
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# 12 факторов, которые мешают работать программистам
Никто не станет требовать от разработчика, чтобы он писал код без доступа к компьютеру, но многие компании считают, что он каким-то образом должен работать без возможности полностью задействовать свои мыслительные возможности. А это примерно настолько же нереально. ... | https://habr.com/ru/post/428293/ | null | ru | null |
# Rhodecode + Redmine — недорогая и функциональная замена хостингу программных проектов на стороне
#### Введение
Встречаются предприятия, на которых доступ к интернету сильно ограничен или не постоянен, не завидую этим ребятам. Иногда, как в моём случае, политика безопасности предприятия не позволяет хранить исходный... | https://habr.com/ru/post/140917/ | null | ru | null |
# Objective C. Практика. События
Событийно-ориентированная логика в Objective C держится на трех китах — протоколы, notification center и key-value observing. Традиционо протоколы используются для расширения функционала базовых классов без наследования, key-value observing – для взаимодействия между визуальной и логич... | https://habr.com/ru/post/168179/ | null | ru | null |
# Формируем тренировочный сэмпл данных при distribution shift
Дисклеймер: статья является переведенным продуктом автора [Max’a Halforda](https://maxhalford.github.io/blog/subsampling-1/). Перевод не чистый, а адаптивный. Такой, чтобы было понимание на любом рубеже знаний.
, но не все хотят давать не понятно кому свой пароль.
Я написал скрипт (на груви ), который создаёт метку... | https://habr.com/ru/post/110738/ | null | ru | null |
# Step-by-step: настройка SpecFlow для русскоязычного проекта при написании тестов в среде .Net
Не нашла в интернете пошаговой русскоязычной инструкции о том, как настроить SpecFlow на работу с русскими спецификациями. Да и вообще нет русской инструкции о том, как начать работать со SpecFlow. Зато обнаружила некоторый... | https://habr.com/ru/post/182160/ | null | ru | null |
# HTML5 Audio — состояние дел. Часть 2
 *(Статья специалиста по фронтенду и медиатегам Марка Боаса (Mark Boas) от 8 мая 2012. Перевод заключительной части. Начало дало понять, что придётся попотеть, прежде че... | https://habr.com/ru/post/149518/ | null | ru | null |
# Как мы делали мониторинг сети на 14 000 объектов
У нас было 14 000 объектов, zabbix, api, python и нежелание добавлять объекты руками. Под катом — о том, как сетевиками внедрялся мониторинг с автоматическим добавлением узлов сети, и немного про боль, через которую пришлось пройти.
Статья больше ориентирована на с... | https://habr.com/ru/post/438754/ | null | ru | null |
# pyqtdeploy, или упаковываем Python-программу в exe'шник… the hard way
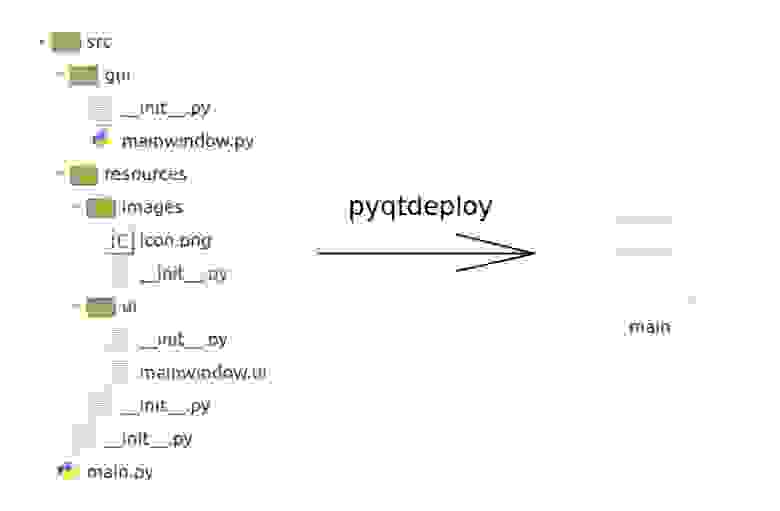
Наверняка, каждый, кто хоть раз писал что-то на Python, задумывался о том, как распространять свою программу (или, пусть даже, простой скрипт) без лишней го... | https://habr.com/ru/post/487900/ | null | ru | null |
# Игра для программистов — Быки и коровы
Привет Хабралюди. Я расскажу вам, как на Питоне написать движок и примерный бот игры для программистов. [Игры для программистов](http://ru.wikipedia.org/wiki/%D0%98%D0%B3%D1%80%D0%B0_%D0%B4%D0%BB%D1%8F_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%81%D1%82%D0%BE%D0%... | https://habr.com/ru/post/74727/ | null | ru | null |
# Получаем SPListItem из SPList. Очень быстро и очень медленно
При профилировании веб-части для SharePoint с удивлением обнаружил узкое место в SPListItemCollection.this[Guid]… Получение элемента списка по Guid'у, фактически первичному ключу, занимало уйму времени на большой коллекции.
Происходило это так
> `va... | https://habr.com/ru/post/71906/ | null | ru | null |
# PODAM Java объекты для Unit-тестирования

Добрый день!
При unit-тестировании часто сталкиваешься с необходимостью заполнять сложные объекты, чтобы возвращать их со стороны заглушек или наоборот — давать их на вход мето... | https://habr.com/ru/post/255425/ | null | ru | null |
# Еще раз об архитектуре Android приложения или джентльменский набор библиотек
Вот надумал написать обзор библиотек с помощью которых легко и удобно писать приложения под Android.
Список вырисовывается такой:
* [Android Annotations](http://androidannotations.org)
* [Groundy](https://github.com/telly/groundy)
* ... | https://habr.com/ru/post/208504/ | null | ru | null |
# Установка Tiny Tiny RSS на роутер Zyxel Keenetic
Совсем недавно «корпорация добра» закрыла Google Reader. Тысячи пользователей встали перед выбором читалки RSS лент. Кто то сразу нашел то, что ему по душе, а кто то до сих пор находится в поиске. Но у всех онлайн читалок есть один существенный недостаток — они так же... | https://habr.com/ru/post/185876/ | null | ru | null |
# Как определить браузер
Оказывается, клиенту можно показать браузер таким вот забавным хаком :)
`первый вариант:
![]()
/''src="firefox.gif"
/""src="sleipnir_gecko.gif"
"src="safari.gif"
""src="konqueror.gif"
/src="ie.gif"
src="opera.gif"
src="lynx.gif"
>
обновленный вариан... | https://habr.com/ru/post/64549/ | null | ru | null |
# Современные Unix программы
Наше внимание привлёк один интересный репозиторий, который называется [Modern Unix](https://github.com/ibraheemdev/modern-unix). В нём собраны, в основном, современные альтернативы классическим Unix-командам. Всего там имеется почти три десятка описаний таких команд. Надеемся, вы найдёте с... | https://habr.com/ru/post/567150/ | null | ru | null |
# Облака на службе СМИ, или Как Amazon помогает обрабатывать большие объемы видеоконтента
Нашему заказчику, одному из крупнейших мировых издательств, потребовалось увеличить производительность приложения для публикации видео новостей в связи с возросшим объемом трафика. Пользователи приложения — редакторы media-ресурс... | https://habr.com/ru/post/264145/ | null | ru | null |
# патч для «простого ответа»
Хочу представить вам [небольшой патч,](http://catap.ru/blog/2008/10/17/nginx-prosto-otvet/) который реализует возможность использовать такие конструкции для настройки:
````
location /response {
response "$pid";
response_type "text/xml";
}
```` | https://habr.com/ru/post/42756/ | null | ru | null |
# Доклад по CSS за 2014 год: Проверка использования CSS в «полевых условиях»
CSS – это инструмент, при помощи которого HTML превращается в полностью сверстанную страницу. CSS – это язык, полный странностей и непредсказуемых поворотов, и поэтому чаще всего создание таблиц стилей представляет собой наименее любимую рабо... | https://habr.com/ru/post/248911/ | null | ru | null |
# Безопасность клиентских приложений: практические советы для Front-end разработчика
Как вы знаете, большая часть атак BlackHat-хакеров направлена на компрометацию серверных данных web-приложений и сервисов. При этом клиентскую часть сегодня атакуют не реже. Согласно сухому определению, любая атака — это комплекс мер ... | https://habr.com/ru/post/445932/ | null | ru | null |
# Самодельный стратостат. Сезон 2022. Vostok-5

Вот мы и вернулись! С "небольшим" опозданием, но нам есть чем оправдаться ;) В прошлом году мы строили и запускали самодельные стратостаты с целью прив... | https://habr.com/ru/post/671290/ | null | ru | null |
# Как мы Ур делали
***This game has no name.
Виктор Пелевин «Generation П»***
***Дорога в тысячу ли начинается с первого шага.
Лао Цзы***
В отношении моей [предыдущей статьи](http://h... | https://habr.com/ru/post/225631/ | null | ru | null |
# Алгоритмы для веб-разработчиков простыми словами
Здравствуйте, друзья! Данным постом мы открываем цикл статей об алгоритмах и структурах данных.
В этой статье мы поговорим о том, зачем вообще их нужно знат... | https://habr.com/ru/post/683128/ | null | ru | null |
# Сказка о потерянном московском времени, или в чем ошиблись ребята из Microsoft

На днях я с сожалением обнаружил, что в семействе операционных систем Windows содержится неверная информация о московском в... | https://habr.com/ru/post/215115/ | null | ru | null |
# Книга «Обработка естественного языка. Python и spaCy на практике»
[](https://habr.com/ru/company/piter/blog/556140/) Привет, Хаброжители! Python и spaCy помогут вам быстро и легко создавать NLP-приложения: чат-боты, сценарии дл... | https://habr.com/ru/post/556140/ | null | ru | null |
# Не уважаю инкапсуляцию, или использование таблицы методов другого типа для быстрого вызова приватных методов
Всем привет. Хотелось бы поделиться примером использования StructLayout для чего-то более интересного, чем примеры с байтами, интами и прочими цифрами, в которых все происходит чуть более, чем ожидаемо.
Пр... | https://habr.com/ru/post/423657/ | null | ru | null |
# Пишем расширение для MediaWiki
В рунете я почти не встречал материалов о том, как писать расширения для MediaWIki (платформы, на которой работает Википедия). Основной стартовой точкой при написании расширений был и остается официальный сайт платформы, но там процесс [расписан](https://www.mediawiki.org/wiki/Manual:D... | https://habr.com/ru/post/544534/ | null | ru | null |
# Релиз GCC-4.7
Сегодня ночью вышел долгожданный GCC 4.7, выпуск которого приурочен к 25-летию проекта.
Долгожданным этот выпуск является прежде всего для программистов C++, так как несет с собой обширную поддержку нового стандарта С++11.
**Наиболее заметные нововведения:**
Расширенный синтаксис friend:
``... | https://habr.com/ru/post/140557/ | null | ru | null |
# AHURATUS Smart Home Voice Assistant
[](https://ahuratus.ir)
[](http://university.i... | https://habr.com/ru/post/475960/ | null | en | null |
# Шаблоны проектирования в Go — Абстрактная Фабрика
Привет, Хабр! Представляю вашему вниманию перевод очередной [статьи](https://shubhamzanwar.com/blog/design-patterns-abstract-factory-pattern/) [«Design Patterns: Abstract Factory Pattern»](https://shubhamzanwar.com/blog/design-patterns-abstract-factory-pattern/) авто... | https://habr.com/ru/post/530096/ | null | ru | null |
# Pythonista. Привет, Python
### Предисловие
Доброго времени суток, Хабр. Запускаю короткий курс статей, который охватывает ключевые навыки Python, необходимые для изучения Data Science. Данные статьи подойдут для тех, кто уже имел опыт в программировании и хочет добавить Python в свою копилку навыков.
### Привет, P... | https://habr.com/ru/post/543650/ | null | ru | null |
# Как сделать платежную систему своими руками
[](https://habr.com/company/rbkmoney/blog/416897/)
Привет, Хабр! Мы в RBKmoney новый платежный процессинг написали. С нуля. Ну не мечта ли?
Правда, как всегда, на пути к мечте, большую ... | https://habr.com/ru/post/416897/ | null | ru | null |
# Использование boost::variant для описания состояний модели
В моделях данных очень часто требуется хранить некоторые переключаемые состояния. Классический способ в С++ для этого — использование перечислимых типов enum.
Например, если у вас в программе пользователь может переключаться между двумя экранами, вы завод... | https://habr.com/ru/post/101114/ | null | ru | null |
# Захват видео с USB камер на устройствах под управлением Linux
#### Предыстория
Некоторое время назад я загорелся желанием “улучшить” танк из известного набора “Танковый бой”, добавив возможность играть, как «если бы я был во... | https://habr.com/ru/post/386273/ | null | ru | null |
# Внедрение WTware
С приходом удаленки в нашу жизнь привычные офисные пространства претерпели серьезные изменения. Многие компании внедряют так называемые «гибкие офисы», ведь индивидуальные рабочие места дл... | https://habr.com/ru/post/677876/ | null | ru | null |
# Верстка писем. Снова баги
 Автор изображения [Eva Galesloot](http://dribbble.com/skwirrol)
Привет!
Прежде всего хочу принести извинения в адрес mail.ru и лично Андрею Сумину [AndrewSumin](http://habrahabr.ru/users/a... | https://habr.com/ru/post/174971/ | null | ru | null |
# Тысячи телевизоров Samsung серии D6x00 содержат дефект — не могут отображать 3D в Full HD
#### 3D S.O.S.: 3D позор Samsung
[](http://wiki.samygo.tv/index.php5/File:Text2D.JPG "2D версия")Как ... | https://habr.com/ru/post/145249/ | null | ru | null |
# Заметка по for each и for in в ActionScript 3
Был неприятно удивлен таким прискорбным фактом, что работают данные конструкции весьма своеобразно и непредсказуемо.
Есть массив начинающийся не с 0, а например 2:
`2 => object ;
3 => string;
4 => object;`
Так вот перебор с помощью конструкций *for each* ... | https://habr.com/ru/post/52136/ | null | ru | null |
# Отрисовка карт с условными координатами

Продолжаю изучать JS, параллельно решая практические задачи, и с некоторыми решениями есть непреодолимое желание поделиться с сообществом, как говориться — хоть чуть чуть но должок ... | https://habr.com/ru/post/317024/ | null | ru | null |
# TypeScript для конфигурации WebPack (FE and BE)
### Легенда
Когда проект зародился, то нравился каждому. Белый лист бумаги и каждый смотрел на него с ожиданием и воображал какие перспективы откроются, каки... | https://habr.com/ru/post/535734/ | null | ru | null |
# Провоцирование сбоев браузера при помощи поведенческого фаззинга

В этой статье я расскажу вам, как я использовал фаззинг, чтобы найти несколько сбоев в Firefox. Обычно целью фаззинга является нахож... | https://habr.com/ru/post/455602/ | null | ru | null |
# Паранормальная сокращалка урлов: «TO.»
Вот такой у неё удивительный адрес: **[http://to./](http://to/)**
~~Например, вот такой урл переадресовывал на этот пост: [http://to./стёрто](#)~~
Похоже, там лимит на количество переходов для одного линка, а также маленькое время жизни застолбленного имени — постоянно пр... | https://habr.com/ru/post/75967/ | null | ru | null |
# Проектирование Data Pipelines в Apache Airflow
Привет, Хабр! Меня зовут Рустем, являюсь Senior DevOps Engineer в компании IBM.
Сегодня я хотел бы познакомить вас с важным инструментом в методологии DataOps... | https://habr.com/ru/post/679104/ | null | ru | null |
# Escape-последовательности и числовые нотации в PHP
> Привет, Хабр. В преддверии старта онлайн-курса [**«PHP-разработчик»**](https://otus.pw/VPIhl/) подготовили традиционный перевод материала. Предлагаем также посмотреть запись прошедшего демо-занятия [**«Экосистема PHP».**](https://otus.pw/q6H0/)
>
>
 о языке Haskell. Автор предлагал читателю проследить за мыслью программиста, решающего типичную ООП задачу но в Хаскеле. Помимо очевидной пользы расширения предста... | https://habr.com/ru/post/270849/ | null | ru | null |
# Умные конструкторы для кейс-классов
В число огромных преимуществ использования Scala входит безопасность типов. Если мы четко и внимательно относимся к используемым нами типам, компилятор способен направить... | https://habr.com/ru/post/697248/ | null | ru | null |
# Загрузка фотографий на сайт c помощью электронной почты
Это мой первый пост на Хабре, по этому не судите строго.
#### Задача.
Реализовать возможность загрузки фотографий в профайл или в фотоленту события посредством электронной почты, поместить их в заданную папку и сделать соответственную запись в БД.
#### А... | https://habr.com/ru/post/77304/ | null | ru | null |
# Настраиваем Vim под Python
Сегодня я хочу рассказать вам, как я настраивал любимый всеми редактор Vim (который в одном режиме пищит, а в другом — все портит) для написания кода на Python. Статья расчитана на начинающих виммеров.
У меня получилась такая картинка:
Мечтаете без проблем развёртывать приложения в облаке, входить под своими учётными данными AWS и чтобы вся настройка облака выполнялась автоматически, а вам «из ... | https://habr.com/ru/post/596675/ | null | ru | null |
# Шифрование и расшифровка — обращение к API OpenSSL с помощью вызовов JNI
В этом блоге перечисляются действия по интеграции инструкций Intel AES-NI в приложение Android с помощью библиотеки OpenSSL. Выполнив приведенную здесь инструкцию, вы сможете создать приложение JNI, использующее ускорение AES-NI.
Новые инстр... | https://habr.com/ru/post/255525/ | null | ru | null |
# От Isolation к Consistency — дорога длиной в 30 лет
Участвую в стартапе, в котором разрабатывается СУБД нового типа (работает поверх некоторых kv-движков, кардинально расширяя их возможности, про это немного можно прочитать [здесь](https://career.habr.com/vacancies/1000110099)). Для того, чтобы сравнить то, что поне... | https://habr.com/ru/post/705332/ | null | ru | null |
# Как запустить программу без операционной системы: часть 4. Параллельные вычисления
После долгого перерыва продолжаем делать интересные штуки, как всегда на чистом железе без операционной системы. В этой части статьи научимся использовать весь потенциал процессоров: будем запускать программу сразу на нескольких ядрах... | https://habr.com/ru/post/181626/ | null | ru | null |
# Инфраструктура для микросервисов. K8s и все-все-все
Как-то я уже писал тут о [переезде из Азии в Европу](https://habr.com/post/370207/), а теперь хочу написать, что я в этой Европе делаю. Есть такая профессия — `DevOps`, точнее нет, но так получилось, что это именно то чем я сейчас занимаюсь. Сейчас для оркестрации ... | https://habr.com/ru/post/427323/ | null | ru | null |
# Моя попытка номер 5
*А я пропатчил, я пропатчил SJ
Опять, опять, опять…
Ох, как намаялся я с тобой
Моя попытка номер пять.*
Крутилось в голове
Это ~~небольшой~~ большой рассказ о попытке привнести сжатые строки в `StringJoiner`, а также о трудностях, вставших на моём пути. Предупреждение: внутри расчлен... | https://habr.com/ru/post/488874/ | null | ru | null |
# Ресайз картинок в браузере. Все может стать еще хуже

Знакомьтесь, это Маня. Маню поразил страшный недуг и теперь она нуждается в вашей помощи. Маня росла обычной девочкой, жизнерадостным счастливым ребенком. Но чуть боль... | https://habr.com/ru/post/302744/ | null | ru | null |
# Проблема первого зрителя, или непростая конвертация WebRTC видеопотоков в HLS

Егор закрыл крышку ноутбука и потер красные от недосыпа глаза. "Клиенты продолжают жаловаться на зависания стрима, новый пакет исправлений совсем не пом... | https://habr.com/ru/post/480432/ | null | ru | null |
# Победа над неочевидным. Схлопывание внешних отступов
Много начинающих верстальщиков и веб-разработчиков сталкиваются с ситуацией, когда элементы на странице ведут себя не так, как ожидается, и данное поведение кажется абсурдным. Но не стоит забывать, что существующие доминирующие технологии созданные людьми думающим... | https://habr.com/ru/post/257327/ | null | ru | null |
# Пишем свой Spliterator
Многие из вас уже попробовали на вкус Stream API — потоки Java 8. Наверняка у некоторых возникло желание не только пользоваться готовыми потоками от коллекций, массивов, случайных чисел, но и создать какой-то принципиально новый поток. Для этого вам потребуется написать свой сплитератор. [Spli... | https://habr.com/ru/post/256905/ | null | ru | null |
# Курс MIT «Безопасность компьютерных систем». Лекция 8: «Модель сетевой безопасности», часть 1
### Массачусетский Технологический институт. Курс лекций #6.858. «Безопасность компьютерных систем». Николай Зельдович, Джеймс Микенс. 2014 год
Computer Systems Security — это курс о разработке и внедрении защищенных компь... | https://habr.com/ru/post/418229/ | null | ru | null |
# PHPmotion на Debian 6 Squeeze
Появилась потребность разместить свои ролики, которые были бы доступны как бля меня, так для родственников из других городов, для этих целей, решил попробовать использование известного движка для организации **видео-хостинга – PHPmotion**, в этой заметке приведу процесс установки на OS ... | https://habr.com/ru/post/144900/ | null | ru | null |
# PostgreSQL 14: Часть 2 или «в тени тринадцатой» (Коммитфест 2020-09)
Главным событием сентября в мире PostgreSQL безусловно является выход 13 версии. Однако жизненный цикл PostgreSQL 14 идет своим чередом и в сентябре прошел [второй коммитфест](https://commitfest.postgresql.org/29/) изменений. О том, что интересного... | https://habr.com/ru/post/522428/ | null | ru | null |
# Unity — Enable Multidex или слишком много методов
С чего все началось
-------------------
Всем привет. На определенном этапе разработки игры под Android на движке Unity я столкнулся с одной проблемой при билде. После добавления в проект таких плагинов как Appodeal и Google Play Games количество используемых методов... | https://habr.com/ru/post/487336/ | null | ru | null |
# Модульное тестирование Pega приложений: меняем жизнь к лучшему с Ninja
Несмотря на парадигму ‘no coding’, модульное тестирование на сложных проектах Pega так же важно, как и на других проектах по разработке ПО. В этом я убедился лично, работая в проектах по сквозной автоматизации бизнес-процессов на базе решений Peg... | https://habr.com/ru/post/334648/ | null | ru | null |
# Getting To Know Angular Components
Angular is one of the most popular front-end development frameworks out there. It is a leading choice for personal as well as industry-level development of web applications due to its robust capabilities. While Angular is popular for many different reasons, one of the main ones is ... | https://habr.com/ru/post/560366/ | null | en | null |
# HTML5: старые теги нового назначения
Всем известно, что теги , , , являются презентационными, а следовательно, исходя из парадигмы «структура, представление, поведение» их использование не приветствуется. Куда более привычными представляются элементы , , . Так было на протяжении долгих лет практики разработки. Одна... | https://habr.com/ru/post/129147/ | null | ru | null |
# Обзор механизма подписания документов ЭЦП с применением QR кодов через приложение eGov mobile (aka QR-подписание)
Осенью 2022 года в Казахстане был анонсирован новый механизм подписания электронных документов - *QR-подписание*. Я расскажу о том, что это такое, как оно работает и как можно его опробовать.
---
В ано... | https://habr.com/ru/post/711388/ | null | ru | null |
# Фреймворк для работы с Telegraph API

20 декабря 2016 года Telegram открыл *API* к *Telegraph*. Для работы с ним я написал простую и функциональную библиотеку под *JavaScript*.
Пару слов о Telegraph
---------------------
Telegraph — это сервис заметок и ра... | https://habr.com/ru/post/318474/ | null | ru | null |
# Проигрывание YouTube видео с помощью WebView
Некоторые разработчики под Андроид ОС могли столкнуться с проблемой проигрывания видео с youtube, в версии операционной системы 2.2 и старше. Когда старый вариант с использованием [shouldOverrideUrlLoading](http://developer.android.com/reference/android/webkit/WebViewClie... | https://habr.com/ru/post/130422/ | null | ru | null |
# Прунинг нейронных сетей (фитнес бывает полезен не только людям)
Всем привет! В данном посте я хотел бы рассказать про весьма интересную и важную деятельность в области глубокого обучения как прореживание (прунинг) нейронных сетей. На просторах сети есть неплохие материалы по данной теме, например, [статья на Хабре т... | https://habr.com/ru/post/575520/ | null | ru | null |
# Файловый AIO в nginx
В последних версиях nginx (начиная с 0.8.11) появилась поддержка асинхронного файлового ввода-вывода. Потенциально, эта фича способна устранить одно из узких мест веб-сервера — полную блокировку процесса при файловом IO.
Проблема состоит в том, что ни один из запросов, которые процесс-воркер ... | https://habr.com/ru/post/68480/ | null | ru | null |
# Godot, Dog Mendonça & Pizza Boy
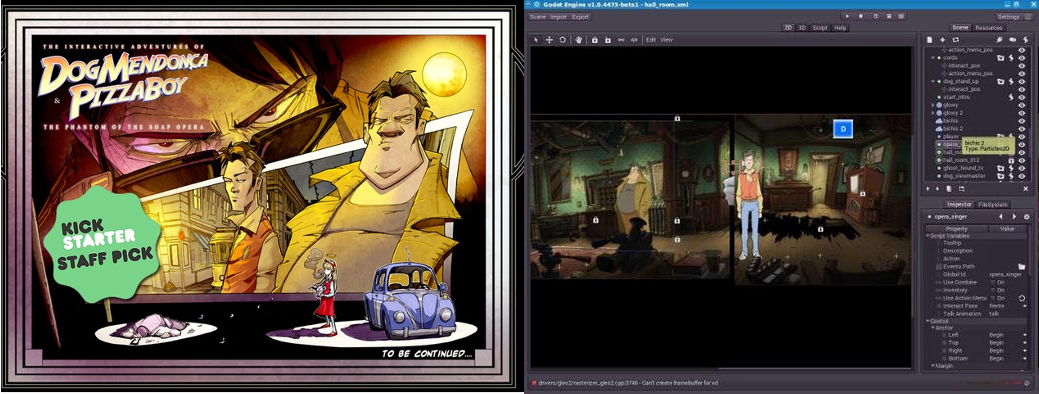
Разработчики замечательно опенсурсного движка Godot для создания 2D и 3D игр под самые разные платформы студия OKAM, совершенно незаметно для меня вышли со своим проектом [на кикстартере](h... | https://habr.com/ru/post/362275/ | null | ru | null |
# Автомонтирование флешек в armbian
Имеем сборку [armbian](https://github.com/armbian/build) для сервера, то есть без какой-либо графической оболочки. Или же такую же сборку от [Xunlong](https://github.com/orangepi-xunlong/orangepi-build) (которая основана на том же armbian).
Пусть в наш компьютер пользователь период... | https://habr.com/ru/post/673134/ | null | ru | null |
# [NES] Пишем редактор уровней для Prince of Persia. Глава четвертая. Он сам бежит! Или скелет в шкафу
[Глава первая](http://habrahabr.ru/post/187876/), [Глава вторая](http://habrahabr.ru/post/191880/), [Глава третья](http://habrahabr.ru/post/192028/), **Глава четвертая**, [Глава пятая](http://habrahabr.ru/post/192832... | https://habr.com/ru/post/192546/ | null | ru | null |
# Реализация технологии SSO на базе Node.js
Веб-приложения создают с использованием клиент-серверной архитектуры, применяя в качестве коммуникационного протокола HTTP. HTTP — это протокол без сохранения состояния. Каждый раз, когда браузер отправляет серверу запрос, сервер обрабатывает этот запрос независимо от других... | https://habr.com/ru/post/517308/ | null | ru | null |
# Путь к непрерывной интеграции. Selenium + TeamCity
#### Вступ
Рассмотрим интегрирование тестов Selenium IDE в процесс непрерывной интеграции с помощью TeamCity. В многих местах встречал когда QA создает тесты ( в лучшем случае, зачастую бывает когда кликери просто по документу «прокликивают» проект и делает отчеты... | https://habr.com/ru/post/230519/ | null | ru | null |
# Шейдеры, голограммы и утечка света на чистом CSS
К старту курса по [Fullstack-разработке на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_120722&utm_term=lead) рассказываем, как на чистом современном CSS имитировать шейдеры ... | https://habr.com/ru/post/675862/ | null | ru | null |
# 256 байт intro «Springs» для компьютера Vectrex
Решение написать что-нибудь для [Chaos Constructions](http://chaosconstructions.ru) пришло, как водится, довольно внезапно (в первую очередь потому, что до последнего момента не было очевидно, состоится он в этом году или нет). Так что, времени написать что-то большее,... | https://habr.com/ru/post/336784/ | null | ru | null |
# Управляем состоянием в Angular при помощи Mobx

Каждый разработчик знает, что управление состоянием довольно сложная штука. Постоянно отслеживать, что где и когда поменялось, это просто кошмар, особенно в больших при... | https://habr.com/ru/post/341564/ | null | ru | null |
# Универсальный способ мониторинга Asterisk с помощью Zabbix

Добрый день, хабровчане.
В этом посте я хотел бы рассказать о том, как мы осуществляем мониторинг серверов Asterisk. Безусловно, посты по использованию Za... | https://habr.com/ru/post/249055/ | null | ru | null |
# Сравнение методов распознавания сигналов. Нейронные сети против согласованного фильтра
Я недавно опубликовал статью "Распознавание радиотехнических сигналов с помощью нейронных сетей"[1]. И там была довольно длинная и интересная дискуссия по поводу возможности использования для этих целей согласованного фильтра(СФ).... | https://habr.com/ru/post/318886/ | null | ru | null |
# ААА! Пришло время переписывать на .NET Coreǃ
Все мы давно хотим перелезть на .NET Core, но постоянно что-то мешает. Например, ничего не поделаешь, когда не хватает важных API. В версии 2.0 процесс упростили благодаря [.NET Standard 2.0](https://blogs.msdn.microsoft.com/dotnet/2017/08/14/announcing-net-standard-2-0/)... | https://habr.com/ru/post/345136/ | null | ru | null |
# Context в Android приложении

### Что такое Context?
Как следует из названия, это контекст текущего состояния приложения или объекта. Это позволяет вновь созданным объектам понять, что вообще происходит... | https://habr.com/ru/post/421115/ | null | ru | null |
# «Пароль неверный». Парольные менеджеры глазами хакера
Привет, Хабр! На проектах по пентестам нам часто удается получить доступ к корпоративному компьютеру «жертвы», а затем и добыть из него плохо защищенные пароли. К чему это приводит, все понимают. А как происходит такая компрометация — сегодня попробуем раскрыть.
... | https://habr.com/ru/post/713284/ | null | ru | null |
# Сбор и визуализация метрик приложения в Graphite и Graph-Explorer
Зачастую возникает необходимость отслеживать различные параметры работы приложения/сервиса. Например, интерес представляет количество запросов в секунду, среднее время ответа сервера, количество ответов сервера с различным HTTP-статусом (технические м... | https://habr.com/ru/post/260753/ | null | ru | null |
# Обновление информации в фоне
Всем добрый день.
Недавно я задумался надо вопросом фонового обновления информации и мне пришла в голову одна идея.
Суть задачи — мы находимся на странице списка новостей. Необходимо обновлять список по мере поступления новых новостей. Серверный язык PHP
Рассмотрим классический... | https://habr.com/ru/post/137863/ | null | ru | null |
# Как подружить React и D3
D3 одна из наиболее популярных javascript-библиотек для создания динамических и интерактивных визуализаций данных. Сегодня ее используют [сотни тысяч сайтов и web-приложений](https://www.wappalyzer.com/technologies/d3).
В интернете огромное количество [примеров](http://bl.ocks.org/) – от б... | https://habr.com/ru/post/354806/ | null | ru | null |
# AQO — адаптивная оптимизация запросов в PostgreSQL
При выполнении запросов современные СУБД используют стоимостную модель оптимизации — на основе сохраненных в конфигурационных файлах коэффициентов и собранной статистики высчитывают “цену” получения и объем результирующих наборов строк. При повторном выполнении запр... | https://habr.com/ru/post/508766/ | null | ru | null |
# Постгрессо №4 (41)

*ИТ-инфраструктура — это как водопровод, без неё жизнь уже почти невозможна. И в эти безрадостные дни мы продолжаем выпускать Postgresso.*
---
**[PostgreSQL 14.3](https://www.postgresql.org/about/news/post... | https://habr.com/ru/post/662820/ | null | ru | null |
# Вышел JRebel 3.6.2
На этой неделе компания [Zeroturnaround](http://www.zeroturnaround.com/) выпустила версию [JRebel 3.6.2](http://www.zeroturnaround.com/blog/jrebel-3-6-2-released/)! Скачать её можно **[здесь](http://www.zeroturnaround.com/jrebel/current).**
Вот некоторые из самых интересных новых возможностей: ... | https://habr.com/ru/post/117958/ | null | ru | null |
# Coingecko & Agent Ftpupload создаем красивые адреса криптокошелька, но помним о сохранности приватного ключа
В криптосообществе за многие годы образовался целый культ по созданию красивых адресов для крипто... | https://habr.com/ru/post/687630/ | null | ru | null |
# DOM-shim для всех браузеров включая IE < 8
Доброе время суток уважаемые хабражители.
Многие javascript-программисты сталкивались с не поддерживанием некоторых функций DOM JS API в некоторых браузерах (не будем показывать пальцем). Наверняка, многие знакомы с замечательными библиотеками [es5-shim](https://github.c... | https://habr.com/ru/post/133328/ | null | ru | null |
# Пара слов о разработке и публикации add-ons для FireFox и Chrome

На днях мне обломился инвайт на лепру. В связи с чем появилось желание поэкспериментировать с плагинами для отображения картин... | https://habr.com/ru/post/119343/ | null | ru | null |
# Предварительный просмотр отправляемого email из Laravel
Как написал Саид в своем канале Твиттера:
> My new package for [@laravelphp](https://twitter.com/laravelphp)
> Converts your sent mail to .html files to check while on dev<https://t.co/2Wp73mL7yI> [pic.twitter.com/Fu12PwfXrX](https://t.co/Fu12PwfXrX)
>
>... | https://habr.com/ru/post/279171/ | null | ru | null |
# Как сделать портативный ремонтный сервер
Портативный ремонтный сервер представляет собой домашний маршрутизатор для загрузки компьютеров по сети с целью ремонта, восстановления, проверки и лечения. Перед загрузочной флешкой данный сервер обладает следующими преимуществами:
* воткнул в сеть и не надо на каждом сис... | https://habr.com/ru/post/259161/ | null | ru | null |
# Как я делал игру индейцев Центральной Америки
Хочу представить вашему вниманию небольшую статью о том, как я делал для Android **пулук** — настольную игру индейцев Центральной Америки.
"Обучать" компьютеры человеческим играм я начал едва научившись программировать. Первым был **калах** (разновидность **манкалы**) д... | https://habr.com/ru/post/310404/ | null | ru | null |
# HTTP/3: развёртывание HTTP/3 на практике. Часть 3

*Фото Wolfgang Rottmann, Unsplash.com*
После почти пятилетних разработок протокол HTTP/3 наконец приближается к окончательному выпуску. Рассказываем, какие трудности могут воз... | https://habr.com/ru/post/588230/ | null | ru | null |
# Как вычитать серии временных промежутков и попробовать алгоритм Бентли-Оттманна
Всем привет!
Недавно мне пришлось решать такую задачу: есть расписание работы трудовых ресурсов. Например, расписание врача. Оно формируется с помощью правил и исключений. Нужно из правил вычесть исключения, но они периодичные и не ср... | https://habr.com/ru/post/506190/ | null | ru | null |
# Злые фишинг картинки
##### Правильно люди говорят: «Все новое — это хорошо забытое старое»
Возможность встраивания удалённых ресурсов (например картинок с других сайтов) на страницу своего сайта — очень плохая практика. Которая может в определённый момент привести к довольно серьёзным последствиям для сайта. Еще 10... | https://habr.com/ru/post/140054/ | null | ru | null |
# COBOL — древний код, который управляет вашими деньгами

Язык программирования COBOL старше Игоря Николаева. Люди, умеющие им пользоваться, часто того же возраста. Он лежит в основе целой финансовой системы и его нельзя оттуда убрать. ... | https://habr.com/ru/post/532554/ | null | ru | null |
# Обещания JavaScript
*Всем привет, и ещё раз всех с прошедшими праздниками. Трудовые будни набирают обороты и вместе с ними растёт информационный голод мучающий нас. Мир разработки переднего конца не дремлет и готовит нам много сюрпризов в наступившем году, и уж поверьте мне, скучно не будет ни кому. Одна из новых ос... | https://habr.com/ru/post/209662/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.