
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Random Forest, метод главных компонент и оптимизация гиперпараметров: пример решения задачи классификации на Python
У специалистов по обработке и анализу данных есть множество средств для создания классификационных моделей. Один из самых популярных и надёжных методов разработки таких моделей заключается в использова... | https://habr.com/ru/post/488342/ | null | ru | null |
# Беседы о функциональном программировании на C++ Siberia 2019
Всем привет!
Недавно в Новосибирске прошла очередная C++ Siberia 2019. На конференции была уютная атмосфера и много хороших докладов. Пользуясь случаем, я побеседовал с двумя нашими докладчиками, которых совсем скоро вы сможете увидеть и в Москве.
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu). Надеюсь, что это поможет х... | https://habr.com/ru/post/541006/ | null | ru | null |
# UDP и проблема доставки ответа

Ниже — перевод статьи о проблеме работы с udp в сетевых приложениях. Переводчик позволил себе сменить примеры: в исходном тексте другие сетевые адреса и код на ruby. В... | https://habr.com/ru/post/146922/ | null | ru | null |
# 2ГИС вам на руку. Как мы добавили карту на Apple Watch

Apple Watch быстро завоевали популярность и стали самыми популярными часами в мире, опередив Rolex и остальных производителей. Идея создания приложения для часов витала в офис... | https://habr.com/ru/post/422935/ | null | ru | null |
# Silverlight 2. Интеграция с HTML и JavaScript
[](http://blogs.msdn.com/blogfiles/mikcher/WindowsLiveWriter/399b0553bd9f_9392/silverlighter-splash-20081203b_4.png)
В начале хотелось бы поделит... | https://habr.com/ru/post/46501/ | null | ru | null |
# Документ в перспективе, что с ним делать? Корректировка результатов бесконтактного сканирования и фотографий документов
Идея данной статьи возникла у нас после прочтения статьи [«Как работает автоматическое выделение документа на изображении в программе ABBYY FineScanner?»](http://habrahabr.ru/company/abbyy/blog/200... | https://habr.com/ru/post/223507/ | null | ru | null |
# Заботливый контроллер событий на странице
 Наверняка вы сталкивались с такими задачами:
— Подгрузить ajax данные на страницу;
— По клику на объект получить ответ от сервера;
— Сделать вывод (не) зависимого с... | https://habr.com/ru/post/233469/ | null | ru | null |
# Поднимаем Apache Superset — необходимый и достаточный гайд
Эта статья вдохновлена опытом знакомства с инструментом Apache Superset: автору было очень интересно, что же представляет из себя один из главных представителей on-premise инструментов BI-визуализации (а также стояла соответствующая задача по работе, но это ... | https://habr.com/ru/post/661159/ | null | ru | null |
# Простейшее рисование с помощью PIL
Недавно потребовалось мне создавать картинку на лету. Решил спользовать библиотеку для питона PIL. Она поддерживает кучу форматов, а также множество цветовых систем (RGB, RGBA и более простые). Итак, рассмотрим простейшее, как создать рисунок и что-либо на нем нарисовать.
Для на... | https://habr.com/ru/post/49361/ | null | ru | null |
# Генератор админок
**Кратко суть проблемы:** нужно было много админок, написал генератор админок.

| | |
| --- | --- |
| **Как работает:*** описали сущности в JSON;
* сгенерировали схему БД (PostgreSQL... | https://habr.com/ru/post/318332/ | null | ru | null |
# Боевой полет на Meteor-e
Обсуждение тем по [Метеору](https://www.meteor.com) редко встретишь среди русскоговорящих (судя по каналу в телеге и паблике вк, Хабр). Обмен опытом возможен, но по большей части на официальном форуме метеора.
На Хабре уже давно не было статей по Метеору, поэтому хотелось бы поделиться на... | https://habr.com/ru/post/437166/ | null | ru | null |
# Как мы спасали глаза с OpenCV
Материалы этого поста задержались с выходом в свет на 4 месяца. Мы — молодая команда разработчиков, и только учимся нарушать dead-лайны, но кажется, что получается уже неплохо. Предыстория в [этой статье](http://habrahabr.ru/post/197986/), где мы и обещали выложить продолжение. Рассказ ... | https://habr.com/ru/post/215771/ | null | ru | null |
# Android in-app purchases, часть 2: инициализация и обработка покупок
Привет всем, я Влад, core разработчик [Android SDK для обработки платежей в мобильных приложениях](https://adapty.io/sdk/android?utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_android_initialization-and-processing) в Adapty
Это втор... | https://habr.com/ru/post/571122/ | null | ru | null |
# Создание простейших структур данных с помощью функций в Python
**Вступление**: Позапрошлым летом я открыл для себя великолепную книгу **SICP** — чтение только первого раздела книги открыло для меня новый мир функционального программирования. Анонимные функции, функции, что возвращают функции, функции высших порядко... | https://habr.com/ru/post/262021/ | null | ru | null |
# Компонент для интеграции строк Ext.grid.Panel с Ext.toolbar.Toolbar
В рамках создания административной части одного из проектов, мне посчастливилось разработать довольно стройный компонент, элегантно дополняющий достаточно богатый функционал библиотеки ExtJS 4.
Пример использования: <http://siterra.org/examples/r... | https://habr.com/ru/post/168413/ | null | ru | null |
# Идентификация клиентов на сайтах без паролей и cookie: заявка на стандарт
Уважаемые Хаброжители! Уважаемые эксперты! Представляю на вашу оценку новую концепцию идентификации пользователей на веб-сайтах, которая, как я надею... | https://habr.com/ru/post/472310/ | null | ru | null |
# Yargy-парсер и библиотека Natasha. Извлечения структурированной информации из текстов на русском языке
> В 2020 году библиотека Natasha значительно обновилась, на Хабре опубликована [статья про актуальную версию](https://habr.com/ru/post/516098/). Чтобы использовать инструменты, описанные в этом тексте, установите с... | https://habr.com/ru/post/349864/ | null | ru | null |
# Доступ к ClickHouse с помощью JDBC
Привет Хабр! Не так давно я имел удовольствие посетить встречу [PyData Moscow](https://events.yandex.ru/events/ds/23-jun-2017/) на площадке Яндекса. Я не могу назвать себя python разрабочиком, но имею интересы в области аналитики и анализа данных. Посетив данное мероприятие, я узна... | https://habr.com/ru/post/332112/ | null | ru | null |
# Scala коллекции: секреты и трюки
Представляю вашему вниманию перевод статьи [Павла Фатина](https://pavelfatin.com/about) [Scala Collections Tips and Tricks](https://pavelfatin.com/scala-collections-tips-and-tricks/). Павел работает в [JetBrains](https://www.jetbrains.com/) и занимается разработкой [Scala плагина](ht... | https://habr.com/ru/post/333362/ | null | ru | null |
# Как я разработал мобильную игру на Android с использованием React.js и выложил её в Google Play Store
В данной статье рассмотрим все этапы разработки: от зарождения идеи до имплементации отдельных частей приложения, в том числе выборочно будут предоставлены некоторые кастомные куски кода.
Данная статья может быть п... | https://habr.com/ru/post/535720/ | null | ru | null |
# Язык программирования J. Взгляд любителя. Часть 3. Массивы
*Предыдущая статья цикла [Язык программирования J. Взгляд любителя. Часть 2. Тацитное программирование](http://habrahabr.ru/post/198066/)*
> *«Я не думаю, что он нам подходит. Я рассказал ему, чем мы занимаемся, и он не стал спорить. Он просто слушал.»
... | https://habr.com/ru/post/198228/ | null | ru | null |
# Установка Zabbix 2.4 на RedHat Openshift
Недавно мне потребовался собственный «облачный» сервер мониторинга бюджетом в 0 рублей. В качестве решения был выбран zabbix на платформе openshift. Данный вариант подходит для резервного базового мониторинга или мониторинга небольшого портала с помошью web-scenarios и кастом... | https://habr.com/ru/post/266327/ | null | ru | null |
# typeof Everything и утиные недоразумения

Каждый, использующий в каких бы то ни было целях замечательный **JavaScript**, задавался вопросом: мол а почему *typeof null* — это *"object"*? *typeof* от функции возвращает *"functio... | https://habr.com/ru/post/427253/ | null | ru | null |
# Мониторинг сетевого оборудования Cisco в системе Observium

Observium — это система, ориентированная на сбор и анализ информации, позволяющая выявлять глубинные проблемы в работе сети. Если перед вами стоит задача провест... | https://habr.com/ru/post/249549/ | null | ru | null |
# Пример web-проекта на VS2010
Выход VS 2010 для меня, в первую очередь, это возможность работать с .Net 4, Entity Framework 4, ASP.NET MVC 2.
Все полученные теоретические знания, на мой взгляд должны быть выражены в практическом опыте. Поэтому как только представилась возможность, я реализовал проект с использован... | https://habr.com/ru/post/93331/ | null | ru | null |
# Разбираемся с not в Python
> *Привет, Хабр. В преддверии старта курса* [*«Python Developer. Professional»*](https://otus.pw/3SAG/) *подготовили традиционный перевод полезного материала.
>
> Также приглашаем всех желающих посетить открытый вебинар на тему* [*«Визуализация данных с помощью matplotlib».*](https:/... | https://habr.com/ru/post/542474/ | null | ru | null |
# Ping-flooding атака с использованием WinPcap

ICMP протокол
=============
Протокол ICMP является одним из компонентов стека TCP/IP (Transmission Control Protocol/Internet Protocol — протокол управления передачей/проток... | https://habr.com/ru/post/157207/ | null | ru | null |
# Визуальное руководство по диагностике неисправностей в Kubernetes
***Прим. перев.**: Эта статья входит в состав опубликованных в свободном доступе материалов проекта [learnk8s](https://learnk8s.io/), обучающего работе с Kubernetes компании и индивидуальных администраторов. В ней Daniele Polencic, руководитель проект... | https://habr.com/ru/post/484954/ | null | ru | null |
# Забудьте про RGB и HEX
В CSS существует несколько способов представления цветов. Один из них — система HSL. В этой статье я покажу вам, какие возможности она открывает для верстальщика.
Что такое HSL
-------------
Название формата HSL образовано от сочетания первых букв Hue (оттенок), Saturate (насыщенность) и L... | https://habr.com/ru/post/496768/ | null | ru | null |
# Power Pivot: Оконные функции под соусом DAX (еще немного специй)

Продолжение статьи о сравнении возможностей оконных функций SQL Server и формул DAX
В [прошлой статье](http://habrahabr.ru/post/229583/#first_unread) были ... | https://habr.com/ru/post/234097/ | null | ru | null |
# Я оглянулся посмотреть не оглянулась ли она — 2 или сам себе датацентр через AWS

Публикуем любые сервисы, расположенные в домашнем гипервизоре через сервис [EC2 Amazon Web Services](https://aws.amazon.com/ec2/) через беспла... | https://habr.com/ru/post/470047/ | null | ru | null |
# Начинаем работать в STM32CubeMX. Часть 2
[Часть 1](https://habrahabr.ru/post/310742/)
[Часть 3](https://habrahabr.ru/post/323674/)
В [прошлый раз](https://habrahabr.ru/post/310742/) мы научились создавать в STM32CubeMX новый проект, настраивать тактовый генератор, таймер и порт ввода-вывода, и немного помигали... | https://habr.com/ru/post/312810/ | null | ru | null |
# Лунный звездный месяц (27.32 дней), лунный месяц по фазам Луны (29.5306 дней) в радиоактивном распаде
Эта статья продолжение серии публикаций по [эффекту Шноля](https://yadi.sk/i/clhVm4XCwqiZUQ) - космо-физических циклов проявляющихся в случайных процессах (прежде всего в радиоактивном распаде). [Здесь приведенный а... | https://habr.com/ru/post/578694/ | null | ru | null |
# Распутывая Ansible Loops
В посте рассматриваются следующие Ansible модули loop: with\_items, with\_nested, with\_subelements, with\_dict.
Все эти with\* уже deprecated, и рекомендуется использовать loop.
[Исходный код](https://github.com/ctorgalson/ansible-loops)
Одна из моих ролей в Chromatic — член команды Dev... | https://habr.com/ru/post/526526/ | null | ru | null |
# Тонкости перегрузки методов по константности *this
[](http://www.picamatic.com/view/6044036_dress11/)Обнаружил, что есть аспект работы C++, о котором я раньше как-то не задумывался. А именно... | https://habr.com/ru/post/76065/ | null | ru | null |
# Knockout, практический опыт использования
Некоторое время назад я обещал рассказать о нашем опыте работы с Knockout. Мы используем данную библиотеку в одном из проектов в течение последних 4 месяцев. Это немного, но за это время команда набрала некоторый опыт, который, я думаю, может быть интересен читателям.
Но ... | https://habr.com/ru/post/124731/ | null | ru | null |
# OpenHAB — стань программистом собственного жилища

##### Дом — это машина для жилья
Ле Корбюзье
В этом посте я расскажу об *opensource* проекте домашней автоматизации [openHAB](http://www.openhab.org/).
openHAB... | https://habr.com/ru/post/232969/ | null | ru | null |
# Произвольный порядок списка инициализации шаблона
Думаю многие кто работает с шаблонами, знакомы со следующей ситуацией. У нас есть некий шаблонный класс с кучей шаблонных параметров
```
struct deferred;
struct deadline;
struct disable;
template
struct some\_container
```
Пускай это будет некий интерфейс отлож... | https://habr.com/ru/post/219999/ | null | ru | null |
# Развертывание и сопровождение Redmine, правильный путь

Дисклеймер: это не обычное руководство вида «Как установить Redmine». В нем я не буду погружаться в настройку базы данных или установку веб-сервера. Я также не буду расск... | https://habr.com/ru/post/329872/ | null | ru | null |
# Реверс-инжиниринг android приложений
В этой статье я постараюсь рассказать про реверс-инжиниринг приложений для android. Этот процесс несколько отличается от оного для win-приложений: здесь нет отладчика и... | https://habr.com/ru/post/111513/ | null | ru | null |
# Liscript — REPL боты онлайн
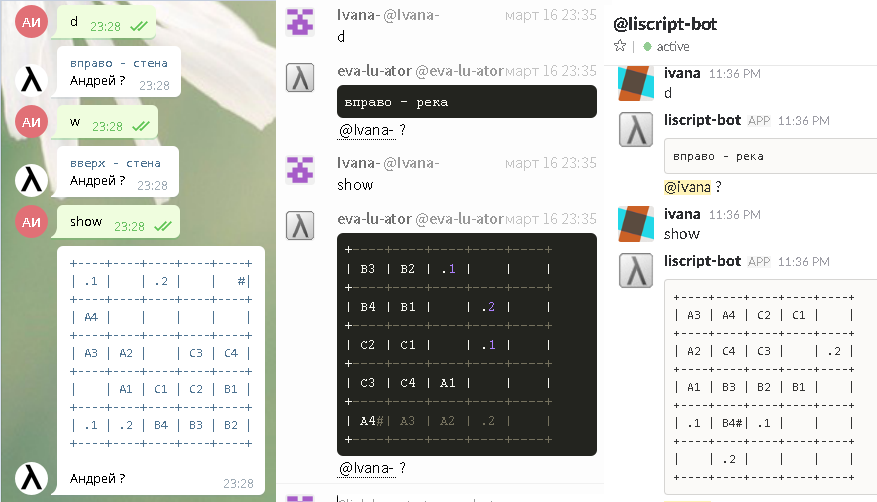
Некоторое время назад, вдохновившись прочтением SICP, я написал пару своих реализаций интерпретаторов лиспоподобного языка со строгой семантикой, добавил десктопный GUI, консольный интерфейс, н... | https://habr.com/ru/post/324166/ | null | ru | null |
# Настоящее модульное тестирование в AngularJS
AngularJS молод и горяч, когда дело доходит до современной веб разработки. Его уникальный подход к компиляции HTML и двусторонней привязки данных делает его эффективным инструментом для создания клиентских веб приложений. Когда я узнал что Quick Left (студия в которой раб... | https://habr.com/ru/post/233705/ | null | ru | null |
# Локализация в СУБД Caché
Предположим, вы написали программу, выводящую «Hello, World!», например:
`write "Hello, World!"`
Приложение работает, всё хорошо.
Но проходит время, ваше приложение развивается, становится популярным и вот, вам нужно эту строку вывести уже на другом языке, причём количество и соста... | https://habr.com/ru/post/144312/ | null | ru | null |
# Сказ про резисторы и неонки
Расчёт цепей постоянного тока на пальцах, или давайте считать ЦАП для троичной логики
-------------------------------------------------------------------------------------
### Но для начала неонки, какой же русский их не любит?
Итак, снова я со своими троичными железками, но в этой стат... | https://habr.com/ru/post/341328/ | null | ru | null |
# Как решить популярную в 2022 головоломку Wordle на Python
К старту курса по [Fullstack-разработке на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campai... | https://habr.com/ru/post/645653/ | null | ru | null |
# Управляем службами Windows с помощью PowerShell. Часть 3. Конфигурируем службы с помощью WMI и CIM

Продолжаем публиковать переводы статей, выходящих на портале [4sysops.com](http://4sysops.com), посвященных управлению... | https://habr.com/ru/post/168011/ | null | ru | null |
# Drupal 8 + Varnish: Кешируем HTML правильно
Drupal 8 – это самый свежий релиз CMS Drupal. Varnish – это HTTP reverse proxy cache, надстройка над вебприложением, которая позволяет кешировать HTTP ответы в ОЗУ сервера.
Когда мы ставим Varnish перед Drupal’ом (либо любым другим вебприложением), схема обработки входя... | https://habr.com/ru/post/350978/ | null | ru | null |
# Шишки, набитые за 15 лет использования акторов в C++. Часть II
Завершаем рассказ, начатый [в первой части](https://habrahabr.ru/post/324420/). Сегодня рассмотрим еще несколько граблей, на которые довелось наступить за годы использования [SObjectizer](https://sourceforge.net/projects/sobjectizer/)-а в повседневной ра... | https://habr.com/ru/post/324978/ | null | ru | null |
# Как создать тему для Magento 2 с нуля

Здравствуйте, уважаемые хабрапользователи! В этой публикации хочу описать процесс создания темы для Magento 2 с нуля. Magento 2 имеет достаточно большое количество нововведений и улуч... | https://habr.com/ru/post/311350/ | null | ru | null |
# Elixir в биоинформатике

В этой статье я расскажу о своей попытке использования библиотеки [GenStage](https://hexdocs.pm/gen_stage/Experimental.GenStage.html), а в частности модуля [Flow](https://hexdocs.pm/gen_stage/Exper... | https://habr.com/ru/post/318104/ | null | ru | null |
# 19 идей для Node.js-разработчиков, которые стремятся вырасти над собой в 2019 году
Автор материала, перевод которого мы публикуем, собрал 19 идей, которые могут оказаться полезными для тех Node.js-разработчиков, которые хотят повысить свой профессиональный уровень в 2019 году. Мир JavaScript огромен, поэтому освоить... | https://habr.com/ru/post/434114/ | null | ru | null |
# Создание и тестирование Firewall в Linux, Часть 1.2. Простой перехват трафика с Netfilter
**Содержание первой части:**
[**1.1** — Создание виртуальной лаборатории (чтобы нам было где работать, я покажу как создать виртуальную сеть на вашем компьютере. Сеть будет состоять из 3х машин Linux ubuntu).](https://habra... | https://habr.com/ru/post/315350/ | null | ru | null |
# ES5 Harmony Proxy — меняем семантику JavaScript внутри самого JavaScript
Прокси — это новые объекты JavaScript для которых программист должен определить своё поведение. Стандартное поведение всех объектов определено в движке JavaScript, который чаще всего написан на C++. Прокси позволяют программисту определить прак... | https://habr.com/ru/post/117915/ | null | ru | null |
# Модификация стоковых прошивок для Android. Часть 1
Здравствуй Хабр!
Несколько лет назад, когда я впервые познакомился с Android, я услышал от своего коллеги по работе, что Android предусматривает возможность установки модифицированных или самодельных прошивок. Признаться, тогда я был далек от этого. И даже пол го... | https://habr.com/ru/post/181826/ | null | ru | null |
# Hack The Box — прохождение Forest. AS-REP Roasting, атаки DCSync и Pass-The-Hash

Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu). Надеюсь, что это поможет хоть... | https://habr.com/ru/post/493478/ | null | ru | null |
# Создание виртуальных хостов в apache под Linux на Python
Занимаюсь разработкой сайтов и всякие эксперименты и основную разработку делаю на локальном компьютере под Debian. В следствии того, что приходилось постоянно ручками создавать виртуальные хосты пришлось поставить себе цель автоматизировать процесс.
Первый... | https://habr.com/ru/post/127996/ | null | ru | null |
# Ошибка в коде AFNetworking позволяет перехватывать HTTPS трафик пользователей
В одном из самых популярных фреймворков для работы с сетью в iOS и OS X системах была найдена критическая уязвимость. Под прицелом специалистов из Minded Security оказался [AFNetworking](https://github.com/AFNetworking/AFNetworking), а име... | https://habr.com/ru/post/257163/ | null | ru | null |
# Беглый взгляд на Async-Await в Android
##### От переводчика
*Это мой первый перевод, поэтому прошу прощения за неточности. Если вы найдете ошибки в переводе, пожалуйста, сообщите об этом. Я не нашел лучшего перевода слова **[сoroutine](https://en.wikipedia.org/wiki/Coroutine)**, чем **[сопрограмма](https://ru.wikip... | https://habr.com/ru/post/314574/ | null | ru | null |
# LIVR — «независимые от языка правила валидации» или валидация данных без «проблем»
Каждый программист неоднократно сталкивался с необходимостью проверки пользовательского ввода. Занимаясь веб-разработкой уже более 10 лет, я перепробовал массу библиотек, но так и не нашел той единственной, которая решала бы поставлен... | https://habr.com/ru/post/246521/ | null | ru | null |
# Мой краткий чек-лист по скилам системного аналитика
**Дисклеймер**. Это не описание вакансии системного аналитика в Альфа-Банке. Это мой **личный чек-лист**, который я составлял для себя и решил им поделиться. Скилами из списка я бы хотел «одновременно хорошо и уверенно владеть».
**Об авторе:**

* [Величины, типы и операторы](http://habrahabr.ru/post/240223/)
* [Структура программ](http://habrahabr.ru/post/240225/)
* [Функции](http://habrahabr.ru/post/240349/)
* [Структуры данных: объекты и массивы](h... | https://habr.com/ru/post/244041/ | null | ru | null |
# SVG с прозрачным фоном в Chrome и Safari
Здравствуйте, дорогие читатели. Те из вас, кто когда-либо работал с форматом svg, знают о противном и, что самое главное, чрезвычайно старом [баге](https://bugs.webkit.org/show_bug.cgi?id=17744), проявляющемся в webkit-браузерах. Суть бага в том, что если вставить svg-картинк... | https://habr.com/ru/post/110367/ | null | ru | null |
# Интеграция iCloud на примере игры Cut the Rope
Привет хабра-житель. Сегодня я хотел бы поведать тебе о своем опыте интеграции iCloud в игру Cut the Rope.
На этот пост меня вдохновил отзыв одного пользователя, пришедший на почтовый адрес технической поддержки:
«I do not need any help, I just wanted to ask you s... | https://habr.com/ru/post/137947/ | null | ru | null |
# Тестируем CSS в Selenium IDE

Я все больше в своей практике пытаюсь использовать автоматизированное тестирование. Стараюсь при этом не плодить инструменты и библиотеки, обходиться простыми подходами. Не так давно, я ... | https://habr.com/ru/post/190358/ | null | ru | null |
# Фронтенд-2017: о самом важном
Много всего произошло в 2017-м, на самом деле — и подумать страшно — сколько всего случилось. Всем нравится шутить о том, как быстро всё меняется в разработке фронтенда, и в последние несколько лет это, вероятно, так и было. Рискуя быть неоригинальным, хочу сказать, что в 2017-м всё был... | https://habr.com/ru/post/345792/ | null | ru | null |
# Проекту ReactOS требуются студенты для участия в Google Summer of Code 2018

Привет, Хабр!
Спешим сообщить, что операционная система ReactOS уже третий год подряд получает слоты на Google Summer of Co... | https://habr.com/ru/post/351382/ | null | ru | null |
# Использование Android Search Dialog. Пример простого приложения
Данная статья предназначена для тех, кто уже написал свой HelloWorld для Android и знает, что такое Activity и Intent, а так же где на... | https://habr.com/ru/post/111475/ | null | ru | null |
# Зачем я написал очередной генератор статических сайтов
Сначала, думаю, нужно представиться. Я не программист, программирование для меня скорее хобби, да и из современных языков на момент написания моего велосипеда я знал только Java Script (и немного Java). Так что делюсь не программистскими наработками, а взглядом ... | https://habr.com/ru/post/172571/ | null | ru | null |
# Как создать изображение штрих-кода на Java
Штрих-коды повсеместно используются в коммерции и розничной торговле для помощи в отслеживании товаров, покупках и инвентаризации. Они позволяют организациям вести... | https://habr.com/ru/post/533194/ | null | ru | null |
# Простейший способ реализации переключения цен в 1С-Битрикс
Довольно часто на интернет-магазинах оптовой торговли можно встретить сразу несколько типов цен — обычно их обозначают как ОПТ1, ОПТ2, ОПТ3 и т.п. В зависимости от того, на какую сумму покупатель набрал добра в корзине и(или) иных условий, для него срабатыва... | https://habr.com/ru/post/184898/ | null | ru | null |
# Docker в браузере, или как создать и «расшарить» среду разработки
Docker нынче не использует только ленивый. Вокруг этой технологии заварилась очень интересная каша, не в последнюю очередь благодаря технологиям и продуктам, интегрировавшим Docker, который стал частью их инфраструктуры. Раннеры на Docker-е — это уже ... | https://habr.com/ru/post/243953/ | null | ru | null |
# Мой личный опыт восстановления старых фотографий с помощью нейросетей
Немного о происхождении фотографий. Напомню, что 26 Апреля 1986 года произошла катастрофа на Чернобыльской АЭС.

Но мало кто знает, ч... | https://habr.com/ru/post/695962/ | null | ru | null |
# TraceMonkey — супер-производительный javascript

Ура! Новое, фантастически быстрое, улучшение движка JavaScript(SpiderMonkey) в Mozilla было опубликовано.
Кодовое имя этого творения — TraceMonkey.
Этот движок использует ~~метод добавления своего ко... | https://habr.com/ru/post/37901/ | null | ru | null |
# Создаем плагин для Netbeans на примере языка Vala
Vala — это язык программирования, который создавался как замена языка C при разработке приложений для Gnome. При этом язык на мой взгляд удался, в своем синтаксисе взял многое из C# и Java. Прочитать подробнее о нем можно на [Хабре](http://habrahabr.ru/blogs/linux/99... | https://habr.com/ru/post/124659/ | null | ru | null |
# NetCat для пентестера
Введение в NetCat
-----------------
Netcat, так-же используемый как “nc” – это сетевая утилита, которая использует TCP и UDP соединения для чтения и записи в сети. Он может быть использован как злоумышленниками, так и аудиторами безопасности. Учитывая сценарий атаки, этот кросс-функциональный ... | https://habr.com/ru/post/678968/ | null | ru | null |
# Монолитные репозитории в Git
Многие выбрали Git за его гибкость: в частности, модель веток и слияний позволяют эффективно децентрализовать разработку. В большинстве случаев эта гибкость является плюсом, однако некоторые сценарии поддержаны не так элегантно. Один из них — это использование Git для больших монолитных ... | https://habr.com/ru/post/280358/ | null | ru | null |
# Паттерн JavaScript псевдо-класс (pseudo-classical)
В паттерне, объект создается в конструкторе, а его методы объявляются в прототипе.
Данный паттерн используется во фреймворках, таких как Google Closure Library. Нативные объекты JavaScript также используют данный паттернт.
#### Объявление Pseudo-class
Термит ... | https://habr.com/ru/post/210596/ | null | ru | null |
# Шаблонный метод
#### Шаблонный метод
Когда приходится спрашивать человека, какие паттерны проектирования ему доводилось использовать, почему-то мало кто называет паттерн «Шаблонный метод» (Template Method). Вероятно, это связано с пробелом в знании номенклатуры паттернов, ибо лично я с трудом представляю себе, чтоб... | https://habr.com/ru/post/277295/ | null | ru | null |
# Выбор инструмента для анализа безопасности кода Terraform

---
Если вы озадачены выбором инструмента для статического анализа кода Terraform, то мы поможем вам с этим. Мы изучили несколько решений по анал... | https://habr.com/ru/post/558398/ | null | ru | null |
# Caché + Java + Flex. Часть 2
В [первой части](http://habrahabr.ru/company/intersystems/blog/149704/) статьи мы рассмотрели комбинацию Caché + Java. Здесь будет показана структура проекта непосредственно реализующего комбинацию Caché + Java + Flex, а также основные инструменты и их настройки, используемые для её реал... | https://habr.com/ru/post/150031/ | null | ru | null |
# Kubernetes tips and tricks: как повысить продуктивность

Kubectl — это эффективный инструмент командной строки Kubernetes и для Kubernetes, пользуемся мы им ежедневно. У него много функций, и с ним можно развертывать систему Kubernet... | https://habr.com/ru/post/463299/ | null | ru | null |
# Static Reverse engineering для web
Львиная доля всех статей, которые посвящены вопросу обратной разработки посвящены темам анализа низкоуровневого представления приложений и работы прошивок устройств. Тольк... | https://habr.com/ru/post/658453/ | null | ru | null |
# Мониторинг Raspberry Pi с помощью Zabbix
Благодаря доступности, небольшим размерам и энергопотреблению, а также возможности подключения различных периферийных устройств микрокомпьютер Raspberry Pi широко и... | https://habr.com/ru/post/692322/ | null | ru | null |
# Экспорт избранного Хабра в FB2
**Ненавижу длинные вступления**И поэтому не буду писать их даже под спойлером.
* **Зачем?**
+ Для оффлайнового просмотра на читалках.
* **Моя читалка не поддерживает FB2!**
+ [Универсальный конвертор](http://calibre-ebook.com/)
* **Хочу!**
1. Обзаводимся [Python 2.7+](ht... | https://habr.com/ru/post/116982/ | null | ru | null |
# Ray: Распределенная система для использования ИИ
Здравствуйте, коллеги.
Надеемся еще до конца августа приступить к переводу небольшой, но поистине [базовой книги](https://www.amazon.com/Pragmatic-AI-Introduction-Cloud-Based-Learning/dp/0134863860/) о реализации возможностей ИИ на языке Python.
. Похоже, с таким количеством переводов он скоро станет топовым хаброавтором, даже не имея здесь аккаунта!
Чем интересна функциональная архитектура? Она имеет тенденцию попадать в так на... | https://habr.com/ru/post/341460/ | null | ru | null |
# Пара советов для начинающих gamedeveloper'ов от начинающего gamedeveloper'а
Добрый день, хабровчане. Данная статья посвящается людям, которые только пытаются связать себя со сферой разработки игр или же просто думают об этом.
Будучи раздосадованным полным (почти) отсутствием каких-либо ресурсов с игровой тематико... | https://habr.com/ru/post/350702/ | null | ru | null |
# Разработка игр под NES на C. Главы 17-21. Своя игра
В этой части соберем все вместе и сделаем простую скроллерную стрелялку на космическую тему: корабль летит и лазерами отстреливает врагов
[<<< предыдущая](https://habrahabr.ru/post/349742/) [следующая >>>](https://habrahabr.ru/post/351034/)
[
В предыдущей [статье](https://habr.com/ru/company/X5Group/blog/572596/) мы поговорили про роль Data Engineer в Х5, какие задачи он решает и с каким технологическим стеком работает. Рассмотрели структуру собеседования, основны... | https://habr.com/ru/post/584966/ | null | ru | null |
# Играемся с комплексными числами
Привет!
Очередной очерк. На этот раз поиграемся с комплексными числами, с формулами и их визуализацией.

### Идея
Комплексное число — это некоторое расширение вещественного числа, по сути вект... | https://habr.com/ru/post/468781/ | null | ru | null |
# Отзывчивые изображения на практике (Часть 1)
[Часть 2](http://habrahabr.ru/company/paysto/blog/244177/)
[Часть 3](http://habrahabr.ru/company/paysto/blog/244241/)
[Шестьдесят два процента данных](http://httparchive.org/interesting.php#bytesperpage) в сети составляют изображения, и мы [каждый день](http://httpa... | https://habr.com/ru/post/244175/ | null | ru | null |
# Представляем .NET 5 Preview 1
В конце прошлого года мы выпустили .NET Core 3.0 и 3.1. В этих версиях добавлены модели настольных приложений Windows Forms (WinForms) и WPF, ASP.NET Blazor для создания одностраничных приложений и gRPC для кроссплатформенного обмена сообщениями на основе контрактов. Мы также добавили ш... | https://habr.com/ru/post/493390/ | null | ru | null |
# JTable и Serializable или таблицы в Java и танцы с бубном при сохранении объектов в файлы
#### Введение
Так получилось, что как дизайнеру, мне необходим простор для творчества при реализации любых зачач в написании программ. Давно я положил глаз на такую платформу как Java, так-как всегда мечтал о кроссплатформенно... | https://habr.com/ru/post/137352/ | null | ru | null |
# MS не осилило верстку под IE8?
Как-то чисто случайно заглянул в исходник страницы [www.microsoft.com/expression](http://www.microsoft.com/expression/).
О боже мой! Что это в секции head?
Для тех, кто не знает, что это значит: восьмой ишак при попадании на данную страницу будет вести себя как седьмой. Я лично ... | https://habr.com/ru/post/55126/ | null | ru | null |
# Антипаттерны деплоя в Kubernetes. Часть 2
Перед вами вторая часть руководства по **антипаттернам деплоя в Kubernetes**. Советуем также ознакомиться с [первой частью](https://habr.com/ru/company/timeweb/bl... | https://habr.com/ru/post/560772/ | null | ru | null |
# Как я нахожу время?

**На фотографии изображен автор оригинального поста, Стив Клабник, со своим отцом**[Стив Клабник](http://github.com/steveklabnik) широко известен в кругах рубистов. Он является контрибьютором во мн... | https://habr.com/ru/post/161713/ | null | ru | null |
# Composer — менеджер зависимостей для PHP
**Composer** ([getcomposer.org](http://getcomposer.org)) — это относительно новый и уже достаточно популярный менеджер зависимостей для PHP. Вы можете описать от каки... | https://habr.com/ru/post/145946/ | null | ru | null |
# Выпуск#26: ITренировка — актуальные вопросы и задачи от ведущих компаний
Срочно в номер! Возрождение рубрики ITренировки. Мы вновь собрали вопросы и задачи, задаваемые на собеседованиях в IT-компании.

Выпуски будут появля... | https://habr.com/ru/post/477460/ | null | ru | null |
# JavaScript без this
Ключевое слово `this` в JavaScript можно назвать одной из наиболее обсуждаемых и неоднозначных особенностей языка. Всё дело в том, что то, на что оно указывает, выглядит по-разному в зависимости от того, где обращаются к `this`. Дело усугубляется тем, что на `this` влияет и то, включён или нет ст... | https://habr.com/ru/post/334222/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.