэтому запускать и тестировать обязательно на девайсе.** | https://habr.com/ru/post/121186/ | null | ru | null |
# Поддержка устройств зонального хранения данных в различных версиях операционных систем на базе Linux

В одной из предыдущих публикаций мы уже рассказывали о [концепции зонального хранения данных](https://habr.com/ru/company/wd/blog/490908/) и о том, какие преимущества обеспечивает эта технология. Но насколько готова ваша IT-инфраструктура к ее внедрению? Хотя работа над поддержкой устройств зонального хранения в операционных системах на базе Linux началась еще в 2014 году, некоторые дистрибутивы и по сей день оказываются неспособны полноценно работать с такими накопителями. Чтобы вам было проще сориентироваться, мы подготовили сегодняшний материал, в котором подробно рассмотрены особенности имплементации зонального хранения данных в различных версиях ядер и популярных дистрибутивах Linux.
Рекомендуемые версии ядер Linux
-------------------------------
Впервые поддержка зональных блочных устройств хранения данных появилась в ядре Linux версии 4.10. Первоначально таковая была ограничена пользовательским интерфейсом ZBD (Zoned Block Device) на уровне блоков, возможностью управления очередью последовательной записи на уровне SCSI и нативной поддержкой файловой системы F2FS. В последующих версиях ядер появились дополнительные функции и инструменты, призванные оптимизировать работу с устройствами зонального хранения данных:
* 4.13.0 — добавлен маппер зональных блочных устройств dm-zoned;
* 4.16.0 — внедрена поддержка блочной инфраструктуры с несколькими очередями;
* 5.6.0 — добавлена поддержка файловой системы zonefs, позволяющей работать с отдельными зонами зональных блочных устройств как с обычными файлами;
* 5.8.0 — представлен общий интерфейс блочного уровня, поддерживающий операции записи Zone Append (добавление зоны); появилась возможность эмуляции этих операций на уровне SCSI с помощью обычных команд записи;
* 5.9 — добавлена поддержка набора команд NVMe ZNS (Zoned Name Spaces — зональное пространство имен).
Хронологию перечисленных изменений легко проследить на представленной ниже схеме.

Учитывая сказанное выше, при выборе операционной системы следует отдавать предпочтение дистрибутиву, использующему последнюю стабильную версию ядра, поскольку она будет включать в себя все имеющиеся функции и инструменты для работы с зональными блочными устройствами, а также содержать исправления всех проблем и ошибок, известных на момент релиза. Если же вы планируете использовать LTS-версии Linux, то оптимальным выбором для вас станут дистрибутивы операционных систем на базе ядер 4.14, 4.19 и 5.4, так как к ним будут гарантированно применены бэкпорты всех патчей, выпущенных для основной, разрабатываемой в настоящий момент ревизии ядра.
Поддерживаемые дистрибутивы Linux
---------------------------------
Предлагаем вашему вниманию сравнительные таблицы, которые помогут оценить уровень поддержки зональных блочных устройств в различных Linux-дистрибутивах, поставляемых с предварительно скомпилированными двоичными ядрами.
### Fedora

Fedora — операционная система, разрабатываемая сообществом Fedora Project под эгидой Red Hat. Впервые поддержку интерфейса ZBD данный дистрибутив получил в версии 26. Начиная с 27-й ревизии Fedora также включает в себя dm-zoned, скомпилированный как предварительно загружаемый модуль ядра. Последняя на сегодняшний день стабильная версия Fedora 33 обзавелась поддержкой набора команд NVMe ZNS.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** | **ZNS** |
| Fedora 26 (EOL) | 4.11 | Да | Нет | Нет |
| Fedora 27 (EOL) | 4.13 | Да | Да | Нет |
| Fedora 28 | 4.16 | Да | Да | Нет |
| Fedora 29 | 4.18 | Да | Да | Нет |
| Fedora 30 | 5.0 | Да | Да | Нет |
| Fedora 31 | 5.3 | Да | Да | Нет |
| Fedora 32 | 5.6 | Да | Да | Нет |
| Fedora 33 | 5.8 | Да | Да | Да |
### Debian

Debian — одна из первых Unix-подобных операционных систем, базирующихся на ядре Linux, оказавшая значительное влияние на развитие этого типа ОС в целом. Поддержка зональных блочных устройств появилась в данном дистрибутиве начиная с 10-й версии, получившей кодовое имя Buster.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** |
| Debian 9 (Stretch) | 4.9 | Нет | Нет |
| Debian 10 (Buster) | 4.19 | Да | Да |
### Ubuntu

Ubuntu — один из самых популярных бесплатных дистрибутивов Linux, код которого был изначально основан на Debian. Новые стабильные версии операционной системы выходят с периодичностью в 6 месяцев, а выпуски с долгосрочной поддержкой (LTS) — каждые два года. Впервые возможность работы с зональными блочными устройствами через ZBD была реализована в версии 17.04 Zesty Zapus с переходом на ядро 4.10, а уже в следующем выпуске была добавлена поддержка dm-zoned.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** |
| 12.04 LTS (Precise Pangolin) | 3.2 | Нет | Нет |
| 14.04 LTS (Trusty Tahr) | 3.13 | Нет | Нет |
| 16.04 LTS (Xenial Xerus) | 4.4 | Нет | Нет |
| 17.04 (Zesty Zapus) | 4.10 | Да | Нет |
| 17.10 (Artful Aardvark) | 4.13 | Да | Да |
| 18.04 LTS (Bionic Beaver) | 4.15 | Да | Да |
| 18.10 (Cosmic Cuttlefish) | 4.18 | Да | Да |
| 19.04 (Disco Dingo) | 5.0 | Да | Да |
| 19.10 (Eoan Ermine) | 5.3 | Да | Да |
| 20.04 LTS (Focal Fossa) | 5.4 | Да | Да |
| 20.10 (Groovy Gorilla) | 5.8 | Да | Да |
### Red Hat Enterprise Linux

Red Hat Enterprise Linux — операционная система от компании Red Hat, ориентированная на корпоративных пользователей. Ее отличительными особенностями являются расширенная коммерческая поддержка (до 10 лет с возможностью продления до 13 лет) и высокая стабильность работы, расплатой за которую являются крайне редкие глобальные обновления: даже наиболее актуальный на данный момент дистрибутив 8.3 базируется на ядре 4.180-240.
Хотя эта версия уже поддерживает ZBD и имеет в своем составе dm-zoned, в RHEL соответствующие опции по умолчанию отключены, поэтому работать с зональными устройствами «из коробки» не получится — ядро придется предварительно перекомпилировать.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** |
| RHEL 8 | 4.180-80 | Нет | Нет |
| RHEL 8.1 | 4.180-147 | Нет | Нет |
| RHEL 8.2 | 4.180-193 | Нет | Нет |
| RHEL 8.3 | 4.180-240 | Нет | Нет |
Что же касается RHEL 6 и 7, то, поскольку перечисленные выпуски были основаны на ядрах 2.6.32 и 3.10 соответственно, они не способны корректно работать с зональными устройствами хранения данных.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** |
| RHEL 6.0 | 2.6.32-71 | Нет | Нет |
| RHEL 6.1 | 2.6.32-131 | Нет | Нет |
| RHEL 6.2 | 2.6.32-220 | Нет | Нет |
| RHEL 6.3 | 2.6.32-279 | Нет | Нет |
| RHEL 6.4 | 2.6.32-358 | Нет | Нет |
| RHEL 6.5 | 2.6.32-431 | Нет | Нет |
| RHEL 6.6 | 2.6.32-504 | Нет | Нет |
| RHEL 6.7 | 2.6.32-573 | Нет | Нет |
| RHEL 6.8 | 2.6.32-642 | Нет | Нет |
| RHEL 6.9 | 2.6.32-696 | Нет | Нет |
| RHEL 6.10 | 2.6.32-754 | Нет | Нет |
| RHEL 6 ELS+ | 2.6.32-754 | Нет | Нет |
| RHEL 7.0 | 3.10.0-123 | Нет | Нет |
| RHEL 7.1 | 3.10.0-229 | Нет | Нет |
| RHEL 7.2 | 3.10.0-327 | Нет | Нет |
| RHEL 7.3 | 3.10.0-514 | Нет | Нет |
| RHEL 7.4 | 3.10.0-693 | Нет | Нет |
| RHEL 7.5 | 3.10.0-862 | Нет | Нет |
| RHEL 7.6 | 3.10.0-957 | Нет | Нет |
| RHEL 7.7 | 3.10.0-1062 | Нет | Нет |
| RHEL 7.8 | 3.10.0-1127 | Нет | Нет |
| RHEL 7.9 | 3.10.0-1160 | Нет | Нет |
### CentOS

CentOS — операционная система, разрабатываемая сообществом на основе исходных кодов Red Hat Enterprise Linux. Нумерации дистрибутивов CentOS и RHEL, равно как и возможности соответствующих выпусков операционных систем, на 100% совпадают. Как и в Red Hat Enterprise Linux, поддержка зональных блочных устройств появилась в 8-й версии CentOS, однако для активации необходимых опций ядро придется самостоятельно перекомпилировать.
### SUSE Linux Enterprise Server

SUSE Linux Enterprise Server (SLES) — операционная система, ориентированная на корпоративных пользователей, которую разработала немецкая компания SUSE на базе одноименного дистрибутива. Основные версии SLES выходят с интервалом 2–3 года, тогда как пакеты обновлений выпускаются примерно каждые 12 месяцев. Полноценная поддержка зональных блочных устройств была добавлена в SUSE Linux Enterprise Server начиная с версии 12.4.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** |
| 11.3 | 3.0.76 | Нет | Нет |
| 11.4 | 3.0.101 | Нет | Нет |
| 12.0 | 3.12 | Нет | Нет |
| 12.1 | 3.12 | Нет | Нет |
| 12.2 | 4.4 | Нет | Нет |
| 12.3 | 4.4 | Нет | Нет |
| 12.4 | 4.12 | Да | Да |
| 15 | 4.12 | Да | Да |
| 15.1 | 4.12.14 | Да | Да |
| 15.2 | 5.3.18 | Да | Да |
### openSUSE

openSUSE (ранее — SUSE Linux и SuSE Professional) — популярный дистрибутив Linux, разработка которого спонсируется SUSE Linux GmbH. В основе концепции openSUSE лежит создание удобных инструментов с открытым исходным кодом для разработчиков программного обеспечения и системных администраторов.
openSUSE получила поддержку интерфейса ZBD, необходимого для работы с зональными блочными хранилищами, начиная с версии Leap 15.0, а с переходом на ядро 5.3 в сборке Leap 15.2 к ней добавился dm-zoned.
| | | |
| --- | --- | --- |
|
**Дистрибутив** |
**Ядро** | **Поддерживаемые технологии** |
| **ZBD** | **dm-zoned** |
| Leap 15.0 | 4.12 | Да | Нет |
| Leap 15.1 | 4.12 | Да | Нет |
| Leap 15.2 | 5.3 | Да | Да |
| Tumbleweed | 5.9+ | Да | Да |
Поддерживает ли ваша операционная система устройства зонального хранения данных?
--------------------------------------------------------------------------------
Как сказано выше, интерфейс для работы с зональными блочными устройствами хранения данных (Zoned Block Device, ZBD), поддерживающий стандарты T10 ZBC и T13 ZAC, был добавлен в ядро Linux начиная с версии 4.10, поэтому первое, что необходимо сделать, — проверить текущую версию ядра с помощью команды терминала uname. Например, при использовании дистрибутива Fedora 29 вывод данной команды будет выглядеть следующим образом:
```
uname -r
5.0.13-200.fc29.x86_64
```
В нашем случае используется пятая версия ядра, в которую поддержка зональных устройств хранения уже добавлена. Однако, для того чтобы подобные накопители смогли взаимодействовать с операционной системой, ядро должно быть изначально скомпилировано с активным параметром CONFIG\_BLK\_DEV\_ZONED.
Чтобы проверить, включена ли данная опция, можно обратиться напрямую к файлу конфигурации операционной системы, расположенному в директории /boot или /, либо воспользоваться командой:
```
cat /boot/config-`uname -r` | grep CONFIG_BLK_DEV_ZONED
```
или же
```
cat /lib/modules/`uname -r`/config | grep CONFIG_BLK_DEV_ZONED
```
Для ядер, экспортирующих параметры конфигурации через виртуальную файловую систему proc, можно использовать команды:
```
modprobe configs
cat /proc/config.gz | gunzip | grep CONFIG_BLK_DEV_ZONED
```
или
```
modprobe configs
zcat /proc/config.gz | grep CONFIG_BLK_DEV_ZONED
```
Если соответствующая опция активна, вы увидите следующий вывод:
```
CONFIG_BLK_DEV_ZONED=y
```
В случае же, если в терминале отобразится
```
CONFIG_BLK_DEV_ZONED=n
```
это будет означать, что поддержка зональных блочных устройств отключена и ядро необходимо предварительно перекомпилировать. Кстати, если перечисленные команды попробовать запустить в операционной системе, использующей ядро более раннее, чем 4.10, их вывод окажется пуст.
От параметра конфигурации CONFIG\_BLK\_DEV\_ZONED зависит поддержка эмуляции зональных блочных устройств на уровне драйвера null\_blk, поддержка подсистемы SCSI для накопителей ZBC и ZAC SMR, а также доступ к набору команд зонального пространства имен, необходимых для работы с NVMe SSD. Что же касается управления порядком команд записи, то здесь все оказывается немного сложнее.
Изначально (в ядрах с 4.10 по 4.15 включительно) данная функция была реализована на уровне ядра. Однако начиная с версии 4.16 управление порядком команд записи было передано планировщикам ввода-вывода блочного уровня deadline (работает с единственной очередью команд) и mq-deadline (реализация deadline с использованием blk-mq, поддерживает множественные очереди), использование которых стало обязательным для корректной работы зональных устройств хранения. Позднее, с релизом ядра 5.0, поддержка deadline была полностью упразднена и планировщик mq-deadline стал основным решением для работы с зональными устройствами хранения.
Таким образом, если вы используете операционную систему, базирующуюся на ядре 4.16 или более позднем, вам необходимо убедиться в том, что в качестве планировщика ввода-вывода выбран deadline или mq-deadline. Для этого достаточно воспользоваться следующей командой:
```
cat /sys/block/sdb/queue/scheduler
[mq-deadline] kyber bfq none
```
Если по умолчанию используется другой планировщик, его можно сменить на нужный, введя команду:
```
echo deadline > /sys/block/sdb/queue/scheduler
```
или
```
echo mq-deadline > /sys/block/sdb/queue/scheduler
```
Теперь вы можете быть уверены в том, что используемая вами операционная система сможет адекватно взаимодействовать с зональными устройствами хранения данных. | https://habr.com/ru/post/547406/ | null | ru | null |
# Тяжелая терапия: лекарство от палева для MacOS
Вы скажете, что тут и из коробки все отлично и вроде все гениально, вплоть до автогенерации такого пароля для web-сайтов, который даже зрительно не воспринимается с пятой попытки, однако, представим себе, что для нас важно защититься не только от повседневных хакеров, но и от самих разработчиков системы.
Исследования мои этих моментов начались еще с момента выхода OS X Lion 10.7 и я изначально использовал для защиты стороннее программное обеспечение, платное и весьма эффективное, пока не разобрался что к чему и посредством чего это программное обеспечение покрывает такой результат.
Собственно, вот простой скрипт, который глушит управление firewall через внутренние сервисы системы MacOS на базе якорей и отдает управление напрямую пакетному фильтру, который блокирует вообще все входящие подключения:
```
#
# Ninja PF configuration file( original located on /etc/pf.conf.backup ).
#
# This file contains the main ruleset, which gets automatically loaded
# at startup. PF will not be automatically enabled, however. Instead,
# each component which utilizes PF is responsible for enabling and disabling
# PF via -E and -X as documented in pfctl(8). That will ensure that PF
# is disabled only when the last enable reference is released.
#
# Care must be taken to ensure that the main ruleset does not get flushed,
# as the nested anchors rely on the anchor point defined here. In addition,
# to the anchors loaded by this file, some system services would dynamically
# insert anchors into the main ruleset. These anchors will be added only when
# the system service is used and would removed on termination of the service.
#
# See pf.conf(5) for syntax.
#
# ICMP configure
icmp_types = "{echoreq, echorep, unreach}"
icmp6_types = "{echoreq, unreach, echorep, 133, 134, 135, 136, 137}"
netbios_types = "{137,138,139}"
interfaces = "{en0, en1, en2, en3, en4}"
# Base policy
set fingerprints "/etc/pf.os"
set block-policy drop
set state-policy if-bound
set require-order yes
set optimization aggressive
set ruleset-optimization none
set skip on lo0
scrub in all fragment reassemble no-df min-ttl 64 max-mss 1440
scrub out all random-id
block in log all
pass out quick flags S/SA modulate state
# Antispoofing
antispoof quick for $interfaces inet
antispoof quick for $interfaces inet6
# More secure settings
block in from urpf-failed to any
block in quick on $interfaces from any to 255.255.255.255
block in quick on $interfaces from any to 255.255.255.0
# ICMP policy
block in inet proto icmp all icmp-type $icmp_types keep state
block in inet6 proto icmp6 all icmp6-type $icmp6_types keep state
block in on $interfaces proto {tcp,udp} from any to any port $netbios_types
```
Не забудьте поставить галку включить firewall в preferences. Чтобы проверить, что PF запущен просто выполните в терминале
```
sudo pfctl -sa
```
Здесь кратко собранны паттерны правил управления соединениями и интерфейсами, а сама настройка максимально блокирует входящий трафик. Если у вас совсем паранойя — просто закоментируйте строчку set skip on lo0 и вы избавите систему от работоспособного web-сервера и заблокируете большинству приложений доступ к loop back интерфейсу(петля терминала).
Lo0 обычно полезно блокировать, если вы любите поиграть в пиратские игры с торрентов, которые нередко пропатчены эксполойом или еще какой-то дрянью.
Второе, что делает скрипт, это по согласию пользователя устанавливает повышенные настройки безопасности ядра.
Вот краткий листинг:
```
# 10.13.4 system ctl configuration
# Kernel IPC overrides
kern.ipc.somaxconn=100
# kernel security level(0, 1 - soft security level or 2 - can't install any software)
kern.securelevel=1
# Speed up TM backups
debug.lowpri_throttle_enabled=0
kern.coredump=0
# Networking settings
net.link.ether.inet.max_age=600
net.inet.ip.redirect=0
net.inet6.ip6.redirect=0
net.inet.ip.sourceroute=0
net.inet.ip.accept_sourceroute=0
net.inet.ip.linklocal.in.allowbadttl=0
net.inet.icmp.bmcastecho=0
net.inet.icmp.icmplim=50
net.inet.icmp.maskrepl=0
net.inet.udp.blackhole=1
net.inet.tcp.blackhole=2
net.inet.tcp.delayed_ack=2
net.inet.tcp.always_keepalive=0
net.inet.tcp.rfc3390=1
net.inet.tcp.rfc1644=1
net.inet.tcp.tso=0
# Incoming and outgoing port ranges
net.inet.tcp.sack_globalmaxholes=2000
net.inet.ip.portrange.first=1024
net.inet.ip.portrange.last=65535
net.inet.ip.portrange.hifirst=1024
net.inet.ip.portrange.hilast=2500
net.inet.ip.check_interface=1
net.inet.tcp.keepidle=50000
net.inet.ip.rtmaxcache=1024
net.inet.tcp.path_mtu_discovery=0
net.inet6.icmp6.rediraccept=0
net.inet.tcp.msl=4500
net.inet6.icmp6.nodeinfo=0
net.inet6.ip6.accept_rtadv=0
net.inet6.ip6.auto_linklocal=1
net.inet6.ip6.only_allow_rfc4193_prefixes=1
net.inet6.icmp6.nd6_onlink_ns_rfc4861=1
```
Данные параметры ядра ужесточают политику сетевых подключений включая все возможные RFC и блокируя все возможные шумы(эхо, редиректы и так далее), а отдельного внимания стоит параметр kern.securelevel=1, который может оказаться крайне полезным для pen тестера.
kern.securelevel=2 полностью заблокирует возможности установки в систему каких либо пакетов. Вообще наглухо. Но система при этом не потеряет работоспособности.
Я также перевернул порты приложений требующих высокие значения и приземлил их пониже, чтобы трафик было не комфортнее «слушать».
Далее скрипту добавлены опции кастомизации некоторых параметров отображения Finder и небольшие настройки для Safari. Например, стоит отключить AV Foundation и прочие медиа функции так, как одной сплойтерной картинкой с web сайта систему можно хакнуть через аудио и видео стримы.
И вообще, странно, но даже iTunes в MacOS следит, поэтому я предпочитаю полный танк.
Заплатка [выложена на GitHub](https://github.com/xShiftx/10.13.4-security-fix). Для запуска используйте
```
sudo ./fix.sh
```
Если у вас есть предложения и поправки — предлагаю поделиться своими соображениями в комментариях. | https://habr.com/ru/post/421221/ | null | ru | null |
# Хватит копировать, пора сливаться. Часть 2. Конфликт слияний, который так и не произошёл (а должен был)
В [последний раз](https://habr.com/ru/post/542516/) мы видели как изменение кода в скопированном коммите создаёт опасность конфликта, который сидит себе тихо пока обе копии где-нибудь не сольются, что может произойти и в очень отдалённом будущем. Но знаете что хуже, чем конфликт слияний?
Отсутствие любого конфликта.
Давайте вернёмся к прежней ситуации:

Представим что ветка "feature" существует уже давно и периодически сливается в "master". Диаграмма показывает срез дерева сразу после последнего слияния А. Мы работаем над спринтом в "feature", полным нового функционала.
Предположим, что строка "apple" находится в файле настроек, управляющим какой-то фичей. Обе ветки фиксируют коммиты M1 и F1, которые не трогают этот файл.
Теперь представим что мы нашли серьёзную ошибку в старой фиче, которая полностью рушит поведение всей программы. Резко пресекая проблему, мы выключаем фичу, меняя строку на "berry" и фиксируя изменения как F2.
В жизни произойдёт что-то похожее на изменение строки c
```
#define IS_FEATURE_ENABLED 1
```
на
```
#define IS_FEATURE_ENABLED 0
```
Но раз уж я начал использовать "apple" и "berry", пусть так они и останутся.
Хорошо, мы отключили фичу, проверили что теперь никаких проблем нет, и скопировали отключение в "master". Фух, теперь можно выдохнуть, кровотечение остановлено, у нас есть время подумать что пошло не так и как это чинить.
Можно также отключить фичу напрямую в "master", а затем скопировать коммит в "feature", картина будет той же.
Пока мы исследуем проблему, работа в "master" ветке продолжается. Позже мы чиним баг, включаем обратно фичу и фиксируем изменения как F3 в "feature" ветке. Дерево коммитов теперь выглядит так:

Новый несвязанный с "berry" коммит M3 был добавлен в ветку "master". В "feature" мы вернули обратно "apple" коммитом F3.
Теперь мы хотим слить ветку "feature" в "master" чтобы временное отключение фичи было заменено нормальным фиксом. Но вместо этого после слияния мы получаем такую картину:

Слияние породило коммит M4, но вопреки ожиданиям строка всё ещё содержит "berry". В "master" перекочевало временное отключение фичи! Даже хуже, в "master" теперь находятся оба фикса: как основной, так и временный. Вполне возможно они плохо друг с другом совмещаются, и появятся только новые баги. Получается, фича работает только в ветке "feature", а в "master" вообще непонятно что.
Разберёмся почему это произошло, в следующей статье я опишу как этого избежать.
Вернёмся к дереву коммитов до слияния:

При слиянии Git смотрит на базу слияния (merge base): ближайшего родственника между двумя ветками, в нашем случае это коммит А. Затем Git выполняет трёх-стороннее слияние (three-way merge), используя А как базу, M3 как HEAD, а F3 как вливающееся изменение. Теперь нас интересует только дельта между базой и двумя последними коммитами, так что уберём вся лишнее из диаграммы:

Сравнивая базу с верхушкой "master" ветки мы видим что "apple" поменялась на "berry". Сравнение с "feature" не даёт никаких изменений. Так как строка "apple" осталась прежней в "feature", слияние её в "master" также оставит всё как есть. В результате "master" будет содержать "berry" после слияния.
Но это ещё не всё, если затем слить "master" в "feature", то неверная строка "berry" распространится и в "feature":

Это происходит потому, что теперь меняются местами принимающая и отдающая сторона. В основании (коммит А) строка "apple", в ветке "feature" она остаётся неизменной, но в неё вливают "berry" из "master". И здесь даже не важно, используется быстрая перемотка (fast-forward) или нет.
Многие думают о копировании коммитов как о "частичных слияниях, предвосхищающих будущее полное слияние", когда вам надо слить часть наработок в главную ветвь. Вы ожидаете, что позже, когда вы полностью сольёте исходную ветку в главную, сольются только новые наработки.
Если же вы настолько аккуратны, что не трогаете строк, задействованных при копировании, ожидания оправдаются. Иначе, вместо слияния вы получите наложение изменений друг на друга. Хуже того, если ваши изменения отменяют скопированные, то вы даже не получите конфликт при слиянии, который показал бы что что-то идёт не так. Внутри нашей команды мы называем это АБА проблемой, т.к. сначала строка содержала А, затем её поменяли на Б, Б скопировали, а затем вернули А прямо перед слиянием в "master".
Хорошо, вкратце получается мы хотели сделать частичное слияние из "feature" в "master", но проблема в том, что никакого "частичного" слияния нет.
Или всё же есть?
В следующей статье я покажу как его осуществить. | https://habr.com/ru/post/542914/ | null | ru | null |
# Искусственный отбор

Всем привет! Нас зовут Ирина (слева) и Женя (справа).
Наши две головы как минимум 15 часов в сутки заняты [«Образовательными программами СКБ Контур»](http://www.skbkontur.ru/career/education). Один из любимых проектов, который мы реализуем второй год, — организация IT-школ [CSEDays](http://www.csedays.ru/). Участие в таких школах бесплатное, это некоммерческий проект. И есть один дискуссионный вопрос, который мы бы хотели обсудить.
Сперва немного расскажем, что это вообще за школы. Школы CSEDays (Computer Science Days) — это неформальные встречи студентов, сотрудников IT-компаний и преподавателей, «больных» какой-то определенной темой. В течение трех дней участниками обсуждается «диагноз». Сперва — доклады, после — свободное общение. Всего у нас уже было две таких тусовки: первая, когда мы не очень-то заморачивались придумыванием конкретной темы, — «Общие вопросы Computer Science» (в марте 2010) и вторая — «Надежность программного обеспечения» (в ноябре 2010).
Совсем скоро, уже в апреле 2011, будет школа по теме «Компьютерная безопасность и криптография». Третья по счету.
И вроде бы всё у нас в целом гуд: и докладчики интересные из университетов и IT-компаний находятся, и спонсоры есть, и заявки из разных городов поступают. Но вот уже третий раз перед нами встает очень важный вопрос: как искать и отбирать ТЕХ САМЫХ участников, которые смогут раскрыться в атмосфере живого общения и сделать нормальный вклад в общий драйв?
Об этом, собственно, и пойдет разговор. Хотим рассказать о своем опыте отбора участников для школы CSEDays и спросить у хабражителей, верной ли дорогой идем, те ли вопросы задаем при отборе (обычно рассматриваем письменные заявки) и вообще, как и где лучше искать «своих» ребят.
##### От простейших до… нормальных?
Когда мы организовывали самую первую школу по общим вопросам компьютерных наук, к отбору подошли просто. Сделали элементарную форму заявки: фамилия/имя, контакты и один-единственный открытый вопрос «А почему именно вы должны принять участие в IT-школе?». Сначала было непонятно, кто вообще откликнется и удастся ли собрать компанию тех, кто в теме. Удалось! Среди ответов были весьма внятные, указывающие на прямой интерес к обсуждаемым темам, как например:
> «В дальнейшем собираюсь заниматься классификацией изображений. Очень интересно послушать Антона Конушина по семантической классификации».
или
> «Интересуюсь последними веяниями в сфере IT и CS, интересно послушать именно про российский опыт/исследования. Являюсь приятным собеседником и могу много рассказать (в частности про Java/OSGi) в кулуарах».
Но некоторых этот вопрос явно смущал. К примеру, нам поступил ответный вопрос:
> «А почему именно Вас посадили разбирать эти заявки? ;-)»
или лаконичная просьба:
> «Пожалуйста!»
На «пожалуйста» решили не реагировать. В итоге на первую школу, которая была весной 2010 года, к нам пришло около 70 заявок, пригласили 50 человек, 20 из 50 дали гранты на проживание и питание (все это дело проходило на базе отдыха). Все прошло круто!
Настолько круто, что осенью 2010 мы решили провести вторую школу, уже на более конкретную тему «Надежность программного обеспечения». Вопрос «Почему именно вы должны поехать?» решили оставить.
О чудо! В отличие от первого раза нам стали приходить целые внятные сочинения, позволяющие выделить «наших людей»:
> «Использование “традиционных” подходов при разработке интерфейсов web-сервисов с богатым функционалом достаточно сильно замедляет разработку и доставляет множество неудобств разработчикам как серверной, так и клиентской частей. Причин множество: необходимость copy-paste разметки страниц и стилей их отображения; дублирование серверного кода клиентским; необходимость поддержки кроссбраузерности; мнимая связь между поведением интерфейса и его отображением; мнимая связь между клиентской и серверной частью; сложность тестирования и обеспечения надёжности. Существует множество как мелких решений, направленных на устранение каких-то отдельных недостатков (например: SASS, LESS для добавления логики в CSS, ASP.NET Code Behind для “реальной” связи клиента с сервером, ASP.NET UserControls для reuse разметки), так и полновесных решений (GWT на Java, Cappuccino на ObjectiveJ, SproutCore на Ruby).
>
> При разработке мне постоянно приходится сталкиваться с подобными проблемами и мне бы очень хотелось разработать решение на C#.Мне бы хотелось заняться этим не только из-за того, что в этом есть реальная необходимость, но и потому, что это было бы отличным опытом. Я осознаю то множество проблем, которые придётся решить при этом и самая главная из них — это обеспечить надёжность работы такой системы. Поэтому мне очень необходима информация, которая будет представлена в рамках школы».
>
>
И таких развернутых ответов было много! Но если на этом вопросе во второй раз мы «выехали», то провалились на другом, новом. Когда мы продумывали, как лучше отбирать участников, возникла идея — а не проверить ли «жаждущих» сразу в деле? Один из наших партнеров — Microsoft Research — дал нам такую возможность, предоставив доступ к проекту [DOM API Testing](http://domapitesting.codeplex.com/). Мы сказали потенциальным «школьникам»: «Вот вам, пожалуйста, код. Потестите?» Задача оказалась не по зубам. То ли ее было лень кусать, то ли зубы не крепкие, но из 130 заявок только 8 содержали в себе графу о том, что человек что-то как-то делал в этом коде. Пришлось смотреть на любимый вопрос «почему вы» и выбирать 50 субъективно достойных.
Кстати, выбирали не мы вдвоем.;) У нас есть небольшой оргкомитет из сотрудников УрГУ, СКБ Контур, Яндекс, Microsoft Research и добровольца — Леонида Волкова. Но координационный центр всей этой движухи — в четырех наших хрупких руках и двух чутких сердцах. :)
##### Три — на счастье
А вот в третий раз, для школы по инфобезопасности и криптографии, которая пройдет в апреле 2011, мы придумали новый ход, отказавшись от горячо любимого вопроса. Предложили участникам решить 3 задачки «по теме», составил их Илья Миронов из Microsoft (кстати, в апреле он будет одним из докладчиков). Одна очень простая, две немного посложнее. Написали их так, чтобы можно было просто «копировать-вставить-унести с собой». Вот эти задачки:
**Задача 1.**
Что находит следующий фрагмент кода?
`int f(int x); // функция f определена в другом месте программы
typedef pair Pair;
stack s;
int n = 0;
int x = 0;
s.push(Pair(x, n));
for(;;)
{
x = f(x); n++;
while(!s.empty() && s.top().first < x)
s.pop();
if(!s.empty() && s.top().first == x)
return n - s.top().second;
s.push(Pair(x, n));
}`
**Задача 2.**
Предположим, что функция f есть случайная функция, отображающая интервал [0..N-1] в себя.
Оцените среднее время работы кода из предыдущего пункта и его требование к памяти.
**Задача 3.**
Покажите, что если задача нахождения коллизий в функции f(x) = g^x mod N,
где g — генератор группы квадратичных вычетов по модулю N, а N — произведение двух простых чисел,
решается за полиномиальное время от длины N, то задача разложения числа N на простые сомножители также решается за полиномиальное время.
И вот сели мы вечером 15 марта и задумались: а так ли мы ищем «своих»…
##### Послесловие
Чего хотят от участников другие IT-школы? Немного помониторили.
[MIDAS](http://logic.pdmi.ras.ru/midas/) — полное резюме + рекомендация от факультета + научная работа (курсовая, диплом).
[RuSSIR 2010](http://romip.ru/russir2010/) — заявка о себе + рекомендация + дополнительным шансом на участие в школе было участие в Конференции молодых ученых.
В общем-то, опять же классика жанра. А наша тусовка — не совсем классика, поэтому и озадачились вопросом: как лучше искать и нормально ли мы это делаем сейчас?
P.S. Кстати, если вдруг захотите принять участие в школе «Информационная безопасность и криптография» (пройдет 14-17 апреля в Екатеринбурге), заявки принимаются до 24 марта.
[Подробности на сайте CSEDays](http://www.csedays.ru/).
Эти люди выдержали искусственный отбор! Кстати, заявки от девушек проходят по отдельному конкурсу ;).
 | https://habr.com/ru/post/115567/ | null | ru | null |
# Хабрамегарейтинг: лучшие статьи и статистика Хабра за 12 лет. Часть 1/2
Привет Хабр.
После публикации рейтинга статей за [2017](https://habr.com/ru/post/441508/) и [2018](https://habr.com/ru/post/441236/) год, следующая идея была очевидна — собрать обобщенный рейтинг за все годы. Но просто собрать ссылки было бы банально (хотя и тоже полезно), поэтому было решено расширить обработку данных и собрать еще немного полезной информации.

Рейтинги, статистика и немного исходного кода на Python под катом.
Обработка данных
----------------
Те, кого сразу интересуют результаты, эту главу могут пропустить. А мы пока выясним, как это работает.
В качестве исходных данных имеется csv-файл примерно такого вида:
```
datetime,link,title,votes,up,down,bookmarks,views,comments
2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ для Хабрахабра",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56
2006-07-13T20:45Z,https://habr.com/ru/post/2/,"Мы знаем много недоделок на сайте… но!",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37
...
2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — бесплатный сервис бэкапов с шифрованием на стороне клиента",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6
2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda-функции в SQL… дайте подумать",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
```
Индекс всех статей в таком виде занимает 42Мб, а для его сбора понадобилось примерно 10 дней работы скрипта на Raspberry Pi (закачка шла в один поток с паузами, чтобы не перегружать сервер). Теперь посмотрим, какие данные из всего этого можно извлечь.
#### Аудитория сайта
Начнем с относительно простого — оценим аудиторию сайта за все годы. Для примерной оценки можно использовать количество комментариев к статьям. Загрузим данные и выведем график числа комментариев.
```
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#')
def to_int(s):
# "bookmarks:22" => 22
num = ''.join(i for i in s if i.isdigit())
return int(num)
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ')
dates += datetime.timedelta(hours=3)
comments = df["comments"].map(to_int, na_action=None)
plt.rcParams["figure.figsize"] = (9, 6)
fig, ax = plt.subplots()
plt.plot(dates, comments, 'go', markersize=1, label='Comments')
ax.xaxis.set_major_locator(mdates.YearLocator())
plt.ylim(bottom=0, top=1000)
plt.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
```
Данные выглядят примерно так:

Результат интересен — оказывается, с 2009 года активная аудитория сайта (те, кто оставляют к статьям комментарии) практически не растет. Хотя может все ИТ-шники просто уже здесь?
Раз уж речь зашла про аудиторию, интересно вспомнить последнее нововведение Хабра — добавление англоязычной версии сайта. Выведем статьи, имеющие "/en/" внутри ссылки.
```
df = df[df['link'].str.contains("/en/")]
```
Результат тоже интересный (масштаб по вертикали специально оставлен тем же):
Всплеск количества публикаций начался с 15 января 2019, когда был опубликован анонс [Hello world! Or Habr in English](https://habr.com/ru/company/tm/blog/435764/), однако за несколько месяцев до этого 3 статьи уже были опубликованы: [1](https://habr.com/en/post/429888/), [2](https://habr.com/en/post/431326/) и [3](https://habr.com/en/post/431468/). Вероятно, это было бета-тестирование?
#### Идентификаторы
Следующий интересный момент, которого мы не касались в предыдущих частях — это сопоставление идентификаторов статей и дат публикации. Каждая статья имеет ссылку вида [habr.com/ru/post/N](https://habr.com/ru/post/N/), нумерация статей сквозная, первая статья имеет идентификатор 1, а та которую вы читаете, 441740. Кажется, все просто. Но не совсем. Проверим соответствие дат и идентификаторов.
Загрузим файл в Pandas Dataframe, выделим даты и id, и построим их график:
```
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f')
dates += datetime.timedelta(hours=3)
df['datetime'] = dates
def link2id(link):
# https://habr.com/ru/post/345936/ => 345936
if link[-1] == '/': link = link[0:-1]
return int(link.split('/')[-1])
df['id'] = df["link"].map(link2id, na_action=None)
plt.rcParams["figure.figsize"] = (9, 6)
fig, ax = plt.subplots()
plt.plot(df_ids['id'], df_ids['datetime'], 'bo', markersize=1, label='Article ID')
ax.yaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y"))
ax.yaxis.set_major_locator(mdates.MonthLocator())
plt.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
```
Результат удивляет — идентификаторы берутся не всегда подряд, как предполагалось изначально, имеются заметные «выбросы».

Отчасти именно из-за них у аудитории были вопросы к рейтингам за 2017 и 2018 годы — такие статьи с «неправильным» ID не учитывались парсером. Почему так, сказать сложно, да и не так важно.
Что может быть интересного в идентификаторах? Есть гипотеза, которую я не могу доказать формально, но которая кажется очевидной. Идентификатор присваивается в момент создания черновика статьи, а дата публикации очевидно, наступает позже. Кто-то выкладывает статью в тот же день, кто-то публикует материал позже. К чему все это? Расположим на оси Х идентификаторы, а по вертикали даты, и посмотрим фрагмент графика более подробно:
Результат — мы видим облако точек над сплошной линией, которое показывает нам распределение времени *продолжительности создания статей*. Как нетрудно видеть, максимум приходится на интервал до 1-2 недели. Почти вся масса статей создается не более чем за месяц, хотя некоторые статьи публикуются и через несколько месяцев после создания черновика (разумеется, это не гарантирует нам что автор работал над статьей несколько месяцев ежедневно, но результат все же вполне интересный).
#### Дата и время публикации
Интересный, хотя и интуитивно понятный момент — время публикации статей.
Выведем статистику по рабочим дням:
```
print("Group by hour (average, working days):")
df_workdays = df[(df['day'] < 5)]
g = df_workdays.groupby(['hour'])
hour_count = g.size().reset_index(name='counts')
grouped = g.median().reset_index()
grouped['counts'] = hour_count['counts']
print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']])
print()
view_hours = grouped['hour'].values
view_hours_avg = grouped['counts'].values
fig, ax = plt.subplots()
plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)')
ax.set_xticks(range(24))
ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00'))
plt.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
```
Зависимость количества статей от времени публикации в будние дни:
Картинка интересна, большинство публикаций приходится на рабочее время. Все же интересно, для большинства авторов написание статей это основная работа, или они просто занимаются этим в рабочее время? ;) А вот график распределения в выходные дни дает другую картину:

Раз уж речь зашла о дате и времени, посмотрим среднее значение просмотров и количество статей по дням недели.
```
g = df.groupby(['day', 'dayofweek'])
dayofweek_count = g.size().reset_index(name='counts')
grouped = g.median().reset_index()
grouped['counts'] = dayofweek_count['counts']
grouped.sort_values('day', ascending=False)
print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']])
print()
view_days = grouped['day'].values
view_per_day = grouped['views'].values
counts_per_day = grouped['counts'].values
days_of_week = grouped['dayofweek'].values
plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day')
plt.bar(view_days, counts_per_day, align='edge', label='Amount/day')
plt.xticks(view_days, days_of_week)
plt.ylim(bottom=0, top=10000)
plt.show()
```
Результат интересен:
Как можно видеть, в выходные публикуется заметно меньше статей. Но зато каждая статья набирает больше просмотров, так что публиковать статьи в выходные кажется довольно-таки целесообразным (как было выяснено еще в [первой части](https://habr.com/ru/post/440366/), активный жизненный цикл статьи не более 3-4х дней, так что первые пара дней являются вполне критичными).
Статья пожалуй, получается слишком длинной. Окончание во [второй части](https://habr.com/ru/post/442168/). | https://habr.com/ru/post/441740/ | null | ru | null |
# Использование быстрых клавиш в командной строке Linux (BASH)
Эта статья посвящена наиболее часто используемым комбинациям клавиш при работе в командной строке Linux (в основном в командном интерпретаторе bash).
Она точно будет полезна начинающим своё знакомство с Linux и, уверен, пригодится тем, кто уже имеет опыт (не всегда годы практики учат работать быстрее).
Никогда не развивал [навыка быстрой печати](https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D0%B5%D0%BF%D0%BE%D0%B9_%D0%BC%D0%B5%D1%82%D0%BE%D0%B4_%D0%BF%D0%B5%D1%87%D0%B0%D1%82%D0%B8), но знание не одного десятка hotkey'ев, перечисленных в этом материале, позволяет набирать команды со скоростью мысли.
Я попытался продемонстрировать многие примеры при помощи анимированных gif'ок – иногда несколько кадров больше скажут, чем несколько абзацев текста.

---
Материал был обкатан на [вебинаре](https://youtu.be/nRDtJ6JkGIk), и оттуда взяты все примеры (под каждым примером указано время, когда об этом рассказывалось в видео). Видео больше часа и без монтажных склеек, в статье же вынесены все главные моменты и попытка дать более точные определения.
Общие слова и замечания
-----------------------
Большинство продемонстрированных клавиш стандартны для «командной строки Linux», но часть из этих комбинаций специфичны для bash (поэтому и пометил это в заголовке). На текущий момент [BASH](https://ru.wikipedia.org/wiki/Bash) – наиболее распространенный командный интерпретатор, используемый по умолчанию в большинстве Linux-дистрибутивов. В других [командных интерпретаторах или, проще говоря, shell'ах](tps://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%B0%D0%BD%D0%B4%D0%BD%D0%B0%D1%8F_%D0%BE%D0%B1%D0%BE%D0%BB%D0%BE%D1%87%D0%BA%D0%B0_Unix) (рекомендую попробовать [zsh](https://ru.wikipedia.org/wiki/Zsh) и [fish](https://ru.wikipedia.org/wiki/Friendly_interactive_shell)) могут быть небольшие отличия в работе. Также часть комбинаций прописана в «настройках по умолчанию» (например, в файле /etc/inputrc или в /etc/bashrc), которые тоже могут различаться в разных дистрибутивах. И бывает, что некоторые клавиши могут быть настроены и перехватываться графической оболочкой, в которой запущен командный интерпретатор.
Если вдруг что-то из указанного мной в этой статье у вас не сработало, пишите в комментариях «название - версию shell и название - версию дистрибутива».
Часть демонстрируемых клавиш относятся к «настройкам терминала». А часть – клавиши из командного интерпретатора BASH, и их можно посмотреть, почитав [мануал по bash'у](https://www.opennet.ru/man.shtml?topic=bash&russian=0) (огромный текст – пользуйтесь поиском):
♯ `man bash`
![[00:10:40]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/a3c/f1c/547/a3cf1c547ed8e06a5f8d9f1aa334659c.png "[00:10:40]")[00:10:40]*^^^ На приведенном фрагменте из мануала: Запись «(C-r)» означает* `Ctrl-r`*, а «M->» означает* `Alt->`*.*
«M» - это «Meta-клавиша»Из истории: «М» - это «[Metа-клавиша](https://ru.wikipedia.org/wiki/Meta_(%D0%BA%D0%BB%D0%B0%D0%B2%D0%B8%D1%88%D0%B0))», сейчас вместо неё используется клавиша `Alt`, либо клавиша`Esc`. Я чаще в её качестве буду использовать клавишу `Alt`.
Замечание: *Если у кого-то настроено переключение раскладки по комбинации* `Alt-Shift`*, то учитывайте, что в комбинациях, перечисленных далее и содержащих* `Alt-Shift`*, вам надо будет использовать скорее клавишу* `Esc-Shift` *(или поменять комбинацию для переключения раскладки клавиатуры, у меня, например, раскладка переключается по* `CapsLock`*).*
![[00:11:18]](https://habrastorage.org/getpro/habr/upload_files/9c0/064/604/9c00646048386574b949b45c626b7a3b.gif "[00:11:18]")[00:11:18]^^^ Здесь показано на примере использования комбинаций для *перемещения по «словам» командной строки:* `Alt-b`*(или, что то же самое,* `Esc-b`*) и* `Alt-f`*(или, что то же самое,* `Esc-f`*)*
Для демонстраций нажатых клавиш использую утилиту «[screenkey](https://gitlab.com/screenkey/screenkey)».
[Upd:](https://habr.com/ru/company/lanit/blog/537596/#comment_22728144) При этом стоит упомянуть, что по умолчанию bash использует emacs-режим редактирования командной строки и поэтому многие комбинации клавиш пришли из редактора emacs. Для знающих редактор vi, могу порекомендовать переключить (добавив "set -o vi" в ~/.bashrc) bash в vi-режим редактирования и пользоваться привычными комбинациями из vi.
Терминал
--------
Итак, начнем с клавиш из настроек терминала. Их можно посмотреть, выполнив команду:
♯ `stty -a`
А перенастроить, например, так:
♯ `stty intr НоваяКлавиша`
### Ctrl-c – сигнал SIGINT
Первые две комбинации клавиш достаточно важные, и часто «недавно перешедшие с Windows на Linux» НЕправильно их используют: продолжая, как в DOS, для завершения команд использовать комбинацию «Ctrl-z», что неверно. В Linux же для того, чтобы попросить (команде посылается сигнал [SIGINT](https://ru.wikipedia.org/wiki/SIGINT)) приложение прервать свою работу, используется `Ctrl-c`.
![[00:14:24]](https://habrastorage.org/getpro/habr/upload_files/f95/afb/416/f95afb41675e8dfe5d9411fde7b10d6a.gif "[00:14:24]")[00:14:24]### Ctrl-z – сигнал SIGTSTP
А комбинация `Ctrl-z` используется, чтобы попросить (команде посылается сигнал [SIGTSTP](https://ru.wikipedia.org/wiki/SIGTSTP)) приложение остановить свою работу (не завершая) – «поставить на паузу». Ну, а «разбудить» его можно командой «fg» (или «bg»).
![[00:14:36]](https://habrastorage.org/getpro/habr/upload_files/c40/923/262/c40923262e9a3cfe8e14e0ed4eb5ab63.gif "[00:14:36]")[00:14:36]### Ctrl-d – EOF(окончание ввода данных)
Далее разберем комбинацию `Ctrl-d`. В выводе «stty -a» эта комбинация значится как «[EOF](https://ru.wikipedia.org/wiki/EOF)», что означает «окончание ввода данных». Для примера покажу, как можно создать текстовый файл с определенным текстом без использования текстового редактора:
![[00:15:51]](https://habrastorage.org/getpro/habr/upload_files/23b/38d/977/23b38d977986e8e92541b9c1f01c44d9.gif "[00:15:51]")[00:15:51]*^^^ Здесь видно, что любой набираемый текст перенаправляется в файл /tmp/File.txt, и нет никакой фразы (типа «*[*Горшочек, не вари*](https://ru.wikipedia.org/wiki/%D0%93%D0%BE%D1%80%D1%88%D0%BE%D1%87%D0%B5%D0%BA_%D0%BA%D0%B0%D1%88%D0%B8_(%D0%BC%D1%83%D0%BB%D1%8C%D1%82%D1%84%D0%B8%D0%BB%D1%8C%D0%BC))*»), которую бы команда cat восприняла как «окончание ввода» – точнее, для этого как раз и надо нажать* `Ctrl-d`*.*
Также пользуюсь комбинаций `Ctrl-d` для того, чтобы выйти из консоли (например, после того как переключился командой su под другого пользователя или зайдя по ssh на другую машину) – вместо набора команды «exit» или «logout»:
![[00:17:44]](https://habrastorage.org/getpro/habr/upload_files/eb3/e17/2f3/eb3e172f3414aa375b4b0940c860a11e.gif "[00:17:44]")[00:17:44]*^^^ В правом терминале отображаю историю команд.*
*...(а внимательный зритель догадается, какой «супер-секретный» пароль у root'а на стенде)*
### Ctrl-v – ввод следующего символа
Комбинация `Ctrl-v` позволяет вставить в командную строку следующий за ней символ, не воспринимая его как спецсимвол. (Параметр [lnext](https://www.gnu.org/software/coreutils/manual/html_node/Characters.html#Characters) в выводе «stty -a»)
![[00:19:19]](https://habrastorage.org/getpro/habr/upload_files/b74/a51/819/b74a51819cb2c06d4bf9f012d3794cfd.gif "[00:19:19]")[00:19:19]*^^^ Здесь для примера показываю, как в скрипте выводить строку текста с использованием табуляции (знаю, что можно использовать \t в команде echo:* `echo -e "\tTEXT"`*, но не у всех утилит есть такая возможность, а подобная необходимость вставить «спецсимвол» случается).*
![[00:20:38]](https://habrastorage.org/getpro/habr/upload_files/1f5/1c9/f92/1f51c9f9200e5ab94d459becea75e61d.gif "[00:20:38]")[00:20:38]*^^^ А в этом примере у меня есть файл «New Text Document.txt», созданный в ОС Windows при помощи программы Notepad в директории, которую я затем открыл на доступ по сети и примонтировал в Linux в директорию /mnt. Программа Notepad (в отличии от Notepad++) создает файл в DOS-формате – в конце каждой строки использует дополнительный символ «*[*Возврат каретки*](ttps://ru.wikipedia.org/wiki/%D0%92%D0%BE%D0%B7%D0%B2%D1%80%D0%B0%D1%82_%D0%BA%D0%B0%D1%80%D0%B5%D1%82%D0%BA%D0%B8)*». Терминалы часто по умолчанию этот символ не отображают, но он есть, и поэтому, например, команда '*`grep "m$" /mnt/New\ Text\ Document.txt`*' не выведет строку, заканчивающуюся на букву «m». Команда cat с опцией «-v» отображает этот символ. А для того, чтобы при выводе заменить или удалить это символ, воспользовался командой tr (хотя можно было бы использовать специальную для этого утилиту* [*unix2dos*](https://en.wikipedia.org/wiki/Unix2dos)*).*
### Ctrl-l – очищает экран
Комбинация `Ctrl-l` – «очищает» экран.
![[00:10:51]](https://habrastorage.org/getpro/habr/upload_files/69f/b22/e37/69fb22e37106a68bb42ec001a9cb5f23.gif "[00:10:51]")[00:10:51]История команд
--------------
«Работа с историей команд» – классическая тема обычно из любого начального курса по Linux (по крайней мере, среди тех курсов, которые читаются у нас в [«Сетевой Академии ЛАНИТ»](https://academy.ru/)). И многие, кто имеет хотя бы небольшой опыт работы с командной строкой, историей команд пользуются – как минимум знают, что она есть, и используют стрелки «вверх» (отобразить предыдущую команду) и «вниз» (отобразить следующую после отображаемой команду в истории команд), чтобы выбрать, какую из ранее введенных команд либо снова выполнить, либо подредактировать и запустить отредактированную. Но помимо стрелок еще есть ряд полезных комбинаций клавиш, которые позволяют работать с историей команд, – быстрее находить нужные команды.
### Ctrl-r – Поиск по истории
Комбинация `Ctrl-r` позволяет искать в истории команд команды, содержащие указанный далее текст.
![[00:25:21]](https://habrastorage.org/getpro/habr/upload_files/cc1/0b2/168/cc10b21688daa1b35d298406cfe19025.gif "[00:25:21]")[00:25:21]*^^^ В этом примере мне понадобилось из истории вытащить команду, содержащую текст «su»: нажав* `Ctrl-r` *и набрав искомый текст «su», я увидел самую недавнюю команду, содержащую «su»; при повторном нажатии* `Ctrl-r` *отображается предыдущая команда, содержащая «su» и т.д. При необходимости изменить команду жму стрелку «вправо» и правлю текст, а чтобы запустить команду - нажимаю* `Enter`*.*
### PgUp/PgDown – Поиск по истории
`PgUp` – отображает предыдущую команду начинающуюся с уже введенного текста, `PgDown` – следующую.
![[00:27:35]](https://habrastorage.org/getpro/habr/upload_files/681/f07/c9a/681f07c9af9329c1929a1423dc7115df.gif "[00:27:35]")[00:27:35]*^^^ В этом примере перемещаюсь между командами, начинающимися с «cat». (Часто также ищу команды, начинающиеся с «sudo». Или если мне нужно снова отредактировать какой-то файл, который недавно редактировал: набираю «vi», жму несколько раз* `PgUp`*, а затем* `Enter`*.)*
В дистрибутивах где это настроено - в /etc/inputrc есть строки:
```
"\e[5~": history-search-backward
"\e[6~": history-search-forward
```
### Alt-\_/Alt-./Alt-- – вставка аргументов
Комбинация `Alt-_` (выполняется нажатием `Alt`, `Shift`, `-`) – вставляет последний аргумент из предыдущих команд. (Аналогично работает комбинация `Esc-.` или, что то же самое, `Alt-.`)
![[00:28:32]](https://habrastorage.org/getpro/habr/upload_files/294/ddd/15d/294ddd15deccd11427f8d5b685354038.gif "[00:28:32]")[00:28:32]*^^^ В данном примере видно, как повторные нажатия* `Alt-_` *вставляют аргументы от пред-пред-…-идущих команд.*
Комбинация `Alt -` – позволяет указать (порядковый номер с конца), какой аргумент вставить клавишей `Alt-_` из предыдущей команды.
![[00:30:13]](https://habrastorage.org/getpro/habr/upload_files/c3b/495/886/c3b495886c4b980ef017bf60b3b5ceba.gif "[00:30:13]")[00:30:13]*^^^ В данном примере вставляю в командную строку различные аргументы из предыдущей команды.*
### Alt-# – текущую команду преобразовать в комментарий
Бывает, во время набора очень длинной команды понимаю, что мне нужно что-нибудь посмотреть или дополнительно сделать (например, глянуть, какие файлы есть в определенной директории, прочитать мануал по команде, установить нужный пакет…). Что делать с уже набранным текстом? Хотелось бы посмотреть нужную информацию и продолжить набирать команду, а не начинать печатать её сначала. `Alt-#` (выполняется нажатием `Alt`, `Shift`, `3`. Также можно использовать `Esc-#`) – преобразует текущую набранную команду в комментарий в истории – добавляет символ «#» в начало строки и добавляет полученную строку в историю команд.
![[00:32:03]](https://habrastorage.org/getpro/habr/upload_files/652/c11/933/652c11933388eb2a444b5a0b68d972bb.gif "[00:32:03]")[00:32:03]### Ctrl-o – повтор команд из истории
Комбинация `Ctrl-o` позволяет повторять серию команд из истории. То есть нужно из истории команд стрелками выбрать первую команду из серии и нажать `Ctrl-o` – это выполнит текущую команду и выведет из истории следующую. Дальше можно продолжать нажимать `Ctrl-o` с тем же эффектом.
![[00:33:58]](https://habrastorage.org/getpro/habr/upload_files/728/284/795/7282847954ec26d48e84ef38f7efdb47.gif "[00:33:58]")[00:33:58]*^^^ В примере я написал три команды: одна увеличивает на 1 переменную, которой соответствует год; вторая выводит переменную-год; третья показывает, сколько дней в феврале в указанном году. Дальше, нажимая* `Ctrl-o`*, повторяю эту серию из трех команд много раз (один кадр соответствует трем нажатиям).*
Автодополнение
--------------
### Tab – автодополнение (в контексте)
Во многих командных интерпретаторах (и в bash в том числе) используется такая возможность, как автодополнение. Как минимум нужно знать, что по нажатию клавиши `Tab` дописывается название команды. В bash по умолчанию обычно настроено так, что если имеется только один вариант дополнения, то он дописывается по нажатию `Tab` (также можно использовать `Ctrl-i` и `Esc-Esc`). Когда вариантов дополнения много, то по первому нажатию `Tab` дописывается только общая часть (если она есть). А по второму нажатию `Tab` отображается список всех доступных вариантов. Дальше можно набрать еще символов – уточнить, какое из дополнений нужно, и снова нажать `Tab`. То же самое с другими дополнениями: имен файлов, имен переменных.
![[00:39:20]](https://habrastorage.org/getpro/habr/upload_files/636/f88/a1e/636f88a1ed85ebb145c80f82576eba3e.gif "[00:39:20]")[00:39:20]*^^^ Здесь, например, смотрю (нажав дважды* `Tab`*), что есть несколько команд, начинающихся с «if», добавив «c» и нажав* `Tab`*, получаю набранной команду «ifconfig».*
![[00:39:31]](https://habrastorage.org/getpro/habr/upload_files/fa6/54b/026/fa654b026654234c1be3fb847c41583c.gif "[00:39:31]")[00:39:31]*^^^ В этом примере дополняю аргументы команды (здесь имена файлов). Также видно, что в случае, когда вариантов много и все не умещаются в окне терминала, их список отображается утилитой для постраничного просмотра (также при очень большом списке вариантов выдается запрос вида «Display all 125 possibilities? (y or n)» или, как в этом примере, при малом количестве - «--More--».*
### Дополнения имен пользователей, переменных
Часто, когда дописываются аргументы команд по `Tab`, дописываются имена файлов. Но стоит также отметить, что, в зависимости от контекста, по `Tab` дописываются и имена переменных (аргументы, начинающиеся с символа «$»), имена пользователей (аргументы, начинающиеся с символа «~»),…
![[00:40:36]](https://habrastorage.org/getpro/habr/upload_files/9af/532/c75/9af532c7513710bc335123dfb03fff40.gif "[00:40:36]")[00:40:36]*^^^ Здесь, чтобы набрать «$HISTFILESIZE», вместо 13 символов набрал 8 символов (*`$``H``I``Tab``F``Tab``S``Tab`*). Помимо того, что так быстрее, это еще и позволяет допускать меньше ошибок при наборе команд, так как не просто печатаю текст, а выбираю из списка установленных переменных.*
![[00:41:44]](https://habrastorage.org/getpro/habr/upload_files/796/33a/059/79633a059a44ae3127d698045dd13101.gif "[00:41:44]")[00:41:44]*^^^ Здесь дописываю имена пользователей (фактически пишу адрес домашней директории).*
Также bash может дополнять не потому, что набранный текст начинается с определенного символа, а по определенным комбинациям клавиш.
Список того, что может дополнять bash, можно посмотреть командой:
♯ bind -P | grep "complet"
```
possible-username-completions can be found on "\C-x~".
complete-username can be found on "\e~".
possible-hostname-completions can be found on "\C-x@".
complete-hostname can be found on "\e@".
possible-variable-completions can be found on "\C-x$".
complete-variable can be found on "\e$".
possible-command-completions can be found on "\C-x!".
complete-command can be found on "\e!".
possible-filename-completions can be found on "\C-x/".
complete-filename can be found on "\e/".
```
![[00:43:50]](https://habrastorage.org/getpro/habr/upload_files/f10/f75/348/f10f75348c71d69ac83fc7f0a6b66a87.gif "[00:43:50]")[00:43:50]Так, например, видно, что:
* `Ctrl-x` `~` – покажет список имен пользователей, начинающихся с набранных символов, а дополнить комбинацией `Esc-~`;
* `Ctrl-x` `@` – список имен машин (согласно /etc/hosts), начинающихся с набранных символов, а дополнить – `Esc-@`;
* `Ctrl-x` `$` – список имен переменных, заданных в этой сессии (можно их также посмотреть командой set), а дополнить – `Esc-$`;
* `Ctrl-x` `!` – список команд (согласно доступных: $PATH, alias, функций, встроенных команд), а дополнить – `Esc-!`;
* `Ctrl-x` `/` – список имен файлов, а дополнить – `Esc-/`.
### Alt-\* – вставить дополнения, Ctrl-x \* – развернуть шаблон
`Esc-*` (точнее, `Esc` `Shift` `8`) или, что, то же самое, `Alt-*` (точнее, `Alt`, `Shift`, `8`), вставит все варианты дополнения в командную строку. Аналогично можно развернуть список файлов, переменных, имен пользователей.
В примерах ниже разворачиваю список файлов:
Вариант с `Alt-*`:
![[00:44:55]](https://habrastorage.org/getpro/habr/upload_files/ad3/c6f/f7d/ad3c6ff7d1198452ea1359611140a107.gif "[00:44:55]")[00:44:55] Вариант с `Esc-*`:
![[00:46:30]](https://habrastorage.org/getpro/habr/upload_files/f14/931/e26/f14931e2633f599f2c178fe3b8ff047d.gif "[00:46:30]")[00:46:30]♯ bind -P | grep '\*'
```
insert-completions can be found on "\e*".
glob-expand-word can be found on "\C-x*".
```
`Ctrl-x` `*` – развернет уже написанный в командной строке шаблон, как в примере ниже:
![[00:48:39]](https://habrastorage.org/getpro/habr/upload_files/7db/eb3/c21/7dbeb3c21613c1dcf672f0c619fab3fd.gif "[00:48:39]")[00:48:39]Редактирование
--------------
### Ctrl-w/u/k – вырезать слово/начало/конец строки
`Ctrl-w` – вырезать слово (от текущего положения курсора до ближайшего ранее в строке пробела/табуляции). Вырезанное можно затем вставить комбинацией `Ctrl-y.`
![[00:52:52]](https://habrastorage.org/getpro/habr/upload_files/846/940/7e6/8469407e6438ccf9dbe1658081718eea.gif "[00:52:52]")[00:52:52]`Ctrl-u` – вырезать начало строки (от текущего положения курсора. Если курсор в конце строки, то вырежет целиком строку). Вырезанное можно затем вставить комбинацией `Ctrl-y`.
`Ctrl-k` – вырезать конец строки (от текущего положения курсора. Если курсор в начале строки, то вырежет целиком строку). Вырезанное можно затем вставить комбинацией `Ctrl-y`.
### Ctrl-y – вставить вырезанное
`Ctrl-y` – вставить вырезанный фрагмент командной строки. (В bash используется свой буфер для хранения вырезанных фрагментов – называется «kill ring»).
Важно: Удобно использовать с `Alt-y` (позволяет «прокручивать» варианты вставки из буфера).
### Ctrl-x Ctrl-e – редактировать в $EDITOR
Нажав комбинацию `Ctrl-x` `Ctrl-e`, можно редактировать командную строку в любом внешнем редакторе (по умолчанию часто используется редактор vim; переназначить редактор можно, указав в переменной EDITOR). Часто редакторы имеют больше продвинутых возможностей в редактировании текста. Особенно удобно, если редактор умеет подкрашивать синтаксис команд и имеет различные встроенные инструменты для быстрого поиска и исправления ошибок.
Также эту возможность часто использую, когда набранную команду, разросшуюся до нескольких строк, хочу сохранить в виде отдельного скрипта – тогда переключаю редактирование команды в редактор и в нём сохраняю набранный текст в файл, как в примере ниже:
![[00:53:40]](https://habrastorage.org/getpro/habr/upload_files/9f9/0ab/5df/9f90ab5df78c6227373378462e1de556.gif "[00:53:40]")[00:53:40]### Ctrl-\_ – undo
`Ctrl-_` (точнее, нужно нажать `Ctrl` `Shift` `-`) или `Ctrl-x` `Ctrl-u` – отменяет последние правки при редактировании командной строки.
Перемещение
-----------
### Ctrl-a/e – в начало/конец строки
`Ctrl-a` и `Ctrl-e` – перемещение в начало и конец командной строки соответственно. Можно, конечно, пользоваться клавишами `Home` и `End`, но так быстрее при использовании, например, таких клавиш, как вырезание `Ctrl-w` и вставка `Ctrl-y`.
![[00:52:05]](https://habrastorage.org/getpro/habr/upload_files/651/abc/f48/651abcf48bcd1ed31b904ed4b335a9fd.gif "[00:52:05]")[00:52:05]### Alt-b/f и Ctrl-←/→ – предыдущее/следующие слово
`Alt-b` (и тот же эффект у `Ctrl-Left`) – переход в начало предыдущего слова.
`Alt-f` (и тот же эффект у `Ctrl-Right`) – переход в конец следующего слова.
![[00:50:10]](https://habrastorage.org/getpro/habr/upload_files/c47/c6a/b30/c47c6ab302b02c95560d30118d9a4de4.gif "[00:50:10]")[00:50:10]Настройки
---------
### bash
Подробнее значения действия редактирования командной строки bash можно посмотреть в [мануал по bash'у](https://www.opennet.ru/man.shtml?topic=bash&russian=0). Действия, упомянутые в этой статье (в порядке упоминания):
♯ man bash* **clear-screen (C-l)** Clear the screen, then redraw the current line, leaving the current line at the top of the screen.
* **reverse-search-history (C-r)** Search backward starting at the current line and moving `up' through the history as necessary. This is an incremental search.
* **reverse-search-history (C-r)** Search backward starting at the current line and moving `up' through the history as necessary. This is an incremental search.
* **history-search-backward** Search backward through the history for the string of characters between the start of the current line and the point. This is a non-incremental search.
* **history-search-forward** Search forward through the history for the string of characters between the start of the current line and the point. This is a non-incremental search.
* **yank-last-arg (M-., M-\_)** Insert the last argument to the previous command (the last word of the previous history entry). With a numeric argument, behave exactly like yank-nth-arg. Successive calls to yank-last-arg move back through the history list, inserting the last word (or the word specified by the argument to the first call) of each line in turn. Any numeric argument supplied to these successive calls determines the direction to move through the history. A negative argument switches the direction through the history (back or forward). The history expansion facilities are used to extract the last word, as if the "!$" history expansion had been specified.
* **digit-argument (M-0, M-1, ..., M--)** Add this digit to the argument already accumulating, or start a new argument. M-- starts a negative argument.
* **insert-comment (M-#)** Without a numeric argument, the value of the readline comment-begin variable is inserted at the beginning of the current line. ... The default value of comment-begin causes this command to make the current line a shell comment.
* **operate-and-get-next (C-o)** Accept the current line for execution and fetch the next line relative to the current line from the history for editing. A numeric argument, if supplied, specifies the history entry to use instead of the current line.
* **complete (TAB)** Attempt to perform completion on the text before point. Bash attempts completion treating the text as a variable (if the text begins with $), username (if the text begins with ~), hostname (if the text begins with @), or command (including aliases and functions) in turn. If none of these produces a match, filename completion is attempted.
* **complete-username (M-~)** Attempt completion on the text before point, treating it as a username.
* **possible-username-completions (C-x ~)** List the possible completions of the text before point, treating it as a username.
* **complete-hostname (M-@)** Attempt completion on the text before point, treating it as a hostname.
* **possible-hostname-completions (C-x @)** List the possible completions of the text before point, treating it as a hostname.
* **complete-variable (M-$)** Attempt completion on the text before point, treating it as a shell variable.
* **possible-variable-completions (C-x $)** List the possible completions of the text before point, treating it as a shell variable.
* **complete-command (M-!)** Attempt completion on the text before point, treating it as a command name. Command completion attempts to match the text against aliases, reserved words, shell functions, shell builtins, and finally executable filenames, in that order.
* **possible-command-completions (C-x !)** List the possible completions of the text before point, treating it as a command name.
* **complete-filename (M-/)** Attempt filename completion on the text before point.
* **possible-filename-completions (C-x /)** List the possible completions of the text before point, treating it as a filename.
* **insert-completions (M-\*)** Insert all completions of the text before point that would have been generated by possible-completions.
* **glob-expand-word (C-x \*)** The word before point is treated as a pattern for pathname expansion, and the list of matching filenames is inserted, replacing the word. If a numeric argument is supplied, an asterisk is appended before pathname expansion.
* **unix-word-rubout (C-w)** Kill the word behind point, using white space as a word boundary. The killed text is saved on the kill-ring.
* **unix-line-discard (C-u)** Kill backward from point to the beginning of the line. The killed text is saved on the kill-ring.
* **kill-line (C-k)** Kill the text from point to the end of the line.
* **yank (C-y)** Yank the top of the kill ring into the buffer at point.
* **yank-pop (M-y)** Rotate the kill ring, and yank the new top. Only works following yank or yank-pop.
* **undo (C-\_, C-x C-u)** Incremental undo, separately remembered for each line.
* **backward-word (M-b)** Move back to the start of the current or previous word. Words are composed of alphanumeric characters (letters and digits).
* **forward-word (M-f)** Move forward to the end of the next word. Words are composed of alphanumeric characters (letters and digits).
### bind -P
Можно посмотреть, какие клавиши к каким действиям редактирования командной строки bash привязаны – для этого можно воспользоваться командой «bind -P».
Есть и много других интересных комбинаций – для примера можно глянуть:
Клавиши, переключающие регистр букв:
♯ `bind -P | egrep "case|capitalize"`
![[00:58:35]](https://habrastorage.org/getpro/habr/upload_files/68c/dad/abc/68cdadabc41f66639064d1a9336ec663.gif "[00:58:35]")[00:58:35] Клавиши, меняющие слова/буквы местами:
♯ `bind -p | grep "transpose"`
Также можно настроить свои привязки – например, чтобы по комбинации «Ctrl-f» выводился результат команды «date»:
♯ `bind -x'"\C-f": date'`
![[01:00:50]](https://habrastorage.org/getpro/habr/upload_files/ee8/24e/5da/ee824e5da13432c7b270779db45d2ed3.gif "[01:00:50]")[01:00:50]### /etc/inputrc (настройки библиотеки readline)
Так как bash и многие shell'ы используют библиотеку [readline](https://wiki.archlinux.org/index.php/Readline_(%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9)) для взаимодействия с командной строкой, то можно перенастроить соответствия комбинаций клавиш и действий в /etc/inputrc.
Например, такие строки меняют поведение по умолчанию клавиш «Вверх» и «Вниз»... вместо предыдущей/последующей команды они будут включать поиск по истории команд – очень удобно, часто этим пользуюсь:
```
"\e[A": history-search-backward
"\e[B": history-search-forward
```
Коды клавиш можно посмотреть, используя комбинацию `Ctrl-v`, упомянутую выше в этой статье.
Итог
----
Полезных клавиш, делающих более удобной и быстрой работу в командной сроке, достаточно много, и в этой статье я перечислил только малую часть этих комбинаций клавиш. Зато наиболее часто используемые комбинации.
Если, по вашему мнению, стоило упомянуть какие-то еще полезные комбинации - напишите в комментариях.
---
На этом всё. Надеюсь, было полезно. Если есть какие-то вопросы и уточнения, пишите, я буду рад ответить. Также буду рад упоминаниям в комментариях, что для вас оказалось полезным/новым в этой статье. Так я пойму, что стоило упоминать, а что можно было и пропустить.
Ну, и приходите к нам учиться в [«Сетевую Академию ЛАНИТ»](https://academy.ru/catalog/unix%20linux/)!
P.S. Также рекомендую к прочтению мою предыдущую Habr-статью:
[Как устроена графика в Linux: обзор различных сред оформления рабочего стола](https://habr.com/ru/company/lanit/blog/516330/).
---
А в завершение конкурс «для внимательных зрителей».
Кто первым правильно напишет в комментариях ответ на три вопроса, получит 25% скидку на [курс по написанию Bash-скриптов](https://academy.ru/catalog/unix%20linux/NL3047.html):
1. Дата, когда проходил вебинар «Сетевой Академии ЛАНИТ» по теме этой статьи.
2. Какой пароль у пользователя root на системе, используемой на вебинаре?
3. Какой дистрибутив Линукс использовался? | https://habr.com/ru/post/537596/ | null | ru | null |
# ImageControl с показом ProgressRing для Win 8/RT
#### Зачем?
В любом Windows 8/RT приложении требуется отображать определенное количество графики. Ресурсы можно черпать повсеместно: напрямую из Web и постоянно выкачивать файлы; единожды получив файлы работать с ними через `IsolatedStorage` и так далее. Все хорошо до того момента, пока загрузка этой графики не начинает занимать продолжительное время (даже секунда это много). В этот момент требуется визуально «обнадежить» пользователя, и занять пустое место, на котором через мгновение появится изображение. Тут нам на помощь приходит `ProgressRing` и, естественно, удобнее всего написать один раз контрол и забыть об это надолго.
#### Идея
Идея действительно банальна: `Border`, `Image`, `ProgressRing` — больше ничего нам не понадобится.
* `Border` : на тот случай, если требуется обвести картинку. Далеко не самый обязательный элемент, но, иногда, очень необходимый.
* `ProgressRing` : будет виден в тот момент, когда `ImageSource` уже назначено, но `Image` еще не открыт.
* `Image`: естественно, самый важный элемент ради которого мы все и затеяли.
#### Принцип работы
Просто играемся с прозрачностью `ProgressRing` . Имеем две точки входа: событие `ImageOpened` (скрываем `ProgressRing`) и место назначения нового `ImageSource`(показываем`ProgressRing`).
#### Код
ProgressImage.xaml
```
```
ProgressImage.cs
```
public sealed partial class ProgressImage : UserControl
{
#region Common
public ProgressImage()
{
InitializeComponent();
}
private void Image_OnImageOpened(object sender, RoutedEventArgs e)
{
Ring.Opacity = 0;
}
#endregion
#region Dependency
private static readonly Color DefRingColor = Colors.BlueViolet;
private static readonly Color DefBorderColor = Colors.White;
private static readonly ImageSource DefSource = null;
private const Stretch DefStretch = Stretch.None;
///
/// Set Image Source
///
public ImageSource Source
{
get { return (ImageSource)GetValue(SourceProperty); }
set { SetValue(SourceProperty, value); }
}
public static readonly DependencyProperty SourceProperty = DependencyProperty.Register("Source", typeof(ImageSource), typeof(ProgressImage), new PropertyMetadata(DefSource,SourceChanged));
private static void SourceChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (ImageSource)e.NewValue;
controll.Image.Source = val;
controll.Ring.Opacity = 100;
}
///
/// Set ProgressRing Size
///
public int ProgressRingSize
{
get { return (int)GetValue(ProgressRingSizeProperty); }
set { SetValue(ProgressRingSizeProperty, value); }
}
public static readonly DependencyProperty ProgressRingSizeProperty = DependencyProperty.Register("ProgressRingSize", typeof(int), typeof(ProgressImage),
new PropertyMetadata(55, ProgressRingSizeChanged));
private static void ProgressRingSizeChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (int)e.NewValue;
controll.Ring.Width = val;
controll.Ring.Height = val;
}
///
/// Set ProgressRing Color
///
public Color ProgressRingColor
{
get { return (Color)GetValue(ProgressRingcolorProperty); }
set { SetValue(ProgressRingcolorProperty, value); }
}
public static readonly DependencyProperty ProgressRingcolorProperty = DependencyProperty.Register("ProgressRingColor", typeof(Color), typeof(ProgressImage),
new PropertyMetadata(DefRingColor, ProgressRingColorChanged));
private static void ProgressRingColorChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (Color)e.NewValue;
controll.Ring.Foreground = new SolidColorBrush(val);
}
///
/// Set Border Color
///
public Color BorderColor
{
get { return (Color)GetValue(BorderColorProperty); }
set { SetValue(BorderColorProperty, value); }
}
public static readonly DependencyProperty BorderColorProperty = DependencyProperty.Register("BorderColor", typeof(Color), typeof(ProgressImage),
new PropertyMetadata(DefBorderColor, BorderColorChanged));
private static void BorderColorChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (Color)e.NewValue;
controll.Border.BorderBrush = new SolidColorBrush(val);
}
///
/// Set BorderThickness
///
public double BorderSize
{
get { return (double)GetValue(BorderSizeProperty); }
set { SetValue(BorderSizeProperty, value); }
}
public static readonly DependencyProperty BorderSizeProperty = DependencyProperty.Register("BorderSize", typeof(double), typeof(ProgressImage), new PropertyMetadata(0.0, BorderSizeChanged));
private static void BorderSizeChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (double)e.NewValue;
controll.Border.BorderThickness = new Thickness(val);
}
///
/// Set Border Corner Radius
///
public int BorderCornerRadius
{
get { return (int)GetValue(BorderCornerRadiusProperty); }
set { SetValue(BorderCornerRadiusProperty, value); }
}
public static readonly DependencyProperty BorderCornerRadiusProperty = DependencyProperty.Register("BorderCornerRadius", typeof(int), typeof(ProgressImage), new PropertyMetadata(0, BorderCornerRadiusChanged));
private static void BorderCornerRadiusChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (int)e.NewValue;
controll.Border.CornerRadius = new CornerRadius(val);
}
///
/// Set Image Stretch
///
public Stretch ImageStretch
{
get { return (Stretch)GetValue(ImageStretchProperty); }
set { SetValue(ImageStretchProperty, value); }
}
public static readonly DependencyProperty ImageStretchProperty = DependencyProperty.Register("ImageStretch", typeof(Stretch), typeof(ProgressImage), new PropertyMetadata(DefStretch, ImageStretchChanged));
private static void ImageStretchChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (Stretch)e.NewValue;
controll.Image.Stretch = val;
}
///
/// Set Image Stretch
///
public double ImageMargin
{
get { return (double)GetValue(ImageMarginProperty); }
set { SetValue(ImageMarginProperty, value); }
}
public static readonly DependencyProperty ImageMarginProperty = DependencyProperty.Register("ImageMargin", typeof(double), typeof(ProgressImage), new PropertyMetadata(0.0, ImageMarginChanged));
private static void ImageMarginChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var controll = (ProgressImage)d;
var val = (double)e.NewValue;
controll.Image.Margin = new Thickness(val);
}
#endregion
}
```
Список настроек включает в себя (имена говорящие, но все равно стоит пояснить):
* `Source` — назначение `ImageSource`
* `ProgressRingSize` — размеры `ProgressRing`
* `ProgressRingColor` — цвет`ProgressRing`
* `BorderColor` — цвет`Border`
* `BorderSize` — размер `BorderThickness`
* `BorderCornerRadius` — размер радиуса углов `Border`
* `ImageStretch` — говорит само за себя
* `ImageMargin` — назначение `Margin` для `Image` относительно `Border`
* `ControlBackground` — назначение цвета фона всего контрола
Использовать крайне просто.
Не забываем про:
```
xmlns:controls="using:test.Controls"
```
И легко используем:
```
```
#### Что мы получаем?
Наличие под рукой такого контрола — позволяет в любую минуту его подправить под свои конкретные нужны. Основные настройки уже включены, а добавить новые — двухминутное дело. Искренне надеюсь, что кому-нибудь сэкономил время. А вот как выглядет это.

Объективная/необъективная критика, а также предложения по улучшению бутут крайне хорошо восприняты. | https://habr.com/ru/post/180067/ | null | ru | null |
# Разработка отладочной платы для К1986ВЕ1QI (авиа)

Несколько лет назад я познакомился с российскими микроконтроллерами фирмы Миландр. Это был 2013 год, когда инженеры бурно обсуждали первые результаты ФЦП «Развития электронной компонентной базы и радиоэлектроники» на 2008-2015 годы. На тот момент уже был выпущен контроллер К1986ВЕ9x (ядро Cortex-M3) и только-только появился контроллер 1986ВЕ1Т (ядро Cortex-M1). Он же в пластиковом корпусе LQFP-144 имел в документации обозначение К1986ВЕ1QI (авиа), а на самой микросхеме обозначение MDR32F1QI. На сайте изготовителя у него стоит суффикс «авиа», так как он имеет интерфейсы специфичные для авиастроения (ARINC 429, MIL\_STD\_1553).
Удивительно, но на момент распространения этих контроллеров фирмой «Миландр» были подготовлены отладочные наборы и библиотека подпрограмм для работы с периферией, «но без каких-либо дополнительных гарантий и обязательств по корректности библиотеки». Библиотека похожа на Standard Peripheral Library от компании STMicroelectronics. В общем, все ARM-контроллеры построенные на ядре Cortex-M имеют много общего. По этой причине ознакомление с новыми российскими контроллерами шло быстро. А для тех, кто покупал фирменные отладочные комплекты предоставлялась техническая поддержка в процессе использования.

*Отладочный комплект для микроконтроллера 1986ВЕ1Т, © Миландр*
Однако, со временем начали проявляться «детские болезни» новых микросхем и библиотек. Тестовые примеры прошивок работали без видимых проблем, но при существенной модификации сыпались сбои и ошибки. Первой «ласточкой» в моей практике были необъяснимые сбои в работе CAN-контроллера. Через год на контроллере 1986ВЕ1Т (авиа) ранней ревизии обнаружилась проблема с модулем [МКИО (мультиплексный канал информационного обмена)](https://ru.wikipedia.org/wiki/MIL-STD-1553). В общем, все ревизии этих микроконтроллеров до 2016 года были ограниченно годными. Много времени и нервов ушло на выявление этих проблем, подтверждение которым сейчас можно найти в [списках ошибок (Errata)](https://ic.milandr.ru/upload/iblock/352/352a1573c08c406a94b976ed95fe4506.pdf).
Неприятной особенностью было то, что работать и разбираться с ошибками приходилось не на отладочных платах, а на платах прототипов приборов, которые планировались для серийного заводского изготовления. Кроме разъёма JTAG там обычно ничего не было. Подключиться логическим анализатором было сложно и неудобно, а светодиодов и экранов обычно не было. По этой причине у меня в голове появилась мысль о создании своей отладочной платы.
С одной стороны, на рынке были фирменные отладочные комплекты, а также замечательные платы от компании LDM-Systems из Зеленограда. С другой стороны, цены на эти изделия вгоняют в ступор, а базовый функционал без плат расширения не соответствует ожиданиям. Плата с распаянным контроллером и штыревым разъёмом не представляет для меня интереса. А более интересные платы стоят дорого.

*Отладочная плата MILANDR LDM-HELPER-K1986BE1QI-FULL, © LDM Systems*
У фирмы «Миландр» ценовая политика и маркетинг своеобразны. Так, есть возможность получить бесплатно образцы некоторых микросхем, но доступно это только юридическим лицам и связано с бюрократическим квестом. В целом микросхемы в металлокерамическом корпусе являются золотыми в прямом и переносном смыслах. Например, контроллер 1986ВЕ1Т стоит в Москве от 14 до 24 тысяч рублей. Микросхема статической памяти 1645РУ6У стоит от 15000 рублей. И такой порядок цен на всю продукцию. В итоге, даже профильные НИИ с госзаказом экономят и шарахаются от таких цен. Микросхемы в пластиковом корпусе для гражданского применения существенно дешевле, но их нет в наличии у популярных поставщиков. Кроме того, качество микросхем в пластиковом корпусе, как мне кажется, хуже «золотых». Например, я не смог запустить контроллер K1986BE1QI на частоте 128МГц без увеличения параметра flash latency. Одновременно температура этого контроллера поднялась до 40-50С. А вот контроллер 1986BE1T («золотой») запустился на 128МГц без дополнительных настроек и оставался холодным. Он действительно хорош.

*«Золотой» микроконтроллер 1986BE1T, (с) Миландр*
Мне повезло, что микроконтроллер в пластиковом корпусе всё-таки можно купить в розницу в компании LDM Systems, а все схемы плат есть в свободном доступе. Плохо то, что на сайте на фотографии контроллера видна маркировка, которая говорит, что это 4 ревизия 2014 года, т.е. с дефектами. Я долго думал – покупать или не покупать. Так прошло несколько лет…
---
Мысль о создании отладочной платы никуда не исчезла. Постепенно я сформировал все требования и думал, как всё это разместить на одной плате, чтобы получилось компактно и не дорого. Параллельно я заказывал у китайцев недостающие комплектующие. Я никуда не спешил – всё делал для себя. Китайские поставщики славятся разгильдяйством – мне пришлось заказывать одно и то же в разных местах, чтобы получить всё, что нужно. Более того, часть микросхем памяти оказались бывшими в употреблении – очевидно выпаянными из сломанных приборов. Это мне позже аукнулось.
Купить микроконтроллер Миландр К1986ВЕ1QI (авиа) – не простая задача. В том же магазине «Чип и Дип» в разделе «Позиции на заказ» я нашёл только K1986BE92QI за 740 рублей, но он мне не подходил. Единственный вариант — купить в компании LDM-Systems за 2000 рублей не свежую ревизию. Так как найти замену я нигде больше не смог, то решил купить то, что было. К моему приятному удивлению мне продали новенький контроллер выпуска декабрь 2018 года, ревизия 6+ (1820). А на сайте до сих пор старая фотография, и на момент написания статьи контроллера в наличии нет…

*Микроконтроллер К1986ВЕ1QI (авиа) в технологической упаковке, (с) Фото автора*
**Основные технические характеристики отладочной платы MDB1986** следующие:
* встроенный отладчик-программатор, совместимый с J-Link и CMSIS-DAP;
* статическая память 4Мбит (256k x 16, 10 ns);
* микросхема флэш памяти 64Мбит, Winbond 25Q64FVSIG;
* приёмопередатчик интерфейса RS-232 с линиями RTS и CTS;
* интерфейсы и разъёмы для Ethernet, USB, CAN;
* контроллер 7-сегментного дисплея MAX7221;
* штыревой разъём для работы с МКИО (MIL\_STD\_1553) и ARINC429;
* фототранзистор Everlight PT17-21C;
* пять цветных светодиодов, кнопка сброса и две пользовательские кнопки;
* питание от порта USB 5 вольт;
* размеры печатной платы 100 х 80, мм
Мне нравились платы серии STM-Discovery тем, что там есть встроенный программатор-отладчик – ST-Link. Фирменный ST-Link работает только с контроллерами фирмы STMicroelectronics, но пару лет назад появилась возможность обновить в ST-Link прошивку и получить SEGGER J-Link OB (on-board) Debugger. Юридически имеется ограничение на использование такого отладчика только с платами STMicroelectronics, но фактически потенциал не ограничен. Таким образом, имея J-Link OB можно на отладочной плате иметь встроенный программатор-отладчик. Отмечу, что в продукции «LDM-Systems» используется преобразователь CP2102 (Usb2Uart), который может только прошивать.

*Микроконтроллеры STM32F103C8T6, настоящие и не очень, (с) Фото автора*
Итак, необходимо было купить оригинальный STM32F103C8T6, так как фирменные прошивки не будут корректно работать с клоном. Я сомневался в этом тезисе и решил попробовать в работе контроллер CS32F103C8T6 китайской фирмы CKS. К самому контроллеру у меня претензий нет, но фирменная прошивка ST-Link в нём не заработала. J-Link работал частично – USB-устройство определялось, но свои функции программатор не выполнял и постоянно напоминал, что он «defective».

*Ошибка при работе отладчика на не оригинальном контроллере*
Я на этом не успокоился и написал сначала прошивку для мигания светодиодом, а потом реализовал запрос IDCODE по протоколу JTAG. Программатор ST-Link, который был у меня на плате Discovery, и программа ST-Link Utility прошивали без проблем CS32F103C8T6.В итоге я убедился в том, что моя плата работает. На мою радость целевой контроллер К1986ВЕ1QI (авиа) бодро выдавал свой IDCODE по линии TDO.

*Осциллограмма сигнальной линии TDO с закодированным ответом IDCODE, (с) Фото автора*
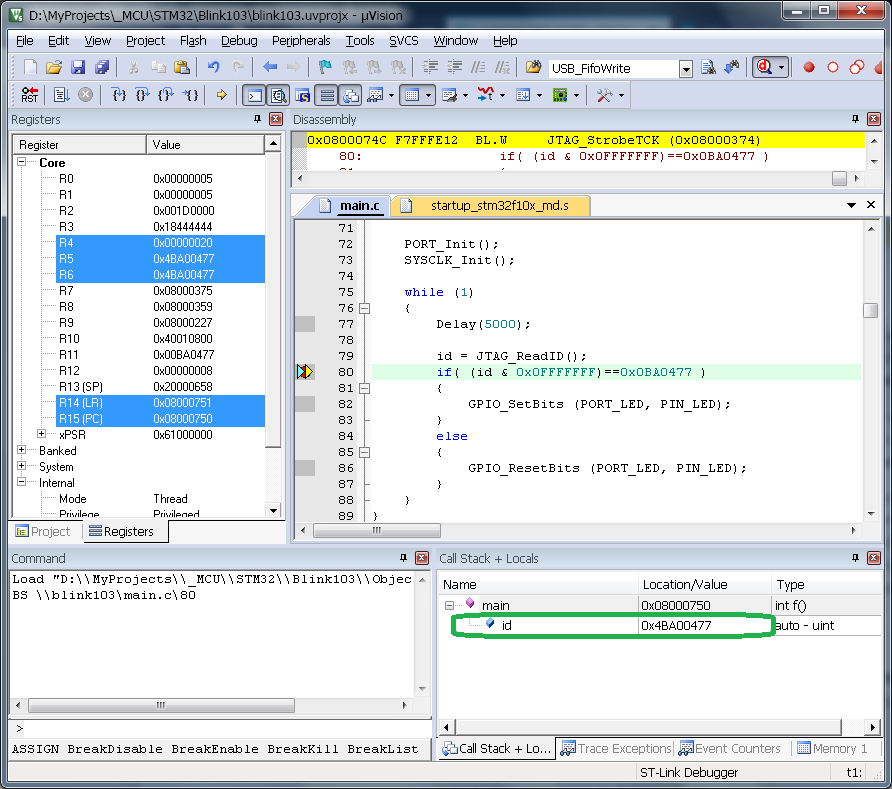
*Вот и пригодился порт SWD для отладки самого отладчика и проверки IDCODE*
Оставался вариант с отладчиком [CMSIS-DAP (Debug Access Port)](https://arm-software.github.io/CMSIS_5/DAP/html/index.html). Собрать проект из исходников от ARM – дело не простое, я взял проект у [X893](https://habr.com/ru/users/x893/), а потом ещё попробовал DAP42. К сожалению, Keil uVision зависал и не хотел с ними работать. В итоге я заменил микросхему отладчика на фирменную STM32F103C8T6 и больше к этому вопросу не возвращался.
*Успешная работа встроенного отладчика J-Link STLink V2*
Когда все ключевые компоненты будущей отладочной платы были в наличии, то я полез в Eagle CAD и обнаружил, что их нет в библиотеке элементов. Деваться некуда – их пришлось чертить самому. Заодно я сделал посадочные места для памяти, разъёма HanRun для Ethernet, а для резисторов и конденсаторов добавил рамочки. Файл проекта и библиотеку компонентов можно найти [у меня на GitHub](https://github.com/makbit/MDB1986).
*Принципиальная схема отладочной платы MDB1986*
Питается плата от источника постоянного тока напряжением 5 вольт, получаемых из порта USB. Всего на плате два порта USB Type-B. Один — для программатора, второй — для контроллера K1986BE1QI. Плата может работать от любого из этих источников или с обоими одновременно. Простейшая регулировка нагрузки и защита линий питания реализованы на диодах Шоттки, на схеме это элементы D2 и D3 (SS24). Также на схеме можно увидеть самовосстанавливающиеся предохранители F1 и F2 на 500мА. Сигнальные линии порта USB защищены диодной сборкой USBLC6-2SC6.
Схема отладчика-программатора ST-Link многим известна, её можно найти в документации на платы STM32-Discovery и других источниках. Для первичной прошивки клона ST-Link/J-Link-OB/DAP (на выбор) я вывел линии SWDIO (PA13), SWCLK (PA14), GND. Многие используют для прошивки UART и вынуждены дёргать перемычки BOOT. Но мне удобнее SWD, к тому же этот протокол позволяет вести отладку.
Почти все компоненты платы питаются от 3.3 вольт, которые поступают от регулятора напряжения AMS1117-3.3. Для подавления электромагнитных помех и бросков тока используются LC-фильтры из конденсаторов и дросселей серии BLM31PG.
Отдельно стоит упомянуть о драйвере 7-сегментного дисплея MAX7221. Согласно спецификации рекомендуемое питание от 4 до 5.5 вольт, а уровень высокого сигнала (логическая единица) не менее 3.5В (0.7 x VCC), при питании 5В. У контроллера К1986ВЕ1QI (авиа) выход логической единицы соответствует напряжению от 2.8 до 3.3В. Очевидно не соответствие уровней сигналов, которые могут нарушить нормальную работу. Я решил запитать MAX7221 от 4В и снизить уровни сигналов до 2.8В (0.7 x 4 = 2.8). Для этого последовательно в цепь питания драйвера установлен диод D4 (RS1A или FR103). Итого падение напряжения составляет 0.9В (диод Шоттки 0.3В и диод 0.6В), и всё работает.
Большинство портов микроконтроллера К1986ВЕ1QI (авиа) совместимы с сигналами до 5В. Поэтому не вызывает проблем использование CAN-приёмопередатчика MCP2551, который также работает от 5В. В качестве RS-232 приёмопередатчика на схеме указана микросхема MAX3232, но на самом деле я использовал SN65C3232D от компании Texas Instruments, т.к. она работает от 3.3В и обеспечивает скорость до 1Mbit/s.
На плате размещены 4 кварцевых резонатора – один для отладчика (8МГц) и три для целевого микроконтроллера К1986ВЕ1QI (авиа) номиналами 32.768кГц, 16МГц, 25Мгц. Это необходимые компоненты, т.к. параметры встроенного RC-генератора находятся в больших пределах от 6 до 10 МГц. Частота 25МГц необходима для работы встроенного Ethernet-контроллера. На сайте Миландра (возможно, по ошибке) почему-то указано, что в пластиковом корпусе Ethernet отсутствует. Но мы будем опираться на спецификацию и факты.
Важным стимулом для создания своей отладочной платы была возможность поработать с внешней системной шиной EBC (external bus controller), которая по сути является параллельным портом. Микроконтроллер К1986ВЕ1QI (авиа) позволяет подключать и работать с внешними микросхемами памяти и периферийными устройствами, например, АЦП, ПЛИС и т.д. Возможности внешней системной шины достаточно большие – можно работать с 8-битными, 16-битными и 32-битными статическими ОЗУ, ПЗУ и NAND Flash. Для считывания/записи 32-битных данных контроллер умеет автоматически выполнять 2 соответствующие операции для 16-битных микросхем, а для 8-битных — 4 операции. Очевидно, что 32-битная операция ввода-вывода выполнится быстрее всего с 32-битной шиной данных. К недостаткам можно отнести необходимость в программе оперировать 32-битными данными, а на плате придётся проложить 32 дорожки.

*Микросхемы статического ОЗУ, б/у (угадай какая с дефектом)*
Сбалансированным решением является использование 16-битных микросхем памяти. У меня оказались в наличии микросхемы Integrated Silicon Solutions Inc. (ISSI IS61LV25616AL, 16 x 256k, 10 ns, 3.3V). Конечно, у фирмы «Миландр» есть свои микросхемы статической памяти [серии 1645РУ](https://ic.milandr.ru/products/mikroskhemy_pamyati/), но они слишком дорогие и недоступные. В качестве альтернативы есть совместимые по выводам Samsung K6R4016V1D. Ранее я упоминал, что микросхемы оказались бывшими в употреблении и экземпляр, который я установил изначально давал сбои и хаотичные значения в 15-ой линии данных. Ушло несколько дней на поиск аппаратных ошибок, и тем больше было чувство удовлетворения, когда я заменил повреждённую микросхему на исправную. Как бы то ни было, скорость работы с внешней памятью оставляет желать лучшего.
**Внешняя шина и режим StandAlone**Микроконтроллер К1986ВЕ1QI (авиа) имеет уникальный режим StandAlone, который предназначен для прямого доступа извне к контроллерам Ethernet и МКИО (MIL\_STD\_1553) по внешней шине, причём ядро находится в состоянии сброса, т.е. не используется. Этот режим удобен для процессоров и ПЛИС, в которых нет Ethernet и/или МКИО.
Схема подключения следующая:
* шина данных MCU(D0-D15) => SRAM(I/O0-I/O15),
* шина адреса MCU(A1-A18) => SRAM(A0-A17),
* управление MCU(nWR,nRD,PortC2) => SRAM (WE,OE,CE),
* SRAM(UB,LB) подключены или подтянуты к земле через резистор.
Линия CE подтянута к питанию через резистор, выводы для выборки байта MCU(BE0-BE3) не используются. Под спойлером привожу код инициализации портов и контроллера внешней шины.
**Инициализация портов и контроллера EBC (external bus controller)**
```
void SRAM_Init (void)
{
EBC_InitTypeDef EBC_InitStruct = { 0 };
EBC_MemRegionInitTypeDef EBC_MemRegionInitStruct = { 0 };
PORT_InitTypeDef initStruct = { 0 };
RST_CLK_PCLKcmd (RST_CLK_PCLK_EBC, ENABLE);
PORT_StructInit (&initStruct);
//--------------------------------------------//
// DATA PA0..PA15 (D0..D15) //
//--------------------------------------------//
initStruct.PORT_MODE = PORT_MODE_DIGITAL;
initStruct.PORT_PD_SHM = PORT_PD_SHM_ON;
initStruct.PORT_SPEED = PORT_SPEED_FAST;
initStruct.PORT_FUNC = PORT_FUNC_MAIN;
initStruct.PORT_Pin = PORT_Pin_All;
PORT_Init (MDR_PORTA, &initStruct);
//--------------------------------------------//
// Address PF3-PF15 (A0..A12), A0 - not used. //
//--------------------------------------------//
initStruct.PORT_FUNC = PORT_FUNC_ALTER;
initStruct.PORT_Pin = PORT_Pin_4 | PORT_Pin_5 |
PORT_Pin_6 | PORT_Pin_7 |
PORT_Pin_8 | PORT_Pin_9 |
PORT_Pin_10 | PORT_Pin_11 |
PORT_Pin_12 | PORT_Pin_13 |
PORT_Pin_14 | PORT_Pin_15;
PORT_Init (MDR_PORTF, &initStruct);
//--------------------------------------------//
// Address PD3..PD0 (A13..A16) //
//--------------------------------------------//
initStruct.PORT_FUNC = PORT_FUNC_OVERRID;
initStruct.PORT_Pin = PORT_Pin_0 | PORT_Pin_1 |
PORT_Pin_2 | PORT_Pin_3;
PORT_Init (MDR_PORTD, &initStruct);
//--------------------------------------------//
// Address PE3, PE4 (A17, A18) //
//--------------------------------------------//
initStruct.PORT_FUNC = PORT_FUNC_ALTER;
initStruct.PORT_Pin = PORT_Pin_3 | PORT_Pin_4;
PORT_Init (MDR_PORTE, &initStruct);
//--------------------------------------------//
// Control PC0,PC1 (nWE,nOE) //
//--------------------------------------------//
initStruct.PORT_FUNC = PORT_FUNC_MAIN;
initStruct.PORT_Pin = PORT_Pin_0 | PORT_Pin_1;
PORT_Init (MDR_PORTC, &initStruct);
//--------------------------------------------//
// Control PC2 (nCE) //
//--------------------------------------------//
initStruct.PORT_PD = PORT_PD_DRIVER;
initStruct.PORT_OE = PORT_OE_OUT;
initStruct.PORT_FUNC = PORT_FUNC_PORT;
initStruct.PORT_Pin = MDB_SRAM_CE;
PORT_Init (MDR_PORTC, &initStruct);
//--------------------------------------------//
// Initialize EBC controler //
//--------------------------------------------//
EBC_DeInit();
EBC_StructInit(&EBC_InitStruct);
EBC_InitStruct.EBC_Mode = EBC_MODE_RAM;
EBC_InitStruct.EBC_WaitState = EBC_WAIT_STATE_3HCLK;
EBC_InitStruct.EBC_DataAlignment = EBC_EBC_DATA_ALIGNMENT_16;
EBC_Init(&EBC_InitStruct);
EBC_MemRegionStructInit(&EBC_MemRegionInitStruct);
EBC_MemRegionInitStruct.WS_Active = 2;
EBC_MemRegionInitStruct.WS_Setup = EBC_WS_SETUP_CYCLE_1HCLK;
EBC_MemRegionInitStruct.WS_Hold = EBC_WS_HOLD_CYCLE_1HCLK;
EBC_MemRegionInitStruct.Enable_Tune = ENABLE;
EBC_MemRegionInit (&EBC_MemRegionInitStruct, EBC_MEM_REGION_60000000);
EBC_MemRegionCMD(EBC_MEM_REGION_60000000, ENABLE);
// Turn ON RAM (nCE)
PORT_ResetBits (MDR_PORTC, MDB_SRAM_CE);
}
```
Микроконтроллер в корпусе LQFP-144 и память в корпусе TSOP-44 имеют много связанных выводов и занимают много места на печатной плате. Имея за плечами опыт решения оптимизационных задач в области экономики, мне было очевидно, что размещать на плате эти микросхемы необходимо в первую очередь. В различных источниках мне встречались хвалебные отзывы о [САПР TopoR (Topological Router)](https://www.eremex.ru/products/delta-design/topor/). Я скачал пробную версию (trial) и смог экспортировать туда свой проект из Eagle CAD только тогда, когда удалил почти все компоненты. К сожалению, даже 10 элементов программа TopoR не помогла мне разместить на плате. Сначала все компоненты были помещены в угол, а потом по краю расставлены. Меня такой вариант не удовлетворил, и я долго выполнял трассировку платы в ручном режиме в привычной среде Eagle CAD.
Важным элементом печатной платы является шелкография. На отладочной плате должны быть не только подписи к электронным компонентам, но и все разъёмы должны быть подписаны. На обратной стороне платы я разместил таблицы-памятки с функциями портов контроллера (основная, альтернативная, переопределённая, фактическая). Изготовление печатных плат я заказал в Китае во всем известной конторе PCBWay. Хвалить не буду, потому что качество хорошее. Они могут сделать лучше, с меньшими допусками, но [за отдельную плату](https://www.pcbway.com/HighQualityOrderOnline.aspx).

*Изготовленные печатные платы MDB1986, (с) Фото автора*
Распаивать компоненты пришлось «на коленке» паяльником 40-ватт и припоем ПОС-61, потому что паяю я редко, 1-2 раза в год, и паяльная паста засохла. Пришлось ещё менять китайский контроллер CS32F103 на оригинальный STM32F103, а потом ещё и память заменить. В общем сейчас меня результат полностью устраивает, хотя ещё не проверил работу RS-232 и CAN.

*Отладочная плата MDB1986 в работе — светит и греет, (с) Фото автора*
На сайте «Миландра» можно найти достаточно [учебных материалов для изучения контроллеров](https://edu.milandr.ru/library/) серии 1986BE9 (ядро Cortex-M3), но для микроконтроллера К1986ВЕ1QI (авиа) я не вижу там ничего. Просмотрев опубликованные там материалы, методички и лабораторные работы для ВУЗов, я радуюсь, что готовятся кадры по всей стране для работы с российскими контроллерами. Большинство учебных материалов готовят к работе с портами ввода-вывода, таймерами, АЦП, ЦАП, SPI, UART. Используются разные среды разработки IDE (Keil, IAR, CodeMaster). Где-то программируют с помощью регистров CMSIS, а где-то используют MDR Library. Необходимо упомянуть ресурс [Start Milandr](https://startmilandr.ru/), который содержит немало статей от программистов-практиков. И, конечно же, следует не забывать про [форум Миландра](https://forum.milandr.ru/).
**Дума о Миландре**Микроэлектроника в России развивается, и в этом процессе компания «Миландр» играет заметную роль. Появляются новые интересные микроконтроллеры, например, 1986ВЕ81Т и «Электросила» с интерфейсами SpaceWire и МКИО (такой же как в 1986BE1 и, возможно, с теми же проблемами), и т.д. Но простым студентам, преподавателям и гражданским инженерам купить такие микросхемы не реально. А значит сообщество инженеров не сможет быстро выявить ошибки и проблемы этой микросхемы. Мне кажется, что сначала необходимо выпускать микросхемы в пластиковом корпусе, распространять среди всех заинтересованных лиц, а уж после апробации (лат. approbatio — одобрение, признание) специалистами можно готовить ревизию в металлокерамическом корпусе с защитами от всех страшных факторов. Надеюсь в ближайшем будущем нас ВСЕХ порадуют заявленными на выставках новыми проектами.
Разработанную мной отладочную плату любой может повторить, модифицировать и использовать в учебном процессе. В первую очередь я делал плату для себя, но получилось настолько хорошо, что [я решил со всеми поделиться](https://github.com/makbit/MDB1986).
К1986ВЕ1QI (авиа) – это очень интересный контроллер с уникальными интерфейсами, который может использоваться в ВУЗах для обучения студентов. Думаю, что после исправления выявленных в контроллере ошибок и прохождения сертификационных испытаний, контроллер полетит в прямом смысле этого слова! | https://habr.com/ru/post/482716/ | null | ru | null |
# Распознаем коды Морзе с использованием Rx.js
Задача: на входе сигналы с клавиатуры (keyup, keydown) — на выходе буквы и слова декодированные по азбуке Морзе. О том, как декларативно решить данную задачу используя FRP подход, в частности Rx.js — ниже под катом. (Зачем? Because we can)
**Для не терпеливых:**
* demo — <http://alexmost.github.io/morse/>
* source — <https://github.com/AlexMost/morse>
#### Основная идея
Данная демка предназначена для демонстрации силы ~~джедая~~ реактивного программирования для решения проблемы композиции асинхронных вычислений. Rx заставляет посмотреть на асинхронный код по другому, рассматривая события как коллекции. Очень много статтей про Rx и функциональное программирования выглядят так:
Поэтому я постараюсь более подробно описать одну из функциональных частей приложения (с живыми примерами и схемами).
#### Логика Морзе
Буква в азбуке Морзе — представляет собой набор длинных и коротких сигналов (точек и тире), разделенных некоторым временным промежутком.
*Основные правила (идеальный вариант):*
1. За единицу времени принимается длительность одной точки.
2. Длительность тире равна трём точкам.
3. Пауза между элементами одного знака — одна точка.
4. Пауза между знаками в слове — 3 точки.
5. Пауза между словами — 7 точек.
Забегая вперед, хочу предупредить, что не сильно заморачивался над размерностъю и «на глаз» взял продолжительность точки в 400 мс. Данный проект не претендует на 100% соответствие с реальной морзянкой (не пытайтесь использовать в военных условиях), но принцип действия остается тем же. Относительно 400 мс вычисляются остальные временные интервалы (размер тире, пауза между буквами и словами). Интерфейс построен так, что дает понять когда он ожидает символ(точку, тире) из буквы, новую букву, или следующее слово.
*— Что? Да я на коленке такое за 5 минут и без Rx сделаю*
#### В чем основная сложность?
Основная сложность заключается в том, что мы имеем дело с асинхронной логикой. Кол-во сигналов в букве недетерминированно. Например, буква 'A' состоит из двух символов — точка и тире (.-), в то время, как '0' это пять тире (-----). Так же, непросто представить, как отсчитывать время от одной буквы до другой. Как между этим всем делом еще понимать, что произошел интервал между словами?.. Данную проблему возможно решить стандартным императивным подходом с кучей callback-ов или promise и setTimeout или новомодным async/await. Я не хочу убеждать вас в том, что это неправильно, просто хочу показать еще один подход, который пришелся мне по душе.
#### Декомпозиция задачи и разные слои абстракции
*— Divide et impera !!!*
Для решения сложной задачи необходимо разбить ее на более мелкие и простые подзадачи и решить каждую из них отдельно. В данном случае мы имеем на входе низкоуровневые сигналы (DOM event-ы), а на выходе буквы и слова. Данную задачу можно сравнить с сетевой моделью [OSI](https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D1%82%D0%B5%D0%B2%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_OSI). Модель представлена разными уровнями, каждый из которых выполняет свою задачу и предоставляет данные для вышестоящего слоя. Основное сходство заключается в том, что каждый из уровней имеет свою четкую логику, но не знает о всей модели вцелом. Давайте выделим основные слои абстракций в нашей задаче:
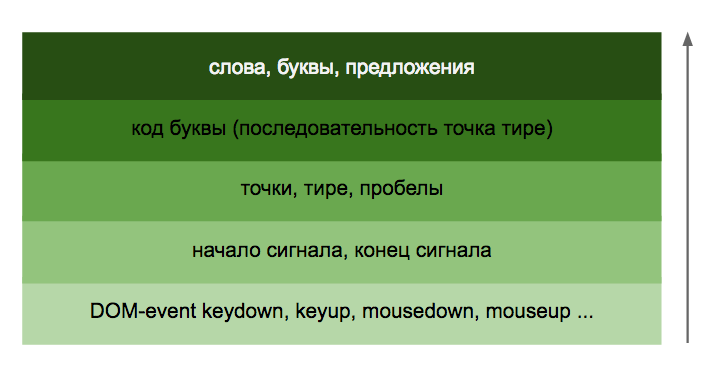
Как видно, каждый cлой оперирует своей логикой, предоставляя данные выше стоящему слою и не знает о всей системе вцелом.
#### Последовательность событий как объект первого класса
Rx позволяет рассматривать любую асинхронную последовательность как объект первого класса. Это значит мы можем сохранить все возникающие keyup-ы и keydown-ы в некую коллекцию (Observable) и оперировать с ней как с обычным массивом данных.
#### Разберем задачу «точка или тире»
Далее я постараюсь подробно описать процесс получения стрима, в котором будут приходить точки или тире. Для начала, получим коллекции всех нажатий клавиш:
```
const keyUps = Rx.Observable.fromEvent(document, 'keyup');
const keyDowns = Rx.Observable.fromEvent(document, 'keydown');
```
[пример на jsfiddle](http://jsfiddle.net/AlexMost/h8yoodpu/)
Получив массивы kyeup и keydown событий, нас интересуют только нажатия по пробелу. Можем получить их c помощью операци filter — это и будет наш первый уровень абстракции с DOM-event-aми:
```
const spaceKeyUps = keyUps.filter((data) => data.keyCode === 32);
const spaceKeyDowns = keyDowns.filter((data) => data.keyCode === 32);
```
[пример на jsfiddle](http://jsfiddle.net/AlexMost/66frLx5r/3/)
Схематически это выглядит так:
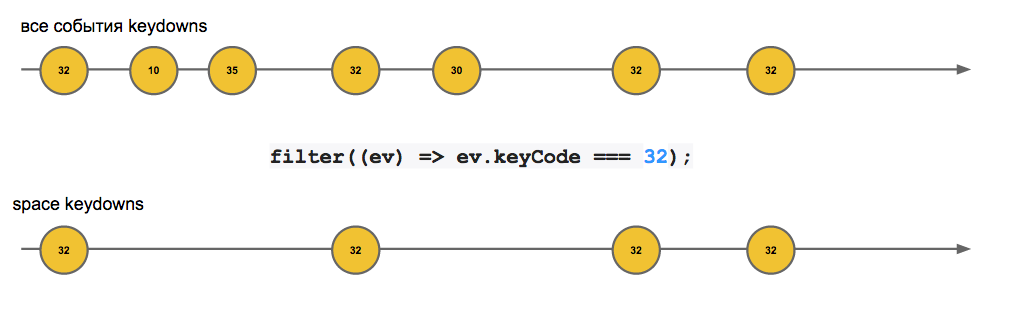
На картинке выше видим 2 стрима. Верхний включает в себя все события keydown. Нижний создан на базе верхнего, но как видим, к нему применили функцию filter, которая фильтрует код нажатой клавиши. В итоге имеем новый стрим с keydown пробела. Вы где нибудь видели событие spaceKeyDown в DOM api? Только что мы создали его на базе существующего DOM event и будем использовать его дальше.
Нас не особо интересует, откуда был получен сигнал (мышь, нажатие клавиши, микрофон, камера), абстрагируемся и передаем дальше просто факт того, что сигнал начался или закончился:
```
const signalStarts = spaceKeyDowns.map(() => "start");
const signalEnds = spaceKeyUps.map(() => "end");
```
[пример на jsfiddle](http://jsfiddle.net/AlexMost/e25h4hmc/4/)
**Но не все так просто с signalStarts :)**Есть небольшая проблемка с событием keydown. DOM api работает таким образом, что событие keydown срабатывает множество раз при зажатии клавиши. Мы это можем лекго побороть, добавив немного кода:
```
const signalStartsRaw = spaceKeyDowns.map(() => "start");
const signalEndsRaw = spaceKeyUps.map(() => "end");
// получаем общий стрим из start и end.
const signalStartsEnds = Rx.Observable.merge(signalStartsRaw, signalEndsRaw).distinctUntilChanged();
// signal star/end with toggle logic
const signalStarts = signalStartsEnds.filter((ev) => ev === "start");
const signalEnds = signalStartsEnds.filter((ev) => ev === "end");
```
Давайте разберем что сдесь произошло. Основная проблема заключается в возникновении двух одинаковых последовательных событий. В данном случае можно получить общий стрим из start и end (signalStartsEnds) и применить к нему функцию **distinctUntilChanged**. Она будет гарантировать, что события не будут повторяться. (подробнее про distinctUntilChanged — [тут](https://github.com/Reactive-Extensions/RxJS/blob/master/doc/api/core/operators/distinctuntilchanged.md))
[рабочий пример на jsfiddle](http://jsfiddle.net/AlexMost/mop8qhgu/1/)
Далее, нам необходимо высчитывать время между началом и окончанием сигнала, для этого давайте добавим временные метки к нашим коллекциям:
```
const signalStarts = signalStartsEnds.filter((ev) => ev === "start").timestamp();
const signalEnds = signalStartsEnds.filter((ev) => ev === "end").timestamp();
```
После этого необходимо возвращать разницу во времени между keydown и keyup. Создадим для этого отдельный стрим. Так как возникновение keyup события не детерменированно. То есть, если рассматривать keydown как stream и засекать время каждого нажатия на клавишу, каждое событие должно возвращать еще один стрим, который вернет первое значение keyup. Очень сложно звучит, проще посмотреть как это выглядит в коде:
```
const spanStream = signalStarts.flatMap((start) => {
return signalEnds.map((end) => end.timestamp - start.timestamp).first();
});
```
[пример на jsfiddle](http://jsfiddle.net/AlexMost/r8djtfpg/1/)
Схематически это выглядит так:
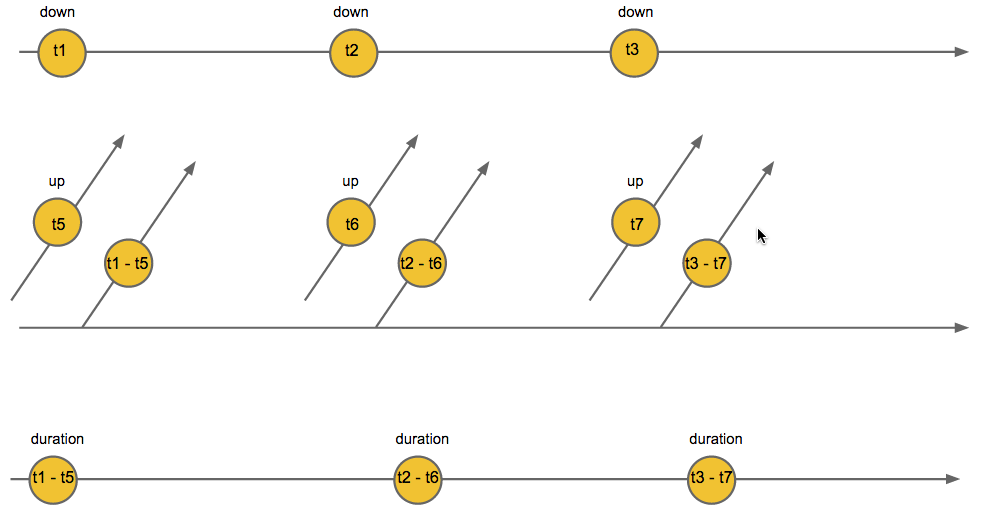
На изображении t1, t2, t3… это время возникновения события. t2 — t1 — разница во времени. Проговорить это можно как: «На каждое начало сигнала, создаем стрим из сигналов окончания сигнала, ждем из него 1й сигнал, далее передаем разницу во времени между началом и окончанием сигналов». Таким образом мы получили стрим из временных интервалов, и по ним можем определить точки и тире:
```
const SPAN = 400;
const dotsStream = spanStream.filter((v) => v <= SPAN).map(() => ".");
const lineStream = spanStream.filter((v) => v > SPAN).map(() => "-");
```
Полный код примера выглядит так — [пример на jsfiddle](http://jsfiddle.net/AlexMost/uv4yh11k/1/). Уберем немного шума и получим более красивый [код](http://jsfiddle.net/AlexMost/myxgubz5/) (субъективное мнение, но если вам не понравилось — у вас нет души).
И вот наш обещаный стрим из точек и тире:
```
const dotsAndLines = Rx.Observable.merge(dotsStream, lineStream);
```
Далее мы оперируем уже более высокоуровневыми стримами и создаем из них еще более высокоуровневые. Например, применив несоколько Rx преобразований мы можем получить стрим пробелов между буквами а потом и букву:
```
const letterCodes = dotsAndLines.buffer(letterWhitespaces) // стрим вида [['.', '.', '-'], ['-', '.', '-'] ... ]
const lettersStream = letterCodes.map((codes) => morse.decode(codes.join(""))).share() // стрим букв ['A', 'B' ...]
```
[Ссылка на исходник](https://github.com/AlexMost/morse/blob/master/src/dispatcher.js#L52)
Красиво не так ли? Нет? Тогда вот так мы можем вывести картинку котика, если пользователь набрал кодами слово «CAT»:
```
const setCatImgStream = wordsStream.filter((word) => word == "CAT").map(setCatImg)
```
**Пруф**
#### Вывод
Таким образом мы видим, что от обычных DOM событий мы пришли к более осмысленным вещам (стримам с буквами и словами). В перспективе это можно компоновать дальше в предложения, абзацы, книги и т. д. Основная идея это то, что Rx дает возможность компоновать ваш существующий функционал для получения нового. Вся ваша логика превращается в некое API для построения новой более сложной и та в свою очередь тоже может быть скомпонована. В этой статье я упустил еще много преимуществ, которые дает вам Rx из коробки (тестирование асинхронных цепочек, чистка ресурсов, обработка ошибок). Надеюсь удалось заинтересовать тех, кто хотел попробовать но никак не решался.
*Спасибо за внимание! Всем ФП =)* | https://habr.com/ru/post/262343/ | null | ru | null |
# Нейросеть для определения хейтеров — «не, ну это бан»
Привет!
Часто ли вы видите токсичные комментарии в соцсетях? Наверное, это зависит от контента, за которым наблюдаешь. Предлагаю немного поэкспериментировать на эту тему и научить нейросеть определять хейтерские комментарии.
Итак, наша глобальная цель — определить является ли комментарий агрессивным, то есть имеем дело с бинарной классификацией. Мы напишем простую нейросеть, обучим ее на датасете комментариев из разных соцсетей, а потом сделаем простой анализ с визуализацией.
Для работы я буду использовать Google Colab. Этот сервис позволяет запускать Jupyter Notebook'и, имея доступ к GPU (NVidia Tesla K80) бесплатно, что ускорит обучение. Мне понадобится backend TensorFlow, дефолтная версия в Colab 1.15.0, поэтому просто обновим до 2.0.0.
Импортируем модуль и обновляем.
```
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
!tf_upgrade_v2 -h
```
Посмотреть текущую версию можно так.
```
print(tf.__version__)
```
Подготовительные работы сделаны, импортируем все необходимые модули.
```
import os
import numpy as np
# For DataFrame object
import pandas as pd
# Neural Network
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
# Text Vectorizing
from keras.preprocessing.text import Tokenizer
# Train-test-split
from sklearn.model_selection import train_test_split
# History visualization
%matplotlib inline
import matplotlib.pyplot as plt
# Normalize
from sklearn.preprocessing import normalize
```
Описание используемых библиотек
-------------------------------
* os — для работы с файловой системой
* numpy — для работы с массивами
* pandas — библиотека для анализа табличных данных
* keras — для построения модели
* keras.preprocessing.Text — для обработки текста, чтобы подать его в числовом виде для обучения нейронной сети
* sklearn.train\_test\_split — для отделения тестовых данных от тренировочных
* matplotlib — для визуализации процесса обучения
* sklearn.normalize — для нормализации тестовых и обучающих данных
Разбор данных с Kaggle
----------------------
Я подгружаю данные прямо в сам Colab-ноутбук. Далее без проблем их уже извлекаю.
```
path = 'labeled.csv'
df = pd.read_csv(path)
df.head()
```

И это шапка нашего датасета… Мне тоже как-то не по себе от «страницу обнови, дебил».
Итак, наши данные находятся в таблице, мы ее разделим на две части: данные для обучения и для теста модели. Но это все текст, надо что-то делать.
Обработка данных
----------------
Удалим символы новой строки из текста.
```
def delete_new_line_symbols(text):
text = text.replace('\n', ' ')
return text
```
```
df['comment'] = df['comment'].apply(delete_new_line_symbols)
df.head()
```
Комментарии имеют вещественный тип данных, нам необходимо перевести их в целочисленный. Далее сохраняем в отдельную переменную.
```
target = np.array(df['toxic'].astype('uint8'))
target[:5]
```
Теперь немного обработаем текст с помощью класса Tokenizer. Напишем его экземпляр.
```
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True,
split=' ',
char_level=False)
```
**Быстро про параметры**
* num\_words — кол-во фиксируемых слов (самых часто встречающихся)
* filters — последовательность символов, которые будут удаляться
* lower — булевый параметр, отвечающий за то, будет ли переведён текст в нижний регистр
* split — основной символ разбиения предложения
* char\_level — указывает на то, будет ли считаться отдельный символ словом
А теперь обработаем текст с помощью класса.
```
tokenizer.fit_on_texts(df['comment'])
matrix = tokenizer.texts_to_matrix(df['comment'], mode='count')
matrix.shape
```
Получили 14к строк-образцов и 30к столбцов-признаков.

Я строю модель из двух слоёв: Dense и Dropout.
```
def get_model():
model = Sequential()
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=RMSprop(lr=0.0001),
loss='binary_crossentropy',
metrics=['accuracy'])
return model
```
Нормализуем матрицу и разобьем данные на две части, как и договаривались (обучение и тест).
```
X = normalize(matrix)
y = target
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2)
X_train.shape, y_train.shape
```
Обучение модели
---------------
```
model = get_model()
history = model.fit(X_train,
y_train,
epochs=150,
batch_size=500,
validation_data=(X_test, y_test))
history
```
Процесс обучения покажу на последних итерациях.

Визуализация процесса обучения
------------------------------
```
history = history.history
fig = plt.figure(figsize=(20, 10))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(223)
x = range(150)
ax1.plot(x, history['acc'], 'b-', label='Accuracy')
ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy')
ax1.legend(loc='lower right')
ax2.plot(x, history['loss'], 'b-', label='Losses')
ax2.plot(x, history['val_loss'], 'r-', label='Validation losses')
ax2.legend(loc='upper right')
```


Заключение
----------
Модель вышла примерно на 75-ой эпохе, а дальше ведет себя плохо. Точность в 0,85 не огорчает. Можно поразвлекаться с количеством слоев, гиперпараметрами и попробовать улучшить результат. Это всегда интересно и является частью работы. О своих мыслях пишите в коменты, посмотрим, сколько хейта наберет эта статья. | https://habr.com/ru/post/476188/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.