
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Единорог заинтересовался микромиром

В этот раз интересные примеры ошибок нам преподнёс микромир. Мы проверили с помощью анализатора кода PVS-Studio открытый проект ... | https://habr.com/ru/post/216157/ | null | ru | null |
# Centos-admin.ru: познаем Ansible

Это не готовая инструкция, с большим количеством кода, а скорее описание алгоритма и результатов чего [мы](http://centos-admin.ru) добились.
Итак, не так давно у... | https://habr.com/ru/post/259107/ | null | ru | null |
# А мы пойдем другим путем. Перемещаем модель в базу данных
В последнее время веб-разработка из наколенного поделия превратилась в серьезную инженерную дисциплину. Все это стало возможным старан... | https://habr.com/ru/post/113124/ | null | ru | null |
# Selenium Manager: история одного интерфейса
Привет, Хабр!
Меня зовут Виталий Котов и я работаю в компании Badoo. В одной из предыдущих [статей](https://habrahabr.ru/company/badoo/blog/337126/) я рассказывал, что у нас есть некий интерфейс, который помогает взаимодействовать с автотестами как тестировщикам, так и ... | https://habr.com/ru/post/344030/ | null | ru | null |
# Умножение матриц: эффективная реализация шаг за шагом

Введение
--------
Умножение матриц — это один из базовых алгоритмов, который широко применяется в различных численных методах, и в частности в алгоритмах машинного обучения.... | https://habr.com/ru/post/359272/ | null | ru | null |
# Кроссплатформенная новогодняя демка на .NET Core и Avalonia
"[ААА! Пришло время переписывать на .NET Coreǃ](https://habrahabr.ru/company/jugru/blog/345136/)", говорили они, WPF в комментариях обсуждали. Так давайте же проверим, можно ли написать кросс-платформенное GUI приложение на .NET / C#.

Данная статья не раскрывает всех премудростей перемещения по тексту или его редактирования. Основные движения можно узнать в vimtutor, остальные комбинации изучаются в процессе работы. Некот... | https://habr.com/ru/post/303524/ | null | ru | null |
# Классовый мутатор Binds.
В обсуждении [недавнего топика](http://habrahabr.ru/blogs/mootools/39794/) хабрасообщество заинтересовалось подробностями написания классов для MooTools и, в частности, мутаторами. В связи с этим мне захотелось что-нибудь написать на эту тему, пока не наткнулся на статью одного из разработчи... | https://habr.com/ru/post/40059/ | null | ru | null |
# Как расширить функционал приложения, размещенного на Mac Store, при помощи Apple Script
С тех пор, как для прохождения модерации на Mac Store стала требоваться поддержка Sandbox, прошло уже 5 лет. Хотя возможности MacOS и Sandbox постепенно расширяются, разработчики, желающие публиковаться в официальном магазине App... | https://habr.com/ru/post/323982/ | null | ru | null |
# Selenium для всех: как мы учим QA-инженеров работать с автотестами

Привет, Хабр! Меня зовут Виталий Котов, я работаю в Badoo в отделе QA, занимаюсь автоматизацией тестирования, а иногда и автоматизацией автоматизации тестиро... | https://habr.com/ru/post/337126/ | null | ru | null |
# Qt? ImGUI? wxWidgets? Пишем свое
Привет, хабровчане! Хочу рассказать о своей системе UI, которую я написал для своего игрового движка, на которой делаю редактор для него же. Вот такой:
Итак, вот уже в кото... | https://habr.com/ru/post/521306/ | null | ru | null |
# Препарируем Яндекс-карты: «Вас поставили подслушивать, а Вы тут подглядываете». Информация о точках доступа Wi-fi используется для определения местоположения
 Эта статья в большей степени совсем не о яндекс-картах, а ... | https://habr.com/ru/post/102332/ | null | ru | null |
# Home видео для Selenium aka WebDriver. Или чем записать экран, если у вас есть java, поломанные тесты и немного времени
Решили мы на работе автоматизировать тесты для нескольких своих веб приложений. И кроме информации, когда упали тесты, захотелось еще и увидеть, как выглядела страница на этот печальный момент.
... | https://habr.com/ru/post/517446/ | null | ru | null |
# Отрабатываем Git hooks на автоматизации commit message
Привет, Хабр! В этой статье я расскажу о Git hooks и о том, как они могут помочь с некоторыми насущными кейсами организации создания commit’ов и commit... | https://habr.com/ru/post/584562/ | null | ru | null |
# Расширяем и улучшаем Cache в ASP.NET
Про ASP.NET-объект [Cache](http://msdn.microsoft.com/ru-ru/library/system.web.caching.cache.aspx "Описание класса") наверняка знает каждый web-разработчик на платформе .NET. Совсем не странно, ведь это единственное решение для кэширования данных web-приложения в ASP.NET, доступно... | https://habr.com/ru/post/61617/ | null | ru | null |
# Интерфейс для Яндекс.Диска в Ubuntu 14.04
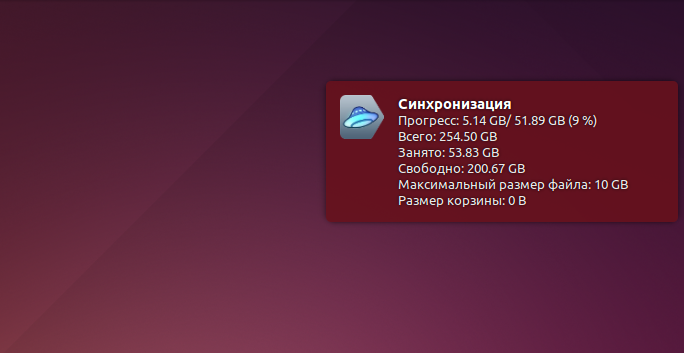
Как известно, Яндекс.Диск на Ubuntu существует только как консольный клиент. Сегодня я решил «хватит это терпеть» и написал для себя простенький скрипт, который значительно у... | https://habr.com/ru/post/249267/ | null | ru | null |
# Пишем свой отладчик под Windows [часть 1]
#### Вступление
Все мы, время от времени, используем дебаггер для отладки программ. Отладчик может использоваться с C++, C#, Java и ещё сотней других языков. Он может быть ка... | https://habr.com/ru/post/154847/ | null | ru | null |
# Снегопад с помощью фильтров FFmpeg
FFmpeg — мощное ПО со большим набором возможностей. В статье я постараюсь рассказать о немного необычном применении фильтров ffmpeg и о том что можно сделать используя исключительно их. Видео ниже сделано с помощью 1 команды ffmpeg (ни один графический редактор не пострадал).
Я ... | https://habr.com/ru/post/203314/ | null | ru | null |
# Вычисляем точный адрес любого пользователя по номеру телефона или адресу электронной почты
С помощью этой инструкции вы сможете без труда вычислить точный адрес (улица, номер дома, номер квартиры) любого человека, который пользуется услугами интернет-провайдера InterZet (или DomRU).
### Предыстория
8-го декабря... | https://habr.com/ru/post/344348/ | null | ru | null |
# Что может сделать стартап за месяц
[](http://picfor.me "Picfor.me -закладки на картинки")
Это юбилейный пост, которым мы хотим отметить первый месяц работы нашего молодого проекта [Picture for me](http://picfor.me). Ровно месяц назад мы сообщ... | https://habr.com/ru/post/39657/ | null | ru | null |
# Удаленная отладка Spring Boot приложений (IntelliJ + Eclipse)
Локальная разработка на вашей машине удобна. Но как только вы развернете свое приложение, у вас будет совсем другая среда, что может привести к непредвиденному поведению или ошибкам. Использование ручной печати
```
System.out.println («Теперь мы находим... | https://habr.com/ru/post/513520/ | null | ru | null |
# Интеграция GNU/Linux и Microsoft Windows
Из недавно опубликованного топика [Mac OS X глазами Windows-юзера](http://habrahabr.ru/post/146880/) я узнал о программе «Parallels Desktop», которая позволяет очень дружелюбным для пользователя образом запускать приложения другой операционной системы. И мне так понравилась э... | https://habr.com/ru/post/146919/ | null | ru | null |
# Функциональное программирование с точки зрения EcmaScript. Рекурсия и её виды
Привет, Хабр!
Сегодня мы продолжим наши изыскания на тему функционального программирования в разрезе EcmaScript, на спецификации которого основан JavaScript. В предыдущих статьях цикла были рассмотрены следующие темы:
1. [Чистые функ... | https://habr.com/ru/post/480520/ | null | ru | null |
# Лексоранги — что это такое и как их использовать для эффективной сортировки списков
В этой статье я расскажу, что такое Лексоранги, как ими пользуются в Jira, и как ими воспользовались мы для эффективной сортировки списков и перетаскивания элементов в нашем мобильном приложении.
. Он дает лучший результат, чем обычное растягива... | https://habr.com/ru/post/183638/ | null | ru | null |
# Новое в Git 3: замыкания
Git — популярная система контроля версий. В ней атомарное изменение одного или нескольких файлов называется коммитом, а несколько последовательно идущих коммитов объединяются в ветку. Ветки используются для того, чтобы реализовывать новые идеи (фичи).
[, опубликованной в октябре 2016 года на Medium.com разработчиком Stan Ostrovskiy.
 где выкладываю интересные статьи на разные темы а так же сам периодически пишу шорт-риды которые могут быть вам полезны.
---
Перевод статьи "[Disabling My Favicon: How and Why](h... | https://habr.com/ru/post/669028/ | null | ru | null |
# Введение в модульное тестирование T-SQL помощью tSQLt
tSQLt — это мощный фреймворк с открытым исходным кодом для модульного тестирования кода SQL Server.
Модульное тестирование SQL-кода — полезная практика в разработке баз данных, которая позволяет обнаруживать ошибки до попадания их в продакшн. Хотя надо сказать,... | https://habr.com/ru/post/710934/ | null | ru | null |
# GNS3 1.0 beta и Cisco IOU

Всем привет!
Совсем недавно вышла [публичная бета](http://new.gns3.net/personal.php) популярного симулятора сетевого оборудования GNS3 1.0. Интересен он в первую очередь тем, что стал поддержи... | https://habr.com/ru/post/234195/ | null | ru | null |
# Вебсокеты: боевое применение
[Вебсокеты](http://en.wikipedia.org/wiki/WebSocket) — это прогрессивный стандарт полнодуплексной (двусторонней) связи с сервером по TCP-соединению, совместимый с HTTP. Он п... | https://habr.com/ru/post/162301/ | null | ru | null |
# Автоматический регулятор температуры газовой колонки
Хочу рассказать о создании несложного устройства, которое сильно облегчило жизнь домашним обитателям — автоматический регулятор температуры газовой колонки. Подобные устройства уже соз... | https://habr.com/ru/post/262437/ | null | ru | null |
# Go: справляемся с конфликтами при блокировках с помощью пакета Atomic
> Перевод материала подготовлен в рамках курса [**"Golang Developer. Professional"**](https://otus.pw/PZDD/). Если вам интересно узнать подробнее о курсе, приглашаем на [**день открытых дверей**](https://otus.pw/eDSS/) онлайн.
>
>
](https://habr.com/ru/company/piter/blog/560650/)Привет, Хаброжители!
На 1 июня 2018 года CSS содержал 415 уникальных свойств, относящихся к объекту style в любом элементе браузера Chrome. Сколько сво... | https://habr.com/ru/post/560650/ | null | ru | null |
# Использование функционала Xen
Доброго времени суток. Среда виртуализации Xen позволяет нам довольно гибко управлять аппаратными ресурсами нашего сервера для получения максимальной производительности. Для комфортного управления виртуальными машинами, отображения более подробных логов, управления выделяемой памятью и ... | https://habr.com/ru/post/254659/ | null | ru | null |
# Rust новости #4 (декабрь 2018)
Поскольку праздники кончились, предлагаю вашему вниманию субъективную подборку ржавых новостей за декабрь. В этой подборке: безумие с растом, страшен ли раст, волна пророчеств, Rust 2018, Rust Analyzer.
, но для игры по сети.
Так как компьютерных сетей у нас ещё не было, мне... | https://habr.com/ru/post/344226/ | null | ru | null |
# AppCode 2016.2: новые рефакторинги и инспекции, live templates, улучшения автодополнения кода, и все это — про Swift
Привет, Хабр!
Недавно вышел **AppCode 2016.2**, новый релиз нашей IDE для разработки под iOS/OSX. Под катом много гифок и размышлений об автоматизированных рефакторингах в Objective-C и Swift.
!... | https://habr.com/ru/post/306738/ | null | ru | null |
# Глубокое обучение при помощи Spark и Hadoop: знакомство с Deeplearning4j
Здравствуйте, уважаемые читатели!
Мы вполне убедились в мегапопулярности глубокого обучения (Deep Learning) на языке Python в нашей целевой аудитории. Теперь предлагаем поговорить о высшей лиге глубокого обучения — то есть, о решении этих за... | https://habr.com/ru/post/344824/ | null | ru | null |
# Cетевое взаимодействие посредством TCP в C# — свой велосипед
Приветствую!
Продолжу серию постов посвященных программированию, на этот раз я хочу поговорить на тему сетевого взаимодействие посредством... | https://habr.com/ru/post/220285/ | null | ru | null |
# Автоматический дымоуловитель для пайки, основанный на Arduino
Автор статьи, перевод которой мы представляем вашему вниманию, хочет рассказать о том, как сделать датчик, основанный на Arduino, который автоматически включает дымоуловитель при извлечении паяльника из держателя.
[
Шифрование дисков предназначено для защиты данных в компьютере от несанкционированного физического доступа. Бытует распространённое заблуждение, что дисковое шифрование с этой задачей действит... | https://habr.com/ru/post/457542/ | null | ru | null |
# Решение задания с pwnable.kr 23 — md5 calculator. Разбираемся со Stack Canary. Подключаем библиотеки C в python

В данной статье решим 23-е задание с сайта [pwnable.kr](https://pwnable.kr/index.php), узнаем, что такое stack ca... | https://habr.com/ru/post/467485/ | null | ru | null |
# Обзор языка функционального программирования Koka
Как-то заглянув на [GitHub](https://github.com/), обнаружил [Koka](https://koka-lang.github.io/koka/doc/index.html) — язык функционального программирования со статической типизацией. Koka разрабатывается с 2012 года [Daan Leijen](https://www.microsoft.com/en-us/resea... | https://habr.com/ru/post/651803/ | null | ru | null |
# Со скрипта на «верфь»
Использование того или иного продукта в проекте - это всегда попытка найти лучшее решение, балансируя между ограниченным бюджетом, возможностями роста практически по любому сценарию и высотой "порога входа". Существует много продуктов, которые связаны с контейнерами, что выбрать подходящий инст... | https://habr.com/ru/post/673014/ | null | ru | null |
# Вызов метода Javascript без его вызова фактически
Иногда мы бываем просто ленивыми. Особенно, когда доходит дело до написания кода. И хоть круглые скобки в вызове функции не приводят к избыточности, иногда все же они могут утомлять, особенно когда javascript-метод... | https://habr.com/ru/post/90432/ | null | ru | null |
# Yii2-advanced: альтернативное размещение папок для нескольких приложений
Хочу поделиться альтернативным рецептом файловой структуры для нескольких приложений в Yii2-advanced, не прибегая к модулям. Внешние отличия, к которым мы придем, выглядят следующим образом:
 *подготовили для вас перевод материала.
>
> Также приглашаем на открытый вебинар по теме* [*«Области видимости и невидимости».*](https://otus.pw/6if... | https://habr.com/ru/post/546158/ | null | ru | null |
# Haskell. Монады. Монадные трансформеры. Игра в типы
*Еще одно введение в монады для совсем совсем начинающих.*
Лучший способ понять монады — это начать их использовать. Нужно забить на монадические законы, теорию категорий, и просто начать писать код.
Написание кода на Haskell похоже на игру, в которой вы дол... | https://habr.com/ru/post/315022/ | null | ru | null |
# Conditional indexing. Оптимизируем процесс полнотекстового поиска

В этой статье я хочу поговорить про интеграцию Apache Lucene и Hibernate Search. Если быть более точным, то про один из механизмов Hibernate Search, котор... | https://habr.com/ru/post/247897/ | null | ru | null |
# Измерение тока в домашней сети
Существует целый класс устройств под названием Ethernet Relay, которые позволяют удаленно управлять подключенной нагрузкой через сеть. Большинство из них достаточно дорогие – ближе к 100 долл., и заведомо уступают по цене и по гибкости настройки связке, скажем, Raspberry Pi + [PiFace](... | https://habr.com/ru/post/212459/ | null | ru | null |
# Разработка на Django под Windows с помощью Docker-machine
В этой статье я расскажу как я решил проблему настройки окружения для разработки на Django под Windows.
Используется следующая связка:
1) Docker-machine
2) PyChar... | https://habr.com/ru/post/282099/ | null | ru | null |
# Android: Вращаем на все четыре стороны AndEngine
Однажды мне пришлось решать задачу — запускать четыре разные игры написанные на andengine в зависимости от ориентации экрана. Обычные положения — landscape и portrait вопросов не вызывали. Вопросы возникли для остальных положений — противоположных для указанных. Четыр... | https://habr.com/ru/post/124845/ | null | ru | null |
# SoC: пишем реализацию framebuffer для контроллера в FPGA

Приветствую!
[В прошлый раз](http://habrahabr.ru/company/metrotek/blog/248145/) мы остановились на том, что подняли DMA в FPGA.
Сегодня мы реализуем в FPGA п... | https://habr.com/ru/post/263571/ | null | ru | null |
# Создание REST API с Node.js и базой данных Oracle. Часть 5
**Часть 5. Создание REST API: разбиение на страницы, сортировка и фильтрация вручную**
В [предыдущей статье](https://habr.com/ru/post/473560/) вы завершили построение базовой функциональности API CRUD.
И теперь, когда на маршруте сотрудников выдается з... | https://habr.com/ru/post/473652/ | null | ru | null |
# Игра для самых маленьких — простая идея, которую не стыдно включить в резюме
#### Предыстория
Мой сын, как, наверное, все дети программистов, получил свою первую клавиатуру ещё когда не умел сидеть. Сейчас ему чуть меньше года, но он уже понимает разницу между «игрушечной» и «настоящей» (папиной) клавиатурой — если... | https://habr.com/ru/post/264029/ | null | ru | null |
# Решение задачи кластеризации методом градиентного спуска
Привет. В этой статье будет рассмотрен способ [кластеризации данных](http://ru.wikipedia.org/wiki/Кластерный_анализ), используя [метод градиентного спуска](http://r... | https://habr.com/ru/post/188638/ | null | ru | null |
# Итак, вы хотите оптимизировать gRPC. Часть 1
Часто возникает вопрос о том, как ускорить gRPC. gRPC позволяет реализовать высокопроизводительный RPC, но не всегда понятно как достичь этого быстродействия. И ... | https://habr.com/ru/post/546142/ | null | ru | null |
# «Выстрелить и забыть» в Cats Effect
Последнее время меня часто спрашивают о паттерне "fire-and-forget": как его применить в Cats Effect и какие потенциальные проблемы могут возникнуть. Поэтому я решил напис... | https://habr.com/ru/post/589297/ | null | ru | null |
# Alljoyn: взгляд embedded разработчика. Часть 3: Портируем на МК SAMD21
В [предыдущих статьях](https://habrahabr.ru/company/rainbow/blog/273859/) мы разбирались с основами Alljoyn и средствами, помогающими отладке. Пришло время писать код для микроконтроллера. Кратко напомню архитектуру LSF (Lighting Software Framewo... | https://habr.com/ru/post/278363/ | null | ru | null |
# Создаем TimePicker аналогичный стандартному в Harmattan
Этот пост участвует в конкурсе „[Умные телефоны за умные посты](http://habrahabr.ru/company/Nokia/blog/132522/)“
](http://habrahabr.ru/company/intersystems/blog/268767/)Введение
--------
Итак, вы разработали своё приложение на тех... | https://habr.com/ru/post/268767/ | null | ru | null |
# Простая программа на Python для гиперболической аппроксимации статистических данных
Зачем это нужно
---------------
Законы Зипфа оописывают закономерности частотного распределения слов в тексте на любом естественном языке[1]. Эти законы кроме лингвистики применяться также в экономике [2]. Для аппроксимации статисти... | https://habr.com/ru/post/322954/ | null | ru | null |
# Выборка из обновляемых материализованных представлений в PostgreSQL 9.3

Здравствуйте, хабрачеловеки! Вы, вероятно, уже пощупали [материализованные представления](http://www.postgresql.org/docs/9.3/static... | https://habr.com/ru/post/209952/ | null | ru | null |
# Браузеры и app specific security mitigation. Часть 2. Internet Explorer и Edge
Internet Explorer & Edge
------------------------
Целью данной статьи является обзор специфичных, интегрированных в браузеры Internet Explorer и Edge, механизмов защиты от эксплойтов.
Мы решили объединить обзор механизмов безопасности I... | https://habr.com/ru/post/311616/ | null | ru | null |
# Как проходит интервью QA-инженеров в Тинькофф
Я Алексей Лапаев, руководитель команды обеспечения качества мобильного приложения Тинькофф и организатор гильдии интервьюеров веб-стрима найма QA. Расскажу, как... | https://habr.com/ru/post/686996/ | null | ru | null |
# IP-адрес удостоверяющего центра Digicert внесен в реестр запрещенных сайтов
29 сентября Роскомнадзор, следуя решению Октябрьского районного суда г. Ставрополя от 2013 года, внес IP-адрес 93.184.220.29 в реестр запрещенных сайтов. Данное решение суда обязывает заблокировать сайты и мобильные приложения некоторых букм... | https://habr.com/ru/post/357196/ | null | ru | null |
# Стартап с другой планеты
Привет, Хабр! Мы стартап Deep.Foundation, и сегодня мы официально публикуем альфа-версию своей портальной пушки Deep.Case!
Что же мы такое создали?
Мы создали универсальную мультипарадигменную архитектуру, поставляемую в качестве кроссплатформенного приложения, которую можно описать так: д... | https://habr.com/ru/post/656879/ | null | ru | null |
# Курс «Языки веб-программирования» (на основе Ruby) от МГТУ им. Н. Э. Баумана на канале Технострим

В этой статье мы расскажем о [курсе «Язы... | https://habr.com/ru/post/419765/ | null | ru | null |
# Серьезная уязвимость прокси-сервера Squid позволяет «отравить кэш»
[](https://habrahabr.ru/company/pt/blog/283028/)
Цзянь-Цзюнь Чэнь (Jianjun Chen) — аспирант китайского Университета Цинхуа — обнаружил [опасную уязвимость]... | https://habr.com/ru/post/283028/ | null | ru | null |
# Сервер дома — AMD, Debian x64, Bind9, Apache 2, PHP5, MySQL5, Trac, Subversion и море удовольствия
Шило в известном месте всё никак не даёт мне покоя.
И решил я поэкспериментировать с установкой сервера дома.
**Итак, дано:**
1. Домашний интернет с внешним ip на роутере, канал туда/обратно — 8 мбит, провайде... | https://habr.com/ru/post/45921/ | null | ru | null |
# Без А/B результат XЗ, или Как построить высоконагруженную платформу А/B-тестов
Один из важных вопросов как в нашей жизни, так и в бизнесе, и в IT — вопрос эффективности. Эффективно ли мы планируем наше время, те ли задачи решает бизнес, тот ли код мы оптимизируем? Чтобы ответить на эти вопросы, **результат** должен ... | https://habr.com/ru/post/689052/ | null | ru | null |
# TextView и Spannable: выделение частей слова

**Привет, Хабрамир!** Меня зовут Оксана и я Android-разработчик в небольшой, но очень классной команде [Trinity Digital](https://www.facebook.com/trinitydigitalrus/).
Сегодня я буду расс... | https://habr.com/ru/post/340232/ | null | ru | null |
# MODx Revo, настройка авторизации Login. Базовая установка
Данная статья в большей части является переводом урока с [официального rtfm](http://rtfm.modx.com/display/ADDON/Login.Basic+Setup "официального rtfm"), а именно компонента «Login», но с вставками переводчика. На лучший перевод не иду, но суть в итоге должна б... | https://habr.com/ru/post/132743/ | null | ru | null |
# Открытый инструмент для аналитики бизнес-процессов и Process Mining’а
В предыдущих хабрапостах мы поделились open source инструментом [для сравнительного анализа метагеномных данных](https://habr.com/ru/company/spbifmo/blog/568338/) и рассказали об [открытых проектах](https://habr.com/ru/company/spbifmo/blog/572186/... | https://habr.com/ru/post/577470/ | null | ru | null |
# Увеличиваем потенциал брошенного производителем сетевого хранилища
В процессе эксплуатации того или иного умного устройства пользователи зачастую сталкиваются с рядом проблем, которые решить может только производитель. Решение, казалось бы, рядом: сообщаем по официальным каналам о найденном баге, производитель испра... | https://habr.com/ru/post/327076/ | null | ru | null |
# Как накрутить рейтинг на Хабре и уйти незамеченным

Как-то пятничным вечером я сидел за домашним компом с чашкой черного чая, писал статью и думал о жизни. Работа спорилась, но голова начинала к тому времени заметно притормажи... | https://habr.com/ru/post/332296/ | null | ru | null |
# Как сделать JSON Vulnerability Protection в ответе сервера под Yii2
В AngularJS [реализована](https://docs.angularjs.org/api/ng/service/$http#json-vulnerability-protection) поддержка JSON Vulnerability Protection, направленная на то, чтобы противодействовать ситуациям, когда злоумышленник может, при определённых усл... | https://habr.com/ru/post/256213/ | null | ru | null |
# Верстка интернет-магазина: список товаров
Требования к верстке каталогов интернет-магазинов имеют свойство повторяться из проекта в проект. Поэтому у меня выработался набор стандартных приемов, которыми я хочу поделиться ... | https://habr.com/ru/post/319280/ | null | ru | null |
# Vim-крокет
*Переводчик из меня совершенно никакой, но я просто не мог пройти мимо этой статьи, ибо она излучает волны крутости, а концентрация дзена в ней зашкаливает. Поэтому welcome.*
Введение
--------
Недавно я обнаружил интересную игру под названием [VimGolf](http://vimgolf.com/). Цель этой игры заключается ... | https://habr.com/ru/post/211108/ | null | ru | null |
# Пример создания WCF-сервиса, работающего внутри службы Windows
Windows Communication Foundation – программная платформа от Microsoft для создания, настройки и развертывания распределенных сетевых сервисов. WCF-runtime и его пространство имен System.ServiceModel, представляющее его главный программный интерфейс, это ... | https://habr.com/ru/post/331952/ | null | ru | null |
# Аллокаторы памяти
Всем привет! Не так давно, после очень плотного изучения аллокаторов и алгоритмов распределения памяти, а также в последующем применении их на практике мне в голову пришла идея написать статью, в которой будет максимально подробно рассказано о них. Считаю, что данная тема будет достаточно востребов... | https://habr.com/ru/post/505632/ | null | ru | null |
# Single Responsibility Principle. Не такой простой, как кажется
 Single responsibility principle, он же принцип единой ответственности,
он же принцип единой изменчивости — крайне скользкий для пониман... | https://habr.com/ru/post/454290/ | null | ru | null |
# Статический анализ и property-based тестирование: вместе мы сила
 Как известно, баги есть во всех программах. Есть множество способов борьбы с ними: юнит-тесты, ревью, статический анализ, динамический анализ, дымовое тестирование и та... | https://habr.com/ru/post/347676/ | null | ru | null |
# Клавиатурный шпион на Arduino
#### Предисловие
Стоит сказать, что область применение данного устройства не так уж и велика. Для работы это мониторинг, контроль за рабочим временем, защита от утечки информации и, наверное, всё.
В быту эта вещь может хорошо облегчить жизнь. Например, нажали определённое сочетание ... | https://habr.com/ru/post/388335/ | null | ru | null |
# ConstraintLayout 101 и новый редактор компоновок в Android Studio
Данная статья является переводом поста из блога Android-разработчицы из ЮАР Ребекки Фрэнкс [riggaroo.co.za](http://riggaroo.co.za/), подготовленным Android-отделом компании [Лайв Тайпинг](http://livetyping.com). Оригинальная статья доступна [здесь](ht... | https://habr.com/ru/post/302106/ | null | ru | null |
# Google Chrome перестал доверять сертификатам WoSign и StartCom

Как [сообщалось ранее](https://habr.com/post/398161/) Google Chrome заблокировал сертификаты WoSign и StartCom.
Сегодня вышла новая версия Google Chrome 56, и ... | https://habr.com/ru/post/400953/ | null | ru | null |
# Микро автоматизация банка [обмен данными между банком и ИФНС в исполнение 440-п ЦБ РФ]
### Или рассказ о том, что «мал золотник, да дорог»
**Этот пост Вам интересен, если:**
* Вы сотрудник Банка;
* Вы работаете в ИТ подразделения Банка;
* Задача, о которой пойдет речь, еще не автоматизирована;
* Банк обслуживает ф... | https://habr.com/ru/post/694866/ | null | ru | null |
# Использование OpenFeint в Unity3d
OpenFeint — достаточно популярная социальная сеть для игроков. Социальная составляющая всегда важна для казуальных (да и не только) игр, ведь она добавляет интерес к игре со стороны пользователей, да и способствует распространению.
Итак, наша задача на текущий момент — **встроить... | https://habr.com/ru/post/127909/ | null | ru | null |
# Один из способов поиска неэкранированных символов с помощью новых средств JavaScript
### 1. C чего всё началось
Недавно у меня возникла необходимость написать очередную утилиту, обрабатывающую текстовый файл в формате, похожем на упрощённый BBCode, а именно в формате исходников для словарей ABBYY Lingvo — DSL (Dict... | https://habr.com/ru/post/282275/ | null | ru | null |
# Пишем платежный метод для Magento на примере Robokassa
Добрый день, Хабровчане!
Сегодня я хочу поделится опытом написания платежного метода в Magento. Платежный метод как пример был выбран не случайно, а как одна из самых важных и в тоже время сильно зависящих от страны пользователя частей интернет магазина. А та... | https://habr.com/ru/post/127916/ | null | ru | null |
# Оптимизация оплаты Webmoney посредством Paymer
 Выкладываю статью о webmoney и паймере [из своего блога.](http://galkin.in.ua) На днях пополнял на очень популярном сайте свой баланс посредством webmoney. Было крайне удивительно обнаружить, что администрация сайта остави... | https://habr.com/ru/post/78688/ | null | ru | null |
# Цифровая модель рельефа с использованием SRTM данных
При создании картографического сервера у меня возникла необходимость в создании высотных профилей местности. В качестве данных для цифровой модели рельефа я решил использовать SRTM (NASA Shuttle Radar Topography Mission). Хотя есть и [альтернативные наборы данных]... | https://habr.com/ru/post/161201/ | null | ru | null |
# Настоящий многопоточный веб-сервер на ассемблере под Linux
Добрый день, хабр!
Сегодня я вам расскажу как написать свой настоящий веб-сервер на асме.
Сразу скажу, что мы не будем использовать дополнительные библиотеки типа libc. А будем пользоваться тем, что предоставляет нам ядро.
Уже только ленивый не писа... | https://habr.com/ru/post/188114/ | null | ru | null |
# Про создание платформера на Unity. Часть третья, долгожданная
Привет, Хабр!
Холодная питерская осень штабелями укладывает людей в кровать с температурой и прочими прелестями той части вселенной, которая отвечает за болезни. Но всему плохому, к счастью, приходит конец. Поэтому, как вы поняли из вступления, сегодня... | https://habr.com/ru/post/238071/ | null | ru | null |
# GStreamer: кодеки с привкусом Linux
Вы когда-нибудь задумывались о том как работают Gnome-плееры, такие как Totem, Rhythmbox или Banshee? Наверное каждый из вас в новоустановленной Ubuntu, при попытке проиграть AVI-шку видел сообщение о необходимости установить дополнительный пакет gst-ffmpeg или gst-plugins-ugly. П... | https://habr.com/ru/post/127023/ | null | ru | null |
# Как нарисовать графики и диаграммы в Atlassian Confluence

[Atlassian](https://www.atlassian.com/) [Confluence](https://www.atlassian.com/software/confluence) — мощное решение для развертывания Enterprise Wiki в орга... | https://habr.com/ru/post/273353/ | null | ru | null |
# Golang + Phaser3 = MMORPG — Клиент и Сервер
В прошлой статье мы сделали с вами заготовку, так сказать основу, на чем будет создаваться наша вселенная, визуализация с помощью консоли может быть и выглядит хорошо, но текстовые символы ... | https://habr.com/ru/post/488794/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.