
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# «Как по нотам!» или Машинное обучение (Data science) на C# с помощью Accord.NET Framework
Вчера после публикации статьи [zarytskiy](https://habrahabr.ru/users/zarytskiy/) «[Какой язык программирования выбрать для работы с данными?](https://habrahabr.ru/post/337330/)» я понял, что .net в целом и C# в частности не рас... | https://habr.com/ru/post/337438/ | null | ru | null |
# Кроссбраузерная одноцветная полупрозрачность
В этой статье я рассмотрю метод создания блоков с одноцветным полупрозрачным фоном.
Например, таких:

Сразу оговорюсь, что я не буду использовать opacity и абсолютное позиционирование, чтобы разм... | https://habr.com/ru/post/50996/ | null | ru | null |
# Определяем ключевые товары с помощью линейной регрессии
Ритейл, все-таки, штука интересная. Особенно, если разрабатываешь сервис для его аналитики. Каждый поход в магазин превращается в мини-исследование. Идешь себе вдоль полок и думаешь:
“С чем лучше сосиски коррелируются с кетчупом или мариноваными огурцами? А ... | https://habr.com/ru/post/264333/ | null | ru | null |
# Контроль диапазонов целых чисел в FindBugs

[FindBugs](http://findbugs.sourceforge.net/) — это статический анализатор кода для Java с открытым исходным кодом (под [LGPL](http://www.gnu.org/licenses/lgpl.h... | https://habr.com/ru/post/240121/ | null | ru | null |
# Yii 2.0.7
Вышла версия 2.0.7 PHP фреймворка Yii. Как установить или обновиться описано на странице <http://www.yiiframework.com/download/>.
Данная версия содержит [более сотни улучшений и исправлений](https://github.com/yiisoft/yii2/blob/2.0.7/framework/CHANGELOG.md), уточнения документации и её переводы.
Для ... | https://habr.com/ru/post/277201/ | null | ru | null |
# Что нового в CakePHP 3.0.0?
Здравствуйте, уважаемые читатели. В данной статье хотелось бы написать о новой версии [CakePHP](http://www.cakephp.org/) и возродить интерес к этому замечательному PHP фреймворку. Последняя заметка в блоге о CakePHP датирована почти годом назад и многие могли подумать, что фреймворк прекр... | https://habr.com/ru/post/239905/ | null | ru | null |
# Правильный анонс к тексту или закрываем незакрытые теги
После добавления статьи и вывода списка статей на главной странице своего самописного блога возник вопрос об анонсе. Если обрезать определенное количество символов, то обрезаются и хтмл теги добавляемые текстовым редактором. От такого «анонсирования» верстка по... | https://habr.com/ru/post/145196/ | null | ru | null |
# Изучаю Scala: Часть 2 — Todo лист с возможностью загрузки картинок

Привет, Хабр! Следующий этап изучения нового языка это старый добрый todo list c картинками. Чтобы научится работе с базой данных и файловой системой. Работе со ст... | https://habr.com/ru/post/508560/ | null | ru | null |
# Автоматическая проверка орфографии, модель Noisy Channel
 Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решен... | https://habr.com/ru/post/202908/ | null | ru | null |
# Унификация и поиск с возвратом на C#
Эта статья является ответом на статью [«Задача Эйнштейна на Прологе»](http://habrahabr.ru/post/122142/). В ней автор пишет, что Пролог очень хорошо подходит для решения этой задачи и что суммарное количество строк почти совпадает с условиями задачи. Здесь я хочу показать, что на ... | https://habr.com/ru/post/248847/ | null | ru | null |
# Топ 10 ошибок в проектах Java за 2020 год

Новый год неумолимо приближается — а, значит, настало время подводить итоги. Продолжая традицию, мы прошлись по нашим статьям о проверках Java-проектов... | https://habr.com/ru/post/535380/ | null | ru | null |
# Маршрутизация в Mac OS при VPN подключении
Появилась как-то задача подключатся по VPN к рабочей сети, чтобы иметь доступ к внутренним ресурсам.
Средствами Мака это можно сделать создав VPN подключение и 2 варианта:
1. поставить галочку «Слать весь трафик через VPN подключение»
2. статически прописать статич... | https://habr.com/ru/post/88946/ | null | ru | null |
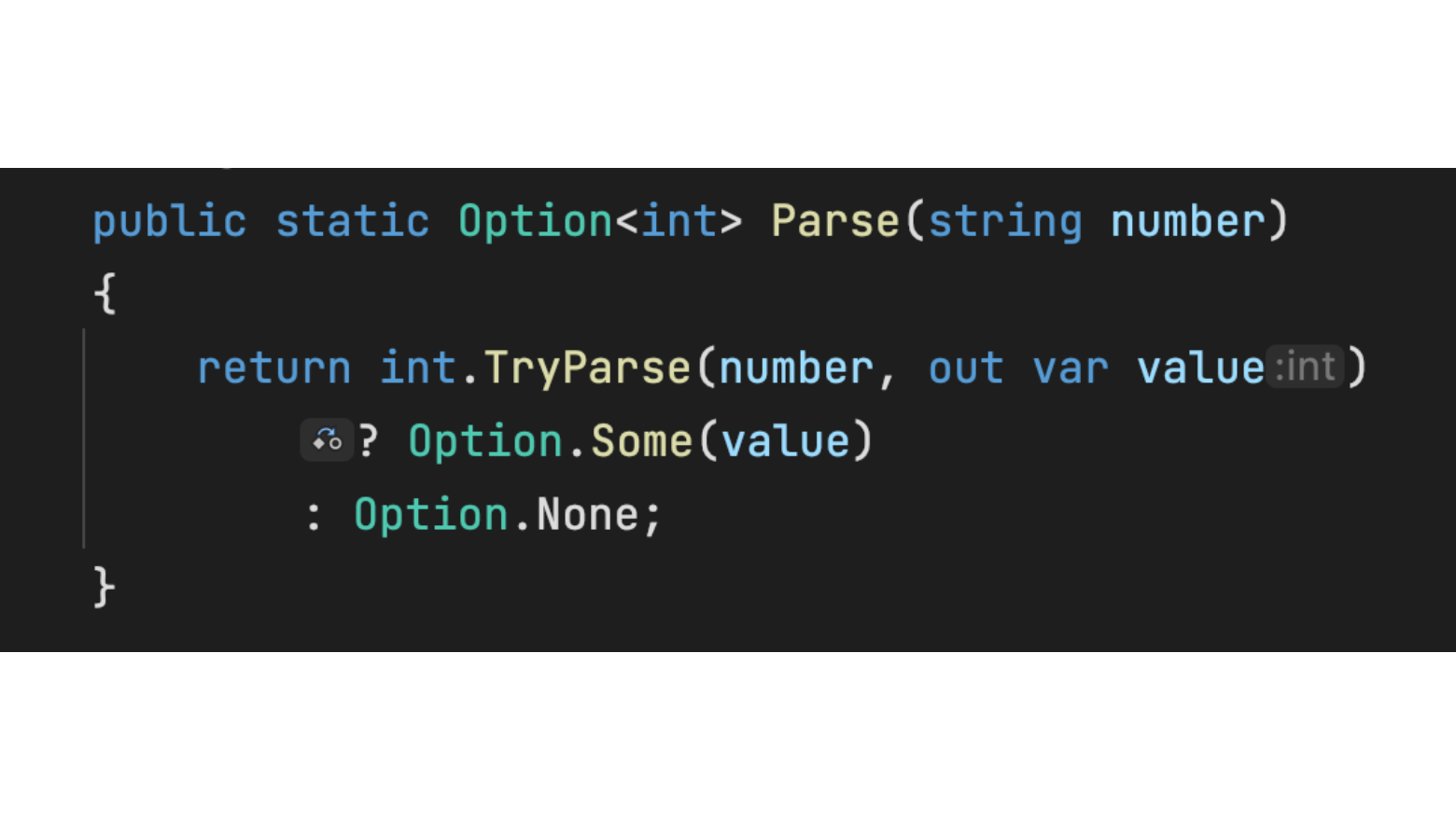
# Simulating Return Type Inference in C#
Мне по-настоящему нравится больше чего-либо в разработке ПО делать фреймворки, позволяющие другим разработчикам создавать что-то крутое. Иногда, в погоне за идеальным ... | https://habr.com/ru/post/673448/ | null | ru | null |
# Продолжаем парсить RSS теперь уже kinozal'a используя grep, wget/curl

В моем [предыдущем посте](http://labinskiy.habrahabr.ru/blog/87042/) про автоматизацию загрузок новых эпизодов с **RSS** ленты [L... | https://habr.com/ru/post/87166/ | null | ru | null |
# Полнотекстовый поиск на App Engine уже сейчас
Все конечно с нетерпением ждут, когда в [App Engine](http://appengine.google.com) появится полнотекстовый поиск, но пока его нет даже в [roadmap](http://code.google.com/appengine/docs/roadmap.html). Тем не менее, для GAE/Java полнотекстовый поиск можно прикрутить самосто... | https://habr.com/ru/post/90223/ | null | ru | null |
# HTML 5: Microdata

HTML 5 продолжает удивлять нас своими возможностями. Вот еще одна.
Одной из функций, которые мы добавили в HTML5 является возможность включить аннотации, чтобы люди могли получить данные простым и определенным способом. Это означ... | https://habr.com/ru/post/66043/ | null | ru | null |
# Стратегии в Moxy (Часть 2)
В [части 1](https://habrahabr.ru/company/redmadrobot/blog/325816/) мы разобрались, для чего нужны стратегии в [Moxy](https://github.com/Arello-Mobile/Moxy) и в каких случаях уместно применять каждую из н... | https://habr.com/ru/post/341108/ | null | ru | null |
# Управление правами доступа в Expressjs при помощи CASL

В современных приложениях, которые поддерживают аутентификацию, мы часто хотим изменить то, что видимо для пользователя, в зависимости от его роли. Например, гостевой пользова... | https://habr.com/ru/post/414951/ | null | ru | null |
# WarCraft III / Dota кратко о создании чита
Добрый день. Прошлая заметка о [принципе создания чита](http://habrahabr.ru/post/143178/), заинтересовала многих. Руководствуясь этим я предположил, что кому-то может оказаться интересным другой способ создания подобных программ. Перед тем как начать скажу: «Все ниже описан... | https://habr.com/ru/post/144453/ | null | ru | null |
# Хочешь вкусного пива, Arduino в помощь
Данная публикация навеяна другой. Она называется [«Контроллер для домашней пивоварни Mega Brewery. Part I»](http://habrahabr.ru/post/122886/) и опубликована за авторством [megadenis](http://habrahabr.ru/users/megadenis/).
С чего все началось?
--------------------
Я студент ... | https://habr.com/ru/post/241463/ | null | ru | null |
# Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 2
MIPSfpga микропроцессор MIPS32 microAptiv описаный на языке Verilog для образовательных целей фирмы Imagination, который имеет кэш-память и блок управления памятью. Код процессора доступен пользователю ([инструкция по скачиванию](http://... | https://habr.com/ru/post/329852/ | null | ru | null |
# Простота и cложность примитивов или как определить ненужный препроцессинг для нейронной сети
Это третья статья по анализу и изучению эллипсов, треугольников и других геометрических фигур.
Предыдущие статьи вызвали у читателей несколько очень интересных вопросов, в частности о сложности или простоте тех или иных о... | https://habr.com/ru/post/439122/ | null | ru | null |
# Java HotSpot JIT компилятор — устройство, мониторинг и настройка (часть 2)
В [предыдущей](https://habr.com/ru/post/536288/) статье мы рассмотрели устройство JIT компилятора и способы мониторинга его работы. В этой статье мы рассмотрим счетчики, которые JVM использует для принятия решения о необходимости компиляции к... | https://habr.com/ru/post/536514/ | null | ru | null |
# Вопрос к почтеннейшей публике
`javascript:alert(0=="")`
я отказываюсь в это верить)). но хочу про это поговорить.
Почему такой результат?
upd. гранмерси, в первом комментарии объяснили. %) вопрос снят. %) | https://habr.com/ru/post/47894/ | null | ru | null |
# Потокобезопасные события в C# или Джон Скит против Джеффри Рихтера

Готовился я как-то к собеседованию по C# и среди прочего нашел вопрос примерно следующего содержания:
> «Как организовать потокобезопасный вызов событ... | https://habr.com/ru/post/240385/ | null | ru | null |
# Cucumber и BDD. Пишем UI-автотесты на iOS
Предисловие
-----------
Привет, Хабр! В данной статье-мануале я хочу рассказать о базовых функциях такого фреймворка как Cucumber и его применение для создания UI-автотестов на мобильных iOS устройствах.
Я ставлю перед собой задачу сделать описание максимально простым и по... | https://habr.com/ru/post/522544/ | null | ru | null |
# Prototype, proto и оператор new
В этой статье я кратко в примерах объясню что такое свойства \_\_proto\_\_, prototype и работу оператора new в JavaScript.
#### Свойство \_\_proto\_\_
Абсолютно любой объект в Jav... | https://habr.com/ru/post/140810/ | null | ru | null |
# Вам больше ничего не принадлежит
##### Предисловие переводчика
После запуска Google Drive по интернету прокатилась очередная волна недовольства условиями использования сервисов Google. На самом деле проблема TOS присуща практически всему современному интернету. Мне показалась интересной статья, пусть не бесспорная ... | https://habr.com/ru/post/143111/ | null | ru | null |
# The Better Parts: доклад Дугласа Крокфорда о JavaScript и языках программирования будущего с конференции .concat() 2015
Кто знает о JS больше, чем один из его «отцов»? На [HolyJS 2017 Piter](https://holyjs-piter.ru) приедет легендарный Дуглас Крокфорд, создатель JSON и автор множества инструментов JavaScript. В пред... | https://habr.com/ru/post/327320/ | null | ru | null |
# Samsung удалённо блокирует свои «серые» Smart TV в России. UPD — заявление Samsung
> Никогда и ничего фирмы Самсунг я больше в жизни не куплю!!! И буду отговаривать всех кто будет спрашивать совет в покупке техники!
*Типичный гнев анонимуса на заданную тему*

Я хочу рассказать о фиче IAM ролей для серверов в AWS. Роль — это совокупность прав доступа, которые можно применить к серверу. Можем рассмотреть на определённом примере — дать д... | https://habr.com/ru/post/160755/ | null | ru | null |
# Мои грабли: из грязи в князи
Предыстория
-----------
Я работаю фронтенд разработчиком уже на протяжение одного года. На моём первом проекте был «вражеский» бэкенд. Бывает так, что это не составляет больших проблем, когда налажена коммуникация.
Но в нашем случае было не так.
Мы разрабатывали код, который опирался ... | https://habr.com/ru/post/453502/ | null | ru | null |
# Spring Cloud Contract. Что такое контрактное тестирование и с чем его едят
Тестирование является неотъемлемой частью процесса разработки ПО. Согласно [пирамиде тестирования Майка Коэна](https://martinfowler... | https://habr.com/ru/post/570544/ | null | ru | null |
# Читаем бинарные файлы iOS-приложений
На хабре есть много статей о том, как работает рантайм Swift/Objective-C, но для еще более полного понимания того, что происходит под капотом, полезно залезть на самый низкий уровень и посмотреть, как код iOS приложений укладывается в бинарные файлы. Кроме того, безусловно, под к... | https://habr.com/ru/post/323346/ | null | ru | null |
# Анализ коммитов и pull request'ов в Travis CI, Buddy и AppVeyor с помощью PVS-Studio

В анализаторе PVS-Studio для языков С и C++ на Linux и macOS, начиная с версии 7.04, появилась тестовая возм... | https://habr.com/ru/post/470984/ | null | ru | null |
# Как я изучаю фреймворк Spring — часть 2 (помощь начинающим — дело рук самих начинающих)

Добрый день!
Я вдохновился приглашением продолжить [публикацию,](https://habr.com/post/420901) поэтому продолжаю.
В этот раз мы рассм... | https://habr.com/ru/post/421093/ | null | ru | null |
# Проверка
`Красный?` | https://habr.com/ru/post/10780/ | null | ru | null |
# Отправка SMS с 3G/GSM модема
Привет Хабр. В данной статье я бы хотел поделиться опытом работы с GSM модемом, а точнее опытом отправки SMS сообщений. Ниже будет описана реализация программы на Delphi для отправки SMS сообщений, а так же чтение и удаление входящих/исходящих сообщений с модема. В моём случае это был мо... | https://habr.com/ru/post/133085/ | null | ru | null |
# Добавляем ссылки на страницы сайта в CKEDITOR 4

Доброго времени суток, %habrauser%!
Очень часто приходится писать мини CMS для разных проектов. Обосновано это, в большей степени, человеческой ленью. Поэтому в такие прое... | https://habr.com/ru/post/183868/ | null | ru | null |
# Автоэнкодеры в Keras, часть 6: VAE + GAN
### Содержание
* Часть 1: [Введение](https://habrahabr.ru/post/331382/)
* Часть 2: [*Manifold learning* и скрытые (*latent*) переменные](https://habrahabr.ru/post/331500/)
* Часть 3: [Вариационные автоэнкодеры (*VAE*)](https://habrahabr.ru/post/331552/)
* Часть 4: [*Condit... | https://habr.com/ru/post/332074/ | null | ru | null |
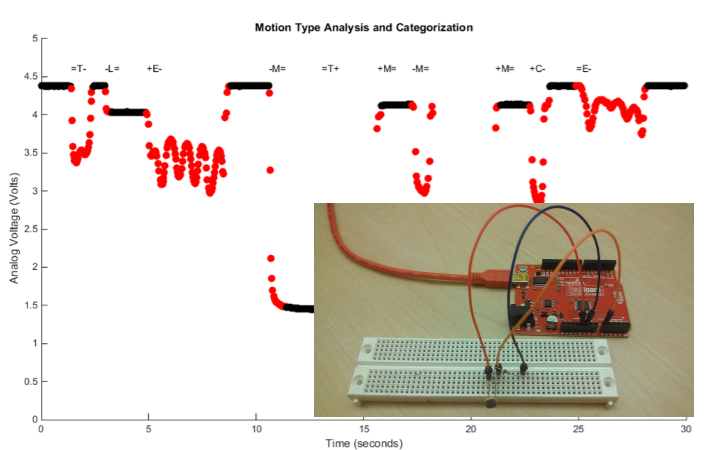
# Создаем комнатный детектор движения на Arduino и MATLAB
В этом примере будет создан простой **детектор движения**, на базе **фоторезистора** и **Arduino**. Управляется при помощи Arduino Support Package для **MATLAB**.
[](ht... | https://habr.com/ru/post/262259/ | null | ru | null |
# Получаем информацию о рабочем месте пользователя

0. Предисловие
--------------
Все началось с очередного звонка пользователя, который с гордостью сообщил сообщил: — „Всё сломалось“, и с моих „потуг“ удаленно найти PC, ... | https://habr.com/ru/post/328914/ | null | ru | null |
# Альтернативный оркестратор nomad на десктопе
В настоящее время оркестрация контейнеров ассоциируется в первую очередь с kubernetes. Но это не единственный возможный выбор. Есть и альтернативные средства оркестрации, например nomad, разработчик HashiCorp (хорошо известный как разработчик средства виртуализации Vagran... | https://habr.com/ru/post/440956/ | null | ru | null |
# Изучаем Docker, часть 1: основы
Технологии контейнеризации приложений нашли широкое применение в сферах разработки ПО и анализа данных. Эти технологии помогают сделать приложения более безопасными, облегчают их развёртывание и улучшают возможности по их масштабированию. Рост и развитие технологий контейнеризации мож... | https://habr.com/ru/post/438796/ | null | ru | null |
# Joomla 1.5 и ЧПУ
Для каждого сайта очень важно ЧПУ (Человекопонятные УРЛ), для того, чтоб его очень «любили» поисковые системы и для того, чтоб можно ключевое слово написать в ссылку.
Для Joomla 1.5 существует очень много компонент для создания ЧПУ. Эти компоненты работают, записывая в БД все ссылки. Это совсем ... | https://habr.com/ru/post/113455/ | null | ru | null |
# Собственный движок WebGL. Статья №2. Матрица
В продолжении [статьи](http://habrahabr.ru/post/227201/).
#### Матрица
Когда только начал разрабатывать матрицу, даже не предполагал — на сколько она в дальнейшем нам упростит жизнь. У матрицы много свойств, но в нашей задаче я бы их все свел к одному — «отделение мух... | https://habr.com/ru/post/227285/ | null | ru | null |
# Python: неочевидное в очевидном
Введение
--------
Изучение любого языка - очень долгий процесс, в ходе которого могут возникать ситуации, когда очевидные с виду вещи ведут себя странно. Даже спустя много лет изучения языка не все и не всегда могут с уверенностью сказать “да, я знаю этот на 100%, несите следующий”.
... | https://habr.com/ru/post/564804/ | null | ru | null |
# Как делаются Z-Wave устройства
В этой статье мы расскажем, как создаются устройства Z-Wave. С точки зрения схемотехники и программирования разработка Z-Wave устройства не сильно отличается от разработки устройства на базе Arduino, AVR или PIC. Однако есть в Z-Wave свои нюансы. О них-то и пойдёт речь под катом.
Поскольку утечки данных случаются в наши дни все чаще, крайне важно делать приложения максимально защищенными. Одной из основных областей,... | https://habr.com/ru/post/696164/ | null | ru | null |
# X-сервер для Android
Австралийский разработчик Мэтт Квэн (Matt Kwan) создал [X-сервер для Android](http://my20percent.wordpress.com/about/) (на Java), который уже можно [скачать в Android Market](https://play.google.com/store/apps/details?id=au.com.darkside.XServer), исходный код также [опубликован на Google Code](h... | https://habr.com/ru/post/139705/ | null | ru | null |
# Перевод: Настройка ваших приложений и игр для устройств с длинным экраном
Привет, Хабр! Представляю вашему вниманию перевод статьи [Tuning your apps and games for long screen devices](https://android-developers.googleblog.com/2017/12/tuning-your-apps-and-games-for-long.html) автора Fred Chung.
В последние месяцы ... | https://habr.com/ru/post/345438/ | null | ru | null |
# Sberbank Online iOS testing
Theory of testing is usually differs from practice. Today we want to talk about our practical experience in testing [application](https://itunes.apple.com/ru/app/%D1%81%D0%B1%D0%B5%D1%80%D0%B1%D0%B0%D0%BD%D0%BA-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD/id492224193?mt=8)'s code which is used by... | https://habr.com/ru/post/511384/ | null | en | null |
# Итоги: что сильнее – ассемблер или Хабраэффект?
 Отшумели страсти после моей [первой статьи](https://habrahabr.ru/post/318916/) на Хабре.
Тема была о веб сайте на ассемблере, так что нет ничего удивительного в количестве ко... | https://habr.com/ru/post/319028/ | null | ru | null |
# Книга «React: современные шаблоны для разработки приложений 2-е издание»
[](https://habr.com/ru/company/piter/blog/577862/) Привет, Хаброжители! Хотите создавать эффективные приложения с помощью React? Тогда эта книга написана ... | https://habr.com/ru/post/577862/ | null | ru | null |
# Типограф Евгения Муравьева для TinyMCE
В топике [Новая версия веб-типографа Студии Муравьёва](http://habrahabr.ru/blogs/typography/67010/) был представлен замечательный типограф.
> Типограф обрабатывает тексты не только по классическим законам (неразрывные пробелы, правильные кавычки, свисающая пунктуация и др.),... | https://habr.com/ru/post/67387/ | null | ru | null |
# Уязвимость старой Ubuntu через аудиофайл, проигрываемый эмуляцией процессора 1975 года

Уязвимость и ошибка логического разделения поселились в плеере [gstreamer](https://ru.wikipedia.org/wiki/GStreamer) версий 0.10.x для... | https://habr.com/ru/post/315378/ | null | ru | null |
# Время Perl
Perl и CPAN предоставляют множество самых разных инструментов для работы с временем. Традиционный и наиболее известный `DateTime` вызывает столь же традиционные серьёзные нарекания к скорости работы и потребле... | https://habr.com/ru/post/254453/ | null | ru | null |
# Реферер Google Search не передается в теле запроса в iOS 6
Риан Джонс [заметил](http://www.dotcult.com/google-not-sending-any-referer-data-on-ios-default-search), что реферер Google Search не передается в теле запроса, когда пользователи используют Google Search на iOS 6 (последняя версия мобильной ОС от Apple).
... | https://habr.com/ru/post/152549/ | null | ru | null |
# Как изучение Smalltalk может улучшить ваши навыки программиста

Smalltalk обычно воспринимается как старый, умирающий язык – антиквариат из ушедшей эпохи. Нет ничего более далёкого от истины.
Smalltalk по-прежнему очен... | https://habr.com/ru/post/328156/ | null | ru | null |
# Еще есть пользователи windows 9x? Пишем утилиту для чтения NTFS
В последнее время найти пользователей windows 9x стало сложно, но возможно. Но все таки они есть такие. Так же известно что использовать жесткие диски с разделами NTFS штатными средствами операционной системы нельзя. Попробуем исправить это написав прог... | https://habr.com/ru/post/126151/ | null | ru | null |
# Настройка аутентификации в OpenVPN через Active Directory в CentOS 7
Представим что у нас уже есть настроенный OpenVPN, и мы решили сделать двухфакторную аутентификацию, включающую в себя проверку логина, пароля и членства пользователя в группе AD.
Традиционный openvpn-auth-ldap.so не существует в CentOS 7, поэто... | https://habr.com/ru/post/276653/ | null | ru | null |
# MVCC-1. Изоляция
Привет, Хабр! Этой статьей я начинаю серию циклов (или цикл серий? в общем, задумка грандиозная) о внутреннем устройстве PostgreSQL.
Материал будет основан на [учебных курсах](https://postgrespro.ru/education/courses) по администрированию, которые делаем мы с Павлом [pluzanov](https://habr.com/ru... | https://habr.com/ru/post/442804/ | null | ru | null |
# IPython: замена стандартного Python shell
Python shell достаточно удобная вещь для тестирования и изучения возможностей языка, кто-то даже использует его в качестве калькулятора(что между прочим весьма удобно), в этом цикле статей я бы хотел рассказать о IPython — замене стандартного Python shell'а, который предоста... | https://habr.com/ru/post/49685/ | null | ru | null |
# Micropython на GSM+GPS модуле A9G
В этот раз я задумался о том, чтобы спрятать в велосипед GPS-трэкер в качестве меры предосторожности. На рынке есть масса автономных устройств для слежения за автомобилями, грузом, велосипедами, багажом, детьми и животными. Подавляющее большинство из них взаимодействуют с пользовате... | https://habr.com/ru/post/446090/ | null | ru | null |
# Адаптируем RoboVM для компиляции под iOS из Windows/Linux
Прошло полтора года как Microsoft закрыл случайно оказавшийся в корзине с Xamarin-ом RoboVM. Уже и официальный robovm.com канул в лету. Последняя opensource версия 1.8 была форкнута группой MobiVM и поддерживается ~~на искусственном дыхании~~ в рабочем состоя... | https://habr.com/ru/post/345348/ | null | ru | null |
# Наш опыт создания API Gateway
Некоторые компании, в том числе наш заказчик, развивают продукт через партнерскую сеть. Например, крупные интернет-магазины интегрированы со службой доставки — вы заказываете товар и вскоре получаете трекинговый номер посылки. Другой пример — вместе с авиабилетом вы покупаете страховку ... | https://habr.com/ru/post/446438/ | null | ru | null |
# PNG в IE. Ссылки должны работать.
В продолжение [темы о лечении Ослика](http://www.habrahabr.ru/blog/la_france/22751.html).
Столкнулся с проблемой — хотя PNG в фоне слоя заработал, и удалось даже как-то изобразить повторяемость по вертикали, ссылки в div'е не работали в IE.
Небольшой гуглинг на тему вскрыл сле... | https://habr.com/ru/post/14471/ | null | ru | null |
# Стиль WS_EX_LAYERED для дочерних окон в Windows 8
В **Windows** Вы не можете просто так сделать полупрозрачный элемент управления, Вы должны либо рисовать все контролы сами(Qt, FMX) либо использовать [DrawThemeParentBackground](http://msdn.microsoft.com/en-us/library/windows/desktop/bb773289(v=vs.85).aspx), что неми... | https://habr.com/ru/post/247397/ | null | ru | null |
# О добавлении репозиториев в Ubuntu 9.10
Начал читать Linux Format 11-2009 (124), дочитал до статьи «Ubuntu: ставим всё подряд», и очень удивился описанному способу добавления репозиториев.
... | https://habr.com/ru/post/74429/ | null | ru | null |
# Flutter: локализация приложений средствами Android Studio

Про локализацию (интернационализацию) приложений Flutter написано уже достаточно много.
Официальная документация довольно [подробно останавливается на этом вопросе](http... | https://habr.com/ru/post/451556/ | null | ru | null |
# В ядро Linux 5.6 включили VPN WireGuard
Сегодня Линус перенёс к себе ветку net-next с VPN-интерфейсами [WireGuard](https://www.wireguard.com/). Об этом событии [сообщили](https://lists.zx2c4.com/pipermail/wireguard/2020-January/004906.html) в списке рассылки WireGuard.

Вы можете использовать фотографии и другие изображения в виде ресурсов приложения для их отображения в пользовательском интерфейсе. Ваше приложе... | https://habr.com/ru/post/118462/ | null | ru | null |
# Безопасно подписываем Android сборки из Jenkins
Перевод <https://www.detroitlabs.com/blog/2017/05/24/securely-signing-jenkins-android-builds/>

Безопасная подпись Android сборок в Jenkins CI (Continuous Integration, далее просто CI)... | https://habr.com/ru/post/345910/ | null | ru | null |
# Гиперпространство на JavaScript
Хабровчане! С днем космонавтики!

В одном проекте, приуроченном к сегодняшнему празднику дизайнерами была поставлена задача создать имитацию гиперпространства. Немного поразмыслив ре... | https://habr.com/ru/post/176325/ | null | ru | null |
# Как запустить UI-автотесты в любом Chromium-браузере
Привет, Хабр! Меня зовут Кристина Курашова и я отвечаю за качество в [**VK Assistant**](https://tech.mail.ru/product/vk-assistant). Это платформа по созданию диалогового ассистента с использованием NLP-моделей. Его можно интегрировать с любой корпоративной системо... | https://habr.com/ru/post/683992/ | null | ru | null |
# Tango Controls RestServer

Все работы произведены на Linux ([**TangoBox 9.3**](https://s2innovation.sharepoint.com/:f:/s/Developers/EovD2IBwhppAp-ZLXtawQ6gB9F6aXPPs2msr2hgPGTO-FQ?e=Ii3tnr) на основе Ubuntu 18.04), который являе... | https://habr.com/ru/post/554686/ | null | ru | null |
# Факты в puppet
Зачастую мы сталкиваемся с проблемой что стандартных фактов которые поставляются вместе с puppet не всегда хватает. Решение этой проблемы может быть достигнуто путем добавления новых фактов. Вы можете добавлять свои факты, написанные на Ruby, на puppet сервер. Затем сервер, используя синхронизацию пла... | https://habr.com/ru/post/165543/ | null | ru | null |
# Разбираем Теорию Игр с python-библиотеками nashpy и axelrod
Начнём с nashpy
---------------
[git-репозиторий](https://github.com/drvinceknight/Nashpy)
[Документация](https://nashpy.readthedocs.io/en/stable/index.html)
"Камень, ножницы, бумага" - кто из нас не играл в эту игру в детстве? Но вы когда-нибудь задумыв... | https://habr.com/ru/post/713120/ | null | ru | null |
# Transcend WiFi. Пишем клиент Shoot&View; для Windows, Mac и Linux
 На хабре неоднократно [упоминали](http://habrahabr.ru/post/191742/) о карте памяти формата SDHC со встроенным WiFi передатчиком. Купив эту ... | https://habr.com/ru/post/216039/ | null | ru | null |
# Реактивные мозговые волны: рассказ о Muse, JS и браузерах
Несколько месяцев назад я наткнулся на интеллектуальную ЭЭГ-гарнитуру с поддержкой Bluetooth и тут же увидел её потенциал в некоторых крайне интересных областях. А именно, эта гарнитура и Web Bluetooth вполне могли позволить напрямую связать мой мозг с веб-ст... | https://habr.com/ru/post/341426/ | null | ru | null |
# Подводные камни при использовании Linked Server
В нашу компанию пришел достаточно интересный проект, связанный с обработкой очереди задач. Проект был разработан ранее другой командой. Нам необходимо было разобраться с проблемами, возникающими при большой нагрузке на очередь, и, соответственно, исправить найденные. ... | https://habr.com/ru/post/302958/ | null | ru | null |
# Chaos Engineering: искусство умышленного разрушения. Часть 2
***Прим. перев.**: Этот материал продолжает замечательный цикл статей от технологического евангелиста из AWS — Adrian Hornsby, — задавшегося целью просто и понятно объяснить важность экспериментов, призванных смягчить последствия сбоев в ИТ-системах.*
!... | https://habr.com/ru/post/465107/ | null | ru | null |
# Парсинг при помощи JAVA
##### Иванов Максим
Младший Java программист
#### Или рецепт по приготовлению своего салата «Простенький парсер»
, которая позволяет организовать сложную валидацию данных. В первую очередь библиотека рассчитана на проверку пользовательского ввода.

* [Часть 2](https://habr.com/ru/post/710368/)
* [Часть 2.5](https://habr.com/ru/post/710550/)
* [Часть 2.6](https://habr.com/ru/post/712328/)
* [Часть 3](https://habr.com/ru/post/710656/)
Пре... | https://habr.com/ru/post/710550/ | null | ru | null |
# Конкурс по программированию: Торговля (промежуточные результаты и объявления)
Большое спасибо всем участникам [конкурса по программированию](https://habr.com/company/hola/blog/414723/)! Приём решений ещё не закончен, но в полночь на 17 июля мы взяли тот набор решений, который был на тот момент, и провели между ними ... | https://habr.com/ru/post/417645/ | null | ru | null |
# Хозяйке на заметку: разбираемся с конфигурационными файлами Linux
Понимая, как работают конфигурационные файлы, вы можете существенно повысить уровень владения Linux. В статье рассказываем, как конфигурационные файлы управляют пользовательскими разрешениями, системными приложениями, демонами и другими административн... | https://habr.com/ru/post/710398/ | null | ru | null |
# ORM — отвратительный анти-паттерн
От автора перевода: Написанный далее текст может не совпадать с мнением автора перевода. Все высказывания идут от лица оригинального автора, просьба воздержаться от неоправданных минусов. Оригинальная статья выпущена в 2014 году, поэтому некоторые фрагменты кода могут быть устаревши... | https://habr.com/ru/post/667078/ | null | ru | null |
# OCR за час? — Не думаю
### О задаче
Одним прекрасным вечером коллега попросил подумать над алгоритмом поворота серийных номеров на металлических брусках — бруски овальные, серийные номера выбиты на их торц... | https://habr.com/ru/post/660405/ | null | ru | null |
# Учимся правильно писать CSS классы в JSX
Казалось бы такая простая тема как написание css-классов не должна быть проблемой, однако я встречал довольно много проектов, где допускаются ошибки, пишутся непроизводительные велосипеды, что приводит к ошибкам на продакшене и плохо читаемому коду.
Где проблема актуальна? В... | https://habr.com/ru/post/649381/ | null | ru | null |
# Пишем свой фондовый индекс (API Тинькофф, FastApi, TradingView)

Здравствуйте дорогие хабровчане, в этом посте я покажу, как написать свой биржевой индекс наподобие S&P 500 или Nasdaq.
О том, как мне это пришло в голову можно прочи... | https://habr.com/ru/post/656547/ | null | ru | null |
# Elixir: Развёртывание приложений с помощью Edeliver

Мы уже обсуждали сборку и развёртывание приложений **Elixir**(*перев: с помощью **[exrm](https://github.com/bitwalker/exrm)***): как [осуществлять миграции поверх релиза... | https://habr.com/ru/post/305564/ | null | ru | null |
# Mikrotik firewall filter: скрипт генерирующий основу для политики фильтрации
Кто хоть раз писал политику фильрации firewall знает, что это дело не простое и сопряжено с кучей ошибок, когда колличество сетевых зон больше 2-х. В этой сутации вам поможет скрипт из этой статьи.
Введение
--------
Под сетевой зоной я ... | https://habr.com/ru/post/500148/ | null | ru | null |
# Версия 0.4 — Stable Release Candidate
[](http://code.google.com/p/web-optimizator/) Веб Оптимизатор (Web Optimizer) — приложение для автоматизации всех действий по клиентской оптимизации — дости... | https://habr.com/ru/post/57780/ | null | ru | null |
# Контейнер LXC для веб-разработки как альтернатива Docker
Разработкой [LXC](https://linuxcontainers.org/lxc/introduction/) занимается компания Canonical, последняя версия LXC 4.0.10 вышла совсем недавно в *июле 2021*, а началась в 2008.
В чем разница LXC и Docker:
* Docker - это контейнер для упаковки одного процес... | https://habr.com/ru/post/563040/ | null | ru | null |
# Получение пути к карте памяти SD Card на Android
Разрабатывая приложение для проведения соревнований, я столкнулся с проблемой хранения базы данных. Проблема состояла в том, как мне определить внешнюю карту памяти. В целом поиск в сети точного ответа не дал. Поэтому, объединив все найденные результаты, я собрал свой... | https://habr.com/ru/post/254813/ | null | ru | null |
# Пишем ХабраКвест на ASP.NET Core и Angular2
Каждый раз с выходом нового фреймворка, хочется попробовать его в деле и написать на нем какое-то приложение. В [прошлый раз](https://habrahabr.ru/post/250009/) отлично зашел формат квеста. По этому предлагаю посмотреть что поменялось за почти полтора года и написать еще о... | https://habr.com/ru/post/306292/ | null | ru | null |
# Тестирование Flutter-приложений: гайд по разработке тестов на Flutter
*Привет! Меня зовут Юрий Петров, я Flutter Team Lead в* [*Friflex*](https://friflex.com/)*. Мы разрабатываем мобильные приложения для ... | https://habr.com/ru/post/666578/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.