
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Postgresso #6 (43)

*ИТ-инфраструктура — это как водопровод, без неё жизнь уже почти невозможна. И мы продолжаем выпускать Postgresso.*
---
**[PostgreSQL 15 Beta 2](https://www.postgresql.org/about/news/postgresql-15-beta-2-r... | https://habr.com/ru/post/675116/ | null | ru | null |
# Получил 1.2K звезд на GitHub с ужасной архитектурой. Как?
Хочу поделится довольно обычной, но показательной историей. Идея проекта появилась 3 месяца назад, за 1 месяц была реализована и вот уже два месяца как проект переодически висит в топе GitHub, попал в какие только можно профильные новостные ресурсы, и даже за... | https://habr.com/ru/post/326620/ | null | ru | null |
# Делаем свой Gmail Motion
Несколько дней назад, не помню точной даты, компания Google представила свой новый инструмент для работы с электронной почтой — [Gmail Motion](http://mail.google.com/mail/help/motion.html). Об этом даже [писали](http://habrahabr.ru/blogs/google/116629/) на Хабре. Решив воспользоваться этой п... | https://habr.com/ru/post/116768/ | null | ru | null |
# Security Week 16: атака на цепочку поставок в компании Codecov
В четверг 15 апреля компания Codecov опубликовала [сообщение](https://therecord.media/codecov-discloses-2-5-month-long-supply-chain-attack/) о взломе собственной инфраструктуры и потенциальной утечке данных у клиентов. Главный продукт Codecov предназначе... | https://habr.com/ru/post/553238/ | null | ru | null |
# Добавляем двухфакторную OTP аутентификацию в SSH за 10 минут
Ситуация: у вас парк Linux-серверов, куда вы регулярно заходите по SSH. Двухфакторная аутентификация для SSH по какому-либо железному ключу или Google Authenticator настраивается, может быть, и просто, но далеко не всегда удобно эту настройку производить н... | https://habr.com/ru/post/335686/ | null | ru | null |
# ZenComment и преодоление «бешеной плитки» на Хабре
В последнее время очень большие кнопки, предусмотренные для пальцевого интерфейса на телефонах и планшетах, занимают не всегда традиционную для себя нишу компьютерных мониторов. Для удобства работы с сайтом Хабра в традиционной десктопно-ноутбучной среде, оттуда уда... | https://habr.com/ru/post/223555/ | null | ru | null |
# Как сменить базу данных, если у вас Entity Framework
Entity Framework (EF) — это удобный фреймворк для работы .NET-приложения с базой данных. По сути, это такая удобная абстракция над БД, которая сама пишет... | https://habr.com/ru/post/677166/ | null | ru | null |
# Замена Google Tag Manager на on-premise-решение без лишних сложностей
Приветствую, дорогие хабровчане. Меня зовут Фёдор Куликов, я руководитель digital-аналитики в компании Tele2.
Хочу поделиться с вами тем, какую альтернативу мы нашли для Google Tag Manager.
Зачем используем GTM и причины необходимости замены
---... | https://habr.com/ru/post/710676/ | null | ru | null |
# Электронная почта и работа с ней в Java-приложениях
`Disclaimer`
Статья написана для новичков и тех, кому хочется шаг за шагом понять как устроена работа с электронной почтой из Java-приложений. Желающие быстро понять как отправлять электронные письма из Spring-приложений могут сразу переходить к 3 части.
Эту ст... | https://habr.com/ru/post/526162/ | null | ru | null |
# Вызываем код на Java, C, NodeJS, C#, Python из InterSystems IRIS
Введение
========
Одно из ключевых направлений развития платформы данных InterSystems IRIS — открытость. Открытость во взаимодействии с языками программирования, технологиями и протоколами. Поддержка языков программирования двусторонняя — возможен как... | https://habr.com/ru/post/536940/ | null | ru | null |
# Прыжок до небес: запускаем телеграм бота на Python в serverless облаке
Одним из современных архитектурных подходов в области облачных вычислений является так называемый ***Serverless*.** Этот способ запуска приложений в облаке освобождает разработчиков от нужды администрировать сервер и заботиться о чем-то, кроме ко... | https://habr.com/ru/post/550456/ | null | ru | null |
# Нюансы шифрования в Git
Если вы захотели воспользоваться публичным ресурсом вроде GitHub или GoogleDrive для хранения своего репозитория, но при этом не готовы делиться со всем миром результатами своего труда, то вам поможет шифрование файлов в гит-репозитории. Это не сверхсекретная технология и на эту тему есть нек... | https://habr.com/ru/post/340076/ | null | ru | null |
# Готовый шаблон для тестирования с использованием Spring
Представляю вам — готовый шаблон для тестирования с использованием Spring.
---------------------------------------------------------------------------
### Введение
Цель этой статьи показать, что писать автотесты со Spring проще нежели на чистой Java.
Так ... | https://habr.com/ru/post/484966/ | null | ru | null |
# Сколько объектов выделяет Python, выполняя скрипты?
Некоторые Python программисты сильно удивляются, когда узнают сколько временных объектов интерпретатор питона выделяет во время работы простого скрипта.
CPython позволяет получить статистику по выделяемым объектам, для этого его нужно скомпилировать с дополните... | https://habr.com/ru/post/418305/ | null | ru | null |
# Создание Web API приложения с использованием .NET Core + MongoDB .NET Driver
Как вы уже знаете, MongoDB — это одно из наиболее развитых, open-source NoSQL решений, которое представляет собой документо-ориентированную базу данных, является кросс-платформенным, а также обеспечивает высокую производительность, доступно... | https://habr.com/ru/post/328954/ | null | ru | null |
# Рельсы сошли с рельс: Почему я переписываю Archaeopteryx на CoffeeScript
Вы бывали на [вечеринках, где друзья с работы и друзья из колледжа не разговаривают](http://www.theonion.com/articles/work-friends-not-mingling-with-other-friends,376/)?
Я запостил видео на Tumblr, которое бы никогда не запостил на Facebook:... | https://habr.com/ru/post/141295/ | null | ru | null |
# Липкие сессии для самых маленьких [Часть 1]
Липкие сессии (**Sticky-session**) — это особый вид балансировки нагрузки, при которой трафик поступает на один определенный сервер группы. Как правило, перед гр... | https://habr.com/ru/post/548610/ | null | ru | null |
# Мобильная версия для Django-проекта
[](http://habrahabr.ru/company/mailru/blog/239343/)
С каждым днем пользователи смартфонов занимают все большую долю интернета. По [данным](http://www.liveinternet.ru/stat/ru/oses.gif?sl... | https://habr.com/ru/post/239343/ | null | ru | null |
# Безболезненное разрешение Merge конфликтов в Git
Предлагаю читателям "Хабрахабра" перевод публикации ["Painless Merge Conflict Resolution in Git"](http://blog.wuwon.id.au/2010/09/painless-merge-conflict-resolution-in.html) из блога blog.wuwon.id.au.
В моей повседневной работе, часто приходится иметь дело со множест... | https://habr.com/ru/post/323234/ | null | ru | null |
# Как бросить кости без OpenGL

**Необязательное вступление**Разработчики приложений под *iOS* зарабатывают не на собственных творениях, а на сторонних заказах. Создав себе имя славного парня, который... | https://habr.com/ru/post/227577/ | null | ru | null |
# pyOpenRPA туториал. Управление оконными GUI приложениями
Специально для Хабр я начинаю серию статей-туториалов по использованию RPA платформы [OpenRPA](https://habr.com/ru/post/506766/). Буду рад получить от вас комментарии и замечания, если возникнут какие-либо вопросы. Надеюсь, что эта история не оставит вас равно... | https://habr.com/ru/post/509644/ | null | ru | null |
# Установка OpenStreetMap Nominatim для нахождения широты и долготы по введенному адресу
Хотел бы поведать свою историю об установке геокодера Nominatim на выделенный сервер. Изначально предполагалос... | https://habr.com/ru/post/259667/ | null | ru | null |
# Мечтают ли YML программисты о тестировании ansible?
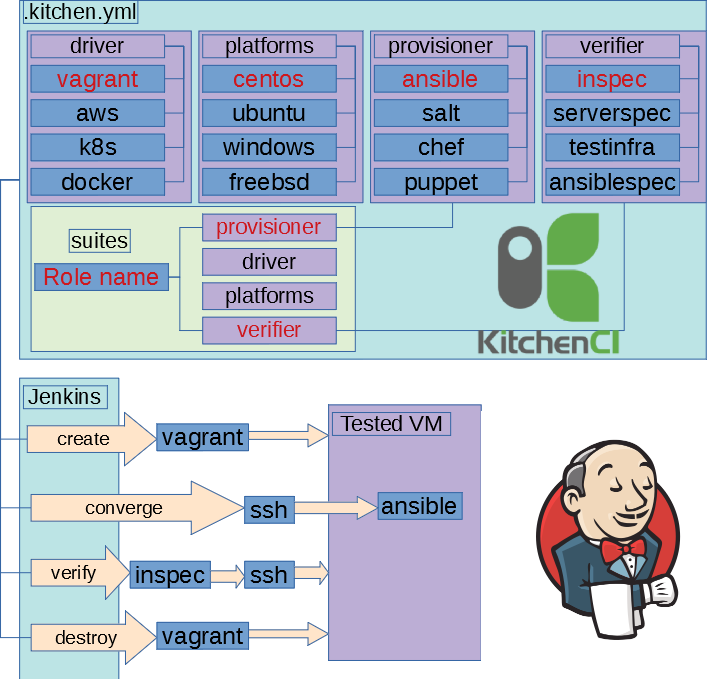
Это текстовая версия [выступления](https://cloud.mail.ru/public/DBuA/7sEMAMRyH) 2018-04-25 на [Saint-Petersburg Linux User Group](http://spblug.org/). Пример кода ... | https://habr.com/ru/post/437004/ | null | ru | null |
# UDP и C# async/await
Недавно возникла необходимость решить следующую несложную задачку: есть несколько десятков устройств (учебных комплексов), у которых нужно регулярно запрашивать их текущее состояние. Комплексы общаются по протоколу UDP, и хотелось сделать так, чтобы не задумываться о цикле опроса и определении, ... | https://habr.com/ru/post/238377/ | null | ru | null |
# Лейся, Fanta: новая тактика старенького Android-трояна

Однажды вы захотите продать что-нибудь на Avito и, выложив подробное описание своего товара (например, модуль оперативной памяти), получите вот такое сообщение:
Введение от автора
------------------
> «У множества языков есть веб-фреймворки, но Rails есть только у Ruby».
>
> *Кирилл Мокевнин, основатель H... | https://habr.com/ru/post/689076/ | null | ru | null |
# Разрегистрация оконного крюка

**Холмс**. А скажите, друг мой Ватсон, доводилось ли вам разрегистрировать оконный крюк, в особенности глобальный?
**Ватсон**. Хм… что же может быть проще, дорогой Холмс.
```
::U... | https://habr.com/ru/post/174565/ | null | ru | null |
# Локализация .NET приложения, а в частности ASP.NET WebForms
Привет Хабрадруг!
Я, конечно, понимаю, что тема это уже заезжена до дыр, но попытаюсь описать мое видение локализации приложения и ее реализацию. И так, что мы хотим получить в итоге: Систему быстрой локализации .NET приложения, а в частности WebForms, ... | https://habr.com/ru/post/111451/ | null | ru | null |
# TinyMCE — получение содержимого редактора.
Хотелось спросить у сообщества совета, так как сам я вследствие неопытности в данном вопросе никак не могу найти решение.
Описываю ситуацию:
Пишу редактор структуры сайта. Сделан он следующим образом: при клике на раздел вслывает окно thickbox, в который загружается р... | https://habr.com/ru/post/37311/ | null | ru | null |
# Magento 2 REST API на примере простого модуля
Приветствую вас, уважаемые хабравчане! Поскольку я занимаюсь разработкой на e-commerce платформе Magento с 2013 года, то набравшись храбрости и посчитав, что в этой области я могу себя назвать, как минимум, уверенным разработчиком, решил написать свою первую статью на ха... | https://habr.com/ru/post/413463/ | null | ru | null |
# Рассказ о 33 расширениях для VS Code, об их разработке и об управлении ими
Автор материала, перевод которого мы сегодня публикуем, создал 33 расширения для VS Code. Он решил поделиться с теми, кому нравится этот редактор, методикой разработки и поддержки расширений. Кроме того, он кратко рассказал о своих проектах. ... | https://habr.com/ru/post/429550/ | null | ru | null |
# Как мы хостили скандальный имиджборд 8chan

**[8chan](https://ru.wikipedia.org/wiki/8chan)** (новое название 8kun) — популярный анонимный форум с возможностью пользователей создавать собственные тематические разделы сайта и самосто... | https://habr.com/ru/post/477002/ | null | ru | null |
# MessageBox for AvaloniaUI
MessageBox — useful window for different GUI frameworks, but you can't find it in AvaloniaUI.
Let's try to do it.
Solution, which I wanna improve and support, you can find on [nuget](https://www.nu... | https://habr.com/ru/post/454386/ | null | en | null |
# Конвергенция в многомодульном приложении
В большой команде разработчики часто сталкиваются с ситуацией, что ранее сильно похожие сущности, которые даже способны пройти «[утиный тест](https://ru.wikipedia.or... | https://habr.com/ru/post/662766/ | null | ru | null |
# Выпуск#24: ITренировка — актуальные вопросы и задачи от ведущих компаний
В новый выпуск ITренировки вошли задачи от «синего гиганта», компании IBM.

В этой компании, с богатым историческим прошлым, тоже задают логические зад... | https://habr.com/ru/post/412879/ | null | ru | null |
# Windows Identity Foundation — для ASP.NET MVC проектов

В этой статье, хотелось бы рассказать о том, как можно использовать Windows Identity Foundation в своих ASP.NET MVC проектах, и написать свой Identity Server, на WIF ... | https://habr.com/ru/post/238121/ | null | ru | null |
# Наступая на грабли. Опыт написания Kubernetes Operator’а
Недавно мной, совместно с [@dkhadm](/users/dkhadm), был реализован оператор для Kubernetes’a - [Vector Operator](https://github.com/kaasops/vector-operator). (Вот [тут](https://habr.com/ru/post/698526/) описано как мы пришли к решению, что там нужен свой опера... | https://habr.com/ru/post/698960/ | null | ru | null |
# Упрощаем работу с Tableau через Телеграм

Всем привет. Предоставление доступа к готовым отчетам часто является отдельной проблемой. Вопрос удобства и оперативного доступа к результатам обработки данных для руководств... | https://habr.com/ru/post/319690/ | null | ru | null |
# Rust должен умереть, МГУ сделал замеры
В предыдущих сериях:
* [Go быстрее Rust, Mail.Ru Group сделала замеры](https://habr.com/ru/post/338268/)
* [C++ быстрее и безопаснее Rust, Yandex сделала замеры](https://habr.com/ru/post/492410/)
Медленно, но верно Раст проникает не только в умы сотрудников больших корпораций... | https://habr.com/ru/post/598219/ | null | ru | null |
# Карусель на Vanilla.JS. Часть 2
Доброго времени суток. Сегодня мы добавим следующие возможности в наш слайдер:
* Зацикленность карусели;
* Автоматическое переключение слайдов;
* Тач-события;
* События мыши.
Первая часть находиться [здесь](https://habrahabr.ru/post/327246/). Разметка карусели и её стили оставим п... | https://habr.com/ru/post/327690/ | null | ru | null |
# Очень быстрое переключение пользователей Windows
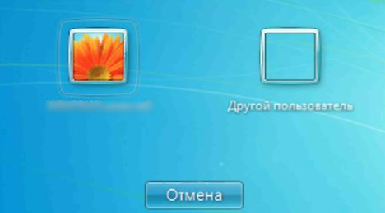Хочу поделиться с вами лайфхаком, которым пользуюсь ежедневно уже на протяжении нескольких лет. Работает безупречно, сберегает время. Так повелось, что у нас с женой разные ... | https://habr.com/ru/post/178105/ | null | ru | null |
# Ускоряем Drupal: Pressflow + Nginx + Varnish
Данная статья достаточно подробно показывает, как можно перейти на разработку сайтов Друпал с серьезной стрессоустойчивостью и возможностью обрабатывать большой трафик.
Это мой первый опыт подобной настройки, но как будет далее видно из статистики достаточно удачно спр... | https://habr.com/ru/post/107094/ | null | ru | null |
# SandboxEscaper/PoC-LPE: что внутри?
> Here is the alpc bug as 0day: <https://t.co/m1T3wDSvPX> I don't fucking care about life anymore. Neither do I ever again want to submit to MSFT anyway. Fuck all of this shit.
>
> — SandboxEscaper (@SandboxEscaper) [August 27, 2018](https://twitter.com/SandboxEscaper/status/1034... | https://habr.com/ru/post/421593/ | null | ru | null |
# Hasura. Архитектура высокопроизводительного GraphQL to SQL сервера
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Architecture of a high performance GraphQL to SQL engine»](https://blog.hasura.io/architecture-of-a-high-performance-graphql-to-sql-server-58d9944b8a87).
Это перевод статьи про то, как уст... | https://habr.com/ru/post/428133/ | null | ru | null |
# Интеграция Primefaces в приложение на Spring Boot. Часть 2 — Готовим контекстное меню для главной страницы
В [первой части](https://habr.com/ru/company/otus/blog/709170/) статьи мы разобрали создание проект... | https://habr.com/ru/post/709726/ | null | ru | null |
# Python 3.8: Что нового и как этим пользоваться?
*Следующий перевод подготовлен специально для «питонистов», которым интересно наверняка интересно почитать о новых функциях Python 3.8. В преддверии запуска нового потока по курсу [«Разработчик Python»](https://otus.pw/QtHC/) мы не смогли пройти мимо этой темы.*
В э... | https://habr.com/ru/post/472432/ | null | ru | null |
# Serverless хранение файлов с AWS lambda
Добрый день, сегодня мы развернем serverless инфраструктуру на базе AWS lambda для загрузки изображений (или любых файлов) с хранением в приватном AWS S3 bucket. Использовать мы будем terraform скрипты, залитые и доступные в моем репозитории [kompotkot/hatchery](https://github... | https://habr.com/ru/post/578974/ | null | ru | null |
# Понимание require() в Node.js

[Node.js](http://nodejs.org/) это асинхронная [JavaScript](http://ru.wikipedia.org/wiki/JavaScript) бибилиотека для построения серверных приложений, которые используют конвенцию [CommonJS](http://... | https://habr.com/ru/post/130035/ | null | ru | null |
# Разработка функций RvaToRaw и RawToRva
#### Цель статьи
Целью этой статьи является желание автора показать некоторые нюансы по разработке функций RvaToRaw/RawToRva, которые являются важными для системных утилит работающих с исполнимыми файлами формата PE.
#### На кого нацелена статья?
* Читатель знаком с формат... | https://habr.com/ru/post/129241/ | null | ru | null |
# RESTful backend приложение. Базовый шаблон
### Постановка задачи
Необходимо собрать базовый шаблон RESTful backend приложения на NodeJS + Express, который:
* легко документируется
* просто наполняется функционалом
* позволяет легко настраивать защиту маршрутов
* имеет простую встроенную автоматическую валидацию
Г... | https://habr.com/ru/post/559136/ | null | ru | null |
# GPU Bound. Часть вторая. Бескрайний лес

Практически в каждой игре необходимо наполнять игровые уровни объектами, которые создают визуальное богатство, красоту и вариативность виртуального мира. Возьмите любую игру с открытым мир... | https://habr.com/ru/post/483946/ | null | ru | null |
# Путеводитель по Bootstrap + Ember.js. Часть 1: Модальные окна в Эмбере или как подружить Bootstrap Modal и Ember.js
Если вы любите Bootstrap, активно используете его в работе и решили с головой окунуться в мир ember.js, то вас ожидает увлекательнейшее путешествие по закоулкам Stack Overflow в поисках ответов на деся... | https://habr.com/ru/post/271153/ | null | ru | null |
# Некоторые советы при работе с PLSQL
Я решил написать цикл небольших заметок благодаря посту [Хорошие привычки в PL/SQL](http://habrahabr.ru/blogs/oracle/124948/), советы которого и рассмотрю.
В этой части обсудим:
1. [Нюансы %TYPE/%ROWTYPE](#1)
2. [Select for update](#2)
3. [Работа с коллекциями](#3)
1. Нюанс... | https://habr.com/ru/post/125893/ | null | ru | null |
# Honeypot на RouterOS
Одним из способов обеспечения информационной безопасности сетевых ресурсов является организация специально подготовленных для легкого взлома «бочонков с медом», детектирования ими угроз, выявления и анализе соответствующих сигнатур с последующей своевременной блокировкой злоумышленников. В стать... | https://habr.com/ru/post/548824/ | null | ru | null |
# Уверены, что отличите ассемблер от других языков?
[](https://habr.com/ru/company/ruvds/blog/554910/)
Немногие смело признают, что могут ошибиться в идентификации ассемблера, ведь это по-своему особенный язык. Однако не спешите с вы... | https://habr.com/ru/post/554910/ | null | ru | null |
# Грустная история забытых символов. Как не сойти с ума при работе с кодировками в C++

Говоря о тексте, большинство программистов C++ думают о массивах кодов символов и кодировке, которой эти коды соответствуют. Наиболее о... | https://habr.com/ru/post/257895/ | null | ru | null |
# Обзор OWASP ZAP. Сканер для поиска уязвимостей в веб-приложениях
Сегодня почти у каждой организации есть собственный веб-сайт. Вместе с ростом интернета возрастают и атаки на веб-сайты, становясь все более... | https://habr.com/ru/post/709586/ | null | ru | null |
# VMware Server :: управляемся с парком машин
Всем привет ;)
Продолжаем… (кто пропустил [шаг назад](http://habrahabr.ru/blogs/i_am_clever/39110/))
Интересно, а как вы управляетесь с виртуальными машинами?!
Каждый раз, когда Вы делаете snapshot, ставите на паузу или выключаете машину(ы) Вы тратите на это время... | https://habr.com/ru/post/39130/ | null | ru | null |
# Делаем чат на ASP.NET с помощью Web Socket
#### Вступление
Я думаю, что многие веб-разработчики задают себе вопрос о том, как передать пользователю какое-либо сообщение, напоминание. Раньше для этого было необходимо постоянно отправлять запросы к веб-серверу, но теперь появилась такая удобная технология, как Web So... | https://habr.com/ru/post/145077/ | null | ru | null |
# Отдельный LOG диск для Kerio Control
Казалось чего проще вынести логи на отдельный диск, но нет, есть свои подковырки.

Предыстория
-----------
Помню, был прекрасный зимний вечер, как вдруг выяснилось, что с Kerio Control бед... | https://habr.com/ru/post/518352/ | null | ru | null |
# Уязвимость в фильтрах AdBlock и uBlock позволяет выполнять произвольный код на стороне пользователя
При соблюдении ряда условий, опция фильтра `$rewrite`, внедренная в AdBlock, AdBlock Plus и uBlock [с обновлением 3.2 от 17 июля 2018 года](https://adblockplus.org/releases/adblock-plus-32-for-chrome-firefox-and-opera... | https://habr.com/ru/post/448302/ | null | ru | null |
# Тройка полезных монад
Внимание: перед тем как читать текст ниже, вы уже должны иметь представление о том, что такое монады. Если это не так, то прежде прочитайте [вот этот пост](http://habrahabr.ru/post/183150/)!
Перед нами функция `half`:
 мы сделали первые шаги в изучении фреймворка NancyFX. В данной статье мы познакомимся со встроенными в Nancy по умолчанию TinyIoC и Nancy Bootstrapper.
Прямо... | https://habr.com/ru/post/198186/ | null | ru | null |
# Что интересного нам расскажет EXPLAIN EXTENDED?
Большинство разработчиков на MySQL знакомы с командой EXPLAIN, однако значительно меньше людей знают о команде EXPLAIN EXTENDED, появившуюся ещё в MySQL 4.1, и ещё меньше умеют ею пользоваться.
EXPLAIN EXTENDED умеет показывать, что же конкретно делает с Вашим запро... | https://habr.com/ru/post/98904/ | null | ru | null |
# Трюки с CSS-анимациями: мгновенные изменения, отрицательные задержки, анимация transform-origin и другое
Применяя CSS-анимации в повседневной работе, я постепенно выработал привычку экспериментировать с ними в свободное время. Постоянно пытаясь реализовать очередную интересную задумку с использованием как можно мень... | https://habr.com/ru/post/209462/ | null | ru | null |
# Замена стандартных селектов в браузере
##### Selectimus
На текущем проекте некоторое время назад стала задача по унификации селектов во всех браузерах. Нужно было изменить их так, чтобы при одинаковом отображении они внешне оставались близкими к стандартным но при этом имели возможность гибкой настройки средствами ... | https://habr.com/ru/post/168973/ | null | ru | null |
# Как я создал собственный алгоритм YouTube (чтобы не тратить время впустую)

Побег от алгоритма YouTube
--------------------------
Я люблю смотреть видео на YouTube, осязаемым образом улучшающие мою жизнь. К сожалению, алгоритм Y... | https://habr.com/ru/post/533080/ | null | ru | null |
# Что нового в Swift 4.0
Практические примеры, которые помогут вам узнать о том, что нового нас ждет в Swift 4.
Swift 4.0 — это новая версия многими любимого языка программирования с новыми функциями, которые позволяют нам писать более простой и безопасный код. Вы с удовольствием узнаете, что это не так драматично ... | https://habr.com/ru/post/333712/ | null | ru | null |
# Новые возможности TypeScript, повышающие удобство разработки
TypeScript, во многих отношениях, больше похож не на язык программирования, а на мощный инструмент для линтинга и документирования кода, который помогает писать более качественные JavaScript-программы.
Одна из наиболее заметных сильных сторон TypeScript... | https://habr.com/ru/post/493712/ | null | ru | null |
# Использование map и reduce в функциональном JavaScript
*Предлагаем вашему вниманию переводной материал об использовании map и reduce в функциональном JavaScript. Эта статья будет интересна в первую очередь начинающим разработчикам.*
За всеми этими разговорами о новых стандартах легко забыть о том, что именно ECMA... | https://habr.com/ru/post/324342/ | null | ru | null |
# One UI своими руками в домашних условиях
One UI существует уже как 3 года (с 2018), а уроков по тому, как сделать похожий дизайн, в мире android, я так и не нашёл. Не порядок… Сегодня же, мы начнём прокладывать этот тяжёлый и тернистый путь.
Зарождение Siesta
-----------------
Я думаю, разделить статьи на версии н... | https://habr.com/ru/post/574904/ | null | ru | null |
# Регулярные выражения для самых маленьких
Привет, Хабр.
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показа... | https://habr.com/ru/post/343310/ | null | ru | null |
# Уравнение Навье-Стокса и симуляция жидкостей на CUDA
Привет, Хабр. В этой статье мы разберемся с уравнением Навье-Стокса для несжимаемой жидкости, численно его решим и сделаем красивую симуляцию, работающую за счет параллельного вычисления на CUDA. Основная цель — показать, как можно применить математику, лежащую в ... | https://habr.com/ru/post/470742/ | null | ru | null |
# learnopengl. Урок 2.6 — Несколько источников освещения
### **Несколько источников освещения**
В предыдущих уроках мы выучили довольно много об освещении в OpenGL. Мы познакомились с моделью освещения по Фонгу, разобрались ... | https://habr.com/ru/post/338254/ | null | ru | null |
# Репликация файлов через rsync: мониторинг с помощью Zabbix
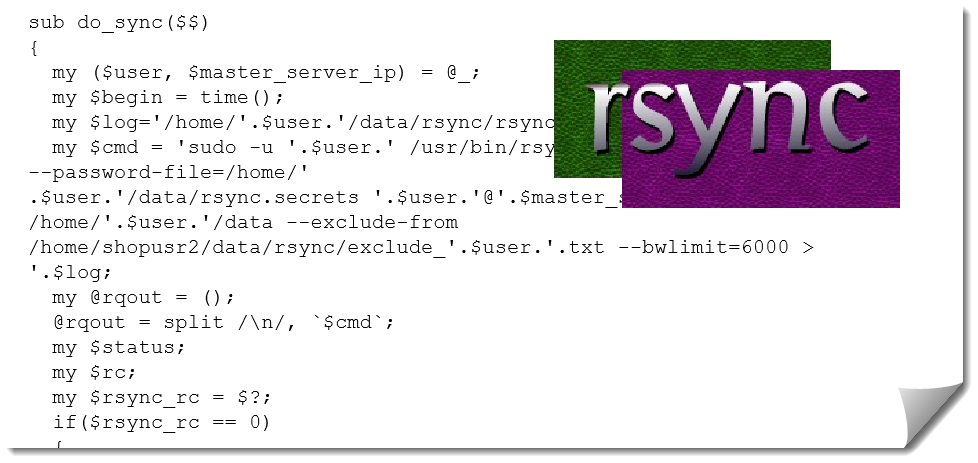В [предыдущей статье](https://habr.com/ru/company/first/blog/690318/) мы рассказывали о том, как настроить и контролировать репликацию базы данных ... | https://habr.com/ru/post/691166/ | null | ru | null |
# По заказам Embedded-разработчиков: ищем ошибки в Amazon FreeRTOS
Каждый, кто программирует микроконтроллеры, наверняка знает о FreeRTOS, или по крайней мере слышал об этой операционной системе. Ребята из Amazon решили расширить возможности этой операционной системы для работы с сервисами AWS Internet of Things – так... | https://habr.com/ru/post/473972/ | null | ru | null |
# Пишем бота для MMORPG с ассемблером и дренейками. Часть 0
 Привет, %username%! Покопавшись в статьях хабра, я нашел несколько оных про написание ботов для MMORPG. Несомненно это очень интересные и познавательные статьи, но во... | https://habr.com/ru/post/251137/ | null | ru | null |
# Пример восстановления таблиц PostgreSQL с помощью новой мега фичи pg_filedump

Позвольте я расскажу вам об одной классной фиче, которую мы с коллегами из [Postgres Pro](https://postgrespro.ru/) недавно запилили в утилите ... | https://habr.com/ru/post/319770/ | null | ru | null |
# UX-команда MailChimp: Разработка [6-я часть книги]
[](http://habrahabr.ru/company/friifond/blog/254307/)
[[TL;DR](http://megamozg.ru/company/friifond/blog/22792/)]
[ [1-я часть книги](http://habrahabr.ru/company/friifon... | https://habr.com/ru/post/254307/ | null | ru | null |
# Как я "<" моноидом делал
 Некоторое время назад в одном уютном камерном собрании я делал доклад о своей разработке — скриптовом лиспоподобном языке Liscript. Начал с азов — семантики вычисления списков, префиксной нотации... | https://habr.com/ru/post/328110/ | null | ru | null |
# Самодельный стратостат. Часть 2

Long, long time ago… Нет, не так. 4 месяца назад я рассказал вам, как из клея и резиновых сапог создать с нуля свой стратост... | https://habr.com/ru/post/577184/ | null | ru | null |
# Джентльменский набор React компонентов FullStack разработчика для управления потоком данных
Существует токсичный стереотип, что FullStack разработчики не могут ни в фронт, ни в бек. Как минимум, так как объем работ большой, часто, программирование фронта на React превращается в формошлепство с сомнительным качеством... | https://habr.com/ru/post/676612/ | null | ru | null |
# Codeception — тестирование по-новому
PHP очень популярный язык программирования, но тестирование в нем, это скорее прерогатива экспертов, а не жизненная необходимость. Неужели это от того, что PHP-разработчики поголовно быдло-кодеры? Я считаю, что нет. Скорее всё от того, что системы тестирования порой излишне услож... | https://habr.com/ru/post/136477/ | null | ru | null |
# Как PVS-Studio оказался внимательнее, чем три с половиной программиста

PVS-Studio, как и другие статические анализаторы кода, часто... | https://habr.com/ru/post/427309/ | null | ru | null |
# Простая криптография: частотный и дифференциальный криптоанализ в задании NeoQUEST-2015
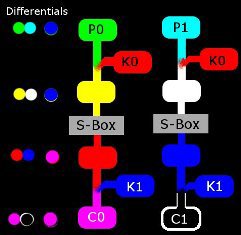 В преддверии скорого [очного тура](http://neoquest.ru/timeline.php?year=2015) NeoQUEST-2015 продолжаем разбирать задания online-этапа. В статье ... | https://habr.com/ru/post/258893/ | null | ru | null |
# Цифровая свобода. Часть 1. Менеджер паролей
Всем привет! Я хочу запустить цикл статей с инструкциями которые помогут, отвязаться от сервисов и вернут вам контроль над вашими данными. Тут будут представлены opensource аналоги сервисов, которыми все мы пользуемся каждый день и утилиты для бекапа ваших данных из цепких... | https://habr.com/ru/post/655283/ | null | ru | null |
# Метеостанция: от идеи до реализации
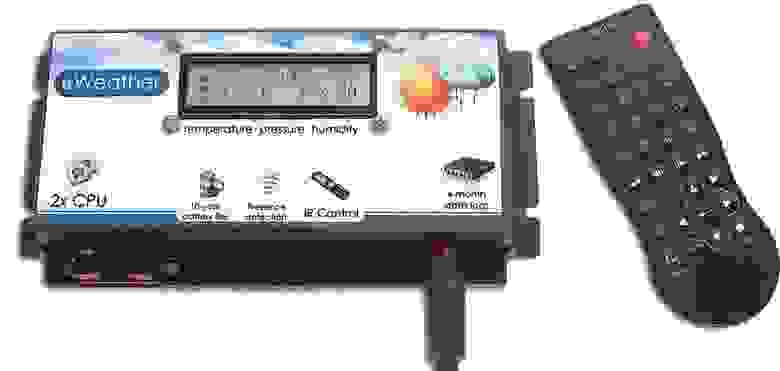
Прочитал множество статей, посвященных разработке своего устройства, и захотел рассказать о своем опыте. Происходило это несколько лет назад, на 4-м курсе универа. Се... | https://habr.com/ru/post/223829/ | null | ru | null |
# Drupal 7. Модуль подписок своими руками
#### Вместо предисловия
Функциональность подписок на какой-либо контент – одна из востребованных в веб-индустрии. Многие сайты могут похвастаться подобным. И наш проект не стал исключением. Дано: сайт на *Drupal 7*. Что требуется: найти или написать модуль, реализующий все не... | https://habr.com/ru/post/200908/ | null | ru | null |
# LaTex: Упражнение
Для того, чтобы старшему ребёнку давать примеры на сложение и вычитание в столбик, написал скрипт на Groovy, который генерирует LaTeX с примерами.
Цель была попрактиковаться в груви, ну и писать примеры от руки надоело.
Раньше на латехе ничего не писал, но что это и зачем нужен знал из Универ... | https://habr.com/ru/post/108431/ | null | ru | null |
# СМИ: неизвестный слил персональные данные 10 тысяч пользователей «Умного голосования»
7 сентября нескольким редакторам «Хабра» прислали ссылку на статью неизвестного пользователя платформы Medium. Он [утверждает](https://medium.com/@leonid.m.volkov.lv/%D0%B2%D1%81%D0%B5%D0%BC-%D0%BF%D1%80%D0%B8%D0%B2%D0%B5%D1%82-ee0... | https://habr.com/ru/post/577024/ | null | ru | null |
# Сценарии заражения в конкретных городах на основе датасета передвижения людей по России

Статистика для Москвы в сценарии «люди стараются сидеть по домам, нет авиасообщения» — к ноябрю модель показывает 5 миллионов переболевших. Э... | https://habr.com/ru/post/494700/ | null | ru | null |
# Зачем выполнять рутинную работу, когда её можно поручить машине?
В очередной раз пересматривая «Железного Человека» вместе с другом, меня снова пропитывало желание ~~стать супергероем~~ создать свой железный костюм, ну или *хотя бы* Джарвиса. И вдруг меня посетила гениальная идея.
**Лирическое отступление**Пару д... | https://habr.com/ru/post/265393/ | null | ru | null |
# Telegram-bot: моя история. Часть первая

Доброго времени суток, Хабрахабр! Целью статьи является рассказать начинающим программистам о возможности не только разработать что-то интересное на основе несложных инструментов, н... | https://habr.com/ru/post/316868/ | null | ru | null |
# Знакомство с Drizzle
[](https://launchpad.net/drizzle)[Drizzle](https://launchpad.net/drizzle) это СПО система управления базами данных (СУБД), которая отпочковалась от MySQL, соответственно обладает клиент-серверной архитектурой и использует SQL в качес... | https://habr.com/ru/post/64050/ | null | ru | null |
# Импорт инфоблоков из 1С-Битрикс в MODx Revolution
Третьего дня задали задачу — написать скрипт для переезда с Битрикс на MODx. Задача показалась интересной, тем более, что с Битрикс толком ни разу не работал.

Ничего... | https://habr.com/ru/post/142430/ | null | ru | null |
# Спецификация D-Bus. Часть 1
Введение
--------
D‑Bus - это простая в использовании система межпроцессного взаимодействия (IPC) с низкими издержками. Более подробно:
* D‑Bus не требует больших затрат , поск... | https://habr.com/ru/post/540170/ | null | ru | null |
# C#: required
Некоторые разработчики предпочитают объектную инициализацию использованию конструкторов. Кто-то негодует из-за вынужденного "перекладывания" аргументов из одного конструктора в другой при наследовании. Кому-то конструкторы не нравятся просто как таковые. Но возможна ли жизнь без конструкторов?
![ л](ht... | https://habr.com/ru/post/678320/ | null | ru | null |
# Go в 2015 году
Уходящий 2015-й год выдался достаточно насыщенным для языка программирования Go и его сообщества. Всё больше людей открывают для себя мощь, скрывающуюся за простотой языка, сообщество растёт, развивается и играет всё более значимую роль в настоящем и будущем Go. Этот — шестой по счёту год существовани... | https://habr.com/ru/post/274057/ | null | ru | null |
# Присматриваем за окнами. Windows + Zabbix
#### Введение
В системе Zabbix есть возможность привязать шаблон к серверам и компьютерам на базе Windows. Называется Template OS Windows.
В один прекрасный момент я понял: а неплохо бы еще туда прикрутить кучу счетчиков
#### Практика «Агента»
Если у Вас установлен ... | https://habr.com/ru/post/164293/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.