
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Сетевой морской бой на bash
Недавно с целью изучения bash написал на нем игру в «морской бой» для игры по сети. Игра получила название «Sink 'em all».

Из внешних программ используются только `nc`... | https://habr.com/ru/post/80122/ | null | ru | null |
# Автоматическая установка Citrix XenServer
Недавно и я стал обладателем сервера [HP ProLiant MicroServer N36L](http://h10010.www1.hp.com/wwpc/by/ru/sm/WF06b/15351-15351-4237916-4237917-4237917-4248009-5037570.html). То, что на нем будет стоять Citrix XenServer, было решено заранее, тем более положительный опыт устано... | https://habr.com/ru/post/123970/ | null | ru | null |
# Свой mapper или немного про ExpressionTrees

Сегодня мы поговорим про то, как написать свой [AutoMapper](https://automapper.org/). Да, мне бы очень хотелось рассказать вам об этом, но я не смогу. Дело в том, что подобные реш... | https://habr.com/ru/post/463961/ | null | ru | null |
# Чиптюн-музыка на ATtiny4 и трехцентовом Padauk
[](https://habr.com/ru/company/ruvds/blog/556386/)
Когда я услышал [«Bitshift Variations in С Minor»](http://txti.es/bitshiftvariationsincminor) Роба Майлза – [16-минутный фрагмент 4... | https://habr.com/ru/post/556386/ | null | ru | null |
# Stripe: сервис вашей мечты для автоматизации денежных переводов
Имевшие дело с сервисом электронных платежей [Stripe](https://stripe.com/) знают, что он отлично заточен под разработчиков. Его документация написана людьми для людей; есть хороший тестовый режим — полная копия реального, и для перехода на live-режим ну... | https://habr.com/ru/post/306338/ | null | ru | null |
# Головоломки TCP
Говорят, что нельзя полностью понять систему, пока не поймёшь её сбои. Ещё будучи студентом я ради забавы написал реализацию TCP, а потом несколько лет проработал в IT, но до сих пор продолжаю глубже и гл... | https://habr.com/ru/post/316128/ | null | ru | null |
# Микроконтроллеры Megawin серии MG32F02: модуль интерфейса I2C
Продолжая цикл публикаций по микроконтроллерам на ядре Cortex-M0 компании Megawin (см. предыдущие статьи [1](https://habr.com/ru/post/674788/), [2](https://habr.com/ru/post/675776/), [3](https://habr.com/ru/post/681702/), [4](https://habr.com/ru/post/6847... | https://habr.com/ru/post/695670/ | null | ru | null |
# Новая жизнь старого синтезатора. Часть 2
Продолжение [истории](http://habrahabr.ru/post/214147/) про старый сгоревший синтезатор, в который я пытаюсь вдохнуть новую жизнь путем полной замены железа, отвечающего за генерацию звука, на программный синтезатор, построенный на базе мини-компьютера EmbedSky E8 с Linux на ... | https://habr.com/ru/post/224987/ | null | ru | null |
# Создание компонента Sidenav
*Приветствую. Представляю вашему вниманию перевод статьи* [*«Building a sidenav component*](https://web.dev/building-a-sidenav-component/)*», опубликованной 21 января 2021 года автором Adam Argyle*
В данной статье я хочу поделиться одним из способов создания адаптивной боковой панели нав... | https://habr.com/ru/post/587864/ | null | ru | null |
# Опубликован закрытый ключ AirPort Express
Американский разработчик Джеймс Лейрд (James Laird), помогая своей девушке наладить связь между точкой доступа и базовой станцией AirPort Express, не нашёл другого выхода, как разобрать AirPort Express, считать ROM и провести обратный инжиниринг программы, после чего он смог... | https://habr.com/ru/post/117212/ | null | ru | null |
# Ранжирование по-байесовски от доктора Кюблера
[](https://habr.com/ru/company/skillfactory/blog/690560/)
Представьте, что в какой-то игре игроки соревнуются один на один. Возникает естественный вопрос: «Как их ранжировать?». За от... | https://habr.com/ru/post/690560/ | null | ru | null |
# Как приручить жесткий диск в ноутбуке и не дать парковаться за 8 секунд простоя
Итак, вы приобрели новый ноутбук, начинаете его настраивать, устанавливаете операционную систему, весь нужный софт, игрушки. Ничто не предвещает беды. И вот, наконец со всем разобравшись, можно расслабиться и почитать интересную статью в... | https://habr.com/ru/post/414271/ | null | ru | null |
# Внутренняя оптимизация для индексов в «широком» плане запроса
В [предыдущей статье](https://habr.com/ru/post/711902/) было показано как SQL Server выполняет изменения в некластерных индексах, но пока только в тех случаях, когда данные в индексе действительно изменяются. В примере из прошлой статьи использовался прос... | https://habr.com/ru/post/713310/ | null | ru | null |
# Новый чемпионат для backend-разработчиков: HighLoad Cup

Проведение конкурсов для IT-специалистов сейчас в моде: Kaggle с его задачами по Data Science, сплоченная тусовка олимпиадного программирования, набирающие популярнос... | https://habr.com/ru/post/335384/ | null | ru | null |
# Другой ответ на вопрос «Нужен ли мне Dart?»
Если вы хотите создавать клиент-серверные веб-приложения, веб-сайты, скрипты, миниигры и вы еще не адепт JS, то ответ однозначно «Да». Если вы флэш разработчик и хочется вновь делать что-то, что запустится в браузере, я бы сказал «Да». Если вы просто хотите научиться прогр... | https://habr.com/ru/post/269239/ | null | ru | null |
# Rekit Studio: IDE для React-приложений
Сегодня мы публикуем перевод материала Нейта Ванга, создателя Rekit. Здесь он рассказывает о новом стабильном релизе системы, [Rekit Studio](https://github.com/supnate/rekit). Это — полноценная IDE для разработки приложений, созданных с использованием технологий React, Redux и ... | https://habr.com/ru/post/349080/ | null | ru | null |
# Программная генерация PDF форм на ABAP или как избавиться от проблем со SPOOL
#### С чего все началось
Специфика компании, в которой я работаю, подразумевает тесный контакт и сотрудничество с нашими клиентами. Одним из таких бизнес-процессов является рассылка различной документации как по почте, так и на бумажных н... | https://habr.com/ru/post/201280/ | null | ru | null |
# Отчёты для NORD POS. Часть 2
### Берём jrxml шаблон и устанавливаем в приложение
В [первой части](http://habrahabr.ru/post/247515/) я рассказал о том, как подготовить в iReport шаблон отчёта для библиотеки JasperReports. А эта статья посвящена тому, как получившийся шаблон интегрировать непосредственно в приложение... | https://habr.com/ru/post/248587/ | null | ru | null |
# Kali Linux получил графический интерфейс для подсистемы Windows для Linux (WSL2). Инструкция по установке
Команда разработчиков Kali Linux [представила](https://www.kali.org/docs/wsl/win-kex/) графический интерфейс для подсистем... | https://habr.com/ru/post/515726/ | null | ru | null |
# Правдоподобная реконструкция Инстаграм-подобных фильтров
Существует куча софта, который позволяет пользователям применять различные цветовые фильтры к своим фотография. Пионером в этом деле был Инстаграм и иногда хочется сделать в своем приложении уже знакомые пользователям фильтры. И я хочу представить набор утилит... | https://habr.com/ru/post/354934/ | null | ru | null |
# Настройка программы Asymptote
Из всех хабов этот показался мне наиболее подходящей для этой темы. Итак.
Скопировано [с моего блога](https://matematikaandinformatika.blogspot.com/) в целях создания еще одного русскоязычного источника информации по данной теме.
Я опишу этот процесс для [Asymptote](https://ru.wik... | https://habr.com/ru/post/466863/ | null | ru | null |
# Как просто наблюдать за состоянием сайта
Чтобы дистанционно следить за работоспособностью серверов, профессионалы используют специальные программные комплексы, вроде [Zabbix](https://www.zabbix.com/) или [Icinga](https://icinga.com/). Но, если вы начинающий владелец или администратор одного-двух веб-сайтов с небольш... | https://habr.com/ru/post/439894/ | null | ru | null |
# VPS как анонимный прокси и не только…
Сегодня каждый пользователь Интернет может приобрести VPS и использовать удаленный сервер, например, для размещения собственного сайта или организации DNS сервера. В данном посте я расскажу о нестандартном использовании VPS: о том как создать личный анонимный прокси сервер и обе... | https://habr.com/ru/post/217629/ | null | ru | null |
# Обгоняем компилятор
На форумах и в других местах общения разработчиков сейчас часто повторяется, что приличный оптимизирующий компилятор всегда будет превосходить жалкие, почти человеческие потуги программы, написанной вручную на ассемблере. Есть редкие случаи, как, например, MPEG-декодеры, где хорошее использование... | https://habr.com/ru/post/317078/ | null | ru | null |
# Отслеживание заполнения форм с помощью Google Analytics
Эффективность работы коммерческого интернет-проекта зависит от количества заказов, регистраций, отзывов и других элементов обратной связи оставленных посетителями сайта через электронную форму.
Соответственно, форма — уязвимое место приема таких обращений, к... | https://habr.com/ru/post/100930/ | null | ru | null |
# PHP-Дайджест № 160 (1 – 15 июля 2019)
[](https://habr.com/ru/post/460022/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.4.0 alpha 3, ReactPHP 1.0 LTS, порция полезных инструментов... | https://habr.com/ru/post/460022/ | null | ru | null |
# Аутентификация пользователей на Arduino с RFID
[](https://habrahabr.ru/company/intersystems/blog/279893/)Введение
--------
В [предыдущей статье](https://habrahabr.ru/company/intersystems/blog/273749/) я тол... | https://habr.com/ru/post/279893/ | null | ru | null |
# Тетрис на микроконтроллере в Tera Term
В этом году компания Atmel анонсировала линейку «младших» кортексов М0+ семейства SAM D09, SAM D10, SAM D11. Эти не сильно «навороченные» контроллеры имеют низкую цену и небольшие корпуса. Причем в линейке присутствуют камни в легкопаяемых корпусах SOIC-14 и SOIC-20. Для ознако... | https://habr.com/ru/post/275401/ | null | ru | null |
# Как звучит сердцебиение: перевод бумажной кардиограммы в WAV-формат

Многим неоднократно приходилось сталкиваться с обследованием сердца в медицинских учреждениях с помощью кардиографа. Данный аппарат измеряет биоэлектрическую ак... | https://habr.com/ru/post/419527/ | null | ru | null |
# 10 противоестественных способов вычисления чисел Фибоначчи
Задача вычисления первых двух десятков чисел Фибоначчи давно потеряла практическую ценность для программистов и используется преимущественно для иллюстрации базовых принципов программирования — рекурсии и итерации. Я же использую ее для демонстрации нескольк... | https://habr.com/ru/post/94421/ | null | ru | null |
# Хаос-инжиниринг, часть 3: Методы и инструменты

> Мы становимся тем, что мы лицезреем. Сначала мы формируем инструменты, потом инструменты формируют нас.
>
>
>
> —Маршал Маклюэн
*Хотелось бы искренне поблагодарить и вырази... | https://habr.com/ru/post/480802/ | null | ru | null |
# Не используйте Java7 ни для чего
Java 7 вышла не так давно, но за 5 дней до её релиза было обнаружено несколько ужасных ошибок в горячей оптимизации циклов, которая включена по умолчанию и приводит Java Virtual Machine к краху (в лучшем случае).
Эти ошибки ([1],[2],[3]) заметили пользователи и разработчики Apache... | https://habr.com/ru/post/125362/ | null | ru | null |
# Подробный мануал «Как создать инфо-тип PA в SAP HR» или «Как приручить SAP?» (часть 1)
SAP – довольно распространенная система на крупных предприятиях не только запада, но и стран постсоветского п... | https://habr.com/ru/post/167935/ | null | ru | null |
# Туториал по AsyncDisplayKit 2.0 (Texture): Начало работы

«Искусство – это все, что вы можете сделать хорошо. Все, что вы можете сделать качественно» (Robert M. Pirsig).
> *От переводчика*:
>
> С появлением autoLayout соз... | https://habr.com/ru/post/329002/ | null | ru | null |
# IpHoster.ru? НЕТ

*Админы делятся на тех, кто не делает бекапы и на тех, кто уже делает*
Привет, читатель! Скажи, было ли у тебя такое, чтобы по какой-то глупой причине ты не успел заплатить за хостинг и просроч... | https://habr.com/ru/post/112249/ | null | ru | null |
# FreePBX и CallBack: видеть номера звонящих
Доброго дня!
Это очень маленькая заметка, но и вопрос прост. Прост, да не так прост, простите за X.
Во FreePBX есть отличный модуль **Callback**. Система сбрасывает звонок и перезванивает, соединяя с указанным номером. Но при этом теряется CallerID, и в софтофонах выс... | https://habr.com/ru/post/301756/ | null | ru | null |
# Программируем императивно в Хаскеле, используя линзы
Хаскель получает много нелестных отзывов, потому что в нём нет встроенного инструментария для работы с изменениями и состояниями. Поэтому, если мы хотим испечь полный состояний яблочный пирог, нам необходимо для начала создать целую вселенную операторов для работы... | https://habr.com/ru/post/190442/ | null | ru | null |
# Berkeley Unified Parallel C (UPC). Установка в среде Windows и Linux
 Unified Parallel C (UPC) — это расширение языка C, разработанное для высокопроизводительных вычислений на крупномасштабных параллельных маши... | https://habr.com/ru/post/315190/ | null | ru | null |
# Запускаем бесплатный мощный сервер Minecraft в облаке
Minecraft — это не просто игра. Его используют в школах для развития детей, для воссоздания архитектурных объектов, улучшения безопасности на реальных ... | https://habr.com/ru/post/563440/ | null | ru | null |
# Библиотеки для декодирования видео. Сравнение на Python и Rust
Многие задаются вопросом — насколько медленный Python в операциях декодирования? Правда ли, что компилируемые языки дают прирост скорости во всем, чего касаются? Что быстрее: OpenCV или ничего? Ответы на эти и другие бесполезные вопросы под катом вы проч... | https://habr.com/ru/post/467537/ | null | ru | null |
# Туннели I2P: Чесночное шифрование и однонаправленная передача информации
Анонимность участников сети I2P достигается путем использования туннелей. Важная особенность I2P заключается в том, что длину туннел... | https://habr.com/ru/post/576094/ | null | ru | null |
# Jinja2 в мире C++, часть вторая. Рендеринг
 Это вторая часть истории о портировании шаблонного движка Jinja2 на C++. Первую можно почитать здесь: [Шаблоны третьего порядка, или как я портировал J... | https://habr.com/ru/post/419011/ | null | ru | null |
# 3 способа задать разметку для различных устройств в C#/XAML приложениях Windows UWP
[](http://habrahabr.ru/post/268695/)
Для начала, хотелось бы напомнить, каким образом можно было создавать универсальные приложения в Win... | https://habr.com/ru/post/268695/ | null | ru | null |
# Раскрашиваем треугольник программным способом
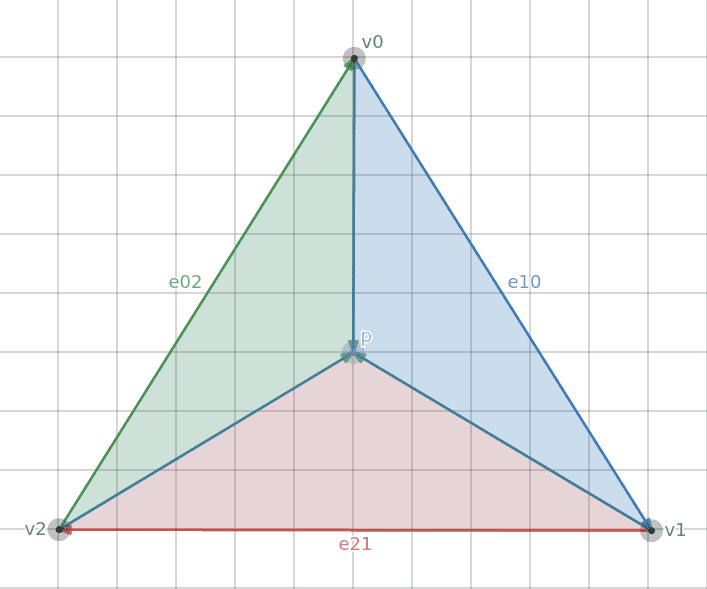
Мне интересно воссоздавать работу GPU программно, поэтому я решил поделиться моим пониманием того, как можно выполнить раскраску треугольников методами простой линейной алгебры.
> Я напиш... | https://habr.com/ru/post/526340/ | null | ru | null |
# Хирургическая операция по увеличению буфера последовательного порта у Arduino IDE

Я не большой фанат инфраструктуры Arduino. Да, сегодня у нас есть уже больше вариантов – к примеру, [pro IDE](https://hac... | https://habr.com/ru/post/512260/ | null | ru | null |
# Визуализация данных для киноманов: скрапим рекомендации фильмов и делаем интерактивный граф

Однажды я наткнулся на [интерактивную карту lastfm](http://sixdegrees.hu/last.fm/interactive_map.html) и решил обязательно сделать подобны... | https://habr.com/ru/post/348110/ | null | ru | null |
# Простой WebSocket-сервер на Node.JS
Сейчас мы с вами напишем простой WebSocket-сервер на node.js. При подключении к этому серверу в ответ придёт приветственное сообщение. А так же будет доступна к выполнению пара не сложных команд.
Для этого потребуется установить [Node.js](https://nodejs.org/en/download/) с менедж... | https://habr.com/ru/post/546758/ | null | ru | null |
# Запуск предустановленной копии Windows в VirtualBox под Ubuntu
Озадачился вчера таким вопросом. Итак, в наличии:
— лаптоп с Pentium Dual-Core 1.86 GHz и 2GB памяти
— стоящие на одном винте Ubuntu 9.04 и Windows XP SP3. Винда побита на два раздела — системный и хранилище.
— желание запустить существующую ... | https://habr.com/ru/post/68421/ | null | ru | null |
# Drag and Drop для вставки картинок
Не так давно был [анонсирован](http://habrahabr.ru/blogs/GMail/91131/) функционал прикладывания файлов к письму через Drag'n'drop. На днях команда GMail расширила эту функцию, добавив возможность прикладывать картинки прямо в тело письма перетаскиванием файлов.
 реализация базовых структур данных, по типу бинарных деревьев и связных списков, довольно легка. Чего не скажешь о хэш картах. В этой статье мы и разберём пример её реализации.
Об устройстве хэш карты
---... | https://habr.com/ru/post/688964/ | null | ru | null |
# Exceptional situations: part 1 of 4
[](https://github.com/sidristij/dotnetbook)
Introduction
------------
It’s time to talk about exceptions or, rather, exceptional situations. Before we start, let’s look at the definition. What is... | https://habr.com/ru/post/454630/ | null | en | null |
# Подборка @pythonetc, июль 2018
Это вторая подборка советов про Python и программирование из моего авторского канала [@pythonetc](http://t.me/pythonetc). Предыдущие подборки:
* [Июнь 2018](https://habr.com/company/mailru/blog/416605... | https://habr.com/ru/post/419025/ | null | ru | null |
# Как обойти капчу: нейросеть на Tensorflow,Keras,python v числовая зашумленная капча
Тема капч не нова, в том числе для Хабра. Тем не менее, алгоритмы капч меняются, как и алгоритмы их решения. Поэтому, предлагается помянуть старое и прооперировать следующий вариант капчи:

***Ключевые слова:*** *DPS (DamagePerSecond); Wolfram Mathematica; дискретность и непрерывность; матанализ; заработок игровой валюты в компьютерных играх; паки ArcheAge.*
Введение
--------
Всем знакомы однотипные вопросы в школьных задачах по математике про... | https://habr.com/ru/post/283208/ | null | ru | null |
# Flutter.dev: Continuous delivery с Flutter
***Перевод статьи подготовлен в преддверии старта курса [«Flutter Mobile Developer»](https://otus.pw/WKU2/).***
---

*Следуйте лучшим практикам непрерывного развертывания (continuous d... | https://habr.com/ru/post/520230/ | null | ru | null |
# Proof Of Concept на Python или как портировать С/С++
Язык программирования Python существует уже 31 год. Это полностью объектно-ориентированный язык. За все время существования на нем стало возможно применя... | https://habr.com/ru/post/649087/ | null | ru | null |
# Обзор новых возможностей в NDepend 6
Что такое NDepend уже было [рассказано](http://habrahabr.ru/post/70387/) на хабре — это статический анализатор кода на .NET'е. Недавно вышла новая — 6-я версия этой замечательной утилиты, о новых возможностях которой рассказывается ниже. Это перевод, оригинальная статья [здесь](h... | https://habr.com/ru/post/261265/ | null | ru | null |
# Пулинг объектов в Unity 2021+
Разрабатывая игры, вы могли заметить, что создание порядка 100 экземпляров пуль в секунд.
* **A**: **уменьшить** количество пуль до 20
* **B**: **реализовать** свою собственну... | https://habr.com/ru/post/560880/ | null | ru | null |
# Functools – сила функций высшего порядка в Python
В стандартной библиотеке Python есть множество замечательных модулей, которые помогают делать ваш код чище и проще, и `functools` определенно является одним... | https://habr.com/ru/post/573164/ | null | ru | null |
# Интеграция PostgreSQL с MS SQL Server для тех, кто желает побыстрее и поглубже

Недавно на хабре уже было опубликовано [описание интеграции](https://habrahabr.ru/company/postgrespro/blog/309490/) PostgreSQL и MSSQL. Но, де... | https://habr.com/ru/post/312090/ | null | ru | null |
# Мой MikroTik – моя цифровая крепость (часть 2)
[](https://habr.com/ru/company/ruvds/blog/575966/)
Статья является продолжением [первой части](https://habr.com/ru/company/ruvds/blog/575808/), посвящённой о... | https://habr.com/ru/post/575966/ | null | ru | null |
# Заголовок Last-Modified, Symfony и ускорение поисковой индексации
Многие разработчики при создании сайтов забывают про очень полезный заголовок Last-Modified, благодаря которому можно оптимизировать загрузку web-страниц и облегчить работу поисковым роботам. Далее я постараюсь восполнить этот досадный пробел.
####... | https://habr.com/ru/post/109043/ | null | ru | null |
# ObjectScript API, интеграция с C++. Часть 2: выполнение скрипта на OS из C++
ObjectScript — новый объектно-ориентированный язык программирования с открытым исходным кодом. ObjectScript расширяет возможности таких языков, как JavaScript, Lua и PHP.
Часть 2: выполнение скрипта на OS из C++
-------------------------... | https://habr.com/ru/post/152813/ | null | ru | null |
# Принципы SOLID в действии: от Slack до Twilio

Похоже, что в наши дни [RESTful API](https://www.twilio.com/docs/api/rest) существует абсолютно для всего. От платежей до бронирования столиков, от простых ... | https://habr.com/ru/post/343966/ | null | ru | null |
# Установка дополнительных версий PHP в VestaCP с помощью Docker
Наверное, многие сталкивались с ситуацией, когда среди проектов, работающих на современном ПО, остается пара полузабытых, а держать отдельную машину под них не хочется. Вариантов решения — масса, но в службе поддержки хостинг-компании данная проблема не ... | https://habr.com/ru/post/569338/ | null | ru | null |
# Как с помощью трансферного обучения обнаружить вулканы на Гавайях
### Геопространственная сегментация изображений с использованием топографических данных и трансферного обучения
Data Science — это не тол... | https://habr.com/ru/post/648417/ | null | ru | null |
# Дональд Кнут — автор «Искусства программирования» и великий мастер ордена программистов Земли
Фото для... | https://habr.com/ru/post/599261/ | null | ru | null |
# Как использовать прогрессивное улучшение для вёрстки писем
[](http://habrahabr.ru/company/pechkin/blog/257915/)
При верстке [email-рассылок](https://pechkin-mail.ru/?utm_source=habr&utm_medium=referral&utm_campaign=progres... | https://habr.com/ru/post/257915/ | null | ru | null |
# Простенький таймер на Javascript
Привет всем рылся у себя в архиве полугодовалой давности и обнаружил один интересный скриптик который должен был выполнять функцию таймера обратного отсчета времени в маленькой системе тестирования, прошу покритиковать, но не сильно :) вот собственно код, надеюсь кому-нибудь будет по... | https://habr.com/ru/post/72460/ | null | ru | null |
# CSS: о выводе коротких и длинных текстов
Когда, пользуясь возможностями CSS, создают макет страницы, важно учитывать то, что в различных элементах этой страницы могут выводиться короткие и длинные текстовые материалы. Страницы, кроме того, нужно тестировать на предмет того, как они отображают тексты разной длины. Ес... | https://habr.com/ru/post/535016/ | null | ru | null |
# Заменяем стандартный элемент input file
Недавно, занимаясь кастомизацией (да простят меня руссоведы) я бы даже назвал это веб-моддингом (ещё раз извините, уважаемые руссоведы) стандартных элементов формы, а в частности элемента file, я наткнулся на большую неприятность: он оказался не профпригоден для настройки. Сут... | https://habr.com/ru/post/13704/ | null | ru | null |
# Гетерогенный поиск в ассоциативных контейнерах на C++
Ассоциативные контейнеры в C++ работают с конкретным типом ключа. Для поиска в них по ключу подобного типа (*std::string*, *std::string\_view*, *const char\**) мы можем нести существенные потери в производительности. В этой статье я расскажу как этого избежать с ... | https://habr.com/ru/post/523668/ | null | ru | null |
# Вышел GitLab 10.7: Web IDE в открытом доступе и отчеты SAST для Go и C/C++

Добавление новой функциональности, ревью изменений и развертывание кода — все это стандартные ра... | https://habr.com/ru/post/354998/ | null | ru | null |
# Собираем свою библиотеку для SSR на React. Роутинг
Привет! Меня зовут Сергей, я занимаюсь фронтендом в [KTS](https://kts.studio/).
В [прошлой статье](https://habr.com/ru/company/kts/blog/566176/) мы создали библиотеку, которая позволяет запускать сервер для рендеринга React-приложения, работает в dev-режиме, а конф... | https://habr.com/ru/post/598571/ | null | ru | null |
# Обзор GraphQL-фреймворков на Java
В [предыдущей статье](https://habr.com/ru/company/hh/blog/677972/) мы поговорили о том, что такое graphQL, почему решили на него переходить, какие у него есть достоинства и недостатки. Но что делать дальше, если вы всё-таки решились внедрить graphQL в java-проект? Какие на данный мо... | https://habr.com/ru/post/681910/ | null | ru | null |
# Cloudflare PHP API Binding
***Перевод статьи подготовлен в преддверии старта курса [«Backend-разработчик на PHP»](https://otus.pw/QCBO/).***

---
Для тех разработчиков, которые используют PHP 7.0 или выше, Cloudflare предоставл... | https://habr.com/ru/post/498936/ | null | ru | null |
# live: новый способ задать обработчик события
[Как известно](http://habrahabr.ru/blogs/jquery/47548/), недавно вышла бета версия jQuery 1.3. Пока она сырая, тестируется, и в ней еще есть неприятные баги. Но знакомится с нововведениями стоит и я хотел бы кратко расс... | https://habr.com/ru/post/47822/ | null | ru | null |
# Docker 1.9 + Weave 1.2.1 bridge mode
Сегодня, после обновления на Docker 1.9 у меня вполне ожидаемо сломался ранее прекрасной работающий [Weave](http://weave.works).
Описание возникших проблем и их решение под катом.
**Проблема №1**.
Проявляется в Ubuntu 14.04.
При попытке выполнить weave launch происход... | https://habr.com/ru/post/270521/ | null | ru | null |
# Метод погруженной границы для чайников
> Отношение между «чистыми» и «прикладными математиками» основаны на доверии и понимании. «Чистые математики» не доверяют «прикладным математикам», а «прикладные математики» не понимают чистых математиков.
>
>
Некоторое время назад я столкнулся с тем, что не смог найти дос... | https://habr.com/ru/post/210276/ | null | ru | null |
# Новое в Symfony 2.4: компонент ExpressionLanguage
В Symfony 2.4 появится новый компонент — **ExpressionLanguage**. Компонент является движком для компиляции и исполнения «выражений».
Этот язык является урезанной версией твига. Выражения укладываются в одну строку и обычно возвращают булево значения, но не огранич... | https://habr.com/ru/post/202058/ | null | ru | null |
# Редактор Urho3D (часть 2)
[Продолжаем](http://habrahabr.ru/post/265749/) постигать редактор Urho3D. В этом уроке мы научимся работать с физикой, познакомимся с префабами, освоим редактор частиц и заставим нашу пушку стрелять. А также, в качестве бонуса, научимся упаковывать ресурсы игры.
**Более актуальная версия... | https://habr.com/ru/post/265837/ | null | ru | null |
# Как мы суслика яблоками кормили или эффективный backend на Go для iOS

Как и обещал, рассказываю о том, как мы мигрировали свой бэкенд на Go и смогли уменьшить объем бизнес логики на клиенте более, чем на треть.
**Для кого**... | https://habr.com/ru/post/331456/ | null | ru | null |
# Прокачиваем навыки отладки JavaScript с помощью консольных трюков
Перед вами перевод статьи из блога Better Programming на сайте Medium.com. Автор, [Indrek Lasn](https://twitter.com/lasnindrek), рассказывает об инструментах для отладки кода, которые предоставляет JavaScript.
 — библиотека алгоритмов компьютерного зрения, обработки изображени... | https://habr.com/ru/post/260741/ | null | ru | null |
# Git for Windows: работа с параметром core.autocrlf
Я работаю в операционной системе «Windows 10». У меня на компьютере [установлена](https://ilyachalov.livejournal.com/237666.html) программа «Git for Windows» версии 2.35.1. В принципе, «Git for Windows» — это та же знаменитая программа (набор программ) «Git» (систем... | https://habr.com/ru/post/703072/ | null | ru | null |
# Flightradar24 — как это работает? Часть 2, ADS-B протокол
Привет Хабр. Наверное каждый, кто хоть раз встречал или провожал родственников или друзей на самолет, пользовался бесплатным сервисом Flightradar24. Это весьма удобный способ отслеживания положения самолета в реальном времени.

Kubernetes становится де-факто стандартом для запуска stateless-приложений. В основном потому, что позволяет значительно сократить time-to-market для доставки новых фич. Запуск stateful-приложений —... | https://habr.com/ru/post/465823/ | null | ru | null |
# Сетки из треугольников в играх

Поговорим о сетках треугольников. Сетки квадратов используются практически повсюду, от пикселей изображения до расположения домов в квартале. Сетки шестиугольников представлены тоже довольно широко, ... | https://habr.com/ru/post/560586/ | null | ru | null |
# Распознавание речи во FreePBX с помощью Яндекс Speechkit
Привет, хабр!
Решил поделиться опытом интеграции Asterisk и сервиса Яндекса по распознаванию речи.
Загорелось моему заказчику внедрить в свою АТС фичу Voice2Text.
В качестве АТС использовался FreePBX.
Сразу в голову пришло использование сервисов ... | https://habr.com/ru/post/242109/ | null | ru | null |
# Windows service. Поиск системных ошибок и отображение их в WinForm C#
В этой статье мы разберем как с нуля создать приложение, которое будет работать со службами windows и отображать системные ошибки в WinForm (C#).
План этой статьи:
* Создание службы
* Event Viewer
* Код службы
* Проверка работы службы(Запус... | https://habr.com/ru/post/452688/ | null | ru | null |
# Как убивать зомби эффективнее с ZeroTier
[](https://habr.com/ru/company/ruvds/blog/500760/)
У вас есть сервер под кроватью, умный дом на даче, а еще IP-камера в гараже. Как их всех объединить в одну сеть чтобы иметь доступ ко все... | https://habr.com/ru/post/500760/ | null | ru | null |
# Анализ шифровальщика Wana Decrypt0r 2.0
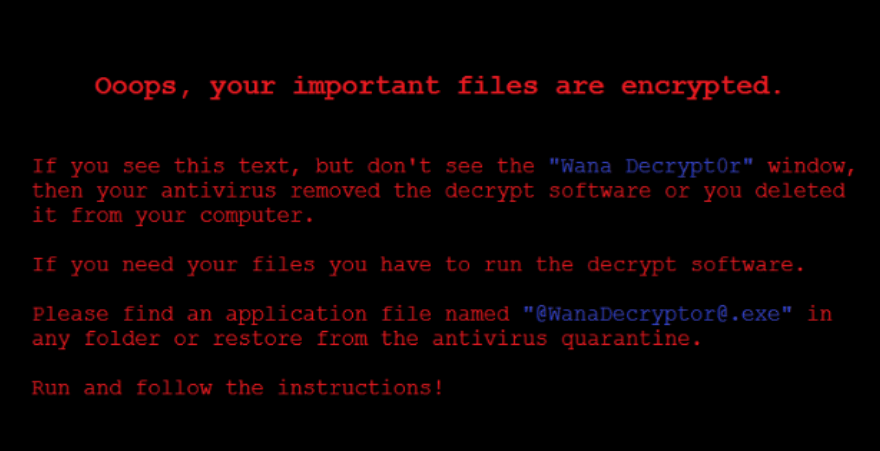
Анализ шифровальщика Wana Decrypt0r 2.0 для выявления функционала, анализа поведения и способов распространения вредоноса.
Wanna Decrypt0r, распространяемый через SMB — это вторая ве... | https://habr.com/ru/post/328606/ | null | ru | null |
# Защита от XSS в Rails 3
Скорее всего вы уже знаете о том, что в Rails 3 по умолчанию добавлена защита от XSS атак. Это значит, что отныне вам никогда не придется вручную фильтровать ввод пользователя используя хелпер `h`, потому что рельсы всегда будут делать это за вас.
Тем не менее, всё не так просто, как кажет... | https://habr.com/ru/post/82726/ | null | ru | null |
# А вы когда-нибудь причиняли себе физическую боль собственным кодом?
Приходилось ли вам когда-нибудь ненароком причинить себе или другим физический вред из-за ошибок в коде? Мне – да.
Примерно год назад я работал со сгенерированными файлами в формате WAV, их было несколько тысяч. Я пытался снабдить их метками, ра... | https://habr.com/ru/post/560960/ | null | ru | null |
# ASP.NET Core: Создание справочных страниц веб-API ASP.NET с помощью Swagger
При создании высоконагруженных приложений бывает сложно разобраться в различных API. Сформировать качественную документацию и справочные страницы в рамках веб-API посредством Swagger с интеграцией Swashbuckle .NET Core так же просто, как доб... | https://habr.com/ru/post/325872/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.