
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# А все ли врут? Продолжаем издеваться над NVME
[](https://habr.com/ru/company/ruvds/blog/599337/)
А пока мои коллеги [пытаются разобраться с проблемами серверных NVME Raid массивов](https://habr.com/ru/company/ruvds/blog/560404/), я... | https://habr.com/ru/post/599337/ | null | ru | null |
# Iptables: немного о действии REDIRECT, его ограничениях и области применения

Данная заметка повествует о действии REDIRECT в iptables, его ограничениях и области применения.
Iptables и REDIRECT
======... | https://habr.com/ru/post/324276/ | null | ru | null |
# Создание бэкенд приложения для онлайн чата Apollo, Node.js
Некоторое время назад я работал над мобильным приложением, функционал которого включал в себя удобный онлайн-чат. И теперь я решил написать статью с краткой инструкцией, как создать чат, используя apollo server и node.js на бэкенде, а так же react native и a... | https://habr.com/ru/post/470756/ | null | ru | null |
# AdvancedApplicationBar. Улучшаем возможности ApplicationBar в WP7
У многих разработчиков WP7 вызывает неприятное удивление реализация ApplicationBar. ~~В шутку ходят грязные слухи, что эта компонента разрабатывалась вообще не в МС, а командой не имеющего к silverilght никакого отношения, которые написали компоненту ... | https://habr.com/ru/post/134641/ | null | ru | null |
# FP на Scala: Что такое функтор?
Специалист, приступающий к изучению функционального программирования, сталкивается как с неоднозначностью и запутанностью терминологии, так и с постоянными ссылками на «серьезную математику».
В этой статье, не используя теорию категорий с одной стороны и эзотерические языковые меха... | https://habr.com/ru/post/266905/ | null | ru | null |
# Школьный DDoS и стоит ли его бояться
Современный интернет предлагает четыреста относительно честных способов зарабатывания денег. К сожалению, не все алчные до наживы персонажи ими ограничиваются. К счастью, только некоторые из них... | https://habr.com/ru/post/133418/ | null | ru | null |
# Машинное обучение с помощью TMVA. Reader модели
[Продолжу обещанный рассказ](https://habrahabr.ru/post/306242/) о том, как можно применять полученную модель на практике, заодно попытаюсь более подробно раскрыть тему эксклюзивности TMVA.
Допустим, Вы работаете в проекте, требующем максимального быстродействия сист... | https://habr.com/ru/post/307154/ | null | ru | null |
# Обработка ошибок в Go 2

Буквально пару дней назад в Денвере закончилась очередная, уже 5-я по счёту, крупнейшая конференция по Go – [GopherCon](https://www.gophercon.com). На ней команда Go сделала [важное заявление](https://bl... | https://habr.com/ru/post/422049/ | null | ru | null |
# Тестирование для мобильных устройств: эмуляторы, симуляторы и удалённая отладка
В давние времена разработки мобильных сайтов и приложений отладка была сложной задачей. Да, можно было заполучить устройство и быстренько проверить работу – но что было делать, если ты обнаруживал баг?
При отсутствии инструментов отла... | https://habr.com/ru/post/237499/ | null | ru | null |
# Своя система сборки на Linux

Здравствуйте! Я давно не появлялся здесь в качестве оратора, но в этот раз я решил поделится кое-чем, что сделал сам, а также узнать — нужно это, не нужно, как можно до... | https://habr.com/ru/post/338698/ | null | ru | null |
# Разгоняем портал ДО на основе Moodle (решение проблем узких мест)
В последнее время все острее встает вопрос об обучении онлайн, во время пандемии, так и в связи с переходом в онлайн всего и вся. На сайте Х... | https://habr.com/ru/post/542452/ | null | ru | null |
# Робот -тележка на ROS.Часть 2. Cофт
Посты серии:
[8. Управляем с телефона-ROS Control, GPS-нода](https://habr.com/ru/post/474650/)
[7. Локализация робота: gmapping, AMCL, реперные точки на карте помещения](https://habr.com/ru/post/472984/)
[6. Одометрия с энкодеров колес, карта помещения, лидар](https://hab... | https://habr.com/ru/post/461131/ | null | ru | null |
# How does strange code hide errors? TensorFlow.NET Analysis
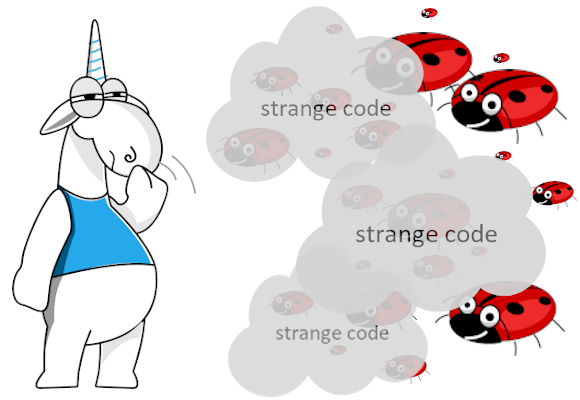
Static analysis is an extremely useful tool for any developer, as it helps to find in time not only errors, but als... | https://habr.com/ru/post/496246/ | null | en | null |
# Автоответчик в postfix
Приветствую читателей сего сайта.
Тема, которую я собираюсь поднять, здесь не нова, но, может быть, кому-то поможет.
Итак…
Дано:
1. Настроенный postfix+cyrus-imap+sasl2. Почтовый сервер обслуживает 3 домена (domain1.ru, domain2.ru, domain3.ru)
Задача:
Сделать «автоответчик» о... | https://habr.com/ru/post/305918/ | null | ru | null |
# Напишем и поймем Decision Tree на Python с нуля! Часть 4. Структуры данных
*Данная статья — четвертая в серии. Ссылки на предыдущие статьи: [первая](https://habr.com/ru/post/517556/), [вторая](https://habr.com/ru/post/518768/), [третья](https://habr.com/ru/post/520204/)*
4.1 Структуры данных
--------------------
... | https://habr.com/ru/post/526316/ | null | ru | null |
# Настройка Xdebug 3 на внешнем сервере в Docker-контейнере через SSH-туннель
В нашей организации используется такой подход к разработке - на локальной машине (Windows 11) установлен PhpStorm и находится репозиторий с кодом. В PhpStorm настроена автоматическая выгрузка изменений на dev-стенд (внешний сервер), где и ис... | https://habr.com/ru/post/665860/ | null | ru | null |
# Cool WSL (Windows Subsystem for Linux) tips and tricks
It's no secret I dig WSL (Windows Subsystem for Linux) and now that [WSL2](https://www.hanselman.com/blog/RubyOnRailsOnWindowsIsNotJustPossibleItsFabulousUsingWSL2AndVSCode.aspx) is available in [Windows Insiders Slow](https://insider.windows.com/) it's a great ... | https://habr.com/ru/post/475994/ | null | en | null |
# Методы протекции важного текста
В современном интернете может существовать огромное количество текстовых данных: статьи, книги, публикации, сканы, заявления, заметки, справочники, энциклопедии, тексты песен. Я ратую за создание уникального контента (в качестве примера можно указать здесь газетные агентства, различны... | https://habr.com/ru/post/227799/ | null | ru | null |
# Небольшой путеводитель по ZPL
#### Добрый день, Хабрахабр.
Благодаря тепло принятой прошлой публикации, я могу опубликовать здесь эту статью. Спасибо всем, кто ставил плюсы.
По долгу службы мне частенько приходится формировать отчеты для этикеточных принтеров семейства Zebra.

Кому будет интересно?
---------------------
Reactor сегодня - это стильно, модно, молодежно. Почему многие из нас практикуют реактивное прогр... | https://habr.com/ru/post/562482/ | null | ru | null |
# Используем быстрые селекторы для jQuery
Как Вы знаете — в разработке объёмного JS-приложения где используется популярнейшая библиотека [jQuery](http://jquery.com) наступает момент когда остро встаёт проблема производительности. Все силы кидаются на амбразуру профайлера, каждый вызов скрупулёзно исследован, каждый фу... | https://habr.com/ru/post/111195/ | null | ru | null |
# Как запускать DBDeploy в Gradle
В данной заметке я покажу, как запускать DBDeploy из скрипта Gradle.

### О чём это... | https://habr.com/ru/post/152765/ | null | ru | null |
# Navigation Editor — новый инструмент в Android Studio
В Android Studio появился интересный инструмент для быстрого прототипирования экранов активностей. Как говорят авторы на [своей страничке](http://tools.android.com/navigation-editor) — это пока только предварительная проба пера и данный инструмент ещё будет дораб... | https://habr.com/ru/post/226297/ | null | ru | null |
# Программатор для ПЛИС
Хочу рассказать о том, как развивается проект <http://marsohod.org>.
Цель проекта — популяризация проектирования для ПЛИС.
Тема ПЛИС постепенно набирает популярность — и совершенно заслуженно. Ведь теперь мы фактически получили простую возможность создать свою цифровую микросхему. Вам не... | https://habr.com/ru/post/134657/ | null | ru | null |
# Интеграционные тесты для Хранилища Данных – Настраиваем Slim CI для DWH
Привет! На связи Артемий – Analytics Engineer из Wheely.
В условиях постоянно растущей сложности аналитических инструментов и распред... | https://habr.com/ru/post/567916/ | null | ru | null |
# OAuth в мобильных приложениях
Привет! Меня зовут Мялкин Максим, я занимаюсь мобильной разработкой в [KTS](https://kts.studio/).
Ни один сервис не обходится без логина. Часто в мобильных приложениях требуе... | https://habr.com/ru/post/654029/ | null | ru | null |
# vPass 2 — простой и удобный генератор безопасных паролей на Javascript
Привет,
я потихоньку сделал версию 2 своего «потустороннего» проекта — [vPass](https://www.vpass.info/2/vpass.html). Если интересно, [вот тут](http://habrahabr.ru/post/149934/) в комментах интересное обсуждение первой версии.

Эта статья предназначена для тех, кто хочет узнать об основах использования этого фреймворка. В ней я постараюсь подробно рассказать о том, как начать работу с Webix. Так... | https://habr.com/ru/post/256505/ | null | ru | null |
# Начни с себя, или 60 дней Kubuntu

В продолжении предыдущей статьи «[Как Prius, но только на Linux](https://habr.com/company/pc-administrator/blog/416569/)» мне хотелось бы рассказать о собственном опыте смены рабочей среды. Перед ... | https://habr.com/ru/post/417997/ | null | ru | null |
# Как я перестал бояться и начал делиться секретами с телефоном
Не знаю как вы, а я – не могу сказать, что люблю, но вижу очень много пользы в интроспекции, или, по простому, самонаблюдении. Вот, допустим, позавчера я проснулся сам, не слишком рано, съел овсянки, выпил кофе без сахара, и весь мой день был очень продук... | https://habr.com/ru/post/665888/ | null | ru | null |
# Russian Code Cup 2013: разбираем задачи финала

23 сентября 2013 года состоялся финал чемпионата по программированию Russian Code Cup 2013.
Первое место занял Петр Митричев (кстати, чемпион RCC 2011). Второй приз в... | https://habr.com/ru/post/195164/ | null | ru | null |
# Автоматическое переименование хостов в Zabbix, по данным из snmp sysName
Цикл статей о Zabbix продолжает не зарегистрированный здесь пользователь. Первую статью можете прочитать [тут](http://osj.habrahabr.ru/blog/81630/).
Зачем это нужно?
----------------
Добавить новый хост в Zabbix можно двумя основными способ... | https://habr.com/ru/post/82465/ | null | ru | null |
# На чем тестировать алгоритмы распознавания и обработки документов, удостоверяющих личность?
Как известно, мы в [Smart Engines](https://smartengines.ru/) занимаемся системами компьютерного зрения и распознавания документов, а также научными исследованиями в этой области. В течение нескольких лет в фокусе нашего внима... | https://habr.com/ru/post/492696/ | null | ru | null |
# Chainvas: изящный и миниатюрный «костыль», добавляющий средства цепного вызова (method chaining) к любому API
Благодаря библиотеке jQuery примерно с 2006 года (то есть лет пять как) никому не надо объяснять, что такое **method chaining**: это та самая техника программирования, в которой методы объекта могут быть выз... | https://habr.com/ru/post/131542/ | null | ru | null |
# Транзакции и многопоточный доступ к базе данных
Недавно мне понадобилось выполнить следующий код (представлен в максимально упрощенном виде):
```
public void Start()
{
using (var transactionScope = new TransactionScope())
{
...
GetOrCreateCompany(someValue);
...
transaction... | https://habr.com/ru/post/115156/ | null | ru | null |
# Краткий экскурс в ruGPT-3. Инструкция и демонстрация
GPT-3 — нейронная сеть, наделавшая шума в 2020 году, как самая сложная, объёмная и многообещающая модель по работе с текстовыми данными. Создана организацией OpenAI в нескольких вариациях, от 125 миллионов до 175 миллиардов признаков. Хотя в названии организации и... | https://habr.com/ru/post/589663/ | null | ru | null |
# Разработка игры под управлением WP8 с использованием Netduino
*Мы столкнулись с интересной статьей от разработчика приложений под Windows Phone и решили поделиться ею с вами.*
Когда я был маленьким, родители подарили мне деревянную игру-лабиринт. Она мне очень нравилась. Не думаю, что меня когда-либо волновал сам... | https://habr.com/ru/post/174731/ | null | ru | null |
# PyMC3 — MCMC и не только
PyMC3 — МСМС и не только
========================

Привет, Хабрахабр!
В [этом](https://habrahabr.ru/company/wunderfund/blog/279545/) посте уже упоминался PyMC3. Там можно почитать про основы MCMC-сэмплирова... | https://habr.com/ru/post/322716/ | null | ru | null |
# Пара слов о спецификациях
Всем доброго времени суток! Удивительно, но упоминание о шаблоне ["Спецификация"](https://en.wikipedia.org/wiki/Specification_pattern) в контексте php встречается крайне редко. А ведь с его помощью можно не только [избежать комбинаторного взрыва методов репозитория](https://beberlei.de/2013... | https://habr.com/ru/post/540082/ | null | ru | null |
# Хабрастатистика: анализируем комментарии читателей
Привет Хабр. В [предыдущей части](https://habr.com/ru/post/467429/) была проанализирована популярность различных разделов сайта, и параллельно возник вопрос — какие данные можно извлечь из комментариев к статьям. Также хотелось проверить одну гипотезу, о которой ска... | https://habr.com/ru/post/467653/ | null | ru | null |
# Хроники ремонта: как мы делали новый умный офис Madrobots. Часть вторая, умная
У нас в компании есть отличная традиция. Раз в полгода мы собираемся вместе и что-нибудь строим. Год назад это была [горбушка](http://habrahabr.ru/company/madrobots/blog/221697/), полгода назад — [мега](http://habrahabr.ru/company/madrobo... | https://habr.com/ru/post/384271/ | null | ru | null |
# Делаем управление «Умным домом» через интернет за пару минут
Доброго дня. У многих из нас, в том числе и у меня, давно возникла идея создания своего «Умного дома». Но она откладывалась в виду большой сложности реализации как с аппаратной стороны так и со стороны программного обеспечения, что требовало от её создател... | https://habr.com/ru/post/219107/ | null | ru | null |
# Оптимизация Java-кода в Android Marshmallow
[](https://habrahabr.ru/company/intel/blog/300934/) Повышение производительности системы, улучшение впечатлений пользователей от работы с приложениями: вот направления, в которых р... | https://habr.com/ru/post/300934/ | null | ru | null |
# Эффективное управление облачными очередями (Azure Queue)
В этой, уже четвертой, статье из цикла «Внутреннее устройство и архитектура сервиса AtContent.com» я предлагаю познакомиться с фоновой обработкой заданий с использованием экземпляров сервиса Azure (Worker Role).
В качестве основного канала коммуникации межд... | https://habr.com/ru/post/141797/ | null | ru | null |
# BatchMarc обрабатывем marc файлы на go + js
Всем бобра!
Сегодня пятница, а это значит время подводить итоги!
Продолжая темы нашего библиотечного клуба спешу немного порадовать всех причастных: я сделяль!
Спустя море потраченных нервных клеток, спустя ад документации по marc форматам, и кучу костылей я всё т... | https://habr.com/ru/post/395377/ | null | ru | null |
# Как тестировать контейнеры RoR с GitLab CI в контейнере
Чем хорош GitLab, так это тем, что будучи по габаритам слоном в посудной лавке, он умеет аккуратно устанавливаться и почти всегда работает с коробки. Но плохо умеет восстанавливаться и заботиться о себе, когда очень прямые руки вроде моих нарушают привычное ему... | https://habr.com/ru/post/320982/ | null | ru | null |
# Asterisk GUI. Первые шаги
Почти всякий раз, когда речь заходит о выборе web-интерфейса к asterisk, в ход идут рекомендации «тяжелой артиллерии»: trixbox, elastix, freepbx. Asterisk GUI остается эдакой «темной лошадкой»: вроде и слышали о нем, вроде и скриншоты симпатишные, а реально работающих систем — с гулькин нос... | https://habr.com/ru/post/54816/ | null | ru | null |
# Хелп по отчетам в Outlook
**UPD** Статья — вопрос, а не мануал. Если вы не знаете ответа, зачем ставить минус, не читая?
Предистория: На мыло валятся письма от пользователей с различными просьбами — создать учетку, добавить права и так далее. В конце недели и в конце месяца нужно отправлять отчет об обращениях. ... | https://habr.com/ru/post/37331/ | null | ru | null |
# Ферритовый ROM для самых маленьких
Готовое устройствоИ снова здравствуйте, дамы и господа. Наш Отдел Перспективных Разработок продолжает свой цикл статей о древних те... | https://habr.com/ru/post/687284/ | null | ru | null |
# Однострочный калькулятор, искусство или порок?
Вводная
-------
Как это часто бывает, когда Вы ищете работу, Вы проходите одно собеседование за другим. Где-то Вас выбирают, где-то Вы. И наверное, в жизни каждого из нас бывали интересные собеседования, о которых можно с удовольствием поведать публике. Я хочу рассказа... | https://habr.com/ru/post/320830/ | null | ru | null |
# Как упавший продакшен делает нас лучше
> Неважно, сколько раз ты упал. Важно — сколько раз ты поднялся.
>
> © Мой домашний сервер
>
>
Вы не ослышались. Речь не о том, что упавший продакшен — это хорошо. Это плохо. Но продакшен иногда падает, надо это признать. Этого надо не допускать, но к этому надо быть ... | https://habr.com/ru/post/598583/ | null | ru | null |
# MongoDB: производительность запросов на диапазонах
Если вы путешествовали по территории индексов MongoDB, вы возможно слышали принцип: *Если ваши запросы содержат сортировку, то добавте сортированное поле в конец индекса который используется в этих запросах.*
Во многих случаях когда запросы содержат условия равен... | https://habr.com/ru/post/147053/ | null | ru | null |
# C#: Этюды, часть 7
Сегодня простой этюд, почти без кода.
Допустим, есть некий класс и его статический конструктор:
`static C()
{ Console.WriteLine("from static ctor"); }`
Как известно, статические конструкторы вызываются до первого использования типа. Других ограничений нет, поэтому время его вызова вы... | https://habr.com/ru/post/113543/ | null | ru | null |
# Acer AOA-110 HOWTO. Часть 2: настройка и введение в эксплуатацию под управлением GNU/Debian Linux
*Статья состоит из нескольких частей: так удобно и писать, и читать.*
В [предыдущей части](http://pas.habrahabr.ru/blog/56797/) нетбук был рассмотрен с аппаратной «точки» зрения, в этой рассмотрены особенности устано... | https://habr.com/ru/post/58315/ | null | ru | null |
# Перенос редактора Unity на Linux: вещи, которые стоило бы сделать заранее
На прошедшей в этом году конференции Unite Europe мы опубликовали наш план развития. И хотя там много классных вещей, лично мне больше всего нравится редактор для Linux. История портирования редактора под Linux похожа на историю добавления под... | https://habr.com/ru/post/263365/ | null | ru | null |
# Как определить каким файлам на диске соответствуют PostgreSQL таблицы
Иногда вам нужно определить какому файлу на диске соответствует таблица. У вас имеется путь, полный цифр, такой как ***base/16499/19401*** и вы хотите разобраться в нем. Вы можете смотреть на сообщение об ошибке, которое упоминает имя файла, напри... | https://habr.com/ru/post/275125/ | null | ru | null |
# Расширение рабочего стола
У ноутбуков Asus EeePC иногда не хватает разрешения экрана. Многие окна не помещаются на рабочем столе и их приходится перемещать мышкой что бы увидеть элементы, выходящие за его границы. Так же возникают проблемы с играми. И если под Windows с помощью драйверов можно расширить рабочий стол... | https://habr.com/ru/post/51968/ | null | ru | null |
# Организация js кода для джуниоров
С недавних пор я стал работать в сфере web разработки, и еще нахожусь в стадии падавана. Однако недавно я открыл для себя способ организации клиентского javascript кода, который может быть легко интегрирован в любой существующий проект и который легко освоить.
Этот подход называю... | https://habr.com/ru/post/218485/ | null | ru | null |
# Оптимизированный доступ к GPIO. Или GPIO как constexpr класс. С++
Добрый день, жители Хабра. Данный пост будет посвящен программированию на C++, и использованию constexpr объектов с целью повышения уровня удобства и одновременно оптимизации кода с точки зрения размера и производительности.
В процессе работы над од... | https://habr.com/ru/post/578836/ | null | ru | null |
# Кюветы Android, Часть 1: SDK
Довольно долгое время я никак не мог понять, в чём же разница между «библиотекой» и «фреймворком». Нет-нет, я умел и читать, и гуглить, но до меня всё никак не доходил смысл этих понятий. Начав же программировать под андроид, я наконец понял, что значат слова «библиотеку использует прогр... | https://habr.com/ru/post/279811/ | null | ru | null |
# Как меня назвали параноиком и что из этого вышло
Когда начались утечки баз паролей/хэшей с разных форумов и соц. сетей я начал задумываться о том как и где хранить свои пароли, что бы их можно было быстро менять и при этом не забыть. Так я наткнулся на программу [KeePass Password Safe](http://keepass.info/), о её во... | https://habr.com/ru/post/216239/ | null | ru | null |
# TypeScript в React-приложениях. 3. Как использовать типизацию
В каждом проекте свои правила и подходы в типизации данных. Некоторые из них общепринятые, кое-какие сомнительны, а иные не достаточно строги. В данной статье предлагается объективный взгляд на законы, придуманные разработчиками для использования TypeScri... | https://habr.com/ru/post/694832/ | null | ru | null |
# C#: Этюды, часть 6
Со времени последнего этюда прошло очень много времени, но я надеюсь, что хабраюзеры не успели утратить интерес к C#.
В этот раз задачка довольно простая, но новичкам в шарпе она может оказаться полезной. Есть следующий код:
`var x = new T(...);
var y = new T(...);
Console.WriteLine... | https://habr.com/ru/post/93875/ | null | ru | null |
# Получить выписку из Росреестра через ФГИС ЕГРН и python. Часть 2
В этой статье попробуем получить выписки из ФГИС ЕГРН с помощью python (selenium) сразу по нескольким объектам недвижимости, решим капчу с помощью сервиса anticaptcha, используя его api. При встрече с капчей нейросети трогать не будем, так как они могу... | https://habr.com/ru/post/492568/ | null | ru | null |
# Корпоративный VPN c ACCEL-PPP+IPsec и авторизацией в Freeradius через AD

В этой заметке я хочу показать пример быстрой реализации корпоративного VPN сервера с поддержкой PPTP, L2TP (как с IPsec так и без), IPSec vpn с ед... | https://habr.com/ru/post/267103/ | null | ru | null |
# Roslyn API: Why PVS-Studio Was Analyzing the Project So Long
How many of you have used third-party libraries when writing code? It's a catchy question. Without third-party libraries the development of some products would be delayed for a very, very long time. One would have to reinvent the wheel to solve each proble... | https://habr.com/ru/post/553786/ | null | en | null |
# Закончен новый модуль базы данных для PHPixie

Сегодня я написал последний тест для версии 3.0 модуля доступа к БД для [PHPixie](http://phpixie.com/). Когда я начал казалось что это займет всего неск... | https://habr.com/ru/post/205710/ | null | ru | null |
# Пишем плагин для поддержки cmake проектов под vim
Сегодня поговорим о создании дополнений для VIM.
Недавно у меня возникла идея вкрутить в него поддержку cmake проектов для удобной навигации по файлам. С этой задачей, конечно, вполне справится NERD Tree, но в последнем нельзя оперировать исключительно файлами про... | https://habr.com/ru/post/153873/ | null | ru | null |
# Глубина резкости в компьютерной графике
В отличии от человеческого глаза, компьютер рендерит всю сцену в фокусе. И камера, и глаз же имеют ограниченную глубину резкости вследствие конечного диаметра апертуры зрачка или... | https://habr.com/ru/post/146136/ | null | ru | null |
# Шифрование сообщений в SecureDialogues
Шифрование, цифровая подпись, защита данных — термины довольно распространенные среди IT-специалистов.
Уже написано очень много интересных публикаций, статей и книг на эти темы. После прочтения одной из них, я решил попробовать свои силы на практике. Так и родился проект, о к... | https://habr.com/ru/post/452736/ | null | ru | null |
# Нагрузочное тестирование с locust
Нагрузочное тестирование не так сильно востребовано и распространено, как иные виды тестирования — инструментов, позволяющих, провести такое тестирование, не так много а простых и удобных вообще можно пересчитать на пальцах одной руки.
Когда речь заходить о тестировании производи... | https://habr.com/ru/post/430502/ | null | ru | null |
# Заходят как-то два браузера в скроллбар…
[](https://habr.com/ru/company/ruvds/blog/468405/) Скроллбар (scrollbar, полоса прокрутки) — это простой, но эффективный механизм, который действует как основно... | https://habr.com/ru/post/468405/ | null | ru | null |
# Рассказ о том, как команда фрилансеров пишет фулстек-приложения на JavaScript
Автор материала, перевод которого мы сегодня публикуем, говорит, что [GitHub-репозиторий](https://github.com/TrillCyborg/fullstack), над которым работал он и ещё несколько фрилансеров, получил, по разным причинам, около 8200 звёзд за 3 дня... | https://habr.com/ru/post/456340/ | null | ru | null |
# No cON Name CTF 2014 Final
С 30 октября по 1 ноября в Барселоне проходила международная конференция по информационной безопасности *No cON Name 2014*, в рамках которой уже второй раз проводился финал соревнований «*Capture The Flag*». Команда университета Иннополис BalalaikaCr3w приняла участие в этом соревновании и... | https://habr.com/ru/post/245011/ | null | ru | null |
# Циклы и функционалы в языке R (бесплатный видео курс)
Друзья, рад представить вам свой новый курс "Циклы и функционалы в R". Курс и все сопутствующие материалы к нему распространяются бесплатно, и являются общедоступными.
 электронную схему, которая распознает мелодии. Упражнения по проект... | https://habr.com/ru/post/577552/ | null | ru | null |
# Телепортация тонн данных в PostgreSQL
Сегодня я поделюсь некоторыми полезными архитектурными решениями, которые возникли в процессе развития нашего **инструмента массового анализа производительности серверов PostgeSQL**, и которые помогают нам сейчас «умещать» полноценный мониторинг и анализ более тысячи хостов в то... | https://habr.com/ru/post/516384/ | null | ru | null |
# Mahou обновился до версии 2.0

Наверно Вы уже читали мою вступительную [статью про Mahou](https://habrahabr.ru/post/321518/), в ней я описал как я создал первую функцию и описал в общих чертах что делает программа. С тех пор прошло не мало времени в Mahou много чего изменилось и... | https://habr.com/ru/post/324592/ | null | ru | null |
# Oracle закручивает гайки
*Это перевод заметки Исчезновение набора тестов или очередная часть MySQL стала закрытой? (Disappearing test cases or did another part of MySQL just become closed source?)*
Около недели назад я изучал MySQL 5.5.27 и заметил любопытную деталь. Несмотря на то, что новый релиз MySQL содержал... | https://habr.com/ru/post/149905/ | null | ru | null |
# Правостороннее присваивание и другие необычные приёмы программирования в C#
В этой статье будут рассмотрены с нового ракурса такие привычные и фундаментальные вещи, как присваивание и передача параметров в методы.
Вероятно, предлагаемые решения поначалу покажутся несколько странными и надуманными, но прелесть их ... | https://habr.com/ru/post/354278/ | null | ru | null |
# Подкуем хаос
Небольшое изменение [скрипта XaosCPS](http://habrahabr.ru/blogs/powershell/76538) для получения кармы.
`$user = ([xml](new-object system.net.WebClient -prop @{encoding=[System.Text.Encoding]::UTF8}).DownloadString("http://habrahabr.ru/api/profile/XaocCPS")).habrauser
Write-Host "$($user.login) - к... | https://habr.com/ru/post/92238/ | null | ru | null |
# Доступ к файловой системе в MarkLogic Server
MarkLogic является сервером приложений и любая программа написанная на XQuery для него может получить доступ не только к объектам хранящимся в самой базе данных, но и к файлам находящимся непосредственно на файловой системе.
API предоставляющий доступ к файловой систем... | https://habr.com/ru/post/196402/ | null | ru | null |
# DRWEB — обновление базы вирусов
Вчера (позор на мою голову) таки словил какой-то вирус блокиратор. Правда он был совсем добрый — всего лишь показывал порнуху в середине экрана и блокировал диспетчер задач.
Перезагружаюсь в безопасный режим, запускаю свежий cureit (времени искать вручную не было), ухожу празднова... | https://habr.com/ru/post/79500/ | null | ru | null |
# Сервис отложенных запросов для Retrofit на Android
Как Вы обрабатываете отсутствие доступа в интернет в своем приложении? Показываете сообщение "Нет интернета, попробуйте позже"? Допустим случай, когда мы хотим гарантировать выполнение сетевого запроса пользователя, а не заставлять его искать интернет и снова повтор... | https://habr.com/ru/post/580056/ | null | ru | null |
# Как проверить данные во фрейме Pandas с помощью Pandera
Убедитесь, что данные соответствуют ожиданиям
---------------------------------------------
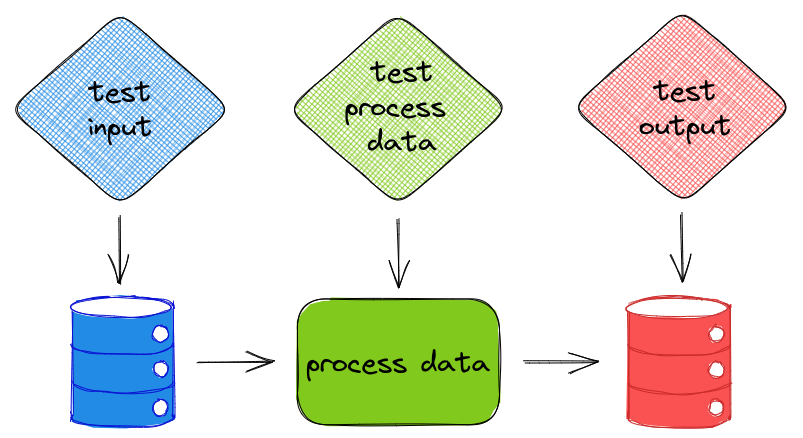В науке о данных важно тестировать не только функции, но ... | https://habr.com/ru/post/658473/ | null | ru | null |
# Машинное обучение в энергетике, или не только лишь все могут смотреть в завтрашний день
Точное предсказание будущих событий — перспективная и интересная задача во многих сферах: от прогноза погоды до финтеха (котировки акций, курсы валют). Машинное обучение уже сегодня позволяет значительно сократить время и трудоза... | https://habr.com/ru/post/487944/ | null | ru | null |
# Частые ошибки программирования на Bash
Качество скриптов, используемых для автоматизации и оптимизации работы системы, является залогом ее стабильности и долголетия, а также сохраняет время и нервы администратора этой системы. Несмотря на кажущуюся примитивность bash как языка программирования, он полон подводных ка... | https://habr.com/ru/post/47706/ | null | ru | null |
# Java библиотека для эффективной передачи CSS и JavaScript
В данной статье описывается способ передачи JavaScript и CSS методом соединения ресурсов, с последующими их минимизацией и сжатием, при помощи небольшой Java библиотеки «Combinatorius», что позволяет ускорить и упростить передачу контента.
Демо: [combinato... | https://habr.com/ru/post/303840/ | null | ru | null |
# Несколько хороших манкал
***Хотя этикетка была не того цвета и содержала немало орфографических ошибок, большая ее часть находилась на месте, включая сделанную крошечным шрифтом надпись «Может содержать орехи».
... | https://habr.com/ru/post/272119/ | null | ru | null |
# Сервер в облаках: готовимся к запуску
В [посте про регату](https://habr.com/company/ruvds/blog/418141/) мы обмолвились, что в августе всех хабражителей ждет конкурс с призами. Пришло время сорвать ~~покровы~~ завесу секретности. Как-то нам пришла мысль, что фразу «сервер в облаках» можно понять буквально. А давайте ... | https://habr.com/ru/post/420451/ | null | ru | null |
# Как вывести рендеринг карт на сверхзвук и не…
Введение
--------
В данной статье я расскажу как я делал тайлер на основе openstreetmaps на С++/Qt. Задача была написать картографический модуль приложению для поисково-спасательных отряд... | https://habr.com/ru/post/567936/ | null | ru | null |
# Чудо свершилось. Вышла «отвязанная» версия Arduino Mega Server
Революция о которой так долго говорили большевики свершилась. Теперь вы можете взять карточку памяти microSD, записать на неё файлы дистрибутива AMS и в... | https://habr.com/ru/post/366189/ | null | ru | null |
# Что запрещает принцип Паули?
*Принцип запрета Паули с однозначной многочастичной волновой функцией эквивалентен требованию, чтобы волновая функция была* [*антисимметричной по отношению к обмену частицами*](https://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D0%B6%D0%B4%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D0%B5_%D... | https://habr.com/ru/post/555522/ | null | ru | null |
# Знакомство с wal-g системой бекапирования PostgreSQL
[WAL-G](https://github.com/wal-g/wal-g) — простой и эффективный инструмент для резервного копирования PostgreSQL в облака. По своей основной функциональности он является наследником популярного инструмента [WAL-E](https://github.com/wal-e/wal-e), но переписанным н... | https://habr.com/ru/post/486188/ | null | ru | null |
# Динамические вызовы: сравнение методов

Динамические вызовы: что это и зачем?
=====================================
Думаю, для каждого разработчика, работающим на статических языках программирования, иногда возникала необходимос... | https://habr.com/ru/post/103558/ | null | ru | null |
# Модульность в Java 9
Основным нововведением Java 9 было именно введение модульности. Про эту фичу было много разговоров, дата релиза несколько раз переносилась, чтобы допилить все должным образом. В этом посте речь пойдет о том, что дает механизм модулей, и чего полезного Java 9 принесла в целом. Основой для поста п... | https://habr.com/ru/post/499872/ | null | ru | null |
# ESM. Выходим за рамки
Итак, работая над... ну не знаю... каким-нибудь замечательным генератором статики, вы, возможно, захотите импортировать в свой код зависимости напрямую из текстовых файлов, таких как: ... | https://habr.com/ru/post/685850/ | null | ru | null |
# Погодная станция на Arduino
Метеостанция предназначена прежде всего для наблюдения за погодой, просмотром текущей температуры, влажности и атмосферного давления. Вещь очень удобная для рыбаков. Я решил сделать свою метеостанцию на основе Arduino, но с отображением данных на мобильном телефоне.
](https://habr.com/ru/company/piter/blog/470598/)Привет, Хаброжители! Преимущество современных приложений — в передовых решениях, включа... | https://habr.com/ru/post/470598/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.