
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# GRUB2. Начало
#### 0. Это что такое?
Расскажу о новой версии самого популярного загрузчика. Она появилась опционально в стабильном Debian 5.0 Lenny, а значит можно сделать вывод о некоторой стабильности. К сожалению, по словам самих разработчиков, на документацию времени нет, поэтому всё пока работает методом тыка,... | https://habr.com/ru/post/56216/ | null | ru | null |
# Запускаем простой блог на Wagtail CMS (Django) — часть 1
Являясь большим фанатом Python и фреймворка Django постоянно искал решение, как сделать разработку новых веб-проектов быстрее и удобнее.
Все, кто знаком с разработкой на Django, знают насколько неудобно строить на нем интуитивно понятную админ.панель. До м... | https://habr.com/ru/post/303900/ | null | ru | null |
# Капелька рефлексии для С++. Часть первая: ретроспектива разработки

**ВАЖНОЕ УТОЧНЕНИЕ. ПОЧИТАЙТЕ ПЕРЕД ТЕМ, КАК ЧИТАТЬ СТАТЬЮ**По моей вине возникли некоторые непонятки по поводу данных публикаций. Поэтому я решил добави... | https://habr.com/ru/post/281993/ | null | ru | null |
# Controlling Brushless Motors using a Linux computer or a PLC
In this video, we will look at how to connect brushless motor controllers to a Linux computer. Specifically, we will use a computer running Debian. The same steps would work for Ubuntu Linux and other Linux distributions derived from Debian.
I've got a s... | https://habr.com/ru/post/573644/ | null | en | null |
# Ускоряем умножение матриц float 4x4 с помощью SIMD
Уже немало лет прошло, как я познакомился с инструкциями MMX, SSE, а позже и AVX на процессорах Intel. В своё время они казались какой-то магией на фоне x86 ассемблера, который уже давно стал чем-то обыденным. Они меня настолько зацепили, что пару лет назад у меня п... | https://habr.com/ru/post/418247/ | null | ru | null |
# Как работает ZFS — часть 1: vdev
Vdev, или Virtual Device — это базовая единица, на которой строится массив данных ZFS (zpool). Для работы ZFS необходим как минимум один vdev — виртуальное устройство, которое позволяет случайный доступ к информации на уровне блоков.
Обычно, в качестве таких блоков используются ц... | https://habr.com/ru/post/160943/ | null | ru | null |
# Как обезопасить Linux-систему: 10 советов
На ежегодной конференции LinuxCon в 2015 году создатель ядра GNU/Linux Линус Торвальдс поделился своим мнением по поводу безопасности системы. Он подчеркнул необходимость смягчения эффекта от наличия тех или иных багов грамотной защитой, чтобы при нарушении работы одного ком... | https://habr.com/ru/post/309696/ | null | ru | null |
# Онлайн-мониторинг транспорта своими руками
[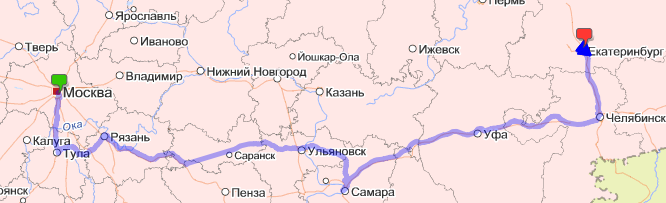](http://smotra.ru/gps/ "Посмотреть в работе")
Всегда нравилась идея онлайн-мониторинга чего-либо на карте. И вот представилась возможность сделать нечто подобное.
Пр... | https://habr.com/ru/post/99508/ | null | ru | null |
# Установка OpenWRT на CheckPoint T-120 (4200 appliance)
")CheckPoint T-120 (4200 appliance)В очередной раз просматривая объявления о продаж... | https://habr.com/ru/post/683088/ | null | ru | null |
# Мониторим активные сессии PostgreSQL 10, как в Oracle

Данный инструмент написан из спортивного интереса, когда мною было обнаружено, что вьюха pg\_stat\_activity в PostgreSQL 10 имеет поля wait\_event\_type и wait\_event, оче... | https://habr.com/ru/post/413411/ | null | ru | null |
# Системы контроля версий: Fossil, часть I
Приветствую вас, коллеги! 
Относительно недавно здесь [публиковался](http://habrahabr.ru/post/233935/) опрос по используемым системам контроля версий. Как и ожидалось, с большим отрывом поб... | https://habr.com/ru/post/235369/ | null | ru | null |
# sspp (Server Status PHP Parser)
sspp маленький парсер написанный на php для сортировки и анализа server-status
Наверное многим известно о существовании замечательного модуля апача [mod\_status](http://httpd.apache.org/docs/2.0/mod/mod_status.html).
Включается он очень просто, в httpd.conf нужно добавить:
`E... | https://habr.com/ru/post/44857/ | null | ru | null |
# Реактивный масштабируемый чат на Kotlin + Spring + WebSockets
Содержание
----------
1. Конфигурация проекта
1. Логгер
2. Домен
3. Маппер
2. Настройка Spring Security
3. Конфигурация веб-сокетов
4. Архитектура решения
5. Реализация
1. Интеграция с Redis
2. Импелементация сервиса
6. Заключение
Предисловие
---... | https://habr.com/ru/post/552234/ | null | ru | null |
# JavaScript-фреймворк для создания веб-калькуляторов
<р>На днях мне понадобилось сделать веб-калькулятор. Это был не первый калькулятор, который я писал, и воспоминания о кодировании на JavaScript логики вычислений, каждый раз заново, вовсе не прибавляли энтузиазма. Очевидно, с этим нужно было что-то сделать, отделив... | https://habr.com/ru/post/13285/ | null | ru | null |
# Автономный LTE роутер своими руками | Часть 3 – Uboot & OpenWRT
Привет, Хабр! Эта статья посвящена программной части собственного роутера, сегодня будем: допиливать OpenSource, терять месяц жизни впустую, р... | https://habr.com/ru/post/701048/ | null | ru | null |
# О верстке, логике, чудаках и порталах МТС
*Ремарка — данный текст есть лишь моё личное оценочное суждение и не претендует на абсолютную истину.*
Предыстория. Осенняя ночь, отсутствие работы, интернет. Кончился. Как обычно это бывает, закончился траффик на мтс-ном тарифе.
«Ок», — подумал я, попробую оплатить с... | https://habr.com/ru/post/314802/ | null | ru | null |
# Windows Native Applications and Acronis Active Restore
We continue telling you about our cooperation with Innopolis University guys to develop Active Restore technology. It will allow users to start working as soon as possible after a failure. Today, we will talk about Native Windows applications, including details ... | https://habr.com/ru/post/499466/ | null | en | null |
# История реверс-инжиниринга одного SMS трояна для Android

Все началось с жалоб одного моего доброго друга, по совместительству владельца устройства на Android. Он жаловался, что оператор постоянно с... | https://habr.com/ru/post/161459/ | null | ru | null |
# Хостим WASM-приложения на github pages в два клика
Приветствую. Хочу донести гениальную и простейшую идею о том, как можно делать несложные бессерверные веб-приложения и бесплатно хостить их на [github pages](https://pages.github.com/).
Слово от меняЯ не дословно перевожу, а скорее адаптирую, опуская совсем очевидн... | https://habr.com/ru/post/566286/ | null | ru | null |
# Непрерывная интеграция с помощью Drone CI, Docker и Ansible

Можете представить, что Вам больше никогда не придется устанавливать зависимости и настраивать конфигурации вручную на вашем сервере непрерывной интеграции? А вы верите... | https://habr.com/ru/post/324588/ | null | ru | null |
# Запуск домашнего веб-сервера без статического IP с помощью Python

Приветствую жителей Хабра!
Задался тут вопросом, как можно обойтись без статического IP для экспериментов в домашних условиях. Наткнулся на вот эту статью.
Если... | https://habr.com/ru/post/557126/ | null | ru | null |
# Хакинг Dendy игр. На примере Road Fighter
Я хочу рассказать про принцип хакинга игрушек для игровой приставки Dendy (она же Nintendo Entertainment System, она же Famicom, она же 100500 китайских клонов, далее по тексту просто NES).
Хакинг (а точнее модинг, но в эмусцене более распространён термин «ROMхакинг») игр... | https://habr.com/ru/post/126720/ | null | ru | null |
# Настройка в OsmAnd карты слоя Strava heatmap
В приложении OsmAnd для телефонов на операционной системе android есть возможность добавления дополнительных слоев на карты OSM (Open Street Map). Полезным дополнением для вашей навигационной системы будет слой Strava heatmap, результат записанных во время путешествий и т... | https://habr.com/ru/post/450124/ | null | ru | null |
# Миграция ОС в OpenVZ контейнер

В данной заметке я хочу рассказать как просто перенести Linux систему с физического сервера или полной виртуализации (KVM,XEN,VMware) в контейнер OpenVZ. По данной теме достаточно мате... | https://habr.com/ru/post/146677/ | null | ru | null |
# HackTheBox endgame. Прохождение лаборатории Professional Offensive Operations. Пентест Active Directory

В данной статье разберем прохождение не просто машины, а целой мини-лаборатории с площадки [HackTheBox](https://www.hackt... | https://habr.com/ru/post/504912/ | null | ru | null |
# Deep Learning в вычислении оптического потока
С появлением множества различных архитектур нейронных сетей, многие классические Computer Vision методы ушли в прошлое. Все реже люди используют SIFT и HOG для object detection, а MBH для action recognition, а если и используют, то скорее как handcrafted-признаки для соо... | https://habr.com/ru/post/446726/ | null | ru | null |
# Вышла Beta Go 1.18 с дженериками. Подробности из блога Go под катом
Официальный релиз Go 1.18 состоится только через пару месяцев. Это первый предварительный выпуск Go 1.18, чтобы вы могли [попробовать его... | https://habr.com/ru/post/595799/ | null | ru | null |
# 9 причин переходить на open-source
В данной статье я хочу указать несколько причин, почему компании любых масштабов должны переходить на open-source технологии. Я постараюсь указать моменты, выжные не только для разработчиков, но и для бизнеса (заказчиков). Оговорюсь, что речь идет не о конечных продуктах ПО, а о пл... | https://habr.com/ru/post/240041/ | null | ru | null |
# Simics: кто не RISC-ует, тот не выигрывает
Добро пожаловать на очередной шабаш любителей испортить себе жизнь странным хобби! Репортаж с предыдущей вечеринки вы можете найти [по ссылке](https://habr.com/ru/company/auriga/blog/582350/). На ней мы практически «с нуля» создали модель начального уровня встраиваемого кон... | https://habr.com/ru/post/585180/ | null | ru | null |
# Приложение для чата в реальном времени с помощью Nestjs и PostgreSQL
[](https://habr.com/ru/company/ruvds/blog/672848/)
При помощи этого руководства вы научитесь добавлять функции чата в реальном времени в ваше веб-приложение Nestj... | https://habr.com/ru/post/672848/ | null | ru | null |
# Пишем спецификацию под Nvidia Kepler (бинарники CUDA, версия языка sm_30) для Ghidra
Для обычных процессорных языков уже написано довольно много спецификаций для Ghidra, однако для графических ничего нет. Оно и понятно, ведь там своя специфика: предикаты, константы, через которые передаются параметры в том числе, и ... | https://habr.com/ru/post/509156/ | null | ru | null |
# Создание минимального Docker-контейнера для Go-приложений
Привет, Хабр! Предлагаю вашему вниманию перевод статьи основателя сервиса Meetspaceapp Nick Gauthier [«Building Minimal Docker Containers for Go Applications»](https://blog.codeship.com/building-minimal-docker-containers-for-go-applications/).
*Время чтени... | https://habr.com/ru/post/460535/ | null | ru | null |
# Microsoft выпустила обновление для часовых поясов России
BUILTIN\Administrator, напоминаю, что 26 октября в России будет перевод часов. У тебя есть целый месяц на подготовку и тестирование, у Microsoft уже [почти все готово](http://support.microsoft.com/kb/2998527)
Также напоминаю, что это не просто перевод стрел... | https://habr.com/ru/post/238019/ | null | ru | null |
# Как жить без const?
Часто, передавая объект в какой-либо метод, нам бы хотелось сказать ему: «Вот, держи этот объект, но ты не имеешь право изменять его», и как-то отметить это при вызове. Плюсы очевидны: помимо того, что код становится надёжнее, он становится ещё и более читаемым. Нам не нужно заходить в реализацию... | https://habr.com/ru/post/199520/ | null | ru | null |
# Репликация MongoDB на Amazon EC2
#### system.indexes
* Предисловие
* Настройка Amazon EC2
* Установка MongoDB
* Настройка репликации
* Что почитать
#### local.abstract
В этой статье я расскажу о том, как максимально безболезненно организовать репликацию MongoDB на базе Amazon EC2. Несомненно, существует отличная ... | https://habr.com/ru/post/168691/ | null | ru | null |
# Composable Architecture — свежий взгляд на архитектуру приложения
Сбалансированная архитектура мобильного приложения продлевает жизнь проекту и разработчикам.
История
-------
Познакомьтесь с Алексом. Ему необходимо разработать приложение для составления списка покупок. Алекс опытный разработчик и первым делом фор... | https://habr.com/ru/post/526782/ | null | ru | null |
# Вышел jQuery 1.4.1
 Ура, товарищи! Встречаем новую версию jQuery и радуемся, что разработчики этой замечательной javascript библиотеки все так же интенсивно развивают и продвигают свое детище! Не успели мы освоиться с jQuery 1.4, как подкатил новый релиз.... | https://habr.com/ru/post/82008/ | null | ru | null |
# Использование библиотеки Volley в Android на примере получения данных из погодного API
Каждому Android-разработчику рано или поздно приходится работать с сетью. В Android есть множество библиотек с открытым исходным кодом, таких как Retrofit, OkHttp или, например, Volley, на которой мы сегодня остановимся подробнее.... | https://habr.com/ru/post/495976/ | null | ru | null |
# Шаблоны, или что общего у приходного кассового ордера и метода ToString()
Вот как-то так оно и выглядит...Задачу генерации текстовых строк... | https://habr.com/ru/post/560722/ | null | ru | null |
# Отзывчивые изображения: CSS-приёмы, которые помогают экономить время
Если вы занимаетесь веб-разработкой, то высока вероятность того, что вам знакомы два чудовища, о которых пойдёт речь в статье, перевод которой мы сегодня публикуем. Речь идёт об изображениях и о дедлайнах. Иногда, по каким-то причинам, картинки ник... | https://habr.com/ru/post/420619/ | null | ru | null |
# Unity3D — кроссфейд, основы работы со звуком (урок)

*картинка для привлечения внимания:
«Acorn» — игра, над которой мы работаем,
в ней используется скрипт из этого урока.*
**В уроке быстро и просто реализуем примерно т... | https://habr.com/ru/post/248371/ | null | ru | null |
# Побеждаем утечки памяти и ускоряем работу Firefox
Про утечки памяти в Огнелисе на Хабре уже было несколько постов, но ни в одном из них нет полного, с моей точки зрения, набора инструкций. Под катом я попыта... | https://habr.com/ru/post/136743/ | null | ru | null |
# Продвинутый Gulp и Browserify: интересные трюки
Пару недель назад я начал цикл о том, как делал некоммерческий музыкальный проект (первый пост есть в «я пиарюсь», не буду ставить ссылок), но, к сожалению, в первой же статье увлекся, и вместо того, чтобы рассказывать о том, как делал конкретно его, начал вспоминать э... | https://habr.com/ru/post/242379/ | null | ru | null |
# Получение данных с датчика углекислого газа Даджет в системы умного дома
Датчик углекислого газа Даджет KIT MT8057S давно зарекомендовал себя как достаточно надежный и недорогой прибор. Один недостаток, на мой взгляд — официально данные с него можно получать только фирменной программой под windows, и никак иначе.
... | https://habr.com/ru/post/509666/ | null | ru | null |
# XEN: Простой скрипт для быстрого открытия VNC-консолей
Постановка задачи
-----------------
#### Описание проблемы
В работе активно используется Xen с HVM виртуализацией. Часто бывает нужно получить доступ к консоли виртуальных машин, причем в том числе и тем, у кого доступа на севера с Xenом нет. У Xenа для этого ... | https://habr.com/ru/post/143694/ | null | ru | null |
# Оптимизация смарт-контрактов. Как разрядность типов Solidity влияет на цену транзакций
> *«Программисты тратят огромное количество времени беспокоясь о скорости работы своих программ, и попытки достичь эффективности зачастую оказывают резко негативное влияние на возможность их отладки и поддержки. Необходимо забыть ... | https://habr.com/ru/post/415791/ | null | ru | null |
# Смарт-контракт ловушка в сети Ethereum
Недавно, просматривая опубликованные смарт контракты в сети Эфириум, наткнулся на один интересный контракт с уязвимостью внутри. С первого взгляда, разработчик ошибся в коде и вы можете получить деньги контракта, но если внимательно проанализировать логику контракта, все выгляд... | https://habr.com/ru/post/349214/ | null | ru | null |
# Mikrotik – сбор и анализ NetFlow трафика
### Предисловие
Когда-то давно, в далекой далекой галактике… Хотя если подумать, это было всего то 15 лет назад.
В общем были времена, когда в качестве центрального шлюза в сеть Интернет использовались решения на базе FreeBSD и Linux. И были эти решения любовно настроены,... | https://habr.com/ru/post/354720/ | null | ru | null |
# Меняем стандартный диалог сбоя приложения в Android на собственный экран
### Как вместо стандартного диалогового окна о сбое использовать собственный экран с сообщением об ошибке
> Будущих учащихся на курсе ["Android Developer. Basic"](https://otus.pw/IqTK/) приглашаем посетить открытый вебинар на тему ["Приложение... | https://habr.com/ru/post/530606/ | null | ru | null |
# MotionLayout: анимации лучше, кода — меньше

*Google продолжает улучшать нашу жизнь, выпуская новые удобные библиотеки и API. Среди которых оказался и новый MotionLayout. Учитывая обилие анимаций в наших приложениях, мой коллега Ce... | https://habr.com/ru/post/458854/ | null | ru | null |
# Построение отказоустойчивой системы Embedded Linux на базе модуля Mars ZX3 фирмы Enclustra
В связи с загруженностью специалистов, несколько лет назад мы вынуждены были отдать одну разработку контрагентам. Разработка велась на модуле Mars ZX3 фирмы Enclustra, в котором используется SOC ARM+FPGA Zynq-7020. Для сборки ... | https://habr.com/ru/post/483900/ | null | ru | null |
# Унификация визуальных компонентов. Часть 1. Стили
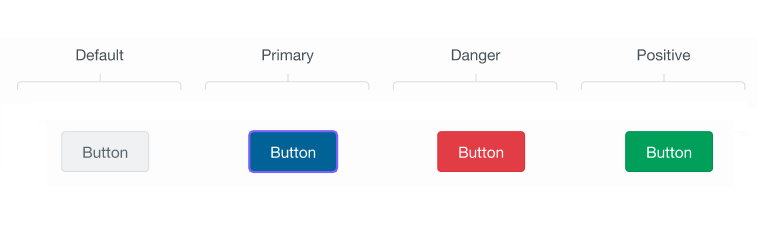
Данная статья будет, прежде всего, полезна разработчикам, которые не работают с готовыми наборами компонентов, такими как, material-ui, а реализуют свои. Например, для продукта раз... | https://habr.com/ru/post/479714/ | null | ru | null |
# Основы безопасности операционной системы Android. Native user space, ч.1
### Вступление
В этой статье я попробую рассмотреть безопасность чуть-чуть повыше ядра, а именно: как работает безопасность в Native user space. Мы коснемся темы процесса загрузки операционной системы и рассмотрим структуру файловой системы An... | https://habr.com/ru/post/176131/ | null | ru | null |
# Gource — визуализируем историю работы над проектом
Спешу рассказать хабрасообществу о, относительно новом, дьявольски завораживающем проекте [Gource](http://code.google.com/p/gource/ "Gource@googlecode") которое еще не упоминалось. Это приложение позволяет визуализировать историю изменений в системе контроля версии.... | https://habr.com/ru/post/75780/ | null | ru | null |
# Как хакнуть что угодно с помощью GNU Guix
Мариус Бакке (Marius Bakke) несколько лет занимается разработкой Guix и недавно начал вести свой блог. Мы решили перевести рассказ о том, почему Мариус увлёкся разработкой собственной операционной системы и как с её помощью можно вносить правки в код любых программ.
### Поч... | https://habr.com/ru/post/690612/ | null | ru | null |
# Git compare: быстрый способ сравнить две ветки
Сегодня я хочу поделиться с вами небольшим [bash-скриптом](https://github.com/andronov-alexey/git-cmp), который я успешно использую уже в течение нескольких лет.
Для начала опишу ситуацию, часто у меня возникающую и по сей день, которая и сподвигла на написание скрипта... | https://habr.com/ru/post/520486/ | null | ru | null |
# Простые алгебраические типы данных
*Это шестая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре:*
[0. Теория категорий для программистов: предисловие](http://habrahabr.ru/post/245797/)
[1. Категория: суть композиции](http://habrahabr.ru/post/246009/)
[2. Тип... | https://habr.com/ru/post/274103/ | null | ru | null |
# Rebase Flow. Способ приготовления и его поддержка в GitHub, GitLab, BitBucket
Немного истории
===============
В самом начале 2010 года [Vincent Driessen](http://nvie.com/about/) пишет отличную статью [A successful Git branching model](http://nvie.com/posts/a-successful-git-branching-model/). Для понимания того, о ч... | https://habr.com/ru/post/283326/ | null | ru | null |
# Делаем UI плагина в IntelliJ Idea «как у maven'a»
Предыстория
===========
Встала задача создать для разработчиков и QA удобный способ стартовать порядка 20 серверных приложений, живущих в общем репозитрии (Spring с XML конфигурацией и общим для все частей приложения бутстрап классом).
Как сделать нечто удобное че... | https://habr.com/ru/post/281851/ | null | ru | null |
# Детекция изменений в сцене и сохранение видеофрагментов в формате h264 на Raspberry Pi без декодирования
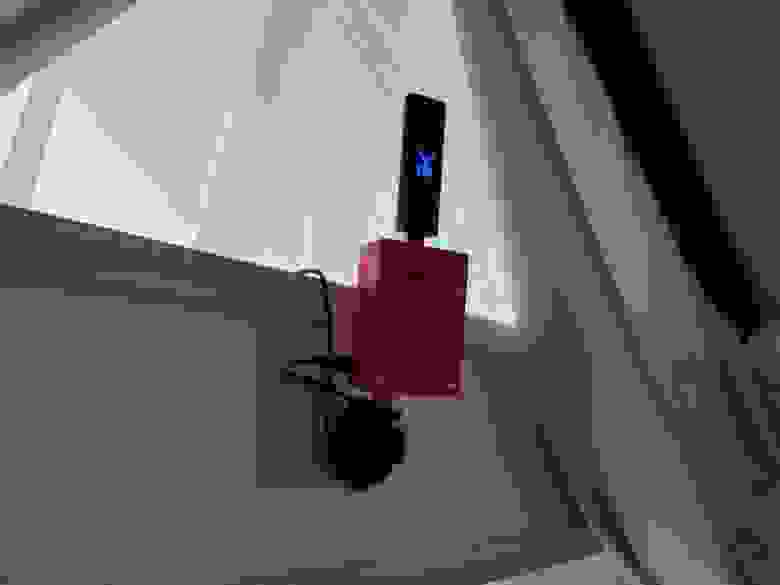
Добрый день. В этой статье я расскажу, далеко не в [первый](https://habr.com/ru/post/424191/) раз, как на Raspberry Pi 3 и бо... | https://habr.com/ru/post/500462/ | null | ru | null |
# Ktor как HTTP клиент для Android
Retrofit2 мне, как Android разработчику, нравится, но как на счет того, чтобы попробовать к качестве HTTP клиента Ktor? На мой взгляд, для Android разработки он не хуже и не лучше, просто один из вариантов, хотя если всё немного обернуть, то может получиться очень неплохо. Я рассмотр... | https://habr.com/ru/post/432310/ | null | ru | null |
# Использование в языке D сторонних библиотек
На волне интереса к языку D решил и я внести свой вклад в его популяризацию. Статья не для новичков, а больше для тех кто рассматривает D как второй язык. Известно, что на заре своего развития, языки программирования имеют небогатый набор библиотек и это часто не позволяет... | https://habr.com/ru/post/226301/ | null | ru | null |
# Уроки по SDL 2: Урок 8 — прозрачный фон
Дисклеймер: почему собрался это делать - потому что нет нигде нормального обучения, для С\С++, поэтому все бросают это дело, так как невозможно разобраться, просто ужас.
**Смысл прозрачного фона для изображения кратко:**
 в Joomla 4
Этот текст - [перевод](https://manual.joomla.org/docs/general-concept/dependencies/) статьи из [нового портала документации для разработчиков Joomla](https://manual.joomla.org/), раздел "Основные концепции".
Введение
--------
Joomla 4 внедряет практику кон... | https://habr.com/ru/post/692342/ | null | ru | null |
# Payment Village at PHDays 11: ATM hacking
The [Positive Hack Days 11 forum](https://www.phdays.com/en/press/news/phdays-11-wrap-up-interest-in-information-security-explodes-rutube-attack-investigated-pipeline-shutd... | https://habr.com/ru/post/688372/ | null | en | null |
# Runtyper — инструмент для проверки типов при выполнении JavaScript кода
[Runtyper](https://github.com/vitalets/babel-plugin-runtyper) — это плагин для [Babel](https://babeljs.io), выполняющий проверку типов прямо во время выполнения JavaScript кода. Он обнаруживает некорректные операции, например строгое сравнение с... | https://habr.com/ru/post/325072/ | null | ru | null |
# Беспроводная настройка ESP8266 в прошивке DeviceHive v 0.3

Good news, everyone! Вышла [новая версия](https://github.com/devicehive/esp8266-firmware/releases) прошивки DeviceHive для ESP8266. Мы реализовали поддержку самых... | https://habr.com/ru/post/383881/ | null | ru | null |
# Создание анимированных tooltips'ов с помощью CSS3
Статьи про создание tooltips'ов уже не раз поднимались на хабре [[1](http://habrahabr.ru/blogs/css/136061/),[2](http://habrahabr.ru/blogs/css/132283/)] в виду большой популярности этого элемента. Сегодня вы узнаете еще один способ как создать простые, анимированные п... | https://habr.com/ru/post/137412/ | null | ru | null |
# R и большие данные: использование Replyr
`replyr` — сокращение от **RE**mote **PLY**ing of big data for **R** (удаленная обработка больших данных в R).
Почему стоит попробовать `[replyr](https://cran.r-project.org/web/packages/replyr/index.html)`? Потому что он позволяет применять стандартные рабочие подходы к у... | https://habr.com/ru/post/334398/ | null | ru | null |
# Реализация Вавилонской библиотеки
В этой статье Вы узнаете всё о Вавилонской библиотеке, а самое главное — как воссоздать её, да и вообще любую библиотеку.
Начнём с цитат произведения «[Вавилонская библиотека](http://www.library.ru/lib/book.php?b_uid=42)» [Луиса Борхеса](https://ru.wikipedia.org/wiki/%D0%91%D0%BE... | https://habr.com/ru/post/433336/ | null | ru | null |
# IL2CPP: вызовы методов
Это четвертая статья из серии по IL2CPP. В ней мы поговорим о том, как il2cpp.exe генерирует код C++ для вызовов методов в управляемом коде.
В частности, мы рассмотрим шесть типов вызовов:
* ... | https://habr.com/ru/post/310614/ | null | ru | null |
# Чиним яркость у ноутбука
Данный пост будет интересен в первую очередь владельцам ноутбуков (под управлением ubuntu), у кого не работаю fn клавиши управлением яркость.
**/etc/acpi/video\_brightnessup.sh**
`#!/bin/bash
CURRENT=$(grep "current:" /proc/acpi/video/VGA/LCD/brightness |awk '{print $2}')
case "$... | https://habr.com/ru/post/19596/ | null | ru | null |
# Создание custom layout в SwiftUI. Кэширование
В предыдущем посте мы рассказали об основах нового протокола *Layout*. Сегодня я собираюсь продолжить серию постов, посвященной созданию многократно используемых custom layouts, рассказав про кэширование информации layout и настройку производительности.
SwiftUI вызывает... | https://habr.com/ru/post/703850/ | null | ru | null |
# Как сделать вашу ИТ-инфраструктуру скучной
Майкл ДеХаан – человек, который создал Ansible. Многие вещи, которые делают системные администраторы, релиз- и DevOps-инженеры на регулярной основе, мягко говоря, неинтересны. ДеХаан хочет, чтобы эти люди освободили свое время для более интересных вещей (на работе или за дв... | https://habr.com/ru/post/412725/ | null | ru | null |
# Анонс иерархических пространств имен для Kubernetes
***Прим. перев.**: недавно в блоге Kubernetes был представлен проект «иерархических пространств имён». Формально он существует с конца прошлого года, но именно теперь авторы сочли уместным анонсировать свой Hierarchical Namespace Controller (HNC) для массовой аудит... | https://habr.com/ru/post/517478/ | null | ru | null |
# Поиск и решение проблем масштабируемости на примере многоядерных процессоров Intel Core 2 (часть 4)
Продолжение статьи: [часть 1](http://habrahabr.ru/blogs/hi/107620/), [часть 2](http://habrahabr.ru/blogs/hi/107621/), [часть 3](http://habrahabr.ru/blogs/hi/107622/)
Вероятно, наиболее простым примером, может послу... | https://habr.com/ru/post/107624/ | null | ru | null |
# Tesseract. Распознаем ошибки в системе распознавания

Tesseract — свободная компьютерная программа для распознавания текстов, разрабатываемая компанией Google. В описании проекта говорится: «Tesseract is ... | https://habr.com/ru/post/223743/ | null | ru | null |
# Миграция без жертв: технический чеклист для переезда сайта на новый домен
Переезд или миграция сайта — событие, которое сулит существенные выгоды в долгосрочной перспективе и не менее существенные хлопоты — в краткосрочной. Увы, избежать последних абсолютно невозможно, но при этом вполне реально заблаговременно прод... | https://habr.com/ru/post/427925/ | null | ru | null |
# Адреса памяти: физические, виртуальные, логические, линейные, эффективные, гостевые
Мне периодически приходится объяснять разным людям некоторые аспекты архитектуры Intel® IA-32, в том числе замысловатость системы адресации данных в памяти, которая, похоже, реализовала почти все когда-то придуманные идеи. Я решил оф... | https://habr.com/ru/post/238091/ | null | ru | null |
# Старичок Compaq Armada 7730MT
Уже достаточно давно у меня лежит без дела старенький ноутбук Compaq Armada 7730MT. Когда-то давно на нем стояла Windows 98 и можна было играть в старкрафт, но в какой-то момент хард приказал долго жить и он был заброшен в шкаф. Теперь, в связи с запланированным переездом начали выбрасы... | https://habr.com/ru/post/143456/ | null | ru | null |
# Playing with null: Checking MonoGame with the PVS-Studio analyzer
The PVS-Studio analyzer often checks code of libraries, frameworks, and engines for game development. Today we check another project — MonoGame, a low-level gamedev framework written in C#.
 Поставить Oracle ... | https://habr.com/ru/post/341138/ | null | ru | null |
# Шпаргалка по переходу на UTF-8
Узелок по UTF-8: есть сайт в кодировке X, нужно перевести в UTF-8
Излогаю краткий список того, что нада переводить в UTF-8, чтоб сайт работал корректно.
1. База MySQL в часности
2. Инсталляция mbstring
3. Конфигурация mbstring
4. Дело с небезопасными мультибайтовыми функциями в P... | https://habr.com/ru/post/13969/ | null | ru | null |
# Играем с потоками в Node.JS 10.5.0
### Доброго времени суток
[](https://habr.com/post/416015/)
У меня на работе возник спор между мной и дотнетчиками насчет потоков в новой версии Node.JS и необходимости их синхронизоровать. Для... | https://habr.com/ru/post/416015/ | null | ru | null |
# Основы Cat Concurrency с Ref и Deferred
Параллельный доступ и ссылочная прозрачность
--------------------------------------------
> *Для будущих учащихся на курсе* [*«Scala-разработчик*](https://otus.pw/aJ1X/)*» приготовили перевод материала.
>
> Приглашаем также на вебинар по теме* [*«Эффекты в Scala»*](https... | https://habr.com/ru/post/546358/ | null | ru | null |
# Представление настроек программы в 1С. Один из способов
Здравствуйте.
В данной статье я хочу рассказать о своем опыте работы с настройками в 1С – их представлении и сохранении. Этот способ особенно актуален для внешни... | https://habr.com/ru/post/272455/ | null | ru | null |
# Разработка автоматизированных тестов на базе Selenium WebDriver 2.x
Здравствуйте, уважаемое Хабросообщество! Хочу поделиться своим способом разработки и организации написания автоматизированных тестов на базе Selenium WebDriver 2.x на языке программирования C#.
Сразу скажу, что многие тезисы, принципы и методы ра... | https://habr.com/ru/post/193174/ | null | ru | null |
# Советы для профессионального использования RecyclerView. Часть 2

Продолжая [предыдущую статью](https://habr.com/post/425945/), в этой я расс... | https://habr.com/ru/post/426773/ | null | ru | null |
# OpenCV. Поиск дорожных знаков методом контурного анализа в Android
Привет Хабр!
Хочу поделиться собственной реализацией алгоритма поиска дорожных знаков.
Почему контурный анализ?
Контурный анализ имеет довольно слабую устойчивость... | https://habr.com/ru/post/339506/ | null | ru | null |
# Функциональное программирование в Python. Генераторы, как питонячий декларативный стиль
* Общее введение
* ФП
+ Введение в ФП
+ Основные принципы ФП
+ Основные термины
+ Встроенное ФП поведение в Python
+ Библиотека Xoltar Toolkit
+ Библиотека returns
+ Литература
* Генераторы
+ Введение в итераторы
+... | https://habr.com/ru/post/517438/ | null | ru | null |
# Расширенная наcтройка EF Core
Что нужно, чтобы начать пользоваться EF Core в .NET? Создать новый проект, добавить пакет с самим EF, добавить пакет с нужным провайдером, унаследовать `DbContext`, настроить его, указав строку подключения и провайдер, подготовить и подключить модель, создать миграции - не так уж много.... | https://habr.com/ru/post/656769/ | null | ru | null |
# Простой, но полезный плагин для Redmine
Продолжаем улучшать быт системного администратора [своими](http://centos-admin.ru/) силами.
Часто бывает, что список активных задач в Redmine достаточно огромен. Однако, среди них есть много тех, которые невозможно выполнить в данный момент: либо ждем ответа клиента, либо в... | https://habr.com/ru/post/272623/ | null | ru | null |
# Wireshark 3.x: анализ кода под macOS и обзор ошибок

Wireshark Foundation выпустила финальную stable-версию популярного сетевого анализатора трафика — Wireshark 3.0.0. В новом релизе устранено н... | https://habr.com/ru/post/447158/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.