
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Пример ускорения расчётов в R путём многопоточности
#### Введение
Как следует из Википедии:
> R — язык программирования для статистической обработки данных и работы с графикой, а также свободная программная среда вычислений с открытым исходным кодом в рамках проекта GNU.
Данный язык, в настоящее время, нашёл широ... | https://habr.com/ru/post/168399/ | null | ru | null |
# Индексы в PostgreSQL — 4
Мы уже рассмотрели [механизм индексирования PostgreSQL](https://habrahabr.ru/company/postgrespro/blog/326096/) и [интерфейс методов доступа](https://habrahabr.ru/company/postgrespro/blog/326106/), а также один из методов доступа — [хеш-индекс](https://habrahabr.ru/company/postgrespro/blog/32... | https://habr.com/ru/post/330544/ | null | ru | null |
# Эффект дизеринга в трёхмерной игре

*Создатель Papers, Please Лукас Поуп работает над новым трёхмерным проектом Return of the Obra Dinn, в котором пытается с помощью эффекта [дизеринга](https://ru.w... | https://habr.com/ru/post/343172/ | null | ru | null |
# Псевдо-пространства имен
В PHP 5.3 добавлена поддержка пространств имен, но [эта версия пока слабо распространена](http://habrahabr.ru/blogs/php/65573/) и непригодна для промышленного использования в распространяемых проектах. А пока новая версия в пути, я сделал простую замену пространств имен для переменных.
Эт... | https://habr.com/ru/post/67596/ | null | ru | null |
# Миграция YAML конфигов или история одного парсера
Есть счастливые люди, которые могут себе позволить просто перезаписывать YAML конфиги в продакшене. Мне же повезло меньше - инсталляции у меня специфичные и конфиги часто настраиваются "под себя". К каждому релизу приходилось готовить отдельную доку для ручного апдей... | https://habr.com/ru/post/579950/ | null | ru | null |
# Мой путь от Python к Go — делюсь советами и ресурсами

***От переводчика:** перевели [для вас статью Илада Леева о переходе с Python на Go](https://medium.com/appsflyer/my-journey-from-python-to-go-385978... | https://habr.com/ru/post/444866/ | null | ru | null |
# Любопытные извращения из мира ИТ — 5

История первая. Роковые буквы
-----------------------------
[[Оригинал](http://thedailywtf.com/articles/drink-from-the-font-of-wisdom)]
Когда-то давно **Джор... | https://habr.com/ru/post/460531/ | null | ru | null |
# Языковая механика стеков и указателей
Прелюдия
--------
Это первая из четырех статей в серии, которая даст представление о механике и дизайне указателей, стеков, куч, escape analysis и семантики значения/указателя в Go. Этот пост посвящен стекам и указателям.
Оглавление цикла статей:
1. [Language Mechanics On... | https://habr.com/ru/post/496846/ | null | ru | null |
# Непрерывная кросс компиляция для Raspberry PI
Мне хотелось развернуть систему непрерывной интеграции, кросс компилирующую CMake проект написанный на c++ с OpenGL на Raspberry PI. Заодно я хотел посмотреть, не появились ли удобные серверы автоматической сборки, не содержащие в себе питона и не потребляющие сотни мега... | https://habr.com/ru/post/318840/ | null | ru | null |
# Unison: настройка и автоматизация двусторонней синхронизации каталогов на двух серверах

Getty Images/iStockphoto
Проблему синхронизации каталогов на двух серверах с операционными системами семейства Linux на борту можно решит... | https://habr.com/ru/post/501426/ | null | ru | null |
# Тренды мобильного веба и два подхода к построению мобильных приложений

Одним из сильнейших трендов современного веба является мобильный веб — специальное представление сайтов для всего многообразия мобильных устройств,... | https://habr.com/ru/post/145341/ | null | ru | null |
# Идентификация мошенничества с использованием Enron dataset. Часть 1-ая, подготовка данных и отбор признков
Корпорация Enron — это одна из наиболее известных фигур в американском бизнесе 2000-ых годов. Этому способствовала не их сфера деятельности (электроэнергия и контракты на ее поставку), а резонанс в связи с моше... | https://habr.com/ru/post/424891/ | null | ru | null |
# Autopolyfiller — Precise polyfills

В этой статье я хочу рассказать об инструменте Autopolyfiller, который помогает вам использовать последние функции ECMAScript и при этом не думать об подключаемых полиф... | https://habr.com/ru/post/229001/ | null | ru | null |
# “Yield” и деликатная работа с памятью в PHP
https://pixabay.comВы когда-нибудь задавались вопросом: “Какая польза от ***yield*** в PHP?”. Позвольте мне избавить ва... | https://habr.com/ru/post/598577/ | null | ru | null |
# Чему я научился делая игры на LibGDX
Привет, Хабр! 👋 В этом топике хочу поговорить о незаслуженно забытом, бесплатном фреймворке для разработки кросс-платформенных игр - LibGDX. Поделиться секретами своей... | https://habr.com/ru/post/578884/ | null | ru | null |
# Пишем и оптимизируем Жизнь Конуэя на JS
Обновляя недавно дизайн своего хомяка, подумал – а не сделать ли мне какую-нибудь необычную страницу с 404-й ошибкой? Поскольку в детстве я был впечатлен [Жизнью Конуэя](http:... | https://habr.com/ru/post/144237/ | null | ru | null |
# Как сделать корутины в Unity немного удобнее
Каждый разработчик находит свои преимущества и недостатки использования корутин в Unity. И сам решает в каких сценариях их применить, а в каких отдать предпочтение альтернативам.
В повседневной практике я достаточно часто использую корутины для различных видов задач. Одн... | https://habr.com/ru/post/442622/ | null | ru | null |
# Новая разновидность AdLoad атакует системы macOS в обход защиты XProtect
[](https://habr.com/ru/company/ruvds/news/t/573862/)
Новая волна атак с применением известного семейства рекламного ПО для macOS в 2021 году разрослась до исп... | https://habr.com/ru/post/573862/ | null | ru | null |
# Работа с поверхностными и глубокими копиями в Python
[](https://habr.com/ru/company/ruvds/blog/702486/)
В этой статье объясняется, как делать копии списков Python, массивов NumPy и датафреймов Pandas при помощи операций получения с... | https://habr.com/ru/post/702486/ | null | ru | null |
# В Chrome Canary заработали новые единицы измерения CSS — vh, vw и vmin
В девелоперской версии Google Chrome (на момент написания статьи — Chrome 20) появилась поддержка новых единиц измерения CSS — vh, vw и vmin, которые пару месяцев назад [были реализованы](http://habrahabr.ru/post/139631/) в движке Webkit. До этог... | https://habr.com/ru/post/143105/ | null | ru | null |
# Простой парсер арифметических операций
Для учёбы необходимо было написать парсер арифметических операций, который мог бы рассчитывать не только простейшие операции, но и работать со скобками и функциями.
В интернете не нашел готовых и подходящих для меня решений (некоторые были чересчур сложные, другие были не по... | https://habr.com/ru/post/439966/ | null | ru | null |
# Как правильно верстать в 2022 году. Часть 1
Вступление
----------
Меня зовут Николай и я Frontend-разработчик в логистическом стартапе Relog. Хочу рассказать о самых распространённых ошибках в вёрстке современных проектов.
Дело в том, что лишь малая часть современных фронтендеров обращает внимание на работу с HTML... | https://habr.com/ru/post/655009/ | null | ru | null |
# Настройка аутентификации SSO ArgoCD через Gitlab CI/CD
Многие компании при внедрении практик gitops выбирают такой инструмент как ArgoCD и сталкиваются с проблемой заведения учетных записей и разграничением прав пользователей. В этой статье мы рассмотрим как настроить авторизацию в ArgoCD через Gitlab CI/CD с разгр... | https://habr.com/ru/post/659137/ | null | ru | null |
# С сожалением об отсутствии в C++ полноценного static if или…
**… как наполнить шаблонный класс разным содержимым в зависимости от значений параметров шаблона?**
Когда-то, уже довольно давно, язык D начали делать как "правильный C++" с учетом накопившегося в C++ опыта. Со временем D стал не менее сложным и более выр... | https://habr.com/ru/post/449122/ | null | ru | null |
# TON: рекомендации и лучшие практики
Эта статья является переводом документа, опубликованного на странице блокчейна TON: [smc-guidelines.txt](https://test.ton.org/smc-guidelines.txt). Возможно кому-то это поможет сделать шаг в сторону разработки для этого блокчейна. Также, в конце я сделал краткое резюме.
Внутренни... | https://habr.com/ru/post/470772/ | null | ru | null |
# Механики для реализации платформера на Godot engine. 2 часть
Здравствуйте, это продолжение предыдущей статьи о создании игрового персонажа в GodotEngine. Я наконец понял, как реализовать некоторые механики, такие как второй прыжок в воздухе, карабканье по, и прыжок от стены. Первая часть была более простой по насыще... | https://habr.com/ru/post/521904/ | null | ru | null |
# Как подружить Vivado и git: с микроблейзом и сабмодулями
Разработка под программируемые логические интегральные схемы (ПЛИС) и систем на кристалле (СНК) отличается монструозностью IDE и их проектов. В одном... | https://habr.com/ru/post/683580/ | null | ru | null |
# Allure-Framework. Работа с кодом
Продолжая [серию публикаций о возможностях Allure-framework](https://habr.com/company/efs/blog/358836/), сегодня мы поговорим о работе с кодом. Под катом разбираем, что такое шаг теста, как выводить информацию в отчет при выполнении шагов и какие бывают категории дефектов. Кроме того... | https://habr.com/ru/post/359302/ | null | ru | null |
# ESP8266 в качестве MQTT брокера для мобильного приложения
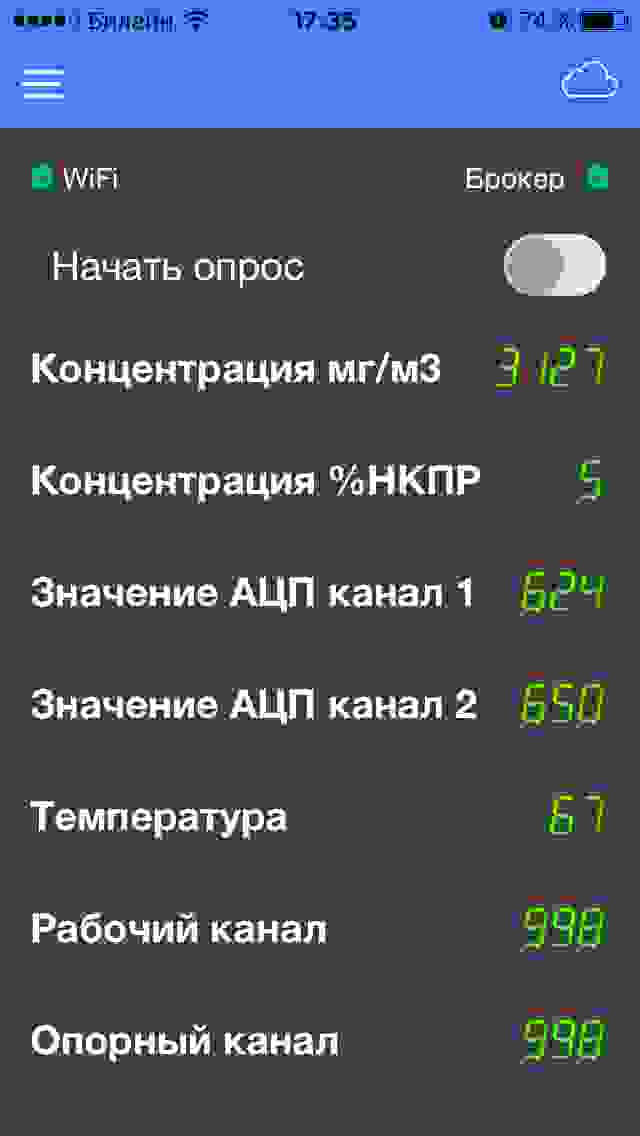 Как говорится, лень — двигатель прогресса. Для облегчения жизни сейчас делаю себе небольшое устройство в виде модуля ESP8266 и преобразователя RS485 для связи с датч... | https://habr.com/ru/post/326794/ | null | ru | null |
# Введение в Scheme

> Наиболее важным, но в то же время и наиболее незаметным свойством любого инструмента является его влияние на формирование привычек людей, которые имеют обыкновение им пользоваться.
>
> Эдсгер Вайб ... | https://habr.com/ru/post/267015/ | null | ru | null |
# Объясняя необъяснимое. Часть 4
*Конференция PG Day’16 с каждым днем всё ближе, а мы продолжаем публиковать серию статей [Hubert Lubaczewski](http://www.depesz.com/) об анализе explain и его основных операциях.*
В этом, надеюсь, [предпоследнем](https://habrahabr.ru/post/275851/) [посте](https://habrahabr.ru/post/2... | https://habr.com/ru/post/281036/ | null | ru | null |
# Свой Bot за несколько часов, или поговорим о пиве с машиной
Тема по улучшению взаимодействия машин и человека сейчас актуальна как никогда. Появились технические возможности для перехода от модели «100 кликов» к парадигме «скажи, что ты хочешь». Да, я имею в виду различные боты, которые уже несколько лет разрабатыва... | https://habr.com/ru/post/328612/ | null | ru | null |
# Интернационализация локального проекта django
Хорошо, когда при разработке проекта под django, разработчики проекта изначально озаботились его интернационализацией.
Минимальными усилиями, проект адаптируется под различные языки. Django имеет богатый набор инструментов, достаточный для почти автоматического добавл... | https://habr.com/ru/post/156879/ | null | ru | null |
# Инструкция по работе с TensorFlow Object Detection API

*Перевод [TensorFlow Object Detection API tutorial — Training and Evaluating Custom Object Detector](https://becominghuman.ai/tensorflow-object-dete... | https://habr.com/ru/post/422353/ | null | ru | null |
# Создание конечного автомата для разбора HTTP запроса
Детерминированный конечный автомат можно использовать для реализации очень быстрого способа разбора входной последовательности. Требуется всего один проход по входной последовательности, и минимальные действия на каждом шаге. К сожалению эта модель имеет ограничен... | https://habr.com/ru/post/141743/ | null | ru | null |
# Приучаем винтажные американские часы кормиться от нашей сети
#### Вместо предисловия
Кто не мечтал о таких часах после просмотра любимого фильма GTD-шников, может дальше не читать. А остальным я расскажу как заполучить себе такие часы и заставить их работать.
#### Шаг первый
К сожалению, чудес не бывает. Сами ч... | https://habr.com/ru/post/130785/ | null | ru | null |
# Перевезу в iframe. Дешево
Представьте, что вы отвечаете за большой веб-сервис со сложным интерфейсом, замысловатой навигацией, авторизацией, платежной системой. Представьте, что однажды к вам приходит ваш P... | https://habr.com/ru/post/694592/ | null | ru | null |
# Nagios — мониторинг vmware, CMC-TC, Synology, ИБП, принтеров и совсем немного Cisco
Первая часть была тут: [Nagios — система мониторинга и некоторые самодельные плагины](https://habrahabr.ru/post/307832/). Как и обещал, часть вторая, интереснее.
Здесь я расскажу, как и что можно в nagios мониторить в vmware, CMC-... | https://habr.com/ru/post/307918/ | null | ru | null |
# От 48k до 10 строк кода — история GitHub JavaScript SDK

`@octokit/rest` изначально не является оригинальной разработкой GitHub, и представляет собой адаптацию [github](https://www.npmjs.com/package/github) — самого популярного пакет... | https://habr.com/ru/post/496598/ | null | ru | null |
# PULP БЖУ
Пусть у нас есть картофель фри, котлета, хлеб, помидор, огурец и молочный коктейль. Сколько чего нужно съесть, чтобы получилось 30 гр. белка, 25 гр. жиров и 60 гр. углеводов? В прошлый раз я балов... | https://habr.com/ru/post/578796/ | null | ru | null |
# Embox — открытая ОС на Эльбрусе
Всем привет.
Конечно, многие знают о том, какие [Эльбрусы](https://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D1%8C%D0%B1%D1%80%D1%83%D1%81_(%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%BD%D0%B0... | https://habr.com/ru/post/665420/ | null | ru | null |
# Срез личного опыта: разработка, пулл реквесты, коммиты, софт скиллы

Привет, Хабрахабр! В этой статье поделюсь своим мнением про разработку програмного обеспечения. В информационных технологиях я не так давно, но у меня сложилось с... | https://habr.com/ru/post/416545/ | null | ru | null |
# CMake: тот случай, когда проекту непростительно качество его кода

CMake — это кроссплатформенная система автоматизации сборки проектов. Эта система намного старше, чем статический анализатор код... | https://habr.com/ru/post/464147/ | null | ru | null |
# PVS-Studio Is Now in Chocolatey: Checking Chocolatey under Azure DevOps

We continue making the use of PVS-Studio more convenient. Our analyzer is now available in Chocolatey, the package manager for Windows. We believe th... | https://habr.com/ru/post/488204/ | null | en | null |
# Плис Achronix – опыт освоения

За более чем десятилетний срок работы с ПЛИС, мне довелось работать с продукцией четырех разных производителей. При таком разнообразии невольно обращаешь внимание как на общ... | https://habr.com/ru/post/231007/ | null | ru | null |
# Keychain API в iOS
Всем привет!
Не так давно столкнулся с необходимостью использования Keychain-а для обеспечения дополнительной защиты при входе в приложение.
Я нашел много хороших статей по этой теме, но в основном там описываются сторонние фреймворки, упрощающие жизнь, а было интересно посмотреть, как работ... | https://habr.com/ru/post/526510/ | null | ru | null |
# Hibernate Cache. Практика
Итак, в продолжение [предыдущей статьи](http://habrahabr.ru/blogs/java/135176/) я попробую на реальных ситуациях рассказать о проблемах, которые возникали у меня при работе в реальных проектах.
##### Миграционные скрипты
Пожалуй, одной из наиболее частых проблем при работе с кешем в мое... | https://habr.com/ru/post/136375/ | null | ru | null |
# Аппаратная виртуализация. Теория, реальность и поддержка в архитектурах процессоров
В данном посте я попытаюсь описать основания и особенности использования аппаратной поддержки виртуализации компьютеров. Начну с определения трёх необходимых условий виртуализации и формулировки теоретических оснований для их достиже... | https://habr.com/ru/post/196444/ | null | ru | null |
# Три кейса инвентаризации рабочих станций в условиях удалённой работы
Управление рабочими станциями при их физическом отсутствии в офисе — новый вызов для компаний, которые перевели сотрудников на удалённый режим работы. При наличии прав администратора, пользователи, непреднамеренно могут установить софт, который ока... | https://habr.com/ru/post/503744/ | null | ru | null |
# Шифрование ключа по умолчанию в OpenSSH хуже его отсутствия
*Авторы этого материала приводят аргументы против стандартных механизмов шифрования ключа в OpenSSH.*

Недавно злоумышленники использовали npm-пакет eslint-scope для ... | https://habr.com/ru/post/419829/ | null | ru | null |
# А как вы определяете свойства переменными окружения в Spring Boot приложениях?

А что, если я скажу, что подобное
```
#application.properties
spring.datasource.url=${SPRING_DATASOURCE_URL}?someProperty=${PROPERTY}
```
с... | https://habr.com/ru/post/588985/ | null | ru | null |
# Украина получила кириллический домен.укр
Вслед за Россией и Украина наконец-то получила кириллический домен `.укр`. Международная корпорация ICANN, управляющая адресным пространством в интернете, на заседании совета директоров 28 февраля приняла решение делегировать Украине домен `.укр`.
Ходят слухи, что регистра... | https://habr.com/ru/post/171265/ | null | ru | null |
# Леворекурсивные PEG грамматики
Я упоминал о левой рекурсии как о камне преткновения несколько раз, и пришло время разобраться с этим. Основная проблема заключается в том, что парсер с лево-рекурсивным спуском мгновенно падает из-за переполнения стека.
**Содержание серии статей о PEG-парсере в Python*** [PEG парсеры... | https://habr.com/ru/post/471986/ | null | ru | null |
# Выделенная память подов и вмешательство OOM Killer
И снова здравствуйте! Перевод следующей статьи подготовлен специально для студентов курса [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/oBRu/), который запускается уже в этом месяце Начнем.
 хоть и называются умными, но вы не може... | https://habr.com/ru/post/508106/ | null | ru | null |
# Беспроводная настройка Raspberry PI 3 B+

*Привет,*
несколько месяцев назад, приобрел себе малинку, с целью попрактиковатся в embedded-типа разработке. Я уверен, много людей знакомых из Raspberry полагают, что для первоначаль... | https://habr.com/ru/post/460503/ | null | ru | null |
# Введение в разработку web-приложений на PSGI/Plack. Часть 4. Асинхронность
С разрешения автора и главного редактора журнала PragmaticPerl.com я публикую эту статью.
Оригинал статьи можно прочитать [здесь](http://pragmaticperl.com/issues/05/pragmaticperl-05-введение-в-разработку-web-приложений-на-psgiplack.-часть... | https://habr.com/ru/post/248457/ | null | ru | null |
# Создание тайлов из растровых карт
Как-то я озадачился вопросом создания карт, пригодных для использования в OsmAnd и OpenLayers. О ГИС я тогда вообще не имел ни малейшего понятия, поэтому разбирался со всем с нуля.
В статье расскажу о результатах своих «исследований», составим алгоритм преобразования произвольной... | https://habr.com/ru/post/522462/ | null | ru | null |
# Добавляем рефлексию для перечислений (enum) в C++
Недавно в нашем проекте возникла необходимость программно получать информацию о перечислениях (enum), например, имена констант в виде строк, а также общий список всех имеющихся в enum-е констант.
```
enum Suit { Spades, Hearts, Diamonds, Clubs };
```
Обычно реше... | https://habr.com/ru/post/276763/ | null | ru | null |
# Изменение калькуляторов расчета на сайте без программистов
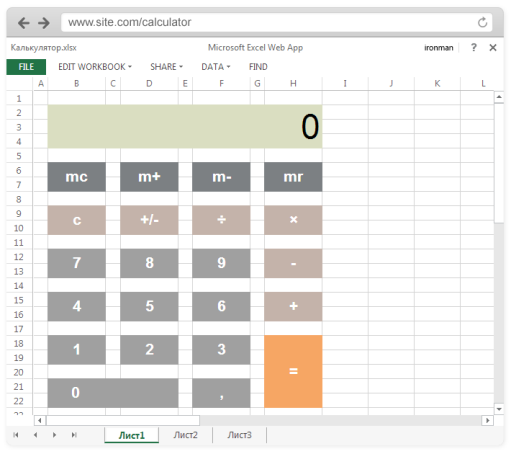
Привет, Хабр!
В данной статье расскажем, какое применение мы нашли для технологии Excel Services, входящей в состав сервера SharePoint, для построения каль... | https://habr.com/ru/post/188338/ | null | ru | null |
# Простой PHP генератор сложных HTML таблиц
Всем привет. Хочу поделиться свеженаписанным генератором HTML таблиц.
Участились случаи сбора различной статистики и компоновки ее в сложные таблицы с различными групировками.

Всем привет! После выхода Metasploit Community, которая мне очень не понравилась, я задался вопросом как же вернуть привычную для меня структуру этого ин... | https://habr.com/ru/post/217017/ | null | ru | null |
# Если хоть раз мечтал написать crack или keygen
Дня 3 назад заглянул на сайт crackmes.one попробовать силы во взломе защит. Просто наугад взялся за "hitTman's Kolay One!": просто по оценке Difficulty: 2.0 и Quality: 4.0. Не примитивно, но и не слишком сложно.
Оказалось, форма ввода пароля с подсказкой: текст кнопки ... | https://habr.com/ru/post/710616/ | null | ru | null |
# Обзор моих любимых фич PHP7

Когда люди обсуждают изменения в PHP7, самое распространенное что вы слышите — это значительно улучшенный движок, который может похвастаться более быстрой скоростью выполнения и значительно меньшим объе... | https://habr.com/ru/post/419625/ | null | ru | null |
# Хакеры выявили массу уязвимостей у современных автомобилей
Если вы приобретали новый автомобиль в последние несколько лет, то велика вероятность, что в нем есть хотя бы один встроенный модем, который нужен для разных полезных функций вроде удалённого прогрева автомобиля, самодиагностики, которая предупреждает о сбоя... | https://habr.com/ru/post/710906/ | null | ru | null |
# Найти комбинацию соседних чисел, имеющих самое большое произведение

Перед вами таблица (20x20) с целым числом от 0 до 99 в каждой из клеток.
Задача — найти 4 соседних числа без разрыва цепочки, одно за другим, имеющих самое бол... | https://habr.com/ru/post/514476/ | null | ru | null |
# Знакомимся с Fabric.js. Часть 4-я
*Это перевод четвертой части серии статей об открытой Javascript canvas библиотеке Fabric.js.*
Мы уже многое знаем из предыдущих частей серии: ([Ч1](http://habrahabr.ru/post/162367/), [Ч2](http://habrahabr.ru/post/167119/), [Ч3](http://habrahabr.ru/post/254763/)) от простых манип... | https://habr.com/ru/post/257401/ | null | ru | null |
# Пиратская копия платного сервиса в 39 строчек Python кода

Во время выполнения заказа по разработке telegram бота у меня возникла необходимость получения скриншота веб-страницы с его доставкой пользователю. Зачем задумываться ... | https://habr.com/ru/post/420513/ | null | ru | null |
# Свой облачный хостинг за 5 минут. Часть 2: Service Discovery
[](http://habrahabr.ru/post/262397/)
Привет Хабр! В [предыдущей статье](http://habrahabr.ru/post/261415/) я рассказал как построить свой облачный х... | https://habr.com/ru/post/262397/ | null | ru | null |
# Need for speed. Пакетная обработка данных с TiSpark
TiSpark – это подключаемый модуль Apache Spark, который работает с платформой [TiDB](https://docs.pingcap.com/tidb/stable) и отвечает на запросы сложной интерактивной аналитической обработки (OLAP). Этот плагин Spark широко используется для пакетной обработки боль... | https://habr.com/ru/post/539072/ | null | ru | null |
# Введение Open Policy Agent (OPA)
### Что такое OPA?
Это проект, стартовавший в 2016 году, направленный на унификацию применения политик в различных технологиях и системах. Сегодня OPA используется гигантскими игроками в технологической индустрии. Например, Netflix использует OPA для управления доступом к своим внут... | https://habr.com/ru/post/555538/ | null | ru | null |
# Делаем игру с управлением улыбкой
Привет! Меня зовут Иван Шафран, недавно я присоединился к команде видео ВКонтакте в роли программиста-разработчика для Android. Участвую в создании как продуктовых приложений, так и SDK. Время от времени я посещаю хакатоны, где можно реализовывать любые безумные идеи. Сегодня расска... | https://habr.com/ru/post/514530/ | null | ru | null |
# Масштабируем CSS спрайты с SVG, убивая сразу трех зайцев
Привет, Хабр.
Сразу хочу отметить, что если мы говорим об иконках, их можно масштабировать двумя способами (других я просто не знаю): конвертировать иконки в шрифт и подключать их через @font-face, либо использовать SVG в качестве формата для этих иконок. ... | https://habr.com/ru/post/141654/ | null | ru | null |
# Автоматизация homebridge с помощью Node-Red
На мой взгляд, одним из главных минусов homebridge является отсутсвие возможности создавать продвинутые сценарии. Вся автоматизация возлагается на домашний центр, которым может быть Ipad (подключенный к зарядке), Apple TV или HomePod. Не у всех эти устройства есть, вдобаво... | https://habr.com/ru/post/462775/ | null | ru | null |
# Полезные техники HTML, CSS и JavaScript
Техника – это способ справиться с заданием, и у нас, разработчиков и дизайнеров фронтэнда, этих способов бывает достаточно много. При это, будучи погруженными в рутинную работу, мы ... | https://habr.com/ru/post/171699/ | null | ru | null |
# Полное руководство по модулю asyncio в Python. Часть 5
Привет, Хабр! Публикуем пятую часть ([первая](https://habr.com/ru/company/wunderfund/blog/700474/), [вторая](https://habr.com/ru/company/wunderfund/blog/701982/), [третья](https://habr.com/ru/company/wunderfund/blog/702484/), [четвёртая](https://habr.com/ru/comp... | https://habr.com/ru/post/709272/ | null | ru | null |
# Эффективный JSON с функциональными концепциями и generics в Swift
Это перевод статьи Tony DiPasquale [«Efficient JSON in Swift with Functional Concepts»](http://robots.thoughtbot.com/efficient-json-in-swift-with-functional-concepts-and-generics).
### Предисловие переводчика
Передо мной была поставлена задача: за... | https://habr.com/ru/post/244821/ | null | ru | null |
# Книга «Внедрение зависимостей на платформе .NET. 2-е издание»
[](https://habr.com/ru/company/piter/blog/545252/) Привет, Хаброжители! Парадигма внедрения зависимостей (DI) в течение минувшего десятилетия де-факто стала одной из... | https://habr.com/ru/post/545252/ | null | ru | null |
# И снова закинул старик невод… (парсинг хабра, продолжение)
Примерно месяц назад я опубликовал пост [Вернулся невод с тиной морскою...](http://habrahabr.ru/post/188678/), речь там шла о сравнении частотных словарей Википедии и Башорга. В комментах было много идей насчёт того, как это сделать правильно, а так же прось... | https://habr.com/ru/post/192670/ | null | ru | null |
# Fucky new year!
Простите за мат в заголовке, это намёк на развлечение, начало которому дал язык «Брейнфак» — написать на каком-либо языке код, выполняющий что-то разумное, не используя букв и цифр. Мы уже видели [*JSFuck*](http://habrahabr.ru/post/112530/), [*PHPFuck*](http://habrahabr.ru/post/193986/), теперь я вам... | https://habr.com/ru/post/247161/ | null | ru | null |
# PHPixie Social — простая интеграция с соцсетями

Авторизация через соцсети это одна из самих частых задач с которыми сталкиваются разработчики развлекательных сайтов. Казалось бы там и делать нечего,... | https://habr.com/ru/post/303108/ | null | ru | null |
# Стандартный Color Picker для веб-дизайнера
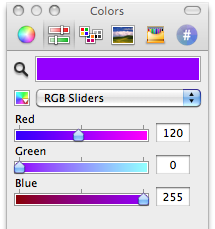
Любой веб-дизайнер трудящийся на Маке не раз сталкивался с проблемой получения цвета напрямую с экрана или из окна браузера. Существует множество спос... | https://habr.com/ru/post/86722/ | null | ru | null |
# А вы знаете где можно применить expression's в вашем проекте или оптимизация создания тестов
#### 0. Лирика
Поговорим про unit тестирование. Для больших и возрастных проектов весьма актуальна проблема «толстых» сервисов. Я сейчас говорю про большое количество зависимостей передаваемых в конструктор. Если к этому до... | https://habr.com/ru/post/350688/ | null | ru | null |
# 7 полезных HTML-атрибутов, о которых вы, возможно, не знаете
Веб-разработчик просто обязан хорошо знать HTML и уметь им пользоваться. Тот, кто не ориентируется в HTML, просто не может называться веб-разработчиком. Ведь каждый сайт в интернете создан с применением HTML. Этот язык разметки обладает массой ценных возмо... | https://habr.com/ru/post/548680/ | null | ru | null |
# 19 концепций, которые нужно изучить для того, чтобы стать эффективным Angular-разработчиком
TODO-приложение во фронтенд-разработке — это то же самое, что «Hello world» в обычном программировании. При создании TODO-приложений можно изучить выполнение CRUD-операций средствами того или иного фреймворка. Но часто подобн... | https://habr.com/ru/post/455503/ | null | ru | null |
# Есть ли жизнь без тестов?
Это история про то, как нам удалось написать довольно сложную business-critical систему, и добиться, чтобы она была стабильной даже *без юнит-тестов* (WAT?!).
Представьте: ERP-система в области логистики. Сложная бизнес-логика, составление расписаний, электронный учет рабочего времени, п... | https://habr.com/ru/post/279943/ | null | ru | null |
# FabEx — block explorer для Hyperledger Fabric
Привет, я хочу рассказать про проект [FabEx](https://github.com/hyperledger-labs/fabex) — block explorer для Hyperledger Fabric, недавно принятый в Hyperledger Labs и имеющий некоторые преимущества относительно официального эксплорера. Проект написан полностью на Golang ... | https://habr.com/ru/post/501422/ | null | ru | null |
# Rust 1.48.0: упрощение создания ссылок и псевдонимы поиска
Команда Rust рада сообщить о выпуске новой версии, 1.48.0. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
Если вы установили предыдущую версию Rust средствами `rustup`, то для обновления до ве... | https://habr.com/ru/post/528204/ | null | ru | null |
# Вертикальный текст
Потребовалось мне использовать вертикальное расположения текста для обозначения заголовков таблицы. Поиски в интернете привели только к устаревшим или еще не утвержденным стандартам, фильтрам IE и не поддерживающих кириллицу или Mozilla Firefox SVG.
Поэтому пришлось самому решать проблему. Немн... | https://habr.com/ru/post/51438/ | null | ru | null |
# Безопасная передача данных между двумя приложениями
Всем привет, сегодня я хотел бы вам рассказать о некоторых вариантах передачи данных между двумя андроид приложениями и рассмотреть их с точки зрения безопасности. Я решил написать эту статью по двум причинам. Первая — я начал часто сталкиваться с непониманием разр... | https://habr.com/ru/post/448198/ | null | ru | null |
# PHP HTML DOM парсер с jQuery подобными селекторами
Добрый день, уважаемые хабровчане. В данном посте речь пойдет о совместном проекте [S. C. Chen](http://sourceforge.net/users/me578022) и [John Schlick](http://sourceforge.net/users/john_schlick) под названием [PHP Simple HTML DOM Parser](http://sourceforge.net/proje... | https://habr.com/ru/post/176635/ | null | ru | null |
# .NET и паттерны проектирования
Шаблон проектирования или паттерн — повторимая архитектурная конструкция, представляющая собой решение проблемы проектирования в рамках некоторого часто возникающего контекста.
Кажется, это определение мы слышали тысячу раз… Помимо знания терминов и паттернов интересно знать, как он... | https://habr.com/ru/post/191934/ | null | ru | null |
# Перенос десктопных приложений на .NET Core
С тех пор, как я начала работать с сообществом над переносом десктопных приложений с .NET Framework на .NET Core, я заметила, что существует «два лагеря»: представители одного хотят очень простой и короткий список инструкций для переноса своих приложений на .NET Core, в то ... | https://habr.com/ru/post/454508/ | null | ru | null |
# Кодирование с изъятием информации. Часть 2-я, математическая
### Введение
В [предыдущей](https://habrahabr.ru/post/318848/) части рассматривалась принципиальная возможность кодирования при котором, в случае, если можно выделить общую часть у ключа и сообщения, то передавать можно меньше информации чем есть в исходн... | https://habr.com/ru/post/345962/ | null | ru | null |
# WordPress 3.0: новые возможности. Более детально

На хабре уже были статьи о новых возможностях WordPress 3.0, но после того как в мои руки попала альфа-версия, я решил рассказать Вам более подробно... | https://habr.com/ru/post/87840/ | null | ru | null |
# Слава баг-репортам, или как мы сократили время анализа проекта пользователя с 80 до 4 часов

Работа в поддержке часто воспринимается как что-то негативное... | https://habr.com/ru/post/588833/ | null | ru | null |
# Передача GPS-трека по SMS
У вас прогрет распределённый и отказоустойчивый бэкенд, написано крутое мобильное приложение под все возможные платформы, но, внезапно, выясняется, что ваши пользователи так далеки от цивилизации, что единственный способ связи с ними — это SMS? Тогда вам будет интересно прочитать историю о ... | https://habr.com/ru/post/318796/ | null | ru | null |
# OceanLotus: атака watering hole в Юго-Восточной Азии
Специалисты ESET выполнили анализ новой кампании watering hole, которая нацелена на несколько сайтов в Юго-Восточной Азии. Предположительно атакующие действуют с начала сентября 2018 года. Кампания отличается масштабом – нам удалось обнаружить 21 скомпрометированн... | https://habr.com/ru/post/436136/ | null | ru | null |
# Простой способ редактирования, хранения и передачи параметров между job'ами Jenkins
Как и любой здоровый человек — могу назвать себя в меру ленивым.
Так, например, мне лень писать длинный pipeline (вообще писать руками pipeline лень). И мне не нравится идея гонять туда — сюда файлик, в который придётся писать пар... | https://habr.com/ru/post/506642/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.