
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
> [Bash-скрипты: начало](https://habrahabr.ru/company/ruvds/blog/325522/)
>
> [Bash-скрипты, часть 2: циклы](https://habrahabr.ru/company/ruvds/blog/325928/)
>
> [Bash-скрипты, часть 3: параметры и ключи командной строки](https://habrahabr.ru/... | https://habr.com/ru/post/328436/ | null | ru | null |
# Пишем telegram бота на языке R (часть 2): Добавляем боту поддержку команд и фильтры сообщений
В [предыдущей публикации](https://habr.com/ru/post/511222/) мы разобрались как создать бота, инициализировали экземпляр класса `Bot` и ознакомились с методами отправки сообщений с его помощью.
В этой статье я продолжаю да... | https://habr.com/ru/post/515148/ | null | ru | null |
# Вам показалось! Все о Perceived Performance
Перед вами быстрый, удобный и отзывчивый сайт? Возможно, это не результат плодотворной работы множества людей, а всего лишь набор психологических и инженерных трюков, направленных на улучшение Perceived Performance.
В большинстве случаев с ростом реальной производительнос... | https://habr.com/ru/post/538466/ | null | ru | null |
# Ansible это вам не bash. Сергей Печенко
**Предлагаю ознакомиться с расшифровкой доклада 2019 года Сергея Печенко "Ansible — это вам не bash!"**

Пара слов обо мне.

Привет, Хабр!
Сегодня я хочу рассказать о замечательной библиотеке для разработке ботов ВКонтакте с помощью языка программирования Python.
VKWave
======
VKWave — это фреймворк д... | https://habr.com/ru/post/515334/ | null | ru | null |
# Top 10 bugs found in C++ projects in 2021
It's freezing outside, everyone has already decorated the Christmas tree and bought tangerines. New Year is coming! So, it's time to meet the Top 10 interesting bugs found by the PVS-Studio C++ analyzer in 2021.

Довольно давно я написал [статью](http://habrahabr.ru/blogs/python/47474/), в которой приводил примеры основ работы с системой с помощью Python-скриптов. Из-за мельком оброненной фразы (достат... | https://habr.com/ru/post/62383/ | null | ru | null |
# Два в одном: данные туристов и билеты на культурные мероприятия находились в открытом доступе
Сегодня рассмотрим сразу два кейса – данные клиентов и партнеров двух совершенно разных компаний оказались в свободном доступе «благодаря» открытым серверам Elasticsearch с логами информационных систем (ИС) этих компаний.
... | https://habr.com/ru/post/452698/ | null | ru | null |
# Психология читабельности кода
Всё, что написано ниже, ни разу не претендует на абсолютную истину, но всё же представляет собой некоторую модель, помогающую лично мне находить способы писать немного лучший код.
Каждый программист старается писать хороший код. Читабельность — один из главных признаков такого кода. ... | https://habr.com/ru/post/399293/ | null | ru | null |
# Нужен ли Mockito, если у вас Kotlin?
Салют, коллеги.
В рамках пятничной статьи предлагаю посмотреть на интересный способ создания моков в [Kotlin](https://kotlinlang.org/), без использования сторонних библ... | https://habr.com/ru/post/590379/ | null | ru | null |
# Путеводитель по реализации 2Д платформеров (начало)
Так как ранее я был разочарован количеством информации по этому вопросу, я решил восполнить этот пробел, собрав разные виды реализации 2Д платформеров, описав их сильные и слабые стороны и порассуждав над деталями реализации.
Моей целью было создать исчерпывающи... | https://habr.com/ru/post/265911/ | null | ru | null |
# Что такое дженерики в TypeScript?
TypeScript, "надмножество JS", облегчает создание поддерживаемых, понятных и масштабируемых приложений благодаря эффективной возможности проверки типов.
**Дженерики** игра... | https://habr.com/ru/post/685652/ | null | ru | null |
# Bitcoin: Заказ и получение Little Jalapeno от Butterfly Labs
Желание поучаствовать в майнинге биткоинов появилось летом прошлого года, когда курс дополз до 20 уе за штуку.
Почитав про то, как люди извращаются в постройках ферм для майнинга, сколько это «кушает» электричества и гудит, было решено сделать pre-order... | https://habr.com/ru/post/185392/ | null | ru | null |
# Использование элементов, в качестве фоновых изображений при помощи -moz-element
Перевод статьи «Use Elements as Background Images with -moz-element», David Walsh
Все мы знаем, что все браузерные вендоры по своему определяют многие CSS и JavaScript фичи, и я благодарен им за это. [Mozilla](http://davidwalsh.name/m... | https://habr.com/ru/post/230431/ | null | ru | null |
# Обнаружены незадокументированные опкоды в системе инструкций процессора x86
Венгерский инженер Кан Бёлюк (Can Bölük) из [Verilave](https://verilave.com/) нашёл неиспользованные и не задокументированные операционные коды в системе инструкций процессора x86-64.
Оказывается, такие опкоды действительно существуют! Не... | https://habr.com/ru/post/560438/ | null | ru | null |
# Отображаем ACF поля красиво и без кодинга
Плагин Advanced Custom Fields используется в WordPress повсеместно, за свою карьеру я встретил лишь несколько сайтов которые обходились без него (весьма специфичес... | https://habr.com/ru/post/699774/ | null | ru | null |
# HAPRoxy для Percona или Galera на CentOS. Его настройка и мониторинг в Zabbix

#### Очень короткая статья, про то как можно использовать HAProxy в качестве балансировщика для multi-master серверов MySQL, ... | https://habr.com/ru/post/198448/ | null | ru | null |
# Microsoft Robotics. Параллельная обработка данных
Один из продуктов Microsoft — [Microsoft Robotics](http://www.microsoft.com/robotics/) включает библиотеку Concurrent and Coordination Runtime. Библиотека очень нужна роботам для организации параллельных вычислений при обработке звука и изображений (да и не только их... | https://habr.com/ru/post/204466/ | null | ru | null |
# Автоматизируем создание VPN пользователей в PFSense

Мне очень нравится PFSense 2.0. Особенно хороша у него стала функция OpenVPN сервера. Сам сервер настраивается в несколько кликов ( [www.youtube.... | https://habr.com/ru/post/132106/ | null | ru | null |
# 9 очень полезных советов по JavaScript
Приветствую, Хабр! Представляю вашему вниманию перевод статьи [«9 Extremely Powerful JavaScript Hacks»](https://dev.to/razgandeanu/9-extremely-powerful-javascript-hacks-4g3p) автора [Klaus](https://dev.to/razgandeanu).
Прим. переводчика: в этом новом (от 10 декабря) посте кл... | https://habr.com/ru/post/480398/ | null | ru | null |
# Переопределение предка (dirty hack)
**UPD:** Лучше конечно такого избегать. Все это страшно, ужасно, и воняет. Но воняет чуть меньше чем VQMOD, и если уж приходится патчить «живой» и обновляемый, но жуткий легаси, то такой подход имеет право на существование. Но НИКОГДА не делайте так в проектах которые вы только на... | https://habr.com/ru/post/152499/ | null | ru | null |
# Практика по Котлину: Создание веб приложений на React и Kotlin/JS
*От переводчика*.
Привет! Про **Kotlin** есть стереотип, будто бы это язык для разработки только под Android. На самом деле, это совсем не так: язык официально поддерживает несколько платформ (**JVM**, **JS**, **Native**), а также умеет работать с би... | https://habr.com/ru/post/555744/ | null | ru | null |
# Агрегации метрик DataDog
*На пути от наблюдаемой системы до пользователя DataDog (здесь и далее - DD) метрические данные неизбежно проходят несколько этапов агрегации. Это означает, что в момент чтения метрик пользователь DD оперирует не конкретными значениями, а их агрегатами. Теоретически возможно записать в DD ме... | https://habr.com/ru/post/681470/ | null | ru | null |
# Анонс Jmix 0.9 — предварительный релиз фреймворка

*Мы в компании Haulmont разрабатываем [Jmix](https://jmix.ru). Это фреймворк с открытым кодом для разработки backend для data-centric приложений, основанный на Spring Boot, наследн... | https://habr.com/ru/post/552592/ | null | ru | null |
# Как удалить фейковый трафик с вашего сайта
Очень часто мы отмечаем всплеск трафика на сайте, анализируя данные, собранные Google Analytics. Это воспринимается как интерес к ресурсу. И, разумеется, такой рост посещаемости не может не радовать.
Но это не всегда повод для радости. Позже мы обнаруживаем, что больша... | https://habr.com/ru/post/292522/ | null | ru | null |
# «Фабричный метод» и «Абстрактная фабрика» во вселенной «Swift» и «iOS»
Слово «фабрика» – безусловно одно из самых часто употребляемых программистами при обсуждении своих (или чужих) программ. Но смысл в него вкладываемый бывает очень разным: это может быть и класс, порождающий объекты (полиморфно или нет); и метод, ... | https://habr.com/ru/post/451324/ | null | ru | null |
# День смерти стандартной библиотеки
На днях в Праге комитет по стандартизации С++ провел ряд опросов по вопросу изменения ABI, и в конечном счете было решено ничего в нем не менять. Аплодисментов в зале слышно не было.
Я думаю, мы не осознавали полностью те последствия, которое повлечет за собой данное решение, и ... | https://habr.com/ru/post/490222/ | null | ru | null |
# Использование паттерна BFF для создания общих типов в бэкенде и фронтенде

Контракт между бэкендным сервисом и фронтендным потребителем (или клиентом) обычно является местом соединения двух миров. Т... | https://habr.com/ru/post/571004/ | null | ru | null |
# Слайдер на CSS
Хочу рассказать простой способ создания слайдера, без использования JS, при помощи анимации CSS.
**1)** Для начала напишем HTML, предположим что в слайдере будут сменять друг друга 4 изображения.
```
```
**2)** Далее оформим размеры блока, и еще несколько настроек, position: relative необходим... | https://habr.com/ru/post/324034/ | null | ru | null |
# К вопросу о языках программирования…
Так как [голосование](http://habrahabr.ru/blogs/programming/48623/) не позволяет оставлять комментарии, то оформлю комментарии отдельной статьёй.
Особо интересует мнение людей, которые считают что у них такого случиться не может (предпоследний пункт в опросе). Почему?
Под к... | https://habr.com/ru/post/48624/ | null | ru | null |
# Криптография простым языком: разбираем симметричное и асимметричное шифрование на примере сюжета Звездных войн (Updated)
Привет всем читателям Хабра! Не так давно решил разобраться с алгоритмами шифрования и принципами работы электронной подписи. Тема, я считаю, интересная и актуальная. В процессе изучения попробова... | https://habr.com/ru/post/452042/ | null | ru | null |
# Интеграция QUIK в инфраструктуру или API
Торговая система QUIK для большинства серьёзных игроков рынка является очень популярной системой предоставления своим клиентам интерфейса для торговли ценными бумагами. Но в большинстве своём внутренности этой системы, как и любого коммерческого продукта являются закрытыми, в... | https://habr.com/ru/post/680872/ | null | ru | null |
# WPF > PDF через PDFSharp.Xps: чиним вывод гиперссылок

Короткий пост в продолжение к моему [предыдущему посту](http://habrahabr.ru/post/201836/) про генерацию PDF из WPF-приложения с помощью PDFSharp. Как... | https://habr.com/ru/post/202810/ | null | ru | null |
# Пользовательские шаблоны и расширения для Visual Studio под проект (Часть 2: шаблоны проектов)
В прошлый раз я рассуждал на тему расширений и шаблонов, что их можно создавать не только для общего пользования, но и для нужд конкретного проекта. А так же показал, как легко можно создать шаблон элемента (класса, наприм... | https://habr.com/ru/post/573930/ | null | ru | null |
# 3D ML. Часть 5: Свертки на графах

В предыдущих заметках данной серии мы уже успели поговорить о датасетах и инструментах, функциях потерь и примерах прикладных задач, а сейчас пора перейти к “ядру” любой подобласти глубокого обуче... | https://habr.com/ru/post/533746/ | null | ru | null |
# Как обложить сервис метриками и не облажаться
Меня зовут Евгений Жиров, я разработчик в инфраструктурной команде [Контур.Экстерна](https://www.kontur-extern.ru). Этот пост — текстовая версия моего [доклада](https://www.youtube.com/watch?v=1WvnifkND2g&list=PLc82OEDeni8TyujauVY7DBM_dA1hZl2tK&index=3) с недавнего митап... | https://habr.com/ru/post/341326/ | null | ru | null |
# Жизнь после Docker: как команда VK Cloud переходила на CRI-O

Kubernetes [прекратил](https://kubernetes.io/blog/2020/12/02/dockershim-faq/) поддержку Docker и отказался от dockershim — прокладки между kubelet и Docker, которая позв... | https://habr.com/ru/post/707312/ | null | ru | null |
# Next.js v13. Что нового и чего ждать в будущем
25 октября команда Next проведёт презентацию, посвящённую новой, 13-ой версии. Данное обновление по традиции именуют крупнейшим. Оно может затронуть буквально ... | https://habr.com/ru/post/695080/ | null | ru | null |
# Строим пайплайн автоматизированного тестирования на Azure DevOps
Недавно я столкнулся с не очень популярным пока зверем в мире DevOps, пайплайнами Azure DevOps. Сразу же ощутил отсутствие каких то внятных инструкций или статей на тему, не знаю с чем это связанно, но Microsoft явно есть над чем поработать в плане поп... | https://habr.com/ru/post/460431/ | null | ru | null |
# Функциональное программирование на Python для самых маленьких — Часть 1 — Lambda Функция

Я решил написать эту серию статей, ибо считаю, что никто не должен сталкиваться с той стеной непонимания, с которой столкнулся когда-то я.
В... | https://habr.com/ru/post/507642/ | null | ru | null |
# Советские «Эльбрусы» — обзор архитектуры

Про предмет статьи ходит много домыслов — от «русский Барроуз» до «не имеющий аналогов». Вызвано это в немалой степени отсутствием (доступной) полноценной документации, немногочисленн... | https://habr.com/ru/post/313376/ | null | ru | null |
# Ограничение доступа в интернет для приложений в Linux
Иногда бывает необходимо запустить программу, предварительно заблокировав для неё доступ в интернет. Существует довольно простой трюк для решения этой задачи.
Итак, идея заключается в том, чтобы при запуске приложения устанавливать особый ID группы, который бу... | https://habr.com/ru/post/82933/ | null | ru | null |
# Определение позы для нескольких людей с Mediapipe
Современные подходы в основном опираются на мощь рабочего компьютера для вывода, в то время как метод Mediapipe способен обеспечить производительность в реальном времени на большинстве современных мобильных телефонов, настольных компьютеров и в Интернете(javascript).... | https://habr.com/ru/post/567534/ | null | ru | null |
# Мультимодельные СУБД — основа современных информационных систем?
Современные информационные системы достаточно сложны. Не в последнюю очередь их сложность обусловлена сложностью обрабатываемых в них данных. Сложность же данных зачастую заключается в многообразии используемых моделей данных. Так, например, когда данн... | https://habr.com/ru/post/462493/ | null | ru | null |
# Фингерпринтинг конкретного ПК с точностью 99,24%: не спасает даже смена браузера

*Задачи рендеринга на клиентской стороне с целью фингерпринтинга*
Практика смены браузера, чтобы сменить личность в интернете, является ... | https://habr.com/ru/post/357238/ | null | ru | null |
# Работа с API HeadHunter при помощи python
Разбираемся на практике с API HeadHunter при помощи python.
Появилась задача анализа вакансий на рынке труда, и осуществлять ее надо базе HeadHunter. Необходимо по... | https://habr.com/ru/post/666062/ | null | ru | null |
# Кодирование цифрового идентификатора
Читая как-то статью [Сессии — всегда ли они нужны?](http://habrahabr.ru/blog/php/37914.html) вспомнил свои давнишние мучения по тому же самому поводу.
Когда-то я тоже строил хеши из полученных и серверных данных, дабы не показывать пользователю его внутренний идентификатор, а ... | https://habr.com/ru/post/23261/ | null | ru | null |
# Как создать внутриигровое меню в Unity
Как создать внутриигровое меню в Unity
======================================
Unity позволяет не делать меню настроек, так как есть встроенный диалог настроек качества и разрешения перед запуском игры. Однако если вы хотите сделать вашу игру неповторимой и показать, на что спо... | https://habr.com/ru/post/346370/ | null | ru | null |
# Полноценный Kubernetes с нуля на Raspberry Pi

Совсем недавно одна известная компания объявила, что переводит линейку своих ноутбуков на ARM-архитектуру. Услышав эту новость, я вспомнил: просматривая в очередной раз цены на EC2 в A... | https://habr.com/ru/post/513908/ | null | ru | null |
# Производительность shared-папок в Vagrant
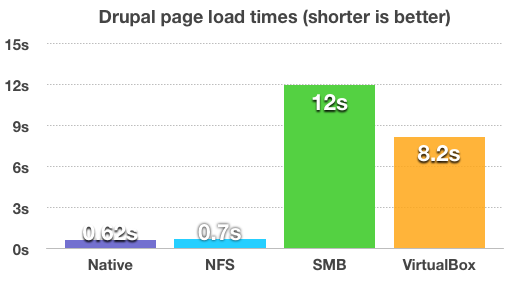
Руководя крупной и регулярно пополняющейся командой программистов, столкнулся с необходимостью быстро разворачивать среду разработки без танцев с бубном в д... | https://habr.com/ru/post/248019/ | null | ru | null |
# Эмоциональный код
Я зарабатываю программированием с 1979 года, и большую часть этого времени мне приходится работать с чужим кодом. Поначалу было: "Добавьте эту маленькую функцию к тому, что у нас уже есть"... | https://habr.com/ru/post/659451/ | null | ru | null |
# Как настроить SQLAlchemy, SQLModel и Alembic для асинхронной работы с FastAPI
В этом руководстве предполагается, что у вас есть опыт работы с FastAPI и Postgres с помощью Docker. Вам нужна помощь, чтобы ускорить работу с FastAPI, Postgres и Docker? Начните со следующих ресурсов:
1. [Разработка и тестирование асинхр... | https://habr.com/ru/post/580866/ | null | ru | null |
# Application performance monitoring and health metrics without APM
I have already written about AIOps and machine learning methods in working with IT incidents, about hybrid umbrella monitoring and various approaches to service management. Now I would like to share a very specific algorithm, how one can quickly get i... | https://habr.com/ru/post/560820/ | null | en | null |
# Делегируй меня полностью, или Новый взгляд на RBCD-атаки в AD
«Злоупотребление ограниченным делегированием Kerberos на основе ресурсов» — как много в этом звуке!
Точнее уже не просто звуке и даже не словос... | https://habr.com/ru/post/680138/ | null | ru | null |
# Создание и тестирование Firewall в Linux, Часть 1.1 Виртуальная лаборатория
Решил написать статью по следам курса, который я делал в прошлом семестре в институте. Конечно, тут я опишу лишь самые главные основы и максимально все упрощу. Постараюсь дать немного теоритической информации, но в основном больше ссылок, ка... | https://habr.com/ru/post/315340/ | null | ru | null |
# Flutter. Асинхронность и параллельность
Привет, Хабр! Представляю вашему вниманию перевод [статьи "Futures — Isolates — Event Loop"](https://www.didierboelens.com/2019/01/futures-isolates-event-loop/) автора Didier Boelens об асинхронности и многопоточности в `Dart` (и `Flutter` в частности).
> TLDR: В целом, стать... | https://habr.com/ru/post/497278/ | null | ru | null |
# Мучаем MS Word из нашего приложения
Перед каждым прикладным разработчиком рано или поздно встает задача экспорта данных из своего приложения в другое. Вот и передо мной она в очередной раз встала: мне потребовалось генерировать сообщения для рассылки (почтовой, которую почтальон носит). Письма должны сохраняться в ф... | https://habr.com/ru/post/106425/ | null | ru | null |
# Оптимизация сравнения this с нулевым указателем в gcc 6.1

Хорошие новостиTM ждут пользователей gcc при [переходе на версию 6.1](https://gcc.gnu.org/gcc-6/porting_to.html) Код такого вида (взят [отсюда](https://habrahabr.... | https://habr.com/ru/post/308346/ | null | ru | null |
# Киски: Рефакторинг. Часть третья или причесываем шероховатости
В [первой](http://habrahabr.ru/post/262995/) и [второй](http://habrahabr.ru/post/263139/) частях серии с... | https://habr.com/ru/post/263333/ | null | ru | null |
# Как бесплатно мониторить массивы HP EVA с помощью Zabbix: два варианта решения
Привет, Хабр! В данной статье мы рассмотрим процесс настройки мониторинга массивов семейства HP EVA (Enterprise Virtual Array) ... | https://habr.com/ru/post/701026/ | null | ru | null |
# GraphQL запрос на GitHub
[В прошлый раз](https://habr.com/ru/post/569556/) мы сделали простой запрос на получение списка репозиториев пользователя. Там был только код и ни чего лишнего. В этот раз попытаем... | https://habr.com/ru/post/569560/ | null | ru | null |
# Адаптивные антенные решётки: как это работает? (Основы)
*Доброго времени суток.*
*Последние несколько лет я посвятил исследованию и созданию различных алгоритмов пространственной обработки сигналов в адаптивных антенных решётках, и продолжаю заниматься этим в рамках своей работы в настоящее время. Здесь я хотел б... | https://habr.com/ru/post/449794/ | null | ru | null |
# CSS: селектор на два и более классов одновременно
Оказывается, чтобы выбрать элемент, принадлежащий классам foo и bar одновременно (, например), то можно писать так:
`div.foo.bar { ... }`
Выяснил случайно экспериментально. Не знал, стыдно. | https://habr.com/ru/post/62983/ | null | ru | null |
# Масштабирование текста в блоке с помощью Jquery
Недавно получил заказ, где между всего прочего нужно было сделать блок, в котором текст должен масштабироваться внутри блока. Т.е не зависит, сколько текста в блоке – весь текст должен быть видимым! Сначала думал считать символы, строки… Сверстал блок в котором должен ... | https://habr.com/ru/post/309678/ | null | ru | null |
# Flutter под капотом
Всем привет! Меня зовут Михаил Зотьев, я работаю Flutter-разработчиком в [Surf](https://surf.ru/). Мне, как, наверное, большинству других разработчиков, которые работают с Flutter, больше всего нравится то, как просто создавать с его помощью красивые и удобные приложения. Чтобы войти во Flutter р... | https://habr.com/ru/post/501862/ | null | ru | null |
# Особенности работы External Type 1 и External Type 2 маршрутов в OSPF. Часть 1
У практически любого сетевого инженера, рано или поздно наступает момент в жизни когда в его сети появляются домены маршрутизации отличные от любимого OSPF, EIGRP или IS-IS. Чаще всего это связано со слиянием двух сетей, но иногда может б... | https://habr.com/ru/post/117099/ | null | ru | null |
# Введение в SVG-анимации для верстальщиков

Время идет, технологии меняются, набитые шишки копятся, настала пора обновить материалы по SVG-анимациям. Тем более, что тема для многих фронтендеров все еще остается странной и запутанной... | https://habr.com/ru/post/667116/ | null | ru | null |
# Scala: Авторизация. Защита API с помошью Bearer токена
В это пример я буду рассматривать только парсинг и валидацию токенов что уже пришли в мое API в Authorization хедере. Для генерации токенов, регистрации пользо... | https://habr.com/ru/post/655081/ | null | ru | null |
# Сборка сложных Node.js проектов утилитой run-z
**Есть** несколько десятков взаимосвязанных пакетов в рабочем дереве ([Yarn Workspaces](https://yarnpkg.com/features/workspaces)).
**Надо** собирать несколько из них. Часто, быстро, и в правильном порядке.
Существующие инструменты либо собирают всё сразу и долго, либо... | https://habr.com/ru/post/517506/ | null | ru | null |
# Анализ вредоносных программ. Интересные трюки
Закрепление в системе с использованием WMI
------------------------------------------
В качестве вступления... Друзья и коллеги мне постоянно твердили, чтобы п... | https://habr.com/ru/post/568228/ | null | ru | null |
# Как разобраться в исходном коде React
React самая популярная библиотека для построения пользовательских интерфейсов. Мы знаем про виртуальное дерево, движок fiber, процедуру reconcilation, хуки и другие прекрасные возможности react. Но как это работает на уровне исходного кода? Ответить на этот вопрос смогут очень н... | https://habr.com/ru/post/569564/ | null | ru | null |
# Уменьшить размер консольного .NET 5.0 приложения
На английском: [Shrinking .NET Console Application](https://habr.com/ru/post/549530/)
Target Framework Moniker
------------------------
Давайте знакомиться. В .NET 5.0 для использования Windows Forms или WPF нам недостаточно просто указать net5.0:
```
net5.0
tru... | https://habr.com/ru/post/548442/ | null | ru | null |
# Пишем плагин к Microsoft DNS server для защиты от IDN spoofing
IDN spoofing — это генерация доменных имён «похожих» на выбранное, обычно применяемая с целью заставить пользователя перейти по ссылке на ресурс злоумышленника. Далее рассмотрим более конкретный вариант атаки.
Представим, что атакуемая компания владее... | https://habr.com/ru/post/348428/ | null | ru | null |
# Funkwhale: наконец-то нормальный децентрализованный музыкальный сервис

Grooveshark уже пять лет как закрыт. За это время появились десятки проектов поменьше с той же идеей — но на базе децентрализованных сетей. Проблема Grooveshar... | https://habr.com/ru/post/528192/ | null | ru | null |
# Получение информации и обход двухфакторной аутентификации по картам банка из ТОП-10 (Украина)
В прошлом году украинский банк из ТОП-10 пригласил меня протестировать свои системы интернет- и мобильного банкинга на предмет уязвимостей.
Первым делом я решил начать с отслеживания запросов мобильного приложения. С по... | https://habr.com/ru/post/441104/ | null | ru | null |
# Реализация инерционных алгоритмов на примере логического моделирование цифровых схем
### 1. Введение
Приступаем ко второй части темы, посвященной вложенным автоматам. В [первой](https://habr.com/ru/post/492958/) мы рассматривали рекурсивные алгоритмы, которые, имея модель вложенных автоматов и подключив возможност... | https://habr.com/ru/post/494874/ | null | ru | null |
# Потокобезопасные сигналы, которыми действительно удобно пользоваться
В мире существует множество библиотек, реализующих сигналы в C++. К сожалению, у всех реализаций, с которыми я сталкивался, есть несколько проблем, которые не позволяют писать простой многопоточный код с использованием этих библиотек. Здесь я расск... | https://habr.com/ru/post/279851/ | null | ru | null |
# Обработка заполняемой пользователем формы: как уменьшить сложность кода?
Работая над написанием административного, да и пользовательского интерфейса, я не раз ловил себя на мысли — а все ли я делаю так, чтобы при минимуме усилий обеспечить оптимальное качество?
Сегодня хотелось бы обсудить вопрос обработки ошибок... | https://habr.com/ru/post/132805/ | null | ru | null |
# Расширяем фреймворк Kivy пакетом XPopup (Часть 1-я)
### Эти забавные зверушки
Не так давно передо мной встала задача в сжатые ~~сра~~ сроки написать работающий прототип GUI-приложения, которое без лишней строки кода хорошо дружило бы как с Windows, так и с OS X. Выбор пал на змеиный фреймворк [Kivy](https://kivy.or... | https://habr.com/ru/post/301712/ | null | ru | null |
# Как включить шифрование в JetBrains Projector
Projector — это способ запускать IntelliJ IDEA на удалённом сервере. Недавно я [писал об этом статью](https://habr.com/ru/post/510210/), но умолчал о важной для любого параноика вещи — шифровании данных на вебсокете.
Генерация и подкладывание ключей — довольно муторный ... | https://habr.com/ru/post/510282/ | null | ru | null |
# System call interception in Linux-kernel module
The module was created as a part of my master thesis in the 2010 year. The master thesis theme is *Keylogging in Linux kernel*. The main idea was to find out a way to intercept system calls for x64 arch Linux kernel, especially for kernel 2.6.34.7-61.fc13.x86\_64.
In... | https://habr.com/ru/post/437182/ | null | en | null |
# Асинхронный django — status update. Проект vinyl
Всем привет.
Некоторое время назад я писал про альтернативные возможности, как можно добавить в django асинхронность (есть официальный подход, изложенный в [DEP-09](https://github.com/django/deps/blob/main/accepted/0009-async.rst)). С тех пор у меня получилось оформи... | https://habr.com/ru/post/660831/ | null | ru | null |
# Глубинное погружение в test-driven JavaScript
Многие JavaScript-фреймворки предлагают свое представление о том, как должен выглядеть код. Более того, речь идет не просто о стиле, речь идет о *способе* написания сценариев. Это обусловлено практически абсолютной демократичностью JavaScript, да-да, именно таким являетс... | https://habr.com/ru/post/209936/ | null | ru | null |
# Helpful service for microservice JSON-RPC based test automation
Test automation approaches for product built in microservice architecture could vary significantly according to the context of testing goals and ways to achieve them. You got an easy life if you are testing a service, that is an isolated entity which is... | https://habr.com/ru/post/581226/ | null | en | null |
# Полный латентно семантический анализ средствами Python
Известные реализация латентно-семантического анализа (LSA) средствами языка программирования Python [1,2] обладают рядом существенных методических недостатков. Не приведены корреляционные матрицы слов и документов. Эти матрицы позволяют выявить скрытые связи. От... | https://habr.com/ru/post/323516/ | null | ru | null |
# Еще одна реализация поля «город» для Django
«Еще одна» — потому что мне кажется, что я что-то упускаю и, в действительности, есть хорошее, но неизвестное мне решение “из коробки”. Тем не менее, вот мой рецепт:
#### Данные
В пер... | https://habr.com/ru/post/128709/ | null | ru | null |
# Coins Classification using Neural Networks
See more at robotics.snowcron.com
This is the first article in a serie dedicated to coins classification. Having countless "dogs vs cats" or "find a pedestrian on the street" classifiers all over the Internet, coins classification doesn't look like a difficult task.
At ... | https://habr.com/ru/post/538958/ | null | en | null |
# Развлекаемся с z-index
Элементы на веб-страницах, в основном, располагаются бок о бок или друг под другом. Но иногда дизайн требует перекрытия элементов. Например, выпадающее меню навигации, панели предварительного просмотра при наведении кур... | https://habr.com/ru/post/459374/ | null | ru | null |
# Знакомство с внутренним устройством .NET Framework. Посмотрим, как CLR создаёт объекты
Вниманию читателей «Хабрахабра» представляется перевод статьи Хану Коммалапати и Тома Кристиана об внутреннем устройстве .NET. Существует альтернативный вариант перевода на сайте [Microsoft](https://msdn.microsoft.com/ru-ru/librar... | https://habr.com/ru/post/263935/ | null | ru | null |
# Мониторинг Spark Streaming в Kubernetes с помощью Prometheus и Grafana
**Введение**
Развертывание Apache Spark в [Kubernetes](https://kubernetes.io/), вместо использования управляемых сервисов таких как [A... | https://habr.com/ru/post/583240/ | null | ru | null |
# Death Note, анонимность и энтропия

В начале “Death Note” местный гениальный детектив по сути занят деанонимизацией: он знает только то, что убийца существует где-то на планете. Никаких улик тот не оставляет, но довольно быстро ока... | https://habr.com/ru/post/516190/ | null | ru | null |
# Идеальный наблюдатель на Swift
*Изобретателям MulticastDelegate посвящается.*
Stateville Correctional CenterВ этой статье речь пойдёт о шабл... | https://habr.com/ru/post/585528/ | null | ru | null |
# Faye как способ не задолбать свой сервер
Здравствуйте, хабралюди. Сегодня я хочу рассказать о том, как в одном из наших проектов мы снизили количество запросов на сервер на пару порядков за счет использования технологии [Comet](http://ru.wikipedia.org/wiki/Comet_(программирование)).
Суть проблемы: веб-приложение ... | https://habr.com/ru/post/124066/ | null | ru | null |
# Kohana vs Codeigniter, Синтетика производительности
Я хочу привести сравнение производительности двух удивительных (и, по моему скромному мнению, восхитительных) фреймворков, [Kohana](http://kohanaphp.com/ "Официальный сайт фреймворка Kohana") и [Codeigniter](http://codeigniter.com/ "Официальный сайт фреймворка Code... | https://habr.com/ru/post/49592/ | null | ru | null |
# Мощь множества ядер для укрощения кодека AV1

Пролог
------
Периодически, я интересуюсь видеокодеками и тем, насколько они становятся эффективнее по сравнению со своими предшественниками. В свое вр... | https://habr.com/ru/post/511512/ | null | ru | null |
# Особенности использования и тестирования кода С++ на микроконтроллерах
 Так сложилось, что основным языком для работы с микроконтроллерами является C. Многие крупные проекты написаны именно на нем. Но жизнь не стоит на месте.... | https://habr.com/ru/post/390837/ | null | ru | null |
# Что случилось с сайтом фонда «Сколково» вкратце

Все началось с [поста](http://habrahabr.ru/blogs/internet/117202/) хабраюзера [oyaso](https://geektimes.ru/users/oyaso/), в котором он сравнил сумму денег заложенную на разра... | https://habr.com/ru/post/117367/ | null | ru | null |
# Перевод Django Documentation: Models. Part 4 (Last)

Доброго времени суток!
Это последняя часть серии моих переводов [раздела о моделях](http://docs.djangoproject.com/en/dev/topics/db/models/) из [документации Django](http://docs.djangoproject.com/e... | https://habr.com/ru/post/80030/ | null | ru | null |
# Что нам стоит сервис email-маркетинга построить? Взгляд изнутри, часть первая
Насколько сложно построить полноценный сервис email-маркетинга? Что для этого нужно предусмотреть? Какие подводные камни могут встретиться на пути пытливых умов разработчиков?
Предлагаю начать с общих черт.
* Статическая типизация
* Бесплатны и с открытым кодом
* Код преобразуется в байт-код
* Интероперабельность
* Объектно-ориентированные языки программ... | https://habr.com/ru/post/580738/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.