
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Создание веб-приложения на Go в 2017 году. Часть 4
**Содержание**1. [Часть 1](https://habrahabr.ru/post/329582/)
2. [Часть 2](https://habrahabr.ru/post/329584/)
3. [Часть 3](https://habrahabr.ru/post/329612/)
4. **Часть 4**
В этой части я попытаюсь кратко пройтись по пропущенным местам нашего очень упрощенного веб-... | https://habr.com/ru/post/329622/ | null | ru | null |
# Wine 3.0 и много плюшек
На Хабре незамеченным прошел выход 3-й версии Wine — открытой реализации `Win32 API`. Трудно найти другой проект с открытыми исходниками, за исключением ядра, который бы так много значил для пользователей Linux, MacOS, FreeBSD и других POSIX-совместимых ОС. Каждый успех разработчиков Wine при... | https://habr.com/ru/post/348184/ | null | ru | null |
# Очисти код свободными монадами
*От переводчика:
Это вольный перевод статьи [«Purify code using free monads»](http://www.haskellforall.com/2012/07/purify-code-using-free-monads.html) Габриэля Гонзалеса, посвященный использованию свободных монад для представления кода как синтаксического дерева с последующей управл... | https://habr.com/ru/post/263959/ | null | ru | null |
# Практическое использование Desired State Configuration для Windows Server 2012 R2
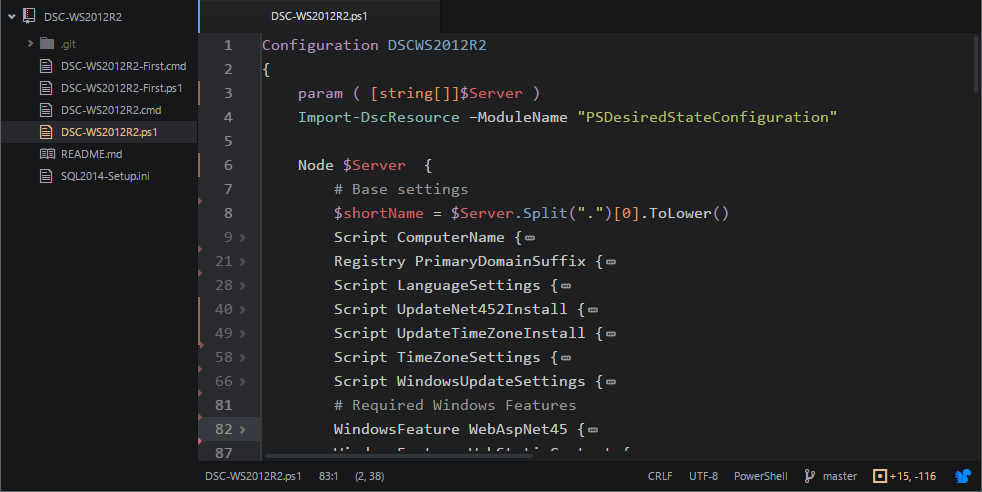
*Администраторам Linux: это статья о “Puppet” для Windows, и уже есть бета-версия DSC для Linux.
Для тех, кто в теме: не будет ничего о ... | https://habr.com/ru/post/267829/ | null | ru | null |
# Число прописью в Laravel 5
Иногда необходимо вывести число прописью при формировании какой-либо формы и нам приходит на помощь модуль [DigitText](https://github.com/andrey-helldar/DigitText), разработанный специально для фреймворка Laravel.
Он позволяет обрабатывать любое число на любом языке
) учат нас, что бросать исключения в деструкторах плохо, потому что в дестр... | https://habr.com/ru/post/433944/ | null | ru | null |
# Электронные часы в духе Qlocktwo
Привет от команды [uMove](https://geektimes.ru/post/262500/)! Как-то раз увидели в интернете такое изображение часов. Текущее время на них задается словами: пять минут третьего, без четверти час, половина пятого и тому подобное с шагом в 5 минут.

Недавно решил ознакомиться с платформой .NET, языком C# и Windows Presentation Foundation.
В процессе изучения (а изучаю языки и технологии я всегда в процессе разработки пробного проекта) мне встретилось довольно много подводных ... | https://habr.com/ru/post/93119/ | null | ru | null |
# 60 FPS? Легко! pointer-events:none!

Вы, наверное, уже читали [интересную статью](http://www.html5rocks.com/en/tutorials/speed/unnecessary-paints/) о том, как можно отключать эффекты `:hover` при скроле ... | https://habr.com/ru/post/204238/ | null | ru | null |
# Пентест-лаборатория Pentestit — полное прохождение

Компания Pentestit 20-го мая запустила новую, уже [девятую лабораторию](https://habrahabr.ru/company/pentestit/blog/301046/) для проверки навыков практического тестирован... | https://habr.com/ru/post/303700/ | null | ru | null |
# Hibernate cache
Довольно часто в java приложениях с целью снижения нагрузки на БД используют кеш. Не много людей реально понимают как работает кеш под капотом, добавить просто аннотацию не всегда достаточно, нужно понимать как работает система. Поэтому этой статье я попытаюсь раскрыть тему про то, как работает кеш п... | https://habr.com/ru/post/135176/ | null | ru | null |
# Назад к микросервисам вместе с Istio. Часть 1

***Прим. перев.**: Service mesh'и определённо стали актуальным решением в современной инфраструктуре для приложений, следующих микросервисной архитектуре. Хотя Istio может быть на слух... | https://habr.com/ru/post/438426/ | null | ru | null |
# Nuxt + Django + GraphQL на примере
Предисловие
-----------
**Nuxt** — "фреймворк над фреймворком Vue" или популярная конфигурация Vue-based приложений с использованием лучших практик разработки на Vue. Среди них: организация ката... | https://habr.com/ru/post/492486/ | null | ru | null |
# Уменьшение размера React Native-приложения на 60% за несколько простых шагов
Я тружусь в компании [Mutual](https://mutual.club/). Она работает в Бразилии, в сфере равноправного кредитования. Мы помогаем заёмщикам и заимодавцам наладить связь друг с другом. Первые ищут хорошие ставки, а вторые — доходы, превышающие т... | https://habr.com/ru/post/502422/ | null | ru | null |
# Математические модели хаоса
### Введение
На Habr уже обсуждалась теория хаоса в статьях [1,2,3]. В этих статьях рассмотрены следующие аспекты теории хаоса: обобщённая схема генератора Чуа; моделирование динамики системы Лоренца; программируемые логическими интегральными схемами аттракторы Лоренца, Ресслера, Рикитак... | https://habr.com/ru/post/436014/ | null | ru | null |
# Глубокое обучение. Федеративное обучение
[](https://habr.com/ru/company/piter/blog/458800/)Привет, Хаброжители! Мы недавно сдали в типографию книгу [Эндрю Траска](https://twitter.com/iamtrask) (Andrew W. Trask), закладывающую ф... | https://habr.com/ru/post/458800/ | null | ru | null |
# Анатомия GNU/Linux
Какое-то время назад на Хабре была небольшая волна постов на тему «Почему я [не] выбрал Linux». Как порядочный фанатик я стриггерился, однако решил, что продуктивнее что-нибудь рассказать о своей любимой системе, чем ломать *копии* в комментариях.
У меня сложилось впечатление, что многие пользова... | https://habr.com/ru/post/531872/ | null | ru | null |
# Практическое применение Backbone.View

В своем прошлом [топике](http://habrahabr.ru/blogs/webdev/123130/), я описал базовые принципы работы с фреймворком [backbone.js](http://documentcloud.github.com/backbone/), теперь предлагаю... | https://habr.com/ru/post/133622/ | null | ru | null |
# Есть ли параллелизм в произвольном алгоритме и как его использовать лучшим образом
Параллелизации обработки данных в настоящее время применяется в основном для сокращения времени вычислений путем одновременной обработки данных по частям на множестве различных вычислительных устройств с последующим объединением полу... | https://habr.com/ru/post/530078/ | null | ru | null |
# ICQ spam в Pidgin — отключаем запросы авторизации
Не знаю кого как, а меня уже задрали запросы на авторизацию через ICQ — приходят по 10-20 штук в день. Наконец-то нашёл способ как это всё отключить полностью. На jabber аккаунты в том же экземпляре пиджина запросы авторизации приходить будут. Когда подобного рода сп... | https://habr.com/ru/post/114122/ | null | ru | null |
# Что такое состояние
[](https://habr.com/ru/company/ruvds/blog/706086/)
Привет! Меня зовут Артём Арутюнян, много где меня можно встретить под ником artalar. 10 лет я разрабатываю крупные веб-сервисы, и вот уже четыре года [менеджер ... | https://habr.com/ru/post/706086/ | null | ru | null |
# Простой Telegram-бот на Python за 30 минут
На Хабре, да и не только, про ботов рассказано уже так много, что даже слишком. Но заинтересовавшись пару недель назад данной темой, найти нормальный материал у меня так и не вышло: все статьи были либо для совсем чайников и ограничивались отправкой сообщения в ответ на соо... | https://habr.com/ru/post/442800/ | null | ru | null |
# Серверный процессинг LESS файлов «на лету» своими руками
[LESS](http://lesscss.org/) — это популярный препроцессор для языка CSS, добавляющий возможности использовать константы, наследование, вложенные стили и много другое, чего так не хватает в CSS. Как только я познакомился с LESS я понял что это то, что мне нужно... | https://habr.com/ru/post/138103/ | null | ru | null |
# Создаем микросервисную архитектуру вместе с Apache Kafka и .NET Core 2.0

Доброго времени суток! Apache Kafka – очень быстрый распределенный брокер сообщений, и сегодня я расскажу как его “готовить” и реализовать с его помо... | https://habr.com/ru/post/336058/ | null | ru | null |
# Парсер цепочки блоков Bitcoin (с исходниками)
Разработчик znort987 выложил на github программу [blockparser](https://github.com/znort987/blockparser) — быстрый парсер на C++ цепочки блоков с транзакциями Bitcoin. Как известно, в Bitcoin все транзакции [публикуются в открытом доступе](http://blockchain.info/) с момен... | https://habr.com/ru/post/146388/ | null | ru | null |
# Основы линейной алгебры для 3D-приложений. Урок 3
#### Матрицы и заключение.
Завершающий урок из цикла про линейную алгебру для 3D-приложений от Александра Паничева — ведущего разработчика логики в UNIGINE... | https://habr.com/ru/post/674540/ | null | ru | null |
# Как начать понимать на слух английский? Подружиться с умными колонками
На Хабре было много статей о том, как выучить английский язык. Это — еще одна, однако здесь будут именно лайфхаки для того, чтобы прокачать навык понимания на слух, или аудирования. Причем мой подход претендует на уникальность в рамках Хабра. Нав... | https://habr.com/ru/post/504928/ | null | ru | null |
# Device Lab от Google: Project Tango
В [Лаборатории Google](http://bit.ly/29I0ANa) мы добрались до самого инновационного и многообещающего устройства. Project Tango - платформа компьютерного зрения для мобильных устройств, разработанная группой инженеров ATAP (Advanced Technology and Projects). Работающее на Android ... | https://habr.com/ru/post/304762/ | null | ru | null |
# Как я учил студентов Северной Кореи разрабатывать ПО с открытым исходным кодом
В 2016 году я отправился в Северную Корею, чтобы учить студентов магистратуры тому, как участвовать в разработке [ПО с открытым исходным кодом](https://en.wikipedia.org/wiki/Open_source). Вот фотография с одной из моих лекций:
" с сайта Dev.to. Автор расскажет нам об интересных и полезных ... | https://habr.com/ru/post/471212/ | null | ru | null |
# Пишем свой std::function (boost::function)
Классы std::function и boost::function являются высокоуровневыми обертками над функциями и функциональными объектами. Объекты таких классов позволяют хранить и вызывать функции и функторы с заданной сигнатурой, что бывает удобно, например, при создании callback вызовов (нап... | https://habr.com/ru/post/159389/ | null | ru | null |
# Как оценить инструменты для тестирования встроенного ПО
#### Введение от автора поста
Имея опыт разработки ПО для ответственных систем более чем 8 лет, хочу познакомить сообщество с некоторыми материалами, связанными с разработкой и верификацией ПО для ответственных систем (аэрокосмическая область, медицина, трансп... | https://habr.com/ru/post/182544/ | null | ru | null |
# Изучаем VoIP-движок Mediastreamer2. Часть 1
Материал статьи взят с моего [дзен-канала](https://zen.yandex.ru/id/5e3f8e0751f5346faab4fc7a).

Все статьи цикла
----------------
[Статья 1](https://habr.com/ru/post/495702/)
[Статья 2... | https://habr.com/ru/post/495702/ | null | ru | null |
# Виртуальные файловые системы в Linux: зачем они нужны и как они работают? Часть 1
Всем привет! Мы продолжаем запуски новых потоков по уже полюбившимся вам курсам и сейчас спешим сообщить о том, что у нас стартует новый набор по курсу [«Администратор Linux»](https://otus.pw/gbcl/), который запустится в конце апреля. ... | https://habr.com/ru/post/446614/ | null | ru | null |
# Ограничения векторизации Python как метода повышения производительности
##### Itamar Turner-Trauring
Автор Python-профайлера Sciagraph
Векторизация NumPy ускоряет операции с объёмными данными за счёт бы... | https://habr.com/ru/post/678406/ | null | ru | null |
# Apache Guacamole и взаимодействие с API: реальный кейс использования oVirt
Производители оборудования предлагают заказчикам разные методы удаленного управления серверами, не зависящие от операционной системы. Мы уже писали [о разработанной специалистами HOSTKEY веб-консоли для материнских плат Supermicro](https://ha... | https://habr.com/ru/post/665810/ | null | ru | null |
# Инструменты для A/B-тестирования iOS-приложений
[](https://habrahabr.ru/company/redmadrobot/blog/276489/)
В данной статье я рассмотрю несколько инструментов для A/B-тестирования мобильных приложений с примерами и дам их кр... | https://habr.com/ru/post/276489/ | null | ru | null |
# Обзор Java 9
Всем доброго времени суток. В ноябре 2017 в Санкт-Петербурге прошло одно из самых примечательных событий года для отечественных Java-разработчиков: конференция Joker. На конференции было озвучено много тем, такие как GC, Concurrency, Spring Boot, JUnit 5 и другие, презентации по которым вы можете найти ... | https://habr.com/ru/post/342170/ | null | ru | null |
# Строим гусеничного Bluetooth-робота с камерой. Часть 3
В предыдущих сериях:
[Часть 1](http://habrahabr.ru/blogs/DIY/133414/)
[Часть 2](http://habrahabr.ru/blogs/DIY/135371/)
Ну что, все уже заказали запчасти и собрали роботов? Пора робота оживить.
Сегодня мы разберем программную начинку.
Вариант, кото... | https://habr.com/ru/post/136224/ | null | ru | null |
# Рекомендательные системы: идеи, подходы, задачи

Многие привыкли ставить оценку фильму на КиноПоиске или imdb после просмотра, а разделы «С этим товаром также покупали» и «Популярные товары» есть в любом ... | https://habr.com/ru/post/453792/ | null | ru | null |
# Реализация exceptions на plain C
Продолжение вот этой статьи [habrahabr.ru/post/131212](http://habrahabr.ru/post/131212/), где я собирался показать, как «и ошибки удобно обрабатывать и exceptions при этом не использовать», да всё руки не доходили.
Итак, будем считать, что у нас ситуация, что «настоящие C++ except... | https://habr.com/ru/post/141507/ | null | ru | null |
# Снимаем «4D видео» с помощью depth-сенсора и триангуляции Делоне

Привет Хабр! Это заметка о небольшом хобби-проекте, которым я занимался в свободное время. Я расскажу, как с помощью несложных алгоритмов превращать карты глубины от ... | https://habr.com/ru/post/333532/ | null | ru | null |
# Как мы готовили распределенный джойн на Spark Structured Streaming. Доклад с RamblerMeetup&Usermodel
***История о том, как суточный ETL-контур карабкался в реалтайм.***

Давно хотел написать целостный туториал по поднятию Owncloud в условиях домашнего сервера или небольшой компании до 500 пользователей. Owncloud... | https://habr.com/ru/post/310144/ | null | ru | null |
# C++ объекты и QML, все по полочкам
На Хабре и в Сети достаточно много статей на тему QML, но все они оставляют за кадром некоторые моменты. Сегодня я попытаюсь приподнять занавес над некоторыми очевидными моментами для тех, кто имел дело со связкой QML и C++, и не таких очевидных для тех, кто только начинает вникать... | https://habr.com/ru/post/140899/ | null | ru | null |
# MR шаблон для написания сервисов на Node.js

Суть такова: node.js не дает готового решения для создания проекта. Первый мой проект на node.js состоял из одного coffeescript файла и run.js для запуска... | https://habr.com/ru/post/143538/ | null | ru | null |
# Применение LibVirt API, InfluxDB и Grafana для сбора и визуализации статистики выполнения VM
В своей практике я достаточно много времени посвящаю проектированию и администрированию облачных инфраструктур различного назначения. В основном это Apache CloudStack. Данная система обладает отличными возможностями, но в ча... | https://habr.com/ru/post/332652/ | null | ru | null |
# Подключение SQLite к мобильному приложению iOS через FMDB на Xcode используя Swift
Столкнувшись с задачей подключить SQLLite к своему мобильному приложению iOS через FMDB, я не нашел ни одного актуального гайда на русском языке. И тем более для Swift. В этой статье я постараюсь этого исправить.
В этом гайде будут... | https://habr.com/ru/post/277423/ | null | ru | null |
# Blazor Client Side Интернет Магазин: Часть 5 — Просмотр корзины и работа с Stateful

Привет, Хабр! Продолжаю делать интернет магазин на Blazor. В этой части расскажу о том как добавил в него возможность просмотра корзины товаров и ... | https://habr.com/ru/post/495812/ | null | ru | null |
# Two languages, one Cup. Размышления о правилах RCC 2016

Здравствуй, Хабр! Вот небольшой пост о проходящем **Russian Code Cup 2016**, а точнее, мои соображения, на которые меня натолкнула одна из задач разогревочного раунд... | https://habr.com/ru/post/282431/ | null | ru | null |
# DiffHTML.js — утилита для патчинга DOM
[](https://habrahabr.ru/post/308856/)
### Что такое DiffHTML.js?
DiffHTML — эта утилита для патчинга (частичного изменения) DOM-дерева. Она умеет находить разницу между существующим... | https://habr.com/ru/post/308856/ | null | ru | null |
# Вычисление CRC32 строк в compile-time
По своей программистской природе я очень не люблю неоптимальность и избыточность в коде. И вот, читая в очередной раз на работе исходный код нашего проекта, вновь наткнулся на одну осо... | https://habr.com/ru/post/143975/ | null | ru | null |
# Этот капризный AdMob. Как помириться с корпорацией добра
Многие из разработчиков мобильных приложений и сайтов, использующие adMob, видели это неприятное сообщение:
*Your account has been disabled for invalid activi... | https://habr.com/ru/post/163339/ | null | ru | null |
# .Net Core Api: получение данных в запросе из разных источников
В .Net Core есть встроенный механизм Model Binding, позволяющий не просто принимать входные параметры в контроллерах, а получать сразу объекты с заполненными полями. Это позволяет встроить в такой объект все нужные проверки с помощью Model Validation. ... | https://habr.com/ru/post/492820/ | null | ru | null |
# Создание собственного React с нуля
Демистификация React путем создания собственных компонентов, включая виртуальный DOM, стейтфул компоненты и хуки жизненного цикла
---------------------------------------------------------------------------------------------------------------------------------

*Локальный мем из русскоязычного чат... | https://habr.com/ru/post/436238/ | null | ru | null |
# Как прогнозировать цены на авиабилеты?
Всем привет!
Это третья статья о там, как я делаю небольшой и уютный сервис, который ~~в теории~~ должен помочь с планированием путешествий. В этой статье я расскажу про то, как предсказывать цены на авиабилеты, имея под рукой Clickhouse, Catboost и 1TB\* данных.
![image... | https://habr.com/ru/post/490762/ | null | ru | null |
# Пример ≈двукратного ускорения загрузки шрифта для заголовков из Google Web Fonts, осуществляемого выборкою оптимальной версии его
[![[иллюстрация-скриншот]](https://habrastorage.org/getpro/habr/post_images/0d3/8af/410/0d38af41015fe17dda1f33d1983c1b56.gif "перейти в Циклопедию")](http://cyclowiki.org/ "перейти в Цикл... | https://habr.com/ru/post/130172/ | null | ru | null |
# Библиотека алгоритмов на графах на языке Go. Часть 1
Предисловие
-----------
Приветствую тебя, дорогой читатель! Мне 21, я студент и младший Go-разработчик, а это - мой первый пост на Хабре. Недавно в компании с одногруппником мы решили взяться за амбициозный проект и я решил, что он, как никакой другой, подходит п... | https://habr.com/ru/post/704730/ | null | ru | null |
# Новая версия Хабра. Ещё не всё потеряно, ещё не всё?… (часть вторая)
[](https://habr.com/ru/company/ruvds/blog/673352/)
*TL;DR — разбираю новую версию Хабра. В статье много текста и изображений.*
В прошлой части я разобрал мот... | https://habr.com/ru/post/673352/ | null | ru | null |
# Порождающие шаблоны проектирования в ES6+ на примере Игры престолов

Шаблоны проектирования — способы решения наиболее часто встречающихся при разработке программного обеспечения проблем. В этой статье мы рассмотрим порождающие ш... | https://habr.com/ru/post/497860/ | null | ru | null |
# Численная проверка abc-гипотезы (да, той самой)
Привет, Habr.
На ~~Geektimes~~ Habr было уже несколько статей про abc-гипотезу (например [в 2013](https://habr.com/post/183374/) и [в 2018](https://habr.com/post/426033/) годах). Сама история про теорему, которую сначала много лет не могут доказать, а потом столько ... | https://habr.com/ru/post/427091/ | null | ru | null |
# О совместимости Android-приложений на различных устройствах
Не секрет, что число устройств на Android велико, они различаются по железу, размерам и качеству экрана, мощности процессора и др.. В отличии от iPhone- программистов, которые знают наверняка на каком устройстве будет запущено их приложение, Android-разрабо... | https://habr.com/ru/post/111560/ | null | ru | null |
# Vue.js для начинающих, урок 4: рендеринг списков
Сегодня, в четвёртом уроке учебного курса по Vue, мы поговорим о том, как выводить на страницу списки элементов.
[](https://habr.com/ru/company/ruvds/blog/510898/)
→ [Vue.js для... | https://habr.com/ru/post/510898/ | null | ru | null |
# Предложение от Яндекс.Денег в новом стандарте платежей W3C
Привет! Меня зовут Евгений Виноградов. Я работаю в Яндекс.Деньгах и участвую в работе группы W3C, посвященной стандартам интернет-платежей. Помимо нас и ещё нескольких платёжных сервисов, в неё вошли международные IT-компании, банки, регуляторы, организации,... | https://habr.com/ru/post/233101/ | null | ru | null |
# Усложнение команд консоли, 1979−2020
[Моё хобби](https://www.xkcd.com/1795/) — открыть [«Философию UNIX»](https://danluu.com/mcilroy-unix/) Макилроя на одном мониторе, одновременно читая маны на другом.
Первый из принципов Макилроя часто перефразируют как «Делайте что-то одно, но делайте хорошо». Это сокращение о... | https://habr.com/ru/post/499090/ | null | ru | null |
# Python Testing с pytest. Использование pytest с другими инструментами, ГЛАВА 7
[Вернуться](https://habr.com/ru/post/448796/)
*Обычно pytest используется не самостоятельно, а в среде тестирования с другими инструментами. В этой главе... | https://habr.com/ru/post/448798/ | null | ru | null |
# Memory and Span pt.1
[](https://github.com/sidristij/dotnetbook) Starting from .NET Core 2.0 and .NET Framework 4.5 we can use new data types: `Span` and `Memory`. To use them, you just need to install the `System.Memory` nuget packag... | https://habr.com/ru/post/443974/ | null | en | null |
# Что же такое этот GraphQL?
*Вашему вниманию предлагаю перевод статьи Sacha Greif ["Что же такое этот GraphQL?"](https://medium.freecodecamp.com/so-whats-this-graphql-thing-i-keep-hearing-about-baf4d36c20cf)*
Если вы такой же, как и я, вы обычно проходите через три этапа, когда узнаёте о новой технологии:
* Отрицан... | https://habr.com/ru/post/326986/ | null | ru | null |
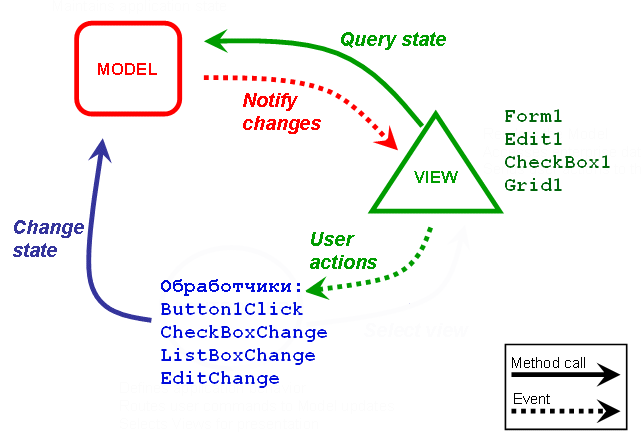
# MVC-подход к разработке пользовательских интерфейсов в Delphi. Часть 1. Галочка
Не буду писать красивых предисловий, потому что статья не развлекательная, а скорее техническая. В ней я хочу обратиться к приемам програм... | https://habr.com/ru/post/147133/ | null | ru | null |
# Android, Google and free content licenses. Who is to blame and what can be done?
#### The story of another ban.
Have you heard about bans on apps and developers in Google Play? This is just such a story. It’s also an attempt to collect similar cases into one place and offer some kind of plan of action to prevent Go... | https://habr.com/ru/post/479336/ | null | en | null |
# C++20 и Modules, Networking, Coroutines, Ranges, Graphics. Итоги встречи в Сан-Диего
До C++20 осталась пара лет, а значит, не за горами feature freeze. В скором времени международный комитет сосредоточится на причёсывании черновика C++20, а нововведения будут добавляться уже в C++23.
Ноябрьская встреча в Сан-Диег... | https://habr.com/ru/post/430406/ | null | ru | null |
# Робот-попрошайка на ROS и нейросетках
Обычно к таким поделкам возникает два вопроса: «как?» и «для чего?» Первому вопросу посвящена сама публикация, а на второй я отвечу сразу:
Этот проект я затеял для того, чтобы освоить робототехнику, начиная с Raspberry Pi и камеры. Как известно, один из лучших способов чему-н... | https://habr.com/ru/post/500150/ | null | ru | null |
# Графика в LaTeX. Часть II
В конце прошлого года я опубликовал [статью](http://alex.kotomanov.com/2009/01/11/graph_in_latex/), посвящённую графике в LaTeX. Сегодня вот наконец собрался написать продолжение. Из-за объёма материала пришлось разбить статью на несколько частей.
В этой статье вы узнаете как импортирова... | https://habr.com/ru/post/48122/ | null | ru | null |
# Использование макросов в MASM на примере создания окна
В далеком 2001-ом году я проводил много времени за изучением ассемблера под Win32. Тогда после долгих мучений с написанием одного и того же кода по сотне раз я взялся написать для себя небольшую библиотеку макросов. В итоге удалось достаточно серьезно облегчить ... | https://habr.com/ru/post/107272/ | null | ru | null |
# Что вернет операция 1 < 3 < 2?
**Ответ: False**
Если предположить, что это выражение состоит из двух отдельных операций, то слева на право: `1 < 3 = True, True(понимаем 1) < 2` также долен вернуть `True`, но почему-то `False`.
Фишка в том, что `1 < 3 < 2` это не две отдельных операции, а одна сложная. Давайте ... | https://habr.com/ru/post/125671/ | null | ru | null |
# QML Самоучитель
Предисловие
-----------
Уже давно вышла версия Qt4 c поддержкой QML. С тех пор многое допиливалось и сейчас технология является довольно успешной и стабильной. Однако нормального описания так и не удавалось найти на русском языке. А на английском написано так, как говорится, "правой рукой, да левое ... | https://habr.com/ru/post/669692/ | null | ru | null |
# Визуализируем в 3D, или как подружить D3 и Three.js
Если Вы уже слышали о [D3](http://habrahabr.ru/search/?q=[d3.js]&target_type=posts) и [Three.js](http://habrahabr.ru/search/?q=[three.js]&target_type=posts), эта статья может показаться Вам интересной. В ней речь пойдёт о том, как заставить эти библиотеки работать ... | https://habr.com/ru/post/200584/ | null | ru | null |
# Общий обзор архитектуры сервиса для оценки внешности на основе нейронных сетей

Вступление
----------
Привет!
В данной статье я поделюсь ... | https://habr.com/ru/post/511332/ | null | ru | null |
# Инфраструктура и торговые роботы: Какие языки программирования используются в сфере финансов
[](http://habrahabr.ru/company/itinvest/blog/271493/)
Биржевая торговля — это высокотехнологичная отрасль. В нашем блоге на Хабр... | https://habr.com/ru/post/271493/ | null | ru | null |
# Всё, точка, приплыли! Учимся работать с числами с плавающей точкой и разрабатываем альтернативу с фиксированной точностью десятичной дроби

Сегодня мы поговорим о вещественных числах. Точнее, о представлении их процессоро... | https://habr.com/ru/post/257897/ | null | ru | null |
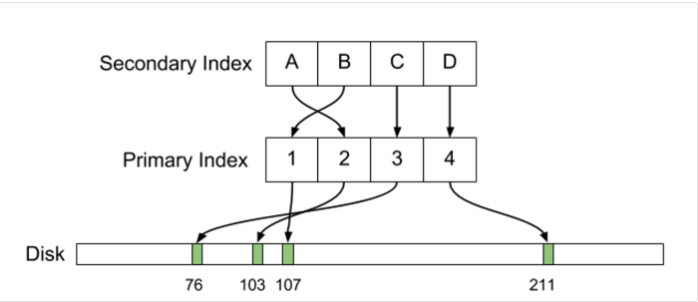
# Uber — причины перехода с Postgres на MySQL
В конце июля 2016 года в корпоративном блоге Uber появилась поистине историческая статья о причинах перехода компании с PostgreSQL на MySQL. С тех пор в жарких обсуждениях этого... | https://habr.com/ru/post/322624/ | null | ru | null |
# Автоматизация мониторинга зарплат с помощью R
Каждая уважающая себя контора регулярно проводит мониторинг заработных плат, чтобы ориентироваться в интересующем ее сегменте рынка труда. Однако несмотря на то, что задача нужная и важная, не все готовы за это платить сторонним сервисам.
В этом случае, чтобы избавить ... | https://habr.com/ru/post/417991/ | null | ru | null |
# Elixir: делаем код расширяемым с помощью Behaviour

Итак, определим диспозицию… Вы написали кусочек кода, который вы хотите использовать с большим количеством разных "вещей" — звучит не очень научно, но всё же. Эти разные... | https://habr.com/ru/post/312442/ | null | ru | null |
# PHP-Дайджест № 68 – интересные новости, материалы и инструменты (27 июля – 24 августа 2015)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
... | https://habr.com/ru/post/265291/ | null | ru | null |
# Ошибка в большинстве браузеров
##### Предыстория :
Как то неожиданно появился заказ на создание интересного эффекта на сайте. Работа вроде и простая но и в одно время требовала немного подумать. Сам я занимаюсь уже 3 ... | https://habr.com/ru/post/141262/ | null | ru | null |
# Когда Atom быстрее чем Core?
Наглухо застряв в пробке за рулем машины, теоретически способной развивать скорость более 200 км\ч, и глядя, как меня обгоняют велосипедисты ~~на трехколесных велосипедах~~, я задумалась… нет,... | https://habr.com/ru/post/148306/ | null | ru | null |
# Простая схема деплоя мультисайтового друпала
Сразу оговорюсь что я во всем что касается друпала новичок и друпало-гуру пользователям наверно ничего нового не расскажу. Все нижеописанное есть результатом немногим больше годичной деятельности в области предоставления хостинга сайтов на друпале нескольким знакомым.
... | https://habr.com/ru/post/78951/ | null | ru | null |
# Тёмная сторона ZRF
У тех, кто читал цикл моих [статей](http://habrahabr.ru/post/211100/), посвященных [Zillions of Games](http://zillionsofgames.com/), могло сложиться впечатление, что я полностью удовлетво... | https://habr.com/ru/post/221779/ | null | ru | null |
# Руководство Google по стилю в C++. Часть 3
[Часть 1. Вступление](https://habr.com/ru/post/480422/)
[Часть 2. Заголовочные файлы](https://habr.com/ru/post/516444/)
**Часть 3. Область видимости**
[Часть 4. Классы](https://habr.com/ru/post/532820/)
…
 Я уже рассказывала на простом языке, [что такое API](https://habr.com/ru/post... | https://habr.com/ru/post/704090/ | null | ru | null |
# Небинарный *ngIf
Вам когда-нибудь хотелось отобразить состояние загрузки, пока `ngIf` ждет ответа от `async`-пайпа? Или, может, вы мечтали передать в `ngFor` шаблон для пустого массива? Возможно, вы бросили это, потому что вам не хотелось реализовывать базовую логику этих директив самому. На самом деле в этом нет ну... | https://habr.com/ru/post/580172/ | null | ru | null |
# ProcInsp — веб-диспетчер задач для Windows
*«Сказать программисту, что уже есть библиотека, делающая Х,* — *это то же самое, что сказать музыканту, что уже есть песня про любовь»* [*(с)*](https://skillbox.r... | https://habr.com/ru/post/543156/ | null | ru | null |
# Когда нет сил ждать Record'ы
Думаю, многие C# разработчики с нетерпением ждали в C# 6.0 появления первичных конструкторов и record'ов и были огорчены тем, что эта фича была отложена до 7-й версии. Под конец рабочего четверга желание иметь неизменяемые типы во что бы то ни стало пересилило во мне терпение и я решил н... | https://habr.com/ru/post/269453/ | null | ru | null |
# Threadripper 3990X: компилируем 1 миллиард строк C++ на 64 ядрах

RAD Studio состоит из Delphi и C++Builder. Компилятор Object Pascal в Delphi является однопроходным компилятором, и сам компилятор не является параллельным, однако... | https://habr.com/ru/post/540962/ | null | ru | null |
# Ломаем и чиним etcd-кластер
**etcd** — это быстрая, надёжная и устойчивая к сбоям key-value база данных. Она лежит в основе Kubernetes и является неотъемлемой частью его control-plane, именно поэтому критически важно уметь бэкапить и ... | https://habr.com/ru/post/544390/ | null | ru | null |
# Проверка PHP 7

Повторная проверка проектов нередко бывает весьма интересной. Она позволяет узнать, какие новые ошибки были допущены в ходе разработке приложения, а какие ошибки уже были исправлены. Раньше мой коллега уже ... | https://habr.com/ru/post/282684/ | null | ru | null |
# Обновление сертификатов на билд сервере

Во многих компаниях используют [Continuous Integration](http://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%BF%D1%80%D0%B5%D1%80%D1%8B%D0%B2%D0%BD%D0%B0%D1%8F_%D0%B8%D0%B... | https://habr.com/ru/post/203426/ | null | ru | null |
# Исследуем бинарные форматы на примере байткода .class файла

Если вас не пугает картинка выше, если вы знаете чем отличается big-endian от little-endian, если вам всегда было интересно как "устроены" бинарные файлы, значит эта с... | https://habr.com/ru/post/481260/ | null | ru | null |
# Часть 1. Создание и настройка проекта, работа в редакторах microStudio
Привет, Хабр!
Я решил повременить с написанием статей на тему microStudio, собрать больше информации, почитать вопросы в своей группе ВК (спасибо большое авторам этих вопросов), чтобы дать больше информации в этой статье.
Если вы не слышали о п... | https://habr.com/ru/post/649415/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.