
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Простой интерпретатор с нуля на Python #4

В предыдущих трех частях мы создали лексер, парсер и AST для нашего игрушечного языка IMP. Мы даже написали нашу собственную библиотеку парсеров комбинаторов. В ... | https://habr.com/ru/post/207662/ | null | ru | null |
# Проектирование на C# глазами первокурсника -NotePad++ №6
Всем привет, меня зовут Аркадий, я студент НИУ ВШЭ и в данной статье мы с вами поговорим о задании PeerReview №6 NotePad++, а именно об архитектурах, которые подойдут для данного задания и некоторых паттернов.
Задание
С рождением ребёнка встал вопрос о ночнике. Где-то прочитали, что он необходим для спокойного сна. Быстро привыкли спать с тусклым светом. Очень удобно просыпаться от криков и воев среди н... | https://habr.com/ru/post/433194/ | null | ru | null |
# Воспроизведение звука в Java
#### Введение
Нормальной русскоязычной информации по теме просто нет. Java-tutorials тоже оставляют желать лучшего. А архитектура javax.sound.sampled хоть и проста, но далеко не тривиальна. Поэтому свой первый пост на Хабре я решил посвятить именно этой теме. Приступим:
#### Воспроиз... | https://habr.com/ru/post/191422/ | null | ru | null |
# Компактный сервер для Django приложений
#### **Введение**
Многие начинающие веб разработчики размышляют о том, где бы разместить свое творение. Обычно для этих целей применяются машины под управлением \*NIX подобных систем. Мой выбор остановился на Raspberry PI, поскольку малинка:
* работает под управлением полн... | https://habr.com/ru/post/357950/ | null | ru | null |
# React hooks, как не выстрелить себе в ноги. Часть 3.2: useMemo, useCallback
Данная статья - продолжение [статьи](https://habr.com/ru/company/otus/blog/669962/) про мемоизацию, в которой мы разбирали, зачем ... | https://habr.com/ru/post/696610/ | null | ru | null |
# Citrix Xen Center – Опыт работы с полностью бесплатной виртуализацией
*Сразу опишу главный плюс такого решения –* ***Это бесплатно!*** *Любой может более менее полноценно администрировать рабочие места(Windows машины/сервера, linux сервера, любые ОС), работать с бекапами и эффективно использовать мощность железа.*
... | https://habr.com/ru/post/599213/ | null | ru | null |
# Качаем файлы в бэкграунде
Здравствуйте.
У меня на работе безлимитка, которой иногда хочется пользоваться. Например, закачивать много-много музыки, так, чтобы оставил, забыл на пару дней, вспомнил, а оно уже закачалось. Проблема в том, что безлимитка, все-таки, ограничена по скорости (30Kb/s), и если в наглую оста... | https://habr.com/ru/post/41969/ | null | ru | null |
# Префиксы в системе команд IA-32
Сегодня я хочу рассказать вам о префиксах в системе команд Intel IA-32 в 32- и 64-битных вариантах (также именуемых как x86 и x86\_64). Но для начала напомню вкратце общую структуру IA-32 инструкции:

В игре [Prehistorik 2](http://en.wikipedia.org/wiki/Prehistorik_2) не предусмотрены сейвы, но на каждом уровне есть (болтается в воздухе в некотором месте уровня) код уровня. Есть два ... | https://habr.com/ru/post/187072/ | null | ru | null |
# Azure Cloud Shell в Windows Terminal
Теперь вы можете подключаться к [Azure Cloud Shell](https://azure.microsoft.com/en-us/features/cloud-shell/) через Windows Terminal!
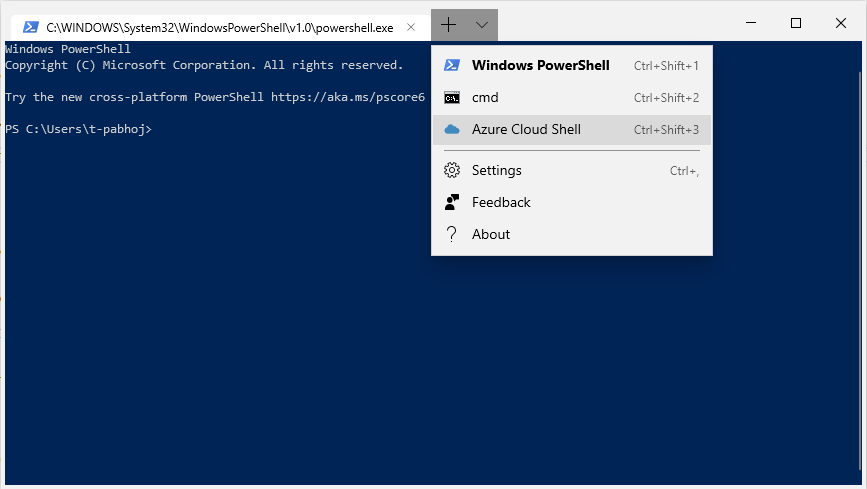
Для этого мы добавили новый профиль по умолчанию – A... | https://habr.com/ru/post/468341/ | null | ru | null |
# Machine Learning for your flat hunt. Part 2
... | https://habr.com/ru/post/470710/ | null | en | null |
# Как найти все битые ссылки на странице с помощью Selenium
Когда вам нужно проверить все ссылки в вашем проекте, вы можете сделать это с помощью Postman или любого другого инструмента тестирования API, но ес... | https://habr.com/ru/post/560170/ | null | ru | null |
# Введение в Spring Data JDBC
> **Для будущих студентов курса** [**"Java Developer. Professional"**](https://otus.pw/FUU0/) **подготовили перевод полезного материала.
>
> Также приглашаем принять участие в открытом уроке на тему** [**"Введение в Spring Data jdbc"**](https://otus.pw/z6ET/)
>
>

В связи с карантином многие сейчас львиную долю времени проводят дома, и это время можно, и даже нужно провести с пользой.
В начале карантина я решил довести до ума некоторые проекты начатые несколько месяцев назад. Одним из таких проектов был видео курс "Язык ... | https://habr.com/ru/post/495438/ | null | ru | null |
# Асинхронное программирование на JavaScript — Остаться в живых
Программисты принимают некоторые особенности как должное — последовательное программирование, к примеру, при записи алгоритма, который делает один шаг только после другого.
Однако, если вы пишете код на JavaScript, который использует блокирующийся ввод... | https://habr.com/ru/post/111634/ | null | ru | null |
# К вопросу о сложении или как я нашел ошибку в gcc (на самом деле нет)
### Многие вещи нам непонятны не потому, что наши понятия слабы; но потому, что сии вещи не входят в круг наших понятий.
Вчера, просматривая новый комментарий к своему старому посту о реализации сдвигов компилятора gcc для МК, обратил внимание на... | https://habr.com/ru/post/535400/ | null | ru | null |
# Замыкания в C#
Перед прочтением статьи, ответьте на следующий вопрос — что будет напечатано, после исполнения следующего кода?
P p = Console.WriteLine; // P объявлен как delegate void P();
foreach (var i in new [] { 1, 2, 3, 4 }) {
p += () => Console.Write(i);
}
p();
(К сожалению, не хватает кар... | https://habr.com/ru/post/36601/ | null | ru | null |
# В поиске бесплатных билетов, исследование игры Аэрофлота
Началось все с того, что я получил ссылку на промо-сайт компании [Аэрофлот](http://www.aeroflotbonus15.ru/). Акция заключается в прохождении небольшой flash игры и получении бонусных миль. Главный приз в 150 000 миль получает игрок, занявший первую строчку в р... | https://habr.com/ru/post/238463/ | null | ru | null |
# Настройка ROS и работа со стереокамерой ZED на NVIDIA Jetson
Добрый день уважаемые читатели! В последних статьях я рассказывал о популярных методах SLAM и визуальной одометрии, которые имеют поддержку в ROS. В этой статье я немного отклонюсь от темы и расскажу о настройке и работе с ROS на микрокомпьютере [NVIDIA Je... | https://habr.com/ru/post/409259/ | null | ru | null |
# Префиксные деревья в Python
Доделал на днях питонью библиотеку [datrie](https://github.com/kmike/datrie), реализующую префиксное дерево (см. [википедию](http://en.wikipedia.org/wiki/Trie) или [хабр](http://habrahabr.ru/post/111874/)), спешу поделиться.
Если вкратце, то можно считать, что datrie.Trie — это замена... | https://habr.com/ru/post/147963/ | null | ru | null |
# Повышаем стабильность сессии в CakePHP 2.x
*От переводчика: при разработке [Web-payment.ru](http://web-payment.ru/) на фреймворке [CakePHP](http://cakephp.org/) мы сталкивались с самого начала с тем, что логаут пользователей происходил каждые несколько часов, а это слишком короткий промежуток времени. При этом сколь... | https://habr.com/ru/post/244645/ | null | ru | null |
# Паяльная станция своими руками на базе Arduino
Всем привет! Как-то я затронул тему паяльной станции на Arduino и сразу меня завалили вопросами (как/где/когда). Учитывая массовость запросов, я решил написать обзор простой паяльной станции (только паяльник) на базе Arduino.
Почему Arduino? Ведь существует уйма конт... | https://habr.com/ru/post/248959/ | null | ru | null |
# Прокачиваем производительность C# с Федерико Луисом
Сегодня мы поговорим о производительности в C#, о способах прокачать её до неузнаваемости. Задача этой статьи — продемонстрировать такие способы повышения производительности, которые, при необходимости, вы смогли бы использовать самостоятельно. Однако эти методики ... | https://habr.com/ru/post/352362/ | null | ru | null |
# Высокопроизводительная сборка мусора для C++
[Мы](https://v8.dev/blog/trash-talk) [уже](https://v8.dev/blog/concurrent-marking) [писали](https://v8.dev/blog/tracing-js-dom) о сборке мусора для JavaScript, о DOM, и о том, как всё это реализовано и оптимизировано в JS-движке V8. Правда, Chromium — это не только JavaSc... | https://habr.com/ru/post/507516/ | null | ru | null |
# Опять про пустые перечисления в C#
На этот пост мня вдохновила свежая [статья на Хабре](https://habrahabr.ru/post/349852/) отсылающая к уже давней проблеме (и [советующей статье](https://habrahabr.ru/post/97464/)) о том, как же проверить, что **IEnumerable** является пустым. Однако в оригинальных статьях, авторы бол... | https://habr.com/ru/post/349920/ | null | ru | null |
# Анализ кода CUBA Platform с помощью PVS-Studio

Для Java программистов существуют полезные инструменты, помогающие писать качественный код, например, мощная среда разработки IntelliJ IDEA, беспл... | https://habr.com/ru/post/449022/ | null | ru | null |
# Arduino и Processing. Как управлять микроконтроллером по COM порту. Двустороннее общение
Всем привет! В интернете бытует заблуждение, что для управления компьютером при помощи самодельной электроники нужны только специальные платы, которые могут распознаваться как USB HID устройства. А касаемо Arduino все только и г... | https://habr.com/ru/post/450518/ | null | ru | null |
# Старт в музыкальном программировании — для начинающих достаточно и простого браузера
Продолжаем нашу [серию](https://www.audiomania.ru/content/art-7405.html) постов о [музыкальном программировании](https://www.audiomania.ru/content/art-6815.html). В ней мы говорим о языках, утилитах и других инструментах, превращающ... | https://habr.com/ru/post/555562/ | null | ru | null |
# Разбор перформансных задач с JBreak (часть 3)
Публикую предпоследнюю часть разбора с третьей задачей. До этого выходил разбор [первой задачи](https://habrahabr.ru/post/350800/) и [второй задачи](https://habrahabr.ru/post/351300/).
Код к третьей задаче:
```
public static double compute(
double x... | https://habr.com/ru/post/351540/ | null | ru | null |
# Java EE 6. Обзор JPA 2.0, часть 1: Введение

Пожалуй, наибольшее количество изменений с выходом спецификации Java EE 6 было привнесено в JPA (Java Persistence API). В серии статей, начиная с этой, я план... | https://habr.com/ru/post/88564/ | null | ru | null |
# Приложения, достигшие самосознания: автоматизированная диагностика в продакшне
Путь к постижению Дзена начинается с разработки приложений, которые могут мониторить сами себя — это позволяет проще и дешевле чинить проблемы на продакшне. В этой статье мы увидим, как современные Windows-приложения могут делать самомони... | https://habr.com/ru/post/353298/ | null | ru | null |
# Эффективный параллакс
Нравится вам это или нет, но параллакс остается. При разумном использовании он может придавать глубину и изящество веб-приложению. Проблема, однако, заключается в том, что эффективно р... | https://habr.com/ru/post/663454/ | null | ru | null |
# Поддержка протокола SPDY в Node.JS
[donnerjack13589](http://habrahabr.ru/users/donnerjack13589/) анонсировал новый модуль для [Node.JS](http://nodejs.org/), — [**node-spdy**](https://github.com/donnerjack13589/node-spdy), который добавляет поддержку протокола [SPDY](https://sites.google.com/a/chromium.org/dev/spdy/s... | https://habr.com/ru/post/117957/ | null | ru | null |
# Redmine на MySQL с RocksDB быстрее, чем с InnoDB, от 20% до 3 раз
Мы собрали форк MySQL от Facebook с движком RocksDB вместо InnoDB и потестировали его с реальными приложениями: Drupal, Wordpress, Redmine.
Это офигенная штука. При низкой нагрузке выигрыш маленький, десятки процентов. Зато при высокой нагрузке выигр... | https://habr.com/ru/post/319500/ | null | ru | null |
# Обзор современных технологий создания RIA-приложений
#### Введение
Несколько лет назад в области создания Интернет-приложений наметилась тенденция к переходу от стандартных HTML/JavaScript/CSS технологий к платформам, которые позволяют запускать в среде веб-браузера программы, по внешенему виду и поведению не отлич... | https://habr.com/ru/post/84320/ | null | ru | null |
# С++17 wrapper для OpenSSL: ECDH и AES 256
При написании одного клиент-серверного приложения на С++ потребовалось организовать защищённое соединение между двумя удалёнными узлами. Я сразу обратил внимание н... | https://habr.com/ru/post/591129/ | null | ru | null |
# Как агрегация решает проблемы перерасчёта полей в Битрикс24
Всем привет! На связи [Владимир Колеснев](https://habr.com/ru/users/milky__space/) из ИТ-команды подразделения ДОМ.РФ Земли. Мы занимаемся автомат... | https://habr.com/ru/post/713030/ | null | ru | null |
# Использование rrd4j для OpenHab2 persistence
OpenHab – популярный сервер «умного дома» (или IoT, как сейчас модно говорить) и уже [обозревался](https://habrahabr.ru/search/?q=%5Bopenhab%5D&target_type=posts) на Хабре. Тем не менее, документации по отдельным аспектам настройки сервера не так много, как хотелось бы. А... | https://habr.com/ru/post/353030/ | null | ru | null |
# OCP против YAGNI
Эта статья является переводом материала [OCP vs YAGNI](https://enterprisecraftsmanship.com/posts/ocp-vs-yagni/).
В этом посте хочется осветить тему OCP и YAGNI – противоречия между принципом открытости/закрытости и принципом «вам это не понадобится».
OCP
---
Давайте начнем с того, что вспомним, ... | https://habr.com/ru/post/567068/ | null | ru | null |
# 100 строк на canvas-е: часть 1
*Предисловием мне хотелось бы поздравить одного хабраюзера с днём рождения. Расти большим, будь умным, и допили уже наконец свой canvas-фреймворк [Graphics2D](http://habrahabr.ru/post/239261/) до того состояния, которое считаешь приемлемым.
**С днём рождения, я.** :P*
Этим летом ... | https://habr.com/ru/post/270255/ | null | ru | null |
# Как QA-инженер может влиять на unit-тесты
Привет! Меня зовут Алёна Луцик, я QA-инженер в команде Авито. За время работы я много раз убеждалась, что разработчик и тестировщик смотрят на код по-разному.
Зачастую перед тестировщиком стоит задача покрытия функциональности автотестами без избыточных проверок, с соблюде... | https://habr.com/ru/post/692940/ | null | ru | null |
# Telegram-bot + Google Analytics
Приветствую хабравчане. Хочу рассказать о том, как мы прикручивали Google Analytics к телеграмм-боту, с какими столкнулись проблемами, и что в итоге пока не получилось настроить.
По старинке Google Analytics устанавливается на сайт с доменом или в приложение с SDK. Погуглив тему, с... | https://habr.com/ru/post/442610/ | null | ru | null |
# Переход с AngularJS на Angular: проблемы и решения гибридного режима (2/3)

Переход в гибридном режиме — естественная процедура, хорошо подготовленная и описанная командой Angular. Тем не менее, на практике возникают сложности и за... | https://habr.com/ru/post/348512/ | null | ru | null |
# Разработка приложения живого поиска по Twitter с помощью Knockout, jQuery и ASP.NET MVC 3
Достаточно не тривиально разработать хорошо спроектированный front-end веб-приложения с уровнем отклика, производительностью и фичами, которые ожидают пользователи сегодня. Легко потеряться в кипящей смеси jQuery обработчиков с... | https://habr.com/ru/post/123692/ | null | ru | null |
# Быстрая десериализация действительно больших JSON-ответов
 Под катом находится небольшое, но полезное описание того, как быстро и просто превратить пришедший JSON-ответ в набор объектов. Никакого ручного па... | https://habr.com/ru/post/200898/ | null | ru | null |
# STM32F3xx + FreeRTOS. Modbus RTU с аппаратным RS485 и CRC без таймеров и семафоров
Всем привет! Относительно недавно, закончив ВУЗ, я попал в небольшую компанию, которая занималась разработкой электроники. Одна из первых задач с которой я столкнулся — необходимость в реализации Modbus RTU Slave протокола с использов... | https://habr.com/ru/post/522960/ | null | ru | null |
# Динамика по подотрезкам: базовые вещи и «одна хорошо, а две лучше»
Добрый вечер.
В этом посте я разберу задачу *B «Дубы»* с практического тура городской олимпиады школьников Санкт-Петербурга по информатике.
Задача эта на динамическое программирование по подотрезкам и идея решения интересна тем, что удобнее пос... | https://habr.com/ru/post/112386/ | null | ru | null |
# Планирование задач в сервере при помощи boost.task
Недавно на профильном ресурсе один программист задал вопрос: *«Что использовать в сервере ММО для работы с потоками?»*. Программист склонялся к [Intel TBB](http://ru.wikipedia.org/wiki/Intel_Threading_Building_Blocks), но даже не к базовым примитивам, а к кастомному... | https://habr.com/ru/post/88288/ | null | ru | null |
# Никогда больше не игнорируйте обучение с подкреплением
Привет, Хабр! Представляю вашему вниманию перевод статьи «Don’t Ever Ignore Reinforcement Learning Again» автора Michel Kana, Ph.D.
Обучение с учителем и обучение без учителя — это ещё не все. Все это знают. Начните с OpenAI Gym.
В этой статье не будет подробного разбора всех аспектов SEO-friendly сайта. Я собрал здесь лишь тот объем информации, с которым мне необходимо было познакомиться для реше... | https://habr.com/ru/post/538892/ | null | ru | null |
# Три редко используемых возможности Python 3, о которых каждый должен знать

Python 3 существует уже какое-то время и довольно много разработчиков, особенно те, кто только начинает свой путь в Python, уже используют эту версию язы... | https://habr.com/ru/post/514444/ | null | ru | null |
# Наследование методов в GO отсутствует? А вот и нет
Дисклаймер
----------
Статья имеет единственную цель - изучение аспектов языка GO. Жду нескончаемый поток критики и готов к ней.
Предисловие
-----------
Недавно начал изучать GO. По моему мнению: концепция полиморфизма в GO достаточно элегантная. "Путь упрощения... | https://habr.com/ru/post/653449/ | null | ru | null |
# Microsoft понадобилось 10 дней, чтобы удалить исходники Windows XP с принадлежащего им GitHub

*В исходниках Windows XP нашли секретную тему в стиле Mac*
В сентябре вся индустрия всполошилась после новости об утечке исходных ко... | https://habr.com/ru/post/523262/ | null | ru | null |
# Гибриды побеждают или холивары дорого
Мотивом для написания данной статьи послужил тот факт, что на habr.com участилось появление материалов маркетингового характера про Apache Kafka. А также тот факт, что из статей складывается впечатление что пишут их немного далекие от реального использования люди — это конечно ж... | https://habr.com/ru/post/536680/ | null | ru | null |
# Git scraping: методика бесплатного хостинга не совсем статических сайтов
Ни для кого не секрет, что, используя GitHub Pages, вы можете бесплатно разместить свой статический веб-сайт в сети Интернет. 1 Гбайт доступного пространства, SSL-сертификат, возможность привязать собственный домен — разве не сказка? Но что дел... | https://habr.com/ru/post/714538/ | null | ru | null |
# Memory on demand
Memory on demand — автоматическое выделение памяти виртуальной машине по необходимости.
Я уже чуть раньше писал об этой идее: [Управление памятью гостевой машины в облаке](http://habrahabr.ru/blogs/cloud_computing/97998/). Тогда это была теория и некоторые наброски с доказательствами, что эта иде... | https://habr.com/ru/post/99157/ | null | ru | null |
# Как узнать реальную версию Windows из режима совместимости
Думаю каждый хотя бы раз сталкивался с ситуацией, когда на современной ОС не удавалось запустить старую программу, и помогал в этом случае режим совместимости Windows.

Моё знакомство с Open XML SDK началось с того, что мне понадобилась библиотека для создания документов Word с некоторой отчётностью. После р... | https://habr.com/ru/post/530178/ | null | ru | null |
# AppCode 3.1 и Swift: быстрое исполнение ваших блестящих идей
Привет, Хабр!
У нас для вас отличные новости — в новой версии нашей IDE для разработчиков под iOS/OS X — AppCode 3.1 — появилась долгожданная поддержка языка Swift, и даже Rename refactoring для кода на этом языке.
 Parallax Mapping
----------------
Техника текстурирования *Parallax Mapping* по своему эффекту несколько схожа с *Normal Mapping*’ом, но основана на другом принципе. Схожесть в то... | https://habr.com/ru/post/416163/ | null | ru | null |
# Однострочники на Си/С++. Часть 2
Ранее я уже публиковал статью о [Однострочниках на С++](http://habrahabr.ru/post/146793/). Так в этом посте я хочу упомянуть ещё несколько алгоритмов, а также несколько реализаций алго... | https://habr.com/ru/post/147277/ | null | ru | null |
# Практическая биоинформатика ч.3. Оценка значимости экспериментальных данных
На каждом этапе эксперимента, начиная от подготовки материала, продолжая проведением PCR и заканчивая секвенированием, происходит накопление ошибки. Нам нужен механизм оценки значимости результата. Какова вероятность, что риды, оказавшиеся н... | https://habr.com/ru/post/137267/ | null | ru | null |
# Уязвимость связки PHP+nginx с кривым конфигом
#### Summary
###### Announced: 2010-05-20
Credits: [80sec](http://www.80sec.com/nginx-securit.html)
Affects: сайты на ngnix+php с возможностью загрузки файлов в директории с fastcgi\_pass
Добрый день, дорогой Хабрахабр!
В этой статье я хочу описать способ, при помощи которого мы сделали такой красивый кастомный progress bar — на иллюстрации — в... | https://habr.com/ru/post/231117/ | null | ru | null |
# Связь биллинга и Cisco Catalyst 2960 через SNMP. Изменение скорости портов, подсчет трафика
Как и обещали, после [приветствия](http://habrahabr.ru/company/serverclub/blog/115169/), начинаем немножко раскрывать технические подробности.
#### Задача
Дать пользователям возможность выбирать скорость подключения и спо... | https://habr.com/ru/post/115539/ | null | ru | null |
# Всё, что вы хотели знать о МАС адресе
Всем известно, что это шесть байт, обычно отображаемых в шестнадцатеричном формате, присвоены сетевой карте на заводе, и на первый взгляд случайны. Некоторые знают, что первые три байта адреса –... | https://habr.com/ru/post/483670/ | null | ru | null |
# Использование Intel HAXM при разработке приложений для Android Wear и TV
За плечами платформы Android долгий путь. Всё началось со смартфонов, потом были планшеты, дальше – устройства, работающие под управлением Google TV, Android Wear, Android TV (вместо Google TV), и, наконец – Android Auto. Сборка и тестирование ... | https://habr.com/ru/post/265791/ | null | ru | null |
# COUNT(*)

У меня есть подборка простеньких вопросов, которые я люблю задавать при собеседовании. Например, как посчитать общее число записей к таблице? Вроде бы ничего сложного, но если копнуть глубже, то можно много интересных ню... | https://habr.com/ru/post/271797/ | null | ru | null |
# PVS-Studio, Blender: цикл заметок о пользе регулярного использования статического анализа

В статьях мы регулярно повторяем важную мысль: статический анализатор должен использоваться регулярно. В этом ... | https://habr.com/ru/post/545354/ | null | ru | null |
# PHPixie против Laravel

Главной причиной написания этой статьи является то что этот вопрос мне задают практически регулярно и было бы хорошо просто иметь под рукой ссылку. Сразу же скажу что холивора... | https://habr.com/ru/post/309176/ | null | ru | null |
# Material Design и AngularJS
Ни для кого не секрет, что Google повсюду в своих продуктах внедряет так называемый material design. Как и любой другой стиль он имеет сторонников и противников. Не буду касаться этих споров. Если вам нравится данный подход, Google подготовил полную спецификацию и описание особенностей: [... | https://habr.com/ru/post/247719/ | null | ru | null |
# Unit тестирование в Laravel
Я часто слышу среди обсуждений в сообществе мнение, что unit тестирование в Laravel неправильное, сложное, а сами тесты долгие и не дающие никакой пользы. Из-за этого эти тесты мало кто пишет, ограничиваясь лишь feature тестами, а польза unit тестов стремится к 0.
Я тоже так считал ког... | https://habr.com/ru/post/457866/ | null | ru | null |
# Как переписать большой проект или безболезненный для бизнеса рефакторинг

> Вопрос, который мне задают чаще всего, — как разговаривать о рефакторинге с руководителем?
>
> В таких случаях я даю несколько спорный сове... | https://habr.com/ru/post/252405/ | null | ru | null |
# Вышла библиотека PyWhat для автоматического парсинга трафика
[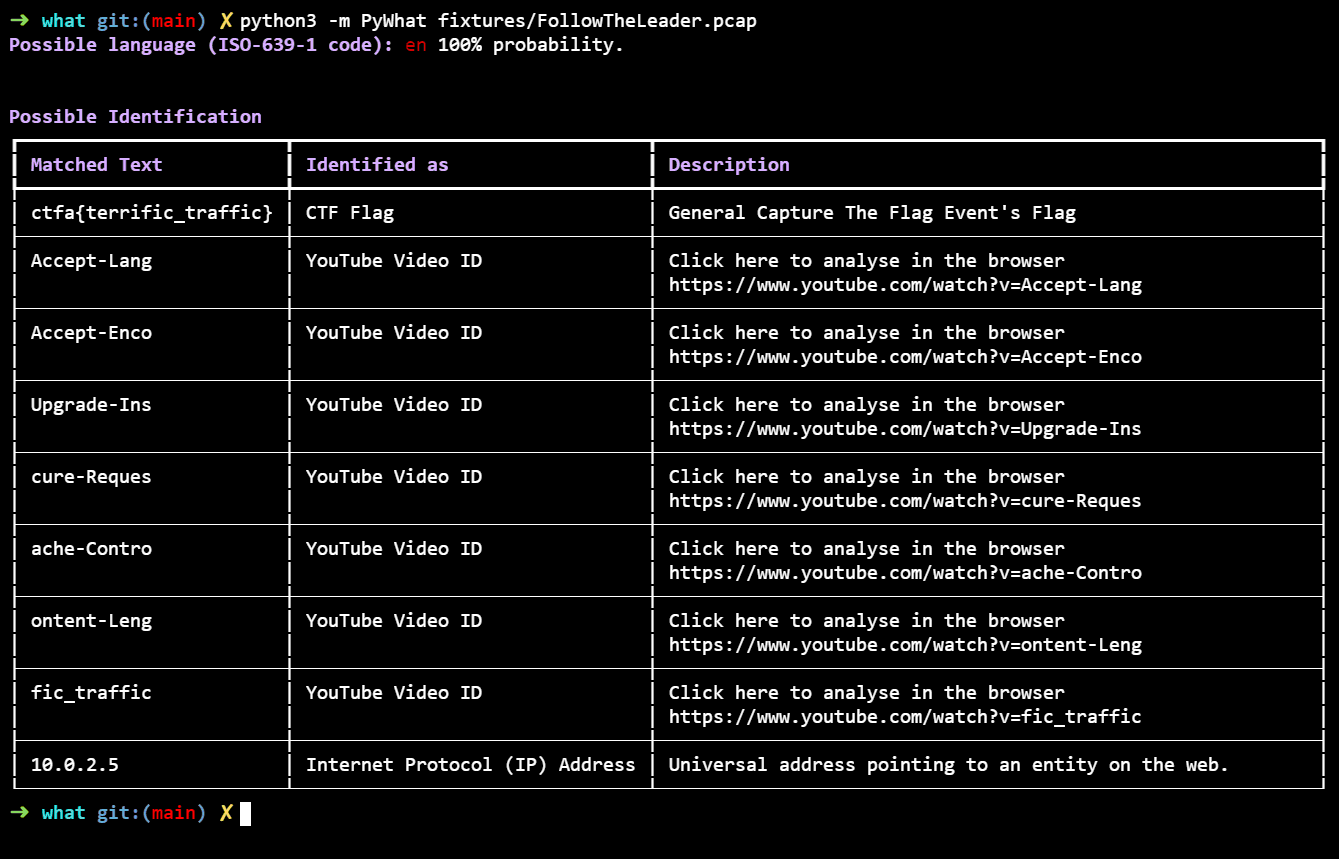](https://habrastorage.org/webt/lh/4q/kv/lh4qkvcjrcirr35oqzeeuxmkoqm.png)
Разработана удобная библиотека [PyWhat](https://github.com/bee-san/pyWhat), которая помогает кл... | https://habr.com/ru/post/563206/ | null | ru | null |
# Mattermost self-hosted хак групповых уведомлений
Недавно мы с командой переехали в мессенджер Mattermost на замену Slack, но мы столкнулись с одной неприятной проблемой. мы не можем в бесплатной версии уведомлять пользователей через тег группы `@groupname` в бесплатной версии этой возможности нет, и групп не предусм... | https://habr.com/ru/post/673036/ | null | ru | null |
# Забавляемся с хешами
Привет. Я хочу показать вам небольшой фокус. Для начала вам потребуется скачать [архив с двумя файлами](http://dl.dropbox.com/u/10864844/ge.rar). Оба имеют одинаковый размер и одну и ту же md5 сумму. Проверьте никакого обмана нет. Md5 хеш обоих равен ecea96a6fea9a1744adcc9802ab7590d. Теперь запу... | https://habr.com/ru/post/113127/ | null | ru | null |
# Визуализация использования GIL в CPython
Интересно, как ведут себя потоки, когда борются за GIL, или немного информации [отсюда](http://www.dabeaz.com/python/GIL.pdf) только для Python3.
Сразу оговорюсь, что использую `Ubuntu 16.04` c ядром `4.15.0-115-generic`, на машине стоит 4-х ядерный процессор `Intel(R) Cor... | https://habr.com/ru/post/523944/ | null | ru | null |
# RAM with Simple direct-mapped cache simulation on FPGA in Verilog
Simple direct-mapped cache simulation on FPGA
=============================================
---
This article is a part of a course work for first year bachelor students of Innopolis University. All work is done in a team. The purpose of this article... | https://habr.com/ru/post/432320/ | null | ru | null |
# Еще раз о Code Review
Не так давно сидел я делал ревью кода одного из коллег. Это было не первое мое ревью, но в этот раз я задался вопросом как все таки формализовать подход и на что конкретно стоит обращать внимание и как аргументировать и формулировать предложения и замечания. Сформулировал я для себя вот такие п... | https://habr.com/ru/post/576826/ | null | ru | null |
# Мой восьмилетний квест по оцифровке 45 видеокассет. Часть 1
За последние восемь лет я перевозил эту коробку с видеокассетами в четыре разные квартиры и один дом. Семейные видеозаписи из моего детства.

Спустя более 600 часов работы я, наконец, оцифровал и норм... | https://habr.com/ru/post/524724/ | null | ru | null |
# Функции для документирования баз данных PostgreSQL. Часть третья
Это третья часть статьи, которая описывает пользовательские функции для работы с системными каталогами: pg\_class, pg\_attribute, pg\_constraints и т.д.
В этой ч... | https://habr.com/ru/post/418597/ | null | ru | null |
# Пришло время бесплатных сайтов
Привет, %username%!
===================

Сегодня многие начинающие веб-разработчики делают большую ошибку, и не одну. Они что-нибудь сверстают, а потом покупают хостинг. Далее покупают домен. Регистр... | https://habr.com/ru/post/495178/ | null | ru | null |
# Домашний сервер. Часть 2. FTP, Samba и rTorrent
Пришло время организовывать файловое хранилище, как внутри сети так и снаружи. Данная статья является продолжением [первой части, посвященной настройки WiFi роутера на Вашем домашнем сервере](http://habrahabr.ru/blogs/sandbox/127879/). Все жесткие диски с Вашего домашн... | https://habr.com/ru/post/128117/ | null | ru | null |
# Работа с формами, списками и «табами» в Samsung Bada
Доброго времени суток!
В топике кратко изложены основные сведения с примерами кода, иллюстрирующие работу с некоторыми пользовательскими элементами управления и формами на платформе Samsung Bada. Пример приложения с кнопками, полями ввода и надписями (Label) им... | https://habr.com/ru/post/112781/ | null | ru | null |
# Тестирование флеш СХД. Huawei Dorado 2100 G2
Наша серия статей посвященная тестированию различных флеш систем хранения данных была бы не полной без продукта компании Huawei. Признаюсь честно, Dorado уже бывал в нашей лаборатории ранее, практически сразу после того, как стал доступен в России. В этот раз, следуя «пож... | https://habr.com/ru/post/265143/ | null | ru | null |
# Резервное копирование веб-проектов на Яндекс.Диск без ООП и натурщиц
Позавчера хабраюзер [vasiatka](https://habrahabr.ru/users/vasiatka/) в посте [№206752](http://habrahabr.ru/post/206752/) поделился с хабрасообществом, а следовательно и со всем остальным миром, продуманным и весьма развитым классом для работы с Янд... | https://habr.com/ru/post/206898/ | null | ru | null |
# Поиск it компаний с аккредитацией минцифры и крупицы Big Data
Времени на раскачку нет - сразу к делу.
На сайте [digital.gov.ru](https://digital.gov.ru/ru/activity/govservices/1/?utm_referrer=https%3a%2f%2fwww.google.com%2f) можно найти документ со списком организаций, прошедших аккредитацию минцифры.
Давайте добав... | https://habr.com/ru/post/690474/ | null | ru | null |
# Как сделать удобное взаимодействие с Kotlin из Swift: решение с помощью плагина MOKO KSwift
Привет! На связи Алексей Михайлов, технический директор компании IceRock Development. [В прошлой статье](https://habr.com/ru/post/697966/) я рассказывал о том, какие проблемы есть в работе с Kotlin со стороны Swift, и рассмат... | https://habr.com/ru/post/700030/ | null | ru | null |
# Первые шаги с Netbeans и Wicket
Доброго времени суток. Недавно пришлось поюзать Java фреймворк по имени **Wicket**. На великом Хабре искал инфу про нее, но ее оказалось слишком мало и вот решил поделиться. Итак, пошли:
После того, как пару лет назад пересел на NetBeans, игры с командной строкой при создании веб-п... | https://habr.com/ru/post/127047/ | null | ru | null |
# Ansible и Docker, почему и зачем?
Достаточно много интереса проявляется среди технического сообщества к [Docker](https://www.docker.io/) и [Ansible](https://github.com/ansible/ansible), я надеюсь, что после прочтения данной статьи, вы тоже разделите этот интерес. Вы так же получите навыки практического применения An... | https://habr.com/ru/post/217689/ | null | ru | null |
# Верстка писем и email рассылок. Немного магии Gmail

Автор изображения [Mike, Creative Mints](http://dribbble.com/shots/310396-Potion-2-0?list=searches&tag=magic)
Добрый день. Я уже не раз писал о том... | https://habr.com/ru/post/193790/ | null | ru | null |
# Варианты создания интерактивной экскурсии для пользователей
 Freepik Storyset")(с) Freepik StorysetДоброго времени суток, уважаемые читатели!
Меня зовут Евгений Когтев, я ведущий ра... | https://habr.com/ru/post/555228/ | null | ru | null |
# Обновление BIOS на сервере Dell PowerEdge R510
Производители серверного оборудования стараются следить за корректной работой своих продуктов. Одной из таких мер есть исправление и совершенствование [BIOS](http://en.wikipedia.org/wiki/BIOS)'a. В данной статье я расскажу как можно обновлять BIOS серверов Dell серии Po... | https://habr.com/ru/post/144575/ | null | ru | null |
# Проектирование типами: Как сделать некорректные состояния невыразимыми
*Представляю вашему вниманию перевод статьи Scott Wlaschin ["Designing with types: Making illegal states unrepresentable"](https://fsharpforfunandprofit.com/posts/designing-with-types-making-illegal-states-unrepresentable/).*
В этой статье мы ра... | https://habr.com/ru/post/424895/ | null | ru | null |
# ConfigureAwait, кто виноват и что делать?
В своей практике я часто встречаю, в *различном* окружении, код вроде того, что приведен ниже:
```
[1] var x = FooWithResultAsync(/*...*/).Result;
//или
[2] FooAsync(/*...*/).Wait();
//или
[3] FooAsync(/*...*/).GetAwaiter().GetResult();
//или
[4] FooAsync(/*...*/)
.C... | https://habr.com/ru/post/463587/ | null | ru | null |
# Как очищать данные при помощи SQL
За время работы автору довелось использовать многие инструменты анализа, включая Excel, R и Python. Попробовав PostgreSQL и TimescaleDB, автор поняла, насколько простыми м... | https://habr.com/ru/post/594753/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.