
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# New features for extension authors in Visual Studio 2019 version 16.1
Earlier this week, we released [Visual Studio 2019 version 16.1 Preview 1](https://visualstudio.microsoft.com/vs/preview/) (see [release notes](https://docs.microsoft.com/en-us/visualstudio/releases/2019/release-notes-preview)). It’s the first pre... | https://habr.com/ru/post/448784/ | null | en | null |
# Memcached plugin: NoSQL в MySQL

Здравствуйте! Меня зовут Максим Матюхин, я PHP-программист [Badoo](https://tech.badoo.com/ru/). В своей работе мы активно используем MySQL. Но иногда нам не хватает её производительности, поэтому ... | https://habr.com/ru/post/453742/ | null | ru | null |
# Обновление Android Jetpack: Activity Result API и рефакторинг Fragment
Привет! С вами Android Broadcast. Прошли 2 недели и очередной релиз библиотек Jetpack от Google уже с нами. Вышло долгожданное исправле... | https://habr.com/ru/post/541942/ | null | ru | null |
# Как избавиться от старого продукта, не удаляя продукт?

Привет! Согласитесь, во многих крупных компаниях рано или поздно возникает проблема — какой-то прибыльный продукт превращается в legacy. Причем обычно менеджмент это осозна... | https://habr.com/ru/post/682894/ | null | ru | null |
# Swift и время компиляции
*Пост основан на статье [medium.com/@RobertGummesson/regarding-swift-build-time-optimizations-fc92cdd91e31](https://medium.com/@RobertGummesson/regarding-swift-build-time-optimizations-fc92cdd91e31) + небольшие изменения/дополнения, то есть текст идет от моего лица, не третьего.*
Всем зна... | https://habr.com/ru/post/283106/ | null | ru | null |
# Стилизуя нестандартно
Вот есть у нас приложение. Серьезное, большое, взрослое. Обходимся практически без стилей, но без беспорядка; используем себе виджеты из AppCompat, но уже затянули тему из Material Design Components (MDC) и подумываем о полноценной миграции.
И вдруг появляется задача на полный redesign. А у но... | https://habr.com/ru/post/552486/ | null | ru | null |
# PHP: Реализация формальных грамматик
Недавно мне нужно было написать парсер для строки поиска, который приводит строки вида
(aa&bb)^(!cc^!(dd^ee)) в строку вида куска SQL: (?f LIKE "%aa%" AND ?f LIKE "%bb%") OR (?f NOT LIKE "%cc%" OR !((?f LIKE "%dd%" OR ?f LIKE "%ee%")) ). Я написал like и SQL для упращения, на ... | https://habr.com/ru/post/73665/ | null | ru | null |
# API смс сервера GoIP
Здесь будет краткое руководство как пользоваться их API. В свое время нужно было привязать отправку и получение смс к своему программному обеспечению. Каждый раз лазить в вебморду смс сервера от GoIP и проверять вх./исх. сообщения было неудобно.
#### API сервера
Для отправки смс используется... | https://habr.com/ru/post/507460/ | null | ru | null |
# Автоматическое освещение для балкона на Arduino
Примерно пару месяцев назад решил увлечь себя электроникой. В частности захотелось поиграться с Arduino. Но для баловства довольно дорого заказывать оригинальный, поэтому полез на всем известный китайский сайт. Там со скидкой нашел клон Arduino Uno в стартовом наборе. ... | https://habr.com/ru/post/248079/ | null | ru | null |
# Принцип единственной ответственности: глубокое погружение
Про **принцип единственной ответственности** (The Single Responsibility Principle, SRP) уже было написано множество статей. В большинстве из них даётся лишь поверхностное его описание мало чем отличающееся от информации в [википедии](https://ru.wikipedia.org/... | https://habr.com/ru/post/465507/ | null | ru | null |
# Газовый шейдер в Cocos2d
Добрый день.
Хотела поделиться своим небольшим опытом оптимизации шейдеров на IOS, и по возможности услышать дельные советы на этот счет. Вроде бы есть прекрасный инструмент OpenGl ES 2.0, и можно сделать неплохие эффекты, но при этом получить более-менее вменяемый fps не всегда получаетс... | https://habr.com/ru/post/227491/ | null | ru | null |
# Легко и непринуждённо: почта и Jabber для пользователей вашего сайта
Допустим, вы развиваете какой-нибудь сайт в интернете. У вас есть постоянные пользователи, кто-то заходит к вам от случая к случаю. И вы конечно же ищете способы у... | https://habr.com/ru/post/104741/ | null | ru | null |
# JPoint 2017 — конференция, которая смогла. Обзор лучших докладов в открытом доступе
Недавно коллега задал привычные уже вопросы про «зачем ходить на конференции» и «зачем смотреть записи на YouTube». Так как это друг, а не просто какой-то произвольный человек, захотелось ответить более обстоятельно, детально и по че... | https://habr.com/ru/post/346364/ | null | ru | null |
# Нужно ли современному программисту уметь создавать алгоритмы?
После негативной реакции хабровчан на мою [прошлую заметку](https://habr.com/ru/post/470407/) про собеседование программистов, пришлось хорошенько порефлексировать, чтобы переосмыслить и скорректировать некоторые свои представления о программировании, про... | https://habr.com/ru/post/490358/ | null | ru | null |
# Интернет-радио «Моминьмай»: будем знакомы
### Здравствуй, Хабр!
Это моя первая статья здесь и сегодня я хочу рассказать о нашем необычном интернет-радио.
В этой статье будет ретроспектива, нынешнее состояние, планы на будущее. Немного философии по теме. Также коснусь технических деталей и приглашу к обсуждению.
... | https://habr.com/ru/post/597729/ | null | ru | null |
# Не нужно обижать «матрас»

Желаю доброго дня уважаемому Хабра-сообществу. Данная заметка навеяна [постом](http://habrahabr.ru/post/143512/) о правильной настройке телевизора. Я не лелею больших надежд на то, что вн... | https://habr.com/ru/post/143854/ | null | ru | null |
# Про бэкапы, черную пятницу и коммуникации между людьми: как мы накосячили и научились больше так не делать
13 октября мы провели вторую конференцию сообщества [Uptime](http://uptime.community). В этот раз дата проведения выпала на пятницу 13-е, поэтому основная тема — аварии, и как с ними справляться. Это первый из ... | https://habr.com/ru/post/341194/ | null | ru | null |
# DNSSec: Что такое и зачем
#### Предисловие
Как оказалось, не так много людей знают что такое DNSSec, для чего он нужен, для чего нет и стоит ли его внедрять у себя. Так как на русском языке информации на этот счет мало, я постараюсь пролить свет на эти вопросы.
#### Что такое DNSSec
##### Немного истории
Изнач... | https://habr.com/ru/post/120620/ | null | ru | null |
# Как организовать ваши зависимости во Vue-приложении
Все, кто знаком с Vue, знают, что у Vue-приложения одна точка входа — файл `main.js`. Там, помимо создания экземпляра Vue, происходит импорт и своего рода Dependency Injection всех ваших глобальных зависимостей (директив, компонентов, плагинов). Чем больше проект, ... | https://habr.com/ru/post/423013/ | null | ru | null |
# Chisel — (не совсем) новый подход к разработке цифровой логики

С развитием микроэлектроники, rtl дизайны становились все больше и больше. Реюзабилити кода на verilog доставляет массу неудобств, даже с использованием generate, макр... | https://habr.com/ru/post/419413/ | null | ru | null |
# Сделай сам: SQL JOIN на Java
Я часто собеседую разработчиков и часто задаю им простой, как кувалда, вопрос — как внутри работает JOIN в SQL? В ответ я обычно слышу [бессвязное мычание](http://feldgendler.livejournal.com/155234.html) про волшебные деревья и индексы, которые быстрее. Когда-то мне казалось, что каждый ... | https://habr.com/ru/post/278087/ | null | ru | null |
# Фронтенд-2019: итоги года
В 2019 году мир фронтенд-разработки, как уже бывало, развивался с головокружительной скоростью. Материал, перевод которого мы сегодня публикуем, посвящён обзору важных событий, новостей и трендов 2019 года.
["
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где рассказываю про ин... | https://habr.com/ru/post/666246/ | null | ru | null |
# Сетевая безопасность — IPS с использованием BGP
В вопросах именно сетевой безопасности функционально выделяются два компонента:
* IDS - Intrusion Detection System, система обнаружения вторжений, компонент, который обнаруживает сам факт злонамеренного сетевого вторжения. Это может быть выделенная система типа DPI (D... | https://habr.com/ru/post/568336/ | null | ru | null |
# Светодиодная матрица: управляем домашним уютом с помощью голоса
Сейчас стало достаточно модно украшать свои дома с помощью светодиодов. Обычной светодиодной лентой, даже с голосовым управлением, уже сложно... | https://habr.com/ru/post/573628/ | null | ru | null |
# Автономный способ обхода DPI и эффективный способ обхода блокировок сайтов по IP-адресу
Провайдеры Российской Федерации, в большинстве своем, применяют системы глубокого анализа трафика (DPI, Deep Packet Inspection) для блокировки сайтов, внесенных в реестр запрещенных. Не существует единого стандарта на DPI, есть б... | https://habr.com/ru/post/335436/ | null | ru | null |
# О сравнении объектов по значению — 3, или Type-specific Equals & Equality operators
#### Ранее мы [рассмотрели](https://habrahabr.ru/post/314500/) корректную реализацию минимально необходимого набора доработок класса для сравнения объектов класса по значению.
Теперь рассмотрим Type-specific реализацию сравнения объ... | https://habr.com/ru/post/315168/ | null | ru | null |
# Создаем установочные пакеты для macOS средствами системы
**Disclaimer:** приведенные здесь методы успешно работают в macOS Mojave, Catalina и Big Sur, но для боевых систем рекомендуется всегда проводить соб... | https://habr.com/ru/post/564490/ | null | ru | null |
# Flutter: флип-анимация
> *Перевод подготовлен в рамках курса* [*"****Flutter Mobile Developer****"*](https://otus.pw/4Iwj/)*.
>
> Всех желающих приглашаем на второй день двухдневного онлайн-интенсива* [***«Создаем приложение на Flutter для Web, iOS и Android»***](https://otus.pw/hVHd/)*. Продолжаем писать прил... | https://habr.com/ru/post/558246/ | null | ru | null |
# Уровень сигнала трансивера через SNMP в Cisco
Иногда нужно узнать уровень сигнала в трансивере. Причины бывают разные: внезапное падение канала связи, подключение новых оптических кроссировок, мониторинг. Инженер с необходимым уровнем доступа решает этот вопрос меньше чем за одну минуту с помощью команды:
```
#sh... | https://habr.com/ru/post/260721/ | null | ru | null |
# Gatling. Тестирование Kafka
Привет! Меня зовут Александра, я работаю в отделе тестирования производительности Тинькофф. Мы продолжаем наш цикл статей, посвященных работе Gatling с различными протоколами. Ранее мы уже рассмотрели работ... | https://habr.com/ru/post/666886/ | null | ru | null |
# ScribeJava — даже ваша бабушка сможет работать с OAuth

Именно этой фразой нас приветствует библиотека для работы с OAuth — ScribeJava (<https://github.com/scribejava/scribejava>). Если быть точнее, то фраза звучит т... | https://habr.com/ru/post/278957/ | null | ru | null |
# Пишем свою ОС: Выпуск 1
Данный цикл статей посвящён низкоуровневому программированию, то есть архитектуре компьютера, устройству операционных систем, программированию на языке ассемблера и смежным областям. Пока что написанием занимаются два хабраюзера — [iley](https://habr.com/ru/users/iley/) и [pehat](https://habr... | https://habr.com/ru/post/101810/ | null | ru | null |
# Как удалить татуировку с помощью глубокого обучения
Глубокое обучение — интересная тема и моя любимая область исследований. Мне очень нравится играть с новыми исследовательскими разработками специалистов п... | https://habr.com/ru/post/553208/ | null | ru | null |
# Введение в графовые базы данных SQL Server 2017
***В преддверии старта курса [«MS SQL Server Developer»](https://otus.pw/ZzuM/) подготовили для вас еще один полезный перевод.***

---
Графовые базы данных — это важная технология... | https://habr.com/ru/post/518586/ | null | ru | null |
# Сбор логов межсетевого экрана Checkpoint (OPSEC LEA)
OPSEC LEA (Log Export API) – интерфейс, позволяющий получать логи с сервера управления (Checkpoint SmartCenter).
В основе OPSEC LEA лежит клиент-серверная архитектура. В качестве сервера выступает Checkpoint SmartCenter, который слушает входящие соединения на п... | https://habr.com/ru/post/281164/ | null | ru | null |
# Аутентификация устройств на Linux по аппаратному ключу в системах верхнего уровня
Industrial IoT — это мониторинг, диспетчеризация и автоматизация инженерных систем промышленных объектов, зданий, бизнес-объектов. Датчики разных параметров, счетчики и контроллеры собирают данные с этих объектов, например, температуру... | https://habr.com/ru/post/476304/ | null | ru | null |
# Пишем Java-френдли Kotlin-код
Со стороны может показаться, что Kotlin упростил Android-разработку, вообще не принеся при этом новых сложностей: язык ведь Java-совместимый, так что даже большой Java-проект можно постепенно переводить на него, не забивая ничем голову, так? Но если заглядывать глубже, в каждой шкатулке... | https://habr.com/ru/post/417951/ | null | ru | null |
# Независимо перегружаемые свойства
Стандартный механизм перегрузки свойств через методы \_\_get и \_\_set весьма не удобен для практического использования, однако с помощью него можно создать удобный dsl для работы со свойствами. Сразу же пример использования (тут и далее используется паттерн [адаптивной типизации](h... | https://habr.com/ru/post/95233/ | null | ru | null |
# Особенности withCredentials
Многие знакомы с таким флагом XmlHttpRequest как withCredentials, знают для чего он нужен, какие заголовки нужно использовать с ним в паре, чтобы браузер нормально обрабатывал ответы сервера. И я вроде тоже знал, а что не знал — нагугливал, и всё работало как надо. Но однажды столкнулся с... | https://habr.com/ru/post/263417/ | null | ru | null |
# JavaScript: захват медиапотока из DOM элементов

Привет, друзья!
Продолжаю исследовать возможности по работе с медиа, предоставляемые современными браузерами, и в этой статье хочу рассказать вам о возможности захвата и записи меди... | https://habr.com/ru/post/646831/ | null | ru | null |
# Теория лоадеров
За последние 5 лет я написал множество лоадеров. Это так называемые программки, которые парсят инфу на сайтах-источниках и сохраняют ее себе в базу. Зачастую они представляют из себя последовательность регулярных выражений, с помощью которых находятся значения в нужных клеточках. Лоадеры могут автори... | https://habr.com/ru/post/68182/ | null | ru | null |
# Как собрать образ Oracle DB для Testcontainers
Код должен тестироваться на той СУБД, с которой он будет работать. Testcontainers — это такая библиотека, которая позволяет использовать в юнит тестах практически любую СУБД с той же лёгкостью, что embedded базы данных типа HSQLDB или H2. Был бы только Docker образ
![]... | https://habr.com/ru/post/480106/ | null | ru | null |
# Тестирование производительности Python 2.7 при обработке списков различными способами

В ходе одного из моих питоновских проектов, с большой примесью ООП и обработкой большого числа данных — у меня в... | https://habr.com/ru/post/181768/ | null | ru | null |
# Собираем кластер PostgreSQL для разработки и тестирования
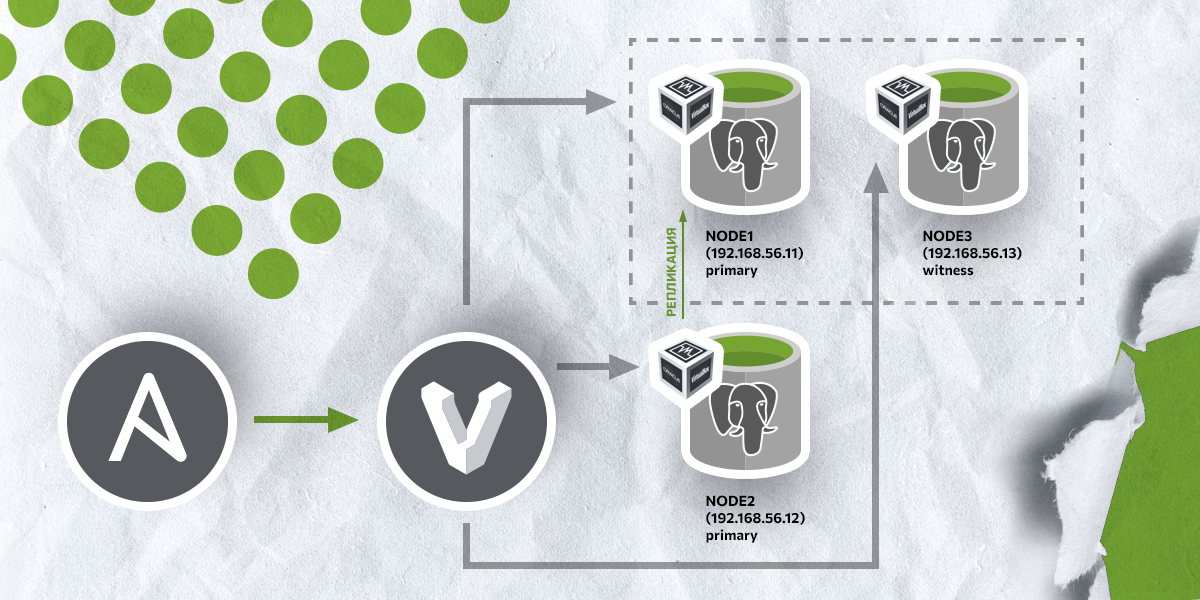Сегодня СУБД PostgreSQL является одной из самых известных и популярных систем управления баз данными в мире. Открытый исходный код, отсутствие платы... | https://habr.com/ru/post/699644/ | null | ru | null |
# Организация рабочих потоков: управление состоянием движка
Данная статья является продолжением статьи — [Организация рабочих потоков: синхронизационный канал](http://habrahabr.ru/post/141509/). Продолжение родилось как попытка написать пример использования подхода с синхронными сообщениями.
В этой части я хочу на ... | https://habr.com/ru/post/141783/ | null | ru | null |
# Управление роботами, созданными с помощью LEGO® Mindstorms® NXT Brick через язык Wolfram Language (Mathematica)

*Скачать статью в виде [документа Mathematica (NB)](http://www.mathematica-journal.com/data/uploads/2013/03/C... | https://habr.com/ru/post/256345/ | null | ru | null |
# Как пропатчить K̶D̶E̶ TCP-стек под FreeBSD
Когда стоит вопрос выбора между проприетарным и открытым программным обеспечением, часто в пользу последнего приводят следующий аргумент: при необходимости можно изменить исходники под нужды своего проекта, или исправить ошибку прямо сейчас, а не дожидаясь месяцами реакции ... | https://habr.com/ru/post/331072/ | null | ru | null |
# Интернет через ICMP
Здравствуйте! Вы забыли заплатить за интернет, провайдер заблокировал TCP и UDP, а про ICMP забыл, и любой ресурс пингуется? Тогда этот топик для вас!
Предполагается, что... | https://habr.com/ru/post/131800/ | null | ru | null |
# «Баг»-не-баг нецентрирования рисунков атрибутом align=center
Как известно, Хабр использует «олдскульные» атрибуты тегов, допускающие форматирование текста и рисунков в статьях и комментариях авторами. Среди таких тегов оказался один, отсутствующий в стандартах W3C. Это — ![](). Обнаружилось, что часть авторов «наивн... | https://habr.com/ru/post/135818/ | null | ru | null |
# Приручение черного дракона. Этичный хакинг с Kali Linux. Часть 1. Подготовка рабочего стенда
Приветствую тебя, дорогой читатель в самой первой вводной части серии статей «Приручение черного дракона. Этичный хакинг с Kali Linux».
Полный список статей прилагается ниже, и будет дополняться по мере появления новых.
... | https://habr.com/ru/post/694886/ | null | ru | null |
# Тем, кто учится программировать и решил написать вопрос на Stack Overflow: «Почему код не работает?»

На сайте Stack Overflow много вопросов от людей, ещё только изучающих языки программиро... | https://habr.com/ru/post/673788/ | null | ru | null |
# Drupal Composer рецепты
В этом посте мы хотим поделиться некоторыми рецептами использования Composer, которые мы накопили работая с Drupal проектами созданными с помощью Drupal Composer template. Так же мы рассмотрим как пере... | https://habr.com/ru/post/313298/ | null | ru | null |
# Мои размышления про экранную клавиатуру для Flipper Zero под экранчик 128х64 пикселя

Недавно я увидел пост с [приглашением разработчиков](https://habr.com/ru/post/514326/) в проект Flipper Zero и подал заявку. Меня добавили в репозиторий ... | https://habr.com/ru/post/517014/ | null | ru | null |
# B+ дерево в реальном проекте
В этой статье мы подробно рассмотрим, как сделано B+ дерево в распределенной БД [Apache Ignite](https://github.com/apache/ignite).

На Хабре уже есть пара статей о B-деревьях ([раз](https://habraha... | https://habr.com/ru/post/413749/ | null | ru | null |
# Настоящий Unix — не есть приемлемый Unix
Командная строка Unix полна сюрпризов. Например, вы знали, что инструмент `ls`, который чаще всего используется для получения списка файлов в текущем каталоге, в вер... | https://habr.com/ru/post/326176/ | null | ru | null |
# Тест производительности: удивительно и просто
Так сложилось, что последние полгода я активно занимался тестами производительности и мне кажется, что в этой области IT царит абсолютное непонимание происходящего. В наше время, когда рост вычислительных мощностей снизился (vertical scalability), а объем задач растет с ... | https://habr.com/ru/post/171475/ | null | ru | null |
# VIM как IDE для разработки на Python

Данная статья будет посвящена настройке vim, в которой я поделюсь своим «скромным» пониманием того, каким должен быть текстовый редактор, чтобы в нем было удобн... | https://habr.com/ru/post/224979/ | null | ru | null |
# Большой Калькулятор выходит из под контроля

Я хочу посвятить эту статью проблеме, о которой мало кто задумывается. Все шире и шире применяется моделирование различных процессов с помощью компью... | https://habr.com/ru/post/192624/ | null | ru | null |
# Ruby on Rails: user friendly URLs
В данной статье будет показан пример как сделать красивые ссылки в Rails проекте. Ссылки вида `/posts/1/` будут преобразованы в `/posts/1-article-name/`
##### Подготовка
Начнем с того что поставим рельсы последней версии, выполнив в консоли `gem install rails -v=3.1.3`
После ... | https://habr.com/ru/post/133627/ | null | ru | null |
# Yii 2.0.12
Вышла версия 2.0.12 PHP фреймворка Yii. Инструкции по установке и обновлению ищите [здесь](http://www.yiiframework.com/download/).

Версия 2.0.12 является минорным релизом Yii 2.0. Она включает в себя [более сотн... | https://habr.com/ru/post/330324/ | null | ru | null |
# Chrome в dev-версии получил поддержку WebRTC
Анонсированная в начале мая прошлого года технология Web Real-Time Communications (WebRTC) интегрирована в dev-версию Chrome и, по всей видимости, официально появится в одном из следующих релизов браузера.
[WebRTC](http://www.webrtc.org/home) представляет собой открыты... | https://habr.com/ru/post/136605/ | null | ru | null |
# Hyperapp для беженцев с React/Redux
[](https://habrahabr.ru/company/devexpress/blog/349810)
Я люблю Redux
=============
Именно благодаря Redux для меня началось путешествие в мир удивительного функционального программирования. ... | https://habr.com/ru/post/349810/ | null | ru | null |
# «…Желают знать, что будет» или пишем гадальный шар в САПР NanoCAD на C# (MultiCAD .NET API)
Если верить одной старой [песне из советского кинофильма](https://www.youtube.com/watch?v=QgGZwy-CLb0), то люди всегда интересуются вопросами будущего в трудной ситуации. Кто-то подбрасывает монетку, кто-то мучает осьминога П... | https://habr.com/ru/post/347720/ | null | ru | null |
# Конфигурация Salt

После успешной установки необходимых пакетов SaltStack приступаем к настройке.
Установка описана [здесь](https://habrahabr.ru/post/315054/).
### Конфигурация Salt
Конфигурац... | https://habr.com/ru/post/315056/ | null | ru | null |
# Ansible-vault decrypt: обходимся без Ansible
Исходные данные
---------------
**Дано**:
* конвейер CI/CD, реализованный, к примеру, в GitLab. Для корректной работы ему требуются, как это очень часто бывает, некие секреты - API-токены, пары логи/пароль, приватные SSH-ключи - да всё, о чём только можно подумать;
* р... | https://habr.com/ru/post/554148/ | null | ru | null |
# Мошенничество при покупке б/у Macbook Pro
Сегодня ко мне обратилась знакомая с просьбой помочь купить б/у Macbook Pro. Я сразу предупредил, что квалификация у меня близка к нулю, но чем могу — помогу. С PC плотно не работаю уже много лет, а Mac владею на верхне-чайниковом уровне. Беглый поиск по фразе «как проверить... | https://habr.com/ru/post/388815/ | null | ru | null |
# Новое в CSS 3: анимация, трансформация, переменные.
Что-то мне кажется, что в этот раз с идеями внедерения новых правил разработчики перестарались…
Dave Hyatt, Dean Jackson и Chris Marrin (все трое работают в Apple) предложили внедрить в CSS 3 поддержку создания анимации, трансформацию объектов, их изменение с ... | https://habr.com/ru/post/23356/ | null | ru | null |
# Вся правда о UTF-8 флаге

Распространённое заблуждение состоит в том, что строки символов, в отличие от строк байтов, имеют UTF-8 флаг установленным.
Многие догадываются, что если данные являются ASCII-7-bit, то UTF... | https://habr.com/ru/post/190584/ | null | ru | null |
# Часть. 2. Создание аналога Moodle. Реализация API для прототипа SPA. Межсайтовые запросы. Первые проблемы архитектуры
В [первой части я рассказал](https://habr.com/ru/post/590605/) про то, почему я пришел к необходимости создания собственной СДО. Итак, на текущий момент имеем: сайт, работающий на самописном PHP fram... | https://habr.com/ru/post/590881/ | null | ru | null |
# Создание карт из функций шума
Одна из самых популярных статей на моём сайте посвящена [генерации полигональных карт](http://www-cs-students.stanford.edu/~amitp/game-programming/polygon-map-generation/) ([перевод](https://habr.com/post/322504/) на Хабре). Создание таких карт требует много усилий. Но начинал я не с эт... | https://habr.com/ru/post/430384/ | null | ru | null |
# Утечка исходного кода Winamp (843 МБ)
В веб-архиве обнаружили [репозиторий с исходным кодом Winamp](https://web.archive.org/web/20210515031018/https://github.com/CONIGUERO/winamp), который был удалён в мае 2021 года или позже. Хот... | https://habr.com/ru/post/592471/ | null | ru | null |
# Создание web приложения на PHP с иcпользованием Firebird и Laravel
 Привет Хабр!
В прошлой [статье](https://habrahabr.ru/post/312874/) я рассказывал о пакете для поддержки СУБД Firebird в фреймворке Laravel. ... | https://habr.com/ru/post/317458/ | null | ru | null |
# EasyMapping, или Путешествие по JSON'у
> Computer programs are the most complex things that humans make. It is also the nature of software to be extensively modified over its productive life. If we can read and understand it, then we can hope to modify and improve it.
>
>
>
> Douglas Crockford, автор специ... | https://habr.com/ru/post/176721/ | null | ru | null |
# Бой антивирусов
Почти беспристрастное сравнение антивирусов LMD, Manul, ClamAV и Вирусдай.
--------------------------------------------------------------------------

За последний год ряды антивирусов, которые борются с ... | https://habr.com/ru/post/263785/ | null | ru | null |
# Выборочное логирование SQL запросов в Hibernate
В начале прошлой недели я стал работать на реальном проекте который управляет аудиоконтентом для радиостанции. Обычная админ панель с использованием VAADIN фреймворка (<https://vaadin.com/home>) предоставляет пользователю веб интерфейс, который позволяет настраивать сп... | https://habr.com/ru/post/149001/ | null | ru | null |
# MPS 2018.3: планы генерации, улучшения в языке сборки и упаковки и в языке редактора, обновленный интерфейс
Привет, Хабр! Недавно мы выпустили [MPS 2018.3](https://www.jetbrains.com/mps/download/). В этой версии много новых функций, с которыми работа над проектами станет еще эффективнее. Мы улучшили планы генерации ... | https://habr.com/ru/post/436652/ | null | ru | null |
# Интеграция шаблонизатора Twig в Symfony 1.4
При попытке интегрировать Twig в Symfony, возникли следующие проблемы: информации практически нет, нет гайда по интеграции, есть мини документация по Twig, которая описывает как работать с Twig, но не как научить его работать с Symfony. Пришлось немного поискать и поспраши... | https://habr.com/ru/post/88634/ | null | ru | null |
# Генератор кликов на Python для программы Data Engineer
Процесс разработки образовательной программы очень похож на процесс разработки нового продукта. И там, и там ты пытаешься вначале понять, а есть ли спрос на то, что ты собираешься производить? Существует ли в реальности та проблема, которую ты хочешь решить?
... | https://habr.com/ru/post/334756/ | null | ru | null |
# Tests vs. Types — Rust version
A few days ago [0xd34df00d](https://habr.com/ru/users/0xd34df00d/) has published the translation of the [article](https://kevinmahoney.co.uk/articles/tests-vs-types), describing the possible information about some function if we use it as a "black box", not trying to read its implement... | https://habr.com/ru/post/468271/ | null | en | null |
# Открыта регистрация на КИБоРИФ
Наконец-то открыта [регистрация](http://ok2009.ru/registration/) на объединённую конференцию по вопросам интернета и бизнеса в России. Регистрируйтесь и приезжайте. Будет приятно пообщаться!
` Релиз [Dart 2.12](https://medium.com/dartlang/announcing-dart-2-12-499a6e689c87) принёс, помимо всего прочего, [поддержку FFI](https://dart.dev/guides/libraries/c-interop) ... | https://habr.com/ru/post/547946/ | null | ru | null |
# Визуализация весов в машинном обучении на примере алгоритма Random Forest и Decision Tree
Привет, Хабр!
Меня зовут Александр Серов, я Data Scientist и являюсь участником [профессионального сообщества NTA](https://newtechaudit.ru/). Сегодня загляну «под капот» алгоритмов, использующих в своей основе деревья решений... | https://habr.com/ru/post/711770/ | null | ru | null |
# Фишинг с поддельным приглашением на встречу
Вы когда-нибудь задумывались о том, как работают приглашения на встречи в Microsoft Teams и Google Meet? Недавно я занимался вопросом социальной инженерии, и у меня в голове возникла случайная мысль: как на самом деле работают приглашения на встречи, можно ли как-то исполь... | https://habr.com/ru/post/562780/ | null | ru | null |
# PHPUnit. Автоматические тесты
*Предисловие переводчика:
Недавно начал изучать PHPUnit (framework семейства [xUnit](http://www.smartyit.ru/testing/82)) и с удивлением обнаружил, что на русском языке нет статей про автоматические тесты для самых-самых чайников.
В первой главе документации по PHPUnit на примерах ... | https://habr.com/ru/post/87922/ | null | ru | null |
# Настройка сетевого оборудования компании HUAWEI (коммутация, статическая маршрутизация)
HUAWEI – одна из крупнейших китайских компаний в сфере телекоммуникаций. Основана в 1988 году.
Компания HUAWEI достаточно недавно вышла на российский рынок сетевого оборудования уровня Enterprise. С учётом тенденции тотальной ... | https://habr.com/ru/post/153401/ | null | ru | null |
# Парсинг Яндекс Карт или как найти целевую аудиторию
Всем привет, меня зовут Стешенко Артем. Я работаю в Data Science и также занимаюсь небольшим проектом по разработке страниц (или мультиссылок) для самозанятых.
, о чем был своевременный [пост на Хабре](https://habr.com/en/company/jetbrains/blog/478866/). Прошло немного времени и уже пора бы попробовать некоторые его осо... | https://habr.com/ru/post/545908/ | null | ru | null |
# Новые форматы графики в CSS с помощью обновлённой функции image-set
Перевод статьи [**Ollie Williams**](https://css-tricks.com/author/olliew/) **"**Using Performant Next-Gen Images in CSS with image-set**"**
CSS функция `image-set`поддерживается в браузерах на основе Chromium с 2012 года, а Safari начиная с версии ... | https://habr.com/ru/post/565920/ | null | ru | null |
# Вопросы совместимости Tibero и Oracle. Часть 2. Разработка Java приложений

Мы продолжаем цикл статей разработчиков приложений для баз данных — [Часть 1. Условная компиляция PL/SQL](https://habrahabr.ru/company/tmaxsoft/blog/350530... | https://habr.com/ru/post/352560/ | null | ru | null |
# Tree — единый AST чтобы править всеми
Здравствуйте, меня зовут Дмитрий Карловский и я… рассекаю на велосипедах… по бездорожью… против ветра… в гору… на лыжах. И сегодня я приглашаю вас прокатиться со мной вдоль и поперёк текстовых форматов данных и вместе спроектировать идеальный формат.
Я уже [рассказывал о нём](h... | https://habr.com/ru/post/503240/ | null | ru | null |
# Hotspot-авторизация за копейки и никаких SMS
[](https://habr.com/ru/company/ruvds/blog/695066/)
В начале этого лета в России произошли изменения в тарифах на рассылку SMS-сообщений. Правила игры изменились, цены выросли на порядо... | https://habr.com/ru/post/695066/ | null | ru | null |
# Используем возможности CSS4 уже сегодня с cssnext
Вот уже на протяжении четырёх лет, с сентября 2011 г. W3C занимается разработкой CSS4. Модули четвёртой версии каскадных таблиц стилей проектируются на базе CSS3 и допо... | https://habr.com/ru/post/267181/ | null | ru | null |
# Оптимизация геометрического алгоритма обучения ИНС при анализе независимых компонент
Добрый день, уважаемые хабровчане. Возможно многие из вас зададутся вопросом: «А где же описание основного алгоритма?».
Так вот, ниже будут указанны ссылки на источники, и переписывать основной алгоритм не буду.
Сразу объяснюс... | https://habr.com/ru/post/216225/ | null | ru | null |
# Цена JavaScript в 2019 году
За последние несколько лет в том, что называют «[ценой JavaScript](https://habr.com/ru/company/ruvds/blog/419369/)», наблюдаются серьёзные положительные изменения благодаря повышению скорости парсинга и компиляции скриптов браузерами. Сейчас, в 2019 году, главными составляющими нагрузки н... | https://habr.com/ru/post/459296/ | null | ru | null |
# О взаимосвязи между корутинами, потоками и проблемами параллелизма
«*Корутины - это легковесные потоки*», сколько раз вы слышали эту формулировку? Она что-нибудь вам говорит? Скорее всего не очень много. Ес... | https://habr.com/ru/post/546070/ | null | ru | null |
# Распознавание символов
Работа с изображениями — одна из самых распространенных задач в машинном обучении. Мы покажем пример обработки изображения, получение матриц (тензоров) чисел, подготовку данных обучаю... | https://habr.com/ru/post/541742/ | null | ru | null |
# Релиз CLion 2017.1: C++14, C++17, код на дизассемблере в отладчике, Catch, MSVC и многое другое
Привет, Хабр! Спешим поделиться радостной новостью – мы выпустили первый в этом году релиз нашей кросс-платформенной IDE для C и C++, **CLion 2017.1**!
. Как и обещал, в данной статье, я хочу затронуть основные варианты реализации фабрики на VXLAN/EVPN, и рассказать почему мы решили выбрать то или иное решение в... | https://habr.com/ru/post/527830/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.