
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Samsung объяснила, что ее Blu-ray плееры сломались из-за неправильного файла XML, а перепрошивкой проблему решить нельзя
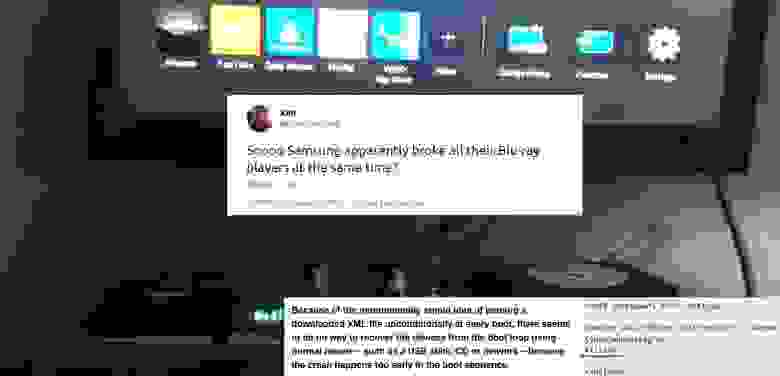
Уже более месяца с 17 июня 2020 года тысячи обладателей домашних кинотеатров, стерео систем и Blu-ray плеер... | https://habr.com/ru/post/511706/ | null | ru | null |
# Chromium: опечатки
Предлагаем вашему вниманию цикл статей, посвященных рекомендациям по написанию качественного кода на примере ошибок, найденных в проекте Chromium. Это четвёртая часть, которая буде... | https://habr.com/ru/post/347826/ | null | ru | null |
# Как CSS специфичность работает в браузере
Многие считают CSS сложным. Они придумывают разные оправдания: не хватает способностей понимать CSS или CSS сам по себе плох. Но реальность такова, что люди просто не нашли время, чтобы действительно изучить его. Если вы читаете эту статью, значит заинтересованы в изучении C... | https://habr.com/ru/post/436610/ | null | ru | null |
# Какую модель памяти следует использовать в языке Rust?

В этой статье рассматривается несколько альтернативных моделей памяти для языка Rust. Надеюсь, эта дискуссия будет ценна всему сообществу Rust – но, в конце концов, это и... | https://habr.com/ru/post/697882/ | null | ru | null |
# Как мы писали SLA
Всем привет. Я с моими коллегами работали(ем) в небольшой аутсорсинговой компании. Таких мелких компаний, предоставляющих услуги по обслуживанию инфраструктуры достаточно много, да и почти каждый Системный администратор или ИТ менеджер задумывался, а не начать ли мне подобный бизнес? Одному ли, или... | https://habr.com/ru/post/128927/ | null | ru | null |
# Работа с аудио в Unity — трассировка и облачные вычисления
Всем привет! Меня зовут Илья, я из команды TinyPlay. В этой статье хотел бы поделиться тем, как мы работаем с аудио. Надеюсь, для вас эта статья будет полезной.

Вы наверняка слышали про эту клавиатуру. IBM Model M называют «лучшей клавиатурой для набора текста», «легендарной неубиваемой клавиатурой», непременно добавляя «таких больше не делают». К п... | https://habr.com/ru/post/409651/ | null | ru | null |
# Перегрузка, которая запрещена, или bridge-методы в Java

В большинстве моих собеседований на технические позиции есть задача, в которой кандидату необходимо реализовать 2 очень похожих интерфейса в одном классе:
*Реализуйте оба ... | https://habr.com/ru/post/426419/ | null | ru | null |
# Порядок выполнения callback-ов при наследовании
Ruby — очень интересный язык. Одной из его особенностей является возможность выполнения заданных функций при добавлении модуля в класс. Стандартный пример выглядит следующим образом:
```
module MyModule
module InstanceMethods
end
module ClassMethods
end
... | https://habr.com/ru/post/141124/ | null | ru | null |
# Электронная подпись ГОСТ Р 34.10 документов формата PDF в офисном пакете LibreOffice
 Пришла пора, несмотря на все [пожары](https://habr.com/post/422539/), исполнить свой гражданский долг – заплатить налоги. Платить налоги мы будем че... | https://habr.com/ru/post/428429/ | null | ru | null |
# Токены PKCS#11: сертификаты и закрытые ключи
 [Токены PKCS#11](https://ru.wikipedia.org/wiki/PKCS_%E2%99%AF11) выполняют не только криптографические функции (генерация ключевых пар, формирование и проверка электронной по... | https://habr.com/ru/post/316328/ | null | ru | null |
# UAC Bypass или история о трех эскалациях
На работе я исследую безопасность ОС или программ. Ниже я расскажу об одном из таких исследований, результатом которого стал полнофункциональный эксплоит типа UAC bypass (да-да, с source-code и гифками).
 вы установили соединение с базой данных.
В этой же добавите логику маршрутизации, контроллера и базы данных для обработки HTTP-запроса GET на ... | https://habr.com/ru/post/473350/ | null | ru | null |
# Настройка SSH в Cisco

**Задача:**
Настроить SSH в Cisco. Сделать SSH средой по умолчанию для терминальных линий.
**Решение:**
`1. cisco> enable
2. cisco# clock set 17:10:00 28 Aug 2009 ... | https://habr.com/ru/post/68262/ | null | ru | null |
# Интересный подход для кэширования моделей
На днях я получил задание реализовать кэширование в моделях. В обсуждениях с коллегами родилась довольно интересная, на мой взгляд, идея, которую я бы хотел выставить на ваш суд.
Реализация идеи на Zend Framework:
... | https://habr.com/ru/post/72828/ | null | ru | null |
# Делаем приём платежей криптовалютой своими руками
Привет, Хабр!
Время от времени замечаю вопросы о том, как принимать платежи Bitcoin на своём сайте без использования сторонних сервисов. Это достаточно просто, но надо учитывать, что есть подводные камни.
В этой статье я постараюсь максимально подробно, без акцента... | https://habr.com/ru/post/350430/ | null | ru | null |
# Разбор форматов: упакованные хешированные ресурсы

В прошлых [двух](http://habrahabr.ru/post/257793/) [статьях](http://habrahabr.ru/post/258397/) я рассказал об особенностях форматов данных звуковой подсистемы современных... | https://habr.com/ru/post/261561/ | null | ru | null |
# Интеграция FreeIPA с Active Directory
В IT-инфраструктуре [HOSTKEY](https://hostkey.ru/) для хранения учетных данных и контроля доступа традиционно использовался FreeIPA. Когда появилась необходимость управлять офисными компьютерами с Windows и оборудованием Cisco Systems, пришлось задуматься об интеграции с Active ... | https://habr.com/ru/post/669978/ | null | ru | null |
# Гайд по архитектуре приложений для Android. Часть 4: доменный слой
> В конце декабря 2021-го Android обновил рекомендации по архитектуре мобильных приложений. Публикуем перевод гайда в пяти частях:
>
> [Обзор архитектуры](https://go.surf.dev/hr/android/habr/architecture_guide_domain_layer)
>
> [Слой UI](https://go... | https://habr.com/ru/post/653673/ | null | ru | null |
# Рецепты под Android: Scroll-To-Dismiss Activity
Привет! Сегодня мы расскажем, как за минимальное количество времени добавить в свою Activity поведение Scroll-To-Dismiss. Scroll-To-Dismiss – это популярный в современном мире жест, позволяющий закрыть текущий экран и вернуться в предыдущую Activity.
](https://habr.com/ru/company/skillfactory/blog/523142/)
К публикуемым в нашем блоге авторским статьям и переводным материалам про лайфхаки/интересные находки мы решили д... | https://habr.com/ru/post/524124/ | null | ru | null |
# Межпланетная файловая система — тривиальный хеш (identity), DAG блок и Protocol Buffers
Недавно в IPFS добавили поддержу [тривиального (identity) хеша](https://github.com/ipfs/go-ipfs/issues/4697). В своей статье я расскажу о нём и покажу как его можно использовать.
> Напомню: InterPlanetary File System — это новая... | https://habr.com/ru/post/423073/ | null | ru | null |
# 10 самых распространенных ошибок при работе с платформой Spring. Часть 1
*Всем привет. Сегодня делимся первой частью статьи, перевод которой подготовлен специально для студентов курса [«Разработчик на Spring Framework»](https://otus.pw/jWL8/). Начнём!*
 всякие DOS-игрухи-проги, ... | https://habr.com/ru/post/699090/ | null | ru | null |
# Как я ускорил обработку изображений на Android в 15 раз
Как оптимизировать обработку изображений в рантайме, когда необходимо создать 6 изображений, каждое из которых состоит из последовательно наложенных 15-16 PNG, не получив OutOfMemoryException по дороге?

Авторы анализатора PVS-Studio предлагают вам проверить свою внимательность и развлечься. Попробуйте быстро отыскать баг в фрагменте исходного кода и ткнуть в не... | https://habr.com/ru/post/673988/ | null | ru | null |
# Эволюция архитектуры Авито, или Как мы монолит в Kubernetes затолкали
Всем привет, я Александр Данковцев, lead engineer команды Antimonolith. Как можно догадаться, в Авито я занимаюсь распилом монолита.
В прошлой статье я рассказывал [про наш CI/CD](https://habr.com/ru/company/avito/blog/560166/). Сегодня речь пой... | https://habr.com/ru/post/650593/ | null | ru | null |
# Fixtures в Rails и их альтернатива
Я на рельсах сижу не так давно, но, тем не менее, уже успел кое в чем покопаться. Одна из тем, с которыми пришлось разобраться довольно тщательно — это fixtures и их альтернативы в тестах rails.
### Немного о самих Fixtures
Маленький обзор для тех, кто не совсем в теме. Fixture... | https://habr.com/ru/post/30387/ | null | ru | null |
# Упрощение аутентификации в Kafka с помощью Node.js
*Содержание:*
Подключение к экземпляру Kafka
Безопасная передача учетных данных
Привязка сервиса в Kubernetes
Простота использования привязок сервис... | https://habr.com/ru/post/593011/ | null | ru | null |
# Приручение черного дракона. Этичный хакинг с Kali Linux. Часть 5. Методы получения доступа к системе
Приветствую тебя, дорогой читатель, в пятой части серии статей «Приручение черного дракона. Этичный хакинг с Kali Linux».
Полный список статей прилагается ниже, и будет дополняться по мере появления новых.
**При... | https://habr.com/ru/post/696840/ | null | ru | null |
# Исправлена серьезная ошибка в официальной документации по настройке SSL в web-ролях Microsoft Azure

Хорошие новостиTM: есть небольшое, но важное развитие сюжета из [этого поста](https://habrahabr.ru/company/abbyy/blog/28... | https://habr.com/ru/post/302530/ | null | ru | null |
# Дружим C# и OpenOffice.org
Не судите строго, это моя первая статья
На работе поставили задачу — написать бюджетный вариант для моей программы (ранее для отчетов использовали MS Office). Сильно озадачился, из — за нехватки материалов по данной теме, так как все материалы разбросаны по разным блогам, и они все в ос... | https://habr.com/ru/post/49373/ | null | ru | null |
# 3DO и Android NDK и как бы во что не вляпаться…

Найдется наверное не мало приложений, которые почти невозможно сделать на Java, в силу большой исходной кодовой базы C++ или требований к производител... | https://habr.com/ru/post/303888/ | null | ru | null |
# Используем tcpdump для анализа и перехвата сетевого трафика

Утилита tcpdump — отличный инструмент командной, который способен перехватывать и анализировать сетевой трафик. Может оказаться большим подспорьем при решении сетевых пробл... | https://habr.com/ru/post/531170/ | null | ru | null |
# Scala. Всем выйти из сумрака!
*А сейчас нужно обязательно дунуть, потому что если не дунуть, то ничего не получится.*
*—Цитаты великих*
И здравствуйте!
Сегодня мы поговорим о неявном в языке Scala.... | https://habr.com/ru/post/209850/ | null | ru | null |
# Мониторинг серверов Trassir
Так сложилось, что есть необходимость администрирования большого количества (более 50 и будет кратно больше) серверов Trassir (сервера видеонаблюдения) расположенных в разных городах СНГ. В целом оборудование не плохое, но присутствуют проблемы с централизованным управлением в силу особен... | https://habr.com/ru/post/344488/ | null | ru | null |
# Webpack 4 и разделение конфигурационного файла на модули
Привет, Хабр! Сегодня я расскажу вам о Webpack 4 с разделением кода на отдельные модули, а также о интересных решениях, которые помогут вам быстрее собрать сборку на webpack 4. В конце, я предоставлю свою базовую сборку на webpack c самыми необходимыми инструм... | https://habr.com/ru/post/422697/ | null | ru | null |
# Псевдо ООП в C
[](http://habrahabr.ru/post/263547/)
Язык Си не является объектно-ориентированным языком. И значит все что будет описано ниже это костыли и велосипеды.
ООП включает в себя три столпа: инкапсуляция, насл... | https://habr.com/ru/post/263547/ | null | ru | null |
# Альтернативная проверка предусловий в Code Contracts
При попытке использования библиотеки [Code Contracts](http://research.microsoft.com/en-us/projects/contracts/) в реальном проекте может возникнуть небольшая сложность: хотя сам класс [Contract](http://msdn.microsoft.com/en-us/library/system.diagnostics.contracts.c... | https://habr.com/ru/post/139773/ | null | ru | null |
# Проектируем процессор постапокалипсиса с помощью openSource
[](https://habr.com/ru/company/ruvds/blog/692236/)
Проектируемый компьютер на [сверхминиатюрных электронных лампах](https://habr.com/ru/company/ruvds/blog/655623/) хоть ... | https://habr.com/ru/post/692236/ | null | ru | null |
# Онлайн-конференция на Ярмарке вакансий для ИТшников

Сегодня, 25-го февраля, HeadHunter устраивает [«Ярмарку вакансий онлайн» специально для IT-специалистов](http://expo.hh.ru/?utm_source=habr&utm_medium=habr&utm_content=... | https://habr.com/ru/post/277851/ | null | ru | null |
# Как разрабатывать неподдерживаемое ПО
Мне платят за то, что я возвращаю чужой технический долг. В своей работе я вижу много сложного в поддержке кода, и я снова и снова вижу много проблем, которых можно было избежать.
Я специализируюсь на отладке, исправлении, поддержке и расширении функциональности старого прогр... | https://habr.com/ru/post/203628/ | null | ru | null |
# Does the latency matter?
Есть исследование от Google, которое говорит, что если ваш сайт открывается больше трех секунд, то вы потеряете около 40% десктопных пользователей и более 50% — мобильных. Еще ест... | https://habr.com/ru/post/577158/ | null | ru | null |
# JavaScript: ускоряем загрузку изображений с помощью Imgproxy, Cache API и Service Worker API

Привет, друзья!
В этой статье я хочу поделиться с вами результатами небольшого эксперимента, связанного с ускорением загрузки изображе... | https://habr.com/ru/post/655775/ | null | ru | null |
# Сниппеты для Chrome DevTools
Возможности встроенного в браузер инструмента Chrome Developer Tools можно расширить с помощью сниппетов. Это ускоряет разработку и упрощает рабочий процесс. Хорошая коллекция сниппетов есть [на GitHub'е](http://bgrins.github.io/devtools-snippets/).
#### Сниппеты в Google Chrome
Подр... | https://habr.com/ru/post/192902/ | null | ru | null |
# Как подружить MATLAB DLL и C#
Когда есть желание пользоваться m-файлами на стороне, например, впихнуть хорошо работающие методы аппроксимации из Curve Fitting Toolbox в какую нибудь стороннюю свою разработку, можно скомпилировать dll-библиотеку и использовать ее по своему разумению.
Данная статья - кратко по шагам... | https://habr.com/ru/post/661223/ | null | ru | null |
# Meteor + MVVM = ❤

Тут мелькнула статья, как чувак, выбирая инструментарий, ничего не мог написать. Это про меня! Под Новый год нашёл [ViewModel.org](https://viewmodel.org/). А внутри прекрасный [Two-Way Binding](https://... | https://habr.com/ru/post/283152/ | null | ru | null |
# Книга «Python, например»
[](https://habr.com/ru/company/piter/blog/564270//) Привет, Хаброжители! Python — стремительно развивающийся язык программирования современности. В этом увлекательном и необычном руководстве материал ра... | https://habr.com/ru/post/564270/ | null | ru | null |
# Используем пайпы для пивотинга
Ни для кого не секрет, что корпоративные IPS становятся все умнее и умнее. Сейчас уже никого не удивишь IPS с SSL-митмом на периметре сети или даже внутри корпоративной сети между сегментами. В то же время, помимо всем известных IPS, стали появляться и распространяться различные EDR-ре... | https://habr.com/ru/post/460659/ | null | ru | null |
# Как сделать DIY-термостат с веб-интерфейсом, чтобы отапливать дом дистанционно
Разработка на фронтенде не ограничивается интернет-ресурсами, а бекенд может оказаться неожиданным. К старту курса о [Fullstac... | https://habr.com/ru/post/569712/ | null | ru | null |
# Класс для редактирования конфигурационных файлов
 В любом веб проекте используются конфигурационные файлы. Чаще всего они редактируются на стадии разработки или переносе проекта а потом надолго остаются нетронутыми. Но бывает что кон... | https://habr.com/ru/post/315384/ | null | ru | null |
# Портирование JS на Эльбрус
Это рассказ про портирование JavaScript на отечественную платформу Эльбрус, выполненное ребятами из компании UniPro. В статье — краткий сравнительный анализ платформ, детали процесса и подводные камни.
... | https://habr.com/ru/post/419155/ | null | ru | null |
# Mina Monitor — convenient monitoring your Mina nodes
Hello everyone!
---------------
My name is Serhii Pimenov. I’m a web developer from Kyiv, Ukraine (maybe you know me by the nickname olton).
Today I'... | https://habr.com/ru/post/583636/ | null | en | null |
# Очередной сбор средств
Wikipedia собирает добровольные пожертвования на сервера, каналы связи, поддержку и обслуживание, развитие.
> В этом году подумайте, пожалуйста, о взносе в 5 долларов, 10 евро, 45 рублей, или о таком,... | https://habr.com/ru/post/132774/ | null | ru | null |
# The first static analysis report: the key problems and how to address them
The main purpose of the static analyzer is to detect and report errors in code - so that you can fix them afterwards. However, reporting errors is not as simple as it may seem. Those just starting out to work with static analysis - and even e... | https://habr.com/ru/post/594361/ | null | en | null |
# Битва C# JSON сериализаторов для .NET Core 3
***Всем привет. В преддверии старта курса [«Разработчик C#»](https://otus.pw/Xy6i/) подготовили для вас интересный перевод, а также предлагаем [бесплатно посмотреть запись урока: «Шаблон проектирования Состояние (State)»](https://otus.pw/Xa1Y/)***
](https://habr.com/ru/company/ruvds/blog/589879/)
Несколько лет назад я открыл для себя DigitalRev TV. В [одном из выпусков](https://youtu.be/qIbrufzgNus) в руки Кая и Лока попадает отечественный фотоаппарат «Люби... | https://habr.com/ru/post/589879/ | null | ru | null |
# Слой кэширования поверх Linq to SQL
За последний год мы перенесли внушительную часть настроек DirectCRM в базу данных. Множество элементов промо-кампаний, которые мы до этого описывали исключительно кодом, теперь создаются и настраиваются менеджером через админку. При этом получилась очень сложная структура БД, насч... | https://habr.com/ru/post/255231/ | null | ru | null |
# Nokia Bell Labs передала сообществу все права на операционную систему Plan 9
Компания Nokia, которой сейчас принадлежит подразделение Bell Labs, передала сообществу все права и копирайты на ОС — и переопубл... | https://habr.com/ru/post/548912/ | null | ru | null |
# Новый jQuery плагин адаптивной галереи c автоматической группировкой

На сайте [tympanus.net](http://tympanus.net/codrops/2012/11/21/adaptive-thumbnail-pile-effect-with-automatic-grouping/) представ... | https://habr.com/ru/post/159733/ | null | ru | null |
# Конструирование сайта, защищенного от блокировок
Привет всем! В связи с ростом блокировок, в том числе необоснованных, сайтов со стороны государства, вашему вниманию предлагается описание идеи, а также **прототип настроек сайта**, защищенного от блокировок по конкретному пути и доменному имени. Идеи по защите от бло... | https://habr.com/ru/post/344536/ | null | ru | null |
# Затухание текста средствами CSS
Иногда бывает необходимость при верстке сайта вывести на экран только часть текста. Чтобы пользователю было понятно, что далее следует продолжение можно, например, поставить троеточие или ссылку «читать далее». Но есть весьма красивый способ сделать так, чтобы текст постепенно затухал... | https://habr.com/ru/post/241485/ | null | ru | null |
# SQL Server — Узнать неделю месяца из недели года
Заинтересовался вопросом, вот если дана дата, то как узнать к какой неделе месяца она принадлежит? Чтобы знать, к примеру, что 7.05.2009 это вторая неделя мая, а 15.06.2009 третья неделя июня. В SQL Server есть встроенная функция, позволяющая определить, к какой недел... | https://habr.com/ru/post/62122/ | null | ru | null |
# nopCommerce CMS на ASP.NET MVC: обзор функционала новой версии
[nopCommerce](http://www.nopcommerce.com/) – это движок для создания интернет-магазинов с открытым исходным кодом и написанный на ASP.NET MVC. Разрабатывается проект нашими соотечественниками из города Ярославль, и на сегодняйшний день на его основе рабо... | https://habr.com/ru/post/276641/ | null | ru | null |
# Асимметричная криптография при лицензировании подписочного ПО на практическом примере
Речь пойдет... | https://habr.com/ru/post/123908/ | null | ru | null |
# Как обнаружить FinFisher. Руководство ESET
Благодаря серьезным мерам противодействия анализу, шпионское ПО FinFisher оставалось малоизученным. Это известный инструмент слежки, тем не менее, по предыдущим образцам был опубликован только частичный анализ.
Ситуация стала меняться летом 2017 года после выполненного ... | https://habr.com/ru/post/354830/ | null | ru | null |
# Можно так просто взять и скрыть информацию
Каждый из читателей наверняка много раз видел фильмы, где супергерой / суперзлодей передавал зашифрованную информацию. Мы привыкли к слову «шифр», «шифрование» и любая тайная передача информации сейчас ассоциируетсяименно с этими словами. Хотя на самом деле, это далеко не т... | https://habr.com/ru/post/166583/ | null | ru | null |
# Как улучшить ваши A/B-тесты: лайфхаки аналитиков Авито. Часть 1
Всем привет! Я Дмитрий Лунин, работаю аналитиком в команде ценообразования Авито. Наш юнит отвечает за все платные услуги площадки. К примеру, [услуги продвижения](https://www.avito.ru/performance) или [платные размещения](https://support.avito.ru/artic... | https://habr.com/ru/post/571094/ | null | ru | null |
# Как найти показатель степени двойки за O(1) с помощью последовательности де Брёйна
#### Аперитив
Всем, наверное, известно, как посчитать количество бит в числе. Например, подойдут следующие два способа:
```
while (n)
{
++count;
n &= (n-1);
}
```
```
while (n)
{
if (n&1)
++count;
n >>= 1... | https://habr.com/ru/post/233127/ | null | ru | null |
# 10 самых распространённых ошибок, которые делают новички в Java
Здравствуйте, меня зовут Александр Акбашев, я Lead QA Engineer в проекте Skyforge. А также по совместительству ассистент [tully](https://habr.com/en/users/tully/) в Технопарке на курсе «Углубленное программирование на Java». Наш курс идет во втором семе... | https://habr.com/ru/post/251365/ | null | ru | null |
# Хайлайтинг больших текстовых полей в ElasticSearch
 В декабре 2016 года мы с товарищем начали заниматься [новым проектом](https://github.com/RD17/ambar) — системой сбора-индексации-поиска по документам. Система построена вокр... | https://habr.com/ru/post/320390/ | null | ru | null |
# Что нового в PostgreSQL 11: встроенный веб-поиск

[Продолжая](https://habrahabr.ru/company/postgrespro/blog/353126/) тему интересных возможностей грядущего релиза PostgreSQL 11, я хотел бы рассказать про **новую встроенную функци... | https://habr.com/ru/post/353848/ | null | ru | null |
# Flexbox для интерфейсов во всей красе: Реализация Tracks (Часть 1)
Дни ухищрений с float и margin наконец позади, так как сегодня CSS предлагает разработчикам новые улучшенные возможности, которые отлично подходят для деликатных раскладок. Такие функции раскладок, как вертикальное выравнивание, равномерное распредел... | https://habr.com/ru/post/271195/ | null | ru | null |
# Как разработать приложение для автоматизации почти не умея программировать. Придется выучить IDE…
Хочешь создать свой проект в «железе», который перевернет мир с ног на голову? Или автоматизировать управление светом в коридоре. При этом ты не специалист в программировании микроконтроллеров, но разобрался с arduino и... | https://habr.com/ru/post/310784/ | null | ru | null |
# Photobucket запретил бесплатное встраивание изображений и поломал тысячи сайтов

Халява закончилась. Больше не получится гонять бесплатный трафик с [Photobucket](http://photobucket.com/) через встро... | https://habr.com/ru/post/405051/ | null | ru | null |
# Семейство тестов хи-квадрат: что у них под капотом и какие выбрать для сравнения воронок
Всем привет, меня зовут Вячеслав Зотов, я аналитик в студии Whalekit. В этом тексте я расскажу про статистические тесты и сравнение воронок, а также мы попробуем разобраться, что объединяет *χ*²-тесты, какова область их применен... | https://habr.com/ru/post/677074/ | null | ru | null |
# «Скрытые» полезности С#
Предлагаю мой вольный перевод вопроса с stackoverflow, который мне показался полезным и сидит в фаворитах. Что-то я взял с MSDN (в основном вырезки из русской редакции), что-то -с блогов.
Все мы, С# разработчики, знаем базовые комманды C#. Я имею ввиду объявления, условия, циклы, операторы... | https://habr.com/ru/post/56279/ | null | ru | null |
# Делаем Smart Point или «Интернет-вещь» своими руками
В этой статье я опишу концепцию и пример практической реализации компактной платформы для создания решений в области домашней автоматики и Интернета Вещей.
. За время, что я работаю с этой ОС, у меня накопились разные наблюдения, которые касаются производительности приложений на Qt и системы в целом, ибо девайсами разнообразными обвешана, аки ёлка нов... | https://habr.com/ru/post/457622/ | null | ru | null |
# Создаем библиотеку для бота telegram
История об и~~зучении~~ использовании python для написания ~~бота~~ библиотеки для ботов в telegram.
Код, описанием и историей которого является эта статья доступен по [ссылке](https://github.com/JouriM66/LinearBotLib).
Предыстория
-----------
Как-то в разговоре со знакомым, н... | https://habr.com/ru/post/677322/ | null | ru | null |
# Поднимаем собственный торрент-трекер на Centos
Зачем нужен собственный торрент-трекер – вопрос не стоит. Причины могут быть разные. Поэтому сразу перейду к делу.
Вероятно, все крупные трекеры пишутся на заказ, либо индивидуально «допиливаются» известные движки. Когда стоит цель поднять собственный, например локал... | https://habr.com/ru/post/308278/ | null | ru | null |
# Каким может быть стек технологий для торговли опционами на Московской бирже
[](https://habrahabr.ru/company/itinvest/blog/277845/)
В блоге на Хабре мы много пишем об использующемся для работы на фондовом ... | https://habr.com/ru/post/277845/ | null | ru | null |
# Команда SED в Linux/Unix с примерами
[](https://habr.com/ru/company/ruvds/blog/667490/)
Компиляция из двух смежных статей на тему использования команды `sed` для редактирования текстовых файлов, включая различные варианты поиска и ... | https://habr.com/ru/post/667490/ | null | ru | null |
# Avalonia Tutorial: Реализация MVVM по шагам с примерами
Avalonia — это?
---------------
[Avalonia](https://avaloniaui.net/docs) – это кроссплатформенный XAML фреймворк для платформы .NET. Для многих разработчиков на WPF/UWP/Xamarin данный фреймворк будет интуитивно понятен и прост в освоении. Avalonia поддерживает ... | https://habr.com/ru/post/505036/ | null | ru | null |
# Оценка ThunderX2 от Cavium: сбылась мечта об Arm сервере (часть 3)
[Первая](https://habr.com/company/ua-hosting/blog/413885/) и [вторая](https://habr.com/company/ua-hosting/blog/413973/) часть «Оценка ThunderX2 от Cavium: сбылась мечта об Arm сервере».
Производительность Java
-----------------------
SPECjbb 2015... | https://habr.com/ru/post/413983/ | null | ru | null |
# RC-лодка на ESP8266 NodeMCU

Примерно полгода мне понадобилось, чтобы собрать такую лодку на дистанционном управлении.
Я расскажу про процесс разработки с самого начала: от лодки из потолочной плитки, гелевой ручки и консервной ба... | https://habr.com/ru/post/513482/ | null | ru | null |
# Работа 3D принтера без компьютера
Здравствуйте, уважаемые хабравчане!
Вот и закончился мой переезд, кандидатский минимум сдан, первая катушка пластика закончилась и пришло время написать обещанную статью об электронной начинке моего принтера.
В этой статье речь пойдет об автоматизации моего 3D принтера PRUSA ... | https://habr.com/ru/post/231743/ | null | ru | null |
# Как реализовать магию Sqoop для загрузки данных через Spark
Очень часто приходится слышать, что Sqoop — это серебряная пуля для загрузки данных большого объёма с реляционных БД в Hadoop, особенно с Oracle, и Spark-ом невозможно достигнуть такой производительности. При этом приводят аргументы, что sqoop — это инструм... | https://habr.com/ru/post/679876/ | null | ru | null |
# HyperBand и BOHB. Понимание современных алгоритмов оптимизации гиперпараметров
Специально к старту курса [«Машинное обучение»](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=251120) в этом материале представляем с... | https://habr.com/ru/post/528240/ | null | ru | null |
# Разбираем алгоритмы компьютерной графики. Часть 6 — Анимация «Плазма»
Разновидностей алгоритмов генерации "плазм" столько же, сколько, наверное, звезд на небе. Но связывает их вместе принцип плавного формирования перехода цветов.
Для бесшовного формирования цвета очень часто используются тригонометрические функции.... | https://habr.com/ru/post/658039/ | null | ru | null |
# Перегружаем стандартные DataAnnotation атрибуты для использования с custom resource provider
Представьте, что у вас есть legacy проект Asp.NET MVC версии 5, которому немало лет. В нем используется самописный ResourceProvider, который умеет доставать из базы ресурс и показывать его на UI. В зависимости от различных у... | https://habr.com/ru/post/281222/ | null | ru | null |
# Логирование и откат правок

В некотором царстве-государстве жил-был грозный царь. И было у царя множество бояр, что день-деньской отчеты готовили: сколько войск на службе, да велика ли казна царская, уродилась ли пшеница в году э... | https://habr.com/ru/post/107745/ | null | ru | null |
# Сервер отчетов на django
Доброго времени суток.
Так случилось, что моя работа связана с написанием отчетов.
Этому я посвятил около 8 лет. Отчеты — это глаза бизнес-процесса и информация,
необходимая для принятия оперативных решений.
Вначале наш отдел делал отчеты,
— Принимая задачи по outlook
—... | https://habr.com/ru/post/177567/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.