
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# IE9 — ещё одна головная боль веб-разработчика
 Сразу после окончательного релиза 14 марта [сырого Internet Explorer 9](http://habrahabr.ru/blogs/ie/115460/) в Твиттере появился аккаунт **[ie9bugs](http://twitter.com/#... | https://habr.com/ru/post/117033/ | null | ru | null |
# Стеганография на Perl
Доброго времени суток, уважаемые читатели.
Я — представитель типичной (для Хабра) современной «школоты». Интересуюсь околокомпьютерной тематикой, знаю пару языков программирования, верю, что что-то в этом смыслю. Но, пост не о том.
Просматривая хабр, я нередко натыкался на посты по теме с... | https://habr.com/ru/post/121989/ | null | ru | null |
# Мастерхост отключил сервера
Сегодня получил письмо следующего содержания.
`Здравствуйте.
в Дата-Центре masterhost произошел сбой системы
кондиционирования, вследствие чего температура поднялась до 40 градусов
Цельсия. В настоящее время ведутся работы по восстановлению работоспособности
систем, по п... | https://habr.com/ru/post/8655/ | null | ru | null |
# Сервис управляемых аудио-конференций своими руками
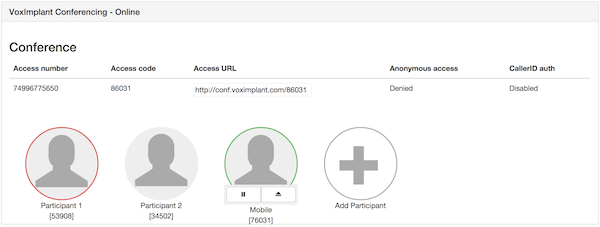Аудио-конференции — удобный инструмент для решения ряда бизнес задач, большинство привыкло пользоваться чем-нибудь готовым, например, Skype. Но есть ряд случаев, когда компан... | https://habr.com/ru/post/229593/ | null | ru | null |
# Формирование данных с помощью шаблонов С++
Однажды была поставлена задача написать некую небольшую программу, она должна была что-то делать, но при это требовалось максимально усложнить процесс анализа кода при дизассемблировании. Один из методов это убрать из exe все упоминания об используемых WinApi функциях, и бы... | https://habr.com/ru/post/113026/ | null | ru | null |
# Проектируем идеальную систему реактивности
Здравствуйте, меня зовут Дмитрий Карловский и я… крайне плох в построение социальных связей, но чуть менее плох в построении программных. Недавно я подытожил свой восьмилетний опыт реактивного программирования, проведя обстоятельный анализ различных подходов к решению типич... | https://habr.com/ru/post/673138/ | null | ru | null |
# Bindon: малоизвестные фишки шаблонов Angular
Недавно вышел Angular 12, а вместе с ним в шаблоны подвезли [оператор нулевого слияния](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Operators/Nullish_coalescing_operator) (`??`). Но что еще умеют шаблоны Angular, о чем вы, возможно, и не слышали? Давайт... | https://habr.com/ru/post/564622/ | null | ru | null |
# Telegraph API: автоматизированное создание заметок
Сервису telegra.ph уже много лет, но информации о том как пользоваться его api почему-то не много, тем временем, крупные телеграм-каналы потихоньку приступили к промышленному освоению. Инструмент вполне себе неплохая альтернатива созданию веб-страниц, к тому же появ... | https://habr.com/ru/post/587430/ | null | ru | null |
# Workflow в Document Approval System
Когда .NET разработчик слышит слова «В проект нужно добавить workflow», то первым приходит в голову идея взять Windows Workflow Foundation.
В 2010 году мы выбрали WF в качестве движка документооборота.
Аргументы просты:
* Бесплатно;
* Встроено в Visual Studio;
* В интерне... | https://habr.com/ru/post/248525/ | null | ru | null |
# Обзор техник реализации игрового ИИ

Введение
========
Эта статья познакомит вас с широким диапазоном концепций искусственного интеллекта в играх («игрового ИИ»), чтобы вы понимали, какие инструмент... | https://habr.com/ru/post/420219/ | null | ru | null |
# Сертификация OSEP, и с чем ее едят
Привет, Хабр!
Относительно недавно (в масштабах вечности) я сдал экзамен [Offensive Security Experienced Penetration Tester](https://www.offensive-security.com/pen300-o... | https://habr.com/ru/post/580078/ | null | ru | null |
# Интеграция Satellite и Ansible Tower
Используете Red Hat Satellite и Red Hat Ansible Automation Platform? Начиная с Satellite 6.3, их можно интегрировать друг с другом, чтобы Dynamic Inventory в Ansible Tower подтягивал списки хостов из Satellite. Кроме того, если хосты RHEL инициализируются средствами Satellite (им... | https://habr.com/ru/post/491138/ | null | ru | null |
# Найти и не обезвредить: пишем пентесты с Kali Linux
#### Kali и другие подобные инструменты помогают обнаружить уязвимости в вашем ПО. И лучше, если первыми их найдёте вы, а не злоумышленники.

Шило в ме... | https://habr.com/ru/post/559562/ | null | ru | null |
# Программирование Arduino с помощью ArduBloсk на примере робота, движущегося по полосе
Здравствуйте! Я Аликин Александр Сергеевич, педагог дополнительного образования, веду кружки «Робототехника» и «Радиотехника» в ЦДЮТТ г. Лабинска. Хотел бы немного рассказать об упрощенном способе программирования Arduino с помощью... | https://habr.com/ru/post/240441/ | null | ru | null |
# Чего ждать, когда ждешь ребенка: PHP 7, часть 2
> Это вторая часть нашей минисерии статей «Чего ждать от PHP7». [Читать часть 1](http://habrahabr.ru/post/257237/)
>
>
Как вы наверное уже знаете, PHP7 придет в этом году! И сейчас самое время узнать что же нового он нам принесет.
В [первой части данной серии](... | https://habr.com/ru/post/258139/ | null | ru | null |
# Dxt сжатие в играх
В этой статье я хочу поделиться своим опытом разработки мобильной игры, поскольку я Windows Phone разработчик, я буду рассказывать про свой опыт применительно к этой системе.
### Память и текстуры
Если Вы уже занимались разработкой мобильных игр, то основное зло не в нехватке ресурсов CPU/GPU,... | https://habr.com/ru/post/206386/ | null | ru | null |
# The New iOS Mobile Enterprise. Часть #1: Кодогенерация для ресурсов
#### Всем привет!
Меня зовут Дмитрий. Так получилось, что я являюсь тим лидом в команде из 13 iOS разработчиков уже на протяжении двух лет. И вместе мы трудимся над приложением [Тинькофф Бизнес](https://itunes.apple.com/ru/app/%D1%82%D0%B8%D0%BD%D1... | https://habr.com/ru/post/431148/ | null | ru | null |
# Загрузчик с шифрованием для STM32
В данной статье хотел бы написать о своем опыте создания загрузчика для STM32 с шифрованием прошивки. Я являюсь индивидуальным разработчиком, поэтому нижеприведенный код может не соответствовать каким-либо корпоративным стандартам
В процессе работы ставились следующие задачи:
... | https://habr.com/ru/post/432966/ | null | ru | null |
# Меню для меню, гриды или Бутстрап, целесообразность удобства
Привет, Хабр! Давно я сюда ничего не писал, со времён моего [золотого поста](https://habr.com/company/opera/blog/169239/) про переход Opera на WebKit прошло уже пять лет. Но тут появился повод: завёл себе [блог на Ютубе](https://www.youtube.com/pepelsbey).... | https://habr.com/ru/post/429844/ | null | ru | null |
# ASP.NET Core: Создание первого веб-API с использованием ASP.NET Core MVC и Visual Studio
Протокол HTTP может использоваться не только для веб-страниц. Это еще и мощная платформа для создания API, предоставляющих сервисы и данные. Протокол HTTP прост, гибок и широко распространен. Практически любая существующая платф... | https://habr.com/ru/post/312878/ | null | ru | null |
# Поисковик новостей (RSS), написанный на Java + SQLite
Данная идея не претендует на уникальность. Суть проста - тратить как можно меньше времени на чтение интересующих вас новостей, отсеивая ненужные заголовки. Проект делал в рамках моего обучения языку Java и SQL, начиная с 2018 года.
Для работы приложения на ПК до... | https://habr.com/ru/post/595749/ | null | ru | null |
# Простые шаги по повышению производительности ASP NET Core приложения
Разработка сложной системы предполагает что вы, рано или поздно, столкнетесь с вопросом повышения производительности вашего приложения. Выполнив поиск по разным источникам вы найдете множество рекомендаций по улучшению производительности как для ко... | https://habr.com/ru/post/669176/ | null | ru | null |
# Знакомство с Fugue — уменьшаем шероховатости при работе с PySpark
*Повышение производительности разработчиков и снижение затрат на проекты Big Data*
### Мотивация
Специалисты по обработке данных часто начинают работать с Pandas ил... | https://habr.com/ru/post/710338/ | null | ru | null |
# Занимательный JavaScript: Без фигурных скобок

Меня всегда удивлял **JavaScript** прежде всего тем, что он наверно как ни один другой широко распространенный язык поддерживает одновременно обе парадигмы: нормальные и ненормально... | https://habr.com/ru/post/428337/ | null | ru | null |
# Идея реализации пакета I/O в Java

*Совершенство достигается не тогда, когда уже нечего прибавить,*
*а когда уже ничего нельзя отнять.*
Антуан де Сент-Экзюпери, Ветер, песок и звезды, 1939
Ч... | https://habr.com/ru/post/132372/ | null | ru | null |
# Сам себе Гутенберг. Делаем параллельные книги

*Upd. 04.12.2021 — [Наш телеграм канал](http://t.me/lingtrain)*
Если вам нравится изучать языки (или вы их преподаете), то вы наверняка сталкивались с таким спос... | https://habr.com/ru/post/557664/ | null | ru | null |
# Приведение типов
Будучи на конференции Qt Developer Days 2010 я узнал, что одним из самых популярных вопросов на собеседовании в разные зарубежные компании, работающие с Qt библиотекой, является вопрос о различиях в способах приведения типов в C++. Поэтому здесь я рассмотрю основные различия между **static\_cast**, ... | https://habr.com/ru/post/106294/ | null | ru | null |
# Вариант работы с вебсокетами в iOS на языке Swift / Написал менеджер для работы с websocket
Всем привет.
4 года назад я уже разбирался с вебсокетами в iOS, тогда я решил задачу с помощью одной из библиотек cocoapods, [статья есть на Хабре](https://habr.com/ru/post/277635/). А сегодня хочу продемонстрировать еще о... | https://habr.com/ru/post/485468/ | null | ru | null |
# PuLP-MiA: Мультииндексный аддон для PuLP (python-библиотека линейного программирования)
Привет, Хабр! Сейчас будет мини-пост без единой строки кода для тех, кто имеет дело с **многоиндексными задачами ЛП** (линейное программирование) в **Python** и решает их при помощи библиотеки-порта **PuLP**… Это ненадолго :-)
... | https://habr.com/ru/post/532126/ | null | ru | null |
# Обзор kubenav для управления Kubernetes-кластерами со смартфона
[Kubenav](https://kubenav.io/) — бесплатное приложение с открытым исходным кодом. Его основная цель — предоставление удобного GUI для управлен... | https://habr.com/ru/post/585990/ | null | ru | null |
# Принцип «Разделяй и властвуй», а также бесконечные потоки в Haskell
Приветствую всех читателей!
Ниже идет моя точка зрения того, как я понял главу 14 из слайдов курса по Haskell у нас в университете.
Итак, сегодня мы поговорим о следующих двух темах:* Принцип «Разделяй и властвуй»
* Работа с бесконеными потока... | https://habr.com/ru/post/162657/ | null | ru | null |
# Как мы оптимизировали скрипты в Unity
Существует множество отличных статей и туториалов о производительности в Unity. Этой статьёй мы не пытаемся заменить или улучшить их, это всего лишь краткое изложение шагов, сделанных нами после прочтения этих статей, а также шагов, позволивших решить наши проблемы. Настоятельно... | https://habr.com/ru/post/481980/ | null | ru | null |
# Flutter for Web: гайд для начинающих
*Изначально Flutter был известен как фреймворк для создания кроссплатформенных мобильных приложений для Android и iOS. Но концепция Flutter не ограничивается мобильной разработкой, фреймворк позволяет создавать пользовательские интерфейсы для любого экрана с помощью кроссплатформ... | https://habr.com/ru/post/666952/ | null | ru | null |
# Основы MPI
Прочитал [статью «Основы MPI для «чайников»»](http://habrahabr.ru/blogs/system_programming/121235/) и понял, что статья новичка способна отпугнуть.
#### Теория
##### Начнем с начала
Первое время не было единого стандарта (API) для параллельных вычислений и программистам приходилось писать для каждого... | https://habr.com/ru/post/121925/ | null | ru | null |
# Андрей Карпати: Bitcoin на Python (часть 1)

*Андрей Карпати — директор по искусственному интеллекту и Autopilot Vision в Tesla.*
Я считаю, что блокчейн — классная штука, потому что он расширяет... | https://habr.com/ru/post/564256/ | null | ru | null |
# Symfony 2.3.0! Первый релиз с долгосрочной поддержкой!
 Symfony 2.3.0
-------------
Мы все долго этого ждали, многие из нас работали последние 4 года что бы это произошло. Сегодня, Symfony 2.3.0 доступна и это первый... | https://habr.com/ru/post/182008/ | null | ru | null |
# Микросервисы для чайников: как на них перейти с монолита с нуля
Меня зовут **Семен Катаев**, я работаю в Авито над процессом перехода от монолитной архитектуры к микросервисам. Переход у нас все еще продолжается, но мне уже есть чем с вами поделиться. Это краткий обзор того, с чем придётся столкнуться, если вы задум... | https://habr.com/ru/post/649319/ | null | ru | null |
# Spring: Реализация TaskExecutor c поддержкой транзакций
Spring, позаботившись о разработчиках, предлагает удобный и простой фасад для взаимодействия с менеджером транзакций. Однако всегда ли стандартного механизма будет достаточно для реализации изощрённых архитектурных идей? Очевидно — нет.
В этом посте пойдёт ... | https://habr.com/ru/post/228953/ | null | ru | null |
# Быстрое добавление ссылок или «прощай Add Reference»
Недавно я допилил одну проблему, которая меня уже очень давно достает. Суть ее в том, что диалог Add Reference в Visual Studio не нужен, если вы берете сборку из одного из тех мест, где их ищет... | https://habr.com/ru/post/75831/ | null | ru | null |
# Munin — рисуем красивые графики
В данной статье рассматривается такой инструмент мониторинга, как Munin. Странно, но поиск уверяет меня, что статьи о нем на Хабре еще не было. Этот инструмент существует под \*NIX (Linux, xBSD, Solaris) и Windows и позволяет централизовано отслеживать и наглядно отображать состояние ... | https://habr.com/ru/post/83958/ | null | ru | null |
# Делаем из массивов объекты

PHP содержит очень мощный инструмент — массивы. Половина функций в PHP возвращает результат как ассоциативные массивы. При работе с такими функциями легко допустить ошибк... | https://habr.com/ru/post/228805/ | null | ru | null |
# Создаем пазл для iPhone
Почему бы не представить в магазине приложений свой собственный пазл — как это сделали мы! В этом уроке я поэтапно расскажу о создании такого приложения. Итоговый результат будет... | https://habr.com/ru/post/68693/ | null | ru | null |
# Реактивность в Vue
Привет, Хабр! Меня зовут Карамушко Александр. Я работаю frontend-разработчиком в компании Nord Clan.
Из [предыдущей статьи](https://habr.com/ru/company/nordclan/blog/699356/) мы уже знаем как происходит первичный рендеринг компонента. Однако, теперь мы зададимся вопросом: как Vue отследит то, что... | https://habr.com/ru/post/706536/ | null | ru | null |
# SOA на Laravel и JSON-RPC 2.0
SOA (Сервис-Ориентированная Архитектура) строится путём комбинации и взаимодействия слабо-связанных сервисов.
Для демонстрации создадим два приложения Клиент и Сервер и организуем их взаимодействие посредством протокола удаленного вызова процедур `JSON-RPC 2.0`.
#### Клиент
Прил... | https://habr.com/ru/post/499626/ | null | ru | null |
# Исследование статистической вероятности значения бита в нонсе bitcoin

Считается, что функция sha256( sha256( BlockHeader ) ), которая используется в алгоритме хэширования bitcoin весьма надежна. Надежна настолько, что существует... | https://habr.com/ru/post/421499/ | null | ru | null |
# Знакомимся с Otto, наследником Vagrant
[Otto](https://www.ottoproject.io) — это новый продукт от Hashicorp, логический наследник Vagrant, призванный упростить процесс разработки и деплоя программ в современном мире облачных технологий. Концептуально новый подход к проблеме, проверенные технологии под капотом и откры... | https://habr.com/ru/post/268497/ | null | ru | null |
# Vertex Wireless VW210: редкий роутер и его внутренний мир
> Лирическое отступление: всё описанное в данной статье производилось исключительно в образовательных целях, цели извлечения материальной выгоды не преследовалось, ни одного котика в процессе (надеюсь) не пострадало. Всё, что здесь описано вы повторяете на св... | https://habr.com/ru/post/336942/ | null | ru | null |
# CSS3 сейчас — transition
CSS3 и HTML5 развиваются всё быстрее и быстрее, браузеры начинают поддерживать всё больше новых фишек и плюшек. В связи с этим, мне хотелось бы заглянуть в наш будущий рай верстальщиков и сделать цикл обзорных статей по новым плюшкам и фишкам этих технологий.
В этом цикле мне хотелось бы ... | https://habr.com/ru/post/111658/ | null | ru | null |
# Тонкости Javascript/Node.js. Увеличиваем производительность в десятки раз
#### Вступление
Появилась необходимость обмениваться сообщениями между сервером и клиентом в бинарном виде, но в формате JSON в конечном итоге. Начал я гуглить, какие существуют библиотеки упаковки в бинарный вид. Пересмотрел немало: Messsage... | https://habr.com/ru/post/277823/ | null | ru | null |
# Безопасный код в Друпале: Работа с базой данных

(ч1. [Подделка межсайтовых запросов](http://habrahabr.ru/blogs/drupal/52132/); ч3. [Работа с пользовательским вводом](http://habrahabr.ru/blogs/drupal/56291/))
Друпал предоставляет свои собственные средства для доступ... | https://habr.com/ru/post/52469/ | null | ru | null |
# Шестая проверка Chromium, послесловие

В начале 2018 года в нашем блоге появился цикл статей, посвящённый шестой проверке исходного кода проекта Chromium. Цикл включает в себя 8 статей, по... | https://habr.com/ru/post/438764/ | null | ru | null |
# Использование Service Worker для создания ботнета

Если кратко: в этом посте мы рассмотрим один из множества способов запуска бесконечного выполнения кода Javascript в браузере с помощью Service Worker, а еще немного покр... | https://habr.com/ru/post/318000/ | null | ru | null |
# Пытаясь композировать некомпозируемое: поднимаем всё
Рекомендуется прочитать [первую статью](https://habr.com/ru/post/467683/), если вы еще этого не сделали. Эта статья будет покороче, меньше сконцентрирована на деталях и больше — на возможностях.
Согласно [Стивену Дилю](http://www.stephendiehl.com/posts/decade.h... | https://habr.com/ru/post/485518/ | null | ru | null |
# Автоматизация тестирования Web-приложений
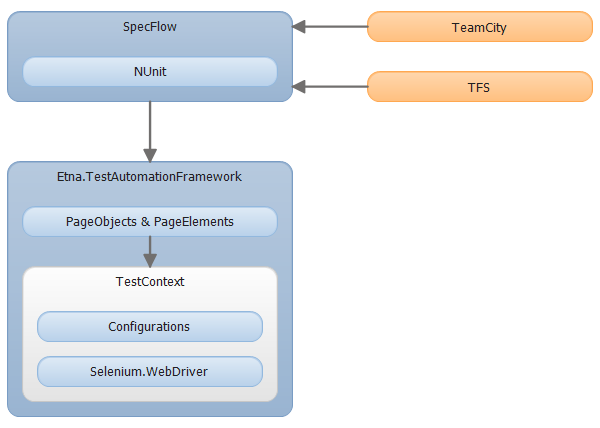
Автоматизация тестирования – место встречи двух дисциплин: разработки и тестирования. Наверное поэтому, я отношу эту практику к сложным, но интересным.
Путем проб и ошибок м... | https://habr.com/ru/post/178407/ | null | ru | null |
# Облако.Mail.Ru + EncFS для резервного копирования домашнего фотоархива
[](http://img.leprosorium.com/2075385) В конце декабря Mail.Ru вновь (впервые... | https://habr.com/ru/post/209500/ | null | ru | null |
# Как Яндекс распознаёт музыку с микрофона
Поиск по каталогу музыки — это задача, которую можно решать разными путями, как с точки зрения пользователя, так и технологически. Яндекс уже довольно давно научился искать и по названиям композиций, и [по текстам песен](http://yande... | https://habr.com/ru/post/181219/ | null | ru | null |
# DIY цифровой тахометр на AVR ATtiny2313, КР514ИД2 и оптопаре
#### DIY цифровой тахометр на AVR ATtiny2313, КР514ИД2 и оптопаре
Добрый день.
Выношу на Ваше рассмотрение схему простенького цифрового тахометра на **AVR ATtiny2313**, **КР514ИД2**, и оптопаре спроектированного мною.
Сразу оговорюсь: аналогичных сх... | https://habr.com/ru/post/153125/ | null | ru | null |
# Как мы стартовали Vivid Money для iOS
Всем привет! Меня зовут Илья. Я - iOS техлид в Vivid Money. Мы больше года занимались разработкой нашего финтех-продукта и теперь готовы поделиться с сообществом приобр... | https://habr.com/ru/post/529522/ | null | ru | null |
# GitLab для Continuous Delivery проекта на технологиях InterSystems: Контейнеры
Эта статья — продолжение [статьи](https://habr.com/company/intersystems/blog/354158/) про организацию процессов [Continuous Integration](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%BF%D1%80%D0%B5%D1%80%D1%8B%D0%B2%D0%BD%D0%B0%D1%8F_%D0%... | https://habr.com/ru/post/420749/ | null | ru | null |
# Javascript — решение асинхронной проблемы?
В этой статье, я хочу рассказать про свое решение проблемы с асинхронной функциональностью javascript, по средствам введения полностью асинхронной модели вычислений. Будет описана сама концепция, и дана ссылка на реализацию. Заинтересовавшихся прошу под кат.
Введение
-----... | https://habr.com/ru/post/347250/ | null | ru | null |
# Swift: ARC и управление памятью
Будучи современным языком высокого уровня, **Swift** в основном берёт на себя управление памятью в ваших приложениях, занимаясь выделением и освобождением памяти. Это происходит благодаря механизму, который называется **Automatic Reference Counting**, или сокращенно **ARC**. В этом ру... | https://habr.com/ru/post/451130/ | null | ru | null |
# Моментальная загрузка десктопных и мобильных сайтов: часть 1
[](http://habrahabr.ru/company/mobilizetoday/blog/269397)
Привет, Хабровчане! Сегодня поговорим об оптимизации скорости загрузки сайта. Это перв... | https://habr.com/ru/post/269397/ | null | ru | null |
# Советы по запуску кластера Kubernetes на Raspberry Pi
Этот небольшой пост — продолжение статьи о создании [кластера Kubernetes на Raspberry Pi](https://habr.com/ru/company/skillfactory/blog/553212/), где ... | https://habr.com/ru/post/553226/ | null | ru | null |
# WSL 2 теперь доступен для Windows Insiders
Мы рады рассказать, что теперь вы можете попробовать Windows Subsystem for Linux 2 установив Windows build 18917 в Insider Fast ring! В этой статье мы расскажем о том, как начать работу, о новых wsl.exe командах, а также поделимся важными заметками. Полная документация о WS... | https://habr.com/ru/post/456204/ | null | ru | null |
# Пример разработки блога на Zend Framework 2. Часть 1. ZendSkeletonApplication
В последние несколько лет моя работа связана с использованием [CMS Drupal](http://drupal.org), но на досуге я изучал и just for fun запускал проекты на питоновских фреймворках [Django](https://www.djangoproject.com/), [Flask](http://flask.... | https://habr.com/ru/post/192522/ | null | ru | null |
# Книга «Объектно-ориентированный подход. 5-е межд. изд.»
[](https://habr.com/ru/company/piter/blog/486888/)Объектно-ориентированное программирование (ООП) лежит в основе языков C++, Java, C#, Visual Basic .NET, Ruby, Objective-C... | https://habr.com/ru/post/486888/ | null | ru | null |
# Hack The Box. Прохождение Scavenger. DNS, FTP и следы другого взлома
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu). Надеюсь, что это поможет хоть кому-то раз... | https://habr.com/ru/post/490602/ | null | ru | null |
# Установка openSUSE 11.3 с помощью чайника
#### Преамбула
Я — «виндузятник», старательно стремящийся приобщиться к миру Linux. Моей главной целью было «вживую» увидеть KDE4.\*, для чего и был выбран дистрибутив openSUSE 11.3. Собственно, выбирать было особо не из чего, т.к. такие объемы данных я могу получать только... | https://habr.com/ru/post/123872/ | null | ru | null |
# Загрузка конфигурации в ПЛИС через USB или разбираем FTDI MPSSE

В жизни каждого плисовода наступает момент, когда требуется написать собственный загрузчик файла конфигурации в ПЛИС. Пришлось мне участвовать в разработке учебного... | https://habr.com/ru/post/426131/ | null | ru | null |
# Android, жизненый цикл Jetpack компонентов
Руководство по работе с жизненным циклом Android компонентов, рассмотрим базовые понятия, что такое LifecycleObserver, события и состояния жизненного цикла, кастомные LifecycleOwner.
Перевод статьи [Lifecycle-Aware Components Using Android Jetpack](https://www.raywenderlic... | https://habr.com/ru/post/577482/ | null | ru | null |
# Игра Жизнь на LiveScript в 30 строк
В продолжение 30-ти строчного мема, выкладываю реализацию известной игры [Жизнь](http://ru.wikipedia.org/wiki/%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_(%D0%B8%D0%B3%D1%80%D0%B0)) на [LiveScript](http://livescript.net/) (язык, транслируемый в Javascript).
Игра жизнь — это клеточный автома... | https://habr.com/ru/post/202766/ | null | ru | null |
# Профилирование и отладка Python, переходим к практике
В [прошлой статье](http://habrahabr.ru/company/mailru/blog/201594/) мы определили понятия профилирования и оптимизации, познакомились с различными подходами к профилированию и видами инструментов. Немного коснулись истории профайлеров.
Сегодня я предлагаю пере... | https://habr.com/ru/post/201778/ | null | ru | null |
# Добавление порядка сортировки в CakePHP
##### О чем будет топик?
О том, как добиться того, чтобы можно было с помощью CSS или иным способом определить/увидеть в html-выводе, в каком порядке (asc|desc) отсортирован столбик таблицы, а не только по какому из столбиков отсортирована таблица.
Короче говоря, сделать к... | https://habr.com/ru/post/84660/ | null | ru | null |
# Разработка Windows 8.1 приложений на XAML/С#. Часть 2. Работа с плитками

Продолжаем модернизировать приложение, которое мы создали в ... | https://habr.com/ru/post/204720/ | null | ru | null |
# 3D-слайдер на CSS
Напишем слайдеры изображений на чистых HTML и СSS. Меняем только CSS, разметка в HTML остается неизменной. Внешний вид из-за разного CSS при этом разительно различается, а в слайдеры можно вставить неограниченное число картинок. Сначала мы создали круговой слайдер с бесконечным вращением, похожий н... | https://habr.com/ru/post/711256/ | null | ru | null |
# Корпоративный Release Manager: муки и радости
Автоматизация процессов разработки и тестирования программного обеспечения (ПО) — лучший способ уйти от рутины и заняться действительно интересными задачами. А... | https://habr.com/ru/post/574734/ | null | ru | null |
# В поисках изофот
Понадобилось мне однажды вычисление изофот (линий равной интенсивности на изображениях), однако, готовых библиотек я не нашел, а копаться в чужом коде (например, в тех же Octave или Iraf) очень не хотелось. В качестве простейшего алгоритма я нашел [метод шагающих квадратов](http://en.wikipedia.org/w... | https://habr.com/ru/post/137028/ | null | ru | null |
# FPV гонки на симуляторе (делаем USB джойстик из пульта радиоуправления)
Зима в северных широтах — время, когда у FPV пилота появляется время, чтобы отдохнуть от гонок и постоянных поломок, взять в руки паяльник, и смастерить что-нибудь полезное для своего хобби.
Раз уж на улице летать холодно, то будем тренироват... | https://habr.com/ru/post/388811/ | null | ru | null |
# Веб-сервер — ваша первая сетевая программа Arduino
### Введение
В моих публикациях [1,2,3] подробно описана цепочка датчик – Arduino-интерфейс Python. В реальных условиях промышленного производства датчики находиться на значительном удалении не только друг от друга но и от места где осуществляется централизованная ... | https://habr.com/ru/post/338844/ | null | ru | null |
# Как подружиться с UIKit

Привет, Хабр! Меня зовут Богдан, в Badoo я работаю в мобильной команде iOS-разработчиком. Мы достаточно редко рассказываем что-либо о нашей мобильной разработке, хотя статьи – один из лучших способов докуме... | https://habr.com/ru/post/341542/ | null | ru | null |
# Unity3D. Балуемся с мешем. Часть 2 — Деформация меша с помощью карты высот
В [первой части](https://habrahabr.ru/post/328498/) мы рассмотрели как сгенерировать меш, используя карту высот. Прошло достаточно времени, поэтому думаю, что пришло время рассмотреть способы деформации меша с помощью той же карты высот. Всех... | https://habr.com/ru/post/328564/ | null | ru | null |
# Вызов Rust функции из Go
На Хабре в свое время была статья о том, [как вызвать Rust код из Go](https://habr.com/ru/post/337348/). Статья неплохая, но довольно сложная для понимания и на самом деле отталкивающая новичков от желания смотреть в сторону обоих языков. Цель этого поста не столько залезть в «кишки» кросс-я... | https://habr.com/ru/post/496192/ | null | ru | null |
# Через тернии к звёздам или LILYGO TTGO T-Internet-POE ESP32 LAN8720A

Попалась мне на глаза плата **LILYGO TTGO T-Internet-POE ESP32 LAN8720A** и конечно я не мог пройти мимо такой интересной новинки: ESP32, LAN8720A, POE, S... | https://habr.com/ru/post/547044/ | null | ru | null |
# Самообучение шахматной программы
Здравствуй, Хабр!
В [статье, опубликованной в прошлом году](https://habrahabr.ru/post/254753/), мы решали задачу определения математически обоснованных стоимостей шахматных фигур. С помощью регрессионного анализа партий, сыгранных компьютерами и людьми, нам удалось получить шкалу ... | https://habr.com/ru/post/305604/ | null | ru | null |
# Canvas-трансформации доступным языком
Доброго времени суток, хабравчане! В этой статье я подробно расскажу вам о трансформации и вращении в javascripte. Матрица трансформаций, на первый взгляд, штука непонятная и мно... | https://habr.com/ru/post/104718/ | null | ru | null |
# Пианино в 24 строки на Javascript: если играть, то музыку
Пока производители телефонов меряются, у кого тоньше, программисты продолжают меряться, у кого короче.
Я тоже решил принять участие в этой ~~специальной~~ спонтанной олимпиаде кодерского мастерства, и вспомнил фразу одной моей подруги-музыканта: «Если уж ... | https://habr.com/ru/post/202646/ | null | ru | null |
# Next.js Layout RFC. Изменить всё и сделать веб ещё быстрее
Nextjs — самый быстрорастущий фреймворк. После создания, в 2016 году, было выпущено уже 12 обновлений, каждое из которых называлось компанией “круп... | https://habr.com/ru/post/695076/ | null | ru | null |
# Нагрузочное тестирование с помощью Selenium
#### Введение
В это статье я расскажу о применении инструмента изначально предназначенного для функционального тестирования при тестировании нагрузочном web части системы электронного документооборота (СЭД).
Зачем вообще это понадобилось? Мы преследовал две цели – введ... | https://habr.com/ru/post/168137/ | null | ru | null |
# Немного истории: Как развивались биржевые технологии
[](http://habrahabr.ru/company/itinvest/blog/267603/)
Для современных биржевых площадок скорость работы является важнейшим фактором в привлечении инвесторов. Торговцы х... | https://habr.com/ru/post/267603/ | null | ru | null |
# Взлом матановой капчи на C# — это просто!
В этом топике я хочу вам рассказать о взломе т.н. «матан-капчи», пример которой был представлен в недавнем топике [Матановая капча на PHP — это просто!](http://habrahabr.ru/blogs/php/120646/... | https://habr.com/ru/post/121032/ | null | ru | null |
# Практическая стеганография. Скрытие информации в изображениях PNG

На хакерских конкурсах и играх CTF (Capture The Flag) иногда попадаются задачки на стеганографию: [вам дают картинку, в которой нужно найти скрытое сообщение](htt... | https://habr.com/ru/post/518292/ | null | ru | null |
# Web3 и NFT: хайп обоснован или нет? Ещё неясно
Основатель Signal [написал](https://moxie.org/2022/01/07/web3-first-impressions.html) на прошлой неделе сильный текст о проблемах web3 и, в частности, NFT. Привожу **краткое саммари** статьи + дискуссии о перспективах самой модной (по ожиданиям венчурных капиталистов) т... | https://habr.com/ru/post/645807/ | null | ru | null |
# Биоинформатический пайплайн с использованием Docker
В этой статье я хочу поделиться опытом разработки [пайплайна](https://en.wikipedia.org/wiki/Pipeline_(computing)) с использованием Docker для анализа биомедицинских данных. Наверное, одним читателям будет интересен сам биоинформатический пайплайн, а кому-то — испол... | https://habr.com/ru/post/346184/ | null | ru | null |
# Russian Code Cup: самое интересное из задач первого этапа
8 мая состоялся первый квалификационный раунд всероссийского кубка по программированию [Russian Code Cup](http://russiancodecup.ru). Победителем раунда стал Евгений Капун, который решил все 5 задач со штрафным временем 130 минут.
Всего в первом квалификаци... | https://habr.com/ru/post/119187/ | null | ru | null |
# История о том, как Apple учила меня делать качественный продукт
Всем привет, суть моего рассказа в том, чтобы рассказать откуда пришла идея, как разрабатывалось приложение и как влияло Apple на разработку.
**Я буду показывать код приложения последней версии.**
*Идея появилась в обыкновенный день, я был в гост... | https://habr.com/ru/post/240881/ | null | ru | null |
# Быстрый старт с WebComponents
Веб-компоненты это набор стандартов определяющих программные интерфейсы для организации компонентной архитектуры. Все они реализованы в современных версиях браузеров, т.е. не требуют подключения библиотек или транспиляторов кода, однако, если нужна совместимость например с Internet Expl... | https://habr.com/ru/post/460397/ | null | ru | null |
# Поиск в строке. Реализация в CPython
Довольно давно на одной из презентаций выпускников одной из так называемых ИТ-академий докладчика спросили о деталях реализации поиска подстроки в строке толи в Java, толи в .Net. Выпускник конечно не смог ничего вразумительного ответить, а я отложил вопрос в и без того длинный t... | https://habr.com/ru/post/132156/ | null | ru | null |
# Видишь архитектуру? И я не вижу, а она есть
В разработке hh.ru сегодня около 150 человек. У нас множество интересных команд, и каждая вносит значительный вклад. Но в этой статье я расскажу лишь про одну из них.

Потому что я ... | https://habr.com/ru/post/488742/ | null | ru | null |
# Как написать свою онлайн-песочницу с поддержкой React и популярных библиотек
Привет, меня зовут Илья, я лидер сообщества фронтенд-разработки в Райффайзенбанке. Среди моих задач — проведение собеседований, ... | https://habr.com/ru/post/568102/ | null | ru | null |
# Волшебная формула или как увидеть угрозу
Всякая система работает по уникальному алгоритму, без алгоритма — это не система. Гибкому, жёсткому, линейному, разветвляющемуся, детерминированному, стохастическому — не важно. Важно, что для достижения наилучшего результата система подчиняется неким правилам. Нам часто зада... | https://habr.com/ru/post/228427/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.