
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# «Привет, Хабр» на частоте 835 кГц
Как-то раз в голове возникла мысль, а что бы сделать такое, чтобы скрестить старый радиоприемник в деревянном корпусе и современный контроллер для интернета-вещей ESP32? То ли с головой не так что-то,... | https://habr.com/ru/post/349330/ | null | ru | null |
# Авторизация пользователей в Django через GSSAPI и делегация прав пользователя серверу
Недавно нам с коллегами понадобилось реализовать прозрачную (SSO) авторизацию в нашем проекте. Сейчас довольно мало информации по теме особенно на русском языке. По этой причине решено было поделиться с потомками реализацией подобн... | https://habr.com/ru/post/427839/ | null | ru | null |
# Плагин jquery.keyfilter.js
Очень нравится мне возможность ограничивать набор вводимых символов в полях ввода с помощью регулярного выражения.
Эта функциональность существует в Ext.JS, но этот каркас несколько тяжеловесен для большинства сайтов. Поэтому я нарисовал плагин для jQuery, выполняющий тот же функционал.... | https://habr.com/ru/post/52245/ | null | ru | null |
# С Hyper-V на VMware и обратно: конвертация виртуальных дисков

Привет, Хабр!
Периодически я слышу от практикующих инженеров странное: VMDK, VHD и VHDX – абсолютно разные форматы виртуальных дисков, чуть ли не закрытые, а конве... | https://habr.com/ru/post/479894/ | null | ru | null |
# Библиотека, облегчающая разработку форм на сайтах
Привет, Хабр!
Хочу поделиться с общественностью своей небольшой (всего 6 Кбайт) [js-библиотекой](https://github.com/paulzi/paulzi-form), которая сильно облегчает мне работу с формами при разработке сайтов, и позволяет сократить написание кода.
В любом, более-ме... | https://habr.com/ru/post/261347/ | null | ru | null |
# Random User-Agent — версия вторая
Прошло два года с того момента, как вышла первая версия этого расширения для Chromium-based браузеров (работает в Google Chrome, Yandex.Browser и т.д[.](https://blog.kplus.pro/)), задача которого проста и понятна — скрывать настоящий User-Agent. На данный момент это расширение работ... | https://habr.com/ru/post/307574/ | null | ru | null |
# Python: надежная защита от потери запятой в вертикальном списке строк
 Списки строк в программах встречаются часто. Для удобства чтения их не менее часто форматируют вертикально, по одной строке. И есть в такой конструкции... | https://habr.com/ru/post/134080/ | null | ru | null |
# Самый простой (для знающих Linux) и дешевый способ разместить IP-камеру на сайте для небольшой аудитории
В чем главная проблема современных недорогих IP-камер? Вы не можете просто так добавить их на свой сайт! Они выдают видео совсем не в том формате, который понимают браузеры. Да, конечно, можно зайти напрямую на к... | https://habr.com/ru/post/545888/ | null | ru | null |
# Disposable pattern (Disposable Design Principle) pt.3
[](https://github.com/sidristij/dotnetbook)
Multithreading
--------------
Now let’s talk about thin ice. In the previous sections about IDisposable we touched one very important... | https://habr.com/ru/post/443962/ | null | en | null |
# Наследуем тип .NET от JavaScript объекта с перегрузками и приватными методами
Да, именно так и никаких уловок. Эта идея мою голову посетила около двух месяцев назад в процессе обдумывания статьи об [Алгоритмах и решениях](http://habrahabr.ru/post/243399/). Типы .NET в том движке использовать легко, а можно ли наобор... | https://habr.com/ru/post/247185/ | null | ru | null |
# Подключаем онлайн-карты к навигатору на смартфоне. Часть 1 — стандартные растровые карты
Что из себя представляют онлайн-карты? Как узнать адрес сервера заинтересовавшей вас карты? Как создать файл с настройками, который позволит навигатору на смартфоне подключиться к этой карте?
### Содержание:
1 – Вступление. Ст... | https://habr.com/ru/post/461031/ | null | ru | null |
# Похищаем сохраненный в Chrome пароль с помощью XSS
Меня зовут Артем Мышенков, я ведущий инженер по технической защите информации в команде безопасности [REG.RU](http://REG.RU). Наша команда занимается тестированием систем компании на безопасность и поиском уязвимостей.
В этой статье я расскажу о том, как с помощью... | https://habr.com/ru/post/680256/ | null | ru | null |
# Ограничение доступа к веб-приложениям в Synology DSM
Системы хранения Synology — достаточно распространенная нынче штука. Они удобные, тихие, компактные, с кучей возможностей. Однако собственное облако — это хорошо, но надо серьезно задуматься о безопасности. Далее мы рассмотрим, как гибко ограничить доступ к пользо... | https://habr.com/ru/post/266991/ | null | ru | null |
# Различия Postgres Pro Enterprise и PostgreSQL
1. Кластер multimaster
----------------------
Расширение `multimaster` и его поддержка в ядре, которые есть только в версии **Postgres Pro Enterprise**, дают возможность строить кластеры серверов высокой доступности (High Availability). После каждой транзакции гарантиру... | https://habr.com/ru/post/337180/ | null | ru | null |
# Исследование протокола системы контроля давления воздуха в шинах автомобиля (TPMS)
Система дистанционного контроля давления воздуха в шинах автомобиля (англ. аббревиатура **TPMS** — Tyre Pressure Monitoring System) предназначена для оперативного информирования пользователя о снижении давления в шинах и о критической... | https://habr.com/ru/post/516460/ | null | ru | null |
# Возможности современного JavaScript, о которых вы могли не знать

Несмотря на то, что в последние семь лет я пишу на JavaScript почти каждый рабочий день, должен признаться, что уделяю мало внимания сообщениям о нововведениях от ... | https://habr.com/ru/post/473816/ | null | ru | null |
# Я запрограммировал кошачью кормушку, чтобы она выдавала мне конфеты за код
Я смеюсь над этой историей все выходные, так что не могу не поделиться. Засидевшись до поздней ночи на Amazon, я купил автокормушку для животных PetKit FreshElement Solo. У меня имелось две проблемы, с решением которых она могла мне помочь: в... | https://habr.com/ru/post/693266/ | null | ru | null |
# Impact анализ на примере инфраструктуры корпоративного хранилища данных
В этой статье я хочу рассказать, как можно решать задачу impact анализа или анализа влияния в сложной, многоуровневой инфраструктуре корпоративного хранилища данных на примере нашего **DWH** в **Тинькофф Банке**.

Так уж вс... | https://habr.com/ru/post/415629/ | null | ru | null |
# Об ужасной документации Apple

В последние год-два я пришёл к осознанию того, что основной преградой к выполнению моей работы является документация. Или, если конкретнее, откровенный дефицит документации, предоставляемой Apple дл... | https://habr.com/ru/post/527770/ | null | ru | null |
# Различные методы загрузки ассоциаций в Ruby on Rails
Rails предоставляют нам 4 различных способа загрузки ассоциаций: preload, eager\_load, includes и joins. Рассмотрим каждый из них:
#### Preload
Этот метод загружает ассоциации в отдельном запросе:
```
User.preload(:posts).to_a
# =>
SELECT "users".* FROM "u... | https://habr.com/ru/post/191762/ | null | ru | null |
# Несколько Gradle фишек для вашего Android приложения

В одну из последних рассылок Android Weekly попала [статья](https://medium.com/@rey5137/how-i-organize-android-project-structure-5ed9b849dc30), в которой упомянули инте... | https://habr.com/ru/post/311100/ | null | ru | null |
# Prometheus
Доброго всем. Делимся тут очень интересной статьёй, на которую натыкались в рамках подготовки нашего [курса](https://otus.pw/jxWy/). Перевод идёт, как есть целиком (за исключением некоторых комментариев).
**Предыстория**
В двух словах — вступление о мониторинге и аппеляционности убеждений. Как мног... | https://habr.com/ru/post/341862/ | null | ru | null |
# 10 игровых механик в HTML Academy
В тот момент, когда начиналась разработка [HTML Academy](http://htmlacademy.ru), мы достаточно серьёзно играли в WOW, да и, вообще, были поклонниками игр Blizzard со стажем. Поэтому с игровыми механиками были знакомы достаточно хорошо, хотя сами этого не подозревали. Многие интересн... | https://habr.com/ru/post/219637/ | null | ru | null |
# Подробнее об анализаторе исходного кода PHP Depend
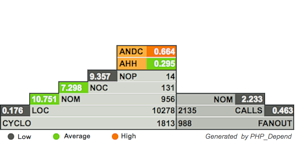 В одном из обзоров на Хабре уже упоминался анализатор кода PHP Depend (<http://pdepend.org/>). В данном материале хотелось бы рассмотреть небольшой пр... | https://habr.com/ru/post/80110/ | null | ru | null |
# Перемещение — прошлый век! Альтернативы std::move в «C++ будущего»
Каждый раз, когда мы пишем класс, управляющий ресурсами, мы задумываемся о том, что, скорее всего, для него придётся писать move-конструктор и move-присваивание. Ведь иначе объекты такого типа становятся неуклюжими, как `std::mutex`, ими тяжело польз... | https://habr.com/ru/post/484380/ | null | ru | null |
# Как я technicalseo.expert проходил (уровень 2)
Введение
--------
Продолжение исследования головоломки [technicalseo.expert](https://technicalseo.expert/) которая будет сломана самым нетривиальным образом.
Предыдущий уровень и чуть подробнее о самой головоломке в первом посте: [ссылка](https://habr.com/ru/post/5978... | https://habr.com/ru/post/597879/ | null | ru | null |
# Интерфейс Javascript < == > PHP
Удивишись, что [мой хабраюмор](http://habrahabr.ru/blog/exhaust/45782.html) хабралюди понимают с трудом, перешел к написанию ещё одного интересного хабратопика. :)
Хочу предложить один удобный метод для взаимодействия Javascript с PHP.
Можно в PHP добавить класс, с возможность '... | https://habr.com/ru/post/28464/ | null | ru | null |
# А какой подход у вас к обработке awr|statspack-данных?
Здравствуйте.
#### Пролог.
Есть пара вопросов, которые уже много лет любопытно уточнить у причастной общественности.
Но. В моём болотистом-низменном крае — и людей в теме: мало и обстановка в ит-направлении, на большинстве предприятий, не способствует. Вот,... | https://habr.com/ru/post/519924/ | null | ru | null |
# Реализация Web API OData в ASP.NET Core 3 и ASP.NET 5 (часть 2). Методы контроллера
[В первой части статьи](https://habr.com/ru/company/alfastrah/blog/568414/) я рассказал о том, как в «АльфаСтрахование» была реализована OData API на .NET Core с использованием EF Core. В этой статье я коснусь реализации методов конт... | https://habr.com/ru/post/569014/ | null | ru | null |
# Разрушаем мифы о производительности Android
### Узнайте, какие мифы о производительности Android выдержали испытание бенчмарком
> **В преддверии старта курса** [**"Android Developer. Basic"**](https://otus.pw/2gJq/) **приглашаем всех желающих посмотреть открытый урок по теме** [**"Unit-тестирование в Android".**](h... | https://habr.com/ru/post/533802/ | null | ru | null |
# Как надо и как не стоит проводить инвентаризацию
На мой взгляд, нет ничего сложнее, чем использование современных технологий в реальной жизни. Любая программа, любой алгоритм в «чистом» виде – вещь в идеальном случае довольно простая. Чуть сложнее оказывается (если оно в принципе возможно) прямое сопряжение таких ал... | https://habr.com/ru/post/102286/ | null | ru | null |
# Разбор решенных задач с чемпионата по программированию от Яндекса (фронт-энд разработка) 2019
Завершилось мое участие в чемпионате по программированию. Я неплохо прошел квалификацию, решив 4 из 6 задач и шел на 20 месте, поэтому были надежды и в финале попасть топ 20.
Но к сожалению не удалось попасть даже в топ-... | https://habr.com/ru/post/474404/ | null | ru | null |
# Арбитражная торговля (Алгоритм Беллмана — Форда)

Торговля на бирже обычно ассоциируется с рисками. Это совершенно верно для большинства торговых стратегий. Успешность торговли в этих случаях определяется исключительно способностью... | https://habr.com/ru/post/487742/ | null | ru | null |
# Непростая линковка Swift и C
Все началось с того, что нашей команде прилетел жирный намек на покачаться в сторону системной разработки под яблочную платформу из за наклевывающихся контрактов. А мы все на виндофс пишем и вижуал студию одобряем который год - так что разнообразие не повредит.
Ну а чтобы покачаться в р... | https://habr.com/ru/post/651885/ | null | ru | null |
# Разбираемся, что же там нового открыли в задаче о ферзях
Пару месяцев назад появилась [занятная статья](http://www.jair.org/papers/paper5512.html) с анализом классической задачи о расстановке ферзей на шахматной доске (см. детали и историю ниже). Задача невероятно известная и вся уже рассмотрена под микроскопом, поэ... | https://habr.com/ru/post/343738/ | null | ru | null |
# Элементы языка С, которые являются неподдерживаемыми в языке С++
Нижеприведенный список является моей небольшой коллекцией примеров кода на языке С, которые не являются корректными с точки зрения языка С++ или имеют какое-то специфичное именно для языка С поведение. (Именно в эту сторону: С код, являющийся некоррект... | https://habr.com/ru/post/680312/ | null | ru | null |
# Технический подход к пониманию интерфейсов мозг — компьютер
Изображение оценки исто... | https://habr.com/ru/post/570586/ | null | ru | null |
# Настраиваем automount в Linux
##### Автор статьи: Рустем Галиев
IBM Senior DevOps engineer & ... | https://habr.com/ru/post/706706/ | null | ru | null |
# Реверс-инжиниринг GPU Apple M1

Новая линейка компьютеров Apple Mac содержит в себе разработанную самой компанией SOC (систему на чипе) под названием M1, имеющую специализированный GPU. Это создаёт проблему для тех, кто учас... | https://habr.com/ru/post/537634/ | null | ru | null |
# Использование gitlab continuous integration для деплоя
Совсем недавно гитлаб героически выкатил версию 8.0 своего конкурента гитхабу. Из интересного — движок continuous integration теперь встроен в платформу, а значит доступе... | https://habr.com/ru/post/269473/ | null | ru | null |
# Analysis of merge requests in GitLab using PVS-Studio for C#

Do you like GitLab and don't like bugs? Do you want to improve the quality of your source code? Then you've come to the right place.... | https://habr.com/ru/post/512294/ | null | en | null |
# Логическое программирование на Prolog для чайников
Prolog - самый популярный язык ло... | https://habr.com/ru/post/552318/ | null | ru | null |
# Quantum Leaps QP и UML statecharts
#### Предисловие
Данная статья, как мне кажется, будет интересна тем, кто знаком с UML диаграммами состояний и последовательности (statecharts diagram и sequence diagram), а также с [событийно-ориентированным программированием](http://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B1%D1%8B... | https://habr.com/ru/post/114239/ | null | ru | null |
# Обучение с подкреплением: практические рекомендации по обучению сетей Deep Q
В [предыдущем материале](https://habr.com/ru/company/wunderfund/blog/671650/) из этой серии мы рассказали о сетях Deep Q (Deep Q Network, DQN) и написали алгоритм их обучения на псевдокоде. Хотя такие сети, в принципе, работоспособны, практ... | https://habr.com/ru/post/672988/ | null | ru | null |
# Шахматы на C++
Введение
--------
Не так давно я захотел написать свой шахматный движок. На удивление в Интернете нашлось не так много хороших статей на эту тему. Были статьи с довольно слабыми программами, многие из которых даже умудрялись пропускать некоторые важные правила. А были статьи с хорошими программами (н... | https://habr.com/ru/post/682122/ | null | ru | null |
# Быстрый поиск совпадений объектов по их контрольным суммам на примере поиска дублирующихся изображений
Исходные данные:
* набор объектов обладающих аттрибутами
* возможность приблизительно точно идентифицировать объект сопоставив ему контрольную сумму.
Конечная цель:
* получить списки объектов по которым легк... | https://habr.com/ru/post/103638/ | null | ru | null |
# Вывод систем хранения данных NetApp из кластера
Добавление в кластер системы хранения NetApp FAS происходит очень просто:
Подключаются порты кластерного интерконнекта в свич и выполняется команда:
```
cluster setup
```
.
Недавно мы выложили первую версию в сторы и тут же получили отзыв от одного из активных пользователей:
 и Замыкание (Closures) в EcmaScript
Привет, Хабр!
Давно ничего не писал, большая загруженность на проекте крайние несколько недель, но сейчас появилось свободное время, поэтому решил представить вашему вниманию новую статью.
Сегодня мы продолжим разбирать ключевые кон... | https://habr.com/ru/post/474852/ | null | ru | null |
# Подружили Go и Zabbix 5.0

Всем привет! Эта новость будет интересна тем, у кого есть микросервисы или утилиты на Go, которым нужно взаимодействовать с API Zabbix.
Возможно, вы уже знаете, что совсем недавно [ребята из Zabbix заре... | https://habr.com/ru/post/503104/ | null | ru | null |
# Заказные блоки в микросхемах (Silicon IP): как это работает
В каждой статье на Хабре, посвященной отечественным микропроцессорам, так или иначе поднимается вопрос лицензионных IP-блоков и того, насколько их наличие и отсутствие уменьшает ценность, отечественность или безопасность разработки. При этом очень многие ко... | https://habr.com/ru/post/414215/ | null | ru | null |
# Организация многопользовательского доступа на сервер GIT
При установке и конфигурировании Git-сервера встаёт вопрос об организации доступа нескольких пользователей к нескольким проектам. Я провёл исследование вопроса и нашёл решение, удовлетворяющее всем моим требованиям: простое, безопасное, надёжное.
Мои пожела... | https://habr.com/ru/post/457056/ | null | ru | null |
# Самозащита антивирусов или режем антивирус без ножа
**Привет всем!**
Недавно мы уже обсудили могущество эвристических технологий современных антивирусов и пришли к мнению, что верить никому нельзя. Даже иногда себе :)
Сегодня мы поговорим о другом спорном моменте антивирусов — самозащите. Некоторые вендоры оче... | https://habr.com/ru/post/98322/ | null | ru | null |
# Разработка конвертера видео из 264 в avi для видеорегистратора QCM-08DL
На самом деле, статья посвящена разработке программы для перепаковки видео DVR из одного контейнера в другой, если это можно назвать конвертацией. Хотя, я всю жизнь считал, что конвертер занимается преобразованием (перекодировкой) формата видео.... | https://habr.com/ru/post/422163/ | null | ru | null |
# Работаем с КОМПАС 3D из DELPHI
Приветствую тебя, %username%.
Куда нас только не закидывает судьбинушка. С какими только порождениями ума человеческого не приходится сталкиваться. Вот и мне пришлос... | https://habr.com/ru/post/91390/ | null | ru | null |
# Представляем программируемую AWS Landing Zone в модуле Terraform
*Всем привет! В декабре OTUS запускает новый курс — [Cloud Solution Architecture](https://otus.pw/YgPj/). В преддверии старта данного курса делимся с вами переводом интересного материала по теме.*
. Зачем? В качестве интересного рисёрча и тренировки. В конце туториала мы получим примерно такую штуку прямо на э... | https://habr.com/ru/post/164341/ | null | ru | null |
# Сайт на Wordpress VS PageSpeed Insights

В это статье мы расскажем как оптимизировали конкретное Wordpress веб приложение. Какие действия были выполнены чтобы попасть из красной зоны оценки PageSpeed Insights в зеленую, тут ... | https://habr.com/ru/post/548118/ | null | ru | null |
# Сравнительное тестирование криптоконтейнеров и шифрованных файловых систем
Неделю назад нарисовалась нетривиальная задача по определению возможностей использования шифрованных контейнеров или файловых систем на вынесенном untrusted хостинге.
Основные задачи:
— Возможность бекапирования данных в любом виде для... | https://habr.com/ru/post/57884/ | null | ru | null |
# Управление ценовыми скидками: модели для количественного измерения эффекта на примере АЗС

Мы продолжаем публиковать доклады, прозвучавшие на [RAIF 2019](https://raif.jet.su/) (Russian Artificial Intelligence Forum). На этот раз ... | https://habr.com/ru/post/490992/ | null | ru | null |
# Управление стейтом с помощью React Hooks – без Redux и Context API
Всем привет! Меня зовут Артур, я работаю ВКонтакте в команде мобильного веба, занимаюсь проектом [VKUI](https://github.com/VKCOM/VKUI) — библиотекой React-компонентов, с помощью которой написаны некоторые наши интерфейсы в мобильных приложениях. Вопр... | https://habr.com/ru/post/454348/ | null | ru | null |
# Улучшаем картинки в чате Skype (обновлено)
#### Предисловие
17 января мне, как и многим другим, прислали ссылку на статью [zhovner](http://habrahabr.ru/users/zhovner/) про картинки в чате скайпа — <http://habrahabr.ru/blogs/skype/136395/>, и понеслось!
Идея прикольная, мы тут же начали перекидываться картинками,... | https://habr.com/ru/post/137707/ | null | ru | null |
# Базовая установка и настройка Puppet 4 с хранением манифестов в SVN
Доброго времени суток!
Сегодня будем готовить Puppet 4 на Ubuntu Server 16.04 c хранением манифестов в SVN. Так же статье будет рассмотрен пример создания простого собственного модуля для установки и конфигурирования агента сбора логов в [Graylo... | https://habr.com/ru/post/342020/ | null | ru | null |
# SIMD Extension to C++ OpenMP in Visual Studio
In the era of ubiquitous AI applications there is an emerging demand of the compiler accelerating computation-intensive machine-learning code for existing hardware. Such code usually does mathematical computation like matrix transformation and manipulation and it is usua... | https://habr.com/ru/post/446688/ | null | en | null |
# Готовим полнотекстовый поиск в Postgres. Часть 2
В [прошлой статье](https://habr.com/ru/post/442170/) мы оптимизировали поиск в PostgreSQL стандартными средствами. В этой статье мы продолжим оптимизацию с помощью [индекса RUM](https://github.com/postgrespro/rum) и проанализируем его плюсы и минусы в сравнении с GIN.... | https://habr.com/ru/post/443368/ | null | ru | null |
# accounting.js — форматирование чисел и валют
В одном из проектов мне понадобилось реализовать переключение валют с последующим реформатированием значений денежных сумм, встречающихся на странице.Как это у меня часто получается, я это реализовал и через пару недель наткнулся на небольшую библиотечку, которая позволяе... | https://habr.com/ru/post/131340/ | null | ru | null |
# Настраиваем любой Linux под себя одной командой
Иногда приходится настраивать различные \*unix системы: персональные компьютеры, VPS, Raspberry Pi и так далее. Но когда их становится много, настраивать их становится всё сложнее и сложнее. Поэтому хочется автоматизировать этот процесс. В данной статье я расскажу, как... | https://habr.com/ru/post/590797/ | null | ru | null |
# Вопросы к собеседованию Java-backend, Java core (60 вопросов)

Добрый день! Представляю вашему вниманию список вопросов к собеседованию Java Backend, которые я оформлял на протяжении около 2х лет.
Вопросы разбиты по тема... | https://habr.com/ru/post/485678/ | null | ru | null |
# Установка расширений в Хром без интернета
Ситуация: Есть некий заказчик, у которого в закрытой сети работают сотрудники. Внутри, помимо прочего, есть веб-сайты с приложениями, для доступа к которым используется обычный Google Chrome. Внезапно уже им поставили задачу - перейти на ГОСТ. Везде. Пришлось им ставить Крип... | https://habr.com/ru/post/594321/ | null | ru | null |
# Фаззинг сокетов: Apache HTTP Server. Часть 1: мутации
> *Прим. Wunder Fund:* наш СТО [Эмиль](https://youtu.be/662q9FVqp50) по совместительству является известным white-hat хакером и специалистом по информационной безопасности, и эту статью он предложил как хорошее знакомство с фаззером afl и вообще с фаззингом как т... | https://habr.com/ru/post/650023/ | null | ru | null |
# Создание иконок для приложений Mac OS X

По роду деятельности я начинающий IOS кодер. Так случилось что недавно собрал совсем маленькую прогу под Mac и мне нужно было сделать иконку для своего же небольшого приложения.... | https://habr.com/ru/post/153857/ | null | ru | null |
# DIY кнопка вызова. Raspberry Pi, MajorDoMo, Freeswitch и Linphonec
Какое-то время назад у меня была потребность в осуществлении связи с человеком после болезни, который не мог физически пользоваться телефоном. Нужно было простое вызывное устройство, по нажатию кнопки происходил голосовой вызов. Потребность исчезла, ... | https://habr.com/ru/post/464309/ | null | ru | null |
# 5++ способов в одну строку на Python решить первую задачу Проекта Эйлера
Однажды меня посетила мысль, а что если попробовать решить первую задачу Проекта Эйлера всевозможными способами, но с условием, что р... | https://habr.com/ru/post/585176/ | null | ru | null |
# Улучшение производительности Python 2.7

*От переводчика: в двух словах, в декабре 2015 выйдет релиз Python 2.7.11, ускоряющий работу интерпретатора CPython до 20%. Ниже перевод статьи с [LWN.net](http://https:/lwn.net/), ... | https://habr.com/ru/post/261575/ | null | ru | null |
# Vue.js SSR & мобильный Safari: неочевидная проблема со слишком умным ПО
На днях столкнулись с такой проблемой. Сгенерированный на стороне сервера код отказывался гидратироваться в Safari.
> Гидратация относится к процессу на стороне клиента, в течение которого Vue берёт статический HTML, отправленный сервером, и... | https://habr.com/ru/post/430618/ | null | ru | null |
# Angular — Имплементация безопасных запросов к GraphQL API посредством JWT-токенов
Привет Хабр! При реализации Angular проекта, остро встал вопрос о безопасности graphql запросов в Angular 4. Выбор пал на [JSON Web Tokens](https://jwt.io/). Это открытый стандарт по [RFC 7519](https://tools.ietf.org/html/rfc7519).
... | https://habr.com/ru/post/336082/ | null | ru | null |
# AngularJS + Webpack = lazyLoad

Вступление
----------
При написании Single Page Application разработчики в большинстве случаев сталкиваются с одной очень распространенной проблемой, а именно — созда... | https://habr.com/ru/post/346406/ | null | ru | null |
# Как найти проблему с производительностью ВМ на VMware ESXi
В этой статье я расскажу, как искать ~~иголку в стоге сена~~ причину проблем с производительностью ВМ на ESXi. Главным способом будет то, что так ... | https://habr.com/ru/post/706858/ | null | ru | null |
# Коды Рида — Соломона в RAID 6
В интернете много статей о восстановлении информации в массиве RAID-6 и о том, как сделать собственную реализацию такого массива. Но большинство этих статей напичканы математическими формулами. Чтобы понять реальный алгоритм, приходится тратить очень много времени.
В этой статье пост... | https://habr.com/ru/post/531154/ | null | ru | null |
# TJBOT как иллюстрация IBM Watson services
Привет, Хабр! Весной 2019 года прошел очередной Think Developers Workshop, на котором все желающие могли собрать картонного робота TJBota под управлением IBM Watson Services. Под катом находится подробная инструкция, из чего и как собрать такого робота, полезные ссылки и про... | https://habr.com/ru/post/458374/ | null | ru | null |
# @ActivityScope с помощью Dagger 2
Привет, Хабр! Хочу поделиться опытом создания ActivityScope. Те примеры, которые я видел на просторах интернета, на мой взгляд, не достаточно полны, неактуальны, искусственны и не учитывают некоторых нюансов практической разработки.
Статья предполагает, что читатель уже знаком с ... | https://habr.com/ru/post/312196/ | null | ru | null |
# Новый механизм JSX трансформации в React 17 Release Candidate
В React 17 Release Candidate появляется новый способ трансформации JSX. С ним, в бандле, не понадобится сам Реакт, хотя для использования хуков он всё ещё нужен. Это и есть основной бенефит нового механизма. Под катом краткий перевод [статьи в блоге React... | https://habr.com/ru/post/521930/ | null | ru | null |
# Межпланетная файловая система — больше нет необходимости копировать в сеть
Всем хороша идея IPFS но вот только был один недостаток у неё. Данные загружаемые в сеть копировались в хранилище блоков удваивая занимаемое ими место. Более того файл резался на блоки которые мало пригодны для повторного использования.
Появ... | https://habr.com/ru/post/331010/ | null | ru | null |
# Пишем простой транслятор на Лиспе — II
[Предыдущая статья](https://habr.com/post/419103/)
### Реализуем оператор присвоения
А теперь научим транслятор обрабатывать оператор присвоения. И здесь перед нами встает классическая задача – обеспечить вычисление алгебраической формулы, заданной в привычной для нас со шк... | https://habr.com/ru/post/421445/ | null | ru | null |
# Воины и волшебники, часть первая
Распространенная задача, которую я вижу в объектно-ориентированном проектировании:
* Волшебник — это разновидность игрока.
* Воин — это разновидность игрока.
* У игрока есть оружие.
* Посох — это разновидность оружия.
* Меч — это разновидность оружия.
Но прежде чем мы углубимся в д... | https://habr.com/ru/post/710748/ | null | ru | null |
# Инструменты хакера в торговле
Для того, чтобы осуществить наш хакерский финансовый эксперимент (чтобы еще на нем и заработать), нам потребуется программа, которая может проводить исследования, тестирование, обучение и торговлю по алгоритму. Ни одна из существующих программ на сегодняшний день по-настоящему не покрыв... | https://habr.com/ru/post/398749/ | null | ru | null |
# Удаление неиспользуемых сборок из .NET проекта
Когда-то во время учебы в университете, преподаватель, проверяя лабораторную работу по C++, вдруг неожиданно для меня задал вопрос: “А зачем вам здесь #include “%имя\_библиотеки%”? Вы можете пояснить, для каких частей кода нужна каждая директива include?” Та директива, ... | https://habr.com/ru/post/129027/ | null | ru | null |
# Туториал по Встроенным Подпискам в iOS с помощью StoreKit 2 и Swift
Пошаговое руководство по созданию рабочего примера приложения с подписками на SwiftUI.
Этот туториал сопровождается примерами кода и образцом пр... | https://habr.com/ru/post/707730/ | null | ru | null |
# Уязвимости в реализации межпроцессного взаимодействия в Android-приложениях
Последние 6 лет я работаю экспертом по информационной безопасности в Одноклассниках и отвечаю за безопасность приложений.
Мой доклад сегодня — о механизмах межпроцессного взаимодействия в Android и уязвимостях, связанных с их неверным испо... | https://habr.com/ru/post/525280/ | null | ru | null |
# DirectX 12 — от Леонардо да Винчи к современному искусству
Компьютерная графика — обширная и быстроразвивающаяся дисциплина. С каждым годом интерфейсы прикладного программирования становятся более гибкими, что позволяет на их основе реализовывать более сложные алгоритмы формирования и обработки изображений. Однако в... | https://habr.com/ru/post/489282/ | null | ru | null |
# Docs as code против или вместе с Confluence? Обзор нескольких способов публикации из репозитория в Confluence
Многие уже давно или активно используют или смотрят в сторону модели хранения и публикации **документации как кода**, это значит применять к документации все те же правила, инструменты и процедуры, что и к п... | https://habr.com/ru/post/483898/ | null | ru | null |
# Замечательные zippers, или как я научился не волноваться и полюбил древовидные структуры данных
Известно, что дерево – довольно сложная структура. И если чтение успешно реализуется в том числе рекурсией (которая не лишена своих проблем), то с изменением дела обстоят совсем не хорошо.
При этом довольно давно сущес... | https://habr.com/ru/post/279623/ | null | ru | null |
# Воссоздаем Minecraft-подобную генерацию мира на Python
*...используя диаграммы Вороного и много шумов Перлина/симплексных шумов*
> *Прим. переводчика*: стоит отметить, что непосредственно в Minecraft используются отличные от описанных ниже подходов — игра не использует диаграммы Вороного, а кроме двумерных шумов пр... | https://habr.com/ru/post/590547/ | null | ru | null |
# Выпадающий jQuery.Treeview
#### Вступление

В ходе реализации текущего проекта мне понабилось выпадающее дерево. Так как я уже пользовался jQuery плагином TreeView, и его функционал меня устраивает... | https://habr.com/ru/post/128990/ | null | ru | null |
# Optimization Unity3d UI by GPU (for example minimap) или создаем миникарту без дополнительных камер и спрайтов
Всем привет!
«Если можешь что-то посчитать на GPU, делай это»
// Конечно в рамках разумного
![image](https://habrastorage.org/r/w780q1/getpro/habr/post_images/269/e28/71a/269e2871a4c0eb98005b71832d... | https://habr.com/ru/post/335524/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.